KR20080110833A - 아밀로이드 형성 질환의 예방 및 치료 방법 - Google Patents
아밀로이드 형성 질환의 예방 및 치료 방법 Download PDFInfo
- Publication number
- KR20080110833A KR20080110833A KR1020087025473A KR20087025473A KR20080110833A KR 20080110833 A KR20080110833 A KR 20080110833A KR 1020087025473 A KR1020087025473 A KR 1020087025473A KR 20087025473 A KR20087025473 A KR 20087025473A KR 20080110833 A KR20080110833 A KR 20080110833A
- Authority
- KR
- South Korea
- Prior art keywords
- antibody
- rage
- binding
- human
- chain variable
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 title claims abstract description 53
- 201000010099 disease Diseases 0.000 title claims abstract description 47
- 102000009091 Amyloidogenic Proteins Human genes 0.000 title description 13
- 108010048112 Amyloidogenic Proteins Proteins 0.000 title description 13
- 230000003942 amyloidogenic effect Effects 0.000 title description 13
- 238000000034 method Methods 0.000 claims abstract description 220
- 230000027455 binding Effects 0.000 claims abstract description 209
- 208000037259 Amyloid Plaque Diseases 0.000 claims abstract description 28
- 101800001718 Amyloid-beta protein Proteins 0.000 claims abstract 8
- 241000282414 Homo sapiens Species 0.000 claims description 182
- 208000024827 Alzheimer disease Diseases 0.000 claims description 81
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 72
- 239000012634 fragment Substances 0.000 claims description 68
- 239000003795 chemical substances by application Substances 0.000 claims description 34
- 208000010877 cognitive disease Diseases 0.000 claims description 33
- 210000004556 brain Anatomy 0.000 claims description 24
- 230000002401 inhibitory effect Effects 0.000 claims description 22
- 230000003920 cognitive function Effects 0.000 claims description 16
- 230000006999 cognitive decline Effects 0.000 claims description 12
- 238000009825 accumulation Methods 0.000 claims description 10
- 230000004770 neurodegeneration Effects 0.000 claims description 10
- 230000001225 therapeutic effect Effects 0.000 claims description 10
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 7
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 7
- 230000002195 synergetic effect Effects 0.000 claims description 6
- 230000003941 amyloidogenesis Effects 0.000 claims description 5
- 230000015572 biosynthetic process Effects 0.000 abstract description 7
- 108090000623 proteins and genes Proteins 0.000 description 101
- 210000004027 cell Anatomy 0.000 description 94
- 102000004169 proteins and genes Human genes 0.000 description 84
- 235000018102 proteins Nutrition 0.000 description 75
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 73
- 108090000765 processed proteins & peptides Proteins 0.000 description 71
- 241000700159 Rattus Species 0.000 description 69
- 230000035772 mutation Effects 0.000 description 68
- 241001529936 Murinae Species 0.000 description 67
- 239000000203 mixture Substances 0.000 description 63
- 150000007523 nucleic acids Chemical class 0.000 description 63
- 102000039446 nucleic acids Human genes 0.000 description 59
- 108020004707 nucleic acids Proteins 0.000 description 59
- 102000004196 processed proteins & peptides Human genes 0.000 description 56
- 125000003729 nucleotide group Chemical group 0.000 description 49
- 239000002773 nucleotide Substances 0.000 description 48
- 229920001184 polypeptide Polymers 0.000 description 47
- 239000000427 antigen Substances 0.000 description 45
- 238000002965 ELISA Methods 0.000 description 44
- 108091007433 antigens Proteins 0.000 description 44
- 102000036639 antigens Human genes 0.000 description 44
- 235000001014 amino acid Nutrition 0.000 description 40
- 229940024606 amino acid Drugs 0.000 description 39
- 101001014223 Homo sapiens MAPK/MAK/MRK overlapping kinase Proteins 0.000 description 38
- 102000049409 human MOK Human genes 0.000 description 38
- 238000011282 treatment Methods 0.000 description 38
- 238000012360 testing method Methods 0.000 description 37
- 150000001413 amino acids Chemical class 0.000 description 35
- 238000009472 formulation Methods 0.000 description 31
- 108060003951 Immunoglobulin Proteins 0.000 description 30
- 102000018358 immunoglobulin Human genes 0.000 description 30
- 241001465754 Metazoa Species 0.000 description 29
- 241000699670 Mus sp. Species 0.000 description 28
- 239000000523 sample Substances 0.000 description 28
- 239000013598 vector Substances 0.000 description 28
- 150000001875 compounds Chemical class 0.000 description 27
- 238000000159 protein binding assay Methods 0.000 description 27
- 241000894007 species Species 0.000 description 27
- 241000699666 Mus <mouse, genus> Species 0.000 description 26
- 210000004602 germ cell Anatomy 0.000 description 26
- 241000283973 Oryctolagus cuniculus Species 0.000 description 25
- 239000002953 phosphate buffered saline Substances 0.000 description 25
- 108020004414 DNA Proteins 0.000 description 24
- 102000053602 DNA Human genes 0.000 description 24
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 24
- 230000015654 memory Effects 0.000 description 24
- 239000002299 complementary DNA Substances 0.000 description 23
- 239000003446 ligand Substances 0.000 description 23
- 230000000694 effects Effects 0.000 description 22
- 230000008569 process Effects 0.000 description 22
- 210000001519 tissue Anatomy 0.000 description 22
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 21
- 108091028043 Nucleic acid sequence Proteins 0.000 description 21
- 108010047495 alanylglycine Proteins 0.000 description 21
- 208000028698 Cognitive impairment Diseases 0.000 description 19
- 230000000875 corresponding effect Effects 0.000 description 19
- 150000003839 salts Chemical class 0.000 description 19
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 18
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 18
- 102000005962 receptors Human genes 0.000 description 18
- 108020003175 receptors Proteins 0.000 description 18
- 208000024891 symptom Diseases 0.000 description 18
- 241001504519 Papio ursinus Species 0.000 description 17
- 239000003814 drug Substances 0.000 description 17
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 17
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 16
- 239000013604 expression vector Substances 0.000 description 16
- 238000012216 screening Methods 0.000 description 16
- 238000005406 washing Methods 0.000 description 16
- 101710137189 Amyloid-beta A4 protein Proteins 0.000 description 15
- 101710151993 Amyloid-beta precursor protein Proteins 0.000 description 15
- 102100022704 Amyloid-beta precursor protein Human genes 0.000 description 15
- 102100037907 High mobility group protein B1 Human genes 0.000 description 15
- 241000282412 Homo Species 0.000 description 15
- 108010087924 alanylproline Proteins 0.000 description 15
- 238000004458 analytical method Methods 0.000 description 15
- 108020001507 fusion proteins Proteins 0.000 description 15
- 102000037865 fusion proteins Human genes 0.000 description 15
- 238000009396 hybridization Methods 0.000 description 15
- 210000004408 hybridoma Anatomy 0.000 description 15
- 230000003993 interaction Effects 0.000 description 15
- 210000004072 lung Anatomy 0.000 description 15
- 210000002966 serum Anatomy 0.000 description 15
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 15
- 241000282567 Macaca fascicularis Species 0.000 description 14
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 14
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 14
- DZHSAHHDTRWUTF-SIQRNXPUSA-N amyloid-beta polypeptide 42 Chemical compound C([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O)[C@@H](C)CC)C(C)C)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O)C(C)C)C(C)C)C1=CC=CC=C1 DZHSAHHDTRWUTF-SIQRNXPUSA-N 0.000 description 14
- 230000006870 function Effects 0.000 description 14
- 108700010013 HMGB1 Proteins 0.000 description 13
- 101150021904 HMGB1 gene Proteins 0.000 description 13
- 241000880493 Leptailurus serval Species 0.000 description 13
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 13
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 13
- 241000282520 Papio Species 0.000 description 13
- 125000000539 amino acid group Chemical group 0.000 description 13
- 238000003556 assay Methods 0.000 description 13
- 238000006243 chemical reaction Methods 0.000 description 13
- 230000000295 complement effect Effects 0.000 description 13
- 238000010494 dissociation reaction Methods 0.000 description 13
- 230000005593 dissociations Effects 0.000 description 13
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 13
- 230000003053 immunization Effects 0.000 description 13
- 229940072221 immunoglobulins Drugs 0.000 description 13
- 239000000243 solution Substances 0.000 description 13
- 101100339431 Arabidopsis thaliana HMGB2 gene Proteins 0.000 description 12
- -1 S100 Proteins 0.000 description 12
- 108010047857 aspartylglycine Proteins 0.000 description 12
- 108010078144 glutaminyl-glycine Proteins 0.000 description 12
- 238000002649 immunization Methods 0.000 description 12
- 238000004519 manufacturing process Methods 0.000 description 12
- 239000000843 powder Substances 0.000 description 12
- 108010061238 threonyl-glycine Proteins 0.000 description 12
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 11
- UAOSDDXCTBIPCA-QXEWZRGKSA-N Arg-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UAOSDDXCTBIPCA-QXEWZRGKSA-N 0.000 description 11
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 11
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 11
- 239000004480 active ingredient Substances 0.000 description 11
- 108010085325 histidylproline Proteins 0.000 description 11
- 230000001965 increasing effect Effects 0.000 description 11
- 108010057821 leucylproline Proteins 0.000 description 11
- 231100000350 mutagenesis Toxicity 0.000 description 11
- 239000008194 pharmaceutical composition Substances 0.000 description 11
- 238000002360 preparation method Methods 0.000 description 11
- 102000009109 Fc receptors Human genes 0.000 description 10
- 108010087819 Fc receptors Proteins 0.000 description 10
- 241000282326 Felis catus Species 0.000 description 10
- LALNXSXEYFUUDD-GUBZILKMSA-N Ser-Glu-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LALNXSXEYFUUDD-GUBZILKMSA-N 0.000 description 10
- 108010064539 amyloid beta-protein (1-42) Proteins 0.000 description 10
- 108010068380 arginylarginine Proteins 0.000 description 10
- 230000007423 decrease Effects 0.000 description 10
- 108010051307 glycyl-glycyl-proline Proteins 0.000 description 10
- 108010089804 glycyl-threonine Proteins 0.000 description 10
- 108010077515 glycylproline Proteins 0.000 description 10
- 230000001976 improved effect Effects 0.000 description 10
- 239000000463 material Substances 0.000 description 10
- 238000005259 measurement Methods 0.000 description 10
- 238000002703 mutagenesis Methods 0.000 description 10
- 229920001223 polyethylene glycol Polymers 0.000 description 10
- 230000009261 transgenic effect Effects 0.000 description 10
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 9
- 206010012289 Dementia Diseases 0.000 description 9
- RWQCWSGOOOEGPB-FXQIFTODSA-N Gln-Ser-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O RWQCWSGOOOEGPB-FXQIFTODSA-N 0.000 description 9
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 9
- YRAWWKUTNBILNT-FXQIFTODSA-N Met-Ala-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YRAWWKUTNBILNT-FXQIFTODSA-N 0.000 description 9
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 9
- 108091034117 Oligonucleotide Proteins 0.000 description 9
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 9
- FTKXYXACXYOHND-XUXIUFHCSA-N Val-Ile-Leu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O FTKXYXACXYOHND-XUXIUFHCSA-N 0.000 description 9
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 9
- 108010036533 arginylvaline Proteins 0.000 description 9
- 239000002585 base Substances 0.000 description 9
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 9
- 230000002860 competitive effect Effects 0.000 description 9
- 239000002552 dosage form Substances 0.000 description 9
- 230000013595 glycosylation Effects 0.000 description 9
- 238000006206 glycosylation reaction Methods 0.000 description 9
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 9
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 9
- 108010037850 glycylvaline Proteins 0.000 description 9
- 238000000338 in vitro Methods 0.000 description 9
- 238000001727 in vivo Methods 0.000 description 9
- 238000002823 phage display Methods 0.000 description 9
- 108010051242 phenylalanylserine Proteins 0.000 description 9
- 108010090894 prolylleucine Proteins 0.000 description 9
- 230000002829 reductive effect Effects 0.000 description 9
- 229920002477 rna polymer Polymers 0.000 description 9
- 239000000126 substance Substances 0.000 description 9
- 239000006228 supernatant Substances 0.000 description 9
- 108010073969 valyllysine Proteins 0.000 description 9
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 8
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 8
- FZWVCYCYWCLQDH-NHCYSSNCSA-N Ile-Leu-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N FZWVCYCYWCLQDH-NHCYSSNCSA-N 0.000 description 8
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 8
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 8
- 108010079364 N-glycylalanine Proteins 0.000 description 8
- SUENWIFTSTWUKD-AVGNSLFASA-N Pro-Leu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SUENWIFTSTWUKD-AVGNSLFASA-N 0.000 description 8
- FYKUEXMZYFIZKA-DCAQKATOSA-N Pro-Pro-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FYKUEXMZYFIZKA-DCAQKATOSA-N 0.000 description 8
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 8
- 229940098773 bovine serum albumin Drugs 0.000 description 8
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 8
- 238000006471 dimerization reaction Methods 0.000 description 8
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 8
- 239000011159 matrix material Substances 0.000 description 8
- 210000002381 plasma Anatomy 0.000 description 8
- 210000003705 ribosome Anatomy 0.000 description 8
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 8
- 229940124597 therapeutic agent Drugs 0.000 description 8
- VHAQSYHSDKERBS-XPUUQOCRSA-N Ala-Val-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O VHAQSYHSDKERBS-XPUUQOCRSA-N 0.000 description 7
- 108020004705 Codon Proteins 0.000 description 7
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 7
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 7
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 7
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 7
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 7
- 108010065920 Insulin Lispro Proteins 0.000 description 7
- ITWQLSZTLBKWJM-YUMQZZPRSA-N Lys-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCCCN ITWQLSZTLBKWJM-YUMQZZPRSA-N 0.000 description 7
- NJNRBRKHOWSGMN-SRVKXCTJSA-N Lys-Leu-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O NJNRBRKHOWSGMN-SRVKXCTJSA-N 0.000 description 7
- 206010028980 Neoplasm Diseases 0.000 description 7
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 7
- DWGFLKQSGRUQTI-IHRRRGAJSA-N Pro-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 DWGFLKQSGRUQTI-IHRRRGAJSA-N 0.000 description 7
- CDBYLPFSWZWCQE-UHFFFAOYSA-L Sodium Carbonate Chemical compound [Na+].[Na+].[O-]C([O-])=O CDBYLPFSWZWCQE-UHFFFAOYSA-L 0.000 description 7
- VGYBYGQXZJDZJU-XQXXSGGOSA-N Thr-Glu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VGYBYGQXZJDZJU-XQXXSGGOSA-N 0.000 description 7
- KCRQEJSKXAIULJ-FJXKBIBVSA-N Thr-Gly-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O KCRQEJSKXAIULJ-FJXKBIBVSA-N 0.000 description 7
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 7
- FEZASNVQLJQBHW-CABZTGNLSA-N Trp-Gly-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O)=CNC2=C1 FEZASNVQLJQBHW-CABZTGNLSA-N 0.000 description 7
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 7
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 7
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 7
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 7
- 108010038633 aspartylglutamate Proteins 0.000 description 7
- 210000004369 blood Anatomy 0.000 description 7
- 239000008280 blood Substances 0.000 description 7
- 230000015556 catabolic process Effects 0.000 description 7
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 7
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical class OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 7
- 238000006731 degradation reaction Methods 0.000 description 7
- 239000003937 drug carrier Substances 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 7
- 108010050848 glycylleucine Proteins 0.000 description 7
- 239000007788 liquid Substances 0.000 description 7
- 150000002482 oligosaccharides Chemical class 0.000 description 7
- 239000000546 pharmaceutical excipient Substances 0.000 description 7
- 102000040430 polynucleotide Human genes 0.000 description 7
- 108091033319 polynucleotide Proteins 0.000 description 7
- 239000002157 polynucleotide Substances 0.000 description 7
- 238000012545 processing Methods 0.000 description 7
- 108010070643 prolylglutamic acid Proteins 0.000 description 7
- 108010029020 prolylglycine Proteins 0.000 description 7
- 230000002441 reversible effect Effects 0.000 description 7
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 7
- 238000012421 spiking Methods 0.000 description 7
- 239000003826 tablet Substances 0.000 description 7
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 6
- MSWSRLGNLKHDEI-ACZMJKKPSA-N Ala-Ser-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O MSWSRLGNLKHDEI-ACZMJKKPSA-N 0.000 description 6
- JGDGLDNAQJJGJI-AVGNSLFASA-N Arg-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N JGDGLDNAQJJGJI-AVGNSLFASA-N 0.000 description 6
- ISVACHFCVRKIDG-SRVKXCTJSA-N Arg-Val-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O ISVACHFCVRKIDG-SRVKXCTJSA-N 0.000 description 6
- VFUXXFVCYZPOQG-WDSKDSINSA-N Asp-Glu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VFUXXFVCYZPOQG-WDSKDSINSA-N 0.000 description 6
- PZXPWHFYZXTFBI-YUMQZZPRSA-N Asp-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O PZXPWHFYZXTFBI-YUMQZZPRSA-N 0.000 description 6
- JDVVGAQPNNXQDW-WCMLQCRESA-N Castanospermine Natural products O[C@H]1[C@@H](O)[C@H]2[C@@H](O)CCN2C[C@H]1O JDVVGAQPNNXQDW-WCMLQCRESA-N 0.000 description 6
- JDVVGAQPNNXQDW-TVNFTVLESA-N Castinospermine Chemical compound C1[C@H](O)[C@@H](O)[C@H](O)[C@H]2[C@@H](O)CCN21 JDVVGAQPNNXQDW-TVNFTVLESA-N 0.000 description 6
- BULIVUZUDBHKKZ-WDSKDSINSA-N Gly-Gln-Asn Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BULIVUZUDBHKKZ-WDSKDSINSA-N 0.000 description 6
- TVUWMSBGMVAHSJ-KBPBESRZSA-N Gly-Leu-Phe Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TVUWMSBGMVAHSJ-KBPBESRZSA-N 0.000 description 6
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 6
- CUVBTVWFVIIDOC-YEPSODPASA-N Gly-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)CN CUVBTVWFVIIDOC-YEPSODPASA-N 0.000 description 6
- KCTIFOCXAIUQQK-QXEWZRGKSA-N Ile-Pro-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O KCTIFOCXAIUQQK-QXEWZRGKSA-N 0.000 description 6
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 6
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 6
- HWMQRQIFVGEAPH-XIRDDKMYSA-N Leu-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 HWMQRQIFVGEAPH-XIRDDKMYSA-N 0.000 description 6
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 6
- CNGOEHJCLVCJHN-SRVKXCTJSA-N Lys-Pro-Glu Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O CNGOEHJCLVCJHN-SRVKXCTJSA-N 0.000 description 6
- GHKXHCMRAUYLBS-CIUDSAMLSA-N Lys-Ser-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O GHKXHCMRAUYLBS-CIUDSAMLSA-N 0.000 description 6
- 241000124008 Mammalia Species 0.000 description 6
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 6
- MCWHYUWXVNRXFV-RWMBFGLXSA-N Pro-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 MCWHYUWXVNRXFV-RWMBFGLXSA-N 0.000 description 6
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 6
- 102000054727 Serum Amyloid A Human genes 0.000 description 6
- 108700028909 Serum Amyloid A Proteins 0.000 description 6
- TYVAWPFQYFPSBR-BFHQHQDPSA-N Thr-Ala-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)NCC(O)=O TYVAWPFQYFPSBR-BFHQHQDPSA-N 0.000 description 6
- XSEPSRUDSPHMPX-KATARQTJSA-N Thr-Lys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O XSEPSRUDSPHMPX-KATARQTJSA-N 0.000 description 6
- LTLBNCDNXQCOLB-UBHSHLNASA-N Trp-Asp-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 LTLBNCDNXQCOLB-UBHSHLNASA-N 0.000 description 6
- KZKMBGXCNLPYKD-YEPSODPASA-N Val-Gly-Thr Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O KZKMBGXCNLPYKD-YEPSODPASA-N 0.000 description 6
- DOBHJKVVACOQTN-DZKIICNBSA-N Val-Tyr-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 DOBHJKVVACOQTN-DZKIICNBSA-N 0.000 description 6
- 241000700605 Viruses Species 0.000 description 6
- 238000010521 absorption reaction Methods 0.000 description 6
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 6
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 6
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 6
- 239000000872 buffer Substances 0.000 description 6
- 239000011248 coating agent Substances 0.000 description 6
- 238000000576 coating method Methods 0.000 description 6
- 230000037029 cross reaction Effects 0.000 description 6
- 238000010790 dilution Methods 0.000 description 6
- 239000012895 dilution Substances 0.000 description 6
- 235000011187 glycerol Nutrition 0.000 description 6
- 108010015792 glycyllysine Proteins 0.000 description 6
- 102000056529 human esRAGE Human genes 0.000 description 6
- 108700022231 human esRAGE Proteins 0.000 description 6
- 125000005647 linker group Chemical group 0.000 description 6
- 108010017391 lysylvaline Proteins 0.000 description 6
- 230000001404 mediated effect Effects 0.000 description 6
- 230000004048 modification Effects 0.000 description 6
- 238000012986 modification Methods 0.000 description 6
- 238000000302 molecular modelling Methods 0.000 description 6
- 231100000252 nontoxic Toxicity 0.000 description 6
- 230000003000 nontoxic effect Effects 0.000 description 6
- 229920001542 oligosaccharide Polymers 0.000 description 6
- 239000013612 plasmid Substances 0.000 description 6
- 229920000642 polymer Polymers 0.000 description 6
- 230000009870 specific binding Effects 0.000 description 6
- 238000010561 standard procedure Methods 0.000 description 6
- 230000000638 stimulation Effects 0.000 description 6
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 6
- 239000000725 suspension Substances 0.000 description 6
- 238000002054 transplantation Methods 0.000 description 6
- 108010029384 tryptophyl-histidine Proteins 0.000 description 6
- PPINMSZPTPRQQB-NHCYSSNCSA-N 2-[[(2s)-1-[(2s)-2-[[(2s)-2-amino-3-methylbutanoyl]amino]propanoyl]pyrrolidine-2-carbonyl]amino]acetic acid Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PPINMSZPTPRQQB-NHCYSSNCSA-N 0.000 description 5
- CSAHOYQKNHGDHX-ACZMJKKPSA-N Ala-Gln-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CSAHOYQKNHGDHX-ACZMJKKPSA-N 0.000 description 5
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 5
- XPSGESXVBSQZPL-SRVKXCTJSA-N Arg-Arg-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XPSGESXVBSQZPL-SRVKXCTJSA-N 0.000 description 5
- FTCGGKNCJZOPNB-WHFBIAKZSA-N Asn-Gly-Ser Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FTCGGKNCJZOPNB-WHFBIAKZSA-N 0.000 description 5
- 241000283707 Capra Species 0.000 description 5
- 241000282693 Cercopithecidae Species 0.000 description 5
- 241000588724 Escherichia coli Species 0.000 description 5
- 108010010803 Gelatin Proteins 0.000 description 5
- ILGFBUGLBSAQQB-GUBZILKMSA-N Glu-Glu-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ILGFBUGLBSAQQB-GUBZILKMSA-N 0.000 description 5
- DXVOKNVIKORTHQ-GUBZILKMSA-N Glu-Pro-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O DXVOKNVIKORTHQ-GUBZILKMSA-N 0.000 description 5
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 5
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 5
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 5
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 5
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 5
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 5
- ZKJZBRHRWKLVSJ-ZDLURKLDSA-N Gly-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN)O ZKJZBRHRWKLVSJ-ZDLURKLDSA-N 0.000 description 5
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 5
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 5
- OVPYIUNCVSOVNF-ZPFDUUQYSA-N Ile-Gln-Pro Natural products CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O OVPYIUNCVSOVNF-ZPFDUUQYSA-N 0.000 description 5
- AGGIYSLVUKVOPT-HTFCKZLJSA-N Ile-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N AGGIYSLVUKVOPT-HTFCKZLJSA-N 0.000 description 5
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 5
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 5
- FIJMQLGQLBLBOL-HJGDQZAQSA-N Leu-Asn-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FIJMQLGQLBLBOL-HJGDQZAQSA-N 0.000 description 5
- DCGXHWINSHEPIR-SRVKXCTJSA-N Leu-Lys-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)O)N DCGXHWINSHEPIR-SRVKXCTJSA-N 0.000 description 5
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 5
- QMKFDEUJGYNFMC-AVGNSLFASA-N Leu-Pro-Arg Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QMKFDEUJGYNFMC-AVGNSLFASA-N 0.000 description 5
- VULJUQZPSOASBZ-SRVKXCTJSA-N Leu-Pro-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O VULJUQZPSOASBZ-SRVKXCTJSA-N 0.000 description 5
- KWLWZYMNUZJKMZ-IHRRRGAJSA-N Leu-Pro-Leu Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O KWLWZYMNUZJKMZ-IHRRRGAJSA-N 0.000 description 5
- AAKRWBIIGKPOKQ-ONGXEEELSA-N Leu-Val-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AAKRWBIIGKPOKQ-ONGXEEELSA-N 0.000 description 5
- 241001460678 Napo <wasp> Species 0.000 description 5
- 239000002202 Polyethylene glycol Substances 0.000 description 5
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 5
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 5
- SBVPYBFMIGDIDX-SRVKXCTJSA-N Pro-Pro-Pro Chemical compound OC(=O)[C@@H]1CCCN1C(=O)[C@H]1N(C(=O)[C@H]2NCCC2)CCC1 SBVPYBFMIGDIDX-SRVKXCTJSA-N 0.000 description 5
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 5
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 5
- 108010090804 Streptavidin Proteins 0.000 description 5
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 5
- 229930006000 Sucrose Natural products 0.000 description 5
- ABWNZPOIUJMNKT-IXOXFDKPSA-N Thr-Phe-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O ABWNZPOIUJMNKT-IXOXFDKPSA-N 0.000 description 5
- NMOIRIIIUVELLY-WDSOQIARSA-N Trp-Val-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)C(C)C)=CNC2=C1 NMOIRIIIUVELLY-WDSOQIARSA-N 0.000 description 5
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 5
- CELJCNRXKZPTCX-XPUUQOCRSA-N Val-Gly-Ala Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O CELJCNRXKZPTCX-XPUUQOCRSA-N 0.000 description 5
- IJGPOONOTBNTFS-GVXVVHGQSA-N Val-Lys-Glu Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O IJGPOONOTBNTFS-GVXVVHGQSA-N 0.000 description 5
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 5
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 5
- 239000003963 antioxidant agent Substances 0.000 description 5
- 235000006708 antioxidants Nutrition 0.000 description 5
- 210000003719 b-lymphocyte Anatomy 0.000 description 5
- 230000006399 behavior Effects 0.000 description 5
- 201000011510 cancer Diseases 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 238000010367 cloning Methods 0.000 description 5
- 239000006071 cream Substances 0.000 description 5
- 208000035475 disorder Diseases 0.000 description 5
- 229940079593 drug Drugs 0.000 description 5
- 238000002474 experimental method Methods 0.000 description 5
- 230000004927 fusion Effects 0.000 description 5
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 5
- 239000000499 gel Substances 0.000 description 5
- 239000008273 gelatin Substances 0.000 description 5
- 229920000159 gelatin Polymers 0.000 description 5
- 235000019322 gelatine Nutrition 0.000 description 5
- 235000011852 gelatine desserts Nutrition 0.000 description 5
- 238000011532 immunohistochemical staining Methods 0.000 description 5
- 230000001771 impaired effect Effects 0.000 description 5
- 230000006872 improvement Effects 0.000 description 5
- 238000003780 insertion Methods 0.000 description 5
- 230000037431 insertion Effects 0.000 description 5
- 239000008101 lactose Substances 0.000 description 5
- 230000006996 mental state Effects 0.000 description 5
- 238000010172 mouse model Methods 0.000 description 5
- 239000006072 paste Substances 0.000 description 5
- 102000013415 peroxidase activity proteins Human genes 0.000 description 5
- 108040007629 peroxidase activity proteins Proteins 0.000 description 5
- 239000003755 preservative agent Substances 0.000 description 5
- 230000008439 repair process Effects 0.000 description 5
- 230000004044 response Effects 0.000 description 5
- 238000003757 reverse transcription PCR Methods 0.000 description 5
- 108010026333 seryl-proline Proteins 0.000 description 5
- 239000007787 solid Substances 0.000 description 5
- 239000007921 spray Substances 0.000 description 5
- 238000006467 substitution reaction Methods 0.000 description 5
- 239000005720 sucrose Substances 0.000 description 5
- 108010026424 tau Proteins Proteins 0.000 description 5
- 102000013498 tau Proteins Human genes 0.000 description 5
- PIDRBUDUWHBYSR-UHFFFAOYSA-N 1-[2-[[2-[(2-amino-4-methylpentanoyl)amino]-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O PIDRBUDUWHBYSR-UHFFFAOYSA-N 0.000 description 4
- 108010005094 Advanced Glycation End Products Proteins 0.000 description 4
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 4
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 4
- PHQXWZGXKAFWAZ-ZLIFDBKOSA-N Ala-Trp-Lys Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 PHQXWZGXKAFWAZ-ZLIFDBKOSA-N 0.000 description 4
- 108700028369 Alleles Proteins 0.000 description 4
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 4
- NONSEUUPKITYQT-BQBZGAKWSA-N Arg-Asn-Gly Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N)CN=C(N)N NONSEUUPKITYQT-BQBZGAKWSA-N 0.000 description 4
- HJAICMSAKODKRF-GUBZILKMSA-N Arg-Cys-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O HJAICMSAKODKRF-GUBZILKMSA-N 0.000 description 4
- UPKMBGAAEZGHOC-RWMBFGLXSA-N Arg-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O UPKMBGAAEZGHOC-RWMBFGLXSA-N 0.000 description 4
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 4
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 4
- QIRJQYQOIKBPBZ-IHRRRGAJSA-N Asn-Tyr-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QIRJQYQOIKBPBZ-IHRRRGAJSA-N 0.000 description 4
- WMLFFCRUSPNENW-ZLUOBGJFSA-N Asp-Ser-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O WMLFFCRUSPNENW-ZLUOBGJFSA-N 0.000 description 4
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 4
- 241000416162 Astragalus gummifer Species 0.000 description 4
- 108020004635 Complementary DNA Proteins 0.000 description 4
- CIVXDCMSSFGWAL-YUMQZZPRSA-N Cys-Lys-Gly Chemical compound C(CCN)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N CIVXDCMSSFGWAL-YUMQZZPRSA-N 0.000 description 4
- HJXSYJVCMUOUNY-SRVKXCTJSA-N Cys-Ser-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N HJXSYJVCMUOUNY-SRVKXCTJSA-N 0.000 description 4
- LPBUBIHAVKXUOT-FXQIFTODSA-N Cys-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N LPBUBIHAVKXUOT-FXQIFTODSA-N 0.000 description 4
- 201000010374 Down Syndrome Diseases 0.000 description 4
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 4
- 102000004190 Enzymes Human genes 0.000 description 4
- 108090000790 Enzymes Proteins 0.000 description 4
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 4
- IKDOHQHEFPPGJG-FXQIFTODSA-N Gln-Asp-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O IKDOHQHEFPPGJG-FXQIFTODSA-N 0.000 description 4
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 4
- VNTGPISAOMAXRK-CIUDSAMLSA-N Gln-Pro-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O VNTGPISAOMAXRK-CIUDSAMLSA-N 0.000 description 4
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 4
- SYWCGQOIIARSIX-SRVKXCTJSA-N Glu-Pro-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O SYWCGQOIIARSIX-SRVKXCTJSA-N 0.000 description 4
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 4
- YOTHMZZSJKKEHZ-SZMVWBNQSA-N Glu-Trp-Lys Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CCC(O)=O)=CNC2=C1 YOTHMZZSJKKEHZ-SZMVWBNQSA-N 0.000 description 4
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 4
- LERGJIVJIIODPZ-ZANVPECISA-N Gly-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)CN)C)C(O)=O)=CNC2=C1 LERGJIVJIIODPZ-ZANVPECISA-N 0.000 description 4
- DTPOVRRYXPJJAZ-FJXKBIBVSA-N Gly-Arg-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N DTPOVRRYXPJJAZ-FJXKBIBVSA-N 0.000 description 4
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 4
- HJARVELKOSZUEW-YUMQZZPRSA-N Gly-Pro-Gln Chemical compound [H]NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O HJARVELKOSZUEW-YUMQZZPRSA-N 0.000 description 4
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 4
- LLWQVJNHMYBLLK-CDMKHQONSA-N Gly-Thr-Phe Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LLWQVJNHMYBLLK-CDMKHQONSA-N 0.000 description 4
- FOKISINOENBSDM-WLTAIBSBSA-N Gly-Thr-Tyr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O FOKISINOENBSDM-WLTAIBSBSA-N 0.000 description 4
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 4
- VFBZWZXKCVBTJR-SRVKXCTJSA-N His-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N VFBZWZXKCVBTJR-SRVKXCTJSA-N 0.000 description 4
- SWTSERYNZQMPBI-WDSOQIARSA-N His-Trp-Met Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCSC)C(O)=O)C1=CN=CN1 SWTSERYNZQMPBI-WDSOQIARSA-N 0.000 description 4
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 4
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 4
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 4
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 4
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 4
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 4
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 4
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 4
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 4
- NJMXCOOEFLMZSR-AVGNSLFASA-N Leu-Met-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O NJMXCOOEFLMZSR-AVGNSLFASA-N 0.000 description 4
- YWKNKRAKOCLOLH-OEAJRASXSA-N Leu-Phe-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=CC=C1 YWKNKRAKOCLOLH-OEAJRASXSA-N 0.000 description 4
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 4
- HOMFINRJHIIZNJ-HOCLYGCPSA-N Leu-Trp-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O HOMFINRJHIIZNJ-HOCLYGCPSA-N 0.000 description 4
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 4
- PBIPLDMFHAICIP-DCAQKATOSA-N Lys-Glu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PBIPLDMFHAICIP-DCAQKATOSA-N 0.000 description 4
- WGLAORUKDGRINI-WDCWCFNPSA-N Lys-Glu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGLAORUKDGRINI-WDCWCFNPSA-N 0.000 description 4
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 4
- UQJOKDAYFULYIX-AVGNSLFASA-N Lys-Pro-Pro Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 UQJOKDAYFULYIX-AVGNSLFASA-N 0.000 description 4
- 108010066427 N-valyltryptophan Proteins 0.000 description 4
- QSWKNJAPHQDAAS-MELADBBJSA-N Phe-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O QSWKNJAPHQDAAS-MELADBBJSA-N 0.000 description 4
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 4
- AJLVKXCNXIJHDV-CIUDSAMLSA-N Pro-Ala-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O AJLVKXCNXIJHDV-CIUDSAMLSA-N 0.000 description 4
- PZSCUPVOJGKHEP-CIUDSAMLSA-N Pro-Gln-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PZSCUPVOJGKHEP-CIUDSAMLSA-N 0.000 description 4
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 4
- UEHYFUCOGHWASA-HJGDQZAQSA-N Pro-Glu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 UEHYFUCOGHWASA-HJGDQZAQSA-N 0.000 description 4
- VYWNORHENYEQDW-YUMQZZPRSA-N Pro-Gly-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 VYWNORHENYEQDW-YUMQZZPRSA-N 0.000 description 4
- BWCZJGJKOFUUCN-ZPFDUUQYSA-N Pro-Ile-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O BWCZJGJKOFUUCN-ZPFDUUQYSA-N 0.000 description 4
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 4
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 4
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 4
- KIEIJCFVGZCUAS-MELADBBJSA-N Ser-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N)C(=O)O KIEIJCFVGZCUAS-MELADBBJSA-N 0.000 description 4
- 229920002472 Starch Polymers 0.000 description 4
- LVHHEVGYAZGXDE-KDXUFGMBSA-N Thr-Ala-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(=O)O)N)O LVHHEVGYAZGXDE-KDXUFGMBSA-N 0.000 description 4
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 4
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 4
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 4
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 4
- 229920001615 Tragacanth Polymers 0.000 description 4
- KDWZQYUTMJSYRJ-BHYGNILZSA-N Trp-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O KDWZQYUTMJSYRJ-BHYGNILZSA-N 0.000 description 4
- UXUFNBVCPAWACG-SIUGBPQLSA-N Tyr-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N UXUFNBVCPAWACG-SIUGBPQLSA-N 0.000 description 4
- XUIOBCQESNDTDE-FQPOAREZSA-N Tyr-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O XUIOBCQESNDTDE-FQPOAREZSA-N 0.000 description 4
- DDRBQONWVBDQOY-GUBZILKMSA-N Val-Ala-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O DDRBQONWVBDQOY-GUBZILKMSA-N 0.000 description 4
- UBTBGUDNDFZLGP-SRVKXCTJSA-N Val-Arg-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C(C)C)C(=O)O)N UBTBGUDNDFZLGP-SRVKXCTJSA-N 0.000 description 4
- PMDOQZFYGWZSTK-LSJOCFKGSA-N Val-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C PMDOQZFYGWZSTK-LSJOCFKGSA-N 0.000 description 4
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 4
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 4
- LGXUZJIQCGXKGZ-QXEWZRGKSA-N Val-Pro-Asn Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)N)C(=O)O)N LGXUZJIQCGXKGZ-QXEWZRGKSA-N 0.000 description 4
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 4
- UFCHCOKFAGOQSF-BQFCYCMXSA-N Val-Trp-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N UFCHCOKFAGOQSF-BQFCYCMXSA-N 0.000 description 4
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 4
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 4
- 239000002253 acid Substances 0.000 description 4
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 4
- 239000002671 adjuvant Substances 0.000 description 4
- 230000009824 affinity maturation Effects 0.000 description 4
- 108010091092 arginyl-glycyl-proline Proteins 0.000 description 4
- 108010062796 arginyllysine Proteins 0.000 description 4
- 108010093581 aspartyl-proline Proteins 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 230000004071 biological effect Effects 0.000 description 4
- 239000002775 capsule Substances 0.000 description 4
- 238000004132 cross linking Methods 0.000 description 4
- 230000009260 cross reactivity Effects 0.000 description 4
- 231100000599 cytotoxic agent Toxicity 0.000 description 4
- 230000007547 defect Effects 0.000 description 4
- 238000012217 deletion Methods 0.000 description 4
- 230000037430 deletion Effects 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 239000000539 dimer Substances 0.000 description 4
- 239000003995 emulsifying agent Substances 0.000 description 4
- 229940088598 enzyme Drugs 0.000 description 4
- 235000019441 ethanol Nutrition 0.000 description 4
- 239000008187 granular material Substances 0.000 description 4
- 239000001963 growth medium Substances 0.000 description 4
- 230000036541 health Effects 0.000 description 4
- 108010036413 histidylglycine Proteins 0.000 description 4
- 230000002163 immunogen Effects 0.000 description 4
- 230000006698 induction Effects 0.000 description 4
- 230000013016 learning Effects 0.000 description 4
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 4
- 230000033001 locomotion Effects 0.000 description 4
- 108010064235 lysylglycine Proteins 0.000 description 4
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 239000002609 medium Substances 0.000 description 4
- 206010027175 memory impairment Diseases 0.000 description 4
- 108010063431 methionyl-aspartyl-glycine Proteins 0.000 description 4
- 235000013336 milk Nutrition 0.000 description 4
- 239000008267 milk Substances 0.000 description 4
- 210000004080 milk Anatomy 0.000 description 4
- 150000007522 mineralic acids Chemical class 0.000 description 4
- 238000010369 molecular cloning Methods 0.000 description 4
- 239000003921 oil Substances 0.000 description 4
- 235000019198 oils Nutrition 0.000 description 4
- 238000005457 optimization Methods 0.000 description 4
- 150000007524 organic acids Chemical class 0.000 description 4
- 238000007911 parenteral administration Methods 0.000 description 4
- 239000006187 pill Substances 0.000 description 4
- 230000000750 progressive effect Effects 0.000 description 4
- 108010007513 prolyl-glycyl-prolyl-leucine Proteins 0.000 description 4
- 108010077112 prolyl-proline Proteins 0.000 description 4
- 239000013074 reference sample Substances 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 239000002904 solvent Substances 0.000 description 4
- 235000019698 starch Nutrition 0.000 description 4
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 239000000454 talc Substances 0.000 description 4
- 235000012222 talc Nutrition 0.000 description 4
- 229910052623 talc Inorganic materials 0.000 description 4
- 238000002560 therapeutic procedure Methods 0.000 description 4
- 235000010487 tragacanth Nutrition 0.000 description 4
- 238000012549 training Methods 0.000 description 4
- 241000701161 unidentified adenovirus Species 0.000 description 4
- 239000004474 valine Substances 0.000 description 4
- 239000001993 wax Substances 0.000 description 4
- VBICKXHEKHSIBG-UHFFFAOYSA-N 1-monostearoylglycerol Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(O)CO VBICKXHEKHSIBG-UHFFFAOYSA-N 0.000 description 3
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- 229920001817 Agar Polymers 0.000 description 3
- CZPAHAKGPDUIPJ-CIUDSAMLSA-N Ala-Gln-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CZPAHAKGPDUIPJ-CIUDSAMLSA-N 0.000 description 3
- HXNNRBHASOSVPG-GUBZILKMSA-N Ala-Glu-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HXNNRBHASOSVPG-GUBZILKMSA-N 0.000 description 3
- AAWLEICNDUHIJM-MBLNEYKQSA-N Ala-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C)N)O AAWLEICNDUHIJM-MBLNEYKQSA-N 0.000 description 3
- REWSWYIDQIELBE-FXQIFTODSA-N Ala-Val-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O REWSWYIDQIELBE-FXQIFTODSA-N 0.000 description 3
- 108010090849 Amyloid beta-Peptides Proteins 0.000 description 3
- 102000013455 Amyloid beta-Peptides Human genes 0.000 description 3
- YVTHEZNOKSAWRW-DCAQKATOSA-N Arg-Lys-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O YVTHEZNOKSAWRW-DCAQKATOSA-N 0.000 description 3
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 3
- KUYKVGODHGHFDI-ACZMJKKPSA-N Asn-Gln-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O KUYKVGODHGHFDI-ACZMJKKPSA-N 0.000 description 3
- NLDNNZKUSLAYFW-NHCYSSNCSA-N Asn-Lys-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLDNNZKUSLAYFW-NHCYSSNCSA-N 0.000 description 3
- 241000699802 Cricetulus griseus Species 0.000 description 3
- FCXJJTRGVAZDER-FXQIFTODSA-N Cys-Val-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O FCXJJTRGVAZDER-FXQIFTODSA-N 0.000 description 3
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 3
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 3
- 101800004490 Endothelin-1 Proteins 0.000 description 3
- 102400000686 Endothelin-1 Human genes 0.000 description 3
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 3
- CGVWDTRDPLOMHZ-FXQIFTODSA-N Gln-Glu-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CGVWDTRDPLOMHZ-FXQIFTODSA-N 0.000 description 3
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 3
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 3
- GIVHPCWYVWUUSG-HVTMNAMFSA-N Gln-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N GIVHPCWYVWUUSG-HVTMNAMFSA-N 0.000 description 3
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 3
- MLCPTRRNICEKIS-FXQIFTODSA-N Glu-Asn-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLCPTRRNICEKIS-FXQIFTODSA-N 0.000 description 3
- CUXJIASLBRJOFV-LAEOZQHASA-N Glu-Gly-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUXJIASLBRJOFV-LAEOZQHASA-N 0.000 description 3
- HPJLZFTUUJKWAJ-JHEQGTHGSA-N Glu-Gly-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HPJLZFTUUJKWAJ-JHEQGTHGSA-N 0.000 description 3
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 3
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 3
- HQTDNEZTGZUWSY-XVKPBYJWSA-N Glu-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)NCC(O)=O HQTDNEZTGZUWSY-XVKPBYJWSA-N 0.000 description 3
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 3
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 3
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 3
- VIIBEIQMLJEUJG-LAEOZQHASA-N Gly-Ile-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O VIIBEIQMLJEUJG-LAEOZQHASA-N 0.000 description 3
- ZLCLYFGMKFCDCN-XPUUQOCRSA-N Gly-Ser-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CO)NC(=O)CN)C(O)=O ZLCLYFGMKFCDCN-XPUUQOCRSA-N 0.000 description 3
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 3
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 3
- AEMRFAOFKBGASW-UHFFFAOYSA-N Glycolic acid Chemical compound OCC(O)=O AEMRFAOFKBGASW-UHFFFAOYSA-N 0.000 description 3
- OWYIDJCNRWRSJY-QTKMDUPCSA-N His-Pro-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O OWYIDJCNRWRSJY-QTKMDUPCSA-N 0.000 description 3
- 101000823051 Homo sapiens Amyloid-beta precursor protein Proteins 0.000 description 3
- GTSAALPQZASLPW-KJYZGMDISA-N Ile-His-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N GTSAALPQZASLPW-KJYZGMDISA-N 0.000 description 3
- CAHCWMVNBZJVAW-NAKRPEOUSA-N Ile-Pro-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)O)N CAHCWMVNBZJVAW-NAKRPEOUSA-N 0.000 description 3
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 3
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 3
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 3
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 3
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 3
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 3
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 3
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 3
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 3
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 3
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 3
- 235000010643 Leucaena leucocephala Nutrition 0.000 description 3
- 240000007472 Leucaena leucocephala Species 0.000 description 3
- AAORVPFVUIHEAB-YUMQZZPRSA-N Lys-Asp-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O AAORVPFVUIHEAB-YUMQZZPRSA-N 0.000 description 3
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 3
- HYSVGEAWTGPMOA-IHRRRGAJSA-N Lys-Pro-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O HYSVGEAWTGPMOA-IHRRRGAJSA-N 0.000 description 3
- 102000043136 MAP kinase family Human genes 0.000 description 3
- 108091054455 MAP kinase family Proteins 0.000 description 3
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 3
- AFVFQIVMOAPDHO-UHFFFAOYSA-N Methanesulfonic acid Chemical class CS(O)(=O)=O AFVFQIVMOAPDHO-UHFFFAOYSA-N 0.000 description 3
- VVQNEPGJFQJSBK-UHFFFAOYSA-N Methyl methacrylate Chemical compound COC(=O)C(C)=C VVQNEPGJFQJSBK-UHFFFAOYSA-N 0.000 description 3
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 3
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 3
- IIEOLPMQYRBZCN-SRVKXCTJSA-N Phe-Ser-Cys Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O IIEOLPMQYRBZCN-SRVKXCTJSA-N 0.000 description 3
- 206010035226 Plasma cell myeloma Diseases 0.000 description 3
- 229920005372 Plexiglas® Polymers 0.000 description 3
- 108010050254 Presenilins Proteins 0.000 description 3
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 3
- ORPZXBQTEHINPB-SRVKXCTJSA-N Pro-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1)C(O)=O ORPZXBQTEHINPB-SRVKXCTJSA-N 0.000 description 3
- RNEFESSBTOQSAC-DCAQKATOSA-N Pro-Ser-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O RNEFESSBTOQSAC-DCAQKATOSA-N 0.000 description 3
- KIDXAAQVMNLJFQ-KZVJFYERSA-N Pro-Thr-Ala Chemical compound C[C@@H](O)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](C)C(O)=O KIDXAAQVMNLJFQ-KZVJFYERSA-N 0.000 description 3
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 3
- 108020004511 Recombinant DNA Proteins 0.000 description 3
- 238000012300 Sequence Analysis Methods 0.000 description 3
- BNFVPSRLHHPQKS-WHFBIAKZSA-N Ser-Asp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O BNFVPSRLHHPQKS-WHFBIAKZSA-N 0.000 description 3
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 3
- SWIQQMYVHIXPEK-FXQIFTODSA-N Ser-Cys-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O SWIQQMYVHIXPEK-FXQIFTODSA-N 0.000 description 3
- SQBLRDDJTUJDMV-ACZMJKKPSA-N Ser-Glu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQBLRDDJTUJDMV-ACZMJKKPSA-N 0.000 description 3
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 3
- QGAHMVHBORDHDC-YUMQZZPRSA-N Ser-His-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CN=CN1 QGAHMVHBORDHDC-YUMQZZPRSA-N 0.000 description 3
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 3
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 3
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 3
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 3
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 3
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 3
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 3
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 3
- QNMIVTOQXUSGLN-SZMVWBNQSA-N Trp-Arg-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 QNMIVTOQXUSGLN-SZMVWBNQSA-N 0.000 description 3
- XZLHHHYSWIYXHD-XIRDDKMYSA-N Trp-Gln-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XZLHHHYSWIYXHD-XIRDDKMYSA-N 0.000 description 3
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 3
- RXEQOXHCHQJMSO-IHPCNDPISA-N Trp-His-Leu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O RXEQOXHCHQJMSO-IHPCNDPISA-N 0.000 description 3
- UOXPLPBMEPLZBW-WDSOQIARSA-N Trp-Val-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 UOXPLPBMEPLZBW-WDSOQIARSA-N 0.000 description 3
- KWKJGBHDYJOVCR-SRVKXCTJSA-N Tyr-Ser-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)O KWKJGBHDYJOVCR-SRVKXCTJSA-N 0.000 description 3
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 3
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 3
- DAVNYIUELQBTAP-XUXIUFHCSA-N Val-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N DAVNYIUELQBTAP-XUXIUFHCSA-N 0.000 description 3
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 3
- NHXZRXLFOBFMDM-AVGNSLFASA-N Val-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C NHXZRXLFOBFMDM-AVGNSLFASA-N 0.000 description 3
- NLNCNKIVJPEFBC-DLOVCJGASA-N Val-Val-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O NLNCNKIVJPEFBC-DLOVCJGASA-N 0.000 description 3
- 230000005856 abnormality Effects 0.000 description 3
- 238000002835 absorbance Methods 0.000 description 3
- 230000002378 acidificating effect Effects 0.000 description 3
- 235000010419 agar Nutrition 0.000 description 3
- 108010005233 alanylglutamic acid Proteins 0.000 description 3
- 108010044940 alanylglutamine Proteins 0.000 description 3
- 235000010443 alginic acid Nutrition 0.000 description 3
- 229920000615 alginic acid Polymers 0.000 description 3
- 150000004781 alginic acids Chemical class 0.000 description 3
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 3
- 210000000628 antibody-producing cell Anatomy 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 108010008355 arginyl-glutamine Proteins 0.000 description 3
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 3
- 230000003542 behavioural effect Effects 0.000 description 3
- 235000012216 bentonite Nutrition 0.000 description 3
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid Chemical compound OC(=O)C1=CC=CC=C1 WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 3
- 230000001588 bifunctional effect Effects 0.000 description 3
- 238000013357 binding ELISA Methods 0.000 description 3
- 229960002685 biotin Drugs 0.000 description 3
- 235000020958 biotin Nutrition 0.000 description 3
- 239000011616 biotin Substances 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 230000008499 blood brain barrier function Effects 0.000 description 3
- 210000001218 blood-brain barrier Anatomy 0.000 description 3
- 239000000969 carrier Substances 0.000 description 3
- 210000003169 central nervous system Anatomy 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 239000012707 chemical precursor Substances 0.000 description 3
- 239000007795 chemical reaction product Substances 0.000 description 3
- 238000012411 cloning technique Methods 0.000 description 3
- 230000001149 cognitive effect Effects 0.000 description 3
- 238000002648 combination therapy Methods 0.000 description 3
- 230000008878 coupling Effects 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 3
- 229940127089 cytotoxic agent Drugs 0.000 description 3
- 239000002254 cytotoxic agent Substances 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 239000003085 diluting agent Substances 0.000 description 3
- 208000037765 diseases and disorders Diseases 0.000 description 3
- 239000012636 effector Substances 0.000 description 3
- MMXKVMNBHPAILY-UHFFFAOYSA-N ethyl laurate Chemical compound CCCCCCCCCCCC(=O)OCC MMXKVMNBHPAILY-UHFFFAOYSA-N 0.000 description 3
- 239000012091 fetal bovine serum Substances 0.000 description 3
- 239000000945 filler Substances 0.000 description 3
- 239000000796 flavoring agent Substances 0.000 description 3
- 230000009969 flowable effect Effects 0.000 description 3
- 235000013355 food flavoring agent Nutrition 0.000 description 3
- 108010008237 glutamyl-valyl-glycine Proteins 0.000 description 3
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 3
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 3
- 102000046783 human APP Human genes 0.000 description 3
- 239000001257 hydrogen Substances 0.000 description 3
- 229910052739 hydrogen Inorganic materials 0.000 description 3
- 230000005847 immunogenicity Effects 0.000 description 3
- 238000011534 incubation Methods 0.000 description 3
- 239000003701 inert diluent Substances 0.000 description 3
- 239000004615 ingredient Substances 0.000 description 3
- 230000003834 intracellular effect Effects 0.000 description 3
- 210000003734 kidney Anatomy 0.000 description 3
- 239000002502 liposome Substances 0.000 description 3
- 239000000314 lubricant Substances 0.000 description 3
- 108010003700 lysyl aspartic acid Proteins 0.000 description 3
- 108010038320 lysylphenylalanine Proteins 0.000 description 3
- 238000004949 mass spectrometry Methods 0.000 description 3
- 230000003340 mental effect Effects 0.000 description 3
- 229910052751 metal Inorganic materials 0.000 description 3
- 239000002184 metal Substances 0.000 description 3
- 229960000485 methotrexate Drugs 0.000 description 3
- 238000002156 mixing Methods 0.000 description 3
- 239000000178 monomer Substances 0.000 description 3
- 201000000050 myeloid neoplasm Diseases 0.000 description 3
- 230000003472 neutralizing effect Effects 0.000 description 3
- 239000002674 ointment Substances 0.000 description 3
- 239000004006 olive oil Substances 0.000 description 3
- 210000001672 ovary Anatomy 0.000 description 3
- 239000002245 particle Substances 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 3
- 229920000136 polysorbate Polymers 0.000 description 3
- 239000000047 product Substances 0.000 description 3
- 108010031719 prolyl-serine Proteins 0.000 description 3
- 108010004914 prolylarginine Proteins 0.000 description 3
- 108010053725 prolylvaline Proteins 0.000 description 3
- 230000001737 promoting effect Effects 0.000 description 3
- 229960004063 propylene glycol Drugs 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 230000009257 reactivity Effects 0.000 description 3
- 238000010188 recombinant method Methods 0.000 description 3
- 238000005070 sampling Methods 0.000 description 3
- 230000019491 signal transduction Effects 0.000 description 3
- RMAQACBXLXPBSY-UHFFFAOYSA-N silicic acid Chemical compound O[Si](O)(O)O RMAQACBXLXPBSY-UHFFFAOYSA-N 0.000 description 3
- 235000012239 silicon dioxide Nutrition 0.000 description 3
- 150000003384 small molecules Chemical class 0.000 description 3
- 235000010356 sorbitol Nutrition 0.000 description 3
- 239000000600 sorbitol Substances 0.000 description 3
- 238000010254 subcutaneous injection Methods 0.000 description 3
- 239000000829 suppository Substances 0.000 description 3
- 239000000375 suspending agent Substances 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 230000000699 topical effect Effects 0.000 description 3
- 239000000196 tragacanth Substances 0.000 description 3
- 229940116362 tragacanth Drugs 0.000 description 3
- 238000001890 transfection Methods 0.000 description 3
- 238000011830 transgenic mouse model Methods 0.000 description 3
- 239000000080 wetting agent Substances 0.000 description 3
- PUPZLCDOIYMWBV-UHFFFAOYSA-N (+/-)-1,3-Butanediol Chemical compound CC(O)CCO PUPZLCDOIYMWBV-UHFFFAOYSA-N 0.000 description 2
- LXBIFEVIBLOUGU-KVTDHHQDSA-N (2r,3r,4r,5r)-2-(hydroxymethyl)piperidine-3,4,5-triol Chemical compound OC[C@H]1NC[C@@H](O)[C@@H](O)[C@@H]1O LXBIFEVIBLOUGU-KVTDHHQDSA-N 0.000 description 2
- JNYAEWCLZODPBN-JGWLITMVSA-N (2r,3r,4s)-2-[(1r)-1,2-dihydroxyethyl]oxolane-3,4-diol Chemical compound OC[C@@H](O)[C@H]1OC[C@H](O)[C@H]1O JNYAEWCLZODPBN-JGWLITMVSA-N 0.000 description 2
- IAKHMKGGTNLKSZ-INIZCTEOSA-N (S)-colchicine Chemical compound C1([C@@H](NC(C)=O)CC2)=CC(=O)C(OC)=CC=C1C1=C2C=C(OC)C(OC)=C1OC IAKHMKGGTNLKSZ-INIZCTEOSA-N 0.000 description 2
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 2
- NHBKXEKEPDILRR-UHFFFAOYSA-N 2,3-bis(butanoylsulfanyl)propyl butanoate Chemical compound CCCC(=O)OCC(SC(=O)CCC)CSC(=O)CCC NHBKXEKEPDILRR-UHFFFAOYSA-N 0.000 description 2
- HZAXFHJVJLSVMW-UHFFFAOYSA-N 2-Aminoethan-1-ol Chemical compound NCCO HZAXFHJVJLSVMW-UHFFFAOYSA-N 0.000 description 2
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 2
- WPXFILQZNKUYQO-BZSNNMDCSA-N 2-[[(2s)-2-[[(2s)-1-[(2s)-2-amino-3-(4-hydroxyphenyl)propanoyl]pyrrolidine-2-carbonyl]amino]-4-methylpentanoyl]amino]acetic acid Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=C(O)C=C1 WPXFILQZNKUYQO-BZSNNMDCSA-N 0.000 description 2
- QMOQBVOBWVNSNO-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(O)=O QMOQBVOBWVNSNO-UHFFFAOYSA-N 0.000 description 2
- HVBSAKJJOYLTQU-UHFFFAOYSA-N 4-aminobenzenesulfonic acid Chemical compound NC1=CC=C(S(O)(=O)=O)C=C1 HVBSAKJJOYLTQU-UHFFFAOYSA-N 0.000 description 2
- ODWSTKXGQGYHSH-FXQIFTODSA-N Ala-Arg-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O ODWSTKXGQGYHSH-FXQIFTODSA-N 0.000 description 2
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 2
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 2
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 2
- TZDNWXDLYFIFPT-BJDJZHNGSA-N Ala-Ile-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O TZDNWXDLYFIFPT-BJDJZHNGSA-N 0.000 description 2
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 2
- RAAWHFXHAACDFT-FXQIFTODSA-N Ala-Met-Asn Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CC(N)=O)C(O)=O RAAWHFXHAACDFT-FXQIFTODSA-N 0.000 description 2
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 2
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 2
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 2
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 2
- 102000002659 Amyloid Precursor Protein Secretases Human genes 0.000 description 2
- 108010043324 Amyloid Precursor Protein Secretases Proteins 0.000 description 2
- 108010032595 Antibody Binding Sites Proteins 0.000 description 2
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 2
- QIWYWCYNUMJBTC-CIUDSAMLSA-N Arg-Cys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QIWYWCYNUMJBTC-CIUDSAMLSA-N 0.000 description 2
- GIVWETPOBCRTND-DCAQKATOSA-N Arg-Gln-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O GIVWETPOBCRTND-DCAQKATOSA-N 0.000 description 2
- JUWQNWXEGDYCIE-YUMQZZPRSA-N Arg-Gln-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O JUWQNWXEGDYCIE-YUMQZZPRSA-N 0.000 description 2
- ZEAYJGRKRUBDOB-GARJFASQSA-N Arg-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ZEAYJGRKRUBDOB-GARJFASQSA-N 0.000 description 2
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 2
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 2
- ZATRYQNPUHGXCU-DTWKUNHWSA-N Arg-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ZATRYQNPUHGXCU-DTWKUNHWSA-N 0.000 description 2
- FSNVAJOPUDVQAR-AVGNSLFASA-N Arg-Lys-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FSNVAJOPUDVQAR-AVGNSLFASA-N 0.000 description 2
- GXMSVVBIAMWMKO-BQBZGAKWSA-N Asn-Arg-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N GXMSVVBIAMWMKO-BQBZGAKWSA-N 0.000 description 2
- NNMUHYLAYUSTTN-FXQIFTODSA-N Asn-Gln-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O NNMUHYLAYUSTTN-FXQIFTODSA-N 0.000 description 2
- GFGUPLIETCNQGF-DCAQKATOSA-N Asn-Pro-His Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O GFGUPLIETCNQGF-DCAQKATOSA-N 0.000 description 2
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 2
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 2
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 2
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 2
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 2
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 2
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 2
- JJQGZGOEDSSHTE-FOHZUACHSA-N Asp-Thr-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O JJQGZGOEDSSHTE-FOHZUACHSA-N 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 201000001320 Atherosclerosis Diseases 0.000 description 2
- 206010063659 Aversion Diseases 0.000 description 2
- 239000004322 Butylated hydroxytoluene Substances 0.000 description 2
- NLZUEZXRPGMBCV-UHFFFAOYSA-N Butylhydroxytoluene Chemical compound CC1=CC(C(C)(C)C)=C(O)C(C(C)(C)C)=C1 NLZUEZXRPGMBCV-UHFFFAOYSA-N 0.000 description 2
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 2
- VTYYLEPIZMXCLO-UHFFFAOYSA-L Calcium carbonate Chemical compound [Ca+2].[O-]C([O-])=O VTYYLEPIZMXCLO-UHFFFAOYSA-L 0.000 description 2
- 208000024172 Cardiovascular disease Diseases 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 208000006545 Chronic Obstructive Pulmonary Disease Diseases 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- 108091035707 Consensus sequence Proteins 0.000 description 2
- 241000655605 Cyanocephalus Species 0.000 description 2
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 2
- BYALSSDCQYHKMY-XGEHTFHBSA-N Cys-Arg-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CS)N)O BYALSSDCQYHKMY-XGEHTFHBSA-N 0.000 description 2
- BVFQOPGFOQVZTE-ACZMJKKPSA-N Cys-Gln-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O BVFQOPGFOQVZTE-ACZMJKKPSA-N 0.000 description 2
- YUZPQIQWXLRFBW-ACZMJKKPSA-N Cys-Glu-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O YUZPQIQWXLRFBW-ACZMJKKPSA-N 0.000 description 2
- VIRYODQIWJNWNU-NRPADANISA-N Cys-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N VIRYODQIWJNWNU-NRPADANISA-N 0.000 description 2
- OZHXXYOHPLLLMI-CIUDSAMLSA-N Cys-Lys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OZHXXYOHPLLLMI-CIUDSAMLSA-N 0.000 description 2
- 102000004127 Cytokines Human genes 0.000 description 2
- 108090000695 Cytokines Proteins 0.000 description 2
- 241000701022 Cytomegalovirus Species 0.000 description 2
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 2
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 2
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 2
- 108010092160 Dactinomycin Proteins 0.000 description 2
- LXBIFEVIBLOUGU-UHFFFAOYSA-N Deoxymannojirimycin Natural products OCC1NCC(O)C(O)C1O LXBIFEVIBLOUGU-UHFFFAOYSA-N 0.000 description 2
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 2
- 238000012286 ELISA Assay Methods 0.000 description 2
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- QUSNBJAOOMFDIB-UHFFFAOYSA-N Ethylamine Chemical compound CCN QUSNBJAOOMFDIB-UHFFFAOYSA-N 0.000 description 2
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 2
- VZCYOOQTPOCHFL-OWOJBTEDSA-N Fumaric acid Chemical compound OC(=O)\C=C\C(O)=O VZCYOOQTPOCHFL-OWOJBTEDSA-N 0.000 description 2
- 241001200922 Gagata Species 0.000 description 2
- JFOKLAPFYCTNHW-SRVKXCTJSA-N Gln-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N JFOKLAPFYCTNHW-SRVKXCTJSA-N 0.000 description 2
- RKAQZCDMSUQTSS-FXQIFTODSA-N Gln-Asp-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RKAQZCDMSUQTSS-FXQIFTODSA-N 0.000 description 2
- SNLOOPZHAQDMJG-CIUDSAMLSA-N Gln-Glu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SNLOOPZHAQDMJG-CIUDSAMLSA-N 0.000 description 2
- MFJAPSYJQJCQDN-BQBZGAKWSA-N Gln-Gly-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O MFJAPSYJQJCQDN-BQBZGAKWSA-N 0.000 description 2
- XUMFMAVDHQDATI-DCAQKATOSA-N Gln-Pro-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUMFMAVDHQDATI-DCAQKATOSA-N 0.000 description 2
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 2
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 2
- DYVMTEWCGAVKSE-HJGDQZAQSA-N Gln-Thr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O DYVMTEWCGAVKSE-HJGDQZAQSA-N 0.000 description 2
- FHPXTPQBODWBIY-CIUDSAMLSA-N Glu-Ala-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FHPXTPQBODWBIY-CIUDSAMLSA-N 0.000 description 2
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 2
- UTKUTMJSWKKHEM-WDSKDSINSA-N Glu-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O UTKUTMJSWKKHEM-WDSKDSINSA-N 0.000 description 2
- HUWSBFYAGXCXKC-CIUDSAMLSA-N Glu-Ala-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O HUWSBFYAGXCXKC-CIUDSAMLSA-N 0.000 description 2
- IRDASPPCLZIERZ-XHNCKOQMSA-N Glu-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N IRDASPPCLZIERZ-XHNCKOQMSA-N 0.000 description 2
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 2
- SRZLHYPAOXBBSB-HJGDQZAQSA-N Glu-Arg-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SRZLHYPAOXBBSB-HJGDQZAQSA-N 0.000 description 2
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 2
- SJPMNHCEWPTRBR-BQBZGAKWSA-N Glu-Glu-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SJPMNHCEWPTRBR-BQBZGAKWSA-N 0.000 description 2
- KUTPGXNAAOQSPD-LPEHRKFASA-N Glu-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O KUTPGXNAAOQSPD-LPEHRKFASA-N 0.000 description 2
- OPAINBJQDQTGJY-JGVFFNPUSA-N Glu-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)O)N)C(=O)O OPAINBJQDQTGJY-JGVFFNPUSA-N 0.000 description 2
- RAUDKMVXNOWDLS-WDSKDSINSA-N Glu-Gly-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O RAUDKMVXNOWDLS-WDSKDSINSA-N 0.000 description 2
- ITBHUUMCJJQUSC-LAEOZQHASA-N Glu-Ile-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O ITBHUUMCJJQUSC-LAEOZQHASA-N 0.000 description 2
- ZCOJVESMNGBGLF-GRLWGSQLSA-N Glu-Ile-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZCOJVESMNGBGLF-GRLWGSQLSA-N 0.000 description 2
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 2
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 2
- OCJRHJZKGGSPRW-IUCAKERBSA-N Glu-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O OCJRHJZKGGSPRW-IUCAKERBSA-N 0.000 description 2
- CQAHWYDHKUWYIX-YUMQZZPRSA-N Glu-Pro-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O CQAHWYDHKUWYIX-YUMQZZPRSA-N 0.000 description 2
- WIKMTDVSCUJIPJ-CIUDSAMLSA-N Glu-Ser-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N WIKMTDVSCUJIPJ-CIUDSAMLSA-N 0.000 description 2
- TWYSSILQABLLME-HJGDQZAQSA-N Glu-Thr-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TWYSSILQABLLME-HJGDQZAQSA-N 0.000 description 2
- DLISPGXMKZTWQG-IFFSRLJSSA-N Glu-Thr-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O DLISPGXMKZTWQG-IFFSRLJSSA-N 0.000 description 2
- RMWAOBGCZZSJHE-UMNHJUIQSA-N Glu-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N RMWAOBGCZZSJHE-UMNHJUIQSA-N 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- XRTDOIOIBMAXCT-NKWVEPMBSA-N Gly-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)CN)C(=O)O XRTDOIOIBMAXCT-NKWVEPMBSA-N 0.000 description 2
- XBWMTPAIUQIWKA-BYULHYEWSA-N Gly-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN XBWMTPAIUQIWKA-BYULHYEWSA-N 0.000 description 2
- SOEATRRYCIPEHA-BQBZGAKWSA-N Gly-Glu-Glu Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SOEATRRYCIPEHA-BQBZGAKWSA-N 0.000 description 2
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 2
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 2
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 2
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 2
- WDEHMRNSGHVNOH-VHSXEESVSA-N Gly-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)CN)C(=O)O WDEHMRNSGHVNOH-VHSXEESVSA-N 0.000 description 2
- OMOZPGCHVWOXHN-BQBZGAKWSA-N Gly-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)CN OMOZPGCHVWOXHN-BQBZGAKWSA-N 0.000 description 2
- GLACUWHUYFBSPJ-FJXKBIBVSA-N Gly-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GLACUWHUYFBSPJ-FJXKBIBVSA-N 0.000 description 2
- ISSDODCYBOWWIP-GJZGRUSLSA-N Gly-Pro-Trp Chemical compound [H]NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ISSDODCYBOWWIP-GJZGRUSLSA-N 0.000 description 2
- IMRNSEPSPFQNHF-STQMWFEESA-N Gly-Ser-Trp Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=CC=CC=C12)C(=O)O IMRNSEPSPFQNHF-STQMWFEESA-N 0.000 description 2
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 2
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 2
- LYZYGGWCBLBDMC-QWHCGFSZSA-N Gly-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)CN)C(=O)O LYZYGGWCBLBDMC-QWHCGFSZSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 2
- 239000007995 HEPES buffer Substances 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- XDIVYNSPYBLSME-DCAQKATOSA-N His-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N XDIVYNSPYBLSME-DCAQKATOSA-N 0.000 description 2
- GNBHSMFBUNEWCJ-DCAQKATOSA-N His-Pro-Asn Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O GNBHSMFBUNEWCJ-DCAQKATOSA-N 0.000 description 2
- BRQKGRLDDDQWQJ-MBLNEYKQSA-N His-Thr-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O BRQKGRLDDDQWQJ-MBLNEYKQSA-N 0.000 description 2
- 101001061840 Homo sapiens Advanced glycosylation end product-specific receptor Proteins 0.000 description 2
- GECLQMBTZCPAFY-PEFMBERDSA-N Ile-Gln-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N GECLQMBTZCPAFY-PEFMBERDSA-N 0.000 description 2
- GQKSJYINYYWPMR-NGZCFLSTSA-N Ile-Gly-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N GQKSJYINYYWPMR-NGZCFLSTSA-N 0.000 description 2
- PWDSHAAAFXISLE-SXTJYALSSA-N Ile-Ile-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O PWDSHAAAFXISLE-SXTJYALSSA-N 0.000 description 2
- SJLVSMMIFYTSGY-GRLWGSQLSA-N Ile-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SJLVSMMIFYTSGY-GRLWGSQLSA-N 0.000 description 2
- OUUCIIJSBIBCHB-ZPFDUUQYSA-N Ile-Leu-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O OUUCIIJSBIBCHB-ZPFDUUQYSA-N 0.000 description 2
- PMMMQRVUMVURGJ-XUXIUFHCSA-N Ile-Leu-Pro Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O PMMMQRVUMVURGJ-XUXIUFHCSA-N 0.000 description 2
- UYNXBNHVWFNVIN-HJWJTTGWSA-N Ile-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)CC)CC1=CC=CC=C1 UYNXBNHVWFNVIN-HJWJTTGWSA-N 0.000 description 2
- OWSWUWDMSNXTNE-GMOBBJLQSA-N Ile-Pro-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N OWSWUWDMSNXTNE-GMOBBJLQSA-N 0.000 description 2
- HXIDVIFHRYRXLZ-NAKRPEOUSA-N Ile-Ser-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)O)N HXIDVIFHRYRXLZ-NAKRPEOUSA-N 0.000 description 2
- YINZYTTZHLPWBO-UHFFFAOYSA-N Kifunensine Natural products COC1C(O)C(O)C(O)C2NC(=O)C(=O)N12 YINZYTTZHLPWBO-UHFFFAOYSA-N 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- 229930182816 L-glutamine Natural products 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 2
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 2
- HVJVUYQWFYMGJS-GVXVVHGQSA-N Leu-Glu-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVJVUYQWFYMGJS-GVXVVHGQSA-N 0.000 description 2
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 2
- KUIDCYNIEJBZBU-AJNGGQMLSA-N Leu-Ile-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O KUIDCYNIEJBZBU-AJNGGQMLSA-N 0.000 description 2
- YUTNOGOMBNYPFH-XUXIUFHCSA-N Leu-Pro-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YUTNOGOMBNYPFH-XUXIUFHCSA-N 0.000 description 2
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 2
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 206010025323 Lymphomas Diseases 0.000 description 2
- GRADYHMSAUIKPS-DCAQKATOSA-N Lys-Glu-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRADYHMSAUIKPS-DCAQKATOSA-N 0.000 description 2
- ULUQBUKAPDUKOC-GVXVVHGQSA-N Lys-Glu-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ULUQBUKAPDUKOC-GVXVVHGQSA-N 0.000 description 2
- HAUUXTXKJNVIFY-ONGXEEELSA-N Lys-Gly-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAUUXTXKJNVIFY-ONGXEEELSA-N 0.000 description 2
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 229930195725 Mannitol Natural products 0.000 description 2
- SBSIKVMCCJUCBZ-GUBZILKMSA-N Met-Asn-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N SBSIKVMCCJUCBZ-GUBZILKMSA-N 0.000 description 2
- HLQWFLJOJRFXHO-CIUDSAMLSA-N Met-Glu-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O HLQWFLJOJRFXHO-CIUDSAMLSA-N 0.000 description 2
- YYEIFXZOBZVDPH-DCAQKATOSA-N Met-Lys-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O YYEIFXZOBZVDPH-DCAQKATOSA-N 0.000 description 2
- HLZORBMOISUNIV-DCAQKATOSA-N Met-Ser-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C HLZORBMOISUNIV-DCAQKATOSA-N 0.000 description 2
- 241000699660 Mus musculus Species 0.000 description 2
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 2
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 2
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 2
- 238000000636 Northern blotting Methods 0.000 description 2
- 102000004316 Oxidoreductases Human genes 0.000 description 2
- 108090000854 Oxidoreductases Proteins 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 235000021314 Palmitic acid Nutrition 0.000 description 2
- 235000019483 Peanut oil Nutrition 0.000 description 2
- 229930182555 Penicillin Natural products 0.000 description 2
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 2
- 206010057249 Phagocytosis Diseases 0.000 description 2
- OSBADCBXAMSPQD-YESZJQIVSA-N Phe-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N OSBADCBXAMSPQD-YESZJQIVSA-N 0.000 description 2
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- GLUUGHFHXGJENI-UHFFFAOYSA-N Piperazine Chemical compound C1CNCCN1 GLUUGHFHXGJENI-UHFFFAOYSA-N 0.000 description 2
- 241000276498 Pollachius virens Species 0.000 description 2
- OBVCYFIHIIYIQF-CIUDSAMLSA-N Pro-Asn-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OBVCYFIHIIYIQF-CIUDSAMLSA-N 0.000 description 2
- SFECXGVELZFBFJ-VEVYYDQMSA-N Pro-Asp-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SFECXGVELZFBFJ-VEVYYDQMSA-N 0.000 description 2
- WGAQWMRJUFQXMF-ZPFDUUQYSA-N Pro-Gln-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WGAQWMRJUFQXMF-ZPFDUUQYSA-N 0.000 description 2
- KIPIKSXPPLABPN-CIUDSAMLSA-N Pro-Glu-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 KIPIKSXPPLABPN-CIUDSAMLSA-N 0.000 description 2
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 2
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 2
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 2
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 2
- JDJMFMVVJHLWDP-UNQGMJICSA-N Pro-Thr-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JDJMFMVVJHLWDP-UNQGMJICSA-N 0.000 description 2
- ZMLRZBWCXPQADC-TUAOUCFPSA-N Pro-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ZMLRZBWCXPQADC-TUAOUCFPSA-N 0.000 description 2
- ATUOYWHBWRKTHZ-UHFFFAOYSA-N Propane Chemical compound CCC ATUOYWHBWRKTHZ-UHFFFAOYSA-N 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- 101100437153 Rattus norvegicus Acvr2b gene Proteins 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 241000283984 Rodentia Species 0.000 description 2
- GXXTUIUYTWGPMV-FXQIFTODSA-N Ser-Arg-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O GXXTUIUYTWGPMV-FXQIFTODSA-N 0.000 description 2
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 2
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 2
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 2
- PMCMLDNPAZUYGI-DCAQKATOSA-N Ser-Lys-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PMCMLDNPAZUYGI-DCAQKATOSA-N 0.000 description 2
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 2
- 238000002105 Southern blotting Methods 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 2
- GFDUZZACIWNMPE-KZVJFYERSA-N Thr-Ala-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O GFDUZZACIWNMPE-KZVJFYERSA-N 0.000 description 2
- IRKWVRSEQFTGGV-VEVYYDQMSA-N Thr-Asn-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IRKWVRSEQFTGGV-VEVYYDQMSA-N 0.000 description 2
- DHPPWTOLRWYIDS-XKBZYTNZSA-N Thr-Cys-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O DHPPWTOLRWYIDS-XKBZYTNZSA-N 0.000 description 2
- YUOCMLNTUZAGNF-KLHWPWHYSA-N Thr-His-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N)O YUOCMLNTUZAGNF-KLHWPWHYSA-N 0.000 description 2
- BVOVIGCHYNFJBZ-JXUBOQSCSA-N Thr-Leu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O BVOVIGCHYNFJBZ-JXUBOQSCSA-N 0.000 description 2
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 2
- WRQLCVIALDUQEQ-UNQGMJICSA-N Thr-Phe-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WRQLCVIALDUQEQ-UNQGMJICSA-N 0.000 description 2
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 2
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 2
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 2
- AAZOYLQUEQRUMZ-GSSVUCPTSA-N Thr-Thr-Asn Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O AAZOYLQUEQRUMZ-GSSVUCPTSA-N 0.000 description 2
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 206010044688 Trisomy 21 Diseases 0.000 description 2
- MVHHTXAUJCIOMZ-WDSOQIARSA-N Trp-Arg-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N MVHHTXAUJCIOMZ-WDSOQIARSA-N 0.000 description 2
- HJXWDGGIORSQQF-WDSOQIARSA-N Trp-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N HJXWDGGIORSQQF-WDSOQIARSA-N 0.000 description 2
- KCZGSXPFPNKGLE-WDSOQIARSA-N Trp-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N KCZGSXPFPNKGLE-WDSOQIARSA-N 0.000 description 2
- FBGDDUKYOBNZJL-WDSOQIARSA-N Trp-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N FBGDDUKYOBNZJL-WDSOQIARSA-N 0.000 description 2
- 108010028230 Trp-Ser- His-Pro-Gln-Phe-Glu-Lys Proteins 0.000 description 2
- SEFNTZYRPGBDCY-IHRRRGAJSA-N Tyr-Arg-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N)O SEFNTZYRPGBDCY-IHRRRGAJSA-N 0.000 description 2
- CDBXVDXSLPLFMD-BPNCWPANSA-N Tyr-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDBXVDXSLPLFMD-BPNCWPANSA-N 0.000 description 2
- 101150117115 V gene Proteins 0.000 description 2
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 2
- LIQJSDDOULTANC-QSFUFRPTSA-N Val-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N LIQJSDDOULTANC-QSFUFRPTSA-N 0.000 description 2
- VLOYGOZDPGYWFO-LAEOZQHASA-N Val-Asp-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VLOYGOZDPGYWFO-LAEOZQHASA-N 0.000 description 2
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 2
- YTPLVNUZZOBFFC-SCZZXKLOSA-N Val-Gly-Pro Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N1CCC[C@@H]1C(O)=O YTPLVNUZZOBFFC-SCZZXKLOSA-N 0.000 description 2
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 2
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 2
- 206010047139 Vasoconstriction Diseases 0.000 description 2
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 2
- XLOMVQKBTHCTTD-UHFFFAOYSA-N Zinc monoxide Chemical compound [Zn]=O XLOMVQKBTHCTTD-UHFFFAOYSA-N 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 2
- 108010081404 acein-2 Proteins 0.000 description 2
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 239000008272 agar Substances 0.000 description 2
- 108010069490 alanyl-glycyl-seryl-glutamic acid Proteins 0.000 description 2
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 2
- 239000000783 alginic acid Substances 0.000 description 2
- 229960001126 alginic acid Drugs 0.000 description 2
- VREFGVBLTWBCJP-UHFFFAOYSA-N alprazolam Chemical compound C12=CC(Cl)=CC=C2N2C(C)=NN=C2CN=C1C1=CC=CC=C1 VREFGVBLTWBCJP-UHFFFAOYSA-N 0.000 description 2
- 229910052782 aluminium Inorganic materials 0.000 description 2
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 2
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 2
- 150000001412 amines Chemical class 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 108010013835 arginine glutamate Proteins 0.000 description 2
- 125000003118 aryl group Chemical group 0.000 description 2
- 235000010323 ascorbic acid Nutrition 0.000 description 2
- 239000011668 ascorbic acid Substances 0.000 description 2
- 229960005070 ascorbic acid Drugs 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 108010092854 aspartyllysine Proteins 0.000 description 2
- 108010068265 aspartyltyrosine Proteins 0.000 description 2
- 238000003149 assay kit Methods 0.000 description 2
- WZSDNEJJUSYNSG-UHFFFAOYSA-N azocan-1-yl-(3,4,5-trimethoxyphenyl)methanone Chemical compound COC1=C(OC)C(OC)=CC(C(=O)N2CCCCCCC2)=C1 WZSDNEJJUSYNSG-UHFFFAOYSA-N 0.000 description 2
- 239000008228 bacteriostatic water for injection Substances 0.000 description 2
- 230000004888 barrier function Effects 0.000 description 2
- 239000000440 bentonite Substances 0.000 description 2
- 229910000278 bentonite Inorganic materials 0.000 description 2
- SVPXDRXYRYOSEX-UHFFFAOYSA-N bentoquatam Chemical compound O.O=[Si]=O.O=[Al]O[Al]=O SVPXDRXYRYOSEX-UHFFFAOYSA-N 0.000 description 2
- SESFRYSPDFLNCH-UHFFFAOYSA-N benzyl benzoate Chemical compound C=1C=CC=CC=1C(=O)OCC1=CC=CC=C1 SESFRYSPDFLNCH-UHFFFAOYSA-N 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- 239000011230 binding agent Substances 0.000 description 2
- 108091008324 binding proteins Proteins 0.000 description 2
- 229920002988 biodegradable polymer Polymers 0.000 description 2
- 239000004621 biodegradable polymer Substances 0.000 description 2
- 230000036760 body temperature Effects 0.000 description 2
- 239000007853 buffer solution Substances 0.000 description 2
- 244000309464 bull Species 0.000 description 2
- 235000010354 butylated hydroxytoluene Nutrition 0.000 description 2
- 229940095259 butylated hydroxytoluene Drugs 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- 150000001720 carbohydrates Chemical group 0.000 description 2
- 239000001768 carboxy methyl cellulose Substances 0.000 description 2
- 239000012876 carrier material Substances 0.000 description 2
- 230000007910 cell fusion Effects 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 235000010980 cellulose Nutrition 0.000 description 2
- 229920002678 cellulose Polymers 0.000 description 2
- 239000001913 cellulose Substances 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 2
- 230000002759 chromosomal effect Effects 0.000 description 2
- 230000001684 chronic effect Effects 0.000 description 2
- 235000015165 citric acid Nutrition 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 229940110456 cocoa butter Drugs 0.000 description 2
- 235000019868 cocoa butter Nutrition 0.000 description 2
- 230000003931 cognitive performance Effects 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 238000012875 competitive assay Methods 0.000 description 2
- 239000003636 conditioned culture medium Substances 0.000 description 2
- 230000021615 conjugation Effects 0.000 description 2
- 239000000356 contaminant Substances 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 235000005687 corn oil Nutrition 0.000 description 2
- 239000002285 corn oil Substances 0.000 description 2
- 235000012343 cottonseed oil Nutrition 0.000 description 2
- 239000002385 cottonseed oil Substances 0.000 description 2
- 230000001086 cytosolic effect Effects 0.000 description 2
- 229960000640 dactinomycin Drugs 0.000 description 2
- 230000006735 deficit Effects 0.000 description 2
- 230000003111 delayed effect Effects 0.000 description 2
- 239000005547 deoxyribonucleotide Substances 0.000 description 2
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 206010012601 diabetes mellitus Diseases 0.000 description 2
- 238000000502 dialysis Methods 0.000 description 2
- XBDQKXXYIPTUBI-UHFFFAOYSA-N dimethylselenoniopropionate Natural products CCC(O)=O XBDQKXXYIPTUBI-UHFFFAOYSA-N 0.000 description 2
- 108010054813 diprotin B Proteins 0.000 description 2
- 239000007884 disintegrant Substances 0.000 description 2
- 239000002270 dispersing agent Substances 0.000 description 2
- 239000006185 dispersion Substances 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 239000008298 dragée Substances 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 2
- 229940093471 ethyl oleate Drugs 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 230000001747 exhibiting effect Effects 0.000 description 2
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 2
- 238000002825 functional assay Methods 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 2
- 210000001035 gastrointestinal tract Anatomy 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 239000008103 glucose Substances 0.000 description 2
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 2
- 108010090037 glycyl-alanyl-isoleucine Proteins 0.000 description 2
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 230000000971 hippocampal effect Effects 0.000 description 2
- 238000002744 homologous recombination Methods 0.000 description 2
- 230000006801 homologous recombination Effects 0.000 description 2
- 102000056986 human AGER Human genes 0.000 description 2
- 210000005260 human cell Anatomy 0.000 description 2
- 238000011577 humanized mouse model Methods 0.000 description 2
- 239000003906 humectant Substances 0.000 description 2
- 125000001165 hydrophobic group Chemical group 0.000 description 2
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 2
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 2
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 2
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 230000002055 immunohistochemical effect Effects 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 238000011065 in-situ storage Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 230000004968 inflammatory condition Effects 0.000 description 2
- 230000028709 inflammatory response Effects 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 238000010255 intramuscular injection Methods 0.000 description 2
- 238000010253 intravenous injection Methods 0.000 description 2
- 230000007794 irritation Effects 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 2
- 108010078274 isoleucylvaline Proteins 0.000 description 2
- 210000003292 kidney cell Anatomy 0.000 description 2
- OIURYJWYVIAOCW-VFUOTHLCSA-N kifunensine Chemical compound OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H]2NC(=O)C(=O)N12 OIURYJWYVIAOCW-VFUOTHLCSA-N 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- 235000010445 lecithin Nutrition 0.000 description 2
- 239000000787 lecithin Substances 0.000 description 2
- 229940067606 lecithin Drugs 0.000 description 2
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 2
- 239000008297 liquid dosage form Substances 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 210000004698 lymphocyte Anatomy 0.000 description 2
- 235000019359 magnesium stearate Nutrition 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000000594 mannitol Substances 0.000 description 2
- 235000010355 mannitol Nutrition 0.000 description 2
- 230000009225 memory damage Effects 0.000 description 2
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 230000002503 metabolic effect Effects 0.000 description 2
- 108010056582 methionylglutamic acid Proteins 0.000 description 2
- 239000004530 micro-emulsion Substances 0.000 description 2
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 2
- 229960004857 mitomycin Drugs 0.000 description 2
- 230000000877 morphologic effect Effects 0.000 description 2
- 238000000465 moulding Methods 0.000 description 2
- 229940126619 mouse monoclonal antibody Drugs 0.000 description 2
- 210000003097 mucus Anatomy 0.000 description 2
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 description 2
- 229930014626 natural product Natural products 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 210000004126 nerve fiber Anatomy 0.000 description 2
- 210000002241 neurite Anatomy 0.000 description 2
- 208000015122 neurodegenerative disease Diseases 0.000 description 2
- 230000002981 neuropathic effect Effects 0.000 description 2
- 238000010855 neuropsychological testing Methods 0.000 description 2
- 239000012457 nonaqueous media Substances 0.000 description 2
- 238000007899 nucleic acid hybridization Methods 0.000 description 2
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 2
- 235000008390 olive oil Nutrition 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 239000000312 peanut oil Substances 0.000 description 2
- 229940049954 penicillin Drugs 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 230000008782 phagocytosis Effects 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 229960003171 plicamycin Drugs 0.000 description 2
- 229920005862 polyol Polymers 0.000 description 2
- 150000003077 polyols Chemical class 0.000 description 2
- 239000013641 positive control Substances 0.000 description 2
- 230000000770 proinflammatory effect Effects 0.000 description 2
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 2
- 239000003380 propellant Substances 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- AQHHHDLHHXJYJD-UHFFFAOYSA-N propranolol Chemical compound C1=CC=C2C(OCC(O)CNC(C)C)=CC=CC2=C1 AQHHHDLHHXJYJD-UHFFFAOYSA-N 0.000 description 2
- 210000002307 prostate Anatomy 0.000 description 2
- 238000001742 protein purification Methods 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- 150000003856 quaternary ammonium compounds Chemical class 0.000 description 2
- 238000010791 quenching Methods 0.000 description 2
- 238000001525 receptor binding assay Methods 0.000 description 2
- 238000003259 recombinant expression Methods 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 238000010839 reverse transcription Methods 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 125000002652 ribonucleotide group Chemical group 0.000 description 2
- 238000002702 ribosome display Methods 0.000 description 2
- YGSDEFSMJLZEOE-UHFFFAOYSA-N salicylic acid Chemical compound OC(=O)C1=CC=CC=C1O YGSDEFSMJLZEOE-UHFFFAOYSA-N 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 238000012163 sequencing technique Methods 0.000 description 2
- 239000008159 sesame oil Substances 0.000 description 2
- 235000011803 sesame oil Nutrition 0.000 description 2
- 238000004088 simulation Methods 0.000 description 2
- 238000002741 site-directed mutagenesis Methods 0.000 description 2
- 229910001415 sodium ion Inorganic materials 0.000 description 2
- GEHJYWRUCIMESM-UHFFFAOYSA-L sodium sulfite Chemical compound [Na+].[Na+].[O-]S([O-])=O GEHJYWRUCIMESM-UHFFFAOYSA-L 0.000 description 2
- 239000007909 solid dosage form Substances 0.000 description 2
- 239000008247 solid mixture Substances 0.000 description 2
- 238000007614 solvation Methods 0.000 description 2
- 125000006850 spacer group Chemical group 0.000 description 2
- 210000004989 spleen cell Anatomy 0.000 description 2
- 239000008107 starch Substances 0.000 description 2
- 229940032147 starch Drugs 0.000 description 2
- 239000008174 sterile solution Substances 0.000 description 2
- 239000008223 sterile water Substances 0.000 description 2
- 239000008227 sterile water for injection Substances 0.000 description 2
- 229960005322 streptomycin Drugs 0.000 description 2
- 239000007929 subcutaneous injection Substances 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 230000003956 synaptic plasticity Effects 0.000 description 2
- 239000006188 syrup Substances 0.000 description 2
- 235000020357 syrup Nutrition 0.000 description 2
- 235000002906 tartaric acid Nutrition 0.000 description 2
- 239000011975 tartaric acid Substances 0.000 description 2
- 238000011285 therapeutic regimen Methods 0.000 description 2
- 229940104230 thymidine Drugs 0.000 description 2
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 2
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 108010044292 tryptophyltyrosine Proteins 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 108700042752 tyrosyl-prolyl-leucyl-glycine Proteins 0.000 description 2
- 108010003137 tyrosyltyrosine Proteins 0.000 description 2
- NQPDZGIKBAWPEJ-UHFFFAOYSA-N valeric acid Chemical compound CCCCC(O)=O NQPDZGIKBAWPEJ-UHFFFAOYSA-N 0.000 description 2
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 2
- 230000025033 vasoconstriction Effects 0.000 description 2
- 239000003981 vehicle Substances 0.000 description 2
- 229960003048 vinblastine Drugs 0.000 description 2
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 2
- 238000001262 western blot Methods 0.000 description 2
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 1
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 1
- VLAFRQCSFRYCLC-FXQIFTODSA-N (2s)-2-[[(2s)-2-[[2-[[(2s)-2-aminopropanoyl]amino]acetyl]amino]-3-hydroxypropanoyl]amino]pentanedioic acid Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O VLAFRQCSFRYCLC-FXQIFTODSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- GVJHHUAWPYXKBD-IEOSBIPESA-N (R)-alpha-Tocopherol Natural products OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 description 1
- BJEPYKJPYRNKOW-REOHCLBHSA-N (S)-malic acid Chemical compound OC(=O)[C@@H](O)CC(O)=O BJEPYKJPYRNKOW-REOHCLBHSA-N 0.000 description 1
- UWYVPFMHMJIBHE-OWOJBTEDSA-N (e)-2-hydroxybut-2-enedioic acid Chemical compound OC(=O)\C=C(\O)C(O)=O UWYVPFMHMJIBHE-OWOJBTEDSA-N 0.000 description 1
- 229940058015 1,3-butylene glycol Drugs 0.000 description 1
- LDMOEFOXLIZJOW-UHFFFAOYSA-N 1-dodecanesulfonic acid Chemical class CCCCCCCCCCCCS(O)(=O)=O LDMOEFOXLIZJOW-UHFFFAOYSA-N 0.000 description 1
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 1
- WNWHHMBRJJOGFJ-UHFFFAOYSA-N 16-methylheptadecan-1-ol Chemical class CC(C)CCCCCCCCCCCCCCCO WNWHHMBRJJOGFJ-UHFFFAOYSA-N 0.000 description 1
- VGONTNSXDCQUGY-RRKCRQDMSA-N 2'-deoxyinosine Chemical group C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC2=O)=C2N=C1 VGONTNSXDCQUGY-RRKCRQDMSA-N 0.000 description 1
- LBLYYCQCTBFVLH-UHFFFAOYSA-N 2-Methylbenzenesulfonic acid Chemical compound CC1=CC=CC=C1S(O)(=O)=O LBLYYCQCTBFVLH-UHFFFAOYSA-N 0.000 description 1
- JNODDICFTDYODH-UHFFFAOYSA-N 2-hydroxytetrahydrofuran Chemical compound OC1CCCO1 JNODDICFTDYODH-UHFFFAOYSA-N 0.000 description 1
- WLJVXDMOQOGPHL-PPJXEINESA-N 2-phenylacetic acid Chemical compound O[14C](=O)CC1=CC=CC=C1 WLJVXDMOQOGPHL-PPJXEINESA-N 0.000 description 1
- NJXWZWXCHBNOOG-UHFFFAOYSA-N 3,3-diphenylpropyl(1-phenylethyl)azanium;chloride Chemical compound [Cl-].C=1C=CC=CC=1C(C)[NH2+]CCC(C=1C=CC=CC=1)C1=CC=CC=C1 NJXWZWXCHBNOOG-UHFFFAOYSA-N 0.000 description 1
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- FHVDTGUDJYJELY-UHFFFAOYSA-N 6-{[2-carboxy-4,5-dihydroxy-6-(phosphanyloxy)oxan-3-yl]oxy}-4,5-dihydroxy-3-phosphanyloxane-2-carboxylic acid Chemical compound O1C(C(O)=O)C(P)C(O)C(O)C1OC1C(C(O)=O)OC(OP)C(O)C1O FHVDTGUDJYJELY-UHFFFAOYSA-N 0.000 description 1
- 208000018282 ACys amyloidosis Diseases 0.000 description 1
- 108010044087 AS-I toxin Proteins 0.000 description 1
- RSWGJHLUYNHPMX-UHFFFAOYSA-N Abietic-Saeure Natural products C12CCC(C(C)C)=CC2=CCC2C1(C)CCCC2(C)C(O)=O RSWGJHLUYNHPMX-UHFFFAOYSA-N 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- 206010069754 Acquired gene mutation Diseases 0.000 description 1
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 1
- SVBXIUDNTRTKHE-CIUDSAMLSA-N Ala-Arg-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O SVBXIUDNTRTKHE-CIUDSAMLSA-N 0.000 description 1
- DWINFPQUSSHSFS-UVBJJODRSA-N Ala-Arg-Trp Chemical compound N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C12)C(=O)O DWINFPQUSSHSFS-UVBJJODRSA-N 0.000 description 1
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 1
- IFTVANMRTIHKML-WDSKDSINSA-N Ala-Gln-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O IFTVANMRTIHKML-WDSKDSINSA-N 0.000 description 1
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 1
- NIZKGBJVCMRDKO-KWQFWETISA-N Ala-Gly-Tyr Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NIZKGBJVCMRDKO-KWQFWETISA-N 0.000 description 1
- SMCGQGDVTPFXKB-XPUUQOCRSA-N Ala-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N SMCGQGDVTPFXKB-XPUUQOCRSA-N 0.000 description 1
- YHKANGMVQWRMAP-DCAQKATOSA-N Ala-Leu-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YHKANGMVQWRMAP-DCAQKATOSA-N 0.000 description 1
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 1
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 1
- DYXOFPBJBAHWFY-JBDRJPRFSA-N Ala-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N DYXOFPBJBAHWFY-JBDRJPRFSA-N 0.000 description 1
- YNOCMHZSWJMGBB-GCJQMDKQSA-N Ala-Thr-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O YNOCMHZSWJMGBB-GCJQMDKQSA-N 0.000 description 1
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 1
- 239000012103 Alexa Fluor 488 Substances 0.000 description 1
- 239000012110 Alexa Fluor 594 Substances 0.000 description 1
- 239000005995 Aluminium silicate Substances 0.000 description 1
- 208000000044 Amnesia Diseases 0.000 description 1
- 229930183010 Amphotericin Natural products 0.000 description 1
- QGGFZZLFKABGNL-UHFFFAOYSA-N Amphotericin A Natural products OC1C(N)C(O)C(C)OC1OC1C=CC=CC=CC=CCCC=CC=CC(C)C(O)C(C)C(C)OC(=O)CC(O)CC(O)CCC(O)C(O)CC(O)CC(O)(CC(O)C2C(O)=O)OC2C1 QGGFZZLFKABGNL-UHFFFAOYSA-N 0.000 description 1
- 206010059245 Angiopathy Diseases 0.000 description 1
- 244000105975 Antidesma platyphyllum Species 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- 102100029470 Apolipoprotein E Human genes 0.000 description 1
- 101710095339 Apolipoprotein E Proteins 0.000 description 1
- 101001053401 Arabidopsis thaliana Acid beta-fructofuranosidase 3, vacuolar Proteins 0.000 description 1
- 101100178203 Arabidopsis thaliana HMGB3 gene Proteins 0.000 description 1
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 1
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 1
- HJWQFFYRVFEWRM-SRVKXCTJSA-N Arg-Arg-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O HJWQFFYRVFEWRM-SRVKXCTJSA-N 0.000 description 1
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 1
- HPKSHFSEXICTLI-CIUDSAMLSA-N Arg-Glu-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HPKSHFSEXICTLI-CIUDSAMLSA-N 0.000 description 1
- HPSVTWMFWCHKFN-GARJFASQSA-N Arg-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O HPSVTWMFWCHKFN-GARJFASQSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- MSILNNHVVMMTHZ-UWVGGRQHSA-N Arg-His-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CN=CN1 MSILNNHVVMMTHZ-UWVGGRQHSA-N 0.000 description 1
- YBZMTKUDWXZLIX-UWVGGRQHSA-N Arg-Leu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YBZMTKUDWXZLIX-UWVGGRQHSA-N 0.000 description 1
- JEXPNDORFYHJTM-IHRRRGAJSA-N Arg-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCN=C(N)N JEXPNDORFYHJTM-IHRRRGAJSA-N 0.000 description 1
- PAPSMOYMQDWIOR-AVGNSLFASA-N Arg-Lys-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PAPSMOYMQDWIOR-AVGNSLFASA-N 0.000 description 1
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 1
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 1
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 1
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 1
- AUZAXCPWMDBWEE-HJGDQZAQSA-N Arg-Thr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O AUZAXCPWMDBWEE-HJGDQZAQSA-N 0.000 description 1
- ZPWMEWYQBWSGAO-ZJDVBMNYSA-N Arg-Thr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZPWMEWYQBWSGAO-ZJDVBMNYSA-N 0.000 description 1
- JWCCFNZJIRZUCL-AVGNSLFASA-N Arg-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N JWCCFNZJIRZUCL-AVGNSLFASA-N 0.000 description 1
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 1
- UTSMXMABBPFVJP-SZMVWBNQSA-N Arg-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UTSMXMABBPFVJP-SZMVWBNQSA-N 0.000 description 1
- WHLDJYNHXOMGMU-JYJNAYRXSA-N Arg-Val-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 WHLDJYNHXOMGMU-JYJNAYRXSA-N 0.000 description 1
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 1
- XHFXZQHTLJVZBN-FXQIFTODSA-N Asn-Arg-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)CN=C(N)N XHFXZQHTLJVZBN-FXQIFTODSA-N 0.000 description 1
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 1
- QNJIRRVTOXNGMH-GUBZILKMSA-N Asn-Gln-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(N)=O QNJIRRVTOXNGMH-GUBZILKMSA-N 0.000 description 1
- OLGCWMNDJTWQAG-GUBZILKMSA-N Asn-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(N)=O OLGCWMNDJTWQAG-GUBZILKMSA-N 0.000 description 1
- CTQIOCMSIJATNX-WHFBIAKZSA-N Asn-Gly-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O CTQIOCMSIJATNX-WHFBIAKZSA-N 0.000 description 1
- SPCONPVIDFMDJI-QSFUFRPTSA-N Asn-Ile-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O SPCONPVIDFMDJI-QSFUFRPTSA-N 0.000 description 1
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 1
- MDDXKBHIMYYJLW-FXQIFTODSA-N Asn-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N MDDXKBHIMYYJLW-FXQIFTODSA-N 0.000 description 1
- KAZKWIKPEPABOO-IHRRRGAJSA-N Asn-Met-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N KAZKWIKPEPABOO-IHRRRGAJSA-N 0.000 description 1
- YRTOMUMWSTUQAX-FXQIFTODSA-N Asn-Pro-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O YRTOMUMWSTUQAX-FXQIFTODSA-N 0.000 description 1
- GMUOCGCDOYYWPD-FXQIFTODSA-N Asn-Pro-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O GMUOCGCDOYYWPD-FXQIFTODSA-N 0.000 description 1
- SONUFGRSSMFHFN-IMJSIDKUSA-N Asn-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(O)=O SONUFGRSSMFHFN-IMJSIDKUSA-N 0.000 description 1
- GHWWTICYPDKPTE-NGZCFLSTSA-N Asn-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N GHWWTICYPDKPTE-NGZCFLSTSA-N 0.000 description 1
- NYQHSUGFEWDWPD-ACZMJKKPSA-N Asp-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N NYQHSUGFEWDWPD-ACZMJKKPSA-N 0.000 description 1
- VHQOCWWKXIOAQI-WDSKDSINSA-N Asp-Gln-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VHQOCWWKXIOAQI-WDSKDSINSA-N 0.000 description 1
- KHBLRHKVXICFMY-GUBZILKMSA-N Asp-Glu-Lys Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O KHBLRHKVXICFMY-GUBZILKMSA-N 0.000 description 1
- DTNUIAJCPRMNBT-WHFBIAKZSA-N Asp-Gly-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O DTNUIAJCPRMNBT-WHFBIAKZSA-N 0.000 description 1
- KHGPWGKPYHPOIK-QWRGUYRKSA-N Asp-Gly-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O KHGPWGKPYHPOIK-QWRGUYRKSA-N 0.000 description 1
- SWTQDYFZVOJVLL-KKUMJFAQSA-N Asp-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)O)N)O SWTQDYFZVOJVLL-KKUMJFAQSA-N 0.000 description 1
- KYQNAIMCTRZLNP-QSFUFRPTSA-N Asp-Ile-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O KYQNAIMCTRZLNP-QSFUFRPTSA-N 0.000 description 1
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 1
- RPUYTJJZXQBWDT-SRVKXCTJSA-N Asp-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N RPUYTJJZXQBWDT-SRVKXCTJSA-N 0.000 description 1
- KBJVTFWQWXCYCQ-IUKAMOBKSA-N Asp-Thr-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KBJVTFWQWXCYCQ-IUKAMOBKSA-N 0.000 description 1
- GHAHOJDCBRXAKC-IHPCNDPISA-N Asp-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N GHAHOJDCBRXAKC-IHPCNDPISA-N 0.000 description 1
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 1
- ZUNMTUPRQMWMHX-LSJOCFKGSA-N Asp-Val-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O ZUNMTUPRQMWMHX-LSJOCFKGSA-N 0.000 description 1
- BSYNRYMUTXBXSQ-UHFFFAOYSA-N Aspirin Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O BSYNRYMUTXBXSQ-UHFFFAOYSA-N 0.000 description 1
- 208000037260 Atherosclerotic Plaque Diseases 0.000 description 1
- 230000007351 Aβ plaque formation Effects 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 239000005711 Benzoic acid Substances 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-M Bicarbonate Chemical class OC([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-M 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- LWFDUMPGOAKHKC-UHFFFAOYSA-N C1=CC=C2C=C(C(=O)C(C(O)=C3O)=O)C3=CC2=C1 Chemical compound C1=CC=C2C=C(C(=O)C(C(O)=C3O)=O)C3=CC2=C1 LWFDUMPGOAKHKC-UHFFFAOYSA-N 0.000 description 1
- 108010059108 CD18 Antigens Proteins 0.000 description 1
- 101100289995 Caenorhabditis elegans mac-1 gene Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 206010051290 Central nervous system lesion Diseases 0.000 description 1
- 208000005145 Cerebral amyloid angiopathy Diseases 0.000 description 1
- 238000011537 Coomassie blue staining Methods 0.000 description 1
- 229920002261 Corn starch Polymers 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 229920002785 Croscarmellose sodium Polymers 0.000 description 1
- 102100021906 Cyclin-O Human genes 0.000 description 1
- FMDCYTBSPZMPQE-JBDRJPRFSA-N Cys-Ala-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FMDCYTBSPZMPQE-JBDRJPRFSA-N 0.000 description 1
- NIXHTNJAGGFBAW-CIUDSAMLSA-N Cys-Lys-Ser Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N NIXHTNJAGGFBAW-CIUDSAMLSA-N 0.000 description 1
- BBQIWFFTTQTNOC-AVGNSLFASA-N Cys-Phe-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N BBQIWFFTTQTNOC-AVGNSLFASA-N 0.000 description 1
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 1
- 101710112752 Cytotoxin Proteins 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- 208000007342 Diabetic Nephropathies Diseases 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 102220467177 Epsin-2_R72A_mutation Human genes 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 239000001856 Ethyl cellulose Substances 0.000 description 1
- ZZSNKZQZMQGXPY-UHFFFAOYSA-N Ethyl cellulose Chemical compound CCOCC1OC(OC)C(OCC)C(OCC)C1OC1C(O)C(O)C(OC)C(CO)O1 ZZSNKZQZMQGXPY-UHFFFAOYSA-N 0.000 description 1
- PIICEJLVQHRZGT-UHFFFAOYSA-N Ethylenediamine Chemical compound NCCN PIICEJLVQHRZGT-UHFFFAOYSA-N 0.000 description 1
- 208000007487 Familial Cerebral Amyloid Angiopathy Diseases 0.000 description 1
- 108091006020 Fc-tagged proteins Proteins 0.000 description 1
- 108010008177 Fd immunoglobulins Proteins 0.000 description 1
- 206010016275 Fear Diseases 0.000 description 1
- 239000004606 Fillers/Extenders Substances 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 238000012424 Freeze-thaw process Methods 0.000 description 1
- 241000206672 Gelidium Species 0.000 description 1
- IGNGBUVODQLMRJ-CIUDSAMLSA-N Gln-Ala-Met Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O IGNGBUVODQLMRJ-CIUDSAMLSA-N 0.000 description 1
- RGXXLQWXBFNXTG-CIUDSAMLSA-N Gln-Arg-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O RGXXLQWXBFNXTG-CIUDSAMLSA-N 0.000 description 1
- RGRMOYQUIJVQQD-SRVKXCTJSA-N Gln-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N RGRMOYQUIJVQQD-SRVKXCTJSA-N 0.000 description 1
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 1
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 1
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 1
- KKCJHBXMYYVWMX-KQXIARHKSA-N Gln-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N KKCJHBXMYYVWMX-KQXIARHKSA-N 0.000 description 1
- HWEINOMSWQSJDC-SRVKXCTJSA-N Gln-Leu-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O HWEINOMSWQSJDC-SRVKXCTJSA-N 0.000 description 1
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 1
- ILKYYKRAULNYMS-JYJNAYRXSA-N Gln-Lys-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ILKYYKRAULNYMS-JYJNAYRXSA-N 0.000 description 1
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 1
- KVQOVQVGVKDZNW-GUBZILKMSA-N Gln-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KVQOVQVGVKDZNW-GUBZILKMSA-N 0.000 description 1
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 1
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 1
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 1
- OACQOWPRWGNKTP-AVGNSLFASA-N Gln-Tyr-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O OACQOWPRWGNKTP-AVGNSLFASA-N 0.000 description 1
- ZMXZGYLINVNTKH-DZKIICNBSA-N Gln-Val-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZMXZGYLINVNTKH-DZKIICNBSA-N 0.000 description 1
- OJGLIOXAKGFFDW-SRVKXCTJSA-N Glu-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N OJGLIOXAKGFFDW-SRVKXCTJSA-N 0.000 description 1
- DYFJZDDQPNIPAB-NHCYSSNCSA-N Glu-Arg-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O DYFJZDDQPNIPAB-NHCYSSNCSA-N 0.000 description 1
- CKRUHITYRFNUKW-WDSKDSINSA-N Glu-Asn-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CKRUHITYRFNUKW-WDSKDSINSA-N 0.000 description 1
- JPHYJQHPILOKHC-ACZMJKKPSA-N Glu-Asp-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JPHYJQHPILOKHC-ACZMJKKPSA-N 0.000 description 1
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 1
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 1
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 1
- WATXSTJXNBOHKD-LAEOZQHASA-N Glu-Asp-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O WATXSTJXNBOHKD-LAEOZQHASA-N 0.000 description 1
- GFLQTABMFBXRIY-GUBZILKMSA-N Glu-Gln-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GFLQTABMFBXRIY-GUBZILKMSA-N 0.000 description 1
- CGOHAEBMDSEKFB-FXQIFTODSA-N Glu-Glu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O CGOHAEBMDSEKFB-FXQIFTODSA-N 0.000 description 1
- WRNAXCVRSBBKGS-BQBZGAKWSA-N Glu-Gly-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O WRNAXCVRSBBKGS-BQBZGAKWSA-N 0.000 description 1
- VGOFRWOTSXVPAU-SDDRHHMPSA-N Glu-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCC(=O)O)N)C(=O)O VGOFRWOTSXVPAU-SDDRHHMPSA-N 0.000 description 1
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 1
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 1
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 1
- NWOUBJNMZDDGDT-AVGNSLFASA-N Glu-Leu-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NWOUBJNMZDDGDT-AVGNSLFASA-N 0.000 description 1
- NJCALAAIGREHDR-WDCWCFNPSA-N Glu-Leu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NJCALAAIGREHDR-WDCWCFNPSA-N 0.000 description 1
- UMHRCVCZUPBBQW-GARJFASQSA-N Glu-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N UMHRCVCZUPBBQW-GARJFASQSA-N 0.000 description 1
- LHIPZASLKPYDPI-AVGNSLFASA-N Glu-Phe-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O LHIPZASLKPYDPI-AVGNSLFASA-N 0.000 description 1
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 1
- DAHLWSFUXOHMIA-FXQIFTODSA-N Glu-Ser-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O DAHLWSFUXOHMIA-FXQIFTODSA-N 0.000 description 1
- HMJULNMJWOZNFI-XHNCKOQMSA-N Glu-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N)C(=O)O HMJULNMJWOZNFI-XHNCKOQMSA-N 0.000 description 1
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 1
- CLODWIOAKCSBAN-BQBZGAKWSA-N Gly-Arg-Asp Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O CLODWIOAKCSBAN-BQBZGAKWSA-N 0.000 description 1
- JVWPPCWUDRJGAE-YUMQZZPRSA-N Gly-Asn-Leu Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JVWPPCWUDRJGAE-YUMQZZPRSA-N 0.000 description 1
- XQHSBNVACKQWAV-WHFBIAKZSA-N Gly-Asp-Asn Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O XQHSBNVACKQWAV-WHFBIAKZSA-N 0.000 description 1
- LXXLEUBUOMCAMR-NKWVEPMBSA-N Gly-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)CN)C(=O)O LXXLEUBUOMCAMR-NKWVEPMBSA-N 0.000 description 1
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 1
- FIQQRCFQXGLOSZ-WDSKDSINSA-N Gly-Glu-Asp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FIQQRCFQXGLOSZ-WDSKDSINSA-N 0.000 description 1
- HFXJIZNEXNIZIJ-BQBZGAKWSA-N Gly-Glu-Gln Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFXJIZNEXNIZIJ-BQBZGAKWSA-N 0.000 description 1
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 1
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 1
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 1
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 1
- XVYKMNXXJXQKME-XEGUGMAKSA-N Gly-Ile-Tyr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 XVYKMNXXJXQKME-XEGUGMAKSA-N 0.000 description 1
- NTBOEZICHOSJEE-YUMQZZPRSA-N Gly-Lys-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NTBOEZICHOSJEE-YUMQZZPRSA-N 0.000 description 1
- OQQKUTVULYLCDG-ONGXEEELSA-N Gly-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)CN)C(O)=O OQQKUTVULYLCDG-ONGXEEELSA-N 0.000 description 1
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 1
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 1
- JYPCXBJRLBHWME-IUCAKERBSA-N Gly-Pro-Arg Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JYPCXBJRLBHWME-IUCAKERBSA-N 0.000 description 1
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 1
- FKYQEVBRZSFAMJ-QWRGUYRKSA-N Gly-Ser-Tyr Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FKYQEVBRZSFAMJ-QWRGUYRKSA-N 0.000 description 1
- MYXNLWDWWOTERK-BHNWBGBOSA-N Gly-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN)O MYXNLWDWWOTERK-BHNWBGBOSA-N 0.000 description 1
- KOYUSMBPJOVSOO-XEGUGMAKSA-N Gly-Tyr-Ile Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KOYUSMBPJOVSOO-XEGUGMAKSA-N 0.000 description 1
- OCRQUYDOYKCOQG-IRXDYDNUSA-N Gly-Tyr-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 OCRQUYDOYKCOQG-IRXDYDNUSA-N 0.000 description 1
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 102000051366 Glycosyltransferases Human genes 0.000 description 1
- 108700023372 Glycosyltransferases Proteins 0.000 description 1
- 101150091750 HMG1 gene Proteins 0.000 description 1
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 1
- 208000032849 Hereditary cerebral hemorrhage with amyloidosis Diseases 0.000 description 1
- 101710168537 High mobility group protein B1 Proteins 0.000 description 1
- 239000004705 High-molecular-weight polyethylene Substances 0.000 description 1
- KZTLOHBDLMIFSH-XVYDVKMFSA-N His-Ala-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O KZTLOHBDLMIFSH-XVYDVKMFSA-N 0.000 description 1
- OHOXVDFVRDGFND-YUMQZZPRSA-N His-Cys-Gly Chemical compound N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CS)C(=O)NCC(O)=O OHOXVDFVRDGFND-YUMQZZPRSA-N 0.000 description 1
- VLPMGIJPAWENQB-SRVKXCTJSA-N His-Cys-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O VLPMGIJPAWENQB-SRVKXCTJSA-N 0.000 description 1
- DVHGLDYMGWTYKW-GUBZILKMSA-N His-Gln-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DVHGLDYMGWTYKW-GUBZILKMSA-N 0.000 description 1
- ZUPVLBAXUUGKKN-VHSXEESVSA-N His-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CC2=CN=CN2)N)C(=O)O ZUPVLBAXUUGKKN-VHSXEESVSA-N 0.000 description 1
- PYNPBMCLAKTHJL-SRVKXCTJSA-N His-Pro-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O PYNPBMCLAKTHJL-SRVKXCTJSA-N 0.000 description 1
- VIJMRAIWYWRXSR-CIUDSAMLSA-N His-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 VIJMRAIWYWRXSR-CIUDSAMLSA-N 0.000 description 1
- CSRRMQFXMBPSIL-SIXJUCDHSA-N His-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CN=CN3)N CSRRMQFXMBPSIL-SIXJUCDHSA-N 0.000 description 1
- FFYYUUWROYYKFY-IHRRRGAJSA-N His-Val-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O FFYYUUWROYYKFY-IHRRRGAJSA-N 0.000 description 1
- 101000897441 Homo sapiens Cyclin-O Proteins 0.000 description 1
- 101001025337 Homo sapiens High mobility group protein B1 Proteins 0.000 description 1
- 101000979342 Homo sapiens Nuclear factor NF-kappa-B p105 subunit Proteins 0.000 description 1
- CPELXLSAUQHCOX-UHFFFAOYSA-N Hydrogen bromide Chemical compound Br CPELXLSAUQHCOX-UHFFFAOYSA-N 0.000 description 1
- 208000035150 Hypercholesterolemia Diseases 0.000 description 1
- 206010020751 Hypersensitivity Diseases 0.000 description 1
- 102000009490 IgG Receptors Human genes 0.000 description 1
- 108010073807 IgG Receptors Proteins 0.000 description 1
- WZPIKDWQVRTATP-SYWGBEHUSA-N Ile-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 WZPIKDWQVRTATP-SYWGBEHUSA-N 0.000 description 1
- AZEYWPUCOYXFOE-CYDGBPFRSA-N Ile-Arg-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C(C)C)C(=O)O)N AZEYWPUCOYXFOE-CYDGBPFRSA-N 0.000 description 1
- FJWYJQRCVNGEAQ-ZPFDUUQYSA-N Ile-Asn-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N FJWYJQRCVNGEAQ-ZPFDUUQYSA-N 0.000 description 1
- KUHFPGIVBOCRMV-MNXVOIDGSA-N Ile-Gln-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(C)C)C(=O)O)N KUHFPGIVBOCRMV-MNXVOIDGSA-N 0.000 description 1
- OVPYIUNCVSOVNF-KQXIARHKSA-N Ile-Gln-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N OVPYIUNCVSOVNF-KQXIARHKSA-N 0.000 description 1
- XLCZWMJPVGRWHJ-KQXIARHKSA-N Ile-Glu-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N XLCZWMJPVGRWHJ-KQXIARHKSA-N 0.000 description 1
- MQFGXJNSUJTXDT-QSFUFRPTSA-N Ile-Gly-Ile Chemical compound N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)O MQFGXJNSUJTXDT-QSFUFRPTSA-N 0.000 description 1
- YKZAMJXNJUWFIK-JBDRJPRFSA-N Ile-Ser-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)O)N YKZAMJXNJUWFIK-JBDRJPRFSA-N 0.000 description 1
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 1
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 1
- WCNWGAUZWWSYDG-SVSWQMSJSA-N Ile-Thr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)O)N WCNWGAUZWWSYDG-SVSWQMSJSA-N 0.000 description 1
- ZUWSVOYKBCHLRR-MGHWNKPDSA-N Ile-Tyr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZUWSVOYKBCHLRR-MGHWNKPDSA-N 0.000 description 1
- NGKPIPCGMLWHBX-WZLNRYEVSA-N Ile-Tyr-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NGKPIPCGMLWHBX-WZLNRYEVSA-N 0.000 description 1
- YJRSIJZUIUANHO-NAKRPEOUSA-N Ile-Val-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(=O)O)N YJRSIJZUIUANHO-NAKRPEOUSA-N 0.000 description 1
- ZYVTXBXHIKGZMD-QSFUFRPTSA-N Ile-Val-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ZYVTXBXHIKGZMD-QSFUFRPTSA-N 0.000 description 1
- BCISUQVFDGYZBO-QSFUFRPTSA-N Ile-Val-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O BCISUQVFDGYZBO-QSFUFRPTSA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 206010022489 Insulin Resistance Diseases 0.000 description 1
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 1
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 125000000510 L-tryptophano group Chemical group [H]C1=C([H])C([H])=C2N([H])C([H])=C(C([H])([H])[C@@]([H])(C(O[H])=O)N([H])[*])C2=C1[H] 0.000 description 1
- JVTAAEKCZFNVCJ-UHFFFAOYSA-M Lactate Chemical compound CC(O)C([O-])=O JVTAAEKCZFNVCJ-UHFFFAOYSA-M 0.000 description 1
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 1
- RFUBXQQFJFGJFV-GUBZILKMSA-N Leu-Asn-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RFUBXQQFJFGJFV-GUBZILKMSA-N 0.000 description 1
- OXKYZSRZKBTVEY-ZPFDUUQYSA-N Leu-Asn-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OXKYZSRZKBTVEY-ZPFDUUQYSA-N 0.000 description 1
- QLQHWWCSCLZUMA-KKUMJFAQSA-N Leu-Asp-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QLQHWWCSCLZUMA-KKUMJFAQSA-N 0.000 description 1
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 1
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 1
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 1
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 1
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 1
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 1
- SYRTUBLKWNDSDK-DKIMLUQUSA-N Leu-Phe-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYRTUBLKWNDSDK-DKIMLUQUSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- SEOXPEFQEOYURL-PMVMPFDFSA-N Leu-Tyr-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SEOXPEFQEOYURL-PMVMPFDFSA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- 102000001109 Leukocyte L1 Antigen Complex Human genes 0.000 description 1
- 108010069316 Leukocyte L1 Antigen Complex Proteins 0.000 description 1
- NNJVILVZKWQKPM-UHFFFAOYSA-N Lidocaine Chemical compound CCN(CC)CC(=O)NC1=C(C)C=CC=C1C NNJVILVZKWQKPM-UHFFFAOYSA-N 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- WHXSMMKQMYFTQS-UHFFFAOYSA-N Lithium Chemical compound [Li] WHXSMMKQMYFTQS-UHFFFAOYSA-N 0.000 description 1
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 1
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 1
- NTEVEUCLFMWSND-SRVKXCTJSA-N Lys-Arg-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O NTEVEUCLFMWSND-SRVKXCTJSA-N 0.000 description 1
- FLCMXEFCTLXBTL-DCAQKATOSA-N Lys-Asp-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N FLCMXEFCTLXBTL-DCAQKATOSA-N 0.000 description 1
- KPJJOZUXFOLGMQ-CIUDSAMLSA-N Lys-Asp-Asn Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N KPJJOZUXFOLGMQ-CIUDSAMLSA-N 0.000 description 1
- LMVOVCYVZBBWQB-SRVKXCTJSA-N Lys-Asp-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LMVOVCYVZBBWQB-SRVKXCTJSA-N 0.000 description 1
- NKKFVJRLCCUJNA-QWRGUYRKSA-N Lys-Gly-Lys Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN NKKFVJRLCCUJNA-QWRGUYRKSA-N 0.000 description 1
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 1
- GOVDTWNJCBRRBJ-DCAQKATOSA-N Lys-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N GOVDTWNJCBRRBJ-DCAQKATOSA-N 0.000 description 1
- JMNRXRPBHFGXQX-GUBZILKMSA-N Lys-Ser-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JMNRXRPBHFGXQX-GUBZILKMSA-N 0.000 description 1
- ZUGVARDEGWMMLK-SRVKXCTJSA-N Lys-Ser-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN ZUGVARDEGWMMLK-SRVKXCTJSA-N 0.000 description 1
- WZVSHTFTCYOFPL-GARJFASQSA-N Lys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N)C(=O)O WZVSHTFTCYOFPL-GARJFASQSA-N 0.000 description 1
- RMOKGALPSPOYKE-KATARQTJSA-N Lys-Thr-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMOKGALPSPOYKE-KATARQTJSA-N 0.000 description 1
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 1
- OZVXDDFYCQOPFD-XQQFMLRXSA-N Lys-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N OZVXDDFYCQOPFD-XQQFMLRXSA-N 0.000 description 1
- 102000019149 MAP kinase activity proteins Human genes 0.000 description 1
- 108040008097 MAP kinase activity proteins Proteins 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- 240000003183 Manihot esculenta Species 0.000 description 1
- 235000016735 Manihot esculenta subsp esculenta Nutrition 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- 208000026139 Memory disease Diseases 0.000 description 1
- VOOINLQYUZOREH-SRVKXCTJSA-N Met-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N VOOINLQYUZOREH-SRVKXCTJSA-N 0.000 description 1
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 1
- TZHFJXDKXGZHEN-IHRRRGAJSA-N Met-His-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O TZHFJXDKXGZHEN-IHRRRGAJSA-N 0.000 description 1
- VQILILSLEFDECU-GUBZILKMSA-N Met-Pro-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O VQILILSLEFDECU-GUBZILKMSA-N 0.000 description 1
- BQHLZUMZOXUWNU-DCAQKATOSA-N Met-Pro-Glu Chemical compound CSCC[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N BQHLZUMZOXUWNU-DCAQKATOSA-N 0.000 description 1
- LUYURUYVNYGKGM-RCWTZXSCSA-N Met-Pro-Thr Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUYURUYVNYGKGM-RCWTZXSCSA-N 0.000 description 1
- WRXOPYNEKGZWAZ-FXQIFTODSA-N Met-Ser-Cys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(O)=O WRXOPYNEKGZWAZ-FXQIFTODSA-N 0.000 description 1
- FIZZULTXMVEIAA-IHRRRGAJSA-N Met-Ser-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FIZZULTXMVEIAA-IHRRRGAJSA-N 0.000 description 1
- IIHMNTBFPMRJCN-RCWTZXSCSA-N Met-Val-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IIHMNTBFPMRJCN-RCWTZXSCSA-N 0.000 description 1
- 208000001145 Metabolic Syndrome Diseases 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- 102000029749 Microtubule Human genes 0.000 description 1
- 108091022875 Microtubule Proteins 0.000 description 1
- VFKZTMPDYBFSTM-KVTDHHQDSA-N Mitobronitol Chemical compound BrC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-KVTDHHQDSA-N 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- 229930191564 Monensin Natural products 0.000 description 1
- GAOZTHIDHYLHMS-UHFFFAOYSA-N Monensin A Natural products O1C(CC)(C2C(CC(O2)C2C(CC(C)C(O)(CO)O2)C)C)CCC1C(O1)(C)CCC21CC(O)C(C)C(C(C)C(OC)C(C)C(O)=O)O2 GAOZTHIDHYLHMS-UHFFFAOYSA-N 0.000 description 1
- 101100193649 Mus musculus Ager gene Proteins 0.000 description 1
- 101100060131 Mus musculus Cdk5rap2 gene Proteins 0.000 description 1
- 102220485208 Myelin proteolipid protein_L46R_mutation Human genes 0.000 description 1
- AUEJLPRZGVVDNU-UHFFFAOYSA-N N-L-tyrosyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CC1=CC=C(O)C=C1 AUEJLPRZGVVDNU-UHFFFAOYSA-N 0.000 description 1
- 108010057466 NF-kappa B Proteins 0.000 description 1
- 102000003945 NF-kappa B Human genes 0.000 description 1
- 229910002651 NO3 Inorganic materials 0.000 description 1
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 1
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 1
- 206010029350 Neurotoxicity Diseases 0.000 description 1
- 238000002940 Newton-Raphson method Methods 0.000 description 1
- NHNBFGGVMKEFGY-UHFFFAOYSA-N Nitrate Chemical compound [O-][N+]([O-])=O NHNBFGGVMKEFGY-UHFFFAOYSA-N 0.000 description 1
- GRYLNZFGIOXLOG-UHFFFAOYSA-N Nitric acid Chemical compound O[N+]([O-])=O GRYLNZFGIOXLOG-UHFFFAOYSA-N 0.000 description 1
- 102100023050 Nuclear factor NF-kappa-B p105 subunit Human genes 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 102220567158 Ornithine decarboxylase antizyme 1_F68A_mutation Human genes 0.000 description 1
- 208000012868 Overgrowth Diseases 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 238000010222 PCR analysis Methods 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 206010034719 Personality change Diseases 0.000 description 1
- YMORXCKTSSGYIG-IHRRRGAJSA-N Phe-Arg-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N YMORXCKTSSGYIG-IHRRRGAJSA-N 0.000 description 1
- HTTYNOXBBOWZTB-SRVKXCTJSA-N Phe-Asn-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N HTTYNOXBBOWZTB-SRVKXCTJSA-N 0.000 description 1
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 1
- IILUKIJNFMUBNF-IHRRRGAJSA-N Phe-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O IILUKIJNFMUBNF-IHRRRGAJSA-N 0.000 description 1
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 1
- BIYWZVCPZIFGPY-QWRGUYRKSA-N Phe-Gly-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CO)C(O)=O BIYWZVCPZIFGPY-QWRGUYRKSA-N 0.000 description 1
- YOFKMVUAZGPFCF-IHRRRGAJSA-N Phe-Met-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(O)=O YOFKMVUAZGPFCF-IHRRRGAJSA-N 0.000 description 1
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 1
- JHSRGEODDALISP-XVSYOHENSA-N Phe-Thr-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O JHSRGEODDALISP-XVSYOHENSA-N 0.000 description 1
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 1
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 1
- YFXXRYFWJFQAFW-JHYOHUSXSA-N Phe-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O YFXXRYFWJFQAFW-JHYOHUSXSA-N 0.000 description 1
- GAMLAXHLYGLQBJ-UFYCRDLUSA-N Phe-Val-Tyr Chemical compound N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)O)CC1=CC=C(C=C1)O)C(C)C)CC1=CC=CC=C1 GAMLAXHLYGLQBJ-UFYCRDLUSA-N 0.000 description 1
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 1
- 239000004952 Polyamide Substances 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 229920000954 Polyglycolide Polymers 0.000 description 1
- 206010036105 Polyneuropathy Diseases 0.000 description 1
- 229920001710 Polyorthoester Polymers 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 208000024777 Prion disease Diseases 0.000 description 1
- VXCHGLYSIOOZIS-GUBZILKMSA-N Pro-Ala-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 VXCHGLYSIOOZIS-GUBZILKMSA-N 0.000 description 1
- IWNOFCGBMSFTBC-CIUDSAMLSA-N Pro-Ala-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IWNOFCGBMSFTBC-CIUDSAMLSA-N 0.000 description 1
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 1
- QBFONMUYNSNKIX-AVGNSLFASA-N Pro-Arg-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O QBFONMUYNSNKIX-AVGNSLFASA-N 0.000 description 1
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 1
- XROLYVMNVIKVEM-BQBZGAKWSA-N Pro-Asn-Gly Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O XROLYVMNVIKVEM-BQBZGAKWSA-N 0.000 description 1
- MTHRMUXESFIAMS-DCAQKATOSA-N Pro-Asn-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O MTHRMUXESFIAMS-DCAQKATOSA-N 0.000 description 1
- ZCXQTRXYZOSGJR-FXQIFTODSA-N Pro-Asp-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZCXQTRXYZOSGJR-FXQIFTODSA-N 0.000 description 1
- HJSCRFZVGXAGNG-SRVKXCTJSA-N Pro-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 HJSCRFZVGXAGNG-SRVKXCTJSA-N 0.000 description 1
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 1
- LHALYDBUDCWMDY-CIUDSAMLSA-N Pro-Glu-Ala Chemical compound C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O LHALYDBUDCWMDY-CIUDSAMLSA-N 0.000 description 1
- WVOXLKUUVCCCSU-ZPFDUUQYSA-N Pro-Glu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVOXLKUUVCCCSU-ZPFDUUQYSA-N 0.000 description 1
- LXVLKXPFIDDHJG-CIUDSAMLSA-N Pro-Glu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O LXVLKXPFIDDHJG-CIUDSAMLSA-N 0.000 description 1
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 1
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 1
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 1
- RUDOLGWDSKQQFF-DCAQKATOSA-N Pro-Leu-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O RUDOLGWDSKQQFF-DCAQKATOSA-N 0.000 description 1
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 1
- HATVCTYBNCNMAA-AVGNSLFASA-N Pro-Leu-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O HATVCTYBNCNMAA-AVGNSLFASA-N 0.000 description 1
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 1
- XZBYTHCRAVAXQQ-DCAQKATOSA-N Pro-Met-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XZBYTHCRAVAXQQ-DCAQKATOSA-N 0.000 description 1
- HRIXMVRZRGFKNQ-HJGDQZAQSA-N Pro-Thr-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HRIXMVRZRGFKNQ-HJGDQZAQSA-N 0.000 description 1
- VVAWNPIOYXAMAL-KJEVXHAQSA-N Pro-Thr-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VVAWNPIOYXAMAL-KJEVXHAQSA-N 0.000 description 1
- BNUKRHFCHHLIGR-JYJNAYRXSA-N Pro-Trp-Asp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CC(=O)O)C(=O)O BNUKRHFCHHLIGR-JYJNAYRXSA-N 0.000 description 1
- DLZBBDSPTJBOOD-BPNCWPANSA-N Pro-Tyr-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O DLZBBDSPTJBOOD-BPNCWPANSA-N 0.000 description 1
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- OFOBLEOULBTSOW-UHFFFAOYSA-N Propanedioic acid Natural products OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102100029812 Protein S100-A12 Human genes 0.000 description 1
- 102100023087 Protein S100-A4 Human genes 0.000 description 1
- 102100032442 Protein S100-A8 Human genes 0.000 description 1
- 102100032420 Protein S100-A9 Human genes 0.000 description 1
- 102100021487 Protein S100-B Human genes 0.000 description 1
- 102220626287 RUN domain-containing protein 3B_L47M_mutation Human genes 0.000 description 1
- 241000700157 Rattus norvegicus Species 0.000 description 1
- 208000001647 Renal Insufficiency Diseases 0.000 description 1
- 201000007737 Retinal degeneration Diseases 0.000 description 1
- KHPCPRHQVVSZAH-HUOMCSJISA-N Rosin Natural products O(C/C=C/c1ccccc1)[C@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 KHPCPRHQVVSZAH-HUOMCSJISA-N 0.000 description 1
- 108010085149 S100 Calcium-Binding Protein A4 Proteins 0.000 description 1
- 102220620951 SHC-transforming protein 4_N52D_mutation Human genes 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 206010040047 Sepsis Diseases 0.000 description 1
- MMGJPDWSIOAGTH-ACZMJKKPSA-N Ser-Ala-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MMGJPDWSIOAGTH-ACZMJKKPSA-N 0.000 description 1
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 1
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 1
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 1
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 1
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 1
- OBXVZEAMXFSGPU-FXQIFTODSA-N Ser-Asn-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)CN=C(N)N OBXVZEAMXFSGPU-FXQIFTODSA-N 0.000 description 1
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 1
- SMIDBHKWSYUBRZ-ACZMJKKPSA-N Ser-Glu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O SMIDBHKWSYUBRZ-ACZMJKKPSA-N 0.000 description 1
- UOLGINIHBRIECN-FXQIFTODSA-N Ser-Glu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UOLGINIHBRIECN-FXQIFTODSA-N 0.000 description 1
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 1
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 1
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 1
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 1
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 1
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 1
- ZIFYDQAFEMIZII-GUBZILKMSA-N Ser-Leu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZIFYDQAFEMIZII-GUBZILKMSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 1
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 1
- VIIJCAQMJBHSJH-FXQIFTODSA-N Ser-Met-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O VIIJCAQMJBHSJH-FXQIFTODSA-N 0.000 description 1
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 1
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 1
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 1
- DINQYZRMXGWWTG-GUBZILKMSA-N Ser-Pro-Pro Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DINQYZRMXGWWTG-GUBZILKMSA-N 0.000 description 1
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 1
- LDEBVRIURYMKQS-WISUUJSJSA-N Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](N)CO LDEBVRIURYMKQS-WISUUJSJSA-N 0.000 description 1
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 1
- UKKROEYWYIHWBD-ZKWXMUAHSA-N Ser-Val-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O UKKROEYWYIHWBD-ZKWXMUAHSA-N 0.000 description 1
- LLSLRQOEAFCZLW-NRPADANISA-N Ser-Val-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LLSLRQOEAFCZLW-NRPADANISA-N 0.000 description 1
- BEBVVQPDSHHWQL-NRPADANISA-N Ser-Val-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BEBVVQPDSHHWQL-NRPADANISA-N 0.000 description 1
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 1
- ANOQEBQWIAYIMV-AEJSXWLSSA-N Ser-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ANOQEBQWIAYIMV-AEJSXWLSSA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 235000002595 Solanum tuberosum Nutrition 0.000 description 1
- 244000061456 Solanum tuberosum Species 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- SSZBUIDZHHWXNJ-UHFFFAOYSA-N Stearinsaeure-hexadecylester Natural products CCCCCCCCCCCCCCCCCC(=O)OCCCCCCCCCCCCCCCC SSZBUIDZHHWXNJ-UHFFFAOYSA-N 0.000 description 1
- ZSJLQEPLLKMAKR-UHFFFAOYSA-N Streptozotocin Natural products O=NN(C)C(=O)NC1C(O)OC(CO)C(O)C1O ZSJLQEPLLKMAKR-UHFFFAOYSA-N 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 1
- XYEXCEPTALHNEV-RCWTZXSCSA-N Thr-Arg-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XYEXCEPTALHNEV-RCWTZXSCSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- SKHPKKYKDYULDH-HJGDQZAQSA-N Thr-Asn-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SKHPKKYKDYULDH-HJGDQZAQSA-N 0.000 description 1
- JVTHIXKSVYEWNI-JRQIVUDYSA-N Thr-Asn-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JVTHIXKSVYEWNI-JRQIVUDYSA-N 0.000 description 1
- YOSLMIPKOUAHKI-OLHMAJIHSA-N Thr-Asp-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O YOSLMIPKOUAHKI-OLHMAJIHSA-N 0.000 description 1
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 1
- QWMPARMKIDVBLV-VZFHVOOUSA-N Thr-Cys-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O QWMPARMKIDVBLV-VZFHVOOUSA-N 0.000 description 1
- UHBPFYOQQPFKQR-JHEQGTHGSA-N Thr-Gln-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O UHBPFYOQQPFKQR-JHEQGTHGSA-N 0.000 description 1
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 1
- LHEZGZQRLDBSRR-WDCWCFNPSA-N Thr-Glu-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LHEZGZQRLDBSRR-WDCWCFNPSA-N 0.000 description 1
- LKEKWDJCJSPXNI-IRIUXVKKSA-N Thr-Glu-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LKEKWDJCJSPXNI-IRIUXVKKSA-N 0.000 description 1
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 1
- AQAMPXBRJJWPNI-JHEQGTHGSA-N Thr-Gly-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AQAMPXBRJJWPNI-JHEQGTHGSA-N 0.000 description 1
- XPNSAQMEAVSQRD-FBCQKBJTSA-N Thr-Gly-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)NCC(O)=O XPNSAQMEAVSQRD-FBCQKBJTSA-N 0.000 description 1
- IMULJHHGAUZZFE-MBLNEYKQSA-N Thr-Gly-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IMULJHHGAUZZFE-MBLNEYKQSA-N 0.000 description 1
- QQWNRERCGGZOKG-WEDXCCLWSA-N Thr-Gly-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O QQWNRERCGGZOKG-WEDXCCLWSA-N 0.000 description 1
- JQAWYCUUFIMTHE-WLTAIBSBSA-N Thr-Gly-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JQAWYCUUFIMTHE-WLTAIBSBSA-N 0.000 description 1
- CRZNCABIJLRFKZ-IUKAMOBKSA-N Thr-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N CRZNCABIJLRFKZ-IUKAMOBKSA-N 0.000 description 1
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 1
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 1
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 1
- UQCNIMDPYICBTR-KYNKHSRBSA-N Thr-Thr-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UQCNIMDPYICBTR-KYNKHSRBSA-N 0.000 description 1
- VGNLMPBYWWNQFS-ZEILLAHLSA-N Thr-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O VGNLMPBYWWNQFS-ZEILLAHLSA-N 0.000 description 1
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 1
- DIHPMRTXPYMDJZ-KAOXEZKKSA-N Thr-Tyr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N)O DIHPMRTXPYMDJZ-KAOXEZKKSA-N 0.000 description 1
- CYCGARJWIQWPQM-YJRXYDGGSA-N Thr-Tyr-Ser Chemical compound C[C@@H](O)[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CO)C([O-])=O)CC1=CC=C(O)C=C1 CYCGARJWIQWPQM-YJRXYDGGSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- VYVBSMCZNHOZGD-RCWTZXSCSA-N Thr-Val-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O VYVBSMCZNHOZGD-RCWTZXSCSA-N 0.000 description 1
- 206010044221 Toxic encephalopathy Diseases 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 101000980463 Treponema pallidum (strain Nichols) Chaperonin GroEL Proteins 0.000 description 1
- GQHAIUPYZPTADF-FDARSICLSA-N Trp-Ile-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 GQHAIUPYZPTADF-FDARSICLSA-N 0.000 description 1
- ILDJYIDXESUBOE-HSCHXYMDSA-N Trp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N ILDJYIDXESUBOE-HSCHXYMDSA-N 0.000 description 1
- MICFJCRQBFSKPA-UMPQAUOISA-N Trp-Met-Thr Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)=CNC2=C1 MICFJCRQBFSKPA-UMPQAUOISA-N 0.000 description 1
- ZHDQRPWESGUDST-JBACZVJFSA-N Trp-Phe-Gln Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CC=CC=C1 ZHDQRPWESGUDST-JBACZVJFSA-N 0.000 description 1
- YXSSXUIBUJGHJY-SFJXLCSZSA-N Trp-Thr-Phe Chemical compound C([C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)[C@H](O)C)C(O)=O)C1=CC=CC=C1 YXSSXUIBUJGHJY-SFJXLCSZSA-N 0.000 description 1
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- HSVPZJLMPLMPOX-BPNCWPANSA-N Tyr-Arg-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O HSVPZJLMPLMPOX-BPNCWPANSA-N 0.000 description 1
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 1
- SCCKSNREWHMKOJ-SRVKXCTJSA-N Tyr-Asn-Ser Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O SCCKSNREWHMKOJ-SRVKXCTJSA-N 0.000 description 1
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 1
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 1
- RIJPHPUJRLEOAK-JYJNAYRXSA-N Tyr-Gln-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O RIJPHPUJRLEOAK-JYJNAYRXSA-N 0.000 description 1
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 1
- OGPKMBOPMDTEDM-IHRRRGAJSA-N Tyr-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N OGPKMBOPMDTEDM-IHRRRGAJSA-N 0.000 description 1
- UPODKYBYUBTWSV-BZSNNMDCSA-N Tyr-Phe-Cys Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CS)C(O)=O)C1=CC=C(O)C=C1 UPODKYBYUBTWSV-BZSNNMDCSA-N 0.000 description 1
- SZEIFUXUTBBQFQ-STQMWFEESA-N Tyr-Pro-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SZEIFUXUTBBQFQ-STQMWFEESA-N 0.000 description 1
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 1
- HRHYJNLMIJWGLF-BZSNNMDCSA-N Tyr-Ser-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 HRHYJNLMIJWGLF-BZSNNMDCSA-N 0.000 description 1
- ZZDYJFVIKVSUFA-WLTAIBSBSA-N Tyr-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ZZDYJFVIKVSUFA-WLTAIBSBSA-N 0.000 description 1
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 1
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 1
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 1
- KSGKJSFPWSMJHK-JNPHEJMOSA-N Tyr-Tyr-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KSGKJSFPWSMJHK-JNPHEJMOSA-N 0.000 description 1
- IZFVRRYRMQFVGX-NRPADANISA-N Val-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N IZFVRRYRMQFVGX-NRPADANISA-N 0.000 description 1
- REJBPZVUHYNMEN-LSJOCFKGSA-N Val-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N REJBPZVUHYNMEN-LSJOCFKGSA-N 0.000 description 1
- KKHRWGYHBZORMQ-NHCYSSNCSA-N Val-Arg-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KKHRWGYHBZORMQ-NHCYSSNCSA-N 0.000 description 1
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 1
- NMPXRFYMZDIBRF-ZOBUZTSGSA-N Val-Asn-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N NMPXRFYMZDIBRF-ZOBUZTSGSA-N 0.000 description 1
- CGGVNFJRZJUVAE-BYULHYEWSA-N Val-Asp-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CGGVNFJRZJUVAE-BYULHYEWSA-N 0.000 description 1
- GMOLURHJBLOBFW-ONGXEEELSA-N Val-Gly-His Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GMOLURHJBLOBFW-ONGXEEELSA-N 0.000 description 1
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 1
- JZWZACGUZVCQPS-RNJOBUHISA-N Val-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N JZWZACGUZVCQPS-RNJOBUHISA-N 0.000 description 1
- MYLNLEIZWHVENT-VKOGCVSHSA-N Val-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](C(C)C)N MYLNLEIZWHVENT-VKOGCVSHSA-N 0.000 description 1
- MJFSRZZJQWZHFQ-SRVKXCTJSA-N Val-Met-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)O)N MJFSRZZJQWZHFQ-SRVKXCTJSA-N 0.000 description 1
- RYQUMYBMOJYYDK-NHCYSSNCSA-N Val-Pro-Glu Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RYQUMYBMOJYYDK-NHCYSSNCSA-N 0.000 description 1
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 1
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 1
- VIKZGAUAKQZDOF-NRPADANISA-N Val-Ser-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O VIKZGAUAKQZDOF-NRPADANISA-N 0.000 description 1
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 1
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 1
- 201000000690 abdominal obesity-metabolic syndrome Diseases 0.000 description 1
- 239000002250 absorbent Substances 0.000 description 1
- 230000002745 absorbent Effects 0.000 description 1
- 229940022663 acetate Drugs 0.000 description 1
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 238000003314 affinity selection Methods 0.000 description 1
- 230000032683 aging Effects 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 229940072056 alginate Drugs 0.000 description 1
- 239000003513 alkali Substances 0.000 description 1
- 125000003282 alkyl amino group Chemical group 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 229940087168 alpha tocopherol Drugs 0.000 description 1
- BJEPYKJPYRNKOW-UHFFFAOYSA-N alpha-hydroxysuccinic acid Natural products OC(=O)C(O)CC(O)=O BJEPYKJPYRNKOW-UHFFFAOYSA-N 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- AZDRQVAHHNSJOQ-UHFFFAOYSA-N alumane Chemical class [AlH3] AZDRQVAHHNSJOQ-UHFFFAOYSA-N 0.000 description 1
- 235000012211 aluminium silicate Nutrition 0.000 description 1
- 230000001668 ameliorated effect Effects 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 229910021529 ammonia Inorganic materials 0.000 description 1
- 229940009444 amphotericin Drugs 0.000 description 1
- APKFDSVGJQXUKY-INPOYWNPSA-N amphotericin B Chemical compound O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1/C=C/C=C/C=C/C=C/C=C/C=C/C=C/[C@H](C)[C@@H](O)[C@@H](C)[C@H](C)OC(=O)C[C@H](O)C[C@H](O)CC[C@@H](O)[C@H](O)C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 APKFDSVGJQXUKY-INPOYWNPSA-N 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 206010002022 amyloidosis Diseases 0.000 description 1
- 238000000540 analysis of variance Methods 0.000 description 1
- 229960003473 androstanolone Drugs 0.000 description 1
- 239000002870 angiogenesis inducing agent Substances 0.000 description 1
- 238000002583 angiography Methods 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 230000001772 anti-angiogenic effect Effects 0.000 description 1
- 230000001745 anti-biotin effect Effects 0.000 description 1
- 229940121363 anti-inflammatory agent Drugs 0.000 description 1
- 239000002260 anti-inflammatory agent Substances 0.000 description 1
- 230000002788 anti-peptide Effects 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 238000011091 antibody purification Methods 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 230000007503 antigenic stimulation Effects 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- 229940041181 antineoplastic drug Drugs 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- 101150031224 app gene Proteins 0.000 description 1
- 239000008365 aqueous carrier Substances 0.000 description 1
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 1
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 108010077245 asparaginyl-proline Proteins 0.000 description 1
- 229940009098 aspartate Drugs 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 239000000022 bacteriostatic agent Substances 0.000 description 1
- 230000003385 bacteriostatic effect Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 235000010233 benzoic acid Nutrition 0.000 description 1
- 229960004365 benzoic acid Drugs 0.000 description 1
- 229960002903 benzyl benzoate Drugs 0.000 description 1
- SQVRNKJHWKZAKO-UHFFFAOYSA-N beta-N-Acetyl-D-neuraminic acid Natural products CC(=O)NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO SQVRNKJHWKZAKO-UHFFFAOYSA-N 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 230000008033 biological extinction Effects 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 238000010170 biological method Methods 0.000 description 1
- 239000012472 biological sample Substances 0.000 description 1
- 239000000090 biomarker Substances 0.000 description 1
- 238000010352 biotechnological method Methods 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 230000036765 blood level Effects 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 210000000988 bone and bone Anatomy 0.000 description 1
- 230000007177 brain activity Effects 0.000 description 1
- 230000006931 brain damage Effects 0.000 description 1
- 231100000874 brain damage Toxicity 0.000 description 1
- 208000029028 brain injury Diseases 0.000 description 1
- 210000005013 brain tissue Anatomy 0.000 description 1
- SXDBWCPKPHAZSM-UHFFFAOYSA-N bromic acid Chemical compound OBr(=O)=O SXDBWCPKPHAZSM-UHFFFAOYSA-N 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- 239000001273 butane Substances 0.000 description 1
- 235000019437 butane-1,3-diol Nutrition 0.000 description 1
- KDYFGRWQOYBRFD-NUQCWPJISA-N butanedioic acid Chemical compound O[14C](=O)CC[14C](O)=O KDYFGRWQOYBRFD-NUQCWPJISA-N 0.000 description 1
- 235000019282 butylated hydroxyanisole Nutrition 0.000 description 1
- 102220346089 c.113G>A Human genes 0.000 description 1
- 108091006374 cAMP receptor proteins Proteins 0.000 description 1
- AIYUHDOJVYHVIT-UHFFFAOYSA-M caesium chloride Chemical compound [Cl-].[Cs+] AIYUHDOJVYHVIT-UHFFFAOYSA-M 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 229910000019 calcium carbonate Inorganic materials 0.000 description 1
- 235000010216 calcium carbonate Nutrition 0.000 description 1
- FUFJGUQYACFECW-UHFFFAOYSA-L calcium hydrogenphosphate Chemical compound [Ca+2].OP([O-])([O-])=O FUFJGUQYACFECW-UHFFFAOYSA-L 0.000 description 1
- 239000000378 calcium silicate Substances 0.000 description 1
- 229910052918 calcium silicate Inorganic materials 0.000 description 1
- CJZGTCYPCWQAJB-UHFFFAOYSA-L calcium stearate Chemical compound [Ca+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O CJZGTCYPCWQAJB-UHFFFAOYSA-L 0.000 description 1
- 235000013539 calcium stearate Nutrition 0.000 description 1
- 239000008116 calcium stearate Substances 0.000 description 1
- OYACROKNLOSFPA-UHFFFAOYSA-N calcium;dioxido(oxo)silane Chemical compound [Ca+2].[O-][Si]([O-])=O OYACROKNLOSFPA-UHFFFAOYSA-N 0.000 description 1
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 1
- 229930195731 calicheamicin Natural products 0.000 description 1
- 239000012830 cancer therapeutic Substances 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 150000004649 carbonic acid derivatives Chemical class 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 210000001715 carotid artery Anatomy 0.000 description 1
- 239000004359 castor oil Substances 0.000 description 1
- 235000019438 castor oil Nutrition 0.000 description 1
- 238000005341 cation exchange Methods 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 238000003163 cell fusion method Methods 0.000 description 1
- 230000012292 cell migration Effects 0.000 description 1
- 108091092356 cellular DNA Proteins 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 230000004637 cellular stress Effects 0.000 description 1
- 229920002301 cellulose acetate Polymers 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 230000002490 cerebral effect Effects 0.000 description 1
- 229960000541 cetyl alcohol Drugs 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 239000013626 chemical specie Substances 0.000 description 1
- 239000012829 chemotherapy agent Substances 0.000 description 1
- 229960004926 chlorobutanol Drugs 0.000 description 1
- 150000005827 chlorofluoro hydrocarbons Chemical class 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- 239000004927 clay Substances 0.000 description 1
- 230000007278 cognition impairment Effects 0.000 description 1
- 229960001338 colchicine Drugs 0.000 description 1
- 238000004040 coloring Methods 0.000 description 1
- 239000007891 compressed tablet Substances 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000002591 computed tomography Methods 0.000 description 1
- 230000001143 conditioned effect Effects 0.000 description 1
- 230000003750 conditioning effect Effects 0.000 description 1
- IQFVPQOLBLOTPF-HKXUKFGYSA-L congo red Chemical compound [Na+].[Na+].C1=CC=CC2=C(N)C(/N=N/C3=CC=C(C=C3)C3=CC=C(C=C3)/N=N/C3=C(C4=CC=CC=C4C(=C3)S([O-])(=O)=O)N)=CC(S([O-])(=O)=O)=C21 IQFVPQOLBLOTPF-HKXUKFGYSA-L 0.000 description 1
- 230000001268 conjugating effect Effects 0.000 description 1
- 108091036078 conserved sequence Proteins 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 239000008120 corn starch Substances 0.000 description 1
- 208000029078 coronary artery disease Diseases 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 235000010947 crosslinked sodium carboxy methyl cellulose Nutrition 0.000 description 1
- 239000001767 crosslinked sodium carboxy methyl cellulose Substances 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 239000002619 cytotoxin Substances 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000008260 defense mechanism Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 210000001947 dentate gyrus Anatomy 0.000 description 1
- 230000008021 deposition Effects 0.000 description 1
- 230000000368 destabilizing effect Effects 0.000 description 1
- 208000033679 diabetic kidney disease Diseases 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000002405 diagnostic procedure Methods 0.000 description 1
- 235000019700 dicalcium phosphate Nutrition 0.000 description 1
- 229940095079 dicalcium phosphate anhydrous Drugs 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- ZBCBWPMODOFKDW-UHFFFAOYSA-N diethanolamine Chemical compound OCCNCCO ZBCBWPMODOFKDW-UHFFFAOYSA-N 0.000 description 1
- HPNMFZURTQLUMO-UHFFFAOYSA-N diethylamine Chemical compound CCNCC HPNMFZURTQLUMO-UHFFFAOYSA-N 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- UGMCXQCYOVCMTB-UHFFFAOYSA-K dihydroxy(stearato)aluminium Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[Al](O)O UGMCXQCYOVCMTB-UHFFFAOYSA-K 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- 238000004090 dissolution Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- POULHZVOKOAJMA-UHFFFAOYSA-M dodecanoate Chemical compound CCCCCCCCCCCC([O-])=O POULHZVOKOAJMA-UHFFFAOYSA-M 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 239000012893 effector ligand Substances 0.000 description 1
- 230000008451 emotion Effects 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 239000002158 endotoxin Substances 0.000 description 1
- 239000002702 enteric coating Substances 0.000 description 1
- 238000009505 enteric coating Methods 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- AFAXGSQYZLGZPG-UHFFFAOYSA-N ethanedisulfonic acid Chemical compound OS(=O)(=O)CCS(O)(=O)=O AFAXGSQYZLGZPG-UHFFFAOYSA-N 0.000 description 1
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- 229940093499 ethyl acetate Drugs 0.000 description 1
- 235000019325 ethyl cellulose Nutrition 0.000 description 1
- 229920001249 ethyl cellulose Polymers 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 229960005420 etoposide Drugs 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 239000003885 eye ointment Substances 0.000 description 1
- 239000003925 fat Substances 0.000 description 1
- 235000019197 fats Nutrition 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 210000001105 femoral artery Anatomy 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 230000004992 fission Effects 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 239000012458 free base Substances 0.000 description 1
- VZCYOOQTPOCHFL-OWOJBTEDSA-L fumarate(2-) Chemical class [O-]C(=O)\C=C\C([O-])=O VZCYOOQTPOCHFL-OWOJBTEDSA-L 0.000 description 1
- 239000001530 fumaric acid Substances 0.000 description 1
- 239000007903 gelatin capsule Substances 0.000 description 1
- 238000003500 gene array Methods 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- 229960002989 glutamic acid Drugs 0.000 description 1
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 1
- 108010049041 glutamylalanine Proteins 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- YQEMORVAKMFKLG-UHFFFAOYSA-N glycerine monostearate Natural products CCCCCCCCCCCCCCCCCC(=O)OC(CO)CO YQEMORVAKMFKLG-UHFFFAOYSA-N 0.000 description 1
- SVUQHVRAGMNPLW-UHFFFAOYSA-N glycerol monostearate Natural products CCCCCCCCCCCCCCCCC(=O)OCC(O)CO SVUQHVRAGMNPLW-UHFFFAOYSA-N 0.000 description 1
- ZEMPKEQAKRGZGQ-XOQCFJPHSA-N glycerol triricinoleate Natural products CCCCCC[C@@H](O)CC=CCCCCCCCC(=O)OC[C@@H](COC(=O)CCCCCCCC=CC[C@@H](O)CCCCCC)OC(=O)CCCCCCCC=CC[C@H](O)CCCCCC ZEMPKEQAKRGZGQ-XOQCFJPHSA-N 0.000 description 1
- KZNQNBZMBZJQJO-YFKPBYRVSA-N glyclproline Chemical compound NCC(=O)N1CCC[C@H]1C(O)=O KZNQNBZMBZJQJO-YFKPBYRVSA-N 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- 108700014210 glycosyltransferase activity proteins Proteins 0.000 description 1
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 1
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 1
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 1
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- ZWCXYZRRTRDGQE-SORVKSEFSA-N gramicidina Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@H](NC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](NC=O)C(C)C)CC(C)C)C(=O)NCCO)=CNC2=C1 ZWCXYZRRTRDGQE-SORVKSEFSA-N 0.000 description 1
- 229940093915 gynecological organic acid Drugs 0.000 description 1
- 235000009424 haa Nutrition 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- BXWNKGSJHAJOGX-UHFFFAOYSA-N hexadecan-1-ol Chemical compound CCCCCCCCCCCCCCCCO BXWNKGSJHAJOGX-UHFFFAOYSA-N 0.000 description 1
- IPCSVZSSVZVIGE-UHFFFAOYSA-M hexadecanoate Chemical compound CCCCCCCCCCCCCCCC([O-])=O IPCSVZSSVZVIGE-UHFFFAOYSA-M 0.000 description 1
- 229930195733 hydrocarbon Natural products 0.000 description 1
- 150000002430 hydrocarbons Chemical class 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-M hydrogensulfate Chemical compound OS([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-M 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 150000004679 hydroxides Chemical class 0.000 description 1
- 230000003345 hyperglycaemic effect Effects 0.000 description 1
- 208000006575 hypertriglyceridemia Diseases 0.000 description 1
- 230000005965 immune activity Effects 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 238000002991 immunohistochemical analysis Methods 0.000 description 1
- 239000007943 implant Substances 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 208000027866 inflammatory disease Diseases 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 230000003933 intellectual function Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 230000031146 intracellular signal transduction Effects 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- NLYAJNPCOHFWQQ-UHFFFAOYSA-N kaolin Chemical compound O.O.O=[Al]O[Si](=O)O[Si](=O)O[Al]=O NLYAJNPCOHFWQQ-UHFFFAOYSA-N 0.000 description 1
- 201000006370 kidney failure Diseases 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 235000014655 lactic acid Nutrition 0.000 description 1
- 239000004310 lactic acid Substances 0.000 description 1
- 229940070765 laurate Drugs 0.000 description 1
- 239000010410 layer Substances 0.000 description 1
- 230000028252 learning or memory Effects 0.000 description 1
- 229960004194 lidocaine Drugs 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 239000006194 liquid suspension Substances 0.000 description 1
- 229910052744 lithium Inorganic materials 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 239000006210 lotion Substances 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- VTHJTEIRLNZDEV-UHFFFAOYSA-L magnesium dihydroxide Chemical compound [OH-].[OH-].[Mg+2] VTHJTEIRLNZDEV-UHFFFAOYSA-L 0.000 description 1
- 239000000347 magnesium hydroxide Substances 0.000 description 1
- 229910001862 magnesium hydroxide Inorganic materials 0.000 description 1
- 238000002595 magnetic resonance imaging Methods 0.000 description 1
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 1
- 239000011976 maleic acid Substances 0.000 description 1
- 150000002688 maleic acid derivatives Chemical class 0.000 description 1
- 239000001630 malic acid Substances 0.000 description 1
- 235000011090 malic acid Nutrition 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 230000006984 memory degeneration Effects 0.000 description 1
- 230000006386 memory function Effects 0.000 description 1
- 208000023060 memory loss Diseases 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- TWXDDNPPQUTEOV-FVGYRXGTSA-N methamphetamine hydrochloride Chemical compound Cl.CN[C@@H](C)CC1=CC=CC=C1 TWXDDNPPQUTEOV-FVGYRXGTSA-N 0.000 description 1
- 229940098779 methanesulfonic acid Drugs 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 239000003094 microcapsule Substances 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- 210000004688 microtubule Anatomy 0.000 description 1
- 239000002480 mineral oil Substances 0.000 description 1
- 235000010446 mineral oil Nutrition 0.000 description 1
- 230000000116 mitigating effect Effects 0.000 description 1
- 229960005485 mitobronitol Drugs 0.000 description 1
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 1
- 229960001156 mitoxantrone Drugs 0.000 description 1
- 239000007932 molded tablet Substances 0.000 description 1
- 229960005358 monensin Drugs 0.000 description 1
- GAOZTHIDHYLHMS-KEOBGNEYSA-N monensin A Chemical compound C([C@@](O1)(C)[C@H]2CC[C@@](O2)(CC)[C@H]2[C@H](C[C@@H](O2)[C@@H]2[C@H](C[C@@H](C)[C@](O)(CO)O2)C)C)C[C@@]21C[C@H](O)[C@@H](C)[C@@H]([C@@H](C)[C@@H](OC)[C@H](C)C(O)=O)O2 GAOZTHIDHYLHMS-KEOBGNEYSA-N 0.000 description 1
- CQDGTJPVBWZJAZ-UHFFFAOYSA-N monoethyl carbonate Chemical compound CCOC(O)=O CQDGTJPVBWZJAZ-UHFFFAOYSA-N 0.000 description 1
- 239000002324 mouth wash Substances 0.000 description 1
- 229940051866 mouthwash Drugs 0.000 description 1
- 231100000219 mutagenic Toxicity 0.000 description 1
- 230000003505 mutagenic effect Effects 0.000 description 1
- 210000003098 myoblast Anatomy 0.000 description 1
- LNOPIUAQISRISI-UHFFFAOYSA-N n'-hydroxy-2-propan-2-ylsulfonylethanimidamide Chemical compound CC(C)S(=O)(=O)CC(N)=NO LNOPIUAQISRISI-UHFFFAOYSA-N 0.000 description 1
- IJDNQMDRQITEOD-UHFFFAOYSA-N n-butane Chemical compound CCCC IJDNQMDRQITEOD-UHFFFAOYSA-N 0.000 description 1
- OFBQJSOFQDEBGM-UHFFFAOYSA-N n-pentane Natural products CCCCC OFBQJSOFQDEBGM-UHFFFAOYSA-N 0.000 description 1
- 125000005487 naphthalate group Chemical group 0.000 description 1
- 210000002682 neurofibrillary tangle Anatomy 0.000 description 1
- 230000004766 neurogenesis Effects 0.000 description 1
- 210000002569 neuron Anatomy 0.000 description 1
- 230000003955 neuronal function Effects 0.000 description 1
- 210000002511 neuropil thread Anatomy 0.000 description 1
- 230000003557 neuropsychological effect Effects 0.000 description 1
- 230000002887 neurotoxic effect Effects 0.000 description 1
- 230000007135 neurotoxicity Effects 0.000 description 1
- 231100000228 neurotoxicity Toxicity 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 229910017604 nitric acid Inorganic materials 0.000 description 1
- 231100000344 non-irritating Toxicity 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 239000007764 o/w emulsion Substances 0.000 description 1
- 230000000414 obstructive effect Effects 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- 229940049964 oleate Drugs 0.000 description 1
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000002895 organic esters Chemical class 0.000 description 1
- 235000006408 oxalic acid Nutrition 0.000 description 1
- 239000007800 oxidant agent Substances 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- FJKROLUGYXJWQN-UHFFFAOYSA-N papa-hydroxy-benzoic acid Natural products OC(=O)C1=CC=C(O)C=C1 FJKROLUGYXJWQN-UHFFFAOYSA-N 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 235000010603 pastilles Nutrition 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 230000008529 pathological progression Effects 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 238000012510 peptide mapping method Methods 0.000 description 1
- 230000035699 permeability Effects 0.000 description 1
- 239000003208 petroleum Substances 0.000 description 1
- 210000001539 phagocyte Anatomy 0.000 description 1
- 239000008177 pharmaceutical agent Substances 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- WVDDGKGOMKODPV-ZQBYOMGUSA-N phenyl(114C)methanol Chemical compound O[14CH2]C1=CC=CC=C1 WVDDGKGOMKODPV-ZQBYOMGUSA-N 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 235000011007 phosphoric acid Nutrition 0.000 description 1
- CEYGNZMCCVVXQW-UHFFFAOYSA-N phosphoric acid;propane-1,2-diol Chemical compound CC(O)CO.OP(O)(O)=O CEYGNZMCCVVXQW-UHFFFAOYSA-N 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000035790 physiological processes and functions Effects 0.000 description 1
- 230000007505 plaque formation Effects 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920002647 polyamide Polymers 0.000 description 1
- 229920002704 polyhistidine Polymers 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 230000007824 polyneuropathy Effects 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 229920001296 polysiloxane Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 238000002600 positron emission tomography Methods 0.000 description 1
- 230000006551 post-translational degradation Effects 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229920001592 potato starch Polymers 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 150000003141 primary amines Chemical class 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 108010014614 prolyl-glycyl-proline Proteins 0.000 description 1
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 1
- 239000001294 propane Substances 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- XJMOSONTPMZWPB-UHFFFAOYSA-M propidium iodide Chemical compound [I-].[I-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CCC[N+](C)(CC)CC)=C1C1=CC=CC=C1 XJMOSONTPMZWPB-UHFFFAOYSA-M 0.000 description 1
- 235000019260 propionic acid Nutrition 0.000 description 1
- 229960003712 propranolol Drugs 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 235000013772 propylene glycol Nutrition 0.000 description 1
- 238000002331 protein detection Methods 0.000 description 1
- 238000000455 protein structure prediction Methods 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 230000001698 pyrogenic effect Effects 0.000 description 1
- 150000003242 quaternary ammonium salts Chemical class 0.000 description 1
- 230000000171 quenching effect Effects 0.000 description 1
- IUVKMZGDUIUOCP-BTNSXGMBSA-N quinbolone Chemical compound O([C@H]1CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)CC[C@@]21C)C1=CCCC1 IUVKMZGDUIUOCP-BTNSXGMBSA-N 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 230000003439 radiotherapeutic effect Effects 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- 239000011541 reaction mixture Substances 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000011514 reflex Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000029058 respiratory gaseous exchange Effects 0.000 description 1
- 208000023504 respiratory system disease Diseases 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 230000004258 retinal degeneration Effects 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- 102220032372 rs104895229 Human genes 0.000 description 1
- 102200004706 rs1060505034 Human genes 0.000 description 1
- 102200017973 rs12259370 Human genes 0.000 description 1
- 102220292847 rs1233421790 Human genes 0.000 description 1
- 102220328919 rs1555631387 Human genes 0.000 description 1
- 102200082919 rs35857380 Human genes 0.000 description 1
- 102220038736 rs532961259 Human genes 0.000 description 1
- 102220014798 rs56204273 Human genes 0.000 description 1
- 102200076366 rs57590980 Human genes 0.000 description 1
- 102200131361 rs57793737 Human genes 0.000 description 1
- 102220092172 rs753180642 Human genes 0.000 description 1
- 102220142342 rs779117189 Human genes 0.000 description 1
- 150000003873 salicylate salts Chemical class 0.000 description 1
- 229960004889 salicylic acid Drugs 0.000 description 1
- 238000013391 scatchard analysis Methods 0.000 description 1
- 150000003335 secondary amines Chemical class 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 1
- 108010071207 serylmethionine Proteins 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- SQVRNKJHWKZAKO-OQPLDHBCSA-N sialic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)OC1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-OQPLDHBCSA-N 0.000 description 1
- 125000005629 sialic acid group Chemical group 0.000 description 1
- 230000037432 silent mutation Effects 0.000 description 1
- 150000004760 silicates Chemical class 0.000 description 1
- 125000005624 silicic acid group Chemical class 0.000 description 1
- 238000002603 single-photon emission computed tomography Methods 0.000 description 1
- 210000002027 skeletal muscle Anatomy 0.000 description 1
- 210000000329 smooth muscle myocyte Anatomy 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- WBHQBSYUUJJSRZ-UHFFFAOYSA-M sodium bisulfate Chemical compound [Na+].OS([O-])(=O)=O WBHQBSYUUJJSRZ-UHFFFAOYSA-M 0.000 description 1
- 229910000342 sodium bisulfate Inorganic materials 0.000 description 1
- 229910000029 sodium carbonate Inorganic materials 0.000 description 1
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 1
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- HRZFUMHJMZEROT-UHFFFAOYSA-L sodium disulfite Chemical compound [Na+].[Na+].[O-]S(=O)S([O-])(=O)=O HRZFUMHJMZEROT-UHFFFAOYSA-L 0.000 description 1
- 229940001584 sodium metabisulfite Drugs 0.000 description 1
- 235000010262 sodium metabisulphite Nutrition 0.000 description 1
- 239000008109 sodium starch glycolate Substances 0.000 description 1
- 229940079832 sodium starch glycolate Drugs 0.000 description 1
- 229920003109 sodium starch glycolate Polymers 0.000 description 1
- 235000010265 sodium sulphite Nutrition 0.000 description 1
- 210000001082 somatic cell Anatomy 0.000 description 1
- 230000037439 somatic mutation Effects 0.000 description 1
- 235000010199 sorbic acid Nutrition 0.000 description 1
- 239000004334 sorbic acid Substances 0.000 description 1
- 229940075582 sorbic acid Drugs 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 230000006886 spatial memory Effects 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 229910001220 stainless steel Inorganic materials 0.000 description 1
- 239000010935 stainless steel Substances 0.000 description 1
- 238000012289 standard assay Methods 0.000 description 1
- 239000008117 stearic acid Substances 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- 230000035882 stress Effects 0.000 description 1
- 150000003900 succinic acid esters Chemical class 0.000 description 1
- 229950000244 sulfanilic acid Drugs 0.000 description 1
- 235000020238 sunflower seed Nutrition 0.000 description 1
- 239000002344 surface layer Substances 0.000 description 1
- FXUAIOOAOAVCGD-FKSUSPILSA-N swainsonine Chemical compound C1CC[C@H](O)[C@H]2[C@H](O)[C@H](O)CN21 FXUAIOOAOAVCGD-FKSUSPILSA-N 0.000 description 1
- 229960005566 swainsonine Drugs 0.000 description 1
- FXUAIOOAOAVCGD-UHFFFAOYSA-N swainsonine Natural products C1CCC(O)C2C(O)C(O)CN21 FXUAIOOAOAVCGD-UHFFFAOYSA-N 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 150000003512 tertiary amines Chemical class 0.000 description 1
- GKCBAIGFKIBETG-UHFFFAOYSA-N tetracaine Chemical compound CCCCNC1=CC=C(C(=O)OCCN(C)C)C=C1 GKCBAIGFKIBETG-UHFFFAOYSA-N 0.000 description 1
- 229960002372 tetracaine Drugs 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 239000002562 thickening agent Substances 0.000 description 1
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 1
- 229960003087 tioguanine Drugs 0.000 description 1
- 230000000451 tissue damage Effects 0.000 description 1
- 231100000827 tissue damage Toxicity 0.000 description 1
- AOBORMOPSGHCAX-DGHZZKTQSA-N tocofersolan Chemical compound OCCOC(=O)CCC(=O)OC1=C(C)C(C)=C2O[C@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C AOBORMOPSGHCAX-DGHZZKTQSA-N 0.000 description 1
- 229960000984 tocofersolan Drugs 0.000 description 1
- JOXIMZWYDAKGHI-UHFFFAOYSA-N toluene-4-sulfonic acid Chemical compound CC1=CC=C(S(O)(=O)=O)C=C1 JOXIMZWYDAKGHI-UHFFFAOYSA-N 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- KHPCPRHQVVSZAH-UHFFFAOYSA-N trans-cinnamyl beta-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OCC=CC1=CC=CC=C1 KHPCPRHQVVSZAH-UHFFFAOYSA-N 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 239000013638 trimer Substances 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 229910052721 tungsten Inorganic materials 0.000 description 1
- 238000007492 two-way ANOVA Methods 0.000 description 1
- 208000001072 type 2 diabetes mellitus Diseases 0.000 description 1
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 108010020532 tyrosyl-proline Proteins 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 229940005605 valeric acid Drugs 0.000 description 1
- 108010072644 valyl-alanyl-prolyl-glycine Proteins 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 235000019871 vegetable fat Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 230000001755 vocal effect Effects 0.000 description 1
- 239000007762 w/o emulsion Substances 0.000 description 1
- 239000010497 wheat germ oil Substances 0.000 description 1
- 230000003936 working memory Effects 0.000 description 1
- 239000011787 zinc oxide Substances 0.000 description 1
- 235000014692 zinc oxide Nutrition 0.000 description 1
- 239000002076 α-tocopherol Substances 0.000 description 1
- 235000004835 α-tocopherol Nutrition 0.000 description 1
Images













































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/04—Drugs for disorders of the alimentary tract or the digestive system for ulcers, gastritis or reflux esophagitis, e.g. antacids, inhibitors of acid secretion, mucosal protectants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
- A61P15/10—Drugs for genital or sexual disorders; Contraceptives for impotence
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/02—Drugs for skeletal disorders for joint disorders, e.g. arthritis, arthrosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/02—Ophthalmic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
- A61P7/12—Antidiuretics, e.g. drugs for diabetes insipidus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/40—Immunoglobulins specific features characterized by post-translational modification
- C07K2317/41—Glycosylation, sialylation, or fucosylation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Immunology (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Molecular Biology (AREA)
- Diabetes (AREA)
- Gastroenterology & Hepatology (AREA)
- Zoology (AREA)
- Toxicology (AREA)
- Cell Biology (AREA)
- Biomedical Technology (AREA)
- Oncology (AREA)
- Cardiology (AREA)
- Neurology (AREA)
- Neurosurgery (AREA)
- Heart & Thoracic Surgery (AREA)
- Hematology (AREA)
- Rheumatology (AREA)
- Urology & Nephrology (AREA)
- Endocrinology (AREA)
- Communicable Diseases (AREA)
- Pain & Pain Management (AREA)
- Psychiatry (AREA)
- Vascular Medicine (AREA)
Abstract
본 발명은 A-베타의 아밀로이드 침착물이 형성되는 것을 특징으로 하는 질병 또는 질환이 발병한 개체를 치료하는 방법으로서, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와의 결합을 억제하는 항체를 치료학적 유효량만큼 상기 개체에 투여하는 단계를 포함하는 방법에 관한 것이다.
Description
관련 출원에 대한 상호 참조 문헌
본 발명은 35 U.S.C §119(e) 하에서, 미국 가 명세서 특허 출원 제60/895,303호(2007년 3월 16일 출원) 및 미국 가 명세서 특허 출원 제60/784,575호(2006년 3월 21일 출원)[이들 출원의 내용은 본원에 그 자체로서 참고용으로 인용됨]의 우선권의 이익을 주장한다.
발명의 분야
본 발명은 일반적으로, 진행성 당화 최종 생성물(advanced glycation endproduct)의 수용체(RAGE)에 특이적으로 결합하는 항체와 이의 단편, 이러한 항체와 이의 단편을 인간 환자와 인간을 제외한 포유동물에 투여하여, RAGE-관련 질병 및 질환을 치료 또는 예방하는 방법에 관한 것이다.
알츠하이머병(AD)은 주로 중장년층에서 발병하는, 진행성이면서, 최종적으로는 치명적인 신경 퇴화 질환이다. 이는 치매의 가장 일반적인 형태로서, 통상적으로는 인지 기능(기억, 추리, 방향 감각 및 판단)이 서서히 상실되고, 다수의 행동 장애가 유발된다. 이 질병은 2가지의 카테고리로 분류될 수 있는데; 노인들(65세 이상)에게 발병하는 후기 발병형과, 노인 이전의 연령층(즉, 35세∼60세)에서 잘 발병하는 조기 발병형이 그것이다. 상기 두 가지 질병 유형에 있어서, 질병의 원인은 동일하지만, 비 정상성(abnormality)은 조기 발병형의 경우에 더욱 심각하고 진행 속도도 빠른 경향이 있다. 상기 질병은 뇌 병변, 신경 섬유원 농축(neurofibrillary tangles) 그리고 노인성 플라크(senile plaque) 중 2가지 이상의 징후를 나타내는 것을 특징으로 한다. 신경 섬유원 농축이란, 2개의 신경 섬유가 쌍을 이루어 서로를 감싸면서 꼬인 형태를 가지는, 미세소관 결합 tau 단백질의 세포 내 침착물을 말한다. 노인성 플라크(즉, 아밀로이드 플라크)란, 중심부로 세포 외 아밀로이드 침착물이 관통하고 있는, 길이 150㎛ 이하의 무질서형 신경 그물 실(disorganized neuropil thread) 부위로서, 뇌 조직 검편을 현미경으로 관찰하였을 때, 눈에 보이는 부위를 말한다. 아밀로이드 플라크가 뇌의 내부에 축적되는 현상은, 다운증후군과 기타 인지 기능 질환 예를 들어, 혈청 아밀로이드 A(SAA) 아밀로이드증 및 해면형 뇌질환에서도 관찰되는 현상이다.
β-아밀로이드 펩티드 또는 Aβ라고 불리는 펩티드는 아밀로이드 플라크의 주요 구성 성분으로서, AD의 발병에 중요한 역할을 하는 것으로 여겨지고 있다. Aβ는, 아밀로이드 전구체 단백질(APP)이라 불리는 대형 경막 당 단백질의 39∼43개의 아미노산 잔기로 이루어진, 소수성의 4kDa인 내부 단편이다. β-세크레타제 및 γ-세크레타제에 의하여 APP가 단백 분해 가공되면, Aβ는 주로 짧은 형태(길이 = 40개 아미노산)와 긴 형태(길이 = 42∼43개 아미노산)로 관찰된다. 뇌에 아밀로이드 플라크가 축적되면, 궁극적으로는 신경 세포가 사멸하게 된다. 알츠하이머 병(AD)의 특징을 이루는 결함과 신체적 증상들은, 적어도 부분적으로나마 Aβ의 신경 독 효과에 의해 유발되는 신경 퇴화에 기인하는 것으로 생각된다. Aβ의 생산을 억제하거나 또는 Aβ의 소멸을 촉진함으로써 Aβ 수준을 감소시키는 것이, 알츠하이머병의 상태를 호전시키는 질병 개선 방법인 것으로 널리 알려져 있다.
APP 단백질 돌연 변이가 수 회 발생하게 되면, 이와 상관하여 알츠하이머병도 발병하게 된다. 이와 같은 돌연 변이의 예로서는, 발린717 → 이소루신, 글리신 또는 페닐알라닌인 경우와, 리신595-메티오닌596 → 아스파라긴595-루신596(이중 돌연 변이)인 경우가 있다. 이와 같은 돌연 변이는 APP에서 Aβ로의 가공 과정, 특히, APP에서 장형(long form)인 Aβ(즉, Aβ1∼42 및 Aβ1∼43)를 다량으로 가공하는 과정을 촉진 또는 변형시킴으로써 알츠하이머병을 유발시키는 것으로 생각된다. 다른 유전자 예를 들어, 프레세닐린 유전자, PS1 및 PS2의 돌연 변이는, APP의 가공에 간접적으로 영향을 미쳐 다량의 장형 Aβ가 생성되도록 만드는 것으로 생각된다.
마우스 모델은 알츠하이머병에 있어서 아밀로이드 플라크의 중요성을 성공적으로 평가하는데 사용되어 왔다[Games외 다수, 1995, Nature, 373:523; Johnson-Wood외 다수, 1997, Proc. Natl. Acad. Sci. USA, 94:1550]. 특히, 인간 APP의 돌연 변이형을 발현하고, 어릴때 알츠하이머병이 발병한 PDAPP 유전자 이식 마우스에 장형의 Aβ를 주사하였을 때, 이 마우스는 알츠하이머병의 발병율이 낮아졌을 뿐만 아니라, Aβ 펩티드에 대한 항체 역가가 증가하였다[Schenk외 다수, 1999, Nature, 400:173]. 상기 관찰 결과는, Aβ(특히, 장형)가 알츠하이머병의 원인이 되는 성분임을 말해주는 것이다.
Aβ는 용액 중에 존재할 수 있으므로, CNS(예를 들어, CSF)와 혈장 중에서 검출될 수 있다. 임의의 조건 하에서, 가용성 Aβ는 AD 환자의 신경 돌기 플라크와 뇌 혈관 내에서 발견되는, 섬유상의 독성을 가지는 β-시트형으로 변형된다. Aβ에 대한 모노클로날 항체를 사용하여 면역화시켜 치료하는 방법이 연구되고 있다. 능동 면역과 수동 면역 둘 다는 AD의 마우스 모델 내에서 테스트되었다. 능동 면역화시켰을 경우, 항체를 비강 내에 투여할 때에만 뇌 내 플라크 양이 어느 정도 감소하였다. PDAPP 유전자 이식 마우스의 수동 면역화에 관하여도 연구되고 있다[Bard외 다수, 2000, Nature Med., 6:916-19]. 효율적인 제거 과정 즉, 중심 분해(central degradation) 및 주변 분해(peripheral degradation)에 관한 2가지 기작이 제안되고 있다. 중심 분해 기작은, 혈액-뇌 장벽을 퉁과하여 플라크와 결합한 후, 이미 존재하고 있던 플라크를 제거시킬 수 있는 항체에 의존한다. 제거는 Fc-수용체-매개 식세포 작용을 통해 촉진되는 것으로 보인다[Bard외 다수 상동]. Aβ 제거에 관한 주변 분해 기작은, 항체를 투여함으로써, Aβ가 하나의 구획에서 다른 구획으로 운반될 때, 뇌, CSF 및 혈장 사이 Aβ의 역동적인 평형 상태를 파괴하는 것에 의존한다. 중심에서 유래한 Aβ는 CSF와 혈장으로 운반되어 분해된다. 최근 연구에 따르면, 가용성이면서 비 결합형인 Aβ가, 뇌 내 아밀로이드 침착물을 감소시키지 않고서도, AD와 관련하여 기억 손상을 일으킨다고 한다[Dodel외 다수, 2003, The Lancet, 2:215].
진행성 당화 최종 생성물의 수용체(RAGE)는 면역 글로불린 상과에 속하는, 다중 리간드 세포 표면 구성원이다. RAGE는 세포 외 도메인, 단일 막-확장 도메인(membrane-spanning domain) 및 시토졸 미부로 이루어져 있다. 상기 수용체의 세포 외 도메인은 하나의 V형 면역 글로불린 도메인을 포함하고, 이 도메인에 이어서는 2개의 C형 면역 글로불린 도메인이 존재한다. RAGE는 또한 가용성 형태로서도 존재한다(sRAGE). RAGE는 다수의 상이한 조직 예를 들어, 폐, 심장, 신장, 골격근 및 뇌를 구성하는 다수의 세포 유형 예를 들어, 내피 세포 및 평활근 세포, 대식 세포 및 림프구에 의해 발현된다. 발현량은 만성 염증 상태 예를 들어, 류머티즘성 관절염과 당뇨병성 신증에서 증가한다. 비록 RAGE의 생리적 기능에 관하여는 별로 알려진 바가 없지만, 이는 염증 반응에 관여하며, 다양한 발생 과정 예를 들어, 근아세포 분화 과정 및 신경 발생 과정에 있어서 중요한 역할을 할 수 있는 것으로 파악된다.
RAGE는 다양한 세포 반응 예를 들어, 시토킨 분비, 세포 내 산화제로 인한 스트레스의 증가, 신경 돌기의 과성장 및 세포 이동을 유도하는 몇몇 상이한 내인성 분자 군에 결합하는 특수한 패턴-인지 수용체이다. RAGE는 다양한 아밀로이드 형성 질병 및 질환에 있어서 활성이며, 발병 원인이 되는 것으로 파악된다.
알츠하이머병과 기타 아밀로이드 형성 질병의 치료용인 신규 치료제와 시약이 요망되고 있다.
발명의 개요
본 발명은 RAGE에 특이적으로 결합하는 항체(즉, 항-RAGE 항체)를 치료학적 유효량으로 투여하여 RAGE 결합 파트너의 결합을 억제함으로써, Aβ의 아밀로이드 침착물의 생성을 특징으로 하는 질병 또는 질환이 발병한 개체를 치료하는 방법을 제공한다. 본원에 개시된 방법에 의해 치료 가능한 질병 또는 질환 예를 들어, 알츠하이머병은 뇌 내 Aβ의 아밀로이드 침착물의 생성을 특징으로 할 수 있다. 본원에 개시된 항-RAGE 항체는 또한, 개체 내 Aβ의 아밀로이드 침착물 축적의 억제 또는 감소, 개체 내 신경 퇴화의 억제 또는 감소, 개체 내 인지 기능 감퇴의 억제 또는 감소, 및/또는 개체 내 인지 기능의 향상을 위해 사용될 수도 있다.
도면의 간단한 설명
도 1a∼1c는 마우스, 래트, 토끼(2개의 아형), 개코 원숭이, 사이노몰거스 원숭이 및 인간의 RAGE의 아미노산 서열(서열 번호 3, 14, 11, 13, 7, 9, 1)을 배열한 것이다.
도 2는 XT-H2와 hRAGE가 EC50 90pM로 결합하는 것과, XT-M4와 hRAGE-Fc가 EC50 300pM로 결합하는 것을 입증하는, 직접 결합 ELISA로부터 얻은 데이터를 그래프로 나타낸 것이다.
도 3은 항체 XT-M4 및 XT-H2와 hRAGE V-도메인-Fc가 EC50 100pM로 결합하는 것을 입증하는, 직접 결합 ELISA 분석으로부터 얻은 데이터를 그래프로 나타낸 것이다.
도 4는 XT-H2 및 XT-M4가, HMG1과 hRAGE-Fc의 결합을 차단하는 능력을 보여주는, 리간드 경쟁 ELISA 결합 검정법으로부터 얻은 데이터를 그래프로 나타낸 것 이다.
도 5는 XT-H2 및 XT-M4가 유사한 에피토프를 공유하며, 또한 인간 RAGE 상에 존재하는 중첩 위치들과 결합하는 것을 보여주는, 항체 경쟁 ELISA 결합 검정법으로부터 얻은 데이터를 그래프로 나타낸 것이다.
도 6은 쥣과 동물 항-RAGE 항체인 XT-H1, XT-H2, XT-H3, XT-H5 및 XT-H7의 중쇄 가변부와, 래트 항-RAGE 항체인 XT-M4의 중쇄 가변부의 아미노산 서열(서열 번호 18, 21, 24, 20, 26, 16)을 배열한 결과를 나타내는 것이다.
도 7은 쥣과 동물 항-RAGE 항체인 XT-H1, XT-H2, XT-H3, XT-H5 및 XT-H7의 경쇄 가변부와, 래트 항-RAGE 항체인 XT-M4의 경쇄 가변부의 아미노산 서열(서열 번호 19, 22, 25, 23, 27, 17)을 배열한 결과를 나타내는 것이다.
도 8은 개코 원숭이 RAGE를 암호화하는 cDNA의 뉴클레오티드 서열(서열 번호 6)을 나타내는 것이다.
도 9는 사이노몰거스 원숭이 RAGE를 암호화하는 cDNA의 뉴클레오티드 서열(서열 번호 8)을 나타내는 것이다.
도 10은 토끼 RAGE 아형 1을 암호화하는 cDNA의 뉴클레오티드 서열(서열 번호 10)을 나타내는 것이다.
도 11은 토끼 RAGE 아형 2를 암호화하는 cDNA의 뉴클레오티드 서열(서열 번호 12)을 나타내는 것이다.
도 12a∼12e는 개코 원숭이 RAGE를 암호화하는, 클로닝된 개코 원숭이 게놈 DNA(클론 18.2)의 뉴클레오티드 서열(서열 번호 15)을 나타내는 것이다.
도 13은 키메라 XT-M4 항체와 래트 항체 XT-M4가, RAGE 리간드인 HMGB1, 아밀로이드 β1-42 펩티드, S100-A 및 S100-B와 hRAGE-Fc가 결합하는 것을 차단하는 능력[경쟁 ELISA 결합 검정법에 의해 측정]을 가지는 것을 보여주는 4개의 그래프를 나타내는 것이다.
도 14는 hRAGE-Fc와의 결합에 대해서, 키메라 XT-M4가 항체 XT-M4 및 XT-H2와 경쟁하는 능력[항체 경쟁 ELISA 결합 검정법에 의해 측정]을 보여주는 그래프를 나타내는 것이다.
도 15는 XT-M4가 폐 조직 내 내인성 세포 표면 RAGE에 결합함을 보여주는, 사이노몰거스 원숭이, 토끼 및 개코 원숭이의 폐 조직의 IHC-염색 결과를 나타내는 것이다. 대조군 시료는 XT-M4와 접촉할 때 hRAGE를 발현하는 CHO 세포, RAGE를 발현하지 않는 NGBCHO 세포, 그리고 대조군 IgG 항체와 접촉할 때 hRAGE를 발현하는 CHO 세포이다.
도 16은 정상인의 폐와 만성 폐색성 폐 질환(COPD)을 앓고 있는 사람의 폐 내에서 RAGE와 래트 항체인 XT-M4가 결합함을 나타낸 것이다.
도 17은 인간화된 쥣과 동물 XT-H2 HV 부위의 아미노산 서열을 나타낸 것이다.
도 18은 인간화된 쥣과 동물 XT-H2 HL 부위의 아미노산 서열을 나타낸 것이다.
도 19는 인간화된 래트의 XT-M4 HV 부위의 아미노산 서열을 나타낸 것이다.
도 20a 및 도 20b는 인간화된 래트의 XT-H2 HL 부위의 아미노산 서열을 나타 낸 것이다.
도 21은 인간화된 경쇄 폴리펩티드와 중쇄 폴리펩티드를 생산하는데 사용되는 발현 벡터를 나타내는 것이다.
도 22는 경쟁 ELISA에 의해 측정된, 인간 RAGE-Fc에 인간화된 XT-H2 항체가 결합할 때의 ED50 값을 나타내는 것이다.
도 23은 XT-M4와 인간화된 항체인 XT-M4-V10, XT-M4-V11 및 XT-M4-V14가 hRAGE-SA와 결합할 때의, 반응 속도 상수(ka 및 kd)와 결합 상수 및 해리 상수(Ka 및 Kd)를 나타낸 것이다[바이어코어(BIACORE)™ 결합 검정법에 의해 측정].
도 24는 XT-M4와 인간화된 항체인 XT-M4-V10, XT-M4-V11 및 XT-M4-V14가 mRAGE-SA와 결합할 때의, 반응 속도 상수(ka 및 kd)와 결합 상수 및 해리 상수(Ka 및 Kd)를 나타낸 것이다[바이어코어™ 결합 검정법에 의해 측정].
도 25는 쥣과 동물 XT-H2 VL-VH ScFv 구조물의 뉴클레오티드 서열(서열 번호 51)을 나타내는 것이다.
도 26은 쥣과 동물 XT-H2 VL-VH ScFv 구조물의 뉴클레오티드 서열(서열 번호 52)을 나타내는 것이다.
도 27은 래트 XT-M4 VL-VH ScFv 구조물의 뉴클레오티드 서열(서열 번호 54)을 나타내는 것이다.
도 28은 래트 XT-M4 VL-VH ScFv 구조물의 뉴클레오티드 서열(서열 번호 53) 을 나타내는 것이다.
도 29는 XT-H2 및 XT-M4 항-RAGE 항체의 ScFv 구조물이 VL/VH 또는 VH/VL 형태일 때, 인간 RAGE-Fc와 결합하는지 여부를 나타내는 ELISA 데이터를 그래프로 나타낸 것이다.
도 30은 에스케리치아 콜라이(Escherichia coli) 내에서 가용성 단백질로서 발현되는 XT-H2 및 XT-M4 항-RAGE 항체의 ScFv 구조물이 VL/VH 또는 VH/VL 형태일 때, 인간 RAGE-Fc 및 BSA와 결합하는지 여부를 나타내는 ELISA 데이터를 그래프로 나타낸 것이다. ActRIIb는 네거티브 대조군과 동일한 벡터로부터 발현되는 비-결합성 단백질이다.
도 31은 스파이킹된(spiked) 돌연 변이를 XT-M4의 CDR에 도입하기 위해 PCR을 사용하는 과정을 도식적으로 나타낸 것이다.
도 32는 XT-M4 VL-VH ScFv 구조물의 C 말단의 뉴클레오티드 서열(서열 번호 56)을 나타내는 것이다. VH-CDR3에는 밑줄을 그어 표시하였다. 각각의 돌연 변이 위치에, 이 위치에 돌연 변이를 발생시키는데 사용되었던 스파이킹 비율(spiking ratio)을 나타내는 숫자와 함께 2개의 스파이킹 올리고뉴클레오티드(서열 번호 57 및 58)를 나타내었다. 이 숫자에 상응하는 스파이킹 비율의 뉴클레오티드 내 조성도 표시하였다.
도 33은 리보좀 디스플레이 벡터인 pWRIL-3을 개략적으로 나타내는 것이다. "T7"은 T7 프로모터를 나타내며, "RBS"는 리보좀 결합 위치를, "스페이서 폴리펩티드"는 폴딩된 단백질을 리보좀에 연결하는 스페이서 폴리펩티드를, "Flag-태그"는 단백질 검출용 Flag 에피토프 태그를 나타낸 것이다.
도 34는 파지 디스플레이 벡터인 pWRIL-1을 개략적으로 나타내는 것이다.
도 35는 Fab 디스플레이 벡터인 pWRIL-6을 사용하는, VL 및 VH 스파이킹된 라이브러리의 조합형 조립체를 개략적으로 나타낸 것이다.
도 36은 52번 위치에 있던 글리코실화 위치를 제거하는 돌연 변이를 수행한 이후에, hRAGE에 대한 XT-M4 항체의 친화성이 증가함을 나타내는 항체 경쟁 ELISA 데이터를 그래프로 나타낸 것이다.
도 37은 마우스에 1회 IV 투여한 이후, 키메라 XT-M4의 혈청 중 농도를 그래프로 나타낸 것이다.
도 38은 키메라 XT-M4가 Tg2576 마우스 모델 내 기억력 상실에 미치는 영향을 그래프로 나타낸 것이다.
항-RAGE 항체
본 발명은 본원에 기술된 바와 같이, RAGE 예를 들어, 가용성 RAGE와 내부 분비형 RAGE에 특이적으로 결합하는 항체를 제공한다. 각각의 항-RAGE 항체는 서열 번호 16∼49에 나타낸 항체 가변부 아미노산 서열 중 하나 이상을 포함할 수 있다.
본 발명의 항-RAGE 항체는 RAGE에 특이적으로 결합하며, 서열 번호 16∼49 중 어느 하나와 동일하거나 또는 실질적으로 동일한 아미노산 서열을 가지는 항체를 포함한다. 실질적으로 동일한 항-RAGE 항체의 아미노산 서열은 서열 번호 16∼49 중 어느 하나와 85%, 85%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5% 또는 99.9% 이상 동일한 서열이다.
RAGE에 특이적으로 결합하고, (a) 서열 번호 19, 22, 25, 23, 27 및 17로 이루어진 군으로부터 선택되는 경쇄 가변부를 포함하거나, 또는 (b) 서열 번호 19, 22, 25, 23, 27 및 17 중 어느 하나와 90% 이상 동일한 아미노산 서열을 가지는 경쇄 가변부를 포함하는 항체, 또는 (a) 또는 (b)의 항체의 RAGE-결합 단편도 본 발명의 항-RAGE 항체에 포함된다.
뿐만 아니라, RAGE에 특이적으로 결합하고, (a) 서열 번호 18, 21, 24, 20, 26 및 16으로 이루어진 군으로부터 선택되는 중쇄 가변부를 포함하거나, 또는 (b) 서열 번호 18, 21, 24, 20, 26 및 16중 어느 하나와 90% 이상 동일한 아미노산 서열을 가지는 중쇄 가변부를 포함하는 항체, 또는 (a) 또는 (b)의 항체의 RAGE-결합 단편도 본 발명의 항-RAGE 항체에 포함된다.
RAGE에 특이적으로 결합하며,
(a) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체와, RAGE와의 결합에 대해 경쟁하고;
(b) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체에 의해 결합되는 RAGE의 에피토프에 결합하며;
(c) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체의 경쇄 또는 중쇄의 하나 이상의 상보성 결정부(CDR)를 포함하는 항-RAGE 항체; 또는
(d) 상기 (a), (b) 또는 (c)의 항체의 RAGE-결합 단편도 본 발명에 포함된다.
본 발명은 시험관 내 및 생체 내에서 RAGE-발현 세포에 특이적으로 결합하는 항-RAGE 항체와, 약 1×10-7∼약 1×10-10M 범위의 해리 상수(Kd)로 인간 RAGE와 결합하는 항체를 포함한다. 또한, 인간 RAGE의 V 도메인에 특이적으로 결합하는 항-RAGE 항체와, RAGE와 RAGE 결합 파트너(RAGE-BP)의 결합을 차단하는 항-RAGE 항체도 본 발명에 포함된다.
본 발명은 또한, RAGE에 특이적으로 결합하고, RAGE와 RAGE-결합 파트너 예를 들어, 리간드 예를 들어, HMGB1, AGE, Aβ, SAA, S100, 암포테린, S100P, S100A(예를 들어, S100A8 및 S100A9), S100A4, CRP, β2-인테그린, Mac-1 및 p150,95의 결합을 차단하며, 다음과 같은 특징들 중 4가지 이상의 특징을 가지는 CDR을 보유하는 항체를 포함한다[여기서, 위치의 번호는 도 6과 도7의 VH 및 VL 서열에 대해 나타낸 아미노산 위치를 참고로 하여 메김]:
1. VH CDR1 내에 아미노산 서열 Y-X-M(Y32; X33; M34)[여기서, X는 바람직하게 W 또는 N임]이 존재함;
2. VH CDR2 내에 아미노산 서열 I-N-X-S(I51; N52; X53 및 S54)[여기서, X는 P 또는 N임]이 존재함;
3. VH의 CDR2 내 58번 위치 아미노산이 트레오닌임;
4. VH의 CDR2 내 60번 위치 아미노산이 티로신임;
5. VH의 CDR3 내 103번 위치 아미노산이 트레오닌임;
6. VH의 CDR3 내에 하나 이상의 티로신 잔기가 존재함;
7. VL의 CDR1 내 24번 위치에 양으로 하전된 잔기(Arg 또는 Lys)가 존재함;
8. VL의 CDR1 내 26번 위치에 친수성 잔기(Thr 또는 Ser)이 존재함;
9. VL의 CDR1 내 25번 위치에 소형 잔기인 Ser 또는 Ala이 존재함;
10. VL의 CDR1 내 33번 위치에 음으로 하전된 잔기(Asp 또는 Glu)가 존재함;
11. VL의 CDR1 내 37번 위치에 방향성 잔기(Phe 또는 Tyr 또는 Trp)가 존재함;
12. VL의 CDR2 내 57번 위치에 친수성 잔기(Ser 또는 Thr)가 존재함;
13. VL의 CDR3 말단부에 P-X-T 서열이 존재함[여기서, X는 소수성 잔기인 Leu 또는 Trp일 수 있음].
본 발명의 항-RAGE 항체는, 인간 RAGE의 V 도메인에 특이적으로 결합하고, RAGE와 이것의 리간드의 결합을 차단하며, 상기 특징들 중 5, 6, 7, 8, 9, 10, 11, 12개 또는 13개 전부를 가지는 CDR을 보유하는 항체를 포함한다.
본 발명의 항-RAGE 항체는 키메라 항체, 인간화된 항체, 단일 사슬 항체, 사량체 항체, 4가 항체, 다중 특이적 항체, 도메인-특이적 항체, 도메인-결실 항체, 융합 단백질, Fab 단편, Fab' 단편, F(ab')2 단편, Fv 단편, ScFv 단편, Fd 단편, 단일 도메인 항체, dAb 단편, 그리고 Fc 융합 단백질(즉, 면역 글로불린 불변부에 융합된 항원 결합 도메인)로 이루어진 군으로부터 선택되는, 전술한 항-RAGE 항체 또는 RAGE-결합 단편을 포함한다. 이러한 항체는 세포 독성 제제, 방사능 치료제 또는 검출 가능한 표지와 커플링될 수 있다.
예를 들어, 래트 XT-M4 항체의 VH 및 VL 도메인을 포함하는 ScFv 항체(서열 번호 63)가 제조되었으며, 세포계 ELISA 분석에 따르면, 이 항체는 키메라 및 야생형 XT-M4 항체의 RAGE에 대한 결합 친화성과 비슷한, 개코 원숭이, 마우스, 토끼 및 인간의 RAGE에 대한 결합 친화성을 가지는 것으로 파악된다.
본 발명의 항체로서는 또한, 항체의 하나 이상의 CDR부에 의해 제공되는, 대상 폴리펩티드 중 하나에 대한 친화성을 가지는, 이종 접합체, 이중 특이적, 단일 사슬 및 키메라 및 인간화된 분자도 포함된다.
RAGE에 특이적으로 결합하는 본 발명의 항체로서는 또한, 공지의 분자 생물학적 기술 및 클로닝 기술에 의해 용이하게 제조될 수 있는, 본원에 기술된 항체 중 임의의 것의 변이체도 포함한다. 예를 들어, 공개된 미국 특허 출원 제2003/0118592호, 동 제2003/0133939호, 동 제2004/0058445호, 동 제2005/0136049호, 동 제2005/0175614호, 동 제2005/0180970호, 동 제2005/0186216호, 동 제2005/0202012호, 동 제2005/0202023호, 동 제2005/0202028호, 동 제2005/0202534호, 동 제2005/0238646호, 및 이의 관련 특허 군(이들은 모두 본원에 그 자체로서 참고용으로 인용됨)을 참조하시오. 예를 들어, 본 발명의 변이 항체는 또한 면역 글로불린 힌지부 또는 힌지-작용부 폴리펩티드에 융합 또는 연결된 후, 다시 IgG 및 IgA의 CH1 이외의 것 예를 들어, IgG 및 IgA의 CH2 및 CH3 부위, 또는 IgE의 CH3 및 CH4 부위와 같이, 면역 글로불린 중쇄로부터 유래하는 하나 이상의 천연 또는 조작된 불변부를 포함하는 부위와 융합 또는 연결된, 결합 도메인 폴리펩티드(예를 들어, scFv)를 포함하는 결합 도메인-면역 글로불린 융합 단백질도 포함할 수 있다[이에 관한 보다 상세한 설명에 관하여는 예를 들어, U.S. 2005/0136049(Ledbetter, J.외 다수)에 개시됨; 본원에 참고용으로 인용됨]. 결합 도메인-면역 글로불린 융합 단백질은 또한, CH2 불변부 폴리펩티드(또는 전체 또는 일부가 IgE로부터 유래하는 구조물의 경우에는 CH3 불변부 폴리펩티드)에 융합 또는 결합되어 있는, 원래의 또는 조작된 면역 글로불린 중쇄 CH3 불변부 폴리펩티드(또는 전체 또는 일부가 IgE로부터 유래하는 구조물의 경우에는 CH4 불변부 폴리펩티드) 및 힌지부 폴리펩티드에 융합 또는 결합되어 있는, 원래의 또는 조작된 면역 글로불린 중쇄 CH2 불변부 폴리펩티드(또는 전체 또는 일부가 IgE로부터 유래하는 구조물의 경우에는 CH3 불변부 폴리펩티드)를 포함하는 부위를 추가로 포함할 수 있다. 통상적으로, 이러한 결합 도메인-면역 글로불린 융합 단백질은 하나 이상의 면역 활성 예를 들어, RAGE와의 특이적 결합, RAGE와 RAGE 결합 파트너 사이의 상호 작용의 억제, 항체 의존적 세포-매개 세포 독성의 유도, 보체 고정화 과정의 유도 등을 나타낼 수 있다.
본 발명의 항체는 또한 그것에 표지를 부착시켜 검출할 수 있다[여기서, 상기 표지로서는 방사성 동위 원소, 형광 화합물, 효소 또는 효소 보조 인자일 수 있음].
RAGE 폴리펩티드
본 발명은 또한, 서열 번호 7, 9, 11 또는 13에 나타낸 아미노산 서열을 가지는, 개코 원숭이, 사이노몰거스 원숭이 및 토끼의 분리된 RAGE 단백질을 제공하며, 또한 서열 번호 7, 9, 11 또는 13에 나타낸 아미노산 서열과 실질적으로 동일한[즉, 서열 번호 7, 9, 11 또는 13 중 임의의 하나의 아미노산 서열과 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5% 또는 99.9% 이상 동일한] 아미노산 서열을 가지는 RAGE 단백질을 추가로 포함한다.
본 발명은 또한 당 업계에 공지된 임의의 수단에 의하여, 본 발명의 항-RAGE 항체 및 이의 RAGE-결합 단편을 생산하는 방법도 포함한다.
본 발명은 또한 서열 번호 1, 3, 7, 9, 11 또는 13 중 임의의 것에 제시된 RAGE 아미노산 서열의 하나 이상의 에피토프에 특이적으로 결합하는 모노클로날 항체의 정제된 제제도 포함한다.
정의
편의상, 발명의 상세한 설명, 실시예 및 청구의 범위에 사용된 임의의 용어들을 여기에 모아두었다. 달리 정의하지 않는 한, 본원에 사용된 모든 기술 용어 및 과학 용어들은 본 발명이 속한 분야의 당 업자가 일반적으로 알고 있는 바와 동일한 의미를 가진다.
본원에 사용된 관사 "하나" 및 "하나의"는, 설명되고 있는 문법적 대상 중 하나 또는 하나 이상(즉, 하나 이상)을 의미한다. 예를 들어, "하나의 요소"는, 하나의 요소 또는 하나 이상의 요소를 의미한다.
본원에 사용된 "또는"이란 용어는, 달리 명확히 언급되어 있지 않는 한, "및/또는"이란 용어와 호환되어 사용된다.
"분리된" 또는 "정제된" 폴리펩티드 또는 단백질 예를 들어, "분리된 항체"는, 그것이 천연의 상태로 존재하는 경우 외의 상태로 정제된 것이다. 예를 들어, "분리된" 또는 "정제된" 폴리펩티드 또는 단백질 예를 들어, "분리된 항체"는, 단백질이 유래하는 세포 또는 조직 공급원으로부터 세포 내 물질 또는 기타 오염 단백질이 실질적으로 제거된 것, 또는 화학 합성시 화학 전구체 또는 기타 화학 물질이 실질적으로 제거된 것일 수 있다. 비-항체 단백질(이를 본원에서 "오염 단백질"이라 칭함) 또는 화학 전구체를 약 50% 미만 가지는 항체 단백질 제제는 "실질적으로 유리된" 것으로 간주한다. 비-항체 단백질 또는 화학 전구체의 40%, 30%, 20%, 10%, 더욱 바람직하게는 5%(건조 중량부)가 실질적으로 제거된 것으로 간주하는 것이다. 항체 단백질 또는 이의 생물 활성부가 재조합 생산될 때, 그것은 또한 배양 배지가 실질적으로 존재하지 않는 것이 바람직한데, 즉, 배양 배지의 부피 또는 질량은 단백질 제제의 부피 또는 질량의 약 30% 미만, 바람직하게는 약 20% 미만, 더욱 바람직하게는 약 10% 미만, 및 가장 바람직하게는 약 5% 미만에 해당하는 것이 바람직하다. 본원에 있어서 "재조합" 단백질 또는 폴리펩티드란, 재조합 핵산의 발현에 의해 생산된 단백질 또는 폴리펩티드를 의미한다.
본원에 있어서, "항체"라는 용어는 "면역 글로불린"이라는 용어와 호환되어 사용되며, 그 예로서는, 비 변형 항체, 항체 단편 예를 들어, Fab, F(ab')2 단편과, 불변부 및/또는 가변부에 돌연 변이[예를 들어, 키메라 항체, 부분적으로 인간화된 항체 또는 완전히 인간화된 항체를 생산하는 돌연 변이, 그리고 원하는 특징 예를 들어, 강화된 IL-13 결합 특성 및/또는 감소한 FcR 결합 특성을 가지는 항체를 생산하는 돌연 변이]가 일어난 비 변형 항체 및 단편을 포함한다. "단편"이란 용어는, 비 변형 또는 완전 항체 또는 항체 사슬의 아미노산 잔기보다 적은 수의 아미노산 잔기를 포함하는 항체 또는 항체 사슬의 일부 또는 부분을 의미한다. 단편은 비 변형 또는 완전 항체 또는 항체 사슬을 화학적으로 처리하거나 효소에 의해 처리함으로써 생성될 수 있다. 단편은 또한 재조합 수단에 의해서도 생성될 수 있다. 대표적인 단편으로서는 Fab, Fab', F(ab')2, Fabc, Fd, dAb 및 scFv 및/또는 Fv 단편을 포함한다. "항원-결합 단편"이라는 용어는, 항원 결합(즉, 특이적 결합)에 대해서, 비 변형 항체(즉, 이 단편이 유래하는 비 변형 항체)와 경쟁하거나, 항원과 결합하는 면역 글로불린 또는 항체의 폴리펩티드 단편을 의미한다. 이와 같은 항체 또는 이의 단편은 본 발명의 범위 내에 포함되되, 다만, 상기 항체 또는 이의 단편은 RAGE에 특이적으로 결합하고, 또한 하나 이상의 RAGE-관련 활성을 중화하거나 억제한다[예를 들어, RAGE 결합 파트너(RAGE-BP)와 RAGE의 결합을 억제함].
항체는 4개의 폴리펩티드 사슬 즉, 2개의 중쇄(H)와 2개의 경쇄(L)가 이황화물 결합에 의해 서로 결합되어 있는 분자 구조를 포함한다. 각각의 중쇄는 중쇄 가변부(본원에서는 이를 HCVR 또는 VH라 약칭함) 및 중쇄 불변부로 이루어져 있다. 중쇄 불변부는 3개의 도메인 즉, CH1, CH2 및 CH3로 이루어져 있다. 각각의 경쇄는 경쇄 가변부(본원에서는 이를 LCVR 또는 VL이라 약칭함) 및 경쇄 불변부로 이루어져 있다. 경쇄 불변부는 하나의 도메인 즉, CL로 이루어져 있다. VH부 및 VL부는 또한 중간에 보다 보존적인 부위(틀 부위(FR)라 칭함)가 삽입되어 있는, 상보성 결정부(CDR)라 칭하여지는 초 변이 부위로 세분될 수 있다. 각각의 VH 및 VL은 다음과 같은 순서대로(아미노 말단→카복시 말단) 3개의 CDR과 4개의 FR이 배열되어 있다: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4.
"항체"라는 용어는 임의의 공급원(예를 들어, 인간 및 인간 이외의 영장류와, 설치류, 토끼목 포유류, 염소, 소, 말 및 양 등)으로부터 얻어지는 임의의 Ig 군 또는 임의의 Ig 하위 군(예를 들어, IgG의 하위 군인 IgG1, lgG2, lgG3 및 IgG4)을 포함한다.
본원에 사용된 "Ig 군" 또는 "면역 글로불린 군"이란 용어는, 인간 및 고등 포유동물에서 동정된 면역 글로불린의 5개의 군 즉, IgG, IgM, IgA, IgD 및 IgE를 의미한다. "Ig 하위 군"이란 용어는, 인간 및 고등 포유동물에서 동정된, IgM의 2개의 하위 군(H 및 L), IgA의 3개의 하위 군(IgA1, lgA2 및 분비형 IgA), 그리고 IgG의 4개의 하위 군(IgG1, IgG2, IgG3 및 IgG4)을 의미한다. 항체는 단량체 또는 중합체의 형태로서 존재할 수 있는데; 예를 들어, IgM 항체는 5량체 형태로 존재하고, IgA 항체는 단량체, 이량체 또는 다량체 형태로 존재한다.
"IgG 하위 군"이란 용어는, 면역 글로불린의 γ 중쇄(γ1∼γ4 각각)에 의해 인간 및 고등 포유동물 내에서 동정된 면역 글로불린 IgG 군의 4개의 하위 군(IgG1, IgG2, IgG3 및 IgG4)을 의미한다.
(본원에서 호환되어 사용되는) "단일 사슬 면역 글로불린" 또는 "단일 사슬 항체"란 용어는, 중쇄 및 경쇄로 이루어진 2-폴리펩티드 사슬 구조를 가지며, 항원과 특이적으로 결합할 수 있는 단백질을 의미하는 것으로서, 여기서, 상기 사슬은 예를 들어, 사슬 간 펩티드 링커에 의해 안정화된다. "도메인"이란 용어는, 예를 들어, 베타-병풍형 시트 구조 및/또는 사슬 내 이황화물 결합에 의해 안정화된 펩티드 루프(예를 들어, 3∼4개의 펩티드 루프)를 포함하는 중쇄 또는 경쇄 폴리펩티드의 구상 부위를 의미한다. 본원에서 도메인은 또한, "불변" 도메인의 경우에는 다양한 군에 속하는 일원의 도메인 내에 발생한 서열 변이, 또는 "가변" 도메인의 경우에는 다양한 군에 속하는 일원의 도메인 내에 발생한 상당한 수준의 변이가 어느 정도로 일어나지 않았는지를 바탕으로 하여 "불변" 도메인 또는 "가변" 도메인이라 부르기도 한다. 항체 또는 폴리펩티드 "도메인"은 종종 당 업계에서 항체 또는 폴리펩티드 "부위"로서 호환되어 칭하여지기도 한다. 항체 경쇄의 "불변" 도메인은 "경쇄 불변부", "경쇄 불변 도메인", "CL" 부위 또는 "CL" 도메인으로서 호환되어 칭하여진다. 항체 중쇄의 "불변" 도메인은 "중쇄 불변부", "중쇄 불변 도메인", "CH" 부위 또는 "CH" 도메인으로서 호환되어 칭하여진다. 항체 경쇄의 "가변" 도메인은 "경쇄 가변부", "경쇄 가변 도메인", "VL" 부위 또는 "VL" 도메인으로서 호환되어 칭하여진다. 항체 중쇄의 "가변" 도메인은 "중쇄 불변부", "중쇄 불변 도메인", "VH" 부위 또는 "VH" 도메인으로서 호환되어 칭하여진다.
"부위"란 용어는 또한, 항체 사슬이나 항체 사슬 도메인의 일부 또는 부분(예를 들어, 상기 정의한 바와 같이, 중쇄 또는 경쇄의 일부 또는 부분, 또는 불변 도메인 또는 가변 도메인의 일부 또는 부분), 그리고 상기 사슬 또는 도메인의 보다 분명한 일부 또는 부분을 의미할 수도 있다. 예를 들어, 경쇄 및 중쇄, 또는 경쇄 및 중쇄 가변 도메인은, 상기 정의한 바와 같이, 사이에 "틀 부위" 또는 "FR"이 삽입되어 있는 "상보성 결정부" 또는 "CDR"을 포함한다.
"형태"란 용어는, 단백질 또는 폴리펩티드(예를 들어, 항체, 항체 사슬, 이의 도메인 또는 부위)의 3차 구조를 의미한다. 예를 들어, "경쇄(또는 중쇄)의 형태"란 어구는, 경쇄(또는 중쇄) 가변부의 3차 구조를 의미하며, "항체의 형태" 또는 "항체 단편의 형태"란 어구는, 항체 또는 이의 단편의 3차 구조를 의미한다.
항체의 "특이적 결합"이란, 항체가 특정 항원 또는 에피토프에 대하여 상당한 친화성을 나타내는 경우로서, 일반적으로, 가교 반응성을 거의 나타내지 않는 경우를 의미하는 것이다. 본원에 사용된 "항-RAGE 항체"란 용어는, RAGE에 특이적으로 결합하는 항체를 의미한다. 항체는 가교 반응성을 나타내지 않을 수 있다[예를 들어, 항체는 비-RAGE 펩티드 또는 RAGE상의 원위(remote) 에피토프와 가교 반응을 하지 않음]. "상당한" 결합이란, 결합 친화도 106, 107, 108, 109 M-1 또는 1010 M-1 이상으로 결합하는 경우를 포함한다. 친화도가 107M-1 또는 108M-1 이상인 항체는 통상적으로, 이에 따라서 더욱 큰 특이성으로 결합한다. 본원에 제시된 수치의 중간 값도 본 발명의 범위 내에 포함되며, 본 발명의 항체는 일정 범위의 친화도(예를 들어, 106∼1010M-1, 또는 107∼1010M-1, 또는 108∼1010M-1)로 RAGE에 결합한다. "가교 반응성을 거의 나타내지 않는" 항체란, 그 항체의 표적 이외의 실체(예를 들어, 상이한 에피토프 또는 상이한 분자)에 거의 결합하지 않을 항체를 의미한다. 예를 들어, RAGE에 특이적으로 결합하는 항체는 RAGE와 상당한 수준으로 결합할 것이지만, 비-RAGE 단백질 또는 펩티드와는 거의 반응하지 않을 것이다. 특정 에피토프에 특이적인 항체는 예를 들어, 동일한 단백질이나 펩티드 상에 존재하는 원위 에피토프와 거의 가교 반응하지 않을 것이다. 특이적 결합은 결합력을 측정하기 위한, 당 업계에서 인정되는 임의의 수단에 의해 측정될 수 있다. 바람직하게, 특이적 결합은 스캐처드 분석법(Scatchard analysis) 및/또는 경쟁적 결합 검정법에 따라서 측정된다.
본원에 사용된 "친화도"란 용어는, 하나의 항원-결합 위치와 항원 결정기의 결합 세기를 의미하는 것이다. 친화도는 항체 경합 위치와 항원 결정기 사이의 입체 화학적 교합 상태의 근접도, 이들 사이의 접촉 영역의 크기, 하전된 소수성 기의 분포 등에 따라서 달라진다. 항체의 친화도는 평형 투석법 또는 동력학적 바이어코어™ 방법에 의해 측정될 수 있다. 상기 바이어코어™ 방법은 표면 플라스몬 파가 금속/액체간 계면에서 여기될 때 발생하는 표면 플라스몬 공명(SPR) 현상을 바탕으로 한다. 빛이 시료와 접촉하지 않는 표면쪽에 유도된 후 이로부터 반사되면, SPR은 각도와 파장을 특이하게 조합하여 반사된 빛의 세기를 약하게 만든다. 2분자성 결합 현상으로 말미암아, 표면 층에서의 굴절률이 변경됨에 따라서 SPR 신호가 바뀌는 것을 확인할 수 있다.
해리 상수(Kd) 및 결합 상수(Ka)는 친화도의 정량적 척도이다. 평형 상태에서, 유리 항원(Ag)과 유리 항체(Ab)는 항원-항체 복합체(Ag-Ab)와 평형을 이루고, 속도 상수인 ka와 kd는 각각의 반응 속도를 정량한다:
ka kd
Ab + Ag → Ab-Ag 및 Ab-Ag → Ab + Ag
평형 상태일 때, ka[Ab][Ag] = kd[Ag-Ab]이다. 해리 상수인 Kd는 다음과 같은 공식에 의해 구할 수 있다: Kd = kd/ka = [Ag][Ab]/[Ag-Ab]. Kd는 농도 단위, 가장 통상적으로는 M, mM, μM, nM 및 pM 등으로 표시된다. Kd로 표시되는 항체의 친화도를 비교할 때, 그 값이 작으면 RAGE에 대한 친화도가 보다 크다는 의미이다. 결합 상수인 Ka는 다음과 같은 공식에 의해 구할 수 있다: Ka = ka/kd = [Ag-Ab]/[Ag][Ab]. Ka는 농도 단위의 역수, 가장 통상적으로는 M-1, mM-1, μM-1, nM-1 및 pM-1 등으로 표시된다. 본원에 사용된 바와 같이, "결합도(avidity)"란 용어는, 항원-항체의 가역적 복합체를 형성한 후의 항원-항체 결합의 세기를 의미한다. 항-RAGE 항체는, 예를 들어, "해리 상수(Kd) 약 (최저 Kd 값)∼약 (최고 Kd 값)으로 결합한다"고 하는 것과 같이, RAGE 단백질과의 결합에 관한 Kd의 관점에서 특징지워 질 수 있다. 여기서, "약"이란 용어는, 소정의 Kd 값 ± 20%의 범위에 있다는 것을 의미하는데; 즉, Kd가 약 1이라는 것은 Kd가 0.8∼1.2의 범위에 있다는 것을 의미한다.
본원에 사용된, "모노클로날 항체"란 용어는, 구조와 항원 특이성이 동질인 항체-생산 세포(예를 들어, B 림프구 또는 B 세포)의 클론 군집으로부터 유래하는 항체를 의미한다. "폴리클로날 항체"란 용어는, 구조와 에피토프 특이성이 이질이되, 공통된 항원을 인지하는 항체-생산 세포의 상이한 클론 군집으로부터 기원하는 다수의 항체를 의미한다. 모노클로날 항체 및 폴리클로날 항체는 체액 중에 미정제 제제로서 존재할 수 있거나, 또는 본원에 기술된 바와 같이 정제될 수 있다.
항체의 "결합부"(또는 "항체 일부")란 용어는, RAGE에 특이적으로 결합하는 능력을 보유하는 하나 이상의 완전한 도메인 예를 들어, 완전한 도메인 쌍, 그리고 항체의 단편을 포함한다. 항체의 결합 기능은 전장 항체의 단편에 의해 나타날 수 있음이 알려져 있다. 결합 단편은 재조합 DNA 기술 또는 비 변형 면역 글로불린의 효소적 절단 또는 화학적 절단에 의해 생산된다. 결합 단편으로서는 Fab, Fab', F(ab')2, Fabc, Fd, dAb, Fv, 단일 사슬, 단일 사슬 항체 예를 들어, scFv, 그리고 단일 도메인 항체(Muyldermans외 다수, 2001, 26:230-5), 그리고 분리된 상보성 결정부(CDR)를 포함한다. Fab 단편은 VL, VH, CL 및 CH1 도메인으로 이루어진 1가 단편이다. F(ab')2 단편은 2개의 Fab 단편들이 힌지부에서 이황화물 결합에 의해 결합되어 있는 2가 단편이다. Fd 단편은 VH 및 CH1 도메인으로 이루어져 있으며, Fv 단편은 항체의 한쪽 팔의 VL 및 VH 도메인으로 이루어져 있다. dAb 단편은 VH 도메인으로 이루어져 있다(Ward외 다수, (1989) Nature 341 :544-546). Fv 단편의 2개의 도메인 즉, VL 및 VH가 별개의 유전자에 의해 암호화될 때, 이 도메인들은 재조합 방법을 사용하여, 이들 도메인을 하나의 단백질 사슬로 만들 수 있는 합성 링커를 통해서 결합될 수 있으며, 이때, VL부 및 VH부의 쌍은 1가 분자(단일 사슬 Fv(scFv)라고 알려짐)를 형성한다[Bird외 다수, 1988, Science 242:423-426]. 이러한 단일 사슬 항체는 또한 항체의 "결합부"라는 용어에 포함되는 것이다. 단일 사슬 항체의 다른 형태 예를 들어, 다이아바디(diabody)도 포함된다. 다이아바디는, VH 도메인 및 VL 도메인이 하나의 폴리펩티드 사슬 상에서 발현되되, 동일한 사슬 상에 존재하는 2개의 도메인 사이에 쌍을 형성하도록 하기에는 짧은 링커를 이용하여, 이 도메인들이 다른 사슬의 상보성 도메인과 쌍을 이루게 한 결과, 2개의 항원 결합 위치가 형성되는 2가의 이중 특이적인 항체이다[예를 들어, Holliger외 다수, 1993, Proc. Natl. Acad. Sci. USA 90:6444-6448 참조]. 항체 또는 이의 결합부는 항체 또는 항체 일부와 하나 이상의 기타 단백질 또는 펩티드를 공유 결합 또는 비공유 결합시켜 형성된 대형 면역 어드헤신(immunoadhesin) 분자의 일부일 수 있다. 이와 같은 면역 어드헤신 분자의 예로서는, 스트렙타비딘 중심부를 사용하여 생산된 사량체 scFv 분자[Kipriyanov, S. M.외 다수 (1995) Human Antibodies and Hybridomas 6:93-101]와, 시스테인 잔기, 마커 펩티드 및 C-말단 폴리히스티딘 태그를 사용하여 생산된 2가의 바이오틴화된 scFv 분자[Kipriyanov, S. M.외 다수 (1994) Mol. Immunol. 31 :1047-1058]를 포함한다. 결합 단편 예를 들어, Fab과 F(ab')2 단편은 통상의 기술 예를 들어, 전체 항체를 파페인이나 펩신으로 절단하는 것과 같은 기술에 의해, 전체 항체로부터 생산될 수 있다. 더욱이, 항체, 항체의 일부 및 면역 어드헤신 분자는, 본원에 기술되어 있고 당 업계에 공지되어 있는 바와 같은, 표준적인 재조합 DNA 기술을 통해 생산될 수 있다. "이중 특이적" 또는 "2 작용성" 항체 이외의 항체는 자체의 결합 위치가 각각 동일한 것으로 생각된다. "이중 특이적" 또는 "2 작용성 항체"는 2개의 상이한 중쇄/경쇄 쌍과 2개의 상이한 결합 위치를 가지는 인공 하이브리드 항체이다. 이중 특이적 항체는 또한 불변부가 사이에 삽입되어 있는 2개의 항원 결합부를 포함할 수도 있다. 이중 특이적 항체는 다양한 방법 예를 들어, 하이브리도마 융합법 또는 Fab' 단편 결합법에 의해 생산될 수 있다. 예를 들어, 문헌[Songsivilai외 다수, Clin. Exp. Immunol. 79:315-321, 1990.; Kostelny외 다수, 1992, J. Immunol. 148, 1547-1553]을 참조하시오.
"복귀 돌연 변이(back mutation)"란 용어는, 인간 항체의 체성 돌연 변이 아미노산의 일부 또는 전부가, 상동성 생식 계열 항체 서열로부터 유래하는, 상응하는 생식 계열 잔기로 치환되는 과정을 의미한다. 본 발명의 인간 항체의 중쇄 및 경쇄 서열은, VBASE 데이터베이스 내 생식 계열 서열과 별도로 배열되어, 상동성이 가장 큰 서열을 동정하게 된다. 본 발명에 의하여 차이가 형성된 인간 항체 서열은, 상이한 아미노산을 암호화하는 특정 뉴클레오티드 위치를 돌연 변이시킴으로 인해 생식 계열 서열로 복구된다. 이와 같이 복귀 돌연 변이에 대한 후보 아미노산으로 동정된 각각의 아미노산의 역할에 관한 연구는, 항원 결합에 있어서 직간접적인 역할에 대해 실시되어야 할 것이며, 또한 인간 항체의 임의의 원하는 특징에 영향을 미치는 돌연 변이가 발생한 이후에 발견되는 임의의 아미노산은 최종 인간 항체에 포함되어서는 안되는데; 예를 들어, 선택적 돌연 변이 유발법에 의해 동정되는 활성 강화 아미노산은 복귀 돌연 변이의 대상이 되지는 않을 것이다. 복귀 돌연 변이의 대상이 되는 아미노산의 수를 최소화하기 위하여, 가장 근접한 생식 계열 서열과 상이하되, 제2의 생식 계열 서열 내 상응하는 아미노산과는 동일한 것으로 파악되는 아미노산 위치들을 남겨둘 수 있는데, 이 경우, 제2의 생식 계열 서열은, 의문 아미노산의 양쪽에 존재하는 10개 이상의 아미노산, 바람직하게는 12개의 아미노산에 대해, 본 발명의 인간 항체의 서열과 동일할 뿐만 아니라 이것과 동일선상에 존재하기도 한다. 복귀 돌연 변이는 항체 최적화 단계 중 임의의 단계에서 발생할 수 있으며; 바람직하게, 복귀 돌연 변이는 선택적 돌연 변이 유발법 실시 직전 또는 직후에 발생한다. 더욱 바람직하게, 복귀 돌연 변이는 선택적 돌연 변이 유발법 실시 직전에 발생한다.
비 변형 면역 글로불린(intact inmmunoglobulin)이라고도 알려진 비 변형 항체(intact antibody)는 통상적으로, 각각 약 25kDa인 2개의 경쇄(L)와 각각 약 50kDa인 2개의 중쇄(H)로 이루어져 있는, 글리코실화된 사량체 단백질이다. 경쇄의 2가지 유형(람다 및 카파)이 항체 내에서 발견된다. 중쇄의 불변 도메인 아미노산 서열에 따라서, 면역 글로불린은 5개의 주요 군 즉, A, D, E, G 및 M으로 구분될 수 있으며, 이것들 중 몇몇은 하위 군(동 기준 표본형) 예를 들어, IgG1 , IgG2, IgG3, IgG4, IgA1 및 IgA2로 세분될 수 있다. 8개의 경쇄는 N 말단 가변(V) 도메인(VL) 및 불변(C) 도메인(CL)으로 이루어져 있다. 각각의 중쇄는 N 말단 V 도메인(VH), 3개 또는 4개의 C 도메인(CH), 그리고 힌지부로 이루어져 있다. VH에 가장 근접하여 존재하는 CH 도메인을 CH1이라 명한다. VH 및 VL 도메인은, 초 변이 서열의 3개의 부위(상보성 결정부, CDR)에 대한 스캐폴드(scaffold)를 형성하며, 틀 부위(FR1, FR2, FR3 및 FR4)라 불리는 비교적 보존된 서열로 된 4개의 부위로 이루어져 있다. 상기 CDR은 항체와 항원의 특이적인 상호 작용에 관여하는 잔기의 대부분을 함유한다. CDR은 CDR1, CDR2 및 CDR3이라 칭하여진다. 그러므로, 중쇄 상에 존재하는 CDR 구성 요소를 H1, H2 및 H3이라 부르고, 경쇄 상에 존재하는 CDR 구성 요소를 L1, L2 및 L3이라 부른다. CDR3은 항체-결합 위치 내 분자의 다양성을 공급하는 주요 공급원이다. 예를 들어, H3은 2개의 아미노산 잔기 정도로 짧거나, 26개의 아미노산 정도로 클 수 있다. 면역 글로불린의 상이한 군의 서브 유닛 구조와 3차원 형태는 당 업계에 널리 공지되어 있다. 항체 구조에 관한 상세한 설명은, 문헌[Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory, eds. Harlow외 다수, 1988]을 참조하시오. 당 업자는, 각각의 서브 유닛 구조 예를 들어, CH, VH, CL, VL, CDR 및 FR 구조가 활성 단편 예를 들어, 항원과 결합하는 CDR 서브 유닛 또는 VH, VL의 일부(즉, 결합 단편)이나, 예를 들어, Fc 수용체 및/또는 상보체와 결합하며/결합하거나 이를 활성화하는 CH 서브 유닛의 일부를 포함한다는 사실을 알 것이다.
항체의 다양성은 가변부를 암호화하는 다수의 생식 계열 유전자를 사용하여 다수의 체내 현상을 통해 나타난다. 체내 현상으로서는, 다양성(D)을 가지는 가변 유전자 분절과 결합(J) 유전자 분절을 재조합하여 완전 VH부를 생산하는 것과, 가변 유전자 분절과 결합 유전자 분절을 재조합하여 완전 VL부를 생산하는 것을 포함한다. 재조합 과정 자체는 부정확하므로, V(D)J 접합부에 아미노산이 결실 또는 부가되기도 한다. 이와 같이 다양성을 만들어내는 기작들은 항원에 노출되기 전인 발생중 B 세포에서 일어난다. 항원에 의하여 자극된 후, B 세포 내 발현된 항체 유전자에서는 체내 돌연 변이가 진행된다. 생식 계열 유전자 분절의 추정 갯수를 바탕으로 하여, 이 분절을 무작위로 재조합하고, VH-VL 간에 무작위로 쌍을 형성하였을 때, 1.6×107개 이하의 상이한 항체가 생산될 수 있었다[Fundamental Immunology, 3rd ed. (1993), ed. Paul, Raven Press, New York, NY]. 항체 다양성을 유발하는 기타 과정(예를 들어, 체내 돌연 변이)을 고려할 때, 1×1010개 이상의 상이한 항체들이 생산될 수 있었던 것으로 생각된다[Immunoglobulin Genes, 2nd ed. (1995), eds. Jonio외 다수, Academic Press, San Diego, CA]. 항체의 다양성을 만드는데 관여하는 다수의 과정으로 인하여, 동일한 항원 특이성을 가지는, 독립적으로 유래하는 모노클로날 항체는 동일한 아미노산 서열을 가지지는 않을 것이다.
"이량체화 폴리펩티드" 또는 "이량체화 도메인"이란 용어로서는, 다른 폴리펩티드와 함께 이량체(또는 그보다 큰 복합체 예를 들어, 삼량체 또는 사량체 등)를 형성하는 임의의 폴리펩티드를 포함한다. 임의로, 상기 이량체화 폴리펩티드는 기타 동일한 이량체화 폴리펩티드와 결합하며, 그 결과 동종 다량체를 형성한다. IgG Fc 요소는 동종 다량체를 형성하는 경향이 있는 이량체화 도메인의 일례이다. 임의로, 상기 이량체화 폴리펩티드는 기타 상이한 이량체화 폴리펩티드와 결합하며, 이로써, 이종 다량체를 형성한다. Jun 루신 지퍼 도메인은 Fos 루신 지퍼 도메인과 이량체를 형성하므로, 이종 다량체를 형성하는 경향이 있는 이량체화 도메인의 일례가 된다. 이량체화 도메인은 이종 다량체 및 동종 다량체 둘 다 25가지 형성할 수 있다.
"인간 항체"란 용어에는, 캐벗(Kabat)외 다수의 문헌에 개시된 바와 같은 인간 생식 계열 면역 글로불린 서열에 상응하는 가변부 및 불변부를 가지는 항체가 포함된다[Kabat외 다수 (1991) Sequences of proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242]. 본 발명의 인간 항체는 예를 들어, CDR, 특히 CDR3 내 인간 생식 계열 면역 글로불린 서열에 의해 암호화되지 않는 아미노산 잔기(예를 들어, 시험관 내 무작위 돌연 변이 또는 위치-특이적 돌연 변이나, 생체 내 체내 돌연 변이에 의해 돌연 변이가 도입된 아미노산 잔기)를 포함할 수 있다. 상기 돌연 변이는 본원에 개시된 "선택적 돌연 변이 유발법(selective mutagenesis approach)"을 통하여 도입되는 것이 바람직하다. 인간 항체는, 인간 생식 계열 면역 글로불린 서열에 의해 암호화되지 않는 아미노산 잔기 예를 들어, 활성 강화 아미노산 잔기로 치환되는 위치를 하나 이상 가질 수 있다. 인간 항체는 인간 생식 계열 면역 글로불린 서열의 일부가 아닌 아미노산 잔기로 치환되는 위치를 20개 이하 가질 수 있다. 또한, 10개 이하, 5개 이하, 3개 이하 또는 2개 이하의 위치가 치환된다. 이와 같은 치환은 이하 상세히 기술된 바와 같이, CDR 부위 내에서 일어날 수 있다. 그러나, 본원에 사용된 "인간 항체"란 용어는, 다른 포유동물 종 예를 들어, 마우스의 생식 계열로부터 유래하는 CDR 서열이 인간 틀 서열상에 이식된 항체를 포함하지는 않는다.
"재조합 인간 항체"란 어구에는, 재조합 수단에 의해 제조, 발현, 생성 또는 분리된 인간 항체 예를 들어, 숙주 세포에 형질 감염된 재조합 발현 벡터를 사용하여 발현된 항체(이하, 섹션 II에 상세히 기술됨), 재조합 조합형 인간 항체 라이브러리로부터 분리된 항체(이하, 섹션 III에 상세히 기술됨), 인간 면역 글로불린 유전자가 유전자 이식된 동물(예를 들어, 마우스)로부터 분리된 항체[예를 들어, Taylor, L. D.외 다수 (1992) Nucl. Acids Res. 20:6287-6295] 또는 인간 면역 글로불린 유전자 서열을 다른 DNA 서열로 스플라이싱하는데 관여하는 기타 임의의 수단에 의해 제조, 발현, 생성 또는 분리된 항체가 포함된다. 이와 같은 재조합 인간 항체는 인간 생식 계열 면역 글로불린 서열로부터 유래하는 가변부 및 불변부를 가진다[Kabat, E. A.외 다수 (1991) Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242 참조]. 그러나, 이와 같은 재조합 인간 항체는 시험관 내 돌연 변이될 수 있으므로(또는 인간 Ig 서열이 동물에 유전자 이식될 때에는 생체 내 체내 돌연 변이될 수 있으므로), 재조합 항체의 VH부 및 VL부의 아미노산 서열은, 인간 생식 계열 VH 및 VL 서열로부터 유래하고 이와 관련되어 있으면서, 생체 내 인간 항체 생식 계열 레퍼토리(repertoire) 내에는 원래 존재할 수 없는 서열이다. 그러나, 임의의 구체예에서, 이와 같은 재조합 항체는 선택적 돌연 변이 유발법 또는 복귀 돌연 변이 또는 이들 둘 다에 의해 생성될 수 있다.
"분리된 항체"로서는, 상이한 항원 특이성을 가지는 기타 항체를 실질적으로 배제한 항체를 포함한다[예를 들어, RAGE에 특이적으로 결합하는 분리된 항체는, hRAGE 이외에 RAGE에 특이적으로 결합하는 항체를 실질적으로 배제한다]. RAGE에 특이적으로 결합하는 분리된 항체는 기타 종으로부터 유래하는 RAGE 분자와 결합할 수 있다. 뿐만 아니라, 분리된 항체는 기타 세포 물질 및/또는 화학 물질을 실질적으로 포함하지 않을 수 있다.
"중화 항체"(또는 "RAGE 활성을 중화하는 항체")로서는, hRAGE에 결합하였을 때, 이 hRAGE의 생물 활성을 조정하는 항체를 포함한다. hRAGE의 생물 활성이 조정되는지 여부는 hRAGE 생물 활성의 하나 이상의 지표 예를 들어, 인간 RAGE 수용체 결합 검정법에서 수용체 결합을 억제하는지 여부를 측정함으로써 평가될 수 있다[예를 들어, 실시예 6 및 7 참조]. hRAGE 생물 활성의 지표는 당 업계에 공지된 시험관 내 또는 생체 내 몇몇 표준적 검정법 중 하나 이상에 의해 평가될 수 있다[예를 들어, 실시예 6 및 7 참조].
인간 이외의 동물(예를 들어, 쥣과 동물) 항체의 "인간화된" 형태로서는, 인간 이외의 동물의 면역 글로불린으로부터 유래하는 최소한의 서열을 함유하는 키메라 항체가 있다. 대부분의 경우, 인간화된 항체는 수용 항체의 초 변이 부위로부터 유래하는 잔기가, 원하는 특이성, 친화성 그리고 기능을 가지는, 인간 이외의 종 예를 들어, 마우스, 래트, 토끼 또는 인간 이외의 영장류 항체(공여 항체)의 초 변이 부위로부터 유래하는 잔기에 의해 치환된 인간 면역 글로불린(수용 항체)이다. 몇몇 경우에 있어서, 인간 면역 글로불린의 FR 잔기는 상응하는 인간 이외의 동물의 잔기에 의해 치환된다. 더욱이, 인간화된 항체는 수용 항체 또는 공여 항체 내에서 발견되지 않는 잔기들을 포함할 수 있다. 이와 같은 변형은 항체의 기능을 더욱 개선하도록 이루어진다. 일반적으로, 인간화된 항체는 실질적으로 1개 이상, 통상적으로는 2개의 가변 도메인 전부를 포함할 것이며, 이때, 초 변이 부위 전부 또는 실질적으로 전부는 인간 이외의 동물의 면역 글로불린의 초 변이 부위와 상응하며, FR부의 전부 또는 실질적으로 전부는 인간 면역 글로불린 서열의 FR부에 해당한다. 또한, 인간화된 항체는 임의로, 면역 글로불린 불변부의 최소한의 부분(Fc), 통상적으로는 인간 면역 글로불린의 최소한의 부분을 포함할 것이다. 보다 상세한 설명은 문헌[Jones외 다수, Nature 321 :522-525 (1986); Riechmann외 다수, Nature 332:323-329 (1988); 및 Presta, Curr. Op. Struct. Biol. 2:593-596 (1992)]을 참조하시오.
"활성"이란 용어에는, 활성 예를 들어, 항체의 항원 예를 들어, RAGE에 결합하는 항-hRAGE 항체에 대한 결합 특이성/친화성, 및/또는 항체 예를 들어, hRAGE와 결합하면 RAGE의 생물 활성을 억제하는 항-hRAGE 항체의 중화 효능 예를 들어, 인간 RAGE 수용체 결합 검정법에서 수용체 결합을 억제하는 효능을 포함한다.
"발현 구조물"은, 적당한 숙주 세포 내에서 발현 가능한 핵산 단백질 또는 폴리펩티드의 발현을 매개하는데 충분한 조절 요소 및 발현 가능 핵산을 포함하는 임의의 재조합 핵산이다.
"융합 단백질" 및 "키메라 단백질"이라는 용어는 호환되어 사용될 수 있는 용어로서, 2개 이상의 단백질로부터 유래하는 아미노산 서열에 상응하는 부분들을 보유하는 아미노산 서열을 가지는 단백질 또는 폴리펩티드를 의미한다. 2개 이상의 단백질로부터 유래하는 서열들은 단백질의 전부 또는 일부(즉, 단편)일 수 있다. 융합 단백질은 또한 단백질의 일부에 상응하는 부분들 사이에 아미노산의 결합 부위를 가질 수도 있다. 이와 같은 융합 단백질은 재조합 방법에 의해 제조될 수 있는데, 여기서, 상응하는 핵산은 핵산 분해 효소와 리가제로 처리하여 결합되며, 또한 발현 벡터에 통합된다. 융합 단백질의 생산 방법은 일반적으로 당 업자가 이해할 수 있다.
"핵산"이라는 용어는, 폴리뉴클레오티드 예를 들어, 데옥시리보핵산(DNA)을 의미하며, 적당한 경우, 리보핵산(RNA)을 의미하기도 한다. 상기 용어는 또한 균등물로서, 뉴클레오티드 유사체로부터 생성된 RNA 또는 DNA의 유사체를 포함하며, 본원에 기술된 구체예에 적용될 때에는 단일 사슬(센스 또는 안티센스) 폴리뉴클레오티드 및 이중 사슬 폴리뉴클레오티드를 포함한다.
"동일%" 또는 "동일성%"란 용어는, 2개의 아미노산 서열들 또는 2개의 뉴클레오티드 서열들 사이의 서열 동일성을 의미한다. 동일성%는 비교의 목적으로 배열될 수 있는 각각의 서열 내 위치를 비교함으로써 특정될 수 있다. 동일성 %라는 표현은 비교되는 서열들이 공유하는 위치에 존재하는 동일 아미노산 또는 핵산의 갯수에 관한 함수이다. 다양한 배열 알고리즘 및/또는 프로그램 예를 들어, FASTA, BLAST 또는 ENTREZ가 사용될 수 있다. FASTA 및 BLAST는 GCG 서열 분석 팩키지(University of Wisconsin, Madison, Wis.)의 일부로서 유용하며, 예를 들어, 디폴트 세팅하여 사용될 수 있다. ENTREZ는 국립 생물 정보 센터(National Center for Biotechnology Information), 국립 의학 도서관(National Library of Medicine) 및 국립 보건원(National Institutes of Health)(Bethesda, Md.)에서 입수할 수 있다. 2개의 서열 간 동일성 %는 GCG 프로그램(갭 가중치 = 1)에 의해 측정될 수 있는데, 예를 들어, 각각의 아미노산 갭이 2개의 서열 간 하나의 아미노산 또는 뉴클레오티드 미스매치인 것처럼 하여 이 아미노산 갭에 가중치를 적용한다.
기타 배열 기술에 관하여는 문헌[Methods in Enzymology, vol. 266: Computer Methods for Macromolecular Sequence Analysis (1996), ed. Doolittle, Academic Press, Inc., Harcourt Brace & Co. 지부, San Diego, California, USA]에 개시되어 있다. 서열을 배열하는데는, 서열 내 갭을 허용하는 배열 프로그램을 사용하는 것이 바람직하다. 스미스-워터맨(Smith-Waterman)은 서열 배열 내 갭을 허용하는 알고리즘의 일종이다. 문헌[Meth. Mol. Viols. 70: 173-187 (1997)]을 참조하시오. 뿐만 아니라, 니들맨과 운치(Needlenan and Wunsch)의 배열 방법을 이용하는 GAP I 프로그램도 서열을 배열하는데 사용될 수 있다. 대안적인 검색 기법에서는 MASPAR 컴퓨터 상에서 운영되는 MPSRCH 소프트웨어를 사용한다. MPSRCH는 대용량의 병렬식 컴퓨터에서 서열에 스코어 5를 메기기 위해 스미스-워터맨 알고리즘을 이용한다. 이 방법을 통하여, 원위의 관련 서열 매치부를 골라내는 기능을 개선하며, 특히, 소형 갭과 뉴클레오티드 서열 오류를 관용할 수 있게 된다. 핵산-암호화 아미노산 서열은 단백질과 DNA 데이터베이스 둘 다를 검색하는데 사용될 수 있다.
"폴리펩티드" 및 "단백질"이란 용어는 본원에서 호환되어 사용된다.
"RAGE" 단백질은 당 업계에 공지되어 있는 바와 같이, "진행성 당화 최종 생성물의 수용체"이다. 각각의 RAGE 단백질이 도 1a∼1c에 제시되어 있다. RAGE 단백질로서는 가용성 RAGE(sRAGE) 및 내인성 분비형 RAGE(esRAGE)를 포함한다. 내인성 분비형 RAGE는 세포의 외부로 방출되는 RAGE 스플라이싱 변이체로서, 이는 AGE 리간드와 결합할 수 있으며, 이 AGE의 활성을 중화할 수 있다. 예를 들어, 문헌[Koyama외 다수, ATVE, 2005; 25:2587-2593]을 참조하시오. 인간 혈장 esRAGE와 대사 증후군(BMI, 인슐린 내성, BP, 고중성지방혈증 및 IGT)과 관련된 몇몇 성분 사이에서는 역 결합 현상이 관찰된다. 혈장 esRAGE 수준은 또한 당뇨병을 앓고 있는 개체 또는 당뇨병을 앓고 있지 않은 개체 내 경동맥 및 대퇴부의 죽상 동맥 경화증(초음파에 의해 정량)과 역으로 관련되어 있다. 뿐만 아니라, 형장 esRAGE 수준은, 연령에 맞추어 건강 관리를 하고 있는 환자보다는, 혈관 조영술에 의해 관상 동맥 질환을 앓고 있는 것으로 확인된 비 당뇨병 환자에서 훨씬 낮다.
"진행성 당화 최종 생성물 리간드 결합 요소의 수용체" 또는 "RAGE-LBE"(본원에서는 "RAGE-Fc" 및 "RAGE-strep"이라고도 부름)는, RAGE 리간드와 결합하는 능력을 보유하는 경막 RAGE 폴리펩티드의 세포 외 임의의 부분과 이의 단편을 포함한다. 상기 용어는 또한, RAGE 리간드 또는 RAGE-BP가 결합할 RAGE 폴리펩티드 예를 들어, 인간 또는 쥣과 동물 폴리펩티드와의 동일성이 85% 이상, 바람직하게는 90% 이상 또는 더욱 바람직하게는 95% 이상인 폴리펩티드를 포함하기도 한다.
"진행성 당화 최종 생성물 결합 파트너의 수용체" 또는 "RAGE-BP"는, 생리적 환경 하에서, RAGE 단백질의 세포 외 부분(수용체 폴리펩티드 예를 들어, RAGE 또는 RAGE-LBE)에 결합하는 임의의 물질(예를 들어, 폴리펩티드, 소형 분자, 탄수화물 구조물 등)을 포함한다.
"RAGE-관련 질환" 또는 "RAGE-연관 질환"으로서는, 발병 세포 또는 조직의 RAGE 또는 하나 이상의 RAGE 리간드의 발현 및/또는 활성이 증가 또는 감소되는 임의의 질환을 포함한다. RAGE-관련 질환으로서는 또한(예를 들어, RAGE:RAGE-BP 상호 작용을 방해하는 제제를 투여함으로써) RAGE 기능을 감소시켜 치료할 수 있는(즉, 하나 이상의 증상을 없애거나 완화할 수 있는) 임의의 질환을 포함한다.
"RAGE의 V-도메인"이란, 도 5에 도시된 면역 글로불린-유사 가변 도메인을 의미한다[Neeper외 다수, "Cloning and expression of RAGE: a cell surface receptor for advanced glycosylation end products of proteins," J. Biol. Chem. 267:14998-15004 (1992); 이 문헌의 내용은 본원에 참고용으로 인용됨]. 상기 V-도메인은 서열 번호 1과 서열 번호 3에 나타낸 바와 같이, 1∼120번 위치 아미노산을 포함한다.
RAGE의 인간 cDNA는 1406 염기쌍으로서, 404개의 아미노산으로 이루어진 성숙한 단백질을 암호화한다. 도 3을 참조하시오[Neeper외 다수, 1992].
"재조합 핵산"이란 용어는, 천연의 상태에서는 함께 존재하지 않는 2개 이상의 서열들을 포함하는 임의의 핵산을 포함한다. 재조합 핵산은 예를 들어, 분자 생물학적 방법에 의해 시험관 내에서 생성될 수 있거나, 아니면 상동성 재조합 또는 비-상동성 재조합에 의해 신규의 염색체상 위치에 핵산을 삽입하여 생체 내에서 생성될 수 있다.
개체를 "치료한다"는 용어는, 개체가 앓고 있는 질병 또는 질환의 증상 중 하나 이상을 호전시키는 것을 의미한다. 치료는 질병 또는 병상을 치유하거나, 또는 이것들을 개선할 수 있다.
"벡터"라는 용어는, 다른 핵산이 결합되어 있던 부위로부터 이 핵산을 이동시킬 수 있는 핵산 분자를 의미한다. 벡터의 한 가지 유형으로서는 에피좀 즉, 염색체 외에서 복제할 수 있는 핵산이 있다. 벡터의 다른 유형으로서는 숙주 세포의 유전 물질과 재조합하도록 디자인된 통합형 벡터가 있다. 벡터는 자기 스스로 복제 및 통합할 수 있으며, 벡터의 특성은 세포 내용물에 따라서 상이할 수 있다[즉, 벡터는 하나의 숙주 세포 유형에서 자기 스스로 복제할 수 있으며, 다른 숙주 세포 유형에서는 오로지 통합만 할 수 있다]. 작동 가능하도록 결합된 발현 가능 핵산을 발현시킬 수 있는 벡터를 본원에서 "발현 벡터"라고 부른다.
"특이적으로 면역 반응성인"이란 용어는, 항체가 특이적 펩티드 서열과 상호 작용할 때, 화합물[항체]이 특정 펩티드 서열에 우선적으로 결합하는 경우를 의미한다.
본원에 사용된 "유효량"이란 어구는, 동물 내에서 원하는 효과를 나타내는데 유효한, 본 발명의 하나 이상의 제제, 물질 또는 이 하나 이상의 제제를 포함하는 조성물의 양을 의미한다. 제제가 치료 효과를 얻는데 사용될 때, "유효량"을 포함하는 실제 투여량은 다수의 조건 예를 들어, 치료될 특정 병상, 질병의 중증도, 환자의 크기와 건강 상태, 투여 경로 등에 따라서 달라질 것이다. 숙련된 의료업계 실무자는 의료업계에 널리 공지된 방법을 이용하여 적절한 투여량을 용이하게 결정할 수 있다.
본원에 사용된 "약학적으로 허용 가능한"이란 어구는, 건전한 의학적 판단 범위 내에서, 과도한 독성, 자극, 알레르기 반응 또는 기타 문제점 또는 합병증을 야기하지 않고, 인간과 동물의 조직과 접촉시키는데 적당한(합리적인 혜택/위험도 비율에 따르는) 화합물, 물질, 조성물 및/또는 투여형을 의미한다.
본원에 사용된 "약학적으로 허용 가능한 담체"란 어구는, 대상 제제를 하나의 기관 또는 신체의 일부분에서 다른 기관 또는 신체의 일부분으로 운반 또는 이동시키는데 관여하는, 약학적으로 허용 가능한 물질, 조성물 또는 비이클 예를 들어, 액체 또는 고체 충전제, 희석제, 부형제, 용매 또는 캡슐화 물질을 의미한다. 각각의 담체는 제형의 기타 성분들과 부합한다는 의미에서 "허용 가능한" 것이어야 한다. 약학적으로 허용 가능한 담체로 사용될 수 있는 물질의 몇몇 예로서는, (1) 당 예를 들어, 락토스, 글루코스 및 수크로스; (2) 전분 예를 들어, 옥수수 전분 및 감자 전분; (3) 셀룰로스 및 이의 유도체 예를 들어, 소듐 카복시메틸 셀룰로스, 에틸 셀룰로스 및 아세트산셀룰로스; (4) 분말형 트래거칸트; (5) 맥아; (6) 젤라틴; (7) 활석; (8) 부형제 예를 들어, 코코아 버터 및 좌제 왁스; (9) 기름 예를 들어, 땅콩 기름, 면실유, 해바라기씨 기름, 참기름, 올리브 기름, 옥수수 기름 및 대두 기름; (10) 글리콜 예를 들어, 프로필렌 글리콜; (11) 폴리올 예를 들어, 글리세린, 솔비톨, 만니톨 및 폴리에틸렌 글리콜; (12) 에스테르 예를 들어, 올레산에틸 및 라우린산에틸; (13) 아가; (14) 완충제 예를 들어, 수산화마그네슘 및 수산화알루미늄; (15) 알긴산; (16) 무 발열원 물; (17) 등장 염수; (18) 링거 용액; (19) 에틸 알콜; (20) 인산염 완충 용액; 및 (21) 기타 약학 제형에 사용되는 무독성 적합 물질을 포함한다.
모노클로날 항체의 제조
포유동물 예를 들어, 마우스, 래트, 햄스터 또는 토끼는 전장 단백질이나 이의 단편, 또는 전장 단백질이나 이의 단편을 암호화하는 cDNA, 그리고 면역원성 펩티드로 면역화될 수 있다. 단백질이나 펩티드에 면역원성을 부여하는 기술로서는, 담체에 접합하는 기술, 또는 당 업계에 널리 공지된 기타 기술을 포함한다. 폴리펩티드의 면역원성 부분은 애쥬반트의 존재 하에 투여될 수 있다. 면역화 과정은 혈장 또는 혈청 중 항체 역가를 검출함으로써 관찰할 수 있다. 표준적인 ELISA 또는 기타 면역 검정법에서는 항체의 수준을 측정하기 위한 항원으로서 면역원을 사용할 수 있다.
동물을 대상 폴리펩티드의 항원 제제로 면역화한 다음에, 항 혈청을 채취할 수 있으며, 원할 경우, 혈청으로부터 폴리클로날 항체를 분리할 수도 있다. 모노클로날 항체를 생산하기 위해, 항체-생산 세포(림프구)를 면역화된 동물로부터 수집할 수 있으며, 또한 무한 증식 세포 예를 들어, 골수종 세포를 사용하는 표준적인 체 세포 융합법에 의해 융합하여, 하이브리도마 세포를 만들 수 있다. 이와 같은 기술은 당 업계에 널리 공지되어 있으며, 그 예로서는 하이브리도마 기술[원천적으로는 콜러(Kohler) 및 밀스타인(Milstein)에 의해 개발됨; Kohler and Milstein, (1975) Nature, 256:495-497], 인간 B 세포 하이브리도마 기술[Kozbar외 다수 (1983) Immunology Today, 4: 72], 그리고 인간 모노클로날 항체를 만드는 EBV-하이브리도마 기술[Cole외 다수, (1985) Monoclonal Antibodies and Cancer Therapy, Alan R. Liss, Inc. pp. 77-96]을 포함한다. 하이브리도마 세포는, RAGE 폴리펩티드의 에피토프와 특이적으로 반응하는 항체와, 하이브리도마 세포를 포함하는 배양액으로부터 분리된 모노클로날 항체를 생산하는지 여부에 대해 면역 화학적으로 스크리닝될 수 있다.
인간화
키메라 항체는 2개 이상의 상이한 종으로부터 유래하는 서열을 포함한다. 하나의 구체예로서, 재조합 클로닝 기술은 인간 이외의 종의 항체(즉, 항원으로 면역화된 인간 이외의 종에서 생산된 항체)로부터 유래하는 항원-결합 위치를 함유하는 가변부와, 인간 면역 글로불린으로부터 유래하는 불변부를 포함시키는데 사용될 수 있다.
인간화된 항체는 키메라 항체의 한 유형으로서, 항원 결합에 관여하는 가변부 잔기(즉, 상보성 결정부의 잔기(상보성 결정부라 약칭함) 또는 항원 결합에 관여하는 임의의 기타 잔기)는 인간 이외의 종으로부터 유래하는 반면에, 나머지 가변부 잔기(즉, 틀 부위의 잔기)와 불변부는 적어도 부분적으로나마 인간 항체 서열로부터 유래한다. 인간화된 항체의 틀 부위 잔기와 불변부 잔기의 하위 세트는 인간 이외의 종과 같은 공급원으로부터 유래할 수 있다. 인간화된 항체의 가변부(즉, 인간화된 경쇄 또는 중쇄 가변부)도 또한 인간화되었다고 볼 수 있다. 인간 이외의 종은 통상적으로 항원으로 면역화하는데 사용되는데, 그 예로서는 마우스, 래트, 토끼, 인간 이외의 영장류 또는 기타 인간 이외의 포유동물 종이 있다. 인간화된 항체의 면역원성은 통상적으로, 보통의 키메라 항체의 면역원성보다 약하며, 인간에 투여된 이후의 안정성도 개선된다. 예를 들어, 문헌[Benincosa외 다수 (2000) J. Pharmacol. Exp. Ther. 292:810-6; Kalofonos외 다수 (1994) Eur. J. Cancer 3OA: 1842-50; Subramanian외 다수 (1998) Pediatr. Infect. Dis. J. 17:110-5]을 참조하시오.
상보성 결정부(CDR)는 항원 결합에 참여하는 항체 가변부의 잔기이다. CDR을 동정함에 있어서 몇 가지 번호 매김 시스템이 일반적으로 사용된다. 캐벗(Kabat) 정의는 서열의 가변성을 바탕으로 하는 것이며, 초시아(Chothia) 정의는 구조적 루프 부위의 위치를 바탕으로 하는 것이다. AbM 정의는 캐벗 방법과 초시아 방법을 절충한 방법이다. 경쇄 가변부의 CDR은 캐벗, 초시아 또는 AbM 알고리즘에 따르면, 24번 및 34번 위치의 잔기(CDR1-L), 50번 및 56번 위치의 잔기(CDR2-L), 그리고 89번 및 97번 위치의 잔기(CDR3-L)에 의해 한정된다. 캐벗 정의에 따르면, 중쇄 가변부의 CDR은 31번 및 35B번 위치의 잔기(CDR1-H), 50번 및 65번 위치의 잔기(CDR2-H), 그리고 95번 및 102번 위치의 잔기(CDR3-H)(번호 메김 방식은 캐벗 방식에 따름)에 의해 한정된다. 초시아 정의에 따르면, 중쇄 가변부의 CDR은 26번 및 32번 위치의 잔기(CDR1-H), 52번 및 56번 위치의 잔기(CDR2-H), 그리고 95번 및 102번 위치의 잔기(CDR3-H)(번호 메김 방식은 초시아 방식에 따름)에 의해 한정된다. AbM의 정의에 따르면, 중쇄 가변부의 CDR은 26번 및 35B번 위치의 잔기(CDR1 -H), 50번 및 58번 위치의 잔기(CDR2-H), 그리고 95번 및 102번 위치의 잔기(CDR3-H)(번호 메김 방식은 캐벗 방식에 따름)에 의해 한정된다. 문헌[Martin외 다수 (1989) Proc. Natl. Acad. Sci. USA 86: 9268-9272; Martin외 다수 (1991) Methods Enzymol. 203: 121-153; Pedersen외 다수 (1992) Immunomethods 1 : 126; 및 Rees외 다수 (1996), Sternberg M.J. E. (ed.), Protein Structure Prediction, Oxford University Press, Oxford, pp. 141-172]을 참조하시오.
본원에 사용된 "CDR"이란 용어는, 캐벗 또는 초시아에 의해 정의되는 바와 같은 CDR을 의미하며; 또한, 본 발명의 가변성 인간화 항체는 캐벗에 의해 정의되는 하나 이상의 CDR을 포함하고, 또한 초시아에 의해 정의되는 하나 이상의 CDR을 포함하도록 구성될 수 있다.
특이성 결정 부위(SDR)는 항원과 직접 상호 작용하는 CDR 내 잔기이다. SDR은 초 변이 잔기와 상응한다. 문헌[Padlan외 다수 (1995) FASEB J. 9: 133-139]을 참조하시오.
틀 잔기는 초 변이 잔기 또는 CDR 잔기 이외의 항체 가변부의 잔기이다. 틀 잔기는 천연 생성 인간 항체로부터 유래할 수 있으며 그 예로서는, 본 발명의 항-RAGE 항체의 틀 부위와 실질적으로 유사한 인간의 틀 잔기가 있다. 각 서열간에 공통된 인공 틀 서열도 사용할 수 있다. 인간화를 위한 틀 부위를 선택할 때, 인간에서 빈번히 출현하는 서열이 출현 빈도가 떨어지는 서열보다 바람직할 수 있다. 항원 접촉에 관여하는 것으로 생각되는 쥣과 동물 잔기 및/또는 항원-결합 위치의 구조적 일체성에 관여하는 잔기를 복구하거나, 항체 발현 수준을 높이기 위해, 인간 틀 수용 서열에 부가적 돌연 변이를 발생시킬 수 있다. 펩티드 구조에 관한 예측 결과는, 인간화된 중쇄 및 경쇄 가변부 서열을 분석하여, 인간화 디자인에 의해 도입된 번역 후 단백질 변형 위치를 동정 및 배제하는데 사용될 수 있다.
인간화된 항체는 이하에 기술된 바와 같은 다양한 방법 예를 들어, 베니어링(veneering), 상보성 결정부(CDR)의 이식법, 단축된 CDR의 이식법, 특이성 결정 부위(SDR)의 이식법, 그리고 프랑켄슈타인(Frankenstein) 조립법 중 어느 하나를 이용하여 생산될 수 있다. 인간화된 항체는 또한 CDR에 하나 이상의 변이가 도입된 초 인간화(superhumanized) 항체를 포함한다. 예를 들어, 인간 잔기는 CDR 내 인간 이외의 종의 잔기에 대해 치환될 수 있다. 이와 같은 일반적인 방법은 임의의 원하는 서열을 가지는 항-RAGE 항체를 생산하기 위한 표준적인 돌연 변이 유발법 및 합성 기술과 병행될 수 있다.
베니어링은, 용매와 접촉할 수 있는 항체의 외부 표면을 인간 아미노산 서열로 다시 포장하여, 설치류 또는 기타 인간 이외의 종의 항체 내 잠재적으로 면역원성인 아미노산 서열을 줄인다는 것을 바탕으로 한다. 그러므로, 베니어링된 항체는, 변형되지 않은 인간 이외의 종의 항체에 비하여, 인간 세포에 대해 이질성이 낮아지는 것으로 파악된다. 문헌[Padlan (1991) Mol. Immunol. 28:489-98]을 참조하시오. 인간 이외의 종의 항체는 인간 이외의 종의 항체 내 노출된 외부 틀 부위 잔기 즉, 인간 항체의 틀 부위 내 동일한 위치에 존재하는 잔기와 상이한 잔기를 동정하여, 이 동정된 잔기들을 인간 항체 내 동일한 위치에 통상적으로 존재하는 아미노산으로 치환함으로써 베니어링된다.
CDR의 이식법은, 수용 항체(예를 들어, 원하는 틀 잔기를 포함하는 인간 항체 또는 기타 항체)의 하나 이상의 CDR을 공여 항체(예를 들어, 인간 이외의 종의 항체)의 CDR과 치환함으로써 수행된다. 수용 항체는 후보 수용 항체와 공여 항체 사이에 존재하는 틀 잔기의 유사성을 바탕으로 하여 선택될 수 있다. 예를 들어, 프랑켄슈타인 방법에 의하면, 인간 틀 부위의 서열은 관련된 인간 이외의 종의 항체의 각 틀 부위의 서열과 실질적으로 상동성인 것으로 확인되며, 인간 이외의 종의 항체 CDR은 상이한 인간 틀 부위의 복합체에 이식된다. 본 발명의 항체를 제조하는데 유용한 관련 방법에 관하여는 미국 특허 출원 공보 제2003/0040606호에 개시되어 있다.
단축된 CDR을 이식하는 방법도 관련되어 있다. 단축된 CDR은 특이성-결정 잔기와 인접한 아미노산들 예를 들어, 경쇄의 27d∼34, 50∼55 및 89∼96번 위치에 존재하는 아미노산과, 중쇄의 31∼35b, 50∼58 및 95∼101번 위치에 존재하는 아미노산을 포함한다[번호 메김 방식은 캐벗 외 다수(1987)의 방식에 의함]. 문헌[Padlan외 다수 (1995) FASEB J. 9: 133-9]을 참조하시오. 특이성-결정 잔기(SDR)의 이식 여부는, 항체 결합 위치의 결합 특이성과 친화성이 각각의 상보성 결정부(CDR) 내 가장 가변성이 큰 잔기에 의해 결정된다는 사실을 파악함에 있어서의 전제 조건이 된다. 항체-항원 복합체의 3차원 구조에 관한 분석은, 입수 가능한 아미노산 서열 데이터의 분석 결과와 함께, CDR 내 각각의 위치에서 발생하는 아미노산 잔기의 구조적 비유사성을 바탕으로 서열의 가변성을 모델링하는데 사용될 수 있다. SDR은, 접촉 잔기들로 이루어진, 면역원성이 최소인 폴리펩티드 서열인 것으로 확인된다. 문헌[Padlan외 다수 (1995) FASEB J. 9: 133-139]을 참조하시오.
CDR 또는 단축된 CDR을 이식하기 위한 수용 틀은 원하는 잔기들을 도입하도록 추가로 변형될 수도 있다. 예를 들어, 수용 틀은 인간 제I 하위 군 공통 서열의 중쇄 가변부와, 임의로는 1, 28, 48, 67, 69, 71 및 93번 위치 중 하나 이상의 위치에 존재하는 인간 이외의 종의 공여 잔기를 함께 포함할 수 있다. 다른 예로서, 인간 수용 틀은 인간 제I 하위 군의 공통 서열의 경쇄 가변부와, 임의로는 2, 3, 4, 37, 38, 45 및 60번 위치 중 하나 이상의 위치에 존재하는, 인간 이외의 종의 공여 잔기를 함께 포함할 수 있다. 이식 후, 공여 서열 및/또는 수용 서열에 부가의 변이를 발생시켜, 항체 결합 특성 및 기능성을 최적화할 수도 있다. 예를 들어, PCT 국제 특허 출원 공보 WO 91/09967을 참조하시오.
인간화된 항-RAGE 항체를 생산하는데 사용될 수 있는 중쇄 가변부의 인간 틀로서는, DP-75, DP54, DP-54 FW VH 3 JH4, DP-54 VH3 3-07, DP-8(VH1-2), DP-25, VI-2b 및 VI-3(VH1-03), DP-15 및 V1-8(VH1-08), DP-14 및 V1-18(VH1-18), DP-5 및 V1-24P(VH1-24), DP-4(VH1-45), DP-7(VH1-46), DP-10, DA-6 및 YAC-7(VH1-69), DP-88(VH1-e), DP-3 및 DA-8(VH1-f)의 틀 잔기를 포함한다.
인간화된 항-RAGE 항체를 생산하는데 사용될 수 있는 경쇄 가변부의 인간 틀로서는, 인간 생식 계열 클론인 DPK24, DPK-12, DPK-9 Vk1, DPK-9 Jk4, DPK9 Vk1 02와, 생식 계열 클론 하위 군인 VκIII 및 VκI의 틀 잔기를 포함한다. DPK24 생식 계열을 돌연 변이시키면, 항체 F10S, T45K, I63S, Y67S, F73L 및 T77S의 발현량이 증가할 수 있다.
본 발명의 인간화된 항-RAGE 항체로서는 각각, 서열 번호 16∼27로부터 선택되는 가변부 아미노산 서열의 하나 이상의 CDR을 가지는 항체를 포함한다. 예를 들어, 인간화된 항-RAGE 항체는 서열 번호 16, 18, 21, 24, 20 및 26 중 임의의 하나의 중쇄 가변부, 또는 서열 번호 17, 19, 22, 25, 23 및 27 중 임의의 하나의 경쇄 가변부의 CDR로부터 선택되는 2개 이상의 CDR을 포함할 수 있다. 인간화된 항-RAGE 항체는 또한 서열 번호 16, 18, 21, 24, 20 및 26 중 임의의 하나의 2개 또는 3개의 CDR을 가지는 가변부를 포함하는 중쇄와, 서열 번호 17, 19, 22, 25, 23 및 27 중 임의의 하나의 2개 또는 3개의 CDR을 가지는 가변부를 포함하는 경쇄를 포함할 수도 있다.
본 발명의 인간화된 항-RAGE 항체 즉, 제1 사슬의 가변부(즉, 경쇄 가변부 또는 중쇄 가변부)가 인간화되고, 제2 사슬의 가변부(즉, 인간 이외의 종에서 생산되는 항체의 가변부)는 인간화되지 않은 항체가 구성될 수도 있다. 이와 같은 항체는 반-인간화 항체라고 불리는, 인간화된 항체의 일종이다.
키메라 및 인간화된 항-RAGE 항체의 불변부는 IgA, IgD, IgE, IgG 및 IgM 중 어느 하나와, 이의 임의의 동 기준 표본형(예를 들어, IgG의 동 기준 표본형인 IgG1, IgG2, IgG3 또는 IgG4)의 불변부로부터 유래할 수 있다. 다수의 항체 불변부의 아미노산 서열에 관하여는 공지되어 있다. 인간 동 기준 표본형을 어떤 것으로 선택하느냐와 이 동 기준 표본형 내 특정 아미노산을 어떻게 변형시키느냐에 따라서, 숙주의 방어 기작의 활성화를 촉진 또는 억제할 수 있으며, 또한 항체의 생체 분포도 바꿀수 있다. 문헌[Reff외 다수 (2002) Cancer Control 9: 152-66]을 참조하시오. 면역 글로불린 불변부를 암호화하는 서열을 클로닝하기 위하여, 인트론 서열을 결실시킬 수 있다.
키메라 및 인간화된 항-RAGE 항체는 당 업계에 공지된 표준적인 기술을 사용하여 구성될 수 있다. 예를 들어, 가변부는, 가변부를 암호화하는 중첩 올리고뉴클레오티드들을 서로 어닐링(annealing)시킨 다음, 이 올리고뉴클레오티드들을 인간 항체 불변부를 함유하는 발현 벡터 내에 결찰시킴으로써 생산될 수 있다. 예를 들어, 문헌[Harlow & Lane (1988) Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York 및 미국 특허 제4,196,265호; 동 제4,946,778호; 동 제5,091,513호; 동 제5,132,405호; 동 제5,260,203호; 동 제5,677,427호; 동 제5,892,019호; 동 제5,985,279호; 동 제6,054,561호]을 참조하시오. 2개의 비 변형 사량 항체 예를 들어, 동종 이량체 및 이종 이량체를 포함하는 4가 항체(H4L4)는, 예를 들어, PCT 국제 특허 출원 공보 WO 02/096948에 개시된 바와 같이 생산될 수 있다. 항체의 이량체는, 이종 2 작용성 가교 링커를 사용하거나[Wolff외 다수 (1993) Cancer Res. 53: 2560-5], 또는 이중 불변부를 포함하는 재조합체를 생산함으로써[Stevenson외 다수 (1989) Anticancer Drug Des. 3: 219-30], 항체의 불변부 내에, 사슬 간 이황화물 결합의 형성을 촉진하는 시스테인 잔기(들)를 도입함으로써 생산될 수도 있다. 본 발명의 항체의 항원-결합 단편은 예를 들어, 절단된 항체 서열을 발현시키거나, 전장 항체를 번역후 분해함으로써 생산될 수 있다.
본 발명의 항-RAGE 항체의 변이체는 다양한 변이 즉, 치환, 삽입 및 결실을 포함하도록 용이하게 생산될 수 있다. 예를 들어, 항체 서열은 항체 발현에 사용되는 세포류 내에서 코돈을 적당히 사용함으로써 최적화될 수 있다. 항체의 혈청 반감기를 증가시키기 위해서는, (구원 수용체 결합 에피토프가 존재하지 않는다면) 구원 수용체 결합 에피토프를 항체 중쇄 서열에 통합할 수 있다. 미국 특허 제5,739,277호를 참조하시오. 항체의 안정성을 강화하기 위한 부가의 변형으로서는, 241번 잔기인 세린을 프롤린으로 치환하는 IgG4 변형을 포함한다. 문헌[Angal외 다수 (1993) Mol. Immunol. 30: 105-108]을 참조하시오. 기타 유용한 변이로서는, 항체와 약물을 접합함에 있어서 그 효율을 최적화하는데 필요한 치환을 포함한다. 예를 들어, 항체는 그것의 카복실 말단이 약물 부착을 위한 아미노산을 포함하도록 변형될 수 있는데, 예를 들어, 하나 이상의 시스테인 잔기가 부가될 수 있다. 불변부는 탄수화물 또는 기타 부분을 결합하기 위한 위치들을 포함하도록 변형될 수 있다.
부가의 변이 항체로서는 기능성이 개선된 글리코실화 아형을 포함한다. 예를 들어, Fc 글리코실화 변형은 효과기 기능을 변경시킬 수 있는데, 예를 들어, Fc 감마 수용체와의 결합성을 증가시키고 ADCC를 개선하며/개선하거나, C1q 결합성 및 CDC를 감소시킬 수 있다[예를 들어, Fc 올리고당을 복합체 형태로부터 고분자량의 만노스 또는 하이브리드 형태로 변형시킬 경우, C1q 결합성 및 CDC가 감소할 수 있다][예를 들어, Kanda외 다수, Glycobiology, 2007:17:104-118 참조]. 상기 변형은, 박테리아, 효모, 식물 세포, 곤충 세포 및 포유동물 세포를 생물 공학적 방법으로 조작함으로써 이루어질 수 있으며; 이는 또한 유전자 조작된 유기체 내에서 단백질 또는 천연 생성물 글리코실화 경로를 조작함으로써 이루어질 수 있다. 글리코실화는 또한, 다양한 범위의 상이한 기질을 관용하는 당-부착 효소(글리코실트랜스퍼라제)의 관대함(liberality)을 탐구함으로써 변경될 수도 있다. 마지막으로, 당 업자는 다양한 화학적 방법(소형 분자 및 효소를 사용하는 방법, 단백질 결찰법, 대사 생물 공학적 방법 또는 완전 합성법)을 통하여 단백질과 천연 생성물을 글리코실화할 수 있다. N-글리칸 가공법의 적당한 소형 분자 억제제의 예로서는, 카스타노스퍼민(Castanospermine; CS), 키푸넨신(Kifunensine; KF), 데옥시만노지리마이신(Deoxymannojirimycin; DMJ), 스와인소닌(Swainsonine; Sw), 모넨신(Monensin; Mn)을 포함한다.
본 발명의 항-RAGE 항체의 변이체는 표준적인 재조합 기술 예를 들어, 위치-배향 돌연 변이 유발법 또는 재조합 클로닝에 의해 생산될 수 있다. 항-RAGE 항체의 다양한 레퍼토리는 유전자 이식된 인간 이외의 동물 내에서의 유전자 배열법 및 유전자 전환법을 통해 생산될 수 있으며[미국 특허 출원 공보 제2003/0017534호], 이후 이 항체는 기능 검정법을 통하여 관련 활성에 대해 테스트된다. 본 발명의 특정 구체예에서, 변이체는 CDR을 돌연 변이시키는 친화성 성숙법(affinity maturation protocol)[Yang외 다수 (1995) J. Mol. Biol. 254: 392-403], 사슬 셔플링(chain shuffling)[Marks외 다수 (1992) Biotechnology (NY) 10: 779-783], 이.콜라이의 돌연 변이 유발 균주를 사용하는 방법[Low외 다수 (1996) J. Mol. Biol. 260: 359-368], DNA 셔플링(DNA shuffling)[Patten외 다수 (1997) Curr. Opin. Biotechnol. 8: 724-733], 파지 디스플레이[Thompson외 다수 (1996) J. Mol. Biol. 256: 77-88], 및 유성 PCR[Crameri외 다수 (1998) Nature 391 : 288-291]에 의해서 생산된다. 면역 요법을 수행함에 있어서, 관련 기능 검정법으로서는, 이하에 기술된 바와 같은, 인간 RAGE 항원과의 특이적 결합법, 항체 내부화, 그리고 항체를 종양-발생 동물에 투여하여 종양 위치(들)를 표적화하는 방법을 포함한다.
본 발명은 또한 본 발명의 항-RAGE 항체를 발현하는 세포와 세포주를 제공한다. 대표적인 숙주 세포로서는 포유동물 및 인간 세포 예를 들어, CHO 세포, HEK-293 세포, HeLa 세포, CV-1 세포 및 COS 세포를 포함한다. 이종 구조물을 숙주 세포에 형질 전환시켜 안정한 세포주를 생산하는 방법은 당 업계에 공지되어 있다. 대표적인 포유동물 이외의 숙주 세포로서는 곤충 세포를 포함한다[Potter외 다수 (1993) Int. Rev. Immunol. 10(2-3):103-112]. 항체는 또한 유전자 이식 동물[Houdebine (2002) Curr. Opin. Biotechnol. 13(6):625-629] 및 유전자 이식 식물[Schillberg외 다수 (2003) Cell Mol. Life Sci. 60(3):433-45] 내에서 생산될 수도 있다.
전술한 바와 같이, 예를 들어, 항체의 기타 부분 예를 들어, 불변부를 결실, 부가 또는 치환함으로써 변형된 모노클로날, 키메라 및 인간화 항체도 본 발명의 범위 내에 포함된다. 예를 들어, 항체는 다음과 같이 변형될 수 있다: (i) 불변부를 결실시킴; (ii) 불변부를 다른 불변부 예를 들어, 항체의 반감기, 안정성 또는 친화성을 증가시키는 불변부, 또는 다른 종이나 항체 군으로부터 유래하는 불변부로 치환함; 또는 (iii) 예를 들어, 글리코실화 위치, 효과기 세포 기능, Fc 수용체(FcR) 결합성, 보체 고정 특성 등을 변경시키도록, 불변부 내에 존재하는 하나 이상의 아미노산을 변형시킴.
항체의 불변부를 변경시키는 방법은 당 업계에 공지되어 있다. 기능이 변경된 항체 예를 들어, 효과기 리간드 예를 들어, 세포상의 FcR 또는 보체의 C1 성분에 대한 친화도가 변경된 항체는, 항체의 불변부 내에 존재하는 하나 이상의 아미노산 잔기를, 상이한 잔기로 치환함으로써 생산될 수 있다[예를 들어, EP 388,151 A1, 미국 특허 제5,624,821호 및 동 제5,648,260호; 이 문헌의 내용은 전부 본원에 참고용으로 인용됨]. 변경이 유사한 방식으로 쥣과 동물이나 기타 종의 면역 글로불린에 가하여지면, 그로 말미암아 상기 기능들은 저하 또는 억제될 것으로 생각된다.
예를 들어, 특정 잔기(들)를, 측쇄에 적당한 작용기가 존재하는 잔기(들)로 치환하거나, 또는 하전된 작용기 예를 들어, 글루타메이트 또는 아스파르테이트, 또는 아마도 방향족 비극성 잔기 예를 들어, 페닐알라닌, 티로신, 트립토판 또는 알라닌을 도입함으로써, 항체(예를 들어, IgG 예를 들어, 인간 IgG) Fc부의, FcR(예를 들어, FcγR1), 또는 C1q 결합에 대한 친화성을 변경시킬 수 있다[예를 들어, 미국 특허 제5,624,821호 참조].
항체 또는 이의 결합 단편은 세포 독소, 치료제 또는 방사성 금속 이온과 접합될 수 있다. 하나의 구체예에서, 접합된 단백질은 항체 또는 이의 단편이다. 세포 독소 또는 세포 독성 제제로서는 세포에 유해한 임의의 제제를 포함한다. 이에 관한 비 제한적인 예로서는, 칼리키아마이신, 탁솔, 사이토칼래신 B, 그래마이시딘 D, 브롬화에티듐, 에메틴, 미토마이신, 에토포시드, 테노포시드, 빈크리스틴, 빈블라스틴, 콜히친, 독소루비신, 도노루비신, 디하이드록시 안트라신 디온, 미토잔트론, 미트라마이신, 악티노마이신 D, 1-디하이드로테스토스테론, 글루코코르티코이드, 프로카인, 테트라카인, 리도카인, 프로프라놀롤, 퓨로마이신 및 이의 유사체 또는 상동제를 포함한다. 치료제로서는 대사 길항 물질(예를 들어, 메토트렉세이트, 6-머캡토퓨린, 6-티오구아닌, 시타라빈 및 5-플루오로우라실 디카바진), 알킬화제(예를 들어, 메클로레타민, 티오에파 클로람부실, 멜파란, 카머스틴(BSNU) 및 로머스틴(CCNU), 사이클로토스파미드, 부설판, 디브로모만니톨, 스트렙토조토신, 마이토마이신 C 및 cis-디클로로디아민 백금(II)(DDP), 시스플라틴), 안트라사이클린(예를 들어, 도노루비신 및 독소루비신), 항생제(예를 들어, 닥티노마이신, 블레오마이신, 미트라마이신 및 안트라마이신) 및 항-유사 분열 제제(예를 들어, 빈크리스틴 및 빈블라스틴)를 포함하나, 이에 한정되는 것은 아니다. 이와 같은 부분들을 단백질에 접합하는 기술에 관하여는 당 업계에 널리 공지되어 있다.
대안적으로, 면역화됨에 따라서 내인성 면역 글로불린이 생산되지 않을 때, 인간 항체의 전체 레퍼토리를 생산할 수 있는 유전자 이식 동물(예를 들어, 마우스)를 생산할 수 있다. 예를 들어, 키메라 및 생식 계열 돌연 변이 마우스 내 항체 중쇄 결합부(JM) 유전자를 동질 결실시키면, 내인성 항체 생산이 완전히 억제된다고 알려져 있다. 인간 생식 계열 면역 글로불린 유전자 어레이를 이와 같은 생식 계열 돌연 변이 마우스에 운반하면, 항원 자극시 인간 항체가 생산될 것이다. 예를 들어, 문헌[Jackobovits외 다수, Proc. Natl. Acad. Sci. USA, 90:2551 (1993); Jakobovits외 다수, Nature, 362:255-258 (1993); Bruggermann외 다수, Year in Immune, 7:33 (1983); 및 Duchosal외 다수 Nature 355:258 (1992)]을 참조하시오. 인간 항체는 또한 파지-디스플레이 라이브러리로부터 유래할 수도 있다[Hoogenboom외 다수, J. Mol. Biol. 227:381 (1991); Marks외 다수, J. Mol. Biol., 222:581 -597 (1991); Vaughan외 다수 Nature Biotech 14:309 (1996)].
임의의 구체예에서, 본 발명의 항체는 병행 요법의 일환으로서 기타 제제와 함께 투여될 수 있다. 예를 들어, 염증 병상의 경우, 대상 항체는 염증 질환 또는 병상의 치료에 유용한 하나 이상의 기타 제제와 함께 투여될 수 있다. 심혈관 질환 병상, 특히 죽상 동맥 경화 플라크(실질적인 염증 성분을 함유하는 것으로 여겨짐)로부터 유래하는 병상의 경우, 대상 항체는 심혈관 질환의 치료에 유용한 하나 이상의 기타 제제와 함께 투여될 수 있다. 암의 경우, 대상 항체는 하나 이상의 항-혈관 신생 인자, 화학 요법 제제와 함께 투여될 수 있거나, 아니면 방사선 요법에 대한 애쥬반트로서 투여될 수도 있다. 대상 항체를 투여하는 것은, 다수의 상이한 암 치료제와 병용될 수 있는 암 치료 방법의 일환으로서 사용될 것이라 여겨진다. IBD의 경우, 대상 항체는 하나 이상의 소염제와 함께 투여될 수 있으며, 또한 변형 섭식법과 함께 행하여질 수도 있다.
RAGE-LBE 및 RAGE-BP 사이의 상호 작용을 억제하는 방법
본 발명은 RAGE와 RAGE-BP 사이의 상호 작용을 억제하거나, 또는 RAGE 활성을 변성시키는 방법을 포함한다. 바람직하게, 이와 같은 방법들은 RAGE-관련 질환의 치료에 사용된다.
이러한 방법은 본원에 개시된 바와 같이, RAGE에 대해 생성된 항체를 투여하는 것을 포함할 수 있다. 이와 같은 방법은, 서열 번호 1, 서열 번호 3, 서열 번호 7, 서열 번호 9, 서열 번호 11 또는 서열 번호 13에 제시된 아미노산 서열을 가지는 RAGE 단백질의 하나 이상의 에피토프에 특이적으로 결합하는 항체를 투여하는 것을 포함한다. 또 다른 구체예에서, 이와 같은 방법은, RAGE가 하나 이상의 RAGE-BP와 결합하는 것을 억제하는 화합물을 투여하는 것을 포함한다. 이러한 화합물을 동정하는 대표적인 방법에 관하여는 이하에 기술되어 있다.
임의의 구체예에서, 상호 작용은 시험관 내 예를 들어, 정제된 단백질, 세포, 생물 시료, 조직, 인공 조직 등을 포함하는 반응 혼합물 중에서 억제된다. 임의의 구체예에서, 상호 작용은 예를 들어, RAGE에 결합하는 항체와 이의 RAGE-결합 단편을 투여함으로써, 생체 내에서 억제된다. 항체 또는 이의 단편은 RAGE와 결합하여, RAGE-BP의 결합을 억제한다.
본 발명은 RAGE와 RAGE-BP 사이의 상호 작용을 억제하거나, RAGE 활성을 조정함으로써, RAGE 관련 질환을 예방 또는 치료하는 방법을 포함한다. 이러한 방법은, 상기 질환을 예방 또는 치료하는데 충분한 시간 동안, 상호 작용을 억제하는데 유효한 양만큼, RAGE에 대한 항체를 투여하는 것을 포함한다.
핵산
핵산으로서는, 단일 사슬, 이중 사슬 또는 3중체의 형태를 가지는, 데옥시리보뉴클레오티드 또는 리보뉴클레오티드 그리고 이의 중합체가 있다. 특별히 제한하지 않는 한, 핵산은 참조 천연 핵산과 유사한 특성을 가지는 천연 뉴클레오티드의 공지된 유사체를 함유할 수 있다. 핵산으로서는, 유전자, cDNA, mRNA 및 cRNA를 포함한다. 핵산은 합성될 수 있거나, 또는 임의의 생물학적 공급원 예를 들어, 임의의 유기체로부터 유래할 수 있다.
본 발명의 대표적인 핵산은, 개코 원숭이, 사이노몰거스 원숭이 및 토끼의 RAGE를 암호화하는, 본원에 개시된 cDNA와 상응하는 서열 번호 6, 8, 10 및 12 중 어느 하나에 나타낸 RAGE 암호화 뉴클레오티드 서열, 또는 개코 원숭이 RAGE를 암호화하는 게놈 DNA 서열에 상응하는, 서열 번호 15에 나타낸 RAGE 암호화 뉴클레오티드 서열을 포함한다. 본 발명의 핵산은 또한 서열 번호 16∼49에 나타낸 항체 가변부 아미노산 서열 중 임의의 것을 암호화하는 뉴클레오티드 서열을 포함하기도 한다.
본 발명의 핵산은 또한 서열 번호 6, 8, 10, 12 및 15 중 어느 하나와 실질적으로 동일한 뉴클레오티드 서열 예를 들어, 서열 번호 6, 8, 10, 12 및 15 중 어느 하나와 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5% 또는 99.9% 이상 동일한 뉴클레오티드 서열을 포함할 수도 있다.
본 발명의 핵산은 또한 서열 번호 7, 9, 11 및 13에 나타낸 아미노산 서열 중 어느 하나와 실질적으로 동일한 아미노산 서열을 가지는 RAGE 단백질 암호화 뉴클레오티드 서열 예를 들어, 서열 번호 7, 9, 11 및 13 중 어느 하나와 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5% 또는 99.9% 이상 동일한 아미노산 서열을 가지는 RAGE 단백질 암호화 뉴클레오티드 서열을 포함할 수도 있다.
본 발명의 핵산은 또한 서열 번호 16∼49에 나타낸 아미노산 서열 중 임의의 것과 실질적으로 동일한 아미노산 서열을 가지는 항-RAGE 항체 가변부 암호화 뉴클레오티드 서열 예를 들어, 서열 번호 16∼49 중 어느 하나와 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5% 또는 99.9% 이상 동일한 아미노산 서열 암호화 뉴클레오티드 서열을 포함할 수도 있다.
서열은, 이하에 기술한 바와 같이, 서열 번호 16∼49 중 어느 하나의 서열을 암호화하는 전장 가변부 암호화 서열, 서열 번호 16∼49에 나타낸 서열 중 어느 하나를 가지는 전장 가변부 암호화 뉴클레오티드 서열(의문 서열)을 사용하는 서열 비교 알고리즘을 이용하거나, 또는 가시적 관찰에 의해, 최대 상응성에 대해 비교된다.
실질적으로 동일한 서열은 다형성 서열 즉, 군집 내 대안적 서열 또는 대립 형질일 수 있다. 대립 형질 간 차이는 하나의 염기쌍 정도로 작을 수 있다. 실질적으로 동일한 서열은 또한 돌연 변이된 서열 예를 들어, 침묵 돌연 변이를 포함하는 서열을 포함할 수도 있다. 돌연 변이로서는 하나 이상의 잔기의 변이, 하나 이상의 잔기의 결실, 또는 하나 이상의 부가 잔기의 삽입을 포함할 수 있다.
실질적으로 동일한 핵산은 또한, 엄중한 조건 하에서, 서열 번호 6, 8, 10, 12 또는 15 중 어느 하나의 전장 서열, 또는 서열 번호 7, 9, 11 및 13에 나타낸 RAGE 아미노산 서열을 암호화하는 임의의 전장 뉴클레오티드 서열, 또는 서열 번호 16∼49에 나타낸 항체 가변부 아미노산 서열을 암호화하는 임의의 전장 뉴클레오티드 서열에 특이적으로 혼성화하거나, 또는 이에 실질적으로 혼성화하는 핵산으로서 동정되기도 한다. 핵산 혼성화 과정에 있어서, 비교될 2개의 핵산 서열들은 프로브 및 표적으로 명명될 수 있다. 프로브는 참조 핵산 분자이며, 표적은 테스트 핵산 분자로서, 종종 핵산 분자의 이종 군집 내에서 발견된다. 표적 서열은 테스트 서열과 동의어이다.
혼성화 연구에 있어서, 유용한 프로브는 본 발명의 핵산 분자의 약 14∼40개 이상의 뉴클레오티드 서열에 상보성이거나 또는 이를 모의하는 것이다. 바람직하게, 프로브는 14∼20개의 뉴클레오티드를 포함하며, 원할 경우, 이보다 더욱 긴 서열 예를 들어, 30, 40, 50, 60, 100, 200, 300 또는 500개의 뉴클레오티드, 또는 서열 번호 6, 8, 10, 12 또는 15 중 어느 하나의 전장 서열 이하의 서열, 또는 서열 번호 7, 9, 11 및 13에 나타낸 RAGE 아미노산 서열을 암호화하는 임의의 전장 뉴클레오티드 서열 이하의 서열, 또는 서열 번호 16∼49에 나타낸 항체 가변부 아미노산 서열을 암호화하는 임의의 전장 뉴클레오티드 서열 이하의 서열을 포함한다. 이러한 단편은 예를 들어, 단편을 화학적으로 합성하거나, 핵산 증폭 기술을 적용시키거나, 또는 선택된 서열들을 재조합 벡터에 도입하여 재조합 생산함으로써, 용이하게 제조될 수 있다.
특이적 혼성화란, 특정 뉴클레오티드 서열이 복합 핵산 혼합물(예를 들어, 총 세포 DNA 또는 RNA) 중에 존재할 때, 엄중한 조건 하에서, 어느 분자가 특정 뉴클레오티드 서열과만 결합, 이중체 형성 또는 혼성화하는 것을 의미한다. 특이적 혼성화는 혼성화 조건의 엄중도에 따라서 프로브와 표적 서열 간 미스매치부를 수용할 수 있다.
핵산 혼성화 실험 예를 들어, 서던 블럿 분석법(Southern blot analysis) 및 노던 블럿 분석법(Northern blot analysis)에 있어서 엄중한 혼성화 조건 및 엄중한 혼성화 세척 조건은, 둘 다 서열-의존적 및 환경-의존적이다. 보다 긴 서열은 고온에서 특이적으로 혼성화한다. 핵산의 혼성화에 관한 상세한 지침은 문헌[Tijssen (1993) Laboratory Techniques in Biochemistry and Molecular Biology-Hybridization with Nucleic Acid Probes, part I chapter 2, Elsevier, New York, New York]에서 살펴볼 수 있다. 일반적으로, 고도로 엄중한 혼성화 조건 및 세척 조건으로서는, 특정 이온 세기 및 pH에서 특이적 서열에 대한 용융점(Tm)보다 약 5℃ 낮은 온도가 선택된다. 통상적으로, 엄중한 조건 하에서, 프로브는 그것의 표적 내부 서열에 특이적으로 혼성화할 것이지만, 다른 서열에는 그러하지 않을 것이다.
Tm은, (특정의 이온 세기 및 pH 하에서) 표적 서열의 50%가 완전히 매치되는 프로브에 혼성화되는 온도를 말한다. 매우 엄중한 조건으로서는, 특정 프로브에 대해 Tm과 동일한 온도가 선택된다. 약 100개 이상의 상보성 잔기를 가지는 상보성 핵산의 서던 블럿 분석법 또는 노던 블럿 분석법에 대한 엄중한 혼성화 조건의 예로서는, 42℃에서 50%의 포름아미드 중 1㎎의 헤파린과 밤새도록 혼성화시키는 것이 있다. 매우 엄중한 세척 조건의 예로서는, 65℃의 0.1×SSC 중에서 15분 동안 세척하는 것이 있다. 엄중한 세척 조건의 예로서는, 65℃의 0.2×SSC 완충액 중에서 15분 동안 세척하는 것이 있다. SSC 완충액에 관하여 설명되어 있는 문헌[Sambrook외 다수, eds (1989) Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York]을 참조하시오. 종종, 고도로 엄중한 세척은, 백그라운드 프로브 신호를 없애기 위해, 낮은 엄중도 세척후 수행되기도 한다. 약 100개 이상의 뉴클레오티드로 이루어진 이중체에 대한 중간 정도의 엄중도 세척 조건의 예로서는, 45℃의 1×SSC 중에서 15분 동안 세척하는 것이 있다. 약 100개 이상의 뉴클레오티드로 이루어진 이중체에 대한 낮은 정도의 엄중도 세척의 예로서는, 40℃의 4∼6×SSC 중에서 15분 동안 세척하는 것이 있다. 짧은 프로브(예를 들어, 약 10∼50개의 뉴클레오티드)의 경우, 엄중한 조건으로서는 통상적으로, pH 7.0∼8.3에서, 염 농도가 약 1M 미만 Na+ 이온, 통상적으로는 약 0.01∼1M Na+ 이온(또는 기타 염)인 경우와, 온도가 통상적으로 약 30℃ 이상인 경우가 있다. 엄중한 조건은 또한 탈안정화제 예를 들어, 포름아미드를 첨가함으로써 이루어질 수도 있다. 일반적으로, 신호 대 노이즈 비율은, 특정 혼성화 검정법에 있어, 관련되지 않은 프로브에서 관찰되는 신호 대 노이즈 비율보다 2배(또는 그 이상) 더 큰데, 이는 곧 특이적 혼성화가 일어남을 말해주는 것이다.
이하에는, 본 발명의 참조 뉴클레오티드 서열과 실질적으로 동일한 뉴클레오티드 서열을 동정하는데 사용될 수 있는 혼성화 조건 및 세척 조건의 예에 관하여 기술되어 있는데: 즉, 바람직하게, 프로브 뉴클레오티드 서열을 7% 소듐 도데실 설페이트(SDS), 0.5M NaPO4, 1mM EDTA 중(50℃)에서 표적 뉴클레오티드 서열과 혼성화시킨 다음, 이를 2×SSC, 0.1% SDS(50℃) 중에서 세척하는 것; 더욱 바람직하게는, 프로브와 표적 서열을 7% 소듐 도데실 설페이트(SDS), 0.5M NaPO4, 1mM EDTA 중(50℃)에서 혼성화시킨 다음, 이를 1×SSC, 0.1% SDS(50℃) 중에서 세척하는 것; 더욱 바람직하게는, 프로브와 표적 서열을 7% 소듐 도데실 설페이트(SDS), 0.5M NaPO4, 1mM EDTA 중(50℃)에서 혼성화시킨 다음, 이를 0.5×SSC, 0.1% SDS(50℃) 중에서 세척하는 것; 더욱 바람직하게는, 프로브와 표적 서열을 7% 소듐 도데실 설페이트(SDS), 0.5M NaPO4, 1mM EDTA 중(50℃)에서 혼성화시킨 다음, 이를 0.1×SSC, 0.1% SDS(50℃) 중에서 세척하는 것; 더욱 바람직하게는 프로브와 표적 서열을 7% 소듐 도데실 설페이트(SDS), 0.5M NaPO4, 1mM EDTA 중(50℃)에서 혼성화시킨 다음, 이를 0.1×SSC, 0.1% SDS(65℃) 중에서 세척하는 것이 있다.
2개의 핵산 서열이 실질적으로 동일하다는 것에 관한 추가의 지표로서는, 핵산에 의해 암호화된 단백질이 실질적으로 동일하고, 전체적으로 3차원 구조를 공유하며, 또는 생물 기능을 가지는 균등물이 있다는 것을 들 수 있다. 이러한 용어들은 이하에 보다 상세히 기술되어 있다. 엄중한 조건 하에서 서로 혼성화하지 않는 핵산 분자는, 상응하는 단백질이 실질적으로 동일하다면, 여전히 실질적으로 동일한 것이다. 이는 예를 들어, 2개의 뉴클레오티드 서열이, 유전자 코드에 의해 허용되는 바와 같이, 보존적으로 치환된 변이체를 포함할 때에 그러할 수 있다.
보존적으로 치환된 변이체로서는 축퇴성 코돈 치환이 일어난 핵산 서열이 있는데, 여기서, 하나 이상의 선택된 코돈(또는 코돈 전부) 중 세번째 위치는 혼합-염기 및/또는 데옥시이노신 잔기로 치환된다. 문헌[Batzer외 다수 (1991) Nucleic Acids Res. 19:5081 ; Ohtsuka외 다수 (1985) J. Biol. Chem. 260:2605-2608; 및Rossolini외 다수 (1994) Mol. Cell Probes 8:91-98]을 참조하시오.
본 발명의 핵산은 또한 서열 번호 6, 8, 10, 12 또는 15 중 어느 하나에 상보성인 핵산, 또는 서열 번호 7, 9, 11 및 13에 나타낸 RAGE 아미노산 서열을 암호화하는 뉴클레오티드 서열, 또는 서열 번호 16∼49에 나타낸 항체 가변부 아미노산 서열을 암호화하는 뉴클레오티드 서열, 그리고 이의 상보성 서열을 포함하기도 한다. 상보성 서열이란, 염기쌍 간에 수소 결합을 형성할 때, 서로 쌍을 이룰 수 있는 역평행 뉴클레오티드 서열을 포함하는 2개의 뉴클레오티드 서열을 말한다. 본원에 사용된 상보성 서열이란 용어는, 이하에 기술된 것과 동일한 뉴클레오티드 비교 방법에 의해 평가될 수 있는 바와 같이, 실질적으로 상보성이거나, 또는 비교적 엄중한 조건 예를 들어, 본원에 개시된 바와 같은 조건 하에서, 의문 핵산 분절에 혼성화할 수 있는 것으로 정의되는 뉴클레오티드 서열을 의미한다. 상보성 핵산 분절의 구체예로서는 안티센스 올리고뉴클레오티드가 있다.
내부 서열은 길이가 긴 핵산 서열의 일부를 포함하는 핵산의 서열을 말한다. 대표적인 내부 서열로서는 전술한 바와 같은 프로브, 또는 프라이머가 있다. 본원에 사용된 프라이머란 용어는, 선택된 핵산 분자 중 약 8개 이상의 데옥시리보뉴클레오티드 또는 리보뉴클레오티드, 바람직하게는 10∼20개의 뉴클레오티드, 그리고 더욱 바람직하게는 20∼30개의 뉴클레오티드를 포함하는 연속 서열을 의미한다. 본 발명의 프라이머는 충분한 길이와 적당한 서열을 가져서, 본 발명의 핵산 분자 상에서 중합을 개시할 수 있는 올리고뉴클레오티드를 포함한다.
연장된 서열은 핵산에 통합된 부가의 뉴클레오티드(또는 기타 유사 분자)를 포함한다. 예를 들어, 중합 효소(예를 들어, DNA 중합 효소)는 핵산 분자의 3' 말단에 서열을 부가할 수 있다. 뿐만 아니라, 뉴클레오티드 서열은 다른 DNA 서열 예를 들어, 프로모터, 프로모터 부위, 인핸서, 폴리아데닐화 신호, 인트론 서열, 부가 제한 효소 위치, 다중 클로닝 위치, 및 기타 암호화 분절과 합하여질 수 있다. 그러므로, 본 발명은 또한, 본원의 핵산을 포함하는 벡터 예를 들어, 재조합 발현을 위한 벡터를 제공하기도 하는데, 여기서, 본 발명의 핵산은 작용성 프로모터에 작동 가능하도록 결합되어 있다. 핵산에 작동 가능하도록 결합될 때, 프로모터는 핵산과 작동 가능하도록 합체되므로, 핵산의 전사는 프로보터 부위에 의해 제어 및 조절된다. 벡터란, 숙주 세포 내에서 복제할 수 있는 핵산 예를 들어, 플라스미드, 코스미드 및 바이러스 벡터를 의미한다.
본 발명의 핵산은 클로닝, 합성, 변경, 돌연 변이될 수 있거나, 또는 이것들이 조합하여 일어날 수 있다. 핵산을 분리하는데 사용된 표준적인 재조합 DNA와 분자 클로닝 기술에 관하여는 당 업계에 공지되어 있다. 염기쌍 변이, 결실 또는 소규모의 삽입을 실시하기 위한 위치-특이적 돌연 변이 유발법에 관하여도 당 업계에 공지되어 있다. 예를 들어, 문헌[Sambrook외 다수 (eds.) (1989) Molecular Cloning: A Laboratory Manual. Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York; Silhavy외 다수 (1984) Experiments with Gene Fusions. Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York; Glover & Hames (1995) DNA Cloning: A Practical Approach, 2nd ed. IRL Press at Oxford University Press, Oxford/New York; Ausubel (ed.) (1995) Short Protocols in Molecular Biology, 3rd ed. Wiley, New York]을 참조하시오.
예방 방법 및 치료 방법
본 발명은 Aβ의 아밀로이드 침착물의 생성을 특징으로 하는 질병 또는 질환 예를 들어, 알츠하이머병이 발병한 개체를 치료하는 방법을 제공하는데, 이 방법은, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와와의 결합을 억제하는 항체를 치료학적 유효량만큼 상기 개체에 투여하는 단계를 포함한다.
본 발명은 또한, 개체 내 Aβ의 아밀로이드 침착물이 축적되는 것을 억제 또는 감소시키는 방법을 제공하는데, 이 방법은, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와의 결합을 억제하는 항체를 유효량만큼 상기 개체에 투여하는 단계를 포함한다. 또한, 본 발명은 개체 내 신경 퇴화를 억제 또는 감소시키는 방법도 포함하는데, 이 방법은, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와의 결합을 억제하는 항체를 유효량만큼 상기 개체에 투여하는 단계를 포함한다. 본 발명은 또한, 개체 내 인지 기능 감퇴를 억제 또는 감소시키는 방법, 또는 인지 기능을 개선하는 방법도 포함하는데, 이 방법은, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와의 결합을 억제하는 항체를 유효량만큼 상기 개체에 투여하는 단계를 포함한다. 본 발명은 또한 아밀로이드 침착물의 생성을 특징으로 하는 아밀로이드 형성 질병 또는 질환이 발병한 개체를 치료하는 방법을 제공하는데, 이 방법은, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와의 결합을 억제하는 항체를 치료학적 유효량만큼 상기 개체에 투여하는 단계를 포함한다.
본 발명은 Aβ의 아밀로이드 침착물의 생성을 특징으로 하는 질병 또는 질환 예를 들어, 알츠하이머병이 발병한 개체를 치료하는 방법을 제공하는데, 이 방법은, 개체 즉 환자의 체 내에서 유리한 치료 반응(예를 들어, 플라크 함량(plaque load) 감소, 플라크 형성 억제, 신경 돌기 이영양증의 완화, 그리고 인지 기능의 개선 예를 들어, 인지 기능의 신속한 개선 및/또는 인지 기능 감퇴의 역전, 치료 또는 예방)을 일으키는 조건 하에, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와의 결합을 억제하는 항체를 치료학적 유효량만큼 상기 개체에 투여하는 단계를 포함한다.
뇌 내 Aβ의 아밀로이드 침착물과 관련된 질병으로서는 알츠하이머병, 다운증후군 및 인지 기능 손상을 포함한다. 후자는 아밀로이드 형성 질환의 기타 특징을 동반하거나 또는 동반하지 않을 수 있다.
고혈당증 상태가 오랜 기간 동안 지속될 때 형성되는 진행성 당화 최종 생성물 이외에, RAGE의 리간드는 아밀로이드 침착물 및 전염증 매개 인자의 특징을 가지는, β-시트 섬유상 구조를 가지는 단백질 예를 들어, 베타-아밀로이드 단백질(Aβ), 혈청 아밀로이드(SAA)(섬유형), S100/칼그래뉼린(예를 들어, S100A12, S100B, S100A8-A9), 그리고 고 이동성 군 박스-1 염색체 단백질 1(High Mobility Group Box-1 chromosomal protein 1; HMGB1; 암포테린이라고도 알려짐)을 포함한다. 아밀로이드 형성 질환의 병리학적 진행 과정에 있어서의 RAGE의 역할에 관한 관심이 점점 높아지고 있다. 알츠하이머병을 발병시키는 것 이외에도, RAGE는 비장 내 세포 스트레스와 혈청 아밀로이드 A(SA)의 침착과 밀접한 관련이 있는 것으로 파악된다[Yan외 다수, 2000, Nature Med., 6:643-51]. RAGE는, 신장 내에 아밀로이드가 축적되는 것, 그리고 가족성 아밀로이드성 다발 신경병증(Familial amyloidotic poly-neuropathy; FAP)을 앓고 있는 개체의 신부전을 유발시키는 조직 손상과도 연관되어 있다[Matsunaga외 다수, 2005, Scand. J. Clin. Lab. Invest.]. RAGE 리간드 암포테린(HMGB1)은 또한 아밀로이드 형성 펩티드(즉, 알츠하이머 Aβ 펩티드와의 상동성이 매우 크며, 원래의 단백질로부터 방출될 때 아밀로이드-유사 펩티드를 형성하는 펩티드)를 함유하기도 한다[Kallijarvi외 다수, 2001 , Biochem., 40:10032-7].
혈관 벽에 존재하는 RAGE-보유 세포와 Aβ의 상호 작용 결과, Aβ가 혈관-뇌 장벽(BBB)을 통과하여 이동하게 되고, 또한 전염증 시토킨과 엔도셀린-1(endothelin-1;ET-1)을 발현하게 되는데, 여기서 상기 엔도셀린-1은 Aβ-유도 혈관 수축을 매개한다. 그러므로, 본 발명은 Aβ-유도성 혈관 수축을 감소시키는 방법도 제공한다.
RAGE-리간드 상호 작용을 억제하면, 알츠하이머-유사 질병에 대한 유전자 이식 마우스 모델에 있어서, 뇌의 실질 조직 내에 Aβ가 축적되는 것을 억제하는 것으로 파악된다[Deane외 다수, 2003, Nature Medicine 9:907-913]. 다양한 범위의 아밀로이드 형성 질병 및 질환에 있어서 활동적이면서 발병을 유도하는 RAGE의 역할로 말미암아, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와의 결합을 억제하는 항체를 제공하는, 본 발명의 방법에 의하여 아밀로이드 형성 질환 환자를 치료학적으로 유리하게 치료할 수 있게 된다.
본 발명의 방법은 무증상성 환자 및 현재 질병에 대한 증상을 나타내는 환자 둘 다에 적용될 수 있다. 이와 같은 방법에 사용된 항체는 본원에 개시된 바와 같은, 인간 항체, 인간화된 항체, 키메라 항체 또는 인간 이외의 동물의 항체 또는 이것들의 단편(예를 들어, RAGE 결합 단편)일 수 있다. 또 다른 측면에서, 본 발명은, Aβ 펩티드로 면역화된 인간으로부터 생산된 항체[이 항체는 단지 결실되었을 것임에도 불구하고, RAGE이어야 하는 것으로 가정됨]를 투여하는 것을 특징으로 하며, 이때, 상기 인간은 항체로 치료받을 환자일 수 있다. 본 발명의 치료 방법은 이하 (a)∼(d)의 특징을 가지는 항체를 사용하여 수행될 수 있다:
(a) RAGE와의 결합에 대해, XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체와 경쟁함;
(b) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체에 의해 결합되는 RAGE의 에피토프에 결합함;
(c) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체의 경쇄 또는 중쇄의 하나 이상의 상보성 결정부(CDR)를 포함함; 또는
(d) 상기 (a)∼(c)에 의한 항체의 RAGE-결합 단편임.
예를 들어, 본 발명의 방법은, XT-M4 경쇄 가변부(서열 번호 17)의 CDR을 포함하는 경쇄 가변부, XT-M4 중쇄 가변부 서열(서열 번호 16)의 CDR을 포함하는 중쇄 가변부, 인간 카파 경쇄 불변부; 그리고 인간 IgG1 중쇄 불변부를 포함하는, 항체 또는 RAGE-결합 항체 단편을 상기 개체에 투여함으로써 수행될 수 있다. 본 발명의 방법은 또한, XT-M4 경쇄 가변부의 아미노산 서열(서열 번호 17)을 가지는 경쇄 가변부, XT-M4 중쇄 가변부 서열의 아미노산 서열(서열 번호 16)을 가지는 중쇄 가변부, 인간 카파 경쇄 불변부; 그리고 인간 IgG1 중쇄 불변부를 포함하는, 항체 또는 이의 RAGE-결합 단편을 사용하여 수행될 수도 있다. 본 발명의 방법에 성공적으로 사용될 수 있는 상기 항체 및 기타 다수의 항체에 관한 설명은 본원에 기술되어 있다.
본 발명의 치료제는 통상적으로, 원치 않는 오염 물질이 실질적으로 존재하지 않는다. 이는 곧, 상기 제제가 통상적으로, 약 50% w/w(중량/중량) 이상 순수하며, 방해 단백질 및 오염 물질이 실질적으로 제거된 상태임을 의미한다. 종종 상기 제제의 순도는 약 80% w/w 이상, 더욱 바람직하게는 90% w/w 이상 또는 약 95% w/w 이상이다. 그러나, 종래의 단백질 정제 기술을 이용하면, 순도 99% w/w 이상인 균질한 펩티드가 얻어질 수 있다.
본 발명은 항체와 약학 담체를 약학 조성물로서 투여하는 것을 포함한다. 대안적으로, 본 발명의 항체는 하나 이상의 항체 사슬을 암호화하는 폴리뉴클레오티드를 투여함으로써 환자에 투여될 수 있다. 이 폴리뉴클레오티드는 환자의 체 내에서 발현되어 항체 사슬을 생산한다. 상기 폴리뉴클레오티드는 상기 항체의 중쇄 및 경쇄를 암호화할 수 있다. 상기 폴리뉴클레오티드는 환자의 체 내에서 발현되어, 중쇄 및 경쇄를 생산한다. 대표적인 구체예에서, 환자는 투여된 항체의 환자의 혈중 수준에 대해 관찰된다.
그러므로, 본 발명은 신경 병리학적 병상(일부 환자의 경우에는 알츠하이머병과 관련된 인지 기능 손상)을 예방 또는 완화하는 치료 방법에 대한 지속적인 요망을 충족하여 주는 것이다.
인지 기능 감퇴의 완화 및/또는 인지 기능의 개선
본 발명은 Aβ-관련 질병 또는 질환, 또는 아밀로이드 형성 질병 또는 질환(예를 들어, AD)이 발병하였거나 또는 발병 위험이 있는 환자에 있어서, 인지 기능 감퇴를 억제 또는 완화하고/하거나 인지 기능을 개선하는 방법을 제공하는데, 이 방법은, RAGE에 특이적으로 결합하여 RAGE 결합 파트너와의 결합을 억제하는 항체를 유효량만큼 상기 개체에 투여하는 단계를 포함한다.
본 발명의 방법은, 본 발명의 항체를 유효량만큼 투여함으로써, 인지 기능 감퇴를 완화하고/완화하거나, 인지 기능을 개선하는 것을 특징으로 한다. 예를 들어, 환자의 하나 이상의 인지 기능 손상(예를 들어, 절차 학습 손상 및/또는 기억력 손상)을 개선할 수 있는 것이다. 인지 기능 손상은 외현적 기억(이를 "서술 기억" 또는 "작동 기억"이라고도 함) 즉, 의식에 적용될 수 있는 특정 정보를 저장 및 절충하는 능력으로 정의될 수 있으며, 언어에 의해 표현할 수 있는 능력(예를 들어, 특정 사실이나 사건을 기억하는 능력)에 손상을 입는 것일 수 있다. 대안적으로, 인지 기능 손상은 절차 기억(이를 "암묵 기억" 또는 "정황 기억(contextual memory)"이라고도 함) 즉, 의식에 적용될 수 없는 일반적인 정보 또는 지식을 습득, 보유 및 절충하는 능력으로서 정의될 수 있으며, 표현될 기능, 연상, 습관 또는 복합적 반사 작용을 학습함으로써 익혀지는 능력 예를 들어, 특정 과제를 수행하는 방법을 기억해내는 능력에 손상을 입는 것일 수 있다. 절차 기억에 손상을 입은 사람들은 정상적으로 행동하는 능력에 더욱 많은 손상을 입게 된다. 그러므로, 절차 기억 손상을 개선할 수 있는 치료법이 매우 요망되며, 또한 유용하다.
치료에 순응하는(amenable) 환자
본 발명의 방법에 의한 치료법에 대하여 순응하는 환자들로서는, Aβ-관련 질병이나 질환, 또는 아밀로이드 형성 질병이나 질환이 발병할 위험이 있되, 증상은 나타내지 않고 있는 사람, 그리고 현재 증상을 나타내는 사람을 포함한다. 알츠하이머병의 경우, 실제로 어떤 사람이 충분히 오래 산다면, 알츠하이머병을 앓고 있을 위험이 있다. 그러므로, 본 발명의 방법은 대상 환자의 발병 위험성을 평가할 필요 없이 일반 군집에 예방적인 차원에서 수행될 수 있다.
본 발명의 방법은 AD의 발병 위험이 있는 사람 예를 들어, AD에 대한 위험 인자를 나타내는 사람에 특히 유용하다. AD에 대한 주요 위험 인자는 고령이다. 군집이 나이를 먹음에 따라서, AD의 발병 빈도도 계속해서 높아진다. 현재 조사 결과에 따르면, 65세 이상의 군집 중 10% 이하, 그리고 85세 이상의 군집 중 50% 이하가 AD를 앓고 있다고 추정되고 있다.
드물기는 하지만, 임의의 개체는 조기에 유전적으로 AD로 진행될 소인이 있는 것으로 확인될 수 있다. 유전적으로 AD("가족성 AD" 또는 "조기-발병 AD"라고 알려져 있음)로 진행될 가능성이 있는 개체는, 예를 들어, APP 또는 프레세닐린 유전자가 돌연 변이될 때, AD로 진행시키는 것으로 알려진 유전자의 분석을 통하여, AD에 대한 가족력을 널리 확립함으로써 확인될 수 있다. 널리 특성 규명된 APP 돌연 변이로서는, APP770의 716번 및 717번 코돈에서 발생하는 "하디(Hardy)" 돌연 변이[예를 들어, 발린717 → 이소루신(Goate외 다수, (1991), Nature 349:704); 발린717 → 글리신(Chartier외 다수 (1991) Nature 353:844; Murrell외 다수 (1991), Science 254:97); 발린717 → 페닐알라닌(Mullan외 다수 (1992), Nature Genet. 1 :345-7)], APP770의 670번 및 671번 코돈에서 발생하는 "스웨디쉬(Swedish)" 돌연 변이, 그리고 APP770의 692번 코돈에서 발생하는 "플레미쉬(Flemish)" 돌연 변이를 포함한다. 이와 같은 돌연 변이들은 APP → Aβ로의 가공을 촉진 또는 변경함으로써, 특히, APP를 가공하여 Aβ의 장형(즉, Aβ1∼42 및 Aβ1∼43)의 양을 증가시킴으로써, 알츠하이머병을 일으키는 것으로 생각된다. 다른 유전자 예를 들어, 프레세닐린 유전자, PS1 및 PS2에서의 돌연 변이는 APP의 가공 과정에 간접적으로 영향을 미쳐 Aβ의 장형의 양을 증가시키는 것으로 생각된다[Hardy, TINS 20: 154 (1997); Kowalska외 다수, (2004), Polish J. Pharmacol., 56: 171-8 참조]. AD 이외에도, APP의 770-아미노산 아형의 692번 또는 693번 아미노산에서 발생하는 돌연 변이는, 더치-유형의 아밀로이드증을 동반하는 유전성 뇌 출혈(Hereditary Cerebral Hemorrhage with Amyloidosis of the Dutch-type; HCHWA-D)이라고 불리는 뇌의 아밀로이드 형성 질환에서 일어난다.
더욱 일반적으로, AD는 환자에 의해 유전되는 질병은 아니지만, 다양한 유전적 요인들의 복합적인 상호 작용에 의해 진행된다. 이러한 개체들을 "산발성 AD"("후기-발병 AD"라고도 함)(진단이 훨씬 어려운 AD의 한 형태임)가 발병한 환자라고 부른다. 그럼에도 불구하고, 환자 집단은, AD는 유발시키지 않으며, AD와는 별개인 것으로 알려진 민감성 대립 형질 또는 특징 예를 들어, 아포지단백 E의 ε2, ε3 및 ε4 대립 형질의 출현 빈도가 일반 집단에 비하여 높은지 여부에 대해 스크리닝될 수 있다[Corder외 다수(1993), Science, 261 : 921-923]. 특히, (바람직하게는 AD에 대한 기타 몇몇 마커 이외에) ε4를 가지고 있지 않은 환자는 AD에 대한 "발병 위험이 있는" 것으로 간주될 수 있다. 예를 들어, AD가 발병한 환자나, 고 콜레스테롤 혈증 또는 죽상 동맥 경화증이 발병한 환자와 친척 관계에 있는, ε4 결핍 환자는 AD에 대한 "발병 위험이 있는" 것으로 간주될 수 있다. 기타 유효한 생물 마커로서는, 뇌 척수액(CSF) Aβ42 및 tau 수준을 종합적으로 평가한 결과가 있다. Aβ42의 수준이 낮고 tau 수준이 높은 것은, AD의 발병 위험이 있는 환자를 동정함에 있어서 전조가 된다.
AD의 발병 위험이 있는 환자에 대한 기타 지표으로서는, 생체 내 역동적 신경 병리학적 데이터 예를 들어, 뇌의 베타 아밀로이드의 생체 내 검출 결과 및 뇌 활동 패턴 등을 포함한다. 이러한 데이터는 예를 들어, 3차원 자기 공명 영상화(MRI), 양전자 방출 단층 촬영술(PET) 스캔 및 단일-양자 방출 컴퓨터 단층 촬영술(SPECT)을 이용하여 얻어질 수 있다. AD가 발병하였을 가능성이 있는 환자에 대한 지표로서는, (1) 치매 환자, (2) 연령 40∼90세인 환자, (3) 예를 들어, 2개 이상의 인지 영역에 있어서 인지 기능에 결함이 있는 경우, (4) 6개월 이상의 기간 동안 결함이 진행된 경우, (5) 의식에 교란이 일어나지 않은 경우, 및/또는 (6) 기타 합리적 진단이 없었던 경우를 포함하나, 이에 한정되는 것은 아니다.
그러나, 산발성 AD 또는 가족성 AD를 앓고 있는 개체는 일반적으로, AD에 관한 하나 이상의 특징적인 증상을 나타낼 경우, 이 개체는 상기 질병이 발병된 것으로 진단된다. AD의 일반적인 증상으로서는, 통상적인 기능이나 과제 수행 능력에 영향을 미치는 인지 기능 장애, 언어 장애, 시간이나 장소에 대하여 혼동하는 증상, 판단력 저하 또는 감퇴, 추상적인 생각을 못하게 되는 경우, 운동 기능 제어력의 상실, 감정 또는 행동의 급변, 성격 변화 또는 창의력 상실을 포함한다. 환자에 의해 나타나는 결함의 수 또는 인지 기능 손상의 정도는, 질병이 진행된 정도를 반영한다. 예를 들어, 환자가 경미한 인지 기능 손상만을 나타낼 수 있다면, 이 환자는 기억(예를 들어, 정황 기억)에 문제가 있지만, 행동하는데는 지장이 없다.
본 발명의 방법은 또한, Aβ-관련 인지 기능 손상 예를 들어, Aβ-관련 치매를 앓고 있는 개체에도 유용하다. 특히, 본 발명의 방법은 중추 신경계(CNS) 예를 들어, 뇌 또는 CSF에 가용성 올리고머 Aβ가 존재함으로 인하여 유발되거나 또는 이 Aβ로 인해 발생하는 인지 기능 손상 또는 이상성을 나타내는 개체에 특히 유용하다. Aβ에 의해 유발되거나 이 Aβ와 관련된 인지 기능 손상으로서는, (1) 뇌 내 β-아밀로이드 플라크 형성; (2) 비정상적인 Aβ 합성률, 가공률, 분해율 또는 소멸률; (3) (예를 들어, 뇌 내) 가용성 올리고머 Aβ 종의 형성 또는 활성; 및/또는 (4) 비정상적인 Aβ형의 형성에 의해 유발되거나 또는 이것과 관련된 증상을 포함한다. 실제로 특정 환자에 있어서 Aβ 비정상성과 인지 기능 손상 간 발병 연관성이 있을 필요는 없으나, AD에 관한 전술한 마커 중 하나와 연관성이 있어서, Aβ 면역 치료제를 사용하는 치료법에 의해서는 혜택을 받을 것으로 예상되지 않는 비-Aβ 관련 인지 기능 손상 환자를 어느 정도 구별할 수 있어야 한다.
인간 개체 예를 들어, 치매 질환(예를 들어, AD)의 증상을 나타낼 위험이 있거나 또는 이를 나타내는 개체, 또는 이 증상에 대한 병리학적 소견을 보이는 개체에서 인지 기능 또는 수행 능력을 평가하기 위한 몇 가지 테스트가 개발되었다. 이 테스트에서 수행 능력이 손상된 것으로 판명되면, 인지 기능 손상이 나타난 것으로 평가될 수 있으며, 이 테스트에서 수행 능력을 개선할 수 있는 능력을 바탕으로 하는 다수의 치료법이 제안되었다. 비록 몇몇 과제가 개체의 행동이나 움직임을 평가하였다고는 하나, 대부분의 과제는 학습 또는 기억을 테스트하도록 디자인되었다.
인간의 인지 기능은 다양한 테스트 예를 들어, 다음과 같은 테스트들을 이용하여 평가될 수 있다. ADAS-Cog(알츠하이머병 평가 스케일-인지 기능; Alzheimer Disease Assessment Scale-Cognitive)는 총 30분이 소요되는, 11개의 파트로 구성된 테스트이다. 상기 ADAS-Cog는 언어 및 기억 기능에 관하여 연구하기 위한 간단한 테스트로서 바람직하다. 문헌[Rosen외 다수 (1984) Am J Psychiatry. 141 (11 ):1356-64; IhI외 다수 (2000) Neuropsychobiol. 41 (2):102-7; 및 Weyer외 다수 (1997) Int Psychogeriatr. 9(2): 123-38]을 참조하시오.
블레스드 테스트(Blessed Test)는, 일상 생활 능력과 기억력, 집중력 및 방향성을 평가하는 속성(약 10분 소요) 인지 기능 테스트의 다른 예이다. 문헌[Blessed외 다수 (1968) Br J Psychiatry 114(512):797-811]을 참조하시오.
캠브리지 신경 심리학 테스트 자동화 배터리(The Cambridge Neuropsychological Test Automated Battery; CANTAB)는 신경 퇴행성 질병 또는 뇌 손상을 입은 인간에 있어서 인지 기능 손상을 평가하는데 사용된다. 이 방법은, 기억, 집중력 및 수행 능력에 관한, 13개의 상관된 컴퓨터 실행 테스트들로 이루어져 있으며, 개인 컴퓨터를 통하여 터치 스크린 방식으로 수행된다. 이 테스트는 언어와 전반적인 문화에 영향을 받지 않는 방법으로서, 알츠하이머병을 조기에 발견하고자 할때와 평상시 스크리닝하고자 할 때 매우 감수성이 높은 것으로 보인다. 문헌[Swainson외 다수 (2001) Dement Geriatr Cogn Disord.; 12:265-280; 및 Fray and Robbins (1996) Neurotoxicol Teratol. 18(4):499-504. Robbins외 다수 (1994) Dementia 5(5):266-81]을 참조하시오.
알츠하이머병에 대한 등록을 확립하기 위한 컨소시엄(The Consortium to Establish a Registry for Alzheimer's Disease; CERAD) 임상 및 신경 심리학적 테스트로서는, 언어 유창성 테스트, 보스톤 명명 테스트(Boston Naming Test), 정신 상태에 관한 소규모 검사법(Mini Mental State Exam; MMSE), 10가지 아이템 단어 기억 테스트, 언어 구사력 및 구조력 테스트(constructional praxis) 및 연습한 단어를 한참 후에 기억해내는 테스트를 포함한다. 상기 테스트는 통상적으로 20∼30분 정도 소요되며, 인지 기능 감퇴를 평가 및 추적하는데 편리하고도 효율적이다. 문헌[Morris외 다수 (1988) Psychopharmacol Bull. 24(4):641-52; Morris외 다수 (1989) Neurology 39(9):1159-65; 및 Welsh외 다수 (1991) Arch Neurol. 48(3):278-81]을 참조하시오.
1975년 폴슈타인(Folestein)외 다수에 의해 개발된 정신 상태에 관한 소규모 검사법(MMSE)은, 정신적인 상태와 인지 기능에 대한 간단한 테스트이다. 이 방법은 기타 정신적 현상에 대해 측정하는 것이 아니므로, 전체적인 상태에 관한 관찰 방법의 대안이 되지 않는다. 이 방법은 치매를 스크리닝하는데 유용하며, 스코어를 메기는 시스템은 시간에 따른 진행 경과를 관찰하는데 유용하다. 상기 정신 상태에 관한 소규모 검사법(MMSE)은 연령과 교육 수준에 맞춘 기준을 바탕으로 하여 널리 사용되고 있다. 이 방법은 인지 기능 손상 여부에 대하여 스크리닝하여, 소정의 시점에서의 인지 기능 손상의 심각성을 평가하고, 시간이 경과함에 따라서 개체 내에서 일어나는 인지 기능 변화의 경과를 추적하며, 치료법에 대한 개체의 반응을 기록하는데 사용될 수 있다. 개체의 인지 기능 평가에는, (인간에 있어서) 9개월 이상의 간격으로 추적 테스트를 수행하는, 정규 신경 심리학적 테스트를 필요로 할 수 있다. 문헌[Folstein외 다수 (1975) J Psychiatr Res. 12:196-198; Cockrell and Folstein (1988) Psychopharm Bull. 24(4):689-692; 및 Crum외 다수 (1993) J. Am. Med. Association 18:2386- 2391]을 참조하시오.
7분 스크리닝법(Seven-Minute Screen)은 알츠하이머병에 대해 평가되어야 할 환자를 동정하도록 도와주는 스크리닝 방법이다. 이 스크리닝 방법은, 상이한 유형의 지적 기능을 평가하기 위한 일련의 질문들을 이용하는 방법으로서, AD에 관한 조기 징후에 대해 감수성이 뛰어나다. 이 테스트는 방향성, 기억력, 공간 시각 기능 및 자기 표출적 언어에 초점을 맞춘 질문들로 이루어진 4개의 세트로 이루어져 있다. 이는 정상적인 노화 과정으로 인한 인지 기능 변화와, 치매로 인한 인지 기능 손상을 구별해낼 수 있다. 문헌[Solomon and Pendlebury (1998) Fam Med. 30(4):265-71, Solomon외 다수 (1998) Arch Neurol. 55(3):349-55]을 참조하시오.
현재 알츠하이머병을 앓고 있는 개체는 치매가 발병하였는지 여부와, 전술한 위험 인자들이 존재하는지 여부를 바탕으로 하여 판단될 수 있다. 또한, 다수의 진단 테스트를 통하여 AD를 앓고 있는 개체를 동정해낼 수 있다. 이에는 CSF tau 수준과 Aβ42 수준을 측정하는 것을 포함한다. tau 수준이 증가하고, Aβ42 수준이 감소하였다는 것은 곧, AD가 발병하였음을 의미하는 것이다. 알츠하이머병을 앓고 있는 개체는 또한 ADRDA 기준에 의해 진단될 수도 있다.
병행 요법
본 발명의 항-RAGE 항체는, 개체에 이 항체와 동시에 또는 임의의 순서대로 연속 투여될 수 있는 하나 이상의 부가 제제와 함께 사용될 수 있다. 본원에 개시된 병행 요법은, 상승 치료 효과 즉, 한가지 제제만을 단독으로 투여하였을 때보다 더욱 큰 효과를 나타낼 수 있다. 측정 가능한 치료 효과에 관하여는 전술하였다. 예를 들어, 상승 치료 효과는 하나의 제제에 의해 나타나는 치료 효과의 약 2배 이상일 수 있거나, 또는 약 5배 이상, 또는 약 10배 이상, 또는 약 20배 이상, 또는 약 50배 이상, 또는 약 100배 이상일 수 있다.
예를 들어, 본 발명은, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와의 결합을 억제하는 항체를, Aβ에 특이적으로 결합하는 다른 항체와 함께 치료학적 유효량만큼 투여하는 단계를 포함한다. Aβ에 결합하는 상기 항체는, 전장 아밀로이드 전구체 단백질(APP)에 결합하지 않고, Aβ 펩티드에 특이적으로 결합하는 항체일 수 있다. 대안적으로, 본 발명의 항체는 가용성 Aβ와 결합하고/결합하거나 이 가용성 Aβ를 포획하는 항체, 또는 환자 내 아밀로이드 침착물에 결합하여 아밀로이드 침착물에 대한 제거 반응을 유도하는 항체와 함께 투여될 수 있다. 이와 같은 제거 반응은 Fc 수용체 매개 식세포 작용에 의해 수행될 수 있다. 예를 들어, Fc 수용체-결합 도메인(예를 들어, IgG2a 불변부)를 포함시킴으로써, 이러한 제거 반응을 나타내도록 항체를 조작할 수 있다. 본 발명의 항체는 또한 Aβ 백신을 투여받았거나 또는 투여중인 환자에게도 투여될 수 있다. 뇌에 아밀로이드가 침착되는 알츠하이머병 및 다운 증후군의 경우, 본 발명의 항체를, 본 발명의 제제가 혈액-뇌 장벽을 통과할 때의 투과성을 증가시키는 기타 제제와 함께 투여할 수 있다. 본 발명의 항체는 또한 치료제가 표적 세포 또는 조직으로 인도될 가능성을 높여주는 기타 제제 예를 들어, 리포좀 등과 함께 투여될 수도 있다. 이러한 제제를 함께 투여함으로써, 원하는 효과를 나타내는데 필요한 치료제(예를 들어, 치료용 항체 또는 항체 사슬)의 투여량을 감소시킬 수 있다.
치료 경과의 관찰
본 발명은 알츠하이머병을 앓고 있거나 또는 이에 대해 만감한 환자에 있어서, 치료 경과를 관찰하는 방법 즉, 환자에게 행하여지는 치료법의 경과를 관찰하는 방법을 제공한다. 이 방법은 증상을 나타내는 환자에 대한 치료 차원의 치료 경과와, 무증상 환자에 대한 예방 차원의 치료 경과를 관찰하는데 사용될 수 있다. 특히, 본 방법은 (예를 들어, 투여된 항체의 수준을 측정함으로써) 수동 면역화를 관찰하는데 유용하다.
몇몇 방법은 예를 들어, 환자의 항체 수준 또는 프로필에 관한 기준 수치를 측정한 후, 일정 투여량의 제제를 투여하고, 이 기준 수치와 치료후 프로필 또는 수준에 대한 수치를 비교하는 단계를 포함한다. 수준 또는 프로필에 관한 수치가 유의적으로(즉, 이와 같은 측정치의 평균으로부터 유래하는 하나의 표준 편차로서 표시되는, 시료의 반복 측정값의 실험상 오차에 관한 통상의 마진 이상으로) 증가함은 곧, 치료 결과가 긍정적임을 의미한다(즉, 제제를 투여하였을 때 원하는 반응을 나타냄을 의미한다). 만일 면역 반응에 대한 수치가 유의적으로 변하지 않거나, 감소하면, 치료 결과는 부정적임을 의미한다.
다른 방법에 있어서, 수준이나 프로필에 관한 대조군 수치(즉, 평균 및 표준 편차)는 대조군에 대해 측정된다. 통상적으로, 대조군 내 개체들은 사전 치료를 받지 않는다. 이후, 치료제를 투여받은 환자에 있어서, 수준 또는 프로필에 대한 측정 수치를 대조군 수치와 비교한다. 대조군 수치에 비하여 유의적으로(즉, 평균으로부터 유래하는 하나의 표준 편차 이상으로) 증가하였음은 곧, 치료 결과가 긍정적이거나 충분함을 의미한다. 그렇지 않고 수치가 유의적으로 증가하지 않았거나 감소하였음은 곧, 치료 결과가 부정적이거나 불충분함을 의미한다. 일반적으로, 수준이 대조군 수치에 비하여 증가할 때, 제제를 계속해서 투여한다. 이전처럼, 대조군 수치에 비하여 일정한 수준에 이르렀음은 곧, 치료를 중단하거나, 투여량 및/또는 투여 횟수를 줄일 수 있음을 의미한다.
다른 방법에서, 수준 또는 프로필에 관한 대조군 수치(예를 들어, 평균 및 표준 편차)는, 치료제로 치료를 수행한 개체의 대조군으로부터 측정되며, 이들이 나타내는 수준 또는 프로필은 치료에 반응하여 일정하게 유지된다. 환자의 체 내 수준 또는 프로필에 관한 측정 수치는 대조군 수치와 비교된다. 만일 환자의 체 내 측정된 수준이 대조군 수치와 거의 다르지 않으면(예를 들어, 표준 편차가 1 이상이면), 치료는 중단될 수 있다. 만일 환자의 체 내 수준이 대조군 수치보다 훨씬 낮으면, 제제를 졔속해서 투여해야 할 것이다. 만일 환자의 체 내 수준이 대조군 수치보다 낮으면, 치료에 변화를 줄 수 있다.
다른 방법에서, 현재 치료를 받고 있지 않되, 예전에 치료를 받은 경험이 있는 환자는, 그의 체 내 항체 수준 또는 프로필을 관찰함으로써, 치료를 재개할 필요가 있는지 여부를 판단한다. 환자의 체 내 측정된 수준 또는 프로필은 예전에 치료를 받은 경험이 있는 환자에서 예전에 얻은 수치와 비교될 수 있다. 예전의 측정 수치에 비하여 상당 수준 감소하였음은(즉, 동일한 시료에 대해 반복 측정한 결과로부터 얻어지는 오차의 통상적인 마진 이상임은) 곧, 치료를 재개할 수 있음을 의미한다. 대안적으로, 환자의 체 내에서 측정되는 수치는 치료를 수행한 경험이 있는 환자 집단 내에서 측정된 대조군 수치(평균 + 표준 편차)와 비교될 수 있다. 대안적으로, 환자의 체 내에서 측정된 수치는 질병에 관한 증상을 나타내지 않는 환자 집단 즉, 예방적 차원에서 치료된 환자 집단, 또는 질병의 특징이 완화된 환자 집단 즉, 치료적 차원에서 치료된 환자 집단에서 측정된 수치와 비교될 수 있다. 이와 같은 모든 경우에 있어서, 대조군 수준에 비하여 유의적으로 감소하였음은(즉, 표준 편차 이상으로 감소하였음은) 곧, 환자의 체 내에서 치료가 재개되어야 함을 의미한다.
분석용 조직 시료로서는 통상적으로, 환자로부터 유래하는 혈액, 혈장, 혈청, 점액 또는 뇌척수액이 있다. 시료는 예를 들어, RAGE 펩티드에 대한 항체의 수준 또는 프로필 예를 들어, 인간화된 항체의 수준 또는 프로필에 대해 분석된다. RAGE에 특이적인 항체를 검출하는 ELISA 방법에 관하여는 실시예에 기술되어 있다. 몇몇 방법에 있어서, 투여된 항체의 수준 또는 프로필은 본원에 기술된 바와 같은, 소멸 검정법(clearing assay)을 이용하여 측정된다. 이와 같은 방법에 있어서, 테스트될 환자로부터 유래하는 조직 시료는 (예를 들어, PDAPP 마우스로부터 유래하는) 아밀로이드 침착물과 Fc 수용체를 보유하는 식세포를 접촉된다. 이후, 아밀로이드 침착물이 소멸되었는지 여부를 관찰한다. 소멸 반응의 발생 및 그 정도는, 테스트 중인 환자의 조직 시료 중 Aβ를 소멸시키는데 유효한 항체의 존부와 그 수준에 대한 지표를 제공한다.
수동 면역후의 항체 프로필을 통하여, 통상적으로 항체의 농도가 즉각적으로 상승하였다가 급속히 떨어지는 것을 알 수 있다. 추가로 투여하지 않으면, 투여된 항체의 반감기에 따라서 수일에서 수개월 이내에 전처리 수준으로 감소하게 된다.
몇몇 방법에 있어서, 환자 내 RAGE에 대한 항체의 기준 농도 측정은 이 항체를 투여하기 전에 행하여지며, 그 후 두번째 측정을 행함으로써, 항체의 최고 수준을 측정할 수 있고, 또한 항체 수준이 떨어지는지를 관찰하기 위해 일정한 간격을 두고 1회 이상 추가로 측정한다. 항체의 수준이 기준선 또는 이 기준선에 못미치는 지점 중 최고점에서의 소정의 비율(예를 들어, 50%, 25% 또는 10%)로 떨어질 때, 항체를 추가로 투여한다. 몇몇 방법에 있어서, 백그라운드에 못미치는 지점 중 최고 수준 또는 이후 측정된 수준은, 다른 환자에서 유효한 예방학적 치료 방식 또는 치료학적 치료 방식을 구성하도록 미리 결정한 참고 수준과 비교된다. 만일, 측정된 항체의 수준이 참고 수준에 훨씬 못미치면(예를 들어, 치료의 혜택을 받는 환자 집단에서의 참고 수치의 평균값에서 하나의 표준 편차를 공제한 값에 못미치면), 항체를 추가로 투여해야 함을 의미한다.
치료 경과와 환자의 상태에 관하여 관찰함에 있어서 측정 가능한 지수로서는, 환자의 뇌 내 Aβ의 수준을 관찰한 결과(이 수준의 감소 여부를 관찰한 결과), 아밀로이드가 침착되었는지 여부를 관찰한 결과, 그리고 신경 기능에 있어서 Aβ-유도성 손상의 완화 여부를 관찰한 결과를 포함한다. 기타 측정 가능한 지수로서는, 알츠하이머병에 있어서 혈관 내 콩고 레드 친화성 아밀로이드 혈관병증(CAA)의 병상 또는 이 병상의 변화를 관찰한 결과를 포함하며, 환자를 관찰한 결과로서는, Aβ에 의해 매개되는 세포 내 염증 과정 및 신호 전달 과정의 변화를 포함한다. 후자는, 분지성 복합 신호 전달 경로(multiple divergent signaling pathway)에 있어서 RAGE의 리간드에 의한 RAGE의 조절 작용과 관련된 정보 예를 들어, 전사 인자 NF-κB의 활성화로 인하여 RAGE 프로모터를 활성화하고, 신경 독성 반응은 세포의 신호 전달 과정(MAP 키나제 케스케이드(MAPK), ERK1/2, Akt, JNK, p38)을 활성화함으로써 매개되며, 항-RAGE mAb은 JNK, p38, NFκB의 인산화를 억제한다는 정보를 제공할 것이다. 유용한 수단으로서는 또한, RAGE에 의해 촉진되는 Aβ-유도성 신호 전달 과정 및 시냅스 가소성을 관찰하는 것을 포함하며, 혈액/뇌 장벽을 관통하여 Aβ가 뇌에 차등적으로 유입/유출되는 과정(RAGE와 LRP에 의해 매개됨)은, 혈액 뇌 장벽을 관통하여 Aβ를 뇌에 차등적으로 유입/유출시키는 과정을 매개할 수 있다. 그러므로, 본 발명은 세포 내 신호 전달 과정을 억제하는 방법(예를 들어, MAPK 케스케이드를 억제하는 방법)과 Aβ와 관련된 염증 반응을 억제하는 방법을 제공한다.
부가의 방법으로서는, 치료 경과에 따라서, 당 업계에서 인정되는 임의의 생리적 증상(예를 들어, 신체적 또는 정신적 증상) 즉, 통상적으로 아밀로이드 형성 질환(예를 들어, 알츠하이머병)을 진단 또는 관찰하는 연구자들 또는 전문의에 의해 평가되는 증상을 관찰하는 방법을 포함한다. 예를 들어, 당 업자는 인지 기능 손상 정도를 관찰할 수 있다. 정신적 증상은 알츠하이머병 및 다운 증후군의 증상이지만, 이들 질병 중 어느 하나의 기타 특징을 동반하지 않고서 발생할 수도 있다. 예를 들어, 인지 기능 손상은 치료 경과를 통한 통상의 방법에 의하여, 정신 상태에 관한 소규모 검사법에서 환자에 스코어를 메겨 관찰할 수 있다.
약학 제제
본 발명의 단백질 또는 핵산은 적당한 조성물의 형태로서 투여되는 것이 가장 바람직하다. 전신 투여 또는 국소 투여 약물로서 일반적으로 사용되는 모든 조성물이 적당할 수 있다. 약학적으로 허용 가능한 담체는 실질적으로 비활성인데, 이는 활성 성분과 반응하지 않게 하기 위함이다. 적당한 비활성 담체로서는 물, 알콜, 폴리에틸렌 글리콜, 광유 또는 석유 겔, 프로필렌 글리콜, 인산염 완충 염수(PBS), 주사용 정균수(BWFI), 주사용 멸균수(SWFI) 등을 포함한다. 상기 약학 제제(본 발명의 항체 또는 이 항체를 암호화하는 핵산 포함)는 인간의 약품이나 수의학 약품에 사용하기 편리한 임의의 방식으로 투여하기 위해 제형화될 수 있다.
그러므로, 본 발명의 다른 측면은 유효량의 항체를 포함하는 약학적으로 허용 가능한 조성물을 제공하는데, 이 조성물은 하나 이상의 약학적으로 허용 가능한 담체(부가제) 및/또는 희석제와 함께 제형된다. 이하에 상세히 기술되어 있는 바와 같이, 본 발명의 약학 조성물은 다음과 같은 투여 경로용으로서 적합하도록, 고형 또는 액체형으로 투여되도록 특별히 제형될 수 있다: (1) 경구 투여용 예를 들어, 설하 투여용인 물약(수성 또는 비수성 용액 또는 현탁액), 정제, 볼루스, 분말, 과립, 페이스트; (2) 비경구 투여용 예를 들어, 피하, 근육 내 또는 정맥 내 주사제 예를 들어, 멸균 용액 또는 현탁액; (3) 국소 투여용 예를 들어, 피부에 도포하는 크림, 연고 또는 스프레이; 또는 (4) 질 내 또는 직장 내 투여용 예를 들어, 페서리, 크림 또는 소포. 그러나, 임의의 구체예에서, 상기 제제는 멸균 수에 간단히 용해 또는 현탁될 수 있다. 임의의 구체예에서, 약학 제제는 비-발열원성 즉, 환자의 체온을 상승시키지 않는 것이다. 비경구 투여, 특히, 피하 주사 및 정맥 내 주사가 바람직한 투여 경로이다.
임의의 구체예에서, 하나 이상의 제제는 염기성 작용기 예를 들어, 아미노기 또는 알킬아미노기를 함유할 수 있으므로, 약학적으로 허용 가능한 산과 함께 약학적으로 허용 가능한 염을 형성할 수 있다. 이 측면에서 "약학적으로 허용 가능한 염"이란 용어는, 비교적 무독성인, 본 발명의 화합물의 무기 및 유기 산 부가 염을 의미한다. 이와 같은 염은 본 발명의 화합물을 최종적으로 분리 및 정제하는 동안 현장에서 제조될 수 있거나, 아니면 본 발명의 정제된 화합물을 그 자체의 유리된 염기의 형태로서 적당한 유기산 또는 무기산과 별도로 반응시킨 다음, 이와 같이 형성된 염을 분리함으로써 제조될 수 있다. 대표적인 염으로서는 브롬화수소산염, 염화수소산염, 황산염, 중황산염, 인산염, 질산염, 아세트산염, 발레르산염, 올레산염, 팔미트산염, 스테아르산염, 라우린산염, 벤조산염, 젖산염, 인산염, 토실레이트, 시트르산염, 말레산염, 푸마르산염, 숙신산염, 주석산염, 나프틸레이트, 메실레이트, 글로코헵타노에이트, 락토비오네이트 및 라우릴설포네이트 염 등을 포함한다[예를 들어, Berge외 다수 (1977) "Pharmaceutical Salts," J. Pharm. Sci. 66: 1-19 참조].
상기 제제의 약학적으로 허용 가능한 염으로서는, 상기 화합물의 통상적인 무독성 염 또는 4차 암모늄 염 예를 들어, 무독성 유기산 또는 무기산으로부터 유래하는 염을 포함한다. 예를 들어, 이와 같은 종래의 무독성 염으로서는, 무기산 예를 들어, 염산, 브롬산, 황산, 설팜산, 인산 및 질산 등으로부터 유래하는 무독성 염; 그리고 유기산 예를 들어, 아세트산, 프로피온산, 숙신산, 글리콜산, 스테아르산, 젖산, 말산, 주석산, 시트르산, 아스코르브산, 팔미트산, 말레산, 하이드록시말레산, 페닐아세트산, 글루탐산, 벤조산, 살리실산, 설파닐산, 2-아세톡시벤조산, 푸마르산, 톨루엔설폰산, 메탄설폰산, 에탄 디설폰산, 옥살산 및 이소티온산 등으로부터 생성되는 염을 포함한다.
다른 경우, 하나 이상의 제제는 하나 이상의 산성 작용기를 함유할 수 있으므로, 약학적으로 허용 가능한 염기와 함께 약학적으로 허용 가능한 염을 형성할 수 있다. 이와 같은 염은 화합물을 최종적으로 분리 및 정제하는 동안 현장에서 제조될 수 있거나, 또는 유리된 산의 형태인 정제 화합물과 적당한 염기 예를 들어, 약학적으로 허용 가능한 금속 양이온의 수산화물, 탄산염 또는 중탄산염을 별도로 반응시킴으로써 제조될 수 있거나, 암모니아 또는 약학적으로 허용 가능한 유기 1차, 2차 또는 3차 아민과 별도로 반응시킴으로써 제조될 수 있다. 각각의 알칼리 염 또는 알칼리토 염으로서는, 리튬, 나트륨, 칼륨, 칼슘, 마그네슘 및 알루미늄 염 등을 포함한다. 염기 부가 염 형성에 유용한 각각의 유기 아민으로서는 에틸아민, 디에틸아민, 에틸렌디아민, 에탄올아민, 디에탄올아민 및 피페라진 등을 포함한다[예를 들어, Berge외 다수(상동) 참조].
습윤제, 유화제 및 윤활제 예를 들어, 소듐 라우릴 설페이트 및 스테아르산마그네슘, 그리고 착색제, 방출제, 코팅제, 감미제, 풍미제 및 향미제, 보존제 및 항산화제도 본 발명의 조성물에 존재할 수 있다.
약학적으로 허용 가능한 항산화제의 예로서는 (1) 수용성 항산화제 예를 들어, 아스코르브산, 염화수소산 시스테인, 중황산나트륨, 메타중아황산나트륨 및 아황산나트륨 등, (2) 유용성 항산화제 예를 들어, 팔미트산아스코르빌, 부틸화 하이드록시아니솔(BHA), 부틸화 하이드록시톨루엔(BHT), 레시틴, 몰식자산 프로필 및 알파-토코페롤 등, 그리고 (3) 금속 킬레이트화제 예를 들어, 시트르산, 에틸렌디아민 테트라아세트산(EDTA), 솔비톨, 주석산 및 인산 등을 포함한다.
본 발명의 제형으로서는, 경구, 비강 내, 국소(예를 들어, 협측 및 설하), 직장, 질 내 및/또는 비경구 투여용으로서 적당한 제형을 포함한다. 제형은 단위 투여형으로서 편리하게 제공될 수 있으며, 제약업계에 널리 공지된 임의의 방법에 의해 제조될 수 있다. 단일 투여형을 생산하기 위해 담체 물질과 혼합될 수 있는 활성 성분의 양은, 치료 받을 숙주 및 구체적인 투여 방식 등에 따라서 달라질 것이다. 단일 투여형을 생산하기 위해 담체 물질과 혼합될 수 있는 활성 성분의 양은 일반적으로, 치료 효과를 나타내는 화합물의 양일 것이다. 일반적으로, 100%를 기준으로 하였을 때, 상기 양은 활성 성분 약 1∼약 99%, 바람직하게는 약 5∼약 70%, 가장 바람직하게는 약 10∼약 30%일 것이다.
이와 같은 제형 또는 조성물을 제조하는 방법은 제제와 담체, 그리고 임의로는 하나 이상의 부가 성분을 혼합하는 단계를 포함한다. 일반적으로, 제형은 본 발명의 제제와 액상 담체, 또는 적시에 투여할 수 있도록 분할해 놓은 고형 담체, 또는 이들 둘 다를 균일하게 그리고 철저하게 혼합하여 제조되며, 필요에 따라서는, 이후에 제품으로 성형하여 제조할 수도 있다.
경구 투여용으로 적당한 본 발명의 제형은 캡슐, 사세트, 알약, 정제, 로진즈(풍미가 가하여진 것으로서, 일반적으로 수크로스 및 아카시아 또는 트래거칸트 사용), 분말, 과립의 형태를 가질 수 있거나, 또는 수성 또는 비 수성 액체 중 용액 또는 현탁액으로서, 또는 수중유 또는 유중수 유액으로서, 또는 엘릭시르 또는 시럽으로서, 또는 향정(비활성 베이스 예를 들어, 젤라틴 및 글리세린, 또는 수크로스 및 아카시아 사용) 및/또는 구강 세척액 등의 형태를 가질 수 있으며, 여기서, 각각의 제형은 활성 성분으로서 본 발명의 화합물을 소정량 함유한다. 본 발명의 화합물은 또한 볼루스, 지제 또는 페이스트로서 투여될 수도 있다.
본 발명의 구강 투여용 고체 투여형(캡슐, 정제, 알약, 당의정, 분말 및 과립 등)에 있어서, 활성 성분은 하나 이상의 약학적으로 허용 가능한 담체 예를 들어, 시트르산나트륨 또는 제2인산칼슘 및/또는 다음과 같은 것 중 임의의 것과 혼합된다: (1) 충전제 또는 증량제 예를 들어, 전분, 락토스, 수크로스, 글루코스, 만니톨 및/또는 규산; (2) 결합제 예를 들어, 카복시메틸셀룰로스, 알기네이트, 젤라틴, 폴리비닐피롤리돈, 수크로스 및/또는 아카시아; (3) 보습제 예를 들어, 글리세롤; (4) 붕해제 예를 들어, 아가-아가, 탄산칼슘, 감자 또는 타피오카 전분, 알긴산, 임의의 규산염 및 탄산나트륨; (5) 용액 완염제 예를 들어, 파라핀; (6) 흡착 촉진제 예를 들어, 4차 암모늄 화합물; (7) 습윤제 예를 들어, 세틸 알콜 및 모노스테아르산글리세롤; (8) 흡수제 예를 들어, 카올린 및 벤토나이트 점토; (9) 윤활제 예를 들어, 활석, 스테아르산칼슘, 스테아르산마그네슘, 고체 폴리에틸렌 글리콜, 소듐 라우릴 설페이트 및 이의 혼합물; 그리고 (10) 착색제. 캡슐, 정제 및 알약의 경우, 약학 조성물은 또한 완충제도 포함할 수 있다. 유사한 유형의 고체 조성물은 또한 부형제 예를 들어, 락토스 또는 유당과, 고분자량 폴리에틸렌글리콜 등을 사용하는, 연질 및 경질 충전 젤라틴 캡슐에서 충전제로서 사용될 수도 있다.
정제는 임의로는, 하나 이상의 부가 성분과 함께 압착(compression) 또는 몰딩(molding)하여 제조될 수 있다. 압착된 정제는 결합제(예를 들어, 젤라틴 또는 하이드록시프로필메틸 셀룰로스), 윤활제, 비활성 희석제, 보존제, 붕해제(예를 들어, 소듐 전분 글리콜레이트 또는 가교 소듐 카복시메틸 셀룰로스), 표면 활성제 또는 분산제를 사용하여 제조될 수 있다. 몰딩된 정제는 비활성 액체 희석제로 습윤화된 분말형 화합물의 혼합물을 적당한 기기 내에서 몰딩함으로써 생산될 수 있다.
본 발명의 약학 조성물의 정제 및 기타 고체 투여형 예를 들어, 당의정, 캡슐, 알약 및 과립은 금을 긋거나(scoring) 또는 코팅 및 외피 예를 들어, 장용 코팅 및 기타 제약-제형 업계에 널리 공지된 코팅이 가하여질 수도 있다. 이는 또한 예를 들어, 하이드록시프로필메틸 셀룰로스를 다양한 비율로 사용하여, 이 투여형에 포함된 활성 성분을 서서히 방출시키거나 또는 조절 방출함으로써 원하는 방출 프로필을 제공하도록 제형될 수 있고, 기타 중합체 매트릭스, 리포좀 및/또는 미소구로서 제형될 수도 있다. 상기 투여형은 예를 들어, 박테리아-체류 필터를 통한 여과, 또는 멸균 수 또는 사용 직전의 기타 주사용 멸균 매질에 용해될 수 있는 멸균 고체 조성물의 형태로 멸균 제제를 통합함으로써 멸균될 수 있다. 이러한 조성물은 또한 불투명화제(opacifying agent)를 함유할 수도 있으며, 또한 오로지 또는 바람직하게 위장관의 임의의 부분에서, 지연된 방식으로 활성 성분(들)을 방출할 수도 있다. 사용될 수 있는 매립형 조성물의 예로서는 중합체 물질 및 왁스를 포함한다. 적당하다면, 활성 성분은 또한 전술한 부형제 중 하나 이상을 포함하는 미세 캡슐형으로 존재할 수도 있다.
본 발명의 화합물의 경구 투여용 액체 투여형으로서는, 약학적으로 허용 가능한 유액, 마이크로에멀젼, 용액, 현탁액, 시럽 및 엘릭시르를 포함한다. 활성 성분 이외에, 액체 투여형은 당 업계에서 일반적으로 사용되는 비활성 희석제 예를 들어, 물 또는 기타 용매, 가용화제 및 유화제 예를 들어, 에틸 알콜, 이소프로필 알콜, 탄산에틸, 아세트산에틸, 벤질 알콜, 벤조산벤질, 프로필렌 글리콜, 1,3-부틸렌 글리콜, 오일(특히, 목화씨 기름, 땅콩 기름, 옥수수 기름, 밀 배아 기름, 올리브 기름, 피마자 기름 및 참기름), 글리세롤, 테트라하이드로푸릴 알콜, 폴리에틸렌 글리콜 및 솔비탄의 지방산 에스테르와 이것들의 혼합물을 함유할 수 있다.
비활성 희석제 이외에, 경구 투여용 조성물은 애쥬반트 예를 들어, 습윤제, 유화제 및 현탁제, 감미제, 풍미제, 착색제, 향미제 및 보존제를 포함할 수도 있다.
현탁액은, 활성 화합물 이외에도, 현탁제 예를 들어, 에톡실화된 이소스테아릴 알콜, 폴리옥시에틸렌 솔비톨 및 솔비탄 에스테르, 미세 결정질 셀룰로스, 알루미늄 메타하이드록시드, 벤토나이트, 아가 및 트래거칸트와, 이것들의 혼합물을 함유할 수 있다.
본 발명의 직장 투여용 또는 질내 투여용 약학 조성물의 제형은 좌제로서도 제공될 수 있는데, 이는 본 발명의 하나 이상의 화합물과, 예를 들어, 코코아 버터, 폴리에틸렌 글리콜, 좌제 왁스 또는 살리실레이트를 포함하는 하나 이상의 적당한 비자극성 부형제 또는 담체를 혼합함으로써 제조될 수 있으며, 또한, 실온에서는 고체이지만 체온에서는 액체로 변하므로, 작장이나 질 내 공동에서 용해되어 제제를 방출하게 될 것이다.
질 내 투여용으로 적당한 본 발명의 제형으로서는 또한, 당 업계에 적당한 것으로서 알려진 담체를 함유하는 페서리, 탐폰, 크림, 겔, 페이스트, 소포 또는 스프레이 제형을 포함한다.
본 발명의 화합물을 국소 투여 또는 경피 투여하기 위한 투여형으로서는 분말, 스프레이, 연고, 페이스트, 크림, 로션, 겔, 용액, 패치 및 흡입제를 포함한다. 활성 화합물은 멸균 조건 하에서 약학적으로 허용 가능한 담체, 그리고 필요할 수 있는 임의의 보존제, 완충제 또는 추진제와 혼합될 수 있다.
연고, 페이스트, 크림 및 겔은 본 발명의 활성 화합물 이외에도, 부형제 예를 들어, 동물성 지방 및 식물성 지방, 기름, 왁스, 파라핀, 전분, 트래거칸트, 셀룰로스 유도체, 폴리에틸렌 글리콜, 실리콘, 벤토나이트, 규산, 활석 및 산화아연 또는 이의 혼합물을 함유할 수 있다.
분말과 스프레이는 본 발명의 화합물 이외에도, 부형제 예를 들어, 락토스, 활석, 규산, 수산화알루미늄, 규산칼슘 및 폴리아미드 분말, 또는 이 성분들의 혼합물을 함유할 수 있다. 스프레이는 시판되고 있는 추진제 예를 들어, 클로로플루오로하이드로카본 및 휘발성 비 치환 탄화수소 예를 들어, 부탄 및 프로판을 추가로 함유할 수 있다.
경피 패치는 본 발명의 화합물을 체 내에 조절 가능하도록 운반할 수 있다는 부가의 이점을 갖는다. 이와 같은 투여형은 적당한 매질 중에 상기 제제를 용해 또는 분산시켜 제조될 수 있다. 흡수 강화제는 또한 슬레인(slain)을 통과하는 상기 제제의 유량을 증가시키는데 사용될 수도 있다. 상기 제제의 유속은 유속 조절 막을 사용하거나 상기 화합물을 중합체 매트릭스 또는 겔에 분산시켜 조절할 수 있다.
안과용 제형, 안연고, 분말 및 용액 등도 본 발명의 범위 내에 포함되는 것으로 간주한다.
비경구 투여용으로서 적당한 본 발명의 약학 조성물은 본 발명의 하나 이상의 화합물과, 하나 이상의 약학적으로 허용 가능한 멸균 등장 수성 용액 또는 비수성 용액, 분산액, 현탁액 또는 유액, 또는 사용 직전에 주사용 멸균 용액 또는 분산액으로 재구성될 수 있는 멸균 분말(항산화제, 완충제, 정균제, 제형을 목적 수용자의 혈액과 등장성이 되도록 만들어주는 용질 또는 현탁제나 증점제를 함유할 수 있음)을 함께 포함한다.
본 발명의 약학 조성물에 사용될 수 있는 적당한 수성 담체 및 비 수성 담체의 예로서는 물, 에탄올, 폴리올(예를 들어, 글리세롤, 프로필렌 글리콜, 폴리에틸렌 글리콜 등), 그리고 이의 적당한 혼합물, 식물성 기름 예를 들어, 올리브 기름과, 주사용 유기 에스테르 예를 들어, 올레산에틸을 포함한다. 유동성은 예를 들어, 코팅 물질 예를 들어, 레시틴을 사용하고, (분산액의 경우) 입자의 크기를 필요한 만큼 유지시키며, 계면활성제를 사용하면 적당히 유지될 수 있다.
이와 같은 조성물은 또한 애쥬반트 예를 들어, 보존제, 습윤제, 유화제 및 분산제를 함유할 수도 있다. 미생물의 활동은 다양한 항 박테리아 제제 및 항 진균제 예를 들어, 파라벤, 클로로부탄올 및 페놀 소르빈산 등을 포함시킴으로써 확실하게 예방할 수 있다. 등장제 예를 들어, 설탕 및 염화나트륨 등을 조성물에 포함시키는 것이 바람직할 수도 있다. 뿐만 아니라, 흡수를 지연시키는 제제 예를 들어, 모노스테아르산알루미늄 및 젤라틴을 포함시켜, 주사 가능한 약학 투여형의 흡수를 지연시킬 수도 있다.
몇몇 경우에 있어서, 제제의 효능을 연장시키기 위해서, 피하 주사제 또는 근육 내 주사제로부터 유래하는 제제의 흡수를 지연시키는 것이 바람직할 수 있다. 이는 수용성이 떨어지는 결정질 또는 비결정질 물질의 액체 현탁액을 사용함으로써 이루어질 수 있다. 이후, 상기 제제의 흡수율은, 결정의 크기와 결정형에 따라서 달라질 수 있는 상기 제제의 용해 속도에 따라서 달라진다. 대안적으로, 유질 비이클 중에 상기 제제를 용해 또는 현탁시킴으로써, 비경구 투여되는 제제의 흡수를 지연시킬 수도 있다.
주사용 데포 제형은 대상 화합물의 미세 캡슐화 매트릭스를 생체 분해 가능한 중합체 예를 들어, 폴리락티드-폴리글리콜리드로 형성함으로써 제조된다. 중합체에 대한 제제의 비율에 따라서, 그리고 사용된 특정 중합체의 특성에 따라서, 제제의 방출 속도는 조절될 수 있다. 기타 생체 분해성 중합체의 예로서는 폴리(오르토에스테르) 및 폴리(무수물)을 포함한다. 주사 가능한 데포 제형은 또한, 체내 조직과 혼화 가능한 리포좀 또는 마이크로에멀젼 내에 제제를 포집시킴으로써 제조되기도 한다.
본 발명의 화합물이 인간 및 동물에 약품으로서 투여될 때, 이 화합물은 그 자체로서 투여될 수 있거나, 아니면 예를 들어, 0.1∼99.5%(더욱 바람직하게는 0.5∼90%)의 활성 성분과 약학적으로 허용 가능한 담체를 함께 포함하는 약학 조성물로서 투여될 수 있다.
전술한 조성물과는 별도로, 적당량의 치료제를 함유하는 커버 예를 들어, 플라스터, 붕대, 드레싱 및 거즈 패드 등이 사용될 수 있다. 상기 자세히 설명한 바와 같이, 치료용 조성물은 스템(stem), 장치, 보철 및 임플란트 상에 투여/전달될 수 있다.
분석용 조직 시료로서는 통상적으로 환자로부터 채취한 혈액, 혈장, 혈청, 점액 또는 뇌척수액이 있다. 이 시료는 예를 들어, RAGE 펩티드에 대한 항체의 수준 또는 프로필 예를 들어, 인간화된 항체의 수준 또는 프로필에 대해 분석된다. RAGE에 특이적인 항체를 검출하는 ELISA 방법에 관하여는 실시예에 기술되어 있다.
수동 면역후의 항체 프로필을 통하여, 통상적으로 항체의 농도가 즉각적으로 상승하였다가 급속히 떨어지는 것을 알 수 있다. 추가로 투여하지 않으면, 투여된 항체의 반감기에 따라서 수일에서 수개월 이내에 전처리 수준으로 감소하게 된다.
몇몇 방법에 있어서, 환자 내 RAGE에 대한 항체의 기준 농도 측정은 이 항체를 투여하기 전에 행하여지며, 그 후 두번째 측정을 행함으로써, 항체의 최고 수준을 측정할 수 있고, 또한 항체 수준이 떨어지는지를 관찰하기 위해 일정한 간격을 두고 1회 이상 추가로 측정한다. 항체의 수준이 기준선 또는 이 기준선에 못미치는 지점 중 최고점에서의 소정의 비율(예를 들어, 50%, 25% 또는 10%)로 떨어질 때, 항체를 추가로 투여한다. 몇몇 방법에 있어서, 백그라운드에 못미치는 지점 중 최고 수준 또는 이후 측정된 수준은, 다른 환자에서 유효한 예방학적 치료 방식 또는 치료학적 치료 방식을 구성하도록 미리 결정한 참고 수준과 비교된다. 만일, 측정된 항체의 수준이 참고 수준에 훨씬 못미치면(예를 들어, 치료의 혜택을 받는 환자 집단 내 참고 수치의 평균에서 하나의 표준 편차를 공제한 값에 못미치면), 항체를 추가로 투여해야 함을 의미한다.
지금까지 일반적으로 기술된 본 발명은 이하의 실시예를 참고로 하여 보다 용이하게 이해될 것이며, 이하 실시예는 오로지 본 발명의 임의의 측면과 구체예를 예시하기 위한 목적으로 포함된 것일 뿐, 본 발명을 제한하고자 하는 것은 아니다.
실시예 1
RAGE 구조물의 제조
쥣과 동물 RAGE의 아미노산 서열(mRAGE, 유전자 은행 승인 번호 NP_031451; 서열 번호 3) 및 인간 RAGE의 아미노산 서열(hRAGE, 유전자 은행 승인 번호 NP_00127.1; 서열 번호 1)을 도 1a∼1c에 나타내었다. mRAGE를 암호화하는 전장 cDNA(승인 번호 NM_007425.1; 서열 번호 4) 및 hRAGE를 암호화하는 전장 cDNA(승인 번호 NM_001136; 서열 번호 2)를, cDNA 서열의 발현을 유도하는 거대 세포 바이러스 (CMV) 프로모터를 포함하고, 바이러스 생산에 필요한 요소인 아데노바이러스 요소를 함유하는 Adori1-2 발현 벡터에 삽입하였다. 인간 RAGE의 1∼344번 아미노산을 인간 IgG의 Fc 도메인에 부착시켜 형성한 인간 RAGE-Fc 융합 단백질을, 상기 Adori 발현 벡터를 사용하여 배양 세포 내 융합 단백질을 암호화하는 DNA 구조물을 발현시킴으로써 생산하였다. 인간 RAGE의 1∼118번 아미노산을 인간 IgG의 Fc 도메인에 부착시켜 형성한 인간 RAGE V-부위-Fc 융합 단백질도 유사하게 제조하였다. 스트렙타비딘(strep) 태그 서열(WSHPQFEK)(서열 번호 5)을 인간 또는 쥣과 동물 RAGE의 1∼344번 아미노산에 부착하여 형성한 인간 및 쥣과 동물의 RAGE-strep 태그 융합 단백질은, 각각 RAGE-strep 태그 융합 단백질을 암호화하는 DNA 구조물을 발현시키고, 또한 Adori 발현 벡터를 사용하여 제조하였다. 광범위한 제한 절단 분석법과 이 플라스미드 내에 존재하는 cDNA 삽입물의 서열을 분석하여 모든 구조물을 확인하였다.
전장 RAGE, hRAGE-Fc 및 hRAGE V-도메인-Fc를 발현하는 재조합 아데노바이러스(Ad5 E1a/E3 결실된 바이러스)를 인간 배 신장 세포주 293(HEK293)(ATCC, Rockland MD) 내에서 상동성 재조합에 의해 생산하였다. 재조합 아데노바이러스를 분리한 다음, 이를 HEK293 세포 내에서 증폭시켰다. 동결-해동 과정을 3회 반복하여 상기 바이러스를 감염된 HEK293 세포로부터 방출시켰다. 염화세슘 원심 분리 구배를 2회 걸어주어 상기 바이러스를 추가로 정제한 다음, 인산염 완충 염수(PBS; pH 7.2)에 대해 투석하였다(4℃). 투석 후, 글리세롤을 농도 10%가 될 때까지 첨가하고, 이 바이러스는 사용하기 전까지 -80℃에 보관하여 두었다. 바이러스 구조물을, 감염성(293 세포상에서의 플라크 형성 단위)을 가지는지 여부에 대해 특성 규명하고, 또한 이 바이러스를 PCR 분석하였으며, 암호화 부위의 서열을 분석하고, 트랜스유전자의 발현 여부와 내독소 수준을 측정하였다.
인간 RAGE-Fc, 인간 RAGE-V 부위-Fc, 그리고 인간 및 쥣과 동물 RAGE-strep 태그 융합 단백질을 암호화하는 DNA를 함유하는 Adori 발현 벡터를, 리포팩틴(Invitrogen)을 이용하여, 중국 햄스터 난소(Chinese Hamster Ovary; CHO) 세포에 안정하게 형질 감염시켰다. 안정한 형질 감염체를 20nM 및 50nM 메토트렉세이트 중에서 선별하였다. 각각의 클론으로부터 컨디셔닝된 배지(conditioned media)를 수집하고, 소듐 도데실 설페이트-폴리아크릴아미드 겔 전기 영동법(SDS-PAGE) 및 웨스턴 블럿팅(Western blotting)을 통하여 이 배지를 분석한 결과, RAGE가 발현되었음을 확인할 수 있었다[Kaufman, R.J., 1990, Methods in Enzymology, 185:537- 66; Kaufman, R.J., 1990, Methods in Enzymology, 185:487-511 ; Pittman, D. D.외 다수, 1993, Methods in Enzymology, 222: 236-237].
가용성 RAGE 융합 단백질을 발현하는 CHO 또는 형질 도입된 HEK 293 세포를 배양하여 단백질 정제용으로 컨디셔닝된 배지를 수집하였다. 소정의 친화성-태그법을 이용하여 단백질을 정제하였다. 정제된 단백질을 환원성 SDS-PAGE 및 비 환원성 SDS-PAGE시킨 다음, 쿠마시 블루(Coomassie Blue) 염색법으로 가시화하여[Current Protocols in Protein Sciences, Wiley Interscience], 예측 분자량을 파악하였다.
실시예 2
쥣과 동물 항-RAGE 모노클로날 항체의 생산
6∼8주령된 암컷 BALB/c 마우스(Charles River, Andover, MA)를, 진건(GeneGun) 장치(BioRad, Hercules, CA)를 사용하여 피하 면역화시켰다. 전장 인간 RAGE를 암호화하는 cDNA를 함유하는 pAdori 발현 벡터를 콜로이드 금 입자(BioRad, Hercules, CA) 상에 미리 흡착시킨 다음, 피하 투여하였다. 1주일마다 2회씩, 2주 동안, 상기 마우스에 3ug의 벡터를 투여하여 이 마우스를 면역화하였다. 마지막으로 면역화한 후 1주일 경과시에 마우스로부터 채혈하여, 항체의 역가를 측정하였다. 세포 융합을 실시하기 사흘 전에, RAGE-항체 역가가 가장 높았던 마우스에 10㎍의 재조합 인간 RAGE-strep 단백질을 1회 더 주사하였다.
50% 폴리에틸렌 글리콜(MW 1500)(Roche Diagnostics Corp, Mannheim, Germany)을 사용하여, 비장 세포를 마우스 골수종 세포 P3X63Ag8.653(ATCC, Rockville, MD)와 4:1의 비율로 융합시켰다. 융합 후, 세포를 접종하고, 이를 96-웰 평판에서, RPMI 1640 선별 배지(20% FBS, 5% 오리젠(Origen; IGEN International Inc. Gaithersburg, MD), 2mM L-글루타민, 100U/㎖ 페니실린, 100㎍/㎖ 스트렙토마이신, 10mM HEPES 및 1×하이포잔틴-아미노프테린-티미딘(Sigma, St. Louis, MO) 함유) 중 웰당 1×105개의 세포가 되도록 배양하였다.
실시예 3
래트 항-RAGE 모노클로날 항체의 생산
LOU 래트(Harlan, Harlan, MA)를, 진건(BioRad, Hercules, CA)을 사용하여 피하 면역화시켰다. 전장 쥣과 동물 RAGE를 암호화하는 cDNA를 함유하는 pAdori 발현 벡터를 콜로이드 금 입자(BioRad, Hercules, CA) 상에 미리 흡착시킨 다음, 피하 투여하였다. 2주일마다 1회씩, 상기 래트에 3ug의 벡터를 투여하여(총 4회) 이 래트를 면역화하였다. 마지막으로 면역화한 후 1주일 경과시에 래트로부터 채혈하여, 항체의 역가를 측정하였다. 세포 융합을 실시하기 사흘 전에, RAGE-항체 역가가 가장 높았던 래트에 10㎍의 재조합 쥣과 동물 RAGE-strep 단백질을 1회 더 주사하였다.
50% 폴리에틸렌 글리콜(MW 1500)(Roche Diagnostics Corp, Mannheim, Germany)을 사용하여, 비장 세포를 마우스 골수종 세포 P3X63Ag8.653(ATCC, Rockville, MD)와 4:1의 비율로 융합시켰다. 융합 후, 세포를 접종하고, 이를 96-웰 평판에서 RPMI 1640 선별 배지(20% FBS, 5% 오리젠(IGEN International Inc. Gaithersburg, MD), 2mM L-글루타민, 100U/㎖ 페니실린, 100㎍/㎖ 스트렙토마이신, 10mM HEPES 및 1×하이포잔틴-아미노프테린-티미딘(Sigma, St. Louis, MO) 함유) 중 웰당 1×105개의 세포가 되도록 배양하였다.
실시예 4
하이브리도마 스크리닝
진건과, 쥣과 동물 또는 인간 RAGE의 전장 암호화 부위를 발현하는 Adori 발현 플라스미드를 사용하여 cDNA로 면역화함으로써, 래트 항-쥣과 동물 RAGE 및 쥣 과 동물 항-인간 RAGE mAb 패널을 생산하였다. RAGE를 일시적으로 발현하는 인간 배 신장 세포(HEK-293)에 대한 FACS 분석과 ELISA를 통하여, 하이브리도마 상청액을, 재조합 인간 또는 쥣과 동물 RAGE-Fc와 결합하였는지 여부에 대해 스크리닝하였다. 포지티브 상청액이 RAGE와 리간드 HMGB1의 결합을 중화시키는 능력을 가지는지 여부를 알아보기 위해, 이 상청액을 추가로 테스트하였다. 7개의 래트 모노클로날 항체(XT-M 시리즈)와 7개의 마우스 모노클로날 항체(XT-H 시리즈)를 동정하였다. 선별된 하이브리도마를 연속적으로 희석하여 4회 서브클로닝시키고, FACS 분류법으로 1회 서브클로닝하였다. 컨디셔닝된 배지를 안정한 하이브리도마 배양액으로부터 수집한 다음, 단백질 A 항체 정제 컬럼(Millipore Billerica, MA)을 이용하여 면역 글로불린을 정제하였다. 각각의 mAb의 Ig군은, 전술한 바와 같이, 마우스 mAb 동 기준 표본형 분석 키트 또는 래트 mAb 동 기준 표본형 분석 키트로 분석하였다(IsoStrip; Boehringer Mannheim Corp.). 선별된 래트 및 마우스 모노클로날 항체의 동 기준 표본형을 이하 표 1에 제시하였다.
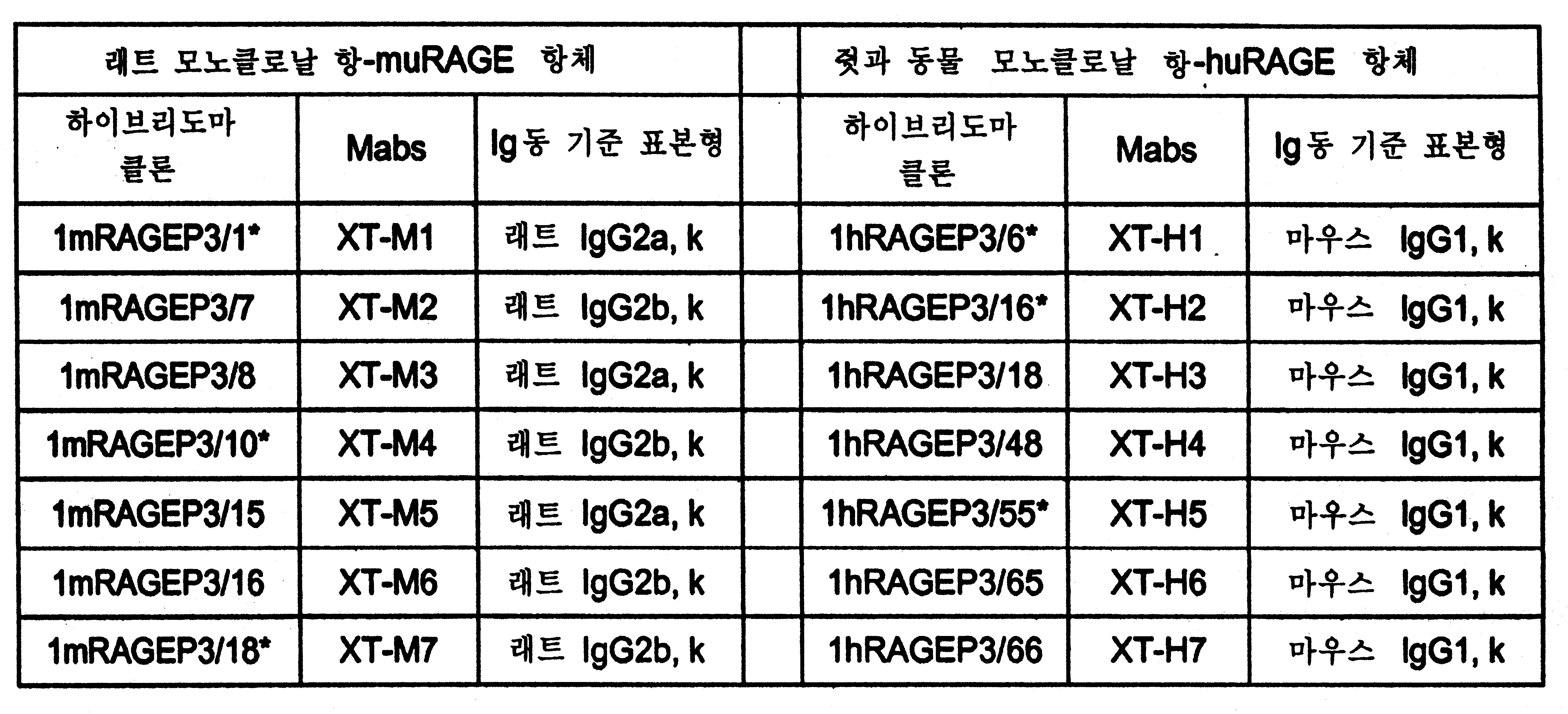
실시예 5
FACS 분석법
인간 293 세포를 인간 및 쥣과 동물 RAGE 아데노바이러스로 감염시켰다. 감염된 세포를 PBS(1% BSA 함유) 중에 밀도가 4×104개 세포/㎖가 되도록 현탁시켰다. 세포를 100ul의 시료(희석된 면역 혈청, 하이브리도마 상청액 또는 정제된 항체)와 함께, 4℃에서 30분 동안 항온 처리하였다. 세척 후, 세포를 PE-표지화 염소 항-마우스 IgG F(ab')2(DAKO Corporation GlostrupDenmark)와 함께 4℃에서 30분 동안 암실에서 항온 처리하였다. 세포-결합 형광 신호를 FACScan 유동성 혈구 계측기(Becton Dickinson)(1회 처리당 5000개의 세포 사용)에 의하여 측정하였다. 요드화프로피듐을 사용하여 사멸된 세포를 골라내어, 이 세포들을 분석에서 제외하였다. 7개의 쥣과 동물 모노클로날 항체 즉, XT-H1∼XT-H7과, 7개의 래트 모노클로날 항체 XT-M1∼XT-M7을 FACS 분석한 결과, 세포-표면 hRAGE와 결합함을 알 수 있었다(표 2).
실시예 6
ELISA 결합 검정법
표준적인 방법을 사용하여 하이브리도마 상청액으로부터 항체를 정제하였다. 정제된 항체를, 이 항체가 RAGE의 가용성 형태와 결합하는지 여부에 대해 평가하였다(ELISA 이용). 96-웰 평판(Corning, Corning, NY)을 100ul의 재조합 인간 RAGE-Fc 또는 재조합 인간 RAGE V-부위-Fc(1㎍/㎖)로 코팅한 다음, 이를 4℃에서 밤새도록 항온 처리하였다. 1% BSA 및 0.05% Tween-20을 함유하는 PBS로 세척 및 차단시킨 다음, 100ul의 시료(이때, 이 시료는 전술한 바와 같이, 몇 가지 형태 즉, 희석된 면역 혈청, 하이브리도마 상청액 또는 정제된 항체의 형태를 가짐)를 첨가하여, 이를 1시간 동안 실온에서 항온 처리하였다. 상기 평판을 PBS(pH 7.2)로 세척하고, 퍼옥시다제-접합 염소 항-마우스 IgG(H+L)(IgG)(Pierce, Rockford, IL)를 사용하여 결합된 항-RAGE 항체를 검출한 다음, 기질인 TMB(BioFX Laboratories Owings Mills, MD Laboratories)와 함께 항온 처리하였다. 흡광도 수치를 분광 분석계 내 450㎚에서 측정하였다. 퍼옥시다제-표지화 염소 항-마우스 IgG(Fcγ)(Pierce Rockford, IL)를 사용하여 모노클로날 항체의 농도를 측정하고, 정제된 동기준 표본형-매칭 마우스 IgG에 의해 표준 곡선을 작성하였다. 7개의 쥣과 동물 모노클로날 항체 즉, XT-H1∼XT-H7과, 7개의 래트 항체 XT-M1∼XT-M7이 hRAGE-Fc, hRAGE V-부위-Fc, mRAGE-Fc 및 mRAGE-strep과 결합하는 능력을 ELISA 분석한 결과를 이하 표 2에 요약하였다. 도 2 및 도 3에 나타낸 바와 같이, 래트 항체인 XT-M4와 마우스 항체인 XT-H2는 둘 다 인간 RAGE-Fc와 hRAGE의 V-도메인과 결합한다. XT-M4와 인간 RAGE의 결합 및 XT-M4와 인간 RAGE V-도메인의 결합에 대한 EC50 값은 각각 300pM 및 100pM이었다. XT-H2와 인간 RAGE 및 인간 RAGE V-도메인의 결합에 대한 EC50 값은 각각 90pM 및 100pM이었다.

실시예 7
RAGE 리간드 및 항체 경쟁 ELISA 결합 검정법
RAGE 모노클로날 항체가 RAGE 리간드(HMGB1; Sigma, St. Louis, MO)와 RAGE의 결합에 영향을 미치는지 여부를 확인하기 위해, 경쟁 ELISA 결합 검정법을 수행하였다. 96-웰 평판을 1㎍/㎖의 HMGB1으로 밤새도록 코팅하였다(4℃). 전술한 바와 같이 웰을 세척 및 차단한 다음, 이를 RAGE-Fc 또는 TrkB-Fc(비 특이적 Fc 대조군)(0.1㎍/㎖)의 예비 항온 처리 혼합물 100㎕와, 다양한 형태의 소정의 항체 제제(면역 혈청, 하이브리도마 상청액 또는 정제된 항체의 희석액)에 노출시켰다(실온, 1시간). 평판을 PBS(pH 7.2)로 세척한 다음, 퍼옥시다제-접합 염소 항-인간 IgG(Fcγ)(Pierce, Rockford, IL)를 기질인 TMB(BioFX Laboratories Owings Mills, MD Laboratories Owings Mills, MD)와 함께 항온 처리하여, 리간드-결합 재조합 인간 RAGE-Fc를 검출하였다. 임의의 항체 부재시 또는 희석된 전 면역 혈청 존재시, 재조합 인간 RAGE-Fc과 리간드의 결합 상태를 대조군으로 삼고, 이를 100% 결합하는 것으로 규정하였다. 7개의 쥣과 동물 항체 즉, XT-H1∼XT-H7과, 7개의 래트 항체 XT-M1∼XT-M7이 HMGB1과 hRAGE-Fc의 결합을 차단하는 능력을 경쟁 ELISA 결합 검정법으로 측정한 결과를 표 3에 나타내었다. 표 3에는 쥣과 동물 XT-H1, XT-H2 및 XT-H5가, hRAGE의 상이한 리간드, 아밀로이드 β 1∼42 펩티드의 RAGE와의 결합을 차단하는 능력과, 래트의 항체 XT-M1∼XT-M7가 HMGB1 및 쥣과 동물 RAGE-Fc의 결합을 차단하는 능력에 관하여 요약되어 있다(유사한 경쟁 ELISA 결합 검정법으로 측정). 도 4에 나타낸 바와 같이, 래트 항체 XT-M4와 쥣과 동물 항체 XT-H2 둘 다는 HMGB1과 인간 RAGE의 결합을 차단하는 것을 알 수 있다.

유사한 경쟁 분석 방법을 사용하여, 항체 쌍 사이의 상대적인 결합 에피토프에 대해 분석하였다. 우선, 1㎍/㎖의 재조합 인간 RAGE-Fc을 4℃에서 밤새도록 96-웰 평판상에 코팅하였다. (전술한 바와 같이) 이 웰을 세척 및 차단한 다음, 이 웰들을, 바이오틴화 표적 항체 및 경쟁 항체 희석물의 예비-항온 처리 혼합물 100㎕에 노출시켰다(1시간, 실온). 퍼옥시다제-접합 스트렙타비딘(Pierce)을 사용하여, 결합된 바이오틴화 항체를 검출하였다. 유사한 경쟁 연구법을 통하여, 항체 쌍 사이의 상대적인 결합 에피토프에 대해 분석하였다. 우선, 1㎍/㎖의 재조합 인간 RAGE-Fc을 4℃에서 밤새도록 96-웰 평판상에 코팅하였다. (전술한 바와 같이) 이 웰을 세척 및 차단한 다음, 이 웰들을, 바이오틴화 표적 항체 및 경쟁 항체 희석물의 예비-항온 처리 혼합물 100㎕에 노출시켰다(1시간, 실온). 퍼옥시다제-접합 스트렙타비딘(Pierce, Rockford, IL)을 사용한 후, 기질 TMB(BioFX Laboratories Owings Mills, MD Laboratories)와 함께 항온 처리하여, 결합된 바이오틴화 항체를 검출하였다. 임의의 경쟁 항체가 존재하지 않을 경우, 재조합 인간 RAGE-Fc와 바이오틴화 항체의 결합 상태를 대조군으로 삼고, 이를 100% 결합하는 것으로 규정하였다. 래트 및 쥣과 동물 항체가 hRAGE와의 결합에 대해 서로 경쟁하는 상태를 분석하는, 경쟁 ELISA 결합 검정법의 결과를 표 3에 나타내었다. 도 5는 래트 XT-M4 및 항체 XT-H1, XT-H2, XT-H5, XT-M2, XT-M4, XT-M6 및 XT-M7이 hRAGE와의 결합에 대해 서로 경쟁하는 상태를 분석하는 경쟁 ELISA 결합 검정법으로부터 얻어진 데이터를 그래프로 나타낸 것이다. 도 5에 나타낸 경쟁 ELISA 결합 데이터를 통하여, XT-M4와 XT-H2가 인간 RAGE상에 중첩되어 존재하는 위치에 결합함을 알 수 있다.
실시예 8
쥣과 동물 및 래트의 항-RAGE 항체와 인간 및 쥣과 동물 RAGE-Fc의 결합에 관한 바이어코어(BIACORE)™ 결합 검정법
A. 인간 및 쥣과 동물 RAGE와의 결합
선택된 쥣과 동물 및 래트의 항-RAGE 항체와 인간 및 쥣과 동물 RAGE의 결합, 그리고 선택된 쥣과 동물 및 래트의 항-RAGE 항체와 인간 및 쥣과 동물 RAGE의 V 도메인의 결합을, 바이어코어(BIACORE)® 직접 결합 검정법으로 분석하였다. 인간 또는 쥣과 동물 RAGE-Fc 코팅된(고밀도(2000 RU)) CM5 칩상에서, 표준적인 아민 커플링에 의해 검정법을 수행하였다. 2가지의 농도 즉, 50nM 및 100nM의 항-RAGE 항체 용액을 고정 RAGE-Fc 단백질에 대해 전개하였다(2회), 바이어코어™ 기술에서는, 항-RAGE 항체와 고정 RAGE 항원이 결합할 때, 표면 층에서의 굴절률 변화를 이용한다. 결합 여부는 표면으로부터 굴절되어 나오는 레이저 빛의 표면 플라스몬 공명(SPR)에 의해 검출된다. 바이어코어™ 직접 결합 검정법의 결과를 표 4에 요약하였다.

쥣과 동물 및 래트의 항-RAGE 항체와 인간 및 쥣과 동물 RAGE의 결합에 관한 반응 속도 상수(ka 및 kd)와, 결합 상수 및 해리 상수(Ka 및 Kd)를 바이어코어™ 직접 결합 검정법으로 측정하였다. 결합율(on-rate) 및 해리율(on-rate)에 관한 신호 역학 데이터를 분석한 결과, 비특이적 상호 작용과 특이적 상호 작용을 구별할 수 있었다. 바이오코어™ 직접 결합 검정법에 의해 측정된, 쥣과 동물 XT-H2 항체 및 래트의 XT-M4 항체와 hRAGE-Fc의 결합에 관한 반응 속도 상수와 평형 상수를 표 5에 나타내었다.

B. 인간 RAGE V-도메인과의 결합
쥣과 동물 및 래트의 항-RAGE 항체와 인간 RAGE V-도메인의 결합에 관한 반응 속도 상수와, 결합 상수 및 해리 상수도 또한 바이어코어™ 직접 결합 검정법으로 측정하였다. 인간의 RAGE V-도메인-Fc를 항-인간 Fc 항체 코팅된 CM5 칩상에 포집시키고, 전술한 바와 같이, 쥣과 동물 및 래트 항-RAGE 항체와 고정된 hRAGE V 도메인-Fc의 결합에 관하여 바이어코어™ 직접 결합 검정법을 수행하여 전장 RAGE-Fc와의 결합에 대해 분석하였다.
실시예 9
항-RAGE 항체 가변부의 아미노산 서열
쥣과 동물 항-RAGE 항체 XT-H1, XT-H2, XT-H3, XT-H5 및 XT-H7과, 래트 항-RAGE 항체 XT-M4의 경쇄 및 중쇄 가변부를 암호화하는 DNA 서열을 클로닝 및 서열 결정하고, 이 가변부의 아미노산 서열을 서열 결정하였다. 상기 6개의 항체의 중쇄 가변부의 배열된 아미노산 서열을 도 6에 나타내었으며, 경쇄 가변부의 배열된 아미노산 서열은 도 7에 나타내었다.
실시예 10
RAGE를 암호화하는 토끼, 개코 원숭이 및 사이노몰거스 원숭이 cDNA 서열의 분리
표준적인 역 전사-중합 효소 연쇄 반응(RT-PCR) 방법에 따라서, RAGE를 암호화하는 cDNA 서열을 분리 및 클로닝하였다. 제조자의 프로토콜에 따라서, 트리졸(Trizol; Gibco Invitrogen, Carlsbad, CA)을 사용하여, 폐 조직으로부터 RNA를 추출 및 정제하였다. 제조자의 프로토콜에 따라서, 택맨 역 전사 시약(TaqMan Reverse Transcription Reagent; Roche Applied Science Indianapolis, IN)을 사용하여, mRNA를 역 전사시켜 cDNA를 생성하였다. 사이노몰거스 원숭이(마카카 파시큘러리스(Macaca fascicularis)) 및 개코 원숭이(파피오 시아노세팔루스(Papio cyanocephalus))의 RAGE 서열을, 인비트로겐 태그 DNA 중합 효소(Invitrogen, Carlsbad CA) 및 프로토콜, 그리고 SpeI 및 EcoRV 제한 위치를 부가하는 올리고뉴클레오티드(5'-GACCCTGGAAGGAAGCAGGATG(서열 번호 59) 및 5'-GGATCTGTCTGTGGGCCCCTCAAGGCC)(서열 번호 60)를 사용하여 cDNA로부터 증폭시켰다. PCR 증폭 생성물을 SpeI/EcoRV로 분해한 다음, 이를 플라스미드 pAdori1-3 내 상응하는 위치에 클로닝하였다. 전술한 바와 같은 RT-PCR에 따라서, 다음과 같은 올리고뉴클레오티드들 즉, SpeI 및 NotI 위치를 부가하는 5'-ACTAGACTAGTCGGACCATGGCAGCAGGGGCAGCGGCCGGA(서열 번호 61) 및 5'-ATAAGAATGCGGCCGCTAAACTATTCAGGGCTCTCCTGTACCGCTCTC(서열 번호 62)을 사용하여 토끼의 RAGE를 클로닝한 다음, pAdori1-3 내 상응하는 위치에 클로닝하였다. 결과로 생성된 플라스미드 내 개코 원숭이, 원숭이 및 토끼 RAGE의 2개의 아형을 암호화하는, 클로닝된 cDNA 서열의 뉴클레오티드 서열을 서열 결정하였다. 개코 원숭이 RAGE를 암호화하는 뉴클레오티드 서열을 도 8에 나타내었으며(서열 번호 6), 사이노몰거스 원숭이 RAGE를 암호화하는 뉴클레오티드 서열을 도 9에 나타내었다(서열 번호 8). 토끼 RAGE의 2가지 아형을 암호화하는 뉴클레오티드 서열은 도 10(서열 번호 10) 및 도 11(서열 번호 12)에 나타내었다.
실시예 11
개코 원숭이 RAGE를 암호화하는 게놈 DNA 서열의 분리
표준적인 게놈 클로닝 기술을 이용하여, RAGE를 암호화하는 개코 원숭이 게놈 DNA 서열을 분리하였다[예를 들어, Sambrook, J.외 다수, Molecular Cloning: A Laboratory Manual, 2nd Ed., 1989, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York 참조]. 람다 DASH II 벡터 내 개코 원숭이(파피오 시아노세팔루스) 람다 게놈 라이브러리(Stratagene, La JoIIa, C)를, 32P 랜덤 프라이밍 인간 RAGE cDNA를 사용하여 스크리닝하였다. 포지티브 파지 플라크를 분리하고, 이를 2회 더 스크리닝시켜, 하나의 분리체를 얻었다. 람다 DNA를 제조하고, 이를 NotI로 분해한 다음, 크기별로 분획화하여, 람다 게놈 팔로부터 삽입 DNA를 분리하였다(일반적인 방법을 이용함). NotI 단편을 NotI-분해 pBluescript SK+와 결찰시키고, RAGE 특이적 프라이머를 사용하여 이 삽입물을 서열 결정하였다. 생산된 클론을 클론 18.2라 명명하였다. 클로닝된 개코 원숭이 RAGE 암호화 개코 원숭이 게놈 DNA의 뉴클레오티드 서열을 도 12a∼도 12e(서열 번호 15)에 나타내었다.
실시예 12
키메라 XT-M4 항체
래트 항-쥣과 동물 RAGE 항체 XT-M4의 경쇄 및 중쇄 가변부를 인간 카파 경쇄 및 IgG1 중쇄 불변부에 각각 융합하여, 키메라 XT-M4를 생산하였다. 이 항체의 유효한 Fc-매개 효과기 활성을 줄이기 위해, 키메라 돌연 변이체인 L234A 및 G237A를 인간 IgG1 Fc부 내 XT-M4에 도입하였다. 키메라 항체를 분자 번호 XT-M4-A-1라 명명하였다. 키메라 XT-M4 항체는 93.83%의 인간 아미노산 서열과, 6.18%의 래트 아미노산 서열을 함유한다.
실시예 13
키메라 XT-M4와 RAGE의 결합에 관한 평가
키메라 항체 XT-M4와 선택된 래트 및 쥣과 동물 항-RAGE 항체가, 인간 RAGE 및 기타 종의 RAGE와 결합하는 능력, 그리고 이 항체가 RAGE 리간드와의 결합을 차단하는 능력을 ELISA 및 바이어코어™ 결합 검정법으로 측정하였다.
A. 바이어코어™ 결합 검정법에 의해 측정된 가용성 인간 RAGE와의 결합
키메라 항체 XT-M4, 부모 래트 항체 XT-M4 및 쥣과 동물 항체 XT-H2 및 XT-H5가 가용성 인간 RAGE(hRAGE-SA)와 결합하는 특성을 바이어코어™ 포획 결합 검정법으로 측정하였다. 항체를 CM5 BIA 칩상에 코팅하여(5000∼7000RU) 이 검정법을 수행하였다. 농도 100nM, 50nM, 25nM, 12.5nM, 6.25nM, 3.12nM, 1.56nM 및 0nM인 정제된 가용성 인간 스트렙타비딘-태깅 RAGE(hRAGE-SA) 용액을 고정된 항체 위로 흘려보내고(3회), hRAGE-SA와의 결합에 대한 반응 속도 상수(ka 및 kd)와 결합 상수 및 해리 상수(Ka 및 Kd)를 측정하였다. 그 결과를 표 6에 나타내었다.

XT-M4 항체와 키메라 항체 XT-M4는 단량체인 가용성 인간 RAGE에 유사한 역학적 비율로 결합하였다. 인간 가용성 단량체 RAGE에 대한 키메라 XT-M4의 친화도는 약 5.5nM이었다.
B. RAGE 리간드 경쟁 ELISA 결합 검정법
키메라 항체인 XT-M4 항체와 래트 항체인 XT-M4가, RAGE 리간드인 HMGB1, 아밀로이드 β1-42 펩티드, S100-A 및 S100-B와 hRAGE-Fc의 결합을 차단하는 능력을, 리간드 경쟁 ELISA 결합 검정법으로 측정하였다(실시예 7 참조). 도 13에 나타낸 바와 같이, 키메라 항체 XT-M4 및 XT-M4는, HMGB1, 아밀로이드 β1-42 펩티드, S100-A 및 S100-B와 인간 RAGE의 결합을 차단하는 능력이 거의 동일하다.
C. 항체 경쟁 ELISA 결합 검정법
키메라 항체인 XT-M4 항체가, 래트 항체인 XT-M4 및 쥣과 동물 항체인 XT-H2와, hRAGE-Fc와 결합함에 있어서 경쟁하는 능력을, 실시예 7에 기술된 방식으로, 바이오틴-결합 XT-M4 및 XT-H2 항체를 사용하여, 항체 경쟁 ELISA 결합 검정법을 통해 측정하였다. 도 14에 나타낸 바와 같이, 키메라 항체 XT-M4는 래트 항체 XT-M4 및 쥣과 동물 항체 XT-H2와, hRAGE-Fc와 결합함에 있어서 경쟁한다.
실시예 14
세포계 ELISA에 의해 측정된 상이한 종의 RAGE와 항체의 결합 특성
세포 형질 감염
인간 배 신장 293 세포(미국 모식균 배양 수집소, Manassas, VA)를 10㎠의 조직 배양 평판 당 5×106개의 세포만큼 도말하여, 이를 37℃에서 밤새도록 항온 처리하였다. 그 다음 날, 제조자의 프로토콜에 따라서, LF2000 시약(Invitrogen, Carlsbad CA)을 이용하여, 세포에 RAGE 발현 플라스미드(마우스, 인간, 개코 원숭이, 사이노몰거스 원숭이 또는 토끼 RAGE를 암호화하는 pAdori1-3 벡터)로 형질 감염시켰다[이때, 시약 대 플라스미드 DNA의 비율 = 4:1]. 트립신을 사용하여 형질 감염시킨 후 48시간 경과시 세포를 수집한 다음, 이를 인산염 완충 염수(PBS)로 1회 세척하고, 다시 혈청을 함유하지 않는 성장 배지에 농도 2×106개 세포/㎖가 되도록 현탁시켰다.
세포계 ELISA
1㎍/㎖의 1차 항체를, 1% 소 혈청 알부민(BSA) 함유 PBS 중에 1:2 또는 1:3의 비율로 연속 희석하였다(96-웰 평판 내 수행). RAGE-형질 감염 293 세포 또는 대조군 부모 293 세포(50㎕)(무혈청 성장 배지 중 2×106개 세포/㎖)를 U-바닥 96-웰 평판에 가하여, 최종 농도가 1×105개 세포/웰이 되도록 하였다. 이 세포를 1600rpm에서 2분 동안 원심 분리하였다. 상청액을 손으로 가볍게 따라낸 후(한 번 흔들어줌), 이 평판을 살짝 두드려줘 세포 펠릿을 털어냈다. 냉각 PBS(10% 소 태아 혈청(FCS) 함유) 중 희석된 1차 항-RAGE 항체 또는 동 기준 표본형-매칭 대조군 항체(100㎕)를 상기 세포에 가하고, 이를 얼음에서 1시간 동안 항온 처리하였다. 이 세포를 100㎕의 희석된 2차 항-IgG 항체 HRP 접합체(Pierce Biotechnology, Rockford, IL)로 염색하였다(얼음 상, 1시간). 1차 항체 항온 처리 및 2차 항체 항온 처리의 각 단계를 수행한 다음, 세포를 얼음 냉각 PBS로 3회 세척하였다. 기질 TMB1 성분(BIO FX, TMBW-0100-01) 100㎕를 상기 평판에 가한 후, 이를 실온에서 5∼30분 동안 항온 처리하였다. 여기에 100㎕의 0.18M H2SO4를 첨가하여 발색을 중지시켰다. 상기 세포를 원심 분리하고, 상청액을 새 평판으로 옮긴 다음, 450㎚에서 판독하였다[Soft MAX pro 4.0, Molecular Devices Corporation, Sunnyvale, CA].
키메라 항체 XT-M4 및 XT-M4가 인간 및 개코 원숭이의 RAGE와 결합하는 능력을 세포계 ELISA로 측정한 결과를 도 14에 나타내었다. 키메라 항체 XT-M4 및 XT-M4가, 293 세포에 의해 발현되는 세포 표면 인간, 개코 원숭이, 원숭이, 마우스 및 토끼 RAGE에 결합하는지에 대한 EC50값을 표 7에 나타내었다[세포계 ELISA에 의해 측정].

실시예 15
상이한 종의 RAGE와의 결합 - 면역 조직 화학적 염색에 의한 분석
키메라 항체 XT-M4, 래트 XT-M4 항체, 그리고 쥣과 동물 항체 XT-H1, XT-H2 및 XT-H5가, 인간, 사이노몰거스 원숭이, 개코 원숭이 및 토끼의 폐 조직 내 내인성 세포 표면 RAGE와 결합하는 능력을, 폐 조직 검편의 면역 조직 화학적(IHC) 염색법으로 측정하였다.
안정하게 형질 감염된 중국 햄스터 난소(CHO) 세포를 조작하여, 쥣과 동물 및 인간 RAGE 전장 단백질을 발현하도록 만들었다. 상기 쥣과 동물 및 인간 RAGE cDNA를 포유동물 발현 벡터에 클로닝한 다음, 이를 선형화하여, 리포팩션에 의해 다시 CHO 세포에 형질 감염시켰다[Kaufman, R.J., 1990, Methods in Enzymology 185:537-66; Kaufman, R.J., 1990, Methods in Enzymology 185:487-511 ;Pittman, D. D.외 다수, 1993, Methods in Enzymology 222; 236]. 세포를 20nM 메토트렉세이트 중에서 추가로 선별해낸 다음, 각각의 클론으로부터 세포 추출물을 수집하고, 이를 SDS 소듐 도데실 설페이트-폴리아크릴아미드 겔 전기 영동법(SDS-PAGE) 및 웨스턴 블럿팅으로 분석하여 발현 여부를 확인하였다.
표준적인 기술을 사용하여, 인간 RAGE를 과발현하는 개코 원숭이, 사이노몰거스 원숭이, 토끼 또는 중국 햄스터 난소 세포, 또는 대조군 CHO 세포로부터 분리된 RAGE 폐 조직에 대한 면역 조직 화학적 분석을 실시하였다. RAGE 항체 및 래트의 IgG2b 동 기준 표본형 대조군 또는 마우스 동 기준 표본형 대조군을 1∼15㎎ 사용하였다. 키메라 XT-M4, XT-M4-hVH-V2.0-2m/hVL-V2.10, XT-M4-hVH-V2.0-2m/hVL-V2.11, XT-M4-hVH-V2.0-2m/hVL-V2.14를 바이오틴화하고, 시그마 IgG1 바이오틴화 대조군 항체는 0.2, 1, 5 및 10㎍/㎖ 사용하였다. HRP 및 알렉사 플루어(Alexa Fluor) 594, 알렉사 플루어 488, 또는 FITC와 접합된 항-바이오틴으로 검출한 다음, 검편도 4'-6-디아미디노-2-페닐린돌(DAPI)로 염색하였다.
도 15는 키메라 항체 XT-M4가 사이노몰거스 원숭이, 토끼 및 개코 원숭이의 폐 조직 내에서 RAGE와 결합한다는 사실을 나타내는 것이다. 시료 중 포지티브 IHC-염색 패턴을 눈으로 확인할 수 있었는데, 이때, RAGE-생산 세포는 키메라 XT-M4와 접촉하였으며, RAGE 또는 RAGE-결합 항체가 존재하지 않는 시료 중에서는 IHC-염색 패턴을 눈으로 확인할 수 없었다. 도 16은 인간의 정상인 폐와 만성 폐색성 호흡기 질환(COPD) 환자의 폐 내, RAGE에 래트 항체인 XT-M4가 결합함을 보여주는 것이다. 폐 조직 검편을 IHC 염색함으로써 측정된 바와 같은, 래트 XT-M4 항체 및 쥣과 동물 항체 XT-H1, XT-H2 및 XT-H5가, 패혈증 개코 원숭이 폐 및 정상 사이노몰거스 원숭이 폐 내 내인성 세포 표면 RAGE와 결합하는지 여부를 표 8에 요약하였다. hRAGE를 암호화하는 DNA를 발현하는 발현 벡터로 안정하게 형질 감염된 CHO 세포를 포지티브 대조군으로 사용하였다.

실시예 16
인간화된 쥣과 동물 항-인간 RAGE 항체 XT-H2의 분자 모델링
쥣과 동물 항-인간 RAGE 항체 XT-H2 HV 도메인의 분자 모델링
쥣과 동물 XT-H2 중쇄를 모델링하기 위한 항체 구조 주형을, 단백질 데이터 은행(Protein Data Bank; PDB) 서열 데이터베이스에 대한 BLASTP 검색 결과를 바탕으로 하여 선택하였다. 6개의 주형 구조, 1SY6(항-CD3 항체), 1MRF(항-RNA 항체), 그리고 1RIH(항-종양 항체)를 바탕으로 하여[인사이트II(InsightII; Accelrys, San Diego)의 상동성 모듈 이용], 쥣과 동물 XT-H2의 분자 모델을 확립하였다. 주형의 구조적으로 보존된 부위(SCR)를, 각각의 분자에 대한 Cα 거리 매트릭스(Cα distance matric)를 바탕으로 하여 분석하고, 이 주형 구조를 SCR 내 상응하는 원자의 최소 RMS 편차를 바탕으로 중첩시켰다. 표적 단백질 래트 XT-H2 VH의 서열을 중첩된 주형 단백질의 서열에 대해 배열하고, 상기 SCR의 원자 좌표를 표적 단백질의 상응하는 잔기에 할당하였다. 각각의 SCR 내 표적과 주형 사이의 서열 유사성 정도를 바탕으로 하여, 상이한 주형으로부터 유래하는 좌표를 상이한 SCR에 대해 이용하였다. 상동성 모듈에서 실행되는 바와 같이, 서치 루프(Search Loop) 또는 비 축퇴성 루프법(Generate Loop method)에 의해, 상기 SCR에 포함되지 않는 루프와 가변부에 대한 좌표를 구하였다.
간단히 말해서, 상기 서치 루프법은, 측접하는 SCR 잔기의 Cα 거리 매트릭스와, 동일한 수의 측접 잔기와 소정의 길이의 삽입 펩티드 분절을 가지는 단백질 구조로부터 유래하는 예비-계산 매트릭스를 비교하여, 2개의 SCR간 부위를 모의하는 단백질 구조를 정밀 분석하는 것이다. 상기 서치 루프법의 출력값은 우선, 측접하는 SCR 잔기 내 최소한의 RMS 편차와 최대 서열 동일성을 가지는 매치부를 찾기 위해 평가되었다. 이후, 잠재적인 매치부와 표적 루프의 서열 사이의 서열 유사성에 대하여 평가하였다. 상기 비 축퇴성 루프법을 통하여, 새로운 원자 좌표를 구하였는데, 이 좌표는 서치 루프가 최적의 매치부를 찾지 못하였을 때 사용하였다. 주형 및 표적의 아미노산 잔기가 동일하면, 아미노산 측쇄의 형태를 주형 내 아미노산 측쇄의 형태와 동일하게 유지시켰다. 그러나, 회전 이성체의 형태학적 검색을 수행하여, 주형 및 표적 내 동일하지 않은 잔기들에 대해 가장 바람직한 활성 형태를 유지시켰다. 좌표를 상이한 주형으로부터 구한 2개의 SCR간 스플라이싱 접합부를 최적화하기 위하여, SCR 및 루프 간 스플라이싱 접합부를 이용하였는데, 즉, 상동성 모듈의 스플라이싱 수선 기능을 이용하였다. 스플라이싱 수선(Splice Repair)을 통하여, 2개의 SCR간 접합부, 또는 SCR과 가변부 사이의 접합부의 결합 길이와 이 접합부의 결합각을 최적으로 만들도록, 분자 기구 시뮬레이션을 셋업하였다. 마지막으로, 최대 파생 계수(maximum derivative)가 5kcal/(molÅ) 또는 500 사이클이 될 때까지 스티피스트 디센트 알고리즘(Steepest Descents algorithm)을 사용하여 에너지를 최소화시키고, 최대 파생 계수가 5kcal/(molÅ) 또는 2000 사이클이 될 때까지 컨쥬게이트 그래디언트 알고리즘(Conjugate Gradients algorithm)을 사용하여 에너지를 최소화시켰다. 모델의 질은 상동성 모듈의 ProStat/Struct_Check 유틸리티를 이용하여 평가하였다.
인간화된 항-RAGE XT-H2 HV 도메인의 분자 모델링
마우스 XT H2 항체 중쇄의 모델링에 관하여 기술된 바와 동일한 방법에 따라서, 인사이트 II를 사용하여 인간화된(CDR 이식된) 항-RAGE 항체 XT-H2 중쇄의 분자 모델을 확립하였는데, 다만, 이때 사용된 주형은 상이하였다. 이 경우 사용된 구조 주형은 1L7I(항-Erb B2 항체), 1FGV(항-CD18 항체), 1JPS(항-조직 인자 항체) 및 1N8Z(항-Her2 항체)였다.
틀 복귀 돌연 변이 - 인간화에 대한 모델 분석법 및 예측법
부모 마우스 항체 모델을 CDR-이식된 인간화 마우스 모델과 다음과 같은 특징들 중 하나 이상이 유사한지 아니면 상이한지에 관하여 비교하였다: CDR-틀 접촉 여부, CDR 형태에 영향을 미치는 잠재적 수소 결합, 그리고 다양한 부위 예를 들어, 틀 1, 틀 2, 틀 3, 틀 4 및 3개의 CDR에서의 RMS 편차.
다음과 같은 복귀 돌연 변이(1회 및 복수 회 돌연 변이)는 CDR 이식에 의해 성공적으로 인간화됨에 있어서 중요한 것으로 예측되었다: E46Y, R72A, N77S, N74K, R67K, K76S, A23K, F68A, R38K, A40R.
실시예 17
인간화된 래트 항-RAGE 항체 XT-M4에 대한 분자 모델링
래트 항-쥣과 동물 RAGE 항체 XT-M4 HV 도메인의 분자 모델링
래트 XT-M4 중쇄를 모델링하기 위한 항체 구조 주형을, 단백질 데이터 은행(Protein Data Bank; PDB) 서열 데이터베이스에 대한 BLASTP 검색 결과를 바탕으로 하여 선택하였다. 6개의 주형 구조, 1QKZ(항-펩티드 항체), 1IGT(항-개 림프종 모노클로날 항체), 8FAB(항-p-아조페닐 아르소네이트 항체), 1MQK(항-시토크롬 C 산화 효소 항체), 1H0D(항-안지오제닌 항체), 그리고 1MHP(항-알파1베타1 항체)를 바탕으로 하여[인사이트II(Accelrys, San Diego)의 상동성 모듈 이용], 래트 XT-M4의 분자 모델을 확립하였다. 상기 주형의 구조적으로 보존된 부위(SCR)를, 각각의 분자에 대한 Cα 거리 매트릭스를 바탕으로 하여 분석하고, 이 주형 구조를 SCR 내 상응하는 원자의 최소 RMS 편차를 바탕으로 중첩시켰다. 표적 단백질 래트 XT-M4 VH의 서열을 중첩된 주형 단백질의 서열에 대해 배열하고, 상기 SCR의 원자 좌표를 표적 단백질의 상응하는 잔기에 할당하였다. 각각의 SCR 내 표적과 주형 사이의 서열 유사성 정도를 바탕으로 하여, 상이한 주형으로부터 유래하는 좌표를 상이한 SCR에 대해 이용하였다. 상동성 모듈에서 실행되는 바와 같이, 서치 루프 또는 비 축퇴성 루프법에 의해, 상기 SCR에 포함되지 않는 루프와 가변부에 대한 좌표를 구하였다.
간단히 말해서, 상기 서치 루프법은, 측접하는 SCR 잔기의 Cα 거리 매트릭스와, 동일한 수의 측접 잔기와 소정의 길이의 삽입 펩티드 분절을 가지는 단백질 구조로부터 유래하는 예비-계산 매트릭스를 비교하여, 2개의 SCR간 부위를 모의하는 단백질 구조를 정밀 분석하는 것이다. 상기 서치 루프법의 출력값은 우선, 측접하는 SCR 잔기 내 최소한의 RMS 편차와 최대 서열 동일성을 가지는 매치부를 찾기위해 평가되었다. 이후, 잠재적인 매치부와 표적 루프의 서열 사이의 서열 유사성에 대하여 평가하였다. 상기 비 축퇴성 루프법을 통하여, 새로운 원자 좌표를 구하였으며, 이 좌표는, 서치 루프가 최적의 매치부를 찾지 못하였을 때 사용하였다. 주형 및 표적의 아미노산 잔기가 동일하면, 아미노산 측쇄의 형태를 주형 내 아미노산 측쇄의 형태와 동일하게 유지시켰다. 그러나, 회전 이성체의 형태학적 검색을 수행하여, 주형 및 표적 내 동일하지 않은 잔기들에 대해 가장 바람직한 활성 형태를 유지시켰다. 좌표를 상이한 주형으로부터 구한 2개의 SCR간 스플라이싱 접합부를 최적화하기 위하여, SCR 및 루프 간 스플라이싱 접합부 즉, 상동성 모듈의 스플라이싱 수선 기능을 이용하였다. 스플라이싱 수선은 2개의 SCR간 접합부, 또는 SCR과 가변부 사이의 접합부의 결합 길이와 이 접합부의 결합각을 최적으로 유도하도록, 분자 기구 시뮬레이션을 셋업하였다. 마지막으로, 최대 파생 계수가 5kcal/(molÅ) 또는 500 사이클이 될 때까지 스티피스트 디센트 알고리즘을 사용하여 에너지를 최소화시키고, 최대 파생 계수가 5kcal/(molÅ) 또는 2000 사이클이 될 때까지 컨쥬게이트 그래디언트 알고리즘을 사용하여 에너지를 최소화시켰다. 모델의 질은 상동성 모듈의 ProStat/Struct_Check 유틸리티를 이용하여 평가하였다.
XT-M4 경쇄 가변 도메인
1K6Q(항-조직 인자 항체), 1WTL, 1D5B(항체 AZ-28) 및 1BOG(항-p24 항체)를 주형으로 사용하는 모델러 8v2(Modeler 8v2)로써, XT M4 경쇄 가변 도메인에 대한 구조 모델을 구성하였다. 각각의 표적에 있어서, 100개의 초기 모델 중, 분자 확률 밀도 함수에 의해 규정되는, 규제 위반이 가장 적은 하나의 모델을 선택하여 추가로 최적화하였다. 모델 최적화를 위해서, 디스커버리 스튜디오 1.6(Discovery Studio 1.6; Accelrys Software Inc.)에서 수행되는 바와 같이, 참 27(Charmm 27) 력장(force field)(Accelrys Software Inc.) 및 제너럴라이즈드 본 내포 용매화(Generalized Born implicit solvation)를 이용하였을 때, RMS 구배가 0.01이 될 때까지, 스티피스트 디센트, 컨쥬게이트 그레디언트 및 어답티드 베이시스 뉴턴 랩슨법(Adopted Basis Newton Raphson methods)을 포함하는 에너지 최적화 케스케이드를 수행하였다. 에너지 최소화가 이루어지는 동안, 조화 구속법(harmonic constraint) 10 질량력(mass force)을 이용하여, 주쇄 원자의 이동을 제한하였다.
인간화된 항-RAGE XT-M4 VH 도메인의 분자 모델링
래트 XT M4 항체 중쇄의 모델링에 관하여 기술된 바와 동일한 방법에 따라서, 인사이트 II를 사용하여, 인간화된(CDR 이식된) 항-RAGE XT M4 항체 중쇄의 분자 모델을 확립하였는데, 다만, 이때 사용된 주형은 상이하였다. 이 경우 사용된 구조 주형은 1MHP(항-알파1베타1 항체), 1IGT(항-개 림프종 모노클로날 항체), 8FAB(항-p-아조페닐 아르소네이트 항체), 1MQK(항-시토크롬 C 산화 효소 항체) 및 1H0D(항-안지오제닌 항체)였다.
인간화된 XT-M4 경쇄 가변 도메인
래트 XT M4 항체 경쇄의 모델링에 관하여 기술된 바와 동일한 방법에 따라서(다만, 이때 사용된 주형은 상이하였음), 모델러 8v2를 사용하여, 인간화된(CDR 이식된) 항-RAGE XT M4 항체 경쇄의 분자 모델을 확립하였다. 이 경우 사용된 구조 주형은 1B6D, 1FGV(항-CD18 항체), 1UJ3(항-조직 인자 항체) 및 1WTL이었다.
틀 복귀 돌연 변이 - 인간화에 대한 모델 분석법 및 예측법
부모 래트 항체 모델을 CDR-이식된 인간화 마우스 모델과 다음과 같은 특징들 중 하나 이상이 유사한지 아니면 상이한지에 관하여 비교하였다: CDR-틀 접촉 여부, CDR 형태에 영향을 미치는 잠재적 수소 결합, 그리고 다양한 부위 예를 들어, 틀 1, 틀 2, 틀 3, 틀 4 및 3개의 CDR에서의 RMS 편차, 그리고 잔기-잔기 상호 작용에 관한 에너지 계측치. 동정된 잠재적 복귀 돌연 변이(들)(1회 또는 복수 회 돌연 변이)는 인사이트 II 또는 모델러 8v2를 사용하여 확립된 모델의 차회 라운드에 통합되었으며, 돌연 변이 모델을 부모 래트 항체 모델과 비교하여, 컴퓨터 상에서 돌연 변이체의 적합성을 평가하였다.
다음과 같은 복귀 돌연 변이(하나 및 복수 개 돌연 변이)는 CDR 이식에 의해 성공적으로 인간화됨에 있어서 중요한 것으로 예측되었다:
중쇄: L114M, T113V 및 A88S;
경쇄: K45R, L46R, L47M, D70I, G66R, T85D, Y87H, T69S, Y36F, F71Y.
실시예 18
쥣과 동물 XT-H2 및 래트 XT-M4 항체의 CDR을 포함하는 인간화된 가변부
쥣과 동물 XT-H2 및 래트 XT-M4 항체의 CDR을 인간 생식 계열 틀 서열(표 9)에 이식하고, 선택된 복귀 돌연 변이를 도입함으로써, 인간화된 중쇄 가변부를 제조하였다.

인간화된 쥣과 동물 XT-H2 중쇄 및 경쇄 가변부의 아미노산 서열을 도 17(서열 번호 28∼31) 및 도 18(서열 번호 32∼35)에 각각 나타내었다.
인간화된 래트 XT-M4 중쇄 및 경쇄 가변부의 아미노산 서열을 도 19(서열 번호 36∼38) 및 도 20a∼20b(서열 번호 39∼49)에 각각 나타내었다.
틀 서열이 유래하는 생식 계열 서열과, 인간화된 가변부 내 특이적 복귀 돌연 변이를 표 10에 나타내었다.
인간화된 가변부를 암호화하는 DNA 서열을, 인간 면역 글로불린 불변부를 암호화하는 서열을 함유하는 발현 벡터에 서브클로닝하고, 전장 경쇄 및 중쇄를 암호화하는 DNA 서열을 COS 세포 내에서 발현시켰다(표준적인 방법 이용함). 중쇄 가변부를 암호화하는 DNA를 pSMED2hIgG1m_(L234, L237)cDNA 벡터에 서브클로닝하여, 인간화된 IgG1 항체 중쇄를 생산하였다. 경쇄 가변부를 암호화하는 DNA를 pSMEN2h 카파 벡터에 서브클로닝하여, 인간화된 카파 항체 경쇄를 생산하였다. 도 21을 참조하시오.

실시예 19
경쟁 ELISA 프로토콜
인간화된 XT-H2 및 XT-M4 항체의 결합과, 키메라 XT-M4와 인간 RAGE-Fc의 결합을, 경쟁 효소-결합 면역 흡착 검정법(ELISA)에 의해 특성 규명하였다. 경쟁 물질을 생성하기 위하여, 부모 래트 XT-M4 항체를 바이오틴화하였다. ELISA 평판을 1ug/㎖의 인간 RAGE-Fc와 함께 밤새도록 코팅하였다. 다양한 농도의 바이오틴화 XT-M4를 웰에 첨가한 후(2개; 0.11∼250ng/㎖), 항온 처리 및 세척후, 스트렙타비딘-HRP로 검출하였다. 바이오틴화 부모 래트 XT-M4의 계측 ED50은 5ng/㎖이었다. 키메라 및 각각의 인간화된 XT-M4 항체가 12.5ng/㎖의 바이오틴화 부모 XT-M4 항체와 경쟁할 때, 상기 키메라 및 각각의 인간화된 XT-M4 항체의 IC50을 계산하였다. 간단히 말해서, 평판을 1ug/㎖의 인간 RAGE-Fc으로 밤새도록 코팅하였다. 12.5ng/㎖의 바이오틴화 부모 래트 XT-M4 항체와 혼합한 다양한 농도의 키메라 항체 또는 인간화된 항체를 상기 웰에 가하였다(2개)(9ng/㎖∼20ug/㎖). 바이오틴화된 부모 래트 XT-M4 항체를 스트렙타비딘-HRP로 검출하고, IC50값을 계산하였다. 경쟁 ELISA 분석법에 의해 측정된, 인간화된 항체에 대한 IC50값을 표 11에 나타내었다.

인간화된 XT-H2 항체와 인간 RAGE-Fc의 결합에 관한 ED50값을 경쟁 ELISA에 의해 유사하게 측정하였으며, 그 결과를 도 22에 나타내었다.
실시예 20
키메라 및 인간화된 XT-M4 항체와 기타 세포 표면 수용체의 교차 반응
인간화된 XT-M4 항체인 XT-M4-hVH-V2.0-2m/hVL-V2.10 및 XT-M4-hVH-V2.0-2m/hVL-V2.11을, 키메라 XT-M4와 함께, 다른 RAGE-유사 수용체와의 교차 반응에 대해 테스트하였다. 이 수용체들은 RAGE와 같이 세포-표면 발현되므로, 이 수용체들을 선택하였으며, 이 수용체와 리간드의 상호 작용은 유사하게 전하에 의존적이다. 테스트된 수용체는 rhVCAM-1, rhICAM-1-Fc, rhTLR4(C-말단 His 태그), rhNCAM-1, rhB7-H1-Fc mLox1-Fc, hLox1-Fc 및 hRAGE-Fc(포지티브 대조군)이었다. ELISA 평판을 상기 나열된 수용체 단백질 1㎍/㎖로 밤새도록 코팅하였다. 상기 나열한 인간화 및 키메라 XT-M4 항체를 웰에 다양한 농도로 첨가하고(2개씩)(0.03∼20㎍/㎖), 이를 항-인간 IgG HRP와 함께 항온 처리, 세척 및 검출하였다. 표 12는 키메라 및 인간화 XT-M4 항체와 인간 및 마우스 세포 표면 단백질의 결합에 관한 직접 결합 ELISA 분석 결과를 나타낸 것이다. 이 표에 제시한 데이터는 수용체와 항체(20㎍/㎖(테스트된 농도 중 최고 농도)) 사이에서 검출된 결합에 대한 OD450값이다.

실시예 21
가용성 인간 RAGE와의 결합에 대한 바이어코어™ 결합 검정법
키메라 항체 XT-M4 및 인간화된 XT-M4 항체와, 가용성 인간 RAGE(hRAGE-SA)와 가용성 쥣과 동물 RAGE(mRAGE-SA)와의 결합을, 바이어코어™ 포획 결합 검정법(BIACORE™ capture binding assay)으로 측정하였다. 이 검정법은 항-인간 Fc 항체를 유동성 세포 1∼4 내 CM5 BIA 칩상에 5000RU(pH 5.0, 7분)만큼 코팅함으로써 수행하였다. 각각의 항체를, 유동성 세포 2∼4 내 항-Fc 항체에 대해 2.0㎍/㎖의 유속으로 흘려보냄으로써 포착되었다(여기서, 유동성 세포 1은 기준으로서 사용됨). 농도 100nM, 50nM, 25nM, 12.5nM, 6.25nM, 3.125nM, 1.25nM 및 0nM인 정제된 가용성 인간 스트렙타비딘-태깅 RAGE(hRAGE-SA)의 용액을, 고정된 항체에 2회 흘려보내었으며(해리, 5분), 이때 hRAGE-SA와의 결합에 대한 반응 속도 상수(ka 및 kd) 및, 결합 및 해리 상수(Ka 및 Kd)를 측정하였다. 키메라 XT-M4 및 인간화된 항체 XT-M4-V10, XT-M4-V11 및 XT-M4-V14와, hRAGE-SA 및 mRAGE-SA의 결합 여부에 대한 결과를 도 23과 도 24에 각각 나타내었다.
실시예 22
리드 항체 XT-H2의 종간 교차 반응의 최적화
종간 교차 반응은, XT-H2 항체를 무작위로 돌연 변이시키켜, 단백질 변이체의 라이브러리를 생성하고, 마우스-인간 RAGE를 교차 반응시키는 돌연 변이가 후천적으로 발생한 분자를 선택적으로 증폭시키는 단계를 포함하는 방법에 의해 조작된다. 리보좀 디스플레이 기술[Hanes외 다수, 2000, Methods Enzymol., 328:404-30]과 파지 디스플레이 기술[McAfferty외 다수, 1989, Nature, 348: 552-4]을 사용한다.
항체 XT-H2 및 HT-M4를 주성분으로 하는 ScFv 항체의 제조
A. XT-H2를 주성분으로 하는 ScFv 항체
XT-H2의 V 부위를 포함하는 2개의 ScFv 구조물을, 가요성 링커인 DGGGSGGGGSGGGGSS(서열 번호 50)에 의해 연결된 VL/VH의 형태 또는 VH/VL의 형태로 합성하였다. VL-VH 및 VH-VL로 배열된 ScFv 구조물의 서열을 각각 도 25(서열 번호 51)와 도 26(서열 번호 52)에 나타내었다.
B. XT-M4를 주성분으로 하는 ScFv 항체
XT-M4의 V 부위를 포함하는 2개의 ScFv 구조물을, 가요성 링커인 DGGGSGGGGSGGGGSS(서열 번호 50)에 의해 연결된 VL/VH의 형태 또는 VH/VL의 형태로 합성하였다. VL-VH 및 VH-VL로 배열된 ScFv 구조물의 서열을 각각 도 27(서열 번호 54)와 도 28(서열 번호 53)에 나타내었다.
도 29는 시험관 내 전사 및 번역된 M4 및 H2 구조물에 관한 ELISA 데이터를 나타내는 것이다. 4℃의 중탄산염 완충액 중에서 밤새도록, ELISA 평판을 인간 RAGE-Fc(5ug/㎖) 또는 BSA(200ug/㎖)로 코팅하고, 이를 PBS+ 트윈 0.05%으로 세척한 후, 이를 실온에서 1시간 동안 2%의 분유 PBS로 차단시켰다. 평판을 실온에서 2시간 동안 번역된 ScFv와 함께 시험관 내에서 항온 처리하였다. 평판을 차단시키고, 항-Flag 항체(1/1000 희석)로 검출한 다음, 다시 토끼 항-마우스 HRP(1/1000 희석)로 검출하였다. 이 데이터를 통하여, XT-H2 및 XT-M4 항-RAGE 항체(VL/VH형 또는 VH/VL형)의 가변부의 ScFv 구조물은, 인간 RAGE에 특이적으로 결합하는, 기능을 나타내도록 폴딩된 단백질을 생산할 수 있음을 알 수 있다. 상기 두 형태를 가지는 ScFv의 Kd값(바이어코어™로 측정됨)은 선별 실험에 최적인 항원 농도를 측정하는데 사용된다.
C. 마우스/인간 RAGE 교차 반응이 개선된 변이체를 회수하기 위한 선별 및 스크리닝 기법
변이체 라이브러리를 오류-유발 PCR(error-prone PCR)에 의해 생성한다[Gram외 다수, 1992, PNAS 89:3576-80]. 이 돌연 변이 유발 기법은 ScFv 유전자의 전체 길이에 무작위로 돌연 변이를 도입하는 기법이다. 이후 상기 라이브러리를 확립된 방법에 의해 시험관 내에서 전사 및 번역시킨다[예를 들어, Hanes외 다수, 2000, Methods Enzymol., 328:404-30]. 이 라이브러리로써 인간-RAGE-Fc를 선별하는 방법 중 제1 라운드를 진행시키고, 미 결합 리보좀 복합체는 씻어낸 다음, 항원-결합 리보좀 복합체를 용출시킨다. RNA를 회수하여, 이를 RT-PCR로써 cDNA로 전환시키고, 다시 이로써 마우스 RAGE-Fc을 선별하는 방법 중 제2 라운드를 진행시킨다. 이와 같은 대안적 선별 기법은 인간 및 마우스 RAGE-Fc 둘 다에 결합하는 클론을 우선적으로 증폭시킨다. 이 선별법으로부터 얻어진 결과물을 사용하여, 2차적으로 오류-유발 PCR을 진행시킨다. 이후, 생성된 라이브러리로써 인간-RAGE-Fc 및 마우스 RAGE-Fc을 선별하는 방법 중 제3 라운드를 진행시켜, 라운드 선별을 수행한다. 이 과정을 필요한 만큼 반복 수행한다. 각각의 선별 단계로부터 얻어진 RNA의 결과 풀을 cDNA로 전환시키고, 이를 단백질 발현 벡터인 pWRIL-1로 클로닝하여, 변이체 ScFv의 종간 교차 반응성을 평가한다. 다양한 풀을 서열 결정하여 다양성을 평가함으로써, 선별이 종간 교차 반응을 나타내는 우성 클론에 대해 이루어졌는지 여부를 측정한다.
실시예 23
리드 항체 XT-M4의 친화성 성숙(affinity maturation)
친화성이 개선되었는지는, 투여량이나 투여 횟수의 감소 및/또는 효능의 증가와 같은 유효한 효능을 나타내는지 여부로 판단된다. hRAGE에 대한 친화성은, VH-CDR3으로의 표적화 돌연 변이 유발법과 무작위 오류-유발 PCR 돌연 변이 유발법을 병행하는 친화성 성숙법에 의해 개선된다[Gram외 다수, 1992, PNAS 89:3576-80]. 이로써, 인간-RAGE에 대한 친화성이 개선되었으며, 또한 마우스-RAGE-Fc에 대한 종간 교차 반응을 유지하는 분자를 회수할 수 있는 변이 항체 라이브러리가 생성된다. 리보좀 디스플레이 기술[Hanes외 다수, 1997, 상동]과 파지 디스플레이 기술[McAfferty외 다수, 1989, 상동]을 사용한다.
도 30은 VL-VH 형태인 pWRIL-1 내 XT-M4 및 XT-H2 ScFv 구조물에 관한 ELISA 결합 데이터를 나타내는 것으로서, 상기 구조물은 에스케리치아 콜라이 내에서 가용성 단백질로 발현되며, 인간 RAGE-Fc 및 BSA와의 결합에 대해 테스트된다. ActRIIb는 네거티브 대조군과 동일한 벡터로부터 발현된 비-결합성 단백질을 나타낸다. ELISA 평판을 중탄산 완충액 중 인간 RAGE-Fc(5ug/㎖) 또는 BSA(200ug/㎖)으로 밤새도록 코팅한 후(4℃), PBS + 트윈 0.05%으로 세척하고, 다시 실온에서 1시간 동안 2% 분유 PBS로 차단하였다. 표준적인 방법에 의해, 20㎖의 이.콜라이 배양액의 세포질 주변 제제를 만들었다. 미정제 ScFv 항체의 세포질 주변 제제의 최종 부피는 1㎖였는데, 이중 50ul는 1/1000 희석된 항-His 항체와 실온에서 1시간 동안 항온 처리하였으며, 이후 2% 분유 PBS로 최종 부피 100ul이 되도록 만들었다. 가교 결합된 세포질 주변 제제를 ELISA 평판에 가한 후, 이를 실온에서 2시간 더 항온 처리하였다. 이 평판을 PBS+0.05% 트윈으로 2회 세척하고, 다시 PBS로 2회 세척한 다음, 2% 분유 PBS 중 토끼 항-마우스 HRP(1/1000 희석)와 함께 항온 처리하였다. 상기 평판을 이전과 같이 세척하고, 표준적인 TMB 시약을 이용하여 결합을 검출하였다. 데이터를 통하여, VL/VH 형태를 가지는 XT-M4 및 XT-H2 항체의 ScFv 구조물은 이.콜라이 내에서 인간 RAGE와 특이적으로 결합하는, 기능을 나타내도록 폴딩된 가용성 단백질을 생산할 수 있음을 알 수 있다. 상기 두 형태를 가지는 ScFv의 출발 Kd값(바이어코어™로 측정함)을 사용하여, 친화성 선별에 최적인 항원 농도를 결정한다.
실시예 24
hRAGE-Fc에 대한 친화성이 개선되었고 종간 교차 반응성은 유지하고 있는 변이체를 회수하는 선별 및 스크리닝 기법
PCR을 이용하여 XT-M4의 VH-CDR3을 스파이킹 돌연 변이시켜(spiked mutagenesis) 변이체 라이브러리를 제조한다. 도 31은 스파이킹된 돌연 변이가 XT-M4의 CDR에 도입되는데 있어서 PCR이 어떻게 이용되는가를 개략적으로 나타내는 것이다. (1) CDR 루프의 전체에 다양성을 부여하는 부위를 운반하는, 스파이킹된 올리고뉴클레오티드를 디자인하고, 이를 FR3 및 FR4 내 표적 V 유전자와 상동성을 가지는 부위와 결합시킨다. (2) 표적 V 부위의 5' 말단에 어닐링되며, FR1 부위에 상동성인 특이적 프라이머와의 PCR 반응에서 상기 올리고뉴클레오티드를 사용한다. 도 32는 XT-M4 VL-VH ScFv 구조물의 C 말단부의 뉴클레오티드 서열(서열 번호 56)을 나타내는 것이다. VH-CDR3에 밑줄을 쳐서 표시하였다. 또한, 각각의 돌연 변이 위치에서 돌연 변이를 일으키는데 이용되는 스파이킹 비율을 규정하는, 상기 각 돌연 변이 위치에 번호를 기재한 2개의 스파이킹 올리고뉴클레오티드(서열 번호 57 및 서열 번호 58)도 나타내었다. 상기 번호에 상응하는 스파이킹 비율을 가지는 뉴클레오티드 조성도 나타내었다.
XT-M4-VHCDR3 스파이킹 PCR 생성물을 리보좀 디스플레이 벡터인 pWRIL-3에 Sfi 단편으로서 클로닝하여, 라이브러리를 제조하였다. 이 라이브러리를, 리보좀 디스플레이법을 이용하여, 인간의 바이오틴화 RAGE에 대해 선별한다[Hanes and Pluckthun., 2000]. 바이오틴 표지된 항원은, 전체적인 과정을 보다 역학적으로 조절할 수 있고, 고 친화성 클론을 우선적으로 증폭시킬 가능성을 증가시키는 용액계 선별을 가능하게 하므로, 이 항원을 사용한다. 출발 친화성에 비하여 낮은 항원 농도에서, 평형 방식으로, 또는 역학적 방식으로 선별을 수행하는데, 이 경우, 개선된 해리 비율은, 실험에 의해 결정된 시간 프레임 안에서 비 표지 항원과의 경쟁 특성을 이용하여 특이적으로 선택된다. 미 결합 리보좀 복합체를 씻어내고, 항원 결합 리보좀 복합체를 용출시켜, RNA를 회수한 다음, 이를 RT-PCR에 의해 cDNA로 전환하고, 바이오틴화 마우스-RAGE-Fc에 대한 선별 과정 중 제2 라운드를 진행시켜, 종간 교차 반응성을 유지시킨다. 이후, 이 선별 단계로부터 얻어진, ScFv 변이체(VH-CDR3에 돌연 변이가 발생함) 함유 결과물로써 돌연 변이 유발법의 제2 순환 단계를 진행한다. 이러한 돌연 변이 유발 단계는, 오류 유발 PCR을 이용하여 무작위 돌연 변이를 발생시키는 것을 포함한다. 이후, 생성된 라이브러리로써 바이오틴화된 인간-RAGE-Fc(10배 낮은 항원 농도로 존재함)에 대한 선별 과정 중 제3 라운드를 진행시킨다. 이 과정을 필요한 만큼 반복 수행한다. 각각의 선별 단계로부터 얻어진 RNA의 결과 풀을 cDNA로 전환시키고, 이를 단백질 발현 벡터인 pWRIL-1로 클로닝하여, 변이체 ScFv의 친화성과 종간 교차 반응성을 평가한다. 다양성을 가지는 풀을 서열 결정하여 다양성을 평가함으로써, 선별이 우성 클론에 대해 이루어졌는지 여부를 측정한다.
실시예 25
파지 디스플레이를 이용한 XT-M4의 친화성 성숙
VH-CDR3 스파이킹 라이브러리를 도 34에 도시한 바와 같이, 파지 디스플레이 벡터인 pWRIL-1에 클로닝하여, 바이오틴화된 hRAGE에 대해 선별한다. 바이오틴 표지된 항원은, 그 형태가 용액 중 친화성 유도 선별에 더욱 잘 적용될 수 있도록 사용될 것이다. 출발 친화성에 비하여 낮은 항원 농도에서, 평형 방식으로, 또는 역학적 방식으로 선별을 수행하는데, 이 경우, 개선된 해리 비율은, 실험에 의해 결정된 시간 프레임 안에서 비표지 항원과의 경쟁 특성을 이용하여 특이적으로 선택된다. 파지 디스플레이에 관한 표준적인 방법이 사용된다.
ScFv는 선별 및 스크리닝 과정을 통하여 이량체화될 수 있다. 이량체화된 ScFv는 잠재적으로 결합도를 바탕으로 하는 결합 특성을 나타내며, 이와 같이 결합 활성이 증가하면 선별 과정을 좌우할 수 있다. 친화성을 개선하는 임의의 내재적 특성보다, ScFv가 이량체를 형성하는 능력이 개선된 것은, 최종적인 치료용 항체(일반적으로, IgG)와 약간 관련되어 있다. 이량체화하는 능력이 변경됨으로 인한 결과를 피하기 위해, Fab 항체형이 사용되는데, 이 항체형은 일반적으로 이량체화되지 않는 것이다. XT-M4는 Fab 항체로서 다시 형태를 갖추어, 새로운 파지 디스플레이 벡터인 pWRIL-6에 클로닝된다. 이 벡터는 VH부 및 VL부 둘 다에 걸쳐 확장되어 존재하며, 인간 생식 계열 V 유전자 내에서는 거의 절단되지 않는 제한 위치를 갖는다. 이와 같은 제한 위치는 VL 및 VH 레퍼토리를 셔플링하고, 조합하여 조립하는데 사용될 수 있다. 하나의 기법에서, VH-CDR3 스파이킹된 라이브러리 및 VL-CDR3 스파이킹된 라이브러리는 둘 다 Fab 디스플레이 벡터 내에서 조합하여 조립되며(도 34 참조), 또한 친화성 개선 여부에 대해 선별된다.
실시예 26
키메라 항체 XT-M4의 물리적 특성 규명
고성능 액체 크로마토그래피(HPLC)/질량 분광 분석법(MS) 펩티드 맵핑과, 온-라인 MS 검출에 의한 서브유닛 분석에 따른 예비적 특성 규명을 통하여, 키메라 XT-M4 DNA 서열로부터 아미노산 서열을 예측할 수 있음을 확인하였다. 이러한 MS 데이터는 또한, 예측 N-결합 올리고당 서열 공통 위치(Asn299SerThr)가 점유하고 있고, 2개의 주요 종들이 말단 갈락토스 잔기를 포함하지 않거나 또는 하나 포함하는 복합 N-결합 바이안테너리(biantennary) 중심부 푸코실화 글리칸임을 보여주는 것이다. 분자의 Fc 부위에 위치하는 예측 N-결합 올리고당 이외에도, N-결합 올리고당은 키메라 XT-M4의 중쇄의 CDR2 부위 내 서열 공통 위치(Asn52AsnSer)에서 관찰되었다. 외부 N-결합 올리고당은 주로 중쇄 중 하나에서만 발견되고, 분자의 약 38%(CEX-HPLC 분석법에 의해 측정)를 포함한다[산성 화학종의 총 백분율을 좌우할 수 있으며, 1차 구조에 의해 분화될 수 없는 기타 산성 화학종이 존재할 수 있음]. 우세 화학 종은 2개의 시알산을 가지는 중심부 푸코실화 바이안테너리 구조를 갖는다. 흡수도는 A280을 측정하여 농도를 계산하는데 사용된다. 키메라 XT-M4의 이론상 흡수도는 1.35㎖/㎎/㎝인 것으로 계산된다.
키메라 XT-M4의 겉보기 분자량(비-환원성 SDS-PAGE에 의해 측정)은 대략 200kDa이다. 항체는 그것의 서열로부터 예상보다 더욱 느리게 이동한다. 이러한 현상은 오늘날 분석될 모든 재조합 항체에서 관찰되었다. 환원 조건 하에서, 키메라 XT-M4는 약 50kDa 위치로 이동하는 하나의 중쇄 밴드와, 약 25kDa의 위치로 이동하는 하나의 경쇄 밴드를 갖는다. 또한, 중쇄 밴드 바로 위까지 이동하는 부가의 밴드도 존재한다. 이 밴드는 자동화된 에드만 분해법(automated Edman degradation)에 의해 특성 규명되며, 또한 키메라 XT-M4의 중쇄에 상응하는 NH2-말단부를 갖는 것으로 파악된다. 이 결과들과, SDS-PAGE에 의해 분자량이 증가하였다는 관찰 결과를 통하여, 상기 부가 밴드는 CDR2 부위 내 외부 N-결합 올리고당을 가지는 중쇄임을 알 수 있다.
아미노산 서열을 바탕으로 하는, 키메라 XT-M4의 예상 등전점(pI)은 (중쇄 내 COOH-말단 Lys이 존재하는 않을 경우) 7.2이다. IEF를 통하여, 키메라 XT-M4는 pI 범위 약 7.4∼8.3에서 이동하는, 대략 10개의 밴드와, pI 약 7.8에서 이동하는 유력한 하나의 밴드를 가짐을 알 수 있다. 모세관 전기 영동 등전 초법에 의해 측정된 pI는 대략 7.7이었다.
양이온 교환 고성능 액체 크로마토그래피(CEX-HPLC)에 의한 물질 전개 분석 결과, 분자 하전이 상이한 키메라 XT-M4 종을 더욱 상세히 분석할 수 있다. 관찰된 전하 이질성은 대부분, 중쇄의 CDR2 부위에 위치하는 부가의 N-결합 올리고당에서 발견되는 시알산에 기인할 가능성이 가장 크다. 관찰된 하전 이질성 중 최소한의 비율의 이질성은 COOH-말단 리신의 이질성에 영향을 미칠수 있다.
실시예 27
글리코실화 위치의 제거
항체 XT-M4의 중쇄 가변부 내 52번 위치(캐벗 번호 메김 방식에 의함)에서 아스파라긴(N)을 아스파르트산(D)으로 전환하는 돌연 변이로 말미암아, XT-M4 항체와 인간 RAGE의 결합 특성이 개선된다[이는 hRAGE-Fc와의 직접 결합에 관한 ELISA 분석을 통하여 측정됨(도 36 참조)]. N52D 돌연 변이는 항체 XT-M4의 중쇄 가변부의 CDR2 중에서 일어나는 돌연 변이이다.
실시예 28
키메라 항-RAGE 항체의 효능에 관한 생체 내 전임상 검정법
A. 약물 동태학(PK)
키메라 항체인 키메라 XT-M4 5㎎/㎏를 수컷 BALB/c 마우스(n=3)에 1회 IV 투여한 이후의 혈청 농도를, 키메라 XT-M4에 대해 평가하였다. IgG ELISA로써 항체의 혈청 중 경시적 농도를 측정하였다. 키메라 XT-M4의 평균 혈청 노출양은 (23,235 gㆍhr/㎖)였으며, 반감기는 약 1주일(152시간)이었다. 도 37을 참조하시오.
실시예 29
기억력 손상에 관한 CFC 모델
정황 공포 조건 조성(contextual fear conditioning; CFC) 패러다임을 이용하여, 키메라 래트 항체인 XT-M4(즉, RAGE에 특이적으로 결합하여, RAGE 결합 파트너와의 결합을 억제하는 항체)를 투여하였을 때, 아밀로이드 침착으로 인한 인지 기능의 감퇴에 관한 동물 모델에 있어서 인지 기능 수행력에 미치는 영향력을 평가하였다.
Tg2576 모델 마우스에서 아밀로이드 플라크를 형성킨 후(18개월까지), 해마 CA1과 치상회에 LTP 결함을 유도함으로써, 변형 수중 미로 내에서의 공간 기억력을 손상시키고, 시냅스 가소성을 손상시키며, 또한 Aβ 응집체와 올리고머의 수준을 증가시킨다(6월령). Aβ는 어리면서 플라크를 보유하지 않는 Tg2576 마우스에서 정황 기억력을 손상시킨다. Aβ가 형성되었으며 아밀로이드가 침착된 Tg2576 유전자 이식 인간 APP 마우스 모델에서 정황 공포 조건 조성 즉, 해마-의존성 학습 및 기억에 관한 테스트를 수행하였다.
정황 학습 과정은, 특정의 우리 내 환경에서 충격을 주어(정황을 형성하여) 혐오 자극(발 자극)을 주는 것을 포함한다. 조성된 조건에 관한 기억은 충격을 주지 않았을 때에도 정황에 의존하여 경직되는 것으로서 알 수 있다. 정황과 간단한 발 자극을 함께 조성하여 조작 챔버 내에서 마우스에 조건을 조성해 준다. 훈련은, 이 동물에 가벼운 발 자극을 2회 줄 때 조작 챔버 내에서 5분간 행해진다. 기억력 테스트는, 상기 동물을, 이전에 충격을 받았던 환경으로 다시 집어넣고 나서 약 24시간 경과 후에 실시한다. 기억력 테스트가 행하여질 때의 활동성 수준을 기록하며, "경직된" 상태로 있는 시간(총 소요 시간 %로 표시함)은, 처리군에 행하여진 ANOVA에 의해 분석한다. 활동성 수준이 감소하였음은 곧, 혐오 현상에 대하여 원래대로 기억해냈음을 의미한다. 유전자 이식되지 않은 상기 동물의 한배 새끼와는 대조적으로, Tg2576(14∼16주령)에서는 정황 기억력이 손상되었으며, 20주령인 동물에서는 기억력이 완전히 손상되었음을 알 수 있었다.
항체의 투여
쥣과 동물 RAGE에 특이적인 키메라 XT-M4 항체를 PBS 중에 희석하고, 이를 20주령된 Tg2576 및 유전자 이식되지 않은(야생형) 한배 새끼(20주령)에 복막 내 투여하였다(1회(10㎎/㎏), 제1일, 제4일, 제7일 및 제10일). 중화(비활성) 항체를 대조군으로서 투여하였다. 항체를 4회 투여하고 나서 마우스를 대상으로하는 훈련을 시작하였으며, 제12일째 되는 날에 테스트를 실시하였다.
제12일 경과시 테스트를 하는 중에 기억력 스코어(memory score)(경직도의 증가)를 메겼다. 효능은, PBS-처리된 유전자 이식 동물에 비하여 기억력 손상 정도가 어느 정도로 역전되었는지를 측정함으로써 평가되었다. 최소 유효 투여량(MED)은, 투여량-의존 곡선(투여량 = 0.1∼30㎎/㎏)을 작성하여 측정되었다. 확립된 MED로 1회 면역화한 후의 효능 지속 기간은, 경시적 분석법과, 인지 기능 개선 훈련 전 시간 간격의 연장 여부를 평가함으로써 측정되었다.
키메라 XT-M4 항체(κ, IgG1)는, 정황 기억 손상을 상당한 수준으로 역전시킨다는 사실을 알 수 있었다. 이와는 대조적으로, 관련성이 없는 항체와 PBS 대조군을 투여한 마우스는 Tg2576 마우스 또는 야생형 한배 새끼에 있어서 CFC에 아무런 영향을 미치지 않았다. 이 데이터를 통하여, 쥣과 동물 RGE에 대해 생성된 키메라 모노클로날 XT-M4 항체를 투여하면, 알츠하이머병의 APP 유전자 이식 모델에 있어서 인지 기능을 개선시킬 수 있음을 알 수 있다(도 38 참조).
재료 및 방법
마우스
본 연구에 사용된 마우스는 인간 APP 단백질을 발현하는, 이종 접합형 수컷 유전자 이식 Tg257618 마우스였다. PCR에 의해 유전자형을 확인하고, 망막 변성증(Rd) 돌연 변이에 대한 모든 동형 접합형 동물을 제외시켰다. 백그라운드 변종으로서는, C57BI6과 129SJL의 교잡종이 있다. 20주령된 마우스(n = 8∼12마리/유전자형/주령)를 대상으로 하여, 정황 공포 조건 조성 연구를 수행하였다.
테스트 장치
알루미늄으로된 측벽과 플렉시글래스(plexiglass)로 된 천장, 문 그리고 후방 벽으로 이루어진 6개의 조작 챔버(30×24×21㎝)(Med Associates, Inc., St. Albans, VT) 내에서, 정황 공포 조건 조성(CFC) 테스트를 수행하였다. 각각의 챔버의 바닥에는 발에 자극을 줄 수 있도록, 36개의 스테인레스 강철 막대를 장착하였다. 또한, 각각의 챔버는 2개의 자극 광원(stimulus light), 하나의 하우스 광원(house light)과 솔레노이드를 포함한다. 조광, 발 자극(US) 및 솔레노이드(CS)는 전부 MED-PC 소프트웨어를 실행하고 있는 PC로 제어하였다. 이 챔버를 적색 광선이 비추고 있는 조용한 격리실에 놓았다.
정황 공포 조건 조성
Tg2576 마우스와 이 마우스와 동일한 주령의 야생형 한배 새끼에 4번째로 키메라 XT-M4 항-RAGE 항체를 투여하고 나서 하루 경과한 날 즉, 제11일째 되는 날부터 상기 마우스들을 훈련시키기 시작하였다.
훈련 과정은, 조작 챔버 내에 마우스를 넣고, 자극 광선과 하우스 광선 둘 다를 비추어, 이 마우스가 2분 동안 이 자극에 대해 탐색할 기회를 부여하는 단계를 포함한다. 2분이 다 되어갈 때 즈음하여, 15초 동안 청각 자극을 가하였다(솔레노이드를 통하여 2Hz의 "철컥"하는 소리를 들려줌; CS). CS를 시작하고 나서 13초 경과시 발 자극(US; 1.5mAp)을 주기 시작하여, CS를 종결할 때 함께 종결하였다. 이 과정을 반복 수행하고, 2차적으로 발 자극을 준 다음 30초 경과시, 마우스를 챔버에서 꺼내어 다시 우리에 집어 넣었다.
동물을 훈련시킨 지 20시간 경과시, 상기 마우스를 예전에 훈련시켰던 챔버로 다시 집어넣었다. 이후, 실험자는, 상기 마우스들이 이전에 자극을 받았던 것과 동일한 환경(정황) 하에서 나타내는 경직 행동을 기록하였다[이때, 뚜껑이 달린 상자 내부에 넣은 후 10초 경과 후부터 행위를 관찰함, 5분(30개의 샘플링 시점)]. 경직이란, 호흡으로 인한 움직임을 제외하고는 움직임이 없는 경우로서 정의하였다. 5분이 끝나갈 때에, 마우스를 다시 우리에 집어 넣었다.
마우스 전부를 임의의 정황하에서 테스트한 후(즉, 처음 정황 테스트를 한후 약 60분 경과시) 신규의 행동 유도 조건 하에서의 경직에 관한 데이터를 수집하였다. 후방 우측 모서리로부터 전방 좌측 모서리에 이르기까지 불투명한 플렉시글래스 칸막이를 포함하는 조작 챔버를 변형시키고, 바닥도 플렉시글래스로 바꾸고, 또한 조광량도 줄여서(하우스 광선만 비춤), 새로운 환경을 조성하였다. 마우스를 새로운 정황에 노출시키고, 행위 관찰을 실시하여, 3분 동안(18 샘플링 시점)의 경직 스코어를 수집하였다. 3분이 끝나갈 무렵, 3분 동안 청각 자극(CD)을 주고, 이때의 경직 상태에 대해 다시 스코어를 메겼다(18샘플링 시점). 각각의 동물에 대한 경직 스코어를 테스트의 각 단계에 대한 경직%로 바꾸었다. 이전 정황에서 관찰된 경직 %에서 새로운 환경에 있을 때의 경직%(기본 활동성에 대한 척도)를 공제하여, 각 동물의 정황에 대한 기억력(정황 기억력)을 구하였다.
항체 처리
키메라 XT-M4 항체를 PBS 중에 희석하고(10㎎/㎏), 이를 20주령된 Tg2576 마우스 또는 20주령된 야생형 한배 새끼에게 복막 내 주사하였다(1회 투여, 제1일, 제4일, 제7일 및 제10일 → 훈련(제11일) → 테스트(제12일)).
데이터 분석
2원 ANOVA를 실시한 후, 피셔의 쌍대 비교(SAS 통계용 소프트웨어(SAS Institute, Inc.) 이용)를 통하여 정황 기억력을 분석하였다. 모든 데이터는 평균 ± SEM으로서 나타내었다.
SEQUENCE LISTING
<110> Jacobsen, Jack Steve
<120> METHODS FOR PREVENTING AND TREATING AMYLOIDOGENIC
DISEASES
<130> 040000-0360546
<150> US 60/784,575
<151> 2006-03-21
<150> US 60/895,303
<151> 2007-03-16
<160> 64
<170> PatentIn version 3.4
<210> 1
<211> 404
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> Genbank Accession No. NP_001127
<400> 1
Met Ala Ala Gly Thr Ala Val Gly Ala Trp Val Leu Val Leu Ser Leu
1 5 10 15
Trp Gly Ala Val Val Gly Ala Gln Asn Ile Thr Ala Arg Ile Gly Glu
20 25 30
Pro Leu Val Leu Lys Cys Lys Gly Ala Pro Lys Lys Pro Pro Gln Arg
35 40 45
Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu Ala Trp Lys Val Leu
50 55 60
Ser Pro Gln Gly Gly Gly Pro Trp Asp Ser Val Ala Arg Val Leu Pro
65 70 75 80
Asn Gly Ser Leu Phe Leu Pro Ala Val Gly Ile Gln Asp Glu Gly Ile
85 90 95
Phe Arg Cys Gln Ala Met Asn Arg Asn Gly Lys Glu Thr Lys Ser Asn
100 105 110
Tyr Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro Glu Ile Val Asp
115 120 125
Ser Ala Ser Glu Leu Thr Ala Gly Val Pro Asn Lys Val Gly Thr Cys
130 135 140
Val Ser Glu Gly Ser Tyr Pro Ala Gly Thr Leu Ser Trp His Leu Asp
145 150 155 160
Gly Lys Pro Leu Val Pro Asn Glu Lys Gly Val Ser Val Lys Glu Gln
165 170 175
Thr Arg Arg His Pro Glu Thr Gly Leu Phe Thr Leu Gln Ser Glu Leu
180 185 190
Met Val Thr Pro Ala Arg Gly Gly Asp Pro Arg Pro Thr Phe Ser Cys
195 200 205
Ser Phe Ser Pro Gly Leu Pro Arg His Arg Ala Leu Arg Thr Ala Pro
210 215 220
Ile Gln Pro Arg Val Trp Glu Pro Val Pro Leu Glu Glu Val Gln Leu
225 230 235 240
Val Val Glu Pro Glu Gly Gly Ala Val Ala Pro Gly Gly Thr Val Thr
245 250 255
Leu Thr Cys Glu Val Pro Ala Gln Pro Ser Pro Gln Ile His Trp Met
260 265 270
Lys Asp Gly Val Pro Leu Pro Leu Pro Pro Ser Pro Val Leu Ile Leu
275 280 285
Pro Glu Ile Gly Pro Gln Asp Gln Gly Thr Tyr Ser Cys Val Ala Thr
290 295 300
His Ser Ser His Gly Pro Gln Glu Ser Arg Ala Val Ser Ile Ser Ile
305 310 315 320
Ile Glu Pro Gly Glu Glu Gly Pro Thr Ala Gly Ser Val Gly Gly Ser
325 330 335
Gly Leu Gly Thr Leu Ala Leu Ala Leu Gly Ile Leu Gly Gly Leu Gly
340 345 350
Thr Ala Ala Leu Leu Ile Gly Val Ile Leu Trp Gln Arg Arg Gln Arg
355 360 365
Arg Gly Glu Glu Arg Lys Ala Pro Glu Asn Gln Glu Glu Glu Glu Glu
370 375 380
Arg Ala Glu Leu Asn Gln Ser Glu Glu Pro Glu Ala Gly Glu Ser Ser
385 390 395 400
Thr Gly Gly Pro
<210> 2
<211> 1414
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<223> Genbank Accession No. NM_001136
<400> 2
gccaggaccc tggaaggaag caggatggca gccggaacag cagttggagc ctgggtgctg 60
gtcctcagtc tgtggggggc agtagtaggt gctcaaaaca tcacagcccg gattggcgag 120
ccactggtgc tgaagtgtaa gggggccccc aagaaaccac cccagcggct ggaatggaaa 180
ctgaacacag gccggacaga agcttggaag gtcctgtctc cccagggagg aggcccctgg 240
gacagtgtgg ctcgtgtcct tcccaacggc tccctcttcc ttccggctgt cgggatccag 300
gatgagggga ttttccggtg ccaggcaatg aacaggaatg gaaaggagac caagtccaac 360
taccgagtcc gtgtctacca gattcctggg aagccagaaa ttgtagattc tgcctctgaa 420
ctcacggctg gtgttcccaa taaggtgggg acatgtgtgt cagagggaag ctaccctgca 480
gggactctta gctggcactt ggatgggaag cccctggtgc ctaatgagaa gggagtatct 540
gtgaaggaac agaccaggag acaccctgag acagggctct tcacactgca gtcggagcta 600
atggtgaccc cagcccgggg aggagatccc cgtcccacct tctcctgtag cttcagccca 660
ggccttcccc gacaccgggc cttgcgcaca gcccccatcc agccccgtgt ctgggagcct 720
gtgcctctgg aggaggtcca attggtggtg gagccagaag gtggagcagt agctcctggt 780
ggaaccgtaa ccctgacctg tgaagtccct gcccagccct ctcctcaaat ccactggatg 840
aaggatggtg tgcccttgcc ccttcccccc agccctgtgc tgatcctccc tgagataggg 900
cctcaggacc agggaaccta cagctgtgtg gccacccatt ccagccacgg gccccaggaa 960
agccgtgctg tcagcatcag catcatcgaa ccaggcgagg aggggccaac tgcaggctct 1020
gtgggaggat cagggctggg aactctagcc ctggccctgg ggatcctggg aggcctgggg 1080
acagccgccc tgctcattgg ggtcatcttg tggcaaaggc ggcaacgccg aggagaggag 1140
aggaaggccc cagaaaacca ggaggaagag gaggagcgtg cagaactgaa tcagtcggag 1200
gaacctgagg caggcgagag tagtactgga gggccttgag gggcccacag acagatccca 1260
tccatcagct cccttttctt tttcccttga actgttctgg cctcagacca actctctcct 1320
gtataatctc tctcctgtat aaccccacct tgccaagctt tcttctacaa ccagagcccc 1380
ccacaatgat gattaaacac ctgacacatc ttga 1414
<210> 3
<211> 403
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> Genbank Accession No. NP_031451
<400> 3
Met Pro Ala Gly Thr Ala Ala Arg Ala Trp Val Leu Val Leu Ala Leu
1 5 10 15
Trp Gly Ala Val Ala Gly Gly Gln Asn Ile Thr Ala Arg Ile Gly Glu
20 25 30
Pro Leu Val Leu Ser Cys Lys Gly Ala Pro Lys Lys Pro Pro Gln Gln
35 40 45
Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu Ala Trp Lys Val Leu
50 55 60
Ser Pro Gln Gly Gly Pro Trp Asp Ser Val Ala Gln Ile Leu Pro Asn
65 70 75 80
Gly Ser Leu Leu Leu Pro Ala Thr Gly Ile Val Asp Glu Gly Thr Phe
85 90 95
Arg Cys Arg Ala Thr Asn Arg Arg Gly Lys Glu Val Lys Ser Asn Tyr
100 105 110
Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro Glu Ile Val Asp Pro
115 120 125
Ala Ser Glu Leu Thr Ala Ser Val Pro Asn Lys Val Gly Thr Cys Val
130 135 140
Ser Glu Gly Ser Tyr Pro Ala Gly Thr Leu Ser Trp His Leu Asp Gly
145 150 155 160
Lys Leu Leu Ile Pro Asp Gly Lys Glu Thr Leu Val Lys Glu Glu Thr
165 170 175
Arg Arg His Pro Glu Thr Gly Leu Phe Thr Leu Arg Ser Glu Leu Thr
180 185 190
Val Ile Pro Thr Gln Gly Gly Thr Thr His Pro Thr Phe Ser Cys Ser
195 200 205
Phe Ser Leu Gly Leu Pro Arg Arg Arg Pro Leu Asn Thr Ala Pro Ile
210 215 220
Gln Leu Arg Val Arg Glu Pro Gly Pro Pro Glu Gly Ile Gln Leu Leu
225 230 235 240
Val Glu Pro Glu Gly Gly Ile Val Ala Pro Gly Gly Thr Val Thr Leu
245 250 255
Thr Cys Ala Ile Ser Ala Gln Pro Pro Pro Gln Val His Trp Ile Lys
260 265 270
Asp Gly Ala Pro Leu Pro Leu Ala Pro Ser Pro Val Leu Leu Leu Pro
275 280 285
Glu Val Gly His Ala Asp Glu Gly Thr Tyr Ser Cys Val Ala Thr His
290 295 300
Pro Ser His Gly Pro Gln Glu Ser Pro Pro Val Ser Ile Arg Val Thr
305 310 315 320
Glu Thr Gly Asp Glu Gly Pro Ala Glu Gly Ser Val Gly Glu Ser Gly
325 330 335
Leu Gly Thr Leu Ala Leu Ala Leu Gly Ile Leu Gly Gly Leu Gly Val
340 345 350
Val Ala Leu Leu Val Gly Ala Ile Leu Trp Arg Lys Arg Gln Pro Arg
355 360 365
Arg Glu Glu Arg Lys Ala Pro Glu Ser Gln Glu Asp Glu Glu Glu Arg
370 375 380
Ala Glu Leu Asn Gln Ser Glu Glu Ala Glu Met Pro Glu Asn Gly Ala
385 390 395 400
Gly Gly Pro
<210> 4
<211> 1348
<212> DNA
<213> Murine
<220>
<221> misc_feature
<223> Genbank Accession No. NM_007425.1
<400> 4
gcaccatgcc agcggggaca gcagctagag cctgggtgct ggttcttgct ctatggggag 60
ctgtagctgg tggtcagaac atcacagccc ggattggaga gccacttgtg ctaagctgta 120
agggggcccc taagaagccg ccccagcagc tagaatggaa actgaacaca ggaagaactg 180
aagcttggaa ggtcctctct ccccagggag gcccctggga cagcgtggct caaatcctcc 240
ccaatggttc cctcctcctt ccagccactg gaattgtcga tgaggggacg ttccggtgtc 300
gggcaactaa caggcgaggg aaggaggtca agtccaacta ccgagtccga gtctaccaga 360
ttcctgggaa gccagaaatt gtggatcctg cctctgaact cacagccagt gtccctaata 420
aggtggggac atgtgtgtct gagggaagct accctgcagg gacccttagc tggcacttag 480
atgggaaact tctgattccc gatggcaaag aaacactcgt gaaggaagag accaggagac 540
accctgagac gggactcttt acactgcggt cagagctgac agtgatcccc acccaaggag 600
gaaccaccca tcctaccttc tcctgcagtt tcagcctggg ccttccccgg cgcagacccc 660
tgaacacagc ccctatccaa ctccgagtca gggagcctgg gcctccagag ggcattcagc 720
tgttggttga gcctgaaggt ggaatagtcg ctcctggtgg gactgtgacc ttgacctgtg 780
ccatctctgc ccagccccct cctcaggtcc actggataaa ggatggtgca cccttgcccc 840
tggctcccag ccctgtgctg ctcctccctg aggtggggca cgcggatgag ggcacctata 900
gctgcgtggc cacccaccct agccacggac ctcaggaaag ccctcctgtc agcatcaggg 960
tcacagaaac cggcgatgag gggccagctg aaggctctgt gggtgagtct gggctgggta 1020
cgctagccct ggccttgggg atcctgggag gcctgggagt agtagccctg ctcgtcgggg 1080
ctatcctgtg gcgaaaacga caacccaggc gtgaggagag gaaggccccg gaaagccagg 1140
aggatgagga ggaacgtgca gagctgaatc agtcagagga agcggagatg ccagagaatg 1200
gtgccggggg accgtaagag cacccagatc gagcctgtgt gatggcccta gagcagctcc 1260
cccacattcc atcccaattc ctccttgagg cacttccttc tccaaccaga gcccacatga 1320
tccatgctga gtaaacattt gatacggc 1348
<210> 5
<211> 8
<212> PRT
<213> Artificial
<220>
<223> Streptavidin tag sequence
<400> 5
Trp Ser His Pro Gln Phe Glu Lys
1 5
<210> 6
<211> 1250
<212> DNA
<213> Baboon
<220>
<221> CDS
<222> (20)..(1231)
<400> 6
gaccctggaa ggaagcagg atg gca gcc gga gca gca gtt gga gcc tgg gtg 52
Met Ala Ala Gly Ala Ala Val Gly Ala Trp Val
1 5 10
ctg gtc ctc agt ctg tgg ggg gca gta gta ggt gct caa aac atc aca 100
Leu Val Leu Ser Leu Trp Gly Ala Val Val Gly Ala Gln Asn Ile Thr
15 20 25
gcc cgg atc ggt gag cca ctg gtg ctg aag tgt aag ggg gcc ccc aag 148
Ala Arg Ile Gly Glu Pro Leu Val Leu Lys Cys Lys Gly Ala Pro Lys
30 35 40
aaa cca ccc cag cag ctg gaa tgg aaa ctg aat aca ggc cgg aca gaa 196
Lys Pro Pro Gln Gln Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu
45 50 55
gct tgg aag gtc cta tct ccc cag gga ggc ccc tgg gat agt gtg gct 244
Ala Trp Lys Val Leu Ser Pro Gln Gly Gly Pro Trp Asp Ser Val Ala
60 65 70 75
cgt gtc ctt ccc aac ggc tcc ctc ttc ctt ccg gct gtc ggg atc cag 292
Arg Val Leu Pro Asn Gly Ser Leu Phe Leu Pro Ala Val Gly Ile Gln
80 85 90
gat gag ggg att ttc cgg tgc cag gca atg aac agg aat gga aag gag 340
Asp Glu Gly Ile Phe Arg Cys Gln Ala Met Asn Arg Asn Gly Lys Glu
95 100 105
acc aag tcc aac tac cga gtc cgt gtc tac cag att cct ggg aag ccg 388
Thr Lys Ser Asn Tyr Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro
110 115 120
gaa att ata gat tct gcc tct gaa ctc acg gct ggt gtt ccc aat aag 436
Glu Ile Ile Asp Ser Ala Ser Glu Leu Thr Ala Gly Val Pro Asn Lys
125 130 135
gtg ggg aca tgt gtg tca gag gga agc tac cct gca ggg act ctt agc 484
Val Gly Thr Cys Val Ser Glu Gly Ser Tyr Pro Ala Gly Thr Leu Ser
140 145 150 155
tgg cac ttg gat ggg aag ccc ctg gtg cct aat gag aag gga gta tct 532
Trp His Leu Asp Gly Lys Pro Leu Val Pro Asn Glu Lys Gly Val Ser
160 165 170
gtg aag gaa gag acc agg aga cac cct gag acg ggg ctc ttc aca ctg 580
Val Lys Glu Glu Thr Arg Arg His Pro Glu Thr Gly Leu Phe Thr Leu
175 180 185
cag tcg gag cta atg gtg acc cca gcc cgg gga gga aat ccc cat ccc 628
Gln Ser Glu Leu Met Val Thr Pro Ala Arg Gly Gly Asn Pro His Pro
190 195 200
acc ttc tcc tgt agc ttc agc cca ggc ctt ccc cga cgc cgg gcc ttg 676
Thr Phe Ser Cys Ser Phe Ser Pro Gly Leu Pro Arg Arg Arg Ala Leu
205 210 215
cac aca gcc cct atc cag ccc cgt gtc tgg gag cct gtg cct ctg gag 724
His Thr Ala Pro Ile Gln Pro Arg Val Trp Glu Pro Val Pro Leu Glu
220 225 230 235
gag gtc caa ttg gtg gta gag cca gaa ggt gga gca gta gct cct ggt 772
Glu Val Gln Leu Val Val Glu Pro Glu Gly Gly Ala Val Ala Pro Gly
240 245 250
gga acc gta acc ctg acc tgt gaa gtc cct gcc cag ccc tct cct cag 820
Gly Thr Val Thr Leu Thr Cys Glu Val Pro Ala Gln Pro Ser Pro Gln
255 260 265
atc cac tgg atg aag gat ggt gtg ccc tta ccc ctt tcc ccc agc cct 868
Ile His Trp Met Lys Asp Gly Val Pro Leu Pro Leu Ser Pro Ser Pro
270 275 280
gtg ctg atc ctc cct gag ata ggg cct cag gac cag gga acc tac agg 916
Val Leu Ile Leu Pro Glu Ile Gly Pro Gln Asp Gln Gly Thr Tyr Arg
285 290 295
tgt gtg gcc acc cat ccc agc cac ggg ccc cag gaa agc cgt gct gtc 964
Cys Val Ala Thr His Pro Ser His Gly Pro Gln Glu Ser Arg Ala Val
300 305 310 315
agc atc agc atc atc gaa cca ggc gag gag ggg cca act gca ggc tct 1012
Ser Ile Ser Ile Ile Glu Pro Gly Glu Glu Gly Pro Thr Ala Gly Ser
320 325 330
gtg gga gga tca ggg cca gga act cta gcc ctg gcc ctg ggg atc ctg 1060
Val Gly Gly Ser Gly Pro Gly Thr Leu Ala Leu Ala Leu Gly Ile Leu
335 340 345
gga ggc ctg ggg aca gcc gct ctg ctc att ggg gtc atc ttg tgg caa 1108
Gly Gly Leu Gly Thr Ala Ala Leu Leu Ile Gly Val Ile Leu Trp Gln
350 355 360
agg cgg cga cgc caa cga gag gag agg aag gcc tca gaa aac cag gag 1156
Arg Arg Arg Arg Gln Arg Glu Glu Arg Lys Ala Ser Glu Asn Gln Glu
365 370 375
gaa gag gag gag cgt gca gag ctg aat cag tcg gag gaa cct gag gca 1204
Glu Glu Glu Glu Arg Ala Glu Leu Asn Gln Ser Glu Glu Pro Glu Ala
380 385 390 395
ggc gag agt ggt act gga ggg cct tga ggggcccaca gacagatcc 1250
Gly Glu Ser Gly Thr Gly Gly Pro
400
<210> 7
<211> 403
<212> PRT
<213> Baboon
<400> 7
Met Ala Ala Gly Ala Ala Val Gly Ala Trp Val Leu Val Leu Ser Leu
1 5 10 15
Trp Gly Ala Val Val Gly Ala Gln Asn Ile Thr Ala Arg Ile Gly Glu
20 25 30
Pro Leu Val Leu Lys Cys Lys Gly Ala Pro Lys Lys Pro Pro Gln Gln
35 40 45
Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu Ala Trp Lys Val Leu
50 55 60
Ser Pro Gln Gly Gly Pro Trp Asp Ser Val Ala Arg Val Leu Pro Asn
65 70 75 80
Gly Ser Leu Phe Leu Pro Ala Val Gly Ile Gln Asp Glu Gly Ile Phe
85 90 95
Arg Cys Gln Ala Met Asn Arg Asn Gly Lys Glu Thr Lys Ser Asn Tyr
100 105 110
Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro Glu Ile Ile Asp Ser
115 120 125
Ala Ser Glu Leu Thr Ala Gly Val Pro Asn Lys Val Gly Thr Cys Val
130 135 140
Ser Glu Gly Ser Tyr Pro Ala Gly Thr Leu Ser Trp His Leu Asp Gly
145 150 155 160
Lys Pro Leu Val Pro Asn Glu Lys Gly Val Ser Val Lys Glu Glu Thr
165 170 175
Arg Arg His Pro Glu Thr Gly Leu Phe Thr Leu Gln Ser Glu Leu Met
180 185 190
Val Thr Pro Ala Arg Gly Gly Asn Pro His Pro Thr Phe Ser Cys Ser
195 200 205
Phe Ser Pro Gly Leu Pro Arg Arg Arg Ala Leu His Thr Ala Pro Ile
210 215 220
Gln Pro Arg Val Trp Glu Pro Val Pro Leu Glu Glu Val Gln Leu Val
225 230 235 240
Val Glu Pro Glu Gly Gly Ala Val Ala Pro Gly Gly Thr Val Thr Leu
245 250 255
Thr Cys Glu Val Pro Ala Gln Pro Ser Pro Gln Ile His Trp Met Lys
260 265 270
Asp Gly Val Pro Leu Pro Leu Ser Pro Ser Pro Val Leu Ile Leu Pro
275 280 285
Glu Ile Gly Pro Gln Asp Gln Gly Thr Tyr Arg Cys Val Ala Thr His
290 295 300
Pro Ser His Gly Pro Gln Glu Ser Arg Ala Val Ser Ile Ser Ile Ile
305 310 315 320
Glu Pro Gly Glu Glu Gly Pro Thr Ala Gly Ser Val Gly Gly Ser Gly
325 330 335
Pro Gly Thr Leu Ala Leu Ala Leu Gly Ile Leu Gly Gly Leu Gly Thr
340 345 350
Ala Ala Leu Leu Ile Gly Val Ile Leu Trp Gln Arg Arg Arg Arg Gln
355 360 365
Arg Glu Glu Arg Lys Ala Ser Glu Asn Gln Glu Glu Glu Glu Glu Arg
370 375 380
Ala Glu Leu Asn Gln Ser Glu Glu Pro Glu Ala Gly Glu Ser Gly Thr
385 390 395 400
Gly Gly Pro
<210> 8
<211> 1250
<212> DNA
<213> Cynomologus Monkey
<220>
<221> CDS
<222> (20)..(1231)
<400> 8
gaccctggaa ggaagcagg atg gca gcc gga gca gca gtt gga gcc tgg gtg 52
Met Ala Ala Gly Ala Ala Val Gly Ala Trp Val
1 5 10
ctg gtc ctc agt ctg tgg ggg gca gta gta ggt gct caa aac atc aca 100
Leu Val Leu Ser Leu Trp Gly Ala Val Val Gly Ala Gln Asn Ile Thr
15 20 25
gcc cgg atc ggt gag cca ctg gtg ctg aag tgt aag ggg gcc ccc aag 148
Ala Arg Ile Gly Glu Pro Leu Val Leu Lys Cys Lys Gly Ala Pro Lys
30 35 40
aaa cca ccc cag cag ctg gaa tgg aaa ctg aat aca ggc cgg aca gaa 196
Lys Pro Pro Gln Gln Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu
45 50 55
gct tgg aag gtc cta tct ccc cag gga ggc ccc tgg gat agt gtg gct 244
Ala Trp Lys Val Leu Ser Pro Gln Gly Gly Pro Trp Asp Ser Val Ala
60 65 70 75
cgt gtc ctt ccc aac ggc tcc ctc ttc ctt ccg gct gtc ggg atc cag 292
Arg Val Leu Pro Asn Gly Ser Leu Phe Leu Pro Ala Val Gly Ile Gln
80 85 90
gat gag ggg att ttc cgg tgc cag gca atg aac agg aat gga aag gag 340
Asp Glu Gly Ile Phe Arg Cys Gln Ala Met Asn Arg Asn Gly Lys Glu
95 100 105
acc aag tcc aac tac cga gtc cgt gtc tac cag att cct ggg aag ccg 388
Thr Lys Ser Asn Tyr Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro
110 115 120
gaa att ata gat tct gcc tct gaa ctc acg gct ggt gtt ccc aat aag 436
Glu Ile Ile Asp Ser Ala Ser Glu Leu Thr Ala Gly Val Pro Asn Lys
125 130 135
gtg ggg aca tgt gtg tca gag gga agc tac cct gca ggg act ctt agc 484
Val Gly Thr Cys Val Ser Glu Gly Ser Tyr Pro Ala Gly Thr Leu Ser
140 145 150 155
tgg cac ttg gat ggg aag ccc ctg gtg cct aat gag aag gga gta tct 532
Trp His Leu Asp Gly Lys Pro Leu Val Pro Asn Glu Lys Gly Val Ser
160 165 170
gtg aag gaa gag acc agg aga cac cct gag acg ggg ctc ttc aca ctg 580
Val Lys Glu Glu Thr Arg Arg His Pro Glu Thr Gly Leu Phe Thr Leu
175 180 185
cag tcg gag cta atg gtg acc cca gcc cgg gga gga aat ccc cat ccc 628
Gln Ser Glu Leu Met Val Thr Pro Ala Arg Gly Gly Asn Pro His Pro
190 195 200
acc ttc tcc tgt agc ttc agc cca ggc ctt ccc cga cgc cgg gcc ttg 676
Thr Phe Ser Cys Ser Phe Ser Pro Gly Leu Pro Arg Arg Arg Ala Leu
205 210 215
cac aca gcc cct atc cag ccc cgt gtc tgg gag cct gtg cct ctg gag 724
His Thr Ala Pro Ile Gln Pro Arg Val Trp Glu Pro Val Pro Leu Glu
220 225 230 235
gag gtc caa ttg gtg gta gag cca gaa ggt gga gca gta gct cct ggt 772
Glu Val Gln Leu Val Val Glu Pro Glu Gly Gly Ala Val Ala Pro Gly
240 245 250
gga acc gta acc ctg acc tgt gaa gtc cct gcc cag ccc tct cct caa 820
Gly Thr Val Thr Leu Thr Cys Glu Val Pro Ala Gln Pro Ser Pro Gln
255 260 265
atc cac tgg atg aag gat ggt gtg ccc tta ccc ctt tcc ccc agc cct 868
Ile His Trp Met Lys Asp Gly Val Pro Leu Pro Leu Ser Pro Ser Pro
270 275 280
gtg ctg atc ctc cct gag ata ggg cct cag gac cag gga acc tac agg 916
Val Leu Ile Leu Pro Glu Ile Gly Pro Gln Asp Gln Gly Thr Tyr Arg
285 290 295
tgt gtg gcc acc cat ccc agc cac ggg ccc cag gaa agc cgt gct gtc 964
Cys Val Ala Thr His Pro Ser His Gly Pro Gln Glu Ser Arg Ala Val
300 305 310 315
agc atc agc atc atc gaa cca ggc gag gag ggg cca act gca ggc tct 1012
Ser Ile Ser Ile Ile Glu Pro Gly Glu Glu Gly Pro Thr Ala Gly Ser
320 325 330
gtg gga gga tca ggg cca gga act cta gcc ctg gcc ctg ggg atc ctg 1060
Val Gly Gly Ser Gly Pro Gly Thr Leu Ala Leu Ala Leu Gly Ile Leu
335 340 345
gga ggc ctg ggg aca gcc gct ctg ctc att ggg gtc atc ttg tgg caa 1108
Gly Gly Leu Gly Thr Ala Ala Leu Leu Ile Gly Val Ile Leu Trp Gln
350 355 360
agg cgg cga cgc caa gga gag gag agg aag gcc tca gaa aac cag gag 1156
Arg Arg Arg Arg Gln Gly Glu Glu Arg Lys Ala Ser Glu Asn Gln Glu
365 370 375
gaa gag gag gag cgt gca gag ctg aat cag tcg gag gaa cct gag gca 1204
Glu Glu Glu Glu Arg Ala Glu Leu Asn Gln Ser Glu Glu Pro Glu Ala
380 385 390 395
ggc gag agt ggt act gga ggg cct tga ggggcccaca gacagatcc 1250
Gly Glu Ser Gly Thr Gly Gly Pro
400
<210> 9
<211> 403
<212> PRT
<213> Cynomologus Monkey
<400> 9
Met Ala Ala Gly Ala Ala Val Gly Ala Trp Val Leu Val Leu Ser Leu
1 5 10 15
Trp Gly Ala Val Val Gly Ala Gln Asn Ile Thr Ala Arg Ile Gly Glu
20 25 30
Pro Leu Val Leu Lys Cys Lys Gly Ala Pro Lys Lys Pro Pro Gln Gln
35 40 45
Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu Ala Trp Lys Val Leu
50 55 60
Ser Pro Gln Gly Gly Pro Trp Asp Ser Val Ala Arg Val Leu Pro Asn
65 70 75 80
Gly Ser Leu Phe Leu Pro Ala Val Gly Ile Gln Asp Glu Gly Ile Phe
85 90 95
Arg Cys Gln Ala Met Asn Arg Asn Gly Lys Glu Thr Lys Ser Asn Tyr
100 105 110
Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro Glu Ile Ile Asp Ser
115 120 125
Ala Ser Glu Leu Thr Ala Gly Val Pro Asn Lys Val Gly Thr Cys Val
130 135 140
Ser Glu Gly Ser Tyr Pro Ala Gly Thr Leu Ser Trp His Leu Asp Gly
145 150 155 160
Lys Pro Leu Val Pro Asn Glu Lys Gly Val Ser Val Lys Glu Glu Thr
165 170 175
Arg Arg His Pro Glu Thr Gly Leu Phe Thr Leu Gln Ser Glu Leu Met
180 185 190
Val Thr Pro Ala Arg Gly Gly Asn Pro His Pro Thr Phe Ser Cys Ser
195 200 205
Phe Ser Pro Gly Leu Pro Arg Arg Arg Ala Leu His Thr Ala Pro Ile
210 215 220
Gln Pro Arg Val Trp Glu Pro Val Pro Leu Glu Glu Val Gln Leu Val
225 230 235 240
Val Glu Pro Glu Gly Gly Ala Val Ala Pro Gly Gly Thr Val Thr Leu
245 250 255
Thr Cys Glu Val Pro Ala Gln Pro Ser Pro Gln Ile His Trp Met Lys
260 265 270
Asp Gly Val Pro Leu Pro Leu Ser Pro Ser Pro Val Leu Ile Leu Pro
275 280 285
Glu Ile Gly Pro Gln Asp Gln Gly Thr Tyr Arg Cys Val Ala Thr His
290 295 300
Pro Ser His Gly Pro Gln Glu Ser Arg Ala Val Ser Ile Ser Ile Ile
305 310 315 320
Glu Pro Gly Glu Glu Gly Pro Thr Ala Gly Ser Val Gly Gly Ser Gly
325 330 335
Pro Gly Thr Leu Ala Leu Ala Leu Gly Ile Leu Gly Gly Leu Gly Thr
340 345 350
Ala Ala Leu Leu Ile Gly Val Ile Leu Trp Gln Arg Arg Arg Arg Gln
355 360 365
Gly Glu Glu Arg Lys Ala Ser Glu Asn Gln Glu Glu Glu Glu Glu Arg
370 375 380
Ala Glu Leu Asn Gln Ser Glu Glu Pro Glu Ala Gly Glu Ser Gly Thr
385 390 395 400
Gly Gly Pro
<210> 10
<211> 1220
<212> DNA
<213> Rabbit
<220>
<221> CDS
<222> (18)..(1196)
<400> 10
actagactag tcggacc atg gca gca ggg gca gcg gcc gga gcc tgg gtg 50
Met Ala Ala Gly Ala Ala Ala Gly Ala Trp Val
1 5 10
ctg gtc ttc agt ctg tgg ggg gca gca gta ggt ggt cag aac atc aca 98
Leu Val Phe Ser Leu Trp Gly Ala Ala Val Gly Gly Gln Asn Ile Thr
15 20 25
gcc cgg att ggg gag ccg ctg gtg ctg aag tgt aag ggg gcc ccc aag 146
Ala Arg Ile Gly Glu Pro Leu Val Leu Lys Cys Lys Gly Ala Pro Lys
30 35 40
aag cca ccc cag cag ctg gaa tgg aaa ctg aac aca ggc agg aca gaa 194
Lys Pro Pro Gln Gln Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu
45 50 55
gct tgg aaa gtc ctt tct ccc cag gga ggc tca tgg gac agt gtg gcc 242
Ala Trp Lys Val Leu Ser Pro Gln Gly Gly Ser Trp Asp Ser Val Ala
60 65 70 75
cgt gtc ctc ccc aat ggc tcc ctc ctc ctt ccg gct gtt ggg atc cag 290
Arg Val Leu Pro Asn Gly Ser Leu Leu Leu Pro Ala Val Gly Ile Gln
80 85 90
gat gag ggg act ttc cgg tgc cgg aca aca aac agg aat gga aag gag 338
Asp Glu Gly Thr Phe Arg Cys Arg Thr Thr Asn Arg Asn Gly Lys Glu
95 100 105
acc aag tcc aat tac cga gtc cgg gtc tac cag att cct ggg aag cca 386
Thr Lys Ser Asn Tyr Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro
110 115 120
gag atc ctg gat cct gcc tct gaa ctc acg gcc ggt atc ccc agt aag 434
Glu Ile Leu Asp Pro Ala Ser Glu Leu Thr Ala Gly Ile Pro Ser Lys
125 130 135
gtg ggg aca tgt gtg tct gat ggg gga tat cct ctg ggg act ctc agc 482
Val Gly Thr Cys Val Ser Asp Gly Gly Tyr Pro Leu Gly Thr Leu Ser
140 145 150 155
tgg cac atg gat ggg aaa ctc ctg gta cct gac ggg aag gga gtg tct 530
Trp His Met Asp Gly Lys Leu Leu Val Pro Asp Gly Lys Gly Val Ser
160 165 170
gtg aag gag cag acc agg agg cac cct gac acg ggg ctc ttc acc ctg 578
Val Lys Glu Gln Thr Arg Arg His Pro Asp Thr Gly Leu Phe Thr Leu
175 180 185
cag tca gag ctg atg gtg act cca gcc ggg gga gga ggg cct ccc ccc 626
Gln Ser Glu Leu Met Val Thr Pro Ala Gly Gly Gly Gly Pro Pro Pro
190 195 200
acc ttc tcc tgt agc ttc agc ccc ggc ctg ccc cgc cgc cgg gcc tca 674
Thr Phe Ser Cys Ser Phe Ser Pro Gly Leu Pro Arg Arg Arg Ala Ser
205 210 215
tac aca gcc ccc atc cag ccc agt gtc tgg gag cct ggg ccc ctg gag 722
Tyr Thr Ala Pro Ile Gln Pro Ser Val Trp Glu Pro Gly Pro Leu Glu
220 225 230 235
gtt cgc ttg ctg gtg gag cca gaa ggt gga gca gta gct cct ggt gag 770
Val Arg Leu Leu Val Glu Pro Glu Gly Gly Ala Val Ala Pro Gly Glu
240 245 250
act gtg acc ctg acc tgc gaa gct cct gcc cag ccc cct cct caa atc 818
Thr Val Thr Leu Thr Cys Glu Ala Pro Ala Gln Pro Pro Pro Gln Ile
255 260 265
cac tgg atg aag gat ggt atg tcc cta ccc ctg ccc ccc agc ccc gtc 866
His Trp Met Lys Asp Gly Met Ser Leu Pro Leu Pro Pro Ser Pro Val
270 275 280
ctg ctc ctc cct gag gtg ggg cct caa gat gag ggg act tac agc tgc 914
Leu Leu Leu Pro Glu Val Gly Pro Gln Asp Glu Gly Thr Tyr Ser Cys
285 290 295
gtg gcc acc cat ccc aac cgt ggg ccc cag gaa agc ctt ccc atc agc 962
Val Ala Thr His Pro Asn Arg Gly Pro Gln Glu Ser Leu Pro Ile Ser
300 305 310 315
atc agt gtc ggc tct gag ggt ggc tca ggc ctg ggg act cta gct ctg 1010
Ile Ser Val Gly Ser Glu Gly Gly Ser Gly Leu Gly Thr Leu Ala Leu
320 325 330
gcc ctg ggg atc ctg gga ggc ctg gga aca gct gcc ctg ctt gtc gga 1058
Ala Leu Gly Ile Leu Gly Gly Leu Gly Thr Ala Ala Leu Leu Val Gly
335 340 345
gtc atc ctg tgg cga agg cgg aaa cgc caa gga gag cag agg aaa gtc 1106
Val Ile Leu Trp Arg Arg Arg Lys Arg Gln Gly Glu Gln Arg Lys Val
350 355 360
cct gaa aac cag gag gac gag gag gaa cgc aca gaa ctg cat cag tcg 1154
Pro Glu Asn Gln Glu Asp Glu Glu Glu Arg Thr Glu Leu His Gln Ser
365 370 375
gag gct cgg gag gcg atg gag agc ggt aca gga gag ccc tga 1196
Glu Ala Arg Glu Ala Met Glu Ser Gly Thr Gly Glu Pro
380 385 390
atagtttagc ggccgcattc ttat 1220
<210> 11
<211> 392
<212> PRT
<213> Rabbit
<400> 11
Met Ala Ala Gly Ala Ala Ala Gly Ala Trp Val Leu Val Phe Ser Leu
1 5 10 15
Trp Gly Ala Ala Val Gly Gly Gln Asn Ile Thr Ala Arg Ile Gly Glu
20 25 30
Pro Leu Val Leu Lys Cys Lys Gly Ala Pro Lys Lys Pro Pro Gln Gln
35 40 45
Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu Ala Trp Lys Val Leu
50 55 60
Ser Pro Gln Gly Gly Ser Trp Asp Ser Val Ala Arg Val Leu Pro Asn
65 70 75 80
Gly Ser Leu Leu Leu Pro Ala Val Gly Ile Gln Asp Glu Gly Thr Phe
85 90 95
Arg Cys Arg Thr Thr Asn Arg Asn Gly Lys Glu Thr Lys Ser Asn Tyr
100 105 110
Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro Glu Ile Leu Asp Pro
115 120 125
Ala Ser Glu Leu Thr Ala Gly Ile Pro Ser Lys Val Gly Thr Cys Val
130 135 140
Ser Asp Gly Gly Tyr Pro Leu Gly Thr Leu Ser Trp His Met Asp Gly
145 150 155 160
Lys Leu Leu Val Pro Asp Gly Lys Gly Val Ser Val Lys Glu Gln Thr
165 170 175
Arg Arg His Pro Asp Thr Gly Leu Phe Thr Leu Gln Ser Glu Leu Met
180 185 190
Val Thr Pro Ala Gly Gly Gly Gly Pro Pro Pro Thr Phe Ser Cys Ser
195 200 205
Phe Ser Pro Gly Leu Pro Arg Arg Arg Ala Ser Tyr Thr Ala Pro Ile
210 215 220
Gln Pro Ser Val Trp Glu Pro Gly Pro Leu Glu Val Arg Leu Leu Val
225 230 235 240
Glu Pro Glu Gly Gly Ala Val Ala Pro Gly Glu Thr Val Thr Leu Thr
245 250 255
Cys Glu Ala Pro Ala Gln Pro Pro Pro Gln Ile His Trp Met Lys Asp
260 265 270
Gly Met Ser Leu Pro Leu Pro Pro Ser Pro Val Leu Leu Leu Pro Glu
275 280 285
Val Gly Pro Gln Asp Glu Gly Thr Tyr Ser Cys Val Ala Thr His Pro
290 295 300
Asn Arg Gly Pro Gln Glu Ser Leu Pro Ile Ser Ile Ser Val Gly Ser
305 310 315 320
Glu Gly Gly Ser Gly Leu Gly Thr Leu Ala Leu Ala Leu Gly Ile Leu
325 330 335
Gly Gly Leu Gly Thr Ala Ala Leu Leu Val Gly Val Ile Leu Trp Arg
340 345 350
Arg Arg Lys Arg Gln Gly Glu Gln Arg Lys Val Pro Glu Asn Gln Glu
355 360 365
Asp Glu Glu Glu Arg Thr Glu Leu His Gln Ser Glu Ala Arg Glu Ala
370 375 380
Met Glu Ser Gly Thr Gly Glu Pro
385 390
<210> 12
<211> 1247
<212> DNA
<213> Rabbit
<220>
<221> CDS
<222> (18)..(1223)
<400> 12
actagactag tcggacc atg gca gca ggg gca gcg gcc gga gcc tgg gtg 50
Met Ala Ala Gly Ala Ala Ala Gly Ala Trp Val
1 5 10
ctg gtc ttc agt ctg tgg ggg gca gca gta ggt ggt cag aac atc aca 98
Leu Val Phe Ser Leu Trp Gly Ala Ala Val Gly Gly Gln Asn Ile Thr
15 20 25
gcc cgg att ggg gag ccg ctg gtg ctg aag tgt aag ggg gcc ccc aag 146
Ala Arg Ile Gly Glu Pro Leu Val Leu Lys Cys Lys Gly Ala Pro Lys
30 35 40
aag cca ccc cag cag ctg gaa tgg aaa ctg aac aca ggc aga aca gaa 194
Lys Pro Pro Gln Gln Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu
45 50 55
gct tgg aaa gtc ctt tct ccc cag gga ggc tca tgg gac agt gtg gcc 242
Ala Trp Lys Val Leu Ser Pro Gln Gly Gly Ser Trp Asp Ser Val Ala
60 65 70 75
cat gtc ctc ccc aat ggc tcc ctc ctc ctt ccg gct gtt ggg atc cag 290
His Val Leu Pro Asn Gly Ser Leu Leu Leu Pro Ala Val Gly Ile Gln
80 85 90
gat gag ggg act ttc cgg tgc cgg aca aca aac agg aat gga aag gag 338
Asp Glu Gly Thr Phe Arg Cys Arg Thr Thr Asn Arg Asn Gly Lys Glu
95 100 105
acc aag tcc aat tac cga gtc cgg gtc tac cag att cct ggg aag cca 386
Thr Lys Ser Asn Tyr Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro
110 115 120
gag atc ctg gat cct gcc tct gaa ctc acg gcc ggt atc ccc agt aag 434
Glu Ile Leu Asp Pro Ala Ser Glu Leu Thr Ala Gly Ile Pro Ser Lys
125 130 135
gtg ggg aca tgt gtg tct gat ggg gga tat cct ctg ggg act ctc agc 482
Val Gly Thr Cys Val Ser Asp Gly Gly Tyr Pro Leu Gly Thr Leu Ser
140 145 150 155
tgg cac atg gat ggg aaa ctc ctg gta cct gac ggg aag gga gtg tct 530
Trp His Met Asp Gly Lys Leu Leu Val Pro Asp Gly Lys Gly Val Ser
160 165 170
gtg aag gag cag acc agg agg cat cct gac acg ggg ctc ttc acc ctg 578
Val Lys Glu Gln Thr Arg Arg His Pro Asp Thr Gly Leu Phe Thr Leu
175 180 185
cag tca gag ctg atg gtg act cca gct ggg gga gga ggg cct ccc ccc 626
Gln Ser Glu Leu Met Val Thr Pro Ala Gly Gly Gly Gly Pro Pro Pro
190 195 200
acc ttc tcc tgt agc ttc agc ccc ggc cta ccc cgc cgc cgg gcc tca 674
Thr Phe Ser Cys Ser Phe Ser Pro Gly Leu Pro Arg Arg Arg Ala Ser
205 210 215
tac aca gcc ccc atc cag ccc agt gtc tgg gag cct ggg ccc ctg gag 722
Tyr Thr Ala Pro Ile Gln Pro Ser Val Trp Glu Pro Gly Pro Leu Glu
220 225 230 235
gtt cgc ttg ctg gtg gag cca gaa ggt gga gca gta gct cct ggt gag 770
Val Arg Leu Leu Val Glu Pro Glu Gly Gly Ala Val Ala Pro Gly Glu
240 245 250
act gtg acc ctg acc tgt gaa gct cct gcc cag ccc cct cct caa atc 818
Thr Val Thr Leu Thr Cys Glu Ala Pro Ala Gln Pro Pro Pro Gln Ile
255 260 265
cac tgg atg aag gat ggt atg tcc cta ccc ctg ccc ccc agc ccc gtc 866
His Trp Met Lys Asp Gly Met Ser Leu Pro Leu Pro Pro Ser Pro Val
270 275 280
ctg ctc ctc cct gag gtg ggg cct caa gat gag ggg act tac agc tgc 914
Leu Leu Leu Pro Glu Val Gly Pro Gln Asp Glu Gly Thr Tyr Ser Cys
285 290 295
gtg gcc acc cat ccc aac cgt ggg ccc cag gaa agc ctt ccc atc agc 962
Val Ala Thr His Pro Asn Arg Gly Pro Gln Glu Ser Leu Pro Ile Ser
300 305 310 315
atc agt gtc gag aca ggc gag gat ggg ccg act gca ggc tct gag ggt 1010
Ile Ser Val Glu Thr Gly Glu Asp Gly Pro Thr Ala Gly Ser Glu Gly
320 325 330
ggc tca ggc ctg ggg act cta gct ctg gcc ctg ggg atc ctg gga ggc 1058
Gly Ser Gly Leu Gly Thr Leu Ala Leu Ala Leu Gly Ile Leu Gly Gly
335 340 345
ctg gga aca gct gcc ctg ctt gtc gga gtc atc ctg tgg cga agg cgg 1106
Leu Gly Thr Ala Ala Leu Leu Val Gly Val Ile Leu Trp Arg Arg Arg
350 355 360
aaa cgc caa gga gag cag agg aaa gtc ccc gaa aac cag gag gac gag 1154
Lys Arg Gln Gly Glu Gln Arg Lys Val Pro Glu Asn Gln Glu Asp Glu
365 370 375
gag gaa cgc aca gaa ctg cat cag tcg gag gct cgg gag gcg atg gag 1202
Glu Glu Arg Thr Glu Leu His Gln Ser Glu Ala Arg Glu Ala Met Glu
380 385 390 395
agc ggt aca gga gag ccc tga atagtttagc ggccgcattc ttat 1247
Ser Gly Thr Gly Glu Pro
400
<210> 13
<211> 401
<212> PRT
<213> Rabbit
<400> 13
Met Ala Ala Gly Ala Ala Ala Gly Ala Trp Val Leu Val Phe Ser Leu
1 5 10 15
Trp Gly Ala Ala Val Gly Gly Gln Asn Ile Thr Ala Arg Ile Gly Glu
20 25 30
Pro Leu Val Leu Lys Cys Lys Gly Ala Pro Lys Lys Pro Pro Gln Gln
35 40 45
Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu Ala Trp Lys Val Leu
50 55 60
Ser Pro Gln Gly Gly Ser Trp Asp Ser Val Ala His Val Leu Pro Asn
65 70 75 80
Gly Ser Leu Leu Leu Pro Ala Val Gly Ile Gln Asp Glu Gly Thr Phe
85 90 95
Arg Cys Arg Thr Thr Asn Arg Asn Gly Lys Glu Thr Lys Ser Asn Tyr
100 105 110
Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro Glu Ile Leu Asp Pro
115 120 125
Ala Ser Glu Leu Thr Ala Gly Ile Pro Ser Lys Val Gly Thr Cys Val
130 135 140
Ser Asp Gly Gly Tyr Pro Leu Gly Thr Leu Ser Trp His Met Asp Gly
145 150 155 160
Lys Leu Leu Val Pro Asp Gly Lys Gly Val Ser Val Lys Glu Gln Thr
165 170 175
Arg Arg His Pro Asp Thr Gly Leu Phe Thr Leu Gln Ser Glu Leu Met
180 185 190
Val Thr Pro Ala Gly Gly Gly Gly Pro Pro Pro Thr Phe Ser Cys Ser
195 200 205
Phe Ser Pro Gly Leu Pro Arg Arg Arg Ala Ser Tyr Thr Ala Pro Ile
210 215 220
Gln Pro Ser Val Trp Glu Pro Gly Pro Leu Glu Val Arg Leu Leu Val
225 230 235 240
Glu Pro Glu Gly Gly Ala Val Ala Pro Gly Glu Thr Val Thr Leu Thr
245 250 255
Cys Glu Ala Pro Ala Gln Pro Pro Pro Gln Ile His Trp Met Lys Asp
260 265 270
Gly Met Ser Leu Pro Leu Pro Pro Ser Pro Val Leu Leu Leu Pro Glu
275 280 285
Val Gly Pro Gln Asp Glu Gly Thr Tyr Ser Cys Val Ala Thr His Pro
290 295 300
Asn Arg Gly Pro Gln Glu Ser Leu Pro Ile Ser Ile Ser Val Glu Thr
305 310 315 320
Gly Glu Asp Gly Pro Thr Ala Gly Ser Glu Gly Gly Ser Gly Leu Gly
325 330 335
Thr Leu Ala Leu Ala Leu Gly Ile Leu Gly Gly Leu Gly Thr Ala Ala
340 345 350
Leu Leu Val Gly Val Ile Leu Trp Arg Arg Arg Lys Arg Gln Gly Glu
355 360 365
Gln Arg Lys Val Pro Glu Asn Gln Glu Asp Glu Glu Glu Arg Thr Glu
370 375 380
Leu His Gln Ser Glu Ala Arg Glu Ala Met Glu Ser Gly Thr Gly Glu
385 390 395 400
Pro
<210> 14
<211> 402
<212> PRT
<213> Rattus norvegicus
<220>
<221> MISC_FEATURE
<223> Genbank No. NP_445788
<400> 14
Met Pro Thr Gly Thr Val Ala Arg Ala Trp Val Leu Val Leu Ala Leu
1 5 10 15
Trp Gly Ala Val Ala Gly Gly Gln Asn Ile Thr Ala Arg Ile Gly Glu
20 25 30
Pro Leu Met Leu Ser Cys Lys Gly Ala Pro Lys Lys Pro Thr Gln Lys
35 40 45
Leu Glu Trp Lys Leu Asn Thr Gly Arg Thr Glu Ala Trp Lys Val Leu
50 55 60
Ser Pro Gln Gly Asp Pro Trp Asp Ser Val Ala Arg Ile Leu Pro Asn
65 70 75 80
Gly Ser Leu Leu Leu Pro Ala Ile Gly Ile Val Asp Glu Gly Thr Phe
85 90 95
Arg Cys Arg Ala Thr Asn Arg Leu Gly Lys Glu Val Lys Ser Asn Tyr
100 105 110
Arg Val Arg Val Tyr Gln Ile Pro Gly Lys Pro Glu Ile Val Asn Pro
115 120 125
Ala Ser Glu Leu Thr Ala Asn Val Pro Asn Lys Val Gly Thr Cys Val
130 135 140
Ser Glu Gly Ser Tyr Pro Ala Gly Thr Leu Ser Trp His Leu Asp Gly
145 150 155 160
Lys Pro Leu Ile Pro Asp Gly Lys Gly Thr Val Val Lys Glu Glu Thr
165 170 175
Arg Arg His Pro Glu Thr Gly Leu Phe Thr Leu Arg Ser Glu Leu Thr
180 185 190
Val Thr Pro Ala Gln Gly Gly Thr Thr Pro Thr Tyr Ser Cys Ser Phe
195 200 205
Ser Leu Gly Leu Pro Arg Arg Arg Pro Leu Asn Thr Ala Pro Ile Gln
210 215 220
Pro Arg Val Arg Glu Pro Leu Pro Pro Glu Gly Ile Gln Leu Leu Val
225 230 235 240
Glu Pro Glu Gly Gly Thr Val Ala Pro Gly Gly Thr Val Thr Leu Thr
245 250 255
Cys Ala Ile Ser Ala Gln Pro Pro Pro Gln Ile His Trp Ile Lys Asp
260 265 270
Gly Thr Pro Leu Pro Leu Ala Pro Ser Pro Val Leu Leu Leu Pro Glu
275 280 285
Val Gly His Glu Asp Glu Gly Ile Tyr Ser Cys Val Ala Thr His Pro
290 295 300
Ser His Gly Pro Gln Glu Ser Pro Pro Val Asn Ile Arg Val Thr Glu
305 310 315 320
Thr Gly Asp Glu Gly Gln Ala Ala Gly Ser Val Asp Gly Ser Gly Leu
325 330 335
Gly Thr Leu Ala Leu Ala Leu Gly Ile Leu Gly Gly Leu Gly Ile Ala
340 345 350
Ala Leu Leu Ile Gly Ala Ile Leu Trp Arg Lys Arg Gln Pro Arg Leu
355 360 365
Glu Glu Arg Lys Ala Pro Glu Ser Gln Glu Asp Glu Glu Glu Arg Ala
370 375 380
Glu Leu Asn Gln Ser Glu Glu Ala Glu Met Pro Glu Asn Gly Ala Gly
385 390 395 400
Gly Pro
<210> 15
<211> 5301
<212> DNA
<213> baboon
<400> 15
ttttttaaaa actactattt gaaaattgga gggggaagag tgggaaggga gttattgcca 60
aatatgttaa atatgggttg gggtgcttgt atatgtatct tcctcaattt ccccagaaat 120
gaggtatctt tttgtcacac caaaatcaag tggtagggag agggaggagg ttgcaaaaag 180
ccaagtgtgg gggaaaagta aaatcaacac tgtcccatcc tcagccctaa accctaccat 240
ctgatcccct cagacattct caggattttg caagactgtc agagtgggga acccctccca 300
ttaaagatct gggcaggact ggggacaggt tggaagtgtg atgggtgggg gggtgggagg 360
catgggctgg gggcagttct ctcctcactt gtaaacttgt gtagtttcac agaaaaaaaa 420
caaaatgcag ttttaaataa agaagtttct ttttttcctg ggtttagttg agaatttttt 480
tcaaaaaaca tgagaaaccc cagaaaaaaa aatatatatt ttctttcacg aagctccaaa 540
caggtttctc tcctgtcccc cagccttgcc ttcacgatgc agtcccaatt gcacccttgc 600
aaacaacagt ctggcctcaa cgctattgat gcaaccttgc ccagtcaaca tggggctcca 660
gtgggtcacc aggcagccct gatggactga tggaataaat aggatagggg gctctgaggg 720
aatgagaccc tagagggtac actccccatc ccccagggaa gtgactgtgt ccagaggctg 780
gtagtgccca ggggtggggt gataattatt tctctagtac ctgaaggact cttgtcccaa 840
aggcatgaat tcctagcatt ccctgtgaca agatgactga aagatggggg ctggagagag 900
ggtacaggcc ccacctaggg cggaggccac agcgcggaga ggggcagaca gagctatgag 960
cctggaagga agcaggatgg cagccggagc agcagttgga gcctgggtgc tggtcctcag 1020
tctgtggggt gagccactcc ccccacccac tgacccttcc tacagaaagc acttgaaccc 1080
cataccccaa ttgccctaga acttttccca gaacccaggg aactgctttt caaggtcccg 1140
cacgcaccct gtccaaattt tgttagccct cattaccttc ctgcccctct accacgatgc 1200
tgtctcccag gggcagtagt aggtgctcaa aacatcacag cccggatcgg tgagccactg 1260
gtgctgaagt gtaagggggc ccccaagaaa ccaccccagc agctggaatg gaaactggta 1320
agtggggatc ctgttgcagc ttcccaactt ccagggagac cagcaatgat tcggatcccc 1380
atcactctgc ctcacagtac tttcccaaag gccttgcact gtttaggccc tgcttctctg 1440
cttctagaat acaggccgga cagaagcttg gaaggtccta tctccccagg gaggcccctg 1500
ggatagtgtg gctcgtgtcc ttcccaacgg ctccctcttc cttccggctg tcgggatcca 1560
ggatgagggg attttccggt gccaggcaat gaacaggaat ggaaaggaga ccaagtccaa 1620
ctaccgagtc cgtgtctacc gtaagaattc cagggccttc tccaaggccc cctctcttat 1680
ctcagaaaaa gccttcaacc ctagccttgg cccatgaggg cctctgactt ccactggccc 1740
catttccaca cacagagttt gagaaccttc acaattacag cctctgattg gatttttcct 1800
tcttcagaga ttcctgggaa gccggaaatt atagattctg cctctgaact cacggctggt 1860
gttcccaaca aggtagtgaa agaaaggaga agtagaaaat ggtcctgtga acaggaggcg 1920
agtgtgtgtg ggtgtgtggc atctctcatt ttcaaaggat tctgaggtca ccactctttc 1980
cccaggtggg gacatgtgtg tcagagggaa gctaccctgc agggactctt agctggcact 2040
tggatgggaa gcccctggtg cctaatgaga agggtgagtc cgaaggtgcc cgccaagctg 2100
ccttctccct gatctcactc ccacacccac cctgggataa tttgtcttat cctcctacca 2160
taggagtatc tgtgaaggaa gagaccagga gacaccctga gacggggctc ttcacactgc 2220
agtcggagct aatggtgacc ccagcccggg gaggaaatcc ccatcccacc ttctcctgta 2280
gcttcagccc aggccttccc cgacgccggg ccttgcacac agcccctatc cagccccgtg 2340
tctggggtga gcagaggtgg ggagggctcc aagctcatgt gagtgcattc tggaagtcgg 2400
acccttaggg aaagagggag tcaagcccat ggccactggg atcactcaca agtgtaactc 2460
tccacctcat aacccttcca actcccagag cctgtgcctc tggaggaggt ccaattggtg 2520
gtagagccag aaggtggagc agtagctcct ggtggaaccg taaccctgac ctgtgaagtc 2580
cctgcccagc cctctcctca gatccactgg atgaaggatg tgagtgacct ggagagaggg 2640
gctgggaggt agggtgaacc ataactagca acagggaggg cagagggcta acgagggaaa 2700
ggcaggctag gagctgagga ggaagagagg gtatttgaag atgtggagac aaaaagataa 2760
gagttttgaa atagtctcct ctccccttcc cccaccaggg tgtgccctta cccctttccc 2820
ccagccctgt gctgatcctc cctgagatag ggcctcagga ccagggaacc tacaggtgtg 2880
tggccaccca tcccagccac gggccccagg aaagccgtgc tgtcagcatc agcatcatcg 2940
gtgagacctc tctccaagcc ctacagaccc tggggctagg gtgcaggata gcacaggctc 3000
taatttcctg ccccattctg gccttacccc caagagccag cccacctctc cctccgtgca 3060
cccacaccca aacctcccct gccccactca aattctgcca agagagcagc caagcctctc 3120
ccttcttccc tctgaactaa aaaaagggaa agacggctgg gcgcagtggc tcacgcctgt 3180
aatcccaaca ctttgggagg ctgaggccgg tggatcacct gaggttggga gttcaagacc 3240
agtctgacca acatggagga accccatttc tactaaaaat acaaaattag ccagttgtgg 3300
tggcacgtgc ctgtaatccc agctacttgg gaggctgaga caggaaaatc acttgaaccc 3360
gggaggcgta agttgcggtg agccaagatc ctgccattgc atgccagcct gggcaacaag 3420
agcgaaactc catctcaaaa aaaaaaaaaa aagaaaggga aagactccac tggagctccc 3480
actaaataac cctctctcaa cccgaagtct tcctttctga ctggatccaa ctttgtcttc 3540
cagaaccagg cgaggagggg ccaactgcag gtgaggggtt cgagaaagtc agggaagcag 3600
aagatagccc ccaacacatg tgactgcggg gatggtcaac aagaaaggaa tggtggccgg 3660
gcgcggtggc tcaagcctgt aatcccagca ctttgggagg ccgagatggg cggatcacga 3720
ggtcaggaga tcgagaccat cctggctaac acagtaaaac cccatctcta ccaaaaaaaa 3780
atacaaaaaa ctagccgggc gacgtggcgg gcgcctgtag tcccagctac tcgggaggct 3840
gaggcaggag aatggtgtaa acccgggagg cggagcttgc agtgagctga gatccggcca 3900
ctgcactcca gcctgggcaa cagagccaga ctccatctca aaaaaaaaaa aaaagaaaga 3960
aaggaatggt gagtggtggg ggctgtgctc tcaattttcc ctgtctccct acaggctctg 4020
tgggaggatc agggccagga actctagccc tggccctggg gatcctggga ggcctgggga 4080
cagccgctct gctcattggg gtcatcttgt ggcaaaggcg gcgacgccaa cgagaggaga 4140
ggtgagtgga gaaagccaga ctcctcagac ctagggcttc caggcagcaa gtgaagaggg 4200
atggggggtg gaacgacaac gtgcagcatt ctccacaatc ttcctcctca ggaaggcctc 4260
agaaaaccag gaggaagagg aggagcgtgc agagctgaat cagtcggagg aacctgaggc 4320
aggcgagagt ggtactggag ggccttgagg ggcccacaga gagatcccat ccatcagctc 4380
ccttttcttc ttcccttgaa ctgttctggc cccagaccaa ctctctcctg tataacccca 4440
ccttgccaaa ctttcttcta caaccagagc cccccacaat gatgagtaaa cacctgacac 4500
atcttgctct tgtgtgtctg tgtatatgtg tgtgagacac aacctcaccc ctacaccctt 4560
gagggccctg aaggaaaggg actcaccccc acactgcacc aaacatctac tcaagttggg 4620
gagaagatgc ttctgtcaag agagggaggg aggaaggtgg ggggcaaact tgggaagaga 4680
tcccatcaat acatttcacc ttttttattg aatttgtatt aaaggaggta gtaaggggga 4740
ggaagcactt aagagtcaga acccatatta gactctgggg agtgaaaaat taaattaaat 4800
caataagatg ggagtggggg aagagtcaga gggagctttg cccccctttc aagatcaaat 4860
caagaaatca gggaaagcaa agacttagaa gagaagaaag acattctctc aatccatcct 4920
ccttccccag ggcagagaat tataatgtta ctgagtgagc ttctgagcag aaggctctcc 4980
catctatgca cagacttcac tcctcctccc caagctttcc tggagaatgt ccagggctgg 5040
ccttagccaa cagaaataga gaggtcaagg gggtccatga gtaaggaagg gtcagcaggg 5100
acccccaata ctgattctcc tctggctgga ggtgggcagg aaggagacat agctcaaata 5160
ctgagcagcc aaaaaaagaa gaagatggcg agaaacagga agagggaatc ctgccagctg 5220
gaggccgggt gaccctgtcc cagatccaca cctgtgggag agaggaaagc tgtggaagca 5280
tatgcttcta ggctgggagg g 5301
<210> 16
<211> 119
<212> PRT
<213> Rat
<220>
<221> MISC_FEATURE
<223> XT-M4 VH
<220>
<221> MISC_FEATURE
<223> Variable Heavy Region
<400> 16
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Lys Leu Ser Cys Val Val Ser Gly Phe Thr Phe Asn Asn Tyr
20 25 30
Trp Met Thr Trp Ile Arg Gln Thr Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Asn Asn Ser Gly Asp Asn Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Thr Arg Gly Gly Asp Ile Thr Thr Gly Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Val Met Val Thr Val Ser Ser
115
<210> 17
<211> 107
<212> PRT
<213> Rat
<220>
<221> MISC_FEATURE
<223> XT-M4 VL
<220>
<221> MISC_FEATURE
<223> Variable Light Region
<400> 17
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Met Ser Val Ser Leu Gly
1 5 10 15
Asp Thr Ile Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Arg Arg Met Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Ser Ile Tyr Ser Leu Thr Ile Ser Ser Leu Glu Ser
65 70 75 80
Glu Asp Val Ala Asp Tyr His Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Ser Gly Thr Lys Val Glu Ile Lys
100 105
<210> 18
<211> 119
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H1 VH
<220>
<221> MISC_FEATURE
<223> Variable Heavy Region
<400> 18
Gln Val Gln Leu Lys Glu Ser Gly Pro Gly Leu Val Ala Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Ile Ser Gly Phe Ser Ile Thr Ser Tyr
20 25 30
Gly Val His Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Val Val Ile Trp Ser Asp Gly Arg Thr Thr Tyr Asn Ser Thr Leu Lys
50 55 60
Ser Arg Leu Ser Ile Ser Lys Asp Asn Ser Lys Ser Gln Val Phe Leu
65 70 75 80
Lys Met Asn Ser Leu Gln Thr Asp Asp Thr Ala Met Tyr Tyr Cys Val
85 90 95
Arg His Gly Gly Tyr Phe Pro Tyr Ala Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 19
<211> 106
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H1 VL
<220>
<221> MISC_FEATURE
<223> Variable Light Region
<400> 19
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Thr Ser Leu Gly
1 5 10 15
Gly Lys Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Phe
20 25 30
Ile Ala Trp Tyr Gln His Thr Pro Gly Lys Gly Pro Arg Leu Phe Ile
35 40 45
Tyr Tyr Thr Ser Thr Leu Gln Pro Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Asn Gly Ser Gly Arg Asp Tyr Ser Phe Ser Ile Ser Asn Leu Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Asn Met Tyr Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 20
<211> 119
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H5 VH
<220>
<221> MISC_FEATURE
<223> Variable Heavy Region
<400> 20
Glu Val Leu Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met Asp Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Asp Ile Asn Pro Asp Asn Gly Gly Thr Ile Tyr Lys Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr His Asp His Tyr Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 21
<211> 117
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H2_VH
<220>
<221> MISC_FEATURE
<223> Variable Heavy Region
<400> 21
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Tyr Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Thr Gly Tyr Thr Glu Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Ala Gly Tyr Thr Ile Asp Tyr Trp Gly Gln Gly Thr Ser
100 105 110
Val Thr Val Ser Ser
115
<210> 22
<211> 112
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H2-VL
<220>
<221> MISC_FEATURE
<223> Variable Light Region
<400> 22
Asp Val Val Leu Thr Gln Thr Pro Leu Ser Leu Pro Val Asn Ile Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Lys Ser Thr Lys Ser Leu Leu Asn Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Val Ser Asp Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe Gln Ser
85 90 95
Asn Ser Leu Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 23
<211> 111
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H5 VL
<220>
<221> MISC_FEATURE
<223> Variable Light Region
<400> 23
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr
20 25 30
Gly Ile Ser Phe Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Arg Leu Leu Ile Tyr Thr Val Ser Asn Gln Gly Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His
65 70 75 80
Pro Met Glu Glu Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 24
<211> 116
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H3 VH
<220>
<221> MISC_FEATURE
<223> Variable Heavy Region
<400> 24
Gln Val Gln Leu Gln Gln Pro Gly Ser Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Trp Met His Trp Val Lys Gln Arg His Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Leu Tyr Pro Gly Ser Gly Arg Thr Asn Tyr Asp Glu Lys Phe
50 55 60
Lys Ser Lys Val Thr Leu Thr Glu Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met His Leu Ser Asn Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Ser Leu Arg Arg Gly Phe Val Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ala
115
<210> 25
<211> 107
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H3 VL
<220>
<221> MISC_FEATURE
<223> Variable Light Region
<400> 25
Asn Ile Val Met Thr Gln Ser Pro Glu Tyr Met Ser Met Ser Phe Gly
1 5 10 15
Glu Arg Val Thr Leu Thr Cys Lys Ala Ser Glu Asn Val Gly Ser Tyr
20 25 30
Val Ser Trp Tyr Gln Gln Lys Ser Glu Gln Ser Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Asn Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly
50 55 60
Ser Gly Ser Ala Thr Asp Phe Thr Leu Thr Ile Thr Ser Val Gln Ala
65 70 75 80
Glu Asp Leu Ala Asp Tyr His Cys Gly Gln Thr Tyr Thr Tyr Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 26
<211> 116
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H7 VH
<220>
<221> MISC_FEATURE
<223> Variable Heavy Region
<400> 26
Gln Val Gln Leu Lys Glu Ser Gly Pro Gly Leu Val Ala Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Gly Val His Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Met Trp Ala Gly Gly Ser Thr Thr Tyr Asn Ser Ala Leu Met
50 55 60
Ser Arg Leu Ser Ile Ser Lys Asp Asn Ser Lys Ser Gln Val Phe Leu
65 70 75 80
Lys Met Asn Ser Leu Gln Thr Asp Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Arg Tyr Gly Asn Tyr Ala Met Asp Tyr Trp Gly Gln Gly Thr Ser Val
100 105 110
Thr Val Ser Ser
115
<210> 27
<211> 106
<212> PRT
<213> Murine
<220>
<221> MISC_FEATURE
<223> XT-H7 VL
<220>
<221> MISC_FEATURE
<223> Variable Light Region
<400> 27
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Gly Lys Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Tyr Lys Tyr
20 25 30
Ile Ala Trp Tyr Gln His Lys Pro Gly Lys Gly Pro Arg Leu Leu Ile
35 40 45
His Tyr Thr Ser Thr Leu Gln Pro Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Arg Asp Tyr Ser Phe Ser Ile Ser Asn Leu Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Arg Tyr Asp Asn Leu Tyr Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 28
<211> 117
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-H2_hVH_V2.0
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized heavy chain variable regions
<400> 28
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Arg Pro Gly Gln Gly Leu Tyr Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Thr Gly Tyr Thr Glu Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Arg Val Thr Met Thr Ala Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Ala Gly Tyr Thr Ile Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 29
<211> 117
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-H2_hVH_V2.7
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized heavy chain variable regions
<400> 29
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Tyr Ile Asn Pro Ser Thr Gly Tyr Thr Glu Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Arg Val Thr Met Thr Arg Asp Lys Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Ala Gly Tyr Thr Ile Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 30
<211> 117
<212> PRT
<213> Artificial
<220>
<223> XT-H2_hVH_V4.0
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized heavy chain variable regions
<400> 30
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Asn Pro Ser Thr Gly Tyr Thr Glu Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Ala Gly Tyr Thr Ile Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 31
<211> 120
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-H2_hVH_V4.1
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized heavy chain variable regions
<400> 31
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
35 40 45
Tyr Trp Val Ala Tyr Ile Asn Pro Ser Thr Gly Tyr Thr Glu Tyr Asn
50 55 60
Gln Lys Phe Lys Asp Arg Phe Thr Ile Ser Ala Asp Lys Ala Lys Ser
65 70 75 80
Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Trp Ala Gly Tyr Thr Ile Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 32
<211> 112
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-H2_hVL_V2.0
<220>
<221> MISC_FEATURE
<223> Amino acid sequence of humanized light chain variable regions
<400> 32
Asp Val Val Leu Thr Gln Thr Pro Leu Ser Leu Ser Val Thr Pro Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Lys Ser Thr Lys Ser Leu Leu Asn Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Val Ser Asp Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Phe Gln Ser
85 90 95
Asn Ser Leu Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 33
<211> 112
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-H2_hVL_V3.0
<220>
<221> MISC_FEATURE
<223> Amino acid sequence of humanized light chain variable regions
<400> 33
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Thr Lys Ser Leu Leu Asn Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Asp Trp Tyr Gln Gln Lys Pro Gly Gln Pro
35 40 45
Pro Lys Leu Leu Ile Tyr Leu Val Ser Asp Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Phe Gln Ser
85 90 95
Asn Ser Leu Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 34
<211> 112
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-H2_hVL_V4.0
<220>
<221> MISC_FEATURE
<223> Amino acid sequence of humanized light chain variable regions
<400> 34
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ser Thr Lys Ser Leu Leu Asn Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Asp Trp Tyr Gln Gln Lys Pro Gly Lys Ala
35 40 45
Pro Lys Leu Leu Ile Tyr Leu Val Ser Asp Arg Phe Ser Gly Val Pro
50 55 60
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Phe Gln Ser
85 90 95
Asn Ser Leu Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 35
<211> 112
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-H2_hVL_V4.1
<220>
<221> MISC_FEATURE
<223> Amino acid sequence of humanized light chain variable regions
<400> 35
Asp Val Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ser Thr Lys Ser Leu Leu Asn Ser
20 25 30
Asp Gly Phe Thr Tyr Leu Asp Trp Tyr Gln Gln Lys Pro Gly Lys Ala
35 40 45
Pro Lys Leu Leu Ile Tyr Leu Val Ser Asp Arg Phe Ser Gly Val Pro
50 55 60
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Phe Gln Ser
85 90 95
Asn Ser Leu Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 36
<211> 119
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVH_V1.0
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized heavy chain variable regions
<400> 36
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Asn Tyr
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Asn Asn Ser Gly Asp Asn Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Asp Ile Thr Thr Gly Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 37
<211> 119
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVH_V1.1
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized heavy chain variable regions
<400> 37
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Asn Tyr
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Asp Asn Ser Gly Asp Asn Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Asp Ile Thr Thr Gly Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 38
<211> 119
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVH_V2.0
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized heavy chain variable regions
<400> 38
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Asn Tyr
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Asp Asn Ser Gly Asp Asn Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Asp Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Asp Ile Thr Thr Gly Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 39
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.4 \ (G66R)
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 39
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 40
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.5 \ (D70I)
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 40
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Ile Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 41
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.6 \ (T69S)
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 41
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Ser Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 42
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.7 \ (L46R)
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 42
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 43
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.8
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 43
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Met Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 44
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.9 \ (F71Y)
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 44
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 45
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.10
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 45
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Phe Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 46
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.11
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 46
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Phe Gln Gln Lys Pro Gly Lys Ala Pro Arg Arg Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 47
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.12
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 47
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Arg Arg Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 48
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.13
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 48
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 49
<211> 107
<212> PRT
<213> Artificial
<220>
<223> Humanized XT-M4_hVL_V2.14
<220>
<221> MISC_FEATURE
<223> Amino acid sequences of humanized light chain variable regions
<400> 49
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Phe Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 50
<211> 16
<212> PRT
<213> Artificial
<220>
<223> Linker
<400> 50
Asp Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ser
1 5 10 15
<210> 51
<211> 783
<212> DNA
<213> Artificial
<220>
<223> XT.H2_VL-VH (direct) ScFv sequence
<400> 51
gtggcccagg cggccggcgc gcactccgac atccagatga cccagtcccc ctcctccctg 60
tccgcctccg tgggcgaccg ggtgaccatc acctgcaagt ccaccaagtc cctgctgaac 120
tccgacggct tcacctacct ggactggtat cagcagaagc ctggcaaggc ccctaagctg 180
ctgatctacc tggtgtccga ccggttctcc ggcgtgcctt cccggttcag cggctccggc 240
tccggcaccg acttcaccct gaccatctcc tccctccagc ctgaggactt cgccacctac 300
tactgcttcc agtccaactc cctgcctctg acctttggcg gcggaacaaa ggtggaaatc 360
aaagatggcg gtggatcggg cggtggtgga tctggaggag gtggaagctc tgaggtgcag 420
ctcgtggagt ctggcggcgg actggtgcag cctggcggct ccctgcggct gtcctgcgcc 480
gcctccggct acaccttcac cacctactgg atgcactggg tgcggcaggc ccctggcaag 540
ggcctggagt gggtcgccta catcaaccct tccaccggct ataccgagta caaccagaag 600
ttcaaggacc ggttcaccat ctcccgggac aacgccaaga actccctgta cctccagatg 660
aactccctgc gggccgagga caccgccgtg tactactgcg ccagatgggc tggctacacc 720
atcgactact ggggccaggg caccctggtg accgtgtcct catctgatca ggcctcaggg 780
gcc 783
<210> 52
<211> 783
<212> DNA
<213> Artificial
<220>
<223> XT.H2_VH-VL (direct) ScFv sequence
<400> 52
gtggcccagg cggccggcgc gcactccgag gtgcagctcg tggagtctgg cggcggactg 60
gtgcagcctg gcggctccct gcggctgtcc tgcgccgcct ccggctacac cttcaccacc 120
tactggatgc actgggtgcg gcaggcccct ggcaagggcc tggagtgggt cgcctacatc 180
aacccttcca ccggctatac cgagtacaac cagaagttca aggaccggtt caccatctcc 240
cgggacaacg ccaagaactc cctgtacctc cagatgaact ccctgcgggc cgaggacacc 300
gccgtgtact actgcgccag atgggctggc tacaccatcg actactgggg ccagggcacc 360
ctggtgaccg tgtcctcaga tggcggtgga tcgggcggtg gtggatctgg aggaggtgga 420
agctctgaca tccagatgac ccagtccccc tcctccctgt ccgcctccgt gggcgaccgg 480
gtgaccatca cctgcaagtc caccaagtcc ctgctgaact ccgacggctt cacctacctg 540
gactggtatc agcagaagcc tggcaaggcc cctaagctgc tgatctacct ggtgtccgac 600
cggttctccg gcgtgccttc ccggttcagc ggctccggct ccggcaccga cttcaccctg 660
accatctcct ccctccagcc tgaggacttc gccacctact actgcttcca gtccaactcc 720
ctgcctctga cctttggcgg cggaacaaag gtggaaatca aatctgatca ggcctcaggg 780
gcc 783
<210> 53
<211> 774
<212> DNA
<213> Artificial
<220>
<223> XT.M4_VH_VL ScFv sequence
<400> 53
gtggcccagg cggccggcgc gcactccgag gtgcagctgg tggagtctgg cggcggactg 60
gtgcagcctg gcggctctct gagactgtct tgtgccgcct ccggcttcac cttcaacaac 120
tactggatga cctgggtgag gcaggcccct ggcaagggcc tggagtgggt ggcctccatc 180
gacaactccg gcgacaacac ctactacccc gactccgtga aggaccggtt caccatctcc 240
agggacaacg ccaagaactc cctgtacctc cagatgaact ccctgagggc cgaggatacc 300
gccgtgtact actgtgccag aggcggcgat atcaccaccg gcttcgacta ctggggccag 360
ggcaccctgg tgaccgtgtc ctctgatggc ggtggatcgg gcggtggtgg atctggagga 420
ggtggaagct ctgacatcca gatgacccag tccccctctt ctctgtctgc ctctgtgggc 480
gacagagtga ccatcacctg tcgggcctct caggatgtgg gcatctacgt gaactggttt 540
cagcagaagc ctggcaaggc tcccaggcgc ctgatctacc gggccaccaa cctggccgat 600
ggcgtgcctt ccagattctc cggctctcgc tctggcaccg atttcaccct gaccatctcc 660
tccctccagc ctgaggattt cgccacctac tactgcctgg agttcgacga gcaccctctg 720
acctttggcg gcggaacaaa ggtggagatc aagtctgatc aggcctcagg ggcc 774
<210> 54
<211> 774
<212> DNA
<213> Artificial
<220>
<223> XT.M4_VL_VH ScFv sequence
<400> 54
gtggcccagg cggccggcgc gcactccgac atccagatga cccagtcccc ctcttctctg 60
tctgcctctg tgggcgacag agtgaccatc acctgtcggg cctctcagga tgtgggcatc 120
tacgtgaact ggtttcagca gaagcctggc aaggctccca ggcgcctgat ctaccgggcc 180
accaacctgg ccgatggcgt gccttccaga ttctccggct ctcgctctgg caccgatttc 240
accctgacca tctcctccct ccagcctgag gatttcgcca cctactactg cctggagttc 300
gacgagcacc ctctgacctt tggcggcgga acaaaggtgg agatcaagga tggcggtgga 360
tcgggcggtg gtggatctgg aggaggtgga agctctgagg tgcagctggt ggagtctggc 420
ggcggactgg tgcagcctgg cggctctctg agactgtctt gtgccgcctc cggcttcacc 480
ttcaacaact actggatgac ctgggtgagg caggcccctg gcaagggcct ggagtgggtg 540
gcctccatcg acaactccgg cgacaacacc tactaccccg actccgtgaa ggaccggttc 600
accatctcca gggacaacgc caagaactcc ctgtacctcc agatgaactc cctgagggcc 660
gaggataccg ccgtgtacta ctgtgccaga ggcggcgata tcaccaccgg cttcgactac 720
tggggccagg gcaccctggt gaccgtgtcc tcttctgatc aggcctcagg ggcc 774
<210> 55
<211> 41
<212> PRT
<213> Artificial
<220>
<223> C terminal end of M4 ScFv - VL/VH format
<400> 55
Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Gly Asp
1 5 10 15
Ile Thr Thr Gly Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
20 25 30
Ser Ser Ser Asp Gln Ala Ser Gly Ala
35 40
<210> 56
<211> 123
<212> DNA
<213> Artificial
<220>
<223> C terminal end of M4 ScFv VL/VH format
<400> 56
ctgagggccg aggataccgc cgtgtactac tgtgccagag gcggcgatat caccaccggc 60
ttcgactact ggggccaggg caccctggtg accgtgtcct cttctgatca ggcctcaggg 120
gcc 123
<210> 57
<211> 86
<212> DNA
<213> Artificial
<220>
<223> Spiking oligonucleotide for VH3-CDR3 mutagenesis of M4 VL/VH
<220>
<221> misc_feature
<222> (61)..(70)
<223> N is A, T, C or G
<400> 57
caggttgtcg gcccctgagg cctgatcaga ggacacggtc accagggtgc cctggcccca 60
nnnnnnnnnn tctggcacag tagtac 86
<210> 58
<211> 53
<212> DNA
<213> Artificial
<220>
<223> Spiking oligonucleotide for VH3-CDR3 mutagenesis of M4 VL/VH
<220>
<221> misc_feature
<222> (28)..(37)
<223> N is A, T, C or G
<400> 58
caggttgtcc agggtgccct ggccccannn nnnnnnntct ggcacagtag tac 53
<210> 59
<211> 22
<212> DNA
<213> Artificial
<220>
<223> Artificial Sequence
<400> 59
gaccctggaa ggaagcagga tg 22
<210> 60
<211> 27
<212> DNA
<213> Artificial
<220>
<223> Artificial Sequence
<400> 60
ggatctgtct gtgggcccct caaggcc 27
<210> 61
<211> 41
<212> DNA
<213> Artificial
<220>
<223> Artificial Sequence
<400> 61
actagactag tcggaccatg gcagcagggg cagcggccgg a 41
<210> 62
<211> 48
<212> DNA
<213> Artificial
<220>
<223> Artificial Sequence
<400> 62
ataagaatgc ggccgctaaa ctattcaggg ctctcctgta ccgctctc 48
<210> 63
<211> 476
<212> PRT
<213> Artificial
<220>
<223> anti-RAGE scFv-Fc fusion protein
<220>
<221> MISC_FEATURE
<223> huXT-M4 V2.11 scFv-Fc with wt human IgG1 Fc VL-linker-VH
<400> 63
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Gly Ile Tyr
20 25 30
Val Asn Trp Phe Gln Gln Lys Pro Gly Lys Ala Pro Arg Arg Leu Ile
35 40 45
Tyr Arg Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Glu Phe Asp Glu His Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Asp Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ser Glu Val Gln Leu Val
115 120 125
Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser
130 135 140
Cys Ala Ala Ser Gly Phe Thr Phe Asn Asn Tyr Trp Met Thr Trp Val
145 150 155 160
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ala Ser Ile Asp Asn
165 170 175
Ser Gly Asp Asn Thr Tyr Tyr Pro Asp Ser Val Lys Asp Arg Phe Thr
180 185 190
Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser
195 200 205
Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Gly Asp
210 215 220
Ile Thr Thr Gly Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
225 230 235 240
Ser Ser Asp Gln Glu Pro Lys Ser Ser Asp Lys Thr His Thr Cys Pro
245 250 255
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
260 265 270
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
275 280 285
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
290 295 300
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
305 310 315 320
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
325 330 335
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
340 345 350
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
355 360 365
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
370 375 380
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
385 390 395 400
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
405 410 415
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
420 425 430
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
435 440 445
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
450 455 460
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
465 470 475
<210> 64
<211> 1428
<212> DNA
<213> Artificial
<220>
<223> Encodes anti-RAGE scFv-Fc fusion protein
<220>
<221> misc_feature
<223> huXT-M4 VL V2.11-VH V2.0 wt-Fc sequence
<400> 64
gacatccaga tgacccagtc cccctcttct ctgtctgcct ctgtgggcga cagagtgacc 60
atcacctgtc gggcctctca ggatgtgggc atctacgtga actggtttca gcagaagcct 120
ggcaaggctc ccaggcgcct gatctaccgg gccaccaacc tggccgatgg cgtgccttcc 180
agattctccg gctctcgctc tggcaccgat ttcaccctga ccatctcctc cctccagcct 240
gaggatttcg ccacctacta ctgcctggag ttcgacgagc accctctgac ctttggcggc 300
ggaacaaagg tggagatcaa ggatggcggt ggatcgggcg gtggtggatc tggaggaggt 360
gggagctctg aggtgcagct ggtggagtct ggcggcggac tggtgcagcc tggcggctct 420
ctgagactgt cttgtgccgc ctccggcttc accttcaaca actactggat gacctgggtg 480
aggcaggccc ctggcaaggg cctggagtgg gtggcctcca tcgacaactc cggcgacaac 540
acctactacc ccgactccgt gaaggaccgg ttcaccatct ccagggacaa cgccaagaac 600
tccctgtacc tccagatgaa ctccctgagg gccgaggata ccgccgtgta ctactgtgcc 660
agaggcggcg atatcaccac cggcttcgac tactggggcc agggcaccct ggtgaccgtg 720
tcctctgatc aggagcccaa atcttctgac aaaactcaca catgtccacc gtgcccagca 780
cctgaactcc tgggtggacc gtcagtcttc ctcttccccc caaaacccaa ggacaccctc 840
atgatctccc ggacccctga ggtcacatgc gtggtggtgg acgtgagcca cgaagaccct 900
gaggtcaagt tcaactggta cgtggacggc gtggaggtgc ataatgccaa gacaaagccg 960
cgggaggagc agtacaacag cacgtaccgt gtggtcagcg tcctcaccgt cctgcaccag 1020
gactggctga atggcaagga gtacaagtgc aaggtctcca acaaagccct cccagccccc 1080
atcgagaaaa ccatctccaa agccaaaggg cagccccgag aaccacaggt gtacaccctg 1140
cccccatccc gggatgagct gaccaagaac caggtcagcc tgacctgcct ggtcaaaggc 1200
ttctatccaa gcgacatcgc cgtggagtgg gagagcaatg ggcagccgga gaacaactac 1260
aagaccacgc ctcccgtgct ggactccgac ggctccttct tcctctacag caagctcacc 1320
gtggacaaga gcaggtggca gcaggggaac gtcttctcat gctccgtgat gcatgaggct 1380
ctgcacaacc actacacgca gaagagcctc tccctgtctc cgggtaaa 1428
Claims (43)
- A-베타의 아밀로이드 침착을 특징으로 하는 질병 또는 질환을 갖는 개체를 치료하는 방법으로서, RAGE에 특이적으로 결합하여 RAGE 결합 파트너의 결합을 억제하는 항체의 치료학적 유효량을 상기 개체에 투여하는 단계를 포함하는 방법.
- 제1항에 있어서, 개체는 인간 개체인 방법.
- 제1항에 있어서, 질병 또는 질환은 뇌에서 A-베타의 아밀로이드 침착을 특징으로 하는 방법.
- 제3항에 있어서, 질병 또는 질환은 알츠하이머병인 방법.
- 제3항에 있어서, 질병 또는 질환은 전임상(preclinical) 알츠하이머병인 방법.
- 제1항에 있어서, 항체는(a) RAGE와의 결합에 대해 XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체와 경쟁하거나;(b) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선 택되는 항체가 결합하는 RAGE의 에피토프에 결합하거나;(c) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체의 경쇄 또는 중쇄의 하나 이상의 상보성 결정 부위(CDR)를 포함하거나; 또는(d) 상기 (a), (b) 또는 (c)에 따른 항체의 RAGE-결합 단편인 방법.
- 제6항에 있어서, 항체 또는 RAGE-결합 항체 단편은XT-M4 경쇄 가변부(서열 번호 17)의 CDR을 포함하는 경쇄 가변부;XT-M4 중쇄 가변부 서열(서열 번호 16)의 CDR을 포함하는 중쇄 가변부;인간 카파 경쇄 불변부; 및인간 IgG1 중쇄 불변부를 포함하는 방법.
- 제7항에 있어서, 항체 또는 이의 RAGE-결합 단편은XT-M4 경쇄 가변부의 아미노산 서열(서열 번호 17)을 가지는 경쇄 가변부;XT-M4 중쇄 가변부 서열의 아미노산 서열(서열 번호 16)을 가지는 중쇄 가변부;인간 카파 경쇄 불변부; 및인간 IgG1 중쇄 불변부를 포함하는 방법.
- 제1항에 있어서, 항체는 키메라 항체, 인간화 항체 또는 인간 항체인 방법.
- 제9항에 있어서, 키메라 항체 또는 인간화 항체는 인간 불변부 또는 이로부터 유래하는 불변부를 포함하는 방법.
- 제1항에 있어서, 항체 또는 이의 RAGE-결합 단편을 알츠하이머병 치료에 유용한 하나 이상의 제제와 함께 투여하여 상승 치료 효과를 유도하는 단계를 포함하는 방법.
- 개체에서 A-베타의 아밀로이드 침착물의 축적을 억제 또는 감소시키는 방법으로서, RAGE에 특이적으로 결합하여 RAGE-결합 파트너의 결합을 억제하는 항체의 유효량을 상기 개체에 투여하는 단계를 포함하는 방법.
- 제12항에 있어서, 개체는 인간 개체인 방법.
- 제12항에 있어서, 뇌에서 A-베타의 아밀로이드 침착물의 축적을 억제 또는 감소시키는 단계를 포함하는 방법.
- 제14항에 있어서, 뇌에서 A-베타의 아밀로이드 침착물의 축적은 알츠하이머 병과 관련된 것인 방법.
- 제14항에 있어서, 뇌에서 A-베타의 아밀로이드 침착물의 축적은 전임상 알츠하이머병과 관련된 것인 방법.
- 제12항에 있어서, 항체는(a) RAGE와의 결합에 대해 XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체와 경쟁하거나;(b) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체가 결합하는 RAGE의 에피토프에 결합하거나;(c) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체의 경쇄 또는 중쇄의 하나 이상의 상보성 결정 부위(CDR)를 포함하거나; 또는(d) 상기 (a), (b) 또는 (c)에 따른 항체의 RAGE-결합 단편인 방법.
- 제17항에 있어서, 항체 또는 RAGE-결합 항체 단편은XT-M4 경쇄 가변부(서열 번호 17)의 CDR을 포함하는 경쇄 가변부;XT-M4 중쇄 가변부 서열(서열 번호 16)의 CDR을 포함하는 중쇄 가변부;인간 카파 경쇄 불변부; 및인간 IgG1 중쇄 불변부를 포함하는 방법.
- 제18항에 있어서, 항체 또는 이의 RAGE-결합 단편은XT-M4 경쇄 가변부의 아미노산 서열(서열 번호 17)을 가지는 경쇄 가변부;XT-M4 중쇄 가변부 서열의 아미노산 서열(서열 번호 16)을 가지는 중쇄 가변부;인간 카파 경쇄 불변부; 및인간 IgG1 중쇄 불변부를 포함하는 방법.
- 제12항에 있어서, 항체는 키메라 항체, 인간화 항체 또는 인간 항체인 방법.
- 제20항에 있어서, 키메라 항체 또는 인간화 항체는 인간 불변부 또는 이로부터 유래하는 불변부를 포함하는 방법.
- 제12항에 있어서, 항체 또는 이의 RAGE-결합 단편을 A-베타의 아밀로이드 침착을 억제 또는 감소시키는데 유용한 하나 이상의 제제와 함께 투여하여 상승 효과를 유도하는 단계를 포함하는 방법.
- 개체에서 신경 퇴행을 억제 또는 완화하는 방법으로서, RAGE에 특이적으로 결합하여 RAGE-결합 파트너와의 결합을 억제하는 항체의 유효량을 상기 개체에 투여하는 단계를 포함하는 방법.
- 제23항에 있어서, 개체는 인간 개체인 방법.
- 제23항에 있어서, 뇌에서 신경 퇴행을 억제 또는 완화하는 단계를 포함하는 방법.
- 제25항에 있어서, 신경 퇴행은 알츠하이머병과 관련된 것인 방법.
- 제25항에 있어서, 신경 퇴행은 전임상 알츠하이머병과 관련된 것인 방법.
- 제23항에 있어서, 항체는(a) RAGE와의 결합에 대해 XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체와 경쟁하거나;(b) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체가 결합하는 RAGE의 에피토프에 결합하거나;(c) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체의 경쇄 또는 중쇄의 하나 이상의 상보성 결정 부위(CDR)를 포함하거나; 또는(d) 상기 (a), (b) 또는 (c)에 따른 항체의 RAGE-결합 단편인 방법.
- 제28항에 있어서, 항체 또는 RAGE-결합 항체 단편은XT-M4 경쇄 가변부(서열 번호 17)의 CDR을 포함하는 경쇄 가변부;XT-M4 중쇄 가변부 서열(서열 번호 16)의 CDR을 포함하는 중쇄 가변부;인간 카파 경쇄 불변부; 및인간 IgG1 중쇄 불변부를 포함하는 방법.
- 제29항에 있어서, 항체 또는 이의 RAGE-결합 단편은XT-M4 경쇄 가변부의 아미노산 서열(서열 번호 17)을 가지는 경쇄 가변부;XT-M4 중쇄 가변부 서열의 아미노산 서열(서열 번호 16)을 가지는 중쇄 가변부;인간 카파 경쇄 불변부; 및인간 IgG1 중쇄 불변부를 포함하는 방법.
- 제23항에 있어서, 항체는 키메라 항체, 인간화 항체 또는 인간 항체인 방법.
- 제31항에 있어서, 키메라 항체 또는 인간화 항체는 인간 불변부 또는 이로부 터 유래하는 불변부를 포함하는 방법.
- 제23항에 있어서, 항체 또는 이의 RAGE-결합 단편을 신경 퇴행을 억제 또는 완화하는데 유용한 하나 이상의 제제와 함께 투여하여 상승 효과를 유도하는 단계를 포함하는 방법.
- 개체에서 인지 기능 감퇴를 억제 또는 완화하거나, 또는 인지 기능을 개선시키는 방법으로서, RAGE에 특이적으로 결합하여 RAGE-결합 파트너의 결합을 억제하는 항체의 유효량을 상기 개체에 투여하는 단계를 포함하는 방법.
- 제34항에 있어서, 개체는 인간 개체인 방법.
- 제34항에 있어서, 인지 기능 감퇴는 알츠하이머병과 관련된 것인 방법.
- 제34항에 있어서, 인지 기능 감퇴는 전임상 알츠하이머병과 관련된 것인 방법.
- 제34항에 있어서, 항체는(a) RAGE와의 결합에 대해 XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체와 경쟁하거나;(b) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체가 결합하는 RAGE의 에피토프에 결합하거나;(c) XT-H1, XT-H2, XT-H3, XT-H5, XT-H7 및 XT-M4로 이루어진 군으로부터 선택되는 항체의 경쇄 또는 중쇄의 하나 이상의 상보성 결정 부위(CDR)를 포함하거나; 또는(d) 상기 (a), (b) 또는 (c)에 따른 항체의 RAGE-결합 단편인 방법.
- 제38항에 있어서, 항체 또는 RAGE-결합 항체 단편은XT-M4 경쇄 가변부(서열 번호 17)의 CDR을 포함하는 경쇄 가변부;XT-M4 중쇄 가변부 서열(서열 번호 16)의 CDR을 포함하는 중쇄 가변부;인간 카파 경쇄 불변부; 및인간 IgG1 중쇄 불변부를 포함하는 방법.
- 제39항에 있어서, 항체 또는 이의 RAGE-결합 단편은XT-M4 경쇄 가변부의 아미노산 서열(서열 번호 17)을 가지는 경쇄 가변부;XT-M4 중쇄 가변부 서열의 아미노산 서열(서열 번호 16)을 가지는 중쇄 가변부;인간 카파 경쇄 불변부; 및인간 IgG1 중쇄 불변부를 포함하는 방법.
- 제34항에 있어서, 항체는 키메라 항체, 인간화 항체 또는 인간 항체인 방법.
- 제41항에 있어서, 키메라 항체 또는 인간화 항체는 인간 불변부 또는 이로부터 유래하는 불변부를 포함하는 방법.
- 제34항에 있어서, 항체 또는 이의 RAGE-결합 단편을 인지 기능 감퇴를 억제 또는 완화하거나, 또는 인지 기능을 개선하는데 유용한 하나 이상의 제제와 함께 투여하여 상승 효과를 유도하는 단계를 포함하는 방법.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US78457506P | 2006-03-21 | 2006-03-21 | |
| US60/784,575 | 2006-03-21 | ||
| US89530307P | 2007-03-16 | 2007-03-16 | |
| US60/895,303 | 2007-03-16 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20080110833A true KR20080110833A (ko) | 2008-12-19 |
Family
ID=38523302
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020087025473A Withdrawn KR20080110833A (ko) | 2006-03-21 | 2007-03-21 | 아밀로이드 형성 질환의 예방 및 치료 방법 |
| KR1020087025056A Withdrawn KR20080113236A (ko) | 2006-03-21 | 2007-03-21 | Rage를 길항하기 위한 방법 및 조성물 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020087025056A Withdrawn KR20080113236A (ko) | 2006-03-21 | 2007-03-21 | Rage를 길항하기 위한 방법 및 조성물 |
Country Status (13)
| Country | Link |
|---|---|
| US (2) | US20070286858A1 (ko) |
| EP (2) | EP2004694A2 (ko) |
| JP (2) | JP2009529920A (ko) |
| KR (2) | KR20080110833A (ko) |
| AU (2) | AU2007226861A1 (ko) |
| BR (2) | BRPI0708998A2 (ko) |
| CA (2) | CA2638755A1 (ko) |
| CR (2) | CR10297A (ko) |
| EC (1) | ECSP088750A (ko) |
| MX (2) | MX2008012023A (ko) |
| NO (2) | NO20083720L (ko) |
| RU (2) | RU2008137764A (ko) |
| WO (2) | WO2007109749A2 (ko) |
Families Citing this family (71)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6136311A (en) | 1996-05-06 | 2000-10-24 | Cornell Research Foundation, Inc. | Treatment and diagnosis of cancer |
| DE10303974A1 (de) | 2003-01-31 | 2004-08-05 | Abbott Gmbh & Co. Kg | Amyloid-β(1-42)-Oligomere, Verfahren zu deren Herstellung und deren Verwendung |
| WO2005122712A2 (en) * | 2003-06-11 | 2005-12-29 | Socratech L.L.C. | Soluble low-density lipoprotein receptor related protein binds directly to alzheimer’s amyloid-beta peptide |
| KR101439828B1 (ko) | 2005-11-30 | 2014-09-17 | 애브비 인코포레이티드 | 아밀로이드 베타 단백질에 대한 모노클로날 항체 및 이의 용도 |
| JP5475994B2 (ja) | 2005-11-30 | 2014-04-16 | アッヴィ・インコーポレイテッド | 抗Aβグロブロマー抗体、その抗原結合部分、対応するハイブリドーマ、核酸、ベクター、宿主細胞、前記抗体を作製する方法、前記抗体を含む組成物、前記抗体の使用及び前記抗体を使用する方法。 |
| JP2009531324A (ja) | 2006-03-20 | 2009-09-03 | ザ リージェンツ オブ ザ ユニバーシティ オブ カリフォルニア | 癌標的化のための操作された抗前立腺幹細胞抗原(psca)抗体 |
| KR20080110833A (ko) * | 2006-03-21 | 2008-12-19 | 와이어쓰 | 아밀로이드 형성 질환의 예방 및 치료 방법 |
| US8455626B2 (en) | 2006-11-30 | 2013-06-04 | Abbott Laboratories | Aβ conformer selective anti-aβ globulomer monoclonal antibodies |
| WO2008104386A2 (en) | 2007-02-27 | 2008-09-04 | Abbott Gmbh & Co. Kg | Method for the treatment of amyloidoses |
| WO2008131908A1 (en) * | 2007-04-26 | 2008-11-06 | Active Biotech Ab | S100a9 interaction screening method |
| EP1986009A1 (en) * | 2007-04-26 | 2008-10-29 | Active Biotech AB | Screening method |
| JP6126773B2 (ja) | 2007-09-04 | 2017-05-10 | ザ リージェンツ オブ ザ ユニバーシティ オブ カリフォルニア | 癌のターゲッティングおよび検出のための高親和性抗前立腺幹細胞抗原(psca)抗体 |
| CA2716801A1 (en) * | 2008-03-12 | 2009-09-17 | Wyeth Llc | Methods for identifying cells suitable for large-scale production of recombinant proteins |
| CN102076355B (zh) | 2008-04-29 | 2014-05-07 | Abbvie公司 | 双重可变结构域免疫球蛋白及其用途 |
| CN104558178A (zh) | 2008-05-09 | 2015-04-29 | Abbvie公司 | 针对渐进性糖化终极产物受体(rage)的抗体及其用途 |
| JP2009276245A (ja) * | 2008-05-15 | 2009-11-26 | Shiseido Co Ltd | 持続性皮膚炎症性疾患の改善剤をスクリーニングする方法及びその改善剤 |
| TW201008580A (en) | 2008-06-03 | 2010-03-01 | Abbott Lab | Dual variable domain immunoglobulin and uses thereof |
| US9109026B2 (en) * | 2008-06-03 | 2015-08-18 | Abbvie, Inc. | Dual variable domain immunoglobulins and uses thereof |
| JP5674654B2 (ja) | 2008-07-08 | 2015-02-25 | アッヴィ・インコーポレイテッド | プロスタグランジンe2二重可変ドメイン免疫グロブリンおよびその使用 |
| EP2313436B1 (en) | 2008-07-22 | 2014-11-26 | Ablynx N.V. | Amino acid sequences directed against multitarget scavenger receptors and polypeptides |
| WO2010019656A1 (en) * | 2008-08-12 | 2010-02-18 | Wyeth | Humanized anti-rage antibody |
| CA2737752A1 (en) * | 2008-09-26 | 2010-04-01 | Wyeth Llc | Compatible display vector systems |
| WO2010036856A2 (en) * | 2008-09-26 | 2010-04-01 | Wyeth Llc | Compatible display vector systems |
| US11299768B2 (en) * | 2009-01-19 | 2022-04-12 | Biomerieux | Methods for determining a patient's susceptibility of contracting a nosocomial infection and for establishing a prognosis of the progression of septic syndrome |
| US10517969B2 (en) | 2009-02-17 | 2019-12-31 | Cornell University | Methods and kits for diagnosis of cancer and prediction of therapeutic value |
| KR20110139292A (ko) * | 2009-04-20 | 2011-12-28 | 화이자 인코포레이티드 | 단백질 글리코실화의 제어 및 그와 관련된 조성물 및 방법 |
| NZ598929A (en) * | 2009-09-01 | 2014-05-30 | Abbvie Inc | Dual variable domain immunoglobulins and uses thereof |
| EP2308896A1 (en) * | 2009-10-09 | 2011-04-13 | Sanofi-aventis | Polypeptides for binding to the "receptor for advanced glycation endproducts" as well as compositions and methods involving the same |
| EP2319871A1 (en) * | 2009-11-05 | 2011-05-11 | Sanofi-aventis | Polypeptides for binding to the "receptor for advanced glycation endproducts" as well as compositions and methods involving the same |
| RU2558301C2 (ru) * | 2009-10-09 | 2015-07-27 | Санофи | Полипептиды для связывания с "рецептором конечных продуктов гликирования", а также их композиции и способы, в которых они принимают участие |
| BR112012008833A2 (pt) | 2009-10-15 | 2015-09-08 | Abbott Lab | imunoglobulinas de dominio variavel duplo e usos das mesmas |
| UY32979A (es) | 2009-10-28 | 2011-02-28 | Abbott Lab | Inmunoglobulinas con dominio variable dual y usos de las mismas |
| US8420083B2 (en) | 2009-10-31 | 2013-04-16 | Abbvie Inc. | Antibodies to receptor for advanced glycation end products (RAGE) and uses thereof |
| JP6251477B2 (ja) | 2009-12-02 | 2017-12-20 | イマジナブ・インコーポレーテッド | ヒト前立腺特異的膜抗原(psma)をターゲッティングするj591ミニボディおよびcysダイアボディならびにこれらを使用するための方法 |
| ES2684475T3 (es) | 2010-04-15 | 2018-10-03 | Abbvie Inc. | Proteínas que se unen a beta amiloide |
| PE20131412A1 (es) | 2010-08-03 | 2014-01-19 | Abbvie Inc | Inmunoglobulinas con dominio variable dual y usos de las mismas |
| EP3533803B1 (en) | 2010-08-14 | 2021-10-27 | AbbVie Inc. | Anti-amyloid-beta antibodies |
| EP2608803A4 (en) | 2010-08-26 | 2014-01-15 | Abbvie Inc | IMMUNOGLOBULINS WITH TWO VARIABLE DOMAINS AND USES THEREOF |
| PT3604339T (pt) | 2011-01-14 | 2021-04-13 | Univ California | Anticorpos terapêuticos contra a proteína ror-1 e métodos para utilização dos mesmos |
| EP2667766A4 (en) * | 2011-01-25 | 2016-08-17 | Oncofluor Inc | PROCESS FOR COMBINED IMAGING AND TREATMENT OF ORGANS AND WOVEN FABRICS |
| CN103460045B (zh) * | 2011-04-05 | 2016-01-20 | 奥林巴斯株式会社 | 胰脏检查方法及胰脏检查试剂盒 |
| WO2012170742A2 (en) | 2011-06-07 | 2012-12-13 | University Of Hawaii | Treatment and prevention of cancer with hmgb1 antagonists |
| WO2012170740A2 (en) | 2011-06-07 | 2012-12-13 | University Of Hawaii | Biomarker of asbestos exposure and mesothelioma |
| UY34558A (es) | 2011-12-30 | 2013-07-31 | Abbvie Inc | Proteínas de unión específicas duales dirigidas contra il-13 y/o il-17 |
| KR101477130B1 (ko) | 2012-01-11 | 2015-01-06 | 연세대학교 산학협력단 | 용해성 rage를 유효성분으로 포함하는 심근염의 예방 또는 치료용 약제학적 조성물 |
| WO2013177035A2 (en) | 2012-05-24 | 2013-11-28 | Alexion Pharmaceuticals, Inc. | Humaneered anti-factor b antibody |
| KR20190096459A (ko) | 2012-11-01 | 2019-08-19 | 애브비 인코포레이티드 | 항-vegf/dll4 이원 가변 도메인 면역글로불린 및 이의 용도 |
| BR112015023797A2 (pt) | 2013-03-15 | 2017-10-24 | Abbvie Inc | proteínas de ligação de especificidade dupla dirigidas contra il-1b e/ou il-17 |
| MX371496B (es) | 2013-08-30 | 2020-01-31 | Immunogen Inc | Anticuerpos y ensayos para la detección del receptor 1 de folato. |
| MX382786B (es) * | 2013-10-31 | 2025-03-13 | Amgen Inc | Uso de monensina para regular la glicosilacion de proteinas recombinantes. |
| US10191033B2 (en) | 2013-12-05 | 2019-01-29 | The Broad Institute, Inc. | Biomarkers for detecting pre-cachexia or cachexia and methods of treatment thereof |
| EP3131581B1 (en) * | 2014-04-18 | 2020-09-23 | The Research Foundation of the State University of New York | Humanized anti-tf-antigen antibodies |
| US10023651B2 (en) | 2014-04-18 | 2018-07-17 | The Research Foundation For The State University Of New York | Humanized anti-TF-antigen antibodies |
| WO2016061532A1 (en) * | 2014-10-16 | 2016-04-21 | The Broad Institute Inc. | Compositions and methods for identifying and treating cachexia or pre-cachexia |
| JP6679096B2 (ja) * | 2014-10-21 | 2020-04-15 | 学校法人 久留米大学 | Rageアプタマーおよびその用途 |
| US10093733B2 (en) | 2014-12-11 | 2018-10-09 | Abbvie Inc. | LRP-8 binding dual variable domain immunoglobulin proteins |
| US20180355033A1 (en) | 2015-06-10 | 2018-12-13 | Dana-Farber Cancer Institute, Inc. | Antibodies, compounds and screens for identifying and treating cachexia or pre-cachexia |
| CN107709366B (zh) * | 2015-06-10 | 2021-10-26 | 干细胞技术公司 | 用于双功能免疫复合物的原位形成的方法 |
| WO2016201319A1 (en) * | 2015-06-10 | 2016-12-15 | The Broad Institute Inc. | Antibodies, compounds and screens for identifying and treating cachexia or pre-cachexia |
| TW201710286A (zh) | 2015-06-15 | 2017-03-16 | 艾伯維有限公司 | 抗vegf、pdgf及/或其受體之結合蛋白 |
| JP7026613B2 (ja) | 2015-08-07 | 2022-02-28 | イマジナブ・インコーポレーテッド | 標的分子に対する抗原結合コンストラクト |
| CN108601828B (zh) | 2015-09-17 | 2023-04-28 | 伊缪诺金公司 | 包含抗folr1免疫缀合物的治疗组合 |
| US11111296B2 (en) | 2015-12-14 | 2021-09-07 | The Broad Institute, Inc. | Compositions and methods for treating cardiac dysfunction |
| US10550184B2 (en) * | 2016-04-11 | 2020-02-04 | The Trustees Of Columbia University In The City Of New York | Humanized anti-rage antibody |
| WO2018147960A1 (en) | 2017-02-08 | 2018-08-16 | Imaginab, Inc. | Extension sequences for diabodies |
| CN110520440A (zh) | 2017-02-17 | 2019-11-29 | 戴纳立制药公司 | 抗τ抗体及其使用方法 |
| EP3672982A4 (en) | 2017-08-22 | 2021-06-09 | Monash University | SCREENING ASSAYS, MODULATORS AND MODULATION OF ACTIVATION OF THE RECEPTOR FOR ADVANCED GLYCING END PRODUCTS (RAGE) |
| WO2020019095A1 (es) * | 2018-07-26 | 2020-01-30 | Universidad Católica Del Maule | Proteína rage (receptor de productos finales de glicacíon avanzada) como biomarcador de sensibilidad tumoral y evaluacion de terapia radiologica y radiomimética |
| US11621087B2 (en) * | 2019-09-24 | 2023-04-04 | International Business Machines Corporation | Machine learning for amyloid and tau pathology prediction |
| WO2023092082A1 (en) * | 2021-11-18 | 2023-05-25 | Bentley Cornelia | Antibodies to receptor of advanced glycation end products (rage) and uses thereof |
| WO2024077122A1 (en) * | 2022-10-05 | 2024-04-11 | The Regents Of The University Of California | Multipurpose, multi-functionalized lipid coated beads and methods of production |
Family Cites Families (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4196265A (en) * | 1977-06-15 | 1980-04-01 | The Wistar Institute | Method of producing antibodies |
| US6054561A (en) * | 1984-02-08 | 2000-04-25 | Chiron Corporation | Antigen-binding sites of antibody molecules specific for cancer antigens |
| US4946778A (en) * | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| US5260203A (en) * | 1986-09-02 | 1993-11-09 | Enzon, Inc. | Single polypeptide chain binding molecules |
| US6893625B1 (en) * | 1986-10-27 | 2005-05-17 | Royalty Pharma Finance Trust | Chimeric antibody with specificity to human B cell surface antigen |
| US5041138A (en) * | 1986-11-20 | 1991-08-20 | Massachusetts Institute Of Technology | Neomorphogenesis of cartilage in vivo from cell culture |
| WO1988007089A1 (en) * | 1987-03-18 | 1988-09-22 | Medical Research Council | Altered antibodies |
| US5132405A (en) * | 1987-05-21 | 1992-07-21 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| US5091513A (en) * | 1987-05-21 | 1992-02-25 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| US5892019A (en) * | 1987-07-15 | 1999-04-06 | The United States Of America, As Represented By The Department Of Health And Human Services | Production of a single-gene-encoded immunoglobulin |
| KR0162259B1 (ko) * | 1989-12-05 | 1998-12-01 | 아미 펙터 | 감염성 병변 및 염증성 병변을 검출 및 치료하기 위한 키메라 항체 |
| US6300129B1 (en) * | 1990-08-29 | 2001-10-09 | Genpharm International | Transgenic non-human animals for producing heterologous antibodies |
| GB9115364D0 (en) * | 1991-07-16 | 1991-08-28 | Wellcome Found | Antibody |
| US5625048A (en) * | 1994-11-10 | 1997-04-29 | The Regents Of The University Of California | Modified green fluorescent proteins |
| US5777079A (en) * | 1994-11-10 | 1998-07-07 | The Regents Of The University Of California | Modified green fluorescent proteins |
| US5871902A (en) * | 1994-12-09 | 1999-02-16 | The Gene Pool, Inc. | Sequence-specific detection of nucleic acid hybrids using a DNA-binding molecule or assembly capable of discriminating perfect hybrids from non-perfect hybrids |
| US5739277A (en) * | 1995-04-14 | 1998-04-14 | Genentech Inc. | Altered polypeptides with increased half-life |
| WO1997026913A1 (en) * | 1996-01-26 | 1997-07-31 | The Trustees Of Columbia University In The City Of New York | A POLYPEPTIDE FROM LUNG EXTRACT WHICH BINDS AMYLOID-β PEPTIDE |
| US5864018A (en) * | 1996-04-16 | 1999-01-26 | Schering Aktiengesellschaft | Antibodies to advanced glycosylation end-product receptor polypeptides and uses therefor |
| US6124128A (en) * | 1996-08-16 | 2000-09-26 | The Regents Of The University Of California | Long wavelength engineered fluorescent proteins |
| EP3034626A1 (en) * | 1997-04-01 | 2016-06-22 | Illumina Cambridge Limited | Method of nucleic acid sequencing |
| WO2001012598A2 (en) * | 1999-08-13 | 2001-02-22 | The Trustees Of Columbia University In The City Of New York | METHODS OF INHIBITING BINDING OF β-SHEET FIBRIL TO RAGE AND CONSEQUENCES THEREOF |
| NZ524523A (en) * | 2000-08-03 | 2006-02-24 | Therapeutic Human Polyclonals | Production of humanized antibodies in transgenic animals |
| US7754208B2 (en) * | 2001-01-17 | 2010-07-13 | Trubion Pharmaceuticals, Inc. | Binding domain-immunoglobulin fusion proteins |
| US20030133939A1 (en) * | 2001-01-17 | 2003-07-17 | Genecraft, Inc. | Binding domain-immunoglobulin fusion proteins |
| US7829084B2 (en) * | 2001-01-17 | 2010-11-09 | Trubion Pharmaceuticals, Inc. | Binding constructs and methods for use thereof |
| JP4171228B2 (ja) * | 2001-03-19 | 2008-10-22 | 第一ファインケミカル株式会社 | 可溶型rage測定法 |
| US20040058445A1 (en) * | 2001-04-26 | 2004-03-25 | Ledbetter Jeffrey Alan | Activation of tumor-reactive lymphocytes via antibodies or genes recognizing CD3 or 4-1BB |
| US7321026B2 (en) * | 2001-06-27 | 2008-01-22 | Skytech Technology Limited | Framework-patched immunoglobulins |
| MXPA05001758A (es) * | 2002-08-16 | 2005-08-19 | Wyeth Corp | Composiciones y metodos para el tratamiento de trastornos asociados a receptor para productos finales de glicatacion avanzada (rage). |
| DE10244202A1 (de) * | 2002-09-23 | 2004-03-25 | Alstom (Switzerland) Ltd. | Elektrische Maschine mit einem Stator mit gekühlten Wicklungsstäben |
| CN102040662A (zh) * | 2003-03-14 | 2011-05-04 | 惠氏有限责任公司 | 抗人il-21受体的抗体及其应用 |
| WO2005042743A2 (en) * | 2003-08-18 | 2005-05-12 | Medimmune, Inc. | Humanization of antibodies |
| JP2007504247A (ja) * | 2003-09-05 | 2007-03-01 | ザ・トラスティーズ・オブ・コランビア・ユニバーシティー・イン・ザ・シティー・オブ・ニューヨーク | 糸球体損傷を治療するためのrageに関連した方法および組成物 |
| KR100570422B1 (ko) * | 2003-10-16 | 2006-04-11 | 한미약품 주식회사 | 대장균 분비서열을 이용하여 항체 단편을 분비·생산하는 발현벡터 및 이를 이용하여 항체 단편을 대량 생산하는 방법 |
| KR20080110833A (ko) * | 2006-03-21 | 2008-12-19 | 와이어쓰 | 아밀로이드 형성 질환의 예방 및 치료 방법 |
-
2007
- 2007-03-21 KR KR1020087025473A patent/KR20080110833A/ko not_active Withdrawn
- 2007-03-21 US US11/689,480 patent/US20070286858A1/en not_active Abandoned
- 2007-03-21 MX MX2008012023A patent/MX2008012023A/es not_active Application Discontinuation
- 2007-03-21 RU RU2008137764/13A patent/RU2008137764A/ru not_active Application Discontinuation
- 2007-03-21 WO PCT/US2007/064571 patent/WO2007109749A2/en not_active Ceased
- 2007-03-21 RU RU2008134135/13A patent/RU2008134135A/ru not_active Application Discontinuation
- 2007-03-21 AU AU2007226861A patent/AU2007226861A1/en not_active Abandoned
- 2007-03-21 KR KR1020087025056A patent/KR20080113236A/ko not_active Withdrawn
- 2007-03-21 MX MX2008011933A patent/MX2008011933A/es unknown
- 2007-03-21 JP JP2009501725A patent/JP2009529920A/ja active Pending
- 2007-03-21 CA CA002638755A patent/CA2638755A1/en not_active Abandoned
- 2007-03-21 WO PCT/US2007/064568 patent/WO2007109747A2/en not_active Ceased
- 2007-03-21 JP JP2009501727A patent/JP2009530423A/ja not_active Withdrawn
- 2007-03-21 EP EP07759060A patent/EP2004694A2/en not_active Withdrawn
- 2007-03-21 BR BRPI0708998-8A patent/BRPI0708998A2/pt not_active IP Right Cessation
- 2007-03-21 CA CA002646643A patent/CA2646643A1/en not_active Abandoned
- 2007-03-21 EP EP07759057A patent/EP2001907A2/en not_active Withdrawn
- 2007-03-21 AU AU2007226863A patent/AU2007226863A1/en not_active Abandoned
- 2007-03-21 BR BRPI0708970-8A patent/BRPI0708970A2/pt not_active IP Right Cessation
- 2007-03-21 US US11/689,501 patent/US20070253950A1/en not_active Abandoned
-
2008
- 2008-08-29 NO NO20083720A patent/NO20083720L/no not_active Application Discontinuation
- 2008-09-19 CR CR10297A patent/CR10297A/es not_active Application Discontinuation
- 2008-09-19 EC EC2008008750A patent/ECSP088750A/es unknown
- 2008-09-19 CR CR10298A patent/CR10298A/es not_active Application Discontinuation
- 2008-09-23 NO NO20084039A patent/NO20084039L/no not_active Application Discontinuation
Also Published As
| Publication number | Publication date |
|---|---|
| ECSP088750A (es) | 2008-10-31 |
| WO2007109747A3 (en) | 2008-05-22 |
| US20070286858A1 (en) | 2007-12-13 |
| AU2007226863A1 (en) | 2007-09-27 |
| CA2646643A1 (en) | 2007-09-27 |
| CR10298A (es) | 2008-11-18 |
| KR20080113236A (ko) | 2008-12-29 |
| US20070253950A1 (en) | 2007-11-01 |
| WO2007109749A2 (en) | 2007-09-27 |
| RU2008134135A (ru) | 2010-04-27 |
| WO2007109749A8 (en) | 2009-06-18 |
| CR10297A (es) | 2008-12-02 |
| JP2009530423A (ja) | 2009-08-27 |
| EP2004694A2 (en) | 2008-12-24 |
| WO2007109747A2 (en) | 2007-09-27 |
| CA2638755A1 (en) | 2007-09-27 |
| EP2001907A2 (en) | 2008-12-17 |
| NO20084039L (no) | 2008-12-15 |
| NO20083720L (no) | 2008-12-12 |
| JP2009529920A (ja) | 2009-08-27 |
| MX2008012023A (es) | 2008-10-01 |
| RU2008137764A (ru) | 2010-04-27 |
| MX2008011933A (es) | 2008-12-18 |
| BRPI0708970A2 (pt) | 2011-06-21 |
| WO2007109749A3 (en) | 2008-03-06 |
| AU2007226861A1 (en) | 2007-09-27 |
| BRPI0708998A2 (pt) | 2011-06-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20080110833A (ko) | 아밀로이드 형성 질환의 예방 및 치료 방법 | |
| US10875910B2 (en) | Antibodies recognizing alpha-synuclein | |
| CN101589062B (zh) | 与胰高血糖素受体抗体相关的组合物和方法 | |
| JP6843868B2 (ja) | Pd−1結合タンパク質及びその使用方法 | |
| RU2426744C2 (ru) | Антитела к ox40l и способы их применения | |
| JP5719596B2 (ja) | 抗体及びその誘導体 | |
| JP6744856B2 (ja) | α−シヌクレインを認識する抗体を含む血液脳関門シャトル | |
| JP7539834B2 (ja) | ガレクチン-3に対する抗体及びその使用方法 | |
| KR20180030917A (ko) | 항-cd154 항체 및 그의 사용 방법 | |
| CN101448857A (zh) | 预防和治疗淀粉样蛋白生成疾病的方法 | |
| HK1212361B (en) | Antibodies recognizing alpha-synuclein |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20081017 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |