JP7628731B2 - 検体に含まれる成分の含有量比の推定方法、組成推定装置、及び、プログラム - Google Patents
検体に含まれる成分の含有量比の推定方法、組成推定装置、及び、プログラム Download PDFInfo
- Publication number
- JP7628731B2 JP7628731B2 JP2023529793A JP2023529793A JP7628731B2 JP 7628731 B2 JP7628731 B2 JP 7628731B2 JP 2023529793 A JP2023529793 A JP 2023529793A JP 2023529793 A JP2023529793 A JP 2023529793A JP 7628731 B2 JP7628731 B2 JP 7628731B2
- Authority
- JP
- Japan
- Prior art keywords
- fine
- black
- brought
- inter
- perfectly
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images















Classifications
-
- H—ELECTRICITY
- H01—ELECTRIC ELEMENTS
- H01J—ELECTRIC DISCHARGE TUBES OR DISCHARGE LAMPS
- H01J49/00—Particle spectrometers or separator tubes
- H01J49/0027—Methods for using particle spectrometers
- H01J49/0036—Step by step routines describing the handling of the data generated during a measurement
-
- H—ELECTRICITY
- H01—ELECTRIC ELEMENTS
- H01J—ELECTRIC DISCHARGE TUBES OR DISCHARGE LAMPS
- H01J49/00—Particle spectrometers or separator tubes
- H01J49/0009—Calibration of the apparatus
Landscapes
- Chemical & Material Sciences (AREA)
- Analytical Chemistry (AREA)
- Other Investigation Or Analysis Of Materials By Electrical Means (AREA)
- Medical Treatment And Welfare Office Work (AREA)
Description
また、本発明は、組成推定装置、及び、プログラムを提供することも課題とする。
[2] 上記Kが2以上の整数であり、上記推定対象検体が、上記成分の混合物である、[1]に記載の方法。
[3] 上記学習用検体が、上記エンドメンバーを含む、[1]又は[2]に記載の方法。
[4] 上記エンドメンバーの決定が、上記学習用検体に付された判別ラベルに基づき行われる、[3]に記載の方法。
[5] 上記エンドメンバーの決定が、上記学習用検体の上記特徴ベクトルの頂点成分分析によって行われる、[3]に記載の方法。
[6] 上記エンドメンバーの決定が、上記K-1次元単体が最小体積となるように頂点を定めるアルゴリズムによって実施される、[1]に記載の方法。
[7] 上記エンドメンバーの決定が、上記補正後強度分布行列を非負値行列因子分解し、上記検体中のK種類の上記成分の重量分率を表す行列と、K種類の個別の上記成分ごとのフラグメント存在強度を表す行列との積に分解する第2のNMF処理により行われる、[6]に記載の方法。
[8] 上記学習用検体が、上記エンドメンバーを含まない、[6]又は[7]に記載の方法。
[9] 上記補正後強度分布行列を得ることは、更に、上記強度分布行列の強度補正を行うことを含む、[1]~[8]のいずれかに記載の方法。
[10] 上記検体セットが、更に、キャリブレーション検体を含み、上記キャリブレーション検体は、上記K種類の成分を全て含み、かつ、その組成が既知であり、上記強度補正は、上記強度分布行列を規格化することを含む、[9]に記載の方法。
[11] 上記強度補正は、上記強度分布行列の少なくとも一部を、上記検体セットのうち対応する上記検体の質量と環境変数の積で割り付けることを含み、
上記環境変数は、上記観測の際における上記成分のイオン化効率への影響を表す変数である、[9]に記載の方法。
[12] 上記環境変数が、上記観測の際に、雰囲気中に所定量含まれる分子量50~1500の化合物、又は、上記検体セットのそれぞれに所定量含まれる分子量50~500の有機低分子化合物のマススペクトルのピークの合計値である、[11]に記載の方法。
[13] Kを1以上の整数としたとき、K種類の成分から選択される少なくとも1種の上記成分を含む推定対象検体における、上記成分の含有量比を推定する組成推定装置であって、上記K種類の成分から選択される少なくとも1種の成分を含み、互いに組成の異なるK個以上の学習用検体、上記成分を含まないバックグラウンド検体、及び、上記推定対象検体を含む検体セットに含まれるそれぞれの検体を加熱しながら、熱脱着、及び/又は、熱分解によって生ずるガス成分を順次イオン化し、マススペクトルを連続的に観測する質量分析装置と、上記観測されたマススペクトルを処理する情報処理装置と、を備え、上記情報処理装置は、加熱温度ごとに得られた上記マススペクトルを各行に格納し、上記検体ごとの二次元マススペクトルを得て、上記二次元マススペクトルの少なくとも2つ以上をまとめてデータ行列に変換する、データ行列作成部と、上記データ行列を非負値行列因子分解し、規格化された基底スペクトル行列とその強度分布行列の積に分解するNMF処理を行う、NMF処理部と、上記基底スペクトル行列と上記データ行列との正準相関分析によって強度分布行列に含まれるノイズ成分を抽出し、上記ノイズ成分の影響を減ずるよう上記強度分布行列を補正して、補正後強度分布行列を作成する、補正処理部と、上記補正後強度分布行列を上記検体セットのそれぞれに対応する小行列に分割し、上記小行列を特徴ベクトルとして、ベクトル空間内で上記検体のそれぞれを表現する、ベクトル処理部と、上記特徴ベクトルの全てを内包するK-1次元単体を設定し、上記K-1次元単体におけるK個のエンドメンバーを決定する、エンドメンバー決定部と、上記K個のエンドメンバーと、上記推定対象検体の特徴ベクトルとの、ユークリッド距離をそれぞれ計算し、上記ユークリッド距離の比により、上記推定対象検体中の上記成分の含有量比を推定する、含有量比計算部と、を含み、上記Kが3以上の場合、上記K-1次元単体に内接する超球体の外側の領域のそれぞれに、上記学習用検体の特徴ベクトルの少なくとも1つが位置する、又は、上記学習用検体が上記エンドメンバーの少なくとも1つを含む、組成推定装置。
[14] 上記エンドメンバー決定部は、上記学習用検体に付された判別ラベルに基づいて上記エンドメンバーを決定する、[13]に記載の組成推定装置。
[15] 上記エンドメンバー決定部は、上記K-1次元単体が最小体積となるように頂点を定めるアルゴリズムによって上記エンドメンバーを決定する、[13]に記載の組成推定装置。
[16] 上記エンドメンバー決定部は、上記補正後強度分布行列を非負値行列因子分解し、上記検体中のK種類の上記成分の重量分率を表す行列と、K種類の個別の上記成分ごとのフラグメント存在強度を表す行列との積に分解する第2のNMF処理により上記エンドメンバーを決定する、[15]に記載の組成推定装置。
[17] 上記補正処理部は更に、上記強度分布行列の強度補正を行う、[15]に記載の組成推定装置。
[18] 上記検体セットが、更に、キャリブレーション検体を含み、上記キャリブレーション検体が、上記K種類の成分を全て含み、かつ、その組成が既知であり、上記強度補正が、上記強度分布行列を規格化することを含む、[17]に記載の組成推定装置。
[19] 上記強度補正は、上記強度分布行列の少なくとも一部を、上記検体セットのうち対応する上記検体の質量と環境変数の積で割り付けることを含み、
上記環境変数は、上記観測の際における上記成分のイオン化効率への影響を表す変数である、[17]に記載の組成推定装置。
[20] 上記質量分析装置は減圧ポンプを更に備え、上記環境変数が、上記減圧ポンプの稼働によって生ずる物質のマススペクトルのピークの合計値である、[19]に記載の組成推定装置。
[21] Kを1以上の整数としたとき、K種類の成分から選択される少なくとも1種の上記成分を含む推定対象検体における、上記成分の含有量比を推定する組成推定装置において用いられるプログラムであって、上記K種類の成分から選択される少なくとも1種の成分を含み、互いに組成の異なるK個以上の学習用検体、上記成分を含まないバックグラウンド検体、及び、上記推定対象検体を含む検体セットに含まれるそれぞれの検体を加熱しながら、熱脱着、及び/又は、熱分解によって生ずるガス成分を順次イオン化し、マススペクトルを連続的に観測する質量分析装置と、上記観測されたマススペクトルを処理する情報処理装置と、を備え、上記質量分析装置によって、加熱温度ごとに取得された上記マススペクトルを各行に格納し、上記検体ごとの二次元マススペクトルを得て、上記二次元マススペクトルの少なくとも2つ以上をまとめてデータ行列に変換する、データ行列作成機能と、上記データ行列を非負値行列因子分解し、規格化された基底スペクトル行列とその強度分布行列の積に分解するNMF処理を行う、NMF処理機能と、上記基底スペクトル行列と上記データ行列との正準相関分析によって強度分布行列に含まれるノイズ成分を抽出し、上記ノイズ成分の影響を減ずるよう上記強度分布行列を補正して、補正後強度分布行列を作成する、補正処理機能と、上記補正後強度分布行列を上記検体のそれぞれに対応する小行列に分割し、上記小行列を特徴ベクトルとして、ベクトル空間内で上記検体のそれぞれを表現する、ベクトル処理機能と、上記特徴ベクトルの全てを内包するK-1次元単体を設定し、上記K-1次元単体におけるK個のエンドメンバーを決定する、エンドメンバー決定機能と、上記K個のエンドメンバーと、上記推定対象検体の特徴ベクトルとの、ユークリッド距離をそれぞれ計算し、上記ユークリッド距離の比により、上記推定対象検体中の上記成分の含有量比を推定する、含有量比計算機能と、を含み、上記Kが3以上の場合、上記K-1次元単体に内接する超球体の外側の領域のそれぞれに、上記学習用検体の特徴ベクトルの少なくとも1つが位置する、又は、上記学習用検体が上記エンドメンバーの少なくとも1つを含む、プログラム。
以下に記載する構成要件の説明は、本発明の代表的な実施形態に基づいてなされることがあるが、本発明はそのような実施形態に制限されるものではない。
なお、本明細書において、「~」を用いて表される数値範囲は、「~」の前後に記載される数値を下限値及び上限値として含む範囲を意味する。
本明細書において使用される用語について説明する。なお、以下に説明のない用語については、当業者の間で普通に理解される意味で使用される。
図1は、本発明の実施形態に係る組成推定方法(以下、「本方法」ともいう。)のフローチャートである。
なお、学習用検体の個数は成分数Kに関係して、K個以上である必要がある。K個以上であれば、学習用検体の数としては特に制限されないが、より多い場合、後述するK-1次元単体の頂点の決定の精度がより高くなりやすく、結果として、より正確な組成推定結果が得られやすい。
すなわち、成分数Kに対する学習用検体の数の比(学習用検体の数/成分数)は、1以上であり、2以上が好ましく、3以上がより好ましく、5以上が更に好ましく、10以上が特に好ましい。一方、上限値は特に制限されないが、一般に、1000以下が好ましい。
推定対象検体と学習用検体との相違点は、学習用検体はそれぞれ組成が異なることが必要である点である。なお、学習用検体は、推定対象検体と組成が同一のものを含んでいてもよい。
質量分析計としては特に制限されず、精密質量分析が可能なものが好ましく、四重極型、及び、飛行時間(TOF)型等のいずれでもよい。
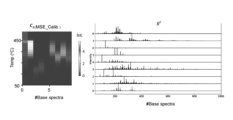
このマススペクトルが各行に格納され、加熱温度が各列に格納されると、検体ごとの二次元マススペクトルが得られる。
データ行列Xの作成に用いられる二次元マススペクトルの個数は2つ以上であれば特に制限されないが、検体セットに含まれる全検体の二次元マススペクトルが用いられることが好ましい。
なお、1つの検体について2回以上、測定が行われる場合には、2回以上の測定で得られた二次元マススペクトルの一部、又は、全てがデータ行列Xの作成に用いられてもよい。







本ステップにおけるNMF処理は、以下に述べる制約を組み込みやすいHierarchical alternating least square (HALS)により、C、Sの列ベクトルワイズに交互に更新していくことで、上記式(数7)をC、Sの各列についての凸最適化問題として解くことが好ましい。
質量分析計は、一般に0.1~0.001m/z程度の分解能を有する。したがって、異なるガス成分のm/zが小数点以下まで一致し、同一のチャネルを占めるという状況は稀にしか生じない。したがって、基底スペクトル行列Sの列ベクトル間にはある程度の直交性を仮定するのが妥当である。
CとSの更新途中で、ほとんど同じ基底スペクトルが複数得られた場合は一つのスペクトルにまとめることで正しい成分数nを得ることができる。EALSのスペクトライメージをNMFに適用すると、Sのk番目の列ベクトルをS:kと書いて、ST :kS:m>thresholdなるk<mが存在するときに、



上記によって得られる更新式について説明する。
モデルの全同時分布は










次に、Sの更新式について説明する。まず、負対数尤度関数からS:kに関連する項J(S:k)のみを取り出すことを考える。Xに対するk成分の寄与、
















具体的には、基底スペクトル行列とデータ行列との正準相関分析によって強度分布行列に含まれるノイズ成分を抽出し、ノイズ成分の影響を減ずるよう強度分布行列を補正して、補正後強度分布行列を得る。
N個のp次元ベクトルからなる行列を



ここで、t1、t2はハイパーパラメータで、NMFのフィッティング精度、すなわちNMFハイパーパラメータであるthresholdの影響を強く受けるので、慎重に吟味する必要がある。経験的にt1=0.9threshold,t2∈[0.1,0.3]程度がよい結果を与える。

強度分布行列の強度補正によれば、上記の影響を減じて、より正確な定量結果を得ることができる。
C行列をサンプルワイズに分割し、サンプルLに由来するC行列をCδ(L)とかくと、




一つのキャリブレーション検体は必ず一つ以上の熱分解サンプルを与えるので、熱分解後の成分数はPは列フルランクな縦長の行列である。したがって一般的には解は不能で、最小二乗の意味での近似解は二次計画法で解くことができる。
しかし、NMFによって成分kのイオン化効率を含めたピーク強度比はS:k Tの中にすでに反映されており、スペクトル間の強度比はC:kに反映されている。
このNMFによって形成された階層的データ構造のおかげで、エンドメンバーにおけるピーク強度比さえ考慮にいれれば、未知のイオン化効率を求めなくても、より正確な定量的な組成分析が可能になる。
ここで、環境変数とは、観測の際における各成分のイオン化効率への影響を表す変数である。
また、検体の質量についても、これが大きくなれば、一般的にピーク強度は大きく成り、小さく成れば、ピーク強度は小さくなる。





さらに、これらの特徴ベクトル(それぞれ各検体に対応する)の全てを内包するK-1次元単体を設定し、K-1次元単体におけるK個のエンドメンバーを決定する(ステップS107)。
なお、上記はRobust Volume Minimization-Based Matrix Factorization for Remote Sensing and Document Clustering, IEEE TRANSACTIONS ON SIGNAL PROCESSING,VOL. 64,NO. 23,DECEMBER 1,2016をベースに考案された。
なかでも、より優れた本発明の効果が得られる点では、他の学習用検体は、エンドメンバーである学習用検体とは異なるエンドメンバーの成分(他のエンドメンバーの成分)を20質量%以上含むことが好ましく、40質量%以上含むことがより好ましい。
本方法の第2実施形態は、すでに説明した第1実施形態におけるステップS107において、学習用検体がエンドメンバーを含まない場合、すなわち、K-1次元単体頂点に位置する学習用検体が1つもない場合のエンドメンバー(頂点)の決定方法を含む。
各検体は、K種類の成分の混合物(以下では、「ポリマー」の混合物として説明する)であるが、実際に観測できるのは、各ポリマーが熱分解して生じたM種類のフラグメントガスのスペクトルSの適当な線形和である。

以下では、図1のフローにおける、ステップS104のNMF処理(以下、「1回目のNMF処理」ともいう。)と、ステップS107におけるエンドメンバーの決定において実施されるNMF処理(以下「2回目のNMF処理」ともいう。)の違い等について詳述する。なお、以下に説明のないステップ等については、原則として、第1実施形態における各ステップと同様である。

ある行列



全体の確率モデルとしては、













となる。λについての更新式Eq.S3を代入し、定数項を落として簡略化すると、



である。これによりL(X,A,S,λ)は成分mごとに分離して書けて、









CCA-filterを用いるためには、バックグラウンドスペクトル
最初のステップは、M-スペクトルからなる







各固有値


CCA-filterから出力された、バックグラウンドに由来するM′-成分除去済みの






















データセットからSとBを推定したのちに、SとBの推定には用いなかったデータ(ここではテストデータと呼ぶ)
まずS-超平面への射影により、
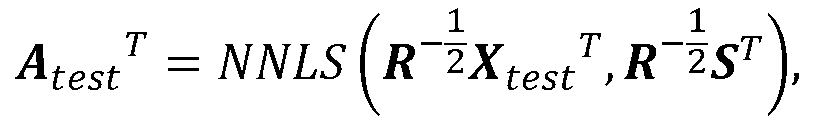



次に、本発明の実施形態に係る組成推定装置について、図面を参照しながら説明する。図3は、本発明の実施形態に係る組成推定装置のハードウェア構成図である。
記憶デバイス35は、例えば、ROM(Read Only Memory)、RAM(Random Access Memory)、HDD(Hard Disk Drive)、フラッシュメモリ、及び、SSD(Solid State Drive)等である。
また、表示デバイス36は、入力デバイス37と一体として構成されていてもよい。この場合、表示デバイス36がタッチパネルディスプレイであって、GUI(Graphical User Interface)を提供する形態が挙げられる。
質量分析部41は、ロードされた検体セット(検体、学習用検体、及び、バックグラウンド検体、図4中、符号a)について、加熱しながら熱脱着、及び/又は、熱分解されて生ずるガス成分をイオン化し、順次質量分析して、マススペクトルを出力する(図4中、符号c)。
この際、質量分析装置31の設置されている環境に起因した環境要因(図4中、符号b、例えば、減圧ポンプ32から生ずる(ポリ)ジメチルシロキサン)も同時に質量分析装置31にロードされ、マススペクトルに影響を与える。
制御部43は、プロセッサ34を含んで構成される。制御部43は、各部を制御して、組成推定装置30の各機能を実現する。
データ行列作成部47は、質量分析部41によって加熱温度ごとに取得されたマススペクトル(図4中、符号c)を各行に格納した二次元マススペクトルからデータ行列Xを作成し、後述するNMF処理部48に渡す(図4中、符号d)。なお、データ行列Xの詳細については、すでに説明したとおりである。
NMF処理部48は、データ行列作成部47によって作成されたデータ行列X(図4中、符号d)を非負値行列因子分解(NMF)し、規格化された基底スペクトル行列(S)とその強度分布行列(C)との積(X=C×ST)に分解する。その結果は、補正処理部49に渡される(図4中、符号e)。なお、NMF処理の詳細はすでに説明したとおりである。
補正処理部49は、NMF処理部48によって作成された基底スペクトル行列とデータ行列との正準相関分析によって強度分布行列を補正して、補正後強度分布行列を作成する機能である。作成された補正後強度分布行列はベクトル処理部50に渡される(図4中、符号f)。
ベクトル処理部50は、補正処理部49により作成された補正後強度分布行列を全検体のそれぞれに対応する小行列に分割し、これを特徴ベクトルとしてベクトル空間内で全検体を表現する。この結果は、エンドメンバー決定部51に渡される(図4中、符号g)。
エンドメンバー決定部51は、ベクトル処理部50によって作成された特徴ベクトルの全てを内包するK-1次元単体を設定し、K-1次元単体におけるK個のエンドメンバーを決定する。この結果は、含有量比計算部52に渡される(図4中、符号h)。
しかし、すでに説明したとおり、エンドメンバーの決定(エンドメンバー決定部51の処理)には判別ラベルは必須ではない。
含有量比計算部52は、エンドメンバー決定部51によって決定されたK個のエンドメンバーと、ベクトル処理部50により作成された推定対象検体の特徴ベクトルとのユークリッド距離をそれぞれ計算し、K個のエンドメンバーと検体の特徴ベクトルとのユークリッド距離の比から、推定対象検体中のK個の成分の含有量比を推定する。この含有量比の推定結果(図4中、符号i)は、出力部46から出力される。
なお、この際、学習用検体の組成推定結果もあわせて出力してもよい。
(検体の準備)
ポリメチルメタクリレート(poly(methyl methacrylate)、記号「M」)、ポリスチレン(polystyrene、記号「S」)、ポリエチルメタクリレート(poly(ethyl methacrylate)、記号「E」)の三種類の高分子のジオキサン溶液(約4質量%、高分子の固形分として0.4mg程度)を、サンプルポット上にキャストした後に一晩風乾して検体を得た。表4は、各検体の組成である。なお、質量分析は、SHIMADZU社製LCMS-2020を検出器として、IonSense社製DARTイオン源として、バイオクロマト社製イオンロケットをサンプルの加熱部として用いて行った。

(ii)NMF最適化中のマージング条件
(iii)CCA-filterによるNMFアーティファクト、及び、バックグラウンド、コンタミネーション除去
(iv)環境変数を補正項にいれることで、キャリブレーション不要の定量分析
NMF:
orthogonal constrain weight w=0.2, initial component number K=50, small positive number a=1+0.1-15, iteration number L=2000, threshold=0.9
CCA-Filter:
t1=0.8,t2=0.2,
図8の結果から、NMFが直交制約を有する方が、より優れた推定結果が得られることがわかった。
図9の結果から、NMF最適化の条件がmerging Sを有する方が、より優れた推定結果が得られることがわかった。
なお、成分数はARDによって36までしか減らせないが、Merging Sの条件を維持したときは成分数9でより精度よく組成が推定できることから、Merging Sの重要性がわかった。
図10においては、検体「SE」は、Mの含有量は0%にも関わらず1%程度入っているという計算結果となった。0%を1%と推定してしまうと、数%の推定精度もないということになり実用的ではない。
この結果から、CCA-filterを解除すると、DOX、BG(図5の説明を参照)のいずれのノイズも除去できていないことがわかった。
(エンドメンバーを含まない検体による推定)
学習用検体を含む検体(群)が、エンドメンバーを含まない場合にも精度よく推定できることを確かめるために、表5に記載したサンプルを調製して実施例1と同様の試験を行った。
なお、表中、記号「M」「S」「E」が意味するものは、表4(実施例1)と同様である。また、各サンプルは、単独の成分(ポリマー)の重量分率が80%を超えないように調整されている。

図中Cでは、本方法によって、推定された組成を丸印で、使用したサンプルの組成(正しい組成)を星印で示している。いずれもよい一致を示している。
ここでは、使用した検体にエンドメンバー、すなわち、E、S、Mのピュアポリマーが含まれていないことが、Cの各頂点にプロットがないことからもわかる。
なお、テストデータがある場合には、XtestをSとBに連続射影してCtestを得る。
(エンドメンバーを1つ含む検体による推定)
次に、(学習用)検体のうち1つがエンドメンバーを含む場合に、他の検体における成分含有量が任意となる(K-1次元単体の内接円の外側の領域でなくてもよい)ことを検証した。
上記原因のひとつは、すでに説明した2回目のNMF処理(Eq.11)において基底の非直交性項
Claims (21)
- Kを1以上の整数としたとき、K種類の成分から選択される少なくとも1種の前記成分を含む推定対象検体における、前記成分の含有量比を推定する方法であって、
前記K種類の成分から選択される少なくとも1種の成分を含み、互いに組成の異なるK個以上の学習用検体、及び、前記成分を含まないバックグラウンド検体を準備することと、
前記推定対象検体、前記学習用検体、及び、バックグラウンド検体を含む検体セットに含まれるそれぞれの検体を加熱しながら、熱脱着、及び/又は、熱分解によって生ずるガス成分を順次イオン化し、マススペクトルを連続的に観測することと、
加熱温度ごとに得られた前記マススペクトルを各行に格納し、前記検体ごとの二次元マススペクトルを得て、前記二次元マススペクトルの少なくとも2つ以上をまとめてデータ行列に変換することと、
前記データ行列を非負値行列因子分解し、規格化された基底スペクトル行列とその強度分布行列の積に分解するNMF処理を行うことと、
前記基底スペクトル行列と前記データ行列との正準相関分析によって強度分布行列に含まれるノイズ成分を抽出し、前記ノイズ成分の影響を減ずるよう前記強度分布行列を補正して、補正後強度分布行列を得ることと、
前記補正後強度分布行列を前記検体のそれぞれに対応する小行列に分割し、前記小行列を特徴ベクトルとして、ベクトル空間内で前記検体のそれぞれを表現することと、
前記特徴ベクトルの全てを内包するK-1次元単体を設定し、前記K-1次元単体におけるK個のエンドメンバーを決定することと、
前記K個のエンドメンバーと、前記推定対象検体の特徴ベクトルとの、ユークリッド距離をそれぞれ計算し、前記ユークリッド距離の比により、前記推定対象検体中の前記成分の含有量比を推定することと、を含み、
前記Kが3以上の場合、前記K-1次元単体に内接する超球体の外側の領域のそれぞれに、前記学習用検体の特徴ベクトルの少なくとも1つが位置する、又は、前記学習用検体が前記エンドメンバーの少なくとも1つを含む、方法。 - 前記Kが2以上の整数であり、前記推定対象検体が、前記成分の混合物である、請求項1に記載の方法。
- 前記学習用検体が、前記エンドメンバーを含む、請求項1又は2に記載の方法。
- 前記エンドメンバーの決定が、前記学習用検体に付された判別ラベルに基づき行われる、請求項3に記載の方法。
- 前記エンドメンバーの決定が、前記学習用検体の前記特徴ベクトルの頂点成分分析によって行われる、請求項3に記載の方法。
- 前記エンドメンバーの決定が、前記K-1次元単体が最小体積となるように頂点を定めるアルゴリズムによって実施される、請求項1に記載の方法。
- 前記エンドメンバーの決定が、前記補正後強度分布行列を非負値行列因子分解し、前記検体中のK種類の前記成分の重量分率を表す行列と、K種類の個別の前記成分ごとのフラグメント存在強度を表す行列との積に分解する第2のNMF処理により行われる、請求項6に記載の方法。
- 前記学習用検体が、前記エンドメンバーを含まない、請求項6又は7に記載の方法。
- 前記補正後強度分布行列を得ることは、更に、前記強度分布行列の強度補正を行うことを含む、請求項1に記載の方法。
- 前記検体セットが、更に、キャリブレーション検体を含み、
前記キャリブレーション検体は、前記K種類の成分を全て含み、かつ、その組成が既知であり、
前記強度補正は、前記強度分布行列を規格化することを含む、請求項9に記載の方法。 - 前記強度補正は、前記強度分布行列の少なくとも一部を、前記検体セットのうち対応する前記検体の質量と環境変数の積で割り付けることを含み、
前記環境変数は、前記観測の際における前記成分のイオン化効率への影響を表す変数である、請求項9に記載の方法。 - 前記環境変数が、前記観測の際に、雰囲気中に所定量含まれる分子量50~1500の化合物、又は、前記検体セットのそれぞれに所定量含まれる分子量50~500の有機低分子化合物のマススペクトルのピークの合計値である、請求項11に記載の方法。
- Kを1以上の整数としたとき、K種類の成分から選択される少なくとも1種の前記成分を含む推定対象検体における、前記成分の含有量比を推定する組成推定装置であって、
前記K種類の成分から選択される少なくとも1種の成分を含み、互いに組成の異なるK個以上の学習用検体、前記成分を含まないバックグラウンド検体、及び、前記推定対象検体を含む検体セットに含まれるそれぞれの検体を加熱しながら、熱脱着、及び/又は、熱分解によって生ずるガス成分を順次イオン化し、マススペクトルを連続的に観測する質量分析装置と、
前記観測されたマススペクトルを処理する情報処理装置と、を備え、
前記情報処理装置は、
加熱温度ごとに得られた前記マススペクトルを各行に格納し、前記検体ごとの二次元マススペクトルを得て、前記二次元マススペクトルの少なくとも2つ以上をまとめてデータ行列に変換する、データ行列作成部と、
前記データ行列を非負値行列因子分解し、規格化された基底スペクトル行列とその強度分布行列の積に分解するNMF処理を行う、NMF処理部と、
前記基底スペクトル行列と前記データ行列との正準相関分析によって強度分布行列に含まれるノイズ成分を抽出し、前記ノイズ成分の影響を減ずるよう前記強度分布行列を補正して、補正後強度分布行列を作成する、補正処理部と、
前記補正後強度分布行列を前記検体セットのそれぞれに対応する小行列に分割し、前記小行列を特徴ベクトルとして、ベクトル空間内で前記検体のそれぞれを表現する、ベクトル処理部と、
前記特徴ベクトルの全てを内包するK-1次元単体を設定し、前記K-1次元単体におけるK個のエンドメンバーを決定する、エンドメンバー決定部と、
前記K個のエンドメンバーと、前記推定対象検体の特徴ベクトルとの、ユークリッド距離をそれぞれ計算し、前記ユークリッド距離の比により、前記推定対象検体中の前記成分の含有量比を推定する、含有量比計算部と、を含み、
前記Kが3以上の場合、前記K-1次元単体に内接する超球体の外側の領域のそれぞれに、前記学習用検体の特徴ベクトルの少なくとも1つが位置する、又は、前記学習用検体が前記エンドメンバーの少なくとも1つを含む、組成推定装置。 - 前記エンドメンバー決定部は、前記学習用検体に付された判別ラベルに基づいて前記エンドメンバーを決定する、請求項13に記載の組成推定装置。
- 前記エンドメンバー決定部は、前記K-1次元単体が最小体積となるように頂点を定めるアルゴリズムによって前記エンドメンバーを決定する、請求項13に記載の組成推定装置。
- 前記エンドメンバー決定部は、前記補正後強度分布行列を非負値行列因子分解し、前記検体中のK種類の前記成分の重量分率を表す行列と、K種類の個別の前記成分ごとのフラグメント存在強度を表す行列との積に分解する第2のNMF処理により前記エンドメンバーを決定する、請求項15に記載の組成推定装置。
- 前記補正処理部は更に、前記強度分布行列の強度補正を行う、請求項15に記載の組成推定装置。
- 前記検体セットが、更に、キャリブレーション検体を含み、
前記キャリブレーション検体が、前記K種類の成分を全て含み、かつ、その組成が既知であり、
前記強度補正が、前記強度分布行列を規格化することを含む、請求項17に記載の組成推定装置。 - 前記強度補正は、前記強度分布行列の少なくとも一部を、前記検体セットのうち対応する前記検体の質量と環境変数の積で割り付けることを含み、
前記環境変数は、前記観測の際における前記成分のイオン化効率への影響を表す変数である、請求項17に記載の組成推定装置。 - 前記質量分析装置は減圧ポンプを更に備え、
前記環境変数が、前記減圧ポンプの稼働によって生ずる物質のマススペクトルのピークの合計値である、請求項19に記載の組成推定装置。 - Kを1以上の整数としたとき、K種類の成分から選択される少なくとも1種の前記成分を含む推定対象検体における、前記成分の含有量比を推定する組成推定装置において用いられるプログラムであって、
前記K種類の成分から選択される少なくとも1種の成分を含み、互いに組成の異なるK個以上の学習用検体、前記成分を含まないバックグラウンド検体、及び、前記推定対象検体を含む検体セットに含まれるそれぞれの検体を加熱しながら、熱脱着、及び/又は、熱分解によって生ずるガス成分を順次イオン化し、マススペクトルを連続的に観測する質量分析装置と、
前記観測されたマススペクトルを処理する情報処理装置と、を備え、
前記質量分析装置によって、加熱温度ごとに取得された前記マススペクトルを各行に格納し、前記検体ごとの二次元マススペクトルを得て、前記二次元マススペクトルの少なくとも2つ以上をまとめてデータ行列に変換する、データ行列作成機能と、
前記データ行列を非負値行列因子分解し、規格化された基底スペクトル行列とその強度分布行列の積に分解するNMF処理を行う、NMF処理機能と、
前記基底スペクトル行列と前記データ行列との正準相関分析によって強度分布行列に含まれるノイズ成分を抽出し、前記ノイズ成分の影響を減ずるよう前記強度分布行列を補正して、補正後強度分布行列を作成する、補正処理機能と、
前記補正後強度分布行列を前記検体のそれぞれに対応する小行列に分割し、前記小行列を特徴ベクトルとして、ベクトル空間内で前記検体のそれぞれを表現する、ベクトル処理機能と、
前記特徴ベクトルの全てを内包するK-1次元単体を設定し、前記K-1次元単体におけるK個のエンドメンバーを決定する、エンドメンバー決定機能と、
前記K個のエンドメンバーと、前記推定対象検体の特徴ベクトルとの、ユークリッド距離をそれぞれ計算し、前記ユークリッド距離の比により、前記推定対象検体中の前記成分の含有量比を推定する、含有量比計算機能と、を含み、
前記Kが3以上の場合、前記K-1次元単体に内接する超球体の外側の領域のそれぞれに、前記学習用検体の特徴ベクトルの少なくとも1つが位置する、又は、前記学習用検体が前記エンドメンバーの少なくとも1つを含む、プログラム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021104510 | 2021-06-24 | ||
| JP2021104510 | 2021-06-24 | ||
| PCT/JP2022/022813 WO2022270289A1 (ja) | 2021-06-24 | 2022-06-06 | 検体に含まれる成分の含有量比の推定方法、組成推定装置、及び、プログラム |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JPWO2022270289A1 JPWO2022270289A1 (ja) | 2022-12-29 |
| JPWO2022270289A5 JPWO2022270289A5 (ja) | 2024-03-06 |
| JP7628731B2 true JP7628731B2 (ja) | 2025-02-12 |
Family
ID=84544540
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2023529793A Active JP7628731B2 (ja) | 2021-06-24 | 2022-06-06 | 検体に含まれる成分の含有量比の推定方法、組成推定装置、及び、プログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20240297031A1 (ja) |
| EP (1) | EP4361624A1 (ja) |
| JP (1) | JP7628731B2 (ja) |
| WO (1) | WO2022270289A1 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025033010A1 (ja) * | 2023-08-09 | 2025-02-13 | 国立研究開発法人物質・材料研究機構 | 組成推定方法、組成推定装置、プログラム、検体容器、及び、熱重量・質量分析方法 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012516445A (ja) | 2009-01-27 | 2012-07-19 | ホロジック,インコーポレイテッド | 体液における新生児敗血症の検出のためのバイオマーカー |
| JP2013528287A (ja) | 2010-06-10 | 2013-07-08 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 質量スペクトルを分析するための方法、コンピュータ・プログラム、およびシステム |
| WO2016120958A1 (ja) | 2015-01-26 | 2016-08-04 | 株式会社島津製作所 | 3次元スペクトルデータ処理装置及び処理方法 |
| WO2018158801A1 (ja) | 2017-02-28 | 2018-09-07 | 株式会社島津製作所 | スペクトルデータの特徴抽出装置および方法 |
| JP2021081365A (ja) | 2019-11-21 | 2021-05-27 | 株式会社島津製作所 | 糖ペプチド解析装置 |
-
2022
- 2022-06-06 JP JP2023529793A patent/JP7628731B2/ja active Active
- 2022-06-06 US US18/569,560 patent/US20240297031A1/en active Pending
- 2022-06-06 EP EP22828206.7A patent/EP4361624A1/en active Pending
- 2022-06-06 WO PCT/JP2022/022813 patent/WO2022270289A1/ja active Application Filing
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012516445A (ja) | 2009-01-27 | 2012-07-19 | ホロジック,インコーポレイテッド | 体液における新生児敗血症の検出のためのバイオマーカー |
| JP2013528287A (ja) | 2010-06-10 | 2013-07-08 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 質量スペクトルを分析するための方法、コンピュータ・プログラム、およびシステム |
| WO2016120958A1 (ja) | 2015-01-26 | 2016-08-04 | 株式会社島津製作所 | 3次元スペクトルデータ処理装置及び処理方法 |
| WO2018158801A1 (ja) | 2017-02-28 | 2018-09-07 | 株式会社島津製作所 | スペクトルデータの特徴抽出装置および方法 |
| JP2021081365A (ja) | 2019-11-21 | 2021-05-27 | 株式会社島津製作所 | 糖ペプチド解析装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2022270289A1 (ja) | 2022-12-29 |
| EP4361624A1 (en) | 2024-05-01 |
| WO2022270289A1 (ja) | 2022-12-29 |
| US20240297031A1 (en) | 2024-09-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7628737B2 (ja) | 眼鏡および光学素子 | |
| JP7628802B2 (ja) | 半導体装置及び電子機器 | |
| JP7628696B2 (ja) | 車両インテリア用制御システム | |
| JP7628764B2 (ja) | Asgr阻害剤 | |
| JP7628742B2 (ja) | 飛行装置 | |
| JP7628781B2 (ja) | 車両速度推定のための方法及びシステム | |
| JP7628732B2 (ja) | 金属酸化物半導体及び薄膜トランジスタと応用 | |
| JP7628743B2 (ja) | 電子タバコカートリッジ | |
| JP7628783B2 (ja) | 塩、酸発生剤、レジスト組成物及びレジストパターンの製造方法 | |
| JP7628705B2 (ja) | 人工心臓システム | |
| JP7628708B2 (ja) | 柱状欠陥のない超電導体磁束ピンニング | |
| JP7628765B2 (ja) | 廃熱回収システムおよびそのためのタービン膨張機 | |
| JP7628809B2 (ja) | ランプ装置 | |
| JP7628712B2 (ja) | 接続構造体 | |
| JP7628690B2 (ja) | 継手ユニットおよび継手ユニットの組立方法 | |
| JP7628731B2 (ja) | 検体に含まれる成分の含有量比の推定方法、組成推定装置、及び、プログラム | |
| JP7628784B2 (ja) | 遊技機 | |
| JP7628786B2 (ja) | 遊技機 | |
| JP7628785B2 (ja) | 遊技機 | |
| JP7628794B2 (ja) | データ生成システム及びデータ生成方法 | |
| JP7628728B2 (ja) | 腫瘍特異的t細胞の検出方法 | |
| JP7628719B2 (ja) | 遊技機 | |
| JP7628797B2 (ja) | 積層体の製造方法、塗装物の製造方法、接合構造体の製造方法、熱転写シート、及び積層体 | |
| JP7628702B2 (ja) | がん検出方法、がん検査方法、及びこれらに用いるキット | |
| JP7628780B2 (ja) | 非水系二次電池用セパレータ及び非水系二次電池 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20231129 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20231129 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20250114 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20250123 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7628731 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |