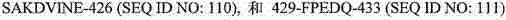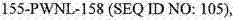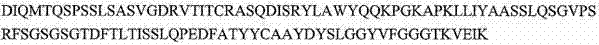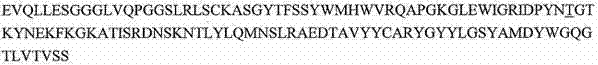具体实施方式
本发明涉及蛋白-特异性的PCSK9拮抗剂,在具体实施方案中,涉及抑制人PCSK9的那些拮抗剂。根据本发明的蛋白-特异性的PCSK9拮抗剂(或“PCSK9-特异性的拮抗剂”)可有效地选择性地结合PCSK9和抑制PCSK9功能,并因而在与PCSK9功能有关或受其影响的病症的治疗中具有重要性,所述病症包括、但不限于:高胆固醇血症、冠心病、代谢综合征、急性冠状动脉综合征和有关病症。使用术语“拮抗剂”表示下述事实:即主题分子可以拮抗PCSK9的功能。使用术语“拮抗”或其派生词表示反抗、对抗、抑制、中和或减小PCSK9的一种或多种功能的行为。在本文中提及的PCSK9功能或PCSK9活性表示被PCSK9驱动、加重或增强的任何功能或活性,或需要PCSK9的任何功能或活性。已经证实,本文所述的PCSK9-特异性的拮抗剂可以有效地对抗细胞的LDL-摄入的人PCSK9-依赖性的抑制。
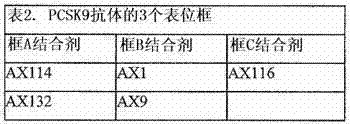
关于此点的一个重要实施方案涉及AX1抗体分子和其变体。本发明的特定实施方案包括这样的AX1抗体分子,其被表征为,包含:(i)含有SEQ ID NO: 41或由其组成的重链可变区(“VH”);和(ii)含有SEQ ID NO: 50或52(AX1DG)或由其组成的轻链可变区(“VL”)。所述VH和VL区分别包含VH区[SEQ ID NO: 2(或SEQ ID NO: 4)作为CDR1;
SEQ ID NO: 9(或SEQ ID NO: 11)作为CDR2;和SEQ ID NO: 16(或SEQ ID NO: 18)作为CDR3]和VL区[SEQ ID NO: 24作为CDR1;SEQ ID NO: 31作为CDR2;和SEQ ID NO: 35作为CDR3]的公开的CDR 1、2和3的全部。AX1抗体分子的实例包括、但不限于:(i)包含含有SEQ ID NO: 73的轻链的Fab,和包含含有SEQ ID NO: 69的氨基酸1-227(或SEQ ID NO: 69)的氨基酸的Fd链;(ii)全长抗体分子,其包含含有SEQ ID NO: 85的轻链和含有SEQ ID NO: 79的重链;和(iii)通过SEQ ID NO: 91的表达生成的抗体。
在具体实施方案中,本文公开的PCSK9-特异性的拮抗剂包含连续次序的一个或两个重链或轻链:(a)框架1(FR1)序列;(b)CDR1序列;(c)框架2(FR2)序列;(d)CDR2序列;(e)框架3(FR3)序列,(f)CDR3序列;和(g)框架4(FR4)序列。在具体实施方案中,所述重链包含连续次序的:(a)FR1序列SEQ ID NO: 94;(b)选自SEQ ID NO: 1、2和6的CDR1序列;(c)FR2序列SEQ ID NO: 95;(d)选自SEQ ID NO: 8、9和13的CDR2序列;(e)FR3序列SEQ ID NO: 96;(f)选自SEQ ID NO: 15、16和20的CDR3序列;和(g)FR4序列SEQ ID NO: 97。在具体实施方案中,所述轻链包含连续次序的:(a)FR1序列SEQ ID NO: 98;(b)选自SEQ ID NO: 22、23、24、26和28的CDR1序列;(c)FR2序列SEQ ID NO: 99;(d)选自SEQ ID NO: 30和31的CDR2序列;(e)FR3序列SEQ ID NO: 100;(f)选自SEQ ID NO: 33、34、35、37和39的CDR3序列;和(g)FR4序列SEQ ID NO: 101或102。本发明包括具有上述重链和轻链的抗体分子以及所述抗体分子的等效物,所述等效物被表征为具有一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换,所述置换不会使对PCSK9的特异性降低超过50% (在具体实施方案中,超过60%、70%、80%和90%)。选择的例证的AX1抗体集合证实、但不限于,本文公开的PCSK9-特异性的拮抗剂可有效地抑制人PCSK9。
本文公开的一种具体的变体AX9抗体分子被表征为,包含:(i)含有SEQ ID NO: 43的重链可变区(“VH”);和(ii)含有SEQ ID NO: 53的轻链可变区(“VL”)。所述VH和VL区分别包含VH区[SEQ ID NO: 6作为CDR1;SEQ ID NO: 13作为CDR2;和SEQ ID NO: 20作为CDR3]和VL区[SEQ ID NO: 26作为CDR1;SEQ ID NO: 31作为CDR2;和SEQ ID NO: 37作为CDR3]的公开的CDR 1、2和3的全部。AX9抗体分子的实例包括、但不限于:(i)包含含有SEQ ID NO: 75的轻链的Fab,和包含含有SEQ ID NO: 71的氨基酸1-229(或SEQ ID NO: 71)的氨基酸的Fd链;(ii)全长抗体分子,其包含含有SEQ ID NO: 87的轻链和含有SEQ ID NO: 81的重链;和(iii)通过SEQ ID NO: 92的表达生成的抗体。
本文公开的一种具体的变体AX189抗体分子被表征为,包含:(i)含有SEQ ID NO: 43的重链可变区(“VH”);和(ii)含有SEQ ID NO: 67的轻链可变区(“VL”)。所述VH和VL区分别包含VH区[SEQ ID NO: 6作为CDR1;SEQ ID NO: 13作为CDR2;和SEQ ID NO: 20作为CDR3]和VL区[SEQ ID NO: 28作为CDR1;SEQ ID NO: 31作为CDR2;和SEQ ID NO: 39作为CDR3]的公开的CDR 1、2和3的全部。AX189抗体分子的实例包括、但不限于:(i)包含含有SEQ ID NO: 77的轻链的Fab,和包含含有SEQ ID NO: 71的氨基酸1-229(或SEQ ID NO: 71)的氨基酸的Fd链;(ii)全长抗体分子,其包含含有SEQ ID NO: 89的轻链和含有SEQ ID NO: 81(或SEQ
ID NO: 83)的重链;和(iii)通过SEQ
ID NO: 93的表达生成的抗体。
使用Abmaxis计算机程序(Luo等人, 美国专利号7,117,096和美国专利公布号US2004/0010376或W003/099999),定义在本文中提及和公开的CDR定义。但是,申请人希望指出,不同的其它方法也可用于描绘和定义CDR序列的起点和终点,包括、但不限于Kabat, 1991 Sequences of Proteins of
Immunological Interest, 第5版, NIH公开号91-3242美国卫生和人类服务部; Clothia等人,
1987 J. Mol. Biol. 196:901-917; Clothia等人,
1989 Nature 342:877-883; Lefranc, 1997 Immunol. Today, 18:509;和Chen等人, 1999 J.
Mol. Biol. 293:865-881。这些和其它方法已经见诸综述,且在本领域技术人员具有的技能范围内;参见,例如,Honegger
& Plückthun, 2001 J. Mol. Biol.
309:657-670。尽管发明人已经采用Abmaxis程序来定义CDR,本发明可以包括关于序列的不同定义,并通过使用任何不同的分析软件或方法,实现不同的CDR描绘。例如,也可以将CDR定义为抗体分子的组分,其结合表位或参与结合抗原。CDR可以包含5-20个氨基酸。在具体实施方案中,所述CDR可以另外包含在CDR的每侧上进入框架区中的2-6个侧接氨基酸。上述方法和基于目前公开的序列而得到的CDR定义完全落入本公开内容的范围内,且在本文中预见到。
PCSK9-特异性的分子也可以用于不同的诊断目的,用于PCSK9的检测和定量。
此外,公开的PCSK9-特异性的拮抗剂的独特之处在于,选择的实施方案已经表现出对处理过的PCSK9(PCSK9的活性形式)的优先识别。
本文公开的PCSK9-特异性的拮抗剂是用于降低血浆LDL胆固醇水平的理想分子,且可用于具有商业或家养兽学重要性的任意灵长类动物、哺乳动物或脊椎动物。PCSK9-特异性的拮抗剂也可用于抑制具有LDL受体的任意细胞群体或组织中的PCSK9活性。通过技术人员可容易地得到的试验,可以直接地测量公开的拮抗剂的实用性。在文献中描述了用于测量LDL摄入的方法;参见,例如,Barak & Webb,1981 J.
Cell Biol. 90:595-604,和Stephan & Yurachek, 1993 J. Lipid
Res. 34:325330。另外,在文献中确定地描述了用于测量血浆中的LDL胆固醇的方法;参见,例如,McNamara等人,
2006 Clinica Chimica Acta 369:158-167。通过特定方法,也可以测量公开的拮抗剂对细胞LDL摄入的具体影响,所述方法包括:将纯化的PCSK9和标记的LDL颗粒提供给细胞样品;将PCSK9拮抗剂提供给细胞样品;温育所述细胞样品足以允许LDL颗粒被细胞摄入的时间段;定量掺入细胞中的标记的量;和鉴别出与单独施用PCSK9时观察到的相应值相比,导致细胞摄入的量化标记的量的增加的那些拮抗剂。用于测量公开的拮抗剂的影响的另一种方法包括:将纯化的PCSK9和标记的LDL颗粒提供给细胞样品;将PCSK9拮抗剂提供给细胞样品;温育所述细胞样品足以允许LDL颗粒被细胞摄入的时间段;通过去除上清液,分离细胞样品的细胞;减少标记的LDL颗粒的非特异性结合(无论是结合平板、细胞还是结合除了LDL受体以外的任何物质);裂解细胞;定量保留在细胞裂解物内的标记的量;和鉴别出与单独施用PCSK9时观察到的相应值相比,导致细胞摄入的量化标记的量的增加的那些拮抗剂。导致量化标记的量的增加的拮抗剂是PCSK9拮抗剂。
携带LDL受体的任意类型的细胞可以用于上述方法中,所述细胞包括、但不限于:HEK细胞、HepG2细胞和CHO细胞。源自任意来源的LDL颗粒可以用于上述试验中。在具体试验中,所述LDL颗粒是源自血液的新鲜颗粒。这可以通过技术人员可得到的任意方法来实现,所述方法包括、但不限于:Havel等人, 1955 J. Clin. Invest.
34: 1345-1353的方法。可以用荧光标记所述LDL颗粒。标记的LDL颗粒可以在其中已经掺入了可见波长激活的荧光团3,3'-双(十八烷基)吲哚羰花青碘化物(dil(3)),以形成高荧光的LDL衍生物dil(3)-LDL。可以使用能够允许技术人员检测细胞裂解物中的LDL的任意标记。可以使用这样的LDL类似物:其仅当在细胞内被代谢时,或例如,如果在被内化的过程中与其它分子结合(或解离),才会变得可检测到(例如,变成荧光的或发出不同波长的荧光等)(例如FRET试验,其中LDL类似物会结合第二荧光素,或从猝灭剂解离)。可以采用本领域中可以用于检测标记的LDL颗粒的内化的任意方法。LDL颗粒和PCSK9与细胞的温育时间是足以允许LDL颗粒被细胞摄入的时间的量。该时间可以是在5分钟至360分钟的范围内。加给细胞的PCSK9的浓度可以是在1 nM至5 μM的范围内,在具体的方法中,是在0.1 nM至3 μM的范围内。技术人员可以用于确定特定PCSK9蛋白的浓度范围的一种具体方法是,在LDL-摄入试验中产生剂量响应曲线。可以选择这样的PCSK9浓度:其促进接近于LDL-摄入的最大损失,且仍然是在剂量响应曲线的线性范围内。通常,该浓度是从剂量响应曲线得到的蛋白的EC-50的约5倍。所述浓度可以随蛋白而异。
广义地讲,本文定义的PCSK9-特异性的拮抗剂会选择性地识别和特异性地结合PCSK9。当解离常数≤1μM,优选地≤100 nM、最优选地≤10 nM时,通常称作抗体特异性地结合抗原。本文使用的术语“选择性的”或“特异性的”另外表示下述事实:即公开的拮抗剂没有表现出与除了PSCK9以外的蛋白的显著结合,但是下述的那些特殊情况除外:其中所述拮抗剂被添加或被设计成赋予PCSK9-特异性的结合部分额外的、独特的特异性(例如,在双特异性的或双功能的分子中,其中所述分子被设计成结合2种分子或实现2种功能,其中至少一种特异性地结合PCSK9)。在具体实施方案中,PCSK9-特异性的拮抗剂以1.2 X
10-6 M或更小的KD结合人PCSK9。在更具体的实施方案中,PCSK9-特异性的拮抗剂以5X10-7M或更小、2X10-7M或更小或1X10-7或更小的KD结合人PCSK9。在额外的实施方案中,PCSK9-特异性的拮抗剂以1 X 10-8 m或更小的KD结合人PCSK9。在其它实施方案中,PCSK9-特异性的拮抗剂以5X10-9M或更小或1X10-9M或更小的KD结合人PCSK9。在选择的实施方案中,PCSK9-特异性的拮抗剂以1 X
10-10 M或更小的KD、1 X 10-11 M或更小的KD、1 X 10-12 M或更小的KD结合人PCSK9。在具体实施方案中,PCSK9-特异性的拮抗剂不以上述KD结合除了PCSK9以外的蛋白。KD表示从Kd(特定结合分子-靶蛋白相互作用的解离速率)与Ka(特定结合分子-靶蛋白相互作用的结合速率)之比得到的解离常数,或表示为摩尔浓度(M)的Kd/Ka。使用本领域众所周知的方法,可以测定KD值。用于测定结合分子的KD的优选方法是,通过使用表面等离子体共振,例如采用生物传感器系统诸如Biacore™(GE Healthcare Life Sciences)系统。
已经证实,本文公开的PCSK9-特异性的拮抗剂会剂量依赖性地抑制人PCSK9依赖性的对LDL摄入的影响。因此,本文公开的PCSK9-特异性的拮抗剂的特征在于,它们的对抗LDL摄入进细胞中的PCSK9依赖性的抑制的能力。LDL受体实现的该LDL向细胞中的摄入在本文中称作“细胞LDL摄入”。在具体实施方案中,PCSK9-特异性的拮抗剂会对抗或拮抗LDL摄入进细胞中的人PCSK9-依赖性的抑制,表现出小于1.0 X10-6
M的IC50,或者按照优选次序,小于1 X 10-7 M、1 X
10-8 M、1 X 10-9
M、1 X 10-10 M、1 X 10-11 M和1 X
10-12 M。在与对照的统计对比中,或通过本领域可得到的用于评估对PCSK9功能的负面效应或抑制的任意替代方法(即,能够评估PCSK9功能的拮抗作用的任意方法),可以定量地测量任意PCSK9-特异性的拮抗剂的抑制程度。在具体实施方案中,所述抑制是至少约10%抑制。在其它实施方案中、所述抑制是至少20%、30%、40%、50%、60%、70%、80%、90%或95%。因此,能够实现PCSK9功能的这些抑制水平的PCSK9-特异性的拮抗剂形成其特定实施方案。特定实施方案提供了本文所述的PCSK9拮抗剂,其在施用给受试者以后,会使LDL降低至少20%、25%、30%、35%、40%、45%、50%、55%、60%、65%和更多。在具体实施方案中,PCSK9拮抗剂使LDL降低那些水平至少7天、10天、15天、20天、25天、30天、35天、40天和更长的时段。在具体实施方案中,所述降低百分比是在超过20、30或40天中的大于或等于10、15、20和25。特定实施方案提供了在超过25天中大于或等于25%的降低(参见,例如,实施例20和图24-25)。特定实施方案也提供了PCSK9-特异性的拮抗剂,其在大约pH
6.0时结合人FcRn,并在大约pH
7.3时解离(参见,例如,实施例18和图17-20)。特定实施方案是这样的,其中公开的PCSK9-特异性的拮抗剂在中性pH时表现出<5% (在具体实施方案中,小于3%或1%)的解离。可以如在实施例18中所述计算解离(或结合百分比)。特定实施方案也提供了本文所述的PCSK-9特异性的拮抗剂,其在小鼠(或猴)中具有大于50、60、70、80、90、95、100、100、120、130或140小时的半衰期(参见,例如,实施例19和图21-23)。在具体实施方案中,提供了在灵长类动物中具有大于50、60、70、80、90、100、110、120、130、140和145天的半衰期的PCSK9-特异性的拮抗剂(参见,例如,实施例19)。在具体实施方案中,本发明也提供了PCSK9-特异性的拮抗剂,其在pH 5、6、7或8缓冲液中在45℃应激1周(在与在实施例22中所述的条件类似的条件下)以后,基本上不增加寡聚体(更高阶聚集体),并不表现出剪切(参见,例如,实施例22和表11)。在具体实施方案中,在人和非人灵长类动物(或在具体指出的情况下,小鼠)中观察到上述效应。在具体实施方案中,在静脉内的或皮下的给药以后,观察到上述效应。
根据本发明的PCSK9-特异性的拮抗剂可以是特异性地结合人PCSK9蛋白的任意结合分子,其包括、但不限于:下面定义的抗体分子、任意PCSK9-特异性的结合结构、特异性地结合PCSK9的任意多肽或核酸结构以及掺入不同蛋白骨架中的任意前述物质;所述蛋白骨架包括、但不限于:不同的非基于抗体的骨架,和能够提供或允许与PCSK9的选择性结合的不同结构,包括、但不限于小模块免疫药物(或“SMIP”;参见,Haan & Maggos, 2004 Biocentury Jan. 26);免疫蛋白(参见,例如,Chak等人, 1996 Proc.
Natl. Acad. Sci. USA 93:6437-6442);细胞色素b562(参见Ku和Schultz, 1995
Proc. Natl. Acad. Sci. USA 92:6552-6556);肽α2p8(参见Barthe等人, 2000 Protein
Sci. 9:942-955); avimers(Avidia;参见:Silverman等人, 2005 Nat.
Biotechnol. 23:1556-1561); DARPins(Molecular Partners;参见:Binz等人, 2003 J. Mol. Biol. 332:489-503;和Forrer等人, 2003 FEBS
Lett. 539:2-6);四连接素(参见,Kastrup等人,
1998 Acta. Crystallogr. D. Biol. Crystallogr. 54:757-766); Adnectins(Adnexus;参见,Xu等人, 2002 Chem.
Biol. 9:933-942), Anticalins(Pieris;参见:Vogt &
Skerra, 2004 Chemobiochem. 5:191-199; Beste等人,1999 Proc. Natl. Acad. Sci. USA 96:1898-1903; Lamia & Erdmann, 2003 J.
Mol. Biol. 329:381-388;和Lamia & Erdmann,2004 Protein Expr. Purif.33:39-47);A-结构域蛋白(参见North 8c Blacklow, 1999 Biochemistry 38:3926-3935), 脂质运载蛋白(参见Schlehuber & Skerra, 2005 DrugDiscov. Today 10:23-33);重复基序蛋白诸如锚蛋白重复蛋白(参见Sedgwick & Smerdon, 1999 Trends Biochem. Sci. 24:311-316; Mosavi等人, 2002 Proc. Natl. Acad. Sci. USA
99:16029-16034;和Binz等人, 2004 Nat. Biotechnol. 22:575-582);昆虫防卫素A(参见Zhao等人, 2004 Peptides
25:629-635); Kunitz结构域(参见Roberts等人, 1992 Proc. Natl.
Acad. Sci. USA 89:2429-2433; Roberts等人,
1992 Gene 121:9-15; Dennis & Lazarus, 1994 J. Biol. Chem.
269:22129-22136;和Dennis &
Lazarus, 1994 J, Biol. Chem. 269:22137-22144);
PDZ-结构域(参见Schneider等人,
1999 Nat. Biotechnol. 17:170-175);全蝎毒素诸如charybdotoxin(参见Vita等人, 1998
Biopolymers 47:93-100);第10种纤连蛋白III型结构域(或10Fn3;参见:Koide等人, 1998 J.
Mol. Biol. 284:1141-1151,和Xu等人, 2002 Chem. Biol. 9:933-942); CTLA-4(胞外结构域;参见:Nuttall等人, 1999 Proteins 36:217-227;和Irving等人, 2001 J. Immunol. Methods 248:31-45); knottins(参见Souriau等人, 2005 Biochemistry 44:7143-7155和Lehtio等人, 2000 Proteins
41:316-322);新制癌菌素(参见Heyd等人2003 Biochemistry 42:5674-5683);碳水化合物结合模块4-2(CBM4-2;参见:Cicortas等人, 2004 Protein
Eng.Des. Sel 17:213-221);淀粉酶抑肽(参见McConnell &
Hoess, 1995 J. Mol. Biol. 250:460-470,和Li等人, 2003 Protein Eng.16:65-72); T细胞受体(参见Holler等人, 2000 Proc.
Natl. Acad. Sci. USA 97:5387-5392; Shusta等人, 2000 Nat. Biotechnol. 18:754-759;和Li等人, 2005 Nat. Biotechnol. 23:349-354);亲和体(Affibody;参见:Nord等人, 1995 Protein Eng. 8:601-608; Nord等人, 1997 Nat. Biotechnol. 15:772-777; Gunneriusson等人, 1999 Protein Eng. 12:873- 878);和在文献中识别出的其它选择性结合蛋白或骨架;参见,例如,Binz & Plückthun, 2005 Curr. Opin. Biotech. 16:1-11; Gill & Damle,2006 Curr. Opin. Biotechnol. 17:1-6; Hosse等人,
2006 Protein Science 15:14-27; Binz等人,
2005 Nat. Biotechnol. 23:1257-1268; Hey等人, 2005 Trends in Biotechnol.
23:514-522;Binz & Plückthun,2005 Curr. Opin. Biotech. 16:459-469; Nygren & Skerra,2004 J.
Immunolog. Methods 290:3-28; Nygren & Uhlen, 1997 Curr. Opin. Struct. Biol.
7:463-469;它们的公开内容通过引用并入本文。抗体和抗原结合片段的应用在文献中被确定定义和理解。用于蛋白结合的替代骨架的应用,也是科学文献中容易理解的,参见,例如,Binz
& Plückthun, 2005 Curr. Opin.
Biotech. 16:1-11; Gill & Damle,2006 Curr. Opin. Biotechnol. 17:1-6; Hosse等人,
2006 Protein Science 15:14-27;Binz等人,
2005 Nat. Biotechnol. 23:1257-1268; Hey等人,2005 Trends in Biotechnol. 23:514-522; Binz & Plückthun, 2005 Curr. Opin. Biotech. 16:459-469; Nygren & Skerra, 2004 J.
Immunolog. Methods 290:3-28; Nygren & Uhlen,1997 Curr. Opin. Struct. Biol. 7:463-469;它们的公开内容通过引用并入本文。因此,表现出对PCSK9的选择性的、对抗细胞的LDL-摄入的PCSK9-依赖性的抑制的、根据本发明的非基于抗体的骨架或拮抗剂分子形成本发明的重要实施方案。适体(能够选择性地结合靶分子的核酸或肽分子)是一个具体实施例。它们可以选自随机的序列库,或从天然来源(诸如riboswitches)中鉴别出。肽适体、核酸适体(例如,结构化的核酸,包括基于DNA和RNA的结构)和核酸诱饵可以有效地用于选择性地结合和抑制目标蛋白;参见,例如,Hoppe-Seyler
& Butz, 2000 J. Mol. Med. 78:426-430; Bock等人, 1992 Nature 355:564-566; Bunka & Stockley,2006 Nat. Rev. Microbiol. 4:588-596; Martell等人, 2002 Molec. Ther. 6:30-34;
Jayasena, 1999 Clin. Chem. 45:1628-1650;它们的公开内容通过引用并入本文。
鉴于AX1的显著中和活性和它的变体的活性,明显感兴趣的是,鉴别以与AX1或它的变体之一相同的方式结合PCSK9的其它PCSK9-特异性的拮抗剂。鉴别拮抗剂、特别是结合与AX1或它的变体相同的区域或表位(或重叠表位)的抗体的一种方法是,通过竞争或类似的试验,其中候选抗体或结合分子必须针对所述表位胜出(out-compete)AX1(或变体)。在本文中包括的竞争拮抗剂是这样的分子:其在1 μM或更小使AX1(或变体)结合抑制(即与对照相比,阻止或干扰AX1(或变体)结合)或减少了至少50%、60%、70%和80%,这是按照优选度递增的次序(甚至更优选地至少90%,且最优选地至少95%),AX1(或变体)在或低于它的KD,尤其是这样的那些分子:其拮抗(i)PCSK9与LDL受体的结合,(ii)PCSK9内化到细胞中,或(iii)PCSK9与LDL受体的结合和PCSK9内化到细胞中。使用例如ELISA和/或通过监测抗体与PCSK9在溶液中的相互作用,可以在体外容易地测定结合成员之间的竞争。用于进行分析的确切方法不是关键的。可以将PCSK9固定化在96-孔板上,或可以置于同质溶液中。在具体实施方案中,使用放射性标记、酶标记或其它标记,可以测量未标记的候选抗体的阻断标记的AX1(或变体)的结合的能力。在相反的试验中,测定未标记的抗体的干扰标记的AX1(或变体)与PCSK9的相互作用的能力,其中所述AX1(或变体)和PCSK9已经结合。在具体实施方案中,(i)使PCSK9接触标记的AX1(或变体);(ii)使PCSK9接触候选抗体或抗体集合;和(iii)鉴别出能够中断或阻止PCSK9和AX1(或变体)之间的复合物的抗体。在这样的实施例中的读出是通过测量结合的标记。AX1(或变体)和候选抗体可以以任意次序或同时加入。
可以测试在上面的或其它合适的试验中被鉴别为AX1(或变体)竞争剂的抗体的下述能力:拮抗或中和(i)PCSK9与LDL受体的结合;和/或(ii)PCSK9内化到细胞中。通过使用与在本说明书中采用或描述的试验类似的试验,可以测量这些参数。在具体实施方案中,竞争性抗体表现出的抑制是至少约10%抑制。在其它实施方案中,所述抑制是至少20%、30%、40%、50%、60%、70%、80%、90%或95%。
本发明具体地包括PCSK9-特异性的拮抗剂,尤其是单克隆抗体分子(和它们的对应的氨基酸和核酸序列),它们会选择性地结合与AX1(或变体)相同的表位或干扰AX1(或变体)与PCSK9的结合的重叠表位。特异性地结合AX1(或变体)的表位或重叠表位的单克隆抗体会拮抗或中和(i)PCSK9与LDL受体的结合;(ii)PCSK9内化进细胞中,或(iii)二者。根据本发明的单克隆抗体分子可以是完整的(完全的或全部的长度)抗体、基本上完整的抗体或包含抗原结合部分的抗体部分或片段,例如,鼠抗体或嵌合抗体或人源化抗体或人抗体的Fab片段、Fab’片段或F(ab')2片段。本文使用的“单克隆的”表示同质的或基本上同质的(或纯的)抗体群体(即所述群体中的至少约90%、91%、92%、93%、94%、95%、96%、更优选至少约97%或98%、或最优选至少99%的抗体是相同的,且在ELISA试验中会竞争相同的抗原或表位)。在本发明的具体实施方案中,本发明提供了单克隆抗体,其:(i)与AX1(或变体)抗体分子竞争结合PCSK9,在1 μM或更小使AX1(或变体)结合减少了至少50%,AX1(或变体)在或低于它的KD,(ii)阻断PCSK9与LDL受体的结合,(iii)抑制PCSK9内化进细胞中,和(iv)包含特定抗原结合区VH、VL、CDR集合或重链CDR3、重链和/或轻链或本文所述的这些组分的任意变体。
在用于鉴别结合与AX1(或变体)相同的或重叠的表位区域的抗体的任意上述试验中,与候选结合剂相比,已知结合剂(即AX1(或变体)抗体分子)的结合应当是可区分的。这可以(但不一定)通过使用在任一种或两种分子上的标记来实现,这是技术人员会容易地理解的。本文使用的“标记”表示掺入/附着到抗体分子上的另一种分子或试剂。在一个实施方案中,所述标记是可检测的标志物,例如,放射性标记的氨基酸,或连接到生物素基部分上的多肽,所述生物素基部分可以通过标记的抗生物素蛋白(例如,含有荧光标志物的抗生蛋白链菌素,或可以通过光学或比色方法检测到的酶活性)检测到。本领域已知且可以使用不同的标记多肽和糖蛋白的方法。多肽的标记的实例包括、但不限于下述的:放射性同位素或放射性核素(例如,3H、14C、15N、35S、90Y、99Tc、111In、125I、131I)、荧光标记(例如,FITC、罗丹明、镧系元素、磷)、酶标记(例如辣根过氧化物酶、β-半乳糖苷酶、萤光素酶、碱性磷酸酶)、化学发光的标志物、生物素基基团、被第二报告物识别的预定多肽表位(例如,亮氨酸拉链对序列、第二抗体的结合位点、金属结合域、表位标签)、磁性试剂、诸如钆螯合物、毒素诸如百日咳毒素、泰素、细胞松弛素B、短杆菌肽D、溴化乙锭、依米丁、丝裂霉素、依托泊苷、tenoposide、长春新碱、长春碱、秋水仙碱、多柔比星、柔红霉素、二羟基炭疽菌素二酮、米托蒽醌、光辉霉素、放线菌素D、1 -脱氢睾酮、糖皮质激素、普鲁卡因、丁卡因、利多卡因、普萘洛尔和普萘洛尔和它们的类似物或同源物。在有些实施方案中,通过不同长度的间隔臂来连接标记,以减少潜在位阻。
在具体实施方案中,本发明包括本文所述的拮抗剂,其被表征为,特异性地结合选自下述的任意表位序列:SEQ ID NO:
105-108、166和其中的区域(诸如157-NL-158)、SEQ ID NO: 109-111和133-134。在具体实施方案中,本发明包括本文所述的拮抗剂,其被表征为,特异性地结合选自下述的任意表位序列:SEQ ID NO:
112-113、158-ER、366EDI和380-SQS。在具体实施方案中,本发明包括这样的拮抗剂,其特异性地结合一个或多个选自下述的序列:157-NL-158和SEQ ID NO: 109-111。在具体实施方案中,本发明也包括这样的拮抗剂,其被表征为,特异性地结合一个或多个选自下述的表位序列:SEQ
ID NO: 114-116和188-SIQ。这些表位另外描述在实施例10和图3、6、7和8中。所述数字编号提供了在人PCSK9上的起始和/或结束位置。
在具体实施方案中,对于具有在下述残基位置366和426处的一个或多个(例如,1、2、3、4、5或更多个)突变的突变体PCSK9蛋白,与野生型PCSK9蛋白(SEQ ID NO: 167)相比,PCSK9-特异性的拮抗剂的结合显著降低。在某些实施方案中,对于具有一个或多个(例如,1、2、3、4、5或更多个)下述突变E366K和E426M的突变体PCSK9蛋白,PCSK9-特异性的拮抗剂的结合显著降低。
在具体实施方案中,对于具有在下述残基位置201、202、206、207、247和248处的一个或多个(例如,1、2、3、4、5或更多个)突变的突变体PCSK9蛋白,与野生型PCSK9蛋白(SEQ ID NO: 167)相比,PCSK9-特异性的拮抗剂的结合显著降低。
用作竞争试验的标准物的AX1或AX189(或变体)抗体可以是本文所述的任意抗体分子。测试的分子(肽、拮抗剂、抗体分子等)可以来自任意来源或文库。在具体实施方案中,所述分子选自:噬菌体展示文库。在具体实施方案中,使用EGF_AB肽
来选择所述分子,所述EGF_AB肽以与在实施例11中所述类似的方式与AX1或AX189(或变体)竞争。
使用合适的技术,可以表达和选择在本申请中描述的任意PCSK9-特异性的拮抗剂,所述技术包括、但不限于:噬菌体展示(参见,例如,国际申请号WO
92/01047, Kay等人,1996 Phage Display of Peptides and
Proteins: A Laboratory Manual San Diego: Academic Press), Wang等人, 2010 J.
Mol. Biol. 395:1088-4101; Wang等人, 美国专利号7,175,983;酵母展示、细菌展示、T7展示和核糖体展示(参见,例如,Lowe &
Jermutus,2004 Curr. Pharm. Biotech 517-527)。
形成本发明的一部分的具体的PCSK9-特异性的拮抗剂是抗体分子或抗体,本文所述的“抗体分子”或“抗体”表示选择性地结合人PCSK9的免疫球蛋白衍生的结构,包括、但不限于:全长或完整抗体、抗原结合片段(从抗体结构物理地或概念地衍生出的片段)、前述任一种的衍生物、前述任一种与另一种多肽的融合体、或为了选择性地结合/抑制PCSK9的功能的目的而掺入前述任一种的任意替代结构/组合物,例如,抗体分子可以作为完整免疫球蛋白或作为许多确定地表征的片段(通过例如用不同的肽酶消化而产生)存在。识别的免疫球蛋白基因包括κ、λ、α、γ、δ、ε和 μ恒定区基因,以及众多的免疫球蛋白可变区基因。轻链被分类为γ、 μ、α、δ或ε,它们又分别定义了免疫球蛋白类别IgG、IgM、IgA、IgD和IgE。“完整”抗体或“全长”抗体经常表示,包含通过二硫键相连的2个重链(H)和2个轻(L)链的蛋白,所述蛋白包含: (1)在重链方面,可变区(在本文中缩写为“VH”)和重链恒定区,所述重链恒定区包含3个结构域CH1、CH2和CH3;和(2)在轻链方面,轻链可变区(在本文中缩写为“VL”)和轻链恒定区,所述轻链恒定区包含1个结构域CL。胃蛋白酶会在铰链区中在二硫键下面消化抗体,生成F(ab)’2,即Fab的二聚体,所述Fab本身是通过二硫键连接到VH-CH1上的轻链。在破坏铰链区中的二硫键的温和条件下,可以还原F(ab)’2,从而将F(ab)’2二聚体转化成Fab’单体。Fab' 单体基本上是铰链区部分断裂的Fab。尽管以消化完整抗体的方式定义了不同抗体片段,技术人员会明白,可以化学地或通过使用重组DNA方法从新合成这样的Fab’片段。因而,本文使用的术语抗体也包括通过修饰整个抗体而生成的抗体片段,或使用重组DNA方法从新合成的那些。
抗体片段和更具体的抗原结合片段是具有抗体可变区或其节段的分子(其包含重链和/或轻链的公开的CDR3或CDR2结构域中的一个或多个,在适当时,在重链和/或轻链的框架区内),其赋予对PCSK9、尤其是人PCSK9的选择性结合。含有这样的抗体可变区的抗体片段包括、但不限于下述的抗体分子:Fab、F(ab)’2、Fd、Fv、scFv、ccFv、双特异性的抗体分子(包含与第二功能部分相连的本文公开的PCSK9-特异性的抗体或抗原结合片段的抗体分子,所述第二功能部分具有不同于所述抗体的结合特异性,所述抗体包括、但不限于另一种肽或蛋白诸如抗体或受体配体)、双特异性的单链Fv二聚体、分离的CDR3、微抗体(minibody)、“scAb”、dAb片段、diabody、triabody、tetrabody、微抗体(minibody)和基于蛋白骨架的人工抗体,包括、但不限于纤连蛋白III型多肽抗体(参见,例如,美国专利号6,703,199和国际申请号WO 02/32925和WO
00/34784)或细胞色素B;参见,例如,Nygren等人, 1997 Curr. Opinion Struct.
Biol. 7:463-469;它们的公开内容通过引用并入本文。抗体部分或结合片段可以是天然的,或部分地或完全合成地生产。通过本领域技术人员已知的不同方法,可以制备这样的抗体部分,所述方法包括但不限于常规技术,诸如木瓜蛋白酶或胃蛋白酶消化。此外,本领域技术人员会理解,可以化学地或通过使用重组DNA方法从新合成任意上述抗体分子(包括全长以及不同的抗体片段)。因而,本文使用的术语抗体也包括通过完整抗体的制备或修饰而生成的全长抗体和抗体片段,或使用重组DNA方法从新合成的那些。
当提及抗体分子、一般的PCSK9-特异性的拮抗剂、编码核酸或其它分子时,本文使用的术语“分离的”描述了公开的PCSK9-特异性的拮抗剂、核酸或其它分子所具有的一种性质,所述性质使它们不同于在自然界中发现的物质。所述差异可以是,例如,它们具有与在自然界中发现的不同的纯度,或它们具有与在自然界中发现的不同的结构或形成不同结构的一部分。在自然界中未发现的结构包括例如重组人免疫球蛋白结构,包括、但不限于具有优化的CDR的重组人免疫球蛋白结构。在自然界中未发现的结构的其它实例是PCSK9-特异性的拮抗剂或基本上不含有其它细胞物质的核酸。分离的PCSK9-特异性的拮抗剂通常不含有具有不同蛋白特异性(即具有对除了PCSK9以外的蛋白的亲和力)的其它蛋白-特异性的拮抗剂。
在一个具体的方面,本发明提供了拮抗PCSK9功能的分离的PCSK9-特异性的拮抗剂。在具体实施方案中,所述PCSK9-特异性的拮抗剂通过干扰PCSK9与LDL受体的结合和得到的PCSK9细胞内化,抑制人PCSK9的细胞LDL摄入的拮抗作用。因而,公开的PCSK9-特异性的拮抗剂形成用于降低血浆LDL-胆固醇水平的理想分子;参见,例如,Cohen等人,2005
Nat. Genet. 37:161-165(其中在等位基因PCSK9的无义突变杂合的个体中,观察到明显更低的血浆LDL胆固醇水平);Rashid等人, 2005 Proc. Natl. Acad. Sci. USA 102: 5374-5379(其中PCSK9-敲除的小鼠表现出肝细胞中增加的LDLR数目、加速的血浆LDL清除和明显更低的血浆胆固醇水平);和Cohen等人, 2006 N. Engl. J. Med. 354:1264-1272(其中突变的、缺失功能PCSK9杂合的人表现出发展动脉粥样硬化性心脏病的长期风险的显著降低)。
通过重复的实验,在本文中测试的抗体分子剂量依赖性地抑制人PCSK9对LDL摄入的影响。因而,在具体实施方案中,本发明包括本文所述的分离的PCSK9-特异性的拮抗剂以及它们的等效物(被表征为,具有一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换,所述氨基酸置换不会降低公开的AX1或变体抗体分子的PCSK9-选择性的性质)或同源物。特定实施方案包括分离的PCSK9-特异性的拮抗剂,所述拮抗剂包含本文公开的CDR结构域或本文公开的重链和/或轻链CDR结构域的集合或它们的等效物,所述等效物被表征为,具有一个或多个氨基酸置换。
术语“结构域”或“区域”在本文中用于简单地表示抗体分子的各个部分,其中将存在被讨论的序列或节段,或在替代方案中,目前存在。
在具体实施方案中,本发明提供了分离的PCSK9-特异性的拮抗剂,且在更具体的实施方案中,提供了抗体分子,其包含:(i)选自SEQ ID NO: 41、43和45-49的重链可变区,和/或(ii)选自SEQ ID NO: 50、52、53、55-66和67的轻链可变区;它们的等效物,所述等效物被表征为,具有一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换和它们的同源物。公开的拮抗剂应当对抗或抑制细胞LDL摄入的人PCSK9-依赖性的抑制。在具体实施方案中,本发明提供了公开的拮抗剂的同源物,所述同源物被表征为,包含分别与下述区域中的任一个或两者具有至少90% (或在具体实施方案中,至少95%、97%或99%)序列同一性的重链可变区和/或轻链可变区:(i)选自SEQ ID NO: 41、43和45-49的重链可变区,和/或(ii)选自SEQ ID NO: 50、52、53、55-66和67的轻链可变区;所述拮抗剂使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制至少10%。
在具体实施方案中,本发明提供了分离的PCSK9-特异性的拮抗剂,且在更具体的实施方案中,提供了PCSK9抗体分子,其包含:(i)选自下述的可变重链CDR3序列:SEQ ID NO: 15、16、18、20、173,和SEQ ID NO: 15、16和20的残基4-15,和/或(ii)选自下述的可变轻链CDR3序列:SEQ ID NO: 33、34、35、37和39;以及它们的等效物,所述等效物被表征为具有一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换;它们的特定实施方案使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制至少10%。特定实施方案提供了分离的拮抗剂,所述拮抗剂在重链和/或轻链可变区中另外包含本文所述的CDR1和/或CDR2序列;或它们的等效物,所述等效物被表征为,具有在任意一个或多个CDR序列中的一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换。在具体实施方案中,本发明提供了公开的拮抗剂的同源物,所述同源物被表征为,与所述CDR3序列具有至少90% (在具体实施方案中,95%、97%或99%)同一性,或在CDR1、CDR2和CDR3序列中的每一个内;所述拮抗剂使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制了至少10%。
在具体实施方案中,本发明提供了分离的PCSK9-特异性的拮抗剂,且在更具体的实施方案中,提供了PCSK9抗体分子,其包含:(i)选自下述的可变重链CDR2序列:SEQ ID NO: 8、9、11、13、171和SEQ ID NO: 8、9和13的残基4-20,和/或(ii)选自下述的可变轻链CDR2序列:SEQ ID NO: 30-31;以及它们的等效物,所述等效物被表征为具有一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换;它们的特定实施方案使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制了至少10%。特定实施方案提供了分离的拮抗剂,所述拮抗剂另外包含本文所述的重链和/或轻链可变区CDR1和/或CDR3序列;或它们的等效物,所述等效物被表征为,具有在任意一个或多个CDR序列中的一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换。在具体实施方案中,本发明提供了公开的拮抗剂的同源物,所述同源物被表征为,与所述CDR2序列具有至少90% (在具体实施方案中,95%、97%或99%)同一性,或在CDR1、CDR2和CDR3序列中的每一个内;所述拮抗剂使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制了至少10%。
选择的可变重链CDR1区包含选自下述的序列:SEQ ID NO:1、2、4、6、169,和SEQ ID NO: 1、2和6的残基4-13;以及它们的等效物,所述等效物被表征为具有一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换。
选择的可变轻链CDR1区包含选自下述的序列:SEQ ID NO: 22、23、24、26和28;以及它们的等效物,所述等效物被表征为具有一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换。
特定实施方案提供了分离的PCSK9-特异性的拮抗剂,且在更具体的实施方案中,提供了抗体分子,其包含:一个或多个(在具体实施方案中,每个CDR1、2和3区中的一个)本文公开的重链可变区CDR1、CDR2和CDR3序列和轻链可变区CDR1、CDR2和CDR3序列;以及它们的等效物,所述等效物被表征为,在所述CDR序列中的任意一个或多个中具有一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换;它们的特定实施方案使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制了至少10%。在具体实施方案中,本发明提供了公开的拮抗剂的同源物,所述同源物被表征为,与公开的重链和轻链可变区CDR1、CDR2和CDR3序列分别具有至少90% (在具体实施方案中,95%、97%或99%)同一性;所述拮抗剂使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制了至少10%。
本发明的一个具体方面包括分离的PCSK9-特异性的拮抗剂,且在更具体的实施方案中,抗体分子(作为上面公开的抗体分子的变体)使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制了至少10%。
额外的独特的实施方案包括分离的PCSK9-特异性的拮抗剂,其包含: (a)重链可变区,其包含CDR1、CDR2和CDR3序列,其中(i)所述CDR1序列选自:SEQ ID NO: 1、2、4、6和169,和SEQ ID NO: 1、2和6的残基4-13;(ii)所述CDR2序列选自:SEQ ID NO: 8、9、11、13、171,和SEQ ID NO: 8、9和13的残基4-20;和(iii)所述CDR3序列选自:SEQ ID NO: 15、16、18、20、173,和SEQ ID NO: 1、2和6的残基4-15,和/或(b)轻链可变区,其包含CDR1、CDR2和CDR3序列,其中(i)所述CDR1序列选自:SEQ ID NO: 22、23、24、26和28;(ii)所述CDR2序列选自:SEQ ID NO: 30-31;和(iii)所述CDR3序列选自:SEQ ID NO: 33、34、35、37和39;以及它们的等效物,所述等效物被表征为具有一个或多个(在具体实施方案中,1-5个或1-3个)氨基酸置换;它们的特定实施方案使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制了至少10%。
在本文中的具体实施方案中,所述CDR替代AX132(或公开的变体)或具有或没有氨基酸置换(在具体实施方案中,1-5个或1-3个)的替代拮抗剂、抗体分子或骨架结构的对应区域;它们的特定实施方案使细胞LDL摄入的人PCSK9-依赖性的抑制被抑制了至少10%。
特定实施方案是分离的PCSK9-特异性的拮抗剂,其包含在全长抗体中的上述的VH和VL区。本文中的特定实施方案另外包含一系列选自下述的氨基酸:SEQ
ID NO: 117(IgG1)、SEQ
ID NO: 118(IgG2)、SEQ
ID NO: 119(IgG4)和SEQ
ID NO: 120(IgG2m4)。
在本文中包括的氨基酸置换可以是保守的或非保守的氨基酸置换。本领域普通技术人员会理解,氨基酸置换是这样的置换:即用提供类似的或更好的(对于预期的目的而言)功能和/或化学特征的氨基酸残基替换氨基酸残基。使用本领域可得到的或本文所述的功能试验,可以测试携带氨基酸置换的拮抗剂的保留的或更好的活性。具有一个或多个氨基酸置换的PCSK9-特异性的拮抗剂(其保留在与本文所述的AX132(或变体)抗体分子相同或更好的水平选择性地结合人PCSK9和拮抗PCSK9功能的能力)在本文中称作公开的拮抗剂的“功能等效物”,并形成本发明的特定实施方案。保守的氨基酸置换经常是这样的置换:其中氨基酸残基被具有类似侧链的氨基酸残基替换。在本领域中已经定义了具有类似侧链的氨基酸残基家族。这些家族包括:具有碱性侧链的氨基酸(例如,赖氨酸、精氨酸、组氨酸),具有酸性侧链的氨基酸(例如,天冬氨酸、谷氨酸),具有不带电荷的极性侧链的氨基酸(例如,甘氨酸、天冬酰胺、谷氨酰胺、丝氨酸、苏氨酸、酪氨酸、半胱氨酸、色氨酸),具有非极性侧链的氨基酸(例如,丙氨酸、缬氨酸、亮氨酸、异亮氨酸、脯氨酸、苯丙氨酸、甲硫氨酸),具有β-分支的侧链的氨基酸(例如,苏氨酸、缬氨酸、异亮氨酸)和具有芳族侧链的氨基酸(例如,酪氨酸、苯丙氨酸、色氨酸、组氨酸)。如上所述的修饰可以设计成或不设计成显著改变PCSK9-特异性的拮抗剂的结合或功能抑制特征,且可以提高这样的性质。产生置换的目的不是重要的,且可以包括、但是绝不限于:用能够更好地维持或增强分子的结构、分子的电荷或疏水性或分子的大小的残基替换残基。例如,可能希望简单地用具有相同极性或电荷的残基置换更不希望的残基。通过本领域已知的标准技术,诸如定位诱变和PCR-介导的诱变,可以导入这样的修饰。本领域技术人员实现保守的氨基酸置换的一种具体方式是,丙氨酸扫描诱变,其讨论在例如,MacLennan等人, 1998 Acta Physiol. Scand. Suppl. 643:55-67和Sasaki等人,1998 Adv.
Biophys. 35:1-24中。
在本发明的一个具体的实施方案中,本文公开的CDR被改变,从而产生更稳定的变体或在更高水平重组地表达的变体。例如,如果Asn-Gly或Asp-Gly存在于CDR中,则本发明包括这样的变体,其中所述Asp或Asn被改变成Glu或Ala,或其中所述Gly被改变成Ala。这样的改变的一个益处是,去除了形成异天冬氨酸酯的可能。另外,如果Met存在于CDR中的暴露位置处,则本发明的范围包括这样的变体,其中Met被改变成Lys、Leu、Ala或Phe。这样的改变的一个益处是,去除了甲硫氨酸氧化的可能。如果Asn存在于本发明的CDR中,则本发明的范围包括这样的变体,其中其中Asn被改变成Gln或Ala。这样的改变的一个益处是,去除了去酰胺化的可能。此外,如果Asn-Pro存在于本发明的CDR中,本发明包括这样的变体,其中Asn被改变成Gln或Ala,或其中Pro被改变成Ala。这样的改变的一个益处是,去除了可能裂开的Asn-Pro肽键。本发明的范围包括这样的实施方案,其中任意公开的抗体分子的重链或轻链CDR在上述的一个或多个位置处被独立地改变。
在另一个方面,本发明提供了分离的PCSK9-特异性的拮抗剂,且在更具体的实施方案中,提供了包含重链和/或轻链可变区的抗体分子,所述可变区包含与公开的抗体的对应氨基酸序列同源的氨基酸序列,其中所述抗体分子抑制细胞LDL摄入的PCSK9依赖性的抑制。特定实施方案是这样的拮抗剂,其包含与公开的重链和/或轻链可变区(或重链和/或轻链)分别具有至少90%同一性的重链和/或轻链可变区。提及的“至少90%同一性”包括:沿着本文公开的分子的全长,至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%和100%同一的序列。
通常生产其氨基酸序列与本文所述的拮抗剂的氨基酸序列同源的PCSK9-特异性的拮抗剂,以提高所述拮抗剂的一种或多种性质,而不不利地影响它对PCSK9的特异性。得到这样的序列的一种方法(其不是技术人员可得到的唯一方法)是,突变编码PCSK9-特异性的拮抗剂或其特异性决定区的序列,表达包含所述突变序列的拮抗剂,并使用可得到的功能试验(包括本文所述的那些)测试编码的拮抗剂的保留的功能。突变可以是通过定位诱变或随机诱变。但是,本领域技术人员会理解,其它诱变方法可以容易地实现相同的效果。例如,在某些方法中,通过非随机地靶向氨基酸置换(基于氨基酸化学或结构特征),或通过蛋白结构考虑,限制突变体的范围。在亲和力成熟实验中,可以在单个选定的分子中发现几个这样的突变,无论它们是随机地还是非随机地选择的。也存在不同的基于结构的亲和力成熟方案,如在例如美国专利号7,117,096、PCT公开号WO 02/084277和WO 03/099999(它们的公开内容通过引用并入本文)中所证实的。
如本文使用的,2个氨基酸或核酸序列之间的同源性百分比等于所述2个序列之间的同一性百分比,这2个术语在本文中可互换地使用。使用Karlin和Altschul的算法(Proc. Natl.
Acad. Sci. USA 90:5873-5877,1993),测定本文使用的2个核酸或氨基酸序列的同一性百分比。这样的算法被集成在Altschul等人, 1990 J. Mol. Biol. 215:403-410的NBLAST和XBLAST程序中。用NBLAST程序进行BLAST核苷酸检索,评分=100,字长=12,以得到与本发明的核酸分子同源的核酸序列。用XBLAST程序进行BLAST蛋白检索,评分=50,字长=3,以得到与本文公开的氨基酸序列同源的氨基酸序列。为了得到用于对比目的的有缺口的比对,使用如在Altschul等人,1997 Nucleic Acids Res. 25:3389-3402中所述的有缺口的BLAST。当使用BLAST和有缺口的BLAST程序时,使用各个程序(例如, XBLAST和NBLAST)的默认参数。
一种或多种公开的PCSK9-特异性的分子的组分用于生产具有类似的或更好的特异性的其它结合分子的应用,是本领域技术人员的范围内。例如,这可以使用重组DNA技术等技术来实现。这方面的一个具体实例包括,将编码抗体的免疫球蛋白可变区或一个或多个CDR的DNA导入不同免疫球蛋白的适当的可变区、恒定区或恒定区+框架区中。这样的分子形成本发明的重要方面。在替代方案中,具体免疫球蛋白或对应的序列(其中可以插入特定公开的序列)形成下述抗体分子(包括、但不限于此)的基本部分,所述抗体分子形成本发明的特定实施方案:Fab(具有可变轻链(VL)、可变重链(VH)、恒定轻链(CL)和恒定重链1(CH1)结构域的单价片段),F(ab)’2(包含通过铰链区中的二硫键或替代键相连的2个Fab片段的二价片段),Fd(VH和CH1结构域),Fv(VL和VH结构域),scFv(单链Fv,其中VL和VH被接头(例如,肽接头)连接到一起,参见,例如,Bird等人,
1988 Science 242:423-426,Huston等人, 1988 PNAS USA 85:5879-5883),双特异性的抗体分子(包含与第二功能部分相连的本文公开的PCSK9-特异性的抗体或抗原结合片段的抗体分子,所述第二功能部分具有不同于所述抗体的结合特异性,所述抗体包括、但不限于另一种肽或蛋白诸如抗体或受体配体),双特异性的单链Fv二聚体(参见,例如,PCT/US92/09965),分离的CDR3,微抗体(minibody)(单链-CH3融合体,其自身装配成约80 kDa的二价二聚体),”scAb”(含有VH和VL以及CL或CH1的抗体片段),dAb片段(VH结构域, 参见,例如,Ward等人,1989 Nature 341:544-546,和McCafferty等人, 1990 Nature 348:552-554;或VL结构域; Holt等人, 2003 Trends in
Biotechnology 21:484-489),diabody(参见,例如,Holliger等人, 1993 PNAS USA
90:6444-6448和国际申请号WO 94/13804),triabody,tetrabody,微抗体(minibody)(与CH3相连的scFv;参见,例如,Hu等人, 1996 Cancer Res. 56:3055-3061),IgG,IgG1,IgG2,IgG3,IgG4,IgM,IgD,IgA,IgE或它们的任意衍生物,和基于蛋白骨架的人工抗体,包括、但不限于纤连蛋白III型多肽抗体(参见,例如,美国专利号6,703,199和国际申请号WO
02/32925)或细胞色素B;参见,例如,Koide等人, 1998 J. Molec. Biol.
284:1141-1151,和Nygren等人, 1997 Current Opinion in Structural Biology
7:463-469;它们的公开内容通过引用并入本文。通过将二硫键掺入VH和VL结构域中,可以稳定某些抗体分子,包括、但不限于:Fv、scFv、diabody分子或结构域抗体(Domantis),参见,例如,Reiter等人, 1996 Nature Biotech. 14:1239-1245;其公开内容通过引用并入本文。使用常规技术(参见,例如,Holliger & Winter, 1993 Current
Opinion Biotechnol. 4:446-449,其具体方法包括化学生产或从杂种杂交瘤生产)和其它技术,包括、但不限于BiTE™技术(具有通过肽接头相连的不同特异性的抗原结合区的分子)和把手进入孔中工程(knobs-into-holes
engineering)(参见,例如,Ridgeway等人,
1996 Protein Eng. 9:616-621;其公开内容通过引用并入本文),可以生产双特异性的抗体。本领域技术人员会明白,可以在大肠杆菌中生产双特异性的diabody,并可以使用在适当的文库中的噬菌体展示,选择这些分子作为其它的PCSK9-特异性的拮抗剂(参见,例如,国际申请号WO 94/13804;其公开内容通过引用并入本文)。
从任意种系或重排的人可变结构域,可以得到在其中可以插入目标CDR的可变结构域。也可以合成地生产可变结构域。使用重组DNA技术,可以将CDR区导入各个可变结构域中。用于实现该目的的一种方法描述在,Marks等人, 1992 Bio/Technology 10:779-783;其公开内容通过引用并入本文。可以使可变重链结构域与可变轻链结构域配对,以提供抗原结合位点。另外,可以使用独立的区域(例如,单独的可变重链结构域)来结合抗原。技术人员还知晓,使用重组方法,通过合成接头,可以连接Fv片段的2个结构域VL和VH(尽管可能由分开的基因编码),所述合成接头使它们能够制成单个蛋白链,其中VL和VH区配对以形成单价分子(scFv)。
特定实施方案提供了在种系框架区中的CDR。框架区(包括、但不限于人框架区)是本领域技术人员已知的(例如,人或非人框架)。框架区可以是天然存在的或共有的框架区。在一个方面,本发明的抗体的框架区是人(关于人框架区的列表,参见,例如,Clothia等人, 1998 J. Mol. Biol. 278:457-479;所述公开内容通过引用整体并入本文)。本文中的特定实施方案提供了公开的重链和/或轻链可变CDR3序列,它们分别在VH3或VK3中,替代有关的CDR。本文中的特定实施方案提供了公开的重链和/或轻链可变CDR1、CDR2和/或CDR3序列,它们分别在VH3或VK3中,替代有关的CDR。
本发明包括人的、人源化的、去免疫化的、嵌合的和灵长类动物化的抗体分子。本发明也包括通过镶盖方法生产的抗体分子;参见,例如,Mark等人,1994 Handbook of Experimental Pharmacology, vol. 113: The
pharmacology of monoclonal Antibodies, Springer-Verlag,第105-134页;其公开内容通过引用并入本文。在提及公开的抗体分子时,“人”具体地表示具有源自人种系免疫球蛋白序列的可变区和/或恒定区的抗体分子,其中所述序列可以、但不一定被修饰/改变成具有不是由人种系免疫球蛋白序列编码的某些氨基酸置换或残基。通过特定方法,可以导入这样的突变,所述方法包括、但不限于:随机的或位点特异性的体外诱变,或通过体内体细胞突变。在文献中讨论的突变技术的具体实例是在下述文献中公开的那些:Gram等人,1992 PNAS USA 89:3576-3580; Barbas等人, 1994 PNAS USA 91:3809-3813,和Schier等人, 1996 J. Mol.
Biol. 263:551-567;它们的公开内容通过引用并入本文。这些仅仅是具体实例,并不代表唯一可得到的技术。在科学文献中存在众多突变技术,它们可被技术人员得到,且被广泛地理解。在提及公开的抗体分子时,“人源化的”具体地表示这样的抗体分子,其中源自另一个哺乳动物物种(诸如小鼠)的CDR序列被移植到人框架序列上,在提及公开的抗体分子时,“灵长类动物化的”具体地表示这样的抗体分子,其中非灵长类动物的CDR序列被插入灵长类动物框架序列中, 参见,例如,WO 93/02108和WO 99/55369;它们的公开内容通过引用并入本文。
本发明的具体抗体是单克隆抗体,且在具体实施方案中,是下述抗体形式之一:IgD、IgA、IgE、IgM、IgG1、IgG2、IgG3、IgG4或前述任一种的任意衍生物。在这方面,措辞“其衍生物”或“衍生物”包括:除了别的以外,(i)具有在一个或两个可变区(即,VH和/或VL)中的氨基酸修饰的抗体和抗体分子,(ii)具有在重链和/或轻链的恒定区中的操纵的抗体和抗体分子,和/或(iii)含有额外化学部分的抗体和抗体分子,所述额外化学部分通常不是免疫球蛋白分子的一部分(例如,聚乙二醇化)。
可变区的操纵可以是在VH和/或VL CDR区中的一个或多个内。用于产生序列或分子多样性的定位诱变、随机诱变或其它方法,可以用于建立突变体,所述突变体随后可以在可得到的体外或体内试验(包括本文所述的那些)中测试感兴趣的特定功能性质。
本发明的抗体也包括这样的抗体:其中已经对在VH和/或VL内的框架残基做出修饰,以提高目标抗体的一种或多种性质。通常,做出这样的框架修饰,以降低抗体的免疫原性。例如,一个方案是,“回复突变”一个或多个框架残基为对应的种系序列。更具体地,已经经历体细胞突变的抗体可以含有这样的框架残基:所述框架残基不同于所述抗体的来源种系序列。通过将抗体框架序列与所述抗体的来源种系序列相对比,可以鉴别出这样的残基。本发明也意图包括这样的“回复突变的”抗体。另一类框架修饰包括:突变在框架区内、或甚至在一个或多个CDR区内的一个或多个残基,以去除T细胞表位,从而降低所述抗体的潜在免疫原性。该方案也称作“去免疫化”,且更详细地描述在Carr等人的美国专利公布号20030153043中;其公开内容通过引用并入本文。
除了在框架区或CDR区内做出的修饰以外,或作为所述修饰的替代方案,可以工程化本发明的抗体,以包括在Fc或恒定区内的修饰,在存在的情况下,通常会改变所述抗体的一种或多种功能性质,诸如血清半衰期、补体结合、Fc受体结合和/或抗原依赖性的细胞的细胞毒性。
已经普遍地描述了制备“杂合体”或“组合的”IgG形式(其包含不同的抗体同种型,以实现希望的效应子功能性)的概念;参见,例如,Tao等人, 1991 J. Exp. Med. 173:1025-1028。本发明的一个具体实施方案包括这样的抗体分子:所述抗体分子具有在Fc区中的特殊操纵,已经发现所述操纵会导致减少的或改变的与在抗体的一部分上的FcγR受体、C1q或FcRn的结合。因此,本发明包括根据本说明书的抗体,其不会引起(或在更低的程度上引起)抗体-依赖性的细胞的细胞毒性(“ADCC”)、补体-介导的细胞毒性(“CMC”)或形成免疫复合物,同时保留正常的药代动力学(“PK”)性质。本发明的特定实施方案提供了根据本发明定义的抗体分子,其包含SEQ
ID NO: 120作为它的免疫球蛋白结构的一部分,且在具体实施方案中,其包含SEQ ID NO: 120的残基107-326作为免疫球蛋白结构的一部分。本发明包括这样的抗体分子,其包含: (i)选自SEQ ID NO: 50、52、53、55-66和67的轻链可变区,和(ii)选自SEQ ID NO: 41、43和45-49的重链可变区,所述可变区连接(邻近)或继之以一系列选自下述的氨基酸:SEQ ID NO: 117(IgG1)、SEQ ID NO: 118(IgG2)、SEQ ID NO: 119(IgG4)和SEQ ID NO: 120(IgG2m4)。在具体实施方案中,上述(i)和(ii)的轻链和重链配对是:(a)SEQ ID NO: 50(或52)和41;或(b)SEQ ID NO: 53(或67)和43。
具体的PCSK9-特异性的拮抗剂可以携带可检测标记,或可以与毒素(例如、细胞毒素)、放射性的同位素、放射性核素、脂质体、靶向部分、生物传感器、阳离子型尾巴或酶(例如、通过肽基键或接头)缀合。这样的PCSK9-特异性的拮抗剂组合物形成本发明的一个额外方面。
在另一个方面,本发明提供了编码公开的PCSK9-特异性的拮抗剂的分离的核酸。如以前提及的,“分离的”表示提及的物质所具有的一种性质,所述性质使它们不同于在自然界中发现的物质。所述差异可以是,例如,它们具有与在自然界中发现的不同的纯度,或它们具有与在自然界中发现的不同的结构或形成不同结构的一部分。在自然界中未发现的核酸的一个实例是,例如,基本上不含有其它细胞物质的核酸。所述核酸可以存在于完整细胞中、在细胞裂解物中,或是部分地纯化的或基本上纯的形式。在特定情况下,当从其它细胞组分或其它污染物(例如,其它细胞核酸或蛋白)中纯化出来时,可以分离核酸,例如,使用标准技术,包括、但不限于碱性/SDS处理、CsCl分带、柱色谱法、琼脂糖凝胶电泳和本领域已知的其它合适的方法。所述核酸可以包括DNA(包括cDNA)和/或RNA。使用标准的分子生物学技术,可以得到本发明的核酸。对于由杂交瘤表达的抗体(例如,从携带人免疫球蛋白基因的转基因小鼠制备的杂交瘤),通过标准的PCR扩增或cDNA克隆技术,可以得到cDNA,其编码由杂交瘤制备的抗体的轻链和重链。对于从免疫球蛋白基因文库得到的抗体(例如,使用噬菌体展示技术),可以从所述文库回收编码所述抗体的核酸。
本发明包括分离的核酸,其编码公开的可变重链和/或轻链及其选择的组分,特别是公开的可变区或各个CDR区。在本文的具体实施方案中,提供了在抗体框架区内的CDR,且在具体实施方案中,提供了在人框架区内的CDR。特定实施方案提供了分离的核酸,其编码在种系框架区(包括、但不限于人种系框架区)中的CDR。本文中的特定实施方案提供了分离的核酸,其编码选自下述的重链CDR3序列:SEQ ID NO: 15、16、18、20、173,和SEQ ID NO: 15、16和20的残基4-15(在具体实施方案中,它们的核酸包含选自SEQ
ID NO: 17、19、21和174的序列)。本文中的特定实施方案提供了分离的核酸,其编码选自下述的重链CDR2序列:SEQ ID NO: 8、9、11、13、171,和SEQ ID NO: 8、9和13的残基4-20(在具体实施方案中,它们的核酸包含选自SEQ
ID NO: 10、12、14和172的序列)。本文中的特定实施方案提供了分离的核酸,其编码选自下述的重链CDR1序列:SEQ ID NO: 1、2、4、6、169,和SEQ ID NO: 1、2和6的残基4-13(在具体实施方案中,其所述核酸包含选自SEQ
ID NO: 3、5、7和170的序列)。本文中的特定实施方案提供了核酸,其编码公开的重链可变CDR1、CDR2和/或CDR3序列,它们在VH3中,替代有关的CDR。本文中的特定实施方案提供了分离的核酸,其编码选自下述的轻链CDR3序列:SEQ ID NO: 33、34、35、37和39(在具体实施方案中,其所述核酸包含选自SEQ
ID NO: 36、38和40的序列)。本文中的特定实施方案提供了分离的核酸,其编码选自下述的轻链CDR2序列:SEQ ID NO: 30和31(在具体实施方案中,其所述核酸包含SEQ ID NO: 32)。本文中的特定实施方案提供了分离的核酸,其编码选自下述的轻链CDR1序列:SEQ ID NO: 22、23、24、26和28(在具体实施方案中,其所述核酸包含选自SEQ
ID NO: 25、27和29的序列)。本文中的特定实施方案提供了核酸,其编码公开的轻链可变CDR1、CDR2和/或CDR3序列,它们在VK3中,替代有关的CDR。特定实施方案提供了重链和轻链CDR(1、2和3)或它们中的一个或多个的一些组合。
编码可变区的分离的核酸可以提供在任意希望的抗体分子形式内,所述抗体分子形式包括、但不限于下述的:F(ab’)2、Fab、Fv、scFv、双特异性的抗体分子(包含与第二功能部分相连的本文公开的PCSK9-特异性的抗体或抗原结合片段的抗体分子,所述第二功能部分具有不同于所述抗体的结合特异性,包括、但不限于另一种肽或蛋白诸如抗体或受体配体)、双特异性的单链Fv二聚体、微抗体(minibody)、dAb片段、diabody、triabody、tetrabody、微抗体(minibody)、IgG、IgG1、IgG2、IgG3、IgG4、IgM、IgD、IgA、IgE或它们的任意衍生物。
特定实施方案提供了分离的核酸,其编码PCSK9-特异性的拮抗剂,且在更具体的实施方案中,其编码抗体分子,所述抗体分子包含:(i)选自下述的重链可变结构域:SEQ ID NO: 41、43和45-49;它们的特定实施方案包含核酸序列SEQ
ID NO: 42或SEQ ID NO: 44;和/或(ii)选自下述的轻链可变结构域:SEQ ID NO: 50、52、53、55-66和67;它们的特定实施方案包含选自SEQ ID NO: 51、54、68的核酸序列。在具体实施方案中,本发明另外提供了上面公开的拮抗剂的同源物,所述同源物被表征为,在重链和/或轻链可变区中具有至少90% (在具体实施方案中,95%、97%或99%)同一性。
额外的实施方案提供了分离的核酸,其编码PCSK9-特异性的拮抗剂,且在更具体的实施方案中,其编码抗体分子,所述抗体分子包含:(i)选自下述的轻链:SEQ ID NO: 73、75、77、85、87和89(它们的特定实施方案包含选自SEQ ID NO: 74、76、78、86、88和90的核酸);和/或(ii)选自下述的重链或Fd链:SEQ ID NO: 69、71、79、81、83,SEQ ID NO: 69的氨基酸1-227,和SEQ ID NO: 71的氨基酸1-229(它们的特定实施方案包含选自下述的核酸:SEQ ID NO: 70、72、80、82、84,和SEQ ID NO: 70和72的核苷酸1-663。在具体实施方案中,本发明另外提供了上面公开的拮抗剂的同源物,所述同源物被表征为,在重链和/或轻链中具有至少90%同一性。
本发明的特定实施方案包括核酸,所述核酸编码具有在Fc区中的操纵的抗体分子,所述操纵会导致减少的或改变的与在抗体的一部分上的FcγR受体、C1q或FcRn的结合。本发明的一个具体实施方案是分离的核酸,所述核酸编码这样的抗体分子:其包含SEQ
ID NO: 120作为它们的免疫球蛋白结构的一部分,且在具体实施方案中,其包含SEQ ID NO: 120的残基107-326作为它们的免疫球蛋白结构的一部分。在具体实施方案中,通过从核酸表达,可以生产合成的PCSK9-特异性的拮抗剂,所述核酸从合成并装配在合适的表达载体中的寡核苷酸制成;参见,例如,Knappick等人, 2000 J. Mol. Biol. 296:57-86和Krebs等人, 2001 J.
Immunol. Methods 254:67-84。
本发明包括编码抗体分子的核酸,所述核酸包含:(i)公开的编码轻链可变区和恒定区的核酸,和(ii)公开的编码重链可变区的核酸,其继之以(邻近)编码选自下述的氨基酸集合的核苷酸集合:SEQ ID NO: 117(IgG1)、SEQ ID NO: 118(IgG2)、SEQ ID NO: 119(IgG4)和SEQ ID NO: 120(IgG2m4)。包含重链和轻链AX1抗-PCSK9抗体分子序列的质粒序列可以作为SEQ ID NO: 91发现。包含重链和轻链AX9抗-PCSK9抗体分子序列的质粒序列可以作为SEQ ID NO: 92发现。包含重链和轻链AX189抗-PCSK9抗体分子序列的质粒序列可以作为SEQ ID NO: 93发现。编码这样的抗体分子的核酸形成本发明的重要实施方案。通过用改变的区域置换在公开的质粒序列中存在的区域,可以得到额外的质粒序列。
本发明也包括分离的核酸,其包含与本文所述的核苷酸序列的全长具有至少约90%同一性、更优选至少约95%同一性的核苷酸序列,且所述核苷酸序列编码PCSK9-特异性的拮抗剂,所述拮抗剂使细胞LDL摄入的PCSK9-依赖性的抑制被抑制至少10%。
在本申请中提及的“至少约90%同一性”包括至少约90、91、92、93、94、95、96、97、98、99或100%同一性。
本发明另外提供了分离的核酸,所述核酸的至少一部分在严谨杂交条件下与编码本文公开的可变重链、可变轻链、重链区和轻链区中的任一种的核酸的互补物杂交,所述核酸赋予抗体分子特异性地结合PCSK9和拮抗PCSK9功能的能力,和采用所述核酸表达的PCSK9-特异性的拮抗剂。杂交核酸的方法是本领域众所周知的;参见,例如,Ausubel, Current Protocols in
Molecular Biology, John Wiley & Sons, N.Y,6.3.1-6.3.6,
1989。严谨杂交条件包括:在5x SSC/5x Denhardt氏溶液(或等效溶液)/1.0% SDS中在68℃杂交,并在0.2x SSC/0.1% SDS中在室温洗涤。适度严谨的条件包括:在3x
SSC中在42℃洗涤。可以改变盐浓度和温度的参数,以实现探针和靶核酸之间的同一性的最佳水平。技术人员可以操纵不同的杂交和/或洗涤条件,以在杂交部分中特异性地靶向核酸,所述部分与本文公开的可变重链、可变轻链、重链区和/或轻链区具有至少80、85、90、95、98或99%同一性。影响杂交条件的选择的基础参数,和关于设计合适的条件的指导,可以参见:Sambrook等人, Molecular Cloning: A Laboratory Manual, Cold Spring
Harbor Laboratory Press,Cold Spring
Harbor,N.Y. 第9和11章, 1989,和Ausubel等人(编)、Current
Protocols in Molecular Biology, John Wiley & Sons,Inc., 第2.10和6.3-6.4部分,1995(它们的公开内容通过引用并入本文),且可以由本领域的普通技术人员容易地确定。PCSK9拮抗剂(具有一个或多个包含核酸的区域,所述核酸在严谨杂交条件下与公开的重链、轻链、可变重链区或可变轻链区杂交)可以有效地拮抗PCSK9的一种或多种功能。所述拮抗剂和编码核酸因而形成本发明的重要实施方案。
在另一个方面,本发明提供了载体,其包含本文公开的核酸。根据本发明的载体包括、但不限于:质粒和适合在适当水平(对于预期目的而言)表达所需的抗体分子的其它表达构建体(例如,适当的噬菌体或噬粒);参见,例如,Sambrook
& Russell, Molecular Cloning: A Laboratory Manual: 第3版, Cold Spring
Harbor Laboratory Press;其公开内容通过引用并入本文。对于大多数克隆目的,可以使用DNA载体。典型的载体包括质粒、修饰的病毒、噬菌体、粘粒、酵母人工染色体、细菌人工染色体和其它形式的附加型或整合型DNA。为特定基因转移、重组PCSK9-特异性的拮抗剂的制备或其它用途确定适当的载体,属于技术人员的技能范围内。在具体实施方案中,除了重组基因以外,所述载体也可以含有在宿主细胞中的自主复制所用的复制起点、适当的调节序列诸如启动子、终止序列、聚腺苷酸化序列、增强子序列、选择标记、有限数目的有用的限制性酶位点和/或适当的其它序列和高拷贝数的潜力。用于生产蛋白-特异性的拮抗剂的表达载体的实例是本领域众所周知的;参见,例如,Persic等人, 1997 Gene 187:9-18; Boel等人,
2000 J. Immunol. Methods 239:153-166,和Liang等人, 2001 J. Immunol. Methods 247:119-130;它们的公开内容通过引用并入本文。如果需要的话,使用本领域众所周知的技术,可以将编码拮抗剂的核酸整合进宿主染色体中;参见,例如,Ausubel,
Current Protocols in Molecular Biology, John Wiley & Sons, 1999和Marks等人,国际申请号WO 95/17516。也可以在附加型地维持的或整合进人工染色体中的质粒上表达核酸;参见,例如,Csonka等人, 2000 J. Cell Science 113:3207-3216; Vanderbyl等人, 2002 Molecular Therapy 5:10。具体地,关于抗体分子,可以将抗体轻链基因和抗体重链基因插入单独的载体中,或者更通常地,可以将2个基因插入相同的表达载体中。使用标准方法(例如,在核酸片段和载体上的互补限制位点的连接,或者如果不存在限制位点,则平端连接),可以将编码任意PCSK9-特异性的拮抗剂或其组分的核酸插入表达载体中。实现该目的的方法的另一个具体实例是,通过使用重组方法,例如,Clontech“InFusion”系统或Invitrogen“TOPO”系统(都是体外地),或细胞内地(例如,Cre-Lox系统)。具体地,关于抗体分子,可以使用轻链和重链可变区建立任意抗体同种型的全长抗体基因,其中将它们插入已经编码所需同种型的重链恒定区和轻链恒定区的表达载体中,使得VH节段可操作地连接到在载体内的CH节段上,VL节段可操作地连接到在载体内的CL节段上。额外地或替换地,包含编码PCSK9-特异性的拮抗剂的核酸的重组表达载体可以编码信号肽,所述信号肽促进所述拮抗剂从宿主细胞的分泌。可以将核酸克隆进载体中,使得编码信号肽的核酸在框架内邻近地连接到编码PCSK9-特异性的拮抗剂的核酸上。所述信号肽可以是免疫球蛋白或非免疫球蛋白信号肽。技术人员可得到的任意技术,可以用于将核酸导入宿主细胞中;参见,例如,Morrison,
1985 Science, 229:1202。将目标核酸分子亚克隆进表达载体中的方法,转化或转染含有所述载体的宿主细胞的方法,和制备基本上纯的蛋白的方法(其包括下述步骤:将各个表达载体导入宿主细胞中,并在适当条件下培养宿主细胞),是众所周知的。以常规方式,可以从宿主细胞收获如此生产的PCSK9-特异性的拮抗剂。适用于将核酸导入目标细胞中的技术取决于使用的细胞的类型。一般的技术包括、但不限于:磷酸钙转染、DEAE-葡聚糖、电穿孔、脂质体-介导的转染和使用适合目标细胞系的病毒(例如,反转录病毒、疫苗、杆状病毒或噬菌体)的转导。
在另一个方面,本发明提供了分离的细胞,其包含编码公开的PCSK9-特异性的拮抗剂的核酸。在本文中预见到多种不同的细胞系,且可以用于PCSK9-特异性的拮抗剂的重组生产,所述细胞系包括、但不限于来自原核生物体(例如,大肠杆菌、芽孢杆菌属和链霉菌属)和来自真核生物体(例如,酵母、杆状病毒和哺乳动物)的那些;参见,例如,Breitling等人, Recombinant antibodies, John Wiley & Sons,Inc.和Spektrum
Akademischer Verlag, 1999;其公开内容通过引用并入本文。也预见到包含本文公开的核酸或拮抗剂的植物细胞(包括转基因植物)和动物细胞(包括转基因动物,除了人以外),作为本发明的一部分。合适的哺乳动物细胞或细胞系形成本发明的额外的实施方案,所述细胞或细胞系包括、但不限于:源自中国仓鼠卵巢的那些(CHO细胞,包括、但不限于DHFR-CHO细胞(描述在Urlaub和Chasin,1980 Proc. Natl.
Acad. Sci.USA 77:4216-4220),其与例如DHFR选择标记一起使用(例如,描述在Kaufman和Sharp,
1982 Mol. Biol. 159:601-621)、NS0骨髓瘤细胞(其中可以使用在WO 87/04462、WO
89/01036和EP 338,841中所述的GS表达系统)、COS细胞、SP2细胞、HeLa细胞、幼仓鼠肾细胞、YB2/0大鼠骨髓瘤细胞、人胚胎肾细胞、人胚胎视网膜细胞和其它细胞,它们包含本文公开的核酸或拮抗剂;前述引用的公开内容通过引用并入本文。包含编码公开的PCSK9-特异性的拮抗剂的核酸的本发明的特定实施方案包括、但不限于:大肠杆菌;参见,例如,Plückthun,1991
Bio/Technology 9:545-551;或酵母,诸如毕赤酵母及其重组衍生物(参见,例如,Li等人, 2006 Nat. Biotechnol. 24:210-215);前述公开内容通过引用并入本文。本发明的特定实施方案涉及真核细胞,其包含编码公开的PCSK9-特异性的拮抗剂的核酸,参见,Chadd & Chamow, 2001 Current Opinion in
Biotechnology 12:188-194,Andersen &
Krummen, 2002 Current Opinion in Biotechnology 13:117,Larrick & Thomas,2001
Current Opinion in Biotechnology 12:411-418;它们的公开内容通过引用并入本文。本发明的特定实施方案涉及哺乳动物细胞,其包含编码公开的PCSK9-特异性的拮抗剂的核酸,所述细胞能够生产具有适当翻译后修饰的PCSK9-特异性的拮抗剂。翻译后修饰包括、但是绝不限于:二硫键形成和糖基化。另一类翻译后修饰是信号肽切割。本文中的优选实施方案具有适当的糖基化;参见,例如,Yoo等人,2002 J. Immunol. Methods
261:1 -20;其公开内容通过引用并入本文。天然存在的抗体含有至少一个与重链相连的N-连接的碳水化合物。出处同上。不同类型的哺乳动物宿主细胞可以用于提供有效的翻译后修饰。这样的宿主细胞的实例包括:中国仓鼠卵巢(CHO)、HeLa、C6、PC 12和骨髓瘤细胞;参见,Yoo等人, 2002 J. Immunol. Methods
261:1-15和Persic等人,
1997 Gene 187:9-18;它们的公开内容通过引用并入本文。
在另一个方面,本发明提供了分离的细胞,其包含本发明的多肽。
在另一个方面,本发明提供了一种制备本发明的PCSK9-特异性的拮抗剂的方法,所述方法包括:在允许表达PCSK9-特异性的拮抗剂或表达所述重链和/或轻链或片段并装配成PCSK9-特异性的拮抗剂的条件下,温育细胞,所述细胞包含编码PCSK9-特异性的拮抗剂或具有对人PCSK9的特异性的所需PCSK9-特异性的拮抗剂(由所需的拮抗剂决定)的重链和/或轻链或其片段(例如,VH和/或VL或一个或多个公开的重链和/或轻链可变区CDR)的核酸,并从所述细胞中分离出所述PCSK9-特异性的拮抗剂。用于制备特定希望的重链和/或轻链序列或片段的一个实例是,首先使用PCR,扩增(并修饰)所述种系重链和/或轻链可变序列或片段。技术人员可容易地得到人重链和/或轻链可变区的种系序列,参见,例如,“Vbase”人种系序列数据库,和Kabat,
E. A. 等人, 1991 Sequences of Proteins of
Immunological Interest第5版, 美国卫生和人类服务部, NIH公开号91-3242; Tomlinson, I.M. 等人,
1992“The Repertoire of Human Germline VH
Sequences Reveals about Fifty Groups of VH Segments with Different
Hypervariable Loops”J. Mol.
Biol. 227:776-798;和Cox, J.P.L.等人, 1994“A Directory of
Human Germ-line Vk Segments Reveals a Strong Bias in their Usage”,Eur. J. Immunol. 24:827-836;它们的公开内容通过引用并入本文。使用标准方法,例如PCR介导的诱变(其中将突变掺入PCR引物中)或定位诱变,可以诱变种系序列。如果需要全长抗体,可以得到人重链恒定区基因的序列;参见,例如,Kabat. E.A. 等人, 1991 Sequences of Proteins of Immunological Interest第5版, 美国卫生和人类服务部,NIH公开号91-3242。可以得到含有这些区域的片段,例如,通过标准的PCR扩增。或者,技术人员可以自己利用已经编码重链和/或轻链恒定区的载体。
可以以许多方式实现Fab表达和纯化。一种常见的方式是,进行整个IgG1的木瓜蛋白酶消化,以释放出2当量的Fab和1当量的Fc区。但是,对于噬菌体展示的文库(其也需要在大肠杆菌中表达),通常通过与蛋白以及与六组氨酸标签(His-标签)的共价键来展示Fab。在一种典型方式中,在IPTG诱导以后,进行Fab的细胞内表达。随后,裂解完整细胞,并使用镍亲和柱纯化所需的Fab。根据具体的情况,这可以在分析型SE-HPLC中产生高背景,据推测是来自错误折叠的、部分地折叠的、二硫化物扰乱的或蛋白酶水解的含有His-标签的Fab,因为His-标签不会区分这些和正确折叠的Fab,因而,在具体实施方案中,如下进行Fab的表达:在表达载体中使用来自噬菌体的周质运输信号,诸如pIII和pVIII外壳蛋白前导序列,以将Fab多肽定位在周质空间的氧化环境中。在那里,分子伴侣样酶可以促进正确的Fab折叠,并因而允许形成正确的二硫键。最初的过夜生长期可以设定在30℃。随后,通过使用更低浓度的IPTG(1 mM、0.5 mM或0.1 mM)来诱导lac操纵子和Fab基因的起始翻译,可以诱导细菌培养物进行Fab生产。可以将温度降低至22-23℃。低IPTG和低温度会减慢大肠杆菌蛋白合成,从而避免过载周质折叠机制。然后,通过低速离心(约4000g),可以收获细胞,并进行周质提取,周质提取是一个温和的渗透性释放过程,其目的主要是通过温和的渗透冲击,使外部的细菌细胞壁渗漏,以允许Fab离开周质进入周围介质中。在提取以后,然后可以在高速(>15000g)离心细胞,保存含有释放的可溶性Fab的上清液,用于亲和色谱法。
在上述的具体实施方案中,可以如下进行亲和色谱法:在中性pH(通常,使用在约7.0
-7.4的PBS或HBS),使用蛋白G树脂的亲和纯化选择性地结合折叠的Fab恒定区。可以在酸性pH(通常使用甘氨酸-HCl,pH 2.7 -4.0)下释放结合的Fab,并洗脱进含有在pH 9的1M Tris碱的试管中,以使Fab向酸性pH的暴露最小化。或者,因为来自周质提取的提取物与整个细胞裂解物相比是相对干净的,可以使用镍亲和柱来纯化具有His-标签的Fab。在两种情况下,对洗脱的Fab进行缓冲液交换(例如,通过透析或离心过滤,使用30 KD分子量截止过滤器)到贮存缓冲液(通常是PBS或任意优选的配制缓冲液中)。使用分析型尺寸排阻(SE)HPLC,可以分析样品,通常显示由>95%的目标产物组成的单个峰。如果需要的话,使用正交方法,诸如阳离子(CEX)或阴离子交换(AEX)或疏水相互作用(HIC)色谱法,可以进行额外的精制。
因此,在具体实施方案中,用于表达公开的PCSK9-特异性的拮抗剂的表达载体包含:噬菌体外壳蛋白pIII或pVIII前导序列,或用于将表达的拮抗剂输出到细菌周质中的其它输出前导序列。在具体实施方案中,这用于表达Fab。在具体实施方案中,本发明包括用于生产PCSK9-特异性的拮抗剂的方法,所述方法包括:(a)将本文所述的载体插入细胞中(在具体实施方案中,所述载体编码Fab);其中所述载体包含噬菌体外壳蛋白PIII或pVIII前导序列;(b)在适合生产PCSK9-特异性的拮抗剂的条件下,培养所述细胞;和(c)通过周质提取分离出生产的PCSK9-特异性的拮抗剂,其中使用温和裂解条件主要破碎外层细胞壁,以释放出周质内容物,并使细胞内的内容物的污染最小化。在具体实施方案中,这可以另外包括,通过下述技术纯化PCSK9-特异性的拮抗剂:(i)恒定结构域对蛋白G的亲和力,以纯化正确折叠的PCSK9-特异性的拮抗剂(诸如Fab);(ii)His-标签对镍亲和柱的亲和力;或(iii)其它合适的纯化技术。这之后,然后可以使用SDS-PAGE、分析型SE-HPLC或质谱法,分析缓冲液交换的Fab或分离的PCSK9-特异性的拮抗剂,以对终产物进行质量控制。
存在可用于重组生产其它抗体分子的技术,所述抗体分子保留所有原始抗体的特异性。这方面的一个具体实例是这样的,其中将编码免疫球蛋白可变区或CDR的DNA导入另一种抗体分子的恒定区、或恒定区和框架区、或仅框架区中;参见,例如,EP-184,187、GB 2188638和EP-239400;它们的公开内容通过引用并入本文。在文献中描述了抗体分子(包括嵌合抗体)的克隆和表达;参见,例如,EP 0120694和EP 0125023;它们的公开内容通过引用并入本文。
在一个实例中,可以生产根据本发明的抗体分子,然后使用已知的技术,筛选在本文中鉴别出的特征。在文献中描述了用于制备单克隆抗体的基本技术,参见,例如,Kohler和Milstein(1975, Nature
256:495-497);其公开内容通过引用并入本文。通过可得到的方法,可以生产全人单克隆抗体。这些方法包括,但是绝不限于,使用遗传工程化的小鼠品系,其具有这样的免疫系统:已经灭活小鼠抗体基因,并已经用有功能的人抗体基因的所有组成部分替换,同时保留小鼠免疫系统的其它组分不变。这样的遗传工程化的小鼠允许天然的体内免疫应答和亲和力成熟过程,该过程产生高亲和力的全人单克隆抗体。该技术是本领域众所周知的,且充分地详述在不同的公开中,包括、但不限于美国专利号5,545,806、5,569,825、5,625,126、5,633,425、5,789,650、5,877,397、5,661,016、5,814,318、5,874,299、5,770,249(指定给GenPharm
International,且可以通过Medarex得到,在“UltraMab
Human Antibody Development System”部分下);以及美国专利号5,939,598、6,075,181、6,114,598、6,150,584和有关的家族成员(指定给Abgenix,公开了它们的XenoMouse®技术);它们的公开内容通过引用并入本文。也参见下述综述:Kellerman和Green, 2002 Curr. Opinion in Biotechnology 13:593-597和Kontermann & Stefan,2001Antibody
Engineering, Springer Laboratory Manuals;它们的公开内容通过引用并入本文。
或者,可以使具有潜在的PCSK9-特异性的拮抗剂的文库或抗体分子的任意文库接触PCSK9,且能够证实选择的特异性结合。然后可以进行功能研究,以确保适当的功能性,例如,细胞LDL摄入的PCSK9-依赖性的抑制的抑制。存在技术人员可用于从文库中选择蛋白-特异性的分子的不同技术,其中使用富集技术,包括、但不限于:噬菌体展示(例如,参见,在美国专利号7,175,983和7,117,096、WO03/099999和Wang等人, 2010 J. Mol.
Biol. 395:1088-1101中公开的来自Abmaxis的技术,以及在美国专利号5,565,332、5,733,743、5,871,907、5,872,215、5,885,793、5,962,255、6,140,471、6,225,447、6,291,650、6,492,160、6,521,404、6,544,731、6,555,313、6,582,915、6,593,081和依赖于1992年5月24日提交的优先权申请GB 9206318的其它美国家族成员和/或申请中公开的坎布里奇抗体技术(Cambridge Antibody Technology,‘‘CAT”);也参见Vaughn等人, 1996,Nature
Biotechnology 14:309-314),核糖体展示(参见,例如,Hanes和Pluckthün,1997 Proc.
Natl. Acad. Sci. 94:4937-4942),细菌展示(参见,例如,Georgiou,等人, 1997 Nature Biotechnology 15:29-34)和/或酵母展示(参见,例如,Kieke, 等人, 1997 Protein Engineering 10:1303-1310, 和Wang等人, 2010 J. Immunol.
Methods 354:11-19);前述公开内容通过引用并入本文。例如,可以在噬菌体颗粒表面上展示文库,在它的表面上表达和展示编码PCSK9-特异性的拮抗剂或其片段的核酸。然后可以从表现出所需活性水平的噬菌体颗粒分离出核酸,并将所述核酸用于开发所需的拮抗剂。已经在文献中充分地描述了噬菌体展示;参见,例如,Wang等人, 2010 J. Mol. Biol. 395:1088-1101, Kontermann
& Stefan,出处同上,和国际申请号WO 92/01047;它们的公开内容通过引用并入本文。具体地,关于抗体分子,也可以使用根据本发明的单个重链或轻链克隆来筛选互补的重链或轻链,所述互补的重链或轻链分别能够与它们相互作用,形成组合的重链和轻链的分子;参见,例如,国际申请号WO
92/01047。技术人员可利用的任意淘选方法,可以用于鉴别PCSK9-特异性的拮抗剂。用于实现该目的的另一种具体方法是,针对在溶液中的靶抗原(例如生物素化的可溶性的PCSK9)进行淘选,然后将PCSK9-特异性的拮抗剂-噬菌体复合物捕获在抗生蛋白链菌素包被的磁珠上,然后洗涤它们,以去除非特异性地结合的噬菌体。然后可以以与本文所述的从平板表面回收它们相同的方式,从珠子回收捕获的噬菌体。
通过本领域技术人员可得到的技术,可以纯化PCSK9-特异性的拮抗剂。通过不同的血清学或免疫学试验,可以测定有关的拮抗剂制品、腹水、杂交瘤培养液或有关的样品的滴度,所述试验包括、但不限于:沉淀, 被动凝集, 酶联免疫吸附抗体(“ELISA”)技术和放射免疫测定(“RIA”)技术。
本发明部分地涉及采用本文所述的PCSK9-特异性的拮抗剂来拮抗PCSK9功能的方法,所述方法在下面进一步描述。在本申请中使用的术语“拮抗”表示反抗、抑制、对抗、中和或减小PCSK9的一种或多种功能的行为。根据本领域已知的方法(参见,例如,Barak & Webb, 1981 J. Cell
Biol. 90:595-604; Stephan & Yurachek, 1993 J. Lipid Res. 34:325330;和McNamara等人, 2006 Clinica
Chimica Acta 369:158-167)以及本文描述的那些方法,可以容易地测定一种或多种PCSK9-相关的功能性质的抑制或拮抗作用。与在没有拮抗剂存在下观察到的活性相比,或与例如当存在无关特异性的对照拮抗剂时观察到的活性相比,抑制或拮抗作用会实现PCSK9活性的降低。优选地,根据本发明的PCSK9-特异性的拮抗剂会拮抗PCSK9功能至下述程度:测量的参数降低了至少10%,所述参数包括、但不限于本文公开的活性,和更优选地,测量的参数降低了至少20%、30%、40%、50%、60%、70%、80%、90%和95%。在PCSK9功能至少部分地促进不利地影响受试者的特定表型、疾病、障碍或病症的那些情况下,这样的PCSK9功能的抑制/拮抗作用是特别有效的。
在一个方面,本发明提供了一种用于拮抗PCSK9活性的方法,所述方法包括:在允许所述拮抗剂结合PCSK9(当存在时)并抑制细胞LDL摄入的PCSK9抑制的条件下,使能够受PCSK9影响的细胞、细胞群体或组织样品(即,其表达和/或包含LDL受体)接触本文公开的PCSK9-特异性的拮抗剂。本发明的特定实施方案包括这样的方法,其中所述细胞是人细胞。
在另一个方面,本发明提供了一种用于拮抗受试者中的PCSK9活性的方法,所述方法包括:给所述受试者施用治疗有效量的本发明的PCSK9-特异性的拮抗剂。在具体实施方案中,所述拮抗PCSK9功能的方法是用于治疗PCSK9有关的疾病、障碍或病症,或者,会从PCSK9拮抗剂的作用受益的疾病、障碍或病症。所述药物可用于这样的受试者:所述受试者表现出与PCSK9活性有关的病症,或其中PCSK9的功能是特定受试者的禁忌的病症。在选择的实施方案中,所述病症可以是高胆固醇血症、冠心病、代谢综合征、急性冠状动脉综合征或有关病症。
因而,本发明预见到本文所述的PCSK9-特异性的拮抗剂在希望拮抗PCSK9功能的不同治疗方法中的应用。所述治疗方法在性质上可以是预防性的或治疗性的。在具体实施方案中,本发明涉及一种治疗方法,所述方法用于与PCSK9活性有关或归因于PCSK9活性的病症,或其中PCSK9的功能是特定受试者的禁忌的病症,所述方法包括:给所述受试者施用治疗有效量的本发明的PCSK9-特异性的拮抗剂。在选择的实施方案中,所述病症可以是高胆固醇血症、冠心病、代谢综合征、急性冠状动脉综合征或有关病症。
根据本发明的治疗方法包括:给个体施用治疗上(或预防上)有效量的本发明的PCSK9特异性的拮抗剂。在提及量时使用的术语“治疗上有效的”或“预防上有效的”表示,在预期的剂量在需要的时间段内实现所需的治疗/预防效果所需的量。所需的效果可以是,例如,与治疗的病症有关的至少一种症状的改善。技术人员会理解,这些量将随不同因素而变化,所述因素包括、但不限于个体的疾病状态、年龄、性别和体重,以及PCSK9-特异性的拮抗剂的在个体中引起所需的效果的能力。通过体外试验、体内非人动物研究,可以记录所述应答,和/或从临床试验进一步支持。
本发明提供了用于治疗或预防胆固醇或脂质体内稳态障碍以及与它们有关的障碍和并发症(例如,高胆固醇血症、高脂血症、高甘油三酯血症、谷固醇血症、动脉粥样硬化、动脉硬化、冠心病、代谢综合征、急性冠状动脉综合征、血管炎症、黄色瘤和有关病症)的方法。
本发明也提供了用于提高与心脏病高危有关的血液胆固醇标志物的方法。这些标志物包括、但不限于:高总胆固醇、高LDL、高总胆固醇与HDL之比和高LDL与HDL之比。
一般而言,小于200 mg/dL的总胆固醇被认为是希望的,200-239 mg/dL被认为是高边界,240 mg/dL和以上被认为是高的。例如,本发明包括通过施用治疗有效量的本发明的PCSK9-特异性的拮抗剂来降低总胆固醇的方法,例如降低至小于或等于约200 mg/dL。
一般而言,小于100 mg/dL的血液LDL水平被认为是最佳的;100-129 mg/dL被认为是接近最佳的/超过最佳的,130-159 mg/dL被认为是高边界,160-189
mg/dL被认为是高的,190 mg/dL和以上被认为是非常高的。例如,本发明包括通过施用治疗有效量的本发明的PCSK9-特异性的拮抗剂来降低LDL例如至小于约100 mg/dL的方法。
一般而言,认为正常的HDL水平是至少35-40 mg/dL。例如,本发明包括通过施用治疗有效量的本发明的抗-PCSK9抗体或其抗原结合片段来增加HDL(例如,增加至大于或等于约35-40 mg/dL)的方法。
心脏病风险的另一个指标是总胆固醇与HDL之比。一般而言,非常低的心脏病风险与<3.4(男性)或<3.3(女性)的比率有关;低风险与4.0(男性)或3.8(女性)的比率有关,平均风险与5.0(男性)或4.5(女性)的比率有关,中等风险与9.5(男性)或7.0(女性)的比率有关,高风险与>23(男性)或>11(女性)的比率有关。例如,本发明包括通过施用治疗有效量的本发明的PCSK9-特异性的拮抗剂来降低总胆固醇与HDL之比(例如,降低至小于约4.5或5.0)的方法。
心脏病风险的另一个指标是LDL与HDL之比。一般而言,非常低的风险与1(男性)或1.5(女性)的比率有关,平均风险与3.6(男性)或3.2(女性)的比率有关,中等风险与6.3(男性)或5.0(女性)的比率有关,高风险与8(男性)或6.1(女性)的比率有关。例如,本发明包括通过施用治疗有效量的本发明的PCSK9-特异性的拮抗剂来降低LDL与HDL之比(例如,降低至小于或等于约3.2或3.6)的方法。
所述PCSK9-特异性的拮抗剂可以作为药物组合物来施用。因而,本发明提供了一种药学上可接受的组合物,其包含本发明的PCSK9-特异性的拮抗剂和药学上可接受的载体,所述载体包括、但不限于赋形剂、稀释剂、稳定剂、缓冲剂,或者所述组合物被设计成促进拮抗剂以所需的形式和量施用给治疗的个体。
通过本领域已知的任意数目的策略,可以配制药物组合物,所述策略参见,例如,McGoff和Scher,2000 Solution
Formulation of Proteins/Peptides:见:McNally,E.J.编. Protein Formulation and Delivery. New York, NY: Marcel
Dekker;第139-158页;
Akers & Defilippis, 2000,Peptides and
Proteins as Parenteral Solutions, 见:Pharmaceutical Formulation Development of Peptides and
Proteins. Philadelphia, 宾夕法尼亚州;
Taylor和Francis;第145-177页; Akers等人, 2002,Pharm. Biotechnol. 14:47-127。适合患者给药的药学上可接受的组合物将含有在制剂中的有效量的PCSK9-特异性的拮抗剂,在可接受的温度范围内贮存期间,所述制剂保留生物活性,同时也促进最大稳定性。
在具体实施方案中,基于拮抗剂的药学上可接受的组合物可以是液体或固体形式,或气体颗粒或气雾化的颗粒的形式。可以使用用于生产液体或固体制剂的任意技术。这样的技术属于技术人员的能力范围内。通过任意可得到的方法,可以生产固体制剂,所述方法包括、但不限于低压冻干法、喷雾干燥法或通过超临界流体技术的干燥。用于口服给药的固体制剂可以是使得拮抗剂可以以规定量和在规定的时间段内被患者接近的任意形式。口服制剂可以采取许多固体制剂的形式,所述固体制剂包括、但不限于、片剂、胶囊剂或散剂。或者,可以低压冻干固体制剂,并在施用之前放入溶液中,用于根据技术人员众所周知的方法进行单次或多次给药。通常在生物学上有关的pH范围内配制拮抗剂组合物,且可以缓冲,以在贮存期间维持适当的pH范围。液体和固体制剂通常需要贮存在更低的温度(例如,2-8℃),以便在更长的时段内保持稳定性。配制的拮抗剂组合物,特别是液体制剂,可以含有抑菌剂,以防止在贮存期间的蛋白酶解或使其最小化,所述抑菌剂包括、但不限于有效浓度(例如,≤1%
w/v)的苯甲醇、苯酚、间甲酚、三氯叔丁醇、对羟基苯甲酸甲酯和/或对羟基苯甲酸丙酯。对于某些患者而言,可能禁用抑菌剂。因此,可以将低压冻干的制剂重构在含有或不含有这样的组分的溶液中。可以将额外的组分加入缓冲的液体或固体拮抗剂制剂中,所述组分包括、但不限于:用作冷冻保护剂的糖类(包括、但不限于多羟基烃类诸如山梨醇、甘露醇、甘油和卫矛醇,和/或二糖类诸如蔗糖、乳糖、麦芽糖或海藻糖)和,在某些情况下,有关的盐(包括、但不限于NaCl、KCl或LiCl)。这样的预定长期贮存的拮抗剂制剂、特别是液体制剂,将依赖于有用范围的总渗透性,以促进在例如2-8℃或更高的温度的长期稳定性,同时也使得所述制剂可用于肠胃外的注射。在适当时,可以包括防腐剂、稳定剂、缓冲剂、抗氧化剂和/或其它添加剂。所述制剂可以含有二价阳离子(包括、但不限于MgCl2、CaCl2和MnCl2);和/或非离子型表面活性剂(包括、但不限于聚山梨酯-80(吐温80™)、聚山梨酯-60(吐温60™)、聚山梨酯-40(吐温40™)和聚山梨酯-20(吐温20™),聚氧乙烯烷基醚,包括、但不限于Brij
58™、Brij35™,以及其它试剂,诸如Triton
X-100™、Triton X-114™、NP40™、Span 85和Pluronic系列的非离子型表面活性剂(例如,Pluronic
121))。这样的组分的任意组合,形成本发明的特定实施方案。
液体形式的药物组合物可以包括液体载体,例如,水、石油、动物油、植物油、矿物油或合成的油。所述液体形式还可以包括生理盐水溶液、葡萄糖或其它糖溶液,或二醇类诸如乙二醇、丙二醇或聚乙二醇。
优选地,所述药物组合物可以是肠胃外地可接受的水溶液形式,所述水溶液是无热原的,具有适当的pH、张度和稳定性。可以配制药物组合物,用于在等渗媒介物(例如、氯化钠注射液、林格氏注射液或乳酸盐化的林格氏注射液)中稀释以后施用。
本发明的一个方面是药物组合物,其包含: (i)约50至约200 mg/mL的本文所述的PCSK9-特异性的拮抗剂;(ii)多羟基烃(包括、但不限于山梨醇、甘露醇、甘油和卫矛醇)和/或二糖(包括、但不限于蔗糖、乳糖、麦芽糖和海藻糖);所述多羟基烃和/或二糖的总量是所述制剂的约1%至约6%(每体积的重量,“w/v”);(iii)约5 mM至约200 mM的组氨酸、咪唑、磷酸盐或醋酸,其用作缓冲剂(以防止pH在药物组合物的贮存期限内漂移)和张度调节剂;(iv)约5 mM至约200 mM的精氨酸、脯氨酸、苯丙氨酸、丙氨酸、甘氨酸、赖氨酸、谷氨酸、天冬氨酸或甲硫氨酸,用于对抗聚集;(v)约0.01M至约0.1M的盐酸(“HCl”),其量足以实现在约5.5至约7.5范围内的pH;和(vi)液体载体,包括、但不限于:无菌水、石油、动物油、植物油、矿物油、合成的油、生理盐水溶液、葡萄糖或其它糖溶液或二醇类,诸如乙二醇、丙二醇或聚乙二醇;其中所述药物组合物具有在约5.5至约7.5范围内的pH;且其中所述药物组合物任选地包含:占制剂的约0.01%至约1%
w/v的非离子型表面活性剂(包括、但不限于聚山梨酯-80(吐温80™)、聚山梨酯-60(吐温60™)、聚山梨酯-40(吐温40™)和聚山梨酯-20(吐温20™),聚氧乙烯烷基醚,包括、但不限于Brij
58™、Brij35™,以及其它试剂,诸如Triton
X-100™、Triton X-114™、NP40™、Span 85和Pluronic系列的非离子型表面活性剂(例如,Pluronic
121))。
HCl可以作为游离酸、组氨酸-HCl或精氨酸-HCl加入。在作为组氨酸-HCl或精氨酸-HCl供给的情况下,在HCl形式中的组氨酸或精氨酸的总量应当是上面指出的量。因此,根据组氨酸和/或精氨酸的量,在适当时,一些或所有HCl可以作为组氨酸-HCl和/或精氨酸-HCl来供给。关于在说明书中公开的量所使用的术语“约”是指,在提供的指定数值的10%以内。例如在“约50至约200”中提供的范围特别地包括在所述范围内的每个数值作为不同的实施方案。象这样,在上述的实例中,实施方案(包括、但不限于具有50、100、125、150和200的那些)形成本文的特定实施方案。不管给药模式,本文公开的药物组合物具有普遍适用性。在具体实施方案中,公开的药物组合物可用于皮下给药,其作为液体或在低压冻干形式重构以后。在公开的制剂中可以采用的蛋白包括:被表征为包含共价地连接的氨基酸残基的任意聚合的蛋白或多肽,其为了实现治疗益处的目的而递送。在本发明的组合物中使用的蛋白包括、但不限于:本文定义的任意抗体分子或任意非-抗体或非-免疫球蛋白的蛋白、肽、聚乙二醇化的蛋白和融合蛋白。
本发明的具体方面涉及上面公开的药物组合物,其包含: (i)约50至约200 mg/mL的本文所述的PCSK9-特异性的拮抗剂;(ii)约1%至约6% (在具体实施方案中,约2%至约6%)w/v的甘露醇、海藻糖或蔗糖;(iii)约10 mM至约100 mM的组氨酸;(iv)约25 mM至约100 mM的精氨酸或脯氨酸;(v)约0.02 M至约0.05M的盐酸(“HCl”),其量足以实现在约5.8至约7范围内的pH;和(vi)液体载体,包括、但不限于:无菌水、石油、动物油、植物油、矿物油、合成的油、生理盐水溶液、葡萄糖或其它糖溶液或二醇类,诸如乙二醇、丙二醇或聚乙二醇;其中所述药物组合物具有在约5.8至约7范围内的pH;且其中所述药物组合物任选地包含:占制剂的约0.01%至约1%
w/v的非离子型表面活性剂(包括、但不限于聚山梨酯-80(吐温80™)、聚山梨酯-60(吐温60™)、聚山梨酯-40(吐温40™)和聚山梨酯-20(吐温20™),聚氧乙烯烷基醚,包括、但不限于Brij
58™、Brij35™,以及其它试剂,诸如Triton
X-100™、Triton X-114™、NP40™、Span 85和Pluronic系列的非离子型表面活性剂(例如,Pluronic
121))。
特定实施方案提供了药物组合物,其包含: (i)50-200 mg/mL的本文所述的PCSK9-特异性的拮抗剂;(ii)约1%至约6% (在具体实施方案中,约2%至约6%)w/v的甘露醇、海藻糖或蔗糖;(iii)约10 mM至约150 mM的组氨酸;(iv)约10 mM至约150 mM的精氨酸或脯氨酸;(v)约0.03 M至约0.05 M的盐酸(“HCl”),其量足以实现在约5.8至约6.5范围内的pH;和(vi)液体载体,包括、但不限于:无菌水、石油、动物油、植物油、矿物油、合成的油、生理盐水溶液、葡萄糖或其它糖溶液或二醇类,诸如乙二醇、丙二醇或聚乙二醇;其中所述药物组合物具有在约5.8至约6.5范围内的pH;且其中所述药物组合物任选地包含:约0.01%至约1%
w/v的聚山梨酯-80(吐温80™)或聚山梨酯-20(吐温20™)。
本文中的特定实施方案提供了药物组合物,其包含: (i)50-200 mg/mL的本文所述的PCSK9-特异性的拮抗剂;(ii)约1%至约6% (在具体实施方案中,约2%至约6%)w/v的蔗糖;(iii)约25 mM至约100 mM的组氨酸;(iv)约25 mM至约100 mM的精氨酸;(v)约0.040 M至约0.045 M的盐酸(“HCl”),其量足以实现约6的pH;和(vi)无菌水;其中所述药物组合物具有约6的pH;且其中所述药物组合物任选地包含约0.01%至约1% w/v的聚山梨酯-80(吐温80™)或聚山梨酯-20(吐温20™)。在其具体实施方案中,组氨酸和精氨酸的水平是各自在25 mM内,且在其它实施方案中,是相同的。
本文中的特定实施方案提供了药物组合物,其包含:(i)50-200
mg/mL的本文所述的PCSK9-特异性的拮抗剂;(ii)下述量之一的蔗糖、组氨酸和精氨酸:(a)约1% w/v蔗糖、约10 mM组氨酸和约25 mM精氨酸;(b)约2% w/v蔗糖、约25 mM组氨酸和约25 mM精氨酸;(c)约3% w/v蔗糖、约50 mM组氨酸和约50 mM精氨酸;或(d)约6% w/v蔗糖、约100 mM组氨酸和约100 mM精氨酸;(iii)约0.04 mol或约1.46 g HCl;和(iv)无菌水;其中所述药物组合物具有约6的pH;且其中所述药物组合物任选地包含约0.01%至约1% w/v的聚山梨酯-80(吐温80™)或聚山梨酯-20(吐温20™)。本文中的特定实施方案是这样的,其中在上面(ii)中的蔗糖、组氨酸和精氨酸的量是在(c)或(d)中所述的量。经发现,采用上述药物制剂(其中蔗糖、组氨酸和精氨酸的量是在(ii)(c)中指出的量)的特定实施方案,会提供与300
mOsm的生理值类似的渗透压,并以液体和低压冻干形式提供稳定性。
本文中的特定实施方案提供了本文所述的药物组合物,其包含50-200 mg/ml的本文所述的不同的PCSK9-特异性的拮抗剂中的任一种。为了例证其一个独特实施方案的目的,且不应解释为限制,一个实施方案是如下的上文所述的药物制剂,其包含PCSK9-特异性的拮抗剂,所述拮抗剂包含:(a)含有SEQ
ID NO: 85的轻链;和(b)含有SEQ
ID NO: 79的重链;其中所述PCSK9-特异性的拮抗剂是拮抗细胞LDL摄入的PCSK9抑制的抗体分子。另一个实施方案是这样的上文所述的药物制剂,其包含PCSK9-特异性的拮抗剂,所述拮抗剂包含:(a)含有SEQ
ID NO: 87的轻链;和(b)含有SEQ
ID NO: 81的重链;其中所述PCSK9-特异性的拮抗剂是拮抗细胞LDL摄入的PCSK9抑制的抗体分子。另一个实施方案是这样的上文所述的药物制剂,其包含PCSK9-特异性的拮抗剂,所述拮抗剂包含:(a)含有SEQ ID
NO: 89的轻链;和(b)含有SEQ
ID NO: 83的重链;其中所述PCSK9-特异性的拮抗剂是拮抗细胞LDL摄入的PCSK9抑制的抗体分子。
本文的特定实施方案是根据上述描述的药物组合物,其被低压冻干和重构。在具体实施方案中,所述低压冻干的和重构的溶液中的蛋白浓度最高是低压冻干前的组合物的2倍。在具体实施方案中,在低压冻干的和/或重构的药物组合物中的蛋白或PCSK9-特异性的拮抗剂浓度是在约50
mg/mL至约300 mg/mL范围内。可应用于重构低压冻干的药物组合物的稀释剂包括、但不限于:无菌水,抑菌的注射用水(“BWFI”)、磷酸盐缓冲盐水、无菌的盐水溶液、生理盐水溶液、林格氏溶液或葡萄糖溶液,且在具体实施方案中,可以含有0.01-1%
(w/v)的聚山梨酯-80(吐温80™)或聚山梨酯-20(吐温20™),在具体实施方案中,可以用1/60.2X原始体积(或0.167 mL)直到1X(1mL)重构低压冻干的粉末。
本发明的示例性的实施方案是本文所述的药物组合物,所述药物组合物是稳定的。本发明的其它实施方案是本文所述的药物组合物,所述药物组合物通过低压冻干和重构来稳定化。技术人员可使用不同的方法来制备低压冻干的组合物;参见,例如,Martin
& Mo, 2007“Stability Considerations for Lyophilized
Biologies”Amer. Pharm. Rev.。本文使用的“稳定的”表示,在4-37℃范围内的温度,在至少约30天内,蛋白或PCSK9-特异性的拮抗剂的保持它的物理或化学稳定性、构象完整性的性质,或它的表现出与对照样品相比更少的变性、蛋白剪切、聚集、片段化、酸性变体形成或生物活性损失的能力。其它实施方案在上述温度保持稳定多达3个月、6个月、12个月、2年或更长的时间段。在具体实施方案中,所述制剂在2-8℃不表现出显著变化至少6个月,优选12个月、2年或更长,按照优选次序。在25-45℃(或者2-8℃)范围内的温度,具体实施方案经历与对照样品相比小于10% 或在具体实施方案中小于5%的变性、蛋白剪切、聚集、片段化、酸性变体形成或生物活性损失,持续至少约30天、3个月、6个月、12个月、2年或更长。通过技术人员已知的几种方法,可以测试制剂的稳定性,所述方法包括、但不限于:用于测量聚集和片段化的尺寸排阻色谱法(SEC-HPLC),用于测量浓缩样品的粒度的动态光散射(DLS),用于测量片段化的毛细管SDS-PAGE,和用于测量酸性变体形成的毛细管等电聚焦(cIEF)或阳离子交换色谱法(“CEX”)。适用于分析蛋白稳定性的技术是本领域技术人员众所周知的,参见下述文献中的综述:Peptide and
Protein Drug Delivery, 247-301, Vincent Lee编,
Marcel Dekker, Inc., New York, N.Y., Pubs. (1991)和Jones, 1993 Adv. Drug Delivery Rev.10:29-90。
本文所述的药物组合物应当是无菌的。技术人员可利用不同技术来实现该目的,包括、但不限于、通过无菌过滤膜的过滤。在采用低压冻干的和重构的组合物的具体实施方案中,这可以在低压冻干和重构之前或之后进行。
拮抗剂治疗剂的定量给药属于技术人员的技能范围内。参见,例如,Lederman等人, 1991 Int. J. Cancer 47:659-664; Bagshawe等人, 1991Antibody, Immunoconjugates and Radiopharmaceuticals
4:915-922,且将随许多因素而变化,所述因素包括、但不限于:使用的具体的PCSK9-特异性的拮抗剂、待治疗的患者、患者的病症、治疗区域、给药途径和预期的治疗。具有普通技术的医师或兽医可以容易地确定和开处方有效治疗量的拮抗剂。剂量范围可以是约0.01-100
mg/kg、更通常0.05-25 mg/kg宿主体重。例如,剂量可以是0.3 mg/kg体重、1
mg/kg体重、3 mg/kg体重、5
mg/kg体重或10 mg/kg体重,或在1-10 mg/kg范围内。为了例证目的,且不限于此,在具体实施方案中,可以使用5 mg至2.0 g的剂量来全身地递送拮抗剂。在具体实施方案中,提供的剂量的浓度是在约8
mg/mL至约200 mg/mL的范围内。在其它实施方案中,预见到用于本发明中的剂量是约50
mg/mL至约150 mg/mL。在具体实施方案中,所述剂量是约0.1
mL至约1.5 mL,在具体实施方案中,所述剂量是1mL。实现在无毒性地产生效力的范围内的拮抗剂浓度的最佳精确度,需要基于靶位点对于药物的利用度的动力学的方案。这涉及考虑PCSK9-特异性的拮抗剂的分布、平衡和消除。本文所述的拮抗剂可以在适当剂量单独使用。或者,可能希望其它药剂的共同施用或相继施用。可能提出与替代治疗方案结合地施用本发明的PCSK9-特异性的拮抗剂的治疗给药方案。例如,PCSK9-特异性的拮抗剂可以与其它药物(治疗性的和/或预防性的)联合地或结合地使用。在具体实施方案中,PCSK9-特异性的拮抗剂与降低胆固醇的药物联合地或结合地使用,所述药物例如胆固醇吸收抑制剂(例如,Zetia®)和胆固醇合成抑制剂(例如,Zocor®和Vytorin®)。本发明预见到这样的组合,且它们形成本发明的重要实施方案。因此,本发明涉及上述的治疗方法,其中与另外一种或多种药物(治疗性的和/或预防性的)同时、在其之后或之前施用/递送PCSK9-特异性的拮抗剂,所述药物包括、但不限于降低胆固醇的药物,包括胆固醇吸收抑制剂。
能够如本文所述进行治疗的个体(受试者)包括灵长类动物、人和非人,包括具有商业或家养兽学重要性的任意非人哺乳动物或脊椎动物。
通过本领域会理解的任意给药途径,可以将PCSK9-特异性的拮抗剂施用给个体,所述途径包括、但不限于:口服给药、注射给药(它们的特定实施方案包括静脉内的、皮下的、腹膜内的或肌肉内的注射)或吸入给药、鼻内给药或局部给药,它们是单独的,或与用于辅助个体的治疗的其它药剂相组合。也可以通过注射装置、注射笔、无针装置和皮下贴剂递送系统,施用PCSK9-特异性的拮抗剂。应当基于技术人员会理解的许多考虑,确定给药途径,所述考虑包括、但不限于治疗的希望的生理化学特征。可以基于每天、每周、每2周或每个月,或在预定的时间将适当量的PCSK9-特异性的拮抗剂递送给个体从而实现和维持所需的治疗的任意其它方案,提供治疗。可以在单次剂量中,或在分开的时间在超过一次剂量中施用制剂。
也预见到的是,在药物的生产中使用公开的拮抗剂的方法,所述药物用于治疗PCS K9-相关的疾病、障碍或病症,或者可从PCSK9拮抗剂的效果受益的疾病、障碍或病症。所述药物可用于这样的受试者:所述受试者表现出与PCSK9活性有关的病症,或其中PCSK9的功能是特定受试者的禁忌的病症。在选择的实施方案中,所述病症可以是高胆固醇血症、冠心病、代谢综合征、急性冠状动脉综合征或有关病症。
本文公开的PCSK9-特异性的拮抗剂也可以用作诊断PCSK9的方法,在选择的实施方案中,本发明包括,鉴别或定量样品(包括、但不限于生物样品,例如血清或血液)中存在的PCSK9的水平的方法,所述方法包括:使样品接触本文所述的PCSK9-特异性的拮抗剂,和分别检测或定量与PCSK9的结合。PCSK9-特异性的拮抗剂可以用于技术人员已知的不同测定形式中,且可以形成试剂盒的一部分(所述试剂盒的一般特征在下面进一步描述)。
本发明另外提供了为了基因治疗目的而施用公开的抗-PCSK9拮抗剂。通过这样的方法,用编码本发明的PCSK9-特异性的拮抗剂的核酸转化受试者的细胞。然后含有此核酸的受试者内源性地生产PCSK9-特异性的拮抗剂。以前,Alvarez等人, Clinical
Cancer Research,6:3081-3087,
2000介绍了使用基因治疗方案将单链抗-ErbB2抗体导入受试者体内。Alvarez等人(出处同上)所公开的方法可以容易地经过修改,用于把编码本发明的抗-PCSK9抗体的核酸导入受试者体内。
可以将编码任意PCSK9-特异性的拮抗剂的核酸导入受试者体内。
所述核酸可以通过任何本领域所熟知的方法导入受试者的细胞中。在优选的实施方案中,所述核酸作为病毒载体的一部分而被导入。载体来源的优选病毒的实例包括慢病毒、疱疹病毒、腺病毒、腺伴随病毒、痘苗病毒、杆状病毒、甲病毒、流感病毒和具有所需细胞向性的其它重组病毒。
许多公司商业化生产病毒载体,包括、但绝不限于:Avigen,Inc.
(Alameda,加利福尼亚州;腺伴随病毒载体)、Cell
Genesys(Foster City,加利福尼亚州;反转录病毒、腺病毒、腺伴随病毒载体和慢病毒载体)、Clontech(反转录病毒和杆状病毒载体)、Genovo,Inc.(Sharon Hill,宾夕法尼亚州;腺病毒和腺伴随病毒载体)、Genvec(腺病毒载体)、IntroGene(Leiden,荷兰;腺病毒载体)、Molecular
Medicine(反转录病毒、腺病毒、腺伴随病毒和疱疹病毒载体)、Norgen(腺病毒载体)、Oxford BioMedica(Oxford,英国;慢病毒载体)和Transgene (Strasbourg,法国;腺病毒、痘苗病毒、反转录病毒和慢病毒载体)。
构建和使用病毒载体的方法为本领域所熟知(参见,例如,Miller,等人,BioTechniques 7:980-990,1992)。优选地,所述病毒载体是复制缺陷的,也就是说,它们不能在靶细胞中自主复制,因而不具有传染性。优选地,复制缺陷病毒是最小的病毒,即它仅保留包装基因组生产病毒颗粒所必需的基因组序列。完全或几乎完全缺失病毒基因的缺陷病毒是优选的。使用缺陷病毒载体,可以将其施用于细胞里特定的局部区域,而不用考虑此载体可以感染其它细胞。因而,可以特异性地靶向特定的组织。
含有减毒的或缺陷的DNA病毒序列的载体的实例包括、但不限于:缺陷型疱疹病毒载体(Kanno等人, Cancer Gen. Ther. 6: 147-154,1999; Kaplitt等人, J.
Neurosci. Meth.71: 125-132, 1997,和Kaplitt等人, J. Neuro. Onc. 19:137-147, 1994)。
腺病毒是真核DNA病毒,其经过改造以将本发明的核酸有效地递送给许多细胞类型。在某些情况下,减毒腺病毒载体(例如Strafford-Perricaudet等人, J.
Clin. Invest. 90:626-630,1992所描述的载体)是合乎需要的。多种复制缺陷的腺病毒和最小腺病毒载体已被描述(PCT公布号WO94/26914、WO94/28938、WO94/28152、WO94/12649、WO95/02697和WO96/22378)。根据本发明的复制缺陷的重组腺病毒可以通过本领域人员已知的任何技术制备(Levrero等人, Gene 101:195,1991; EP 185573; Graham, EMBO J.
3:2917,1984; Graham等人,J. Gen. Virol. 36:59,1977)。
腺伴随病毒(AAV)是相对较小尺寸的DNA病毒,该病毒可以以稳定的和位点特异性方式整合进它们所感染的细胞的基因组中。它们能够感染广谱的细胞,而不会对细胞的生长、形态或分化产生任何影响,它们也似乎不会涉入人病理学。源自腺伴随病毒的载体用于在体内或在体外转移基因的应用已有描述(参见Daly,
等人, Gene Ther. 8:1343-1346, 2001, Larson等人, Adv. Exp. Med. Bio. 489:45-57,2001; PCT公开号WO 91/18088和WO
93/09239;美国专利号4,797,368和5,139,941和EP 488528B1)。
在另一个实施方案中,所述基因可以在反转录病毒载体中导入,例如如在下列文献中所描述:美国专利号5,399,346、4,650,764、4,980,289和5,124,263; Mann等人,
Cell 33:153, 1983; Markowitz等人, J. Virol. 62:1120,1988; EP 453242和EP178220。反转录病毒是整合中的病毒,其感染正在分裂的细胞。
慢病毒载体可以用作这样的试剂:所述试剂用于在几种组织类型(包括脑、视网膜、肌肉、肝脏和血液)中直接递送和持续表达编码本发明的PCSK9-特异性的拮抗剂的核酸。所述载体可以有效转导这些组织中的正在分裂的和未在分裂的细胞,并可维持PCSK9-特异性的拮抗剂的长期表达。关于综述,参见:Zufferey等人, J.
Virol. 72:9873-80,1998和Kafri等人, Curr. Opin. Mol. Ther. 3:316-326, 2001。
慢病毒的包装细胞系是可获得的,且为本领域一般所知。它们会促进用于基因治疗的高滴度慢病毒载体的生产。一个实例是四环素诱导的VSV-G假型慢病毒包装细胞系,其可以在至少3-4天内产生滴度大于106 IU/ml的病毒颗粒;参见:Kafri等人, J. Virol.
73:576-584,1999。根据需要,可以浓缩由可诱导的细胞系所生产的载体,用于在体内或体外有效地转导非分裂的细胞。
Sindbis病毒是甲病毒属中的一个成员,自从最初于1953年在世界各地发现以来,已对其进行了广泛的研究。基于甲病毒属、尤其是Sindbis病毒的基因转导,已在体外进行了充分研究(参见Straus,等人,
Microbiol. Rev., 58:491-562, 1994; Bredenbeek等人, J.
Virol. 67:6439-6446,1993; Ijima等人,
Int. J. Cancer 80:110-1188,1999和Sawai等人, Biochim. Biophyr. Res. Comm. 248:315-323, 1998)。甲病毒属载体的许多性质使它们成为正在开发的其它病毒衍生的载体系统的理想替代载体,所述性质包括表达构建体的快速工程构建、感染颗粒的高滴度储备物的生产、未分裂的细胞的感染、以及高表达水平(Strauss等人,
1994,出处同上)。Sindbis病毒用于基因治疗的应用已有描述(Wahlfors,等人, Gene. Ther. 7:472-480, 2000和Lundstrom, J. Recep. Sig. Transduct. Res. 19(1-4):673-686,1999)。
在另一个实施方案中,通过脂转染或使用其它转染促进剂(肽、聚合物等),可以将载体导入细胞中。合成的阳离子脂质可用于制备脂质体,用于在体内或体外转染编码标记物的基因(Feigner等人, Proc. Natl. Acad. Sci. USA 84:7413-7417, 1987和Wang等人, Proc. Natl.
Acad. Sci.USA 84:7851-7855, 1987)。可用于核酸转移的的脂质化合物和组合物,描述在:PCT公开号WO95/18863和WO96/17823以及美国专利号5,459,127。
也可能将载体作为裸DNA质粒导入体内。通过本领域已知的方法,可以将用于基因治疗的裸DNA载体导入所需的宿主细胞中,所述方法例如电穿孔、显微注射、细胞融合、DEAE葡聚糖、磷酸钙沉淀、使用基因枪或使用DNA载体运载体(参见,例如,Wilson,
等人, J. Biol. Chem. 267:963-967,1992;
Williams等人, Proc. Natl. Acad. Sci. USA
88:2726-2730, 1991)。常用于质粒转染的其它试剂包括、但是绝不限于FuGene、脂质体转染和Lipofectamine。也可使用受体介导的DNA递送方案(Wu等人, J. Biol. Chem. 263:14621-14624,1988)。美国专利号5,580,859和5,589,466公开了不用转染促进剂将外源DNA序列导入哺乳动物中。最近,已经描述了一种相对低电压、高效体内DNA转移技术,称为电转移(Vilquin等人,
Gene Ther. 8:1097, 2001; Payen等人, Exp. Hematol.
29:295-300, 2001; Mir, Bioelectrochemistry 53: 1-10, 2001; PCT公开号WO 99/01157、WO
99/01158和WO 99/01175)。
适用于这样的基因治疗方案且包含编码本发明的抗-PCSK9拮抗剂的核酸的药物组合物,被包括在本发明的范围内。
在另一个方面,本发明提供了用于鉴别、分离、定量或拮抗目标样品中的PCSK9的方法,其中使用本发明的PCSK9-特异性的拮抗剂。PCSK9-特异性的拮抗剂可以在免疫化学测定中用作研究工具,所述免疫化学测定例如蛋白印迹、ELISA、放射免疫测定、免疫组织化学测定、免疫沉淀或本领域已知的其它免疫化学测定(参见,例如,Immunological
Techniques Laboratoxy Manual, Goers编, J.
1993, Academic Press)或不同的纯化方案。所述拮抗剂可以具有掺入其中的或附着于其上面的标记,以促进与其有关的活性的容易鉴别或测量。本领域技术人员可以容易地熟知不同类型的可检测标记(例如,酶、染料或其它合适的分子,它们可容易地检测到,或会造成可容易地检测到的某种活性/结果),它们被用于或可用于上述方案中。
本发明的另一个方面是试剂盒,其包含本文公开的PCSK9-特异性的拮抗剂或药物组合物和使用说明书。试剂盒通常、但是不一定包括标签,所述标签指示试剂盒的内容物的预期用途。术语标签包括任何书面的或记录的材料,其提供在试剂盒上或与试剂盒一起提供,或以其它方式伴随试剂盒。在其中提供的药物组合物被低压冻干的具体实施方案中,所述试剂盒可以包括无菌水或盐水,用于将所述制剂重构成液体形式。在具体实施方案中,水或盐水的量是约0.1
ml-1.0 ml。
提供下面的实施例来例证本发明,而不将本发明限于此:
实施例22
分析型尺寸排阻色谱法
高效-尺寸排阻色谱法(HP-SEC)是一种用于分离蛋白(基于递减尺寸次序)的分析方法。使用该方法来定量在处理和纯化以后(时间零点)和在加速稳定性研究以后的蛋白的聚集和/或片段化的水平。使用Waters 2690分离模块/996光电二极管阵列检测器,进行尺寸排阻色谱法。使用具有Phenomenex预滤器GFC
4000(4x3 mm)的TSKgel
G3000SWXL(4.6 x 300 mm)柱,分离物质。给该柱装载10 μg物质,并以0.5 ml/min的流速用25 mM磷酸钠、300 mM氯化钠pH 7.0流动相洗脱30分钟。报告从200-500 nm和220 nm获得的数据。
在0.5 mg/ml,在pH 5、6、7和8缓冲液中配制单克隆抗体。所述缓冲液含有150
mM氯化钠和10 mM乙酸盐、组氨酸、磷酸盐和TRIS(分别对于pH 5、6、7和8)。使用HP-SEC来表征在时间零点和在45 ℃ 1周以后的物质纯度。稳定性结果总结在下面的表11中。图26显示了时间零点SEC特性。该图中带框的标记定义了更高阶聚集体(HOA)、寡聚体、单体和剪切的蛋白的近似洗脱时间。
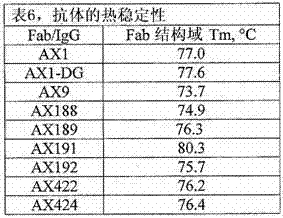
表11. 在时间零点和在热应激(45℃ 1周)以后的物理稳定性数据
lmAb: 单克隆抗体
2Mon: 单体
3O1ig: 寡聚体
4HOA: 更高阶聚集体
5Clip: 剪切的蛋白。
序列表
<110> Merck Sharp &
Dohme Corp.
Luo, Peter Peizhi
Wang, Kevin Caili
Zhong, Pingyu
Hsieh, Mark
Li, Yan
Wang, Xinwei
Dong, Feng
Golosov, Andrei
Ni, Yan
Wang, Weirong
Peterson, Laurence B.
Cubbon, Rose
<120> AX1和AX189 PCSK9拮抗剂和变体
<130> MRL-ACV-00028
<150> 61/323,117
<151> 2010-04-12
<150> 61/256,720
<151> 2009-10-30
<160> 174
<170> FastSEQ for Windows
Version 4.0
<210> 1
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> 共有的 VH CDR1 抗体序列
<220>
<221> 变体
<222> (1)...(1)
<223> Xaa = K 或 A
<220>
<221> 变体
<222> (5)...(5)
<223> Xaa = Y 或 F
<220>
<221> 变体
<222> (6)...(6)
<223> Xaa = T 或 D
<220>
<221> 变体
<222> (8)...(8)
<223> Xaa = S 或 T
<220>
<221> 变体
<222> (9)...(9)
<223> Xaa = S 或 D
<220>
<221> 变体
<222> (11)...(11)
<223> Xaa = W, Y, T 或 D
<220>
<221> 变体
<222> (12)...(12)
<223> Xaa = M, F, Y 或 I
<220>
<221> 变体
<222> (13)...(13)
<223> Xaa = H, S 或 N
<400> 1
Xaa Ala Ser Gly Xaa Xaa Phe Xaa
Xaa Tyr Xaa Xaa Xaa Trp Val Arg
1
5 10 15
<210> 2
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> AX1 VH CDR1 抗体序列
<400> 2
Lys Ala Ser Gly Phe Thr Phe Thr
Ser Tyr Tyr Met His Trp Val Arg
1
5 10 15
<210> 3
<211> 48
<212> DNA
<213> 人工序列
<220>
<223> AX1 VH CDR1 抗体序列
<400> 3
aaggcctctg gtttcacctt cacttcttac
tacatgcact gggtgcgt 48
<210> 4
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> AX1 VH CDR1 抗体序列
<400> 4
Gly Phe Thr Phe Thr Ser Tyr Tyr
Met His
1
5 10
<210> 5
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> AX1 VH CDR1 抗体序列
<400> 5
ggtttcacct tcacttctta
ctacatgcac
30
<210> 6
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR1 抗体序列
<400> 6
Lys Ala Ser Gly Tyr Thr Phe Ser
Ser Tyr Trp Met His Trp Val Arg
1
5 10 15
<210> 7
<211> 48
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR1 抗体序列
<400> 7
aaggcctctg gttacacctt ctcttcttac
tggatgcact gggtgcgt 48
<210> 8
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 共有的 VH CDR2 抗体序列
<220>
<221> 变体
<222> (2)...(2)
<223> Xaa = I 或 V
<220>
<221> 变体
<222> (3)...(3)
<223> Xaa = G 或 S
<220>
<221> 变体
<222> (4)...(4)
<223> Xaa = R 或 Y
<220>
<221> 变体
<222> (6)...(6)
<223> Xaa = D, Y, E 或 N
<220>
<221> 变体
<222> (8)...(8)
<223> Xaa = Y 或 D
<220>
<221> 变体
<222> (9)...(9)
<223> Xaa = N, S 或 T
<220>
<221> 变体
<222> (10)...(10)
<223> Xaa = G, E 或 T
<220>
<221> 变体
<222> (11)...(11)
<223> Xaa = G, Y, D 或 S
<220>
<221> 变体
<222> (19)...(19)
<223> Xaa = K, A 或 D
<220>
<221> 变体
<222> (20)...(20)
<223> Xaa = G, S 或 D
<220>
<221> 变体
<222> (21)...(21)
<223> Xaa = K 或 R
<220>
<221> 变体
<222> (22)...(22)
<223> Xaa = A 或 F
<400> 8
Trp Xaa Xaa Xaa Ile Xaa Pro Xaa
Xaa Xaa Xaa Thr Lys Tyr Asn Glu
1
5 10 15
Lys Arg Xaa Xaa Xaa Xaa Thr
20
<210> 9
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> AX1 VH CDR2 抗体序列
<400> 9
Trp Ile Gly Arg Ile Asn Pro Asp
Ser Gly Ser Thr Lys Tyr Asn Glu
1
5 10 15
Lys Phe Lys Gly Arg Ala Thr
20
<210> 10
<211> 74
<212> DNA
<213> 人工序列
<220>
<223> AX1 VH CDR2 抗体序列
<400> 10
tggaatggat cggtcggatc aacccagatt
ctggtagtac taagtacaac gagaagttca 60
agggtcgtgc cacc
74
<210> 11
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> AX1 VH CDR2 抗体序列
<400> 11
Arg Ile Asn Pro Asp Ser Gly Ser
Thr Lys Tyr Asn Glu Lys Phe Lys
1
5 10 15
Gly
<210> 12
<211> 51
<212> DNA
<213> 人工序列
<220>
<223> AX1 VH CDR2 抗体序列
<400> 12
cggatcaacc cagattctgg tagtactaag
tacaacgaga agttcaaggg t 51
<210> 13
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR2 抗体序列
<400> 13
Trp Ile Gly Arg Ile Asp Pro Tyr
Asn Gly Gly Thr Lys Tyr Asn Glu
1
5 10 15
Lys Phe Lys Gly Lys Ala Thr
20
<210> 14
<211> 69
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR2 抗体序列
<400> 14
tggatcggtc gtatcgaccc atataacggt
ggcaccaagt acaacgagaa gttcaagggt 60
aaggccacc
69
<210> 15
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 共有的 VH CDR3 抗体序列
<220>
<221> 变体
<222> (4)...(4)
<223> Xaa = Y, S, D 或 E
<220>
<221> 变体
<222> (5)...(5)
<223> Xaa = G, T 或 R
<220>
<221> 变体
<222> (8)...(8)
<223> Xaa = L, E, D, G 或 S
<220>
<221> 变体
<222> (9)...(9)
<223> Xaa = G, D 或 E
<220>
<221> 变体
<222> (10)...(10)
<223> Xaa = S, Y 或 F
<220>
<221> 变体
<222> (13)...(13)
<223> Xaa = M, F, Y, L 或 E
<400> 15
Cys Ala Arg Xaa Xaa Tyr Tyr Xaa
Xaa Xaa Tyr Ala Xaa Asp Tyr Trp
1
5 10 15
Gly Gln
<210> 16
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> AX1 VH CDR3 抗体序列
<400> 16
Cys Ala Arg Gly Gly Arg Leu Ser
Trp Asp Phe Asp Val Trp Gly Gln
1
5 10 15
<210> 17
<211> 48
<212> DNA
<213> 人工序列
<220>
<223> AX1 VH CDR3 抗体序列
<400> 17
tgcgcccgtg gtggtcgttt atcctgggac
ttcgacgtct ggggtcag 48
<210> 18
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> AX1 VH CDR3 抗体序列
<400> 18
Gly Gly Arg Leu Ser Trp Asp Phe
Asp Val
1
5 10
<210> 19
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> AX1 VH CDR3 抗体序列
<400> 19
ggtggtcgtt tatcctggga
cttcgacgtc 30
<210> 20
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR3 抗体序列
<400> 20
Cys Ala Arg Tyr Gly Tyr Tyr Leu
Gly Ser Tyr Ala Met Asp Tyr Trp
1
5 10 15
Gly Gln
<210> 21
<211> 54
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR3 抗体序列
<400> 21
tgcgcccgtt atggttacta ccttggctct
tacgccatgg actactgggg tcag 54
<210> 22
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 共有的 VL CDR1 抗体序列
<220>
<221> 变体
<222> (1)...(1)
<223> Xaa = R 或 K
<220>
<221> 变体
<222> (5)...(5)
<223> Xaa = D 或 S
<220>
<221> 变体
<222> (6)...(6)
<223> Xaa = V 或 I
<220>
<221> 变体
<222> (8)...(8)
<223> Xaa = R, K, T 或 N
<220>
<221> 变体
<222> (11)...(11)
<223> Xaa = T, A 或 S
<400> 22
Xaa Ala Ser Gln Xaa Xaa Ser Xaa
Tyr Leu Xaa
1
5 10
<210> 23
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 共有的 VL CDR1 抗体序列
<220>
<221> 变体
<222> (5)...(5)
<223> Xaa = A, D 或 S
<220>
<221> 变体
<222> (6)...(6)
<223> Xaa = V 或 I
<220>
<221> 变体
<222> (8)...(8)
<223> Xaa = R, K, N 或 S
<220>
<221> 变体
<222> (11)...(11)
<223> Xaa = A, T, N 或 H
<400> 23
Arg Ala Ser Gln Xaa Xaa Ser Xaa
Tyr Leu Xaa
1
5 10
<210> 24
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> AX1 VL CDR1 抗体序列
<400> 24
Arg Ala Ser Gln Asp Ile Ser Arg
Tyr Leu Ala
1
5 10
<210> 25
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> AX1 VL CDR1 抗体序列
<400> 25
cgtgcctctc aggatatctc taggtatctg
gcc 33
<210> 26
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> AX9 VL CDR1 抗体序列
<400> 26
Arg Ala Ser Gln Asp Val Ser Lys
Tyr Leu Ala
1
5 10
<210> 27
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> AX9 VL CDR1 抗体序列
<400> 27
cgtgcctctc aggatgtctc taagtatctg
gcc 33
<210> 28
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> AX189 VL CDR1 抗体序列
<400> 28
Arg Ala Ser Gln Asp Val Ser Arg
Tyr Leu Thr
1
5 10
<210> 29
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> AX189 VL CDR1 抗体序列
<400> 29
cgtgcctctc aggatgtctc taggtatctg
acc 33
<210> 30
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 共有的 VL CDR2 抗体序列
<220>
<221> 变体
<222> (1)...(1)
<223> Xaa = A 或 R
<220>
<221> 变体
<222> (3)...(3)
<223> Xaa = S, E 或 T
<220>
<221> 变体
<222> (4)...(4)
<223> Xaa = S, E, D 或 T
<220>
<221> 变体
<222> (6)...(6)
<223> Xaa = Q, R, K, Y 或 E
<220>
<221> 变体
<222> (7)...(7)
<223> Xaa = S, T 或 A
<400> 30
Xaa Ala Xaa Xaa Leu Xaa Xaa
1
5
<210> 31
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> AX1 AX9 AX189 VL CDR2
抗体序列
<400> 31
Ala Ala Ser Ser Leu Gln Ser
1
5
<210> 32
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> AX1 AX9 AX189 VL CDR2
抗体序列
<400> 32
gccgcctctt ctttgcagtc t 21
<210> 33
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 共有的 VL CDR3 抗体序列
<220>
<221> 变体
<222> (1)...(1)
<223> Xaa = Q, E, Y 或 A
<220>
<221> 变体
<222> (2)...(2)
<223> Xaa = A, V 或 S
<220>
<221> 变体
<222> (3)...(3)
<223> Xaa = Y, E 或 W
<220>
<221> 变体
<222> (5)...(5)
<223> Xaa = Y, S 或 K
<220>
<221> 变体
<222> (6)...(6)
<223> Xaa = S 或 E
<220>
<221> 变体
<222> (7)...(7)
<223> Xaa = L, S, P, G, D 或 T
<220>
<221> 变体
<222> (8)...(8)
<223> Xaa = S, D, N, E, G 或 A
<220>
<221> 变体
<222> (9)...(9)
<223> Xaa = G, A, D, R, S 或 H
<220>
<221> 变体
<222> (10)...(10)
<223> Xaa = Y 或 V
<400> 33
Xaa Xaa Xaa Asp Xaa Xaa Xaa Xaa
Xaa Xaa Val
1
5 10
<210> 34
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 共有的 VL CDR3 抗体序列
<220>
<221> 变体
<222> (1)...(1)
<223> Xaa = Q 或 E
<220>
<221> 变体
<222> (2)...(2)
<223> Xaa = A, S 或 V
<220>
<221> 变体
<222> (5)...(5)
<223> Xaa = Y 或 S
<220>
<221> 变体
<222> (7)...(7)
<223> Xaa = L, S 或 P
<220>
<221> 变体
<222> (8)...(8)
<223> Xaa = G, S 或 N
<220>
<221> 变体
<222> (9)...(9)
<223> Xaa = A, H, P, R, G 或 D
<220>
<221> 变体
<222> (10)...(10)
<223> Xaa = Y 或 W
<400> 34
Xaa Xaa Tyr Asp Xaa Ser Xaa Xaa
Xaa Xaa Val
1
5 10
<210> 35
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> AX1 VL CDR3 抗体序列
<400> 35
Ala Ala Tyr Asp Tyr Ser Leu Gly
Gly Tyr Val
1
5 10
<210> 36
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> AX1 VL CDR3 抗体序列
<400> 36
gcggcttacg actattcttt gggcggttac
gtg 33
<210> 37
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> AX9 VL CDR3 抗体序列
<400> 37
Gln Val Tyr Asp Ser Ser Pro Asn
Ala Tyr Val
1 5 10
<210> 38
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> AX9 VL CDR3 抗体序列
<400> 38
caggtatacg acagctctcc aaacgcttat
gtg 33
<210> 39
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> AX189 VL CDR3 抗体序列
<400> 39
Gln Ala Tyr Asp Tyr Ser Leu Ser
Gly Tyr Val
1
5 10
<210> 40
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> AX189 VL CDR3 抗体序列
<400> 40
caggcttacg actattcttt gagcggttac
gtg 33
<210> 41
<211> 119
<212> PRT
<213> 人工序列
<220>
<223> AX1 VH 抗体序列
<400> 41
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Phe Thr Phe Thr Ser Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asn Pro Asp Ser Gly
Ser Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Arg Leu Ser Trp
Asp Phe Asp Val Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 42
<211> 357
<212> DNA
<213> 人工序列
<220>
<223> AX1 VH 抗体序列
<400> 42
gaagtgcagc tgctggaatc tggtggtggt
ctggtgcagc caggtggttc tctgcgtctg 60
tcttgcaagg cctctggttt caccttcact
tcttactaca tgcactgggt gcgtcaggca 120
ccaggtaagg gtctggaatg gatcggtcgg
atcaacccag attctggtag tactaagtac 180
aacgagaagt tcaagggtcg tgccaccatc
tctagagaca actctaagaa caccctgtac 240
ttgcagatga actctctgcg tgccgaggac
actgcagtgt actactgcgc ccgtggtggt 300
cgtttatcct gggacttcga cgtctggggt
cagggtacgc tggtgactgt ctcgagc 357
<210> 43
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 VH 抗体序列
<400> 43
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Tyr Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Asn Gly
Gly Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Gly Tyr Tyr Leu Gly
Ser Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser
Ser
115 120
<210> 44
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 VH 抗体序列
<400> 44
gaagtgcagc tgttggaatc tggtggtggt
ctggtgcagc caggtggttc tctgcgtctg 60
tcttgcaagg cctctggtta caccttctct
tcttactgga tgcactgggt gcgtcaggca 120
ccaggtaagg gtctggaatg gatcggtcgt
atcgacccat ataacggtgg caccaagtac 180
aacgagaagt tcaagggtaa ggccaccatc
tctagagaca actctaagaa caccctgtac 240
ttgcagatga actctctgcg tgccgaggac
actgcagtgt actactgcgc ccgttatggt 300
tactaccttg gctcttacgc catggactac
tggggtcagg gtacgctggt gactgtctcg 360
agc 363
<210> 45
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> AX421 VH 抗体序列
<400> 45
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Tyr Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Asn Glu
Gly Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Gly Tyr Tyr Leu Gly
Ser Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser
Ser
115 120
<210> 46
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> AX422 VH 抗体序列
<400> 46
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Tyr Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Ser Gly
Gly Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Gly Tyr Tyr Leu Gly
Ser Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser
Ser
115 120
<210> 47
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> AX423 VH 抗体序列
<400> 47
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Tyr Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Asn Thr
Gly Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Gly Tyr Tyr Leu Gly
Ser Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser
Ser
115 120
<210> 48
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> AX424 VH 抗体序列
<400> 48
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Tyr Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Thr Gly
Gly Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Gly Tyr Tyr Leu Gly
Ser Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser
Ser
115 120
<210> 49
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> AX425 VH 抗体序列
<400> 49
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Tyr Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Asp Gly
Gly Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Gly Tyr Tyr Leu Gly
Ser Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser
Ser
115 120
<210> 50
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX1 VL 抗体序列
<400> 50
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Ile Ser Arg Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Ala Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
Gly Tyr Val Phe Gly Asp Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 51
<211> 327
<212> DNA
<213> 人工序列
<220>
<223> AX1 VL 抗体序列
<400> 51
gacatccaga tgacccagtc tccatcttct
ctgtctgcct ctgtgggcga ccgggtgacc 60
atcacctgcc gtgcctctca ggatatctct
aggtatctgg cctggtatca gcagaagcca 120
ggtaaggcgc caaagctgct gatctacgcc
gcctcttctt tgcagtctgg tgtgccatct 180
cgtttctctg gttctggttc tggcaccgac
ttcaccctga ccatctcttc tttgcagcca 240
gaagacttcg ccacctacta ctgcgcggct
tacgactatt ctttgggcgg ttacgtgttc 300
ggtgatggta ccaaagtgga
gatcaaa
327
<210> 52
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX1DG VL 抗体序列
<400> 52
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Ile Ser Arg Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Ala Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
Gly Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 53
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX9 VL 抗体序列
<400> 53
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Val Ser Lys Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Val Tyr Asp Ser Ser Pro Asn
85 90 95
Ala Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 54
<211> 327
<212> DNA
<213> 人工序列
<220>
<223> AX9 VL 抗体序列
<400> 54
gacatccaga tgacccagtc tccatcttct
ctgtctgcct ctgtgggcga ccgggtgacc 60
atcacctgcc gtgcctctca ggatgtctct
aagtatctgg cctggtatca gcagaagcca 120
ggtaaggcgc caaagctgct gatctacgcc
gcctcttctt tgcagtctgg tgtgccatct 180
cgtttctctg gttctggttc tggcaccgac
ttcaccctga ccatctcttc tttgcagcca 240
gaagacttcg ccacctacta ctgccaggta
tacgacagct ctccaaacgc ttatgtgttc 300
ggtggtggta ccaaagtgga
gatcaaa
327
<210> 55
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX188 VL 抗体序列
<400> 55
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Ser Val Ser Arg Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Glu Ala Tyr Asp Tyr Ser Ser Gly
85 90 95
Pro Trp Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 56
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX190 VL 抗体序列
<400> 56
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Ser Val Ser Arg Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Ser Tyr Asp Tyr Ser Leu Ser
85 90 95
Asp Tyr Val Phe Gly Gly Gly Thr Lys
Val Glu Ile Lys
100 105
<210> 57
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX191 VL 抗体序列
<400> 57
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Ile Ser Lys Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Ala Tyr Asp Tyr Ser Ser Ser
85 90 95
Ala Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 58
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX192 VL 抗体序列
<400> 58
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Ala Val Ser Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Glu Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
Arg Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 59
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX193 VL 抗体序列
<400> 59
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Ala Ile Ser Lys Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Glu Ser Tyr Asp Tyr Ser Leu Gly
85 90 95
Arg Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 60
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX194 VL 抗体序列
<400> 60
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Thr Thr Cys Arg
Ala Ser Gln Ala Val Ser Arg Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
Ala Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 61
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX195 VL 抗体序列
<400> 61
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Ala Val Ser Lys Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
Asp Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 62
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX196 VL 抗体序列
<400> 62
Asp Ile Gln Ile Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Val Ser Arg Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Glu Ser Tyr Asp Tyr Ser Leu Ser
85 90 95
His Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 63
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX197 VL 抗体序列
<400> 63
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Ala Ile Ser Arg Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
His Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 64
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX198 VL 抗体序列
<400> 64
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Ala Val Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Glu Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
Gly Trp Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 65
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX199 VL 抗体序列
<400> 65
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Ser Val Ser Asn Tyr
20 25 30
Leu His Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
Pro Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 66
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX200 VL 抗体序列
<400> 66
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Val Ser Lys Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Glu Ala Tyr Asp Tyr Ser Leu Ser
85 90 95
His Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 67
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> AX189 VL 抗体序列
<400> 67
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Val Ser Arg Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Ala Tyr Asp Tyr Ser Leu Ser
85 90 95
Gly Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys
100 105
<210> 68
<211> 327
<212> DNA
<213> 人工序列
<220>
<223> AX189 VL 抗体序列
<400> 68
gacatccaga tgacccagtc tccatcttct
ctgtctgcct ctgtgggcga ccgggtgacc 60
atcacctgcc gtgcctctca ggatgtctct
aggtatctga cctggtatca gcagaagcca 120
ggtaaggcgc caaagctgct gatctacgcc
gcctcttctt tgcagtctgg tgtgccatct 180
cgtttctctg gttctggttc tggcaccgac
ttcaccctga ccatctcttc tttgcagcca 240
gaagacttcg ccacctacta ctgccaggct
tacgactatt ctttgagcgg ttacgtgttc 300
ggtggtggta ccaaagtgga
gatcaaa
327
<210> 69
<211> 227
<212> PRT
<213> 人工序列
<220>
<223> AX1 FD 链抗体序列
<400> 69
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Phe Thr Phe Thr Ser Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asn Pro Asp Ser Gly
Ser Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Arg Leu Ser Trp
Asp Phe Asp Val Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val Phe
115
120 125
Pro Leu Ala Pro Ser Ser Lys Ser
Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe
Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly
Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu
Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr
Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys
Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr
225
<210> 70
<211> 681
<212> DNA
<213> 人工序列
<220>
<223> AX1 FD 链抗体序列
<400> 70
gaagtgcagc tgctggaatc tggtggtggt
ctggtgcagc caggtggttc tctgcgtctg 60
tcttgcaagg cctctggttt caccttcact
tcttactaca tgcactgggt gcgtcaggca 120
ccaggtaagg gtctggaatg gatcggtcgg
atcaacccag attctggtag tactaagtac 180
aacgagaagt tcaagggtcg tgccaccatc
tctagagaca actctaagaa caccctgtac 240
ttgcagatga actctctgcg tgccgaggac
actgcagtgt actactgcgc ccgtggtggt 300
cgtttatcct gggacttcga cgtctggggt
cagggtacgc tggtgactgt ctcgagcgca 360
agcaccaaag gcccatcggt attccccctg
gcaccctcct ccaagagcac ctctgggggc 420
acagcggccc tgggctgcct ggtcaaggac
tacttccccg agccggtgac ggtgtcgtgg 480
aactcaggcg ctctgaccag cggcgtgcac
accttcccgg ctgtcctaca gtcctcagga 540
ctctactccc tcagcagcgt ggtgactgtg
ccctccagca gcttgggcac ccagacctac 600
atctgcaacg tgaatcacaa gcccagcaac
actaaggtgg acaagaaagt tgagcccaaa 660
tcttgtgaca aaactcacac a 681
<210> 71
<211> 229
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 FD 链抗体序列
<400> 71
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Tyr Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Asn Gly
Gly Thr Lys Tyr Asn Glu Lys Phe
50
55 60
Lys Gly Lys Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Gly Tyr Tyr Leu Gly
Ser Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser
Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp
Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr
Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr
Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln
Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp
Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Lys Thr His Thr
225
<210> 72
<211> 687
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 FD 链抗体序列
<400> 72
gaagtgcagc tgttggaatc tggtggtggt
ctggtgcagc caggtggttc tctgcgtctg 60
tcttgcaagg cctctggtta caccttctct
tcttactgga tgcactgggt gcgtcaggca 120
ccaggtaagg gtctggaatg gatcggtcgt
atcgacccat ataacggtgg caccaagtac 180
aacgagaagt tcaagggtaa ggccaccatc
tctagagaca actctaagaa caccctgtac 240
ttgcagatga actctctgcg tgccgaggac
actgcagtgt actactgcgc ccgttatggt 300
tactaccttg gctcttacgc catggactac
tggggtcagg gtacgctggt gactgtctcg 360
agcgcaagca ccaaaggccc atcggtattc
cccctggcac cctcctccaa gagcacctct 420
gggggcacag cggccctggg ctgcctggtc
aaggactact tccccgagcc ggtgacggtg 480
tcgtggaact caggcgctct gaccagcggc
gtgcacacct tcccggctgt cctacagtcc 540
tcaggactct actccctcag cagcgtggtg
actgtgccct ccagcagctt gggcacccag 600
acctacatct gcaacgtgaa tcacaagccc
agcaacacta aggtggacaa gaaagttgag 660
cccaaatctt gtgacaaaac
tcacaca
687
<210> 73
<211> 216
<212> PRT
<213> 人工序列
<220>
<223> AX1 Fab 轻链抗体序列
<400> 73
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Ile Ser Arg Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50
55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Ala Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
Gly Tyr Val Phe Gly Asp Gly Thr
Lys Val Glu Ile Lys Arg Thr Val
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe
Pro Pro Ser Asp Glu Gln Leu Lys
115
120 125
Ser Gly Thr Ala Ser Val Val Cys
Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val
Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser
Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 74
<211> 648
<212> DNA
<213> 人工序列
<220>
<223> AX1 Fab 轻链抗体序列
<400> 74
gacatccaga tgacccagtc tccatcttct
ctgtctgcct ctgtgggcga ccgggtgacc 60
atcacctgcc gtgcctctca ggatatctct
aggtatctgg cctggtatca gcagaagcca 120
ggtaaggcgc caaagctgct gatctacgcc
gcctcttctt tgcagtctgg tgtgccatct 180
cgtttctctg gttctggttc tggcaccgac
ttcaccctga ccatctcttc tttgcagcca 240
gaagacttcg ccacctacta ctgcgcggct
tacgactatt ctttgggcgg ttacgtgttc 300
ggtgatggta ccaaagtgga gatcaaacgt
acggtggctg caccatctgt cttcatcttc 360
ccgccatctg atgagcagtt gaaatctgga
actgcctctg ttgtgtgcct gctgaataac 420
ttctatccca gagaggccaa agtacagtgg
aaggtggata acgccctcca atcgggtaac 480
tcccaggaga gtgtcacaga gcaggacagc
aaggacagca cctacagcct cagcagcacc 540
ctgacgctga gcaaagcaga ctacgagaaa
cacaaagtct acgcctgcga agtcacccat 600
cagggcctga gctcgcccgt cacaaagagc
ttcaacaggg gagagtgt 648
<210> 75
<211> 216
<212> PRT
<213> 人工序列
<220>
<223> AX9 Fab 轻链抗体序列
<400> 75
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Val Ser Lys Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Val Tyr Asp Ser Ser Pro Asn
85 90 95
Ala Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys Arg Thr Val
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe
Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys
Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val
Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser
Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 76
<211> 648
<212> DNA
<213> 人工序列
<220>
<223> AX9 Fab 轻链抗体序列
<400> 76
gacatccaga tgacccagtc tccatcttct
ctgtctgcct ctgtgggcga ccgggtgacc 60
atcacctgcc gtgcctctca ggatgtctct
aagtatctgg cctggtatca gcagaagcca 120
ggtaaggcgc caaagctgct gatctacgcc
gcctcttctt tgcagtctgg tgtgccatct 180
cgtttctctg gttctggttc tggcaccgac
ttcaccctga ccatctcttc tttgcagcca 240
gaagacttcg ccacctacta ctgccaggta
tacgacagct ctccaaacgc ttatgtgttc 300
ggtggtggta ccaaagtgga gatcaaacgt
acggtggctg caccatctgt cttcatcttc 360
ccgccatctg atgagcagtt gaaatctgga
actgcctctg ttgtgtgcct gctgaataac 420
ttctatccca gagaggccaa agtacagtgg
aaggtggata acgccctcca atcgggtaac 480
tcccaggaga gtgtcacaga gcaggacagc
aaggacagca cctacagcct cagcagcacc 540
ctgacgctga gcaaagcaga ctacgagaaa
cacaaagtct acgcctgcga agtcacccat 600
cagggcctga gctcgcccgt cacaaagagc
ttcaacaggg gagagtgt 648
<210> 77
<211> 216
<212> PRT
<213> 人工序列
<220>
<223> AX189 Fab 轻链抗体序列
<400> 77
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Val Ser Arg Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Ala Tyr Asp Tyr Ser Leu Ser
85 90 95
Gly Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys Arg Thr Val
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe
Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys
Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val
Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser
Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 78
<211> 648
<212> DNA
<213> 人工序列
<220>
<223> AX189 Fab 轻链抗体序列
<400> 78
gacatccaga tgacccagtc tccatcttct
ctgtctgcct ctgtgggcga ccgggtgacc 60
atcacctgcc gtgcctctca ggatgtctct
aggtatctga cctggtatca gcagaagcca 120
ggtaaggcgc caaagctgct gatctacgcc
gcctcttctt tgcagtctgg tgtgccatct 180
cgtttctctg gttctggttc tggcaccgac
ttcaccctga ccatctcttc tttgcagcca 240
gaagacttcg ccacctacta ctgccaggct
tacgactatt ctttgagcgg ttacgtgttc 300
ggtggtggta ccaaagtgga gatcaaacgt
acggtggctg caccatctgt attcatcttc 360
ccgccatctg atgagcagtt gaaatctgga
actgcctctg ttgtgtgcct gctgaataac 420
ttctatccca gagaggccaa agtacagtgg
aaggtggata acgccctcca atcgggtaac 480
tcccaggaga gtgtcacaga gcaggacagc
aaggacagca cctacagcct cagcagcacc 540
ctgacgctga gcaaagcaga ctacgagaaa
cacaaagtct acgcctgcga agtcacccat 600
cagggcctga gctcgcccgt cacaaagagc
ttcaacaggg gagagtgt 648
<210> 79
<211> 445
<212> PRT
<213> 人工序列
<220>
<223> AX1 IgG2 重链抗体序列
<400> 79
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Phe Thr Phe Thr Ser Tyr
20 25 30
Tyr Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asn Pro Asp Ser Gly
Ser Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Arg Leu Ser Trp
Asp Phe Asp Val Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Arg Ser
Thr Ser Glu Ser Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe
Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly
Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu
Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr
Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr
Val Glu Arg Lys Cys Cys Val Glu
210 215 220
Cys Pro Pro Cys Pro Ala Pro Pro
Val Ala Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr
Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val
Ser His Glu Asp Pro Glu Val Gln
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val
Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Phe Asn Ser
Thr Phe Arg Val Val Ser Val Leu
290 295 300
Thr Val Val His Gln Asp Trp Leu
Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Gly Leu Pro Ala
Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Thr Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Glu Glu Met Thr Lys Asn Gln
Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala
Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr
Pro Pro Met Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu
Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser
Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser
Leu Ser Pro Gly Lys
435 440 445
<210> 80
<211> 1335
<212> DNA
<213> 人工序列
<220>
<223> AX1 IgG2 重链抗体序列
<400> 80
gaagtgcagc tgctggaatc tggtggtggt
ctggtgcagc caggtggttc tctgcgtctg 60
tcttgcaagg cctctggttt caccttcact
tcttactaca tgcactgggt gcgtcaggca 120
ccaggtaagg gtctggaatg gatcggtcgg
atcaacccag attctggtag tactaagtac 180
aacgagaagt tcaagggtcg tgccaccatc
tctagagaca actctaagaa caccctgtac 240
ttgcagatga actctctgcg tgccgaggac
actgcagtgt actactgcgc ccgtggtggt 300
cgtttatcct gggacttcga cgtctggggt
cagggtacgc tggtgactgt ctcgagcgca 360
tccaccaagg gcccatccgt cttccccctg
gcgccctgct ccaggagcac ctccgagagc 420
acagccgccc tgggctgcct ggtcaaggac
tacttccccg aaccggtgac ggtgtcctgg 480
aactctggcg ccctgacctc tggcgtgcac
accttccctg ctgtgctgca atcctctggc 540
ctgtactccc tgtcctctgt ggtgacagtg
ccatcctcca acttcggcac ccagacctac 600
acatgcaatg tggaccacaa gccatccaac
accaaggtgg acaagacagt ggagcggaag 660
tgctgtgtgg agtgcccccc atgccctgcc
ccccctgtgg ctggcccatc tgtgttcctg 720
ttccccccca agcccaagga caccctgatg
atctcccgga cccctgaggt gacctgtgtg 780
gtggtggacg tgtcccatga ggaccctgag
gtgcagttca actggtatgt ggatggcgtg 840
gaggtgcaca atgccaagac caagccccgg
gaggagcagt tcaactccac cttccgggtg 900
gtgtctgtgc tgacagtggt gcaccaggac
tggctgaatg gcaaggagta caagtgcaag 960
gtgtccaaca agggcctgcc tgcccccatc
gagaagacca tctccaagac caagggccag 1020
ccccgggagc cccaggtgta caccctgccc
ccatcccggg aggagatgac caagaaccag 1080
gtgtccctga cctgcctggt gaagggcttc
tacccatccg acattgctgt ggagtgggag 1140
tccaatggcc agcctgagaa caactacaag
accacccccc ccatgctgga ctctgatggc 1200
tccttcttcc tgtactccaa gctgacagtg
gacaagtccc ggtggcagca gggcaatgtg 1260
ttctcctgct ctgtgatgca tgaggccctg
cacaaccact acacccagaa gtccctgtcc 1320
ctgtcccctg gcaag
1335
<210> 81
<211> 447
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 IgG2 重链抗体序列
<400> 81
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala
Ser Gly Tyr Thr Phe Ser Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala
Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Asn Gly
Gly Thr Lys Tyr Asn Glu Lys Phe
50
55 60
Lys Gly Lys Ala Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Gly Tyr Tyr Leu Gly
Ser Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser
Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Cys Ser
Arg Ser Thr Ser Glu Ser Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp
Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr
Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr
Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Asn Phe Gly Thr Gln
Thr Tyr Thr Cys Asn Val Asp His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp
Lys Thr Val Glu Arg Lys Cys Cys
210 215 220
Val Glu Cys Pro Pro Cys Pro Ala
Pro Pro Val Ala Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys
Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val
Asp Val Ser His Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp
Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe
Asn Ser Thr Phe Arg Val Val Ser
290 295 300
Val Leu Thr Val Val His Gln Asp
Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu
Pro Ala Pro Ile Glu Lys Thr Ile
325 330 335
Ser Lys Thr Lys Gly Gln Pro Arg
Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Arg Glu Glu Met Thr Lys
Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp
Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys
Thr Thr Pro Pro Met Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser
Lys Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Gln Gly Asn Val Phe Ser
Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser
Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 82
<211> 1341
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 IgG2 重链抗体序列
<400> 82
gaagtgcagc tgttggaatc tggtggtggt
ctggtgcagc caggtggttc tctgcgtctg 60
tcttgcaagg cctctggtta caccttctct
tcttactgga tgcactgggt gcgtcaggca 120
ccaggtaagg gtctggaatg gatcggtcgt
atcgacccat ataacggtgg caccaagtac 180
aacgagaagt tcaagggtaa ggccaccatc
tctagagaca actctaagaa caccctgtac 240
ttgcagatga actctctgcg tgccgaggac
actgcagtgt actactgcgc ccgttatggt 300
tactaccttg gctcttacgc catggactac
tggggtcagg gtacgctggt gactgtctcg 360
agcgcatcca ccaagggccc atccgtcttc
cccctggcgc cctgctccag gagcacctcc 420
gagagcacag ccgccctggg ctgcctggtc
aaggactact tccccgaacc ggtgacggtg 480
tcctggaact ctggcgccct gacctctggc
gtgcacacct tccctgctgt gctgcaatcc 540
tctggcctgt actccctgtc ctctgtggtg
acagtgccat cctccaactt cggcacccag 600
acctacacat gcaatgtgga ccacaagcca
tccaacacca aggtggacaa gacagtggag 660
cggaagtgct gtgtggagtg ccccccatgc
cctgcccccc ctgtggctgg cccatctgtg 720
ttcctgttcc cccccaagcc caaggacacc
ctgatgatct cccggacccc tgaggtgacc 780
tgtgtggtgg tggacgtgtc ccatgaggac
cctgaggtgc agttcaactg gtatgtggat 840
ggcgtggagg tgcacaatgc caagaccaag
ccccgggagg agcagttcaa ctccaccttc 900
cgggtggtgt ctgtgctgac agtggtgcac
caggactggc tgaatggcaa ggagtacaag 960
tgcaaggtgt ccaacaaggg cctgcctgcc
cccatcgaga agaccatctc caagaccaag 1020
ggccagcccc gggagcccca ggtgtacacc
ctgcccccat cccgggagga gatgaccaag 1080
aaccaggtgt ccctgacctg cctggtgaag
ggcttctacc catccgacat tgctgtggag 1140
tgggagtcca atggccagcc tgagaacaac
tacaagacca ccccccccat gctggactct 1200
gatggctcct tcttcctgta ctccaagctg
acagtggaca agtcccggtg gcagcagggc 1260
aatgtgttct cctgctctgt gatgcatgag
gccctgcaca accactacac ccagaagtcc 1320
ctgtccctgt cccctggcaa g 1341
<210> 83
<211> 466
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 IgG2 重链抗体序列加上前导序列
<400> 83
Met Gly Trp Ser Leu Ile Leu Leu
Phe Leu Val Ala Val Ala Thr Arg
1
5 10 15
Val Leu Ser Glu Val Gln Leu Leu
Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser
Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Ser Ser Tyr Trp Met His Trp Val
Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Ile Gly Arg Ile Asp Pro
Tyr Asn Gly Gly Thr Lys Tyr Asn
65 70 75 80
Glu Lys Phe Lys Gly Lys Ala Thr
Ile Ser Arg Asp Asn Ser Lys Asn
85 90 95
Thr Leu Tyr Leu Gln Met Asn Ser
Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Tyr Gly Tyr
Tyr Leu Gly Ser Tyr Ala Met Asp
115 120 125
Tyr Trp Gly Gln Gly Thr Leu Val
Thr Val Ser Ser Ala Ser Thr Lys
130 135 140
Gly Pro Ser Val Phe Pro Leu Ala
Pro Cys Ser Arg Ser Thr Ser Glu
145 150 155 160
Ser Thr Ala Ala Leu Gly Cys Leu
Val Lys Asp Tyr Phe Pro Glu Pro
165 170 175
Val Thr Val Ser Trp Asn Ser Gly
Ala Leu Thr Ser Gly Val His Thr
180 185 190
Phe Pro Ala Val Leu Gln Ser Ser
Gly Leu Tyr Ser Leu Ser Ser Val
195 200 205
Val Thr Val Pro Ser Ser Asn Phe
Gly Thr Gln Thr Tyr Thr Cys Asn
210 215 220
Val Asp His Lys Pro Ser Asn Thr
Lys Val Asp Lys Thr Val Glu Arg
225 230 235 240
Lys Cys Cys Val Glu Cys Pro Pro
Cys Pro Ala Pro Pro Val Ala Gly
245 250 255
Pro Ser Val Phe Leu Phe Pro Pro
Lys Pro Lys Asp Thr Leu Met Ile
260 265 270
Ser Arg Thr Pro Glu Val Thr Cys
Val Val Val Asp Val Ser His Glu
275 280 285
Asp Pro Glu Val Gln Phe Asn Trp
Tyr Val Asp Gly Val Glu Val His
290 295 300
Asn Ala Lys Thr Lys Pro Arg Glu
Glu Gln Phe Asn Ser Thr Phe Arg
305 310 315 320
Val Val Ser Val Leu Thr Val Val
His Gln Asp Trp Leu Asn Gly Lys
325 330 335
Glu Tyr Lys Cys Lys Val Ser Asn
Lys Gly Leu Pro Ala Pro Ile Glu
340 345 350
Lys Thr Ile Ser Lys Thr Lys Gly
Gln Pro Arg Glu Pro Gln Val Tyr
355 360 365
Thr Leu Pro Pro Ser Arg Glu Glu
Met Thr Lys Asn Gln Val Ser Leu
370 375 380
Thr Cys Leu Val Lys Gly Phe Tyr
Pro Ser Asp Ile Ala Val Glu Trp
385 390 395 400
Glu Ser Asn Gly Gln Pro Glu Asn
Asn Tyr Lys Thr Thr Pro Pro Met
405 410 415
Leu Asp Ser Asp Gly Ser Phe Phe
Leu Tyr Ser Lys Leu Thr Val Asp
420 425 430
Lys Ser Arg Trp Gln Gln Gly Asn
Val Phe Ser Cys Ser Val Met His
435 440 445
Glu Ala Leu His Asn His Tyr Thr
Gln Lys Ser Leu Ser Leu Ser Pro
450 455 460
Gly Lys
465
<210> 84
<211> 1398
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 IgG2 重链抗体序列加上前导序列
<400> 84
atgggctggt ccctgattct gctgttcctg
gtggctgtgg ctaccagggt gctgtctgag 60
gtccaacttt tggagtctgg aggaggactg
gtccaacctg gaggctccct gagactgtcc 120
tgtaaggcat ctggctacac cttctcctcc
tactggatgc actgggtgag acaggctcct 180
ggcaagggat tggagtggat tggcaggatt
gacccataca atggaggcac caaatacaat 240
gagaagttca agggcaaggc taccatcagc
agggacaaca gcaagaacac cctctacctc 300
caaatgaact ccctgagggc tgaggacaca
gcagtctact actgtgccag atatggctac 360
tacctgggct cctatgctat ggactactgg
ggacaaggca ccctggtgac agtgtcctct 420
gctagcacca agggcccatc ggtcttcccc
ctggcgccct gctccaggag cacctccgag 480
agcacagcgg ccctgggctg cctggtcaag
gactacttcc ccgaaccggt gacggtgtcg 540
tggaactcag gcgctctgac cagcggcgtg
cacaccttcc cggctgtcct acagtcctca 600
ggactctact ccctcagcag cgtggtgacc
gtgccctcca gcaacttcgg cacccagacc 660
tacacctgca acgtagatca caagcccagc
aacaccaagg tggacaagac agttgagcgc 720
aaatgttgtg tcgagtgccc accgtgccca
gcaccacctg tggcaggacc gtcagtcttc 780
ctcttccccc caaaacccaa ggacaccctc
atgatctccc ggacccctga ggtcacgtgc 840
gtggtggtgg acgtgagcca cgaagacccc
gaggtccagt tcaactggta cgtggacggc 900
gtggaggtgc ataatgccaa gacaaagcca
cgggaggagc agttcaacag cacgttccgt 960
gtggtcagcg tcctcaccgt cgtgcaccag
gactggctga acggcaagga gtacaagtgc 1020
aaggtctcca acaaaggcct cccagccccc
atcgagaaaa ccatctccaa aaccaaaggg 1080
cagccccgag aaccacaggt gtacaccctg
cccccatccc gggaggagat gaccaagaac 1140
caggtcagcc tgacctgcct ggtcaaaggc
ttctacccca gcgacatcgc cgtggagtgg 1200
gagagcaatg ggcagccgga gaacaactac
aagaccacac ctcccatgct ggactccgac 1260
ggctccttct tcctctacag caagctcacc
gtggacaaga gcaggtggca gcaggggaac 1320
gtcttctcat gctccgtgat gcatgaggct
ctgcacaacc actacacaca gaagagcctc 1380
tccctgtctc cgggtaaa
1398
<210> 85
<211> 216
<212> PRT
<213> 人工序列
<220>
<223> AX1 IgG2 轻链抗体序列
<400> 85
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Ile Ser Arg Tyr
20
25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50
55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Ala Ala Tyr Asp Tyr Ser Leu Gly
85 90 95
Gly Tyr Val Phe Gly Asp Gly Thr
Lys Val Glu Ile Lys Arg Thr Val
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe
Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys
Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val
Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser
Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 86
<211> 648
<212> DNA
<213> 人工序列
<220>
<223> AX1 IgG2 轻链抗体序列
<400> 86
gacatccaga tgacccagtc tccatcttct
ctgtctgcct ctgtgggcga ccgggtgacc 60
atcacctgcc gtgcctctca ggatatctct
aggtatctgg cctggtatca gcagaagcca 120
ggtaaggcgc caaagctgct gatctacgcc
gcctcttctt tgcagtctgg tgtgccatct 180
cgtttctctg gttctggttc tggcaccgac
ttcaccctga ccatctcttc tttgcagcca 240
gaagacttcg ccacctacta ctgcgcggct
tacgactatt ctttgggcgg ttacgtgttc 300
ggtgatggta ccaaagtgga gatcaaacgt
acggtggctg caccatctgt cttcatcttc 360
ccgccatctg atgagcagtt gaaatctgga
actgcctctg ttgtgtgcct gctgaataac 420
ttctatccca gagaggccaa agtacagtgg
aaggtggata acgccctcca atcgggtaac 480
tcccaggaga gtgtcacaga gcaggacagc
aaggacagca cctacagcct cagcagcacc 540
ctgacgctga gcaaagcaga ctacgagaaa
cacaaagtct acgcctgcga agtcacccat 600
cagggcctga gctcgcccgt cacaaagagc
ttcaacaggg gagagtgt 648
<210> 87
<211> 216
<212> PRT
<213> 人工序列
<220>
<223> AX9 IgG2 轻链抗体序列
<400> 87
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys Arg
Ala Ser Gln Asp Val Ser Lys Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser
Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr
Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys
Gln Val Tyr Asp Ser Ser Pro Asn
85 90 95
Ala Tyr Val Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys Arg Thr Val
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe
Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys
Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val
Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser
Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 88
<211> 648
<212> DNA
<213> 人工序列
<220>
<223> AX9 IgG2 轻链抗体序列
<400> 88
gacatccaga tgacccagtc tccatcttct
ctgtctgcct ctgtgggcga ccgggtgacc 60
atcacctgcc gtgcctctca ggatgtctct
aagtatctgg cctggtatca gcagaagcca 120
ggtaaggcgc caaagctgct gatctacgcc
gcctcttctt tgcagtctgg tgtgccatct 180
cgtttctctg gttctggttc tggcaccgac
ttcaccctga ccatctcttc tttgcagcca 240
gaagacttcg ccacctacta ctgccaggta
tacgacagct ctccaaacgc ttatgtgttc 300
ggtggtggta ccaaagtgga gatcaaacgt
acggtggctg caccatctgt cttcatcttc 360
ccgccatctg atgagcagtt gaaatctgga
actgcctctg ttgtgtgcct gctgaataac 420
ttctatccca gagaggccaa agtacagtgg
aaggtggata acgccctcca atcgggtaac 480
tcccaggaga gtgtcacaga gcaggacagc
aaggacagca cctacagcct cagcagcacc 540
ctgacgctga gcaaagcaga ctacgagaaa
cacaaagtct acgcctgcga agtcacccat 600
cagggcctga gctcgcccgt cacaaagagc
ttcaacaggg gagagtgt 648
<210> 89
<211> 235
<212> PRT
<213> 人工序列
<220>
<223> AX189 IgG2 轻链抗体序列
<400> 89
Met Gly Trp Ser Cys Ile Ile Leu
Phe Leu Val Ala Thr Ala Thr Gly
1
5 10 15
Val His Ser Asp Ile Gln Met Thr
Gln Ser Pro Ser Ser Leu Ser Ala
20 25 30
Ser Val Gly Asp Arg Val Thr Ile
Thr Cys Arg Ala Ser Gln Asp Val
35 40 45
Ser Arg Tyr Leu Thr Trp Tyr Gln
Gln Lys Pro Gly Lys Ala Pro Lys
50 55 60
Leu Leu Ile Tyr Ala Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg
65 70 75 80
Phe Ser Gly Ser Gly Ser Gly Thr
Asp Phe Thr Leu Thr Ile Ser Ser
85 90 95
Leu Gln Pro Glu Asp Phe Ala Thr
Tyr Tyr Cys Gln Ala Tyr Asp Tyr
100 105 110
Ser Leu Ser Gly Tyr Val Phe Gly
Gly Gly Thr Lys Val Glu Ile Lys
115 120 125
Arg Thr Val Ala Ala Pro Ser Val
Phe Ile Phe Pro Pro Ser Asp Glu
130 135 140
Gln Leu Lys Ser Gly Thr Ala Ser
Val Val Cys Leu Leu Asn Asn Phe
145 150 155 160
Tyr Pro Arg Glu Ala Lys Val Gln
Trp Lys Val Asp Asn Ala Leu Gln
165 170 175
Ser Gly Asn Ser Gln Glu Ser Val
Thr Glu Gln Asp Ser Lys Asp Ser
180 185 190
Thr Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr Glu
195 200 205
Lys His Lys Val Tyr Ala Cys Glu
Val Thr His Gln Gly Leu Ser Ser
210 215 220
Pro Val Thr Lys Ser Phe Asn Arg
Gly Glu Cys
225 230 235
<210> 90
<211> 705
<212> DNA
<213> 人工序列
<220>
<223> AX189 IgG2 轻链抗体序列
<400> 90
atgggctggt cctgtatcat cctgttcctg
gtggctacag ccacaggagt gcattctgac 60
atccagatga cccagagccc atcctccctg
tctgcctctg tgggagacag ggtgaccatc 120
acttgtaggg caagccagga tgtgagcaga
tacctgacct ggtatcaaca gaagcctggc 180
aaggctccaa aactgctgat ttatgctgcc
tcctccctcc aatctggagt gccaagcagg 240
ttctctggct ctggctctgg cacagacttc
accctgacca tctcctccct ccaacctgag 300
gactttgcca cctactactg tcaggcttat
gactactccc tgtctggcta tgtgtttgga 360
ggaggcacca aggtggagat taagcgtacg
gtggctgcac catctgtctt catcttcccg 420
ccatctgatg agcagttgaa atctggaact
gcctctgttg tgtgcctgct gaataacttc 480
tatcccagag aggccaaagt acagtggaag
gtggataacg ccctccaatc gggtaactcc 540
caggagagtg tcacagagca ggacagcaag
gacagcacct acagcctcag cagcaccctg 600
acgctgagca aagcagacta cgagaaacac
aaagtctacg cctgcgaagt cacccatcag 660
ggcctgagct cgcccgtcac aaagagcttc
aacaggggag agtgt 705
<210> 91
<211> 4752
<212> DNA
<213> 人工序列
<220>
<223> AX1 抗体质粒序列
<400> 91
gcgcaacgca attaatgtga gttagctcac
tcattaggca ccccaggctt tacactttat 60
gcttccggct cgtatgttgt gtggaattgt
gagcggataa caatttaccg gttcttgtaa 120
ggaggaatta aaaaatgaaa aagtctttag
tcctcaaagc ctccgtagcc gttgctaccc 180
tcgttccgat gctaagcttc gctgacatcc
agatgaccca gtctccatct tctctgtctg 240
cctctgtggg cgaccgggtg accatcacct
gccgtgcctc tcaggatatc tctaggtatc 300
tggcctggta tcagcagaag ccaggtaagg
cgccaaagct gctgatctac gccgcctctt 360
ctttgcagtc tggtgtgcca tctcgtttct
ctggttctgg ttctggcacc gacttcaccc 420
tgaccatctc ttctttgcag ccagaagact
tcgccaccta ctactgcgcg gcttacgact 480
attctttggg cggttacgtg ttcggtgatg
gtaccaaagt ggagatcaaa cgtacggtgg 540
ctgcaccatc tgtcttcatc ttcccgccat
ctgatgagca gttgaaatct ggaactgcct 600
ctgttgtgtg cctgctgaat aacttctatc
ccagagaggc caaagtacag tggaaggtgg 660
ataacgccct ccaatcgggt aactcccagg
agagtgtcac agagcaggac agcaaggaca 720
gcacctacag cctcagcagc accctgacgc
tgagcaaagc agactacgag aaacacaaag 780
tctacgcctg cgaagtcacc catcagggcc
tgagctcgcc cgtcacaaag agcttcaaca 840
ggggagagtg ttgataaggc gcgccacaat
ttcacagtaa ggaggtttaa cttatgaaaa 900
aattattatt cgcaattcct ttagttgttc
ctttctattc tcactccgct ggatccgaag 960
tgcagctgct ggaatctggt ggtggtctgg
tgcagccagg tggttctctg cgtctgtctt 1020
gcaaggcctc tggtttcacc ttcacttctt
actacatgca ctgggtgcgt caggcaccag 1080
gtaagggtct ggaatggatc ggtcggatca
acccagattc tggtagtact aagtacaacg 1140
agaagttcaa gggtcgtgcc accatctcta
gagacaactc taagaacacc ctgtacttgc 1200
agatgaactc tctgcgtgcc gaggacactg
cagtgtacta ctgcgcccgt ggtggtcgtt 1260
tatcctggga cttcgacgtc tggggtcagg
gtacgctggt gactgtctcg agcgcaagca 1320
ccaaaggccc atcggtattc cccctggcac
cctcctccaa gagcacctct gggggcacag 1380
cggccctggg ctgcctggtc aaggactact
tccccgagcc ggtgacggtg tcgtggaact 1440
caggcgctct gaccagcggc gtgcacacct
tcccggctgt cctacagtcc tcaggactct 1500
actccctcag cagcgtggtg actgtgccct
ccagcagctt gggcacccag acctacatct 1560
gcaacgtgaa tcacaagccc agcaacacta
aggtggacaa gaaagttgag cccaaatctt 1620
gtgacaaaac tcacacagcg gccgcttatc
catacgacgt accagactac gcaggaggtc 1680
atcaccatca tcaccatgtc gacagatctg
gaggaggtga ggagaagtcc cggctgttgg 1740
agaaggagaa ccgtgaactg gaaaagatca
ttgctgagaa agaggagcgt gtctctgaac 1800
tgcgccatca actccagtct gtaggaggtt
gttaataagt cgacgtttaa acggtctcca 1860
gcttggctgt tttggcggat gagagaagat
tttcagcctg atacagatta aatcagaacg 1920
cagaagcggt ctgataaaac agaatttgcc
tggcggcagt agcgcggtgg tcccacctga 1980
ccccatgccg aactcagaag tgaaacgccg
tagcgccgat ggtagtgtgg ggtctcccca 2040
tgcgagagta gggaactgcc aggcatcaaa
taaaacgaaa ggctcagtcg aaagactggg 2100
cctttacgcg ctcactggcc gtcgttttac
aacgtcgtga ctgggaaaac cctggcgtta 2160
cccaacttaa tcgccttgca gcacatcccc
ctttcgccag ctggcgtaat agcgaagagg 2220
cccgcaccga tcgcccttcc caacagttgc
gcagcctgaa tggcgaatgg gacgcgccct 2280
gtagcggcgc attaagcgcg gcgggtgtgg
tggttacgcg cagcgtgacc gctacacttg 2340
ccagcgccct agcgcccgct cctttcgctt
tcttcccttc ctttctcgcc acgttcgccg 2400
gctttccccg tcaagctcta aatcgggggc
tccctttagg gttccgattt agtgctttac 2460
ggcacctcga ccccaaaaaa cttgattagg
gtgatggttc acgtagtggg ccatcgccct 2520
gatagacggt ttttcgccct ttgacgttgg
agtccacgtt ctttaatagt ggactcttgt 2580
tccaaactgg aacaacactc aaccctatct
cggtctattc ttttgattta taagggattt 2640
tgccgatttc ggcctattgg ttaaaaaatg
agctgattta acaaaaattt aacgcgaatt 2700
ttaacaaaat attaacgctt acaatttagg
tggcactttt cggggaaatg tgcgcggaac 2760
ccctatttgt ttatttttct aaatacattc
aaatatgtat ccgctcatga gacaataacc 2820
ctgataaatg cttcaataat attgaaaaag
gaagagtatg agtattcaac atttccgtgt 2880
cgcccttatt cccttttttg cggcattttg
ccttcctgtt tttgctcacc cagaaacgct 2940
ggtgaaagta aaagatgctg aagatcagtt
gggtgcacga gtgggttaca tcgaactgga 3000
tctcaacagc ggtaagatcc ttgagagttt
tcgccccgaa gaacgttttc caatgatgag 3060
cacttttaaa gttctgctat gtggcgcggt
attatcccgt attgacgccg ggcaagagca 3120
actcggtcgc cgcatacact attctcagaa
tgacttggtt gagtactcac cagtcacaga 3180
aaagcatctt acggatggca tgacagtaag
agaattatgc agtgctgcca taaccatgag 3240
tgataacact gcggccaact tacttctgac
aacgatcgga ggaccgaagg agctaaccgc 3300
ttttttgcac aacatggggg atcatgtaac
tcgccttgat cgttgggaac cggagctgaa 3360
tgaagccata ccaaacgacg agcgtgacac
cacgatgcct gtagcaatgg caacaacgtt 3420
gcgcaaacta ttaactggcg aactacttac
tctagcttcc cggcaacaat taatagactg 3480
gatggaggcg gataaagttg caggaccact
tctgcgctcg gcccttccgg ctggctggtt 3540
tattgctgat aaatctggag ccggtgagcg
tgggtctcgc ggtatcattg cagcactggg 3600
gccagatggt aagccctccc gtatcgtagt
tatctacacg acggggagtc aggcaactat 3660
ggatgaacga aatagacaga tcgctgagat
aggtgcctca ctgattaagc attggtaact 3720
gtcagaccaa gtttactcat atatacttta
gattgattta aaacttcatt tttaatttaa 3780
aaggatctag gtgaagatcc tttttgataa
tctcatgacc aaaatccctt aacgtgagtt 3840
ttcgttccac tgagcgtcag accccgtaga
aaagatcaaa ggatcttctt gagatccttt 3900
ttttctgcgc gtaatctgct gcttgcaaac
aaaaaaacca ccgctaccag cggtggtttg 3960
tttgccggat caagagctac caactctttt
tccgaaggta actggcttca gcagagcgca 4020
gataccaaat actgtccttc tagtgtagcc
gtagttaggc caccacttca agaactctgt 4080
agcaccgcct acatacctcg ctctgctaat
cctgttacca gtggctgctg ccagtggcga 4140
taagtcgtgt cttaccgggt tggactcaag
acgatagtta ccggataagg cgcagcggtc 4200
gggctgaacg gggggttcgt gcacacagcc
cagcttggag cgaacgacct acaccgaact 4260
gagataccta cagcgtgagc tatgagaaag
cgccacgctt cccgaaggga gaaaggcgga 4320
caggtatccg gtaagcggca gggtcggaac
aggagagcgc acgagggagc ttccaggggg 4380
aaacgcctgg tatctttata gtcctgtcgg
gtttcgccac ctctgacttg agcgtcgatt 4440
tttgtgatgc tcgtcagggg ggcggagcct
atggaaaaac gccagcaacg cggccttttt 4500
acggttcctg gccttttgct ggccttttgc
tcacatgttc tttcctgcgt tatcccctga 4560
ttctgtggat aaccgtatta ccgcctttga
gtgagctgat accgctcgcc gcagccgaac 4620
gaccgagcgc agcgagtcag tgagcgagga
agcggaagag cgcccaatac gcaaaccgcc 4680
tctccccgcg cgttggccga ttcattaatg
cagctggcac gacaggtttc ccgactggaa 4740
agcgggcagt ga
4752
<210> 92
<211> 4758
<212> DNA
<213> 人工序列
<220>
<223> AX9 抗体质粒序列
<400> 92
gcgcaacgca attaatgtga gttagctcac
tcattaggca ccccaggctt tacactttat 60
gcttccggct cgtatgttgt gtggaattgt
gagcggataa caatttaccg gttcttgtaa 120
ggaggaatta aaaaatgaaa aagtctttag
tcctcaaagc ctccgtagcc gttgctaccc 180
tcgttccgat gctaagcttc gctgacatcc
agatgaccca gtctccatct tctctgtctg 240
cctctgtggg cgaccgggtg accatcacct
gccgtgcctc tcaggatgtc tctaagtatc 300
tggcctggta tcagcagaag ccaggtaagg
cgccaaagct gctgatctac gccgcctctt 360
ctttgcagtc tggtgtgcca tctcgtttct
ctggttctgg ttctggcacc gacttcaccc 420
tgaccatctc ttctttgcag ccagaagact
tcgccaccta ctactgccag gtatacgaca 480
gctctccaaa cgcttatgtg ttcggtggtg
gtaccaaagt ggagatcaaa cgtacggtgg 540
ctgcaccatc tgtcttcatc ttcccgccat
ctgatgagca gttgaaatct ggaactgcct 600
ctgttgtgtg cctgctgaat aacttctatc
ccagagaggc caaagtacag tggaaggtgg 660
ataacgccct ccaatcgggt aactcccagg
agagtgtcac agagcaggac agcaaggaca 720
gcacctacag cctcagcagc accctgacgc
tgagcaaagc agactacgag aaacacaaag 780
tctacgcctg cgaagtcacc catcagggcc
tgagctcgcc cgtcacaaag agcttcaaca 840
ggggagagtg ttgataaggc gcgccacaat
ttcacagtaa ggaggtttaa cttatgaaaa 900
aattattatt cgcaattcct ttagttgttc
ctttctattc tcactccgct ggatccgaag 960
tgcagctgtt ggaatctggt ggtggtctgg
tgcagccagg tggttctctg cgtctgtctt 1020
gcaaggcctc tggttacacc ttctcttctt
actggatgca ctgggtgcgt caggcaccag 1080
gtaagggtct ggaatggatc ggtcgtatcg
acccatataa cggtggcacc aagtacaacg 1140
agaagttcaa gggtaaggcc accatctcta
gagacaactc taagaacacc ctgtacttgc 1200
agatgaactc tctgcgtgcc gaggacactg
cagtgtacta ctgcgcccgt tatggttact 1260
accttggctc ttacgccatg gactactggg
gtcagggtac gctggtgact gtctcgagcg 1320
caagcaccaa aggcccatcg gtattccccc
tggcaccctc ctccaagagc acctctgggg 1380
gcacagcggc cctgggctgc ctggtcaagg
actacttccc cgagccggtg acggtgtcgt 1440
ggaactcagg cgctctgacc agcggcgtgc
acaccttccc ggctgtccta cagtcctcag 1500
gactctactc cctcagcagc gtggtgactg
tgccctccag cagcttgggc acccagacct 1560
acatctgcaa cgtgaatcac aagcccagca
acactaaggt ggacaagaaa gttgagccca 1620
aatcttgtga caaaactcac acagcggccg
cttatccata cgacgtacca gactacgcag 1680
gaggtcatca ccatcatcac catgtcgaca
gatctggagg aggtgaggag aagtcccggc 1740
tgttggagaa ggagaaccgt gaactggaaa
agatcattgc tgagaaagag gagcgtgtct 1800
ctgaactgcg ccatcaactc cagtctgtag
gaggttgtta ataagtcgac gtttaaacgg 1860
tctccagctt ggctgttttg gcggatgaga
gaagattttc agcctgatac agattaaatc 1920
agaacgcaga agcggtctga taaaacagaa
tttgcctggc ggcagtagcg cggtggtccc 1980
acctgacccc atgccgaact cagaagtgaa
acgccgtagc gccgatggta gtgtggggtc 2040
tccccatgcg agagtaggga actgccaggc
atcaaataaa acgaaaggct cagtcgaaag 2100
actgggcctt tacgcgctca ctggccgtcg
ttttacaacg tcgtgactgg gaaaaccctg 2160
gcgttaccca acttaatcgc cttgcagcac
atcccccttt cgccagctgg cgtaatagcg 2220
aagaggcccg caccgatcgc ccttcccaac
agttgcgcag cctgaatggc gaatgggacg 2280
cgccctgtag cggcgcatta agcgcggcgg
gtgtggtggt tacgcgcagc gtgaccgcta 2340
cacttgccag cgccctagcg cccgctcctt
tcgctttctt cccttccttt ctcgccacgt 2400
tcgccggctt tccccgtcaa gctctaaatc
gggggctccc tttagggttc cgatttagtg 2460
ctttacggca cctcgacccc aaaaaacttg
attagggtga tggttcacgt agtgggccat 2520
cgccctgata gacggttttt cgccctttga
cgttggagtc cacgttcttt aatagtggac 2580
tcttgttcca aactggaaca acactcaacc
ctatctcggt ctattctttt gatttataag 2640
ggattttgcc gatttcggcc tattggttaa
aaaatgagct gatttaacaa aaatttaacg 2700
cgaattttaa caaaatatta acgcttacaa
tttaggtggc acttttcggg gaaatgtgcg 2760
cggaacccct atttgtttat ttttctaaat
acattcaaat atgtatccgc tcatgagaca 2820
ataaccctga taaatgcttc aataatattg
aaaaaggaag agtatgagta ttcaacattt 2880
ccgtgtcgcc cttattccct tttttgcggc
attttgcctt cctgtttttg ctcacccaga 2940
aacgctggtg aaagtaaaag atgctgaaga
tcagttgggt gcacgagtgg gttacatcga 3000
actggatctc aacagcggta agatccttga
gagttttcgc cccgaagaac gttttccaat 3060
gatgagcact tttaaagttc tgctatgtgg
cgcggtatta tcccgtattg acgccgggca 3120
agagcaactc ggtcgccgca tacactattc
tcagaatgac ttggttgagt actcaccagt 3180
cacagaaaag catcttacgg atggcatgac
agtaagagaa ttatgcagtg ctgccataac 3240
catgagtgat aacactgcgg ccaacttact
tctgacaacg atcggaggac cgaaggagct 3300
aaccgctttt ttgcacaaca tgggggatca
tgtaactcgc cttgatcgtt gggaaccgga 3360
gctgaatgaa gccataccaa acgacgagcg
tgacaccacg atgcctgtag caatggcaac 3420
aacgttgcgc aaactattaa ctggcgaact
acttactcta gcttcccggc aacaattaat 3480
agactggatg gaggcggata aagttgcagg
accacttctg cgctcggccc ttccggctgg 3540
ctggtttatt gctgataaat ctggagccgg
tgagcgtggg tctcgcggta tcattgcagc 3600
actggggcca gatggtaagc cctcccgtat
cgtagttatc tacacgacgg ggagtcaggc 3660
aactatggat gaacgaaata gacagatcgc
tgagataggt gcctcactga ttaagcattg 3720
gtaactgtca gaccaagttt actcatatat
actttagatt gatttaaaac ttcattttta 3780
atttaaaagg atctaggtga agatcctttt
tgataatctc atgaccaaaa tcccttaacg 3840
tgagttttcg ttccactgag cgtcagaccc
cgtagaaaag atcaaaggat cttcttgaga 3900
tccttttttt ctgcgcgtaa tctgctgctt
gcaaacaaaa aaaccaccgc taccagcggt 3960
ggtttgtttg ccggatcaag agctaccaac
tctttttccg aaggtaactg gcttcagcag 4020
agcgcagata ccaaatactg tccttctagt
gtagccgtag ttaggccacc acttcaagaa 4080
ctctgtagca ccgcctacat acctcgctct
gctaatcctg ttaccagtgg ctgctgccag 4140
tggcgataag tcgtgtctta ccgggttgga
ctcaagacga tagttaccgg ataaggcgca 4200
gcggtcgggc tgaacggggg gttcgtgcac
acagcccagc ttggagcgaa cgacctacac 4260
cgaactgaga tacctacagc gtgagctatg
agaaagcgcc acgcttcccg aagggagaaa 4320
ggcggacagg tatccggtaa gcggcagggt
cggaacagga gagcgcacga gggagcttcc 4380
agggggaaac gcctggtatc tttatagtcc
tgtcgggttt cgccacctct gacttgagcg 4440
tcgatttttg tgatgctcgt caggggggcg
gagcctatgg aaaaacgcca gcaacgcggc 4500
ctttttacgg ttcctggcct tttgctggcc
ttttgctcac atgttctttc ctgcgttatc 4560
ccctgattct gtggataacc gtattaccgc
ctttgagtga gctgataccg ctcgccgcag 4620
ccgaacgacc gagcgcagcg agtcagtgag
cgaggaagcg gaagagcgcc caatacgcaa 4680
accgcctctc cccgcgcgtt ggccgattca
ttaatgcagc tggcacgaca ggtttcccga 4740
ctggaaagcg ggcagtga
4758
<210> 93
<211> 4534
<212> DNA
<213> 人工序列
<220>
<223> AX189 抗体质粒序列
<400> 93
gcgcaacgca attaatgtga gttagctcac
tcattaggca ccccaggctt tacactttat 60
gcttccggct cgtatgttgt gtggaattgt
gagcggataa caatttaccg gttcttgtaa 120
ggaggaatta aaaaatgaaa aagtctttag
tcctcaaagc ctccgtagcc gttgctaccc 180
tcgttccgat gctaagcttc gctgacatcc
agatgaccca gtctccatct tctctgtctg 240
cctctgtggg cgaccgggtg accatcacct
gccgtgcctc tcaggatgtc tctaggtatc 300
tgacctggta tcagcagaag ccaggtaagg
cgccaaagct gctgatctac gccgcctctt 360
ctttgcagtc tggtgtgcca tctcgtttct
ctggttctgg ttctggcacc gacttcaccc 420
tgaccatctc ttctttgcag ccagaagact
tcgccaccta ctactgccag gcttacgact 480
attctttgag cggttacgtg ttcggtggtg
gtaccaaagt ggagatcaaa cgtacggtgg 540
ctgcaccatc tgtattcatc ttcccgccat
ctgatgagca gttgaaatct ggaactgcct 600
ctgttgtgtg cctgctgaat aacttctatc
ccagagaggc caaagtacag tggaaggtgg 660
ataacgccct ccaatcgggt aactcccagg
agagtgtcac agagcaggac agcaaggaca 720
gcacctacag cctcagcagc accctgacgc
tgagcaaagc agactacgag aaacacaaag 780
tctacgcctg cgaagtcacc catcagggcc
tgagctcgcc cgtcacaaag agcttcaaca 840
ggggagagtg ttaatgatgt accggcgcgc
cacaatttca cagtaaggag gtttaactta 900
tgaaaaaatt attattcgca attcctttag
ttgttccttt ctattctcac tccgctggat 960
ccgaagtgca gctgttggaa tctggtggtg
gtctggtgca gccaggtggt tctctgcgtc 1020
tgtcttgcaa ggcctctggt tacaccttct
cttcttactg gatgcactgg gtgcgtcagg 1080
caccaggtaa gggtctggaa tggatcggtc
gtatcgaccc atataacggt ggcaccaagt 1140
acaacgagaa gttcaagggt aaggccacca
tctctagaga caactctaag aacaccctgt 1200
acttgcagat gaactctctg cgtgccgagg
acactgcagt gtactactgc gcccgttatg 1260
gttactacct tggctcttac gccatggact
actggggtca gggtacgctg gtgactgtct 1320
cgagcgcaag caccaaaggc ccatcggtat
tccccctggc accctcctcc aagagcacct 1380
ctgggggcac agcggccctg ggctgcctgg
tcaaggacta cttccccgag ccggtgacgg 1440
tgtcgtggaa ctcaggcgct ctgaccagcg
gcgtgcacac cttcccggct gtcctacagt 1500
cctcaggact ctactccctc agcagcgtgg
tgactgtgcc ctccagcagc ttgggcaccc 1560
agacctacat ctgcaacgtg aatcacaagc
ccagcaacac taaggtggac aagaaagttg 1620
agcccaaatc ttgtgacaaa actcacacag
cggccgctta tccatacgac gtaccagact 1680
acgcaggagg tcatcaccat catcaccatt
agagatctgg aggaggtgag gagaagtccc 1740
ggctgttgga gaaggagaac cgtgaactgg
aaaagatcat tgctgagaaa gaggagcgtg 1800
tctctgaact gcgccatcaa ctccagtctg
taggaggttg ttaataagtc gacctcgacc 1860
aattcgccct atagtgagtc gtattacgcg
cgctcactgg ccgtcgtttt acaacgtcgt 1920
gactgggaaa accctggcgt tacccaactt
aatcgccttg cagcacatcc ccctttcgcc 1980
agctggcgta atagcgaaga ggcccgcacc
gatcgccctt cccaacagtt gcgcagcctg 2040
aatggcgaat gggacgcgcc ctgtagcggc
gcattaagcg cggcgggtgt ggtggttacg 2100
cgcagcgtga ccgctacact tgccagcgcc
ctagcgcccg ctcctttcgc tttcttccct 2160
tcctttctcg ccacgttcgc cggctttccc
cgtcaagctc taaatcgggg gctcccttta 2220
gggttccgat ttagtgcttt acggcacctc
gaccccaaaa aacttgatta gggtgatggt 2280
tcacgtagtg ggccatcgcc ctgatagacg
gtttttcgcc ctttgacgtt ggagtccacg 2340
ttctttaata gtggactctt gttccaaact
ggaacaacac tcaaccctat ctcggtctat 2400
tcttttgatt tataagggat tttgccgatt
tcggcctatt ggttaaaaaa tgagctgatt 2460
taacaaaaat ttaacgcgaa ttttaacaaa
atattaacgc ttacaattta ggtggcactt 2520
ttcggggaaa tgtgcgcgga acccctattt
gtttattttt ctaaatacat tcaaatatgt 2580
atccgctcat gagacaataa ccctgataaa
tgcttcaata atattgaaaa aggaagagta 2640
tgagtattca acatttccgt gtcgccctta
ttcccttttt tgcggcattt tgccttcctg 2700
tttttgctca cccagaaacg ctggtgaaag
taaaagatgc tgaagatcag ttgggtgcac 2760
gagtgggtta catcgaactg gatctcaaca
gcggtaagat ccttgagagt tttcgccccg 2820
aagaacgttt tccaatgatg agcactttta
aagttctgct atgtggcgcg gtattatccc 2880
gtattgacgc cgggcaagag caactcggtc
gccgcataca ctattctcag aatgacttgg 2940
ttgagtactc accagtcaca gaaaagcatc
ttacggatgg catgacagta agagaattat 3000
gcagtgctgc cataaccatg agtgataaca
ctgcggccaa cttacttctg acaacgatcg 3060
gaggaccgaa ggagctaacc gcttttttgc
acaacatggg ggatcatgta actcgccttg 3120
atcgttggga accggagctg aatgaagcca
taccaaacga cgagcgtgac accacgatgc 3180
ctgtagcaat ggcaacaacg ttgcgcaaac
tattaactgg cgaactactt actctagctt 3240
cccggcaaca attaatagac tggatggagg
cggataaagt tgcaggacca cttctgcgct 3300
cggcccttcc ggctggctgg tttattgctg
ataaatctgg agccggtgag cgtgggtctc 3360
gcggtatcat tgcagcactg gggccagatg
gtaagccctc ccgtatcgta gttatctaca 3420
cgacggggag tcaggcaact atggatgaac
gaaatagaca gatcgctgag ataggtgcct 3480
cactgattaa gcattggtaa ctgtcagacc
aagtttactc atatatactt tagattgatt 3540
taaaacttca tttttaattt aaaaggatct
aggtgaagat cctttttgat aatctcatga 3600
ccaaaatccc ttaacgtgag ttttcgttcc
actgagcgtc agaccccgta gaaaagatca 3660
aaggatcttc ttgagatcct ttttttctgc
gcgtaatctg ctgcttgcaa acaaaaaaac 3720
caccgctacc agcggtggtt tgtttgccgg
atcaagagct accaactctt tttccgaagg 3780
taactggctt cagcagagcg cagataccaa
atactgtcct tctagtgtag ccgtagttag 3840
gccaccactt caagaactct gtagcaccgc
ctacatacct cgctctgcta atcctgttac 3900
cagtggctgc tgccagtggc gataagtcgt
gtcttaccgg gttggactca agacgatagt 3960
taccggataa ggcgcagcgg tcgggctgaa
cggggggttc gtgcacacag cccagcttgg 4020
agcgaacgac ctacaccgaa ctgagatacc
tacagcgtga gctatgagaa agcgccacgc 4080
ttcccgaagg gagaaaggcg gacaggtatc
cggtaagcgg cagggtcgga acaggagagc 4140
gcacgaggga gcttccaggg ggaaacgcct
ggtatcttta tagtcctgtc gggtttcgcc 4200
acctctgact tgagcgtcga tttttgtgat
gctcgtcagg ggggcggagc ctatggaaaa 4260
acgccagcaa cgcggccttt ttacggttcc
tggccttttg ctggcctttt gctcacatgt 4320
tctttcctgc gttatcccct gattctgtgg
ataaccgtat taccgccttt gagtgagctg 4380
ataccgctcg ccgcagccga acgaccgagc
gcagcgagtc agtgagcgag gaagcggaag 4440
agcgcccaat acgcaaaccg cctctccccg
cgcgttggcc gattcattaa tgcagctggc 4500
acgacaggtt tcccgactgg aaagcgggca
gtga 4534
<210> 94
<211> 22
<212> PRT
<213> 人工序列
<220>
<223> 抗体重链框架序列
<400> 94
Glu Val Gln Leu Leu Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly
1
5 10 15
Ser Leu Arg Leu Ser Cys
20
<210> 95
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 抗体重链框架序列
<400> 95
Gln Ala Pro Gly Lys Gly Leu Glu
1
5
<210> 96
<211> 26
<212> PRT
<213> 人工序列
<220>
<223> 抗体重链框架序列
<400> 96
Ile Ser Arg Asp Asn Ser Lys Asn
Thr Leu Tyr Leu Gln Met Asn Ser
1
5 10 15
Leu Arg Ala Glu Asp Thr Ala Val
Tyr Tyr
20 25
<210> 97
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 抗体重链框架序列
<400> 97
Gly Thr Leu Val Thr Val Ser Ser
1
5
<210> 98
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 抗体轻链框架序列
<400> 98
Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly
1
5 10 15
Asp Arg Val Thr Ile Thr Cys
20
<210> 99
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 抗体轻链框架序列
<400> 99
Trp Tyr Gln Gln Lys Pro Gly Lys
Ala Pro Lys Leu Leu Ile Tyr
1
5 10 15
<210> 100
<211> 32
<212> PRT
<213> 人工序列
<220>
<223> 抗体轻链框架序列
<400> 100
Gly Val Pro Ser Arg Phe Ser Gly
Ser Gly Ser Gly Thr Asp Phe Thr
1
5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro
Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 101
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 抗体轻链框架序列
<400> 101
Phe Gly Asp Gly Thr Lys Val Glu
Ile Lys
1
5 10
<210> 102
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 抗体轻链框架序列
<400> 102
Phe Gly Gly Gly Thr Lys Val Glu
Ile Lys
1
5 10
<210> 103
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 内部加工位点
<400> 103
Ser Ser Val Phe Ala Gln
1
5
<210> 104
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 内部加工位点
<400> 104
Ser Ile Pro Trp Asn Leu
1
5
<210> 105
<211> 4
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 105
Pro Trp Asn Leu
1
<210> 106
<211> 22
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 106
Pro Ala Ser Ala Pro Glu Val Ile
Thr Val Gly Ala Thr Asn Ala Gln
1
5 10 15
Asp Gln Pro Val Thr Leu
20
<210> 107
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 107
Arg Leu Ile His Phe Ser Ala Lys
Asp Val Ile Asn Glu
1
5 10
<210> 108
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 108
Phe Pro Glu Asp Gln Arg Val Leu
Thr Pro Asn Leu
1
5 10
<210> 109
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 109
Val Gly Ala Thr Asn Ala Gln Asp
Gln Pro Val Thr Leu
1
5 10
<210> 110
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 110
Ser Ala Lys Asp Val Ile Asn Glu
1
5
<210> 111
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 111
Phe Pro Glu Asp Gln
1 5
<210> 112
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 112
Thr Asn Ala Gln Asp Gln Pro Val
Thr Leu Gly Thr Leu Gly
1
5 10
<210> 113
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 113
Asp Val Ile Asn Glu Ala Trp Phe
Pro Glu
1
5 10
<210> 114
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 114
Phe Glu Asn Val Pro Glu Glu Asp
Gly Thr Arg
1
5 10
<210> 115
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 115
Gln Ala Ser Lys Cys Asp
1
5
<210> 116
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 116
Arg Val Leu Asn Cys Gln Gly Lys
Gly
1
5
<210> 117
<211> 330
<212> PRT
<213> 人工序列
<220>
<223> 包含IgG1的FC结构域的序列
<400> 117
Ala Ser Thr Lys Gly Pro Ser Val
Phe Pro Leu Ala Pro Ser Ser Lys
1
5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala
Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser
Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val
Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro
Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro
Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Ala Glu Pro Lys Ser Cys Asp
Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly
Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile
Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu
Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His
Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg
Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys
Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu
Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr
Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu
Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp
Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val
Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp
Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His
Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro
Gly Lys
325 330
<210> 118
<211> 326
<212> PRT
<213> 人工序列
<220>
<223> 包含IgG2的FC结构域的序列
<400> 118
Ala Ser Thr Lys Gly Pro Ser Val
Phe Pro Leu Ala Pro Cys Ser Arg
1
5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala
Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser
Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val
Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Thr
Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys
Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Cys Val
Glu Cys Pro Pro Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe
Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro
Glu Val Thr Cys Val Val Val Asp
130 135 140
Val Ser His Glu Asp Pro Glu Val
Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr
Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val
Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys
Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ala Pro Ile Glu Lys Thr Ile Ser
Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro
Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val
Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly
Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp
Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp
Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His
Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 119
<211> 327
<212> PRT
<213> 人工序列
<220>
<223> 包含IgG4的FC结构域的序列
<400> 119
Ala Ser Thr Lys Gly Pro Ser Val
Phe Pro Leu Ala Pro Cys Ser Arg
1
5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala
Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser
Trp Asn Ser Gly Ala Leu Thr Ser
35
40 45
Gly Val His Thr Phe Pro Ala Val
Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro
Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys
Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro
Pro Cys Pro Ser Cys Pro Ala Pro
100 105 110
Glu Phe Leu Gly Gly Pro Ser Val
Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr
Pro Glu Val Thr Cys Val Val Val
130
135 140
Asp Val Ser Gln Glu Asp Pro Glu
Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys
Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser
Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys
Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile
Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro
Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu
Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn
Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser
Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg
Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu
His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 120
<211> 326
<212> PRT
<213> 人工序列
<220>
<223> 包含IgG2m4的FC结构域的序列
<400> 120
Ala Ser Thr Lys Gly Pro Ser Val
Phe Pro Leu Ala Pro Cys Ser Arg
1
5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala
Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser
Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val
Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Thr
Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys
Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Cys Val
Glu Cys Pro Pro Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe
Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro
Glu Val Thr Cys Val Val Val Asp
130 135 140
Val Ser Gln Glu Asp Pro Glu Val
Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr
Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val
Leu Thr Val Leu His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys
Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ser Ser Ile Glu Lys Thr Ile Ser
Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro
Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys
Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly
Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp
Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp
Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His
Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 121
<211> 21
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 121
Ala Leu Arg Ser Glu Glu Asp Gly
Leu Ala Glu Ala Pro Glu His Gly
1
5 10 15
Thr Thr Ala Thr Phe
20
<210> 122
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 122
Arg Ser Glu Glu Asp Gly Leu
1
5
<210> 123
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 123
Arg Ser Glu Glu Asp Gly Leu Ala
Glu Ala Pro Glu His Gly Thr Thr
1
5 10 15
Ala Thr Phe
<210> 124
<211> 24
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 124
Ala Pro Glu His Gly Thr Thr Ala
Thr Phe His Arg Cys Ala Lys Asp
1
5 10 15
Pro Trp Arg Leu Pro Gly Thr Tyr
20
<210> 125
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 125
Arg Cys Ala Lys Asp Pro Trp Arg
Leu Pro Gly Thr Tyr
1
5 10
<210> 126
<211> 38
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 126
Glu Thr His Leu Ser Gln Ser Glu
Arg Thr Ala Arg Arg Leu Gln Ala
1
5 10 15
Gln Ala Ala Arg Arg Gly Tyr Leu
Thr Lys Ile Leu His Val Phe His
20 25 30
Gly Leu Leu Pro Gly Phe
35
<210> 127
<211> 39
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 127
Glu Thr His Leu Ser Gln Ser Glu
Arg Thr Ala Arg Arg Leu Gln Ala
1
5 10 15
Gln Ala Ala Arg Arg Gly Tyr Leu
Thr Lys Ile Leu His Val Phe His
20 25 30
Gly Leu Leu Pro Gly Phe Leu
35
<210> 128
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 128
Ile Leu His Val Phe His Gly Leu
Leu Pro Gly Phe Leu
1
5 10
<210> 129
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 129
Met Ser Gly Asp Leu
1
5
<210> 130
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 130
Met Ser Gly Asp Leu Leu Glu
1
5
<210> 131
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 131
Leu Lys Leu Pro His Val Asp Tyr
1
5
<210> 132
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 132
Lys Leu Pro His Val Asp Tyr
1
5
<210> 133
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 133
Ile Thr Pro Pro Arg Tyr Arg Ala
Asp Glu Tyr Gln Pro Pro Asp Gly
1
5 10 15
Gly Ser Leu
<210> 134
<211> 21
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 134
Ile Thr Pro Pro Arg Tyr Arg Ala
Asp Glu Tyr Gln Pro Pro Asp Gly
1
5 10 15
Gly Ser Leu Val Glu
20
<210> 135
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 135
Thr Ser Ile Gln Ser Asp His Arg
Glu Ile Glu Gly Arg Val
1
5 10
<210> 136
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 136
Ile Gln Ser Asp His Arg Glu Ile
Glu Gly Arg Val Met Val Thr Asp
1
5 10 15
Phe
<210> 137
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 137
Val Pro Glu Glu Asp Gly Thr Arg
Phe His Arg Gln Ala Ser Lys Cys
1
5 10 15
Asp Ser His Gly Thr His Leu
20
<210> 138
<211> 40
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 138
Val Pro Glu Glu Asp Gly Thr Arg
Phe His Arg Gln Ala Ser Lys Cys
1
5 10 15
Asp Ser His Gly Thr His Leu Ala
Gly Val Val Ser Gly Arg Asp Ala
20 25 30
Gly Val Ala Lys Gly Ala Ser Met
35 40
<210> 139
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 139
Val Val Ser Gly Arg Asp Ala Gly
Val Ala Lys Gly Ala Ser Met
1
5 10 15
<210> 140
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 140
Leu Arg Val Leu Asn Cys Gln Gly
Lys Gly Thr Val Ser Gly Thr Leu
1
5 10 15
<210> 141
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 141
Ile Arg Lys Ser Gln Leu Val Gln
Pro Val Gly Pro Leu Val Val Leu
1
5 10 15
<210> 142
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 142
Arg Lys Ser Gln Leu Val Gln Pro
Val Gly Pro Leu Val Val Leu
1
5 10 15
<210> 143
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 143
Leu Leu Pro Leu Ala Gly Gly Tyr
1
5
<210> 144
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 144
Leu Ala Gly Gly Tyr Ser Arg Val
Leu Asn Ala
1
5 10
<210> 145
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 145
Leu Ala Gly Gly Tyr Ser Arg Val
Leu Asn Ala Ala Cys
1
5 10
<210> 146
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 146
Leu Ala Arg Ala Gly Val Val Leu
1
5
<210> 147
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 147
Ala Gly Val Val Leu
1
5
<210> 148
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 148
Ala Ala Gly Asn Phe
1
5
<210> 149
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 149
Asp Asp Ala Cys Leu
1
5
<210> 150
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 150
Pro Ala Ser Ala Pro Glu Val
1
5
<210> 151
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 151
Leu Gly Thr Asn Phe Gly Arg Cys
1
5
<210> 152
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 152
Leu Phe Ala Pro Gly Glu Asp
1
5
<210> 153
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 153
Pro Gly Glu Asp Ile Ile Gly Ala
Ser Ser Asp Cys Ser Thr Cys
1
5 10 15
<210> 154
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 154
Gly Ala Ser Ser Asp Cys Ser Thr
Cys
1
5
<210> 155
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 155
Gln Ser Gly Thr Ser Gln Ala Ala
Ala His Val Ala Gly Ile Ala
1
5 10 15
<210> 156
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 156
Ser Ala Glu Pro Glu Leu Thr Leu
1
5
<210> 157
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 157
Ala Glu Pro Glu Leu Thr Leu
1
5
<210> 158
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 158
Leu Arg Gln Arg Leu Ile His Phe
1
5
<210> 159
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 159
Leu Arg Gln Arg Leu Ile His Phe
Ser Ala Lys Asp Val Ile Asn Glu
1
5 10 15
<210> 160
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 160
Arg Leu Ile His Phe
1
5
<210> 161
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 161
Val Leu Thr Pro Asn Leu
1
5
<210> 162
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 162
Leu Thr Pro Asn Leu
1
5
<210> 163
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 163
Ala Leu Pro Pro Ser Thr His Gly
Ala Gly Trp Gln Leu
1
5 10
<210> 164
<211> 21
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 164
Met Gly Thr Arg Val His Cys His
Gln Gln Gly His Val Leu Thr Gly
1
5 10 15
Cys Ser Ser His Trp
20
<210> 165
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> PCSK9 片段
<400> 165
Arg Val His Cys His Gln Gln Gly
His Val Leu Thr Gly Cys Ser Ser
1
5 10 15
His Trp
<210> 166
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> 表位序列
<400> 166
Glu Arg Ile Thr Pro Pro Arg Tyr
Arg Ala Asp Glu Tyr Gln Pro Pro
1
5 10 15
Asp Gly Gly Ser Leu Val Glu
20
<210> 167
<211> 692
<212> PRT
<213> 智人
<220>
<223> 人 PCSK9
<400> 167
Met Gly Thr Val Ser Ser Arg Arg
Ser Trp Trp Pro Leu Pro Leu Leu
1
5 10 15
Leu Leu Leu Leu Leu Leu Leu Gly
Pro Ala Gly Ala Arg Ala Gln Glu
20 25 30
Asp Glu Asp Gly Asp Tyr Glu Glu
Leu Val Leu Ala Leu Arg Ser Glu
35 40 45
Glu Asp Gly Leu Ala Glu Ala Pro
Glu His Gly Thr Thr Ala Thr Phe
50 55 60
His Arg Cys Ala Lys Asp Pro Trp
Arg Leu Pro Gly Thr Tyr Val Val
65 70 75 80
Val Leu Lys Glu Glu Thr His Leu
Ser Gln Ser Glu Arg Thr Ala Arg
85 90 95
Arg Leu Gln Ala Gln Ala Ala Arg
Arg Gly Tyr Leu Thr Lys Ile Leu
100 105 110
His Val Phe His Gly Leu Leu Pro
Gly Phe Leu Val Lys Met Ser Gly
115 120 125
Asp Leu Leu Glu Leu Ala Leu Lys
Leu Pro His Val Asp Tyr Ile Glu
130 135 140
Glu Asp Ser Ser Val Phe Ala Gln
Ser Ile Pro Trp Asn Leu Glu Arg
145 150 155 160
Ile Thr Pro Pro Arg Tyr Arg Ala
Asp Glu Tyr Gln Pro Pro Asp Gly
165 170 175
Gly Ser Leu Val Glu Val Tyr Leu
Leu Asp Thr Ser Ile Gln Ser Asp
180 185 190
His Arg Glu Ile Glu Gly Arg Val
Met Val Thr Asp Phe Glu Asn Val
195 200 205
Pro Glu Glu Asp Gly Thr Arg Phe
His Arg Gln Ala Ser Lys Cys Asp
210 215 220
Ser His Gly Thr His Leu Ala Gly
Val Val Ser Gly Arg Asp Ala Gly
225 230 235 240
Val Ala Lys Gly Ala Ser Met Arg
Ser Leu Arg Val Leu Asn Cys Gln
245 250 255
Gly Lys Gly Thr Val Ser Gly Thr
Leu Ile Gly Leu Glu Phe Ile Arg
260 265 270
Lys Ser Gln Leu Val Gln Pro Val
Gly Pro Leu Val Val Leu Leu Pro
275 280 285
Leu Ala Gly Gly Tyr Ser Arg Val
Leu Asn Ala Ala Cys Gln Arg Leu
290 295 300
Ala Arg Ala Gly Val Val Leu Val
Thr Ala Ala Gly Asn Phe Arg Asp
305 310 315 320
Asp Ala Cys Leu Tyr Ser Pro Ala
Ser Ala Pro Glu Val Ile Thr Val
325 330 335
Gly Ala Thr Asn Ala Gln Asp Gln
Pro Val Thr Leu Gly Thr Leu Gly
340 345 350
Thr Asn Phe Gly Arg Cys Val Asp
Leu Phe Ala Pro Gly Glu Asp Ile
355 360 365
Ile Gly Ala Ser Ser Asp Cys Ser
Thr Cys Phe Val Ser Gln Ser Gly
370 375 380
Thr Ser Gln Ala Ala Ala His Val
Ala Gly Ile Ala Ala Met Met Leu
385 390 395 400
Ser Ala Glu Pro Glu Leu Thr Leu
Ala Glu Leu Arg Gln Arg Leu Ile
405 410 415
His Phe Ser Ala Lys Asp Val Ile Asn
Glu Ala Trp Phe Pro Glu Asp
420 425 430
Gln Arg Val Leu Thr Pro Asn Leu
Val Ala Ala Leu Pro Pro Ser Thr
435 440 445
His Gly Ala Gly Trp Gln Leu Phe
Cys Arg Thr Val Trp Ser Ala His
450 455 460
Ser Gly Pro Thr Arg Met Ala Thr
Ala Val Ala Arg Cys Ala Pro Asp
465 470 475 480
Glu Glu Leu Leu Ser Cys Ser Ser
Phe Ser Arg Ser Gly Lys Arg Arg
485 490 495
Gly Glu Arg Met Glu Ala Gln Gly
Gly Lys Leu Val Cys Arg Ala His
500 505 510
Asn Ala Phe Gly Gly Glu Gly Val
Tyr Ala Ile Ala Arg Cys Cys Leu
515 520 525
Leu Pro Gln Ala Asn Cys Ser Val
His Thr Ala Pro Pro Ala Glu Ala
530 535 540
Ser Met Gly Thr Arg Val His Cys
His Gln Gln Gly His Val Leu Thr
545 550 555 560
Gly Cys Ser Ser His Trp Glu Val
Glu Asp Leu Gly Thr His Lys Pro
565 570 575
Pro Val Leu Arg Pro Arg Gly Gln
Pro Asn Gln Cys Val Gly His Arg
580 585 590
Glu Ala Ser Ile His Ala Ser Cys
Cys His Ala Pro Gly Leu Glu Cys
595 600 605
Lys Val Lys Glu His Gly Ile Pro
Ala Pro Gln Glu Gln Val Thr Val
610 615 620
Ala Cys Glu Glu Gly Trp Thr Leu
Thr Gly Cys Ser Ala Leu Pro Gly
625 630 635 640
Thr Ser His Val Leu Gly Ala Tyr
Ala Val Asp Asn Thr Cys Val Val
645 650 655
Arg Ser Arg Asp Val Ser Thr Thr
Gly Ser Thr Ser Glu Gly Ala Val
660 665 670
Thr Ala Val Ala Ile Cys Cys Arg
Ser Arg His Leu Ala Gln Ala Ser
675 680 685
Gln Glu Leu Gln
690
<210> 168
<211> 80
<212> PRT
<213> 人工序列
<220>
<223> EGF_AB 肽
<400> 168
Asp Lys Val Cys Asn Met Ala Arg
Asp Cys Arg Asp Trp Ser Asp Glu
1
5 10 15
Pro Ile Lys Glu Cys Gly Thr Asn
Glu Cys Leu Asp Asn Asn Gly Gly
20 25 30
Cys Ser His Val Cys Asn Asp Leu Lys
Ile Gly Tyr Glu Cys Leu Cys
35 40 45
Pro Asp Gly Phe Gln Leu Val Ala
Gln Arg Arg Cys Glu Asp Ile Asp
50 55 60
Glu Cys Gln Asp Pro Asp Thr Cys
Ser Gln Leu Cys Val Asn Leu Glu
65 70 75 80
<210> 169
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR1
<400> 169
Gly Tyr Thr Phe Ser Ser Tyr Trp
Met His
1
5 10
<210> 170
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR1
<400> 170
ggttacacct tctcttctta
ctggatgcac
30
<210> 171
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR2
<400> 171
Arg Ile Asp Pro Tyr Asn Gly Gly
Thr Lys Tyr Asn Glu Lys Phe Lys
1
5 10 15
Gly
<210> 172
<211> 51
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR2
<400> 172
cgtatcgacc catataacgg tggcaccaag
tacaacgaga agttcaacac c 51
<210> 173
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR3
<400> 173
Tyr Gly Tyr Tyr Leu Gly Ser Tyr
Ala Met Asp Tyr
1
5 10
<210> 174
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> AX9 AX189 VH CDR3
<400> 174
tatggttact
accttggctc ttacgccatg gactac 36