WO2025049690A1 - Circular polyethylene glycol lipids - Google Patents
Circular polyethylene glycol lipids Download PDFInfo
- Publication number
- WO2025049690A1 WO2025049690A1 PCT/US2024/044348 US2024044348W WO2025049690A1 WO 2025049690 A1 WO2025049690 A1 WO 2025049690A1 US 2024044348 W US2024044348 W US 2024044348W WO 2025049690 A1 WO2025049690 A1 WO 2025049690A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- compound
- kda
- lipid
- peg
- formula
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/69—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the conjugate being characterised by physical or galenical forms, e.g. emulsion, particle, inclusion complex, stent or kit
- A61K47/6921—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the conjugate being characterised by physical or galenical forms, e.g. emulsion, particle, inclusion complex, stent or kit the form being a particulate, a powder, an adsorbate, a bead or a sphere
- A61K47/6927—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the conjugate being characterised by physical or galenical forms, e.g. emulsion, particle, inclusion complex, stent or kit the form being a particulate, a powder, an adsorbate, a bead or a sphere the form being a solid microparticle having no hollow or gas-filled cores
- A61K47/6929—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the conjugate being characterised by physical or galenical forms, e.g. emulsion, particle, inclusion complex, stent or kit the form being a particulate, a powder, an adsorbate, a bead or a sphere the form being a solid microparticle having no hollow or gas-filled cores the form being a nanoparticle, e.g. an immuno-nanoparticle
- A61K47/6931—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the conjugate being characterised by physical or galenical forms, e.g. emulsion, particle, inclusion complex, stent or kit the form being a particulate, a powder, an adsorbate, a bead or a sphere the form being a solid microparticle having no hollow or gas-filled cores the form being a nanoparticle, e.g. an immuno-nanoparticle the material constituting the nanoparticle being a polymer
- A61K47/6935—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the conjugate being characterised by physical or galenical forms, e.g. emulsion, particle, inclusion complex, stent or kit the form being a particulate, a powder, an adsorbate, a bead or a sphere the form being a solid microparticle having no hollow or gas-filled cores the form being a nanoparticle, e.g. an immuno-nanoparticle the material constituting the nanoparticle being a polymer the polymer being obtained otherwise than by reactions involving carbon to carbon unsaturated bonds, e.g. polyesters, polyamides or polyglycerol
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/69—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the conjugate being characterised by physical or galenical forms, e.g. emulsion, particle, inclusion complex, stent or kit
- A61K47/6905—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the conjugate being characterised by physical or galenical forms, e.g. emulsion, particle, inclusion complex, stent or kit the form being a colloid or an emulsion
- A61K47/6911—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the conjugate being characterised by physical or galenical forms, e.g. emulsion, particle, inclusion complex, stent or kit the form being a colloid or an emulsion the form being a liposome
-
- C—CHEMISTRY; METALLURGY
- C08—ORGANIC MACROMOLECULAR COMPOUNDS; THEIR PREPARATION OR CHEMICAL WORKING-UP; COMPOSITIONS BASED THEREON
- C08G—MACROMOLECULAR COMPOUNDS OBTAINED OTHERWISE THAN BY REACTIONS ONLY INVOLVING UNSATURATED CARBON-TO-CARBON BONDS
- C08G65/00—Macromolecular compounds obtained by reactions forming an ether link in the main chain of the macromolecule
- C08G65/02—Macromolecular compounds obtained by reactions forming an ether link in the main chain of the macromolecule from cyclic ethers by opening of the heterocyclic ring
- C08G65/32—Polymers modified by chemical after-treatment
- C08G65/329—Polymers modified by chemical after-treatment with organic compounds
- C08G65/331—Polymers modified by chemical after-treatment with organic compounds containing oxygen
- C08G65/332—Polymers modified by chemical after-treatment with organic compounds containing oxygen containing carboxyl groups, or halides, or esters thereof
-
- C—CHEMISTRY; METALLURGY
- C08—ORGANIC MACROMOLECULAR COMPOUNDS; THEIR PREPARATION OR CHEMICAL WORKING-UP; COMPOSITIONS BASED THEREON
- C08G—MACROMOLECULAR COMPOUNDS OBTAINED OTHERWISE THAN BY REACTIONS ONLY INVOLVING UNSATURATED CARBON-TO-CARBON BONDS
- C08G65/00—Macromolecular compounds obtained by reactions forming an ether link in the main chain of the macromolecule
- C08G65/02—Macromolecular compounds obtained by reactions forming an ether link in the main chain of the macromolecule from cyclic ethers by opening of the heterocyclic ring
- C08G65/32—Polymers modified by chemical after-treatment
- C08G65/329—Polymers modified by chemical after-treatment with organic compounds
- C08G65/333—Polymers modified by chemical after-treatment with organic compounds containing nitrogen
Definitions
- 60287WO_CRF_sequencelisting.xml 60287WO_CRF_sequencelisting.xml, and is 103,849 bytes in size.
- the present disclosure generally relates to circular polymeric (e.g., polyethylene glycol (PEG)) lipid structures that can be incorporated into lipid nanoparticle (LNP) compositions.
- PEG polyethylene glycol
- PEG polyethylene glycol
- PEGylated drugs can elicit immune responses, including the production of anti-PEG antibodies, which can lead to accelerated blood clearance (ABC) and reduced or ablated efficacy upon repeated dosing.
- PEG lipids traditionally incorporated into lipid nanoparticles (LNPs) for gene delivery are thought to mainly elicit a thymus independent (TI) immune response which does not lead to the formation of PEG-specific antibodies.
- TI thymus independent
- the present disclosure provides circular polymeric (e.g.. PEG) lipids.
- PEG polymeric lipids.
- these can have reduced antibody binding capacity and therefore reduced accelerated blood clearance (ABC).
- the present application provides circular polymeric (e.g., PEG) lipid compounds, and methods for preparing and using the same.
- the circular polymeric lipid compounds can comprise a macrocycle comprising one or more polymer blocks (e.g., such as one or more polyethylene gly col (PEG) blocks) and at least one lipid.
- one or more lipids are covalently attached to the macrocycle and is outside the macrocycle's backbone.
- the macrocycle comprises two or more PEG blocks in the macrocycle's backbone, and at least one lipid covalently attached to the macrocycle outside of its backbone.
- the macrocycle includes two lipids within the macrocycle’s backbone, wherein all the polymeric blocks are between the two lipids.
- the present application also provides methods of preparing the subject circular polymeric lipid compounds, and their use in lipid nanoparticle formulations.
- a compound comprising: a macrocycle comprising one or more polymer, e.g., polyethylene glycol (PEG), blocks in the macrocycle’s backbone; and at least one lipid; wherein either
- PEG polyethylene glycol
- the at least one lipid is covalently attached to the macrocycle and is outside the macrocycle’s backbone;
- the compound comprises one or more PEG blocks in the macrocycle’s backbone and at least one lipid, wherein the at least one lipid is covalently attached to the macrocycle, and is outside the macrocycle’s backbone.
- the compound comprises one or more PEG block in the macrocycle and two lipids, wherein the one or more PEG blocks are all between the two lipids.
- a and A’ are independently a lipid
- LP is a linking moiety comprising one or more polyethylene glycol (PEG) blocks.
- a and A’ each form a link to a core-shell structure of a lipid nanoparticle to form a macrocycle.
- FIG. 1 is a schematic outlining the constrained PEG theory .
- FIG. 2 illustrates a compound of Formula (IV) forming a link to a core-shell structure of a lipid nanoparticle to form a macrocycle.
- FIG. 3B depicts fLuc expression of circular RNAs formulated with LNP 5 comprising Ionizable Lipid 3 and circular polymeric lipid Compound 6-17.
- FIG. 3C depicts fLuc expression of circular RNAs formulated with LNP 7 comprising Ionizable Lipid 3 and polymeric lipid DMG- PEG2000 (control). Luminescence in FIGs. 3A-3C is depicted as radiance measured in p/sec/cm 2 /sr.
- FIGs. 4A and 4B depict total firefly luminescence in p/s measured in BL/6 mice liver (provided in FIG. 4A) and spleen (provided in FIG. 4B) post intravenous administration of circular RNAs encoding firefly luciferase (fLuc) formulated with lipid nanoparticles from FIGs. 3A-3C (LNP 4. LNP 5 and LNP 7) or a phosphate buffered saline (“PBS”) solution (negative control).
- PBS phosphate buffered saline
- the present application provides, among other things, circular polymeric lipid compounds, and methods for preparing and using the same.
- the subject circular polymeric lipids e.g., circular PEG lipids
- LNP lipid nanoparticle
- the subject lipid nanoparticles can comprise RNA polynucleotides, particularly circular RNA polynucleotides (aka circRNA or oRNATM).
- RNA therapy also disclosed herein is RNA therapy, along with associated compositions and methods.
- the RNA therapy allows for increased RNA stability, expression, and prolonged half-life, among other things.
- methods comprising administration of circular RNA polynucleotides provided herein into cells for therapy or production of useful proteins.
- the method is advantageous in providing the production of a desired polypeptide inside eukaryotic cells with a longer half-life than linear RNA, due to the resistance of the circular RNA to ribonucleases.
- the present disclosure provides circular polymeric lipid compounds, wherein the compound comprises a macrocycle comprising one or more polymer blocks (e.g., one or more polyethylene glycol (PEG) blocks) in the macrocycle’s backbone; and at least one lipid; wherein either:
- PEG polyethylene glycol
- the at least one lipid is covalently attached to the macrocycle and is outside the macrocycle’s backbone;
- tw o lipids are in the macrocycle’s backbone, wherein all polymer blocks are between the two lipids.
- any convenient polymer block may be used in the macrocycle’s backbone.
- the polymer block is a hydrophilic polymer block.
- the macrocycle’s backbone comprises two or more polymer blocks, and the polymer blocks are made up of a combination of hydrophilic polymer blocks and hydrophobic polymer blocks.
- the macrocycle’s backbone comprises two or more polymer blocks, and all the polymer blocks are hydrophilic polymer blocks.
- a hydrophilic polymer can be one generally that attracts water, and a hydrophobic polymer can be one that generally repels water.
- the macrocycle comprises one or more polyethylene glycol (PEG) blocks.
- PEG polyethylene glycol
- the compound satisfies (a), and the macrocycle comprises one or more PEG blocks in the macrocycle’s backbone and at least one lipid covalently attached to the macrocycle outside the macrocycle’s backbone. In some embodiments, the compound satisfies (a), and the macrocycle comprises two or more PEG blocks in the macrocycle’s backbone and at least one lipid covalently attached to the macrocycle outside the macrocycle’s backbone. [0025] In some embodiments, the compound satisfies (b), and the macrocycle comprises a PEG block between two lipids as part of the macrocycle’s backbone. In some embodiments, the compound satisfies (b), and the macrocycle comprises two or more PEG blocks between two lipids as part of the macrocycle's backbone.
- the circular polymeric lipid compound satisfies (a), and the at least one lipid is covalently attached to the macrocycle and is outside the macrocycle’s backbone.
- the compound satisfies (a) and is of Formula (I): wherein:
- P is the macrocycle; and n is an integer selected from 1 to 6, preferably an integer from 1 to 3.
- the compound of Formula (I) includes a core branching moiety (X).
- X comprises one or more amino acid residues.
- the one or more amino acid residues are selected from lysine, ornithine, aspartate, glutamate, serine, cysteine, and tyrosine.
- X comprises a lysine residue.
- X comprises an ornithine residue.
- X comprises an aspartate residue.
- X comprises a glutamate residue.
- X comprises a serine residue.
- X comprises a cysteine residue.
- X comprises a tyrosine residue.
- X comprises XA: wherein zl and z2 are each independently 0, 1, 2, 3. 4, or 5; and two represent the point of attachment to P and the other represents the points of attachment to A.
- X comprises XA’ : wherein zl and z2 are each independently 0, 1, 2, 3, 4, or 5; and represents the point of attachment to P and represents the points of attachment to A.
- zl and z2 are each 0.
- XA, zl and z2 are each 1.
- XA, zl and z2 are each 2.
- XA, zl and z2 are each 3.
- XA, zl and z2 are each 4.
- XA, zl and z2 are each 5.
- X comprises:
- X comprises:
- X comprises XB: wherein z3 and 7.4 are each independently 0, 1 , 2, 3, 4, or 5; and two represent the point of attachment to P and the other represents the points of attachment to A.
- X comprises XB’:
- z3 and z4 are each independently 0, 1, 2, 3, 4, or 5; and represent the point of attachment to P and represents the points of attachment to A.
- z3 and z4 are each 0.
- z3 and z4 are each 1.
- XB, z3 and z4 are each 2.
- z3 and z4 are each 3.
- XB, z3 and z4 are each 4.
- XB, z3 and z4 arc each 5.
- X comprises:
- X comprises:
- X comprises a substituted linear or branched C1-C6 alkylene. In some cases, X comprises a substituted linear C1-C6 alkylene. In some cases, X comprises a substituted branched C3-C6 alkylene. In some cases, X comprises a substituted branched C3- alkylene. In some cases, X comprises a substituted branched C 4 -alkylene. In some cases, X comprises a substituted branched C5-alkylene. In some cases, X comprises a substituted branched C6-alkylene.
- X comprises: wherein two represent the point of attachment to P and the other represents the point of attachment to A.
- X comprises: wherein two represent the point of attachment to P and the other two represent the points of attachment to each A. [0042] In some embodiments of Formula (I), X comprises a substituted trivalent nitrogen atom. In some embodiments of Formula (I), X comprises: wherein two represent the point of attachment to P and the other represents the point of attachment to A.
- X comprises a phosphonatc. In some embodiments of Formula (I), X comprises: wherein two represent the point of attachment to P and the other represents the point of attachment to A.
- the compound of Formula (I) is of the Formula (II): wherein:
- A is the at least one lipid;
- X 1 is a branching moiety;
- n 1 or 2.
- Branching moiety X 1 [0045] As described herein, the compound of Formula (II) includes a branching moiety (X 1 ). In some embodiments of Formula (II), X 1 comprises an optionally substituted branched C1-C6 alkylene.
- X 1 is of the Formula (X 1 -1); wherein: W 1 -W 3 are each independently a C0-C20 alkylene; and each represent a point of attachment to each of Z A , Z B and Z c .
- W 1 -W 3 are each a CO alkylene, such that X 1 is: wherein each represent a point of attachment to each of Z A , Z B and Z c .
- two of W 1 -W are a CO alkylene, and the other is a Cl- C20 alkylene, such as a Cl-alkylene.
- C2 -alkylene C3-alkylene, C4-alkylene. or a C5-alkylene.
- X 1 comprises:
- each represent a point of attachment to each of Z A , Z B and Z c .
- one of W 1 -W 3 is a CO alkylene, and the other two are C1-C20 alkylene, such as a C1-alkylene.
- X 1 comprises: wherein each represent a point of attachment to each of Z A , Z B and Z c .
- W 1 -W 3 are each independently C1-C20 alkylene, such as a Cl-alkylene, C2-alkylene, C3-alkylene, C4-alkylcne. or a C5-alkylene.
- X 1 comprises: wherein each represent a point of attachment to each of Z A .
- X 1 comprises a phosphonate. In some embodiments of Formula (II). X 1 comprises: wherein each represent a point of attachment to each of Z A , Z B and Z c .
- linking moiety Z A is an ether, ester, carbonate, amide, carbamate, urea, amine, anhydride or a disulfide group.
- Z A is selected from - SS-, -C(O)OC(O)-, -NH-, -NHC(O)NH-, -OC(O)NH-, -C(O)NH(CH 2 )z-, -NHC(O)(CH 2 )z-, - OC(O)O-, -OC(O)-, and -O-, where z is 0, 1, 2, 3, 4. or 5.
- Z A is -SS-.
- Z A is -C(O)OC(O)-. In some embodiments. Z A is -NH-. In some embodiments, Z A is - NHC(O)NH-. In some embodiments, Z A is -OC(O)NH-. In some embodiments, Z A is -NHC(O)-. In some embodiments, Z A is -OC(O)O-. In some embodiments, Z A is -OC(O)-. In some embodiments, Z A is -O-.
- linking moiety Z A is selected from -C(O)NH-, -NHC(O)- , -C(O)O-, -OC(O)-, -O-, -OC(O)O-, -OC(O)NH-, -NHC(O)O-, -OP(O)(OH)O-, a maleimide-thiol conjugation, and a triazole.
- Z A is -O-.
- Z A is -C(O)O-.
- Z A is -OC(O)-.
- Z A is -OP(O)(OH)O-.
- the compound of Formula (II) comprises linking moieties Z B and Z c that covalently attach the branching moiety (X 1 ) to the polymer containing macrocycle (P).
- Z B and Z c are optional moieties, and thus in some cases Z B and/or Z c are absent such that the branching moiety (X 1 ) is covalently attached directly to polymer containing macrocycle (P).
- linking moiety Z B is an ether, ester, carbonate, amide, carbamate, urea, amine, anhydride or a disulfide group.
- Z B is selected from - SS-, -C(O)OC(O)-, -NH-, -NHC(O)NH-. -OC(O)NH-, -C(O)NH(CH 2 ) Z -, -NHC(O)(CH 2 ) Z -, - OC(O)O-. -OC(O)-. and -O-. wherein z is 0. 1. 2, 3, 4, or 5.
- Z B is -SS-. In some embodiments, Z B is -C(O)OC(O)-. In some embodiments, Z B is -NH-. In some embodiments. Z B is - NHC(O)NH-. In some embodiments, Z B is -OC(O)NH-. In some embodiments, Z B is -NHC(O)-. In some embodiments, Z B is -NHC(O)CH2-. In some embodiments, Z B is -NHCO(CH2)2-. In some embodiments, Z B is -OC(O)O-. In some embodiments, Z B is -OC(O)-. In some embodiments, Z B is - O-.
- linking moiety Z B is selected from -C(O)NH-, - C(O)NHCH 2 -, -C(O)NH(CH 2 ) 2 -, -NHC(O)-, -NHC(O)CH 2 -, -NHC(O)(CH 2 ) 2 -, -C(O)O-OC(O)-, -O-, OCO2-, -OC(O)NH-, -NHC(O)O-, -OP(O)(OH)O-, a maleimide-thiol conjugation, and a triazole.
- Z B is -C(O)NH-.
- Z B is -NHC(O)-. In some embodiments, Z B is -NHC(O)CH 2 -. In some embodiments, Z B is -NHC(O)(CH 2 )2-. In some embodiments. Z B is - OC(O)-.
- linking moiety Z c is an ether, ester, carbonate, amide, carbamate, urea, amine, anhydride or a disulfide group.
- Z c is selected from - SS-, -C(O)OC(O)-, -NH-, -NHC(O)NH-. -OC(O)NH-, -C(O)NH(CH 2 )z-, -NHC(O)(CH 2 )z-, - OC(O)O-. -OC(O)-, and -O-. wherein z is 0. 1. 2, 3, 4, or 5.
- Z c is -SS-.
- Z c is -C(O)OC(O)-. In some embodiments, Z c is -NH-. In some embodiments, Z c is - NHC(O)NH-. In some embodiments. Z c is -OC(O)NH-. In some embodiments, Z c is -NHC(O)-. In some embodiments, Z c is -NHC(O)CH 2 -. In some embodiments. Z c is -NHC(O)(CH2) 2 -. In some embodiments, Z c is -OC(O)O-. In some embodiments, Z c is -OC(O)-. In some embodiments. Z c is - O-.
- linking moiety Z c is selected from -C(O)NH-, -C(O)NHCH 2 -, - C(O)NH(CH 2 ) 2 -. -NHC(O)-, -NHC(O)CH 2 -, -NHC(O)(CH 2 ) 2 -, -C(O)O-, -OC(O)-, -O-, OCO2-, - OC(O)NH-, -NHC(O)O-, -OP(O)(OH)O-, a maleimide-thiol conjugation, and a triazole.
- Z is -C(O)NH-.
- Z c is -NHC(O)-. In some embodiments, Z' is -NHC(O)CH 2 -. In some embodiments, Z c is -NHC(O)(CH 2 ) 2 -. In some embodiments, Z c is -OC(O)-.
- the compound of Formula (II) comprises all optional linking moieties Z A , Z B and Z c .
- Z A , Z B and Z are the same linking moiety.
- Z A -Z C are each -OC(O)-.
- Z A -Z C are each -O-.
- Z A -Z C are each -NHC(O)-.
- Z A -Z C are each -NHC(O)CH 2 -.
- Z A -Z C are each -NHC(O)(CH 2 ) 2 -.
- Z A -Z C are each - C(O)NH-.
- Z B and Z c are the same and Z A is a different linking moiety.
- Z A is -C(O)O-; and Z B and Z c are each -OC(O)-.
- Z A is -OP(O)(OH)O-; and Z B and Z c are each -OC(O)-.
- Z A is -OC(O)-; and Z B and Z c are each -NHC(O)-.
- Z A is -0C(0)-; and Z B and Z c are each -NHC(O)CH 2 -.
- Z A is - OC(O)-; and Z B and Z c are each -NHC(O)(CH 2 ) 2 -.
- Z A , Z B and Z are each different linking moieties.
- Z A is -OC(O)-; Z B is -NHC(O)-; and Z c is -C(O)NH-.
- the macrocycle (P in Formulae I and II) comprises one or more polymer blocks in the macrocycle’s backbone. Any convenient polymer block may be used in the macrocycle’s backbone.
- the macrocycle comprises one or more hydrophilic polymer blocks.
- the macrocycle comprises two or more polymer blocks, and the polymer blocks are made up of a combination of hydrophilic polymer blocks and hydrophobic polymer blocks.
- the macrocycle comprises two or more polymer blocks, and the polymer blocks are all hydrophilic polymer blocks.
- Polymer blocks can be natural or unnatural (synthetic) polymers.
- Polymer blocks can be copolymers comprising two or more monomers.
- copolymers can be random, block, or comprise a combination of random and block sequences.
- polymer as used herein, is given its ordinary meaning as used in the art, i.e., a molecular structure comprising one or more repeat units (monomers), connected by covalent bonds.
- the repeat units may all be identical, or in some cases, there may be more than one type of repeat unit present within the polymer. If more than one type of repeat unit is present within the polymer, then the polymer is said to be a “copolymer.” It is to be understood that in any embodiment employing a polymer, the polymer being employed may be a copolymer in some cases.
- the repeat units forming the copolymer may be arranged in any fashion.
- the repeat units may be arranged in a random order, in an alternating order, or as a block copolymer, i.e., comprising one or more regions each comprising a first repeat unit (e.g.. a first block), and one or more regions each comprising a second repeat unit (e.g.. a second block), etc.
- Block copolymers may have two (a di-block copolymer), three (a tri-block copolymer), or more numbers of distinct blocks.
- the polymer block has a molecular weight from 500 Da to 20 kDa, such as 500 Da to 10 kDa, 500 Da to 7 kDa. 500 Da to 5 kDa, or 500 Da to 2 kDa. In some embodiments, the polymer block has a molecular weight from 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa. 1 kDa to 10 kDa, 5 kDa to 20 KDa, 5 kDa to 17.5 kDa, 5 kDa to 15 kDa.
- the polymer block has a molecular weight from 1.5 kDa to 3.5 kDa, such as 1.5 kDa to 3 kDa, 1.5 kDa to 2.5 kDa, or 1.5 kDa to 2 kDa.
- the polymer block has a molecular weight of 500 Da, 1 kDa, 1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa, 3.5 kDa, 4 kDa, 4.5 kDa, 5 kDa, 5.5 kDa, 6 kDa, 6.5 kDa, 7 kDa, 7.5 kDa, 8 kDa, 8.5 kDa, 9 kDa, 9.5 kDa, 10 kDa, 10.5 kDa, 11 kDa, 11.5 kDa, 12 kDa, 12.5 kDa. 13 kDa, 13.5 kDa, 14 kDa, 14.5 kDa, 15 kDa,
- the macrocycle (P) comprises one or more polymeric blocks selected from a polyethylene glycol (PEG), a polypeptoid (e.g., polysarcosine), a polypropylene glycol, a polyvinylpyrrolidone, a polyglycerol, a polyoxazoline, a polyacrylamide.
- PEG polyethylene glycol
- Peptoid e.g., polysarcosine
- PAcM poly(N-acryloylmorpholine)
- polysialic acid poly (N.N -dimethyl acrylamide) (PDMA), poly(N-(2- hydroxypropyl) methacrylamide), poly(2-hydroxyethyl methacrylamide), poly(hydroxypropyl methacrylate) (PHPMA), poly(2-hydroxyethyl methacrylate) (PHEMA), (HPMA), hyaluronic acid, heparin, and polysialic acid.
- one or more polymer blocks comprises a polymer selected from a polyethylene glycol (PEG) polymer, a polyethylene oxide (PEG) polymer, a polyglutamic acid (PGA) polymer, a poly[N-(2-hydroxypropyl) methacrylamide] (HPMA) polymer, a poly(vinylpyrrolidone) (PVP) polymer, a poly(2-methyl-2-oxazoline) (PMOX) polymer, a poly(N,N- dimethyl acrylamide) (PDMA) polymer, a poly(N -acryloyl morpholine) (PAcM) polymer, and any combination thereof.
- PEG polyethylene glycol
- PEG polyethylene oxide
- PGA polyglutamic acid
- HPMA poly[N-(2-hydroxypropyl) methacrylamide]
- HPMA poly(vinylpyrrolidone)
- PMOX poly(2-methyl-2-oxazoline)
- PDMA poly(N,N- di
- one or more polymer blocks is selected from a polysaccharide polymer and a polypeptide.
- the polysaccharide polymer block is selected from a chitosan polymer, a hyaluronic acid (HA) polymer, a heparin polymer, and a polysialic acid polymer, or a combination thereof.
- one or more polymer blocks is a polyethylene glycol (PEG).
- the macrocycle (P) comprises at least 10 ethylene monomer units, such as at least 12, at least 15. at least 20, at least 25, at least 30. at least 35, at least 40, at least 45, at least 50, at least 55, at least 60, at least 65. at least 70, at least 75. at least 80, at least 85. at least 90, at least 95, or at least 100 ethylene glycol monomer units.
- P comprises at least 100 ethylene glycol monomer units, such as at least 110. at least 115, at least 120, at least 125, at least 130. at least 135. at least 140. at least 145, at least 150 ethylene glycol monomer units.
- P comprises at least 150 ethylene glycol monomer units, such as at least 155, at least 160, at least 165, at least 170, at least 175, at least 180. at least 185. at least 190, at least 195, at least 200, at least 205, at least 210, at least 215, or at least 220 ethylene glycol monomer units, (e g., at least 12, at least 20, at least 30, at least 40, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220) ethylene glycol monomer units.
- ethylene glycol monomer units such as at least 155, at least 160, at least 165, at least 170, at least 175, at least 180. at least 185. at least 190, at least 195, at least 200, at least 205, at least 210, at least 215, or at least 220 ethylene glycol monomer units, (e g., at least 12, at least 20, at least 30, at least
- P comprises 10, 12, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 210, or 220 ethylene glycol monomer units, +/- 10%.
- P comprises a PEG block of 500 Da to 20 kDa, such as 500 Da to 10 kDa, 500 Da to 7 kDa, 500 Da to 5 kDa, or 500 Da to 2 kDa.
- P comprises a PEG block of 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa, 1 kDa to 10 kDa, 5 kDa to 20 KDa, 5 kDa to 17.5 kDa, 5 kDa to 15 kDa, 5 kDa to 10 kDa, or 5 kDa to 7.5 kDa.
- P comprises a PEG block of 1.5 kDa to 3.5 kDa, such as 1.5 kDa to 3 kDa, 1.5 kDa to 2.5 kDa, or 1.5 kDa to 2 kDa.
- P comprises a PEG block of 500 Da, 1 kDa,
- kDa 1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa, 3.5 kDa. 4 kDa, 4.5 kDa, 5 kDa, 5.5 kDa, 6 kDa, 6.5 kDa, 7 kDa. 7.5 kDa, 8 kDa, 8.5 kDa, 9 kDa, 9.5 kDa. 10 kDa. 10.5 kDa, 11 kDa, 11.5 kDa, 12 kDa, 12.5 kDa, 13 kDa,
- P comprises one PEG block.
- P comprises two or more PEG blocks.
- P comprises the Formula Pl : wherein:
- P A and P B are each independently tire two or more PEG blocks
- Y is an optional linking group; and m is an integer from 1 to 6.
- m is an integer from 1 to 3. In some embodiments, m is 1. In some embodiments, m is 2. In some embodiments, m is 3.
- P A and P B are the same PEG blocks. In some embodiments of Formula Pl, P A and P B are different PEG blocks.
- Formula Pl does not comprise a linking group (Y).
- Formula Pl comprises a linking group (Y)' .
- Any suitable linking group can find use in the compound of Fonnula Pl.
- Y comprises, a triazole, a maleimide, -S-, -NH-, -CO-, -C(O)NH-, -NHC(O)-, -C(O)O-, -OC(O)-, -O-, OCO 2 -, -OC(O)NH-, - NHC(O)O-, -OP(O)(OH)O-, or any combination thereof.
- Formula Pl comprises a linking group (Y) that is a cleavable linker.
- the clcavablc linker can render the compound biodegradable. Any convenient clcavablc linker can find use in the subject macrocycles comprising Formula Pl.
- the cleavable linker can be cleaved by exposure to a stimulus. Anon-exhaustive list of stimulus includes pH, temperature, light, redox change, over-expressed enzymes, hypoxia, sound, magnetic force, electrical energy, and any combination thereof.
- Formula Pl comprises a linking group (Y) is the cleavable linker comprising a group selected from disulfide, hydrazone, vinyl ether, imine, ortho ester, borate ester, amide, a peptide, an azo, and any combination thereof.
- the compounds of Formulae (I) and (II) comprise at least one lipid (A).
- n is 1 such that the compound comprises one lipid.
- n is 2 such that the compound comprises two lipids.
- n is 3 such that the compound comprises 3 lipids.
- lipid (A) comprises a linear or branched C6-C30 alkyl, C6-C30 alkeny l, or C6-C30 hctcroalky l, optionally substituted by one or more substituents selected from oxo, halo, hydroxy, cyano, alkyl, alkenyl, aldehyde, heterocyclylalkyl, hydroxyalkyl, dihydroxyalkyl, hydroxyalkylaminoalkyl, aminoalkyl, alkylaminoalkyl, dialkylaminoalkyl,
- heterocyclyl (alkyl)aminoalkyl
- heterocyclyl heteroaryl
- alkylheteroaryl alkynyl
- alkoxy amino, dialkylamino, aminoalkylcarbonylamino, aminocarbonylalkylamino
- aminocarbonylalky l (alkyl)amino, alkenylcarbonylamino, hydroxycarbonyl, alkyloxycarbonyl, aminocarbonyl, aminoalkylaminocarbonyl. alkylaminoalkylaminocarbonyl, dialkylaminoalkylaminocarbonyl, heterocyclylalkylaminocarbonyl,
- alkylaminoalkyl (alkyl)aminocarbonyl, alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkenylcarbonyl, alkynylcarbonyl, alkylsulfoxide, alkylsulfoxidealkyl, alkylsulfonyl, alkylsulfonealkyl, and phosphonate.
- At least one lipid (A) comprises a C8-C30 linear or branched alkyl. In some embodiments, at least one lipid (A) comprises a linear C8- C30 alkyl. In some embodiments of Formulae (I) or (11), at least one lipid (A) comprises decane, undecane, dodecane, tridecane, tetradecane, pentadecane, hexadecane, heptadecane, octadecane, nonadecane, or icosane.
- At least one lipid A comprises octadecane.
- at least one lipid (A) comprises a branched C8-C30 alkyl.
- the branched C8-C30 alkyl comprises two lipid tails, wherein each lipid tail comprises a C7-C14 alkyl chain.
- each lipid tail comprises a C7-alkyl chain.
- each lipid tail comprises a C8-alkyl chain.
- each lipid tail comprises a C9-alkyl chain.
- each lipid tail comprises a ClO-alkyl chain.
- each lipid tail comprises a Cll-alkyl chain. In some cases, each lipid tail comprises a C12-alkyl chain. In some cases, each lipid tail comprises a C13-alkyl chain. In some cases, each lipid tail comprises a C14-alkyl chain.
- At least one lipid (A) comprises a C8-C30 linear or branched alkenyl. In some embodiments, at least one lipid (A) comprises a linear C8-C30 alkenyl. In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises myristoleane, palmitoleane, oleane, or linoleane.
- At least one lipid (A or A-Z A -) comprises:
- R 1 is hydrogen or R 3 ;
- R 2 , and R 3 are each independently Cl -Cl 2 alkyl, or C2-C12-alkenyl.
- At least one lipid (A) comprises di-myristoyl- glycerol (DMG):
- At least one lipid (A) comprises di-palmitoyl- [0097] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises di-stearoyl- glycerol (DSG):
- At least one lipid (A) comprises a phospholipid.
- At least one lipid (A) comprises di-myristoyl- phosphatidy 1-ethanolamine (DMPE): [0100] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises di-palmitoyl- phosphatidy 1-ethanolamine (DPPE) :
- At least one lipid (A) comprises di-stearoyl- phosphatidy 1-ethanolamine (DSPE):
- At least one lipid (A) comprises di-oleoyl- phosphatidy 1-ethanolamine (DOPE) : [0103] In some embodiments of Formulae (I) or (II), at least one lipid (A or A-Z A -) comprises: each t is independently an integer from 0 to 6. In some embodiments, t is 1. In some embodiments, t is 2. In some embodiments, t is 3. In some embodiments, t is 4. In some embodiments, t is 5. In some embodiments, t is 6.
- At least one lipid (A or A-Z A -) comprises:
- At least one lipid (A) comprises:
- At least one lipid (A) comprises:
- At least one lipid (A) comprises a sterol or cholesterol.
- At least one lipid (A) comprises cholesterol:
- At least one lipid (A) comprises [3-sitosterol:
- At least one lipid (A) comprises stigmasterol:
- At least one lipid (A) comprises lanosterol:
- At least one lipid (A) comprises 7- dehydrocholesterol:
- At least one lipid (A) comprises zymosterol:
- At least one lipid (A) comprises lanosterol:
- At least one lipid (A) comprises brassicasterol:
- At least one lipid (A) comprises campesterol:
- the compound is of the Formula (VI): wherein: m is an integer from 10 to 500; each z is independently 1. 2, 3, 4, or 5; and
- A is a lipid (e.g., as described herein).
- m is 10 to 300, such as 10 to 250, 10 to 220, 10 to 200, 10 to 180, 10 to 150, 10 to 120, 10 to 100, 10 to 80, or 10 to 50.
- m is 10 to 100, such as 10 to 90. 10 to 80, 10 to 70. 10 to 60, 10 to 50. 15 to 50, 20 to 50. 25 to 50, 30 to 50. 35 to 50, or 40 to 50.
- each z is less than 5, such as less than 4, or less than 3.
- each z is independently 1, 2. 3 or 4, such as 1, 2 or 3.
- each z is 5.
- each z is 4.
- each z is 3.
- each z is 2.
- each z is 1.
- one z is 1
- the other z is 2.
- A comprises a C8-C30 linear or branched alkyl. In some embodiments, A comprises a linear C8-C30 alkyl. In some embodiments A comprises decane, undecane, dodecane, tridecane, tetradecane, pentadecane, hexadecane, heptadecane, octadecane, nonadecane, or icosane. In some embodiments of Formula (VI), A is octadecane. [0121] In some embodiments of Formulae (VI), A comprises a C8-C30 linear or branched alkenyl. In some embodiments, A comprises a linear C8-C30 alkenyl. In some embodiments, A comprises myristoleane, palmitoleane, oleane, or linoleane.
- A comprises di-myristoyl-glyccrol (DMG), di- pahnitoyl-glycerol (DPG), or di-stearoyl-glycerol (DSG). In some embodiments of Formula (VI), A is DMG.
- A is:
- A comprises a phospholipid.
- A comprises di-myristoyl-phosphatidyl-ethanolamine (DMPE), di-palmitoyl-phosphatidyl-ethanolamine (DPPE), di-stearoyl-phosphatidyl-ethanolamine (DSPE), or di-oleoyl-phosphatidyl-ethanolamine (DOPE).
- DMPE di-myristoyl-phosphatidyl-ethanolamine
- DPPE di-palmitoyl-phosphatidyl-ethanolamine
- DSPE di-stearoyl-phosphatidyl-ethanolamine
- DOPE di-oleoyl-phosphatidyl-ethanolamine
- A comprises a sterol or cholesterol.
- A comprisescholesterol,
- the compound is of the Formula (VII): wherein: p is an integer from 10 to 500; and
- A is a lipid (e.g., as described herein).
- p is 10 to 300, such as 10 to 250, 10 to 220, 10 to 200, 10 to 180, 10 to 150, 10 to 120, 10 to 100. 10 to 80, or 10 to 50.
- p is 10 to 100, such as 10 to 90. 10 to 80, 10 to 70. 10 to 60, 10 to 50. 15 to 50, 20 to 50. 25 to 50, 30 to 50. 35 to 50, or 40 to 50.
- A comprises a C8-C30 linear or branched alkyl. In some embodiments, A comprises a linear C8-C30 alkyl.
- A comprises decane, undecane, dodecane, tridecane, tetradecane, pentadecane, hexadecane, heptadecane, octadecane, nonadecane, or icosane.
- A is octadecane.
- A comprises a C8-C30 linear or branched alkenyl. In some embodiments, A comprises a linear C8-C30 alkenyl. In some embodiments, A comprises myristoleane, palmitoleane, oleane, or linoleane.
- A comprises di-myristoyl-glycerol (DMG), di- pahnitoyl-glycerol (DPG), or di-stearoyl-glycerol (DSG). In some embodiments of Formula (VII), A is DMG.
- A is:
- A comprises a phospholipid.
- A comprisesdi-myristoyl-phosphatidyl-ethanolamine (DMPE), di-palmitoyl-phosphatidyl- ethanolamine (DPPE), di-stearoyl-phosphatidyl-ethanolamine (DSPE), or di-oleoyl-phosphatidyl- ethanolamine (DOPE).
- DMPE di-myristoyl-phosphatidyl-ethanolamine
- DPPE di-palmitoyl-phosphatidyl- ethanolamine
- DSPE di-stearoyl-phosphatidyl-ethanolamine
- DOPE di-oleoyl-phosphatidyl- ethanolamine
- A comprises a sterol or cholesterol.
- A compriscscholcstcrol,
- the polymeric lipid comprises Compound 10, Compound 2-12, Compound 6-17, Compound 7-17, or Compound 8-17.
- the polymeric lipid comprises Compound 10: [0136] In some embodiments, the polymeric lipid comprises Compound 2-12:
- the polymeric lipid comprises Compound 6-17:
- the polymeric lipid comprises Compound 7-17:
- the polymeric lipid comprises Compound 8-17:
- the circular polymeric lipid compound satisfies (b), and two lipids are in the macrocycle’s backbone, wherein all PEG blocks are between the two lipids.
- the compound satisfies (b) and is of Formula (III): wherein:
- a 1 and A 2 are independently a lipid as described herein;
- Z’ and Z 2 are independently an optional core moiety wherein:
- a 1 and A 2 are covalently linked to define the macrocycle P when Z 1 and Z 2 , if present, are part of A 1 and A 2 , respectively; or A 1 -Z’ is non-covalently bound with A 2 -Z 2 to define the macrocycle P.
- a 1 and A 2 are covalently linked to define the macrocycle. In some embodiments, A 1 and A 2 are linked by one or more disulfide bonds. In some embodiments, A 1 and A 2 are linked by one disulfide bond. In some embodiments, A 1 and A 2 are linked by two or more disulfide bonds.
- a 1 -Z’ is non-covalently bound with A 2 -Z 2 to define the macrocycle P. It will be understood that any non-covalent interaction can bind A 1 -Z 2 with A 2 -Z 2 .
- a 1 -Z 2 is bound to A 2 -Z 2 by hydrogen bonding.
- a 1 -Z 2 is bound to A 2 -Z 2 by ionic interactions.
- a 1 -Z 2 is bound to A 2 -Z 2 by Van dcr Waals interactions.
- a 1 -Z 2 is bound to A 2 -Z 2 by hydrophobic interactions.
- the macrocycle (P in Formula III) comprises one or more polymer blocks in the macrocycle’s backbone. Any convenient polymer block may be used in the macrocycle’s backbone (as described herein above).
- the polymer block has a molecular weight from 500 Da to 20 kDa, such as 500 Da to 10 kDa, 500 Da to 7 kDa, 500 Da to 5 kDa, or 500 Da to 2 kDa.
- the polymer block has a molecular weight from 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa, 1 kDa to 10 kDa, 5 kDa to 20 kDa, 5 kDa to 17.5 kDa, 5 kDa to 15 kDa, 5 kDa to 10 kDa, or 5 kDa to 7.5 kDa. In some embodiments, the polymer block has a molecular weight from 1.5 kDa to
- the polymer block has a molecular weight of 500 Da, 1 kDa, 1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa, 3.5 kDa, 4 kDa, 4.5 kDa, 5 kDa, 5.5 kDa, 6 kDa, 6.5 kDa, 7 kDa.
- kDa 7.5 kDa, 8 kDa, 8.5 kDa, 9 kDa, 9.5 kDa, 10 kDa, 10.5 kDa, 11 kDa, 11.5 kDa, 12 kDa. 12.5 kDa. 13 kDa, 13.5 kDa, 14 kDa, 14.5 kDa, 15 kDa,
- the macrocycle (P) comprises one or more polymeric blocks selected from a polyethylene glycol (PEG), a polypeptoid (e g., polysarcosine), a polypropylene glycol, a polyvinylpyrrolidone, a polyglycerol, a polyoxazoline. a polyacrylamide.
- PAcM poly(N- acryloylmorpholine)
- PDMA poly(N,N-dimethyl acrylamide)
- PPMA poly(N-(2-hydroxypropyl) methacrylamide)
- PHEMA poly (2 -hydroxy ethyl methacrylate)
- HPMA hyaluronic acid, heparin, and polysialic acid.
- one or more polymer blocks comprises a polymer selected from a polyethylene glycol (PEG) polymer, a polyethylene oxide (PEG) polymer, a polyglutamic acid (PGA) polymer, a poly[N-(2 -hydroxy propyl) methacrylamide] (HPMA) polymer, a poly(vinylpyrrolidone) (PVP) polymer, a poly(2-methyl-2-oxazoline) (PMOX) polymer, a poly(N,N- dimethyl acrylamide) (PDMA) polymer, a poly (N -acryloyl morpholine) (PAcM) polymer, and any combination thereof.
- PEG polyethylene glycol
- PEG polyethylene oxide
- PGA polyglutamic acid
- HPMA poly[N-(2 -hydroxy propyl) methacrylamide]
- HPMA poly(vinylpyrrolidone)
- PMOX poly(2-methyl-2-oxazoline)
- PDMA poly(N
- one or more polymer blocks is selected from a polysaccharide polymer and a polypeptide.
- the polysaccharide polymer block is selected from a chitosan polymer, a hyaluronic acid (HA) polymer, a heparin polymer, and a polysialic acid polymer, or a combination thereof.
- one or more polymer blocks is a polyethylene glycol (PEG).
- the macrocycle (P) comprises at least 10 ethylene monomer units, such as at least 12, at least 15. at least 20, at least 25. at least 30. at least 35, at least 40. at least 45. at least 50, at least 55. at least 60, at least 65, at least 70. at least 75, at least 80. at least 85, at least 90, at least 95, or at least 100 ethylene glycol monomer units.
- P comprises at least 100 ethylene glycol monomer units, such as at least 110, at least 115, at least 120, at least 125, at least 130, at least 135. at least 140. at least 145, at least 150 ethylene glycol monomer units.
- P comprises at least 150 ethylene glycol monomer units, such as at least 155, at least 160, at least 165, at least 170, at least 175. at least 180, at least 185, at least 190, at least 195, at least 200, at least 205, at least 210, at least 215, or at least 220 ethylene glycol monomer units, (e.g., at least 12, at least 20, at least 30, at least 40, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220) ethylene glycol monomer units.
- P comprises 10, 12, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120. 130, 140, 150. 160, 170, 180, 190, 200. 210, or 220 ethylene glycol monomer units. +/- 10%.
- P comprises a PEG block of 500 Da to 20 kDa, such as 500 Da to 10k Da. 500 Da to 7 kDa, 500 Da to 5 kDa, or 500 Da to 2 kDa.
- P comprises a PEG block of 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa, 1 kDa to 10 kDa, 5 kDa to 20 kDa, 5 kDa to 17.5 kDa, 5 kDa to 15 kDa, 5 kDa to 10 kDa.
- P comprises a PEG block of 1.5 kDa to 3.5 kDa, such as 1.5 kDa to 3 kDa, 1.5 kDa to 2.5 kDa, or 1.5 kDa to 2 kDa. In some embodiments, P comprises a PEG block of 500 Da, 1 kDa,
- kDa 1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa, 3.5 kDa. 4 kDa, 4.5 kDa, 5 kDa, 5.5 kDa, 6 kDa, 6.5 kDa, 7 kDa. 7.5 kDa, 8 kDa. 8.5 kDa, 9 kDa, 9.5 kDa. 10 kDa. 10.5 kDa. 11 kDa. 11.5 kDa. 12 kDa. 12.5 kDa, 13 kDa,
- P comprises one PEG block.
- P comprises two or more PEG blocks.
- P comprises the Formula Pl : wherein:
- P A and P B are each independently tire tw o or more PEG blocks
- Y is an optional linking group; and m is an integer from 1 to 6.
- m is an integer from 1 to 3. In some embodiments, m is 1. In some embodiments, in is 2. In some embodiments, m is 3.
- P A and P B are the same PEG blocks. In some embodiments of Formula Pl , P A and P B are different PEG blocks.
- Formula Pl does not comprise a linking group (Y).
- Formula Pl comprises a linking group (Y). Any suitable linking group can find use in the compound of Formula Pl.
- Y comprises, a triazole, a maleimide, -S-, -NH-, -C(O)-, -C(O)NH-, -NHC(O)-, -C(O)O-, -OC(O)-, -O-, OCO 2 -, -OC(O)NH-, - NHC(O)O-, -OP(O)(OH)O-, or any combination thereof.
- Formula Pl comprises a linking group (Y) that is a cleavable linker.
- the cleavable linker can render the compound biodegradable. Any convenient cleavable linker can find use in the subject macrocycles comprising Formula Pl.
- the cleavable linker can be cleaved by exposure to a stimulus. Anon-exhaustive list of stimulus includes pH, temperature, light, redox change, over-expressed enzymes, hypoxia, sound, magnetic force, electrical energy, and any combination thereof.
- Formula Pl comprises a linking group (Y) is the cleavable linker comprising a group selected from disulfide, hydrazone, vinyl ether, imine, ortho ester, borate ester, amide, a peptide, an azo, and any combination thereof.
- the compounds of Formula (III) comprise tw o lipids, A 1 and A 2 .
- a 1 and A 2 are the same lipid.
- a 1 and A 2 are different.
- lipids A 1 and A 2 each independently comprise a linear or branched C6- C30 alky l, C6-C30 alkenyl, or C6-C30 heteroalkyl, optionally substituted by one or more substituents selected from oxo, halo, hydroxy , cyano, alkyl, alkenyl, aldehyde, heterocyclylalkyl, hydroxyalkyl, dihydroxyalkyl, hydroxyalkylaminoalkyl, aminoalkyl, alkydaminoalkyl, dialkylaminoalkyl, (heterocyclyl)(alkyl)aminoalkyl, heterocyclyl, heteroaryl, alkylheteroaryl, alkynyl, alkoxy, amino, dialkylamino, aminoalkylcarbonylamino, aminocarbonylalkylamino,
- aminocarbonylalky l (alkyl)amino, alkenylcarbonylamino, hydroxycarbonyl, alky loxycarbonyl, aminocarbonyl, aminoalkylaminocarbonyl. alkylaminoalkylaminocarbonyl, dialkylaminoalkylaminocarbonyl, heterocyclylalkylaminocarbonyl,
- alkylaminoalkyl (alkyl)aminocarbonyl, alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkenylcarbonyl, alkynylcarbonyl, alkylsulfoxide, alkylsulfoxidealkyl, alky Isulfonyl, alkylsulfonealkyl, and phosphonate.
- At least one lipid of A 1 or A 2 comprises a branched C8-C30 alkyd, such as a branched C12-C30 alkyl.
- the branched C8-C30 alkyl comprises two lipid tails, wherein each lipid tail comprises a C7-C12 alkyl chain.
- each lipid tail comprises a C7-alkyl chain.
- each lipid tail comprises a C8-alkyl chain.
- each lipid tail comprises a C9-alkyl chain.
- each lipid tail comprises a ClO-alkyl chain.
- each lipid tail comprises a Cll-alkyl chain.
- each lipid tail comprises a C12-alkyl chain.
- At least one of A 1 or A 2 comprises a C8-C30 linear or branched alkenyl. In some embodiments, at least one of A 1 or A 2 comprises a linear C8-C30 alkenyl. In some embodiments of Fonnula (III), at least one of A 1 or A 2 comprises myristoleane, palmitoleane, oleane, or linoleane.
- At least one of A 1 or A 2 comprises:
- R 1 is hydrogen or R 3 ;
- R 2 , and R 3 are each independently C1-C12 alkyl, or C2-C12-alkenyl.
- At least one of A 1 or A 2 comprises di-myristoyl-glycerol (DMG):
- At least one of A 1 or A 2 comprises di-palmitoyl-glycerol (DPG): [0168] In some embodiments of Formula (III), at least one of A 1 or A 2 comprises di-stearoyl-glycerol
- At least one of A 1 or A 2 comprises a phospholipid.
- At least one of A 1 or A 2 comprises di-myristoyl- phosphatidy 1-ethanolamine (DMPE): [0171] In some embodiments of Formula (III), at least one of A 1 or A 2 comprises di-palmitoyl- phosphatidy 1-etlianolamine (DPPE) :
- At least one of A 1 or A 2 comprises di-stearoyl- phosphatidy 1-ethanolamine (DSPE):
- At least one of A 1 or A 2 comprises di-oleoyl- phosphatidy 1-ethanolamine (DOPE) :
- DOPE di-oleoyl- phosphatidy 1-ethanolamine
- at least one of A 1 or A 2 comprises: wherein: each t is independently an integer from 0 to 6. In some embodiments, t is 1. In some embodiments, t is 2. In some embodiments, t is 3. In some embodiments, t is 4. In some embodiments, t is 5. In some embodiments, t is 6. [0175] In some embodiments of Formula (III), at least one of A 1 or A 2 comprises:
- At least one of A 1 or A 2 comprises a sterol or cholesterol.
- At least one of A 1 or A 2 comprises cholesterol:
- At least one of A 1 or A 2 comprises (3-sitosterol:
- At least one of A 1 or A 2 comprises stigmasterol:
- At least one of A 1 or A 2 comprises lanosterol:
- At least one of A 1 or A 2 comprises 7-dehydrocholesterol:
- At least one of A 1 or A 2 comprises zymosterol:
- At least one of A 1 or A 2 comprises lanosterol:
- At least one of A 1 or A 2 comprises brassicasterol:
- At least one of A 1 or A 2 comprises campesterol:
- a 1 and A 2 are independently a lipid as described herein; and LP is a linking moiety comprising one or more polyethylene glycol (PEG) blocks.
- PEG polyethylene glycol
- a 1 and A 2 are independently selected from a lipid as described herein above.
- a 1 and A 2 each form a link to a core-shell structure of a lipid nanoparticle to form a macrocycle (e.g., a macrocyclic compound of Formula (III)).
- a macrocycle e.g., a macrocyclic compound of Formula (III)
- the linking moiety LP comprises at least 10 ethylene monomer units, such as at least 12, at least 15, at least 20, at least 25, at least 30, at least 35, at least 40, at least 45, at least 50, at least 55. at least 60, at least 65, at least 70, at least 75, at least 80, at least 85, at least 90, at least 95, or at least 100 ethylene glycol monomer units.
- LP comprises at least 100 ethylene glycol monomer units, such as at least 110, at least 115, at least 120, at least 125, at least 130, at least 135, at least 140, at least 145, at least 150 ethylene glycol monomer units.
- LP comprises at least 150 ethylene glycol monomer units, such as at least 155, at least 160, at least 165, at least 170, at least 175, at least 180, at least 185, at least 190, at least 195, at least 200, at least 205, at least 210, at least 215, or at least 220 ethylene glycol monomer units, (e.g., at least 12, at least 20, at least 30, at least 40, at least 50. at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220) ethylene glycol monomer units.
- LP comprises 10, 12, 20, 30. 40, 50, 60, 70, 80. 90, 100, 110, 120. 130, 140, 150, 160, 170, 180, 190. 200, 210, or 220 ethylene glycol monomer units, +/- 10%.
- LP comprises a PEG block of 500 Da to 20 kDa, such as 500 Da to 10 kDa, 500 Da to 7 kDa, 500 Da to 5 kDa, or 500 Da to 2 kDa.
- LP comprises a PEG block of 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa, 1 kDa to 10 kDa.
- LP comprises a PEG block of 1.5 kDa to 3.5 kDa, such as 1.5 kDa to 3 kDa. 1.5 kDa to 2.5 kDa, or 1.5 kDa to 2 kDa. In some embodiments, LP comprises a PEG block of 500 Da. 1 kDa, 1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa. 3.5 kDa, 4 kDa, 4.5 kDa. 5 kDa, 5.5 kDa, 6 kDa. 6.5 kDa, 7 kDa,
- kDa 7.5 kDa, 8 kDa. 8.5 kDa, 9 kDa, 9.5 kDa. 10 kDa, 10.5 kDa. 11 kDa, 11.5 kDa, 12 kDa, 12.5 kDa, 13 kDa, 13.5 kDa, 14 kDa, 14.5 kDa, 15 kDa, 15.5 kDa, 16 kDa, 16.5 kDa, 17 kDa, 17.5 kDa, 18 kDa,
- LP comprises one PEG block.
- LP comprises two or more PEG blocks.
- the compound of Formula (IV) is of the Fonnula (V): wherein:
- P A and P B are each independently two or more PEG blocks
- Y is an optional linking group; and m is an integer from 1 to 6, preferably an integer from 1 to 3.
- m is an integer from 1 to 3. In some embodiments, m is 1 . In some embodiments, m is 2. In some embodiments, m is 3.
- P A and P B are the same PEG blocks. In some embodiments of Formula (V). P A and P B are different PEG blocks.
- Formula (V) does not comprise a linking group (Y).
- Formula (V) comprises a linking group (Y). Any suitable linking group can find use in the compound of Formula Pl.
- Y comprises, a triazole, a maleimide, -S-, -NH-. -C(O)-. -C(O)NH-, -NHC(O)-, -C(O)O-. -OCO-. -O-, OCO 2 -, -OC(O)NH-. - NHC(O)O-, -OP(O)(OH)O-, or any combination thereof.
- Formula (V) comprises a linking group (Y) that is a cleavable linker.
- the cleavable linker can render the compound biodegradable. Any convenient cleavable linker can find use in the subject macrocycles comprising Formula (V).
- the cleavable linker can be cleaved by exposure to a stimulus.
- a non-exhaustive list of stimulus includes pH. temperature, light, redox change, over-expressed enzymes, hypoxia, sound, magnetic force, electrical energy, and any combination thereof.
- Formula (V) comprises a linking group (Y) is the cleavable linker comprising a group selected from disulfide, hydrazone, vinyl ether, imine, ortho ester, borate ester, amide, a peptide, an azo, and any combination thereof.
- the present disclosure provides formulations comprising a subject circular polymeric lipid.
- the formulation is a circular PEG-lipid in a liposomal formulation.
- the molar ratio of the circular PEG-lipid is from about 0.1% to 100% of the total lipid. In some embodiments, the molar ratio of the circular PEG-lipid is about 5%, 10%, 15%, 20%. 25%, 30%, 35%, 40%. 45%, 50%, 55%. 60%, 65%, 70%, 75%. 80%, 85%, 90%. 95%, or 100% of the total lipid.
- the circular PEG-lipid is of Formula (I) (as described herein). In some embodiments, the circular PEG-lipid is of Formula (II) (as described herein). In some embodiments, the circular PEG-lipid is of Formula (III) (as described herein). All values are inclusive of all endpoints.
- the liposomal formulation comprises a helper lipid, a structural lipid, and a circular PEG-lipid.
- the molar ratio of helper lipid: structural lipid:circular PEG-lipid in the liposomal formulation is about 56:38:5.
- the molar ratio of helper lipid structural lipid:circular PEG-lipid in the liposomal formulation is about 50:45:5.
- the molar ratio of helper lipid: structural lipid:circular PEG-lipid in the liposomal formulation is about 45:45:10.
- the helper lipid is a phospholipid (e.g., as described herein).
- the phospholipid is hydrogenated soy phosphatidylcholine (HSPC).
- the structure lipid is cholesterol.
- the liposomal formulation comprises a molar ratio of HSPC:cholesterol:circular PEG- lipid of about 56:38:5. In some embodiments, the molar ratio of each of HSPC. cholesterol, and the circular PEG-lipid is within 10%, 9%, 8%. 7%. 6%, 5%, 4%, 3%. 2%.
- the present disclosure provides lipid nanoparticles (LNPs) comprising a subject circular polymeric lipid.
- LNPs lipid nanoparticles
- the subject LNP formulation can also include one or more ionizable lipids, helper lipids, structural lipids, and polynucleotides (as described herein below).
- lipid nanoparticle described herein may be accomplished by any methods known in the art. For example, as described in U.S. Pat. Pub. No. US2012/0178702 Al, which is incorporated herein by reference in its entirety. Non-limiting examples of lipid nanoparticle compositions and methods of making them are described, for example, in Semple et al. (2010) Nat. Biotechnol. 28:172-176; Jayarama et al. (2012). Angew. Chem. Int. Ed., 51:8529-8533; and Maier et al. (2013) Molecular Therapy 21, 1570-1578 (the contents of each of which are incorporated herein by reference in their entirety).
- the LNP formulation may be prepared by, e.g., the methods described in International Pat. Pub. No. WO 2011/127255 or WO 2008/103276, the contents of each of which are herein incorporated by reference in their entirety'.
- LNP formulations described herein may comprise a polycationic composition.
- the polycationic composition may be a composition selected from Formulae 1-60 of U.S. Pat. Pub. No. US2005/0222064 Al, the content of which is herein incorporated by reference in its entirety.
- the lipid nanoparticle may be fonnulated by the methods described in U.S. Pat. Pub. No. US2013/0156845 Al, and International Pat. Pub. No. WO2013/093648 A2 or WO2012/024526 A2, each of which is herein incorporated by reference in its entirety.
- the lipid nanoparticles described herein may be made in a sterile environment by the system and/or methods described in U.S. Pat. Pub. No. US2013/0164400 Al, which is incorporated herein by reference in its entirety.
- the LNP formulation may be formulated in a nanoparticle such as a nucleic acid-lipid particle described in U.S. Pat. No. 8,492.359. which is incorporated herein by reference in its entirety'.
- a nanoparticle composition may optionally comprise one or more coatings.
- a nanoparticle composition may be formulated in a capsule, film, or tablet having a coating.
- a capsule, film, or tablet including a composition described herein may' have any useful size, tensile strength, hardness, or density.
- the lipid nanoparticles described herein may be synthesized using methods comprising microfluidic mixers.
- Exemplary microfluidic mixers may include, but are not limited to, a slit interdigitial micromixer including, but not limited to, those manufactured by Precision Nanosystems (Vancouver, BC. Canada), Microinnova (Allerheiligen bei Wildon, Austria) and/or a staggered herringbone micromixer (SHM) (Zhigaltsev, I.V. et al. (2012) Langmuir. 28:3633-40; Belliveau, N.M. et al. Mol. Ther. Nucleic. Acids. (2012) l:e37; Chen, D. et al. J. Am. Chem. Soc. (2012) 134(22):6948-51; each of which is herein incorporated by reference in its entirety ).
- SHM staggered herringbone micromixer
- methods of LNP generation comprising SHM, further comprise the mixing of at least two input streams wherein mixing occurs by microstructurc-induccd chaotic advection (MICA).
- MICA microstructurc-induccd chaotic advection
- fluid streams flow through channels present in a herringbone pattern causing rotational flow and folding the fluids around each other.
- This method may also comprise a surface for fluid mixing wherein tire surface changes orientations during fluid cycling.
- Methods of generating LNPs using SHM include those disclosed in U.S. Pat. Pub. Nos. US2004/0262223 Al and US2012/0276209 Al, each of which is incorporated herein by reference in their entirety .
- the lipid nanoparticles may be formulated using a micromixer such as, but not limited to, a Slit Interdigital Microstructured Mixer (SIMM-V2) or a Standard Slit Interdigital Micro Mixer (SSIMM) or Caterpillar (CPMM) or Impinging-jet (IJMM)from the Institut fur Mikrotechnik Mainz GmbH, Mainz Germany).
- a micromixer such as, but not limited to, a Slit Interdigital Microstructured Mixer (SIMM-V2) or a Standard Slit Interdigital Micro Mixer (SSIMM) or Caterpillar (CPMM) or Impinging-jet (IJMM)from the Institut fur Mikrotechnik Mainz GmbH, Mainz Germany).
- the lipid nanoparticles are created using microfluidic technology' (see, Whitesides (2006) Nature. 442: 368-373; and Abraham et al. (2002) Science. 295: 647-651; each of which is herein incorporated by reference in its entirety).
- controlled microfluidic formulation includes a passive method for mixing streams of steady pressure-driven flows in micro channels at a low Reynolds number (see, e.g., Abraham et al. (2002) Science. 295: 647651; which is herein incorporated by reference in its entirety).
- the polynucleotide (e.g.. circRNA) of the present disclosure may be formulated in lipid nanoparticles created using a micromixer chip such as. but not limited to, those from Harvard Apparatus (Holliston, MA), Dolomite Microfluidics (Royston, UK), or Precision Nanosystems (Van Couver, BC, Canada).
- a micromixer chip can be used for rapid mixing of two or more fluid streams with a split and recombine mechanism.
- the LNP of the present disclosure comprises a molar ratio of betw een about 40% and about 60 % ionizable lipid, a molar ratio of between about 3.5% and about 14% helper lipid, a molar ratio of between about 28% and about 50% structural lipid, and a molar ratio of betw een about 0.5% and about 5% circular PEG-lipid, inclusive of all endpoints.
- the total molar percentage of the ionizable lipid, the helper lipid, the structural lipid, and the circular PEG-lipid is 100% in the LNP.
- the molar ratio of the ionizable lipid in the LNP is from about 40 to about 60% of the total lipid present in the LNP. In some embodiments, the molar ratio of the ionizable lipid in the LNP is about 40%, about 41%, about 42%, about 43%, about 44%, about 45%, about 46%, about 47%, about 48%, about 49%, about 50%, about 51%, about 52%, about 53%, about 54%, about 55%, about 56%, about 57%, about 58%, about 59%, or about 60% of the total lipid present in the LNP. All values are inclusive of all endpoints.
- the molar ratio of the helper lipid in the LNP is from about 3.5% to about 14% of the total lipid present in the LNP. In some embodiments, the molar ratio of the helper lipid in the LNP is about 3, about 4%, about 5%, about 6%, about 7%, about 8%, about 9%. about 10%, about 11%, about 12%, about 13%, or about 14% of the total lipid present in the LNP.
- the helper lipid is DSPC. In some embodiments, the helper lipid is DOPE. All values are inclusive of all endpoints.
- the molar ratio of the structural lipid in the LNP is from about 28% to about 50% of the total lipid present in the LNP. In some embodiments, the molar ratio of tire structural lipid in the LNP is about 28%, about 29%, about 30%, about 31%, about 32%, about 33%. about 34%, about 35%, about 36%, about 37%. about 38%, about 39%, about 40%, about 41%. about 42%, about 43%, about 44%, about 45%, about 46%, about 47%, about 48%. about 49%, or about 50% of the total lipid present in the LNP. In some embodiments, the structural lipid is cholesterol. All values are inclusive of all endpoints.
- the molar ratio of the circular PEG-lipid in the LNP is from about 0.1% to about 5% of the total lipid present in the LNP. In some embodiments, the molar ratio of the circular PEG-lipid in the LNP is about 0.1%, about 0.2%, about 0.3%, about 0.4%, about 0.5%, about 0.6%. about 0.7%. about 0.8%, about 0.9%, about 1.0%, about 1.1%, about 1.2%, about 1.3%, about
- the circular PEG-lipid is of Formula (I) (as described herein). In some embodiments, the circular PEG-lipid is of Formula (II) (as described herein). In some embodiments, the circular PEG-lipid is of Formula (III) (as described herein). All values are inclusive of all endpoints.
- the molar ratio of ionizable lipid:helper lipid: structural lipid circular PEG-lipid in tire LNP is about 45:9:44:2. In some embodiments, the molar ratio of ionizable lipid:helper lipid structural lipid:circular PEG-lipid in the LNP is about 50:10:38.5:1.5. In some embodiments, the molar ratio of ionizable lipid:helper lipid structural lipid circular PEG-lipid in the LNP is about 41 : 12:45:2. In some embodiments, the molar ratio of ionizable lipid:helper lipid structural lipid circular PEG-lipid in tire LNP is about 62:4:33: 1.
- the molar ratio of ionizable lipid:helper lipid structural lipid:circular PEG-lipid in the LNP is about 53:5:41: 1. In some embodiments, the molar ratio of each of the ionizable lipid, helper lipid, structural lipid, and circular PEG-lipid is within 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 1%, 0.9%, 0.8%, 0.7%, 0.6%, 0.5%, 0.4%, 0.3%, 0.2%, 0.1%, 0.09%, 0.08%, 0.07%, 0.06%, 0.05%, 0.04%, 0.03%, 0.02%. or 0.01% of the stated value.
- the lipid nanoparticles may have a diameter from about 10 to about 100 mn such as, but not limited to, about 10 to about 20 nm, about 10 to about 30 nm, about 10 to about 40 mn, about 10 to about 50 mn, about 10 to about 60 nm, about 10 to about 70 nm, about 10 to about 80 mn.
- the lipid nanoparticles may have a diameter from about 10 to 500 nm. In one embodiment, the lipid nanoparticle may have a diameter greater than 100 mn.
- nm greater than 150 nm, greater than 200 nm, greater than 250 nm, greater than 300 mn. greater than 350 nm, greater than 400 nm, greater than 450 nm, greater than 500 nm. greater than 550 nm, greater than 600 nm, greater than 650 nm, greater than 700 nm. greater than 750 nm, greater than 800 nm, greater than 850 nm. greater than 900 nm, greater than 950 nm or greater than 1000 nm.
- Each possibility represents a separate embodiment of the present disclosure.
- a nanoparticle e.g.. a lipid nanoparticle
- a nanoparticle has a mean diameter of 10- 500 nm. 20-400 nm, 30-300 nm, or 40-200 nm.
- a nanoparticle e.g.. a lipid nanoparticle
- the lipid nanoparticles described herein can have a diameter from below 0 .1 pm to up to 1 mm such as. but not limited to, less than 0 .1 pm, less than 1.0 pm. less than 5 pm, less than 10 pm, less than 15 pm, less than 20 pm, less than 25 pm, less than 30 pm, less than 35 pm, less than 40 pm. less than 50 pm, less than 55 pm, less than 60 pm, less than 65 pm, less than 70 pm, less than 75 pm, less than 80 pm. less than 85 pm.
- less than 90 pm less than 95 pm, less than 100 pm, less than 125 pm, less than 150 pm, less than 175 pm, less than 200 pm, less than 225 pm, less than 250 pm, less than 275 pm, less than 300 pm, less than 325 pm, less than 350 pm, less than 375 pm, less than 400 pm, less than 425 pm, less than 450 pm, less than 475 pm, less than 500 pm, less than 525 pm, less than 550 pm, less than 575 pm, less than 600 pm, less than 625 pm, less than 650 pm, less than 675 pm, less than 700 pm, less than 725 pm, less than 750 pm, less than 775 pm, less than 800 pm, less than 825 pm, less than 850 pm, less than 875 pm, less than 900 pm. less than 925 pm. less than 950 pm, less than 975 pm.
- LNPs may have a diameter from about 1 nm to about 100 nm, from about 1 nm to about 10 nm, about 1 nm to about 20 nm, from about 1 mn to about 30 mn, from about 1 mn to about 40 mn, from about 1 nm to about 50 nm, from about 1 nm to about 60 mn, from about 1 mn to about 70 mn, from about 1 nm to about 80 nm, from about 1 nm to about 90 nm, from about 5 nm to about from 100 mu, from about 5 nm to about 10 nm, about 5 nm to about 20 nm, from about 5 nm to about 30 mn, from about 5 nm to about 40 mn, from about 5 nm to about 50 nm, from about 5 nm to about 60 mn, from about 5 nm to about 70 nm, from about 5 nm to about
- a nanoparticle composition may be relatively homogenous.
- a polydispersity index may be used to indicate the homogeneity of a nanoparticle composition, e.g., the particle size distribution of the nanoparticle compositions.
- a small (e.g.. less than 0.3) polydispersity index generally indicates a narrow particle size distribution.
- a nanoparticle composition may have a polydispersity index from about O to about 0.25. such as 0.01, 0.02. 0.03, 0.04, 0.05. 0.06, 0.07, 0.08. 0.09, 0.10. 0.1 1. 0.12, 0.13, 0.14, 0.15. 0.16. 0.17, 0.18, 0.19, 0.20. 0.21. 0.22, 0.23, 0.24, or 0.25.
- the polydispersity index of a nanoparticle composition may be from about 0.10 to about 0.20. Each possibility represents a separate embodiment of the present disclosure.
- the zeta potential of a nanoparticle composition may be used to indicate the electrokinetic potential of the composition.
- the zeta potential may describe the surface charge of a nanoparticle composition.
- Nanoparticle compositions with relatively low charges, positive or negative, are generally desirable, as more highly charged species may interact undesirably with cells, tissues, and other elements in the body.
- the zeta potential of a nanoparticle composition may be from about -20 mV to about +20 mV, from about -20 mV to about +15 mV, from about -20 mV to about +10 mV, from about -20 mV to about +5 mV, from about -20 mV to about 0 mV, from about -20 mV to about -5 mV, from about -20 mV to about -10 mV, from about -20 mV to about -15 mV from about -20 mV to about +20 mV, from about -20 mV to about +15 mV, from about -20 mV to about +10 mV, from about -20 mV to about +5 mV, from about -20 mV to about 0 mV, from about 0 mV to about +20 mV, from about 0 mV to about +15 mV, from about 0 mV to about +10 mV,
- the efficiency of encapsulation of a therapeutic agent describes the amount of therapeutic agent that is encapsulated or otherwise associated with a nanoparticle composition after preparation, relative to the initial amount provided.
- the encapsulation efficiency is desirably high (e.g., close to 100%).
- the encapsulation efficiency may be measured, for example, by comparing the amount of therapeutic agent in a solution containing the nanoparticle composition before and after breaking up the nanoparticle composition with one or more organic solvents or detergents. Fluorescence may be used to measure tire amount of free therapeutic agent (e.g., nucleic acids) in a solution.
- the encapsulation efficiency of a therapeutic agent may be at least 50%, for example 50%, 55%, 60%, 65%, 70%, 75%. 80%, 85%, 90%, 91%, 92%, 93%, 94%. 95%, 96%, 97%, 98%, 99%, or 100%. In some embodiments, the encapsulation efficiency may be at least 80%. In certain embodiments, the encapsulation efficiency may be at least 90%. Each possibility represents a separate embodiment of the present disclosure.
- the lipid nanoparticle has a polydiversity value of less than 0.4. In some embodiments, the lipid nanoparticle has a net neutral charge at a neutral pH. In some embodiments, the lipid nanoparticle has a mean diameter of 50-200nm.
- the properties of a lipid nanoparticle formulation may be influenced by factors including, but not limited to, the selection of the cationic lipid component, the degree of cationic lipid saturation, the selection of the non-cationic lipid component, the degree of noncationic lipid saturation, the selection of the structural lipid component, the nature of the PEGylation, ratio of all components and biophysical parameters such as size. As described herein, the purity of a circular PEG lipid component is also important to an LNP’s properties and performance.
- a lipid nanoparticle formulation may be prepared by the methods described in International Publication Nos. WO2011127255 or W02008103276. each of which is herein incorporated by reference in their entirety. In some embodiments, lipid nanoparticle formulations may be as described in International Publication No. W02019131770. which is herein incorporated by reference in its entirety.
- circular RNA is formulated according to a process described in US patent application 15/809,680.
- the present disclosure provides a process of encapsulating circular RNA in transfer vehicles comprising the steps of forming lipids into pre-formed transfer vehicles (i.e., formed in the absence of RNA) and then combining the pre-formed transfer vehicles with RNA.
- the novel formulation process results in an RNA formulation with higher potency (peptide or protein expression) and higher efficacy (improvement of a biologically relevant endpoint) both in vitro and in vivo with potentially better tolerability as compared to the same RNA formulation prepared without the step of preforming the lipid nanoparticles (e.g., combining the lipids directly with the RNA).
- the RNA in buffer e.g., citrate buffer
- the heating is required to occur before the formulation process (i.e., heating the separate components) as heating post-formulation (post-formation of nanoparticles) does not increase the encapsulation efficiency of the RNA in the lipid nanoparticles.
- the order of heating of RNA does not appear to affect the RNA encapsulation percentage.
- no heating i.e., maintaining at ambient temperature
- the solution comprising the RNA and the mixed solution comprising the lipid nanoparticle encapsulated RNA is required to occur before or after the formulation process.
- RNA may be provided in a solution to be mixed with a lipid solution such that the RNA may be encapsulated in lipid nanoparticles.
- a suitable RNA solution may be any aqueous solution containing RNA to be encapsulated at various concentrations.
- a suitable RNA solution may contain an RNA at a concentration of or greater than about 0.01 mg/ml, 0.05 mg/ml, 0.06 mg/ml, 0.07 mg/ml. 0.08 mg/ml. 0.09 mg/ml, 0.1 mg/ml. 0.15 mg/ml, 0.2 mg/ml. 0.3 mg/ml, 0.4 mg/ml, 0.5 mg/ml. 0.6 mg/ml.
- a suitable RNA solution may contain an RNA at a concentration in a range from about 0.01-1.0 mg/ml, 0.01-0.9 mg/ml, 0.01- 0.8 mg/ml. 0.01-0.7 mg/ml. 0.01-0.6 mg/ml, 0.01-0.5 mg/ml, 0.01-0.4 mg/ml, 0.01-0.3 mg/ml, 0.01-0.2 mg/ml, 0.01 -0.1 mg/ml, 0.05-1.0 mg/ml, 0.05-0.9 mg/ml, 0.05-0.8 mg/ml. 0.05-0.7 mg/ml.
- 0.05-0.6 mg/ml 0.05-0.5 mg/ml, 0.05-0.4 mg/ml, 0.05-0.3 mg/ml, 0.05-0.2 mg/ml, 0.05-0.1 mg/ml, 0.1-1.0 mg/ml, 0.2-0.9 mg/ml, 0.3-0. mg/ml. 0.4-0.7 mg/ml, or 0.5-0.6 mg/ml.
- RNA solution may also contain a buffering agent and/or salt.
- buffering agents can include HEPES, Tris, ammonium sulfate, sodium bicarbonate, sodium citrate, sodium acetate, potassium phosphate or sodium phosphate.
- suitable concentration of the buffering agent may be in a range from about 0.1 mM to 100 mM, 0.5 mM to 90 mM, 1.0 mM to 80 mM, 2 mM to 70 mM, 3 mM to 60 mM, 4 mM to 50 mM, 5 mM to 40 mM, 6 mM to 30 mM, 7 mM to 20 mM, 8 mM to 15 mM, or 9 to 12 mM.
- Exemplary salts can include sodium chloride, magnesium chloride, and potassium chloride.
- suitable concentration of salts in an RNA solution may be in a range from about 1 mM to 500 mM, 5 mM to 400 mM, 10 mM to 350 mM, 15 mM to 300 mM, 20 mM to 250 mM, 30 mM to 200 mM, 40 mM to 190 mM, 50 mM to 180 mM, 50 mM to 170 mM, 50 mM to 160 mM, 50 mM to 150 mM, or 50 mM to 100 mM.
- a suitable RNA solution may have a pH in a range from about 3.5-6.5, 3.5-6.0, 3.5-5.5, 3.5-5.0, 3.5-4.5, 4.0-5.5, 4.0-5.0, 4.0-4.9, 4.0-4.8, 4.0-4.7, 4.0-4.6, or 4.0-4.5.
- RNA may be directly dissolved in a buffer solution described herein.
- an RNA solution may be generated by mixing an RNA stock solution with a buffer solution prior to mixing with a lipid solution for encapsulation.
- an RNA solution may be generated by mixing an RNA stock solution with a buffer solution immediately before mixing with a lipid solution for encapsulation.
- a lipid solution contains a mixture of lipids suitable to form transfer vehicles for encapsulation of RNA.
- a suitable lipid solution is ethanol based.
- a suitable lipid solution may contain a mixture of desired lipids dissolved in pure ethanol (i.e., 100% ethanol).
- a suitable lipid solution is isopropyl alcohol based.
- a suitable lipid solution is dimethylsulfoxide-based.
- a suitable lipid solution is a mixture of suitable solvents including, but not limited to, ethanol, isopropyl alcohol and dimethylsulfoxide.
- a suitable lipid solution may contain a mixture of desired lipids at various concentrations.
- a suitable lipid solution may contain a mixture of desired lipids at a total concentration in a range from about 0.1-100 mg/ml, 0.5-90 mg/ml. 1.0-80 mg/ml. 1.0-70 mg/ml, 1.
- fl- 60 mg/ml 1.0-50 mg/ml, 1.0-40 mg/ml, 1.0-30 mg/ml, 1.0-20 mg/ml, 1.0-15 mg/ml, 1.0-10 mg/ml, 1.0- 9 mg/ml, 1.0-8 mg/ml, 1.0-7 mg/ml, 1.0-6 mg/ml, or 1.0-5 mg/ml.
- the lipid nanoparticle formulations disclosed herein comprise ionizable lipids.
- the subject ionizable lipids may be used as a component of a composition to facilitate encapsulation and release of nucleic acid cargo (e.g., circular RNA) to one or more target cells.
- an ionizable lipid comprises one or more cleavable functional groups (e.g., a disulfide) that allow, for example, a hydrophilic functional head-group to dissociate from a lipophilic functional tail-group of the compound (e.g.. upon exposure to oxidative, reducing or acidic conditions).
- the ionizable lipid has a pKa from 6 to 12. In some embodiments, the ionizable lipid has a pKa from 7 to 9. In some embodiments, the ionizable lipid has a pK.a of 6.0, 6.1, 6.2. 6.3. 6.4, 6.5, 6.6, 6.7, 6.8, 6.9. 7.0. 7.1, 7.2, 7.3, 7.4, 7.5, 7.6. 7.7. 7.8. 7.9. 8.0, 8.1, 8.2, 8.3, 8.4.
- the ionizable lipid comprises an amino group.
- the ionizable lipid comprises a divalent headgroup and one or more straight hydrocarbon lipid tails.
- the straight hydrocarbon lipid tails are from 3- 25 carbon atoms in length, such as 5 to 25, 5 to 20, 5 to 15, 5 to 10, 10 to 15, 10 to 20, or 10 to 25 carbon atoms in length.
- the ionizable lipid comprises a divalent headgroup and one or more branched hydrocarbon lipid tails.
- the branched hydrocarbon lipid tails arc from 3-25 carbon atoms in length, such as 5 to 25, 5 to 20, 5 to 15, 5 to 10, 10 to 15, 10 to 20, or 10 to 25 carbon atoms in length.
- the divalent headgroup is selected from guanidine and squaramidc.
- the squaramide headgroup is of the following formula: wherein RA and RB are each independently a C1-C6 alkyl group or H; and represents the point of attachment of the headgroup to a straight or branched hydrocarbon lipid tail.
- the ionizable lipid comprises a head group selected from:
- the ionizable lipid comprises a head group selected from: wherein represents the point of attachment of the headgroup to a straight or branched hydrocarbon lipid tail.
- the ionizable lipid comprises a hydrophilic headgroup as disclosed in Jayaraman et al. Angew. Chem. Int. Ed. (2012), 51, 8529-8533.
- the ionizable lipid is ethyl lauryl arginate (EL A). In some embodiments, the ionizable lipid is ionizable lipid 1, wherein ionizable lipid 1 comprises:
- the one or more of the cationic or ionizable lipids are represented by Formula (LI): wherein: n is an integer between 1 and 4:
- R a is hydrogen or hydroxy l
- R 1 and R 2 arc each independently a linear or branched C 6 -C 30 alkyl, C 6 -C 30 alkenyl, or C 6 -C 30 heteroalky l, optionally substituted by one or more substituents selected from a group consisting of oxo, halo, hydroxy , cyano, alkyl, alkenyl, aldehyde, heterocyclylalkyl, hydroxyalkyl, dihydroxyalkyl, hydroxy alkylaminoalkyl, aminoalkyl, alkylaminoalkyl, dialkylaminoalkyl, (heterocyclyl)(alkyl)aminoalkyl, heterocyclyl.
- heteroaiyl alkylheteroaryl, alkynyl, alkoxy, amino, dialkylamino, aminoalkylcarbonylamino, aminocarbonylalkylamino, (aminocarbonylalkyl)(alkyl)amino, alkenylcarbonylamino, hydroxy carbonyl, alkyloxycarbonyl, aminocarbonyl, aminoalkylaminocarbonyl, alkylaminoalkylaminocarbonyl, dialkylaminoalkylaminocarbonyl, heterocyclylalkylaminocarbonyl.
- alkylaminoalky l (alkyl)aminocarbonyl.
- alkylaminoalkylcarbonyl dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkenylcarbonyl, alkynylcarbonyl, alkylsulfoxide, alkylsulfoxidealkyl, alkylsulfonyl, and alkylsulfonealkyl.
- Ra is hydrogen. In some embodiments. Ra is hydroxyl.
- the ionizable lipid is represented by Fonnula (Lla -1), Formula (LIa-2), or Formula (LIa-3):
- the ionizable lipid is represented by Formula (LIb-1).
- the ionizable lipid is represented by Formula (Llb-4), Formula (LIb-5), Fonnula (LIb-6), Formula (Lib- 7), Formula (LIb-8). or Formula (LIb-9):
- the one or more of the cationic or ionizable lipids are represented by Fonnula (LI), wherein R 1 and R 2 are each independently selected from:
- R 1 and R 2 are the same. In some embodiments. R 1 and R 2 are different.
- the one or more of the cationic or ionizable lipids are represented by
- n* is an integer between 1 to 7
- R a is hydrogen or hydroxyl.
- R b is hydrogen or C 1 -C 6 alkyl
- R 1 and R 2 are each independently a linear or branched C 1 -C 30 alkyl, C 2 -C 30 alkenyl, or C 1 -C 30 heteroalkyl, optionally substituted by one or more substituents selected from oxo. halo, hydroxy, cyano, alkyd, alkenyl, aldehyde, heterocyclylalkyl.
- alkylaminoalkyl (alkyl)aminocarbonyl, alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkeny Icarbony 1, alky nylcarbony 1, alkylsulfoxide, alkydsulfoxidealkyl, alky dsulfonyl, and alkylsulfonealkyl.
- tire one or more of the cationic or ionizable lipids are represented by Formula (LII): wherein: each n is independently an integer from 2-15;
- L 1 and L 3 are each independently -OC(O)-* or -C(O)O-*, wherein indicates the attachment point to R 1 or R 3 ;
- R 1 and R 3 are each independently a linear or branched C 9 -C 20 alky l or C 9 -C 20 alkenyl, optionally substituted by one or more substituents selected from a group consisting of oxo, halo, hydroxy, cyano, alky l, alkenyl, aldehyde, hctcrocycly lalkyl, hydroxyalkyl, dihy droxyalkyl, hy droxy alky laminoalky l, aminoalkyl, alkylaminoalkyl, dialky laminoalky l, (lieterocyclyl)(alkyl)aminoalkyl, heterocyclyl, heteroaryl, alkydheteroaryl, alkynyl, alkoxy, amino, dialky lamino, aminoalkylcarbonylamino, aminocarbonylalky lamino, (aminocarbony lalky l)(alkyl)amino
- the ionizable lipid is selected from an ionizable lipid of Formula LII, wherein R 1 and R 3 are each independently selected from a group consisting of:
- R 1 and R 3 are the same. In some embodiments, R 1 and R 3 are different. [0260] In some embodiments, tire one or more of the cationic or ionizable lipids are represented by
- the ionizable lipid is selected from an ionizable lipid of W02015/095340. In some embodiments, the ionizable lipid is selected from an ionizable lipid of WO2021/021634, WO2020/237227, or WO2019/23 673. In some embodiments, the ionizable lipid is selected from an ionizable lipid of WO2021226597 and WO2021113777. In some embodiments, the ionizable lipid is selected from an ionizable lipid of W02023056033. In some embodiments, the ionizable lipid is selected from an ionizable lipid of WO2023081526.
- tire one or more of the cationic or ionizable lipids are represented by Formula (LIII): or a pharmaceutically acceptable salt thereof, wherein
- the one or more of the cationic or ionizable lipids are represented by Fonnula (LIII*): or a pharmaceutically acceptable salt thereof, wherein heteroalk l, optionally substituted by one or more substituents selected from oxo, halo, hydroxy, cyano, alky l, alkenyl, aldehy de, heterocyclylalkyl, hy droxyalky l, dihydroxyalkyl, hydroxy alkylaminoalkyl, aminoalkyl, alkylaminoalkyl, dialkylaminoalkyl, (lreterocyclyl)(alkyl)aminoalkyl, heterocyclyl, heteroaryl, alkylheteroaryl, alkynyl, alkoxy, amino, dialkylamino, aminoalkylcarbonylamino, aminocarbonylalkylamino, (aminocarbony lalky 1) (alkyl)
- alkylaminoalkyl (alkyl)aminocarbonyl, alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkenylcarbonyl, alkynylcarbonyl, alk lsulfoxide, alkylsulfoxidealk l, alkydsulfonyl, and alkylsulfonealkyl.
- an ionizable lipid is a compound of Formula (LIV): or is a pharmaceutically acceptable salt thereof, wherein: n’ is an integer from 1 to 7;
- R a is hydrogen or hydroxyl
- R h is hydrogen or C 1 -C 6 alky 1
- R 1 is C 1 -C 30 alkyl or R 1 ’ ;
- R 2 is C 1 -C 30 alkyl or R 2 *;
- R 1 * and R 2 * are independently selected from:
- q is an integer from 0 to 12.
- r is an integer from 0 to 6, wherein at least one occurrence of r is not 0;
- R 8 is H or R 11 ;
- R 9 , R 10 , and R 11 are each independently C 1 -C 20 alky 1 or C 2 -C 20 -alkenyl; and wherein (i) R 1 is R 1 *, (ii) R 2 is R 2* , or (iii) R 1 is R 1* and R 2 is R 2* .
- an ionizable lipid of the present disclosure is represented by Formula (LV): or is a pharmaceutically acceptable salt thereof, wherein:
- R a is hydrogen or hydroxyl
- R 1 is C 1 -C 30 alkyl or R 1 * ;
- R 2 is C 1 -C 30 alkyl or R 2 *;
- R 1 * and R 2 * are independently selected from:
- R 4 is hydrogen or R 7 ;
- R 5 , R 6 . and R 7 are each independently C 1 -C 20 alkyl or C 2 -C 2 o-alkenyl; wherein (i) R 1 is R 1 * , (ii) R 2 is R 2 ’, or (iii) R 1 is R 1 * and R 2 is R 2 *; and
- R 3 is L-R’, wherein L is linear or branched C1-C10 alkylene, and R’ is (i) mono- or bicyclic heterocyclyl or heteroary l, such as imidazolyl, pyrazolyl, 1,2,4-triazolyl, or benzimidazolyl, each optionally substituted at one or more available carbon and nitrogen by C 1 -C 6 alkyl, or (ii) R A , R B , or R c , wherein R A is selected from:
- R c is selected from:
- the cationic or ionizable lipid is Ionizable Lipid 2, wherein
- ionizable lipid 2 comprises: [0267] In certain embodiments, cationic or ionizable lipid is Ionizable Lipid 3, wherein ionizable lipid 3 comprises:
- Exemplary ionizable and/or cationic lipids are described in International PCT patent publications W02015/095340, WO2015/199952, W02018/011633, WO2017/049245,
- WO2015/061467 WO2012/040184, WO2012/000104, WO2015/074085, W02016/081029.
- WO2017/004 143 WO2017/075531, WO2017/117528, WO2011/022460.
- the LNP described herein comprises one or more non-cationic helper lipids.
- the helper lipid is a phospholipid.
- the helper lipid is a phospholipid substitute or replacement.
- the phospholipid or phospholipid substitute can be, for example, one or more saturated or (poly)unsaturated phospholipids, or phospholipid substitutes, or a combination thereof.
- phospholipids comprise a phospholipid moiety and one or more Patty acid moieties.
- a phospholipid moiety can be selected, for example, from the non-limiting group consisting of phosphatidyl choline, phosphatidyl ethanolamine, phosphatidyl glycerol, phosphatidyl serine, phosphatidic acid, 2-lysophosphatidyl choline, and a sphingomyelin.
- a fatly acid moiety can be selected, for example, from the non-limiting group consisting of lauric acid, myristic acid, myristoleic acid, palmitic acid, palmitoleic acid, stearic acid, oleic acid, linoleic acid, alpha-linolenic acid, erucic acid, phytanoic acid, arachidic acid, arachidonic acid, eicosapentaenoic acid, behenic acid, docosapentaenoic acid, and docosahexaenoic acid.
- Phospholipids include, but are not limited to, glycerophospholipids such as phosphatidylcholines, phosphatidylethanolamines, phosphatidylserines, phosphatidylinositols, phosphatidy glycerols, and phosphatidic acids. Phospholipids also include phosphosphingolipid, such as sphingomyelin.
- the helper lipid is a 1.2-distearoyl-177-glycero-3-phosphocholine (DSPC) analog, a DSPC substitute, oleic acid, or an oleic acid analog.
- DSPC 1.2-distearoyl-177-glycero-3-phosphocholine
- a helper lipid is a non-phosphatidyl choline (PC) zwitterionic lipid, a DSPC analog, oleic acid, an oleic acid analog, or a DSPC substitute.
- PC non-phosphatidyl choline
- helper lipid is described in PCT/US2018/053569.
- Helper lipids suitable for use in a lipid composition of the disclosure include, for example, a variety of neutral, uncharged or zwiterionic lipids. Such helper lipids are used in combination with one or more of the compounds and lipids disclosed herein. Examples of helper lipids include, but are not limited to.
- 5- heptadecylbenzene-l,3-diol resorcinol
- dipalmitoylphosphatidylcholine DPPC
- distearoylphosphatidylcholine DSPC
- dioleoylphosphatidylcholine DOPC
- dimyristoylphosphatidylcholine DMPC
- PLPC phosphatidylcholine
- DAPC l,2-distearoylsn-glycero-3- phosphocholine
- PE phosphatidylethanolamine
- EPC egg phosphatidylcholine
- DLPC dilauryloylphosphatidylcholine
- DMPC dimyristoylphosphatidylcholine
- MPPC dimyristoylphosphatidylcholine
- PMPC 1-paimitoy 1-2 -myristoyl phosphatidylcholine
- PSPC 1- pahnitoy 1-2-stearoy 1 phosphatidylcholine
- PSPC 1- ,2-diarachidoyl-sn-gly cero-3 -phosphocholine
- SPPC l,2-dicicoscnoyl-sn-glyccro-3- phosphocholine
- POPC paimitoyioieoyl phosphatidylcholine
- POPC paimitoyioieoyl phosphatidylcholine
- POPC paimitoyioieoyl phosphatidyl
- tire helper lipid may be distearoylphosphatidy leholine (DSPC) or dimyristoyl phosphatidyl ethanolamine (DMPE).
- the helper lipid may be distearoylphosphatidylcholine (DSPC).
- Helper lipids function to stabilize and improve processing of the transfer vehicles.
- Such helper lipids are used in combination with other excipients, for example, one or more of the ionizable lipids disclosed herein.
- the helper lipid when used in combination with an ionizable lipid, may comprise a molar ratio of 5% to about 90%, or about 10% to about 70% of the total lipid present in the lipid nanoparticle.
- the LNP described herein comprises one or more structural lipids. Incorporation of structural lipid(s) in the lipid nanoparticle may help mitigate aggregation of other lipids in the particle.
- Structural lipids can include, but are not limited to, cholesterol, fecosterol, ergosterol, bassicasterol, tomatidine, tomatine, ursolic, alphatocopherol. and mixtures thereof.
- the structural lipid is cholesterol.
- the structural lipid includes cholesterol and a corticosteroid (such as. for example, prednisolone, dexamethasone, prednisone, and hydrocortisone), or a combination thereof.
- a structural lipid is described in international patent application PCT/US2019/015913.
- the structural lipid is a sterol. In certain embodiments, the structural lipid is a steroid. In certain embodiments, the structural lipid is cholesterol. In certain embodiments, the structural lipid is an analog of cholesterol. In certain embodiments, tire structural lipid is alphatocopherol.
- the LNPs described herein comprise one or more structural lipids. Incorporation of structural lipids in a transfer vehicle, e.g., a lipid nanoparticle, may help mitigate aggregation of other lipids in the particle.
- the structural lipid includes cholesterol and a corticosteroid (such as, for example, prednisolone, dexamethasone, prednisone, and hydrocortisone), or a combination thereof.
- the structural lipid is a sterol.
- Structural lipids can include, but are not limited to. sterols (e.g., phytosterols or zoosterols).
- the structural lipid is a steroid.
- sterols can include, but are not limited to, cholesterol, ⁇ -sitosterol, fecosterol, ergosterol, sitosterol, campesterol, stigmasterol, brassicasterol, ergosterol, tomatidine, tomatine, ursolic acid, or alpha-tocopherol.
- LNP includes an effective amount of an immune cell delivery potentiating lipid, e.g., a cholesterol analog or an amino lipid or combination thereof, that, when present in a transfer vehicle, e.g., an lipid nanoparticle, may function by enhancing cellular association and/or uptake, internalization, intracellular trafficking and/or processing, and/or endosomal escape and/or may enhance recognition by and/or binding to immune cells, relative to a transfer vehicle lacking the immune cell delivery potentiating lipid.
- an immune cell delivery potentiating lipid e.g., a cholesterol analog or an amino lipid or combination thereof
- a structural lipid or other immune cell delivery potentiating lipid of the disclosure binds to Clq or promotes the binding of a transfer vehicle comprising such lipid to Clq.
- culture conditions that include Clq are used (e.g., use of culture media that includes serum or addition of exogenous Clq to serum -free media).
- the requirement for Clq is supplied by endogenous Clq.
- the structural lipid is cholesterol. In certain embodiments, the structural lipid is an analog of cholesterol. In some embodiments, the structural lipid is a lipid in the Table below:
- the lipid nanoparticle compositions described herein comprise a polynucleotide.
- the polynucleotide is DNA.
- the polynucleotide is RNA.
- the polynucleotide is linear RNA.
- the polynucleotide is circular RNA.
- a DNA template e.g.. comprising a 3’ intron element, 3’ exon element, a core functional element, a 5’ exon element, and a 5’ intron element
- this DNA template comprises a vector, PCR product, plasmid, minicircle DNA, cosmid, artificial chromosome, complementary DNA (cDNA), extrachromosomal DNA (ecDNA), or a fragment therein.
- the minicircle DNA may be linearized or non-linearized.
- the plasmid may be linearized or non-linearized.
- the DNA template may be single-stranded.
- the DNA template may be double-stranded.
- the DNA template comprises in whole or in part from a viral, bacterial, or eukaryotic vector.
- the precursor linear RNA polynucleotide circularizes when incubated in the presence of one or more guanosine nucleotides or nucleoside (e.g., GTP) and a divalent cation (e.g., Mg 2+ ).
- the 3’ exon element, 5‘ exon element, and/or core functional element in whole or in part promotes the circularization of the precursor linear RNA polynucleotide to fonn the circular RNA polynucleotide provided herein.
- the circular RNA provided herein is injected into an animal (e.g., a human), such that a polypeptide encoded by the circular RNA molecule is expressed inside the animal.
- an animal e.g., a human
- the DNA template e.g., vector
- linear RNA e.g., precursor RNA
- circular RNA polynucleotide is between 300 and 10000, 400 and 9000, 500 and 8000, 600 and 7000, 700 and 6000, 800 and 5000, 900 and 5000, 1000 and 5000, 1100 and 5000. 1200 and 5000. 1300 and 5000, 1400 and 5000, and/or 1500 and 5000 nucleotides (nt) in length.
- the polynucleotide is at least 300 nt, 400 nt. 500 nt, 600 nt, 700 nt, 800 nt, 900 nt.
- the polynucleotide is no more than 3000 nt, 3500 nt, 4000 nt, 4500 nt. 5000 nt, 6000 nt, 7000 nt. 8000 nt. 9000 nt, or 10000 nt in length.
- the circular RNA provided herein has higher functional stability than mRNA comprising the same expression sequence. In some embodiments, the circular RNA provided herein has higher functional stability than mRNA comprising the same expression sequence, 5moU modifications, an optimized UTR, a cap, and/or a polyA tail.
- the circular RNA polynucleotide provided herein has a functional halflife of at least 5 hours, 10 hours, 15 hours, 20 hours. 30 hours, 40 hours, 50 hours, 60 hours, 70 hours or 80 hours. In some embodiments, the circular RNA polynucleotide provided herein has a functional half-life of 5-80, 10-70, 15-60, or 20-50 hours. In some embodiments, the circular RNA polynucleotide provided herein has a functional half-life greater than (e.g.. at least 1.5-fold greater than, at least 2-fold greater than) that of an equivalent linear RNA polynucleotide encoding the same protein. In some embodiments, functional half-life can be assessed through the detection of functional protein synthesis.
- the circular RNA polynucleotide, or pharmaceutical composition thereof has a functional half-life in a human cell greater than or equal to that of a pre-determined threshold value.
- the functional half-life is determined by a functional protein assay.
- the functional half-life is determined by an in vitro luciferase assay, wherein the activity of Gaussia luciferase (GLuc) is measured in the media of human cells (e.g. HepG2) expressing the circular RNA polynucleotide every 1, 2, 6, 12, or 24 hours over 1, 2, 3. 4, 5, 6. 7, or 14 days.
- the functional half-life is detennined by an in vivo assay, wherein levels of a protein encoded by the expression sequence of the circular RNA polynucleotide are measured in patient serum or tissue samples every 1, 2, 6, 12, or 24 hours over 1, 2. 3, 4, 5, 6, 7, or 14 days.
- the pre-determined threshold value is the functional half-life of a reference linear RNA polynucleotide comprising the same expression sequence as the circular RNA polynucleotide.
- the circular RNA provided herein may have a higher magnitude of expression than equivalent linear mRNA, e.g., a higher magnitude of expression 24 hours after administration of RNA to cells.
- the circular RNA provided herein has a higher magnitude of expression than mRNA comprising the same expression sequence. 5moU modifications, an optimized UTR. a cap. and/or a polyA tail.
- the circular RNA provided herein may be less immunogenic than an equivalent mRNA when exposed to an immune system of an organism or a certain type of immune cell.
- the circular RNA provided herein is associated with modulated production of cytokines when exposed to an immune system of an organism or a certain type of immune cell.
- the circular RNA provided herein is associated with reduced production of IFN-(31, RIG-I, IL-2, IL-6, IFNy, and/or TNFa when exposed to an immune system of an organism or a certain ty pe of immune cell as compared to mRNA comprising the same expression sequence.
- the circular RNA provided herein is associated with less IFN-(31, RIG-I, IL-2, IL-6, IFNy, and/or TNFa transcript induction when exposed to an immune system of an organism or a certain type of immune cell as compared to mRNA comprising the same expression sequence.
- the circular RNA provided herein is less immunogenic than mRNA comprising the same expression sequence.
- the circular RNA provided herein is less immunogenic than mRNA comprising the same expression sequence, 5moU modifications, an optimized UTR, a cap. and/or a polyA tail.
- the DNA template e.g., vector
- linear RNA e.g., precursor RNA
- the DNA template comprises an enhanced intron element and/or enhanced exon element.
- the enhanced intron elements and enhanced exon elements may comprise spacers, duplex regions, affinity sequences, intron fragments, exon fragments and various untranslated elements. These sequences within the enhanced intron elements or enhanced exon elements are arranged to optimize circularization or protein expression.
- the DNA template, precursor linear RNA polynucleotide and circular RNA provided herein comprise a first (5 ’) and/or a second (3 ’) spacer.
- the DNA template or precursor linear RNA polynucleotide comprises one or more spacers in the enhanced intron elements.
- the DNA template, precursor linear RNA polynucleotide comprises one or more spacers in the enhanced exon elements.
- the DNA template or linear RNA polynucleotide comprises a spacer in the 3’ enhanced intron fragment and a spacer in the 5’ enhanced intron fragment.
- DNA template, precursor linear RNA polynucleotide, or circular RNA comprises a spacer in the 3’ enhanced exon fragment and another spacer in the 5’ enhanced exon fragment to aid with circularization or protein expression due to symmetry created in the overall sequence.
- including a spacer between the 3 ’ group I intron fragment and the core functional element may conserve secondary structures in those regions by preventing them from interacting, thus increasing splicing efficiency.
- the first (between 3’ group I intron fragment and core functional element) and second (between the two expression sequences and core functional element) spacers comprise additional base pairing regions that are predicted to base pair with each other and not to the first and second duplex regions.
- the first (between 3’ group I intron fragment and core functional element) and second (between the one of the core functional element and 5’ group I intron fragment) spacers comprise additional base pairing regions that are predicted to base pair with each other and not to the first and second duplex regions.
- such spacer base pairing brings the group I intron fragments in close proximity to each other, further increasing splicing efficiency. Additionally, in some embodiments, the combination of base pairing between the first and second duplex regions, and separately, base pairing between the first and second spacers, promotes the formation of a splicing bubble containing the group I intron fragments flanked by adjacent regions of base pairing.
- Typical spacers are contiguous sequences with one or more of the following qualities: 1) predicted to avoid interfering with proximal structures, for example, the IRES, expression sequence, aptamer, or intron; 2) is at least 7 nt long and no longer than 100 nt; 3) is located after and adjacent to the 3 ’ intron fragment and/or before and adjacent to the 5 ’ intron fragment; and 4) contains one or more of the following: a) an unstructured region at least 5 nt long, b) a region of base pairing at least 5 nt long to a distal sequence, including another spacer, and c) a structured region at least 7 nt long limited in scope to the sequence of the spacer.
- Spacers may have several regions, including an unstructured region, a base pairing region, a hairpin/structured region, and combinations thereof.
- the spacer has a structured region with high GC content.
- a spacer comprises one or more hairpin structures.
- a spacer comprises one or more hairpin structures with a stem of 4 to 12 nucleotides and a loop of 2 to 10 nucleotides.
- this additional spacer prevents the structured regions of the IRES or aptamer of a TIE from interfering w ith the folding of the 3’ group I intron fragment or reduces the extent to which this occurs.
- the 5’ spacer sequence is at least 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25 or 30 nucleotides in length. In some embodiments, the 5‘ spacer sequence is no more than 100, 90, 80, 70, 60, 50, 45, 40, 35 or 30 nucleotides in length. In some embodiments the 5’ spacer sequence is between 5 and 50, 10 and 50, 20 and 50, 20 and 40, and/or 25 and 35 nucleotides in length.
- the 5’ spacer sequence is 10, 11, 12, 13, 14, 15, 16, 17. 18, 19, 20, 21, 22, 23, 24, 25, 26, 27. 28, 29, 30, 31, 32, 33, 34, 35, 36. 37, 38, 39, 40, 41. 42, 43, 44, 45, 46, 47, 48, 49 or 50 nucleotides in length.
- the 5’ spacer sequence is a poly A sequence.
- the 5’ spacer sequence is a poly AC sequence.
- a spacer comprises 10%, 20%, 30%, 40%. 50%. 60%, 70%, 80%, 90%. or 100% poly AC content.
- a spacer comprises 10%. 20%, 30%, 40%, 50%. 60%, 70%, 80%, 90%.
- the DNA template and precursor linear RNA polynucleotides and circular RNA polynucleotide provided herein comprise a first (5’) duplex region and a second (3’) duplex region.
- the DNA template and precursor linear RNA polynucleotide comprises a 5' external duplex region located within the 3‘ enhanced intron fragment and a 3’ external duplex region located within the 5‘ enhanced intron fragment.
- the DNA template, precursor linear RNA polynucleotide and circular RNA polynucleotide comprise a 5 ‘ internal duplex region located within the 3’ enhanced exon fragment and a 3’ internal duplex region located within the 5’ enhanced exon fragment.
- the DNA polynucleotide and precursor linear RN A polynucleotide comprises a 5 ’ external duplex region. 5 ’ internal duplex region, a 3 ’ internal duplex region, and a 3‘ external duplex region.
- the first and second duplex regions may form perfect or imperfect duplexes. Thus, in certain embodiments at least 75%. 80%, 85%, 90%, 91%, 92%, 93%. 94%. 95%, 96%, 97%, 98%, 99%, or 100% of the first and second duplex regions may be base paired with one another. In some embodiments, the duplex regions are predicted to have less than 50% (e.g., less than 45%, less than 40%, less than 35%, less than 30%. less than 25%) base pairing with unintended sequences in the RNA (e.g., non-duplex region sequences).
- the duplex regions are 3 to 100 nucleotides in length (e.g., 3-75 nucleotides in length, 3-50 nucleotides in length. 20-50 nucleotides in length. 35-50 nucleotides in length, 5-25 nucleotides in length, 9-19 nucleotides in length). In some embodiments, the duplex regions are 3, 4. 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21. 22, 23, 24, 25. 26, l, 28, 29. 30, 31, 32, 33, 34.
- the duplex regions have a length of 9 to 50 nucleotides. In one embodiment, the duplex regions have a length of 9 to 19 nucleotides. In some embodiments, the duplex regions have a length of 20 to 40 nucleotides. In certain embodiments, the duplex regions have a length of 30 nucleotides.
- the DNA template, precursor linear RNA polynucleotide, or circular RNA polynucleotide does not comprise of any duplex regions to optimize translation or circularization.
- the DNA template or precursor linear RNA polynucleotide may comprise an affinity tag.
- the affinity' tag is located in the 3 ’ enhanced intron element.
- the affinity tag is located in the 5’ enhanced intron element.
- both (3 ’ and 5 ) enhanced intron elements each comprise an affinity tag.
- an affinity tag of the 3 ’ enhanced intron element is the length as an affinity tag in the 5 ’ enhanced intron element.
- an affinity tag of the 3‘ enhanced intron element is the same sequence as an affinity tag in the 5 ’ enhanced intron element.
- the affinity sequence is placed to optimize oligo-dT purification.
- an affinity tag comprises a polyA region.
- the polyA region is at least 15, 30, or 60 nucleotides long.
- one or both polyA regions is 15-50 nucleotides long.
- one or both polyA regions is 20-25 nucleotides long.
- the polyA sequence is removed upon circularization.
- an oligonucleotide hybridizing with the polyA sequence such as a deoxythymine oligonucleotide (oligo(dT)) conjugated to a solid surface (e.g., a resin), can be used to separate circular RNA from its precursor RNA.
- the 3’ enhanced intron element comprises a leading untranslated sequence.
- the leading untranslated sequence is a the 5’ end of the 3‘ enhanced intron fragment.
- the leading untranslated sequence comprises of the last nucleotide of a transcription start site (TSS).
- TSS transcription start site
- the TSS is chosen from a viral, bacterial, or eukary otic DNA template.
- the leading untranslated sequence comprise the last nucleotide of a TSS and 0 to 100 additional nucleotides.
- the TSS is a terminal spacer.
- the leading untranslated sequence contains a guanosine at the 5’ end upon translation of an RNA T7 polymerase.
- the 5’ enhanced intron element comprises a trailing untranslated sequence.
- the 5' trailing untranslated sequence is located at the 3’ end of the 5’ enhanced intron element.
- the trailing untranslated sequence is a partial restriction digest sequence.
- the trailing untranslated sequence is in whole or in part a restriction digest site used to linearize the DNA template.
- the restriction digest site is in whole or in part from a natural viral, bacterial or eukaryotic DNA template.
- the trailing untranslated sequence is a terminal restriction site fragment.
- the 3’ enhanced intron element and 5’ enhanced intron element each comprise an intron fragment.
- a 3 ’ intron fragment is a contiguous sequence at least 75% homologous (e.g.. at least 80%, 85%, 90%. 91%. 92%, 93%, 94%, 95%, 96%. 97%. 98%, 99% or 100% homologous) to a 3’ proximal fragment of a natural group I or II intron including the 3’ splice site dinucleotide.
- a 5’ intron fragment is a contiguous sequence at least 75% homologous (e.g.. at least 80%. 85%. 90%, 91%. 92%.
- the 3’ intron fragment includes the first nucleotide of a 3’ group I or II splice site dinucleotide.
- the 5’ intron fragment includes the first nucleotide of a 5’ group I or II splice site dinucleotide.
- the 3’ intron fragment includes the first and second nucleotides of a 3’ group I or II intron fragment splice site dinucleotide; and the 5’ intron fragment includes the first and second nucleotides of a 3’ group I or II intron fragment dinucleotide.
- the 3' enhanced intron element and 5’ enhanced intron element comprises a synthetic intron fragment.
- the DNA template, linear precursor RNA polynucleotide, and circular RNA polynucleotide each comprise an enhanced exon fragment.
- the 3’ enhanced exon element is located upstream to core functional element.
- the 5’ enhanced intron element is located downstream to the core functional element.
- the 3’ enhanced exon element and 5’ enhanced exon element each comprise an exon fragment.
- the 3’ enhanced exon element comprises a 3' exon fragment.
- the 5’ enhanced exon element comprises a 5’ exon fragment.
- the 3 ’ exon fragment and 5 ’ exon fragment each comprises a group I or II intron fragment and 1 to 100 nucleotides of an exon sequence.
- a 3’ intron fragment is a contiguous sequence at least 75% homologous (e.g., at least 80%. 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%.
- a 5’ group I or II intron fragment is a contiguous sequence at least 75% homologous (e.g., at least 80%, 85%, 90%, 91%. 92%, 93%, 94%, 95%, 96%. 97%. 98%, 99% or 100% homologous) to a 5’ proximal fragment of a natural group I or II intron including the 5 ’ splice site dinucleotide.
- the 3 ’ exon fragment comprises a second nucleotide of a 3’ group I or II intron splice site dinucleotide and 1 to 100 nucleotides of an exon sequence.
- the 5’ exon fragment comprises the first nucleotide of a 5’ group I or II intron splice site dinucleotide and 1 to 100 nucleotides of an exon sequence.
- the exon sequence comprises in part or in whole from a naturally occurring exon sequence from a virus, bacterium or eukaryotic DNA vector.
- the exon sequence further comprises a synthetic, genetically modified (e.g.. containing modified nucleotide), or other engineered exon sequence.
- the exon fragments located within the 5’ enhanced exon element and 3’ enhanced exon element does not comprise of a group I or II splice site dinucleotide.
- the 3 ’ enhanced intron element comprises in the following 5 ’ to 3 ’ order: a 5 ’ intron fragment, a 3’ external spacer, an optional 3' external duplex region, a 3’ affinity tag, and a trailing untranslated sequence.
- the DNA template, linear precursor RNA polynucleotide, and circular RNA polynucleotide comprise a core functional element.
- the core functional element comprises a coding or noncoding element.
- the core functional element may contain both a coding and noncoding element.
- the core functional element further comprises translation initiation element (TIE) upstream to the coding or noncoding element.
- the core functional element comprises a tennination element.
- the termination element is located downstream to the TIE and coding element.
- the termination element is located downstream to the coding element but upstream to the TIE.
- a core functional element lacks a TIE and/or a termination element.
- the polynucleotides herein comprise a coding element, a noncoding element, or a combination of both.
- the coding element comprises an expression sequence.
- the coding element encodes at least one therapeutic protein.
- the circular RNA encodes two or more polypeptides.
- the circular RNA is a bicistronic RNA.
- the sequences encoding the two or more polypeptides can be separated by a ribosomal skipping element or a nucleotide sequence encoding a protease cleavage site.
- the ribosomal skipping element encodes thosea-asigna virus 2A peptide (T2A). porcine teschoviros-1 2 A peptide (P2A), foot-and-mouth disease virus 2 A peptide (F2A), equine rhinitis A vims 2A peptide (E2A). cytoplasmic polyhedrosis vims 2A peptide (BmCPV 2A). or flacherie vims of B. mori 2A peptide (BmIFV 2A).
- TIE Translation Initiation Element
- the core functional element comprises at least one translation initiation element (TIE).
- TIEs are designed to allow translation efficiency of an encoded protein.
- optimal core functional elements comprising only of noncoding elements lack any TIEs.
- core functional elements comprising one or more coding element will further comprise one or more TIEs.
- a TIE comprises an untranslated region (UTR).
- the TIE provided herein comprise an internal ribosome entry site (IRES).
- IRES internal ribosome entry site
- IRES pennits the translation of one or more open reading frames from a circular RNA (e.g., open reading frames that form the expression sequences).
- the IRES element attracts a eukaryotic ribosomal translation initiation complex and promotes translation initiation. See, e.g., Kaufman et al., Nuc. Acids Res. (1991) 19:4485- 4490; Gurtu et al., Biochem. Biophys. Res. Comm.
- the IRES element is selected from those disclosed in international publication WO/2022/261490, the contents of which are hereby incorporated in their entireties. iv. Additional Accessory Elements (Sequence Elements)
- the circular RNA polynucleotide, linear RNA polynucleotide, and/or DNA template may further comprise of accessory elements.
- these accessory elements may be included within the sequences of the circular RNA, linear RNA polynucleotide and/or DNA template for enhancing circularization, translation or both.
- Accessory elements are sequences, in certain embodiments that are located with specificity between or within the enhanced intron elements, enhanced exon elements, or core functional element of the respective polynucleotide.
- an accessory element includes, a IRES transacting factor region, a miRNA binding site, a restriction site, an RNA editing region, a structural or sequence element, a granule site, a zip code element, an RNA trafficking element or another specialized sequence as found in the art that enhances promotes circularization and/or translation of the protein encoded within the circular RNA polynucleotide.
- the accessory element comprises an IRES transacting factor (ITAF) region.
- IRES transacting factor region modulates the initiation of translation through binding to PCBP1 - PCBP4 (polyC binding protein), PABP1 (poly A binding protein). PTB (polyprimidine tract binding), Argonaute protein family, HNRNPK (Heterogeneous nuclear ribonucleoprotein K protein), or La protein.
- the IRES transacting factor region comprises a poly A. polyC, poly AC. or polyprimidine track.
- the ITAF region is located within the core functional element. In some embodiments, the ITAF region is located within the TIE. [0320] In certain embodiments, the accessory element comprises a miRNA binding site. In some embodiments the miRNA binding site is located within the 5’ intron element, 5’ exon element, core functional element, 3’ exon element, and/or 3’ intron element.
- the miRNA binding site is located within the spacer within the intron element or exon element. In certain embodiments, the miRNA binding site comprises the entire spacer regions.
- the 5’ intron element and 3' intron elements each comprise identical miRNA binding sites.
- the miRNA binding site of the 5’ intron element comprises a different, in length or nucleotides, miRNA binding site than the 3’ intron element.
- the 5’ exon element and 3' exon element comprise identical miRNA binding sites.
- the 5’ exon element and 3’ exon element comprises different, in length or nucleotides, miRNA binding sites.
- the miRNA binding sites are located adjacent to each other within the circular RNA polynucleotide, linear RNA polynucleotide precursor, and/or DNA template.
- the first nucleotide of one of the miRNA binding sites follows the first nucleotide last nucleotide of the second miRNA binding site.
- the miRNA binding site is located within a translation initiation element (TIE) of a core functional element. In one embodiment, the miRNA binding site is located before, trailing or within an internal ribosome entry site (IRES). In another embodiment, the miRNA binding site is located before, trailing, or within an aptamer complex.
- TIE translation initiation element
- IRS internal ribosome entry site
- IRES sequences include sequences derived from a wide variety of viruses, such as from leader sequences of piccircRNAviruses such as the encephalomyocarditis virus (EMCV) UTR (lang et al., J. Virol. (1989) 63: 1651-1660), the polio leader sequence, the hepatitis A virus leader, the hepatitis C virus IRES, human rhinovirus type 2 IRES (Dobrikova et al., Proc. Natl. Acad. Sci. (2003) 100(25): 15125- 15130). an IRES element from the foot and mouth disease virus (Ramesh et al., Nucl. Acid Res.
- EMCV encephalomyocarditis virus
- UTR the polio leader sequence
- the hepatitis A virus leader the hepatitis C virus IRES
- human rhinovirus type 2 IRES Dobrikova et al., Proc. Natl. Acad. Sci. (2003) 100(
- the circular RNA comprises an IRES operably linked to a protein coding sequence.
- IRES operably linked to a protein coding sequence.
- Modifications of IRES and accessory sequences are disclosed herein to increase or reduce IRES activities, for example, by truncating the 5’ and/or 3’ ends of the IRES, adding a spacer 5’ to the IRES, modifying tire 6 nucleotides 5’ to the translation initiation site (Kozak sequence), modification of alternative translation initiation sites, and creating chimeric/hybrid IRES sequences.
- the IRES sequence in the circular RNA disclosed herein comprises one or more of these modifications relative to a native IRES.
- Drosophila C Virus Human coxsackievirus B3, Crucifer tobamovirus, Cricket paralysis virus, Bovine viral diarrhea virus 1, Black Queen Cell Virus. Aphid lethal paralysis virus. Avian encephalomyelitis virus, Acute bee paralysis virus. Hibiscus chlorotic ringspot virus. Classical swine fever virus. Human FGF2, Human SFTPA1, Human AML1/RUNX1, Drosophila antennapedia. Human AQP4, Human AT1R, Human BAG-1, Human BCL2. Human BiP. Human c- IAP1, Human c-myc. Human eIF4G. Mouse NDST4L. Human LEF1, Mouse HIF1 alpha, Human n.myc. Mouse Gtx.
- Human p27kipl Human PDGF2/c-sis, Human p53.
- Human Pim-1 Mouse Rbm3, Drosophila reaper, Canine Scamper, Drosophila Ubx, Human UNR, Mouse UtrA, Human VEGF-A, Human XIAP, Drosophila hairless, S. cerevisiae TFIID, S.
- the IRES comprises in whole or in part from a eukaryotic or cellular IRES.
- the IRES is from a human gene, where the human gene is ABCF1, ABCG1, ACAD10, ACOT7, ACSS3, ACTG2, ADCYAP1, ADK, AGTR1, AHCYL2, AHI1, AKAP8L, AKR1A1, ALDH3A1, ALDOA, ALG13, AMMECR1L, ANGPTL4, ANK3, AOC3, AP4B1, AP4E1, APAF1, APBB1, APC, APH1A, APOBEC3D, APOM, APP, AQP4, ARHGAP36, ARL13B, ARMC8, ARMCX6, ARPC1A, ARPC2.
- the human gene is ABCF1, ABCG1, ACAD10, ACOT7, ACSS3, ACTG2, ADCYAP1, ADK, AGTR1, AHCYL2, AHI1, AKAP8L, AKR1A1, ALDH3A1, ALDOA, ALG13, AMMECR1L, ANGPTL4, ANK3, AOC3, AP
- CD2BP2. CD9. CDC25C, CDC42, CDC7, CDCA7L, CDIP1.
- CDKN1B. CEACAM7, CEP295NL, CFLAR, CHCHD7. CHIA, CHICI, CHMP2A. CHRNA2, CLCN3, CLEC12A, CLEC7A, CLECL1, CLRN1. CMSS1, CNIH1, CNR1, CNTN5, COG4, COMMD1, COMMD5, CPEB1.
- MAGEB3, MAPT MARS. MC1R, MCCC1, METTL12, METTL7A, MGC16025. MGC16025, MIA2, MIA2.
- MITF MKLN1, MNT, MORF4L2.
- MPD6 MRFAP1, MRPL21, MRPS12, MSI2.
- MTRR MTUS1, MYB, MYC, MYCL, MYCN, MYL10, MYL3, MYLK, MYO1A, MYT2, MZB1, NAP1L1, NAVI, NBAS, NCF2, NDRG1, NDST2, NDUFA7, NDUFB11, NDUFC1, NDUFS1, NEDD4L, NFAT5, NFE2L2, NFE2L2, NFIA, NHEJ1, NHP2, NITI, NKRF, NME1-NME2, NPAT, NR3C1, NRBF2, NRF1, NTRK2, NUDCD1, NXF2, NXT2, ODC1, ODF2, OPTN, OR10R2, OR11L1, OR2M2, OR2M3, OR2M5, OR2T10, OR4C15, OR4F17, OR4F5, OR5H1, OR5K1, OR6C3, OR6C75, OR6N1, OR7G2, p53.
- RXRG. S100A13, S100A4.
- SULT2B1 SYK, SYNPR, TAF1C, TAGLN, TANK, TAS2R40, TBC1D15, TBXAS1, TCF4, TDGF1, TDP2, TDRD3, TDRD5, TESK2, THAP6, THBD, THTPA, TIAM2, TKFC, TKTL1, TLR10.
- a translation initiation element comprises a synthetic TIE.
- a synthetic TIE comprises aptamer complexes, synthetic IRES or other engineered TIES capable of initiating translation of a linear RNA or circular RNA polynucleotide.
- one or more aptamer sequences is capable of binding to a component of a eukary otic initiation factor to either enhance or initiate translation.
- aptamer may be used to enhance translation in vivo and in vitro by promoting specific eukary otic initiation factors (elF) (e.g., aptamer in WO2019081383A1 is capable of binding to eukary otic initiation factor 4F (eIF4F).
- elF eukary otic initiation factors
- the aptamer or a complex of aptamers may be capable of binding to EIF4G, EIF4E, EIF4A, EIF4B, EIF3, EIF2, EIF5, EIF1, EIF1A, 40S ribosome, PCBP1 (polyC binding protein), PCBP2, PCBP3, PCBP4, PABP1 (polyA binding protein), PTB, Argonaute protein family, HNRNPK (heterogeneous nuclear ribonucleoprotein K), or La protein. vii. Termination Sequence
- the core functional element comprises a termination sequence.
- the termination sequence comprises a stop codon.
- the termination sequence comprises a stop cassette.
- the stop cassette comprises at least 2 stop codons.
- the stop cassette comprises at least 2 frames of stop codons.
- the frames of the stop codons in a stop cassette each comprise 1, 2 or more stop codons.
- the stop cassette comprises a LoxP or a RoxStopRox, or frt-flanked stop cassette.
- the stop cassette comprises a lox-stop-lox stop cassette.
- a circular RNA polynucleotide provided herein comprises modified RNA nucleotides and/or modified nucleosides.
- the modified nucleoside is nr C (5 -methylcytidine).
- the modified nucleoside is m 5 U (5 -methyluridine).
- the modified nucleoside is m 6 A (N 6 -methyladenosine).
- the modified nucleoside is s 2 U (2-thiouridine).
- the modified nucleoside is T (pseudouridine).
- the modified nucleoside is Um (2'-O-methyluridine).
- the modified nucleoside is m’A (1 -methyladenosine); m 2 A (2 -methyladenosine); Am (2’-0-methyladenosine); ms 2 m 6 A (2-methylthio-N 6 -methyladenosine); i 6 A (N 6 -isopentenyladenosine); ms 2 i6A (2-methylthio-N 6 isopentenyladenosine); io 6 A (N 6 -(cis-hydroxyisopentenyl)adenosine); ms 2 io 6 A (2-methylthio-N 6 -(cis-hydroxyisopentenyl)adenosine); g 6 A (N 6 - glycinylcarbamoyladenosine); t 6 A (N 6 -threonylcarbamoyladenosine); ms 2 t 6 A (2-methylthio-N 6 - threon
- the modified nucleoside may include a compound selected from: pyridin-4-one ribonucleoside, 5 -aza-uridine, 2-thio-5 -aza-uridine, 2-thiouridine, 4-thio-pseudouridine, 2-thio-pseudouridine, 5-hydroxyuridine, 3 -methyluridine, 5-carboxymethyl-uridine, 1-carboxymethyl- pseudouridine, 5-propynyl-uridine, 1-propynyl-pseudouridine, 5-taurinomethyluridine, 1- taurinomethy 1-pseudouridine, 5-taurinomethy 1-2-thio-uridine, 1 -taurinome thy 1-4-thio-uridine, 5 - methyl-uridine, 1-methy 1-pseudouridine, 4-thio-l-methy 1-pseudouridine, 2-thio-l -methyl
- 4-thio- 1 -methy 1-pseudoisocy tidine 4-thio- 1 -methy 1- 1 -deaza-pseudoisocy tidine, 1 - methyl- 1-deaza-pseudoisocytidine, zebularine, 5-aza-zebularine, 5-methyl-zebularine, 5-aza-2-thio- zebularine, 2-thio-zebularine, 2-methoxy-cytidine, 2-methoxy-5-methyl-cytidine, 4-methoxy- pseudoisocytidine.
- N6.N6-dimethyladenosine 7-methyladenine, 2- methylthio-adenine, 2-methoxy-adenine, inosine, 1 -methy 1-inosine, wyosine, wybutosine, 7-deaza- guanosine. 7-deaza-8-aza-guanosine, 6-thio-guanosine, 6-thio-7-deaza-guanosine, 6-thio-7-deaza-8- aza-guanosine. 7-methyl-guanosine. 6-thio-7-methyl-guanosine, 7-methylinosine, 6-methoxy- guanosine.
- the modifications are independently selected from 5-methylcytosine, pseudouridine and 1 -methylpseudouridine.
- polynucleotides may be codon-optimized.
- a codon optimized sequence may be one in which codons in a polynucleotide encoding a polypeptide have been substituted in order to increase the expression, stability and/or activity of the polypeptide.
- Factors that influence codon optimization include, but are not limited to one or more of: (i) variation of codon biases between two or more organisms or genes or synthetically constructed bias tables, (ii) variation in the degree of codon bias within an organism, gene, or set of genes, (iii) systematic variation of codons including context, (iv) variation of codons according to their decoding tRNAs, (v) variation of codons according to GC %, either overall or in one position of the triplet, (vi) variation in degree of similarity to a reference sequence for example a naturally occurring sequence, (vii) variation in the codon frequency cutoff, (viii) structural properties of mRNAs transcribed from the DNA sequence, (ix) prior knowledge the function of the DNA sequences upon which design of the codon substitution set is to be based, and/or (x) systematic variation of codon sets for each amino acid.
- a codon optimized polynucleotide may minimize ribozyme collisions and/or limit structural interference between the expression sequence and the core functional element.
- the polynucleotide (e.g., circRNA) expression sequence encodes a therapeutic protein.
- the therapeutic protein is selected from the proteins listed in the following table.
- the expression sequence encodes a therapeutic protein.
- the expression sequence encodes a cytokine, e.g., IL-12p70, IL-15. IL-2, IL-18, IL-21, IFN-a, IFN- ⁇ , IL-10, TGF-beta, IL-4, or IL-35, or a functional fragment thereof.
- the expression sequence encodes an immune checkpoint inhibitor.
- the expression sequence encodes an agonist (e.g., a TNFR family member such as CD137L, OX40L, ICOSL, LIGHT, or CD70).
- the expression sequence encodes a chimeric antigen receptor.
- the antigen is selected from or derived from the group consisting of rotavirus, foot and mouth disease virus, influenza A virus, influenza B virus, influenza C virus. H1N1, H2N2, H3N2, H5N1. H7N7, H1N2. H9N2, H7N2. H7N3, H10N7, human parainfluenza type 2, herpes simplex virus, Epstein -Barr virus, varicella virus, porcine herpesvirus 1, cytomegalovirus, lyssavirus, Bacillus anthracis. anthrax PA and derivatives, poliovirus, Hepatitis A, Hepatitis B. Hepatitis C, Hepatitis E, distemper virus.
- Influenza hemagglutinin, cancer antigen, tumor antigens, toxins, Clostridium perfringens epsilon toxin, ricin toxin, pseudomonas exotoxin, exotoxins, neurotoxins, cytokines, cytokine receptors, monokines, monokine receptors, plant pollens, animal dander, and dust mites.
- the antigenic polypeptide is a viral polypeptide from an adenovirus; Herpes simplex, type 1; Herpes simplex, type 2; encephalitis virus, papillomavirus, Varicella-zoster virus; Epstein-barr virus; Human cytomegalovirus; Human herpes virus, type 8; Human papillomavirus; BK virus; JC virus; Smallpox; polio virus; Hepatitis B virus; Human bocavirus; Parvovirus B19; Human astrovirus; Norwalk virus; coxsackievirus; hepatitis A virus; poliovirus; rhinovirus; Severe acute respiratory syndrome virus; Hepatitis C virus; Yellow Fever virus; Dengue virus; West Nile virus; Rubella virus; Hepatitis E virus; Human Immunodeficiency virus (HIV); Influenza virus; Guanarito virus; Junin virus; Lassa virus; Machupo virus; Sabia virus; Crime
- Additional polynucleotides, including expression sequences, and lipids are in WO2019236673; WO2020237227; WO2021113777; WO2021226597; WO2021189059; WO2021236855;
- Chimeric antigen receptors are genetically -engineered receptors. These engineered receptors may be inserted into and expressed by immune cells, including T cells via circular RNA as described herein. With a CAR, a single receptor may be programmed to both recognize a specific antigen and. when bound to that antigen, activate the immune cell to attack and destroy the cell bearing that antigen. When these antigens exist on tumor cells, an immune cell that expresses the CAR may target and kill the tumor cell.
- the CAR encoded by the polynucleotide comprises (i) an antigen-binding molecule that specifically binds to a target antigen, (ii) a hinge domain, a transmembrane domain, and an intracellular domain, and (iii) an activating domain.
- an orientation of the CARs in accordance with the disclosure comprises an antigen binding domain (such as an scFv) in tandem with a costimulatory domain and an activating domain.
- the costimulatory domain may comprise one or more of an extracellular portion, a transmembrane portion, and an intracellular portion. In other embodiments, multiple costimulatory domains may be utilized in tandem.
- CARs may be engineered to bind to an antigen (such as a cell-surface antigen) by incorporating an antigen binding molecule that interacts with that targeted antigen.
- the antigen binding molecule is an antibody fragment thereof, e.g., one or more single chain antibody fragment (scFv).
- scFv is a single chain antibody fragment having the variable regions of the heavy and light chains of an antibody linked together. See U.S. Patent Nos. 7.741.465. and 6.319,494 as well as Eshhar et al., Cancer Immunol Immunotherapy (1997) 45: 131- 136.
- An scFv retains the parent antibody's ability to specifically interact with target antigen.
- scFvs are useful in chimeric antigen receptors because they may be engineered to be expressed as part of a single chain along with the other CAR components. Id. See also Krause et al., J. Exp. Med., Volume 188, No. 4, 1998 (619-626); Finney et al., loumal of Immunolog ⁇ ', 1998, 161 : 2791-2797. It will be appreciated that the antigen binding molecule is typically contained within the extracellular portion of the CAR such that it is capable of recognizing and binding to the antigen of interest. Bispecific and multispecific CARs are contemplated within the scope of the present disclosure, with specificity to more than one target of interest.
- the antigen binding molecule comprises a single chain, wherein the heavy chain variable region and the light chain variable region are connected by a linker.
- the VH is located at the N terminus of the linker and the VL is located at the C terminus of the linker.
- the VL is located at the N terminus of the linker and the VH is located at the C tenninus of the linker.
- the linker comprises at least 5, at least 8, at least 10, at least 13, at least 15, at least 18, at least 20. at least 25, at least 30, at least 35, at least 40, at least 45, at least 50, at least 60. at least 70, at least 80, at least 90, or at least 100 amino acids.
- the antigen binding molecule comprises a nanobody. In some embodiments, the antigen binding molecule comprises a DARPin. In some embodiments, the antigen binding molecule comprises an anticalin or other synthetic protein capable of specific binding to target protein.
- the CAR comprises an antigen binding domain specific for an antigen selected from CD19, CD123, CD22, CD30, CD171, CS-1, C-type lectin-like molecule-1.
- CD33 epidermal growth factor receptor variant III (EGFRvIII), ganglioside G2 (GD2), ganglioside GD3, TNF receptor family member B cell maturation (BCMA).
- EGFRvIII epidermal growth factor receptor variant III
- GD2 ganglioside G2
- BCMA TNF receptor family member B cell maturation
- Tn antigen (Tn Ag) or (GalNAca-Ser/Thr)
- PSMA prostate-specific membrane antigen
- ROR1 Receptor tyrosine kinase-like orphan receptor 1
- FLT3 Fms-Like Tyrosine Kinase 3
- TAG72 Tumor-associated glycoprotein 72
- CD38 CD44v6, Carcinoembryonic antigen (CEA), Epithelial cell adhesion molecule (EPCAM), B7H3 (CD276), KIT (CD117).
- PSCA prostate stem cell antigen
- VEGFR2 vascular endothelial growth factor receptor 2
- Lewis(Y) antigen CD24
- PDGFR-beta Platelet-derived growth factor receptor beta
- SSEA-4 Stage-specific embryonic antigen-4
- CD20 Folate receptor alpha
- EGFR epidermal growth factor receptor
- NCAM neural cell adhesion molecule
- PAP prostatic acid phosphatase
- ELF2M elongation factor 2 mutated
- Ephrin B2 fibroblast activation protein alpha
- FAP insulin-like growth factor 1 receptor
- IGF-I receptor insulin-like growth factor 1 receptor
- CAIX carbonic anhydrase IX
- Proteasome Prosome, Macropain
- Beta Type, 9 LMP2
- glycoprotein 100 glycoprotein 100
- BCR breakpoint cluster region
- BCR breakpoint cluster region
- Abl bcr-abl
- tyrosinase ephrin ty pc- A receptor 2
- EphA2 Fucosyl GM1, sialyl Lewis adhesion molecule (sLe)
- ganglioside GM3 transglutaminase 5 (TGS5)
- chromosome X open reading frame 61 CD97, CD179a, anaplastic lymphoma kinase (ALK), Polysialic acid, placenta-specific 1 (PLAC1), hexasaccharide portion of globoH glycoceramide (GloboH), mammary gland differentiation antigen (NY-BR-1), uroplakin 2 (UPK2), Hepatitis A virus cellular receptor 1 (HAVCR1), adrenoceptor beta 3 (ADRB3), pannexin 3 (PANX3), G protein-coupled receptor 20 (GPR20), lymphocyte antigen 6 complex, locus K 9 (LY6K), Olfactory receptor 51E2 (OR51E2), TCR Gamma Alternate Reading Frame Protein (TARP), Wilms tumor protein (WT1), Cancer/testis antigen 1 (NY-ESO-1), Cancer/testis antigen 2 (LAGE-la), MAGE family members (including MAGE-A1, MAGE-
- melanoma cancer testis antigen-2 (MAD-CT-2), Fos-related antigen 1, tumor protein p53 (p53), p53 mutant, prostein, surviving, telomerase, prostate carcinoma tumor antigen- 1, melanoma antigen recognized by T cells 1, Rat sarcoma (Ras) mutant, human Telomerase reverse transcriptase (hTERT), sarcoma translocation breakpoints, melanoma inhibitor of apoptosis (ML-IAP), ERG (transmembrane protease, serine 2 (TMPRSS2) ETS fusion gene).
- MAD-CT-2 melanoma cancer testis antigen-2
- Fos-related antigen 1, tumor protein p53 (p53), p53 mutant, prostein, surviving, telomerase, prostate carcinoma tumor antigen- 1, melanoma antigen recognized by T cells 1
- Rat sarcoma (Ras) mutant Rat sarcoma (Ras) mutant, human Telome
- proacrosin binding protein sp32 OY-TES1
- LCK lymphocyte-specific protein tyrosine kinase
- AKAP-4 A kinase anchor protein 4
- SSX2 synovial sarcoma
- RAGE-1 Receptor for Advanced Glycation Endproducts
- RU1 renal ubiquitous 1
- RU2 renal ubiquitous 2
- legumain human papilloma virus E6
- HPV E7 human papilloma virus E7
- intestinal carboxyl esterase heat shock protein 70-2 mutated (mut hsp70-2), CD79a.
- ErbB4 epithelial tumor antigen (ETA), folate binding protein (FBP), kinase insert domain receptor (KDR), k-light chain. LI cell adhesion molecule. MUC18, NKG2D, oncofetal antigen (h5T4). tumor/testis-antigen IB. GAGE. GAGE-1, BAGE, SCP-1, CTZ9.
- an antigen binding domain comprises SEQ ID NO: 321 and/or 322.
- a CAR comprises a hinge or spacer domain.
- the hinge/spacer domain may comprise a truncated hinge/spacer domain (THD) the THD domain is a truncated version of a complete hinge/spacer domain (“CHD”).
- an extracellular domain is from or derived from (e.g., comprises all or a fragment of) ErbB2, glycophorin A (GpA), CD2.
- GpA glycophorin A
- CD3 delta CD3 epsilon.
- CD79B B-cell antigen receptor complex-associated beta chain
- CD84 SLAMF5
- CD96 Tactile
- CD100 SEMA4D
- CD103 CD133
- CD134 0.X40
- CD137 4- 1BB
- CD150 SLAMF1
- CD158A KIR2DL1
- CD158B1 KIR2DL2
- CD158B2 KIR2DL3
- CD158C KIR3DP1
- CD158D KIRDL4
- CD158F1 KIR2DL5A
- CD158F2 KIR2DL5B
- a hinge or spacer domain may be derived either from a natural or from a synthetic source.
- a hinge or spacer domain is positioned between an antigen binding molecule (e.g., an scFv) and a transmembrane domain. In this orientation, the hinge/spacer domain provides distance between the antigen binding molecule and the surface of a cell membrane on which the CAR is expressed.
- a hinge or spacer domain is from or derived from an immunoglobulin.
- a hinge or spacer domain is selected from the hinge/spacer regions of IgGl, IgG2, IgG3, IgG4, IgA, IgD, IgE, IgM, or a fragment thereof.
- a hinge or spacer domain comprises, is from, or is derived from the hinge/spacer region of CD8 alpha. In some embodiments, a hinge or spacer domain comprises, is from, or is derived from the hinge/spacer region of CD28. In some embodiments, a hinge or spacer domain comprises a fragment of the hinge/spacer region of CD8 alpha or a fragment of the hinge/spacer region of CD28, wherein the fragment is anything less than the whole hinge/spacer region. In some embodiments, the fragment of the CD8 alpha hinge/spacer region or the fragment of the CD28 hinge/spacer region comprises an amino acid sequence that excludes at least 1, at least 2, at least 3. at least 4. at least 5.
- the CAR may further comprise a transmembrane domain and/or an intracellular signaling domain.
- the transmembrane domain may be designed to be fused to the extracellular domain of the CAR. It may similarly be fused to the intracellular domain of the CAR.
- the transmembrane domain that naturally is associated with one of the domains in a CAR is used.
- the transmembrane domain may be selected or modified (e.g.. by an amino acid substitution) to avoid binding of such domains to the transmembrane domains of the same or different surface membrane proteins to minimize interactions with other members of the receptor complex.
- the transmembrane domain may be derived either from a natural or from a synthetic source. Where the source is natural, the domain may be derived from any membrane -bound or transmembrane protein.
- Transmembrane regions may be derived from (i.e., comprise) a receptor tyrosine kinase (e.g., ErbB2), glycophorin A (GpA), 4-1BB/CD137, activating NK cell receptors, an immunoglobulin protein, B7-H3, BAFFR. BFAME (SEAMF8), BTEA, CD100 (SEMA4D), CD103, CD160 (BY55), CD18, CD19, CD19a, CD2, CD247, CD27.
- a receptor tyrosine kinase e.g., ErbB2
- GpA glycophorin A
- 4-1BB/CD137 activating NK cell receptors
- an immunoglobulin protein B7-H3, BAFFR.
- BFAME BFAME
- BTEA BTEA
- CD100 SEMA4D
- CD103 CD160
- CD160 BY55
- CD18 CD19, CD19a, CD2, CD247, CD27
- CD276 (B7-H3), CD28, CD29, CD3 delta, CD3 epsilon, CD3 gamma, CD30, CD4, CD40, CD49a, CD49D, CD49f, CD69, CD7, CD84, CDSalpha, CD8beta, CD96 (Tactile), CD1 la, CD1 lb, CD1 1c, CD1 Id, CDS, CEACAM1, CRT AM, cytokine receptor, DAP-10, DNAM1 (CD226), Fc gamma receptor, GADS, GITR, HVEM (EIGHTR), IA4, ICAM-1, ICAM-1, Ig alpha (CD79a), IE-2R beta, IE-2R gamma, IE-7R alpha, inducible T cell costimulator (ICOS), integrins, ITGA4.
- CD79a CD79a
- IE-2R beta IE-2R gamma
- IE-7R alpha inducible T cell
- PSGL1, SELPLG CD162
- SLAM proteins Signaling Lymphocytic Activation Molecules
- SLAMF1; CD150; IPO-3 Signaling Lymphocytic Activation Molecules
- SLAMF4 CD244; 2B4
- SLAMF6 NTB-A; Lyl08
- SLAMF7 SLP-76
- TNF receptor proteins TNF receptor proteins
- TNFR2, TNFSF14 TNF receptor proteins
- suitable intracellular signaling domain include, but are not limited to, activating Macrophage/Myeloid cell receptors CSFR1, MYD88, CD14, TIE2, TLR4, CR3. CD64, TREM2, DAP10, DAP12, CD169, DECTIN1, CD206, CD47, CD163. CD36, MARCO. TIM4, MERTK, F4/80. CD91, C1QR, LOX-1, CD68, SRA, BAI-1, ABCA7, CD36, CD31, Lactoferrin, or a fragment, truncation, or combination thereof.
- a receptor tyrosine kinase may be derived from (e.g., comprise) Insulin receptor (InsR), Insulin-like growth factor I receptor (IGF1R), Insulin receptor-related receptor (IRR), platelet derived growth factor receptor alpha (PDGFRa), platelet derived growth factor receptor beta (PDGFRfi).
- Insulin receptor Insulin receptor
- IGF1R Insulin-like growth factor I receptor
- IRR Insulin receptor-related receptor
- PDGFRa platelet derived growth factor receptor alpha
- PDGFRfi platelet derived growth factor receptor beta
- FGFR4 fibroblast growth factor receptor 4
- CCK4 protein tyrosine kinase 7
- trkA neurotrophic receptor tyrosine kinase 1
- trkB neurotrophic receptor tyrosine kinase 2
- trkC neurotrophic receptor tyrosine kinase 3
- ROR1 receptor tyrosine kinase like orphan receptor 1
- receptor tyrosine kinase like orphan receptor 2 (ROR2), muscle associated receptor tyrosine kinase (MuSK), MET protooncogene, receptor tyrosine kinase (MET), macrophage stimulating 1 receptor (Ron), AXL receptor tyrosine kinase (Axl), TYR03 protein tyrosine kinase (Tyro3).
- TIE1 TEK receptor tyrosine kinase with immunoglobulin like and EGF like domains 1
- TIE2 TEK receptor tyrosine kinase
- EPH receptor Al Eph Al
- EPH receptor A2 EphA2
- EPH receptor A3 EphA3, EPH receptor A4
- EPH receptor A5 EphA5
- EPH receptor A6 EphA6
- EPH receptor A7 EphA7
- EPH receptor A8 EphA8
- EPH receptor A10 EphAlO
- EPH receptor Bl EphBl
- EPH receptor B2 EphB2
- EPH receptor B3 EPH receptor B3
- EPH receptor B4 EPH receptor B4
- EPH receptor B6 EphB6
- Ret ret proto oncogene
- RYK receptor-like tyrosine kinase
- DDR1 discoidin domain receptor tyrosine kinase 1
- DDR2 discoidin domain receptor tyrosine kinase 2
- ROS receptor tyrosine kinase
- Lmrl apoptosis associated ty rosine kinase
- Lmr2 lemur tyrosine kinase 2
- Lmr3 leukocyte receptor tyrosine kinase
- LLK ALK receptor tyrosine kinase
- STYK serine/threonine/tyrosine kinase 1
- the CAR comprises a costimulatory domain.
- the costimulatory domain comprises 4-1BB (CD137), CD28, or both, and/or an intracellular T cell signaling domain.
- the costimulatory domain is human CD28, human 4- IBB, or both, and the intracellular T cell signaling domain is human CD3 zeta (Q. 4- IBB, CD28, CD3 zeta may comprise less than the whole 4- IBB, CD28 or CD3 zeta, respectively.
- Chimeric antigen receptors may incorporate costimulatory (signaling) domains to increase their potency. See U.S. Patent Nos.
- the intracellular (signaling) domain of the engineered T cells disclosed herein may provide signaling to an activating domain, which then activates at least one of the normal effector functions of the immune cell.
- Effector function of a T cell for example, may be cytolytic activity or helper activity including the secretion of cytokines.
- NKp30, NKp44, NKp46, NKp80 (KLRF1), OX-40, PAG/Cbp, programmed death-1 (PD-1), PSGL1, SELPLG (CD162), Signaling Lymphocytic Activation Molecules (SLAM proteins), SLAM (SLAMF1; CD150; IPO-3), SLAMF4 (CD244; 2B4), SLAMF6 (NTB-A), SLAMF7, SLP-76, TNF receptor proteins, TNFR2, TNFSF14, a Toll ligand receptor, TRANCE/RANKL, VLA1. or VLA-6, or a fragment, truncation, or a combination thereof.
- SLAM proteins Signaling Lymphocytic Activation Molecules
- SLAMF1 SLAMF1; CD150; IPO-3
- SLAMF4 CD244; 2B4
- SLAMF6 NTB-A
- SLAMF7 SLP-76
- CD3 is an element of the T cell receptor on native T cells, and has been shown to be an important intracellular activating element in CARs.
- the CD3 is CD3 zeta.
- the activating domain comprises an amino acid sequence at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical to the polypeptide sequence of SEQ ID NO: 319.
- the sequence encoding the CAR comprises a sequence from Table a.
- TCR T-Cell Receptors
- TCRs are described using the International Immunogenetics (IMGT) TCR nomenclature, and links to the IMGT public database of TCR sequences.
- Native alpha-beta heterodimeric TCRs have an alpha chain and a beta chain.
- each chain may comprise variable, joining and constant regions, and the beta chain also usually contains a short diversity region between the variable and joining regions, but this diversity region is often considered as part of the joining region.
- Each variable region may comprise three CDRs (Complementarity Determining Regions) embedded in a framework sequence, one being the hypervariable region named CDR3.
- Va alpha chain variable
- V ⁇ beta chain variable
- TRAV21 defines a TCR Va region having unique framework and CDR1 and CDR2 sequences, and a CDR3 sequence which is partly defined by an amino acid sequence which is preserved from TCR to TCR but which also includes an amino acid sequence which varies from TCR to TCR.
- TRBV5-1 defines a TCR V ⁇ region having unique framework and CDR1 and CDR2 sequences, but with only a partly defined CDR3 sequence.
- the joining regions of the TCR are similarly defined by the unique IMGT TRAJ and TRBJ nomenclature, and the constant regions by the IMGT TRAC and TRBC nomenclature.
- the beta chain diversity region is referred to in IMGT nomenclature by the abbreviation TRBD, and, as mentioned, the concatenated TRBD/TRBJ regions are often considered together as the joining region.
- TRBD abbreviation
- TRBJ concatenated TRBD/TRBJ regions
- TRBD concatenated TRBD/TRBJ regions
- TRBD concatenated TRBD/TRBJ regions
- the unique sequences defined by the IMGT nomenclature are widely known and accessible to those working in the TCR field. For example, they can be found in the IMGT public database.
- the “T cell Receptor Factsbook”, (2001) LeFranc and LeFranc, Academic Press, ISBN 0-12-441352-8 also discloses sequences defined by the IMGT nomenclature, but because of its publication date and consequent time-lag, the information therein sometimes needs to be confirmed by reference to
- TCRs exist in heterodimeric ⁇ or ⁇ forms. However, recombinant TCRs consisting of aa or 00 homodimers have previously been shown to bind to peptide MHC molecules. Therefore, the TCR of the present disclosure may be a heterodimeric ⁇ TCR or may be an aa or 00 homodimeric TCR.
- Binding affinity (inversely proportional to the equilibrium constant K D ) and binding half-life (expressed as T1 ⁇ 2 ) can be determined by any appropriate method. It will be appreciated that doubling the affinity of a TCR results in halving the K D . T1 ⁇ 2 is calculated as In 2 divided by the off-rate (koff). So doubling of T‘/z results in a halving in koff. K D and koff values for TCRs are usually measured for soluble forms of the TCR, i.e., those forms which are truncated to remove cytoplasmic and transmembrane domain residues.
- a TCR may be specific for an antigen in the group MAGE-A1, MAGE-A2, MAGE -A3, MAGE-A4.
- MAGE-A5. MAGE-A6.
- GAGE-8 BAGE-1, RAGE-1, LB33/MUM-1, PRAME.
- NAG MAGE-Xp2 (MAGE-B2).
- MAGE-Xp3 MAGE-B3), MAGE-Xp4 (AGE-B4).
- tyrosinase brain glycogen phosphorylase.
- Melan-A MAGE-CI, MAGE-C2, NY-ESO-1, LAGE-1.
- SSX-1 SSX-2(HOM-MEL-40), SSX-1.
- cdkn2a coa-1, dek-can fusion protein.
- a BCR is expressed by mature B cells. These B cells work with immunoglobulins (Igs) in recognizing and tagging pathogens.
- the typical BCR comprises a membrane-bound immunoglobulin (e.g., mlgA, mlgD, mlgE, mlgG, and mlgM), along with associated and Ig /Ig ⁇ (CD79a/CD79b) heterodimers ( ⁇ ).
- membrane-bound immunoglobulins are tetramers consisting of two identical heavy and two light chains.
- the immune checkpoint inhibitor is an inhibitor of IDO1, CTLA4, PD-1, LAG3, PD-L1, TIM3, or combinations thereof. In some embodiments, the immune checkpoint inhibitor is an inhibitor of PD-L1. In some embodiments, the immune checkpoint inhibitor is an inhibitor of PD-1. In some embodiments, the immune checkpoint inhibitor is an inhibitor of CTLA-4. In some embodiments, the immune checkpoint inhibitor is an inhibitor of LAG3. In some embodiments, the immune checkpoint inhibitor is an inhibitor of TIM3. In some embodiments, the immune checkpoint inhibitor is an inhibitor of IDOL
- the present disclosure encompasses the use of immune checkpoint antagonists.
- immune checkpoint antagonists include antagonists of immune checkpoint molecules such as Cytotoxic T-Lymphocyte Antigen 4 (CTLA-4), Programmed Cell Death Protein 1 (PD-1), Programmed Death-Ligand 1 (PDL-1), Lymphocyte- activation gene 3 (LAG-3), and T-cell immunoglobulin and mucin domain 3 (TIM-3).
- CTLA-4 Cytotoxic T-Lymphocyte Antigen 4
- PD-1 Programmed Cell Death Protein 1
- PDL-1 Programmed Death-Ligand 1
- LAG-3 Lymphocyte- activation gene 3
- TIM-3 T-cell immunoglobulin and mucin domain 3
- An antagonist of CTLA-4, PD-1. PDL-1, LAG-3, or TIM-3 interferes with CTLA-4.
- PD-1, PDL-1, LAG-3, or TIM-3 function, respectively.
- DNA templates can be made using standard techniques of molecular biology.
- the various elements of the vectors provided herein can be obtained using recombinant methods, such as by screening cDNA and genomic libraries from cells, or by deriving the polynucleotides from a DNA template known to include the same.
- the various elements of the DNA template can also be produced synthetically, rather than cloned, based on the known sequences.
- the complete sequence can be assembled from overlapping oligonucleotides prepared by standard methods and assembled into the complete sequence. See, e.g., Edge, Nature (1981) 292:756; Nambair et al., Science (1984) 223: 1299; and Jay et al., J. Biol. Chem. (1984) 259:631 1.
- nucleotide sequences can be obtained from DNA template harboring the desired sequences or synthesized completely, or in part, using various oligonucleotide synthesis techniques known in the art, such as site-directed mutagenesis and polymerase chain reaction (PCR) techniques where appropriate.
- oligonucleotide synthesis techniques known in the art, such as site-directed mutagenesis and polymerase chain reaction (PCR) techniques where appropriate.
- PCR polymerase chain reaction
- One method of obtaining nucleotide sequences encoding the desired DNA template elements is by annealing complementary sets of overlapping synthetic oligonucleotides produced in a conventional, automated polynucleotide synthesizer, followed by ligation with an appropriate DNA ligase and amplification of the ligated nucleotide sequence via PCR. See, e.g., Jayaraman et al., Proc. Natl.
- oligonucleotide- directed synthesis Jones et al., Nature (1986) 54:75-82
- oligonucleotide directed mutagenesis of preexisting nucleotide regions Riechmann et al.. Nature (1988) 332:323-327 and Verhoeyen et al., Science (1988) 239: 1534-1536
- enzymatic filling-in of gapped oligonucleotides using T4 DNA polymerase Queen et al., Proc. Natl. Acad. Sci. USA (1989) 86: 10029-10033
- compositions comprising a therapeutic agent provided herein.
- the therapeutic agent is a circular RNA polynucleotide.
- the therapeutic agent is a vector.
- the therapeutic agent is a cell comprising a circular RNA or vector (e.g, a human cell, such as a human T cell).
- the composition further comprises a pharmaceutically acceptable carrier.
- compositions provided herein comprise a therapeutic agent provided herein in combination with other pharmaceutically active agents or drugs, such as antiinflammatory drugs or antibodies capable of targeting B cell antigens, e.g., anti-CD20 antibodies, e.g., rituximab.
- the pharmaceutically acceptable carrier can be any of those conventionally used and is limited only by chemical-physical considerations, such as solubility and lack of reactivity with the active agent(s), and by the route of administration.
- the pharmaceutically acceptable carriers described herein, for example, vehicles, adjuvants, excipients, and diluents, are well-known to those skilled in the art and are readily available to the public. It is preferred that the pharmaceutically acceptable carrier be one which is chemically inert to the therapeutic agent(s) and one which has no detrimental side effects or toxicity under the conditions of use.
- carrier w ill be determined in part by the particular therapeutic agent, as w ell as by the particular method used to administer the therapeutic agent. Accordingly, there are a variety of suitable formulations of the pharmaceutical compositions provided herein.
- the pharmaceutical composition comprises a preservative.
- suitable preservatives may include, for example, methylparaben, propylparaben, sodium benzoate, and benzalkonium chloride.
- a mixture of tw o or more preservatives may be used.
- the preservative or mixtures thereof are typically present in an amount of 0.0001% to 2% by weight of the total composition.
- the pharmaceutical composition comprises a buffering agent.
- suitable buffering agents may include, for example, citric acid, sodium citrate, phosphoric acid, potassium phosphate, and various other acids and salts. A mixture of two or more buffering agents optionally may be used. The buffering agent or mixtures thereof are typically present in an amount of 0.001% to 4% by weight of the total composition.
- the concentration of therapeutic agent in the pharmaceutical composition can vary, e.g., less than 1%, or at least 1%, 2%, 3%, 4%, 5%. 6%, 7%, 8%, 9% 10%. 15%, 20%, 25%, 30%, 35%, 40%. 45%, or 50% or more by weight, and can be selected primarily by fluid volumes, and viscosities, in accordance with the particular mode of administration selected.
- compositions for oral, aerosol, parenteral (e.g., subcutaneous, intravenous, intraarterial, intramuscular, intradermal, intraperitoneal, and intrathecal), and topical administration are merely exemplary and are in no way limiting. More than one route can be used to administer the therapeutic agents provided herein, and in certain instances, a particular route can provide a more immediate and more effective response than another route.
- Formulations suitable for oral administration can comprise or consist of (a) liquid solutions, such as an effective amount of the therapeutic agent dissolved in diluents, such as water, saline, or orange juice; (b) capsules, sachets, tablets, lozenges, and troches, each containing a predetermined amount of the active ingredient, as solids or granules: (c) powders; (d) suspensions in an appropriate liquid; and (e) suitable emulsions.
- Liquid formulations may include diluents, such as water and alcohols, for example, ethanol, benzy l alcohol and the polyethylene alcohols, either with or without the addition of a pharmaceutically acceptable surfactant.
- Capsule forms can be of the ordinary hard- or soft-shelled gelatin type containing, for example, surfactants, lubricants, and inert fillers, such as lactose, sucrose, calcium phosphate, and com starch.
- Tablet forms can include one or more of lactose, sucrose, mannitol, corn starch, potato starch, alginic acid, microcrystalline cellulose, acacia, gelatin, guar gum, colloidal silicon dioxide, croscarmellose sodium, talc, magnesium stearate, calcium stearate, zinc stearate, stearic acid, and other excipients, colorants, diluents, buffering agents, disintegrating agents, moistening agents, preservatives, flavoring agents, and other pharmacologically compatible excipients.
- Lozenge forms can comprise the therapeutic agent with a flavorant, usually sucrose, acacia or tragacanth.
- Pastilles can comprise the therapeutic agent with an inert base, such as gelatin and glycerin, or sucrose and acacia, emulsions, gels, and the like containing, in addition to, such excipients as are known in the art.
- an inert base such as gelatin and glycerin, or sucrose and acacia, emulsions, gels, and the like containing, in addition to, such excipients as are known in the art.
- Formulations suitable for parenteral administration include aqueous and nonaqueous isotonic sterile injection solutions, which can contain antioxidants, buffers, bacteriostats, and solutes that render the formulation isotonic with the blood of the intended recipient, and aqueous and nonaqueous sterile suspensions that can include suspending agents, solubilizers, thickening agents, stabilizers, and preservatives.
- the parenteral formulations will contain, for example, from 0.5% to 25% by weight of the therapeutic agent in solution. Preservatives and buffers may be used. In order to minimize or eliminate irritation at the site of injection, such compositions may contain one or more nonionic surfactants having, for example, a hydrophile-lipophile balance (HLB) of from 12 to 17. The quantity of surfactant in such formulations will ty pically range, for example, from 5% to 15% by weight.
- HLB hydrophile-lipophile balance
- injectable formulations are provided herein.
- the requirements for effective pharmaceutical carriers for injectable compositions are well-known to those of ordinary skill in the art (see. e.g., Pharmaceutics and Pharmacy Practice, J.B. Lippincott Company, Philadelphia, PA. Banker and Chalmers, eds., pages 238-250 (1982), and ASHP Handbook on Injectable Drugs, ToisseL 4th ed. pages 622-630 (1986)).
- the expression of the polypeptide is sustained at least at a therapeutic level.
- the polypeptide is expressed at least at a therapeutic level for more than one, more than four, more than six, more than 12, more than 24, more than 48, or more than 72 hours after administration.
- the polypeptide is detectable at a therapeutic level in patient tissue (e.g., liver or lung).
- the level of detectable polypeptide is from continuous expression from the circRNA composition over periods of time of more than one, more than four, more than six, more than 12, more than 24. more than 48, or more than 72 hours after administration.
- the levels of a protein encoded by a circRNA are detectable at 3 days, 4 days, 5 days, or 1 week or more after administration. Increased levels of protein may be observed in a tissue (e.g., liver or lung).
- the method yields a sustained circulation half-life of a protein encoded by a circRNA.
- the protein may be detected for hours or days longer than the half-life observed via subcutaneous injection of the protein or mRNA encoding the protein.
- the half-life of the protein is 1 day, 2 days. 3 days, 4 days, 5 days, or 1 week or more.
- Delivery systems also include non-polymer systems drat are lipids including sterols such as cholesterol, cholesterol esters, and fatty acids or neutral fats such as mono-di-and tri-glycerides; hydrogel release systems; sylastic systems; peptide based systems: wax coatings; compressed tablets using conventional binders and excipients; partially fused implants; and the like.
- lipids including sterols such as cholesterol, cholesterol esters, and fatty acids or neutral fats such as mono-di-and tri-glycerides
- hydrogel release systems such as sterols such as cholesterol, cholesterol esters, and fatty acids or neutral fats such as mono-di-and tri-glycerides
- sylastic systems such as sterols such as cholesterol, cholesterol esters, and fatty acids or neutral fats such as mono-di-and tri-glycerides
- sylastic systems such as sterols such as cholesterol, cholesterol esters, and fatty acids or neutral fats
- the therapeutic agent can be conjugated either directly or indirectly through a linking moiety to a targeting moiety.
- Methods for conjugating therapeutic agents to targeting moieties is known in the art. See. for instance, Wadwa et al.. J, Drug Targeting 3:111 (1995) and U.S. Patent 5,087,616.
- the therapeutic agents provided herein are formulated into a depot form, such that the manner in which the therapeutic agent is released into the body to which it is administered is controlled with respect to time and location within the body (see, for example, U.S. Patent 4,450, 150).
- Depot fonns of therapeutic agents can be, for example, an implantable composition comprising the therapeutic agents and a porous or non-porous material, such as a polymer, wherein the therapeutic agents are encapsulated by or diffused throughout the material and/or degradation of the non-porous material.
- the depot is then implanted into the desired location within the body and the therapeutic agents are released from the implant at a predetermined rate.
- the present disclosure also contemplates the discriminatory' targeting of target cells and tissues by both passive and active targeting means.
- the phenomenon of passive targeting exploits the natural distributions patterns of a transfer vehicle in vivo without relying upon the use of additional excipients or means to enhance recognition of the transfer vehicle by target cells.
- transfer vehicles which are subject to phagocytosis by the cells of the reticulo-endothelial system are likely to accumulate in the liver or spleen, and accordingly may provide a means to passively direct the delivery of the subject compositions to such target cells.
- the present disclosure contemplates active targeting, which involves the use of targeting moieties that may be bound (either covalently or non-covalently) to the lipid nanoparticle to encourage localization of such at certain target cells or target tissues.
- targeting may be mediated by’ the inclusion of one or more endogenous targeting moieties in or on the lipid nanoparticle to encourage distribution to the target cells or tissues.
- Recognition of the targeting moiety by the target tissues actively facilitates tissue distribution and cellular uptake of the lipid nanoparticle and/or its contents in the target cells and tissues (e.g..
- the composition can comprise a moiety capable of enhancing affinity of the composition to the target cell.
- Targeting moieties may be linked to the outer layer of the lipid nanoparticle during formulation or post-formulation.
- some lipid nanoparticle formulations may employ fusogenic polymers such as PEAA, hemagluttinin, other lipopeptides (see U.S. patent application Ser. No. 08/835,281, and 60/083,294, which are incorporated herein by reference) and other features useful for in vivo and/or intracellular delivery.
- compositions of the present disclosure demonstrate improved transfection efficacies, and/or demonstrate enhanced selectivity towards target cells or tissues of interest.
- Contemplated therefore are compositions which comprise one or more moieties (e.g., peptides, aptamers, oligonucleotides, vitamins or other molecules) that are capable of enhancing the affinity of the compositions and their nucleic acid contents for the target cells or tissues.
- Suitable moieties may optionally be bound or linked to the surface of the nanoparticle.
- the targeting moiety may span the surface of a nanoparticle or be encapsulated within the nanoparticle.
- Suitable moieties and are selected based upon their physical, chemical or biological properties (e.g..
- compositions of the present disclosure may 7 include surface markers (e.g., apolipoprotein-B (APOB) or apolipoprotein-E (APOE)) that selectively enhance recognition of. or affinity 7 to hepatocytes (e.g., by receptor -mediated recognition of and binding to such surface markers).
- surface markers e.g., apolipoprotein-B (APOB) or apolipoprotein-E (APOE)
- the use of galactose as a targeting moiety would be expected to direct the compositions of the present disclosure to parenchymal hepatocytes, or alternatively the use of mannose containing sugar residues as a targeting ligand would be expected to direct the compositions of the present disclosure to liver endothelial cells (e.g., mannose containing sugar residues that may bind preferentially to the asialoglycoprotein receptor present in hepatocytes).
- liver endothelial cells e.g., mannose containing sugar residues that may bind preferentially to the asialoglycoprotein receptor present in hepatocytes.
- targeting moieties that have been conjugated to moieties present in the lipid nanoparticle composition therefore facilitate recognition and uptake of the compositions of the present disclosure in target cells and tissues.
- suitable targeting moieties include one or more peptides, proteins, aptamers, vitamins and oligonucleotides.
- a LNP composition comprises a targeting moiety, hi some embodiments, the targeting moiety mediates receptor-mediated endocytosis selectively into a specific population of cells.
- the targeting moiety is operably connected, or linked, to the transfer vehicle.
- the targeting moiety is capable of binding to an immune cell antigen.
- the targeting moiety is capable of binding to a T cell antigen.
- Exemplary T cell antigens include, but are not limited to, CD2, CD3, CD5, CD7, CD8, CD4, beta7 integrin, beta2ingetrin, and ClqR.
- the targeting moiety is capable of binding to a NK, NKT, or macrophage antigen.
- the targeting moiety is capable of binding to a protein selected from CD3, CD4, CD8. PD-1, 4- IBB. and CD2.
- the targeting moiety is a single chain Fv (scFv) fragment, nanobody, peptide, peptide-based macrocycle, minibody, heavy chain variable region, light chain variable region or fragment thereof.
- the targeting moiety is selected from T-cell receptor motif antibodies. T-cell a chain antibodies, T-cell p chain antibodies, T-cell y chain antibodies, T-cell 8 chain antibodies, CCR7 antibodies, CD3 antibodies, CD4 antibodies, CD5 antibodies. CD7 antibodies. CD8 antibodies, CDl lb antibodies, CDl lc antibodies, CD 16 antibodies.
- the immune cell represents the target cell.
- the compositions of the present disclosure transfect the target cells on a discriminatory basis (i.e.. do not transfect non-target cells).
- the compositions of the present disclosure may also be prepared to preferentially target a variety of target cells, which include, but are not limited to, T cells, B cells, macrophages, and dendritic cells.
- the target cells are deficient in a protein or enzyme of interest.
- the hepatocyte represents the target cell.
- the compositions of the present disclosure transfect the target cells on a discriminatory basis (i.e.. do not transfect non-target cells).
- compositions of the present disclosure may also be prepared to preferentially target a variety of target cells, which include, but are not limited to, hepatocytes, epithelial cells, hematopoietic cells, epithelial cells, endothelial cells, lung cells, bone cells, stem cells, mesenchymal cells, neural cells (e.g., meninges, astrocytes, motor neurons, cells of the dorsal root ganglia and anterior horn motor neurons), photoreceptor cells (e.g., rods and cones), retinal pigmented epithelial cells, secretory cells, cardiac cells, adipocytes, vascular smooth muscle cells, cardiomyocytes, skeletal muscle cells, beta cells, pituitary cells, synovial lining cells, ovarian cells, testicular cells, fibroblasts, B cells, T cells, reticulocytes, leukocytes, granulocytes and tumor cells.
- target cells include, but are not limited to, hepatocytes,
- compositions of the present disclosure may be prepared to preferentially distribute to target cells such as in the heart, lungs, kidneys, liver, and spleen.
- the compositions of the present disclosure distribute into the cells of the liver or spleen to facilitate the delivery and the subsequent expression of the circRNA comprised therein by the cells of the liver (e.g., hepatocytes) or the cells of spleen (e.g., immune cells).
- the targeted cells may function as a biological “reservoir” or “depot” capable of producing, and systemically excreting a functional protein or enzyme.
- the transfer vehicle may target hepatocytes or immune cells and/or preferentially distribute to the cells of the liver or spleen upon delivery'.
- the circRNA loaded in the nanoparticle are translated and a functional protein product is produced, excreted and systemically distributed.
- cells other than hepatocytes e.g., lung, spleen, heart, ocular, or cells of the central nervous system
- the compositions of the present disclosure facilitate a subject's endogenous production of one or more functional proteins and/or enzymes.
- the lipid nanoparticles comprise circRNA which encode a deficient protein or enzyme.
- the exogenous circRNA loaded into the nanoparticle may be translated in vivo to produce a functional protein or enzyme encoded by the exogenously administered circRNA (e.g., a protein or enzyme in which the subject is deficient).
- compositions of the present disclosure exploit a subject's ability to translate exogenously- or recombinantly-prepared circRNA to produce an endogenously-translated protein or enzyme, and thereby produce (and where applicable excrete) a functional protein or enzyme.
- the expressed or translated proteins or enzymes may also be characterized by the in vivo inclusion of native post-translational modifications which may often be absent in recombinantly-prepared proteins or enzymes, thereby further reducing the immunogenicity of the translated protein or enzyme.
- a circular RNA comprises one or more miRNA binding sites.
- a circular RNA comprises one or more miRNA binding sites recognized by miRNA present in one or more non-target cells or non-target cell types (e.g., Kupffer cells or hepatic cells) and not present in one or more target cells or target cell types (e.g., hepatocytes or T cells).
- a circular RNA comprises one or more miRNA binding sites recognized by miRNA present in an increased concentration in one or more non-target cells or non-target cell types (e.g., Kupffer cells or hepatic cells) compared to one or more target cells or target cell types (e.g., hepatocytes or T cells). miRNAs are thought to function by pairing with complementary sequences within RNA molecules, resulting in gene silencing.
- compositions of the present disclosure transfect or distribute to target cells on a discriminatory basis (i.e.. do not transfect non-target cells).
- the compositions of the present disclosure may also be prepared to preferentially target a variety of target cells, which include, but are not limited to, hepatocytes, epithelial cells, hematopoietic cells, epithelial cells, endothelial cells, lung cells, bone cells, stem cells, mesenchymal cells, neural cells (e.g..).
- astrocytes meninges, astrocytes, motor neurons, cells of the dorsal root ganglia and anterior horn motor neurons), photoreceptor cells (e.g., rods and cones), retinal pigmented epithelial cells, secretory cells, cardiac cells, adipocytes, vascular smooth muscle cells, cardiomyocytes, skeletal muscle cells, beta cells, pituitary cells, synovial lining cells, ovarian cells, testicular cells, fibroblasts.
- B cells T cells, reticulocytes, leukocytes, granulocytes and tumor cells.
- provided herein is a method of producing a protein of interest in a subject in need thereof by introducing or administering an effective amount of a pharmaceutical composition described herein comprising at least one lipid nanoparticle described herein.
- provided herein is a method of treating and/or preventing a condition comprising administering an effective amount of a pharmaceutical composition described herein comprising at least one LNP as described herein.
- the pharmaceutical compositions described herein are co-administered with one or more additional therapeutic agents (e.g., in the same pharmaceutical composition or in separate pharmaceutical compositions).
- the pharmaceutical compositions provided herein can be administered first and the one or more additional therapeutic agents can be administered second, or vice versa.
- the pharmaceutical compositions provided herein and the one or more additional therapeutic agents can be administered simultaneously.
- the subject is a mammal.
- the mammal referred to herein can be any mammal, including, but not limited to, mammals of the order Rodentia, such as mice and hamsters, or mammals of the order Logomorpha, such as rabbits.
- the mammals may be from the order Carnivora, including Felines (cats) and Canines (dogs).
- the mammals may be from the order Artiodactyla, including Bovines (cows) and Swines (pigs), or of the order Perssodactyla, including Equines (horses).
- the mammals may be of the order Primates, Ceboids, or Simoids (monkeys) or of the order Anthropoids (humans and apes).
- the mammal is a human.
- provided herein is a method of vaccinating a subject by introducing or administering an effective amount of a pharmaceutical composition described herein comprising at least one lipid nanoparticle described herein.
- the method of vaccinating comprises administering an effective amount of an antigen comprising a viral polypeptide from an adenovirus; Herpes simplex, type 1; Herpes simplex, type 2; encephalitis virus, papillomavirus, Varicella-zoster virus; Epstein-barr virus; Human cytomegalovirus; Human herpes virus, type 8; Human papillomavirus; BK virus; JC virus; Smallpox: polio virus; Hepatitis B virus; Human bocavirus; Parvovirus B19; Human astrovirus; Norwalk virus; coxsackievirus; hepatitis A virus; poliovirus; rhinovirus; Severe acute respiratory syndrome virus; Hepatitis C virus; Yellow Fever virus; Dengue virus; West Nile virus; Rubella virus; Hepatitis E virus; Human Immunodeficiency virus (HIV); Influenza virus: Guanarito virus: Junin virus;
- provided herein is a method of treating an autoimmune disorder in a subject by introducing or administering an effective amount of a pharmaceutical composition described herein comprising at least one lipid nanoparticle described herein.
- provided herein is a method of treating cancer in a subject by introducing or administering an effective amount of a pharmaceutical composition described herein comprising at least one lipid nanoparticle described herein.
- the circular RNA construct encodes a CAR
- the CARs have biological activity, e.g., ability to recognize an antigen, e.g.. CD19, HER2. or BCMA, such that the CAR. when expressed by a cell, is able to mediate an immune response against the cell expressing the antigen, e.g.. CD 19, HER2. or BCMA, for which the CAR is specific.
- CAR-T chimeric antigen receptor
- CAR-T CAR-T
- CRS cytokine release syndrome
- CRES CAR-T cell-related encephalopathy syndrome
- CRS is tire most common and well-described toxicity associated with CAR-T therapy, occurring in over 90% of patients at any grade and is characterized by high fever, hypotension, hypoxia and/ or multiple organ toxicity and can lead to death.
- Neurotoxicity is characterized by damage to nervous tissue that can cause tremors, encephalopathy, dizziness or seizures.
- lymphodepletion is known to increase CAR- T cell expansion and enhanced efficacy of infused CAR-T cells by, for example, altering the tumor phenotype and microenvironment.
- lymphodepletion agents often cause side effects to the patients.
- lymphodepletion can cause neutropenia, anemia, thrombocytopenia, and immunosuppression, leading to a greater risk of infection, along with other toxicities.
- CAR-T therapies require an assortment of protocols to isolate, genetically modify, and selectively expand the redirected cells before infusing them back into the patient.
- the subject has a cancer selected from the group consisting of: acute myeloid leukemia (AML); alveolar rhabdomyosarcoma; B cell malignancies; bladder cancer (e.g., bladder carcinoma); bone cancer; brain cancer (e.g..
- AML acute myeloid leukemia
- alveolar rhabdomyosarcoma B cell malignancies
- bladder cancer e.g., bladder carcinoma
- bone cancer e.g., brain cancer
- breast cancer cancer; cancer of the anus, anal canal, or anorectum; cancer of the eye; cancer of the intrahepatic bile duct; cancer of the joints; cancer of the neck; gallbladder cancer; cancer of the pleura; cancer of the nose, nasal cavity, or middle ear; cancer of the oral cavity; cancer of the vulva; chronic lymphocytic leukemia; chronic myeloid cancer; colon cancer; esophageal cancer, cervical cancer; fibrosarcoma; gastrointestinal carcinoid tumor; head and neck cancer (e.g., head and neck squamous cell carcinoma); Hodgkin lymphoma; hypopharynx cancer; kidney cancer; larynx cancer; leukemia; liquid tumors; lipoma; liver cancer; lung cancer (e.g., non-small cell lung carcinoma, lung adenocarcinoma, and small cell lung carcinoma); lymphoma; mesothelio
- the subject has an autoimmune disorder selected from scleroderma, Grave's disease, Crohn's disease, Sjogren's disease, multiple sclerosis, Hashimoto's disease, psoriasis, myasthenia gravis, autoimmune polyendocrinopathy syndromes, Type I diabetes mellitus (TIDM), autoimmune gastritis, autoimmune uveoretinitis, polymyositis, colitis, thyroiditis, and the generalized autoimmune diseases ty pified by human Lupus.
- an autoimmune disorder selected from scleroderma, Grave's disease, Crohn's disease, Sjogren's disease, multiple sclerosis, Hashimoto's disease, psoriasis, myasthenia gravis, autoimmune polyendocrinopathy syndromes, Type I diabetes mellitus (TIDM), autoimmune gastritis, autoimmune uveoretinitis, polymyositis, colitis, thyroiditis, and the general
- circRNA or ‘‘circular polyribonucleotide” or “circular RNA” or “circular RNA polynucleotide” or “oRNA” are used interchangeably and refers to a single-stranded RNA polynucleotide wherein the 3’ and 5’ ends that are normally present in a linear RNA polynucleotide have been joined together e.g., by covalent bonds. As used herein, such terms also include preparations comprising circRNAs.
- DNA template refers to a DNA sequence capable of transcribing a linear RNA polynucleotide.
- a DNA template may include a DNA vector, PCR product or plasmid.
- the term “3 ’ intron segment” refers to a sequence with at least 75%. at least 80%, at least 85%. at least 90%, at least 91%. at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% similarity to the 3’- proximal end of a natural intron (e.g., a group I or group II intron).
- the 3 ’ intron segment includes the 5’ nucleotide of the splice site dinucleotide.
- 3’ exon segment refers to a sequence with at least 75%, at least 80%, at least 85%. at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%. at least 97%, at least 98%, at least 99%, or 100% similarity' to the 5 ’-proximal end of an exon adjacent to a “3’ intron segment” as described herein.
- the 3’ exon segment includes the 3’ nucleotide of the splice site dinucleotide.
- 5’ intron segment refers to a sequence with at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or higher 100% similarity to the 5‘-proximal end of a natural intron (e.g., a group I or group II intron).
- the 5’ intron segment includes the 3’ nucleotide of the splice site dinucleotide.
- “5’ exon segment” refers to a sequence with at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%. at least 94%, at least 95%, at least 96%, at least 97%, at least 98%. at least 99%, or higher 100% similarity to the 3’-proximal end of an exon adjacent to a “5’ intron segment” as described herein.
- the 5’ exon segment includes the 5’ nucleotide of the splice site dinucleotide.
- the 3’ intron segment and the 3’ exon segment together form a first portion of an autocatalytic or self-splicing intron-exon sequence.
- the 5 ’ intron segment and the 5‘ exon segment together form the remainder (i.e., second portion) of the autocatalytic or self-splicing intron-exon sequence.
- a linear nucleic acid molecule e.g., RNA, comprising the 3‘ intron segment and the 3‘ exon segment at the 5’ end of the linear nucleic acid molecule and further the 5 ‘ intron segment and the 5 ’ exon segment at the 3 ' end the linear nucleic acid molecule, is capable of autocatalytically self-splicing and thereby capable of fonning a circular nucleic acid molecule, e.g., circular RNA.
- the 3’ intron segment and the 5’ intron segments are excised from the circular nucleic acid molecule, e.g..
- Each retained post-splicing exon segment may be referred to as a self-splicing or self-spliced exon segment, e.g.. a 3’ self-splicing or self-spliced exon segment and a 5’ self-splicing or self-spliced exon segment.
- the intron segment is a “Group I intron” and the corresponding exon segment may be referred to as a “Group I exon” or “Group 1 self-splicing exon” or “Group 1 self-spliced exon segment” or the like.
- the intron segment is a “Group II intron” and the corresponding exon segment may be referred to as a “Group II exon” or “Group II self-splicing exon” or “Group II self-spliced exon segment” or the like.
- the retained, post-splicing, self-splicing 3 ’ or 5 ’ exon segment is a noncoding sequence in the circular nucleic acid molecule, e.g., circular RNA.
- the circular nucleic acid molecule, e.g., circular RNA further comprises a desired coding sequence
- the retained, post-splicing, self-splicing 3’ or 5’ exon segment is (e.g., designed) to be a portion of the desired expression sequence, contiguous with the desired coding sequence, and/or in frame with the desired coding sequence.
- a circular nucleic acid molecule e.g.. derived from a linear nucleic acid precursor, and comprising a coding sequence
- the 5’ to 3’ orientation of the coding sequence may be used to inform whether other sequences within the circular nucleic acid are 5’ and/or 3’, e.g., for example. 5’ is nearer to the 5’ of the coding sequence, and the 3’ end is downstream of the coding sequence.
- reference to a “5”’ or “3”’ portion of the molecule may correspond to the orientation of the sequence within the linear nucleic acid precursor.
- circular RNA polynucleotides comprising a post splicing 3’ group I or II intron fragment (e.g., a stretch of exon sequence), optionally a first spacer, an IRES, an expression sequence, optionally a second spacer, and a post splicing 5’ group I or II intron fragment (e.g., a stretch of exon sequence).
- splice site refers to the junction consisting of a dinucleotide betw een an exon and an intron in an unspliccd RNA.
- splice site refers to a dinuclcotidc that is partially or fully included in a group I or group II intron and/or exon and between which a phosphodiester bond is cleaved during RNA circularization.
- a “splice site dinucleotide’’ refers two nucleotides: a 5’ splice site nucleotide and the 3’ splice site nucleotide.
- a “5’ splice site” refers to the natural 5’ dinucleotide of the intron and/or exon e.g., group I or group II intron and/or exon, while a “3’ splice site” refers to the natural 3’ dinucleotide of the intron and/or exon. Exemplary' splice site dinucleotides are shown in Table 1 below.
- permutation site refers to a site in an intron and/or exon (e.g., a group I or II intron and/or exon) where a cut is made prior to permutation of the intron/or exon.
- a cut generates an intron sequence comprising a 3’ intron segment and a sequence comprising a 5’ intron segment (e.g., group I or group II intron fragments) that are permuted to be on either side of a stretch of precursor RNA to be circularized.
- permuted intron segments are thereby called “3’ permuted intron segments” or “3’ permuted elements” and “5’ permuted intron segments” or “5’ permuted elements” in the context of said precursor RNA.
- permuted intron segment and “permuted intron element” are used interchangeably.
- the permutation site consists of a dinucleotide.
- expression sequence refers to a nucleic acid sequence that encodes a product, e.g., a peptide or polypeptide, regulatory nucleic acid, or non-coding nucleic acid.
- An exemplary' expression sequence that codes for a peptide or polypeptide can comprise a plurality of nucleotide triads, each of which can code for an amino acid and is termed as a “codon.”
- coding element or “coding region” is region located within the expression sequence and encodings for one or more proteins or polypeptides (e.g., therapeutic protein).
- a “noncoding element” or “non-coding nucleic acid” is a region located within the expression sequence. This sequence, but itself docs not encode for a protein or polypeptide, but may have other regulatory functions, including but not limited, allow the overall poly nucleotide to act as a biomarker or adjuvant to a specific cell.
- translation efficiency refers to a rate or amount of protein or peptide production from a ribonucleotide transcript. In some embodiments, translation efficiency can be expressed as amount of protein or peptide produced per given amount of transcript that codes for the protein or peptide.
- nucleotide refers to a ribonucleotide, a deoxyribonucleotide, a modified fonn thereof, or an analog thereof.
- Nucleotides include species that comprise purines, e.g., adenine, hypoxanthine, guanine, and their derivatives and analogs, as well as pyrimidines, e.g., cytosine, uracil, thymine, and their derivatives and analogs.
- Nucleotide analogs include nucleotides having modifications in the chemical structure of the base, sugar and/or phosphate, including, but not limited to, 5 ’-position pyrimidine modifications.
- Nucleotide analogs are also meant to include nucleotides with bases such as inosine, queuosine, xanthine; sugars such as 2’-methyl ribose; non-natural phosphodiester linkages such as methylphosphonate, phosphorothioate and peptide linkages. Nucleotide analogs include 5- methoxyuridine, 1 -methylpseudouridine, and 6-methyladenosine.
- nucleic acid and “polynucleotide” are used interchangeably herein to describe a polymer of any length, e.g.. greater than 2 bases, greater than 10 bases, greater than 100 bases, greater than 500 bases, greater than 1000 bases, or up to 10,000 or more bases, composed of nucleotides, e.g., deoxyribonucleotides or ribonucleotides, and may be produced enzymatically or synthetically (e.g., as described in U.S. Pat. No.
- Naturally occurring nucleic acids are comprised of nucleotides including guanine, cytosine, adenine, thymine, and uracil (G, C, A, T, and U respectively).
- ribonucleic acid and “RNA” as used herein mean a polymer composed of ribonucleotides.
- deoxyribonucleic acid and “DNA” as used herein mean a polymer composed of deoxy ribonucleotides.
- Isolated or “purified” generally refers to isolation of a substance (for example, in some embodiments, a compound, a polynucleotide, a protein, a polypeptide, a polynucleotide composition, or a polypeptide composition) such that the substance comprises a significant percent (e.g., greater than 1%, greater than 2%, greater than 5%, greater than 10%, greater than 20%, greater than 50%, or more, usually up to 90%-100%) of the sample in which it resides.
- a substantially purified component comprises at least 50%, 80%-85%, or 90%-95% of the sample.
- Techniques for purifying polynucleotides and polypeptides of interest include, for example, ion-exchange chromatography, affinity chromatography and sedimentation according to density.
- a substance is purified when it exists in a sample in an amount, relative to other components of the sample, that is more than as it is found naturally.
- duplexed double-stranded
- hybridized refers to nucleic acids formed by hybridization of two single strands of nucleic acids containing complementary sequences. In most cases, genomic DNA is double-stranded. Sequences can be fully complementary or partially complementary.
- unstructured with regard to RNA refers to an RNA sequence that is not predicted by the RNAFold software or similar predictive tools to form a structure (e.g., a hairpin loop) with itself or other sequences in the same RNA molecule.
- unstructured RNA can be functionally characterized using nuclease protection assays.
- RNA refers to an RNA sequence that is predicted by the RNAFold software or similar predictive tools to form a structure (e.g., a hairpin loop) with itself or other sequences in the same RNA molecule.
- two “duplex sequences,” “duplex forming sequences,” “duplex region,” “duplex regions,” “homology arms.” or “homology regions” may be any two regions that are thermodynamically favored to cross-pair in a sequence specific interaction.
- two duplex sequences, duplex regions, homology arms, or homology regions share a sufficient level of sequence identity to one another’s reverse complement to act as substrates for a hybridization reaction.
- polynucleotide sequences have “homology” when they are either identical or share sequence identity to a reverse complement or “complementary” sequence.
- an internal duplex region of an inventive polynucleotide is capable of forming a duplex with another internal duplex region and does not form a duplex with an external duplex region.
- an "affinity sequence” or “affinity tag” is a region of polynucleotide sequences polynucleotide sequence ranging from 1 nucleotide to hundreds or thousands of nucleotides containing a repeated set of nucleotides for the purposes of aiding purification of a polynucleotide sequence.
- an affinity sequence may comprise, but is not limited to, a polyA or poly AC sequence.
- a "spacer” refers to a region of a polynucleotide sequence ranging from 1 nucleotide to hundreds or thousands of nucleotides separating two other elements along a polynucleotide sequence.
- the sequences can be defined or can be random.
- a spacer is typically noncoding. In some embodiments, spacers include duplex regions.
- Linear nucleic acid molecules are said to have a “5 ’-terminus” (5‘ end) and a “3 ‘-terminus” (3’ end) because nucleic acid phosphodiester linkages occur at the 5‘ carbon and 3‘ carbon of the sugar moieties of the substituent mononucleotides.
- the end nucleotide of a polynucleotide at which a new linkage would be to a 5’ carbon is its 5’ terminal nucleotide.
- the end nucleotide of a polynucleotide at which a new linkage would be to a 3’ carbon is its 3’ tenninal nucleotide.
- a terminal nucleotide, as used herein, is the nucleotide at the end position of the 3’- or 5 ’-terminus.
- a "leading untranslated sequence” is a region of polynucleotide sequences ranging from 1 nucleotide to hundreds of nucleotides located at the upmost 5' end of a polynucleotide sequence.
- the sequences can be defined or can be random.
- a leading untranslated sequence is noncoding.
- a "leading untranslated sequence” is a region of polynucleotide sequences ranging from 1 nucleotide to hundreds of nucleotides located at the downmost 3' end of a polynucleotide sequence.
- the sequences can be defined or can be random.
- a leading untranslated sequence is noncoding.
- Transcription means the formation or synthesis of an RNA molecule by an RNA polymerase using a DNA molecule as a template.
- the invention is not limited with respect to the RNA polymerase that is used for transcription.
- a T7-type RNA polymerase can be used.
- the term “encode” refers broadly to any process whereby the information in a polymeric macromolecule is used to direct the production of a second molecule that is different from the first.
- the second molecule may have a chemical structure that is different from the chemical nature of the first molecule.
- co-administering is meant administering a therapeutic agent provided herein in conjunction with one or more additional therapeutic agents sufficiently close in time such that the therapeutic agent provided herein can enhance the effect of the one or more additional therapeutic agents, or vice versa.
- treatment or prevention can include treatment or prevention of one or more conditions or symptoms of the disease. Also, for purposes herein, “prevention” can encompass delaying the onset of the disease, or a symptom or condition thereof.
- an “internal ribosome entry site” or “IRES” refers to an RNA sequence or structural element ranging in size from 10 nt to 1000 nt or more, capable of initiating translation of a polypeptide in the absence of a typical RNA cap structure.
- An IRES is typically 500 nt to 700 nt in length.
- aptamer refers in general to either an oligonucleotide of a single defined sequence or a mixture of said nucleotides, wherein the mixture retains the properties of binding specifically to the target molecule (e.g., eukaryotic initiation factor, 40S ribosome.
- target molecule e.g., eukaryotic initiation factor, 40S ribosome.
- aptamer denotes both singular and plural sequences of nucleotides, as defined hereinabove.
- aptamer is meant to refer to a single- or double-stranded nucleic acid which is capable of binding to a protein or other molecule.
- aptamers comprise 10 to 100 nucleotides (e.g., 15 to 40 nucleotides, 20 to 40 nucleotides), in that oligonucleotides of a length that falls within these ranges are readily prepared by conventional techniques.
- aptamers can further comprise a minimum of approximately 6 nucleotides that are necessary to effect specific binding.
- aptamers can further comprise approximately 10 nucleotides that are necessary to effect specific binding.
- aptamers can further comprise approximately 14 or 15 nucleotides that are necessary to effect specific binding.
- an “eukaryotic initiation factor” or “elF” refers to a protein or protein complex used in assembling an initiator tRNA, 40S and 60S ribosomal submits required for initiating eukaryotic translation.
- an “internal ribosome entry site” or “IRES” refers to an RNA sequence or structural element ranging in size from 10 nt to 1000 nt or more, capable of initiating translation of a polypeptide in the absence of a typical RNA cap structure.
- An IRES is typically 500 nt to 700 nt in length.
- a “miRNA site” refers to a stretch of nucleotides within a polynucleotide that is capable of forming a duplex with at least 8 nucleotides of a natural miRNA sequence.
- an "endonuclease site” refers to a stretch of nucleotides within a polynucleotide that is capable of being recognized and cleaved by an endonuclease protein.
- bicistronic RNA refers to a polynucleotide that includes two expression sequences coding for two distinct proteins. These expression sequences can be separated by a nucleotide sequence encoding a cleavable peptide such as a protease cleavage site. They can also be separated by a ribosomal skipping element.
- ribosomal skipping element refers to a nucleotide sequence encoding a short peptide sequence capable of causing generation of two peptide chains from translation of one RNA molecule. While not wishing to be bound by theory, it is hypothesized that ribosomal skipping elements function by (1) terminating translation of the first peptide chain and re-initiating translation of the second peptide chain; or (2) cleavage of a peptide bond in the peptide sequence encoded by the ribosomai skipping element by an intrinsic protease activity of the encoded peptide, or by another protease in the environment (e.g.. cytosol).
- a lipid or compound described herein comprises one or more cleavable groups.
- cleave and clcavablc arc used herein to mean that one or more chemical bonds (e.g., one or more of covalent bonds, hydrogen-bonds, van der Waals' forces and/or ionic interactions) between atoms in or adjacent to the subject functional group are broken (e.g., hydrolyzed) or are capable of being broken upon exposure to selected conditions (e.g., upon exposure to enzymatic conditions).
- a hydrophilic head-group e.g., an amino group
- a hydrophobic tail-group e.g., cholesterol
- a “self-cleaving peptide” refers to a peptide which is translated without a peptide bond between two adjacent amino acids, or functions such that when the polypeptide comprising the proteins and the self-cleaving peptide is produced, it is immediately cleaved or separated into distinct and discrete first and second polypeptides without the need for any external cleavage activity.
- TCR alpha variable domain therefore refers to the concatenation of TRAV and TRAJ regions
- TCR alpha constant domain refers to the extracellular TRAC region, or to a C-terminal truncated TRAC sequence.
- a “vaccine” refers to a composition for generating immunity’ for the prophylaxis and/or treatment of diseases. Accordingly , vaccines arc medicaments which comprise antigens and arc intended to be used in humans or animals for generating specific defense and protective substances upon administration to the human or animal.
- X is a core branching moiety
- P is the macrocycle; and n is an integer selected from 1 to 6, preferably an integer from 1 to 3.
- P A and P B are each independently the two or more PEG blocks
- Y is an optional linking group; and m is an integer from 1 to 6, preferably an integer from 1 to 3.
- Clause 14 The compound of clause 13, wherein the one or more amino acid residues are selected from lysine, ornithine, aspartate, glutamate, serine, cysteine, and tyrosine.
- A is the at least one lipid
- X 1 is a branching moiety
- P is the macrocycle; each Z A . Z B and Z c is independently an optional linking moiety; and n is 1 or 2.
- Clause 23 The compound of clause 22. wherein Z A is selected from -O-, -C(O)O-, -OC(O)-. and -OP(O)(OH)O-.
- Clause 24 The compound of clause 22 or 23, wherein Z B is selected from -C(O)NH(CH 2 ) Z - - NHC(O)(CH 2 ) Z -, and -OC(O)-.
- Clause 25 The compound of any one of clauses 22 to 24, wherein Z c is selected from - C(O)NH(CH 2 ) Z - -NHC(O)(CH 2 ) z -,and -OC(O)-.
- Z A is -C(O)O-
- Z B and Z c are each -OC(O)-.
- Z A is -OP(O)(OH)O-
- Z B and Z c are each -OC(O)-.
- Z A is -OC(O)-
- Z B and Z c are each -NHC(O)(CH 2 ) Z -, wherein z is 0, 1, or 2.
- Z A is -OC(O)-;
- Z B is -NHC(O)(CH 2 ) Z -;
- Z c is -C(O)NH(CH 2 ) Z -, wherein each z is independently 0, 1, or 2.
- Clause 30 The compound of any one of clauses 21 to 29, wherein X 1 comprises an optionally substituted branched Cl -C 6 alkylene.
- Clause 32 The compound of any one of clauses 3 to 31. wherein the compound is of the Fonnula (VI): wherein: m is an integer from 10 to 500; each z is independently 1, 2, 3, 4, or 5; and A is a lipid.
- R 1 is hydrogen or R 3 ;
- R 2 , and R 3 are each independently C1-C12 alky l, or C2-C12-alkenyl.
- each t is independently an integer from 0 to 6 . preferably 7C long branched, 8C long branched, 9C long branched, or 10C long branched.
- Clause 40 The compound of any one of clauses 3 to 38, wherein each A- or A-Z A - comprises a phospholipid.
- Clause 41 The compound of any one of clauses 3 to 38, wherein each A- or A-Z '- comprises a sterol or a cholesterol.
- Clause 42 The compound of clause 1, wherein the compound satisfies (b).
- a 1 and A 2 are independently the lipids
- Z 1 and Z 2 are independently an optional core moiety wherein:
- a 1 and A 2 are covalently linked to define the macrocycle P when Z 1 and Z 2 , if present, are part of A 1 and A 2 , respectively; or
- A'-Z 1 is non-covalcntly bound with A 2 -Z 2 to define the macrocycle P.
- Clause 45 The compound of clause 43 or 44, wherein P comprises at least 10 ethylene glycol monomer units, preferably at least 12. at least 20, at least 30, at least 40, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220 ethylene glycol monomer units.
- Clause 46 The compound of any one of clauses 43 to 45, wherein P comprises a PEG block of 500Da to 20kDa.
- Clause 48 The compound of clause 46, wherein P comprises a PEG block of 5 kDa to 20 kDa.
- Clause 50 The compound of any one of clauses 43 to 49, wherein P comprises one PEG block.
- Clause 51 The compound of any one of clauses 43 to 49, wherein P comprises two or more PEG blocks.
- P A and P B are each independently the tw o or more PEG blocks
- C12-C30 optionally substituted linear or branched alkylene; and C12-C30 optionally substituted linear or branched alkenylene.
- a lipid nanoparticle (LNP) comprising a compound of any one of clauses 1 to 54.
- Clause 56 The LNP of clause 55, wherein the LNP exhibits reduced immunogenicity compared to a LNP that comprises a corresponding linear PEG lipid rather than a compound of any one of clauses 1 to 54.
- LP is a linking moiety comprising one or more polyethylene glycol (PEG) blocks.
- Clause 62 The compound of clause 60 or 61, wherein LP comprises at least 10 ethylene glycol monomer units, preferably at least 12, at least 20, at least 30, at least 40, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220 ethylene glycol monomer units.
- Clause 63 The compound of any one of clauses 60 to 62, wherein LP comprises a PEG block of 500 Da to 20 kDa.
- Clause 64 The compound of clause 63, wherein LP comprises a PEG block of 600 Da to 2 kDa.
- Clause 65 The compound of clause 63, wherein LP comprises a PEG block of 5 kDa to 20 kDa.
- Y is an optional linking group; and m is an integer from 1 to 6, preferably an integer from 1 to 3.
- Clause 70 The compound of clause 69, wherein m is 1.
- the present disclosure further includes the following examples that provide those of ordinary skill in the art with a description of how to make and use the various embodiments of the present disclosure. These examples are not intended to limit the scope of what is regarded as the claimed invention.
- EXAMPLE 1
- the MTT-protected (Methyltrityl-protected) amine in the lysine linker of the resin 1 is dcprotonatcd using a solution of 1-2% trifluoroacctic acid (TFA) in dichloromcthanc (DCM) with triisopropylsilane (TIS).
- TFA trifluoroacctic acid
- DCM dichloromcthanc
- TIS triisopropylsilane
- AA-PEG-AA (1g, MW: 2000) (e.g.. from CreativePEGWorks) is dissolved in 10 mL of trifluorotoluene to form Solution A. Then 342 mg of 2-Benzyloxy-l -methylpyridinium triflate (or 2 molar equivalents to the resin 1) is dissolved in 10 mL of trifluorotoluene with 99 mg of triethylamine to form Solution B. Solution A and Solution B are then combined and left to react at 83 °C for 1 day to form a mono-protected AA-PEG2000-AA, Intermediate 4. The mono-protected AA-PEG2000-AA, Intermediate 4, is purified using methods known in the art.
- the polypropy lene column is shaken at room temperature under inert gas for 4 hours to allow the amine group in Intermediate 2 to be coupled with the AA-PEG2000-AA, Intermediate 4.
- the resulting solution is tested for completion of the reaction using a ninhydrin test (i.e., if the ninhydrin test is negative, the reaction has reached completion; if not, the steps used to couple Intermediate 2 to be coupled with the AA-PEG2000-AA 4 are repeated).
- the polypropylene column is washed three times with DMF, three times with DIC then three times with DCM leaving behind Intermediate 5.
- Oxalyl chloride (33 mg, 1.3 molar equivalent of the resin 1) is dissolved in DCM with DMF and added to the polypropylene column to react with the lysine-PEG of Intermediate 9.
- Stearyl alcohol 70 mg is dissolved in DCM and placed in the polypropylene column with the acyl chloride version of the amino acid-circular PEG.
- the resulting solution contains a circular PEG-lysine-stearoyl product, Compound 10 that is then purified using methods known in the art.
- Fmoc-Asp(Wang resin)-OPP (1 g, 100-200 mesh) resin 2-3 (with loading capacity of 0.18-0.22 mmol/g) is dissolved in 10 mL of in N,N-dimethylformamide (DMF) and then loaded into a commercially available polypropylene column (e.g.. Poly-Prep Chromatography Column, Biorad 731- 1550). The polypropylene column is washed with 10 milliliters of DMF then the solvent is flushed with the pressure of a septum.
- DMF N,N-dimethylformamide
- Fmoc-Asp(0-2-PhiPr)-OH 2-1 (1 g, or 10 molar equivalents to the resin 2-3) is dissolved in DCM with a few drops of DMF.
- N,N'-Diisopropylcarbodiimide (Sigma DI 25407) (25 mg, or 5 molar equivalents to the resin 2-3) is then added to the Fmoc-Asp(O-2-PhiPr)-OH 2-1 mixture.
- Zinc bromide (3 eq., 135.1 mg, or 3 equivalent molars to the resin 2-3) and trimethylsilyl iodide (TMSI) (48 mg, or 1.2 equivalent molars to the resin 2-3) is added dropwise into DMF (2 mL) and then placed into the polypropylene column comprising Intermediate 2-7 to deprotect the Boc-protected amine in substance 2-7.
- the deprotection reaction is allowed to proceed for 24 hours then the deprotection solution (i.e., ZnBr, TMSI, DMF solution) is drained from the polypropylene column.
- the polypropylene column is then washed several times with DMF leaving Intermediate 2-8.
- the intermediate 2-9 is suspended in DCM (10 mL). Then, hydroxybenzotriazole (HOBT) (148.5 mg. or 5.5 equivalent molars to the resin 2-3) is dissolved in DMF and added to the column. N.N'-Diisopropylcarbodiimide (DIC) (139 mg. or 5.5 equivalent molars to the resin 2-3) is dissolved in DMF and added to the column to couple the aspartic acid linker and amine on the Intermediate 2-9.
- the polypropylene column is shaken at room temperature under inert gas for 4 hours. The solution within the polypropylene column is then tested for completion of the reaction (e.g., the ninhydrin test is negative). The column is washed three times with DMF, three times with DIC, and then three times with DCM leaving behind a circular PEG-aspartic acid, Intermediate 2-10.
- HOBT hydroxybenzotriazole
- DIC N.N'-Diisopropylcarbodi
- oFLuc expression is measured following intraperitoneal administration of D-luciferin (e.g., 200pL of at a 15 mg/mL concentration) by quantifying luminescence using an In Vivo Imaging System (e.g., IVIS Spectrum In Vivo Imaging System from Perkin Elmer). 15 minutes after injection of D-luciferin, the mice are scanned for luminescence. Blood draws are collected at 6 hours, 24 hours, 3 days and 5 days post-administration of the oFLuc or ohEPO.
- D-luciferin e.g. 200pL of at a 15 mg/mL concentration
- IVIS Spectrum In Vivo Imaging System from Perkin Elmer
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Pharmacology & Pharmacy (AREA)
- Epidemiology (AREA)
- Nanotechnology (AREA)
- Animal Behavior & Ethology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Dispersion Chemistry (AREA)
- Immunology (AREA)
- Medicinal Preparation (AREA)
- Polyethers (AREA)
Abstract
The present application provides, circular polymeric lipid compounds, and methods for preparing and using the same. The circular polymeric lipid compounds can comprise a macrocycle comprising one or more polymer blocks, such as one or more polyethylene glycol (PEG) blocks, and at least one lipid. In some embodiments, one or more lipids are covalently attached to the macrocycle and is outside the macrocycle's backbone. In some embodiments, the macrocycle includes two lipids within the macrocycle's backbone, wherein all the polymeric blocks are between the two lipids. The present application also provides methods of preparing the subject circular polymeric lipid compounds, and their use in lipid nanoparticle formulations.
Description
CIRCULAR POLYETHYLENE GLYCOL LIPIDS
SEQUENCE LISTING
[0001] The instant application contains a Sequence Listing and is hereby incorporated by reference in its entirety. Said XML copy, created on August 26, 2024, is named
60287WO_CRF_sequencelisting.xml, and is 103,849 bytes in size.
FIELD
[0002] The present disclosure generally relates to circular polymeric (e.g., polyethylene glycol (PEG)) lipid structures that can be incorporated into lipid nanoparticle (LNP) compositions.
BACKGROUND
[0003] Polyethylene glycol (PEG) lipids have been incorporated into lipid nanoparticles for decades due to their ability to help control nanoparticle size and reduce immune cell interaction and clearance. It is known, however, that therapeutics including polyethylene glycol (PEGylated drugs) can elicit immune responses, including the production of anti-PEG antibodies, which can lead to accelerated blood clearance (ABC) and reduced or ablated efficacy upon repeated dosing. PEG lipids traditionally incorporated into lipid nanoparticles (LNPs) for gene delivery are thought to mainly elicit a thymus independent (TI) immune response which does not lead to the formation of PEG-specific antibodies. However, with sufficient interaction of stably anchored PEG lipids with existing B cells, these B cells can produce anti-PEG IgM antibodies which can bind to LNPs and cause ABC upon subsequent repeat dosing.
[0004] The present disclosure provides circular polymeric (e.g.. PEG) lipids. In some embodiments, these can have reduced antibody binding capacity and therefore reduced accelerated blood clearance (ABC).
SUMMARY
[0005] The present application provides circular polymeric (e.g., PEG) lipid compounds, and methods for preparing and using the same. The circular polymeric lipid compounds can comprise a macrocycle comprising one or more polymer blocks (e.g., such as one or more polyethylene gly col (PEG) blocks) and at least one lipid. In some embodiments, one or more lipids are covalently attached to the macrocycle and is outside the macrocycle's backbone. In some embodiments the macrocycle comprises two or more PEG blocks in the macrocycle's backbone, and at least one lipid covalently attached to the macrocycle outside of its backbone. In some embodiments, the macrocycle includes two lipids within the macrocycle’s backbone, wherein all the polymeric blocks are between the two lipids. The present
application also provides methods of preparing the subject circular polymeric lipid compounds, and their use in lipid nanoparticle formulations.
[0006] In one aspect, provided herein is a compound comprising: a macrocycle comprising one or more polymer, e.g., polyethylene glycol (PEG), blocks in the macrocycle’s backbone; and at least one lipid; wherein either
(a) the at least one lipid is covalently attached to the macrocycle and is outside the macrocycle’s backbone; or
(b) two lipids are in the macrocycle’s backbone, wherein all polymer blocks are between the two lipids.
[0007] In some embodiments, the compound comprises one or more PEG blocks in the macrocycle’s backbone and at least one lipid, wherein the at least one lipid is covalently attached to the macrocycle, and is outside the macrocycle’s backbone.
[0008] In some embodiments, the compound comprises one or more PEG block in the macrocycle and two lipids, wherein the one or more PEG blocks are all between the two lipids.
|0009| In another aspect, there is provided a lipid nanoparticle (LNP) comprising a subject circular polymeric lipid compound.
[0010] In another aspect, there is provided a compound of Formula (IV):
A- LP -A’ (IV) wherein:
A and A’ are independently a lipid; and
LP is a linking moiety comprising one or more polyethylene glycol (PEG) blocks.
[0011] In some embodiments, A and A’ each form a link to a core-shell structure of a lipid nanoparticle to form a macrocycle.
BRIEF DESCRIPTION OF THE DRAWINGS
[0012] FIG. 1 is a schematic outlining the constrained PEG theory .
[0013] FIG. 2 illustrates a compound of Formula (IV) forming a link to a core-shell structure of a lipid nanoparticle to form a macrocycle.
[0014] FIGs. 3A-3C depict ex vivo IVIS imaging of BL/6 mice liver (left) and splenic (right) tissue post intravenous administration of circular RNAs expressing firefly luciferase (fLuc) formulated with lipid nanoparticles LNP 4, LNP 5 and LNP 7 comprising either Compound 10, Compound 6-17 or Compound 7-17, or DMG-PEG2000 (control) polymeric lipid. FIG. 3A depicts fLuc expression of circular RNAs formulated with LNP 4 comprising Ionizable Lipid 3 and circular polymeric lipid Compound 7-17. FIG. 3B depicts fLuc expression of circular RNAs formulated with LNP 5 comprising Ionizable Lipid 3 and circular polymeric lipid Compound 6-17. FIG. 3C depicts fLuc expression of circular RNAs formulated with LNP 7 comprising Ionizable Lipid 3 and polymeric lipid DMG- PEG2000 (control). Luminescence in FIGs. 3A-3C is depicted as radiance measured in p/sec/cm2/sr.
[0015] FIGs. 4A and 4B depict total firefly luminescence in p/s measured in BL/6 mice liver (provided in FIG. 4A) and spleen (provided in FIG. 4B) post intravenous administration of circular RNAs encoding firefly luciferase (fLuc) formulated with lipid nanoparticles from FIGs. 3A-3C (LNP 4. LNP 5 and LNP 7) or a phosphate buffered saline (“PBS”) solution (negative control).
DETAILED DESCRIPTION
[0016] The present application provides, among other things, circular polymeric lipid compounds, and methods for preparing and using the same. The subject circular polymeric lipids (e.g., circular PEG lipids) can be incorporated into lipid nanoparticle (LNP) formulations. The subject lipid nanoparticles can comprise RNA polynucleotides, particularly circular RNA polynucleotides (aka circRNA or oRNA™).
[0017] Without being bound to any particular theory, since the binding pocket of anti-PEG antibodies is known to interact with the hy drophobic regions of the polyethylene gly col polymer, it is thought that constraining the PEG-lipid by making it circular (as described herein) instead of a free linear polyethylene glycol polymer, could inhibit the binding of the antibody to the PEG-lipid, which in turn could reduce the occurrence of accelerated blood clearance (ABC) to lipid nanoparticles. See FIG. 1, which illustrates the binding capacity of an anti-PEG antibody for a free PEG polymer (coiled in the binding pocket maximizing hydrophobic binding) vs the subject circular PEG lipids of formula I, II and III (constrained with reduced antibody binding capacity).
[0018] Also disclosed herein is RNA therapy, along with associated compositions and methods. In some embodiments, the RNA therapy allows for increased RNA stability, expression, and prolonged half-life, among other things.
[0019] In some embodiments, provided herein are methods comprising administration of circular RNA polynucleotides provided herein into cells for therapy or production of useful proteins. In some embodiments, the method is advantageous in providing the production of a desired polypeptide inside eukaryotic cells with a longer half-life than linear RNA, due to the resistance of the circular RNA to ribonucleases.
[0020] Various aspects of the disclosure are described in detail in the following sections. The use of sections is not meant to limit the disclosure. Each section can apply to any aspect of the disclosure. In this application, the use of ’‘or’’ means “and/or” unless stated otherwise.
1. CIRCULAR POLYMERIC LIPIDS
[0021] As summarized herein, the present disclosure provides circular polymeric lipid compounds, wherein the compound comprises a macrocycle comprising one or more polymer blocks (e.g., one or more polyethylene glycol (PEG) blocks) in the macrocycle’s backbone; and at least one lipid; wherein either:
(a) the at least one lipid is covalently attached to the macrocycle and is outside the macrocycle’s backbone; or
(b) tw o lipids are in the macrocycle’s backbone, wherein all polymer blocks are between the two lipids.
[0022] Any convenient polymer block may be used in the macrocycle’s backbone. In some embodiments, the polymer block is a hydrophilic polymer block. In some embodiments, the macrocycle’s backbone comprises two or more polymer blocks, and the polymer blocks are made up of a combination of hydrophilic polymer blocks and hydrophobic polymer blocks. In some embodiments, the macrocycle’s backbone comprises two or more polymer blocks, and all the polymer blocks are hydrophilic polymer blocks. A hydrophilic polymer can be one generally that attracts water, and a hydrophobic polymer can be one that generally repels water.
[0023] In some embodiments, the macrocycle comprises one or more polyethylene glycol (PEG) blocks.
[0024] In some embodiments, the compound satisfies (a), and the macrocycle comprises one or more PEG blocks in the macrocycle’s backbone and at least one lipid covalently attached to the macrocycle outside the macrocycle’s backbone. In some embodiments, the compound satisfies (a), and the macrocycle comprises two or more PEG blocks in the macrocycle’s backbone and at least one lipid covalently attached to the macrocycle outside the macrocycle’s backbone.
[0025] In some embodiments, the compound satisfies (b), and the macrocycle comprises a PEG block between two lipids as part of the macrocycle’s backbone. In some embodiments, the compound satisfies (b), and the macrocycle comprises two or more PEG blocks between two lipids as part of the macrocycle's backbone.
A. COMPOUNDS THAT SATISFY (a) - LIPID COVALENTLY ATTACHED OUTSIDE OF THE MACROCYCLE’S BACKBONE
[0026] In certain embodiments, the circular polymeric lipid compound satisfies (a), and the at least one lipid is covalently attached to the macrocycle and is outside the macrocycle’s backbone.
[0027] In some embodiments, the compound satisfies (a) and is of Formula (I):
 wherein:
wherein:
A is the at least one lipid;
X is a core branching moiety;
P is the macrocycle; and n is an integer selected from 1 to 6, preferably an integer from 1 to 3.
Branching Moiety (X)
[0028] As described herein, the compound of Formula (I) includes a core branching moiety (X). In some embodiments of Formula (I). X comprises one or more amino acid residues. In some embodiments, the one or more amino acid residues are selected from lysine, ornithine, aspartate, glutamate, serine, cysteine, and tyrosine. In some embodiments, X comprises a lysine residue. In some embodiments, X comprises an ornithine residue. In some embodiments, X comprises an aspartate residue. In some embodiments. X comprises a glutamate residue. In some embodiments, X comprises a serine residue. In some embodiments, X comprises a cysteine residue. In some embodiments, X comprises a tyrosine residue.
[0029] In some embodiments of Formula (I), X comprises XA:
 wherein zl and z2 are each independently 0, 1, 2, 3. 4, or 5; and two represent the point of attachment to P and the other
wherein zl and z2 are each independently 0, 1, 2, 3. 4, or 5; and two represent the point of attachment to P and the other
 represents the points of attachment to A. [0030] In some embodiments of Formula (I), X comprises XA’ :
represents the points of attachment to A. [0030] In some embodiments of Formula (I), X comprises XA’ :
 wherein zl and z2 are each independently 0, 1, 2, 3, 4, or 5; and
wherein zl and z2 are each independently 0, 1, 2, 3, 4, or 5; and
 represents the point of attachment to P and
represents the point of attachment to P and
 represents the points of attachment to A. [0031] In some embodiments of XA, zl and z2 are each 0. In some embodiments of XA, zl and z2 are each 1. In some embodiments of XA, zl and z2 are each 2. In some embodiments of XA, zl and z2 are each 3. In some embodiments of XA, zl and z2 are each 4. In some embodiments of XA, zl and z2 are each 5.
represents the points of attachment to A. [0031] In some embodiments of XA, zl and z2 are each 0. In some embodiments of XA, zl and z2 are each 1. In some embodiments of XA, zl and z2 are each 2. In some embodiments of XA, zl and z2 are each 3. In some embodiments of XA, zl and z2 are each 4. In some embodiments of XA, zl and z2 are each 5.
[0032] In some embodiments of Formula (I). X comprises:

[0033] In some embodiments of Formula (I), X comprises:

[0034] In some embodiments of Formula (I), X comprises XB:
 wherein z3 and 7.4 are each independently 0, 1 , 2, 3, 4, or 5; and two
wherein z3 and 7.4 are each independently 0, 1 , 2, 3, 4, or 5; and two
 represent the point of attachment to P and the other represents the points
represent the point of attachment to P and the other represents the points
 of attachment to A.
of attachment to A.
[0035] In some embodiments of Formula (I), X comprises XB’:

[0037] In some embodiments of Formula (I), X comprises:

[0038] In some embodiments of Formula (I), X comprises:

[0039] In some embodiments of Formula (I), X comprises a substituted linear or branched C1-C6 alkylene. In some cases, X comprises a substituted linear C1-C6 alkylene. In some cases, X comprises a substituted branched C3-C6 alkylene. In some cases, X comprises a substituted branched C3- alkylene. In some cases, X comprises a substituted branched C4-alkylene. In some cases, X comprises a substituted branched C5-alkylene. In some cases, X comprises a substituted branched C6-alkylene.
[0040] In some embodiments of Formula (I). X comprises:
 wherein two
wherein two
 represent the point of attachment to P and the other
represent the point of attachment to P and the other
 represents the point of attachment to A.
represents the point of attachment to A.
[0041] In some embodiments of Formula (I), X comprises:
 wherein two represent the point of attachment to P and the other two represent the
wherein two represent the point of attachment to P and the other two represent the

 points of attachment to each A.
[0042] In some embodiments of Formula (I), X comprises a substituted trivalent nitrogen atom. In some embodiments of Formula (I), X comprises:
points of attachment to each A.
[0042] In some embodiments of Formula (I), X comprises a substituted trivalent nitrogen atom. In some embodiments of Formula (I), X comprises:
 wherein two
wherein two
 represent the point of attachment to P and the other represents the point
represent the point of attachment to P and the other represents the point
 of attachment to A.
of attachment to A.
[0043] In some embodiments of Formula (I), X comprises a phosphonatc. In some embodiments of Formula (I), X comprises:
 wherein two
wherein two
 represent the point of attachment to P and the other
represent the point of attachment to P and the other
 represents the point of attachment to A.
represents the point of attachment to A.
[0044] In some embodiments, the compound of Formula (I) is of the Formula (II):
 wherein:
wherein:
A is the at least one lipid; X1 is a branching moiety;
P is the macrocycle; each ZA, ZB and Zc is independently an optional linking moiety; and n is 1 or 2.
Branching moiety X1
[0045] As described herein, the compound of Formula (II) includes a branching moiety (X1). In some embodiments of Formula (II), X1 comprises an optionally substituted branched C1-C6 alkylene.
[0046] In some embodiments of Formula (II), X1 is of the Formula (X1-1);
 wherein: W1-W3 are each independently a C0-C20 alkylene; and each
wherein: W1-W3 are each independently a C0-C20 alkylene; and each
 represent a point of attachment to each of ZA, ZB and Zc.
represent a point of attachment to each of ZA, ZB and Zc.
[0047] In some embodiments of Formula (X’-l), W1 -W3 are each a CO alkylene, such that X1 is:
 wherein each
wherein each
 represent a point of attachment to each of ZA, ZB and Zc.
represent a point of attachment to each of ZA, ZB and Zc.
[0048] In some embodiments of Formula X1-1. two of W1-W are a CO alkylene, and the other is a Cl- C20 alkylene, such as a Cl-alkylene. C2 -alkylene. C3-alkylene, C4-alkylene. or a C5-alkylene.
[0049] In some embodiments. X1 comprises:

[0050] wherein each
 represent a point of attachment to each of ZA, ZB and Zc.In some embodiments of Formula X1-1. one of W1-W3 is a CO alkylene, and the other two are C1-C20 alkylene, such as a C1-alkylene. C2-alkylene, C3-alkylene, C4-alkylene. or a C5-alkylene.
represent a point of attachment to each of ZA, ZB and Zc.In some embodiments of Formula X1-1. one of W1-W3 is a CO alkylene, and the other two are C1-C20 alkylene, such as a C1-alkylene. C2-alkylene, C3-alkylene, C4-alkylene. or a C5-alkylene.
[0051] In some embodiments, X1 comprises:
 wherein each
wherein each
 represent a point of attachment to each of ZA, ZB and Zc.
represent a point of attachment to each of ZA, ZB and Zc.
[0052] In some embodiments of Formula X1-1, W1 -W3 are each independently C1-C20 alkylene, such as a Cl-alkylene, C2-alkylene, C3-alkylene, C4-alkylcne. or a C5-alkylene.
[0053] In some embodiments, X1 comprises:
 wherein each
wherein each
 represent a point of attachment to each of ZA, ZB and Zc.
represent a point of attachment to each of ZA, ZB and Zc.
[0054] In some embodiments of Formula (II). X1 comprises:
 wherein each represent a point of attachment to each of ZA. ZB and Z
wherein each represent a point of attachment to each of ZA. ZB and Z
 c
c
[0055] In some embodiments of Formula (II). X1 comprises:
 wherein each
wherein each
 represent a point of attachment to each of ZA, ZB and Zc.
represent a point of attachment to each of ZA, ZB and Zc.
[0056] In some embodiments of Formula (II). X1 comprises:
 wherein each represent a point of attachment to each of ZA, ZB and Zc.
wherein each represent a point of attachment to each of ZA, ZB and Zc.

[0057] In some embodiments of Formula (II). X1 comprises:
 wherein two represent the points of attachment to each of ZA. and the other tw o
wherein two represent the points of attachment to each of ZA. and the other tw o

 represent points of attachment to ZB and Zc. [0058] In some embodiments of Formula (II), X1 comprises a trivalent nitrogen. In some embodiments of Formula (II), X1 comprises:
represent points of attachment to ZB and Zc. [0058] In some embodiments of Formula (II), X1 comprises a trivalent nitrogen. In some embodiments of Formula (II), X1 comprises:
 w herein each
w herein each
 represent a point of attachment to each of ZA. ZB and Zc
represent a point of attachment to each of ZA. ZB and Zc
[0059] In some embodiments of Formula (II). X1 comprises a phosphonate. In some embodiments of Formula (II). X1 comprises:
 wherein each represent a point of attachment to each of ZA, ZB and Zc.
wherein each represent a point of attachment to each of ZA, ZB and Zc.

Optional linking moieties ZA, ZB and Zc
[0060] In some embodiments, the compound of Formula (II) comprises a linking moiety ZA that covalently attaches the lipid to the branching moiety (X1). As described herein, ZA is an optional moiety, and thus in some cases ZA is absent such that the one or more lipids (A) are covalently attached directly to the branching moiety (X1).
[0061] In some embodiments of Formula (II), linking moiety ZA is an ether, ester, carbonate, amide, carbamate, urea, amine, anhydride or a disulfide group. In some embodiments, ZA is selected from - SS-, -C(O)OC(O)-, -NH-, -NHC(O)NH-, -OC(O)NH-, -C(O)NH(CH2)z-, -NHC(O)(CH2)z-, - OC(O)O-, -OC(O)-, and -O-, where z is 0, 1, 2, 3, 4. or 5. In some embodiments, ZA is -SS-. In some embodiments, ZA is -C(O)OC(O)-. In some embodiments. ZA is -NH-. In some embodiments, ZA is - NHC(O)NH-. In some embodiments, ZA is -OC(O)NH-. In some embodiments, ZA is -NHC(O)-. In some embodiments, ZA is -OC(O)O-. In some embodiments, ZA is -OC(O)-. In some embodiments, ZA is -O-.
[0062] In some embodiments of Formula (II), linking moiety ZA is selected from -C(O)NH-, -NHC(O)- , -C(O)O-, -OC(O)-, -O-, -OC(O)O-, -OC(O)NH-, -NHC(O)O-, -OP(O)(OH)O-, a maleimide-thiol conjugation, and a triazole. In some embodiments, ZA is -O-. In some embodiments, ZA is -C(O)O-. In some embodiments, ZA is -OC(O)-. In some embodiments, ZA is -OP(O)(OH)O-.
[0063] In some embodiments, the compound of Formula (II) comprises linking moieties ZB and Zc that covalently attach the branching moiety (X1) to the polymer containing macrocycle (P). As described herein, ZB and Zc are optional moieties, and thus in some cases ZB and/or Zc are absent such that the branching moiety (X1) is covalently attached directly to polymer containing macrocycle (P).
[0064] In some embodiments of Fonnula (II), linking moiety ZB is an ether, ester, carbonate, amide, carbamate, urea, amine, anhydride or a disulfide group. In some embodiments, ZB is selected from - SS-, -C(O)OC(O)-, -NH-, -NHC(O)NH-. -OC(O)NH-, -C(O)NH(CH2)Z-, -NHC(O)(CH2)Z-, - OC(O)O-. -OC(O)-. and -O-. wherein z is 0. 1. 2, 3, 4, or 5. In some embodiments, ZB is -SS-. In some embodiments, ZB is -C(O)OC(O)-. In some embodiments, ZB is -NH-. In some embodiments. ZB is -
NHC(O)NH-. In some embodiments, ZB is -OC(O)NH-. In some embodiments, ZB is -NHC(O)-. In some embodiments, ZB is -NHC(O)CH2-. In some embodiments, ZB is -NHCO(CH2)2-. In some embodiments, ZB is -OC(O)O-. In some embodiments, ZB is -OC(O)-. In some embodiments, ZB is - O-.
[0065] In some embodiments of Formula (II), linking moiety ZB is selected from -C(O)NH-, - C(O)NHCH2-, -C(O)NH(CH2)2-, -NHC(O)-, -NHC(O)CH2-, -NHC(O)(CH2)2-, -C(O)O-OC(O)-, -O-, OCO2-, -OC(O)NH-, -NHC(O)O-, -OP(O)(OH)O-, a maleimide-thiol conjugation, and a triazole. In some embodiments, ZB is -C(O)NH-. In some embodiments, ZB is -NHC(O)-. In some embodiments, ZB is -NHC(O)CH2-. In some embodiments, ZB is -NHC(O)(CH2)2-. In some embodiments. ZB is - OC(O)-.
[0066] In some embodiments of Formula (II), linking moiety Zc is an ether, ester, carbonate, amide, carbamate, urea, amine, anhydride or a disulfide group. In some embodiments, Zc is selected from - SS-, -C(O)OC(O)-, -NH-, -NHC(O)NH-. -OC(O)NH-, -C(O)NH(CH2)z-, -NHC(O)(CH2)z-, - OC(O)O-. -OC(O)-, and -O-. wherein z is 0. 1. 2, 3, 4, or 5. In some embodiments, Zc is -SS-. In some embodiments. Zc is -C(O)OC(O)-. In some embodiments, Zc is -NH-. In some embodiments, Zc is - NHC(O)NH-. In some embodiments. Zc is -OC(O)NH-. In some embodiments, Zc is -NHC(O)-. In some embodiments, Zc is -NHC(O)CH2-. In some embodiments. Zc is -NHC(O)(CH2)2-. In some embodiments, Zc is -OC(O)O-. In some embodiments, Zc is -OC(O)-. In some embodiments. Zc is - O-.
[0067] In some embodiments, linking moiety Zc is selected from -C(O)NH-, -C(O)NHCH2-, - C(O)NH(CH2)2-. -NHC(O)-, -NHC(O)CH2-, -NHC(O)(CH2)2-, -C(O)O-, -OC(O)-, -O-, OCO2-, - OC(O)NH-, -NHC(O)O-, -OP(O)(OH)O-, a maleimide-thiol conjugation, and a triazole. In some embodiments, Z is -C(O)NH-. In some embodiments, Zc is -NHC(O)-. In some embodiments, Z' is -NHC(O)CH2-. In some embodiments, Zc is -NHC(O)(CH2)2-. In some embodiments, Zc is -OC(O)-.
[0068] In some embodiments, the compound of Formula (II) comprises all optional linking moieties ZA, ZB and Zc. In some embodiments. ZA, ZB and Z are the same linking moiety. In some embodiments, Z A-ZC are each -OC(O)-. In some embodiments, ZA-ZC are each -O-. In some embodiments, ZA-ZC are each -NHC(O)-. In some embodiments, ZA-ZC are each -NHC(O)CH2-. In some embodiments, ZA-ZC are each -NHC(O)(CH2)2-. In some embodiments, ZA-ZC are each - C(O)NH-.
[0069] In some embodiments, ZB and Zc are the same and ZA is a different linking moiety. In some embodiments of Formula (II), ZA is -C(O)O-; and ZB and Zc are each -OC(O)-. In some embodiments of Formula (II), ZA is -OP(O)(OH)O-; and ZB and Zc are each -OC(O)-. In some embodiments of Formula (II), ZA is -OC(O)-; and ZB and Zc are each -NHC(O)-. In some embodiments of Formula (II),
ZA is -0C(0)-; and ZB and Zc are each -NHC(O)CH2-. In some embodiments of Formula (II), ZA is - OC(O)-; and ZB and Zc are each -NHC(O)(CH2)2-.
[0070] In some embodiments, ZA, ZB and Z are each different linking moieties. In some embodiments of Formula (II), ZA is -OC(O)-; ZB is -NHC(O)-; and Zc is -C(O)NH-. In some embodiments of Formula (II), ZA is -OC(O)-; ZB is -NHC(O)CH2-; and Zc is -C(O)NH-. In some embodiments of Formula (II), ZA is -OC(O)-; ZB is -NHC(O)(CH2)2-; and Zc is -C(O)NH-.
Macrocycle (P)
[0071] As summarized above, the macrocycle (P in Formulae I and II) comprises one or more polymer blocks in the macrocycle’s backbone. Any convenient polymer block may be used in the macrocycle’s backbone. In some embodiments, the macrocycle comprises one or more hydrophilic polymer blocks. In some embodiments, the macrocycle comprises two or more polymer blocks, and the polymer blocks are made up of a combination of hydrophilic polymer blocks and hydrophobic polymer blocks. In some embodiments, the macrocycle comprises two or more polymer blocks, and the polymer blocks are all hydrophilic polymer blocks.
[0072] Polymer blocks can be natural or unnatural (synthetic) polymers. Polymer blocks can be copolymers comprising two or more monomers. In terms of sequence, copolymers can be random, block, or comprise a combination of random and block sequences.
[0073] The term “polymer,” as used herein, is given its ordinary meaning as used in the art, i.e., a molecular structure comprising one or more repeat units (monomers), connected by covalent bonds. The repeat units may all be identical, or in some cases, there may be more than one type of repeat unit present within the polymer. If more than one type of repeat unit is present within the polymer, then the polymer is said to be a “copolymer.” It is to be understood that in any embodiment employing a polymer, the polymer being employed may be a copolymer in some cases. The repeat units forming the copolymer may be arranged in any fashion. For example, the repeat units may be arranged in a random order, in an alternating order, or as a block copolymer, i.e., comprising one or more regions each comprising a first repeat unit (e.g.. a first block), and one or more regions each comprising a second repeat unit (e.g.. a second block), etc. Block copolymers may have two (a di-block copolymer), three (a tri-block copolymer), or more numbers of distinct blocks.
[0074] In some embodiments, the polymer block has a molecular weight from 500 Da to 20 kDa, such as 500 Da to 10 kDa, 500 Da to 7 kDa. 500 Da to 5 kDa, or 500 Da to 2 kDa. In some embodiments, the polymer block has a molecular weight from 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa. 1 kDa to 10 kDa, 5 kDa to 20 KDa, 5 kDa to 17.5 kDa, 5 kDa to 15 kDa. 5 kDa to 10 kDa, or 5 kDa to 7.5 kDa. In some embodiments, the polymer block has a molecular weight from 1.5 kDa to
3.5 kDa, such as 1.5 kDa to 3 kDa, 1.5 kDa to 2.5 kDa, or 1.5 kDa to 2 kDa. In some embodiments, the polymer block has a molecular weight of 500 Da, 1 kDa, 1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa, 3.5 kDa, 4 kDa, 4.5 kDa, 5 kDa, 5.5 kDa, 6 kDa, 6.5 kDa, 7 kDa, 7.5 kDa, 8 kDa, 8.5 kDa, 9 kDa, 9.5 kDa, 10 kDa, 10.5 kDa, 11 kDa, 11.5 kDa, 12 kDa, 12.5 kDa. 13 kDa, 13.5 kDa, 14 kDa, 14.5 kDa, 15 kDa,
15.5 kDa, 16 kDa. 16.5 kDa, 17 kDa, 17.5 kDa, 18 kDa, 18.5 kDa, 19 kDa, 19.5 kDa, or 20 kDa +/- 10%.
[0075] In some embodiments of Formulae (I) or (II), the macrocycle (P) comprises one or more polymeric blocks selected from a polyethylene glycol (PEG), a polypeptoid (e.g., polysarcosine), a polypropylene glycol, a polyvinylpyrrolidone, a polyglycerol, a polyoxazoline, a polyacrylamide. poly(N-acryloylmorpholine) (PAcM). poly (N.N -dimethyl acrylamide) (PDMA), poly(N-(2- hydroxypropyl) methacrylamide), poly(2-hydroxyethyl methacrylamide), poly(hydroxypropyl methacrylate) (PHPMA), poly(2-hydroxyethyl methacrylate) (PHEMA), (HPMA), hyaluronic acid, heparin, and polysialic acid.
[0076] In some embodiments of Formulae (I) or (II), one or more polymer blocks comprises a polymer selected from a polyethylene glycol (PEG) polymer, a polyethylene oxide (PEG) polymer, a polyglutamic acid (PGA) polymer, a poly[N-(2-hydroxypropyl) methacrylamide] (HPMA) polymer, a poly(vinylpyrrolidone) (PVP) polymer, a poly(2-methyl-2-oxazoline) (PMOX) polymer, a poly(N,N- dimethyl acrylamide) (PDMA) polymer, a poly(N -acryloyl morpholine) (PAcM) polymer, and any combination thereof.
[0077] In some embodiments of Formulae (I) or (II). one or more polymer blocks is selected from a polysaccharide polymer and a polypeptide. In some embodiments, the polysaccharide polymer block is selected from a chitosan polymer, a hyaluronic acid (HA) polymer, a heparin polymer, and a polysialic acid polymer, or a combination thereof.
[0078] In some embodiments of Formulae (I) or (II), one or more polymer blocks is a polyethylene glycol (PEG).
[0079] In some embodiments of Formulae (I) or (II), the macrocycle (P) comprises at least 10 ethylene monomer units, such as at least 12, at least 15. at least 20, at least 25, at least 30. at least 35, at least 40, at least 45, at least 50, at least 55, at least 60, at least 65. at least 70, at least 75. at least 80, at least 85. at least 90, at least 95, or at least 100 ethylene glycol monomer units. In some embodiments, P comprises at least 100 ethylene glycol monomer units, such as at least 110. at least 115, at least 120, at least 125, at least 130. at least 135. at least 140. at least 145, at least 150 ethylene glycol monomer units. In some embodiments, P comprises at least 150 ethylene glycol monomer units, such as at least 155, at least 160, at least 165, at least 170, at least 175, at least 180. at least 185. at least 190, at least 195, at least 200, at least 205, at least 210, at least 215, or at least 220 ethylene glycol monomer units, (e g.,
at least 12, at least 20, at least 30, at least 40, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220) ethylene glycol monomer units. In some embodiments, P comprises 10, 12, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 210, or 220 ethylene glycol monomer units, +/- 10%.
[0080] In some embodiments of Formulae (I) or (II), P comprises a PEG block of 500 Da to 20 kDa, such as 500 Da to 10 kDa, 500 Da to 7 kDa, 500 Da to 5 kDa, or 500 Da to 2 kDa. In some embodiments, P comprises a PEG block of 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa, 1 kDa to 10 kDa, 5 kDa to 20 KDa, 5 kDa to 17.5 kDa, 5 kDa to 15 kDa, 5 kDa to 10 kDa, or 5 kDa to 7.5 kDa. In some embodiments, P comprises a PEG block of 1.5 kDa to 3.5 kDa, such as 1.5 kDa to 3 kDa, 1.5 kDa to 2.5 kDa, or 1.5 kDa to 2 kDa. In some embodiments, P comprises a PEG block of 500 Da, 1 kDa,
1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa, 3.5 kDa. 4 kDa, 4.5 kDa, 5 kDa, 5.5 kDa, 6 kDa, 6.5 kDa, 7 kDa. 7.5 kDa, 8 kDa, 8.5 kDa, 9 kDa, 9.5 kDa. 10 kDa. 10.5 kDa, 11 kDa, 11.5 kDa, 12 kDa, 12.5 kDa, 13 kDa,
13.5 kDa. 14 kDa, 14.5 kDa, 15 kDa, 15.5 kDa, 16 kDa, 16.5 kDa, 17 kDa. 17.5 kDa. 18 kDa, 18.5 kDa, 19 kDa, 19.5 kDa, or 20 kDa +/- 10%.
[0081] In some embodiments of Formulae (I) or (II), P comprises one PEG block.
[0082] In some embodiments of Formulae (I) or (II), P comprises two or more PEG blocks.
[0083] In some embodiments of Formulae (I) or (II), P comprises the Formula Pl :
 wherein:
wherein:
PA and PB are each independently tire two or more PEG blocks;
Y is an optional linking group; and m is an integer from 1 to 6.
[0084] In some embodiments of Formula Pl, m is an integer from 1 to 3. In some embodiments, m is 1. In some embodiments, m is 2. In some embodiments, m is 3.
[0085] In some embodiments of Formula Pl, PA and PB are the same PEG blocks. In some embodiments of Formula Pl, PA and PB are different PEG blocks.
|0086| In some embodiments. Formula Pl does not comprise a linking group (Y).
[0087] In some embodiments, Formula Pl comprises a linking group (Y)' . Any suitable linking group can find use in the compound of Fonnula Pl. In some embodiments, Y comprises, a triazole, a
maleimide, -S-, -NH-, -CO-, -C(O)NH-, -NHC(O)-, -C(O)O-, -OC(O)-, -O-, OCO2-, -OC(O)NH-, - NHC(O)O-, -OP(O)(OH)O-, or any combination thereof.
[0088] In some embodiments, Formula Pl comprises a linking group (Y) that is a cleavable linker. The clcavablc linker can render the compound biodegradable. Any convenient clcavablc linker can find use in the subject macrocycles comprising Formula Pl. In some embodiments, the cleavable linker can be cleaved by exposure to a stimulus. Anon-exhaustive list of stimulus includes pH, temperature, light, redox change, over-expressed enzymes, hypoxia, sound, magnetic force, electrical energy, and any combination thereof.
[0089] In some embodiments, Formula Pl comprises a linking group (Y) is the cleavable linker comprising a group selected from disulfide, hydrazone, vinyl ether, imine, ortho ester, borate ester, amide, a peptide, an azo, and any combination thereof.
Lipid (A)
[0090] As described herein, the compounds of Formulae (I) and (II) comprise at least one lipid (A). In some embodiments of Formulae (I) or (II), n is 1 such that the compound comprises one lipid. In some embodiments, n is 2 such that the compound comprises two lipids. In some embodiments, n is 3 such that the compound comprises 3 lipids.
[0091] In some embodiments, lipid (A) comprises a linear or branched C6-C30 alkyl, C6-C30 alkeny l, or C6-C30 hctcroalky l, optionally substituted by one or more substituents selected from oxo, halo, hydroxy, cyano, alkyl, alkenyl, aldehyde, heterocyclylalkyl, hydroxyalkyl, dihydroxyalkyl, hydroxyalkylaminoalkyl, aminoalkyl, alkylaminoalkyl, dialkylaminoalkyl,
(heterocyclyl)(alkyl)aminoalkyl, heterocyclyl, heteroaryl, alkylheteroaryl, alkynyl, alkoxy, amino, dialkylamino, aminoalkylcarbonylamino, aminocarbonylalkylamino,
(aminocarbonylalky l)(alkyl)amino, alkenylcarbonylamino, hydroxycarbonyl, alkyloxycarbonyl, aminocarbonyl, aminoalkylaminocarbonyl. alkylaminoalkylaminocarbonyl, dialkylaminoalkylaminocarbonyl, heterocyclylalkylaminocarbonyl,
(alkylaminoalkyl)(alkyl)aminocarbonyl, alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkenylcarbonyl, alkynylcarbonyl, alkylsulfoxide, alkylsulfoxidealkyl, alkylsulfonyl, alkylsulfonealkyl, and phosphonate.
[0092] In some embodiments of the compound of Formulae (I) or (II), at least one lipid (A) comprises a C8-C30 linear or branched alkyl. In some embodiments, at least one lipid (A) comprises a linear C8- C30 alkyl. In some embodiments of Formulae (I) or (11), at least one lipid (A) comprises decane, undecane, dodecane, tridecane, tetradecane, pentadecane, hexadecane, heptadecane, octadecane, nonadecane, or icosane. In some embodiments of Formulae (I) or (II), at least one lipid A comprises
octadecane. In some embodiments, at least one lipid (A) comprises a branched C8-C30 alkyl. In some embodiments, the branched C8-C30 alkyl comprises two lipid tails, wherein each lipid tail comprises a C7-C14 alkyl chain. In some cases, each lipid tail comprises a C7-alkyl chain. In some cases, each lipid tail comprises a C8-alkyl chain. In some cases, each lipid tail comprises a C9-alkyl chain. In some cases, each lipid tail comprises a ClO-alkyl chain. In some cases, each lipid tail comprises a Cll-alkyl chain. In some cases, each lipid tail comprises a C12-alkyl chain. In some cases, each lipid tail comprises a C13-alkyl chain. In some cases, each lipid tail comprises a C14-alkyl chain.
[0093] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises a C8-C30 linear or branched alkenyl. In some embodiments, at least one lipid (A) comprises a linear C8-C30 alkenyl. In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises myristoleane, palmitoleane, oleane, or linoleane.
[0094] In some embodiments of Formulae (I) or (II), at least one lipid (A or A-ZA-) comprises:
-C10-C30 linear or branched alkyl;
-C10-C30 linear or branched alkenyl;
-(CH2)qC(O)O(CH2)rCH(R1)(R2);
-(CH2)qOC(O)(CH2)rCH(R1)(R2);
-(CH2)qOC(O)O(CH2)rCH(R1)(R2);
-(CH2)qOCH(R')(R2);
-(CH2)qOC(O)CH(R1)(R2);
-(CH2)qC(O)OCH(R1)(R2); or
-(CH2)qOC(O)OCH(R')(R2), wherein: q is an integer from 0 to 12, each r is independently an integer from 0 to 6;
R1 is hydrogen or R3; and
R2, and R3 are each independently Cl -Cl 2 alkyl, or C2-C12-alkenyl.
[0095] In some embodiments of Formulae (I) or (II). at least one lipid (A) comprises di-myristoyl- glycerol (DMG):

[0096] In some embodiments of Formulae (I) or (II). at least one lipid (A) comprises di-palmitoyl-
 [0097] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises di-stearoyl- glycerol (DSG):
[0097] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises di-stearoyl- glycerol (DSG):

[0098] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises a phospholipid.
[0099] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises di-myristoyl- phosphatidy 1-ethanolamine (DMPE):
 [0100] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises di-palmitoyl- phosphatidy 1-ethanolamine (DPPE) :
[0100] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises di-palmitoyl- phosphatidy 1-ethanolamine (DPPE) :

[0101] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises di-stearoyl- phosphatidy 1-ethanolamine (DSPE):

[0102] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises di-oleoyl- phosphatidy 1-ethanolamine (DOPE) :
 [0103] In some embodiments of Formulae (I) or (II), at least one lipid (A or A-ZA-) comprises:
[0103] In some embodiments of Formulae (I) or (II), at least one lipid (A or A-ZA-) comprises:
 each t is independently an integer from 0 to 6. In some embodiments, t is 1. In some embodiments, t is 2. In some embodiments, t is 3. In some embodiments, t is 4. In some embodiments, t is 5. In some embodiments, t is 6.
each t is independently an integer from 0 to 6. In some embodiments, t is 1. In some embodiments, t is 2. In some embodiments, t is 3. In some embodiments, t is 4. In some embodiments, t is 5. In some embodiments, t is 6.
[0104] In some embodiments of Formulae (I) or (II), at least one lipid (A or A-ZA-) comprises:


[0105] In some embodiments of Formula (I) or (II), at least one lipid (A) comprises:

[0106] In some embodiments of Formula (I) or (II). at least one lipid (A) comprises:

[0107] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises a sterol or cholesterol.
[0108] In some embodiments of Formula (I) or (II), at least one lipid (A) comprises cholesterol:

[0109] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises [3-sitosterol:

[0110] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises stigmasterol:

[0111] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises lanosterol:

[0112] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises 7- dehydrocholesterol:

[0113] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises zymosterol:

[0114] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises lanosterol:

[0115] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises brassicasterol:

[0116] In some embodiments of Formulae (I) or (II), at least one lipid (A) comprises campesterol:

[0117] In some embodiments of Formulae (I) or (II), the compound is of the Formula (VI):
 wherein: m is an integer from 10 to 500; each z is independently 1. 2, 3, 4, or 5; and
wherein: m is an integer from 10 to 500; each z is independently 1. 2, 3, 4, or 5; and
A is a lipid (e.g., as described herein).
[0118] In some embodiments of Formula (VI), m is 10 to 300, such as 10 to 250, 10 to 220, 10 to 200, 10 to 180, 10 to 150, 10 to 120, 10 to 100, 10 to 80, or 10 to 50. In some embodiments, m is 10 to 100, such as 10 to 90. 10 to 80, 10 to 70. 10 to 60, 10 to 50. 15 to 50, 20 to 50. 25 to 50, 30 to 50. 35 to 50, or 40 to 50.
[0119] In some embodiments of Formula (VI), each z is less than 5, such as less than 4, or less than 3. In some embodiments, each z is independently 1, 2. 3 or 4, such as 1, 2 or 3. In some embodiments each z is 5. In some embodiments, each z is 4. In some embodiments, each z is 3. In some embodiments, each z is 2. In some embodiments, each z is 1. In some embodiments, one z is 1 , and the other z is 2.
[0120] In some embodiments of Formula (VI). A comprises a C8-C30 linear or branched alkyl. In some embodiments, A comprises a linear C8-C30 alkyl. In some embodiments A comprises decane, undecane, dodecane, tridecane, tetradecane, pentadecane, hexadecane, heptadecane, octadecane, nonadecane, or icosane. In some embodiments of Formula (VI), A is octadecane.
[0121] In some embodiments of Formulae (VI), A comprises a C8-C30 linear or branched alkenyl. In some embodiments, A comprises a linear C8-C30 alkenyl. In some embodiments, A comprises myristoleane, palmitoleane, oleane, or linoleane.
[0122] In some embodiments of Formula (VI), A comprises di-myristoyl-glyccrol (DMG), di- pahnitoyl-glycerol (DPG), or di-stearoyl-glycerol (DSG). In some embodiments of Formula (VI), A is DMG.
[0123] In some embodiments of Formula (VI), A is:

[0124] In some embodiments of Formula (VI), A comprises a phospholipid. In some embodiments, A comprises di-myristoyl-phosphatidyl-ethanolamine (DMPE), di-palmitoyl-phosphatidyl-ethanolamine (DPPE), di-stearoyl-phosphatidyl-ethanolamine (DSPE), or di-oleoyl-phosphatidyl-ethanolamine (DOPE).
[0125] In some embodiments of Formula (VI), A comprises a sterol or cholesterol. In some embodiments, A comprisescholesterol, |3-sitosterol, desmosterol, stigmasterol, lanosterol, 7- dehydrocholesterol, zymosterol, brassicasterol, or campesterol.
[0126] In some embodiments of Formulae (I) or (II), the compound is of the Formula (VII):
 wherein: p is an integer from 10 to 500; and
wherein: p is an integer from 10 to 500; and
A is a lipid (e.g., as described herein).
[0127] In some embodiments of Formula (VII), p is 10 to 300, such as 10 to 250, 10 to 220, 10 to 200, 10 to 180, 10 to 150, 10 to 120, 10 to 100. 10 to 80, or 10 to 50. In some embodiments, p is 10 to 100, such as 10 to 90. 10 to 80, 10 to 70. 10 to 60, 10 to 50. 15 to 50, 20 to 50. 25 to 50, 30 to 50. 35 to 50, or 40 to 50.
[0128] In some embodiments of Formula (VII), A comprises a C8-C30 linear or branched alkyl. In some embodiments, A comprises a linear C8-C30 alkyl. In some embodiments A comprises decane, undecane, dodecane, tridecane, tetradecane, pentadecane, hexadecane, heptadecane, octadecane, nonadecane, or icosane. In some embodiments of Formula (VI), A is octadecane.
[0129] In some embodiments of Formulae (VII), A comprises a C8-C30 linear or branched alkenyl. In some embodiments, A comprises a linear C8-C30 alkenyl. In some embodiments, A comprises myristoleane, palmitoleane, oleane, or linoleane.
[0130] In some embodiments of Formula (VII), A comprises di-myristoyl-glycerol (DMG), di- pahnitoyl-glycerol (DPG), or di-stearoyl-glycerol (DSG). In some embodiments of Formula (VII), A is DMG.
[0131] In some embodiments of Formula (VII), A is:

[0132] In some embodiments of Formula (VII), A comprises a phospholipid. In some embodiments, A comprisesdi-myristoyl-phosphatidyl-ethanolamine (DMPE), di-palmitoyl-phosphatidyl- ethanolamine (DPPE), di-stearoyl-phosphatidyl-ethanolamine (DSPE), or di-oleoyl-phosphatidyl- ethanolamine (DOPE).
[0133] In some embodiments of Formula (VII), A comprises a sterol or cholesterol. In some embodiments, A compriscscholcstcrol, |3-sitostcrol, dcsmostcrol, stigmastcrol, lanosterol, 7- dehydrocholesterol, zymosterol, brassicasterol, or campesterol.
[0134] In some embodiments, the polymeric lipid comprises Compound 10, Compound 2-12, Compound 6-17, Compound 7-17, or Compound 8-17.
[0135] In some embodiments, the polymeric lipid comprises Compound 10:
 [0136] In some embodiments, the polymeric lipid comprises Compound 2-12:
[0136] In some embodiments, the polymeric lipid comprises Compound 2-12:

[0137] In some embodiments, the polymeric lipid comprises Compound 6-17:

[0138] In some embodiments, the polymeric lipid comprises Compound 7-17:

[0139] In some embodiments, the polymeric lipid comprises Compound 8-17:

B. COMPOUNDS THAT SATISFY (b) - POLYMER BLOCKS BETWEEN TWO LIPIDS IN THE MACROCYCLE’S BACKBONE
[0140] In certain embodiments, the circular polymeric lipid compound satisfies (b), and two lipids are in the macrocycle’s backbone, wherein all PEG blocks are between the two lipids.
[0141] In some embodiments, the compound satisfies (b) and is of Formula (III):
 wherein:
wherein:
P is the macrocycle;
A1 and A2 are independently a lipid as described herein; and
Z’ and Z2 are independently an optional core moiety wherein:
A1 and A2 are covalently linked to define the macrocycle P when Z1 and Z2, if present, are part of A1 and A2, respectively; or A1-Z’ is non-covalently bound with A2-Z2 to define the macrocycle P.
[0142] In some embodiments of Formula (III), A1 and A2 are covalently linked to define the macrocycle. In some embodiments, A1 and A2 are linked by one or more disulfide bonds. In some embodiments, A1 and A2 are linked by one disulfide bond. In some embodiments, A1 and A2 are linked by two or more disulfide bonds.
[0143] In some embodiments of Formula (III), A1-Z’ is non-covalently bound with A2-Z2 to define the macrocycle P. It will be understood that any non-covalent interaction can bind A1-Z2 with A2-Z2. In some embodiments, A1-Z2 is bound to A2-Z2 by hydrogen bonding. In some embodiments, A1-Z2 is bound to A2-Z2 by ionic interactions. In some embodiments, A1-Z2 is bound to A2-Z2 by Van dcr Waals interactions. In some embodiments, A1-Z2 is bound to A2-Z2 by hydrophobic interactions.
[0144] As summarized above, the macrocycle (P in Formula III) comprises one or more polymer blocks in the macrocycle’s backbone. Any convenient polymer block may be used in the macrocycle’s backbone (as described herein above).
[0145] In some embodiments, the polymer block has a molecular weight from 500 Da to 20 kDa, such as 500 Da to 10 kDa, 500 Da to 7 kDa, 500 Da to 5 kDa, or 500 Da to 2 kDa. In some embodiments,
the polymer block has a molecular weight from 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa, 1 kDa to 10 kDa, 5 kDa to 20 kDa, 5 kDa to 17.5 kDa, 5 kDa to 15 kDa, 5 kDa to 10 kDa, or 5 kDa to 7.5 kDa. In some embodiments, the polymer block has a molecular weight from 1.5 kDa to
3.5 kDa, such as 1.5 kDa to 3 kDa. 1.5 kDa to 2.5 kDa, or 1.5 kDa to 2 kDa. In some embodiments, the polymer block has a molecular weight of 500 Da, 1 kDa, 1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa, 3.5 kDa, 4 kDa, 4.5 kDa, 5 kDa, 5.5 kDa, 6 kDa, 6.5 kDa, 7 kDa. 7.5 kDa, 8 kDa, 8.5 kDa, 9 kDa, 9.5 kDa, 10 kDa, 10.5 kDa, 11 kDa, 11.5 kDa, 12 kDa. 12.5 kDa. 13 kDa, 13.5 kDa, 14 kDa, 14.5 kDa, 15 kDa,
15.5 kDa, 16 kDa. 16.5 kDa, 17 kDa, 17.5 kDa, 18 kDa, 18.5 kDa, 19 kDa, 19.5 kDa, or 20 kDa +/- 10%.
[0146] In some embodiments of Fonnula (III), the macrocycle (P) comprises one or more polymeric blocks selected from a polyethylene glycol (PEG), a polypeptoid (e g., polysarcosine), a polypropylene glycol, a polyvinylpyrrolidone, a polyglycerol, a polyoxazoline. a polyacrylamide. poly(N- acryloylmorpholine) (PAcM), poly(N,N-dimethyl acrylamide) (PDMA), poly(N-(2-hydroxypropyl) methacrylamide), poly(2-hydroxyethyl methacrylamide), poly (hydroxy propyl methacrylate) (PHPMA), poly (2 -hydroxy ethyl methacrylate) (PHEMA), (HPMA), hyaluronic acid, heparin, and polysialic acid.
[0147] In some embodiments of Formula (III), one or more polymer blocks comprises a polymer selected from a polyethylene glycol (PEG) polymer, a polyethylene oxide (PEG) polymer, a polyglutamic acid (PGA) polymer, a poly[N-(2 -hydroxy propyl) methacrylamide] (HPMA) polymer, a poly(vinylpyrrolidone) (PVP) polymer, a poly(2-methyl-2-oxazoline) (PMOX) polymer, a poly(N,N- dimethyl acrylamide) (PDMA) polymer, a poly (N -acryloyl morpholine) (PAcM) polymer, and any combination thereof.
[0148] In some embodiments of Formula (III), one or more polymer blocks is selected from a polysaccharide polymer and a polypeptide. In some embodiments, the polysaccharide polymer block is selected from a chitosan polymer, a hyaluronic acid (HA) polymer, a heparin polymer, and a polysialic acid polymer, or a combination thereof.
[0149] In some embodiments of Formula (III), one or more polymer blocks is a polyethylene glycol (PEG).
[0150] In some embodiments of Formula (III), the macrocycle (P) comprises at least 10 ethylene monomer units, such as at least 12, at least 15. at least 20, at least 25. at least 30. at least 35, at least 40. at least 45. at least 50, at least 55. at least 60, at least 65, at least 70. at least 75, at least 80. at least 85, at least 90, at least 95, or at least 100 ethylene glycol monomer units. In some embodiments, P comprises at least 100 ethylene glycol monomer units, such as at least 110, at least 115, at least 120, at least 125, at least 130, at least 135. at least 140. at least 145, at least 150 ethylene glycol monomer units.
In some embodiments, P comprises at least 150 ethylene glycol monomer units, such as at least 155, at least 160, at least 165, at least 170, at least 175. at least 180, at least 185, at least 190, at least 195, at least 200, at least 205, at least 210, at least 215, or at least 220 ethylene glycol monomer units, (e.g., at least 12, at least 20, at least 30, at least 40, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220) ethylene glycol monomer units. In some embodiments, P comprises 10, 12, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120. 130, 140, 150. 160, 170, 180, 190, 200. 210, or 220 ethylene glycol monomer units. +/- 10%.
[0151] In some embodiments of Formula (III), P comprises a PEG block of 500 Da to 20 kDa, such as 500 Da to 10k Da. 500 Da to 7 kDa, 500 Da to 5 kDa, or 500 Da to 2 kDa. In some embodiments, P comprises a PEG block of 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa, 1 kDa to 10 kDa, 5 kDa to 20 kDa, 5 kDa to 17.5 kDa, 5 kDa to 15 kDa, 5 kDa to 10 kDa. or 5 kDa to 7.5 kDa. In some embodiments, P comprises a PEG block of 1.5 kDa to 3.5 kDa, such as 1.5 kDa to 3 kDa, 1.5 kDa to 2.5 kDa, or 1.5 kDa to 2 kDa. In some embodiments, P comprises a PEG block of 500 Da, 1 kDa,
1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa, 3.5 kDa. 4 kDa, 4.5 kDa, 5 kDa, 5.5 kDa, 6 kDa, 6.5 kDa, 7 kDa. 7.5 kDa, 8 kDa. 8.5 kDa, 9 kDa, 9.5 kDa. 10 kDa. 10.5 kDa. 11 kDa. 11.5 kDa. 12 kDa. 12.5 kDa, 13 kDa,
13.5 kDa. 14 kDa, 14.5 kDa, 15 kDa, 15.5 kDa, 16 kDa. 16.5 kDa. 17 kDa. 17.5 kDa. 18 kDa, 18.5 kDa, 19 kDa, 19.5 kDa, or 20 kDa +/- 10%.
[0152] In some embodiments of Formula (Ill), P comprises one PEG block.
[0153] In some embodiments of Formula (III), P comprises two or more PEG blocks.
[0154] In some embodiments of Formula (III), P comprises the Formula Pl :
 wherein:
wherein:
PA and PB are each independently tire tw o or more PEG blocks;
Y is an optional linking group; and m is an integer from 1 to 6.
[0155] In some embodiments of Formula Pl, m is an integer from 1 to 3. In some embodiments, m is 1. In some embodiments, in is 2. In some embodiments, m is 3.
[0156] In some embodiments of Formula Pl, PA and PB are the same PEG blocks. In some embodiments of Formula Pl , PA and PB are different PEG blocks.
[0157] In some embodiments. Formula Pl does not comprise a linking group (Y).
[0158] In some embodiments, Formula Pl comprises a linking group (Y). Any suitable linking group can find use in the compound of Formula Pl. In some embodiments, Y comprises, a triazole, a maleimide, -S-, -NH-, -C(O)-, -C(O)NH-, -NHC(O)-, -C(O)O-, -OC(O)-, -O-, OCO2-, -OC(O)NH-, - NHC(O)O-, -OP(O)(OH)O-, or any combination thereof.
[0159] In some embodiments, Formula Pl comprises a linking group (Y) that is a cleavable linker. The cleavable linker can render the compound biodegradable. Any convenient cleavable linker can find use in the subject macrocycles comprising Formula Pl. In some embodiments, the cleavable linker can be cleaved by exposure to a stimulus. Anon-exhaustive list of stimulus includes pH, temperature, light, redox change, over-expressed enzymes, hypoxia, sound, magnetic force, electrical energy, and any combination thereof.
[0160] In some embodiments, Formula Pl comprises a linking group (Y) is the cleavable linker comprising a group selected from disulfide, hydrazone, vinyl ether, imine, ortho ester, borate ester, amide, a peptide, an azo, and any combination thereof.
Lipids (A1 and A2)
[0161] As described herein, the compounds of Formula (III) comprise tw o lipids, A1 and A2. In some embodiments A1 and A2 are the same lipid. In some embodiments, A1 and A2 are different.
[0162] In some embodiments, lipids A1 and A2 each independently comprise a linear or branched C6- C30 alky l, C6-C30 alkenyl, or C6-C30 heteroalkyl, optionally substituted by one or more substituents selected from oxo, halo, hydroxy , cyano, alkyl, alkenyl, aldehyde, heterocyclylalkyl, hydroxyalkyl, dihydroxyalkyl, hydroxyalkylaminoalkyl, aminoalkyl, alkydaminoalkyl, dialkylaminoalkyl, (heterocyclyl)(alkyl)aminoalkyl, heterocyclyl, heteroaryl, alkylheteroaryl, alkynyl, alkoxy, amino, dialkylamino, aminoalkylcarbonylamino, aminocarbonylalkylamino,
(aminocarbonylalky l)(alkyl)amino, alkenylcarbonylamino, hydroxycarbonyl, alky loxycarbonyl, aminocarbonyl, aminoalkylaminocarbonyl. alkylaminoalkylaminocarbonyl, dialkylaminoalkylaminocarbonyl, heterocyclylalkylaminocarbonyl,
(alkylaminoalkyl)(alkyl)aminocarbonyl, alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkenylcarbonyl, alkynylcarbonyl, alkylsulfoxide, alkylsulfoxidealkyl, alky Isulfonyl, alkylsulfonealkyl, and phosphonate.
[0163] In some embodiments of the compound of Formula (III), at least one of A1 or A2 comprises a C8-C30 linear or branched alkyl, such as a C12-C30 linear or branched alkyl. In some embodiments, at least one of A1 or A2 comprises a linear C8-C30 alkyl. In some embodiments of Formula (111), at least one of A1 or A2 comprises decane, undecane, dodecane, tridecane, tetradecane, pentadecane, hexadecane, heptadecane, octadecane, nonadecane, or icosane. In some embodiments, at least one lipid
of A1 or A2 comprises a branched C8-C30 alkyd, such as a branched C12-C30 alkyl. In some embodiments, the branched C8-C30 alkyl comprises two lipid tails, wherein each lipid tail comprises a C7-C12 alkyl chain. In some cases, each lipid tail comprises a C7-alkyl chain. In some cases, each lipid tail comprises a C8-alkyl chain. In some cases, each lipid tail comprises a C9-alkyl chain. In some cases, each lipid tail comprises a ClO-alkyl chain. In some cases, each lipid tail comprises a Cll-alkyl chain. In some cases, each lipid tail comprises a C12-alkyl chain.
[0164] In some embodiments of Formula (III), at least one of A1 or A2 comprises a C8-C30 linear or branched alkenyl. In some embodiments, at least one of A1 or A2 comprises a linear C8-C30 alkenyl. In some embodiments of Fonnula (III), at least one of A1 or A2 comprises myristoleane, palmitoleane, oleane, or linoleane.
[0165] In some embodiments of Fonnula (III), at least one of A1 or A2 comprises:
-C10-C30 linear or branched alkyl;
-C10-C30 linear or branched alkenyl;
-(CH2)qC(O)O(CH2)rCH(R1)(R2);
-(CH2)qOC(O)(CH2)rCH(R1)(R2);
-(CH2)qOC(O)O(CH2)rCH(R1)(R2);
-(CH2)qOCH(R1)(R2);
-(CH2)qOC(O)CH(R1)(R2);
-(CH2)qC(O)OCH(R1)(R2); or
-(CH2)qOC(O)OCH(R1)(R2), wherein: q is an integer from 0 to 12, each r is independently an integer from 0 to 6;
R1 is hydrogen or R3; and
R2, and R3 are each independently C1-C12 alkyl, or C2-C12-alkenyl.
[0166] In some embodiments of Formula (III), at least one of A1 or A2 comprises di-myristoyl-glycerol (DMG):

[0167] In some embodiments of Formula (III), at least one of A1 or A2 comprises di-palmitoyl-glycerol (DPG):
 [0168] In some embodiments of Formula (III), at least one of A1 or A2 comprises di-stearoyl-glycerol
[0168] In some embodiments of Formula (III), at least one of A1 or A2 comprises di-stearoyl-glycerol
(DSG):

[0169] In some embodiments of Formula (III), at least one of A1 or A2 comprises a phospholipid.
[0170] In some embodiments of Formula (III), at least one of A1 or A2 comprises di-myristoyl- phosphatidy 1-ethanolamine (DMPE):
 [0171] In some embodiments of Formula (III), at least one of A1 or A2 comprises di-palmitoyl- phosphatidy 1-etlianolamine (DPPE) :
[0171] In some embodiments of Formula (III), at least one of A1 or A2 comprises di-palmitoyl- phosphatidy 1-etlianolamine (DPPE) :

[0172] In some embodiments of Formula (III), at least one of A1 or A2 comprises di-stearoyl- phosphatidy 1-ethanolamine (DSPE):

[0173] In some embodiments of Formula (III), at least one of A1 or A2 comprises di-oleoyl- phosphatidy 1-ethanolamine (DOPE) :
 [0174] In some embodiments of Formula (III), at least one of A1 or A2 comprises:
[0174] In some embodiments of Formula (III), at least one of A1 or A2 comprises:
 wherein: each t is independently an integer from 0 to 6. In some embodiments, t is 1. In some embodiments, t is 2. In some embodiments, t is 3. In some embodiments, t is 4. In some embodiments, t is 5. In some embodiments, t is 6. [0175] In some embodiments of Formula (III), at least one of A1 or A2 comprises:
wherein: each t is independently an integer from 0 to 6. In some embodiments, t is 1. In some embodiments, t is 2. In some embodiments, t is 3. In some embodiments, t is 4. In some embodiments, t is 5. In some embodiments, t is 6. [0175] In some embodiments of Formula (III), at least one of A1 or A2 comprises:


[0176] In some embodiments of Formula (III), at least one of A1 or A2 comprises a sterol or cholesterol.
[0177] In some embodiments of Formula (III), at least one of A1 or A2 comprises cholesterol:

[0178] In some embodiments of Formula (III), at least one of A1 or A2 comprises (3-sitosterol:

[0179] In some embodiments of Formula (III), at least one of A1 or A2 comprises stigmasterol:

[0180] In some embodiments of Formula (III), at least one of A1 or A2 comprises lanosterol:

[0181] In some embodiments of Formula (III), at least one of A1 or A2 comprises 7-dehydrocholesterol:

[0182] In some embodiments of Formula (III), at least one of A1 or A2 comprises zymosterol:

[0183] In some embodiments of Formula (III), at least one of A1 or A2 comprises lanosterol:

[0184] In some embodiments of Formula (III), at least one of A1 or A2 comprises brassicasterol:

[0185] In some embodiments of Formula (III), at least one of A1 or A2 comprises campesterol:

|0186] In some embodiments, provided herein is a compound of Formula (IV):
 wherein:
wherein:
A1 and A2 are independently a lipid as described herein; and
LP is a linking moiety comprising one or more polyethylene glycol (PEG) blocks.
[0187] In some embodiments of Formula (IV), A1 and A2 are independently selected from a lipid as described herein above.
[0188] In some embodiments of Formula (IV), A1 and A2 each form a link to a core-shell structure of a lipid nanoparticle to form a macrocycle (e.g., a macrocyclic compound of Formula (III)).
[0189] In some embodiments of Formula (IV), the linking moiety LP comprises at least 10 ethylene monomer units, such as at least 12, at least 15, at least 20, at least 25, at least 30, at least 35, at least 40, at least 45, at least 50, at least 55. at least 60, at least 65, at least 70, at least 75, at least 80, at least 85, at least 90, at least 95, or at least 100 ethylene glycol monomer units. In some embodiments, LP comprises at least 100 ethylene glycol monomer units, such as at least 110, at least 115, at least 120, at least 125, at least 130, at least 135, at least 140, at least 145, at least 150 ethylene glycol monomer units. In some embodiments, LP comprises at least 150 ethylene glycol monomer units, such as at least 155, at least 160, at least 165, at least 170, at least 175, at least 180, at least 185, at least 190, at least 195, at least 200, at least 205, at least 210, at least 215, or at least 220 ethylene glycol monomer units, (e.g., at least 12, at least 20, at least 30, at least 40, at least 50. at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220) ethylene glycol monomer units. In some embodiments, LP comprises 10, 12, 20, 30. 40, 50, 60, 70, 80. 90, 100, 110, 120. 130, 140, 150, 160, 170, 180, 190. 200, 210, or 220 ethylene glycol monomer units, +/- 10%.
[0190] In some embodiments of Fonnula (IV), LP comprises a PEG block of 500 Da to 20 kDa, such as 500 Da to 10 kDa, 500 Da to 7 kDa, 500 Da to 5 kDa, or 500 Da to 2 kDa. In some embodiments, LP comprises a PEG block of 1 kDa to 20 kDa, such as 1 kDa to 17.5 kDa, 1 kDa to 15 kDa, 1 kDa to 10 kDa. 5 kDa to 20 kDa, 5 kDa to 17.5 kDa, 5 kDa to 15 kDa, 5 kDa to 10 kDa, or 5 kDa to 7.5 kDa. In some embodiments. LP comprises a PEG block of 1.5 kDa to 3.5 kDa, such as 1.5 kDa to 3 kDa. 1.5 kDa to 2.5 kDa, or 1.5 kDa to 2 kDa. In some embodiments, LP comprises a PEG block of 500 Da. 1 kDa, 1.5 kDa, 2 kDa, 2.5 kDa, 3 kDa. 3.5 kDa, 4 kDa, 4.5 kDa. 5 kDa, 5.5 kDa, 6 kDa. 6.5 kDa, 7 kDa,
7.5 kDa, 8 kDa. 8.5 kDa, 9 kDa, 9.5 kDa. 10 kDa, 10.5 kDa. 11 kDa, 11.5 kDa, 12 kDa, 12.5 kDa, 13 kDa, 13.5 kDa, 14 kDa, 14.5 kDa, 15 kDa, 15.5 kDa, 16 kDa, 16.5 kDa, 17 kDa, 17.5 kDa, 18 kDa,
18.5 kDa, 19 kDa, 19.5 kDa, or 20 kDa +/- 10%.
[0191] In some embodiments of Fonnula (IV). LP comprises one PEG block.
[0192] In some embodiments of Formula (IV), LP comprises two or more PEG blocks.
[0193] In some embodiments, the compound of Formula (IV) is of the Fonnula (V):
 wherein:
wherein:
PA and PB are each independently two or more PEG blocks;
Y is an optional linking group; and m is an integer from 1 to 6, preferably an integer from 1 to 3.
[0194] In some embodiments of Formula (V), m is an integer from 1 to 3. In some embodiments, m is 1 . In some embodiments, m is 2. In some embodiments, m is 3.
[0195] In some embodiments of Formula (V), PA and PB are the same PEG blocks. In some embodiments of Formula (V). PA and PB are different PEG blocks.
[0196] In some embodiments. Formula (V) does not comprise a linking group (Y).
[0197] In some embodiments, Formula (V) comprises a linking group (Y). Any suitable linking group can find use in the compound of Formula Pl. In some embodiments, Y comprises, a triazole, a maleimide, -S-, -NH-. -C(O)-. -C(O)NH-, -NHC(O)-, -C(O)O-. -OCO-. -O-, OCO2-, -OC(O)NH-. - NHC(O)O-, -OP(O)(OH)O-, or any combination thereof.
[0198] In some embodiments. Formula (V) comprises a linking group (Y) that is a cleavable linker. The cleavable linker can render the compound biodegradable. Any convenient cleavable linker can find use in the subject macrocycles comprising Formula (V). In some embodiments, the cleavable linker can be cleaved by exposure to a stimulus. A non-exhaustive list of stimulus includes pH. temperature, light, redox change, over-expressed enzymes, hypoxia, sound, magnetic force, electrical energy, and any combination thereof.
In some embodiments. Formula (V) comprises a linking group (Y) is the cleavable linker comprising a group selected from disulfide, hydrazone, vinyl ether, imine, ortho ester, borate ester, amide, a peptide, an azo, and any combination thereof.
2. LIPOSOMAL FORMULATIONS
[0199] In some embodiments, the present disclosure provides formulations comprising a subject circular polymeric lipid. In some embodiments, the formulation is a circular PEG-lipid in a liposomal formulation. In these embodiments, the molar ratio of the circular PEG-lipid is from about 0.1% to 100% of the total lipid. In some embodiments, the molar ratio of the circular PEG-lipid is about 5%, 10%, 15%, 20%. 25%, 30%, 35%, 40%. 45%, 50%, 55%. 60%, 65%, 70%, 75%. 80%, 85%, 90%. 95%, or 100% of the total lipid. In some embodiments, the circular PEG-lipid is of Formula (I) (as described herein). In some embodiments, the circular PEG-lipid is of Formula (II) (as described herein). In some
embodiments, the circular PEG-lipid is of Formula (III) (as described herein). All values are inclusive of all endpoints.
[0200] In some embodiments, the liposomal formulation comprises a helper lipid, a structural lipid, and a circular PEG-lipid. In some embodiments, the molar ratio of helper lipid: structural lipid:circular PEG-lipid in the liposomal formulation is about 56:38:5. In some embodiments, the molar ratio of helper lipid structural lipid:circular PEG-lipid in the liposomal formulation is about 50:45:5. In some embodiments, the molar ratio of helper lipid: structural lipid:circular PEG-lipid in the liposomal formulation is about 45:45:10. In some embodiments, the molar ratio of helper lipid: structural lipid circular PEG-lipid in the liposomal fonnulation is about 60:38:2. In some embodiments, the molar ratio of helper lipid structural lipid circular PEG-lipid in the liposomal formulation is about 60:35:5. In some embodiments, the molar ratio of each of the helper lipid, structural lipid, and circular PEG-lipid is within 10%, 9%, 8%, 7%, 6%. 5%, 4%, 3%, 2%, 1%. 0.9%, 0.8%, 0.7%, 0.6%, 0.5%, 0.4%, 0.3%, 0.2%. 0.1%. 0.09%, 0.08%, 0.07%. 0.06%, 0.05%, 0.04%, 0.03%, 0.02%. or 0.01% of the stated value.
[0201] In some embodiments of the liposomal formulation, the helper lipid is a phospholipid (e.g., as described herein). In some embodiments, the phospholipid is hydrogenated soy phosphatidylcholine (HSPC). In some embodiments of the liposomal formulation, the structure lipid is cholesterol. In some embodiments, the liposomal formulation comprises a molar ratio of HSPC:cholesterol:circular PEG- lipid of about 56:38:5. In some embodiments, the molar ratio of each of HSPC. cholesterol, and the circular PEG-lipid is within 10%, 9%, 8%. 7%. 6%, 5%, 4%, 3%. 2%. 1%, 0.9%, 0.8%, 0.7%, 0.6%. 0.5%. 0.4%. 0.3%. 0.2%. 0.1%. 0.09%. 0.08%, 0.07%. 0.06%, 0.05%, 0.04%. 0.03%, 0.02%, or 0.01% of the stated value.
3. LIPID NANOPARTICLE FORMULATIONS
[0202] In some embodiments, the present disclosure provides lipid nanoparticles (LNPs) comprising a subject circular polymeric lipid. The subject LNP formulation can also include one or more ionizable lipids, helper lipids, structural lipids, and polynucleotides (as described herein below).
[0203] The formation of a lipid nanoparticle (LNP) described herein may be accomplished by any methods known in the art. For example, as described in U.S. Pat. Pub. No. US2012/0178702 Al, which is incorporated herein by reference in its entirety. Non-limiting examples of lipid nanoparticle compositions and methods of making them are described, for example, in Semple et al. (2010) Nat. Biotechnol. 28:172-176; Jayarama et al. (2012). Angew. Chem. Int. Ed., 51:8529-8533; and Maier et al. (2013) Molecular Therapy 21, 1570-1578 (the contents of each of which are incorporated herein by reference in their entirety).
[0204] In one embodiment, the LNP formulation may be prepared by, e.g., the methods described in International Pat. Pub. No. WO 2011/127255 or WO 2008/103276, the contents of each of which are herein incorporated by reference in their entirety'.
[0205] In one embodiment. LNP formulations described herein may comprise a polycationic composition. As a non-limiting example, the polycationic composition may be a composition selected from Formulae 1-60 of U.S. Pat. Pub. No. US2005/0222064 Al, the content of which is herein incorporated by reference in its entirety.
[0206] In one embodiment, the lipid nanoparticle may be fonnulated by the methods described in U.S. Pat. Pub. No. US2013/0156845 Al, and International Pat. Pub. No. WO2013/093648 A2 or WO2012/024526 A2, each of which is herein incorporated by reference in its entirety.
[0207] In one embodiment, the lipid nanoparticles described herein may be made in a sterile environment by the system and/or methods described in U.S. Pat. Pub. No. US2013/0164400 Al, which is incorporated herein by reference in its entirety.
[0208] In one embodiment, the LNP formulation may be formulated in a nanoparticle such as a nucleic acid-lipid particle described in U.S. Pat. No. 8,492.359. which is incorporated herein by reference in its entirety'.
[0209] A nanoparticle composition may optionally comprise one or more coatings. For example, a nanoparticle composition may be formulated in a capsule, film, or tablet having a coating. A capsule, film, or tablet including a composition described herein may' have any useful size, tensile strength, hardness, or density.
[0210] In some embodiments, the lipid nanoparticles described herein may be synthesized using methods comprising microfluidic mixers. Exemplary microfluidic mixers may include, but are not limited to, a slit interdigitial micromixer including, but not limited to, those manufactured by Precision Nanosystems (Vancouver, BC. Canada), Microinnova (Allerheiligen bei Wildon, Austria) and/or a staggered herringbone micromixer (SHM) (Zhigaltsev, I.V. et al. (2012) Langmuir. 28:3633-40; Belliveau, N.M. et al. Mol. Ther. Nucleic. Acids. (2012) l:e37; Chen, D. et al. J. Am. Chem. Soc. (2012) 134(22):6948-51; each of which is herein incorporated by reference in its entirety ).
[0211] In some embodiments, methods of LNP generation comprising SHM, further comprise the mixing of at least two input streams wherein mixing occurs by microstructurc-induccd chaotic advection (MICA). According to this method, fluid streams flow through channels present in a herringbone pattern causing rotational flow and folding the fluids around each other. This method may also comprise a surface for fluid mixing wherein tire surface changes orientations during fluid cycling.
Methods of generating LNPs using SHM include those disclosed in U.S. Pat. Pub. Nos. US2004/0262223 Al and US2012/0276209 Al, each of which is incorporated herein by reference in their entirety .
[0212] In one embodiment, the lipid nanoparticles may be formulated using a micromixer such as, but not limited to, a Slit Interdigital Microstructured Mixer (SIMM-V2) or a Standard Slit Interdigital Micro Mixer (SSIMM) or Caterpillar (CPMM) or Impinging-jet (IJMM)from the Institut fur Mikrotechnik Mainz GmbH, Mainz Germany). In one embodiment, the lipid nanoparticles are created using microfluidic technology' (see, Whitesides (2006) Nature. 442: 368-373; and Abraham et al. (2002) Science. 295: 647-651; each of which is herein incorporated by reference in its entirety). As a nonlimiting example, controlled microfluidic formulation includes a passive method for mixing streams of steady pressure-driven flows in micro channels at a low Reynolds number (see, e.g., Abraham et al. (2002) Science. 295: 647651; which is herein incorporated by reference in its entirety).
[0213] In one embodiment, the polynucleotide (e.g.. circRNA) of the present disclosure may be formulated in lipid nanoparticles created using a micromixer chip such as. but not limited to, those from Harvard Apparatus (Holliston, MA), Dolomite Microfluidics (Royston, UK), or Precision Nanosystems (Van Couver, BC, Canada). A micromixer chip can be used for rapid mixing of two or more fluid streams with a split and recombine mechanism.
[0214] In some embodiments, the LNP of the present disclosure comprises a molar ratio of betw een about 40% and about 60 % ionizable lipid, a molar ratio of between about 3.5% and about 14% helper lipid, a molar ratio of between about 28% and about 50% structural lipid, and a molar ratio of betw een about 0.5% and about 5% circular PEG-lipid, inclusive of all endpoints. In some embodiments, the total molar percentage of the ionizable lipid, the helper lipid, the structural lipid, and the circular PEG-lipid is 100% in the LNP.
[0215] In some embodiments, the molar ratio of the ionizable lipid in the LNP is from about 40 to about 60% of the total lipid present in the LNP. In some embodiments, the molar ratio of the ionizable lipid in the LNP is about 40%, about 41%, about 42%, about 43%, about 44%, about 45%, about 46%, about 47%, about 48%, about 49%, about 50%, about 51%, about 52%, about 53%, about 54%, about 55%, about 56%, about 57%, about 58%, about 59%, or about 60% of the total lipid present in the LNP. All values are inclusive of all endpoints.
[0216] In some embodiments, the molar ratio of the helper lipid in the LNP is from about 3.5% to about 14% of the total lipid present in the LNP. In some embodiments, the molar ratio of the helper lipid in the LNP is about 3, about 4%, about 5%, about 6%, about 7%, about 8%, about 9%. about 10%, about 11%, about 12%, about 13%, or about 14% of the total lipid present in the LNP. In some
embodiments, the helper lipid is DSPC. In some embodiments, the helper lipid is DOPE. All values are inclusive of all endpoints.
[0217] In some embodiments, the molar ratio of the structural lipid in the LNP is from about 28% to about 50% of the total lipid present in the LNP. In some embodiments, the molar ratio of tire structural lipid in the LNP is about 28%, about 29%, about 30%, about 31%, about 32%, about 33%. about 34%, about 35%, about 36%, about 37%. about 38%, about 39%, about 40%, about 41%. about 42%, about 43%, about 44%, about 45%, about 46%, about 47%, about 48%. about 49%, or about 50% of the total lipid present in the LNP. In some embodiments, the structural lipid is cholesterol. All values are inclusive of all endpoints.
[0218] In some embodiments, the molar ratio of the circular PEG-lipid in the LNP is from about 0.1% to about 5% of the total lipid present in the LNP. In some embodiments, the molar ratio of the circular PEG-lipid in the LNP is about 0.1%, about 0.2%, about 0.3%, about 0.4%, about 0.5%, about 0.6%. about 0.7%. about 0.8%, about 0.9%, about 1.0%, about 1.1%, about 1.2%, about 1.3%, about
1.4%. about 1.5%. about 1.6%, about 1.7%, about 1.8%, about 1.9%, about 2.0%, about 2.1%, about
2.2%, about 2.3%. about 2.4%, about 2.5%, about 2.6%, about 2.7%, about 2.8%, about 2.9%, about
3.0%, about 3.1%, about 3.2%, about 3.3%. 3.4%, about 3.5%, about 4.0%, about 4.5%, or about 5% of the total lipid present in the LNP. In some embodiments, the circular PEG-lipid is of Formula (I) (as described herein). In some embodiments, the circular PEG-lipid is of Formula (II) (as described herein). In some embodiments, the circular PEG-lipid is of Formula (III) (as described herein). All values are inclusive of all endpoints.
[0219] In some embodiments, the molar ratio of ionizable lipid:helper lipid: structural lipid circular PEG-lipid in tire LNP is about 45:9:44:2. In some embodiments, the molar ratio of ionizable lipid:helper lipid structural lipid:circular PEG-lipid in the LNP is about 50:10:38.5:1.5. In some embodiments, the molar ratio of ionizable lipid:helper lipid structural lipid circular PEG-lipid in the LNP is about 41 : 12:45:2. In some embodiments, the molar ratio of ionizable lipid:helper lipid structural lipid circular PEG-lipid in tire LNP is about 62:4:33: 1. In some embodiments, the molar ratio of ionizable lipid:helper lipid structural lipid:circular PEG-lipid in the LNP is about 53:5:41: 1. In some embodiments, the molar ratio of each of the ionizable lipid, helper lipid, structural lipid, and circular PEG-lipid is within 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 1%, 0.9%, 0.8%, 0.7%, 0.6%, 0.5%, 0.4%, 0.3%, 0.2%, 0.1%, 0.09%, 0.08%, 0.07%, 0.06%, 0.05%, 0.04%, 0.03%, 0.02%. or 0.01% of the stated value.
[0220] In one embodiment, the lipid nanoparticles may have a diameter from about 10 to about 100 mn such as, but not limited to, about 10 to about 20 nm, about 10 to about 30 nm, about 10 to about 40 mn, about 10 to about 50 mn, about 10 to about 60 nm, about 10 to about 70 nm, about 10 to about 80 mn. about 10 to about 90 mn, about 20 to about 30 nm, about 20 to about 40 mn, about 20 to about 50
nm, about 20 to about 60 mn, about 20 to about 70 nm, about 20 to about 80 mu, about 20 to about 90 nm, about 20 to about 100 nm, about 30 to about 40 mn, about 30 to about 50 nm, about 30 to about 60 nm, about 30 to about 70 nm, about 30 to about 80 nm. about 30 to about 90 nm, about 30 to about 100 mn, about 40 to about 50 mn, about 40 to about 60 mn, about 40 to about 70 mn, about 40 to about 80 mn, about 40 to about 90 mn. about 40 to about 100 mn, about 50 to about 60 mn, about 50 to about 70 mn about 50 to about 80 nm, about 50 to about 90 nm, about 50 to about 100 nm, about 60 to about 70 mn. about 60 to about 80 mn. about 60 to about 90 nm. about 60 to about 100 nm, about 70 to about 80 mn. about 70 to about 90 nm, about 70 to about 100 nm, about 80 to about 90 nm. about 80 to about 100 nm and/or about 90 to about 100 nm. In one embodiment, the lipid nanoparticles may have a diameter from about 10 to 500 nm. In one embodiment, the lipid nanoparticle may have a diameter greater than 100 mn. greater than 150 nm, greater than 200 nm, greater than 250 nm, greater than 300 mn. greater than 350 nm, greater than 400 nm, greater than 450 nm, greater than 500 nm. greater than 550 nm, greater than 600 nm, greater than 650 nm, greater than 700 nm. greater than 750 nm, greater than 800 nm, greater than 850 nm. greater than 900 nm, greater than 950 nm or greater than 1000 nm. Each possibility represents a separate embodiment of the present disclosure.
[0221] In some embodiments, a nanoparticle (e.g.. a lipid nanoparticle) has a mean diameter of 10- 500 nm. 20-400 nm, 30-300 nm, or 40-200 nm. In some embodiments, a nanoparticle (e.g.. a lipid nanoparticle) has a mean diameter of 50-150 nm, 50-200 nm. 80-100 nm, or 80-200 nm.
[0222] In some embodiments, the lipid nanoparticles described herein can have a diameter from below 0 .1 pm to up to 1 mm such as. but not limited to, less than 0 .1 pm, less than 1.0 pm. less than 5 pm, less than 10 pm, less than 15 pm, less than 20 pm, less than 25 pm, less than 30 pm, less than 35 pm, less than 40 pm. less than 50 pm, less than 55 pm, less than 60 pm, less than 65 pm, less than 70 pm, less than 75 pm, less than 80 pm. less than 85 pm. less than 90 pm, less than 95 pm, less than 100 pm, less than 125 pm, less than 150 pm, less than 175 pm, less than 200 pm, less than 225 pm, less than 250 pm, less than 275 pm, less than 300 pm, less than 325 pm, less than 350 pm, less than 375 pm, less than 400 pm, less than 425 pm, less than 450 pm, less than 475 pm, less than 500 pm, less than 525 pm, less than 550 pm, less than 575 pm, less than 600 pm, less than 625 pm, less than 650 pm, less than 675 pm, less than 700 pm, less than 725 pm, less than 750 pm, less than 775 pm, less than 800 pm, less than 825 pm, less than 850 pm, less than 875 pm, less than 900 pm. less than 925 pm. less than 950 pm, less than 975 pm.
[0223] In another embodiment, LNPs may have a diameter from about 1 nm to about 100 nm, from about 1 nm to about 10 nm, about 1 nm to about 20 nm, from about 1 mn to about 30 mn, from about 1 mn to about 40 mn, from about 1 nm to about 50 nm, from about 1 nm to about 60 mn, from about 1 mn to about 70 mn, from about 1 nm to about 80 nm, from about 1 nm to about 90 nm, from about 5
nm to about from 100 mu, from about 5 nm to about 10 nm, about 5 nm to about 20 nm, from about 5 nm to about 30 mn, from about 5 nm to about 40 mn, from about 5 nm to about 50 nm, from about 5 nm to about 60 mn, from about 5 nm to about 70 nm, from about 5 nm to about 80 nm, from about 5 mn to about 90 nm, about 10 to about 50 nm, from about 20 to about 50 nm, from about 30 to about 50 mn, from about 40 to about 50 nm, from about 20 to about 60 nm, from about 30 to about 60 nm, from about 40 to about 60 nm. from about 20 to about 70 nm, from about 30 to about 70 nm, from about 40 to about 70 nm, from about 50 to about 70 mn, from about 60 to about 70 nm, from about 20 to about 80 nm, from about 30 to about 80 mn, from about 40 to about 80 mn, from about 50 to about 80 nm, from about 60 to about 80 nm, from about 20 to about 90 nm, from about 30 to about 90 nm, from about 40 to about 90 nm, from about 50 to about 90 mn. from about 60 to about 90 nm and/or from about 70 to about 90 nm. Each possibility represents a separate embodiment of the present disclosure.
[0224] A nanoparticle composition may be relatively homogenous. A polydispersity index may be used to indicate the homogeneity of a nanoparticle composition, e.g., the particle size distribution of the nanoparticle compositions. A small (e.g.. less than 0.3) polydispersity index generally indicates a narrow particle size distribution. A nanoparticle composition may have a polydispersity index from about O to about 0.25. such as 0.01, 0.02. 0.03, 0.04, 0.05. 0.06, 0.07, 0.08. 0.09, 0.10. 0.1 1. 0.12, 0.13, 0.14, 0.15. 0.16. 0.17, 0.18, 0.19, 0.20. 0.21. 0.22, 0.23, 0.24, or 0.25. In some embodiments, the polydispersity index of a nanoparticle composition may be from about 0.10 to about 0.20. Each possibility represents a separate embodiment of the present disclosure.
[0225] The zeta potential of a nanoparticle composition may be used to indicate the electrokinetic potential of the composition. For example, the zeta potential may describe the surface charge of a nanoparticle composition. Nanoparticle compositions with relatively low charges, positive or negative, are generally desirable, as more highly charged species may interact undesirably with cells, tissues, and other elements in the body. In some embodiments, the zeta potential of a nanoparticle composition may be from about -20 mV to about +20 mV, from about -20 mV to about +15 mV, from about -20 mV to about +10 mV, from about -20 mV to about +5 mV, from about -20 mV to about 0 mV, from about -20 mV to about -5 mV, from about -20 mV to about -10 mV, from about -20 mV to about -15 mV from about -20 mV to about +20 mV, from about -20 mV to about +15 mV, from about -20 mV to about +10 mV, from about -20 mV to about +5 mV, from about -20 mV to about 0 mV, from about 0 mV to about +20 mV, from about 0 mV to about +15 mV, from about 0 mV to about +10 mV, from about 0 mV to about +5 mV, from about +5 mV to about +20 mV, from about +5 mV to about +15 mV, or from about +5 mV to about +10 mV. Each possibility represents a separate embodiment of the present disclosure.
[0226] The efficiency of encapsulation of a therapeutic agent describes the amount of therapeutic agent that is encapsulated or otherwise associated with a nanoparticle composition after preparation,
relative to the initial amount provided. The encapsulation efficiency is desirably high (e.g., close to 100%). The encapsulation efficiency may be measured, for example, by comparing the amount of therapeutic agent in a solution containing the nanoparticle composition before and after breaking up the nanoparticle composition with one or more organic solvents or detergents. Fluorescence may be used to measure tire amount of free therapeutic agent (e.g., nucleic acids) in a solution. For the nanoparticle compositions described herein, the encapsulation efficiency of a therapeutic agent may be at least 50%, for example 50%, 55%, 60%, 65%, 70%, 75%. 80%, 85%, 90%, 91%, 92%, 93%, 94%. 95%, 96%, 97%, 98%, 99%, or 100%. In some embodiments, the encapsulation efficiency may be at least 80%. In certain embodiments, the encapsulation efficiency may be at least 90%. Each possibility represents a separate embodiment of the present disclosure. In some embodiments, the lipid nanoparticle has a polydiversity value of less than 0.4. In some embodiments, the lipid nanoparticle has a net neutral charge at a neutral pH. In some embodiments, the lipid nanoparticle has a mean diameter of 50-200nm.
[0227] The properties of a lipid nanoparticle formulation may be influenced by factors including, but not limited to, the selection of the cationic lipid component, the degree of cationic lipid saturation, the selection of the non-cationic lipid component, the degree of noncationic lipid saturation, the selection of the structural lipid component, the nature of the PEGylation, ratio of all components and biophysical parameters such as size. As described herein, the purity of a circular PEG lipid component is also important to an LNP’s properties and performance.
A. Methods for Preparing Lipid Nanoparticles (LNP)
[0228] In one embodiment, a lipid nanoparticle formulation may be prepared by the methods described in International Publication Nos. WO2011127255 or W02008103276. each of which is herein incorporated by reference in their entirety. In some embodiments, lipid nanoparticle formulations may be as described in International Publication No. W02019131770. which is herein incorporated by reference in its entirety.
[0229] In some embodiments, circular RNA is formulated according to a process described in US patent application 15/809,680. In some embodiments, the present disclosure provides a process of encapsulating circular RNA in transfer vehicles comprising the steps of forming lipids into pre-formed transfer vehicles (i.e., formed in the absence of RNA) and then combining the pre-formed transfer vehicles with RNA. In some embodiments, the novel formulation process results in an RNA formulation with higher potency (peptide or protein expression) and higher efficacy (improvement of a biologically relevant endpoint) both in vitro and in vivo with potentially better tolerability as compared to the same RNA formulation prepared without the step of preforming the lipid nanoparticles (e.g., combining the lipids directly with the RNA).
[0230] For certain cationic lipid nanoparticle formulations of RNA, in order to achieve high
encapsulation of RNA, the RNA in buffer (e.g., citrate buffer) has to be heated. In those processes or methods, the heating is required to occur before the formulation process (i.e., heating the separate components) as heating post-formulation (post-formation of nanoparticles) does not increase the encapsulation efficiency of the RNA in the lipid nanoparticles. In contrast, in some embodiments of the novel processes of the present disclosure, the order of heating of RNA does not appear to affect the RNA encapsulation percentage. In some embodiments, no heating (i.e., maintaining at ambient temperature) of one or more of the solutions comprising the pre-formed lipid nanoparticles, the solution comprising the RNA and the mixed solution comprising the lipid nanoparticle encapsulated RNA is required to occur before or after the formulation process.
[0231] RNA may be provided in a solution to be mixed with a lipid solution such that the RNA may be encapsulated in lipid nanoparticles. A suitable RNA solution may be any aqueous solution containing RNA to be encapsulated at various concentrations. For example, a suitable RNA solution may contain an RNA at a concentration of or greater than about 0.01 mg/ml, 0.05 mg/ml, 0.06 mg/ml, 0.07 mg/ml. 0.08 mg/ml. 0.09 mg/ml, 0.1 mg/ml. 0.15 mg/ml, 0.2 mg/ml. 0.3 mg/ml, 0.4 mg/ml, 0.5 mg/ml. 0.6 mg/ml. 0.7 mg/ml, 0.8 mg/ml, 0.9 mg/ml, or 1.0 mg/ml. In some embodiments, a suitable RNA solution may contain an RNA at a concentration in a range from about 0.01-1.0 mg/ml, 0.01-0.9 mg/ml, 0.01- 0.8 mg/ml. 0.01-0.7 mg/ml. 0.01-0.6 mg/ml, 0.01-0.5 mg/ml, 0.01-0.4 mg/ml, 0.01-0.3 mg/ml, 0.01-0.2 mg/ml, 0.01 -0.1 mg/ml, 0.05-1.0 mg/ml, 0.05-0.9 mg/ml, 0.05-0.8 mg/ml. 0.05-0.7 mg/ml. 0.05-0.6 mg/ml, 0.05-0.5 mg/ml, 0.05-0.4 mg/ml, 0.05-0.3 mg/ml, 0.05-0.2 mg/ml, 0.05-0.1 mg/ml, 0.1-1.0 mg/ml, 0.2-0.9 mg/ml, 0.3-0. mg/ml. 0.4-0.7 mg/ml, or 0.5-0.6 mg/ml.
[0232] Typically, a suitable RNA solution may also contain a buffering agent and/or salt. Generally, buffering agents can include HEPES, Tris, ammonium sulfate, sodium bicarbonate, sodium citrate, sodium acetate, potassium phosphate or sodium phosphate. In some embodiments, suitable concentration of the buffering agent may be in a range from about 0.1 mM to 100 mM, 0.5 mM to 90 mM, 1.0 mM to 80 mM, 2 mM to 70 mM, 3 mM to 60 mM, 4 mM to 50 mM, 5 mM to 40 mM, 6 mM to 30 mM, 7 mM to 20 mM, 8 mM to 15 mM, or 9 to 12 mM.
[0233] Exemplary salts can include sodium chloride, magnesium chloride, and potassium chloride. In some embodiments, suitable concentration of salts in an RNA solution may be in a range from about 1 mM to 500 mM, 5 mM to 400 mM, 10 mM to 350 mM, 15 mM to 300 mM, 20 mM to 250 mM, 30 mM to 200 mM, 40 mM to 190 mM, 50 mM to 180 mM, 50 mM to 170 mM, 50 mM to 160 mM, 50 mM to 150 mM, or 50 mM to 100 mM.
[0234] In some embodiments, a suitable RNA solution may have a pH in a range from about 3.5-6.5, 3.5-6.0, 3.5-5.5, 3.5-5.0, 3.5-4.5, 4.0-5.5, 4.0-5.0, 4.0-4.9, 4.0-4.8, 4.0-4.7, 4.0-4.6, or 4.0-4.5.
[0235] Various methods may be used to prepare an RNA solution suitable for the present disclosure. In some embodiments. RNA may be directly dissolved in a buffer solution described herein. In some embodiments, an RNA solution may be generated by mixing an RNA stock solution with a buffer solution prior to mixing with a lipid solution for encapsulation. In some embodiments, an RNA solution may be generated by mixing an RNA stock solution with a buffer solution immediately before mixing with a lipid solution for encapsulation.
[0236] According to the present disclosure, a lipid solution contains a mixture of lipids suitable to form transfer vehicles for encapsulation of RNA. In some embodiments, a suitable lipid solution is ethanol based. For example, a suitable lipid solution may contain a mixture of desired lipids dissolved in pure ethanol (i.e., 100% ethanol). In another embodiment, a suitable lipid solution is isopropyl alcohol based. In another embodiment, a suitable lipid solution is dimethylsulfoxide-based. In another embodiment, a suitable lipid solution is a mixture of suitable solvents including, but not limited to, ethanol, isopropyl alcohol and dimethylsulfoxide.
[0237] A suitable lipid solution may contain a mixture of desired lipids at various concentrations. In some embodiments, a suitable lipid solution may contain a mixture of desired lipids at a total concentration in a range from about 0.1-100 mg/ml, 0.5-90 mg/ml. 1.0-80 mg/ml. 1.0-70 mg/ml, 1. fl- 60 mg/ml, 1.0-50 mg/ml, 1.0-40 mg/ml, 1.0-30 mg/ml, 1.0-20 mg/ml, 1.0-15 mg/ml, 1.0-10 mg/ml, 1.0- 9 mg/ml, 1.0-8 mg/ml, 1.0-7 mg/ml, 1.0-6 mg/ml, or 1.0-5 mg/ml.
B. IONIZABLE LIPIDS
[0238] In certain embodiments, the lipid nanoparticle formulations disclosed herein comprise ionizable lipids. The subject ionizable lipids may be used as a component of a composition to facilitate encapsulation and release of nucleic acid cargo (e.g., circular RNA) to one or more target cells. In certain embodiments, an ionizable lipid comprises one or more cleavable functional groups (e.g., a disulfide) that allow, for example, a hydrophilic functional head-group to dissociate from a lipophilic functional tail-group of the compound (e.g.. upon exposure to oxidative, reducing or acidic conditions).
[0239] In some embodiments, the ionizable lipid has a pKa from 6 to 12. In some embodiments, the ionizable lipid has a pKa from 7 to 9. In some embodiments, the ionizable lipid has a pK.a of 6.0, 6.1, 6.2. 6.3. 6.4, 6.5, 6.6, 6.7, 6.8, 6.9. 7.0. 7.1, 7.2, 7.3, 7.4, 7.5, 7.6. 7.7. 7.8. 7.9. 8.0, 8.1, 8.2, 8.3, 8.4.
8.5, 8.6, 8.7, 8.8, 8.9, or 9.0 or any ranges created by these.
[0240] In some embodiments, the ionizable lipid comprises an amino group.
[0241] In some embodiments, the ionizable lipid comprises a divalent headgroup and one or more straight hydrocarbon lipid tails. In some embodiments, the straight hydrocarbon lipid tails are from 3-
25 carbon atoms in length, such as 5 to 25, 5 to 20, 5 to 15, 5 to 10, 10 to 15, 10 to 20, or 10 to 25 carbon atoms in length.
[0242] In some embodiments, the ionizable lipid comprises a divalent headgroup and one or more branched hydrocarbon lipid tails. In some embodiments, the branched hydrocarbon lipid tails arc from 3-25 carbon atoms in length, such as 5 to 25, 5 to 20, 5 to 15, 5 to 10, 10 to 15, 10 to 20, or 10 to 25 carbon atoms in length.
[0243] In some embodiments, the divalent headgroup is selected from guanidine and squaramidc.
[0244] In some embodiments, the squaramide headgroup is of the following formula:
 wherein RA and RB are each independently a C1-C6 alkyl group or H; and represents the point of attachment of the headgroup to a straight or branched hydrocarbon lipid tail.
wherein RA and RB are each independently a C1-C6 alkyl group or H; and represents the point of attachment of the headgroup to a straight or branched hydrocarbon lipid tail.
[0245] In some embodiments, the ionizable lipid comprises a head group selected from:






[0246] In some embodiments, the ionizable lipid comprises a head group selected from:
 wherein
wherein
 represents the point of attachment of the headgroup to a straight or branched hydrocarbon lipid tail.
represents the point of attachment of the headgroup to a straight or branched hydrocarbon lipid tail.
[0247] In some embodiments, the ionizable lipid comprises a hydrophilic headgroup as disclosed in Jayaraman et al. Angew. Chem. Int. Ed. (2012), 51, 8529-8533.
[0248] In some embodiments, the ionizable lipid is ethyl lauryl arginate (EL A). In some embodiments, the ionizable lipid is ionizable lipid 1, wherein ionizable lipid 1 comprises:

[0249] In some embodiments, the one or more of the cationic or ionizable lipids are represented by Formula (LI):
 wherein: n is an integer between 1 and 4:
wherein: n is an integer between 1 and 4:
Ra is hydrogen or hydroxy l; and
R1 and R2 arc each independently a linear or branched C6-C30 alkyl, C6-C30 alkenyl, or C6-C30 heteroalky l, optionally substituted by one or more substituents selected from a group consisting of oxo, halo, hydroxy , cyano, alkyl, alkenyl, aldehyde, heterocyclylalkyl, hydroxyalkyl, dihydroxyalkyl, hydroxy alkylaminoalkyl, aminoalkyl, alkylaminoalkyl, dialkylaminoalkyl, (heterocyclyl)(alkyl)aminoalkyl, heterocyclyl. heteroaiyl, alkylheteroaryl, alkynyl, alkoxy, amino, dialkylamino, aminoalkylcarbonylamino, aminocarbonylalkylamino, (aminocarbonylalkyl)(alkyl)amino, alkenylcarbonylamino, hydroxy carbonyl, alkyloxycarbonyl, aminocarbonyl, aminoalkylaminocarbonyl, alkylaminoalkylaminocarbonyl, dialkylaminoalkylaminocarbonyl, heterocyclylalkylaminocarbonyl.
(alkylaminoalky l)(alkyl)aminocarbonyl. alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkenylcarbonyl, alkynylcarbonyl, alkylsulfoxide, alkylsulfoxidealkyl, alkylsulfonyl, and alkylsulfonealkyl.
[0250] In some embodiments, Ra is hydrogen. In some embodiments. Ra is hydroxyl.
[0251] In some embodiments, the ionizable lipid is represented by Fonnula (Lla -1), Formula (LIa-2), or Formula (LIa-3):

[0252] In some embodiments, the ionizable lipid is represented by Formula (LIb-1). Formula (LIb-2), or Formula (LIb-3):

|0253| In some embodiments, the ionizable lipid is represented by Formula (Llb-4), Formula (LIb-5), Fonnula (LIb-6), Formula (Lib- 7), Formula (LIb-8). or Formula (LIb-9):

[0254] In some embodiments, the one or more of the cationic or ionizable lipids are represented by Fonnula (LI), wherein R1 and R2 are each independently selected from:


[0255] In some embodiments, R1 and R2 are the same. In some embodiments. R1 and R2 are different.
[0256] In various embodiments, the one or more of the cationic or ionizable lipids are represented by
Formula (LI*):
 wherein: n* is an integer between 1 to 7,
wherein: n* is an integer between 1 to 7,
Ra is hydrogen or hydroxyl.
Rb is hydrogen or C1-C6 alkyl,
R1 and R2 are each independently a linear or branched C1-C30 alkyl, C2-C30 alkenyl, or C1-C30 heteroalkyl, optionally substituted by one or more substituents selected from oxo. halo, hydroxy, cyano, alkyd, alkenyl, aldehyde, heterocyclylalkyl. hydroxyalkyl, dihydroxyalkyl, hydroxyalkylaminoalky 1, aminoalkyl, alkylaminoalkyl, dialkylaminoalkyl, (heterocycly d)(alky d)aminoalkyl, heterocyclyl, heteroaiyl, alkylheteroary l, alkynyl, alkoxy, amino, dialkylamino, aminoalk lcarbonylamino, aminocarbony lalkylamino, (aminocarbony lalky l)(alkyl)amino, alkenylcarbony lamino, hydroxycarbonyl, alkyloxycarbonyl, alky lcarbony loxy , alky lcarbonate, alkenyloxycarbonyl, alkcnylcarbonyloxy, alkcnylcarbonatc, alkynyloxycarbonyl, alkynylcarbony doxy, alkynylcarbonatc, aminocarbonyl, aminoalky daminocarbonyl, alkylaminoalkylaminocarbonyl, dialkydaminoalkylaminocarbonyl, heterocycly lalkylaminocarbonyl,
(alkylaminoalkyl)(alkyl)aminocarbonyl, alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkeny Icarbony 1, alky nylcarbony 1, alkylsulfoxide, alkydsulfoxidealkyl, alky dsulfonyl, and alkylsulfonealkyl.
[0257] In some embodiments, tire one or more of the cationic or ionizable lipids are represented by Formula (LII):
 wherein: each n is independently an integer from 2-15;
wherein: each n is independently an integer from 2-15;
L1 and L3 are each independently -OC(O)-* or -C(O)O-*, wherein indicates the
attachment point to R1 or R3;
R1 and R3 are each independently a linear or branched C9-C20 alky l or C9-C20 alkenyl, optionally substituted by one or more substituents selected from a group consisting of oxo, halo, hydroxy, cyano, alky l, alkenyl, aldehyde, hctcrocycly lalkyl, hydroxyalkyl, dihy droxyalkyl, hy droxy alky laminoalky l, aminoalkyl, alkylaminoalkyl, dialky laminoalky l, (lieterocyclyl)(alkyl)aminoalkyl, heterocyclyl, heteroaryl, alkydheteroaryl, alkynyl, alkoxy, amino, dialky lamino, aminoalkylcarbonylamino, aminocarbonylalky lamino, (aminocarbony lalky l)(alkyl)amino, alkenylcarbonylamino, hydroxycarbonyl, alkyloxycarbony l, aminocarbonyl, aminoalkylaminocarbonyl, alky laminoalkylaminocarbonyl, dialkylaminoalkylaminocarbonyl, heterocyclylalkylaminocarbonyl, (alkylaminoalkyl)(alkyl)aminocarbonyl, alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl, heterocyclylcarbonyl, alkenylcarbony l, alkynylcarbonyl, alkylsulfoxide, alkylsulfoxidealkyl, alky lsulfonyl, and alkylsulfonealkyl; and R2 is selected from a group consisting of:

[0258] In some embodiments, the ionizable lipid is selected from an ionizable lipid of Formula LII, wherein R1 and R3 are each independently selected from a group consisting of:

[0259] In some embodiments, R1 and R3 are the same. In some embodiments, R1 and R3 are different. [0260] In some embodiments, tire one or more of the cationic or ionizable lipids are represented by
Formula (LII-1) or Formula (LII-2):


[0261] In some embodiments, the ionizable lipid is selected from an ionizable lipid of W02015/095340. In some embodiments, the ionizable lipid is selected from an ionizable lipid of WO2021/021634, WO2020/237227, or WO2019/23 673. In some embodiments, the ionizable lipid is selected from an ionizable lipid of WO2021226597 and WO2021113777. In some embodiments, the ionizable lipid is selected from an ionizable lipid of W02023056033. In some embodiments, the ionizable lipid is selected from an ionizable lipid of WO2023081526.
[0262] In some embodiments, tire one or more of the cationic or ionizable lipids are represented by Formula (LIII):
 or a pharmaceutically acceptable salt thereof, wherein
or a pharmaceutically acceptable salt thereof, wherein

[0263] In some embodiments, the one or more of the cationic or ionizable lipids are represented by Fonnula (LIII*):
 or a pharmaceutically acceptable salt thereof, wherein
or a pharmaceutically acceptable salt thereof, wherein
 heteroalk l, optionally substituted by one or more substituents selected from oxo, halo, hydroxy, cyano, alky l, alkenyl, aldehy de, heterocyclylalkyl, hy droxyalky l, dihydroxyalkyl, hydroxy alkylaminoalkyl, aminoalkyl, alkylaminoalkyl, dialkylaminoalkyl, (lreterocyclyl)(alkyl)aminoalkyl, heterocyclyl, heteroaryl, alkylheteroaryl, alkynyl, alkoxy, amino, dialkylamino, aminoalkylcarbonylamino, aminocarbonylalkylamino, (aminocarbony lalky 1) (alkyl) amino, alkenylcarbonylamino, hydroxycarbonyl, alkyloxy carbonyl, alkylcarbonyloxy, alkylcarbonate, alkenyloxy carbonyl, alkenylcarbonyloxy, alkenylcarbonate, alkynyloxycarbonyl, alkynylcarbonyloxy, alkynylcarbonate, aminocarbonyl, aminoalkylaminocarbonyl. alkylaminoalkylaminocarbonyl, dialkylaminoalkylaminocarbonyl, heterocyclylalkylaminocarbonyl,
heteroalk l, optionally substituted by one or more substituents selected from oxo, halo, hydroxy, cyano, alky l, alkenyl, aldehy de, heterocyclylalkyl, hy droxyalky l, dihydroxyalkyl, hydroxy alkylaminoalkyl, aminoalkyl, alkylaminoalkyl, dialkylaminoalkyl, (lreterocyclyl)(alkyl)aminoalkyl, heterocyclyl, heteroaryl, alkylheteroaryl, alkynyl, alkoxy, amino, dialkylamino, aminoalkylcarbonylamino, aminocarbonylalkylamino, (aminocarbony lalky 1) (alkyl) amino, alkenylcarbonylamino, hydroxycarbonyl, alkyloxy carbonyl, alkylcarbonyloxy, alkylcarbonate, alkenyloxy carbonyl, alkenylcarbonyloxy, alkenylcarbonate, alkynyloxycarbonyl, alkynylcarbonyloxy, alkynylcarbonate, aminocarbonyl, aminoalkylaminocarbonyl. alkylaminoalkylaminocarbonyl, dialkylaminoalkylaminocarbonyl, heterocyclylalkylaminocarbonyl,
(alkylaminoalkyl)(alkyl)aminocarbonyl, alkylaminoalkylcarbonyl, dialkylaminoalkylcarbonyl,
heterocyclylcarbonyl, alkenylcarbonyl, alkynylcarbonyl, alk lsulfoxide, alkylsulfoxidealk l, alkydsulfonyl, and alkylsulfonealkyl.
[0264] In some embodiments, an ionizable lipid is a compound of Formula (LIV):
 or is a pharmaceutically acceptable salt thereof, wherein: n’ is an integer from 1 to 7;
or is a pharmaceutically acceptable salt thereof, wherein: n’ is an integer from 1 to 7;
Ra is hydrogen or hydroxyl;
Rh is hydrogen or C1-C6 alky 1;
R1 is C1-C30 alkyl or R1’;
R2 is C1-C30 alkyl or R2*;
R1* and R2* are independently selected from:
-(CH2)qC(O)O(CH2)rC(R8)(R9)(R10),
-(CH2)qOC(O)(CH2)rC(R8)(R9)(R10), and
-(CH2)qOC(O)O(CH2)rC(R8)(R9)(R10); wherein: q is an integer from 0 to 12. r is an integer from 0 to 6, wherein at least one occurrence of r is not 0;
R8 is H or R11;
R9, R10, and R11 are each independently C1-C20 alky 1 or C2-C20-alkenyl; and wherein (i) R1 is R1*, (ii) R2 is R2*, or (iii) R1 is R1* and R2 is R2*.
[0265] In some embodiments, an ionizable lipid of the present disclosure is represented by Formula (LV):
 or is a pharmaceutically acceptable salt thereof, wherein:
or is a pharmaceutically acceptable salt thereof, wherein:
Ra is hydrogen or hydroxyl;
R1 is C1-C30 alkyl or R1*;
R2 is C1-C30 alkyl or R2*;
R1* and R2* are independently selected from:
-(CH2)qC(O)O(CH2)rC(R4)(R5)(R6),
-(CH2)qOC(O)(CH2)rC(R4)(R5)(R6), and
-(CH2)qOC(O)O(CH2)rC(R4)(R5)(R6); wherein: q is an integer from 0 to 12, r is an integer from 0 to 6, wherein at least one occurrence of r is not 0;
R4 is hydrogen or R7;
R5, R6. and R7 are each independently C1-C20 alkyl or C2-C2o-alkenyl; wherein (i) R1 is R1 *, (ii) R2 is R2’, or (iii) R1 is R1 * and R2 is R2*; and
R3 is L-R’, wherein L is linear or branched C1-C10 alkylene, and R’ is (i) mono- or bicyclic heterocyclyl or heteroary l, such as imidazolyl, pyrazolyl, 1,2,4-triazolyl, or benzimidazolyl, each optionally substituted at one or more available carbon and nitrogen by C1-C6 alkyl, or (ii) RA, RB, or Rc, wherein
RA is selected from:




Rc is selected from:


[0266] In certain embodiments, the cationic or ionizable lipid is Ionizable Lipid 2, wherein
10 ionizable lipid 2 comprises:
 [0267] In certain embodiments, cationic or ionizable lipid is Ionizable Lipid 3, wherein ionizable lipid 3 comprises:
[0267] In certain embodiments, cationic or ionizable lipid is Ionizable Lipid 3, wherein ionizable lipid 3 comprises:

[0268] Exemplary ionizable and/or cationic lipids are described in International PCT patent publications W02015/095340, WO2015/199952, W02018/011633, WO2017/049245,
WO2015/061467, WO2012/040184, WO2012/000104, WO2015/074085, W02016/081029. WO2017/004 143, WO2017/075531, WO2017/117528, WO2011/022460. WO2013/148541, WO2013/116126, W02011/153120, WO2012/044638, WO2012/054365, WO2011/090965, W02013/016058, W02012/162210, W02008/042973, W02010/129709, WO2010/144740, WO2012/099755, WO2013/049328, WO2013/086322, WO2013/086373, W02011/071860, W02009/132131, W02010/048536, WO2010/088537, W02010/054401, WO2010/054406, WO2010/054405, WO2010/054384, W02012/016184, W02009/086558, WO2010/042877, WO2011/000106, WO2 11/000107, W02005/120152, WO2011/141705, WO2013/126803,
W02006/007712, WO2011/038160, WO2005/121348, WO2011/066651, W02009/127060. WO2011/141704. W02006/069782. WO2012/031043. WO2013/006825. WO2013/033563. WO2013/089151, WO2017/099823. WO2015/095346, WO2013/086354, WO 2022/261490, WO2022/251665, WO2023044343, WO2023044333, WO2023122752, WO2023196931,
WO2023196931. WO 2023/056033, and US patent publications US2016/0311759, US2015/0376115,
US2016/0151284, US2017/0210697, US2015/0140070, US2013/0178541, US2013/0303587, US2015/0141678, US2015/0239926, US2016/0376224, US2017/0119904, US2012/0149894, US2015/0057373, US2013/0090372, US2013/0274523, US2013/0274504, US2013/0274504, US2009/0023673, US2012/0128760, US2010/0324120, US2014/0200257, US2015/0203446, US2018/0005363, US2014/0308304, US2013/0338210, US2012/0101148, US2012/0027796, US2012/0058144, US2013/0323269, US2011/0117125, US2011/0256175, US2012/0202871, US2011/0076335, US2006/0083780, US2013/0123338, US2015/0064242, US2006/0051405, US2013/0065939, US2006/0008910, US2003/0022649, US2010/0130588, US2013/0116307, US2010/0062967, US2013/0202684, US2014/0141070, US2014/0255472, US2014/0039032, US2018/0028664, US2016/0317458, and US2013/0195920, the contents of all of which are incorporated herein by reference in their entirety'. International patent application WO 2019/131770 is also incorporated herein by reference in its entirety'.
B. HELPER LIPIDS
[0269] In some embodiments, the LNP described herein comprises one or more non-cationic
helper lipids. In some embodiments, the helper lipid is a phospholipid. In some embodiments, the helper lipid is a phospholipid substitute or replacement. In some embodiments, the phospholipid or phospholipid substitute can be, for example, one or more saturated or (poly)unsaturated phospholipids, or phospholipid substitutes, or a combination thereof. In general, phospholipids comprise a phospholipid moiety and one or more Patty acid moieties.
[0270] A phospholipid moiety can be selected, for example, from the non-limiting group consisting of phosphatidyl choline, phosphatidyl ethanolamine, phosphatidyl glycerol, phosphatidyl serine, phosphatidic acid, 2-lysophosphatidyl choline, and a sphingomyelin.
[0271] A fatly acid moiety can be selected, for example, from the non-limiting group consisting of lauric acid, myristic acid, myristoleic acid, palmitic acid, palmitoleic acid, stearic acid, oleic acid, linoleic acid, alpha-linolenic acid, erucic acid, phytanoic acid, arachidic acid, arachidonic acid, eicosapentaenoic acid, behenic acid, docosapentaenoic acid, and docosahexaenoic acid.
[0272] Phospholipids include, but are not limited to, glycerophospholipids such as phosphatidylcholines, phosphatidylethanolamines, phosphatidylserines, phosphatidylinositols, phosphatidy glycerols, and phosphatidic acids. Phospholipids also include phosphosphingolipid, such as sphingomyelin.
[0273] In some embodiments, the helper lipid is a 1.2-distearoyl-177-glycero-3-phosphocholine (DSPC) analog, a DSPC substitute, oleic acid, or an oleic acid analog.
[0274] In some embodiments, a helper lipid is a non-phosphatidyl choline (PC) zwitterionic lipid, a DSPC analog, oleic acid, an oleic acid analog, or a DSPC substitute.
[0275] In some embodiments, a helper lipid is described in PCT/US2018/053569. Helper lipids suitable for use in a lipid composition of the disclosure include, for example, a variety of neutral, uncharged or zwiterionic lipids. Such helper lipids are used in combination with one or more of the compounds and lipids disclosed herein. Examples of helper lipids include, but are not limited to. 5- heptadecylbenzene-l,3-diol (resorcinol), dipalmitoylphosphatidylcholine (DPPC), distearoylphosphatidylcholine (DSPC), dioleoylphosphatidylcholine (DOPC), dimyristoylphosphatidylcholine (DMPC), phosphatidylcholine (PLPC). l,2-distearoylsn-glycero-3- phosphocholine (DAPC). phosphatidylethanolamine (PE), egg phosphatidylcholine (EPC), dilauryloylphosphatidylcholine (DLPC), dimyristoylphosphatidylcholine (DMPC), 1 -myristoyl-2- pahnitoyl phosphatidylcholine (MPPC), 1-paimitoy 1-2 -myristoyl phosphatidylcholine (PMPC), 1- pahnitoy 1-2-stearoy 1 phosphatidylcholine (PSPC), 1 ,2-diarachidoyl-sn-gly cero-3 -phosphocholine (DBPC), 1-stcaroy 1-2 -palmitoyl phosphatidylcholine (SPPC), l,2-dicicoscnoyl-sn-glyccro-3- phosphocholine (DEPC), paimitoyioieoyl phosphatidylcholine (POPC), lysophosphatidyl choline,
dioleoyl phosphatidylethanol amine (DOPE) dilinoleoylphosphatidylcholine distearoylphosphatidylethanolamine (DSPE), dimyristoyl phosphatidylethanolamine (DMPE), dipalmitoyl phosphatidylethanolamine (DPPE), palmitoyloleoyl phosphatidylethanolamine (POPE), lysophosphatidylethanolamine and combinations thereof. In one embodiment, tire helper lipid may be distearoylphosphatidy leholine (DSPC) or dimyristoyl phosphatidyl ethanolamine (DMPE). In another embodiment, the helper lipid may be distearoylphosphatidylcholine (DSPC). Helper lipids function to stabilize and improve processing of the transfer vehicles. Such helper lipids are used in combination with other excipients, for example, one or more of the ionizable lipids disclosed herein. In some embodiments, when used in combination with an ionizable lipid, the helper lipid may comprise a molar ratio of 5% to about 90%, or about 10% to about 70% of the total lipid present in the lipid nanoparticle.
C. STRUCTURAL LIPIDS
[0276] In some embodiments, the LNP described herein comprises one or more structural lipids. Incorporation of structural lipid(s) in the lipid nanoparticle may help mitigate aggregation of other lipids in the particle. Structural lipids can include, but are not limited to, cholesterol, fecosterol, ergosterol, bassicasterol, tomatidine, tomatine, ursolic, alphatocopherol. and mixtures thereof. In certain embodiments, the structural lipid is cholesterol. In certain embodiments, the structural lipid includes cholesterol and a corticosteroid (such as. for example, prednisolone, dexamethasone, prednisone, and hydrocortisone), or a combination thereof.
[0277] In some embodiments, a structural lipid is described in international patent application PCT/US2019/015913.
[0278] In some embodiments, the structural lipid is a sterol. In certain embodiments, the structural lipid is a steroid. In certain embodiments, the structural lipid is cholesterol. In certain embodiments, the structural lipid is an analog of cholesterol. In certain embodiments, tire structural lipid is alphatocopherol.
[0279] The LNPs described herein comprise one or more structural lipids. Incorporation of structural lipids in a transfer vehicle, e.g., a lipid nanoparticle, may help mitigate aggregation of other lipids in the particle. In certain embodiments, the structural lipid includes cholesterol and a corticosteroid (such as, for example, prednisolone, dexamethasone, prednisone, and hydrocortisone), or a combination thereof.
[0280] In some embodiments, the structural lipid is a sterol. Structural lipids can include, but are not limited to. sterols (e.g., phytosterols or zoosterols).
[0281] In certain embodiments, the structural lipid is a steroid. For example, sterols can include, but are not limited to, cholesterol, β-sitosterol, fecosterol, ergosterol, sitosterol, campesterol, stigmasterol, brassicasterol, ergosterol, tomatidine, tomatine, ursolic acid, or alpha-tocopherol.
[0282] In some embodiments, LNP includes an effective amount of an immune cell delivery potentiating lipid, e.g., a cholesterol analog or an amino lipid or combination thereof, that, when present in a transfer vehicle, e.g., an lipid nanoparticle, may function by enhancing cellular association and/or uptake, internalization, intracellular trafficking and/or processing, and/or endosomal escape and/or may enhance recognition by and/or binding to immune cells, relative to a transfer vehicle lacking the immune cell delivery potentiating lipid. Accordingly, while not intending to be bound by any particular mechanism or theory, in one embodiment, a structural lipid or other immune cell delivery potentiating lipid of the disclosure binds to Clq or promotes the binding of a transfer vehicle comprising such lipid to Clq. Thus, for in vitro use of the transfer vehicles of the disclosure for delivery of a nucleic acid molecule to an immune cell, culture conditions that include Clq are used (e.g., use of culture media that includes serum or addition of exogenous Clq to serum -free media). For in vivo use of the transfer vehicles of the disclosure, the requirement for Clq is supplied by endogenous Clq.
[0283] In certain embodiments, the structural lipid is cholesterol. In certain embodiments, the structural lipid is an analog of cholesterol. In some embodiments, the structural lipid is a lipid in the Table below:




















D. POLYNUCLEOTIDES
[0284] In certain embodiments, the lipid nanoparticle compositions described herein comprise a polynucleotide. In some embodiments, the polynucleotide is DNA. In some embodiments, the polynucleotide is RNA. In some embodiments, the polynucleotide is linear RNA. In preferred embodiments, the polynucleotide is circular RNA.
[0285] Transcription of a DNA template (e.g.. comprising a 3’ intron element, 3’ exon element, a core functional element, a 5’ exon element, and a 5’ intron element) results in formation of a precursor linear RNA polynucleotide capable of circularizing. In some embodiments, this DNA template comprises a vector, PCR product, plasmid, minicircle DNA, cosmid, artificial chromosome, complementary DNA (cDNA), extrachromosomal DNA (ecDNA), or a fragment therein. In certain embodiments, the minicircle DNA may be linearized or non-linearized. In certain embodiments, the plasmid may be linearized or non-linearized. In some embodiments, the DNA template may be single-stranded. In
other embodiments, the DNA template may be double-stranded. In some embodiments, the DNA template comprises in whole or in part from a viral, bacterial, or eukaryotic vector.
[0286] The present disclosure, as provided herein, comprises a DNA template that shares the same sequence as the precursor linear RNA polynucleotide prior to splicing of the precursor linear RNA polynucleotide (e.g., a 3’ intron element, a 3‘ exon element, a core functional element, and a 5‘ exon element, a 5’ intron element). In some embodiments, said linear precursor RNA polynucleotide undergoes splicing leading to the removal of the 3’ intron element and 5‘ intron element during the process of circularization. In some embodiments, the resulting circular RNA polynucleotide lacks a 3 ’ intron fragment and a 5’ intron fragment, but maintains a 3’ exon fragment, a core functional element, and a 5‘ exon element.
[0287] In some embodiments, the precursor linear RNA polynucleotide circularizes when incubated in the presence of one or more guanosine nucleotides or nucleoside (e.g., GTP) and a divalent cation (e.g., Mg2+). In some embodiments, the 3’ exon element, 5‘ exon element, and/or core functional element in whole or in part promotes the circularization of the precursor linear RNA polynucleotide to fonn the circular RNA polynucleotide provided herein.
[0288] In certain embodiments circular RNA provided herein is produced inside a cell. In some embodiments, precursor RNA is transcribed using a DNA template (e.g., in some embodiments, using a vector provided herein) in the cytoplasm by a bacteriophage RNA polymerase, or in the nucleus by host RNA polymerase II and then circularized.
[0289] In certain embodiments, the circular RNA provided herein is injected into an animal (e.g., a human), such that a polypeptide encoded by the circular RNA molecule is expressed inside the animal.
[0290] In some embodiments, the DNA template (e.g., vector), linear RNA (e.g., precursor RNA), and/or circular RNA polynucleotide provided herein is between 300 and 10000, 400 and 9000, 500 and 8000, 600 and 7000, 700 and 6000, 800 and 5000, 900 and 5000, 1000 and 5000, 1100 and 5000. 1200 and 5000. 1300 and 5000, 1400 and 5000, and/or 1500 and 5000 nucleotides (nt) in length. In some embodiments, the polynucleotide is at least 300 nt, 400 nt. 500 nt, 600 nt, 700 nt, 800 nt, 900 nt. 1000 nt, 1100 nt, 1200 nt, 1300 nt. 1400 nt, 1500 nt, 2000 nt, 2500 nt, 3000 nt. 3500 nt. 4000 nt, 4500 nt, or 5000 nt in length. In some embodiments, the polynucleotide is no more than 3000 nt, 3500 nt, 4000 nt, 4500 nt. 5000 nt, 6000 nt, 7000 nt. 8000 nt. 9000 nt, or 10000 nt in length. In some embodiments, the length of a DNA, linear RNA. and/or circular RNA polynucleotide provided herein is 300 nt. 400 nt. 500 nt. 600 nt. 700 nt, 800 nt, 900 nt. 1000 nt, 1100 nt. 1200 nt. 1300 nt, 1400 nt. 1500 nt. 2000 nt, 2500 nt, 3000 nt. 3500 nt. 4000 nt, 4500 nt, 5000 nt, 6000 nt, 7000 nt. 8000 nt. 9000 nt, or 10000 nt.
[0291] In some embodiments, the circular RNA provided herein has higher functional stability than mRNA comprising the same expression sequence. In some embodiments, the circular RNA provided herein has higher functional stability than mRNA comprising the same expression sequence, 5moU modifications, an optimized UTR, a cap, and/or a polyA tail.
[0292] In some embodiments, the circular RNA polynucleotide provided herein has a functional halflife of at least 5 hours, 10 hours, 15 hours, 20 hours. 30 hours, 40 hours, 50 hours, 60 hours, 70 hours or 80 hours. In some embodiments, the circular RNA polynucleotide provided herein has a functional half-life of 5-80, 10-70, 15-60, or 20-50 hours. In some embodiments, the circular RNA polynucleotide provided herein has a functional half-life greater than (e.g.. at least 1.5-fold greater than, at least 2-fold greater than) that of an equivalent linear RNA polynucleotide encoding the same protein. In some embodiments, functional half-life can be assessed through the detection of functional protein synthesis.
[0293] In some embodiments, the circular RNA polynucleotide, or pharmaceutical composition thereof, has a functional half-life in a human cell greater than or equal to that of a pre-determined threshold value. In some embodiments, the functional half-life is determined by a functional protein assay. For example, in some embodiments, the functional half-life is determined by an in vitro luciferase assay, wherein the activity of Gaussia luciferase (GLuc) is measured in the media of human cells (e.g. HepG2) expressing the circular RNA polynucleotide every 1, 2, 6, 12, or 24 hours over 1, 2, 3. 4, 5, 6. 7, or 14 days. In other embodiments, the functional half-life is detennined by an in vivo assay, wherein levels of a protein encoded by the expression sequence of the circular RNA polynucleotide are measured in patient serum or tissue samples every 1, 2, 6, 12, or 24 hours over 1, 2. 3, 4, 5, 6, 7, or 14 days. In some embodiments, the pre-determined threshold value is the functional half-life of a reference linear RNA polynucleotide comprising the same expression sequence as the circular RNA polynucleotide.
[0294] In some embodiments, the circular RNA provided herein may have a higher magnitude of expression than equivalent linear mRNA, e.g., a higher magnitude of expression 24 hours after administration of RNA to cells. In some embodiments, the circular RNA provided herein has a higher magnitude of expression than mRNA comprising the same expression sequence. 5moU modifications, an optimized UTR. a cap. and/or a polyA tail.
[0295] In some embodiments, the circular RNA provided herein may be less immunogenic than an equivalent mRNA when exposed to an immune system of an organism or a certain type of immune cell. In some embodiments, the circular RNA provided herein is associated with modulated production of cytokines when exposed to an immune system of an organism or a certain type of immune cell. For example, in some embodiments, the circular RNA provided herein is associated with reduced production of IFN-(31, RIG-I, IL-2, IL-6, IFNy, and/or TNFa when exposed to an immune system of an
organism or a certain ty pe of immune cell as compared to mRNA comprising the same expression sequence. In some embodiments, the circular RNA provided herein is associated with less IFN-(31, RIG-I, IL-2, IL-6, IFNy, and/or TNFa transcript induction when exposed to an immune system of an organism or a certain type of immune cell as compared to mRNA comprising the same expression sequence. In some embodiments, the circular RNA provided herein is less immunogenic than mRNA comprising the same expression sequence. In some embodiments, the circular RNA provided herein is less immunogenic than mRNA comprising the same expression sequence, 5moU modifications, an optimized UTR, a cap. and/or a polyA tail.
[0296] In certain embodiments, the circular RNA provided herein can be transfected into a cell as is or can be transfected in DNA vector form and transcribed in the cell. Transcription of circular RNA from a transfected DNA vector can be via added polymerases or polymerases encoded by nucleic acids transfected into the cell, or via endogenous polymerases. In some embodiments, transcription of circular RNA from a transfected DNA vector is via endogenous polymerases. i. Enhanced Intron Elements & Enhanced Exon Elements
[0297] In some embodiments, the DNA template (e.g., vector) or linear RNA (e.g., precursor RNA) comprises an enhanced intron element and/or enhanced exon element. The enhanced intron elements and enhanced exon elements may comprise spacers, duplex regions, affinity sequences, intron fragments, exon fragments and various untranslated elements. These sequences within the enhanced intron elements or enhanced exon elements are arranged to optimize circularization or protein expression.
[0298] In certain embodiments, the DNA template, precursor linear RNA polynucleotide and circular RNA provided herein comprise a first (5 ’) and/or a second (3 ’) spacer. In some embodiments, the DNA template or precursor linear RNA polynucleotide comprises one or more spacers in the enhanced intron elements. In some embodiments, the DNA template, precursor linear RNA polynucleotide comprises one or more spacers in the enhanced exon elements. In certain embodiments, the DNA template or linear RNA polynucleotide comprises a spacer in the 3’ enhanced intron fragment and a spacer in the 5’ enhanced intron fragment. In certain embodiments, DNA template, precursor linear RNA polynucleotide, or circular RNA comprises a spacer in the 3’ enhanced exon fragment and another spacer in the 5’ enhanced exon fragment to aid with circularization or protein expression due to symmetry created in the overall sequence.
[0299] In some embodiments, including a spacer between the 3 ’ group I intron fragment and the core functional element may conserve secondary structures in those regions by preventing them from interacting, thus increasing splicing efficiency. In some embodiments, the first (between 3’ group I intron fragment and core functional element) and second (between the two expression sequences and
core functional element) spacers comprise additional base pairing regions that are predicted to base pair with each other and not to the first and second duplex regions. In other embodiments, the first (between 3’ group I intron fragment and core functional element) and second (between the one of the core functional element and 5’ group I intron fragment) spacers comprise additional base pairing regions that are predicted to base pair with each other and not to the first and second duplex regions. In some embodiments, such spacer base pairing brings the group I intron fragments in close proximity to each other, further increasing splicing efficiency. Additionally, in some embodiments, the combination of base pairing between the first and second duplex regions, and separately, base pairing between the first and second spacers, promotes the formation of a splicing bubble containing the group I intron fragments flanked by adjacent regions of base pairing. Typical spacers are contiguous sequences with one or more of the following qualities: 1) predicted to avoid interfering with proximal structures, for example, the IRES, expression sequence, aptamer, or intron; 2) is at least 7 nt long and no longer than 100 nt; 3) is located after and adjacent to the 3 ’ intron fragment and/or before and adjacent to the 5 ’ intron fragment; and 4) contains one or more of the following: a) an unstructured region at least 5 nt long, b) a region of base pairing at least 5 nt long to a distal sequence, including another spacer, and c) a structured region at least 7 nt long limited in scope to the sequence of the spacer. Spacers may have several regions, including an unstructured region, a base pairing region, a hairpin/structured region, and combinations thereof. In an embodiment, the spacer has a structured region with high GC content. In an embodiment, a region within a spacer base pairs with another region within the same spacer. In an embodiment, a region within a spacer base pairs with a region within another spacer. In an embodiment, a spacer comprises one or more hairpin structures. In an embodiment, a spacer comprises one or more hairpin structures with a stem of 4 to 12 nucleotides and a loop of 2 to 10 nucleotides. In an embodiment, there is an additional spacer between the 3’ group I intron fragment and the core functional element. In an embodiment, this additional spacer prevents the structured regions of the IRES or aptamer of a TIE from interfering w ith the folding of the 3’ group I intron fragment or reduces the extent to which this occurs. In some embodiments, the 5’ spacer sequence is at least 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25 or 30 nucleotides in length. In some embodiments, the 5‘ spacer sequence is no more than 100, 90, 80, 70, 60, 50, 45, 40, 35 or 30 nucleotides in length. In some embodiments the 5’ spacer sequence is between 5 and 50, 10 and 50, 20 and 50, 20 and 40, and/or 25 and 35 nucleotides in length. In certain embodiments, the 5’ spacer sequence is 10, 11, 12, 13, 14, 15, 16, 17. 18, 19, 20, 21, 22, 23, 24, 25, 26, 27. 28, 29, 30, 31, 32, 33, 34, 35, 36. 37, 38, 39, 40, 41. 42, 43, 44, 45, 46, 47, 48, 49 or 50 nucleotides in length. In one embodiment, the 5’ spacer sequence is a poly A sequence. In another embodiment, the 5’ spacer sequence is a poly AC sequence. In one embodiment, a spacer comprises 10%, 20%, 30%, 40%. 50%. 60%, 70%, 80%, 90%. or 100% poly AC content. In one embodiment, a spacer comprises 10%. 20%, 30%, 40%, 50%. 60%, 70%, 80%, 90%. or 100% polypyrimidine (C/T or C/U) content.
[0300] In some embodiments, the DNA template and precursor linear RNA polynucleotides and circular RNA polynucleotide provided herein comprise a first (5’) duplex region and a second (3’) duplex region. In certain embodiments, the DNA template and precursor linear RNA polynucleotide comprises a 5' external duplex region located within the 3‘ enhanced intron fragment and a 3’ external duplex region located within the 5‘ enhanced intron fragment. In some embodiments, the DNA template, precursor linear RNA polynucleotide and circular RNA polynucleotide comprise a 5 ‘ internal duplex region located within the 3’ enhanced exon fragment and a 3’ internal duplex region located within the 5’ enhanced exon fragment. In some embodiments, the DNA polynucleotide and precursor linear RN A polynucleotide comprises a 5 ’ external duplex region. 5 ’ internal duplex region, a 3 ’ internal duplex region, and a 3‘ external duplex region.
[0301] In certain embodiments, the first and second duplex regions may form perfect or imperfect duplexes. Thus, in certain embodiments at least 75%. 80%, 85%, 90%, 91%, 92%, 93%. 94%. 95%, 96%, 97%, 98%, 99%, or 100% of the first and second duplex regions may be base paired with one another. In some embodiments, the duplex regions are predicted to have less than 50% (e.g., less than 45%, less than 40%, less than 35%, less than 30%. less than 25%) base pairing with unintended sequences in the RNA (e.g., non-duplex region sequences). In some embodiments, including such duplex regions on the ends of the precursor RNA strand, and adjacent or very close to the group I intron fragment, bring the group I intron fragments in close proximity to each other, increasing splicing efficiency. In some embodiments, the duplex regions are 3 to 100 nucleotides in length (e.g., 3-75 nucleotides in length, 3-50 nucleotides in length. 20-50 nucleotides in length. 35-50 nucleotides in length, 5-25 nucleotides in length, 9-19 nucleotides in length). In some embodiments, the duplex regions are 3, 4. 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21. 22, 23, 24, 25. 26, l, 28, 29. 30, 31, 32, 33, 34. 35, 36, 37, 38. 39, 40, 41, 42. 43, 44, 45, 46. 47, 48, 49, or 50 nucleotides in length. In some embodiments, the duplex regions have a length of 9 to 50 nucleotides. In one embodiment, the duplex regions have a length of 9 to 19 nucleotides. In some embodiments, the duplex regions have a length of 20 to 40 nucleotides. In certain embodiments, the duplex regions have a length of 30 nucleotides.
[0302] In other embodiments, the DNA template, precursor linear RNA polynucleotide, or circular RNA polynucleotide does not comprise of any duplex regions to optimize translation or circularization.
[0303] As provided herein, the DNA template or precursor linear RNA polynucleotide may comprise an affinity tag. In some embodiments, the affinity' tag is located in the 3 ’ enhanced intron element. In some embodiments, the affinity tag is located in the 5’ enhanced intron element. In some embodiments, both (3 ’ and 5 ) enhanced intron elements each comprise an affinity tag. In one embodiment, an affinity tag of the 3 ’ enhanced intron element is the length as an affinity tag in the 5 ’ enhanced intron element. In some embodiments, an affinity tag of the 3‘ enhanced intron element is the same sequence as an
affinity tag in the 5 ’ enhanced intron element. In some embodiments, the affinity sequence is placed to optimize oligo-dT purification.
[0304] In some embodiments, an affinity tag comprises a polyA region. In some embodiments the polyA region is at least 15, 30, or 60 nucleotides long. In some embodiments, one or both polyA regions is 15-50 nucleotides long. In some embodiments, one or both polyA regions is 20-25 nucleotides long. The polyA sequence is removed upon circularization. Thus, an oligonucleotide hybridizing with the polyA sequence, such as a deoxythymine oligonucleotide (oligo(dT)) conjugated to a solid surface (e.g., a resin), can be used to separate circular RNA from its precursor RNA.
[0305] In certain embodiments, the 3’ enhanced intron element comprises a leading untranslated sequence. In some embodiments, the leading untranslated sequence is a the 5’ end of the 3‘ enhanced intron fragment. In some embodiments, the leading untranslated sequence comprises of the last nucleotide of a transcription start site (TSS). In some embodiments, the TSS is chosen from a viral, bacterial, or eukary otic DNA template. In one embodiment, the leading untranslated sequence comprise the last nucleotide of a TSS and 0 to 100 additional nucleotides. In some embodiments, the TSS is a terminal spacer. In one embodiment, the leading untranslated sequence contains a guanosine at the 5’ end upon translation of an RNA T7 polymerase.
[0306] In certain embodiments, the 5’ enhanced intron element comprises a trailing untranslated sequence. In some embodiments, the 5' trailing untranslated sequence is located at the 3’ end of the 5’ enhanced intron element. In some embodiments, the trailing untranslated sequence is a partial restriction digest sequence. In one embodiment, the trailing untranslated sequence is in whole or in part a restriction digest site used to linearize the DNA template. In some embodiments, the restriction digest site is in whole or in part from a natural viral, bacterial or eukaryotic DNA template. In some embodiments, the trailing untranslated sequence is a terminal restriction site fragment. a. Enhanced Intron Fragments
[0307] In some embodiments, the 3’ enhanced intron element and 5’ enhanced intron element each comprise an intron fragment. In certain embodiments, a 3 ’ intron fragment is a contiguous sequence at least 75% homologous (e.g.. at least 80%, 85%, 90%. 91%. 92%, 93%, 94%, 95%, 96%. 97%. 98%, 99% or 100% homologous) to a 3’ proximal fragment of a natural group I or II intron including the 3’ splice site dinucleotide. Typically, a 5’ intron fragment is a contiguous sequence at least 75% homologous (e.g.. at least 80%. 85%. 90%, 91%. 92%. 93%, 94%, 95%. 96%, 97%, 98%. 99% or 100% homologous) to a 5’ proximal fragment of a natural group I or II intron including the 5’ splice site dinucleotide. In some embodiments, the 3’ intron fragment includes the first nucleotide of a 3’ group I or II splice site dinucleotide. In some embodiments, the 5’ intron fragment includes the first nucleotide of a 5’ group I or II splice site dinucleotide. In other embodiments, the 3’ intron fragment includes the
first and second nucleotides of a 3’ group I or II intron fragment splice site dinucleotide; and the 5’ intron fragment includes the first and second nucleotides of a 3’ group I or II intron fragment dinucleotide. In some embodiments the 3' enhanced intron element and 5’ enhanced intron element comprises a synthetic intron fragment. b. Enhanced Exon Fragments
[0308] In certain embodiments, as provided herein, the DNA template, linear precursor RNA polynucleotide, and circular RNA polynucleotide each comprise an enhanced exon fragment. In some embodiments, following a 5’ to 3’ order, the 3’ enhanced exon element is located upstream to core functional element. In some embodiments, following a 5’ to 3’ order, the 5’ enhanced intron element is located downstream to the core functional element.
[0309] In some embodiments, the 3’ enhanced exon element and 5’ enhanced exon element each comprise an exon fragment. In some embodiments, the 3’ enhanced exon element comprises a 3' exon fragment. In some embodiments, the 5’ enhanced exon element comprises a 5’ exon fragment. In certain embodiments, as provided herein, the 3 ’ exon fragment and 5 ’ exon fragment each comprises a group I or II intron fragment and 1 to 100 nucleotides of an exon sequence. In certain embodiments, a 3’ intron fragment is a contiguous sequence at least 75% homologous (e.g., at least 80%. 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%. 98%, 99% or 100% homologous) to a 3’ proximal fragment of a natural group I or II intron including the 3' splice site dinucleotide. Typically, a 5’ group I or II intron fragment is a contiguous sequence at least 75% homologous (e.g., at least 80%, 85%, 90%, 91%. 92%, 93%, 94%, 95%, 96%. 97%. 98%, 99% or 100% homologous) to a 5’ proximal fragment of a natural group I or II intron including the 5 ’ splice site dinucleotide. In some embodiments, the 3 ’ exon fragment comprises a second nucleotide of a 3’ group I or II intron splice site dinucleotide and 1 to 100 nucleotides of an exon sequence. In some embodiments, the 5’ exon fragment comprises the first nucleotide of a 5’ group I or II intron splice site dinucleotide and 1 to 100 nucleotides of an exon sequence. In some embodiments, the exon sequence comprises in part or in whole from a naturally occurring exon sequence from a virus, bacterium or eukaryotic DNA vector. In other embodiments, the exon sequence further comprises a synthetic, genetically modified (e.g.. containing modified nucleotide), or other engineered exon sequence.
[0310] In one embodiment, where the 3’ intron fragment comprises both nucleotides of a 3’ group I or II splice site dinucleotide and the 5’ intron fragment comprises both nucleotides of a 5’ group I or II splice site dinucleotide, the exon fragments located within the 5’ enhanced exon element and 3’ enhanced exon element does not comprise of a group I or II splice site dinucleotide.
[0311] For means of example and not intended to be limiting, in some embodiment, a 3’ enhanced intron element comprises in the following 5’ to 3’ order: a leading untranslated sequence, a 5’ affinity
tag, an optional 5’ external duplex region, a 5’ external spacer, and a 3' intron fragment. In same embodiments, the 3’ enhanced exon element comprises in the following 5’ to 3’ order: a 3‘ exon fragment, an optional 5’ internal duplex region, an optional 5’ internal duplex region, and a 5’ internal spacer. In the same embodiments, the 5‘ enhanced exon element comprises in the following 5' to 3’ order: a 3’ internal spacer, an optional 3‘ internal duplex region, and a 5’ exon fragment. In still the same embodiments, the 3 ’ enhanced intron element comprises in the following 5 ’ to 3 ’ order: a 5 ’ intron fragment, a 3’ external spacer, an optional 3' external duplex region, a 3’ affinity tag, and a trailing untranslated sequence. ii. Core Functional Element
[0312] In some embodiments, the DNA template, linear precursor RNA polynucleotide, and circular RNA polynucleotide comprise a core functional element. In some embodiments, the core functional element comprises a coding or noncoding element. In certain embodiments, the core functional element may contain both a coding and noncoding element. In some embodiments, the core functional element further comprises translation initiation element (TIE) upstream to the coding or noncoding element. In some embodiments, the core functional element comprises a tennination element. In some embodiments, the termination element is located downstream to the TIE and coding element. In some embodiments, the termination element is located downstream to the coding element but upstream to the TIE. In certain embodiments, where the coding element comprises a noncoding region, a core functional element lacks a TIE and/or a termination element.
Hi. Coding or Noncoding Element
[0313] In some embodiments, the polynucleotides herein comprise a coding element, a noncoding element, or a combination of both. In some embodiments, the coding element comprises an expression sequence. In some embodiments, the coding element encodes at least one therapeutic protein.
[0314] In some embodiments, the circular RNA encodes two or more polypeptides. In some embodiments, the circular RNA is a bicistronic RNA. The sequences encoding the two or more polypeptides can be separated by a ribosomal skipping element or a nucleotide sequence encoding a protease cleavage site. In certain embodiments, the ribosomal skipping element encodes thosea-asigna virus 2A peptide (T2A). porcine teschoviros-1 2 A peptide (P2A), foot-and-mouth disease virus 2 A peptide (F2A), equine rhinitis A vims 2A peptide (E2A). cytoplasmic polyhedrosis vims 2A peptide (BmCPV 2A). or flacherie vims of B. mori 2A peptide (BmIFV 2A).
Hi. Translation Initiation Element (TIE)
[0315] As provided herein in some embodiments, the core functional element comprises at least one translation initiation element (TIE). TIEs are designed to allow translation efficiency of an encoded
protein. Thus, optimal core functional elements comprising only of noncoding elements lack any TIEs. In some embodiments, core functional elements comprising one or more coding element will further comprise one or more TIEs.
[0316] In some embodiments, a TIE comprises an untranslated region (UTR). In certain embodiments, the TIE provided herein comprise an internal ribosome entry site (IRES). Inclusion of an IRES pennits the translation of one or more open reading frames from a circular RNA (e.g., open reading frames that form the expression sequences). The IRES element attracts a eukaryotic ribosomal translation initiation complex and promotes translation initiation. See, e.g., Kaufman et al., Nuc. Acids Res. (1991) 19:4485- 4490; Gurtu et al., Biochem. Biophys. Res. Comm. (1996) 229:295-298; Rees et al., BioTechniques (1996) 20: 102-110; Kobayashi et al., BioTechniques (1996) 21 :399-402; and Mosser et al., BioTechniques 1997 22 150-161. In some embodiments, the IRES element is selected from those disclosed in international publication WO/2022/261490, the contents of which are hereby incorporated in their entireties. iv. Additional Accessory Elements (Sequence Elements)
[0317] As described in this disclosure, the circular RNA polynucleotide, linear RNA polynucleotide, and/or DNA template may further comprise of accessory elements. In certain embodiments, these accessory elements may be included within the sequences of the circular RNA, linear RNA polynucleotide and/or DNA template for enhancing circularization, translation or both. Accessory elements are sequences, in certain embodiments that are located with specificity between or within the enhanced intron elements, enhanced exon elements, or core functional element of the respective polynucleotide. As an example, but not intended to be limiting, an accessory element includes, a IRES transacting factor region, a miRNA binding site, a restriction site, an RNA editing region, a structural or sequence element, a granule site, a zip code element, an RNA trafficking element or another specialized sequence as found in the art that enhances promotes circularization and/or translation of the protein encoded within the circular RNA polynucleotide.
[0318] In certain embodiments, the accessory element comprises an IRES transacting factor (ITAF) region. In some embodiments, the IRES transacting factor region modulates the initiation of translation through binding to PCBP1 - PCBP4 (polyC binding protein), PABP1 (poly A binding protein). PTB (polyprimidine tract binding), Argonaute protein family, HNRNPK (Heterogeneous nuclear ribonucleoprotein K protein), or La protein. In some embodiments, the IRES transacting factor region comprises a poly A. polyC, poly AC. or polyprimidine track.
[0319] In some embodiments, the ITAF region is located within the core functional element. In some embodiments, the ITAF region is located within the TIE.
[0320] In certain embodiments, the accessory element comprises a miRNA binding site. In some embodiments the miRNA binding site is located within the 5’ intron element, 5’ exon element, core functional element, 3’ exon element, and/or 3’ intron element.
[0321] In some embodiments, wherein the miRNA binding site is located within the spacer within the intron element or exon element. In certain embodiments, the miRNA binding site comprises the entire spacer regions.
[0322] In some embodiments, the 5’ intron element and 3' intron elements each comprise identical miRNA binding sites. In another embodiment, the miRNA binding site of the 5’ intron element comprises a different, in length or nucleotides, miRNA binding site than the 3’ intron element. In one embodiment, the 5’ exon element and 3' exon element comprise identical miRNA binding sites. In other embodiments, the 5’ exon element and 3’ exon element comprises different, in length or nucleotides, miRNA binding sites.
[0323] In some embodiments, the miRNA binding sites are located adjacent to each other within the circular RNA polynucleotide, linear RNA polynucleotide precursor, and/or DNA template. In certain embodiments, the first nucleotide of one of the miRNA binding sites follows the first nucleotide last nucleotide of the second miRNA binding site.
[0324] In some embodiments, the miRNA binding site is located within a translation initiation element (TIE) of a core functional element. In one embodiment, the miRNA binding site is located before, trailing or within an internal ribosome entry site (IRES). In another embodiment, the miRNA binding site is located before, trailing, or within an aptamer complex.
[0325] The unique sequences defined by the miRNA nomenclature are widely known and accessible to those working in the micrcircRNA field. For example, they can be found in the miRDB public database. v. Natural Ties: Viral & Eukaryotic'Cellular Internal Ribosome Entry: Sites (IRES)
[0326] A multitude of IRES sequences are available and include sequences derived from a wide variety of viruses, such as from leader sequences of piccircRNAviruses such as the encephalomyocarditis virus (EMCV) UTR (lang et al., J. Virol. (1989) 63: 1651-1660), the polio leader sequence, the hepatitis A virus leader, the hepatitis C virus IRES, human rhinovirus type 2 IRES (Dobrikova et al., Proc. Natl. Acad. Sci. (2003) 100(25): 15125- 15130). an IRES element from the foot and mouth disease virus (Ramesh et al., Nucl. Acid Res. (1996) 24:2697-2700), a giardiavirus IRES (Garlapati et al., J. Biol. Chem. (2004) 279(5):3389-3397), and the like.
[0327] For driving protein expression, the circular RNA comprises an IRES operably linked to a protein coding sequence. Modifications of IRES and accessory sequences are disclosed herein to increase or reduce IRES activities, for example, by truncating the 5’ and/or 3’ ends of the IRES, adding a spacer 5’ to the IRES, modifying tire 6 nucleotides 5’ to the translation initiation site (Kozak sequence), modification of alternative translation initiation sites, and creating chimeric/hybrid IRES sequences. In some embodiments, the IRES sequence in the circular RNA disclosed herein comprises one or more of these modifications relative to a native IRES.
[0328] In some embodiments, the IRES is an IRES sequence of Taura syndrome virus, Triatoma virus, Theiler's encephalomyelitis virus, Simian Virus 40, Solenopsis invicta virus 1, Rhopalosiphum padi virus, Reticuloendotheliosis virus, Human poliovirus 1, Plautia stali intestine virus, Kashmir bee virus, Human rhinovirus 2, Homalodisca coagulata virus- 1, Human Immunodeficiency Virus type 1, Himetobi P virus, Hepatitis C virus, Hepatitis A virus, Hepatitis GB virus , Foot and mouth disease virus, Human enterovirus 71, Equine rhinitis virus, Ectropis obliqua piccircRNA-like virus, Encephalomyocarditis virus. Drosophila C Virus, Human coxsackievirus B3, Crucifer tobamovirus, Cricket paralysis virus, Bovine viral diarrhea virus 1, Black Queen Cell Virus. Aphid lethal paralysis virus. Avian encephalomyelitis virus, Acute bee paralysis virus. Hibiscus chlorotic ringspot virus. Classical swine fever virus. Human FGF2, Human SFTPA1, Human AML1/RUNX1, Drosophila antennapedia. Human AQP4, Human AT1R, Human BAG-1, Human BCL2. Human BiP. Human c- IAP1, Human c-myc. Human eIF4G. Mouse NDST4L. Human LEF1, Mouse HIF1 alpha, Human n.myc. Mouse Gtx. Human p27kipl, Human PDGF2/c-sis, Human p53. Human Pim-1, Mouse Rbm3, Drosophila reaper, Canine Scamper, Drosophila Ubx, Human UNR, Mouse UtrA, Human VEGF-A, Human XIAP, Drosophila hairless, S. cerevisiae TFIID, S. cerevisiae YAP1, tobacco etch virus, turnip crinkle virus, EMCV-A, EMCV-B, EMCV-Bf, EMCV-Cf, EMCV pEC9, Picobirnavirus, HCV QC64, Human Cosavirus E/D, Human Cosavirus F, Human Cosavirus JMY, Rhinovirus NAT001, HRV14, HRV89. HRVC-02, HRV-A21, Salivirus A SHI. Salivirus FHB, Salivirus NG-J1, Human Parechovirus 1, Crohivirus B, Yc-3, Rosavirus M-7. Shanbavirus A, Pasivirus A, Pasivirus A 2, Echovirus E14, Human Parechovirus 5, Aichi Virus, Hepatitis A Virus HA16, Phopivirus, CVA10, Enterovirus C, Enterovirus D, Enterovirus J, Human Pcgivirus 2, GBV-C GT110, GBV-C K1737, GBV-C Iowa, Pegivirus A 1220, Pasivirus A 3, Sapelovirus, Rosavirus B, Bakunsa Virus, Tremovirus A, Swine Pasivirus 1, PLV-CHN, Pasivirus A, Sicinivirus, Hepacivirus K, Hepacivirus A, BVDV1, Border Disease Virus, BVDV2, CSFV-PK15C, SF573 Dicistrovirus, Hubei PiccircRNA-like Virus, CRPV, Salivirus A BN5, Salivirus A BN2, Salivirus A 02394, Salivirus A GUT. Salivirus A CH. Salivirus A SZ1, Salivirus FHB, CVB3, CVB1. Echovirus 7, CVB5, EVA71. CVA3, CVA12, EV24 or an aptamer to eIF4G.
[0329] In some embodiments, the IRES comprises in whole or in part from a eukaryotic or cellular IRES. In certain embodiments, the IRES is from a human gene, where the human gene is ABCF1, ABCG1, ACAD10, ACOT7, ACSS3, ACTG2, ADCYAP1, ADK, AGTR1, AHCYL2, AHI1, AKAP8L, AKR1A1, ALDH3A1, ALDOA, ALG13, AMMECR1L, ANGPTL4, ANK3, AOC3, AP4B1, AP4E1, APAF1, APBB1, APC, APH1A, APOBEC3D, APOM, APP, AQP4, ARHGAP36, ARL13B, ARMC8, ARMCX6, ARPC1A, ARPC2. ARRDC3, ASAP1, ASB3, ASB5, ASCL1, ASMTL, ATF2, ATF3, ATG4A. ATP5B, ATP6V0A1, ATXN3, AURKA, AURKA, AURKA, AURKA, B3GALNT1, B3GNTL1. B4GALT3, BAAT, BAG1, BAIAP2, BAIAP2L2, BAZ2A, BBX, BCAR1, BCL2, BCS1L. BET1, BID, BIRC2, BPGM, BPIFA2, BRINP2, BSG, BTN3A2, C12orf43, C14orf93. C17orf62, Clorf226, C21orf62. C2orfl5, C4BPB. C4orf22. C9orf84. CACNA1A, CALCOCO2, CAPN11. CASP12. CASP8AP2, CAV1, CBX5, CCDC120, CCDC17. CCDC186, CCDC51. CCN1, CCND1, CCNT1. CD2BP2. CD9. CDC25C, CDC42, CDC7, CDCA7L, CDIP1. CDK1, CDK11 A. CDKN1B. CEACAM7, CEP295NL, CFLAR, CHCHD7. CHIA, CHICI, CHMP2A. CHRNA2, CLCN3, CLEC12A, CLEC7A, CLECL1, CLRN1. CMSS1, CNIH1, CNR1, CNTN5, COG4, COMMD1, COMMD5, CPEB1. CPS1, CRACR2B. CRBN. CREM, CRYBG1. CSDE1, CSF2RA, CSNK2A1, CSTF3. CTCFL, CTH, CTNNA3, CTNNB1, CTNNB1. CTNND1, CTSL, CUTA, CXCR5. CYB5R3, CYP24A1, CYP3A5. DAG1, DAP3, DAP5, DAXX, DCAF4. DCAF7, DCLRE1A, DCP1A, DCTN1, DCTN2, DDX19B. DDX46, DEFB123, DGKA, DGKD, DHRS4, DHX15. DIO3, DLG1, DLL4, DMD UTR, DMD ex5, DMKN, DNAH6, DNAL4. DUSP13, DUSP19, DYNC1I2, DYNLRB2, DYRK1A, ECI2, ECT2, EIF1AD, EIF2B4, EIF4G1. EIF4G2, EIF4G3, ELANE, ELOVL6, ELP5, EMCN. ENO1, EPB41, ERMN, ERVV-1. ESRRG, ETFB, ETFBKMT, ETV1, ETV4, EXD1, EXT1, EZH2, FAM111B, FAM157A, FAM213A, FBXO25, FBXO9, FBXW7, FCMR, FGF1, FGF1, FGF1A, FGF2, FGF2, FGF-9. FHL5, FMRI, FN1, FOXP1, FTH1, FUBP1, G3BP1, GABBR1, GALC, GART, GAS7, gastrin, GATA1, GATA4, GFM2, GHR, GJB2, GLI1, GLRA2, GMNN, GPAT3, GPATCH3, GPR137, GPR34, GPR55, GPR89A, GPRASP1, GRAP2, GSDMB, GSTO2, GTF2B, GTF2H4, GUCY1B2, HAX1, HCST, HIGD1A, HIGD1B, HIPK1, HIST1H1C, HIST1H3H, HK1, HLA-DRB4, HMBS, HMGA1, HNRNPC, HOPX, HOXA2, HOXA3, HPCAL1, HR, HSP90AB1, HSPA1A, HSPA4L, HSPA5, HYPK, IFFO1, IFT74, IFT81, IGF1, IGF1R, IGF1R, IGF2, IL11, IL17RE, IL1RL1, IL1RN, IL32, IL6, ILF2, ILVBL, INSR, INTS13, IP6K1, ITGA4, ITGAE, KCNE4, KERA. KIAA0355, KIAA0895L, KIAA1324, KIAA1522, KIAA1683, KIF2C, KIZ, KLHL31, KLK7, KRR1, KRT14, KRT17, KRT33A, KRT6A, KRTAP10-2, KRTAP13- 3. KRTAP13-4. KRTAP5-11, KRTCAP2. LACRT, LAMB1, LAMB3, LANCL1. LBX2, LCAT, LDHA, LDHAL6A, LEF1, LINC-PINT, LMO3, LRRC4C. LRRC7, LRTOMT, LSM5, LTB4R, LYRM1, LYRM2. MAGEA11. MAGEA8, MAGEB1. MAGEB16. MAGEB3, MAPT, MARS. MC1R, MCCC1, METTL12, METTL7A, MGC16025. MGC16025, MIA2, MIA2. MITF, MKLN1, MNT, MORF4L2. MPD6, MRFAP1, MRPL21, MRPS12, MSI2. MSLN. MSN. MT2A. MTFR1L. MTMR2.
MTRR, MTUS1, MYB, MYC, MYCL, MYCN, MYL10, MYL3, MYLK, MYO1A, MYT2, MZB1, NAP1L1, NAVI, NBAS, NCF2, NDRG1, NDST2, NDUFA7, NDUFB11, NDUFC1, NDUFS1, NEDD4L, NFAT5, NFE2L2, NFE2L2, NFIA, NHEJ1, NHP2, NITI, NKRF, NME1-NME2, NPAT, NR3C1, NRBF2, NRF1, NTRK2, NUDCD1, NXF2, NXT2, ODC1, ODF2, OPTN, OR10R2, OR11L1, OR2M2, OR2M3, OR2M5, OR2T10, OR4C15, OR4F17, OR4F5, OR5H1, OR5K1, OR6C3, OR6C75, OR6N1, OR7G2, p53. P2RY4, PAN2, PAQR6, PARP4, PARP9, PC. PCBP4, PCDHGC3, PCLAF, PDGFB, PDZRN4, PELO, PEMT, PEX2, PFKM, PGBD4, PGLYRP3, PHLDA2, PHTF1, PI4KB, PIGC, PIM1, PKD2L1, PKM, PLCB4. PLD3, PLEKHA1, PLEKHB1, PLS3, PML. PNMA5, PNN, POC1A, POC1B, POLD2, POLD4. POU5F1. PPIG, PQBP1, PRAME, PRPF4. PRR11, PRRT1, PRSS8. PSMA2, PSMA3. PSMA4, PSMD11, PSMD4. PSMD6, PSME3, PSMG3, PTBP3, PTCHI, PTHLH, PTPRD. PUS7L, PVRIG, QPRT, RAB27A, RAB7B, RABGGTB. RAET1E, RALGDS, RALYL, RARB, RCVRN, REG3G. RFC5, RGL4, RGS19, RGS3. RHD, RINL. RIPOR2, RITA1. RMDN2, RNASE 1. RNASE4, RNF4. RPA2, RPL17. RPL21. RPL26L1, RPL28, RPL29, RPL41. RPL9, RPS11, RPS13, RPS14, RRBP1, RSU1, RTP2, RUNX1, RUNX1T1, RUNX1T1, RUNX2, RUSC1. RXRG. S100A13, S100A4. SAT1, SCHIP1, SCMH1. SEC14L1, SEMA4A. SERPINA1, SERPINB4, SERTAD3, SFTPD, SH3D19, SHC1, SHMT1. SHPRH. SIM1, SIRT5, SLC11A2, SLC12A4. SLC16A1, SLC25A3, SLC26A9, SLC5A11, SLC6A12. SLC6A19, SLC7A1, SLFN11, SLIRP, SMAD5. SMARCAD1. SMN1, SNCA, SNRNP200, SNRPB2, SNX12, SOD1. SOX 13. SOX5, SP8, SPARCL1, SPATA12, SPATA31C2, SPN, SPOP, SQSTM1. SRBD1, SRC, SREBF1, SRPK2, SSB, SSB, SSBP1, ST3GAL6, STAB1. STAMBP, STAU1, STAU1, STAU1, STAU1. STAU1, STK16, STK24. STK38, STMN1, STX7. SULT2B1, SYK, SYNPR, TAF1C, TAGLN, TANK, TAS2R40, TBC1D15, TBXAS1, TCF4, TDGF1, TDP2, TDRD3, TDRD5, TESK2, THAP6, THBD, THTPA, TIAM2, TKFC, TKTL1, TLR10. TM9SF2, TMC6, TMCO2, TMED10, TMEM116, TMEM126A, TMEM159, TMEM208, TMEM230, TMEM67, TMPRSS13, TMUB2, TNFSF4, TNIP3, TP53, TP53, TP73, TRAF1, TRAK1, TRIM31, TRIM6, TRMT1, TRMT2B, TRPM7, TRPM8, TSPEAR, TTC39B, TTLL11, TUBB6, TXLNB, TXNIP, TXNL1, TXNRD1, TYROBP, U2AF1, UBA1, UBE2D3, UBE2I, UBE2L3, UBE2V1, UBE2V2, UMPS, UNG, UPP2, USMG5, USP18, UTP14A, UTRN, UTS2, VDR, VEGFA, VEGFA, VEPH1, VIPAS39, VPS29, VSIG10L, WDHD1, WDR12, WDR4, WDR45, WDYHV1, WRAP53, XIAP, XPNPEP3, YAP1, YWHAZ, YY1AP1, ZBTB32, ZNF146, ZNF250, ZNF385A, ZNF408. ZNF410, ZNF423, ZNF43, ZNF502, ZNF512, ZNF513, ZNF580. ZNF609, ZNF707, or ZNRD1. vi. Synthetic Ties: Aptamer Complexes, Modified Nucleotides, IRES Variants & Other Engineered Ties
[0330] As contemplated herein, in some embodiments, a translation initiation element (TIE) comprises a synthetic TIE. In some embodiments, a synthetic TIE comprises aptamer complexes, synthetic IRES
or other engineered TIES capable of initiating translation of a linear RNA or circular RNA polynucleotide.
[0331] In some embodiments, one or more aptamer sequences is capable of binding to a component of a eukary otic initiation factor to either enhance or initiate translation. In some embodiments, aptamer may be used to enhance translation in vivo and in vitro by promoting specific eukary otic initiation factors (elF) (e.g., aptamer in WO2019081383A1 is capable of binding to eukary otic initiation factor 4F (eIF4F). In some embodiments, the aptamer or a complex of aptamers may be capable of binding to EIF4G, EIF4E, EIF4A, EIF4B, EIF3, EIF2, EIF5, EIF1, EIF1A, 40S ribosome, PCBP1 (polyC binding protein), PCBP2, PCBP3, PCBP4, PABP1 (polyA binding protein), PTB, Argonaute protein family, HNRNPK (heterogeneous nuclear ribonucleoprotein K), or La protein. vii. Termination Sequence
[0332] In some embodiments, the core functional element comprises a termination sequence. In some embodiments, the termination sequence comprises a stop codon. In one embodiment, the termination sequence comprises a stop cassette. In some embodiments, the stop cassette comprises at least 2 stop codons. In some embodiments, the stop cassette comprises at least 2 frames of stop codons. In the same embodiment, the frames of the stop codons in a stop cassette each comprise 1, 2 or more stop codons. In some embodiments, the stop cassette comprises a LoxP or a RoxStopRox, or frt-flanked stop cassette. In the same embodiment, the stop cassette comprises a lox-stop-lox stop cassette. viii. Variants
[0333] In some embodiments, a circular RNA polynucleotide provided herein comprises modified RNA nucleotides and/or modified nucleosides. In some embodiments, the modified nucleoside is nr C (5 -methylcytidine). In one embodiment, the modified nucleoside is m5U (5 -methyluridine). In another embodiment, the modified nucleoside is m6A (N6-methyladenosine). In another embodiment, the modified nucleoside is s2U (2-thiouridine). In another embodiment, the modified nucleoside is T (pseudouridine). In another embodiment, the modified nucleoside is Um (2'-O-methyluridine). In other embodiments, the modified nucleoside is m’A (1 -methyladenosine); m2A (2 -methyladenosine); Am (2’-0-methyladenosine); ms2m6A (2-methylthio-N6-methyladenosine); i6A (N6-isopentenyladenosine); ms2i6A (2-methylthio-N6isopentenyladenosine); io6A (N6-(cis-hydroxyisopentenyl)adenosine); ms2io6A (2-methylthio-N6-(cis-hydroxyisopentenyl)adenosine); g6A (N6- glycinylcarbamoyladenosine); t6A (N6-threonylcarbamoyladenosine); ms2t6A (2-methylthio-N6- threonyl carbamoyladenosine); m6t6A (N6-methyl-N6-threonylcarbamoyladenosine); hn6A(N6- hydroxynorvalylcarbamoyladenosine); ms2hn6A (2-methylthio-N6-hydroxynorvalyl carbamoyladenosine); Ar(p) (2’-O-ribosyladenosine (phosphate)); I (inosine); m11 (1 -methylinosine); m'lm (l,2’-O-dimethylinosine); m3C (3 -methylcytidine); Cm (2’-O-methylcytidine); s2C (2-
thiocytidine); ac4C (N4-acetylcytidine); f5C (5 -formylcytidine); m5Cm (5,2'-O-dimethylcytidine); ac4Cm (N4-acetyl-2’-O-methylcytidine); k2C (lysidine); m'G (1 -methylguanosine); m2G (N2- methylguanosine); m7G (7-methylguanosine); Gm (2'-O-methylguanosine); m2 2G (N2,N2- dimethylguanosine); m2Gm (N2,2’-O-dimethylguanosine); m2 2Gm (N2,N2,2’-O-trimethylguanosme); Gr(p) (2‘-O-ribosylguanosine(phosphate)); yW (wybutosine); 02yW (peroxywybutosine); OHyW (hydroxywybutosine); OHyW* (undennodified hydroxy wybutosine): imG (wyosine); mimG (methylwyosine); Q (queuosine); oQ (epoxy queuosine); galQ (galactosyl-queuosine); manQ (mannosy 1-queuosine); preQo (7-cyano-7-deazaguanosine); preQi (7-aminomethyl-7-deazaguanosine); G+ (archaeosine); D (dihydrouridine); m5Um (5,2’-O-dimethyluridine): s4U (4-thiouridine); m5s2U (5- methyl-2-thiouridine); s2Um (2-thio-2’-O-methyluridine); acp3U (3-(3-amino-3- carboxypropyl)uridine); ho5U (5-hydroxyuridine); mo5U (5-methoxyuridine); cmo5U (uridine 5- oxyacetic acid); mcmo5U (uridine 5-oxyacetic acid methyl ester); chm 'U (5- (carboxyhydroxymethyl)uridine)); mchm5U (5-(carboxyhydroxymethyl)uridine methyl ester); mcm5U (5-methoxy carbonylmethyluridine); mcm5Um (5-mcthoxycarbonylmctliyl-2'-O-mcthyluridinc): mcm5s2U (5-methoxycarbonylmethyl-2-thiouridine); nm7S2U (5-aminomethyl-2-thiouridine); mnm5U (5 -methylaminomethyluridine); mnm5s2U (5-methylaminomethyl-2-thiouridine); mnm5se2U (5- methylaminomethyl-2-selenouridine); ncm5U (5-carbamoylmethyluridine); ncm5Um (5- carbamoylmethyl-2'-O-methyluridine); cmnni5U (5-carboxymethylaminomethyluridine); cmnm5Um (5-carboxymethylaminomethyl-2'-O-methyluridine); cmnm5s2U (5-carboxymethylaminomethyl-2- thiouridine); m6 2A (N6,N6-dimethyladenosine); Im (2’-O-methylinosine); m4C (N4-methylcytidine); m4Cm (N4,2’-O-dimethylcytidine); hm’C (5-hydroxymethylcytidine); m3U (3 -methyluridine); cm5U (5 -carboxy methyluridine); m6Am (N6.2’-O-dimethyladenosine); m6 2Am (N6,N6,O-2’- trimethyladenosine); m27G (N2,7-dimethylguanosine); m2,27G (N2,N2,7-trimethylguanosine); m3Um (3,2’-O-dimethyluridine); m5D (5-methyldihydrouridine); fC 111 (5-formyl-2’-O-methylcytidine); m’Gm (l,2’-O-dimethylguanosine); m1Am (l,2’-O-dimethyladenosine); rm 5U (5- taurinomethyluridine); rm5s2U (5-taurinomethyl-2-thiouridine)); imG-14 (4-demethylwyosine); imG2 (isowyosine); or ac6A (N6-acetyladenosine).
[0334] In some embodiments, the modified nucleoside may include a compound selected from: pyridin-4-one ribonucleoside, 5 -aza-uridine, 2-thio-5 -aza-uridine, 2-thiouridine, 4-thio-pseudouridine, 2-thio-pseudouridine, 5-hydroxyuridine, 3 -methyluridine, 5-carboxymethyl-uridine, 1-carboxymethyl- pseudouridine, 5-propynyl-uridine, 1-propynyl-pseudouridine, 5-taurinomethyluridine, 1- taurinomethy 1-pseudouridine, 5-taurinomethy 1-2-thio-uridine, 1 -taurinome thy 1-4-thio-uridine, 5 - methyl-uridine, 1-methy 1-pseudouridine, 4-thio-l-methy 1-pseudouridine, 2-thio-l -methylpseudouridine, 1 -methyl- 1-deaza-pseudouridine, 2-thio-l-methyl-l-deaza-pseudouridine, dihydrouridine, dihydropseudouridine, 2-thio-dihydrouridine, 2-thio-dihydropseudouridine, 2-
methoxyuridine, 2-metlioxy-4-tliio-uridine, 4-methoxy-pseudouridine, 4-m ethoxy-2-thio- pseudouridine, 5-aza-cytidine, pseudoisocytidine, 3-methyl-cytidine, N4-acetylcytidine, 5- formylcytidine, N4-methylcytidine, 5-hydroxymethylcytidine, 1-metliyl-pseudoisocytidine, pyrrolo- cytidine, pyrrolo-pseudoisocytidine, 2-thio-cytidine, 2-thio-5-methyl-cytidine, 4-thio- pseudoisocy tidine. 4-thio- 1 -methy 1-pseudoisocy tidine, 4-thio- 1 -methy 1- 1 -deaza-pseudoisocy tidine, 1 - methyl- 1-deaza-pseudoisocytidine, zebularine, 5-aza-zebularine, 5-methyl-zebularine, 5-aza-2-thio- zebularine, 2-thio-zebularine, 2-methoxy-cytidine, 2-methoxy-5-methyl-cytidine, 4-methoxy- pseudoisocytidine. 4-methoxy-l-methyl-pseudoisocytidine, 2-aminopurine, 2, 6-diaminopurine. 7- deaza-adenme, 7-deaza-8-aza-adenine, 7-deaza-2-aminopurine, 7-deaza-8-aza-2-aminopurine, 7- deaza-2, 6-diaminopurine, 7-deaza-8-aza-2, 6-diaminopurine, 1 -methyladenosine, N6-methyladenosine, N6-isopentenyladenosine, N6-(cis-hydroxyisopentenyl)adenosine, 2-methylthio-N6-(cis- hydroxyisopentenyl) adenosine, N6-glycinylcarbamoyladenosine, N6-threonylcarbamoyladenosine, 2- methylthio-N6-threonyl carbamoyladenosine. N6.N6-dimethyladenosine. 7-methyladenine, 2- methylthio-adenine, 2-methoxy-adenine, inosine, 1 -methy 1-inosine, wyosine, wybutosine, 7-deaza- guanosine. 7-deaza-8-aza-guanosine, 6-thio-guanosine, 6-thio-7-deaza-guanosine, 6-thio-7-deaza-8- aza-guanosine. 7-methyl-guanosine. 6-thio-7-methyl-guanosine, 7-methylinosine, 6-methoxy- guanosine. 1 -methylguanosine, N2-methylguanosine, N2,N2-dimethylguanosine, 8-oxo-guanosine. 7- methyl-8-oxo-guanosine. 1 -methyl-6-thio-guanosine. N2-methyl-6-thio-guanosine. and N2,N2- dimethyl-6-thio-guanosine. In another embodiment, the modifications are independently selected from 5-methylcytosine, pseudouridine and 1 -methylpseudouridine.
[0335] In some embodiments, the modified ribonucleosides include 5-methylcytidine, 5- methoxyuridine, 1-methyl-pseudouridine, N6-methyladenosine, and/or pseudouridine. In some embodiments, such modified nucleosides provide additional stability and resistance to immune activation.
[0336] In particular embodiments, polynucleotides may be codon-optimized. A codon optimized sequence may be one in which codons in a polynucleotide encoding a polypeptide have been substituted in order to increase the expression, stability and/or activity of the polypeptide. Factors that influence codon optimization include, but are not limited to one or more of: (i) variation of codon biases between two or more organisms or genes or synthetically constructed bias tables, (ii) variation in the degree of codon bias within an organism, gene, or set of genes, (iii) systematic variation of codons including context, (iv) variation of codons according to their decoding tRNAs, (v) variation of codons according to GC %, either overall or in one position of the triplet, (vi) variation in degree of similarity to a reference sequence for example a naturally occurring sequence, (vii) variation in the codon frequency cutoff, (viii) structural properties of mRNAs transcribed from the DNA sequence, (ix) prior knowledge the function of the DNA sequences upon which design of the codon substitution set is to be based,
and/or (x) systematic variation of codon sets for each amino acid. In some embodiments, a codon optimized polynucleotide may minimize ribozyme collisions and/or limit structural interference between the expression sequence and the core functional element. ix. Payloads [0337] In some embodiments, the polynucleotide (e.g., circRNA) expression sequence encodes a therapeutic protein. In some embodiments, the therapeutic protein is selected from the proteins listed in the following table.
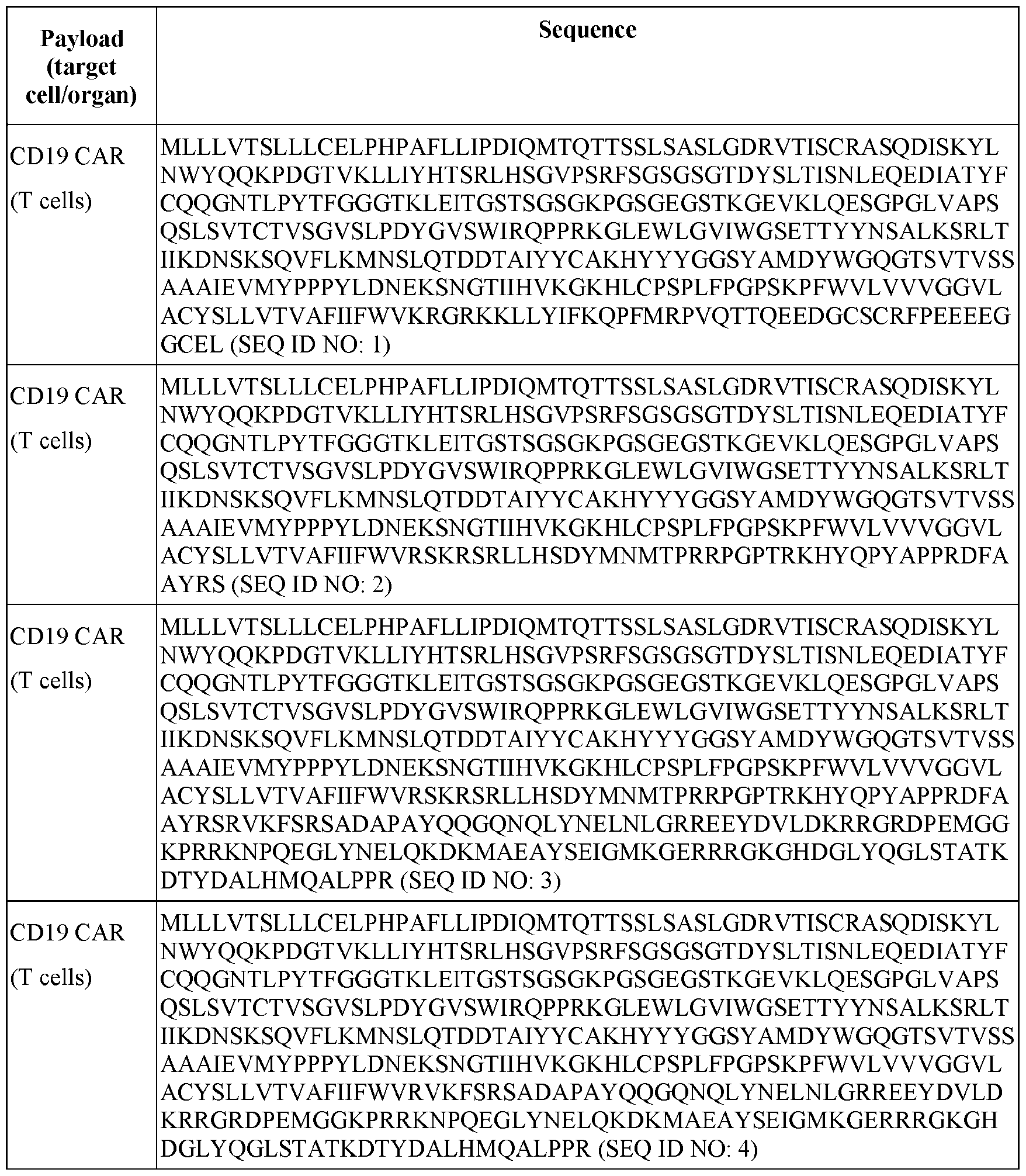

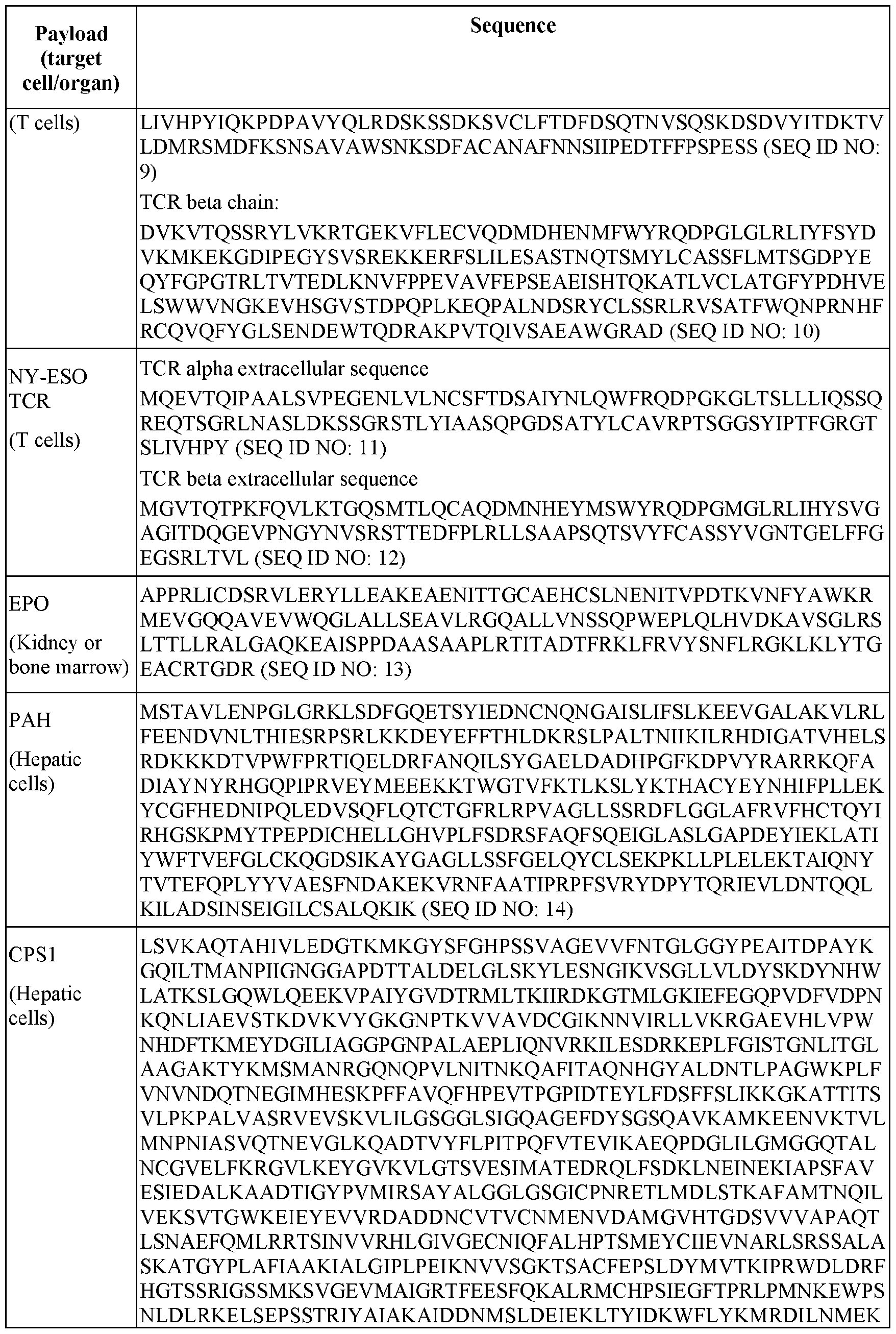
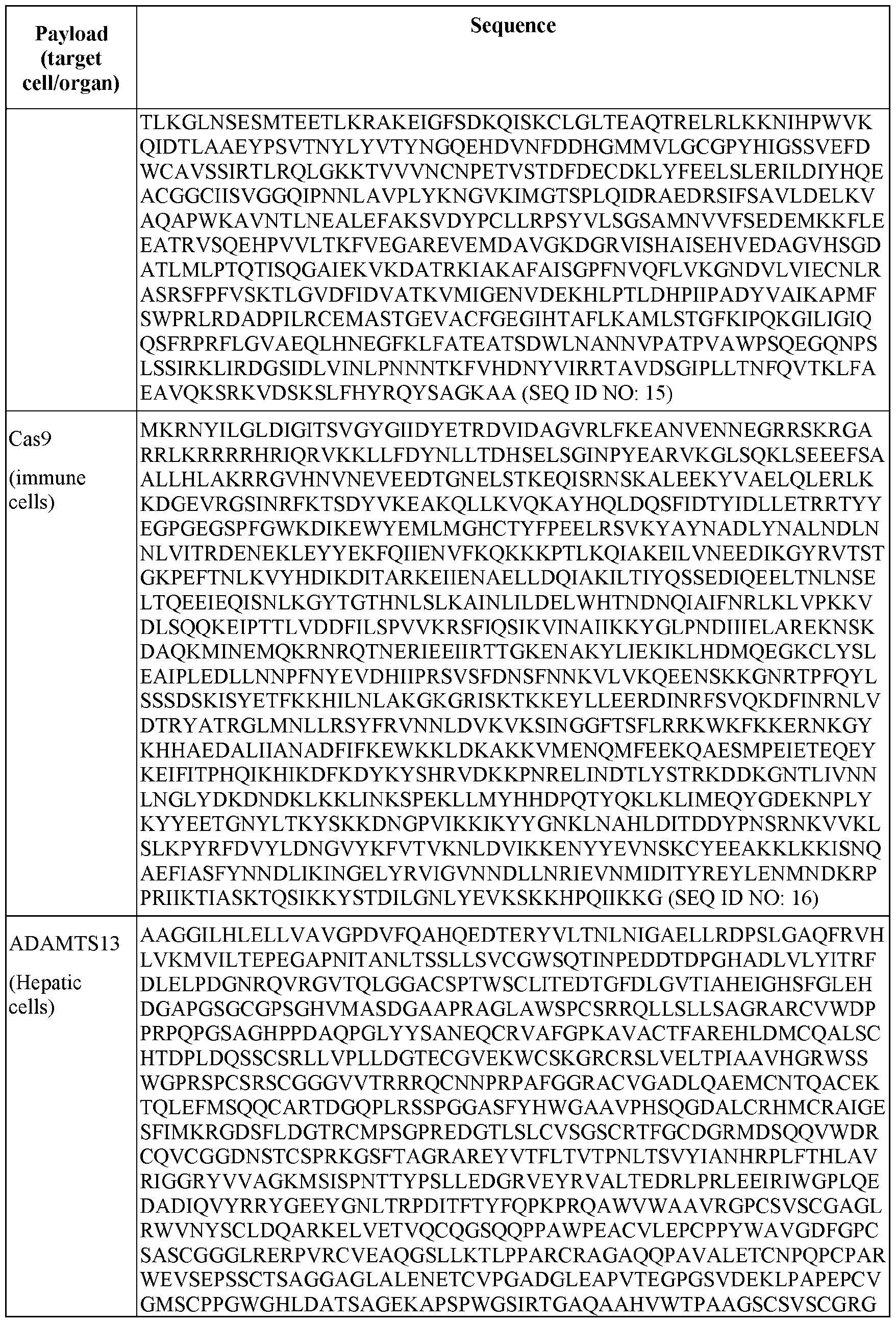


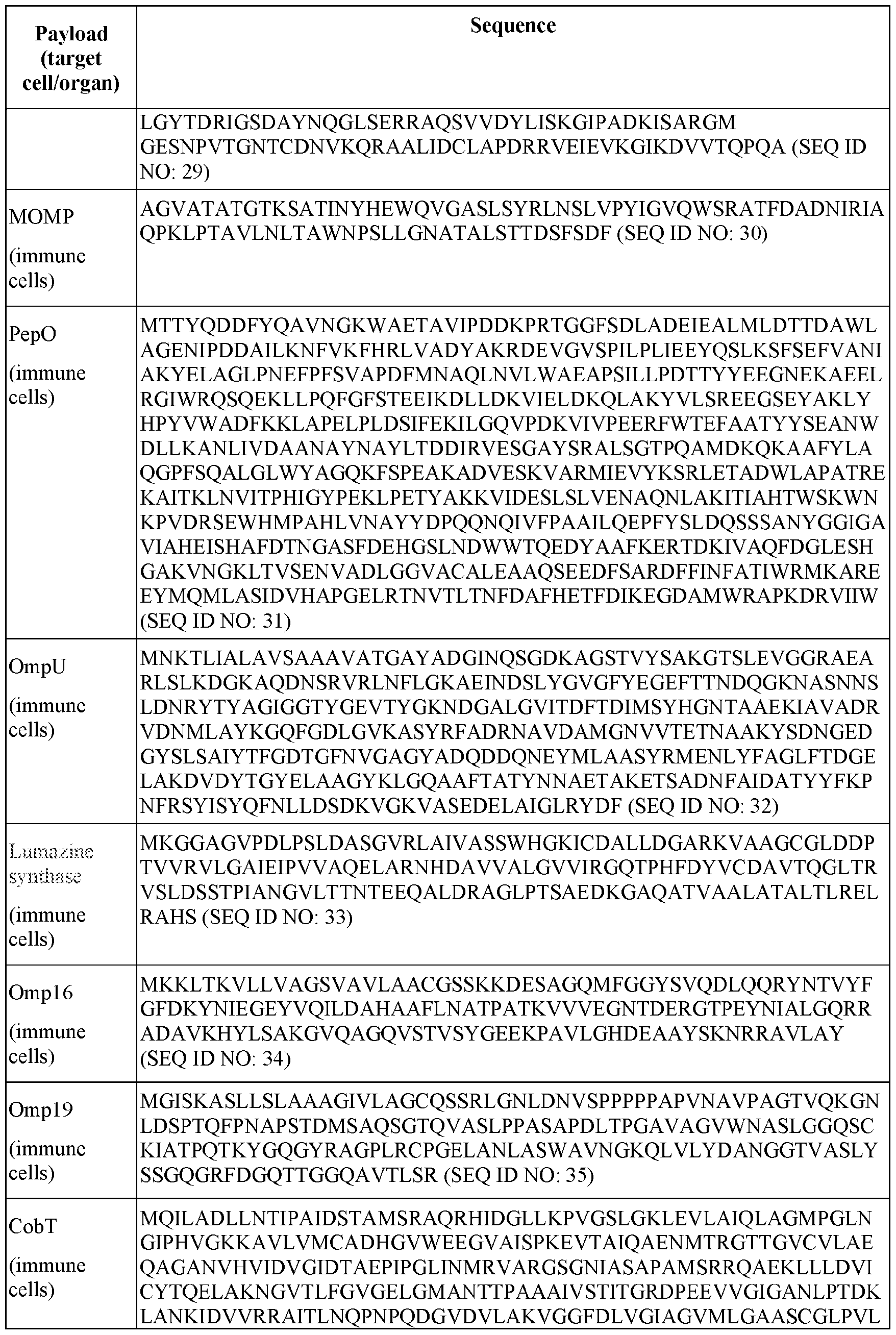

[0338] In some embodiments, the expression sequence encodes a therapeutic protein. In some embodiments, the expression sequence encodes a cytokine, e.g., IL-12p70, IL-15. IL-2, IL-18, IL-21,
IFN-a, IFN- β, IL-10, TGF-beta, IL-4, or IL-35, or a functional fragment thereof. In some embodiments, the expression sequence encodes an immune checkpoint inhibitor. In some embodiments, the expression sequence encodes an agonist (e.g., a TNFR family member such as CD137L, OX40L, ICOSL, LIGHT, or CD70). In some embodiments, the expression sequence encodes a chimeric antigen receptor. In some embodiments, the expression sequence encodes an inhibitory receptor agonist (e.g., PDL1, PDL2, Galectin-9, VISTA, B7H4, or MHCII) or inhibitory receptor (e.g., PD1, CTLA4. TIGIT, LAG3, or TIM3). In some embodiments, the expression sequence encodes an inhibitory receptor antagonist. In some embodiments, the expression sequence encodes one or more TCR chains (alpha and beta chains or gamma and delta chains). In some embodiments, the expression sequence encodes a secreted T cell or immune cell engager (e.g., a bispecific antibody such as BiTE, targeting, e.g.. CD3, CD137. or CD28 and a tumor-expressed protein e.g., CD19. CD20. or BCMA etc.). In some embodiments, the expression sequence encodes a transcription factor (e.g., F0XP3, HELIOS, TOX1, or T0X2). In some embodiments, the expression sequence encodes an immunosuppressive enzyme (e.g.. IDO or CD39/CD73). In some embodiments, the expression sequence encodes a GvHD (e.g., anti-HLA- A2 CAR-Tregs).
[0339] In some embodiments, the precursor RNA polynucleotide and circular RNA constructs comprise at least one expression sequence encoding an antigen, adjuvant, or adjuvant-like protein, e.g., from an infectious agent. In these embodiments, the circular RNA construct may be used as a vaccine. In some embodiments, the one or more circular RNA polynucleotide encodes an antigen or adjuvant derived from an infectious agent. In some embodiments the infectious agent from which the antigen or adjuvant is derived or engineered includes, but is not limited to a virus, bacterium, fungus, protozoan, and/or parasite. In some embodiments, the antigen is a viral antigen or viral antigenic polypeptide.
[0340] In an embodiment, the antigen is selected from or derived from the group consisting of rotavirus, foot and mouth disease virus, influenza A virus, influenza B virus, influenza C virus. H1N1, H2N2, H3N2, H5N1. H7N7, H1N2. H9N2, H7N2. H7N3, H10N7, human parainfluenza type 2, herpes simplex virus, Epstein -Barr virus, varicella virus, porcine herpesvirus 1, cytomegalovirus, lyssavirus, Bacillus anthracis. anthrax PA and derivatives, poliovirus, Hepatitis A, Hepatitis B. Hepatitis C, Hepatitis E, distemper virus. Venezuelan equine encephalomyelitis, feline leukemia virus, reovirus, respirator}' syncytial virus, Lassa fever virus, polyoma tumor virus, canine parv ovirus, papilloma virus, tick borne encephalitis virus, rinderpest virus, human rhinovirus species, Enterovirus species, Mcngovirus, paramy xovirus, avian infectious bronchitis virus, human T-cell leukemia-lymphoma virus 1, human immunodeficiency virus- 1, human immunodeficiency virus-2, lymphocytic choriomeningitis virus, parvovirus B19, adenovirus, rubella virus, yellow fever virus, dengue virus, bovine respiratory syncitial virus, corona virus, Bordetella pertussis, Bordetella bronchiseptica, Bordetella parapertussis, Brucella abortis. Brucella melitensis, Brucella suis, Brucella ovis, Brucella species, Escherichia coli,
Salmonella species, Salmonella typhi, Streptococci, Vibrio cholera, Vibrio parahaemolyticus, Shigella, Pseudomonas, tuberculosis, avium, Bacille Calmette Guerin, Mycobacterium leprae, Pneumococci, Staphlylococci, Enterobacter species, Rochalimaia henselae, Pasteurella haemolytica, Pasteurella multocida, Chlamydia trachomatis, Chlamydia psittaci, Lymphogranuloma venereum, Treponema pallidum, Haemophilus species, Mycoplasma bovigenitalium, Mycoplasma pulmonis, Mycoplasma species, Borrelia burgdorferi, Legionalla pneumophila, Colstridium botulinum, Corynebacterium diphtheriae, Yersinia entercolitica, Rickettsia rickettsii. Rickettsia typhi. Rickettsia prowsaekii, Ehrlichia chaffeensis, Anaplasma phagocytophilum. Plasmodium falciparum, Plasmodium vivax, Plasmodium malariae, Schistosomes, trypanosomes. Leishmania species. Filarial nematodes, trichomoniasis, sarcosporidiasis. Taenia saginata, Taenia solium, Leishmania, Toxoplasma gondii, Trichinella spiralis, coccidiosis, Eimeria tenella, Cryptococcus neoformans, Candida albican, Aspergillus fumigatus. coccidioidomycosis. Neisseria gonorrhoeae, malaria circumsporozoite protein, malaria merozoite protein, trypanosome surface antigen protein, pertussis, alphaviruses, adenovirus, diphtheria toxoid, tetanus toxoid, meningococcal outer membrane protein, streptococcal M protein. Influenza hemagglutinin, cancer antigen, tumor antigens, toxins, Clostridium perfringens epsilon toxin, ricin toxin, pseudomonas exotoxin, exotoxins, neurotoxins, cytokines, cytokine receptors, monokines, monokine receptors, plant pollens, animal dander, and dust mites.
[0341] In some embodiments, the antigenic polypeptide is a viral polypeptide from an adenovirus; Herpes simplex, type 1; Herpes simplex, type 2; encephalitis virus, papillomavirus, Varicella-zoster virus; Epstein-barr virus; Human cytomegalovirus; Human herpes virus, type 8; Human papillomavirus; BK virus; JC virus; Smallpox; polio virus; Hepatitis B virus; Human bocavirus; Parvovirus B19; Human astrovirus; Norwalk virus; coxsackievirus; hepatitis A virus; poliovirus; rhinovirus; Severe acute respiratory syndrome virus; Hepatitis C virus; Yellow Fever virus; Dengue virus; West Nile virus; Rubella virus; Hepatitis E virus; Human Immunodeficiency virus (HIV); Influenza virus; Guanarito virus; Junin virus; Lassa virus; Machupo virus; Sabia virus; Crimean-Congo hemorrhagic fever virus; Ebola virus; Marburg virus; Measles virus; Mumps virus; Parainfluenza virus; Respiratory syncytial virus; Human metapneumo virus; Hendra virus; Nipah virus; Rabies virus; Hepatitis D; Rotavirus; Orbivirus; Coltivirus; Banna virus; Human Enterovirus; Hanta virus; West Nile virus; Middle East Respiratory Syndrome Corona Virus; Japanese encephalitis virus; Vesicular exanthemavirus; SARS- CoV-2; Eastern equine encephalitis, or a combination of any tw o or more of the foregoing.
[0342] In some embodiments, the adjuvant is selected from or derived from the group consisting of BCSP31, MOMP, FomA, MymA, ESAT6, PorB, PVL, Porin, OmpA, PepO, OmpU, Lumazine synthase, 0mpl6, Ompl9, CobT, RpfE, Rv0652, HBHA, NhlrA, DnaJ, Pneumolysin, Falgellin, IFN- alpha, IFN-gamma, IL-2, IL-12, IL-15, IL-18, IL-21, GM-CSF, IL-lb, IL-6, TNF-a, IL-7, IL-17, IL- IBeta, anti-CTLA4, anti-PDl, anti-41BB. PD-L1, Tim-3, Lag-3, TIGIT, GITR, and andti-CD3.
[0343] In some embodiments, a polynucleotide encodes a protein that is made up of subunits that are encoded by more than one gene. For example, the protein may be a heterodimer, wherein each chain or subunit of the protein is encoded by a separate gene. It is possible that more than one circRNA molecule is delivered in the transfer vehicle and each circRNA encodes a separate subunit of the protein. Alternatively, a single circRNA may be engineered to encode more than one subunit. In certain embodiments, separate circRNA molecules encoding the individual submits may be administered in separate transfer vehicles.
[0344] Additional polynucleotides, including expression sequences, and lipids are in WO2019236673; WO2020237227; WO2021113777; WO2021226597; WO2021189059; WO2021236855;
WO2022261490; W02023056033; WO2023081526; the contents of which are hereby incorporated by reference in their entireties.
(1) Chimeric Antigen Receptors (CARS)
[0345] Chimeric antigen receptors (CARs or CAR-Ts) are genetically -engineered receptors. These engineered receptors may be inserted into and expressed by immune cells, including T cells via circular RNA as described herein. With a CAR, a single receptor may be programmed to both recognize a specific antigen and. when bound to that antigen, activate the immune cell to attack and destroy the cell bearing that antigen. When these antigens exist on tumor cells, an immune cell that expresses the CAR may target and kill the tumor cell. In some embodiments, the CAR encoded by the polynucleotide comprises (i) an antigen-binding molecule that specifically binds to a target antigen, (ii) a hinge domain, a transmembrane domain, and an intracellular domain, and (iii) an activating domain.
[0346] In some embodiments, an orientation of the CARs in accordance with the disclosure comprises an antigen binding domain (such as an scFv) in tandem with a costimulatory domain and an activating domain. The costimulatory domain may comprise one or more of an extracellular portion, a transmembrane portion, and an intracellular portion. In other embodiments, multiple costimulatory domains may be utilized in tandem.
[0347] CARs may be engineered to bind to an antigen (such as a cell-surface antigen) by incorporating an antigen binding molecule that interacts with that targeted antigen. In some embodiments, the antigen binding molecule is an antibody fragment thereof, e.g., one or more single chain antibody fragment (scFv). An scFv is a single chain antibody fragment having the variable regions of the heavy and light chains of an antibody linked together. See U.S. Patent Nos. 7.741.465. and 6.319,494 as well as Eshhar et al., Cancer Immunol Immunotherapy (1997) 45: 131- 136. An scFv retains the parent antibody's ability to specifically interact with target antigen. scFvs are useful in chimeric antigen receptors because they may be engineered to be expressed as part of a single chain along with the other CAR components. Id. See also Krause et al., J. Exp. Med., Volume 188, No. 4, 1998 (619-626); Finney et al., loumal of
Immunolog}', 1998, 161 : 2791-2797. It will be appreciated that the antigen binding molecule is typically contained within the extracellular portion of the CAR such that it is capable of recognizing and binding to the antigen of interest. Bispecific and multispecific CARs are contemplated within the scope of the present disclosure, with specificity to more than one target of interest.
[0348] In some embodiments, the antigen binding molecule comprises a single chain, wherein the heavy chain variable region and the light chain variable region are connected by a linker. In some embodiments, the VH is located at the N terminus of the linker and the VL is located at the C terminus of the linker. In other embodiments, the VL is located at the N terminus of the linker and the VH is located at the C tenninus of the linker. In some embodiments, the linker comprises at least 5, at least 8, at least 10, at least 13, at least 15, at least 18, at least 20. at least 25, at least 30, at least 35, at least 40, at least 45, at least 50, at least 60. at least 70, at least 80, at least 90, or at least 100 amino acids.
[0349] In some embodiments, the antigen binding molecule comprises a nanobody. In some embodiments, the antigen binding molecule comprises a DARPin. In some embodiments, the antigen binding molecule comprises an anticalin or other synthetic protein capable of specific binding to target protein.
[0350] In some embodiments, the CAR comprises an antigen binding domain specific for an antigen selected from CD19, CD123, CD22, CD30, CD171, CS-1, C-type lectin-like molecule-1. CD33, epidermal growth factor receptor variant III (EGFRvIII), ganglioside G2 (GD2), ganglioside GD3, TNF receptor family member B cell maturation (BCMA). Tn antigen ((Tn Ag) or (GalNAca-Ser/Thr)), prostate-specific membrane antigen (PSMA), Receptor tyrosine kinase-like orphan receptor 1 (ROR1), Fms-Like Tyrosine Kinase 3 (FLT3), Tumor-associated glycoprotein 72 (TAG72), CD38. CD44v6, Carcinoembryonic antigen (CEA), Epithelial cell adhesion molecule (EPCAM), B7H3 (CD276), KIT (CD117). Interleukin- 13 receptor subunit alpha-2, mesothelin, Interleukin 11 receptor alpha (IL-1 IRa). prostate stem cell antigen (PSCA), Protease Serine 21, vascular endothelial growth factor receptor 2 (VEGFR2), Lewis(Y) antigen, CD24, Platelet-derived growth factor receptor beta (PDGFR-beta), Stage-specific embryonic antigen-4 (SSEA-4), CD20, Folate receptor alpha, HER2. HER3, Mucin 1, cell surface associated (MUC1). epidermal growth factor receptor (EGFR), neural cell adhesion molecule (NCAM), Prostase, prostatic acid phosphatase (PAP), elongation factor 2 mutated (ELF2M), Ephrin B2, fibroblast activation protein alpha (FAP), insulin-like growth factor 1 receptor (IGF-I receptor), carbonic anhydrase IX (CAIX), Proteasome (Prosome, Macropain) Subunit, Beta Type, 9 (LMP2), glycoprotein 100 (gplOO), oncogene fusion protein consisting of breakpoint cluster region (BCR) and Abelson murine leukemia viral oncogene homolog 1 (Abl) (bcr-abl), tyrosinase, ephrin ty pc- A receptor 2 (EphA2), Fucosyl GM1, sialyl Lewis adhesion molecule (sLe), ganglioside GM3, transglutaminase 5 (TGS5), high molecular weight-melanoma-associated antigen (HMWMAA), o- acctyl-GD2 ganglioside (OAcGD2), Folate receptor beta, tumor endothelial marker 1 (TEM1/CD248),
tumor endothelial marker 7-related (TEM7R), claudin 6 (CLDN6), thyroid stimulating hormone receptor (TSHR), G protein-coupled receptor class C group 5, member D (GPRC5D). chromosome X open reading frame 61 (CXORF61), CD97, CD179a, anaplastic lymphoma kinase (ALK), Polysialic acid, placenta-specific 1 (PLAC1), hexasaccharide portion of globoH glycoceramide (GloboH), mammary gland differentiation antigen (NY-BR-1), uroplakin 2 (UPK2), Hepatitis A virus cellular receptor 1 (HAVCR1), adrenoceptor beta 3 (ADRB3), pannexin 3 (PANX3), G protein-coupled receptor 20 (GPR20), lymphocyte antigen 6 complex, locus K 9 (LY6K), Olfactory receptor 51E2 (OR51E2), TCR Gamma Alternate Reading Frame Protein (TARP), Wilms tumor protein (WT1), Cancer/testis antigen 1 (NY-ESO-1), Cancer/testis antigen 2 (LAGE-la), MAGE family members (including MAGE-A1, MAGE-A3 and MAGE-A4). ETS translocation-variant gene 6. located on chromosome 12p (ETV6-AML), sperm protein 17 (SPA17), X Antigen Family, Member 1A (XAGE1), angiopoietin-binding cell surface receptor 2 (Tie 2), melanoma cancer testis antigen-1 (MAD-CT-1). melanoma cancer testis antigen-2 (MAD-CT-2), Fos-related antigen 1, tumor protein p53 (p53), p53 mutant, prostein, surviving, telomerase, prostate carcinoma tumor antigen- 1, melanoma antigen recognized by T cells 1, Rat sarcoma (Ras) mutant, human Telomerase reverse transcriptase (hTERT), sarcoma translocation breakpoints, melanoma inhibitor of apoptosis (ML-IAP), ERG (transmembrane protease, serine 2 (TMPRSS2) ETS fusion gene). N-Acetyl glucosaminyl-transferase V (NA17), paired box protein Pax-3 (PAX3), Androgen receptor, Cyclin Bl, v-myc avian myelocytomatosis viral oncogene neuroblastoma derived homolog (MYCN), Ras Homolog Family Member C (RhoC), Tyrosinase-related protein 2 (TRP-2), Cytochrome P450 1B1 (CYP1B1), CCCTC-Binding Factor (Zinc Finger Protein)-Like, Squamous Cell Carcinoma Antigen Recognized By T Cells 3 (SART3), Paired box protein Pax-5 (PAX5). proacrosin binding protein sp32 (OY-TES1), lymphocyte-specific protein tyrosine kinase (LCK), A kinase anchor protein 4 (AKAP-4), synovial sarcoma, X breakpoint 2 (SSX2), Receptor for Advanced Glycation Endproducts (RAGE-1), renal ubiquitous 1 (RU1), renal ubiquitous 2 (RU2), legumain, human papilloma virus E6 (HPV E6), human papilloma virus E7 (HPV E7), intestinal carboxyl esterase, heat shock protein 70-2 mutated (mut hsp70-2), CD79a. CD79b, CD72, Leukocyte-associated immunoglobulin-like receptor 1 (LAIR1), Fc fragment of IgA receptor (FCAR or CD89), Leukocyte immunoglobulin-like receptor subfamily A member 2 (LILRA2), CD300 molecule-like family member f (CD300LF), C-type lectin domain family 12 member A (CLEC12A), bone marrow stromal cell antigen 2 (BST2), EGF-like module-containing mucin-like hormone receptorlike 2 (EMR2), lymphocyte antigen 75 (LY75), Glypican-3 (GPC3), Fc receptor-like 5 (FCRL5), MUC16, 5T4, 8H9, av|30 integrin, av06 integrin, alphafetoprotein (AFP), B7-H6, ca-125, CA9, CD44, CD44v7/8, CD52, E-cadlierin, EMA (epithelial membrane antigen), epithelial glycoprotein-2 (EGP-2), epithelial glycoprotein-40 (EGP-40). ErbB4, epithelial tumor antigen (ETA), folate binding protein (FBP), kinase insert domain receptor (KDR), k-light chain. LI cell adhesion molecule. MUC18, NKG2D, oncofetal antigen (h5T4). tumor/testis-antigen IB. GAGE. GAGE-1, BAGE, SCP-1, CTZ9.
SAGE, CAGE, CT10, MART-1, immunoglobulin lambda-like polypeptide 1 (IGLL1), Hepatitis B Surface Antigen Binding Protein (HBsAg), viral capsid antigen (VGA), early antigen (EA), EBV nuclear antigen (EBNA), HHV-6 p41 early antigen, HHV-6B U94 latent antigen, HHV-6B p98 late antigen , cytomegalovirus (CMV) antigen, large T antigen, small T antigen, adenovirus antigen, respiratory syncytial virus (RSV) antigen, haemagglutinin (HA), neuraminidase (NA), parainfluenza type 1 antigen, parainfluenza type 2 antigen, parainfluenza type 3 antigen, parainfluenza type 4 antigen, Human Metapneumovirus (HMPV) antigen, hepatitis C virus (HCV) core antigen, HIV p24 antigen, human T-cell lympotrophic virus (HTLV-1) antigen, Merkel cell polyoma virus small T antigen. Merkel cell polyoma virus large T antigen. Kaposi sarcoma-associated herpesvirus (KSHV) lytic nuclear antigen and KSHV latent nuclear antigen. In some embodiments, an antigen binding domain comprises SEQ ID NO: 321 and/or 322.
[0351] In some embodiments, a CAR comprises a hinge or spacer domain. In some embodiments, the hinge/spacer domain may comprise a truncated hinge/spacer domain (THD) the THD domain is a truncated version of a complete hinge/spacer domain (“CHD”). In some embodiments, an extracellular domain is from or derived from (e.g., comprises all or a fragment of) ErbB2, glycophorin A (GpA), CD2. CD3 delta, CD3 epsilon. CD3 gamma, CD4, CD7, CD8a. CD8[T CD1 la (IT GAL), CD1 lb (IT GAM), CD1 1c (ITGAX), CD1 Id (IT GAD), CD18 (ITGB2), CD19 (B4), CD27 (TNFRSF7), CD28, CD28T, CD29 (ITGB1), CD30 (TNFRSF8), CD40 (TNFRSF5), CD48 (SLAMF2). CD49a (ITGA1), CD49d (ITGA4). CD49f (ITGA6), CD66a (CEACAM1). CD66b (CEACAM8), CD66c (CEACAM6), CD66d (CEACAM3), CD66e (CEACAM5), CD69 (CLEC2), CD79A (B-cell antigen receptor complex-associated alpha chain). CD79B (B-cell antigen receptor complex-associated beta chain), CD84 (SLAMF5), CD96 (Tactile), CD100 (SEMA4D), CD103 (ITGAE), CD134 (0X40). CD137 (4- 1BB), CD150 (SLAMF1), CD158A (KIR2DL1), CD158B1 (KIR2DL2), CD158B2 (KIR2DL3), CD158C (KIR3DP1), CD158D (KIRDL4), CD158F1 (KIR2DL5A), CD158F2 (KIR2DL5B). CD158K (KIR3DL2), CD160 (BY55), CD162 (SELPLG), CD226 (DNAM1), CD229 (SLAMF3), CD244 (SLAMF4), CD247 (CD3-zeta), CD258 (LIGHT), CD268 (BAFFR), CD270 (TNFSF14), CD272 (BTLA), CD276 (B7-H3), CD279 (PD-1), CD314 (NKG2D), CD319 (SLAMF7), CD335 (NK-p46), CD336 (NK-p44), CD337 (NK-p30), CD352 (SLAMF6), CD353 (SLAMF8), CD355 (CRT AM), CD357 (TNFRSF18), inducible T cell co-stimulator (ICOS), LFA-1 (CD1 la/CD18), NKG2C, DAP-10, ICAM-1, NKp80 (KLRF1), IL-2R beta, IL-2R gamma, IL-7R alpha, LFA-1, SLAMF9, LAT, GADS (GrpL), SLP-76 (LCP2), PAG1/CBP, a CD83 ligand, Fc gamma receptor, MHC class 1 molecule, MHC class 2 molecule, a TNF receptor protein, an immunoglobulin protein, a cytokine receptor, an integrin, activating NK cell receptors, a Toll ligand receptor, and fragments or combinations thereof. A hinge or spacer domain may be derived either from a natural or from a synthetic source.
[0352] In some embodiments, a hinge or spacer domain is positioned between an antigen binding molecule (e.g., an scFv) and a transmembrane domain. In this orientation, the hinge/spacer domain provides distance between the antigen binding molecule and the surface of a cell membrane on which the CAR is expressed. In some embodiments, a hinge or spacer domain is from or derived from an immunoglobulin. In some embodiments, a hinge or spacer domain is selected from the hinge/spacer regions of IgGl, IgG2, IgG3, IgG4, IgA, IgD, IgE, IgM, or a fragment thereof. In some embodiments, a hinge or spacer domain comprises, is from, or is derived from the hinge/spacer region of CD8 alpha. In some embodiments, a hinge or spacer domain comprises, is from, or is derived from the hinge/spacer region of CD28. In some embodiments, a hinge or spacer domain comprises a fragment of the hinge/spacer region of CD8 alpha or a fragment of the hinge/spacer region of CD28, wherein the fragment is anything less than the whole hinge/spacer region. In some embodiments, the fragment of the CD8 alpha hinge/spacer region or the fragment of the CD28 hinge/spacer region comprises an amino acid sequence that excludes at least 1, at least 2, at least 3. at least 4. at least 5. at least 6, at least 7, at least 8, at least 9, at least 10, at least 11, at least 12, at least 13, at least 14, at least 15, at least 16, at least 17, at least 18, at least 19, or at least 20 amino acids at the N-terminus or C-Terminus. or both, of the CD8 alpha hinge/spacer region, or of the CD28 hinge/spacer region.
[0353] The CAR may further comprise a transmembrane domain and/or an intracellular signaling domain. The transmembrane domain may be designed to be fused to the extracellular domain of the CAR. It may similarly be fused to the intracellular domain of the CAR. In some embodiments, the transmembrane domain that naturally is associated with one of the domains in a CAR is used. In some instances, the transmembrane domain may be selected or modified (e.g.. by an amino acid substitution) to avoid binding of such domains to the transmembrane domains of the same or different surface membrane proteins to minimize interactions with other members of the receptor complex. The transmembrane domain may be derived either from a natural or from a synthetic source. Where the source is natural, the domain may be derived from any membrane -bound or transmembrane protein.
[0354] Transmembrane regions may be derived from (i.e., comprise) a receptor tyrosine kinase (e.g., ErbB2), glycophorin A (GpA), 4-1BB/CD137, activating NK cell receptors, an immunoglobulin protein, B7-H3, BAFFR. BFAME (SEAMF8), BTEA, CD100 (SEMA4D), CD103, CD160 (BY55), CD18, CD19, CD19a, CD2, CD247, CD27. CD276 (B7-H3), CD28, CD29, CD3 delta, CD3 epsilon, CD3 gamma, CD30, CD4, CD40, CD49a, CD49D, CD49f, CD69, CD7, CD84, CDSalpha, CD8beta, CD96 (Tactile), CD1 la, CD1 lb, CD1 1c, CD1 Id, CDS, CEACAM1, CRT AM, cytokine receptor, DAP-10, DNAM1 (CD226), Fc gamma receptor, GADS, GITR, HVEM (EIGHTR), IA4, ICAM-1, ICAM-1, Ig alpha (CD79a), IE-2R beta, IE-2R gamma, IE-7R alpha, inducible T cell costimulator (ICOS), integrins, ITGA4. ITGA4, ITGA6, IT GAD, ITGAE, ITGAE, IT GAM, ITGAX, ITGB2, ITGB7, ITGB1, KIRDS2, EAT, LFA-1, LFA-1, a ligand that specifically binds with CD83, LIGHT,
LIGHT, LTBR, Ly9 (CD229), lymphocyte function-associated antigen-1 (LFA-1; CDl-la/CD18), MHC class 1 molecule, NKG2C, NKG2D, NKp30, NKp44, NKp46, NKp80 (KLRF1), OX-40, PAG/Cbp, programmed death-1 (PD-1). PSGL1, SELPLG (CD162), Signaling Lymphocytic Activation Molecules (SLAM proteins), SLAM (SLAMF1; CD150; IPO-3), SLAMF4 (CD244; 2B4), SLAMF6 (NTB-A; Lyl08), SLAMF7, SLP-76, TNF receptor proteins, TNFR2, TNFSF14. a Toll ligand receptor, TRANCE/RANKL, VLA1, or VLA-6, or a fragment, truncation, or a combination thereof.
[0355] In some embodiments, suitable intracellular signaling domain include, but are not limited to, activating Macrophage/Myeloid cell receptors CSFR1, MYD88, CD14, TIE2, TLR4, CR3. CD64, TREM2, DAP10, DAP12, CD169, DECTIN1, CD206, CD47, CD163. CD36, MARCO. TIM4, MERTK, F4/80. CD91, C1QR, LOX-1, CD68, SRA, BAI-1, ABCA7, CD36, CD31, Lactoferrin, or a fragment, truncation, or combination thereof.
[0356] In some embodiments, a receptor tyrosine kinase may be derived from (e.g., comprise) Insulin receptor (InsR), Insulin-like growth factor I receptor (IGF1R), Insulin receptor-related receptor (IRR), platelet derived growth factor receptor alpha (PDGFRa), platelet derived growth factor receptor beta (PDGFRfi). KIT proto-oncogene receptor tyrosine kinase (Kit), colony stimulating factor 1 receptor (CSFR), fms related tyrosine kinase 3 (FLT3), fms related tyrosine kinase 1 (VEGFR-1), kinase insert domain receptor (VEGFR-2), fms related tyrosine kinase 4 (VEGFR-3), fibroblast growth factor receptor 1 (FGFR1). fibroblast growth factor receptor 2 (FGFR2). fibroblast growth factor receptor 3 (FGFR3). fibroblast growth factor receptor 4 (FGFR4), protein tyrosine kinase 7 (CCK4), neurotrophic receptor tyrosine kinase 1 (trkA). neurotrophic receptor tyrosine kinase 2 (trkB), neurotrophic receptor tyrosine kinase 3 (trkC). receptor tyrosine kinase like orphan receptor 1 (ROR1). receptor tyrosine kinase like orphan receptor 2 (ROR2), muscle associated receptor tyrosine kinase (MuSK), MET protooncogene, receptor tyrosine kinase (MET), macrophage stimulating 1 receptor (Ron), AXL receptor tyrosine kinase (Axl), TYR03 protein tyrosine kinase (Tyro3). MER proto-oncogene, tyrosine kinase (Mer). tyrosine kinase with immunoglobulin like and EGF like domains 1 (TIE1), TEK receptor tyrosine kinase (TIE2), EPH receptor Al (Eph Al), EPH receptor A2 (EphA2), (EPH receptor A3) EphA3, EPH receptor A4 (EphA4), EPH receptor A5 (EphA5), EPH receptor A6 (EphA6), EPH receptor A7 (EphA7), EPH receptor A8 (EphA8), EPH receptor A10 (EphAlO), EPH receptor Bl (EphBl), EPH receptor B2 (EphB2). EPH receptor B3 (EphB3), EPH receptor B4 (EphB4), EPH receptor B6 (EphB6), ret proto oncogene (Ret), receptor-like tyrosine kinase (RYK), discoidin domain receptor tyrosine kinase 1 (DDR1), discoidin domain receptor tyrosine kinase 2 (DDR2), c-ros oncogene 1, receptor tyrosine kinase (ROS), apoptosis associated ty rosine kinase (Lmrl), lemur tyrosine kinase 2 (Lmr2), lemur tyrosine kinase 3 (Lmr3), leukocyte receptor tyrosine kinase (LTK), ALK receptor tyrosine kinase (ALK), or serine/threonine/tyrosine kinase 1 (STYK1).
[0357] In some embodiments, the CAR comprises a costimulatory domain. In some embodiments, the costimulatory domain comprises 4-1BB (CD137), CD28, or both, and/or an intracellular T cell signaling domain. In a preferred embodiment, the costimulatory domain is human CD28, human 4- IBB, or both, and the intracellular T cell signaling domain is human CD3 zeta (Q. 4- IBB, CD28, CD3 zeta may comprise less than the whole 4- IBB, CD28 or CD3 zeta, respectively. Chimeric antigen receptors may incorporate costimulatory (signaling) domains to increase their potency. See U.S. Patent Nos. 7.741,465, and 6,319,494, as well as Krause et al. and Finney et al. (supra), Song et al.. Blood 119:696- 706 (2012); Kalos et al., Sci Transl. Med. 3:95 (2011); Porter etal., ~N. Engl. I. Med. 365:725-33 (2011), and Gross et al.. Amur. Rev. Pharmacol. Toxicol. 56:59-83 (2016).
[0358] In some embodiments, a costimulatory domain comprises the amino acid sequence of SEQ ID NO: 318 or 320.
[0359] The intracellular (signaling) domain of the engineered T cells disclosed herein may provide signaling to an activating domain, which then activates at least one of the normal effector functions of the immune cell. Effector function of a T cell, for example, may be cytolytic activity or helper activity including the secretion of cytokines.
[0360] In some embodiments, suitable intracellular signaling domain include (e.g., comprise), but are not limited to 4-1BB/CD137. activating NK cell receptors, an Immunoglobulin protein, B7-H3, BAFFR, BLAME (SLAMF8), BTLA, CD100 (SEMA4D). CD103. CD160 (BY55). CD18, CD19, CD 19a, CD2. CD247. CD27, CD276 (B7-H3), CD28, CD29, CD3 delta, CD3 epsilon, CD3 gamma, CD30, CD4, CD40, CD49a, CD49D, CD49f, CD69, CD7, CD84. CD8alpha, CD8beta, CD96 (Tactile), CD1 la, CD1 lb. CD1 1c, CD1 Id. CDS. CEACAM1, CRT AM. cytokine receptor, DAP-10. DNAM1 (CD226), Fc gamma receptor, GADS, GITR, HVEM (LIGHTR). IA4, ICAM-1. Ig alpha (CD79a). IL- 2R beta, IL-2R gamma, IL-7R alpha, inducible T cell costimulator (ICOS). integrins. ITGA4. ITGA6. ITGAD, ITGAE, ITGAL, ITGAM, ITGAX, ITGB2, ITGB7, ITGB1, KIRDS2, LAT, LFA-1, ligand that specifically binds with CD83, LIGHT. LTBR. Ly9 (CD229), Lyl08, lymphocyte function- associated antigen- 1 (LFA-1 ; CDl-la/CD18), MHC class 1 molecule, NKG2C, NKG2D. NKp30, NKp44, NKp46, NKp80 (KLRF1), OX-40, PAG/Cbp, programmed death-1 (PD-1), PSGL1, SELPLG (CD162), Signaling Lymphocytic Activation Molecules (SLAM proteins), SLAM (SLAMF1; CD150; IPO-3), SLAMF4 (CD244; 2B4), SLAMF6 (NTB-A), SLAMF7, SLP-76, TNF receptor proteins, TNFR2, TNFSF14, a Toll ligand receptor, TRANCE/RANKL, VLA1. or VLA-6, or a fragment, truncation, or a combination thereof.
[0361] CD3 is an element of the T cell receptor on native T cells, and has been shown to be an important intracellular activating element in CARs. In some embodiments, the CD3 is CD3 zeta. In some embodiments, the activating domain comprises an amino acid sequence at least 60%, at least 65%,
at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical to the polypeptide sequence of SEQ ID NO: 319.
[0362] In some embodiments, the sequence encoding the CAR comprises a sequence from Table a.
Table a








(2) T-Cell Receptors (TCR)
[0363] TCRs are described using the International Immunogenetics (IMGT) TCR nomenclature, and links to the IMGT public database of TCR sequences. Native alpha-beta heterodimeric TCRs have an alpha chain and a beta chain. Broadly, each chain may comprise variable, joining and constant regions, and the beta chain also usually contains a short diversity region between the variable and joining regions, but this diversity region is often considered as part of the joining region. Each variable region may comprise three CDRs (Complementarity Determining Regions) embedded in a framework sequence, one being the hypervariable region named CDR3. There are several types of alpha chain variable (Va) regions and several types of beta chain variable (Vβ) regions distinguished by their framework, CDR1 and CDR2 sequences, and by a partly defined CDR3 sequence. The Va types are referred to in IMGT nomenclature by a unique TRAV number. Thus “TRAV21” defines a TCR Va region having unique framework and CDR1 and CDR2 sequences, and a CDR3 sequence which is partly defined by an amino acid sequence which is preserved from TCR to TCR but which also includes an amino acid sequence which varies from TCR to TCR. In the same way, “TRBV5-1” defines a TCR Vβ region having unique framework and CDR1 and CDR2 sequences, but with only a partly defined CDR3 sequence.
[0364] The joining regions of the TCR are similarly defined by the unique IMGT TRAJ and TRBJ nomenclature, and the constant regions by the IMGT TRAC and TRBC nomenclature.
[0365] The beta chain diversity region is referred to in IMGT nomenclature by the abbreviation TRBD, and, as mentioned, the concatenated TRBD/TRBJ regions are often considered together as the joining region.
[0366] The unique sequences defined by the IMGT nomenclature are widely known and accessible to those working in the TCR field. For example, they can be found in the IMGT public database. The “T cell Receptor Factsbook”, (2001) LeFranc and LeFranc, Academic Press, ISBN 0-12-441352-8 also discloses sequences defined by the IMGT nomenclature, but because of its publication date and consequent time-lag, the information therein sometimes needs to be confirmed by reference to the IMGT database.
[0367] Native TCRs exist in heterodimeric αβ or γδ forms. However, recombinant TCRs consisting of aa or 00 homodimers have previously been shown to bind to peptide MHC molecules. Therefore, the TCR of the present disclosure may be a heterodimeric αβ TCR or may be an aa or 00 homodimeric TCR.
[0368] For use in adoptive therapy, an αβ heterodimeric TCR may, for example, be transfected as full length chains having both cytoplasmic and transmembrane domains. In certain embodiments TCRs of the present disclosure may have an introduced disulfide bond between residues of the respective constant domains, as described, for example, in WO 2006/000830.
[0369] TCRs of the present disclosure, particularly alpha-beta heterodimeric TCRs, may comprise an alpha chain TRAC constant domain sequence and/or a beta chain TRBC1 or TRBC2 constant domain sequence. The alpha and beta chain constant domain sequences may be modified by truncation or substitution to delete the native disulfide bond between Cys4 of exon 2 of TRAC and Cys2 of exon 2 of TRBC1 or TRBC2. The alpha and/or beta chain constant domain sequence(s) may also be modified by substitution of cysteine residues for Thr 48 of TRAC and Ser 57 of TRBC1 or TRBC2, the said cysteines forming a disulfide bond betw een the alpha and beta constant domains of the TCR.
[0370] Binding affinity (inversely proportional to the equilibrium constant KD) and binding half-life (expressed as T½ ) can be determined by any appropriate method. It will be appreciated that doubling the affinity of a TCR results in halving the KD. T½ is calculated as In 2 divided by the off-rate (koff). So doubling of T‘/z results in a halving in koff. KD and koff values for TCRs are usually measured for soluble forms of the TCR, i.e., those forms which are truncated to remove cytoplasmic and transmembrane domain residues. Therefore, it is to be understood that a given TCR has an improved binding affinity for, and/or a binding half-life for the parental TCR if a soluble form of that TCR has the said characteristics. In some embodiments, the binding affinity or binding half-life of a given TCR is measured several times, for example 3 or more times, using the same assay protocol, and an average of the results is taken.
[0371] Since the TCRs of the present disclosure have utility in adoptive therapy, the present disclosure includes a non-naturally occurring and/or purified and/or or engineered cell, especially a T-cell, presenting a TCR of the present disclosure. There are a number of methods suitable for the transfection
of T cells with nucleic acid (such as DNA, cDNA or RNA) encoding the TCRs of the present disclosure (see for example Robbins et al., (2008) J Immunol. 180: 6116-6131). T cells expressing the TCRs of the present disclosure will be suitable for use in adoptive therapy-based treatment of cancers such as those of the pancreas and liver. As will be known to those skilled in the art, there are a number of suitable methods by which adoptive therapy can be carried out (see for example Rosenberg et al., (2008) Nat Rev Cancer 8(4): 299-308).
[0372] As is well-known in the art TCRs of the present disclosure may be subject to post-translational modifications when expressed by transfected cells. Glycosylation is one such modification, which may comprise the covalent attachment of oligosaccharide moieties to defined amino acids in the TCR chain. For example, asparagine residues, or serine/threonine residues are well-known locations for oligosaccharide attachment. The glycosylation status of a particular protein depends on a number of factors, including protein sequence, protein conformation and the availability of certain enzymes. Furthermore, glycosylation status (i.e oligosaccharide type, covalent linkage and total number of attachments) can influence protein function. Therefore, when producing recombinant proteins, controlling glycosylation is often desirable. Glycosylation of transfected TCRs may be controlled by mutations of the transfected gene (Kuball J et al. (2009), J Exp Med 206(2):463-475). Such mutations are also encompassed in this disclosure.
[0373] A TCR may be specific for an antigen in the group MAGE-A1, MAGE-A2, MAGE -A3, MAGE-A4. MAGE-A5. MAGE-A6. MAGE-A7, MAGE-A8, MAGE-A9, MAGE-A10, MAGE-AIL MAGE-A12, MAGE-A13, GAGE-1, GAGE-2, GAGE-3, GAGE-4, GAGE-5, GAGE-6, GAGE-7. GAGE-8, BAGE-1, RAGE-1, LB33/MUM-1, PRAME. NAG, MAGE-Xp2 (MAGE-B2). MAGE-Xp3 (MAGE-B3), MAGE-Xp4 (AGE-B4). tyrosinase, brain glycogen phosphorylase. Melan-A, MAGE-CI, MAGE-C2, NY-ESO-1, LAGE-1. SSX-1, SSX-2(HOM-MEL-40), SSX-1. SSX-4. SSX-5, SCP-1, CT- 7, alpha-actinin-4, Bcr-Abl fusion protein, Casp-8, beta-catenin, cdc27. cdk4. cdkn2a. coa-1, dek-can fusion protein. EF2, ETV6-AML1 fusion protein, LDLR-fucosyltransferaseAS fusion protein, HLA- A2, HLA-A11, hsp70-2, KIAAO205, Mart2. Mum-2, and 3, neo-PAP, myosin class I. OS-9, pml-RARa fusion protein. PTPRK, K-ras, N-ras, Triosephosphate isomeras. GnTV, Herv-K-mel, Lage-1, Mage- C2, NA-88, Lage-2, SP17. and TRP2-Int2, (MART-I), gplOO (Pmel 17), TRP-1, TRP-2, MAGE-1, MAGE-3, pl5(58), CEA, NY-ESO (LAGE). SCP-1, Hom/Mel-40, p53, H-Ras, HER-2/neu, BCR- ABL, E2A-PRL, H4-RET, IGH-IGK, MYL-RAR, Epstein Barr virus antigens, EBNA, human papillomavirus (HPV) antigens E6 and E7, TSP-180, MAGE-4, MAGE-5, MAGE-6, pl85crbB2, pl80erbB-3, c-met, mn-23Hl, PSA, TAG-72-4, CA 19-9, CA 72-4, CAM 17.1, NuMa, K-ras, beta- catenin, CDK4, Mum-1, pl6, TAGE, PSMA, PSCA, CT7, telomerase, 43-9F, 5T4, 791Tgp72, a- fetoprotein, 13HCG, BCA225, BTAA, CA 125, CA 15-3 (CA 27.29\BCAA), CA 195, CA 242, CA- 50, CAM43, CD68\KP1. CO-029, FGF-5, G250, Ga733 (EpCAM), HTgp-175, M344, MA-50, MG7-
Ag, M0V18, NBM70K, NY-CO-1, RCAS1, SDCCAG16, TA-90 (Mac-2 binding protein\cyclopliilin C-associated protein), TAAL6, TAG72, TLP, and TPS.
(3) B-Cell Receptors (BCR)
[0374] B-cell receptors (BCRs) or B-cell antigen receptors are immunoglobulin molecules that form a ty pe I transmembrane protein on the surface of a B cell. A BCR is capable of transmitting activatory signal into a B cell following recognition of a specific antigen. Prior to binding of a B cell to an antigen, the BCR will remain in an unstimulated or “resting"’ stage. Binding of an antigen to a BCR leads to signaling that initiates a humoral immune response.
[0375] A BCR is expressed by mature B cells. These B cells work with immunoglobulins (Igs) in recognizing and tagging pathogens. The typical BCR comprises a membrane-bound immunoglobulin (e.g., mlgA, mlgD, mlgE, mlgG, and mlgM), along with associated and Ig /Igβ (CD79a/CD79b) heterodimers ( αβ ). These membrane -bound immunoglobulins are tetramers consisting of two identical heavy and two light chains. Within the BCR, the membrane bound immunoglobulins is capable of responding to antigen binding by signal transmission across the plasma membrane leading to B cell activation and consequently clonal expansion and specific antibody production (Friess M el al. (2018), Front. Immunol. 2947(9)). The Iga/Igβ heterodimers is responsible for transducing signals to the cell interior.
[0376] A Igα/Igβ heterodimer signaling relies on the presence of immunoreceptor tyrosine-based activation motifs (IT AMs) located on each of the cytosolic tails of the heterodimers. ITAMs comprise two tyrosine residues separated by 9-12 amino acids (e.g., tyrosine, leucine, and/or valine). Upon binding of an antigen, the tyrosine of the BCR’s ITAMs become phosphorylated by Src-family tyrosine kinases Blk. Fyn, or Lyn (Janeway C etal., Immunobiology: The Immune System in Health and Disease (Garland Science, 5th ed. 2001)).
(4) Other Chimeric Proteins
[0377] In addition to the chimeric proteins provided above, the circular RNA polynucleotide may encode for a various number of other chimeric proteins available in the art. The chimeric proteins may include recombinant fusion proteins, chimeric mutant protein, or other fusion proteins.
[0378] In some embodiments, the circular RNA polynucleotide encodes for an immune modulatory ligand. In certain embodiments, the immune modulatory ligand may be immunostimulatory; while in other embodiments, the immune modulatory ligand may be immunosuppressive.
[0379] In some embodiments, the circular RNA polynucleotide encodes for a cytokine. In some embodiments, the cytokine comprises a chemokine, interferon, interleukin, lymphokine, and tumor necrosis factor. Chemokines are chemotactic cytokine produced by a variety of cell types in acute and
chronic inflammation that mobilizes and activates white blood cells. An interferon comprises a family of secreted a-helical cytokines induced in response to specific extracellular molecules through stimulation of TLRs (Borden, Molecular Basis of Cancer (Fourth Edition) 2015). Interleukins are cytokines expressed by leukocytes.
[0380] Descriptions and/or amino acid sequences of IL -2, IL-7, IL-10, IL-12, IL-15, IL-18, IL -270, IFNy, and/or TGF01 are provided herein and at the www.uniprot.org database at accession numbers: P60568 (IL-2), P29459 (IL-12A), P29460 (IL-12B), P13232 (IL-7), P22301 (IL-10), P40933 (IL-15), Q14116 (IL-18). Q14213 (IL-270), P01579 (IFNy), and/or P01137 (TGF01).
[0381] In some embodiments, the circular RNA polynucleotide may encode for a transcription factor. Regulatory T cells (Treg) are important in maintaining homeostasis, controlling the magnitude and duration of the inflammatory response, and in preventing autoimmune and allergic responses.
[0382] In general, Tregs are thought to be mainly involved in suppressing immune responses, functioning in part as a “self-check’’ for the immune system to prevent excessive reactions. In particular, Tregs are involved in maintaining tolerance to self-antigens, harmless agents such as pollen or food, and abrogating autoimmune disease.
[0383] Tregs are found throughout the body including, without limitation, the gut, skin, lung, and liver. Additionally, Treg cells may also be found in certain compartments of the body that are not directly exposed to tire external environment such as the spleen, lymph nodes, and even adipose tissue. Each of these Treg cell populations is known or suspected to have one or more unique features and additional information may be found in Lehtimaki and Lahesmaa, Regulatory' T cells control immune responses through their non-redundant tissue specific features, 2013, FRONTIERS IN IMMUNOL., 4(294): 1- 10, the disclosure of which is hereby incorporated in its entirety.
[0384] Typically, Tregs are kno vn to require TGF-0 and IL-2 for proper activation and development. Tregs, expressing abundant amounts of the IL-2 receptor (IL-2R), are reliant on IL-2 produced by activated T cells. Tregs are known to produce both IL- 10 and TGF-0. both potent immune suppressive cytokines. Additionally, Tregs are known to inhibit the ability of antigen presenting cells (APCs) to stimulate T cells. One proposed mechanism for APC inhibition is via CTLA-4. which is expressed by Foxp3+ Tregs. It is thought that CTLA-4 may bind to B7 molecules on APCs and either block these molecules or remove them by causing internalization resulting in reduced availability of B7 and an inability’ to provide adequate co-stimulation for immune responses. Additional discussion regarding the origin, differentiation and function of Tregs may be found in Dhamne et al., Peripheral and thymic Foxp3+ regulatory' T cells in search of origin, distinction, and function, 2013, Frontiers in Immunol., 4 (253): 1-11, the disclosure of which is hereby incorporated in its entirety.
[0385] As provided herein, in certain embodiments, the coding element of the circular RNA polynucleotide encodes for one or more checkpoint inhibitors or agonists.
[0386] In some embodiments, the immune checkpoint inhibitor is an inhibitor of Programmed Death- Ligand 1 (PD-L1, also known as B7-H1, CD274), Programmed Death 1 (PD-1), CTLA-4, PD-L2 (B7- DC, CD273), LAG3, TIM3, 2B4, A2aR, B7H1, B7H3, B7H4, BTLA, CD2, CD27, CD28, CD30, CD40, CD70, CD80, CD86, CD137, CD160, CD226, CD276, DR3, GAL9, GITR, HAVCR2, HVEM, IDO1, IDO2, ICOS (inducible T cell costimulator), KIR, LAIR1, LIGHT, MARCO (macrophage receptor with collageneous structure), PS (phosphatidylserine), OX-40, SLAM, TIGHT, VISTA, VTCN1, or any combinations thereof. In some embodiments, the immune checkpoint inhibitor is an inhibitor of IDO1, CTLA4, PD-1, LAG3, PD-L1, TIM3, or combinations thereof. In some embodiments, the immune checkpoint inhibitor is an inhibitor of PD-L1. In some embodiments, the immune checkpoint inhibitor is an inhibitor of PD-1. In some embodiments, the immune checkpoint inhibitor is an inhibitor of CTLA-4. In some embodiments, the immune checkpoint inhibitor is an inhibitor of LAG3. In some embodiments, the immune checkpoint inhibitor is an inhibitor of TIM3. In some embodiments, the immune checkpoint inhibitor is an inhibitor of IDOL
[0387] As described herein, at least in one aspect, the present disclosure encompasses the use of immune checkpoint antagonists. Such immune checkpoint antagonists include antagonists of immune checkpoint molecules such as Cytotoxic T-Lymphocyte Antigen 4 (CTLA-4), Programmed Cell Death Protein 1 (PD-1), Programmed Death-Ligand 1 (PDL-1), Lymphocyte- activation gene 3 (LAG-3), and T-cell immunoglobulin and mucin domain 3 (TIM-3). An antagonist of CTLA-4, PD-1. PDL-1, LAG-3, or TIM-3 interferes with CTLA-4. PD-1, PDL-1, LAG-3, or TIM-3 function, respectively. Such antagonists of CTLA-4, PD-1. PDL-1, LAG-3, and TIM-3 can include antibodies which specifically bind to CTLA-4. PD-1. PDL-1, LAG-3, and TIM-3, respectively and inhibit and/or block biological activity and function.
[0388] In some embodiments, the payload encoded within one or more of the coding elements is a hormone, FC fusion protein, anticoagulant, blood clotting factor, protein associated with deficiencies and genetic disease, a chaperone protein, an antimicrobial protein, an enzyme (e.g.. metabolic enzyme), a structural protein (e g., a channel or nuclear pore protein), protein variant, small molecule, antibody, nanobody, an engineered non-body antibody, or a combination thereof.
A. PRODUCTION OF POLYNUCLEOTIDES
[0389] DNA templates can be made using standard techniques of molecular biology. For example, the various elements of the vectors provided herein can be obtained using recombinant methods, such as by screening cDNA and genomic libraries from cells, or by deriving the polynucleotides from a DNA template known to include the same.
[0390] The various elements of the DNA template can also be produced synthetically, rather than cloned, based on the known sequences. The complete sequence can be assembled from overlapping oligonucleotides prepared by standard methods and assembled into the complete sequence. See, e.g., Edge, Nature (1981) 292:756; Nambair et al., Science (1984) 223: 1299; and Jay et al., J. Biol. Chem. (1984) 259:631 1.
[0391] Thus, particular nucleotide sequences can be obtained from DNA template harboring the desired sequences or synthesized completely, or in part, using various oligonucleotide synthesis techniques known in the art, such as site-directed mutagenesis and polymerase chain reaction (PCR) techniques where appropriate. One method of obtaining nucleotide sequences encoding the desired DNA template elements is by annealing complementary sets of overlapping synthetic oligonucleotides produced in a conventional, automated polynucleotide synthesizer, followed by ligation with an appropriate DNA ligase and amplification of the ligated nucleotide sequence via PCR. See, e.g., Jayaraman et al., Proc. Natl. Acad. Sci. USA (1991) 88:4084-4088. Additionally, oligonucleotide- directed synthesis (Jones et al., Nature (1986) 54:75-82), oligonucleotide directed mutagenesis of preexisting nucleotide regions (Riechmann et al.. Nature (1988) 332:323-327 and Verhoeyen et al., Science (1988) 239: 1534-1536). and enzymatic filling-in of gapped oligonucleotides using T4 DNA polymerase (Queen et al., Proc. Natl. Acad. Sci. USA (1989) 86: 10029-10033) can be used.
[0392] The precursor RNA can be generated by incubating a DNA template under conditions permissive of transcription of the precursor RNA encoded by the DNA template. For example, in some embodiments a precursor RNA is synthesized by incubating a DNA template provided herein that comprises an RNA polymerase promoter upstream of its 5’ duplex sequence and/or expression sequences with a compatible RNA polymerase enzyme under conditions permissive of in vitro transcription. In some embodiments, the DNA template is incubated inside of a cell by a bacteriophage RNA polymerase or in the nucleus of a cell by host RNA polymerase II.
4. PHARMACEUTICAL COMPOSITIONS
[0393] In certain embodiments, provided herein are compositions (e.g., pharmaceutical compositions) comprising a therapeutic agent provided herein. In some embodiments, the therapeutic agent is a circular RNA polynucleotide. In some embodiments the therapeutic agent is a vector. In some embodiments, the therapeutic agent is a cell comprising a circular RNA or vector (e.g, a human cell, such as a human T cell). In certain embodiments, the composition further comprises a pharmaceutically acceptable carrier. In some embodiments, the compositions provided herein comprise a therapeutic agent provided herein in combination with other pharmaceutically active agents or drugs, such as antiinflammatory drugs or antibodies capable of targeting B cell antigens, e.g., anti-CD20 antibodies, e.g., rituximab.
[0394] With respect to pharmaceutical compositions, the pharmaceutically acceptable carrier can be any of those conventionally used and is limited only by chemical-physical considerations, such as solubility and lack of reactivity with the active agent(s), and by the route of administration. The pharmaceutically acceptable carriers described herein, for example, vehicles, adjuvants, excipients, and diluents, are well-known to those skilled in the art and are readily available to the public. It is preferred that the pharmaceutically acceptable carrier be one which is chemically inert to the therapeutic agent(s) and one which has no detrimental side effects or toxicity under the conditions of use.
[0395] The choice of carrier w ill be determined in part by the particular therapeutic agent, as w ell as by the particular method used to administer the therapeutic agent. Accordingly, there are a variety of suitable formulations of the pharmaceutical compositions provided herein.
[0396] In certain embodiments, the pharmaceutical composition comprises a preservative. In certain embodiments, suitable preservatives may include, for example, methylparaben, propylparaben, sodium benzoate, and benzalkonium chloride. Optionally, a mixture of tw o or more preservatives may be used. The preservative or mixtures thereof are typically present in an amount of 0.0001% to 2% by weight of the total composition.
[0397] In some embodiments, the pharmaceutical composition comprises a buffering agent. In some embodiments, suitable buffering agents may include, for example, citric acid, sodium citrate, phosphoric acid, potassium phosphate, and various other acids and salts. A mixture of two or more buffering agents optionally may be used. The buffering agent or mixtures thereof are typically present in an amount of 0.001% to 4% by weight of the total composition.
[0398] In some embodiments, the concentration of therapeutic agent in the pharmaceutical composition can vary, e.g., less than 1%, or at least 1%, 2%, 3%, 4%, 5%. 6%, 7%, 8%, 9% 10%. 15%, 20%, 25%, 30%, 35%, 40%. 45%, or 50% or more by weight, and can be selected primarily by fluid volumes, and viscosities, in accordance with the particular mode of administration selected.
[0399] The following formulations for oral, aerosol, parenteral (e.g., subcutaneous, intravenous, intraarterial, intramuscular, intradermal, intraperitoneal, and intrathecal), and topical administration are merely exemplary and are in no way limiting. More than one route can be used to administer the therapeutic agents provided herein, and in certain instances, a particular route can provide a more immediate and more effective response than another route.
[0400] Formulations suitable for oral administration can comprise or consist of (a) liquid solutions, such as an effective amount of the therapeutic agent dissolved in diluents, such as water, saline, or orange juice; (b) capsules, sachets, tablets, lozenges, and troches, each containing a predetermined amount of the active ingredient, as solids or granules: (c) powders; (d) suspensions in an appropriate
liquid; and (e) suitable emulsions. Liquid formulations may include diluents, such as water and alcohols, for example, ethanol, benzy l alcohol and the polyethylene alcohols, either with or without the addition of a pharmaceutically acceptable surfactant. Capsule forms can be of the ordinary hard- or soft-shelled gelatin type containing, for example, surfactants, lubricants, and inert fillers, such as lactose, sucrose, calcium phosphate, and com starch. Tablet forms can include one or more of lactose, sucrose, mannitol, corn starch, potato starch, alginic acid, microcrystalline cellulose, acacia, gelatin, guar gum, colloidal silicon dioxide, croscarmellose sodium, talc, magnesium stearate, calcium stearate, zinc stearate, stearic acid, and other excipients, colorants, diluents, buffering agents, disintegrating agents, moistening agents, preservatives, flavoring agents, and other pharmacologically compatible excipients. Lozenge forms can comprise the therapeutic agent with a flavorant, usually sucrose, acacia or tragacanth. Pastilles can comprise the therapeutic agent with an inert base, such as gelatin and glycerin, or sucrose and acacia, emulsions, gels, and the like containing, in addition to, such excipients as are known in the art.
[0401] Formulations suitable for parenteral administration include aqueous and nonaqueous isotonic sterile injection solutions, which can contain antioxidants, buffers, bacteriostats, and solutes that render the formulation isotonic with the blood of the intended recipient, and aqueous and nonaqueous sterile suspensions that can include suspending agents, solubilizers, thickening agents, stabilizers, and preservatives. In some embodiments, the therapeutic agents provided herein can be administered in a physiologically acceptable diluent in a pharmaceutical carrier, such as a sterile liquid or mixture of liquids including water, saline, aqueous dextrose and related sugar solutions, an alcohol such as ethanol or hexadecyl alcohol, a glycol such as propylene glycol or polyethylene glycol, dimethylsulfoxide, glycerol, ketals such as 2.2-dimethyl-l,3-dioxolane-4-methanol, ethers, poly(ethyleneglycol) 400, oils, fatty acids, fatty acid esters or glycerides, or acetylated fatty acid glycerides with or without the addition of a pharmaceutically acceptable surfactant such as a soap or a detergent, suspending agent such as pectin, carbomers, methylcellulose, hydroxypropylmethylcellulose, or carboxymethylcellulose, or emulsifying agents and other pharmaceutical adjuvants.
[0402] Oils, which can be used in parenteral formulations in some embodiments, include petroleum, animal oils, vegetable oils, or synthetic oils. Specific examples of oils include peanut, soybean, sesame, cottonseed, corn, olive, petrolatum, and mineral oil. Suitable fatty7 acids for use in parenteral formulations include oleic acid, stearic acid, and isostearic acid. Ethyl oleate and isopropyl myristate arc examples of suitable fatty acid esters.
[0403] Suitable soaps for use in certain embodiments of parenteral formulations include fatty alkali metal, ammonium, and triethanolamine salts, and suitable detergents include (a) cationic detergents such as, for example, dimethyl dialkyl ammonium halides, and alky l pyridinium halides, (b) anionic detergents such as, for example, alkyl, aryl, and olefin sulfonates, alky l, olefin, ether, and
monoglyceride sulfates, and sulfosuccinates, (c) nonionic detergents such as, for example, fatty’ amine oxides, fatty’ acid alkanolamides, and polyoxyethylenepolypropylene copolymers, (d) amphoteric detergents such as, for example, alkyl-β-aminopropionates, and 2-alkyl-imidazoline quaternary ammonium salts, and (e) mixtures thereof.
[0404] In some embodiments, the parenteral formulations will contain, for example, from 0.5% to 25% by weight of the therapeutic agent in solution. Preservatives and buffers may be used. In order to minimize or eliminate irritation at the site of injection, such compositions may contain one or more nonionic surfactants having, for example, a hydrophile-lipophile balance (HLB) of from 12 to 17. The quantity of surfactant in such formulations will ty pically range, for example, from 5% to 15% by weight. Suitable surfactants include polyethylene glycol, sorbitan, fatty acid esters such as sorbitan monooleate, and high molecular weight adducts of ethylene oxide with a hydrophobic base formed by the condensation of propylene oxide with propylene glycol. The parenteral formulations can be presented in unit-dose or multi-dose sealed containers, such as ampoules or vials, and can be stored in a freeze- dried (lyophilized) condition requiring only the addition of a sterile liquid excipient, for example, water for injections, immediately prior to use. Extemporaneous injection solutions and suspensions can be prepared from sterile powders, granules, and tablets of the kind previously described.
[0405] In certain embodiments, injectable formulations are provided herein. The requirements for effective pharmaceutical carriers for injectable compositions are well-known to those of ordinary skill in the art (see. e.g., Pharmaceutics and Pharmacy Practice, J.B. Lippincott Company, Philadelphia, PA. Banker and Chalmers, eds., pages 238-250 (1982), and ASHP Handbook on Injectable Drugs, ToisseL 4th ed. pages 622-630 (1986)).
[0406] In some embodiments, the therapeutic agents provided herein are formulated in time-released, delayed release, or sustained release delivery systems such that the delivery' of the composition occurs prior to, and with sufficient time to, cause sensitization of the site to be treated. Such systems can avoid repeated administrations of the therapeutic agent, thereby increasing convenience to the subject and the physician, and may be particularly suitable for certain composition embodiments provided herein. In one embodiment, the compositions of the invention are formulated such that they are suitable for extended release of the circRNA contained therein. Such extended-release compositions may be conveniently administered to a subject at extended dosing intervals. For example, in one embodiment, the compositions of the present invention are administered to a subject twice a day. daily' or every other day. In an embodiment, the compositions of the present invention are administered to a subject tw ice a week, once a week, every’ ten days, every two weeks, every three weeks, every four weeks, once a month, every’ six weeks, every eight weeks, every’ three months, every’ four months, every six months, every eight months, every’ nine months or annually.
[0407] In some embodiments, a protein encoded by a circRNA is produced by a target cell for sustained amounts of time. For example, the protein may be produced for more than one hour, more than four, more than six, more than 12, more than 24, more than 48 hours, or more than 72 hours after administration. In some embodiments the polypeptide is expressed at a peak level six horns after administration. In some embodiments the expression of the polypeptide is sustained at least at a therapeutic level. In some embodiments, the polypeptide is expressed at least at a therapeutic level for more than one, more than four, more than six, more than 12, more than 24, more than 48, or more than 72 hours after administration. In some embodiments, the polypeptide is detectable at a therapeutic level in patient tissue (e.g., liver or lung). In some embodiments, the level of detectable polypeptide is from continuous expression from the circRNA composition over periods of time of more than one, more than four, more than six, more than 12, more than 24. more than 48, or more than 72 hours after administration.
[0408] In certain embodiments, a protein encoded by circRNA is produced at levels above normal physiological levels. The level of protein may be increased as compared to a control. In some embodiments, the control is the baseline physiological level of the polypeptide in a nonnal individual or in a population of normal individuals. In other embodiments, the control is the baseline physiological level of the polypeptide in an individual having a deficiency in the relevant protein or polypeptide or in a population of individuals having a deficiency in the relevant protein or polypeptide. In some embodiments, the control can be the normal level of the relevant protein or polypeptide in the individual to whom the composition is administered. In other embodiments, the control is the expression level of the polypeptide upon other therapeutic intervention, e.g., upon direct injection of the corresponding polypeptide, at one or more comparable time points.
[0409] In certain embodiments, the levels of a protein encoded by a circRNA are detectable at 3 days, 4 days, 5 days, or 1 week or more after administration. Increased levels of protein may be observed in a tissue (e.g., liver or lung).
[0410] In some embodiments, the method yields a sustained circulation half-life of a protein encoded by a circRNA. For example, the protein may be detected for hours or days longer than the half-life observed via subcutaneous injection of the protein or mRNA encoding the protein. In some embodiments, the half-life of the protein is 1 day, 2 days. 3 days, 4 days, 5 days, or 1 week or more.
[0411] Many types of release delivery systems are available and known to those of ordinary skill in the art. They include polymer-based systems such as poly(lactide-glycolide), copolyoxalates, polycaprolactones, polyesteramides, polyorthoesters, polyhydroxybutyric acid, and polyanhydrides. Microcapsules of the foregoing polymers containing drugs are described in, for example, U.S. Patent 5,075.109. Delivery systems also include non-polymer systems drat are lipids including sterols such as
cholesterol, cholesterol esters, and fatty acids or neutral fats such as mono-di-and tri-glycerides; hydrogel release systems; sylastic systems; peptide based systems: wax coatings; compressed tablets using conventional binders and excipients; partially fused implants; and the like. Specific examples include but are not limited to: (a) erosional systems in which the active composition is contained in a form within a matrix such as those described in U.S. Patents 4,452,775, 4,667.014, 4,748,034, and 5.239,660 and (b) diffusional systems in which an active component penneates at a controlled rate from a polymer such as described in U.S. Patents 3,832,253 and 3,854,480. In addition, pump-based hardware delivery systems can be used, some of which are adapted for implantation.
[0412] In some embodiments, the therapeutic agent can be conjugated either directly or indirectly through a linking moiety to a targeting moiety. Methods for conjugating therapeutic agents to targeting moieties is known in the art. See. for instance, Wadwa et al.. J, Drug Targeting 3:111 (1995) and U.S. Patent 5,087,616.
[0413] In some embodiments, the therapeutic agents provided herein are formulated into a depot form, such that the manner in which the therapeutic agent is released into the body to which it is administered is controlled with respect to time and location within the body (see, for example, U.S. Patent 4,450, 150). Depot fonns of therapeutic agents can be, for example, an implantable composition comprising the therapeutic agents and a porous or non-porous material, such as a polymer, wherein the therapeutic agents are encapsulated by or diffused throughout the material and/or degradation of the non-porous material. The depot is then implanted into the desired location within the body and the therapeutic agents are released from the implant at a predetermined rate.
[0414] The present disclosure also contemplates the discriminatory' targeting of target cells and tissues by both passive and active targeting means. The phenomenon of passive targeting exploits the natural distributions patterns of a transfer vehicle in vivo without relying upon the use of additional excipients or means to enhance recognition of the transfer vehicle by target cells. For example, transfer vehicles which are subject to phagocytosis by the cells of the reticulo-endothelial system are likely to accumulate in the liver or spleen, and accordingly may provide a means to passively direct the delivery of the subject compositions to such target cells.
[0415] Alternatively, the present disclosure contemplates active targeting, which involves the use of targeting moieties that may be bound (either covalently or non-covalently) to the lipid nanoparticle to encourage localization of such at certain target cells or target tissues. For example, targeting may be mediated by’ the inclusion of one or more endogenous targeting moieties in or on the lipid nanoparticle to encourage distribution to the target cells or tissues. Recognition of the targeting moiety by the target tissues actively facilitates tissue distribution and cellular uptake of the lipid nanoparticle and/or its contents in the target cells and tissues (e.g.. the inclusion of an apolipoprotein-E targeting ligand
encourages recognition and binding of the lipid nanoparticle o endogenous low density lipoprotein receptors expressed by hepatocytes). As provided herein, the composition can comprise a moiety capable of enhancing affinity of the composition to the target cell. Targeting moieties may be linked to the outer layer of the lipid nanoparticle during formulation or post-formulation. In addition, some lipid nanoparticle formulations may employ fusogenic polymers such as PEAA, hemagluttinin, other lipopeptides (see U.S. patent application Ser. No. 08/835,281, and 60/083,294, which are incorporated herein by reference) and other features useful for in vivo and/or intracellular delivery. In some embodiments, the compositions of the present disclosure demonstrate improved transfection efficacies, and/or demonstrate enhanced selectivity towards target cells or tissues of interest. Contemplated therefore are compositions which comprise one or more moieties (e.g., peptides, aptamers, oligonucleotides, vitamins or other molecules) that are capable of enhancing the affinity of the compositions and their nucleic acid contents for the target cells or tissues. Suitable moieties may optionally be bound or linked to the surface of the nanoparticle. In some embodiments, the targeting moiety may span the surface of a nanoparticle or be encapsulated within the nanoparticle. Suitable moieties and are selected based upon their physical, chemical or biological properties (e.g.. selective affinity and/or recognition of target cell surface markers or features). Cell-specific target sites and their corresponding targeting ligand can vary widely. Suitable targeting moieties are selected such that the unique characteristics of a target cell are exploited, thus allowing the composition to discriminate between target and non-target cells. For example, compositions of the present disclosure may7 include surface markers (e.g., apolipoprotein-B (APOB) or apolipoprotein-E (APOE)) that selectively enhance recognition of. or affinity7 to hepatocytes (e.g., by receptor -mediated recognition of and binding to such surface markers). As an example, the use of galactose as a targeting moiety would be expected to direct the compositions of the present disclosure to parenchymal hepatocytes, or alternatively the use of mannose containing sugar residues as a targeting ligand would be expected to direct the compositions of the present disclosure to liver endothelial cells (e.g., mannose containing sugar residues that may bind preferentially to the asialoglycoprotein receptor present in hepatocytes). (See Hillery A M, et al. “Drug Delivery and Targeting: For Pharmacists and Pharmaceutical Scientists” (2002) Taylor & Francis, Inc.) The presentation of such targeting moieties that have been conjugated to moieties present in the lipid nanoparticle composition therefore facilitate recognition and uptake of the compositions of the present disclosure in target cells and tissues. Examples of suitable targeting moieties include one or more peptides, proteins, aptamers, vitamins and oligonucleotides.
[0416] In particular embodiments, a LNP composition comprises a targeting moiety, hi some embodiments, the targeting moiety mediates receptor-mediated endocytosis selectively into a specific population of cells. In some embodiments, the targeting moiety is operably connected, or linked, to the transfer vehicle. In some embodiments, the targeting moiety is capable of binding to an immune cell
antigen. In some embodiments, the targeting moiety is capable of binding to a T cell antigen. Exemplary T cell antigens include, but are not limited to, CD2, CD3, CD5, CD7, CD8, CD4, beta7 integrin, beta2ingetrin, and ClqR. In some embodiments, the targeting moiety is capable of binding to a NK, NKT, or macrophage antigen. In some embodiments, the targeting moiety is capable of binding to a protein selected from CD3, CD4, CD8. PD-1, 4- IBB. and CD2. In some embodiments, the targeting moiety is a single chain Fv (scFv) fragment, nanobody, peptide, peptide-based macrocycle, minibody, heavy chain variable region, light chain variable region or fragment thereof. In some embodiments, the targeting moiety is selected from T-cell receptor motif antibodies. T-cell a chain antibodies, T-cell p chain antibodies, T-cell y chain antibodies, T-cell 8 chain antibodies, CCR7 antibodies, CD3 antibodies, CD4 antibodies, CD5 antibodies. CD7 antibodies. CD8 antibodies, CDl lb antibodies, CDl lc antibodies, CD 16 antibodies. CD 19 antibodies, CD20 antibodies, CD21 antibodies. CD 22 antibodies, CD25 antibodies, CD28 antibodies, CD34 antibodies, CD35 antibodies. CD40 antibodies. CD45RA antibodies, CD45RO antibodies, CD52 antibodies. CD56 antibodies, CD62L antibodies, CD68 antibodies, CD80 antibodies, CD95 antibodies, CD117 antibodies, CD127 antibodies, CD133 antibodies. CD137 (4-1BB) antibodies, CD163 antibodies, F4/80 antibodies. IL-4Ra antibodies, Sca-1 antibodies. CTLA-4 antibodies, GITR antibodies GARP antibodies, LAP antibodies, granzyme B antibodies. LFA-1 antibodies, transferrin receptor antibodies, and fragments thereof. In some embodiments, the targeting moiety is a small molecule binder of an ectoenzyme on lymphocytes. Small molecule binders of ectoenzymes include A2A inhibitors CD73 inhibitors, CD39 or adesines receptors A2aR and A2bR. Potential small molecules include AB928.
[0417] Where it is desired to deliver a nucleic acid to an immune cell, the immune cell represents the target cell. In some embodiments, the compositions of the present disclosure transfect the target cells on a discriminatory basis (i.e.. do not transfect non-target cells). The compositions of the present disclosure may also be prepared to preferentially target a variety of target cells, which include, but are not limited to, T cells, B cells, macrophages, and dendritic cells.
[0418] In some embodiments, the target cells are deficient in a protein or enzyme of interest. For example, where it is desired to deliver a nucleic acid to a hepatocyte, the hepatocyte represents the target cell. In some embodiments, the compositions of the present disclosure transfect the target cells on a discriminatory basis (i.e.. do not transfect non-target cells). The compositions of the present disclosure may also be prepared to preferentially target a variety of target cells, which include, but are not limited to, hepatocytes, epithelial cells, hematopoietic cells, epithelial cells, endothelial cells, lung cells, bone cells, stem cells, mesenchymal cells, neural cells (e.g., meninges, astrocytes, motor neurons, cells of the dorsal root ganglia and anterior horn motor neurons), photoreceptor cells (e.g., rods and cones), retinal pigmented epithelial cells, secretory cells, cardiac cells, adipocytes, vascular smooth muscle cells,
cardiomyocytes, skeletal muscle cells, beta cells, pituitary cells, synovial lining cells, ovarian cells, testicular cells, fibroblasts, B cells, T cells, reticulocytes, leukocytes, granulocytes and tumor cells.
[0419] The compositions of the present disclosure may be prepared to preferentially distribute to target cells such as in the heart, lungs, kidneys, liver, and spleen. In some embodiments, the compositions of the present disclosure distribute into the cells of the liver or spleen to facilitate the delivery and the subsequent expression of the circRNA comprised therein by the cells of the liver (e.g., hepatocytes) or the cells of spleen (e.g., immune cells). The targeted cells may function as a biological “reservoir” or “depot” capable of producing, and systemically excreting a functional protein or enzyme. Accordingly, in one embodiment of the present disclosure the transfer vehicle may target hepatocytes or immune cells and/or preferentially distribute to the cells of the liver or spleen upon delivery'. In an embodiment, following transfection of the target hepatocytes or immune cells, the circRNA loaded in the nanoparticle are translated and a functional protein product is produced, excreted and systemically distributed. In other embodiments, cells other than hepatocytes (e.g., lung, spleen, heart, ocular, or cells of the central nervous system) can serve as a depot location for protein production.
[0420] In one embodiment, the compositions of the present disclosure facilitate a subject's endogenous production of one or more functional proteins and/or enzymes. In an embodiment of the present disclosure, the lipid nanoparticles comprise circRNA which encode a deficient protein or enzyme. Upon distribution of such compositions to the target tissues and the subsequent transfection of such target cells, the exogenous circRNA loaded into the nanoparticle may be translated in vivo to produce a functional protein or enzyme encoded by the exogenously administered circRNA (e.g., a protein or enzyme in which the subject is deficient). Accordingly, the compositions of the present disclosure exploit a subject's ability to translate exogenously- or recombinantly-prepared circRNA to produce an endogenously-translated protein or enzyme, and thereby produce (and where applicable excrete) a functional protein or enzyme. The expressed or translated proteins or enzymes may also be characterized by the in vivo inclusion of native post-translational modifications which may often be absent in recombinantly-prepared proteins or enzymes, thereby further reducing the immunogenicity of the translated protein or enzyme.
[0421] The administration of circRNA encoding a deficient protein or enzyme avoids the need to deliver the nucleic acids to specific organelles within a target cell. Rather, upon transfection of a target cell and delivery of the nucleic acids to the cytoplasm of the target cell, the circRNA contents of a transfer vehicle may be translated and a functional protein or enzyme expressed.
[0422] In some embodiments, a circular RNA comprises one or more miRNA binding sites. In some embodiments, a circular RNA comprises one or more miRNA binding sites recognized by miRNA present in one or more non-target cells or non-target cell types (e.g., Kupffer cells or hepatic cells) and
not present in one or more target cells or target cell types (e.g., hepatocytes or T cells). In some embodiments, a circular RNA comprises one or more miRNA binding sites recognized by miRNA present in an increased concentration in one or more non-target cells or non-target cell types (e.g., Kupffer cells or hepatic cells) compared to one or more target cells or target cell types (e.g., hepatocytes or T cells). miRNAs are thought to function by pairing with complementary sequences within RNA molecules, resulting in gene silencing.
[0423] In some embodiments, the compositions of the present disclosure transfect or distribute to target cells on a discriminatory basis (i.e.. do not transfect non-target cells). The compositions of the present disclosure may also be prepared to preferentially target a variety of target cells, which include, but are not limited to, hepatocytes, epithelial cells, hematopoietic cells, epithelial cells, endothelial cells, lung cells, bone cells, stem cells, mesenchymal cells, neural cells (e.g.. meninges, astrocytes, motor neurons, cells of the dorsal root ganglia and anterior horn motor neurons), photoreceptor cells (e.g., rods and cones), retinal pigmented epithelial cells, secretory cells, cardiac cells, adipocytes, vascular smooth muscle cells, cardiomyocytes, skeletal muscle cells, beta cells, pituitary cells, synovial lining cells, ovarian cells, testicular cells, fibroblasts. B cells. T cells, reticulocytes, leukocytes, granulocytes and tumor cells.
5. THERAPEUTIC METHODS
[0424] In certain aspects, provided herein is a method of producing a protein of interest in a subject in need thereof by introducing or administering an effective amount of a pharmaceutical composition described herein comprising at least one lipid nanoparticle described herein.
[0425] In certain aspects, provided herein is a method of treating and/or preventing a condition comprising administering an effective amount of a pharmaceutical composition described herein comprising at least one LNP as described herein.
[0426] In certain embodiments, the pharmaceutical compositions described herein are co-administered with one or more additional therapeutic agents (e.g., in the same pharmaceutical composition or in separate pharmaceutical compositions). In some embodiments, the pharmaceutical compositions provided herein can be administered first and the one or more additional therapeutic agents can be administered second, or vice versa. Alternatively, the pharmaceutical compositions provided herein and the one or more additional therapeutic agents can be administered simultaneously.
[0427] In some embodiments, the subject is a mammal. In some embodiments, the mammal referred to herein can be any mammal, including, but not limited to, mammals of the order Rodentia, such as mice and hamsters, or mammals of the order Logomorpha, such as rabbits. The mammals may be from the order Carnivora, including Felines (cats) and Canines (dogs). The mammals may be from the order
Artiodactyla, including Bovines (cows) and Swines (pigs), or of the order Perssodactyla, including Equines (horses). The mammals may be of the order Primates, Ceboids, or Simoids (monkeys) or of the order Anthropoids (humans and apes). In some embodiments, the mammal is a human.
[0428] In some embodiments, provided herein is a method of vaccinating a subject by introducing or administering an effective amount of a pharmaceutical composition described herein comprising at least one lipid nanoparticle described herein.
[0429] In some embodiments, provided herein the method of vaccinating comprises administering an effective amount of an antigen comprising a viral polypeptide from an adenovirus; Herpes simplex, type 1; Herpes simplex, type 2; encephalitis virus, papillomavirus, Varicella-zoster virus; Epstein-barr virus; Human cytomegalovirus; Human herpes virus, type 8; Human papillomavirus; BK virus; JC virus; Smallpox: polio virus; Hepatitis B virus; Human bocavirus; Parvovirus B19; Human astrovirus; Norwalk virus; coxsackievirus; hepatitis A virus; poliovirus; rhinovirus; Severe acute respiratory syndrome virus; Hepatitis C virus; Yellow Fever virus; Dengue virus; West Nile virus; Rubella virus; Hepatitis E virus; Human Immunodeficiency virus (HIV); Influenza virus: Guanarito virus: Junin virus; Lassa virus; Machupo virus; Sabia virus: Crimean-Congo hemorrhagic fever virus; Ebola virus; Marburg virus; Measles virus; Mumps virus; Parainfluenza virus; Respiratory syncytial virus; Human metapneumo virus; Hendra virus; Nipah virus; Rabies virus; Hepatitis D; Rotavirus; Orbivirus; Coltivirus; Banna virus; Human Enterovirus; Hanta virus; West Nile virus; Middle East Respiratory Syndrome Corona Virus; Japanese encephalitis virus; Vesicular exanthemavirus; SARS-CoV-2; Eastern equine encephalitis, or a combination of any two or more of the foregoing.
[0430] In some embodiments, provided herein is a method of treating an autoimmune disorder in a subject by introducing or administering an effective amount of a pharmaceutical composition described herein comprising at least one lipid nanoparticle described herein.
[0431] In some embodiments, provided herein is a method of treating cancer in a subject by introducing or administering an effective amount of a pharmaceutical composition described herein comprising at least one lipid nanoparticle described herein.
[0432] In some embodiments, the circular RNA construct encodes a CAR, the CARs have biological activity, e.g., ability to recognize an antigen, e.g.. CD19, HER2. or BCMA, such that the CAR. when expressed by a cell, is able to mediate an immune response against the cell expressing the antigen, e.g.. CD 19, HER2. or BCMA, for which the CAR is specific.
|0433| Adoptive T-cell immunotherapy is a rapidly growing field, in particular in cancer treatments. In general, chimeric antigen receptor (CAR) T cell or “CAR-T” engagement of CD19-expressing cancer cells results in T-cell activation, proliferation and secretion of inflammatory cytokines and chemokines
resulting in tumor cell lysis. However, while CAR-T therapies have become an important tool in cancer treatments, they have toxic side effects and involve complex procedures. Treatment with CAR-T can lead to a large and rapid release of cytokines into the blood and can cause cytokine release syndrome (CRS) or CAR-T cell-related encephalopathy syndrome (CRES), also referred to as nemotoxicity associated with CAR-T. CRS is tire most common and well-described toxicity associated with CAR-T therapy, occurring in over 90% of patients at any grade and is characterized by high fever, hypotension, hypoxia and/ or multiple organ toxicity and can lead to death. Neurotoxicity is characterized by damage to nervous tissue that can cause tremors, encephalopathy, dizziness or seizures. Additionally, prior to infusion, the patients generally undergo lymphodepletion. Lymphodepletion is known to increase CAR- T cell expansion and enhanced efficacy of infused CAR-T cells by, for example, altering the tumor phenotype and microenvironment. However, lymphodepletion agents often cause side effects to the patients. For example, lymphodepletion can cause neutropenia, anemia, thrombocytopenia, and immunosuppression, leading to a greater risk of infection, along with other toxicities. In addition to the toxicities associated with targeted CAR-T therapies, there are procedures, specialized equipment, and costs involved in producing the modified lymphocytes. CAR-T therapies require an assortment of protocols to isolate, genetically modify, and selectively expand the redirected cells before infusing them back into the patient.
[0434] In some embodiments, the subject has a cancer selected from the group consisting of: acute myeloid leukemia (AML); alveolar rhabdomyosarcoma; B cell malignancies; bladder cancer (e.g., bladder carcinoma); bone cancer; brain cancer (e.g.. medulloblastoma and glioblastoma multiforme); breast cancer; cancer of the anus, anal canal, or anorectum; cancer of the eye; cancer of the intrahepatic bile duct; cancer of the joints; cancer of the neck; gallbladder cancer; cancer of the pleura; cancer of the nose, nasal cavity, or middle ear; cancer of the oral cavity; cancer of the vulva; chronic lymphocytic leukemia; chronic myeloid cancer; colon cancer; esophageal cancer, cervical cancer; fibrosarcoma; gastrointestinal carcinoid tumor; head and neck cancer (e.g., head and neck squamous cell carcinoma); Hodgkin lymphoma; hypopharynx cancer; kidney cancer; larynx cancer; leukemia; liquid tumors; lipoma; liver cancer; lung cancer (e.g., non-small cell lung carcinoma, lung adenocarcinoma, and small cell lung carcinoma); lymphoma; mesothelioma; mastocytoma; melanoma; multiple myeloma; nasopharynx cancer; non-Hodgkin ly mphoma; B-chronic ly mphocytic leukemia; hairy cell leukemia; Burkitt's lymphoma; ovarian cancer; pancreatic cancer; cancer of the peritoneum; cancer of the omentum; mesentery cancer; pharynx cancer; prostate cancer; rectal cancer; renal cancer; skin cancer; small intestine cancer: soft tissue cancer; solid tumors; synovial sarcoma; gastric cancer; teratoma; testicular cancer; thyroid cancer; and ureter cancer.
[0435] In some embodiments, the subject has an autoimmune disorder selected from scleroderma, Grave's disease, Crohn's disease, Sjogren's disease, multiple sclerosis, Hashimoto's disease, psoriasis,
myasthenia gravis, autoimmune polyendocrinopathy syndromes, Type I diabetes mellitus (TIDM), autoimmune gastritis, autoimmune uveoretinitis, polymyositis, colitis, thyroiditis, and the generalized autoimmune diseases ty pified by human Lupus.
6. DEFINITIONS
[0436] As used herein, the terms “circRNA” or ‘‘circular polyribonucleotide” or “circular RNA” or “circular RNA polynucleotide” or “oRNA” are used interchangeably and refers to a single-stranded RNA polynucleotide wherein the 3’ and 5’ ends that are normally present in a linear RNA polynucleotide have been joined together e.g., by covalent bonds. As used herein, such terms also include preparations comprising circRNAs.
[0437] As used herein, the term "DNA template” refers to a DNA sequence capable of transcribing a linear RNA polynucleotide. For example, but not intending to be limiting, a DNA template may include a DNA vector, PCR product or plasmid.
[0438] As used herein, the term “3 ’ intron segment” (or “3’ intron fragment”) refers to a sequence with at least 75%. at least 80%, at least 85%. at least 90%, at least 91%. at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% similarity to the 3’- proximal end of a natural intron (e.g., a group I or group II intron). In certain embodiments, the 3 ’ intron segment includes the 5’ nucleotide of the splice site dinucleotide. “3’ exon segment” (or “3’ exon fragment”) refers to a sequence with at least 75%, at least 80%, at least 85%. at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%. at least 97%, at least 98%, at least 99%, or 100% similarity' to the 5 ’-proximal end of an exon adjacent to a “3’ intron segment” as described herein. In certain embodiments, the 3’ exon segment includes the 3’ nucleotide of the splice site dinucleotide.
[0439] The term “5’ intron segment” (or “5’ intron fragment”) refers to a sequence with at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or higher 100% similarity to the 5‘-proximal end of a natural intron (e.g., a group I or group II intron). In certain embodiments, the 5’ intron segment includes the 3’ nucleotide of the splice site dinucleotide. “5’ exon segment” (or “5’ exon fragment”) refers to a sequence with at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%. at least 94%, at least 95%, at least 96%, at least 97%, at least 98%. at least 99%, or higher 100% similarity to the 3’-proximal end of an exon adjacent to a “5’ intron segment” as described herein. In certain embodiments, the 5’ exon segment includes the 5’ nucleotide of the splice site dinucleotide.
[0440] In some embodiments, the 3’ intron segment and the 3’ exon segment together form a first portion of an autocatalytic or self-splicing intron-exon sequence. In some embodiments, the 5 ’ intron segment and the 5‘ exon segment together form the remainder (i.e., second portion) of the autocatalytic or self-splicing intron-exon sequence. In these embodiments, a linear nucleic acid molecule, e.g., RNA, comprising the 3‘ intron segment and the 3‘ exon segment at the 5’ end of the linear nucleic acid molecule and further the 5 ‘ intron segment and the 5 ’ exon segment at the 3 ' end the linear nucleic acid molecule, is capable of autocatalytically self-splicing and thereby capable of fonning a circular nucleic acid molecule, e.g., circular RNA. In these embodiments, the 3’ intron segment and the 5’ intron segments are excised from the circular nucleic acid molecule, e.g.. circular RNA, and the 3’ exon segment and the 5’ exon segment are retained in the circular nucleic acid molecule, e.g., circular RNA. Each retained post-splicing exon segment may be referred to as a self-splicing or self-spliced exon segment, e.g.. a 3’ self-splicing or self-spliced exon segment and a 5’ self-splicing or self-spliced exon segment.
[0441] In some embodiments, the intron segment is a “Group I intron” and the corresponding exon segment may be referred to as a “Group I exon” or “Group 1 self-splicing exon” or “Group 1 self-spliced exon segment” or the like. In some embodiments, the intron segment is a “Group II intron” and the corresponding exon segment may be referred to as a “Group II exon” or “Group II self-splicing exon” or “Group II self-spliced exon segment” or the like.
[0442] In some embodiments, the retained, post-splicing, self-splicing 3 ’ or 5 ’ exon segment is a noncoding sequence in the circular nucleic acid molecule, e.g., circular RNA. In some embodiments, the circular nucleic acid molecule, e.g., circular RNA, further comprises a desired coding sequence, and the retained, post-splicing, self-splicing 3’ or 5’ exon segment is (e.g., designed) to be a portion of the desired expression sequence, contiguous with the desired coding sequence, and/or in frame with the desired coding sequence.
[0443] Within a circular nucleic acid molecule, e.g.. derived from a linear nucleic acid precursor, and comprising a coding sequence, the 5’ to 3’ orientation of the coding sequence may be used to inform whether other sequences within the circular nucleic acid are 5’ and/or 3’, e.g., for example. 5’ is nearer to the 5’ of the coding sequence, and the 3’ end is downstream of the coding sequence. As used herein, within a circular nucleic acid molecule, e.g.. derived from a linear nucleic acid precursor, reference to a “5”’ or “3”’ portion of the molecule may correspond to the orientation of the sequence within the linear nucleic acid precursor.
[0444] In some embodiments, provided herein are circular RNA polynucleotides comprising a post splicing 3’ group I or II intron fragment (e.g., a stretch of exon sequence), optionally a first spacer, an
IRES, an expression sequence, optionally a second spacer, and a post splicing 5’ group I or II intron fragment (e.g., a stretch of exon sequence).
[0445] As used herein, “splice site’’ refers to the junction consisting of a dinucleotide betw een an exon and an intron in an unspliccd RNA. As used herein, the term “splice site” refers to a dinuclcotidc that is partially or fully included in a group I or group II intron and/or exon and between which a phosphodiester bond is cleaved during RNA circularization. A “splice site dinucleotide’’ refers two nucleotides: a 5’ splice site nucleotide and the 3’ splice site nucleotide. A “5‘ splice site” refers to the natural 5’ dinucleotide of the intron and/or exon e.g., group I or group II intron and/or exon, while a “3’ splice site” refers to the natural 3’ dinucleotide of the intron and/or exon. Exemplary' splice site dinucleotides are shown in Table 1 below.
[0446] The following table includes example splice site dinucleotides:




[0447] As used herein, the term “permutation site” refers to a site in an intron and/or exon (e.g., a group I or II intron and/or exon) where a cut is made prior to permutation of the intron/or exon. For example, such a cut generates an intron sequence comprising a 3’ intron segment and a sequence comprising a 5’ intron segment (e.g., group I or group II intron fragments) that are permuted to be on either side of a stretch of precursor RNA to be circularized. The permuted intron segments are thereby called “3’ permuted intron segments” or “3’ permuted elements” and “5’ permuted intron segments” or “5’ permuted elements” in the context of said precursor RNA. As used herein, “permuted intron segment” and “permuted intron element” are used interchangeably. In some embodiments, the permutation site consists of a dinucleotide.
[0448] As used herein, the term “expression sequence” refers to a nucleic acid sequence that encodes a product, e.g., a peptide or polypeptide, regulatory nucleic acid, or non-coding nucleic acid. An exemplary' expression sequence that codes for a peptide or polypeptide can comprise a plurality of nucleotide triads, each of which can code for an amino acid and is termed as a “codon.”
[0449] As used herein, “coding element” or “coding region” is region located within the expression sequence and encodings for one or more proteins or polypeptides (e.g., therapeutic protein).
[0450] As used herein, a "noncoding element" or "non-coding nucleic acid" is a region located within the expression sequence. This sequence, but itself docs not encode for a protein or polypeptide, but may have other regulatory functions, including but not limited, allow the overall poly nucleotide to act as a biomarker or adjuvant to a specific cell.
[0451] As used herein, the term “therapeutic protein” refers to any protein that, when administered to a subject directly or indirectly in the form of a translated nucleic acid, has a therapeutic, diagnostic, and/or prophylactic effect and/or elicits a desired biological and/or pharmacological effect.
[0452] As used herein, the term “immunogenic” or “immunostimulatory” refers to a potential to induce an immune response to a substance. An immune response may be induced when an immune system of an organism or a certain type of immune cells is exposed to an immunogenic substance. The term “non- immunogenic” refers to a lack of or absence of an immune response above a detectable threshold to a substance. No immune response is detected when an immune system of an organism or a certain type
of immune cells is exposed to a non-immunogenic substance. In some embodiments, a non- immunogenic circular polyribonucleotide as provided herein, does not induce an immune response above a pre-determined threshold when measured by an immunogenicity assay. In some embodiments, no innate immune response is detected when an immune system of an organism or a certain t pe of immune cells is exposed to a non-immunogenic circular polyribonucleotide as provided herein. In some embodiments, no adaptive immune response is detected when an immune system of an organism or a certain type of immune cell is exposed to a non-immunogenic circular polyribonucleotide as provided herein.
[0453] As used herein, the term “circularization efficiency" refers to a measurement of resultant circular polyribonucleotide as compared to its linear starting material.
[0454] As used herein, the term “translation efficiency " refers to a rate or amount of protein or peptide production from a ribonucleotide transcript. In some embodiments, translation efficiency can be expressed as amount of protein or peptide produced per given amount of transcript that codes for the protein or peptide.
[0455] The term “nucleotide" refers to a ribonucleotide, a deoxyribonucleotide, a modified fonn thereof, or an analog thereof. Nucleotides include species that comprise purines, e.g., adenine, hypoxanthine, guanine, and their derivatives and analogs, as well as pyrimidines, e.g., cytosine, uracil, thymine, and their derivatives and analogs. Nucleotide analogs include nucleotides having modifications in the chemical structure of the base, sugar and/or phosphate, including, but not limited to, 5 ’-position pyrimidine modifications. 8’ -position purine modifications, modifications at cytosine exocyclic amines, and substitution of 5-bromo-uracil; and 2’ -position sugar modifications, including but not limited to, sugar-modified ribonucleotides in which the 2’-OH is replaced by a group such as an H, OR. R, halo. SH, SR, NH2, NHR, NR2, or CN, wherein R is an alkyl moiety as defined herein. Nucleotide analogs are also meant to include nucleotides with bases such as inosine, queuosine, xanthine; sugars such as 2’-methyl ribose; non-natural phosphodiester linkages such as methylphosphonate, phosphorothioate and peptide linkages. Nucleotide analogs include 5- methoxyuridine, 1 -methylpseudouridine, and 6-methyladenosine.
[0456] The term "nucleic acid” and “polynucleotide” are used interchangeably herein to describe a polymer of any length, e.g.. greater than 2 bases, greater than 10 bases, greater than 100 bases, greater than 500 bases, greater than 1000 bases, or up to 10,000 or more bases, composed of nucleotides, e.g., deoxyribonucleotides or ribonucleotides, and may be produced enzymatically or synthetically (e.g., as described in U.S. Pat. No. 5,948,902 and the references cited therein), which can hybridize with naturally occurring nucleic acids in a sequence specific manner analogous to that of two naturally occurring nucleic acids, e.g., can participate in Watson-Crick base pairing interactions. Naturally
occurring nucleic acids are comprised of nucleotides including guanine, cytosine, adenine, thymine, and uracil (G, C, A, T, and U respectively).
[0457] The terms “ribonucleic acid” and “RNA” as used herein mean a polymer composed of ribonucleotides.
[0458] The terms “deoxyribonucleic acid” and “DNA” as used herein mean a polymer composed of deoxy ribonucleotides.
[0459] “ Isolated” or “purified” generally refers to isolation of a substance (for example, in some embodiments, a compound, a polynucleotide, a protein, a polypeptide, a polynucleotide composition, or a polypeptide composition) such that the substance comprises a significant percent (e.g., greater than 1%, greater than 2%, greater than 5%, greater than 10%, greater than 20%, greater than 50%, or more, usually up to 90%-100%) of the sample in which it resides. In certain embodiments, a substantially purified component comprises at least 50%, 80%-85%, or 90%-95% of the sample. Techniques for purifying polynucleotides and polypeptides of interest are well-known in the art and include, for example, ion-exchange chromatography, affinity chromatography and sedimentation according to density. Generally, a substance is purified when it exists in a sample in an amount, relative to other components of the sample, that is more than as it is found naturally.
[0460] The terms “duplexed,” “double-stranded,” or “hybridized” as used herein refer to nucleic acids formed by hybridization of two single strands of nucleic acids containing complementary sequences. In most cases, genomic DNA is double-stranded. Sequences can be fully complementary or partially complementary.
[0461] As used herein, “unstructured" with regard to RNA refers to an RNA sequence that is not predicted by the RNAFold software or similar predictive tools to form a structure (e.g., a hairpin loop) with itself or other sequences in the same RNA molecule. In some embodiments, unstructured RNA can be functionally characterized using nuclease protection assays.
[0462] As used herein, “structured” with regard to RNA refers to an RNA sequence that is predicted by the RNAFold software or similar predictive tools to form a structure (e.g., a hairpin loop) with itself or other sequences in the same RNA molecule.
[0463] As used herein, two “duplex sequences," “duplex forming sequences,” “duplex region,” "duplex regions," "homology arms." or "homology regions" may be any two regions that are thermodynamically favored to cross-pair in a sequence specific interaction. In some embodiments, two duplex sequences, duplex regions, homology arms, or homology regions, share a sufficient level of sequence identity to one another’s reverse complement to act as substrates for a hybridization reaction. As used herein polynucleotide sequences have “homology” when they are either identical or share
sequence identity to a reverse complement or “complementary” sequence. The percent sequence identity between a homology region and a counterpart homology region’s reverse complement can be any percent of sequence identity that allows for hybridization to occur. In some embodiments, an internal duplex region of an inventive polynucleotide is capable of forming a duplex with another internal duplex region and does not form a duplex with an external duplex region.
[0464] As used herein, an "affinity sequence" or “affinity tag” is a region of polynucleotide sequences polynucleotide sequence ranging from 1 nucleotide to hundreds or thousands of nucleotides containing a repeated set of nucleotides for the purposes of aiding purification of a polynucleotide sequence. For example, an affinity sequence may comprise, but is not limited to, a polyA or poly AC sequence.
[0465] As used herein, a "spacer" refers to a region of a polynucleotide sequence ranging from 1 nucleotide to hundreds or thousands of nucleotides separating two other elements along a polynucleotide sequence. The sequences can be defined or can be random. A spacer is typically noncoding. In some embodiments, spacers include duplex regions.
[0466] Linear nucleic acid molecules are said to have a “5 ’-terminus” (5‘ end) and a “3 ‘-terminus" (3’ end) because nucleic acid phosphodiester linkages occur at the 5‘ carbon and 3‘ carbon of the sugar moieties of the substituent mononucleotides. The end nucleotide of a polynucleotide at which a new linkage would be to a 5’ carbon is its 5’ terminal nucleotide. The end nucleotide of a polynucleotide at which a new linkage would be to a 3’ carbon is its 3’ tenninal nucleotide. A terminal nucleotide, as used herein, is the nucleotide at the end position of the 3’- or 5 ’-terminus.
[0467] As used herein, a "leading untranslated sequence" is a region of polynucleotide sequences ranging from 1 nucleotide to hundreds of nucleotides located at the upmost 5' end of a polynucleotide sequence. The sequences can be defined or can be random. A leading untranslated sequence is noncoding.
[0468] As used herein, a "leading untranslated sequence" is a region of polynucleotide sequences ranging from 1 nucleotide to hundreds of nucleotides located at the downmost 3' end of a polynucleotide sequence. The sequences can be defined or can be random. A leading untranslated sequence is noncoding.
[0469] “Transcription” means the formation or synthesis of an RNA molecule by an RNA polymerase using a DNA molecule as a template. The invention is not limited with respect to the RNA polymerase that is used for transcription. For example, in some embodiments, a T7-type RNA polymerase can be used.
[0470] “Translation” means the formation of a polypeptide molecule by a ribosome based upon an RNA template.
[0471] It is to be understood that the terminology used herein is for the purpose of describing particular embodiments only and is not intended to be limiting. As used in this specification and the appended claims, the singular forms “a,” “an,’' and “the” include plural referents unless the content clearly dictates otherwise. Thus, for example, reference to “a cell” includes combinations of two or more cells, or entire cultures of cells; reference to “a polynucleotide” includes, as a practical matter, many copies of that polynucleotide. Unless specifically stated or obvious from context, as used herein, the term “or” is understood to be inclusive. Unless defined herein and below in the reminder of the specification, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which the invention pertains.
[0472] As used herein, the term “encode” refers broadly to any process whereby the information in a polymeric macromolecule is used to direct the production of a second molecule that is different from the first. The second molecule may have a chemical structure that is different from the chemical nature of the first molecule.
[0473] By "co-administering" is meant administering a therapeutic agent provided herein in conjunction with one or more additional therapeutic agents sufficiently close in time such that the therapeutic agent provided herein can enhance the effect of the one or more additional therapeutic agents, or vice versa.
[0474] The terms “treat.” and “prevent” as well as words stemming therefrom, as used herein, do not necessarily imply 100% or complete treatment or prevention. Rather, there are varying degrees of treatment or prevention of which one of ordinary skill in the art recognizes as having a potential benefit or therapeutic effect. The treatment or prevention provided by the method disclosed herein can include treatment or prevention of one or more conditions or symptoms of the disease. Also, for purposes herein, “prevention” can encompass delaying the onset of the disease, or a symptom or condition thereof.
[0475] As used herein, an “internal ribosome entry site” or "IRES” refers to an RNA sequence or structural element ranging in size from 10 nt to 1000 nt or more, capable of initiating translation of a polypeptide in the absence of a typical RNA cap structure. An IRES is typically 500 nt to 700 nt in length.
[0476] As used herein, “aptamer” refers in general to either an oligonucleotide of a single defined sequence or a mixture of said nucleotides, wherein the mixture retains the properties of binding specifically to the target molecule (e.g., eukaryotic initiation factor, 40S ribosome. polyC binding protein, polyA binding protein, polypyrimidine tract-binding protein, argonaute protein family, Heterogeneous nuclear ribonucleoprotein K and La and related RNA-binding protein). Thus, as used herein “aptamer” denotes both singular and plural sequences of nucleotides, as defined hereinabove.
The term “aptamer” is meant to refer to a single- or double-stranded nucleic acid which is capable of binding to a protein or other molecule. In general, aptamers comprise 10 to 100 nucleotides (e.g., 15 to 40 nucleotides, 20 to 40 nucleotides), in that oligonucleotides of a length that falls within these ranges are readily prepared by conventional techniques. Optionally, aptamers can further comprise a minimum of approximately 6 nucleotides that are necessary to effect specific binding. In some embodiments, aptamers can further comprise approximately 10 nucleotides that are necessary to effect specific binding. In some embodiments, aptamers can further comprise approximately 14 or 15 nucleotides that are necessary to effect specific binding.
[0477] An “eukaryotic initiation factor” or “elF” refers to a protein or protein complex used in assembling an initiator tRNA, 40S and 60S ribosomal submits required for initiating eukaryotic translation.
[0478] As used herein, an “internal ribosome entry site" or “IRES” refers to an RNA sequence or structural element ranging in size from 10 nt to 1000 nt or more, capable of initiating translation of a polypeptide in the absence of a typical RNA cap structure. An IRES is typically 500 nt to 700 nt in length.
[0479] As used herein, a “miRNA site” refers to a stretch of nucleotides within a polynucleotide that is capable of forming a duplex with at least 8 nucleotides of a natural miRNA sequence.
[0480] As used herein, an "endonuclease site" refers to a stretch of nucleotides within a polynucleotide that is capable of being recognized and cleaved by an endonuclease protein.
[0481] As used herein, “bicistronic RNA” refers to a polynucleotide that includes two expression sequences coding for two distinct proteins. These expression sequences can be separated by a nucleotide sequence encoding a cleavable peptide such as a protease cleavage site. They can also be separated by a ribosomal skipping element.
[0482] As used herein, the term “ribosomal skipping element” refers to a nucleotide sequence encoding a short peptide sequence capable of causing generation of two peptide chains from translation of one RNA molecule. While not wishing to be bound by theory, it is hypothesized that ribosomal skipping elements function by (1) terminating translation of the first peptide chain and re-initiating translation of the second peptide chain; or (2) cleavage of a peptide bond in the peptide sequence encoded by the ribosomai skipping element by an intrinsic protease activity of the encoded peptide, or by another protease in the environment (e.g.. cytosol).
[0483] As used herein, the term “co-formulate” refers to a nanoparticle formulation comprising two or more nucleic acids or a nucleic acid and other active drug substance. Typically, the ratios are equimolar
or defined in the ratiometric amount of the tw o or more nucleic acids or the nucleic acid and other active drug substance.
[0484] As used herein, the phrase “ionizable lipid” refers to any of a number of lipid species that carry a net positive charge at a selected pH, such as physiological pH 4 and a neutral charge at other pHs such as physiological pH 7.
[0485] In some embodiments, a lipid or compound described herein comprises one or more cleavable groups. The terms “cleave” and “clcavablc” arc used herein to mean that one or more chemical bonds (e.g., one or more of covalent bonds, hydrogen-bonds, van der Waals' forces and/or ionic interactions) between atoms in or adjacent to the subject functional group are broken (e.g., hydrolyzed) or are capable of being broken upon exposure to selected conditions (e.g., upon exposure to enzymatic conditions). In certain embodiments, the cleavable group is a disulfide functional group, and in particular embodiments is a disulfide group that is capable of being cleaved upon exposure to selected biological conditions (e.g., intracellular conditions). In certain embodiments, the cleavable group is an ester functional group that is capable of being cleaved upon exposure to selected biological conditions. For example, the disulfide groups may be cleaved enzymatically or by a hydrolysis, oxidation or reduction reaction. Upon cleavage of such disulfide functional group, the one or more functional moieties or groups (e.g., one or more of a head-group and/or a tail-group) that are bound thereto may be liberated. In some embodiments, a cleavable group is bound (e.g., bound by one or more of hydrogen-bonds, van der Waals' forces, ionic interactions and covalent bonds) to one or more functional moieties or groups.
[0486] Compound described herein may also comprise one or more isotopic substitutions. For example, H may be in any isotopic form, including 1H, 2H (D or deuterium), and 3H (T or tritium); C may be in any isotopic form, including 12C, 13C. and 14C; O may be in any isotopic form, including 160 and 180; F may be in any isotopic form, including 18F and 19F; and the like.
[0487] When describing the invention, which may include compounds and pharmaceutically acceptable salts thereof, pharmaceutical compositions containing such compounds and methods of using such compounds and compositions, the following terms, if present, have the following meanings unless otherwise indicated. It should also be understood that when described herein any of the moieties defined forth below may be substituted with a variety of substituents, and that the respective definitions are intended to include such substituted moieties within their scope as set out below. Unless otherwise stated, the term “substituted” is to be defined as set out below. It should be further understood that the terms “groups” and “radicals” can be considered interchangeable when used herein.
[0488] When a range of values is listed, it is intended to encompass each value and sub-range within the range. For example, “Cl-6 alkyl” is intended to encompass, Cl, C2, C3, C4, C5. C6. Cl-6, Cl-5, Cl^l, Cl-3. Cl-2. C2-6, C2-5, C2^1. C2-3, C3-6. C3-5. C3-4. C4-6, C4-5, and C5-6 alkyl.
[0489] It should be noted that the term “head-group’‘ as used describe the compounds of the present invention, and in particular functional groups that comprise such compounds, are used for ease of reference to describe the orientation of one or more functional groups relative to other functional groups. For example, in certain embodiments a hydrophilic head-group (e.g., an amino group) is bound (e.g., by one or more of hydrogen-bonds, van der Waals' forces, ionic interactions and covalent bonds) to a hydrophobic tail-group (e.g., cholesterol).
[0490] In typical embodiments, the present invention is intended to encompass the compounds disclosed herein, and the pharmaceutically acceptable salts, pharmaceutically acceptable esters, tautomeric forms, polymorphs, and prodrugs of such compounds. In some embodiments, the present invention includes a pharmaceutically acceptable addition salt, a pharmaceutically acceptable ester, a solvate (e.g., hydrate) of an addition salt, a tautomeric form, a polymorph, an enantiomer, a mixture of enantiomers, a stereoisomer or mixture of stereoisomers (pure or as a racemic or non-racemic mixture) of a compound described herein.
[0491] Compounds described herein can comprise one or more asymmetric centers, and thus can exist in various isomeric forms, e.g., enantiomers and/or diastereomers. For example, the compounds described herein can be in the form of an individual enantiomer, diastereomer or geometric isomer, or can be in the form of a mixture of stereoisomers, including racemic mixtures and mixtures enriched in one or more stereoisomer. Isomers can be isolated from mixtures by methods known to those skilled in the art, including chiral high pressure liquid chromatography (HPLC) and the formation and crystallization of chiral salts; or preferred isomers can be prepared by asymmetric syntheses. See. for example. Jacques et al.. Enantiomers, Racemates and Resolutions (Wiley Interscience, New York, 1981); Wilen et al.. Tetrahedron 33:2725 (1977); Eliel. Stereochemistry of Carbon Compounds (McGraw-Hill, NY, 1962); and Wilen. Tables of Resolving Agents and Optical Resolutions p. 268 (E.L. Eliel, Ed., Univ, of Notre Dame Press, Notre Dame, IN 1972). The invention additionally encompasses compounds described herein as individual isomers substantially free of other isomers, and alternatively, as mixtures of various isomers.
[0492] In certain embodiments the subject compositions (e.g., LNPs) exhibit an enhanced (e.g., increased) ability to transfect one or more target cells. Accordingly, also provided herein are methods of transfecting one or more target cells. Such methods generally comprise the step of contacting the one or more target cells with the compositions disclosed herein such that the one or more target cells are transfected with the circular RNA encapsulated therein. As used herein, the terms “transfect” or “transfection” refer to the intracellular introduction of one or more encapsulated materials (e.g., nucleic acids and/or polynucleotides) into a cell (e.g., a target cell). The term “transfection efficiency” refers to the relative amount of such encapsulated material (e.g., poly nucleotides) up-taken by, introduced into and/or expressed by the target cell which is subject to transfection.
[0493] All nucleotide sequences disclosed herein can represent an RNA sequence or a corresponding DNA sequence. It is understood that deoxythymidine (dT or T) in a DNA is transcribed into a uridine (U) in an RNA. As such, “T” and “U” are used interchangeably herein in nucleotide sequences.
[0494] The recitations “sequence identity ” or, for example, comprising a “sequence 50% identical to,” as used herein, refer to the extent that sequences are identical on a nucleotide-by -nucleotide basis or an amino acid-by-amino acid basis over a window of comparison. Thus, a “percentage of sequence identity” may be calculated by comparing two optimally aligned sequences over the window of comparison, determining the number of positions at which the identical nucleic acid base (e.g., A. T, C, G, I) or the identical amino acid residue (e.g., Ala, Pro, Ser, Thr, Gly, Vai, Leu, He, Phe, Tyr. Trp, Lys, Arg, His, Asp, Glu, Asn. Gin, Cys and Met) occurs in both sequences to yield the number of matched positions, dividing the number of matched positions by the total number of positions in the window of comparison (i.e.. the window size), and multiplying the result by 100 to yield the percentage of sequence identity. Included are nucleotides and polypeptides having at least 50%, 55%, 60%, 65%, 70%. 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% sequence identity to any of the reference sequences described herein, typically where the polypeptide variant maintains at least one biological activity of the reference polypeptide.
[0495] The expression sequences in the polynucleotide construct may be separated by a “cleavage site” sequence which enables polypeptides encoded by the expression sequences, once translated, to be expressed separately by the cell.
[0496] A “self-cleaving peptide” refers to a peptide which is translated without a peptide bond between two adjacent amino acids, or functions such that when the polypeptide comprising the proteins and the self-cleaving peptide is produced, it is immediately cleaved or separated into distinct and discrete first and second polypeptides without the need for any external cleavage activity.
[0497] The a and (3 chains of αβ TCR's are generally regarded as each having two domains or regions, namely variable and constant domains/regions. The variable domain consists of a concatenation of variable regions and joining regions. In the present specification and claims, the term “TCR alpha variable domain” therefore refers to the concatenation of TRAV and TRAJ regions, and the term TCR alpha constant domain refers to the extracellular TRAC region, or to a C-terminal truncated TRAC sequence. Likewise, the term “TCR beta variable domain” refers to the concatenation of TRBV and TRBD/TRBJ regions, and the term TCR beta constant domain refers to the extracellular TRBC region, or to a C-terminal truncated TRBC sequence.
[0498] The terms “duplexed.” “double-stranded.” or “hybridized” as used herein refer to nucleic acids formed by hybridization of two single strands of nucleic acids containing complementary sequences. In
most cases, genomic DNA is double-stranded. Sequences can be fully complementary or partially complementary.
[0499] As used herein, a “vaccine” refers to a composition for generating immunity’ for the prophylaxis and/or treatment of diseases. Accordingly , vaccines arc medicaments which comprise antigens and arc intended to be used in humans or animals for generating specific defense and protective substances upon administration to the human or animal.
7. ADDITIONAL EMBODIMENTS
[0500] Aspects of this disclosure are set forth in the following clauses:
[0501] Clause 1. A compound comprising: a macrocycle comprising one or more polymer, preferably polyethylene glycol (PEG), blocks in the macrocycle’s backbone; and at least one lipid; wherein either
(a) the at least one lipid is covalently attached to the macrocycle and is outside the macrocycle's backbone; or
(b) two lipids arc in the macrocycle’s backbone, wherein all polymer blocks arc between the tw o lipids.
[0502] Clause 2. The compound of clause 1, wherein the compound satisfies (a), and the macrocycle comprises two or more polymer blocks, preferably PEG blocks.
[0503] Clause 3. The compound of clause 1 or 2, w herein the compound satisfies (a) and is of Formula (I):
 wherein:
wherein:
A is the at least one lipid;
X is a core branching moiety;
P is the macrocycle; and n is an integer selected from 1 to 6, preferably an integer from 1 to 3.
[0504] Clause 4. The compound of clause 3, w herein P comprises at least 10 ethylene glycol monomer units, preferably at least 12. at least 20, at least 30, at least 40. at least 50, at least 60, at least 70, at least 80, at least 90. at least 100, at least 150. at least 200. or at least 220 ethylene glycol monomer units.
[0505] Clause 5. The compound of clause 3 or 4, wherein P comprises a PEG block of 500 Da to 20 kDa.
[0506] Clause 6. The compound of clause 5, wherein P comprises a PEG block of 600 Da to 2 kDa.
[0507] Clause 7. The compound of clause 5, wherein P comprises a PEG block of 5 kDa to 20 kDa.
[0508] Clause 8. The compound of clause 5, wherein P comprises a PEG block of 1.5 kDa to 3.5 kDa.
[0509] Clause 9. The compound of any one of clauses 2 to 8, wherein P comprises one PEG block.
[0510] Clause 10. The compound of any one of clauses 2 to 8. wherein P comprises two or more PEG blocks.
[0511] Clause 11. The compound of clause 10, wherein P comprises the Formula Pl :
 wherein:
wherein:
PA and PB are each independently the two or more PEG blocks;
Y is an optional linking group; and m is an integer from 1 to 6, preferably an integer from 1 to 3.
[0512] Clause 12. The compound of clause 11, wherein m is 1.
[0513] Clause 13. The compound of any one of clauses 2 to 12, wherein X comprises one or more amino acid residues.
[0514] Clause 14. The compound of clause 13, wherein the one or more amino acid residues are selected from lysine, ornithine, aspartate, glutamate, serine, cysteine, and tyrosine.
[0515] Clause 15. The compound of clause 13 or 14, wherein X comprises:


[0517] Clause 17. The compound of clause 16, wherein X comprises:
 wherein two >zvvv' represent the point of attachment to P and the remaining represent the
wherein two >zvvv' represent the point of attachment to P and the remaining represent the
 points of attachment to A.
points of attachment to A.
[0518] Clause 18. The compound of any one of clauses 3 to 17, wherein n is 1.
[0519] Clause 19. The compound of any one of clauses 3 to 17, wherein n is 2.
[0520] Clause 20. The compound of any one of clauses 3 to 17, wherein n is 3.
[0521] Clause 21. The compound of any one of clauses 1 to 20, wherein the compound is of Formula
(II):
 wherein:
wherein:
A is the at least one lipid;
X1 is a branching moiety;
P is the macrocycle; each ZA. ZB and Zc is independently an optional linking moiety; and n is 1 or 2.
[0522] Clause 22. The compound of clause 21. wherein ZA, ZB and Zc are independently selected from -C(O)NH(CH2)Z-, -NHC(O)(CH2)Z-, -C(O)O-, -OC(O)-, -O-, OCO2-, -OC(O)NH-, -NHC(O)O-, - OP(O)(OH)O- a maleimide-thiol conjugation, and a triazole, wherein each z is independently 0, 1, 2, 3. 4, or 5.
[0523] Clause 23. The compound of clause 22. wherein ZA is selected from -O-, -C(O)O-, -OC(O)-. and -OP(O)(OH)O-.
[0524] Clause 24. The compound of clause 22 or 23, wherein ZB is selected from -C(O)NH(CH2)Z- - NHC(O)(CH2)Z-, and -OC(O)-.
[0525] Clause 25. The compound of any one of clauses 22 to 24, wherein Zc is selected from - C(O)NH(CH2)Z- -NHC(O)(CH2)z-,and -OC(O)-.
[0526] Clause 26. The compound of any one of clauses 22 to 25, wherein:
ZA is -C(O)O-; and
ZB and Zc are each -OC(O)-.
[0527] Clausel 'l . The compound of any one of clauses 22 to 25, wherein:
ZA is -OP(O)(OH)O-; and
ZB and Zc are each -OC(O)-.
[0528] Clause 28. The compound of any one of clauses 22 to 25, wherein:
ZA is -OC(O)-;
ZB and Zc are each -NHC(O)(CH2)Z-, wherein z is 0, 1, or 2.
[0529] Clause 29. The compound of any one of clauses 22 to 25, wherein:
ZA is -OC(O)-;
ZB is -NHC(O)(CH2)Z-; and
Zc is -C(O)NH(CH2)Z-, wherein each z is independently 0, 1, or 2.
[0530] Clause 30. The compound of any one of clauses 21 to 29, wherein X1 comprises an optionally substituted branched Cl -C 6 alkylene.
[0531] Clause 31. The compound of clause 30, wherein X1 is:
 wherein each »/wv' represent a point of attachment to each of ZA, ZB and Zc.
wherein each »/wv' represent a point of attachment to each of ZA, ZB and Zc.
[0532] Clause 32. The compound of any one of clauses 3 to 31. wherein the compound is of the Fonnula (VI):
 wherein: m is an integer from 10 to 500; each z is independently 1, 2, 3, 4, or 5; and
A is a lipid.
wherein: m is an integer from 10 to 500; each z is independently 1, 2, 3, 4, or 5; and
A is a lipid.
[0533] Clause 33. The compound of clause 32, wherein each z is independently 1 or 2.
[0534] Clause 34. The compound of clause 32 or 33, wherein m is an integer from 10 to 300.
[0535] Clause 35. The compound of any one of clauses 3 to 31, wherein the compound is of Formula
(VII):
 wherein: p is an integer from 10 to 500; and A is a lipid.
wherein: p is an integer from 10 to 500; and A is a lipid.
[0536] Clause 36. The compound of clause 35. wherein m is an integer from 10 to 300. [0537] Clause 37. The compound of any one of clauses 3 to 36. wherein each A- or A-ZA- comprises:
-C12-C30 linear or branched alkyl;
-C12-C30 linear or branched alkenyl;
-(CH2)qC(O)O(CH2)rCH(R1)(R2);
-(CH2)qOC(O)(CH2)rCH(R1)(R2);
-(CH2)qOC(O)O(CH2)rCH(R1)(R2);
-(CH2)qOCH(R')(R2);
-(CH2)qOC(O)CH(R1)(R2);
-(CH2)qC(O)OCH(R1)(R2); or
-(CH2)qOC(O)OCH(R1)(R2), wherein: q is an integer from 0 to 12. each r is independently an integer from 0 to 6; s is an integer from 1 to 100 (e.g., 44);
R1 is hydrogen or R3; and
R2, and R3 are each independently C1-C12 alky l, or C2-C12-alkenyl.
[0538] Clause 38. The compound of clause 37, wherein A- or A-ZA- comprises:

[0539] Clause 39. The compound of any one of clauses 3 to 38, wherein each A- or A-ZA- comprises:


[0540] Clause 40. The compound of any one of clauses 3 to 38, wherein each A- or A-ZA- comprises a phospholipid.
[0541] Clause 41. The compound of any one of clauses 3 to 38, wherein each A- or A-Z '- comprises a sterol or a cholesterol.
[0542] Clause 42. The compound of clause 1, wherein the compound satisfies (b).
[0543] Clause 43. The compound of clause 42, wherein the compound satisfies (b) and is of Formula
(III):
 wherein:
wherein:
P is the macrocycle;
A1 and A2 are independently the lipids; and
Z1 and Z2 are independently an optional core moiety wherein:
A1 and A2 are covalently linked to define the macrocycle P when Z1 and Z2, if present, are part of A1 and A2, respectively; or
A'-Z1 is non-covalcntly bound with A2-Z2 to define the macrocycle P.
[0544] Clause 44. The compound of clause 43, wherein A1 and A2 are covalently linked.
[0545] Clause 45. The compound of clause 43 or 44, wherein P comprises at least 10 ethylene glycol monomer units, preferably at least 12. at least 20, at least 30, at least 40, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220 ethylene glycol monomer units.
[0546] Clause 46. The compound of any one of clauses 43 to 45, wherein P comprises a PEG block of 500Da to 20kDa.
[0547] Clause 47. The compound of clause 46, wherein P comprises a PEG block of 600 Da to 2 kDa.
[0548] Clause 48. The compound of clause 46, wherein P comprises a PEG block of 5 kDa to 20 kDa.
[0549] Clause 49. The compound of clause 46, wherein P comprises a PEG block of 1.5 kDa to 3.5 kDa.
[0550] Clause 50. The compound of any one of clauses 43 to 49, wherein P comprises one PEG block.
[0551] Clause 51. The compound of any one of clauses 43 to 49, wherein P comprises two or more PEG blocks.
[0552] Clause 52. The compound of clause 51, wherein P comprises the Formula (Pl):
 wherein:
wherein:
PA and PB are each independently the tw o or more PEG blocks;
Y is an optional linking group; and m is an integer from 1 to 6, preferably an integer from 1 to 3.
[0553] Clause 53. The compound of clause 52, wherein m is 1.
[0554] Clause 54. The compound of any one of clauses 43 to 53, wherein A1 and A2 are each independently selected from:
C12-C30 optionally substituted linear or branched alkylene; and C12-C30 optionally substituted linear or branched alkenylene.
[0555] Clause 55. A lipid nanoparticle (LNP) comprising a compound of any one of clauses 1 to 54.
[0556] Clause 56. The LNP of clause 55, wherein the LNP exhibits reduced immunogenicity compared to a LNP that comprises a corresponding linear PEG lipid rather than a compound of any one of clauses 1 to 54.
[0557] Clause 57. The LNP of clause 55 or 56, further comprising: an ionizable lipid; and a nucleic acid.
[0558] Clause 58. The LNP of clause 57, wherein the nucleic acid is an RNA polynucleotide.
[0559] Clause 59. The LNP of clause 58, wherein the RNA polynucleotide is a circular RNA polynucleotide.
[0560] Clause 60. A compound of Formula (IV):
 wherein:
wherein:
A and A’ are independently a lipid; and
LP is a linking moiety comprising one or more polyethylene glycol (PEG) blocks.
[0561] Clause 61. The compound of clause 60, wherein A and A’ each form a link to a core-shell structure of a lipid nanoparticle to form a macrocycle.
[0562] Clause 62. The compound of clause 60 or 61, wherein LP comprises at least 10 ethylene glycol monomer units, preferably at least 12, at least 20, at least 30, at least 40, at least 50, at least 60,
at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, or at least 220 ethylene glycol monomer units.
[0563] Clause 63. The compound of any one of clauses 60 to 62, wherein LP comprises a PEG block of 500 Da to 20 kDa.
[0564] Clause 64. The compound of clause 63, wherein LP comprises a PEG block of 600 Da to 2 kDa.
[0565] Clause 65. The compound of clause 63, wherein LP comprises a PEG block of 5 kDa to 20 kDa.
[0566] Clause 66. The compound of clause 63, wherein LP comprises a PEG block of 1.5 kDa to
3.5k Da.
[0567] Clause 67. The compound of any one of clauses 60 to 66, wherein LP comprises one PEG block.
[0568] Clause 68. The compound of any one of clauses 60 to 66, wherein LP comprises two or more
PEG blocks.
[0569] Clause 69. The compound of clause 68, wherein the compound is of the Formula (V):
 wherein:
wherein:
PA and PB are each independently the two or more PEG blocks;
Y is an optional linking group; and m is an integer from 1 to 6, preferably an integer from 1 to 3.
[0570] Clause 70. The compound of clause 69, wherein m is 1.
EXAMPLES
[0571] Wesselhoeft et al., (2019) RNA Circularization Diminishes Immunogenicity and Can Extend Translation Duration In vivo. Molecular Cell. 74(3). 508-520 and Wesselhoeft et al., (2018) Engineering circular RNA for Potent and Stable Translation in Eukaryotic Cells. Nature Communications. 9, 2629 are incorporated by reference in their entirety.
[0572] The present disclosure further includes the following examples that provide those of ordinary skill in the art with a description of how to make and use the various embodiments of the present disclosure. These examples are not intended to limit the scope of what is regarded as the claimed invention.
EXAMPLE 1
Preparation of circular polyethylene glycol lipid (Compound 10)
[0573] Scheme 1 below outlines the synthetic procedure for the preparation of an example circular polyethylene glycol lipid (Compound 10). While this scheme summarizes the synthesis of example Compound 10, it will be understood that this procedure can be adapted to prepare a wide range of example circular polyethylene glycol lipids as disclosed herein.
[0574] Scheme 1
 (i) Preparation of Intermediate 2
(i) Preparation of Intermediate 2

[0575] Fmoc-Lys(Mtt)-Wang (1 g, 100-200 mesh) resin 1 (with loading capacity of 0.40-1.00 mrnol/g) is dissolved in 10 mL of in N,N-dimethylformamide (DMF) and then loaded into a commercially available polypropylene column (e.g., Poly-Prep Chromatography Column, Biorad 731-1550). The polypropy lene column is w ashed with lOmL of DMF. A septum is then used to push the solvent of the polypropylene column with pressure according to manufacturer instructions.
[0576] The MTT-protected (Methyltrityl-protected) amine in the lysine linker of the resin 1 is dcprotonatcd using a solution of 1-2% trifluoroacctic acid (TFA) in dichloromcthanc (DCM) with triisopropylsilane (TIS). The resin 1 is suspended in 10 mL with a TFA:TIS:DCM volume to volume to volume ratio of 1:2:97. The resulting resin solution is gently shaken at room temperature for 30 minutes. Completion of deprotonation reaction of the resin 1 is confirmed by removing a few beads from the resin solution and adding 1-2 drops of TFA; if the beads from the resin solution turned orange (i.e., deprotonation may not be complete), the resin solution are shaken for an additional 30 minutes and a few of the newly shaken beads are retested with TFA to determine completion of deprotonation reaction (i.e.. the tested beads do not turn immediately orange). Once the deprotonation reaction is completed, the resin is filtered using methods known in the art and washed twice with DCM. The resin solution is washed twice with methanol and then washed twice again with DCM. The resin solution is washed twice with 1% diisopropylamine (DIEA) in N,N-dimethylformamide (DMF) and then washed twice again with DMF producing Intermediate 2.
(ii) Intermediate 4

[0577] AA-PEG-AA (1g, MW: 2000) (e.g.. from CreativePEGWorks) is dissolved in 10 mL of trifluorotoluene to form Solution A. Then 342 mg of 2-Benzyloxy-l -methylpyridinium triflate (or 2
molar equivalents to the resin 1) is dissolved in 10 mL of trifluorotoluene with 99 mg of triethylamine to form Solution B. Solution A and Solution B are then combined and left to react at 83 °C for 1 day to form a mono-protected AA-PEG2000-AA, Intermediate 4. The mono-protected AA-PEG2000-AA, Intermediate 4, is purified using methods known in the art.
(iii) Intermediate 5

[0578] Intermediate 2 is suspended in 10 mL of DCM. 10.27 g (or 5 equivalent molars to the resin 3) of the mono-protected AA-PEG2000-AA 4 is dissolved in DCM and added to the polypropylene column. Hydroxybenzotriazole (HOBT) (743 mg, or 5.5 molar equivalents to the resin 1) is dissolved in DMF and added to the polypropylene column. N,N'-Diisopropylcarbodiimide (DIC) (694 mg, or 5.5 molar equivalents to the resin 1) is dissolved in DMF and added to the polypropylene column. The polypropy lene column is shaken at room temperature under inert gas for 4 hours to allow the amine group in Intermediate 2 to be coupled with the AA-PEG2000-AA, Intermediate 4. The resulting solution is tested for completion of the reaction using a ninhydrin test (i.e., if the ninhydrin test is negative, the reaction has reached completion; if not, the steps used to couple Intermediate 2 to be coupled with the AA-PEG2000-AA 4 are repeated). The polypropylene column is washed three times with DMF, three times with DIC then three times with DCM leaving behind Intermediate 5.
(iv) Intermediate 6

[0579] At room temperature, 20% piperidine in DMF (10 mL) is added to the polypropy lene column to deprotect the Fmoc-protected amine of Intermediate 5. The column is vortexed for 15 minutes and excess gas is let off as pressure builds up. Then, the deprotection solution (i.e., 20% piperidine in DMF)
is removed from the column and the polypropy lene column is washed several times with DMF. The resulting solution in the polypropylene column is Intermediate 6.
(v) Intermediate 7
 [0580] 4.4% Formic acid in methanol is placed into the polypropylene column. The resulting solution in the polypropylene column is allowed to sit for 10 minutes to allow the benzyl ester protection on Intermediate 6 to be removed. The resulting solution is then washed several times with DCM resulting in Intermediate 7.
[0580] 4.4% Formic acid in methanol is placed into the polypropylene column. The resulting solution in the polypropylene column is allowed to sit for 10 minutes to allow the benzyl ester protection on Intermediate 6 to be removed. The resulting solution is then washed several times with DCM resulting in Intermediate 7.
(vi) Intermediate 8

[0581] The resin solution within the polypropylene column is suspended in DCM (10 mL). Then, hydroxybenzotriazole (HOBT) (743 mg, or 5.5 molar equivalents to the resin 1) is dissolved in DMF and added to the polypropylene column. N,N'-Diisopropylcarbodiimide (DIC) (694 mg) is separately dissolved in DMF and added to the polypropylene column. The polypropylene column is then shaken at room temperature under inert gas for 4 hours to allow the PEG polymer in Intermediate 7 to attach to the free amine in Intermediate 7. Reaction completion is tested using the ninhydrin test (i.e.. the ninhydrin test is negative). The polypropylene column is washed three times with DMF, three times with DIC. and then three times with DCM. This results in circular PEG with lysine linker, Intermediate 8.
(vii) Intermediate 9

[0582] The resin solution comprising Intermediate 8 is suspended in DMF (1 mL). Then, the hydrazine hydrate is dissolved in DMF at a concentration of 5% (20 mL/g) and 1 mL of the hydrazine hydrate/DMF mixture is added to the polypropylene column. The reaction is allowed to proceed for 1 hour at room temperature. The resin solution is washed with DMF and then with TFA into a separate flask to remove any DMF insoluble peptides. The filtrates are evaporated separately on rotary evaporators. The peptides are precipitated with ether and isolated via filtration to result in Intermediate 9
(viii) Intermediate 10

[0583] Oxalyl chloride (33 mg, 1.3 molar equivalent of the resin 1) is dissolved in DCM with DMF and added to the polypropylene column to react with the lysine-PEG of Intermediate 9. Stearyl alcohol (70 mg) is dissolved in DCM and placed in the polypropylene column with the acyl chloride version of the amino acid-circular PEG. The resulting solution contains a circular PEG-lysine-stearoyl product, Compound 10 that is then purified using methods known in the art.
EXAMPLE 2
Preparation of circular polyethylene glycol lipid (Compound 2-12)
[0584] Scheme 2 below outlines the synthetic procedure for the preparation of another example circular polyethylene glycol lipid (Compound 2-12). While this scheme summarizes the synthesis of example Compound 2-12, it will be understood that this procedure can be adapted to prepare a wide range of example circular polyethylene glycol lipids disclosed herein.
[0585] Scheme 2
 (i) Intermediate 2-2
(i) Intermediate 2-2

[0586] Fmoc-Asp(Wang resin)-OPP (1 g, 100-200 mesh) resin 2-3 (with loading capacity of 0.18-0.22 mmol/g) is dissolved in 10 mL of in N,N-dimethylformamide (DMF) and then loaded into a commercially available polypropylene column (e.g.. Poly-Prep Chromatography Column, Biorad 731- 1550). The polypropylene column is washed with 10 milliliters of DMF then the solvent is flushed with the pressure of a septum.
[0587] Fmoc-Asp(0-2-PhiPr)-OH 2-1 (1 g, or 10 molar equivalents to the resin 2-3) is dissolved in DCM with a few drops of DMF. N,N'-Diisopropylcarbodiimide (Sigma DI 25407) (25 mg, or 5 molar equivalents to the resin 2-3) is then added to the Fmoc-Asp(O-2-PhiPr)-OH 2-1 mixture. The mixture comprising the N,N'-Diisopropylcarbodiimide (Sigma D125407) and Fmoc-Asp(O-2-PhiPr)-OH 2-1 is stirred for 20 minutes at 0 °C in a moisture free CaCl2 drying tube to produce Intermediate 2-2.
(ii) Intermediate 2-4

[0588] 4-Dimethylaminopyridine (DMAP) (2.44 mg, or one-tenth of a molar equivalent to the resin 2- 3) is dissolved in DMF and added to the polypropylene column comprising Intermediate 2-2. The polypropylene column is sealed with a stopper and allowed to react for 1 hour at room temperature with occasional stirring via a rotary evaporator. The polypropylene column is drained and washed several times with DMF. The resulting substance is a protected aspartic acid modified HMBA resin, Intermediate 2-4.
(iii) Intermediate 2-5

[0589] 20% Piperidine in DMF (10 mL) at room te perature is added to the polypropylene column comprising Intermediate 2-4. The polypropylene column is vortexed for 15 minutes and excess gas is let off as pressure builds up. Then, the deprotection solution (e g., 20% piperidine in DMF) is removed from the polypropylene column. The polypropylene column is washed several times with DMF leaving Intermediate 2-5.
(iv) Intermediate 2- 7

[0590] Intermediate 2-5 is suspended in DCM (10 mL). Hydroxybenzotriazole (HOBT) (148.5 mg, or 5.5 equivalent molars to the resin 2-3) of is dissolved in DMF and added to the polypropylene column. N,N'-Diisopropylcarbodiimide (DIC) (139 mg, or 5.5 equivalent molars to the resin 2-3) is dissolved in DMF and added to the polypropylene column. The polypropylene column is then shaken at room temperature under inert gas for 4 hours. The solution within the polypropylene column is then tested for completion of the reaction (e.g., the ninhydrin test is negative). The polypropylene column is washed three times with DMF, three times with DIC, and then 3 times with DCM. The resulting substance is Intermediate 2-7.
(v) Intermediate 2-8

[0591] Zinc bromide (3 eq., 135.1 mg, or 3 equivalent molars to the resin 2-3) and trimethylsilyl iodide (TMSI) (48 mg, or 1.2 equivalent molars to the resin 2-3) is added dropwise into DMF (2 mL) and then placed into the polypropylene column comprising Intermediate 2-7 to deprotect the Boc-protected amine in substance 2-7. The deprotection reaction is allowed to proceed for 24 hours then the
deprotection solution (i.e., ZnBr, TMSI, DMF solution) is drained from the polypropylene column. The polypropylene column is then washed several times with DMF leaving Intermediate 2-8.
(vi) Intermediate 2-9
 [0592] 1 % TFA in DCM ( 10 mL) is added to the polypropylene column and the polypropylene column is shaken for 30 minutes to deprotect the OPP-protected carboxylic acid in the aspartic acid linker of Intermediate 2-8. After 30 minutes, the polypropylene column is washed several times with DCM leaving behind Intermediate 2-9.
[0592] 1 % TFA in DCM ( 10 mL) is added to the polypropylene column and the polypropylene column is shaken for 30 minutes to deprotect the OPP-protected carboxylic acid in the aspartic acid linker of Intermediate 2-8. After 30 minutes, the polypropylene column is washed several times with DCM leaving behind Intermediate 2-9.
(vii) Intermediate 2-10

[0593] The intermediate 2-9 is suspended in DCM (10 mL). Then, hydroxybenzotriazole (HOBT) (148.5 mg. or 5.5 equivalent molars to the resin 2-3) is dissolved in DMF and added to the column. N.N'-Diisopropylcarbodiimide (DIC) (139 mg. or 5.5 equivalent molars to the resin 2-3) is dissolved in DMF and added to the column to couple the aspartic acid linker and amine on the Intermediate 2-9. The polypropylene column is shaken at room temperature under inert gas for 4 hours. The solution within the polypropylene column is then tested for completion of the reaction (e.g., the ninhydrin test is negative). The column is washed three times with DMF, three times with DIC, and then three times with DCM leaving behind a circular PEG-aspartic acid, Intermediate 2-10.
(viii) Intermediate 11

[0594] Intermediate 2-10 is suspended in DMF (1 mL). 5% Hydrazine hydrate dissolved in DMF (1 mL) is added to the polypropylene column. The polypropylene column is left for 1 hour at room temperature to allow the hydrazine hydrate remove intermediate 2-10 from the resin 2-3. The resin 2- 3 is washed with DMF and then TFA into a separate flask to remove any DMF insoluble peptides. Filtrates are evaporated separately on rotary evaporators. The products are precipitated with ether and isolated via filtration using methods used in the art leaving behind Intermediate 2-11.
(ix) Compound 2-12

[0595] Oxalyl chloride (33 mg, or 1.3 equivalent molars to the resin 2-3) is dissolved in DCM with DMF and reacted with the aspartic acid-PEG. Then, stearyl alcohol (70.32 mg. or 1.3 equivalent molars to the resin 2-3) is dissolved in DCM and reacted with the acyl chloride version of the amino acidcircular PEG to add an alkyl tail to the aspartic acid linker in Intermediate 2-11. The resulting product, a circular PEG-aspartic acid sterol is then purified leaving behind Compound 2-12.
EXAMPLE 3
[0596] Circular RNA used in subject lipid nanoparticle (LNP) compositions as described herein can be prepared and purified according to procedures in Wesselhoeft et al. (PCT/US2020/034418, filed May 22, 2020, published as WO2020237227), and Goodman ct al. (PCT/US2021/031629, filed May 10, 2021, published as WO2021226597), the contents of which are hereby incorporated by reference in their entirety for all purposes. Additional polynucleotides, including expression sequences, and lipids are disclosed in WO2019236673; WO2020237227; WO2021113777; WO2021226597;
WO2021189059; WO2021236855; WO2022261490; W02023056033; WO2023081526; the contents of which are hereby incorporated by reference in their entireties.
EXAMPLE 4
Testing of circular polyethylene glycol lipids (e.g., as compared to linear PEG lipids).
[0597] To test circular-PEG-lipids, they are formulated into lipid nanoparticles (LNPs) encapsulating circular RNAs encoding firefly luciferase (oFLuc) or circular RNAs encoding human erythropoietin (ohEPO). Circular RNA constructs are generated with IRES elements operably linked to the coding sequence (e.g.. firefly luciferase or hEPO). The LNPs are administered intravenously to mice either once or weekly for four weeks at 0.05 mg/kg, 0.1 mg/kg. 0.25 mg/kg, or 1.0 mg/kg dosages of circular RNA formulated in LNPs. oFLuc expression is measured following intraperitoneal administration of D-luciferin (e.g., 200pL of at a 15 mg/mL concentration) by quantifying luminescence using an In Vivo Imaging System (e.g., IVIS Spectrum In Vivo Imaging System from Perkin Elmer). 15 minutes after injection of D-luciferin, the mice are scanned for luminescence. Blood draws are collected at 6 hours, 24 hours, 3 days and 5 days post-administration of the oFLuc or ohEPO. The expression of the injected ohEPO is assayed using a commercially available ELISA kits for hEPO (e.g., a commercially available anti-PEG IgM ELISA kit) to extract levels of anti-PEG IgM antibodies present in the blood draws.
EXAMPLE 5
Circular polyethylene glycol lipids in vivo delivery of circular RNAs a. Preparation and formulation of circular RNA-LNPs
[0598] Ionizable lipids (i.e.. Ionizable Lipid 2 or Ionizable Lipid 3), helper lipid (i.e., DSPC), structural lipid (i.e., cholesterol), and polymeric lipids (i.e.. compound 10. Compound 7-17, Compound 6-17 or DMG-PEG2000 (control)) were dissolved in ethanol at a molar ratio of 50:10:38.5:1.5 (i.e.. ionizable lipid: DSPC: cholesterol: polymeric lipid). The resulting lipid mixture was combined with an aqueous solution comprising circular RNAs in 6.25 mM sodium acetate buffer at a volume ratio of 3:1 (i.e.. aqueous solution: ethanol) using a commercially available microfluidic mixer to form circular RNA-LNPs. Circular RNAs were engineered to comprise intron fragments, exon fragments, an internal ribosome entry site (IRES) and an expression sequence encoding firefly luciferase (fLuc) as described in Example 3. The circular RNA-LNPs were purified using dialysis at 4°C. Size-average diameter (in nm), poly dispersity index (PDI), circular RNA encapsulation percentage (%) was calculated (shown in Table (3). Circular RNA-LNP underwent a single freeze-thaw cycle and size growth was calculated (shown in Table y).
[0599] Table [3

[0600] Table y
 b. In vivo protein expression of circular RNA-LNPs
b. In vivo protein expression of circular RNA-LNPs
[0601] To assess protein expression levels in vivo, C57BL/6 mice (female, 6-8 weeks, n=4) were intravenously injected with 0.5mg/kg of the circular RNA-LNPs. As a control, C57BL/6 mice were administered a IX phosphate buffer solution (PBS). 6 horns post dosing the circular RNA-LNPs. the C57BL/6 mice were intraperitoneally injected with 3 mg of luciferin. The mice were then euthanized 10 minutes after injection of luciferin and both the liver and spleen were resected. The resected murine liver and spleen were imaged for luminescence using a commercially available IVIS imaging equipment (e.g., IVIS Lumina, Rewity). Total flux was then calculated in the liver and spleen of the mice. As shown in the exemplary ex vivo IVIS imaging in FIGs. 3A-3C (depicting the murine liver and spleen 6 hours post intravenous injection of circular RNA-LNPs comprising either LNP 4. LNP 5, or LNP 7) and total flux calculations of FIG. 4A and 4B (depicting the total flux calculated for the circular RNA- LNPs comprising either LNP 4. LNP5 or LNP 7 or control PBS solution), circular RNA-LNPs comprising circular polyethylene glycol lipids expressed luciferase in vivo.
EXAMPLE 6
Preparation of circular polyethylene glycol lipid (Compound 6-17)
[0602] Scheme 3 below outlines the synthetic procedure for the preparation of an example circular polyethylene glycol lipid (Compound 6-17). While this scheme summarizes the synthesis of example Compound 6-17, it will be understood that this procedure can be adapted to prepare a wide range of example circular polyethylene glycol lipids as disclosed herein.
[0603] Scheme 3

Preparation of Intermediate (6-2)

[0604] BenzyloxyPEG2k 1 (5.0 g, 2.4 mmol, 1 eq.). tert-butyl acrylate (1.5 g. mmol, 5 eq.) and THF (60 mL) were added to a round bottom flask under N2. Saturated aqueous KOH (343 μ L, 4.78 mmol. 1
eq.) was added to the cloudy reaction mixture and stirred overnight. The clear solution was concentrated and directly loaded onto an ISCO column and purified (0-10% MeOH:DCM) to yield Intermediate 6-2 as a white solid (6.48 g, 61%).
[0605] 1H NMR (400 MHz, CHLOROFORM-/)) 5 7.32-7.22 (m, 5H), 4.55 (s, 2H), 3.76-3.53 (broad m, 173H), 2.48 (t, J = 6.6 Hz, 2H), 1.42 (s, 9H).
Preparation of Intermediate (6-3)

[0606] Pd/C (10% carbon) (2.00 g) was added to a Parr reaction vessel under N2. Intermediate 6-2 (10.46 g. 4.71 mmol, 1 eq.) and MeOH (125 mL) were then added. The reaction mixture was degassed and backfilled with N2 (3x) and H2 (3x) and then the vessel was charged with 40 psi of H2. The reaction was shaken on a Parr hydrogenator at room temperature overnight. The reaction was degassed and backfdled with N2 (3x) and fdtered through a pad of celite. The celite pad was washed with DCM (3 x 100 mL) and the filtrate was concentrated to yield Intermediate 6-3 as a white solid (9.4 g, 94%). The white solid was used without further purification.
[0607] 1H NMR (400 MHz, CHLOROFORM-D) 5 3.85-3.37 (in, 165H), 2.47 (t, J = 6.6 Hz. 2H), 1.41 (s, 9H).
Preparation of Intermediate (6-4)

[0608] In a 20 mL vial, Intermediate 6-3 (5.0 g, 2.3 mmol, 1 eq.) and methyl acrylate (10 mL) was added and stirred until reaction mixture was mostly clear. Triton B (0.46 mL, 1.2 mmol, 0.5 eq.) was added to the solution and stirred overnight. DCM (200 mL) was added to the reaction mixture and washed with H2O (2 x 50 mL), dried (MgSO4), filtered and concentrated to yield a white crude (5.18 g) comprising Intermediate 6-4 and Intermediate 6-4’. The white crude mixture was carried onto the next
reaction without further purification.
Preparation of Intermediate (6-5)

[0609] In a 250 rnL round bottom flask, Intermediate 6-4 and/or Intermediate 6-4’ (5.18 g, 2.34 mmol, 1 eq.) and MeOH:H2O (3:1, 35.1:11.7 mL) was added. LiOH (393 mg, 9.36 mmol, 4 eq,) was added and left to stir until reaction was complete (3-4 hrs). The reaction mixture was then acidified with IN HC1 until pH ~6. DCM (200 mL) was added to the reaction mixture and layers were separated. The organic layer was washed with H2O (2 x 100 mL). dried (MgSCL), filtered, and concentrated to yield a white crude solid (4.2 g) comprising Intermediate 6-5 and Intermediate 6-5’. The crude solid was carried onto the next reaction without further purification.
Preparation of Intermediate (6-11)

[0610] Fmoc-Lys(Boc)-OH 6-10 (1.00 g, 2.13 mmol, 1 eq.). 1-octadecanol (1.15 g. 4.26 mmol. 2 eq.) and DCM (11 mL) were added to a round bottom flask under N2. 4-Dimethylaminopyridine (DMAP) (52 mg. 0.43 mmol, 0.2 eq.), N, N-diisopropy lethy laminc (DIPEA) (1.5 mL, 8.52 mmol, 4 eq.), and l-Ethyl-3-(3-dimethylaminopropyl)carbodiimide (EDC) (817.92 mg, 4.26 mmol. 2 eq.) were added to the solution sequentially and the reaction mixture was stirred overnight. The reaction mixture was directly added onto silica gel and purified by flash chromatography (Hexanes:EtOAc 100:0-60:40) to yield octadecyl A-(((9H-fluoren-9-yl)methoxy)carbonyl)-A-(tert-butoxycarbonyl)-L-lysinate Intermediate 6-11 as a white solid (629 mg, 41%).
[0611] 1H NMR (400 MHz, CDC13): <5 ppm 7.78-7.72 (m, 2H), 7.63-7.48 (m, 2H), 7.43-7.35 (m, 2H), 7.34-7.27 (m, 1H), 4.60-3.96 (m, 7H), 3.15-2.99 (m, 2H), 2.08-2.00 (m, 1H) 1.90-1.79 (m, 1H), 1.74- 1.56 (m, 1H), 1.54-1.38 (m, 9H), 1.35-1.18 (m, 30H) 0.86 (t, J = 6.4 Hz, 3H).
Preparation of Intermediate (6-12)

[0612] Octadecyl A-(((9H-fluoren-9-yl)methoxy)carbonyl)-A-(tert-butoxycarbonyl)-L-lysinate Intermediate 6-11 (629 mg, 0.871 mmol, 1 eq.) and DMF (20 mL) was added to a round bottom flask under N2. Piperidine (20% in DMF) (20 mL) was added to the reaction mixture and stirred overnight. The reaction solution was concentrated, added onto silica gel, and purified by flash chromatography (MeOH:NH4OH:DCM 0:1:99-10:1:89) to yield octadecyl A-(tert-butoxycarbonyl)-L-lysinate Intermediate 6-12 as a waxy solid (325 mg, 75%).
[0613] 1H NMR (400 MHz, CDC13): 3 ppm 4.08 (t, J= 6.8 Hz, 2H), 3.47 (t, J= 5.6 Hz, 2H), 3.43- 3.35 (m, 1H), 3.29 (t, J = 5.5 Hz, 2H), 3.15-3.02 (m, 2H), 1.74-1.47 (m, 9H), 1.46-1.38 (m, 9H), 1.29- 1.24 (m, 29H), 0.86 (t, J= 6.8 Hz, 3H).
Preparation of Intermediate (6-13)

[0614] Intermediate 6-5, Intermediate 6-5’ (857 mg. 0.39 mmol. 1 eq.) and DMF (15 mL) were added to a round bottom flask under N2 and cooled to 0 °C. HATU (296 mg, 0.78 mmol, 2 eq.) and DIPEA (204 pL, 0.20 mmol. 3 eq) were added sequentially to the reaction mixture. Octadecyl /V-( tert- butoxy carbonyl )-L-lysinatc 6-8 (253 mg, 0.51 mmol, 1.3 eq.) was added to the reaction solution and
stirred overnight at room temperature. H2O (50 mL) was then added to the reaction mixture and extracted with DCM (2 x 50 mL). The organic extracts were washed with H2O (3 x 100 mL), dried (MgSCL), filtered, and concentrated. The crude was loaded and purified on ISCO gold column (0-10% MeOH:DCM) to yield Intermediate 6-13 as a white solid (418 mg, 40%).
[0615] 1H NMR (400 MHz, CHLOROFORM-D) δ 4.60 - 4.50 (m, 1H), 4.09 (t, J = 6.8 Hz, 2H), 3.83-3.52 (m, 195H), 3.12-3.00 (m, 2H), 2.55-2.44 (m, 4H), 1.88 - 1.75 (m, 2H), 1.70-1.55 (m, 3H), 1.52-1.37 (m, 18H), 1.36-1.16 (m, 30H), 0.86 (t, J = 6.8 Hz, 3H).
Preparation of Intermediate (6-15)

[0616] Intermediate 6-13 (1.0 g, 0.373 mmol, 1 eq.) and DCM (24 mL) was added to a round bottom flask rmdcr N2 and cooled to 0 °C. TFA (8 mL) was added dropwisc and then stirred at room temperature overnight. The reaction solution was concentrated and redissolved in DCM 10 mL. After washing with saturated NaHCO3 (50 mL), the organic layer was acidified with IN HCI (50 mL), separated. The HCI layer was extracted with DCM (50 mL) again. The combined organic layer was washed with H2O (50 mL), brine (50 mL), dried (MgSCL), filtered, and concentrated to yield Intermediate 6-15 as a waxy solid (587 mg. 61%). The crude was used directly in the next reaction.
[0617] 1H NMR (400 MHz, CHLOROFORM-D) δ 4.57-4.46 (m, 1H), 4.09 (t, J= 6.7 Hz, 2H), 3.84- 3.40 (s, 170H), 2.91-2.79 (m. 2H), 2.62-2.49 (m, 4H), 1.89-1.71 (m, 3H), 1.68-1.55 (m, 4H), 1.50-1.36 (m, 2H), 1.35-1.17 (s, 30H), 0.87 (t, J = 6.7 Hz, 3H).
Preparation of Compound 6-17

[0618] In a round bottom flask, DIPEA (0.08 mL, 0.46 mmol. 2 eq.), DMAP (2.8 mg, 0.023 mmol, 0.1 eq.), EDC (52.7 mg, 0.28 mmol, 1.2 eq ), and DCM (450 mL) were added under N2. Intermediate 6-15 in DCM (50 mL) was added via addition funnel over 1 hour. Overall concentration was 0.0005M. Reaction was then stirred over the weekend. Reaction was concentrated and directly loaded on an ISCO
gold column and purified (0-20% MeOH:DCM). A second purification was completed by reverse phase C18 column using only MeOH. A waxy solid was isolated (i.e., Compound 6-17) (126 mg, 22%).
[0619] 1H NMR (400 MHz, CHLOROFORM-D) 5 4.56-4.43 (m, 1H), 4.12-3.02 (m, 2H), 3.83-3.40 (m, 173H), 3.23-3.13 (m, 2H), 2.55-2.38 (m, 4H), 1.94-1.74 (m, 2H), 1.72-1.42 (m, 5H), 1.41-1.12 (m, 33H), 0.85 (t, J = 4.0 Hz, 3H).
[0620] MALDI-TOF MS: 2376.0 (average).
EXAMPLE 7
Preparation of circular polyethylene glycol lipid (Compound 7-17)
[0621] Scheme 4 below outlines the synthetic procedure for the preparation of an example circular polyethylene glycol lipid (i.e., Compound 7-17). While this scheme summarizes the synthesis of example Compound 7-17, it will be understood that this procedure can be adapted to prepare a wide range of example circular polyethylene glycol lipids as disclosed herein.
[0622] Scheme 4

Preparation Intermediate (7-7)

[0623] Under 0 °C ice-water bath, to a mixture of PEGlk 7-6 (50.0 g, 48 mmol, 1 eq.) in THF (60 mL) was added NaH (97 mg, 2.4 mmol. 0.05 eq) until bubbling stopped. Tert -butyl acry late (3.1 g. 24 mmol. 0.5 eq.) was added under N2. The reaction mixture was stirred at room temperature overnight. TLC showed expected product (less polar spot, 10%MeOH in CH2CI2, Rf =0.6) and unreacted PEGlk.
The reaction mixture was quenched with H2O (1 inL) and concentrated, and the crude compound was directly loaded onto a ISCO column and purified (0-10% MeOH:DCM) to yield Intermediate 7-7 as a white solid (12.3 g, 22%).
[0624] 1H NMR (400 MHz, CHLOROFORM-/)) 5 3.83-3.46 (broad m, 95H), 2.68 (t, J = 6.4 Hz, 1H, -OH), 2.50 (t, J= 6.4 Hz, 2H), 1.44 (s, 9H).
Preparation of Intermediate (7-8)

[0625] In a 250 mL round bottom flask, Intennediate 7-7 (12.3 g, 11.0 mmol, 1 eq.) and methyl acry late (80 mL) were added, until the reaction mixture was mostly clear. Benzyltrimethylammonium hydroxide (Triton B) (0.87 mL, 2.2 mmol. 0.2 eq.) was added and the reaction was stirred at room temperature overnight. TLC showed complete reaction with expected product (less polar spot, 10%MeOH in CH2C12. Rf =0.8). The reaction mixture was concentrated, and the crude residue was dissolved in CH2C12 (200 mL) and washed with H2O (2 x 50 mL), brine (2 x 50 mL), dried (Na2SO4), filtered and concentrated to yield a white crude mixture (14 g) comprising Intermediate 7-8 and Intermediate 7-8’. The crude mixture was carried onto the next reaction without further purification.
Preparation of Intermediate (7-9)

[0626] In a 250 mL round bottom flask, to a mixture of Intermediate 7-8 and Intermediate 7-8’ (12 g, 9.99 mmol, 1 eq.) in MeOH:H2O (3:1. 90 mL:30 mL) was added LiOH monohydrate (1.68 g. 40 mmol. 4 eq) and left to stir until reaction was complete (2-3 hrs). The reaction mixture was concentrated, and then acidified with IN HO until pH ~6. DCM (200 mL) was added to the reaction mixture and
layers were separated. The organic layer was washed with H2O (2 x 100 mL), Brine (2 x 100 mL), dried (Na2SO4), filtered, and concentrated to yield a white solid (5.3 g) comprising Intermediate 7-9 and Intermediate 7-9’. The crude solid was carried onto the next reaction without further purification.
[0627] 1H NMR (400 MHz, CDCl3) 5 ppm 3.83-3.46 (broad m, 155H), 2.58-2.52 (m, 2H), 2.50-2.44 (m, 3.49H), 1.41 (s, 14H).
Preparation of Intermediate (7-11)

[0628] Fmoc-Lys(Boc)-OH 7-10 (1.00 g, 2.13 mmol, 1 eq.), 1-octadecanol (1.15 g. 4.26 mmol, 2 eq.) and DCM (11 mL) was added to a round bottom flask under N2. 4-Dimethylaminopyridine (DMAP) (52 mg. 0.43 mmol, 0.2 eq.). AA'-diisopropylcthylaininc (DIPEA) (1.5 mL, 8.52 mmol. 4 eq.), and 1-
Ethyl-3-(3-dimethylaminopropyl)carbodiimide (EDC) (817.92 mg. 4.26 mmol, 2 eq.) were added to the solution sequentially and the reaction mixture was stirred overnight. The reaction mixture was directly added onto silica gel and purified by flash chromatography (Hexane s:EtO Ac 100:0-60:40) to yield octadecyl A-(((9H-fluoren-9-yl)methoxy)carbonyl)-A-(tert-butoxycarbonyl)-L-lysinate 7-11 as a white solid (629 mg, 41%).
[0629] 1H NMR (400 MHz. CDC13): P ppm 7.78-7.72 (m. 2H), 7.63-7.48 (m. 2H), 7.43-7.35 (m. 2H), 7.34-7.27 (m, 1H). 4.60-3.96 (m, 7H), 3.15-2.99 (m. 2H), 2.08-2.00 (m, 1H) 1.90-1.79 (m, 1H), 1.74- 1.56 (m. 1H), 1.54-1.38 (m, 9H), 1.35-1.18 (m, 30H) 0.86 (t, J= 6.4 Hz, 3H).
Preparation of Intermediate (7-12)

[0630] Octadecyl A-(((9H-fluoren-9-yl)methoxy)carbonyl)- V-(tert-butoxycarbonyl)-L-lysinate 7- 11 (629 mg. 0.871 mmol, 1 eq.) and DMF (20 mL) was added to a round bottom flask under N2. Piperidine (20% in DMF) (20 mL) was added to the reaction mixture and stirred overnight. The reaction solution was concentrated, added onto silica gel. and purified by flash chromatography (MeOH:NH4OH:DCM 0:1:99-10:1:89) to yield octadecyl A-(tert-butoxycarbonyl)-L-lysinate 7-12 as a waxy solid (325 mg, 75%).
[0631] 1H NMR (400 MHz, CDCl3): δ ppm 4.08 (t, J= 6.8 Hz, 2H), 3.47 (t, J= 5.6 Hz, 2H), 3.43- 3.35 (m, 1H), 3.29 (t, J= 5.5 Hz, 2H), 3.15-3.02 (m, 2H), 1.74-1.47 (m, 9H), 1.46-1.38 (m, 9H), 1.29- 1.24 (m, 29H), 0.86 (t, J= 6.8 Hz, 3H).
Preparation of Intermediate (7-14)

[0632] Intermediate 7-9. Intermediate 7-9’ (857 mg, 0.39 mmol, 1 eq.) and DMF (15 mL) were added to a round bottom flask under N2 and cooled to 0 °C. HATU (296 mg, 0.78 mmol, 2 eq.) and DIPEA (204 pL. 0.20 mmol, 3 eq) were added sequentially to the reaction mixture. Octadecyl N-(tert- butoxycarbonyl)-L-lysinate 7-12 (253 mg, 0.51 mmol, 1.3 eq.) was added to the reaction solution and stirred overnight at room temperature. H2O (50 mL) was added to the reaction mixture and extracted with DCM (2 x 50 mL). The organic extracts were washed with H2O (3 x 100 mL), dried (MgSCL), filtered, and concentrated. The crude was loaded and purified on ISCO gold column (0-10%
MeOH:DCM) to yield Intermediate 7-13 as a white solid .
[0633] *H NMR (400 MHz, CHLOROFORM-D) δ 4.60 - 4.50 (m, 1H), 4.09 (t, J = 6.8 Hz, 2H), 3.83-3.52 (m, 99H), 3.12-3.00 (m, 2H), 2.65-245 (m, 4H), 1.70-1.55 (m, 8H), 1.52-1.37 (m, 18H), 1.4- 1.1 (m, 30H), 0.86 (t, J = 6.8 Hz, 3H).
Preparation of Intermediate (7-16)

[0634] Intermediate 7-14 (1 eq.) and DCM (24 mL) was added to a round bottom flask under N2 and cooled to 0 °C. TFA (8 mL) was added dropwise and then stirred at room temperature overnight. The reaction solution was concentrated and redissolved in DCM 10 mL. After washing with saturated NaHCOi (50 mL), the organic layer was acidified with IN HCI (50 mL), and separated. The HO layer was extracted with DCM (50 mL) again. The combined organic layer was washed with H2O (50 mL), brine (50 mL), dried (MgSO4), filtered, and concentrated to yield Intermediate 7-16 as a waxy solid. The crude was used directly in the next reaction.
[0635] 1H NMR (400 MHz, CHLOROFORM-D) 5 4.55-4.45 (m, 1H), 4.08 (t, J = 6.7 Hz, 2H), 3.85- 3.40 (s, 99H), 2.90-2.80 (m, 2H). 2.65-2.45 (m, 4H), 1.89-1.71 (m, 4H), 1.68-1.55 (m, 4H), 1.50-1.36 (m, 2H), 1.5-1.15 (m, 30H), 0.86 (t. J = 6.7 Hz, 3H).
Preparation of Compound 7-17

[0636] In a round bottom flask, DIPEA (0.08 mL, 0.46 mmol. 2 eq.), DMAP (2.8 mg, 0.023 mmol, 0.1 eq.), EDC (52.7 mg, 0.28 mmol, 1.2 eq ), and DCM (450 mL) were added under N2. Intermediate 7-16 in DCM (50 mL) was added via addition funnel over 1 hour. Overall concentration was 0.0005M. Reaction was then stirred over the weekend. Reaction was concentrated and directly loaded on an ISCO gold column and purified (0-20% MeOH:DCM). A second purification was completed by reverse phase C18 column using only MeOH. A waxy solid (i.e., Compound 7-17) was isolated.
[0637] 1H NMR (400 MHz, CHLOROFORM-D) 54.55-4.45 (m, 1H), 4.08 (t, J = 6.7 Hz. 2H), 3.83- 3.40 (m, 100H), 3.2 (q, J = 6.4 Hz, 2H). 2.50 (t, J = 6 Hz, 2H), 2.40 (t, J = 6Hz, 2H), 2.0-1.45 (m, 6H), 1.45-1.15 (m, 32H), 0.85 (t, J = 6.4 Hz, 3H).
[0638] MALDI-TOF MS: 1496.7 (average) EXAMPLE 8
Preparation of circular polyethylene glycol lipid (Compound 8-17)
[0639] Scheme 5 below outlines the synthetic procedure for the preparation of an example circular polyethylene glycol lipid (Compound 8-17). While this scheme summarizes the synthesis of example Compound 8-17, it will be understood that this procedure can be adapted to prepare a wide range of example circular polyethylene glycol lipids as disclosed herein.
[0640] Scheme 5

[0641] Under 0 °C (ice-water bath), to a mixture of (5)-(2.2-dimethyl-l,3-dioxolan-4-yl)methanol (10 g. 76 mmol, 1 eq.) in THF (500 mL) was slowly added sodium hydride (6.1 g, 60% Wt. 0.15 mol,
2 eq.) (a lot bubbling was observed), and followed by the addition of (bromo inethyl)benzene (17 g, 12 mL, 98 mmol, 1.3 eq.) and tetrabutylammonium iodide (2.8 g,7.6 mmol, 0.1 eq.). The reaction was stirred at room temperature overnight. TLC showed the expected product (EtOAc: Hexane =3: 7, Rf=0.6). The mixture was quenched with water, until no bubbling was observed, and then concentrated. The crude was dissolved in EtOAc (300 mL), washed with H2O (150 mL) and brine (150 mL). After drying by anhydrous Na2SO4, the solvent was evaporated, and the crude was purified by ISCO 120 g silica gel chromatography (Hexane=100% to 50% of EtOAc in Hexane) to yield Intermediate 8-7 as a yellowish oil (11.8 g, 70%)
[0642] 1H NMR (400 MHz, CDCI3) 5 ppm 7.37-7.27 (m, 5H), 4.60 (d, J= 12.4 Hz, 1H). 4.55 (d.J = 12.4 Hz, 1H), 4.30 (m. 1H), 4.06 (dd, J= 8.4, 6.4 Hz, 1H). 3.74 (dd, J= 8.4, 6.4 Hz. 1H), 3.56 (dd. J = 9.6. 5.6 Hz, 1H), 3.47 (dd, J= 9.6, 5.6 Hz, 1H), 1.42 (s, 3H). 1.36 (s, 3H).
Preparation of Intermediate (8-8)
[0643] To a mixture of (S)-4-(benzyloxy)methyl)-2,2-dimethyl- 1.3 -dioxolane Intermediate 8-7 (11 .8 g, 53.1 mmol, 1 eq.) in MEOH (50 mL) was added hydrogen chloride (2.0 mL, 2.0M, 4.0 mmol, 0.075 eq ), and the reaction mixture was placed in a pre-heated oil bath (80 °C). The mixture was stirred for 2 hours. TLC showed no starting material left (EtOAc: Hexane =3: 7. Rf=0.1). The reaction mixture was concentrated in vacuo and re-dissolved in DCM (50 mL), dried with anhydrous Na2SO4. The solvent was evaporated, and the residue was co-evaporated with toluene, then dried under vacuum overnight, to yield Intermediate 8-8 as brownish oil (9.4 g, 97%, crude).
[0644] 1H NMR (400 MHz, CDCl3) δ ppm 7.37-7.28 (m, 5H), 4.54 (s, 2H), 3.89 (m, 1H). 3.70 (dd, J= 11.2, 3.6 Hz, 1H), 3.62 (dd, J= 11.6, 5.6 Hz, 1H), 3.58-3.51 (m, 2H).
Preparation of Intermediate (8-10)

[0645] Under 0 °C ice-water bath, to a mixture of (R)-3-(benzylo.xy)propane-l,2-diol Intermediate
8-8 (6.2 g, 34 mmol, 1 eq.) in DCM (200 mL) was added N,N-dimethylpyridin-4-amine (0.83 g, 6.8 mmol, 0.2 eq.) and Diisopropylethylamine (35 mL, 0.20 mol, 6 eq.). Then a mixture of tetradecanoyl chloride (25 g, 0.10 mol, 3 eq.) in DCM (10 mL) was added into the reaction mixture over 2 hrs. The reaction was stirred at room temperature overnight.
[0646] TLC showed the expected product (EtOAc: Hexane =9: 1, Rf=0.5). The mixture was concentrated, and the crude was dissolved in EtOAc (500 mL), washed with IN HC1 (250 mL), saturated NaHCO;, (250 mL), H2O (250 mL) and Brine (250 mL). After drying by anhydrous Na2SO4, the solvent was evaporated, and the crude was purified by ISCO 220 g silica gel chromatography (Hexane=100% to 20% of EtOAc in Hexane) to yield 8-10 as yellowish solid (6.2 g, 30%).
[0647] 1H NMR (400 MHz, CDCl3) 5 ppm 7.36-7.28 (m, 5H), 5.23 (m, 1H), 4.56 (d, J = 12.4 Hz, 1H), 4.52 (d, J= 12.0 Hz, 1H), 4.34 (dd, J = 12.0, 4.0 Hz, 1H), 4.19 (dd, J= 12.0. 6.4 Hz, 1H), 3.59 (dd. J= 16.4, 11.2 Hz. 2H), 2.31 (t. J= 7.6 Hz, 2H). 1.T1 (t,J= 7.6 Hz, 2H), 1.62-1.56 (m, 4H). 1.41- 1.12 (m, 44H), 0.88 (t. J = 6.4 Hz, 6H).
Preparation of Intermediate (8-11)

[0648] Pd/C (1.5 g, 10% Wt, 0.12 Eq, 1.3 mmol) was added into the flask containing (S) -3- (benzyloxy)propane-l,2-diyl ditetradecanoate 8-10 (6.2 g, 10 mmol, 1 eq ), followed by addition of MEOH (100 mL) under N2. The reaction mixture was degassed via vacuum/N2 exchanges (3 times), followed by vacuum/H2 exchanges (3 times). The reaction was hydrogenated under H2 balloon overnight. The catalyst was filtered through celite and the celite pad was rinsed with CH2Cl2 (150 mL). The filtrate was concentrated, and the crude white solid product 8-11 was dried under vacuum (5 g, 95%).
[0649] 1H NMR (400 MHz, CDCl3) δ ppm 5.07 (m, 1H), 4.30 (dd, J = 12.0. 4.4 Hz, 1H), 4.22 (dd, J= 12.0, 6.0 Hz. 1H), 3.71 (t, J= 16.4, 11.2 Hz. 2H), 2.31 (t, J = 8.0 Hz, 2H). 2.31 (t,J = 7.6 Hz, 2H), 1.98 (t, J= 6.4 Hz, 1H, -OH), 1.63-1.58 (in. 4H), 1.37-1.16 (m, 40H), 0.86 (t. J= 6.4 Hz, 6H).
Preparation of Intermediate (8-13)

[0650] (S -3-Hvdroxvpropanc-l ,2-divl ditetradecanoate Intermediate 8-11 (5.0 g. 9.8 mmol, 1 eq.), Fmoc-Lys(Boc)-OH 12 (5.5 g, 12 mmol, 1.2 eq.) and DCM (100 rnL) were added to a 500 mL round bottom flask under N2. 4-Dimethylaminopyridine (DMAP) (240 mg, 2.0 mmol, 0.2 eq.), N,N- diisopropylethylamine (DIPEA) (6.8 mL, 39 mmol, 4 eq.), and l-Ethyl-3-(3- dimethylaminopropyl)carbodiimide (EDC) (2.2 g, 12 mmol, 1.2 eq.) were added to the solution sequentially and the reaction mixture was stirred overnight. TLC showed the expected product (EtOAc: Hexane =3: 7, Rf=0.5). The mixture was concentrated, and the crude was dissolved in EtOAc (500 mL), washed with IN HC1 (250 mL). saturated NaHCO? (250 mL), H2O (250 mL) and brine (250 mL). After drying by anhydrous Na2SO4, the solvent was evaporated, and the crude was purified by ISCO 220 g silica gel chromatography (Hexane=100% to 20% of EtOAc in Hexane) to yield Intermediate 8-13 as white solid (7.0 g, 75%).
[0651] *H NMR (400 MHz, CDC13): 3 ppm 7.77 (d. J = 8.0 Hz, 2H), 7.61 (d, J = 8.0 Hz, 2H), 7.40 (t, J= 8.0 Hz, 2H), 7.32 (t. J = 8.0 Hz, 2H). 5.37-5.28 (m, 2H), 4.70-4.60 (m. 1H), 4.44-4.12 (m, 7H), 3.13-3.11 (m, 2H). 2.31 (t, J= 4.0 Hz, 4H), 1.90-1.79 (m, 1H), 1.74-1.56 (m, 1H). 1.60-1.50 (m, 10H), 1.45-1.43 (m, 11H), 1.35-1.18 (m, 42H), 0.88 (t, J= 4 Hz, 6H).
Preparation of Intermediate (8-14)

[0652] (R)-3-((A2-(((9H-fluoren-9-yl)methoxy)carbonyl)-A6-(tert-butoxy carbonyl)-L- lysyl)oxy)propane-l,2-diyl ditetradecanoate Intermediate 8-13 (4.0 g, 4.2 mmol, 1 eq.) and DMF (20 mL) was added to a rormd bottom flaks under N2. Piperidine (4.1 mL, 10 eq.) was added to the reaction mixture and stirred overnight. The mixture was concentrated, and the crude was dissolved in EtOAc (500 mL), washed with IN HC1 (150 mL), saturated NaHCO 3 (150 mL), H2O (150 mL) and brine (150 mL). After dry ing by anhydrous Na2SO4, the solvent was evaporated, and tire crude was purified by
ISCO 80 g silica gel chromatography (Hexane=100% to 100% of EtOAc) to yield Intermediate 8-14 as clear syrup (2.2 g, 71%).
[0653] 1H NMR (400 MHz, CDCL): <5 ppm 5.29-5.24 (m, 1H), 4.70-4.60 (m, 1H), 4.36 (dd, J= 12.0, 4.0 Hz, 1H). 4.28 (dd, J= 12.0, 4.0 Hz, 1H), 4.18-4.08 (m, 3H), 3.43 (t, J= 4.0 Hz, 1H), 3.13-3.08 (m, 2H), 2.30 (t, J = 8.0 Hz, 4H), 1.75-1.68 (m, 1H), 1.63-1.36 (m, 22H), 1.45-1.43 (m, 43H), 0.88 (t. J= 4 Hz, 6H).
Preparation of Intermediate (8-15)

[0654] PEG2K tert-butyl ester propionic acid 5 (5.0 g, 2.3 mmol, 1 eq. seen synthesis experimental from Compound 6-17) and DMF (20 mL) was added to a 500 mL round bottom flask under N2 and cooled to 0 °C. HATU (1.7 g, 4.5 mmol, 2 eq.) and DIPEA (1.2 mL, 6.8 mmol, 3 eq) were added sequentially to the reaction mixture. (R)-3-((A%(tcrt-butoxycarbonyl)-£-lysyl)oxy)propanc-l,2-diyl ditetradecanoate Intermediate 8-14 (2.2 g, 3.0 mmol, 1.3 eq.) was added to the reaction solution and stirred overnight at room temperature. The mixture was concentrated, and the crude was dissolved in CH2CI2 (500 mL), washed with IN HC1 (150 mL), saturated NaHCO3 (150 mL), H2O (150 mL) and brine (150 mL). After drying by anhydrous Na2SO i. the solvent was evaporated, and the crude was purified by ISCO 80 g silica gel chromatography (CH2Cl2=100% to 1%NH4OH/10% of MeOH in CH2C12) to yield Intermediate 8-15 as white solid (2.5 g, 38%).
[0655] 1H NMR (400 MHz, CDCl3): δ ppm 6.86 (d, J = 8.0 Hz. 1H), 5.30-5.26 (m, 1H), 4.85-4.75 (m, 1H), 4.60-4.55 (in. 1H), 4.39 (dd. J= 12.0, 4.0 Hz, 1H), 4.30 (dd, J= 12.0, 4.0 Hz, 1H), 4.18-4.12 (m, 2H), 3.83-3.45 (m. 165H), 3.13-3.08 (m, 2H), 2.53-2.48 (m, 4H), 2.34-2.29 (m, 4H). 1.75-1.68 (m, 4H), 1.50-1.43 (m. 18H), 1.45-1.43 (m. 43H). 0.88 (t, J= 4 Hz, 6H).
Preparation of Intermediate (8-16)

[0656] Intermediate 8-15 (1.5 g. 0.5 mmol, 1 eq.) and formic acid (20 mL) was added to a 100 mL
round botom flask under N2 and stirred at room temperature for 2 hours. The reaction solution was concentrated and redissolved in CH2Q2 (200 mL). After washing with saturated Nal ICO;, (200 mL), H2O (200 mL), brine (200 mL), the organic layer was dried by anhydrous Na2SO4. The solvent was evaporated, and the crude was purified by ISCO 40 g silica gel chromatography (CH2C12=100% to 1%NH4OH/15% of MeOH in CH2Cl2) to yield ammonium salt of 8-16 as white foam solid (1 g). Ammonium salt was re-dissolved in CH2O2 (200 mL), and washed with IN HC1 (200 mL), H2O (200 mL), brine (200 mL), dried by anhydrous Na2SO4. filtered, and concentrated to yield Intermediate 8-16 as white foam (970 mg, 67%).
[0657] 1H NMR (400 MHz, CDCI3): δ ppm 7.82 (d, J = 8.0 Hz. 1H), 5.30-5.26 (m, 1H), 4.49-4.46 (m, 1H), 4.32-4.27 (m. 2H), 4.23-4.12 (m. 2H), 3.83-3.45 (m, 180H), 3.03-2.95 (m, 2H). 2.68-2.56 (m, 4H), 2.33-2.27 (dd, J= 16.0, 8.0 Hz. 4H), 1.88-1.78 (m, 4H). 1.32-1.26 (m. 42H). 0.86 (t, J = 4 Hz, 6H).
Preparation of Compound 8-17

[0658] In a 250 mL round botom flask, intermediate 8-16 (100 mg, 35.7 pmol. 1 eq.), HATU (17.6 mg, 46.4 pmol, 3 eq.) and DCM (60 mL) was added under N2. DIPEA (18.6 pL, 107 pmol, 3 eq.) in CH2Cl2 (20 mL) was added dropwise to the vigorously stirred reaction mixture over 3 h and the solution was stirred overnight (overall concentration: 0.45 inM). The mixture was diluted with CH2Cl2 (150 mL), washed with IN HC1 (150 mL), saturated NaHCO3 (150 mL), H2O (150 mL) and brine (150 mL). After drying by anhydrous Na2SO4, the solvent was evaporated, and the crude was purified by ISCO 4 g silica gel chromatography (CH2C12=100% to 1%NH4OH/15% of MeOH in CH2Cl2) to yield Compound 8-17 as a white foam solid (50 mg, 50%).
[0659] 1H NMR (400 MHz, CD3OD) 5 ppm 7.88-7.77 (m, 1H), 5.30 - 5.21 (m, 1H), 4.42 - 4.31 (m, 3H), 4.21 - 4.12 (in, 2H), 3.80-3.39 (m, 182H), 3.19 - 3.13 (m, 2H), 2.56 - 2.43 (m, 2H), 2.41 (t, J = 8.0 Hz, 2H). 2.34-2.26 (m, 4H), 1.87 - 1.62 (m. 2H), 1.62 - 1.34 (m, 9H), 1.34 - 1.20 (m, 42H), 0.88 (t, J = 8.0 Hz, 3H).
[0660] MALDI - TOF MS: 2617.33 (average).
INCORPORATION BY REFERENCE
[0661] All publications, patents, and patent applications mentioned in this specification are herein incorporated by reference to the same extent as if each individual publication, patent, or patent application was specifically and individually indicated as being incorporated by reference herein, including, for example, U.S. provisional patent application no. 63/579.482 and International patent application nos. PCT/US2019/035531. PCT/US2020/034418. PCT/US2020/063494.
PCT/US2021/031629, PCT/US2021/023540, PCT/US2021/033276. PCT/US2022/033091,
PCT/US2022/045408, PCT/US2023/061018. PCT/US2023/068812. PCT/US2023/078875, and PCT/US2022/049313.
Claims
WHAT IS CLAIMED IS
1 . A compound comprising: a macrocycle comprising one or more polymer, preferably polyethylene glycol (PEG), blocks in the macrocycle’s backbone; and at least one lipid; wherein either
(a) the at least one lipid is covalently attached to the macrocycle and is outside the macrocycle’s backbone; or
(b) two lipids are in the macrocycle’s backbone, wherein all polymer blocks are betw een the tw o lipids.
2. The compound of claim 1, wherein the compound satisfies (a), and the macrocycle comprises two or more polymer blocks, preferably PEG blocks.
3. The compound of claim 1 or 2, wherein the compound satisfies (a) and is of Formula (I):
 wherein:
wherein:
A is the at least one lipid;
X is a core branching moiety;
P is the macrocycle; and n is an integer selected from 1 to 6, preferably an integer from 1 to 3.
4. The compound of claim 3, wherein P comprises at least 10 ethylene glycol monomer units, preferably at least 12, at least 20, at least 30, at least 40, at least 50, at least 60, at least 70, at least 80. at least 90, at least 100, at least 150, at least 200, or at least 220 ethylene glycol monomer units.
5. The compound of claim 3 or 4, wherein P comprises a PEG block of 500 Da to 20 kDa.
6. The compound of claim 5, wherein P comprises a PEG block of 600 Da to 2 kDa.
7. The compound of claim 5, wherein P comprises a PEG block of 5 kDa to 20 kDa.
8. The compound of claim 5, wherein P comprises a PEG block of 1.5 kDa to 3.5 kDa.
9. The compound of any one of claims 2 to 8, wherein P comprises one PEG block.
10. The compound of any one of claims 2 to 8, wherein P comprises two or more PEG blocks.
11. The compound of claim 10, wherein P comprises the Fonnula Pl:
PA - (Y - PB)m-(Pl) wherein:
PA and PB are each independently the two or more PEG blocks;
Y is an optional linking group; and m is an integer from 1 to 6. preferably an integer from 1 to 3.
12. The compound of claim 11, wherein m is 1.
13. The compound of any one of claims 2 to 12, wherein X comprises one or more amino acid residues.
14. The compound of claim 13. wherein the one or more amino acid residues are selected from lysine, ornithine, aspartate, glutamate, serine, cysteine, and tyrosine.
15. The compound of claim 13 or 14, wherein X comprises:


16. The compound of any one of claims 2 to 12, wherein X comprises a substituted linear or branched C1-C6 alkylene.
17. The compound of claim 16. wherein X comprises:
 wherein two represent the point of attachment to P and the remaining 'A/w' represent the
wherein two represent the point of attachment to P and the remaining 'A/w' represent the
 points of attachment to A.
points of attachment to A.
18. The compound of any one of claims 3 to 17. wherein n is 1.
19. The compound of any one of claims 3 to 17. wherein n is 2.
20. The compound of any one of claims 3 to 17, wherein n is 3.
21. The compound of any one of claims 1 to 20, wherein the compound is of Formula (II):
 wherein:
wherein:
A is the at least one lipid:
X1 is a branching moiety;
P is the macrocycle; each ZA. ZB and Zc is independently an optional linking moiety; and n is 1 or 2.
22. The compound of claim 21, wherein ZA, ZB and Zc are independently selected from - C(O)NH(CH2)Z-, -NHC(O)(CH2)Z-. -C(O)O-, -OC(O)-, -O-, OCO2-, -OC(O)NH-, -NHC(O)O-. - OP(O)(OH)O- a maleimide-thiol conjugation, and a triazole, wherein each z is independently 0, 1, 2, 3, 4. or 5.
23. The compound of claim 22. wherein ZA is selected from -O-, -C(O)O-, -OC(O)-. and - OP(O)(OH)O-.
24. The compound of claim 22 or 23, wherein ZB is selected from -C(O)NH(CH2)Z- - NHC(O)(CH2)Z-. and -OC(O)-.
25. The compound of any one of claims 22 to 24, wherein Zc is selected from -C(O)NH(CH2)Z- - NHC(O)(CH2)z-,and -OC(O)-.
26. The compound of any one of claims 22 to 25, wherein:
ZA is -C(O)O-; and
ZB and Zc are each -OC(O)-.
27. The compound of any one of claims 22 to 25, wherein:
ZA is -OP(O)(OH)O-; and
ZB and Zc are each -OC(O)-.
The compound of any one of claims 22 to 25, wherein: ZA is -OC(O)-;
ZB and Zc are each -NHC(O)(CH2)Z-, wherein z is 0, 1, or 2.
29. The compound of any one of claims 22 to 25, wherein:
ZA is -OC(O)-:
ZB is -NHC(O)(CH2)Z-: and
Zc is -C(O)NH(CH2)Z-. wherein each z is independently 0, 1, or 2.
30. The compound of any one of claims 21 to 29, wherein X1 comprises an optionally substituted branched C1-C6 alkylene.
31. The compound of claim 30. wherein X1 comprises:
 wherein each »A/W' represent a point of attachment to each of ZA, ZB and Zc.
wherein each »A/W' represent a point of attachment to each of ZA, ZB and Zc.
32. The compound of any one of claims 3 to 31, wherein the compound is of the Formula (VI):
 wherein: m is an integer from 10 to 500; each z is independently 1, 2, 3. 4. or 5; and
wherein: m is an integer from 10 to 500; each z is independently 1, 2, 3. 4. or 5; and
A is a lipid.
33. The compound of claim 32. wherein each z is independently 1 or 2.
34. The compound of claim 32 or 33, wherein m is an integer from 10 to 300.
35. The compound of any one of claims 3 to 31, wherein the compound is of Formula (VII): wherein:
 p is an integer from 10 to 500; and
p is an integer from 10 to 500; and
A is a lipid.
36. The compound of claim 35, wherein m is an integer from 10 to 300.
37. The compound of any one of claims 3 to 36. wherein each A- or A-ZA- comprises:
-C12-C30 linear or branched alkyl;
-C12-C30 linear or branched alkenyl;
-(CH2)qC(O)O(CH2)rCH(R1)(R2);
-(CH2)qOC(O)(CH2)rCH(R1)(R2);
-(CH2)qOC(O)O(CH2)rCH(R1)(R2);
-(CH2)qOCH(R1)(R2);
-(CH2)qOC(O)CH(R1)(R2);
-(CH2)qC(O)OCH(R1)(R2); or
-(CH2)qOC(O)OCH(R1)(R2), wherein: q is an integer from 0 to 12, each r is independently an integer from 0 to 6; s is an integer from 1 to 100 (e.g., 44):
R1 is hydrogen or R3; and
R2, and R3 are each independently C1-C12 alkyl, or C2 -Cl 2 -alkenyl.
38. The compound of claim 37, wherein A- or A-ZA- comprises:
 each t is independently an integer from 0 to 6, preferably7C long branched, 8C long branched, 9C long branched, or 10C long branched.
each t is independently an integer from 0 to 6, preferably7C long branched, 8C long branched, 9C long branched, or 10C long branched.
39. The compound of any one of claims 3 to 38, wherein each A- or A-ZA- comprises:



40. The compound of any one of claims 3 to 38, wherein each A- or A-ZA- comprises a phospholipid.
41. The compound of any one of claims 3 to 38, wherein each A- or A-ZA- comprises a sterol or a cholesterol.
42. The compound of claim 1, wherein the compound satisfies (b).
43. The compound of claim 42, wherein the compound satisfies (b) and is of Formula (III):
 wherein:
wherein:
P is the macrocycle;
A1 and A2 are independently the lipids; and
Z1 and Z2 are independently an optional core moiety wherein:
A1 and A2 are covalently linked to define the macrocycle P when Z1 and Z2, if present, are part of A1 and A2, respectively; or
A'-Z1 is non-covalently bound with A2-Z2 to define the macrocycle P.
44. The compound of claim 43, wherein A1 and A2 are covalently linked.
45. The compound of claim 43 or 44. wherein P comprises at least 10 ethylene glycol monomer miits. preferably at least 12, at least 20. at least 30, at least 40. at least 50, at least 60, at least 70. at
least 80, at least 90, at least 100, at least 150, at least 200, or at least 220 ethylene glycol monomer units.
46. The compound of any one of claims 43 to 45, wherein P comprises a PEG block of 500 Da to 20 kDa.
47. The compound of claim 46, wherein P comprises a PEG block of 600 Da to 2 kDa.
48. The compound of claim 46, wherein P comprises a PEG block of 5 kDa to 20 kDa.
49. The compound of claim 46, wherein P comprises a PEG block of 1.5 kDa to 3.5 kDa.
50. The compound of any one of claims 43 to 49, wherein P comprises one PEG block.
51. The compound of any one of claims 43 to 49, wherein P comprises two or more PEG blocks.
52. The compound of claim 51. wherein P comprises the Formula (Pl):
 wherein:
wherein:
PA and PB are each independently the two or more PEG blocks;
Y is an optional linking group; and m is an integer from 1 to 6, preferably an integer from 1 to 3.
53. The compound of claim 52, wherein m is 1.
54. The compound of any one of claims 43 to 53, wherein A1 and A2 are each independently selected from:
C12-C30 optionally substituted linear or branched alkylene; and C12-C30 optionally substituted linear or branched alkenylene.
55. A lipid nanoparticle (LNP) comprising a compound of any one of claims 1 to 54.
56. The LNP of claim 55, wherein the LNP exhibits reduced immunogenicity compared to a LNP that comprises a corresponding linear PEG lipid rather than a compound of any one of claims 1 to 54.
57. The LNP of claim 55 or 56, further comprising:
an ionizable lipid; and a nucleic acid.
58. The LNP of claim 57, wherein the nucleic acid is an RNA polynucleotide.
59. The LNP of claim 58, wherein the RNA polynucleotide is a circular RNA polynucleotide.
60. A compound of Formula (IV):
 wherein:
wherein:
A and A’ are independently a lipid; and
LP is a linking moiety comprising one or more polyethylene glycol (PEG) blocks.
61. The compound of claim 60, wherein A and A’ each form a link to a core-shell structure of a lipid nanoparticle to form a macrocycle.
62. The compound of claim 60 or 61, wherein LP comprises at least 10 ethylene glycol monomer units, preferably at least 12, at least 20, at least 30, at least 40, at least 50. at least 60, at least 70, at least 80. at least 90, at least 100, at least 150, at least 200, or at least 220 ethylene glycol monomer units.
63. The compound of any one of claims 60 to 62, wherein LP comprises a PEG block of 500 Da to 20 kDa.
64. The compound of claim 63, wherein LP comprises a PEG block of 600 Da to 2 kDa.
65. The compound of claim 63, wherein LP comprises a PEG block of 5 kDa to 20 kDa.
66. The compound of claim 63, wherein LP comprises a PEG block of 1.5 kDa to 3.5 kDa.
67. The compound of any one of claims 60 to 66, wherein LP comprises one PEG block.
68. The compound of any one of claims 60 to 66, wherein LP comprises two or more PEG blocks.
69. The compound of claim 68, wherein the compound is of the Formula (V):
 wherein:
wherein:
PA and PB are each independently the two or more PEG blocks;
Y is an optional linking group; and m is an integer from 1 to 6, preferably an integer from 1 to 3.
70. The compound of claim 69, wherein m is 1.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202363579482P | 2023-08-29 | 2023-08-29 | |
| US63/579,482 | 2023-08-29 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2025049690A1 true WO2025049690A1 (en) | 2025-03-06 |
Family
ID=92800533
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2024/044348 Pending WO2025049690A1 (en) | 2023-08-29 | 2024-08-29 | Circular polyethylene glycol lipids |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2025049690A1 (en) |
Citations (103)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3832253A (en) | 1973-03-21 | 1974-08-27 | Baxter Laboratories Inc | Method of making an inflatable balloon catheter |
| US3854480A (en) | 1969-04-01 | 1974-12-17 | Alza Corp | Drug-delivery system |
| US4450150A (en) | 1973-05-17 | 1984-05-22 | Arthur D. Little, Inc. | Biodegradable, implantable drug delivery depots, and method for preparing and using the same |
| US4452775A (en) | 1982-12-03 | 1984-06-05 | Syntex (U.S.A.) Inc. | Cholesterol matrix delivery system for sustained release of macromolecules |
| US4667014A (en) | 1983-03-07 | 1987-05-19 | Syntex (U.S.A.) Inc. | Nonapeptide and decapeptide analogs of LHRH, useful as LHRH antagonists |
| US4748034A (en) | 1983-05-13 | 1988-05-31 | Nestec S.A. | Preparing a heat stable aqueous solution of whey proteins |
| US5075109A (en) | 1986-10-24 | 1991-12-24 | Southern Research Institute | Method of potentiating an immune response |
| US5087616A (en) | 1986-08-07 | 1992-02-11 | Battelle Memorial Institute | Cytotoxic drug conjugates and their delivery to tumor cells |
| US5239660A (en) | 1990-10-31 | 1993-08-24 | Nec Corporation | Vector processor which can be formed by an integrated circuit of a small size |
| US5948902A (en) | 1997-11-20 | 1999-09-07 | South Alabama Medical Science Foundation | Antisense oligonucleotides to human serine/threonine protein phosphatase genes |
| US6319494B1 (en) | 1990-12-14 | 2001-11-20 | Cell Genesys, Inc. | Chimeric chains for receptor-associated signal transduction pathways |
| US20030022649A1 (en) | 2001-05-03 | 2003-01-30 | Mitsubishi Denki Kabushiki Kaisha | Signal reception method and device |
| US20040262223A1 (en) | 2001-07-27 | 2004-12-30 | President And Fellows Of Harvard College | Laminar mixing apparatus and methods |
| US20050222064A1 (en) | 2002-02-20 | 2005-10-06 | Sirna Therapeutics, Inc. | Polycationic compositions for cellular delivery of polynucleotides |
| WO2005121348A1 (en) | 2004-06-07 | 2005-12-22 | Protiva Biotherapeutics, Inc. | Lipid encapsulated interfering rna |
| WO2005120152A2 (en) | 2004-06-07 | 2005-12-22 | Protiva Biotherapeutics, Inc. | Cationic lipids and methods of use |
| WO2006000830A2 (en) | 2004-06-29 | 2006-01-05 | Avidex Ltd | Cells expressing a modified t cell receptor |
| WO2006007712A1 (en) | 2004-07-19 | 2006-01-26 | Protiva Biotherapeutics, Inc. | Methods comprising polyethylene glycol-lipid conjugates for delivery of therapeutic agents |
| WO2006069782A2 (en) | 2004-12-27 | 2006-07-06 | Silence Therapeutics Ag. | Lipid complexes coated with peg and their use |
| WO2008042973A2 (en) | 2006-10-03 | 2008-04-10 | Alnylam Pharmaceuticals, Inc. | Lipid containing formulations |
| WO2008103276A2 (en) | 2007-02-16 | 2008-08-28 | Merck & Co., Inc. | Compositions and methods for potentiated activity of biologicaly active molecules |
| WO2009086558A1 (en) | 2008-01-02 | 2009-07-09 | Tekmira Pharmaceuticals Corporation | Improved compositions and methods for the delivery of nucleic acids |
| WO2009127060A1 (en) | 2008-04-15 | 2009-10-22 | Protiva Biotherapeutics, Inc. | Novel lipid formulations for nucleic acid delivery |
| WO2009132131A1 (en) | 2008-04-22 | 2009-10-29 | Alnylam Pharmaceuticals, Inc. | Amino lipid based improved lipid formulation |
| WO2010042877A1 (en) | 2008-10-09 | 2010-04-15 | Tekmira Pharmaceuticals Corporation | Improved amino lipids and methods for the delivery of nucleic acids |
| WO2010048536A2 (en) | 2008-10-23 | 2010-04-29 | Alnylam Pharmaceuticals, Inc. | Processes for preparing lipids |
| WO2010054401A1 (en) | 2008-11-10 | 2010-05-14 | Alnylam Pharmaceuticals, Inc. | Novel lipids and compositions for the delivery of therapeutics |
| WO2010054384A1 (en) | 2008-11-10 | 2010-05-14 | Alnylam Pharmaceuticals, Inc. | Lipids and compositions for the delivery of therapeutics |
| US7741465B1 (en) | 1992-03-18 | 2010-06-22 | Zelig Eshhar | Chimeric receptor genes and cells transformed therewith |
| WO2010088537A2 (en) | 2009-01-29 | 2010-08-05 | Alnylam Pharmaceuticals, Inc. | Improved lipid formulation |
| WO2010129709A1 (en) | 2009-05-05 | 2010-11-11 | Alnylam Pharmaceuticals, Inc. | Lipid compositions |
| WO2010144740A1 (en) | 2009-06-10 | 2010-12-16 | Alnylam Pharmaceuticals, Inc. | Improved lipid formulation |
| WO2011000107A1 (en) | 2009-07-01 | 2011-01-06 | Protiva Biotherapeutics, Inc. | Novel lipid formulations for delivery of therapeutic agents to solid tumors |
| WO2011000106A1 (en) | 2009-07-01 | 2011-01-06 | Protiva Biotherapeutics, Inc. | Improved cationic lipids and methods for the delivery of therapeutic agents |
| WO2011022460A1 (en) | 2009-08-20 | 2011-02-24 | Merck Sharp & Dohme Corp. | Novel cationic lipids with various head groups for oligonucleotide delivery |
| WO2011038160A2 (en) | 2009-09-23 | 2011-03-31 | Protiva Biotherapeutics, Inc. | Compositions and methods for silencing genes expressed in cancer |
| WO2011066651A1 (en) | 2009-12-01 | 2011-06-09 | Protiva Biotherapeutics, Inc. | Snalp formulations containing antioxidants |
| WO2011071860A2 (en) | 2009-12-07 | 2011-06-16 | Alnylam Pharmaceuticals, Inc. | Compositions for nucleic acid delivery |
| WO2011090965A1 (en) | 2010-01-22 | 2011-07-28 | Merck Sharp & Dohme Corp. | Novel cationic lipids for oligonucleotide delivery |
| WO2011127255A1 (en) | 2010-04-08 | 2011-10-13 | Merck Sharp & Dohme Corp. | Preparation of lipid nanoparticles |
| WO2011141704A1 (en) | 2010-05-12 | 2011-11-17 | Protiva Biotherapeutics, Inc | Novel cyclic cationic lipids and methods of use |
| WO2011141705A1 (en) | 2010-05-12 | 2011-11-17 | Protiva Biotherapeutics, Inc. | Novel cationic lipids and methods of use thereof |
| WO2011153120A1 (en) | 2010-06-04 | 2011-12-08 | Merck Sharp & Dohme Corp. | Novel low molecular weight cationic lipids for oligonucleotide delivery |
| CN102295768A (en) * | 2011-06-02 | 2011-12-28 | 复旦大学 | Circular polyethylene glycol containing single active functional group, and preparation method thereof |
| WO2012000104A1 (en) | 2010-06-30 | 2012-01-05 | Protiva Biotherapeutics, Inc. | Non-liposomal systems for nucleic acid delivery |
| WO2012016184A2 (en) | 2010-07-30 | 2012-02-02 | Alnylam Pharmaceuticals, Inc. | Methods and compositions for delivery of active agents |
| WO2012024526A2 (en) | 2010-08-20 | 2012-02-23 | Cerulean Pharma Inc. | Conjugates, particles, compositions, and related methods |
| WO2012031043A1 (en) | 2010-08-31 | 2012-03-08 | Novartis Ag | Pegylated liposomes for delivery of immunogen-encoding rna |
| WO2012040184A2 (en) | 2010-09-20 | 2012-03-29 | Merck Sharp & Dohme Corp. | Novel low molecular weight cationic lipids for oligonucleotide delivery |
| WO2012044638A1 (en) | 2010-09-30 | 2012-04-05 | Merck Sharp & Dohme Corp. | Low molecular weight cationic lipids for oligonucleotide delivery |
| WO2012054365A2 (en) | 2010-10-21 | 2012-04-26 | Merck Sharp & Dohme Corp. | Novel low molecular weight cationic lipids for oligonucleotide delivery |
| US20120178702A1 (en) | 1995-01-23 | 2012-07-12 | University Of Pittsburgh | Stable lipid-comprising drug delivery complexes and methods for their production |
| WO2012099755A1 (en) | 2011-01-11 | 2012-07-26 | Alnylam Pharmaceuticals, Inc. | Pegylated lipids and their use for drug delivery |
| US20120276209A1 (en) | 2009-11-04 | 2012-11-01 | The University Of British Columbia | Nucleic acid-containing lipid particles and related methods |
| WO2012162210A1 (en) | 2011-05-26 | 2012-11-29 | Merck Sharp & Dohme Corp. | Ring constrained cationic lipids for oligonucleotide delivery |
| WO2013006825A1 (en) | 2011-07-06 | 2013-01-10 | Novartis Ag | Liposomes having useful n:p ratio for delivery of rna molecules |
| WO2013016058A1 (en) | 2011-07-22 | 2013-01-31 | Merck Sharp & Dohme Corp. | Novel bis-nitrogen containing cationic lipids for oligonucleotide delivery |
| WO2013033563A1 (en) | 2011-08-31 | 2013-03-07 | Novartis Ag | Pegylated liposomes for delivery of immunogen-encoding rna |
| WO2013049328A1 (en) | 2011-09-27 | 2013-04-04 | Alnylam Pharmaceuticals, Inc. | Di-aliphatic substituted pegylated lipids |
| WO2013086354A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Biodegradable lipids for the delivery of active agents |
| WO2013086373A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Lipids for the delivery of active agents |
| WO2013086322A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Branched alkyl and cycloalkyl terminated biodegradable lipids for the delivery of active agents |
| US20130156845A1 (en) | 2010-04-29 | 2013-06-20 | Alnylam Pharmaceuticals, Inc. | Lipid formulated single stranded rna |
| WO2013089151A1 (en) | 2011-12-12 | 2013-06-20 | 協和発酵キリン株式会社 | Lipid nanoparticles for drug delivery system containing cationic lipids |
| WO2013093648A2 (en) | 2011-11-04 | 2013-06-27 | Nitto Denko Corporation | Method of producing lipid nanoparticles for drug delivery |
| WO2013116126A1 (en) | 2012-02-01 | 2013-08-08 | Merck Sharp & Dohme Corp. | Novel low molecular weight, biodegradable cationic lipids for oligonucleotide delivery |
| WO2013126803A1 (en) | 2012-02-24 | 2013-08-29 | Protiva Biotherapeutics Inc. | Trialkyl cationic lipids and methods of use thereof |
| WO2013148541A1 (en) | 2012-03-27 | 2013-10-03 | Merck Sharp & Dohme Corp. | DIETHER BASED BIODEGRADABLE CATIONIC LIPIDS FOR siRNA DELIVERY |
| WO2015061467A1 (en) | 2013-10-22 | 2015-04-30 | Shire Human Genetic Therapies, Inc. | Lipid formulations for delivery of messenger rna |
| WO2015074085A1 (en) | 2013-11-18 | 2015-05-21 | Arcturus Therapeutics, Inc. | Ionizable cationic lipid for rna delivery |
| WO2015095346A1 (en) | 2013-12-19 | 2015-06-25 | Novartis Ag | Lipids and lipid compositions for the delivery of active agents |
| WO2015095340A1 (en) | 2013-12-19 | 2015-06-25 | Novartis Ag | Lipids and lipid compositions for the delivery of active agents |
| US20150239926A1 (en) | 2013-11-18 | 2015-08-27 | Arcturus Therapeutics, Inc. | Asymmetric ionizable cationic lipid for rna delivery |
| WO2015199952A1 (en) | 2014-06-25 | 2015-12-30 | Acuitas Therapeutics Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2016081029A1 (en) | 2014-11-18 | 2016-05-26 | Arcturus Therapeutics, Inc. | Ionizable cationic lipid for rna delivery |
| US20160151284A1 (en) | 2013-07-23 | 2016-06-02 | Protiva Biotherapeutics, Inc. | Compositions and methods for delivering messenger rna |
| US20160376224A1 (en) | 2015-06-29 | 2016-12-29 | Acuitas Therapeutics, Inc. | Lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2017049245A2 (en) | 2015-09-17 | 2017-03-23 | Modernatx, Inc. | Compounds and compositions for intracellular delivery of therapeutic agents |
| WO2017075531A1 (en) | 2015-10-28 | 2017-05-04 | Acuitas Therapeutics, Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2017099823A1 (en) | 2015-12-10 | 2017-06-15 | Modernatx, Inc. | Compositions and methods for delivery of therapeutic agents |
| WO2017117528A1 (en) | 2015-12-30 | 2017-07-06 | Acuitas Therapeutics, Inc. | Lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| US20180005363A1 (en) | 2015-01-30 | 2018-01-04 | Hitachi High-Technologies Corporation | Pattern Matching Device and Computer Program for Pattern Matching |
| WO2018011633A1 (en) | 2016-07-13 | 2018-01-18 | Alcatel Lucent | Underlying recessed component placement |
| WO2019081383A1 (en) | 2017-10-25 | 2019-05-02 | Universität Zürich | Eukaryotic initiation factor 4 recruiting aptamers for enhancing translation |
| WO2019131770A1 (en) | 2017-12-27 | 2019-07-04 | 武田薬品工業株式会社 | Nucleic acid-containing lipid nano-particle and use thereof |
| WO2019236673A1 (en) | 2018-06-06 | 2019-12-12 | Massachusetts Institute Of Technology | Circular rna for translation in eukaryotic cells |
| WO2020237227A1 (en) | 2019-05-22 | 2020-11-26 | Massachusetts Institute Of Technology | Circular rna compositions and methods |
| WO2021014217A1 (en) * | 2019-07-25 | 2021-01-28 | Ripple Therapeutics Corporation | Articles comprising steroid dimers and their use in the delivery of therapeutic agents |
| WO2021021634A1 (en) | 2019-07-29 | 2021-02-04 | Georgia Tech Research Corporation | Nanomaterials containing constrained lipids and uses thereof |
| WO2021113777A2 (en) | 2019-12-04 | 2021-06-10 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2021168284A1 (en) * | 2020-02-21 | 2021-08-26 | GIE Medical, Inc. | Polymer-encapsulated drug particles |
| WO2021189059A2 (en) | 2020-03-20 | 2021-09-23 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2021226597A2 (en) | 2020-05-08 | 2021-11-11 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2021236855A1 (en) | 2020-05-19 | 2021-11-25 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2022251665A1 (en) | 2021-05-28 | 2022-12-01 | Renagade Therapeutics Management Inc. | Lipid nanoparticles and methods of use thereof |
| WO2022261490A2 (en) | 2021-06-10 | 2022-12-15 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2023044343A1 (en) | 2021-09-14 | 2023-03-23 | Renagade Therapeutics Management Inc. | Acyclic lipids and methods of use thereof |
| WO2023044333A1 (en) | 2021-09-14 | 2023-03-23 | Renagade Therapeutics Management Inc. | Cyclic lipids and methods of use thereof |
| WO2023056033A1 (en) | 2021-09-30 | 2023-04-06 | Orna Therapeutics, Inc. | Lipid nanoparticle compositions for delivering circular polynucleotides |
| WO2023081526A1 (en) | 2021-11-08 | 2023-05-11 | Orna Therapeutics, Inc. | Lipid nanoparticle compositions for delivering circular polynucleotides |
| WO2023122752A1 (en) | 2021-12-23 | 2023-06-29 | Renagade Therapeutics Management Inc. | Constrained lipids and methods of use thereof |
| WO2023196931A1 (en) | 2022-04-07 | 2023-10-12 | Renagade Therapeutics Management Inc. | Cyclic lipids and lipid nanoparticles (lnp) for the delivery of nucleic acids or peptides for use in vaccinating against infectious agents |
| CN117126391A (en) * | 2023-08-18 | 2023-11-28 | 中国科学技术大学 | Single molecular weight cyclic polyethylene glycol lipid and application thereof |
-
2024
- 2024-08-29 WO PCT/US2024/044348 patent/WO2025049690A1/en active Pending
Patent Citations (152)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3854480A (en) | 1969-04-01 | 1974-12-17 | Alza Corp | Drug-delivery system |
| US3832253A (en) | 1973-03-21 | 1974-08-27 | Baxter Laboratories Inc | Method of making an inflatable balloon catheter |
| US4450150A (en) | 1973-05-17 | 1984-05-22 | Arthur D. Little, Inc. | Biodegradable, implantable drug delivery depots, and method for preparing and using the same |
| US4452775A (en) | 1982-12-03 | 1984-06-05 | Syntex (U.S.A.) Inc. | Cholesterol matrix delivery system for sustained release of macromolecules |
| US4667014A (en) | 1983-03-07 | 1987-05-19 | Syntex (U.S.A.) Inc. | Nonapeptide and decapeptide analogs of LHRH, useful as LHRH antagonists |
| US4748034A (en) | 1983-05-13 | 1988-05-31 | Nestec S.A. | Preparing a heat stable aqueous solution of whey proteins |
| US5087616A (en) | 1986-08-07 | 1992-02-11 | Battelle Memorial Institute | Cytotoxic drug conjugates and their delivery to tumor cells |
| US5075109A (en) | 1986-10-24 | 1991-12-24 | Southern Research Institute | Method of potentiating an immune response |
| US5239660A (en) | 1990-10-31 | 1993-08-24 | Nec Corporation | Vector processor which can be formed by an integrated circuit of a small size |
| US6319494B1 (en) | 1990-12-14 | 2001-11-20 | Cell Genesys, Inc. | Chimeric chains for receptor-associated signal transduction pathways |
| US7741465B1 (en) | 1992-03-18 | 2010-06-22 | Zelig Eshhar | Chimeric receptor genes and cells transformed therewith |
| US20120178702A1 (en) | 1995-01-23 | 2012-07-12 | University Of Pittsburgh | Stable lipid-comprising drug delivery complexes and methods for their production |
| US5948902A (en) | 1997-11-20 | 1999-09-07 | South Alabama Medical Science Foundation | Antisense oligonucleotides to human serine/threonine protein phosphatase genes |
| US20030022649A1 (en) | 2001-05-03 | 2003-01-30 | Mitsubishi Denki Kabushiki Kaisha | Signal reception method and device |
| US20040262223A1 (en) | 2001-07-27 | 2004-12-30 | President And Fellows Of Harvard College | Laminar mixing apparatus and methods |
| US20050222064A1 (en) | 2002-02-20 | 2005-10-06 | Sirna Therapeutics, Inc. | Polycationic compositions for cellular delivery of polynucleotides |
| WO2005121348A1 (en) | 2004-06-07 | 2005-12-22 | Protiva Biotherapeutics, Inc. | Lipid encapsulated interfering rna |
| US20060083780A1 (en) | 2004-06-07 | 2006-04-20 | Protiva Biotherapeutics, Inc. | Cationic lipids and methods of use |
| WO2005120152A2 (en) | 2004-06-07 | 2005-12-22 | Protiva Biotherapeutics, Inc. | Cationic lipids and methods of use |
| US20060008910A1 (en) | 2004-06-07 | 2006-01-12 | Protiva Biotherapeuties, Inc. | Lipid encapsulated interfering RNA |
| WO2006000830A2 (en) | 2004-06-29 | 2006-01-05 | Avidex Ltd | Cells expressing a modified t cell receptor |
| US20060051405A1 (en) | 2004-07-19 | 2006-03-09 | Protiva Biotherapeutics, Inc. | Compositions for the delivery of therapeutic agents and uses thereof |
| WO2006007712A1 (en) | 2004-07-19 | 2006-01-26 | Protiva Biotherapeutics, Inc. | Methods comprising polyethylene glycol-lipid conjugates for delivery of therapeutic agents |
| WO2006069782A2 (en) | 2004-12-27 | 2006-07-06 | Silence Therapeutics Ag. | Lipid complexes coated with peg and their use |
| US20100062967A1 (en) | 2004-12-27 | 2010-03-11 | Silence Therapeutics Ag | Coated lipid complexes and their use |
| WO2008042973A2 (en) | 2006-10-03 | 2008-04-10 | Alnylam Pharmaceuticals, Inc. | Lipid containing formulations |
| US20090023673A1 (en) | 2006-10-03 | 2009-01-22 | Muthiah Manoharan | Lipid containing formulations |
| WO2008103276A2 (en) | 2007-02-16 | 2008-08-28 | Merck & Co., Inc. | Compositions and methods for potentiated activity of biologicaly active molecules |
| WO2009086558A1 (en) | 2008-01-02 | 2009-07-09 | Tekmira Pharmaceuticals Corporation | Improved compositions and methods for the delivery of nucleic acids |
| US20110117125A1 (en) | 2008-01-02 | 2011-05-19 | Tekmira Pharmaceuticals Corporation | Compositions and methods for the delivery of nucleic acids |
| WO2009127060A1 (en) | 2008-04-15 | 2009-10-22 | Protiva Biotherapeutics, Inc. | Novel lipid formulations for nucleic acid delivery |
| US8492359B2 (en) | 2008-04-15 | 2013-07-23 | Protiva Biotherapeutics, Inc. | Lipid formulations for nucleic acid delivery |
| US20100130588A1 (en) | 2008-04-15 | 2010-05-27 | Protiva Biotherapeutics, Inc. | Novel lipid formulations for nucleic acid delivery |
| WO2009132131A1 (en) | 2008-04-22 | 2009-10-29 | Alnylam Pharmaceuticals, Inc. | Amino lipid based improved lipid formulation |
| US20110256175A1 (en) | 2008-10-09 | 2011-10-20 | The University Of British Columbia | Amino lipids and methods for the delivery of nucleic acids |
| WO2010042877A1 (en) | 2008-10-09 | 2010-04-15 | Tekmira Pharmaceuticals Corporation | Improved amino lipids and methods for the delivery of nucleic acids |
| WO2010048536A2 (en) | 2008-10-23 | 2010-04-29 | Alnylam Pharmaceuticals, Inc. | Processes for preparing lipids |
| WO2010054384A1 (en) | 2008-11-10 | 2010-05-14 | Alnylam Pharmaceuticals, Inc. | Lipids and compositions for the delivery of therapeutics |
| US20120058144A1 (en) | 2008-11-10 | 2012-03-08 | Alnylam Pharmaceuticals, Inc. | Lipids and compositions for the delivery of therapeutics |
| WO2010054405A1 (en) | 2008-11-10 | 2010-05-14 | Alnylam Pharmaceuticals, Inc. | Novel lipids and compositions for the delivery of therapeutics |
| US20120027796A1 (en) | 2008-11-10 | 2012-02-02 | Alnylam Pharmaceuticals, Inc. | Novel lipids and compositions for the delivery of therapeutics |
| WO2010054401A1 (en) | 2008-11-10 | 2010-05-14 | Alnylam Pharmaceuticals, Inc. | Novel lipids and compositions for the delivery of therapeutics |
| WO2010054406A1 (en) | 2008-11-10 | 2010-05-14 | Alnylam Pharmaceuticals, Inc. | Novel lipids and compositions for the delivery of therapeutics |
| US20120101148A1 (en) | 2009-01-29 | 2012-04-26 | Alnylam Pharmaceuticals, Inc. | lipid formulation |
| WO2010088537A2 (en) | 2009-01-29 | 2010-08-05 | Alnylam Pharmaceuticals, Inc. | Improved lipid formulation |
| US20120128760A1 (en) | 2009-05-05 | 2012-05-24 | Alnylam Pharmaceuticals, Inc. | Lipid compositions |
| WO2010129709A1 (en) | 2009-05-05 | 2010-11-11 | Alnylam Pharmaceuticals, Inc. | Lipid compositions |
| US20100324120A1 (en) | 2009-06-10 | 2010-12-23 | Jianxin Chen | Lipid formulation |
| WO2010144740A1 (en) | 2009-06-10 | 2010-12-16 | Alnylam Pharmaceuticals, Inc. | Improved lipid formulation |
| US20110076335A1 (en) | 2009-07-01 | 2011-03-31 | Protiva Biotherapeutics, Inc. | Novel lipid formulations for delivery of therapeutic agents to solid tumors |
| US20120202871A1 (en) | 2009-07-01 | 2012-08-09 | Protiva Biotherapeutics, Inc. | Cationic lipids and methods for the delivery of therapeutic agents |
| WO2011000106A1 (en) | 2009-07-01 | 2011-01-06 | Protiva Biotherapeutics, Inc. | Improved cationic lipids and methods for the delivery of therapeutic agents |
| WO2011000107A1 (en) | 2009-07-01 | 2011-01-06 | Protiva Biotherapeutics, Inc. | Novel lipid formulations for delivery of therapeutic agents to solid tumors |
| WO2011022460A1 (en) | 2009-08-20 | 2011-02-24 | Merck Sharp & Dohme Corp. | Novel cationic lipids with various head groups for oligonucleotide delivery |
| US20120149894A1 (en) | 2009-08-20 | 2012-06-14 | Mark Cameron | Novel cationic lipids with various head groups for oligonucleotide delivery |
| US20130065939A1 (en) | 2009-09-23 | 2013-03-14 | Protiva Biotherapeutics, Inc. | Compositions and methods for silencing genes expressed in cancer |
| WO2011038160A2 (en) | 2009-09-23 | 2011-03-31 | Protiva Biotherapeutics, Inc. | Compositions and methods for silencing genes expressed in cancer |
| US20120276209A1 (en) | 2009-11-04 | 2012-11-01 | The University Of British Columbia | Nucleic acid-containing lipid particles and related methods |
| WO2011066651A1 (en) | 2009-12-01 | 2011-06-09 | Protiva Biotherapeutics, Inc. | Snalp formulations containing antioxidants |
| WO2011071860A2 (en) | 2009-12-07 | 2011-06-16 | Alnylam Pharmaceuticals, Inc. | Compositions for nucleic acid delivery |
| US20130338210A1 (en) | 2009-12-07 | 2013-12-19 | Alnylam Pharmaceuticals, Inc. | Compositions for nucleic acid delivery |
| WO2011090965A1 (en) | 2010-01-22 | 2011-07-28 | Merck Sharp & Dohme Corp. | Novel cationic lipids for oligonucleotide delivery |
| WO2011127255A1 (en) | 2010-04-08 | 2011-10-13 | Merck Sharp & Dohme Corp. | Preparation of lipid nanoparticles |
| US20130156845A1 (en) | 2010-04-29 | 2013-06-20 | Alnylam Pharmaceuticals, Inc. | Lipid formulated single stranded rna |
| WO2011141705A1 (en) | 2010-05-12 | 2011-11-17 | Protiva Biotherapeutics, Inc. | Novel cationic lipids and methods of use thereof |
| US20130123338A1 (en) | 2010-05-12 | 2013-05-16 | Protiva Biotherapeutics, Inc. | Novel cationic lipids and methods of use thereof |
| US20130116307A1 (en) | 2010-05-12 | 2013-05-09 | Protiva Biotherapeutics Inc. | Novel cyclic cationic lipids and methods of use |
| WO2011141704A1 (en) | 2010-05-12 | 2011-11-17 | Protiva Biotherapeutics, Inc | Novel cyclic cationic lipids and methods of use |
| WO2011153120A1 (en) | 2010-06-04 | 2011-12-08 | Merck Sharp & Dohme Corp. | Novel low molecular weight cationic lipids for oligonucleotide delivery |
| US20130090372A1 (en) | 2010-06-04 | 2013-04-11 | Brian W. Budzik | Novel Low Molecular Weight Cationic Lipids for Oligonucleotide Delivery |
| US20130303587A1 (en) | 2010-06-30 | 2013-11-14 | Protiva Biotherapeutics, Inc. | Non-liposomal systems for nucleic acid delivery |
| WO2012000104A1 (en) | 2010-06-30 | 2012-01-05 | Protiva Biotherapeutics, Inc. | Non-liposomal systems for nucleic acid delivery |
| WO2012016184A2 (en) | 2010-07-30 | 2012-02-02 | Alnylam Pharmaceuticals, Inc. | Methods and compositions for delivery of active agents |
| US20130323269A1 (en) | 2010-07-30 | 2013-12-05 | Muthiah Manoharan | Methods and compositions for delivery of active agents |
| WO2012024526A2 (en) | 2010-08-20 | 2012-02-23 | Cerulean Pharma Inc. | Conjugates, particles, compositions, and related methods |
| US20130202684A1 (en) | 2010-08-31 | 2013-08-08 | Lichtstrasse | Pegylated liposomes for delivery of immunogen encoding rna |
| WO2012031043A1 (en) | 2010-08-31 | 2012-03-08 | Novartis Ag | Pegylated liposomes for delivery of immunogen-encoding rna |
| WO2012040184A2 (en) | 2010-09-20 | 2012-03-29 | Merck Sharp & Dohme Corp. | Novel low molecular weight cationic lipids for oligonucleotide delivery |
| US20130178541A1 (en) | 2010-09-20 | 2013-07-11 | Matthew G. Stanton | Novel low molecular weight cationic lipids for oligonucleotide delivery |
| US20130274523A1 (en) | 2010-09-30 | 2013-10-17 | John A. Bawiec, III | Low molecular weight cationic lipids for oligonucleotide delivery |
| WO2012044638A1 (en) | 2010-09-30 | 2012-04-05 | Merck Sharp & Dohme Corp. | Low molecular weight cationic lipids for oligonucleotide delivery |
| US20130274504A1 (en) | 2010-10-21 | 2013-10-17 | Steven L. Colletti | Novel Low Molecular Weight Cationic Lipids For Oligonucleotide Delivery |
| WO2012054365A2 (en) | 2010-10-21 | 2012-04-26 | Merck Sharp & Dohme Corp. | Novel low molecular weight cationic lipids for oligonucleotide delivery |
| WO2012099755A1 (en) | 2011-01-11 | 2012-07-26 | Alnylam Pharmaceuticals, Inc. | Pegylated lipids and their use for drug delivery |
| US20140200257A1 (en) | 2011-01-11 | 2014-07-17 | Alnylam Pharmaceuticals, Inc. | Pegylated lipids and their use for drug delivery |
| WO2012162210A1 (en) | 2011-05-26 | 2012-11-29 | Merck Sharp & Dohme Corp. | Ring constrained cationic lipids for oligonucleotide delivery |
| CN102295768A (en) * | 2011-06-02 | 2011-12-28 | 复旦大学 | Circular polyethylene glycol containing single active functional group, and preparation method thereof |
| US20140141070A1 (en) | 2011-07-06 | 2014-05-22 | Andrew Geall | Liposomes having useful n:p ratio for delivery of rna molecules |
| WO2013006825A1 (en) | 2011-07-06 | 2013-01-10 | Novartis Ag | Liposomes having useful n:p ratio for delivery of rna molecules |
| WO2013016058A1 (en) | 2011-07-22 | 2013-01-31 | Merck Sharp & Dohme Corp. | Novel bis-nitrogen containing cationic lipids for oligonucleotide delivery |
| WO2013033563A1 (en) | 2011-08-31 | 2013-03-07 | Novartis Ag | Pegylated liposomes for delivery of immunogen-encoding rna |
| US20140255472A1 (en) | 2011-08-31 | 2014-09-11 | Andrew Geall | Pegylated liposomes for delivery of immunogen-encoding rna |
| US20150203446A1 (en) | 2011-09-27 | 2015-07-23 | Takeda Pharmaceutical Company Limited | Di-aliphatic substituted pegylated lipids |
| WO2013049328A1 (en) | 2011-09-27 | 2013-04-04 | Alnylam Pharmaceuticals, Inc. | Di-aliphatic substituted pegylated lipids |
| US20130164400A1 (en) | 2011-11-04 | 2013-06-27 | Nitto Denko Corporation | Single use system for sterilely producing lipid-nucleic acid particles |
| WO2013093648A2 (en) | 2011-11-04 | 2013-06-27 | Nitto Denko Corporation | Method of producing lipid nanoparticles for drug delivery |
| WO2013086354A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Biodegradable lipids for the delivery of active agents |
| US20140308304A1 (en) | 2011-12-07 | 2014-10-16 | Alnylam Pharmaceuticals, Inc. | Lipids for the delivery of active agents |
| US20130195920A1 (en) | 2011-12-07 | 2013-08-01 | Alnylam Pharmaceuticals, Inc. | Biodegradable lipids for the delivery of active agents |
| WO2013086322A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Branched alkyl and cycloalkyl terminated biodegradable lipids for the delivery of active agents |
| WO2013086373A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Lipids for the delivery of active agents |
| WO2013089151A1 (en) | 2011-12-12 | 2013-06-20 | 協和発酵キリン株式会社 | Lipid nanoparticles for drug delivery system containing cationic lipids |
| US20140039032A1 (en) | 2011-12-12 | 2014-02-06 | Kyowa Hakko Kirin Co., Ltd. | Lipid nano particles comprising cationic lipid for drug delivery system |
| WO2013116126A1 (en) | 2012-02-01 | 2013-08-08 | Merck Sharp & Dohme Corp. | Novel low molecular weight, biodegradable cationic lipids for oligonucleotide delivery |
| US20150064242A1 (en) | 2012-02-24 | 2015-03-05 | Protiva Biotherapeutics, Inc. | Trialkyl cationic lipids and methods of use thereof |
| WO2013126803A1 (en) | 2012-02-24 | 2013-08-29 | Protiva Biotherapeutics Inc. | Trialkyl cationic lipids and methods of use thereof |
| US20150057373A1 (en) | 2012-03-27 | 2015-02-26 | Sirna Therapeutics, Inc | DIETHER BASED BIODEGRADABLE CATIONIC LIPIDS FOR siRNA DELIVERY |
| WO2013148541A1 (en) | 2012-03-27 | 2013-10-03 | Merck Sharp & Dohme Corp. | DIETHER BASED BIODEGRADABLE CATIONIC LIPIDS FOR siRNA DELIVERY |
| US20160151284A1 (en) | 2013-07-23 | 2016-06-02 | Protiva Biotherapeutics, Inc. | Compositions and methods for delivering messenger rna |
| US20150140070A1 (en) | 2013-10-22 | 2015-05-21 | Shire Human Genetic Therapies, Inc. | Lipid formulations for delivery of messenger rna |
| WO2015061467A1 (en) | 2013-10-22 | 2015-04-30 | Shire Human Genetic Therapies, Inc. | Lipid formulations for delivery of messenger rna |
| WO2015074085A1 (en) | 2013-11-18 | 2015-05-21 | Arcturus Therapeutics, Inc. | Ionizable cationic lipid for rna delivery |
| US20150141678A1 (en) | 2013-11-18 | 2015-05-21 | Arcturus Therapeutics, Inc. | Ionizable cationic lipid for rna delivery |
| US20150239926A1 (en) | 2013-11-18 | 2015-08-27 | Arcturus Therapeutics, Inc. | Asymmetric ionizable cationic lipid for rna delivery |
| WO2015095346A1 (en) | 2013-12-19 | 2015-06-25 | Novartis Ag | Lipids and lipid compositions for the delivery of active agents |
| WO2015095340A1 (en) | 2013-12-19 | 2015-06-25 | Novartis Ag | Lipids and lipid compositions for the delivery of active agents |
| US20160317458A1 (en) | 2013-12-19 | 2016-11-03 | Luis Brito | Lipids and Lipid Compositions for the Delivery of Active Agents |
| US20160311759A1 (en) | 2013-12-19 | 2016-10-27 | Luis Brito | Lipids and Lipid Compositions for the Delivery of Active Agents |
| US20150376115A1 (en) | 2014-06-25 | 2015-12-31 | Acuitas Therapeutics Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2015199952A1 (en) | 2014-06-25 | 2015-12-30 | Acuitas Therapeutics Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2016081029A1 (en) | 2014-11-18 | 2016-05-26 | Arcturus Therapeutics, Inc. | Ionizable cationic lipid for rna delivery |
| US20180005363A1 (en) | 2015-01-30 | 2018-01-04 | Hitachi High-Technologies Corporation | Pattern Matching Device and Computer Program for Pattern Matching |
| US20160376224A1 (en) | 2015-06-29 | 2016-12-29 | Acuitas Therapeutics, Inc. | Lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2017004143A1 (en) | 2015-06-29 | 2017-01-05 | Acuitas Therapeutics Inc. | Lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| US20170210697A1 (en) | 2015-09-17 | 2017-07-27 | Modernatx, Inc. | Compounds and compositions for intracellular delivery of therapeutic agents |
| WO2017049245A2 (en) | 2015-09-17 | 2017-03-23 | Modernatx, Inc. | Compounds and compositions for intracellular delivery of therapeutic agents |
| WO2017075531A1 (en) | 2015-10-28 | 2017-05-04 | Acuitas Therapeutics, Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| US20170119904A1 (en) | 2015-10-28 | 2017-05-04 | Acuitas Therapeutics, Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2017099823A1 (en) | 2015-12-10 | 2017-06-15 | Modernatx, Inc. | Compositions and methods for delivery of therapeutic agents |
| US20180028664A1 (en) | 2015-12-10 | 2018-02-01 | Modernatx, Inc. | Compositions and methods for delivery of agents |
| WO2017117528A1 (en) | 2015-12-30 | 2017-07-06 | Acuitas Therapeutics, Inc. | Lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2018011633A1 (en) | 2016-07-13 | 2018-01-18 | Alcatel Lucent | Underlying recessed component placement |
| WO2019081383A1 (en) | 2017-10-25 | 2019-05-02 | Universität Zürich | Eukaryotic initiation factor 4 recruiting aptamers for enhancing translation |
| WO2019131770A1 (en) | 2017-12-27 | 2019-07-04 | 武田薬品工業株式会社 | Nucleic acid-containing lipid nano-particle and use thereof |
| WO2019236673A1 (en) | 2018-06-06 | 2019-12-12 | Massachusetts Institute Of Technology | Circular rna for translation in eukaryotic cells |
| WO2020237227A1 (en) | 2019-05-22 | 2020-11-26 | Massachusetts Institute Of Technology | Circular rna compositions and methods |
| WO2021014217A1 (en) * | 2019-07-25 | 2021-01-28 | Ripple Therapeutics Corporation | Articles comprising steroid dimers and their use in the delivery of therapeutic agents |
| WO2021021634A1 (en) | 2019-07-29 | 2021-02-04 | Georgia Tech Research Corporation | Nanomaterials containing constrained lipids and uses thereof |
| WO2021113777A2 (en) | 2019-12-04 | 2021-06-10 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2021168284A1 (en) * | 2020-02-21 | 2021-08-26 | GIE Medical, Inc. | Polymer-encapsulated drug particles |
| WO2021189059A2 (en) | 2020-03-20 | 2021-09-23 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2021226597A2 (en) | 2020-05-08 | 2021-11-11 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2021236855A1 (en) | 2020-05-19 | 2021-11-25 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2022251665A1 (en) | 2021-05-28 | 2022-12-01 | Renagade Therapeutics Management Inc. | Lipid nanoparticles and methods of use thereof |
| WO2022261490A2 (en) | 2021-06-10 | 2022-12-15 | Orna Therapeutics, Inc. | Circular rna compositions and methods |
| WO2023044343A1 (en) | 2021-09-14 | 2023-03-23 | Renagade Therapeutics Management Inc. | Acyclic lipids and methods of use thereof |
| WO2023044333A1 (en) | 2021-09-14 | 2023-03-23 | Renagade Therapeutics Management Inc. | Cyclic lipids and methods of use thereof |
| WO2023056033A1 (en) | 2021-09-30 | 2023-04-06 | Orna Therapeutics, Inc. | Lipid nanoparticle compositions for delivering circular polynucleotides |
| WO2023081526A1 (en) | 2021-11-08 | 2023-05-11 | Orna Therapeutics, Inc. | Lipid nanoparticle compositions for delivering circular polynucleotides |
| WO2023122752A1 (en) | 2021-12-23 | 2023-06-29 | Renagade Therapeutics Management Inc. | Constrained lipids and methods of use thereof |
| WO2023196931A1 (en) | 2022-04-07 | 2023-10-12 | Renagade Therapeutics Management Inc. | Cyclic lipids and lipid nanoparticles (lnp) for the delivery of nucleic acids or peptides for use in vaccinating against infectious agents |
| CN117126391A (en) * | 2023-08-18 | 2023-11-28 | 中国科学技术大学 | Single molecular weight cyclic polyethylene glycol lipid and application thereof |
Non-Patent Citations (51)
| Title |
|---|
| "Pharmaceutics and Pharmacy Practice", 1982, J.B. LIPPINCOTT COMPANY, pages: 238 - 250 |
| ABRAHAM ET AL., SCIENCE, vol. 295, 2002, pages 647651 - 651 |
| ANGELINI GUIDO ET AL: "Neutral liposomes containing crown ether-lipids as potential DNA vectors", BIOCHIMICA ET BIOPHYSICA ACTA, vol. 1828, no. 11, 1 November 2013 (2013-11-01), AMSTERDAM, NL, pages 2506 - 2512, XP093227369, ISSN: 0005-2736, DOI: 10.1016/j.bbamem.2013.06.003 * |
| BELLIVEAU, N.M. ET AL., MOL. THER. NUCLEIC. ACIDS, vol. 1, 2012, pages 37 |
| BORDEN: "Molecular Basis of Cancer", 2015 |
| CHEN, D ET AL., J. AM. CHEM. SOC., vol. 134, no. 22, 2012, pages 6984 - 51 |
| DHAMNE ET AL.: "Peripheral and thymic Foxp3+ regulatory T cells in search of origin, distinction. and function", FRONTIERS IN IMMUNOL, vol. 4, no. 253, 2013, pages 1 - 11 |
| DOBRIKOVA ET AL., PROC. NATL. ACAD. SCI., vol. 100, no. 25, 2003, pages 15125 - 15130 |
| EDGE, NATURE, vol. 292, 1981, pages 756 |
| ELIEL: "Stereochemistry of Carbon Compounds", 1962, MCGRAW-HILL |
| ESHHAR ET AL., CANCER IMMUNOL IMMUNOTHERAPY, vol. 45, 1997, pages 131 - 136 |
| FINNEY ET AL., JOURNAL OF IMMUNOLOGY, vol. 161, 1998, pages 2791 - 2797 |
| GARLAPATI ET AL., J. BIOL. CHEM., vol. 279, no. 5, 2004, pages 3389 - 3397 |
| GROSS ET AL., AMUR. REV. PHARMACOL. TOXICOL, vol. 56, 2016, pages 59 - 83 |
| GURTU ET AL., BIOCHEM. BIOPHYS. RES. COMM., vol. 229, 1996, pages 295 - 298 |
| HILLERY A M ET AL.: "Drug Delivery and Targeting: For Pharmacists and Pharmaceutical Scientists", 2002, TAYLOR & FRANCIS, INC |
| JACQUES ET AL.: "Enantiomers, Racemates and Resolutions", 1981, WILEY INTERSCIENCE |
| JANEWAY C ET AL.: "Immunobiology: The Immune System in Health and Disease", 2001, GARLAND SCIENCE |
| JANG ET AL., J. VIROL, vol. 63, 1989, pages 1651 - 1660 |
| JAY ET AL., J. BIOL. CHEM., vol. 259, 1984, pages 6311 |
| JAYARAMA ET AL., ANGEW. CHEM. INT. ED, vol. 51, 2012, pages 8529 - 8533 |
| JAYARAMAN ET AL., ANGEW. CHEM. INT. ED., vol. 51, 2012, pages 8529 - 8533 |
| JAYARAMAN ET AL., PROC. NATL. ACAD. SCI. USA, vol. 88, 1991, pages 4084 - 4088 |
| JONES ET AL., NATURE, vol. 54, 1986, pages 75 - 82 |
| KALOS ET AL., SCI TRANSL. MED, vol. 3, 2011, pages 95 |
| KAUFMAN ET AL., NUC. ACIDS RES, vol. 19, 1991, pages 4485 - 4490 |
| KOBAYASHI ET AL., BIOTECHNIQUES, vol. 21, 1996, pages 399 - 402 |
| KRAUSE ET AL., J. EXP. MED., vol. 188, no. 4, pages 1998 |
| KUBALL J ET AL., J EXP MED, vol. 206, no. 2, 2009, pages 463 - 475 |
| LEHTIMAKILAHESMAA: "Regulatory T cells control immune responses through their non-redundant tissue specific features", FRONTIERS IN IMMUNOL, vol. 4, no. 294, 2013, pages 1 - 10 |
| MAIER ET AL., MOLECULAR THERAPY, vol. 21, 2013, pages 1570 - 1578 |
| MOSSER ET AL., BIOTECHNIQUES, vol. 22, 1997, pages 150 - 161 |
| NAMBAIR ET AL., SCIENCE, vol. 223, 1984, pages 1299 |
| PORTER ET AL., N. ENGL. J. MED, vol. 365, 2011, pages 725 - 33 |
| QUEEN ET AL., PROC. NATL. ACAD. SCI. USA, vol. 86, 1989, pages 10029 - 10033 |
| RAMESH ET AL., NUCL. ACID RES, vol. 24, 1996, pages 2697 - 2700 |
| RIECHMANN ET AL., NATURE, vol. 332, 1988, pages 323 - 327 |
| ROBBINS ET AL., J IMMUNOL., vol. 180, 2008, pages 6116 - 6131 |
| ROSENBERG ET AL., NAT REV CANCER, vol. 8, no. 4, 2008, pages 299 - 308 |
| SEMPLE ET AL., NAT. BIOTECHNOL., vol. 28, 2010, pages 172 - 176 |
| SEWBALAS ALISHA ET AL: "Enhancement of transfection activity in HEK293 cells by lipoplexes containing cholesteryl nitrogen-pivoted aza-crown ethers", MEDICINAL CHEMISTRY RESEARCH, vol. 22, no. 6, 1 June 2013 (2013-06-01), US, pages 2561 - 2569, XP093227370, ISSN: 1054-2523, Retrieved from the Internet <URL:https://link.springer.com/content/pdf/10.1007/s00044-012-0252-2.pdf> DOI: 10.1007/s00044-012-0252-2 * |
| SONG ET AL., BLOOD, vol. 119, 2012, pages 696 - 706 |
| TOISSEL: "ASHP Handbook on Injectable Drugs", 1986, pages: 622 - 630 |
| VERHOEYEN ET AL., SCIENCE, vol. 239, 1988, pages 1534 - 1536 |
| WADWA ET AL., ., J, DRUG TARGETING, vol. 3, 1995, pages 111 |
| WESSELHOEFT ET AL.: "Engineering circular RNA for Potent and Stable Translation in Eukaryotic Cells", NATURE COMMUNICATIONS, vol. 9, 2018, pages 2629, XP055622155, DOI: 10.1038/s41467-018-05096-6 |
| WESSELHOEFT ET AL.: "RNA Circularization Diminishes Immunogenicity and Can Extend", TRANSLATION DURATION IN VIVO. MOLECULAR CELL, vol. 74, no. 3, 2019, pages 508 - 520, XP093042911, DOI: 10.1016/j.molcel.2019.02.015 |
| WHITESIDES, NATURE, vol. 442, 2006, pages 368 - 373 |
| WILEN ET AL., TETRAHEDRON, vol. 33, 1977, pages 2725 |
| WILEN: "Tables of Resolving Agents and Optical Resolutions", 1972, UNIV. OF NOTRE DAME PRESS, pages: 268 |
| ZHIGALTSEV, I.V. ET AL., LANGMUIR, vol. 28, 2012, pages 3633 - 40 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12384741B2 (en) | Lipid nanoparticle compositions for delivering circular polynucleotides | |
| US20250283073A1 (en) | Circular RNA Compositions and Methods | |
| EP4408825A1 (en) | Lipid nanoparticle compositions for delivering circular polynucleotides | |
| WO2021113777A2 (en) | Circular rna compositions and methods | |
| KR20230069042A (en) | Circular RNA compositions and methods | |
| US20250304994A1 (en) | Circular RNA Compositions and Methods | |
| TW202409282A (en) | Circular rna encoding chimeric antigen receptors targeting bcma | |
| WO2024102762A1 (en) | Lipids and lipid nanoparticle compositions for delivering polynucleotides | |
| WO2024233308A2 (en) | Circular rna compositions and methods | |
| WO2024205657A2 (en) | Lipids and lipid nanoparticle compositions for delivering polynucleotides | |
| WO2025049690A1 (en) | Circular polyethylene glycol lipids | |
| WO2025117969A1 (en) | Process for manufacturing lipid nanoparticles | |
| WO2025007148A1 (en) | Polymer lipid nanoparticle compositions for delivering circular polynucleotides | |
| WO2025166238A1 (en) | Fast-shedding polyethylene glycol lipids | |
| WO2026006593A1 (en) | Synthetic internal ribosome entry sites | |
| TW202425959A (en) | Lipids and nanoparticle compositions for delivering polynucleotides | |
| EA049788B1 (en) | CIRCULAR RNA COMPOSITIONS AND METHODS |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24772517 Country of ref document: EP Kind code of ref document: A1 |