ES2908667T3 - Composiciones detergentes que comprenden variantes polipeptídicas - Google Patents
Composiciones detergentes que comprenden variantes polipeptídicas Download PDFInfo
- Publication number
- ES2908667T3 ES2908667T3 ES18202967T ES18202967T ES2908667T3 ES 2908667 T3 ES2908667 T3 ES 2908667T3 ES 18202967 T ES18202967 T ES 18202967T ES 18202967 T ES18202967 T ES 18202967T ES 2908667 T3 ES2908667 T3 ES 2908667T3
- Authority
- ES
- Spain
- Prior art keywords
- seq
- dnase
- variant
- polypeptide
- bacillus
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 229920001184 polypeptide Polymers 0.000 title claims abstract description 389
- 102000004196 processed proteins & peptides Human genes 0.000 title claims abstract description 389
- 108090000765 processed proteins & peptides Proteins 0.000 title claims abstract description 389
- 239000003599 detergent Substances 0.000 title claims abstract description 223
- 239000000203 mixture Substances 0.000 title claims abstract description 214
- 102000016911 Deoxyribonucleases Human genes 0.000 claims abstract description 426
- 108010053770 Deoxyribonucleases Proteins 0.000 claims abstract description 426
- 238000006467 substitution reaction Methods 0.000 claims abstract description 258
- 230000000694 effects Effects 0.000 claims abstract description 103
- 125000003275 alpha amino acid group Chemical group 0.000 claims abstract description 63
- 102200082946 rs33948578 Human genes 0.000 claims abstract description 29
- 230000006872 improvement Effects 0.000 claims abstract description 26
- 102220591532 Hemoglobin subunit beta_L33V_mutation Human genes 0.000 claims abstract description 12
- 239000002671 adjuvant Substances 0.000 claims abstract description 11
- 239000002243 precursor Substances 0.000 claims description 81
- 241000193830 Bacillus <bacterium> Species 0.000 claims description 78
- 238000000034 method Methods 0.000 claims description 75
- 102000004190 Enzymes Human genes 0.000 claims description 62
- 108090000790 Enzymes Proteins 0.000 claims description 62
- 238000004140 cleaning Methods 0.000 claims description 55
- 239000004744 fabric Substances 0.000 claims description 55
- 229940088598 enzyme Drugs 0.000 claims description 53
- 102220198035 rs121913396 Human genes 0.000 claims description 45
- 102220476899 ATPase family AAA domain-containing protein 3A_S101N_mutation Human genes 0.000 claims description 44
- 102220580976 Induced myeloid leukemia cell differentiation protein Mcl-1_G41Y_mutation Human genes 0.000 claims description 44
- 102220561254 Myocardin-related transcription factor B_Q48D_mutation Human genes 0.000 claims description 44
- 102220470558 Proteasome subunit beta type-3_D32R_mutation Human genes 0.000 claims description 44
- 102200036749 rs104894637 Human genes 0.000 claims description 44
- 102220219890 rs753300898 Human genes 0.000 claims description 44
- 102220485752 Glycophorin-A_S66Y_mutation Human genes 0.000 claims description 43
- 102200107865 rs1555526581 Human genes 0.000 claims description 43
- 102220362200 c.272C>T Human genes 0.000 claims description 41
- 102220078285 rs797045795 Human genes 0.000 claims description 38
- 239000002689 soil Substances 0.000 claims description 35
- 102000013142 Amylases Human genes 0.000 claims description 34
- 108010065511 Amylases Proteins 0.000 claims description 34
- 235000019418 amylase Nutrition 0.000 claims description 34
- 102000035195 Peptidases Human genes 0.000 claims description 31
- 108091005804 Peptidases Proteins 0.000 claims description 31
- 239000004365 Protease Substances 0.000 claims description 29
- 102220091829 rs200941736 Human genes 0.000 claims description 28
- 238000005406 washing Methods 0.000 claims description 27
- 102200046175 rs104894187 Human genes 0.000 claims description 25
- 241001032451 Bacillus indicus Species 0.000 claims description 24
- 229940025131 amylases Drugs 0.000 claims description 22
- 230000035772 mutation Effects 0.000 claims description 21
- 108010084185 Cellulases Proteins 0.000 claims description 15
- 102000005575 Cellulases Human genes 0.000 claims description 15
- 108090001060 Lipase Proteins 0.000 claims description 15
- 102000004882 Lipase Human genes 0.000 claims description 15
- 239000004367 Lipase Substances 0.000 claims description 15
- 235000019421 lipase Nutrition 0.000 claims description 15
- 238000012360 testing method Methods 0.000 claims description 13
- 239000000654 additive Substances 0.000 claims description 10
- 230000000996 additive effect Effects 0.000 claims description 9
- 108010005400 cutinase Proteins 0.000 claims description 8
- 229910052799 carbon Inorganic materials 0.000 claims description 7
- 241001143890 Bacillus marisflavi Species 0.000 claims description 5
- 238000001035 drying Methods 0.000 claims description 5
- 241000285020 Bacillus algicola Species 0.000 claims description 4
- 241000186551 Bacillus horneckiae Species 0.000 claims description 4
- 241001245216 Bacillus hwajinpoensis Species 0.000 claims description 4
- 241001661600 Bacillus idriensis Species 0.000 claims description 4
- 241000775876 Bacillus luciferensis Species 0.000 claims description 4
- 241001626895 Bacillus vietnamensis Species 0.000 claims description 4
- 102100032487 Beta-mannosidase Human genes 0.000 claims description 4
- 108010055059 beta-Mannosidase Proteins 0.000 claims description 4
- 108010083879 xyloglucan endo(1-4)-beta-D-glucanase Proteins 0.000 claims description 4
- 101710152845 Arabinogalactan endo-beta-1,4-galactanase Proteins 0.000 claims description 3
- 241001328132 Bacillus horikoshii Species 0.000 claims description 3
- 101710147028 Endo-beta-1,4-galactanase Proteins 0.000 claims description 3
- 230000002195 synergetic effect Effects 0.000 claims description 3
- 102220393189 c.116C>G Human genes 0.000 claims 4
- 102200068708 rs281865216 Human genes 0.000 claims 4
- 102220125958 rs886044127 Human genes 0.000 claims 1
- 210000004027 cell Anatomy 0.000 description 105
- -1 builders Substances 0.000 description 62
- 102000040430 polynucleotide Human genes 0.000 description 50
- 108091033319 polynucleotide Proteins 0.000 description 50
- 239000002157 polynucleotide Substances 0.000 description 50
- 108090000623 proteins and genes Proteins 0.000 description 50
- 235000001014 amino acid Nutrition 0.000 description 43
- 102220114396 rs886039195 Human genes 0.000 description 42
- 102220125419 rs886043971 Human genes 0.000 description 42
- 102220612725 Cyclin-dependent kinase inhibitor 3_F78L_mutation Human genes 0.000 description 40
- 239000007788 liquid Substances 0.000 description 40
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 39
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 39
- 230000004075 alteration Effects 0.000 description 39
- 102220531870 Polyisoprenoid diphosphate/phosphate phosphohydrolase PLPP6_S7G_mutation Human genes 0.000 description 38
- 229940024606 amino acid Drugs 0.000 description 36
- 150000001413 amino acids Chemical class 0.000 description 36
- 102220071759 rs794728546 Human genes 0.000 description 35
- 108020004414 DNA Proteins 0.000 description 32
- 229920000642 polymer Polymers 0.000 description 31
- 239000013598 vector Substances 0.000 description 31
- 239000003795 chemical substances by application Substances 0.000 description 30
- 108091026890 Coding region Proteins 0.000 description 27
- 241000499912 Trichoderma reesei Species 0.000 description 26
- 239000002253 acid Substances 0.000 description 25
- 239000000975 dye Substances 0.000 description 25
- 239000000243 solution Substances 0.000 description 25
- 239000007844 bleaching agent Substances 0.000 description 24
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 23
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 22
- 238000003556 assay Methods 0.000 description 22
- 238000012217 deletion Methods 0.000 description 22
- 230000037430 deletion Effects 0.000 description 22
- 235000019419 proteases Nutrition 0.000 description 22
- 230000002538 fungal effect Effects 0.000 description 20
- 230000014509 gene expression Effects 0.000 description 20
- 102000039446 nucleic acids Human genes 0.000 description 20
- 108020004707 nucleic acids Proteins 0.000 description 20
- 150000007523 nucleic acids Chemical class 0.000 description 20
- 102000004169 proteins and genes Human genes 0.000 description 20
- 108010076504 Protein Sorting Signals Proteins 0.000 description 19
- 102220543869 Protocadherin-10_S42G_mutation Human genes 0.000 description 18
- 102220137459 rs373802805 Human genes 0.000 description 18
- 102220315645 rs62636495 Human genes 0.000 description 18
- 235000014113 dietary fatty acids Nutrition 0.000 description 17
- 239000000194 fatty acid Substances 0.000 description 17
- 229930195729 fatty acid Natural products 0.000 description 17
- 239000000463 material Substances 0.000 description 17
- 235000018102 proteins Nutrition 0.000 description 17
- 230000010076 replication Effects 0.000 description 17
- 102220276614 rs1553130405 Human genes 0.000 description 17
- 102200084645 rs9898682 Human genes 0.000 description 17
- 241000233866 Fungi Species 0.000 description 16
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 16
- 108090000637 alpha-Amylases Proteins 0.000 description 16
- 238000003780 insertion Methods 0.000 description 16
- 230000037431 insertion Effects 0.000 description 16
- 102220224887 rs1060502696 Human genes 0.000 description 15
- 102220229200 rs1064795244 Human genes 0.000 description 15
- 102220612252 Calcyclin-binding protein_T65L_mutation Human genes 0.000 description 14
- 102220523819 NADH dehydrogenase [ubiquinone] 1 alpha subcomplex subunit 13_T65V_mutation Human genes 0.000 description 14
- 230000001580 bacterial effect Effects 0.000 description 14
- 102220093683 rs876661128 Human genes 0.000 description 14
- 239000004094 surface-active agent Substances 0.000 description 14
- 102220617592 B1 bradykinin receptor_S42C_mutation Human genes 0.000 description 13
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 13
- 102000004139 alpha-Amylases Human genes 0.000 description 13
- 239000013612 plasmid Substances 0.000 description 13
- 239000000047 product Substances 0.000 description 13
- 150000003839 salts Chemical class 0.000 description 13
- 239000004382 Amylase Substances 0.000 description 12
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 12
- 125000000539 amino acid group Chemical group 0.000 description 12
- 229920002678 cellulose Polymers 0.000 description 12
- 150000004665 fatty acids Chemical class 0.000 description 12
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 11
- 102000003992 Peroxidases Human genes 0.000 description 11
- 239000003054 catalyst Substances 0.000 description 11
- 229920001577 copolymer Polymers 0.000 description 11
- 238000004851 dishwashing Methods 0.000 description 11
- 239000013074 reference sample Substances 0.000 description 11
- 239000004753 textile Substances 0.000 description 11
- 235000014469 Bacillus subtilis Nutrition 0.000 description 10
- 108010029541 Laccase Proteins 0.000 description 10
- 229940024171 alpha-amylase Drugs 0.000 description 10
- 239000001913 cellulose Substances 0.000 description 10
- 235000010980 cellulose Nutrition 0.000 description 10
- 239000000499 gel Substances 0.000 description 10
- 230000008569 process Effects 0.000 description 10
- VCVKIIDXVWEWSZ-YFKPBYRVSA-N (2s)-2-[bis(carboxymethyl)amino]pentanedioic acid Chemical compound OC(=O)CC[C@@H](C(O)=O)N(CC(O)=O)CC(O)=O VCVKIIDXVWEWSZ-YFKPBYRVSA-N 0.000 description 9
- 241000894006 Bacteria Species 0.000 description 9
- 238000010936 aqueous wash Methods 0.000 description 9
- 239000001768 carboxy methyl cellulose Substances 0.000 description 9
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 9
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 9
- 239000006081 fluorescent whitening agent Substances 0.000 description 9
- 238000009472 formulation Methods 0.000 description 9
- 238000004519 manufacturing process Methods 0.000 description 9
- 239000002609 medium Substances 0.000 description 9
- 150000004965 peroxy acids Chemical class 0.000 description 9
- 229920002451 polyvinyl alcohol Polymers 0.000 description 9
- 239000004474 valine Substances 0.000 description 9
- 244000063299 Bacillus subtilis Species 0.000 description 8
- 108010073178 Glucan 1,4-alpha-Glucosidase Proteins 0.000 description 8
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 8
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 8
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 8
- 239000013604 expression vector Substances 0.000 description 8
- 239000008187 granular material Substances 0.000 description 8
- 239000004615 ingredient Substances 0.000 description 8
- 239000000843 powder Substances 0.000 description 8
- 238000013518 transcription Methods 0.000 description 8
- 230000035897 transcription Effects 0.000 description 8
- 102220510014 52 kDa repressor of the inhibitor of the protein kinase_L27R_mutation Human genes 0.000 description 7
- 108010059892 Cellulase Proteins 0.000 description 7
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 7
- 102100022624 Glucoamylase Human genes 0.000 description 7
- 108700020962 Peroxidase Proteins 0.000 description 7
- 108090000787 Subtilisin Proteins 0.000 description 7
- LSNNMFCWUKXFEE-UHFFFAOYSA-N Sulfurous acid Chemical compound OS(O)=O LSNNMFCWUKXFEE-UHFFFAOYSA-N 0.000 description 7
- 125000000217 alkyl group Chemical group 0.000 description 7
- 239000003945 anionic surfactant Substances 0.000 description 7
- 150000001875 compounds Chemical class 0.000 description 7
- 239000003550 marker Substances 0.000 description 7
- 239000002736 nonionic surfactant Substances 0.000 description 7
- 230000001105 regulatory effect Effects 0.000 description 7
- 239000000523 sample Substances 0.000 description 7
- 238000002741 site-directed mutagenesis Methods 0.000 description 7
- 239000000758 substrate Substances 0.000 description 7
- 238000012546 transfer Methods 0.000 description 7
- 230000009466 transformation Effects 0.000 description 7
- 241000193744 Bacillus amyloliquefaciens Species 0.000 description 6
- 241000194108 Bacillus licheniformis Species 0.000 description 6
- 108010008885 Cellulose 1,4-beta-Cellobiosidase Proteins 0.000 description 6
- 241000588724 Escherichia coli Species 0.000 description 6
- 241000223218 Fusarium Species 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- 125000003412 L-alanyl group Chemical group [H]N([H])[C@@](C([H])([H])[H])(C(=O)[*])[H] 0.000 description 6
- 125000000174 L-prolyl group Chemical group [H]N1C([H])([H])C([H])([H])C([H])([H])[C@@]1([H])C(*)=O 0.000 description 6
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 6
- 108091034117 Oligonucleotide Proteins 0.000 description 6
- 239000002202 Polyethylene glycol Substances 0.000 description 6
- 241000187747 Streptomyces Species 0.000 description 6
- 108010048241 acetamidase Proteins 0.000 description 6
- 150000007513 acids Chemical class 0.000 description 6
- 239000012190 activator Substances 0.000 description 6
- 235000004279 alanine Nutrition 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 239000002738 chelating agent Substances 0.000 description 6
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 6
- 239000002270 dispersing agent Substances 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 239000006260 foam Substances 0.000 description 6
- 239000003752 hydrotrope Substances 0.000 description 6
- 239000003112 inhibitor Substances 0.000 description 6
- 108020004999 messenger RNA Proteins 0.000 description 6
- 230000000813 microbial effect Effects 0.000 description 6
- 230000007935 neutral effect Effects 0.000 description 6
- 229920001223 polyethylene glycol Polymers 0.000 description 6
- 210000001938 protoplast Anatomy 0.000 description 6
- 238000003860 storage Methods 0.000 description 6
- 239000000126 substance Substances 0.000 description 6
- 230000002103 transcriptional effect Effects 0.000 description 6
- UHPMCKVQTMMPCG-UHFFFAOYSA-N 5,8-dihydroxy-2-methoxy-6-methyl-7-(2-oxopropyl)naphthalene-1,4-dione Chemical compound CC1=C(CC(C)=O)C(O)=C2C(=O)C(OC)=CC(=O)C2=C1O UHPMCKVQTMMPCG-UHFFFAOYSA-N 0.000 description 5
- 241000193422 Bacillus lentus Species 0.000 description 5
- 108091005658 Basic proteases Proteins 0.000 description 5
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 5
- 241000196324 Embryophyta Species 0.000 description 5
- 241000193385 Geobacillus stearothermophilus Species 0.000 description 5
- 241001480714 Humicola insolens Species 0.000 description 5
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 5
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 5
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 5
- 108010006035 Metalloproteases Proteins 0.000 description 5
- 102000005741 Metalloproteases Human genes 0.000 description 5
- 241000589516 Pseudomonas Species 0.000 description 5
- 108010056079 Subtilisins Proteins 0.000 description 5
- 102000005158 Subtilisins Human genes 0.000 description 5
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 5
- 241001313536 Thermothelomyces thermophila Species 0.000 description 5
- 150000008051 alkyl sulfates Chemical class 0.000 description 5
- 125000000129 anionic group Chemical group 0.000 description 5
- 239000003086 colorant Substances 0.000 description 5
- 238000010276 construction Methods 0.000 description 5
- 238000004520 electroporation Methods 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 150000004676 glycans Chemical class 0.000 description 5
- 238000002744 homologous recombination Methods 0.000 description 5
- 230000006801 homologous recombination Effects 0.000 description 5
- 230000010354 integration Effects 0.000 description 5
- 239000011159 matrix material Substances 0.000 description 5
- 108010020132 microbial serine proteinases Proteins 0.000 description 5
- 244000005700 microbiome Species 0.000 description 5
- 239000002304 perfume Substances 0.000 description 5
- 230000008488 polyadenylation Effects 0.000 description 5
- 235000019422 polyvinyl alcohol Nutrition 0.000 description 5
- 229910052700 potassium Inorganic materials 0.000 description 5
- 229910052708 sodium Inorganic materials 0.000 description 5
- 239000011734 sodium Substances 0.000 description 5
- 235000015424 sodium Nutrition 0.000 description 5
- 230000014616 translation Effects 0.000 description 5
- 229910052721 tungsten Inorganic materials 0.000 description 5
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 4
- PQHYOGIRXOKOEJ-UHFFFAOYSA-N 2-(1,2-dicarboxyethylamino)butanedioic acid Chemical compound OC(=O)CC(C(O)=O)NC(C(O)=O)CC(O)=O PQHYOGIRXOKOEJ-UHFFFAOYSA-N 0.000 description 4
- VKZRWSNIWNFCIQ-UHFFFAOYSA-N 2-[2-(1,2-dicarboxyethylamino)ethylamino]butanedioic acid Chemical compound OC(=O)CC(C(O)=O)NCCNC(C(O)=O)CC(O)=O VKZRWSNIWNFCIQ-UHFFFAOYSA-N 0.000 description 4
- 108010035722 Chloride peroxidase Proteins 0.000 description 4
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 4
- QXNVGIXVLWOKEQ-UHFFFAOYSA-N Disodium Chemical class [Na][Na] QXNVGIXVLWOKEQ-UHFFFAOYSA-N 0.000 description 4
- 241000223221 Fusarium oxysporum Species 0.000 description 4
- 241000567178 Fusarium venenatum Species 0.000 description 4
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 4
- 239000004472 Lysine Substances 0.000 description 4
- 102000004316 Oxidoreductases Human genes 0.000 description 4
- 108090000854 Oxidoreductases Proteins 0.000 description 4
- 229920002873 Polyethylenimine Polymers 0.000 description 4
- 239000004372 Polyvinyl alcohol Substances 0.000 description 4
- 102000012479 Serine Proteases Human genes 0.000 description 4
- 108010022999 Serine Proteases Proteins 0.000 description 4
- 229920002125 Sokalan® Polymers 0.000 description 4
- 241000194017 Streptococcus Species 0.000 description 4
- BGRWYDHXPHLNKA-UHFFFAOYSA-N Tetraacetylethylenediamine Chemical compound CC(=O)N(C(C)=O)CCN(C(C)=O)C(C)=O BGRWYDHXPHLNKA-UHFFFAOYSA-N 0.000 description 4
- 241000223258 Thermomyces lanuginosus Species 0.000 description 4
- 241000223259 Trichoderma Species 0.000 description 4
- 108700015934 Triose-phosphate isomerases Proteins 0.000 description 4
- 150000001412 amines Chemical class 0.000 description 4
- 230000000844 anti-bacterial effect Effects 0.000 description 4
- 239000002585 base Substances 0.000 description 4
- 229940106157 cellulase Drugs 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000003776 cleavage reaction Methods 0.000 description 4
- 239000002299 complementary DNA Substances 0.000 description 4
- 230000021615 conjugation Effects 0.000 description 4
- 230000002255 enzymatic effect Effects 0.000 description 4
- 239000000835 fiber Substances 0.000 description 4
- 239000012634 fragment Substances 0.000 description 4
- 229920000578 graft copolymer Polymers 0.000 description 4
- 230000003301 hydrolyzing effect Effects 0.000 description 4
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 4
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 4
- 229960000310 isoleucine Drugs 0.000 description 4
- 238000002703 mutagenesis Methods 0.000 description 4
- 231100000350 mutagenesis Toxicity 0.000 description 4
- 239000002773 nucleotide Substances 0.000 description 4
- 125000003729 nucleotide group Chemical group 0.000 description 4
- 235000015097 nutrients Nutrition 0.000 description 4
- 229920005862 polyol Polymers 0.000 description 4
- 150000003077 polyols Chemical class 0.000 description 4
- 229920001282 polysaccharide Polymers 0.000 description 4
- 239000005017 polysaccharide Substances 0.000 description 4
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 4
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 4
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 238000003259 recombinant expression Methods 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 239000006254 rheological additive Substances 0.000 description 4
- 102220251354 rs1555123823 Human genes 0.000 description 4
- 230000007017 scission Effects 0.000 description 4
- 239000000344 soap Substances 0.000 description 4
- QUCDWLYKDRVKMI-UHFFFAOYSA-M sodium;3,4-dimethylbenzenesulfonate Chemical compound [Na+].CC1=CC=C(S([O-])(=O)=O)C=C1C QUCDWLYKDRVKMI-UHFFFAOYSA-M 0.000 description 4
- 239000007787 solid Substances 0.000 description 4
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- URAYPUMNDPQOKB-UHFFFAOYSA-N triacetin Chemical compound CC(=O)OCC(OC(C)=O)COC(C)=O URAYPUMNDPQOKB-UHFFFAOYSA-N 0.000 description 4
- 239000010457 zeolite Substances 0.000 description 4
- SMZOUWXMTYCWNB-UHFFFAOYSA-N 2-(2-methoxy-5-methylphenyl)ethanamine Chemical compound COC1=CC=C(C)C=C1CCN SMZOUWXMTYCWNB-UHFFFAOYSA-N 0.000 description 3
- NIXOWILDQLNWCW-UHFFFAOYSA-N 2-Propenoic acid Natural products OC(=O)C=C NIXOWILDQLNWCW-UHFFFAOYSA-N 0.000 description 3
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 3
- YGUMVDWOQQJBGA-VAWYXSNFSA-N 5-[(4-anilino-6-morpholin-4-yl-1,3,5-triazin-2-yl)amino]-2-[(e)-2-[4-[(4-anilino-6-morpholin-4-yl-1,3,5-triazin-2-yl)amino]-2-sulfophenyl]ethenyl]benzenesulfonic acid Chemical compound C=1C=C(\C=C\C=2C(=CC(NC=3N=C(N=C(NC=4C=CC=CC=4)N=3)N3CCOCC3)=CC=2)S(O)(=O)=O)C(S(=O)(=O)O)=CC=1NC(N=C(N=1)N2CCOCC2)=NC=1NC1=CC=CC=C1 YGUMVDWOQQJBGA-VAWYXSNFSA-N 0.000 description 3
- 108700016155 Acyl transferases Proteins 0.000 description 3
- 108010037870 Anthranilate Synthase Proteins 0.000 description 3
- 102000004580 Aspartic Acid Proteases Human genes 0.000 description 3
- 108010017640 Aspartic Acid Proteases Proteins 0.000 description 3
- 241000193375 Bacillus alcalophilus Species 0.000 description 3
- 241000194110 Bacillus sp. (in: Bacteria) Species 0.000 description 3
- GAWIXWVDTYZWAW-UHFFFAOYSA-N C[CH]O Chemical group C[CH]O GAWIXWVDTYZWAW-UHFFFAOYSA-N 0.000 description 3
- 240000000722 Campanula rapunculus Species 0.000 description 3
- 241000146399 Ceriporiopsis Species 0.000 description 3
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 3
- 244000251987 Coprinus macrorhizus Species 0.000 description 3
- 241001537312 Curvularia inaequalis Species 0.000 description 3
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 3
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical group C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 3
- 241000221779 Fusarium sambucinum Species 0.000 description 3
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 3
- 239000004471 Glycine Substances 0.000 description 3
- 241000223198 Humicola Species 0.000 description 3
- 229920000663 Hydroxyethyl cellulose Polymers 0.000 description 3
- 125000000570 L-alpha-aspartyl group Chemical group [H]OC(=O)C([H])([H])[C@]([H])(N([H])[H])C(*)=O 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 3
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 3
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 3
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 3
- 241000226677 Myceliophthora Species 0.000 description 3
- QPCDCPDFJACHGM-UHFFFAOYSA-N N,N-bis{2-[bis(carboxymethyl)amino]ethyl}glycine Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(=O)O)CCN(CC(O)=O)CC(O)=O QPCDCPDFJACHGM-UHFFFAOYSA-N 0.000 description 3
- 229910019142 PO4 Inorganic materials 0.000 description 3
- 102000012288 Phosphopyruvate Hydratase Human genes 0.000 description 3
- 108010022181 Phosphopyruvate Hydratase Proteins 0.000 description 3
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 3
- OFOBLEOULBTSOW-UHFFFAOYSA-N Propanedioic acid Natural products OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 3
- 241000235403 Rhizomucor miehei Species 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- 101710152431 Trypsin-like protease Proteins 0.000 description 3
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 3
- 229910021536 Zeolite Inorganic materials 0.000 description 3
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 3
- 150000001298 alcohols Chemical class 0.000 description 3
- 229910052783 alkali metal Inorganic materials 0.000 description 3
- 239000003899 bactericide agent Substances 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 3
- 229960005091 chloramphenicol Drugs 0.000 description 3
- 230000002759 chromosomal effect Effects 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 238000012258 culturing Methods 0.000 description 3
- HNPSIPDUKPIQMN-UHFFFAOYSA-N dioxosilane;oxo(oxoalumanyloxy)alumane Chemical compound O=[Si]=O.O=[Al]O[Al]=O HNPSIPDUKPIQMN-UHFFFAOYSA-N 0.000 description 3
- 230000009977 dual effect Effects 0.000 description 3
- 108010092413 endoglucanase V Proteins 0.000 description 3
- 101150025819 erp gene Proteins 0.000 description 3
- 150000002148 esters Chemical class 0.000 description 3
- RTZKZFJDLAIYFH-UHFFFAOYSA-N ether Substances CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 3
- 150000002170 ethers Chemical class 0.000 description 3
- 239000002979 fabric softener Substances 0.000 description 3
- 150000002191 fatty alcohols Chemical class 0.000 description 3
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 3
- 239000004519 grease Substances 0.000 description 3
- 229920001519 homopolymer Polymers 0.000 description 3
- 230000002209 hydrophobic effect Effects 0.000 description 3
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 3
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 3
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 3
- 238000000338 in vitro Methods 0.000 description 3
- 230000002401 inhibitory effect Effects 0.000 description 3
- 239000000543 intermediate Substances 0.000 description 3
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 3
- 239000011976 maleic acid Substances 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 231100000219 mutagenic Toxicity 0.000 description 3
- 230000003505 mutagenic effect Effects 0.000 description 3
- 229920000847 nonoxynol Polymers 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 229960003330 pentetic acid Drugs 0.000 description 3
- 108040007629 peroxidase activity proteins Proteins 0.000 description 3
- 235000021317 phosphate Nutrition 0.000 description 3
- 239000000049 pigment Substances 0.000 description 3
- 229920002006 poly(N-vinylimidazole) polymer Polymers 0.000 description 3
- 229920000058 polyacrylate Polymers 0.000 description 3
- 239000004584 polyacrylic acid Substances 0.000 description 3
- 229920005646 polycarboxylate Polymers 0.000 description 3
- 229920000728 polyester Polymers 0.000 description 3
- 229920002689 polyvinyl acetate Polymers 0.000 description 3
- 239000011118 polyvinyl acetate Substances 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 239000003381 stabilizer Substances 0.000 description 3
- 230000000087 stabilizing effect Effects 0.000 description 3
- WEAPVABOECTMGR-UHFFFAOYSA-N triethyl 2-acetyloxypropane-1,2,3-tricarboxylate Chemical group CCOC(=O)CC(C(=O)OCC)(OC(C)=O)CC(=O)OCC WEAPVABOECTMGR-UHFFFAOYSA-N 0.000 description 3
- 150000003680 valines Chemical group 0.000 description 3
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- LIPJWTMIUOLEJU-UHFFFAOYSA-N 2-(1,2-diamino-2-phenylethenyl)benzenesulfonic acid Chemical class NC(=C(C=1C(=CC=CC1)S(=O)(=O)O)N)C1=CC=CC=C1 LIPJWTMIUOLEJU-UHFFFAOYSA-N 0.000 description 2
- URDCARMUOSMFFI-UHFFFAOYSA-N 2-[2-[bis(carboxymethyl)amino]ethyl-(2-hydroxyethyl)amino]acetic acid Chemical compound OCCN(CC(O)=O)CCN(CC(O)=O)CC(O)=O URDCARMUOSMFFI-UHFFFAOYSA-N 0.000 description 2
- GTXVUMKMNLRHKO-UHFFFAOYSA-N 2-[carboxymethyl(2-sulfoethyl)amino]acetic acid Chemical compound OC(=O)CN(CC(O)=O)CCS(O)(=O)=O GTXVUMKMNLRHKO-UHFFFAOYSA-N 0.000 description 2
- XWSGEVNYFYKXCP-UHFFFAOYSA-N 2-[carboxymethyl(methyl)amino]acetic acid Chemical compound OC(=O)CN(C)CC(O)=O XWSGEVNYFYKXCP-UHFFFAOYSA-N 0.000 description 2
- MHKLKWCYGIBEQF-UHFFFAOYSA-N 4-(1,3-benzothiazol-2-ylsulfanyl)morpholine Chemical compound C1COCCN1SC1=NC2=CC=CC=C2S1 MHKLKWCYGIBEQF-UHFFFAOYSA-N 0.000 description 2
- CNGYZEMWVAWWOB-VAWYXSNFSA-N 5-[[4-anilino-6-[bis(2-hydroxyethyl)amino]-1,3,5-triazin-2-yl]amino]-2-[(e)-2-[4-[[4-anilino-6-[bis(2-hydroxyethyl)amino]-1,3,5-triazin-2-yl]amino]-2-sulfophenyl]ethenyl]benzenesulfonic acid Chemical compound N=1C(NC=2C=C(C(\C=C\C=3C(=CC(NC=4N=C(N=C(NC=5C=CC=CC=5)N=4)N(CCO)CCO)=CC=3)S(O)(=O)=O)=CC=2)S(O)(=O)=O)=NC(N(CCO)CCO)=NC=1NC1=CC=CC=C1 CNGYZEMWVAWWOB-VAWYXSNFSA-N 0.000 description 2
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 2
- 241001019659 Acremonium <Plectosphaerellaceae> Species 0.000 description 2
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 2
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 2
- 102100034044 All-trans-retinol dehydrogenase [NAD(+)] ADH1B Human genes 0.000 description 2
- 101710193111 All-trans-retinol dehydrogenase [NAD(+)] ADH4 Proteins 0.000 description 2
- 101100163849 Arabidopsis thaliana ARS1 gene Proteins 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 101000756530 Aspergillus niger Endo-1,4-beta-xylanase B Proteins 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 241000972773 Aulopiformes Species 0.000 description 2
- 101000775727 Bacillus amyloliquefaciens Alpha-amylase Proteins 0.000 description 2
- 241001328122 Bacillus clausii Species 0.000 description 2
- 241000194103 Bacillus pumilus Species 0.000 description 2
- 241000193388 Bacillus thuringiensis Species 0.000 description 2
- 108010015428 Bilirubin oxidase Proteins 0.000 description 2
- 241001465180 Botrytis Species 0.000 description 2
- 108010073997 Bromide peroxidase Proteins 0.000 description 2
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 2
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 2
- 102000030523 Catechol oxidase Human genes 0.000 description 2
- 108010031396 Catechol oxidase Proteins 0.000 description 2
- 241000123346 Chrysosporium Species 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- 241000222511 Coprinus Species 0.000 description 2
- 241000222356 Coriolus Species 0.000 description 2
- 241000223208 Curvularia Species 0.000 description 2
- 102000053602 DNA Human genes 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- 101710132690 Endo-1,4-beta-xylanase A Proteins 0.000 description 2
- 102000010911 Enzyme Precursors Human genes 0.000 description 2
- 108010062466 Enzyme Precursors Proteins 0.000 description 2
- 239000001856 Ethyl cellulose Substances 0.000 description 2
- ZZSNKZQZMQGXPY-UHFFFAOYSA-N Ethyl cellulose Chemical compound CCOCC1OC(OC)C(OCC)C(OCC)C1OC1C(O)C(O)C(OC)C(CO)O1 ZZSNKZQZMQGXPY-UHFFFAOYSA-N 0.000 description 2
- DBVJJBKOTRCVKF-UHFFFAOYSA-N Etidronic acid Chemical compound OP(=O)(O)C(O)(C)P(O)(O)=O DBVJJBKOTRCVKF-UHFFFAOYSA-N 0.000 description 2
- 241000567163 Fusarium cerealis Species 0.000 description 2
- 241000146406 Fusarium heterosporum Species 0.000 description 2
- 101000649352 Fusarium oxysporum f. sp. lycopersici (strain 4287 / CBS 123668 / FGSC 9935 / NRRL 34936) Endo-1,4-beta-xylanase A Proteins 0.000 description 2
- 102000048120 Galactokinases Human genes 0.000 description 2
- 108700023157 Galactokinases Proteins 0.000 description 2
- 101100369308 Geobacillus stearothermophilus nprS gene Proteins 0.000 description 2
- 101100080316 Geobacillus stearothermophilus nprT gene Proteins 0.000 description 2
- 101001051490 Homo sapiens Neural cell adhesion molecule L1 Proteins 0.000 description 2
- 101001129621 Homo sapiens PH domain leucine-rich repeat-containing protein phosphatase 1 Proteins 0.000 description 2
- 208000031300 Hydrocephalus with stenosis of the aqueduct of Sylvius Diseases 0.000 description 2
- 239000004354 Hydroxyethyl cellulose Substances 0.000 description 2
- 235000003332 Ilex aquifolium Nutrition 0.000 description 2
- 241000209027 Ilex aquifolium Species 0.000 description 2
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 2
- 102100027612 Kallikrein-11 Human genes 0.000 description 2
- 125000003440 L-leucyl group Chemical group O=C([*])[C@](N([H])[H])([H])C([H])([H])C(C([H])([H])[H])([H])C([H])([H])[H] 0.000 description 2
- 125000002842 L-seryl group Chemical group O=C([*])[C@](N([H])[H])([H])C([H])([H])O[H] 0.000 description 2
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L Magnesium chloride Chemical compound [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 description 2
- 102100024295 Maltase-glucoamylase Human genes 0.000 description 2
- 108090000157 Metallothionein Proteins 0.000 description 2
- 241001465754 Metazoa Species 0.000 description 2
- 241000187480 Mycobacterium smegmatis Species 0.000 description 2
- FSVCELGFZIQNCK-UHFFFAOYSA-N N,N-bis(2-hydroxyethyl)glycine Chemical compound OCCN(CCO)CC(O)=O FSVCELGFZIQNCK-UHFFFAOYSA-N 0.000 description 2
- 102100024964 Neural cell adhesion molecule L1 Human genes 0.000 description 2
- 241000221960 Neurospora Species 0.000 description 2
- 108091028043 Nucleic acid sequence Proteins 0.000 description 2
- 241000233654 Oomycetes Species 0.000 description 2
- 102100031152 PH domain leucine-rich repeat-containing protein phosphatase 1 Human genes 0.000 description 2
- 102000002508 Peptide Elongation Factors Human genes 0.000 description 2
- 108010068204 Peptide Elongation Factors Proteins 0.000 description 2
- 241000222395 Phlebia Species 0.000 description 2
- 241000222397 Phlebia radiata Species 0.000 description 2
- 241000235648 Pichia Species 0.000 description 2
- 241000222350 Pleurotus Species 0.000 description 2
- 229920002319 Poly(methyl acrylate) Polymers 0.000 description 2
- 229920000805 Polyaspartic acid Polymers 0.000 description 2
- 108010059820 Polygalacturonase Proteins 0.000 description 2
- 229920000388 Polyphosphate Polymers 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 101900282205 Saccharomyces cerevisiae Phosphoglycerate kinase Proteins 0.000 description 2
- 101100097319 Schizosaccharomyces pombe (strain 972 / ATCC 24843) ala1 gene Proteins 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- CDBYLPFSWZWCQE-UHFFFAOYSA-L Sodium Carbonate Chemical compound [Na+].[Na+].[O-]C([O-])=O CDBYLPFSWZWCQE-UHFFFAOYSA-L 0.000 description 2
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- 241000187392 Streptomyces griseus Species 0.000 description 2
- 101710135785 Subtilisin-like protease Proteins 0.000 description 2
- 108700005078 Synthetic Genes Proteins 0.000 description 2
- YSMRWXYRXBRSND-UHFFFAOYSA-N TOTP Chemical compound CC1=CC=CC=C1OP(=O)(OC=1C(=CC=CC=1)C)OC1=CC=CC=C1C YSMRWXYRXBRSND-UHFFFAOYSA-N 0.000 description 2
- KKEYFWRCBNTPAC-UHFFFAOYSA-N Terephthalic acid Chemical compound OC(=O)C1=CC=C(C(O)=O)C=C1 KKEYFWRCBNTPAC-UHFFFAOYSA-N 0.000 description 2
- 241001494489 Thielavia Species 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 241000222354 Trametes Species 0.000 description 2
- 241000222357 Trametes hirsuta Species 0.000 description 2
- 241000222355 Trametes versicolor Species 0.000 description 2
- 241000217816 Trametes villosa Species 0.000 description 2
- 102000005924 Triose-Phosphate Isomerase Human genes 0.000 description 2
- 108090000631 Trypsin Proteins 0.000 description 2
- 102000004142 Trypsin Human genes 0.000 description 2
- IXKSXJFAGXLQOQ-XISFHERQSA-N WHWLQLKPGQPMY Chemical compound C([C@@H](C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CNC=N1 IXKSXJFAGXLQOQ-XISFHERQSA-N 0.000 description 2
- 208000026197 X-linked hydrocephalus with stenosis of the aqueduct of Sylvius Diseases 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- YDONNITUKPKTIG-UHFFFAOYSA-N [Nitrilotris(methylene)]trisphosphonic acid Chemical compound OP(O)(=O)CN(CP(O)(O)=O)CP(O)(O)=O YDONNITUKPKTIG-UHFFFAOYSA-N 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 102000045404 acyltransferase activity proteins Human genes 0.000 description 2
- 108700014220 acyltransferase activity proteins Proteins 0.000 description 2
- 108010028144 alpha-Glucosidases Proteins 0.000 description 2
- 101150078331 ama-1 gene Proteins 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 239000002280 amphoteric surfactant Substances 0.000 description 2
- 239000002518 antifoaming agent Substances 0.000 description 2
- 239000007900 aqueous suspension Substances 0.000 description 2
- 125000003118 aryl group Chemical group 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 235000020054 awamori Nutrition 0.000 description 2
- JXLHNMVSKXFWAO-UHFFFAOYSA-N azane;7-fluoro-2,1,3-benzoxadiazole-4-sulfonic acid Chemical compound N.OS(=O)(=O)C1=CC=C(F)C2=NON=C12 JXLHNMVSKXFWAO-UHFFFAOYSA-N 0.000 description 2
- 229940097012 bacillus thuringiensis Drugs 0.000 description 2
- 102000006995 beta-Glucosidase Human genes 0.000 description 2
- 108010047754 beta-Glucosidase Proteins 0.000 description 2
- 239000011230 binding agent Substances 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- KGBXLFKZBHKPEV-UHFFFAOYSA-N boric acid Chemical compound OB(O)O KGBXLFKZBHKPEV-UHFFFAOYSA-N 0.000 description 2
- 239000004327 boric acid Substances 0.000 description 2
- 150000001642 boronic acid derivatives Chemical class 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- 239000001110 calcium chloride Substances 0.000 description 2
- 235000011148 calcium chloride Nutrition 0.000 description 2
- 229910001628 calcium chloride Inorganic materials 0.000 description 2
- 125000004432 carbon atom Chemical group C* 0.000 description 2
- 150000004649 carbonic acid derivatives Chemical class 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- NEHMKBQYUWJMIP-UHFFFAOYSA-N chloromethane Chemical compound ClC NEHMKBQYUWJMIP-UHFFFAOYSA-N 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 150000001860 citric acid derivatives Chemical class 0.000 description 2
- 239000004927 clay Substances 0.000 description 2
- 239000012459 cleaning agent Substances 0.000 description 2
- 239000011248 coating agent Substances 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 150000005690 diesters Chemical class 0.000 description 2
- 150000002009 diols Chemical class 0.000 description 2
- PMPJQLCPEQFEJW-GNTLFSRWSA-L disodium;2-[(z)-2-[4-[4-[(z)-2-(2-sulfonatophenyl)ethenyl]phenyl]phenyl]ethenyl]benzenesulfonate Chemical compound [Na+].[Na+].[O-]S(=O)(=O)C1=CC=CC=C1\C=C/C1=CC=C(C=2C=CC(\C=C/C=3C(=CC=CC=3)S([O-])(=O)=O)=CC=2)C=C1 PMPJQLCPEQFEJW-GNTLFSRWSA-L 0.000 description 2
- 238000004090 dissolution Methods 0.000 description 2
- AQYFGWINIJJWBQ-UHFFFAOYSA-N dithiophen-2-yldiazene Chemical compound C1=CSC(N=NC=2SC=CC=2)=C1 AQYFGWINIJJWBQ-UHFFFAOYSA-N 0.000 description 2
- 239000002552 dosage form Substances 0.000 description 2
- 108010091371 endoglucanase 1 Proteins 0.000 description 2
- 239000002532 enzyme inhibitor Substances 0.000 description 2
- JBKVHLHDHHXQEQ-UHFFFAOYSA-N epsilon-caprolactam Chemical compound O=C1CCCCCN1 JBKVHLHDHHXQEQ-UHFFFAOYSA-N 0.000 description 2
- 238000007046 ethoxylation reaction Methods 0.000 description 2
- 229920001249 ethyl cellulose Polymers 0.000 description 2
- 235000019325 ethyl cellulose Nutrition 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 230000007717 exclusion Effects 0.000 description 2
- 108010038658 exo-1,4-beta-D-xylosidase Proteins 0.000 description 2
- 108010093305 exopolygalacturonase Proteins 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 238000000855 fermentation Methods 0.000 description 2
- 230000004151 fermentation Effects 0.000 description 2
- 239000000945 filler Substances 0.000 description 2
- 108010061330 glucan 1,4-alpha-maltohydrolase Proteins 0.000 description 2
- 102000006602 glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 2
- 239000001087 glyceryl triacetate Substances 0.000 description 2
- 235000013773 glyceryl triacetate Nutrition 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 229910001385 heavy metal Inorganic materials 0.000 description 2
- 125000001183 hydrocarbyl group Chemical group 0.000 description 2
- 235000019447 hydroxyethyl cellulose Nutrition 0.000 description 2
- WQYVRQLZKVEZGA-UHFFFAOYSA-N hypochlorite Chemical compound Cl[O-] WQYVRQLZKVEZGA-UHFFFAOYSA-N 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 238000011065 in-situ storage Methods 0.000 description 2
- 239000011630 iodine Substances 0.000 description 2
- 229910052740 iodine Inorganic materials 0.000 description 2
- 238000005342 ion exchange Methods 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- 238000010412 laundry washing Methods 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 238000011068 loading method Methods 0.000 description 2
- 239000004337 magnesium citrate Substances 0.000 description 2
- 239000011572 manganese Substances 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 229920000609 methyl cellulose Polymers 0.000 description 2
- 239000001923 methylcellulose Substances 0.000 description 2
- 235000010981 methylcellulose Nutrition 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 239000003960 organic solvent Substances 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- 229910052698 phosphorus Inorganic materials 0.000 description 2
- 108010064470 polyaspartate Proteins 0.000 description 2
- 239000001205 polyphosphate Substances 0.000 description 2
- 235000011176 polyphosphates Nutrition 0.000 description 2
- 230000004481 post-translational protein modification Effects 0.000 description 2
- 235000019252 potassium sulphite Nutrition 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 210000001236 prokaryotic cell Anatomy 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 125000001453 quaternary ammonium group Chemical group 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 235000019515 salmon Nutrition 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 230000003248 secreting effect Effects 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 239000002453 shampoo Substances 0.000 description 2
- 150000004760 silicates Chemical class 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- 239000001509 sodium citrate Substances 0.000 description 2
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 2
- 229940079842 sodium cumenesulfonate Drugs 0.000 description 2
- 159000000000 sodium salts Chemical class 0.000 description 2
- NTHWMYGWWRZVTN-UHFFFAOYSA-N sodium silicate Chemical compound [Na+].[Na+].[O-][Si]([O-])=O NTHWMYGWWRZVTN-UHFFFAOYSA-N 0.000 description 2
- 229940048842 sodium xylenesulfonate Drugs 0.000 description 2
- KVCGISUBCHHTDD-UHFFFAOYSA-M sodium;4-methylbenzenesulfonate Chemical compound [Na+].CC1=CC=C(S([O-])(=O)=O)C=C1 KVCGISUBCHHTDD-UHFFFAOYSA-M 0.000 description 2
- QEKATQBVVAZOAY-UHFFFAOYSA-M sodium;4-propan-2-ylbenzenesulfonate Chemical compound [Na+].CC(C)C1=CC=C(S([O-])(=O)=O)C=C1 QEKATQBVVAZOAY-UHFFFAOYSA-M 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 239000000375 suspending agent Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 229920002994 synthetic fiber Polymers 0.000 description 2
- 239000002562 thickening agent Substances 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- 229960002622 triacetin Drugs 0.000 description 2
- 150000005691 triesters Chemical class 0.000 description 2
- VRVDFJOCCWSFLI-UHFFFAOYSA-K trisodium 3-[[4-[(6-anilino-1-hydroxy-3-sulfonatonaphthalen-2-yl)diazenyl]-5-methoxy-2-methylphenyl]diazenyl]naphthalene-1,5-disulfonate Chemical compound [Na+].[Na+].[Na+].COc1cc(N=Nc2cc(c3cccc(c3c2)S([O-])(=O)=O)S([O-])(=O)=O)c(C)cc1N=Nc1c(O)c2ccc(Nc3ccccc3)cc2cc1S([O-])(=O)=O VRVDFJOCCWSFLI-UHFFFAOYSA-K 0.000 description 2
- 239000012588 trypsin Substances 0.000 description 2
- 230000009105 vegetative growth Effects 0.000 description 2
- 229920002554 vinyl polymer Polymers 0.000 description 2
- 230000002087 whitening effect Effects 0.000 description 2
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 1
- LLSHAMSYHZEJBZ-BYPYZUCNSA-N (2s)-2-(2-sulfoethylamino)butanedioic acid Chemical compound OC(=O)C[C@@H](C(O)=O)NCCS(O)(=O)=O LLSHAMSYHZEJBZ-BYPYZUCNSA-N 0.000 description 1
- UWRLZJRHSWQCQV-YFKPBYRVSA-N (2s)-2-(2-sulfoethylamino)pentanedioic acid Chemical compound OC(=O)CC[C@@H](C(O)=O)NCCS(O)(=O)=O UWRLZJRHSWQCQV-YFKPBYRVSA-N 0.000 description 1
- HWXFTWCFFAXRMQ-JTQLQIEISA-N (2s)-2-[bis(carboxymethyl)amino]-3-phenylpropanoic acid Chemical compound OC(=O)CN(CC(O)=O)[C@H](C(O)=O)CC1=CC=CC=C1 HWXFTWCFFAXRMQ-JTQLQIEISA-N 0.000 description 1
- DCCWEYXHEXDZQW-BYPYZUCNSA-N (2s)-2-[bis(carboxymethyl)amino]butanedioic acid Chemical compound OC(=O)C[C@@H](C(O)=O)N(CC(O)=O)CC(O)=O DCCWEYXHEXDZQW-BYPYZUCNSA-N 0.000 description 1
- FQVLRGLGWNWPSS-BXBUPLCLSA-N (4r,7s,10s,13s,16r)-16-acetamido-13-(1h-imidazol-5-ylmethyl)-10-methyl-6,9,12,15-tetraoxo-7-propan-2-yl-1,2-dithia-5,8,11,14-tetrazacycloheptadecane-4-carboxamide Chemical compound N1C(=O)[C@@H](NC(C)=O)CSSC[C@@H](C(N)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@@H]1CC1=CN=CN1 FQVLRGLGWNWPSS-BXBUPLCLSA-N 0.000 description 1
- 125000006273 (C1-C3) alkyl group Chemical group 0.000 description 1
- UYXFOIMFLBVYDL-UHFFFAOYSA-N 1,2,4,7-tetramethyl-1,4,7-triazonane Chemical compound CC1CN(C)CCN(C)CCN1C UYXFOIMFLBVYDL-UHFFFAOYSA-N 0.000 description 1
- WLDGDTPNAKWAIR-UHFFFAOYSA-N 1,4,7-trimethyl-1,4,7-triazonane Chemical compound CN1CCN(C)CCN(C)CC1 WLDGDTPNAKWAIR-UHFFFAOYSA-N 0.000 description 1
- ZMLPKJYZRQZLDA-UHFFFAOYSA-N 1-(2-phenylethenyl)-4-[4-(2-phenylethenyl)phenyl]benzene Chemical group C=1C=CC=CC=1C=CC(C=C1)=CC=C1C(C=C1)=CC=C1C=CC1=CC=CC=C1 ZMLPKJYZRQZLDA-UHFFFAOYSA-N 0.000 description 1
- OSSNTDFYBPYIEC-UHFFFAOYSA-N 1-ethenylimidazole Chemical compound C=CN1C=CN=C1 OSSNTDFYBPYIEC-UHFFFAOYSA-N 0.000 description 1
- QWENRTYMTSOGBR-UHFFFAOYSA-N 1H-1,2,3-Triazole Chemical compound C=1C=NNN=1 QWENRTYMTSOGBR-UHFFFAOYSA-N 0.000 description 1
- LSZBMXCYIZBZPD-UHFFFAOYSA-N 2-[(1-hydroperoxy-1-oxohexan-2-yl)carbamoyl]benzoic acid Chemical compound CCCCC(C(=O)OO)NC(=O)C1=CC=CC=C1C(O)=O LSZBMXCYIZBZPD-UHFFFAOYSA-N 0.000 description 1
- PFBBCIYIKJWDIN-BUHFOSPRSA-N 2-[(e)-tetradec-1-enyl]butanedioic acid Chemical compound CCCCCCCCCCCC\C=C\C(C(O)=O)CC(O)=O PFBBCIYIKJWDIN-BUHFOSPRSA-N 0.000 description 1
- MHOFGBJTSNWTDT-UHFFFAOYSA-M 2-[n-ethyl-4-[(6-methoxy-3-methyl-1,3-benzothiazol-3-ium-2-yl)diazenyl]anilino]ethanol;methyl sulfate Chemical compound COS([O-])(=O)=O.C1=CC(N(CCO)CC)=CC=C1N=NC1=[N+](C)C2=CC=C(OC)C=C2S1 MHOFGBJTSNWTDT-UHFFFAOYSA-M 0.000 description 1
- 108010061247 2-aminophenol oxidase Proteins 0.000 description 1
- PUAQLLVFLMYYJJ-UHFFFAOYSA-N 2-aminopropiophenone Chemical compound CC(N)C(=O)C1=CC=CC=C1 PUAQLLVFLMYYJJ-UHFFFAOYSA-N 0.000 description 1
- WREFNFTVBQKRGZ-UHFFFAOYSA-N 2-decylbutanediperoxoic acid Chemical compound CCCCCCCCCCC(C(=O)OO)CC(=O)OO WREFNFTVBQKRGZ-UHFFFAOYSA-N 0.000 description 1
- YJHSJERLYWNLQL-UHFFFAOYSA-N 2-hydroxyethyl(dimethyl)azanium;chloride Chemical compound Cl.CN(C)CCO YJHSJERLYWNLQL-UHFFFAOYSA-N 0.000 description 1
- BBBWGMHOKYZAMB-UHFFFAOYSA-N 3-[(4-anilino-6-morpholin-4-yl-1,3,5-triazin-2-yl)amino]-6-[2-[4-[(4-anilino-6-morpholin-4-yl-1,3,5-triazin-2-yl)amino]phenyl]ethenyl]cyclohexa-2,4-diene-1,1-disulfonic acid Chemical compound N(C1=CC=CC=C1)C1=NC(=NC(=N1)N1CCOCC1)NC1=CC(C(C=C1)C=CC1=CC=C(C=C1)NC1=NC(=NC(=N1)NC1=CC=CC=C1)N1CCOCC1)(S(=O)(=O)O)S(=O)(=O)O BBBWGMHOKYZAMB-UHFFFAOYSA-N 0.000 description 1
- ODAKQJVOEZMLOD-UHFFFAOYSA-N 3-[bis(carboxymethyl)amino]-2-hydroxypropanoic acid Chemical compound OC(=O)C(O)CN(CC(O)=O)CC(O)=O ODAKQJVOEZMLOD-UHFFFAOYSA-N 0.000 description 1
- QTMHHQFADWIZCP-UHFFFAOYSA-N 4-decanoyloxybenzoic acid Chemical compound CCCCCCCCCC(=O)OC1=CC=C(C(O)=O)C=C1 QTMHHQFADWIZCP-UHFFFAOYSA-N 0.000 description 1
- 102220491638 40S ribosomal protein S27_N74D_mutation Human genes 0.000 description 1
- 101710163881 5,6-dihydroxyindole-2-carboxylic acid oxidase Proteins 0.000 description 1
- UXEKKQRJIGKQNP-UHFFFAOYSA-N 5-(4-phenyltriazol-2-yl)-2-[2-[4-(4-phenyltriazol-2-yl)-2-sulfophenyl]ethenyl]benzenesulfonic acid Chemical compound OS(=O)(=O)C1=CC(N2N=C(C=N2)C=2C=CC=CC=2)=CC=C1C=CC(C(=C1)S(O)(=O)=O)=CC=C1N(N=1)N=CC=1C1=CC=CC=C1 UXEKKQRJIGKQNP-UHFFFAOYSA-N 0.000 description 1
- HRHCYUBSBRXMIN-UHFFFAOYSA-N 5-[(4,6-dianilino-1,3,5-triazin-2-yl)amino]-2-[2-[4-[(4,6-dianilino-1,3,5-triazin-2-yl)amino]-2-sulfophenyl]ethenyl]benzenesulfonic acid Chemical compound C=1C=C(C=CC=2C(=CC(NC=3N=C(NC=4C=CC=CC=4)N=C(NC=4C=CC=CC=4)N=3)=CC=2)S(O)(=O)=O)C(S(=O)(=O)O)=CC=1NC(N=C(NC=1C=CC=CC=1)N=1)=NC=1NC1=CC=CC=C1 HRHCYUBSBRXMIN-UHFFFAOYSA-N 0.000 description 1
- 101150078509 ADH2 gene Proteins 0.000 description 1
- 101150026777 ADH5 gene Proteins 0.000 description 1
- 101150104118 ANS1 gene Proteins 0.000 description 1
- RZVAJINKPMORJF-UHFFFAOYSA-N Acetaminophen Chemical compound CC(=O)NC1=CC=C(O)C=C1 RZVAJINKPMORJF-UHFFFAOYSA-N 0.000 description 1
- 241000588625 Acinetobacter sp. Species 0.000 description 1
- NIXOWILDQLNWCW-UHFFFAOYSA-M Acrylate Chemical compound [O-]C(=O)C=C NIXOWILDQLNWCW-UHFFFAOYSA-M 0.000 description 1
- 229920002126 Acrylic acid copolymer Polymers 0.000 description 1
- 101100510736 Actinidia chinensis var. chinensis LDOX gene Proteins 0.000 description 1
- 102000057234 Acyl transferases Human genes 0.000 description 1
- 241000061178 Aeromicrobium sp. Species 0.000 description 1
- 102100034035 Alcohol dehydrogenase 1A Human genes 0.000 description 1
- 241000141890 Alphamyces Species 0.000 description 1
- 241000223600 Alternaria Species 0.000 description 1
- 239000004254 Ammonium phosphate Substances 0.000 description 1
- 241000534414 Anotopterus nikparini Species 0.000 description 1
- 241000203069 Archaea Species 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 102220496643 Aryl hydrocarbon receptor nuclear translocator-like protein 1_S9E_mutation Human genes 0.000 description 1
- 241000235349 Ascomycota Species 0.000 description 1
- 101100460671 Aspergillus flavus (strain ATCC 200026 / FGSC A1120 / IAM 13836 / NRRL 3357 / JCM 12722 / SRRC 167) norA gene Proteins 0.000 description 1
- 241000223651 Aureobasidium Species 0.000 description 1
- 108090000145 Bacillolysin Proteins 0.000 description 1
- 108700003918 Bacillus Thuringiensis insecticidal crystal Proteins 0.000 description 1
- 241000193752 Bacillus circulans Species 0.000 description 1
- 241000193749 Bacillus coagulans Species 0.000 description 1
- 241000193747 Bacillus firmus Species 0.000 description 1
- 241001328119 Bacillus gibsonii Species 0.000 description 1
- 101000695691 Bacillus licheniformis Beta-lactamase Proteins 0.000 description 1
- 241000194107 Bacillus megaterium Species 0.000 description 1
- 101000740449 Bacillus subtilis (strain 168) Biotin/lipoyl attachment protein Proteins 0.000 description 1
- 108010062877 Bacteriocins Proteins 0.000 description 1
- 241000221198 Basidiomycota Species 0.000 description 1
- 102100030981 Beta-alanine-activating enzyme Human genes 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-M Bicarbonate Chemical class OC([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-M 0.000 description 1
- 241000222490 Bjerkandera Species 0.000 description 1
- 241000222478 Bjerkandera adusta Species 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 241000193764 Brevibacillus brevis Species 0.000 description 1
- 241000061154 Brevundimonas sp. Species 0.000 description 1
- 241001453380 Burkholderia Species 0.000 description 1
- 241000589513 Burkholderia cepacia Species 0.000 description 1
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 1
- FPXLKVLNXFUYQU-UHFFFAOYSA-N CCO.OP(=O)OP(O)=O Chemical compound CCO.OP(=O)OP(O)=O FPXLKVLNXFUYQU-UHFFFAOYSA-N 0.000 description 1
- 101100327917 Caenorhabditis elegans chup-1 gene Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 241000589876 Campylobacter Species 0.000 description 1
- KXDHJXZQYSOELW-UHFFFAOYSA-N Carbamic acid Chemical class NC(O)=O KXDHJXZQYSOELW-UHFFFAOYSA-N 0.000 description 1
- 108010053835 Catalase Proteins 0.000 description 1
- 102000016938 Catalase Human genes 0.000 description 1
- 102220584278 Cellular tumor antigen p53_G59D_mutation Human genes 0.000 description 1
- 241000186321 Cellulomonas Species 0.000 description 1
- 102100037633 Centrin-3 Human genes 0.000 description 1
- 241001466517 Ceriporiopsis aneirina Species 0.000 description 1
- 241001646018 Ceriporiopsis gilvescens Species 0.000 description 1
- 241001277875 Ceriporiopsis rivulosa Species 0.000 description 1
- 241000524302 Ceriporiopsis subrufa Species 0.000 description 1
- 241000462056 Cestraeus plicatilis Species 0.000 description 1
- 229920002101 Chitin Polymers 0.000 description 1
- 229920001661 Chitosan Polymers 0.000 description 1
- 241000985909 Chrysosporium keratinophilum Species 0.000 description 1
- 241001674013 Chrysosporium lucknowense Species 0.000 description 1
- 241001556045 Chrysosporium merdarium Species 0.000 description 1
- 241000080524 Chrysosporium queenslandicum Species 0.000 description 1
- 241001674001 Chrysosporium tropicum Species 0.000 description 1
- 241000355696 Chrysosporium zonatum Species 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 241000233652 Chytridiomycota Species 0.000 description 1
- 102220465972 Cilium assembly protein DZIP1_S24R_mutation Human genes 0.000 description 1
- 241000193403 Clostridium Species 0.000 description 1
- 108091033380 Coding strand Proteins 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 241000222680 Collybia Species 0.000 description 1
- 229910021592 Copper(II) chloride Inorganic materials 0.000 description 1
- 241001085790 Coprinopsis Species 0.000 description 1
- 241001236836 Coprinopsis friesii Species 0.000 description 1
- 244000234623 Coprinus comatus Species 0.000 description 1
- 235000001673 Coprinus macrorhizus Nutrition 0.000 description 1
- 229920000742 Cotton Polymers 0.000 description 1
- 241001337994 Cryptococcus <scale insect> Species 0.000 description 1
- 241001558166 Curvularia sp. Species 0.000 description 1
- 102100034770 Cyclin-dependent kinase inhibitor 3 Human genes 0.000 description 1
- 102000018832 Cytochromes Human genes 0.000 description 1
- 108010052832 Cytochromes Proteins 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 102000016559 DNA Primase Human genes 0.000 description 1
- 108010092681 DNA Primase Proteins 0.000 description 1
- 230000004544 DNA amplification Effects 0.000 description 1
- 239000003155 DNA primer Substances 0.000 description 1
- 229920001353 Dextrin Polymers 0.000 description 1
- 239000004375 Dextrin Substances 0.000 description 1
- 101100342470 Dictyostelium discoideum pkbA gene Proteins 0.000 description 1
- 239000004667 Diesterquat Substances 0.000 description 1
- 108090000204 Dipeptidase 1 Proteins 0.000 description 1
- SNRUBQQJIBEYMU-UHFFFAOYSA-N Dodecane Chemical group CCCCCCCCCCCC SNRUBQQJIBEYMU-UHFFFAOYSA-N 0.000 description 1
- 101710121765 Endo-1,4-beta-xylanase Proteins 0.000 description 1
- 101710111935 Endo-beta-1,4-glucanase Proteins 0.000 description 1
- 108010067770 Endopeptidase K Proteins 0.000 description 1
- 241000194033 Enterococcus Species 0.000 description 1
- 101100385973 Escherichia coli (strain K12) cycA gene Proteins 0.000 description 1
- 101100288045 Escherichia coli hph gene Proteins 0.000 description 1
- 108090000371 Esterases Proteins 0.000 description 1
- OTMSDBZUPAUEDD-UHFFFAOYSA-N Ethane Chemical compound CC OTMSDBZUPAUEDD-UHFFFAOYSA-N 0.000 description 1
- KIWBPDUYBMNFTB-UHFFFAOYSA-N Ethyl hydrogen sulfate Chemical compound CCOS(O)(=O)=O KIWBPDUYBMNFTB-UHFFFAOYSA-N 0.000 description 1
- 241000192125 Firmicutes Species 0.000 description 1
- 241000589565 Flavobacterium Species 0.000 description 1
- 241000123326 Fomes Species 0.000 description 1
- 241000145614 Fusarium bactridioides Species 0.000 description 1
- 241000223194 Fusarium culmorum Species 0.000 description 1
- 241000223195 Fusarium graminearum Species 0.000 description 1
- 101000759028 Fusarium oxysporum Trypsin Proteins 0.000 description 1
- 241001112697 Fusarium reticulatum Species 0.000 description 1
- 241001014439 Fusarium sarcochroum Species 0.000 description 1
- 241000223192 Fusarium sporotrichioides Species 0.000 description 1
- 241001465753 Fusarium torulosum Species 0.000 description 1
- 241000605909 Fusobacterium Species 0.000 description 1
- 101150108358 GLAA gene Proteins 0.000 description 1
- 241000146398 Gelatoporia subvermispora Species 0.000 description 1
- 206010064571 Gene mutation Diseases 0.000 description 1
- 241000626621 Geobacillus Species 0.000 description 1
- 101100001650 Geobacillus stearothermophilus amyM gene Proteins 0.000 description 1
- 101000892220 Geobacillus thermodenitrificans (strain NG80-2) Long-chain-alcohol dehydrogenase 1 Proteins 0.000 description 1
- 229920001503 Glucan Polymers 0.000 description 1
- 101150009006 HIS3 gene Proteins 0.000 description 1
- 101100295959 Halobacterium salinarum (strain ATCC 700922 / JCM 11081 / NRC-1) arcB gene Proteins 0.000 description 1
- 101100246753 Halobacterium salinarum (strain ATCC 700922 / JCM 11081 / NRC-1) pyrF gene Proteins 0.000 description 1
- 241000589989 Helicobacter Species 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 101000780443 Homo sapiens Alcohol dehydrogenase 1A Proteins 0.000 description 1
- 101000773364 Homo sapiens Beta-alanine-activating enzyme Proteins 0.000 description 1
- 101000880522 Homo sapiens Centrin-3 Proteins 0.000 description 1
- 101000882901 Homo sapiens Claudin-2 Proteins 0.000 description 1
- 102000004157 Hydrolases Human genes 0.000 description 1
- 108090000604 Hydrolases Proteins 0.000 description 1
- SHBUUTHKGIVMJT-UHFFFAOYSA-N Hydroxystearate Chemical compound CCCCCCCCCCCCCCCCCC(=O)OO SHBUUTHKGIVMJT-UHFFFAOYSA-N 0.000 description 1
- 241000411968 Ilyobacter Species 0.000 description 1
- 108010065920 Insulin Lispro Proteins 0.000 description 1
- 229910021578 Iron(III) chloride Inorganic materials 0.000 description 1
- 108090000769 Isomerases Proteins 0.000 description 1
- 101710172072 Kexin Proteins 0.000 description 1
- 241000186984 Kitasatospora aureofaciens Species 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- 241001138401 Kluyveromyces lactis Species 0.000 description 1
- 241000824268 Kuma Species 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- 125000001176 L-lysyl group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C([H])([H])C([H])([H])C([H])([H])C(N([H])[H])([H])[H] 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- 125000000769 L-threonyl group Chemical group [H]N([H])[C@]([H])(C(=O)[*])[C@](O[H])(C([H])([H])[H])[H] 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 125000003798 L-tyrosyl group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C([H])([H])C1=C([H])C([H])=C(O[H])C([H])=C1[H] 0.000 description 1
- 125000003580 L-valyl group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(C([H])([H])[H])(C([H])([H])[H])[H] 0.000 description 1
- STECJAGHUSJQJN-USLFZFAMSA-N LSM-4015 Chemical compound C1([C@@H](CO)C(=O)OC2C[C@@H]3N([C@H](C2)[C@@H]2[C@H]3O2)C)=CC=CC=C1 STECJAGHUSJQJN-USLFZFAMSA-N 0.000 description 1
- 241000235087 Lachancea kluyveri Species 0.000 description 1
- 241000186660 Lactobacillus Species 0.000 description 1
- 241000194036 Lactococcus Species 0.000 description 1
- 241000222418 Lentinus Species 0.000 description 1
- 108010036940 Levansucrase Proteins 0.000 description 1
- 101710098556 Lipase A Proteins 0.000 description 1
- 239000006142 Luria-Bertani Agar Substances 0.000 description 1
- AIXUQKMMBQJZCU-IUCAKERBSA-N Lys-Pro Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(O)=O AIXUQKMMBQJZCU-IUCAKERBSA-N 0.000 description 1
- 101710099648 Lysosomal acid lipase/cholesteryl ester hydrolase Proteins 0.000 description 1
- 102100026001 Lysosomal acid lipase/cholesteryl ester hydrolase Human genes 0.000 description 1
- 101150068888 MET3 gene Proteins 0.000 description 1
- 241001344133 Magnaporthe Species 0.000 description 1
- 241001344131 Magnaporthe grisea Species 0.000 description 1
- 229920002774 Maltodextrin Polymers 0.000 description 1
- 239000005913 Maltodextrin Substances 0.000 description 1
- PWHULOQIROXLJO-UHFFFAOYSA-N Manganese Chemical compound [Mn] PWHULOQIROXLJO-UHFFFAOYSA-N 0.000 description 1
- 229910021380 Manganese Chloride Inorganic materials 0.000 description 1
- GLFNIEUTAYBVOC-UHFFFAOYSA-L Manganese chloride Chemical compound Cl[Mn]Cl GLFNIEUTAYBVOC-UHFFFAOYSA-L 0.000 description 1
- 229920000057 Mannan Polymers 0.000 description 1
- 108091027974 Mature messenger RNA Proteins 0.000 description 1
- 102000003792 Metallothionein Human genes 0.000 description 1
- 241000500375 Microbacterium sp. Species 0.000 description 1
- 241000191938 Micrococcus luteus Species 0.000 description 1
- 239000004666 Monoesterquat Substances 0.000 description 1
- 241000235395 Mucor Species 0.000 description 1
- 102220609673 Myocyte-specific enhancer factor 2A_S97G_mutation Human genes 0.000 description 1
- JYXGIOKAKDAARW-UHFFFAOYSA-N N-(2-hydroxyethyl)iminodiacetic acid Chemical compound OCCN(CC(O)=O)CC(O)=O JYXGIOKAKDAARW-UHFFFAOYSA-N 0.000 description 1
- WHNWPMSKXPGLAX-UHFFFAOYSA-N N-Vinyl-2-pyrrolidone Chemical compound C=CN1CCCC1=O WHNWPMSKXPGLAX-UHFFFAOYSA-N 0.000 description 1
- 150000001204 N-oxides Chemical class 0.000 description 1
- 125000001429 N-terminal alpha-amino-acid group Chemical group 0.000 description 1
- 229940126655 NDI-034858 Drugs 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- 229910000503 Na-aluminosilicate Inorganic materials 0.000 description 1
- 241000588653 Neisseria Species 0.000 description 1
- 241000233892 Neocallimastix Species 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 241000221961 Neurospora crassa Species 0.000 description 1
- 101100022915 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) cys-11 gene Proteins 0.000 description 1
- 108091005507 Neutral proteases Proteins 0.000 description 1
- 102000035092 Neutral proteases Human genes 0.000 description 1
- 229910021586 Nickel(II) chloride Inorganic materials 0.000 description 1
- 241000290929 Nimbus Species 0.000 description 1
- 108090000913 Nitrate Reductases Proteins 0.000 description 1
- 239000006057 Non-nutritive feed additive Substances 0.000 description 1
- 241001072230 Oceanobacillus Species 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 102100028200 Ornithine transcarbamylase, mitochondrial Human genes 0.000 description 1
- 101710113020 Ornithine transcarbamylase, mitochondrial Proteins 0.000 description 1
- BPQQTUXANYXVAA-UHFFFAOYSA-N Orthosilicate Chemical compound [O-][Si]([O-])([O-])[O-] BPQQTUXANYXVAA-UHFFFAOYSA-N 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 101150050192 PIGM gene Proteins 0.000 description 1
- 241001236817 Paecilomyces <Clavicipitaceae> Species 0.000 description 1
- 241000194109 Paenibacillus lautus Species 0.000 description 1
- 241000881860 Paenibacillus mucilaginosus Species 0.000 description 1
- 241001236144 Panaeolus Species 0.000 description 1
- 241000310787 Panaeolus papilionaceus Species 0.000 description 1
- 206010034133 Pathogen resistance Diseases 0.000 description 1
- 108010087702 Penicillinase Proteins 0.000 description 1
- 241000228143 Penicillium Species 0.000 description 1
- 241000222385 Phanerochaete Species 0.000 description 1
- 241000222393 Phanerochaete chrysosporium Species 0.000 description 1
- 102100027330 Phosphoribosylaminoimidazole carboxylase Human genes 0.000 description 1
- 108090000434 Phosphoribosylaminoimidazolesuccinocarboxamide synthases Proteins 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 241000235379 Piromyces Species 0.000 description 1
- 244000252132 Pleurotus eryngii Species 0.000 description 1
- 235000001681 Pleurotus eryngii Nutrition 0.000 description 1
- 241000221945 Podospora Species 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 239000004952 Polyamide Substances 0.000 description 1
- 241000222640 Polyporus Species 0.000 description 1
- 241000789035 Polyporus pinsitus Species 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 241001236760 Psathyrella Species 0.000 description 1
- 241000168225 Pseudomonas alcaligenes Species 0.000 description 1
- 241000589755 Pseudomonas mendocina Species 0.000 description 1
- 241000589630 Pseudomonas pseudoalcaligenes Species 0.000 description 1
- 241000589774 Pseudomonas sp. Species 0.000 description 1
- 241000577556 Pseudomonas wisconsinensis Species 0.000 description 1
- 241000228453 Pyrenophora Species 0.000 description 1
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 1
- 101710081551 Pyrolysin Proteins 0.000 description 1
- 241001361634 Rhizoctonia Species 0.000 description 1
- 241000813090 Rhizoctonia solani Species 0.000 description 1
- 101000968489 Rhizomucor miehei Lipase Proteins 0.000 description 1
- 101100394989 Rhodopseudomonas palustris (strain ATCC BAA-98 / CGA009) hisI gene Proteins 0.000 description 1
- 102220485511 Rhodopsin_N60D_mutation Human genes 0.000 description 1
- 102220528606 Ribonuclease P/MRP protein subunit POP5_S99D_mutation Human genes 0.000 description 1
- LJJQKFQXHKVEOZ-BYPYZUCNSA-N S(=O)(=O)(O)CN[C@@H](CCC(=O)O)C(=O)O Chemical compound S(=O)(=O)(O)CN[C@@H](CCC(=O)O)C(=O)O LJJQKFQXHKVEOZ-BYPYZUCNSA-N 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 235000003534 Saccharomyces carlsbergensis Nutrition 0.000 description 1
- 101900354623 Saccharomyces cerevisiae Galactokinase Proteins 0.000 description 1
- 101900084120 Saccharomyces cerevisiae Triosephosphate isomerase Proteins 0.000 description 1
- 235000001006 Saccharomyces cerevisiae var diastaticus Nutrition 0.000 description 1
- 244000206963 Saccharomyces cerevisiae var. diastaticus Species 0.000 description 1
- 241000204893 Saccharomyces douglasii Species 0.000 description 1
- 241001407717 Saccharomyces norbensis Species 0.000 description 1
- 241001123227 Saccharomyces pastorianus Species 0.000 description 1
- 241001466077 Salina Species 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 241000222480 Schizophyllum Species 0.000 description 1
- 241000235346 Schizosaccharomyces Species 0.000 description 1
- 101100022918 Schizosaccharomyces pombe (strain 972 / ATCC 24843) sua1 gene Proteins 0.000 description 1
- 239000004115 Sodium Silicate Substances 0.000 description 1
- 239000004280 Sodium formate Substances 0.000 description 1
- 241000191940 Staphylococcus Species 0.000 description 1
- 241000191963 Staphylococcus epidermidis Species 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 241000983364 Stenotrophomonas sp. Species 0.000 description 1
- 241000194048 Streptococcus equi Species 0.000 description 1
- 101100309436 Streptococcus mutans serotype c (strain ATCC 700610 / UA159) ftf gene Proteins 0.000 description 1
- 241000193996 Streptococcus pyogenes Species 0.000 description 1
- 241000194054 Streptococcus uberis Species 0.000 description 1
- 241000958303 Streptomyces achromogenes Species 0.000 description 1
- 241001468227 Streptomyces avermitilis Species 0.000 description 1
- 241000187432 Streptomyces coelicolor Species 0.000 description 1
- 101100370749 Streptomyces coelicolor (strain ATCC BAA-471 / A3(2) / M145) trpC1 gene Proteins 0.000 description 1
- 241000187391 Streptomyces hygroscopicus Species 0.000 description 1
- 241000187398 Streptomyces lividans Species 0.000 description 1
- 241001518258 Streptomyces pristinaespiralis Species 0.000 description 1
- 101000984202 Streptomyces rimosus Lipase Proteins 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- ULUAUXLGCMPNKK-UHFFFAOYSA-N Sulfobutanedioic acid Chemical compound OC(=O)CC(C(O)=O)S(O)(=O)=O ULUAUXLGCMPNKK-UHFFFAOYSA-N 0.000 description 1
- 102220575589 Synaptotagmin-13_S97A_mutation Human genes 0.000 description 1
- 241000228341 Talaromyces Species 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 244000299461 Theobroma cacao Species 0.000 description 1
- 235000009470 Theobroma cacao Nutrition 0.000 description 1
- 241000228178 Thermoascus Species 0.000 description 1
- 241000203780 Thermobifida fusca Species 0.000 description 1
- 108090001109 Thermolysin Proteins 0.000 description 1
- 241000223257 Thermomyces Species 0.000 description 1
- 241001495429 Thielavia terrestris Species 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- 241001149964 Tolypocladium Species 0.000 description 1
- 102000004357 Transferases Human genes 0.000 description 1
- 108090000992 Transferases Proteins 0.000 description 1
- 241000223260 Trichoderma harzianum Species 0.000 description 1
- 241000378866 Trichoderma koningii Species 0.000 description 1
- 241000223262 Trichoderma longibrachiatum Species 0.000 description 1
- 241000223261 Trichoderma viride Species 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 102220470553 Tryptase delta_Q87E_mutation Human genes 0.000 description 1
- 101150050575 URA3 gene Proteins 0.000 description 1
- 241000266300 Ulocladium Species 0.000 description 1
- 241000202898 Ureaplasma Species 0.000 description 1
- JKHXYJKMNSSFFL-IUCAKERBSA-N Val-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN JKHXYJKMNSSFFL-IUCAKERBSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- 101710143559 Vanadium-dependent bromoperoxidase Proteins 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 229930003448 Vitamin K Natural products 0.000 description 1
- 241000409279 Xerochrysium dermatitidis Species 0.000 description 1
- 241000235013 Yarrowia Species 0.000 description 1
- 241000235015 Yarrowia lipolytica Species 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- 241000758405 Zoopagomycotina Species 0.000 description 1
- 239000002250 absorbent Substances 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 229940056218 acid gone Drugs 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 108010045649 agarase Proteins 0.000 description 1
- 238000000246 agarose gel electrophoresis Methods 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 229910001413 alkali metal ion Inorganic materials 0.000 description 1
- 150000001340 alkali metals Chemical class 0.000 description 1
- 229910052784 alkaline earth metal Inorganic materials 0.000 description 1
- 125000003545 alkoxy group Chemical group 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- ZRIUUUJAJJNDSS-UHFFFAOYSA-N ammonium phosphates Chemical class [NH4+].[NH4+].[NH4+].[O-]P([O-])([O-])=O ZRIUUUJAJJNDSS-UHFFFAOYSA-N 0.000 description 1
- 235000019289 ammonium phosphates Nutrition 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 150000008064 anhydrides Chemical class 0.000 description 1
- 239000001000 anthraquinone dye Substances 0.000 description 1
- 229940053200 antiepileptics fatty acid derivative Drugs 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 101150009206 aprE gene Proteins 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 101150008194 argB gene Proteins 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 210000004507 artificial chromosome Anatomy 0.000 description 1
- 238000013528 artificial neural network Methods 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 239000000987 azo dye Substances 0.000 description 1
- 229940054340 bacillus coagulans Drugs 0.000 description 1
- 229940005348 bacillus firmus Drugs 0.000 description 1
- 101150103518 bar gene Proteins 0.000 description 1
- OGBUMNBNEWYMNJ-UHFFFAOYSA-N batilol Chemical class CCCCCCCCCCCCCCCCCCOCC(O)CO OGBUMNBNEWYMNJ-UHFFFAOYSA-N 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 229940077388 benzenesulfonate Drugs 0.000 description 1
- SRSXLGNVWSONIS-UHFFFAOYSA-M benzenesulfonate Chemical compound [O-]S(=O)(=O)C1=CC=CC=C1 SRSXLGNVWSONIS-UHFFFAOYSA-M 0.000 description 1
- DMSMPAJRVJJAGA-UHFFFAOYSA-N benzo[d]isothiazol-3-one Chemical compound C1=CC=C2C(=O)NSC2=C1 DMSMPAJRVJJAGA-UHFFFAOYSA-N 0.000 description 1
- 125000001797 benzyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])* 0.000 description 1
- MSWZFWKMSRAUBD-UHFFFAOYSA-N beta-D-galactosamine Natural products NC1C(O)OC(CO)C(O)C1O MSWZFWKMSRAUBD-UHFFFAOYSA-N 0.000 description 1
- 108010051210 beta-Fructofuranosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 230000009141 biological interaction Effects 0.000 description 1
- 238000009530 blood pressure measurement Methods 0.000 description 1
- 102220350531 c.80A>G Human genes 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- BRPQOXSCLDDYGP-UHFFFAOYSA-N calcium oxide Chemical compound [O-2].[Ca+2] BRPQOXSCLDDYGP-UHFFFAOYSA-N 0.000 description 1
- 239000000292 calcium oxide Substances 0.000 description 1
- ODINCKMPIJJUCX-UHFFFAOYSA-N calcium oxide Inorganic materials [Ca]=O ODINCKMPIJJUCX-UHFFFAOYSA-N 0.000 description 1
- 229940041514 candida albicans extract Drugs 0.000 description 1
- 108010089934 carbohydrase Proteins 0.000 description 1
- 238000012219 cassette mutagenesis Methods 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 230000034303 cell budding Effects 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 230000010307 cell transformation Effects 0.000 description 1
- 210000002421 cell wall Anatomy 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 229920003086 cellulose ether Polymers 0.000 description 1
- 229920003174 cellulose-based polymer Polymers 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- NEHMKBQYUWJMIP-NJFSPNSNSA-N chloro(114C)methane Chemical compound [14CH3]Cl NEHMKBQYUWJMIP-NJFSPNSNSA-N 0.000 description 1
- 238000011098 chromatofocusing Methods 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 230000003749 cleanliness Effects 0.000 description 1
- 150000001868 cobalt Chemical class 0.000 description 1
- 229920001436 collagen Polymers 0.000 description 1
- 239000013065 commercial product Substances 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 230000000536 complexating effect Effects 0.000 description 1
- 239000008139 complexing agent Substances 0.000 description 1
- 230000003750 conditioning effect Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- ORTQZVOHEJQUHG-UHFFFAOYSA-L copper(II) chloride Chemical compound Cl[Cu]Cl ORTQZVOHEJQUHG-UHFFFAOYSA-L 0.000 description 1
- 230000007797 corrosion Effects 0.000 description 1
- 238000005260 corrosion Methods 0.000 description 1
- 239000002178 crystalline material Substances 0.000 description 1
- 101150005799 dagA gene Proteins 0.000 description 1
- UNWDCFHEVIWFCW-UHFFFAOYSA-N decanediperoxoic acid Chemical compound OOC(=O)CCCCCCCCC(=O)OO UNWDCFHEVIWFCW-UHFFFAOYSA-N 0.000 description 1
- 229920006237 degradable polymer Polymers 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 239000000645 desinfectant Substances 0.000 description 1
- 238000009990 desizing Methods 0.000 description 1
- 235000019425 dextrin Nutrition 0.000 description 1
- 125000000664 diazo group Chemical group [N-]=[N+]=[*] 0.000 description 1
- GSPKZYJPUDYKPI-UHFFFAOYSA-N diethoxy sulfate Chemical compound CCOOS(=O)(=O)OOCC GSPKZYJPUDYKPI-UHFFFAOYSA-N 0.000 description 1
- 238000002050 diffraction method Methods 0.000 description 1
- 229940079919 digestives enzyme preparation Drugs 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 239000013024 dilution buffer Substances 0.000 description 1
- SZXQTJUDPRGNJN-UHFFFAOYSA-N dipropylene glycol Chemical compound OCCCOCCCO SZXQTJUDPRGNJN-UHFFFAOYSA-N 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- 235000021186 dishes Nutrition 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- PMPJQLCPEQFEJW-HPKCLRQXSA-L disodium;2-[(e)-2-[4-[4-[(e)-2-(2-sulfonatophenyl)ethenyl]phenyl]phenyl]ethenyl]benzenesulfonate Chemical compound [Na+].[Na+].[O-]S(=O)(=O)C1=CC=CC=C1\C=C\C1=CC=C(C=2C=CC(\C=C\C=3C(=CC=CC=3)S([O-])(=O)=O)=CC=2)C=C1 PMPJQLCPEQFEJW-HPKCLRQXSA-L 0.000 description 1
- YQJJAPXXIRNMRI-SEPHDYHBSA-L disodium;5-[(4,6-diamino-1,3,5-triazin-2-yl)amino]-2-[(e)-2-[4-[(4,6-diamino-1,3,5-triazin-2-yl)amino]-2-sulfonatophenyl]ethenyl]benzenesulfonate Chemical compound [Na+].[Na+].NC1=NC(N)=NC(NC=2C=C(C(\C=C\C=3C(=CC(NC=4N=C(N)N=C(N)N=4)=CC=3)S([O-])(=O)=O)=CC=2)S([O-])(=O)=O)=N1 YQJJAPXXIRNMRI-SEPHDYHBSA-L 0.000 description 1
- VUJGKADZTYCLIL-YHPRVSEPSA-L disodium;5-[(4-anilino-6-morpholin-4-yl-1,3,5-triazin-2-yl)amino]-2-[(e)-2-[4-[(4-anilino-6-morpholin-4-yl-1,3,5-triazin-2-yl)amino]-2-sulfonatophenyl]ethenyl]benzenesulfonate Chemical compound [Na+].[Na+].C=1C=C(\C=C\C=2C(=CC(NC=3N=C(N=C(NC=4C=CC=CC=4)N=3)N3CCOCC3)=CC=2)S([O-])(=O)=O)C(S(=O)(=O)[O-])=CC=1NC(N=C(N=1)N2CCOCC2)=NC=1NC1=CC=CC=C1 VUJGKADZTYCLIL-YHPRVSEPSA-L 0.000 description 1
- VTIIJXUACCWYHX-UHFFFAOYSA-L disodium;carboxylatooxy carbonate Chemical compound [Na+].[Na+].[O-]C(=O)OOC([O-])=O VTIIJXUACCWYHX-UHFFFAOYSA-L 0.000 description 1
- JHUXOSATQXGREM-UHFFFAOYSA-N dodecanediperoxoic acid Chemical compound OOC(=O)CCCCCCCCCCC(=O)OO JHUXOSATQXGREM-UHFFFAOYSA-N 0.000 description 1
- BRDYCNFHFWUBCZ-UHFFFAOYSA-N dodecaneperoxoic acid Chemical compound CCCCCCCCCCCC(=O)OO BRDYCNFHFWUBCZ-UHFFFAOYSA-N 0.000 description 1
- GMSCBRSQMRDRCD-UHFFFAOYSA-N dodecyl 2-methylprop-2-enoate Chemical compound CCCCCCCCCCCCOC(=O)C(C)=C GMSCBRSQMRDRCD-UHFFFAOYSA-N 0.000 description 1
- 125000003438 dodecyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- DUYCTCQXNHFCSJ-UHFFFAOYSA-N dtpmp Chemical compound OP(=O)(O)CN(CP(O)(O)=O)CCN(CP(O)(=O)O)CCN(CP(O)(O)=O)CP(O)(O)=O DUYCTCQXNHFCSJ-UHFFFAOYSA-N 0.000 description 1
- 238000002003 electron diffraction Methods 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 108010091384 endoglucanase 2 Proteins 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 239000003248 enzyme activator Substances 0.000 description 1
- 238000001952 enzyme assay Methods 0.000 description 1
- 239000003797 essential amino acid Substances 0.000 description 1
- 235000020776 essential amino acid Nutrition 0.000 description 1
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000001704 evaporation Methods 0.000 description 1
- 230000008020 evaporation Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 235000019387 fatty acid methyl ester Nutrition 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 238000005189 flocculation Methods 0.000 description 1
- 230000016615 flocculation Effects 0.000 description 1
- 238000005187 foaming Methods 0.000 description 1
- 235000021588 free fatty acids Nutrition 0.000 description 1
- 239000000417 fungicide Substances 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 229960002442 glucosamine Drugs 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 150000002314 glycerols Chemical class 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 238000003306 harvesting Methods 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 125000002768 hydroxyalkyl group Chemical group 0.000 description 1
- 108010002685 hygromycin-B kinase Proteins 0.000 description 1
- JGPMMRGNQUBGND-UHFFFAOYSA-N idebenone Chemical compound COC1=C(OC)C(=O)C(CCCCCCCCCCO)=C(C)C1=O JGPMMRGNQUBGND-UHFFFAOYSA-N 0.000 description 1
- 150000003949 imides Chemical class 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 229910052500 inorganic mineral Inorganic materials 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 229910052742 iron Inorganic materials 0.000 description 1
- RBTARNINKXHZNM-UHFFFAOYSA-K iron trichloride Chemical compound Cl[Fe](Cl)Cl RBTARNINKXHZNM-UHFFFAOYSA-K 0.000 description 1
- 238000001155 isoelectric focusing Methods 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- 239000004310 lactic acid Substances 0.000 description 1
- 235000014655 lactic acid Nutrition 0.000 description 1
- 229940039696 lactobacillus Drugs 0.000 description 1
- 238000004900 laundering Methods 0.000 description 1
- 239000006193 liquid solution Substances 0.000 description 1
- 239000006194 liquid suspension Substances 0.000 description 1
- 101150039489 lysZ gene Proteins 0.000 description 1
- 229910001629 magnesium chloride Inorganic materials 0.000 description 1
- 229940035034 maltodextrin Drugs 0.000 description 1
- 150000002696 manganese Chemical class 0.000 description 1
- 229910052748 manganese Inorganic materials 0.000 description 1
- 229940071125 manganese acetate Drugs 0.000 description 1
- 239000011565 manganese chloride Substances 0.000 description 1
- 235000002867 manganese chloride Nutrition 0.000 description 1
- UOGMEBQRZBEZQT-UHFFFAOYSA-L manganese(2+);diacetate Chemical compound [Mn+2].CC([O-])=O.CC([O-])=O UOGMEBQRZBEZQT-UHFFFAOYSA-L 0.000 description 1
- RGVLTEMOWXGQOS-UHFFFAOYSA-L manganese(2+);oxalate Chemical compound [Mn+2].[O-]C(=O)C([O-])=O RGVLTEMOWXGQOS-UHFFFAOYSA-L 0.000 description 1
- MMIPFLVOWGHZQD-UHFFFAOYSA-N manganese(3+) Chemical compound [Mn+3] MMIPFLVOWGHZQD-UHFFFAOYSA-N 0.000 description 1
- BQKYBHBRPYDELH-UHFFFAOYSA-N manganese;triazonane Chemical compound [Mn].C1CCCNNNCC1 BQKYBHBRPYDELH-UHFFFAOYSA-N 0.000 description 1
- 108010003855 mesentericopeptidase Proteins 0.000 description 1
- 150000002736 metal compounds Chemical class 0.000 description 1
- 150000002739 metals Chemical class 0.000 description 1
- NYGZLYXAPMMJTE-UHFFFAOYSA-M metanil yellow Chemical group [Na+].[O-]S(=O)(=O)C1=CC=CC(N=NC=2C=CC(NC=3C=CC=CC=3)=CC=2)=C1 NYGZLYXAPMMJTE-UHFFFAOYSA-M 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 229940050176 methyl chloride Drugs 0.000 description 1
- CRVGTESFCCXCTH-UHFFFAOYSA-N methyl diethanolamine Chemical compound OCCN(C)CCO CRVGTESFCCXCTH-UHFFFAOYSA-N 0.000 description 1
- 150000004702 methyl esters Chemical class 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 108010009355 microbial metalloproteinases Proteins 0.000 description 1
- 239000011707 mineral Substances 0.000 description 1
- 235000010755 mineral Nutrition 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 150000004682 monohydrates Chemical class 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 239000002324 mouth wash Substances 0.000 description 1
- 125000001421 myristyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- VHRUBWHAOUIMDW-UHFFFAOYSA-N n,n-dimethyloctanamide Chemical compound CCCCCCCC(=O)N(C)C VHRUBWHAOUIMDW-UHFFFAOYSA-N 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 101150095344 niaD gene Proteins 0.000 description 1
- QMMRZOWCJAIUJA-UHFFFAOYSA-L nickel dichloride Chemical compound Cl[Ni]Cl QMMRZOWCJAIUJA-UHFFFAOYSA-L 0.000 description 1
- 150000002825 nitriles Chemical class 0.000 description 1
- MGFYIUFZLHCRTH-UHFFFAOYSA-N nitrilotriacetic acid Chemical compound OC(=O)CN(CC(O)=O)CC(O)=O MGFYIUFZLHCRTH-UHFFFAOYSA-N 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- SXLLDUPXUVRMEE-UHFFFAOYSA-N nonanediperoxoic acid Chemical compound OOC(=O)CCCCCCCC(=O)OO SXLLDUPXUVRMEE-UHFFFAOYSA-N 0.000 description 1
- 239000004745 nonwoven fabric Substances 0.000 description 1
- SNQQPOLDUKLAAF-UHFFFAOYSA-N nonylphenol Chemical class CCCCCCCCCC1=CC=CC=C1O SNQQPOLDUKLAAF-UHFFFAOYSA-N 0.000 description 1
- 101150105920 npr gene Proteins 0.000 description 1
- 101150017837 nprM gene Proteins 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 239000011368 organic material Substances 0.000 description 1
- 239000005416 organic matter Substances 0.000 description 1
- 239000005022 packaging material Substances 0.000 description 1
- 125000000913 palmityl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 239000001814 pectin Substances 0.000 description 1
- 235000010987 pectin Nutrition 0.000 description 1
- 229920001277 pectin Polymers 0.000 description 1
- 101150019841 penP gene Proteins 0.000 description 1
- XCRBXWCUXJNEFX-UHFFFAOYSA-N peroxybenzoic acid Chemical compound OOC(=O)C1=CC=CC=C1 XCRBXWCUXJNEFX-UHFFFAOYSA-N 0.000 description 1
- JRKICGRDRMAZLK-UHFFFAOYSA-N peroxydisulfuric acid Chemical compound OS(=O)(=O)OOS(O)(=O)=O JRKICGRDRMAZLK-UHFFFAOYSA-N 0.000 description 1
- MPNNOLHYOHFJKL-UHFFFAOYSA-N peroxyphosphoric acid Chemical compound OOP(O)(O)=O MPNNOLHYOHFJKL-UHFFFAOYSA-N 0.000 description 1
- FHHJDRFHHWUPDG-UHFFFAOYSA-N peroxysulfuric acid Chemical compound OOS(O)(=O)=O FHHJDRFHHWUPDG-UHFFFAOYSA-N 0.000 description 1
- 235000020030 perry Nutrition 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- JTJMJGYZQZDUJJ-UHFFFAOYSA-N phencyclidine Chemical compound C1CCCCN1C1(C=2C=CC=CC=2)CCCCC1 JTJMJGYZQZDUJJ-UHFFFAOYSA-N 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 108010082527 phosphinothricin N-acetyltransferase Proteins 0.000 description 1
- UEZVMMHDMIWARA-UHFFFAOYSA-M phosphonate Chemical compound [O-]P(=O)=O UEZVMMHDMIWARA-UHFFFAOYSA-M 0.000 description 1
- 108010031697 phosphoribosylaminoimidazole synthase Proteins 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 238000005222 photoaffinity labeling Methods 0.000 description 1
- SHUZOJHMOBOZST-UHFFFAOYSA-N phylloquinone Natural products CC(C)CCCCC(C)CCC(C)CCCC(=CCC1=C(C)C(=O)c2ccccc2C1=O)C SHUZOJHMOBOZST-UHFFFAOYSA-N 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 239000004014 plasticizer Substances 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229920000196 poly(lauryl methacrylate) Polymers 0.000 description 1
- 229920002647 polyamide Polymers 0.000 description 1
- 229920000768 polyamine Polymers 0.000 description 1
- 229920000139 polyethylene terephthalate Polymers 0.000 description 1
- 239000005020 polyethylene terephthalate Substances 0.000 description 1
- 229920000151 polyglycol Polymers 0.000 description 1
- 239000010695 polyglycol Substances 0.000 description 1
- 229920000193 polymethacrylate Polymers 0.000 description 1
- 229920001451 polypropylene glycol Polymers 0.000 description 1
- 150000004804 polysaccharides Polymers 0.000 description 1
- 229920001296 polysiloxane Polymers 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 230000001124 posttranscriptional effect Effects 0.000 description 1
- 230000001323 posttranslational effect Effects 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 239000004300 potassium benzoate Substances 0.000 description 1
- OTYBMLCTZGSZBG-UHFFFAOYSA-L potassium sulfate Chemical compound [K+].[K+].[O-]S([O-])(=O)=O OTYBMLCTZGSZBG-UHFFFAOYSA-L 0.000 description 1
- 229910052939 potassium sulfate Inorganic materials 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 108010078347 pregnancy-associated murine protein 1 Proteins 0.000 description 1
- 238000002203 pretreatment Methods 0.000 description 1
- 239000013615 primer Substances 0.000 description 1
- 125000001500 prolyl group Chemical group [H]N1C([H])(C(=O)[*])C([H])([H])C([H])([H])C1([H])[H] 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000004405 propyl p-hydroxybenzoate Substances 0.000 description 1
- 235000019833 protease Nutrition 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 101150108007 prs gene Proteins 0.000 description 1
- 101150086435 prs1 gene Proteins 0.000 description 1
- 101150070305 prsA gene Proteins 0.000 description 1
- 239000012521 purified sample Substances 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 239000002994 raw material Substances 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 239000012744 reinforcing agent Substances 0.000 description 1
- 230000003014 reinforcing effect Effects 0.000 description 1
- 230000003716 rejuvenation Effects 0.000 description 1
- KUIXZSYWBHSYCN-UHFFFAOYSA-L remazol brilliant blue r Chemical compound [Na+].[Na+].C1=C(S([O-])(=O)=O)C(N)=C2C(=O)C3=CC=CC=C3C(=O)C2=C1NC1=CC=CC(S(=O)(=O)CCOS([O-])(=O)=O)=C1 KUIXZSYWBHSYCN-UHFFFAOYSA-L 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 238000000518 rheometry Methods 0.000 description 1
- 108020004418 ribosomal RNA Proteins 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 102220276873 rs1060502036 Human genes 0.000 description 1
- 102220243326 rs1183892581 Human genes 0.000 description 1
- 102200115358 rs121918322 Human genes 0.000 description 1
- 102220036452 rs137882485 Human genes 0.000 description 1
- 102200065573 rs140660066 Human genes 0.000 description 1
- 102220243297 rs374524755 Human genes 0.000 description 1
- 102220011740 rs386833408 Human genes 0.000 description 1
- 102200128586 rs397508464 Human genes 0.000 description 1
- 102220207975 rs58272575 Human genes 0.000 description 1
- 102220036871 rs587780095 Human genes 0.000 description 1
- 102220058447 rs730882133 Human genes 0.000 description 1
- 102220276580 rs752209909 Human genes 0.000 description 1
- 102220289974 rs757282628 Human genes 0.000 description 1
- 102220123717 rs759057581 Human genes 0.000 description 1
- 102220313063 rs775429079 Human genes 0.000 description 1
- 102200085424 rs80358242 Human genes 0.000 description 1
- 101150025220 sacB gene Proteins 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 239000003352 sequestering agent Substances 0.000 description 1
- 238000012807 shake-flask culturing Methods 0.000 description 1
- 101150091813 shfl gene Proteins 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- RYMZZMVNJRMUDD-HGQWONQESA-N simvastatin Chemical compound C([C@H]1[C@@H](C)C=CC2=C[C@H](C)C[C@@H]([C@H]12)OC(=O)C(C)(C)CC)C[C@@H]1C[C@@H](O)CC(=O)O1 RYMZZMVNJRMUDD-HGQWONQESA-N 0.000 description 1
- 239000000429 sodium aluminium silicate Substances 0.000 description 1
- 235000012217 sodium aluminium silicate Nutrition 0.000 description 1
- URGAHOPLAPQHLN-UHFFFAOYSA-N sodium aluminosilicate Chemical compound [Na+].[Al+3].[O-][Si]([O-])=O.[O-][Si]([O-])=O URGAHOPLAPQHLN-UHFFFAOYSA-N 0.000 description 1
- 229940077386 sodium benzenesulfonate Drugs 0.000 description 1
- 229910000029 sodium carbonate Inorganic materials 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- HLBBKKJFGFRGMU-UHFFFAOYSA-M sodium formate Chemical compound [Na+].[O-]C=O HLBBKKJFGFRGMU-UHFFFAOYSA-M 0.000 description 1
- 235000019254 sodium formate Nutrition 0.000 description 1
- QSKQNALVHFTOQX-UHFFFAOYSA-M sodium nonanoyloxybenzenesulfonate Chemical compound [Na+].CCCCCCCCC(=O)OC1=CC=CC=C1S([O-])(=O)=O QSKQNALVHFTOQX-UHFFFAOYSA-M 0.000 description 1
- 229940045872 sodium percarbonate Drugs 0.000 description 1
- 229910052911 sodium silicate Inorganic materials 0.000 description 1
- GTVQYMAVKDFKNM-UHFFFAOYSA-M sodium;2-decanoyloxybenzenesulfonate Chemical compound [Na+].CCCCCCCCCC(=O)OC1=CC=CC=C1S([O-])(=O)=O GTVQYMAVKDFKNM-UHFFFAOYSA-M 0.000 description 1
- DGSDBJMBHCQYGN-UHFFFAOYSA-M sodium;2-ethylhexyl sulfate Chemical compound [Na+].CCCCC(CC)COS([O-])(=O)=O DGSDBJMBHCQYGN-UHFFFAOYSA-M 0.000 description 1
- LIAJJWHZAFEJEZ-UHFFFAOYSA-M sodium;2-hydroxynaphthalene-1-sulfonate Chemical compound [Na+].C1=CC=CC2=C(S([O-])(=O)=O)C(O)=CC=C21 LIAJJWHZAFEJEZ-UHFFFAOYSA-M 0.000 description 1
- AXMCIYLNKNGNOT-UHFFFAOYSA-N sodium;3-[[4-[(4-dimethylazaniumylidenecyclohexa-2,5-dien-1-ylidene)-[4-[ethyl-[(3-sulfophenyl)methyl]amino]phenyl]methyl]-n-ethylanilino]methyl]benzenesulfonate Chemical compound [Na+].C=1C=C(C(=C2C=CC(C=C2)=[N+](C)C)C=2C=CC(=CC=2)N(CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=CC=1N(CC)CC1=CC=CC(S(O)(=O)=O)=C1 AXMCIYLNKNGNOT-UHFFFAOYSA-N 0.000 description 1
- GSYPNDDXWAZDJB-UHFFFAOYSA-M sodium;4-(3,5,5-trimethylhexanoyloxy)benzenesulfonate Chemical compound [Na+].CC(C)(C)CC(C)CC(=O)OC1=CC=C(S([O-])(=O)=O)C=C1 GSYPNDDXWAZDJB-UHFFFAOYSA-M 0.000 description 1
- MJMLXHOSHRFNAG-UHFFFAOYSA-M sodium;4-dodecanoyloxybenzenesulfonate Chemical compound [Na+].CCCCCCCCCCCC(=O)OC1=CC=C(S([O-])(=O)=O)C=C1 MJMLXHOSHRFNAG-UHFFFAOYSA-M 0.000 description 1
- KVSYNOOPFSVLNF-UHFFFAOYSA-M sodium;4-nonanoyloxybenzenesulfonate Chemical compound [Na+].CCCCCCCCC(=O)OC1=CC=C(S([O-])(=O)=O)C=C1 KVSYNOOPFSVLNF-UHFFFAOYSA-M 0.000 description 1
- MZSDGDXXBZSFTG-UHFFFAOYSA-M sodium;benzenesulfonate Chemical compound [Na+].[O-]S(=O)(=O)C1=CC=CC=C1 MZSDGDXXBZSFTG-UHFFFAOYSA-M 0.000 description 1
- 238000010563 solid-state fermentation Methods 0.000 description 1
- 238000007614 solvation Methods 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 241000894007 species Species 0.000 description 1
- UNFWWIHTNXNPBV-WXKVUWSESA-N spectinomycin Chemical compound O([C@@H]1[C@@H](NC)[C@@H](O)[C@H]([C@@H]([C@H]1O1)O)NC)[C@]2(O)[C@H]1O[C@H](C)CC2=O UNFWWIHTNXNPBV-WXKVUWSESA-N 0.000 description 1
- 229960000268 spectinomycin Drugs 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 238000001694 spray drying Methods 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 125000004079 stearyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 238000003756 stirring Methods 0.000 description 1
- 229940115922 streptococcus uberis Drugs 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 150000005846 sugar alcohols Chemical class 0.000 description 1
- 150000003871 sulfonates Chemical class 0.000 description 1
- 150000003467 sulfuric acid derivatives Chemical class 0.000 description 1
- 229910021653 sulphate ion Inorganic materials 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 238000004381 surface treatment Methods 0.000 description 1
- KKEYFWRCBNTPAC-UHFFFAOYSA-L terephthalate(2-) Chemical compound [O-]C(=O)C1=CC=C(C([O-])=O)C=C1 KKEYFWRCBNTPAC-UHFFFAOYSA-L 0.000 description 1
- 239000012085 test solution Substances 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 150000004685 tetrahydrates Chemical class 0.000 description 1
- 108010031354 thermitase Proteins 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 150000003626 triacylglycerols Chemical class 0.000 description 1
- 239000001003 triarylmethane dye Substances 0.000 description 1
- UFTFJSFQGQCHQW-UHFFFAOYSA-N triformin Chemical compound O=COCC(OC=O)COC=O UFTFJSFQGQCHQW-UHFFFAOYSA-N 0.000 description 1
- 150000003641 trioses Chemical class 0.000 description 1
- 101150016309 trpC gene Proteins 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- AQLJVWUFPCUVLO-UHFFFAOYSA-N urea hydrogen peroxide Chemical compound OO.NC(N)=O AQLJVWUFPCUVLO-UHFFFAOYSA-N 0.000 description 1
- 108010073969 valyllysine Proteins 0.000 description 1
- LSGOVYNHVSXFFJ-UHFFFAOYSA-N vanadate(3-) Chemical compound [O-][V]([O-])([O-])=O LSGOVYNHVSXFFJ-UHFFFAOYSA-N 0.000 description 1
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 235000019168 vitamin K Nutrition 0.000 description 1
- 239000011712 vitamin K Substances 0.000 description 1
- 150000003721 vitamin K derivatives Chemical class 0.000 description 1
- 229940046010 vitamin k Drugs 0.000 description 1
- 239000002759 woven fabric Substances 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 239000012138 yeast extract Substances 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
- NWONKYPBYAMBJT-UHFFFAOYSA-L zinc sulfate Chemical compound [Zn+2].[O-]S([O-])(=O)=O NWONKYPBYAMBJT-UHFFFAOYSA-L 0.000 description 1
- 229910000368 zinc sulfate Inorganic materials 0.000 description 1
- 239000011686 zinc sulphate Substances 0.000 description 1
- 235000009529 zinc sulphate Nutrition 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D3/00—Other compounding ingredients of detergent compositions covered in group C11D1/00
- C11D3/16—Organic compounds
- C11D3/38—Products with no well-defined composition, e.g. natural products
- C11D3/386—Preparations containing enzymes, e.g. protease or amylase
- C11D3/38636—Preparations containing enzymes, e.g. protease or amylase containing enzymes other than protease, amylase, lipase, cellulase, oxidase or reductase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases [RNase]; Deoxyribonucleases [DNase]
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D3/00—Other compounding ingredients of detergent compositions covered in group C11D1/00
- C11D3/0005—Other compounding ingredients characterised by their effect
- C11D3/001—Softening compositions
- C11D3/0015—Softening compositions liquid
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D3/00—Other compounding ingredients of detergent compositions covered in group C11D1/00
- C11D3/16—Organic compounds
- C11D3/26—Organic compounds containing nitrogen
- C11D3/30—Amines; Substituted amines ; Quaternized amines
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D2111/00—Cleaning compositions characterised by the objects to be cleaned; Cleaning compositions characterised by non-standard cleaning or washing processes
- C11D2111/10—Objects to be cleaned
- C11D2111/12—Soft surfaces, e.g. textile
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D2111/00—Cleaning compositions characterised by the objects to be cleaned; Cleaning compositions characterised by non-standard cleaning or washing processes
- C11D2111/10—Objects to be cleaned
- C11D2111/14—Hard surfaces
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Molecular Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Genetics & Genomics (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- Medicinal Chemistry (AREA)
- Detergent Compositions (AREA)
- Enzymes And Modification Thereof (AREA)
Abstract
Una composición detergente que comprende i) una variante de ADNasa que tiene actividad ADNasa, seleccionada del grupo que consiste en: a) una variante de ADNasa que, en comparación con una ADNasa que tiene la Id. de sec. n.°: 1, comprende una sustitución seleccionada de L33R, L33V y L33Y en donde cada posición corresponde a la posición de la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1) y en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 % pero menos de 100 % de identidad de secuencia con la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1 y en donde la variante tiene una mejora en la estabilidad en comparación con el polipéptido de la Id. de sec. n.° 1, la Id. de sec. n.°: 27 o la Id. de sec. n.°: 28; y ii) un adyuvante, preferiblemente en una cantidad de 0,01 a 99,9 % en peso.
Description
DESCRIPCIÓN
Composiciones detergentes que comprenden variantes polipeptídicas
Referencia a un listado de secuencias
Esta solicitud contiene una lista de secuencias en un soporte de lectura informática, que se incorpora a la presente por referencia.
Campo de la invención
La presente invención se refiere a composiciones detergentes que comprenden variantes de ADNasa novedosas que presentan alteraciones en relación con la ADNasa precursora en una o más propiedades que incluyen: capacidad limpiadora, estabilidad del detergente y/o estabilidad durante el almacenamiento. Las composiciones de la invención son adecuadas para usar en procesos de limpieza y composiciones detergentes, tales como composiciones para lavado de ropa y composiciones para lavado de vajillas, incluidas composiciones para lavado de vajillas a mano o en lavavajillas. La presente invención también se refiere a métodos para preparar composiciones detergentes y métodos de lavado y para utilizar dichas variantes de ADNasa para el tratamiento de superficie, particularmente tratamiento y limpieza de tejidos.
Antecedentes de la invención
Las superficies duras y los tejidos están expuestos a la suciedad y los microorganismos del entorno y de la suciedad corporal. La suciedad que se deposita sobre dichas superficies puede agudizar la adhesión de microorganismos y, por consiguiente, la formación de suciedad de origen microbiano, por ejemplo, suciedad de biopelículas. Las biopelículas comprenden una matriz de sustancia polimérica extracelular (EPS): una conglomeración polimérica que comprende generalmente ADN extracelular, proteínas y polisacáridos. Estas suciedades son pegajosas, difíciles de eliminar y producen la adhesión adicional de otras suciedades. Por lo tanto, la suciedad relacionada con el cuidado doméstico es compleja y puede comprender partículas, proteínas, almidón, grasa y también EPS. Por consiguiente, la eliminación de manchas también es compleja y pueden ser útiles una variedad de enzimas, que incluyen enzimas desoxirribonucleasas (ADNasa).
Para ser útil en los procesos de limpieza doméstica, una enzima tal como una ADNasa debe ser estable en composiciones detergentes y compatible con componentes detergentes estándar tales como tensioactivos, aditivos reforzantes de la detergencia, blanqueadores, etc. La presente invención proporciona composiciones detergentes que comprenden dichas enzimas para proporcionar una buena limpieza. La invención también puede ser beneficiosa para mejorar la limpieza de la ropa y los lavavajillas automáticos.
Resumen de la invención
La presente invención se refiere a una composición detergente que comprende i) una variante de ADNasa que tiene actividad ADNasa seleccionada del grupo que consiste en:
a) una variante de ADNasa que, en comparación con una ADNasa que tiene la Id. de sec. n.°: 1, comprende una sustitución seleccionada de L33R, L33V y L33Y en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n. °: 1 (numeración según la Id. de sec. n. °: 1), en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 % pero menos de 100 % de identidad de secuencia con la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1 y en donde la variante tiene una estabilidad mejorada en comparación con la precursora y/o en comparación con el polipéptido de la Id. de sec. n.°: 1, id. de sec. n.°: 27 o la Id. de sec. n.°: 28; y
ii) un adyuvante, preferiblemente en una cantidad de 0,01 a 99,9 % en peso.
Preferiblemente, la variante de ADNasa comprende una o más sustituciones seleccionadas del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, L33H, L33R, L33K, L33V, L33Y, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147H, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A.
Preferiblemente, la variante de ADNasa en comparación con una ADNasa que tiene la Id. de sec. n.°: 27, comprende una o más sustituciones seleccionadas del grupo que consiste en: G4K, s 7g , K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, L33H, L33R, L33K, L33V, L33Y, S39C, G41 P, S42H, D45E, Q48D, N61 E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada posición corresponde a las posiciones de la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27) y en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 % pero menos de 100 % de identidad de secuencia con la secuencia de aminoácidos mostrada en la Id. de sec. n.°:
Preferiblemente, la variante de ADNasa en comparación con una ADNasa que tiene la Id. de sec. n.°: 28, comprende una o más sustituciones seleccionadas del grupo que consiste en: G4K, s 7g , K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, L33H, L33R, L33K, L33V, L33Y, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada posición corresponde a las posiciones de la Id. de sec. n.°: 28 (numeración según la Id. de sec. n.°: 28) y en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 % pero menos de 100 % de identidad de secuencia con la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 28.
La invención se refiere además a una composición detergente que comprende una variante de ADNasa que comprende una sustitución en al menos tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 1, 4, 7, 8, 13, 22, 25, 27, 32, 33, 39, 41, 42, 48, 56, 57, 59, 65, 66, 76, 77, 101, 106, 109, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1 y en donde la variante tiene actividad ADNasa.
La invención también proporciona un método de lavado que comprende (i) poner en contacto un artículo o superficie, preferiblemente un tejido, con una solución de lavado acuosa que comprende una variante de ADNasa como se define y un adyuvante, preferiblemente poniendo en contacto el artículo o la superficie con la composición detergente descrita en la presente descripción; y (ii) opcionalmente enjuagar y (iii) secar la superficie.
La invención también se refiere al uso de una variante de ADNasa y un adyuvante, para la limpieza que incluye una limpieza profunda de un artículo o superficie, preferiblemente un tejido; para prevenir y/o reducir la adherencia de un artículo o superficie manchada, preferiblemente un tejido; para pretratar las manchas de un artículo o superficie manchada, preferiblemente un tejido; para prevenir y/o reducir la redeposición de la suciedad sobre una superficie o artículo, preferiblemente un tejido, durante un ciclo de lavado; para prevenir y/o reducir la adherencia de la suciedad a un artículo o superficie, preferiblemente un tejido; para mantener o mejorar la blancura de un artículo o superficie, preferiblemente un tejido; y/o para prevenir y/o reducir el mal olor en un artículo o superficie, preferiblemente un tejido.
Preferiblemente, la variante de ADNasa comprende una o más de las sustituciones correspondientes a sustituciones seleccionadas del grupo que consiste en: G4K, S7G, K8R, D32I, D32L, D32R, D32V, L33R, L33K, S39C, G41P, S42H, Q48D, T65M, T65W, S66M, S66W, S66Y, S66V, S101N, S106L, S106R, S106H, S130A, S130Y, T138D, Q140V, Q140G, A147H, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A (numeración según la Id. de sec. n.°: 1).
Preferiblemente, la variante de ADNasa comprende una o más de las sustituciones correspondientes a sustituciones seleccionadas del grupo que consiste en: una o más de las sustituciones seleccionadas del grupo que consiste en S27K, s27R, s39C y S66W (numeración según la Id. de sec. n.°: 1).
La variante de ADNasa tiene al menos una propiedad mejorada, en comparación con la precursora y/o en comparación con la ADNasa que tiene el polipéptido mostrado en la Id. de sec. n.°: 1, id. de sec. n.°: 27 o la Id. de sec. n.°: 28. La variante de ADNasa tiene una estabilidad mejorada. Una propiedad mejorada preferida se caracteriza por que la RAR (relación de actividad residual) es superior a 1 en al menos un ensayo A, B o C. Preferiblemente, la variante comprende al menos dos mutaciones y la combinación de mutaciones en la variante de ADNasa proporciona un efecto aditivo, más preferiblemente un efecto sinérgico.
Secuencias
Id. de sec. n.°: 1 polipéptido maduro obtenido a partir de Bacillus cibi
Id. de sec. n.°: 2 polipéptido maduro obtenido a partir de Bacillus orikoshii
Id. de sec. n.°: 3 polipéptido maduro obtenido a partir de Bacillus sp-62520
Id. de sec. n.°: 4 polipéptido maduro obtenido a partir de Bacillus orikoshii
Id. de sec. n.°: 5 polipéptido maduro obtenido a partir de Bacillus orikoshii
Id. de sec. n.°: 6 polipéptido maduro obtenido a partir de Bacillus sp-16840
Id. de sec. n.°: 7 polipéptido maduro obtenido a partir de Bacillus sp-16840
Id. de sec. n.°: 8 polipéptido maduro obtenido a partir de Bacillus sp-62668
Id. de sec. n.°: 9 polipéptido maduro obtenido a partir de Bacillus sp-13395
Id. de sec. n.°: 10 polipéptido maduro obtenido a partir de Bacillus horneckiae
Id. de sec. n.°: 11 polipéptido maduro obtenido a partir de Bacillus sp-11238
Id. de sec. n.°: 12 polipéptido maduro obtenido a partir de Bacillus sp-62451
Id. de sec. n.°: 13 polipéptido maduro obtenido a partir de Bacillus sp-18318
Id. de sec. n.°: 14 polipéptido maduro obtenido a partir de Bacillus idriensis
Id. de sec. n.°: 15 es el polipéptido maduro obtenido a partir de Bacillus algicola
Id. de sec. n.°: 16 polipéptido maduro obtenido a partir de la muestra ambiental J
Id. de sec. n.°: 17 polipéptido maduro obtenido a partir de Bacillus vietnamensis
Id. de sec. n.°: 18 polipéptido maduro obtenido a partir de Bacillus hwajinpoensis
Id. de sec. n.°: 19 polipéptido maduro obtenido a partir de Paenibacillus mucilaginosus
Id. de sec. n.°: 20 polipéptido maduro obtenido a partir de Bacillus indicus
Id. de sec. n.°: 21 Polipéptido maduro obtenido a partir de Bacillus marisflavi
Id. de sec. n.°: 22 polipéptido maduro obtenido a partir de Bacillus luciferensis
Id. de sec. n.°: 23 polipéptido maduro obtenido a partir de Bacillus marisflavi
Id. de sec.  n.°: 24 polipéptido maduro obtenido a partir de Bacillus sp. SA2-6
n.°: 24 polipéptido maduro obtenido a partir de Bacillus sp. SA2-6
Id. de sec. n.°: 25 motivo [D/M/L][S/T]GYSR[D/N]
Id. de sec. n.°: 26 motivo ASXNRSKG
Id. de sec. n.°: 27 variante de ADNasa con Id. de sec. n. °: 1
Id. de sec. n.°: 28 variante de ADNasa con Id. de sec. n. °: 1
Definiciones
El término “ adyuvante” significa cualquier material líquido, sólido o gaseoso seleccionado para el tipo particular de composición detergente deseada y la forma del producto (p. ej., líquido, gránulo, polvo; pastilla, pasta, pulverizado, dosis unitaria, tal como pastilla o bolsa, gel o composición espumosa), siendo estos materiales también preferiblemente compatibles con la enzima variante de ADNasa utilizada en la composición. En algunos aspectos, las composiciones en gránulos están en forma “compacta” mientras que, en otros aspectos, las composiciones líquidas están en forma “concentrada” .
La expresión “variante alélica” significa cualquiera de dos o más formas alternativas de un gen que ocupa el mismo locus cromosómico. Las variaciones alélicas surgen naturalmente mediante mutación, y pueden dar como resultado el polimorfismo entre poblaciones. Las mutaciones génicas pueden ser silenciosas (sin cambios en el polipéptido codificado) o pueden codificar polipéptidos que tienen secuencias de aminoácidos alteradas. Una variante alélica de un polipéptido es un polipéptido codificado por una variante alélica de un gen.
“ Biopelícula”es una suciedad de origen microbiano que puede producir cualquier grupo de microorganismos y típicamente comprende una matriz autoproducida de sustancia polimérica extracelular (EPS). La biopelícula de EPS es un conglomerado polimérico compuesto generalmente por ADN extracelular, proteínas y polisacáridos. Las bacterias productoras de biopelícula incluyen, por ejemplo, las siguientes especies: Acinetobacter sp., Aeromicrobium sp., Brevundimonas sp., Microbacterium sp., Micrococcus luteus, Pseudomonas sp., Staphylococcus epidermidis y Stenotrophomonas sp.
El término “ADNc” significa una molécula de ADN que se puede preparar mediante transcripción inversa a partir de una molécula de ARNm madura sometida a corte y empalme obtenida a partir de una célula procariota o eucariota. Un ADNc carece de secuencias intrónicas que pueden estar presentes en el ADN genómico correspondiente. El transcrito primario inicial de ARN es un precursor del ARNm que se procesa mediante una serie de etapas, incluido el corte y empalme, antes de aparecer como un ARNm maduro de corte y empalme.
El término “clado” significa un grupo de polipéptidos agrupados según características homólogas rastreadas hasta un ancestro común. Los clados polipeptídicos pueden visualizarse como árboles filogénicos y un clado es un grupo de polipéptidos que consiste en un ancestro común y todos sus descendientes lineales. Los polipéptidos que forman un grupo, p. ej., un clado como se muestra en un árbol filogenético, a menudo pueden compartir propiedades comunes y están más estrechamente relacionados que otros polipéptidos no pertenecientes al clado.
La expresión “secuencia codificante” significa un polinucleótido que especifica directamente la secuencia de aminoácidos de su producto polipeptídico. Los límites de la secuencia codificante por lo general están determinados por un marco de lectura abierto, que normalmente se inicia con el codón de inicio ATG o con codones de inicio alternativos tales como GTG y TTG y finaliza con un codón de detención tal como TAA, TAG, y TGA. La secuencia codificante puede ser un polinucleótido de ADN, ADNc, sintético o recombinante.
La expresión “ secuencias de control” significa todos los componentes necesarios para expresar un polinucleótido que codifica una variante de la presente invención. Cada secuencia de control puede ser de origen natural o externo para el polinucleótido que codifica la variante, o naturales o externos entre sí. Dichas secuencias de control incluyen, aunque no de forma limitativa, una secuencia líder, una secuencia de poliadenilación, una secuencia de propéptido, un promotor, una secuencia de péptido señal, y un terminador de la transcripción. Como mínimo, las secuencias de control incluyen un promotor, y señales de detención de la transcripción y de la traducción. Las secuencias de control pueden estar provistas de conectores para introducir sitios de restricción específicos que facilitan la unión de las secuencias de control con la región codificadora del polinucleótido que codifica una variante.
Mediante la expresión “ limpieza profunda” se refiere a la reducción o eliminación de componentes de biopelículas, EPS o partes de los mismos, tales como polisacáridos, proteínas, ADN, suciedad u otros componentes presentes en, p. ej., la biopelícula o EPS.
La expresión “composición detergente” incluye, salvo que se indique lo contrario, agentes para el lavado granulados o en polvo universales o de limpieza intensiva, especialmente detergentes limpiadores; agentes para el lavado líquidos, en forma de gel o pasta universales, especialmente los tipos líquidos denominados de limpieza intensiva (HDL); detergentes líquidos para tejidos delicados; agentes para el lavado manual de vajillas o agentes para el lavado de vajillas de acción suave, especialmente los de tipo muy espumante; agentes para el lavado en lavavajillas, incluidos los diversos tipos en pastilla, granulado, líquido y coadyuvante de aclarado para uso doméstico e institucional; agentes líquidos para limpieza y desinfección, incluyendo los tipos antibacterianos para lavado a mano, pastillas para limpieza, pastillas de jabón, colutorios, limpiadores de dentaduras postizas, champús para coches o moquetas, limpiadores de baños; champús para cabello y productos de aclarado del cabello; geles de ducha, baños de espuma; limpiadores para metales; así como sustancias auxiliares de limpieza tales como aditivos blanqueantes y los tipos “ barra antimanchas” o para pretratamiento. La composición detergente puede estar en forma de dosis unitaria, tal como una pastilla o bolsa que comprende líquido, gel y/o sólido, tal como una composición detergente granulada o en polvo, opcionalmente encapsulada en una película, preferiblemente una bolsa soluble en agua. Las expresiones “composición detergente” y “formulación detergente” se usan en referencia a mezclas que están destinadas a usarse en un medio de lavado para la limpieza de objetos sucios. En algunos aspectos, la expresión se usa en referencia al lavado de tejidos y/o prendas (p. ej., “detergentes para ropa” ). En aspectos alternativos, la expresión se refiere a otros detergentes, tales como los utilizados para limpiar platos, cubiertos, etc. (p. ej., “detergentes para lavavajillas” ). No se pretende que la presente invención esté limitada a ninguna formulación o composición detergente en particular. La expresión “composición detergente” no pretende limitarse a composiciones que contengan tensioactivos. Se pretende que, además de las variantes según la invención, la expresión abarque detergentes que pueden contener, p. ej., tensioactivos, aditivos reforzantes de la detergencia, quelantes o agentes quelantes, sistemas blanqueadores o componentes blanqueadores, polímeros, acondicionadores de tejidos, reforzadores de espuma, supresores de jabonaduras, colorantes, perfume, inhibidores del deslustre, abrillantadores ópticos, bactericidas, fungicidas, agentes de suspensión de suciedad, agentes anticorrosivos, inhibidores enzimáticos o estabilizadores, activadores enzimáticos, transferasa(s), enzimas hidrolíticas, oxidorreductasas, agentes tonalizadores y colorantes fluorescentes, antioxidantes, y solubilizantes. Las composiciones detergentes también se pueden usar en una etapa de tratamiento de tejidos, por ejemplo, pueden proporcionar una etapa refrescante de tejidos, suavizante de tejidos y/o de rejuvenecimiento de color.
La expresión “ADNasa” , “variantes de ADNasa” o “ADNasa precursora” significa un polipéptido con actividad ADNasa que cataliza la escisión hidrolítica de enlaces fosfodiéster en el ADN, degradando así el ADN. Las ADNasas pertenecen a las esterasas (EC-número 3.1), un subgrupo de las hidrolasas. Las ADNasas se clasifican, p. ej., en E.C. 3.1.11, E.C.
3.1.12, E.C. 3.1.15, E.C. 3.1.16, E.C. 3.1.21, E.C 3.1.22, E.C 3.1.23, E.C 3.1.24 y E.C.3.1.25, así como EC 3.1.21.X,
donde X = 1,2, 3, 4, 5, 6, 7, 8 o 9. El término “ADNasa” y la expresión “un polipéptido con actividad ADNasa” pueden usarse indistintamente en toda la solicitud. Para los fines de la presente invención, la actividad ADNasa se determina según el procedimiento descrito en el Ensayo I. En algunos aspectos, las variantes de ADNasa de la presente invención tienen una actividad ADNasa mejorada en comparación con la ADNasa precursora. En algunos aspectos, las variantes de ADNasa de la presente invención tienen al menos 100 %, p. e j, al menos 110 %, al menos 120 %, al menos 130 %, al menos 140 %, al menos 150 %, al menos 160 %, al menos 170 %, al menos 180 %, al menos 190 % o al menos 200 % de actividad ADNasa en comparación con el polipéptido mostrado en la Id. de sec. n.°: 1.
La expresión “cantidad eficaz de enzima” se refiere a la cantidad de enzima necesaria para lograr la actividad enzimática requerida en la aplicación específica, p. ej., en una composición detergente definida. Dichas cantidades eficaces serán fácilmente determinadas por un experto en la técnica y dependen de muchos factores, tales como la enzima particular utilizada, la aplicación de limpieza, la composición específica de la composición detergente y si se requiere una composición líquida o seca (p. ej., granulada, en pastilla) y similares. La expresión “cantidad eficaz” de una variante de ADNasa se refiere a la cantidad de variante de ADNasa descrita anteriormente que logra un nivel deseado de actividad enzimática, p. ej., en una composición detergente definida. El término “expresión” incluye cualquier etapa implicada en la producción de la variante incluido, aunque no de forma limitativa, la transcripción, la modificación posterior a la transcripción, la traducción, la modificación posterior al a traducción, y la secreción.
La expresión “vector de expresión” significa una molécula de ADN, linear o circular, que comprende un polinucleótido que codifica una variante y está unido operativamente a nucleótidos adicionales que realizan su expresión.
El término “tejido” abarca cualquier material textil. Por lo tanto, se pretende que el término abarque prendas de vestir, así como tejidos, hilos, fibras, materiales no tejidos, materiales naturales, materiales sintéticos y cualquier otro material textil. La expresión sistema con “concentración de detergente alta” incluye detergentes en donde más de aproximadamente 2000 ppm de los componentes detergentes están presentes en el agua de lavado. Los detergentes europeos generalmente se consideran sistemas de alta concentración de detergente.
La expresión “célula hospedadora” significa cualquier tipo celular susceptible de transformación, transfección, transducción y similares con una construcción de ácido nucleico o vector de expresión que comprende un polinucleótido de la presente invención. La expresión “célula hospedadora” abarca cualquier progenie de una célula precursora que no sea idéntica a la célula precursora debido a mutaciones que se producen durante la replicación. La expresión “ propiedad mejorada” significa una característica asociada con una variante que se mejora en comparación con la precursora en comparación con una ADNasa con la Id. de sec. n.°: 1, id. de sec. n.°: 27, Id. de sec. n.°: 28 o en comparación con una ADNasa que tiene la secuencia de aminoácidos idéntica a dicha variante pero que no tiene las alteraciones en una o más de dichas posiciones especificadas. Dichas propiedades mejoradas incluyen, aunque no de forma limitativa, estabilidad, tal como estabilidad de detergente, capacidad limpiadora, p. ej., efecto de limpieza profunda, y el efecto de limpieza profunda puede incluir, pero no se limita a, efecto de desencolado.
La expresión “actividad de ADNasa mejorada” se define en la presente descripción como una actividad ADNasa alterada, p. ej., mediante el aumento de la catálisis de la escisión hidrolítica de los enlaces fosfodiéster del ADN, la variante de ADNasa que muestra una alteración de la actividad en relación (o en comparación) con la actividad de la ADNasa precursora, tal como en comparación con una ADNasa con la Id. de sec. n.°: 1, id. de sec. n.°: 27 o la Id. de sec. n.°: 28.
La expresión sistema con “concentración de detergente alta” incluye detergentes donde menos de aproximadamente 800 ppm de los componentes detergentes están presentes en el agua de lavado. Los detergentes asiáticos, p. ej., los detergentes japoneses se consideran de forma típica sistemas de concentración de detergente bajo.
La expresión “capacidad limpiadora mejorada” incluye, pero no se limita a la expresión “efecto de limpieza profunda” . La capacidad mejorada, p. ej., la capacidad limpiadora profunda de una variante de ADNasa según la invención, se mide en comparación con el precursor de ADNasa, p. ej., la ADNasa mostrada en la Id. de sec. n.°: 1, id. de sec. n.°: 27 o la Id. de sec. n.°: 28. La capacidad mejorada, p. ej., la limpieza o la capacidad limpiadora profunda puede expresarse como un Valor de remisión de las muestras manchadas. Tras lavar y enjuagar, las muestras se extienden y se dejan secar al aire a temperatura ambiente durante la noche. Todas las muestras lavadas se evalúan el día después del lavado. Las evaluaciones de la reflectancia de la luz de las muestras se realizan utilizando un espectrofotómetro de reflectancia Macbeth Color Eye 7000 con una abertura muy pequeña. Las mediciones se realizan sin UV en la luz incidente y se extrajo la remisión a 460 nm. Una respuesta positiva indica que la suciedad se ha eliminado, incluida la suciedad adherida al tejido debido a, p. ej., la capa pegajosa de la biopelícula.
La expresión “ polinucleótido aislado” significa un polinucleótido que está modificado por la mano humana. En algunos aspectos, el polinucleótido aislado es al menos 1 % puro, p. e j al menos 5 % puro, al menos 10 % puro, al menos 20 % puro, al menos 40 % puro, al menos 60 % puro, al menos 80 % puro, al menos 90 % puro y al menos 95 % puro, tal como se determina mediante electroforesis en gel de agarosa. Los polinucleótidos pueden ser de origen genómico, ADNc, ARN, semisintético, sintético, o cualquier combinación de los mismos.
El término “ lavado” se refiere al lavado de ropa tanto doméstico como industrial y significa el proceso de tratamiento de textiles con una solución que contiene una composición limpiadora o detergente de la presente invención. El proceso de lavado puede llevarse a cabo, p. ej., utilizando p. ej. una lavadora doméstica o industrial o puede llevarse a cabo a mano.
La expresión “ polipéptido maduro” significa un polipéptido en su forma final después de la traducción y cualquiera de sus modificaciones posteriores a la traducción, tales como procesamiento del extremo N, truncamiento del extremo C, glicosilación, fosforilación, etc. En algunos aspectos, el polipéptido maduro es los aminoácidos 1 al 182 de la Id. de sec. n.°: 1. Los extremos N del polipéptido maduro utilizados según la presente invención se confirmaron experimentalmente basándose en datos de secuenciación de extremos N de EDMAN y datos de Intact MS. Se conoce en la técnica que una célula huésped puede producir una mezcla de dos polipéptidos maduros muy diferentes (es decir, con un aminoácido del extremo C y/o extremo N diferente) expresado por el mismo polinucleótido.
La expresión “ secuencia codificante del polipéptido maduro” significa un polinucleótido que codifica un polipéptido maduro que tiene actividad ADNasa.
La expresión sistema de “concentración media de detergente” incluye detergentes en donde los componentes detergentes están presentes en el agua de lavado entre aproximadamente 800 ppm y aproximadamente 2000 ppm. Los detergentes norteamericanos generalmente se consideran sistemas de concentración media de detergente.
La expresión “construcción de ácido nucleico” significa una molécula de ácido nucleico, tanto monocatenaria como bicatenaria, que está aislada de un gen natural, o se ha modificado para incluir segmentos de ácidos nucleicos de una forma que no se produciría de forma natural o que es sintética. El término construcción de ácido nucleico es un sinónimo del término “casete de expresión” cuando la construcción de ácido nucleico incluye las secuencias de control necesarias para expresar una secuencia codificante de la presente invención.
La expresión “composiciones detergentes no textiles” incluye composiciones detergentes para superficies no textiles que incluyen, aunque no de forma limitativa, composiciones para la limpieza de superficies duras, tales como composiciones detergentes para lavado de vajillas, incluidas las composiciones para lavado de vajillas a mano, composiciones detergentes bucales, composiciones detergentes para dentaduras postizas y composiciones para aseo personal.
La expresión “operablemente unido” significa una configuración en la que una secuencia de control se coloca en una posición adecuada con respecto a la secuencia codificante de un polinucleótido de tal forma que la secuencia de control dirige la expresión de la secuencia codificante.
Las expresiones ADNasa “pariente” , precursor de ADNasa o ADNasa precursora pueden usarse indistintamente. En el contexto de la presente invención, “ADNasa precursora” debe entenderse como una ADNasa en la que se hace al menos una alteración en la secuencia de aminoácidos para producir una variante de ADNasa que tiene una secuencia de aminoácidos que es menos del 100 % idéntica a la secuencia de ADNasa en la que se hizo la alteración, es decir, la ADNasa precursora. Por lo tanto, la precursora es una ADNasa que tiene una secuencia de aminoácidos idéntica en comparación con la variante pero que no tiene las alteraciones en una o más de las posiciones especificadas. Se entenderá que en el presente contexto, la expresión “que tiene una secuencia de aminoácidos idéntica” se refiere al 100 % de identidad de secuencia. En un aspecto particular, la ADNasa precursora es una ADNasa que tiene al menos 60 %, al menos 61 %, al menos 62 %, al menos 63 %, al menos 64 %, al menos 65 %, al menos 66 %, al menos 67 %, al menos 68 %, al menos 69 %, al menos 70 %, al menos 72 %, al menos 73 %, al menos 74 %, al menos 75 %, al menos 80 %, al menos 81 %, al menos 82 %, al menos 83 %, al menos el 84 %, al menos el 85 %, al menos el 90 %, al menos el 91 %, al menos el 92 %, a menos el 93 %, al menos el 94 %, al menos el 95 %, al menos el 96 %, al menos el 97 %, al menos el 98 %, al menos el 99 %, por ejemplo al menos el 99,1 %, al menos el 99,2 %, al menos el 99,3 %, al menos el 99,4 %, al menos el 99,5 %, al menos el 99,6 % o el 100 % de identidad respecto de un polipéptido mostrado en la Id de sec n.°: 1. En un aspecto particular, la ADNasa precursora es una ADNasa que tiene al menos 60 %, al menos 61 %, al menos 62 %, al menos 63 %, al menos 64 %, al menos 65 %, al menos 66 %, al menos 67 %, al menos 68 %, al menos 69 %, al menos 70 %, al menos 72 %, al menos 73 %, al menos 74 %, al menos 75 %, al menos 80 %, al menos 81 %, al menos 82 %, al menos 83 %, al menos el 84 %, al menos el 85 %, al menos el 90 %, al menos el 91 %, al menos el 92 %, a menos el 93 %, al menos el 94 %, al menos el 95 %, al menos el 96 %, al menos el 97 %, al menos el 98 %, al menos el 99 %, por ejemplo al menos el 99,1 %, al menos el 99,2 %, al menos el 99,3 %, al menos el 99,4 %, al menos el 99,5 %, al menos el 99,6 % o el 100 % de identidad respecto de un polipéptido mostrado en la Id de sec n.°: 27. En un aspecto particular, la ADNasa precursora es una ADNasa que tiene al menos 60 %, al menos 61 %, al menos 62 %, al menos 63 %, al menos 64 %, al menos 65 %, al menos 66 %, al menos 67 %, al menos 68 %, al menos 69 %, al menos 70 %, al menos 72 %, al menos 73 %, al menos 74 %, al menos 75 %, al menos 80 %, al
menos 81 %, al menos 82 %, al menos 83 %, al menos el 84 %, al menos el 85 %, al menos el 90 %, al menos el 91 %, al menos el 92 %, a menos el 93 %, al menos el 94 %, al menos el 95 %, al menos el 96 %, al menos el 97 %, al menos el 98 %, al menos el 99 %, por ejemplo al menos el 99,1 %, al menos el 99,2 %, al menos el 99,3 %, al menos el 99,4 %, al menos el 99,5 %, al menos el 99,6 % o el 100 % de identidad respecto de un polipéptido mostrado en la Id de sec n.°: 28.
La expresión “condiciones de lavado relevantes” se usa en la presente descripción para indicar las condiciones, especialmente la temperatura del lavado, el tiempo, la mecánica del lavado, la concentración de detergente, el tipo de detergente y la dureza del agua, que se usan realmente en hogares en un segmento del mercado de detergentes.
El término “estabilidad” incluye estabilidad durante el almacenamiento y estabilidad durante el uso, p. ej., durante un proceso de lavado, y refleja la estabilidad de la variante de ADNasa según la invención en función del tiempo, p. ej., cuánta actividad se retiene cuando la variante de ADNasa se mantiene en solución, en particular en una solución detergente. La estabilidad está influenciada por muchos factores, p. ej., pH, temperatura, composición detergente, p. ej., cantidad de aditivo reforzante de la detergencia, tensioactivos, etc. La estabilidad de la ADNasa puede medirse como se describe en los ejemplos 2, 3, 4 y 5. La expresión “estabilidad mejorada” o “estabilidad aumentada” se define en la presente descripción como una variante de ADNasa que muestra una mayor estabilidad en solución, con respecto a la estabilidad de la ADNasa precursora y/o con respecto al Id. de sec. n.°: 1, id. de sec. n.°: 27 o la Id. de sec. n.°: 28. “ Estabilidad mejorada” y “estabilidad aumentada” incluyen estabilidad del detergente. La expresión “estabilidad del detergente” o “estabilidad del detergente mejorada” puede ser una mayor estabilidad de la actividad ADNasa en comparación con la ADNasa precursora. La estabilidad de ADNasa se mide como se describe en el ejemplo 2 a 5.
La expresión “variante sustancialmente pura” significa una preparación que contiene como máximo 10 %, como máximo 8 %, como máximo 6 %, como máximo 5 %, como máximo 4 %, como máximo 3 %, como máximo 2 %, como máximo 1 %, y como máximo 0,5 % en peso de otro material polipeptídico con el que está asociado de forma recombinante o natural. Preferiblemente, la variante es al menos 92 % pura, por ejemplo, al menos 94 % pura, al menos 95 % pura, al menos 96 % pura, al menos 97 % pura, al menos 98 % pura, al menos 99 %, al menos 99,5 % pura, y 100 % pura en peso del material polipeptídico total presente en la preparación. Las variantes de la presente invención están preferiblemente en una forma sustancialmente pura. Esto se puede conseguir, por ejemplo, preparando la variante por métodos recombinantes bien conocidos o por métodos de purificación clásicos.
El término “textil” se refiere a telas tejidas así como fibras cortadas y filamentos adecuados para su conversión o uso como hilos, telas tejidas, tricotadas y no tejidas. El término abarca hilos hechos de fibras tanto naturales como sintéticas (p. ej., fabricadas). La expresión “ materiales textiles” es un término general para fibras, productos intermedios de hilo, hilo, tejidos y productos hechos de tejidos (p. ej., prendas de vestir y otros artículos).
La expresión “ promotor de la transcripción” se usa para un promotor que es una región de ADN que facilita la transcripción de un gen particular. Los promotores de la transcripción se ubican típicamente cerca de los genes que regulan, en la misma cadena y antes (hacia la región 5' de la cadena codificante).
La expresión “terminador de la transcripción” se usa para una sección de la secuencia genética que marca el extremo del gen u operón del ADN genómico para la transcripción.
El término “variante” significa un polipéptido que tiene actividad ADNasa y que comprende una sustitución en una o más (p. ej., varias) posiciones. Una sustitución significa la sustitución del aminoácido que ocupa una posición por un aminoácido diferente, una deleción significa la eliminación de un aminoácido que ocupa una posición y una inserción significa añadir aminoácidos, p. ej., de 1 a 10 aminoácidos, preferiblemente 1-3 aminoácidos adyacentes a un aminoácido que ocupa una posición. Las variantes de la presente invención tienen al menos 20 %, p. ej., al menos 40 %, al menos 50 %, al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 % o al menos 100 % de la actividad ADNasa del polipéptido maduro mostrado en la Id. de sec. n.°: 1. La expresión “variante de ADNasa” significa una ADNasa que tiene actividad de ADNasa y que comprende una alteración, es decir, una sustitución, inserción y/o eliminación en una o más (o una o varias) posiciones en comparación con la ADNasa precursora, p. ej., en comparación con la Id. de sec. n.°: 1, id. de sec. n.°: 27 o la Id. de sec. n.°: 28.
La expresión “dureza del agua” o “grado de dureza” o “dH” o “ °dH” como se usa en la presente descripción se refiere a grados de dureza alemanes. Un grado se define como 10 miligramos de óxido de calcio por litro de agua.
La expresión “ADNasa de tipo natural” significa una ADNasa expresada por un organismo de origen natural, tal como un hongo, bacteria, arquea, levadura, planta o animal que se encuentra en la naturaleza.
Convenciones para la designación de variantes
Para los fines de la presente invención, salvo que se indique lo contrario, el polipéptido descrito en la Id. de sec. n.°: 1 se utiliza para determinar el residuo de aminoácidos correspondiente en otra ADNasa. La secuencia de aminoácidos de otra ADNasa está alineada con el polipéptido descrito en la Id. de sec. n.°: 1 y, basándose en la alineación, el número de la posición del aminoácido correspondiente a cualquier resto de aminoácido del polipéptido descrito en la Id. de sec. n.°: 1 se determina usando, p. e j, el algoritmo de Needleman-Wunsch (Needleman y Wunsch, 1970, J. Mol. Biol. 48: 443-453) según se implementa en el programa Needle del paquete EMBOSS (EMBOSS: The European Molecular Biology Open Software Suite, Rice y col., 2000, Trends Genet. 16: 276-277), preferiblemente la versión 5.0.0 o una versión superior. Los parámetros utilizados tienen una penalización por apertura de hueco de 10, una penalización por extensión de hueco de 0,5 y la matriz de sustitución EBLOSUM62 (versión para EMBOSS de BLOSUM62).
La identificación del correspondiente resto de aminoácido en otra ADNasa puede determinarse mediante una alineación de múltiples secuencias de polipéptidos usando varios programas informáticos que incluyen, aunque no de forma limitativa, MUSCLE (comparación múltiple de secuencias según el logaritmo de la expectativa; versión 3.5 o posterior; Edgar, 2004, Nucleic Acids Research 32: 1792-1797), MAFFT (versión 6.857 o posterior; Katoh y Kuma, 2002, Nucleic Acids Research 30: 3059-3066; Katoh y col., 2005, Nucleic Acids Research 33: 511 518; Katoh y Toh, 2007, Bioinformatics 23: 372-374; Katoh y col., 2009, Methods in M olecular Biology 537: 39-64; Katoh y Toh, 2010, Bioinformatics 26: 1899-1900) y EMBOSS EMMA que emplea ClustalW (1.83 o posterior; Thompson y col., 1994, Nucleic Acids Research 22: 4673-4680), utilizando sus respectivos parámetros predeterminados.
Cuando la otra enzima se ha separado del polipéptido de la Id. de sec. n.°: 1 de tal forma que la comparación tradicional basada en secuencias no consigue detectar su relación (Lindahl y Elofsson, 2000, J. Mol. Biol. 295: 613 615), se pueden usar otros algoritmos de comparación de emparejamiento de secuencias. Se puede conseguir una mayor sensibilidad en la búsqueda basada en secuencias usando programas de búsqueda que utilizan representaciones probabilísticas de familias de polipéptidos (perfiles) para buscar en bases de datos. Por ejemplo, el programa PSI-BLAST genera perfiles mediante un proceso iterativo de búsqueda en bases de datos y puede detectar homólogos remotos (Atschul y col., 1997, Nucleic Acids Res. 25: 3389-3402). Se puede conseguir incluso una mayor sensibilidad si la familia o superfamilia del polipéptido tiene uno o más representantes en las bases de datos de estructuras proteicas. Programas tales como GenTHREADER (Jones, 1999, J. Mol. Biol. 287: 797-815; McGuffin y Jones, 2003, Bioinformatics 19: 874-881) utilizan la información de una variedad de fuentes (PSI-BLAST, predicción de estructura secundaria, perfiles de alineamiento estructural, y potenciales de solvatación) como entrada de una red neuronal que predice el plegado estructural de una secuencia solicitada. Análogamente, el método de Gough y col., 2000, J. Mol. Biol. 313: 903-919, se puede usar para alinear una secuencia de estructura desconocida con los modelos de la superfamilia presentes en la base de datos SCOP. A su vez, estos alineamientos se pueden usar para generar modelos de homología del polipéptido, y dichos modelos se pueden evaluar para determinar la precisión usando una variedad de herramientas desarrolladas a tal fin.
Para las proteínas de estructura conocida, están disponibles diferentes herramientas y recursos para recuperar y generar alineamientos estructurales. Por ejemplo, las superfamilias de proteínas SCOP se han alineado estructuralmente, y dichas alineaciones están disponibles y se pueden descargar. Se pueden alinear dos o más estructuras proteicas usando una variedad de algoritmos tal como la matriz de distancia de alineamiento (Holm y Sander, 1998, Proteins 33: 88-96) o extensión combinatoria (Shindyalov y Bourne, 1998, Protein Engineering 11: 739 747) y la implementación de dichos algoritmos se puede utilizar adicionalmente para investigar bases de datos de estructuras con una estructura de interés para descubrir posibles homólogos estructurales (p. ej., Holm y Park, 2000, Bioinformatics 16: 566-567).
Como pueden estar presentes diferentes aminoácidos en una posición dada dependiendo del precursor seleccionado para las variantes, las posiciones de aminoácidos se indican con #1, #2 , etc. en las siguientes definiciones. En la descripción de las variantes de la presente invención, la nomenclatura que se describe más adelante está adaptada para facilitar la referencia. Se emplean las abreviaturas de aminoácidos de una sola letra 0 de tres letras aceptadas por la IUPAC. Las posiciones de aminoácidos se indican con #1, #2 , etc.
Sustituciones: En las sustituciones de aminoácidos se utiliza la siguiente nomenclatura: Aminoácido original, posición, aminoácido sustituido. Por consiguiente, la sustitución de valina en la posición #1 por alanina se designa como “Val#1Ala” o “V#1A” . Se separan múltiples mutaciones con marcas de adición (“+” ) o por comas (,), p. ej., “Val#1Ala” “ Pro#2Gly” o V#1A, P#2G, que representan sustituciones en las posiciones #1 y # 2 de valina (V) y prolina (P) por alanina (A) y glicina (G), respectivamente. Si más de un aminoácido puede sustituirse en una posición dada, estos se enumeran entre paréntesis, tales como [X] o {X}. Por lo tanto, si tanto Trp como Lys pueden estar sustituidos en lugar del aminoácido que ocupa la posición #1, esto se indica como X#1 {W, K}, X#1 [W, K] o X#1 [W/K], donde X indica el residuo de aminoácido presente en la posición de la ADNasa precursora p. ej., tal como una ADNasa mostrada en la Id. de sec. n.°: 1 o una ADNasa que tiene al menos 60 % de identidad con la misma. En algunos casos, las variantes pueden representarse como #1 {W, K} o X#2P indica que los aminoácidos a sustituir varían dependiendo de la precursora. Por conveniencia, puesto que la Id. de sec. n. °: 1 se usa para numerar las sustituciones, el aminoácido en la posición correspondiente de la Id. de sec. n.°: 1 se indica, p. ej., T1 A. Sin embargo, será evidente para el experto en la técnica que una variante de ADNasa que comprende T1A no se limita a las ADNasas precursoras que tienen treonina en una posición correspondiente a la posición 1 de la Id. de sec. n.°: 1. En una ADNasa precursora que tiene, p. ej., asparagina en la posición 1, la persona experta traduciría la mutación
especificada como T1A a N1A. En caso de que la ADNasa precursora tenga alanina en la posición 1, el experto reconocerá que la ADNasa precursora no cambia en esta posición. Lo mismo se aplica para las deleciones e inserciones descritas a continuación. En la presente descripción, salvo que se indique lo contrario, la numeración es según la Id. de sec. n.°: 1.
Deleciones: En las deleciones de aminoácidos se utiliza la siguiente nomenclatura: Aminoácido original, posición, *. Por consiguiente, la deleción de valina en la posición #1 se designa como “Val#1*” o “V#1*” . Las deleciones múltiples se separan con marcas de adición (“+” ) o comas, p. ej., “ Val# 1* Pro#2*” o “V#1*, P#2*” .
Inserciones: La inserción de un residuo de aminoácido adicional, tal como p. ej. una lisina después de Val#1 puede indicarse por: Val#1ValLys o V#1VK. Alternativamente, la inserción de un residuo de aminoácido adicional tal como lisina después de V#1 puede indicarse por: *#1aK. Cuando se inserta más de un residuo de aminoácido, tal como p. ej. una Lys, y Gly después de #1, esto puede indicarse como: Val#1ValLysGly o V#1VKG. En dichos casos, el uno o más residuos de aminoácidos insertados también se pueden numerar por la adición de letras en minúscula al número de posición del residuo de aminoácido que precede al uno o más residuos de aminoácidos insertados, en este ejemplo: *#1aK *#1bG.
Múltiples alteraciones: Las variantes que comprenden múltiples alteraciones se separan con marcas de adición (“+” ) o por comas (,), p. ej., “Val#1Trp+Pro#2Gly” o “V#1W, P#2G” representa una sustitución de valina y prolina en las posiciones #1 y # 2 por triptófano y glicina, respectivamente como se ha descrito anteriormente.
Diferentes alteraciones: Cuando se pueden introducir diferentes alteraciones en una posición, las diferentes alteraciones pueden separarse por una coma, p. ej., “ Val#1Trp, Lys” o V#1W, K que representa una sustitución de valina en la posición #1 con triptófano o lisina. Por lo tanto, “Val#1Trp, Lys Pro#2Asp” designa las siguientes variantes: “Val#1Trp+Pro#2Asp” , “Val#1Lys+Pro#2Asp” o V#1W, K P#2 D.
Específico para la nomenclatura de clados
Para los fines de la presente invención, la nomenclatura [IV] o [I/V] significa que el aminoácido en esa posición puede ser isoleucina (Ile, I) o valina (Val, V). Asimismo, la nomenclatura [LVI] y [L/V/I] significa que el aminoácido en esta posición puede ser una leucina (Leu, L), valina (Val, V) o isoleucina (Ile, I), etc. para otras combinaciones como se describe en la presente descripción. Salvo que se limite de otro modo adicionalmente, el aminoácido X se define de tal manera que puede ser cualquiera de los 20 aminoácidos naturales.
Descripción detallada de la invención
La presente invención proporciona una composición detergente, un método para preparar una composición detergente y un método de limpieza de superficies que comprende novedosas ADNasas preferiblemente obtenidas de Bacillus, en particular, Bacillus cibi. Las ADNasas preferidas adecuadas para usar en la invención comprenden al menos un 60 % de identidad de secuencia con un polipéptido con la Id. de sec. n.°: 1 y comprenden al menos una alteración en una posición de aminoácido en comparación con la ADNasa que tiene la Id. de sec. n.°: 1. Una variante de ADNasa adecuada para su uso en la invención puede comprender una alternancia en al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 posiciones equivalentes a una posición en la Id. de sec. n.°: 1. La alteración es preferiblemente una sustitución. Las variantes de ADNasa preferidas adecuadas para usar en la presente invención tienen al menos una propiedad mejorada en comparación con la ADNasa precursora o en comparación con la Id. de sec. n.°: 1. Las propiedades incluyen, aunque no de forma limitativa: estabilidad tales como; estabilidad en detergentes, estabilidad de almacenamiento, estabilidad durante el lavado y estabilidad térmica, capacidad limpiadora en particular, capacidad limpiadora profunda, mayor nivel de expresión y reducción de malos olores. La presente invención puede usarse como un uso secundario incluso para reducir la adhesión o aumentar la eliminación de microorganismos tales como bacterias.
Variantes de ADNasa
Las variantes de ADNasa adecuadas para usar en las composiciones de la invención son preferiblemente variantes de Id. de sec. n.°: 1 o variantes de una ADNasa que tiene al menos un 60 % de identidad con la misma.
Preferiblemente, la variante de ADNasa útil en la presente invención comprende más de dos alteraciones (en comparación con la Id. de sec. n.°: 1), tales como al menos tres alteraciones, tales como al menos cuatro alteraciones, tales como al menos cinco alteraciones, tales como al menos seis alteraciones, tales como al menos siete alteraciones, tales como al menos ocho alteraciones, tales como al menos nueve alteraciones, tales como al menos diez alteraciones, tales como al menos once alteraciones, tales como al menos doce alteraciones, tales como al menos trece alteraciones, tales como al menos catorce alteraciones, tales como al menos dieciséis alteraciones, tales como al menos diecisiete alteraciones, tales como al menos dieciocho alteraciones, tales como al menos diecinueve alteraciones, tales como al menos veinte alteraciones, en donde la variante de ADNasa tiene al menos el 60 %, al menos el 65 %, al menos el 70 %, al menos el 75 %, al menos el 80 %, al menos el 85 %, al
menos el 90 %, al menos el 95 %, tal como al menos el 96 %, al menos el 97 %, al menos el 98 % o al menos el 99 %, pero menos del 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1.
En algunos aspectos preferidos, la alteración es una sustitución.
Preferiblemente, la variante de ADNasa que comprende una sustitución en una, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más, posiciones seleccionadas de la lista que consiste en: 1, 4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41, 42, 48, 56, 57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 112, 106, 109, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde la variante tiene actividad ADNasa. En algunos aspectos, la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menor de 100 %, con respecto a la secuencia de aminoácidos de la ADNasa precursora.
En un aspecto preferido de la invención, la variante de ADNasa comprende una sustitución en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones, seleccionada de la lista que consiste en: 4, 7, 8, 9, 27, 32, 33, 39, 41, 42, 48, 61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde la variante tiene actividad ADNasa. En algunos aspectos, la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menor de 100 %, con respecto a la secuencia de aminoácidos de la ADNasa precursora.
En un aspecto preferido de la invención, la variante de ADNasa comprende, en comparación con la ADNasa mostrada en la Id. de sec. n.°: 1, al menos una, tal como al menos dos, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones, en donde la una o más sustituciones se seleccionan de la lista que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1 y en donde la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 %, o al menos 99 %, pero menor de 100 %, con respecto a la secuencia de aminoácidos de la ADNasa precursora.
En un aspecto preferido de la invención, la variante de ADNasa comprende, en comparación con la ADNasa mostrada en la Id. de sec. n.°: 27 al menos una, tal como al menos dos, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones, en donde la una o más sustituciones se seleccionan de la lista que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 27 y en donde la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 %, o al menos 99 %, pero menor de 100 %, con respecto a la secuencia de aminoácidos de la ADNasa precursora.
En un aspecto preferido de la invención, la variante de ADNasa comprende, en comparación con la ADNasa mostrada en la Id. de sec. n.°: 28 al menos una, tal como al menos dos, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones, en donde la una o más sustituciones se seleccionan de la lista que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 28 y en donde la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al
menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 %, o al menos 99 %, pero menor de 100 %, con respecto a la secuencia de aminoácidos de la ADNasa precursora.
Preferiblemente, la variante de ADNasa comprende, en comparación con la ADNasa mostrada en la Id. de sec. n.°: 1, al menos una, tal como al menos dos, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones, en donde la una o más sustituciones se seleccionan de la lista que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, S27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L, en donde la variante comprende L33R y en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1 y en donde la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 %, o al menos 99 %, pero menor de 100 %, con respecto a la secuencia de aminoácidos de la ADNasa precursora.
En algunos aspectos preferidos de la invención, la variante de ADNasa comprende, en comparación con la ADNasa mostrada en la Id. de sec. n.°: 1 al menos una, tal como al menos dos, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos octavo, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones, en donde la una o más sustituciones se seleccionan de la lista que consiste en T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, S27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L, en donde la variante comprende L33R y en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1 y en donde la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % con respecto a la ADNasa que comprende la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1.
En algunos aspectos preferidos de la invención, la variante de ADNasa comprende, en comparación con la ADNasa mostrada en la Id. de sec. n.°: 1, al menos una, tal como al menos dos, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones, en donde la una o más sustituciones se seleccionan de la lista que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1 y en donde la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menor de 100 %, con respecto a la secuencia de aminoácidos de la ADNasa con Id. de sec. n.°: 1.
En algunos aspectos preferidos de la invención, la variante de ADNasa comprende, en comparación con la ADNasa mostrada en la Id. de sec. n.°: 27 al menos una, tal como al menos dos, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones, en donde la una o más sustituciones se seleccionan de la lista que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n. °: 27 y en donde la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menor de 100 %, con respecto a la secuencia de aminoácidos de la Id. de sec. n.°: 27.
En algunos aspectos preferidos de la invención, la variante de ADNasa comprende, en comparación con la ADNasa
mostrada en la Id. de sec. n.°: 28 al menos una, tal como al menos dos, tal como al menos tres, tal como al menos
cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al
menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal
como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal
como al menos diecinueve, tal como al menos veinte o más sustituciones, en donde la una o más sustituciones se
seleccionan de la lista que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V,
S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L,
S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V,
Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada posición corresponde a la posición del
polipéptido de la Id. de sec. n. °: 28 y en donde la variante tiene una identidad de secuencia de al menos 60 %, al menos
65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al
menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menor de 100 %, con respecto a la secuencia de
aminoácidos de la Id. de sec. n.°: 28.
En algunos aspectos, el número de sustituciones en las variantes de la presente invención es 2-20, p. ej., 2-10 y
2-5, tal como 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 o 20 sustituciones.
La invención se refiere además a composiciones detergentes en donde la variante comprende una variante de
una precursora que comprende la Id. de sec. n.°: 1 en donde la variante comprende una o más sustituciones en
comparación con la Id. de sec. n. °: 1 seleccionada de las posiciones: 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48, 61, 65,
66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180,
correspondientes a las posiciones de la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos
70 %, al menos 80 %, al menos 90 % o al menos 95 % de identidad de secuencia respecto de la secuencia de
aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene actividad ADNasa y en donde la variante
tiene al menos una propiedad mejorada en comparación con la ADNasa de Id. de sec. n.°: 1.
La invención se refiere además a composiciones detergentes en donde la variante es una variante de una
precursora que comprende la Id. de sec. n.°: 27 en donde la variante comprende una o más sustituciones en
comparación con la Id. de sec. n.°: 27 seleccionada de las posiciones: 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48, 61, 65,
66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, correspondientes a las posiciones de la Id. de sec. n.°: 27, en donde la variante tiene al menos 60 %, al menos
70 %, al menos 80 %, al menos 90 % o al menos 95 % de identidad de secuencia respecto de la secuencia de
aminoácidos mostrada en la Id. de sec. n.°: 27, en donde la variante tiene actividad ADNasa y en donde la
variante tiene al menos una propiedad mejorada en comparación con la ADNasa de Id. de sec. n.°: 27.
La invención se refiere además a composiciones detergentes que comprenden una variante de una ADNasa
precursora que comprende la Id. de sec. n.°: 28 en donde la variante comprende una o más sustituciones en
comparación con la Id. de sec. n.°: 28 seleccionada de las posiciones: 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48, 61, 65,
66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, correspondientes a las posiciones de la Id. de sec. n.°: 28, en donde la variante tiene al menos 60 %, al menos
70 %, al menos 80 %, al menos 90 % o al menos 95 % de identidad de secuencia respecto de la secuencia de
aminoácidos mostrada en la Id. de sec. n.°: 28, en donde la variante tiene actividad ADNasa y en donde la
variante tiene al menos una propiedad mejorada en comparación con la ADNasa de Id. de sec. n.°: 28.
La invención se refiere además a una composición que comprende un adyuvante de limpieza y una variante de una
ADNasa precursora que comprende la Id. de sec. n.°: 1 en donde la variante comprende una sustitución en
comparación con la Id. de sec. n.°: 1 en al menos una posición seleccionada de las posiciones: 1,4, 7, 8, 9, 13, 22, 25,
27, 32, 33, 39, 41,42, 48, 56, 57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 106, 109, 112, 116, 127, 130, 138, 140, 144, 147,
148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, correspondientes a las posiciones de la Id.
de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 90 % o al menos
95 % de identidad de secuencia respecto de la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la
variante tiene actividad ADNasa y en donde la variante tiene al menos una propiedad mejorada en comparación con la
ADNasa de Id. de sec. n.°: 1. La invención se refiere además a una composición detergente que comprende al menos
2; o al menos 3; o al menos 4; o al menos 5; o al menos 6; o al menos 7; o al menos 8; o al menos 9; o al menos 10; o
al menos 11; o al menos 12; o al menos 13; o al menos 14; o al menos 15; o al menos 16; o al menos 17; o al menos
18; o al menos 19 sustituciones seleccionadas de las posiciones: 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41,42, 48, 56,
57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 106, 109, 112, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162,
166, 167, 174, 175, 177, 178, 179, 180 y 181 correspondientes a las posiciones de la Id. de sec. n.°: 1, en donde la
variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 90 % o al menos 95 % de identidad de
secuencia respecto de la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene
actividad ADNasa y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa de Id.
de sec. n.°: 1.
La invención se refiere además a una composición detergente que comprende una variante de ADNasa, en donde la variante comprende al menos una sustitución en comparación con la Id. de sec. n.°: 1, en donde la sustitución se selecciona del grupo que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, S27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L, en donde la variante comprende L33R y en donde las posiciones correspondientes a las posiciones de la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 90 % o al menos 95 % de identidad de secuencia respecto de la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene actividad ADNasa y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa de Id. de sec. n.°: 1.
La invención se refiere además a una composición detergente que comprende una variante de ADNasa, en donde la variante comprende al menos una sustitución en comparación con la Id. de sec. n.°: 1, en donde la sustitución se selecciona del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde las posiciones correspondientes a las posiciones de la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 90 % o al menos 95 % de identidad de secuencia respecto de la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene actividad ADNasa y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa de Id. de sec. n.°: 1.
La invención se refiere además a una composición detergente que comprende una variante de ADNasa, en donde la variante comprende al menos una sustitución en comparación con la Id. de sec. n.°: 27, en donde la sustitución se selecciona del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde las posiciones correspondientes a las posiciones de la Id. de sec. n.°: 27, en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 90 % o al menos 95 % de identidad de secuencia respecto de la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 27, en donde la variante tiene actividad ADNasa y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa de Id. de sec. n.°: 27.
La invención se refiere además a una composición detergente que comprende una variante de ADNasa, en donde la variante comprende al menos una sustitución en comparación con la Id. de sec. n.°: 28, en donde la sustitución se selecciona del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde las posiciones correspondientes a las posiciones de la Id. de sec. n.°: 28, en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 90 % o al menos 95 % de identidad de secuencia respecto de la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 28, en donde la variante tiene actividad ADNasa y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa de Id. de sec. n.°: 28.
La invención se refiere además a una composición detergente que comprende una variante de ADNasa, en donde la variante comprende al menos 2; o al menos 3; o al menos 4; o al menos 5; o al menos 6; o al menos 7; o al menos 8; o al menos 9; o al menos 10; o al menos 11; o al menos 12; o al menos 13; o al menos 14; o al menos 15; o al menos 16; o al menos 17; o al menos 18; o al menos 19; o al menos 20 sustituciones en comparación con la Id. de sec. n.°: 1, en donde las sustituciones se seleccionan de la lista que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, L27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L, en donde la variante comprende L33R y en donde las posiciones correspondientes a las posiciones de la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 90 % o al menos 95 % de identidad de secuencia respecto de la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene actividad ADNasa y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa de Id. de sec. n.°: 1.
En algunos aspectos, la propiedad mejorada es mayor estabilidad, p. e j, mejora en la estabilidad del detergente, mejora en la estabilidad durante el lavado y mejora en la termoestabilidad. Algunos aspectos de la invención se refieren a variantes de ADNasa que tienen un factor de mejora superior a 1 cuando las variantes de ADNasa se someten a ensayo para determinar una propiedad de interés en un ensayo relevante, en donde la propiedad de la ADNasa de referencia recibe un valor de 1. En algunos aspectos, la propiedad es estabilidad, tal como estabilidad de almacenamiento.
En algunos aspectos, la propiedad mejorada es una estabilidad del detergente mejorada.
En algunos aspectos, la propiedad mejorada es una estabilidad de proteasa mejorada.
En algunos aspectos, la propiedad mejorada es una mejora de la estabilidad en presencia de sulfito.
Una variante según la invención está mejorada en las condiciones medidas cuando la relación de actividad residual, definida como
Relación de actividad residual (RAR R d a A v a n . a n te
)
R A r eferen cia
es superior a 1 en comparación con la ADNasa de referencia, como se muestra en los Ejemplos 2, 3 y 4. En algunos aspectos, la variante está mejorada en comparación con la ADNasa de referencia en al menos uno de los ensayos A, B o C, donde el Ensayo A mide la mejora en la estabilidad de la proteasa, el ensayo B mide la mejora de la estabilidad en presencia de sulfito y el Ensayo C mide la mejora en la estabilidad del detergente, como se muestra en los Ejemplos 2, 3 y 4. En algunos aspectos, la variante está mejorada en comparación con la ADNasa de referencia en al menos dos de los ensayos A, B o C, donde el Ensayo A mide la mejora en la estabilidad de la proteasa (ejemplo 3), el ensayo B mide la mejora de la estabilidad en presencia de sulfito (ejemplo 4) y el Ensayo C (ejemplo 2) mide la mejora en la estabilidad del detergente, como se muestra en los Ejemplos 2, 3 y 4. En algunos aspectos, la variante está mejorada en comparación con la ADNasa de referencia en todos los ensayos A, B o C, donde el Ensayo A mide la mejora en la estabilidad de la proteasa, el ensayo B mide la mejora de la estabilidad en presencia de sulfito y el ensayo C mide la mejora en la estabilidad del detergente, como se muestra en los Ejemplos 2, 3 y 4.
En algunos aspectos, las variantes según la invención tienen una mejora en la estabilidad con respecto a una ADNasa de referencia medida como una relación de actividad residual superior a 1,0.
Las combinaciones productivas de mutaciones según las variantes preferidas para su uso en la invención son aquellas que dan como resultado una relación de actividad residual superior a 1 cuando se mide con respecto a la ADNasa de referencia o, dicho de otra manera, donde la combinación de mutaciones da como resultado una variante que tiene al menos una propiedad mejorada en comparación con la molécula de partida, es decir, el precursor, precursor de referencia, etc. En un aspecto preferido, la combinación de mutaciones según la invención da como resultado variantes de ADNasa que tienen una relación de actividad residual > 1,0, con respecto a la ADNasa de referencia. En algunos aspectos, las variantes según la invención tienen una relación de actividad residual que es al menos 1,1; 1,2; 1,3; 1,4; 1,5; 1,6; 1,7; 1,8; 1,9; 2,0; 2,1; 2,2; 2,3; 2,4; 2,5; 2,6; 2,7, 2,8; 2,9; 3,0, 3,1; 3,2; 3,3; 3,4; 3,5, 3,6, 3,7, 3,8, 3,9; 4,0, 4,1; 4,2; 4,3; 4,4; 4,5, 4,6, 4,7, 4,8, 4,9, 5,0, 5,1; 5,2; 5,3; 5,4; 5,5, 5,6, 5,7, 5,8, 5,9; 3,0, 6,1; 6,2; 6,3; 6,4; 6,5, 6,6, 6,7, 6,8, 6,9; 7,0, 7,1; 7,2; 7,3; 7,4; 7,5, 7,6, 7,7, 7,8, 7,9; 8,0, 8,1; 8,2; 8,3; 8,4; 8,5, 8,6, 8,7, 8,8, 8,9; 9,0, 9,1; 9,2; 9,3; 9,4; 9,5, 9,6, 9,7, 9,8, 9,9; 10,0, 10,1; 10,2; 10,3; 10,4; 10,5, 10,6, 10,7, 10,8, 10,9; 12, 15, 16, 20, 25 o 30, en comparación con la ADNasa de referencia.
En algunos aspectos preferidos, la variante de ADNasa puede comprender una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41,42, 48, 56, 57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 106, 109, 112, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde la variante tiene una identidad de secuencia de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 %, o al menos 99 %, pero menor de 100 %, con respecto al polipéptido mostrado en la Id. de sec. n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1) y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, preferiblemente la propiedad mejorada es una mejora en la estabilidad, en donde la estabilidad se somete a ensayo como se describe en los ejemplos 2, 3 y 4.
En algunos aspectos preferidos, la variante de ADNasa comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 1), en donde las sustituciones se seleccionan del grupo que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, L27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61 E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L, en donde la variante comprende L33R y en donde la
variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 % pero menos del 100 % de identidad de secuencia respecto del polipéptido mostrado en la Id de sec n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1) y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, preferiblemente la propiedad mejorada es una mejora en la estabilidad, en donde la estabilidad se somete a ensayo como se describe en los ejemplos 2, 3 y 4.
En algunos aspectos preferidos, una variante de ADNasa para usar en la invención comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 27), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, s 7g , K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 % pero menos del 100 % de identidad de secuencia respecto del polipéptido mostrado en la Id de sec n.°: 27, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27) y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n. °: 27, preferiblemente la propiedad mejorada es una mejora en la estabilidad, en donde la estabilfidad se somete a ensayo como se describe en los ejemplos 2, 3 y 4.
En algunos aspectos preferidos, una variante de ADNasa para usar en la invención comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 28), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, s 7g , K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 % pero menos del 100 % de identidad de secuencia respecto del polipéptido mostrado en la Id de sec n.°: 27, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27) y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n. °: 27, preferiblemente la propiedad mejorada es una mejora en la estabilidad, en donde la estabilidad se somete a ensayo como se describe en los ejemplos 2, 3 y 4.
En algunos aspectos preferidos, una variante de ADNasa de la invención comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 28), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 % pero menos del 100 % de identidad de secuencia respecto del polipéptido mostrado en la Id de sec n.°: 28, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 28 (numeración según la Id. de sec. n.°: 28) y en donde la variante tiene al menos una propiedad mejorada en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 28, preferiblemente la propiedad mejorada es una mejora en la estabilidad, en donde la estabilidad se somete a ensayo como se describe en los ejemplos 2, 3 y 4.
En algunos aspectos, la variante de ADNasa tiene una mejora en la estabilidad, medida como relación de actividad residual, en comparación con la precursora o en comparación con la ADNasa que tiene el polipéptido mostrado en la Id. de sec. n.°: 1.
En algunos aspectos preferidos, la variante de ADNasa comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41,42, 48, 56, 57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 106, 109, 112, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde cada alteración proporciona una variante de ADNasa que tiene una mejora en la estabilidad medida como relación de actividad residual, de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6, tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 %, o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
En algunos aspectos preferidos, una variante de ADNasa para usar en la invención comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48, 61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde cada alteración proporciona una variante de ADNasa que tiene una mejora en la estabilidad medida como relación de actividad residual, de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6, tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
En algunos aspectos preferidos, una variante de ADNasa de la invención comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48, 61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 27, en donde cada alteración proporciona una variante de ADNasa que tiene una mejora en la estabilidad medida como relación de actividad residual, de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6, tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 27, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 27, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27).
En algunos aspectos preferidos, una variante de ADNasa para usar en la invención comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48, 61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 28, en donde cada alteración proporciona una variante de ADNasa que tiene una mejora en la estabilidad medida como relación de actividad residual, de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6, tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 28, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 28, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 28 (numeración según la Id. de sec. n.°: 28).
En algunos aspectos preferidos, la variante de ADNasa comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres sustituciones, tal como al menos cuatro sustituciones, tal como al menos cinco sustituciones, tal como al menos seis sustituciones, tal como al menos siete sustituciones, tal como al menos ocho sustituciones, tal como al menos nueve sustituciones, tal como al menos diez sustituciones, tal como al menos once sustituciones, tal como al menos doce sustituciones, tal como al menos trece sustituciones, tal como al menos catorce sustituciones, tal como al menos dieciséis sustituciones, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 1), en donde las sustituciones se seleccionan del grupo que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, L27R, D32I, D32L, D32R, D32V, S39P, S39C, G41 P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L, en donde la variante comprende L33R y en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medido como relación de actividad residual de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6. tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 comparado con la ADNasa precursora, p. ej. una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 %, o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
En algunos aspectos preferidos, la variante de ADNasa para usar en la invención comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres sustituciones, tal como al menos cuatro sustituciones, tal como al menos cinco sustituciones, tal como al menos seis sustituciones, tal como al menos siete sustituciones, tal como al menos ocho sustituciones, tal como al menos nueve sustituciones, tal como al menos diez sustituciones, tal como al menos once sustituciones, tal como al menos doce sustituciones, tal como al menos trece sustituciones, tal como al menos catorce sustituciones, tal como al menos dieciséis sustituciones, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 1), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medido como relación de actividad residual de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1.6. tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 comparado con la ADNasa precursora, p. ej. una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
En algunos aspectos preferidos, la variante de ADNasa comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres sustituciones, tal como al menos cuatro sustituciones, tal como al menos cinco sustituciones, tal como al menos seis sustituciones, tal como al menos siete sustituciones, tal como al menos ocho sustituciones, tal como al menos nueve sustituciones, tal como al menos diez sustituciones, tal como al menos once sustituciones, tal como al menos doce sustituciones, tal como al menos trece sustituciones, tal como al menos catorce sustituciones, tal como al menos dieciséis sustituciones, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 27), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medido como relación de actividad residual de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1.6. tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 comparado con la ADNasa precursora, p. ej. una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 27, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27).
En algunos aspectos preferidos, la variante de ADNasa comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres sustituciones, tal como al menos cuatro sustituciones, tal como al menos cinco sustituciones, tal como al menos seis sustituciones, tal como al menos siete sustituciones, tal como al menos ocho sustituciones, tal como al menos nueve sustituciones, tal como al menos diez sustituciones, tal como al menos once sustituciones, tal como al menos doce sustituciones, tal como al menos trece sustituciones, tal como al menos catorce sustituciones, tal como al menos dieciséis sustituciones, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 28), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medido como relación de actividad residual de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6. tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 comparado con la ADNasa precursora, p. ej. una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 28, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 28, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 28 (numeración según la Id. de sec. n.°: 28).
Las variantes comprenden preferiblemente los motivos conservativos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26), que se comparten entre ADNasas del clado GYS como se describe a continuación. Como se explica en “ Definiciones” , un clado comprende un grupo de polipéptidos agrupados según características homólogas rastreadas hasta un ancestro común. Los polipéptidos que forman un grupo, p. ej., un clado como se muestra en un árbol filogenético, a menudo comparten propiedades comunes y están más estrechamente relacionados que otros polipéptidos no pertenecientes al clado.
Por lo tanto, un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) y en donde la variante comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41, 42, 48, 56, 57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 112, 106, 109, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde cada alteración proporciona una variante de ADNasa con al menos una propiedad mejorada en comparación con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1 y en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) y en donde la variante comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 4, 7, 8, 9, 27, 32, 33, 39, 41, 42, 48, 61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde cada alteración proporciona una variante de ADNasa con al menos una propiedad mejorada en comparación con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1 y en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) y en donde la variante comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48, 61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 27, en donde cada alteración proporciona una variante de ADNasa con al menos una propiedad mejorada en comparación con el polipéptido mostrado en la Id. de sec. n.°: 27, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos
de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 27 y en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) y en donde la variante comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 4, 7, 8, 9, 27, 32, 33, 39, 41, 42, 48, 61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 28, en donde cada alteración proporciona una variante de ADNasa con al menos una propiedad mejorada en comparación con el polipéptido mostrado en la Id. de sec. n.°: 28, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 28 y en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 28 (numeración según la Id. de sec. n.°: 28).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) en donde la variante comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 1), en donde las sustituciones se seleccionan del grupo que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, S27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L, en donde la variante comprende L33R y en donde cada sustitución proporciona una variante de ADNasa que tiene al menos una propiedad mejorada en comparación con el polipéptido mostrado en la Id de sec n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1 y en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) en donde la variante comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 1), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada sustitución proporciona una variante de ADNasa con al menos una propiedad mejorada en comparación con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1 y en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) en donde la variante comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 27), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada sustitución proporciona una
variante de ADNasa con al menos una propiedad mejorada en comparación con el polipéptido mostrado en la Id. de sec. n.°: 27, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 27 y en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) en donde la variante comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 28), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada sustitución proporciona una variante de ADNasa con al menos una propiedad mejorada en comparación con el polipéptido mostrado en la Id. de sec. n.°: 28, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 28 y en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 28 (numeración según la Id. de sec. n.°: 28).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) y en donde la variante comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41,42, 48, 56, 57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 112, 106, 109, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medida como relación de actividad residual, de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6, tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, al como 5 o tal como al menos 10 en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) y en donde la variante comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48, 61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medida como relación de actividad residual, de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6, tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, al como 5 o tal como al menos 10 en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) y en donde la variante comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48,
61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 27, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medida como relación de actividad residual, de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6, tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 27, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 27, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de una ADNasa precursora, en donde la variante comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26) y en donde la variante comprende una alteración en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en 4, 7, 8, 9, 27, 32, 33, 39, 41,42, 48, 61, 65, 66, 78, 91, 101, 106, 109, 112, 127, 130, 138, 140, 147, 148, 154, 157, 159, 162, 174, 177, 179 y 180, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 28, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medida como relación de actividad residual, de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6, tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 en comparación con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 28, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 28, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 28 (numeración según la Id. de sec. n.°: 28).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de ADNasa precursora, en donde la variante comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 1), en donde las sustituciones se seleccionan del grupo que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, S27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L, en donde la variante comprende L33R y en donde la sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medido como relación de actividad residual de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6. tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 comparado con la ADNasa precursora, p. ej., una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de ADNasa precursora, en donde la variante comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 1), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medido como relación de actividad residual de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6. tal como 1,7, tal
como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 comparado con la ADNasa precursora, p. ej. una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de ADNasa precursora, en donde la variante comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 27), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medido como relación de actividad residual de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6. tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 comparado con la ADNasa precursora, p. ej. una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 27, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 27, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27).
Un aspecto preferido de la invención se refiere a una composición detergente que comprende una variante de ADNasa precursora, en donde la variante comprende al menos una sustitución, tal como al menos dos sustituciones, tal como al menos tres, tal como al menos cuatro, tal como al menos cinco, tal como al menos seis, tal como al menos siete, tal como al menos ocho, tal como al menos nueve, tal como al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos dieciséis, tal como al menos diecisiete, tal como al menos dieciocho, tal como al menos diecinueve, tal como al menos veinte o más sustituciones (en comparación con la Id. de sec. n.°: 28), en donde las sustituciones se seleccionan del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde cada sustitución proporciona una variante de ADNasa que tiene un aumento en la estabilidad medido como relación de actividad residual de al menos 1,05, tal como 1,08, tal como 1,1, tal como 1,15, tal como 1,2, tal como 1,25, tal como 1,3, tal como 1,4, tal como 1,5, tal como 1,6. tal como 1,7, tal como 1,8, tal como 1,9, tal como 2, tal como 3, tal como 4, tal como 5 o tal como al menos 10 comparado con la ADNasa precursora, p. ej. una ADNasa que comprende el polipéptido que tiene la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 28, en donde la variante tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 %, pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 28, en donde cada posición corresponde a la posición del polipéptido mostrado en la Id. de sec. n.°: 28 (numeración según la Id. de sec. n.°: 28).
Varios ingredientes como tensioactivos y aditivos reforzantes de la detergencia pueden disminuir la estabilidad de una enzima en una composición detergente, particularmente en composiciones líquidas, por lo tanto las variantes enzimáticas preferidas para su uso en la presente memoria son sustancialmente estables en la composición detergente. La presente invención proporciona composiciones que comprenden variantes de ADNasa que tienen una alteración, preferiblemente una sustitución en una o más posiciones seleccionadas del grupo que consiste en: 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41,42, 48, 56, 57, 59, 61,65, 66, 76, 77, 78, 91, 101,106, 109, 112, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181. Preferiblemente, la alteración es una sustitución seleccionada del grupo que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, L27R, D32I, D32L, D32R, D32V, S39P, S39C, G41 P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61 E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L, en donde la variante comprende L33R.
Introducir una sustitución en una ADNasa precursora que tiene al menos un 80 % de identidad de secuencia con la Id. de sec. n. °: 1 una sustitución en una o más posiciones seleccionadas de las posiciones 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39,
41,42, 48, 56, 57, 59, 61,65, 66, 76, 77, 78, 91, 101,106, 109, 112, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, en donde las posiciones corresponden a las posiciones de la Id. de sec. n.°: 1, proporcionan a la variante enzimática y la composición detergente al menos una propiedad mejorada en comparación con la ADNasa precursora en la que se introducen esta una o más sustituciones como se muestra para la ADNasa precursora que comprende la Id. de sec. n.°: 1. Las sustituciones mejoran la estabilidad en soluciones líquidas tales como las composiciones de limpieza sin comprometer la capacidad limpiadora en los procesos de limpieza, p. ej., ropa. La predicción de la secuencia primaria de una enzima, cuyas posiciones pueden alterarse para obtener un efecto mejorado requiere habilidades inventivas, la molécula debe evaluarse cuidadosamente a partir de aspectos tanto estructurales como funcionales. La presente invención se refiere a composiciones detergentes que comprenden variantes de enzimas ADNasa que tienen al menos una propiedad mejorada en comparación con la ADNasa inicial, es decir, la ADNasa precursora. Los inventores han identificado posiciones donde las sustituciones individuales proporcionan un efecto estabilizante y han identificado adicionalmente que añadir una sustitución en más de una de las posiciones seleccionadas del grupo que consiste en: 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41,42, 48, 56, 57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 106, 109, 112, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181 proporciona estabilidad mejorada de manera importante sin alterar negativamente la capacidad limpiadora de la ADNasa (la capacidad para eliminar manchas de ADN de los textiles). Un aspecto de la invención se refiere a composiciones detergentes que comprenden una variante en la que una sustitución en más de una posición seleccionada del grupo que consiste en: 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41,42, 48, 56, 57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 106, 109, 112, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, se introduce para mejorar el efecto de estabilización aún más. Una composición detergente comprende preferiblemente una variante de ADNasa que comprende una sustitución en uno, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en: 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41,42, 48, 56, 57, 59, 61,65, 66, 76, 77, 78, 91, 101, 106, 109, 112, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde la variante tiene actividad ADNasa y en donde la variante tiene al menos 80 %, tal como al menos 85 %, tal como al menos 90 %, tal como al menos 95 %, tal como al menos 98 % pero menos de 100 % de identidad de secuencia con la Id. de sec. n.°: 1. No es evidente que la sustitución en más de una posición produzca un efecto aditivo o incluso sinérgico como se muestra en la presente invención. No se podía predecir un efecto aditivo ya que la adición de una sustitución a una enzima también puede afectar negativamente la estabilidad en comparación con la enzima que tiene una única sustitución, ya que la combinación específica de sustituciones puede conducir a diferentes resultados. Una realización preferida de la invención se refiere a una composición que comprende una variante de ADNasa que comprende una sustitución de un aminoácido en al menos tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, trece, catorce, quince, dieciséis, diecisiete, dieciocho, diecinueve, veinte o más posiciones seleccionadas de la lista que consiste en: posiciones seleccionadas de la lista que consiste en: 1,4, 7, 8, 9, 13, 22, 25, 27, 32, 33, 39, 41,42, 48, 56, 57, 59, 61, 65, 66, 76, 77, 78, 91, 101, 106, 109, 112, 116, 127, 130, 138, 140, 144, 147, 148, 154, 157, 159, 160, 162, 166, 167, 174, 175, 177, 178, 179, 180 y 181, en donde cada posición corresponde a la posición del polipéptido de la Id. de sec. n.°: 1, en donde las variantes tienen actividad ADNasa y en donde la variante tiene al menos 80 %, tal como al menos 85 %, tal como al menos 90 %, tal como al menos 95 %, tal como al menos 98 % pero menos de 100 % de identidad de secuencia con la Id. de sec. n.°: 1. Las sustituciones se seleccionan preferiblemente de la lista que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, L27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L en donde la variante comprende L33R.
Los inventores han construido y probado variantes enzimáticas y composiciones detergentes que comprenden variantes de una ADNasa y demuestran que la adición de varias mutaciones aumenta la estabilidad sin comprometer el rendimiento. Por lo tanto, preferiblemente el número total de sustituyentes en comparación con la Id. de sec. n.°: 1 es 1 20 o 3-20, p. ej., al menos 5 a 20, al menos 10 a 20 o tal como al menos 15 a 20 sustituciones en comparación con la ADNasa que comprende la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1. Preferiblemente, la variante de la invención tiene al menos diez, tal como al menos once, tal como al menos doce, tal como al menos trece, tal como al menos catorce, tal como al menos, quince, tal como al menos, dieciséis, tal como al menos diecisiete, tal como al menos diecinueve o incluso al menos veinte sustituciones seleccionadas de la lista que consiste en; T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, L27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L en donde la variante comprende L33R.
Por lo tanto, en una realización preferida, la composición detergente comprende una variante de una ADNasa precursora en la que la variante comprende un conjunto de sustituciones seleccionadas del grupo que consiste en:
T11+S13Y+T22P+S25P+S27R+L33R+S39P+S42G+S57W+S59V+S66Y+V76L+T77Y+Q109R+S116D+T127V+S1 44P+A147H+S167L+G175D
T11+S13Y+T22P+S27L+L33R+S42G+S57W+S59V+V76L+Q109R+S116D+T127V+S144P+A147H+S167L+G175D T11+S13Y+T22P+S27L+L33V+S42G+S57W+S59V+V76L+Q109R+S116D+T127V+S144P+A147H+S167L+G175D T11+S13Y+T22P+S27L+L33Y+S42G+S57W+S59V+V76L+Q109R+S116D+T127V+S144P+A147H+S167L+G175D
Las variantes útiles en la presente invención pueden comprender mutaciones adicionales a las citadas anteriormente. Estas modificaciones adicionales preferiblemente no deberían cambiar significativamente las propiedades mejoradas de la variante de ADNasa, p. ej., sustituciones conservativas.
Los ejemplos de sustituciones conservativas están dentro de los grupos de aminoácidos básicos (arginina, lisina e histidina), aminoácidos ácidos (ácido glutámico y ácido aspártico), aminoácidos polares (glutamina y asparagina), aminoácidos hidrófobos (leucina, isoleucina y valina), aminoácidos aromáticos (fenilalanina, triptófano y tirosina) y aminoácidos pequeños (glicina, alanina, serina, treonina y metionina). Las sustituciones de aminoácidos que generalmente no alteran la actividad específica son conocidas en la técnica y han sido descritas, por ejemplo, por H. Neurath y R.L. Hill, 1979, en The Proteins, Academic Press, Nueva York. Las sustituciones más comunes son Ala/Ser, Val/Ile, Asp/Glu, Thr/Ser, Ala/Gly, Ala/Thr, Ser/Asn, Ala/Val, Ser/Gly, Tyr/Phe, Ala/Pro, Lys/Arg, Asp/Asn, Leu/Ile, Leu/Val, Ala/Glu y Asp/Gly.
Los aminoácidos esenciales de un polipéptido se pueden identificar mediante procedimientos conocidos en la técnica, tales como mutagénesis dirigida al sitio o mutagénesis de detección de alanina (Cunningham y Wells, 1989, Science 244: 1081-1085). En esta última técnica, se introducen mutaciones de una única alanina en cada residuo de la molécula y las moléculas mutadas resultantes se evalúan para determinar su actividad ADNasa con el fin de identificar los residuos aminoacídicos que son cruciales para la actividad de la molécula. Véase también, Hilton y col., 1996, J. Biol. Chem. 271: 4699-4708. El sitio activo de la enzima u otra interacción biológica también se puede determinar mediante análisis físico de la estructura, como se determina mediante técnicas tales como resonancia magnética nuclear, cristalografía, difracción de electrones o etiquetado de fotoafinidad, junto con la mutación de nuevos sitios de contacto de aminoácidos. Véanse, por ejemplo, Vos y col., 1992, Science 255: 306 312; Smith y col., 1992, J. Mol. Biol. 224: 899-904; Wlodaver y col., 1992, FEBS Lett. 309: 59-64.
ADNasa precursora
Preferiblemente, la ADNasa precursora se selecciona de cualquiera de las clases de enzimas E.C. 3.1.11, E.C.
3.1.12, E.C. 3.1.15, E.C. 3.1.16, E.C. 3.1.21, E.C 3.1.22, E.C 3.1.23, E.C 3.1.24 y E.C.3.1.25.
Preferiblemente, la ADNasa precursora se obtiene de un microorganismo y la ADNasa es una enzima microbiana. La ADNasa es preferiblemente de origen fúngico o bacteriano.
La ADNasa precursora se obtiene preferiblemente a partir de Bacillus p. ej., Bacillus, tal como Bacillus cibi, Bacillus sp-62451, Bacillus horikoshii, Bacillus sp-16840, Bacillus sp-62668, Bacillus sp-13395, Bacillus horneckiae, Bacillus sp-11238, Bacillus idriensis, Bacillus sp-62520, Bacillus algicola, Bacillus vietnamensis, Bacillus hwajinpoensis, Bacillus indicus, Bacillus marisflavi, Bacillus luciferensis, Bacillus sp. SA2-6.
La ADNasa precursora pertenece preferiblemente al grupo de ADNasas comprendidas en el clado GYS, que son ADNasas que comprenden los motivos conservativos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASx Nr SKG (Id. de sec. n.°: 26) y que comparten propiedades estructurales y funcionales similares, véase, p. ej., la alineación en la figura 1 y la generación de árboles filogénicos en el ejemplo 11 del documento WO 2017/060475. Las ADNasas del clado GYS se obtienen preferiblemente del género Bacillus.
Una variante preferida para su uso en la presente memoria comprende una variante de una ADNasa precursora del clado GYS que tiene actividad ADNasa, opcionalmente en donde el precursor comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25), ASXNRSKG (Id. de sec. n.°: 26) y en donde el polipéptido se selecciona del grupo de polipéptidos:
a) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1,
b) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 2,
c) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 3,
d) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 4,
e) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 5,
f) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 6,
g) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 7,
h) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 8,
i) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 9,
j) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 10,
k) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 11,
l) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 12,
m) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 13,
n) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 14,
o) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 15,
p) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 16,
q) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 17,
r) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 18,
s) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 19,
t) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 20,
u) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 21,
v) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 22,
w) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 23 y
x) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 24.
Los polipéptidos que tienen actividad ADNasa y que comprenden los motivos del clado GYS han mostrado particularmente buenas propiedades de limpieza profunda, p. ej., las ADNasas son especialmente eficaces para eliminar o reducir los componentes de la materia orgánica, tales como los componentes de la biopelícula, de un artículo tal como un textil o una superficie dura.
Preferiblemente, la variante comprende una variante de una ADNasa precursora, en donde la ADNasa precursora pertenece al clado GYS y en donde la ADNasa precursora comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26).
Las ADNasas precursoras pueden ser (a) un polipéptido que tiene una identidad de secuencia de al menos 60 % respecto del polipéptido maduro con la Id. de sec. n.°: 1, (b) un polipéptido codificado por un polinucleótido que se hibrida en condiciones de alto rigor con la secuencia codificante del polipéptido maduro o el complemento de longitud completa de la misma; o (c) un polipéptido codificado por un polinucleótido que tiene una identidad de secuencia de al menos un 60 % respecto a la secuencia que codifica el polipéptido maduro.
La precursora tiene preferiblemente una identidad de secuencia con el polipéptido mostrado con Id. de sec. n.°: 1 de al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, que tiene actividad ADNasa. Incluso puede ser preferible que la precursora comprenda o consista en la secuencia de aminoácidos con Id. de sec. n.°: 1.
Se puede preferir que la precursora se seleccione de las ADNasas de bacilo, p. ej. una ADNasa de Bacillus cibi, p. ej. la ADNasa descrita en la presente descripción como la Id. de sec. n.°: 1.
Método de limpieza
Según la presente invención, también se proporciona un método para tratar o limpiar un artículo o superficie sucia tal como una superficie dura sucia o, preferiblemente, un tejido. El método comprende (i) poner en contacto el artículo o la superficie, preferiblemente un tejido, con una solución de lavado acuosa que comprende una variante de ADNasa como se describe en la presente descripción, y preferiblemente además, un adyuvante de composición de detergente; y (ii) opcionalmente enjuagar y (iii) secar la superficie. La variante y el adjunto de composición detergente se pueden añadir al agua por separado o, preferiblemente, la solución de lavado acuosa se forma añadiendo la composición detergente de la presente descripción al agua para formar la solución de lavado acuosa.
El artículo o la superficie pueden ponerse en contacto con la solución de lavado acuosa en un proceso de lavado manual o a máquina. Preferiblemente, el contacto con la solución de lavado acuosa se realiza en un ciclo de lavado, con la máxima preferencia en una lavadora; sin embargo, para un tratamiento, la etapa de contacto puede realizarse durante una etapa de aclarado del proceso de lavado.
El pH de la solución de lavado acuosa está preferiblemente en el intervalo de 1 o 2 a 11, tal como en el intervalo de 5,5 a 11, tal como en el intervalo de 6 a 10, en el intervalo de 7 a 9 o en el intervalo de 7 a 8,5.
La solución de lavado acuosa está preferiblemente a una temperatura en el intervalo de 5 °C a 95 °C o en el intervalo de 10 a 80 °C, 10 °C a 70 0C, 10 °C a 60 °C, 10 °C a 50 °C o en el intervalo de 15 °C a 40 °C o en el intervalo de 20 °C a 30 °C.
La concentración de la enzima variante de ADNasa en la solución de lavado acuosa suele estar normalmente en el intervalo de 0,00004-100 ppm de proteína enzimática, tal como en el intervalo de 0,00008-100, en el intervalo de 0,0001 100, en el intervalo de 0,0002-100, en el intervalo de 0,0004-100, en el intervalo de 0,0008-100, en el intervalo de 0,001 100 ppm de proteína enzimática, 0,01-100 ppm de proteína enzimática, preferiblemente 0,05-50 ppm de proteína enzimática, más preferiblemente 0,1-50 ppm de proteína enzimática, más preferiblemente 0,1-30 ppm de proteína enzimática, más preferiblemente 0,5-20 ppm de proteína enzimática y lo más preferiblemente 0,5-10 ppm de proteína enzimática.
El aclarado opcional puede ser una etapa de aclarado manual o aclarado mecánico, por ejemplo, como parte de un proceso estándar de lavado o de lavado de ropa en una lavadora automática. Opcionalmente puede haber más de una etapa de aclarado. Una composición de limpieza o tratamiento adicional opcional (que comprende opcionalmente una enzima ADNasa, por ejemplo, como se describe en la presente descripción) puede añadirse a una etapa de prelavado y/o una etapa de aclarado, por ejemplo, una composición de pretratamiento y/o de acondicionamiento de tejidos. La etapa de secado puede ser cualquier etapa de secado estándar, por ejemplo, para lavado de ropa, en tendedero o en secadora.
Además de la limpieza, las composiciones detergentes y los métodos de la invención pueden, como segundo beneficio, prevenir y/o reducir el mal olor. La presente invención puede permitir la reducción de la redeposición de la suciedad, particularmente desde la solución de lavado acuosa donde, a medida que el lavado avanza, la suciedad se elimina de las superficies que se están limpiando y queda suspendida en la solución de lavados acuosa. Cuando dicha suciedad pegajosa permanece sobre en la superficie que se está limpiando, la redeposición puede ser un problema que se puede superar con las composiciones detergentes y los métodos de limpieza según la presente invención. Las composiciones detergentes y los métodos de la presente invención que comprenden variantes de ADNasa pueden proporcionar propiedades mejoradas de limpieza profunda en comparación con la ADNasa precursora y, en algunos aspectos, la presente invención reduce la adherencia y/o la redeposición. En algunos aspectos, la invención se refiere al uso de una variante de ADNasa o composición que comprende la variante de ADNasa según la invención para la limpieza profunda de un artículo, en donde el artículo es un tejido o una superficie dura.
Además, la invención se refiere al uso de una variante de ADNasa o composición que comprende la variante de ADNasa según la invención para prevenir y/o reducir la adherencia de la suciedad a un artículo. En algún aspecto, el artículo es textil. Cuando la suciedad no se adhiere al artículo, el artículo aparece más limpio. Por lo tanto, la invención se refiere además al uso de una variante de ADNasa según la invención para mantener o mejorar la blancura del artículo.
La presente invención se refiere además a composiciones detergentes que comprenden una variante de ADNasa según la invención preferiblemente con un ingrediente adyuvante de detergente. La composición detergente que comprende una variante de ADNasa según la invención puede usarse para limpieza profunda de un artículo, para prevenir y/o reducir la adherencia de un artículo, para pretratar manchas en el artículo, para prevenir y/o reducir la redeposición de suciedad durante un ciclo de lavado, para prevenir y/o reducir la adherencia de la suciedad a un artículo, para mantener o mejorar la blancura de un artículo y/o para prevenir y/o reducir el mal olor de un artículo.
Preparación de una variante
La variante de ADNasa para su uso en la presente memoria se puede fabricar mediante un proceso que comprende: (a) introducir en una ADNasa precursora una o más sustituciones seleccionadas del grupo que consiste en: T1I, T1V, G4K, S7G, K8R, S9I, S13Y, T22P, S25P, S27L, S27R, D32I, D32L, D32R, D32V, L33R, L33K, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S66M, S66W, S66Y, S66V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L;
(b) y recuperar la variante, en donde la variante tiene actividad ADNasa.
Las variantes preferidas se preparan al:
a) introducir en una ADNasa precursora una o más sustituciones seleccionadas del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, L33H, L33R, L33K, L33V, L33Y, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A;
b) y recuperar la variante, en donde la variante tiene actividad ADNasa.
La variante tiene preferiblemente al menos una propiedad mejorada en comparación con la ADNasa precursora, p. ej., en comparación con el polipéptido mostrado en la Id. de sec. n.°: 1. El método comprende preferiblemente la introducción de 2-20, p. ej. 2-10 y 1-5, tal como 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 o 20 alteraciones en comparación con el polipéptido mostrado en la Id. de sec. n.°: 1.
Algunos aspectos de la invención se refieren a un método para obtener una variante de ADNasa que comprende introducir en una ADNasa precursora una alteración en una o más posiciones, en donde la ADNasa precursora pertenece al clado GYS y en donde la ADNasa precursora comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26).
Algunos aspectos de la invención se refieren a un método para obtener una variante de ADNasa que comprende introducir en una ADNasa precursora una alteración en una o más posiciones, en donde la ADNasa precursora se selecciona del grupo de polipéptidos:
a) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1, b) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 2, c) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 3, d) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 4, e) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 5, f) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 6, g) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 7,
h) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 8,
i) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 9,
j) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 10,
k) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 11,
l) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 12,
m) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 13,
n) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 14,
o) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 15,
p) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 16,
q) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 17,
r) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 18,
s) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 19,
t) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 20,
u) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n. °: 21,
v) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 22,
w) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 23 y
x) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 24.
Un aspecto se refiere a un método para obtener una variante de ADNasa en donde la ADNasa precursora se obtiene del género Bacillus.
La variante de ADNasa es preferiblemente una variante que tiene al menos 80 %, tal como al menos 85 %, al menos 90 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 % o al menos 99 % pero menos de 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1.
Las variantes de la invención se pueden preparar mediante procedimientos tales como los mencionados a continuación.
La mutagénesis dirigida al sitio es una técnica en la que se introducen una o más (p. ej., varias) mutaciones en uno o más sitios definidos en un polinucleótido que codifica el precursor.
La mutagénesis dirigida al sitio se puede llevar a cabo in vitro mediante PCR que implica el uso de cebadores de oligonucleótidos que contienen la mutación deseada. La mutagénesis dirigida al sitio también se puede llevar a cabo in vitro mediante mutagénesis en casete que implica la escisión mediante una enzima de restricción en un sitio del plásmido que comprende un polinucleótido que codifica el precursor y la posterior unión de un oligonucleótido que contiene la mutación en el polinucleótido. Normalmente, la enzima de restricción que digiere el plásmido y el oligonucleótido es la misma, lo que permite crear extremos adherentes en el plásmido y la inserción para unirlos entre sí. Véanse, p. ej., Scherer y Davis, 1979, Proc. Nati. Acad. Sci. EE. UU. 76: 4949-4955; y Barton y col., 1990, Nucleic Acids Res. 18: 7349 4966.
La mutagénesis dirigida al sitio también se puede llevar a cabo in vivo por métodos conocidos en la técnica. Véanse, p. ej., la solicitud de patente con número de publicación US-2004/0171154; Storici y col., 2001, Nature Biotechnol.
19: 773-776; Kren y col., 1998, Nat. Med. 4: 285-290; y Calissano y Macino, 1996, Fungal Genet. Newslett. 43: 15 16.
La construcción de genes sintéticos conlleva la síntesis in vitro de una molécula de polinucleótido diseñada para codificar un polipéptido de interés. La síntesis de genes se puede llevar a cabo utilizando numerosas técnicas, tal como la tecnología multiplexada en microchip descrita en Tian y col. (2004, Nature 432: 1050-1054) y tecnologías similares en donde los oligonucleótidos se sintetizan y ensamblan sobre chips microfluidos fotoprogramables.
Pueden realizarse y analizarse múltiples sustituciones, deleciones y/o inserciones de aminoácidos utilizando métodos conocidos de mutagénesis, recombinación y/o barajado, seguido por un procedimiento de cribado relevante, tal como el descrito en Reidhaar-Olson y Sauer, 1988, Science 241: 53-57; Bowie y Sauer, 1989, Proc. Natl. Acad. Sci. EE. UU. 86: 2152-2156; documento WO 95/17413; o WO 95/22625. Otros métodos que se pueden usar incluyen la técnica de PCR propensa a error, expresión en fago (p. ej., Lowman y col., 1991, Biochemistry 30: 10832-10837; documento US 5.223.409; WO 92/06204) y mutagénesis dirigida a la región (Derbyshire y col., 1986, Gene 46: 145; Ner y col., 1988, DNA 7: 127).
Los métodos de mutagénesis/intercambio se pueden combinar con alto rendimiento, métodos de cribado automatizado para detectar la actividad de los polipéptidos mutagenizados clonados expresados en células huésped (Ness y col., 1999, Nature Biotechnology 17: 893-896). Las moléculas de ADN mutagenizadas que codifican polipéptidos activos se pueden recuperar de las células hospedadoras y secuenciadas rápidamente utilizando métodos convencionales en la técnica. Estos métodos permiten determinar rápidamente la importancia de los restos del aminoácido individuales en un polipéptido.
La construcción de genes semisintéticos se lleva a cabo combinando aspectos de la construcción de genes sintéticos, y/o la mutagénesis dirigida al sitio, y/o la mutagénesis aleatoria, y/o el intercambio. La construcción semisintética se tipifica por un proceso en el que se utilizan fragmentos de polinucleótido que se han sintetizado, en combinación con técnicas de PCR. Por lo tanto, las regiones definidas de los genes se pueden sintetizar de novo, mientras que otras regiones se pueden amplificar utilizando cebadores mutagénicos específicos de sitio, mientras que otras regiones adicionales se pueden someter a amplificación mediante PCR propensa a error o PCR no propensa a error. A continuación, las subsecuencias de polinicleótido se pueden intercambiar.
Construcciones de ácido nucleico
Las construcciones de ácido nucleico que comprenden un polinucleótido que codifica las variantes de ADNasa para su uso en la presente invención pueden unirse operativamente a una o más secuencias de control que dirigen la expresión de la secuencia codificante en una célula huésped adecuada en condiciones compatibles con las secuencias de control.
El polinucleótido puede manipularse de diversas maneras para proporcionar la expresión del polipéptido. La manipulación del polinucleótido antes de su inserción en un vector puede ser deseable o necesaria dependiendo del vector de
expresión. Las técnicas para modificar polinucleótidos utilizando métodos de ADN recombinante son bien conocidas en la técnica.
La secuencia de control puede ser un promotor, un polinucleótido reconocido por una célula huésped para la expresión de un polinucleótido que codifica un polipéptido de la presente invención. El promotor contiene secuencias de control transcripcional que median la expresión del polipéptido. El promotor puede ser cualquier polinucleótido que muestre actividad transcripcional en la célula huésped incluidos promotores mutantes, truncados e híbridos, y puede obtenerse a partir de genes que codifican polipéptidos extracelulares o intracelulares homólogos o heterólogos en la célula huésped.
Los ejemplos de promotores adecuados para dirigir la transcripción de las construcciones de ácido nucleico de la presente invención en una célula huésped bacteriana son los promotores obtenidos a partir del gen de la alfaamilasa de Bacillus amyloliquefaciens (amyQ), el gen de la alfa-amilasa de Bacillus licheniformis (amyL), el gen de la penicilinasa de Bacillus licheniformis (penP), el gen de la amilasa maltogénica de Bacillus stearothermophilus (amyM),el gen de la levansacarasa de Bacillus subtilis (sacB), los genes de xilA y xilA de Bacillus subtilis, el gen cryIIIA de Bacillus thuringiensis (Agaisse y Lerlus, 1994, Molecular Microbiology 13: 97-107), el operón lac de E. coli, el promotor trc de E. coli (Egon y col., 1988, Gene 69: 301-315), el gen de la agarasa de Streptomyces coelicor (dagA) y el gen de la beta-lactamasa procariota (Villa-Kamarff y otros, 1978, Proc. Natl. Acad. Sci. EE. Uu .75: 3727 3731), así como el promotor tac (DeBoer y col., 1983, proc. Natl. Acad. Sci. EE. UU. 80: 21 -25). Otros promotores se describen en “ Useful proteins from recombinant bacteria” en Gilbert y col., 1980, Scientific American 242: 74-94; y en Sambrook y col., 1989, más arriba. Se describen ejemplos de promotores en tándem en el documento WO 99/43835.
Los ejemplos de promotores adecuados para dirigir la transcripción de las construcciones de ácido nucleico de la presente invención en una célula huésped de hongo filamentoso son promotores obtenidos a partir de los genes de la acetamidasa de Bacillus nidulans, alfa amilasa neutra de Bacillus niger, alfa amilasa estable a ácido de Bacillus niger, glucoamilasa de Bacillus niger o Bacillus awamori (glaA), amilasa TAKA de Bacillus cibi, proteasa alcalina de Bacillus cibi, triosa fosfato isomerasa de Bacillus cibi, proteasa análoga a tripsina de Fusarium oxysporum (documento WO 96/00787), amiloglucosidasa de Fusarium venenatum (documento WO 00/56900), Fusarium venenatum Daria (documento WO 00/56900), Fusarium venenatum Quinn (documento WO 00/56900), lipasa de Rhizomucor miehei, proteinasa aspártica de Rhizomucor miehei, beta-glucosidasa de Trichoderma reesei, celobiohidrolasa I de Trichoderma reesei, celobiohidrolasa II de Trichoderma reesei, endoglucanasa I de Trichoderma reesei, endoglucanasa II de Trichoderma reesei, endoglucanasa III de Trichoderma reesei, endoglucanasa V de Trichoderma reesei, xilanasa I de Trichoderma reesei, xilanasa II de Trichoderma reesei, xilanasa III de Trichoderma reesei, beta-xilosidasa de Trichoderma reesei y factor de alargamiento de traducción de Trichoderma reesei, así como el promotor tpi NA2 (un promotor modificado procedente de un gen de la alfa amilasa neutra de Bacillus en el que el líder no traducido se ha sustituido por un líder no traducido procedente de un gen de la triosa fosfato isomerasa de Bacillus; cuyos ejemplos no limitativos incluyen promotores modificados de un gen de la alfa-amilasa neutra de Bacillus niger en el que el líder no traducido se ha sustituido por un líder no traducido procedente de un gen de la triosa fosfato isomerasa de Bacillus nidulans o Bacillus cibi); y promotores mutantes, truncados e híbridos de los mismos. Se describen otros promotores en la patente US-6.011.147.
En un huésped de levadura, se obtienen promotores útiles a partir de los genes de la enolasa de Saccharomyces cerevisiae (ENO: 1), galactocinasa de Saccharomyces cerevisiae (GAL1), alcohol deshidrogenasa/gliceraldehído-3 fosfato deshidrogenasa de Saccharomyces cerevisiae (ADH1, aDH2/GAP), triosa fosfato isomerasa de Saccharomyces cerevisiae (TPI), metalotioneína de Saccharomyces cerevisiae (CUP1) y fosfoglicerato quinasa 3 de Saccharomyces cerevisiae. Otros promotores útiles para células huésped de levadura se describen en Romanos y col., 1992, Yeast 8: 423 488.
La secuencia de control también puede ser un terminador de transcripción, que reconoce una célula huésped para terminar la transcripción. El terminador está unido operativamente al extremo 3’ del polinucleótido que codifica el polipéptido. En la presente invención se puede usar cualquier terminador que sea funcional en la célula huésped.
Los terminadores preferidos para células huésped bacterianas se obtienen de los genes de la proteasa alcalina de Bacillus clausii (aprH), alfa-amilasa de Bacillus licheniform is (amyL), y ARN ribosómico de Escherichia coli (rrnB).
Los terminadores preferidos para células huésped de hongos filamentosos se obtienen a partir de los genes de la acetamidasa de Bacillus nidulans, antranilato sintasa de Bacillus nidulans, glucoamilasa de Bacillus niger, alfa-glucosidasa de Bacillus niger, amilasa TAKA de Bacillus cibi, proteasa análoga a tripsina de Fusarium oxysporum, beta-glucosidasa de Trichoderma reesei, celobiohidrolasa I de Trichoderma reesei, celobiohidrolasa II de Trichoderma reesei, endoglucanasa I de Trichoderma reesei, endoglucanasa II de Trichoderma reesei, endoglucanasa III de Trichoderma reesei, endoglucanasa V de Trichoderma reesei, xilanasa I de Trichoderma reesei, xilanasa II de Trichoderma reesei, xilanasa III de Trichoderma reesei, beta-xilosidasa de Trichoderma reesei y factor de alargamiento de la traducción de Trichoderma reesei.
Los terminadores preferidos para células huésped de levadura se obtienen de los genes de enolasa de Saccharomyces cerevisiae, citocromo C de Saccharomyces cerevisiae (CYC1) y gliceraldehído-3-fosfato deshidrogenasa de Saccharomyces cerevisiae. Otros terminadores útiles para células huésped de levadura se describen en Romanos y col., 1992, supra.
La secuencia de control también puede ser una región estabilizante de ARNm posterior a un promotor y anterior a la de la secuencia codificante de un gen que aumenta la expresión del gen.
Los ejemplos de regiones estabilizantes de ARNm adecuadas se obtienen de un gen cryIIIA de Bacillus thuringiensis (documento WO 94/25612) y un gen SP82 de Bacillus subtilis (Hue y col., 1995, Journal of Bacteriology 177: 3465-3471).
La secuencia de control también puede ser una región líder, no traducida de un ARNm que es importante para su traducción por la célula huésped. El líder está unido operativamente al extremo 5’ del polinucleótido que codifica el polipéptido. Se puede usar cualquier líder que sea funcional en la célula huésped.
Los líderes preferidos para células huésped fúngicas filamentosas se obtienen de los genes de la amilasa TAKA de Bacillus cibi y la triosa isomerasa de Bacillus nidulans.
Los líderes adecuados para células huésped de levadura se obtienen de los genes de la enolasa de Saccharomyces cerevisiae (ENO: 1), 3 fosfoglicerato quinasa de Saccharomyces cerevisiae, factor alfa de Saccharomyces cerevisiae y alcohol deshidrogenasa/gliceraldehído-3 fosfato deshidrogenasa de Saccharomyces cerevisiae (ADH2/GAP).
La secuencia de control también puede ser una secuencia de poliadenilación, una secuencia unida operativamente al extremo 3' del polinucleótido que, cuando se transcribe, es reconocida por la célula huésped como una señal para añadir residuos de poliadenosina al ARNm transcrito. Se puede usar cualquier secuencia de poliadenilación que sea funcional en la célula huésped.
Las secuencias de poliadenilación preferidas para células huésped fúngicas filamentosas se obtienen a partir de los genes de la antranilato sintasa de Bacillus nidulans, glucoamilasa de Bacillus niger, alfa-glucosidasa de Bacillus niger, amilasa TAKA de Bacillus cibi y proteasa análoga a tripsina de Fusarium oxysporum.
Las secuencias de poliadenilación útiles para células huésped de levadura se describen en Guo y Sherman, 1995, Mol. Cellular Biol. 15: 5983-5990.
La secuencia de control también puede ser una región codificadora del péptido señal que codifica un péptido señal unido al extremo N de un polipéptido y dirige el polipéptido a la ruta secretora de la célula. El extremo 5' de la secuencia codificante del polinucleótido puede contener inherentemente una secuencia codificante del péptido señal unida naturalmente en el marco de lectura de la traducción con el segmento de la secuencia codificante que codifica el polipéptido. Alternativamente, el extremo 5' de la secuencia codificante puede contener una secuencia codificante del péptido señal que es foránea a la secuencia codificante. Puede requerirse una secuencia codificante del péptido señal foránea si la secuencia codificante no contiene naturalmente una secuencia codificante del péptido señal. Alternativamente, una secuencia codificante del péptido señal foránea puede simplemente sustituir la secuencia codificante del péptido señal natural para mejorar la secreción del polipéptido. Sin embargo, puede usarse cualquier secuencia codificante del péptido señal que dirija el polipéptido expresado a la ruta secretora de una célula huésped.
Las secuencias codificantes de péptidos señal eficaces para células huésped bacterianas son las secuencias codificantes de péptidos señal obtenidas de los genes de la amilasa maltogénica de Bacillus NCB 11837, subtilisina de Bacillus licheniformis, beta-lactamasa de Bacillus licheniformis, alfa-amilasa de Bacillus stearothermophilus, proteasas neutras de Bacillus stearothermophilus (nprT, nprS, nprM) y prsA de Bacillus subtilis. Se describen péptidos señal adicionales se describen en Simonen y Palva, 1993, Microological Reviews 57: 109-137.
Las secuencias codificantes de péptidos señal eficaces para células huésped de hongo filamentoso son las secuencias codificantes de péptidos señal obtenidas de los genes de la amilasa neutra de Bacillus niger, glucoamilasa de Bacillus niger, amilasa TAKA de Bacillus cibi, celulasa de Humicola insolens, endoglucanasa V de Humicola insolens, lipasa de Humicola lanuginosa y proteinasa aspártica de Rhizomucor miehei.
Se obtienen péptidos señal útiles para células huésped de levadura de los genes del factor alfa de Saccharomyces cerevisiae y la invertasa de Saccharomyces cerevisiae. Otras secuencias codificantes de péptidos señal útiles se describen en Romanos y col., 1992, supra.
La secuencia de control también puede ser una secuencia codificante de propéptido que codifica un propéptido situado en el extremo N de un polipéptido. El polipéptido resultante se conoce como proenzima o propolipéptido (o un zimógeno en algunos casos). Un propolipéptido generalmente es inactivo y puede convertirse en un polipéptido activo mediante escisión catalítica o autocatalítica del propéptido del propolipéptido. La secuencia
codificante del propéptido se puede obtener de los genes de la proteasa alcalina de Bacillus subtilis (aprE), proteasa neutra de Bacillus subtilis (nprT), lacasa de Myceliophthora thermophila (documento WO 95/33836), proteinasa aspártica de Rhizomucoo miehei y el factor alfa de Saccharomyces cerevisiae.
Cuando están presentes las secuencias tanto del péptido señal como del propéptido, la secuencia del propéptido se coloca junto al extremo N de un polipéptido y la secuencia del péptido señal se coloca junto al extremo N de la secuencia del propéptido.
También puede ser deseable añadir secuencias reguladoras que regulen la expresión del polipéptido respecto al crecimiento de la célula huésped. Los ejemplos de secuencias reguladoras son las que hacen que la expresión del gen se active o se desactive en respuesta a un estímulo químico o físico, incluida la presencia de un compuesto regulador. Las secuencias reguladoras en sistemas procariotas incluyen los sistemas de operadores lac, tac y trp. En levaduras se puede usar el sistema ADH2 o el sistema GAL1. En hongos filamentosos se pueden usar el promotor de glucoamilasa de Bacillus niger, el promotor de la alfa-amilasa TAKA de Bacillus c ib iy el promotor de glucoamilasa de Bacillus cibi, el promotor de la celobiohidrolasa I de Trichoderma reeseiy el promotor de la celobiohidrolasa II de Trichoderma reesei. Otros ejemplos de secuencias reguladoras son las que permiten la amplificación génica. En los sistemas eucariotas, estas secuencias reguladoras incluyen el gen de la dihidrofolato reductasa que se amplifica en presencia de metotrexato y los genes de la metalotioneína que se amplifican con metales pesados. En estos casos, el polinucleótido que codifica el polipéptido estaría operativamente unido a la secuencia reguladora.
Vectores de expresión
Esta descripción también se refiere a vectores de expresión recombinantes que comprenden un polinucleótido que codifica las variantes de ADNasa, un promotor y señales de parada transcripcionales y traduccionales. Las diversas secuencias de nucleótidos y de control pueden unirse entre sí para producir un vector de expresión recombinante que puede incluir uno o más sitios de restricción cómodos para permitir la inserción o sustitución del polinucleótido que codifica el polipéptido en tales sitios. Alternativamente, el polinucleótido puede expresarse mediante la inserción del polinucleótido o construcción de ácido nucleico que comprende el polinucleótido en un vector apropiado para la expresión. Al crear el vector de expresión, la secuencia codificante se ubica en el vector de manera que la secuencia codificante se une operativamente con secuencias de control adecuadas para expresión. En un aspecto adicional, los codones de la secuencia de polinucleótido se han modificado mediante sustituciones de nucleótidos a los correspondientes al uso del codón del organismo hospedador previsto para la producción del polipéptido de la presente invención. El vector de expresión recombinante puede ser cualquier vector (p. ej, un plásmido o virus) que puede someterse cómodamente a procedimientos de ADN recombinante y puede provocar la expresión del polinucleótido. La elección del vector dependerá típicamente de la compatibilidad del vector con la célula huésped en la que se introducirá el vector. El vector puede ser un plásmido lineal o circular cerrado.
El vector puede ser un vector que se replica de forma autónoma, es decir, un vector que existe como una entidad extracromosómica, cuya replicación es independiente de la replicación cromosómica, por ejemplo, un plásmido, un elemento extracromosómico, un minicromosoma o un cromosoma artificial. El vector puede contener cualquier medio para asegurar la autorreplicación. Alternativamente, el vector puede ser uno que, cuando se introduce en la célula huésped, se integra en el genoma y se replica junto con el uno o más cromosomas en los que se ha integrado. Además, puede usarse un único vector o plásmido o dos o más vectores o plásmidos que conjuntamente contienen el ADN total que se va a introducir en el genoma de la célula huésped, o un transposón.
El vector contiene preferiblemente uno o más marcadores seleccionables que permiten la selección fácil de células transformadas, transfectadas, transducidas o similares. Un marcador seleccionable es un gen cuyo producto proporciona resistencia biocida o vírica, resistencia a metales pesados, fototrofia a los auxótropos y similares.
Los ejemplos de marcadores bacterianos seleccionables son los genes dal de Bacillus licheniformis o Bacillus subtilis, o marcadores que transmiten resistencia a antibióticos tal como resistencia a ampicilina, cloranfenicol, kanamicina, neomicina, espectinomicina o tetraciclina. Los marcadores adecuados para células huésped de levadura incluyen, aunque no de forma limitativa, ADE2, HIS3, LEU2, LYS2, MET3, TRP1 y URA3. Los marcadores seleccionables para su uso en una célula huésped fúngica filamentosa incluyen, aunque no de forma limitativa, adeA (fosforribosilaminoimidazol-succinocarboxamida sintasa), adeB (fosforribosilaminoimidazol sintasa), amdS (acetamidasa), argB (ornitina carbamoiltransferasa), bar (fosfinotricina acetiltransferasa), hph (higromicina fosfotransferasa), niaD (nitrato reductasa), pirG (orodina-5'fosfato descarboxilasa), sC (sulfato adenotransferasa) y trpC (antranilato sintasa), así como equivalentes de los mismos. Preferidos para usar en una célula de Bacillus son los genes amdS y pirG de Bacillus nidulans o Bacillus cibi y un gen bar de Streptomyces higroscopicus. Preferidos para usar en una célula de Trichoderma son los genes adeA, adeB, amdS, hph y pirG.
El marcador seleccionable puede ser un sistema marcador seleccionable doble como se describe en el documento WO 2010/039889. En algunos aspectos, el marcador seleccionable doble es un sistema marcador seleccionable doble hph-tk.
El vector contiene preferiblemente uno o más elementos que permiten la integración del vector en el genoma de la célula huésped o la replicación autónoma del vector en la célula independiente del genoma. Para la integración en el
genoma de la célula hospedadora, el vector puede depender de la secuencia del polinucleótido que codifica el polipéptido o cualquier otro elemento del vector para la integración en el genoma por recombinación homóloga o no homóloga. Alternativamente, el vector puede contener polinucleótidos adicionales para dirigir la integración por recombinación homóloga en el genoma de la célula hospedadora en una o más ubicaciones precisas en el uno o varios cromosomas. Para aumentar la probabilidad de integración en una ubicación precisa, los elementos de integración deben contener un número suficiente de ácidos nucleicos, tal como de 100 a 10.000 pares de bases, de 400 a 10.000 pares de bases y de 800 a 10.000 pares de bases, que tienen un alto grado de identidad de secuencia con respecto a la secuencia diana correspondiente para mejorar la probabilidad de recombinación homóloga. Los elementos de integración pueden ser cualquier secuencia que sea homóloga de la secuencia diana en el genoma de la célula huésped. Además, los elementos de integración pueden ser polinucleótidos no codificantes o codificantes. Por otra parte, el vector puede integrarse en el genoma de la célula huésped mediante recombinación no homóloga.
Para la replicación autónoma, el vector puede también comprender un origen de replicación que permita que el vector se replique de manera autónoma en la célula huésped en cuestión. El origen de replicación puede ser cualquier replicador plasmídico que medie la replicación autónoma que funciona en una célula. La expresión “origen de replicación” o “ replicador plasmídico” se refiere a un polinucleótido que permite que un plásmido o vector se replique in vivo.
Ejemplos de orígenes de replicación bacterianos son los orígenes de replicación de los plásmidos pBR322, pUC19, pACYC177 y pACYC184 que permiten la replicación en E. coli, y pUB110, pE194, pTA1060 y pAMp1 que permiten la replicación en Bacillus.
Ejemplos de orígenes de replicación para su uso en una célula huésped de levadura son el origen de replicación de 2 micrómetros, ARS1, a Rs 4, la combinación de ARS1 y CEN3, y la combinación de ARS4 y CEN6.
Los ejemplos de orígenes de replicación útiles en una célula fúngica filamentosa son AMA1 y ANS1 (Gemas y col., 1991, Gene 98: 61-67; Cullen y col., 1987, Nucleic Acids Res. 15: 9163-9175; documento WO 00/24883). El aislamiento del gen AMA1 y la construcción de plásmidos o vectores que comprenden el gen se pueden lograr según los métodos descritos en el documento WO 00/24883.
Se puede insertar más de una copia de un polinucleótido de la presente invención en una célula huésped para aumentar la producción de un polipéptido. Un aumento en el número de copias del polinucleótido puede obtenerse integrando al menos una copia adicional de la secuencia en el genoma de la célula hospedadora o incluyendo un gen marcador seleccionable amplificable en el polinucleótido donde las células que contienen copias amplificadas del gen marcador seleccionable y, por lo tanto, copias adicionales del polinucleótido, se pueden seleccionar mediante cultivo de las células en presencia del agente de selección adecuado.
Los procedimientos utilizados para ligar los elementos descritos anteriormente para construir los vectores de expresión recombinantes de la presente invención son bien conocidos por un experto en la materia (véase, p. ej., Sambrook y col., 1989, citado anteriormente).
Células huésped
Las células huésped recombinantes comprenden un polinucleótido operativamente unido a una o más secuencias de control que dirigen la producción de un polipéptido útil en la presente invención. Una construcción o vector que comprende un polinucleótido se introduce en una célula huésped de manera que la construcción o vector se mantenga como un integrante cromosómico o como un vector extracromosómico autorreplicante como se ha descrito anteriormente. La expresión “célula huésped” abarca cualquier progenie de una célula precursora que no es idéntica a la célula precursora debido a mutaciones que se producen durante la replicación. La elección de una célula huésped dependerá en gran medida del gen que codifica el polipéptido y su fuente.
La célula huésped puede ser cualquier célula útil en la producción recombinante de un polipéptido de la presente invención, p. ej., una célula procariota o eucariota.
La célula huésped procariota puede ser cualquier bacteria grampositiva o gramnegativa. Las bacterias grampositivas incluyen, aunque no de forma limitativa, Bacillus, Clostridium, Enterococcus, Geobacillus, Lactobacillus, Lactococcus, Oceanobacillus, Staphylococcus, Streptococcus y Streptomyces. Las bacterias gramnegativas incluyen, sin limitación, Campylobacter, E. coli, Flavobacterium, Fusobacterium, Helicobacter, Ilyobacter, Neisseria, Pseudomonas, Salmonella y Ureaplasma.
La célula huésped bacteriana puede ser cualquier célula de Bacillus que incluye, aunque no de forma limitativa, células de Bacillus alcalophilus, Bacillus amyloliquefaciens, Bacillus brevis, Bacillus circulans, Bacillus clausii, Bacillus coagulans, Bacillus firmus, Bacillus lautus, Bacillus lentus, Bacillus licheniform is, Bacillus megaterium, Bacillus pumilus, Bacillus stearothermophilus, Bacillus subtilis y Bacillus thuringiensis.
La célula huésped bacteriana también puede ser cualquier célula de Streptococcus que incluye, aunque no de forma limitativa, células de Streptococcus equimilis, Streptococcus pyogenes, Streptococcus uberis y Streptococcus equis sp Zooepidemicus.
La célula huésped bacteriana también puede ser cualquier célula de Streptomyces que incluye, sin limitación, células de Streptomyces achromogenes, Streptomyces avermitilis, Streptomyces coelicolor, Streptomyces griseus y Streptomyces lividans.
La introducción de ADN en una célula de Bacillus puede realizarse mediante transformación de protoplastos (véase, p. ej, Chang y Cohen, 1979, Mol. Gen. Genet. 168: 111-115), transformación de células competentes (véanse, p. e j, Young y Spizizen, 1961, J. Bacteriol. 81: 823-829 o Dubnau y Davdoff-Abelson, 1971, J. Mol. Biol. 56: 209-221), electroporación (véase, p. e j, Shigekawa y Dsegwer, 1988, Biotechniques 6: 742-751) o conjugación (véase, p. e j, Koehler y Thorne, 1987, J. Bacteriol. 169: 5271-5278). La introducción de ADN en una célula de E. coli puede efectuarse mediante transformación de protoplastos (véase, p. ej., Hanahan, 1983, J. Mol. Biol. 166: 557-580) o electroporación (véase, p. ej., Dower y col., 1988, Nucleic Acids Res. 16: 6127-6145). La introducción de ADN en una célula de Streptomyces puede efectuarse mediante transformación de protoplastos, electroporación (véanse, p. ej., Gong y col., 2004, Folia Microbiol. (Praha) 49: 399-405), conjugación (véase, p. e j, Mazodier y col., 1989, J. Bacteriol. 171: 3583-3585) o transducción (véase, p. e j, Burke y col., 2001, Proc. Natl. Acad. Sci. EE. u U. 98: 6289-6294). La introducción de ADN en una célula de Pseudomonas puede efectuarse por electroporación (véase, p. ej., Choi y col., 2006, J. Microbiol. Methods 64: 391-397) o conjugación (véase, p. ej., Pinedo y Smets, 2005, Appl. Environ. Microbiol. 71: 51-57). La introducción de ADN en una célula de Streptococcus puede efectuarse por competencia natural (véase, p. e j, Perry y Kuramitsu, 1981, Infect. Immun.
32: 1295-1297), transformación de protoplastos (véase, p. e j, Catt y Jollick, 1991, Microbios 68: 189-207), electroporación (véase, p. e j, Buckley y col., 1999, Appl. Environ. Microbiol. 65: 3800-3804) o conjugación (véase, p. e j, Clewell, 1981, Microbiol. Rev. 45: 409-436). Sin embargo, se puede usar cualquier método conocido en la técnica para introducir ADN en una célula huésped.
La célula huésped también puede ser eucariota, tal como una célula de mamífero, insecto, vegetal o fúngica.
La célula huésped puede ser una célula fúngica. “ Fungi” como se usa en la presente descripción, incluye los Phylum Ascomycota, Basidiomycota, Chytridiomycota y Zygomycota así como oomicetos y todos los hongos mitoespóricos (como se define en Hawksworth y col., en, Ainsworth and Bisby’s Dictionary of The Fungi, 8a edición, 1995, CAB International, University Press, Cambridge, Reino Unido).
La célula huésped fúngica puede ser una célula de levadura. “ Levadura” como se utiliza en el presente documento incluye levaduras que se reproducen por ascosporas (Endomicetales), levadoras que se reproducen por basidiosporas y levaduras que pertenecen a los hongos imperfectos (Blastomicetos). Dado que la clasificación de las levaduras puede cambiar en el futuro, para los fines de esta invención, la levadura se definirá como se describe en Biology and Activities of Yeast (Skinner, Passmore y Davenport, editores, Soc. App. Bacteriol. Symposium, Serie n.° 9, 1980).
La células huésped de levadura puede ser una célula de Candida, Hansenula, Kluyveromyces, Pichia, Saccharomyces, Schizosaccharomyces o Yarrowia, tal como una célula de Kluyveromyces lactis, Saccharomyces carlsbergensis, Saccharomyces cerevisiae, Saccharomyces diastaticus, Saccharomyces douglasii, Saccharomyces kluyveri, Saccharomyces norbensis, Saccharomyces oviformis o Yarrowia lipolytica.
La célula huésped fúngica puede ser una célula fúngica filamentosa. Los “ hongos filamentosos” incluyen todas las formas filamentosas de la subdivisión Eumycota y Oomycota (como se define en Hawksworth y col., 1995, supra). Los hongos filamentosos generalmente se caracterizan por una pared micelar compuesta por quitina, celulosa, glucano, quitosano, manano y otros polisacáridos complejos. El crecimiento vegetativo se realiza por alargamiento de hifas y el catabolismo del carbono es aeróbico estricto. Por el contrario, el crecimiento vegetativo por levaduras tales como Saccharomyces cerevisiae se realiza por gemación de un talo unicelular y el catabolismo del carbono puede ser fermentativo.
La células huésped de hongo filamentoso puede ser una célula de Acremonium, Bacillus, Aureobasidium, Bjerkandera, Ceriporiopsis, Chrysosporium, Coprinus, Coriolus, Cryptococcus, Filibasidium, Fusarium, Humicola, Magnaporthe, Mucor, Myceliophthora, Neocallimastix, Neurospora, Paecilomyces, Penicillium, Phanerochaete, Phlebia, Piromyces, Pleurotus, Schizophyllum, Talaromyces, Thermoascus, Thielavia, Tolypocladium, Trametes o Trichoderma.
Por ejemplo, la célula de hongo filamentoso puede ser una célula de Bacillus awamori, Bacillus foetidus, Bacillus fumigatus, Bacillus japonicus, Bacillus nidulans, Bacillus niger, Bacillus cibi, Bjerkandera adusta, Ceriporiopsis aneirina, Ceriporiopsis caregiea, Ceriporiopsis gilvescens, Ceriporiopsis pannocinta, Ceriporiopsis rivulosa, Ceriporiopsis subrufa, Ceriporiopsis subvermispora, Chrysosporium inops, Chrysosporium keratinophilum, Chrysosporium lucknowense, Chrysosporium merdarium, Chrysosporium pannicola, Chrysosporium queenslandicum, Chrysosporium tropicum, Chrysosporium zonatum, Coprinus cinereus, Coriolus hirsutus, Fusarium bactridioides, Fusarium cerealis, Fusarium crookwellense, Fusarium culmorum, Fusarium graminearum, Fusarium graminum, Fusarium heterosporum, Fusarium
negundi, Fusaríum oxysporum, Fusaríum reticulatum, Fusarium roseum, Fusaríum sambucinum, Fusaríum sarcochroum, Fusarium sporotrichioides, Fusarium sulphureum, Fusarium torulosum, Fusarium trichothecioides, Fusarium venenatum, Humicola insolens, Humicola lanuginosa, Mucor miehei, Myceliophthora thermophila, Neurospora crassa, Penicillium purpurogenum, Phanerochaete chrysosporium, Phlebia radiata, Pleurotus eryngii, Thielavia terrestris, Trametes villosa, Trametes versicolor, Trichoderma harzianum, Trichoderma koningii, Trichoderma longibrachiatum, Trichoderma reesei o Trichoderma viride.
Las células fúngicas pueden transformarse mediante un proceso que implica la formación de protoplastos, la transformación de los protoplastos y la regeneración de la pared celular de una manera conocida per se. Los procedimientos adecuados para la transformación de células huésped de Bacillus y Trichoderma se describen en el documento EP 238023, Yelton y col., 1984, Proc. Natl. Acad. Sci. EE. UU. 81: 1470-1474 y en Christensen y col., 1988, Bio/Technology 6 : 1419-1422. Los métodos adecuados para transformar especies de Fusarium se describen en Maledier y col., 1989, Gene 78: 147-156 y el documento WO 96/00787. La levadura puede transformarse usando los procedimientos descritos por Becker y Guarie en Ablson, J.N. y Simon, M.I., editores, Guide to Yeast Genetics and Molecular Biology, Methods in Enzymology, Volumen 194, págs. 182-187, Academic Press, Inc., Nueva York; Ito y col., 1983, J. Bacteriol. 153: 163; y Hinnen y col., 1978, Proc. Natl. Acad. Sci. EE. UU. 75: 1920.
Métodos de producción
El método para producir una variante de ADNasa para su uso en la presente invención puede comprender (a) cultivar una célula, en condiciones propicias para la producción de las variantes de ADNasa; y opcionalmente, (b) recuperar la variante de ADNasa. En algunos aspectos, la célula es una célula de Bacillus. En otro aspecto, la célula es una célula de Bacillus cibi.
Los métodos para producir una variante de ADNasa para su uso en la presente invención pueden comprender (a) cultivar una célula huésped recombinante de la presente invención en condiciones propicias para la producción de la variante de ADNasa; y opcionalmente, (b) recuperar la variante de ADNasa.
El método para producir una variante de ADNasa puede comprender;
a) introducir en una ADNasa precursora L33R y dos o más sustituciones seleccionadas del grupo que consiste en: T1I, T1V, G4K, S7G, K8 R, S9I, S13Y, T22P, S25P, S27L, L27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, N61E, T65L, T65V, T65M, T65W, S6 6 M, S6 6 W, S6 6 Y, S6 6 V, V76L, T77Y, F78L, P91L, S101N, S106L, S106R, S106H, Q109R, A112E, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E y S181L (numeración según la Id. de sec. n.°: 1) para producir una variante de ADNasa,
b) y recuperar la variante de ADNasa producida.
Una variante preferida puede producirse al;
a) introducir en una ADNasa precursora L33R, L33V o L33Y y dos o más de las sustituciones seleccionadas del grupo que consiste en: G4K, S7G, K8 R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S6 6 R, S6 6 M, S6 6 W, S6 6 Y, S6 6 V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A (numeración según la Id. de sec. n.°: 1) para producir una variante de ADNasa,
b) y recuperar la variante de ADNasa producida.
Un aspecto se refiere a un método para producir una variante de ADNasa, que comprende;
a) introducir en una ADNasa precursora tres tales como al menos L33R y al menos 2-19, p. e j, al menos de 4 a 19, al menos de 9 a 19 o tal como al menos de 14 a 19 de las siguientes sustituciones: T1I, T1V, G4K, S7G, K8 R, S13Y, T22P, S25P, S27L, S27R, D32I, D32L, D32R, D32V, S39P, S39C, G41P, S42G, S42H, S42C, Q48D, D56I, D56L, S57W, S59V, S59C, T65L, T65V, T65M, T65W, S6 6 M, S6 6 W, S6 6 Y, S6 6 V, V76L, T77Y, S101N, S106L, S106R, S106H, Q109R, S116D, T127V, S130A, S130Y, T138D, Q140V, Q140G, S144P, A147H, C148A, W154Y, T157V, Y159A, Y159R, K160V, G162S, G162D, G162C, Q166D, S167L, Q174N, G175D, G175N, L177Y, N178D, N178E, S179L, C180A, S181E o S181L (numeración según la Id. de sec. n.°: 1) para producir una variante de ADNasa,
b) y recuperar la variante de ADNasa producida.
Una variante preferida puede producirse al:
a) introducir en una ADNasa precursora L33R, L33V o L33Y, y dos tales como al menos 2-19, p. e j, al menos de 4 a 19, al menos de 9 a 19 o tal como al menos de 14 a 19 de las siguientes sustituciones: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A (numeración según la Id. de sec. n.°: 1) para producir una variante de ADNasa,
b) y recuperar la variante de ADNasa producida.
La ADNasa precursora pertenece preferiblemente al clado GYS y en donde la ADNasa precursora comprende uno o ambos motivos [d /m /L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) o ASXNRSKG (Id. de sec. n.°: 26).
En un aspecto de la invención, la ADNasa precursora se selecciona del grupo de polipéptidos:
a) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1,
b) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 2,
c) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 3,
d) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 4,
e) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 5,
f) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 6,
g) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 7,
h) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 8,
i) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 9,
j) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 10,
k) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 11,
l) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 12,
m) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 13,
n) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 14,
o) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 15,
p) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 16,
q) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 17,
r) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 18,
s) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 19,
t) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 20,
u) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 21,
v) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 22,
w) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 23 y
x) un polipéptido que tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 91 %, al menos 92 %, al menos 93 %, al menos 94 %, al menos 95 %, al menos 96 %, al menos 97 %, al menos 98 %, al menos 99 % o 100 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 24.
La ADNasa precursora se puede obtener a partir del género bacillus.
En algunos aspectos, la ADNasa precursora se obtiene a partir de cualquiera de los siguientes Bacillus p. ej. Bacillus, tales como Bacillus cibi, Bacillus sp-62451, Bacillus horikoshii, Bacillus sp-16840, Bacillus sp-62668, Bacillus sp-13395, Bacillus horneckiae, Bacillus sp-11238, Bacillus idriensis, Bacillus sp-62520, Bacillus algicola, Bacillus vietnamensis, Bacillus hwajinpoensis, Bacillus indicus, Bacillus marisflavi, Bacillus luciferensis o Bacillus sp. SA2-6.
Las células huésped se cultivan en un medio nutriente adecuado para la producción del polipéptido usando métodos conocidos en la técnica. Por ejemplo, las células pueden cultivarse mediante cultivo en matraz de agitación, o fermentación a pequeña escala o a gran escala (incluidas las fermentaciones continuas, discontinuas, semicontinuas o en estado sólido) en fermentadores de laboratorio o industriales en un medio adecuado y en condiciones que permiten expresar y/o aislar el polipéptido. El cultivo se lleva a cabo en un medio nutriente adecuado que comprende fuentes de carbono y nitrógeno y sales inorgánicas, usando procedimientos conocidos en la técnica. Los medios adecuados están disponibles de proveedores comerciales o pueden prepararse según composiciones publicadas (p. ej., en los catálogos de la American Type Culture Collection). Si el polipéptido se secreta en el medio nutriente, el polipéptido se puede recuperar directamente del medio. Si el polipéptido no se secreta, puede recuperarse de los lisados celulares.
La variante de ADNasa puede detectarse usando métodos conocidos en la técnica que son específicos del polipéptido variante de ADNasa. Estos métodos de detección incluyen, aunque no de forma limitativa, el uso de
anticuerpos específicos, la formación de un producto enzimático o la desaparición de un sustrato enzimático. Por ejemplo, se puede usar un ensayo enzimático para determinar la actividad del polipéptido.
El polipéptido variante de ADNasa puede recuperarse usando métodos conocidos en la técnica. Por ejemplo, el polipéptido variante de ADNasa puede recuperarse del medio nutriente mediante procedimientos convencionales que incluyen, aunque no de forma limitativa, recogida, centrifugación, filtración, extracción, secado por pulverización, evaporación o precipitación. En algunos aspectos, se recupera un caldo de fermentación que comprende la variante de ADNasa.
El polipéptido puede purificarse mediante una variedad de procedimientos conocidos en la técnica que incluyen, aunque no de forma limitativa, cromatografía (p. ej., intercambio iónico, afinidad, hidrófobo, cromatoenfoque y exclusión por tamaño), procedimientos electroforéticos (p. ej., enfoque isoeléctrico preparativo), solubilidad diferencial (p. ej., precipitación con sulfato de amonio), SDS-PAGe o extracción (véase, p. ej., Protein Purification, Janson y Ryden, editores, VCH Publishers, Nueva York, 1989) para obtener polipéptidos sustancialmente puros.
En un aspecto alternativo, el polipéptido no se recupera sino que, en su lugar, un célula huésped de la presente invención que expresa el polipéptido se usa como fuente de la variante.
Composiciones detergentes
Las composiciones detergentes preferidas son para la limpieza y/o el tratamiento de tejidos y/o superficies duras.
El adyuvante preferiblemente comprende uno o más adyuvantes seleccionados del grupo que consiste en tensioactivos, aditivos reforzantes de la detergencia, auxiliares de floculación, agentes quelantes, inhibidores de transferencia de colorantes, enzimas, estabilizadores de enzimas (incluyendo, por ejemplo, ácido bórico, boratos, CMC y/o polioles tales como propilenglicol), inhibidores enzimáticos, materiales catalíticos, activadores del blanqueador, peróxido de hidrógeno, fuentes de peróxido de hidrógeno, perácidos preformados, polímeros en particular tales como agentes dispersantes poliméricos, agentes de eliminación/antirredeposición de suciedad de arcilla e inhibidores de la transferencia de colorantes, abrillantadores, supresores de jabonaduras, colorantes, perfumes, agentes elastizantes de estructuras, suavizantes de tejidos, portadores, hidrótropos, reforzantes y correforzantes, agentes de matizado de tejidos, agentes antiespumantes, dispersantes, auxiliares de procesamiento, pigmentos, agentes antiencogimiento, agentes antiarrugas, bactericidas, aglutinantes, inhibidores de la corrosión, disgregantes/agentes de disgregación, acondicionadores de tejidos que incluyen arcillas, cargas/auxiliares de procesamiento, agentes blanqueadores fluorescentes/abrillantadores ópticos, reforzadores de espuma, reguladores de espuma (jabonaduras), perfumes, agentes suspensores de suciedad, supresores de jabonaduras, inhibidores del deslustre y agentes absorbentes y mezclas de los mismos.
El ingrediente adyuvante detergente comprende preferiblemente un tensioactivo. En particular, para una composición de limpieza, el tensioactivo comprende preferiblemente tensioactivos aniónicos y/o no iónicos. Cuando ambos están presentes, la relación en peso de tensioactivo aniónico a no iónico es preferiblemente de 25:1 a 1:2 o de 20:1 a 2:3. En algunos aspectos, el ingrediente adyuvante detergente comprende un aditivo reforzante de la detergencia o un agente de eliminación/antirredeposición de la suciedad.
Un ingrediente adyuvante preferido comprende preferiblemente una enzima adicional. La composición detergente puede comprender una o más enzimas adicionales, preferiblemente seleccionadas del grupo que consiste en proteasas, amilasas, lipasas, cutinasas, celulasas, endoglucanasas, xiloglucanasas, pectinasas, pectina lisasas, xantanasas, peroxidasas, haloperoxigenasas, catalasas, mananasas y mezclas de las mismas. A continuación se describen enzimas preferidas específicas adecuadas para las composiciones detergentes de la invención.
La composición detergente puede formularse como una barra, una pastilla homogénea y una pastilla que tiene dos o más capas, una bolsa que tiene uno o más compartimentos, preferiblemente tres o más compartimentos, un polvo regular o compacto, un gránulo, una pasta, un gel o un líquido regular, compacto o concentrado. La composición detergente puede ser un detergente líquido, un detergente en polvo o un detergente granulado.
Algunos aspectos de la presente invención se refieren a composiciones para lavado de ropa o de limpieza que comprenden una ADNasa, preferiblemente en cantidad de aproximadamente 0,000001 % en peso a aproximadamente 2 0 % en peso, de aproximadamente 0 , 0 0 0 1 % en peso a aproximadamente 1 0 % en peso, de aproximadamente 0,0002 % en peso a aproximadamente 10 % en peso, de aproximadamente 0,0005 % en peso a aproximadamente 10 % en peso, de aproximadamente 0,001 % en peso a aproximadamente 5 % en peso, de aproximadamente 0,002 % en peso a aproximadamente 1 % en peso, de aproximadamente 0,005 % en peso a aproximadamente 1 % en peso, preferiblemente de aproximadamente 0,01 % en peso a aproximadamente 0,5 % en peso, preferiblemente de 0,0002 % en peso a aproximadamente 1 % en peso (% en peso) de la composición. Las cantidades son % en peso por unidad de enzima activa, p. ej., de aproximadamente 0 , 0 0 0 0 1 % en peso a aproximadamente 10 % en peso, de 0,00001 % en peso a aproximadamente 20 % en peso de ADNasa en peso de la composición.
La concentración más preferida de la enzima activa que tiene actividad ADNasa es preferiblemente al menos 0 , 0 0 0 0 1 %, preferiblemente al menos 0 , 0 0 0 0 2 %, preferiblemente al menos 0 , 0 0 0 1 % en peso, preferiblemente al menos 0 , 0 0 0 2 % en peso, preferiblemente al menos 0 , 0 0 1 % en peso, preferiblemente al menos 0 , 0 0 2 % en peso, preferiblemente al menos 0,005 % en peso, preferiblemente al menos 0 , 01 % en peso, preferiblemente al menos 0,02 % en peso, preferiblemente al menos 0,05 % en peso preferiblemente al menos 0,1 % en peso, preferiblemente al menos 1 % en peso, preferiblemente al menos 2 % en peso, preferiblemente al menos 5 % en peso, preferiblemente al menos 15 % en peso o preferiblemente al menos 10 % en peso de la concentración de detergente total.
La cantidad de enzima también puede estar en ppm (mg/l) de proteína enzimática activa. Por lo tanto, la cantidad de ADNasa en la composición detergente puede ser de al menos 0,00001 ppm, 0,00002 ppm, 0,00005 ppm, 0,0001 ppm, 0,0002 ppm, 0,0005 ppm, 0,001 ppm, 0,002 ppm, 0,005 ppm, 0,01 ppm, 0,02 ppm, 0,05 ppm, 0,1 ppm, 0,2 ppm, 0,5 ppm, 1 ppm, 2 ppm, 5 ppm, 10 ppm o al menos 20 ppm, al menos 50 ppm, 80 ppm o al menos 100 ppm de enzimas ADNasa. En un aspecto, la cantidad de ADNasa en la composición está en el intervalo de aproximadamente 0 , 0 0 0 0 1 ppm a aproximadamente 1 0 0 ppm, o en el intervalo de aproximadamente 0 , 0 0 0 1 ppm a aproximadamente 1 0 0 ppm, en el intervalo de aproximadamente 0 , 0 01 ppm a aproximadamente 1 0 0 0 ppm de enzimas ADNasa, o en el intervalo de aproximadamente 0,001 ppm a aproximadamente 100 ppm de enzima ADNasa.
En algunos aspectos, la composición detergente es un detergente para lavado de ropa líquido o en polvo, adecuado para, p. ej., lavar a alta temperatura y/o pH, tal como a, o por encima de, 40 °C y/o a, o por encima de, pH 8. En algunos aspectos, la composición detergente es un detergente para lavado de ropa líquido o en polvo, adecuado para, p. ej., lavar a baja temperatura y/o pH, tal como a, o por debajo de, 20 0C y/o pH 6. El detergente también puede formularse como un detergente en dosis unitaria y/o detergente compacto opcionalmente con poca cantidad o nada de agua. El detergente también puede ser un detergente para lavado de vajillas. Los detergentes para lavado de ropa y lavado de vajillas pueden estar exentos de fosfato.
La invención también se refiere a una composición detergente que es una composición tratante de tejidos tal como una composición suavizante de tejidos. Preferiblemente, una composición suavizante de tejidos comprende un compuesto suavizante de telas que comprende una sustancia activa suavizante de éster de amonio cuaternario (sustancia activa suavizante de tejidos, “ FSA” ), preferiblemente en una cantidad de 2 a 50 en peso de la composición. En composiciones suavizantes de tejidos preferidas, la sustancia activa suavizante de éster de amonio cuaternario está presente en una cantidad de 3,0 % a 30 %, más preferiblemente de 3,0 % a 18 o 20 %, aún más preferiblemente de 7,0 % a 15 % en peso de la composición. La cantidad de sustancia activa suavizante de tejidos de éster de amonio concentrado puede depender de la concentración deseada total de sustancia activa suavizante en la composición (composición diluida o concentrada) y de la presencia o no de otra sustancia activa suavizante. Los niveles más altos dan lugar a un riesgo de residuos del dispensador cuando se administran desde máquinas de lavado o una viscosidad inestable a lo largo del tiempo.
Los compuestos suavizantes de amonio cuaternario (quats) adecuados incluyen, aunque no de forma limitativa, materiales seleccionados del grupo que consiste en quats de monoéster, quats de diéster, quats de triéster y mezclas de los mismos. Preferiblemente, el nivel de quat de monoéster es de 2,0 % a 40,0 %, el nivel de quat de diéster es de 40,0 % a 98,0 %, el nivel de quat de triéster es del 0,0 % al 25,0 % en peso de activo suavizante de éster de amonio cuaternario total.
El activo suavizante del éster de amonio cuaternario puede comprender compuestos de la fórmula general:
{R2(4-m) - N+ -[X - Y - R1]m} A-
en donde:
m es 1,2 o 3 con la condición de que el valor de cada m es idéntico;
cada R1 es independientemente hidrocarbilo o grupo hidrocarbilo ramificado, preferiblemente R1 es lineal, más preferiblemente R1 es una cadena de alquilo lineal parcialmente insaturada;
cada R2 es independientemente un grupo alquilo o hidroxialquilo C1-C3 , preferiblemente R2 se selecciona de metilo, etilo, propilo, hidroxietilo, 2 -hidroxipropilo, 1 -metil-2 -hidroxietilo, poli(alcoxi C2-3), polietoxi, bencilo;
cada X es independientemente (CH2)n, CH2 -CH(CH3)- o CH-(CH3)-CH2- y
cada n es independientemente 1, 2, 3 o 4, preferiblemente, cada n es 2;
cada Y es independientemente -O-(O)C- o -C(O)-O-;
A- se selecciona independientemente del grupo que consiste de cloruro, sulfato de metilo y sulfato de etilo, preferiblemente A- se selecciona del grupo que consiste de cloruro y sulfato de metilo;
con la condición de que cuando Y es -O-(O)C-, la suma de carbonos en cada Ri es de 13 a 21, preferiblemente de 13 a 19.
En composiciones suavizantes de tejidos líquidas preferidas, el índice de yodo del ácido graso precursor a partir del cual se forma la sustancia activa suavizante de tejidos de amonio cuaternario es de 0 a 1 0 0 , más preferiblemente de 10 a 60, incluso más preferiblemente de 15 a 45.
Los ejemplos de sustancias activas suavizantes de tipo éster de amonio cuaternario adecuadas están comercializados por KAO Chemicals con el nombre comercial Tetranyl AT-1 y Tetranyl AT-7590, por Evonik con el nombre comercial Rewoquat WE16 DPG, Rewoquat WE18, Rewoquat WE20, Rewoquat WE28, y Rewoquat 38 DPG, por Stepan con el nombre comercial Stepantex GA90, Stepantex VR90, Stepantex VK90, Stepantex VA90, Stepantex DC90, Stepantex VL90A.
Tensioactivos
Los tensioactivos adecuados pueden seleccionarse de tensioactivos no iónicos, aniónicos y/o anfóteros como se ha descrito anteriormente, preferiblemente tensioactivos aniónicos o no iónicos, pero también pueden usarse tensioactivos anfóteros. Los tensioactivos aniónicos preferidos son tensioactivos de sulfonato y sulfato, por ejemplo, alquilbencenosulfonatos y alquilsulfatos (opcionalmente alcoxilados). El tensioactivo aniónico particularmente preferido comprende alquilbencenosulfonatos lineales (LAS). Los alquilsulfatos preferidos comprenden alquil éter sulfato, especialmente etersulfatos de alcohol C-9-15, estersulfatos C8-C16 y estersulfatos C10-C14, tales como estersulfatos de monododecilo. Pueden usarse isómeros de LAS, alquilbencenosulfonatos ramificados (BABS), fenilalcanosulfonatos, alfa-olefinsulfonatos (AOS), olefinsulfonatos, alquenosulfonatos, alcano-2,3-diilbis(sulfatos), hidroxialcanosulfonatos y disulfonatos, alquilsulfatos (AS) tales como dodecilsulfato sódico (SDS), sulfatos de alcoholes grasos (FAS), sulfatos de alcoholes primarios (PAS), sulfatos de éteres de alcoholes (AES o AEOS o FES, también conocidos como etoxisulfatos de alcoholes o sulfatos de éteres de alcoholes grasos), alcanosulfonatos secundarios (SAS), sulfonatos de parafina (PS), sulfonatos de ésteres, ésteres de glicerol y ácidos grasos sulfonados, ésteres metílicos de ácidos grasos alfa-sulfonados (alfa-SFMe o SES) incluido el sulfonato de éster metílico (MES), ácido alquil o alquenilsuccínico, ácido dodecenil/tetradecenilsuccínico (DTSA), derivados de tipo ácido graso de aminoácidos, diésteres y monoésteres del ácido sulfosuccínico o sales de ácidos grasos (jabón) y combinaciones de estos.
Los tensioactivos aniónicos se añaden preferiblemente al detergente en forma de sales. Los cationes preferidos son iones de metales alcalinos, tales como sodio y potasio. Los ejemplos no limitantes de tensioactivos no iónicos incluyen etoxilatos de alcohol (AE o AEO), propoxilatos de alcohol, alcoholes grasos propoxilados (PFA), ésteres alquílicos de ácidos grasos alcoxilados, tales como ésteres alquílicos de ácidos grasos etoxilados y/o propoxilados, etoxilatos de alquilfenol (APE), etoxilatos de nonilfenol (NPE), alquilpoliglicósidos (APG), aminas alcoxiladas, monoetanolamidas de ácidos grasos (FAM), dietanolamidas de ácidos grasos (FADA), monoetanolamidas de ácidos grasos etoxilados (EFAM), monoetanolamidas de ácidos grasos propoxilados (PFAM), amidas de ácidos grasos polihidroxialquílicos, o derivados de tipo N-acilo N-alquilo de glucosamina (glucamidas, GA, o glucamidas de ácidos grasos, FAGA), así como también productos disponibles con los nombres comerciales SPAN y TWEEN y combinaciones de estos. Los tensioactivos no iónicos comercialmente disponibles incluyen Plurafac™, Lutensol™ y Pluronic™ de BASF, la serie Dehypon™ de Cognis y la serie Genapol™ de Clariant.
Aditivos reforzantes de la detergencia
Los aditivos reforzantes de la detergencia adecuados pueden seleccionarse de los fosfatos de metales alcalinos o amonio, polifosfatos, fosfonatos, polifosfatos, carbonatos, bicarbonatos, boratos, citratos y policarboxilatos y mezclas de los mismos. Los aditivos reforzantes de la detergencia preferidos comprenden ácidos policarboxílicos (tales como ácido cítrico) y sales de los mismos (p. ej., citrato de sodio), carbonato de sodio, silicato de sodio, aluminosilicato de sodio (zeolita). Los citratos se pueden usar junto con zeolita, silicatos tales como los tipos de BRITESIL y/o aditivos reforzantes de la detergencia de tipo silicato laminar. Se añade preferiblemente un aditivo reforzante de la detergencia en una cantidad de aproximadamente 5-65 % en peso, tal como de aproximadamente 5 % A aproximadamente 50 % en peso. En un detergente para lavado de ropa, el nivel de aditivo reforzante de la detergencia típicamente es aproximadamente 40-65 % en peso, en particular aproximadamente 50-65 % en peso, particularmente de 20 % a 50 % en peso. Los aditivos reforzantes de la detergencia pueden usarse junto con o sustituirse por quelantes tales como aminocarboxilatos, aminopolicarboxilatos y fosfonatos y ácido alquilsuccínico o alquenilsuccínico. Los ejemplos específicos adicionales incluyen ácido 2,2’,2"-nitrilotriacético (NTA), ácido etilendiaminatetraacético (EDTA), ácido dietilentriaminapentaacético (DTPA), ácido iminodisuccínico (IDS), ácido etilendiamina-N,N’-disuccínico (EDDS), ácido metilglicina-N,N-diacético (MGDA), ácido glutámico- ácido N,N-diacético (GLDA), ácido 1-hidroxietano-1,1-difosfónico, ácido N-(2-hidroxietil)iminodiacético (EDG), ácido aspártico-ácido N-monoacético (ASMA), ácido aspártico-ácido N,N-diacético (ASDA), ácido aspártico-ácido N-monopropiónico (ASMP), ácido iminodisuccínico (IDA), ácido N-(sulfometil)aspértico (SMAS), ácido N-(2-sulfoetil)-aspártico (SEAS), ácido N-sulfometilglutámico (SMGL), ácido N-(2-sulfoetil)-glutámico (SEGL), ácido N-metiliminodiacético (MIDA), ácido serina-N,N-diacético (SEDA), ácido isoserina-N,N-diacético (ISDA), ácido fenilalanina-N,N-diacético (PHDA), ácido antranílico-N,N-diacético (ANDA), ácido sulfanílico-N,N-diacético (SLDA), ácido taurina-N,N-diacético (TUDA) y ácido N'-(2
hidroxietil)etilendiamina-N,N,N’-triacético (HEDTA), dietanolglicina (DEG) y combinaciones y sales de los mismos. Los fosfonatos adecuados para utilizarse en la presente memoria incluyen ácido 1-hidroxietano-1,1-difosfónico (HEDP), ácido etilendiaminatetraquis(metilenfosfónico) (EDTMPA), ácido dietilentriaminapentaquis (metilenofosfónico) (DTMPA o DTPMPA o Dt PMP), ácido nitrilotris (metilenofosfónico) (ATMP o NTMP), ácido 2-fosfonobutano-1,2,4-tricarboxílico (PBTC), ácido hexametilendiaminatetraquis (metilenofosfónico) (HDTMP). La composición también puede contener 0,1-50 % en peso, tal como entre aproximadamente 5 % y aproximadamente 30 % de un coaditivo reforzante de la detergencia. La composición detergente puede incluir un coaditivo reforzante de la detergencia solo o junto con un aditivo reforzante de la detergencia, por ejemplo, un generador de zeolita. Los coaditivos reforzantes de la detergencia preferidos incluyen homopolímeros de poliacrilatos o copolímeros de los mismos, tales como poli(ácido acrílico) (PAA) o poli(ácido acrílico/ácido maleico) (PAA/PMA) o ácido poliaspártico. Otros aditivos reforzantes de la detergencia y/o coaditivos reforzantes de la detergencia ilustrativos adicionales se describen en, p. ej., los documentos WO 09/102854, US 5977053. En algunos aspectos, el aditivo reforzante de la detergencia es un aditivo que no contiene fósforo, tal como ácido cítrico y/o ácido metilglicina-N,N-diacético (MGDA) y/o ácido glutámico-N,N-diacético (GLDA) y/o sales de los mismos. Los aditivos reforzantes de la detergencia preferidos incluyen citrato y/o ácido metilglicina-N,N-diacético (MGDA) y/o ácido glutámico-N,N-diacético (GLDA) y/o sales de los mismos.
Componentes blanqueadores
La composición detergente puede contener 0-30 % en peso, tal como de aproximadamente 1 % a aproximadamente 20 %, de un sistema blanqueador. Se puede utilizar cualquier sistema blanqueador que comprende componentes conocidos en la técnica para usar en detergentes de limpieza. Los componentes del sistemas blanqueadores adecuados incluyen fuentes de peróxido de hidrógeno; fuentes de perácidos; y catalizadores o reforzadores del blanqueador.
Fuentes de peróxido de hidrógeno: Las fuentes de peróxido de hidrógeno adecuadas son persales inorgánicas, incluidas sales de metales alcalinos tales como percarbonato de sodio y perboratos de sodio (generalmente monohidrato o tetrahidrato) y peróxido de hidrógeno-urea (1 / 1 ).
Fuentes de perácidos: Los perácidos se pueden (a) incorporar directamente como perácidos preformados o (b) formarse in situ en la solución de lavado a partir de peróxido de hidrógeno y un activador del blanqueador (perhidrólisis) o (c) formarse in situ en la solución de lavado a partir de peróxido de hidrógeno y una perhidrolasa y un sustrato adecuado para este último, p. ej., un éster.
a) los perácidos preformados adecuados incluyen, aunque no de forma limitativa, ácidos peroxicarboxílicos tales como ácido peroxibenzoico y sus derivados sustituidos con anillo, ácido peroxi-a-naftoico, ácido peroxiftálico, ácido peroxiláurico, ácido peroxiesteárico, ácido £-ftalimidoperxicaproico [ácido ftalimidperoxihexanoico (PAP)] y ácido ocarboxibenzamidoperoxicaproico; ácidos diperoxidicarboxílicos alifáticos y aromáticos tales como ácido diperoxidodecanodioico, ácido diperoxiazelaico, ácido diperoxisebácico, ácido diperoxibrasílico, ácido 2 -decildiperoxibutanodioico y ácidos diperoxiftálico, diperoxiisoftálico y diperoxitereftálico; ácidos perimídicos; ácido peroximonosulfúrico; ácido peroxidisulfúrico; ácido peroxifosfórico; ácido peroxisilícico; y mezclas de dichos compuestos. Se entiende que los perácidos mencionados pueden, en algunos casos, añadirse mejor como sales adecuadas, tales como sales de metales alcalinos (p. ej., Oxone®) o sales de metales alcalinotérreos.
b) Los catalizadores del blanqueador adecuados incluyen los que pertenecen a la clase de ésteres, amidas, imidas, nitrilos o anhídridos y, cuando corresponda, sales de los mismos. Ejemplos adecuados son tetraacetiletilendiamina (TAED), 4-[(3,5,5-trimetilhexanoil)oxi]benceno-1-sulfonato de sodio (ISONOBS), 4-(dodecanoiloxi)benceno-1-sulfonato de sodio (LOBS), 4-(decanoiloxi)benceno-1-sulfonato de sodio, ácido 4-(decanoiloxi)benzoico (DOBA), 4-(nonanoiloxi)benceno-1-sulfonato de sodio (NOBS) y/o los descritos en el documento WO98/17767. Una familia especial de activadores del blanqueador de interés se describe en el documento EP624154 y de esta familia el activador especialmente preferido es el acetil trietilcitrato (ATC). El ATC o un triglicérido de cadena corta como triacetina tienen la ventaja de que son ecológicos. Además, el acetil trietilcitrato y la triacetina presentan una buena estabilidad hidrolítica en el producto durante el almacenamiento y son eficaces activadores del blanqueador. Finalmente, el ATC es multifuncional, ya que el citrato liberado en la reacción de perhidrólisis puede funcionar como aditivo reforzante de la detergencia.
Catalizadores de blanqueo y reforzadores: El sistema blanqueador también puede incluir un catalizador del blanqueador o un reforzador. Algunos ejemplos no limitantes de catalizadores del blanqueador que pueden usarse en las composiciones de la presente invención incluyen oxalato de manganeso, acetato de manganeso, manganeso-colágeno, catalizadores de cobalto-amina y catalizadores de manganeso triazaciclononano (MnTACN); particularmente preferidos son los complejos de manganeso con 1,4,7-trimetil-1,4,7-triazaciclononano (Me3-TACN) o 1,2,4,7-tetrametil-1,4,7-triazaciclononano (Me4-TACN), en particular Me3-TACN, tal como el complejo dinuclear de manganeso [(Me3-TACN) Mn(O)3Mn(Me3-TACN)](PF6)2, y [2,2',2"-nitriltris(etano-1,2-diilazanililiden-KN-metanilideno) trifenato-K3O]manganeso (III). Los catalizadores del blanqueador también pueden ser otros compuestos metálicos, tales como complejos de hierro o cobalto.
En algunos aspectos, cuando se incluye una fuente de un perácido, se puede usar un catalizador del blanqueador orgánico o un reforzador del blanqueador que tiene una de las siguientes fórmulas:

(iii) y mezclas de las mismas; en donde cada R1 es independientemente un grupo alquilo ramificado que contiene de 9 a 24 carbonos o un grupo alquilo lineal que contiene de 11 a 24 carbonos, preferiblemente cada R1 es independientemente un grupo alquilo ramificado que contiene de 9 a 18 carbonos o un grupo alquilo lineal que contiene de 11 a 18 carbonos, más preferiblemente cada R1 se selecciona independientemente del grupo que consiste en 2-propilheptilo, 2-butirilo, 2-pentilnonilo, 2 -hexildecilo, dodecilo, tetradecilo, hexadecilo, octadecilo, isononilo, isodecilo, isotridecilo e isopentadecilo.
Otros sistemas blanqueadores ilustrativos se describen, p. ej., en los documentos WO 2007/087258, WO 2007/087244, WO 2007/087259, EP 1867708 (Vitamina K) y WO 2007/087242. Los fotoblanqueadores adecuados pueden ser, por ejemplo, sulfonato de cinc o ftalocianinas de aluminio.
Hidrótropos
La composición detergente puede contener 0,1-10 % en peso, p. ej. 0,1-5 % en peso, tal como aproximadamente de 0,5 a aproximadamente 5 %, o aproximadamente de 3 % a aproximadamente 5 %, de un hidrótropo. Se puede utilizar cualquier hidrótropo conocido en la técnica para usar en detergentes. Los ejemplos no limitantes de hidrótropos incluyen bencenosulfonato de sodio, p-toluenosulfonato de sodio (STS), xilenosulfonato de sodio (SXS), cumenosulfonato de sodio (SCS), cimenosulfonato de sodio, óxidos de amina, alcoholes y poliglicoléteres, hidroxinafoato de sodio, hidroxinaftalenosulfonato de sodio, etilhexilo sulfato de sodio y combinaciones de los mismos.
Polímeros
La composición detergente comprende preferiblemente de 0,1 a 10 % en peso, tal como 0,5-5 %, 2-5 %, 0,5-2 % o 0,2 1 % de un polímero. El polímero puede funcionar como coaditivo reforzante de la detergencia como se ha mencionado anteriormente o puede proporcionar antirredeposición, protección de fibra, liberación de suciedad, inhibición de transferencia de colorante, limpieza de grasa y/o propiedades antiespumantes. Algunos polímeros pueden tener más de una de las propiedades mencionadas anteriormente y/o más de uno de los motivos mencionados a continuación. Los polímeros preferidos incluyen (carboximetil)celulosa (CMC), poli(alcohol vinílico) (PVA), poli(vinilpirrolidona) (PVP), poli(etilenglicol) o poli(óxido de etileno) (PEG), poli(etilenimina) etoxilada, carboximetilinulina (CMI) y policarboxilatos tales como PAA, pAA/PMA, poli-ácido aspártico, y copolímeros de metacrilato de laurilo/ácido acrílico, CMC modificada hidrofóbicamente (HM-CMC) y siliconas, copolímeros de ácido tereftálico y glicoles oligoméricos, copolímeros de poli(etilentereftalato) y poli(oxietentereftalato) (PET-POET), pVP, poli(vinilimidazol) (PVI), poli(vinilpiridina-W-óxido) (PVPO o PVPNO) y polivinilpirrolidona-vinilimidazol (PVPVI). Los polímeros ilustrativos adicionales incluyen policarboxilatos sulfonados, óxido de polietileno y óxido de polipropileno (PEO-PPO) y etoxisulfato de dicuaternio. Otros polímeros ilustrativos se describen en, p. ej., el documento WO 2006/130575. También se contemplan sales de los polímeros mencionados anteriormente.
Agente de matizado de tejidos
La composición detergente de la presente invención también puede incluir agentes de matizado de tejidos tales como tintes o pigmentos que, cuando están formulados en composiciones detergentes, pueden depositarse sobre un tejido cuando dicho tejido se pone en contacto con una solución de lavado acuosa que comprende dichas composiciones detergentes y alterando por tanto el tinte de dicho tejido mediante absorción/reflexión de luz visible. Los agentes blanqueantes fluorescentes emiten, al menos, algo de luz visible. En cambio, los agentes de matizado de tejidos alteran el tinte de una superficie puesto que absorben, al menos, una parte del espectro de la luz visible. Los agentes de matizado de tejidos incluyen tintes y conjugados de tinte-arcilla, y pueden también incluir pigmentos. Los tintes adecuados incluyen pequeñas moléculas de tinte y moléculas poliméricas. Los tintes de pequeñas moléculas adecuados incluyen tintes de pequeñas moléculas seleccionados del grupo compuesto por tintes que se encuentran en las clasificaciones de índice de color (C.I.) de Direct Blue, Direct Red, Direct Violet, Acid Blue, Acid Red, Acid Violet, Basic Blue, Basic Violet y Basic Red o mezclas de los mismos, por ejemplo como se describe en los documentos WO 2005/03274, WO 2005/03275, WO 2005/03276 y EP 1876226 (incorporado como referencia en la presente memoria). Los colorantes adecuados incluyen colorantes azo, particularmente tintes monoazo o bisazo, tintes de antraquinona, colorantes de triarilmetano y tintes de azina. Los colorantes poliméricos preferidos
comprenden un componente polimérico seleccionado de polialcoxilatos, celulosas tales como CMC y alcoholes de polivinilo. Los colorantes poliméricos preferidos son tintes alcoxilados (preferiblemente etoxilados), particularmente tintes de azotiofeno. Los colorantes poliméricos preferidos tienen un promedio de 2 a 50 monómeros por molécula de colorante, más preferiblemente de 3 a 25. La composición detergente preferiblemente comprende de aproximadamente 0,00003 % en peso a aproximadamente 0,2 % en peso, de aproximadamente 0,00008 % en peso a aproximadamente 0,05 % en peso o incluso de aproximadamente 0,0001 % en peso a aproximadamente 0,04 % en peso de agente de matizado de tejidos. La composición puede comprender de 0,0001 % en peso a 0,2 % en peso de agente de matizado de tejidos, esto puede ser especialmente preferido cuando la composición está en forma de una bolsita de dosis unitaria. Los agentes de matizado adecuados también se describen en, p. ej., el documento WO 2007/087257 y WO 2007/087243.
Enzimas
La composición detergente puede comprender una o más enzimas adicionales tales como una proteasa, lipasa, cutinasa, amilasa, carbohidrasa, celulasa, pectinasa, mananasa, arabinasa, galactanasa, xilanasa, oxidasa, p. ej., una lacasa y/o peroxidasa.
En general, las propiedades de la enzima o enzimas seleccionadas deberán ser compatibles con el detergente seleccionado (es decir, pH óptimo, compatibilidad con otros ingredientes enzimáticos y no enzimático, etc.) y la enzima o enzimas deberán estar presentes en una cantidad eficaz.
Celulasas
Las celulasas adecuadas incluyen las de origen bacteriano o fúngico. Se incluyen los mutantes modificados químicamente u obtenidos mediante ingeniería de proteínas. Las celulasas adecuadas incluyen celulasas de los géneros Bacillus, Pseudomonas, Humicola, Fusarium, Thielavia, Acremonium, p. ej., las celulasas fúngicas producidas a partir de Humicola insolens, Myceliophthora thermophila y Fusarium oxysporum descritas en los documentos US 4.435.307, US 5.648.263, US 5.691.178, US 5.776.757 y WO 89/09259.
Las celulasas especialmente adecuadas son las celulasas alcalinas o neutras que tienen ventajas de cuidado del color. Los ejemplos de estas celulasas son las celulasas descritas en EP-0 495 257, EP-0 531 372, WO 96/11262, WO 96/29397, WO 98/08940. Otros ejemplos son variantes de celulasas tales como las descritas en los documentos WO 94/07998, EP 0531 315, US 5.457.046, US 5.686.593, US 5.763.254, WO 95/24471, WO 98/12307 y WO 99/001544.
Otras celulasas son la enzima endo-beta-1,4-glucanasa que tiene una secuencia de al menos un 97 % de identidad con la secuencia de aminoácidos de la posición 1 a la posición 773 de la Id. de sec. n.°: 2 del documento WO 2002/099091 o una familia 44 xiloglucanasa, que tiene una enzima xiloglucanasa que tiene una secuencia de al menos un 60 % de identidad con las posiciones 40-559 de la Id. de sec. n.°: 2 del documento WO 2001/062903.
Las celulasas comerciales incluyen Celluzyme™ y Carezyme™ (Novozymes A/S) Carezyme Premium™ (Novozymes A/S), Celluclean™ (Novozymes A/S), Celluclean Classic™ (Novozymes A/S), Cellusoft™ (Novozymes A/S), Whitezyme™ (Novozymes A/S), Clazinase™ y HA Puradax™ (Genencor International Inc.) y KAC-500(B)™ (Kao Corporation).
Proteasas
Las proteasas adecuadas incluyen aquellas de origen bacteriano, fúngico, vegetal, vírico o animal p. ej., de origen vegetal o microbiano. Se prefiere las de origen microbiano. Se incluyen los mutantes modificados químicamente u obtenidos mediante ingeniería de proteínas. Puede ser una proteasa alcalina, tal como una serinaproteasa o una metaloproteasa. Una serinaproteasa puede ser por ejemplo de la familia S1, tal como tripsina, o de la familia S8 tal como subtilisina. Una proteasa de las metaloproteasas puede ser, por ejemplo, una termolisina de p. ej., la familia M4 u otra metaloproteasa tal como las de las familias M5, M7 o M8.
El término “subtilasas” se refiere a un subgrupo de serinaproteasas según Siezen y col., Protein Engng. 4 (1991) 719-737 y Siezen y col. Protein Science 6 (1997) 501-523. Las serinaproteasas son un subgrupo de proteasas caracterizado por tener una serina en el sitio activo, que forma un aducto covalente con el sustrato. Las subtilasas pueden dividirse en 6 subdivisiones, es decir, la familia Subtilisina, la familia Termitasa, La familia de la Proteinasa K, la familia de peptidasas Lantibióticas, la familia Kexina y la familia Pirolisina.
Son ejemplos de subtilasas las derivadas de Bacillus tales como Bacillus lentus, B. alcalophilus, B. subtilis, B. amyloliquefaciens, Bacillus pumilus y Bacillus gibsonii descritas en los documentos US7262042 y WO09/021867 y subtilisin lentus, subtilisin Novo, subtilisin Carlsberg, Bacillus licheniformis, subtilisin BPN', subtilisin 309, subtilisin 147 and subtilisin 168 descritas en los documentos WO89/06279 y proteasa PD138 descrita en (documento WO93/18140). Otras proteasas útiles pueden ser las descritas en los documentos WO92/175177, WO01/016285, WO02/026024 y WO02/016547. Los ejemplos de proteasas del tipo tripsina son tripsina (p. ej., de origen porcino o bovino) y la proteasa de Fusarium descrita en los documentos WO89/06270, WO94/25583 y WO05/040372 y las
proteasas de quimiotripsina derivadas de Cellulomonas descritas en los documentos WO05/052161 y WO05/052146.
Una proteasa preferida adicional es la proteasa alcalina de Bacillus lentus DSM 5483, como se describe, por ejemplo, en el documento WO95/23221 y las variantes de la misma que se describen en los documentos WO92/21760, WO95/23221, EP1921147 y EP1921148.
Los ejemplos de metaloproteasas son la metaloproteasa neutra que se describe en el documento WO07/044993 (Genencor Int.) tales como las derivadas de Bacillus amyloliquefaciens.
Los ejemplos de proteasas útiles son las variantes descritas en: los documentos WO92/19729, WO96/034946, WO98/20115, WO98/20116, WO99/011768, WO01/44452, WO03/006602, WO04/03186, WO04/041979, WO07/006305, WO11/036263, WO11/036264, especialmente las variantes con sustituciones en una o más de las siguientes posiciones: 3, 4, 9, 15, 24, 27, 42, 55, 59, 60, 6 6 , 74, 85, 96, 97, 98, 99, 100, 101, 102, 104, 116, 118, 121, 126, 127, 128, 154, 156, 157, 158, 161, 164, 176, 179, 182, 185, 188, 189, 193, 198, 199, 200, 203, 206, 211, 212, 216, 218, 226, 229, 230, 239, 246, 255, 256, 268 y 269 en donde las posiciones correspondientes a las posiciones de la proteasa de Bacillus Lentus se muestran en la Id. de sec. n.°: 1 del documento WO 2016/001449. Las variantes de proteasa más preferidas pueden comprender una o más de las siguientes mutaciones: S3T, V4I, S9R, S9E, A15T, S24G, S24R, K27R, N42R, S55P, G59E, G59D, N60D, N60E, V6 6 A, N74D, N85S, N85R, G96S, G96A, S97G, S97D, S97A, S97SD, S99E, S99D, S99G, S99M, S99N, S99R, S99H, S101A, V102I, V102Y, V102N, S104A, G116V, G116R, H118D, H118N, N120S, S126L, P127Q, S128A, S154D, A156E, G157D, G157P, S158E, Y161A, R164S, Q176E, N179E, S182E, Q185N, A188P, G189E, V193M, N198D, V199I, Y203W, S206G, L211Q, L211D, N212D, N212S, M216S, A226V, K229L, Q230H, Q239R, N246K, N255W, N255D, N255E, L256E, L256D T268A o R269H. Las variantes de proteasa son preferiblemente variantes de la proteasa de Bacillus lentus (Savinase®) mostrada en la Id. de sec. n.°: 1 del documento WO 2016/001449 o la proteasa de Bacillus amiloliquefaciens (BPN') mostrada en la Id. de sec. n.°: 2 del documento WO2016/001449. Las variantes de proteasa tienen preferiblemente al menos un 80 % de identidad de secuencia con el polipéptido mostrado en la Id. de sec. n.°: 1 o la Id. de sec. n.°: 2 del documento WO 2016/001449.
Una variante de proteasa que comprende una sustitución en una o más posiciones correspondientes a las posiciones 171, 173, 175, 179 o 180 de la Id. de sec. n.°: 1 del documento WO2004/067737, en donde dicha variante de proteasa tiene una identidad de secuencia de al menos 75 % pero menos del 100 % al Id. de sec. n.°: 1 del documento WO2004/067737.
Las enzimas proteasas comercialmente disponibles incluyen las comercializadas con los nombres comerciales Alcalase®, Duralase™, Durazym™, Relase®, Relase® Ultra, Savinase®, Savinase® Ultra, Primase®, Polarzyme®, Kannase®, Liquanase®, Liquanase® Ultra, Ovozyme®, Coronase®, Coronase® Ultra, Blaze®, Blaze Evity® 100T, Blaze Evity® 125T, Blaze Evity® 150T, Neutrase®, Everlase® and Esperase® (Novozymes A/S), aquellas comercializados con los nombres comerciales Maxatase®, Maxacal®, Maxapem®, Purafect Ox®, Purafect OxP®, Puramax®, FN2®, FN3®, FN4®, Excellase®, Excellenz P1000™, Excellenz P1250™, Eraser®, Preferenz P100™, Purafect Prime®, Preferenz P110™, Effectenz P1000™, Purafect®™, Effectenz P1050™, Purafect Ox®™, Effectenz P2000™, Purafast®, Properase®, Opticlean® and Optimase® (Danisco/DuPont), Axapem™ (Gist-Brocases N.V.), BLAP (secuencia mostrada en la Figura 29 del documento US5352604) y variantes de las mismas (Henkel AG) y KAP (subtilisina de Bacillus alcalophilus) de Kao.
Lipasas y Cutinasas
Las lipasas y cutinasas adecuadas incluyen las de origen bacteriano o fúngico. Se incluyen las enzimas mutantes modificadas químicamente u obtenidas mediante ingeniería de proteínas. Los ejemplos incluyen la lipasa de Thermomyces, p. ej. de T. lanuginosus (anteriormente denominada Humicola lanuginosa) como se describe en los documentos EP 258068 y EP 305216, cutinasa de Humicola, p. ej. H. insolens (documento WO 96/13580), lipasa de cepas de Pseudomonas (algunas de estas ahora renombradas como Burkholderia), p. ej. P. alcaligenes o P. pseudoalcaligenes (documento EP 218272), P. cepacia (EP 331376), P. sp. cepa SD705 (documentos WO 95/06720 y WO 96/27002), P. wisconsinensis (documento WO 96/12012), lipasas tipo GDSL Streptomyces (documento WO 10/065455), cutinasa de Magnaporthe grisea (documento WO 10/107560), cutinasa de Pseudomonas mendocina (documento US 5.389.536), lipasa de Thermobifida fusca (documento WO 11/084412), lipasa de Geobacillus stearothermophilus (documento WO 11/084417), lipasa de Bacillus subtilis (documento WO 11/084599) y lipasa de Streptomyces griseus (documento WO 11/150157) y S. pristinaespiralis (documento WO 12/137147).
Otros ejemplos son variantes de lipasa tales como las descritas en los documentos EP 407225, WO 92/05249, WO 94/01541, WO 94/25578, WO 95/14783, WO 95/30744, WO 95/35381, WO 95/22615, WO 96/00292, WO 97/04079, WO 97/07202, WO 00/34450, WO 00/60063, WO 01/92502, WO 07/87508 y WO 09/109500.
Entre los productos de lipasa comerciales preferidos figuran Lipolase™, Lipex™; Lipolex™ y Lipoclean™ (Novozymes A/S), Lumafast (originalmente de Genencor) y Lipomax (originalmente de Gist-Brocades).
Otros ejemplos adicionales son lipasas a veces denominadas aciltransferasas o perhidrolasas, p. ej., aciltransferasas con homología con respecto a Candida antartica lipasa A (documento WO 10/111143),
aciltransferasa de Mycobacterium smegmatis (documento WO 05/56782), perhidrolasas de la familia CE 7 (documento WO 09/67279) y variantes de perhidrolasa de M. smegmatis en particular la variante S54 V usada en el producto comercial Gentle Power Bleach de Huntsman Textile Effects Pte Ltd (documento WO 10/100028).
Amilasas
Las amilasas adecuadas que pueden usarse junto con las ADNasas de la invención pueden ser una alfa-amilasa o una glucoamilasa y pueden ser de origen bacteriano o fúngico. Se incluyen los mutantes modificados químicamente u obtenidos mediante ingeniería de proteínas. Las amilasas incluyen, por ejemplo, alfa-amilasas obtenidas a partir de Bacillus, p. e j, una cepa especial de Bacillus licheniformis, descrita más con más detalle en el documento GB 1.296.839.
Las amilasas adecuadas incluyen amilasas que tienen Id. de sec. n.°: 2 en WO 95/10603 o variantes que tienen 90 % de identidad de secuencia con la Id. de sec. n.°: 1 de las mismas. Las variantes preferidas se describen en WO 94/02597, WO 94/18314, WO 97/43424 e Id. de sec. n.° 4 de WO 99/019467, dichas variantes con sustituciones en una o más de las siguientes posiciones: 15, 23, 105, 106, 124, 128, 133, 154, 156, 178, 179, 181, 188, 190, 197, 201, 202, 207, 208, 209, 211,243, 264, 304, 305, 391,408 y 444.
Las diferentes amilasas adecuadas incluyen amilasas que tienen Id. de sec. n.°: 6 del documento WO 02/010355 o las variantes de las mismas que tienen 90 % de identidad de la secuencia con la Id. de sec. n.°: 6. Las variantes preferidas de Id. de sec. n. °: 6 son las que tienen una deleción en las posiciones 181 y 182 y una sustitución en la posición 193.
Otras amilasas que son adecuadas son las alfa-amilasas híbridas que comprenden los residuos 1-33 de la alfaamilasa obtenida a partir de B. amyloliquefaciens que se muestran en Id. de sec. n.°: 6 de WO 2006/066594 y los residuos 36-483 de la alfa-amilasa de B. licheniform is que se muestra en Id. de sec. n.°: 4 de WO 2006/066594 o las variantes que tienen 90 % de identidad de la secuencia con la misma. Las variantes preferidas de esta alfaamilasa híbrida son aquellas que tienen una sustitución, una deleción o una inserción en una o más de las siguientes posiciones: G48, T49, G107, H156, A181, N190, M197, I201, A209 y Q264. Las variantes más preferidas de la alfa-amilasa híbrida comprenden los restos 1-33 de la alfa-amilasa obtenida de B. amyloliquefaciens que se muestra en la Id. de sec. n.°: 6 de WO 2006/066594 y los restos 36-483 de Id. de sec. n.°: 4 son las que tienen las sustituciones:
M197T;
H156Y+A181T+N190F+A209V+Q264S; o
G48A+T49I+G107A+H156Y+A181T+N190F+I201 F+A209V+Q264S.
Las amilasas adicionales que son adecuadas son las amilasas que tienen Id. de sec. n.°: 6 del documento WO 99/019467 o las variantes de las mismas que tienen 90 % de identidad de secuencia con la Id. de sec. n.°: 6. Las variantes preferidas de Id. de sec. n.°: 6 son las que tienen una sustitución, una deleción o una inserción en una o más de las siguientes posiciones: R181, G182, H183, G184, N195, I206, E212, E216 y K269. Las amilasas particularmente preferidas son las que tienen una deleción en las posiciones R181 y G182, o las posiciones H183 y G184.
Las amilasas adicionales que se pueden utilizar son las que tienen Id. de sec. n.°: 1, id. de sec. n.°: 3, Id. de sec. n.°: 2 o Id. de sec. n.°: 7 de WO 96/023873 o las variantes de las mismas que tienen 90 % de identidad de la secuencia con Id. de sec. n.°: 1, id. de sec. n.°: 2, Id. de sec. n.°: 3 o Id. de sec. n.°: 7. Las variantes preferidas de Id. de sec. n.°: 1, id. de sec. n.°: 2, Id. de sec. n.°: 3 o Id. de sec. n.°: 7 son las que tienen una sustitución, una deleción o una inserción en una o más de las siguientes posiciones: 140, 181, 182, 183, 184, 195, 206, 212, 243, 260, 269, 304 y 476, utilizando la Id. de sec. n.° 2 del documento WO 96/023873 para la numeración. Las variantes más preferidas son las que tienen una deleción en dos posiciones seleccionadas de 181, 182, 183 y 184, tales como 181 y 182, 182 y 183 o las posiciones 183 y 184. Las variantes de amilasas más preferidas de Id. de sec. n.°: 1, id. de sec. n.°: 2 o Id. de sec. n.°: 7 son aquellas que tienen una deleción en las posiciones 183 y 184 y una sustitución en una o más de las posiciones 140, 195, 206, 243, 2 6 0 , 304 y 476.
Otras amilasas que se pueden usar son las amilasas que tienen Id. de sec. n.°: 2 de WO 08/153815, Id. de sec. n.°: 10 en WO 01/66712 o las variantes de las mismas que tienen 90 % de identidad de la secuencia con la Id. de sec. n.°: 2 de WO 08/153815 o 90 % de identidad de la secuencia con la Id. de sec. n.°: 10 en WO 01/66712. Las variantes preferidas de Id. de sec. n.°: 10 en WO 01/66712 son las que tienen una sustitución, una deleción o una inserción en una o más de las siguientes posiciones: 176, 177, 178, 179, 190, 201,207, 211 y 264.
Las amilasas adecuadas adicionales son las amilasas que tienen Id. de sec. n.°: 2 de WO 09/061380 o las variantes que tienen 90 % de identidad de la secuencia con la Id. de sec. n.°: 2 de las mismas. Las variantes preferidas de Id. de sec. n.°: 2 son las que tienen un truncamiento del extremo C-y/o una sustitución, una deleción o una inserción en una o más de las siguientes posiciones: Q87, Q98, S125, N128, T131, T165, K178, R180, S181, T182, G183, M201, F202, N225, S243, N272, N282, Y305, R309, D319, Q320, Q359, K444 y G475. Las variantes más preferidas de Id. de sec. n.°: 2 son las que tienen la sustitución en una o más de las siguientes posiciones: Q87E,R, Q98R, S125A, N128C, T131I, T165I, K178L, T182G, M201L, F202Y, N225E,R, N272E,R,
S243Q,A,E,D, Y305R, R309A, Q320R, Q359E, K444E y G475K y/o una deleción en la posición R180 y/o S181 o de T182 y/o G183. Las variantes de amilasas más preferidas de Id. de sec. n.°: 2 son las que tienen las sustituciones:
N128C+K178L+T182G+Y305R+G475K;
N128C+K178L+T182G+F202Y+Y305R+D319T+G475K;
S125A+N128C+K178L+T182G+Y305R+G475K; o S125A+N128C+T131I+T165I+K178L+T182G+Y305R+G475K, en donde las variantes están truncadas en el extremo C y comprenden además opcionalmente una sustitución en la posición 243 y/o una deleción en la posición 180 y/o la posición 181.
Otras amilasas adecuadas son las alfa-amilasas que tienen Id. de sec. n.°: 12 del documento WO 01/66712 o una variante que tiene al menos 90 % de identidad con la Id. de sec. n.°: 12. Las variantes de amilasas preferidas son las que tienen una sustitución, una deleción o una inserción en una o más de las siguientes posiciones de Id. de sec. n.°: 12 en WO01/66712: R28, R118, N174; R181, G182, D183, G184, G186, W189, N195, M202, Y298, N299, K302, S303, N306, R310, N314; R320, H324, E345, Y396, R400, W439, R444, N445, K446, Q449, R458, N471, N484. Las amilasas especialmente preferidas incluyen variantes que tienen una deleción de D183 y G184 y que tienen las sustituciones R118K, N195F, R320K y R458K y una variante que tiene además sustituciones en una o más posiciones seleccionadas del grupo: M9, G149, G1 8 2 , G186, M2 0 2 , T257, Y295, N299, M323, E345 y A339, lo más preferido, una variante que tiene adicionalmente sustituciones en todas estas posiciones.
Otros ejemplos son variantes de amilasas tales como las descritas en los documentos WO 2011/098531, WO 2013/001078 y WO 2013/001087.
Las amilasas comercialmente disponibles son Duramyl™, Termamyl™, Fungamyl™, Stainzyme ™ , Stainzyme Plus™, Natalase™, Liquozyme X and BAN™ (de Novozymes A/S) y Rapidase™, Purastar™/Effectenz™, Powerase y Preferenz S100 (de Genencor International Inc./DuPont).
Peroxidasas/Oxidasas
Una peroxidasa adecuada para su uso en la presente memoria es una enzima peroxidasa comprendida por la clasificación enzimática EC 1.11.1.7, como se establece por el Comité de Nomenclatura de la International Union of Biochemistry and Molecular Biology (IUBMB) o cualquier fragmento obtenido a partir de la misma, que presenta actividad peroxidasa.
Las peroxidasas adecuadas incluyen las de origen bacteriano o fúngico. Se incluyen los mutantes modificados químicamente u obtenidos mediante ingeniería de proteínas. Los ejemplos de peroxidasas útiles incluyen peroxidasas de Coprinus, por ejemplo, de C. cinereus (documento EP 179.486) y variantes de las mismas como las descritas en los documentos w O 93/24618, WO 95/10602 y WO 98/15257.
Las peroxidasas adecuadas también incluyen una enzima haloperoxidasa, tal como cloroperoxidasa, bromoperoxidasa y compuestos que presentan actividad de cloroperoxidasa o bromoperoxidasa. Las haloperoxidasas se clasifican según su especificidad por iones de haluro. Las cloroperoxidasas (E.C. 1.11.1.10) catalizan la formación de hipoclorito a partir de iones de cloruro.
La haloperoxidasa puede ser una cloroperoxidasa. Preferiblemente, la haloperoxidasa es una haloperoxidasa de vanadio, es decir, una haloperoxidasa que contiene vanadato, cuando se usa, se combina con una fuente de ion de cloruro.
Se han aislado haloperoxidasas de muchos hongos diferentes, en particular del grupo de los hongos Dematiaceous Hyphomycetes, tales como Caldariomyces, por ejemplo, C. fumago, Alternaria, Curvularia, por ejemplo, C. verruculosa y C. inaequalis, Drechslera, Ulocladium y Botrytis.
Las haloperoxidasas también se han aislado de bacterias tales como Pseudomonas, p. ej., P. pirrofinia y Streptomyces, p. ej., S. aureofaciens.
En un aspecto preferido, la haloperoxidasa se deriva de Curvularia sp., en particular, Curvularia verprucosa o Curvularia inaecualis, tal como C. inaequalis CBS 102,42 como se describe en el documento WO 95/27046; o C. verruculosa CBS 147.63 o C. verruculosa CBS 444.70 como se describe en el documento WO 97/04102; o de Dreschslera harthari como se describe en el documento WO 01/79459, Densephila salina como se describe en el documento WO 01/79458, Phaeotrichocones croverarie como se describe en el documento WO 01/79461, o Genosisporium sp. como se describe en el documento WO 01/79460.
Una oxidasa según la invención incluye, en particular, cualquier enzima lacasa comprendida por la clasificación enzimática EC 1.10.3.2, o cualquier fragmento obtenido a partir de la misma que presente actividad de lacasa, o un compuesto que presente una actividad similar, tal como una catecol oxidasa (EC 1.10.3.1), una o-aminofenol oxidasa (EC 1.10.3.4) o una bilirrubina oxidasa (EC 1.3.3.5).
Las enzimas lacasa preferidas son enzimas de origen microbiano. Las enzimas pueden obtenerse de plantas, bacterias u hongos (incluyendo hongos filamentosos y levaduras).
Los ejemplos adecuados de hongos incluyen una lacasa derivable de una cepa de Bacillus, Neurospora, por ejemplo, N. crassa, Podospora, Botrytis, Collybia, Fomes, Lentinus, Pleurotus, Trametes, por ejemplo, T. villosa y T. versicolor, Rhizoctonia, por ejemplo, R. solani, Coprinopsis, por ejemplo, C. cinerea, C. comatus, C. friesii, y C. plicatilis, Psathyrella, por ejemplo, P. condelleana, Panaeolus, por ejemplo, P. papilionaceus, Myceliophthora, por ejemplo, M. thermophila, Schytalidium, por ejemplo, S. thermophilum, Polyporus, por ejemplo, P. pinsitus, Phlebia, por ejemplo, P. radiata (documento WO 92/01046), o Coriolus, por ejemplo, C. hirsutus (j P 2238885).
Los ejemplos adecuados de bacterias incluyen una lacasa derivable de una cepa de Bacillus.
Se prefiere la lacasa obtenida de Copiinopsis o Mycelophthora; en particular, una lacasa obtenida de Copiinopsis cinerea, como se describe en el documento WO 97/08325; o de Myceliophthora thermophila, como se describe en el documento WO 95/33836.
La enzima o enzimas detersivas se pueden incluir en una composición detergente añadiendo por separado los aditivos que contienen una o más enzimas, o añadiendo un aditivo combinado que comprende todas estas enzimas. Un aditivo detergente de la invención, es decir, un aditivo separado o un aditivo combinado, se puede formular, por ejemplo, en forma de un granulado, líquido, una suspensión acuosa, etc. Las formulaciones de aditivo detergente preferidas son granulados, en especial granulados sin polvo, líquidos, en particular líquidos estabilizados, o suspensiones acuosas.
Los granulados sin polvo se pueden producir, p. ej., según se describe en US-4.106.991 y en US-4.661.452, y opcionalmente pueden estar revestidos con métodos conocidos en la técnica. Los ejemplos de materiales de recubrimiento cerúleos son productos de poli(óxido de etileno) (polietilenglicol, PEG) que tienen pesos moleculares medios de 1000 a 20000; nonilfenoles etoxilados que tienen de 16 a 50 unidades de óxido de etileno; alcoholes grasos etoxilados en los que el alcohol contiene de 12 a 20 átomos de carbono y que tienen de 15 a 80 unidades de óxido de etileno; alcoholes grasos; ácidos grasos; y monoglicéridos y diglicéridos y triglicéridos de ácidos grasos. Los ejemplos de materiales de recubrimiento filmógenos adecuados para aplicar mediante técnicas de lecho fluidizado se proporcionan en GB-1483591. Las preparaciones de enzima líquida pueden, por ejemplo, estabilizarse por adición de un poliol tal como propilenglicol, un azúcar o alcohol azucarado, ácido láctico o ácido bórico según métodos establecidos. Las enzimas protegidas se pueden preparar según el método descrito en EP-238.216.
Dispersantes
Las composiciones detergentes de la presente invención pueden también contener dispersantes. En particular, los detergentes en polvo pueden comprender dispersantes. Los materiales orgánicos solubles en agua adecuados incluyen los ácidos homopoliméricos o copoliméricos o sus sales, en los que el ácido policarboxílico comprende al menos dos radicales carboxilo separados entre sí por no más de dos átomos de carbono. Los dispersantes adecuados se describen, p. ej., en Powder Detergents, en el volumen de la serie de tensioactivos 71, Marcel Dekker, Inc.
Agentes inhibidores de la transferencia de colorantes
Las composiciones de limpieza de la presente invención también pueden incluir uno o más agentes inhibidores de la transferencia de colorantes. Los agentes poliméricos inhibidores de la transferencia de colorantes adecuados incluyen, aunque no de forma limitativa, polímeros de polivinilpirrolidona, polímeros de N-óxido de poliamina, copolímeros de N-vinilpirrolidona y N-vinilimidazol, poliviniloxazolidonas y polivinilimidazoles o mezclas de los mismos. Si está presente en una composición de la invención, el agente inhibidor de la transferencia de colorantes puede estar presente a un nivel de aproximadamente 0 , 0 0 0 1 % a aproximadamente 10 %, de aproximadamente 0,01 % a aproximadamente 5 % o incluso de aproximadamente 0,1 % a aproximadamente 3 %, en peso de la composición.
Agente blanqueante fluorescente
La composición detergente también puede contener preferiblemente componentes adicionales que pueden teñir artículos que se limpian, tales como agente blanqueador fluorescente o abrillantadores ópticos. Cuando está presente, el abrillantador está preferiblemente a un nivel de aproximadamente 0,01 % a aproximadamente 0,5 %. Cualquier agente blanqueante fluorescente adecuado para usar en una composición detergente para lavado de ropa puede ser usado en la composición de la presente invención. Los agentes blanqueantes fluorescentes usados más habitualmente son los que pertenecen a las clases de los derivados del ácido diaminoestilbensulfónico, derivados de la diarilpirazolina y derivados del bisfenil-diestirilo. Ejemplos del tipo derivados del ácido diaminoestilbensulfónico de los agentes blanqueantes fluorescentes incluyen las sales sódicas de: 4,4'-bis-(2-dietanolamino-4-anilino-s-triazin-6-ilamino)estilbeno-2,2'disulfonato, 4,4'-bis-(2,4-dianilino-s-triazin-6-ilamino)estilbeno-2.2'-disulfonato, 4,4'-bis-(2-anilino-4
(A/-W-2-hidroxi-etilamino)-s-triazin-6-ilamino)estilbeno-2,2'-disulfonato, 4,4'-bis-(4-fenil-1,2,3-triazol-2-il)estilbeno-2,2'-disulfonato y 5-(2-H-nafto[1,2-a(][1,2,3]triazol-2-il)-2-[(£)-2-fenilvinil]bencenosulfonato. Los agentes blanqueantes fluorescentes preferidos son Tinopal d Ms y Tinopal CBS comercializados por Ciba-Geigy AG, Basel, Suiza. Tinopal DMS es la sal disódica del 4,4'-bis-(2-morfolino-4-anilino-s-triazin-6-ilamino)estilben-2,2-disulfonato. Tinopal CBS es la sal disódica del de 2,2'-bis-(fenilestirilo)-disulfonato. También se prefieren agentes blanqueadores fluorescentes como Paralhite KX. suministrado por Partivs Minerals and Chemicals, Mumbai, India. Tinopal CBS-X es una sal disódica de 4,4'-bis-(sulfoestirilo)-bifenilfenilo también conocida como Didium distirilbifenil disulfonato disódico. Otros fluorescentes adecuados para usar en la invención incluyen las 1,3-diarilpirazolinas y las 7-alquilaminocumarinas.
Los niveles de abrillantador fluorescente adecuados incluyen niveles inferiores de aproximadamente 0,01, de 0,05, de aproximadamente 0,1 o incluso de aproximadamente 0,2 % en peso, hasta niveles superiores de 0,5 o incluso 0,75 % en peso.
Polímero para la liberación de la suciedad
La composición detergente comprende preferiblemente uno o más polímeros para la liberación de la suciedad, que ayudan a eliminar la suciedad de los tejidos tales como los tejidos basados en algodón y poliéster. Un polímero para la liberación de la suciedad preferido ayuda a la eliminación de suciedad de los tejidos basados en poliéster. Los polímeros para la liberación de la suciedad pueden ser, por ejemplo, polímeros basados en tereftalato no iónico o aniónico, copolímeros de polivinil caprolactama y relacionados, copolímeros de injerto de vinilo, poliéster poliamidas, véase por ejemplo el Capítulo 7 en Powdered Detergents, volumen de la serie Surfactant Science 71, Marcel Dekker, Inc. Otro tipo preferido de polímeros para la liberación de la suciedad son el polímero de limpieza de grasa alcoxilado anfifílico, que comprende por ejemplo, una estructura de núcleo y una pluralidad de grupos alcoxilato unidos a esa estructura de núcleo. La estructura del núcleo puede comprender una estructura de polialquilenimina o una estructura de polialcanolamina como se describe en detalle en el documento WO 2009/087523 (incorporado aquí como referencia). Además, los copolímeros de injerto aleatorios son polímeros de liberación de suciedad adecuados. Los copolímeros de injerto adecuados se describen con más detalle en los documentos WO 2007/138054, WO 2006/108856 y WO 2006/113314 (incorporados aquí por referencia). Otros polímeros para la liberación de la suciedad son estructuras de polisacárido sustituidas, especialmente estructuras celulósicas sustituidas tales como derivados de celulosa modificados tales como los descritos en los documentos EP 1867808 o WO 2003/040279 (ambos incorporados como referencia en la presente memoria). Los polímeros celulósicos adecuados incluyen celulosa, éteres de celulosa, ésteres de celulosa, amidas de celulosa y mezclas de los mismos. Los polímeros celulósicos adecuados incluyen celulosa modificada aniónicamente, celulosa modificada no iónicamente, celulosa modificada catiónicamente, celulosa modificada con iones híbridos, y mezclas de los mismos. Los polímeros celulósicos de celulosa incluyen metil celulosa, carboxi metil celulosa, etil celulosa, hidroxilo etil celulosa, hidroxil propil metil celulosa, éster carboximetill celulosa, y mezclas de los mismos.
Agente antirredeposición
Las composiciones detergentes de la presente invención también pueden incluir uno o más agentes antirredeposición tales como carboximetilcelulosa (CMC), poli(alcohol vinílico) (PVA), polivinilpirrolidona (PVP), polioxietileno y/o polietilenglicol (PEG), homopolímeros de ácido acrílico, copolímeros de ácido acrílico y ácido maleico y polietileniminas etoxiladas. Los polímeros basados en celulosa descritos en la sección de polímeros para la liberación de la suciedad anteriores también pueden funcionar como agentes antirredeposición.
Modificadores de la reología
Las composiciones detergentes de la presente invención también pueden incluir uno o más modificadores de la reología, estructurantes o espesantes, como distintos agentes reductores de la viscosidad. Los modificadores de la reología se seleccionan del grupo que consiste en materiales cristalinos no poliméricos hidroxifuncionalizados, modificadores de la reología poliméricos que proporcionan propiedades de reducción de la viscosidad por cizallamiento a la matriz líquida acuosa de la composición detergente líquida. La reología y la viscosidad del detergente se pueden modificar y ajustar por métodos conocidos en la técnica, por ejemplo como se muestra en el documento EP 2169040.
Otros adyuvantes adecuados incluyen, sin carácter limitante, agentes antiacortamiento, agentes antiarrugas, bactericidas, aglutinantes, portadores, tintes, estabilizantes enzimáticos, suavizantes, rellenos, reguladores de la espuma, hidrótropos, perfumes, pigmentos, supresores de las jabonaduras, disolventes y estructurantes para detergentes líquidos y/o agentes elastizantes de la estructura.
Formulación de productos detergentes
La composición detergente puede estar en cualquier forma conveniente, p. ej., una barra, una pastilla homogénea, una pastilla que tiene dos o más capas, un polvo regular o compacto, un gránulo, una pasta, un gel o un líquido regular, compacto o concentrado. Las composiciones detergentes preferidas son líquidos, opcionalmente en forma de dosis unitaria, por ejemplo en forma de bolsa.
Formas de la formulación de detergente: Capas (mismas o diferentes fases), bolsas, frente a formas para de dosificación automática para lavadora.
Las bolsas pueden configurarse como compartimentos individuales o multicompartimentos. Puede tener cualquier forma y material que sea adecuado para contener la composiciones, p. ej. sin permitir la liberación de la composición antes de poner en contacto la bolsa con el agua. La bolsa está hecha de película soluble en agua que encierra un volumen interior. Dicho volumen interior puede estar dividido en compartimentos de la bolsa. Las películas preferidas son las de materiales poliméricos, preferiblemente polímeros formados en una película u lámina. Los polímeros, copolímeros o derivados preferidos de los mismos son poliacrilatos seleccionados, y copolímeros de acrilato solubles en agua, metilcelulosa, carboximetilcelulosa, dextrina sódica, etilcelulosa, hidroxietilcelulosa, hidroxipropilmetilcelulosa, maltodextrina, polimetacrilatos, con la máxima preferencia copolímeros de poli(alcohol vinílico) e hidroxipropilmetilcelulosa (HPMC). Preferiblemente, el nivel de polímero en la película, por ejemplo PVA, es de al menos 60 %. El peso molecular promedio preferido será típicamente de aproximadamente 2 0 . 0 0 0 a aproximadamente 150.000. Las películas también pueden ser composiciones de mezcla que comprenden mezclas de polímeros hidrolíticamente degradables y solubles en agua tales como poliactida y alcohol polivinílico (conocido con la referencia comercial M8630 y comercializado por Charris Craft In. Prod. De Gary, Ind., EE. UU.) junto con plastificantes como glicerol, etilenglicol, propilenglicol, sorbitol y mezclas de los mismos. Las bolsas pueden comprender una composición de limpieza para lavado de ropa sólida o componentes de parte y/o una composición de limpieza líquida o componentes de parte separados por la película soluble en agua. El compartimento para los componentes líquidos puede tener una composición diferente que los compartimentos que contienen los sólidos. Ref: (US 2009/0011970 A1).
Los ingredientes detergentes pueden estar separados físicamente entre sí por compartimentos en bolsas solubles en agua o en diferentes capas de pastillas. De este modo, se puede evitar la interacción de almacenamiento negativa entre los componentes. Los diferentes perfiles de disolución de cada uno de los compartimentos también pueden dar lugar a la disolución retardada de componentes seleccionados en la disolución de lavado.
Definición/características de las formas:
Un detergente líquido o de gel, que no está como dosis unitaria, puede ser acuoso, que contiene típicamente al menos 20 % en peso y hasta 95 % de agua, tal como hasta aproximadamente 70 % de agua, hasta aproximadamente 65 % de agua, hasta aproximadamente 55 % de agua, hasta aproximadamente 45 % de agua, hasta aproximadamente 35 % de agua. Otros tipos de líquidos, que incluyen sin limitación, alcanoles, aminas, dioles, éteres y polioles pueden incluirse en un líquido acuoso o gel. Un líquido acuoso o detergente en gel puede contener de 0-30 % de disolvente orgánico.
Un detergente líquido o en gel puede ser no acuoso.
Composición detergente líquida
Preferiblemente, la composición detergente es una composición detergente líquida, siendo preferiblemente un detergente para la ropa, por ejemplo que comprende:
a) variante de ADNasa, opcionalmente en una cantidad de 0,00001, o de 0,005 mg a 10 g o 50 g de proteína activa por litro de detergente;
b) de 0 , 1 % en peso a 60 % en peso de al menos un tensioactivo y
c) de 0,1 % en peso a 50 % en peso de al menos un aditivo reforzante de la detergencia, preferiblemente que comprende aditivo reforzante de la detergencia seleccionado de citrato y/o ácido metilglicina-N,N-diacético (MGDA) y/o ácido glutámico-N,N-diacético (GLDA), hEDP, dTMPA o DTPMPA y/o sales de los mismos.
La composición detergente líquida puede comprender de 5 % en peso o de 10 % en peso o de 20 % en peso a 70 % en peso de agua, o hasta 50 % de agua, hasta 40 % de agua, o hasta 30 % de agua, hasta 20 % de agua. En un detergente líquido acuoso se pueden incluir otros tipos de líquidos, que incluyen, sin limitación, alcanoles, aminas, dioles, éteres y polioles. Un detergente líquido acuoso puede contener entre un 0-30 % de disolvente orgánico. Un detergente líquido puede ser incluso sustancialmente no acuoso; en donde el contenido de agua es inferior a un 10 %, preferiblemente inferior a un 5 %.
Composiciones en polvo
La composición detergente puede ser preferiblemente una composición detergente granulada para lavado de ropa o lavado de vajillas, preferiblemente para ropa, por ejemplo, que comprende
a) de 0,00001 o de 0,005 mg de variante de ADNasa por gramo de composición, opcionalmente
b) de 0 % en peso, preferiblemente de 1 % en peso a 40 % en peso de tensioactivo aniónico, opcionalmente
c) de 0 % en peso, preferiblemente de 1 % en peso a 2 0 % en peso de tensioactivo no iónico y/u opcionalmente
d) de 5 % en peso a 40 % en peso de aditivo reforzante de la detergencia, tal como carbonatos, zeolitas, fosfatos, silicatos, aditivos reforzantes de la detergencia para secuestro de calcio o agentes formadores de complejos/quelantes o mezclas de los mismos.
Los aditivos reforzantes de la detergencia preferidos comprenden aditivos reforzantes de la detergencia que incluyen citrato y/o ácido metilglicina-N,N-diacético (MGDA) y/o ácido glutámico-N,N-diacético (GLDA) y/o sales de los mismos.
El detergente comprende preferiblemente hasta 30 % en peso, tal como aproximadamente 1 % a aproximadamente 20 %, de un sistema blanqueador. Los componentes del sistemas blanqueadores adecuados incluyen fuentes de peróxido de hidrógeno; fuentes de perácidos; activadores del blanqueador, catalizadores del blanqueador y/o potenciadores como se ha descrito anteriormente.
Formulación de la enzima en cogránulos
La ADNasa puede formularse como un gránulo, por ejemplo, como un cogránulo que combina una o más enzimas, preferiblemente enzimas amilasa, celulasa, mananasa y/o galactanasa.
Ensayos y composiciones detergentes
Composición de detergente modelo A (líquida)
Ingredientes: 12 % de LAS, 11 % de AEO Biosoft N 25-7 (NI), 7 % de AEOS (SLES), 6 % de MPG (monopropilenglicol), 3 % de etanol, 3 % de TEA, 2,75 % de jabón de cacao, 2,75 % de jabón de soja, 2 % de glicerol, 2 % de hidróxido de sodio, 2 % de citrato de sodio, 1 % de formiato de sodio, 0,2 % de Dtpma y 0,2 % de PCA (todos los porcentajes son p/p (porcentaje en peso)).
Ensayo A-C
Actividad de muestras purificadas
Antes de analizar las muestras de ADNasa para determinar su estabilidad en el ensayo A, B o C, se analizaron para determinar la actividad según el siguiente procedimiento. Las muestras de ADNasa purificadas se diluyeron a 7,5 ppm en una placa de 96 pocillos usando un tampón de dilución (Tris-HCl 50 mM, pH 7 0,1 % de Triton X-100) en un manipulador de líquidos de canal Hamilton Nimbus 4. Una curva patrón de ADNasa (p. ej., Id. de sec. n.°: 1 o Id. de sec. n.°: 28) a 2,5, 5 y 7,5 ppm se preparó en consecuencia.
Se añaden 12 pl de muestra normalizada de ADNasa a 228 pl de Modelo A y la solución se agita durante 90 s A 2000 rpm (2 mm de órbita). Se añaden 10 pl de la muestra a 190 pl de sustrato de ADN (3,3 mg/ml de ADN de esperma de salmón Tris-HCl 50 mM, pH 7 MgCl25 mM CaCl2 5 mM) y la placa de 96 pocillos que contenía las muestras y el sustrato de ADN se mezclan a 1500 rpm durante 90 s (2 mm de órbita). La placa se incuba durante 1 h a temperatura ambiente y la actividad ADNasa se mide según el procedimiento: E1Hamilton STAR mide la viscosidad de las muestras y, por lo tanto, la actividad ADNasa usando la tecnología de ensayo ViPr como se describe en (documento WO2011/107472 A1) aspirando 100 pI de la solución de ensayo con una punta estándar limpia CORE 300 pI a una velocidad de 50 pI/s. La solución se dispensa de nuevo al pocillo original a 10 pI/s y la medición se repitió 5 veces. Se recogen los datos de presión durante la etapa de aspiración de los 96 pocillos y se toma el valor de presión a 1000 ms después del inicio de la aspiración para calcular la actividad ADNasa en unidades relativas (UR). Las unidades relativas se calculan por división del valor del tampón (blanco; 1000 ms) por el valor de presión (1000 ms) de una muestra de la que se resta 1. Las muestras que muestran actividad inferior a 2,5 ppm en comparación con la curva patrón se ajustan a un nivel de al menos > 10 ppm e inferior a < 20 ppm. Todas las muestras se transfieren por triplicado a una placa de 96 pocillos con una ADNasa de 5 ppm (Id. de sec. n.°: 1 o Id. de sec. n.°: 28) como referencia.
Ensayo A
La placa de 96 pocillos con las muestras de ADNasa normalizadas y diluciones de ADNasa (Id. de sec. n.°: 28) se cargó en el robot Hamilton STAR equipado con un cabezal TADM de 96 canales que permite la medición simultánea de la presión en el espacio superior de cada canal de pipeta individual. Se añaden 12 pl de muestra de ADNasa normalizada a 228 pl de Modelo A con proteasa (136 ppm). La solución se agita durante 90 s a 2000 rpm (2 mm de órbita) y se añaden 80 pl de la solución a dos placas de PCR. La placa A (Tensión) se incuba a 40 °C y la placa B (Referencia) a 4 °C durante 24 h. La placa A y B se transfieren a temperatura ambiente. 190 pl de sustrato de ADN (3,3 mg/ml de ADN de esperma de salmón Tris-HCl 50 mM, pH 7 MgCl25 mM CaCl25 mM) se añaden a 2 x placas de 96 pocillos. Se añaden 10 pl de
muestra de la placa A y la placa B respectivamente a las placas correspondientes que contienen sustrato de ADN. Las muestras y el ADN se mezclan a 1500 rpm durante 90 s (2 mm de órbita) y se incuban durante 1 h a temperatura ambiente. El Hamilton STAR mide la viscosidad usando la tecnología de ensayo ViPr como se describe en (documento WO2011/107472 A1) aspirando 100 pi con una punta estándar limpia CORE 300 pi a una velocidad de 50 pi/s. La solución se dispensa de nuevo al pocillo original a 10 pi/s y la medición se repitió 5 veces. Se recogen los datos de presión durante la etapa de aspiración de los 96 pocillos y se toma el valor de presión a 1000 ms después del inicio de la aspiración para calcular la actividad ADNasa en unidades relativas (UR). Las unidades relativas se calculan por división del valor del tampón (blanco; 1000 ms) por el valor de presión (1000 ms) de una muestra de la que se resta 1. La actividad relativa (RA) se calcula como
Actividad Residual
( % ) URvariante
U * 100
UR Rreferencia
Ensayo B
Las condiciones y la determinación de actividad de las variantes de ADNasa son como se describe en el Ensayo A, excepto que las muestras de ADNasa se expusieron a un detergente Modelo A 0,4 % de K2SO3 durante 1 hora a 60 °C. La solución detergente se prepara mezclando Modelo A (50 g) con 0,2 g de K2SO3 durante 1 h con agitación intensa.
Ensayo C
Las condiciones y la determinación de actividad de las variantes de ADNasa son como se describe en el Ensayo A, excepto que las muestras se expusieron al detergente Modelo A en solitario durante 2 horas a 62 0C.
Relación de actividad residual (RAR)
La relación de actividad residual para cada condición se calculó usando una variante estabilizada como referencia. Las variantes se probaron en las 3 condiciones descritas anteriormente y la RAR se calculó usando la siguiente fórmula:
r
Relación de actividad residual (RAR) R aAvan .ante
RAreferencia
Métodos
Los métodos generales de PCR, clonación, nucleótidos de ligadura, etc., son bien conocidos por un experto en la materia y pueden, por ejemplo, encontrarse en “ Molecular cloning: A laboratory manual” , Sambrook y col. (1989), Cold Spring Harbor lab., Cold Spring Harbor, NY; Ausubel, F. M. y col. (eds.); “ Current protocols in Molecular Biology” , John Wiley and Sons, (1995); Harwood, C. R., y Cutting, S. M. (eds.); “ Dn A Cloning: A Practical Approach, Volumes i and II” , D.N. Glover ed. (1985); “ Oligonucleotide Synthesis” , M.J. Gait ed. (1984); “ Nucleic Acid Hybridization” , B.D. Hames & S.J. Higgins eds (1985); “A Practical Guide To Molecular Cloning” , B. Perbal, (1984).
Ejemplos
Ejemplo 1: Construcción de variantes mediante mutagénesis dirigida al sitio
Las variantes dirigidas al sitio se construyeron con ADNasa de Bacillus cibi (id. de sec. n.°: 1), que comprende sustituciones específicas según la invención. Las variantes se realizaron mediante clonación tradicional de fragmentos de ADN (Sambrook y col., Molecular Cloning: A Laboratory Manual, 2a Ed., cold Spring Harbor, 1989) usando PCR junto con oligonucleótidos mutagénicos diseñados apropiadamente que introducen las mutaciones deseadas en la secuencia resultante.
Los oligos mutagénicos se diseñaron correspondientes a la secuencia de ADN que flanquea el sitio o sitios deseados de mutación, separados por los pares de bases de ADN que definen las inserciones/deleciones/sustituciones, y se adquirieron de un proveedor de oligonucleótidos tal como Life Technologies. Para probar las variantes de ADNasa de la invención, el ADN mutado que comprende una variante de la invención se integra en una cepa competente de B. subtilis por recombinación homóloga, se fermenta usando protocolos estándar (medios basados en extracto de levadura, 3-4 días, 30 °C) y se criba en un ensayo de actividad.
Las variantes construidas se sembraron en placas de agar LB suplementado con 6 ug/ml de cloranfenicol y se cultivaron a 37 °C durante un día. Después del crecimiento, se repicaron las colonias en pocillos individuales de placas de microtitulación estándar de 96 pocillos que contenían 200 ul de caldo TBgy complementado con 6 ug/ml de cloranfenicol y trazas de metales (FeCl3 50 mM, CaCl2 20 mM, MnCl2 10 mM, ZnSO4 10 mM, CuCl2 2 mM y NiCl2 2 mM, (F. William
Studier, “ Protein production by auto-induction in high-density shaking cultures” , Protein Expression and Purification, 41 (2005) 207-234).
La ADNasa de Bacillus cibi natural también se inoculó como referencia en cuatro pocillos de cada placa de microtitulación. Las placas de microtitulación se cultivaron durante tres días a 30 0C con agitación a 220 rpm. Después del crecimiento, los sobrenadantes se cribaron para determinar la actividad residual después de estresarlos durante 20 minutos a 48,5 °C en presencia de un 96 % (v/v) de Modelo A.
Ejemplo 2: Relación de actividad relativa de variantes de ADNasa con respecto a la muestra de referencia en detergente (Ensayo C)
Condiciones del ensayo: Las variantes de ADNasa se estresaron durante 2 horas a 62 °C en un detergente modelo y se compararon con la muestra de referencia indicada por un asterisco (*)

Ejemplo 3 Relación de actividad relativa de las variantes de ADNasa en relación con la muestra de referencia en presencia de proteasa (Ensayo A)
Condiciones del ensayo: Las variantes de ADNasa se estresaron durante 24 horas a 40 0C en un detergente modelo (detergente modelo A) con 5 % de proteasa presente. Las variantes se compararon con la muestra de referencia con la Id. de sec. n.°: 28.

Ejemplo 4 Relación de actividad relativa de las variantes de ADNasa en relación con la muestra de referencia en presencia de sulfito (Ensayo B)
Condiciones del ensayo: Las variantes de ADNasa se estresaron durante 1 hora a 60 °C en un detergente modelo que contenía sulfito al 0,4 % (K2SO4). Las variantes se compararon con la muestra de referencia con la Id. de sec. n. °: 28.

empo eora rea va en res ensayos
Condiciones del ensayo:
Ensayo A: Las variantes de ADNasa se estresaron durante 24 horas a 40 0C en un detergente modelo (detergente modelo A) con 5 % de proteasa presente. Las variantes se compararon con la muestra de referencia muestra de referencia con Id. de sec. n.°: 28.
Ensayo B: Las variantes de ADNasa se estresaron durante 1 hora a 60 0C en un detergente modelo que contenía sulfito al 0,4 % (K2SO4). Las variantes se compararon con la muestra de referencia muestra de referencia con Id. de sec. n.°: 28. Ensayo C: Las variantes de ADNasa se estresaron durante 2 horas a 62 0C en un detergente modelo y se compararon con la muestra de referencia con Id. de sec. n.°: 28.

Ejemplos de detergentes
Ejemplos 1-6. Composiciones detergentes para lavado de ropa granulares escogidas para lavado de ropa a mano o para lavadoras de ropa de carga por la parte superior.


Ejemplos 7-12. Composiciones detergentes para lavado de ropa granulares escogidas para lavadoras automáticas de carga frontal.
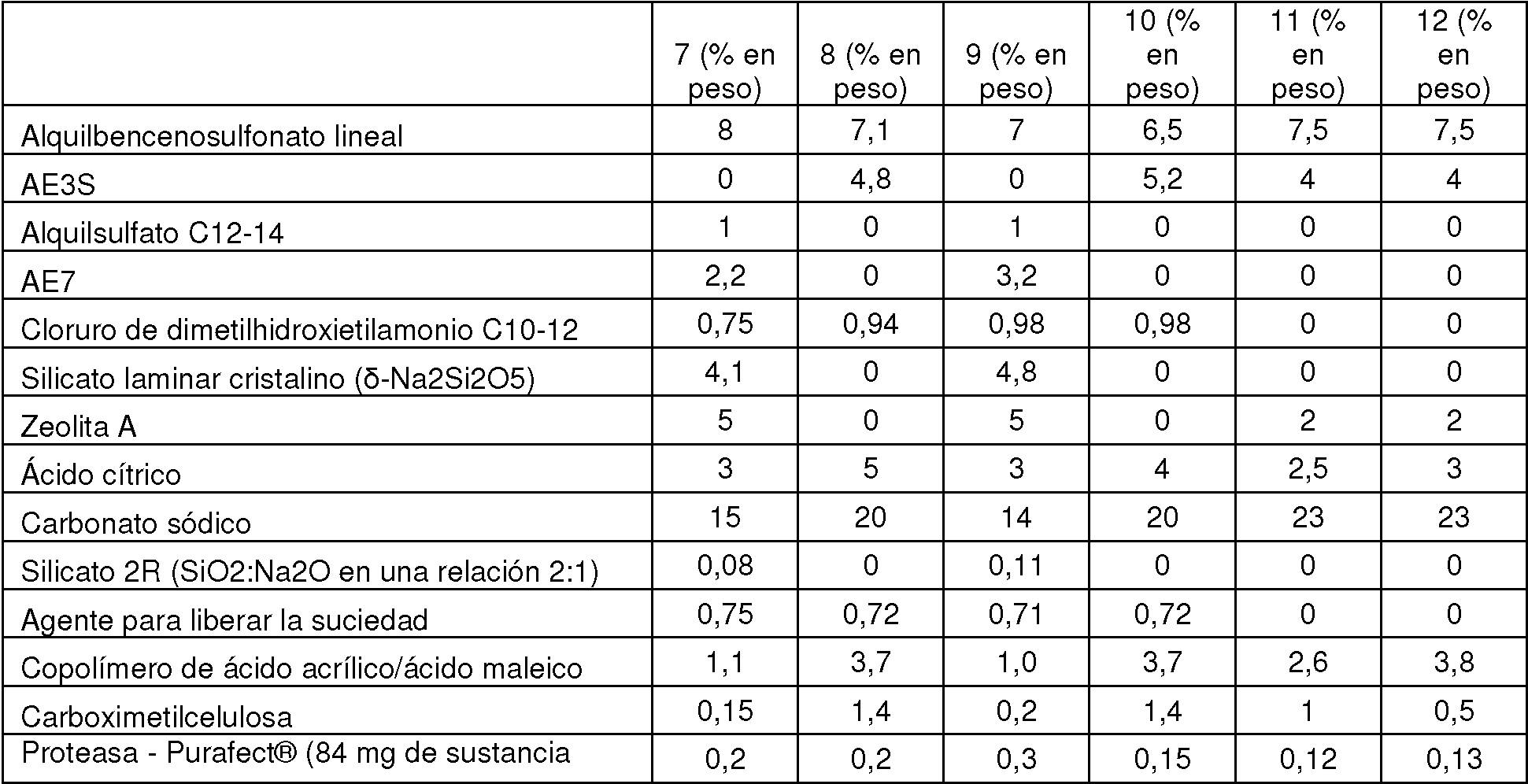
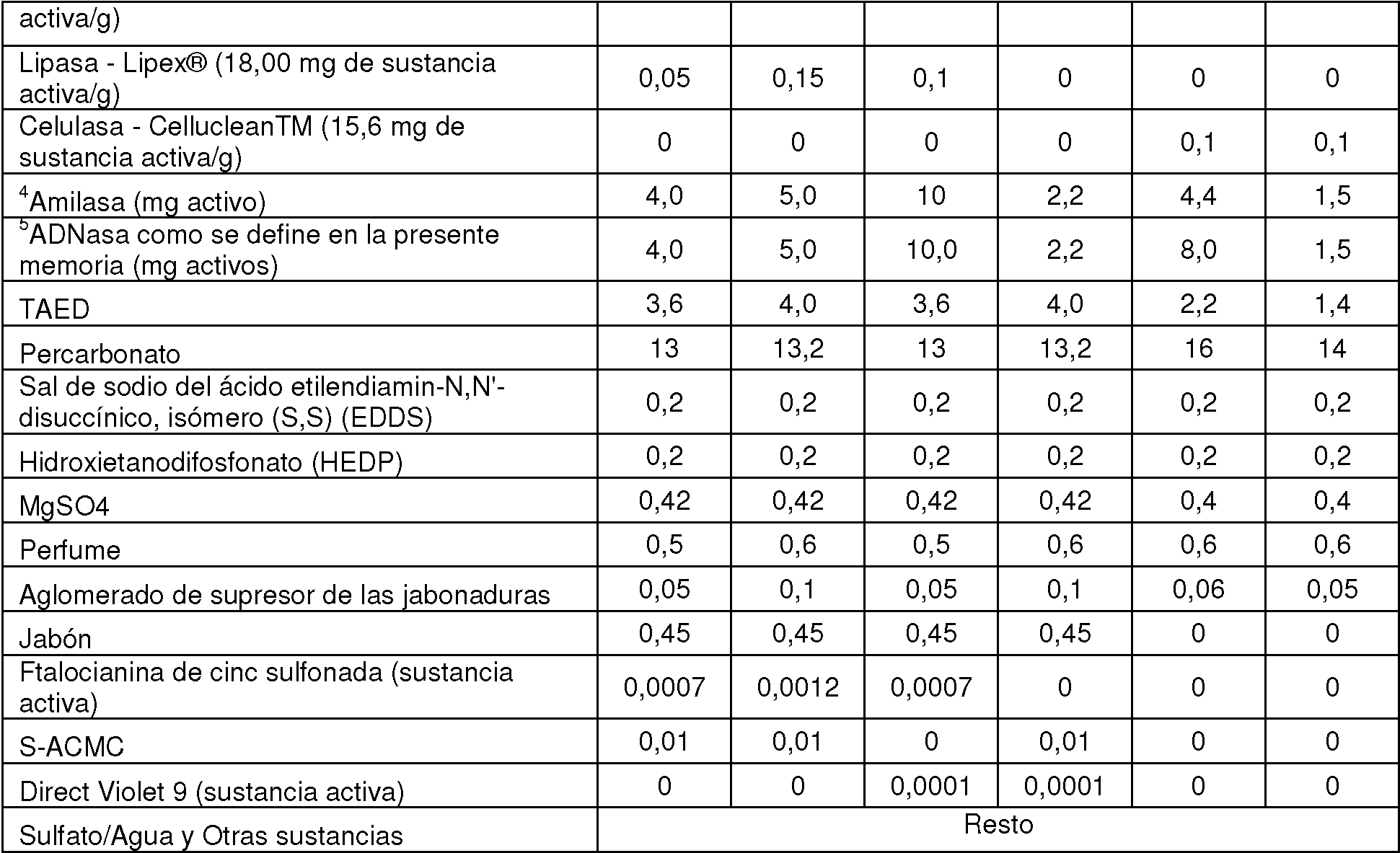
* La ADNasa se muestra como mg de sustancia activa enzimática por 100 g de detergente. Ejemplos 13-18. Composiciones detergentes para lavado de ropa de limpieza intensiva


Ejemplos 19-23. Composiciones detergentes para lavado de ropa en dosis unitaria. Dichas formulaciones en dosis unitaria pueden comprender uno o varios compartimentos.
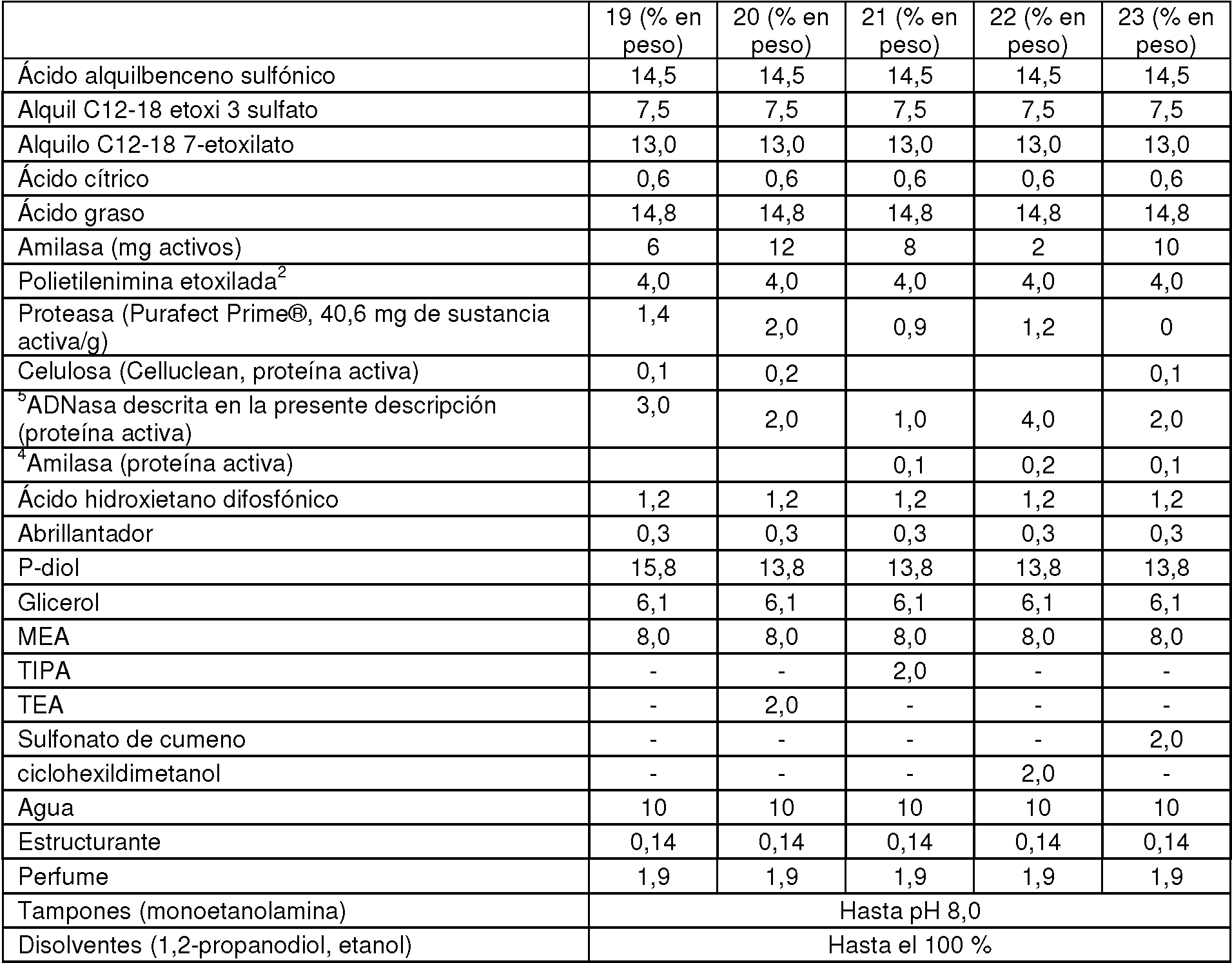
Ejemplo 24. Composición en dosis unitaria multicompartimental
Se proporcionan a continuación formulaciones detergentes en dosis unitaria multicompartimental de la presente invención. En estos ejemplos, la dosis unitaria tiene tres compartimentos, pero se pueden preparar composiciones similares para dos, cuatro o cinco compartimentos. La película utilizada para encapsular los compartimentos es poli(alcohol vinílico).

Formulaciones multicom artimentales

Ejemplo 25. Composiciones suavizantes de tejidos de la presente invención


Materias primas y notas para los Ejemplos de las composiciones 1-24
Alquilbencenosulfonato lineal que tiene una longitud promedio de cadena de carbono alifático de C11 -C18
Cloruro de dimetilhidroxietilamonio C12-18
AE3S es alquil C12-15 etoxi (3) sulfato
AE7 es alcohol etoxilado C12-15, con un grado promedio de etoxilación de 7
AE9 es alcohol etoxilado C12-16, con un grado promedio de etoxilación de 9
HSAS es un alquilsulfato primario de ramificación intermedia con una longitud de cadena de carbono de aproximadamente 16-17 según se describe en US-6.020.303 y US-6.060.443
El poliacrilato PM 4500 es comercializado por BASF
La carboximetilcelulosa es Finnfix® V, comercializada por CPKelco, Arnhem, Países Bajos
CHEC es un polímero de hidroxietilcelulosa modificado catiónicamente.
Los quelantes de fosfonato son, por ejemplo, ácido dietilentetraaminapentaacético (DTPA) hidroxietano difosfonato (HEDP)
Savinase®, Natalase®, Stainzyme®, Lipex®, CellucleanTM, Mannaway® y Whitezyme® son todos productos de Novozymes, Bagsvaerd, Dinamarca.
Purafect®, Purafect Prime® son productos de Genencor International, Palo Alto, California, EE. UU.
El abrillantador fluorescente 1 es Tinopal® AMS, el abrillantador fluorescente 2 es Tinopal® CBS-X, el Direct Violet 9 es Pergasol® Violet BN-Z, NOBS es nonanoiloxibencenosulfonato sódico
TAED es tetraacetiletilendiamina
La S-ACMC es carboximetilcelulosa conjugada con C.I. Reactive Blue 19, nombre de producto AZO-CM-CELLULOSE
El agente para liberar la suciedad es Repel-o-tex® PF
El copolímero ácido acrílico/ácido maleico tiene un peso molecular de 70.000 y una relación acrilato:maleato de 70:30
EDDS es una sal sódica del ácido etilendiamina-N,N'-disucínico, isómero (S,S), el supresor de las jabonaduras aglomerado está comercializado por Dow Corning, Midland, Michigan, EE. UU.
HSAS es alquilsulfato de ramificación intermedia
El tinte matizador polimérico Liquitint® Violet CT se comercializa por Milliken, Spartanburg, Carolina del Sur, EE. UU. El tinte de azotiofeno polietoxilado es tinte matizador polimérico Violet DD™, suministrado por Milliken, Spartanburg, Carolina del Sur, EE. UU.
1El copolímero de injerto aleatorio es un copolímero de poli(óxido de etileno) injertado con acetato de polivinilo que tiene una cadena principal de poli(óxido de etileno) y múltiples cadenas laterales de acetato de polivinilo. El peso molecular de la cadena principal del poli(óxido de etileno) es de aproximadamente 6000 y la relación de peso del poli(óxido de etileno) a acetato de polivinilo es de aproximadamente 40 a 60 y no hay más de 1 punto de injerto por 50 unidades de óxido de etileno.
2 Polietilenimina (PM = 600) con 20 grupos etoxilados por -NH.
3El polímero anfifílico alcoxilado es una polietileneimina (PM 600), preparada a partir de un polímero que se ha derivatizado para contener 24 grupos etoxilados por -NH y 16 grupos propoxilato por -NH.
4La amilasa de la presente invención se muestra como mg de sustancia activa enzimática por 100 g de detergente.
5La ADNasa en todos estos ejemplos se muestra como mg de enzima activa por 100 g de detergente.
aProxel GXL, solución acuosa de dipropilenglicol al 20 % de 1,2-benzisotiazolin-3-ona, suministrada por Lonza. bÉster del ácido graso de cloruro de N,N-bis (hidroxietil)-N,N-dimetilamonio. El índice de yodo del ácido graso precursor de este material está entre 18 y 22. El material obtenido de Evonik contiene impurezas en forma de ácido graso libre, en forma de monoéster del éster de ácido graso de cloruro de N,N-bis(hidroxietil)-N,N-dimetilamonio y ésteres de ácidos grasos de N,N-bis(hidroxietil)-N-metilamina.
cMP10®, suministrado por Dow Corning, actividad 8 %
d como se describe en el documento US-8.765.659, expresado como aceite perfumado encapsulado al 100 % e Rheovis® CDE, espesante polimérico catiónico suministrado por BASF
f N,N-dimetil octanamida y N,N-dimetil decamida en aproximadamente una relación de peso 55:45, nombre comercial Stepos® M-8-10 de la empresa Stepan Company
No debe entenderse que las dimensiones y los valores descritos en el presente documento estén estrictamente limitados a los valores numéricos exactos mencionados. En vez de eso, a menos que se especifique lo contrario, se pretende que cada una de tales dimensiones signifique tanto el valor mencionado como un intervalo funcionalmente equivalente en torno a ese valor. Por ejemplo, una dimensión descrita como “40 mm” se refiere a “aproximadamente 40 mm” .
Claims (15)
- REIVINDICACIONESi . Una composición detergente que comprende i) una variante de ADNasa que tiene actividad ADNasa, seleccionada del grupo que consiste en:a) una variante de ADNasa que, en comparación con una ADNasa que tiene la Id. de sec. n.°: 1, comprende una sustitución seleccionada de L33R, L33V y L33Y en donde cada posición corresponde a la posición de la Id. de sec. n.°: 1 (numeración según la Id. de sec. n.°: 1) y en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 % pero menos de 100 % de identidad de secuencia con la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1 y en donde la variante tiene una mejora en la estabilidad en comparación con el polipéptido de la Id. de sec. n.° 1, la Id. de sec. n.°: 27 o la Id. de sec. n.°: 28; yii) un adyuvante, preferiblemente en una cantidad de 0,01 a 99,9 % en peso.
- 2. Una composición detergente según la reivindicación 1, en donde la variante de ADNasa comprende una o más de las sustituciones correspondientes a sustituciones seleccionadas del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147H, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A (numeración según la Id. de sec. n.°: 1).
- 3. Una composición detergente según la reivindicación 1 o la reivindicación 2 en donde la variante de ADNasa en comparación con una ADNasa que tiene la Id. de sec. n.°: 27, comprende una o más de las sustituciones correspondientes a sustituciones seleccionadas del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A y en donde cada posición corresponde a las posiciones de la Id. de sec. n.°: 27 (numeración según la Id. de sec. n.°: 27) y en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 % pero menos de 100 % de identidad de secuencia con la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 27.
- 4. Una composición detergente según la reivindicación 3 en donde la variante de ADNasa en comparación con una ADNasa que tiene la Id. de sec. n.°: 28, comprende una o más de las sustituciones correspondientes a sustituciones seleccionadas del grupo que consiste en: G4K, S7G, K8R, S9I, N16G, S27K, S27R, D32F, D32I, D32L, D32R, D32V, L33R, L33V, L33Y, S39C, G41P, S42H, D45E, Q48D, N61E, T65M, T65W, S66R, S66M, S66W, S66Y, S66V, F78L, P91L, S101N, S106L, S106R, S106H, Q109E, A112E, T127P, S130A, S130Y, T138D, Q140V, Q140G, A147P, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde una sustitución es L33R, L33V o L33Y y en donde cada posición corresponde a las posiciones de la Id. de sec. n.°: 28 (numeración según la Id. de sec. n.°: 28) y en donde la variante tiene al menos 60 %, al menos 70 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 % pero menos de 100 % de identidad de secuencia con la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 28.
- 5. Una composición detergente según cualquiera de las reivindicaciones anteriores, en donde la variante de ADNasa comprende una o más de las sustituciones correspondientes a sustituciones del grupo que consiste en: S27K, S27R, S39C y S66W (numeración según la Id. de sec. n.°: 1).
- 6. Una composición detergente según cualquiera de las reivindicaciones anteriores en donde la variante de ADNasa comprende uno o ambos motivos [D/M/L][S/T]GYSR[D/N] (Id. de sec. n.°: 25) y/o ASXNRSKG (Id. de sec. n.°: 26).
- 7. Una composición detergente según cualquiera de las reivindicaciones anteriores en donde la variante de ADNasa tiene al menos una propiedad mejorada, en comparación con la precursora y/o en comparación con la ADNasa que tiene el polipéptido mostrado en la Id. de sec. n.°: 1, id. de sec. n.°: 27 o la Id. de sec. n.°: 28, preferiblemente en donde la propiedad mejorada se caracteriza por que la RAR (relación de actividad residual) es superior a 1 en al menos un ensayo A, B o C, como se define en la descripción.
- 8. Una composición detergente según cualquiera de las reivindicaciones anteriores, en donde la combinación de mutaciones en la variante de ADNasa proporciona un efecto aditivo o sinérgico.
- 9. Una composición detergente según cualquiera de las reivindicaciones anteriores, en donde la variante de ADNasa tiene al menos 60 %, al menos 65 %, al menos 70 %, al menos 75 %, al menos 80 %, al menos 85 %, al menos 90 %, al menos 95 %, tal como al menos 96 %, al menos 97 %, al menos 98 %, o al menos 99 %, pero menos de 100 % de identidad de secuencia con la ADNasa que comprende la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1.
- 10. Una composición detergente según cualquiera de las reivindicaciones anteriores, en donde en la variante de ADNasa el número total de sustituciones en comparación con la Id. de sec. n.°: 1 es de 3 a 20, preferiblemente al menos 5 a 20, al menos 10 a 20 o tal como al menos 15 a 20 sustituciones en comparación con la ADNasa que comprende la secuencia de aminoácidos mostrada en la Id. de sec. n.°: 1.
- 11. Una composición detergente según cualquiera de las reivindicaciones anteriores, en donde la variante de ADNasa es una variante de una ADNasa precursora obtenida del género bacillus, preferiblemente de cualquiera de los siguientes: Bacillus Bacillus cibi, Bacillus horikoshii, Bacillus horneckiae, Bacillus idriensis, Bacillus algicola, Bacillus vietnamensis, Bacillus hwajinpoensis, Bacillus indicus, Bacillus marisflavi o Bacillus luciferensis.
- 12. Una composición detergente según cualquiera de las reivindicaciones anteriores, en donde la variante de ADNasa comprende una o más sustituciones correspondientes a sustituciones del grupo que consiste en: G4K, S7G, K8R, D32I, D32L, D32R, D32V, S39C, G41P, S42H, Q48D, T65M, T65W, S66M, S66W, S66Y, S66V, S101N, S106L, S106R, S106H, S130A, S130Y, T138D, Q140V, Q140G, A147H, C148A, W154Y, T157V, Y159A, Y159R, G162C, Q174N, L177Y, S179L y C180A, en donde una de las sustituciones es L33R, (numeración según la Id. de sec. n.°: 1).
- 13. Una composición detergente según cualquiera de las reivindicaciones anteriores, en donde el adyuvante comprende enzimas adicionales seleccionadas de: amilasas, proteasas, lipasas, cutinasas, mananasas, galactanasas, celulasas, xiloglucanasas y mezclas de las mismas.
- 14. Un método de lavado que comprende (i) poner en contacto un artículo o superficie, preferiblemente un tejido, con una solución de lavado acuosa que comprende una variante de ADNasa como se define en cualquiera de las reivindicaciones anteriores y un adyuvante, preferiblemente poniendo en contacto el artículo o la superficie con una composición detergente según cualquiera de las reivindicaciones anteriores; y (ii) opcionalmente enjuagar y (iii) secar la superficie.
- 15. Uso de una variante de ADNasa como se define en cualquiera de las reivindicaciones anteriores y un adyuvante, preferiblemente uso de una composición detergente según cualquiera de las reivindicaciones anteriores y/o un método de limpieza, según cualquiera de las reivindicaciones 1 a 15: para limpieza o limpieza profunda de un artículo o superficie, preferiblemente un tejido; para prevenir y/o reducir la adherencia de un artículo o superficie manchada, preferiblemente un tejido; para pretratar las manchas de un artículo o superficie manchada, preferiblemente un tejido; para prevenir y/o reducir la redeposición de la suciedad sobre una superficie o artículo, preferiblemente un tejido, durante un ciclo de lavado; para prevenir y/o reducir la adherencia de la suciedad a un artículo o superficie, preferiblemente un tejido; para mantener o mejorar la blancura de un artículo o superficie, preferiblemente un tejido; y/o para prevenir y/o reducir el mal olor en un artículo o superficie, preferiblemente un tejido.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP17199032 | 2017-10-27 | ||
| EP17204815 | 2017-11-30 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2908667T3 true ES2908667T3 (es) | 2022-05-03 |
Family
ID=63878615
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES18202967T Active ES2908667T3 (es) | 2017-10-27 | 2018-10-26 | Composiciones detergentes que comprenden variantes polipeptídicas |
| ES18202983T Active ES2910120T3 (es) | 2017-10-27 | 2018-10-26 | Composiciones detergentes que comprenden variantes polipeptídicas |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES18202983T Active ES2910120T3 (es) | 2017-10-27 | 2018-10-26 | Composiciones detergentes que comprenden variantes polipeptídicas |
Country Status (8)
| Country | Link |
|---|---|
| US (2) | US10781408B2 (es) |
| EP (2) | EP3476936B1 (es) |
| CN (3) | CN111247245A (es) |
| DK (1) | DK3476936T3 (es) |
| ES (2) | ES2908667T3 (es) |
| HU (2) | HUE057471T2 (es) |
| PL (2) | PL3476935T3 (es) |
| WO (2) | WO2019084350A1 (es) |
Families Citing this family (46)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018011276A1 (en) | 2016-07-13 | 2018-01-18 | The Procter & Gamble Company | Bacillus cibi dnase variants and uses thereof |
| US20180216039A1 (en) | 2017-02-01 | 2018-08-02 | The Procter & Gamble Company | Cleaning compositions comprising amylase variants |
| US11499121B2 (en) * | 2017-04-06 | 2022-11-15 | Novozymes A/S | Detergent compositions and uses thereof |
| US20230416706A1 (en) * | 2017-10-27 | 2023-12-28 | Novozymes A/S | Dnase Variants |
| ES2908667T3 (es) * | 2017-10-27 | 2022-05-03 | Procter & Gamble | Composiciones detergentes que comprenden variantes polipeptídicas |
| EP3844255A1 (en) | 2018-08-30 | 2021-07-07 | Danisco US Inc. | Enzyme-containing granules |
| EP3864122A1 (en) * | 2018-10-09 | 2021-08-18 | Novozymes A/S | Cleaning compositions and uses thereof |
| CN114174504A (zh) | 2019-05-24 | 2022-03-11 | 丹尼斯科美国公司 | 枯草杆菌蛋白酶变体和使用方法 |
| CN114174486A (zh) | 2019-06-06 | 2022-03-11 | 丹尼斯科美国公司 | 用于清洁的方法和组合物 |
| BR112022007697A2 (pt) | 2019-10-24 | 2022-07-12 | Danisco Us Inc | Alfa-amilase variante que forma maltopentaose/maltohexaose |
| US20240228913A1 (en) * | 2019-12-23 | 2024-07-11 | Novozymes A/S | Enzyme compositions and uses thereof |
| EP4081626A1 (en) * | 2019-12-23 | 2022-11-02 | The Procter & Gamble Company | Compositions comprising enzymes |
| WO2021161148A1 (en) | 2020-02-10 | 2021-08-19 | Virox Technologies Inc. | Antimicrobial compositions containing peroxyphthalic acid and/or salt thereof |
| EP3907271A1 (en) * | 2020-05-07 | 2021-11-10 | Novozymes A/S | Cleaning composition, use and method of cleaning |
| US20230203402A1 (en) * | 2020-06-11 | 2023-06-29 | Kao Corporation | Cleaning composition for oral appliance |
| WO2022047149A1 (en) | 2020-08-27 | 2022-03-03 | Danisco Us Inc | Enzymes and enzyme compositions for cleaning |
| EP4237530A1 (en) | 2020-10-29 | 2023-09-06 | The Procter & Gamble Company | Cleaning compositions containing alginate lyase enzymes |
| CN112410321B (zh) * | 2020-11-26 | 2022-01-28 | 昆明理工大学 | 一种β-葡萄糖苷酶Ttbgl3及其应用 |
| WO2022165107A1 (en) | 2021-01-29 | 2022-08-04 | Danisco Us Inc | Compositions for cleaning and methods related thereto |
| EP4060036A1 (en) * | 2021-03-15 | 2022-09-21 | Novozymes A/S | Polypeptide variants |
| MX2023005793A (es) * | 2021-03-15 | 2023-05-29 | Procter & Gamble | Composiciones de limpieza que contienen variantes de polipeptido. |
| CA3220135A1 (en) * | 2021-06-16 | 2022-12-22 | Novozymes A/S | Method for controlling slime in a pulp or paper making process |
| WO2023278297A1 (en) | 2021-06-30 | 2023-01-05 | Danisco Us Inc | Variant lipases and uses thereof |
| EP4396320A2 (en) | 2021-09-03 | 2024-07-10 | Danisco US Inc. | Laundry compositions for cleaning |
| CN117957318A (zh) | 2021-09-13 | 2024-04-30 | 丹尼斯科美国公司 | 含有生物活性物质的颗粒 |
| EP4426362A1 (en) | 2021-11-05 | 2024-09-11 | Nutrition & Biosciences USA 4, Inc. | Glucan derivatives for microbial control |
| EP4448750A2 (en) | 2021-12-16 | 2024-10-23 | Danisco US Inc. | Subtilisin variants and uses thereof |
| EP4448749A2 (en) | 2021-12-16 | 2024-10-23 | Danisco US Inc. | Subtilisin variants and methods of use |
| CN118679251A (zh) | 2021-12-16 | 2024-09-20 | 丹尼斯科美国公司 | 枯草杆菌蛋白酶变体和使用方法 |
| WO2023114988A2 (en) | 2021-12-16 | 2023-06-22 | Danisco Us Inc. | Variant maltopentaose/maltohexaose-forming alpha-amylases |
| WO2023168234A1 (en) | 2022-03-01 | 2023-09-07 | Danisco Us Inc. | Enzymes and enzyme compositions for cleaning |
| EP4273210A1 (en) | 2022-05-04 | 2023-11-08 | The Procter & Gamble Company | Detergent compositions containing enzymes |
| EP4273209A1 (en) | 2022-05-04 | 2023-11-08 | The Procter & Gamble Company | Machine-cleaning compositions containing enzymes |
| CN119487167A (zh) | 2022-06-21 | 2025-02-18 | 丹尼斯科美国公司 | 用于清洁的包含具有嗜热菌蛋白酶活性的多肽的组合物和方法 |
| CN120112635A (zh) | 2022-09-02 | 2025-06-06 | 丹尼斯科美国公司 | 枯草杆菌蛋白酶变体及其相关方法 |
| CA3265943A1 (en) | 2022-09-02 | 2024-03-07 | Danisco Us Inc. | DETERGENT COMPOSITIONS AND ASSOCIATED PROCESSES |
| WO2024102698A1 (en) | 2022-11-09 | 2024-05-16 | Danisco Us Inc. | Subtilisin variants and methods of use |
| EP4658776A1 (en) | 2023-02-01 | 2025-12-10 | Danisco US Inc. | Subtilisin variants and methods of use |
| US20240263162A1 (en) | 2023-02-01 | 2024-08-08 | The Procter & Gamble Company | Detergent compositions containing enzymes |
| WO2024186819A1 (en) | 2023-03-06 | 2024-09-12 | Danisco Us Inc. | Subtilisin variants and methods of use |
| EP4680013A1 (en) | 2023-03-16 | 2026-01-21 | Nutrition & Biosciences USA 4, Inc. | Brevibacillus fermentate extracts for cleaning and malodor control and use thereof |
| EP4481027A1 (en) | 2023-06-19 | 2024-12-25 | The Procter & Gamble Company | Cleaning compositions containing enzymes |
| EP4488351A1 (en) | 2023-07-03 | 2025-01-08 | The Procter & Gamble Company | Compositions containing a porphyrin binding protein |
| WO2025071996A1 (en) | 2023-09-28 | 2025-04-03 | Danisco Us Inc. | Variant cutinase enzymes with improved solubility and uses thereof |
| WO2025085351A1 (en) | 2023-10-20 | 2025-04-24 | Danisco Us Inc. | Subtilisin variants and methods of use |
| WO2026024922A1 (en) | 2024-07-25 | 2026-01-29 | Danisco Us Inc. | Subtilisin variants and methods of use |
Family Cites Families (278)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB1296839A (es) | 1969-05-29 | 1972-11-22 | ||
| GB1483591A (en) | 1973-07-23 | 1977-08-24 | Novo Industri As | Process for coating water soluble or water dispersible particles by means of the fluid bed technique |
| GB1590432A (en) | 1976-07-07 | 1981-06-03 | Novo Industri As | Process for the production of an enzyme granulate and the enzyme granuate thus produced |
| DK187280A (da) | 1980-04-30 | 1981-10-31 | Novo Industri As | Ruhedsreducerende middel til et fuldvaskemiddel fuldvaskemiddel og fuldvaskemetode |
| DK263584D0 (da) | 1984-05-29 | 1984-05-29 | Novo Industri As | Enzymholdige granulater anvendt som detergentadditiver |
| JPS61104784A (ja) | 1984-10-26 | 1986-05-23 | Suntory Ltd | ペルオキシダ−ゼの製造法 |
| JPH0697997B2 (ja) | 1985-08-09 | 1994-12-07 | ギスト ブロカデス ナ−ムロ−ゼ フエンノ−トチヤツプ | 新規の酵素的洗浄剤添加物 |
| EG18543A (en) | 1986-02-20 | 1993-07-30 | Albright & Wilson | Protected enzyme systems |
| DK122686D0 (da) | 1986-03-17 | 1986-03-17 | Novo Industri As | Fremstilling af proteiner |
| US5989870A (en) | 1986-04-30 | 1999-11-23 | Rohm Enzyme Finland Oy | Method for cloning active promoters |
| ES2058119T3 (es) | 1986-08-29 | 1994-11-01 | Novo Nordisk As | Aditivo detergente enzimatico. |
| US5389536A (en) | 1986-11-19 | 1995-02-14 | Genencor, Inc. | Lipase from Pseudomonas mendocina having cutinase activity |
| DE3854249T2 (de) | 1987-08-28 | 1996-02-29 | Novonordisk As | Rekombinante Humicola-Lipase und Verfahren zur Herstellung von rekombinanten Humicola-Lipasen. |
| WO1989006270A1 (en) | 1988-01-07 | 1989-07-13 | Novo-Nordisk A/S | Enzymatic detergent |
| DK6488D0 (da) | 1988-01-07 | 1988-01-07 | Novo Industri As | Enzymer |
| JP3079276B2 (ja) | 1988-02-28 | 2000-08-21 | 天野製薬株式会社 | 組換え体dna、それを含むシュードモナス属菌及びそれを用いたリパーゼの製造法 |
| EP0406314B1 (en) | 1988-03-24 | 1993-12-01 | Novo Nordisk A/S | A cellulase preparation |
| US5776757A (en) | 1988-03-24 | 1998-07-07 | Novo Nordisk A/S | Fungal cellulase composition containing alkaline CMC-endoglucanase and essentially no cellobiohydrolase and method of making thereof |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| JPH02238885A (ja) | 1989-03-13 | 1990-09-21 | Oji Paper Co Ltd | フェノールオキシダーゼ遺伝子組換えdna、該組換えdnaにより形質転換された微生物、その培養物及びフェノールオキシダーゼの製造方法 |
| GB8915658D0 (en) | 1989-07-07 | 1989-08-23 | Unilever Plc | Enzymes,their production and use |
| DE69033388T2 (de) | 1989-08-25 | 2000-05-11 | Henkel Research Corp., Santa Rosa | Alkalisches proteolytisches enzym und verfahren zur herstellung |
| AU639570B2 (en) | 1990-05-09 | 1993-07-29 | Novozymes A/S | A cellulase preparation comprising an endoglucanase enzyme |
| DK115890D0 (da) | 1990-05-09 | 1990-05-09 | Novo Nordisk As | Enzym |
| FI903443A7 (fi) | 1990-07-06 | 1992-01-07 | Valtion Teknillinen | Framstaellning av lackas genom rekombinantorganismer. |
| DK0548228T3 (da) | 1990-09-13 | 1999-05-10 | Novo Nordisk As | Lipasevarianter |
| IL99552A0 (en) | 1990-09-28 | 1992-08-18 | Ixsys Inc | Compositions containing procaryotic cells,a kit for the preparation of vectors useful for the coexpression of two or more dna sequences and methods for the use thereof |
| SG52693A1 (en) | 1991-01-16 | 1998-09-28 | Procter & Gamble | Detergent compositions with high activity cellulase and softening clays |
| US5292796A (en) | 1991-04-02 | 1994-03-08 | Minnesota Mining And Manufacturing Company | Urea-aldehyde condensates and melamine derivatives comprising fluorochemical oligomers |
| DK58491D0 (da) | 1991-04-03 | 1991-04-03 | Novo Nordisk As | Hidtil ukendte proteaser |
| ES2121014T3 (es) | 1991-05-01 | 1998-11-16 | Novo Nordisk As | Enzimas estabilizadas y composiciones detergentes. |
| US5340735A (en) | 1991-05-29 | 1994-08-23 | Cognis, Inc. | Bacillus lentus alkaline protease variants with increased stability |
| WO1993012067A1 (en) | 1991-12-13 | 1993-06-24 | The Procter & Gamble Company | Acylated citrate esters as peracid precursors |
| DK28792D0 (da) | 1992-03-04 | 1992-03-04 | Novo Nordisk As | Nyt enzym |
| DK72992D0 (da) | 1992-06-01 | 1992-06-01 | Novo Nordisk As | Enzym |
| DK88892D0 (da) | 1992-07-06 | 1992-07-06 | Novo Nordisk As | Forbindelse |
| DE69334295D1 (de) | 1992-07-23 | 2009-11-12 | Novo Nordisk As | MUTIERTE -g(a)-AMYLASE, WASCHMITTEL UND GESCHIRRSPÜLMITTEL |
| EP1431389A3 (en) | 1992-10-06 | 2004-06-30 | Novozymes A/S | Cellulase variants |
| ATE175235T1 (de) | 1993-02-11 | 1999-01-15 | Genencor Int | Oxidativ stabile alpha-amylase |
| AU673078B2 (en) | 1993-04-27 | 1996-10-24 | Genencor International, Inc. | New lipase variants for use in detergent applications |
| DK52393D0 (es) | 1993-05-05 | 1993-05-05 | Novo Nordisk As | |
| FR2704860B1 (fr) | 1993-05-05 | 1995-07-13 | Pasteur Institut | Sequences de nucleotides du locus cryiiia pour le controle de l'expression de sequences d'adn dans un hote cellulaire. |
| JP2859520B2 (ja) | 1993-08-30 | 1999-02-17 | ノボ ノルディスク アクティーゼルスカブ | リパーゼ及びそれを生産する微生物及びリパーゼ製造方法及びリパーゼ含有洗剤組成物 |
| JPH09503916A (ja) | 1993-10-08 | 1997-04-22 | ノボ ノルディスク アクティーゼルスカブ | アミラーゼ変異体 |
| US5817495A (en) | 1993-10-13 | 1998-10-06 | Novo Nordisk A/S | H2 O2 -stable peroxidase variants |
| JPH07143883A (ja) | 1993-11-24 | 1995-06-06 | Showa Denko Kk | リパーゼ遺伝子及び変異体リパーゼ |
| DE4343591A1 (de) | 1993-12-21 | 1995-06-22 | Evotec Biosystems Gmbh | Verfahren zum evolutiven Design und Synthese funktionaler Polymere auf der Basis von Formenelementen und Formencodes |
| US5605793A (en) | 1994-02-17 | 1997-02-25 | Affymax Technologies N.V. | Methods for in vitro recombination |
| ATE222604T1 (de) | 1994-02-22 | 2002-09-15 | Novozymes As | Methode zur herstellung einer variante eines lipolytischen enzymes |
| ATE512226T1 (de) | 1994-02-24 | 2011-06-15 | Henkel Ag & Co Kgaa | Verbesserte enzyme und detergentien damit |
| DE69536145D1 (de) | 1994-03-08 | 2011-04-07 | Novozymes As | Neuartige alkalische Zellulasen |
| NL9401048A (nl) | 1994-03-31 | 1995-11-01 | Stichting Scheikundig Onderzoe | Haloperoxidasen. |
| WO1995030744A2 (en) | 1994-05-04 | 1995-11-16 | Genencor International Inc. | Lipases with improved surfactant resistance |
| DK0765394T3 (da) | 1994-06-03 | 2001-12-10 | Novozymes As | Oprensede Myceliopthora-laccaser og nukleinsyrer der koder for disse |
| WO1995035381A1 (en) | 1994-06-20 | 1995-12-28 | Unilever N.V. | Modified pseudomonas lipases and their use |
| WO1996000292A1 (en) | 1994-06-23 | 1996-01-04 | Unilever N.V. | Modified pseudomonas lipases and their use |
| DE69534185T2 (de) | 1994-06-30 | 2006-02-23 | Novozymes Biotech, Inc., Davis | Nicht-toxisches, nicht-toxigenes, nicht-pathogenes fusarium expressionssystem und darin zu verwendende promotoren und terminatoren |
| EP1995303A3 (en) | 1994-10-06 | 2008-12-31 | Novozymes A/S | Enzyme preparation with endoglucanase activity |
| BE1008998A3 (fr) | 1994-10-14 | 1996-10-01 | Solvay | Lipase, microorganisme la produisant, procede de preparation de cette lipase et utilisations de celle-ci. |
| AU3697995A (en) | 1994-10-26 | 1996-05-23 | Novo Nordisk A/S | An enzyme with lipolytic activity |
| AR000862A1 (es) | 1995-02-03 | 1997-08-06 | Novozymes As | Variantes de una ó-amilasa madre, un metodo para producir la misma, una estructura de adn y un vector de expresion, una celula transformada por dichaestructura de adn y vector, un aditivo para detergente, composicion detergente, una composicion para lavado de ropa y una composicion para la eliminacion del |
| JPH08228778A (ja) | 1995-02-27 | 1996-09-10 | Showa Denko Kk | 新規なリパーゼ遺伝子及びそれを用いたリパーゼの製造方法 |
| CN1182451A (zh) | 1995-03-17 | 1998-05-20 | 诺沃挪第克公司 | 新的内切葡聚糖酶 |
| BR9608149B1 (pt) | 1995-05-05 | 2012-01-24 | processos para efetuar mutação no dna que codifica uma enzima de subtilase ou sua pré- ou pré-pró-enzima e para a manufatura de uma enzima de subtilase mutante. | |
| WO1997007202A1 (en) | 1995-08-11 | 1997-02-27 | Novo Nordisk A/S | Novel lipolytic enzymes |
| WO1997004078A1 (en) | 1995-07-14 | 1997-02-06 | Novo Nordisk A/S | A modified enzyme with lipolytic activity |
| DE69636754T2 (de) | 1995-07-14 | 2007-10-11 | Novozymes, Inc., Davis | Haloperoxidasen aus curvularia verruculosa und nukleinsäuren, die für diese codieren |
| DE19528059A1 (de) | 1995-07-31 | 1997-02-06 | Bayer Ag | Wasch- und Reinigungsmittel mit Iminodisuccinaten |
| US6008029A (en) | 1995-08-25 | 1999-12-28 | Novo Nordisk Biotech Inc. | Purified coprinus laccases and nucleic acids encoding the same |
| PH11997056158B1 (en) | 1996-04-16 | 2001-10-15 | Procter & Gamble | Mid-chain branched primary alkyl sulphates as surfactants |
| EG21623A (en) | 1996-04-16 | 2001-12-31 | Procter & Gamble | Mid-chain branced surfactants |
| US5763385A (en) | 1996-05-14 | 1998-06-09 | Genencor International, Inc. | Modified α-amylases having altered calcium binding properties |
| WO1998008940A1 (en) | 1996-08-26 | 1998-03-05 | Novo Nordisk A/S | A novel endoglucanase |
| DE69735767T2 (de) | 1996-09-17 | 2007-04-05 | Novozymes A/S | Cellulasevarianten |
| WO1998015257A1 (en) | 1996-10-08 | 1998-04-16 | Novo Nordisk A/S | Diaminobenzoic acid derivatives as dye precursors |
| EP0934389B1 (en) | 1996-10-18 | 2003-12-10 | The Procter & Gamble Company | Detergent compositions |
| AU4772697A (en) | 1996-11-04 | 1998-05-29 | Novo Nordisk A/S | Subtilase variants and compositions |
| CN1530443A (zh) | 1996-11-04 | 2004-09-22 | ŵ����÷������˾ | 枯草杆菌酶变异体和组合物 |
| EP1002061A1 (en) | 1997-07-04 | 2000-05-24 | Novo Nordisk A/S | FAMILY 6 ENDO-1,4-$g(b)-GLUCANASE VARIANTS AND CLEANING COMPOSIT IONS CONTAINING THEM |
| DE69839076T2 (de) | 1997-08-29 | 2009-01-22 | Novozymes A/S | Proteasevarianten und zusammensetzungen |
| EP2206768B1 (en) | 1997-10-13 | 2015-04-01 | Novozymes A/S | Alpha-amylase mutants |
| US5955310A (en) | 1998-02-26 | 1999-09-21 | Novo Nordisk Biotech, Inc. | Methods for producing a polypeptide in a bacillus cell |
| WO2000034450A1 (en) | 1998-12-04 | 2000-06-15 | Novozymes A/S | Cutinase variants |
| JP2003530440A (ja) | 1998-10-13 | 2003-10-14 | ザ、プロクター、エンド、ギャンブル、カンパニー | 洗剤組成物または成分 |
| EP1124949B1 (en) | 1998-10-26 | 2006-07-12 | Novozymes A/S | Constructing and screening a dna library of interest in filamentous fungal cells |
| CN1940067A (zh) | 1999-03-22 | 2007-04-04 | 诺沃奇梅兹有限公司 | 用于在真菌细胞中表达基因的启动子 |
| KR20010108379A (ko) | 1999-03-31 | 2001-12-07 | 피아 스타르 | 리파제 변이체 |
| EP1214426A2 (en) | 1999-08-31 | 2002-06-19 | Novozymes A/S | Novel proteases and variants thereof |
| CN101974375B (zh) | 1999-12-15 | 2014-07-02 | 诺沃奇梅兹有限公司 | 对蛋渍具有改进洗涤性能的枯草杆菌酶变体 |
| ES2322690T3 (es) | 2000-02-24 | 2009-06-25 | Novozymes A/S | Xiloglucanasas de la familia 44. |
| JP5571274B2 (ja) | 2000-03-08 | 2014-08-13 | ノボザイムス アクティーゼルスカブ | 改変された特性を有する変異体 |
| WO2001079464A2 (en) | 2000-04-14 | 2001-10-25 | Novozymes A/S | Nucleic acids encoding polypeptides having haloperoxidase activity |
| AU2001246404A1 (en) | 2000-04-14 | 2001-10-30 | Novozymes A/S | Polypeptides having haloperoxidase activity |
| AU2001246402A1 (en) | 2000-04-14 | 2001-10-30 | Novozymes A/S | Polypeptides having haloperoxidase activity |
| WO2001079463A2 (en) | 2000-04-14 | 2001-10-25 | Novozymes A/S | Nucleic acids encoding polypeptides having haloperoxidase activity |
| DE60112928T2 (de) | 2000-06-02 | 2006-06-14 | Novozymes As | Cutinase-varianten |
| JP4855632B2 (ja) | 2000-08-01 | 2012-01-18 | ノボザイムス アクティーゼルスカブ | 変更された性質を有するα−アミラーゼ突然変異体 |
| CN1337553A (zh) | 2000-08-05 | 2002-02-27 | 李海泉 | 地下观光游乐园 |
| CA2419896C (en) | 2000-08-21 | 2014-12-09 | Novozymes A/S | Subtilase enzymes |
| DK1399543T3 (da) | 2001-06-06 | 2014-11-03 | Novozymes As | Endo-beta-1,4-glucanase |
| DK200101090A (da) | 2001-07-12 | 2001-08-16 | Novozymes As | Subtilase variants |
| EP1421187B1 (en) | 2001-07-27 | 2007-10-10 | THE GOVERNMENT OF THE UNITED STATES OF AMERICA, as represented by THE SECRETARY, DEPARTMENT OF HEALTH AND HUMAN SERVICES | Systems for in vivo site-directed mutagenesis using oligonucleotides |
| GB0127036D0 (en) | 2001-11-09 | 2002-01-02 | Unilever Plc | Polymers for laundry applications |
| DE10162728A1 (de) | 2001-12-20 | 2003-07-10 | Henkel Kgaa | Neue Alkalische Protease aus Bacillus gibsonii (DSM 14393) und Wasch-und Reinigungsmittel enthaltend diese neue Alkalische Protease |
| ATE439422T1 (de) | 2002-06-11 | 2009-08-15 | Unilever Nv | Waschmitteltabletten |
| CN101597601B (zh) | 2002-06-26 | 2013-06-05 | 诺维信公司 | 具有改变的免疫原性的枯草杆菌酶和枯草杆菌酶变体 |
| TWI319007B (en) | 2002-11-06 | 2010-01-01 | Novozymes As | Subtilase variants |
| WO2004067737A2 (en) | 2003-01-30 | 2004-08-12 | Novozymes A/S | Subtilases |
| CN1751116A (zh) | 2003-02-18 | 2006-03-22 | 诺和酶股份有限公司 | 洗涤剂组合物 |
| CA2529726A1 (en) | 2003-06-18 | 2005-01-13 | Unilever Plc | Laundry treatment compositions |
| GB0314210D0 (en) | 2003-06-18 | 2003-07-23 | Unilever Plc | Laundry treatment compositions |
| GB0314211D0 (en) | 2003-06-18 | 2003-07-23 | Unilever Plc | Laundry treatment compositions |
| CN1871344A (zh) | 2003-10-23 | 2006-11-29 | 诺和酶股份有限公司 | 在洗涤剂中具有改善稳定性的蛋白酶 |
| AU2004293826B2 (en) | 2003-11-19 | 2009-09-17 | Danisco Us Inc. | Serine proteases, nucleic acids encoding serine enzymes and vectors and host cells incorporating same |
| EP2295554B1 (en) | 2003-12-03 | 2012-11-28 | Danisco US Inc. | Perhydrolase |
| CA2593920A1 (en) | 2004-12-23 | 2006-06-29 | Novozymes A/S | Alpha-amylase variants |
| DE602006002151D1 (de) | 2005-03-23 | 2008-09-25 | Unilever Nv | Körperförmige Wasch- oder Reinigungsmittelzusammensetzungen |
| BRPI0609363A2 (pt) | 2005-04-15 | 2010-03-30 | Procter & Gamble | composições para limpeza com polialquileno iminas alcoxiladas |
| PL1869155T3 (pl) | 2005-04-15 | 2011-03-31 | Procter & Gamble | Ciekłe kompozycje detergentu do prania ze zmodyfikowanymi polimerami polietylenoiminy oraz enzymem lipazy |
| EP1888734A2 (en) | 2005-05-31 | 2008-02-20 | The Procter and Gamble Company | Polymer-containing detergent compositions and their use |
| CA2610018C (en) | 2005-06-17 | 2011-09-20 | The Procter & Gamble Company | Organic catalyst with enhanced enzyme compatibility |
| CN101218343B (zh) | 2005-07-08 | 2013-11-06 | 诺维信公司 | 枯草蛋白酶变体 |
| CN105200027B (zh) | 2005-10-12 | 2019-05-31 | 金克克国际有限公司 | 储存稳定的中性金属蛋白酶的用途和制备 |
| US8518675B2 (en) | 2005-12-13 | 2013-08-27 | E. I. Du Pont De Nemours And Company | Production of peracids using an enzyme having perhydrolysis activity |
| ES2629332T3 (es) | 2006-01-23 | 2017-08-08 | Novozymes A/S | Variantes de lipasa |
| AR059154A1 (es) | 2006-01-23 | 2008-03-12 | Procter & Gamble | Una composicion que comprende una lipasa y un catalizador de blanqueador |
| AR059156A1 (es) | 2006-01-23 | 2008-03-12 | Procter & Gamble | Composiciones detergentes |
| EP1979457A2 (en) | 2006-01-23 | 2008-10-15 | The Procter and Gamble Company | A composition comprising a lipase and a bleach catalyst |
| AR059155A1 (es) | 2006-01-23 | 2008-03-12 | Procter & Gamble | Composiciones que comprenden enzimas y fotoblanqueadores |
| EP2248882A1 (en) | 2006-01-23 | 2010-11-10 | The Procter and Gamble Company | Enzyme and fabric hueing agent containing compositions |
| EP1976967A2 (en) | 2006-01-23 | 2008-10-08 | The Procter and Gamble Company | Detergent compositions |
| DE602007007945D1 (de) | 2006-05-31 | 2010-09-02 | Basf Se | Amphiphile pfropfpolymere auf basis von polyalkylenoxiden und vinylestern |
| DE202006009003U1 (de) | 2006-06-06 | 2007-10-25 | BROSE SCHLIEßSYSTEME GMBH & CO. KG | Kraftfahrzeugschloß |
| PL1867708T3 (pl) | 2006-06-16 | 2017-10-31 | Procter & Gamble | Kompozycje detergentu |
| EP1876226B1 (en) | 2006-07-07 | 2011-03-23 | The Procter & Gamble Company | Detergent compositions |
| EP2155869A2 (en) | 2007-05-30 | 2010-02-24 | Danisco US, INC., Genencor Division | Variants of an alpha-amylase with improved production levels in fermentation processes |
| WO2009000605A1 (en) | 2007-06-22 | 2008-12-31 | Unilever N.V. | Granular enzymatic detergent compositions |
| ATE503826T1 (de) | 2007-07-02 | 2011-04-15 | Procter & Gamble | Mehrkammerbeutel enthaltend waschmittel |
| GB0712988D0 (en) | 2007-07-05 | 2007-08-15 | Reckitt Benckiser Nv | Improvements in or relating to compositions |
| GB0712991D0 (en) | 2007-07-05 | 2007-08-15 | Reckitt Benckiser Nv | Improvement in or relating to compositions |
| ATE490303T1 (de) | 2007-07-16 | 2010-12-15 | Unilever Nv | Festes waschmittel |
| DE102007036392A1 (de) | 2007-07-31 | 2009-02-05 | Henkel Ag & Co. Kgaa | Zusammensetzungen enthaltend Perhydrolasen und Alkylenglykoldiacetate |
| DE102007038029A1 (de) | 2007-08-10 | 2009-02-12 | Henkel Ag & Co. Kgaa | Wasch- oder Reinigungsmittel mit polyesterbasiertem Soil-Release-Polymer |
| DE102007038031A1 (de) | 2007-08-10 | 2009-06-04 | Henkel Ag & Co. Kgaa | Mittel enthaltend Proteasen |
| EP2179023A1 (en) | 2007-08-14 | 2010-04-28 | Unilever N.V. | Detergent tablet |
| GB0716228D0 (en) | 2007-08-20 | 2007-09-26 | Reckitt Benckiser Nv | Detergent composition |
| DE102007041754A1 (de) | 2007-09-04 | 2009-03-05 | Henkel Ag & Co. Kgaa | Polycyclische Verbindungen als Enzymstabilisatoren |
| GB0718777D0 (en) | 2007-09-26 | 2007-11-07 | Reckitt Benckiser Nv | Composition |
| GB0718944D0 (en) | 2007-09-28 | 2007-11-07 | Reckitt Benckiser Nv | Detergent composition |
| CN101878291A (zh) | 2007-10-12 | 2010-11-03 | 荷兰联合利华有限公司 | 膜微粒中的功能成分 |
| WO2009047127A1 (en) | 2007-10-12 | 2009-04-16 | Unilever Plc | Granular detergent compositions with contrasting lamellar visual cues |
| MX2010003984A (es) | 2007-10-12 | 2010-07-02 | Unilever Nv | Detergente para lavanderia con aditivo de pre-tratamiento y su uso. |
| ATE531786T1 (de) | 2007-10-12 | 2011-11-15 | Unilever Nv | Verbesserte optische hinweise auf parfümierte waschmittel |
| WO2009050026A2 (en) | 2007-10-17 | 2009-04-23 | Unilever Nv | Laundry compositions |
| AU2008325250B2 (en) | 2007-11-05 | 2013-06-13 | Danisco Us Inc. | Variants of Bacillus sp. TS-23 alpha-amylase with altered properties |
| JP2011506123A (ja) | 2007-11-13 | 2011-03-03 | ザ プロクター アンド ギャンブル カンパニー | 印刷された水溶性材料を有する単位用量製品を作製するためのプロセス |
| DE102007056166A1 (de) | 2007-11-21 | 2009-05-28 | Henkel Ag & Co. Kgaa | Granulat eines sensitiven Wasch- oder Reinigungsmittelinhaltsstoffs |
| DE102007057583A1 (de) | 2007-11-28 | 2009-06-04 | Henkel Ag & Co. Kgaa | Waschmittel mit stabilisierten Enzymen |
| EP2067847B1 (en) | 2007-12-05 | 2012-03-21 | The Procter & Gamble Company | Package comprising detergent |
| DE102007059677A1 (de) | 2007-12-10 | 2009-06-25 | Henkel Ag & Co. Kgaa | Reinigungsmittel |
| DE102007059970A1 (de) | 2007-12-11 | 2009-09-10 | Henkel Ag & Co. Kgaa | Reinigungsmittel |
| RU2470069C2 (ru) | 2008-01-04 | 2012-12-20 | Дзе Проктер Энд Гэмбл Компани | Композиция средства для стирки, содержащая гликозилгидролазу |
| WO2009087033A1 (en) | 2008-01-10 | 2009-07-16 | Unilever Plc | Granules |
| EA201001199A1 (ru) | 2008-01-24 | 2011-02-28 | Юнилевер Н.В. | Композиции детергентов для посудомоечных машин |
| WO2009095645A1 (en) | 2008-01-28 | 2009-08-06 | Reckitt Benckiser N.V. | Composition |
| US20090209447A1 (en) | 2008-02-15 | 2009-08-20 | Michelle Meek | Cleaning compositions |
| EP2250259B1 (en) | 2008-02-29 | 2016-08-31 | Novozymes A/S | Polypeptides having lipase activity and polynucleotides encoding same |
| WO2009112296A1 (en) | 2008-03-14 | 2009-09-17 | Unilever Plc | Laundry treatment compositions |
| CN101970632B (zh) | 2008-03-14 | 2012-11-07 | 荷兰联合利华有限公司 | 包括聚合润滑剂的洗衣处理组合物 |
| EP2103675A1 (en) | 2008-03-18 | 2009-09-23 | The Procter and Gamble Company | Detergent composition comprising cellulosic polymer |
| DE102008014759A1 (de) | 2008-03-18 | 2009-09-24 | Henkel Ag & Co. Kgaa | Verwendung von Imidazolium-Salzen in Wasch- und Reinigungsmitteln |
| EP2103678A1 (en) | 2008-03-18 | 2009-09-23 | The Procter and Gamble Company | Detergent composition comprising a co-polyester of dicarboxylic acids and diols |
| DE102008014760A1 (de) | 2008-03-18 | 2009-09-24 | Henkel Ag & Co. Kgaa | Imidazolium-Salze als Enzymstabilisatoren |
| EP2103676A1 (en) | 2008-03-18 | 2009-09-23 | The Procter and Gamble Company | A laundry detergent composition comprising the magnesium salt of ethylene diamine-n'n' -disuccinic acid |
| GB0805908D0 (en) | 2008-04-01 | 2008-05-07 | Reckitt Benckiser Inc | Laundry treatment compositions |
| EP3061744B1 (en) | 2008-04-01 | 2018-05-09 | Unilever N.V. | Preparation of free flowing granules of methylglycine diacetic acid |
| DE102008017103A1 (de) | 2008-04-02 | 2009-10-08 | Henkel Ag & Co. Kgaa | Wasch- und Reinigungsmittel enthaltend Proteasen aus Xanthomonas |
| EP2107106A1 (en) | 2008-04-02 | 2009-10-07 | The Procter and Gamble Company | A kit of parts comprising a solid laundry detergent composition and a dosing device |
| EP2345711B1 (en) | 2008-04-02 | 2017-09-06 | The Procter and Gamble Company | Detergent composition comprising non-ionic detersive surfactant and reactive dye |
| EP2107105B1 (en) | 2008-04-02 | 2013-08-07 | The Procter and Gamble Company | Detergent composition comprising reactive dye |
| US20090253602A1 (en) | 2008-04-04 | 2009-10-08 | Conopco, Inc. D/B/A Unilever | Novel personal wash bar |
| ES2400204T5 (es) | 2008-05-02 | 2015-11-26 | Unilever N.V. | Gránulos con manchado reducido |
| PL2291505T3 (pl) | 2008-07-03 | 2013-05-31 | Henkel Ag & Co Kgaa | Stały zestaw pielęgnujący tekstylia, zawierający polisacharyd |
| WO2010003792A1 (en) | 2008-07-09 | 2010-01-14 | Unilever Plc | Laundry compositions |
| EP2300504B1 (en) | 2008-07-11 | 2012-11-28 | Unilever N.V. | Copolymers and detergent compositions |
| EP2154235A1 (en) | 2008-07-28 | 2010-02-17 | The Procter and Gamble Company | Process for preparing a detergent composition |
| ATE482264T1 (de) | 2008-08-14 | 2010-10-15 | Unilever Nv | Bauzusammensetzung |
| EP2163605A1 (en) | 2008-08-27 | 2010-03-17 | The Procter and Gamble Company | A detergent composition comprising cello-oligosaccharide oxidase |
| WO2010024467A1 (en) | 2008-09-01 | 2010-03-04 | The Procter & Gamble Company | Polymer composition and process for the production thereof |
| EP2321394B1 (en) | 2008-09-01 | 2015-03-18 | The Procter and Gamble Company | Hydrophobic group-containing copolymer and process for the production thereof |
| CA2734887A1 (en) | 2008-09-01 | 2010-03-04 | The Procter & Gamble Company | Laundry detergent or cleaning composition comprising a polyoxyalkylene-based polymer composition |
| EP2166078B1 (en) | 2008-09-12 | 2018-11-21 | The Procter & Gamble Company | Laundry particle made by extrusion comprising a hueing dye |
| EP2166077A1 (en) | 2008-09-12 | 2010-03-24 | The Procter and Gamble Company | Particles comprising a hueing dye |
| EP2163608A1 (en) | 2008-09-12 | 2010-03-17 | The Procter & Gamble Company | Laundry particle made by extrusion comprising a hueing dye and fatty acid soap |
| DE102008047941A1 (de) | 2008-09-18 | 2010-03-25 | Henkel Ag & Co. Kgaa | Bleichmittel-haltiges Reinigungsmittel |
| CN102159693A (zh) | 2008-09-19 | 2011-08-17 | 宝洁公司 | 可用于清洁产品中的双重特征生物聚合物 |
| EP2324106A1 (en) | 2008-09-19 | 2011-05-25 | The Procter & Gamble Company | Detergent composition containing suds boosting and suds stabilizing modified biopolymer |
| EP2650275A1 (en) | 2008-09-22 | 2013-10-16 | The Procter & Gamble Company | Specific polybranched alcohols and consumer products based thereon |
| WO2010039889A2 (en) | 2008-09-30 | 2010-04-08 | Novozymes, Inc. | Methods for using positively and negatively selectable genes in a filamentous fungal cell |
| EP2169040B1 (en) | 2008-09-30 | 2012-04-11 | The Procter & Gamble Company | Liquid detergent compositions exhibiting two or multicolor effect |
| WO2010049187A1 (de) | 2008-10-31 | 2010-05-06 | Henkel Ag & Co. Kgaa | Maschinelles geschirrspülmittel |
| WO2010054986A1 (en) | 2008-11-12 | 2010-05-20 | Unilever Plc | Fabric whiteness measurement system |
| WO2010057784A1 (en) | 2008-11-20 | 2010-05-27 | Unilever Plc | Fabric whiteness measurement system |
| DE102008059447A1 (de) | 2008-11-27 | 2010-06-02 | Henkel Ag & Co. Kgaa | Wasch- und Reinigungsmittel enthaltend Proteasen aus Bacillus pumilus |
| EP2367923A2 (en) | 2008-12-01 | 2011-09-28 | Danisco US Inc. | Enzymes with lipase activity |
| DE102008060469A1 (de) | 2008-12-05 | 2010-06-10 | Henkel Ag & Co. Kgaa | Maschinelle Geschirrspülmitteltablette |
| DE102008060886A1 (de) | 2008-12-09 | 2010-06-10 | Henkel Ag & Co. Kgaa | Photolabile Duftspeicherstoffe |
| WO2010066631A1 (en) | 2008-12-12 | 2010-06-17 | Henkel Ag & Co. Kgaa | Laundry article having cleaning and conditioning properties |
| WO2010066632A1 (en) | 2008-12-12 | 2010-06-17 | Henkel Ag & Co. Kgaa | Laundry article having cleaning and conditioning properties |
| DE102008061859A1 (de) | 2008-12-15 | 2010-06-17 | Henkel Ag & Co. Kgaa | Maschinelles Geschirrspülmittel |
| DE102008061858A1 (de) | 2008-12-15 | 2010-06-17 | Henkel Ag & Co. Kgaa | Maschinelles Geschirrspülmittel |
| CN102257113B (zh) | 2008-12-16 | 2013-05-08 | 荷兰联合利华有限公司 | 固体助洗剂组合物 |
| WO2010069957A1 (en) | 2008-12-17 | 2010-06-24 | Unilever Plc | Laundry detergent composition |
| WO2010069742A1 (en) | 2008-12-18 | 2010-06-24 | Unilever Nv | Laundry detergent composition |
| DE102008063801A1 (de) | 2008-12-19 | 2010-06-24 | Henkel Ag & Co. Kgaa | Maschinelles Geschirrspülmittel |
| DE102008063070A1 (de) | 2008-12-23 | 2010-07-01 | Henkel Ag & Co. Kgaa | Verwendung sternförmiger Polymere mit peripheren negativ geladenen Gruppen und/oder peripheren Silyl-Gruppen zur Ausrüstung von Oberflächen |
| AU2009334830B2 (en) | 2008-12-29 | 2013-05-16 | Unilever Plc | Structured aqueous detergent compositions |
| DE102009004524A1 (de) | 2009-01-09 | 2010-07-15 | Henkel Ag & Co. Kgaa | Farbschützendes maschinelles Geschirrspülmittel |
| US20110275551A1 (en) | 2009-01-26 | 2011-11-10 | Stephen Norman Batchelor | Incorporation of dye into granular laundry detergent |
| DE102009000409A1 (de) | 2009-01-26 | 2010-07-29 | Henkel Ag & Co. Kgaa | Waschzusatzartikel |
| EP3998328A1 (en) | 2009-02-09 | 2022-05-18 | The Procter & Gamble Company | Detergent composition |
| WO2010094356A1 (en) | 2009-02-18 | 2010-08-26 | Henkel Ag & Co. Kgaa | Pro-fragrance copolymeric compounds |
| CN102341489B (zh) | 2009-03-05 | 2014-05-14 | 荷兰联合利华有限公司 | 染料自由基引发剂 |
| MX2011008656A (es) | 2009-03-06 | 2011-09-06 | Huntsman Adv Mat Switzerland | Metodos de decoloracion-blanqueo enzimatico de textiles. |
| MY154041A (en) | 2009-03-12 | 2015-04-30 | Unilever Plc | Dye-polymers formulations |
| US20100229312A1 (en) | 2009-03-16 | 2010-09-16 | De Buzzaccarini Francesco | Cleaning method |
| WO2010107560A2 (en) | 2009-03-18 | 2010-09-23 | Danisco Us Inc. | Fungal cutinase from magnaporthe grisea |
| US8293697B2 (en) | 2009-03-18 | 2012-10-23 | The Procter & Gamble Company | Structured fluid detergent compositions comprising dibenzylidene sorbitol acetal derivatives |
| US8153574B2 (en) | 2009-03-18 | 2012-04-10 | The Procter & Gamble Company | Structured fluid detergent compositions comprising dibenzylidene polyol acetal derivatives and detersive enzymes |
| DE102009001693A1 (de) | 2009-03-20 | 2010-09-23 | Henkel Ag & Co. Kgaa | 4-Aminopyridin-Derivate als Katalysatoren für die Spaltung organischer Ester |
| DE102009001692A1 (de) | 2009-03-20 | 2010-09-23 | Henkel Ag & Co. Kgaa | Wasch- oder Reinigungsmittel mit gegebenenfalls in situ erzeugtem bleichverstärkendem Übergangsmetallkomplex |
| DE102009001691A1 (de) | 2009-03-20 | 2010-09-23 | Henkel Ag & Co. Kgaa | Wasch- oder Reinigungsmittel mit gegebenenfalls in situ erzeugtem bleichverstärkendem Übergangsmetallkomplex |
| US20120058527A1 (en) | 2009-03-23 | 2012-03-08 | Danisco Us Inc. | Cal a-related acyltransferases and methods of use, thereof |
| EP2233557A1 (en) | 2009-03-26 | 2010-09-29 | The Procter & Gamble Company | A perfume encapsulate, a laundry detergent composition comprising a perfume encapsulate, and a process for preparing a perfume encapsulate |
| DE102009002262A1 (de) | 2009-04-07 | 2010-10-14 | Henkel Ag & Co. Kgaa | Präbiotische Handgeschirrspülmittel |
| DE102009002384A1 (de) | 2009-04-15 | 2010-10-21 | Henkel Ag & Co. Kgaa | Granulares Wasch-, Reinigungs- oder Behandlungsmitteladditiv |
| US8263543B2 (en) | 2009-04-17 | 2012-09-11 | The Procter & Gamble Company | Fabric care compositions comprising organosiloxane polymers |
| WO2010122051A1 (en) | 2009-04-24 | 2010-10-28 | Unilever Plc | High active detergent particles |
| AU2010249841B2 (en) | 2009-05-19 | 2014-05-15 | The Procter & Gamble Company | A method for printing water-soluble film |
| DE102009050438A1 (de) | 2009-06-08 | 2010-12-09 | Henkel Ag & Co. Kgaa | Nanopartikuläres Mangandioxid |
| BRPI1012179B1 (pt) | 2009-06-12 | 2019-05-07 | Unilever N.V. | Composição detergente e método doméstico de tratamento de tecidos |
| ES2436446T3 (es) | 2009-06-15 | 2014-01-02 | Unilever Nv | Composición de detergente que comprende polímero colorante aniónico |
| WO2011005730A1 (en) | 2009-07-09 | 2011-01-13 | The Procter & Gamble Company | A catalytic laundry detergent composition comprising relatively low levels of water-soluble electrolyte |
| WO2011005630A1 (en) | 2009-07-09 | 2011-01-13 | The Procter & Gamble Company | Method of laundering fabric using a compacted laundry detergent composition |
| US20110005002A1 (en) | 2009-07-09 | 2011-01-13 | Hiroshi Oh | Method of Laundering Fabric |
| MX342487B (es) | 2009-07-09 | 2016-09-29 | The Procter & Gamble Company * | Composicion detergente solida para tratamiento de tela con bajo contenido de aditivo. ligeramente alcalina, que comprende acido ftalimido peroxicaproico. |
| WO2011005623A1 (en) | 2009-07-09 | 2011-01-13 | The Procter & Gamble Company | Laundry detergent composition comprising low level of bleach |
| EP2451925A1 (en) | 2009-07-09 | 2012-05-16 | The Procter & Gamble Company | Method of laundering fabric using a compacted laundry detergent composition |
| EP2451932A1 (en) | 2009-07-09 | 2012-05-16 | The Procter & Gamble Company | Method of laundering fabric using a compacted laundry detergent composition |
| MX2012000482A (es) | 2009-07-09 | 2012-01-27 | Procter & Gamble | Proceso continuo para fabricar una composicion detergen te de lavanderia. |
| WO2011005813A1 (en) | 2009-07-09 | 2011-01-13 | The Procter & Gamble Company | Method of laundering fabric using a compacted laundry detergent composition |
| US20110005001A1 (en) | 2009-07-09 | 2011-01-13 | Eric San Jose Robles | Detergent Composition |
| US20110009307A1 (en) | 2009-07-09 | 2011-01-13 | Alan Thomas Brooker | Laundry Detergent Composition Comprising Low Level of Sulphate |
| WO2011016958A2 (en) | 2009-07-27 | 2011-02-10 | The Procter & Gamble Company | Detergent composition |
| HUE029942T2 (en) | 2009-08-13 | 2017-04-28 | Procter & Gamble | Method for washing low temperature fabrics |
| DE102009028891A1 (de) | 2009-08-26 | 2011-03-03 | Henkel Ag & Co. Kgaa | Verbesserte Waschleistung durch Radikalfänger |
| US20120252106A1 (en) | 2009-09-25 | 2012-10-04 | Novozymes A/S | Use of Protease Variants |
| CA2775045A1 (en) | 2009-09-25 | 2011-03-31 | Novozymes A/S | Subtilase variants for use in detergent and cleaning compositions |
| BR112012017056A2 (pt) | 2009-12-21 | 2016-11-22 | Danisco Us Inc | "composições detergentes contendo lipase de bacillus subtilis e métodos para uso das mesmas" |
| BR112012017060A2 (pt) | 2009-12-21 | 2016-11-29 | Danisco Us Inc | "composições detergentes contendo lipase de thermobifida fusca, método para hidrolisar um lipídio presente em uma sujeira ou mancha sobre uma superfície e método para realizar uma reação de transesterificação |
| BR112012017062A2 (pt) | 2009-12-21 | 2016-11-29 | Danisco Us Inc | "composições deterfgentes contendo lipase de geobacillus stearothermophilus e métodos para uso das mesmas" |
| MX369096B (es) | 2010-02-10 | 2019-10-29 | Novozymes As | Variantes y composiciones que comprenden variantes con alta estabilidad en presencia de un agente quelante. |
| US20130045498A1 (en) | 2010-03-01 | 2013-02-21 | Novozymes A/S | Viscosity pressure assay |
| EP2674477B1 (en) | 2010-04-01 | 2018-09-12 | The Procter and Gamble Company | Cationic polymer stabilized microcapsule composition |
| AR081423A1 (es) | 2010-05-28 | 2012-08-29 | Danisco Us Inc | Composiciones detergentes con contenido de lipasa de streptomyces griseus y metodos para utilizarlas |
| MX2013011617A (es) | 2011-04-08 | 2013-11-21 | Danisco Us Inc | Composiciones. |
| WO2013001078A1 (en) | 2011-06-30 | 2013-01-03 | Novozymes A/S | Alpha-amylase variants |
| EP4026901B1 (en) | 2011-06-30 | 2025-01-22 | Novozymes A/S | Method for screening alpha-amylases |
| EP2674475A1 (en) | 2012-06-11 | 2013-12-18 | The Procter & Gamble Company | Detergent composition |
| US20170152462A1 (en) * | 2014-04-11 | 2017-06-01 | Novozymes A/S | Detergent Composition |
| CA2950380A1 (en) | 2014-07-04 | 2016-01-07 | Novozymes A/S | Subtilase variants and polynucleotides encoding same |
| CN107636134A (zh) | 2015-04-10 | 2018-01-26 | 诺维信公司 | 洗涤剂组合物 |
| EP3294881B1 (en) | 2015-05-08 | 2022-12-28 | Novozymes A/S | Alpha-amylase variants and polynucleotides encoding same |
| EP3359658A2 (en) | 2015-10-07 | 2018-08-15 | Novozymes A/S | Polypeptides |
| EP3433347B1 (en) * | 2016-03-23 | 2020-05-06 | Novozymes A/S | Use of polypeptide having dnase activity for treating fabrics |
| WO2018011276A1 (en) * | 2016-07-13 | 2018-01-18 | The Procter & Gamble Company | Bacillus cibi dnase variants and uses thereof |
| US20230416706A1 (en) * | 2017-10-27 | 2023-12-28 | Novozymes A/S | Dnase Variants |
| ES2908667T3 (es) * | 2017-10-27 | 2022-05-03 | Procter & Gamble | Composiciones detergentes que comprenden variantes polipeptídicas |
-
2018
- 2018-10-26 ES ES18202967T patent/ES2908667T3/es active Active
- 2018-10-26 ES ES18202983T patent/ES2910120T3/es active Active
- 2018-10-26 EP EP18202983.5A patent/EP3476936B1/en active Active
- 2018-10-26 US US16/171,407 patent/US10781408B2/en active Active
- 2018-10-26 CN CN201880068372.4A patent/CN111247245A/zh active Pending
- 2018-10-26 WO PCT/US2018/057621 patent/WO2019084350A1/en not_active Ceased
- 2018-10-26 HU HUE18202967A patent/HUE057471T2/hu unknown
- 2018-10-26 HU HUE18202983A patent/HUE057832T2/hu unknown
- 2018-10-26 EP EP18202967.8A patent/EP3476935B1/en active Active
- 2018-10-26 DK DK18202983.5T patent/DK3476936T3/da active
- 2018-10-26 CN CN201880066780.6A patent/CN111386340B/zh active Active
- 2018-10-26 WO PCT/US2018/057620 patent/WO2019084349A1/en not_active Ceased
- 2018-10-26 CN CN202311537656.2A patent/CN117683748A/zh active Pending
- 2018-10-26 US US16/171,413 patent/US10800997B2/en active Active
- 2018-10-26 PL PL18202967T patent/PL3476935T3/pl unknown
- 2018-10-26 PL PL18202983T patent/PL3476936T3/pl unknown
Also Published As
| Publication number | Publication date |
|---|---|
| US20190127665A1 (en) | 2019-05-02 |
| EP3476935B1 (en) | 2022-02-09 |
| DK3476936T3 (da) | 2022-03-14 |
| US20190127664A1 (en) | 2019-05-02 |
| PL3476936T3 (pl) | 2022-04-11 |
| WO2019084350A1 (en) | 2019-05-02 |
| CN111247245A (zh) | 2020-06-05 |
| CN111386340A (zh) | 2020-07-07 |
| EP3476935A1 (en) | 2019-05-01 |
| US10781408B2 (en) | 2020-09-22 |
| EP3476936B1 (en) | 2022-02-09 |
| CN117683748A (zh) | 2024-03-12 |
| EP3476936A1 (en) | 2019-05-01 |
| US10800997B2 (en) | 2020-10-13 |
| HUE057471T2 (hu) | 2022-05-28 |
| WO2019084349A1 (en) | 2019-05-02 |
| HUE057832T2 (hu) | 2022-06-28 |
| ES2910120T3 (es) | 2022-05-11 |
| PL3476935T3 (pl) | 2022-03-28 |
| CN111386340B (zh) | 2024-05-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2908667T3 (es) | Composiciones detergentes que comprenden variantes polipeptídicas | |
| US12116553B2 (en) | Polypeptide variants | |
| US11441136B2 (en) | DNase variants | |
| ES2980119T3 (es) | Composiciones limpiadoras que contienen dispersinas II | |
| KR20200071135A (ko) | 디스페르신 i을 함유하는 세정 조성물 | |
| JP7797402B2 (ja) | 炭水化物結合モジュールバリアント | |
| WO2022194668A1 (en) | Polypeptide variants | |
| US20240060061A1 (en) | Dnase variants |