Recent
Nov. 5, 2024
You already know Donald Trump. He is unfit to lead. Watch him. Listen to those who know him best. He tried to subvert an election and remains a threat to democracy. He helped overturn Roe, with terrible consequences. Mr. Trump's corruption and lawlessness go beyond elections: It's his whole ethos. He lies without limit. If he's re-elected, the G.O.P. won't restrain him. Mr. Trump will use the government to go after opponents. He will pursue a cruel policy of mass deportations. He will wreak havoc on the poor, the middle class and employers. Another Trump term will damage the climate, shatter alliances and strengthen autocrats. Americans should demand better. Vote.
Nov. 4, 2024
New OpenAI feature: Predicted Outputs (via) Interesting new ability of the OpenAI API - the first time I've seen this from any vendor.
If you know your prompt is mostly going to return the same content - you're requesting an edit to some existing code, for example - you can now send that content as a "prediction" and have GPT-4o or GPT-4o mini use that to accelerate the returned result.
OpenAI's documentation says:
When providing a prediction, any tokens provided that are not part of the final completion are charged at completion token rates.
I initially misunderstood this as meaning you got a price reduction in addition to the latency improvement, but that's not the case: in the best possible case it will return faster and you won't be charged anything extra over the expected cost for the prompt, but the more it differs from your permission the more extra tokens you'll be billed for.
I ran the example from the documentation both with and without the prediction and got these results. Without the prediction:
"usage": {
"prompt_tokens": 150,
"completion_tokens": 118,
"total_tokens": 268,
"completion_tokens_details": {
"accepted_prediction_tokens": 0,
"audio_tokens": null,
"reasoning_tokens": 0,
"rejected_prediction_tokens": 0
}
That took 5.2 seconds and cost 0.1555 cents.
With the prediction:
"usage": {
"prompt_tokens": 166,
"completion_tokens": 226,
"total_tokens": 392,
"completion_tokens_details": {
"accepted_prediction_tokens": 49,
"audio_tokens": null,
"reasoning_tokens": 0,
"rejected_prediction_tokens": 107
}
That took 3.3 seconds and cost 0.2675 cents.
Further details from OpenAI's Steve Coffey:
We are using the prediction to do speculative decoding during inference, which allows us to validate large batches of the input in parallel, instead of sampling token-by-token!
[...] If the prediction is 100% accurate, then you would see no cost difference. When the model diverges from your speculation, we do additional sampling to “discover” the net-new tokens, which is why we charge rejected tokens at completion time rates.
Claude 3.5 Haiku
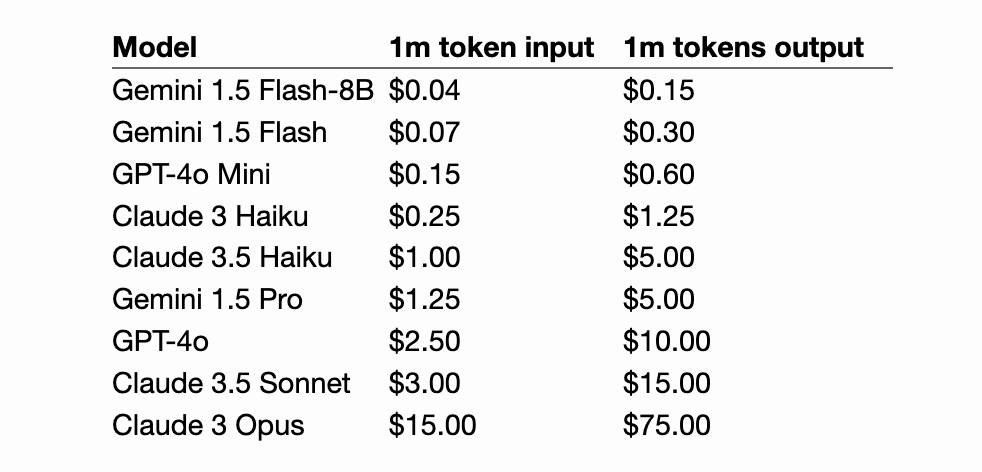
Anthropic released Claude 3.5 Haiku today, a few days later than expected (they said it would be out by the end of October).
[... 478 words]Nous Hermes 3. The Nous Hermes family of fine-tuned models have a solid reputation. Their most recent release came out in August, based on Meta's Llama 3.1:
Our training data aggressively encourages the model to follow the system and instruction prompts exactly and in an adaptive manner. Hermes 3 was created by fine-tuning Llama 3.1 8B, 70B and 405B, and training on a dataset of primarily synthetically generated responses. The model boasts comparable and superior performance to Llama 3.1 while unlocking deeper capabilities in reasoning and creativity.
The model weights are on Hugging Face, including GGUF versions of the 70B and 8B models. Here's how to try the 8B model (a 4.58GB download) using the llm-gguf plugin:
llm install llm-gguf
llm gguf download-model 'https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B-GGUF/resolve/main/Hermes-3-Llama-3.1-8B.Q4_K_M.gguf' -a Hermes-3-Llama-3.1-8B
llm -m Hermes-3-Llama-3.1-8B 'hello in spanish'
Nous Research partnered with Lambda Labs to provide inference APIs. It turns out Lambda host quite a few models now, currently providing free inference to users with an API key.
I just released the first alpha of a llm-lambda-labs plugin. You can use that to try the larger 405b model (very hard to run on a consumer device) like this:
llm install llm-lambda-labs
llm keys set lambdalabs
# Paste key here
llm -m lambdalabs/hermes3-405b 'short poem about a pelican with a twist'
Here's the source code for the new plugin, which I based on llm-mistral. The plugin uses httpx-sse to consume the stream of tokens from the API.
Nov. 3, 2024
Building technology in startups is all about having the right level of tech debt. If you have none, you’re probably going too slow and not prioritizing product-market fit and the important business stuff. If you get too much, everything grinds to a halt. Plus, tech debt is a “know it when you see it” kind of thing, and I know that my definition of “a bunch of tech debt” is, to other people, “very little tech debt.”
California Clock Change. The clocks go back in California tonight and I finally built my dream application for helping me remember if I get an hour extra of sleep or not, using a Claude Artifact. Here's the transcript.

This is one of my favorite examples yet of the kind of tiny low stakes utilities I'm building with Claude Artifacts because the friction involved in churning out a working application has dropped almost to zero.
(I added another feature: it now includes a note of what time my Dog thinks it is if the clocks have recently changed.)
Docling. MIT licensed document extraction Python library from the Deep Search team at IBM, who released Docling v2 on October 16th.
Here's the Docling Technical Report paper from August, which provides details of two custom models: a layout analysis model for figuring out the structure of the document (sections, figures, text, tables etc) and a TableFormer model specifically for extracting structured data from tables.
Those models are available on Hugging Face.
Here's how to try out the Docling CLI interface using uvx (avoiding the need to install it first - though since it downloads models it will take a while to run the first time):
uvx docling mydoc.pdf --to json --to md
This will output a mydoc.json file with complex layout information and a mydoc.md Markdown file which includes Markdown tables where appropriate.
The Python API is a lot more comprehensive. It can even extract tables as Pandas DataFrames:
from docling.document_converter import DocumentConverter converter = DocumentConverter() result = converter.convert("document.pdf") for table in result.document.tables: df = table.export_to_dataframe() print(df)
I ran that inside uv run --with docling python. It took a little while to run, but it demonstrated that the library works.
Nov. 2, 2024
Claude Token Counter. Anthropic released a token counting API for Claude a few days ago.
I built this tool for running prompts, images and PDFs against that API to count the tokens in them.
The API is free (albeit rate limited), but you'll still need to provide your own API key in order to use it.
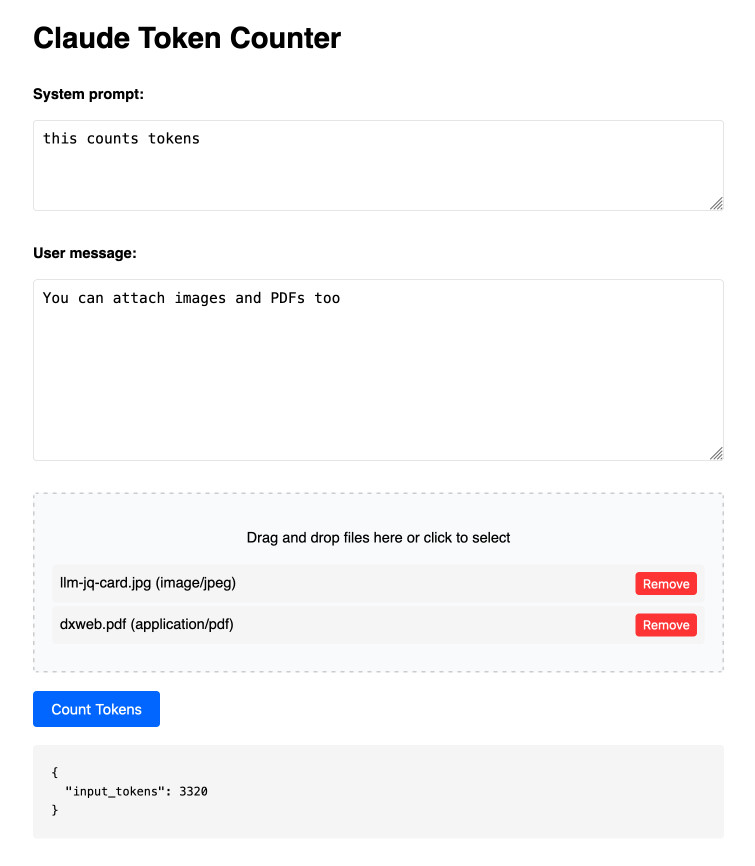
Here's the source code. I built this using two sessions with Claude - one to build the initial tool and a second to add PDF and image support. That second one is a bit of a mess - it turns out if you drop an HTML file onto a Claude conversation it converts it to Markdown for you, but I wanted it to modify the original HTML source.
The API endpoint also allows you to specify a model, but as far as I can tell from running some experiments the token count was the same for Haiku, Opus and Sonnet 3.5.
Please publish and share more. 💯 to all of this by Jeff Triplett:
Friends, I encourage you to publish more, indirectly meaning you should write more and then share it. [...]
You don’t have to change the world with every post. You might publish a quick thought or two that helps encourage someone else to try something new, listen to a new song, or binge-watch a new series.
Jeff shares my opinion on conclusions: giving myself permission to hit publish even when I haven't wrapped everything up neatly was a huge productivity boost for me:
Our posts are done when you say they are. You do not have to fret about sticking to landing and having a perfect conclusion. Your posts, like this post, are done after we stop writing.
And another 💯 to this footnote:
PS: Write and publish before you write your own static site generator or perfect blogging platform. We have lost billions of good writers to this side quest because they spend all their time working on the platform instead of writing.
SmolLM2 (via) New from Loubna Ben Allal and her research team at Hugging Face:
SmolLM2 is a family of compact language models available in three size: 135M, 360M, and 1.7B parameters. They are capable of solving a wide range of tasks while being lightweight enough to run on-device. [...]
It was trained on 11 trillion tokens using a diverse dataset combination: FineWeb-Edu, DCLM, The Stack, along with new mathematics and coding datasets that we curated and will release soon.
The model weights are released under an Apache 2 license. I've been trying these out using my llm-gguf plugin for LLM and my first impressions are really positive.
Here's a recipe to run a 1.7GB Q8 quantized model from lmstudio-community:
llm install llm-gguf
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-1.7B-Instruct-GGUF/resolve/main/SmolLM2-1.7B-Instruct-Q8_0.gguf -a smol17
llm chat -m smol17

Or at the other end of the scale, here's how to run the 138MB Q8 quantized 135M model:
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-135M-Instruct-GGUF/resolve/main/SmolLM2-135M-Instruct-Q8_0.gguf' -a smol135m
llm chat -m smol135m
The blog entry to accompany SmolLM2 should be coming soon, but in the meantime here's the entry from July introducing the first version: SmolLM - blazingly fast and remarkably powerful .
Nov. 1, 2024
From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code (via) Google's Project Zero security team used a system based around Gemini 1.5 Pro to find a previously unreported security vulnerability in SQLite (a stack buffer underflow), in time for it to be fixed prior to making it into a release.
A key insight here is that LLMs are well suited for checking for new variants of previously reported vulnerabilities:
A key motivating factor for Naptime and now for Big Sleep has been the continued in-the-wild discovery of exploits for variants of previously found and patched vulnerabilities. As this trend continues, it's clear that fuzzing is not succeeding at catching such variants, and that for attackers, manual variant analysis is a cost-effective approach.
We also feel that this variant-analysis task is a better fit for current LLMs than the more general open-ended vulnerability research problem. By providing a starting point – such as the details of a previously fixed vulnerability – we remove a lot of ambiguity from vulnerability research, and start from a concrete, well-founded theory: "This was a previous bug; there is probably another similar one somewhere".
LLMs are great at pattern matching. It turns out feeding in a pattern describing a prior vulnerability is a great way to identify potential new ones.
Claude API: PDF support (beta) (via) Claude 3.5 Sonnet now accepts PDFs as attachments:
The new Claude 3.5 Sonnet (
claude-3-5-sonnet-20241022) model now supports PDF input and understands both text and visual content within documents.
I just released llm-claude-3 0.7 with support for the new attachment type (attachments are a very new feature), so now you can do this:
llm install llm-claude-3 --upgrade
llm -m claude-3.5-sonnet 'extract text' -a mydoc.pdf
Visual PDF analysis can also be turned on for the Claude.ai application:

Also new today: Claude now offers a free (albeit rate-limited) token counting API. This addresses a complaint I've had for a while: previously it wasn't possible to accurately estimate the cost of a prompt before sending it to be executed.
Lord Clement-Jones: To ask His Majesty's Government what assessment they have made of the cybersecurity risks posed by prompt injection attacks to the processing by generative artificial intelligence of material provided from outside government, and whether any such attacks have been detected thus far.
Lord Vallance of Balham: Security is central to HMG's Generative AI Framework, which was published in January this year and sets out principles for using generative AI safely and responsibly. The risks posed by prompt injection attacks, including from material provided outside of government, have been assessed as part of this framework and are continually reviewed. The published Generative AI Framework for HMG specifically includes Prompt Injection attacks, alongside other AI specific cyber risks.
— Question for Department for Science, Innovation and Technology, UIN HL1541, tabled on 14 Oct 2024
Control your smart home devices with the Gemini mobile app on Android (via) Google are adding smart home integration to their Gemini chatbot - so far on Android only.
Have they considered the risk of prompt injection? It looks like they have, at least a bit:
Important: Home controls are for convenience only, not safety- or security-critical purposes. Don't rely on Gemini for requests that could result in injury or harm if they fail to start or stop.
The Google Home extension can’t perform some actions on security devices, like gates, cameras, locks, doors, and garage doors. For unsupported actions, the Gemini app gives you a link to the Google Home app where you can control those devices.
It can control lights and power, climate control, window coverings, TVs and speakers and "other smart devices, like washers, coffee makers, and vacuums".
I imagine we will see some security researchers having a lot of fun with this shortly.
Oct. 31, 2024
Cerebras Coder (via) Val Town founder Steve Krouse has been building demos on top of the Cerebras API that runs Llama3.1-70b at 2,000 tokens/second.
Having a capable LLM with that kind of performance turns out to be really interesting. Cerebras Coder is a demo that implements Claude Artifact-style on-demand JavaScript apps, and having it run at that speed means changes you request are visible within less than a second:
Steve's implementation (created with the help of Townie, the Val Town code assistant) demonstrates the simplest possible version of an iframe sandbox:
<iframe
srcDoc={code}
sandbox="allow-scripts allow-modals allow-forms allow-popups allow-same-origin allow-top-navigation allow-downloads allow-presentation allow-pointer-lock"
/>
Where code is populated by a setCode(...) call inside a React component.
The most interesting applications of LLMs continue to be where they operate in a tight loop with a human - this can make those review loops potentially much faster and more productive.
Australia/Lord_Howe is the weirdest timezone (via) Lord Howe Island - part of Australia, population 382 - is unique in that the island's standard time zone is UTC+10:30 but is UTC+11 when daylight saving time applies. It's the only time zone where DST represents a 30 minute offset.
Oct. 30, 2024
Creating a LLM-as-a-Judge that drives business results (via) Hamel Husain's sequel to Your AI product needs evals. This is packed with hard-won actionable advice.
Hamel warns against using scores on a 1-5 scale, instead promoting an alternative he calls "Critique Shadowing". Find a domain expert (one is better than many, because you want to keep their scores consistent) and have them answer the yes/no question "Did the AI achieve the desired outcome?" - providing a critique explaining their reasoning for each of their answers.
This gives you a reliable score to optimize against, and the critiques mean you can capture nuance and improve the system based on that captured knowledge.
Most importantly, the critique should be detailed enough so that you can use it in a few-shot prompt for a LLM judge. In other words, it should be detailed enough that a new employee could understand it.
Once you've gathered this expert data system you can switch to using an LLM-as-a-judge. You can then iterate on the prompt you use for it in order to converge its "opinions" with those of your domain expert.
Hamel concludes:
The real value of this process is looking at your data and doing careful analysis. Even though an AI judge can be a helpful tool, going through this process is what drives results. I would go as far as saying that creating a LLM judge is a nice “hack” I use to trick people into carefully looking at their data!
docs.jina.ai—the Jina meta-prompt. From Jina AI on Twitter:
curl docs.jina.ai- This is our Meta-Prompt. It allows LLMs to understand our Reader, Embeddings, Reranker, and Classifier APIs for improved codegen. Using the meta-prompt is straightforward. Just copy the prompt into your preferred LLM interface like ChatGPT, Claude, or whatever works for you, add your instructions, and you're set.
The page is served using content negotiation. If you hit it with curl you get plain text, but a browser with text/html in the accept: header gets an explanation along with a convenient copy to clipboard button.

W̶e̶e̶k̶n̶o̶t̶e̶s̶ Monthnotes for October
I try to publish weeknotes at least once every two weeks. It’s been four since the last entry, so I guess this one counts as monthnotes instead.
[... 797 words]Bringing developer choice to Copilot with Anthropic’s Claude 3.5 Sonnet, Google’s Gemini 1.5 Pro, and OpenAI’s o1-preview. The big announcement from GitHub Universe: Copilot is growing support for alternative models.
GitHub Copilot predated the release of ChatGPT by more than year, and was the first widely used LLM-powered tool. This announcement includes a brief history lesson:
The first public version of Copilot was launched using Codex, an early version of OpenAI GPT-3, specifically fine-tuned for coding tasks. Copilot Chat was launched in 2023 with GPT-3.5 and later GPT-4. Since then, we have updated the base model versions multiple times, using a range from GPT 3.5-turbo to GPT 4o and 4o-mini models for different latency and quality requirements.
It's increasingly clear that any strategy that ties you to models from exclusively one provider is short-sighted. The best available model for a task can change every few months, and for something like AI code assistance model quality matters a lot. Getting stuck with a model that's no longer best in class could be a serious competitive disadvantage.
The other big announcement from the keynote was GitHub Spark, described like this:
Sparks are fully functional micro apps that can integrate AI features and external data sources without requiring any management of cloud resources.
I got to play with this at the event. It's effectively a cross between Claude Artifacts and GitHub Gists, with some very neat UI details. The features that really differentiate it from Artifacts is that Spark apps gain access to a server-side key/value store which they can use to persist JSON - and they can also access an API against which they can execute their own prompts.
The prompt integration is particularly neat because prompts used by the Spark apps are extracted into a separate UI so users can view and modify them without having to dig into the (editable) React JavaScript code.
Oct. 29, 2024
Generating Descriptive Weather Reports with LLMs. Drew Breunig produces the first example I've seen in the wild of the new LLM attachments Python API. Drew's Downtown San Francisco Weather Vibes project combines output from a JSON weather API with the latest image from a webcam pointed at downtown San Francisco to produce a weather report "with a style somewhere between Jack Kerouac and J. Peterman".
Here's the Python code that constructs and executes the prompt. The code runs in GitHub Actions.
You can now run prompts against images, audio and video in your terminal using LLM

I released LLM 0.17 last night, the latest version of my combined CLI tool and Python library for interacting with hundreds of different Large Language Models such as GPT-4o, Llama, Claude and Gemini.
[... 1,363 words]Matt Webb’s Colophon. I love a good colophon (here's mine, I should really expand it). Matt Webb has been publishing his thoughts online for 24 years, so his colophon is a delightful accumulation of ideas and principles.
So following the principles of web longevity, what matters is the data, i.e. the posts, and simplicity. I want to minimise maintenance, not panic if a post gets popular, and be able to add new features without thinking too hard. [...]
I don’t deliberately choose boring technology but I think a lot about longevity on the web (that’s me writing about it in 2017) and boring technology is a consequence.
I'm tempted to adopt Matt's XSL template that he uses to style his RSS feed for my own sites.
Oct. 28, 2024
If you want to make a good RAG tool that uses your documentation, you should start by making a search engine over those documents that would be good enough for a human to use themselves.
Hugging Face Hub: Configure progress bars.
This has been driving me a little bit spare. Every time I try and build anything against a library that uses huggingface_hub somewhere under the hood to access models (most recently trying out MLX-VLM) I inevitably get output like this every single time I execute the model:
Fetching 11 files: 100%|██████████████████| 11/11 [00:00<00:00, 15871.12it/s]
I finally tracked down a solution, after many breakpoint() interceptions. You can fix it like this:
from huggingface_hub.utils import disable_progress_bars disable_progress_bars()
Or by setting the HF_HUB_DISABLE_PROGRESS_BARS environment variable, which in Python code looks like this:
os.environ["HF_HUB_DISABLE_PROGRESS_BARS"] = '1'
python-imgcat (via) I was investigating options for displaying images in a terminal window (for multi-modal logging output of LLM) and I found this neat Python library for displaying images using iTerm 2.
It includes a CLI tool, which means you can run it without installation using uvx like this:
uvx imgcat filename.png

Prompt GPT-4o audio. A week and a half ago I built a tool for experimenting with OpenAI's new audio input. I just put together the other side of that, for experimenting with audio output.
Once you've provided an API key (which is saved in localStorage) you can use this to prompt the gpt-4o-audio-preview model with a system and regular prompt and select a voice for the response.
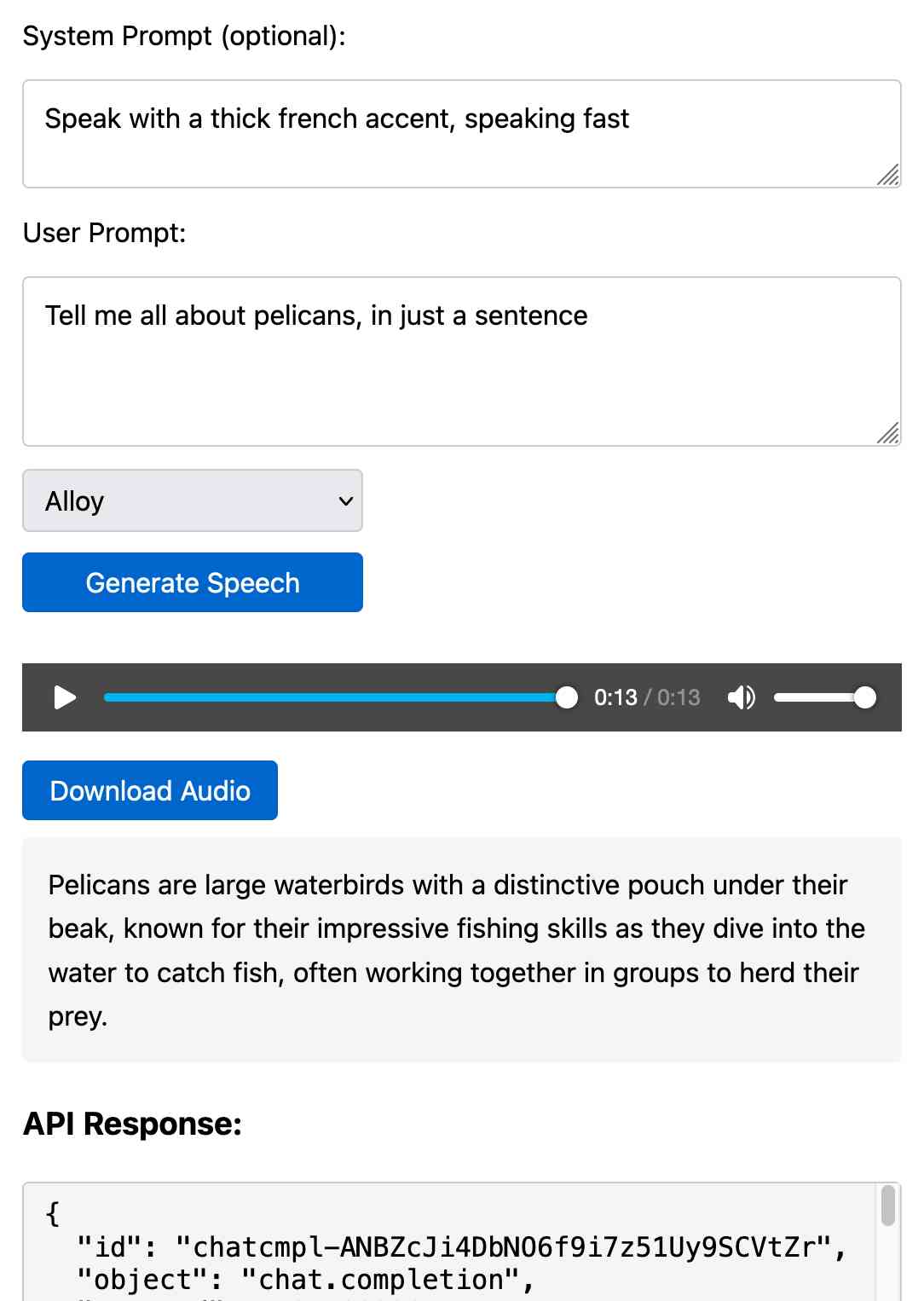
I built it with assistance from Claude: initial app, adding system prompt support.
You can preview and download the resulting wav file, and you can also copy out the raw JSON. If you save that in a Gist you can then feed its Gist ID to https://tools.simonwillison.net/gpt-4o-audio-player?gist=GIST_ID_HERE (Claude transcript) to play it back again.
You can try using that to listen to my French accented pelican description.
There's something really interesting to me here about this form of application which exists entirely as HTML and JavaScript that uses CORS to talk to various APIs. GitHub's Gist API is accessible via CORS too, so it wouldn't take much more work to add a "save" button which writes out a new Gist after prompting for a personal access token. I prototyped that a bit here.
Oct. 27, 2024
llm-whisper-api. I wanted to run an experiment through the OpenAI Whisper API this morning so I knocked up a very quick plugin for LLM that provides the following interface:
llm install llm-whisper-api
llm whisper-api myfile.mp3 > transcript.txt
It uses the API key that you previously configured using the llm keys set openai command. If you haven't configured one you can pass it as --key XXX instead.
It's a tiny plugin: the source code is here.
Run a prompt to generate and execute jq programs using llm-jq

llm-jq is a brand new plugin for LLM which lets you pipe JSON directly into the llm jq command along with a human-language description of how you’d like to manipulate that JSON and have a jq program generated and executed for you on the fly.
Oct. 26, 2024
As an independent writer and publisher, I am the legal team. I am the fact-checking department. I am the editorial staff. I am the one responsible for triple-checking every single statement I make in the type of original reporting that I know carries a serious risk of baseless but ruinously expensive litigation regularly used to silence journalists, critics, and whistleblowers. I am the one deciding if that risk is worth taking, or if I should just shut up and write about something less risky.