CN110651040A - 具有dna酶活性的多肽 - Google Patents
具有dna酶活性的多肽 Download PDFInfo
- Publication number
- CN110651040A CN110651040A CN201880023402.XA CN201880023402A CN110651040A CN 110651040 A CN110651040 A CN 110651040A CN 201880023402 A CN201880023402 A CN 201880023402A CN 110651040 A CN110651040 A CN 110651040A
- Authority
- CN
- China
- Prior art keywords
- seq
- polypeptide
- sequence identity
- mature
- mature polypeptide
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


Classifications
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D3/00—Other compounding ingredients of detergent compositions covered in group C11D1/00
- C11D3/16—Organic compounds
- C11D3/38—Products with no well-defined composition, e.g. natural products
- C11D3/386—Preparations containing enzymes, e.g. protease or amylase
- C11D3/38636—Preparations containing enzymes, e.g. protease or amylase containing enzymes other than protease, amylase, lipase, cellulase, oxidase or reductase
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D3/00—Other compounding ingredients of detergent compositions covered in group C11D1/00
- C11D3/0005—Other compounding ingredients characterised by their effect
- C11D3/0036—Soil deposition preventing compositions; Antiredeposition agents
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D3/00—Other compounding ingredients of detergent compositions covered in group C11D1/00
- C11D3/0005—Other compounding ingredients characterised by their effect
- C11D3/0068—Deodorant compositions
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D3/00—Other compounding ingredients of detergent compositions covered in group C11D1/00
- C11D3/16—Organic compounds
- C11D3/38—Products with no well-defined composition, e.g. natural products
- C11D3/386—Preparations containing enzymes, e.g. protease or amylase
- C11D3/38663—Stabilised liquid enzyme compositions
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/52—Genes encoding for enzymes or proenzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases [RNase]; Deoxyribonucleases [DNase]
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D2111/00—Cleaning compositions characterised by the objects to be cleaned; Cleaning compositions characterised by non-standard cleaning or washing processes
- C11D2111/10—Objects to be cleaned
- C11D2111/12—Soft surfaces, e.g. textile
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Zoology (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Enzymes And Modification Thereof (AREA)
- Detergent Compositions (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
本发明提供了具有DNA酶活性的多肽和编码这些多肽的多核苷酸。本发明还提供了包含这些多核苷酸的核酸构建体、载体和宿主细胞,以及产生和使用这些多肽的方法。
Description
序列表的引用
本申请包含处于计算机可读形式的序列表,将其通过引用并入本文。
发明背景
技术领域
本发明涉及具有DNA酶活性的多肽和编码这些多肽的多核苷酸。本发明还涉及包含这些多核苷酸的核酸构建体、载体和宿主细胞,以及产生和使用这些多肽的方法。
背景技术
几十年来,酶一直被用于洗涤剂中。通常将多种酶的混合物添加到洗涤剂组合物中。酶混合物通常包含多种酶,其中每种酶各自靶向其特异性底物,例如淀粉酶对淀粉污渍有活性,蛋白酶对蛋白质污渍有活性等。纺织品和表面(如衣物和餐具)会被许多不同类型的污垢弄脏。污垢可能由蛋白质、油脂、淀粉等组成。污垢的一种类型来自有机物质,如生物膜。生物膜的存在产生了若干缺点。生物膜包含细胞外聚合物基质,其由多糖、细胞外DNA(eDNA)和蛋白质组成。细胞外聚合物基质可以是粘性的或粘合的,当其存在于纺织品上时,可引起污垢的再沉积或反染色,从而导致织物变灰。另一个缺点是恶臭可能被滞留在有机结构中。因此,有机物质(如生物膜)在纺织品和与清洁(如洗衣机等)相关的表面中是不可取的。由于有机污垢是多糖、蛋白质、DNA等的复杂混合物,因此需要有效地防止、去除或减少在物品(如织物)上的此类污垢组分(如DNA)的酶。
发明内容
本发明涉及具有DNA酶活性的多肽。特别地,本发明涉及具有DNA酶活性的RTTDA进化枝的多肽,其中该多肽选自由以下组成的组:
(a)与SEQ ID NO:3的多肽具有至少80%序列同一性的多肽;
(b)与SEQ ID NO:6的多肽具有至少80%序列同一性的多肽;
(c)与SEQ ID NO:9的多肽具有至少80%序列同一性的多肽;
(d)与SEQ ID NO:12的多肽具有至少80%序列同一性的多肽;
(e)与SEQ ID NO:15的多肽具有至少80%序列同一性的多肽;
(f)与SEQ ID NO:18的多肽具有至少80%序列同一性的多肽;
(g)与SEQ ID NO:21的多肽具有至少80%序列同一性的多肽;
(h)与SEQ ID NO:24的多肽具有至少80%序列同一性的多肽;
(i)与SEQ ID NO:27的多肽具有至少80%序列同一性的多肽;
(j)与SEQ ID NO:30的多肽具有至少80%序列同一性的多肽;
(k)与SEQ ID NO:33的多肽具有至少80%序列同一性的多肽;
(l)与SEQ ID NO:36的多肽具有至少80%序列同一性的多肽;
(m)与SEQ ID NO:39的多肽具有至少80%序列同一性的多肽;
(n)与SEQ ID NO:42的多肽具有至少80%序列同一性的多肽;
(o)多肽的变体,该多肽选自由以下组成的组:SEQ ID NO:3、SEQ ID NO:6、SEQ IDNO:9、SEQ ID NO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ IDNO:27、SEQ ID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39和SEQ ID NO:42,其中该变体具有DNA酶活性并且包含在1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个位置中的一个或多个氨基酸取代、和/或一个或多个氨基酸缺失、和/或一个或多个氨基酸插入或其任何组合;
(p)多肽,该多肽包含(a)至(n)的多肽以及N-末端和/或C-末端His-标签和/或HQ-标签;
(q)多肽,该多肽包含(a)至(n)的多肽以及1与10个氨基酸之间的N-末端和/或C-末端延伸;
(r)(a)至(n)的多肽的片段,该片段具有DNA酶活性并且具有成熟多肽的至少90%的长度;和
(s)多肽,该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)。
本发明进一步涉及组合物(例如清洁或洗涤剂组合物、自动餐具洗涤(ADW)组合物、洗衣组合物),其包含根据本发明的多肽。
本发明进一步涉及根据本发明的多肽用于深度清洁物品(如纺织品(例如织物))的用途。本发明进一步涉及根据本发明的DNA酶的以下用途:
(i)用于防止、减少或去除该物品的粘性;
(ii)用于预处理该物品上的污渍;
(iii)用于在洗涤循环期间防止、减少或去除污垢的再沉积;
(iv)用于防止、减少或去除污垢在该物品上的附着;
(v)用于维持或改进该物品的白度;
(vi)用于防止、减少或去除该物品的恶臭,
其中该物品是纺织品。
本发明还涉及用于洗涤物品的方法,该方法包括以下步骤:
a.将物品暴露于包含根据本发明的多肽的洗涤液或包含根据本发明的多肽的清洁组合物;
b.完成至少一个洗涤循环;和
c.任选地冲洗该物品,
其中该物品是纺织品。
本发明进一步涉及编码本发明的多肽的多核苷酸、和核酸构建体或表达载体,该核酸构建体或表达载体包含编码本发明的多肽的多核苷酸,该多核苷酸可操作地连接至指导该多肽在表达宿主中的产生的一个或多个控制序列。本发明进一步涉及重组宿主细胞和方法,该重组宿主细胞包含编码本发明的多肽的多核苷酸,该多核苷酸可操作地连接至指导该多肽的产生的一个或多个控制序列,该方法包括在有益于产生该多肽的条件下培养细胞(该细胞以其野生型形式产生该多肽)和任选地回收该多肽。本发明还涉及产生具有DNA酶活性的多肽的方法,该方法包括在有益于产生该多肽的条件下培养重组宿主细胞,该重组宿主细胞包含编码该多肽的多核苷酸。
附图说明
图1显示了包含在进化枝中的本发明的多肽的比对。
图2显示了RTTDA进化枝的系统发育树。
序列综述
SEQ ID NO 1:编码来自stictoideus粪盘菌(Ascobolusstictoideus)的全长多肽的DNA
SEQ ID NO 2:来源于SEQ ID NO 1的多肽
SEQ ID NO 3:获得自Ascobolusstictoideus的成熟多肽
SEQ ID NO 4:编码来自乌奴属物种(Urnulasp)-56769的全长多肽的DNA
SEQ ID NO 5:来源于SEQ ID NO 4的多肽
SEQ ID NO 6:获得自乌奴属物种-56769的成熟多肽
SEQ ID NO 7:编码来自粪盘菌属物种ZY179的全长多肽的DNA
SEQ ID NO 8:来源于SEQ ID NO 7的多肽
SEQ ID NO 9:获得自粪盘菌属物种ZY179的成熟多肽
SEQ ID NO 10:编码来自宽肋羊肚菌(Morchellacostata)的全长多肽的DNA
SEQ ID NO 11:来源于SEQ ID NO 10的多肽
SEQ ID NO 12:获得自宽肋羊肚菌的成熟多肽
SEQ ID NO 13:编码来自Trichoboluszukalii的全长多肽的DNA
SEQ ID NO 14:来源于SEQ ID NO 13的多肽
SEQ ID NO 15:获得自Trichoboluszukalii的成熟多肽
SEQ ID NO 16:编码来自褐孢长毛盘菌(Trichophaeasaccata)的全长多肽的DNA
SEQ ID NO 17:来源于SEQ ID NO 16的多肽
SEQ ID NO 18:获得自褐孢长毛盘菌的成熟多肽
SEQ ID NO 19:编码来自微小长毛盘菌(Trichophaeaminuta)的全长多肽的DNA
SEQ ID NO 20:来源于SEQ ID NO 19的多肽
SEQ ID NO 21:获得自微小长毛盘菌的成熟多肽
SEQ ID NO 22:编码来自微小长毛盘菌(Trichophaeaminuta)的全长多肽的DNA
SEQ ID NO 23:来源于SEQ ID NO 22的多肽
SEQ ID NO 24:获得自微小长毛盘菌的成熟多肽
SEQ ID NO 25:编码来自茂长毛盘菌(Trichophaeaabundans)的全长多肽的DNA
SEQ ID NO 26:来源于SEQ ID NO 25的多肽
SEQ ID NO 27:获得自茂长毛盘菌的成熟多肽
SEQ ID NO 28:编码来自淡黑假黑盘菌(Pseudoplectanianigrella)的全长多肽的DNA
SEQ ID NO 29:来源于SEQ ID NO 28的多肽
SEQ ID NO 30:获得自淡黑假黑盘菌的成熟多肽
SEQ ID NO 31:编码来自大脑蘑菇(Gyromitra esculenta)的全长多肽的DNA
SEQ ID NO 32:来源于SEQ ID NO 31的多肽
SEQ ID NO 33:获得自大脑蘑菇的成熟多肽
SEQ ID NO 34:编码来自春羊肚菌(Morchella esculenta)的全长多肽的DNA
SEQ ID NO 35:来源于SEQ ID NO 34的多肽
SEQ ID NO 36:获得自春羊肚菌的成熟多肽
SEQ ID NO 37:编码来自粗柄羊肚菌(Morchellacrassipes)的全长多肽的DNA
SEQ ID NO 38:来源于SEQ ID NO 37的多肽
SEQ ID NO 39:获得自粗柄羊肚菌的成熟多肽
SEQ ID NO 40:编码来自肋状皱盘菌(Disciotisvenosa)的全长多肽的DNA
SEQ ID NO 41:来源于SEQ ID NO 40的多肽
SEQ ID NO 42:获得自肋状皱盘菌的成熟多肽
SEQ ID NO 43-48是本文披露的基序。
定义
术语“DNA酶”意指具有DNA酶活性的多肽,该多肽催化DNA主链中的磷酸二酯键的水解切割,从而降解DNA。术语“DNA酶”和表述“具有DNA酶活性的多肽”在整个申请中可互换使用。出于本发明的目的,根据测定I或测定II中描述的程序确定DNA酶活性。在一个方面,本发明的多肽具有SEQ ID NO:3、6、9、12、15、18、21、24、27、30、33、36、39或42中所示成熟多肽的至少20%,例如至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少95%或至少100%的DNA酶活性。
术语“等位基因变体”意指占据同一染色体基因座的基因的两种或更多种替代形式中的任一种。等位基因变异通过突变而自然产生,并且可以导致群体内部的多态性。基因突变可以是沉默的(所编码的多肽无变化)或可以编码具有改变的氨基酸序列的多肽。多肽的等位基因变体是由基因的等位基因变体编码的多肽。
术语“生物膜”意指由其中细胞彼此粘附在一起或粘附至表面(如纺织品、餐具或硬表面)或另一种表面的任何群组的微生物产生的有机物质。这些附着细胞经常包埋在细胞外聚合物(EPS)的自身产生的基质内。生物膜EPS是通常由细胞外DNA、蛋白质、和多糖组成的聚合物团块。生物膜可以形成在活的或非活的表面上。在生物膜中生长的微生物细胞与同一有机体的浮游细胞(相比之下,浮游细胞是可以在液体介质中漂浮或浮游的单个细胞)在生理上是不同的。生活在生物膜中的细菌通常与同一物种的浮游细菌具有显著不同的特性,因为膜的密集并且受保护的环境允许它们以不同方式协作和相互作用。微生物的这一环境的一个益处是增加对洗涤剂和抗生素的抗性,因为,密集的细胞外基质和细胞的外层保护群落的内部。关于洗衣生物膜生产细菌可以在以下物种中找到,这些物种包括:不动杆菌属物种(Acinetobacter sp.)、气微菌属物种(Aeromicrobium sp.)、短波单胞菌属物种(Brevundimonas sp.)、微杆菌属物种(Microbacterium sp.)、滕黄微球菌(Micrococcus luteus)、假单胞菌属物种(Pseudomonas sp.)、表皮葡萄球菌(Staphylococcus epidermidis)以及寡养单胞菌属物种(Stenotrophomonas sp.)。关于硬表面生物膜生产细菌可以在以下物种中找到:不动杆菌属物种、气微菌属物种、短波单胞菌属物种、微杆菌属物种、滕黄微球菌、假单胞菌属物种、表皮葡萄球菌、金黄色葡萄球菌(Staphylococcus aureus)以及寡养单胞菌属物种。
术语“cDNA”意指可以通过从获得自真核或原核细胞的成熟的、剪接的mRNA分子进行反转录而制备的DNA分子。cDNA缺乏可以存在于对应基因组DNA中的内含子序列。初始的初级RNA转录物是mRNA的前体,其要通过一系列的步骤(包括剪接)进行加工,然后呈现为成熟的剪接的mRNA。
术语“eDNA”在本文上下文中意指细胞外DNA。
术语“编码序列”意指直接指定多肽的氨基酸序列的多核苷酸。编码序列的边界通常由可读框确定,该可读框以起始密码子(如ATG、GTG或TTG)开始并且以终止密码子(如TAA、TAG或TGA)结束。编码序列可为基因组DNA、cDNA、合成DNA或其组合。
术语“控制序列”意指表达编码本发明的成熟多肽的多核苷酸所必需的核酸序列。每个控制序列对于编码该多肽的多核苷酸来说可以是天然的(即,来自相同基因)或外源的(即,来自不同基因),或相对于彼此是天然的或外源的。此类控制序列包括但不限于前导序列、多腺苷酸化序列、前肽序列、启动子、信号肽序列、和转录终止子。最少,控制序列包括启动子、以及转录和翻译终止信号。出于引入有利于将控制序列与编码多肽的多核苷酸的编码区连接的特异性限制位点的目的,这些控制序列可以提供有多个接头。
术语“深度清洁”意指破坏、减少或去除有机组分,如多糖、蛋白质、DNA、污垢或存在于有机物质(如生物膜)中的其他组分。
术语“洗涤剂佐剂成分”不同于本发明的DNA酶。这些另外的佐剂组分的精确性质及其掺入水平将取决于组合物的物理形式和将在其中使用组合物的操作的性质。适合的佐剂材料包括,但不限于:以下描述的组分,如表面活性剂、助洗剂、絮凝助剂、螯合试剂、染料转移抑制剂、酶、酶稳定剂、酶抑制剂、催化材料、漂白活化剂、过氧化氢、过氧化氢源、预形成的过酸、聚合剂、粘土去污剂/抗再沉积剂、增亮剂、抑泡剂、染料、香料、结构弹力剂、织物软化剂、运载体、水溶助剂、助洗剂和共助洗剂、织物调色剂、防沫剂、分散剂、加工助剂、和/或颜料。
术语“洗涤剂组合物”是指用于从有待清洁的物品(如纺织品)去除不希望的化合物的组合物。术语“洗涤剂组合物”和“清洁组合物”在本申请中可互换使用。该洗涤剂组合物可以用于例如清洁纺织品,用于家用清洁和工业清洁两者。这些术语涵盖选择用于希望的具体类型的清洁组合物和产品的形式(例如、液体、凝胶、粉末、颗粒、糊状、或喷雾组合物)的任何材料/化合物,并且包括但不限于洗涤剂组合物(例如,液体和/或固体衣物洗涤剂和精细织物洗涤剂;织物清新剂;织物软化剂;以及纺织品和衣物预去污剂/预处理)。除了包含本发明的酶之外,该洗涤剂配制品还可以含有一种或多种另外的酶(如蛋白酶、淀粉酶、脂肪酶、角质酶、纤维素酶、内切葡聚糖酶、木葡聚糖酶、果胶酶、果胶裂解酶、黄原胶酶、过氧化物酶、卤代过氧合酶、过氧化氢酶以及甘露聚糖酶、或其任何混合物),和/或洗涤剂佐剂成分,如表面活性剂、助洗剂、螯合剂(chelator)或螯合试剂(chelating agent)、漂白系统或漂白组分、聚合物、织物柔顺剂、增泡剂、抑泡剂、染料、香料、晦暗抑制剂、光学增亮剂、杀细菌剂、杀真菌剂、污垢悬浮剂、防蚀剂、酶抑制剂或稳定剂、酶激活剂、一种或多种转移酶、水解酶、氧化还原酶、上蓝剂和荧光染料、抗氧化剂以及增溶剂。
术语“表达”包括涉及多肽产生的任何步骤,包括但不限于:转录、转录后修饰、翻译、翻译后修饰、以及分泌。
术语“表达载体”意指直链或环状DNA分子,其包含编码多肽的多核苷酸并且可操作地连接至提供用于其表达的控制序列。控制序列对于表达载体可以是外源的或异源的。
“His-标签”是指典型地包含至少6个组氨酸残基的多组氨酸标签,其可以添加到N-或C-末端上。His标签在本领域已知用于例如蛋白质纯化,但也可以用于改进低pH值下的溶解度。类似地,如本领域已知的,“HQ-标签”(即组氨酸-谷氨酰胺标签)也可以用于纯化目的。
术语“宿主细胞”意指易于用包含本发明的多核苷酸的核酸构建体或表达载体进行转化、转染、转导等的任何细胞类型。术语“宿主细胞”涵盖由于复制期间出现的突变而与亲本细胞不完全相同的任何亲本细胞子代。
术语“分离的”意指处于自然界中不存在的形式或环境中的物质。分离的物质的非限制性实例包括(1)任何非天然存在的物质,(2)包括但不限于任何酶、变体、核酸、蛋白质、肽或辅因子的任何物质,该物质至少部分地从与其性质相关的一种或多种或所有天然存在的成分中去除;(3)相对于自然界中发现的物质通过人工修饰的任何物质;或(4)通过相对于与其天然相关的其他组分,增加物质的量而修饰的任何物质(例如,宿主细胞中的重组产生;编码该物质的基因的多个拷贝;以及使用比与编码该物质的基因天然相关的启动子更强的启动子)。分离的物质可以存在于发酵液样品中;例如宿主细胞可以经遗传修饰以表达本发明的多肽。来自该宿主细胞的发酵液将包含分离的多肽。
术语“洗涤”涉及家用洗涤和工业洗涤两者并且意指用一种包含本发明的清洁或洗涤剂组合物的溶液处理纺织品的过程。洗涤过程可以例如使用例如家用或工业洗衣机进行或可以手动进行。
关于术语“恶臭”意指在清洁物品上不希望的气味。清洁的物品应气味清新并且干净,而没有附着于该物品上的恶臭。恶臭的一个实例是具有令人不快的气味的化合物,其可以由微生物产生并且被在生物膜内捕获或粘附到生物膜的“胶”上。令人不快的气味的其他实例是附着于已经与人或动物接触的物品的汗味或体味。恶臭的其他实例是来自香料的气味,其粘附于物品,例如气味强烈的咖喱或其他异国香料。
术语“成熟多肽”意指在翻译和任何翻译后修饰(如N-末端加工、C-末端截短、糖基化作用、磷酸化作用等)之后处于其最终形式的多肽。
在一个方面,该成熟多肽是SEQ ID NO:2的氨基酸1至187。SEQ ID NO:2的氨基酸-18至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:5的氨基酸1至197。SEQ ID NO:5的氨基酸-16至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:8的氨基酸1至187。SEQ ID NO:8的氨基酸-18至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:11的氨基酸1至188。SEQ ID NO:11的氨基酸-15至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:14的氨基酸1至192。SEQ ID NO:14的氨基酸-19至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:17的氨基酸1至187。SEQ ID NO:17的氨基酸-17至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:20的氨基酸1至187。SEQ ID NO:20的氨基酸-17至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:23的氨基酸1至187。SEQ ID NO:23的氨基酸-17至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:26的氨基酸1至187。SEQ ID NO:26的氨基酸-17至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:29的氨基酸1至187。SEQ ID NO:29的氨基酸-18至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:32的氨基酸1至188。SEQ ID NO:32的氨基酸-15至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:35的氨基酸1至188。SEQ ID NO:35的氨基酸-15至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:38的氨基酸1至188。SEQ ID NO:38的氨基酸-15至-1是信号肽。
在一个方面,该成熟多肽是SEQ ID NO:41的氨基酸1至188。SEQ ID NO:41的氨基酸-15至-1是信号肽。
在本领域已知的是,宿主细胞可以产生由相同多核苷酸表达的两种或多种不同的成熟多肽(即,具有不同的C-末端和/或N-末端氨基酸)的混合物。在本领域还已知的是,不同的宿主细胞以不同的方式加工多肽,且因此表达多核苷酸的一种宿主细胞当与表达相同多核苷酸的另一种宿主细胞相比时可产生不同的成熟多肽(例如,具有不同的C-末端和/或N-末端氨基酸)。
术语“成熟多肽编码序列”意指编码具有DNA酶活性的成熟多肽的多核苷酸。
在一个方面,该成熟多肽编码序列是SEQ ID NO:1的核苷酸55至748,并且SEQ IDNO:1的核苷酸1至54编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:4的核苷酸49至970,并且SEQ IDNO:1的核苷酸4至48编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:7的核苷酸55至725,并且SEQ IDNO:1的核苷酸7至54编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:10的核苷酸46至904,并且SEQ IDNO:1的核苷酸10至45编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:13的核苷酸58至819,并且SEQ IDNO:1的核苷酸13至57编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:16的核苷酸52至784,并且SEQ IDNO:1的核苷酸16至51编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:19的核苷酸52至781,并且SEQ IDNO:1的核苷酸19至51编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:22的核苷酸52至784,并且SEQ IDNO:1的核苷酸22至51编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:25的核苷酸52至790,并且SEQ IDNO:1的核苷酸25至51编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:28的核苷酸55至615,并且SEQ IDNO:1的核苷酸28至54编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:31的核苷酸46至954,并且SEQ IDNO:1的核苷酸31至45编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:34的核苷酸46至901,并且SEQ IDNO:1的核苷酸34至45编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:37的核苷酸46至902,并且SEQ IDNO:1的核苷酸37至45编码信号肽。
在一个方面,该成熟多肽编码序列是SEQ ID NO:40的核苷酸46至838,并且SEQ IDNO:1的核苷酸40至45编码信号肽。
术语“核酸构建体”意指单-链或双链的核酸分子,该核酸分子是从天然存在的基因中分离的,或以本来不存在于自然界中的方式被修饰成含有核酸的区段,或者是合成的,并且该核酸分子包含可以是异源的一个或多个控制序列。
术语“可操作地连接”意指如下的构型,在该构型中,控制序列被放置在相对于多核苷酸的编码序列适当的位置处,使得该控制序列引导该编码序列的表达。
两个氨基酸序列之间或两个核苷酸序列之间的关联度通过参数“序列同一性”来描述。
出于本发明的目的,使用尼德曼-翁施算法(Needleman-Wunsch algorithm)(Needleman和Wunsch,1970,J.Mol.Biol.[分子生物学杂志]48:443-453)来确定两个氨基酸序列之间的序列同一性,该算法如EMBOSS软件包(EMBOSS:欧洲分子生物学开放软件套件(The European Molecular Biology Open Software Suite),Rice等人,2000,TrendsGenet.[遗传学趋势]16:276-277)(优选5.0.0版或更新版本)的尼德尔(Needle)程序中所实施的。使用的参数是空位开放罚分10、空位延伸罚分0.5、以及EBLOSUM62(BLOSUM62的EMBOSS版本)取代矩阵。使用尼德尔标记的“最长同一性”的输出(使用非简化(-nobrief)选项获得)作为同一性百分比并且如下计算:
(同一的残基x 100)/(比对长度-比对中的空位总数)
术语“变体”意指具有DNA酶活性的、在一个或多个(例如,若干个)位置处包含改变(即,取代、插入和/或缺失)的多肽。取代意指用不同的氨基酸替代占用某一位置的氨基酸;缺失意指去除占用某一位置的氨基酸;而插入意指添加一个氨基酸邻近且紧接着占据某一位置的氨基酸。
命名法
出于本发明的目的,命名法[E/Q]意指在该位置的氨基酸可以是谷氨酸(Glu,E)或谷氨酰胺(Gln,Q)。同样,命名法[V/G/A/I]意指在此位置的氨基酸可以是缬氨酸(Val,V)、甘氨酸(Gly,G)、丙氨酸(Ala,A)或异亮氨酸(Ile,I),对于如本文所描述的其他组合,依次类推。除非进一步另有限制,否则氨基酸X被这样定义,使得它可以是20种天然氨基酸中的任一种。
具体实施方式
本发明涉及具有脱氧核糖核酸酶(DNA酶)活性的新颖多肽,该多肽可以用于防止、减少或去除物品如纺织品和/或织物上的生物膜污垢。具有DNA酶活性的多肽或脱氧核糖核酸酶(DNA酶)是催化DNA主链中的磷酸二酯键的水解切割从而降解DNA的任何酶。可互换使用两个术语:具有DNA酶活性的多肽和DNA酶。
具有DNA酶活性的多肽
本发明涉及具有DNA酶活性的多肽,即DNA酶。具有DNA酶活性的多肽的实例是包含PFAM结构域DUF1524(http://pfam.xfam.org/)的多肽(“The Pfam protein familiesdatabase:towards a more sustainable future[Pfam蛋白家族数据库:迈向更可持续的未来]”,R.D.Finn等人,Nucleic Acids Research[核酸研究](2016)Database Issue[数据库卷]44:D279-D285”)。DUF1524结构域含有通常在核酸酶中发现的保守HXXP序列基序(M.A.Machnicka等人,Phylogenomics and sequence-structure-functionrelationships in the GmrSD family of Type IV restriction enzymes[IV型限制性酶的GmrSD家族中的系统基因组学和序列-结构-功能关系],BMC Bioinformatics[BMC生物信息学],2015,16,336)。DUF意指未知功能的结构域,并且包含例如DUF的多肽家族已经一起收集在Pfam数据库中。Pfam数据库提供限定收集的蛋白质结构域的序列比对和隐马尔可夫模型。蛋白质结构域是给定蛋白质序列的保守部分。每个结构域形成一个紧凑的三维结构,并且通常可以独立地稳定和折叠。许多蛋白质由若干个结构域组成。一个结构域可能出现在多种不同的蛋白质中。
可以使用前缀DUF,随后是数字(例如1524)来鉴别一个特定的DUF。DUF1524是一组蛋白质家族(全部包含HXXP基序),其中H是氨基酸组氨酸、P是氨基酸脯氨酸、且X是任何氨基酸。在本发明的一个实施例中,具有DNA酶活性的多肽包含DUF1524结构域。因此,根据一个实施例,本发明涉及具有DNA酶活性的多肽,其中该多肽包含DUF1524结构域。本发明还涉及此类DNA酶的用途,例如用于清洁纺织品和/或织物。本发明进一步涉及组合物,这些组合物包含具有DNA酶活性的多肽,并且该多肽包含DUF1524结构域,例如HXXP。此类组合物可以是但不限于:液体或粉末洗衣组合物、片剂、单位剂量、喷雾或皂条。包含DUF1524结构域的多肽包含若干个基序,这些基序的一个实例是[E/D/H]H[I/V/L/F/M]X[P/A/S](SEQ ID NO:43),其位于与来自宽肋羊肚菌(M.costata)(SEQ ID NO 12)的预测的成熟DNA酶多肽中的位置95至99对应的位置。H96是涉及DUF1524的催化活性的催化残基,并且是HXXP基序的部分。可以由本发明的多肽包含的另一个基序是[T/D/S][G/N]PQL(SEQ ID NO:44)(对应于SEQ ID NO 12中的位置124至128),其中Q涉及稳定HXXP基序的骨架。
如已经描述的,具有DNA酶活性的本发明的多肽可以包含DUF1524的结构域。鉴别了优选由本发明的DNA酶共享的另外的结构域。该结构域被称为NUC1,并且该结构域的多肽除了具有DNA酶活性之外,其特征在于包含某些基序,例如基序[F/L/Y/I]A[N/R]D[L/I/P/V](SEQ ID NO:45)(对应于SEQ ID NO 12中的位置119至123)或C[D/N]T[A/R](SEQ ID NO:46)(对应于SEQ ID NO 12中的位置50至53)中的一个或多个。从NUC1结构域,已经鉴别了一个子结构域,并且该结构域被称为NUC1_A结构域。除包含任何上述结构域之外,属于NUC1_A结构域的具有DNA酶活性的多肽可以具有共同的基序[D/Q][I/V]DH(SEQ ID NO 47),其对应于参考多肽(SEQ ID NO:12)中的氨基酸93至96。预测在对应于SEQ ID NO 12的位置93的位置处的D涉及催化性金属离子辅因子的结合。在一个实施例中,本发明涉及包含基序[D/Q][I/V]DH(SEQ ID NO:47)的多肽,其中该多肽具有DNA酶活性。在本发明的一些实施例中,本发明的DNA酶属于特定亚组或进化枝,其包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO48),该基序对应于SEQ ID NO 12的位置28至35,其中D对应于SEQ ID NO 12的位置31。在一个方面,具有DNA酶活性的本发明的多肽属于RTTDA进化枝并且包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)。在一个方面,具有DNA酶活性的本发明的多肽属于RTTDA进化枝并且包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48),其中该DNA酶来源于真菌,例如是真菌来源的。
包含在进化枝中的本发明的多肽的比对示于图1中。RTTDA进化枝的系统发育树示于图2中。RTTDA进化枝在本文上下文中被定义为NUC1_A DNA酶的亚组,其共享基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48),并且在结构上和任选地在功能上也比其他NUC1_A DNA酶更相关,即它是密切相关的DNA酶的亚组。在一个方面,本发明涉及具有DNA酶活性的多肽,其中该多肽属于RTTDA进化枝,并且包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO48),其中该DNA酶是真菌DNA酶(即是真菌来源的)。在一个方面,本发明涉及具有DNA酶活性的多肽,其中该多肽属于RTTDA进化枝,并且包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO48),其中该多肽选自由以下组成的组:SEQ ID NO:3、SEQ ID NO:6、SEQ ID NO:9、SEQ IDNO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ ID NO:27、SEQ IDNO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39、SEQ ID NO:42中所示的多肽,和与其具有至少80%序列同一性的多肽。
在本发明的一个方面,DNA酶是如下多肽,该多肽包含选自由以下组成的组的基序中的一个或多个:[E/D/H]H[I/V/L/F/M]X[P/A/S](SEQ ID NO 43)、[T/D/S][G/N]PQL(SEQID NO 44)、[F/L/Y/I]A[N/R]D[L/I/P/V](SEQ ID NO:45)、C[D/N]T[A/R](SEQ ID NO 46)、[D/Q][I/V]DH(SEQ ID NO 47)和RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)。优选地,本发明的DNA酶包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)。本发明的一个实施例涉及具有DNA酶活性的多肽,其中该多肽包含以下基序中的任一个:[E/D/H]H[I/V/L/F/M]X[P/A/S](SEQ ID NO 43)、[T/D/S][G/N]PQL(SEQ ID NO:44)、[F/L/Y/I]A[N/R]D[L/I/P/V](SEQ ID NO:45)、C[D/N]T[A/R](SEQ ID NO 46)、[D/Q][I/V]DH(SEQ ID NO 47)、和RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48),并且其中该多肽选自由以下组成的组:
i)包含SEQ ID NO 3或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
ii)包含SEQ ID NO 6或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
iii)包含SEQ ID NO 9或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
iv)包含SEQ ID NO 12或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
v)包含SEQ ID NO 15或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
vi)包含SEQ ID NO 18或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
vii)包含SEQ ID NO 21或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
viii)包含SEQ ID NO 24或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
ix)包含SEQ ID NO 27或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
x)包含SEQ ID NO 30或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
xi)包含SEQ ID NO 33或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
xii)包含SEQ ID NO 36或由其组成的多肽,或与其具有至少80%序列同一性的多肽;
xiii)包含SEQ ID NO 39或由其组成的多肽,或与其具有至少80%序列同一性的多肽;和
xiv)包含SEQ ID NO 42或由其组成的多肽,或与其具有至少80%序列同一性的多肽。
在一个实施例中,DNA酶多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48),并且优选地选自下组,该组选自包含SEQ ID NO:3、SEQ ID NO:6、SEQ ID NO:9、SEQ ID NO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ ID NO:27、SEQ IDNO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39和SEQ ID NO:42中所示氨基酸序列的多肽,或与其具有至少80%序列同一性的多肽。在一个实施例中,DNA酶多肽获得自或可获得自分类学上的盘菌目(Pezizales),并且优选地选自下组,该组选自SEQ ID NO:3、SEQ IDNO:6、SEQ ID NO:9、SEQ ID NO:12、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ IDNO:27、SEQ ID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39和SEQ ID NO:42,或与其具有至少80%序列同一性的多肽。
在一个实施例中,DNA酶多肽获得自或可获得自分类学上的盘菌目。在一个实施例中,DNA酶多肽获得自或可获得自分类学上的盘菌目科,并且优选地选自下组,该组选自SEQID NO:3、SEQ ID NO:6、SEQ ID NO:9、SEQ ID NO:12、SEQ ID NO:18、SEQ ID NO:21、SEQ IDNO:24、SEQ ID NO:27、SEQ ID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39和SEQID NO:42,或与其具有至少80%序列同一性的多肽。
基序和结构域定义为跨域,意思是结构域和基序包含真菌和细菌DNA酶两者。熟知的是,来源于属于不同分类群的有机体的DNA酶可以共享共同的结构元件,这可以通过比较主要结构(例如氨基酸序列)和根据序列同源性将DNA酶分组来鉴别。然而,通过比较多种DNA酶的三维(3D)结构也可以鉴别常见结构元件。这两种方法都已应用于本发明中。
结构方法鉴别了来源于不同分类群的有机体的DNA酶,但对于所鉴别的群共享共同的结构元件。结构域和子域是来自不同分类群的DNA酶组,其共享结构元件。进化枝是一个分组,其包括一个共同的祖先和该祖先的所有后代(现存的和灭绝的)(http://evolution.berkeley.edu/evolibrary/article/0_0_0/evo_06)。进化枝具有共同的系统发育。在实例中描述了系统发育树的构建,此类树具有代表进化枝的分枝,参见图1和2。
本发明的一个实施例涉及RTTDA进化枝的多肽,其中该多肽具有DNA酶活性,并且其中该多肽选自由以下组成的组:
(a)与SEQ ID NO:3的多肽具有至少80%序列同一性的多肽;
(b)与SEQ ID NO:6的多肽具有至少80%序列同一性的多肽;
(c)与SEQ ID NO:9的多肽具有至少80%序列同一性的多肽;
(d)与SEQ ID NO:12的多肽具有至少80%序列同一性的多肽;
(e)与SEQ ID NO:15的多肽具有至少80%序列同一性的多肽;
(f)与SEQ ID NO:18的多肽具有至少80%序列同一性的多肽;
(g)与SEQ ID NO:21的多肽具有至少80%序列同一性的多肽;
(h)与SEQ ID NO:24的多肽具有至少80%序列同一性的多肽;
(i)与SEQ ID NO:27的多肽具有至少80%序列同一性的多肽;
(j)与SEQ ID NO:30的多肽具有至少80%序列同一性的多肽;
(k)与SEQ ID NO:33的多肽具有至少80%序列同一性的多肽;
(l)与SEQ ID NO:36的多肽具有至少80%序列同一性的多肽;
(m)与SEQ ID NO:39的多肽具有至少80%序列同一性的多肽;
(n)与SEQ ID NO:42的多肽具有至少80%序列同一性的多肽;
(o)多肽的变体,该多肽选自由以下组成的组:SEQ ID NO:3、SEQ ID NO:6、SEQ IDNO:9、SEQ ID NO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ IDNO:27、SEQ ID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39和SEQ ID NO:42,其中该变体具有DNA酶活性并且包含在1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个位置中的一个或多个氨基酸取代、和/或一个或多个氨基酸缺失、和/或一个或多个氨基酸插入或其任何组合;
(p)多肽,该多肽包含(a)至(o)的多肽以及N-末端和/或C-末端His-标签和/或HQ-标签;
(q)多肽,该多肽包含(a)至(o)的多肽以及1与10个氨基酸之间的N-末端和/或C-末端延伸;
(r)(a)至(o)的多肽的片段,该片段具有DNA酶活性并且具有成熟多肽的至少90%的长度;和
(s)多肽,该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)。
本发明的DNA酶可以用于清洁组合物,并且可有效深层清洁表面如织物。本发明的DNA酶可有效减少或去除来自例如有机物质的DNA污垢。有机物质的一个实例是生物膜,其是由多种微生物产生的细胞外基质。细胞外聚合物基质由多糖、细胞外DNA和蛋白质组成。有机物质(如生物膜)可以是粘性的或粘合的,当其存在于纺织品上时,可引起污垢的再沉积或反染色,从而导致织物变灰。有机物(如生物膜)的另一个缺点是恶臭,因为多种恶臭相关分子通常与有机物质(如生物膜)相关。
本发明的一个方面涉及用于洗涤物品的方法,该方法包括以下步骤:
a.将物品暴露于包含多肽的洗涤液或清洁组合物,该清洁组合物包含选自由以下组成的组的多肽:SEQ ID NO:3、SEQ ID NO:6、SEQ ID NO:9、SEQ ID NO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ ID NO:27、SEQ ID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39和SEQ ID NO:42或与其具有至少80%序列同一性的多肽,其中该多肽具有DNA酶活性;
b.完成至少一个洗涤循环;和
c.任选地冲洗该物品,
其中该物品是纺织品。
因此,本发明的DNA酶可以用于防止、减少或去除恶臭以及用于防止、减少再沉积和改进白度。
本发明的一个实施例涉及选自由以下组成的组的多肽用于深度清洁物品的用途:SEQ ID NO:3、SEQ ID NO:6、SEQ ID NO:9、SEQ ID NO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ ID NO:27、SEQ ID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39和SEQ ID NO:42或与其具有至少80%序列同一性的多肽,其中该物品是纺织品。本发明的一个实施例涉及选自由以下组成的组的多肽的用途:SEQ ID NO:3、SEQID NO:6、SEQ ID NO:9、SEQ ID NO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQID NO:24、SEQ ID NO:27、SEQ ID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39和SEQ ID NO:42或与其具有至少80%序列同一性的多肽,该用途为:
(i)用于防止、减少或去除该物品的粘性;
(ii)用于预处理该物品上的污渍;
(iii)用于在洗涤循环期间防止、减少或去除污垢的再沉积;
(iv)用于防止、减少或去除污垢在该物品上的附着;
(v)用于维持或改进该物品的白度;
(vi)用于防止、减少或去除该物品的恶臭,
其中该物品是纺织品。
纺织品可以是例如棉或聚酯或其混合物。
本发明的一个实施例涉及多肽,该多肽与SEQ ID NO:3、SEQ ID NO:6、SEQ ID NO:9、SEQ ID NO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ ID NO:27、SEQ ID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39或SEQ ID NO:42中所示多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
在一个实施例中,本发明涉及与SEQ ID NO:2的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:2的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:2的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:5的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:5的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:5的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:8的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:8的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:8的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:11的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:11的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:11的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:14的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:14的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:14的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:17的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:17的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:17的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:20的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:20的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:20的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:23的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:23的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:23的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:26的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:26的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:26的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:29的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:29的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:29的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:32的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:32的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:32的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:35的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:35的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:35的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:38的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:38的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:38的成熟多肽的至少80%或至少90%的DNA酶活性。
在一个具体实施例中,本发明涉及与SEQ ID NO:41的成熟多肽具有至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%的序列同一性的多肽,并且其中该多肽具有SEQ ID NO:41的成熟多肽的至少70%的DNA酶活性,例如SEQ ID NO:41的成熟多肽的至少80%或至少90%的DNA酶活性。
本发明的一个实施例涉及选自由以下多肽组成的组的多肽:
(a)多肽,该多肽包含SEQ ID NO:3、或SEQ ID NO:2的成熟多肽或由其组成;
(b)多肽,该多肽包含SEQ ID NO:6、或SEQ ID NO:5的成熟多肽或由其组成;
(c)多肽,该多肽包含SEQ ID NO:9、或SEQ ID NO:8的成熟多肽或由其组成;
(d)多肽,该多肽包含SEQ ID NO:12、或SEQ ID NO:11的成熟多肽或由其组成;
(e)多肽,该多肽包含SEQ ID NO:15、或SEQ ID NO:14的成熟多肽或由其组成;
(f)多肽,该多肽包含SEQ ID NO:18、或SEQ ID NO:17的成熟多肽或由其组成;
(g)多肽,该多肽包含SEQ ID NO:21、或SEQ ID NO:20的成熟多肽或由其组成;
(h)多肽,该多肽包含SEQ ID NO:24、或SEQ ID NO:23的成熟多肽或由其组成;
(i)多肽,该多肽包含SEQ ID NO:27、或SEQ ID NO:26的成熟多肽或由其组成;
(j)多肽,该多肽包含SEQ ID NO:30、或SEQ ID NO:29的成熟多肽或由其组成;
(k)多肽,该多肽包含SEQ ID NO:33、或SEQ ID NO:32的成熟多肽或由其组成;
(l)多肽,该多肽包含SEQ ID NO:36、或SEQ ID NO:35的成熟多肽或由其组成;
(m)多肽,该多肽包含SEQ ID NO:39、或SEQ ID NO:38的成熟多肽或由其组成;和
(n)多肽,该多肽包含SEQ ID NO:42、或SEQ ID NO:41的成熟多肽或由其组成;
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:3中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:2的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:2的氨基酸1至187或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:3中所示的氨基酸序列或由其组成;包含SEQ ID NO:3中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:3的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:3长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:6中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:5的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:5的氨基酸1至197或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:6中所示的氨基酸序列或由其组成;包含SEQ ID NO:6中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:6的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:6长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:9中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:8的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:8的氨基酸1至187或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:9中所示的氨基酸序列或由其组成;包含SEQ ID NO:9中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:9的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:9长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:12中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:11的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:11的氨基酸1至188或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:12中所示的氨基酸序列或由其组成;包含SEQ ID NO:12中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:12的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:12长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:15中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:14的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:14的氨基酸1至192或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:15中所示的氨基酸序列或由其组成;包含SEQ ID NO:15中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:15的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:15长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:15中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:17的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:17的氨基酸1至187或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:18中所示的氨基酸序列或由其组成;包含SEQ ID NO:18中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:18的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:18长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:21中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:20的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:20的氨基酸1至187或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:21中所示的氨基酸序列或由其组成;包含SEQ ID NO:21中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:21的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:21长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:24中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:23的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:23的氨基酸1至187或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:24中所示的氨基酸序列或由其组成;包含SEQ ID NO:24中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:24的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:24长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:27中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:26的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:26的氨基酸1至187或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:27中所示的氨基酸序列或由其组成;包含SEQ ID NO:27中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:27的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:27长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:30中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:29的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:29的氨基酸1至187或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:30中所示的氨基酸序列或由其组成;包含SEQ ID NO:30中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:30的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:30长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:33中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:32的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:32的氨基酸1至188或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:33中所示的氨基酸序列或由其组成;包含SEQ ID NO:33中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:33的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:33长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:36中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:35的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:35的氨基酸1至188或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:36中所示的氨基酸序列或由其组成;包含SEQ ID NO:36中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:36的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:36长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:39中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:38的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:38的氨基酸1至188或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:39中所示的氨基酸序列或由其组成;包含SEQ ID NO:39中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:39的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:39长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,该多肽已经被分离。本发明的多肽优选地包含SEQ ID NO:42中所示的氨基酸序列或其等位基因变体或由其组成;或为具有DNA酶活性的其片段。在另一方面,该多肽包含SEQ ID NO:41的成熟多肽或由其组成。在另一方面,该多肽包含SEQ ID NO:41的氨基酸1至188或由其组成。
在一个实施例中,该多肽优选地包含SEQ ID NO:42中所示的氨基酸序列或由其组成;包含SEQ ID NO:42中所示的氨基酸序列以及N-末端和/或C-末端His-标签和/或HQ-标签;包含SEQ ID NO:42的氨基酸序列以及1与10个氨基酸之间的N-末端和/或C-末端延伸;或者是其片段,该片段具有DNA酶活性并且具有SEQ ID NO:42长度的至少50%,如至少60%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%。
在一些实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:3中所示的成熟多肽的变体。在一些实施例中,引入SEQ ID NO:3中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:6中所示的成熟多肽的变体。在一些实施例中,引入SEQ ID NO:6中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:9中所示的成熟多肽的变体。在一些实施例中,引入SEQ ID NO:9中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:12中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:12中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:15中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:15中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:18中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:18中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:21中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:21中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:24中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:24中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:27中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:27中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:30中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:30中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:33中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:33中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:36中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:36中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:39中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:39中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
在一个实施例中,本发明涉及在一个或多个(例如,若干个)位置处包含取代、缺失、和/或插入的SEQ ID NO:42中所示的成熟多肽的变体。在一些实施例中,引入SEQ IDNO:42中所示的成熟多肽中的氨基酸取代、缺失和/或插入的数目多达10个,例如1、2、3、4、5、6、7、8、9或10个。
这些氨基酸改变可以具有微小性质,即,不会显著地影响蛋白质的折叠和/或活性的保守氨基酸取代或插入;典型地为1-30个氨基酸的小缺失;小的氨基-末端或羧基末端延伸,如氨基末端的甲硫氨酸残基;多达20-25个残基的小接头肽;或小的延伸,其通过改变净电荷或另一官能(如聚组氨酸段、抗原表位或结合结构域)来促进纯化。
保守取代的实例是在下组之内:碱性氨基酸(精氨酸、赖氨酸及组氨酸)、酸性氨基酸(谷氨酸和天冬氨酸)、极性氨基酸(谷氨酰胺和天冬酰胺)、疏水性氨基酸(亮氨酸、异亮氨酸及缬氨酸)、芳香族氨基酸(苯丙氨酸、色氨酸及酪氨酸)及小氨基酸(甘氨酸、丙氨酸、丝氨酸、苏氨酸及甲硫氨酸)。通常不会改变比活性的氨基酸取代是本领域已知的并且例如由H.Neurath和R.L.Hill,1979,于The Proteins[蛋白质],Academic Press[学术出版社],纽约中描述。常见取代为Ala/Ser、Val/Ile、Asp/Glu、Thr/Ser、Ala/Gly、Ala/Thr、Ser/Asn、Ala/Val、Ser/Gly、Tyr/Phe、Ala/Pro、Lys/Arg、Asp/Asn、Leu/Ile、Leu/Val、Ala/Glu和Asp/Gly。
可以根据本领域已知的程序,如定点诱变或丙氨酸扫描诱变(Cunningham和Wells,1989,Science[科学]244:1081-1085)来鉴别多肽中的必需氨基酸。在后一项技术中,在该分子中的每个残基处引入单个丙氨酸突变,并且测试所得分子的DNA酶活性以鉴别对于该分子的活性关键的氨基酸残基。还参见,Hilton等人,1996,J.Biol.Chem.[生物化学杂志]271:4699-4708。酶或其他生物学相互作用的活性部位还可通过对结构的物理分析来确定,如由下述技术确定:核磁共振、晶体学(crystallography)、电子衍射、或光亲和标记,连同对推定的接触位点(contract site)氨基酸进行突变。参见,例如,de Vos等人,1992,Science[科学]255:306-312;Smith等人,1992,J.Mol.Biol.[分子生物学杂志]224:899-904;Wlodaver等人,1992,FEBS Lett.[欧洲生物化学学会联盟通讯]309:59-64。还可以从与相关多肽的比对来推断必需氨基酸的身份。
使用已知的诱变、重组和/或改组方法、随后进行一个相关的筛选程序可以做出单或多氨基酸取代、缺失和/或插入并对其进行测试,这些相关的筛选程序例如由Reidhaar-Olson和Sauer,1988,Science[科学]241:53-57;Bowie和Sauer,1989,Proc.Natl.Acad.Sci.USA[美国国家科学院院刊]86:2152-2156;WO 95/17413;或WO 95/22625中披露的那些。其他可以使用的方法包括易错PCR、噬菌体展示(例如Lowman等人,1991,Biochemistry[生物化学]30:10832-10837;美国专利号5,223,409;WO 92/06204)以及区域定向诱变(Derbyshire等人,1986,Gene[基因]46:145;Ner等人,1988,DNA 7:127)。
诱变/改组方法可以与高通量、自动化的筛选方法组合以检测由宿主细胞表达的克隆的、诱变的多肽的活性(Ness等人,1999,Nature Biotechnology[自然生物技术]17:893-896)。可从宿主细胞回收编码活性多肽的诱变的DNA分子,并使用本领域的标准方法快速测序。这些方法允许快速确定多肽中各个氨基酸残基的重要性。
该多肽可以是杂合多肽,其中一种多肽的区域在另一种多肽的区域的N-末端或C-末端处融合。
该多肽可以是融合多肽或可切割的融合多肽,其中另一个多肽在本发明多肽的N-末端或C-末端处融合。通过将编码另一种多肽的多核苷酸融合于本发明的多核苷酸来产生融合多肽。用于产生融合多肽的技术是本领域已知的,且包括连接编码多肽的编码序列使得它们符合读框,而且融合多肽的表达处于一个或多个相同的启动子和终止子的控制之下。还可以使用内含肽技术构建融合多肽,其中在翻译后产生融合多肽(Cooper等人,1993,EMBO J.[欧洲分子生物学学会杂志]12:2575-2583;Dawson等人,1994,Science[科学]266:776-779)。
融合多肽可进一步包含两个多肽之间的切割位点。在融合蛋白分泌之时,该位点被切割,从而释放出这两种多肽。切割位点的实例包括但不限于以下文献中披露的位点:Martin等人,2003,J.Ind.Microbiol.Biotechnol.[工业微生物学与生物技术杂志]3:568-576;Svetina等人,2000,J.Biotechnol.[生物技术杂志]76:245-251;Rasmussen-Wilson等人,1997,Appl.Environ.Microbiol.[应用环境微生物学]63:3488-3493;Ward等人,1995,Biotechnology[生物技术]13:498-503;以及Contreras等人,1991,Biotechnology[生物技术]9:378-381;Eaton等人,1986,Biochemistry[生物化学]25:505-512;Collins-Racie等人,1995,Biotechnology[生物技术],13:982-987;Carter等人,1989,Proteins:Structure,Function,and Genetics[蛋白质:结构、功能和遗传学]6:240-248;以及Stevens,2003,Drug Discovery World[世界药物发现]4:35-48。
具有DNA酶活性的多肽的来源
具有DNA酶活性的本发明的多肽可以获得自任何属的微生物,但优选地获得自属于盘菌目的属。出于本发明的目的,如本文结合给定来源使用的术语“从……获得”应当意指由多核苷酸编码的多肽是由该来源或由已经插入了来自该来源的多核苷酸的菌株产生的。在一个方面,获得自给定来源的多肽被分泌到细胞外。
在一个方面,该肽是粪盘菌属多肽,例如获得自stictoideus粪盘菌(Ascobolusstictoideus)或粪盘菌属物种ZY179的多肽。
在一个方面,该多肽是乌奴属(Urnula)多肽,例如获得自乌奴属物种-56769的多肽。
在一个方面,该肽是羊肚菌属(Morchella)多肽,例如获得自宽肋羊肚菌、春羊肚菌或粗柄羊肚菌的多肽。
在一个方面,该多肽是Trichobolus多肽,例如获得自Trichoboluszukalii的多肽。
在一个方面,该多肽是长毛盘菌属(Trichophaea)多肽,例如获得自褐孢长毛盘菌、微小长毛盘菌或茂长毛盘菌的多肽。
在一个方面,该多肽是假黑盘菌属(Pseudoplectania)多肽,例如获得自淡黑假黑盘菌的多肽。
在一个方面,该多肽是鹿花菌属(Gyromitra)多肽,例如获得自大脑蘑菇的多肽。
在一个方面,该多肽是皱盘菌属(Disciotis)多肽,例如获得自肋状皱盘菌的多肽。
在一个方面,该多肽是假黑盘菌属(Pseudoplectania)多肽,例如获得自淡黑假黑盘菌的多肽。
应理解的是对于前述物种,本发明涵盖完全和不完全阶段(perfect andimperfect states)两者,和其他分类学的等同物(equivalent),例如无性型(anamorph),而与它们已知的物种名称无关。本领域的技术人员会容易地识别适当等同物的身份。
这些物种的菌株可容易地在许多培养物保藏中心为公众所获得,如美国典型培养物保藏中心(American Type Culture Collection,ATCC)、德国微生物和细胞培养物保藏中心(Deutsche Sammlung von Mikroorganismen und Zellkulturen GmbH,DSMZ)、荷兰菌种保藏中心(CentraalbureauVoorSchimmelcultures,CBS)以及美国农业研究服务专利培养物保藏中心北方地区研究中心(Agricultural Research Service Patent CultureCollection,Northern Regional Research Center,NRRL)。
可以使用以上提到的探针从其他来源,包括从自然界(例如,土壤、堆肥、水等)分离的微生物或直接从天然材料(例如,土壤、堆肥、水等)获得的DNA样品鉴别和获得该多肽。用于从天然生境中直接分离微生物和DNA的技术是本领域熟知的。然后可以通过类似地筛选另一微生物的基因组DNA或cDNA文库或混合的DNA样品来获得编码该多肽的多核苷酸。一旦已经用一种或多种探针检测到编码多肽的多核苷酸,则可以通过利用本领域普通技术人员已知的技术(参见例如,Sambrook等人,1989,同上)分离或克隆多核苷酸。
多核苷酸
本发明还涉及编码本发明的多肽的多核苷酸,如本文所描述的。在一些实施例中,编码本发明的多肽的多核苷酸已经被分离。
本发明的一个实施例涉及多肽,该多肽由以下多核苷酸编码,该多核苷酸与SEQID NO 1、SEQ ID NO:4、SEQ ID NO:7、SEQ ID NO:10、SEQ ID NO:13、SEQ ID NO:16、SEQ IDNO:19、SEQ ID NO:22、SEQ ID NO:25、SEQ ID NO:28、SEQ ID NO:31、SEQ ID NO:34、SEQ IDNO:37或SEQ ID NO:40的成熟多肽编码序列具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:1的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:4的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:7的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:10的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:13的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:16的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:19的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:22的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:25的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:28的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:31的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:34的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:37的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
在一个实施例中,本发明涉及编码具有DNA酶活性的多肽的多核苷酸,其中该多核苷酸与SEQ ID NO:40的成熟多肽编码序列具有至少60%,例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%序列同一性。在另外的实施例中,该多核苷酸已经被分离。
用于分离或克隆多核苷酸的技术是本领域已知的且包括从基因组DNA或cDNA或其组合进行分离。可以例如通过使用熟知的聚合酶链式反应(PCR)或表达文库的抗体筛选来检测具有共有结构特征的克隆DNA片段,实现从基因组DNA克隆多核苷酸。参见例如,Innis等人,1990,PCR:A Guideto Methods and Application[PCR:方法和应用指南],AcademicPress[学术出版社],纽约。可以使用其他核酸扩增程序如连接酶链式反应(LCR)、连接激活转录(LAT)和基于多核苷酸的扩增(NASBA)。编码本发明的多肽的多核苷酸的修饰对于合成基本上类似于该多肽的多肽可以是必需的。术语“基本上类似”于该多肽是指多肽的非天然存在的形式。
核酸构建体
本发明还涉及核酸构建体,其包含可操作地连接至一个或多个控制序列的本发明的多核苷酸,在与控制序列相容的条件下,该一个或多个控制序列指导该编码序列在适合的宿主细胞中的表达。控制序列对于宿主细胞可以是异源的。
可用多种不同的方式操作该多核苷酸以提供多肽的表达。取决于表达载体,在多核苷酸插入载体之前对其进行操作可以是理想的或必需的。用于利用重组DNA方法修饰多核苷酸的技术是本领域熟知的。
该控制序列可为启动子,即,被宿主细胞识别用于表达编码本发明的多肽的多核苷酸的多核苷酸。该启动子包含转录控制序列,其介导该多肽的表达。该启动子可以是在宿主细胞中显示出转录活性的任何多核苷酸,包括变体、截短型及杂合型启动子,并且可以从编码与该宿主细胞同源或异源的细胞外或细胞内多肽的基因获得。
用于在细菌宿主细胞中指导本发明核酸构建体的转录的适合启动子的实例是从以下基因中获得的启动子:解淀粉芽孢杆菌(Bacillus amyloliquefaciens)α-淀粉酶基因(amyQ)、地衣芽孢杆菌(Bacillus licheniformis)α-淀粉酶基因(amyL)、地衣芽孢杆菌青霉素酶基因(penP)、嗜热脂肪芽孢杆菌(Bacillus stearothermophilus)产麦芽糖淀粉酶基因(amyM)、枯草芽孢杆菌(Bacillus subtilis)果聚糖蔗糖酶基因(sacB)、枯草芽孢杆菌xylA和xylB基因、苏云金芽孢杆菌(Bacillus thuringiensis)cryIIIA基因(Agaisse和Lereclus,1994,Molecular Microbiology[分子微生物学]13:97-107)、大肠杆菌lac操纵子、大肠杆菌trc启动子(Egon等人,1988,Gene[基因]69:301-315)、天蓝链霉菌(Streptomyces coelicolor)琼脂水解酶基因(dagA)和原核β-内酰胺酶基因(Villa-Kamaroff等人,1978,Natl.Acad.Sci.USA[美国国家科学院院刊]75:3727-3731)以及tac启动子(DeBoer等人,1983,Natl.Acad.Sci.USA[美国国家科学院院刊]80:21-25)。其他启动子描述于Gilbert等人,1980,Scientific American[科学美国人]242:74-94的“Usefulproteins from recombinant bacteria[来自重组细菌的有用蛋白质]”;和上文的Sambrook等人,1989中。串联启动子的实例披露于WO 99/43835中。
在丝状真菌宿主细胞中,用于指导本发明的核酸构建体的转录的适合启动子的实例是从以下的基因获得的启动子:构巢曲霉(Aspergillus nidulans)乙酰胺酶、黑曲霉(Aspergillus niger)中性α-淀粉酶、黑曲霉酸稳定性α-淀粉酶、黑曲霉或泡盛曲霉(Aspergillus awamori)葡萄糖淀粉酶(glaA)、米曲霉(Aspergillus oryzae)TAKA淀粉酶、米曲霉碱性蛋白酶、米曲霉丙糖磷酸异构酶、尖孢镰孢(Fusarium oxysporum)胰蛋白酶–样蛋白酶(WO 96/00787)、镶片镰孢(Fusarium venenatum)淀粉葡糖苷酶(WO 00/56900)、镶片镰孢Daria(达莉亚)(WO 00/56900)、镶片镰孢Quinn(奎恩)(WO 00/56900)、米黑根毛霉(Rhizomucormiehei)脂肪酶、米黑根毛霉天冬氨酸蛋白酶、里氏木霉(Trichodermareesei)β-葡糖苷酶、里氏木霉纤维二糖水解酶I、里氏木霉纤维二糖水解酶II、里氏木霉内切葡聚糖酶I、里氏木霉内切葡聚糖酶II、里氏木霉内切葡聚糖酶III、里氏木霉内切葡聚糖酶V、里氏木霉木聚糖酶I、里氏木霉木聚糖酶II、里氏木霉木聚糖酶III、里氏木霉β-木糖苷酶,以及里氏木霉翻译延伸因子,连同NA2-tpi启动子(来自编码中性α-淀粉酶的曲霉属基因的修饰的启动子,其中已经用来自编码丙糖磷酸异构酶的曲霉属基因的未翻译的前导序列替换未翻译的前导序列;非限制性实例包括来自黑曲霉中性α-淀粉酶基因的修饰的启动子,其中已经用来自构巢曲霉或米曲霉丙糖磷酸异构酶基因的未翻译的前导序列替换未翻译的前导序列);及其变体、截短型、以及杂合型启动子。其他启动子在美国专利号6,011,147中描述。
在酵母宿主中,从以下酶的基因获得有用的启动子:酿酒酵母(Saccharomycescerevisiae)烯醇化酶(ENO-1)、酿酒酵母半乳糖激酶(GAL1)、酿酒酵母乙醇脱氢酶/甘油醛-3-磷酸脱氢酶(ADH1,ADH2/GAP)、酿酒酵母磷酸丙糖异构酶(TPI)、酿酒酵母金属硫蛋白(CUP1)、和酿酒酵母3-磷酸甘油酸激酶。酵母宿主细胞的其他有用的启动子由Romanos等人,1992,Yeast[酵母]8:423-488描述。
控制序列也可为由宿主细胞识别以终止转录的转录终止子。该终止子可操作地连接到编码该多肽的多核苷酸的3'-末端。在宿主细胞中有功能的任何终止子可以用于本发明中。
细菌宿主细胞的优选的终止子从以下的基因获得:克劳氏芽孢杆菌(Bacillusclausii)碱性蛋白酶(aprH)、地衣芽孢杆菌α-淀粉酶(amyL)、和大肠杆菌核糖体RNA(rrnB)。
用于丝状真菌宿主细胞的优选的终止子从以下酶的基因获得:构巢曲霉乙酰胺酶、构巢曲霉邻氨基苯甲酸合酶、黑曲霉葡糖淀粉酶、黑曲霉α-葡糖苷酶、米曲霉TAKA淀粉酶、尖孢镰孢胰蛋白酶-样蛋白酶、里氏木霉β-葡糖苷酶、里氏木霉纤维二糖水解酶I、里氏木霉纤维二糖水解酶II、里氏木霉内切葡聚糖酶I、里氏木霉内切葡聚糖酶II、里氏木霉内切葡聚糖酶III、里氏木霉内切葡聚糖酶V、里氏木霉木聚糖酶I、里氏木霉木聚糖酶II、里氏木霉木聚糖酶III、里氏木霉β-木糖苷酶以及里氏木霉翻译延长因子。
用于酵母宿主细胞的优选的终止子从以下酶的基因获得:酿酒酵母烯醇化酶、酿酒酵母细胞色素C(CYC1)、以及酿酒酵母甘油醛-3-磷酸脱氢酶。酵母宿主细胞的其他有用的终止子由Romanos等人,1992,同上描述。
控制序列还可以是启动子下游和基因的编码序列上游的mRNA稳定子区域,其增加该基因的表达。
适合的mRNA稳定子区域的实例是从以下获得的:苏云金芽孢杆菌cryIIIA基因(WO94/25612)和枯草芽孢杆菌SP82基因(Hue等人,1995,Journal of Bacteriology[细菌学杂志]177:3465-3471)。
控制序列也可以是前导序列,即对宿主细胞翻译很重要的mRNA的非翻译区域。该前导序列可操作地连接至编码该多肽的多核苷酸的5'-末端。可以使用在宿主细胞中有功能的任何前导序列。
用于丝状真菌宿主细胞的优选的前导序列从米曲霉TAKA淀粉酶和构巢曲霉丙糖磷酸异构酶的基因获得。
酵母宿主细胞的适合的前导序列从以下酶的基因获得:酿酒酵母烯醇化酶(ENO-1)、酿酒酵母3-磷酸甘油酸激酶、酿酒酵母α因子、和酿酒酵母醇脱氢酶/甘油醛-3-磷酸脱氢酶(ADH2/GAP)。
控制序列也可以是多腺苷酸化序列,一种与多核苷酸3’-末端可操作地连接并在转录时由宿主细胞识别为向转录的mRNA添加多腺苷酸残基的信号序列。可以使用在宿主细胞中有功能的任何多腺苷酸化序列。
用于丝状真菌宿主细胞的优选的多腺苷酸化序列从以下酶的基因获得:构巢曲霉邻氨基苯甲酸合酶、黑曲霉葡糖淀粉酶、黑曲霉α-葡糖苷酶、米曲霉TAKA淀粉酶以及尖孢镰孢胰蛋白酶样蛋白酶。
酵母宿主细胞的有用的多腺苷酸化序列由Guo和Sherman,1995,Mol.CellularBiol.[分子细胞生物学]15:5983-5990描述。
控制序列也可为编码与多肽的N-末端连接的信号肽并指导多肽进入细胞的分泌途径的信号肽编码区。多核苷酸的编码序列的5'-端可固有地包含在翻译阅读框中与编码多肽的编码序列的区段天然地连接的信号肽编码序列。可替代地,编码序列的5'-端可包含对于编码序列为外源的信号肽编码序列。在编码序列天然地不包含信号肽编码序列的情况下,可能需要外源信号肽编码序列。可替代地,外源信号肽编码序列可以单纯地替换天然信号肽编码序列以便增强多肽的分泌。然而,可以使用指导已表达多肽进入宿主细胞的分泌途径的任何信号肽编码序列。
用于细菌宿主细胞的有效信号肽编码序列是从芽孢杆菌NCIB 11837产麦芽糖淀粉酶、地衣芽孢杆菌枯草杆菌蛋白酶、地衣芽孢杆菌β-内酰胺酶、嗜热脂肪芽孢杆菌α-淀粉酶、嗜热脂肪芽孢杆菌中性蛋白酶(nprT、nprS、nprM)和枯草芽孢杆菌prsA的基因获得的信号肽编码序列。另外的信号肽由Simonen和Palva,1993,Microbiological Reviews[微生物评论]57:109-137描述。
用于丝状真菌宿主细胞的有效的信号肽编码序列是从以下酶的基因获得的信号肽编码序列:黑曲霉中性淀粉酶、黑曲霉葡糖淀粉酶、米曲霉TAKA淀粉酶、特异腐质霉纤维素酶、特异腐质霉内切葡聚糖酶V、疏棉状腐质霉脂肪酶和米黑根毛霉天冬氨酸蛋白酶。
用于酵母宿主细胞的有用的信号肽从酿酒酵母α-因子和酿酒酵母转化酶的基因获得。其他的有用的信号肽编码序列由Romanos等人,1992,同上描述。
控制序列也可以是编码位于多肽N-末端处的前肽的前肽编码序列。所得的多肽被称为前体酶(proenzyme)或多肽原(或在一些情况下被称为酶原(zymogen))。多肽原通常是无活性的并且可通过催化切割或自身催化切割来自多肽原的前肽而转化为活性多肽。前肽编码序列可以从以下的基因获得:枯草芽孢杆菌碱性蛋白酶(aprE)、枯草芽孢杆菌中性蛋白酶(nprT)、嗜热毁丝霉漆酶(WO 95/33836)、米黑根毛霉天冬氨酸蛋白酶和酿酒酵母α-因子。
在信号肽序列和前肽序列两者都存在的情况下,该前肽序列位于紧邻多肽的N-末端且该信号肽序列位于紧邻该前肽序列的N-末端。
也可为希望的是添加调节序列,该调节序列调节宿主细胞生长相关的多肽的表达。调节序列的实例是引起基因表达以响应于化学或物理刺激(包括调节化合物的存在)而开启或关闭的那些。原核系统中的调节序列包括lac、tac、和trp操纵子系统。在酵母中,可以使用ADH2系统或GAL1系统。在丝状真菌中,可以使用黑曲霉葡糖淀粉酶启动子、米曲霉TAKAα-淀粉酶启动子和米曲霉葡糖淀粉酶启动子、里氏木霉纤维二糖水解酶I启动子以及里氏木霉纤维二糖水解酶II启动子。调节序列的其他实例是允许基因扩增的那些序列。在真核系统中,这些调节序列包括在甲氨蝶呤存在下扩增的二氢叶酸还原酶基因以及用重金属扩增的金属硫蛋白基因。在这些情况中,编码多肽的多核苷酸会与调节序列可操作地连接。
表达载体
本发明还涉及包含本发明的多核苷酸、启动子、以及转录和翻译终止信号的重组表达载体。可以彼此异源的多个核苷酸和控制序列可连接在一起以产生重组表达载体,该重组表达载体可包括一个或多个便利的限制位点以允许编码该多肽的多核苷酸在此类位点处的插入或取代。可替代地,可以通过将多核苷酸或包含该多核苷酸的核酸构建体插入用于表达的适当载体中而表达该多核苷酸。在产生该表达载体时,该编码序列位于该载体中,这样使得该编码序列与该用于表达的适当控制序列可操作地连接。
重组表达载体可以是可以方便地经受重组DNA程序并且可以引起多核苷酸表达的任何载体(例如,质粒或病毒)。载体的选择将典型地取决于载体与待引入载体的宿主细胞的相容性。载体可以是直链或闭合环状质粒。
载体可以是自主复制载体,即作为染色体外实体存在的载体,其复制独立于染色体复制,例如质粒、染色体外元件、微染色体或人工染色体。载体可以包含用于确保自我复制的任何手段。可替代地,载体可以是这样的载体,当它引入宿主细胞中时整合入基因组中并与其中已整合了它的一个或多个染色体一起复制。此外,可以使用单独的载体或质粒或两个或更多个载体或质粒,其共同包含待引入宿主细胞基因组的总DNA,或可以使用转座子。
载体优选地包含允许方便地选择转化细胞、转染细胞、转导细胞等细胞的一个或多个选择性标记。选择性标记是一种基因,其产物提供了杀生物剂抗性或病毒抗性、对重金属抗性、对营养缺陷型的原养型等。
细菌选择性标记的实例是地衣芽孢杆菌或枯草芽孢杆菌dal基因、或赋予抗生素抗性(如氨苄青霉素、氯霉素、卡那霉素、新霉素、大观霉素、或四环素抗性)的标记。酵母宿主细胞的适合的标记包括但不限于:ADE2、HIS3、LEU2、LYS2、MET3、TRP1和URA3。用于丝状真菌宿主细胞中的选择性标记包括但不限于:adeA(磷酸核糖酰氨基咪唑-琥珀酸甲酰胺合酶)、adeB(磷酸核糖酰-氨基咪唑合酶)、amdS(乙酰胺酶)、argB(鸟氨酸氨甲酰基转移酶)、bar(草丁膦乙酰转移酶)、hph(潮霉素磷酸转移酶)、niaD(硝酸还原酶)、pyrG(乳清酸核苷-5'-磷酸脱羧酶)、sC(硫酸腺苷酰基转移酶)、以及trpC(邻氨基苯甲酸合酶)、以及其等同物。优选的用于曲霉细胞中的是构巢曲霉或米曲霉amdS和pyrG基因以及吸水链霉菌(Streptomyces hygroscopicus)bar基因。优选的地用于木霉属细胞的是adeA、adeB、amdS、hph以及pyrG基因。
选择性标记可以是如WO 2010/039889中所描述的双选择性标记系统。在一个方面,双选择性标记是hph-tk双选择性标记系统。
载体优选地包含允许载体整合到宿主细胞的基因组中或载体在细胞中独立于基因组自主复制的一个或多个元件。
对于整合到该宿主细胞基因组中,该载体可以依靠编码该多肽的多核苷酸序列或用于通过同源或非同源重组整合到该基因组中的该载体的任何其他元件。可替代地,该载体可包含用于指导通过同源重组而整合入宿主细胞基因组中的染色体中的精确位置处的另外的多核苷酸。为了增加在精确位置处整合的可能性,整合元件应当包含足够数目的核酸,如100至10,000个碱基对、400至10,000个碱基对和800至10,000个碱基对,这些核酸与对应的靶序列具有高度序列同一性以增强同源重组的概率。整合元件可以是与宿主细胞基因组内的靶序列同源的任何序列。此外,整合元件可以是非编码或编码的多核苷酸。另一方面,载体可以通过非同源重组整合入宿主细胞的基因组中。
为了自主复制,载体还可以另外包含复制起点,该复制起点使得载体在讨论中的宿主细胞中自主复制成为可能。复制起点可以是在细胞中发挥作用的介导自主复制的任何质粒复制子。术语“复制起点”或“质粒复制子”意指使质粒或载体能够在体内复制的多核苷酸。
细菌复制起点的实例是允许在大肠杆菌中复制的质粒pBR322、pUC19、pACYC177、和pACYC184的复制起点,以及允许在芽孢杆菌属中复制的质粒pUB110、pE194、pTA1060、和pAMβ1的复制起点。
用于酵母宿主细胞中的复制起点的实例是2微米复制起点、ARS1、ARS4、ARS1与CEN3的组合、及ARS4与CEN6的组合。
在丝状真菌细胞中有用的复制起点的实例是AMA1和ANS1(Gems等人,1991,Gene[基因]98:61-67;Cullen等人,1987,Nucleic Acids Res.[核酸研究]15:9163-9175;WO00/24883)。可以根据WO 00/24883中披露的方法完成AMA1基因的分离和包含该基因的质粒或载体的构建。
可将本发明多核苷酸的多于一个拷贝插入宿主细胞以增加多肽的产生。通过将序列的至少一个另外的拷贝整合到宿主细胞基因组中或者通过包括与该多核苷酸一起的可扩增的选择性标记基因可以获得多核苷酸的增加的拷贝数目,其中通过在适当的选择性试剂的存在下培养细胞可以选择包含选择性标记基因的经扩增的拷贝以及由此该多核苷酸的另外的拷贝的细胞。
用于连接以上所述的元件以构建本发明的重组表达载体的程序是本领域的普通技术人员熟知的(参见例如,Sambrook等人,1989,同上)。
宿主细胞
本发明还涉及重组宿主细胞,这些宿主细胞包含可操作地连接至一个或多个控制序列的本发明的多核苷酸,该一个或多个控制序列指导本发明的多肽的产生。一个或多个控制序列对于宿主细胞可以是异源的。将包含多核苷酸的构建体或载体引入宿主细胞中,这样使得该构建体或载体作为染色体整合体或作为自主复制的染色体外载体维持,如较早前所描述。术语“宿主细胞”涵盖由于复制期间出现的突变而与亲本细胞不完全相同的任何亲本细胞子代。宿主细胞的选择将在很大程度上取决于编码该多肽的基因及其来源。
该宿主细胞可以是在本发明的多肽的重组产生中有用的任何细胞,例如原核细胞或真核细胞。
原核宿主细胞可以是任何革兰氏阳性或革兰氏阴性细菌。革兰氏阳性细菌包括但不限于:芽孢杆菌属(Bacillus)、梭菌属(Clostridium)、肠球菌属(Enterococcus)、土芽孢杆菌属(Geobacillus)、乳杆菌属(Lactobacillus)、乳球菌属(Lactococcus)、大洋芽孢杆菌属(Oceanobacillus)、葡萄球菌属(Staphylococcus)、链球菌属(Streptococcus)和链霉菌属(Streptomyces)。革兰氏阴性细菌包括但不限于弯曲杆菌属(Campylobacter)、大肠杆菌、黄杆菌属(Flavobacterium)、梭杆菌属(Fusobacterium)、螺杆菌属(Helicobacter)、泥杆菌属(Ilyobacter)、奈瑟氏菌属(Neisseria)、假单孢菌属(Pseudomonas)、沙门氏菌属(Salmonella)和脲原体属(Ureaplasma)。
细菌宿主细胞可以是任何芽孢杆菌属细胞,包括但不限于:嗜碱芽孢杆菌(Bacillus alkalophilus)、高地芽孢杆菌(Bacillus altitudinis)、解淀粉芽孢杆菌、植物解淀粉芽孢杆菌(B.amyloliquefaciens plantarum)亚种、短芽孢杆菌(Bacillusbrevis)、环状芽孢杆菌(Bacillus circulans)、克劳氏芽孢杆菌、凝结芽孢杆菌(Bacilluscoagulans)、坚强芽孢杆菌(Bacillus firmus)、灿烂芽孢杆菌(Bacillus lautus)、迟缓芽孢杆菌(Bacillus lentus)、地衣芽孢杆菌、巨大芽孢杆菌(Bacillus megaterium)、甲基营养型芽孢杆菌(Bacillus methylotrophicus)、短小芽孢杆菌(Bacillus pumilus)、沙福芽孢杆菌(Bacillus safensis)、嗜热脂肪芽孢杆菌、枯草芽孢杆菌和苏云金芽孢杆菌细胞。
细菌宿主细胞还可以是任何链球菌属细胞,包括但不限于类马链球菌(Streptococcus equisimilis)、酿脓链球菌(Streptococcus pyogenes)、乳房链球菌(Streptococcus uberis)和马链球菌兽疫亚种(Streptococcus equisubsp.Zooepidemicus)细胞。
细菌宿主细胞还可以是任何链霉菌属细胞,包括但不限于:不产色链霉菌(Streptomyces achromogenes)、除虫链霉菌(Streptomyces avermitilis)、天蓝链霉菌、灰色链霉菌(Streptomyces griseus)以及浅青紫链霉菌(Streptomyces lividans)细胞。
将DNA引入芽孢杆菌属细胞中可以通过以下方式来实现:原生质体转化(参见例如,Chang和Cohen,1979,Mol.Gen.Genet.[分子遗传学与基因组学]168:111-115)、感受态细胞转化(参见例如,Young和Spizizen,1961,J.Bacteriol.[细菌学杂志]81:823-829;或Dubnau和Davidoff-Abelson,1971,J.Mol.Biol.[分子生物学杂志]56:209-221)、电穿孔(参见例如,Shigekawa和Dower,1988,Biotechniques[生物技术]6:742-751)或接合(参见例如,Koehler和Thorne,1987,J.Bacteriol.[细菌学杂志]169:5271-5278)。将DNA引入大肠杆菌细胞中可以通过以下方式来实现:原生质体转化(参见例如,Hanahan,1983,J.Mol.Biol.[分子生物学杂志]166:557-580)或电穿孔(参见例如,Dower等人,1988,Nucleic Acids Res.[核酸研究]16:6127-6145)。将DNA引入链霉菌属细胞中可以通过以下方式来实现:原生质体转化、电穿孔(参见例如,Gong等人,2004,Folia Microbiol.(Praha)[叶线形微生物学(布拉格)]49:399-405)、接合(参见例如,Mazodier等人,1989,J.Bacteriol.[细菌学杂志]171:3583-3585)、或转导(参见例如,Burke等人,2001,Proc.Natl.Acad.Sci.USA[美国国家科学院院刊]98:6289-6294)。将DNA引入假单孢菌属细胞中可以通过以下方式来实现:电穿孔(参见例如,Choi等人,2006,J.Microbiol.Methods[微生物学方法杂志]64:391-397)或接合(参见例如,Pinedo和Smets,2005,Appl.Environ.Microbiol.[应用与环境微生物学]71:51-57)。将DNA引入链球菌属细胞中可以通过以下方式来实现:天然感受态(natural competence)(参见例如,Perry和Kuramitsu,1981,Infect.Immun.[感染与免疫]32:1295-1297)、原生质体转化(参见例如,Catt和Jollick,1991,Microbios[微生物学]68:189-207)、电穿孔(参见例如,Buckley等人,1999,Appl.Environ.Microbiol.[应用与环境微生物学]65:3800-3804)、或接合(参见例如,Clewell,1981,Microbiol.Rev.[微生物学评论]45:409-436)。然而,可以使用本领域已知的将DNA引入宿主细胞中的任何方法。
宿主细胞还可以是真核生物,如哺乳动物、昆虫、植物或真菌细胞。
宿主细胞可以是真菌细胞。如本文使用的“真菌”包括子囊菌门(Ascomycota)、担子菌门(Basidiomycota)、壶菌门(Chytridiomycota)、和接合菌门(Zygomycota)以及卵菌门(Oomycota)和全部有丝分裂孢子真菌(如由Hawksworth等人,在Ainsworth and Bisby’sDictionary of The Fungi[安斯沃思和拜斯比真菌词典],第8版,1995,CABInternational[国际应用生物科学中心],University Press[大学出版社],Cambridge,UK[英国剑桥]中定义的)。
真菌宿主细胞可以为酵母细胞。如本文使用的“酵母”包括产子囊酵母(ascosporogenous yeast)(内孢霉目(Endomycetales))、产担子酵母(basidiosporogenous yeast)和属于半知菌类(Fungi Imperfecti)(芽孢纲(Blastomycetes))的酵母。由于酵母的分类可能在将来变化,出于本发明的目的,酵母应当如Biology and Activities of Yeast[酵母的生物学与活性](Skinner、Passmore和Davenport编辑,Soc.App.Bacteriol.Symposium Series No.9[应用细菌学学会专题论文集系列9],1980)中所描述的那样定义。
酵母宿主细胞可以是假丝酵母属(Candida)、汉逊酵母属(Hansenula)、克鲁弗酵母属(Kluyveromyces)、毕赤酵母属(Pichia)、酵母菌属(Saccharomyces)、裂殖酵母属(Schizosaccharomyces)或耶氏酵母属(Yarrowia)细胞,如乳酸克鲁维酵母(Kluyveromyces lactis)、卡尔酵母(Saccharomyces carlsbergensis)、酿酒酵母(Saccharomyces cerevisiae)、糖化酵母(Saccharomyces diastaticus)、道格拉氏酵母(Saccharomyces douglasii)、克鲁弗酵母(Saccharomyces kluyveri)、诺地酵母(Saccharomyces norbensis)、卵形酵母(Saccharomyces oviformis)或解脂耶氏酵母(Yarrowialipolytica)细胞。
真菌宿主细胞可为丝状真菌细胞。“丝状真菌”包括真菌门(Eumycota)和卵菌门(Oomycota)的亚门的所有丝状形式(如由Hawksworth等人,1995(见上文)所定义的)。丝状真菌通常的特征在于由几丁质、纤维素、葡聚糖、壳多糖、甘露聚糖和其他复杂多糖构成的菌丝体壁。营养生长是通过菌丝延长来进行的,而碳分解代谢是专性需氧的。相反,酵母(如酿酒酵母)的营养生长是通过单细胞菌体的出芽(budding)来进行的,而碳分解代谢可以是发酵性的。
丝状真菌宿主细胞可以是枝顶孢属(Acremonium)、曲霉属(Aspergillus)、短梗霉属(Aureobasidium)、烟管霉属(Bjerkandera)、拟腊菌属(Ceriporiopsis)、金孢子菌属(Chrysosporium)、鬼伞属(Coprinus)、革盖菌属(Coriolus)、隐球菌属(Cryptococcus)、线黑粉菌属(Filibasidium)、镰孢属(Fusarium)、腐质霉属(Humicola)、梨孢菌属(Magnaporthe)、毛霉属(Mucor)、毁丝霉属(Myceliophthora)、新美鞭菌属(Neocallimastix)、链孢菌属(Neurospora)、拟青霉属(Paecilomyces)、青霉属(Penicillium)、平革菌属(Phanerochaete)、射脉菌属(Phlebia)、梨囊鞭菌属(Piromyces)、侧耳属(Pleurotus)、裂褶菌属(Schizophyllum)、篮状菌属(Talaromyces)、嗜热子囊菌属(Thermoascus)、梭孢壳属(Thielavia)、弯颈霉属(Tolypocladium)、栓菌属(Trametes)或木霉属(Trichoderma)细胞。
例如,丝状真菌宿主细胞可以是泡盛曲霉(Aspergillus awamori)、臭曲霉(Aspergillus foetidus)、烟曲霉(Aspergillus fumigatus)、日本曲霉(Aspergillusjaponicus)、构巢曲霉(Aspergillus nidulans)、黑曲霉(Aspergillus niger)、米曲霉(Aspergillus oryzae)、黑刺烟管菌(Bjerkanderaadusta)、干拟蜡菌(Ceriporiopsisaneirina)、卡内基拟蜡菌(Ceriporiopsiscaregiea)、浅黄拟蜡孔菌(Ceriporiopsisgilvescens)、潘诺希塔拟蜡菌(Ceriporiopsispannocinta)、环带拟蜡菌(Ceriporiopsisrivulosa)、微红拟蜡菌(Ceriporiopsissubrufa)、虫拟蜡菌(Ceriporiopsissubvermispora)、狭边金孢子菌(Chrysosporiuminops)、嗜角质金孢子菌(Chrysosporiumkeratinophilum)、卢克诺文思金孢子菌(Chrysosporiumlucknowense)、粪状金孢子菌(Chrysosporiummerdarium)、租金孢子菌(Chrysosporiumpannicola)、女王杜香金孢子菌(Chrysosporiumqueenslandicum)、热带金孢子菌(Chrysosporiumtropicum)、褐薄金孢子菌(Chrysosporiumzonatum)、灰盖鬼伞(Coprinus cinereus)、毛革盖菌(Coriolushirsutus)、杆孢状镰孢(Fusarium bactridioides)、谷类镰孢(Fusariumcerealis)、库威镰孢(Fusarium crookwellense)、大刀镰孢(Fusarium culmorum)、禾谷镰孢(Fusarium graminearum)、禾赤镰孢(Fusarium graminum)、异孢镰孢(Fusariumheterosporum)、合欢木镰孢(Fusarium negundi)、尖孢镰孢(Fusarium oxysporum)、多枝镰孢(Fusarium reticulatum)、粉红镰孢(Fusarium roseum)、接骨木镰孢(Fusariumsambucinum)、肤色镰孢(Fusarium sarcochroum)、拟分枝孢镰孢(Fusariumsporotrichioides)、硫色镰孢(Fusarium sulphureum)、圆镰孢(Fusarium torulosum)、拟丝孢镰孢(Fusarium trichothecioides)、镶片镰孢(Fusarium venenatum)、特异腐质霉(Humicolainsolens)、柔毛腐质霉(Humicolalanuginosa)、米黑毛霉(Mucor miehei)、嗜热毁丝霉(Myceliophthorathermophila)、粗糙脉孢菌(Neurospora crassa)、产紫青霉(Penicillium purpurogenum)、黄孢原毛平革菌(Phanerochaetechrysosporium)、射脉菌(Phlebia radiata)、刺芹侧耳(Pleurotuseryngii)、土生梭孢壳霉(Thielaviaterrestris)、长域毛栓菌(Trametesvillosa)、变色栓菌(Trametesversicolor)、哈茨木霉(Trichoderma harzianum)、康宁木霉(Trichoderma koningii)、长枝木霉(Trichoderma longibrachiatum)、里氏木霉(Trichoderma reesei)或绿色木霉(Trichoderma viride)细胞。
真菌细胞可以通过以下过程转化,该过程涉及原生质体形成、原生质体转化以及以本身已知的方式再生细胞壁。用于转化曲霉属和木霉属宿主细胞的适合程序描述于以下文献中:EP 238023,Yelton等人,1984,Proc.Natl.Acad.Sci.USA[美国国家科学院院刊]81:1470-1474以及Christensen等人,1988,Bio/Technology[生物/技术]6:1419-1422。用于转化镰孢属物种的适合方法由Malardier等人,1989,Gene[基因]78:147-156和WO 96/00787描述。可以使用由如以下文献描述的程序转化酵母:Becker和Guarente,于Abelson,J.N.和Simon,M.I.编辑,Guide to Yeast Genetics and Molecular Biology[酵母遗传学与分子生物学指南],Methods in Enzymology[酶学方法],第194卷,第182-187页,Academic Press,Inc.[学术出版社有限公司],纽约中;Ito等人,1983,J.Bacteriol.[细菌学杂志]153:163;以及Hinnen等人,1978,Proc.Natl.Acad.Sci.USA[美国国家科学院院刊]75:1920。
产生方法
本发明还涉及产生本发明的多肽的方法,这些方法包括(a)在有益于产生该多肽的条件下培养细胞,该细胞以其野生型形式产生该多肽;和任选地(b)回收该多肽。
本发明还涉及产生本发明的多肽的方法,这些方法包括(a)在有益于产生该多肽的条件下培养本发明的重组宿主细胞;和任选地(b)回收该多肽。
宿主细胞是在适合使用本领域已知的方法产生多肽的营养培养基中培养的。例如,可以通过摇瓶培养、或在实验室或工业发酵器中小规模或大规模发酵(包括连续、分批、补料分批或固态发酵)培养细胞,该培养在适合的培养基中并且在允许表达和/或分离多肽的条件下进行。使用本领域中已知的程序,培养发生在包含碳和氮来源及无机盐的适合的营养介质中。适合的培养基可从商业供应商获得或可以根据公开的组成(例如,在美国典型培养物保藏中心(American Type Culture Collection)的目录中)制备。如果多肽被分泌到该营养培养基中,那么可以直接从该培养基中回收该多肽。如果多肽不进行分泌,那么其可以从细胞裂解液中进行回收。
可以使用特异性针对具有DNA酶活性的多肽的本领域已知的方法来检测该多肽。这些检测方法包括但不限于:特异性抗体的使用、酶产物的形成或酶底物的消失。例如,可以使用酶测定来确定多肽的活性。
可以使用本领域已知的方法来回收多肽。例如,可通过常规方法,包括但不限于,收集、离心、过滤、提取、喷雾干燥、蒸发或沉淀,从营养培养基回收多肽。在一个方面,回收包含多肽的发酵液。
可以通过本领域已知的多种不同的程序纯化多肽以获得基本上纯的多肽,这些程序包括但不限于:色谱法(例如,离子交换、亲和、疏水、色谱聚焦和尺寸排阻)、电泳程序(例如,制备型等电聚焦)、差示溶解度(例如,硫酸铵沉淀)、SDS-PAGE、或提取(参见例如,Protein Purification[蛋白质纯化],Janson和Ryden编辑,VCH Publishers[VCH出版公司],纽约,1989)。
在一个替代性方面,不回收多肽,而是将表达该多肽的本发明的宿主细胞用作多肽的来源。
发酵液配制品或细胞组合物
本发明还涉及包含本发明的多肽的发酵液配制品或细胞组合物。该发酵液产物进一步包含在发酵过程中使用的另外的成分,例如像细胞(包括含有编码本发明的多肽的基因的宿主细胞,这些宿主细胞用于产生感兴趣的多肽)、细胞碎片、生物质、发酵培养基和/或发酵产物。在一些实施例中,组合物是含有一种或多种有机酸、杀灭的细胞和/或细胞碎片以及培养基的细胞杀灭的全培养液。
如本文使用的术语“发酵液”是指由细胞发酵产生的、不经历或经历最少的回收和/或纯化的制剂。例如,当微生物培养物在允许蛋白质合成(例如,由宿主细胞表达酶)并且将蛋白质分泌到细胞培养基中的碳限制条件下孵育生长到饱和时,产生发酵液。该发酵液可以含有在发酵结束时得到的发酵材料的未分级的或分级的内容物。典型地,该发酵液是未分级的并且包含用过的培养基以及例如通过离心去除微生物细胞(例如,丝状真菌细胞)之后存在的细胞碎片。在一些实施例中,该发酵液含有用过的细胞培养基、胞外酶以及有活力的和/或无活力的微生物细胞。
在一些实施例中,该发酵液配制品和细胞组合物包括第一有机酸组分(包括至少一种1-5碳的有机酸和/或其盐)以及第二有机酸组分(包括至少一种6碳或更多碳的有机酸和/或其盐)。在一个特定实施例中,该第一有机酸组分是乙酸、甲酸、丙酸、其盐,或前述中的两种或更多种的混合物;并且该第二有机酸组分是苯甲酸、环己烷羧酸、4-甲基戊酸、苯乙酸、其盐,或前述中的两种或更多种的混合物。
在一个方面,组合物含有一种或多种有机酸,并且任选地进一步含有杀灭的细胞和/或细胞碎片。在一个实施例中,从细胞杀灭的全培养液中去除这些杀灭的细胞和/或细胞碎片,以提供不含这些组分的组合物。
这些发酵液配制品或细胞组合物可以进一步包含防腐剂和/或抗微生物(例如,抑菌)剂,包括但不限于山梨醇、氯化钠、山梨酸钾、以及本领域已知的其他试剂。
该细胞杀灭的全培养液或组合物可以含有在发酵结束时得到的发酵材料的未分级的内容物。典型地,该细胞杀灭的全培养液或组合物包含用过的培养基以及在微生物细胞(例如,丝状真菌细胞)生长至饱和、在碳限制条件下孵育以允许蛋白合成之后存在的细胞碎片。在一些实施例中,该细胞杀灭的全培养液或组合物含有用过的细胞培养基、胞外酶和杀灭的丝状真菌细胞。在一些实施例中,可以使用本领域已知的方法来使细胞杀灭的全培养液或组合物中存在的微生物细胞透性化和/或裂解。
如本文所描述的全培养液或细胞组合物典型地是液体,但是可以含有不溶性组分,如杀灭的细胞、细胞碎片、培养基组分和/或一种或多种不溶性酶。在一些实施例中,可以去除不溶性组分以提供澄清的液体组合物。
本发明的全培养液配制品和细胞组合物可以例如通过WO 90/15861或WO 2010/096673中描述的方法来产生。
酶组合物
本发明涉及组合物,这些组合物包含与一种或多种另外的组分组合的本发明的DNA酶。另外的组分的选择处于技术人员的能力范围内并且包括常规的成分,包括下文所述的示例性非限制性组分。
本发明的一个实施例涉及组合物,该组合物包含:
a)至少0.001ppm的至少一种具有DNA酶活性的多肽,其中该DNA酶选自由以下组成的组:SEQ ID NO 3、SEQ ID NO 6、SEQ ID NO 9、SEQ ID NO 12、SEQ ID NO 15、SEQ ID NO18、SEQ ID NO 21、SEQ ID NO 24、SEQ ID NO 27、SEQ ID NO 30、SEQ ID NO 33、SEQ ID NO36、SEQ ID NO 39、SEQ ID NO 42和与其具有至少80%序列同一性的多肽;
b)一种或多种佐剂成分。
本发明的一个实施例涉及清洁组合物,该清洁组合物包含:
a)至少0.001ppm的至少一种具有DNA酶活性的多肽,其中该DNA酶选自由以下组成的组:SEQ ID NO 3、SEQ ID NO 6、SEQ ID NO 9、SEQ ID NO 12、SEQ ID NO 15、SEQ ID NO18、SEQ ID NO 21、SEQ ID NO 24、SEQ ID NO 27、SEQ ID NO 30、SEQ ID NO 33、SEQ ID NO36、SEQ ID NO 39、SEQ ID NO 42和与其具有至少80%序列同一性的多肽;
b)一种或多种清洁组合物组分,优选地选自表面活性剂、助洗剂、漂白组分、聚合物、分散剂和另外的酶。
清洁组分的选择可以包括(用于纺织品护理)有待清洁的纺织品的类型、污垢的类型和/或程度、进行清洁时的温度、以及洗涤剂产品的配制的考虑。尽管根据具体的功能性对以下提及的组分由通用标题进行分类,但是这并不被解释为限制,因为如将被普通技术人员所理解,组分可以包含另外的功能性。
表面活性剂
该洗涤剂组合物可以包含一种或多种表面活性剂,它们可以是阴离子型和/或阳离子型和/或非离子型和/或半极性型和/或两性离子型、或其混合物。在一个具体实施例中,该洗涤剂组合物包含一种或多种非离子型表面活性剂和一种或多种阴离子型表面活性剂的混合物。该一种或多种表面活性剂典型地以按重量计从约0.1%至60%(如约1%至约40%、或约3%至约20%、或约3%至约10%)的水平存在。基于所希望的清洁应用来选择该一种或多种表面活性剂,并且该一种或多种表面活性剂可以包括本领域已知的任何常规表面活性剂。
当被包括在其中时,该洗涤剂通常将含有按重量计从约1%至约40%的阴离子型表面活性剂,如从约5%至约30%,包括从约5%至约15%,或从约15%至约20%,或从约20%至约25%的阴离子型表面活性剂。阴离子型表面活性剂的非限制性实例包括硫酸盐和磺酸盐,特别地,直链烷基苯磺酸盐(LAS)、LAS的异构体、支链烷基苯磺酸盐(BABS)、苯基链烷磺酸盐、α-烯烃磺酸盐(AOS)、烯烃磺酸盐、链烯烃磺酸盐、链烷-2,3-二基双(硫酸盐)、羟基链烷磺酸盐以及二磺酸盐、烷基硫酸盐(AS)如十二烷基硫酸钠(SDS)、脂肪醇硫酸盐(FAS)、伯醇硫酸盐(PAS)、醇醚硫酸盐(AES或AEOS或FES,也被称为醇乙氧基硫酸盐或脂肪醇醚硫酸盐)、仲链烷磺酸盐(SAS)、石蜡磺酸盐(PS)、酯磺酸盐、磺化的脂肪酸甘油酯、α-磺酸基肪酸甲酯(α-SFMe或SES)(包括甲酯磺酸盐(MES))、烷基琥珀酸或烯基琥珀酸、十二烯基/十四烯基琥珀酸(DTSA)、氨基酸的脂肪酸衍生物、磺酸基琥珀酸或脂肪酸盐(皂)的二酯和单酯及其组合。
当被包括在其中时,该洗涤剂将通常含有按重量计从约1%至约40%的阳离子型表面活性剂,例如从约0.5%至约30%,特别是从约1%至约20%、从约3%至约10%,如从约3%至约5%、从约8%至约12%或从约10%至约12%。阳离子型表面活性剂的非限制性实例包括烷基二甲基乙醇季胺(ADMEAQ)、十六烷基三甲基溴化铵(CTAB)、二甲基二硬脂酰氯化铵(DSDMAC)、以及烷基苄基二甲基铵、烷基季铵化合物、烷氧基化季铵(AQA)化合物、酯季铵及其组合。
当被包括在其中时,该洗涤剂将通常含有按重量计从约0.2%至约40%的非离子型表面活性剂,例如从约0.5%至约30%,特别是从约1%至约20%、从约3%至约10%,如从约3%至约5%、从约8%至约12%或从约10%至约12%。非离子型表面活性剂的非限制性实例包括:醇乙氧基化物(AE或AEO)、醇丙氧基化物、丙氧基化的脂肪醇(PFA)、烷氧基化的脂肪酸烷基酯(如乙氧基化的和/或丙氧基化的脂肪酸烷基酯)、烷基酚乙氧基化物(APE)、壬基酚乙氧基化物(NPE)、烷基多糖苷(APG)、烷氧基化胺、脂肪酸单乙醇酰胺(FAM)、脂肪酸二乙醇酰胺(FADA)、乙氧基化的脂肪酸单乙醇酰胺(EFAM)、丙氧基化的脂肪酸单乙醇酰胺(PFAM)、多羟基烷基脂肪酸酰胺、或葡糖胺的N-酰基N-烷基衍生物(葡糖酰胺(GA)、或脂肪酸葡糖酰胺(FAGA))、以及能以商品名SPAN和TWEEN获得的产品、及其组合。
当被包括在其中时,该洗涤剂将通常包含按重量计从约0.1%至约10%的半极性表面活性剂。半极性表面活性剂的非限制性实例包括氧化胺(AO),如烷基二甲胺氧化物、N-(椰油基烷基)-N,N-二甲胺氧化物和N-(牛油-烷基)-N,N-双(2-羟乙基)胺氧化物,及其组合。
当被包括在其中时,该洗涤剂将通常包含按重量计从约0.1%至约10%的两性离子型表面活性剂。两性离子型表面活性剂的非限制性实例包括甜菜碱,如烷基二甲基甜菜碱、磺基甜菜碱、及其组合。
助洗剂和共助洗剂
该洗涤剂组合物可以包含按重量计约0%-65%(如约5%至约50%)的洗涤剂助洗剂或共助洗剂、或其混合物。在餐具洗涤洗涤剂中,助洗剂的水平典型地是40%-65%、特别是50%-65%。助洗剂和/或共助洗剂可以具体是形成具有Ca和Mg的水溶性络合物的螯合试剂。可以利用本领域已知的用于在清洁洗涤剂中使用的任何助洗剂和/或共助洗剂。助洗剂的非限制性实例包括沸石、二磷酸盐(焦磷酸盐)、三磷酸盐例如三磷酸钠(STP或STPP)、碳酸盐例如碳酸钠、可溶性硅酸盐例如硅酸钠、层状硅酸盐(例如来自赫斯特公司(Hoechst)的SKS-6)、乙醇胺例如2-氨基乙-1-醇(MEA)、二乙醇胺(DEA,也称为2,2’-亚氨基二乙-1-醇)、三乙醇胺(TEA,也称为2,2’,2”-次氮基三乙-1-醇)、以及羧甲基菊粉(CMI)、及其组合。
该洗涤剂组合物还可以包含按重量计0%-50%,如约5%至约30%的洗涤剂共助洗剂。洗涤剂组合物可以包括单独的共助洗剂,或与助洗剂(例如沸石助洗剂)组合。共助洗剂的非限制性实例包括聚丙烯酸酯的均聚物或其共聚物,如聚(丙烯酸)(PAA)或共聚(丙烯酸/马来酸)(PAA/PMA)。另外的非限制性实例包括柠檬酸盐、螯合剂(如氨基羧酸盐、氨基多羧酸盐和磷酸盐)、以及烷基琥珀酸或烯基琥珀酸。另外的具体实例包括2,2’,2”-次氨基三乙酸(NTA)、乙二胺四乙酸(EDTA)、二亚乙基三胺五乙酸(DTPA)、亚氨基二琥珀酸(IDS)、乙二胺-N,N’-二丁二酸(EDDS)、甲基甘氨酸二乙酸(MGDA)、谷氨酸-N,N-二乙酸(GLDA)、1-羟基乙烷-1,1-二膦酸(HEDP)、乙二胺四(亚甲基膦酸)(EDTMPA)、二亚乙基三胺五(亚甲基膦酸)(DTMPA或DTPMPA)、N-(2-羟乙基)亚氨基二乙酸(EDG)、天冬氨酸-N-单乙酸(ASMA)、天冬氨酸-N,N-二乙酸(ASDA)、天冬氨酸-N-单丙酸(ASMP)、亚氨基二琥珀酸(IDA)、N-(2-磺甲基)-天冬氨酸(SMAS)、N-(2-磺乙基)-天冬氨酸(SEAS)、N-(2-磺甲基)-谷氨酸(SMGL)、N-(2-磺乙基)-谷氨酸(SEGL)、N-甲基亚氨基二乙酸(MIDA)、α-丙氨酸-N,N-二乙酸(α-ALDA)、丝氨酸-N,N-二乙酸(SEDA)、异丝氨酸-N,N-二乙酸(ISDA)、苯丙氨酸-N,N-二乙酸(PHDA)、邻氨基苯甲酸-N,N-二乙酸(ANDA)、磺胺酸-N,N-二乙酸(SLDA)、牛磺酸-N,N-二乙酸(TUDA)以及磺甲基-N,N-二乙酸(SMDA)、N-(2-羟乙基)-亚乙基二胺-N,N’,N”-三乙酸盐(HEDTA)、二乙醇甘氨酸(DEG)、二亚乙基三胺五(亚甲基膦酸)(DTPMP)、氨基三(亚甲基膦酸)(ATMP)、及其组合和盐。另外的示例性助洗剂和/或共助洗剂描述于例如WO 09/102854、US 5977053中。
漂白系统
洗涤剂可以含有按重量计0%-30%,例如约1%至约20%的漂白系统。可以利用包含本领域已知的用于在清洁洗涤剂中使用的组分的任何漂白系统。适合的漂白系统组分包括过氧化氢源;过酸源;和漂白催化剂或增效剂。
过氧化氢源:
适合的过氧化氢源是无机过酸盐,包括碱金属盐(如过碳酸钠和过硼酸钠(通常是一水合物或四水合物)),以及过氧化氢―尿素(1/1)。
过酸源:
过酸可以是(a)直接作为预形成过酸掺入,或(b)从过氧化氢和漂白活化剂(过水解)在洗涤液中原位形成,或(c)从过氧化氢和过氧化氢酶和后者适合的底物(例如酯)在洗涤液中原位形成。
a)适合的预形成过酸包括但不限于过氧羧酸(如过氧苯甲酸)及其环取代的衍生物、过氧-α-萘甲酸、过氧邻苯二甲酸、过氧月桂酸、过氧硬脂酸、ε-邻苯二甲酰亚氨基过氧己酸[邻苯二甲酰亚氨基过氧己酸(PAP)]、和邻-羧基苯甲酰氨基过氧己酸;脂族和芳族二过氧二羧酸,如二过氧十二烷二酸、二过氧壬二酸、二过氧癸二酸、二过氧巴西基酸、2-癸基二过氧丁二酸、以及二过氧邻苯二甲酸、-间苯二甲酸和-对苯二甲酸;过亚氨酸;过氧单硫酸;过氧二硫酸;过氧磷酸;过氧硅酸;以及所述化合物的混合物。应理解的是,在一些情况下,所提到的过酸可能最好是作为适合的盐的添加,如碱金属盐(例如 )或碱土金属盐。
)或碱土金属盐。
b)适合的漂白活化剂包括属于酯、酰胺、酰亚胺、腈类或酸酐类别的那些,以及适用时,其盐。适合的实例是四乙酰基乙二胺(TAED)、4-[(3,5,5-三甲基己酰基)氧基]苯-1-磺酸钠(ISONOBS)、4-(十二酰基氧基)苯-1-磺酸钠(LOBS)、4-(癸酰基氧基)苯-1-磺酸钠、4-(癸酰基氧基)苯甲酸(DOBA)、4-(壬酰基氧基)苯-1-磺酸钠(NOBS)、和/或披露于WO98/17767中的那些。感兴趣的漂白活化剂的具体家族披露于EP624154中并且在该家族中特别优选的是乙酰柠檬酸三乙酯(ATC)。ATC或短链甘油三酸酯(像三醋精)具有它们是环境友好的优点。此外,乙酰柠檬酸三乙酯和三醋精在存储时在产品中具有良好的水解稳定性,并且是有效的漂白活化剂。最后,ATC是多功能的,因为在过水解反应中释放的柠檬酸盐可以作为助洗剂起作用。
漂白催化剂和增效剂
该漂白系统还可以包括漂白催化剂或增效剂。
可以用于本发明组合物中的漂白催化剂的一些非限制性实例包括草酸锰、乙酸锰、锰胶原、钴-胺催化剂和锰三氮杂环壬烷(MnTACN)催化剂;特别优选的锰与1,4,7-三甲基-1,4,7-三氮杂环壬烷(Me3-TACN)或1,2,4,7-四甲基-1,4,7-三氮杂环壬烷(Me4-TACN)的络合物,具体地是Me3-TACN,如双核锰络合物[(Me3-TACN)Mn(O)3Mn(Me3-TACN)](PF6)2、和[2,2′,2″-次氮基三(乙烷-1,2-二基氮烷基亚基-κN-甲基亚基)三酚并-κ3O]锰(III)。这些漂白催化剂还可以是其他金属化合物,如铁或钴络合物。
在其中过酸的来源包括在内的一些实施例中,可以使用具有下式之一的有机漂白催化剂或漂白增效剂:
(i)
(ii)
(iii)及其混合物;其中每个R1独立地是含有从9至24个碳的支链烷基或含有从11至24个碳的直链烷基,优选地每个R1独立地是含有从9至18个碳的支链烷基或含有从11至18个碳的直链烷基,更优选地每个R1独立地选自由以下组成的组:2-丙基庚基、2-丁基辛基、2-戊基壬基、2-己基癸基、十二烷基、十四烷基、十六烷基、十八烷基、异壬基、异癸基、异十三烷基以及异十五烷基。
其他示例性漂白系统描述于例如WO2007/087258、WO2007/087244、WO2007/087259、EP1867708(维生素K)以及WO2007/087242中。适合的光漂白剂可以例如是磺化的酞菁锌或酞菁铝。
金属护理剂
金属护理剂可以防止或减少金属的锈蚀、腐蚀或氧化,这些金属包括铝、不锈钢和非铁金属,如银和铜。适合的实例包括以下的一个或多个:
(a)苯并三唑类,包括苯并三唑或双-苯并三唑及其取代衍生物。苯并三唑衍生物是其中芳环上可获得的取代位点被部分或完全取代的那些化合物。适合的取代基包括直链或支链Ci-C20-烷基基团(例如C1-C20-烷基基团)和羟基、硫代、苯基或卤素(如氟、氯、溴和碘)。
(b)选自由以下组成的组的金属盐和络合物:锌、锰、钛、锆、铪、钒、钴,镓和铯盐和/或络合物,这些金属处于氧化态II、III、IV、V或VI之一。在一个方面,适合的金属盐和/或金属络合物可以选自由以下组成的组:Mn(II)硫酸盐、Mn(II)柠檬酸盐、Mn(II)硬脂酸盐、Mn(II)乙酰丙酮酸盐、K^TiF6(例如,K2TiF6)、K^ZrF6(例如,K2ZrF6)、CoSO4、Co(NOs)2和Ce(NOs)3、锌盐,例如,硫酸锌、水锌矿、或乙酸锌;
(c)硅酸盐,包括硅酸钠或硅酸钾、二硅酸钠、硅酸钠、结晶层状硅酸盐及其混合物。
WO 94/26860和WO 94/26859中披露了用作银/铜腐蚀抑制剂的另外适合的有机和无机氧化还原活性物质。优选地,本发明的组合物按重量计包含从0.1%至5%的金属护理剂的组合物,优选地该金属护理剂是锌盐。
水溶助剂
洗涤剂可以包含按重量计0%-10%,例如按重量计0-5%,例如约0.5%至约5%、或约3%至约5%的水溶助剂。可以利用本领域中已知的用于在洗涤剂中使用的任何水溶助剂。水溶助剂的非限制性实例包括苯磺酸钠、对甲苯磺酸钠(STS)、二甲苯磺酸钠(SXS)、枯烯磺酸钠(SCS)、伞花烃磺酸钠、氧化胺、醇和聚乙二醇醚、羟基萘甲酸钠、羟基萘磺酸钠、乙基己基磺酸钠及其组合。
聚合物
洗涤剂可以含有按重量计0%-10%(如0.5%-5%、2%-5%、0.5%-2%或0.2%-1%)的聚合物。可以利用本领域中已知的在洗涤剂中使用的任何聚合物。该聚合物可以作为如上文提到的共助洗剂起作用,或可以提供抗再沉积、纤维保护、污垢释放、染料转移抑制、油污清洁和/或抑泡特性。一些聚合物可以具有多于一种的上文提到的特性和/或多于一种的下文提到的基序。示例性聚合物包括(羧甲基)纤维素(CMC)、聚(乙烯醇)(PVA)、聚(乙烯吡咯烷酮)(PVP)、聚(乙二醇)或聚(环氧乙烷)(PEG)、乙氧基化的聚(亚乙基亚胺)、羧甲基菊粉(CMI)、和聚羧化物,如PAA、PAA/PMA、聚-天冬氨酸、和甲基丙烯酸月桂酯/丙烯酸共聚物、疏水修饰的CMC(HM-CMC)和硅酮、对苯二甲酸和低聚乙二醇的共聚物、聚(对苯二甲酸乙二酯)和聚(氧乙烯对苯二甲酸乙二酯)的共聚物(PET-POET)、PVP、聚(乙烯基咪唑)(PVI)、聚(乙烯吡啶-N-氧化物)(PVPO或PVPNO)以及聚乙烯吡咯烷酮-乙烯基咪唑(PVPVI)。适合的实例包括来自亚什兰亚跨龙公司(Ashland Aqualon)的PVP-K15、PVP-K30、ChromaBond S-400、ChromaBond S-403E和Chromabond S-100,以及来自BASF公司的HP 165、 HP 50(分散剂)、
HP 50(分散剂)、 HP 53(分散剂)、
HP 53(分散剂)、 HP59(分散剂)、
HP59(分散剂)、 HP 56(染料转移抑制剂)、
HP 56(染料转移抑制剂)、 HP 66K(染料转移抑制剂)。另外的示例性聚合物包括磺化的聚羧酸酯、聚环氧乙烷和聚环氧丙烷(PEO-PPO)以及乙氧基硫酸二季铵盐。其他示例性聚合物披露于例如WO 2006/130575中。还考虑了以上提到的聚合物的盐。特别优选的聚合物是来自BASF公司的乙氧基化均聚物
HP 66K(染料转移抑制剂)。另外的示例性聚合物包括磺化的聚羧酸酯、聚环氧乙烷和聚环氧丙烷(PEO-PPO)以及乙氧基硫酸二季铵盐。其他示例性聚合物披露于例如WO 2006/130575中。还考虑了以上提到的聚合物的盐。特别优选的聚合物是来自BASF公司的乙氧基化均聚物 HP 20,其有助于防止洗涤液中的污垢再沉积。
HP 20,其有助于防止洗涤液中的污垢再沉积。
织物调色剂
本发明的洗涤剂组合物还可以包括织物调色剂,如染料或颜料,当配制在洗涤剂组合物中时,当所述织物与洗涤液接触时织物调色剂可以沉积在织物上,所述洗涤液包含所述洗涤剂组合物,并且因此通过可见光的吸收/反射改变所述织物的色彩。荧光增白剂发射至少一些可见光。相比之下,当织物调色剂吸收至少部分可见光谱时,它们改变表面的色彩。适合的织物调色剂包括染料和染料-粘土轭合物,并且还可以包括颜料。适合的染料包括小分子染料和聚合物染料。适合的小分子染料包括选自下组的小分子染料,该组由落入颜色索引(Colour Index)(C.I.)分类的以下染料组成:直接蓝、直接红、直接紫、酸性蓝、酸性红、酸性紫、碱性蓝、碱性紫和碱性红、或其混合物,例如于WO2005/03274、WO2005/03275、WO2005/03276和EP1876226中所描述的(通过引用特此并入)。洗涤剂组合物优选地包含从约0.00003wt%至约0.2wt%、从约0.00008wt%至约0.05wt%、或甚至从约0.0001wt%至约0.04wt%的织物调色剂。该组合物可以包含从0.0001wt%至0.2wt%的织物调色剂,当该组合物处于单位剂量袋的形式时,这可以是尤其优选的。适合的调色剂还披露于例如WO2007/087257和WO2007/087243中。
酶
洗涤剂添加剂连同洗涤剂组合物可以包括一种或多种另外的酶,例如一种或多种脂肪酶、角质酶、淀粉酶、糖酶、纤维素酶、果胶酶、甘露聚糖酶、阿拉伯糖酶、半乳聚糖酶、木聚糖酶、氧化酶,例如漆酶、和/或过氧化物酶。
一般而言,一种或多种所选酶的特性应与所选洗涤剂相容(即,最适pH,与其他酶和非酶成分的相容性等),并且该一种或多种酶应以有效量存在。
纤维素酶
适合的纤维素酶包括细菌来源或真菌来源的那些。包括化学修饰的突变体或蛋白质工程化的突变体。适合的纤维素酶包括来自芽孢杆菌属、假单胞菌属、腐质霉属、镰孢属、梭孢壳菌属、枝顶孢属的纤维素酶,例如披露于US 4,435,307、US 5,648,263、US 5,691,178、US 5,776,757以及WO 89/09259中的由特异腐质霉、嗜热毁丝霉和尖孢镰孢产生的真菌纤维素酶。
尤其适合的纤维素酶是具有颜色护理益处的碱性或中性纤维素酶。此类纤维素酶的实例是描述于EP 0 495 257、EP 0 531 372、WO 96/11262、WO 96/29397、WO 98/08940中的纤维素酶。其他实例是如描述于WO 94/07998、EP 0 531 315、US 5,457,046、US 5,686,593、US 5,763,254、WO 95/24471、WO 98/12307以及WO99/001544中的那些纤维素酶变体。
其他纤维素酶是具有以下序列的内切-β-1,4-葡聚糖酶,该序列与WO 2002/099091的SEQ ID NO:2的位置1至位置773的氨基酸序列具有至少97%同一性,或家族44木葡聚糖酶,该木葡聚糖酶具有以下序列,该序列与WO 2001/062903的SEQ ID NO:2的位置40-559具有至少60%同一性。
可商购的纤维素酶包括CelluzymeTM和CarezymeTM(诺维信公司(Novozymes A/S))、Carezyme PremiumTM(诺维信公司)、CellucleanTM(诺维信公司)、CellucleanClassicTM(诺维信公司)、CellusoftTM(诺维信公司)、WhitezymeTM(诺维信公司)、ClazinaseTM和Puradax HATM(杰能科国际有限公司(Genencor International Inc.))以及KAC-500(B)TM(花王株式会社(Kao Corporation))。
甘露聚糖酶
适合的甘露聚糖酶包括细菌或真菌来源的那些。包括化学或基因修饰的突变体。甘露聚糖酶可以是家族5或26的碱性甘露聚糖酶。它可以是来自芽孢杆菌属或腐质霉属的野生型,特别是粘琼脂芽孢杆菌、地衣芽孢杆菌、嗜碱芽孢杆菌、克劳氏芽孢杆菌或特异腐质霉。适合的甘露聚糖酶描述于WO 1999/064619中。可商购的甘露聚糖酶是Mannaway(诺维信公司)。
过氧化物酶/氧化酶
适合的过氧化物酶/氧化酶包括植物、细菌或真菌来源的那些。包括化学修饰的突变体或蛋白质工程化的突变体。有用的过氧化物酶的实例包括来自鬼伞属,例如来自灰盖鬼伞(C.cinereus)的过氧化物酶,及其变体,如在WO 93/24618、WO 95/10602、以及WO 98/15257中描述的那些。可商购的过氧化物酶包括GuardzymeTM(诺维信公司)。
脂肪酶和角质酶:
适合的脂肪酶和角质酶包括细菌或真菌来源的那些。包括化学修饰的或蛋白质工程化的突变体酶。实例包括如在EP 258 068和EP 305 216中所描述的来自嗜热丝孢菌属(Thermomyces)(例如来自疏绵状嗜热丝孢菌(T.lanuginosus)(以前命名为柔毛腐质霉(Humicolalanuginosa))的脂肪酶、来自腐质霉(例如特异腐质霉(H.insolens)(WO96/13580))的角质酶、来自假单胞菌属(Pseudomonas)(这些假单胞菌属中的一些现在重命名为伯克氏菌属)的脂肪酶(例如,产碱假单胞菌(P.alcaligenes)或类产碱假单胞菌(P.pseudoalcaligene)(EP218272))、洋葱假单胞菌(P.cepacia)(EP 331 376)、菌株SD705(WO 95/06720和WO 96/27002)、威斯康星假单胞菌(P.wisconsinensis)(WO 96/12012)、GDSL型链霉菌属脂肪酶(WO10/065455)、来自稻瘟病菌(WO10/107560)的角质酶、来自门多萨假多胞菌(US5,389,536)的角质酶、来自嗜热裂孢菌(WO11/084412)的脂肪酶、嗜热脂肪土芽孢杆菌脂肪酶(WO11/084417)、来自枯草芽孢杆菌(WO11/084599)的脂肪酶、以及来自灰色链霉菌(WO11/150157)的脂肪酶和始旋链霉菌(WO12/137147)。
其他实例是脂肪酶变体,如描述于EP407225、WO92/05249、WO94/01541、WO94/25578、WO95/14783、WO95/30744、WO95/35381、WO95/22615、WO96/00292、WO97/04079、WO97/07202、WO00/34450、WO00/60063、WO01/92502、WO07/87508以及WO09/109500中的那些。
优选的商业化脂肪酶产品包括LipolaseTM、LipexTM;LipolexTM和LipocleanTM(诺维信公司),Lumafast(来自杰能科公司(Genencor))以及Lipomax(来自吉斯特布罗卡德斯公司(Gist-Brocades))。
仍其他实例是有时称为酰基转移酶或过水解酶的脂肪酶,例如与南极假丝酵母(Candida antarctica)脂肪酶A具有同源性的酰基转移酶(WO10/111143)、来自耻垢分枝杆菌(Mycobacterium smegmatis)的酰基转移酶(WO05/56782)、来自CE 7家族的过水解酶(WO09/67279)以及耻垢分枝杆菌过水解酶的变体(特别是来自亨斯迈纺织品染化有限公司(Huntsman Textile Effects Pte Ltd)的商业产品Gentle Power Bleach中所用的S54V变体)(WO10/100028)。
淀粉酶:
适合的淀粉酶包括α-淀粉酶和/或葡糖淀粉酶并且可以是细菌或真菌来源的。包括化学修饰的突变体或蛋白质工程化的突变体。淀粉酶包括例如从芽孢杆菌属、例如地衣芽孢杆菌的特定菌株(更详细地描述于GB 1,296,839中)获得的α-淀粉酶。
适合的淀粉酶包括具有WO 95/10603中的SEQ ID NO:2的淀粉酶或其与SEQ IDNO:3具有90%序列同一性的变体。优选的变体描述于WO 94/02597、WO 94/18314、WO 97/43424中以及WO 99/019467的SEQ ID NO:4中,如在一个或多个以下位置中具有取代的变体:15、23、105、106、124、128、133、154、156、178、179、181、188、190、197、201、202、207、208、209、211、243、264、304、305、391、408和444。
不同的适合的淀粉酶包括具有WO 02/010355中的SEQ ID NO:6的淀粉酶或其与SEQ ID NO:6具有90%序列同一性的变体。SEQ ID NO:6的优选的变体是在位置181和182中具有缺失并且在位置193中具有取代的那些。
其他适合的淀粉酶是包括WO 2006/066594的SEQ ID NO:6中所示的来源于解淀粉芽孢杆菌的α-淀粉酶的残基1-33和示于WO 2006/066594的SEQ ID NO:4中的地衣芽孢杆菌α-淀粉酶的残基36-483的杂合α-淀粉酶或其具有90%序列同一性的变体。此杂合α-淀粉酶的优选的变体是在以下位置中的一个或多个中具有取代、缺失或插入的那些:G48、T49、G107、H156、A181、N190、M197、I201、A209和Q264。包含WO 2006/066594的SEQ ID NO:6中所示的来源于解淀粉芽孢杆菌的α-淀粉酶的残基1-33和SEQ ID NO:4的残基36-483的杂合α-淀粉酶的最优选的变体是具有以下取代的那些:
M197T;
H156Y+A181T+N190F+A209V+Q264S;或
G48A+T49I+G107A+H156Y+A181T+N190F+I201F+A209V+Q264S。
另外的适合的淀粉酶是具有WO 99/019467中的SEQ ID NO:6的淀粉酶或其与SEQID NO:6具有90%序列同一性的变体。SEQ ID NO:6的优选的变体是在以下位置中的一个或多个中具有取代、缺失或插入的那些:R181、G182、H183、G184、N195、I206、E212、E216和K269。特别优选的淀粉酶是在位置R181和G182、或位置H183和G184中具有缺失的那些。
可以使用的另外的淀粉酶是具有WO 96/023873的SEQ ID NO:1、SEQ ID NO:3、SEQID NO:2或SEQ ID NO:7的那些或其与SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ IDNO:7具有90%序列同一性的变体。SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:7的优选的变体是在以下位置中的一个或多个中具有取代、缺失或插入的那些:140、181、182、183、184、195、206、212、243、260、269、304和476,使用WO 96/023873的SEQ ID 2用于编号。更优选的变体是在选自181、182、183和184的两个位置(如181和182、182和183、或位置183和184)中具有缺失的那些。SEQ ID NO:1、SEQ ID NO:2或SEQ ID NO:7的最优选的淀粉酶变体是在位置183和184中具有缺失并且在位置140、195、206、243、260、304和476中的一个或多个中具有取代的那些。
可以使用的其他淀粉酶是具有WO 08/153815的SEQ ID NO:2、WO 01/66712中的SEQ ID NO:10的淀粉酶或其与WO 08/153815的SEQ ID NO:2具有90%序列同一性或与WO01/66712中的SEQ ID NO:10具有90%序列同一性的变体。WO 01/66712中的SEQ ID NO:10的优选的变体是在以下位置中的一个或多个中具有取代、缺失或插入的那些:176、177、178、179、190、201、207、211和264。
另外的适合的淀粉酶是具有WO 09/061380的SEQ ID NO:2的淀粉酶或其与SEQ IDNO:2具有90%序列同一性的变体。SEQ ID NO:2的优选的变体是在以下位置中的一个或多个中具有C-末端截短和/或取代、缺失或插入的那些:Q87、Q98、S125、N128、T131、T165、K178、R180、S181、T182、G183、M201、F202、N225、S243、N272、N282、Y305、R309、D319、Q320、Q359、K444和G475。SEQ ID NO:2的更优选的变体是在以下位置中的一个或多个处具有取代的那些:Q87E,R、Q98R、S125A、N128C、T131I、T165I、K178L、T182G、M201L、F202Y、N225E,R、N272E,R、S243Q,A,E,D、Y305R、R309A、Q320R、Q359E、K444E以及G475K,和/或在位置R180和/或S181或T182和/或G183处具有缺失的那些。SEQ ID NO:2的最优选的淀粉酶变体是具有以下取代的那些:
N128C+K178L+T182G+Y305R+G475K;
N128C+K178L+T182G+F202Y+Y305R+D319T+G475K;
S125A+N128C+K178L+T182G+Y305R+G475K;或
S125A+N128C+T131I+T165I+K178L+T182G+Y305R+G475K,其中这些变体是C-末端截短的,并且任选地进一步包含在位置243处的取代和/或在位置180和/或位置181处的缺失。
另外的适合的淀粉酶是具有WO 13184577的SEQ ID NO:1的淀粉酶或其与SEQ IDNO:1具有90%序列同一性的变体。SEQ ID NO:1的优选的变体是在以下位置中的一个或多个中具有取代、缺失或插入的那些:K176、R178、G179、T180、G181、E187、N192、M199、I203、S241、R458、T459、D460、G476和G477。SEQ ID NO:1的更优选的变体是在以下位置中的一个或多个处具有取代的那些:K176L、E187P、N192FYH、M199L、I203YF、S241QADN、R458N、T459S、D460T、G476K、以及G477K,和/或在位置R178和/或S179或T180和/或G181中具有缺失的那些。SEQ ID NO:1的最优选的淀粉酶变体是具有以下取代的那些:
E187P+I203Y+G476K
E187P+I203Y+R458N+T459S+D460T+G476K
其中这些变体任选地进一步包含在位置241处的取代和/或在位置178和/或位置179处的缺失。
另外的适合的淀粉酶是具有WO10104675的SEQ ID NO:1的淀粉酶或其与SEQ IDNO:1具有90%序列同一性的变体。SEQ ID NO:1的优选的变体是在以下位置中的一个或多个中具有取代、缺失或插入的那些:N21、D97、V128、K177、R179、S180、I181、G182、M200、L204、E242、G477和G478。SEQ ID NO:1的更优选的变体是在以下位置中的一个或多个处具有取代的那些:N21D、D97N、V128I、K177L、M200L、L204YF、E242QA、G477K、以及G478K,和/或在位置R179和/或S180或I181和/或G182中具有缺失的那些。SEQ ID NO:1的最优选的淀粉酶变体是具有以下取代的那些:
N21D+D97N+V128I
其中这些变体任选地进一步包含在位置200处的取代和/或在位置180和/或位置181处的缺失。
其他适合的淀粉酶是具有WO 01/66712中的SEQ ID NO:12的α-淀粉酶或与SEQ IDNO:12具有至少90%序列同一性的变体。优选的淀粉酶变体是在WO 01/66712中的SEQ IDNO:12中的以下位置中的一个或多个中具有取代、缺失或插入的那些:R28、R118、N174;R181、G182、D183、G184、G186、W189、N195、M202、Y298、N299、K302、S303、N306、R310、N314;R320、H324、E345、Y396、R400、W439、R444、N445、K446、Q449、R458、N471、N484。特别优选的淀粉酶包括具有D183和G184的缺失并且具有取代R118K、N195F、R320K和R458K的变体,以及另外在一个或多个选自下组的位置中具有取代的变体:M9、G149、G182、G186、M202、T257、Y295、N299、M323、E345和A339,最优选的是另外在所有这些位置中具有取代的变体。
其他实例是淀粉酶变体,如在WO 2011/098531、WO 2013/001078和WO 2013/001087中描述的那些。
可商购的淀粉酶是DuramylTM、TermamylTM、FungamylTM、StainzymeTM、StainzymePlusTM、NatalaseTM、Liquozyme X和BANTM(来自诺维信公司),和RapidaseTM、PurastarTM/EffectenzTM、Powerase、Preferenz S1000、Preferenz S100和Preferenz S110(来自杰能科国际有限公司/杜邦公司(DuPont))。
蛋白酶:
适合的蛋白酶包括细菌、真菌、植物、病毒或动物来源的那些,例如植物或微生物来源。优选的是微生物来源。包括化学修饰的突变体或蛋白质工程化的突变体。它可以是碱性蛋白酶,如丝氨酸蛋白酶或金属蛋白酶。丝氨酸蛋白酶可以例如是S1家族的(如胰蛋白酶)或S8家族的(如枯草杆菌蛋白酶)。金属蛋白酶可以例如是来自例如M4家族的嗜热菌蛋白酶或其他金属蛋白酶,如来自M5、M7或M8家族的那些。
术语“枯草杆菌酶”是指根据Siezen等人,Protein Engng.[蛋白质工程]4(1991)719-737和Siezen等人,Protein Science[蛋白质科学]6(1997)501-523的丝氨酸蛋白酶的亚组。丝氨酸蛋白酶是特征在于在活性位点具有与底物形成共价加合物的丝氨酸的蛋白酶的亚组。枯草杆菌酶可以被划分为6个亚类,即,枯草杆菌蛋白酶家族、嗜热蛋白酶家族、蛋白酶K家族、羊毛硫氨酸抗生素肽酶家族、Kexin家族和Pyrolysin家族。
枯草杆菌酶的实例是来源于芽孢杆菌属的那些,如描述于US 7262042和WO 09/021867中的迟缓芽孢杆菌、嗜碱芽孢杆菌(B.alkalophilus)、枯草芽孢杆菌(B.subtilis)、解淀粉芽孢杆菌(B.amyloliquefaciens)、短小芽孢杆菌和吉氏芽孢杆菌(Bacillusgibsonii);以及描述于WO 89/06279中的迟缓枯草杆菌蛋白酶(subtilisin lentus)、枯草杆菌蛋白酶Novo、枯草杆菌蛋白酶Carlsberg、地衣芽孢杆菌、枯草杆菌蛋白酶BPN’、枯草杆菌蛋白酶309、枯草杆菌蛋白酶147和枯草杆菌蛋白酶168以及描述于(WO 93/18140)中的蛋白酶PD138。其他有用的蛋白酶可以是描述于WO 92/175177、WO 01/016285、WO 02/026024以及WO 02/016547中的那些。胰蛋白酶样蛋白酶的实例是胰蛋白酶(例如猪或牛来源的)和镰孢属蛋白酶(描述于WO 89/06270、WO 94/25583和WO 05/040372中),以及来源于纤维单胞菌(Cellumonas)的糜蛋白酶(描述于WO 05/052161和WO 05/052146中)。
另外的优选的蛋白酶是来自迟缓芽孢杆菌DSM 5483的碱性蛋白酶(如在(例如)WO95/23221中所描述)、以及其变体(在WO 92/21760、WO 95/23221、EP 1921147以及EP1921148中描述的)。
金属蛋白酶的实例是如描述于WO 07/044993(杰能科国际有限公司(GenencorInt.))中的中性金属蛋白酶,如来源于解淀粉芽孢杆菌的那些。
有用的蛋白酶的实例是描述于以下中的变体:WO 92/19729、WO 96/034946、WO98/20115、WO 98/20116、WO 99/011768、WO 01/44452、WO 03/006602、WO 04/03186、WO 04/041979、WO 07/006305、WO 11/036263、WO 11/036264,尤其是在以下一个或多个位置中具有取代的变体:3、4、9、15、24、27、42、55、59、60、66、74、85、96、97、98、99、100、101、102、104、116、118、121、126、127、128、154、156、157、158、161、164、176、179、182、185、188、189、193、198、199、200、203、206、211、212、216、218、226、229、230、239、246、255、256、268和269,其中这些位置对应于WO 2016/001449的SEQ ID NO 1中所示的迟缓芽孢杆菌蛋白酶的位置。更优选的枯草杆菌酶变体可以包括以下突变中的一个或多个:S3T、V4I、S9R、S9E、A15T、S24G、S24R、K27R、N42R、S55P、G59E、G59D、N60D、N60E、V66A、N74D、N85S、N85R、、G96S、G96A、S97G、S97D、S97A、S97SD、S99E、S99D、S99G、S99M、S99N、S99R、S99H、S101A、V102I、V102Y、V102N、S104A、G116V、G116R、H118D、H118N、N120S、S126L、P127Q、S128A、S154D、A156E、G157D、G157P、S158E、Y161A、R164S、Q176E、N179E、S182E、Q185N、A188P、G189E、V193M、N198D、V199I、Y203W、S206G、L211Q、L211D、N212D、N212S、M216S、A226V、K229L、Q230H、Q239R、N246K、N255W、N255D、N255E、L256E、L256D、T268A、R269H。这些蛋白酶变体优选地是在WO2016/001449的SEQ ID NO 1中所示的迟缓芽孢杆菌蛋白酶的变体、或在WO2016/001449的SEQ ID NO 2中所示的解淀粉芽孢杆菌蛋白酶(BPN’)的变体。这些蛋白酶变体与WO 2016/001449的SEQ ID NO 1或SEQ ID NO 2优选地具有至少80%序列同一性。
在以下一个或多个位置(对应于WO 2004/067737的SEQ ID NO:1的位置171、173、175、179或180)处包含取代的蛋白酶变体,其中所述蛋白酶变体与WO 2004/067737的SEQID NO:1具有至少75%但少于100%的序列同一性。
适合的可商购蛋白酶包括以下列商品名出售的那些: DuralaseTm、DurazymTm、
DuralaseTm、DurazymTm、 Ultra、
Ultra、 Ultra、
Ultra、 Ultra、
Ultra、 Ultra、
Ultra、 Blaze
Blaze 100T、Blaze
100T、Blaze 125T、Blaze
125T、Blaze 150T、
150T、 和
和 (诺维信公司),在以下商品名下出售的那些:
(诺维信公司),在以下商品名下出售的那些:  Excellenz P1000TM、Excellenz P1250TM、
Excellenz P1000TM、Excellenz P1250TM、 Preferenz P100TM、Purafect
Preferenz P100TM、Purafect Preferenz P110TM、Effectenz P1000TM、
Preferenz P110TM、Effectenz P1000TM、 Effectenz P1050TM、
Effectenz P1050TM、 Effectenz P2000TM、
Effectenz P2000TM、
 和(丹斯尼克公司(Danisco)/杜邦公司)、AxapemTM(吉斯特布罗卡德斯公司(Gist-Brocases N.V.))、BLAP(在US5352604的图29中示出的序列)及其变体(汉高公司(Henkel AG))和来自花王株式会社(Kao)的KAP(嗜碱芽孢杆菌枯草杆菌蛋白酶)。
和(丹斯尼克公司(Danisco)/杜邦公司)、AxapemTM(吉斯特布罗卡德斯公司(Gist-Brocases N.V.))、BLAP(在US5352604的图29中示出的序列)及其变体(汉高公司(Henkel AG))和来自花王株式会社(Kao)的KAP(嗜碱芽孢杆菌枯草杆菌蛋白酶)。
过氧化物酶/氧化酶
根据本发明的过氧化物酶是由酶分类EC 1.11.1.7囊括的由国际生物化学和分子生物学联盟命名委员会(IUBMB)规定的酶,或来源于其中的展示出过氧化物酶活性的任何片段。
适合的过氧化物酶包括植物、细菌或真菌来源的那些。包括化学修饰的突变体或蛋白质工程化的突变体。有用的过氧化物酶的实例包括来自拟鬼伞属,例如来自灰盖拟鬼伞(C.cinerea)的过氧化物酶(EP 179,486),及其变体,如在WO 93/24618、WO 95/10602以及WO 98/15257中所描述的那些。
适合的过氧化物酶包括卤代过氧化物酶,如氯过氧化物酶、溴过氧化物酶以及表现出氯过氧化物酶或溴过氧化物酶活性的化合物。根据其对卤素离子的特异性将卤代过氧化物酶进行分类。氯过氧化物酶(E.C.1.11.1.10)催化从氯根离子形成次氯酸盐。优选地,该卤代过氧化物酶是钒卤代过氧化物酶,即含钒酸盐的卤代过氧化物酶。已从许多不同真菌,特别是从暗色丝孢菌(dematiaceous hyphomycete)真菌组中分离出了卤代过氧化物酶,如卡尔黑霉属(Caldariomyces)(例如,煤卡尔黑霉(C.fumago))、链格孢属、弯孢属(例如,疣枝弯孢(C.verruculosa)和不等弯孢(C.inaequalis))、内脐蠕孢属、细基格孢属以及葡萄孢属。
还已从细菌,如假单胞菌属(例如吡咯假单胞菌(P.pyrrocinia))和链霉菌属(例如,金色链霉菌(S.aureofaciens))中分离出了卤代过氧化物酶。
适合的氧化酶特别包括由酶分类EC 1.10.3.2所包含的任何漆酶或来源于其的展现出漆酶活性的任何片段、或展现出类似活性的化合物,如儿茶酚氧化酶(EC 1.10.3.1)、邻氨基苯酚氧化酶(EC 1.10.3.4)或胆红素氧化酶(EC 1.3.3.5)。优选的漆酶是微生物来源的酶。该酶可以来源于植物、细菌或真菌(包括丝状真菌和酵母)。来自真菌的适合实例包括可来源于以下的菌株的漆酶:曲霉属,脉孢菌属(例如,粗糙脉孢菌),柄孢壳菌属,葡萄孢属,金钱菌属(Collybia),层孔菌属(Fomes),香菇属,侧耳属,栓菌属(例如,长绒毛栓菌和变色栓菌),丝核菌属(例如,立枯丝核菌(R.solani)),拟鬼伞属(例如,灰盖拟鬼伞、毛头拟鬼伞(C.comatus)、弗瑞氏拟鬼伞(C.friesii)及C.plicatilis),小脆柄菇属(Psathyrella)(例如,白黄小脆柄菇(P.condelleana)),斑褶菇属(例如,蝶形斑褶菇(P.papilionaceus)),毁丝霉属(例如,嗜热毁丝霉),Schytalidium(例如,S.thermophilum),多孔菌属(例如,P.pinsitus),射脉菌属(例如,射脉侧菌(P.radiata))(WO 92/01046)或革盖菌属(例如,毛革盖菌(C.hirsutus))(JP 2238885)。来自细菌的适合的实例包括可来源于芽孢杆菌属的菌株的漆酶。优选的是来源于拟鬼伞属或毁丝霉属的漆酶;特别是来源于灰盖拟鬼伞的漆酶,如披露于WO 97/08325中;或来源于嗜热毁丝霉,如披露于WO 95/33836中。
分散剂
本发明的洗涤剂组合物还可以包含分散剂。特别地,粉状洗涤剂可以包含分散剂。适合的水溶性有机材料包括均聚合或共聚合的酸或其盐,其中聚羧酸包含被不多于两个碳原子彼此分开的至少两个羧基。适合的分散剂例如描述于Powdered Detergents[粉末洗涤剂],Surfactant science series[表面活性剂科学系列],第71卷,Marcel Dekker,Inc[马塞尔德克尔公司]中。
染料转移抑制剂
本发明的洗涤剂组合物还可以包括一种或多种染料转移抑制剂。适合的聚合物染料转移抑制剂包括但不限于聚乙烯吡咯烷酮聚合物、多胺N-氧化物聚合物、N-乙烯吡咯烷酮和N-乙烯基咪唑的共聚物、聚乙烯噁唑烷酮和聚乙烯咪唑或其混合物。当在主题组合物中存在时,染料转移抑制剂可以按该组合物的重量计以从约0.0001%至约10%、从约0.01%至约5%或甚至从约0.1%至约3%的水平存在。
荧光增白剂
本发明的洗涤剂组合物将优选地还包含另外的组分,这些组分可以给正在清洁的物品着色,例如荧光增白剂或光学增亮剂。当存在时,该增亮剂优选地以约0.01%至约0.5%的水平存在。在本发明的组合物中可以使用适合用于在衣物洗涤剂组合物中使用的任何荧光增白剂。最常用的荧光增白剂是属于以下类别的那些:二氨基芪-磺酸衍生物、二芳基吡唑啉衍生物和二苯基-联苯乙烯基衍生物。荧光增白剂的二氨基芪-磺酸衍生物型的实例包括以下的钠盐:4,4'-双-(2-二乙醇氨基-4-苯胺基-s-三嗪-6-基氨基)芪-2,2'-二磺酸盐、4,4'-双-(2,4-二苯胺基-s-三嗪-6-基氨基)芪-2.2'-二磺酸盐、4,4'-双-(2-苯胺基-4-(N-甲基-N-2-羟基-乙基氨基)-s-三嗪-6-基氨基)芪-2,2'-二磺酸盐、4,4'-双-(4-苯基-1,2,3-三唑-2-基)芪-2,2'-二磺酸盐以及5-(2H-萘并[1,2-d][1,2,3]三唑-2-基)-2-[(E)-2-苯基乙烯基]苯磺酸钠。优选的荧光增白剂是可从汽巴–嘉基股份有限公司(Ciba-Geigy AG)(巴塞尔,瑞士)获得的天来宝(Tinopal)DMS和天来宝CBS。天来宝DMS是4,4'-双-(2-吗啉代-4-苯胺基-s-三嗪-6-基氨基)芪-2,2'-二磺酸盐的二钠盐。天来宝CBS是2,2'-双-(苯基-苯乙烯基)-二磺酸盐的二钠盐。还优选的是荧光增白剂是可商购的Parawhite KX,由印度孟买的派拉蒙矿物与化学品公司(Paramount Minerals andChemicals)供应。适合用于本发明中使用的其他荧光剂包括1-3-二芳基吡唑啉和7-氨烷基香豆素。适合的荧光增亮剂水平包括从约0.01wt%、从0.05wt%、从约0.1wt%或甚至从约0.2wt%的较低水平至0.5wt%或甚至0.75wt%的较高水平。
污垢释放聚合物
本发明的洗涤剂组合物还可以包括一种或多种污垢释放聚合物,这些聚合物帮助从织物(如棉和基于聚酯的织物)去除污垢,特别是从基于聚酯的织物去除疏水性污垢。污垢释放聚合物可以例如是基于非离子型或阴离子型对苯二甲酸的聚合物、聚乙烯基己内酰胺和相关共聚物、乙烯基接枝共聚物、聚酯聚酰胺,参见例如Powdered Detergents[粉末洗涤剂],Surfactant science series[表面活性剂科学系列]第71卷,第7章,马塞尔·德克尔公司(Marcel Dekker,Inc.)。另一种类型的污垢释放聚合物是包含核心结构和附接至该核心结构的多个烷氧基化基团的两亲性烷氧基化油污清洁聚合物。核心结构可以包含聚烷基亚胺结构或聚烷醇胺结构,如在WO 2009/087523中详细描述的(通过引用特此并入)。此外,随机接枝共聚物是适合的污垢释放聚合物。适合的接枝共聚物更详细地描述于WO2007/138054、WO 2006/108856以及WO 2006/113314中(通过引用特此并入)。适合的聚乙二醇聚合物包括随机接枝共聚物,该随机接枝共聚物包含:(i)含有聚乙二醇的亲水主链;和(ii)选自由以下组成的组的一个或多个侧链:C4-C25烷基基团、聚丙烯、聚丁烯、饱和C1-C6单羧酸的乙烯基酯、丙烯酸或甲基丙烯酸的C1-C6烷基酯、及其混合物。适合的聚乙二醇聚合物具有聚乙二醇主链和随机接枝的聚乙酸乙烯酯侧链。聚乙二醇主链的平均分子量可以在2,000Da至20,000Da的范围内、或在4,000Da至8,000Da的范围内。聚乙二醇主链与聚乙酸乙烯酯侧链的分子量比率可以在1:1至1:5的范围内、或在1:1.2至1:2的范围内。每个环氧乙烷单元的平均接枝位数可小于1、或小于0.8,每个环氧乙烷单元的平均接枝位数可以在0.5至0.9的范围内,或每个环氧乙烷单元的平均接枝位数可以在0.1至0.5的范围内、或在0.2至0.4的范围内。适合的聚乙二醇聚合物是Sokalan HP22。其他污垢释放聚合物是取代的多糖结构,尤其是取代的纤维素结构,如修饰的纤维素衍生物,如EP 1867808或WO 2003/040279中所描述的那些(将两者都通过引用特此并入)。适合的纤维素聚合物包括纤维素、纤维素醚、纤维素酯、纤维素酰胺以及其混合物。适合的纤维素聚合物包括阴离子修饰的纤维素、非离子修饰的纤维素、阳离子修饰的纤维素、两性离子修饰的纤维素及其混合物。适合的纤维素聚合物包括甲基纤维素、羧甲基纤维素、乙基纤维素、羟乙基纤维素、羟丙基甲基纤维素、酯羧甲基纤维素及其混合物。
抗再沉积剂
本发明的洗涤剂组合物还可以包括一种或多种抗再沉积剂,如羧甲基纤维素(CMC)、聚乙烯醇(PVA)、聚乙烯吡咯烷酮(PVP)、聚氧乙烯和/或聚乙二醇(PEG)、丙烯酸的均聚物、丙烯酸和马来酸的共聚物、和乙氧基化的聚乙亚胺。以上在污垢释放聚合物下所描述的基于纤维素的聚合物还可以作为抗再沉积剂起作用。
流变改性剂
本发明的洗涤剂组合物还可以包括一种或多种流变改性剂、结构剂或增稠剂,不同于降粘剂。流变改性剂选自由以下组成的组:非聚合物结晶、羟基功能材料、聚合物流变改性剂,它们为液体洗涤剂组合物的水性液相基质赋予剪切稀化特征。可以通过本领域已知的方法修饰和调整洗涤剂的流变学和粘度,例如,如在EP 2169040中所示。其他适合的清洁组合物组分包括但不限于防缩剂、抗皱剂、杀细菌剂、粘合剂、运载体、染料、酶稳定剂、织物软化剂、填充剂、泡沫调节剂、水溶助剂、香料、颜料、抑泡剂、溶剂以及用于液体洗涤剂的结构剂和/或结构弹力剂。
洗涤剂产品的配制品
本发明的洗涤剂组合物可以处于任何常规形式,例如条,均匀的片剂,具有两层或更多层的片剂,具有一个或多个室的袋,规则的或压缩的粉末,颗粒,膏,凝胶,或规则的、压缩的或浓缩的液体。
袋可以被配置为单一室或多室。它可以具有适合用于容持该组合物的任何形式、形状和材料,例如在与水接触之前,不允许该组合物从袋中释放出来。该袋由水溶性膜制成,它包含了一个内部体积。可以将所述内部体积分成袋的室。优选的膜是聚合物材料,优选地形成膜或薄片的聚合物。优选的聚合物、共聚物或其衍生物选自聚丙烯酸酯、和水溶性丙烯酸酯共聚物、甲基纤维素、羧甲基纤维素、糊精钠、乙基纤维素、羟乙基纤维素、羟丙基甲基纤维素、麦芽糊精、聚甲基丙烯酸酯,最优选地是聚乙烯醇共聚物以及羟丙基甲基纤维素(HPMC)。优选地,聚合物在膜例如PVA中的水平是至少约60%。优选的平均分子量将典型地是约20,000至约150,000。膜还可以是共混组合物,其包含可水解降解并且水可溶的聚合物共混物,如聚乳酸和聚乙烯醇(已知在贸易参考号M8630下,如由美国印第安纳州的MonoSol有限责任公司(MonoSol LLC)销售)加增塑剂,像甘油、乙二醇、丙二醇、山梨醇及其混合物。这些袋可以包含固体洗衣清洁组合物或部分组分和/或液体清洁组合物或由水溶性膜分开的部分组分。可以用于液体组分的室在构成上可以与包含固体的室不同:US2009/0011970 A1。
可以由水可溶袋中的或片剂的不同层中的室来将洗涤剂成分彼此物理分开。因此,可以避免组分间的不良的储存相互作用。在洗涤溶液中,每个室的不同溶解曲线还可以引起选择的组分的延迟溶解。
非单位剂量的液体或凝胶洗涤剂可以是水性的,典型地包含按重量计至少20%并且最高达95%的水,例如高达约70%的水、高达约65%的水、高达约55%的水、高达约45%的水、高达约35%的水。包括但不限于链烷醇、胺、二醇、醚以及多元醇的其他类型的液体可以被包括在水性液体或凝胶中。水性液体或凝胶洗涤剂可以包含从0%-30%的有机溶剂。液体或凝胶洗涤剂可以是非水性的。
颗粒洗涤剂配制品
本发明的一种或多种组合物可以被配制为颗粒,例如,配制为结合一种或多种酶的共颗粒。然后,每种酶将存在于多种颗粒中,这些颗粒确保酶在洗涤剂中的分布更均匀。这还减少了由于不同的粒度,不同酶的物理隔离。用于生产针对洗涤剂工业的多酶共颗粒的方法披露于IP.com披露内容IPCOM000200739D中。
通过使用共颗粒的酶的配制品的另一个实例披露于WO 2013/188331中,其涉及包含以下项的洗涤剂组合物:(a)多酶共颗粒;(b)少于10wt沸石(无水的基础上);和(c)少于10wt磷酸盐(无水的基础上),其中所述酶共颗粒包含从10wt%至98wt%的水分汇组分(sink component),并且该组合物另外还包含从20wt%至80wt%的洗涤剂水分汇组分。多酶共颗粒可以包含本发明的DNA酶和(a)一种或多种选自以下的酶:蛋白酶、脂肪酶、纤维素酶、木葡聚糖酶、过水解酶、过氧化物酶、脂氧合酶、漆酶、半纤维素酶、蛋白酶、护理纤维素酶、纤维二糖脱氢酶、木聚糖酶、磷脂酶、酯酶、角质酶、果胶酶、甘露聚糖酶、果胶裂解酶、角蛋白酶、还原酶、氧化酶、酚氧化酶、木质素酶、支链淀粉酶、鞣酸酶、戊聚糖酶、地衣多糖酶、葡聚糖酶、阿拉伯糖苷酶、透明质酸酶、软骨素酶、淀粉酶及其混合物。
在一个方面,本发明提供了颗粒,该颗粒包含:
(a)核心,该核心包含:含有SEQ ID NO 3、SEQ ID NO 6、SEQ ID NO 9、SEQ ID NO12、SEQ ID NO 15、SEQ ID NO 18、SEQ ID NO 21、SEQ ID NO 24、SEQ ID NO 27、SEQ ID NO30、SEQ ID NO 33、SEQ ID NO 36、SEQ ID NO 39、SEQ ID NO 42中所示的氨基酸序列的多肽,或与其具有至少80%序列同一性的多肽,以及
(b)任选地由包围该核心的一个或多个层组成的包衣。
用途
具有DNA酶活性的本发明的多肽可以用于深度清洁物品,例如纺织品。本发明的一个实施例涉及根据本发明的DNA酶用于防止减少或去除恶臭的用途。本发明的一个实施例涉及本发明的DNA酶用于对经过多次洗涤的纺织品进行抗再沉积的防止或减少和改进白度的用途。本发明的一个实施例涉及根据本发明的多肽用于深度清洁物品的用途,其中该物品是纺织品。本发明的一个实施例涉及根据本发明的多肽的以下用途:
(i)用于防止、减少或去除该物品的粘性;
(ii)用于预处理该物品上的污渍;
(iii)用于在洗涤循环期间防止、减少或去除污垢的再沉积;
(iv)用于防止、减少或去除污垢在该物品上的附着;
(v)用于维持或改进该物品的白度;
(vi)用于防止、减少或去除该物品的恶臭,
其中该物品是纺织品。
在以下段落中进一步概述本发明:
1.多肽用于深度清洁物品的用途,该多肽具有DNA酶活性并且包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48),其中该物品是纺织品。
2.根据段落1所述的用途,用于防止、减少或去除该物品的粘性。
3.根据段落1或2中任一项所述的用途,用于预处理该物品上的污渍。
4.根据段落1-3中任一项所述的用途,用于防止、减少或去除洗涤周期期间污垢的再沉积。
5.根据段落1-4中任一项所述的用途,用于防止、减少或去除污垢在该物品上的附着。
6.根据前述段落中任一项所述的用途,用于维持或改进该物品的白度。
7.根据前述段落中任一项所述的用途,其中从该物品减少或去除恶臭。
8.根据前述组合物段落中任一项所述的用途,其中该表面是纺织品表面。
9.根据前述组合物段落中任一项所述的用途,其中该纺织品由棉、棉/聚酯、聚酯、聚酰胺、聚丙烯和/或丝绸制成。
10.根据前述段落中任一项所述的用途,其中该多肽是根据段落47-61所述的多肽。
11.一种组合物,该组合物包含具有DNA酶活性的多肽,该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)和至少一种洗涤剂佐剂成分。
12.根据段落11所述的组合物,其中该多肽是根据段落45-59所述的多肽。
13.根据前述组合物段落中任一项所述的组合物,其中该洗涤剂佐剂成分选自由以下组成的组:表面活性剂、助洗剂、絮凝助剂、螯合试剂、染料转移抑制剂、酶、酶稳定剂、酶抑制剂、催化材料、漂白活化剂、过氧化氢、过氧化氢源、预形成的过酸、聚合的分散剂、粘土去污剂/抗再沉积剂、增亮剂、抑泡剂、染料、香料、结构弹力剂、织物软化剂、运载体、水溶助剂、助洗剂和共助洗剂、织物调色剂、防沫剂、分散剂、加工助剂、和/或颜料。
14.根据前述组合物段落中任一项所述的组合物,其中该组合物包含从约5wt%至约50wt%、从约5wt%至约40wt%、从约5wt%至约30wt%、从约5wt%至约20wt%、从约5wt%至约10wt%的阴离子型表面活性剂,优选地选自直链烷基苯磺酸盐(LAS)、LAS的异构体、支链烷基苯磺酸盐(BABS)、苯基链烷磺酸盐、α-烯烃磺酸盐(AOS)、烯烃磺酸盐、链烯烃磺酸盐、链烷-2,3-二基双(硫酸盐)、羟基链烷磺酸盐以及二磺酸盐、烷基硫酸盐(AS)如十二烷基硫酸钠(SDS)、脂肪醇硫酸盐(FAS)、伯醇硫酸盐(PAS)、醇醚硫酸盐(AES或AEOS或FES)、仲链烷磺酸盐(SAS)、石蜡烃磺酸盐(PS)、酯磺酸盐、磺化的脂肪酸甘油酯、包括甲酯磺酸盐(MES)在内的α-磺酸基脂肪酸甲酯(α-SFMe或SES)、烷基琥珀酸或烯基琥珀酸、十二烯基/十四烯基琥珀酸(DTSA)、氨基酸的脂肪酸衍生物、磺酸基琥珀酸或脂肪酸盐(皂)的二酯和单酯及其组合。
15.根据前述组合物段落中任一项所述的组合物,其中该组合物包含从约10wt%至约50wt%的至少一种助洗剂,优选地选自柠檬酸、甲基甘氨酸-N,N-二乙酸(MGDA)和/或谷氨酸-N,N-二乙酸(GLDA)及其混合物。
16.根据前述段落中任一项所述的组合物,该组合物包含从约5wt%至约40wt%的非离子型表面活性剂、和从约0wt%至约5wt%的阴离子型表面活性剂。
17.根据段落16所述的组合物,其中该非离子型表面活性剂选自:醇乙氧基化物(AE或AEO)、醇丙氧基化物、丙氧基化的脂肪醇(PFA)、烷氧基化的脂肪酸烷基酯如乙氧基化的和/或丙氧基化的脂肪酸烷基酯、烷基酚乙氧基化物(APE)、壬基酚乙氧基化物(NPE)、烷基多糖苷(APG)、烷氧基化胺、脂肪酸单乙醇酰胺(FAM)、脂肪酸二乙醇酰胺(FADA)、乙氧基化的脂肪酸单乙醇酰胺(EFAM)、丙氧基化的脂肪酸单乙醇酰胺(PFAM)、多羟基烷基脂肪酸酰胺、或葡萄糖胺的N-酰基N-烷基衍生物(葡糖酰胺(GA)、或脂肪酸葡糖酰胺(FAGA))及其组合。
18.根据前述组合物段落中任一项所述的组合物,其中该组合物进一步包括选自由以下组成的组的一种或多种酶:蛋白酶、脂肪酶、角质酶、淀粉酶、糖酶、纤维素酶、果胶酶、甘露聚糖酶、阿拉伯糖酶、半乳聚糖酶、木聚糖酶和氧化酶。
19.根据前述组合物段落中任一项所述的组合物,其中该组合物是条,均匀的片剂,具有两个或更多个层的片剂,具有一个或多个室的袋,规则的或压缩的粉末,颗粒,膏,凝胶,或规则的、压缩的或浓缩的液体。
20.根据前述组合物段落中任一项所述的组合物,其中该组合物是选自液体洗涤剂、粉末洗涤剂和颗粒洗涤剂组合物的清洁组合物。
21.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48),并且任选地选自由以下组成的组:具有SEQ ID NO 3、6、9、12、15、18、21、24、27、30、33、36、39或42中所示的氨基酸序列的多肽,和与其具有至少80%序列同一性的多肽。
22.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 3中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
23.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 6中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
24.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 9中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
25.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 12中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
26.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 15中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
27.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 18中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
28.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 21中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
29.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 24中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
30.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 27中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
31.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 30中所示的氨基酸序列或与其具有至少60%序列同一性的序列,例如至少70%、至少80%或至少90%。
32.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 33中所示的氨基酸序列或与其具有至少60%序列同一性的序列。
33.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 36中所示的氨基酸序列或与其具有至少60%序列同一性的序列。
34.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 39中所示的氨基酸序列或与其具有至少60%序列同一性的序列。
35.根据前述组合物段落中任一项所述的组合物,其中该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)并且包含SEQ ID NO 42中所示的氨基酸序列或与其具有至少60%序列同一性的多肽。
36.一种用于洗涤物品的方法,该方法包括以下步骤:
a.将物品暴露于包含根据段落50-64所述的多肽的洗涤液或根据段落11-35中任一项所述的组合物;
b.完成至少一个洗涤循环;和
c.任选地冲洗该物品,
其中该物品是纺织品。
37.一种处理物品的方法,其中该物品优选为纺织品,如织物,所述方法包括以下步骤:将物品暴露于选自由以下组成的组的多肽:与SEQ ID NO:2、5、8、11、14、17、20、23、26、29、32、35、38或41的成熟多肽具有至少80%序列同一性的多肽;包含所述多肽的洗涤液或根据任一前述段落所述的洗涤剂组合物。
38.根据任一前述段落所述的方法,其中该洗涤液的pH在1至11的范围内。
39.根据前述方法段落中任一项所述的方法,其中该洗涤液的pH在5.5至11的范围内,如在7至9的范围内,在7至8的范围内或在7至8.5的范围内。
40.根据前述方法段落中任一项所述的方法,其中该洗涤液的温度在5℃至95℃的范围内、或在10℃至80℃的范围内、在10℃至70℃的范围内、在10℃至60℃的范围内、在10℃至50℃的范围内、在15℃至40℃的范围内、在20℃至40℃的范围内、在15℃至30℃的范围内或在20℃至30℃的范围内。
41.根据前述方法段落中任一项所述的方法,其中该洗涤液的温度是从约20℃至约40℃。
42.根据前述方法段落中任一项所述的方法,其中该洗涤液的温度是从约15℃至约30℃。
43.根据前述方法段落中任一项所述的方法,其中将该物品上存在的污渍用根据段落50-64所述的多肽或根据段落11-35中任一项所述的洗涤剂组合物进行预处理。
44.根据前述方法段落中任一项所述的方法,其中该物品的粘性被减少。
45.根据前述方法段落中任一项所述的方法,其中污垢的再沉积被减少。
46.根据前述方法段落中任一项所述的方法,其中污垢在该物品上的附着被减少或去除。
47.根据前述方法段落中任一项所述的方法,其中该物品的白度被维持或改进。
48.根据前述方法段落中任一项所述的方法,其中从该物品减少或去除恶臭。
49.根据前述方法段落中任一项所述的方法,其中在洗涤液中具有DNA酶活性的多肽的浓度为每升洗涤液中至少0,001mg多肽,如至少5mg的蛋白质、优选至少10mg的蛋白质、更优选至少15mg的蛋白质;任选地洗涤液中该多肽的浓度是每升洗涤液中在0,002mg/L至2mg/L、如0,02mg/L至2mg/L、如0,2mg/L至2mg/L的范围内,或在0,0001mg/L至10mg/L的范围内、或在0,001mg/L至10mg/L的范围内、或在0,01mg/L至10mg/L的范围内、或在0,1mg/L至10mg/L的范围内;任选地本发明的多肽的浓度为在总洗涤剂浓度中0.0001%至2wt%,如0.001至0.1wt%、如0.005至0.1wt%、如0.01至0.1wt%、如0.01至0.5wt%、或最优选的0.002至0.09wt%。
50.一种具有DNA酶活性的多肽,该多肽选自由以下组成的组:
a.与SEQ ID NO:2、5、8、11、14、17、20、23、26、29、32、35、38、41的成熟多肽具有至少80%序列同一性的多肽或与SEQ ID NO:3、6、9、12、15、18、21、24、27、30、33、36、39、42中所示的成熟多肽具有至少80%序列同一性的多肽;
b.由以下多核苷酸编码的多肽,该多核苷酸在低严格条件下与以下杂交:
i.SEQ ID NO:1、4、7、10、13、16、19、22、25、28、31、34、37或40的成熟多肽编码序列;
ii.其cDNA序列,或
iii.(i)或(ii)的全长互补序列;
c.由以下多核苷酸所编码的多肽,该多核苷酸与SEQ ID NO:1、4、7、10、13、16、19、22、25、28、31、34、37或40的成熟多肽编码序列或其cDNA序列具有至少60%序列同一性;
d.在一个或多个位置处包含取代、缺失、和/或插入的SEQ ID NO:23、6、9、12、15、18、21、24、27、30、33、36、39、42中所示的成熟多肽的变体,或在一个或多个位置处包含取代、缺失、和/或插入的SEQ ID NO:3、6、9、12、15、18、21、24、27、30、33、36、39、42中所示的成熟多肽的变体;和
e.(a)、(b)、(c)或(d)的多肽的片段,该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO 48)中的一个或多个。
51.根据段落50所述的多肽,该多肽与SEQ ID NO:2、5、8、11、14、17、20、23、26、29、32、35、38、或41的成熟多肽或与SEQ ID NO:3、6、9、12、15、18、21、24、27、30、33、36、39、42中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
52.根据段落50所述的多肽,该多肽与SEQ ID NO:2的成熟多肽或与SEQ ID NO:3中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
53.根据段落50所述的多肽,该多肽与SEQ ID NO:5的成熟多肽或与SEQ ID NO:6中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
54.根据段落50所述的多肽,该多肽与SEQ ID NO:8的成熟多肽或与SEQ ID NO:9中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
55.根据段落50所述的多肽,该多肽与SEQ ID NO:11的成熟多肽或与SEQ ID NO:12中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
56.根据段落50所述的多肽,该多肽与SEQ ID NO:14的成熟多肽或与SEQ ID NO:15中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
57.根据段落50所述的多肽,该多肽与SEQ ID NO:17的成熟多肽或与SEQ ID NO:18中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
58.根据段落50所述的多肽,该多肽与SEQ ID NO:20的成熟多肽或与SEQ ID NO:21中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
59.根据段落50所述的多肽,该多肽与SEQ ID NO:23的成熟多肽或与SEQ ID NO:24中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
60.根据段落50所述的多肽,该多肽与SEQ ID NO:26的成熟多肽或与SEQ ID NO:27中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
61.根据段落50所述的多肽,该多肽与SEQ ID NO:29的成熟多肽或与SEQ ID NO:30中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
62.根据段落50所述的多肽,该多肽与SEQ ID NO:32的成熟多肽或与SEQ ID NO:33中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
63.根据段落50所述的多肽,该多肽与SEQ ID NO:35的成熟多肽或与SEQ ID NO:36中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
64.根据段落50所述的多肽,该多肽与SEQ ID NO:38的成熟多肽或与SEQ ID NO:39中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
65.根据段落50所述的多肽,该多肽与SEQ ID NO:41的成熟多肽或与SEQ ID NO:42中所示的成熟多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
66.根据段落50至65中任一项所述的多肽,该多肽由以下多核苷酸编码,该多核苷酸在低严格条件、低-中严格条件、中严格条件、中-高严格条件、高严格条件、或非常高严格条件下与以下杂交:
i.SEQ ID NO:1、4、7、10、13、16、19、22、25、28、31、34、37或40的成熟多肽编码序列;
ii.其cDNA序列,或
iii.(i)或(ii)的全长互补序列。
67.根据段落50-66中任一项所述的多肽,该多肽由以下多核苷酸编码,该多核苷酸与SEQ ID NO:1、4、7、10、13、16、19、22、25、28、31、34、37或40的成熟多肽编码序列或其cDNA序列具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
68.根据段落50至67中任一项所述的多肽,该多肽包含以下或由以下组成:SEQ IDNO:3、6、9、12、15、18、21、24、27、30、33、36、39或42,或SEQ ID NO:2、5、8、11、14、17、20、23、26、29、32、35、38或41的成熟多肽。
69.根据段落50至68中任一项所述的多肽,该多肽是具有SEQ ID NO:3、6、9、12、15、18、21、24、27、30、33、36、39或42的多肽中的任一个的变体,该变体在一个或多个位置处包含取代、缺失和/或插入。
70.一种多核苷酸,该多核苷酸编码根据段落50-69中任一项所述的多肽。
71.一种核酸构建体或表达载体,该核酸构建体或表达载体包含根据段落70所述的多核苷酸,该多核苷酸可操作地连接至指导该多肽在表达宿主中的产生的一个或多个任选地异源控制序列。
72.一种重组宿主细胞,该重组宿主细胞包含根据段落70所述的多核苷酸,该多核苷酸可操作地连接至指导该多肽的产生的一个或多个任选地异源控制序列。
73.一种产生根据段落50-69中任一项所述的多肽的方法,该方法包括:在有益于产生该多肽的条件下培养细胞,该细胞以其野生型形式产生该多肽。
74.根据段落73所述的方法,该方法进一步包括回收该多肽。
75.一种产生根据段落50-69中任一项所述的多肽的方法,该方法包括:在有益于产生该多肽的条件下培养根据段落72所述的宿主细胞。
76.根据段落75所述的方法,该方法进一步包括回收该多肽。
77.一种核酸构建体或表达载体,该核酸构建体或表达载体包含编码蛋白质的可操作地连接至根据段落70所述的多核苷酸的基因,其中该基因对于编码信号肽的多核苷酸是外源的或异源的。
78.一种重组宿主细胞,该重组宿主细胞包含编码蛋白质的可操作地连接至根据段落70所述的多核苷酸的基因,其中该基因对于编码信号肽的多核苷酸是外源的或异源的。
79.一种产生蛋白质的方法,该方法包括:在有益于产生该蛋白质的条件下培养重组宿主细胞,该重组宿主细胞包含编码蛋白质的可操作地连接至根据段落70所述的多核苷酸的基因,其中该基因对于编码信号肽的多核苷酸是外源的。
80.根据段落79所述的方法,该方法进一步包括回收该蛋白质。
应当理解的是贯穿本说明书给出的每一最大数值限度包括每一较低的数值限度,如同此类较低数值限度在本文被明确写出。贯穿本说明书给出的每一最小数值限度将包括每一较高的数值限度,如同此类较高数值限度本文被明确写出。本说明书中所给出的每个数值范围将包括落入在这样更宽泛数值范围内的每一狭小的范围,如同此类狭小的数值范围都在本文被明确写出。
实例
测定I
DNA酶活性的测试
可以在具有甲基绿(BD公司,富兰克林湖(Franklin Lakes),新泽西州(NJ),美国)的DNA酶测试琼脂上确定DNA酶活性,其根据供应商的手册制备。简言之,将21g琼脂溶解于500ml水中,并且然后在121℃高压灭菌15min。将高压灭菌的琼脂在水浴中温和至48℃,并且将20ml的琼脂倒入皮氏培养皿(Petri dish)并且允许在室温通过孵育过夜来固化。在固化的琼脂板上,添加5μl的酶溶液,并且DNA酶活性被观察为斑点酶溶液周围的无色区域。
测定II
可以使用荧光猝灭的DNA寡核苷酸探针通过荧光确定DNA酶活性。根据供应商的手册(DNA酶警报试剂盒(DNase alert kit),DNA集成技术公司(Integrated DNATechnology),科拉尔维尔(Coralville),爱荷华州(Iowa),美国),该探针在核酸酶降解后发出信号。简言之,将5μl底物添加到95μl的DNA酶中。如果信号太高,则在适合的缓冲液中进一步稀释DNA酶。在22℃使用Clariostar酶标仪(在536nm处激发,在556nm处发射)测量动力学曲线20min。
菌株
使用购自天根(TIANGEN)(天根生物科技有限公司(TIANGEN Biotech Co.Ltd.),北京,中国)的大肠杆菌Top-10菌株来繁殖本文的表达载体。使用米曲霉MT3568菌株用于编码多肽的基因的异源表达,该多肽与具有DNA酶活性的多肽具有同源性。米曲霉MT3568是米曲霉JaL355的amdS(乙酰胺酶)破坏的基因衍生物(WO 02/40694),其中通过用pyrG基因破坏米曲霉乙酰胺酶(amdS)基因恢复pyrG营养缺陷型。
培养基
YPM培养基由10g的酵母提取物、20g的细菌用蛋白胨、20g的麦芽糖、以及补足至1000ml的去离子水构成。LB板是由10g的细菌用胰蛋白胨、5g的酵母提取物、10g的氯化钠、15g的细菌用琼脂及补足至1000ml的去离子水构成。LB培养基由1g的细菌用胰蛋白胨、5g的酵母提取物及10g的氯化钠,以及补足至1000ml的去离子水构成。
COVE蔗糖板由342g的蔗糖、20g的琼脂粉、20ml的COVE盐溶液及补足至1升的去离子水构成。将培养基在15psi下通过高压灭菌进行灭菌15分钟。将该培养基冷却至60℃并且添加10mM的乙酰胺、15mM的CsCl、曲通X-100(50μl/500ml)。
用于分离的COVE-2板/管:30g/L蔗糖、20ml/L COVE盐溶液、10mM乙酰胺、30g/L诺布尔(noble)琼脂(Difco,目录号214220)。
COVE盐溶液由26g的MgSO4·7H2O、26g的KCL、26g的KH2PO4、50ml的COVE痕量金属溶液、以及补足至1000ml的去离子水组成。
COVE痕量金属溶液由以下构成:0.04g的Na2B4O7·10H2O、0.4g的CuSO4·5H2O、1.2g的FeSO4·7H2O、0.7g的MnSO4·H2O、0.8g的Na2MoO4·2H2O、10g的ZnSO4·7H2O、以及去离子水补足至1000ml。
甲基绿DNA测试琼脂板是通过在1000ml蒸馏水中悬浮42.05g“含甲基绿的DNA酶测试琼脂”(海美迪实验室有限公司(HiMedia Laboratories Pvt.Ltd.),印度)并通过高压灭菌的灭菌来制备的。
实例1:真菌DNA酶的克隆、表达和发酵
DNA酶来源于通过标准微生物分离技术从环境样品分离的真菌菌株。鉴别菌株并基于ITS的DNA测序对分类进行指定(表1)。
表1:
| DNA | 蛋白质 | 供体生物名称 | 来源国 |
| SEQ ID NO 7 | SEQ ID NO 9 | 粪盘菌属物种ZY179 | 中国 |
通过QIAamp DNA血液迷你试剂盒(凯杰公司(Qiagen),希尔登(Hilden),德国)分离来自粪盘菌属物种ZY179的染色体DNA。使用Illumina技术将5μg染色体DNA发送进行全基因组测序。基因组测序,随后的读取的组装和基因发现(即基因功能的注释)对于本领域技术人员是已知的并且这些服务是可商购的。
分析来自PFAM数据库家族PF07510(R.D.Finn等人,Nucleic Acids Research[核酸研究](2014),42:D222-D230)的推定的DNA酶的基因组序列。该分析鉴别了一种编码推定的DNA酶的基因,这些基因随后被克隆并在米曲霉中重组表达。
通过PCR从上述分离的基因组DNA扩增来自粪盘菌属物种ZY179的DNA酶基因。根据制造商的说明书,通过与IN-FUSIONTM CF脱水克隆试剂盒(克隆技术实验室有限公司(Clontech Laboratories,Inc.),山景城(Mountain View),加利福尼亚州,美国)连接,将这种纯化的PCR产物克隆到之前消化的表达载体pCaHj505中。使用连接混合物转化大肠杆菌TOP10化学感受态细胞(描述于Strains[菌株]中)。选择含有SEQ ID NO:7的正确菌落并通过DNA测序验证(由中国北京的诺赛基因有限公司(SinoGenoMax Company Limited)进行)。包含菌落的SEQ ID NO:7在3ml的、每ml补充有100μg的氨苄青霉素的LB培养基中培养过夜。根据制造商的说明,使用凯杰公司旋转迷你制备型(Spin Miniprep)试剂盒(目录27106)(凯杰股份有限公司(QIAGEN GmbH),希尔登,德国)纯化质粒DNA。
使用SignalP程序v.3(Nielsen等人,1997,Protein Engineering[蛋白质工程]10:1-6)预测出信号肽和相应的SEQ ID NO:9的成熟肽(参见序列文件)。
米曲霉MT3568(参见菌株部分)的原生质体是根据WO 95/002043制备的。将100μl的原生质体与2.5-10μg的包含SEQ ID NO:7的每个曲霉属表达载体和250μl的60%PEG4000、10mM CaCl2、和10mM Tris-HCl(pH 7.5)分别混合,并且轻轻混合。将混合物在37℃孵育30分钟并且将这些原生质体涂布到COVE蔗糖板上用于选择。在37℃孵育4-7天后,将4个转化体的孢子接种到3ml的YPM培养基中。在30℃培养3天之后,使用4%-20%Tris-甘氨酸凝胶(英杰公司(Invitrogen Corporation),卡尔斯巴德(Carlsbad),加利福尼亚州,美国)通过SDS-PAGE分析培养液,以鉴别产生具有各自估计的成熟肽大小的最大量的重组DNA酶的转化体。使用甲基绿DNA测试琼脂板研究由曲霉属转化体产生的DNA酶的水解活性。将来自不同转化体的20μl等分试样的培养液或缓冲液(阴性对照)分配到直径为3mm的冲孔中并且在37℃孵育1小时。随后检查这些板中的孔周围存在或不存在对应于磷脂酶活性的白色区。基于这两个选择标准,将最好的转化体的孢子涂布于用于再分离的COVE-2板上,以分离单个菌落。然后将单个菌落涂布于COVE-2管上直到孢子形成。在80rpm搅拌下在30℃温度下的3天期间,将来自最好表达的转化体的孢子在摇瓶的2400ml的YPM培养基中培养。通过使用0.2μm过滤装置过滤收获培养肉汤。过滤的发酵液用于酶表征。
实例2:通过金属离子亲和色谱法(IMAC)纯化重组DNA酶(SEQ ID NO 9)
用硫酸铵(80%饱和)沉淀实例1中收获的培养液。将沉淀物重新溶解于50ml的20mM PBS pH 7.0中,然后通过0.45μm滤器过滤。将经过滤的粗蛋白溶液施加至用20mM PBSpH 7.0和300mM氯化钠平衡的50ml自填充Ni琼脂糖凝胶excel亲和柱(通用医疗集团(GEHealthcare),白金汉郡(Buckinghamshire),英国)上。使用0-0.5M咪唑线性梯度对这些蛋白质进行洗脱。使用Mini-PROTEAN TGX无染色4%-15%预制凝胶(伯乐实验室(Bio-RadLaboratories),加利福尼亚州,美国)通过SDS-PAGE分析级分。在具有甲基绿(贝迪公司(Becton,Dickinson and Company),新泽西州,美国)的BD DifcoTMDNA酶测试琼脂上,在pH8.0、40℃评估级分的DNA酶活性。合并含有重组蛋白带并显示出阳性活性的级分。然后将合并的溶液通过超滤进行浓缩。
实例3:DNA酶的克隆、表达和发酵
从多种不同的真菌菌株克隆DNA酶,这些真菌菌株从环境样品中分离或从培养物保藏中心获得,并来源于下表2和3中列出的来源。
表2


表3
| 菌株 | 保藏 | 来源国 | 成熟蛋白质 |
| 褐孢长毛盘菌 | CBS | 英国 | SEQ ID 18 |
| Trichoboluszukalii | CBS | 美国 | SEQ ID 15 |
| 微小长毛盘菌 | CBS | 加拿大 | SEQ ID 21 |
| 微小长毛盘菌 | CBS | 加拿大 | SEQ ID 24 |
| 茂长毛盘菌 | CBS | 荷兰 | SEQ ID 27 |
CBS=CBS-KNAW真菌生物多样性中心(乌得勒支(Utrecht),荷兰(TheNetherlands))
对于淡黑假黑盘菌,制作淡黑假黑盘菌(P.nigrella)的cDNA文库,并且如WO 03/044049(通过引用并入本文)中鉴别了编码分泌的蛋白质的cDNA的选择。所选择的cDNA中的一个编码SEQ ID NO 30中的成熟肽。
对于其他菌株,从菌株中分离染色体DNA,并通过本领域技术人员已知的标准方法或通过商业购买服务对每个菌株的全基因组进行测序、组装和注释。在注释的基因组中搜索具有NUC1_A结构域的预测的肽,并鉴别了12种推定的DNA酶。通过使用PCR从基因组DNA扩增DNA酶基因或通过购买编码DNA酶的定制合成基因,将编码这些推定的DNA酶的基因克隆到曲霉属表达载体中。用于每种DNA酶的克隆方法在下表4中给出。
表4


曲霉属表达载体pMStr57描述于WO 04/032648中,pDAu222描述于WO 13/024021中。用基因特异性引物从基因组DNA扩增通过PCR克隆的DNA酶,这些引物也在起始密码子的5'附近附加Kozak翻译起始序列“TCACC”,并克隆到BamHI和XhoI消化的pMStr57中。将通过合成克隆的DNA酶用优先地利用密码子的方法反向翻译,这些密码子常用于米曲霉中,并且用设计以鉴别和去除会阻碍克隆或表达的序列特点的算法分析所得的DNA序列(如WO 06/066595中所描述)。这些DNA酶编码基因购自赛默飞世尔科技公司(Thermo FisherScientific)/GeneArt公司(雷根斯堡(Regensburg),德国)作为定制合成克隆到pDAu222的BamHI和HindIII位点。
对于淡黑假黑盘菌,将原始cDNA文库的等分试样用于PCR扩增SEQ ID NO.28的可读框,并将该可读框克隆到pDAu222的BamHI和HindIII位点。对克隆的NUC1_A编码基因进行测序并确认其与基因组序列或先前确定的cDNA序列中发现的相应基因相同,并通过Christensen等人,1988,Biotechnology[生物技术]6,1419-1422和WO 04/032648中描述的方法转化到米曲霉菌株BECh2(WO/039322)(针对淡黑假黑盘菌DNA酶)或MT3568(WO 11/057140)(针对其他DNA酶)中。基于利用乙酰胺作为氮源(由表达载体中的选择性标记赋予)的能力,在从原生质体再生期间选择转化体,并随后在选择下重新分离。通过在96孔深孔微量滴定板中在30℃在YPG培养基(WO 05/066338)中将转化体培养4天并通过SDS-PAGE监测DNA酶表达来评估重组DNA酶的产生。为了更大规模地生产重组DNA酶,将选择转化体在含有150ml DAP-4C-1培养基(WO 12/103350)的500ml带挡板的烧瓶中培养。将培养物在旋转台上以150RPM振荡4天。随后将培养液通过穿过0.22um过滤单元与细胞材料分离。
实例4:DNA酶的纯化
将经过滤的样品的pH调节至约pH 7.5,并添加1.8M硫酸铵。将该样品施加至 Explorer上的5ml HiTrapTM Phenyl(HS)柱上。在加载之前,该柱已在5个柱体积(CV)的50mMHEPES+1.8M AMS(pH 7)中平衡。为了去除未结合的材料,将该柱用5CV的50mM HEPES+1.8MAMS(pH 7)进行洗涤。使用50mM HEPES+20%异丙醇pH 7将靶蛋白从柱洗脱到10ml环中。从该环中,将样品加载到已经用3CV的50mM HEPES+100mM NaCl pH 7.0平衡的脱盐柱(HiPrepTM 26/10脱盐)上。将靶蛋白用50mM HEPES+100mM NaCl pH 7.0洗脱,选择相关级分,并基于色谱图进行合并。
Explorer上的5ml HiTrapTM Phenyl(HS)柱上。在加载之前,该柱已在5个柱体积(CV)的50mMHEPES+1.8M AMS(pH 7)中平衡。为了去除未结合的材料,将该柱用5CV的50mM HEPES+1.8MAMS(pH 7)进行洗涤。使用50mM HEPES+20%异丙醇pH 7将靶蛋白从柱洗脱到10ml环中。从该环中,将样品加载到已经用3CV的50mM HEPES+100mM NaCl pH 7.0平衡的脱盐柱(HiPrepTM 26/10脱盐)上。将靶蛋白用50mM HEPES+100mM NaCl pH 7.0洗脱,选择相关级分,并基于色谱图进行合并。
流速为5ml/min。
通过测量280nm处的吸收来估计最终样品中的蛋白质浓度。
实例5:DNA酶的深度清洁作用
分离衣物特定细菌菌株
在本实例中使用分离自衣物的短波单胞菌属物种的一种菌株。在研究期间分离短波单胞菌属物种,其中对分别在15℃、40℃和60℃洗涤后衣物中的细菌多样性进行调研。在从丹麦家庭收集的衣物上进行该研究。对于每种洗涤,使用4:3:2:2:1:1:1比率的20g的衣物物品(茶巾、毛巾、洗碗布、背带裤、打底T恤、T恤领、袜子)。在15℃、40℃或60℃于Laundr-O-Meter(LOM)中进行洗涤。对于15℃和40℃的洗涤,使用碧浪灵敏性白色与彩色衣物洗涤剂(Ariel Sensitive White&Color),而对于60℃的洗涤,使用WFK IEC-A*标准洗涤剂。通过称出5.1g并添加自来水直到1000ml,随后搅拌5分钟来制备碧浪灵敏性白色与彩色衣物洗涤剂。通过称出5g并添加自来水直到1300ml,随后搅拌15min来制备WFK IEC-A*标准洗涤剂(其可从WFK测试织物有限公司(WFK Testgewebe GmbH)有限公司获得)。洗涤分别在15℃、40℃和60℃进行1小时,随后在15℃用自来水冲洗2次持续20min。
分别在15℃、40℃和60℃洗涤后立即对衣物进行取样。向二十克洗衣液中添加0.9%(w/v)NaCl(1.06404;默克公司(Merck),达姆施塔特(Darmstadt),德国)和0.5%(w/w)tween 80,以在匀质器(stomacher)袋中产生1:10稀释液。使用匀质器在中速下将混合物均质化2分钟。均质化后,在0.9%(w/v)NaCl中制备十倍稀释液。将细菌在30℃于胰胨大豆琼脂(Tryptone Soya Agar)(TSA)(CM0129,Oxoid公司,贝辛斯托克(Basingstoke),汉普郡(Hampshire),英国)上需氧地孵育5-7天并对其计数。为了抑制酵母和霉菌的生长T,添加0.2%山梨酸(359769,西格玛公司(Sigma))和0.1%放线酮(18079;西格玛公司)。从可计数的板中选择细菌菌落并且通过在TSA上再划线两次进行纯化。对于长期存储,将纯化的分离株于-80℃存储在含有20%(w/v)甘油(49779;西格玛公司)的TSB中。
制备具有生物膜的小块布样
具有短波单胞菌属物种和滕黄微球菌NN60909生物膜的小块布样包括在本研究中。在30℃,使细菌在胰胨大豆琼脂(TSA)(pH 7.3)(CM0131;Oxoid有限公司(Oxoid Ltd),贝辛斯托克,英国)上预生长2-5天。将来自单菌落的满环物转移至10mL的TSB中并且伴随振荡(240rpm)于30℃孵育1天。繁殖后,通过离心(西格玛实验室离心机(Sigma LaboratoryCentrifuge)6K15)(3000g,在21℃,7min内)沉淀细胞并且将其重悬于10mL用水稀释两次的TSB中。使用分光光度计(POLARstar Omega(BMG莱伯泰科(BMG Labtech),奥滕贝格(Ortenberg),德国))测量600nm处的光密度(OD)。将用水稀释两次的新鲜TSB接种至OD600nm为0.03,并将20mL添加到皮氏培养皿(petridish)(直径9mm)中,其中放置了无菌棉(WFK10A)、聚酯-棉(WFK20A)或聚酯(WFK30A)的小块布样(50mm x 50mm)。伴随振荡(100rpm)在15℃孵育48h后,将小块布样用0.9%(w/v)NaCl冲洗两次。
洗涤实验
通过称出洗涤剂并将其溶解于水硬度为15°dH的水中来制备液体碧浪彩色&风格(Ariel Color&Style)的洗涤液。将(Pigmentschmutz,09V,wfk,克雷费尔德(Krefeld),德国)(0.7g/L)添加到洗涤液中,并向每个TOM烧杯中添加1000ml。添加具有短波单胞菌属物种生物膜的两个冲洗过的WFK10A小块布样、具有短波单胞菌属物种生物膜的两个冲洗过的WFK20A小块布样、具有短波单胞菌属物种生物膜的两个冲洗过的WFK30A小块布样、具有滕黄微球菌生物膜的两个冲洗过的WFK10A小块布样、具有滕黄微球菌生物膜的两个冲洗过的WFK20A小块布样、具有滕黄微球菌生物膜的两个冲洗过的WFK30A小块布样、两个无菌WFK10A小块布样、两个无菌WFK20A小块布样和两个无菌WFK30A小块布样,并在30℃洗涤35min。在洗涤中,当包括DNA酶时,向洗涤液中以0.2、0.02或0.002ppm施用DNA酶。洗涤后,将所有小块布样在自来水中冲洗两次并在滤纸上干燥过夜。使用Color Eye(MacbethColor Eye 7000反射分光光度计)测量色差(L值)。在入射光中没有UV的情况下进行测量并且从CIE Lab色空间中提取L值。
色差(L值,L*)代表在L*=0下的最暗的黑色,并且在L*=100下的最亮白色。数据表示为ΔL值,意指用DNA酶洗涤的小块布样的L值减去不用DNA酶洗涤的小块布样的L值。
表5.宽肋羊肚菌(SEQ ID NO 12)DNA酶对短波单胞菌属物种生物膜的深度清洁。
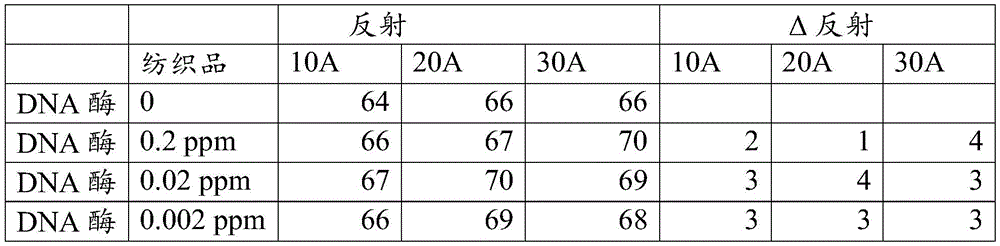
表6.宽肋羊肚菌(SEQ ID NO 12)DNA酶对滕黄微球菌生物膜的深度清洁
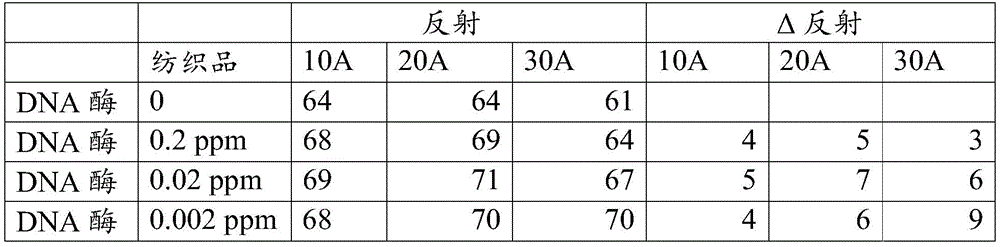
表7.宽肋羊肚菌(SEQ ID NO 12)DNA酶无菌小块布样(无生物膜)的土壤抑制转移。
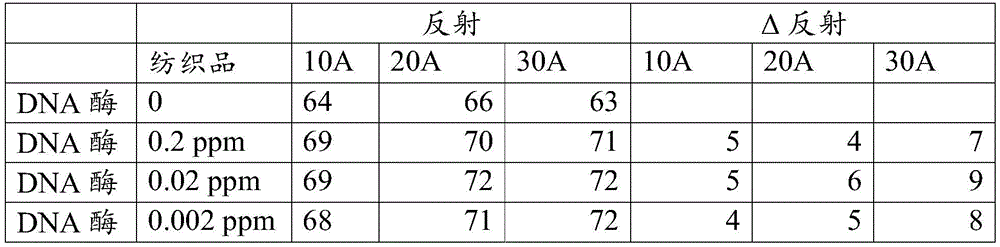
实例6:DNA酶的洗涤性能
生物膜小块布样的制备
生物膜小块布样是通过在聚酯小块布样上使短波单胞菌属物种生长两天来制备的。将生物膜小块布样在水中冲洗两次并在流动下干燥1h,随后冲压成小圆圈并在4℃储存以供进一步使用。
洗涤实验
将生物膜小块布样冲压物放置于深孔96孔格式板中。将96孔板置于Hamilton机器人中并使用以下条件进行洗涤模拟程序:振荡速度:在1000rpm下30秒;洗涤循环的持续时间:伴随振荡30分钟;温度30℃;洗涤液量(总量):0.5ml/孔;(490洗涤液+10uL样品)。为了筛选WT DNA酶的洗涤性能,使用溶解于水硬度15°dH的标准洗涤剂A(3.3g/L)。
通过将含有12%LAS、11%AEO Biosoft N25-7(Nl)、5%AEOS(SLES)、6%MPG(单丙二醇)、3%乙醇、3%TEA(三乙醇胺)、2.75%可可皂、2.75%大豆皂、2%甘油、2%氢氧化钠、2%柠檬酸钠、1%甲酸钠、0.2%DTMPA和0.2%PCA(丙烯酸=丙烯酸马来酸共聚物)(所有的百分数都是w/w(重量体积))的3.33g/l标准洗涤剂A溶解在具有硬度15dH的水中制备标准洗涤剂A洗液(100%)。
随后添加污垢以达到0.7g污垢/L(WFK 09V颜料污垢)的浓度。将96孔板用每个酶样品装满,并在机器人上启动程序。测试DNA酶的浓度为0.5-0.05ppm。空白由没有添加任何酶的生物膜小块布样组成。在完成洗涤模拟循环之后,将小块布样冲压物从洗涤液中取出并在滤纸上干燥。将干燥的小块布样冲压物固定在一张白纸上以用于扫描。扫描的图像进一步由软件颜色分析仪使用。每个样品具有强度测量(来自颜色分析仪软件分析),其用于通过减去不含酶的空白强度来计算Δ强度(反射)。70之上的值是人眼可见的。
表8.DNA酶的洗涤性能
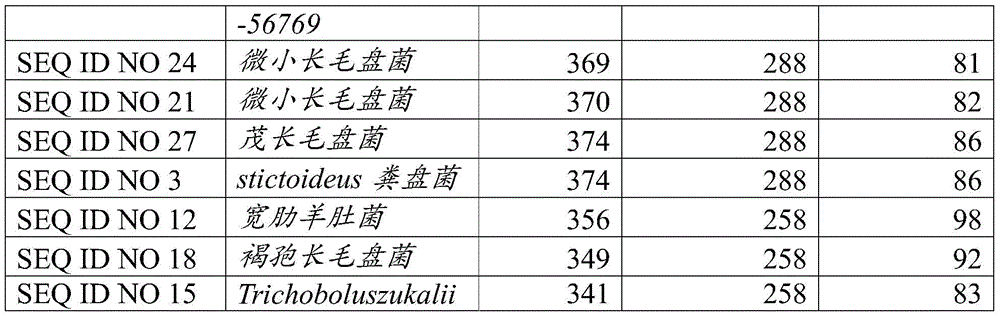
实例7:系统发育树的构建
NUC1结构域包括本发明的具有DNA酶活性的多肽并且包含NUC1_A结构域以及如进化枝的簇。
如PFAM(PF07510,Pfam版本30.0,Finn(2016).Nucleic Acids Research[核酸研究],Database Issue[数据库卷]44:D279-D285)中所定义的,构建含有DUF1524结构域的多肽序列的系统发育树。系统发育树是从包含至少一个DUF1524结构域的成熟多肽序列的多重比对构建。使用MUSCLE算法版本3.8.31(Edgar,2004.Nucleic Acids Research[核酸研究]32(5):1792-1797)对序列进行比对,并且使用FastTree版本2.1.8(Price等人,2010,PloS one[公共科学图书馆·综合]5(3))构建树并使用iTOL(Letunic和Bork,2007.Bioinformatics[生物信息学]23(1):127-128)对树进行可视化。
包含DUF1524结构域的多肽包含若干个基序。一个实例是[E/D/H]H[I/V/L/F/M]X[P/A/S](SEQ ID NO:43),其位于与来自宽肋羊肚菌(M.costata)(SEQ ID NO 12)的DNA酶多肽中的位置95至99对应的位置。H96是涉及DUF1524的催化活性的催化残基,并且是HXXP基序的部分。可以由本发明的多肽包含的另一个基序是[T/D/S][G/N]PQL(SEQ ID NO:44),其中Q涉及稳定HXXP基序。
DUF1524中的多肽可以分成不同的子簇。子簇由一个或多个短序列基序定义,以及通过含有如PFAM(PF07510,Pfam版本30.0)中所定义的DUF1524结构域定义。我们将包含基序[F/L/Y/I]A[N/R]D[L/I/P/V][(SEQ ID NO 45)的一个子簇表示为家族NUC1。这种结构域的另一个基序特征是C[D/N]T[A/R](SEQ ID NO 46)。含有DUF1524以及两个基序的所有多肽序列将表示为含有NUC1结构域。
NUC1_A结构域的生成
如上所定义的构建含有NUC1结构域的多肽序列的系统发育树。系统发育树是从包含至少一个NUC1结构域的成熟多肽序列的多重比对构建。使用MUSCLE算法版本3.8.31(Edgar,2004.Nucleic Acids Research[核酸研究]32(5):1792-1797)对序列进行比对,并且使用FastTree版本2.1.8(Price等人,2010,PloS one[公共科学图书馆·综合]5(3))构建树并使用iTOL(Letunic和Bork,2007.Bioinformatics[生物信息学]23(1):127-128)对树进行可视化。NUC1中的多肽可以分成至少不同的子簇,其中一个表示为NUC1_A。这种亚组的特征基序是基序[DQ][IV]DH(SEQ ID NO 47),其对应于参考多肽(SEQ ID NO:12)中的氨基酸93至96。预测在对应于SEQ ID NO 12的位置93的位置处的D涉及催化性金属离子辅因子的结合。
系统发育树的生成
如上所定义的构建含有DUF1524结构域、NUC1结构域和NUC1_A结构域的多肽序列的系统发育树。系统发育树是从包含至少一个NUC1_A结构域的成熟多肽序列的多重比对构建。使用MUSCLE算法版本3.8.31(Edgar,2004.Nucleic Acids Research[核酸研究]32(5):1792-1797)对序列进行比对,并且使用FastTree版本2.1.8(Price等人,2010,PloS one[公共科学图书馆·综合]5(3))构建树并使用iTOL(Letunic和Bork,2007.Bioinformatics[生物信息学]23(1):127-128)对树进行可视化。NUC1_A中的多肽可以分成多个不同的子簇或进化枝,其中我们表示了下面列出的进化枝。下面详细描述每个进化枝的不同基序。
RTTDA进化枝的生成
RTTDA进化枝包含真菌来源的NUC1_A多肽,该多肽含有DUF1524结构域、NUC1结构域和NUC1_A结构域,具有DNA酶活性。该进化枝的多肽包含基序实例RT[TS][DN][AP][TDPS]GY(SEQ ID NO:48),对应于SEQ ID NO 12的位置28至35,其中R和T(对应于SEQ ID NO 12的位置31和32)在RTTDA进化枝中是完全保守的。包含在进化枝中的本发明的多肽的比对示于图1中。RTTDA进化枝的系统发育树示于图2中。
Claims (16)
1.一种具有DNA酶活性的RTTDA进化枝的多肽,其中该多肽选自由以下组成的组:
(a)与SEQ ID NO:3的多肽具有至少80%序列同一性的多肽;
(b)与SEQ ID NO:6的多肽具有至少80%序列同一性的多肽;
(c)与SEQ ID NO:9的多肽具有至少80%序列同一性的多肽;
(d)与SEQ ID NO:12的多肽具有至少80%序列同一性的多肽;
(e)与SEQ ID NO:15的多肽具有至少80%序列同一性的多肽;
(f)与SEQ ID NO:18的多肽具有至少80%序列同一性的多肽;
(g)与SEQ ID NO:21的多肽具有至少80%序列同一性的多肽;
(h)与SEQ ID NO:24的多肽具有至少80%序列同一性的多肽;
(i)与SEQ ID NO:27的多肽具有至少80%序列同一性的多肽;
(j)与SEQ ID NO:30的多肽具有至少80%序列同一性的多肽;
(k)与SEQ ID NO:33的多肽具有至少80%序列同一性的多肽;
(l)与SEQ ID NO:36的多肽具有至少80%序列同一性的多肽;
(m)与SEQ ID NO:39的多肽具有至少80%序列同一性的多肽;
(n)与SEQ ID NO:42的多肽具有至少80%序列同一性的多肽;
(o)多肽的变体,该多肽选自由以下组成的组:SEQ ID NO:3、SEQ ID NO:6、SEQ ID NO:9、SEQ ID NO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ ID NO:27、SEQ ID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39和SEQ ID NO:42,其中该变体具有DNA酶活性并且包含在1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个位置中的一个或多个氨基酸取代、和/或一个或多个氨基酸缺失、和/或一个或多个氨基酸插入或其任何组合;
(p)多肽,该多肽包含(a)至(n)的多肽以及N-末端和/或C-末端His-标签和/或HQ-标签;
(q)多肽,该多肽包含(a)至(n)的多肽以及1与10个氨基酸之间的N-末端和/或C-末端延伸;
(r)(a)至(n)的多肽的片段,该片段具有DNA酶活性并且具有成熟多肽的至少90%的长度;和
(s)多肽,该多肽包含基序RT[TS][DN][AP][TDPS]GY(SEQ ID NO48)。
2.如权利要求1所述的多肽,该多肽与SEQ ID NO:3、SEQ ID NO:6、SEQ ID NO:9、SEQID NO:12、SEQ ID NO:15、SEQ ID NO:18、SEQ ID NO:21、SEQ ID NO:24、SEQ ID NO:27、SEQID NO:30、SEQ ID NO:33、SEQ ID NO:36、SEQ ID NO:39或SEQ ID NO:42中所示多肽具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
3.如权利要求1或2所述的多肽,该多肽由以下多核苷酸编码,该多核苷酸与SEQ ID NO1、SEQ ID NO:4、SEQ ID NO:7、SEQ ID NO:10、SEQ ID NO:13、SEQ ID NO:16、SEQ ID NO:19、SEQ ID NO:22、SEQ ID NO:25、SEQ ID NO:28、SEQ ID NO:31、SEQ ID NO:34、SEQ IDNO:37或SEQ ID NO:40的成熟多肽编码序列具有至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列同一性。
4.如权利要求1-3中任一项所述的多肽,该多肽选自由以下多肽组成的组:
(a)多肽,该多肽包含SEQ ID NO:3、或SEQ ID NO:2的成熟多肽或由其组成;
(b)多肽,该多肽包含SEQ ID NO:6、或SEQ ID NO:5的成熟多肽或由其组成;
(c)多肽,该多肽包含SEQ ID NO:9、或SEQ ID NO:8的成熟多肽或由其组成;
(d)多肽,该多肽包含SEQ ID NO:12、或SEQ ID NO:11的成熟多肽或由其组成;
(e)多肽,该多肽包含SEQ ID NO:15、或SEQ ID NO:14的成熟多肽或由其组成;
(f)多肽,该多肽包含SEQ ID NO:18、或SEQ ID NO:17的成熟多肽或由其组成;
(g)多肽,该多肽包含SEQ ID NO:21、或SEQ ID NO:20的成熟多肽或由其组成;
(h)多肽,该多肽包含SEQ ID NO:24、或SEQ ID NO:23的成熟多肽或由其组成;
(i)多肽,该多肽包含SEQ ID NO:27、或SEQ ID NO:26的成熟多肽或由其组成;
(j)多肽,该多肽包含SEQ ID NO:30、或SEQ ID NO:29的成熟多肽或由其组成;
(k)多肽,该多肽包含SEQ ID NO:33、或SEQ ID NO:32的成熟多肽或由其组成;
(l)多肽,该多肽包含SEQ ID NO:36、或SEQ ID NO:35的成熟多肽或由其组成;
(m)多肽,该多肽包含SEQ ID NO:39、或SEQ ID NO:38的成熟多肽或由其组成;
(n)多肽,该多肽包含SEQ ID NO:42、或SEQ ID NO:41的成熟多肽或由其组成。
5.一种多核苷酸,该多核苷酸编码如权利要求1-4中任一项所述的多肽。
6.一种核酸构建体或表达载体,该核酸构建体或表达载体包含如权利要求5所述的多核苷酸,该多核苷酸可操作地连接至指导该多肽在表达宿主中的产生的一个或多个控制序列。
7.一种重组宿主细胞,该重组宿主细胞包含如权利要求5所述的多核苷酸,该多核苷酸可操作地连接至指导该多肽的产生的一个或多个控制序列。
8.一种产生如权利要求1-4中任一项所述的多肽的方法,该方法包括在有益于产生该多肽的条件下培养细胞,该细胞以其野生型形式产生该多肽。
9.如权利要求8所述的方法,该方法进一步包括:回收该多肽。
10.一种产生具有DNA酶活性的多肽的方法,该方法包括:在有益于产生该多肽的条件下培养如权利要求7所述的宿主细胞。
11.如权利要求10所述的方法,该方法进一步包括:回收该多肽。
12.一种组合物,该组合物包含如权利要求1-4中任一项所述的多肽和至少一种洗涤剂佐剂成分。
13.如权利要求12所述的组合物,其中该组合物是清洁或洗涤剂组合物、自动餐具洗涤(ADW)组合物或洗衣组合物。
14.如权利要求1至4中任一项所述的多肽用于深度清洁物品的用途,其中该物品是纺织品。
15.如权利要求14所述的用途,
(i)用于防止、减少或去除该物品的粘性;
(ii)用于预处理该物品上的污渍;
(iii)用于在洗涤循环期间防止、减少或去除污垢的再沉积;
(iv)用于防止、减少或去除污垢在该物品上的附着;
(v)用于维持或改进该物品的白度;
(vi)用于防止、减少或去除该物品的恶臭,
其中该物品是纺织品。
16.一种用于洗涤物品的方法,该方法包括以下步骤:
a.将物品暴露于包含如权利要求1至4中任一项所述的多肽的洗涤液或如权利要求12或13所述的组合物;
b.完成至少一个洗涤循环;和
c.任选地冲洗该物品,
其中该物品是纺织品。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP17164340.6 | 2017-03-31 | ||
| EP17164340 | 2017-03-31 | ||
| PCT/CN2018/080156 WO2018177203A1 (en) | 2017-03-31 | 2018-03-23 | Polypeptides having dnase activity |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN110651040A true CN110651040A (zh) | 2020-01-03 |
Family
ID=58488845
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201880023402.XA Pending CN110651040A (zh) | 2017-03-31 | 2018-03-23 | 具有dna酶活性的多肽 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US11180720B2 (zh) |
| EP (1) | EP3601552A4 (zh) |
| CN (1) | CN110651040A (zh) |
| WO (1) | WO2018177203A1 (zh) |
Families Citing this family (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210071116A1 (en) * | 2018-06-29 | 2021-03-11 | Novozymes A/S | Detergent Compositions and Uses Thereof |
| EP3844255A1 (en) | 2018-08-30 | 2021-07-07 | Danisco US Inc. | Enzyme-containing granules |
| CN114174504A (zh) | 2019-05-24 | 2022-03-11 | 丹尼斯科美国公司 | 枯草杆菌蛋白酶变体和使用方法 |
| CN114174486A (zh) | 2019-06-06 | 2022-03-11 | 丹尼斯科美国公司 | 用于清洁的方法和组合物 |
| BR112022007697A2 (pt) | 2019-10-24 | 2022-07-12 | Danisco Us Inc | Alfa-amilase variante que forma maltopentaose/maltohexaose |
| WO2022047149A1 (en) | 2020-08-27 | 2022-03-03 | Danisco Us Inc | Enzymes and enzyme compositions for cleaning |
| EP4232539A2 (en) | 2020-10-20 | 2023-08-30 | Novozymes A/S | Use of polypeptides having dnase activity |
| WO2022165107A1 (en) | 2021-01-29 | 2022-08-04 | Danisco Us Inc | Compositions for cleaning and methods related thereto |
| WO2023278297A1 (en) | 2021-06-30 | 2023-01-05 | Danisco Us Inc | Variant lipases and uses thereof |
| EP4396320A2 (en) | 2021-09-03 | 2024-07-10 | Danisco US Inc. | Laundry compositions for cleaning |
| CN117957318A (zh) | 2021-09-13 | 2024-04-30 | 丹尼斯科美国公司 | 含有生物活性物质的颗粒 |
| EP4426362A1 (en) | 2021-11-05 | 2024-09-11 | Nutrition & Biosciences USA 4, Inc. | Glucan derivatives for microbial control |
| EP4448750A2 (en) | 2021-12-16 | 2024-10-23 | Danisco US Inc. | Subtilisin variants and uses thereof |
| WO2023114988A2 (en) | 2021-12-16 | 2023-06-22 | Danisco Us Inc. | Variant maltopentaose/maltohexaose-forming alpha-amylases |
| CN118679251A (zh) | 2021-12-16 | 2024-09-20 | 丹尼斯科美国公司 | 枯草杆菌蛋白酶变体和使用方法 |
| EP4448749A2 (en) | 2021-12-16 | 2024-10-23 | Danisco US Inc. | Subtilisin variants and methods of use |
| WO2023168234A1 (en) | 2022-03-01 | 2023-09-07 | Danisco Us Inc. | Enzymes and enzyme compositions for cleaning |
| CN118974228A (zh) | 2022-04-08 | 2024-11-15 | 诺维信公司 | 氨基己糖苷酶变体和组合物 |
| WO2023201048A2 (en) * | 2022-04-14 | 2023-10-19 | Omeat Inc. | Systems and methods of preparing cultivated meat and meat analogs from plant-based proteins |
| CN119487167A (zh) | 2022-06-21 | 2025-02-18 | 丹尼斯科美国公司 | 用于清洁的包含具有嗜热菌蛋白酶活性的多肽的组合物和方法 |
| CA3265943A1 (en) | 2022-09-02 | 2024-03-07 | Danisco Us Inc. | DETERGENT COMPOSITIONS AND ASSOCIATED PROCESSES |
| CN120112635A (zh) | 2022-09-02 | 2025-06-06 | 丹尼斯科美国公司 | 枯草杆菌蛋白酶变体及其相关方法 |
| WO2024102698A1 (en) | 2022-11-09 | 2024-05-16 | Danisco Us Inc. | Subtilisin variants and methods of use |
| EP4658776A1 (en) | 2023-02-01 | 2025-12-10 | Danisco US Inc. | Subtilisin variants and methods of use |
| WO2024186819A1 (en) | 2023-03-06 | 2024-09-12 | Danisco Us Inc. | Subtilisin variants and methods of use |
| EP4680013A1 (en) | 2023-03-16 | 2026-01-21 | Nutrition & Biosciences USA 4, Inc. | Brevibacillus fermentate extracts for cleaning and malodor control and use thereof |
| KR20250174069A (ko) | 2023-04-12 | 2025-12-11 | 노보자임스 에이/에스 | 알칼리성 포스파타아제 활성을 갖는 폴리펩타이드를 포함하는 조성물 |
| WO2025071996A1 (en) | 2023-09-28 | 2025-04-03 | Danisco Us Inc. | Variant cutinase enzymes with improved solubility and uses thereof |
| WO2025085351A1 (en) | 2023-10-20 | 2025-04-24 | Danisco Us Inc. | Subtilisin variants and methods of use |
| WO2026024922A1 (en) | 2024-07-25 | 2026-01-29 | Danisco Us Inc. | Subtilisin variants and methods of use |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015155350A1 (en) * | 2014-04-11 | 2015-10-15 | Novozymes A/S | Detergent composition |
| US20150299623A1 (en) * | 2012-12-07 | 2015-10-22 | Novozymes A/S | Preventing Adhesion of Bacteria |
| WO2016162556A1 (en) * | 2015-04-10 | 2016-10-13 | Novozymes A/S | Laundry method, use of dnase and detergent composition |
| US20160319226A1 (en) * | 2015-04-29 | 2016-11-03 | The Procter & Gamble Company | Method of treating a fabric |
| WO2017001472A1 (en) * | 2015-06-29 | 2017-01-05 | Novozymes A/S | Laundry method, use of polypeptide and detergent composition |
| WO2017001471A1 (en) * | 2015-06-29 | 2017-01-05 | Novozymes A/S | Laundry method, use of polypeptide and detergent composition |
Family Cites Families (162)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB1296839A (zh) | 1969-05-29 | 1972-11-22 | ||
| DK187280A (da) | 1980-04-30 | 1981-10-31 | Novo Industri As | Ruhedsreducerende middel til et fuldvaskemiddel fuldvaskemiddel og fuldvaskemetode |
| JPS61104784A (ja) | 1984-10-26 | 1986-05-23 | Suntory Ltd | ペルオキシダ−ゼの製造法 |
| JPH0697997B2 (ja) | 1985-08-09 | 1994-12-07 | ギスト ブロカデス ナ−ムロ−ゼ フエンノ−トチヤツプ | 新規の酵素的洗浄剤添加物 |
| DK122686D0 (da) | 1986-03-17 | 1986-03-17 | Novo Industri As | Fremstilling af proteiner |
| US5989870A (en) | 1986-04-30 | 1999-11-23 | Rohm Enzyme Finland Oy | Method for cloning active promoters |
| ES2058119T3 (es) | 1986-08-29 | 1994-11-01 | Novo Nordisk As | Aditivo detergente enzimatico. |
| US5389536A (en) | 1986-11-19 | 1995-02-14 | Genencor, Inc. | Lipase from Pseudomonas mendocina having cutinase activity |
| DE3854249T2 (de) | 1987-08-28 | 1996-02-29 | Novonordisk As | Rekombinante Humicola-Lipase und Verfahren zur Herstellung von rekombinanten Humicola-Lipasen. |
| DK6488D0 (da) | 1988-01-07 | 1988-01-07 | Novo Industri As | Enzymer |
| WO1989006270A1 (en) | 1988-01-07 | 1989-07-13 | Novo-Nordisk A/S | Enzymatic detergent |
| JP3079276B2 (ja) | 1988-02-28 | 2000-08-21 | 天野製薬株式会社 | 組換え体dna、それを含むシュードモナス属菌及びそれを用いたリパーゼの製造法 |
| EP0406314B1 (en) | 1988-03-24 | 1993-12-01 | Novo Nordisk A/S | A cellulase preparation |
| US5776757A (en) | 1988-03-24 | 1998-07-07 | Novo Nordisk A/S | Fungal cellulase composition containing alkaline CMC-endoglucanase and essentially no cellobiohydrolase and method of making thereof |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| JPH02238885A (ja) | 1989-03-13 | 1990-09-21 | Oji Paper Co Ltd | フェノールオキシダーゼ遺伝子組換えdna、該組換えdnaにより形質転換された微生物、その培養物及びフェノールオキシダーゼの製造方法 |
| DK0477280T3 (zh) | 1989-06-13 | 1997-02-10 | Genencor Int | |
| GB8915658D0 (en) | 1989-07-07 | 1989-08-23 | Unilever Plc | Enzymes,their production and use |
| DE69033388T2 (de) | 1989-08-25 | 2000-05-11 | Henkel Research Corp., Santa Rosa | Alkalisches proteolytisches enzym und verfahren zur herstellung |
| AU639570B2 (en) | 1990-05-09 | 1993-07-29 | Novozymes A/S | A cellulase preparation comprising an endoglucanase enzyme |
| DK115890D0 (da) | 1990-05-09 | 1990-05-09 | Novo Nordisk As | Enzym |
| FI903443A7 (fi) | 1990-07-06 | 1992-01-07 | Valtion Teknillinen | Framstaellning av lackas genom rekombinantorganismer. |
| DK0548228T3 (da) | 1990-09-13 | 1999-05-10 | Novo Nordisk As | Lipasevarianter |
| IL99552A0 (en) | 1990-09-28 | 1992-08-18 | Ixsys Inc | Compositions containing procaryotic cells,a kit for the preparation of vectors useful for the coexpression of two or more dna sequences and methods for the use thereof |
| SG52693A1 (en) | 1991-01-16 | 1998-09-28 | Procter & Gamble | Detergent compositions with high activity cellulase and softening clays |
| US5292796A (en) | 1991-04-02 | 1994-03-08 | Minnesota Mining And Manufacturing Company | Urea-aldehyde condensates and melamine derivatives comprising fluorochemical oligomers |
| ES2121014T3 (es) | 1991-05-01 | 1998-11-16 | Novo Nordisk As | Enzimas estabilizadas y composiciones detergentes. |
| US5340735A (en) | 1991-05-29 | 1994-08-23 | Cognis, Inc. | Bacillus lentus alkaline protease variants with increased stability |
| WO1993012067A1 (en) | 1991-12-13 | 1993-06-24 | The Procter & Gamble Company | Acylated citrate esters as peracid precursors |
| DK28792D0 (da) | 1992-03-04 | 1992-03-04 | Novo Nordisk As | Nyt enzym |
| DK72992D0 (da) | 1992-06-01 | 1992-06-01 | Novo Nordisk As | Enzym |
| DK88892D0 (da) | 1992-07-06 | 1992-07-06 | Novo Nordisk As | Forbindelse |
| DE69334295D1 (de) | 1992-07-23 | 2009-11-12 | Novo Nordisk As | MUTIERTE -g(a)-AMYLASE, WASCHMITTEL UND GESCHIRRSPÜLMITTEL |
| EP1431389A3 (en) | 1992-10-06 | 2004-06-30 | Novozymes A/S | Cellulase variants |
| ATE175235T1 (de) | 1993-02-11 | 1999-01-15 | Genencor Int | Oxidativ stabile alpha-amylase |
| AU673078B2 (en) | 1993-04-27 | 1996-10-24 | Genencor International, Inc. | New lipase variants for use in detergent applications |
| DK52393D0 (zh) | 1993-05-05 | 1993-05-05 | Novo Nordisk As | |
| FR2704860B1 (fr) | 1993-05-05 | 1995-07-13 | Pasteur Institut | Sequences de nucleotides du locus cryiiia pour le controle de l'expression de sequences d'adn dans un hote cellulaire. |
| HU218008B (hu) | 1993-05-08 | 2000-05-28 | Henkel Kg. Auf Aktien | Ezüst korróziója ellen védő szerek (I) és ezeket tartalmazó gépi tisztítószerek |
| DK0697035T3 (da) | 1993-05-08 | 1998-09-28 | Henkel Kgaa | Sølvbeskyttelsesmiddel med korrosion I |
| DK81293D0 (da) | 1993-07-06 | 1993-07-06 | Novo Nordisk As | Enzym |
| JP2859520B2 (ja) | 1993-08-30 | 1999-02-17 | ノボ ノルディスク アクティーゼルスカブ | リパーゼ及びそれを生産する微生物及びリパーゼ製造方法及びリパーゼ含有洗剤組成物 |
| JPH09503916A (ja) | 1993-10-08 | 1997-04-22 | ノボ ノルディスク アクティーゼルスカブ | アミラーゼ変異体 |
| US5817495A (en) | 1993-10-13 | 1998-10-06 | Novo Nordisk A/S | H2 O2 -stable peroxidase variants |
| JPH07143883A (ja) | 1993-11-24 | 1995-06-06 | Showa Denko Kk | リパーゼ遺伝子及び変異体リパーゼ |
| DE4343591A1 (de) | 1993-12-21 | 1995-06-22 | Evotec Biosystems Gmbh | Verfahren zum evolutiven Design und Synthese funktionaler Polymere auf der Basis von Formenelementen und Formencodes |
| US5605793A (en) | 1994-02-17 | 1997-02-25 | Affymax Technologies N.V. | Methods for in vitro recombination |
| ATE222604T1 (de) | 1994-02-22 | 2002-09-15 | Novozymes As | Methode zur herstellung einer variante eines lipolytischen enzymes |
| ATE512226T1 (de) | 1994-02-24 | 2011-06-15 | Henkel Ag & Co Kgaa | Verbesserte enzyme und detergentien damit |
| DE69536145D1 (de) | 1994-03-08 | 2011-04-07 | Novozymes As | Neuartige alkalische Zellulasen |
| WO1995030744A2 (en) | 1994-05-04 | 1995-11-16 | Genencor International Inc. | Lipases with improved surfactant resistance |
| DK0765394T3 (da) | 1994-06-03 | 2001-12-10 | Novozymes As | Oprensede Myceliopthora-laccaser og nukleinsyrer der koder for disse |
| WO1995035381A1 (en) | 1994-06-20 | 1995-12-28 | Unilever N.V. | Modified pseudomonas lipases and their use |
| WO1996000292A1 (en) | 1994-06-23 | 1996-01-04 | Unilever N.V. | Modified pseudomonas lipases and their use |
| DE69534185T2 (de) | 1994-06-30 | 2006-02-23 | Novozymes Biotech, Inc., Davis | Nicht-toxisches, nicht-toxigenes, nicht-pathogenes fusarium expressionssystem und darin zu verwendende promotoren und terminatoren |
| EP1995303A3 (en) | 1994-10-06 | 2008-12-31 | Novozymes A/S | Enzyme preparation with endoglucanase activity |
| BE1008998A3 (fr) | 1994-10-14 | 1996-10-01 | Solvay | Lipase, microorganisme la produisant, procede de preparation de cette lipase et utilisations de celle-ci. |
| AU3697995A (en) | 1994-10-26 | 1996-05-23 | Novo Nordisk A/S | An enzyme with lipolytic activity |
| AR000862A1 (es) | 1995-02-03 | 1997-08-06 | Novozymes As | Variantes de una ó-amilasa madre, un metodo para producir la misma, una estructura de adn y un vector de expresion, una celula transformada por dichaestructura de adn y vector, un aditivo para detergente, composicion detergente, una composicion para lavado de ropa y una composicion para la eliminacion del |
| JPH08228778A (ja) | 1995-02-27 | 1996-09-10 | Showa Denko Kk | 新規なリパーゼ遺伝子及びそれを用いたリパーゼの製造方法 |
| CN1182451A (zh) | 1995-03-17 | 1998-05-20 | 诺沃挪第克公司 | 新的内切葡聚糖酶 |
| BR9608149B1 (pt) | 1995-05-05 | 2012-01-24 | processos para efetuar mutação no dna que codifica uma enzima de subtilase ou sua pré- ou pré-pró-enzima e para a manufatura de uma enzima de subtilase mutante. | |
| WO1997007202A1 (en) | 1995-08-11 | 1997-02-27 | Novo Nordisk A/S | Novel lipolytic enzymes |
| WO1997004078A1 (en) | 1995-07-14 | 1997-02-06 | Novo Nordisk A/S | A modified enzyme with lipolytic activity |
| DE19528059A1 (de) | 1995-07-31 | 1997-02-06 | Bayer Ag | Wasch- und Reinigungsmittel mit Iminodisuccinaten |
| US6008029A (en) | 1995-08-25 | 1999-12-28 | Novo Nordisk Biotech Inc. | Purified coprinus laccases and nucleic acids encoding the same |
| US5763385A (en) | 1996-05-14 | 1998-06-09 | Genencor International, Inc. | Modified α-amylases having altered calcium binding properties |
| WO1998008940A1 (en) | 1996-08-26 | 1998-03-05 | Novo Nordisk A/S | A novel endoglucanase |
| DE69735767T2 (de) | 1996-09-17 | 2007-04-05 | Novozymes A/S | Cellulasevarianten |
| WO1998015257A1 (en) | 1996-10-08 | 1998-04-16 | Novo Nordisk A/S | Diaminobenzoic acid derivatives as dye precursors |
| EP0934389B1 (en) | 1996-10-18 | 2003-12-10 | The Procter & Gamble Company | Detergent compositions |
| AU4772697A (en) | 1996-11-04 | 1998-05-29 | Novo Nordisk A/S | Subtilase variants and compositions |
| CN1530443A (zh) | 1996-11-04 | 2004-09-22 | ŵ����÷������˾ | 枯草杆菌酶变异体和组合物 |
| EP1002061A1 (en) | 1997-07-04 | 2000-05-24 | Novo Nordisk A/S | FAMILY 6 ENDO-1,4-$g(b)-GLUCANASE VARIANTS AND CLEANING COMPOSIT IONS CONTAINING THEM |
| DE69839076T2 (de) | 1997-08-29 | 2009-01-22 | Novozymes A/S | Proteasevarianten und zusammensetzungen |
| EP2206768B1 (en) | 1997-10-13 | 2015-04-01 | Novozymes A/S | Alpha-amylase mutants |
| US5955310A (en) | 1998-02-26 | 1999-09-21 | Novo Nordisk Biotech, Inc. | Methods for producing a polypeptide in a bacillus cell |
| WO2000034450A1 (en) | 1998-12-04 | 2000-06-15 | Novozymes A/S | Cutinase variants |
| CN100497614C (zh) | 1998-06-10 | 2009-06-10 | 诺沃奇梅兹有限公司 | 甘露聚糖酶 |
| EP1124949B1 (en) | 1998-10-26 | 2006-07-12 | Novozymes A/S | Constructing and screening a dna library of interest in filamentous fungal cells |
| CN1940067A (zh) | 1999-03-22 | 2007-04-04 | 诺沃奇梅兹有限公司 | 用于在真菌细胞中表达基因的启动子 |
| KR20010108379A (ko) | 1999-03-31 | 2001-12-07 | 피아 스타르 | 리파제 변이체 |
| EP1214426A2 (en) | 1999-08-31 | 2002-06-19 | Novozymes A/S | Novel proteases and variants thereof |
| CN101974375B (zh) | 1999-12-15 | 2014-07-02 | 诺沃奇梅兹有限公司 | 对蛋渍具有改进洗涤性能的枯草杆菌酶变体 |
| ES2322690T3 (es) | 2000-02-24 | 2009-06-25 | Novozymes A/S | Xiloglucanasas de la familia 44. |
| JP5571274B2 (ja) | 2000-03-08 | 2014-08-13 | ノボザイムス アクティーゼルスカブ | 改変された特性を有する変異体 |
| DE60112928T2 (de) | 2000-06-02 | 2006-06-14 | Novozymes As | Cutinase-varianten |
| JP4855632B2 (ja) | 2000-08-01 | 2012-01-18 | ノボザイムス アクティーゼルスカブ | 変更された性質を有するα−アミラーゼ突然変異体 |
| CN1337553A (zh) | 2000-08-05 | 2002-02-27 | 李海泉 | 地下观光游乐园 |
| CA2419896C (en) | 2000-08-21 | 2014-12-09 | Novozymes A/S | Subtilase enzymes |
| EP1337657A2 (en) | 2000-11-17 | 2003-08-27 | Novozymes A/S | Heterologous expression of taxanes |
| DK1399543T3 (da) | 2001-06-06 | 2014-11-03 | Novozymes As | Endo-beta-1,4-glucanase |
| DK200101090A (da) | 2001-07-12 | 2001-08-16 | Novozymes As | Subtilase variants |
| US6506987B1 (en) | 2001-07-19 | 2003-01-14 | Randy Woods | Magnetic switch |
| GB0127036D0 (en) | 2001-11-09 | 2002-01-02 | Unilever Plc | Polymers for laundry applications |
| DK1448595T3 (da) | 2001-11-20 | 2007-02-19 | Novozymes As | Antimikrobielle polypeptider |
| DE10162728A1 (de) | 2001-12-20 | 2003-07-10 | Henkel Kgaa | Neue Alkalische Protease aus Bacillus gibsonii (DSM 14393) und Wasch-und Reinigungsmittel enthaltend diese neue Alkalische Protease |
| CN101597601B (zh) | 2002-06-26 | 2013-06-05 | 诺维信公司 | 具有改变的免疫原性的枯草杆菌酶和枯草杆菌酶变体 |
| DK1886582T3 (en) | 2002-10-11 | 2015-04-20 | Novozymes As | Process for preparing a heat treated product |
| TWI319007B (en) | 2002-11-06 | 2010-01-01 | Novozymes As | Subtilase variants |
| WO2004067737A2 (en) | 2003-01-30 | 2004-08-12 | Novozymes A/S | Subtilases |
| CA2529726A1 (en) | 2003-06-18 | 2005-01-13 | Unilever Plc | Laundry treatment compositions |
| GB0314210D0 (en) | 2003-06-18 | 2003-07-23 | Unilever Plc | Laundry treatment compositions |
| GB0314211D0 (en) | 2003-06-18 | 2003-07-23 | Unilever Plc | Laundry treatment compositions |
| CN1871344A (zh) | 2003-10-23 | 2006-11-29 | 诺和酶股份有限公司 | 在洗涤剂中具有改善稳定性的蛋白酶 |
| AU2004293826B2 (en) | 2003-11-19 | 2009-09-17 | Danisco Us Inc. | Serine proteases, nucleic acids encoding serine enzymes and vectors and host cells incorporating same |
| EP2295554B1 (en) | 2003-12-03 | 2012-11-28 | Danisco US Inc. | Perhydrolase |
| DK1709167T3 (da) | 2004-01-08 | 2010-08-16 | Novozymes As | Amylase |
| US20090280534A1 (en) | 2004-12-22 | 2009-11-12 | Novozymes A/S | Recombinant Production of Serum Albumin |
| CA2593920A1 (en) | 2004-12-23 | 2006-06-29 | Novozymes A/S | Alpha-amylase variants |
| PL1869155T3 (pl) | 2005-04-15 | 2011-03-31 | Procter & Gamble | Ciekłe kompozycje detergentu do prania ze zmodyfikowanymi polimerami polietylenoiminy oraz enzymem lipazy |
| BRPI0609363A2 (pt) | 2005-04-15 | 2010-03-30 | Procter & Gamble | composições para limpeza com polialquileno iminas alcoxiladas |
| EP1888734A2 (en) | 2005-05-31 | 2008-02-20 | The Procter and Gamble Company | Polymer-containing detergent compositions and their use |
| CN101218343B (zh) | 2005-07-08 | 2013-11-06 | 诺维信公司 | 枯草蛋白酶变体 |
| CN105200027B (zh) | 2005-10-12 | 2019-05-31 | 金克克国际有限公司 | 储存稳定的中性金属蛋白酶的用途和制备 |
| US8518675B2 (en) | 2005-12-13 | 2013-08-27 | E. I. Du Pont De Nemours And Company | Production of peracids using an enzyme having perhydrolysis activity |
| AR059154A1 (es) | 2006-01-23 | 2008-03-12 | Procter & Gamble | Una composicion que comprende una lipasa y un catalizador de blanqueador |
| AR059156A1 (es) | 2006-01-23 | 2008-03-12 | Procter & Gamble | Composiciones detergentes |
| ES2629332T3 (es) | 2006-01-23 | 2017-08-08 | Novozymes A/S | Variantes de lipasa |
| EP2248882A1 (en) | 2006-01-23 | 2010-11-10 | The Procter and Gamble Company | Enzyme and fabric hueing agent containing compositions |
| AR059155A1 (es) | 2006-01-23 | 2008-03-12 | Procter & Gamble | Composiciones que comprenden enzimas y fotoblanqueadores |
| EP1976967A2 (en) | 2006-01-23 | 2008-10-08 | The Procter and Gamble Company | Detergent compositions |
| EP1979457A2 (en) | 2006-01-23 | 2008-10-15 | The Procter and Gamble Company | A composition comprising a lipase and a bleach catalyst |
| DE602007007945D1 (de) | 2006-05-31 | 2010-09-02 | Basf Se | Amphiphile pfropfpolymere auf basis von polyalkylenoxiden und vinylestern |
| DE202006009003U1 (de) | 2006-06-06 | 2007-10-25 | BROSE SCHLIEßSYSTEME GMBH & CO. KG | Kraftfahrzeugschloß |
| PL1867708T3 (pl) | 2006-06-16 | 2017-10-31 | Procter & Gamble | Kompozycje detergentu |
| EP1876226B1 (en) | 2006-07-07 | 2011-03-23 | The Procter & Gamble Company | Detergent compositions |
| EP2155869A2 (en) | 2007-05-30 | 2010-02-24 | Danisco US, INC., Genencor Division | Variants of an alpha-amylase with improved production levels in fermentation processes |
| ATE503826T1 (de) | 2007-07-02 | 2011-04-15 | Procter & Gamble | Mehrkammerbeutel enthaltend waschmittel |
| DE102007038031A1 (de) | 2007-08-10 | 2009-06-04 | Henkel Ag & Co. Kgaa | Mittel enthaltend Proteasen |
| AU2008325250B2 (en) | 2007-11-05 | 2013-06-13 | Danisco Us Inc. | Variants of Bacillus sp. TS-23 alpha-amylase with altered properties |
| RU2470069C2 (ru) | 2008-01-04 | 2012-12-20 | Дзе Проктер Энд Гэмбл Компани | Композиция средства для стирки, содержащая гликозилгидролазу |
| US20090209447A1 (en) | 2008-02-15 | 2009-08-20 | Michelle Meek | Cleaning compositions |
| EP2250259B1 (en) | 2008-02-29 | 2016-08-31 | Novozymes A/S | Polypeptides having lipase activity and polynucleotides encoding same |
| EP2169040B1 (en) | 2008-09-30 | 2012-04-11 | The Procter & Gamble Company | Liquid detergent compositions exhibiting two or multicolor effect |
| WO2010039889A2 (en) | 2008-09-30 | 2010-04-08 | Novozymes, Inc. | Methods for using positively and negatively selectable genes in a filamentous fungal cell |
| EP2367923A2 (en) | 2008-12-01 | 2011-09-28 | Danisco US Inc. | Enzymes with lipase activity |
| CA2753075A1 (en) | 2009-02-20 | 2010-08-26 | Danisco Us Inc. | Fermentation broth formulations |
| MX2011008656A (es) | 2009-03-06 | 2011-09-06 | Huntsman Adv Mat Switzerland | Metodos de decoloracion-blanqueo enzimatico de textiles. |
| US20120172275A1 (en) | 2009-03-10 | 2012-07-05 | Danisco Us Inc. | Bacillus Megaterium Strain DSM90-Related Alpha-Amylases, and Methods of Use, Thereof |
| WO2010107560A2 (en) | 2009-03-18 | 2010-09-23 | Danisco Us Inc. | Fungal cutinase from magnaporthe grisea |
| US20120058527A1 (en) | 2009-03-23 | 2012-03-08 | Danisco Us Inc. | Cal a-related acyltransferases and methods of use, thereof |
| CA2775045A1 (en) | 2009-09-25 | 2011-03-31 | Novozymes A/S | Subtilase variants for use in detergent and cleaning compositions |
| US20120252106A1 (en) | 2009-09-25 | 2012-10-04 | Novozymes A/S | Use of Protease Variants |
| DK2496694T3 (en) | 2009-11-06 | 2017-06-06 | Novozymes Inc | COMPOSITIONS FOR SACCHARIFYING CELLULOS MATERIAL |
| BR112012017056A2 (pt) | 2009-12-21 | 2016-11-22 | Danisco Us Inc | "composições detergentes contendo lipase de bacillus subtilis e métodos para uso das mesmas" |
| BR112012017062A2 (pt) | 2009-12-21 | 2016-11-29 | Danisco Us Inc | "composições deterfgentes contendo lipase de geobacillus stearothermophilus e métodos para uso das mesmas" |
| BR112012017060A2 (pt) | 2009-12-21 | 2016-11-29 | Danisco Us Inc | "composições detergentes contendo lipase de thermobifida fusca, método para hidrolisar um lipídio presente em uma sujeira ou mancha sobre uma superfície e método para realizar uma reação de transesterificação |
| MX369096B (es) | 2010-02-10 | 2019-10-29 | Novozymes As | Variantes y composiciones que comprenden variantes con alta estabilidad en presencia de un agente quelante. |
| AR081423A1 (es) | 2010-05-28 | 2012-08-29 | Danisco Us Inc | Composiciones detergentes con contenido de lipasa de streptomyces griseus y metodos para utilizarlas |
| JP5757580B2 (ja) | 2010-09-16 | 2015-07-29 | 国立研究開発法人海洋研究開発機構 | 新規な細胞外分泌型ヌクレアーゼ |
| MX2013007720A (es) | 2011-01-26 | 2013-08-09 | Novozymes As | Polipeptidos que tienen actividad celobiohidrolasa y polinucleotidos que codifican para los mismos. |
| MX2013011617A (es) | 2011-04-08 | 2013-11-21 | Danisco Us Inc | Composiciones. |
| WO2013001078A1 (en) | 2011-06-30 | 2013-01-03 | Novozymes A/S | Alpha-amylase variants |
| EP4026901B1 (en) | 2011-06-30 | 2025-01-22 | Novozymes A/S | Method for screening alpha-amylases |
| US9000138B2 (en) | 2011-08-15 | 2015-04-07 | Novozymes A/S | Expression constructs comprising a Terebella lapidaria nucleic acid encoding a cellulase, host cells, and methods of making the cellulase |
| ES3035568T3 (en) | 2012-06-08 | 2025-09-04 | Danisco Us Inc | Variant alpha amylases with enhanced activity on starch polymers |
| EP2674475A1 (en) | 2012-06-11 | 2013-12-18 | The Procter & Gamble Company | Detergent composition |
| US20170152462A1 (en) | 2014-04-11 | 2017-06-01 | Novozymes A/S | Detergent Composition |
| CA2950380A1 (en) | 2014-07-04 | 2016-01-07 | Novozymes A/S | Subtilase variants and polynucleotides encoding same |
| WO2016176240A1 (en) | 2015-04-29 | 2016-11-03 | The Procter & Gamble Company | Method of treating a fabric |
| US10081783B2 (en) * | 2016-06-09 | 2018-09-25 | The Procter & Gamble Company | Cleaning compositions having an enzyme system |
-
2018
- 2018-03-23 CN CN201880023402.XA patent/CN110651040A/zh active Pending
- 2018-03-23 EP EP18775964.2A patent/EP3601552A4/en active Pending
- 2018-03-23 US US16/495,147 patent/US11180720B2/en active Active
- 2018-03-23 WO PCT/CN2018/080156 patent/WO2018177203A1/en not_active Ceased
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150299623A1 (en) * | 2012-12-07 | 2015-10-22 | Novozymes A/S | Preventing Adhesion of Bacteria |
| WO2015155350A1 (en) * | 2014-04-11 | 2015-10-15 | Novozymes A/S | Detergent composition |
| CN106164236A (zh) * | 2014-04-11 | 2016-11-23 | 诺维信公司 | 洗涤剂组合物 |
| WO2016162556A1 (en) * | 2015-04-10 | 2016-10-13 | Novozymes A/S | Laundry method, use of dnase and detergent composition |
| US20160319226A1 (en) * | 2015-04-29 | 2016-11-03 | The Procter & Gamble Company | Method of treating a fabric |
| WO2017001472A1 (en) * | 2015-06-29 | 2017-01-05 | Novozymes A/S | Laundry method, use of polypeptide and detergent composition |
| WO2017001471A1 (en) * | 2015-06-29 | 2017-01-05 | Novozymes A/S | Laundry method, use of polypeptide and detergent composition |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3601552A1 (en) | 2020-02-05 |
| WO2018177203A1 (en) | 2018-10-04 |
| US11180720B2 (en) | 2021-11-23 |
| EP3601552A4 (en) | 2022-01-12 |
| US20200032169A1 (en) | 2020-01-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11180720B2 (en) | Polypeptides having DNase activity | |
| US11208639B2 (en) | Polypeptides having DNase activity | |
| US11053483B2 (en) | Polypeptides having DNase activity | |
| US11149233B2 (en) | Polypeptides having RNase activity | |
| CN106459944B (zh) | α-淀粉酶变体 | |
| CN110651029A (zh) | 糖基水解酶 | |
| US12297470B2 (en) | Polypeptides having peptidoglycan degrading activity and polynucleotides encoding same | |
| WO2021214059A1 (en) | Cleaning compositions comprising polypeptides having fructan degrading activity | |
| US20250043264A1 (en) | Polypeptides Having Nuclease Activity | |
| US20200109354A1 (en) | Polypeptides | |
| US20220411773A1 (en) | Polypeptides having proteolytic activity and use thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |