ES2827774T3 - Codificador de audio y método relacionado usando procesamiento de dos canales dentro de un marco de referencia de relleno inteligente de espacios - Google Patents
Codificador de audio y método relacionado usando procesamiento de dos canales dentro de un marco de referencia de relleno inteligente de espacios Download PDFInfo
- Publication number
- ES2827774T3 ES2827774T3 ES18180168T ES18180168T ES2827774T3 ES 2827774 T3 ES2827774 T3 ES 2827774T3 ES 18180168 T ES18180168 T ES 18180168T ES 18180168 T ES18180168 T ES 18180168T ES 2827774 T3 ES2827774 T3 ES 2827774T3
- Authority
- ES
- Spain
- Prior art keywords
- spectral
- channel
- representation
- portions
- frequency
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 82
- 238000012545 processing Methods 0.000 title description 36
- 230000003595 spectral effect Effects 0.000 claims abstract description 600
- 238000001228 spectrum Methods 0.000 claims abstract description 107
- 230000005236 sound signal Effects 0.000 claims abstract description 84
- 238000004364 calculation method Methods 0.000 claims description 24
- 238000011049 filling Methods 0.000 claims description 22
- 238000004458 analytical method Methods 0.000 claims description 13
- 230000006978 adaptation Effects 0.000 claims description 12
- 238000004590 computer program Methods 0.000 claims description 12
- 230000001131 transforming effect Effects 0.000 claims description 4
- 230000002123 temporal effect Effects 0.000 description 86
- 238000007493 shaping process Methods 0.000 description 27
- 230000000875 corresponding effect Effects 0.000 description 26
- 230000008929 regeneration Effects 0.000 description 20
- 238000011069 regeneration method Methods 0.000 description 20
- 238000013139 quantization Methods 0.000 description 18
- 238000001914 filtration Methods 0.000 description 15
- 238000004061 bleaching Methods 0.000 description 13
- 230000000873 masking effect Effects 0.000 description 13
- 230000009466 transformation Effects 0.000 description 13
- 230000008901 benefit Effects 0.000 description 12
- 230000002596 correlated effect Effects 0.000 description 12
- 230000002829 reductive effect Effects 0.000 description 12
- 238000013459 approach Methods 0.000 description 11
- 230000015572 biosynthetic process Effects 0.000 description 10
- 238000010586 diagram Methods 0.000 description 10
- 238000002592 echocardiography Methods 0.000 description 10
- 238000012805 post-processing Methods 0.000 description 9
- 230000003044 adaptive effect Effects 0.000 description 8
- 238000003786 synthesis reaction Methods 0.000 description 8
- 230000001052 transient effect Effects 0.000 description 8
- 230000001934 delay Effects 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 7
- 230000005540 biological transmission Effects 0.000 description 6
- 230000006641 stabilisation Effects 0.000 description 6
- 238000011105 stabilization Methods 0.000 description 6
- 238000004422 calculation algorithm Methods 0.000 description 5
- 238000007906 compression Methods 0.000 description 5
- 230000006835 compression Effects 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 230000010076 replication Effects 0.000 description 5
- 238000005070 sampling Methods 0.000 description 5
- XRKZVXDFKCVICZ-IJLUTSLNSA-N SCB1 Chemical compound CC(C)CCCC[C@@H](O)[C@H]1[C@H](CO)COC1=O XRKZVXDFKCVICZ-IJLUTSLNSA-N 0.000 description 4
- 101100439280 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) CLB1 gene Proteins 0.000 description 4
- 239000007844 bleaching agent Substances 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 230000009467 reduction Effects 0.000 description 4
- 230000002441 reversible effect Effects 0.000 description 4
- 230000002087 whitening effect Effects 0.000 description 4
- 238000009499 grossing Methods 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 238000011524 similarity measure Methods 0.000 description 3
- 238000009966 trimming Methods 0.000 description 3
- 101000969688 Homo sapiens Macrophage-expressed gene 1 protein Proteins 0.000 description 2
- 102100021285 Macrophage-expressed gene 1 protein Human genes 0.000 description 2
- QZOCOXOCSGUGFC-KIGPFUIMSA-N SCB3 Chemical compound CCC(C)CCCC[C@@H](O)[C@H]1[C@H](CO)COC1=O QZOCOXOCSGUGFC-KIGPFUIMSA-N 0.000 description 2
- QZOCOXOCSGUGFC-UHFFFAOYSA-N SCB3 Natural products CCC(C)CCCCC(O)C1C(CO)COC1=O QZOCOXOCSGUGFC-UHFFFAOYSA-N 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 239000006185 dispersion Substances 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 238000005192 partition Methods 0.000 description 2
- 230000008447 perception Effects 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 238000010183 spectrum analysis Methods 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 230000017105 transposition Effects 0.000 description 2
- 101100476202 Caenorhabditis elegans mog-2 gene Proteins 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 238000013144 data compression Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 238000005204 segregation Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 229920006132 styrene block copolymer Polymers 0.000 description 1
Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/008—Multichannel audio signal coding or decoding using interchannel correlation to reduce redundancy, e.g. joint-stereo, intensity-coding or matrixing
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0204—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using subband decomposition
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0212—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using orthogonal transformation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/022—Blocking, i.e. grouping of samples in time; Choice of analysis windows; Overlap factoring
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/022—Blocking, i.e. grouping of samples in time; Choice of analysis windows; Overlap factoring
- G10L19/025—Detection of transients or attacks for time/frequency resolution switching
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/028—Noise substitution, i.e. substituting non-tonal spectral components by noisy source
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/03—Spectral prediction for preventing pre-echo; Temporary noise shaping [TNS], e.g. in MPEG2 or MPEG4
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/032—Quantisation or dequantisation of spectral components
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/06—Determination or coding of the spectral characteristics, e.g. of the short-term prediction coefficients
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/18—Vocoders using multiple modes
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/038—Speech enhancement, e.g. noise reduction or echo cancellation using band spreading techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/038—Speech enhancement, e.g. noise reduction or echo cancellation using band spreading techniques
- G10L21/0388—Details of processing therefor
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/06—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being correlation coefficients
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/18—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being spectral information of each sub-band
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/21—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being power information
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0204—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using subband decomposition
- G10L19/0208—Subband vocoders
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S1/00—Two-channel systems
- H04S1/007—Two-channel systems in which the audio signals are in digital form
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Acoustics & Sound (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Quality & Reliability (AREA)
- Mathematical Physics (AREA)
- Theoretical Computer Science (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Stereophonic System (AREA)
Abstract
Codificador de audio para codificar una señal de audio de dos canales, que comprende: un convertidor de espectro de tiempo (860) para convertir la señal de audio de dos canales en una representación espectral; un analizador espectral (866) para proporcionar una indicación de un primer conjunto de primeras porciones espectrales que van a codificarse con una primera resolución espectral y de un segundo conjunto de segundas porciones espectrales que van a codificarse con una segunda resolución espectral, siendo la segunda resolución espectral más pequeña que la primera resolución espectral, representando el segundo conjunto de segundas porciones espectrales bandas de reconstrucción; un analizador de dos canales (864) para analizar las segundas porciones espectrales del segundo conjunto de segundas porciones espectrales de la señal de audio de dos canales dentro de la banda de reconstrucción para determinar una identificación de dos canales (835) para cada segunda porción espectral del segundo conjunto de segundas porciones espectrales identificando o bien una primera representación de dos canales o bien una segunda representación de dos canales para obtener las identificaciones de dos canales (835) para las segundas porciones espectrales del segundo conjunto de segundas porciones espectrales; un codificador central (870) para codificar el primer conjunto de primeras porciones espectrales para proporcionar una primera representación codificada; y una calculadora de parámetros (868) para calcular datos paramétricos en el segundo conjunto de segundas porciones espectrales usando las identificaciones de dos canales tal como se determina por el analizador de dos canales (864) para obtener una representación paramétrica codificada, en el que una señal de audio de dos canales codificada (873) comprende la primera representación codificada, la representación paramétrica codificada y las identificaciones de dos canales (835) para las segundas porciones espectrales del segundo conjunto de segundas porciones espectrales.
Description
DESCRIPCIÓN
Codificador de audio y método relacionado usando procesamiento de dos canales dentro de un marco de referencia de relleno inteligente de espacios
Memoria descriptiva
La presente invención se refiere a codificación/decodificación de audio y, particularmente, a codificación de audio mediante el Relleno Inteligente de Espacios (IGF).
La codificación de audio es el dominio de la compresión de la señal que trata el aprovechamiento de la redundancia y la irrelevancia de señales de audio utilizando el conocimiento psicoacústico. Actualmente, los códecs de audio generalmente necesitan alrededor de 60 kbps/canal para la codificación perceptual transparente de casi cualquier tipo de señal de audio. Los códecs más nuevos tienen como objetivo reducir la tasa de bits de codificación aprovechando las similitudes espectrales en la señal y utilizando técnicas tales como la extensión de ancho de banda (BWE, por sus siglas en inglés). Un esquema de extensión de ancho de banda (BWE) utiliza un parámetro bajo de tasa de bits establecido para representar los componentes de alta frecuencia (HF) de una señal de audio. El espectro de alta frecuencia (HF) se rellena con el contenido espectral de regiones de baja frecuencia (LF) y la forma espectral, pendiente y continuidad temporal se ajustan para mantener el timbre y el color de la señal original. Estos métodos de extensión de ancho de banda (BWE) permiten que los códecs de audio retengan buena calidad a tasas de bits incluso bajas de alrededor de 24 kbps/canal.
El almacenamiento o la transmisión de señales de audio a menudo están sujetos a estrictas limitaciones de tasas de bits. En el pasado, los codificadores se vieron obligados a reducir drásticamente el ancho de banda de audio transmitida cuando solo estaba disponible una tasa de bits muy baja.
Los códecs de audio modernos ahora son capaces de codificar señales de banda ancha utilizando los métodos de extensión de ancho de banda (BWE) [1]. Estos algoritmos se basan en una representación paramétrica del contenido de alta frecuencia (HF) - que se genera a partir de la parte de baja frecuencia (LF) codificada en forma de onda de la señal decodificada por medio de transposición a la región espectral de alta frecuencia (HF) ("interconexión") y la aplicación de un procesamiento posterior basado en parámetros. En los esquemas de extensión de ancho de banda (BWE), la reconstrucción de la región espectral de alta frecuencia (HF) por encima de una así denominada frecuencia de cruce determinada se basa a menudo en la interconexión espectral. En general, la región de alta frecuencia (HF) consta de múltiples conexiones adyacentes y cada una de estas conexiones se obtiene de regiones de paso de banda (BP) del espectro de baja frecuencia (LF) por debajo de la frecuencia de cruce determinada. Los sistemas del estado actual de la técnica desempeñan con eficiencia la interconexión dentro de una representación de bancos de filtros, por ejemplo, Banco de Filtros Espejo en Cuadratura (QMF, por sus siglas en inglés), copiando un conjunto de coeficientes de sub-bandas adyacentes desde una región de origen a la región de destino.
Otra técnica que se encuentra en los códecs de audio actuales que aumenta la eficiencia de compresión y permite así el ancho de banda de audio extendida en tasas de bits bajas es el reemplazo sintético basado en parámetros de partes apropiadas de los espectros de audio. Por ejemplo, las partes de la señal tipo ruido de la señal de audio original pueden ser reemplazadas sin pérdida sustancial de calidad subjetiva por ruido artificial generado en el decodificador y ajustado a escala por parámetros de información lateral. Un ejemplo es la herramienta de Sustitución de Ruido Perceptual herramienta (PNS, por sus siglas en inglés) contenida en la Codificación Avanzada de Audio MPEG-4 (AAC, por sus siglas en inglés) [5].
Otra disposición que también permite un ancho de banda de audio extendida en tasas de bits bajas es la técnica de relleno de ruido contenida en el Sistema Unificado de Codificación de Voz y Audio MPEG-D (USAC, por sus siglas en inglés) [7]. Los espacios espectrales (ceros) que se deducen por la zona muerta del cuantificador debido a una cuantificación demasiado gruesa, posteriormente se llenan de ruido artificial en el decodificador y se ajustan a escala por un procesamiento posterior basado en parámetros.
Otro sistema del estado actual de la técnica se denomina Reemplazo Espectral Preciso (ASR, por sus siglas en inglés) [2-4]. Además de un códec de forma de onda, el reemplazo espectral preciso (ASR) emplea una etapa de síntesis de señal dedicada que restaura perceptualmente porciones sinusoidales importantes de la señal en el decodificador. Asimismo, un sistema descrito en [5] se basa en el modelado sinusoidal en la región de alta frecuencia (HF) de un codificador de forma de onda para permitir que el ancho de banda de audio extendido tenga una calidad perceptual adecuada a tasas de bits bajas. Todos estos métodos implican la transformación de los datos en un segundo dominio aparte de la Transformada Coseno Discreta Modificada (MDCT, por sus siglas en inglés) y también etapas de análisis/síntesis bastante complejas para la conservación de componentes sinusoidales de alta frecuencia (HF).
La figura 13a ilustra un diagrama esquemático de un codificador de audio para una tecnología de extensión de ancho de banda como, por ejemplo, la que se utiliza en la Codificación Avanzada de Audio de Alta Eficiencia (HE-AAC, por
sus siglas en inglés). Una señal de audio en la línea 1300 se introduce en un sistema de filtro que comprende un paso bajo 1302 y un paso alto 1304. La señal emitida por el filtro de paso alto 1304 es introducida en un extractor/codificador de parámetros 1306. El extractor/codificador de parámetros 1306 está configurado para calcular y codificar parámetros tales como, por ejemplo, un parámetro de envolvente espectral, un parámetro de adición de ruido, un parámetro de armónicos faltantes, o un parámetro de filtrado inverso. Estos parámetros extraídos se introducen en un multiplexor de corriente de bits 1308. La señal de salida de paso bajo se introduce en un procesador que generalmente comprende la funcionalidad de un muestreador descendente 1310 y un codificador central 1312. El paso bajo 1302 restringe el ancho de banda para ser codificado en un ancho de banda significativamente menor que el producido en la señal de audio de entrada original en la línea 1300. Esto proporciona una ganancia de codificación significativa debido al hecho de que la totalidad de las funcionalidades que se producen en el codificador central solo tienen que operar en una señal con un ancho de banda reducido. Cuando, por ejemplo, el ancho de banda de la señal de audio en la línea 1300 es de 20 kHz y cuando el filtro de paso bajo 1302 tiene a modo de ejemplo un ancho de banda de 4 kHz, con el fin de cumplir el teorema de muestreo, es teóricamente suficiente que la señal subsiguiente al muestreador descendente tenga una frecuencia de muestreo de 8 kHz, que es una reducción sustancial de la tasa de muestreo requerida para la señal de audio 1300 que tiene que ser de al menos 40 kHz.
La figura 13b ilustra un diagrama esquemático de un decodificador de extensión de ancho de banda respectivo. El decodificador comprende un multiplexor de corriente de bits 1320. El demultiplexor de corriente de bits 1320 extrae una señal de entrada para un decodificador central 1322 y una señal de entrada para un decodificador de parámetros 1324. Una señal de salida del decodificador central tiene, en el ejemplo anterior, una tasa de muestreo de 8 kHz y, por lo tanto, un ancho de banda de 4 kHz mientras que, para una reconstrucción completa de ancho de banda, la señal de salida de un reconstructor de alta frecuencia 1330 debe ser de 20 kHz lo que requiere una tasa de muestreo de al menos 40 kHz. Con el fin de hacer esto posible, se requiere un procesador de decodificador que tenga la funcionalidad de un muestreador ascendente 1325 y un banco de filtros 1326. El reconstructor de alta frecuencia 1330 recibe entonces la señal de baja frecuencia analizada por frecuencia emitida por el banco de filtros 1326 y reconstruye el rango de frecuencias definido por el filtro de paso alto 1304 de la figura 13a utilizando la representación paramétrica de la banda de alta frecuencia. El reconstructor de alta frecuencia 1330 tiene varias funcionalidades tales como la regeneración del rango de frecuencias superior que utiliza el rango de origen en el rango de baja frecuencia, un ajuste de envolvente espectral, una funcionalidad de adición de ruido y una funcionalidad para introducir armónicos faltantes en el rango de frecuencia superior y, si se aplica y calcula en el codificador de la figura 13a, una operación de filtrado inverso con el fin de tener en cuenta el hecho de que el rango de frecuencia superior normalmente no es tan tonal como el rango de frecuencia inferior. En la Codificación Avanzada de Audio de Alta Eficiencia (HE-AAC), los armónicos faltantes se resintetizan en el lado del decodificador y se colocan exactamente en el medio de una banda de reconstrucción. Por lo tanto, todas las líneas de armónicos faltantes que se han determinado en una cierta banda de reconstrucción no se colocan en los valores de frecuencia en donde estaban ubicadas en la señal original. En cambio, dichas líneas de armónicos faltantes se colocan en frecuencias en el centro de la banda determinada. Por lo tanto, cuando una línea de armónico faltante en la señal original se colocó muy cerca del límite de la banda de reconstrucción en la señal original, el error en la frecuencia introducida al colocar esta línea de armónico faltante en la señal reconstruida en el centro de la banda está cerca de 50 % de la banda de reconstrucción individual, para la que se han generado y transmitido parámetros.
Además, a pesar de que los codificadores centrales de audio típicos operan en el dominio espectral, el decodificador central, no obstante, genera una señal de dominio temporal que, a continuación, es convertida nuevamente en un dominio espectral por la funcionalidad del banco de filtros 1326. Esto introduce retardos de procesamiento adicionales, puede introducir fallos debido al procesamiento en tándem de la transformación en primer lugar del dominio espectral en el dominio de frecuencia y nuevamente la transformación en generalmente un dominio de frecuencia diferente y, por supuesto, esto también requiere una cantidad sustancial de complejidad computacional y, por lo tanto, potencia eléctrica, que representa básicamente un problema cuando se aplica la tecnología de extensión de ancho de banda en dispositivos móviles como, por ejemplo, teléfonos móviles, tabletas u ordenadores portátiles, etc.
Los códecs de audio actuales llevan a cabo la codificación de audio de baja tasa de bits utilizando la extensión de ancho de banda (BWE) como parte integral del esquema de codificación. Sin embargo, las técnicas de extensión de ancho de banda (BWE) se limitan a reemplazar solo contenido de alta frecuencia (HF). Asimismo, no permiten la codificación de forma de onda del contenido perceptivamente importante por encima de una frecuencia de cruce determinada. Por lo tanto, los códecs de audio contemporáneos, ya sea pierden detalle de alta frecuencia (HF) o timbre cuando se implementa la extensión de ancho de banda (BWE), ya que la alineación exacta de los armónicos tonales de la señal no se tiene en cuenta en la mayoría de los sistemas.
Otra desventaja de los sistemas de extensión de ancho de banda (BWE) del estado actual de la técnica es la necesidad de transformación de la señal de audio en un nuevo dominio para la implementación de la BWE (por ejemplo, transformación de la Transformada Coseno Discreta Modificada (MDCT) al dominio de Filtros Espejo en Cuadratura (QMF). Esto genera complicaciones de sincronización, complejidad computacional adicional y aumento de requisitos de memoria.
En el caso de pares de dos canales, existen básicamente varias representaciones de canal tales como una representación conjunta de canal o una representación de canal por separado. Una representación conjunta conocida es una representación media/lateral donde el canal medio es la suma del canal izquierdo y derecho y donde el canal lateral es la diferencia entre el canal izquierdo y derecho.
Otra representación es un canal de mezcla descendente y un canal residual y un coeficiente de predicción adicional que permite recrear el canal izquierdo y derecho a partir del de mezcla descendente y del residual. La representación por separado sería, en este caso, el canal por separado izquierdo y derecho o generalmente, el primer canal y el segundo canal.
Asimismo, existe una situación, donde un rango de origen para operaciones de relleno de espacios puede mostrar una correlación fuerte, mientras que el rango de destino no muestra esta correlación fuerte. Cuando el rango de origen, en esta realización, se codifica usando una primera representación de estéreo tal como una representación media/lateral con el fin de reducir la tasa de bits para la porción de frecuencia central, entonces se genera una imagen de dos canales errónea para la porción de reconstrucción o el rango de destino. Cuando, por otra parte, el rango de origen no muestra ninguna correlación o solo tiene una pequeña correlación y el rango de destino tiene una pequeña correlación o ninguna correlación, entonces de nuevo una operación de relleno de espacios simple daría como resultado fallos.
El documento US 2005/165611 A1 da a conocer un codificador de audio usando similitud perceptual en sentido amplio, que mejora la calidad codificando una versión perceptualmente similar de los coeficientes espectrales omitidos, representados como una versión a escala del espectro ya codificado. Los coeficientes espectrales omitidos se dividen en un número de sub-bandas. Las sub-bandas se codifican como dos parámetros: un factor de escala, que puede representar la potencia en la banda; y un parámetro de forma, que puede representar una forma de la banda. El parámetro de forma puede ser en la forma de un vector de movimiento que apunta a una porción del espectro ya codificado, un índice a una forma espectral en un libro de claves fijo o un vector de ruido aleatorio. La codificación representa, por tanto, de manera eficiente una versión a escala de una porción con forma similar del espectro que va a copiarse en la decodificación.
El documento US 2004/008615 A1 da a conocer un método y un aparato para reducir la cantidad de cálculo en el procesamiento posterior de audio y, más particularmente, se proporcionan un método y un aparato para realizar procesamiento posterior de audio usando información de modo que indica el grado de similitud entre una señal de canal derecho y una señal de canal izquierdo en datos de audio MPEG-1 capa 3. Si la diferencia entre las dos señales de canal es pequeña, se usa un primer modo en el que se recupera el componente de alta frecuencia solo de un canal y el componente de alta frecuencia recuperado se usa para recuperar el componente de alta frecuencia del otro canal. Si la diferencia entre las dos señales de canal es grande, se selecciona un segundo modo en el que se recupera el componente de alta frecuencia en solo uno de cada dos marcos alternativamente en el canal izquierdo y el canal derecho y el componente de alta frecuencia de cada uno de los marcos saltados se interpola basándose en los componentes de alta frecuencia del marco anterior y el marco posterior. De esta manera, el nuevo método y aparato de decodificación de audio recuperan componentes de alta frecuencia con una cantidad pequeña de cálculo. El método reduce la cantidad de cálculo a menos de la mitad de la cantidad de cálculo usada en la técnica anterior en la recuperación de componentes de alta frecuencia.
El documento US 2010/241437 A1 da a conocer un método para la decodificación espectral perceptual que comprende la decodificación de coeficientes espectrales recuperados de un flujo binario en los coeficientes espectrales decodificados de un conjunto inicial de coeficientes espectrales. El conjunto inicial de coeficientes espectrales se llena de espectro. El relleno de espectro comprende el relleno de ruido de espacios espectrales ajustando coeficientes espectrales en el conjunto inicial de coeficientes espectrales que no se decodifican a partir del flujo binario igual a los elementos derivados de los coeficientes espectrales decodificados. El conjunto de coeficientes espectrales reconstruidos de un dominio de frecuencia formado por el relleno de espectro se convierte en una señal de audio de un dominio de tiempo. Un decodificador espectral perceptual comprende un rellenador de ruido, que funciona de acuerdo con el método para la decodificación espectral perceptual.
Un objeto de la presente invención es, por tanto, proporcionar un concepto de codificación mejorado para representaciones de dos canales.
Este objeto se consigue por un codificador de audio de acuerdo con la reivindicación 1, un método de codificación de audio de acuerdo con la reivindicación 10 o un programa informático de acuerdo con la reivindicación 11.
La presente invención se basa en el descubrimiento de que la situación de correlación no solo es importante para el rango de origen, sino también es importante para el rango de destino. Además, la presente invención reconoce el hecho de que pueden ocurrir diferentes situaciones de correlación en el rango de origen y en el rango de destino. Cuando se considera, por ejemplo, una señal de voz con ruido de alta frecuencia, puede ocurrir que la banda de baja frecuencia que comprende la señal de voz con un pequeño número de armónicos superiores está altamente
correlacionada en el canal izquierdo y el canal derecho, cuando el altavoz se coloca en el medio. La porción de alta frecuencia, sin embargo, puede estar fuertemente correlacionada debido al hecho de que podría haber un ruido de alta frecuencia diferente en el lado izquierdo en comparación con otro ruido de alta frecuencia o ningún ruido de alta frecuencia en el lado derecho. Por lo tanto, cuando se lleva a cabo una operación simple de relleno de espacios que ignora esta situación, entonces la porción de alta frecuencia estaría correlacionada también, y esto podría generar graves fallos de segregación espacial en la señal reconstruida. Con el fin de abordar esta cuestión, los datos paramétricos para una banda de reconstrucción o, en general, para el segundo conjunto de segundas porciones espectrales que tiene que ser reconstruido utilizando un primer conjunto de primeras porciones espectrales, se calculan para identificar, ya sea una primera o una segunda representación de dos canales diferente para la segunda porción espectral o, dicho de otra manera, para la banda de reconstrucción. Por lo tanto, en el lado del codificador se calcula una identificación de dos canales para las segundas porciones espectrales, es decir, para las porciones para las que se calcula adicionalmente la información de potencia para las bandas de reconstrucción. A continuación, un regenerador de frecuencia en el lado del decodificador regenera una segunda porción espectral en función de una primera porción del primer conjunto de primeras porciones espectrales, es decir, el rango de origen y los datos paramétricos para la segunda porción tal como la información de potencia de la envolvente espectral o cualquier otro dato de la envolvente espectral y, adicionalmente, depende de la identificación de dos canales para la segunda porción, es decir, para esta banda de reconstrucción bajo reconsideración.
La identificación de dos canales se transmite preferentemente como una etiqueta para cada banda de reconstrucción y estos datos se transmiten desde un codificador a un decodificador y el decodificador luego decodifica la señal central indicada preferentemente por etiquetas calculadas para las bandas centrales. A continuación, en una implementación, la señal central se almacena en ambas representaciones estéreo (por ejemplo, izquierda/derecha y media/lateral) y, para el relleno de mosaicos de frecuencia de relleno inteligente de espacios (IGF), se elige la representación de mosaicos de origen para adaptar la representación de mosaicos de destino indicada por las etiquetas de identificación de dos canales para el relleno inteligente de espacios o las bandas de reconstrucción, es decir, para el rango de destino.
Se hace hincapié en que este procedimiento no solo funciona para las señales estéreo, es decir, por un canal izquierdo y el canal derecho, sino que también funciona para las señales multicanal. En el caso de las señales multicanal se pueden procesar varios pares de canales diferentes, por ejemplo, como un canal izquierdo y un canal derecho como un primer par, un canal envolvente izquierdo y un canal envolvente derecho como el segundo par y un canal central y un canal LFE como el tercer par. Otras formaciones de pares se pueden determinar para los formatos de canal de salida superiores tales como 7.1, 11.1 y así sucesivamente.
Un aspecto adicional se basa en el descubrimiento de que los problemas relacionados con la separación de la extensión de ancho de banda por un lado y la codificación central por otro lado se pueden abordar y superar llevando a cabo la extensión de ancho de banda en el mismo dominio espectral en el que opera el decodificador central. Por lo tanto, se proporciona un decodificador central de tasa completa que codifica y decodifica todo el rango de la señal de audio. Esto no genera la necesidad de un muestreador descendente en el lado del codificador y un muestreador ascendente en el lado del decodificador. En cambio, todo el procesamiento se lleva a cabo en toda la tasa de muestreo o en todo el dominio de ancho de banda. Con el fin de obtener una alta ganancia de codificación, la señal de audio se analiza con el fin de encontrar un primer conjunto de primeras porciones espectrales que tiene que ser codificado con una alta resolución, en donde este primer conjunto de primeras porciones espectrales puede incluir, en una realización, porciones tonales de la señal de audio. Por otra parte, los componentes no tonales o ruidosos en la señal de audio que constituyen un segundo conjunto de segunda porciones espectrales son codificados paramétricamente con baja resolución espectral. Entonces, la señal de audio codificada solo requiere que el primer conjunto de primeras porciones espectrales esté codificado de manera que conserve la forma de onda con una alta resolución espectral y, adicionalmente, que el segundo conjunto de segundas porciones espectrales esté codificado paramétricamente con una baja resolución utilizando "mosaicos" de frecuencia obtenidos del primer conjunto. En el lado del decodificador, el decodificador central, que es un decodificador de banda completa, reconstruye el primer conjunto de primeras porciones espectrales de manera que conserve la forma de onda, es decir, desconociendo si hay una regeneración de frecuencia adicional. Sin embargo, el espectro así generado tiene un montón de espacios espectrales. Estos espacios se rellenan posteriormente con la tecnología de relleno inteligente de espacios (IGF, por sus siglas en inglés) de la invención utilizando una regeneración de frecuencia que aplica datos paramétricos, por un lado, y que utiliza un rango espectral de origen, es decir, primeras porciones espectrales reconstruidas por el decodificador de audio de tasa completa por otro lado.
En otras realizaciones, las porciones espectrales, que son reconstruidas por relleno de ruido solamente en lugar de replicación de ancho de banda o relleno de mosaicos de frecuencia, constituyen un tercer conjunto de terceras porciones espectrales. Debido al hecho de que el concepto de codificación opera en un dominio único para la codificación/decodificación central por un lado, y la regeneración de frecuencia por otro lado, el relleno inteligente de espacios (IGF) no solo se limita a llenar un rango de frecuencia superior sino que puede llenar rangos de frecuencia inferiores, ya sea por relleno de ruido sin regeneración de frecuencia o por regeneración de frecuencia utilizando un mosaico de frecuencia en un rango de frecuencia diferente.
Asimismo, se insiste en que una información sobre potencias espectrales, una información sobre potencias individuales o una información de potencia individual, una información sobre una potencia de conservación o una información de potencia de conservación, una información sobre una potencia de mosaico o una información de potencia de mosaico, o una información sobre una potencia faltante o una información de potencia faltante pueden comprender no solo un valor de potencia sino también un valor de amplitud (por ejemplo, absoluto), un valor de nivel o cualquier otro valor, del que se puede obtener un valor de potencia final. Por lo tanto, la información sobre una potencia puede comprender, por ejemplo, el valor de potencia propiamente dicho, y/o un valor de un nivel y/o de una amplitud y/o de una amplitud absoluta.
Un aspecto adicional se basa en el descubrimiento de que la calidad de audio de la señal reconstruida se puede mejorar a través de IGF ya que todo el espectro es accesible para el codificador central de manera que, por ejemplo, las porciones tonales perceptualmente importantes en un alto rango espectral todavía pueden ser codificadas por el codificador central en lugar de la sustitución paramétrica. Adicionalmente se lleva a cabo la operación de relleno de espacios que utiliza mosaicos de frecuencia de un primer conjunto de primeras porciones espectrales que es, por ejemplo, un conjunto de porciones tonales generalmente de un rango de frecuencia inferior, pero también de un rango de frecuencia superior, si está disponible. Sin embargo, para el ajuste de la envolvente espectral en el lado del decodificador, las porciones espectrales del primer conjunto de porciones espectrales ubicadas en la banda de reconstrucción no se procesan posteriormente otra vez por el ajuste de la envolvente espectral, por ejemplo. Solo los valores espectrales restantes en la banda de reconstrucción que no provienen del decodificador central deben ajustarse por la envolvente utilizando información de la envolvente. Preferentemente, la información de la envolvente es una información de la envolvente de banda completa que representa la potencia del primer conjunto de primeras porciones espectrales en la banda de reconstrucción y el segundo conjunto de segundas porciones espectrales en la misma banda de reconstrucción, en donde los últimos valores espectrales en el segundo conjunto de segunda porciones espectrales se indican como cero y, por lo tanto, no están codificados por el codificador central, pero están paramétricamente codificados con información de potencia de baja resolución.
Se ha descubierto que los valores absolutos de potencia, ya sea normalizados o no con respecto al ancho de banda de la banda correspondiente, son útiles y muy eficientes en una aplicación en el lado del decodificador. Esto se aplica especialmente cuando los factores de ganancia tienen que calcularse sobre la base de una potencia residual en la banda de reconstrucción, la potencia faltante en la banda de reconstrucción y la información de mosaicos de frecuencia en la banda de reconstrucción.
Asimismo, se prefiere que la corriente de bits codificada no solo abarque información de potencia para las bandas de reconstrucción sino, además, factores de ajuste de escala para bandas de factor de escala que se extienden hasta la frecuencia máxima. Esto asegura que, para cada banda de reconstrucción, para la que está disponible una cierta porción tonal, es decir, una primera porción espectral, este primer conjunto de primera porción espectral pueda ser decodificado realmente con la amplitud correcta. Por otra parte, además del factor de escala para cada banda de reconstrucción, una potencia para esta banda de reconstrucción es generada en un codificador y transmitida a un decodificador. Además, se prefiere que las bandas de reconstrucción coincidan con las bandas de factor de escala o en el caso de agrupamiento de potencia, al menos los límites de una banda de reconstrucción coincidan con los límites de las bandas de factor de escala.
Otro aspecto se basa en el hallazgo de que ciertas degradaciones en la calidad de audio se pueden remediar mediante la aplicación de un esquema de relleno de señal de frecuencia adaptable. Con este fin, se realiza un análisis en el lado del codificador con el fin de encontrar la región de origen más adecuada para una determinada región de destino. Una información coincidente que identifica, para una región de destino, cierta región de origen junto con, opcionalmente, alguna información adicional, se genera y se transmite como información lateral al decodificador. A continuación, el descodificador aplica una operación de relleno de mosaicos de frecuencia utilizando la información coincidente. Con este fin, el decodificador lee la información coincidente del flujo de datos transmitido o del archivo de datos y accede a la región de origen identificada para una determinada banda de reconstrucción y, si se indica en la información coincidente, realiza adicionalmente algún procesamiento de los datos de esta región de origen para generar datos espectrales brutos para la banda de reconstrucción. Entonces, esto resulta de la operación de relleno de los mosaicos de frecuencia, es decir, los datos espectrales en bruto para la banda de reconstrucción, se conforma utilizando información de la envolvente espectral con el fin de obtener finalmente una banda de reconstrucción que comprende también las primeras porciones espectrales, tales como las porciones tonales también. Estas porciones tonales, sin embargo, no se generan por el esquema de relleno adaptativo de mosaicos, sino que estas primeras porciones espectrales son emitidas directamente por el decodificador de audio o el decodificador de núcleo.
El esquema de selección espectral adaptativa de mosaicos puede operar con una baja granularidad. En esta implementación, una región de procedencia se subdivide en regiones de origen típicamente superpuestas y la región de destino o las bandas de reconstrucción están dadas por regiones de destino de frecuencia no superpuesta. Entonces, las similitudes entre cada región de origen y cada región de destino se determinan en el lado del codificador y el mejor par de una región de origen y la región de destino se identifican por la información de coincidencia y, en el
lado del decodificador, la región de origen identificada en la información coincidente se utiliza para generar los datos espectrales brutos para la banda de reconstrucción.
Con el fin de obtener una mayor granularidad, se permite que cada región de origen cambie para obtener un cierto retraso donde las similitudes son máximas. Este retraso puede ser tan fino como un compartimento de frecuencias y permite una mejor correspondencia entre una región de origen y la región de destino.
Asimismo, además de identificar sólo un par coincidente mejor, este retraso de correlación también puede ser transmitido dentro de la información correspondiente y, adicionalmente, incluso una señal puede ser transmitida. Cuando se determina que el signo es negativo en el lado del codificador, también se transmite un indicador de señal correspondiente dentro de la información de correspondencia y, en el lado del decodificador, los valores espectrales de la región de origen se multiplican por "-1" o, en una representación compleja, son "girados" 180 grados.
Una implementación adicional aplica una operación de blanqueamiento de mosaicos. El blanqueamiento de un espectro elimina la información de la envoltura espectral gruesa y enfatiza la estructura fina espectral que es de mayor interés para evaluar la similitud de los mosaicos. Por lo tanto, una bandeja de frecuencias, por un lado, y/o la señal de la fuente, por otro lado, se blanquean antes de calcular una medida de correlación cruzada. Cuando sólo se blanquea el mosaico mediante un procedimiento predefinido, se transmite un indicador de blanqueamiento que indica al decodificador que se aplicará el mismo proceso de blanqueamiento predefinido al mosaico de frecuencia dentro del IGF.
En cuanto a la selección de mosaicos, es preferente utilizar el retraso de la correlación para desplazar espectralmente el espectro regenerado mediante un número entero de intervalos de transformación. Dependiendo de la transformación subyacente, el desplazamiento espectral puede requerir correcciones adicionales. En caso de retardos impares, el mosaico se modula adicionalmente a través de la multiplicación por una secuencia temporal alternativa de -1/1 para compensar la representación de frecuencia inversa de cualquier otra banda dentro de la Transformada Coseno Discreta Modificada (MDCT). Asimismo, el signo del resultado de la correlación se aplica al generar el mosaico de frecuencias.
Asimismo, es preferente utilizar el recorte y estabilización de mosaicos para asegurarse de que se eviten los artefactos creados por regiones de origen que cambian rápidamente para la misma región de reconstrucción o región objetivo. Con este fin, se realiza un análisis de similitud entre las diferentes regiones de procedencia identificadas y cuando un mosaico de origen es similar a otros mosaicos de origen con una similitud superior a un umbral, entonces este mosaico de origen puede ser eliminado del conjunto de mosaicos de origen potenciales ya que está altamente correlacionada con otros mosaicos de origen. Asimismo, como una especie de estabilización de la selección de mosaicos, es preferente mantener el orden de los mosaicos del marco anterior si ninguno de los mosaicos de origen del marco actual se correlaciona (mejor que un umbral determinado) con los mosaicos de destino del marco actual.
Un aspecto adicional se basa en el descubrimiento de que una mejora de la calidad y la reducción de la tasa de bits específicamente para señales que comprenden porciones de transición, como ocurre muy a menudo en las señales de audio, se obtiene combinando la tecnología de Modelado de Ruido Temporal (TNS, por sus siglas en inglés) o Modelado de Mosaico Temporal (TTS, por sus siglas en inglés) con reconstrucción de alta frecuencia. El procesamiento de Modelado de Ruido Temporal (TNS)/Modelado de Mosaico Temporal (TTS) en el lado del codificador implementado por una predicción sobre la frecuencia reconstruye la envolvente de tiempo de la señal de audio. Dependiendo de la implementación, es decir, cuando el filtro de modelado de ruido temporal se determina dentro de un rango de frecuencia no solo abarcando el rango de frecuencia de origen sino también el rango de frecuencia de destino para ser reconstruido en un decodificador de regeneración de frecuencia, la envolvente temporal se aplica no solo a la señal de audio central hasta una frecuencia de inicio de relleno de espacios, sino que también se aplica la envolvente temporal a los rangos espectrales de segundas porciones espectrales reconstruidas. Por lo tanto, los pre-ecos o los post-ecos que se producirían sin el modelado de mosaico temporal se reducen o eliminan. Esto se logra aplicando una predicción inversa sobre la frecuencia no solo dentro del rango de frecuencia central hasta una cierta frecuencia de inicio de relleno de espacios sino también dentro de un rango de frecuencia por encima del rango de frecuencia central. Para este fin, la regeneración de frecuencia o la generación de mosaicos de frecuencia se llevan a cabo en el lado del decodificador antes de aplicar una predicción sobre la frecuencia. Sin embargo, la predicción sobre la frecuencia se puede aplicar, ya sea antes o después del modelado de la envolvente espectral, dependiendo de si el cálculo de información de potencia se ha llevado a cabo sobre los valores espectrales residuales posteriores al filtrado o los valores espectrales (completos) antes del modelado de la envolvente.
El procesamiento del Modelado de Mosaico Temporal (TTS) sobre uno o más mosaicos de frecuencia establece adicionalmente una continuidad de correlación entre el rango de origen y el rango de reconstrucción o en dos rangos de reconstrucción adyacentes o mosaicos de frecuencia.
En una implementación, se prefiere utilizar el filtrado complejo de Modelado de Ruido Temporal (TNS)/Modelado de Mosaico Temporal (TTS). De este modo se evitan los fallos de solapamiento (temporales) de una representación real
muestreado críticamente, como la Transformada Coseno Discreta Modificada (MDCT). Un filtro complejo de Modelado de Ruido Temporal (TNS) se puede calcular en el lado del codificador aplicando no solo una transformada de coseno discreta modificada, sino también una transformada sinusoidal discreta modificada para obtener adicionalmente una transformada modificada compleja. Sin embargo, solo se transmiten los valores de la transformada de coseno discreta modificada, es decir, la parte real de la transformada compleja. Sin embargo, en el lado del decodificador, es posible estimar la parte imaginaria de la transformada utilizando los espectros de la MDCT de cuadros anteriores o posteriores de modo que, en el lado del decodificador, el filtro complejo se puede aplicar nuevamente en la predicción inversa sobre la frecuencia y, específicamente, la predicción sobre el límite entre el rango de origen y el rango de reconstrucción y también sobre el límite entre los mosaicos de frecuencia adyacentes de la frecuencia dentro del rango de reconstrucción.
El sistema de codificación de audio de la invención codifica de manera eficiente las señales de audio arbitrarias en un rango amplio de tasas de bits. Por consiguiente, para las tasas altas de bits, el sistema de la invención converge con la transparencia, para tasas bajas de bits se reduce al mínimo la molestia perceptual. Por lo tanto, la parte principal de tasa de bits disponible se utiliza para codificar en forma de onda solo la estructura perceptualmente más relevante de la señal en el codificador, y los espacios espectrales resultantes se rellenan en el decodificador con el contenido de la señal que se aproxima en líneas generales al espectro original. Un presupuesto de bits muy limitado se consume para controlar el así denominado relleno inteligente de espacios (IGF) basado en parámetros por información lateral dedicada transmitida desde el codificador al decodificador.
A continuación, realizaciones preferidas de la presente invención se describirán con referencia a los dibujos adjuntos, en los cuales:
La figura 1a ilustra un aparato para codificar una señal de audio.
La figura 1b ilustra un decodificador para decodificar una señal de audio codificada que concuerda con el codificador de la figura 1a;
La figura 2a ilustra una implementación preferida del decodificador;
La figura 2b ilustra una implementación preferida del codificador.
La figura 3a ilustra una representación esquemática de un espectro generado por el decodificador de dominio espectral de la figura 1b.
La figura 3b ilustra una tabla que indica la relación entre los factores de ajuste de escala para las bandas de factor de escala y las potencias para las bandas de reconstrucción y la información de relleno de ruido para una banda de relleno de ruido.
La figura 4a ilustra la funcionalidad del codificador de dominio espectral para aplicar la selección de porciones espectrales en el primer y el segundo conjunto de porciones espectrales.
La figura 4b ilustra una implementación de la funcionalidad de la figura 4a.
La figura 5a ilustra una funcionalidad de un codificador de la Transformada Coseno Discreta Modificada (MDCT). La figura 5b ilustra una funcionalidad del decodificador con una tecnología de MDCT.
La figura 5c ilustra una implementación del regenerador de frecuencia.
La figura 6a ilustra un codificador de audio con la funcionalidad de modelado de ruido temporal/modelado de mosaico temporal.
La figura 6b ilustra un decodificador con la tecnología de modelado de ruido temporal/modelado de mosaico temporal.
La figura 6c ilustra una funcionalidad adicional de modelado de ruido temporal/modelado de mosaico temporal con un orden diferente del filtro de predicción espectral y el modelador espectral.
La figura 7a ilustra una implementación de la funcionalidad del modelado de mosaico temporal (TTS).
La figura 7b ilustra una implementación del decodificador que se adapta a la implementación del codificador de la figura 7a.
La figura 7c ilustra un espectrograma de una señal original y una señal extendida sin Modelado de Mosaico Temporal (TTS).
La figura 7d ilustra una representación de frecuencia que ilustra la correspondencia entre las frecuencias de relleno inteligente de espacios y las potencias de modelado de mosaico temporal.
La figura 7e ilustra un espectrograma de una señal original y una señal extendida sin Modelado de Mosaico Temporal (TTS).
La figura 8a ilustra un decodificador de dos canales con regeneración de frecuencia.
La figura 8b ilustra una tabla que ilustra combinaciones diferentes de las representaciones y los rangos de origen/destino.
La figura 8c ilustra un diagrama de flujo que ilustra la funcionalidad del decodificador de dos canales con regeneración de frecuencia de la figura 8a.
La figura 8d ilustra una implementación más detallada del decodificador de la figura 8a.
La figura 8e ilustra una implementación de un codificador de la invención para el procesamiento de dos canales que será decodificado por el decodificador de la figura 8a.
La figura 9a ilustra un decodificador con la tecnología de regeneración de frecuencia utilizando valores de potencia para el rango de frecuencia de regeneración.
La figura 9b ilustra una implementación más detallada del regenerador de frecuencia de la figura 9a.
La figura 9c ilustra un esquema que ilustra la funcionalidad de la figura 9b.
La figura 9d ilustra una implementación adicional del decodificador de la figura 9a.
La figura 10a ilustra un diagrama de bloques de un codificador que concuerda con el decodificador de la figura 9a. La figura 10b ilustra un diagrama de bloques para ilustrar una funcionalidad adicional de la calculadora de parámetros de la figura 10a.
La figura 10c ilustra un diagrama de bloques para ilustrar una funcionalidad adicional de la calculadora de parámetros de la figura 10a.
La figura 10d ilustra un diagrama de bloques que ilustra una funcionalidad adicional de la calculadora de parámetros de la figura 10a.
La figura 11a ilustra un decodificador adicional que tiene una identificación específica del rango de origen para una operación de relleno de mosaicos espectrales en el decodificador.
La figura 11b ilustra la funcionalidad adicional del regenerador de frecuencia de la figura 11 a.
La figura 11c ilustra un codificador utilizado para cooperar con el decodificador de la figura 11 a.
La figura 11d ilustra un diagrama de bloques de una implementación de la calculadora de parámetros de la figura 11c.
La figura 12a y 12b ilustran esquemas de frecuencia para ilustrar un rango de origen y un rango de destino. La figura 12c ilustra un esquema de ejemplo de correlación de dos señales.
La figura 13a ilustra un codificador de la técnica anterior con extensión de ancho de banda.
La figura 13b ilustra un decodificador de la técnica anterior con extensión de ancho de banda.
La figura 1 a ilustra un aparato para codificar una señal de audio 99. La señal de audio 99 se introduce en un convertidor de espectro de tiempo 100 para convertir una señal de audio que tiene una tasa de muestreo en una representación espectral 101 emitida por el convertidor de espectro de tiempo. El espectro 101 se introduce en un analizador espectral 102 para analizar la representación espectral 101. El analizador espectral 101 está configurado para determinar un
primer conjunto de primeras porciones espectrales 103 para ser codificado con una primera resolución espectral y un segundo conjunto diferente de segundas porciones espectrales 105 para ser codificado con una segunda resolución espectral. La segunda resolución espectral es más pequeña que la primera resolución espectral. El segundo conjunto de segundas porciones espectrales 105 se introduce en una calculadora de parámetros o codificador paramétrico 104 para calcular la información de envolvente espectral que tiene la segunda resolución espectral. Asimismo, se proporciona un codificador de audio de dominio espectral 106 para generar una primera representación codificada 107 del primer conjunto de primeras porciones espectrales que tiene la primera resolución espectral. Además, la calculadora de parámetros/codificador paramétrico 104 está configurado para generar una segunda representación codificada 109 del segundo conjunto de segundas porciones espectrales. La primera representación codificada 107 y la segunda representación codificada 109 se introducen en un multiplexor de corriente de bits o formador de corriente de bits 108 y el bloque 108 finalmente emite la señal de audio codificada para la transmisión o el almacenamiento en un dispositivo de almacenamiento.
Típicamente, una primera porción espectral tal como 306 de la figura 3a estará rodeada por dos segundas porciones espectrales tales como 307a, 307b. Esto no se aplica en la Codificación Avanzada de Audio de Alta Eficiencia (HE AAC), en donde el rango de frecuencia del codificador central es de banda limitada.
La figura 1b ilustra un decodificador que concuerda con el codificador de la figura 1a. La primera representación codificada 107 se introduce en un decodificador de audio de dominio espectral 112 para generar una primera representación decodificada de un primer conjunto de primeras porciones espectrales, en donde la representación decodificada tiene una primera resolución espectral. Además, la segunda representación codificada 109 se introduce en un decodificador paramétrico 114 para generar una segunda representación decodificada de un segundo conjunto de segundas porciones espectrales que tiene una segunda resolución espectral que es más baja que la primera resolución espectral.
El decodificador comprende además un regenerador de frecuencia 116 para regenerar una segunda porción espectral reconstruida que tiene la primera resolución espectral que utiliza una primera porción espectral. El regenerador de frecuencia 116 lleva a cabo una operación de relleno de mosaicos, es decir utiliza un mosaico o una porción del primer conjunto de primeras porciones espectrales y copia este primer conjunto de primeras porciones espectrales en el rango de reconstrucción o banda de reconstrucción que tiene la segunda porción espectral y generalmente lleva a cabo el modelado de la envolvente espectral u otra operación indicada por la segunda representación decodificada emitida por el decodificador paramétrico 114, es decir utilizando la información sobre el segundo conjunto de segundas porciones espectrales. El primer conjunto decodificado de primeras porciones espectrales y el segundo conjunto reconstruido de porciones espectrales indicado en la salida del regenerador de frecuencia 116en la línea 117 se introduce en un convertidor de espectro-tiempo 118 configurado para convertir la primera representación decodificada y la segunda porción espectral reconstruida en una representación de tiempo 119, en donde la representación de tiempo tiene una tasa alta de muestreo determinada.
La figura 2b ilustra una implementación del codificador de la figura 1a. Una señal de entrada de audio 99 se introduce en un banco de filtros de análisis 220 correspondiente al convertidor de espectro de tiempo 100 de la figura 1a. A continuación, se lleva a cabo la operación de modelado de ruido temporal en el bloque de modelado de ruido temporal (TNS) 222. Por lo tanto, la entrada en el analizador espectral 102 de la figura 1a correspondiente a un enmascaramiento tonal de bloque 226 de la figura 2b puede ser, ya sea un valor espectral completo, cuando no se aplica la operación de modelado de ruido temporal/modelado de mosaico temporal o puede ser un valor residual espectral, cuando se aplica la operación de modelado de ruido temporal (TNS) como se ilustra en la figura 2b, bloque 222. Para las señales de dos canales o señales multicanal se puede llevar a cabo además una codificación conjunta de canal 228, por lo que el codificador de dominio espectral 106 de la figura 1a puede comprender el bloque de codificación conjunta de canal 228. Asimismo, se proporciona un codificador por entropía 232 para llevar a cabo una compresión de datos sin pérdidas que es también una porción del codificador de dominio espectral 106 de la figura 1a.
El analizador espectral/enmascaramiento tonal 226 separa la salida del bloque de modelado de ruido temporal (TNS) 222 en la banda central y los componentes tonales correspondientes al primer conjunto de primeras porciones espectrales 103 y los componentes residuales correspondientes al segundo conjunto de segundas porciones espectrales 105 de la figura 1a. El bloque 224 indicado como la codificación de extracción de parámetros de relleno inteligente de espacios (IGF) corresponde al codificador paramétrico 104 de la figura 1a y el multiplexor de la corriente de bits 230 corresponde al multiplexor de corriente de bits 108 de la figura 1a.
Preferentemente, el banco de filtros de análisis 222 se implementa como una MDCT (banco de filtros de la transformada de coseno discreta modificada) y la MDCT se utiliza para transformar la señal 99 en un dominio de frecuencia temporal con la transformada de coseno discreta modificada que actúa como la herramienta de análisis de frecuencia. El analizador espectral 226 aplica preferentemente un enmascaramiento de tonalidad. Esta etapa de estimación de enmascaramiento de tonalidad se utiliza para separar los componentes tonales de los componentes tipo ruido en la señal. Esto permite que el codificador central 228 codifique todos los componentes tonales con un
módulo psicoacústico. La etapa de estimación de enmascaramiento de tonalidad se puede implementar de muchas maneras diferentes y se implementa preferentemente de manera similar en su funcionalidad a la etapa de estimación de pista sinusoidal utilizada en el modelado sinusoidal y de ruido para la codificación de voz/audio [8, 9] o un codificador de audio basado en el modelo HILN descrito en [10]. Preferentemente se utiliza una implementación que es fácil de implementar sin la necesidad de mantener trayectorias de nacimiento- muerte, pero también se puede utilizar cualquier otro detector de tonalidad o ruido.
El módulo de relleno inteligente de espacios (IGF) calcula la similitud que existe entre una región de origen y una región de destino. La región de destino estará representada por el espectro de la región de origen. La medida de la similitud entre las regiones de origen y de destino se realiza utilizando un enfoque de correlación cruzada. La región de destino se divide en nTar mosaicos de frecuencia que no se superponen. Para cada mosaico en la región de destino, nSrc se crea un mosaico de origen a partir de una frecuencia fija de inicio. Estos mosaicos de origen se superponen por un factor entre 0 y 1, en donde 0 significa 0 % de solapamiento y 1 significa 100 % de solapamiento. Cada uno de estos mosaicos de origen está correlacionado con el mosaico de destino en diversos retardos para encontrar el mosaico de origen que se adapte mejor al mosaico de destino. El mejor número de mosaico de adaptación se almacena en tileNum[idx_tar], el retardo en el que se correlaciona mejor con el objetivo se almacena en xcorr_lag[idx_tar][idx_src] y el signo de la correlación se almacena en xcorr_sign[idx_tar][idx_src]. En caso de que la correlación sea muy negativa, el mosaico de origen debe ser multiplicado por -1 antes del proceso de relleno de mosaico en el decodificador. El módulo de relleno inteligente de espacios (IGF) también se encarga de no sobrescribir los componentes tonales en el espectro ya que los componentes tonales se conservan utilizando el enmascaramiento de tonalidad. Se utiliza un parámetro de potencia por bandas para almacenar la potencia de la región de destino que permita reconstruir el espectro con precisión.
Este método tiene ciertas ventajas en comparación con la SBR clásica [1] en donde la cuadrícula de armónicos de una señal multitono es conservada por el codificador central en tanto que solo los espacios entre las sinusoides se llenan con el mejor "ruido modelado" de adaptación de la región de origen. Otra ventaja de este sistema en comparación con ASR (Reemplazo Espectral Preciso) [2-4] es la ausencia de una etapa de síntesis de la señal que crea las porciones importantes de la señal en el decodificador. En cambio, esta tarea es asumida por el codificador central, lo que permite la conservación de los componentes importantes del espectro. Otra ventaja del sistema propuesto es la escalabilidad continua que ofrecen las características. Solo el uso de tileNum[idx_tar] y xcorr_lag = 0, para cada mosaico se denomina adaptación de granularidad en bruto y se puede utilizar para tasas bajas de bits mientras que el uso de la variable xcorr_lag para cada mosaico permite adaptar mejor los espectros de destino y de origen.
Además, se propone una técnica de estabilización de elección de mosaicos que elimina los fallos de dominio de frecuencia tales como trino y ruido musical.
En caso de pares de canales estéreo se aplica un procesamiento de estéreo conjunto adicional. Esto es necesario, ya que, para un determinado rango de destino, la señal puede ser una fuente de sonido panoramizada y altamente correlacionada. En caso de que las regiones de origen elegidas para esta región en particular no estén bien correlacionadas, a pesar de que las potencias se adaptan a las regiones de destino, la imagen espacial puede sufrir debido a las regiones de origen no correlacionadas. El codificador analiza cada banda de potencia de la región de destino, por lo general llevando a cabo una correlación cruzada de los valores espectrales y si se supera un determinado umbral, establece una etiqueta conjunta para esta banda de potencia. En el decodificador, las bandas de potencia de los canales izquierdo y derecho son tratadas individualmente si no se establece esta etiqueta conjunta de estéreo. En caso de que se establezca la etiqueta de estéreo conjunto, tanto las potencias como la interconexión se llevan a cabo en el dominio de estéreo conjunto. La información de estéreo conjunto para las regiones de relleno inteligente de espacios (IGF) se señala de manera similar a la información conjunta de estéreo para la codificación central, que incluye una etiqueta que indica en el caso de la predicción si la dirección de la predicción es de mezcla descendente a residual o viceversa.
Las potencias pueden calcularse a partir de las potencias transmitidas en el dominio L/R.
NrgMedia[k] = Nvglzq uierda[ A '] NrgDerecha[k ] ;
NrgLatera\k\ = Nrglzquierda[k] - NrgDerecha[k]
con k siendo el índice de frecuencia en el dominio de la transformada.
Otra solución es calcular y transmitir las potencias directamente en el dominio de estéreo conjunto para las bandas en donde el estéreo conjunto está activo, por lo que no es necesaria la transformación de potencia adicional en el lado del decodificador.
Los mosaicos de origen se crean siempre de acuerdo con la Matriz Media/Lateral:
MosaicoMedi(^)¿\ =0.5 ■(Mosaicolzquierdo[k\ M osaicoDerecho[k])
MosaicoLatera![Ic\ = 0.5 (M osaicoIzquierdo[Ic\ - M osaicoDerecho[k])
Ajuste de potencia:
MosaicoMedio[I¿\
=
M osaicoMedio[k\ *NrgMedia[k\\
Mosaico Lateral[l<\ = MosaicoLateraI[k\ *NrgLateral[k\
;
Transformación conjunta de estéreo -> LR:
Si no se codifica ningún parámetro de predicción adicional:
Mosaico Izquierdo\k] = MosaicoMedio[k\ MosaicoLateraJ[k\
MosaicoDerecho[k\
=
MosaicoMedio[k\
+
MosaicoLateral[k]
Si se codifica un parámetro de predicción adicional y si la dirección señalada es del medio al lateral:
MosaicoLaterai[k]=MosaicoLaterai[k] - Coefpredicción ■ MosaicoMedio[k\
MosaicoIzquierdo[k
] =
MosaicoMedio[k] MosaicoLaterai[k]
MosaicoDerecho[k\
=
MosaicoMedio[k\ MosaicoLatera/[k\
Si la dirección señalada es del lateral al medio:
MosaicoMedio[k\=MosaicoLatera/\k\ - Coefpredicción • MosaicoLateraI[k\
MosaicoIzquierdo[k\ = MosaicoMedio[k\ MosaicoLatera![k\
MosaicoDerecho[k
] =
MosaicoMedio[k] MosaicoLatera![k\
Este procesamiento asegura que a partir de los mosaicos utilizados para regenerar regiones de destino altamente correlacionadas y regiones de destino panoramizadas, los canales izquierdo y derecho resultantes siguen representando una fuente de sonido correlacionada y panoramizada incluso si las regiones de origen no están correlacionadas, conservando la imagen estéreo para dichas regiones.
En otras palabras, en la corriente de bits se transmiten etiquetas conjuntas de estéreo que indican si se utilizará L/R o M/S como un ejemplo para la codificación conjunta de estéreo general. En el decodificador, en primer lugar, la señal central se decodifica como lo indican las etiquetas conjuntas de estéreo para las bandas centrales. En segundo lugar, la señal central se almacena en ambas representaciones L/R y M/S. Para el relleno de mosaicos del relleno inteligente de espacios (IGF), la representación de mosaicos de origen se selecciona para ajustar la representación de mosaicos de destino como lo indica la información conjunta de estéreo para las bandas de IGF.
El modelado de ruido temporal (TNS) es una técnica estándar y forma parte de la Codificación Avanzada de Audio (AAC) [11 - 13]. El modelado de ruido temporal (TNS) se puede considerar como una extensión del esquema básico de un codificador perceptual, mediante la inserción de un paso de procesamiento opcional entre el banco de filtros y la etapa de cuantificación. La tarea principal del módulo de modelado de ruido temporal (TNS) consiste en ocultar el ruido de cuantificación producido en la región de enmascaramiento temporal de señales de transición y, por lo tanto, produce un esquema de codificación más eficiente. En primer lugar, el modelado de ruido temporal (TNS) calcula un conjunto de coeficientes de predicción utilizando "predicción directa" en el dominio de la transformada, por ejemplo, la Transformada Coseno Discreta Modificada (MDCT). Estos coeficientes luego se utilizan para aplanar la envolvente temporal de la señal. A medida que la cuantificación afecta el espectro filtrado del modelado de ruido temporal (TNS), también el ruido de cuantificación es temporalmente plano. Mediante la aplicación del filtrado inverso del modelado de ruido temporal (TNS) en el lado del decodificador, el ruido de cuantificación se modela de acuerdo con la envolvente temporal del filtro de TNS y, por lo tanto, el ruido de cuantificación es enmascarado por el transitorio.
El relleno inteligente de espacios (IGF) se basa en una representación de MDCT. Preferentemente, para la codificación eficiente se tienen que utilizar bloques largos bloques de aproximadamente 20 ms. Si la señal dentro de dicho bloque largo contiene transitorios, en las bandas espectrales del relleno inteligente de espacios (IGF) ocurren pre- y post
ecos audibles debido al relleno de mosaicos. La figura 7c muestra un efecto de pre-eco típico antes del inicio del transitorio debido al relleno inteligente de espacios (IGF). En el lado izquierdo se muestra el espectrograma de la señal original y en el lado derecho se muestra el espectrograma de la señal extendida de ancho de banda sin filtrado del modelado de ruido temporal (TNS).
Este efecto de pre-eco se reduce utilizando TNS en el contexto del relleno inteligente de espacios (IGF). En esta instancia, el TNS se utiliza como una herramienta de modelado de mosaico temporal (TTS) ya que la regeneración espectral en el decodificador se lleva a cabo sobre la señal residual del TNS. Los coeficientes de predicción del TTS requeridos se calculan y aplican utilizando el espectro completo en el lado del codificador como es habitual. Las frecuencias de inicio y fin del modelado de ruido temporal (TNS)/modelado de mosaico temporal (TTS) no resultan afectadas por la frecuencia de inicio del relleno inteligente de espacios (IGF) fiGFstart de la herramienta de IGF. En comparación con el modelado de ruido temporal (TNS) de la técnica anterior, la frecuencia de fin del modelado de mosaico temporal (TTS) aumenta a la frecuencia de fin de la herramienta de relleno inteligente de espacios (IGF), que es mayor que fiGFstart. En el lado del decodificador se aplican los coeficientes de TNS/TTS sobre el espectro completo nuevamente, es decir el espectro central más el espectro regenerado más los componentes tonales del mapa de tonalidad (véase la figura 7e). La aplicación de modelado de mosaico temporal (TTS) es necesaria para formar la envolvente temporal del espectro regenerado para adaptarse a la envolvente de la señal original nuevamente. Por lo tanto, los pre-ecos ilustrados se reducen. Adicionalmente, todavía modela el ruido de cuantificación en la señal por debajo fiGFstart como es habitual en el modelado de ruido temporal (TNS).
En los decodificadores de la técnica anterior, la interconexión espectral en una señal de audio altera la correlación espectral en los límites de interconexión y, por lo tanto, afecta la envolvente temporal de la señal de audio introduciendo dispersión. Por lo tanto, otra ventaja de la aplicación del relleno de mosaicos del relleno inteligente de espacios (IGF) en la señal residual es que, luego de la aplicación del filtro de modelado, los límites del mosaico se correlacionan perfectamente, lo que resulta en una reproducción temporal más fiel de la señal.
En un codificador, el espectro que ha sido sometido al filtrado de TNS/TTS, el procesamiento de enmascaramiento de tonalidad y la estimación de parámetros de relleno inteligente de espacios (IGF), carece de cualquier señal por encima de la frecuencia de inicio de IGF excepto los componentes tonales. Este espectro disperso está codificado ahora por el codificador central utilizando los principios de codificación aritmética y codificación predictiva. Estos componentes codificados junto con los bits de señalización forman la corriente de bits del audio.
La figura 2a ilustra la implementación correspondiente del decodificador. La corriente de bits en la figura 2a correspondiente a la señal de audio codificada se introduce en el demultiplexor/decodificador que estaría conectado, con respecto a la figura 1b, a los bloques 112 y 114. El demultiplexor de corriente de bits separa la señal de audio de entrada en la primera representación codificada 107 de la figura 1b y la segunda representación codificada 109 de la figura 1b. La primera representación codificada que tiene el primer conjunto de primeras porciones espectrales se introduce en el bloque de decodificación conjunta de canales 204 correspondiente al decodificador de dominio espectral 112 de la figura 1b. La segunda representación codificada se introduce en el decodificador paramétrico 114 que no se ilustra en la figura 2a y luego se introduce en el bloque de relleno inteligente de espacios (IGF) 202 correspondiente al regenerador de frecuencia 116 de la figura 1b. El primer conjunto de primeras porciones espectrales necesario para la regeneración de frecuencia se introduce en el bloque de IGF 202 a través de la línea 203. Asimismo, luego de la decodificación conjunta de canales 204, la decodificación central específica se aplica en el bloque de enmascaramiento tonal 206 de manera que la salida del enmascaramiento tonal 206 corresponda a la salida del decodificador de dominio espectral 112. A continuación, el combinador 208 lleva a cabo una combinación, es decir una construcción de cuadros en donde la salida del combinador 208 tiene ahora el espectro de rango completo, pero todavía en el dominio filtrado de modelado de ruido temporal (TNS)/modelado de mosaico temporal (TTS). Posteriormente, en el bloque 210 se lleva a cabo una operación inversa de TNS/TTS utilizando información de filtro de TNS/TTS proporcionada a través de la línea 109, es decir la información lateral de TTS está incluida preferentemente en la primera representación codificada generada por el codificador de dominio espectral 106 que puede ser, por ejemplo, un codificador central de codificación avanzada de audio (AAC) directa o codificación unificada de voz y audio (USAC), o puede estar incluida también en la segunda representación codificada. En la salida del bloque 210 se proporciona un espectro completo hasta la frecuencia máxima que es la frecuencia de rango completo definida por la tasa de muestreo de la señal de entrada original. A continuación, se lleva a cabo una conversión de espectro/tiempo en el banco de filtros de síntesis 212 para obtener finalmente la señal de salida de audio.
La figura 3a ilustra una representación esquemática del espectro. El espectro se subdivide en bandas de factor de escala SCB en donde hay siete bandas de factor de escala SCB1 a SCB7 en el ejemplo ilustrado de la figura 3a. Las bandas de factor de escala pueden ser bandas de factor de escala de codificación avanzada de audio (AAC) que están definidas en la norma AAC y tienen un ancho de banda cada vez mayor hasta frecuencias superiores como se ilustra en la figura 3a esquemáticamente. Se prefiere llevar a cabo el relleno inteligente de espacios (IGF) no desde el comienzo del espectro, es decir a bajas frecuencias, sino iniciar la operación de IGF a una frecuencia de inicio de IGF ilustrada en 309. Por lo tanto, la banda de frecuencia central se extiende desde la frecuencia más baja a la frecuencia de inicio de IGF. Por encima de la frecuencia de inicio de IGF se aplica el análisis de espectro para separar los
componentes espectrales de alta resolución 304, 305, 306, 307 (el primer conjunto de primeras porciones espectrales) de componentes de baja resolución representados por el segundo conjunto de segundas porciones espectrales. La figura 3a ilustra un espectro que se introduce a modo de ejemplo en el codificador de dominio espectral 106 o en el codificador conjunto de canales 228, es decir, el codificador central opera en todo el rango, pero codifica una cantidad significativa de valores espectrales cero, es decir estos valores espectrales cero se cuantifican a cero o se fijan en cero antes de la cuantificación o luego de la cuantificación. De todos modos, el codificador central opera en el rango completo, es decir, como si el espectro fuera como el ilustrado, es decir, el decodificador central no necesariamente tiene que estar al tanto de cualquier relleno inteligente de espacios del segundo conjunto de segunda porciones espectrales con una resolución espectral inferior.
Preferentemente, la alta resolución está definida por una codificación por líneas de líneas espectrales, tales como las líneas de la transformada de coseno discreta modificada (MDCT), mientras que la segunda resolución o baja resolución se define, por ejemplo, calculando solo un único valor espectral por banda de factor de escala, en donde una banda de factor de escala abarca varias líneas de frecuencia. Por lo tanto, la segunda resolución baja, con respecto a su resolución espectral, mucho menor que la primera o alta resolución definida por la codificación por líneas es generalmente aplicada por el codificador central tal como un codificador central de codificación avanzada de audio (AAC) o codificación unificada de voz y audio (USAC).
En cuanto al factor de ajuste de escala o cálculo de potencia, la situación se ilustra en la figura 3b. Debido al hecho de que el codificador es un codificador central y debido al hecho de que puede haber, pero no necesariamente, componentes del primer conjunto de porciones espectrales en cada banda, el codificador central calcula un factor de ajuste de escala para cada banda no solo en el rango central por debajo de la frecuencia de inicio de relleno inteligente de espacios (IGF) 309, sino también por encima de la frecuencia de inicio de IGF hasta la frecuencia máxima fiGFstop que es menor o igual a la mitad de la frecuencia de muestreo, es decir, fs /2. Por lo tanto, las porciones tonales codificadas 302, 304, 305, 306, 307 de la figura 3a y, en esta realización junto con los factores de ajuste de escala SCB1 a SCB7 corresponden a los datos espectrales de alta resolución. Los datos espectrales de baja resolución se calculan a partir de la frecuencia de inicio de IGF y corresponden a los valores de información de potencia E 1 , E2 , E3, E4, que se transmiten junto con los factores de ajuste de escala SF4 a SF7.
En particular, cuando el codificador central se encuentra en una condición de baja tasa de bits se puede aplicar además la operación de relleno de ruido adicional en la banda central, es decir una frecuencia inferior a la frecuencia de inicio del relleno inteligente de espacios (IGF), es decir, en las bandas de factor de escala SCB1 a SCB3. En el relleno de ruido, existen varias líneas espectrales adyacentes que han sido cuantificadas a cero. En el lado del decodificador, estos valores espectrales cuantificados a cero se re-sintetizan y los valores espectrales re-sintetizados se ajustan en su magnitud utilizando una potencia de relleno de ruido tal como NF2 ilustrada en 308 en la figura 3b. La potencia de relleno de ruido, que se puede dar en términos absolutos o en términos relativos particularmente con respecto al factor de ajuste de escala como en la codificación unificada de voz y audio (USAC) corresponde a la potencia del conjunto de valores espectrales cuantificados a cero. Estas líneas espectrales de relleno de ruido también pueden ser consideradas un tercer conjunto de terceras porciones espectrales que son regeneradas por la síntesis de relleno de ruido simple sin ninguna operación de relleno inteligente de espacios (IGF) basada en la regeneración de frecuencia utilizando mosaicos de frecuencia de otras frecuencias para la reconstrucción de mosaicos de frecuencia utilizando valores espectrales de un rango de origen y la información de potencia E1 , E2 , E3 , E4.
Preferentemente, las bandas para las cuales se calcula la información de potencia coinciden con las bandas de factor de escala. En otras realizaciones se aplica un agrupamiento de valores de información de potencia de manera que, por ejemplo, para las bandas de factor de escala 4 y 5 solo se transmite un único valor de información de potencia, pero incluso en esta realización, los límites de las bandas de reconstrucción agrupadas coinciden con los límites de las bandas de factor de escala. Si se aplican diferentes separaciones de bandas, entonces se pueden aplicar nuevos cálculos o cálculos de sincronización, y esto puede tener sentido en función de la aplicación determinada.
Preferentemente, el codificador de dominio espectral 106 de la figura 1a es un codificador activado psicoacústicamente como se ilustra en la figura 4a. Generalmente, como se ilustra por ejemplo en la norma MPEG2/4 AAC o MPEG1/2, Capa 3, la señal de audio para codificar después de haber sido transformada en el rango espectral (401 en la Figura.
4a) se envía a una calculadora de factor de escala 400. La calculadora de factor de ajuste de escala se controla mediante un modelo psicoacústico que recibe adicionalmente la señal de audio para cuantificar o recibe, como en la norma MPEG1/2 Capa 3 o MPEG AAC, una representación espectral compleja de la señal de audio. El modelo psicoacústico calcula, para cada banda de factor de escala, un factor de escala que representa el umbral psicoacústico. Adicionalmente, los factores de ajuste de escala luego se ajustan, por la cooperación bien conocida de los bucles de iteración interna y externa o por cualquier otro procedimiento de codificación adecuado de manera que se cumplan determinadas condiciones de tasas de bits. A continuación, los valores espectrales para cuantificar, por un lado, y los factores de ajuste de escala calculados por otro lado se introducen en un procesador cuantificador 404. En la operación de codificación de audio simple, los valores espectrales para cuantificar son ponderados por los factores de ajuste de escala y los valores espectrales ponderados luego se introducen en un cuantificador fijo que generalmente tiene una funcionalidad de compresión para rangos de amplitud superiores. Entonces, en la salida del procesador cuantificador
sí existen índices de cuantificación que luego se envían a un codificador por entropía que generalmente tiene codificación específica y muy eficiente para un conjunto de índices de cuantificación cero para valores de frecuencia adyacentes o, como también se denomina en la técnica, una "corrida" de valores cero.
En el codificador de audio de la figura 1a, sin embargo, el procesador cuantificador generalmente recibe información sobre las segundas porciones espectrales del analizador espectral. Por lo tanto, el procesador cuantificador 404 se asegura de que, en la salida del procesador cuantificador 404, las segundas porciones espectrales identificadas por el analizador espectral 102 son cero o tienen una representación reconocida por un codificador o un decodificador como una representación cero que puede ser codificada de manera muy eficiente, específicamente cuando existen "corridas" de valores cero en el espectro.
La figura 4b ilustra una implementación del procesador cuantificador. Los valores espectrales de la transformada de coseno discreta modificada (MDCT) se pueden introducir en un bloque fijado en cero 410. Posteriormente, las segundas porciones espectrales ya se fijan en cero antes de llevar a cabo una ponderación por los factores de ajuste de escala en el bloque 412. En una implementación adicional, el bloque 410 no se proporciona, pero la cooperación fijada en cero se lleva a cabo en el bloque 418 posterior al bloque de ponderación 412. Incluso en otra implementación, la operación fijada en cero también se puede llevar a cabo en un bloque fijado en cero 422 posterior a una cuantificación en el bloque cuantificador 420. En esta implementación, los bloques 410 y 418 no estarían presentes. En general se proporcionan al menos uno de los bloques 410, 418, 422 dependiendo de la implementación específica.
Entonces, en la salida del bloque 422 se obtiene un espectro cuantificado correspondiente a lo que se ilustra en la figura 3a. Este espectro cuantificado se introduce entonces en un codificador por entropía tal como 232 en la figura 2b que puede ser un codificador Huffman o un codificador aritmético como se define, por ejemplo, en la norma de codificación unificada de voz y audio (USAC).
Los bloques fijados en cero 410, 418, 422, que se proporcionan alternativamente entre sí o en paralelo son controlados por el analizador espectral 424. El analizador espectral comprende preferentemente cualquier implementación de un detector de tonalidad bien conocido o comprende cualquier tipo diferente de detector operativo para separar un espectro en componentes para codificar con una alta resolución y componentes para codificar con una baja resolución. Otros de estos algoritmos implementados en el analizador espectral pueden ser un detector de actividad de voz, un detector de ruido, un detector de voz o cualquier otro detector que determine, en función de la información espectral o metadatos asociados, los requisitos de resolución para diferentes porciones espectrales.
La figura 5a ilustra una implementación preferida del convertidor de espectro de tiempo 100 de la figura 1a como se implementa, por ejemplo, en la codificación avanzada de audio (AAC) o en la codificación unificada de voz y audio (USAC). El convertidor de espectro de tiempo 100 comprende un divisor de ventanas 502 controlado por un detector de transitorios 504. Cuando el detector de transitorios 504 detecta un transitorio, entonces señala un intercambio de ventanas largas a ventanas cortas al divisor de ventanas. A continuación, el divisor de ventanas 502 calcula para los bloques superpuestos, cuadros divididos en ventanas, en donde cada cuadro dividido en ventanas normalmente tiene dos valores N como, por ejemplo, los valores 2048. Luego se lleva a cabo una transformación dentro de un transformador de bloques 506, y generalmente este transformador de bloques proporciona además una eliminación de manera que realiza una eliminación/transformada combinada para obtener un cuadro espectral con valores N tales como los valores espectrales de la transformada de coseno discreta modificada (MDCT). Por lo tanto, para una operación de ventanas largas, el cuadro en la entrada del bloque 506 comprende dos valores N como, por ejemplo, 2048 valores y un cuadro espectral entonces tiene 1024 valores. Sin embargo, a continuación, se lleva a cabo un intercambio en los bloques cortos, es decir cuando se llevan a cabo ocho bloques cortos en donde cada bloque corto tiene 1/8 valores de dominio temporal divididos en ventanas en comparación con una ventana larga y cada bloque espectral tiene 1/8 valores espectrales en comparación con un bloque largo. Por lo tanto, cuando esta eliminación se combina con una operación de 50 % de solapamiento del divisor de ventanas, el espectro es una versión muestreada críticamente de la señal de audio de dominio temporal 99.
Posteriormente se hace referencia a la figura 5b que ilustra una implementación específica del regenerador de frecuencia 116 y el convertidor de tiempo de espectro 118 de la figura 1b, o de la operación combinada de los bloques 208, 212 de la figura 2a. En la figura 5b se ilustra una banda de reconstrucción específica tal como la banda de factor de escala 6 de la figura 3a. La primera porción espectral en esta banda de reconstrucción, es decir, la primera porción espectral 306 de la figura 3a se introduce en el bloque constructor/regulador de cuadros 510. Asimismo, una segunda porción espectral reconstruida para la banda de factor de escala 6 se introduce también en el constructor/regulador de cuadros 510. Además, la información de la potencia tal como E3 de la figura 3b para una banda de factor de escala 6 también se introduce en el bloque 510. La segunda porción espectral reconstruida en la banda de reconstrucción ya ha sido generada por el relleno de mosaicos de frecuencia utilizando un rango de origen y la banda de reconstrucción luego corresponde al rango de destino. En esta instancia se lleva a cabo un ajuste de potencia del cuadro para obtener finalmente el cuadro reconstruido completo que tiene los valores N como, por ejemplo, los que se obtienen en la salida del combinador 208 de la figura 2a. Luego, en el bloque 512 se lleva a cabo una transformada/interpolación inversa de bloques para obtener 248 valores de dominio temporal para los 124 valores espectrales, por ejemplo, en la entrada
del bloque 512. A continuación, en el bloque 514 se lleva a cabo una operación de síntesis de división de ventanas que está controlada nuevamente por una indicación de ventana larga/ventana corta transmitida como información lateral en la señal de audio codificada. Luego, en el bloque 516 se lleva a cabo una operación de solapamiento/adición con un cuadro de tiempo anterior. Preferentemente, la transformada de coseno discreta modificada (MDCT) aplica un solapamiento del 50 % de manera que, para cada nuevo cuadro de tiempo de valores 2N se emiten finalmente los valores de dominio temporal N. Se prefiere un solapamiento del 50 % debido al hecho de que proporciona un muestreo crítico y un cruce continuo de un cuadro al cuadro siguiente debido a la operación de solapamiento/adición del bloque 516.
Tal como se ilustra en 301 en la figura 3a se puede aplicar adicionalmente una operación de relleno de ruido, no solo por debajo de la frecuencia de inicio de relleno inteligente de espacios (IGF) sino también por encima de la frecuencia de inicio de IGF como para la banda de reconstrucción contemplada coincidiendo con la banda de factor de escala 6 de la figura 3a. A continuación, los valores espectrales de relleno de ruido también se pueden introducir en el constructor/regulador de cuadros 510 y el ajuste de los valores espectrales de relleno de ruido también se puede aplicar dentro de este bloque o los valores espectrales de relleno de ruido ya se pueden ajustar utilizando la potencia de relleno de ruido antes de ser introducidos en el constructor/regulador de cuadros 510.
Preferentemente, una operación de IGF, es decir una operación de relleno de mosaicos de frecuencia que utiliza valores espectrales de otras porciones se puede aplicar en el espectro completo. Por lo tanto, una operación de relleno de mosaicos espectrales no solo se puede aplicar en la banda alta por encima de una frecuencia de inicio de relleno inteligente de espacios (IGF) sino que también se puede aplicar en la banda baja. Asimismo, el relleno de ruido sin relleno de mosaicos de frecuencia también se puede aplicar no solo por debajo de la frecuencia de inicio de relleno inteligente de espacios (IGF) sino también por encima de la frecuencia de inicio de IGF. Sin embargo, se ha descubierto que la alta calidad y la alta eficiencia de la codificación de audio se pueden obtener cuando la operación de relleno de ruido está limitada al rango de frecuencia por debajo de la frecuencia de inicio de IGF y cuando la operación de relleno de mosaicos de frecuencia está limitada al rango de frecuencia por encima de la frecuencia de inicio de IGF, como se ilustra en la figura 3a.
Preferentemente, los mosaicos de destino (TT) (que tienen frecuencias superiores a la frecuencia de inicio de IGF) están sujetos a los límites de la banda de factor de escala del codificador de tasa completa. Los mosaicos de origen (ST), de los cuales se obtiene información, es decir para frecuencias inferiores a la frecuencia de inicio de IGF no están sujetos a los límites de la banda de factor de escala. El tamaño de los mosaicos de origen (ST) debe corresponder al tamaño del mosaico de destino (TT) asociado. Esto se demuestra utilizando el siguiente ejemplo. TT[0] tiene una longitud de 10 Intervalos de MDCT. Esto corresponde exactamente a la longitud de dos SBC posteriores (tal como 4 6). Entonces, todos los mosaicos de origen (ST) posibles que deben correlacionarse con TT[0], también tienen una longitud de 10 intervalos. Un segundo mosaico de destino TT[1] que es adyacente a TT[0] tiene una longitud de 15 intervalos I (SCB tiene una longitud de 7 8). Entonces, el mosaico de origen (ST) para lo anterior tiene una longitud de 15 intervalos en lugar de 10 intervalos como para TT[0].
En caso de que no se pueda encontrar un mosaico de destino (TT) para un mosaico de origen (ST) con la longitud del mosaico de destino (por ejemplo, cuando la longitud del TT es mayor que el rango de origen disponible), entonces no se calcula una correlación y el rango de origen se copia un número de veces en este TT (la copia se lleva a cabo una después de la otra de manera que una línea de frecuencia para la frecuencia más baja de la segunda copia sigue inmediatamente - en la frecuencia - la línea de frecuencia para la frecuencia más alta de la primera copia), hasta que mosaico de destino (TT) se rellene completamente.
Posteriormente se hace referencia a la figura 5c que ilustra una realización preferida adicional del regenerador de frecuencia 116 de la figura 1b o el bloque de relleno inteligente de espacios (IGF) 202 de la figura 2a. El bloque 522 es un generador de mosaicos de frecuencia que no solo recibe una ID de la banda de destino, sino que además recibe una ID de la banda de origen. A modo de ejemplo, se ha determinado en el lado del codificador que la banda de factor de escala 3 de la figura 3a es muy adecuada para la reconstrucción de la banda de factor de escala 7. Por lo tanto, la ID de la banda de origen sería 2 y la ID de la banda de destino sería 7. Basándose en esta información, el generador de mosaicos de frecuencia 522 aplica una operación de copiado o de relleno de mosaicos de armónicos o cualquier otra operación de relleno de mosaicos para generar la segunda porción en bruto de los componentes espectrales 523. La segunda porción en bruto de los componentes espectrales tiene una resolución de frecuencia idéntica a la resolución de frecuencia incluida en el primer conjunto de primeras porciones espectrales.
Entonces, la primera porción espectral de la banda de reconstrucción tal como 307 de la figura 3a se introduce en un constructor de cuadros 524 y la segunda porción en bruto 523 se introduce también en el constructor de cuadros 524. Luego, el cuadro reconstruido es ajustado por el regulador 526 utilizando un factor de ganancia para la banda de reconstrucción calculada por la calculadora de factor de ganancia 528. Es importante destacar, sin embargo, que la primera porción espectral en el cuadro no resulta afectada por el regulador 526, sino que solo la segunda porción en bruto para el cuadro de reconstrucción resulta afectada por el regulador 526. Para este fin, la calculadora del factor de ganancia 528 analiza la banda de origen o la segunda porción en bruto 523 y además analiza la primera porción
espectral en la banda de reconstrucción para encontrar finalmente el factor de ganancia correcto 527 de manera que la potencia del cuadro ajustado emitido por el regulador 526 tiene la potencia E4 cuando se contempla una banda de factor de escala 7.
En este contexto, es muy importante evaluar la precisión de la reconstrucción de alta frecuencia de la presente invención en comparación con la codificación avanzada de audio de alta eficiencia (HE-AAC). Esto se explica con respecto a la banda de factor de escala 7 en la figura 3a. Se supone que un codificador de la técnica anterior ilustrado en la figura 13a detectaría la porción espectral 307 a codificar con una alta resolución como un "armónico faltante". Entonces, la potencia de este componente espectral se transmitiría junto con una información de la envolvente espectral para la banda de reconstrucción tal como la banda de factor de escala 7 al decodificador. A continuación, el decodificador recrearía el armónico faltante. Sin embargo, el valor espectral, en el que el armónico faltante 307 sería reconstruido por el decodificador de la técnica anterior de la figura 13b estaría en el medio de la banda 7 a una frecuencia indicada por la frecuencia de reconstrucción 390. Por lo tanto, la presente invención evita un error de frecuencia 391 que sería introducido por el decodificador de la técnica anterior de la figura 13d.
En una implementación, el analizador espectral también se implementa para el cálculo de similitudes entre primeras porciones espectrales y segundas porciones espectrales y para determinar, sobre la base de las similitudes calculadas, para una segunda porción espectral en un rango de reconstrucción una primera porción espectral que se adapte a la segunda porción espectral tanto como sea posible. Entonces, en esta implementación de rango de origen/rango de destino variable, el codificador paramétrico introducirá además en la segunda representación codificada una información de adaptación que indica un rango de origen de adaptación para cada rango de destino. En el lado del descodificador, esta información luego podría ser utilizada por un generador de mosaicos de frecuencia 522 de la figura 5c que ilustra una generación de una segunda porción en bruto 523 sobre la base de una ID de la banda de origen y una ID de la banda de destino.
Asimismo, tal como se ilustra en la figura 3a, el analizador espectral está configurado para analizar la representación espectral hasta una frecuencia máxima de análisis que es solo una pequeña cantidad por debajo de la mitad de la frecuencia de muestreo y que es preferentemente al menos un cuarto de la frecuencia de muestreo o generalmente superior.
Tal como se ilustra, el codificador opera sin reducción de muestreo y el decodificador opera sin funciona sin muestreo ascendente. En otras palabras, el codificador de audio de dominio espectral está configurado para generar una representación espectral que tiene una frecuencia de Nyquist definida por la tasa de muestreo de la señal de audio introducida originalmente.
Asimismo, tal como se ilustra en la figura 3a, el analizador espectral está configurado para analizar la representación espectral que se inicia con una frecuencia de relleno de espacios y que termina con una frecuencia máxima representada por una frecuencia máxima incluida en la representación espectral, en donde una porción espectral que se extiende desde una frecuencia mínima hasta la frecuencia de inicio de relleno de espacios pertenece al primer conjunto de porciones espectrales y en donde otra porción espectral tal como 304, 305, 306, 307 que tiene valores de frecuencia por encima de la frecuencia de relleno de espacios, está incluida adicionalmente en el primer conjunto de primeras porciones espectrales.
Como se explicó, el decodificador de audio de dominio espectral 112 está configurado de manera que una frecuencia máxima representada por un valor espectral en la primera representación decodificada es igual a una frecuencia máxima incluida en la representación de tiempo que tiene la tasa de muestreo, en donde el valor espectral para la frecuencia máxima en el primer conjunto de primeras porciones espectrales es cero o diferente de cero. De todos modos, para esta frecuencia máxima en el primer conjunto de componentes espectrales existe un factor de ajuste de escala para la banda de factor de escala, que es generado y transmitido sin importar si todos los valores espectrales en esta banda de factor de escala se fijan en cero o no, como se describe en el contexto de las figuras 3a y 3b.
Por lo tanto, la invención es ventajosa con respecto a otras técnicas paramétricas para aumentar la eficiencia de compresión, por ejemplo, la sustitución de ruido y el relleno de ruido (estas técnicas son exclusivamente para la representación eficiente de contenido de señal local tipo ruido), por lo que la invención permite una reproducción de frecuencia precisa de componentes tonales. Hasta la fecha, ningún método del estado actual de la técnica aborda la representación paramétrica eficiente del contenido arbitrario de la señal por relleno de espacios espectrales sin la restricción de una división fija a priori en la banda baja (LF) y en la banda alta (HF).
Realizaciones del sistema de la invención mejoran los enfoques del estado actual de la técnica y, por lo tanto, proporcionan una alta eficiencia de compresión, ninguna o solo una pequeña molestia perceptual y ancho de banda de audio completo, incluso para tasas bajas de bits.
El sistema general consiste en
codificación central de banda completa
relleno inteligente de espacios (relleno de mosaicos o relleno de ruido)
partes tonales dispersas en núcleo, seleccionadas por enmascaramiento tonal
codificación conjunta de par de estéreo para la banda completa, incluyendo el relleno de mosaicos
TNS en el mosaico
blanqueo espectral en el rango de relleno inteligente de espacios (IGF)
Un primer paso hacia un sistema más eficiente consiste en eliminar la necesidad de transformar datos espectrales en un segundo dominio de transformada diferente del dominio del codificador central. Como la mayoría de los códecs de audio tal como, por ejemplo, la codificación avanzada de audio (AAC), utilizan la transformada de coseno discreta modificada (MDCT) como transformada básico, también es útil llevar a cabo la extensión de ancho de banda (BWE) en el dominio de la MDCT. Un segundo requisito para el sistema de BWE sería la necesidad de conservar la cuadrícula tonal mediante la cual se conservan incluso componentes tonales de alta frecuencia (HF) y, por lo tanto, la calidad del audio codificado es superior a los sistemas existentes. Para tener en cuenta ambos requisitos mencionados anteriormente para un esquema de extensión de ancho de banda (BWE) se propone un nuevo sistema denominado Relleno Inteligente de Espacios (IGF). La figura 2b muestra el diagrama de bloques del sistema propuesto en el lado del codificador y la figura 2a muestra el sistema en el lado del decodificador.
La figura 6a ilustra un aparato para decodificar una señal de audio codificada en otra implementación. El aparato para decodificar comprende un decodificador de audio de dominio espectral 602 para generar una primera representación decodificada de un primer conjunto de porciones espectrales y como el regenerador de frecuencia 604 conectado corriente abajo del decodificador de audio de dominio espectral 602 para generar una segunda porción espectral reconstruida utilizando una primera porción espectral del primer conjunto de primeras porciones espectrales. Como se ilustra en 603, los valores espectrales en la primera porción espectral y en la segunda porción espectral son valores residuales de predicción espectral. Con el fin de transformar estos valores residuales de predicción espectral en una representación espectral completa se proporciona un filtro de predicción espectral 606. Este filtro de predicción inversa está configurado para llevar a cabo una predicción inversa sobre la frecuencia utilizando los valores residuales espectrales para el primer conjunto de la primera frecuencia y las segundas porciones espectrales reconstruidas. El filtro de predicción inversa espectral 606 está configurado por la información de filtro incluida en la señal de audio codificada. La figura 6b ilustra una implementación más detallada de la realización de la figura 6a. Los valores residuales de predicción espectral 603 se introducen en un generador de mosaicos de frecuencia 612 que genera valores espectrales en bruto para una banda de reconstrucción o para una determinada segunda porción de frecuencia y estos datos en bruto que ahora tienen la misma resolución que la primera representación espectral de alta resolución se introducen en el modelador espectral 614. El modelador espectral ahora modela el espectro utilizando información de la envolvente transmitida en la corriente de bits y los datos modelados espectralmente luego se aplican al filtro de predicción espectral 616 generando finalmente un cuadro de valores espectrales completos utilizando la información de filtro 607 transmitida desde el codificador al decodificador a través de la corriente de bits.
En la figura 6b se supone que, en el lado del codificador, el cálculo de la información de filtro transmitida a través de la corriente de bits y utilizada a través de la línea 607 se lleva a cabo con posterioridad al cálculo de la información de la envolvente. Por lo tanto, en otras palabras, un codificador que concuerda con el decodificador de la figura 6b primero calcularía los valores residuales espectrales y luego calcularía la información de la envolvente con los valores residuales espectrales tal como se ilustra, por ejemplo, en la figura 7a. Sin embargo, la otra implementación también es útil para ciertas implementaciones, cuando la información de la envolvente se calcula antes de llevar a cabo el filtrado de modelado de ruido temporal (TNS) o de modelado de mosaico temporal (TTS) en el lado del codificador. A continuación, el filtro de predicción espectral 622 se aplica antes de llevar a cabo el modelado espectral en el bloque 624. Por lo tanto, en otras palabras, los valores espectrales (completos) se generan antes de aplicar la operación de modelado espectral 624.
Preferentemente, se calcula un filtro de TNS o un filtro de TTS de valor complejo. Esto se ilustra en la figura 7a. La señal de audio original se introduce en un bloque de transformada de coseno discreta modificada (MDCT) compleja 702. Luego se lleva a cabo el cálculo del filtro de TTS y el filtrado de TTS en el dominio complejo. A continuación, en el bloque 706 se calcula la información lateral del relleno inteligente de espacios (IGF) y también se calcula cualquier otra operación tal como el análisis espectral para la codificación, etc. Posteriormente, el primer conjunto de primera porción espectral generado por el bloque 706 se codifica con un codificador activado por modelo psicoacústico que se ilustra en 708 para obtener el primer conjunto de primeras porciones espectrales indicado en X(k) en la figura 7a y todos estos datos se envían al multiplexor de corriente de bits 710.
En el lado del decodificador, los datos codificados se introducen en un demultiplexor 720 para separar la información
lateral de IGF, por un lado, la información lateral de TTS por otro lado y la representación codificada del primer conjunto de primeras porciones espectrales.
Entonces, el bloque 724 se utiliza para calcular un espectro complejo a partir de uno o más espectros de valor real. A continuación, tanto los espectros de valor real como los espectros complejos se introducen en el bloque 726 para generar valores de frecuencia reconstruidos en el segundo conjunto de segundas porciones espectrales para una banda de reconstrucción. Entonces, en el cuadro de banda completa obtenido completamente y relleno de mosaicos se lleva a cabo la operación inversa de modelado de mosaico temporal (TTS) 728 y, en el lado del decodificador se lleva a cabo una operación inversa final de MDCT compleja en el bloque 730. Por lo tanto, el uso de la información de filtro de TNS complejo permite generar automáticamente, cuando se aplica no solo dentro de la banda central o dentro de las bandas de mosaicos por separado sino también sobre los límites centrales/de mosaicos o sobre los límites de mosaicos/mosaicos, un procesamiento de límites de mosaicos que finalmente vuelve a introducir una correlación espectral entre los mosaicos. Esta correlación espectral sobre los límites de los mosaicos no se obtiene generando solamente mosaicos de frecuencia y llevando a cabo un ajuste de la envolvente espectral en estos datos en bruto de los mosaicos de frecuencia.
La figura 7c ilustra una comparación de una señal original (panel izquierdo) y una señal extendida sin Modelado de Mosaico Temporal (TTS). Se puede observar que hay fallos fuertes ilustrados por las porciones ampliadas en el rango de frecuencias superior ilustrado en 750. Esto, sin embargo, no ocurre en la figura 7e cuando la misma porción espectral en 750 se compara con el componente relacionado con los fallos 750 de la figura 7c.
Las realizaciones o el sistema de codificación de audio de la invención utilizan la parte principal de tasa de bits disponible para codificar en forma de onda solo la estructura perceptualmente más relevante de la señal en el codificador, y los espacios espectrales resultantes se rellenan en el decodificador con el contenido de la señal que se aproxima en líneas generales al espectro original. Un presupuesto de bits muy limitado se consume para controlar el así denominado Relleno de Espacios Inteligente (IGF) basado en parámetros por información lateral dedicada transmitida desde el codificador al decodificador.
El almacenamiento o la transmisión de señales de audio a menudo están sujetos a estrictas limitaciones de tasas de bits. En el pasado, los codificadores se vieron obligados a reducir drásticamente el ancho de banda de audio transmitida cuando solo estaba disponible una tasa de bits muy baja. Los códecs de audio modernos ahora son capaces de codificar señales de banda ancha utilizando los métodos de extensión de ancho de banda (BWE) tales como la Replicación de Ancho de Banda Espectral (SBR, por sus siglas en inglés) [1]. Estos algoritmos se basan en una representación paramétrica del contenido de alta frecuencia (HF) - que se genera a partir de la parte de baja frecuencia (LF) codificada en forma de onda de la señal decodificada por medio de transposición a la región espectral de alta frecuencia (HF) ("interconexión") y la aplicación de un procesamiento posterior basado en parámetros. En los esquemas de extensión de ancho de banda (BWE), la reconstrucción de la región espectral de alta frecuencia (HF) por encima de una así denominada frecuencia de cruce determinada se basa a menudo en la interconexión espectral. En general, la región de alta frecuencia (HF) consta de múltiples conexiones adyacentes y cada una de estas conexiones se obtiene de regiones de paso de banda (BP) del espectro de baja frecuencia (LF) por debajo de la frecuencia de cruce determinada. Los sistemas del estado actual de la técnica desempeñan con eficiencia la interconexión dentro de una representación de bancos de filtros copiando un conjunto de coeficientes de sub-bandas adyacentes desde una región de origen a la región de destino.
Si se implementa un sistema de BWE en un banco de filtros o el dominio de la transformada de tiempo-frecuencia, solo hay una posibilidad limitada para controlar la forma temporal de la señal de extensión de ancho de banda. Generalmente, la granularidad temporal está limitada por el tamaño de salto utilizado entre ventanas adyacentes de la transformada. Esto puede conducir a pre o post-ecos no deseados en el rango espectral de la extensión de ancho de banda (BWE).
A partir de la codificación de audio perceptual, se sabe que la forma de la envolvente temporal de una señal de audio se puede restaurar utilizando técnicas de filtrado espectral como el Modelado de la Envolvente Temporal (TNS) [14]. Sin embargo, el filtro del TNS conocido del estado actual de la técnica es un filtro de valor real en los espectros de valor real. Dicho filtro de valor real en los espectros de valor real puede verse seriamente afectado por fallos de solapamiento, especialmente si la transformada real subyacente es una Transformada Coseno Discreta Modificada (MDCT).
El modelado de mosaicos de la envolvente temporal aplica filtrado complejo en espectros de valor complejo, tales como los obtenidos, por ejemplo, a través de una Transformada Coseno Discreta Modificada Compleja (CMDCT). De esta manera se evitan los fallos de solapamiento.
El modelado de mosaicos temporal consiste en
• estimación de coeficientes de filtro complejo y aplicación de un filtro de aplanamiento en el espectro de la señal
original en el codificador
• transmisión de los coeficientes de filtro en la información lateral
• aplicación de un filtro de modelado en el espectro reconstruido relleno de mosaicos en el decodificador
El ejemplo extiende la técnica del estado actual de la técnica conocida a partir de la codificación por transformada de audio, específicamente el Modelado de Ruido Temporal (TNS) por predicción lineal a lo largo de la dirección de la frecuencia, para el uso en una forma modificada en el contexto de extensión de ancho de banda.
Asimismo, el algoritmo de extensión de ancho de banda de la invención se basa en un Relleno Inteligente de Espacios (IGF), pero emplea una transformada de valor complejo (CMDCT) sobremuestreada en oposición a la configuración estándar de relleno inteligente de espacios (IGF) que se basa en una representación de la transformada de coseno discreta modificada (MDCT) críticamente muestreada de valor real de una señal. La CMDCT puede ser vista como la combinación de los coeficientes de la MDCT en la parte real y los coeficientes de la transformada sinusoidal discreta modificada (MDST) en la parte imaginaria de cada coeficiente espectral de valor complejo.
Aunque el nuevo enfoque se describe en el contexto de IGF, el procesamiento de la invención puede utilizarse en combinación con cualquier método de extensión de ancho de banda (BWE) que se basa en una representación de bancos de filtros de la señal de audio.
En este nuevo contexto, la predicción lineal a lo largo de la dirección de la frecuencia no se utiliza como modelado de ruido temporal, sino más bien como una técnica de modelado de mosaico temporal (TTS). El cambio de nombre se justifica por el hecho de que los componentes de la señal rellenos de mosaicos se modelan temporalmente por TTS en comparación con el modelado de ruido de cuantificación por TNS en los códecs de la transformada perceptual del estado actual de la técnica.
La figura 7a muestra un diagrama de bloques de un codificador de BWE que utiliza IGF y el nuevo enfoque de TTS. Por lo tanto, el esquema básico de codificación funciona de la siguiente manera:
- calcular la CMDCT de una señal de dominio temporal x(n) para obtener la señal de dominio de frecuencia X(k) - calcular el filtro de TTS de valor complejo
- obtener la información lateral para la BWE y eliminar la información espectral que tiene que ser replicada por el decodificador
- aplicar la cuantificación utilizando el módulo psicoacústico (PAM, por sus siglas en inglés)
- almacenar/transmitir los datos, solo se transmiten los coeficientes de MDCT de valor real
La figura 7b muestra el decodificador correspondiente. Este invierte principalmente los pasos realizados en el codificador.
Aquí, el esquema básico de decodificación funciona de la siguiente manera:
- estimar los coeficientes de la transformada sinusoidal discreta modificada (MDST) partir de los valores de la transformada de coseno discreta modificada (MDCT) (este procesamiento agrega un retardo de decodificador de bloques) y combinar los coeficientes de la MDCT y la MDST en coeficientes de la transformada de coseno discreta modificada compleja (CMDCT) de valor complejo
- llevar a cabo el relleno de mosaicos con su procesamiento posterior
- aplicar el filtrado de modelado de mosaico temporal (TTS) inverso con los coeficientes transmitidos del filtro de TTS
- calcular la CMDCT inversa
Alternativamente, cabe destacar que el orden de la síntesis de TTS y el procesamiento posterior de IGF también se puede invertir en el decodificador si el análisis de TTS y la estimación de parámetros de IGF se invierten sistemáticamente en el codificador.
Para una codificación de transformada eficiente se deben utilizar preferentemente los así denominados "bloques
largos" de aproximadamente 20 ms para lograr una ganancia de transformada razonable. Si la señal dentro de dicho bloque largo contiene transitorios, en las bandas espectrales reconstruidas ocurren pre- y post-ecos audibles debido al relleno de mosaicos. La figura 7c muestra efectos típicos de pre-y post-ecos que alteran los transitorios debido al relleno inteligente de espacios (IGF). En el panel izquierdo de la figura 7c se muestra el espectrograma de la señal original y en el panel derecho se muestra el espectrograma de la señal de relleno de mosaicos sin el filtrado del modelado de mosaico temporal (TTS). En este ejemplo, la frecuencia de inicio de IGF fiGFstart o fSplit entre la banda central y la banda rellena de mosaicos se selecciona como fs/4. En el panel derecho de la figura 7c se observan distintos pre-y post-ecos alrededor de los transitorios, especialmente prominentes en el extremo espectral superior de la región de frecuencia replicada.
La tarea principal del módulo de TTS consiste en restringir estos componentes de señal no deseados en estrecha proximidad alrededor de un transitorio y de ese modo ocultarlos en la región temporal gobernada por el efecto de enmascaramiento temporal de la percepción humana. Por lo tanto, los coeficientes de predicción necesarios de TTS se calculan y aplican utilizando "predicción directa" en el dominio de la CMDCT.
En una realización que combina TTS e IGF en un códec, es importante alinear determinados parámetros de TTS y parámetros de IGF de manera que un mosaico de IGF se filtre completamente por un filtro de TTS (filtro de aplanamiento o modelado) o no. Por lo tanto, todas las frecuencias TTSstart[..] o TTSstop[..] no estarán comprendidas dentro de un mosaico de IGF, sino más bien estarán alineadas con las frecuencias fiG F ... respectivas. La figura 7d muestra un ejemplo de áreas operativas de TTS e IGF para un conjunto de tres filtros de TTS.
La frecuencia de fin del modelado de mosaico temporal (TTS) se ajusta a la frecuencia de fin de la herramienta de relleno inteligente de espacios (IGF), que es mayor que fiGFstart. Si el modelado de mosaico temporal (TTS) utiliza más de un filtro tiene que asegurarse de que la frecuencia de cruce entre dos filtros de TTS tiene que coincidir con la frecuencia dividida del relleno inteligente de espacios (IGF). De lo contrario, un sub-filtro de TTS se excederá del límite fiGFstart lo que producirá fallos no deseados como, por ejemplo, sobremodelado.
En la variante de implementación representada en la figura 7a y en la figura 7b, se debe tener especial cuidado de que en ese decodificador, las potencias de IGF estén ajustadas correctamente. Esto ocurre especialmente si, en el curso del procesamiento de t Ts e IGF, diferentes filtros de TTS que tienen diferentes ganancias de predicción se aplican a la región de origen (como un filtro de aplanamiento) y a la región espectral de destino (como un filtro de modelado que no es la contrapartida exacta de dicho filtro de aplanamiento) de un mosaico del IGF. En este caso, la relación de la ganancia de predicción de los dos filtros de TTS aplicados ya no es igual a uno y, por lo tanto, debe aplicarse un ajuste de potencia por esta relación.
En la variante de implementación alternativa, el orden de procesamiento posterior de IGF y TTS se invierte. En el decodificador, esto significa que el ajuste de potencia por el procesamiento posterior de IGF se calcula después del filtrado de TTS y, de este modo, es el paso de procesamiento final antes de la transformada de síntesis. Por lo tanto, independientemente de las diferentes ganancias de filtro de TTS aplicadas a un mosaico durante la codificación, la potencia final se ajusta siempre correctamente por el procesamiento de IGF.
En el lado del decodificador se aplican los coeficientes de filtro de TTS en todo el espectro completo nuevamente, es decir el espectro central extendido por el espectro regenerado. La aplicación de modelado de mosaico temporal (TTS) es necesaria para formar la envolvente temporal del espectro regenerado para adaptarse a la envolvente de la señal original nuevamente. Por lo tanto, los pre-ecos ilustrados se reducen. Adicionalmente, todavía modela temporalmente el ruido de cuantificación en la señal por debajo fiGFstart como es habitual en el modelado de ruido temporal (TNS) de la técnica anterior.
En los codificadores de la técnica anterior, la interconexión espectral de una señal de audio (por ejemplo, la Replicación de Ancho de Banda Espectral (SBR)) altera la correlación espectral en los límites de interconexión y, por lo tanto, afecta la envolvente temporal de la señal de audio introduciendo dispersión. Por lo tanto, otra ventaja de la aplicación del relleno de mosaicos del relleno inteligente de espacios (IGF) en la señal residual es que, luego de la aplicación del filtro de modelado de mosaico temporal (TTS), los límites del mosaico se correlacionan perfectamente, lo que resulta en una reproducción temporal más fiel de la señal.
El resultado de la señal procesada correspondiente se muestra en la figura 7e. En comparación, la versión sin filtrar (figura 7c, panel derecho) la señal filtrada de TTS muestra una buena reducción de pre- y post-ecos no deseados (figura 7e, panel derecho).
Asimismo, de acuerdo con la descripción, la figura 7a ilustra un codificador que concuerda con el decodificador de la figura 7b o el decodificador de la figura 6a. Básicamente, un aparato para codificar una señal de audio comprende un convertidor de espectro de tiempo tal como 702 para la conversión de una señal de audio en una representación espectral. La representación espectral puede ser una representación espectral de valor real o, como se ilustra en el bloque 702, una representación espectral de valor complejo. Además, se proporciona un filtro de predicción tal como
704 para llevar a cabo una predicción sobre la frecuencia para generar valores residuales espectrales, en donde el filtro de predicción 704 se define por la información del filtro de predicción obtenida de la señal de audio y enviada a un multiplexor de corriente de bits 710, como se ilustra en 714 en la figura 7a. Asimismo, se proporciona un codificador de audio tal como el codificador de audio activado psicoacústicamente 704. El codificador de audio está configurado para codificar un primer conjunto de primeras porciones espectrales de los valores residuales espectrales para obtener un primer conjunto codificado de primeros valores espectrales. Adicionalmente, un codificador paramétrico tal como el que se ilustra en 706 en la figura 7a se proporciona para codificar un segundo conjunto de segundas porciones espectrales. Preferentemente, el primer conjunto de primeras porciones espectrales se codifica con resolución espectral superior en comparación con el segundo conjunto de segundas porciones espectrales.
Finalmente, tal como se ilustra en la figura 7a, se proporciona una interfaz de salida para emitir la señal codificada que comprende el segundo conjunto paramétricamente codificado de segundas porciones espectrales, el primer conjunto codificado de primeras porciones espectrales y la información del filtro ilustrada como "información lateral de modelado de mosaico temporal (TTS)" en 714 en la figura 7a.
Preferentemente, el filtro de predicción 704 comprende una calculadora de información de filtro configurado para utilizar los valores espectrales de la representación espectral para calcular la información de filtro. Asimismo, el filtro de predicción está configurado para calcular los valores residuales espectrales utilizando los mismos valores espectrales de la representación espectral utilizada para calcular la información de filtro.
Preferentemente, el filtro de TTS 704 está configurado de la misma manera conocida para los codificadores de audio de la técnica anterior que aplican la herramienta de modelado de ruido temporal (TNS) de acuerdo con la norma de codificación avanzada de audio (AAC).
Posteriormente, una aplicación adicional que utiliza la decodificación de dos canales se analiza en el contexto de las figuras 8a a 8e. Asimismo, se hace referencia a la descripción de los elementos correspondientes en el contexto de las figuras 2a, 2b (codificación de canal conjunto 228 y decodificación de canal conjunto 204).
La figura 8a ilustra un decodificador de audio para generar una señal decodificada de dos canales. El decodificador de audio comprende cuatro decodificadores de audio 802 para decodificar una señal codificada de dos canales para obtener un primer conjunto de primeras porciones espectrales y adicionalmente un decodificador paramétrico 804 para proporcionar datos paramétricos para un segundo conjunto de segundas porciones espectrales y, adicionalmente, una identificación de dos canales que identifica, ya sea una primera o una segunda representación diferente de dos canales para las segundas porciones espectrales. Adicionalmente, se proporciona un regenerador de frecuencia 806 para regenerar una segunda porción espectral en función de una primera porción espectral del primer conjunto de primeras porciones espectrales y datos paramétricos para la segunda porción y la identificación de dos canales para la segunda porción. La figura 8b ilustra diferentes combinaciones para las representaciones de dos canales en el rango de origen y en el rango de destino. El rango de origen puede estar en la primera representación de dos canales y el rango de destino también puede estar en la primera representación de dos canales. Alternativamente, el rango de origen puede estar en la primera representación de dos canales y el rango de destino puede estar en la segunda representación de dos canales. Además, el rango de origen puede estar en la segunda representación de dos canales y el rango de destino puede estar en la primera representación de dos canales como se indica en la tercera columna de la figura 8b. Por último, tanto el rango de origen como el rango de destino pueden estar en la segunda representación de dos canales. En una realización, la primera representación de dos canales es una representación de dos canales por separado, en donde los dos canales de la señal de dos canales están representados individualmente. Entonces, la segunda representación de dos canales es una representación conjunta en donde los dos canales de la representación de dos canales están representados en forma conjunta, es decir, cuando un procesamiento posterior o la transformada de representación son necesarios para recalcular una representación de dos canales por separado que es necesaria para la salida a los altavoces correspondientes.
En una implementación, la primera representación de dos canales puede ser una representación izquierda/derecha (L/R) y la segunda representación de dos canales es una representación conjunta de estéreo. Sin embargo, otras representaciones de dos canales además de izquierda/derecha o M/S o la predicción estéreo se pueden aplicar y utilizar para la presente invención.
La figura 8c ilustra un diagrama de flujo para las operaciones llevadas a cabo por el decodificador de audio de la figura 8a. En un paso 812, el decodificador de audio 802 lleva a cabo una decodificación del rango de origen. El rango de origen puede comprender, con respecto a la figura 3a, bandas de factor de escala SCB1 a SCB3. Asimismo, puede haber una identificación de dos canales para cada banda de factor de escala y la banda de factor de escala 1 puede estar, por ejemplo, en la primera representación (tal como L/R) y la tercera banda de factor de escala puede estar en la segundo representación de dos canales tal como M/S o predicción de mezcla descendente/residual. Por lo tanto, el paso 812 puede resultar en diferentes representaciones para diferentes bandas. Entonces, en el paso 814, el regenerador de frecuencia 806 está configurado para seleccionar un rango de origen para una regeneración de frecuencia. En el paso 816, el regenerador de frecuencia 806 comprueba entonces la representación del rango de
origen y en el bloque 818, el regenerador de frecuencia 806 compara la representación de dos canales del rango de origen con la representación de dos canales del rango de destino. Si ambas representaciones son idénticas, el regenerador de frecuencia 806 proporciona una frecuencia de regeneración por separado para cada canal de la señal de dos canales. Cuando, sin embargo, ambas representaciones detectadas en el bloque 818 no son idénticas, entonces se toma el flujo de la señal 824 y el bloque 822 calcula la otra representación de dos canales del rango de origen y utiliza esta otra representación calculada de dos canales para la regeneración del rango de destino. Por lo tanto, el decodificador de la figura 8a hace que sea posible regenerar un rango de destino que se indica que tiene la segunda identificación de dos canales utilizando un rango de origen que está en la primera representación de dos canales. Naturalmente, la presente invención permite regenerar, además, un rango de destino utilizando un rango de origen que tiene la misma identificación de dos canales. Y, adicionalmente, la presente invención permite regenerar un rango de destino que tiene una identificación de dos canales que indica una representación conjunta de dos canales y a continuación transformar esta representación en una representación de canales por separado, necesaria para el almacenamiento o la transmisión a los altavoces correspondientes para la señal de dos canales.
Se hace hincapié en que los dos canales de la representación de dos canales pueden ser dos canales estéreo, tales como el canal izquierdo y el canal derecho. Sin embargo, la señal también puede ser una señal multicanal que tiene, por ejemplo, cinco canales y un canal de altavoz de graves o que tiene incluso más canales. Entonces, un procesamiento de dos canales por pares descrito en el contexto de la figura 8a a 8e se puede llevar a cabo cuando los pares pueden ser, por ejemplo, un canal izquierdo y un canal derecho, canal envolvente izquierdo y un canal envolvente derecho y un canal central y un canal LFE (altavoz de graves). Cualquier otra formación de pares se puede utilizar con el fin de representar, por ejemplo, seis canales de entrada por tres procedimientos de procesamiento de dos canales.
La figura 8d ilustra un diagrama de bloques de un decodificador correspondiente a la figura 8a. Un rango de origen o un decodificador central 830 pueden corresponder al decodificador de audio 802. Los otros bloques 832, 834, 836, 838, 840, 842 y 846 pueden ser partes del regenerador de frecuencia 806 de la figura 8a. En particular, el bloque 832 es un transformador de representación para transformar representaciones del rango de origen en bandas individuales de manera que, en la salida del bloque 832 está presente un conjunto completo del rango de origen en la primera representación por un lado y en la segunda representación de dos canales por otro lado. Estas dos representaciones completas del rango de origen se pueden almacenar en el almacenamiento 834 para ambas representaciones del rango de origen.
Entonces, el bloque 836 aplica una generación de mosaicos de frecuencia utilizando, como entrada, una ID del rango de origen y utilizando, además, una ID de dos canales como entrada para el rango de destino. Sobre la base de la ID de dos canales para el rango de destino, el generador de mosaicos de frecuencia accede al almacenamiento 834 y recibe la representación de dos canales del rango de origen que concuerda con la ID de dos canales para el rango de destino introducido en el generador de mosaicos de frecuencia en 835. Por lo tanto, cuando la ID de dos canales para el rango de destino indica el procesamiento conjunto de estéreo, entonces el generador de mosaicos de frecuencia 836 accede al almacenamiento 834 con el fin de obtener la representación conjunta de estéreo del rango de origen indicado por la ID del rango de origen 833.
El generador de mosaicos de frecuencia 836 lleva a cabo esta operación para cada rango de destino y la salida del generador de mosaicos de frecuencia es tal que cada canal de la representación de canales identificada por la identificación de dos canales está presente. Luego un regulador de envolventes 838 lleva a cabo un ajuste de la envolvente. El ajuste de envolvente se lleva a cabo en el dominio de dos canales identificado por la identificación de dos canales. Para este fin se requieren parámetros de ajuste de la envolvente y estos parámetros se transmiten desde el codificador al decodificador en la misma representación de dos canales descrita. Cuando la identificación de dos canales en el rango de destino para procesar por el regulador de envolventes tiene una identificación de dos canales que indica una representación de dos canales diferentes de los datos de la envolvente para este rango de destino, a continuación, un transformador de parámetros 840 transforma los parámetros de la envolvente en la representación de dos canales requerida. Cuando, por ejemplo, la identificación de dos canales para una banda indica la codificación conjunta de estéreo y cuando los parámetros para este rango de destino han sido transmitidos como parámetros de la envolvente L/R, entonces el transformador parámetro calcula los parámetros conjuntos de la envolvente estéreo a partir de los parámetros de la envolvente L/R descrita de manera que la representación paramétrica correcta se utiliza para el ajuste de la envolvente espectral de un rango de destino.
En otra realización preferida, los parámetros de la envolvente ya se transmiten como parámetros conjuntos de estéreo cuando se utiliza el estéreo conjunto en una banda de destino.
Cuando se supone que la entrada en el regulador de la envolvente 838 es un conjunto de rangos de destino que tienen diferentes representaciones de dos canales, entonces la salida del regulador de la envolvente 838 también es un conjunto de rangos de destino en diferentes representaciones de dos canales. Cuando un rango de destino tiene una representación conjunta tal como M/S, entonces este rango de destino es procesado por un transformador de representaciones 842 para calcular la representación por separado necesaria para un almacenamiento o la transmisión
a los altavoces. Sin embargo, cuando un rango de destino ya tiene una representación por separado se toma el flujo de la señal 844 y se evita el transformador de representaciones 842. En la salida del bloque 842 se obtiene una representación espectral de dos canales que es una representación de dos canales por separado que luego se puede procesar adicionalmente como lo indica el bloque 846, en donde este procesamiento adicional puede ser, por ejemplo, una conversión de frecuencia/tiempo o cualquier otro procesamiento requerido.
Preferentemente, las segundas porciones espectrales corresponden a las bandas de frecuencia, y la identificación de dos canales se proporciona como un arreglo de etiquetas correspondientes a la tabla de la figura 8b, en donde existe una etiqueta para cada banda de frecuencia. Entonces, el decodificador paramétrico está configurado para comprobar si la etiqueta se ha fijado o no y para controlar el regenerador de frecuencia 106 de acuerdo con una etiqueta para utilizar, ya sea una primera representación o una segunda representación de la primera porción espectral.
En una realización, solo el rango de reconstrucción que se inicia con la frecuencia de inicio del relleno inteligente de espacios (IGF) 309 de la figura 3a tiene identificaciones de dos canales para diferentes bandas de reconstrucción. En otra realización, esto también se aplica para el rango de frecuencia por debajo de la frecuencia de inicio de IGF 309.
En una realización adicional, la identificación de la banda de origen y la identificación de la banda de destino se pueden determinar de forma adaptativa por un análisis de similitud. Sin embargo, el procesamiento de dos canales de la invención también se puede aplicar cuando hay una asociación fija de un rango de origen a un rango de destino. Un rango de origen se puede utilizar para recrear, con respecto a la frecuencia, un rango de destino más amplio, ya sea por una operación de relleno de mosaicos de frecuencia de armónicos o una operación de relleno de mosaicos de frecuencia de copiado utilizando dos o más operaciones de relleno de mosaicos de frecuencia similares al procesamiento para múltiples interconexiones conocidas a partir del procesamiento de codificación avanzada de audio (AAC) de alta eficiencia.
La figura 8e ilustra un codificador de audio de la invención para codificar una señal de audio de dos canales. El codificador comprende un convertidor de espectro de tiempo 860 para convertir la señal de audio de dos canales en una representación espectral. Además, se proporciona un analizador espectral 866 para llevar a cabo un análisis con el fin de determinar las porciones espectrales que serán codificadas con una alta resolución, es decir para descubrir el primer conjunto de primeras porciones espectrales y para descubrir adicionalmente el segundo conjunto de segundas porciones espectrales.
Adicionalmente, se proporciona un analizador de dos canales 864 para analizar el segundo conjunto de segundas porciones espectrales para determinar una identificación de dos canales que identifica una primera representación de dos canales o una segunda representación de dos canales.
Dependiendo del resultado del analizador de dos canales, una banda en la segunda representación espectral es parametrizada utilizando la primera representación de dos canales o la segunda representación de dos canales, y esto se lleva a cabo mediante un codificador de parámetros 868. El rango de frecuencia central, es decir la banda de frecuencia por debajo de la frecuencia de inicio del relleno inteligente de espacios (IGF) 309 de la figura 3a es codificado por un codificador central 870. Los resultados de los bloques 868 y 870 se introducen en una interfaz de salida 872. Como se indicó anteriormente, el analizador de dos canales proporciona una identificación de dos canales para cada banda, ya sea por encima de la frecuencia de inicio de IGF o para todo el rango de frecuencia, y esta identificación de dos canales también se envía a la interfaz de salida 872 de manera que estos datos también están incluidos en una señal codificada 873 emitida por la interfaz de salida 872.
Asimismo, se prefiere que el codificador de audio comprenda un transformador por bandas 862. Sobre la base de la decisión del analizador de dos canales 862, la señal de salida del convertidor de espectro de tiempo 860 se transforma en una representación indicada por el analizador de dos canales y, en particular, por la ID de dos canales 835. Por lo tanto, una salida del transformador por bandas 862 es un conjunto de bandas de frecuencia en donde cada banda de frecuencia puede estar en la primera representación de dos canales o en la segunda representación diferente de dos canales. Cuando se aplica la presente invención en banda completa, es decir cuando ambos rangos, el rango de origen y el rango de reconstrucción, son procesados por el transformador por bandas, el analizador espectral 866 puede analizar esta representación. Alternativamente, sin embargo, el analizador espectral 866 también puede analizar la salida de la señal por el convertidor de espectro de tiempo indicado por la línea de control 861. Por lo tanto, el analizador espectral 866 puede aplicar el análisis de tonalidad preferido en la salida del transformador por bandas 862 o la salida del convertidor de espectro de tiempo 860 antes de haber sido procesada por el transformador por bandas 862. Asimismo, el analizador espectral puede aplicar la identificación del mejor rango de origen de adaptación para un cierto rango de destino, ya sea en el resultado del transformador por bandas 862 o en el resultado del convertidor de espectro de tiempo 860.
Posteriormente, se hace referencia a las figuras 9a a 9d para ilustrar un cálculo preferido de los valores de información de potencia ya analizados en el contexto de la figura 3a y la figura 3b.
Los codificadores de audio del estado moderno de la técnica aplican diversas técnicas para reducir al mínimo la cantidad de datos que representan una señal de audio determinada. Los codificadores de audio como, por ejemplo, la codificación unificada de voz y audio (USAC) [1] aplican una transformación de tiempo a frecuencia como la transformada de coseno discreta modificada (MDCT) para obtener una representación espectral de una señal de audio determinada. Estos coeficientes de la MDCT se cuantifican aprovechando los aspectos psicoacústicos del sistema auditivo humano. Si se reduce la tasa de bits disponible, la cuantificación se vuelve más gruesa introduciendo un gran número de valores espectrales reducidos a cero que generan fallos audibles en el lado del decodificador. Para mejorar la calidad de percepción, los decodificadores del estado de la técnica llenan estas partes espectrales reducidas a cero con ruido aleatorio. El método de relleno inteligente de espacios (IGF) recolecta mosaicos de la señal que no es cero restantes para llenar esos espacios en el espectro. Es crucial para la calidad perceptual de la señal de audio decodificada que la envolvente espectral y la distribución de potencia de los coeficientes espectrales se conserven. El método de ajuste de potencia presentado en la presente invención utiliza la información lateral transmitida para reconstruir la envolvente espectral de la MDCT de la señal de audio.
Dentro de la replicación de ancho de banda espectral (eSBR) [15] la señal de audio se submuestrea al menos por un factor de dos y la parte de alta frecuencia del espectro se reduce completamente a cero [1, 17]. Esta parte borrada se sustituye por técnicas paramétricas, eSBR, en el lado del decodificador. La eSBR implica el uso de una transformada adicional, la transformación de filtros espejo en cuadratura (QMF) que se utiliza para sustituir la parte de alta frecuencia vacía y para volver a muestrear la señal de audio [17]. Esto agrega complejidad computacional y consumo de memoria a un codificador de audio.
El codificador de USAC [15] ofrece la posibilidad de llenar espacios espectrales (líneas espectrales reducidas a cero) con ruido aleatorio, pero presenta los siguientes inconvenientes: el ruido aleatorio no puede conservar la estructura fina temporal de una señal transitoria y no se puede conservar la estructura armónica de una señal tonal.
El área donde opera la eSBR en el lado del decodificador fue completamente eliminada por el codificador [1]. Por lo tanto, la eSBR tiende a eliminar líneas tonales en la región de alta frecuencia o distorsionar las estructuras armónicas de la señal original. Como la resolución de frecuencia de filtros espejo en cuadratura (QMF) de la replicación de ancho de banda espectral (eSBR) es muy baja y la reinserción de componentes sinusoidales solo es posible en la resolución gruesa del banco de filtros subyacente, la regeneración de componentes tonales en la eSBR en el rango de frecuencia replicado tiene muy poca precisión.
La eSBR utiliza técnicas para ajustar las potencias de las áreas interconectadas, el ajuste de la envolvente espectral [1]. Esta técnica utiliza los valores de potencia transmitidos en una cuadrícula de tiempo de frecuencia de QMF para remodelar la envolvente espectral. Este estado de la técnica no se ocupa de espectros parcialmente eliminados y debido a la alta resolución temporal tiende a necesitar una cantidad relativamente grande de bits para transmitir valores de potencia apropiados o para aplicar una cuantificación gruesa a los valores de potencia.
El método de IGF no necesita una transformación adicional, ya que utiliza la transformación de la MDCT de la técnica anterior que se calcula como se describe en [15].
El método de ajuste de potencia presentado en la presente invención utiliza la información lateral generada por el codificador para reconstruir la envolvente espectral de la señal de audio. Esta información lateral es generada por el codificador como se indica a continuación:
Aplicar una transformada de coseno discreta modificada (MDCT) dividida en ventanas a la señal de audio de entrada [16, sección 4.6], opcionalmente calcular una transformada sinusoidal discreta modificada (MDST) dividida en ventanas, o estimar una MDST dividida en ventanas a partir de la MDCT calculada.
Aplicar modelado de ruido temporal (TNS)/modelado de mosaico temporal (TTS) en los coeficientes de la MDCT [15, sección 7.8]
Calcular la potencia media para cada banda de factor de escala de la MDCT por encima de la frecuencia de inicio de relleno inteligente de espacios (IGF) (fiGFstart) hasta la frecuencia de fin de IGF(fiGFstop)
Cuantificar los valores medios de potencia
fiGFstart y fiGFstop son parámetros dados por el usuario.
Los valores calculados en el paso c) y d) están codificados sin pérdidas y se transmiten como información lateral con la corriente de bits al decodificador.
El decodificador recibe los valores transmitidos y los utiliza para ajustar la envolvente espectral.
Decuantificar los valores transmitidos de la MDCT
Aplicar el relleno de ruido de la codificación unificada de voz y audio (USAC) de la técnica anterior si está indicado Aplicar el relleno de mosaicos del relleno inteligente de espacios (IGF)
Decuantificar los valores de potencia transmitidos
Ajustar la envolvente espectral por banda de factor de escala
Aplicar TNS/TTS si está indicado
Dejar que
* e ^ sea la transformada MDCT, la representación espectral de valor real de una señal de audio dividida en ventanas de longitud de ventana 2N. Esta transformación se describe en [16]. El codificador aplica opcionalmente TNS en x.
En [16, 4.6.2] se describe una partición de x en bandas de factor de escala. Las bandas de factor de escala son un conjunto de un conjunto de índices y se indican en este texto con scb.
Los límites de cada scbk con k = 0,1,2, ... max_sfb están definidos por un arreglo swb_offset (16, 4.6.2), en donde swb_offset[k] y swb_offset[k + 1]-1 definen el primer y el último índice para la línea de coeficiente espectral más baja y más alta contenida en scbk. La banda de factor de escala se indica de la siguiente manera:
scbk\ ={swb_offset[k],1+ swb_offset[k],2+ swb_offset[k],..., swb_offset[k+1]-1} Si la herramienta de IGF es utilizada por el codificador, el usuario define una frecuencia de inicio de IGF y una frecuencia de fin de IGF. Estos dos valores se asignan al índice de banda de factor de escala de ajuste óptimo igfStartSfb y igfStopSfb. Ambos son enviados en la corriente de bits al decodificador.
describe una transformación de bloque largo y de bloque corto. Para los bloques largos solo se transmite un conjunto de coeficientes espectrales junto con un conjunto de factores de escala al decodificador. Para los bloques cortos se calculan ocho ventanas cortas con ocho conjuntos diferentes de coeficientes espectrales. Para guardar la tasa de bits, los factores de escala de dichas ocho ventanas de bloques cortos son agrupados por el codificador.
En el caso del relleno inteligente de espacios (IGF), el método presentado en esta invención utiliza bandas de factor de escala de la técnica anterior para agrupar valores espectrales que son transmitidos al decodificador:
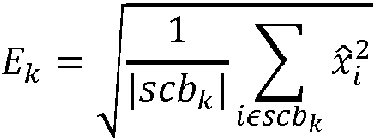
Donde k = igfStartSfb, 1 igfStartSfb, 2 igfStartSfb,..., igfEndSfb. Para cuantificar
_ Ék = n lN T (4 log2(Ek))
se calcula. Todos los valores Ék son transmitidos al decodificador.
Se supone que el codificador decide agrupar los conjuntos de factor de escala num_window_group.
Se indica con w este agrupamiento-partición del conjunto {0,1,2, ..,7} que son los índices de las ocho ventanas cortas. wi indica el -ésimo subconjunto de w, donde l indica el índice del grupo de ventana, 0 < l < num_window_group. Para el cálculo de bloques cortos, el usuario definió que la frecuencia de inicio/fin de IGF se asigna a bandas de factor de escala apropiadas. Sin embargo, por razones de simplicidad también se indica para bloques cortos k = igfStartSfb, 1 igfStartSfb, 2 igfStartSfb,..., igfEndSfb.
El cálculo de la potencia de IGF utiliza la información de agrupamiento para agrupar los valores Ek,i:
Para cuantificar
^ ÉK l= n I N m o g 2(EK l))
se calcula. Todos los valores &,/ son transmitidos al decodificador.
Las fórmulas de codificación mencionadas anteriormente operan utilizando solo coeficientes de la MDCT de valor real x. Para obtener una distribución de potencia más estable en el rango de IGF, es decir para reducir las fluctuaciones de amplitud temporal, se puede utilizar un método alternativo para calcular los valores Éki
Dejar que Y Ar f ^ - sea la transformada MDCT, la representación espectral de valor real de una señal de audio dividida en ventanas de longitud de ventana 2N, y x¡ e MN |a representación espectral de transformada MDST de valor real de la misma porción de la señal de audio. La representación espectral MDST x¡ podría o bien calcularse de manera exacta
sea la transformada MDCT, la representación espectral de valor real de una señal de audio dividida en ventanas de longitud de ventana 2N, y x¡ e MN |a representación espectral de transformada MDST de valor real de la misma porción de la señal de audio. La representación espectral MDST x¡ podría o bien calcularse de manera exacta
o bien estimarse a partir de xr. ^ — ( ^ r ^ i ) e ^ indica la representación espectral compleja de la señal de audio dividida en ventanas, que tiene xr como su parte real y x ¡ como su parte imaginaria. El codificador aplica opcionalmente modelado de ruido temporal (TNS) en xr y x ¡.
Ahora, la potencia de la señal original en el rango de IGF se puede medir con
1
Eok — I scbk |
Las potencias de valor real y complejo de la banda de reconstrucción, es decir el mosaico que se debe utilizar en el lado del decodificador en la reconstrucción del rango de IGF scbk, se calcula con:

donde trk es un conjunto de índices - el rango de mosaico de origen asociado, en función de scbk. En las dos fórmulas anteriores, en lugar del conjunto de índices scbk se podría utilizar el conjunto scbk (definido más adelante en este texto) para crear trk para lograr valores más precisos Et y Er.
Se calcula
Eok
fk =
-tk
si Etk > 0, de lo contrario fk = 0.
Con:
^k — V^k^rk
ahora se calcula una versión más estable de Ek, ya que un cálculo de Ek con los valores de MDCT solo resulta afectado por el hecho de que los valores de MDCT no obedecen el teorema de Parseval y, por lo tanto, no reflejan la información de potencia completa de los valores espectrales. Ék se calcula como se indicó anteriormente.
Como se indicó anteriormente, para los bloques cortes se supone que el codificador decide agrupar los conjuntos de factor de escala num_window_group. Como anteriormente, wl indica el /-ésimo subconjunto de w, en donde l indica el índice del grupo de ventana, 0 < l < num_window_group.
Una vez más podría aplicarse la versión alternativa descrita anteriormente para calcular una versión más estable de
Ek,i. Con las definiciones de = ( ^ r ^ i) e ^ , xr E M siendo la transformada MDCT y e ^ siendo la señal de audio dividida en ventanas de transformada MDST de longitud 2N, se calcula

Se calcula de manera análoga
y continuar con el factor

que se utiliza para ajustar Erk,i calculado anteriormente:
Ek,l - V % Erk,l
É k ,i se calcula como se indicó anteriormente.
El procedimiento que no solo utiliza la potencia de la banda de reconstrucción, ya sea derivada de la banda de reconstrucción compleja o de los valores de la MDCT, sino que también utiliza una información de potencia del rango de origen proporciona una reconstrucción de potencia mejorada.
Específicamente, la calculadora de parámetros 1006 está configurado para calcular la información de potencia para la banda de reconstrucción utilizando información sobre la potencia de la banda de reconstrucción y utilizando, además, la información sobre una potencia de un rango de origen para ser utilizado para la reconstrucción de la banda de reconstrucción.
Asimismo, la calculadora de parámetros 1006 está configurado para calcular una información de potencia (Eok) en la banda de reconstrucción de un espectro complejo de la señal original, para calcular una información de potencia adicional (Erk) en un rango de origen de una parte de valor real del espectro complejo de la señal original para ser utilizada para reconstruir la banda de reconstrucción, y en el que la calculadora de parámetros está configurada para calcular la información de potencia para la banda de reconstrucción utilizando la información de potencia (Eok) y la información de potencia adicional (Erk).
Además, la calculadora de parámetros 1006 está configurada para determinar una primera información de potencia (Eok) en una banda de factor de escala que debe ser reconstruida de un espectro complejo de la señal original, para determinar una segunda información de potencia (Etk) en un rango de origen del espectro complejo de la señal original para ser utilizada para reconstruir la banda de factor de escala que debe ser reconstruida, para determinar una tercera información de potencia (Erk) en un rango de origen de una parte de valor real del espectro complejo de la señal original para ser utilizada para reconstruir la banda de factor de escala que debe ser reconstruida, para determinar una información de ponderación sobre la base de una relación entre al menos dos de la primera información de potencia, la segunda información de potencia, y la tercera información de potencia, y para ponderar una de la primera información de potencia y la tercera información de potencia utilizando la información de ponderación para obtener una información de potencia ponderada y para utilizar la información de potencia ponderada como la información de potencia para la banda de reconstrucción.
A continuación, se presentan ejemplos para los cálculos si bien muchos otros ejemplos pueden quedar a criterio de los expertos en la técnica en vista del principio general anterior:
A)
f_k = E_ok/E_tk;
E_k = sqrt( f_k * E_rk);
B)
f_k = E_tk/E_ok;
E_k = sqrt((l/f_k) * E_rk);
C)
f_k = E_rk/E_tk;
E_k = sqrt(f_k * E_ok)
D)
f_k = E_tk/E_rk;
E_k = sqrt((l/f_k) * E_ok)
Todos estos ejemplos confirman que, aunque solo se procesan valores reales de la MDCT en el lado del decodificador, el cálculo real es - debido al solapamiento y la adición - del procedimiento de cancelación de solapamiento de dominio temporal realizado implícitamente utilizando números complejos. Sin embargo, en particular, la determinación 918 de la información de potencia de mosaico de las porciones espectrales adicionales 922, 923 de la banda de reconstrucción 920, para valores de frecuencia diferentes de la primera porción espectral 921 que tiene frecuencias en la banda de reconstrucción 920, se basa en valores reales de la MDCT. Por lo tanto, la información de potencia transmitida al decodificador será generalmente menor que la información de potencia Eok sobre la banda de reconstrucción del espectro complejo de la señal original. Por ejemplo, para el caso C anterior, esto significa que el factor f_k (información de ponderación) será menor que 1.
En el lado del decodificador, si la herramienta de relleno inteligente de espacios (IGF) se señala como ON, los valores transmitidos Ek se obtienen a partir de la corriente de bits y serán decuantificados con
u
E k = 24£*
para todos
k = igflnicioSfb, 1 + igflnicioSfb, 2 igfInicioSfb, ...,igfFin Sfb.
Y Un decodificador decuantifica los valores de MDCT transmitidos a A ( c= ^ y calcula la potencia de conservación restante:

Indicamos que scbk = {/|/ e scbk a x = 0}. Este conjunto contiene todos los índices de la banda de factor de escala scbk que han sido cuantificados a cero por el codificador.
El método de sub-banda de relleno inteligente de espacios (IGF) (no descrito en el presente documento) se utiliza para llenar espacios espectrales que resultan de una cuantificación gruesa de los valores espectrales de la MDCT en el lado del codificador utilizando valores no cero de la MDCT transmitida. x contendrá adicionalmente los valores que reemplazan a todos los valores anteriores reducidos a cero. La potencia del mosaico se calcula por:

donde k está en el rango definido anteriormente.
La potencia faltante en la banda de reconstrucción se calcula por:
mEk •= |scbk\Ek2 - sEk
Y el factor de ganancia para el ajuste se obtiene por:

Con:
g' = m in(g, 10)
El ajuste de la envolvente espectral que utiliza el factor de ganancia es:
Xí- = g'Xí
para todos los i e scbk y k está en el rango definido anteriormente.
Esto remodela la envolvente espectral de x a la forma de la envolvente espectral original x.
En principio, con la secuencia de ventanas cortas, todos los cálculos definidos anteriormente permanecen igual, pero se tiene en cuenta el agrupamiento de bandas de factor de escala. Se indica como Ek,i los valores de potencia agrupados y decuantificados, obtenidos de la corriente de bits. Se calcula
y 
El índice j describe el índice de ventanas de la secuencia de bloques cortos.
Se calcula
mEkl ■= \scbk \Ek l2 — sE¡k,l
y

Con
g ' = min (g, 10)
Se aplica
J,l ■ = 9 H i
para todos los i e scbk,i.
Para las aplicaciones de tasas bajas de bits es posible un agrupamiento por pares de los valores Ek sin perder demasiada precisión. Este método se aplica solo con bloques largos:
donde
Nuevamente, luego de la decuantificación, todos los valores Ek>>i son transmitidos al decodificador.
La figura 9a ilustra un aparato para decodificar una señal de audio codificada que comprende una representación codificada de un primer conjunto de primeras porciones espectrales y una representación codificada de datos paramétricos que indica las potencias espectrales para un segundo conjunto de segundas porciones espectrales. El primer conjunto de primeras porciones espectrales se indica en 901a en la figura 9a, y la representación codificada de los datos paramétricos se indica en 901b en la figura 9a. Un decodificador de audio 900 se proporciona para decodificar la representación codificada 901a del primer conjunto de primeras porciones espectrales para obtener un primer conjunto decodificado de primeras porciones espectrales 904 y para decodificar la representación codificada de los datos paramétricos para obtener datos paramétricos decodificados 902 para el segundo conjunto de segundas porciones espectrales que indican las potencias individuales para las bandas de reconstrucción, en donde las segundas porciones espectrales están ubicadas en las bandas de reconstrucción. Además, se proporciona un regenerador de frecuencia 906 para reconstruir valores espectrales de una banda de reconstrucción que comprende una segunda porción espectral. El regenerador de frecuencia 906 utiliza una primera porción espectral del primer conjunto de primeras porciones espectrales y una información de potencia individual para la banda de reconstrucción, en donde la banda de reconstrucción comprende una primera porción espectral y la segunda porción espectral. El
regenerador de frecuencia 906 comprende una calculadora 912 para determinar una información de potencia de conservación que comprende una potencia acumulada de la primera porción espectral que tiene frecuencias en la banda de la reconstrucción. Asimismo, el regenerador de frecuencia 906 comprende una calculadora 918 para determinar una información de potencia de mosaico de otras porciones espectrales de la banda de reconstrucción y para valores de frecuencia que son diferentes de la primera porción espectral, en donde estos valores de frecuencia tienen frecuencias en la banda de reconstrucción, en donde las otras porciones espectrales deben ser generadas por la regeneración de frecuencia utilizando una primera porción espectral diferente de la primera porción espectral en la banda de reconstrucción.
El regenerador de frecuencia 906 comprende además una calculadora 914 para una potencia faltante en la banda de reconstrucción, y la calculadora 914 funciona utilizando la potencia individual para la banda de reconstrucción y la potencia de conservación generada por el bloque 912. Además, el regenerador 906 de frecuencia comprende un regulador de la envolvente espectral 916 para el ajuste de las porciones espectrales adicionales en la banda de reconstrucción sobre la base de la información de potencia faltante y la información de potencia de mosaicos generada por el bloque 918.
Con referencia a la figura 9c, allí se ilustra una cierta banda de reconstrucción 920. La banda de reconstrucción comprende una primera porción espectral en la banda de reconstrucción tal como la primera porción espectral 306 en la figura 3a ilustrada esquemáticamente en 921. Asimismo, el resto de los valores espectrales en la banda de reconstrucción 920 se debe generar utilizando una región de origen, por ejemplo, de la banda de factor de escala 1, 2, 3 por debajo de la frecuencia de inicio del relleno inteligente de espacios 309 de la figura 3a. El regenerador de frecuencia 906 está configurado para generar valores espectrales en bruto para las segundas porciones espectrales 922 y 923. Luego se calcula un factor de ganancia g como se ilustra en la figura 9c con el fin de ajustar finalmente los valores espectrales en bruto en las bandas de frecuencia 922, 923 con el fin de obtener las segundas porciones espectrales reconstruidas y ajustadas en la banda de reconstrucción 920, que ahora tienen la misma resolución espectral, es decir, la misma distancia de línea que la primera porción espectral 921. Es importante entender que la primera porción espectral en la banda de reconstrucción ilustrada en 921 en la figura 9c está decodificada por el decodificador de audio 900 y no está influenciada por el ajuste de la envolvente llevado a cabo por el bloque 916 de la figura 9b. En cambio, la primera porción espectral en la banda de reconstrucción indicada en 921 se deja como está, ya que esta primera porción espectral es emitida por el decodificador de ancho de banda completa o de audio de tasa completa 900 a través de la línea 904.
A continuación, se analizará un ejemplo determinado con números reales. La potencia de conservación restante calculada por el bloque 912, por ejemplo, es de cinco unidades de potencia y esta potencia es la potencia de las cuatro líneas espectrales indicadas a modo de ejemplo en la primera porción espectral 921.
Asimismo, el valor de la potencia E3 para la banda de reconstrucción que corresponde a la banda de factor de escala 6 de la figura 3b o la figura 3a es igual a 10 unidades. Es importante destacar que el valor de la potencia no solo comprende la potencia de las porciones espectrales 922, 923, sino también la potencia total de la banda de reconstrucción 920 calculada en el lado del codificador, es decir, antes de llevar a cabo el análisis espectral, utilizando, por ejemplo, el enmascaramiento de la tonalidad. Por lo tanto, las diez unidades de potencia abarcan las primeras y las segundas porciones espectrales en la banda de reconstrucción. Entonces, se supone que la potencia de los datos del rango de origen para los bloques 922, 923 o de los datos en bruto del rango de destino para el bloque 922, 923 es igual a ocho unidades de potencia. Por lo tanto, se calcula una potencia faltante de cinco unidades.
Se calcula un factor de ganancia de 0,79 sobre la base de la potencia faltante dividida por la potencia de mosaico tEk. Entonces, las líneas espectrales en bruto para las segundas porciones espectrales 922, 923 se multiplican por el factor de ganancia calculado. De este modo, solo se ajustan los valores espectrales para las segundas porciones espectrales 922, 923 y las líneas espectrales para la primera porción espectral 921 no están influenciadas por este ajuste de la envolvente. Después de la multiplicación de los valores espectrales en bruto para las segundas porciones espectrales 922, 923 se ha calculado una banda de reconstrucción completa que consta de las primeras porciones espectrales en la banda de reconstrucción, y que consta de líneas espectrales en las segundas porciones espectrales 922, 923 en la banda de reconstrucción 920.
Preferentemente, el rango de origen para generar los datos espectrales en bruto en las bandas 922, 923 está, con respecto a la frecuencia, por debajo de la frecuencia de inicio del relleno inteligente de espacios (IGF) 309 y la banda de reconstrucción 920 está por encima de la frecuencia de inicio de IGF 309.
Además, se prefiere que los límites de la banda de reconstrucción coincidan con los límites de la banda de factor de escala. Por lo tanto, una banda de reconstrucción tiene, en una realización, el tamaño de las bandas de factor de escala respectivas del decodificador de audio central o se dimensiona de manera que, cuando se aplica la formación de pares de potencia, un valor de potencia para una banda de reconstrucción proporciona la potencia de dos o un número entero superior de bandas de factor de escala. Por lo tanto, cuando se supone que la acumulación de potencia es llevada a cabo para la banda de factor de escala 4, la banda de factor de escala 5 y la banda de factor de escala
6, entonces el límite de frecuencia inferior de la banda de reconstrucción 920 es igual al límite inferior de la banda de factor de escala 4 y el límite de potencia superior de la banda de reconstrucción 920 coincide con el límite superior de la banda de factor de escala 6.
A continuación, se describe la figura 9d con el fin de mostrar las funcionalidades adicionales del decodificador de la figura 9a. El decodificador de audio 900 recibe los valores espectrales decuantificados correspondientes a las primeras porciones espectrales del primer conjunto de porciones espectrales y, adicionalmente, los factores de escala para las bandas de factor de escala, tal como se ilustra en la figura 3b se proporcionan a un bloque de ajuste de escala inverso 940. El bloque de ajuste de escala inverso 940 proporciona todos los primeros conjuntos de primeras porciones espectrales por debajo de la frecuencia de inicio de IGF 309 de la figura 3a y, adicionalmente, las primeras porciones espectrales por encima de la frecuencia de inicio de IGF, es decir, las primeras porciones espectrales 304, 305, 306, 307 de la figura 3a que están todas ubicadas en una banda de reconstrucción ilustrada en 941 en la figura 9d. Por otra parte, las primeras porciones espectrales en la banda de origen para el relleno de mosaicos de frecuencia en la banda de la reconstrucción se proporcionan al regulador/calculadora de la envolvente 942 y este bloque recibe además la información de potencia para la banda de reconstrucción proporcionada como información lateral paramétrica de la señal de audio codificada ilustrada en 943 en la figura 9d. Luego, el regulador/calculadora de la envolvente 942 proporciona las funcionalidades de la figura 9b y 9c y por último emite los valores espectrales ajustados para las segundas porciones espectrales en la banda de reconstrucción. Estos valores espectrales ajustados 922, 923 para las segundas porciones espectrales en la banda de reconstrucción y las primeras porciones espectrales 921 en la banda de reconstrucción indicada en la línea 941 en la figura 9d representan conjuntamente la representación espectral completa de la banda de reconstrucción.
Posteriormente se hace referencia a las figuras 10a a 10b para explicar las realizaciones preferidas de un codificador de audio que codifica una señal de audio para proporcionar o generar una señal de audio codificada. El codificador comprende un convertidor de tiempo/espectro 1002 que alimenta un analizador espectral 1004, y el analizador espectral 1004 está conectado a una calculadora de parámetros 1006 por un lado y a un codificador de audio 1008 por otro lado. El codificador de audio 1008 proporciona la representación codificada de un primer conjunto de primeras porciones espectrales y no abarca el segundo conjunto de segundas porciones espectrales. Por otra parte, la calculadora de parámetros 1006 proporciona información de la potencia para una banda de reconstrucción que abarca las primeras y las segundas porciones espectrales. Asimismo, el codificador de audio 1008 está configurado para generar una primera representación codificada del primer conjunto de primeras porciones espectrales que tiene la primera resolución espectral, donde el codificador de audio 1008 proporciona factores de ajuste de escala para todas las bandas de la representación espectral generada por el bloque 1002. Adicionalmente, tal como se ilustra en la figura 3b, el codificador proporciona información de la potencia al menos para las bandas de reconstrucción ubicadas, con respecto a la frecuencia, por encima de la frecuencia de inicio de IGF 309 como se ilustra en la figura 3a. Por lo tanto, para que las bandas de reconstrucción coincidan preferentemente con las bandas de factor de escala o con grupos de bandas de factor de escala, se proporcionan dos valores, es decir, el factor de ajuste de escala correspondiente del codificador de audio 1008 y, adicionalmente, la información de la potencia emitida por la calculadora de parámetros 1006.
Preferentemente, el codificador de audio tiene bandas de factor de escala con diferentes anchos de banda de frecuencia, es decir, con un número diferente de valores espectrales. Por lo tanto, la calculadora paramétrica comprende un normalizador 1012 para normalizar las potencias para el ancho de banda diferente con respecto al ancho de banda de la banda de reconstrucción específica. Para este fin, el normalizador 1012 recibe, como entradas, una potencia en la banda y un número de valores espectrales en la banda y el normalizador 1012 luego emite una potencia normalizada por banda de reconstrucción/banda de factor de escala.
Además, la calculadora paramétrica 1006a de la figura 10a comprende una calculadora de valor de la potencia que recibe información de control del codificador de audio o central 1008 como se ilustra en la línea 1007 en la figura 10a. Esta información de control puede comprender información sobre los bloques largos/cortos utilizados por el codificador de audio y/o información de agrupamiento. Por consiguiente, mientras que la información sobre los bloques largos/cortos y la información de agrupamiento sobre ventanas cortas se refieren a un agrupamiento "temporal", la información de agrupamiento puede referirse además a un agrupamiento espectral, es decir, el agrupamiento de dos bandas de factor de escala en una sola banda de reconstrucción. Por lo tanto, la calculadora del valor de potencia 1014 emite un único valor de potencia para cada banda agrupada que abarca una primera y una segunda porción espectral cuando solo se han agrupado las porciones espectrales.
La figura 10d ilustra una realización adicional para la implementación del agrupamiento espectral. Para este fin, el bloque 1016 está configurado para calcular los valores de la potencia para dos bandas adyacentes. A continuación, en el bloque 1018 se comparan los valores de la potencia para las bandas adyacentes y, cuando los valores de la potencia no son tan diferentes o menos diferentes que lo definido, por ejemplo, por un umbral, entonces se genera un único valor (normalizado) para ambas bandas como se indica en el bloque 1020. Como se ilustra en la línea 1019, el bloque 1018 se puede omitir. Asimismo, la generación de un valor único para dos o más bandas que se lleva a cabo en el bloque 1020 puede ser controlado por un control de tasa de bits del codificador 1024. Por lo tanto, cuando la
tasa de bits se debe reducir, el control codificado de tasa de bits 1024 controla al bloque 1020 para generar un único valor normalizado para dos o más bandas, incluso cuando la comparación en el bloque 1018 no habría sido permitida para agrupar los valores de información de la potencia.
En caso de que el codificador de audio lleve a cabo el agolpamiento de dos o más ventanas cortas, este agrupamiento se aplica también para la información de la potencia. Cuando el codificador central lleva a cabo un agrupamiento de dos o más bloques cortos, entonces, para estos dos o más bloques, se calcula y se transmite solamente un único conjunto de factores de ajuste de escala. En el lado del decodificador, el decodificador de audio luego aplica el mismo conjunto de factores de ajuste de escala para ambas ventanas agrupadas.
En cuanto al cálculo de la información de la potencia, los valores espectrales en la banda de la reconstrucción se acumulan sobre dos o más ventanas cortas. En otras palabras, esto significa que los valores espectrales en una determinada banda de reconstrucción para un bloque corto y para el bloque corto posterior se acumulan y solo se transmite un valor único de información de la potencia para esta banda de reconstrucción que abarca dos bloques cortos. A continuación, en el lado del decodificador, el ajuste de la envolvente que se describe en la figura 9a a 9d no se lleva a cabo individualmente para cada bloque corto, pero se lleva a cabo conjuntamente para el conjunto de ventanas cortas agrupadas.
Luego se aplica nuevamente la normalización correspondiente de manera que, aunque se haya llevado a cabo cualquier agrupamiento en la frecuencia o agrupamiento temporal, la normalización permite fácilmente que, para el cálculo de la información del valor de potencia en el lado del decodificador, solo debe conocerse el valor de la información de potencia por un lado y la cantidad de líneas espectrales en la banda de reconstrucción o en el conjunto de bandas de reconstrucción agrupadas.
En los esquemas de extensión de ancho de banda (BWE) del estado de la técnica, la reconstrucción de la región espectral de alta frecuencia (HF) por encima de una así denominada frecuencia de cruce determinada se basa a menudo en la interconexión espectral. En general, la región de alta frecuencia (HF) consta de múltiples conexiones adyacentes y cada una de estas conexiones se obtiene de regiones de paso de banda (BP) del espectro de baja frecuencia (Lf ) por debajo de la frecuencia de cruce determinada. Dentro de una representación de banco de filtros de la señal, dichos sistemas copian un conjunto de coeficientes de sub-bandas adyacentes del espectro de baja frecuencia (LF) en la región de destino. Los límites de los conjuntos seleccionados suelen depender del sistema y no dependen de la señal. Para algunos contenidos de la señal, esta selección de interconexión estática puede provocar un timbre desagradable y la coloración de la señal reconstruida.
Otros enfoques transfieren la señal de baja frecuencia (LF) a la alta frecuencia (HF) a través de una modulación de banda lateral única adaptativa de la señal (SSB). Dichos enfoques son de alta complejidad computacional en comparación con [1] ya que operan a alta velocidad de muestreo en muestras de dominio temporal. Además, la interconexión puede volverse inestable, especialmente para señales no tonales (por ejemplo, de voz sorda) y, por lo tanto, la interconexión adaptativa del estado de la técnica puede introducir alteraciones en la señal.
El enfoque de la invención se denomina Relleno Inteligente de Espacios (IGF) y, en su configuración preferida, se aplica en un sistema de extensión de ancho de banda (BWE) sobre la base de una transformada de frecuencia temporal como, por ejemplo, la Transformada Coseno Discreta Modificada (MDCT). Sin embargo, las enseñanzas de la invención son de aplicación general, por ejemplo, de manera análoga dentro de un sistema basado en el Banco de Filtros Espejo en Cuadratura (QMF).
Una ventaja de la configuración de IGF basado en la MDCT es la integración perfecta en los codificadores de audio basados en la MDCT, por ejemplo, la Codificación Avanzada de Audio (AAC) de MPEG. Compartiendo la misma transformada para la codificación de audio de forma de onda y para BWE reduce significativamente la complejidad computacional general para el códec de audio.
Por otra parte, la invención proporciona una solución para los problemas inherentes de estabilidad que se encuentran en los esquemas de interconexión adaptativa del estado de la técnica.
El sistema propuesto se basa en la observación de que, para algunas señales, una selección de interconexión sin guía puede generar cambios de timbre y coloraciones en la señal. Si una señal que es tonal en la región espectral de origen (SSR) pero es tipo ruido en la región espectral de destino (STR), la interconexión de la STR tipo ruido por la SSR tonal puede generar un timbre antinatural. El timbre de la señal también puede cambiar ya que la estructura tonal de la señal podría desalinearse o incluso destruirse por el proceso de interconexión.
El sistema de IGF propuesto lleva a cabo una selección inteligente de mosaicos utilizando la correlación cruzada como medida de similitud entre una SSR en particular y una STR específica. La correlación cruzada de dos señales proporciona una medida de similitud de esas señales y también el retardo de correlación máxima y su signo. Por lo tanto, el enfoque de una selección de mosaicos basada en la correlación también se puede utilizar para ajustar con
precisión el desplazamiento espectral del espectro copiado para que esté tan cerca como sea posible de la estructura espectral original.
La contribución fundamental del sistema propuesto es la elección de una medida de similitud adecuada, y también técnicas para estabilizar el proceso de selección de mosaicos. La técnica propuesta proporciona un equilibrio óptimo entre la adaptación de la señal instantánea y, al mismo tiempo, la estabilidad temporal. La provisión de estabilidad temporal es especialmente importante para las señales que tienen poca similitud de SSR y STR y que, por lo tanto, exhiben valores bajos de correlación cruzada o cuando se emplean medidas de similitud que son ambiguas. En dichos casos, la estabilización impide el comportamiento pseudo-aleatorio de la selección adaptativa de mosaicos.
Por ejemplo, una clase de señales que a menudo plantea problemas para la extensión de ancho de banda del estado de la técnica se caracteriza por una concentración distinta de la potencia en regiones espectrales arbitrarias, tal como se muestra en la figura 12a (a la izquierda). Aunque hay métodos disponibles para ajustar la envolvente espectral y la tonalidad del espectro reconstruido en la región de destino, para algunas señales, estos métodos no son capaces de conservar bien el timbre como se muestra en la figura 12a (a la derecha). En el ejemplo ilustrado en la figura 12a, la magnitud del espectro en la región de destino de la señal original por encima de una así denominada frecuencia de cruce fxover (Figura 12a, a la izquierda) disminuye casi linealmente. Por el contrario, en el espectro reconstruido (figura 12a, a la derecha) hay un conjunto distinto de pendientes y picos que se percibe como un fallo de coloración del timbre.
Un paso importante del nuevo enfoque consiste en definir un conjunto de mosaicos entre los que puede tener lugar la elección basada en la similitud posterior. En primer lugar, los límites de los mosaicos, tanto de la región de origen como de la región de destino, tienen que estar definidos unos con otros. Por lo tanto, la región de destino entre la frecuencia de inicio de IGF del codificador central fiGFstarty una frecuencia más alta disponible fiGFstop se divide en un número entero arbitrario nTar de mosaicos, cada uno de los cuales tiene un tamaño individual predefinido. Entonces, para cada mosaico de destino tar[idx_tar] se genera un conjunto de mosaicos de origen de igual tamaño src[idx_src]. Por lo anterior se determina el grado básico de libertad del sistema de IGF. El número total de mosaicos de origen nSrc está determinado por el ancho de banda de la región de origen,
b Wsrc — ( fiG Fstart ~ flGFmín)
donde fiGFmin es la frecuencia más baja disponible para la selección de mosaicos de manera que un número entero nSrc de mosaicos de origen se adapta en bwsrc. El número mínimo de mosaicos de origen es 0.
Para aumentar aún más el grado de libertad para la selección y el ajuste, se puede definir que los mosaicos de origen se superponen entre sí por un factor de solapamiento entre 0 y 1, en donde 0 significa ningún solapamiento y 1 significa 100 % de solapamiento. El caso de 100 % de solapamiento implica que solo uno o ningún mosaico de origen está disponible.
La figura 12b muestra un ejemplo de los límites de mosaicos de un conjunto de mosaicos. En este caso, todos los mosaicos de destino están correlacionados con cada uno de los mosaicos de origen. En este ejemplo, los mosaicos de origen se solapan en un 50 %.
Para un mosaico de destino, la correlación cruzada se calcula con varios mosaicos de origen en retardos de hasta xcorr_maxLag intervalos. Para un mosaico de destino determinado idx_tar y un mosaico de origen idx_src, xcorr_val[idx_tar][idx_scr] proporciona el valor máximo de la correlación cruzada absoluta entre los mosaicos, mientras que xcorr_lag[idx_tar][idx_src] proporciona el retardo en el que se produce este máximo y xcorr_sign[idx_tar][idx_src] proporciona el signo de la correlación cruzada en xcorr_lag[idx_tar][idx_src\.
El parámetro xcorr_lag se utiliza para controlar la proximidad de la coincidencia entre el mosaico de origen y el mosaico de destino. Este parámetro da lugar a una reducción de fallos y ayuda a conservar mejor el timbre y el color de la señal.
En algunos casos puede ocurrir que el tamaño de un mosaico de destino específico es mayor que el tamaño de los mosaicos de origen disponibles. En este caso, el mosaico de origen disponible se repite tan a menudo como sea necesario para llenar completamente el mosaico de destino específico. Todavía es posible llevar a cabo la correlación cruzada entre el mosaico grande de destino y el mosaico de origen más pequeño con el fin de obtener la mejor posición del mosaico de origen en el mosaico de destino en términos del retardo de la correlación cruzada xcorr_lag y el signo xcorr_sign.
La correlación cruzada de los mosaicos espectrales en bruto y la señal original pueden no ser la medida de similitud más adecuada aplicada a los espectros de audio con una estructura fuerte de formantes. El blanqueo de un espectro quita la información de la envolvente en bruto y, por lo tanto, enfatiza la estructura fina espectral que es de interés principal para la evaluación de la similitud de mosaicos. El blanqueo también ayuda en un modelado fácil de la envolvente fácil de la región espectral de destino (STR) en el decodificador para las regiones procesadas por IGF. Por lo tanto, opcionalmente, el mosaico y la señal de origen se blanquean antes de calcular la correlación cruzada.
En otras configuraciones, solo se blanquea el mosaico utilizando un procedimiento predefinido. Una etiqueta de "blanqueo" transmitida indica al decodificador que se aplicará el mismo proceso de blanqueo predefinido al mosaico de frecuencia dentro del relleno inteligente de espacios (IGF).
Para blanquear la señal, primero se calcula una estimación de la envolvente espectral. A continuación, el espectro de la MDCT se divide por la envolvente espectral. La estimación de la envolvente espectral se puede estimar en el espectro de la MDCT, las potencias del espectro de la MDCT, las estimaciones del espectro de potencia complejo basado en la MDCT o las estimaciones del espectro de potencia. La señal en la que se estima la envolvente se llamará señal de base de aquí en adelante.
Las envolventes calculadas sobre estimaciones de espectro de potencia complejo basado en la MDCT o el espectro de potencia como señal de base tienen la ventaja de no tener fluctuación temporal en los componentes tonales.
Si la señal de base está en un dominio de potencia, el espectro de la MDCT tiene que dividirse por la raíz cuadrada de la envolvente para blanquear la señal correctamente.
Existen diferentes métodos para calcular la envolvente:
• transformando la señal de base con una transformada de coseno discreta (DCT), reteniendo solo los coeficientes más bajos de la DCT (fijando la más alta en cero) y luego calculando una DCT inversa
• calculando una envolvente espectral de un conjunto de Coeficientes de Predicción Lineal (LPC, por sus siglas en inglés) calculado sobre el cuadro de audio de dominio temporal
• filtrando la señal de base con un filtro de paso bajo
Preferentemente, se elige el último enfoque. Para aplicaciones que requieren baja complejidad computacional se puede llevar a cabo una cierta simplificación para el blanqueo de un espectro de la MDCT: En primer lugar, la envolvente se calcula por medio de una media móvil. Esto solo necesita dos ciclos de procesador por intervalo de la MDCT. Entonces, con el fin de evitar el cálculo de la división y la raíz cuadrada, la envolvente espectral se aproxima por 2n, en donde n es el logaritmo de número entero de la envolvente. En este dominio, la operación de raíz cuadrada se convierte simplemente en una operación de desplazamiento y, además, la división por la envolvente se puede llevar a cabo por otra operación de desplazamiento.
Después de calcular la correlación de cada mosaico de origen con cada mosaico de destino, para todos los mosaicos de destino nTar se selecciona el mosaico de origen con la correlación más alta para que lo sustituya. Para coincidir mejor con la estructura espectral original, el retardo de la correlación se utiliza para modular el espectro replicado por un número entero de intervalos de la transformada. En caso de retardos impares, el mosaico se modula adicionalmente a través de la multiplicación por una secuencia temporal alternativa de -1/1 para compensar la representación de frecuencia inversa de cualquier otra banda dentro de la Transformada Coseno Discreta Modificada (MDCT).
La Figura 12c muestra un ejemplo de una correlación entre un mosaico de origen y un mosaico de destino. En este ejemplo, el retardo de la correlación es 5, por lo que el mosaico de origen tiene que modularse por 5 intervalos hacia los intervalos de frecuencia más altos en la etapa de copiado del algoritmo de extensión de ancho de banda (BWE). Adicionalmente, el signo del mosaico tiene que invertirse ya que el valor máximo de correlación es negativo y una modulación adicional como se describió anteriormente representa el retardo impar.
Por lo tanto, la cantidad total de información lateral para transmitir desde el codificador al decodificador podría constar de los siguientes datos:
• tileNum[nTar]: índice del mosaico de origen seleccionado por mosaico de destino
• tileSign[nTar]: signo del mosaico de destino
• tileMod[nTar]: retardo de la correlación por mosaico de destino
El recorte y la estabilización de mosaicos constituyen un paso importante en el relleno inteligente de espacios (IGF). Su necesidad y ventajas se explican con un ejemplo, en el supuesto de una señal de audio tonal estacionaria como, por ejemplo, una nota de altura de tono estable. La lógica determina que se introducen menos fallos si, para una región de destino determinada, siempre se seleccionan los mosaicos de origen de la misma región de origen a través de los cuadros. A pesar de que se supone que la señal es estacionaria, esta condición no se aplicaría bien en cada cuadro ya que la medida de similitud (por ejemplo, correlación) de otra región de origen similar igual podría dominar el resultado de la similitud (por ejemplo, correlación cruzada). Esto hace que tileNum[nTar] entre cuadros adyacentes
dude entre dos o tres opciones muy similares. Este puede ser el origen de un fallo de tipo de ruido musical molesto.
Con el fin de eliminar este tipo de fallos, el conjunto de mosaicos de origen se recortará de manera que los elementos restantes del conjunto de origen sean máximamente disímiles. Esto se logra a través de un conjunto de mosaicos de origen
S = {S-|,S2,---Sn}
de la siguiente manera. Para cualquier mosaico de origen si, lo correlacionamos con todos los otros mosaicos de origen, encontrando la mejor correlación entre si y sj y almacenándola en una matriz Sx. Aquí, Sx[i][j] contiene el valor máximo absoluto de correlación cruzada entre si y sj. La adición de la matriz Sx a lo largo de las columnas, proporciona la suma de las correlaciones cruzadas de un mosaico de origen si con todos los otros mosaicos de origen T.
T[¡] = Sx[i][1] Sx[i][2]...+ Sx[i][n]
Aquí, T representa una buena medida de similitud entre un mosaico de origen y otros mosaicos de origen. Si, para cualquier mosaico de origen i,
T > u m b ra l
el mosaico de origen i puede ser retirado del conjunto de fuentes potenciales, ya que está muy correlacionado con otras fuentes. El mosaico que tiene la correlación más baja del conjunto de mosaicos que cumple la condición en la ecuación 1 se elige como un mosaico representativo para este subconjunto. De este modo, nos aseguramos de que los mosaicos de origen sean máximamente disímiles entre sí.
El método de recorte de mosaicos implica también una memoria del conjunto de mosaicos recortados utilizados en el cuadro anterior. Los mosaicos que estuvieron activos en el cuadro anterior se retienen en el siguiente cuadro si existen también candidatos alternativos para el recorte.
Dejar que los mosaicos s3, s4 t s5 estén activos a partir de los mosaicos {s1, s2..., s5} en el cuadro k, luego en el cuadro k+1, incluso si los mosaicos s1, s3 y s2 compiten por ser recortados en donde s3 está correlacionado máximamente con los otros, s3 se retiene ya que fue un mosaico de origen útil en el cuadro anterior y, por lo tanto, su retención en el conjunto de mosaicos de origen es beneficioso para reforzar la continuidad temporal en la selección de mosaicos. Este método se aplica preferentemente si la correlación cruzada entre el origen i y el destino j, representada como Tx[i][j] es alta
Un método adicional para la estabilización de mosaicos consiste en retener el orden de los mosaicos del cuadro k-1 anterior si ninguno de los mosaicos de origen en el cuadro k actual se correlaciona bien con los mosaicos de destino. Esto puede suceder si la correlación cruzada entre el origen i y el destino j, representada como Tx[i][j] es muy baja para todos los i, j
Por ejemplo, si
Tx[i][j] < 0.6
entonces se utiliza un umbral provisorio, luego
tileNum[nTar]k = tileNumtnTarlk.-i
para todos los nTar de este cuadro k.
Las dos técnicas anteriores reducen en gran medida los fallos que se producen a partir del cambio rápido de números de mosaicos fijos a través de los cuadros. Otra ventaja adicional de este recorte y estabilización de mosaicos es que no se necesita enviar información extra al decodificador y tampoco se necesita un cambio de arquitectura del decodificador. Esta propuesta de recorte de mosaicos resulta una manera elegante de reducir el ruido musical potencia en forma de fallos o ruido excesivo en las regiones espectrales de los mosaicos.
La figura 11 a ilustra un decodificador de audio para decodificar una señal de audio codificada. El primer decodificador de audio comprende un decodificador de audio (central) 1102 para generar una primera representación decodificada de un primer conjunto de primeras porciones espectrales, en donde la representación decodificada tiene una primera resolución espectral.
Asimismo, el decodificador de audio comprende un decodificador paramétrico 1104 para generar una segunda representación decodificada de un segundo conjunto de segundas porciones espectrales que tiene una segunda resolución espectral que es más baja que la primera resolución espectral. Además, se proporciona un regenerador de
frecuencia 1106 que recibe, como una primera entrada 1101, primeras porciones espectrales decodificadas y como una segunda entrada en 1103 la información paramétrica que incluye, para cada mosaico de frecuencia de destino o banda de reconstrucción de destino, una información de rango de origen. El regenerador de frecuencia de 1106 luego aplica la regeneración de frecuencia utilizando valores espectrales del rango de origen identificado por la información de adaptación con el fin de generar los datos espectrales para el rango de destino. A continuación, las primeras porciones espectrales 1101 y la salida del regenerador de frecuencia 1107 se introducen ambas en un convertidor de espectro-tiempo 1108 para generar finalmente la señal de audio decodificada.
Preferentemente, el decodificador de audio 1102 es un decodificador de audio de dominio espectral, aunque el decodificador de audio también se puede implementar como cualquier otro decodificador de audio tal como, por ejemplo, un decodificador de audio de dominio temporal o paramétrico.
Como se indica en la figura 11b, el regenerador de frecuencia 1106 puede comprender las funcionalidades del bloque 1120 que ilustra un modulador de mosaicos - selector del rango de origen para retardos impares, un filtro blanqueado 1122, cuando se proporciona una etiqueta de blanqueo 1123 y, adicionalmente, una envolvente espectral con funcionalidades de ajuste implementadas como se ilustra en el bloque 1128 utilizando datos espectrales en bruto generados por cualquiera de los bloques 1120 o 1122 o la cooperación de ambos bloques. De todos modos, el regenerador de frecuencia 1106 puede comprender un conmutador 1124 reactivo a una etiqueta de blanqueo recibida 1123. Cuando se fija la etiqueta de blanqueo, la salida del selector de rango de origen/modulador de mosaicos para retardos impares se introduce en el filtro de blanqueo 1122. Sin embargo, la etiqueta de blanqueo 1123 no se fija para una cierta banda de reconstrucción, por lo que entonces se activa una línea de desvío 1126 de manera que la salida del bloque 1120 se proporciona al bloque de ajuste de la envolvente espectral 1128 sin ningún blanqueo.
Puede haber más de un nivel de blanqueo (1123) señalado en la corriente de bits y estos niveles pueden estar señalados por mosaico. En caso de que haya tres niveles señalados por mosaico, los niveles se codificarán de la siguiente manera:
bit = readBit(1);
si(bit == 1) {
para(tile_index = 0..nT)
/*los mismos niveles que el último cuadro*/
whitening_level[tile_index] = whitening_level_prev_frame[tile_index];
} o bien {
/*primer mosaico:*/
tile_index = 0;
bit = readBit(1);
si(bit == 1) {
whitening_level[tile_index] = MID_WHITENING;
} o bien {
bit = readBit(1);
si(bit == 1) {
whitenin g_level[ti le_index] = STRONG_WHITENING;
} o bien {
whitening_level[tile_index] = OFF; /*sin blanqueo*/
}
}
/*mosaicos restantes:*/
bit = readBit(1);
si(bit == 1) {
/*los niveles de aplanamiento para los mosaicos restantes son iguales que para el primero.*/
/*No tienen que leerse otros rangos*/
para(tile_index = 1..nT)
whitening_level[tile_index] = whitening_level[0];
} o bien {
/*bits leídos para los mosaicos restantes como para el primer mosaico*/ para(tile_index = 1..nT) {
bit = readBit(1);
si(bit == 1) {
whitening_level[tile_index] = MID_WHITENING;
} o bien {
bit = readBit(1);
si(bit == 1) {
whitening_level[tile_index] = STRONG_WHITENING;
} o bien {
whitening_level[tile_index] = OFF; /*sin blanqueo*/
}
}
}
}
}
MID_WHITENING y STRONG_WHITENING se refieren a distintos filtros de blanqueo (1122) que pueden diferir en la forma en que se calcula la envolvente (como se describió anteriormente).
El regenerador de frecuencia del lado del decodificador puede ser controlado por una ID de rango de origen 1121 cuando se aplica solo un esquema de selección de mosaicos espectrales en bruto. Sin embargo, cuando se aplica un esquema de selección de mosaicos espectrales de sincronización precisa, entonces se proporciona además un retardo de rango de origen 1119. Asimismo, siempre que el cálculo de la correlación proporcione un resultado negativo, entonces, adicionalmente se puede aplicar también un signo de la correlación al bloque 1120 de manera que cada una de las líneas espectrales de datos de página se multiplican por "-1" para representar el signo negativo.
Por lo tanto, el ejemplo tal como se describe en la figura 11a, 11b garantiza la obtención de una calidad óptima de audio debido al hecho de que el mejor rango de origen coincidente para un destino determinado o rango de destino se calcula en el lado del codificador y se aplica en el lado del decodificador.
La figura 11c es un codificador de audio determinado para codificar una señal de audio que comprende un convertidor de tiempo-espectro 1130, un analizador espectral conectado posteriormente 1132 y, adicionalmente, una calculadora de parámetros 1134 y un codificador central 1136. El codificador central 1136 emite rangos de origen codificados y la calculadora de parámetros 1134 emite información de adaptación para rangos de destino.
Los rangos de origen codificados se transmiten a un decodificador junto con información de adaptación para los rangos de destino de manera que el decodificador ilustrado en la figura 11a se encuentra en la posición para llevar a cabo una regeneración de frecuencia.
La calculadora de parámetros 1134 está configurada para calcular similitudes entre primeras porciones espectrales y segundas porciones espectrales y para determinar, sobre la base de las similitudes calculadas para una segunda porción espectral, una primera porción espectral coincidente que se adapte a la segunda porción espectral. Preferiblemente, los resultados de adaptación para diferentes rangos de origen y rangos de destino tal como se ilustra en las figuras 12a, 12b para determinar un par de adaptación seleccionado comprenden la segunda porción espectral, y la calculadora de parámetros está configurada para proporcionar esta información de adaptación que identifica el par de adaptación en una señal de audio codificada. Preferentemente, la calculadora de parámetros 1134 de la presente invención está configurada para utilizar regiones de destino predefinidas en el segundo conjunto de segundas porciones espectrales o regiones de origen predefinidas en el primer conjunto de primeras porciones espectrales como se ilustra, por ejemplo, en la figura 12b. Preferentemente, las regiones de destino predefinidas no se solapan o las regiones de origen predefinidas se solapan. Cuando las regiones de origen predefinidas son un subconjunto del primer conjunto de primeras porciones espectrales por debajo de una frecuencia de inicio de relleno de espacios 309 de la figura 3a, y preferentemente, la región de destino predefinida que abarca una región espectral inferior coincide, con su límite de frecuencia inferior, con la frecuencia de inicio de relleno de espacios de manera que cualquier rango de destino se encuentra por encima de la frecuencia de inicio de relleno de espacios y los rangos de origen se encuentran por debajo de la frecuencia de inicio de relleno de espacios.
Como se explicó anteriormente, una granularidad fina se obtiene comparando una región de destino con una región de origen sin ningún retardo en la región de origen y la misma región de origen, pero con un cierto retardo. Estos retardos se aplican en la calculadora de correlación cruzada 1140 de la figura 11d y la selección de pares de adaptación es llevada a cabo finalmente por el selector de mosaicos 1144.
Además, se prefiere llevar a cabo un blanqueo de rangos de origen y/o rangos de destino como se ilustra en el bloque 1142. A continuación, este bloque 1142 proporciona una etiqueta de blanqueo a la corriente de bits que se utiliza para controlar el conmutador del lado del decodificador 1123 de la figura 11b. Asimismo, si la calculadora de correlación cruzada 1140 proporciona un resultado negativo, entonces este resultado negativo también se señala a un decodificador. Por lo tanto, en una realización preferida, el selector de mosaicos emite una ID de rango de origen para un rango de destino, un retardo, un signo y el bloque 1142 proporciona además una etiqueta de blanqueo. Asimismo, la calculadora de parámetros 1134 está configurada para llevar a cabo un recorte de mosaicos de origen 1146 reduciendo el número de rangos de origen potenciales por lo que una interconexión de origen se retira de un conjunto de mosaicos de origen potenciales sobre la base de un umbral de similitud. Por lo tanto, cuando dos mosaicos de origen son más similares o iguales a un umbral de similitud, entonces uno de estos dos mosaicos de origen se retira del conjunto de fuentes potenciales y el mosaico de origen eliminado ya no se utiliza para el procesamiento posterior y, específicamente, no puede ser seleccionado por el selector de mosaicos 1144 o no se utiliza para el cálculo de la correlación cruzada entre diferentes rangos de origen y rangos de destino como se llevó a cabo en el bloque 1140.
Se han descrito diferentes implementaciones con respecto a diferentes figuras. Las figuras 1a-5c se refieren a un esquema de codificador/decodificador de ancho de banda completa o de tasa completa. Las figuras 6a-7e se refieren a un esquema de codificador/decodificador con procesamiento de modelado de ruido temporal (TNS) o modelo de mosaico temporal (TTS). Las figuras 8a-8e se refieren a un esquema de codificador/decodificador con procesamiento específico de dos canales. Las figuras 9a-10d se refieren a un cálculo específico de información de potencia y la aplicación, y las figuras 11a-12c se refieren a un modo específico de selección de mosaicos.
Todos estos aspectos diferentes pueden ser de uso inventivo y son independientes entre sí pero, adicionalmente, también se pueden aplicar juntos como se ilustra básicamente en la figura 2a y 2b. Sin embargo, el procesamiento específico de dos canales se puede aplicar también a un esquema de codificador/descodificador ilustrado en la figura 13, y esto mismo se aplica al procesamiento de TNS/TTS, al cálculo de información de potencia de la envolvente y la aplicación en la banda de reconstrucción o la identificación del rango de origen de adaptación y la aplicación correspondiente en el lado del decodificador. Por otro lado, el aspecto de tasa completa se puede aplicar con o sin procesamiento de TNS/TTS, con o sin procesamiento de dos canales, con o sin una identificación del rango de origen de adaptación o con otros tipos de cálculos de potencia para la representación de la envolvente espectral. Por lo tanto, es evidente que las características de uno de estos aspectos individuales se pueden aplicar también en otros aspectos.
Aunque algunos aspectos se han descrito en el contexto de un aparato para codificar o decodificar, es evidente que estos aspectos también representan una descripción del método correspondiente, en donde un bloque o dispositivo corresponde a un paso del método o a una característica de un paso del método. En forma análoga, los aspectos descritos en el contexto de un paso del método también representan una descripción de un bloque o elemento o característica correspondiente de un aparato respectivo. Algunos o todos los pasos del método se pueden llevar a cabo por (o con) un aparato de hardware tal como, por ejemplo, un microprocesador, un ordenador programable o un
circuito electrónico. En algunas realizaciones, alguno o más de la mayoría de los pasos importantes del método se pueden llevar a cabo por dicho aparato.
En función de determinados requisitos de implementación, las realizaciones de la invención se pueden implementar en hardware o en software. La implementación se puede llevar a cabo utilizando un medio de almacenamiento no transitorio tal como un medio de almacenamiento digital, por ejemplo un disco flexible, un Disco Duro (HDD), un DVD, un Blu-Ray, un CD, una memoria ROM, una memoria PROM, y una memoria EPROM, una memoria EEPROM o una memoria FLASH, que tienen señales de control de lectura electrónica almacenadas en ellos, que cooperan (o son capaces de cooperar) con un sistema informático programable de forma tal que se lleva a cabo el método respectivo. Por lo tanto, el medio de almacenamiento digital puede ser legible por ordenador.
Algunas realizaciones de acuerdo con la invención comprenden un portador de datos que tiene señales de control de lectura electrónica, las cuales son capaces de cooperar con un sistema de ordenador programable, de tal manera que uno de los métodos descritos aquí se realice.
En general, las realizaciones de la presente invención se pueden implementar como un producto de programa informático con un código de programa, cuyo código de programa es operativo para llevar a cabo uno de los métodos cuando el producto de programa informático se ejecuta en un ordenador. El código del programa se puede almacenar, por ejemplo, en un portador legible por ordenador.
Otras realizaciones comprenden los programas informáticos para llevar a cabo uno de los métodos descritos en la presente, almacenados en un portador legible por ordenador.
En otras palabras, una realización del método de la invención es, por lo tanto, un programa informático que tiene un código de programa para llevar a cabo uno de los métodos descritos en la presente, cuando el programa informático se ejecuta en un ordenador.
Por lo tanto, otra realización del método de la invención es un portador de datos (o un medio de almacenamiento digital, o un medio legible por ordenador) que comprende, grabado en el mismo, el programa informático para llevar a cabo uno de los métodos descritos en la presente. El portador de datos, el medio de almacenamiento digital o el medio grabado son generalmente tangibles y/o no transitorios.
Por lo tanto, una realización adicional de la invención es una corriente de datos o una secuencia de señales que representan el programa informático para llevar a cabo uno de los métodos descritos en la presente. La corriente de datos o la secuencia de señales, por ejemplo, pueden estar configuradas para ser transferidas a través de una conexión de comunicación de datos, por ejemplo, a través de Internet.
Una realización adicional comprende un medio de procesamiento, por ejemplo, un ordenador o un dispositivo lógico programable configurado o adaptado para llevar a cabo uno de los métodos descritos en la presente invención.
Otra realización comprende un ordenador que tiene el programa informático instalado en la misma para llevar a cabo uno de los métodos descritos en la presente.
Otra realización de acuerdo con la invención comprende un aparato o un sistema configurado para transferir (por ejemplo, por vía electrónica u óptica) un programa informático para llevar a cabo uno de los métodos descritos en la presente a un receptor. El receptor puede ser, por ejemplo, un ordenador, un dispositivo móvil, un dispositivo de memoria o similar. El aparato o sistema puede comprender, por ejemplo, un servidor de archivos para transferir el programa informático al receptor.
En algunas realizaciones, un dispositivo lógico programable (por ejemplo, un arreglo de puerta programable de campo) se puede utilizar para llevar a cabo algunas o todas las funcionalidades de los métodos descritos en la presente invención. En algunas realizaciones, un arreglo de puerta programable de campo puede cooperar con un microprocesador para llevar a cabo uno de los métodos descritos en la presente. En general, los métodos serán llevados a cabo, preferentemente, por cualquier aparato de hardware.
Las realizaciones anteriormente descritas son simplemente ilustrativas de los principios de la presente invención. Se entiende que las modificaciones y variaciones de los arreglos y los detalles descritos en la presente serán evidentes para otros expertos en la materia. Es la intención, por lo tanto, de que la invención esté limitada solamente por el alcance de las reivindicaciones inminentes de la patente y no por los detalles específicos presentados a modo de descripción y explicación de las realizaciones del presente documento.
Lista de Referencias
[1] M. Dietz, L. Liljeryd, K. Kjorling and O. Kunz, “Spectral Band Replication, a novel approach in audio coding,”
in 112° AES Convention, Munich, mayo de 2002.
[2] Ferreira, D. Sinha, “Accurate Spectral Replacement”, Audio Engineering Society Convention, Barcelona, España 2005.
[3] D. Sinha, A. Ferreira1 and E. Harinarayanan, “A Novel Integrated Audio Bandwidth Extension Toolkit (ABET)”, Audio Engineering Society Convention, Paris, Francia 2006.
[4] R. Annadana, E. Harinarayanan, A. Ferreira and D. Sinha, “New Results in Low Bit Rate Speech Coding and Bandwidth Extension”, Audio Engineering Society Convention, San Francisco, EE.UU. 2006.
[5] T. Zernicki, M. Bartkowiak, “Audio bandwidth extension by frequency scaling of sinusoidal partials”, Audio Engineering Society Convention, San Francisco, EE.UU. 2008.
[6] J. Herre, D. Schulz, Extending the MPEG-4 AAC Codec by Perceptual Noise Substitution, 104th AES Convention, Amsterdam, 1998, Preprint 4720.
[7] M. Neuendorf, M. Multrus, N. Rettelbach, et al., MPEG Unified Speech and Audio Coding-The ISO/MPEG Standard for High-Efficiency Audio Coding of all Content Types, 132nd AES Convention, Budapest, Hungary, abril de 2012.
[8] McAulay, Robert J., Quatieri, Thomas F. “Speech Analysis/Synthesis Based on a Sinusoidal Representation”. IEEE Transactions on Acoustics, Speech, And Signal Processing, Vol 34(4), agosto de 1986.
[9] Smith, J.O., Serra, X. “PARSHL: An analysis/synthesis program for non-harmonic sounds based on a sinusoidal representation”, Proceedings of the International Computer Music Conference, 1987.
[10] Purnhagen, H.; Meine, Nikolaus, "HILN-the MPEG-4 parametric audio coding tools," Circuits and Systems, 2000. Proceedings. ISCAS 2000 Ginebra. The 2000 IEEE International Symposium on, vol.3, no., pp.201, 204 vol.3, 2000
[11] International Standard ISO/IEC 13818-3, Generic Coding of Moving Pictures and Associated Audio: Audio", Ginebra, 1998.
[12] M. Bosi, K. Brandenburg, S. Quackenbush, L. Fielder, K. Akagiri, H. Fuchs, M. Dietz, J. Herre, G. Davidson, Oikawa: "MPEG-2 Advanced Audio Coding", 101st AES Convention, Los Angeles 1996
[13] J. Herre, “Temporal Noise Shaping, Quantization and Coding methods in Perceptual Audio Coding: A Tutorial introduction”, 17th AES International Conference on High Quality Audio Coding, Agosto de 1999
[14] J. Herre, “Temporal Noise Shaping, Quantization and Coding methods in Perceptual Audio Coding: A Tutorial introduction”, 17th AES International Conference on High Quality Audio Coding, agosto de 1999
[15] International Standard ISO/IEC 23001-3:2010, Unified speech and audio coding Audio, Ginebra, 2010.
[16] International Standard ISO/IEC 14496-3:2005, Information technology - Coding of audio-visual objects - Part 3: Audio, Ginebra, 2005.
[17] P. Ekstrand, “Bandwidth Extension of Audio Signals by Spectral Band Replication”, in Proceedings of 1 st IEEE Benelux Workshop on MPCA, Leuven, noviembre de 2002
[18] F. Nagel, S. Disch, S. Wilde, A continuous modulated single sideband bandwidth extension, ICASSP International Conference on Acoustics, Speech and Signal Processing, Dallas, Texas (EE.UU.), abril de 2010
Claims (5)
1. Codificador de audio para codificar una señal de audio de dos canales, que comprende:
un convertidor de espectro de tiempo (860) para convertir la señal de audio de dos canales en una representación espectral;
un analizador espectral (866) para proporcionar una indicación de un primer conjunto de primeras porciones espectrales que van a codificarse con una primera resolución espectral y de un segundo conjunto de segundas porciones espectrales que van a codificarse con una segunda resolución espectral, siendo la segunda resolución espectral más pequeña que la primera resolución espectral, representando el segundo conjunto de segundas porciones espectrales bandas de reconstrucción;
un analizador de dos canales (864) para analizar las segundas porciones espectrales del segundo conjunto de segundas porciones espectrales de la señal de audio de dos canales dentro de la banda de reconstrucción para determinar una identificación de dos canales (835) para cada segunda porción espectral del segundo conjunto de segundas porciones espectrales identificando o bien una primera representación de dos canales o bien una segunda representación de dos canales para obtener las identificaciones de dos canales (835) para las segundas porciones espectrales del segundo conjunto de segundas porciones espectrales;
un codificador central (870) para codificar el primer conjunto de primeras porciones espectrales para proporcionar una primera representación codificada; y
una calculadora de parámetros (868) para calcular datos paramétricos en el segundo conjunto de segundas porciones espectrales usando las identificaciones de dos canales tal como se determina por el analizador de dos canales (864) para obtener una representación paramétrica codificada,
en el que una señal de audio de dos canales codificada (873) comprende la primera representación codificada, la representación paramétrica codificada y las identificaciones de dos canales (835) para las segundas porciones espectrales del segundo conjunto de segundas porciones espectrales.
2. Codificador de audio de acuerdo con la reivindicación 1, que comprende además un transformador (862) para transformar las primeras porciones espectrales del primer conjunto de primeras porciones espectrales en una representación de dos canales indicada por identificaciones de dos canales (835) determinadas por el analizador de dos canales (864) para cada primera porción espectral del primer conjunto de primeras porciones espectrales, y en el que el analizador espectral (866) se configura para analizar la representación de dos canales emitida por el transformador por bandas (862).
3. Codificador de audio de acuerdo con una de las reivindicaciones 1 o 2,
en el que el analizador de dos canales (864) se configura para realizar un cálculo de correlación entre una segunda porción espectral del segundo conjunto de segundas porciones espectrales del primer canal de la representación de dos canales y una segunda porción espectral del segundo conjunto de segundas porciones espectrales del segundo canal de la representación de dos canales para determinar o bien una representación de dos canales por separado o bien una representación conjunta de dos canales.
4. Codificador de audio de acuerdo con una de las reivindicaciones 1 a 3,
en el que el analizador espectral (866) se configura para comparar resultados de adaptación para segundas porciones espectrales diferentes del segundo conjunto de segundas porciones espectrales de al menos un canal de la representación de dos canales con primeras porciones espectrales diferentes del primer conjunto de primeras porciones espectrales de al menos un canal de la representación de dos canales para determinar un par de adaptación de una primera porción espectral del primer conjunto de primeras porciones espectrales de al menos un canal y la segunda porción espectral del segundo conjunto de segundas porciones espectrales de al menos un canal y para proporcionar una información de adaptación (833) para un par de adaptación mejor, y
en el que el codificador de audio se configura para emitir, además de la señal de audio codificada (873), la información de adaptación (833) para la segunda porción espectral del segundo conjunto de segundas porciones espectrales.
5. Codificador de audio de acuerdo con una de las reivindicaciones 1 a 4, que comprende además un transformador por bandas (862) que tiene una entrada conectada a una salida del convertidor de espectro de tiempo (860),
en el que el analizador espectral (866) se configura para recibir, como una entrada, una salida del transformador por bandas (862);
en el que el analizador de dos canales (864) se configura para analizar una salida del convertidor de espectro de tiempo (860) y para proporcionar un resultado de análisis para controlar el transformador por bandas (862),
en el que el codificador de audio se configura para codificar, tal como se controla por el analizador espectral (866), una salida del transformador por bandas (862), de modo que solo el primer conjunto de las primeras porciones espectrales se codifica por el codificador central (870), y
en el que el codificador de parámetros (868) se configura para codificar de manera paramétrica el segundo conjunto de las segundas porciones espectrales tal como se indica por el analizador espectral (866) en una salida del transformador por bandas (862).
Codificador de audio de acuerdo con la reivindicación 1, en el que el analizador espectral (866) se configura para analizar la representación espectral que empieza con una frecuencia de inicio del relleno de espacios (309) y que termina con una frecuencia máxima representada por una frecuencia máxima incluida en la representación espectral, de manera que
una porción espectral (302) que se extiende desde una frecuencia mínima hasta la frecuencia de inicio del relleno de espacios (309) pertenece al primer conjunto de primeras porciones espectrales,
una porción espectral adicional (304) por encima de la frecuencia de inicio del relleno de espacios (309) es una segunda porción espectral del segundo conjunto de segundas porciones espectrales en la banda de reconstrucción de la representación espectral, y
una porción espectral incluso adicional (305, 306, 307) que tiene un valor de frecuencia por encima de la frecuencia de inicio del relleno de espacios (309) y por encima de un valor de frecuencia de la segunda porción espectral (304) del segundo conjunto de segundas porciones espectrales por encima de la frecuencia de inicio del relleno de espacios (309) en la banda de reconstrucción también pertenece al primer conjunto de primeras porciones espectrales,
en el que el espectro se subdivide en bandas de factor de escala, y
en el que el codificador central (870) se configura para funcionar en un rango de frecuencia completo de la representación espectral.
Codificador de audio de acuerdo con la reivindicación 1, en el que el analizador de dos canales (864) se configura para analizar una primera porción espectral del primer conjunto de primeras porciones espectrales para determinar una identificación de dos canales adicional (835) para la primera porción espectral del primer conjunto de primeras porciones espectrales, identificando la identificación de dos canales adicional o bien una primera representación de dos canales para la primera porción espectral del primer conjunto de primeras porciones espectrales o bien una segunda representación de dos canales diferente para la primera porción espectral del primer conjunto de primeras porciones espectrales, y
en el que la identificación de dos canales adicional (835) se envía a una interfaz de salida (872), de modo que la identificación de dos canales adicional también se incluye en la señal de audio de dos canales codificada (873) emitida por la interfaz de salida (872).
Codificador de audio de acuerdo con la reivindicación 1, en el que la calculadora de parámetros (868) se configura para calcular los datos paramétricos para una segunda porción espectral del segundo conjunto de segundas porciones espectrales dependiendo de la identificación de dos canales (835) usando o bien la primera representación de dos canales de la segunda porción espectral o bien la segunda representación de dos canales de la segunda porción espectral tal como se indica por la identificación de dos canales (835).
Codificador de audio de acuerdo con la reivindicación 1, en el que la primera representación de dos canales para una segunda porción espectral del segundo conjunto de segundas porciones espectrales y la segunda representación de dos canales diferente para la segunda porción espectral del segundo conjunto de segundas porciones espectrales se seleccionan de un grupo de representaciones de dos canales que comprende una representación de dos canales izquierdo-derecho, una representación de dos canales medio-lateral y una representación de dos canales de predicción de mezcla descendente-residual, y
en el que una primera representación de dos canales para una primera porción espectral del primer conjunto
de primeras porciones espectrales y una segunda representación de dos canales diferente para la primera porción espectral del primer conjunto de primeras porciones espectrales se seleccionan de un grupo de representaciones de dos canales que comprende la representación de dos canales izquierdo-derecho, la representación de dos canales medio-lateral y la representación de dos canales de predicción de mezcla descendente-residual.
Método de codificación de una señal de audio de dos canales, que comprende:
convertir (860) la señal de audio de dos canales en una representación espectral;
proporcionar (866) una indicación de un primer conjunto de primeras porciones espectrales que van a codificarse con una primera resolución espectral y de un segundo conjunto de segundas porciones espectrales que van a codificarse con una segunda resolución espectral, siendo la segunda resolución espectral más pequeña que la primera resolución espectral, representando el segundo conjunto de segundas porciones espectrales bandas de reconstrucción;
analizar (864) las segundas porciones espectrales del segundo conjunto de segundas porciones espectrales de la señal de audio de dos canales dentro de la banda de reconstrucción para determinar una identificación de dos canales (835) para cada segunda porción espectral del segundo conjunto de segundas porciones espectrales identificando o bien una primera representación de dos canales o bien una segunda representación de dos canales para obtener las identificaciones de dos canales (835) para las segundas porciones espectrales del segundo conjunto de segundas porciones espectrales;
codificar (870) el primer conjunto de primeras porciones espectrales para proporcionar una primera representación codificada; y
calcular (868) datos paramétricos en el segundo conjunto de segundas porciones espectrales usando las identificaciones de dos canales tal como se determina por el analizador (864) para obtener una representación paramétrica codificada, en el que una señal de audio de dos canales codificada (873) comprende la primera representación codificada, la representación paramétrica codificada y las identificaciones de dos canales (835) para las segundas porciones espectrales del segundo conjunto de segundas porciones espectrales.
Programa informático que comprende instrucciones que, cuando el programa se ejecuta por un ordenador o un procesador, hacen que el ordenador o el procesador lleve a cabo el método de acuerdo con la reivindicación 10.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP13177346 | 2013-07-22 | ||
| EP13177350 | 2013-07-22 | ||
| EP13177353 | 2013-07-22 | ||
| EP13177348 | 2013-07-22 | ||
| EP13189366.1A EP2830054A1 (en) | 2013-07-22 | 2013-10-18 | Audio encoder, audio decoder and related methods using two-channel processing within an intelligent gap filling framework |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2827774T3 true ES2827774T3 (es) | 2021-05-24 |
Family
ID=49385156
Family Applications (9)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14741264.7T Active ES2638498T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y procedimiento para decodificar una señal de audio codificada mediante un filtro de cruce en torno a una frecuencia de transición |
| ES14738854T Active ES2728329T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y método para decodificar o codificar una señal de audio utilizando valores de información para una banda de reconstrucción |
| ES14738857.3T Active ES2599007T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y método para codificar y decodificar una señal de audio codificada utilizando modelado de ruido/parche temporal |
| ES18180168T Active ES2827774T3 (es) | 2013-07-22 | 2014-07-15 | Codificador de audio y método relacionado usando procesamiento de dos canales dentro de un marco de referencia de relleno inteligente de espacios |
| ES14738853T Active ES2908624T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y procedimiento para codificar y decodificar una señal de audio con relleno inteligente de espacios en el dominio espectral |
| ES19157850T Active ES2959641T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y método para decodificar o codificar una señal de audio utilizando valores de información para una banda de reconstrucción |
| ES14739161.9T Active ES2667221T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y método para decodificar y codificar una señal de audio utilizando selección de mosaicos espectrales adaptativos |
| ES14739811T Active ES2813940T3 (es) | 2013-07-22 | 2014-07-15 | Aparato, método y programa informático para decodificar una señal de audio codificada |
| ES14739160T Active ES2698023T3 (es) | 2013-07-22 | 2014-07-15 | Decodificador de audio y método relacionado que usan procesamiento de dos canales dentro de un marco de relleno inteligente de huecos |
Family Applications Before (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14741264.7T Active ES2638498T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y procedimiento para decodificar una señal de audio codificada mediante un filtro de cruce en torno a una frecuencia de transición |
| ES14738854T Active ES2728329T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y método para decodificar o codificar una señal de audio utilizando valores de información para una banda de reconstrucción |
| ES14738857.3T Active ES2599007T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y método para codificar y decodificar una señal de audio codificada utilizando modelado de ruido/parche temporal |
Family Applications After (5)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14738853T Active ES2908624T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y procedimiento para codificar y decodificar una señal de audio con relleno inteligente de espacios en el dominio espectral |
| ES19157850T Active ES2959641T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y método para decodificar o codificar una señal de audio utilizando valores de información para una banda de reconstrucción |
| ES14739161.9T Active ES2667221T3 (es) | 2013-07-22 | 2014-07-15 | Aparato y método para decodificar y codificar una señal de audio utilizando selección de mosaicos espectrales adaptativos |
| ES14739811T Active ES2813940T3 (es) | 2013-07-22 | 2014-07-15 | Aparato, método y programa informático para decodificar una señal de audio codificada |
| ES14739160T Active ES2698023T3 (es) | 2013-07-22 | 2014-07-15 | Decodificador de audio y método relacionado que usan procesamiento de dos canales dentro de un marco de relleno inteligente de huecos |
Country Status (20)
| Country | Link |
|---|---|
| US (24) | US10332539B2 (es) |
| EP (20) | EP2830065A1 (es) |
| JP (12) | JP6389254B2 (es) |
| KR (7) | KR101826723B1 (es) |
| CN (12) | CN112466312B (es) |
| AU (7) | AU2014295302B2 (es) |
| BR (12) | BR122022010960B1 (es) |
| CA (8) | CA2918701C (es) |
| ES (9) | ES2638498T3 (es) |
| HK (1) | HK1211378A1 (es) |
| MX (7) | MX354657B (es) |
| MY (5) | MY187943A (es) |
| PL (8) | PL3506260T3 (es) |
| PT (7) | PT3017448T (es) |
| RU (7) | RU2651229C2 (es) |
| SG (7) | SG11201502691QA (es) |
| TR (1) | TR201816157T4 (es) |
| TW (7) | TWI555008B (es) |
| WO (7) | WO2015010947A1 (es) |
| ZA (5) | ZA201502262B (es) |
Families Citing this family (90)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2610293C2 (ru) * | 2012-03-29 | 2017-02-08 | Телефонактиеболагет Лм Эрикссон (Пабл) | Расширение полосы частот гармонического аудиосигнала |
| TWI546799B (zh) * | 2013-04-05 | 2016-08-21 | 杜比國際公司 | 音頻編碼器及解碼器 |
| EP2830065A1 (en) | 2013-07-22 | 2015-01-28 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for decoding an encoded audio signal using a cross-over filter around a transition frequency |
| EP2830051A3 (en) | 2013-07-22 | 2015-03-04 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio encoder, audio decoder, methods and computer program using jointly encoded residual signals |
| KR101790641B1 (ko) * | 2013-08-28 | 2017-10-26 | 돌비 레버러토리즈 라이쎈싱 코오포레이션 | 하이브리드 파형-코딩 및 파라미터-코딩된 스피치 인핸스 |
| FR3011408A1 (fr) * | 2013-09-30 | 2015-04-03 | Orange | Re-echantillonnage d'un signal audio pour un codage/decodage a bas retard |
| US9741349B2 (en) | 2014-03-14 | 2017-08-22 | Telefonaktiebolaget L M Ericsson (Publ) | Audio coding method and apparatus |
| EP2980795A1 (en) | 2014-07-28 | 2016-02-03 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio encoding and decoding using a frequency domain processor, a time domain processor and a cross processor for initialization of the time domain processor |
| EP2980794A1 (en) * | 2014-07-28 | 2016-02-03 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio encoder and decoder using a frequency domain processor and a time domain processor |
| WO2016091893A1 (en) | 2014-12-09 | 2016-06-16 | Dolby International Ab | Mdct-domain error concealment |
| WO2016142002A1 (en) | 2015-03-09 | 2016-09-15 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Audio encoder, audio decoder, method for encoding an audio signal and method for decoding an encoded audio signal |
| TWI856342B (zh) * | 2015-03-13 | 2024-09-21 | 瑞典商杜比國際公司 | 音訊處理單元、用於將經編碼的音訊位元流解碼之方法以及非暫態電腦可讀媒體 |
| GB201504403D0 (en) | 2015-03-16 | 2015-04-29 | Microsoft Technology Licensing Llc | Adapting encoded bandwidth |
| EP3107096A1 (en) * | 2015-06-16 | 2016-12-21 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Downscaled decoding |
| US10847170B2 (en) | 2015-06-18 | 2020-11-24 | Qualcomm Incorporated | Device and method for generating a high-band signal from non-linearly processed sub-ranges |
| EP3171362B1 (en) * | 2015-11-19 | 2019-08-28 | Harman Becker Automotive Systems GmbH | Bass enhancement and separation of an audio signal into a harmonic and transient signal component |
| EP3182411A1 (en) | 2015-12-14 | 2017-06-21 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for processing an encoded audio signal |
| EP3405949B1 (en) * | 2016-01-22 | 2020-01-08 | Fraunhofer Gesellschaft zur Förderung der Angewand | Apparatus and method for estimating an inter-channel time difference |
| CN117542365A (zh) * | 2016-01-22 | 2024-02-09 | 弗劳恩霍夫应用研究促进协会 | 用于具有全局ild和改进的中/侧决策的mdct m/s立体声的装置和方法 |
| EP3208800A1 (en) | 2016-02-17 | 2017-08-23 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for stereo filing in multichannel coding |
| DE102016104665A1 (de) | 2016-03-14 | 2017-09-14 | Ask Industries Gmbh | Verfahren und Vorrichtung zur Aufbereitung eines verlustbehaftet komprimierten Audiosignals |
| US10741196B2 (en) | 2016-03-24 | 2020-08-11 | Harman International Industries, Incorporated | Signal quality-based enhancement and compensation of compressed audio signals |
| US10141005B2 (en) | 2016-06-10 | 2018-11-27 | Apple Inc. | Noise detection and removal systems, and related methods |
| EP3475944B1 (en) | 2016-06-22 | 2020-07-15 | Dolby International AB | Audio decoder and method for transforming a digital audio signal from a first to a second frequency domain |
| US10249307B2 (en) * | 2016-06-27 | 2019-04-02 | Qualcomm Incorporated | Audio decoding using intermediate sampling rate |
| US10812550B1 (en) * | 2016-08-03 | 2020-10-20 | Amazon Technologies, Inc. | Bitrate allocation for a multichannel media stream |
| EP3288031A1 (en) | 2016-08-23 | 2018-02-28 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for encoding an audio signal using a compensation value |
| US9679578B1 (en) | 2016-08-31 | 2017-06-13 | Sorenson Ip Holdings, Llc | Signal clipping compensation |
| EP3306609A1 (en) * | 2016-10-04 | 2018-04-11 | Fraunhofer Gesellschaft zur Förderung der Angewand | Apparatus and method for determining a pitch information |
| US10362423B2 (en) * | 2016-10-13 | 2019-07-23 | Qualcomm Incorporated | Parametric audio decoding |
| EP3324406A1 (en) | 2016-11-17 | 2018-05-23 | Fraunhofer Gesellschaft zur Förderung der Angewand | Apparatus and method for decomposing an audio signal using a variable threshold |
| JP6769299B2 (ja) * | 2016-12-27 | 2020-10-14 | 富士通株式会社 | オーディオ符号化装置およびオーディオ符号化方法 |
| US10304468B2 (en) | 2017-03-20 | 2019-05-28 | Qualcomm Incorporated | Target sample generation |
| US10090892B1 (en) * | 2017-03-20 | 2018-10-02 | Intel Corporation | Apparatus and a method for data detecting using a low bit analog-to-digital converter |
| US10354669B2 (en) | 2017-03-22 | 2019-07-16 | Immersion Networks, Inc. | System and method for processing audio data |
| EP3382701A1 (en) | 2017-03-31 | 2018-10-03 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for post-processing an audio signal using prediction based shaping |
| EP3382700A1 (en) | 2017-03-31 | 2018-10-03 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for post-processing an audio signal using a transient location detection |
| EP3382704A1 (en) | 2017-03-31 | 2018-10-03 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for determining a predetermined characteristic related to a spectral enhancement processing of an audio signal |
| RU2727794C1 (ru) | 2017-05-18 | 2020-07-24 | Фраунхофер-Гезелльшафт Цур Фердерунг Дер Ангевандтен Форшунг Е.Ф. | Управляющее сетевое устройство |
| US11550665B2 (en) | 2017-06-02 | 2023-01-10 | Apple Inc. | Techniques for preserving clone relationships between files |
| US11545164B2 (en) * | 2017-06-19 | 2023-01-03 | Rtx A/S | Audio signal encoding and decoding |
| JP7257975B2 (ja) | 2017-07-03 | 2023-04-14 | ドルビー・インターナショナル・アーベー | 密集性の過渡事象の検出及び符号化の複雑さの低減 |
| JP6904209B2 (ja) * | 2017-07-28 | 2021-07-14 | 富士通株式会社 | オーディオ符号化装置、オーディオ符号化方法およびオーディオ符号化プログラム |
| BR112020008216A2 (pt) * | 2017-10-27 | 2020-10-27 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | aparelho e seu método para gerar um sinal de áudio intensificado, sistema para processar um sinal de áudio |
| EP3483883A1 (en) | 2017-11-10 | 2019-05-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio coding and decoding with selective postfiltering |
| EP3483879A1 (en) | 2017-11-10 | 2019-05-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Analysis/synthesis windowing function for modulated lapped transformation |
| EP3483880A1 (en) | 2017-11-10 | 2019-05-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Temporal noise shaping |
| EP3483878A1 (en) | 2017-11-10 | 2019-05-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio decoder supporting a set of different loss concealment tools |
| EP3483882A1 (en) * | 2017-11-10 | 2019-05-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Controlling bandwidth in encoders and/or decoders |
| EP3483886A1 (en) | 2017-11-10 | 2019-05-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Selecting pitch lag |
| EP3483884A1 (en) | 2017-11-10 | 2019-05-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Signal filtering |
| WO2019091576A1 (en) | 2017-11-10 | 2019-05-16 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio encoders, audio decoders, methods and computer programs adapting an encoding and decoding of least significant bits |
| WO2019091573A1 (en) | 2017-11-10 | 2019-05-16 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for encoding and decoding an audio signal using downsampling or interpolation of scale parameters |
| TWI702594B (zh) | 2018-01-26 | 2020-08-21 | 瑞典商都比國際公司 | 用於音訊信號之高頻重建技術之回溯相容整合 |
| DE112018006786B4 (de) * | 2018-02-09 | 2021-12-23 | Mitsubishi Electric Corporation | Audiosignal-Verarbeitungsvorrichtung und Audiosignal-Verarbeitungsverfahren |
| US10950251B2 (en) * | 2018-03-05 | 2021-03-16 | Dts, Inc. | Coding of harmonic signals in transform-based audio codecs |
| EP3576088A1 (en) * | 2018-05-30 | 2019-12-04 | Fraunhofer Gesellschaft zur Förderung der Angewand | Audio similarity evaluator, audio encoder, methods and computer program |
| AU2019298307A1 (en) | 2018-07-04 | 2021-02-25 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Multisignal audio coding using signal whitening as preprocessing |
| CN109088617B (zh) * | 2018-09-20 | 2021-06-04 | 电子科技大学 | 比率可变数字重采样滤波器 |
| US10847172B2 (en) * | 2018-12-17 | 2020-11-24 | Microsoft Technology Licensing, Llc | Phase quantization in a speech encoder |
| US10957331B2 (en) | 2018-12-17 | 2021-03-23 | Microsoft Technology Licensing, Llc | Phase reconstruction in a speech decoder |
| EP3671741A1 (en) * | 2018-12-21 | 2020-06-24 | FRAUNHOFER-GESELLSCHAFT zur Förderung der angewandten Forschung e.V. | Audio processor and method for generating a frequency-enhanced audio signal using pulse processing |
| CN113348507B (zh) * | 2019-01-13 | 2025-02-21 | 华为技术有限公司 | 高分辨率音频编解码 |
| JP7262593B2 (ja) * | 2019-01-13 | 2023-04-21 | 華為技術有限公司 | ハイレゾリューションオーディオ符号化 |
| KR102470429B1 (ko) * | 2019-03-14 | 2022-11-23 | 붐클라우드 360 인코포레이티드 | 우선순위에 의한 공간 인식 다중 대역 압축 시스템 |
| CN110265043B (zh) * | 2019-06-03 | 2021-06-01 | 同响科技股份有限公司 | 自适应有损或无损的音频压缩和解压缩演算方法 |
| WO2020253941A1 (en) * | 2019-06-17 | 2020-12-24 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio encoder with a signal-dependent number and precision control, audio decoder, and related methods and computer programs |
| MX2022001162A (es) | 2019-07-30 | 2022-02-22 | Dolby Laboratories Licensing Corp | Coordinacion de dispositivos de audio. |
| DE102020210917B4 (de) | 2019-08-30 | 2023-10-19 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung eingetragener Verein | Verbesserter M/S-Stereo-Codierer und -Decodierer |
| TWI702780B (zh) * | 2019-12-03 | 2020-08-21 | 財團法人工業技術研究院 | 提升共模瞬變抗擾度的隔離器及訊號產生方法 |
| CN111862953B (zh) * | 2019-12-05 | 2023-08-22 | 北京嘀嘀无限科技发展有限公司 | 语音识别模型的训练方法、语音识别方法及装置 |
| US11158297B2 (en) * | 2020-01-13 | 2021-10-26 | International Business Machines Corporation | Timbre creation system |
| CN113192517B (zh) * | 2020-01-13 | 2024-04-26 | 华为技术有限公司 | 一种音频编解码方法和音频编解码设备 |
| US20230085013A1 (en) * | 2020-01-28 | 2023-03-16 | Hewlett-Packard Development Company, L.P. | Multi-channel decomposition and harmonic synthesis |
| CN111199743B (zh) * | 2020-02-28 | 2023-08-18 | Oppo广东移动通信有限公司 | 音频编码格式确定方法、装置、存储介质及电子设备 |
| CN111429925B (zh) * | 2020-04-10 | 2023-04-07 | 北京百瑞互联技术有限公司 | 一种降低音频编码速率的方法及系统 |
| CN113593586B (zh) * | 2020-04-15 | 2025-01-10 | 华为技术有限公司 | 音频信号编码方法、解码方法、编码设备以及解码设备 |
| CN111371459B (zh) * | 2020-04-26 | 2023-04-18 | 宁夏隆基宁光仪表股份有限公司 | 一种适用于智能电表的多操作高频替换式数据压缩方法 |
| CN113782040B (zh) * | 2020-05-22 | 2024-07-30 | 华为技术有限公司 | 基于心理声学的音频编码方法及装置 |
| CN113808596B (zh) | 2020-05-30 | 2025-01-03 | 华为技术有限公司 | 一种音频编码方法和音频编码装置 |
| CN113808597B (zh) * | 2020-05-30 | 2024-10-29 | 华为技术有限公司 | 一种音频编码方法和音频编码装置 |
| EP4193357A1 (en) * | 2020-08-28 | 2023-06-14 | Google LLC | Maintaining invariance of sensory dissonance and sound localization cues in audio codecs |
| CN113113033B (zh) * | 2021-04-29 | 2025-03-07 | 腾讯音乐娱乐科技(深圳)有限公司 | 一种音频处理方法、设备及可读存储介质 |
| CN113365189B (zh) * | 2021-06-04 | 2022-08-05 | 上海傅硅电子科技有限公司 | 多声道无缝切换方法 |
| CN115472171B (zh) * | 2021-06-11 | 2024-11-22 | 华为技术有限公司 | 编解码方法、装置、设备、存储介质及计算机程序 |
| CN113593604B (zh) * | 2021-07-22 | 2024-07-19 | 腾讯音乐娱乐科技(深圳)有限公司 | 检测音频质量方法、装置及存储介质 |
| TWI794002B (zh) * | 2022-01-28 | 2023-02-21 | 緯創資通股份有限公司 | 多媒體系統以及多媒體操作方法 |
| CN114582361B (zh) * | 2022-04-29 | 2022-07-08 | 北京百瑞互联技术有限公司 | 基于生成对抗网络的高解析度音频编解码方法及系统 |
| EP4500524A1 (en) * | 2022-05-17 | 2025-02-05 | Google LLC | Asymmetric and adaptive strength for windowing at encoding and decoding time for audio compression |
| WO2024085551A1 (ko) * | 2022-10-16 | 2024-04-25 | 삼성전자주식회사 | 패킷 손실 은닉을 위한 전자 장치 및 방법 |
Family Cites Families (266)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS62234435A (ja) * | 1986-04-04 | 1987-10-14 | Kokusai Denshin Denwa Co Ltd <Kdd> | 符号化音声の復号化方式 |
| US6289308B1 (en) | 1990-06-01 | 2001-09-11 | U.S. Philips Corporation | Encoded wideband digital transmission signal and record carrier recorded with such a signal |
| JP3465697B2 (ja) * | 1993-05-31 | 2003-11-10 | ソニー株式会社 | 信号記録媒体 |
| CA2140779C (en) | 1993-05-31 | 2005-09-20 | Kyoya Tsutsui | Method, apparatus and recording medium for coding of separated tone and noise characteristics spectral components of an acoustic signal |
| TW272341B (es) * | 1993-07-16 | 1996-03-11 | Sony Co Ltd | |
| GB2281680B (en) * | 1993-08-27 | 1998-08-26 | Motorola Inc | A voice activity detector for an echo suppressor and an echo suppressor |
| BE1007617A3 (nl) * | 1993-10-11 | 1995-08-22 | Philips Electronics Nv | Transmissiesysteem met gebruik van verschillende codeerprincipes. |
| US5502713A (en) * | 1993-12-07 | 1996-03-26 | Telefonaktiebolaget Lm Ericsson | Soft error concealment in a TDMA radio system |
| JPH07336231A (ja) * | 1994-06-13 | 1995-12-22 | Sony Corp | 信号符号化方法及び装置、信号復号化方法及び装置、並びに記録媒体 |
| EP0732687B2 (en) * | 1995-03-13 | 2005-10-12 | Matsushita Electric Industrial Co., Ltd. | Apparatus for expanding speech bandwidth |
| EP0820624A1 (en) | 1995-04-10 | 1998-01-28 | Corporate Computer Systems, Inc. | System for compression and decompression of audio signals for digital transmission |
| JP3747492B2 (ja) | 1995-06-20 | 2006-02-22 | ソニー株式会社 | 音声信号の再生方法及び再生装置 |
| JP3246715B2 (ja) * | 1996-07-01 | 2002-01-15 | 松下電器産業株式会社 | オーディオ信号圧縮方法,およびオーディオ信号圧縮装置 |
| JPH10124088A (ja) * | 1996-10-24 | 1998-05-15 | Sony Corp | 音声帯域幅拡張装置及び方法 |
| SE512719C2 (sv) * | 1997-06-10 | 2000-05-02 | Lars Gustaf Liljeryd | En metod och anordning för reduktion av dataflöde baserad på harmonisk bandbreddsexpansion |
| DE19730130C2 (de) * | 1997-07-14 | 2002-02-28 | Fraunhofer Ges Forschung | Verfahren zum Codieren eines Audiosignals |
| US6253172B1 (en) * | 1997-10-16 | 2001-06-26 | Texas Instruments Incorporated | Spectral transformation of acoustic signals |
| US5913191A (en) | 1997-10-17 | 1999-06-15 | Dolby Laboratories Licensing Corporation | Frame-based audio coding with additional filterbank to suppress aliasing artifacts at frame boundaries |
| DE19747132C2 (de) * | 1997-10-24 | 2002-11-28 | Fraunhofer Ges Forschung | Verfahren und Vorrichtungen zum Codieren von Audiosignalen sowie Verfahren und Vorrichtungen zum Decodieren eines Bitstroms |
| US6029126A (en) * | 1998-06-30 | 2000-02-22 | Microsoft Corporation | Scalable audio coder and decoder |
| US6253165B1 (en) * | 1998-06-30 | 2001-06-26 | Microsoft Corporation | System and method for modeling probability distribution functions of transform coefficients of encoded signal |
| US6453289B1 (en) | 1998-07-24 | 2002-09-17 | Hughes Electronics Corporation | Method of noise reduction for speech codecs |
| US6061555A (en) | 1998-10-21 | 2000-05-09 | Parkervision, Inc. | Method and system for ensuring reception of a communications signal |
| US6400310B1 (en) * | 1998-10-22 | 2002-06-04 | Washington University | Method and apparatus for a tunable high-resolution spectral estimator |
| SE9903553D0 (sv) | 1999-01-27 | 1999-10-01 | Lars Liljeryd | Enhancing percepptual performance of SBR and related coding methods by adaptive noise addition (ANA) and noise substitution limiting (NSL) |
| JP3762579B2 (ja) | 1999-08-05 | 2006-04-05 | 株式会社リコー | デジタル音響信号符号化装置、デジタル音響信号符号化方法及びデジタル音響信号符号化プログラムを記録した媒体 |
| US6978236B1 (en) | 1999-10-01 | 2005-12-20 | Coding Technologies Ab | Efficient spectral envelope coding using variable time/frequency resolution and time/frequency switching |
| KR100675309B1 (ko) * | 1999-11-16 | 2007-01-29 | 코닌클리케 필립스 일렉트로닉스 엔.브이. | 광대역 오디오 송신 시스템, 송신기, 수신기, 코딩 디바이스, 디코딩 디바이스와, 송신 시스템에서 사용하기 위한 코딩 방법 및 디코딩 방법 |
| US7742927B2 (en) | 2000-04-18 | 2010-06-22 | France Telecom | Spectral enhancing method and device |
| SE0001926D0 (sv) | 2000-05-23 | 2000-05-23 | Lars Liljeryd | Improved spectral translation/folding in the subband domain |
| AU2001284910B2 (en) * | 2000-08-16 | 2007-03-22 | Dolby Laboratories Licensing Corporation | Modulating one or more parameters of an audio or video perceptual coding system in response to supplemental information |
| US7003467B1 (en) | 2000-10-06 | 2006-02-21 | Digital Theater Systems, Inc. | Method of decoding two-channel matrix encoded audio to reconstruct multichannel audio |
| SE0004163D0 (sv) | 2000-11-14 | 2000-11-14 | Coding Technologies Sweden Ab | Enhancing perceptual performance of high frequency reconstruction coding methods by adaptive filtering |
| US20020128839A1 (en) | 2001-01-12 | 2002-09-12 | Ulf Lindgren | Speech bandwidth extension |
| WO2002058053A1 (en) | 2001-01-22 | 2002-07-25 | Kanars Data Corporation | Encoding method and decoding method for digital voice data |
| JP2002268693A (ja) | 2001-03-12 | 2002-09-20 | Mitsubishi Electric Corp | オーディオ符号化装置 |
| SE522553C2 (sv) | 2001-04-23 | 2004-02-17 | Ericsson Telefon Ab L M | Bandbreddsutsträckning av akustiska signaler |
| US6934676B2 (en) | 2001-05-11 | 2005-08-23 | Nokia Mobile Phones Ltd. | Method and system for inter-channel signal redundancy removal in perceptual audio coding |
| SE0202159D0 (sv) | 2001-07-10 | 2002-07-09 | Coding Technologies Sweden Ab | Efficientand scalable parametric stereo coding for low bitrate applications |
| JP2003108197A (ja) * | 2001-07-13 | 2003-04-11 | Matsushita Electric Ind Co Ltd | オーディオ信号復号化装置およびオーディオ信号符号化装置 |
| MXPA03002115A (es) * | 2001-07-13 | 2003-08-26 | Matsushita Electric Ind Co Ltd | DISPOSITIVO DE DECODIFICACION Y CODIFICACION DE SEnAL DE AUDIO. |
| EP1446797B1 (en) * | 2001-10-25 | 2007-05-23 | Koninklijke Philips Electronics N.V. | Method of transmission of wideband audio signals on a transmission channel with reduced bandwidth |
| JP3923783B2 (ja) * | 2001-11-02 | 2007-06-06 | 松下電器産業株式会社 | 符号化装置及び復号化装置 |
| JP4308229B2 (ja) | 2001-11-14 | 2009-08-05 | パナソニック株式会社 | 符号化装置および復号化装置 |
| EP1423847B1 (en) | 2001-11-29 | 2005-02-02 | Coding Technologies AB | Reconstruction of high frequency components |
| US7240001B2 (en) | 2001-12-14 | 2007-07-03 | Microsoft Corporation | Quality improvement techniques in an audio encoder |
| US6934677B2 (en) | 2001-12-14 | 2005-08-23 | Microsoft Corporation | Quantization matrices based on critical band pattern information for digital audio wherein quantization bands differ from critical bands |
| US7146313B2 (en) | 2001-12-14 | 2006-12-05 | Microsoft Corporation | Techniques for measurement of perceptual audio quality |
| US7206740B2 (en) * | 2002-01-04 | 2007-04-17 | Broadcom Corporation | Efficient excitation quantization in noise feedback coding with general noise shaping |
| DE60323331D1 (de) | 2002-01-30 | 2008-10-16 | Matsushita Electric Ind Co Ltd | Verfahren und vorrichtung zur audio-kodierung und -dekodierung |
| US20030187663A1 (en) * | 2002-03-28 | 2003-10-02 | Truman Michael Mead | Broadband frequency translation for high frequency regeneration |
| RU2316154C2 (ru) * | 2002-04-10 | 2008-01-27 | Конинклейке Филипс Электроникс Н.В. | Кодирование стереофонических сигналов |
| US20030220800A1 (en) * | 2002-05-21 | 2003-11-27 | Budnikov Dmitry N. | Coding multichannel audio signals |
| US7447631B2 (en) * | 2002-06-17 | 2008-11-04 | Dolby Laboratories Licensing Corporation | Audio coding system using spectral hole filling |
| EP1516514A1 (en) * | 2002-06-12 | 2005-03-23 | Equtech APS | Method of digital equalisation of a sound from loudspeakers in rooms and use of the method |
| KR100462615B1 (ko) * | 2002-07-11 | 2004-12-20 | 삼성전자주식회사 | 적은 계산량으로 고주파수 성분을 복원하는 오디오 디코딩방법 및 장치 |
| DE20321883U1 (de) | 2002-09-04 | 2012-01-20 | Microsoft Corp. | Computervorrichtung und -system zum Entropiedecodieren quantisierter Transformationskoeffizienten eines Blockes |
| US7299190B2 (en) * | 2002-09-04 | 2007-11-20 | Microsoft Corporation | Quantization and inverse quantization for audio |
| US7502743B2 (en) * | 2002-09-04 | 2009-03-10 | Microsoft Corporation | Multi-channel audio encoding and decoding with multi-channel transform selection |
| KR100501930B1 (ko) * | 2002-11-29 | 2005-07-18 | 삼성전자주식회사 | 적은 계산량으로 고주파수 성분을 복원하는 오디오 디코딩방법 및 장치 |
| US7318027B2 (en) | 2003-02-06 | 2008-01-08 | Dolby Laboratories Licensing Corporation | Conversion of synthesized spectral components for encoding and low-complexity transcoding |
| FR2852172A1 (fr) * | 2003-03-04 | 2004-09-10 | France Telecom | Procede et dispositif de reconstruction spectrale d'un signal audio |
| RU2244386C2 (ru) | 2003-03-28 | 2005-01-10 | Корпорация "Самсунг Электроникс" | Способ восстановления высокочастотной составляющей аудиосигнала и устройство для его реализации |
| US8311809B2 (en) | 2003-04-17 | 2012-11-13 | Koninklijke Philips Electronics N.V. | Converting decoded sub-band signal into a stereo signal |
| US7318035B2 (en) * | 2003-05-08 | 2008-01-08 | Dolby Laboratories Licensing Corporation | Audio coding systems and methods using spectral component coupling and spectral component regeneration |
| US20050004793A1 (en) | 2003-07-03 | 2005-01-06 | Pasi Ojala | Signal adaptation for higher band coding in a codec utilizing band split coding |
| CN1839426A (zh) * | 2003-09-17 | 2006-09-27 | 北京阜国数字技术有限公司 | 多分辨率矢量量化的音频编解码方法及装置 |
| DE10345996A1 (de) * | 2003-10-02 | 2005-04-28 | Fraunhofer Ges Forschung | Vorrichtung und Verfahren zum Verarbeiten von wenigstens zwei Eingangswerten |
| US7447317B2 (en) | 2003-10-02 | 2008-11-04 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V | Compatible multi-channel coding/decoding by weighting the downmix channel |
| DE10345995B4 (de) * | 2003-10-02 | 2005-07-07 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Vorrichtung und Verfahren zum Verarbeiten eines Signals mit einer Sequenz von diskreten Werten |
| ES2282899T3 (es) | 2003-10-30 | 2007-10-16 | Koninklijke Philips Electronics N.V. | Codificacion o descodificacion de señales de audio. |
| US7460990B2 (en) * | 2004-01-23 | 2008-12-02 | Microsoft Corporation | Efficient coding of digital media spectral data using wide-sense perceptual similarity |
| DE102004007184B3 (de) | 2004-02-13 | 2005-09-22 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Verfahren und Vorrichtung zum Quantisieren eines Informationssignals |
| DE102004007200B3 (de) | 2004-02-13 | 2005-08-11 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audiocodierung |
| DE102004007191B3 (de) | 2004-02-13 | 2005-09-01 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audiocodierung |
| CA2457988A1 (en) * | 2004-02-18 | 2005-08-18 | Voiceage Corporation | Methods and devices for audio compression based on acelp/tcx coding and multi-rate lattice vector quantization |
| DE602005014288D1 (de) | 2004-03-01 | 2009-06-10 | Dolby Lab Licensing Corp | Mehrkanalige Audiodekodierung |
| US7739119B2 (en) | 2004-03-02 | 2010-06-15 | Ittiam Systems (P) Ltd. | Technique for implementing Huffman decoding |
| US7392195B2 (en) * | 2004-03-25 | 2008-06-24 | Dts, Inc. | Lossless multi-channel audio codec |
| CN1677492A (zh) * | 2004-04-01 | 2005-10-05 | 北京宫羽数字技术有限责任公司 | 一种增强音频编解码装置及方法 |
| CN1677493A (zh) * | 2004-04-01 | 2005-10-05 | 北京宫羽数字技术有限责任公司 | 一种增强音频编解码装置及方法 |
| WO2005096274A1 (fr) * | 2004-04-01 | 2005-10-13 | Beijing Media Works Co., Ltd | Dispositif et procede de codage/decodage audio ameliores |
| CN1677491A (zh) * | 2004-04-01 | 2005-10-05 | 北京宫羽数字技术有限责任公司 | 一种增强音频编解码装置及方法 |
| JP4938648B2 (ja) * | 2004-04-05 | 2012-05-23 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | マルチチャンネル・エンコーダ |
| US7668711B2 (en) | 2004-04-23 | 2010-02-23 | Panasonic Corporation | Coding equipment |
| CN1947174B (zh) * | 2004-04-27 | 2012-03-14 | 松下电器产业株式会社 | 可扩展编码装置、可扩展解码装置、可扩展编码方法以及可扩展解码方法 |
| DE102004021403A1 (de) * | 2004-04-30 | 2005-11-24 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Informationssignalverarbeitung durch Modifikation in der Spektral-/Modulationsspektralbereichsdarstellung |
| ATE394774T1 (de) * | 2004-05-19 | 2008-05-15 | Matsushita Electric Ind Co Ltd | Kodierungs-, dekodierungsvorrichtung und methode dafür |
| US7649988B2 (en) | 2004-06-15 | 2010-01-19 | Acoustic Technologies, Inc. | Comfort noise generator using modified Doblinger noise estimate |
| JP2006003580A (ja) * | 2004-06-17 | 2006-01-05 | Matsushita Electric Ind Co Ltd | オーディオ信号符号化装置及びオーディオ信号符号化方法 |
| CA2572805C (en) * | 2004-07-02 | 2013-08-13 | Matsushita Electric Industrial Co., Ltd. | Audio signal decoding device and audio signal encoding device |
| US7465389B2 (en) | 2004-07-09 | 2008-12-16 | Exxonmobil Research And Engineering Company | Production of extra-heavy lube oils from Fischer-Tropsch wax |
| US6963405B1 (en) | 2004-07-19 | 2005-11-08 | Itt Manufacturing Enterprises, Inc. | Laser counter-measure using fourier transform imaging spectrometers |
| KR100608062B1 (ko) * | 2004-08-04 | 2006-08-02 | 삼성전자주식회사 | 오디오 데이터의 고주파수 복원 방법 및 그 장치 |
| TWI498882B (zh) | 2004-08-25 | 2015-09-01 | Dolby Lab Licensing Corp | 音訊解碼器 |
| RU2404506C2 (ru) | 2004-11-05 | 2010-11-20 | Панасоник Корпорэйшн | Устройство масштабируемого декодирования и устройство масштабируемого кодирования |
| EP2752843A1 (en) | 2004-11-05 | 2014-07-09 | Panasonic Corporation | Encoder, decoder, encoding method, and decoding method |
| KR100721537B1 (ko) * | 2004-12-08 | 2007-05-23 | 한국전자통신연구원 | 광대역 음성 부호화기의 고대역 음성 부호화 장치 및 그방법 |
| JP4903053B2 (ja) * | 2004-12-10 | 2012-03-21 | パナソニック株式会社 | 広帯域符号化装置、広帯域lsp予測装置、帯域スケーラブル符号化装置及び広帯域符号化方法 |
| KR100707174B1 (ko) * | 2004-12-31 | 2007-04-13 | 삼성전자주식회사 | 광대역 음성 부호화 및 복호화 시스템에서 고대역 음성부호화 및 복호화 장치와 그 방법 |
| US20070147518A1 (en) * | 2005-02-18 | 2007-06-28 | Bruno Bessette | Methods and devices for low-frequency emphasis during audio compression based on ACELP/TCX |
| SG163556A1 (en) | 2005-04-01 | 2010-08-30 | Qualcomm Inc | Systems, methods, and apparatus for wideband speech coding |
| UA91853C2 (ru) * | 2005-04-01 | 2010-09-10 | Квелкомм Инкорпорейтед | Способ и устройство для векторного квантования спектрального представления огибающей |
| WO2006108543A1 (en) * | 2005-04-15 | 2006-10-19 | Coding Technologies Ab | Temporal envelope shaping of decorrelated signal |
| US7983922B2 (en) | 2005-04-15 | 2011-07-19 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method for generating multi-channel synthesizer control signal and apparatus and method for multi-channel synthesizing |
| PT1875463T (pt) | 2005-04-22 | 2019-01-24 | Qualcomm Inc | Sistemas, métodos e aparelho para nivelamento de fator de ganho |
| US7698143B2 (en) | 2005-05-17 | 2010-04-13 | Mitsubishi Electric Research Laboratories, Inc. | Constructing broad-band acoustic signals from lower-band acoustic signals |
| JP2006323037A (ja) * | 2005-05-18 | 2006-11-30 | Matsushita Electric Ind Co Ltd | オーディオ信号復号化装置 |
| JP5118022B2 (ja) | 2005-05-26 | 2013-01-16 | エルジー エレクトロニクス インコーポレイティド | オーディオ信号の符号化/復号化方法及び符号化/復号化装置 |
| WO2006134992A1 (ja) * | 2005-06-17 | 2006-12-21 | Matsushita Electric Industrial Co., Ltd. | ポストフィルタ、復号化装置及びポストフィルタ処理方法 |
| US7548853B2 (en) * | 2005-06-17 | 2009-06-16 | Shmunk Dmitry V | Scalable compressed audio bit stream and codec using a hierarchical filterbank and multichannel joint coding |
| JP2009500656A (ja) | 2005-06-30 | 2009-01-08 | エルジー エレクトロニクス インコーポレイティド | オーディオ信号をエンコーディング及びデコーディングするための装置とその方法 |
| US7411528B2 (en) * | 2005-07-11 | 2008-08-12 | Lg Electronics Co., Ltd. | Apparatus and method of processing an audio signal |
| US7539612B2 (en) * | 2005-07-15 | 2009-05-26 | Microsoft Corporation | Coding and decoding scale factor information |
| KR100803205B1 (ko) | 2005-07-15 | 2008-02-14 | 삼성전자주식회사 | 저비트율 오디오 신호 부호화/복호화 방법 및 장치 |
| JP4640020B2 (ja) | 2005-07-29 | 2011-03-02 | ソニー株式会社 | 音声符号化装置及び方法、並びに音声復号装置及び方法 |
| CN100539437C (zh) | 2005-07-29 | 2009-09-09 | 上海杰得微电子有限公司 | 一种音频编解码器的实现方法 |
| WO2007055462A1 (en) | 2005-08-30 | 2007-05-18 | Lg Electronics Inc. | Apparatus for encoding and decoding audio signal and method thereof |
| US7974713B2 (en) | 2005-10-12 | 2011-07-05 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Temporal and spatial shaping of multi-channel audio signals |
| US20080255859A1 (en) * | 2005-10-20 | 2008-10-16 | Lg Electronics, Inc. | Method for Encoding and Decoding Multi-Channel Audio Signal and Apparatus Thereof |
| US8620644B2 (en) | 2005-10-26 | 2013-12-31 | Qualcomm Incorporated | Encoder-assisted frame loss concealment techniques for audio coding |
| KR20070046752A (ko) * | 2005-10-31 | 2007-05-03 | 엘지전자 주식회사 | 신호 처리 방법 및 장치 |
| US7720677B2 (en) * | 2005-11-03 | 2010-05-18 | Coding Technologies Ab | Time warped modified transform coding of audio signals |
| KR100717058B1 (ko) * | 2005-11-28 | 2007-05-14 | 삼성전자주식회사 | 고주파 성분 복원 방법 및 그 장치 |
| US8255207B2 (en) | 2005-12-28 | 2012-08-28 | Voiceage Corporation | Method and device for efficient frame erasure concealment in speech codecs |
| US7831434B2 (en) | 2006-01-20 | 2010-11-09 | Microsoft Corporation | Complex-transform channel coding with extended-band frequency coding |
| HUE066862T2 (hu) * | 2006-01-27 | 2024-09-28 | Dolby Int Ab | Hatékony szûrés komplex modulált szûrõbankkal |
| EP1852848A1 (en) * | 2006-05-05 | 2007-11-07 | Deutsche Thomson-Brandt GmbH | Method and apparatus for lossless encoding of a source signal using a lossy encoded data stream and a lossless extension data stream |
| KR20070115637A (ko) * | 2006-06-03 | 2007-12-06 | 삼성전자주식회사 | 대역폭 확장 부호화 및 복호화 방법 및 장치 |
| US7873511B2 (en) * | 2006-06-30 | 2011-01-18 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Audio encoder, audio decoder and audio processor having a dynamically variable warping characteristic |
| US8682652B2 (en) * | 2006-06-30 | 2014-03-25 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Audio encoder, audio decoder and audio processor having a dynamically variable warping characteristic |
| CN101512899B (zh) * | 2006-07-04 | 2012-12-26 | 杜比国际公司 | 滤波器压缩器以及用于产生压缩子带滤波器冲激响应的方法 |
| US9454974B2 (en) * | 2006-07-31 | 2016-09-27 | Qualcomm Incorporated | Systems, methods, and apparatus for gain factor limiting |
| US8260609B2 (en) * | 2006-07-31 | 2012-09-04 | Qualcomm Incorporated | Systems, methods, and apparatus for wideband encoding and decoding of inactive frames |
| US8135047B2 (en) | 2006-07-31 | 2012-03-13 | Qualcomm Incorporated | Systems and methods for including an identifier with a packet associated with a speech signal |
| DE602006013359D1 (de) | 2006-09-13 | 2010-05-12 | Ericsson Telefon Ab L M | Ender und empfänger |
| CN102892070B (zh) * | 2006-10-16 | 2016-02-24 | 杜比国际公司 | 多声道下混对象编码的增强编码和参数表示 |
| JP4936569B2 (ja) | 2006-10-25 | 2012-05-23 | フラウンホーファー−ゲゼルシャフト・ツール・フェルデルング・デル・アンゲヴァンテン・フォルシュング・アインゲトラーゲネル・フェライン | オーディオ副帯値を生成する装置及び方法、並びに、時間領域オーディオサンプルを生成する装置及び方法 |
| US20080243518A1 (en) * | 2006-11-16 | 2008-10-02 | Alexey Oraevsky | System And Method For Compressing And Reconstructing Audio Files |
| JP5231243B2 (ja) * | 2006-11-28 | 2013-07-10 | パナソニック株式会社 | 符号化装置及び符号化方法 |
| JP5238512B2 (ja) | 2006-12-13 | 2013-07-17 | パナソニック株式会社 | オーディオ信号符号化方法及び復号化方法 |
| US8200351B2 (en) | 2007-01-05 | 2012-06-12 | STMicroelectronics Asia PTE., Ltd. | Low power downmix energy equalization in parametric stereo encoders |
| MX2009007412A (es) | 2007-01-10 | 2009-07-17 | Koninkl Philips Electronics Nv | Decodificador de audio. |
| JP2010519602A (ja) | 2007-02-26 | 2010-06-03 | クゥアルコム・インコーポレイテッド | 信号分離のためのシステム、方法、および装置 |
| US20080208575A1 (en) * | 2007-02-27 | 2008-08-28 | Nokia Corporation | Split-band encoding and decoding of an audio signal |
| JP5294713B2 (ja) | 2007-03-02 | 2013-09-18 | パナソニック株式会社 | 符号化装置、復号装置およびそれらの方法 |
| KR101355376B1 (ko) | 2007-04-30 | 2014-01-23 | 삼성전자주식회사 | 고주파수 영역 부호화 및 복호화 방법 및 장치 |
| KR101411900B1 (ko) | 2007-05-08 | 2014-06-26 | 삼성전자주식회사 | 오디오 신호의 부호화 및 복호화 방법 및 장치 |
| CN101067931B (zh) * | 2007-05-10 | 2011-04-20 | 芯晟(北京)科技有限公司 | 一种高效可配置的频域参数立体声及多声道编解码方法与系统 |
| ES2358786T3 (es) * | 2007-06-08 | 2011-05-13 | Dolby Laboratories Licensing Corporation | Derivación híbrida de canales de audio de sonido envolvente combinando de manera controlable componentes de señal de sonido ambiente y con decodificación matricial. |
| CN101325059B (zh) * | 2007-06-15 | 2011-12-21 | 华为技术有限公司 | 语音编解码收发方法及装置 |
| US7774205B2 (en) | 2007-06-15 | 2010-08-10 | Microsoft Corporation | Coding of sparse digital media spectral data |
| US7885819B2 (en) * | 2007-06-29 | 2011-02-08 | Microsoft Corporation | Bitstream syntax for multi-process audio decoding |
| US8428957B2 (en) * | 2007-08-24 | 2013-04-23 | Qualcomm Incorporated | Spectral noise shaping in audio coding based on spectral dynamics in frequency sub-bands |
| EP2571024B1 (en) * | 2007-08-27 | 2014-10-22 | Telefonaktiebolaget L M Ericsson AB (Publ) | Adaptive transition frequency between noise fill and bandwidth extension |
| JP5255638B2 (ja) * | 2007-08-27 | 2013-08-07 | テレフオンアクチーボラゲット エル エム エリクソン(パブル) | ノイズ補充の方法及び装置 |
| DE102007048973B4 (de) * | 2007-10-12 | 2010-11-18 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Vorrichtung und Verfahren zum Erzeugen eines Multikanalsignals mit einer Sprachsignalverarbeitung |
| US8527265B2 (en) | 2007-10-22 | 2013-09-03 | Qualcomm Incorporated | Low-complexity encoding/decoding of quantized MDCT spectrum in scalable speech and audio codecs |
| US9177569B2 (en) * | 2007-10-30 | 2015-11-03 | Samsung Electronics Co., Ltd. | Apparatus, medium and method to encode and decode high frequency signal |
| KR101373004B1 (ko) * | 2007-10-30 | 2014-03-26 | 삼성전자주식회사 | 고주파수 신호 부호화 및 복호화 장치 및 방법 |
| EP2207166B1 (en) * | 2007-11-02 | 2013-06-19 | Huawei Technologies Co., Ltd. | An audio decoding method and device |
| KR101586317B1 (ko) | 2007-11-21 | 2016-01-18 | 엘지전자 주식회사 | 신호 처리 방법 및 장치 |
| US8688441B2 (en) * | 2007-11-29 | 2014-04-01 | Motorola Mobility Llc | Method and apparatus to facilitate provision and use of an energy value to determine a spectral envelope shape for out-of-signal bandwidth content |
| AU2008344134B2 (en) | 2007-12-31 | 2011-08-25 | Lg Electronics Inc. | A method and an apparatus for processing an audio signal |
| DE602008005250D1 (de) * | 2008-01-04 | 2011-04-14 | Dolby Sweden Ab | Audiokodierer und -dekodierer |
| US20090180531A1 (en) | 2008-01-07 | 2009-07-16 | Radlive Ltd. | codec with plc capabilities |
| KR101413967B1 (ko) | 2008-01-29 | 2014-07-01 | 삼성전자주식회사 | 오디오 신호의 부호화 방법 및 복호화 방법, 및 그에 대한 기록 매체, 오디오 신호의 부호화 장치 및 복호화 장치 |
| EP2248263B1 (en) | 2008-01-31 | 2012-12-26 | Agency for Science, Technology And Research | Method and device of bitrate distribution/truncation for scalable audio coding |
| US8391498B2 (en) | 2008-02-14 | 2013-03-05 | Dolby Laboratories Licensing Corporation | Stereophonic widening |
| AU2009221444B2 (en) * | 2008-03-04 | 2012-06-14 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Mixing of input data streams and generation of an output data stream therefrom |
| WO2009109050A1 (en) * | 2008-03-05 | 2009-09-11 | Voiceage Corporation | System and method for enhancing a decoded tonal sound signal |
| EP3296992B1 (en) | 2008-03-20 | 2021-09-22 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for modifying a parameterized representation |
| KR20090110244A (ko) * | 2008-04-17 | 2009-10-21 | 삼성전자주식회사 | 오디오 시맨틱 정보를 이용한 오디오 신호의 부호화/복호화 방법 및 그 장치 |
| EP2301017B1 (en) * | 2008-05-09 | 2016-12-21 | Nokia Technologies Oy | Audio apparatus |
| US20090319263A1 (en) | 2008-06-20 | 2009-12-24 | Qualcomm Incorporated | Coding of transitional speech frames for low-bit-rate applications |
| CN103077722B (zh) | 2008-07-11 | 2015-07-22 | 弗劳恩霍夫应用研究促进协会 | 提供时间扭曲激活信号以及使用该时间扭曲激活信号对音频信号编码 |
| MX2011000367A (es) | 2008-07-11 | 2011-03-02 | Fraunhofer Ges Forschung | Un aparato y un metodo para calcular una cantidad de envolventes espectrales. |
| PL2346030T3 (pl) | 2008-07-11 | 2015-03-31 | Fraunhofer Ges Forschung | Koder audio, sposób kodowania sygnału audio oraz program komputerowy |
| ES2683077T3 (es) * | 2008-07-11 | 2018-09-24 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Codificador y decodificador de audio para codificar y decodificar tramas de una señal de audio muestreada |
| ES2422412T3 (es) | 2008-07-11 | 2013-09-11 | Fraunhofer Ges Forschung | Codificador de audio, procedimiento para la codificación de audio y programa de ordenador |
| CN102089813B (zh) * | 2008-07-11 | 2013-11-20 | 弗劳恩霍夫应用研究促进协会 | 音频编码器和音频解码器 |
| EP2144230A1 (en) | 2008-07-11 | 2010-01-13 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Low bitrate audio encoding/decoding scheme having cascaded switches |
| ATE522901T1 (de) | 2008-07-11 | 2011-09-15 | Fraunhofer Ges Forschung | Vorrichtung und verfahren zur berechnung von bandbreitenerweiterungsdaten mit hilfe eines spektralneigungs-steuerungsrahmens |
| RU2491658C2 (ru) * | 2008-07-11 | 2013-08-27 | Фраунхофер-Гезелльшафт цур Фёрдерунг дер ангевандтен Форшунг Е.Ф. | Синтезатор аудиосигнала и кодирующее устройство аудиосигнала |
| EP2154911A1 (en) | 2008-08-13 | 2010-02-17 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | An apparatus for determining a spatial output multi-channel audio signal |
| WO2010028292A1 (en) | 2008-09-06 | 2010-03-11 | Huawei Technologies Co., Ltd. | Adaptive frequency prediction |
| US8463603B2 (en) | 2008-09-06 | 2013-06-11 | Huawei Technologies Co., Ltd. | Spectral envelope coding of energy attack signal |
| WO2010031049A1 (en) | 2008-09-15 | 2010-03-18 | GH Innovation, Inc. | Improving celp post-processing for music signals |
| JP5295372B2 (ja) * | 2008-09-17 | 2013-09-18 | フランス・テレコム | デジタルオーディオ信号におけるプリエコーの減衰 |
| EP2224433B1 (en) * | 2008-09-25 | 2020-05-27 | Lg Electronics Inc. | An apparatus for processing an audio signal and method thereof |
| US9947340B2 (en) * | 2008-12-10 | 2018-04-17 | Skype | Regeneration of wideband speech |
| ES2976382T3 (es) | 2008-12-15 | 2024-07-31 | Fraunhofer Ges Zur Foerderungder Angewandten Forschung E V | Decodificador de extensión de ancho de banda |
| JP5423684B2 (ja) * | 2008-12-19 | 2014-02-19 | 富士通株式会社 | 音声帯域拡張装置及び音声帯域拡張方法 |
| BR122019023704B1 (pt) | 2009-01-16 | 2020-05-05 | Dolby Int Ab | sistema para gerar um componente de frequência alta de um sinal de áudio e método para realizar reconstrução de frequência alta de um componente de frequência alta |
| JP4977157B2 (ja) * | 2009-03-06 | 2012-07-18 | 株式会社エヌ・ティ・ティ・ドコモ | 音信号符号化方法、音信号復号方法、符号化装置、復号装置、音信号処理システム、音信号符号化プログラム、及び、音信号復号プログラム |
| JP5214058B2 (ja) * | 2009-03-17 | 2013-06-19 | ドルビー インターナショナル アーベー | 適応的に選択可能な左/右又はミッド/サイド・ステレオ符号化及びパラメトリック・ステレオ符号化の組み合わせに基づいた高度ステレオ符号化 |
| EP2239732A1 (en) | 2009-04-09 | 2010-10-13 | Fraunhofer-Gesellschaft zur Förderung der Angewandten Forschung e.V. | Apparatus and method for generating a synthesis audio signal and for encoding an audio signal |
| JP4932917B2 (ja) * | 2009-04-03 | 2012-05-16 | 株式会社エヌ・ティ・ティ・ドコモ | 音声復号装置、音声復号方法、及び音声復号プログラム |
| CN101521014B (zh) * | 2009-04-08 | 2011-09-14 | 武汉大学 | 音频带宽扩展编解码装置 |
| US8391212B2 (en) * | 2009-05-05 | 2013-03-05 | Huawei Technologies Co., Ltd. | System and method for frequency domain audio post-processing based on perceptual masking |
| EP2249333B1 (en) * | 2009-05-06 | 2014-08-27 | Nuance Communications, Inc. | Method and apparatus for estimating a fundamental frequency of a speech signal |
| CN101556799B (zh) | 2009-05-14 | 2013-08-28 | 华为技术有限公司 | 一种音频解码方法和音频解码器 |
| TWI556227B (zh) | 2009-05-27 | 2016-11-01 | 杜比國際公司 | 從訊號的低頻成份產生該訊號之高頻成份的系統與方法,及其機上盒、電腦程式產品、軟體程式及儲存媒體 |
| CN101609680B (zh) * | 2009-06-01 | 2012-01-04 | 华为技术有限公司 | 压缩编码和解码的方法、编码器和解码器以及编码装置 |
| EP2273493B1 (en) | 2009-06-29 | 2012-12-19 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Bandwidth extension encoding and decoding |
| MY167512A (en) | 2009-07-07 | 2018-09-04 | Xtralis Technologies Ltd | Chamber condition |
| US8793617B2 (en) * | 2009-07-30 | 2014-07-29 | Microsoft Corporation | Integrating transport modes into a communication stream |
| US9031834B2 (en) | 2009-09-04 | 2015-05-12 | Nuance Communications, Inc. | Speech enhancement techniques on the power spectrum |
| GB2473267A (en) | 2009-09-07 | 2011-03-09 | Nokia Corp | Processing audio signals to reduce noise |
| AU2010305383B2 (en) * | 2009-10-08 | 2013-10-03 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Multi-mode audio signal decoder, multi-mode audio signal encoder, methods and computer program using a linear-prediction-coding based noise shaping |
| KR101137652B1 (ko) | 2009-10-14 | 2012-04-23 | 광운대학교 산학협력단 | 천이 구간에 기초하여 윈도우의 오버랩 영역을 조절하는 통합 음성/오디오 부호화/복호화 장치 및 방법 |
| EP4358082A1 (en) | 2009-10-20 | 2024-04-24 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio signal encoder, audio signal decoder, method for encoding or decoding an audio signal using an aliasing-cancellation |
| EP2491555B1 (en) | 2009-10-20 | 2014-03-05 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Multi-mode audio codec |
| EP3998606B8 (en) * | 2009-10-21 | 2022-12-07 | Dolby International AB | Oversampling in a combined transposer filter bank |
| US8484020B2 (en) * | 2009-10-23 | 2013-07-09 | Qualcomm Incorporated | Determining an upperband signal from a narrowband signal |
| US8856011B2 (en) | 2009-11-19 | 2014-10-07 | Telefonaktiebolaget L M Ericsson (Publ) | Excitation signal bandwidth extension |
| CN102081927B (zh) | 2009-11-27 | 2012-07-18 | 中兴通讯股份有限公司 | 一种可分层音频编码、解码方法及系统 |
| SI2510515T1 (sl) | 2009-12-07 | 2014-06-30 | Dolby Laboratories Licensing Corporation | Dekodiranje večkanalnih avdio kodiranih bitnih prenosov s pomočjo adaptivne hibridne transformacije |
| KR101764926B1 (ko) | 2009-12-10 | 2017-08-03 | 삼성전자주식회사 | 음향 통신을 위한 장치 및 방법 |
| CN102667920B (zh) * | 2009-12-16 | 2014-03-12 | 杜比国际公司 | Sbr比特流参数缩混 |
| EP2357649B1 (en) | 2010-01-21 | 2012-12-19 | Electronics and Telecommunications Research Institute | Method and apparatus for decoding audio signal |
| CN102194457B (zh) * | 2010-03-02 | 2013-02-27 | 中兴通讯股份有限公司 | 音频编解码方法、系统及噪声水平估计方法 |
| JP5523589B2 (ja) | 2010-03-09 | 2014-06-18 | フラウンホーファーゲゼルシャフト ツール フォルデルング デル アンゲヴァンテン フォルシユング エー.フアー. | カスケード式フィルタバンクを用いて入力オーディオ信号を処理するための装置および方法 |
| EP2369861B1 (en) | 2010-03-25 | 2016-07-27 | Nxp B.V. | Multi-channel audio signal processing |
| RU2683175C2 (ru) * | 2010-04-09 | 2019-03-26 | Долби Интернешнл Аб | Стереофоническое кодирование на основе mdct с комплексным предсказанием |
| EP2375409A1 (en) | 2010-04-09 | 2011-10-12 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio encoder, audio decoder and related methods for processing multi-channel audio signals using complex prediction |
| PL3779979T3 (pl) | 2010-04-13 | 2024-01-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Sposób dekodowania audio do przetwarzania sygnałów audio stereo z wykorzystaniem zmiennego kierunku predykcji |
| US8886523B2 (en) | 2010-04-14 | 2014-11-11 | Huawei Technologies Co., Ltd. | Audio decoding based on audio class with control code for post-processing modes |
| TR201904117T4 (tr) | 2010-04-16 | 2019-05-21 | Fraunhofer Ges Forschung | Kılavuzlu bant genişliği uzantısı ve gözü kapalı bant genişliği uzantısı kullanılarak bir geniş bantlı sinyal üretilmesine yönelik aparat, yöntem ve bilgisayar programı. |
| US8600737B2 (en) | 2010-06-01 | 2013-12-03 | Qualcomm Incorporated | Systems, methods, apparatus, and computer program products for wideband speech coding |
| PL2581905T3 (pl) | 2010-06-09 | 2016-06-30 | Panasonic Ip Corp America | Sposób rozszerzania pasma częstotliwości, urządzenie do rozszerzania pasma częstotliwości, program, układ scalony oraz urządzenie dekodujące audio |
| US9047875B2 (en) * | 2010-07-19 | 2015-06-02 | Futurewei Technologies, Inc. | Spectrum flatness control for bandwidth extension |
| US9236063B2 (en) * | 2010-07-30 | 2016-01-12 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for dynamic bit allocation |
| JP6075743B2 (ja) | 2010-08-03 | 2017-02-08 | ソニー株式会社 | 信号処理装置および方法、並びにプログラム |
| US8489403B1 (en) | 2010-08-25 | 2013-07-16 | Foundation For Research and Technology—Institute of Computer Science ‘FORTH-ICS’ | Apparatuses, methods and systems for sparse sinusoidal audio processing and transmission |
| KR101826331B1 (ko) | 2010-09-15 | 2018-03-22 | 삼성전자주식회사 | 고주파수 대역폭 확장을 위한 부호화/복호화 장치 및 방법 |
| KR101624019B1 (ko) * | 2011-02-14 | 2016-06-07 | 프라운호퍼 게젤샤프트 쭈르 푀르데룽 데어 안겐반텐 포르슝 에. 베. | 오디오 코덱에서 잡음 생성 |
| JP6185457B2 (ja) | 2011-04-28 | 2017-08-23 | ドルビー・インターナショナル・アーベー | 効率的なコンテンツ分類及びラウドネス推定 |
| US9311923B2 (en) | 2011-05-19 | 2016-04-12 | Dolby Laboratories Licensing Corporation | Adaptive audio processing based on forensic detection of media processing history |
| WO2012158333A1 (en) * | 2011-05-19 | 2012-11-22 | Dolby Laboratories Licensing Corporation | Forensic detection of parametric audio coding schemes |
| KR102078865B1 (ko) | 2011-06-30 | 2020-02-19 | 삼성전자주식회사 | 대역폭 확장신호 생성장치 및 방법 |
| DE102011106033A1 (de) * | 2011-06-30 | 2013-01-03 | Zte Corporation | Verfahren und System zur Audiocodierung und -decodierung und Verfahren zur Schätzung des Rauschpegels |
| US20130006644A1 (en) | 2011-06-30 | 2013-01-03 | Zte Corporation | Method and device for spectral band replication, and method and system for audio decoding |
| JP5942358B2 (ja) | 2011-08-24 | 2016-06-29 | ソニー株式会社 | 符号化装置および方法、復号装置および方法、並びにプログラム |
| JP6037156B2 (ja) * | 2011-08-24 | 2016-11-30 | ソニー株式会社 | 符号化装置および方法、並びにプログラム |
| KR20130022549A (ko) | 2011-08-25 | 2013-03-07 | 삼성전자주식회사 | 마이크 노이즈 제거 방법 및 이를 지원하는 휴대 단말기 |
| CN103718240B (zh) | 2011-09-09 | 2017-02-15 | 松下电器(美国)知识产权公司 | 编码装置、解码装置、编码方法和解码方法 |
| IN2014CN01270A (es) | 2011-09-29 | 2015-06-19 | Dolby Int Ab | |
| PL3624119T3 (pl) * | 2011-10-28 | 2022-06-20 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Urządzenie kodujące i sposób kodowania |
| ES2592522T3 (es) * | 2011-11-02 | 2016-11-30 | Telefonaktiebolaget L M Ericsson (Publ) | Codificación de audio basada en representación de coeficientes auto-regresivos |
| CN103959375B (zh) * | 2011-11-30 | 2016-11-09 | 杜比国际公司 | 增强的从音频编解码器的色度提取 |
| JP5817499B2 (ja) | 2011-12-15 | 2015-11-18 | 富士通株式会社 | 復号装置、符号化装置、符号化復号システム、復号方法、符号化方法、復号プログラム、及び符号化プログラム |
| CN103165136A (zh) | 2011-12-15 | 2013-06-19 | 杜比实验室特许公司 | 音频处理方法及音频处理设备 |
| US9390721B2 (en) | 2012-01-20 | 2016-07-12 | Panasonic Intellectual Property Corporation Of America | Speech decoding device and speech decoding method |
| KR101398189B1 (ko) | 2012-03-27 | 2014-05-22 | 광주과학기술원 | 음성수신장치 및 음성수신방법 |
| KR102123770B1 (ko) * | 2012-03-29 | 2020-06-16 | 텔레폰악티에볼라겟엘엠에릭슨(펍) | 하모닉 오디오 신호의 변환 인코딩/디코딩 |
| RU2610293C2 (ru) * | 2012-03-29 | 2017-02-08 | Телефонактиеболагет Лм Эрикссон (Пабл) | Расширение полосы частот гармонического аудиосигнала |
| CN102750955B (zh) * | 2012-07-20 | 2014-06-18 | 中国科学院自动化研究所 | 基于残差信号频谱重构的声码器 |
| US9589570B2 (en) | 2012-09-18 | 2017-03-07 | Huawei Technologies Co., Ltd. | Audio classification based on perceptual quality for low or medium bit rates |
| WO2014046526A1 (ko) | 2012-09-24 | 2014-03-27 | 삼성전자 주식회사 | 프레임 에러 은닉방법 및 장치와 오디오 복호화방법 및 장치 |
| US9129600B2 (en) | 2012-09-26 | 2015-09-08 | Google Technology Holdings LLC | Method and apparatus for encoding an audio signal |
| US9135920B2 (en) | 2012-11-26 | 2015-09-15 | Harman International Industries, Incorporated | System for perceived enhancement and restoration of compressed audio signals |
| PL3067890T3 (pl) | 2013-01-29 | 2018-06-29 | Fraunhofer Ges Forschung | Koder audio, dekoder audio, sposób dostarczania zakodowanej informacji audio, sposób dostarczania zdekodowanej informacji audio, program komputerowy i zakodowana reprezentacja, wykorzystujące adaptacyjne względem sygnału powiększanie szerokości pasma |
| EP2830055A1 (en) | 2013-07-22 | 2015-01-28 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Context-based entropy coding of sample values of a spectral envelope |
| EP2830065A1 (en) | 2013-07-22 | 2015-01-28 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for decoding an encoded audio signal using a cross-over filter around a transition frequency |
| EP2980795A1 (en) | 2014-07-28 | 2016-02-03 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio encoding and decoding using a frequency domain processor, a time domain processor and a cross processor for initialization of the time domain processor |
-
2013
- 2013-10-18 EP EP13189389.3A patent/EP2830065A1/en not_active Withdrawn
- 2013-10-18 EP EP13189358.8A patent/EP2830061A1/en not_active Withdrawn
- 2013-10-18 EP EP13189366.1A patent/EP2830054A1/en not_active Withdrawn
- 2013-10-18 EP EP13189362.0A patent/EP2830056A1/en not_active Withdrawn
- 2013-10-18 EP EP13189368.7A patent/EP2830064A1/en not_active Withdrawn
- 2013-10-18 EP EP13189382.8A patent/EP2830063A1/en not_active Withdrawn
- 2013-10-18 EP EP13189374.5A patent/EP2830059A1/en not_active Withdrawn
-
2014
- 2014-07-15 RU RU2016105618A patent/RU2651229C2/ru active
- 2014-07-15 PL PL19157850.9T patent/PL3506260T3/pl unknown
- 2014-07-15 PL PL14738854T patent/PL3025340T3/pl unknown
- 2014-07-15 EP EP19157850.9A patent/EP3506260B1/en active Active
- 2014-07-15 ES ES14741264.7T patent/ES2638498T3/es active Active
- 2014-07-15 MX MX2016000924A patent/MX354657B/es active IP Right Grant
- 2014-07-15 JP JP2016528414A patent/JP6389254B2/ja active Active
- 2014-07-15 CN CN202011075098.9A patent/CN112466312B/zh active Active
- 2014-07-15 PT PT147398119T patent/PT3017448T/pt unknown
- 2014-07-15 AU AU2014295302A patent/AU2014295302B2/en active Active
- 2014-07-15 WO PCT/EP2014/065106 patent/WO2015010947A1/en active Application Filing
- 2014-07-15 MX MX2016000943A patent/MX355448B/es active IP Right Grant
- 2014-07-15 ES ES14738854T patent/ES2728329T3/es active Active
- 2014-07-15 MX MX2016000940A patent/MX362036B/es active IP Right Grant
- 2014-07-15 ES ES14738857.3T patent/ES2599007T3/es active Active
- 2014-07-15 CA CA2918701A patent/CA2918701C/en active Active
- 2014-07-15 MY MYPI2016000112A patent/MY187943A/en unknown
- 2014-07-15 RU RU2016105619A patent/RU2649940C2/ru active
- 2014-07-15 MY MYPI2016000099A patent/MY175978A/en unknown
- 2014-07-15 EP EP20176783.7A patent/EP3742444A1/en active Pending
- 2014-07-15 EP EP23188679.7A patent/EP4246512A3/en active Pending
- 2014-07-15 CN CN202010010552.6A patent/CN111179963B/zh active Active
- 2014-07-15 EP EP14738857.3A patent/EP2883227B1/en active Active
- 2014-07-15 WO PCT/EP2014/065112 patent/WO2015010950A1/en active Application Filing
- 2014-07-15 BR BR122022010960-8A patent/BR122022010960B1/pt active IP Right Grant
- 2014-07-15 RU RU2015112591A patent/RU2607263C2/ru active
- 2014-07-15 CN CN201480041218.XA patent/CN105556603B/zh active Active
- 2014-07-15 EP EP14738853.2A patent/EP3025337B1/en active Active
- 2014-07-15 PT PT147388532T patent/PT3025337T/pt unknown
- 2014-07-15 SG SG11201502691QA patent/SG11201502691QA/en unknown
- 2014-07-15 JP JP2016528417A patent/JP6400702B2/ja active Active
- 2014-07-15 AU AU2014295301A patent/AU2014295301B2/en active Active
- 2014-07-15 CN CN201910689687.7A patent/CN110660410B/zh active Active
- 2014-07-15 TR TR2018/16157T patent/TR201816157T4/tr unknown
- 2014-07-15 AU AU2014295297A patent/AU2014295297B2/en active Active
- 2014-07-15 JP JP2016528412A patent/JP6310074B2/ja active Active
- 2014-07-15 MY MYPI2016000069A patent/MY184847A/en unknown
- 2014-07-15 CN CN201480002625.XA patent/CN104769671B/zh active Active
- 2014-07-15 BR BR122022011231-5A patent/BR122022011231B1/pt active IP Right Grant
- 2014-07-15 CA CA2918807A patent/CA2918807C/en active Active
- 2014-07-15 ES ES18180168T patent/ES2827774T3/es active Active
- 2014-07-15 SG SG11201600496XA patent/SG11201600496XA/en unknown
- 2014-07-15 CN CN201480041226.4A patent/CN105453176B/zh active Active
- 2014-07-15 ES ES14738853T patent/ES2908624T3/es active Active
- 2014-07-15 CA CA2886505A patent/CA2886505C/en active Active
- 2014-07-15 WO PCT/EP2014/065123 patent/WO2015010954A1/en active Application Filing
- 2014-07-15 JP JP2016528415A patent/JP6306702B2/ja active Active
- 2014-07-15 WO PCT/EP2014/065116 patent/WO2015010952A1/en active Application Filing
- 2014-07-15 WO PCT/EP2014/065118 patent/WO2015010953A1/en active Application Filing
- 2014-07-15 MY MYPI2016000067A patent/MY182831A/en unknown
- 2014-07-15 SG SG11201600401RA patent/SG11201600401RA/en unknown
- 2014-07-15 RU RU2016105473A patent/RU2643641C2/ru active
- 2014-07-15 KR KR1020167004276A patent/KR101826723B1/ko active Active
- 2014-07-15 KR KR1020167003487A patent/KR101764723B1/ko active Active
- 2014-07-15 SG SG11201600506VA patent/SG11201600506VA/en unknown
- 2014-07-15 RU RU2016105610A patent/RU2640634C2/ru active
- 2014-07-15 PL PL14739160T patent/PL3025328T3/pl unknown
- 2014-07-15 KR KR1020167001755A patent/KR101809592B1/ko active Active
- 2014-07-15 AU AU2014295295A patent/AU2014295295B2/en active Active
- 2014-07-15 PT PT147388573T patent/PT2883227T/pt unknown
- 2014-07-15 EP EP20175810.9A patent/EP3723091B1/en active Active
- 2014-07-15 CN CN201480041248.0A patent/CN105518777B/zh active Active
- 2014-07-15 JP JP2016528416A patent/JP6186082B2/ja active Active
- 2014-07-15 EP EP14739161.9A patent/EP3025343B1/en active Active
- 2014-07-15 MX MX2016000854A patent/MX354002B/es active IP Right Grant
- 2014-07-15 PT PT181801689T patent/PT3407350T/pt unknown
- 2014-07-15 PL PL14739161T patent/PL3025343T3/pl unknown
- 2014-07-15 RU RU2016105613A patent/RU2646316C2/ru active
- 2014-07-15 CA CA2918810A patent/CA2918810C/en active Active
- 2014-07-15 AU AU2014295296A patent/AU2014295296B2/en active Active
- 2014-07-15 MY MYPI2016000118A patent/MY180759A/en unknown
- 2014-07-15 EP EP14739160.1A patent/EP3025328B1/en active Active
- 2014-07-15 CN CN201480041246.1A patent/CN105453175B/zh active Active
- 2014-07-15 EP EP18180168.9A patent/EP3407350B1/en active Active
- 2014-07-15 JP JP2016528413A patent/JP6321797B2/ja active Active
- 2014-07-15 ES ES19157850T patent/ES2959641T3/es active Active
- 2014-07-15 CA CA2918524A patent/CA2918524C/en active Active
- 2014-07-15 SG SG11201600464WA patent/SG11201600464WA/en unknown
- 2014-07-15 CN CN201480041267.3A patent/CN105518776B/zh active Active
- 2014-07-15 EP EP21207282.1A patent/EP3975180A1/en active Pending
- 2014-07-15 BR BR112016001072-8A patent/BR112016001072B1/pt active IP Right Grant
- 2014-07-15 PT PT14738854T patent/PT3025340T/pt unknown
- 2014-07-15 PL PL14739811T patent/PL3017448T3/pl unknown
- 2014-07-15 BR BR122022010965-9A patent/BR122022010965B1/pt active IP Right Grant
- 2014-07-15 BR BR112016000740-9A patent/BR112016000740B1/pt active IP Right Grant
- 2014-07-15 AU AU2014295298A patent/AU2014295298B2/en active Active
- 2014-07-15 SG SG11201600422SA patent/SG11201600422SA/en unknown
- 2014-07-15 PL PL14738853T patent/PL3025337T3/pl unknown
- 2014-07-15 MX MX2015004022A patent/MX340575B/es active IP Right Grant
- 2014-07-15 BR BR122022010958-6A patent/BR122022010958B1/pt active IP Right Grant
- 2014-07-15 CA CA2973841A patent/CA2973841C/en active Active
- 2014-07-15 JP JP2015544509A patent/JP6144773B2/ja active Active
- 2014-07-15 BR BR112016001398-0A patent/BR112016001398B1/pt active IP Right Grant
- 2014-07-15 MX MX2016000857A patent/MX356161B/es active IP Right Grant
- 2014-07-15 AU AU2014295300A patent/AU2014295300B2/en active Active
- 2014-07-15 BR BR122022011238-2A patent/BR122022011238B1/pt active IP Right Grant
- 2014-07-15 ES ES14739161.9T patent/ES2667221T3/es active Active
- 2014-07-15 PL PL14738857T patent/PL2883227T3/pl unknown
- 2014-07-15 KR KR1020167001383A patent/KR101822032B1/ko active Active
- 2014-07-15 BR BR112016000947-9A patent/BR112016000947B1/pt active IP Right Grant
- 2014-07-15 EP EP14741264.7A patent/EP3025344B1/en active Active
- 2014-07-15 RU RU2016105759A patent/RU2635890C2/ru active
- 2014-07-15 SG SG11201600494UA patent/SG11201600494UA/en unknown
- 2014-07-15 CN CN201910412164.8A patent/CN110310659B/zh active Active
- 2014-07-15 PT PT14739160T patent/PT3025328T/pt unknown
- 2014-07-15 BR BR112015007533-9A patent/BR112015007533B1/pt active IP Right Grant
- 2014-07-15 PT PT147391619T patent/PT3025343T/pt unknown
- 2014-07-15 EP EP14738854.0A patent/EP3025340B1/en active Active
- 2014-07-15 CA CA2918835A patent/CA2918835C/en active Active
- 2014-07-15 CN CN201911415693.XA patent/CN111554310B/zh active Active
- 2014-07-15 BR BR112016000852-9A patent/BR112016000852B1/pt active IP Right Grant
- 2014-07-15 KR KR1020167004258A patent/KR101774795B1/ko active Active
- 2014-07-15 BR BR112016001125-2A patent/BR112016001125B1/pt active IP Right Grant
- 2014-07-15 CN CN201480041566.7A patent/CN105580075B/zh active Active
- 2014-07-15 ES ES14739811T patent/ES2813940T3/es active Active
- 2014-07-15 WO PCT/EP2014/065109 patent/WO2015010948A1/en active Application Filing
- 2014-07-15 CA CA2918804A patent/CA2918804C/en active Active
- 2014-07-15 KR KR1020167004481A patent/KR101807836B1/ko active Active
- 2014-07-15 EP EP14739811.9A patent/EP3017448B1/en active Active
- 2014-07-15 ES ES14739160T patent/ES2698023T3/es active Active
- 2014-07-15 MX MX2016000935A patent/MX353999B/es active IP Right Grant
- 2014-07-15 KR KR1020157008843A patent/KR101681253B1/ko active Active
- 2014-07-15 PL PL18180168T patent/PL3407350T3/pl unknown
- 2014-07-15 WO PCT/EP2014/065110 patent/WO2015010949A1/en active Application Filing
- 2014-07-17 TW TW103124623A patent/TWI555008B/zh active
- 2014-07-17 TW TW103124626A patent/TWI545558B/zh active
- 2014-07-17 TW TW103124628A patent/TWI555009B/zh active
- 2014-07-17 TW TW103124630A patent/TWI541797B/zh active
- 2014-07-17 TW TW103124622A patent/TWI545560B/zh active
- 2014-07-17 TW TW103124629A patent/TWI545561B/zh active
- 2014-07-18 TW TW103124811A patent/TWI549121B/zh active
-
2015
- 2015-04-07 ZA ZA2015/02262A patent/ZA201502262B/en unknown
- 2015-04-07 US US14/680,743 patent/US10332539B2/en active Active
- 2015-12-08 HK HK15112062.1A patent/HK1211378A1/xx unknown
-
2016
- 2016-01-19 US US15/000,902 patent/US10134404B2/en active Active
- 2016-01-20 US US15/002,370 patent/US10573334B2/en active Active
- 2016-01-20 US US15/002,343 patent/US10002621B2/en active Active
- 2016-01-20 US US15/002,361 patent/US10276183B2/en active Active
- 2016-01-20 US US15/002,350 patent/US10593345B2/en active Active
- 2016-01-21 US US15/003,334 patent/US10147430B2/en active Active
- 2016-02-15 ZA ZA2016/01011A patent/ZA201601011B/en unknown
- 2016-02-15 ZA ZA2016/01010A patent/ZA201601010B/en unknown
- 2016-02-16 ZA ZA2016/01046A patent/ZA201601046B/en unknown
- 2016-02-18 ZA ZA2016/01111A patent/ZA201601111B/en unknown
-
2017
- 2017-02-13 US US15/431,571 patent/US10347274B2/en active Active
- 2017-09-22 JP JP2017182327A patent/JP6705787B2/ja active Active
- 2017-11-09 JP JP2017216774A patent/JP6568566B2/ja active Active
- 2017-12-06 JP JP2017234677A patent/JP6691093B2/ja active Active
- 2017-12-07 US US15/834,260 patent/US10311892B2/en active Active
-
2018
- 2018-01-18 US US15/874,536 patent/US10332531B2/en active Active
- 2018-05-22 US US15/985,930 patent/US10515652B2/en active Active
- 2018-10-10 US US16/156,683 patent/US10847167B2/en active Active
- 2018-11-02 US US16/178,835 patent/US10984805B2/en active Active
-
2019
- 2019-02-26 US US16/286,263 patent/US11289104B2/en active Active
- 2019-04-26 US US16/395,653 patent/US11250862B2/en active Active
- 2019-05-20 US US16/417,471 patent/US11049506B2/en active Active
- 2019-09-25 US US16/582,336 patent/US11222643B2/en active Active
-
2020
- 2020-01-06 JP JP2020000087A patent/JP7092809B2/ja active Active
- 2020-11-10 US US17/094,791 patent/US11257505B2/en active Active
-
2021
- 2021-03-30 US US17/217,533 patent/US11769512B2/en active Active
- 2021-06-04 US US17/339,270 patent/US11996106B2/en active Active
-
2022
- 2022-01-14 US US17/576,780 patent/US11735192B2/en active Active
- 2022-01-25 US US17/583,612 patent/US11769513B2/en active Active
- 2022-03-03 US US17/653,332 patent/US11922956B2/en active Active
- 2022-06-16 JP JP2022097243A patent/JP7483792B2/ja active Active
-
2023
- 2023-07-11 US US18/220,677 patent/US12142284B2/en active Active
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2827774T3 (es) | Codificador de audio y método relacionado usando procesamiento de dos canales dentro de un marco de referencia de relleno inteligente de espacios |