I highly recommend Remy’s State Of The Gap post—it’s ace. He summarises it like this:
I strongly believe in the concepts behind progressive web apps and even though native hacks (Flash, PhoneGap, etc) will always be ahead, the web, always gets there. Now, today, is an incredibly exciting time to be build on the web.
I agree completely. That might sound odd after I wrote about Regressive Web Apps, but it’s precisely because I’m so excited by the technologies behind progressive web apps that I think it’s vital that we do them justice. As Remy says:
Without HTTPS and without service workers, you can’t add to homescreen. This is an intentionally high bar of entry with damn good reasons.
When the user installs a PWA, it has to work. It’s our job as web developers to provide the most excellent experience for our users.
It has to work.
That’s why I don’t agree with Dion’s metrics for what makes a progressive web app:
If you deliver an experience that only works on mobile is that a PWA? Yes.
I think it’s important to keep quality control high. Being responsive is literally the first item in the list of qualities that help define what a progressive web app is. That’s why I wrote about “regressive” web apps: sites that are supposed to showcase what we can do but instead take a step backwards into the bad old days of separate sites for separate device classes: washingtonpost.com/pwa, m.flipkart.com, lite.5milesapp.com, app.babe.co.id, m.aliexpress.com.
A lot of people on Twitter misinterpreted my post as saying “the current crop of progressive web apps are missing the mark, therefore progressive web apps suck”. What I was hoping to get across was “the current crop of progressive web apps are missing the mark, so let’s make better ones!”
Now, I totally understand that many of these examples are a first stab, a way of testing the waters. I absolutely want to encourage these first attempts and push them further. But I don’t think that waiving the qualifications for progressive web apps helps achieves that. As much as I want to acknowledge the hard work that people have done to create those device-specific examples, I don’t think we should settle for anything less than high-quality progressive web apps that are as much about the web as they are about apps.
Simply put, in this instance, I don’t think good intentions are enough.
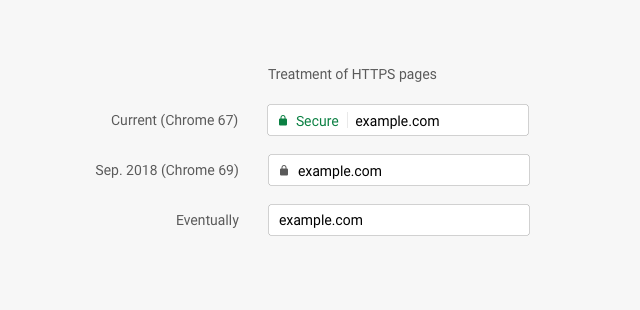
Which brings me to the second part of Regressive Web Apps, the bit about Chrome refusing to show the “add to home screen” prompt for sites that want to have their URL still visible when launched from the home screen.
Alex was upset by what I wrote:
if you think the URL is going to get killed on my watch then you aren’t paying any attention whatsoever.
so, your choices are to think that I have a secret plan to kill URLs, or conclude I’m still Team Web.
I’m galled that anyone, particularly you @adactio, would think the former…but contrarianism uber alles?
I am very, very sorry that I upset Alex like this.
But I stand by my criticism of the actions of the Chrome team. Because good intentions are not enough.
I know that Alex is huge fan of URLs, and of the web. Heck, just about everybody I know that works on Chrome in some capacity are working for the web first and foremost: Alex, Jake, various and sundry Pauls. But that doesn’t mean I’m going to stay quiet when I see the Chrome team do something I think is bad for the web. If anything, it’s precisely because I hold them to a high standard that I’m going to sound the alarm when I see what I consider to be missteps.
I think that good people can make bad decisions with the best of intentions. Usually it involves long-term thinking—something I think is very important. “The ends justify the means” is a way of thinking that can create a lot of immediate pain, even if it means a better future overall. Balancing those concerns is front and centre of the Chromium project:
As browser implementers, we find that there’s often tension between (a) moving the web forward and (b) preserving compatibility. On one hand, the web platform API surface must evolve to stay relevant. On the other hand, the web’s primary strength is its reach, which is largely a function of interoperability.
For example, when Alex talks of the Web Component era as though it were an inevitability, I get nervous. Not for myself, but for the millions of Opera Mini users out there. How do we get to a better future without leaving anyone behind? Or do we sacrifice those people for the greater good? Do the needs of the many outweigh the needs of the few? Do the ends justify the means?
Now, I know for a fact that the end-game that Alex is pursuing with web components—and the extensible web manifesto in general—is a more declarative web: solutions that first get tackled as web components end up landing in browsers. But to get there, the solutions are first created using modern JavaScript that simply doesn’t work everywhere. Is that the price we’re going to have to pay for a better web?
I hope not. I hope we can find ways to have our accessible cake and eat it too. But it will be really, really hard.
Returning to progressive web apps, I was genuinely shocked and appalled at the way that the Chrome team altered the criteria for the “add to home screen” prompt to discourage exposing URLs. I was also surprised at how badly the change was communicated—it was buried in a bug report that five people contributed to before pushing the change. I only found out about it through a conversation with Paul Kinlan. Paul encouraged me to give feedback, and that’s what I did on my website, just like Stuart did on his.
Of course the Chrome team are working on ways of exposing URLs within progressive web apps that are launched in from the home screen. Opera are working on it too. But it’s a really tricky problem to solve. It’s not enough to say “we’ll figure it out”. It’s not enough to say “trust us.”
I do trust the people I know working on Chrome. I also trust the people I know at Mozilla, Opera and Microsoft. That doesn’t mean I’m going to let their actions go unquestioned. Good intentions are not enough.
As Alex readily acknowledges, the harder problem (figuring out how to expose URLs) should have been solved first—then the change to the “add to home screen” metrics would be uncontentious. Putting the cart before the horse, discouraging display:browser now, while saying “trust us, we’ll figure it out”, is another example of saying the ends justify the means.
But the stakes are too high here to let this pass. Good intentions are not enough. Knowing that the people working on Chrome (or Firefox, or Opera, or Edge) are good people is not reason enough to passively accept every decision they make.
Alex called me out for not getting in touch with him directly about the Chrome team’s future plans with URLs, but again, that kind of rough consensus to do something is trumped by running code. Also, I did talk to Chrome people—this all came out of a discussion with Paul Kinlan. I don’t know who’s who in the company’s political hierarchy and I don’t think I should need an org chart to give feedback to Google (or Mozilla, or Opera, or Microsoft).
You’ll notice that I didn’t include Apple there. I don’t hold them to the same high standard. As it turns out, I know some very good people at Apple working on WebKit and Safari. As individuals, they care about the web. But as a company, Apple has shown indifference towards web developers. As Remy put it:
Even getting the hint of interest from Apple is a process of dumpster-diving the mailing lists scanning for the smallest hint of interest.
With that in mind, I completely understand Alex’s frustration with my post on “regressive” web apps. Although I intended it as a push towards making better progressive web apps, I can see how it could be taken as confirmation by those who think that progressive web apps aren’t worth investing in. Apple, for example. As it is, they’ll have to be carried kicking and screaming into adding support for Service Workers, manifest files, and other building blocks. From the reaction to my post from at least one WebKit developer on Twitter, not only did I fail to get across just how important the technologies behind progressive web apps are, I may have done more harm than good, giving ammunition to sceptics.
Still, I hope that most people took my words in the right spirit, like Addy:
We should push them to do much better. I’ll file bugs. Per @adactio post, can’t forget the ‘Progressive’ part of PWAs
Seeing that reaction makes me feel good …but seeing Alex’s reaction makes me feel bad. Very bad. I’m genuinely sorry that I made Alex feel that way. It wasn’t my intention but, well …good intentions are not enough.
I’ve been looking back at what I wrote, trying to see it through Alex’s eyes, looking for the parts that could be taken as a personal attack:
Chrome developers have decided that displaying URLs is not “best practice” … To declare that all users of all websites will be confused by seeing a URL is so presumptuous and arrogant that it beggars belief. … Withholding the “add to home screen” prompt like that has a whiff of blackmail about it. … This isn’t the first time that Chrome developers have made a move against the address bar. It’s starting to grind me down.
Some pretty strong words there. I stand by them, but the tone is definitely strident.
When we criticise something—a piece of software, a book, a website, a film, a piece of music—it’s all too easy to forget that there are real people behind it. But that isn’t the case here. I know that there are real people working on Chrome, because I know quite a few of those people. I also know that their intentions are good. That’s not a reason for me to remain silent—that’s a reason for me to speak up.
If I had known that my post was going to upset Alex, would I have still written it? That’s a tough one. On the one hand, this is a topic I care passionately about. I think it’s vital that we don’t compromise on the very things that make the web great. On the other hand, who knows if what I wrote will make the slightest bit of difference? In which case, I got the catharsis of getting it off my chest but at the price of upsetting somebody I respect. That price feels too high.
I love the fact that I can publish whatever I want on my own website. It can be a place for me to be enthusiastic about things that excite me, and a place for me to rant about things that upset me. I estimate that the enthusiastic stuff outnumbers the ranty stuff by about ten to one, but negativity casts a disproportionately large shadow.
I need to get better at tempering my words. Not that I’m going to stop criticising bad decisions when I see them, but I need to make my intentions clearer …because just having good intentions is not enough. Throughout this post, I’ve mentioned repeatedly how much I respect the people I know working on the Chrome team. I should have said that in my original post.