CN109689688B - 抗icos抗体 - Google Patents
抗icos抗体 Download PDFInfo
- Publication number
- CN109689688B CN109689688B CN201780045638.9A CN201780045638A CN109689688B CN 109689688 B CN109689688 B CN 109689688B CN 201780045638 A CN201780045638 A CN 201780045638A CN 109689688 B CN109689688 B CN 109689688B
- Authority
- CN
- China
- Prior art keywords
- seq
- antibody
- icos
- amino acid
- acid sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 225
- 238000000034 method Methods 0.000 claims abstract description 196
- 238000011282 treatment Methods 0.000 claims abstract description 105
- 201000011510 cancer Diseases 0.000 claims abstract description 93
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 371
- 210000004027 cell Anatomy 0.000 claims description 322
- 241000282414 Homo sapiens Species 0.000 claims description 305
- 230000027455 binding Effects 0.000 claims description 178
- 150000007523 nucleic acids Chemical class 0.000 claims description 175
- 101001042104 Homo sapiens Inducible T-cell costimulator Proteins 0.000 claims description 157
- 102000043396 human ICOS Human genes 0.000 claims description 120
- 101100179075 Mus musculus Icos gene Proteins 0.000 claims description 93
- 239000000203 mixture Substances 0.000 claims description 87
- 239000012636 effector Substances 0.000 claims description 74
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims description 71
- 102000039446 nucleic acids Human genes 0.000 claims description 64
- 108020004707 nucleic acids Proteins 0.000 claims description 64
- 108010002350 Interleukin-2 Proteins 0.000 claims description 58
- 239000003814 drug Substances 0.000 claims description 53
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 claims description 51
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 42
- 229940124597 therapeutic agent Drugs 0.000 claims description 41
- 229920001184 polypeptide Polymers 0.000 claims description 28
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 28
- 239000003446 ligand Substances 0.000 claims description 27
- 238000004519 manufacturing process Methods 0.000 claims description 27
- 230000005888 antibody-dependent cellular phagocytosis Effects 0.000 claims description 26
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 claims description 22
- 210000003719 b-lymphocyte Anatomy 0.000 claims description 20
- 201000001441 melanoma Diseases 0.000 claims description 15
- 229940002612 prodrug Drugs 0.000 claims description 15
- 239000000651 prodrug Substances 0.000 claims description 15
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 12
- 229940127089 cytotoxic agent Drugs 0.000 claims description 11
- 208000006265 Renal cell carcinoma Diseases 0.000 claims description 10
- 210000000612 antigen-presenting cell Anatomy 0.000 claims description 8
- 239000002254 cytotoxic agent Substances 0.000 claims description 8
- 238000001959 radiotherapy Methods 0.000 claims description 8
- 238000012258 culturing Methods 0.000 claims description 6
- 208000031671 Large B-Cell Diffuse Lymphoma Diseases 0.000 claims description 5
- 206010012818 diffuse large B-cell lymphoma Diseases 0.000 claims description 5
- 201000010536 head and neck cancer Diseases 0.000 claims description 5
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 5
- 239000007788 liquid Substances 0.000 claims description 5
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 5
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 5
- 206010008342 Cervix carcinoma Diseases 0.000 claims description 4
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 claims description 4
- 201000010881 cervical cancer Diseases 0.000 claims description 4
- 239000013598 vector Substances 0.000 claims description 4
- 230000008569 process Effects 0.000 claims description 3
- 229960000548 alemtuzumab Drugs 0.000 claims description 2
- 208000019691 hematopoietic and lymphoid cell neoplasm Diseases 0.000 claims description 2
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims 1
- 201000004101 esophageal cancer Diseases 0.000 claims 1
- 210000001744 T-lymphocyte Anatomy 0.000 abstract description 83
- 210000003289 regulatory T cell Anatomy 0.000 abstract description 67
- 210000003162 effector t lymphocyte Anatomy 0.000 abstract description 47
- 230000001225 therapeutic effect Effects 0.000 abstract description 46
- 241000894007 species Species 0.000 abstract description 24
- 230000009261 transgenic effect Effects 0.000 abstract description 15
- 210000000987 immune system Anatomy 0.000 abstract description 10
- 238000011813 knockout mouse model Methods 0.000 abstract description 7
- 230000001939 inductive effect Effects 0.000 abstract description 6
- 230000000139 costimulatory effect Effects 0.000 abstract description 3
- 208000003028 Stuttering Diseases 0.000 abstract 1
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 121
- 235000001014 amino acid Nutrition 0.000 description 115
- 108091028043 Nucleic acid sequence Proteins 0.000 description 113
- 239000000427 antigen Substances 0.000 description 111
- 108091007433 antigens Proteins 0.000 description 109
- 102000036639 antigens Human genes 0.000 description 109
- 229940024606 amino acid Drugs 0.000 description 101
- 150000001413 amino acids Chemical class 0.000 description 99
- 230000000694 effects Effects 0.000 description 90
- 241001465754 Metazoa Species 0.000 description 87
- 238000003556 assay Methods 0.000 description 78
- 230000014509 gene expression Effects 0.000 description 78
- 108090000623 proteins and genes Proteins 0.000 description 72
- 238000006467 substitution reaction Methods 0.000 description 61
- 102000000588 Interleukin-2 Human genes 0.000 description 57
- 241000699666 Mus <mouse, genus> Species 0.000 description 50
- 238000012360 testing method Methods 0.000 description 50
- 239000012634 fragment Substances 0.000 description 44
- 238000002560 therapeutic procedure Methods 0.000 description 44
- 210000004602 germ cell Anatomy 0.000 description 42
- 230000006870 function Effects 0.000 description 41
- 102000005962 receptors Human genes 0.000 description 41
- 108020003175 receptors Proteins 0.000 description 41
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 40
- 102000004169 proteins and genes Human genes 0.000 description 39
- 241000699670 Mus sp. Species 0.000 description 38
- 201000010099 disease Diseases 0.000 description 38
- 102100034980 ICOS ligand Human genes 0.000 description 37
- 230000035772 mutation Effects 0.000 description 34
- 230000006044 T cell activation Effects 0.000 description 33
- 235000018102 proteins Nutrition 0.000 description 33
- 239000011324 bead Substances 0.000 description 30
- 238000004458 analytical method Methods 0.000 description 29
- 210000004881 tumor cell Anatomy 0.000 description 29
- 101710093458 ICOS ligand Proteins 0.000 description 28
- 230000008901 benefit Effects 0.000 description 28
- 230000001965 increasing effect Effects 0.000 description 28
- 238000001727 in vivo Methods 0.000 description 27
- 239000002609 medium Substances 0.000 description 27
- 235000014966 Eragrostis abyssinica Nutrition 0.000 description 26
- 241000124008 Mammalia Species 0.000 description 26
- 239000003795 chemical substances by application Substances 0.000 description 26
- 230000000875 corresponding effect Effects 0.000 description 26
- 238000002868 homogeneous time resolved fluorescence Methods 0.000 description 26
- 238000006386 neutralization reaction Methods 0.000 description 26
- 239000000556 agonist Substances 0.000 description 25
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 25
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 25
- 239000006228 supernatant Substances 0.000 description 25
- 101150117115 V gene Proteins 0.000 description 24
- 230000008484 agonism Effects 0.000 description 24
- 101100043696 Drosophila melanogaster Stim gene Proteins 0.000 description 23
- 230000005867 T cell response Effects 0.000 description 23
- 210000002865 immune cell Anatomy 0.000 description 23
- 238000002474 experimental method Methods 0.000 description 21
- 101001047627 Homo sapiens Immunoglobulin kappa variable 2-28 Proteins 0.000 description 20
- 102100022950 Immunoglobulin kappa variable 2-28 Human genes 0.000 description 20
- 239000000872 buffer Substances 0.000 description 20
- 230000003053 immunization Effects 0.000 description 20
- 239000000523 sample Substances 0.000 description 20
- 108060003951 Immunoglobulin Proteins 0.000 description 19
- 101150008942 J gene Proteins 0.000 description 19
- 102000018358 immunoglobulin Human genes 0.000 description 19
- 239000007924 injection Substances 0.000 description 19
- 238000002347 injection Methods 0.000 description 19
- 239000002953 phosphate buffered saline Substances 0.000 description 19
- 238000009097 single-agent therapy Methods 0.000 description 19
- 230000004083 survival effect Effects 0.000 description 19
- 101001047617 Homo sapiens Immunoglobulin kappa variable 3-11 Proteins 0.000 description 18
- 102100022955 Immunoglobulin kappa variable 3-11 Human genes 0.000 description 18
- 230000004913 activation Effects 0.000 description 18
- 230000004048 modification Effects 0.000 description 18
- 238000012986 modification Methods 0.000 description 18
- 101001019455 Homo sapiens ICOS ligand Proteins 0.000 description 17
- 101001008313 Homo sapiens Immunoglobulin kappa variable 1D-39 Proteins 0.000 description 17
- 102100027404 Immunoglobulin kappa variable 1D-39 Human genes 0.000 description 17
- 230000000259 anti-tumor effect Effects 0.000 description 17
- BVKZGUZCCUSVTD-UHFFFAOYSA-N carbonic acid Chemical compound OC(O)=O BVKZGUZCCUSVTD-UHFFFAOYSA-N 0.000 description 17
- 230000001419 dependent effect Effects 0.000 description 17
- 210000001519 tissue Anatomy 0.000 description 17
- 238000002649 immunization Methods 0.000 description 16
- 230000004044 response Effects 0.000 description 16
- 230000004614 tumor growth Effects 0.000 description 16
- 238000002648 combination therapy Methods 0.000 description 15
- 238000000338 in vitro Methods 0.000 description 15
- 239000008194 pharmaceutical composition Substances 0.000 description 15
- 238000012216 screening Methods 0.000 description 15
- 230000030833 cell death Effects 0.000 description 14
- 230000009260 cross reactivity Effects 0.000 description 14
- 238000009472 formulation Methods 0.000 description 14
- 239000000463 material Substances 0.000 description 14
- 108020004414 DNA Proteins 0.000 description 13
- 101001042093 Mus musculus ICOS ligand Proteins 0.000 description 13
- 238000007792 addition Methods 0.000 description 13
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 13
- 238000012217 deletion Methods 0.000 description 13
- 230000037430 deletion Effects 0.000 description 13
- 238000005516 engineering process Methods 0.000 description 13
- 230000002708 enhancing effect Effects 0.000 description 13
- 230000028993 immune response Effects 0.000 description 13
- 230000001404 mediated effect Effects 0.000 description 13
- 210000000822 natural killer cell Anatomy 0.000 description 13
- 210000002966 serum Anatomy 0.000 description 13
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 12
- 241000699800 Cricetinae Species 0.000 description 12
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 12
- 238000002255 vaccination Methods 0.000 description 12
- 229940045513 CTLA4 antagonist Drugs 0.000 description 11
- 102000004127 Cytokines Human genes 0.000 description 11
- 108090000695 Cytokines Proteins 0.000 description 11
- 108010087819 Fc receptors Proteins 0.000 description 11
- 102000009109 Fc receptors Human genes 0.000 description 11
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 11
- -1 IFNγ Proteins 0.000 description 11
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 11
- 230000004075 alteration Effects 0.000 description 11
- 230000009286 beneficial effect Effects 0.000 description 11
- 230000037396 body weight Effects 0.000 description 11
- 230000008859 change Effects 0.000 description 11
- 102000046492 human ICOSLG Human genes 0.000 description 11
- 230000002519 immonomodulatory effect Effects 0.000 description 11
- 230000003472 neutralizing effect Effects 0.000 description 11
- 238000007920 subcutaneous administration Methods 0.000 description 11
- OZFAFGSSMRRTDW-UHFFFAOYSA-N (2,4-dichlorophenyl) benzenesulfonate Chemical compound ClC1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=CC=C1 OZFAFGSSMRRTDW-UHFFFAOYSA-N 0.000 description 10
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 10
- 101001091242 Homo sapiens Immunoglobulin kappa joining 1 Proteins 0.000 description 10
- 102100034892 Immunoglobulin kappa joining 1 Human genes 0.000 description 10
- 125000000539 amino acid group Chemical group 0.000 description 10
- 229940079593 drug Drugs 0.000 description 10
- 238000000684 flow cytometry Methods 0.000 description 10
- 238000007912 intraperitoneal administration Methods 0.000 description 10
- 239000013642 negative control Substances 0.000 description 10
- 244000052769 pathogen Species 0.000 description 10
- 102100027581 Forkhead box protein P3 Human genes 0.000 description 9
- 101000861452 Homo sapiens Forkhead box protein P3 Proteins 0.000 description 9
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 9
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 9
- 241000700159 Rattus Species 0.000 description 9
- 239000012131 assay buffer Substances 0.000 description 9
- 238000001574 biopsy Methods 0.000 description 9
- 239000012091 fetal bovine serum Substances 0.000 description 9
- 208000015181 infectious disease Diseases 0.000 description 9
- 238000003780 insertion Methods 0.000 description 9
- 230000037431 insertion Effects 0.000 description 9
- 238000002955 isolation Methods 0.000 description 9
- 229920000136 polysorbate Polymers 0.000 description 9
- 210000004986 primary T-cell Anatomy 0.000 description 9
- 238000000159 protein binding assay Methods 0.000 description 9
- 239000002904 solvent Substances 0.000 description 9
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 8
- 108010074708 B7-H1 Antigen Proteins 0.000 description 8
- 102000008096 B7-H1 Antigen Human genes 0.000 description 8
- 208000035473 Communicable disease Diseases 0.000 description 8
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 8
- 239000012911 assay medium Substances 0.000 description 8
- 238000002513 implantation Methods 0.000 description 8
- 230000001717 pathogenic effect Effects 0.000 description 8
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 8
- 108091033319 polynucleotide Proteins 0.000 description 8
- 102000040430 polynucleotide Human genes 0.000 description 8
- 239000002157 polynucleotide Substances 0.000 description 8
- 230000006798 recombination Effects 0.000 description 8
- 238000005215 recombination Methods 0.000 description 8
- 230000002829 reductive effect Effects 0.000 description 8
- 101150097493 D gene Proteins 0.000 description 7
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 description 7
- 239000004698 Polyethylene Substances 0.000 description 7
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 7
- 230000022534 cell killing Effects 0.000 description 7
- 230000001413 cellular effect Effects 0.000 description 7
- 210000004408 hybridoma Anatomy 0.000 description 7
- 230000001976 improved effect Effects 0.000 description 7
- 230000006698 induction Effects 0.000 description 7
- 230000002401 inhibitory effect Effects 0.000 description 7
- 230000005764 inhibitory process Effects 0.000 description 7
- 239000002773 nucleotide Substances 0.000 description 7
- 125000003729 nucleotide group Chemical group 0.000 description 7
- 239000002504 physiological saline solution Substances 0.000 description 7
- 238000011160 research Methods 0.000 description 7
- 210000000952 spleen Anatomy 0.000 description 7
- 230000000638 stimulation Effects 0.000 description 7
- 208000024891 symptom Diseases 0.000 description 7
- 230000008685 targeting Effects 0.000 description 7
- 241000239290 Araneae Species 0.000 description 6
- 206010009944 Colon cancer Diseases 0.000 description 6
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 6
- 241000282412 Homo Species 0.000 description 6
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 6
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 6
- PXIPVTKHYLBLMZ-UHFFFAOYSA-N Sodium azide Chemical compound [Na+].[N-]=[N+]=[N-] PXIPVTKHYLBLMZ-UHFFFAOYSA-N 0.000 description 6
- 239000002671 adjuvant Substances 0.000 description 6
- 210000004369 blood Anatomy 0.000 description 6
- 239000008280 blood Substances 0.000 description 6
- 210000004899 c-terminal region Anatomy 0.000 description 6
- 229910002091 carbon monoxide Inorganic materials 0.000 description 6
- 230000000779 depleting effect Effects 0.000 description 6
- 238000001514 detection method Methods 0.000 description 6
- 238000010790 dilution Methods 0.000 description 6
- 239000012895 dilution Substances 0.000 description 6
- 230000001506 immunosuppresive effect Effects 0.000 description 6
- 238000009169 immunotherapy Methods 0.000 description 6
- 238000001802 infusion Methods 0.000 description 6
- 230000002601 intratumoral effect Effects 0.000 description 6
- 238000001990 intravenous administration Methods 0.000 description 6
- 229960005386 ipilimumab Drugs 0.000 description 6
- 210000004698 lymphocyte Anatomy 0.000 description 6
- 230000007246 mechanism Effects 0.000 description 6
- 239000013612 plasmid Substances 0.000 description 6
- DBABZHXKTCFAPX-UHFFFAOYSA-N probenecid Chemical compound CCCN(CCC)S(=O)(=O)C1=CC=C(C(O)=O)C=C1 DBABZHXKTCFAPX-UHFFFAOYSA-N 0.000 description 6
- 229960003081 probenecid Drugs 0.000 description 6
- 230000001737 promoting effect Effects 0.000 description 6
- 229950010131 puromycin Drugs 0.000 description 6
- 230000000284 resting effect Effects 0.000 description 6
- 229960004641 rituximab Drugs 0.000 description 6
- 239000000758 substrate Substances 0.000 description 6
- 229910052717 sulfur Inorganic materials 0.000 description 6
- 238000004448 titration Methods 0.000 description 6
- 229960005486 vaccine Drugs 0.000 description 6
- 208000003950 B-cell lymphoma Diseases 0.000 description 5
- 241000283707 Capra Species 0.000 description 5
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 5
- 229910052693 Europium Inorganic materials 0.000 description 5
- 241000701806 Human papillomavirus Species 0.000 description 5
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 5
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 5
- 206010027480 Metastatic malignant melanoma Diseases 0.000 description 5
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 5
- 230000002411 adverse Effects 0.000 description 5
- 230000006023 anti-tumor response Effects 0.000 description 5
- 239000000611 antibody drug conjugate Substances 0.000 description 5
- 229940049595 antibody-drug conjugate Drugs 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 229940098773 bovine serum albumin Drugs 0.000 description 5
- 210000004970 cd4 cell Anatomy 0.000 description 5
- 238000013270 controlled release Methods 0.000 description 5
- 230000008878 coupling Effects 0.000 description 5
- 238000010168 coupling process Methods 0.000 description 5
- 238000005859 coupling reaction Methods 0.000 description 5
- 230000007423 decrease Effects 0.000 description 5
- 239000002552 dosage form Substances 0.000 description 5
- 231100000673 dose–response relationship Toxicity 0.000 description 5
- 239000013604 expression vector Substances 0.000 description 5
- 230000004927 fusion Effects 0.000 description 5
- 238000009396 hybridization Methods 0.000 description 5
- 229940127130 immunocytokine Drugs 0.000 description 5
- 238000011534 incubation Methods 0.000 description 5
- 208000021039 metastatic melanoma Diseases 0.000 description 5
- 229960002621 pembrolizumab Drugs 0.000 description 5
- 238000011002 quantification Methods 0.000 description 5
- 230000001105 regulatory effect Effects 0.000 description 5
- 239000011780 sodium chloride Substances 0.000 description 5
- 230000002459 sustained effect Effects 0.000 description 5
- 238000001890 transfection Methods 0.000 description 5
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 4
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 4
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 4
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 4
- 241000711549 Hepacivirus C Species 0.000 description 4
- 102000037982 Immune checkpoint proteins Human genes 0.000 description 4
- 108091008036 Immune checkpoint proteins Proteins 0.000 description 4
- 102100037850 Interferon gamma Human genes 0.000 description 4
- 108010074328 Interferon-gamma Proteins 0.000 description 4
- 241000700605 Viruses Species 0.000 description 4
- 230000003213 activating effect Effects 0.000 description 4
- 239000004480 active ingredient Substances 0.000 description 4
- 230000001580 bacterial effect Effects 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 4
- 238000004422 calculation algorithm Methods 0.000 description 4
- 238000004364 calculation method Methods 0.000 description 4
- 239000006285 cell suspension Substances 0.000 description 4
- 238000005119 centrifugation Methods 0.000 description 4
- 238000012512 characterization method Methods 0.000 description 4
- 208000029742 colonic neoplasm Diseases 0.000 description 4
- 239000000562 conjugate Substances 0.000 description 4
- 239000000539 dimer Substances 0.000 description 4
- 238000010494 dissociation reaction Methods 0.000 description 4
- 230000005593 dissociations Effects 0.000 description 4
- 210000003527 eukaryotic cell Anatomy 0.000 description 4
- OGPBJKLSAFTDLK-UHFFFAOYSA-N europium atom Chemical compound [Eu] OGPBJKLSAFTDLK-UHFFFAOYSA-N 0.000 description 4
- 230000001747 exhibiting effect Effects 0.000 description 4
- 238000005755 formation reaction Methods 0.000 description 4
- 230000013595 glycosylation Effects 0.000 description 4
- 238000006206 glycosylation reaction Methods 0.000 description 4
- 239000003112 inhibitor Substances 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 230000002147 killing effect Effects 0.000 description 4
- 239000002502 liposome Substances 0.000 description 4
- 230000004660 morphological change Effects 0.000 description 4
- 229910052700 potassium Inorganic materials 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 238000000746 purification Methods 0.000 description 4
- 102200072304 rs1057519530 Human genes 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 210000000130 stem cell Anatomy 0.000 description 4
- 230000009885 systemic effect Effects 0.000 description 4
- 238000011269 treatment regimen Methods 0.000 description 4
- OPUPHQHVRPYOTC-UHFFFAOYSA-N vgf3hm1rrf Chemical compound C1=NC(C(=O)C=2C3=CC=CN=2)=C2C3=NC=CC2=C1 OPUPHQHVRPYOTC-UHFFFAOYSA-N 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- 208000024827 Alzheimer disease Diseases 0.000 description 3
- 108091006146 Channels Proteins 0.000 description 3
- 241001327965 Clonorchis sinensis Species 0.000 description 3
- 241000699802 Cricetulus griseus Species 0.000 description 3
- 238000002965 ELISA Methods 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- 208000017604 Hodgkin disease Diseases 0.000 description 3
- 208000021519 Hodgkin lymphoma Diseases 0.000 description 3
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 3
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 3
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 3
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 3
- 206010062016 Immunosuppression Diseases 0.000 description 3
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical group C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 3
- 206010027476 Metastases Diseases 0.000 description 3
- 206010033128 Ovarian cancer Diseases 0.000 description 3
- 206010061535 Ovarian neoplasm Diseases 0.000 description 3
- 229930040373 Paraformaldehyde Natural products 0.000 description 3
- 208000037581 Persistent Infection Diseases 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 101100179076 Rattus norvegicus Icos gene Proteins 0.000 description 3
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- 108010088160 Staphylococcal Protein A Proteins 0.000 description 3
- 230000001270 agonistic effect Effects 0.000 description 3
- 235000004279 alanine Nutrition 0.000 description 3
- 230000005875 antibody response Effects 0.000 description 3
- 238000009175 antibody therapy Methods 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- 239000011230 binding agent Substances 0.000 description 3
- 230000005880 cancer cell killing Effects 0.000 description 3
- 230000020411 cell activation Effects 0.000 description 3
- 230000003915 cell function Effects 0.000 description 3
- 210000000170 cell membrane Anatomy 0.000 description 3
- 230000003833 cell viability Effects 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 210000000349 chromosome Anatomy 0.000 description 3
- 239000011248 coating agent Substances 0.000 description 3
- 238000000576 coating method Methods 0.000 description 3
- 230000000295 complement effect Effects 0.000 description 3
- 230000016396 cytokine production Effects 0.000 description 3
- 231100000433 cytotoxic Toxicity 0.000 description 3
- 231100000599 cytotoxic agent Toxicity 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- 210000004443 dendritic cell Anatomy 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 238000004520 electroporation Methods 0.000 description 3
- 229940088598 enzyme Drugs 0.000 description 3
- GWQVMPWSEVRGPY-UHFFFAOYSA-N europium cryptate Chemical compound [Eu+3].N=1C2=CC=CC=1CN(CC=1N=C(C=CC=1)C=1N=C(C3)C=CC=1)CC(N=1)=CC(C(=O)NCCN)=CC=1C(N=1)=CC(C(=O)NCCN)=CC=1CN3CC1=CC=CC2=N1 GWQVMPWSEVRGPY-UHFFFAOYSA-N 0.000 description 3
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 3
- 229910052731 fluorine Inorganic materials 0.000 description 3
- 229940072221 immunoglobulins Drugs 0.000 description 3
- 238000003364 immunohistochemistry Methods 0.000 description 3
- 239000012678 infectious agent Substances 0.000 description 3
- 239000007972 injectable composition Substances 0.000 description 3
- 230000003902 lesion Effects 0.000 description 3
- 150000002632 lipids Chemical class 0.000 description 3
- 230000007774 longterm Effects 0.000 description 3
- 229960005558 mertansine Drugs 0.000 description 3
- 108020004999 messenger RNA Proteins 0.000 description 3
- 210000001616 monocyte Anatomy 0.000 description 3
- 229920002866 paraformaldehyde Polymers 0.000 description 3
- 210000005259 peripheral blood Anatomy 0.000 description 3
- 239000011886 peripheral blood Substances 0.000 description 3
- ORMNNUPLFAPCFD-DVLYDCSHSA-M phenethicillin potassium Chemical compound [K+].N([C@@H]1C(N2[C@H](C(C)(C)S[C@@H]21)C([O-])=O)=O)C(=O)C(C)OC1=CC=CC=C1 ORMNNUPLFAPCFD-DVLYDCSHSA-M 0.000 description 3
- 229910052698 phosphorus Inorganic materials 0.000 description 3
- 150000003141 primary amines Chemical class 0.000 description 3
- 230000005855 radiation Effects 0.000 description 3
- 230000035945 sensitivity Effects 0.000 description 3
- 238000002864 sequence alignment Methods 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 230000002269 spontaneous effect Effects 0.000 description 3
- 238000000528 statistical test Methods 0.000 description 3
- 230000004936 stimulating effect Effects 0.000 description 3
- 238000011830 transgenic mouse model Methods 0.000 description 3
- 229910052720 vanadium Inorganic materials 0.000 description 3
- UZOVYGYOLBIAJR-UHFFFAOYSA-N 4-isocyanato-4'-methyldiphenylmethane Chemical compound C1=CC(C)=CC=C1CC1=CC=C(N=C=O)C=C1 UZOVYGYOLBIAJR-UHFFFAOYSA-N 0.000 description 2
- GOZMBJCYMQQACI-UHFFFAOYSA-N 6,7-dimethyl-3-[[methyl-[2-[methyl-[[1-[3-(trifluoromethyl)phenyl]indol-3-yl]methyl]amino]ethyl]amino]methyl]chromen-4-one;dihydrochloride Chemical compound Cl.Cl.C=1OC2=CC(C)=C(C)C=C2C(=O)C=1CN(C)CCN(C)CC(C1=CC=CC=C11)=CN1C1=CC=CC(C(F)(F)F)=C1 GOZMBJCYMQQACI-UHFFFAOYSA-N 0.000 description 2
- HJCMDXDYPOUFDY-WHFBIAKZSA-N Ala-Gln Chemical compound C[C@H](N)C(=O)N[C@H](C(O)=O)CCC(N)=O HJCMDXDYPOUFDY-WHFBIAKZSA-N 0.000 description 2
- 108010088751 Albumins Proteins 0.000 description 2
- 102000009027 Albumins Human genes 0.000 description 2
- 239000012114 Alexa Fluor 647 Substances 0.000 description 2
- 241000134916 Amanita Species 0.000 description 2
- 108010032595 Antibody Binding Sites Proteins 0.000 description 2
- 241000534000 Berula erecta Species 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 208000011691 Burkitt lymphomas Diseases 0.000 description 2
- AIRYAONNMGRCGJ-FHFVDXKLSA-N CC[C@H](C)[C@H](NC(=O)CN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H]1CSSC[C@@H]2NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CSSC[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc3c[nH]cn3)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)Cc3ccccc3)C(C)C)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](Cc3c[nH]cn3)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](Cc3ccc(O)cc3)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](Cc3ccc(O)cc3)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](Cc3ccc(O)cc3)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC2=O)C(=O)N[C@@H](CC(N)=O)C(O)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](Cc2ccccc2)C(=O)N[C@@H](Cc2ccccc2)C(=O)N[C@@H](Cc2ccc(O)cc2)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@H]2C(=O)N[C@@H]([C@@H](C)O)C(O)=O)NC1=O)[C@@H](C)O)[C@@H](C)CC Chemical compound CC[C@H](C)[C@H](NC(=O)CN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H]1CSSC[C@@H]2NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CSSC[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc3c[nH]cn3)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)Cc3ccccc3)C(C)C)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](Cc3c[nH]cn3)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](Cc3ccc(O)cc3)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](Cc3ccc(O)cc3)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](Cc3ccc(O)cc3)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC2=O)C(=O)N[C@@H](CC(N)=O)C(O)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](Cc2ccccc2)C(=O)N[C@@H](Cc2ccccc2)C(=O)N[C@@H](Cc2ccc(O)cc2)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@H]2C(=O)N[C@@H]([C@@H](C)O)C(O)=O)NC1=O)[C@@H](C)O)[C@@H](C)CC AIRYAONNMGRCGJ-FHFVDXKLSA-N 0.000 description 2
- 101150100936 CD28 gene Proteins 0.000 description 2
- 101100463133 Caenorhabditis elegans pdl-1 gene Proteins 0.000 description 2
- 102000005600 Cathepsins Human genes 0.000 description 2
- 108010084457 Cathepsins Proteins 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 2
- 206010061818 Disease progression Diseases 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 241000590002 Helicobacter pylori Species 0.000 description 2
- 101001037145 Homo sapiens Immunoglobulin heavy variable 2-5 Proteins 0.000 description 2
- 101001037138 Homo sapiens Immunoglobulin heavy variable 3-11 Proteins 0.000 description 2
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 description 2
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 2
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 2
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 2
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 2
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 2
- 229940126528 Immuno-Oncology Drug Drugs 0.000 description 2
- 102100040235 Immunoglobulin heavy variable 2-5 Human genes 0.000 description 2
- 102100040222 Immunoglobulin heavy variable 3-11 Human genes 0.000 description 2
- 102100040061 Indoleamine 2,3-dioxygenase 1 Human genes 0.000 description 2
- 102000037984 Inhibitory immune checkpoint proteins Human genes 0.000 description 2
- 108091008026 Inhibitory immune checkpoint proteins Proteins 0.000 description 2
- 108010038453 Interleukin-2 Receptors Proteins 0.000 description 2
- 102000010789 Interleukin-2 Receptors Human genes 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- 239000005411 L01XE02 - Gefitinib Substances 0.000 description 2
- 239000005551 L01XE03 - Erlotinib Substances 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 206010025323 Lymphomas Diseases 0.000 description 2
- 241000282553 Macaca Species 0.000 description 2
- 229930126263 Maytansine Natural products 0.000 description 2
- 208000002030 Merkel cell carcinoma Diseases 0.000 description 2
- 241000699660 Mus musculus Species 0.000 description 2
- 206010029266 Neuroendocrine carcinoma of the skin Diseases 0.000 description 2
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 2
- 108091034117 Oligonucleotide Proteins 0.000 description 2
- 206010057249 Phagocytosis Diseases 0.000 description 2
- 108091000080 Phosphotransferase Proteins 0.000 description 2
- 206010035226 Plasma cell myeloma Diseases 0.000 description 2
- 241000223960 Plasmodium falciparum Species 0.000 description 2
- 239000004793 Polystyrene Substances 0.000 description 2
- 108010029485 Protein Isoforms Proteins 0.000 description 2
- 102000001708 Protein Isoforms Human genes 0.000 description 2
- 108091008611 Protein Kinase B Proteins 0.000 description 2
- 108010076504 Protein Sorting Signals Proteins 0.000 description 2
- 102000005765 Proto-Oncogene Proteins c-akt Human genes 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- 244000191761 Sida cordifolia Species 0.000 description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- 108010090804 Streptavidin Proteins 0.000 description 2
- 210000000662 T-lymphocyte subset Anatomy 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 102000008579 Transposases Human genes 0.000 description 2
- 108010020764 Transposases Proteins 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 description 2
- 206010050283 Tumour ulceration Diseases 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 2
- 238000010521 absorption reaction Methods 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- 239000012190 activator Substances 0.000 description 2
- 238000010171 animal model Methods 0.000 description 2
- 239000005557 antagonist Substances 0.000 description 2
- 230000009830 antibody antigen interaction Effects 0.000 description 2
- 210000000436 anus Anatomy 0.000 description 2
- 235000003704 aspartic acid Nutrition 0.000 description 2
- 229950002916 avelumab Drugs 0.000 description 2
- SESFRYSPDFLNCH-UHFFFAOYSA-N benzyl benzoate Chemical compound C=1C=CC=CC=1C(=O)OCC1=CC=CC=C1 SESFRYSPDFLNCH-UHFFFAOYSA-N 0.000 description 2
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 2
- GXJABQQUPOEUTA-RDJZCZTQSA-N bortezomib Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)B(O)O)NC(=O)C=1N=CC=NC=1)C1=CC=CC=C1 GXJABQQUPOEUTA-RDJZCZTQSA-N 0.000 description 2
- 229960001467 bortezomib Drugs 0.000 description 2
- 238000002619 cancer immunotherapy Methods 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 229940097217 cardiac glycoside Drugs 0.000 description 2
- 239000002368 cardiac glycoside Substances 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 239000006143 cell culture medium Substances 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 238000013329 compounding Methods 0.000 description 2
- 230000021615 conjugation Effects 0.000 description 2
- 239000000356 contaminant Substances 0.000 description 2
- 208000017763 cutaneous neuroendocrine carcinoma Diseases 0.000 description 2
- 238000002784 cytotoxicity assay Methods 0.000 description 2
- 231100000263 cytotoxicity test Toxicity 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 230000005750 disease progression Effects 0.000 description 2
- 208000035475 disorder Diseases 0.000 description 2
- 230000002222 downregulating effect Effects 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 239000003937 drug carrier Substances 0.000 description 2
- 229950009791 durvalumab Drugs 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 2
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 2
- 229960001433 erlotinib Drugs 0.000 description 2
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 description 2
- 230000005284 excitation Effects 0.000 description 2
- 239000013613 expression plasmid Substances 0.000 description 2
- 239000012894 fetal calf serum Substances 0.000 description 2
- 230000003325 follicular Effects 0.000 description 2
- 230000033581 fucosylation Effects 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 206010017758 gastric cancer Diseases 0.000 description 2
- 229960002584 gefitinib Drugs 0.000 description 2
- XGALLCVXEZPNRQ-UHFFFAOYSA-N gefitinib Chemical compound C=12C=C(OCCCN3CCOCC3)C(OC)=CC2=NC=NC=1NC1=CC=C(F)C(Cl)=C1 XGALLCVXEZPNRQ-UHFFFAOYSA-N 0.000 description 2
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 2
- 229960005277 gemcitabine Drugs 0.000 description 2
- 210000001280 germinal center Anatomy 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- 239000008187 granular material Substances 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 230000009036 growth inhibition Effects 0.000 description 2
- 229940037467 helicobacter pylori Drugs 0.000 description 2
- 210000002443 helper t lymphocyte Anatomy 0.000 description 2
- 208000002672 hepatitis B Diseases 0.000 description 2
- 229960000908 idarubicin Drugs 0.000 description 2
- 229940126546 immune checkpoint molecule Drugs 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 2
- 229940045207 immuno-oncology agent Drugs 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 239000002584 immunological anticancer agent Substances 0.000 description 2
- 230000005917 in vivo anti-tumor Effects 0.000 description 2
- 230000010354 integration Effects 0.000 description 2
- 235000014705 isoleucine Nutrition 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 210000003292 kidney cell Anatomy 0.000 description 2
- 239000012139 lysis buffer Substances 0.000 description 2
- 210000002540 macrophage Anatomy 0.000 description 2
- 201000004792 malaria Diseases 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical class CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- ANZJBCHSOXCCRQ-FKUXLPTCSA-N mertansine Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCS)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 ANZJBCHSOXCCRQ-FKUXLPTCSA-N 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- 229960001156 mitoxantrone Drugs 0.000 description 2
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 2
- 108010093470 monomethyl auristatin E Proteins 0.000 description 2
- 201000000050 myeloid neoplasm Diseases 0.000 description 2
- LWGJTAZLEJHCPA-UHFFFAOYSA-N n-(2-chloroethyl)-n-nitrosomorpholine-4-carboxamide Chemical compound ClCCN(N=O)C(=O)N1CCOCC1 LWGJTAZLEJHCPA-UHFFFAOYSA-N 0.000 description 2
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 2
- 229960003301 nivolumab Drugs 0.000 description 2
- 230000009871 nonspecific binding Effects 0.000 description 2
- 231100000252 nontoxic Toxicity 0.000 description 2
- 230000003000 nontoxic effect Effects 0.000 description 2
- 239000003921 oil Substances 0.000 description 2
- 210000001672 ovary Anatomy 0.000 description 2
- 229960001756 oxaliplatin Drugs 0.000 description 2
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 238000002823 phage display Methods 0.000 description 2
- 230000008782 phagocytosis Effects 0.000 description 2
- 239000008177 pharmaceutical agent Substances 0.000 description 2
- 102000020233 phosphotransferase Human genes 0.000 description 2
- 229920001223 polyethylene glycol Polymers 0.000 description 2
- 229920002223 polystyrene Polymers 0.000 description 2
- 239000011148 porous material Substances 0.000 description 2
- 239000013641 positive control Substances 0.000 description 2
- OIGNJSKKLXVSLS-VWUMJDOOSA-N prednisolone Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OIGNJSKKLXVSLS-VWUMJDOOSA-N 0.000 description 2
- 208000023594 primary pulmonary diffuse large B-cell lymphoma Diseases 0.000 description 2
- 238000004393 prognosis Methods 0.000 description 2
- 210000001236 prokaryotic cell Anatomy 0.000 description 2
- 230000002035 prolonged effect Effects 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- 238000003259 recombinant expression Methods 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 229930002534 steroid glycoside Natural products 0.000 description 2
- 150000008143 steroidal glycosides Chemical class 0.000 description 2
- 238000003756 stirring Methods 0.000 description 2
- 210000002784 stomach Anatomy 0.000 description 2
- 201000011549 stomach cancer Diseases 0.000 description 2
- 238000001356 surgical procedure Methods 0.000 description 2
- 229940124598 therapeutic candidate Drugs 0.000 description 2
- 125000002088 tosyl group Chemical group [H]C1=C([H])C(=C([H])C([H])=C1C([H])([H])[H])S(*)(=O)=O 0.000 description 2
- 231100000331 toxic Toxicity 0.000 description 2
- 230000002588 toxic effect Effects 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 2
- 241000701447 unidentified baculovirus Species 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 235000014393 valine Nutrition 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 229910052727 yttrium Inorganic materials 0.000 description 2
- MHVJRKBZMUDEEV-APQLOABGSA-N (+)-Pimaric acid Chemical compound [C@H]1([C@](CCC2)(C)C(O)=O)[C@@]2(C)[C@H]2CC[C@](C=C)(C)C=C2CC1 MHVJRKBZMUDEEV-APQLOABGSA-N 0.000 description 1
- MHVJRKBZMUDEEV-UHFFFAOYSA-N (-)-ent-pimara-8(14),15-dien-19-oic acid Natural products C1CCC(C(O)=O)(C)C2C1(C)C1CCC(C=C)(C)C=C1CC2 MHVJRKBZMUDEEV-UHFFFAOYSA-N 0.000 description 1
- KWTSXDURSIMDCE-QMMMGPOBSA-N (S)-amphetamine Chemical compound C[C@H](N)CC1=CC=CC=C1 KWTSXDURSIMDCE-QMMMGPOBSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- 102100023990 60S ribosomal protein L17 Human genes 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 1
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 1
- 102000007471 Adenosine A2A receptor Human genes 0.000 description 1
- 108010085277 Adenosine A2A receptor Proteins 0.000 description 1
- 239000012103 Alexa Fluor 488 Substances 0.000 description 1
- 102100026882 Alpha-synuclein Human genes 0.000 description 1
- 101100339431 Arabidopsis thaliana HMGB2 gene Proteins 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 208000002109 Argyria Diseases 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- HFOBENSCBRZVSP-LKXGYXEUSA-N C[C@@H](O)[C@H](NC(=O)N[C@@H](CC(N)=O)c1nc(no1)[C@@H](N)CO)C(O)=O Chemical compound C[C@@H](O)[C@H](NC(=O)N[C@@H](CC(N)=O)c1nc(no1)[C@@H](N)CO)C(O)=O HFOBENSCBRZVSP-LKXGYXEUSA-N 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 102100023073 Calcium-activated potassium channel subunit alpha-1 Human genes 0.000 description 1
- 102100029968 Calreticulin Human genes 0.000 description 1
- 108090000549 Calreticulin Proteins 0.000 description 1
- 241000282832 Camelidae Species 0.000 description 1
- KXLUWEYBZBGJRZ-POEOZHCLSA-N Canin Chemical compound O([C@H]12)[C@]1([C@](CC[C@H]1C(=C)C(=O)O[C@@H]11)(C)O)[C@@H]1[C@@]1(C)[C@@H]2O1 KXLUWEYBZBGJRZ-POEOZHCLSA-N 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 241000251730 Chondrichthyes Species 0.000 description 1
- GPFVKTQSZOQXLY-UHFFFAOYSA-N Chrysartemin A Natural products CC1(O)C2OC2C34OC3(C)CC5C(CC14)OC(=O)C5=C GPFVKTQSZOQXLY-UHFFFAOYSA-N 0.000 description 1
- 208000030808 Clear cell renal carcinoma Diseases 0.000 description 1
- 241000699679 Cricetulus migratorius Species 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 206010052804 Drug tolerance Diseases 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 238000008157 ELISA kit Methods 0.000 description 1
- LLQPHQFNMLZJMP-UHFFFAOYSA-N Fentrazamide Chemical compound N1=NN(C=2C(=CC=CC=2)Cl)C(=O)N1C(=O)N(CC)C1CCCCC1 LLQPHQFNMLZJMP-UHFFFAOYSA-N 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 208000012766 Growth delay Diseases 0.000 description 1
- 206010053759 Growth retardation Diseases 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 108700010013 HMGB1 Proteins 0.000 description 1
- 101150021904 HMGB1 gene Proteins 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 102100037907 High mobility group protein B1 Human genes 0.000 description 1
- 101000834898 Homo sapiens Alpha-synuclein Proteins 0.000 description 1
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 1
- 101100166600 Homo sapiens CD28 gene Proteins 0.000 description 1
- 101000959820 Homo sapiens Interferon alpha-1/13 Proteins 0.000 description 1
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 1
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 1
- 101001023379 Homo sapiens Lysosome-associated membrane glycoprotein 1 Proteins 0.000 description 1
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 1
- 101000611936 Homo sapiens Programmed cell death protein 1 Proteins 0.000 description 1
- 101000611643 Homo sapiens Protein phosphatase 1 regulatory subunit 15A Proteins 0.000 description 1
- 101000652359 Homo sapiens Spermatogenesis-associated protein 2 Proteins 0.000 description 1
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 1
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 description 1
- 102000003839 Human Proteins Human genes 0.000 description 1
- 108090000144 Human Proteins Proteins 0.000 description 1
- 241000598436 Human T-cell lymphotropic virus Species 0.000 description 1
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 1
- 102000009490 IgG Receptors Human genes 0.000 description 1
- 108010073807 IgG Receptors Proteins 0.000 description 1
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 1
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 1
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 1
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 102000053646 Inducible T-Cell Co-Stimulator Human genes 0.000 description 1
- 108700013161 Inducible T-Cell Co-Stimulator Proteins 0.000 description 1
- 108010065920 Insulin Lispro Proteins 0.000 description 1
- 102000003777 Interleukin-1 beta Human genes 0.000 description 1
- 108090000193 Interleukin-1 beta Proteins 0.000 description 1
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 208000007766 Kaposi sarcoma Diseases 0.000 description 1
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 description 1
- 150000008575 L-amino acids Chemical class 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 108010092555 Large-Conductance Calcium-Activated Potassium Channels Proteins 0.000 description 1
- 101710177649 Low affinity immunoglobulin gamma Fc region receptor III Proteins 0.000 description 1
- 101710099301 Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 1
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 1
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 101100504121 Mus musculus Ighg gene Proteins 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 1
- RRMJMHOQSALEJJ-UHFFFAOYSA-N N-[5-[[4-[4-[(dimethylamino)methyl]-3-phenylpyrazol-1-yl]pyrimidin-2-yl]amino]-4-methoxy-2-morpholin-4-ylphenyl]prop-2-enamide Chemical compound CN(C)CC=1C(=NN(C=1)C1=NC(=NC=C1)NC=1C(=CC(=C(C=1)NC(C=C)=O)N1CCOCC1)OC)C1=CC=CC=C1 RRMJMHOQSALEJJ-UHFFFAOYSA-N 0.000 description 1
- 125000000729 N-terminal amino-acid group Chemical group 0.000 description 1
- 208000001894 Nasopharyngeal Neoplasms Diseases 0.000 description 1
- 206010061306 Nasopharyngeal cancer Diseases 0.000 description 1
- 206010061309 Neoplasm progression Diseases 0.000 description 1
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 1
- 244000061176 Nicotiana tabacum Species 0.000 description 1
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 1
- 108010075563 No. 407 Proteins 0.000 description 1
- 102220596838 Non-structural maintenance of chromosomes element 1 homolog_R38A_mutation Human genes 0.000 description 1
- 241000242726 Opisthorchis viverrini Species 0.000 description 1
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 description 1
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 1
- 206010031096 Oropharyngeal cancer Diseases 0.000 description 1
- 206010057444 Oropharyngeal neoplasm Diseases 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 102000038030 PI3Ks Human genes 0.000 description 1
- 108091007960 PI3Ks Proteins 0.000 description 1
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 241000224016 Plasmodium Species 0.000 description 1
- 206010035500 Plasmodium falciparum infection Diseases 0.000 description 1
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102100040714 Protein phosphatase 1 regulatory subunit 15A Human genes 0.000 description 1
- 239000012979 RPMI medium Substances 0.000 description 1
- 102100029986 Receptor tyrosine-protein kinase erbB-3 Human genes 0.000 description 1
- 101710100969 Receptor tyrosine-protein kinase erbB-3 Proteins 0.000 description 1
- 108091081062 Repeated sequence (DNA) Proteins 0.000 description 1
- 101001117144 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) [Pyruvate dehydrogenase (acetyl-transferring)] kinase 1, mitochondrial Proteins 0.000 description 1
- 241000242683 Schistosoma haematobium Species 0.000 description 1
- 206010040047 Sepsis Diseases 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 208000000102 Squamous Cell Carcinoma of Head and Neck Diseases 0.000 description 1
- 108091081024 Start codon Proteins 0.000 description 1
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 1
- 201000000331 Testicular germ cell cancer Diseases 0.000 description 1
- HATRDXDCPOXQJX-UHFFFAOYSA-N Thapsigargin Natural products CCCCCCCC(=O)OC1C(OC(O)C(=C/C)C)C(=C2C3OC(=O)C(C)(O)C3(O)C(CC(C)(OC(=O)C)C12)OC(=O)CCC)C HATRDXDCPOXQJX-UHFFFAOYSA-N 0.000 description 1
- 241000242541 Trematoda Species 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 1
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 description 1
- 229940127174 UCHT1 Drugs 0.000 description 1
- 208000025865 Ulcer Diseases 0.000 description 1
- 206010046865 Vaccinia virus infection Diseases 0.000 description 1
- HMNZFMSWFCAGGW-XPWSMXQVSA-N [3-[hydroxy(2-hydroxyethoxy)phosphoryl]oxy-2-[(e)-octadec-9-enoyl]oxypropyl] (e)-octadec-9-enoate Chemical compound CCCCCCCC\C=C\CCCCCCCC(=O)OCC(COP(O)(=O)OCCO)OC(=O)CCCCCCC\C=C\CCCCCCCC HMNZFMSWFCAGGW-XPWSMXQVSA-N 0.000 description 1
- 238000002679 ablation Methods 0.000 description 1
- 239000006096 absorbing agent Substances 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 208000009956 adenocarcinoma Diseases 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 1
- 229940025084 amphetamine Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 239000003708 ampul Substances 0.000 description 1
- 229940035676 analgesics Drugs 0.000 description 1
- 125000000129 anionic group Chemical group 0.000 description 1
- 239000000730 antalgic agent Substances 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 230000002927 anti-mitotic effect Effects 0.000 description 1
- 238000011394 anticancer treatment Methods 0.000 description 1
- 239000003080 antimitotic agent Substances 0.000 description 1
- 230000005975 antitumor immune response Effects 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 239000012736 aqueous medium Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 210000004507 artificial chromosome Anatomy 0.000 description 1
- 230000001174 ascending effect Effects 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 229960003852 atezolizumab Drugs 0.000 description 1
- 229940090047 auto-injector Drugs 0.000 description 1
- 230000006472 autoimmune response Effects 0.000 description 1
- 238000003705 background correction Methods 0.000 description 1
- 244000052616 bacterial pathogen Species 0.000 description 1
- 229960002903 benzyl benzoate Drugs 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 238000013357 binding ELISA Methods 0.000 description 1
- 239000012867 bioactive agent Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 210000002459 blastocyst Anatomy 0.000 description 1
- 102220346328 c.82G>T Human genes 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 239000004359 castor oil Substances 0.000 description 1
- 235000019438 castor oil Nutrition 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 238000000423 cell based assay Methods 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 238000002659 cell therapy Methods 0.000 description 1
- 230000019522 cellular metabolic process Effects 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 239000013522 chelant Substances 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 235000013330 chicken meat Nutrition 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 206010073251 clear cell renal cell carcinoma Diseases 0.000 description 1
- 238000011198 co-culture assay Methods 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 229940000425 combination drug Drugs 0.000 description 1
- 230000002301 combined effect Effects 0.000 description 1
- 230000024203 complement activation Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 230000001268 conjugating effect Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 239000003431 cross linking reagent Substances 0.000 description 1
- 238000002425 crystallisation Methods 0.000 description 1
- 230000008025 crystallization Effects 0.000 description 1
- 208000035250 cutaneous malignant susceptibility to 1 melanoma Diseases 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 206010052015 cytokine release syndrome Diseases 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000000432 density-gradient centrifugation Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- 150000002019 disulfides Chemical class 0.000 description 1
- 230000007783 downstream signaling Effects 0.000 description 1
- 210000002257 embryonic structure Anatomy 0.000 description 1
- 230000001804 emulsifying effect Effects 0.000 description 1
- 239000012645 endogenous antigen Substances 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 230000017188 evasion or tolerance of host immune response Effects 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 239000012997 ficoll-paque Substances 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 230000005251 gamma ray Effects 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 210000004392 genitalia Anatomy 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-L glutamate group Chemical group N[C@@H](CCC(=O)[O-])C(=O)[O-] WHUUTDBJXJRKMK-VKHMYHEASA-L 0.000 description 1
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- ZEMPKEQAKRGZGQ-XOQCFJPHSA-N glycerol triricinoleate Natural products CCCCCC[C@@H](O)CC=CCCCCCCCC(=O)OC[C@@H](COC(=O)CCCCCCCC=CC[C@@H](O)CCCCCC)OC(=O)CCCCCCCC=CC[C@H](O)CCCCCC ZEMPKEQAKRGZGQ-XOQCFJPHSA-N 0.000 description 1
- 208000035474 group of disease Diseases 0.000 description 1
- 231100000001 growth retardation Toxicity 0.000 description 1
- 201000000459 head and neck squamous cell carcinoma Diseases 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 201000005787 hematologic cancer Diseases 0.000 description 1
- 230000002489 hematologic effect Effects 0.000 description 1
- 229940022353 herceptin Drugs 0.000 description 1
- 231100000086 high toxicity Toxicity 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 229940038661 humalog Drugs 0.000 description 1
- 102000048776 human CD274 Human genes 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 230000028996 humoral immune response Effects 0.000 description 1
- 230000008348 humoral response Effects 0.000 description 1
- 150000007857 hydrazones Chemical class 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- BTXNYTINYBABQR-UHFFFAOYSA-N hypericin Chemical compound C12=C(O)C=C(O)C(C(C=3C(O)=CC(C)=C4C=33)=O)=C2C3=C2C3=C4C(C)=CC(O)=C3C(=O)C3=C(O)C=C(O)C1=C32 BTXNYTINYBABQR-UHFFFAOYSA-N 0.000 description 1
- 229940005608 hypericin Drugs 0.000 description 1
- PHOKTTKFQUYZPI-UHFFFAOYSA-N hypericin Natural products Cc1cc(O)c2c3C(=O)C(=Cc4c(O)c5c(O)cc(O)c6c7C(=O)C(=Cc8c(C)c1c2c(c78)c(c34)c56)O)O PHOKTTKFQUYZPI-UHFFFAOYSA-N 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 230000005934 immune activation Effects 0.000 description 1
- 230000008004 immune attack Effects 0.000 description 1
- 238000011502 immune monitoring Methods 0.000 description 1
- 230000008073 immune recognition Effects 0.000 description 1
- 230000006058 immune tolerance Effects 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 210000005008 immunosuppressive cell Anatomy 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 108020004201 indoleamine 2,3-dioxygenase Proteins 0.000 description 1
- 102000006639 indoleamine 2,3-dioxygenase Human genes 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 210000004347 intestinal mucosa Anatomy 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000010212 intracellular staining Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 230000005865 ionizing radiation Effects 0.000 description 1
- 239000000644 isotonic solution Substances 0.000 description 1
- 235000015110 jellies Nutrition 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 231100000518 lethal Toxicity 0.000 description 1
- 230000001665 lethal effect Effects 0.000 description 1
- 125000001909 leucine group Chemical group [H]N(*)C(C(*)=O)C([H])([H])C(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- 238000010999 medical injection Methods 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 210000004379 membrane Anatomy 0.000 description 1
- 210000001806 memory b lymphocyte Anatomy 0.000 description 1
- 210000003071 memory t lymphocyte Anatomy 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 231100000782 microtubule inhibitor Toxicity 0.000 description 1
- 229960004857 mitomycin Drugs 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 210000002200 mouth mucosa Anatomy 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 230000000869 mutational effect Effects 0.000 description 1
- 210000004296 naive t lymphocyte Anatomy 0.000 description 1
- 210000001989 nasopharynx Anatomy 0.000 description 1
- 230000001613 neoplastic effect Effects 0.000 description 1
- 230000004770 neurodegeneration Effects 0.000 description 1
- 208000015122 neurodegenerative disease Diseases 0.000 description 1
- 230000002314 neuroinflammatory effect Effects 0.000 description 1
- 238000007481 next generation sequencing Methods 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 210000004882 non-tumor cell Anatomy 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 201000011330 nonpapillary renal cell carcinoma Diseases 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 239000002674 ointment Substances 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 229960003104 ornithine Drugs 0.000 description 1
- 210000003300 oropharynx Anatomy 0.000 description 1
- 201000006958 oropharynx cancer Diseases 0.000 description 1
- 230000001151 other effect Effects 0.000 description 1
- NMHMNPHRMNGLLB-UHFFFAOYSA-N p-hydroxybenzene propanoic acid Natural products OC(=O)CCC1=CC=C(O)C=C1 NMHMNPHRMNGLLB-UHFFFAOYSA-N 0.000 description 1
- 238000004806 packaging method and process Methods 0.000 description 1
- 238000002638 palliative care Methods 0.000 description 1
- 201000002528 pancreatic cancer Diseases 0.000 description 1
- 208000008443 pancreatic carcinoma Diseases 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 239000006072 paste Substances 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 210000003899 penis Anatomy 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 210000001539 phagocyte Anatomy 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- WVDDGKGOMKODPV-ZQBYOMGUSA-N phenyl(114C)methanol Chemical compound O[14CH2]C1=CC=CC=C1 WVDDGKGOMKODPV-ZQBYOMGUSA-N 0.000 description 1
- VGEREEWJJVICBM-UHFFFAOYSA-N phloretin Chemical compound C1=CC(O)=CC=C1CCC(=O)C1=C(O)C=C(O)C=C1O VGEREEWJJVICBM-UHFFFAOYSA-N 0.000 description 1
- 150000003906 phosphoinositides Chemical class 0.000 description 1
- LFGREXWGYUGZLY-UHFFFAOYSA-N phosphoryl Chemical group [P]=O LFGREXWGYUGZLY-UHFFFAOYSA-N 0.000 description 1
- 230000002186 photoactivation Effects 0.000 description 1
- 239000001007 phthalocyanine dye Substances 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 239000000244 polyoxyethylene sorbitan monooleate Substances 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 229940068968 polysorbate 80 Drugs 0.000 description 1
- 230000008092 positive effect Effects 0.000 description 1
- 208000017805 post-transplant lymphoproliferative disease Diseases 0.000 description 1
- NROKBHXJSPEDAR-UHFFFAOYSA-M potassium fluoride Chemical compound [F-].[K+] NROKBHXJSPEDAR-UHFFFAOYSA-M 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 230000007112 pro inflammatory response Effects 0.000 description 1
- 230000000770 proinflammatory effect Effects 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 238000002818 protein evolution Methods 0.000 description 1
- 244000079416 protozoan pathogen Species 0.000 description 1
- SSKVDVBQSWQEGJ-UHFFFAOYSA-N pseudohypericin Natural products C12=C(O)C=C(O)C(C(C=3C(O)=CC(O)=C4C=33)=O)=C2C3=C2C3=C4C(C)=CC(O)=C3C(=O)C3=C(O)C=C(O)C1=C32 SSKVDVBQSWQEGJ-UHFFFAOYSA-N 0.000 description 1
- QHGVXILFMXYDRS-UHFFFAOYSA-N pyraclofos Chemical compound C1=C(OP(=O)(OCC)SCCC)C=NN1C1=CC=C(Cl)C=C1 QHGVXILFMXYDRS-UHFFFAOYSA-N 0.000 description 1
- 208000016691 refractory malignant neoplasm Diseases 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000012121 regulation of immune response Effects 0.000 description 1
- 208000015347 renal cell adenocarcinoma Diseases 0.000 description 1
- 230000002207 retinal effect Effects 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 238000002702 ribosome display Methods 0.000 description 1
- 102200017779 rs10132601 Human genes 0.000 description 1
- 102220232822 rs1085307660 Human genes 0.000 description 1
- 102220139548 rs61735306 Human genes 0.000 description 1
- 102200124087 rs76057237 Human genes 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- JACPFCQFVIAGDN-UHFFFAOYSA-M sipc iv Chemical compound [OH-].[Si+4].CN(C)CCC[Si](C)(C)[O-].C=1C=CC=C(C(N=C2[N-]C(C3=CC=CC=C32)=N2)=N3)C=1C3=CC([C]1C=CC=CC1=1)=NC=1N=C1[C]3C=CC=CC3=C2[N-]1 JACPFCQFVIAGDN-UHFFFAOYSA-M 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 239000008247 solid mixture Substances 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 210000004989 spleen cell Anatomy 0.000 description 1
- 239000012086 standard solution Substances 0.000 description 1
- 238000011301 standard therapy Methods 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- IXFPJGBNCFXKPI-FSIHEZPISA-N thapsigargin Chemical compound CCCC(=O)O[C@H]1C[C@](C)(OC(C)=O)[C@H]2[C@H](OC(=O)CCCCCCC)[C@@H](OC(=O)C(\C)=C/C)C(C)=C2[C@@H]2OC(=O)[C@@](C)(O)[C@]21O IXFPJGBNCFXKPI-FSIHEZPISA-N 0.000 description 1
- 238000011287 therapeutic dose Methods 0.000 description 1
- 150000003568 thioethers Chemical class 0.000 description 1
- 238000000954 titration curve Methods 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 229950007217 tremelimumab Drugs 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 201000008827 tuberculosis Diseases 0.000 description 1
- 230000005751 tumor progression Effects 0.000 description 1
- 229910052721 tungsten Inorganic materials 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 231100000397 ulcer Toxicity 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 208000007089 vaccinia Diseases 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 244000052613 viral pathogen Species 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 210000003905 vulva Anatomy 0.000 description 1
- 239000011534 wash buffer Substances 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 239000001993 wax Substances 0.000 description 1
Images






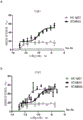






















































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New or modified breeds of animals
- A01K67/027—New or modified breeds of vertebrates
- A01K67/0275—Genetically modified vertebrates, e.g. transgenic
- A01K67/0276—Knock-out vertebrates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/28—Compounds containing heavy metals
- A61K31/282—Platinum compounds
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/19—Cytokines; Lymphokines; Interferons
- A61K38/20—Interleukins [IL]
- A61K38/2013—IL-2
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/6811—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a protein or peptide, e.g. transferrin or bleomycin
- A61K47/6813—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a protein or peptide, e.g. transferrin or bleomycin the drug being a peptidic cytokine, e.g. an interleukin or interferon
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/55—IL-2
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/5005—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells
- G01N33/5008—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics
- G01N33/5011—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics for testing antineoplastic activity
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/5005—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells
- G01N33/5008—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics
- G01N33/502—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics for testing non-proliferative effects
- G01N33/5026—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics for testing non-proliferative effects on cell morphology
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/5005—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells
- G01N33/5008—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics
- G01N33/5044—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics involving specific cell types
- G01N33/5047—Cells of the immune system
- G01N33/505—Cells of the immune system involving T-cells
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6803—General methods of protein analysis not limited to specific proteins or families of proteins
- G01N33/6845—Methods of identifying protein-protein interactions in protein mixtures
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6854—Immunoglobulins
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
- A61K2039/507—Comprising a combination of two or more separate antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/545—Medicinal preparations containing antigens or antibodies characterised by the dose, timing or administration schedule
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/40—Immunoglobulins specific features characterized by post-translational modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/524—CH2 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/54—F(ab')2
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/71—Decreased effector function due to an Fc-modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/734—Complement-dependent cytotoxicity [CDC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/75—Agonist effect on antigen
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/74—Fusion polypeptide containing domain for protein-protein interaction containing a fusion for binding to a cell surface receptor
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Organic Chemistry (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Urology & Nephrology (AREA)
- Hematology (AREA)
- Biophysics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Cell Biology (AREA)
- Genetics & Genomics (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Biotechnology (AREA)
- Epidemiology (AREA)
- Pathology (AREA)
- Analytical Chemistry (AREA)
- General Physics & Mathematics (AREA)
- Food Science & Technology (AREA)
- Toxicology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Tropical Medicine & Parasitology (AREA)
- Zoology (AREA)
- Gastroenterology & Hepatology (AREA)
- Physiology (AREA)
- Mycology (AREA)
- Environmental Sciences (AREA)
Abstract
本发明提供结合可诱导T细胞共刺激分子(Inducible T cell Co‑Stimulator;ICOS)的抗体。抗ICOS抗体用于调节调节性T细胞与效应T细胞之间的比率以刺激患者的免疫系统的治疗用途,包括治疗癌症中的用途。使用转基因敲除小鼠产生抗ICOS抗体,包括物种交叉反应性抗体的方法。
Description
技术领域
本发明涉及用于刺激哺乳动物免疫反应,尤其是T细胞反应的组合物。本发明还涉及此类组合物在免疫肿瘤学中的医疗用途,包括通过促进患者的抗肿瘤T细胞反应进行抗肿瘤治疗,并且涉及组合物在其它疾病和病状中的用途,在所述疾病和病状中组合物具有调节效应T细胞与调节性T细胞之间有利于效应T细胞活性的平衡的治疗益处,所述平衡例如通过刺激效应T细胞和/或通过耗减调节性T细胞来调节。
背景技术
可诱导T细胞共刺激分子(Inducible T cell Co-Stimulator;ICOS)为与调节免疫反应,特别是1999年首次鉴别出的体液性免疫反应有关的CD28基因家族成员[1]。其为55kDa跨膜蛋白,具有两个差异性糖基化的子单元的二硫键连接的同型二聚体形式存在。ICOS仅仅在T淋巴细胞上表达,且发现于多种T细胞亚群上。其以低含量存在于初始T淋巴细胞上,但在免疫活化后快速诱导其表达,例如在结合TCR且用CD28共刺激时响应于促炎性刺激上调[2、3]。ICOS在T细胞活化的后期阶段、记忆T细胞形成时且重要的是在通过T细胞依赖性B细胞反应调节体液性反应时起作用[4、5]。在细胞内,ICOS结合PI3K且活化激酶磷酸肌醇依赖性激酶1(PDK1)和蛋白激酶B(PKB)。ICOS活化防止细胞死亡且上调细胞代谢。在ICOS不存在(ICOS敲除)的情况下或在抗ICOS中和抗体存在的情况下都将抑制促炎性反应。
ICOS与在B细胞和抗原呈递细胞(antigen presenting cell;APC)上表达的ICOS配体(ICOS ligand;ICOSL)结合[6,7]。作为共刺激分子,其用以调节TCR介导的对抗原的免疫反应和抗体反应。ICOS在T调节性细胞上的表达可具有重要性,这是因为已表明此细胞类型在癌细胞的免疫监视中起负面作用-在卵巢癌中出现证明这一点的证据[8]。重要的是,已报告与存在于肿瘤微环境中的CD4+和CD8+效应细胞相比,在肿瘤内调节性T细胞(regulatory T cell;TReg)上ICOS表达较高。使用具有Fc介导的细胞效应子功能的抗体耗减TReg在临床前模型中已展现很强的抗肿瘤功效[9]。越来越多证据表明ICOS在用免疫检查点抑制剂治疗的动物模型以及患者中的抗肿瘤效应。在缺乏ICOS或ICOSL的小鼠中,抗CTLA4疗法的抗肿瘤效应减弱[10],而在正常小鼠中,ICOS配体增加了黑素瘤和前列腺癌中抗CTLA4治疗的效力[11]。此外,在人体内,晚期黑素瘤患者的回顾性研究显示在伊匹单抗(ipilimumab)(抗CTLA4)治疗之后ICOS的含量增加[12]。另外,ICOS表达在用抗CTLA4治疗的膀胱癌患者中上调[13]。也已观测到在用抗CTLA4疗法治疗的癌症患者中,产生CD4 T细胞的大部分肿瘤特异性IFN为ICOS阳性,而ICOS阳性CD4 T细胞的持续升高与存活率相关[12、13、14]。
WO2016/120789描述了抗ICOS抗体且提议其用于活化T细胞和用于治疗癌症、感染性疾病和/或脓毒症。产生许多鼠类抗ICOS抗体,其亚群报告为人类ICOS受体的激动剂。选择抗体“422.2”作为前导抗ICOS抗体,且将其人源化以生产命名为“H2L5”的人类“IgG4PE”抗体。据报导H2L5对人类ICOS具有1.34nM的亲和力且对猕猴ICOS具有0.95nM的亲和力,以在T细胞中诱导细胞因子产生并结合CD3刺激上调T细胞活化标记。然而,据报导与对照治疗组相比,携带移植的人类黑素瘤细胞的小鼠在用H2L5hIgG4PE治疗时显示仅微小肿瘤生长延迟或存活率增加。与伊匹单抗(抗CTLA-4)或派姆单抗(pembrolizumab)(抗PD-1)单药疗法相比,在与伊匹单抗或派姆单抗的组合实验中抗体也未能对肿瘤生长产生显著的进一步抑制。最后,在携带移植的结肠癌细胞(CT26)的小鼠中,与单独的抗CTL4和抗PD1疗法相比,低剂量的H2L5的小鼠交叉反应性替代物与伊匹单抗或派姆单抗的小鼠替代物组合仅轻微地提高总存活率。在携带移植的EMT6细胞的小鼠中显示强力治疗益处的类似缺乏。
WO2016/154177描述了抗ICOS抗体的其它实例。据报导这些抗体为CD4+T细胞(包括效应CD8+ T细胞(TEff))的激动剂,且耗减T调节子细胞(TReg)。描述了抗体对TEff与TReg细胞的选择性效应,借此抗体可优先耗减TReg同时具有对表达较低量ICOS的TEff的微小效应。提议抗ICOS抗体用于治疗癌症,且描述与抗PD-1或抗PD-L1抗体的组合疗法。
发明内容
用以增加效应T细胞活性的ICOS的抗体代表在免疫肿瘤学中和在CD8+ T细胞反应有益的其它医学情形(包括各种疾病和病状)下以及在疫苗接种方案中的治疗途径。在涉及免疫组分的许多疾病和病状中,在发挥CD8+ T细胞免疫反应的效应T细胞(TEff)与通过下调TEff来抑制所述免疫反应的调节性T细胞(TReg)之间存在平衡。本发明涉及调节有利于效应T细胞活性的此TEff/TReg平衡的抗体。引起ICOS高度阳性调节性T细胞的耗减的抗体将减轻TEff的抑制,且因此具有促进效应T细胞反应的净效应。抗ICOS抗体的额外或互补机构通过在ICOS受体含量下的激动活性来刺激效应T细胞反应。
与调节性T细胞(TReg)相比,ICOS在效应T细胞(TEff)上的相对表达和这些细胞群的相对活性将影响抗ICOS抗体活体内的整体效应。设想的作用模式将效应T细胞的激动作用与ICOS阳性调节性T细胞的耗减组合。对这两种不同T细胞群体的有差别且甚至相反的效应可由于其不同的ICOS表达水平而能够实现。抗ICOS抗体的可变区和恒定区分别的双重工程化可提供一种分子,其通过影响CD8/TReg比率来发挥对效应T细胞反应的净正效应。活化ICOS受体的激动剂抗体的抗原结合结构域可以与抗体恒定(Fc)区组合,所述抗体Fc区有助于下调和/或清除抗体所结合的高度表达细胞。效应子正恒定区可以用于募集针对靶细胞(TReg)的细胞效应子功能,例如用于促进抗体依赖性细胞介导的细胞毒性(antibody-dependent cell-mediated cytotoxicity;ADCC)或抗体依赖性细胞吞噬作用(antibodydependent cell phagocytosis;ADCP)。因此,抗体可对促进效应T细胞活化和对下调免疫抑制性T调节性细胞都起作用。由于ICOS在TReg上比在TEff上更高度表达,因此可以实现借此促进Teff功能同时耗减TReg的治疗平衡,从而导致T细胞免疫反应(例如,抗肿瘤反应或其它治疗有益的T细胞反应)的净增加。
数个临床前和临床研究已显示出肿瘤微环境(tumour microenvironment;TME)中的高效应T细胞与T-reg细胞比率与总存活率之间的很强的正相关。在卵巢癌患者中,CD8:T-reg细胞的比率已报导为良好临床结果的指示[15]。在接受伊匹单抗之后在转移性黑素瘤中进行类似观测[16]。在临床前研究中,也已显示TME中的高效应细胞:T-reg比率与抗肿瘤反应相关联[43]。
本发明提供结合人类ICOS的抗体。所述抗体靶向ICOS胞外结构域且因此与表达ICOS的T细胞结合。提供了已设计成对ICOS具有激动效应,因此增强效应T细胞的功能(如由增加IFNγ表达和分泌的能力指示)的抗体实例。如所提到,抗ICOS抗体也可以工程改造成耗减其所结合的细胞,这应该具有优先下调调节性T细胞、提升这些细胞对效应T细胞反应的抑制作用以及因此整体促进效应T细胞反应的效应。无论所述抗体的作用机制如何,都在经验上证明了根据本发明的抗ICOS抗体的确刺激T细胞反应且具有活体内抗肿瘤效应,如实例中所示。通过选择适当的抗体形式,例如包括具有Fc效应子功能期望水平的恒定区的那些抗体形式,或在适当时缺少此类效应子功能,可调适抗ICOS抗体以用于各种医学情形(包括疾病和病状的治疗)中,其中效应T细胞反应是有益的且/或其中期望抑制调节性T细胞。
示范性的抗体包括STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009,其序列陈述于本文中。
根据本发明的抗体可以是一种与包含STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的重链和轻链互补决定区(CDR)的抗体(例如,人类IgG1或ScFv),任选地包含STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的VH和VL结构域的抗体竞争以结合于人类ICOS的抗体。
根据本发明的抗体可包含STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009中的任一个的一个或多个CDR(例如,任何此类抗体的全部6个CDR或一组HCDR和/或LCDR)或如本文中所描述的其变体。
抗体可包含:抗体VH结构域,其包含CDR HCDR1、HCDR2和HCDR3;和抗体VL结构域,其包含CDR LCDR1、LCDR2和LCDR3,其中HCDR3为选自STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009的抗体的HCDR3或包含具有1、2、3、4或5个氨基酸改变的HCDR3。HCDR2可以是所选抗体的HCDR2,或其可包含具有1、2、3、4或5个氨基酸改变的HCDR2。HCDR1可以是所选抗体的HCDR1,或其可包含具有1、2、3、4或5个氨基酸改变的HCDR1。
抗体可包含:抗体VL结构域,其包含CDR HCDR1、HCDR2和HCDR3;和抗体VL结构域,其包含CDR LCDR1、LCDR2和LCDR3,其中LCDR3为选自STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009的抗体的LCDR3或包含具有1、2、3、4或5个氨基酸改变的LCDR3。LCDR2可以是所选抗体的LCDR2,或其可包含具有1、2、3、4或5个氨基酸改变的LCDR2。LCDR1可以是所选抗体的LCDR1,或其可包含具有1、2、3、4或5个氨基酸改变的LCDR1。
一种抗体可包含:
抗体VH结构域,包含互补决定区HCDR1、HCDR2和HCDR3,和
抗体VL结构域,包含互补决定区LCDR1、LCDR2和LCDR3,
其中重链互补决定区为STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的那些重链互补决定区,或包含具有1、2、3、4或5个氨基酸改变的STIM001、STIM002、STIM002-B、STIM003、STIM004或STIM005、STIM006、STIM007、STIM008或STIM009重链互补决定区;且/或
其中轻链互补决定区为抗体STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的那些轻链互补决定区,或包含具有1、2、3、4或5个氨基酸改变的STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009轻链互补决定区。
抗体可包含VH结构域,其包含一组重链互补决定区(HCDR)HCDR1、HCDR2和HCDR3,其中
HCDR1为STIM003的HCDR1,
HCDR2为STIM003的HCDR2,
HCDR3为STIM003的HCDR3,
或包含具有1、2、3、4、5或6个氨基酸改变的所述组HCDR。
抗体可包含VL结构域,其包含一组轻链互补决定区(LCDR)LCDR1、LCDR2和LCDR3,其中
LCDR1为STIM003的LCDR1,
LCDR2为STIM003的LCDR2,
LCDR3为STIM003的LCDR3,
或包含具有1、2、3、4、5或6个氨基酸改变的所述组LCDR。
氨基酸改变(例如,取代)可以在CDR中的任何残基位置处。氨基酸改变的实例为图35、图36和图37中所示出的那些氨基酸改变,所述诸图示出了抗ICOS抗体的变体序列比对。因此,STIM003CDR中的氨基酸改变可为存在于抗体CL-74570或抗体CL-71642中的对应位置处的残基的取代,如图36中所指示。
STIM003CDR中的实例氨基酸改变为根据IMGT限定的以下残基位置处的取代:
在HCDR1中,IMGT位置28处的取代,任选地为保守性取代,例如V28F。
在HCDR2中,IMGT位置59、63和/或64处的取代。任选地,位置59处的取代为N59I,位置63处的取代为G63D,且/或位置64处的取代为D64N和/或D64S。
在HCDR3中,IMGT位置106、108、109和/或112处的取代。任选地,位置106处的取代为R106A,位置108处的取代为F108Y,位置109处的取代为Y109F,且/或位置112处的取代为H112N。
在LCDR1中,位置36处的取代,例如R36S。
在LCDR3中,位置105、108和/或109处的取代。任选地,位置105处的取代为H105Q,位置108处的取代为D108G,且/或位置109处的取代为M109N或M109S。
本发明抗体可包含对应于人类生殖系基因段序列的VH和/或VL结构域构架区。举例来说,其可包含STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的一个或多个构架区。一个或多个构架区可为FR1、FR2、FR3和/或FR4。
如实例12中所描述,表E12-1展示了通过重组产生这些抗体的VH结构域的人类生殖系V、D和J基因段,且表E12-2展示了通过重组产生这些抗体的VL结构域的人类生殖系V和J基因段。本发明的抗体VH和VL结构域可基于这些V(D)J片段。
本发明抗体可包含抗体VH结构域,其:
(i)来源于人类重链V基因段、人类重链D基因段与人类重链J基因段的重组,其中
V片段为IGHV1-18(例如V1-18*01)、IGVH3-20(例如V3-20*d01)、IGVH3-11(例如V3-11*01)或IGVH2-5(例如V2-5*10);
D基因段为IGHD6-19(例如IGHD6-19*01)、IGHD3-10(例如IGHD3-10*01)或IGHD3-9(例如IGHD3-9*01);且/或
J基因段为IGHJ6(例如IGHJ6*02)、IGHJ4(例如IGHJ4*02)或IGHJ3(例如IGHJ3*02),或
(ii)包含构架区FR1、FR2、FR3和FR4,其中
FR1与任选地具有1、2、3、4或5个氨基酸改变的人类生殖系V基因段IGHV1-18(例如V1-18*01)、IGVH3-20(例如V3-20*d01)、IGVH3-11(例如V3-11*01)或IGVH2-5(例如V2-5*10)对准,
FR2与任选地具有1、2、3、4或5个氨基酸改变的人类生殖系V基因段IGHV1-18(例如V1-18*01)、IGVH3-20(例如V3-20*d01)、IGVH3-11(例如V3-11*01)或IGVH2-5(例如V2-5*10)对准,
FR3与任选地具有1、2、3、4或5个氨基酸改变的人类生殖系V基因段IGHV1-18(例如V1-18*01)、IGVH3-20(例如V3-20*d01)、IGVH3-11(例如V3-11*01)或IGVH2-5(例如V2-5*10)对准,且/或
FR4与任选地具有1、2、3、4或5个氨基酸改变的人类生殖系J基因段IGJH6(例如JH6*02)、IGJH4(例如JH4*02)或IGJH3(例如JH3*02)对准。
VH结构域的FR1、FR2和FR3通常与同一生殖系V基因段对准。因此,举例来说,抗体可包含来源于人类重链V基因段IGHV3-20(例如VH3-20*d01)、人类重链D基因段与人类重链J基因段IGJH4(例如JH4*02)的重组的VH结构域。抗体可包含VH结构域构架区FR1、FR2、FR3和FR4,其中FR1、FR2和FR3各自与具有至多1、2、3、4或5个氨基酸改变的人类生殖系V基因段IGHV3-20(例如IGVH3-20*d01)对准,且FR4与具有至多1、2、3、4或5个氨基酸改变的人类生殖系J基因段IGHJ4(例如IGHJ4*02)对准。对准可以很精确,但在一些情况下,一个或多个残基可以由生殖系突变,因此可能存在氨基酸取代,或在更罕见的情况下存在缺失或插入。
本发明抗体可包含抗体VL结构域,其:
(i)来源于人类轻链V基因段与人类轻链J基因段的重组,其中
V片段为IGKV2-28(例如IGKV2-28*01)、IGKV3-20(例如IGKV3-20*01)、IGKV1D-39(例如IGKV1D-39*01)或IGKV3-11(例如IGKV3-11*01),且/或
J基因段为IGKJ4(例如IGKJ4*01)、IGKJ2(例如IGKJ2*04)、IGLJ3(例如IGKJ3*01)或IGKJ1(例如IGKJ1*01);或
(ii)包含构架区FR1、FR2、FR3和FR4,其中
FR1与任选地具有1、2、3、4或5个氨基酸改变的人类生殖系V基因段IGKV2-28(例如IGKV2-28*01)、IGKV3-20(例如IGKV3-20*01)、IGKV1D-39(例如IGKV1D-39*01)或IGKV3-11(例如IGKV3-11*01)对准,
FR2与任选地具有1、2、3、4或5个氨基酸改变的人类生殖系V基因段IGKV2-28(例如IGKV2-28*01)、IGKV3-20(例如IGKV3-20*01)、IGKV1D-39(例如IGKV1D-39*01)或IGKV3-11(例如IGKV3-11*01)对准,
FR3与任选地具有1、2、3、4或5个氨基酸改变的人类生殖系V基因段IGKV2-28(例如IGKV2-18*01)、IGVH3-20(例如V3-20*01)、IGKV1D-39(例如IGKV1D-39*01)或IGKV3-11(例如IGKV3-11*01)对准,且/或
FR4与任选地具有1、2、3、4或5个氨基酸改变的人类生殖系J基因段IGKJ4(例如IGKJ4*01)、IGKJ2(例如IGKJ2*04)、IGKJ3(例如IGKJ3*01)或IGKJ1(例如IGKJ1*01)对准。
VL结构域的FR1、FR2和FR3通常与同一生殖系V基因段对准。因此,举例来说,抗体可包含来源于人类轻链V基因段IGKV3-20(例如IGKV3-20*01)与人类轻链J基因段IGKJ3(例如IGKJ3*01)的重组的VL结构域。抗体可包含VL结构域构架区FR1、FR2、FR3和FR4,其中FR1、FR2和FR3各自与具有至多1、2、3、4或5个氨基酸改变的人类生殖系V基因段IGKV3-20(例如IGKV3-20*01)对准,且FR4与具有至多1、2、3、4或5个氨基酸改变的人类生殖系J基因段IGKJ3(例如IGKJ3*01)对准。对准可以很精确,但在一些情况下,一个或多个残基可以由生殖系突变,因此可能存在氨基酸取代,或在更罕见的情况下存在缺失或插入。
根据本发明的抗体可包含抗体VH结构域,其为STIM001、STIM002、STIM002-B、STIM003、STIM004或STIM005、STIM006、STIM007、STIM008或STIM009的VH结构域,或其具有与STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的抗体VH结构域序列至少90%一致的氨基酸序列。氨基酸序列一致性可为至少95%。
抗体可包含抗体VL结构域,其为STIM001、STIM002、STIM002-B、STIM003、STIM004或STIM005、STIM006、STIM007、STIM008或STIM009的VL结构域,或其具有与STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的抗体VL结构域序列至少90%一致的氨基酸序列。氨基酸序列一致性可为至少95%。
具有STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的HCDR或具有那些CDR的变体的抗体VH结构域可以与具有同一抗体的LCDR或具有那些CDR的变体的抗体VL结构域配对。类似地,STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009中的任一个的VH结构域或所述VH结构域的变体可以与同一抗体的VL结构域或同一抗体的VL结构域变体配对。
举例来说,抗体可包含抗体STIM001 VH结构域和STIM001 VL结构域。在另一实例中,抗体可包含抗体STIM002 VH结构域和STIM002 VL结构域。在另一实例中,抗体可包含抗体STIM003 VH结构域和STIM003 VL结构域。
抗体可包含恒定区,任选地人类重链和/或轻链恒定区。示范性同种型为IgG,例如人类IgG1。
本发明的其它方面包括编码本文中所描述的抗体序列的核酸分子、含有此类核酸的宿主细胞和通过培养宿主细胞并且表达且任选地分离或纯化抗体来产生抗体的方法。由此获得所表达的抗体。本文中所描述的抗体的VH和VL结构域可以类似方式产生且为本发明的各方面。还提供了包含所述抗体的医药组合物。
本发明的其它方面涉及ICOS敲除的非人类动物和其用于产生人类ICOS的抗体的用途。在ICOS敲除的动物中,例如由于编码ICOS的基因已失活或从动物基因组中缺失而不表达ICOS。此类动物适用于产生物种交叉反应性抗体,所述抗体同时识别人类ICOS和来自非人类物种的ICOS。免疫耐受的正态过程意味着识别“自身”抗原的淋巴细胞缺失或失活以防止体内的自身免疫反应,而在非人类敲除动物中缺少内源性ICOS抗原意味着在以重组蛋白形式注射或使用表达ICOS的细胞系或囊泡时,动物的免疫系统不应对所述抗原耐受,且因此可建立针对ICOS的免疫反应。敲除动物的免疫组库应含有能够识别来自所述动物物种的ICOS蛋白质的淋巴细胞。用人类ICOS进行免疫的非人类测试动物(例如小鼠)可因此产生同时结合人类ICOS和所述测试动物ICOS(例如小鼠ICOS)的抗体。
这种方法具有至少两个优点。第一,物种交叉反应性抗体可以用于在投入人类临床试验的研发之前在非人类测试动物中进行临床前测试。第二,敲除动物的免疫系统可能能够识别与表达ICOS动物识别到的那些表位相比更大数量的人类ICOS分子上的潜在表位,使得敲除动物的免疫组库可以含有抗体的更大功能多样性。由于在来自不同物种的同源ICOS分子的序列之间存在相似度,因此非人类动物的免疫系统通常可耐受匹配非人类动物ICOS的那些序列的人类ICOS蛋白质的那些区域,而此耐受化并不发生在敲除动物中。
实例中展示了使用ICOS敲除动物的能力以及其用于产生交叉反应性抗体的优势。尤其出人意料的是,ICOS敲除动物可成功地免疫以产生抗体反应,这是因为ICOS自身与例如生发中心的形成和维持的免疫系统生物学有关并且有助于通过其对作为ICOS+ve细胞的T滤泡辅助细胞的作用产生免疫反应[37]。出于这种考虑,可以预测ICOS敲除动物最多产生不良抗体反应。出人意料地,在ICOS敲除小鼠中获得强力滴度,且高度功能性抗体从抗体组库(包括合乎需要的交叉反应性抗体)当中分离。
在所附权利要求书中陈述本发明的示范性实施例。
附图说明
现将参考附图更详细地描述本发明的某些方面和实施例。
图1:ICOS KO和野生型Kymouse针对在CHO细胞上表达的人类和小鼠ICOS两种的血清滴度通过流式细胞测量术来确定。数据说明了各自用人类ICOS表达MEF细胞和人类ICOS蛋白进行免疫的(a)ICOS KO小鼠(KO)或(b)野生型非ICOS KO小鼠(HK或HL)的血清中的免疫球蛋白结合在CHO细胞上表达的人类ICOS(人类ICOS结合)或小鼠ICOS(小鼠ICOS结合)的能力。几何平均值为如通过流式细胞测量术所确定的与细胞结合的免疫球蛋白的荧光强度的量度。
图2:人类ICOS配体用人类ICOS受体中和HTRF。与C398.4A和相应同种型对照相比,呈人类IgG1格式的STIM001到STIM009抗ICOS mAb的中和图谱。数据代表四个实验。
图3:小鼠ICOS配体用小鼠ICOS受体中和HTRF。与C398.4A和相应同种型对照相比,呈人类IgG1格式的STIM001到STIM009抗ICOS mAb的中和图谱。数据代表三个实验。
图4:人类ICOS配体用人类ICOS受体直接中和HTRF。与C398.4A和相应同种型对照相比,呈人类IgG4.PE格式的STIM001到STIM009抗ICOS mAb的中和图谱。数据代表四个实验。
图5:小鼠ICOS配体用小鼠ICOS受体中和HTRF。与C398.4A和相应同种型对照相比,呈人类IgG4.PE格式的STIM001到STIM009抗ICOS mAb的中和图谱。数据代表四个实验。
图6a:通过使用新制分离的NK细胞作为效应细胞进行STIM001介导的ADCC对MJ细胞的浓度依赖性研究。将效应细胞和靶细胞(效应细胞:靶细胞比率为5:1)与抗体一起培育2小时。从溶解靶细胞中释放的BATDA如制造商试剂盒说明书中所描述来测量。HC为杂交同种型对照。
图6b、图6c、图6d:用新制分离的NK细胞作为效应细胞进行STIM001和STIM003介导的ADCC对MJ细胞的浓度依赖性研究。将效应细胞和靶细胞(效应细胞:靶细胞比率为5:1)与抗体一起培育2小时。从溶解靶细胞中释放的BATDA如制造商试剂盒说明书中所描述来测量。HC为杂交同种型对照。
图6e、图6f、图6g:用新制分离的NK细胞作为效应细胞进行STIM001(hIgG1)和STIM003(hIgG1)介导的ADCC对转染ICOS的CCRF-CEM细胞的浓度依赖性研究。将效应细胞和靶细胞(效应细胞:靶细胞比率为5:1)与抗体一起培育4小时。从溶解靶细胞中释放的BATDA如制造商试剂盒说明书中所描述来测量。HC为杂交同种型对照。
图7、图8、图9:抗ICOS抗体抑制CT26肿瘤生长且在作为单药疗法或与抗PDL1组合给药时提高存活率。STIM001 mIgG2a比mIgG1格式更有效。在每个曲线图上指示已治愈或患有稳定疾病的动物的数量。
图10:2×2组合CT26活体内功效研究。每个治疗组由展示出单个动物的肿瘤尺寸的“蛛状曲线图”表示(n=10/组)。当与抗PDL1抗体组合时,STIM001延缓经过治疗的动物的肿瘤生长且提高其存活率。在STIM001 mIgG2a存在的情况下观测到的功效优于STIM001mIgG1的功效。最后,STIM001 mIgG2a与抗PDL1 mIgG2a组合为用以引起抗肿瘤反应使得60%的动物的疾病被治愈的最有效组合。对于每个组来说,在相应曲线图的右上指示其疾病被治愈的动物的数量。在第6、8、10、13、15和17天给药。
图11:曲线图展示出用抗ICOS或抗PDL1单药疗法或组合疗法治疗的动物随时间推移的CT26肿瘤体积。每个治疗组由展示出单个动物的肿瘤尺寸的“蛛状曲线图”表示(n=10/组)。对于每个组来说,在相应曲线图的右上指示肿瘤尺寸小于100mm3(其疾病稳定/被治愈)的动物的数量。在第6、8、10、13、15和17天进行给药。给药时间由阴影区域指示。(a)同种型对照;(b)抗PDL1 mIgG2a AbW;(c)抗ICOS STIM003 mIgG1;(d)抗ICOS STIM003mIgG2a;(e)抗PDL1 mIgG2a AbW+STIM003 mIgG1;(f)抗PDL1 mIgG2a AbW+STIM003mIgG2a。STIM003 mIgG2在与抗PDL1(AbW)mIgG2a组合时显著抑制CT26肿瘤生长。
图12:MJ细胞活体外活化分析——珠粒结合。与抗ICOS C398.4A和相应同种型对照相比,与珠粒结合的STIM001、STIM002和STIM003抗ICOS mAb的刺激图谱。数据代表两个实验的平均值(在C398.4A同种型对照珠粒的情况下n=1)。
图13:MJ细胞活体外活化分析-培养板结合。与抗ICOS C398.4A和相应同种型对照相比,与培养板结合的STIM001、STIM002、STIM003和STIM004抗ICOS mAb的刺激图谱。数据代表两个实验的平均值。
图14:与活化T细胞结合的STIM001和STIM003 hIgG1的FACS分析。(a)展示了与活化T细胞结合的预标记抗体的剂量反应的代表性实验,而(b)展示了根据裸抗体的剂量反应的结合接着展示了用二级标记抗体进行的检测。表格指示如使用GraphPad Prism所确定的相关EC50(M)。
图15:STIM001和STIM003展示了在肿瘤部位处对T细胞区室的同种型依赖性效应。将总共1×10E5 CT-26肿瘤细胞皮下植入Balb/c雌性小鼠中。在植入后第13天和第15天,腹膜内给予动物抗体或生理盐水(n=10/一组)。在植入后第16天,从肿瘤携带动物(n=8/一组)中采集脾脏和肿瘤,将其解离和染色以用于FACS分析。A,对于CD4细胞来说为阳性的CD3细胞的百分比。B,对于CD8细胞来说为阳性的CD3细胞的百分比。C,作为Foxp3+和CD25+的CD4细胞的百分比。D,对于Foxp3+和CD25+来说为阳性的脾脏中的CD4细胞的百分比。E,在全部CD4细胞中CD4效应细胞的百分比。F,CD8效应细胞与T-Reg细胞的比率。G,CD4效应细胞与T-Reg细胞的比率。使用GraphPad Prism进行统计分析,将全部经过抗体治疗的组与经过生理盐水治疗的组进行比较,P值在显著(p<0.05)时标注。各值表示平均值+SD(n=8小鼠/组)。对于F:各值表示平均值+SEM。
图16:来自对分离人类T细胞的STIM001(hIgG1)和STIM003(hIgG1)激动剂效应的浓度依赖性研究的实例数据,所述分离人类T细胞用抗CD3/抗CD28戴诺珠粒(dynabead)在T细胞活化分析1(参见实例9b)中共刺激3天。IFN-γ产生用作激动效应的指示。STIM001(hIgG1)和STIM003(hIgG1)以培养板结合可溶性或交联可溶性(Fc连接的Ab)格式测试且与杂交同种型对照(HC hIgG1)进行比较。培养板结合分析中的比较包括的是仓鼠抗体C398.4A和其同种型对照(仓鼠IgG)。上部图展示了来自培养板结合抗体的数据。下部图展示了来自呈可溶性和交联格式的IgG1抗体的数据。左部图和右部图分别使用来自两个独立人类供体的T细胞。
图17:T细胞活化分析1(参见实例9)中STIM001的实例数据集。数据指示在来自8个独立人类供体的T细胞的一种给定剂量下由STIM001(hIgG1)或其杂交同种型对照(HCIgG1)诱导的IFN-γ水平。在5μg/ml下使用培养板结合的抗体(图17a)。在15μg/ml下使用可溶性抗体(图17b)。每个点代表一个由编号(例如D214)识别的供体。使用威尔科克森(Wilcoxon)统计测试评估显著性:*,p<0.05和**,p<0.01。
图18:T细胞活化分析1(参见实例9)中STIM003的实例数据集。数据指示在来自8个独立人类健康供体的T细胞的一种给定剂量下由STIM003(hIgG1)或其杂交同种型对照(HCIgG1)诱导的IFN-γ水平。在15μg/ml下使用可溶性抗体(图18a)。在5μg/ml下使用培养板结合的抗体(图18b)。每个点代表一个由编号(例如D214)识别的供体。使用威尔科克森统计测试评估显著性:*,p<0.05和**,p<0.01。
图19:来自T细胞活化分析2(参见实例9c)的实例数据。对分离人类T细胞的STIM001(hIgG1)和STIM003(hIgG1)激动剂效应的研究,所述分离人类T细胞用抗CD3/抗CD28戴诺珠粒刺激3天,接着在培养基中静置3天且最后用培养板结合的STIM001、STIM003或C398.4A Ab+/-CD3Ab重新刺激。数据将在一个给定剂量下且与CD3Ab组合(TCR接合)由STIM001、STIM003与其杂交对照IgG1(A、C、E)或C398.4A与其仓鼠IgG对照(B、D、F)诱导的IFN-γ(A、B)、TNF-α(C、D)和IL-2(E、F)水平进行比较。每个点代表可由其编号(例如D190)识别的独立供体。Ab与其同种型对照之间的统计显著性使用威尔科克森统计测试和所指示的p值评估。应注意STIM003浓度稍微不同于HC IgG1的浓度(5.4μg/ml与5μg/ml)。
图20:展示出在CT26肿瘤中和在携带肿瘤的动物的在其表面上表达ICOS的脾脏中免疫细胞(CD8 T效应细胞、CD4 T效应细胞和CD4/FoxP3 TReg细胞)的百分比的曲线图。各值表示平均值±SD(n=8)。使用非参数邓恩氏(Dunn's)多重比较测试计算P值。NS=不显著;***=p<0.001;****=p<0.0001。
图21:如由平均荧光强度(MFI)所确定的ICOS在免疫细胞(CD8 T效应、CD4 T效应和CD4/FoxP3 TReg)表面上的相对表达。各值表示平均值±SD(n=8)。使用非参数邓恩氏多重比较测试计算P值。****=p<0.0001,**=p<0.01。应注意脾脏(低)与肿瘤(高)之间的荧光强度的差异。
图22:STIM001和STIM003对CT26肿瘤微环境中不同免疫细胞的百分比的影响。*=p<0.05。
图23:抗体STIM001和STIM003对CT26肿瘤微环境中调节性T细胞(CD4+/FoxP3+细胞)的百分比的影响。**=p<0.05,****=p<0.0001。各值表示平均值±SD(n=8)。使用非参数邓恩氏多重比较测试计算P值。
图24:STIM001和STIM003 mIgG2显著增加CT26肿瘤中CD8效应T细胞与TReg比率和CD4效应T细胞与TReg比率。通过将肿瘤中效应细胞的百分比除以肿瘤中调节性T细胞的百分比来确定比率。
图25:抗体对携带CT26肿瘤的动物的脾脏中免疫细胞的百分比的影响。
图26:抗体对携带CT26肿瘤的动物的脾脏中调节性T细胞(CD4+/FoxP3+细胞)的百分比的影响。
图27:携带CT26肿瘤的动物的脾脏中的(A)CD8效应:Treg比率和(B)CD4:TReg比率。
图28:AF647共轭STIM001、STIM003和hIgG1杂交对照(HC IgG1)在活化毛里求斯猕猴(Mauritian cynomolgus)泛T细胞上的表面染色。来自使用不同T细胞供体来源的分析的数据分别展示于A和B中。EC50值指示于表中。
图29:CT26 Balb/C模型的卡普兰迈耶曲线(Kaplan Meier curve)。阴影展示了给药窗。对数秩(LogRank)p<0.0001。
图30、图31、图32、图33:展示出用于实例20中描述的研究的小鼠的A20肿瘤体积随时间推移的曲线图。每个治疗组由展示出单个动物的肿瘤尺寸的蛛状曲线图表示,n=8/组。对于每个组来说,无肿瘤迹象(指示疾病的治愈)的动物的数量在曲线图的左下指示。在肿瘤细胞植入后第8天、第11天、第15天、第18天、第22天、第25天和第29天进行给药且给药时间由灰色阴影区域指示。与对照组(图30)和抗PD-L1治疗组(图31)相比,STIM001 mIgG2a(图32)和STIM003 mIgG2a(图33)治疗组展示了A20肿瘤生长的显著抑制。
图34:来自实例11c中描述的使用抗PD-L1 mIgG2a抗体与单次剂量的STIM003mIgG2a对比多次剂量的STIM003 mIgG2a的组合的CT26活体内功效研究的数据。每个治疗组由展示出单个动物的肿瘤尺寸的“蛛状曲线图”表示(n=8/组)。对于每个组,在相应曲线图的右下指示其疾病被治愈的动物的数量。每种抗体的给药天数由相应曲线图下方的箭头指示。
图35:STIM002 VH(顶部)和VL(底部)结构域氨基酸序列,其展示出在STIM001、STIM002B和相关抗体CL-61091、CL-64536、CL-64837、CL-64841和CL-64912的对应序列方面和/或在人类生殖系方面不同的残基。根据IMGT进行序列编号。
图36:STIM003 VH(顶部)和VL(底部)结构域氨基酸序列,其展示出在相关抗体CL-71642和CL-74570的对应序列方面和/或在人类生殖系方面不同的残基。根据IMGT进行序列编号。此处示出了从测序获得的抗体CL-71642的VL结构域而未示出N端残基。从比对中可以看出完整VH结构域序列将包含N端谷氨酸。
图37:STIM007 VH(顶部)和VL(底部)结构域氨基酸序列,其展示出在STIM008的对应序列方面和/或在人类生殖系方面不同的残基。根据IMGT进行序列编号。
图38:STIM003(抗ICOS)和AbW(抗PD-L1)mIgG2a抗体在J558同基因模型中的效应。每个治疗组由展示出单个动物的肿瘤尺寸的“蛛状曲线图”表示(n=10或n=8/组)。STIM003单药疗法在3/8的动物的疾病痊愈的情况下证实了某种功效。类似地,抗PDL1在这个模型中是有效的,其中6/8的动物在第37天疾病痊愈。STIM003 mIgG2在与抗PDL1抗体组合时完全抑制肿瘤生长且提高经过治疗的动物的存活率。对于每个组,在相应曲线图的右下指示其疾病被治愈的动物的数量。给药天数由虚线指示(第11天、第15天、第18天、第22天、第25天和第29天)。
图39:量化肿瘤组织中不同TILS细胞亚型上的ICOS表达(阳性细胞百分比和相对表达/dMFI)。(A)对于ICOS表达为阳性的免疫细胞亚型%和(B)用生理盐水或抗PD-L1或抗PD-1替代性抗体治疗的动物的免疫细胞亚型的ICOS dMFI(ICOS阳性细胞上的相对ICOS表达)。在第0天将1×106个活细胞/毫升的100μl植入小鼠(n=7或n=8)。在第13天和第15天将130μg的抗体腹膜内给予动物。在第16天分离组织样本并分析。TReg种群仅包括CD4+/FOXP3+细胞(右端侧曲线图)且全部为Foxp3阴性的“效应”CD4细胞不包括CD4+/FOXP3+细胞(左端侧曲线图)。参见实例22。
图40:来自A20活体内功效研究的数据。每个治疗组由展示出单个动物的肿瘤尺寸的“蛛状曲线图”表示(n=10/组)。对于每个组,在相应曲线图上指示其疾病被治愈的动物的数量。对于多次剂量来说,在由虚线指示的第8天、第11天、第15天、第18天、第22天和第25天给药。对于单次剂量来说,动物仅在第8天接受腹膜内(IP)注射。(A)生理盐水;(B)STIM003 mIgG2a多次剂量;(C)STIM003 mIgG2a单次剂量。参见实例23。
图41:在STIM003 mIgG2a 60μg固定剂量下实例23中所报告的研究的卡普兰-迈耶曲线。SD=单次剂量,第8天。MD=从第8天起多次剂量BIW。
图42:在来自给予生理盐水的携带CT26肿瘤的动物(n=4/时间点)的主要T细胞亚群(T-reg[CD4+/FoxP3+]、CD4 Eff[CD4+/FoxP3-]细胞和CD8+)上的ICOS表达。在治疗后第1天、第2天、第第3天、第4天和第8天进行免疫细胞表型且在全部时间点在所有组织中对ICOS表达染色。A-D示出在四种不同组织中在全部时间点的ICOS阳性细胞百分比。E-H示出在所有四种不同组织中在全部时间点的ICOS dMFI(相对表达)。参见实例24。
图43:FACS分析展现TME中响应于STIM003 mIgG2a抗体的T-reg耗减。携带CT-26肿瘤的动物在肿瘤细胞植入后第12天用单次剂量(6μg、60μg或200μg)的STIM003治疗。在治疗后第1天、第2天、第3天、第4天和第8天采集用于FACS分析的组织(n=4/时间点)。在不同时间点示出T-reg细胞(CD4+CD25+Foxp3+)在全部肿瘤中的百分比(A)和T-reg细胞在血液中的百分比(B)。参见实例24。
图44:CD8:T-reg比率和CD4效应:T-reg比率响应于STIM003 mIgG2a的增加。携带CT-26肿瘤的动物在肿瘤细胞植入后第12天接受单次剂量(6μg、60μg或200μg)的STIM003mIgG2a。在治疗后第1天、第2天、第3天、第4天和第8天采集用于FACS分析的组织(n=4/时间点),且计算T效应与T-reg比率。(A)和(B)肿瘤和血液中的CD8:T-reg比率,(C)和(D)肿瘤和血液中的CD4效应:T-reg比率。参见实例24。
图45:STIM003治疗通过TIL与增加的脱粒和Th1细胞因子产生相关。在治疗后第8天,分离TIL且进行FACS分析以检测CD4和CD8 T细胞上的CD107a表达(A-B)。并行地,来自解离肿瘤的细胞在布雷菲德菌素(Brefeldin)-A存在的情况下静置4小时,细胞对T细胞标记进行染色且渗透以进行胞内染色从而检测IFN-γ和TNF-α(C-H)。参见实例24。
具体实施方式
ICOS
根据本发明的抗体结合人类ICOS的胞外结构域。因此,抗体结合ICOS表达T淋巴细胞。除非上下文另外指示,否则本文中所提及的“ICOS”或“ICOS受体”可为人类ICOS。人类、猕猴和小鼠ICOS的序列展示于随附序列表中,且可从NCBI获得,如人类NCBIID:NP_036224.1、小鼠NCBIID:NP_059508.2和猕猴GenBank ID:EHH55098.1。
交叉反应性
根据本发明的抗体优选地具交叉反应性,且可例如结合小鼠ICOS以及人类ICOS的胞外结构域。抗体可以结合其它非人类ICOS,包括例如猕猴等灵长类动物的ICOS。意图在人体内用于治疗用途的抗ICOS抗体必须结合人类ICOS,而与其它物种的ICOS结合在人类临床环境中将不具有直接治疗相关性。尽管如此,本文中的数据指示同时结合人类和小鼠ICOS的抗体具有使得其尤其适用作激动剂且耗减分子的特性。这可以由正被交叉反应性抗体靶向的一个或多个特定表位引起。然而,无论基础理论如何,交叉反应性抗体具有高值且为作为用于临床前和临床研究的治疗性分子的极佳候选对象。
如实验性实例中所解释,此处所描述的STIM抗体使用KymouseTM技术产生,其中小鼠已工程改造成缺乏小鼠ICOS的表达(ICOS敲除)。ICOS敲除转基因动物和它们用于产生交叉反应性抗体的用途为本发明的其它方面。
与一个物种的抗原相比,一种量化抗体的物种交叉反应性程度的方法在其对另一物种的抗原的亲和力方面呈倍数差,例如对人类ICOS对比小鼠ICOS的亲和力的倍数差。亲和力可量化为KD,其是指如通过SPR测定的抗体-抗原反应的平衡解离常数,其中呈Fab格式的抗体如本文中其它地方所描述。物种交叉反应性抗ICOS抗体在结合人类和小鼠ICOS的亲和力方面可具有30倍或更小、25倍或更小、20倍或更小、15倍或更小、10倍或更小或5倍或更小的倍数差。换句话说,结合人类ICOS的胞外结构域的KD可以在结合小鼠ICOS的胞外结构域的KD的30倍、25倍、20倍、15倍、10倍或5倍数内。如果结合两种物种的抗原的KD都满足阈值,例如如果结合人类ICOS的KD和结合小鼠ICOS的KD都为10mM或更小,优选地5mM或更小,更优选地1mM或更小,那么抗体也可以被视为具有交叉反应性。KD可为10nM或更小、5nM或更小、2nM或更小或1nM或更小。KD可为0.9nM或更小、0.8nM或更小、0.7nM或更小、0.6nM或更小、0.5nM或更小、0.4nM或更小、0.3nM或更小、0.2nM或更小或0.1nM或更小。
结合人类ICOS和小鼠ICOS的交叉反应性的替代性量度为例如在HTRF分析(参见实例8)中抗体中和与ICOS受体结合的ICOS配体的能力。本文提供物种交叉反应抗体的实例,包括STIM001、STIM002、STIM002-B、STIM003、STIM005和STIM006,在HTRF分析中,其中的每一个确认为中和人类B7-H2(ICOS配体)与人类ICOS的结合,且中和小鼠B7-H2与小鼠ICOS的结合。当需要人类和小鼠ICOS的交叉反应性抗体时,可选择这些抗体或其变体中的任一个。物种交叉反应性抗ICOS抗体可具有抑制人类ICOS与人类ICOS受体的结合的IC50,如HTRF分析中所测定,其在抑制小鼠ICOS与小鼠ICOS受体的结合的IC50的25倍、20倍、15倍、10倍或5倍内。如果抑制人类ICOS与人类ICOS受体结合的IC50和抑制小鼠ICOS与小鼠ICOS受体结合的IC50都是1mM或更小、优选地0.5mM或更小,例如30nM或更小、20nM或更小、10nM或更小,那么抗体也可以被视为具有交叉反应性。IC50可为5nM或更小、4nM或更小、3nM或更小或2nM或更小。在一些情况下,IC50将为至少0.1nM、至少0.5nM或至少1nM。
特异性
根据本发明的抗体对ICOS优选地具有特异性。也就是说,抗体结合其在靶蛋白上的表位、ICOS(人类ICOS和优选地如上文所提及的小鼠和/或猕猴ICOS),但未展示出与不呈递所述表位的分子(包括CD28基因家族中的其它分子)的显著结合。根据本发明的抗体优选地不结合人类CD28。抗体优选地也不结合小鼠或猕猴CD28。
CD28在由其配体CD80和CD86在通过TCR进行抗原识别的情形下接合到专业抗原呈递细胞上时共刺激T细胞反应。对于本文中所描述的抗体的各种活体内用途,避免与CD28结合视为有利的。抗ICOS抗体不与CD28结合应允许CD28与其天然配体相互作用并产生用于T细胞活化的适当共刺激信号。另外,抗ICOS抗体不与CD28结合避免了过度激动的风险。CD28的过度刺激可在不需要通过TCR识别同源抗原的正常需要的情况下诱导静息T细胞的增殖,从而可能导致尤其人类受试者中T细胞的失控活化和随之而来的细胞因子释放综合征。因此,不由根据本发明的抗体识别CD28代表了所述抗体在人体内的安全临床使用方面的优势。
如本文中其它地方所论述,本发明延伸到多特异性抗体(例如,双特异性抗体)。多特异性(例如,双特异性)抗体可包含(i)用于ICOS的抗体抗原结合位点和(ii)识别另一抗原(例如,PD-L1)的另一抗原结合位点(任选地如本文中所描述的抗体抗原结合位点)。可以测定单个抗原结合位点的特异性结合。因此,特异性结合ICOS的抗体包括包含特异性结合ICOS的抗原结合位点的抗体,其中任选地用于ICOS的抗原结合位点包含在抗原结合分子内,所述抗原结合分子进一步包括用于一个或多个其它抗原的一个或多个额外结合位点,例如结合ICOS和PD-L1的双特异性抗体。
亲和力
可以测定抗体与ICOS的结合亲和力。抗体对其抗原的亲和力可以关于平衡解离常数KD、抗体-抗原相互作用的缔合或结合速率(Ka)与解离或解离速率(kd)的比率Ka/Kd量化。可以使用表面等离子共振(SPR)测量抗体-抗原结合的Kd、Ka与Kd。
根据本发明的抗体可以结合KD为10mM或更小、优选地5mM或更小、更优选地1mM或更小的人类ICOS的EC结构域。KD可为50nM或更小、10nM或更小、5nM或更小、2nM或更小或1nM或更小。KD可为0.9nM或更小、0.8nM或更小、0.7nM或更小、0.6nM或更小、0.5nM或更小、0.4nM或更小、0.3nM或更小、0.2nM或更小或0.1nM或更小。KD可至少为0.1nM,例如至少0.01nM或至少0.1nM。
可以使用SPR用Fab格式的抗体进行亲和力的量化。合适的方法如下:
1.将抗人类(或其它物种匹配的抗体恒定区)IgG例如通过伯胺偶联来与生物传感器芯片(例如,GLM芯片)偶联;
2.使抗人类IgG(或其它匹配物种抗体)暴露于例如呈Fab格式的测试抗体来捕获芯片上的测试抗体;
3.在一系列浓度下将测试抗原通过芯片的捕获表面,例如在5000nM、1000nM、200nM、40nM、8nM和2nM下,和在0nM(即,仅缓冲液)下;以及
4.在25℃下使用SPR测定将测试抗体与测试抗原的结合亲和力。缓冲液可以为pH7.6、150mM NaCl、0.05%清洁剂(例如,P20)和3mM EDTA。缓冲液可以任选地含有10mMHEPES。HBS-EP可以用作操作缓冲液。HBS-EP可从Teknova公司(加利福尼亚;目录编号H8022)获得。
捕获表面的再生可利用pH 1.7的10mM甘氨酸进行。这移除了所捕获抗体且允许表面用于另一相互作用。结合数据可以使用标准技术与1:1固有模型拟合,例如使用ProteOnXPR36TM分析软件固有的模型。
多种SPR仪器为已知的,例如BiacoreTM、ProteOn XPR36TM(生物- )和
)和 (萨皮达因仪器公司(Sapidyne Instruments))。SPR的工作实例发现于实例7中。
(萨皮达因仪器公司(Sapidyne Instruments))。SPR的工作实例发现于实例7中。
如所描述,亲和力可以通过SPR用Fab格式的抗体来测定,其中抗原与芯片表面偶联且测试抗体通过溶液中呈Fab格式的芯片,以测定单体抗体-抗原相互作用的亲和力。亲和力可以在任何期望pH(例如pH 5.5或pH 7.6)和任何期望温度(例如25℃或37℃)下测定。如实例7中所报告,根据本发明的抗体结合表观亲和力小于2nM的人类ICOS,如通过SPR使用呈单价(Fab)格式的抗体所测定。
测量抗体与ICOS的结合的其它方式包括荧光激活细胞分选术(fluorescenceactivated cell sorting;FACS),例如,使用具有ICOS的外源性表面表达的细胞(例如CHO细胞)或表达ICOS的内源性水平的活化原代T细胞。如利用FACS所量测与ICOS表达细胞结合的抗体指示抗体能够结合ICOS的胞外(EC)结构域。
ICOS受体激动作用
ICOS配体(ICOSL,又称为B7-H2)为与ICOS受体结合的细胞表面表达分子[17]。这种胞间配体-受体相互作用有助于ICOS在T细胞表面上多聚化,活化受体以及在T细胞中刺激下游信号传导。在效应T细胞中,这种受体活化刺激效应T细胞反应。
抗ICOS抗体可以充当ICOS的激动剂,模拟且甚至超过天然ICOS配体对受体的这种刺激作用。此类激动作用可以由抗体促进ICOS在T细胞上的多聚化的能力引起。这种情况的一个机制为其中抗体在T细胞表面上的ICOS与相邻细胞(例如,B细胞、抗原呈递细胞或其它免疫细胞)上的受体(例如Fc受体)之间形成胞间桥。另一机制为其中具有多个(例如两个)抗原结合位点(例如两个VH-VL结构域对)的抗体桥接多个ICOS受体分子且因此促进多聚化。这些机制的组合可能会出现。
可以使用呈可溶形式(例如,呈免疫球蛋白格式或包含两个空间分离的抗原结合位点(例如两个VH-VL对)的其它抗体格式)的抗体(包括或不包括交联剂)或使用结合于固体表面以提供抗原结合位点的系拴阵列的抗体针对活体外T细胞活化分析测试激动作用。在此类分析中,激动作用分析可使用人类ICOS阳性T淋巴细胞细胞系,例如MJ细胞(ATCCCRL-8294)作为用于活化的靶标T细胞。可以测定测试抗体的一个或多个T细胞活化量度且将其与参考分子或阴性对照进行比较,以确定在通过与参考分子或对照相比的测试抗体实现的T细胞活化中是否存在统计显著(p<0.05)差异。一个合适的T细胞活化量度是产生细胞因子,例如IFNγ、TNFα或IL-2。熟练的技术人员将包括按需要合适的对照、测试抗体与对照之间的标准化分析条件。合适的阴性对照为呈相同格式(例如,同种型对照)的不结合ICOS的抗体,例如,对不存在于分析系统中的抗原具有特异性的抗体。观测到测试抗体相对于同源同型对照的显著差异,在分析的动态范围内指示抗体在所述分析中充当ICOS受体的激动剂。
激动剂抗体可定义为一种抗体,其在T细胞活化分析中测试时:
与对照抗体相比,具有明显较低的诱导IFNγ产生的EC50;
与对照抗体相比,诱导明显较高的最大IFNγ产生;
与ICOSL-Fc相比,具有明显较低的诱导IFNγ产生的EC50;
与ICOSL-Fc相比,诱导明显较高的最大IFNγ产生;
与参考抗体C398.4A相比,具有明显较低的诱发IFNγ产生的EC50;且/或
与C398.4A相比,诱导明显较高的最大IFNγ产生。
活体外T细胞分析包括实例13的珠粒结合分析、实例14的培养板结合分析和实例15的可溶形式分析。
与参考值或对照值相比,明显较低值或明显较高值可例如至多0.5倍差、至多0.75倍差、至多2倍差、至多3倍差、至多4倍差或至多5倍差。
因此,在一个实例中,与对照相比,根据本发明的抗体在使用呈珠粒结合格式的抗体的MJ细胞活化分析中具有明显较低,例如至少低2倍的诱导IFNγ的EC50。
珠粒结合分析使用结合于珠粒表面的抗体(以及,对于对照或参考实验,使用对照抗体、参考抗体或ICOSL-Fc)。可使用磁珠,且不同种类是可商购的,例如甲苯磺酰基活化的DYNABEADS M-450(DYNAL公司,5Delaware Drive,Lake Success,N.Y.11042产品编号140.03、140.04)。珠粒可以如实例13中所描述来涂布,或通常通过使涂布材料溶解于碳酸盐缓冲液(pH 9.6,0.2M)中或所属领域中已知的其它方法涂布。使用珠粒方便地允许以良好程度的精确度测定结合于珠粒表面的蛋白质的量。标准Fc蛋白质量化方法可用于珠粒上的偶联蛋白质量化。可参考分析的动态范围内的相关标准使用任何合适的方法。虽然实例13中例示了DELFIA,但可以使用ELISA或其它方法。
还可以在活体外原代人类T淋巴细胞中测量抗体的激动活性。抗体诱导此类T细胞中IFNγ的表达的能力指示ICOS激动作用。本文中描述了使用原代细胞的两个T细胞活化分析(参见实例2):T细胞活化分析1和T细胞活化分析2。优选地,在T细胞活化分析1和/或T细胞活化分析2中,与对照抗体相比,抗体将在5μg/ml下展示出IFNγ的显著(p<0.05)诱导。如上文所提及,抗ICOS抗体可以在比此类分析中的ICOS-L或C398.4更大程度上刺激T细胞活化。因此,在T细胞活化分析1或2中,与对照抗体或参考抗体相比,所述抗体可以在5μg/ml下展示出明显(p<0.05)更大的IFNγ诱导。TNFα或IL-2诱导可测量为替代分析读数。
抗ICOS抗体的激动作用可有助于其改变活体内,例如病变部位(例如肿瘤微环境)中的TReg与TEff细胞群之间的有利于TEff细胞的平衡的能力。如本文中其它地方所论述,可测定抗体通过活化的ICOS阳性效应T细胞增强肿瘤细胞杀灭的能力。
T细胞依赖性杀灭
可以在生物学上相关的环境中使用活体外共培养分析测定效应T细胞功能,在活体外共培养分析中,将肿瘤细胞与相关免疫细胞一起培育以引起免疫细胞依赖性杀灭,其中观测抗ICOS抗体对由TEff进行的肿瘤细胞杀灭的作用。
可测定抗体通过活化的ICOS阳性效应T细胞增强肿瘤细胞杀灭的能力。与对照抗体相比,抗ICOS抗体可以刺激明显更大的(p<0.05)肿瘤细胞杀灭。与参考分子(例如ICOS配体或C398.4抗体)相比,在此类分析中,抗ICOS抗体可以刺激类似或更大的肿瘤细胞杀灭。类似程度的肿瘤细胞杀灭可以表示为与参考分子的分析读数小于两倍差的测试抗体的分析读数。
ICOS配体-受体中和效能
根据本发明的抗体可以是抑制ICOS与其配体ICOSL结合的一种抗体。
抗体抑制ICOS受体与其配体结合的程度被称作其配体-受体中和效能。除非另外说明,否则效能通常表示为以pM为单位的IC50值。在配体结合研究中,IC50为使受体结合减少最大50%的特异性结合水平的浓度。IC50可以通过标绘特异性受体结合%作为抗体浓度的对数函数且使用例如Prism(GraphPad)等软件程序将西格摩德函数(sigmoidalfunction)拟合到数据以产生IC50值来计算。在HTRF分析中,可以测定中和效能。针对配体-受体中和效能的HTRF分析的详细工作实例陈述于实例8中。
IC50值可以代表多个测量值的平均值。因此,举例来说,IC50值可从三次实验的结果获得,且可接着计算平均IC50值。
在配体-受体中和分析中,抗体的IC50可为1mM或更小,例如0.5mM或更小。IC50可为30nM或更小、20nM或更小、10nM或更小、5nM或更小、4nM或更小、3nM或更小或2nM或更小。IC50可为至少0.1nM、至少0.5nM或至少1nM。
抗体
如实例中更详细描述,我们分离和表征了命名为以下的备受关注的抗体:STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009。在本发明的各种方面中,除非上下文另外指示,否则抗体可以选自这些抗体中的任一个,或选自STIM001、STIM002、STIM003、STIM004和STIM005的子集。这些抗体中的每一个的序列提供于随附序列表中,其中对于每个抗体来说,分别示出以下序列:编码VH结构域的核苷酸序列;VH结构域的氨基酸序列;VH CDR1氨基酸序列;VH CDR2氨基酸序列;VH CDR3氨基酸序列;编码VL结构域的核苷酸序列;VL结构域的氨基酸序列;VL CDR1氨基酸序列;VLCDR2氨基酸序列;以及VL CDR3氨基酸序列。本发明涵盖具有展示于随附序列表和/或附图中的所有抗体的VH和/或VL结构域序列的抗ICOS抗体,以及包含那些抗体的HCDR和/或LCDR且任选地具有完整重链和/或完整轻链氨基酸序列的抗体。
STIM001具有Seq ID No:366的重链可变区(VH)氨基酸序列,其包含Seq ID No:363的CDRH1氨基酸序列、Seq ID No:364的CDRH2氨基酸序列和Seq ID No:365的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:367。STIM001具有Seq ID No:373的轻链可变区(VL)氨基酸序列,其包含Seq ID No:370的CDRL1氨基酸序列、Seq ID No:371的CDRL2氨基酸序列和Seq ID No:372的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:374。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq IDNo:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、SeqID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:368(重链核酸序列Seq ID No:369)。全长轻链氨基酸序列为Seq ID No:375(轻链核酸序列Seq ID No:376)。
STIM002具有Seq ID No:380的重链可变区(VH)氨基酸序列,其包含Seq ID No:377的CDRH1氨基酸序列、Seq ID No:378的CDRH2氨基酸序列和Seq ID No:379的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:381。STIM002具有Seq ID No:387的轻链可变区(VL)氨基酸序列,其包含Seq ID No:384的CDRL1氨基酸序列、Seq ID No:385的CDRL2氨基酸序列和Seq ID No:386的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:388或Seq ID No:519。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、SeqID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq IDNo:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq IDNo:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq IDNo:382(重链核酸序列Seq ID No:383)。全长轻链氨基酸序列为Seq ID No:389(轻链核酸序列Seq ID No:390或Seq ID No:520)。
STIM002-B具有Seq ID No:394的重链可变区(VH)氨基酸序列,其包含Seq ID No:391的CDRH1氨基酸序列、Seq ID No:392的CDRH2氨基酸序列和Seq ID No:393的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:395。STIM002-B具有Seq ID No:401的轻链可变区(VL)氨基酸序列,其包含Seq ID No:398的CDRL1氨基酸序列、Seq ID No:399的CDRL2氨基酸序列和Seq ID No:400的CDRL3氨基酸序列。VL结构域的轻链核酸序列为SeqID No:402。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq IDNo:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq IDNo:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq IDNo:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:396(重链核酸序列Seq ID No:397)。全长轻链氨基酸序列为Seq ID No:403(轻链核酸序列SeqID No:404)。
STIM003具有Seq ID No:408的重链可变区(VH)氨基酸序列,其包含Seq ID No:405的CDRH1氨基酸序列、Seq ID No:406的CDRH2氨基酸序列和Seq ID No:407的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:409或Seq ID No:521。STIM003具有Seq IDNo:415的轻链可变区(VL)氨基酸序列,其包含Seq ID No:412的CDRL1氨基酸序列、Seq IDNo:413的CDRL2氨基酸序列和Seq ID No:414的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:4416。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、SeqID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq IDNo:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq IDNo:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq IDNo:410(重链核酸序列Seq ID No:411或Seq ID No:522)。全长轻链氨基酸序列为Seq IDNo:417(轻链核酸序列Seq ID No:418)。
STIM004具有Seq ID No:422的重链可变区(VH)氨基酸序列,其包含Seq ID No:419的CDRH1氨基酸序列、Seq ID No:420的CDRH2氨基酸序列和Seq ID No:421的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:423。STIM004具有Seq ID No:429的轻链可变区(VL)氨基酸序列,其包含Seq ID No:426的CDRL1氨基酸序列、Seq ID No:427的CDRL2氨基酸序列和Seq ID No:428的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:430或Seq ID No:431。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、SeqID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq IDNo:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq IDNo:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq IDNo:424(重链核酸序列Seq ID No:425)。全长轻链氨基酸序列为Seq ID No:432(轻链核酸序列Seq ID No:433或Seq ID No:434)。
STIM005具有Seq ID No:438的重链可变区(VH)氨基酸序列,其包含Seq ID No:435的CDRH1氨基酸序列、Seq ID No:436的CDRH2氨基酸序列和Seq ID No:437的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:439。STIM005具有Seq ID No:445的轻链可变区(VL)氨基酸序列,其包含Seq ID No:442的CDRL1氨基酸序列、Seq ID No:443的CDRL2氨基酸序列和Seq ID No:444的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:446。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq IDNo:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、SeqID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:440(重链核酸序列Seq ID No:441)。全长轻链氨基酸序列为Seq ID No:447(轻链核酸序列Seq ID No:448)。
STIM006具有Seq ID No:452的重链可变区(VH)氨基酸序列,其包含Seq ID No:449的CDRH1氨基酸序列、Seq ID No:450的CDRH2氨基酸序列和Seq ID No:451的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:453。STIM006具有Seq ID No:459的轻链可变区(VL)氨基酸序列,其包含Seq ID No:456的CDRL1氨基酸序列、Seq ID No:457的CDRL2氨基酸序列和Seq ID No:458的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:460。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq IDNo:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、SeqID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:454(重链核酸序列Seq ID No:455)。全长轻链氨基酸序列为Seq ID No:461(轻链核酸序列Seq ID No:462)。
STIM007具有Seq ID No:466的重链可变区(VH)氨基酸序列,其包含Seq ID No:463的CDRH1氨基酸序列、Seq ID No:464的CDRH2氨基酸序列和Seq ID No:465的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:467。STIM007具有Seq ID No:473的轻链可变区(VL)氨基酸序列,其包含Seq ID No:470的CDRL1氨基酸序列、Seq ID No:471的CDRL2氨基酸序列和Seq ID No:472的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:474。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq IDNo:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、SeqID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:468(重链核酸序列Seq ID No:469)。全长轻链氨基酸序列为Seq ID No:475(轻链核酸序列Seq ID No:476)。
STIM008具有Seq ID No:480的重链可变区(VH)氨基酸序列,其包含Seq ID No:477的CDRH1氨基酸序列、Seq ID No:478的CDRH2氨基酸序列和Seq ID No:479的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:481。STIM008具有Seq ID No:487的轻链可变区(VL)氨基酸序列,其包含Seq ID No:484的CDRL1氨基酸序列、Seq ID No:485的CDRL2氨基酸序列和Seq ID No:486的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:488。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq IDNo:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、SeqID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:482(重链核酸序列Seq ID No:483)。全长轻链氨基酸序列为Seq ID No:489(轻链核酸序列Seq ID No:490)。
STIM009具有Seq ID No:494的重链可变区(VH)氨基酸序列,其包含Seq ID No:491的CDRH1氨基酸序列、Seq ID No:492的CDRH2氨基酸序列和Seq ID No:493的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:495。STIM009具有Seq ID No:501的轻链可变区(VL)氨基酸序列,其包含Seq ID No:498的CDRL1氨基酸序列、Seq ID No:499的CDRL2氨基酸序列和Seq ID No:500的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:502。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq IDNo:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、SeqID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:496(重链核酸序列Seq ID No:497)。全长轻链氨基酸序列为Seq ID No:503(轻链核酸序列Seq ID No:504)。
根据本发明的抗体为包含免疫球蛋白结构域的免疫球蛋白或分子,无论是天然的或是部分或完全合成制造的。抗体可以是IgG、IgM、IgA、IgD或IgE分子或其抗原特异性抗体片段(包括但不限于Fab、F(ab')2、Fv、二硫键连接的Fv、scFv、单域抗体、封闭构形多特异性抗体、二硫键连接的scfv、双功能抗体),无论是来源于天然地生产抗体的任何物种或是由重组DNA技术产生;无论是从血清、B细胞、杂交瘤、转染瘤、酵母菌或是细菌分离。可使用常规技术将抗体人源化。术语抗体覆盖包含抗体抗原结合位点的任何多肽或蛋白质。抗原结合位点(互补位)为抗体与其靶抗原(ICOS)的表位结合且与所述表位互补的部分。
术语“表位”是指由抗体结合的抗原区域。表位可限定为结构性或功能性的。功能性表位通常为结构性表位的子集且具有直接有助于相互作用的亲和力的那些残基。表位还可以是构形性的,即,由非线性氨基酸构成。在某些实施例中,表位可以包括作为分子的化学活性表面基团的决定子,所述基团例如氨基酸、糖侧链、磷酰基或磺酰基,并且在某些实施例中,可具有特异性三维结构性特征和/或特异性电荷特征。
抗原结合位点为包含抗体的一个或多个CDR且能够结合抗原的多肽或结构域。举例来说,多肽包含CDR3(例如,HCDR3)。举例来说,多肽包含抗体的可变结构域的CDR1和CDR2(例如,HCDR1和HCDR2)或CDR1到CDR3(例如,HCDR1到HCDR3)。
抗体抗原结合位点可以由一个或多个抗体可变结构域提供。在实例中,抗体结合位点由单一可变结构域,例如重链可变结构域(VH结构域)或轻链可变结构域(VL结构域)提供。在另一实例中,结合位点包含VH/VL对或两对或更多对此类对。因此,抗体抗原结合位点可以包含VH和VL。
抗体可为包括恒定区的整个免疫球蛋白,或可为抗体片段。抗体片段为完整抗体的一部分,例如包含完整抗体的抗原结合区或可变区。抗体片段的实例包括:
(i)Fab片段,一种由VL、VH、CL和CH1结构域组成的单价片段;(ii)F(ab')2片段,一种包括两个在铰链区处通过二硫桥键连接的Fab片段的二价片段;
(iii)Fd片段,由VH和CH1结构域组成;
(iv)Fv片段,其由抗体的单臂的VL和VH结构域组成;
(v)dAb片段(Ward等人,(1989)《自然》341:544-546;其以全文引用的方式并入本文中),其由VH或VL结构域组成;和
(vi)保留特异性抗原结合功能的分离的互补决定区(CDR)。
抗体的其它实例为包含重链(5'-VH-(任选铰链)-CH2-CH3-3')的二聚体且不含轻链的H2抗体。
单链抗体(例如,ScFv)为常用片段。多特异性抗体可以由抗体片段形成。本发明抗体可以按需要采用任何此类格式。
任选地,抗体免疫球蛋白结构域可以融合或共轭到额外多肽序列和/或标记、标签、毒素或其它分子。抗体免疫球蛋白结构域可以融合或共轭到一个或多个不同抗原结合区,得到能够结合除了ICOS以外的第二抗原的分子。本发明抗体可为多特异性抗体,例如双特异性抗体,其包含(i)用于ICOS的抗体抗原结合位点和(ii)识别另一抗原(例如,PD-L1)的另一抗原结合位点(任选地如本文中所描述的抗体抗原结合位点)。
抗体通常包含抗体VH和/或VL结构域。抗体的分离的VH和VL结构域也是本发明的部分。抗体可变结构域为抗体的轻链和重链的部分,所述轻链和重链包括互补决定区(CDR;即,CDR1、CDR2和CDR3)和构架区(FR)的氨基酸序列。因此,在VH和VL结构域中的每一个内的是CDR和FR。VH结构域包含一组HCDR,且VL结构域包含一组LCDR。VH是指重链的可变结构域。VL是指轻链的可变结构域。每个VH和VL通常由从氨基端到羧基端按以下顺序配置的三个CDR及四个FR构成:FR1、CDR1、FR2、CDR2、FR3、CDR3、FR4。根据本发明中使用的方法,指配给CDR和FR的氨基酸位置可根据Kabat(免疫学感兴趣的蛋白质的序列(美国国家卫生研究院,贝塞斯达,马里兰州,1987和1991))或根据IMGT命名法界定。抗体可包含抗体VH结构域,其包含VH CDR1、CDR2和CDR3以及构架。所述抗体可替代地包含或还包含抗体VL结构域,其包含VL CDR1、CDR2和CDR3以及构架。根据本发明的抗体VH和VL结构域和CDR的实例如形成本发明的部分的随附序列表中所列。展示于序列表中的CDR根据IMGT系统限定[18]。本文中所公开的所有VH和VL序列、CDR序列、CDR组和HCDR组和LCDR组代表本发明的方面和实施例。如本文所描述,“CDR组”包含CDR1、CDR2和CDR3。因此,HCDR组是指HCDR1、HCDR2和HCDR3,且LCDR组是指LCDR1、LCDR2和LCDR3。除非另外说明,否则“CDR组”包括HCDR和LCDR。
本发明抗体可包含如本文中所描述的一个或多个CDR,例如CDR3,且任选地还包含CDR1和CDR2以形成CDR组。CDR或CDR组可为STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009中的任一个的CDR或CDR组,或可为如本文中所描述的其变体。
本发明提供包含抗体STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009中的任一个的HCDR1、HCDR2和/或HCDR3和/或这些抗体中的任一个的LCDR1、LCDR2和/或LCDR3(例如CDR组)的抗体。抗体可包含这些抗体中的一个的VH CDR组。任选地,所述抗体还可以包含这些抗体中的一个的VL CDR组,且VL CDR可来自与VH CDR相同或不同的抗体。
本发明还提供了包含所公开HCDR组的VH结构域和/或包含所公开LCDR组的VL结构域。
通常,尽管如下文进一步所论述,VH或VL结构域单独可用于结合抗原,但VH结构域与VL结构域配对以提供抗体抗原结合位点。STIM003 VH结构域可以与STIM003 VL结构域配对,使得形成同时包含STIM003 VH和VL结构域的抗体抗原结合位点。提供了本文中所公开的其它VH和VL结构域的类似实施例。在其它实施例中,STIM003 VH与除STIM003 VL外的VL结构域配对。轻链杂乱性在所属领域中为明确的。同样,本发明提供了本文中所公开的其它VH和VL结构域的类似实施例。
因此,抗体STIM001、STIM002、STIM003、STIM004和STIM005中的任一个的VH可以与抗体STIM001、STIM002、STIM003、STIM004和STIM005中的任一个的VL配对。另外,抗体STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009中的任一个的VH可以与抗体STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009中的任一个的VL配对。
在抗体构架内,抗体可包含一个或多个CDR,例如CDR组。构架区可具有人类生殖系基因段序列。因此,抗体可为具有VH结构域的人类抗体,所述VH结构域包含人类生殖系构架中的HCDR组。通常,抗体还具有包含例如人类生殖系构架中的LCDR组的VL结构域。抗体“基因段”(例如VH基因段、D基因段或JH基因段)是指具有作为抗体的部分来源的核酸序列的寡核苷酸,例如,VH基因段为包含从FR1到CDR3的部分对应于多肽VH结构域的核酸序列的寡核苷酸。人类V、D与J基因段重组以产生VH结构域,且人类V与J片段重组以产生VL结构域。D结构域或区域是指抗体链的多样性结构域或区域。J结构域或区域是指抗体链的接合结构域或区域。体细胞超突变可产生具有构架区的抗体VH或VL结构域,所述构架区不与对应的基因段精确匹配或对准,但序列比对可用于识别最接近基因段,且因此识别作为特定VH或VL结构域来源的特定基因段组合。当使抗体序列与基因段对准时,抗体氨基酸序列可以与由基因段编码的氨基酸序列对准,或抗体核苷酸序列可以与基因段的核苷酸序列直接对准。
STIM抗体VH和VL结构域序列针对相关抗体和针对人类生殖系序列的比对展示于图35、图36和图37中。
本发明抗体可为包含人类可变区和非人类(例如,小鼠)恒定区的人类抗体或嵌合抗体。举例来说,本发明抗体具有人类可变区,且任选地还具有人类恒定区。
因此,抗体任选地包括恒定区或其部分,例如人类抗体恒定区或其部分。举例来说,VL结构域可在其C端末端附接到抗体轻链κ或λ恒定结构域。类似地,抗体VH结构域可在其C端末端附接到所有或部分免疫球蛋白重链恒定区(例如CH1结构域或Fc区),所述免疫球蛋白重链恒定区来源于任何抗体同种型(例如IgG、IgA、IgE和IgM)和同种型亚类中的任一个(例如IgG1或IgG4)。
人类重链恒定区的实例展示于表S1中。
本发明抗体的恒定区可替代地为非人类恒定区。举例来说,当抗体产生于转基因动物(在本文中其它地方描述其实例)中时,可产生包含人类可变区和非人类(宿主动物)恒定区的嵌合抗体。一些转基因动物产生完全人类抗体。已将其它转基因动物工程改造以产生包含嵌合重链和完全人类轻链的抗体。当抗体包含一个或多个非人类恒定区时,这些非人类恒定区可置换为人类恒定区以提供更适用于作为治疗性组合物向人类给予的抗体,这是由于所述抗体的免疫原性由此减小。
利用木瓜蛋白酶分解抗体产生不具有抗原结合活性但具有结晶能力的两个相同抗原结合片段,也已知为“Fab”片段和“Fc”片段。当在本文中使用时,“Fab”是指包括重链和轻链中的每一个的一个恒定结构域和一个可变结构域的抗体的片段。本文中的术语“Fc区”用于限定免疫球蛋白重链的C端区,包括天然序列Fc区和变体Fc区。“Fc片段”是指通过二硫键连接在一起的两个H链的羧基端部分。抗体的效应子功能由Fc区的序列决定,也通过Fc受体(FcR)识别的区发现于某些类型细胞上。利用胃蛋白酶分解抗体产生F(ab')2片段,其中抗体分子的两个臂保持连接且包含两个抗原结合位点。F(ab')2片段具有交联抗原的能力。
当在本文中使用时,“Fv”是指同时保留抗原识别位点和抗原结合位点的抗体的最小片段。这一区域由紧密的非共价或共价缔合的一个重链可变结构域与一个轻链可变结构域的二聚体组成。在这种配置中,每个可变结构域的三个CDR相互作用以限定VH-VL二聚体表面上的抗原结合位点。六个CDR共同地赋予抗体以抗原结合特异性。然而,尽管在比整个结合位点低的亲和力下,但甚至单一可变结构域(或仅包含三个对抗原具有特异性的CDR的Fv的一半)也具有识别和结合抗原的能力。
本文中所公开的抗体可经过修饰以延长或缩短血清半衰期。在一个实施例中,引入以下突变体:T252L、T254S或T256F中的一个或多个以延长抗体的生物半衰期。生物半衰期还可以通过改变重链恒定区CH1结构域或CL区以含有结合表位的救助受体来延长,所述表位取自IgG的Fc区的CH2结构域的两个环,如美国专利第5,869,046号和第6,121,022号中所描述,描述于其中的修饰以引入的方式并入本文中。在另一实施例中,本发明的抗体或抗原结合片段的Fc铰链区经过突变以缩短抗体或片段的生物半衰期。将一个或多个氨基酸突变引入到Fc铰链片段的CH2-CH3结构域界面区中,使得抗体或片段具有相对于天然Fc铰链结构域葡萄球菌A蛋白(SpA)结合而言减弱的SpA结合。所属领域的技术人员已知延长血清半衰期的其它方法。因此,在一个实施例中,抗体或片段经聚乙二醇化。在另一实施例中,抗体或片段融合到白蛋白结合结构域,例如白蛋白结合单域抗体(dAb)。在另一实施例中,抗体或片段经PAS化(即由PAS(XL-Protein GmbH)构成的多肽序列的基因融合,其形成具有较大流体动力体积的不带电无规线圈结构)。在另一实施例中,抗体或片段是 /rPEG化的(即非精确重复肽序列(Amunix、Versartis)与治疗性肽的基因融合)。在另一实施例中,抗体或片段经ELP化(即与ELP重复序列(PhaseBio)基因融合)。这些不同半衰期延长融合体更详细地描述于Strohl,《生物药物(BioDrugs)》(2015)29:215-239中,例如表2和表6中的融合体以引入的方式并入本文中。
/rPEG化的(即非精确重复肽序列(Amunix、Versartis)与治疗性肽的基因融合)。在另一实施例中,抗体或片段经ELP化(即与ELP重复序列(PhaseBio)基因融合)。这些不同半衰期延长融合体更详细地描述于Strohl,《生物药物(BioDrugs)》(2015)29:215-239中,例如表2和表6中的融合体以引入的方式并入本文中。
抗体可具有增强稳定性的经过修饰的恒定区。因此,在一个实施例中,重链恒定区包含Ser228Pro突变。在另一实施例中,本文中所公开的抗体和片段包含已经过修饰以改变半胱氨酸残基数量的重链铰链区。这种修饰可用于促进轻链和重链的装配或用于提高或降低抗体的稳定性。
Fc效应子功能:ADCC、ADCP和CDC
如上文所论述,抗ICOS抗体可以不同同种型提供且具有不同恒定区。人类IgG抗体重链恒定区序列的实例展示于表S1中。抗体的Fc区主要根据Fc结合、抗体依赖性细胞介导的细胞毒性(ADCC)活性、补体依赖性细胞毒性(CDC)活性和抗体依赖性细胞吞噬作用(ADCP)活性测定其效应子功能。这些“细胞效应子功能”由于不同于效应T细胞功能而涉及将携带Fc受体的细胞募集到靶细胞的位点,使得杀灭结合抗体的细胞。除了ADCC和CDC以外,还有ADCP机制[19]代表使结合抗体的T细胞缺失,且因此针对缺失靶向表达TReg的高ICOS的手段。
细胞效应子功能ADCC、ADCP和/或CDC还可以由不具有Fc区的抗体呈现。抗体可包含多个不同抗原结合位点,一个针对ICOS且另一个针对靶分子,其中靶分子的接合诱发ADCC、ADCP和/或CDC,例如包含由连接子接合的两个scFv区域的抗体,其中一个scFv可接合效应细胞。
根据本发明的抗体可为一种呈现ADCC、ADCP和/或CDC的抗体。替代地,根据本发明的抗体可缺乏ADCC活性、ADCP活性和/或CDC活性。在任一情况下,根据本发明的抗体可包含或可任选地缺乏与一种或多种类型的Fc受体结合的Fc区。不同抗体形式的使用和FcR结合和细胞效应子功能的存在与否使得抗体适用于特定治疗性目的,如本文中其它地方所论述。
适用于一些治疗性应用的抗体格式采用野生型人类IgG1恒定区。恒定区可为效应子启用IgG1恒定区,任选地具有ADCC活性和/或CDC活性和/或ADCP活性。合适的野生型人类IgG1恒定区序列为SEQ ID NO:340(IGHG1*01)。人类IgG1恒定区的其它实例展示于表S1中。
对于人类疾病的小鼠模型中候选治疗抗体的测试来说,可包括效应子阳性小鼠恒定区,例如小鼠IgG2a(mIgG2a),而非效应子阳性人类恒定区。
可针对增强的ADCC和/或CDC和/或ADCP将恒定区工程化。
Fc介导的效应的效能可以通过利用各种已建立的技术将Fc结构域工程改造来增强。此类方法增加对某些Fc受体的亲和力,因此产生活化增强的潜在不同型态。这可以通过修饰一个或几个氨基酸残基来实现[20]。已示出增强与Fc受体的结合的人类IgG1恒定区,其含有残基Asn297(例如N297Q,EU索引编号)上的特异性突变或改变糖基化。实例突变为选自人类IgG1恒定区的239、332和330(或其它IgG同种型中的等效位置)的残基中的一个或多个。因此,抗体可包含具有独立选自N297Q、S239D、I332E和A330L(EU索引编号)的一个或多个突变的人类IgG1恒定区。三重突变(M252Y/S254T/T256E)可用于增强与FcRn的结合,且影响FcRn结合的其它突变论述于[21]的表2中,其中的任一个可用于本发明中。
对Fc受体增加的亲和力还可以通过改变Fc结构域的天然糖基化型态,通过例如在岩藻糖基化或去岩藻糖基化变体下产生来实现[22]。非岩藻糖基化抗体具有Fc的复合型N-聚糖的三甘露糖基核心结构而无岩藻糖残基。由于 结合能力的增强,不具有来自Fc N-聚糖的核心岩藻糖残基的这些糖改造抗体可呈现比岩藻糖基化等效物更强烈的ADCC。举例来说,为了增强ADCC,可以改变铰链区中的残基以增强与Fc-γRIII的结合[23]。因此,抗体可包含作为野生型人类IgG重链恒定区的变体的人类IgG重链恒定区,其中变体人类IgG重链恒定区以比野生型人类IgG重链恒定区结合人类
结合能力的增强,不具有来自Fc N-聚糖的核心岩藻糖残基的这些糖改造抗体可呈现比岩藻糖基化等效物更强烈的ADCC。举例来说,为了增强ADCC,可以改变铰链区中的残基以增强与Fc-γRIII的结合[23]。因此,抗体可包含作为野生型人类IgG重链恒定区的变体的人类IgG重链恒定区,其中变体人类IgG重链恒定区以比野生型人类IgG重链恒定区结合人类 受体更高的亲和力结合选自由FcyRIIB和FcyRIIA组成的组的人类
受体更高的亲和力结合选自由FcyRIIB和FcyRIIA组成的组的人类 受体。抗体可包含作为野生型人类IgG重链恒定区的变体的人类IgG重链恒定区,其中变体人类IgG重链恒定区以比野生型人类IgG重链恒定区结合人类
受体。抗体可包含作为野生型人类IgG重链恒定区的变体的人类IgG重链恒定区,其中变体人类IgG重链恒定区以比野生型人类IgG重链恒定区结合人类 更高的亲和力结合人类
更高的亲和力结合人类 变体人类IgG重链恒定区可为变体人类IgG1重链恒定区、变体人类IgG2重链恒定区或变体人类IgG4重链恒定区。在一个实施例中,变体人类IgG重链恒定区包含选自G236D、P238D、S239D、S267E、L328F和L328E(EU索引编号系统)的一个或多个氨基酸突变。在另一实施例中,变体人类IgG重链恒定区包含选自以下组成的组的氨基酸突变集合:S267E和L328F;P238D和L328E;P238D和选自以下组成的组的一个或多个取代:E233D、G237D、H268D、P271G和A330R;P238D、E233D、G237D、H268D、P271G和A330R;G236D和S267E;S239D和S267E;V262E、S267E和L328F;以及V264E、S267E和L328F(EU索引编号系统)。CDC的增强可以通过增强对C1q(典型补体活化级联的第一组分)的亲和力的氨基酸变化来实现[24]。另一方法是产生由人类IgG1及人类IgG3区段产生的嵌合Fc结构域,所述片段利用IgG3对C1q更高的亲和力[25]。本发明抗体可包含在残基329、331和/或322处突变的氨基酸,以改变C1q结合和/或减小或消除的CDC活性。在另一实施例中,本文中所公开的抗体或抗体片段可含有在残基231和239处具有修饰的Fc区,借此将氨基酸置换以改变抗体固定补体的能力。在一个实施例中,抗体或片段具有包含一个或多个突变的恒定区,所述突变选自E345K、E430G、R344D和D356R,具体地说,包含R344D和D356R(EU索引编号系统)的双重突变。
变体人类IgG重链恒定区可为变体人类IgG1重链恒定区、变体人类IgG2重链恒定区或变体人类IgG4重链恒定区。在一个实施例中,变体人类IgG重链恒定区包含选自G236D、P238D、S239D、S267E、L328F和L328E(EU索引编号系统)的一个或多个氨基酸突变。在另一实施例中,变体人类IgG重链恒定区包含选自以下组成的组的氨基酸突变集合:S267E和L328F;P238D和L328E;P238D和选自以下组成的组的一个或多个取代:E233D、G237D、H268D、P271G和A330R;P238D、E233D、G237D、H268D、P271G和A330R;G236D和S267E;S239D和S267E;V262E、S267E和L328F;以及V264E、S267E和L328F(EU索引编号系统)。CDC的增强可以通过增强对C1q(典型补体活化级联的第一组分)的亲和力的氨基酸变化来实现[24]。另一方法是产生由人类IgG1及人类IgG3区段产生的嵌合Fc结构域,所述片段利用IgG3对C1q更高的亲和力[25]。本发明抗体可包含在残基329、331和/或322处突变的氨基酸,以改变C1q结合和/或减小或消除的CDC活性。在另一实施例中,本文中所公开的抗体或抗体片段可含有在残基231和239处具有修饰的Fc区,借此将氨基酸置换以改变抗体固定补体的能力。在一个实施例中,抗体或片段具有包含一个或多个突变的恒定区,所述突变选自E345K、E430G、R344D和D356R,具体地说,包含R344D和D356R(EU索引编号系统)的双重突变。
WO2008/137915描述了具有经过修饰的Fc区的抗ICOS抗体,所述区域具有增强的效应子功能。据报告,所述抗体介导与由亲本抗体介导的ADCC活性水平相比增强的ADCC活性,所述亲本抗体包含VH和VK结构域和野生型Fc区。根据本发明的抗体可采用具有如其中所描述的效应子功能的此类变体Fc区。
可在如本文中所描述的分析中测定抗体的ADCC活性。可使用如实例10中所描述的ICOS阳性T细胞系活体外测定抗ICOS抗体的ADCC活性。可使用PD-L1表达细胞在ADCC分析中活体外测定抗PD-L1抗体的ADCC活性。
对于某些应用(例如在疫苗接种的情形下),可优选使用不具有Fc效应子功能的抗体。可提供不具有恒定区或不具有Fc区的抗体——此类抗体格式的实例描述于本文中的其它地方。替代地,抗体可具有效应子无效的恒定区。抗体可具有不结合Fcγ受体的重链恒定区,例如恒定区可包含Leu235Glu突变(即,其中野生型白氨酸残基突变成谷氨酸残基)。重链恒定区的另一任选突变为增加稳定性的Ser228Pro。重链恒定区可为包含Leu235Glu突变和Ser228Pro突变两种突变的IgG4。这一“IgG4-PE”重链恒定区为效应子无效的。
替代效应子无效人类恒定区为禁用IgG1。禁用IgG1重链恒定区可在位置235和/或237(EU索引编号)处含有丙氨酸,例如,其可为包含L235A和/或G237A突变(“LAGA”)的IgG1*01序列。
变体人类IgG重链恒定区可包含减小IgG对人类 人类
人类 或人类
或人类 的亲和力的一个或多个氨基酸突变。在一个实施例中,
的亲和力的一个或多个氨基酸突变。在一个实施例中, 在选自以下组成的组的细胞上表现:巨噬细胞、单核细胞、B细胞、树突状细胞、内皮细胞和活化T细胞。在一个实施例中,变体人类IgG重链恒定区包含以下氨基酸突变中的一个或多个:G236A、S239D、F243L、T256A、K290A、R292P、S298A、Y300L、V305I、A330L、I332E、E333A、K334A、A339T和P396L(EU索引编号系统)。在一个实施例中,变体人类IgG重链恒定区包含选自以下组成的组的氨基酸突变集合:S239D;T256A;K290A;S298A;I332E;E333A;K334A;A339T;S239D和I332E;S239D、A330L和I332E;S298A、E333A和K334A;G236A、S239D和I332E;以及F243L、R292P、Y300L、V305I和P396L(EU索引编号系统)。在一个实施例中,变体人类IgG重链恒定区包含S239D、A330L或I332E氨基酸突变(EU索引编号系统)。在一个实施例中,变体人类IgG重链恒定区包含S239D和I332E氨基酸突变(EU索引编号系统)。在一个实施例中,变体人类IgG重链恒定区为包含S239D和I332E氨基酸突变(EU索引编号系统)的变体人类IgG1重链恒定区。在一个实施例中,抗体或片段包含无岩藻糖基化Fc区。在另一实施例中,将抗体或其片段去岩藻糖基化。在另一实施例中,抗体或片段处于岩藻糖基化下。
在选自以下组成的组的细胞上表现:巨噬细胞、单核细胞、B细胞、树突状细胞、内皮细胞和活化T细胞。在一个实施例中,变体人类IgG重链恒定区包含以下氨基酸突变中的一个或多个:G236A、S239D、F243L、T256A、K290A、R292P、S298A、Y300L、V305I、A330L、I332E、E333A、K334A、A339T和P396L(EU索引编号系统)。在一个实施例中,变体人类IgG重链恒定区包含选自以下组成的组的氨基酸突变集合:S239D;T256A;K290A;S298A;I332E;E333A;K334A;A339T;S239D和I332E;S239D、A330L和I332E;S298A、E333A和K334A;G236A、S239D和I332E;以及F243L、R292P、Y300L、V305I和P396L(EU索引编号系统)。在一个实施例中,变体人类IgG重链恒定区包含S239D、A330L或I332E氨基酸突变(EU索引编号系统)。在一个实施例中,变体人类IgG重链恒定区包含S239D和I332E氨基酸突变(EU索引编号系统)。在一个实施例中,变体人类IgG重链恒定区为包含S239D和I332E氨基酸突变(EU索引编号系统)的变体人类IgG1重链恒定区。在一个实施例中,抗体或片段包含无岩藻糖基化Fc区。在另一实施例中,将抗体或其片段去岩藻糖基化。在另一实施例中,抗体或片段处于岩藻糖基化下。
抗体可具有重链恒定区,所述重链恒定区结合一种或多种类型的Fc受体但不诱导细胞效应子功能,即,不介导ADCC活性、CDC活性或ADCP活性。此类恒定区可能不能够结合负责触发ADCC活性、CDC活性或ADCP活性的特定Fc受体。
产生并修饰抗体
识别和制备抗体的方法为众所周知的。可使用转基因小鼠(例如,KymouseTM、 HuMab
HuMab  或MeMo
或MeMo  )、大鼠(例如,
)、大鼠(例如, )、骆驼、鲨鱼、兔、鸡或其它非人类动物产生抗体,所述动物利用ICOS或其片段或包含所关注的ICOS序列基元的合成肽免疫,接着任选地将恒定区和/或可变区人源化以生产人类或人源化抗体。在实例中,可以使用例如酵母展示、噬菌体展示或核糖体展示等展示技术,如技术人员将显而易知。例如使用展示技术,可以在从转基因动物、噬菌体展示库或其它库分离抗体导联之后的另一步骤中进行标准亲和力成熟。合适技术的代表性实例描述于US20120093818(安进公司(Amgen,Inc))中,其以全文引用的方式并入本文中,例如,在第[0309]段到第[0346]段中陈述的方法。
)、骆驼、鲨鱼、兔、鸡或其它非人类动物产生抗体,所述动物利用ICOS或其片段或包含所关注的ICOS序列基元的合成肽免疫,接着任选地将恒定区和/或可变区人源化以生产人类或人源化抗体。在实例中,可以使用例如酵母展示、噬菌体展示或核糖体展示等展示技术,如技术人员将显而易知。例如使用展示技术,可以在从转基因动物、噬菌体展示库或其它库分离抗体导联之后的另一步骤中进行标准亲和力成熟。合适技术的代表性实例描述于US20120093818(安进公司(Amgen,Inc))中,其以全文引用的方式并入本文中,例如,在第[0309]段到第[0346]段中陈述的方法。
用人类ICOS抗原使ICOS敲除非人类动物免疫有助于识别人类ICOS和非人类ICOS的抗体的产生。如本文中所描述和实例中所说明,ICOS敲除小鼠可以用表达人类ICOS的细胞进行免疫以刺激小鼠中针对人类和小鼠ICOS的抗体的产生,可以回收所述小鼠并测试其与人类ICOS和小鼠ICOS的结合。可因此选择具有交叉反应性的抗体,其可针对如本文中所描述的其它期望特性进行筛选。通过用抗原对动物进行免疫(其中内源性抗原(例如内源性小鼠抗原)的表达已在动物中敲除)而产生针对抗原(例如,人类抗原)的抗体的方法可以在能够产生包含人类可变结构域的抗体的动物中进行。此类动物的基因组可以经工程改造以包含人类或人源化免疫球蛋白基因座,其编码人类可变区基因段和任选地内源性恒定区或人类恒定区。人类可变区基因段的重组产生可具有非人类恒定区或人类恒定区的人类抗体。非人类恒定区随后可置换为人类恒定区,其中抗体打算用于人体内。此类方法和敲除转基因动物描述于WO2013/061078中。
一般来说,可以用所关注的抗原攻击KymouseTM、 或其它小鼠或大鼠(任选地如所提及的ICOS敲除小鼠或大鼠),且将淋巴细胞(例如B细胞)从表达抗体的小鼠中回收。淋巴细胞可与骨髓瘤细胞系融合以制备无限增殖杂交瘤细胞系,且此类杂交瘤细胞系经筛选和选择以识别产生对所关注的抗原具有特异性的抗体的杂交瘤细胞系。可将编码重链和轻链可变区的DNA分离并连接到重链和轻链的合乎需要的同型恒定区。此类抗体蛋白可产生于细胞(例如CHO细胞)中。替代地,可将编码抗原特异性嵌合抗体或轻链和重链可变结构域的DNA从抗原特异性淋巴细胞中直接分离。
或其它小鼠或大鼠(任选地如所提及的ICOS敲除小鼠或大鼠),且将淋巴细胞(例如B细胞)从表达抗体的小鼠中回收。淋巴细胞可与骨髓瘤细胞系融合以制备无限增殖杂交瘤细胞系,且此类杂交瘤细胞系经筛选和选择以识别产生对所关注的抗原具有特异性的抗体的杂交瘤细胞系。可将编码重链和轻链可变区的DNA分离并连接到重链和轻链的合乎需要的同型恒定区。此类抗体蛋白可产生于细胞(例如CHO细胞)中。替代地,可将编码抗原特异性嵌合抗体或轻链和重链可变结构域的DNA从抗原特异性淋巴细胞中直接分离。
首先,将具有人类可变区和小鼠恒定区的高亲和力嵌合抗体分离。针对合乎需要的特征而表征和选择抗体,所述特征包括亲和力、选择性、激动作用、T细胞依赖性杀灭、中和效能、表位等。小鼠恒定区任选地置换为期望人类恒定区以产生本发明的完全人类抗体,例如野生型或经过修饰的IgG1或IgG4(例如,US2011/0065902(其以全文引用的方式并入本文中)中的SEQ ID NO:751、SEQ ID NO:752、SEQ ID NO:753)。虽然选择的恒定区可根据特定用途而变化,但是高亲和力抗原结合和靶特异性特征存在于可变区中。
因此,在另一方面,本发明提供具有包含人类或人源化免疫球蛋白基因座的基因的转基因非人类哺乳动物,其中所述哺乳动物不表达ICOS。举例来说,哺乳动物可为敲除小鼠或大鼠,或其它实验动物物种。例如KymouseTM转基因小鼠含有插入对应的内源性小鼠免疫球蛋白基因座处的人类重链和轻链免疫球蛋白基因座。根据本发明的转基因哺乳动物可为一种含有此类靶向插入的哺乳动物,或其可含有人类重链和轻链免疫球蛋白基因座或随机插入其基因组中,插入除内源性Ig基因座以外的基因座处,或提供在额外染色体或染色体片段上的免疫球蛋白基因。
本发明的其它方面为此类非人类哺乳动物用于产生针对ICOS的抗体的用途和在此类哺乳动物中产生抗体或抗体重链可变结构域和/或轻链可变结构域的方法。
产生结合人类和非人类ICOS的胞外结构域的抗体的方法可包含:提供具有包含人类或人源化免疫球蛋白基因座的基因组的转基因非人类哺乳动物,其中所述哺乳动物不表达ICOS,以及
(a)用人类ICOS抗原(例如,用表达人类ICOS的细胞或用纯化的重组ICOS蛋白质)使哺乳动物免疫;
(b)分离由哺乳动物产生的抗体;
(c)测试抗体结合人类ICOS和非人类ICOS的能力;和
(d)选择结合人类ICOS和非人类ICOS的一个或多个抗体。
测试结合人类ICOS和非人类ICOS的能力可以使用表面等离子共振、HTRF、FACS或本文中所描述的任何其它方法进行。任选地,测定对人类和小鼠ICOS的结合亲和力。可以测定与人类ICOS和小鼠ICOS的结合的亲和力或亲和力倍数差,且可因此选择展示物种交叉反应性的抗体(可用作选择标准的亲和力阈值和倍数差例示于本文中的其它地方)。用于抑制人类和小鼠ICOS配体与人类和小鼠ICOS受体结合的抗体的中和效能或中和效能倍数差还可以分别或替代地例如在HTRF分析中根据筛选交叉反应抗体的方式测定。同样,可用作选择标准的可能阈值和倍数差例示于本文中的其它地方。
方法可包含测试抗体结合来自与免疫哺乳动物相同或不同的物种的非人类ICOS的能力。因此,当转基因哺乳动物为小鼠(例如,KymouseTM)时,可测试抗体结合小鼠ICOS的能力。当转基因哺乳动物为大鼠时,可测试抗体结合大鼠ICOS的能力。然而,可同样适用于测定分离抗体对另一物种的非人类ICOS的交叉反应性。因此,可测试山羊中产生的抗体与大鼠或小鼠ICOS的结合。任选地,可替代地或另外测定与山羊ICOS的结合。
在其它实施例中,转基因非人类哺乳动物可以用非人类ICOS,任选地相同哺乳动物物种的ICOS而非人类ICOS进行免疫(例如,ICOS敲除小鼠可以用小鼠ICOS进行免疫)。接着以相同方式测定分离抗体结合人类ICOS和非人类ICOS的亲和力,且选择同时结合人类和非人类ICOS的抗体。
可将编码所选择抗体的抗体重链可变结构域和/或抗体轻链可变结构域的核酸分离。此类核酸可编码完整抗体重链和/或轻链或不具有相关联恒定区的可变结构域。如所提及,编码核苷酸序列可直接从产生抗体的小鼠细胞中获得,或可无限增殖或融合B细胞以产生表达抗体且编码从此类细胞中获得的核酸的杂交瘤。任选地,编码可变结构域的核酸接着共轭到编码人类重链恒定区和/或人类轻链恒定区的核苷酸序列,以提供编码人类抗体重链和/或人类抗体轻链,例如编码同时包含重链和轻链的抗体的核酸。如本文中其它地方所描述,这一步骤在免疫的哺乳动物产生具有非人类恒定区的嵌合抗体时特别适用,所述非人类恒定区优选地置换为人类恒定区以产生在作为药剂向人类给予时将具有较小免疫原性的抗体。特定人类同种型恒定区的提供对于测定抗体的效应子功能来说也是重要的,且本文中论述了多个合适的重链恒定区。
可以对编码抗体重链可变结构域和/或轻链可变结构域的核酸进行其它改变,例如如本文中所描述的残基的突变和变体的产生。
可将分离的(任选地,突变的)核酸引入到宿主细胞,例如如所论述的CHO细胞中。接着在表达呈任何期望抗体格式的抗体或抗体重链可变结构域和/或轻链可变结构域的条件下培养宿主细胞。本文中描述了一些可能的抗体格式,例如,完整免疫球蛋白、抗原结合片段和其它设计。
如所论述,可根据本发明采用VH和VL结构域或CDR中的任一个的可变结构域氨基酸序列变体,本文中特异性地公开了其序列。
可能需要形成变体的原因有很多,包括优化抗体序列以用于大规模制造,促进纯化,增强稳定性或提高适用性以用于包括在期望药物配制品中。蛋白质工程化操作可以在抗体序列中的一个或多个靶标残基处进行,例如用替代氨基酸取代一个氨基酸(任选地,除了可能的Cys和Met以外,在这一位置处产生含有所有天然存在的氨基酸的变体),且监测对功能和表达的影响以确定最佳取代。在一些情况下,不希望用Cys或Met取代残基或将这些残基引入到序列中,为此,可能会在制造时(例如通过形成新的分子内或分子间半胱氨酸-半胱氨酸键)产生困难。当已选择主要候选且正将其优化以用于制造和临床研发时,尽可能少地改变其抗原结合特性或至少保留亲本分子的亲和力和效能通常将是合乎需要的。然而,还可能产生变体以便调节例如亲和力、交叉反应性或中和效能的关键抗体特征。
抗体可包含所公开抗体中的任一个的H CDR和/或L CDR集合,所述公开抗体在所公开的H CDR和/或L CDR集合内具有一个或多个氨基酸突变。突变可为氨基酸取代、缺失或插入。因此,举例来说,在所公开的H CDR和/或L CDR集合内可能存在一个或多个氨基酸取代。举例来说,在H CDR和/或L CDR集合内可能存在至多12、11、10、9、8、7、6、5、4、3或2个突变,例如取代。举例来说,在HCDR3中可能存在至多6、5、4、3或2个突变,例如取代,且/或在LCDR3中可能存在至多6、5、4、3或2个突变,例如取代。抗体可包含示出用于本文中任何STIM抗体的HCDR、LCDR集合或6个(H和L)CDR集合,或可包含具有一个或两个保守取代的CDR集合。
一个或多个氨基酸突变可以任选地在本文中所公开的抗体VH或VL结构域的构架区中进行。举例来说,不同于对应的人类生殖系片段序列的一个或多个残基可恢复到生殖系。对应于实例抗ICOS抗体的VH和VL结构域的人类生殖系基因段序列指示于表E12-1、表E12-2和表E12-3中,且抗体VH和VL结构域与对应生殖系序列的比对展示于附图中。
抗体可包含与展示于随附序列表中的抗体中的任一个的VH结构域具有至少60%、70%、80%、85%、90%、95%、98%或99%氨基酸序列一致性的VH结构域,且/或包含与那些抗体中的任一个的VL结构域具有至少60%、70%、80%、85%、90%、95%、98%或99%氨基酸序列一致性的VL结构域。可用于计算两个氨基酸序列的一致性%的算法包括例如BLAST、FASTA或史密斯-沃特曼算法(Smith-Waterman algorithm),例如采用默认参数。特定变体可包括一个或多个氨基酸序列改变(氨基酸残基的添加、缺失、取代和/或插入)。
可在一个或多个构架区和/或一个或多个CDR中进行改变。变体任选地通过CDR诱变提供。改变通常不会导致功能缺失,因此,包含由此改变的氨基酸序列的抗体可保留结合ICOS的能力。其可保留与其中不进行改变的抗体相同的定量结合能力,例如如本文中所描述的分析中所测量。包含由此改变的氨基酸序列的抗体可具有提高的结合ICOS的能力。
改变可包含用非天然存在或非标准的氨基酸替换一个或多个氨基酸残基,将一个或多个氨基酸残基修饰成非天然存在或非标准的形式,或将一个或多个非天然存在或非标准的氨基酸插入序列中。本发明序列中改变的编号和位置的实例描述于本文中的其它地方。天然存在的氨基酸包括由其标准单个字母代码识别为以下的20个“标准”L-氨基酸:G、A、V、L、I、M、P、F、W、S、T、N、Q、Y、C、K、R、H、D、E。非标准氨基酸包括可并入多肽主链中的任何其它残基或由现有氨基酸残基的修饰产生。非标准氨基酸可以是天然存在的或非天然存在的。
如本文中所用的术语“变体”是指因一个或多个氨基酸或核酸缺失、取代或添加而不同于亲本多肽或核酸,但保留亲本分子的一个或多个特异性功能或生物活性的肽或核酸。氨基酸取代包括改变,其中氨基酸被置换为不同的天然存在的氨基酸残基。此类取代可以归类为“保守”取代,在此情况下,多肽中所含的氨基酸残基被置换为具有关于极性、侧链功能或大小的类似特征的另一天然存在的氨基酸。此类保守取代在所属领域中众所周知。本发明所涵盖的取代还可以是“非保守”取代,其中存在于肽中的氨基酸残基被具有不同特性的氨基酸,例如来自不同基团的天然存在的氨基酸取代(例如,用丙氨酸取代带电荷或疏水性氨基酸),或替代地,其中天然存在的氨基酸被非常规氨基酸取代。在一些实施例中,氨基酸取代为保守取代。同样涵盖在内,术语变体在参考聚核苷酸或多肽使用时是指与参考聚核苷酸或多肽相比(例如,与野生型多核苷酸或多肽相比),可分别在一级、二级或三级结构方面不同的聚核苷酸或多肽。
在一些方面中,我们可以使用利用所属领域中众所周知的方法分离或产生的“合成变体”、“重组变体”或“经过化学修饰的”聚核苷酸变体或多肽变体。如下文所描述,“经过修饰的变体”可包括保守或非保守氨基酸变化。聚核苷酸变化可在由参考序列编码的多肽中引起氨基酸取代、添加、缺失、融合和截断。一些方面包括插入变体、缺失变体或具有氨基酸取代的经取代变体,所述取代包括氨基酸和通常不出现在肽序列中的作为变体基础的其它分子的插入和取代,例如但不限于通常不出现在人类蛋白质中的鸟氨酸的插入。术语“保守取代”在描述多肽时,是指多肽的氨基酸组合物的变化,所述变化实质上不会改变多肽的活性。举例来说,保守取代是指将氨基酸残基取代为具有类似化学特性(例如,酸性、碱性、带正电或带负电、极性或非极性等)的不同氨基酸残基。保守氨基酸取代包括用异白氨酸或缬氨酸置换白氨酸、用谷氨酸置换天冬氨酸或用丝氨酸置换苏氨酸。提供功能上类似的氨基酸的保守取代表在所属领域中众所周知。举例来说,以下六组各自含有为彼此的保守取代的氨基酸:1)丙氨酸(A)、丝氨酸(S)、苏氨酸(T);2)天冬氨酸(D)、谷氨酸(E);3)天冬酰胺(N)、谷氨酰胺(Q);4)精氨酸(R)、赖氨酸(K);5)异白氨酸(I)、白氨酸(L)、甲硫氨酸(M)、缬氨酸(V);和6)苯丙胺酸(F)、酪氨酸(Y)、色氨酸(W)。(也参见Creighton,Proteins,W.H.Freeman and Company(1984),其以全文引用的方式并入本文中)。在一些实施例中,如果改变不会降低肽的活性,那么改变、添加或缺失单个氨基酸或小百分比氨基酸的单个取代、缺失或添加也可以被视为“保守取代”。插入或缺失通常在约1到5个氨基酸的范围内。保守氨基酸的选择可基于肽中待取代的氨基酸的位置而选择,例如在氨基酸处于肽的外部上且暴露于溶剂,或处于内部上且未暴露于溶剂的情况下。
我们可以基于现有氨基酸的位置而选择将取代现有氨基酸的氨基酸,包括其暴露于溶剂(即,与不暴露于溶剂的内部定位的氨基酸相比,在氨基酸暴露于溶剂或存在于肽或多肽的外表面上的情况下)。此类保守氨基酸取代的选择在所属领域中众所周知,例如,如Dordo等人,《分子生物学杂志(J.Mol Biol)》,1999,217,721-739和Taylor等人,《理论生物学杂志(J.Theor.Biol.)》119(1986);205-218以及S.French和B.Robson,《分子进化杂志(J.Mol.Evol.)》19(1983)171中所公开。因此,人们可以选择适用于蛋白质或肽的外部上的氨基酸(即暴露于溶剂的氨基酸)的保守氨基酸取代,例如但不限于此,可以使用以下取代:用F取代Y、用S或K取代T、用A取代P、用D或Q取代E、用D或G取代N、用K取代R、用N或A取代G、用S或K取代T、用N或E取代D、用L或V取代I、用Y取代F、用T或A取代S、用K取代R、用N或A取代G、用R取代K、用S、K或P取代A。
在替代实施例中,我们还可以选择所涵盖的适用于蛋白质或肽的内部上的氨基酸的保守氨基酸取代,例如我们可以使用适用于蛋白质或肽的内部上的氨基酸的保守取代(即,氨基酸不暴露于溶剂),例如但不限于此,我们可以使用以下保守取代:其中用F取代Y,用A或S取代T,用L或V取代I,用Y取代W,用L取代M,用D取代N,用A取代G,用A或S取代T,用N取代D,用L或V取代I,用Y或L取代F,用A或T取代S,且用S、G、T或V取代A。在一些实施例中,非保守氨基酸取代也涵盖在术语变体内。
本发明包括产生含有抗体VH和/或VL结构域的VH和/或VL结构域变体的抗体的方法,所述结构域展示于随附序列表中。此类抗体可以通过包含以下的方法产生:
(i)借助于在亲本抗体VH结构域的氨基酸序列中添加、缺失、取代或插入一个或多个氨基酸来提供作为亲本抗体VH结构域的氨基酸序列变体的抗体VH结构域,
其中亲本抗体VH结构域为抗体STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009中的任一个的VH结构域或包含那些抗体中的任一个的重链互补决定区的VH结构域,
(ii)任选地将由此提供的VH结构域与VL结构域组合,以提供VH/VL组合,以及
(iii)测试VH结构域或由此提供的VH/VL结构域组合,以识别具有一个或多个期望特征的抗体。
期望特征包括与人类ICOS的结合、与小鼠ICOS的结合以及与例如猕猴ICOS的其它非人类ICOS的结合。可识别对于人类和/或小鼠ICOS具有相当或更高亲和力的抗体。其它期望特征包括通过耗减免疫抑制性TReg间接地或通过在T效应细胞上进行ICOS信号传导活化直接地增强效应T细胞功能。识别具有期望特征的抗体可包含识别具有本文中所描述的功能性属性的抗体,例如其亲和力、交叉反应性、特异性、ICOS受体激动作用、中和效能和/或促进T细胞依赖性杀灭,其中的任一个可在如本文中所描述的分析中测定。
当VL结构域包括在所述方法中时,VL结构域可为STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009中的任一个的VL结构域,或可为借助于在亲本VL结构域的氨基酸序列中添加、缺失、取代或插入一个或多个氨基酸而提供的变体,其中亲本VL结构域为STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009中的任一个的VL结构域或包含那些抗体中的任一个的轻链互补决定区的VL结构域。
产生变体抗体的方法可以任选地包含产生抗体或VH/VL结构域组合的复本。方法可进一步包含表达所得抗体。有可能任选地在一个或多个表达载体中生产对应于期望抗体VH和/或VL结构域的核苷酸序列。合适的表达方法(包括宿主细胞中的重组表达)详细地陈述于本文中。
编码核酸和表达方法
可以提供分离的核酸,从而编码根据本发明的抗体。核酸可为DNA和/或RNA。合成来源的基因组DNA、cDNA、mRNA或其它RNA或其任何组合可编码抗体。
本发明提供呈质粒、载体、转录或表达盒形式的构筑体,其包含至少一个如上的聚核苷酸。示范性的核苷酸序列包括在序列表中。除非上下文另外要求,否则对如本文中所陈述的核苷酸序列的参考涵盖具有指定序列的DNA分子,且涵盖具有指定序列的RNA分子,其中用T取代U。
本发明还提供包含一个或多个编码抗体的核酸的重组宿主细胞。产生经编码抗体的方法可包含例如通过培养含有核酸的重组宿主细胞来表达核酸。抗体可由此获得,且可使用任何合适的技术分离和/或纯化,接着在适当时使用。产生方法可包含将产物配制成包括至少一种额外组分的组合物,例如药学上可接受的赋形剂。
用于在各种不同宿主细胞中克隆和表达多肽的系统众所周知。合适的宿主细胞包括细菌、哺乳动物细胞、植物细胞、丝状真菌、酵母和杆状病毒系统以及转基因植物和动物。
抗体和抗体片段在原核细胞中的表达在所属领域中沿用已久。常见的细菌宿主为大肠杆菌(E.coli)。作为用于产生的一个选项,所属领域的技术人员也可获得在真核细胞培养物中的表达。在所属领域中可获得的用于表达异源多肽的哺乳动物细胞系包括中国仓鼠卵巢(Chinese hamster ovary;CHO)细胞、HeLa细胞、幼仓鼠肾细胞、NSO小鼠黑素瘤细胞、YB2/0大鼠骨髓瘤细胞、人类胚胎肾细胞、人类胚胎视网膜细胞和许多其它细胞。
载体可含有适当的调节序列,视需要包括启动子序列、终止子序列、多腺苷酸化序列、增强子序列、标记基因和其它适当序列。可以将编码抗体的核酸引入到宿主细胞中。可以通过各种方法将核酸引入到真核细胞,包括磷酸钙转染、DEAE-葡聚糖、电穿孔、脂质体介导的转染和使用反转录病毒或其它病毒(例如牛痘,或对于昆虫细胞,杆状病毒)进行的转导。将核酸引入宿主细胞,具体地说真核细胞中可以使用基于病毒或质粒的系统。质粒系统可以保持游离状态或可以并入宿主细胞中或人工染色体中。可通过在单个或多个基因座处随机或定向整合一个或多个复本进行并入。对于细菌细胞来说,合适的技术包括氯化钙转化、电穿孔和使用噬菌体进行的转染。引入之后可以例如通过在表达基因的条件下培养宿主细胞接着任选地分离或纯化抗体来表达核酸。
本发明的核酸可以整合到宿主细胞的基因组(例如染色体)中。整合可以根据标准技术通过纳入促进与基因组的重组的序列来促进。
本发明还提供包含在表达系统中使用本文中所描述的核酸来表达抗体的方法。
治疗用途
本文中所描述的抗体可用于通过疗法治疗人类或动物身体的方法中。抗体被发现用于增强效应T细胞反应,其具有对一系列疾病或病况的益处,包括治疗癌症或实体肿瘤和在疫苗接种的情形下。可以使用调节Teff与Treg之间有利于Teff活性的平衡或比率的抗体实现增强Teff反应。
抗ICOS抗体可用于在患者中耗减调节性T细胞和/或增强效应T细胞反应,且可向患者给药以通过耗减调节性T细胞和/或增强效应T细胞反应来治疗适合于疗法的疾病或病况。
本发明的抗体或包含此类抗体分子或其编码核酸的组合物可用于或提供用于任何此类方法中。还设想了抗体或包含其或其编码核酸的组合物用于制造供任何此类方法中使用的药剂的用途。方法通常包含向哺乳动物给予抗体或组合物。合适的调配物和给药方法描述于本文中的其它地方。
一种设想的抗体治疗用途为治疗癌症。癌症可为实体肿瘤,例如肾细胞癌(renalcell cancer)(任选地肾细胞癌(renal cell carcinoma),例如透明细胞肾细胞癌)、头颈癌、黑素瘤(任选地恶性黑素瘤)、非小细胞肺癌(例如,腺癌)、膀胱癌、卵巢癌、子宫颈癌、胃癌、肝癌、胰脏癌、乳癌、睾丸生殖细胞癌或例如所列举的那些实体肿瘤的转移,或其可为液体血液病学肿瘤,例如淋巴瘤(例如霍奇金氏淋巴瘤(Hodgkin's lymphoma)或非霍奇金氏淋巴瘤,例如弥漫性大B细胞淋巴瘤(diffuse large B-cell lymphoma;DLBCL))或白血病(例如,急性骨髓白血病)。抗ICOS抗体可增强具有中度到高度突变负载的黑素瘤、头颈癌和非小细胞肺癌以及其它癌症的肿瘤清除[26]。通过增强患者对其肿瘤病变的免疫反应,使用抗ICOS抗体的免疫疗法可能即使在晚期疾病的情形下仍提供持久治愈或长期缓解的前景。
虽然癌症为不同疾病群组,但抗ICOS抗体提供通过利用患者自身的免疫系统来治疗一系列不同癌症的可能性,其具有通过识别突变型或过度表达的表位来杀灭任何癌细胞的潜能,所述表位从正常组织中辨别癌细胞。通过调节Teff/Treg平衡,抗ICOS抗体可实现和/或促进癌细胞的免疫识别和杀灭。虽然抗ICOS抗体因此为适用于广泛多种癌症的治疗剂,但是存在特定分类的癌症,其中抗ICOS疗法尤其适用,且/或其中抗ICOS疗法可在其它治疗剂无效时有效。
这样一个群组是ICOS配体表达呈阳性的癌症。癌细胞可获取ICOS配体表达,如已针对黑素瘤所描述[27]。由于表面表达配体结合Treg上的ICOS,从而促进Treg的扩增和活化且由此抑制针对癌症的免疫反应,因此ICOS配体表达可提供具有选择性优势的细胞。表达ICOS配体的癌细胞的存活率可取决于通过Treg对免疫系统的这种抑制,且将由此易受用靶向Treg的抗ICOS抗体治疗的影响。这也应用于来源于天然表达ICOS配体的细胞的癌症。ICOS配体通过这些细胞进行的持续表达同样通过免疫抑制提供存活率优势。表达ICOS配体的癌症可来源于抗原呈递细胞,例如B细胞、树突状细胞和单核细胞,且可为例如本文中所提及的那些液体血液病肿瘤。有趣的是,已经证明这些类型的癌症在ICOS和FOXP3表达(TCGA数据)中也是较高的——参见实例25。在本文中,实例20表明示范性抗ICOS抗体在治疗来源于表达ICOS配体的癌性B细胞(A20同基因细胞)的肿瘤时的功效。
因此,抗ICOS抗体可以在治疗ICOS配体表达呈阳性的癌症的方法中使用。另外,待用根据本发明的抗ICOS抗体治疗的癌症可为ICOS和/或FOXP3表达呈阳性且任选地也表达ICOS配体的一种癌症。
患者可以进行测试以测定其癌症的目标蛋白(例如,ICOS配体、ICOS和/或FOXP3)表达是否呈阳性,所述测定例如通过从患者获取测试样本(例如,肿瘤活组织检查)并且测定目标蛋白表达来进行。癌症的一个、两个或所有此类目标蛋白表达已表征为阳性的患者选用于用抗ICOS抗体进行治疗。如本文中其它地方所论述,抗ICOS抗体可用作单药疗法或与一种或多种其它治疗剂组合使用。
抗ICOS抗体也为其癌症用抗体或针对例如CTLA-4、PD-1、PD-L1、CD137、GITR或CD73等免疫检查点分子的其它药物的治疗难治愈的患者提供希望。这些免疫疗法针对一些癌症是有效的,但在一些情况下,癌症可能不会响应,或其可能变得对用抗体持续治疗无响应。与针对免疫检查点抑制剂的抗体一样,抗ICOS抗体调节患者的免疫系统——然而,抗ICOS抗体可在此类其它抗体失败时成功。本文中表明了携带A20B细胞淋巴瘤的动物可以用抗ICOS抗体治疗以减少肿瘤的生长,缩小肿瘤且实际上从体内清除肿瘤,而用抗PD-L1抗体的疗法并不优于对照。A20细胞系也已报告为对抗CTLA-4具有耐药性[28]。
因此,抗ICOS抗体可以在治疗对用一种或多种免疫疗法治疗难治愈的癌症的方法中使用,一种或多种免疫疗法例如抗CTLA-4抗体、抗PD1抗体、抗PD-L1抗体、抗CD137抗体、抗GITR抗体或抗CD73抗体(中的任一个或全部)。在用抗体或其它药物治疗并不显著减少癌症的生长的情况下,例如,在肿瘤继续生长或大小不减小的情况下或在响应期之后肿瘤重新引发其生长的情况下,癌症可表征为对用所述抗体或药物治疗难治愈。通过测试用于癌细胞杀灭或生长抑制的样本(例如,肿瘤活检样本),和/或在临床配置中通过观测(例如,使用成像技术,包括MRI)用所述疗法治疗的患者不对治疗作出响应,可以活体外测定对治疗剂无响应。其癌症已表征为对用此类免疫疗法治疗难治愈的患者选用于用抗ICOS抗体治疗。
另外,抗ICOS抗体可用于治疗对用抗CD20抗体治疗具有耐药性的来源于B细胞的癌症。抗ICOS抗体代表未能对用抗CD20抗体,如利妥昔单抗(rituximab)的疗法作出响应,或变得对所述疗法具有耐药性的癌症治疗。抗ICOS抗体可用作此类癌症的二线(或另外,或额外)治疗。抗CD20抗体耐药性癌症可为B细胞癌症,例如B细胞淋巴瘤,例如弥漫性大B细胞淋巴瘤通过利用抗CD20抗体测试用于癌细胞杀灭或生长抑制的样本(例如,肿瘤活检样本),和/或在临床配置中通过观测用抗CD20抗体治疗的患者不对治疗作出响应,可以活体外测定癌症对抗CD20的耐药性。替代地或另外,可以测试癌症(例如,肿瘤活检样本)以评估CD20的表达,其中无或低CD20表达水平指示对抗CD20抗体的敏感性丧失。
可由此测试从患者获得的样本,以测定目标蛋白,例如ICOS配体、ICOS、FOXP3和/或另一治疗剂(例如,抗受体抗体)所针对的靶受体的表面表达。靶受体可为CD20(例如利妥昔单抗的抗CD20抗体疗法所针对的受体)或另一受体,例如PD1、EGFR、HER2或HER3。ICOS配体、ICOS、FOXP3的表面表达和/或缺乏或丧失靶受体的表面表达指示癌症对抗ICOS抗体疗法敏感。可以提供抗ICOS抗体以用于对患者给药,所述患者的癌症通过ICOS配体、ICOS、FOXP3的表面表达和/或缺乏或丧失靶受体的表面表达来表征,任选地其中患者先前已用抗CTLA4、抗PD1、抗PD-L1或用靶受体的抗体治疗且尚未响应或已停止对用所述抗体治疗作出响应,如例如通过持续或再生癌细胞生长,例如肿瘤大小增大所测量。
可以采用任何合适的方法来测定癌细胞测试对于例如ICOS配体、CD20或本文中所提及的其它靶受体的蛋白质的表面表达是否呈阳性。典型方法为免疫组织化学法,其中细胞样本(例如,肿瘤活检样本)与目标蛋白的抗体接触,且使用标记试剂(通常为识别第一抗体的Fc区且携带例如荧光标记的可检测标记的第二抗体)检测抗体的结合。可宣告测试呈阳性的样本,其中至少5%的细胞被标记,如通过细胞染色或其它检测标记可见。任选地可使用例如10%或25%的更高截止值。通常将过量使用抗体。针对所关注分子的试剂抗体可供使用或可通过简单明了的方法产生。为了对ICOS配体进行测试,抗体MAB1651目前可从安迪生物公司(R&D systems)获得作为识别人类ICOS配体的小鼠IgG。为了对CD20表达进行测试,可使用利妥昔单抗。对所关注的ICOS配体或靶受体的mRNA水平的检测为替代技术[27]。
肿瘤将对用抗ICOS抗体治疗作出响应的另一指示为肿瘤微环境中存在Treg。活化Treg通过ICOS高表面表达和Foxp3高表面表达来表征。Treg在尤其数目增多的肿瘤中的存在提供了患者可选用于用抗ICOS抗体治疗的另一依据。例如通过免疫组织化学法(使用针对靶蛋白的抗体分析Foxp3与ICOS的共表达,随后检测标记,如上文所描述),或通过在利用ICOS和Foxp3的标记抗体的FACS中使用的样本的单细胞分散,可在肿瘤活检样本中离体检测Treg。FACS方法例示于实例17和实例18中。
抗ICOS抗体可用于治疗与感染物相关的癌症,例如病毒诱导的癌症。在这一类别中的为头颈鳞状细胞癌、宫颈癌、梅克尔细胞癌(Merkel cell carcinoma)和许多其它癌症。与癌症相关的病毒包括HBV、HCV、HPV(宫颈癌、口咽癌)和EBV(伯基特氏淋巴瘤(Burkitts lymphoma)、胃癌、霍奇金氏淋巴瘤、其它EBV阳性B细胞淋巴瘤、鼻咽癌和移植后淋巴增生性疾病)。国际癌症研究机构(International Agency for Research on Cancer)(专著100B)识别与感染物相关的以下主要癌症部位:
·胃(Stomach/Gastric):幽门螺杆菌(Heliobacter pylori)
·肝脏:B型肝炎病毒、C型肝炎病毒(HCV)、麝猫后睾吸虫(Opisthorchisviverrini)、华支睾吸虫(Clonorchis sinensis)
·子宫颈:人类乳头瘤病毒(HPV),有或无HIV
·肛门与生殖器(阴茎、外阴、阴道肛门):HPV,有或无HIV
·鼻咽:艾伯斯坦-巴尔病毒(Epstein-Barr virus;EBV)
·口咽:HPV,有或无烟草或酒精摄取
·卡波西肉瘤(Kaposi's sarcoma):8型人类疱疹病毒,有或无HIV
·非霍奇金淋巴瘤:幽门螺杆菌、有或无HIV的EBV、HCV、1型人类嗜T淋巴细胞病毒
·霍奇金氏淋巴瘤:EBV,有或无HIV
·膀胱:埃及裂体吸虫(Schistosoma haematobium)。
根据本发明的抗体可用于治疗与这些感染物中的任一种相关或由其诱导的癌症,例如以上指示的癌症。
效应T细胞反应的刺激还可以有助于针对感染性疾病的免疫性且/或有助于患者感染性疾病的恢复。因此,抗ICOS抗体可用于通过向患者给予抗体来治疗感染性疾病。
感染性疾病包括由病原体(例如,细菌病原体、真菌病原体、病毒病原体或原生动物病原体)引起的那些疾病,且治疗可针对病原体感染促进患者体内的免疫反应。细菌病原体的实例为结核。病毒病原体的实例为B型肝炎和HIV。原生动物病原体的实例为导致疟疾的疟原虫物种,例如恶性疟原虫(P.falciparum)。
抗体可用于治疗感染,例如通过本文中所提及的任何病原体发生的感染。感染可为持久性感染或慢性感染。感染可为局部的或全身性的。病原体与免疫系统之间的长期接触可导致免疫系统枯竭或耐受性产生(例如通过Treg水平增加和Treg:Teff平衡有利于Treg的倾斜来体现),且/或导致通过展示的病原体抗原的演变和修饰由病原体产生的免疫逃避。这些特征反映被认为出现在癌症中的类似过程。抗ICOS抗体呈现通过调节有利于Teff和/或本文中所描述的其它效应的Treg:Teff比率治疗病原体感染,例如慢性感染的治疗方法。
可治疗已被诊断为患有感染性疾病或感染的患者。替代地,治疗可为预防性的,且例如作为疫苗向患者给予以防止感染疾病,如本文中其它地方所描述。
也已提出,免疫反应,尤其是IFNγ依赖性全身性免疫反应可有利于治疗阿尔茨海默病(Alzheimer's disease)和共用部分神经炎性组分的其它CNS病变[29]。WO2015/136541提出了使用抗PD-1抗体治疗阿尔茨海默病。抗ICOS抗体可用于任选地与一种多种其它免疫调节剂(例如,PD-1的抗体)组合治疗阿尔茨海默病或其它神经变性疾病。
组合疗法
用例如抗CTLA4、抗PD1或抗PDL1的免疫调节抗体,尤其是具有Fc效应子功能的抗体治疗可产生其中有益于ICOS高度表达免疫抑制细胞的进一步耗减的环境。可能有利的是使抗ICOS抗体与此类免疫调节剂组合以增强其治疗作用。
已用免疫调节抗体(例如,抗PDL-1、抗PD-1、抗CTLA-4)治疗的患者可尤其受益于用抗ICOS抗体治疗。其原因之一是免疫调节抗体可增加患者的ICOS阳性Treg(例如,肿瘤内Treg)的数量。还使用某些其它治疗剂,例如重组IL-2观测到这一作用。抗ICOS抗体可减小和/或逆转由用另一治疗剂治疗患者引起的ICOS+Treg(例如,肿瘤内Treg)的骤增或上升。因此,选用于用抗ICOS抗体治疗的患者可为已接受用第一治疗剂治疗的患者,所述第一治疗剂为增加患者体内ICOS+Treg的数量的抗体(例如,免疫调节剂抗体)或其它药剂(例如,IL-2)。
可与抗ICOS抗体组合的免疫调节剂包括针对以下中的任一个的抗体:PDL1(例如,阿维鲁单抗(avelumab))、PD-1(例如,派姆单抗(pembrolizumab)或纳武单抗(nivolumab))或CTLA-4(例如,伊匹单抗或曲美木单抗)。抗ICOS抗体可与匹立珠单抗(pidilizumab)组合。在其它实施例中,抗ICOS抗体不与抗CTLA-4抗体组合给予,且/或任选地与不是抗CTLA-4抗体的治疗抗体组合给予。
举例来说,抗ICOS抗体可以与用抗PDL1抗体的疗法组合使用。优选地,抗ICOS抗体为介导ADCC、ADCP和/或CDC的一种抗体。优选地,抗PDL1抗体为介导ADCC、ADCP和/或CDC的一种抗体。此类组合疗法的实例为给予抗ICOS抗体与抗PDL1抗体,其中两种抗体具有效应子阳性恒定区。因此,抗ICOS抗体和抗PDL1抗体可能都能够介导ADCC、CDC和/或ADCP。恒定区的Fc效应子功能和选择详细地描述于本文中的其它地方,但作为一个实例,抗ICOS人类IgG1可与抗PD-L1人类IgG1组合。抗ICOS抗体和/或抗PD-L1抗体可包含野生型人类IgG1恒定区。替代地,抗体的效应子阳性恒定区可为经过工程改造以增强效应子功能,例如增强CDC、ADCC和/或ADCP的一个恒定区。包括改变效应子功能的野生型人类IgG1序列和突变的实例抗体恒定区详细地论述于本文中的其它地方。
可与抗ICOS抗体组合的抗PDL1抗体包括:
·抗PDL1抗体,其任选地作为效应子阳性人类IgG1抑制PD-1与PDL1的结合且/或抑制PDL1;
·抗PD-1抗体,其抑制PD-1与PDL1和/或PDL2的结合;
·阿维鲁单抗(Avelumab),一种抑制PD-1与PDL-1结合的人类IgG1抗体。参见WO2013/079174;
·度伐单抗(Durvalumab)(或“MEDI4736”),一种具有突变L234A、L235A和331的变体人类IgG1抗体。参见WO2011/066389;
·阿特珠单抗(Atezolizumab),一种具有突变N297A、D356E和L358M的变体人类IgG1抗体。参见US2010/0203056;
·BMS-936559,一种包含突变S228P的人类IgG4抗体。参见WO2007/005874。
抗PD-L1抗体的大量其它实例公开于本文中且其它实例在所属领域中已知。许多此处所提及的抗PD-L1抗体的特征化数据已公布于US9,567,399和US9,617,338中,其以引用的方式并入本文中。实例抗PD-L1抗体具有包含以下中的任一个的HCDR和/或LCDR的VH和/或VL结构域:如US9,567,399或US9,617,338中所陈述的1D05、84G09、1D05HC突变体1、1D05HC突变体2、1D05HC突变体3、1D05HC突变体4、1D05LC突变体1、1D05LC突变体2、1D05LC突变体3、411B08、411C04、411D07、385F01、386H03、389A03、413D08、413G05、413F09、414B06或416E01。抗体可包含这些抗体中的任一个的VH和VL结构域,且可任选地包含具有这些抗体中的任一个的重链氨基酸序列和/或轻链氨基酸序列的重链和/或轻链。这些抗PD-L1抗体的VH和VL结构域进一步描述于本文中的其它地方。
其它实例抗PD-L1抗体具有包含KN-035、CA-170、FAZ-053、M7824、ABBV-368、LY-3300054、GNS-1480、YW243.55.S70、REGN3504或公开于以下中的任一个中的抗PD-L1抗体的HCDR和/或LCDR的VH和/或VL结构域:WO2017/034916、WO2017/020291、WO2017/020858、WO2017/020801、WO2016/111645、WO2016/197367、WO2016/061142、WO2016/149201、WO2016/000619、WO2016/160792、WO2016/022630、WO2016/007235、WO2015/179654、WO2015/173267、WO2015/181342、WO2015/109124、WO2015/112805、WO2015/061668、WO2014/159562、WO2014/165082、WO2014/100079、WO2014/055897、WO2013/181634、WO2013/173223、WO2013/079174、WO2012/145493、WO2011/066389、WO2010/077634、WO2010/036959、WO2010/089411和WO2007/005874。抗体可包含这些抗体中的任一个的VH和VL结构域,且可任选地包含具有这些抗体中的任一个的重链氨基酸序列和/或轻链氨基酸序列的重链和/或轻链。在与抗PD-L1的组合疗法中使用的抗ICOS抗体可为如本文中所公开的本发明抗体。替代地,抗ICOS抗体可包含公开于以下公开案中的任一个中的抗ICOS抗体的CDR或VH和/或VL结构域:
WO2016154177、US2016304610-例如抗体7F12、37A10、35A9、36E10、16G10、37A10S713、37A10S714、37A10S715、37A10S716、37A10S717、37A10S718、16G10S71、16G10S72、16G10S73、16G10S83、35A9S79、35A9S710或35A9S89中的任一个;
WO16120789、US2016215059-例如被称为422.2和/或H2L5的抗体;
WO14033327、EP2892928、US2015239978-例如被称为314-8和/或由杂交瘤CNCM I-4180产生的抗体;
WO12131004、EP2691419、US9376493、US20160264666-例如抗体Icos145-1和/或通过杂交瘤CNCM I-4179产生的抗体;
WO10056804-例如抗体JMAb136或“136”;
WO9915553、EP1017723B1、US7259247、US7132099、US7125551、US7306800、US7722872、WO05103086、EP1740617、US8318905、US8916155-例如抗体MIC-944或9F3;
WO983821、US7932358B2、US2002156242、EP0984023、EP1502920、US7030225、US7045615、US7279560、US7226909、US7196175、US7932358、US8389690、WO02070010、EP1286668、EP1374901、US7438905、US7438905、WO0187981、EP1158004、US6803039、US7166283、US7988965、WO0115732、EP1125585、US7465445、US7998478-例如任何JMAb抗体,例如JMAb-124、JMAb-126、JMAb-127、JMAb-128、JMAb-135、JMAb-136、JMAb-137、JMAb-138、JMAb-139、JMAb-140、JMAb-141中的任一个,例如JMAb136;
WO2014/089113-例如抗体17G9;
WO12174338;
US2016145344;
WO11020024、EP2464661、US2016002336、US2016024211、US8840889;
US8497244。
抗ICOS抗体任选地包含如公开于WO2016154177中的37A10S713的CDR。其可包含37A10S713的VH和VL结构域,且可任选地具有37A10S713的抗体重链和轻链。
与单药疗法相比,抗ICOS抗体与免疫调节剂的组合可提供增大的治疗作用,且可使得用较低剂量的免疫调节剂获得治疗益处。因此,举例来说,与抗ICOS抗体组合使用的抗体(例如,抗PD-L1抗体,任选地伊匹单抗)可以3mg/kg而不是10mg/kg的更常见剂量给药。抗PD-L1或其它抗体的给药方案可涉及每3周在90分钟的时间段内静脉内给药,总共4次给药。
抗ICOS抗体可用于增加肿瘤对用抗PD-L1抗体治疗的敏感性,其可随着抗PD-L1抗体借以发挥治疗益处的剂量减小而识别出。因此,可向患者给予抗ICOS抗体以减小有效治疗患者的癌症或肿瘤的抗PD-L1抗体的剂量。与在给药抗PD-L1抗体而不给药抗ICOS时的剂量相比,给药抗ICOS抗体可将给予所述患者的建议或所需的抗PD-L1抗体的剂量减小到例如75%、50%、25%、20%、10%或更少。患者可通过以如本文中所描述的组合疗法给药抗ICOS抗体和抗PD-L1抗体来治疗。
将抗PD-L1与抗ICOS组合的益处与其用作为单药疗法相比时可延长到每种药剂剂量的减小。抗PD-L1抗体可用于减小抗ICOS抗体借以发挥治疗益处的剂量,且由此可向患者给予以减小有效治疗患者的癌症或肿瘤的抗ICOS抗体的剂量。因此,与在给药抗ICOS抗体而不给药抗PD-L1时的剂量相比,抗PD-L1抗体可将给予患者的建议或所需的抗ICOS抗体的剂量减小到例如75%、50%、25%、20%、10%或更少。患者可通过以如本文中所描述的组合疗法给药抗ICOS抗体和抗PD-L1抗体来治疗。
如在本文中实例22中所论述,用抗PD-L1抗体,尤其是具有效应子阳性Fc的抗体治疗未表现出ICOS在Teff细胞上的表达增加。在与效应子阳性抗ICOS抗体组合给药此类抗体时这是有利的,其中Teff上ICOS表达的增加将不合期望地使得这些细胞对由抗ICOS抗体耗减更敏感。在与抗PD-L1的组合中,抗ICOS疗法可由此利用ICOS在Teff相比于Treg上的差异表达,优先靶向用于耗减的ICOS高Treg。这继而减轻了TEff的抑制且具有促进患者的效应T细胞反应的净效应。关于ICOS在T细胞上的表达靶向免疫检查点分子的效应此前也已研究——参见参考文献中的图S6C[30](补充材料),其中据报告用CTLA-4抗体和/或抗PD-1抗体治疗增加了表达ICOS的CD4+Treg的百分比。治疗剂对Treg和Teff中ICOS表达的效应可为用于与抗ICOS抗体组合使用的适当试剂的选择因素,应注意,抗ICOS抗体的效应可在ICOS在Treg与Teff上存在高差异表达的条件下增强。
如本文中所描述,抗ICOS抗体的单次剂量(尤其与例如抗PD-L1抗体的其它治疗剂组合)可足以提供治疗作用。在肿瘤疗法中,这个单次剂量益处的基本原理可为抗ICOS抗体至少部分地通过充分重置或改变肿瘤微环境,以使得肿瘤对免疫攻击和/或对例如所提及的其它免疫调节剂的效应更敏感来介导其效应。肿瘤微环境重置通过例如耗减ICOS阳性肿瘤浸润性T-reg来触发。因此,举例来说,患者可以用单次剂量的抗ICOS抗体接着一次或多次剂量的抗PD-L1抗体治疗。在治疗时间内,例如六个月或一年内,可以单次剂量给药抗ICOS抗体,同时在所述治疗时间内任选地多次给药其它试剂,例如抗PD-L1抗体,优选地以在用抗ICOS抗体治疗之后给药的至少一个此类剂量给药。
组合疗法的其它实例包括抗ICOS抗体与以下的组合:
-腺苷A2A受体的拮抗剂(“A2AR抑制剂”);
-CD137激动剂(例如,激动剂抗体);
-酶吲哚胺-2,3双加氧酶的拮抗剂(“IDO抑制剂”),其催化色氨酸的分解。IDO为在树突状细胞和巨噬细胞中活化的免疫检查点,其有助于免疫抑制/耐受。
抗ICOS抗体可在与IL-2(例如,重组IL-2,例如阿地白介素(aldesleukin))的组合疗法中使用。可以高剂量(HD)给药IL-2。典型HD IL-2疗法涉及每疗法周期超过500,000IU/kg的大剂量输注(bolus infusion),例如600,000或720,000IU/kg的大剂量输注,其中每5小时到10小时之间的间隔给予10到15次此类大剂量输注,例如每隔8小时至多15次大剂量输注,且大约每隔14天到21天重复疗法周期,持续至多6到8个周期。HD IL-2疗法已在治疗肿瘤,尤其是黑素瘤(例如,转移性黑素瘤)和肾细胞癌方面有成效,但其用途受限于可导致严重副作用的IL-2的高毒性。
用高剂量IL-2治疗已展示出增加癌症患者中ICOS阳性Treg的细胞群。[31]。据报告,HD IL-2疗法的第一周期之后ICOS+Treg的这种增加与更遭的临床结果相关-ICOS+Treg的数量越高,预后越遭。已提出IL-2变体F42K作为替代疗法以避免这种不合期望的ICOS+Treg细胞的增加[32]。然而,另一方法将为通过使用根据本发明的抗体作为二线治疗剂而利用ICOS+Treg的增加。
可有益的是将IL-2疗法与抗ICOS抗体组合,以利用抗ICOS抗体靶向高度表达ICOS的TReg的能力,进而抑制这些细胞且为进行IL-2疗法的患者改善预后。同时给药IL-2和抗ICOS抗体可增加反应速率同时避免或减少经过治疗的患者群体中的不良事件。与IL-2单药疗法相比,组合可准许以较低剂量使用IL-2,以降低由IL-2疗法产生的不良事件的风险或程度,同时保持或增强临床益处(例如,减小肿瘤生长,清除实体肿瘤和/或减少转移)。以这种方式,添加抗ICOS可以改善接受IL-2的患者的治疗,无论是高剂量(HD)或是低剂量(LD)IL-2。
因此,本发明的一个方面提供一种通过向患者给药抗ICOS抗体来治疗患者的方法,其中所述患者也用IL-2,例如HD IL-2治疗。本发明的另一方面为用于治疗患者的抗ICOS抗体,其中所述患者也用IL-2,例如HD IL-2治疗。抗ICOS抗体可用作二线疗法。因此,患者可为已用IL-2治疗,例如已接受至少一个周期HD IL-2疗法,且ICOS+Treg水平已增加的患者。可以使用免疫组织化学法或如本文中其它地方所描述的FACS对癌细胞样本,例如肿瘤活检样本进行分析,以检测对ICOS、Foxp3、ICOSL和任选地一种或多种所关注的其它标记呈阳性的细胞。方法可包含确定患者在IL-2治疗之后具有增加的ICOS+Treg(例如,在外周血液中,或在肿瘤活检中)水平,其中增加的水平指示患者将受益于用抗ICOS抗体治疗。Treg的增加可与对照(未治疗)个体或与在IL-2疗法之前的患者有关。具有较高Treg的此类患者代表可能未受益于持续的IL-2单独治疗的群体,但抗ICOS抗体与IL-2疗法组合或用抗ICOS抗体单独治疗为患者提供治疗益处。因此,在患者具有增加的ICOS+Treg水平的阳性确定之后,可给予抗ICOS抗体和/或另外IL-2疗法。用抗ICOS抗体治疗可相对于此类患者中的其它T细胞群选择性地靶向和耗减ICOS+Treg。这通过缓解由这些细胞介导的免疫抑制且由此增强Teff针对靶细胞,例如肿瘤细胞或感染细胞的活性来提供治疗作用。
用抗ICOS抗体与IL-2的组合疗法可用于本文中所描述的任何治疗性适应症,且具体来说用于治疗肿瘤,例如黑素瘤(例如转移性黑素瘤)或肾细胞癌。因此,在一个实例中,用抗ICOS抗体治疗的患者为呈递转移性黑素瘤且已用IL-2,例如HD IL-2疗法或LD IL-2疗法治疗的患者。
一般来说,当向已接受用第一治疗剂(例如,免疫调节剂抗体)或其它药剂(例如,IL-2)治疗的患者给予抗ICOS抗体时,可在给予第一治疗剂之后例如24小时、48小时、72小时、1周或2周的最小时间段之后给予抗ICOS抗体。可在给予第一治疗剂之后的2周、3周、4周或5周内给予抗ICOS抗体。尽管可能需要使给予的治疗数量最小化以便于患者的顺从性并减少成本,但这并不排除在任何时间额外给药任一种药剂。实际上,将选择相关给药时间安排以最佳化其组合效应,第一治疗剂创建其中抗ICOS抗体的作用尤其有利的免疫学环境(例如,较高ICOS+Treg,或如下文所论述的抗原释放)。因此,依序给予第一治疗剂并接着给予抗ICOS抗体可使得第一药剂起作用的时间创建其中抗ICOS抗体可呈现其增强效应的活体内条件。不同给药方案(包括同时或依序组合治疗)描述于本文中并且可以按需要利用。当第一治疗剂为一种增加患者中ICOS+Treg的数量的药剂时,用于患者的治疗方案可包含确定患者具有增加的ICOS+Treg数量,并且接着给予抗ICOS抗体。
如所提及,抗ICOS抗体在组合疗法中的用途可提供以下优点:减少治疗剂的有效剂量和/或抵消治疗剂增加患者的ICOS+Treg的不良作用。又另外治疗益处可通过以下获得:选择使得通过“免疫细胞死亡”从靶细胞中释放抗原的第一治疗剂,并且与抗ICOS抗体组合给予第一治疗剂。如所提及,给予抗ICOS抗体可依序跟随在给予第一治疗剂、相隔如上文所论述的某一时间窗给予两种药剂之后。
与细胞凋亡对比,免疫细胞死亡是细胞死亡的识别模式。其特征在于将ATP和HMGB1从细胞中释放且使钙网蛋白暴露于质膜上[33,34]。
靶组织或靶细胞中的免疫细胞死亡促使抗原呈递细胞吞噬细胞,使得展示来自靶细胞的抗原,其继而诱导抗原特异性Teff细胞。抗ICOS抗体可以通过充当ICOS在Teff细胞上的激动剂来增加Teff响应的量级和/或持续时间。另外,当抗ICOS抗体为Fc效应子功能启用抗体(例如,人类IgG1抗体)时,抗ICOS抗体可导致抗原特异性Treg的耗减。因此,通过组合这些效应中的任一个或两个,调节Teff与Treg细胞之间的平衡有利于增强Teff活性。抗ICOS抗体与诱导靶组织或靶细胞类型中,例如肿瘤或癌细胞中的免疫细胞死亡的治疗的组合由此促进患者的针对靶组织或靶细胞的免疫反应,从而呈现其中活体内产生疫苗抗原的疫苗接种形式。
因此,本发明的一个方面为通过针对患者的癌细胞对其进行活体内疫苗接种来治疗患者的癌症的方法。本发明的另一方面为用于此类方法中的抗ICOS抗体。抗ICOS抗体可用于包含以下的方法中:
利用致使癌细胞的免疫细胞死亡的疗法治疗患者,使得向抗原特异性效应T细胞呈递抗原,和
向患者给予抗ICOS抗体,其中抗ICOS抗体增强针对癌细胞的抗原特异性效应T细胞反应。
诱导免疫细胞死亡的治疗包括放射(例如,使用UVC光或γ射线电离辐射细胞)、化疗剂(例如,奥沙利铂(oxaliplatin),蒽环霉素,例如多柔比星(doxorubicin)、伊达比星(idarubicin)或米托蒽醌(mitoxantrone),例如根皮素或海松酸的BK通道激动剂,硼替佐米(bortezomib)、强心甙(cardiac glycosides)、环磷酰胺、GADD34/PP1抑制剂伴丝裂霉素、PDT伴金丝桃素、聚肌苷-聚胞苷酸、5-氟尿嘧啶、吉西他滨(gemcitabine)、吉非替尼(gefitinib)、埃罗替尼(erlotinib)或毒胡萝卜素伴顺铂)和针对肿瘤相关抗原的抗体。肿瘤相关抗原可以是相对于同一组织的非肿瘤细胞(例如,HER2、CD20、EGFR)被肿瘤细胞过度表达的任何抗原。合适的抗体包括赫赛汀(herceptin)(抗HER2)、利妥昔单抗(rituximab)(抗CD20)或西妥昔单抗(cetuximab)(抗EGFR)。
因此,将抗ICOS抗体与一种或多种此类治疗组合是有利的。任选地,向已接受此类治疗的患者给予抗ICOS抗体。抗ICOS抗体可在诱导免疫细胞死亡的治疗后例如24小时、48小时、72小时、1周或2周的一段时间之后给药,例如治疗之后24小时到72小时之间。抗ICOS抗体可在治疗之后的2周、3周、4周或5周内给药。组合疗法的其它方案论述于本文中的其它地方。
虽然上文已描述“活体内疫苗接种”,但是治疗肿瘤细胞以活体外诱导免疫细胞死亡也是可能的,此后可向患者再引入细胞。并非直接向患者给予诱导免疫细胞死亡的药剂或治疗,而是向患者给予经过治疗的肿瘤细胞。可以根据上述给药方案治疗患者。
如已标注,单次剂量的抗ICOS抗体可足以提供治疗益处。因此,在本文中所描述的治疗方法中,抗ICOS抗体任选地以单次剂量给药。单次剂量的抗ICOS抗体可耗减患者的Treg,伴随对例如癌症的疾病的有益效应。此前已报告Treg的短暂消融具有抗肿瘤效应,包括减缓肿瘤进展、治疗已形成肿瘤和转移以及延长存活期,并且所述消融可增强肿瘤辐射的治疗作用[35]。给予单次剂量的抗ICOS可提供此类Treg耗减,且可用于增强组合使用的其它治疗方法,例如放射线疗法的效应。
针对PD-L1的抗体
与抗ICOS抗体组合使用的针对PD-L1的抗体无论作为单独治疗剂或呈如本文中所描述的多特异性抗体形式都可以包含任何抗PD-L1抗体的抗原结合位点。抗PD-L1抗体的大量实例公开于本文中且其它实例在所属领域中已知。许多此处所提及的抗PD-L1抗体的特征化数据已公布于US9,567,399和US9,617,338中,其以引用的方式并入本文中。
1D05具有Seq ID No:33的重链可变区(VH)氨基酸序列,包含Seq ID No:27(IMGT)或Seq ID No:30(Kabat)的CDRH1氨基酸序列、Seq ID No:28(IMGT)或Seq ID No:31(Kabat)的CDRH2氨基酸序列和Seq ID No:29(IMGT)或Seq ID No:32(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:34。1D05具有Seq ID No:43的轻链可变区(VL)氨基酸序列,包含Seq ID No:37(IMGT)或Seq ID No:40(Kabat)的CDRL1氨基酸序列、Seq ID No:38(IMGT)或Seq ID No:41(Kabat)的CDRL2氨基酸序列和Seq ID No:39(IMGT)或Seq ID No:42(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列是Seq ID No:44。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq IDNo:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq IDNo:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、SeqID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、SeqID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:35(重链核酸序列Seq IDNo:36)。全长轻链氨基酸序列为Seq ID No:45(轻链核酸序列Seq ID No:46)。
84G09具有Seq ID No:13的重链可变(VH)区氨基酸序列,包含Seq ID No:7(IMGT)或Seq ID No:10(Kabat)的CDRH1氨基酸序列、Seq ID No:8(IMGT)或Seq ID No:11(Kabat)的CDRH2氨基酸序列和Seq ID No:9(IMGT)或Seq ID No:12(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:14。84G09具有Seq ID No:23的轻链可变区(VL)氨基酸序列,包含Seq ID No:17(IMGT)或Seq ID No:20(Kabat)的CDRL1氨基酸序列、Seq IDNo:18(IMGT)或Seq ID No:21(Kabat)的CDRL2氨基酸序列和Seq ID No:19(IMGT)或Seq IDNo:22(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:24。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq IDNo:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq IDNo:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq IDNo:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:15(重链核酸序列Seq ID No:16)。全长轻链氨基酸序列为Seq ID No:25(轻链核酸序列Seq ID No:26)。
1D05 HC突变体1具有Seq ID No:47的重链可变(VH)区氨基酸序列,包含Seq IDNo:27(IMGT)或Seq ID No:30(Kabat)的CDRH1氨基酸序列、Seq ID No:28(IMGT)或Seq IDNo:31(Kabat)的CDRH2氨基酸序列和Seq ID No:29(IMGT)或Seq ID No:32(Kabat)的CDRH3氨基酸序列。1D05HC突变体1具有Seq ID No:43的轻链可变区(VL)氨基酸序列,包含Seq IDNo:37(IMGT)或Seq ID No:40(Kabat)的CDRL1氨基酸序列、Seq ID No:38(IMGT)或Seq IDNo:41(Kabat)的CDRL2氨基酸序列和Seq ID No:39(IMGT)或Seq ID No:42(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:44。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq IDNo:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、SeqID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长轻链氨基酸序列为Seq ID No:45(轻链核酸序列Seq ID No:46)。
1D05 HC突变体2具有Seq ID No:48的重链可变(VH)区氨基酸序列,包含Seq IDNo:27(IMGT)或Seq ID No:30(Kabat)的CDRH1氨基酸序列、Seq ID No:28(IMGT)或Seq IDNo:31(Kabat)的CDRH2氨基酸序列和Seq ID No:29(IMGT)或Seq ID No:32(Kabat)的CDRH3氨基酸序列。1D05HC突变体2具有Seq ID No:43的轻链可变区(VL)氨基酸序列,包含Seq IDNo:37(IMGT)或Seq ID No:40(Kabat)的CDRL1氨基酸序列、Seq ID No:38(IMGT)或Seq IDNo:41(Kabat)的CDRL2氨基酸序列和Seq ID No:39(IMGT)或Seq ID No:42(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:44。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq IDNo:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、SeqID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长轻链氨基酸序列为Seq ID No:45(轻链核酸序列Seq ID No:46)。
1D05 HC突变体3具有Seq ID No:49的重链可变(VH)区氨基酸序列,包含Seq IDNo:27(IMGT)或Seq ID No:30(Kabat)的CDRH1氨基酸序列、Seq ID No:28(IMGT)或Seq IDNo:31(Kabat)的CDRH2氨基酸序列和Seq ID No:29(IMGT)或Seq ID No:32(Kabat)的CDRH3氨基酸序列。1D05HC突变体3具有Seq ID No:43的轻链可变区(VL)氨基酸序列,包含SEQ IDNO:37(IMGT)或Seq ID No:40(Kabat)的CDRL1氨基酸序列、Seq ID No:38(IMGT)或Seq IDNo:41(Kabat)的CDRL2氨基酸序列和Seq ID No:39(IMGT)或Seq ID No:42(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:44。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq IDNo:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、SeqID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长轻链氨基酸序列为Seq ID No:45(轻链核酸序列Seq ID No:46)。
1D05 HC突变体4具有Seq ID No:342的重链可变(VH)区氨基酸序列,包含Seq IDNo:27(IMGT)或Seq ID No:30(Kabat)的CDRH1氨基酸序列、Seq ID No:28(IMGT)或Seq IDNo:31(Kabat)的CDRH2氨基酸序列和Seq ID No:29(IMGT)或Seq ID No:32(Kabat)的CDRH3氨基酸序列。1D05HC突变体4具有Seq ID No:43的轻链可变区(VL)氨基酸序列,包含SEQ IDNO:37(IMGT)或Seq ID No:40(Kabat)的CDRL1氨基酸序列、Seq ID No:38(IMGT)或Seq IDNo:41(Kabat)的CDRL2氨基酸序列和Seq ID No:39(IMGT)或Seq ID No:42(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:44。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq IDNo:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、SeqID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长轻链氨基酸序列为Seq ID No:45(轻链核酸序列Seq ID No:46)。
1D05 LC突变体1具有Seq ID No:33的重链可变(VH)区氨基酸序列,包含Seq IDNo:27(IMGT)或Seq ID No:30(Kabat)的CDRH1氨基酸序列、Seq ID No:28(IMGT)或Seq IDNo:31(Kabat)的CDRH2氨基酸序列和Seq ID No:29(IMGT)或Seq ID No:32(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:34。1D05LC突变体1具有Seq ID No:50的轻链可变区(VL)氨基酸序列,包含Seq ID No:37(IMGT)或Seq ID No:40(Kabat)的CDRL1氨基酸序列和Seq ID No:39(IMGT)或Seq ID No:42(Kabat)的CDRL3氨基酸序列。1D05LC突变体1的CDRL2序列如由Kabat或IMGT系统所限定来自Seq ID No:50的VL序列。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq IDNo:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq IDNo:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq IDNo:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:35(重链核酸序列Seq ID No:36)。
1D05 LC突变体2具有Seq ID No:33的重链可变(VH)区氨基酸序列,包含Seq IDNo:27(IMGT)或Seq ID No:30(Kabat)的CDRH1氨基酸序列、Seq ID No:28(IMGT)或Seq IDNo:31(Kabat)的CDRH2氨基酸序列和Seq ID No:29(IMGT)或Seq ID No:32(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:34。1D05LC突变体2具有Seq ID No:51的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:37(IMGT)或Seq ID No:40(Kabat)的CDRL1氨基酸序列、Seq ID No:38(IMGT)或Seq ID No:41(Kabat)的CDRL2氨基酸序列和Seq IDNo:39(IMGT)或Seq ID No:42(Kabat)的CDRL3氨基酸序列。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq IDNo:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq IDNo:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq IDNo:538。全长重链氨基酸序列为Seq ID No:35(重链核酸序列Seq ID No:36)。
1D05 LC突变体3具有Seq ID No:33的重链可变(VH)区氨基酸序列,包含Seq IDNo:27(IMGT)或Seq ID No:30(Kabat)的CDRH1氨基酸序列、Seq ID No:28(IMGT)或Seq IDNo:31(Kabat)的CDRH2氨基酸序列和Seq ID No:29(IMGT)或Seq ID No:32(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:34。1D05LC突变体3具有Seq ID No:298的轻链可变区(VL)氨基酸序列,包含Seq ID No:37(IMGT)或Seq ID No:40(Kabat)的CDRL1氨基酸序列和Seq ID No:39(IMGT)或Seq ID No:42(Kabat)的CDRL3氨基酸序列。1D05LC突变体3的CDRL2序列如由Kabat或IMGT系统限定来自Seq ID No:298的VL序列。VL结构域的轻链核酸序列为Seq ID No:44。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq IDNo:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、SeqID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:35(重链核酸序列Seq ID No:36)。全长轻链氨基酸序列为Seq ID No:45(轻链核酸序列Seq ID No:46)。
411B08具有Seq ID No:58的重链可变(VH)区氨基酸序列,包含Seq ID No:52(IMGT)或Seq ID No:55(Kabat)的CDRH1氨基酸序列、Seq ID No:53(IMGT)或Seq ID No:56(Kabat)的CDRH2氨基酸序列和Seq ID No:54(IMGT)或Seq ID No:57(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:59。411B08具有Seq ID No:68的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:62(IMGT)或Seq ID No:65(Kabat)的CDRL1氨基酸序列、Seq ID No:63(IMGT)或Seq ID No:66(Kabat)的CDRL2氨基酸序列和Seq ID No:64(IMGT)或Seq ID No:67(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq IDNo:69。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、SeqID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq IDNo:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq IDNo:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:60(重链核酸序列Seq ID No:61)。全长轻链氨基酸序列为Seq ID No:70(轻链核酸序列Seq ID No:71)。
411C04具有Seq ID No:78的重链可变(VH)区氨基酸序列,包含Seq ID No:72(IMGT)或Seq ID No:75(Kabat)的CDRH1氨基酸序列、Seq ID No:73(IMGT)或Seq ID No:76(Kabat)的CDRH2氨基酸序列和Seq ID No:74(IMGT)或Seq ID No:77(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:79。411C04具有Seq ID No:88的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:82(IMGT)或Seq ID No:85(Kabat)的CDRL1氨基酸序列、Seq ID No:83(IMGT)或Seq ID No:86(Kabat)的CDRL2氨基酸序列和Seq ID No:84(IMGT)或Seq ID No:87(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq IDNo:89。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、SeqID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq IDNo:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq IDNo:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:80(重链核酸序列Seq ID No:81)。全长轻链氨基酸序列为Seq ID No:90(轻链核酸序列Seq ID No:91)。
411D07具有Seq ID No:98的重链可变(VH)区氨基酸序列,包含Seq ID No:92(IMGT)或Seq ID No:95(Kabat)的CDRH1氨基酸序列、Seq ID No:93(IMGT)或Seq ID No:96(Kabat)的CDRH2氨基酸序列和Seq ID No:94(IMGT)或Seq ID No:97(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:99。411D07具有Seq ID No:108的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:102(IMGT)或Seq ID No:105(Kabat)的CDRL1氨基酸序列、Seq ID No:103(IMGT)或Seq ID No:106(Kabat)的CDRL2氨基酸序列和Seq ID No:104(IMGT)或Seq ID No:107(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq IDNo:109。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如Seq ID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、SeqID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、Seq ID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq IDNo:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq ID No:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq IDNo:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:100(重链核酸序列Seq ID No:101)。全长轻链氨基酸序列为Seq ID No:110(轻链核酸序列Seq ID No:111)。
385F01具有Seq ID No:118的重链可变(VH)区氨基酸序列,包含Seq ID No:112(IMGT)或Seq ID No:115(Kabat)的CDRH1氨基酸序列、Seq ID No:113(IMGT)或Seq ID No:116(Kabat)的CDRH2氨基酸序列和Seq ID No:114(IMGT)或Seq ID No:117(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:119。385F01具有Seq ID No:128的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:122(IMGT)或Seq ID No:125(Kabat)的CDRL1氨基酸序列、Seq ID No:123(IMGT)或Seq ID No:126(Kabat)的CDRL2氨基酸序列和Seq IDNo:124(IMGT)或Seq ID No:127(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:129。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如SeqID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、SeqID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq IDNo:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:120(重链核酸序列Seq ID No:121)。全长轻链氨基酸序列为Seq ID No:130(轻链核酸序列SeqID No:131)。
386H03具有Seq ID No:158的重链可变(VH)区氨基酸序列,包含Seq ID No:152(IMGT)或Seq ID No:155(Kabat)的CDRH1氨基酸序列、Seq ID No:153(IMGT)或Seq ID No:156(Kabat)的CDRH2氨基酸序列和Seq ID No:154(IMGT)或Seq ID No:157(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:159。386H03具有Seq ID No:168的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:162(IMGT)或Seq ID No:165(Kabat)的CDRL1氨基酸序列、Seq ID No:163(IMGT)或Seq ID No:166(Kabat)的CDRL2氨基酸序列和Seq IDNo:164(IMGT)或Seq ID No:167(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:169。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如SeqID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、SeqID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq IDNo:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:160(重链核酸序列Seq ID No:161)。全长轻链氨基酸序列为Seq ID No:170(轻链核酸序列SeqID No:171)。
389A03具有Seq ID No:178的重链可变(VH)区氨基酸序列,包含Seq ID No:172(IMGT)或Seq ID No:175(Kabat)的CDRH1氨基酸序列、Seq ID No:173(IMGT)或Seq ID No:176(Kabat)的CDRH2氨基酸序列和Seq ID No:174(IMGT)或Seq ID No:177(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:179。389A03具有Seq ID No:188的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:182(IMGT)或Seq ID No:185(Kabat)的CDRL1氨基酸序列、Seq ID No:183(IMGT)或Seq ID No:186(Kabat)的CDRL2氨基酸序列和Seq IDNo:184(IMGT)或Seq ID No:187(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:189。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如SeqID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、SeqID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq IDNo:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:180(重链核酸序列Seq ID No:181)。全长轻链氨基酸序列为Seq ID No:190(轻链核酸序列SeqID No:191)。
413D08具有Seq ID No:138的重链可变(VH)区氨基酸序列,包含Seq ID No:132(IMGT)或Seq ID No:135(Kabat)的CDRH1氨基酸序列、Seq ID No:133(IMGT)或Seq ID No:136(Kabat)的CDRH2氨基酸序列和Seq ID No:134(IMGT)或Seq ID No:137(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:139。413D08具有Seq ID No:148的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:142(IMGT)或Seq ID No:145(Kabat)的CDRL1氨基酸序列、Seq ID No:143(IMGT)或Seq ID No:146(Kabat)的CDRL2氨基酸序列和Seq IDNo:144(IMGT)或Seq ID No:147(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:149。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如SeqID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、SeqID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq IDNo:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:140(重链核酸序列Seq ID No:141)。全长轻链氨基酸序列为Seq ID No:150(轻链核酸序列SeqID No:151)。
413G05具有Seq ID No:244的重链可变(VH)区氨基酸序列,包含Seq ID No:238(IMGT)或Seq ID No:241(Kabat)的CDRH1氨基酸序列、Seq ID No:239(IMGT)或Seq ID No:242(Kabat)的CDRH2氨基酸序列和Seq ID No:240(IMGT)或Seq ID No:243(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:245。413G05具有Seq ID No:254的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:248(IMGT)或Seq ID No:251(Kabat)的CDRL1氨基酸序列、Seq ID No:249(IMGT)或Seq ID No:252(Kabat)的CDRL2氨基酸序列和Seq IDNo:250(IMGT)或Seq ID No:253(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:255。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如SeqID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、SeqID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq IDNo:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:246(重链核酸序列Seq ID No:247)。全长轻链氨基酸序列为Seq ID No:256(轻链核酸序列SeqID No:257)。
413F09具有Seq ID No:264的重链可变(VH)区氨基酸序列,包含Seq ID No:258(IMGT)或Seq ID No:261(Kabat)的CDRH1氨基酸序列、Seq ID No:259(IMGT)或Seq ID No:262(Kabat)的CDRH2氨基酸序列和Seq ID No:260(IMGT)或Seq ID No:263(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:265。413F09具有Seq ID No:274的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:268(IMGT)或Seq ID No:271(Kabat)的CDRL1氨基酸序列、Seq ID No:269(IMGT)或Seq ID No:272(Kabat)的CDRL2氨基酸序列和Seq IDNo:270(IMGT)或Seq ID No:273(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:275。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如SeqID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、SeqID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq IDNo:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:266(重链核酸序列Seq ID No:267)。全长轻链氨基酸序列为Seq ID No:276(轻链核酸序列SeqID No:277)。
414B06具有Seq ID No:284的重链可变(VH)区氨基酸序列,包含Seq ID No:278(IMGT)或Seq ID No:281(Kabat)的CDRH1氨基酸序列、Seq ID No:279(IMGT)或Seq ID No:282(Kabat)的CDRH2氨基酸序列和Seq ID No:280(IMGT)或Seq ID No:283(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:285。414B06具有Seq ID No:294的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:288(IMGT)或Seq ID No:291(Kabat)的CDRL1氨基酸序列、Seq ID No:289(IMGT)或Seq ID No:292(Kabat)的CDRL2氨基酸序列和Seq IDNo:290(IMGT)或Seq ID No:293(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:295。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如SeqID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、SeqID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq IDNo:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:286(重链核酸序列Seq ID No:287)。全长轻链氨基酸序列为Seq ID No:296(轻链核酸序列SeqID No:297)。
416E01具有Seq ID No:349的重链可变区(VH)氨基酸序列,包含Seq ID No:343(IMGT)或Seq ID No:346(Kabat)的CDRH1氨基酸序列、Seq ID No:344(IMGT)或Seq ID No:347(Kabat)的CDRH2氨基酸序列和Seq ID No:345(IMGT)或Seq ID No:348(Kabat)的CDRH3氨基酸序列。VH结构域的重链核酸序列为Seq ID No:350。416E01具有Seq ID No:359的轻链可变区(VL)氨基酸序列,包含SEQ ID NO:353(IMGT)或Seq ID No:356(Kabat)的CDRL1氨基酸序列、Seq ID No:354(IMGT)或Seq ID No:357(Kabat)的CDRL2氨基酸序列和Seq IDNo:355(IMGT)或Seq ID No:358(Kabat)的CDRL3氨基酸序列。VL结构域的轻链核酸序列为Seq ID No:360。VH结构域可与本文中所描述的重链恒定区序列中的任一个组合,例如SeqID No:193、Seq ID No:195、Seq ID No:197、Seq ID No:199、Seq ID No:201、Seq ID No:203、Seq ID No:205、Seq ID No:340、Seq ID No:524、Seq ID No:526、Seq ID No:528、SeqID No:530、Seq ID No:532或Seq ID No:534。VL结构域可与本文中所描述的轻链恒定区序列中的任一个组合,例如Seq ID No:207、Seq ID No:209、Seq ID No:211、Seq ID No:213、Seq ID No:215、Seq ID No:217、Seq ID No:219、Seq ID No:221、Seq ID No:223、Seq IDNo:225、Seq ID No:227、Seq ID No:229、Seq ID No:231、Seq ID No:233、Seq ID No:235、Seq ID No:237、Seq ID No:536和Seq ID No:538。全长重链氨基酸序列为Seq ID No:351(重链核酸序列Seq ID No:352)。全长轻链氨基酸序列为Seq ID No:361(轻链核酸序列SeqID No:362)。
抗体-药物共轭物
抗ICOS抗体可以用作细胞毒性剂的载剂以靶向Treg。如实例18中所报告,定位于肿瘤微环境(TME)中的Treg强烈表达ICOS。在肿瘤内Treg上比在肿瘤内Teff或外周Treg上更强烈表达ICOS。因此,用毒性药物或前药标记的抗ICOS抗体可以优先靶向TME中的Treg以传递毒性有效负载,从而选择性地抑制那些细胞。细胞毒性剂的此类靶向提供了移除Treg的免疫抑制作用的额外途径,由此改变了有利于Teff活性的Treg:Teff平衡,并且可以作为本文中所论述的其它治疗方法(例如,对Treg的Fc效应子介导的抑制、效应T细胞的激动作用)中的任何一个或多个的替代方案或与其组合使用。
因此,本发明提供了一种共轭到细胞毒性药物或前药的抗ICOS抗体。在前药的情况下,前药可在TME或治疗活性的其它靶位点中活化以产生细胞毒性剂。活化可响应于例如光活化的触发子,例如使用近红外光来活化光吸收剂共轭物[36]。前药的空间选择性活化进一步增强抗体-药物共轭物的细胞毒性效应,从而与肿瘤内Treg上的高ICOS表达组合以提供针对这些细胞具高度选择性的细胞毒性效应。
为在抗体-药物共轭物中使用,细胞毒性药物或前药在抗体-药物共轭物循环于血液中期间优选地为非免疫原性的和无毒的(休眠或失活)。优选地,细胞毒性药物(或在活化时,前药)有效——例如,药物的两个到四个分子可足以杀灭靶细胞。光活化前药为硅酞菁染料(IRDye 700DX),其在近红外暴光之后诱导对细胞膜的致死性损伤。细胞毒性药物包括例如单甲基奥瑞他汀E(monomethyl auristatin E)的抗有丝分裂剂和例如美登素衍生物(maytansine derivative)的微管抑制剂,例如美坦辛(mertansine)、DM1、恩他新(emtansine)。
药物(或前药)与抗体的共轭通常将通过连接子进行。连接子可为可裂解连接子,例如二硫键、腙或肽键。可使用组织蛋白酶可裂解的连接子,使得药物通过肿瘤细胞中的组织蛋白酶来释放。替代地,可使用不可裂解连接子,例如硫醚键。还可以包括额外连接基和/或间隔基。
抗体-药物共轭物中的抗体可为抗体片段,例如Fab'2或如本文中所描述的其它抗原结合片段,这是因为此类片段的小尺寸可以帮助渗透到组织部位(例如,实体肿瘤)。
根据本发明的抗ICOS抗体可以作为免疫细胞因子提供。抗ICOS抗体还可以与组合疗法中的免疫细胞因子一起给予。在组合疗法中与抗ICOS一起使用的抗体的多个实例描述于本文中,并且这些抗体中的任一种(例如,抗PD-L1抗体)可作为用于本发明中的免疫细胞因子提供。免疫细胞因子包含共轭到例如IL-2的细胞因子的抗体分子。抗ICOS:IL-2共轭物和抗PD-L1:IL-2共轭物由此为本发明的另外方面。
IL-2细胞因子可在高 亲和力IL-2受体和/或中等亲和力(αβ)IL-2受体处具有活性。如用于免疫细胞因子中的IL-2可为人类野生型IL-2或具有一个或多个氨基酸缺失、取代或添加的变体IL-2细胞因子,例如在N端处具有1到10个氨基酸缺失的IL-2。其它IL-2变体包括突变R38A或R38Q。
亲和力IL-2受体和/或中等亲和力(αβ)IL-2受体处具有活性。如用于免疫细胞因子中的IL-2可为人类野生型IL-2或具有一个或多个氨基酸缺失、取代或添加的变体IL-2细胞因子,例如在N端处具有1到10个氨基酸缺失的IL-2。其它IL-2变体包括突变R38A或R38Q。
实例抗PD-L1免疫细胞因子包含免疫球蛋白重链和免疫球蛋白轻链,其中重链在N端到C端方向上包含:
a)VH结构域,其包含CDRH1、CDRH2和CDRH3;和
b)重链恒定区;
并且其中轻链在N端到C端方向上包含:
c)VL结构域,其包含CDRL1、CDRL2和CDRL3;
d)轻链恒定区(CL);
e)任选地,连接子(L);和
f)IL-2细胞因子;
其中VH结构域和VL结构域由特异性结合到人类PD-L1的抗原结合位点构成;并且
其中免疫细胞因子包含VH结构域,其包含含有基元X1GSGX2YGX3X4FD的CDRH3(SeqID No:609),其中X1、X2和X3独立地为任何氨基酸,且X4存在或不存在,并且如果存在,可以是任何氨基酸。
VH和VL结构域可为本文中所提及的任何抗PD-L1抗体的VH和VL结构域,例如1D05VH和VL结构域。
IL-2可为人类野生型IL-2或变体IL-2。
疫苗接种
抗ICOS抗体可提供于疫苗组合物中或与疫苗制剂共给予。ICOS与T滤泡辅助细胞形成和生发中心反应有关[37]。激动剂ICOS抗体作为分子佐剂由此具有增强疫苗功效的潜在临床效用。抗体可以用于增加多种疫苗(例如针对B型肝炎、疟疾、HIV的那些疫苗)的保护功效。
在疫苗接种的情形下,抗ICOS抗体将通常是缺乏Fc效应子功能并且因此不介导ADCC、CDC或ADCP的一种抗体。抗体可以不具有Fc区或具有效应子无效恒定区的形式提供。任选地,抗ICOS抗体可具有结合一种或多种类型的Fc受体但不诱导ADCC、CDC或ADCP活性,或与野生型人类IgG1相比呈现较低ADCC、CDC和ADCP活性的重链恒定区。此类恒定区可能不能够结合或可能以较低亲和力结合负责触发ADCC、CDC或ADCP活性的特定Fc受体。替代地,当细胞效应子功能在疫苗接种的情形下可接受或合乎需要时,抗ICOS抗体可包含Fc效应子功能呈阳性的重链恒定区。举例来说,IgG1、IgG4和IgG4.PE格式中的任一个可用于疫苗接种方案中的抗ICOS抗体,并且合适的同种型和抗体恒定区的其它实例更详细地陈述于本文中的其它地方。
调配物和给药
抗体可为单克隆或多克隆的,但优选地作为单克隆抗体提供用于治疗用途。其可作为其它抗体的混合物的部分提供,任选地包括具有不同结合特异性的抗体。
根据本发明的抗体和编码核酸将通常以分离形式提供。因此,可提供根据其天然环境或其产生环境纯化的抗体、VH和/或VL结构域和核酸。分离的抗体和分离的核酸将不含或实质上不含与其天然相关的材料,例如与其一起发现于活体内的其它多肽或核酸,或在通过活体外重组DNA技术进行制备时其中制备所述抗体或核酸的环境。任选地,分离的抗体或核酸(1)不含将通常与其一起发现的至少一些其它蛋白质,(2)基本上不含来自相同来源,例如来自相同物种的其它蛋白质,(3)通过来自不同物种的细胞表达,(4)已从至少约50%的聚核苷酸、脂质、碳水化合物或在自然界中与其相关的其它材料中分离出,(5)与在自然界中与其不相关的多肽可操作地相关(通过共价或非共价相互作用),或(6)在自然界中不存在。
抗体或核酸可以用稀释剂或佐剂配制且出于实用目的仍然是分离的——例如如果使用的话其可与载剂混合以涂布微量滴定板以用于免疫分析中,并且在用于疗法中时可以与药学上可接受的载剂或稀释剂混合。如本文中的其它地方所描述,其它活性成分还可以包括在治疗性制剂中。抗体可天然地在活体内或通过例如CHO细胞的异源真核细胞的系统糖基化,或其可(例如在通过在原核细胞中表达来产生的情况下)未糖基化。本发明涵盖具有经过修饰的糖基化模式的抗体。在一些应用中,移除不合需要的糖基化位点的修饰或例如增加ADCC功能的岩藻糖部分的移除可为适用的[38]。在其它应用中,可以进行半乳糖基化的修饰以便修饰CDC。
通常,分离的产物占给出样本的至少约5%、至少约10%、至少约25%或至少约50%。抗体可实质上不含蛋白质或多肽或发现于其天然或产生环境中的其它污染物,所述环境将干涉其治疗、诊断、预防、研究或其它用途。
抗体可能已经从其产生环境的组分中识别、分离和/或回收(例如,天然地或重组地)。分离的抗体可摆脱与来自其产生环境的所有其它组分的关联,例如使得抗体已与FDA可审批通过或已审批通过的标准分离。其产生环境的污染物组分(例如由重组转染细胞产生的)为将通常干涉针对抗体的研究、诊断或治疗用途的材料,且可包括酶、激素和其它蛋白质或非蛋白质溶解物。在一些实施例中,抗体将被纯化:(1)到大于抗体的95重量%,如通过例如劳里法(Lowry method)测定,并且在一些实施例中,到大于99重量%;(2)到通过使用旋杯式测序仪足以获得至少15个N端残基或内部氨基酸序列的程度,或(3)使用考马斯(Coomassie)蓝或银染色在还原或非还原条件下通过SDS-PAGE纯化至均质。分离的抗体包括在重组细胞内的原位抗体,因为抗体天然环境的至少一种组分将不存在。然而,通常,分离的抗体或其编码核酸将通过至少一个纯化步骤制备。
本发明提供了包含本文中所描述的抗体的治疗性组合物。还提供了包含编码此类抗体的核酸的治疗性组合物。编码核酸更详细地描述于本文中的其它地方且包括DNA和RNA,例如mRNA。在本文中所描述的治疗方法中,编码抗体的核酸和/或含有此类核酸的细胞的用途可作为包含抗体自身的组合物的替代物(或添加)使用。含有编码抗体的核酸的细胞(任选地,其中核酸稳定地整合到基因组中)因此相当于用于患者的治疗用途的药剂。编码抗ICOS抗体的核酸可引入到人类B淋巴细胞,任选地来源于目标患者的B淋巴细胞中并且在活体外修饰。任选地,使用记忆B细胞。给予患者含有编码核酸的细胞提供了能够表达抗ICOS抗体的细胞的贮库,与给予分离的核酸或分离的抗体相比,这可以在较长时期内提供治疗益处。
组合物可含有合适的载剂、赋形剂和并入到调配物中以提供改进的转移、传递、耐受度等的其它试剂。众多的适当调配物可发现于所有医药化学家已知的处方集中:《雷氏药学大全(Remington's Pharmaceutical Sciences)》,麦克出版公司(Mack PublishingCompany),宾夕法尼亚州伊斯顿(Easton,PA)。这些调配物包括例如散剂、糊剂、软膏、胶状物、蜡、油、脂质、含有囊泡的脂质(阳离子型或阴离子型)(例如LIPOFECTINTM)、DNA共轭物、无水吸收糊剂、水包油和油包水乳剂、乳剂卞巴蜡(各种分子量的聚乙二醇)、半固体凝胶和含有卞巴蜡的半固体混合物。也参见Powell等人,“用于肠胃外调配物的赋形剂的概略(Compendium of excipients for parenteral formulations)”PDA(1998)《药学科学与技术杂志(J Pharm Sci Technol)》52:238-311。组合物可包含抗体或核酸以及医学注射缓冲液和/或佐剂。
抗体或其编码核酸可调配成用于例如呈注射液体(任选地水溶液)形式的对患者的期望给药途径。各种传递系统已知并且可以用于给予本发明的医药组合物。引入方法包括但不限于皮内、肌肉内、腹膜内、静脉内、皮下、鼻内、硬膜外和口服途径。与静脉内制剂相比,调配用于皮下给药的抗体通常需要将其浓缩到较小体积。根据本发明的抗体高效能可使其以足够低的剂量使用以进行皮下调配物实践,与较低效能的抗ICOS抗体相比更具优势。
所述组合物可以通过任何方便的途径,例如通过输注或大剂量注射、通过经上皮或粘膜皮肤内层(例如口腔粘膜、直肠和肠道粘膜等)吸收来给予,并且可以与其它生物活性剂一起给予。可以全身或局部给药。
医药组合物还可以囊泡,特别是脂质体形式递送(参见Langer(1990)《科学(Science)》249:1527-1533;Treat等人,(1989)治疗感染性疾病和癌症的脂质体(Liposomes in the Therapy of Infectious Disease and Cancer),Lopez Berestein和Fidler(编),纽约利斯,第353到365页;Lopez-Berestein,同上,第317到327页;通常参见同上)。
在某些情形下,医药组合物可以在控制释放系统中递送。在一个实施例中,可以使用气泵(参见Langer,同上;Sefton(1987)CRC《生物医学工程评论综述(Crit.Ref.Biomed.Eng.)》14:201)。在另一实施例中,可以使用聚合材料;参见《控制释放的医学应用(Medical Applications of Controlled Release)》,Langer和Wise(编),CRC出版社,佛罗里达州波卡拉顿(1974)。在又另一实施例中,控制释放系统可接近组合物的目标放置,由此仅需要一部分全身剂量(参见例如Goodson,《控制释放的医学应用》,同上,第2卷,第115到138页,1984)。
可注射制剂可包括用于静脉内、皮下、皮內和肌肉内注射、滴液输注等的剂型。这些可注射制剂可以通过众所周知的方法制备。举例来说,可注射制剂可例如通过将上述抗体或其盐溶解、悬浮或乳化于常规地用于注射的无菌水性介质或油性介质中来制备。作为用于注射的水性介质,存在例如生理盐水、含有葡萄糖的等渗溶液和其它助剂等,其可与例如醇(例如,乙醇)、多元醇(例如,丙二醇、聚乙二醇)等适当增溶剂、非离子型表面活性剂[例如,聚山梨醇酯80、HCO-50(氢化蓖麻油的聚氧化乙烯(50摩尔)加合物)]等组合使用。作为油性介质,采用了例如芝麻油、大豆油等,其可与例如苯甲酸苄酯、苄醇等增溶剂组合使用。由此制备的注射剂可以填充于适当安瓿中。可用标准针和注射器皮下或静脉内递送本发明的医药组合物。设想治疗将不限于临床用途。因此,使用无针装置的皮下注射也是有利的。相对于皮下递送,笔式递送装置易于应用于递送本发明的医药组合物。这种笔式递送装置可重复使用或是一次性的。可重复使用的笔式递送装置通常利用含有医药组合物的可更换的药筒。一旦在药筒内的所有医药组合物都已施用并且排空药筒,就可以容易地丢弃空药筒且替换成含有医药组合物的新药筒。笔式递送装置随后可再使用。在一次性笔式递送装置中,没有可更换的药筒。实际上,一次性笔式递送装置预填充有保持在装置内的储液槽中的医药组合物。一旦排空储液槽中的医药组合物,就丢弃整个装置。多种可重复使用的笔式递送装置和自动注射器递送装置应用于皮下递送本发明的医药组合物。实例包括但当然不限于AUTOPENTM(英国伍德斯托克(Woodstock,UK)的Owen Mumford,Inc.)、DISETRONICTM笔(瑞士布格多夫(Bergdorf,Switzerland)的Disetronic Systems)、HUMALOG MIX 75/25TM笔、HUMALOGTM笔、HUMALIN 70/30TM笔(印第安纳州印第安纳波利斯(Indianapolis,Ind)的Eli Lilly and Co.)、NOVOPENTMI、II和III(丹麦哥本哈根(Copenhagen,Denmark)的NovoNordisk)、NOVOPEN JUNIORTM(丹麦哥本哈根的Novo Nordisk)、BDTM笔(新泽西州富兰克林湖(Franklin Lakes,N.J.)的Becton Dickinson)、OPTIPENTM、OPTIPEN PROTM、OPTIPENSTARLETTM及OPTICLIKTM(德国法兰克福(Frankfurt,Germany)的sanofi-aventis),在此仅举几例。应用于皮下递送本发明的医药组合物的一次性笔式递送装置的实例包括但当然不限于SOLOSTARTM笔(Sanofi-Aventis)、FLEXPENTM(Novo Nordisk)和KWIKPENTM(Eli Lilly)。
有利地,用于上述口服或肠胃外使用的医药组合物制备成适合于满足活性成分剂量的单位剂量的剂型。这类单位剂量的剂型包括例如片剂、丸剂、胶囊、注射剂(安瓿)、栓剂等。所含有的前述抗体的量通常为约5mg到约500mg每单位剂量的剂型;尤其以注射剂形式,针对其它剂型可含有约5mg到约100mg和约10mg到约250mg的前述抗体。
抗体、核酸或包含其的组合物可含于医学容器中,例如小瓶、注射器、IV容器或注射装置。在一实例中,抗体、核酸或组合物在活体外,并且可在无菌容器中。在一实例中,提供了用于如本文中所描述的治疗方法中的包含抗体、包装和说明书的试剂盒。
本发明的一个方面为包含本发明的抗体或核酸和一种或多种药学上可接受的赋形剂的组合物,其实例列出于上文。“药学上可接受”是指得到美国联邦监管机构或州政府批准或可批准或在美国药典(U.S.Pharmacopeia)或其它公认药典中列出供用于动物,包括人类。药学上可接受的载剂、赋形剂或佐剂可以与药剂,例如本文中所描述的任何抗体或抗体链一起向患者给予,并且在以足以递送治疗量的药剂的剂量给药时不破坏其药理学活性且无毒。
在一些实施例中,抗ICOS抗体将是根据本发明的组合物中的唯一活性成分。因此,组合物可由抗体组成或其可由抗体与一种或多种药学上可接受的赋形剂组成。然而,根据本发明的组合物任选地包括一种或多种额外活性成分。可与抗ICOS抗体组合的药剂的详细描述提供于本文中的其它地方。任选地,组合物在组合制剂中含有多种抗体(或编码核酸),例如单一调配物包含抗ICOS抗体和一种或多种其它抗体。可能需要与根据本发明的抗体或核酸一起给药的其它治疗剂包括镇痛剂。任何此类药剂或药剂组合可与根据本发明的抗体或核酸组合给予,或提供于具有所述抗体或核酸的组合物中,无论作为组合或单独制剂。根据本发明的抗体或核酸可单独且依序给予,或并行且任选地作为组合制剂与另一治疗剂或例如所提及的那些药剂一起给予。
用于特定治疗适应症的抗ICOS抗体可与公认的标准治疗组合。因此,对于抗癌治疗,抗体疗法可用于治疗方案中,所述治疗方案还包括例如化疗、手术和/或放射疗法。可以单次剂量或以分次剂量将放射线疗法直接地递送到患病组织或递送到全身。
多种组合物可以单独或同时给予。单独给予是指在不同时间,例如相隔至少10分钟、20分钟、30分钟或10分钟到60分钟,或相隔1小时、2小时、3小时、4小时、5小时、6小时、7小时、8小时、9小时、10小时、12小时给予两种组合物。我们还可以相隔24小时或甚至相隔更久来给予组合物。替代地,两种或多于两种组合物可以同时,例如相隔小于10分钟或小于5分钟来给予。在一些方面中,同时给予的组合物可以混合物形式给予,针对每一种组分有或没有类似或不同定时释放机制。
抗体和其编码核酸可以用作治疗剂。本文中的患者通常是哺乳动物,典型地人类。可以例如通过本文中所提及的任何给药途径向哺乳动物给予抗体或核酸。
通常以“治疗有效量”给药,这是产生期望效应的量,为了所述效应向患者给予足以展示出益处的量。确切量将视治疗目的而定,并且将可由所属领域的技术人员使用已知技术确定(参见例如Lloyd(1999)《药物复合的艺术、科学和技术(The Art,Science andTechnology of Pharmaceutical Compounding)》)。治疗处方(例如对剂量等的决定)在全科医生和其它医生的职责范围内,并且可视正在治疗的疾病的症状和/或进展的严重程度而定。抗体或核酸的治疗有效量或合适的剂量可以通过将其在动物模型中的活体外活性与活体内活性进行比较来确定。小鼠和其它测试动物的有效剂量外推到人类的方法是已知的。
如由描述于本文中的实例中的活体内研究指示,抗ICOS抗体可在一系列剂量下有效。药效动力学研究报告于实例24中。
抗ICOS抗体可以以下剂量范围中的一个的量给予:
约10μg/kg体重到约100mg/kg体重,
约50μg/kg体重到约5mg/kg体重,
约100μg/kg体重到约10mg/kg体重,
约100μg/kg体重到约20mg/kg体重,
约0.5mg/kg体重到约20mg/kg体重,或
约5mg/kg体重或更小,例如小于4mg/kg、小于3mg/kg、小于2mg/kg或小于1mg/kg的抗体。
人类的最佳治疗剂量可在0.1mg/kg与0.5mg/kg之间,例如约0.1mg/千克、0.15mg/kg、0.2mg/千克、0.25mg/kg、0.3mg/kg、0.35mg/kg、0.4mg/kg、0.45mg/kg或0.5mg/kg。对于成年人类的固定给药方案,合适的剂量可在8mg与50mg之间或在8mg与25mg之间,例如15mg或20mg。
在本文中所描述的治疗方法中,可给予一次或多次剂量。在某些情况下,单次剂量可有效地获得长期益处。因此,方法可包含给予单次剂量的抗体、其编码核酸或组合物。替代地,通常可以依序且相隔数天、数周或数月的时间给予多次剂量。抗ICOS抗体可每隔4到6周的间隔,例如每隔4周、每隔5周或每隔6周向患者重复给予。任选地,抗ICOS抗体可一月一次或更小频率,例如每隔两个月或每隔三个月向患者给予。因此,治疗患者的方法可包含向患者给予单次剂量的抗ICOS抗体,和至少一个月、至少两个月、至少三个月不重复给药,和任选地至少12个月不重复给药。
如实例11c中所论述,类似的治疗作用可使用一次或多次剂量的抗ICOS抗体获得,其可为单次剂量的抗体可有效重置肿瘤微环境的结果。考虑到疾病状态和正与抗ICOS抗体组合的任何其它治疗剂或治疗措施(例如,手术、放射线疗法等),医生可以调整疾病和经受疗法的患者的抗ICOS抗体的给药方案。在一些实施例中,比一月一次更频繁地,例如每三周一次、每两周一次或每周一次给予有效剂量的抗ICOS抗体。用抗ICOS抗体的治疗可包括在至少一个月、至少六个月或至少一年的时间段内给予的多次剂量。
如本文所使用,术语“治疗(treat/treatment/treating)”或“改善”是指治疗性治疗,其中所述目标是逆转、减轻、改善、抑制、减缓或停止与疾病或病症相关的病状的进展或严重程度。术语“治疗”包括减小或减轻病状、疾病或病症的至少一个不良作用或症状。治疗通常在一种或多种症状或临床标记减小的情况下“有效”。替代地,治疗在疾病的进展减小或停止的情况下“有效”。也就是说,与在没有治疗的情况下将预期的情形相比,“治疗”不仅包括改善症状或标记,并且还包括终止或至少减缓症状的进展或恶化。有益或期望的临床结果包括但不限于一种或多种症状的缓解、疾病程度的减轻、疾病的稳定(即,不恶化)状态、疾病进展的延缓或减缓、疾病状态的改善或缓和、缓解(无论部分或总体)和/或下降的死亡率,无论可检测或不可检测。术语“治疗”疾病还包括提供疾病的症状或副作用的缓解(包括缓解性治疗)。对于将有效的治疗,未预期完全治愈。在某些方面,方法也可以包括治愈。在本发明的上下文中,治疗可以是预防性治疗。
T细胞疗法
WO2011/097477描述了抗ICOS抗体用于通过使T细胞群与提供初级活化信号的第一药剂(例如,抗CD3抗体)和活化ICOS的第二药剂(例如,抗ICOS抗体)任选地在极化例如IL-1β、IL-6的药剂、中和抗IFNγ和/或抗IL-4的Th17存在的情况下接触来产生和扩增T细胞的用途。本文中所描述的抗ICOS抗体可用于此类方法中以得到T细胞群。可产生具有治疗活性(例如,抗肿瘤活性)的培养的扩增T细胞群。如WO2011/097477中所描述,此类T细胞可治疗性地用于通过免疫疗法治疗患者的方法中。
抗ICOS抗体作为治疗性候选的形态学分析
观测到在候选治疗性抗ICOS抗体与固体表面偶联并且与ICOS表达T细胞接触时,其能够诱导细胞中的形态变化。在将ICOS+T细胞添加到内部用抗ICOS抗体涂布的孔时,可见细胞从其初始圆形形状改变,采用纺锤形,扩散并粘附到经抗体涂布的表面。用对照抗体没有观测到这种形态变化。此外,发现效应具有剂量依赖性,其中更快和/或更明显的形状变化随着表面上抗体的浓度增加而发生。形状变化提供了T细胞与ICOS结合和/或通过抗ICOS抗体激动的替代性指示器。分析可用于识别促进ICOS在T细胞表面上的多聚化的抗体。此类抗体代表治疗性候选激动剂抗体。方便地,由此分析提供的视觉指示器是筛选抗体或细胞,尤其是大量抗体或细胞的简单方法。分析可自动进行以在高通量系统中运行。
因此,本发明的一个方面为用于选择结合ICOS的抗体,任选地用于选择ICOS激动剂抗体的分析,所述分析包含:
提供固定(附着或粘附)到测试孔中的衬底的抗体阵列;
将ICOS表达细胞(例如,活化的原代T细胞或MJ细胞)添加到测试孔;
观测细胞的形态;
检测细胞形状从圆形变化到展平紧贴孔内的衬底;其中形状变化指示抗体是结合ICOS的抗体,任选地ICOS激动剂抗体,以及
从测试孔中选择抗体。
分析可以用多个测试孔运行,每个孔含有用于测试的不同抗体,任选地例如在96孔培养板格式中并行地运行。衬底优选地是孔的内表面。因此,提供了可观测到紧贴其展平细胞的二维表面。举例来说,孔底和/或孔壁可以用抗体涂布。可以通过抗体的恒定区将抗体系栓到衬底。
阴性对照可包括在内,此类抗体已知不结合ICOS,优选地使用不结合ICOS表达细胞表面上的抗原的抗体。分析可以包含量化形态变化程度以及在测试多种抗体时,选择引发比一种或多种其它测试抗体更大的形态变化的抗体。
选择抗体可以包含表达编码存在于目标测试孔中的抗体的核酸,或表达包含抗体的CDR或抗原结合结构域的抗体。可以任选地将抗体重新格式化,例如以提供包含所选抗体的抗原结合结构域的抗体,例如抗体片段或包含不同恒定区的抗体。所选抗体优选地具有如本文中所描述的人类IgG1恒定区或其它恒定区。所选抗体可进一步调配于包含一种或多种额外成分的组合物中-合适的医药形成物论述于本文中的其它地方。
条款
本发明的实施例陈述于以下编号条款中,其是实施方式的部分。
条款1.一种结合人类和/或小鼠ICOS的胞外结构域的分离抗体,其中抗体包含:VH结构域,其包含与STIM003 VH结构域SEQ ID NO:408具有至少95%序列一致性的氨基酸序列;和VL结构域,其包含与STIM003 VL结构域SEQ ID NO:415具有至少95%序列一致性的氨基酸序列。
条款2.根据条款1的抗体,其中VH结构域包含重链互补决定区(HCDR)集合HCDR1、HCDR2和HCDR3,其中
HCDR1为具有氨基酸序列SEQ ID NO:405的STIM003HCDR1,
HCDR2为具有氨基酸序列SEQ ID NO:406的STIM003HCDR2,
HCDR3为具有氨基酸序列SEQ ID NO:407的STIM003HCDR3。
条款3.根据条款1或条款2的抗体,其中VL结构域包含轻链互补决定区(LCDR)集合LCDR1、LCDR2和LCDR3,其中
LCDR1为具有氨基酸序列SEQ ID NO:412的STIM003LCDR1,
LCDR2为具有氨基酸序列SEQ ID NO:413的STIM003LCDR2,
LCDR3为具有氨基酸序列SEQ ID NO:414的STIM003LCDR3。
条款4.根据条款1的抗体,其中VH结构域氨基酸序列为SEQ ID NO:408,且/或其中VL结构域氨基酸序列为SEQ ID NO:415。
条款5.一种结合人类和/或小鼠ICOS的胞外结构域的分离抗体,其包含抗体VH结构域,其包含互补决定区(CDR)HCDR1、HCDR2和HCDR3,和
抗体VL结构域,其包含互补决定区LCDR1、LCDR2和LCDR3,其中
HCDR1是STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的HCDR1,或包含具有1、2、3、4或5个氨基酸更改的所述HCDR1,
HCDR2是STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的HCDR2,或包含具有1、2、3、4或5个氨基酸更改的所述HCDR2,且/或
HCDR3是STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的HCDR3,或包含具有1、2、3、4或5个氨基酸更改的所述HCDR3。
条款6.根据条款5的抗体,其中抗体重链CDR是STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的那些抗体重链CDR,或包含具有1、2、3、4或5个氨基酸更改的STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009重链CDR。
条款7.根据条款6的抗体,其中抗体VH结构域具有STIM003的重链CDR。
条款8.一种结合人类和/或小鼠ICOS的胞外结构域的分离抗体,其包含抗体VH结构域,其包含互补决定区HCDR1、HCDR2和HCDR3,和
抗体VL结构域,其包含互补决定区LCDR1、LCDR2和LCDR3,
其中LCDR1是STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的LCDR1,或包含具有1、2、3、4或5个氨基酸更改的所述LCDR1,
LCDR2是STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的LCDR2,或包含具有1、2、3、4或5个氨基酸更改的所述LCDR2,且/或
LCDR3是STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的LCDR3,或包含具有1、2、3、4或5个氨基酸更改的所述LCDR3。
条款9.根据条款5到8中任一项的抗体,其中抗体轻链CDR是STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的那些抗体轻链CDR,或包含具有1、2、3、4或5个氨基酸更改的STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009轻链CDR。
条款10.根据条款9的抗体,其中抗体VL结构域具有STIM003的轻链CDR。
条款11.根据条款5到10中任一项的抗体,其包含人类生殖系基因段序列的VH和/或VL结构域构架区。
条款12.根据条款5到11中任一项的抗体,其包含VH结构域,所述VH结构域
(i)来源于人类重链V基因段、人类重链D基因段与人类重链J基因段的重组,其中
V片段是IGHV1-18(例如,V1-18*01)、IGVH3-20(例如,V3-20*d01)、IGVH3-11(例如,V3-11*01)或IGVH2-5(例如,V2-5*10);
D基因段是IGHD6-19(例如,IGHD6-19*01)、IGHD3-10(例如,IGHD3-10*01)或IGHD3-9(例如,IGHD3-9*01);且/或
J基因段是IGHJ6(例如,IGHJ6*02)、IGHJ4(例如,IGHJ4*02)或IGHJ3(例如,IGHJ3*02),或
(ii)包含构架区FR1、FR2、FR3和FR4,其中
FR1与人类生殖系V基因段IGHV1-18(例如,V1-18*01)、IGVH3-20(例如,V3-20*d01)、IGVH3-11(例如,V3-11*01)或IGVH2-5(例如,V2-5*10)比对,任选地具有1、2、3、4或5个氨基酸更改,
FR2与人类生殖系V基因段IGHV1-18(例如,V1-18*01)、IGVH3-20(例如,V3-20*d01)、IGVH3-11(例如,V3-11*01)或IGVH2-5(例如,V2-5*10)比对,任选地具有1、2、3、4或5个氨基酸更改,
FR3与人类生殖系V基因段IGHV1-18(例如,V1-18*01)、IGVH3-20(例如,V3-20*d01)、IGVH3-11(例如,V3-11*01)或IGVH2-5(例如,V2-5*10)比对,任选地具有1、2、3、4或5个氨基酸更改,且/或
FR4与人类生殖系J基因段IGJH6(例如,JH6*02)、IGJH4(例如,JH4*02)或IGJH3(例如,JH3*02)比对,任选地具有1、2、3、4或5个氨基酸更改。
条款13.根据条款5到12中任一项的抗体,其包含抗体VL结构域,所述VL结构域
(i)来源于人类轻链V基因段与人类轻链J基因段的重组,其中
V片段是IGKV2-28(例如,IGKV2-28*01)、IGKV3-20(例如,IGKV3-20*01)、IGKV1D-39(例如,IGKV1D-39*01)或IGKV3-11(例如,IGKV3-11*01),且/或
J基因段是IGKJ4(例如,IGKJ4*01)、IGKJ2(例如,IGKJ2*04)、IGLJ3(例如,IGKJ3*01)或IGKJ1(例如,IGKJ1*01);或
(ii)包含构架区FR1、FR2、FR3和FR4,其中
FR1与人类生殖系V基因段IGKV2-28(例如,IGKV2-28*01)、IGKV3-20(例如,IGKV3-20*01)、IGKV1D-39(例如,IGKV1D-39*01)或IGKV3-11(例如,IGKV3-11*01)比对,任选地具有1、2、3、4或5个氨基酸更改,
FR2与人类生殖系V基因段IGKV2-28(例如,IGKV2-28*01)、IGKV3-20(例如,IGKV3-20*01)、IGKV1D-39(例如,IGKV1D-39*01)或IGKV3-11(例如,IGKV3-11*01)比对,任选地具有1、2、3、4或5个氨基酸改变,
FR3与人类生殖系V基因段IGKV2-28(例如,IGKV2-28*01)、IGKV3-20(例如,IGKV3-20*01)、IGKV1D-39(例如,IGKV1D-39*01)或IGKV3-11(例如,IGKV3-11*01)比对,任选地具有1、2、3、4或5个氨基酸更改,且/或
FR4与人类生殖系J基因段IGKJ4(例如,IGKJ4*01)、IGKJ2(例如,IGKJ2*04)、IGKJ3(例如,IGKJ3*01)或IGKJ1(例如,IGKJ1*01)比对,任选地具有1、2、3、4或5个氨基酸更改。
条款14.根据条款5到13中任一项的抗体,其包含抗体VH结构域,所述VH结构域是STIM001、STIM002、STIM002-B、STIM003、STIM004或STIM005、STIM006、STIM007、STIM008或STIM009的VH结构域,或其具有与STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的抗体VH结构域序列至少90%一致的氨基酸序列。
条款15.根据条款5到14中任一项的抗体,其包含抗体VL结构域,所述VL结构域是STIM001、STIM002、STIM002-B、STIM003、STIM004或STIM005、STIM006、STIM007、STIM008或STIM009的VL结构域,或其具有与STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的抗体VL结构域序列至少90%一致的氨基酸序列。
条款16.根据条款15的抗体,其包含
抗体VH结构域,其选自STIM001、STIM002、STIM002-B、STIM003、STIM004或STIM005、STIM006、STIM007、STIM008或STIM009的VH结构域,或其具有与STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008或STIM009的抗体VH结构域序列至少90%一致的氨基酸序列,和
抗体VL结构域,其是所述选定抗体的VL结构域,或其具有与所述选定抗体的抗体VL结构域序列至少90%一致的氨基酸序列。
条款17.根据条款16的抗体,其包含STIM003 VH结构域和STIM003 VL结构域。
条款18.根据前述条款中任一项的抗体,其包含抗体恒定区。
条款19.根据条款18的抗体,其中恒定区包含人类重链恒定区和/或轻链恒定区。
条款20.根据条款18或条款19的抗体,其中恒定区呈Fc效应子阳性。
条款21.根据条款20的抗体,其包含具有与原生人类Fc区相比增强的ADCC、ADCP和/或CDC功能的Fc区。
条款22.根据条款18到21中任一项的抗体,其中抗体是IgG1。
条款23根据条款21或条款22的抗体,其中抗体经无岩藻糖基化。
条款24.根据前述条款中任一项的抗体,其共轭到细胞毒性药物或前药。
条款25.根据前述条款中任一项的抗体,其是多特异性抗体。
条款26.一种分离抗体,其以如通过表面等离子共振测定的小于50nM的亲和力(KD)结合人类和小鼠ICOS的胞外结构域。
条款27.根据条款26的抗体,其中抗体以如通过表面等离子共振测定的小于5nM的亲和力(KD)结合人类和小鼠ICOS的胞外结构域。
条款28.根据条款26或条款27的抗体,其中结合人类ICOS的胞外结构域的KD在结合小鼠ICOS的胞外结构域的KD的10倍内。
条款29.一种组合物,其包含根据前述条款中任一项的分离抗体和药学上可接受的赋形剂。
条款30.一种组合物,其包含编码根据条款1到28中任一项的抗体的分离核酸和药学上可接受的赋形剂。
条款31.一种在患者体内调节调节性T细胞(Treg)与效应T细胞(Teff)的平衡以增强Teff反应的方法,其包含向患者给予根据条款1到28中任一项的抗体或根据条款29的组合物。
条款32.一种通过在患者体内耗减调节性T细胞(Treg)且/或增强效应T细胞(Teff)反应来治疗易受疗法影响的疾病或病况的方法,所述方法包含向患者给予根据条款1到28中任一项的抗体或根据条款29的组合物。
条款33.根据条款1到28中任一项的抗体或根据条款29的组合物,其用于通过疗法来治疗人体的方法中。
条款34.根据条款33的供使用的抗体或组合物,其用于在患者体内调节调节性T细胞(Treg)与效应T细胞(Teff)的平衡以增强效应T细胞反应。
条款35.根据条款33的供使用的抗体或组合物,其用于通过在患者体内耗减调节性T细胞(Treg)和/或增强效应T细胞(Teff)反应来治疗易受疗法影响的疾病或病况。
条款36.根据条款32的方法或根据条款35的供使用的抗体或组合物,其中疾病是癌症或实体肿瘤。
条款37.根据条款1到28中任一项的抗体或根据条款29的组合物,其用于治疗人类患者的癌症的方法中。
条款38.一种治疗人类患者的癌症的方法,其包含向患者给予根据条款1到28中任一项的抗体或根据条款29的组合物。
条款39.根据条款36到38中任一项的方法或供使用的抗体或组合物,其中癌症是肾细胞癌、头颈癌、黑素瘤、非小细胞肺癌或弥漫性大B细胞淋巴瘤。
条款40.根据条款31到39中任一项的方法或供使用的抗体或组合物,其中方法包含向患者给予抗体和另一治疗剂和/或放射疗法。
条款41.根据条款40的方法或供使用的抗体或组合物,其中治疗剂是抗PD-L1抗体。
条款42.根据条款41的方法或供使用的抗体或组合物,其中抗PD-L1抗体包含具有氨基酸序列SEQ ID NO:299的VH结构域和具有氨基酸序列SEQ ID NO:300的VL结构域。
条款43.根据条款41或条款42的方法或供使用的抗体或组合物,其中治疗剂是抗PD-L1IL-2免疫细胞因子。
条款44.根据条款43的方法或供使用的抗体或组合物,其中抗PD-L1抗体是包含人类野生型或变体IL-2的免疫细胞因子。
条款45.根据条款44的方法或供使用的抗体或组合物,其中抗ICOS抗体和抗PDL1抗体各自能够介导ADCC、ADCP和/或CDC。
条款46.根据条款41到45中任一项的方法或供使用的抗体或组合物,其中抗ICOS抗体是人类IgG1抗体且抗PDL1抗体是人类IgG1抗体。
条款47.根据条款40的方法或供使用的抗体或组合物,其中治疗剂是抗PD-1抗体。
条款48.根据条款40的方法或供使用的抗体或组合物,其中另一治疗剂是IL-2。
条款49.根据条款40到48中任一项的方法或供使用的抗体或组合物,其中方法包含在给予另一治疗剂和/或放射疗法之后给予抗ICOS抗体。
条款50.根据条款31到49中任一项的方法或供使用的抗体或组合物,其中
抗ICOS抗体共轭到前药,且其中
方法或用途包含
向患者给予抗ICOS抗体且
选择性地活化靶组织部位处的前药。
条款51.根据条款50的方法或供使用的抗体或组合物,其中患者患有实体肿瘤,且方法包含选择性地活化肿瘤中的前药。
条款52.根据条款50或条款51的方法或供使用的抗体或组合物,其包含通过光活化选择性地活化前药。
条款53.一种抗ICOS人类IgG1抗体与抗PDL1人类IgG1抗体的组合,其用于治疗患者的癌症的方法中。
条款54.一种治疗患者的癌症的方法,其包含向患者给予抗ICOS人类IgG1抗体和抗PD-L1人类IgG1抗体。
条款55.一种用于治疗患者的癌症的方法中的抗ICOS抗体,所述方法包含向患者给予抗ICOS抗体和抗PD-L1抗体,其中给予单次剂量的抗ICOS抗体。
条款56.根据条款55的供使用的抗ICOS抗体,其中抗ICOS抗体是人类IgG1抗体且抗PD-L1抗体是人类IgG1抗体。
条款57.根据条款53的组合、根据条款54的方法或根据条款55或条款56的供使用的抗ICOS抗体,其中癌症是肾细胞癌、头颈癌、黑素瘤、非小细胞肺癌或弥漫性大B细胞淋巴瘤。
条款58.根据条款41到46或53到54中任一项的方法或供使用的抗体、组合物或组合,所述方法包含向患者给予抗ICOS抗体和抗PD-L1抗体,其中给予单次剂量的抗ICOS抗体。
条款59.根据条款58的方法或供使用的抗体、组合物或组合,其中所述方法包含给予单次剂量的抗ICOS抗体接着给予多次剂量的抗PD-L1抗体。
条款60.根据条款41到46或53到54中任一项的方法或供使用的抗体、组合物或组合,其中以单独组合物形式提供抗ICOS抗体和抗PDL1抗体用于给药。
条款61.根据条款41到46或53到60中任一项的方法或供使用的抗体、组合物或组合,其中抗ICOS抗体和/或抗PD-L1抗体包含人类IgG1恒定区,所述恒定区包含氨基酸序列SEQ ID NO:340。
条款62.一种用于治疗患者的方法中的抗ICOS抗体,所述方法包含包含向在用另一治疗剂治疗之后具有增加的ICOS阳性调节T细胞含量的患者给予抗ICOS抗体。
条款63.一种治疗患者的方法,所述方法包含向在用另一治疗剂治疗之后具有增加的ICOS阳性调节性T细胞含量的患者给予抗ICOS抗体。
条款64.根据条款62的供使用的抗ICOS抗体或根据条款63的方法,其中所述方法包含向患者给予治疗剂,确定患者在用所述药剂治疗后具有增加的ICOS阳性调节性T细胞含量,和向患者给予抗ICOS抗体以减少调节性T细胞含量。
条款65.根据条款62到64中任一项的供使用的抗ICOS抗体或方法,其中治疗剂是IL-2或免疫调节抗体(例如,抗PDL-1、抗PD-1或抗CTLA-4)。
条款66.根据条款62到65中任一项的供使用的抗ICOS抗体或方法,其中方法包含治疗肿瘤,例如黑素瘤,如转移性黑素瘤。
条款67.一种抗ICOS抗体,其用于通过对患者癌细胞进行体内疫苗接种来治疗患者癌症的方法中,所述方法包含
利用致使癌细胞的免疫细胞死亡的疗法治疗患者,使得向抗原特异性效应T细胞呈递抗原,和
向患者给予抗ICOS抗体,其中抗ICOS抗体增强抗原特异性效应T细胞反应。
条款68.一种通过对患者癌细胞进行体内疫苗接种来治疗患者癌症的方法,所述方法包含
利用致使癌细胞的免疫细胞死亡的疗法治疗患者,使得向抗原特异性效应T细胞呈递抗原,和
向患者给予抗ICOS抗体,其中抗ICOS抗体增强抗原特异性效应T细胞反应。
条款69.一种通过对患者癌细胞进行体内疫苗接种来治疗患者癌症的方法,所述方法包含向患者给予抗ICOS抗体,其中
患者是先前已利用致使癌细胞的免疫细胞死亡的疗法治疗,使得向抗原特异性效应T细胞呈递抗原的患者,且其中
抗ICOS抗体增强抗原特异性效应T细胞反应。
条款70.根据条款67到69中任一项的供使用的抗ICOS抗体或方法,其中致使免疫细胞死亡的疗法是放射癌细胞,给予化疗剂和/或给予针对肿瘤相关抗原的抗体。
条款71.根据条款70的供使用的抗ICOS抗体或方法,其中化疗剂是奥沙利铂(oxaliplatin)。
条款72.根据条款70的供使用的抗ICOS抗体或方法,其中肿瘤相关抗原是HER2或CD20。
条款73.一种用于治疗患者癌症的方法中的抗ICOS抗体,其中癌症是或已表征为对ICOS配体和/或FOXP3的表达呈阳性。
条款74.一种治疗患者癌症的方法,其中癌症是或已表征为对ICOS配体和/或FOXP3的表达呈阳性,所述方法包含向患者给予抗ICOS抗体。
条款75.根据条款73的供使用的抗ICOS抗体或根据条款74的方法,其中所述方法包含:
测试来自患者的样本以确定癌症表达ICOS配体和/或FOXP3;
选择患者以用抗ICOS抗体治疗;和
向患者给予抗ICOS抗体。
条款76.根据条款73的供使用的抗ICOS抗体或根据条款74的方法,其中方法包含向患者给予抗ICOS抗体,所述患者的测试样本指示癌症对ICOS配体和/或FOXP3的表达呈阳性。
条款77.根据条款75或条款76的供使用的抗ICOS抗体或方法,其中样本是实体肿瘤的活检样本。
条款78.一种用于治疗患者癌症的方法中的抗ICOS抗体,其中癌症是或已表征为对于利用免疫肿瘤学药物,例如抗CTLA-4抗体、抗PD1抗体、抗PD-L1抗体、抗CD137抗体或抗GITR抗体治疗呈顽固性。
条款79.一种治疗患者癌症的方法,其中癌症是或已表征为对于利用免疫肿瘤学药物,例如抗CTLA-4抗体、抗PD1抗体、抗PD-L1抗体、抗CD137抗体或抗GITR抗体治疗呈顽固性,所述方法包含向患者给予抗ICOS抗体。
条款80.根据条款78的供使用的抗ICOS抗体或根据条款79的方法,其中所述方法包含:
利用免疫肿瘤学药物治疗患者;
确定癌症对药物不起反应;
选择患者以用抗ICOS抗体治疗;和
向患者给予抗ICOS抗体。
条款81.根据条款78的供使用的抗ICOS抗体或根据条款79的方法,其中方法包含向患者给予抗ICOS抗体,所述患者的癌症对利用免疫肿瘤学药物的先前治疗不起反应。
条款82.根据条款73到81中任一项的供使用的抗ICOS抗体或方法,其中癌症是来源于能够后天表达ICOS配体的细胞的肿瘤。
条款83.根据条款82的供使用的抗ICOS抗体或方法,其中癌症是黑素瘤。
条款84.根据条款73到81中任一项的供使用的抗ICOS抗体或方法,其中癌症来源于抗原呈递细胞,例如B淋巴细胞(例如B细胞淋巴瘤,如弥漫性大B细胞淋巴瘤)或T淋巴细胞。
条款85.根据条款73到81中任一项的供使用的抗ICOS抗体或方法,其中癌症对利用抗CD20抗体的治疗具有耐药性。
条款86.根据条款85的供使用的抗ICOS抗体或方法,其中癌症是B细胞淋巴瘤。
条款87.根据条款86的供使用的抗ICOS抗体或方法,其中抗CD20抗体是利妥昔单抗。
条款88.根据条款85到87中任一项的供使用的抗ICOS抗体或方法,其中方法包含用抗CD20抗体治疗患者;
确定癌症对抗CD20抗体不起反应;
测试来自患者的样本以确定癌症表达ICOS配体;
选择患者以用抗ICOS抗体治疗;和
向患者给予抗ICOS抗体。
条款89.根据条款85到87中任一项的供使用的抗ICOS抗体或方法,其中方法包含向患者给予抗ICOS抗体,所述患者的癌症对利用抗CD20抗体的先前治疗不起反应。
条款90.根据条款67到89中任一项的供使用的抗ICOS抗体或方法,其中癌症是实体肿瘤。
条款91.根据条款67到89中任一项的供使用的抗ICOS抗体或方法,其中癌症是血液病液体肿瘤。
条款92.根据条款90或91的供使用的抗ICOS抗体或方法,其中肿瘤的调节性T细胞较高。
条款93.根据条款53到92中任一项的供使用的抗ICOS抗体或方法,其中抗ICOS抗体如条款1到28中的任一项中所限定或以根据条款29的组合物形式提供。
条款94.一种转基因非人类哺乳动物,其具有包含编码人类可变区基因段的人类或人源化免疫球蛋白基因座的基因组,其中所述哺乳动物并不表达ICOS。
条款95.一种产生结合人类和非人类ICOS的胞外结构域的抗体的方法,其包含
(a)利用人类ICOS抗原使根据条款94的哺乳动物免疫;
(b)将由哺乳动物产生的抗体分离;
(c)测试抗体结合人类ICOS和非人类ICOS的能力;和
(d)选择同时结合人类和非人类ICOS的一种或多种。
条款96.根据条款95的方法,其包含利用表达人类ICOS的细胞使哺乳动物免疫。
条款97.根据条款95或条款96的方法,其包含
(c)使用表面等离子共振测试抗体结合人类ICOS和非人类ICOS的能力并且测定结合亲和力;和
(d)选择结合于人类ICOS的KD小于50nM且结合于非人类ICOS的KD小于500nM的一种或多种。
条款98.根据条款97的方法,其包含
(d)选择结合于人类ICOS的KD小于10nM且结合于非人类ICOS的KD小于100nM的一种或多种。
条款99.根据条款95到98中任一项的方法,其包含
(c)使用表面等离子共振测试抗体结合人类ICOS和非人类ICOS的能力并且测定结合亲和力;和
(d)选择结合于人类ICOS的KD在结合于非人类ICOS的KD的10倍内的一种或多种。
条款100.根据条款99的方法,其包含
(d)选择结合于人类ICOS的KD在结合于非人类ICOS的KD的5倍内的一种或多种。
条款101.根据条款95到100中任一项的方法,其包含测试抗体结合来自相同物种,如哺乳动物的非人类ICOS的能力。
条款102.根据条款95到101中任一项的方法,其包含测试抗体结合来自不同物种,如哺乳动物的非人类ICOS的能力。
条款103.根据条款95到102中任一项的方法,其中所述哺乳动物是小鼠或大鼠。
条款104.根据条款95到103中任一项的方法,其中所述非人类ICOS是小鼠ICOS或大鼠ICOS。
条款105.根据条款95到104中任一项的方法,其中所述人类或人源化免疫球蛋白基因座包含内源性恒定区上游的人类可变区基因段。
条款106.根据条款105的方法,其包含
(a)利用人类ICOS抗原使根据条款94的哺乳动物免疫,其中所述哺乳动物是小鼠;
(b)将由小鼠产生的抗体分离;
(c)测试抗体结合人类ICOS和小鼠ICOS的能力;以及
(d)选择结合人类和小鼠ICOS两者的一种或多种抗体。
条款107.根据条款95到106中任一项的方法,其包含将编码抗体重链可变结构域和/或抗体轻链可变结构域的核酸分离。
条款108.根据条款95到107中任一项的方法,其中所述哺乳动物通过人类可变区基因段和内源性恒定区的重组来产生抗体。
条款109.根据条款107或条款108的方法,其包含将编码重链可变结构域和/或轻链可变结构域的核酸分别共轭到编码人类重链恒定区和/或人类轻链恒定区的核苷酸序列。
条款110.根据条款107到109中任一项的方法,其包含将核酸引入宿主细胞中。
条款111.根据条款110的方法,其包含在表达抗体或抗体重链可变结构域和/或轻链可变结构域的条件下培养宿主细胞。
条款112.一种抗体或抗体重链可变结构域和/或轻链可变结构域,其通过根据条款95到111中任一项的方法产生。
条款113.一种选择结合ICOS的抗体的方法,其任选地用于选择ICOS激动剂抗体,所述分析包含:
提供固定(附着或粘附)到测试孔中的衬底的抗体阵列;
将ICOS表达细胞(例如,活化的原代T细胞或MJ细胞)添加到测试孔;
观测所述细胞形态;
检测细胞形状从圆形变化到展平紧贴孔内的衬底;其中形状变化指示抗体是结合ICOS的抗体,任选地ICOS激动剂抗体;
从测试孔中选择抗体。
表达编码选定抗体的CDR的核酸;和
将抗体调配成包含一种或多种额外组分的组合物。
鉴于本公开,本领域技术人员将显而易知本发明的各种其它方面和实施例。本说明书中所提及的所有文献,包括公布的美国同行所提及的任何专利或专利申请,所述专利以全文引用的方式并入本文中。
实验实例
以下实例描述抗ICOS抗体的产生、特征化和效能。使用KymouseTM(能够产生具有人类可变结构域的抗体的转基因小鼠平台)产生抗体。来自KymouseTM的抗体具有由人类V(D)和J片段产生的人类可变结构域和小鼠恒定结构域。内源性小鼠可变基因已沉默且占组库的极小部分(小于0.5%的全部重链可变区属于小鼠来源)。KymouseTM系统描述于Lee等人2014[39],WO2011/004192、WO2011/158009和WO2013/061098中。这个项目采用KymouseTMHK菌株,其中将重链基因座和轻链κ基因座人源化。
ICOS敲除KymouseTM用ICOS蛋白质或表达人类和小鼠ICOS的蛋白质和细胞的交替加强的组合进行免疫。
识别与人类ICOS结合的命中物。用于筛选的初级选择标准为与表达ICOS的人类细胞(CHO细胞)的结合和与ICOS蛋白质(HTRF)的结合。在选择初级筛选命中物时也评估与小鼠ICOS蛋白质和表达ICOS的小鼠细胞(CHO细胞)的结合并将其纳入考虑。使用这些标准命中物进行二级筛选。在二级筛选命中物中是通过利用流式细胞测量术确定与在CHO细胞上表达的人类和小鼠ICOS的结合来确认。
根据筛选的大量抗体,识别与人类/猕猴和小鼠ICOS结合的小面区,如通过表面等离子共振和流式细胞测量术测定。这些抗体包括STIM001、STIM002和其变体STIM002-B、STIM003、STIM004以及STIM005。还选择额外四种抗体STIM006、STIM007、STIM008和STIM009,展示出与小鼠ICOS的较小交叉反应性但展现人类ICOS受体的激动作用。此处呈现的数据指示抗ICOS抗体充当ICOS阳性CD4+细胞系中的ICOS受体的激动剂的能力,并且还在基于原代T细胞的分析中展示出ADCC分析中的细胞杀灭能力和促进活体内抗肿瘤免疫反应的能力。
实例1:产生ICOS敲除小鼠
ICOS敲除KymouseTM系通过在KymouseTMHK ES细胞中进行同源重组来产生。简单来说,将编码嘌呤霉素选择的3.5kb靶向载体靶向到ES细胞中。成功靶向使得小鼠ICOS基因座的小区域(72bp)替换为嘌呤霉素盒,从而干扰基因的信号肽/起始密码子。扩增阳性ES克隆并且微注射到小鼠胚泡中且产生培育的嵌合体,以最终产生人源化重和κ免疫球蛋白基因座与经过修饰的功能缺失ICOS基因座两者的纯合型动物。
实例2:抗原和细胞系制备
产生表达人类或小鼠ICOS的稳定转染MEF和CHO-S细胞
编码人类和小鼠ICOS的全长DNA序列为优化用于哺乳动物表达,排序为合成串DNA并在CMV启动子的控制下克隆到表现载体中,并且侧接3'和5'piggyBac特异性末端重复序列有助于稳定整合到细胞基因组中的密码子(参见[40])。表达载体含有嘌呤霉素选择盒以促进稳定的细胞系产生。为了分别产生人类ICOS表达细胞系和小鼠ICOS表达细胞系,使用FreeStyle Max转染试剂(英杰公司(Invitrogen))根据制造商说明书将人类或小鼠ICOS表达质粒与编码piggyBac转座酶的质粒共转染到小鼠胚胎纤维母细胞(MEF)细胞系和CHO-S细胞中。MEF细胞由从129S5与C57BL6交叉的雌性小鼠获得的胚胎产生。转染之后二十四小时,培养基补充有嘌呤霉素且生长至少两周以选择稳定细胞系。细胞培养基每隔3-4天替换一次。人类或小鼠ICOS蛋白质的表达通过流式细胞测量术分别使用抗人类或抗小鼠ICOS-PE共轭的抗体(电子生物科学(eBioscience))来评定。完整MEF培养基由补充有10%v/v胎牛血清(吉毕科公司(Gibco))的杜尔贝科氏改良伊格尔氏培养基(Dulbecco's ModifiedEagle's Medium)(吉毕科公司)构成。完整CHO-S培养基由补充有8mM Glutamax(吉毕科公司)的CD-CHO培养基(吉毕科公司)构成。CHO-S细胞为包括有可购自加拿大国家研究委员会(National Research Council of Canada)的pTT5系统的CHO-3E7细胞系,但可采用其它CHO细胞系。
制备用于小鼠免疫的MEF细胞
将细胞培养基去除并将细胞用1×PBS洗涤一次。将细胞用胰蛋白酶处理5分钟以使细胞从组织培养物表面松开。收集细胞并通过添加含有10%v/v胎牛血清(FCS)的完全培养基来中和胰蛋白酶。细胞随后在300g下离心10分钟并用25ml 1×PBS洗涤。对细胞进行计数且以恰当浓度再悬浮于1×PBS中。
重组蛋白的克隆和表达
使用标准分子生物学技术将编码人类ICOS(NCBIID:NP_036224.1)、小鼠ICOS(NCBIID:NP_059508.2)和猕猴ICOS(GenBank ID:EHH55098.1)的胞外结构域的合成DNA克隆到pREP4(英杰公司)或pTT5(加拿大国家研究委员会)表达质粒中。构筑体也含有人类Fc、小鼠Fc或FLAG His肽基元以帮助纯化和检测。通过重叠延伸来将这些添加到DNA构筑体中。在表达之前将全部构筑体定序以确保其正确序列组成。
实例3:免疫
根据展示于表E3中的方案使ICOS敲除HK KymiceTM(参见实例1)、KymouseTM野生型HK菌株和KymouseTM野生型HL菌株免疫。KymouseTM野生型HK和HL菌株表达野生型小鼠ICOS。在HK菌株中,将免疫球蛋白重链基因座和轻链κ基因座人源化,并且在HL菌株中,将免疫球蛋白重链基因座和轻链λ基因座人源化。

表E3.用于KymouseTM菌株的免疫方案
表的关键词:
mICOS Fc=具有人类Fc的小鼠ICOS蛋白质
hICOS Fc=具有人类Fc的人类ICOS蛋白质
mICOS MEF=在MEF细胞上表达的小鼠ICOS
hICOS MEF=在MEF细胞上表达的人类ICOS
mICOS Fc+hICOS Fc=同时给予具有人类Fc的小鼠ICOS蛋白质+具有人类Fc的人类ICOS蛋白质
mICOS MEF+hICOS MEF=同时给予在MEF细胞上表达的小鼠ICOS+在MEF细胞上表达的人类ICOS
ICOS KO=ICOS敲除HK Kymouse
HK和HL=野生型Kymouse HK和HL基因型
RIMMS为经过修饰的皮下免疫过程(在多个部位进行快速免疫);在Kilpatrick等人之后的修饰[41])。通过腹膜内(i.p.)给药来起动-静息-加强免疫方案KM103和KM111。西格玛辅助系统(Sigma Adjuvant System)用于所有免疫疗法且静息间隔通常在2周与3周之间。在不存在佐剂的情况下通过静脉内给予最终加强。
通过流式细胞测量术来分析来自连续或末端血液样本的血清的特异性抗体的存在并使用滴定数据(在可能的情况下)来选择待用于B细胞分选的小鼠。
实例4:比较ICOS KO与野生型小鼠之间的血清滴定
使用流式细胞术测定免疫ICOS KO和免疫野生型Kymouse的血清滴定。在ICOS KO小鼠中,利用人类ICOS抗原进行的免疫诱导血清免疫球蛋白反应,其中Ig与在CHO细胞上表达的人类和小鼠ICOS两者结合(图1a)。相对来说,在野生型Kymouse(表达小鼠ICOS)中,利用相同人类ICOS抗原进行的免疫产生血清,其显示与相同血清与人类ICOS的结合相比大大地减少与小鼠ICOS的结合(图1b)。
方法
表达人类ICOS或小鼠ICOS的CHO-S细胞(参见实例2)或悬浮于FACS缓冲液(PBS+1%w/v BSA+0.1%w/v叠氮化钠)中的未转染CHO-S细胞(称为野生型(WT))以105个细胞/孔的密度分布到96孔V型底部培养板(葛莱娜(Greiner))。制备小鼠血清滴定,将样本稀释于FACS缓冲液中。随后将50微升/孔的这一滴定添加到细胞培养板中。为测定由于免疫导致的活性程度的改变,在免疫之前,将来自每种动物的血清在FACS缓冲液中稀释到1/100并且以50微升/孔添加到细胞中。将细胞在4℃下培育1小时。将细胞用150μL PBS洗涤两次,在每个洗涤步骤之后离心且抽吸上清液(在300×g下离心3分钟)。为了检测抗体结合,将APC山羊-抗小鼠IgG(杰克逊免疫研究(Jackson ImmunoResearch))在FACS缓冲液中稀释1/500并且将50μL添加到细胞中。在一些情况下,使用AF647山羊-抗小鼠IgG(杰克逊免疫研究)。将细胞在4℃下在暗处培育1小时,随后如上用150μL PBS洗涤两次。为了固定细胞,添加100μL2%v/v多聚甲醛并且在4℃下将细胞培育30分钟。随后通过在300×g下离心将细胞粒化且将培养板再悬浮于50μL FACS缓冲液中。通过流式细胞测量术使用BD FACS Array仪器来测量荧光信号强度(几何平均值)。
实例5:通过FACS来分选抗原特异性B细胞
使用大致上如WO2015/040401的实例1中所描述的技术从免疫小鼠中回收表达抗ICOS抗体的B细胞。简单来说,从所述免疫方案中分离的脾细胞和/或淋巴结细胞由含有标记物的抗体混合液染色以用于选择目标细胞(CD19),而不需要的细胞从最终分选的群体(IgM、IgD、7AAD)中排除。CD19+B细胞利用荧光标记的人类ICOS ECD-Fc二聚物和荧光标记的小鼠ICOS ECD-Fc进行进一步标记以检测产生抗ICOS抗体的B细胞。分别用AlexaFluor647和AlexaFluor488对人类和小鼠ICOS进行荧光标记——参见实例6。选择结合人类ICOS或人类和小鼠ICOS两者的细胞。这些细胞是通过FACS分选到裂解缓冲液中的单一细胞。使用RT-PCR和另外两轮PCR回收V区序列,接着将其桥接到小鼠IgG1恒定区且在HEK293细胞中表达。筛选来自HEK293细胞的上清液以用于呈现ICOS结合和官能性抗体。这一方法在下文中被称为BCT。
实例6:根据BCT筛选抗体
HTRF筛选BCT上澄液以用于与重组人类和小鼠ICOS-Fc结合
针对分泌抗体结合表达为重组蛋白的人类ICOS Fc和小鼠ICOS Fc的能力筛选根据实例5中的BCT收集的上清液。通过 (匀相时间分辨荧光,Cisbio)分析形式使用
(匀相时间分辨荧光,Cisbio)分析形式使用 647H(创新生物科学(Innova Biosciences))标记的ICOS(针对用
647H(创新生物科学(Innova Biosciences))标记的ICOS(针对用 647H标记的人类ICOS和小鼠ICOS,在本文中分别称为647hICOS或647mICOS)来识别分泌抗体与重组人类和小鼠ICOS的结合。将5μL BCT上清液转移到白色384孔小体积非结合表面聚苯乙烯培养板(葛莱娜)。将稀释于HTRF分析缓冲液中的5μL的20nM 647hICOS或647mICOS添加到所有孔中。针对人类ICOS结合分析,将参考抗体在BCT培养基(吉毕科#A14351-01)稀释到120nM并将5μL添加到培养板中。对于用于人类ICOS结合分析的阴性对照孔,将5μL的小鼠IgG1(西格玛M9269,在一些情况下被称为CM7)在BCT培养基中稀释到120nM。就小鼠ICOS结合分析而论,将参考抗体在BCT培养基(吉毕科#A14351-01)中稀释到120nM并将5μL添加到培养板中。将大鼠IgG2b同种型对照(安迪生物公司)添加到在BCT培养基中稀释到120nM的阴性对照孔(安迪生物公司)中并将5μL添加到培养板中。通过添加10μL山羊抗小鼠IgG(南方生物技术(Southern Biotech))来检测分泌抗体与人类ICOS的结合,所述山羊抗小鼠IgG用HTRF分析缓冲液中1/2000稀释的铕穴状化合物(Cisbio)直接标记。就小鼠ICOS结合分析而论,将5μL小鼠抗大鼠IgG2b-UBLB(南方生物技术)添加到阳性和阴性对照孔中,并将5μL的HTRF分析缓冲液添加到培养板的所有其它孔中。随后添加用在HTRF分析缓冲液中1/1000稀释的铕穴状化合物(Cisbio)直接标记的5μL山羊抗小鼠IgG(南方生物技术)以检测结合。在使用Envision板式读取器(珀金埃尔默(Perkin Elmer))读取620nm和665nm发射波长下的时间分辨荧光之前,将培养板静置以在暗处培育2小时。
647H标记的人类ICOS和小鼠ICOS,在本文中分别称为647hICOS或647mICOS)来识别分泌抗体与重组人类和小鼠ICOS的结合。将5μL BCT上清液转移到白色384孔小体积非结合表面聚苯乙烯培养板(葛莱娜)。将稀释于HTRF分析缓冲液中的5μL的20nM 647hICOS或647mICOS添加到所有孔中。针对人类ICOS结合分析,将参考抗体在BCT培养基(吉毕科#A14351-01)稀释到120nM并将5μL添加到培养板中。对于用于人类ICOS结合分析的阴性对照孔,将5μL的小鼠IgG1(西格玛M9269,在一些情况下被称为CM7)在BCT培养基中稀释到120nM。就小鼠ICOS结合分析而论,将参考抗体在BCT培养基(吉毕科#A14351-01)中稀释到120nM并将5μL添加到培养板中。将大鼠IgG2b同种型对照(安迪生物公司)添加到在BCT培养基中稀释到120nM的阴性对照孔(安迪生物公司)中并将5μL添加到培养板中。通过添加10μL山羊抗小鼠IgG(南方生物技术(Southern Biotech))来检测分泌抗体与人类ICOS的结合,所述山羊抗小鼠IgG用HTRF分析缓冲液中1/2000稀释的铕穴状化合物(Cisbio)直接标记。就小鼠ICOS结合分析而论,将5μL小鼠抗大鼠IgG2b-UBLB(南方生物技术)添加到阳性和阴性对照孔中,并将5μL的HTRF分析缓冲液添加到培养板的所有其它孔中。随后添加用在HTRF分析缓冲液中1/1000稀释的铕穴状化合物(Cisbio)直接标记的5μL山羊抗小鼠IgG(南方生物技术)以检测结合。在使用Envision板式读取器(珀金埃尔默(Perkin Elmer))读取620nm和665nm发射波长下的时间分辨荧光之前,将培养板静置以在暗处培育2小时。
通过根据等式2和等式1分别计算每个样本的665/620比率和效果%来分析数据。
对于KM103和KM11-B1,基于大于或等于5效果%而选择初次命中物以用于与人类和小鼠ICOS结合。对于KM135,基于大于或等于10效果%而选择初次命中物以用于与人类和小鼠ICOS结合。对于KM111-B2,初次命中物限定为大于或等于4效果%以用于与人类ICOS结合且限定为大于或等于3效果%以用于与小鼠ICOS结合。
等式1:根据初级筛选Envision细胞结合和HTRF计算效果%
使用孔比率值(等式3)或665/620nm比率(参见等式2)(HTRF)

非特异性结合=含有同种型对照小鼠IgG1的孔的值
总结合=含有参考抗体的孔的值
等式2:计算665/620比率
665/620比率=(样本665/620nm值)×10,000
等式3:计算647/FITC比率
通过将mAb通道(647)除以FITC(细胞染料)通道来将细胞数的数据初次归一化以得到“孔比率值”:

筛选BCT上清液以用于与表达人类和小鼠ICOS的细胞结合
针对分泌抗体与在CHO-S细胞表面上表达的人类或小鼠ICOS结合的能力筛选从实例5中BCT收集的上清液。为了测定CHO-S人类和小鼠ICOS结合,将细胞在黑色壁、透明底部组织培养物处理的384孔培养板(珀金埃尔默)中以4×104个/孔接种于补充有10%FBS(吉毕科)的F12培养基(吉毕科)中并培养隔夜。从384孔分析培养板中去除培养基。将BCT培养基中呈2μg/mL的至少50μL的BCT上清液或50μL的参考抗体或稀释于BCT培养基中的同种型IgG1对照抗体(在一些情况下称为Cm7,西格玛M9269,最终浓度为2μg/mL)添加到每个孔中。将培养板在4℃下培育1小时。抽吸上清液,并且添加呈5μg/ml的50μL山羊抗小鼠647(杰克逊免疫研究)与1/500稀释于二级抗体缓冲液(1×PBS+1%BSA+0.1%叠氮化钠)中的亮绿色DNA染料(生命技术(Life Technologies))以检测抗体结合并使细胞可见。将培养板在4度下培育1小时。抽吸上清液并且添加25μL的4%v/v多聚甲醛并且将培养板在室温下培育15分钟。将培养板用100μL PBS洗涤两次并且接着将洗涤缓冲液完全去除。使用测量FITC(激发494nm,发射520nm)和alexafluor 647(激发650nm,发射668nm)的Envision板式读取器(珀金埃尔默)测量荧光强度。如等式3中所描述测定分析信号且如等式1中测定效果%。使用呈2μg/mL最终分析浓度的参考抗体来限定总结合。使用呈2μg/mL最终分析浓度的小鼠IgG1同种型对照(西格玛)来限定非特异性结合。命中选择的标准是基于分析信号和效果%。
对于KM103、KM111-B1和KM135,基于大于或等于10效果%而选择初次命中物。对于KM111-B2,基于大于或等于4效果%而选择初次命中物。
初级筛选结果汇总
| 实验ID | 筛选的上清液 | 选择的初次命中物 |
| KM103 | 1232 | 40 |
| KM111-B1 | 1056 | 198 |
| KM111-B2 | 1056 | 136 |
| KM135 | 704 | 31 |
表E6.根据免疫筛选的BCT上清液的数量汇总和针对与人类和小鼠ICOS的结合符合初级筛选选择标准的上清液数量。
针对与表达人类和小鼠ICOS的细胞结合的FACS筛选
测试来自实例5的BCT上清液和HEK293表达抗体与表达人类或小鼠ICOS的CHO-S细胞结合的能力。
将表达人类或小鼠ICOS的CHO-S细胞(参见实例2)稀释于FACS缓冲液(PBS1%BSA0.1%叠氮化钠)中并以1×105个细胞/孔的密度分布到96孔的V型底部培养板(葛莱娜)。将细胞用150μL PBS洗涤并以300g离心3分钟。对于上清液筛选,抽吸上清液并添加150μLPBS。重复这一洗液步骤。将30μL未经BCT稀释上清液或在BCT培养基中稀释到5μg/ml的50μL的参考抗体或对照抗体添加到经过洗涤的细胞中。将细胞在4℃下培育60分钟。添加150μLFACS缓冲液且如上文所描述洗涤细胞。为了检测抗体结合,将在FACS缓冲液中稀释到2μg/ml的50μL山羊-抗小鼠APC(杰克逊免疫研究)添加到细胞中。将细胞在4℃下培育60分钟。将细胞用150μL FACS缓冲液洗涤两次,在每个洗涤步骤之后以300g离心3分钟并抽吸上清液。通过在室温下添加25μL 4%多聚甲醛持续20分钟来固定细胞。将细胞如上洗涤一次并再悬浮于FACS缓冲液中用于分析。通过流式细胞测量术使用BD FACS Array仪器来测量APC信号强度(几何平均值)。将数据标绘为几何平均值而无需进一步计算。
与初级筛选相比,在这进一步的筛选中根据符合更严格的物种交叉反应性标准选择小子集的抗体。简单来说:
根据KM103,通过获取与hICOS、mICOS和WT CHO细胞结合的杂交对照的几何平均值且识别>4倍以上的小鼠和人类结合子来选择4种抗体。这4种抗体命名为STIM001、STIM002-B、STIM007和STIM009。
对于KM111-B1,通过获取与hICOS、mICOS和WT CHO细胞结合的阴性对照(亚美尼亚仓鼠:克隆系HTK888)的几何平均值且识别>10倍以上的小鼠和人类结合子来选择4种抗体。
对于KM111-B2,通过获取与hICOS、mICOS和WT CHO细胞结合的阴性对照(亚美尼亚仓鼠:克隆系HTK888)的几何平均值且识别>4倍以上的小鼠和人类结合子来选择4种抗体。这些4种抗体包括STIM003、STIM004和STIM005。
对于KM135,识别非交叉反应性抗体。由于FACS二级筛选方法的技术失败,还使用SPR和HTRF进行筛选,但未发现符合所需交叉反应性水平的抗体。
总之,根据实例3中描述的不同多个免疫方案,针对与人类ICOS和小鼠ICOS的结合筛选上升的4000BCT上清液(仅来自ICOS KO小鼠),并且包括STIM001、STIM002-B、STIM003、STIM004、STIM005、STIM007和STIM009的候选小组识别为对于进一步研发具有最有前景的特征。将这些抗体用于更详细的特征化。
单独地,还选择了并不符合物种交叉反应性标准的两种抗体STIM006和STIM008,以基于其结合人类ICOS的能力进一步特征化。
实例7:通过表面等离子共振(SPR)进行亲和力测定
通过SPR使用ProteOn XPR3 6(伯乐(BioRad))来产生ICOS导联的Fab亲和力。通过伯胺偶联来在GLC生物传感器芯片上形成抗人类IgG捕获表面,从而固定三种抗人类IgG抗体(杰克逊实验室(Jackson Labs)109-005-008、109-006-008和309-006-008)。人类Fc标记的人类ICOS(hICOS)和小鼠ICOS(mICOS)单独地捕获在抗人类IgG表面上,并且除了以1000nM、200nM、40nM、8nM和2nM使用的STIM003以外,将纯化Fab以5000nM、1000nM、200nM、40nM和8nM用作分析物。使用缓冲液注射(即0nM)双重参考结合传感图,并且将数据拟合到ProteOn XPR36分析软件固有的1:1模型。在25℃下且使用HBS-EP作为操作缓冲液来执行分析。

表E7-1.如利用SPR所量测的选定抗体的亲和力和动力学数据。
另外,在不同pH值下对抗体:抗原结合亲和力进行比较。如前所述,将呈现为融合到人类Fc区的ICOS的胞外结构域的二聚人类ICOS蛋白质捕获在使用3种抗体混合液形成的抗人类Fc捕获表面上,通过伯胺偶联来固定在GLC生物传感器芯片上。重组地表达抗ICOSFab的SPR分析在ProteOn XPR36 Array系统(伯乐)上进行。将Fab片段用作分析物以产生结合传感图,其使用缓冲液注射(即,0nM)进行双重参考。将后续参考的传感图拟合到ProteOn分析软件固有的1:1模型。表E7-2显示抗体的亲和力和动力学数据,除非已有规定,否则如所指示使用HBS-EP在pH 7.4/7.6或pH 5.5下在37℃下运行全部。将数据拟合到1:1模型。应注意,在pH 7.4和5.5两者下不佳地拟合到1:1模型的STIM002的数据(这种抗体的亲和力)可因此比表中所指示的低。

表E7-2.除了在已规定的情况下之外,在37℃下STIM001、STIM002、STIM002-B和STIM003Fab针对重组人类ICOS的相对亲和力。
在不同pH值下的亲和力数据的比较指示抗体在生理pH范围内保持与其靶点结合。肿瘤微环境与血液相比可为相对酸性的,由此在较低pH下维持亲和力是活体内提高肿瘤内T-reg耗减的潜在优势。
实例8:通过HTRF分析ICOS配体与ICOS受体结合中和
使用均相时间分辨荧光(HTRF)对所选抗ICOS抗体进一步评定其中和ICOS配体(B7-H2)与ICOS结合的能力。在以下中评定人类IgG1和人类IgG4.PE(无效效应子)同种型的mAb:
-HTRF分析,其用于中和人类B7-H2与人类ICOS结合;和
-HTRF分析,其用于中和小鼠B7-H2与小鼠ICOS结合。
包括将抗ICOS抗体C398.4A(在各种情况下为仓鼠IgG)用以进行比较。
发现多种抗体对人类和/或小鼠ICOS受体-配体结合具有高度中和效能,且结果指示这些抗体中的一些显示良好交叉反应性。抗体同种型不具有显著效果,IgG1与IgG4.PE分析之间的结果差在实验误差内。
IgG1
在人类IgG1分析中,抗体C398.4A对于人类ICOS配体的中和产生1.2±0.30nM的IC50且对于小鼠ICOS配体的中和产生0.14±0.01nM的IC50。
IgG1 mAb STIM001、STIM002、STIM003和STIM005使用人类ICOS配体中和系统产生与C398.4A类似的IC50,且其中和小鼠ICOS配体与小鼠ICOS受体的结合也具有交叉反应性,
另外两种具交叉反应性的mAb(STIM002-B和STIM004)显示较弱的人类和小鼠ICOS配体中和。
STIM006、STIM007、STIM008和STIM009显示人类ICOS配体的中和但在小鼠ICOS配体中和系统中并不展现显著交叉反应性。针对这些抗体可能不能计算出小鼠B7-H2配体的中和IC50值。
| 平均IC50(nM) | SD(nM)(n=4) | |
| STIM001 | 2.2 | 1.3 |
| STIM002 | 1.9 | 0.8 |
| STIM002-B | 3.6 | 3.5 |
| STIM003 | 1.3 | 0.5 |
| STIM004 | 233 | 123 |
| STIM005 | 2.5 | 0.8 |
| STIM006 | 2.2 | 1.5 |
| STIM007 | 1.1 | 0.5 |
| STIM008 | 1.6 | 1.4 |
| STIM009 | 30.5 | 53 |
| C398.4A | 1.2 | 0.3 |
表E8-1.用于中和人类ICOS受体与人类B7-H2结合的人类IgG1同种型mAb的IC50值。也参见图2。
| 平均IC50(nM) | SD(nM)(n=3) | |
| STIM001 | 6.5 | 2.5 |
| STIM002 | 6.9 | 2.1 |
| STIM002-B | 30 | 11.4 |
| STIM003 | 0.1 | 0 |
| STIM004 | 22.1 | 15.4 |
| STIM005 | 0.3 | 0.2 |
| C398.4A | 0.1 | 0 |
表E8-2.用于中和小鼠ICOS受体与小鼠B7-H2结合的人类IgG1同种型mAb的IC50值。也参见图3。
IgG4.PE
正如期望,IgG4.PE mAb产生与IgG1同种型类似的结果。
使用人类ICOS配体中和系统,STIM001、STIM003和STIM005显示与C398.4A类似的IC50值。这些mAb在中和小鼠ICOS配体时也具有交叉反应性。STIM002-B和STIM004针对人类ICOS B7-H2中和和小鼠B7-H2配体产生较弱IC50值。STIM007、STIM008和STIM009显示人类ICOS配体与人类ICOS受体结合的中和,但在这些分析中可能不能计算出小鼠B7-H2配体的中和IC50值。
不分析STIM006和STIM002的IgG4.PE同种型。

表E8-3.用于中和人类ICOS受体与人类B7-H2结合的人类IgG4.PE同种型mAb的IC50值。也参见图4。
| 平均IC50(nM) | SD(nM)(n=3) | |
| STIM001 | 4.7 | 2.1 |
| STIM002-B | 43.9 | 25.7 |
| STIM003 | 0.2 | 0.1 |
| STIM004 | 30 | 14 |
| STIM005 | 0.3 | 0.1 |
| C398.4A | 0.2 | 0.1 |
表E8-4.用于中和小鼠ICOS受体与小鼠B7-H2结合的人类IgG4.PE同种型mAb的IC50值。也参见图5。
材料和方法
将测试抗体和同种型对照在分析缓冲液(含0.53M氟化钾(KF)、0.1%牛血清白蛋白(BSA)的1×PBS)中从至多4μM、1μM的起始工作浓度最终稀释到0.002nM、5.64e-4nM,最终通过11点滴定,1/3稀释。将5μl的抗体滴定添加到384孔白色壁的分析板(葛莱娜生物一号(Greiner Bio-One))中。阳性对照孔仅接受5μl分析缓冲液。
将5μl的ICOS受体(人类ICOS-mFc,20nM,最终5nM或小鼠ICOS-mFc,4nM,最终1nM(Chimerigen))添加到要求的孔中。在室温(RT)下培育培养板1小时。培育后,将5μl共轭到Alexa 647(创新生物科学)的小鼠或人类ICOS配体(B7-H2,安迪生物公司)针对人类B7-H2稀释到32nM(最终8nM)或针对小鼠B7-H2稀释到30nM,最终7.5nM,并且将其添加到分析板中除了实际上接受5μl分析缓冲液的阴性对照孔之外的所有孔中。
最后,将5μl用铕穴状化合物(CisBio)标记的,40nM,最终10nM抗小鼠IgG供体mAb(南方生物技术)添加到每个孔中,且在暗处在RT下将分析静置,再培育2小时。培育后,使用标准HTRF方法在Envision板式读取器(珀金埃尔默)上读取分析。将620nm和665nm通道值导出到微软电子表格(微软)且进行△-F%和中和%计算。使用Graphpad(Prism)标绘滴定曲线和IC50值[M]。通过使用等式X=Log(X)初次转化数据来计算IC50值。随后使用非线性回归、使用拟合算法,对数(抑制剂)与反应-可变斜率(四参数)拟合转化的数据。
△-F%计算:
用于比率度量数据简化的665/620nm比率。

信号阴性对照=最小信号比率的平均值
中和%:

实例9a:T细胞活化
当将抗CD3和抗CD28Ab并行添加到抗ICOS Ab中以诱导效应T细胞上的ICOS表达时,在人类原代T细胞活化分析中以培养板-结合和可溶形式测试细胞因子产生时的STIM001和STIM003激动可能性。在活化后72小时使用ELISA评定ICOS共刺激对由这些活化T细胞产生的IFNγ水平的效果。
材料和方法
T细胞活化分析1:
分离来自人类外周血液的单核细胞(PBMC):
从健康供体中收集白细胞锥,并且用磷酸盐缓冲盐水(PBS,来自吉毕科)将其内含物稀释至多50ml且在15mL Ficoll-Paque(来自通用电气医疗集团(GE Healthcare))顶部上分层到2个离心管中。通过密度梯度离心(400g,40分钟,没有制动器)将PBMC分离,转移到清洁离心管并且接着用50mL PBS洗涤,以300g离心洗涤两次持续5分钟且以200g离心洗涤两次持续5分钟。随后将PBMC再悬浮于R10培养基(RPMI+10%热失活胎牛血清,两者都来自吉毕科),且用EVETM自动化细胞计数器(来自NanoEnTek)对其细胞计数并评定存活力。
ICOS抗体(Ab)制备和稀释:
以以下3种形式测试STIM001和STIM003:板-结合形式、可溶形式或交联抗ICOS Ab的可溶加F(ab')2片段(来自杰克逊免疫研究的109-006-170)形式。
对于板-结合形式:将抗ICOS Ab和其同种型对照1:3连续稀释于PBS中以得到在45μg/mL到0.19μg/mL范围内的最终抗体浓度。在4℃下将100μL稀释抗体重复两次涂布到96孔高度结合的平底培养板(康宁(Corning)EIA/RIA培养板)中隔夜。随后用PBS洗涤培养板并将125μl的R10添加到每个孔中。
对于可溶形式:将抗ICOS Ab和其同种型对照1:3连续稀释于R10培养基中以得到在90μg/mL到0.38μg/mL范围内的2×Ab储备浓度。将125μl稀释的Ab重复两次吸取到96孔平底培养板中。
对于交联的可溶形式:将抗ICOS Ab和其同种型对照与F(ab')2片段以1M比1M比率混合。随后将Ab/F(ab')2片段混合物1:3连续稀释于R10培养基中以得到针对ICOS在90μg/mL到0.38μg/mL范围内的2×Ab浓度和针对F(ab')2片段在60μg/mL到0.24μg/mL的2×Ab浓度。将125μl稀释的Ab重复两次吸取到96孔平底培养板中。
T细胞分离、培养和IFN-γ量化:
使用EasySep人类T细胞分离试剂盒(来自干细胞技术(Stemcell Technologies))从PBMC中负向地分离T细胞,并将其以2×106个/mL再悬浮于补充有40μl/ml的戴诺珠粒人类T-活化子CD3/CD28(来自生命技术公司)的R10培养基中。
将125μl的T细胞悬浮液添加到含Ab的培养板中以得到1×106个细胞/毫升的最终细胞浓度并在37℃和5%CO2下将其培养72小时。随后收集无细胞上清液并将其保持在-20℃下,直到通过ELISA(来自安迪生物公司的duoset试剂盒)分析分泌的IFNγ。
在从6个非依赖性供体中分离的T细胞上重复这一实验,且每个分析条件包括2个技术重复。
T细胞活化分析2(STIM-REST-STIM分析):
当在静息3天以降低T细胞的活化水平之前用抗CD3和抗CD28Ab将T细胞预刺激3天以诱导ICOS表达时,在人类T细胞分析中还以板结合测试对细胞因子释放的STIM001和STIM003激动可能性。在刺激(第3天)和静息(第6天)之后通过FACS染色来确认ICOS表达。随后在存在或不存在CD3Ab的情况下将这些刺激静息后的T细胞与STIM001或STIM003一起培养以评定TCR结合的需求。在72小时之后评定ICOS共刺激对存在于培养物中的IFNγ、TNFα和IL-2的含量的影响。
ICOS Ab稀释和涂布:
将抗人类CD3(来自电子生物科学的克隆系UCHT1)在PBS中稀释到10μg/mL的2×Ab浓度。将50μl的PBS或50μl的稀释CD3Ab吸取到96孔高度结合的平底培养板中。将STIM001、和其同种型对照1:2连续稀释于PBS中以得到在20μg/mL到0.62μg/mL范围内的2×抗体浓度。将50μL的稀释抗ICOS Ab添加到含有PBS(无TCR结合)或稀释CD3Ab(TCR结合)的孔中。将培养板在4℃下涂布隔夜。
T细胞分离、培养和IFN-γ量化:
如T细胞活化分析1中所描述获得来自白细胞锥的PBMC。使用EasySep人类T细胞分离试剂盒(来自干细胞技术)将T细胞从这种PBMC中负向地分离。将T细胞以1×106个/ml再悬浮于补充有20μl/mL的戴诺珠粒人类T-活化子CD3/CD28(来自生命技术公司)的R10培养基中并在37℃和5%CO2(刺激)下培养3天。在第3天从培养物中去除戴诺珠粒。随后将T细胞洗涤(300g持续5分钟)、计数并以1.5×106个/ml再悬浮于R10培养基中,且在37℃和5%CO2下再培养3天(静息阶段)。
在第6天,接着将刺激静息后的T细胞洗涤(300g持续5分钟)、计数并以1×106个/mL再悬浮于R10培养基中,并且将250μl的T细胞悬浮液添加到经ICOS Ab涂布的培养板中且在37℃和5%CO2下培养72小时。随后收集无细胞上清液并将其保持在-20℃,直到在MSD平台上分析分泌的细胞因子。
用从5个独立供体中分离的T细胞重复这一实验,且每个分析条件包括3个技术重复。
结果
测试出对诱导IFNγ表达呈阳性的两个STIM001和STIM003因此在两个分析中都显示激动作用。
实例9b:T细胞活化分析1数据
使用从8个独立供体中分离的T细胞如实例9a中所描述进行T细胞活化分析1,测试呈人类IgG1形式的每个STIM001和STIM003。包括仓鼠抗ICOS抗体C398.4A和仓鼠抗体同种型对照用于比较。每个分析条件包括2个技术重复。
结果展示于图16、图17和图18中。如之前所提及,测试出对诱导IFNγ表达呈阳性的两个STIM001和STIM003因此对人类原代T细胞显示激动作用。
与可溶抗体或与对照相比,交联抗体充当T细胞活化的激动剂,如在连接Fc的F(ab')2片段存在的情况下由IFNγ诱导的强力增强所指示。T细胞中的IFNγ表达随着交联STIM001或STIM003的浓度增加而增加(图16,下部图)。也观测到STIM001和STIM003两者以板结合形式的激动作用,并且仓鼠抗体C398.4A更微弱地激动作用,如随着抗体浓度增加在T细胞中观测到IFNγ表达增加所指示(图16,上部图)。
IFNγ反应的量值在从不同供体中获得的T细胞之间变化,但与用对照抗体(HCIgG1)观测到的IFNγ表达相比,STIM001的IFNγ表达不断增加。在考虑来自用全部8个供体的T细胞进行的分析的数据时,可见与用同种型对照抗体处理相比,用STIM001处理T细胞在板结合形式、可溶形式和交联形式中显著增加IFNγ表达(图17)。STIM001由此在所有三个形式中表现为T细胞活化的激动剂。
用STIM003观测到类似作用(图18)。针对8个独立供体在分析中在给定剂量的抗体下,将由STIM003hIgG1诱导的IFNγ水平与由其同种型对照(HC IgG1)诱导的IFNγ水平进行比较。不管供体之间的变化如何,由STIM003诱导的IFNγ水平的平均增加与HC IgG1相比是显著的。提出了此处描述的STIM001和其他STIM抗体具有类似地促进活体内T细胞活化的潜能。如先前所论述,活化ICOS表达T细胞的激动作用可由与T细胞表面上的ICOS受体结合且诱导其多聚化的抗ICOS抗体介导。实例9c:T细胞活化分析2数据
如实例9a中所描述进行T细胞活化分析2。
在不存在TCR结合(无抗CD3抗体)的情况下,由原代T细胞产生的细胞因子的含量较低,且即使在10μg/ml的最高浓度下通过STIM001(hIgG1)、STIM003(hIgG1)或抗体C398.4A诱导的也不增加。相比之下,当将抗ICOS抗体与抗CD3抗体组合添加到T细胞中时,STIM001(hIgG1)、STIM003(hIgG1)和C398.4A中的每一个显示出剂量依赖性趋势以增加IFNγ、TNFα以及在较小程度上IL-2的表达。
在TCR结合的条件下用抗ICOS抗体处理原代T细胞的数据展示于图19中。尽管观测到STIM001、STIM003和C389.4A中的每一个相对于其对应同种型对照在细胞因子表达上明显增加,但在这一分析中差值并未达到统计显著性。利用来自更多供体的反应性原代T细胞进行的其它分析重复将预期产生统计显著性结果。
实例10a:ADCC分析
使用人类原代NK细胞作为效应子和ICOS高MJ细胞系(ATCC,CRL-8294)作为靶细胞在Delfia BATDA细胞毒性分析(珀金埃尔默)中测试STIM001和STIM003通过ADCC进行杀灭的潜能。MJ细胞是表达高含量的ICOS蛋白质的人类CD4 T淋巴细胞。
这一方法是基于使靶细胞装载有快速穿透细胞膜的荧光增强配体乙酰氧基甲基酯(BATDA)。在细胞内,酯键水解以形成不再穿过膜的亲水性配体(TDA)。细胞溶解后,配体释放且可以通过添加铕来检测,所述铕与BATDA形成高度荧光且稳定的螯合物(EuTDA)。测量的信号与溶解细胞的量直接相关。
材料和方法
靶细胞标记:
根据制造商的说明书,将MJ细胞以1×106个/mL再悬浮于分析培养基(RPMI+10%超低IgG FBS,来自吉毕科)中且在37℃下装载有5μl/ml的Delfia BATDA试剂(珀金埃尔默)持续30分钟。随后将MJ细胞用50mL PBS洗涤3次(300g,5分钟)且以8×105个/ml再悬浮于补充有2mM丙磺舒(来自生命技术公司)的分析培养基中以减少BATDA从细胞的自发释放。
ICOS Ab稀释:
将STIM001、STIM003和其同种型对照1:4连续稀释于分析培养基+2mM丙磺舒中以得到在降至80pg/mL范围内的最终4×抗体浓度。
NK细胞分离和培养:
如T细胞活化分析1中所描述获得来自白细胞锥的PBMC。使用EasySep人类NK细胞分离试剂盒(来自干细胞技术)将NK细胞从这种PBMC中负向地分离且以4×106个/ml再悬浮于R10培养基+2mM丙磺舒中。通过染色CD3-/CD56+检查到NK细胞纯度大于90%。
在每个孔中添加50μl的稀释Ab、装载MJ细胞的50μl BATDA、50μl的NK细胞和50μl的分析培养基+2mM丙磺舒(最终体积为200微升/孔)以得到在降至20pg/mL范围内的最终Ab浓度和5:1的效应子:靶标比率。含有仅MJ细胞或MJ细胞+delfia溶解缓冲液(珀金埃尔默)的孔用于测定自发释放和100%BATDA释放。
在将50μl的无细胞上清液转移到DELFIA微量滴定培养板(珀金埃尔默)中之前,在37℃、5%CO2下执行分析2小时。将200μl的Delfia铕溶液(珀金埃尔默)添加到上清液中并在室温下培育15分钟。随后利用Envision多标记读取器(珀金埃尔默)量化荧光信号。
根据试剂盒说明书计算由STIM001和STIM003诱导的特异性释放。用来自独立供体的NK细胞重复这一实验,且每个分析条件包括3个技术重复。
结果
在原代NK依赖性ADCC分析(2小时时间点)中,抗ICOS抗体STIM001(hIgG1)和STIM003(hIgG1)杀灭ICOS阳性人类MJ细胞。也参见图6a。在这一分析中获得两个已测试分子的亚纳摩尔EC50。
| EC50 | 供体1 | 供体2 |
| STIM001 | 1.21e-10 | 5.29e-10 |
表E10-1:来自2个供体的NK原代细胞ADCC分析(2小时时间点)中STIM001的EC50(摩尔单位)。
实例10b:用MJ靶细胞进行的ADCC分析
根据实例10a中所阐述的材料和方法进行实验。将STIM001、STIM003和同种型对照1:4连续稀释于分析培养基+2mM丙磺舒中以得到在40μg/mL到80pg/mL范围内的最终4×抗体浓度。在每个孔中添加50μl的稀释Ab、装载MJ细胞的50μl BATDA、50μl的NK细胞和50μl的分析培养基+2mM丙磺舒(最终体积为200微升/孔)以得到在10μg/mL到20pg/mL范围内的最终Ab浓度和5:1的效应子:靶标比率。
结果展示于图6(6b到6d)和下表中。在原代NK依赖性ADCC分析(在两小时时间点时所测量)中,STIM001(hIgG1)和STIM003(hIgG1)杀灭ICOS阳性人类MJ细胞。
| EC50 | 供体1 | 供体2 | 供体3 |
| STIM001 | 1.21e-10(0.121nM) | 5.29e-10(0.529nM) | 2.92e-09(2.92nM) |
| STIM003 | 2.33e-12(2.33pM) | 3.58-e-11(35.8pM) | 1.01e-10(0.101nM) |
表E10-2:来自3个供体的NK原代细胞ADCC分析(2小时时间点)中STIM001和STIM003的EC50(摩尔单位)。
实例10c:用经ICOS转染的CCRF-CEM靶细胞进行的ADCC分析
使用人类原代NK细胞作为效应子和经ICOS转染的CCRF-CEM细胞(ATCC,CRL-119)作为靶细胞在Delfia BATDA细胞毒性分析(珀金埃尔默)中进一步测试STIM001和STIM003hIgG1通过ADCC进行杀灭的潜能。CCRF-CEM是一种人类T淋巴母细胞系,其来源于患有急性淋巴母细胞性白血病的患者中的外周血液。在这一分析中对于STIM001和STIM003两者确认抗体介导的CCRF-CEM细胞杀灭。
材料和方法
材料和方法如实例10a中所阐述,但使用从ATCC(ATCC CCL-119)获得的CCRF-CEM细胞而不是MJ细胞作为靶细胞,且使用4小时的孵育时间。
CCRF-CEM细胞经ICOS转染。编码全长人类ICOS的合成串DNA(具有信号肽,如随附序列表中所示)(其针对哺乳动物表达进行密码子优化)在CMV启动子的控制下克隆到表达载体中,并且侧接3'和5'piggyBac特异性末端重复序列从而有助于稳定整合到细胞基因组中来(参见[40])。表达载体含有嘌呤霉素选择盒以促进稳定的细胞系产生。通过电穿孔将人类ICOS表达质粒与编码piggyBac转座酶的质粒共转染到CEM CCRF细胞中。转染后24小时,培养基补充有嘌呤霉素且生长至少两周以选择稳定细胞系,其中培养基每隔3-4天更换。使用抗人类ICOS-PE共轭抗体(电子生物科学)通过流式细胞测量术评定人类ICOS的表达。完整CEM培养基由含有10%(v/v)FBS和2mM Glutamax的高级RPMI培养基构成。
将STIM001(hIgG1)、STIM003(hIgG1)和同种型对照抗体(HC IgG1)连续稀释于分析培养基中以得到在20μg/mL到80pg/mL范围内的最终4×抗体浓度。
在每个孔中添加50μl的稀释Ab、装载经ICOS转染的CEM细胞的50μl BATDA、50μl的NK细胞和50μl的分析培养基(最终体积为200微升/孔)以得到在5μg/mL到20pg/mL范围内的最终Ab浓度和5:1的效应子:靶标比率。
结果
在原代NK依赖性ADCC分析(在四小时时间点时所测量)中,STIM001(hIgG1)和STIM003(hIgG1)杀灭经ICOS转染的CCRF-CEM细胞。结果展示于图6(6e到6g)和下表中。
| EC50 | 供体4 | 供体5 | 供体6 |
| STIM001 | 3.92e-12(3.92pM) | 3.95e-12(3.95pM) | 3.75e-12(3.75pM) |
| STIM003 | 大致3pM* | 8.95e-13(0.895pM) | 1.03e-12(1.03pM) |
*根据不完整曲线估计的值。
表E10-3:来自3个供体的NK原代细胞ADCC分析(4小时时间点)中STIM001和STIM003的EC50(摩尔单位)。
实例11a:CT26同基因模型
在CT26同基因模型中展示通过将抗ICOS(STIM001 mIgG2a,效应子启动)与抗PDL1(10F9G2)组合改良的抗肿瘤活体内功效。
材料和方法
在Balb/c小鼠中使用皮下CT26结肠癌模型(ATCC,CRL-2638)进行功效研究。这一模型对PD1/PDL1阻断具有较低敏感性,且通常观测到响应于10F9.G2(抗PDL1)和RMT1-14(抗PD1)单药疗法的仅肿瘤生长延缓(未稳定疾病或治愈)。因此,这一模型构成用于查看组合研究的抗PD1、抗PDL1内在耐药性的相关模型。所有活体内实验根据英国动物(科学程序)法(UK Animal(Scientific Procedures)Act)1986和欧盟指令(EU Directive)86/609在英国内政部项目许可(UK Home Office Project Licence)下进行,并由巴布拉罕动物福利研究所(Babraham Institute Animal Welfare)和伦理审核机构Ethical Review Body)审批通过。
由Charles River UK供应6到8周龄且>18g的Balb/c小鼠并在无特定病原体条件下圈养。将总共1×105个CT26细胞(传代数低于P20)皮下注射到小鼠的右侧腹中。除非另外说明,否则在肿瘤细胞注射后第6天开始治疗。通过使用细胞消化液(西格玛)将CT26细胞活体外传代,在PBS中洗涤两次并且再悬浮于补充有10%胎牛血清的RPMI中。在肿瘤细胞注射时确认细胞存活率高于90%。
对于活体内研究,将STIM001抗ICOS激动剂(对小鼠ICOS蛋白质具有交叉反应性)重新格式化为小鼠IgG1和小鼠IgG2a以分别在效应子功能无效时和在效应子功能启用时进行测试。抗PDL1来源于联想生物科技有限公司(Biolegend)(目录号:124325)。杂交对照产生于Kymab(mIgG2a同种型)中或来自商业来源(仓鼠同种型HTK888,联想生物科技有限公司(产品编号92257,批次B215504))。所有抗体以10mg/kg(1mg/ml于0.9%生理盐水中)作为单药疗法或通过将抗PDL1与抗ICOS抗体组合来从第6天开始一周三次腹膜内(IP)给药(给药2周,第6到18天)。从肿瘤细胞注射当天开始每周3次测量动物重量和肿瘤体积。通过使用修改后的椭球公式1/2(长度×宽度2)来计算肿瘤体积。持续研究小鼠直到小鼠肿瘤达到12mm3的平均直径为止或在罕见情况下在观测到肿瘤溃疡发生(福利(welfare))时。在第50天停止实验。人类终点存活期统计数据是使用卡普兰-迈耶方法(Kaplan-Meier method)通过Prism计算的。此方法用于确定特异性治疗是否与改善的存活期相关。


表E11-1:治疗组
结果
如图7、图8和图9中所示,ICOS激动剂可作为单药疗法或与抗PDL1组合延缓疾病进程且治愈一部分动物的CT-26皮下肿瘤。抗PDL1单药疗法诱导肿瘤生长延缓但未观测到稳定疾病或治愈性潜能。在治疗肿瘤时所述组合比抗ICOS单药疗法更有效。本研究也突显出,在引起此模型中的抗肿瘤反应时,呈小鼠IgG2a形式(效应子功能启用)的STIM001比呈小鼠IgG1(效应子无效)形式的更有效。
实例11b:在CT26同基因模型中抗ICOS mIgG2a与抗PDL1 mIgG2a的组合的较强活
体内抗肿瘤功效
用STIM001与小鼠交叉反应性抗人PDL1抗体指定的AbW执行活体内组合研究。关于此活体内作用,STIM001重新格式化为小鼠IgG1和小鼠IgG2a,以分别将其功效与低效应子功能进行比较或比较其作为效应子功能启用分子的功效。以相同形式(小鼠IgG1和小鼠IgG2a)产生抗PDL1 AbW。
在Balb/c小鼠中使用皮下CT26结肠癌模型(ATCC,CRL-2638)执行功效研究。由Charles River UK供应6到8周龄且>18g的Balb/c小鼠并在无特定病原体条件下圈养。将总共1×10E5 CT26细胞(传代数低于P20)皮下注射到小鼠的右侧腹中。除非另外说明,否则在肿瘤细胞注射后第6天开始治疗。CT26细胞通过使用TrypLETM表达酶(赛默飞世尔(Thermofisher))活体外传代,在PBS中洗涤两次,且再悬浮于补充有10%胎牛血清的RPMI中。在肿瘤细胞注射时确认细胞存活率高于90%。
从肿瘤细胞植入后第6天以组合形式同时腹膜内(IP)给予各自200μg(1mg/ml于0.9%生理盐水中)的STIM001和抗PDL1抗体一周三次(在第6天到第17天之间给药2周)。监测肿瘤生长且将肿瘤生长与用同种型对照抗体(mIgG1和mIgG2A)的混合物治疗的动物肿瘤相比较。从肿瘤细胞注射当天开始一周3次测量动物重量和肿瘤体积。通过使用修改后的椭球公式1/2(长度×宽度2)来计算肿瘤体积。持续研究小鼠直到小鼠肿瘤达到12mm3的平均直径为止或在罕见情况下在观测到肿瘤溃疡发生(福利)时。在第60天停止实验。人类终点存活期统计数据是使用卡普兰-迈耶方法(Kaplan-Meier method)通过Prism计算的。此方法用于确定特异性治疗是否与改善的存活期相关。
| 组别 | 动物数量 | 治疗方案(一周3次持续2周) |
| 1 | 10 | mIgG2a+mIgG1同种型各自200μg |
| 2 | 10 | 抗ICOS mIgG1 STIM001+抗PD-L1 mIGg1(AbW)各自200μg |
| 3 | 10 | 抗ICOS mIgG2a STIM001+抗PD-L1 mIGg2a(AbW)各自200μg |
| 4 | 10 | 抗ICOS mIgG2a STIM001+抗PD-L1 mIGg1(AbW)各自200μg |
| 5 | 10 | 抗ICOS mIgG1 STIM001+抗PD-L1 mIGg2a(AbW)各自200μg |
表E11-2:STIM001 2×2组合的治疗组
结果展示于图10中。在与同种型对照治疗的动物相比时,所有抗体组合延缓肿瘤生长且延长所治疗动物的存活期(到达人类终点的时间)。有趣的是,在与抗PDL1(与其形式无关,mIgG1或mIgG2a)组合时,STIM001 mIgG2a抗体在抑制肿瘤生长时比呈mIgG1形式的STIM001更有效。这些数据表明抗ICOS抗体具有最大化抗肿瘤功效的效应子功能的优点。值得注意的是,与aPD-L1 mIgG2a组合的STIM001 mIgG2a已展现最强抗肿瘤功效和改善的存活期(90%的动物展示反应,且60%在第60天时从疾病中治愈)。
类似地,STIM003 mIgG1和mIgG2a作为单药疗法或与抗PDL1(AbW)mIgG2a组合在相同CT26肿瘤模型中测试。从肿瘤细胞植入后第6天开始,STIM003和抗PDL1抗体作为单药疗法或以组合形式通过腹膜内注射(IP)给予动物各自200μg抗体(1mg/ml于0.9%生理盐水中)一周三次(在第6到17天之间给药2周)。在此实验中,监测肿瘤大小41天。人类终点存活期统计数据是使用卡普兰-迈耶方法(Kaplan-Meier method)通过Prism计算的。此方法用于确定特异性治疗是否与改善的存活期相关。
| 组别 | 动物数量 | 治疗方案(从第6天开始一周3次持续2周) |
| 1 | 10 | mIgG2a+mIgG1同种型对照各自200μg |
| 2 | 10 | 抗PD-L1 mIgG2a(AbW)200μg |
| 3 | 10 | STIM003 mIgG1 200μg |
| 4 | 10 | STIM003 mIgG2a 200μg |
| 5 | 10 | STIM003 mIgG1+抗PD-L1 mIGg2a(AbW)各自200μg |
| 6 | 10 | STIM003 mIgG2a+抗PD-L1 mIGg2a(AbW)各自200μg |
表E11-3:STIM003与抗PDL1 AbW IgG2a组合的治疗组
结果展示于图11中。使用aPDL1(AbW)和STIM003 mIgG2a的单药疗法已展现轻度抗肿瘤活性(在每组中治愈一只动物的疾病)。STIM003 mIgG1或mIgG2a与aPDL1(AbW)mIgG2a的组合已展示较强抗肿瘤功效。有趣的是,到第41天,在与aPDL1 mIgG2a组合时,STIM003mIgG2a在抑制肿瘤生长时比STIM003 mIgG1更有效(分别是60%对30%的动物治愈了疾病)。数据进一步突显出抗ICOS抗体最大化抗肿瘤功效的效应子形式的优点。
总之,这些数据展现,抗ICOS抗体STIM001或STIM003与抗PDL1的组合在两种抗体具有效应子启用功能时产生最强抗肿瘤反应。适合的对应人类抗体同种型将包括视情况具有进一步增强的效应子功能的人类IgG1,例如,无岩藻糖基化IgG1。
用抗PDL1 mIgG2a和STIM003 mIgG2a的组合治疗的小鼠和单独地用每种药剂治疗的卡普兰迈耶曲线展示于图29中。
实例11c:单次剂量的STIM003抗体与持续抗PD-L1给药组合重设肿瘤微环境
(tumour microenvironment,TME)且产生较强抗肿瘤功效
本研究比较单个剂量与多个剂量的STIM003 mIgG2A以及多个剂量的抗PDL1抗体(AbW)。数据指示单个剂量的抗ICOS抗体可改变肿瘤微环境,以便允许抗PD-L1抗体发挥更大效果。可将这一情况设想为通过抗ICOS抗体“重设”TME。
如前所述,在Balb/c小鼠中使用皮下CT26结肠癌模型(ATCC,CRL-2638)执行这些功效研究。由Charles River UK供应6到8周龄且>18g的Balb/c小鼠并在无特定病原体条件下圈养。将总共1×10E5CT26细胞(传代数低于P20)皮下注射到小鼠的右侧腹中。除非另外说明,否则在肿瘤细胞注射后第6天开始治疗。CT26细胞通过使用TrypLETM表达酶(赛默飞世尔)活体外传代,在PBS中洗涤两次,且再悬浮于补充有10%胎牛血清的RPMI中。在肿瘤细胞注射时确认细胞存活率高于90%。
治疗组展示于表E11-4中。以10mg/kg(1mg/mL于0.9%生理盐水中)腹膜内(赛默飞世尔,IP)给药STIM003和抗PDL1抗体。从肿瘤细胞植入后第6天开始治疗。监测肿瘤生长,且与用生理盐水治疗的动物的肿瘤相比较。从肿瘤细胞注射当天开始一周3次测量动物重量和肿瘤体积。通过使用修改后的椭球公式1/2(长度×宽度2)来计算肿瘤体积。持续研究小鼠直到小鼠肿瘤达到12mm3的平均直径为止或在罕见情况下在观测到肿瘤溃疡发生(福利)时。在第55天停止实验。
数据展示于图34中。从第6天开始并行给予STIM003和抗PDL1 6个剂量在CT26模型中产生较强抗肿瘤功效,其中5/8的动物在研究结束(第55天)时无肿瘤。有趣的是,已用单个剂量的STIM003随后多个剂量的抗PDL1作为单药疗法实现类似抗肿瘤功效。在与抗PD-L1mIgG2a组合时,在给予STIM003一次(C)对比给予6次(B)之间观测到类似总体功效。当与仅一只动物具有自发肿瘤排斥(此模型中罕见)的生理盐水治疗组(A)比较时,用组合药物治疗的组到实验结束(第55天)在62.5%的动物中具有完全肿瘤排斥。数据表明,STIM003抗体可用以重设肿瘤微环境,且抗体允许免疫检查点耐药肿瘤变得对抗PDL1敏感。如先前所展示(实例11b),CT26肿瘤细胞系并不对抗PDL1单药疗法起强烈反应。显示出STIM003产生促进抗PDL1疗法的抗肿瘤活性的变化。
实例12:抗体序列分析
将抗体STIM001、STIM002、STIM002-B、STIM003、STIM004、STIM005、STIM006、STIM007、STIM008和STIM009的构架区与人类生殖系基因段相比较,以识别最接近的匹配。参见表E12-1和表E12-2。
| 重链 | V | D | J |
| STIM001 | IGHV1-18*01 | IGHD6-19*01 | IGHJ6*02 |
| STIM002 | IGHV1-18*01 | IGHD3-10*01 | IGHJ6*02 |
| STIM002-B | IGHV1-18*01 | IGHD3-10*01 | IGHJ6*02 |
| STIM003 | IGHV3-20*d01 | IGHD3-10*01 | IGHJ4*02 |
| STIM004 | IGHV3-20*d01 | IGHD3-10*01 | IGHJ4*02 |
| STIM005 | IGHV1-18*01 | IGHD3-9*01 | IGHJ3*02 |
| STIM006 | IGHV3-11*01 | IGHD3-10*01 | IGHJ6*02 |
| STIM007 | IGHV2-5*10 | IGHD3-10*01 | IGHJ6*02 |
| STIM008 | IGHV2-5*10 | IGHD3-10*01 | IGHJ6*02 |
| STIM009 | IGHV3-11*01 | IGHD3-9*01 | IGHJ6*02 |
表E12-1.抗ICOS Ab的重链生殖系基因段
| 轻链 | V | J |
| STIM001 | IGKV2-28*01 | IGKJ4*01 |
| STIM002 | IGKV2-28*01 | IGKJ2*04 |
| STIM002-B | IGKV2-28*01 | IGKJ2*04 |
| STIM003 | IGKV3-20*01 | IGKJ3*01 |
| STIM004 | IGKV3-20*01 | IGKJ3*01 |
| STIM005 | IGKV1D-39*01 | IGKJ1*01 |
| STIM006 | IGKV2-28*01 | IGKJ2*04 |
| STIM007 | IGKV3-11*01 | IGKJ4*01 |
| STIM008 | IGKV3-11*01 | IGKJ4*01 |
| STIM009 | IGKV2-28*01 | IGKJ1*01 |
表E12-2.抗ICOS Ab的κ轻链生殖系基因段
通过对来自其它ICOS特异细胞的经PCR放大抗体DNA的下一代测序而获得额外抗体序列,所述ICOS特异细胞是从如实例3中所描述的免疫小鼠中分选的。此识别出可基于其重链v和轻链j基因段和CDR3长度而分组成具有STIM001、STIM002或STIM003的丛集的大量抗体。CL-61091与STIM001成丛集;CL-64536、CL-64837、CL-64841和CL-64912与STIM002成丛集;且CL-71642和CL-74570与STIM003成丛集。抗体VH结构域和VL结构域的序列比对展示于图35到37中。

表E12-3.通过序列成丛集的抗体。
实例13:通过珠粒结合抗体对ICOS表达MJ细胞的激动作用
抗体STIM001、STIM002和STIM003、抗ICOS抗体C398.4A和ICOS配位体(ICOSL-Fc)各自共价偶联到珠粒,且评估其诱发从培养物中生长的MJ细胞中细胞因子IFN-γ的表达的能力。同时评估偶联到珠粒的人类IgG1和克隆C398.4A同种型对照。
数据展示于图12和下文表E13中。
抗ICOS抗体中的每个在此分析中已展现激动作用,在分析的动态范围内,如通过IFN-γ定量所确定刺激MJ细胞明显地超过通过其同源同种型对照所观测到的。
STIM003和克隆C398.4A与STIM001(顶部95%CI:7.21到8.88和LogEC5095%CI:-8.82到-8.63)和STIM002(顶部95%CI:5.38到6.95和LogEC50 95%CI:-9.00到-8.74)相比较,产生更低顶部渐近值(95%CI分别为:3.79到5.13和3.07到4.22)但更有效的LogEC50值(95%CI分别为:-9.40到-9.11和-9.56到-9.23)。因为ICOSL-Fc和克隆C398.4A同种型对照产生不完整曲线(分析的动态范围外的顶部),不认为所拟合的顶部和LogEC50值可靠。人类IgG1杂交对照产生完整曲线,然而,曲线下的面积与0差异不显著,且因而不将其视为激动剂。

表E13.珠粒结合MJ细胞活体外活化分析的汇总表。NA--不适用。
MJ细胞活化分析材料和方法--珠粒结合
将目标蛋白偶联到磁性粒子
将抗ICOS抗体、对照抗体和ICOSL-Fc如下偶联到珠粒。
将M-450甲苯磺酰基活化的(Tosylactivated)戴诺珠粒(英杰公司;大致2×108个珠粒/样本)与100μg的每种蛋白质样本在室温下在搅拌下一起培育隔夜。珠粒用DPBS(吉毕科)洗涤三次且与pH 8.0的1MTris-HCI(UltraPureTM,吉毕科)在室温下在搅拌下一起培育1小时,以阻断非偶联反应性部位。珠粒再次用DPBS洗涤三次且最后再悬浮于0.5ml的DPBS/样本中。
随后如下确定珠粒上的每种目标蛋白的数量。黑色平底高结合ELISA培养板(葛莱娜)涂布有含4μg/ml抗人类IgG(南方生物技术)或抗亚美尼亚仓鼠IgG(杰克逊免疫研究)捕获抗体的DPBS,50微升/孔,在4℃下隔夜。各孔随后用DPBS+0.1%Tween、200微升/孔洗涤三次且用200微升/孔的DPBS+1%BSA在室温下阻断1小时。各孔再次用DPBS+0.1%Tween洗涤三次。储备蛋白质样本用光谱测量法量化,且用细胞计数器对珠粒计数。随后在再次用DPBS+0.1%Tween洗涤三次之前,蛋白质样本和珠粒的稀释系列以50微升/孔在室温下在培养板中培育1小时。添加50微升/孔的含生物素化的抗亚美尼亚仓鼠抗体或抗人类IgG-铕的DPBS+0.1%BSA且在室温下培育1小时。在添加生物素化抗亚美尼亚仓鼠抗体C398.4A的情况下,另一培育步骤添加在分析缓冲液(珀金埃尔默)中稀释1:500的50微升/孔的抗生蛋白链菌素铕(珀金埃尔默)且在室温下培育1小时。在通过添加50微升/孔的Delfia增强溶液(珀金埃尔默)、在室温下培育10min且在EnVision多标记板式读取器上测量在615nm下所发射的荧光来研发分析之前,各孔用200微升/孔的TBS+0.1%Tween洗涤三次。通过推断从已知浓度的非偶联蛋白质样本获得的信号的值来确定珠粒上的蛋白质数量。
MJ细胞活体外活化分析--珠粒结合
MJ[G11]细胞系(ATCC CRL-8294)在补充有20%热灭活FBS的IMDM(吉毕科或ATCC)中生长。对细胞计数,且将15000个细胞/孔(50微升/孔)的细胞悬浮液添加到96孔透明平底聚苯乙烯无菌TC处理的微量培养板中。对珠粒计数,且将范围介于1.5×106个珠粒/孔到大致5860个珠粒/孔(50微升/孔)的连续1:2稀释液添加到细胞中重复两次或重复三次。为了考虑背景,培养板的数个孔仅含有MJ细胞(100微升/孔)。细胞和珠粒在培养板中在37℃和5%CO2下共培养3天,其后,上清液通过离心来采集并收集用于IFN-γ含量确定。
测量IFN-γ含量
使用人类IFN-γDuoSet ELISA试剂盒(安迪生物公司)的改良来确定每个孔中的IFN-γ含量。捕获抗体(50微升/孔)以4μg/ml于DPBS中涂布于黑色平底较高结合培养板(葛莱娜)上隔夜。各孔用200微升/孔的DPBS+0.1%Tween洗涤三次。各孔用200微升/孔的1%BSA在DPBS(w/v)中阻断,用200微升/孔的DPBS+0.1%Tween洗涤三次,且随后将50微升/孔的含IFN-γ标准溶液的RPMI或纯细胞上清液添加到每个孔中并在室温下培育1小时。在添加50微升/孔的含200ng/ml生物素化检测抗体的DPBS+0.1%BSA且在室温下培育1小时之前,各孔用200微升/孔的DPBS+0.1%Tween洗涤三次。在添加50微升/孔的在分析缓冲液(珀金埃尔默)中稀释1:500的抗生蛋白链菌素铕(珀金埃尔默)且在室温下培育1小时之前,各孔用200微升/孔的DPBS+0.1%Tween洗涤三次。在通过添加50微升/孔的Delfia增强溶液(珀金埃尔默)且在室温下培育10min且在EnVision多标记板式读取器上测量在615nm下所发射的荧光来研发分析之前,各孔用200微升/孔的TBS+0.1%Tween洗涤三次。
数据分析
从标准曲线内插每个孔的IFN-γ值,且减去来自仅细胞孔的平均值背景含量。背景校正值随后用于GraphPad prism中以拟合4参数log对数浓度反应曲线。
实例14:通过培养板结合抗体对ICOS表达MJ细胞的激动作用
ICOS表达T细胞的激动作用的替代分析使用呈培养板结合形式的抗体。
MJ细胞活化分析材料和方法--培养板结合
抗体涂布:96孔无菌平坦较高结合板(Costar)在4℃下用100微升/孔的含目标蛋白(抗ICOS抗体、对照抗体和ICOSL-Fc)的DPBS(吉毕科)的连续1:2稀释液(范围介于10μg/ml到0.02μg/ml)重复两次或重复三次涂布隔夜。考虑到背景,培养板的数个孔仅涂布有DPBS。随后在添加细胞之前将培养板用200微升/孔的DPBS洗涤三次。
细胞刺激:MJ[G11]细胞系(ATCC CRL-8294)在补充有20%热灭活FBS的IMDM(吉毕科或ATCC)中生长。对细胞计数,且将15000个细胞/孔(100微升/孔)的细胞悬浮液添加到蛋白质涂布的培养板中。细胞在培养板中在37℃和5%CO2下培养3天。细胞通过离心从培养基中分离,且收集上清液以用于IFN-γ含量确定。
IFNγ含量的测量和数据分析如实例13中所描述。
结果
结果展示于图13和下文表E14-1中。综上所述,STIM001、STIM002和STIM003皆展示如由IFN-γ分泌测量的有效激动作用,具有类似LogEC50值(LogEC50 95%CI分别为:-7.76到-7.64、-7.79到-7.70和-7.82到-7.73)和顶部值(顶部95%CI分别为:2.06到2.54、2.44到2.93和2.01到2.41)。克隆C398.4A呈现与STIM001到STIM003类似的LogEC50值(LogEC5095%CI:-7.78到-7.60)但更低的顶部值(顶部95%CI:1.22到1.63)。STIM004也在此分析中展示激动作用,但效果较低,达成适中的顶部值(顶部95%CI:0.16到0.82)以及类似的LogEC50值(LogEC50 95%CI:-7.91到-7.21)。STIM001、STIM002和STIM003为比ICOSL-Fc(LogEC50 95%CI:-7.85到-7.31和顶部95%CI:0.87到2.45)更强的激动剂。

表E14-1.培养板结合MJ细胞活体外活化分析的汇总。IgG1=人类IgG1杂交对照抗体。
实例15:通过呈可溶形式的抗体对ICOS表达MJ细胞的激动作用
与在实例13和实例14中所描述的使用在固体表面上排列的抗体的分析相比,此分析确定呈可溶形式的抗体是否充当ICOS表达T细胞的激动剂。
MJ细胞活化分析材料和方法——可溶
MJ[G11]细胞系(ATCC CRL-8294)在补充有20%热灭活FBS的IMDM(吉毕科或ATCC)中生长。对细胞计数,且将15000个细胞/孔(50微升/孔)的细胞悬浮液添加到96孔透明平底聚苯乙烯无菌TC处理的微量培养板。将范围介于10μg/ml到0.01953125μg/ml的目标蛋白独自或在添加交联剂(AffiniPure F(ab')2片段山羊抗人类IgG,Fc片段特异性;杰克逊免疫研究)的情况下的连续1:2稀释液添加到细胞中重复两次或重复三次(50微升/孔)。为了考虑背景,培养板的数个孔仅含有MJ细胞(100微升/孔)。细胞和珠粒在培养板中在37℃和5%CO2下共培养3天,其后,上清液通过离心来采集并收集用于IFN-γ含量确定。
IFNγ含量的测量和数据分析如实例13中所描述。
结果
STIM001和STIM002与人类IgG4.PE杂交对照相比皆展示如由IFN-γ分泌测量的显著可溶激动作用。经由山羊抗人类IgG Fc F(ab')2片段的mAb交联甚至更增加所分泌的IFN-γ含量。
实例16:抗体与活化T细胞的结合
A.人类ICOS
在此分析中确认抗ICOS抗体在其原生情形下辨识活化的原代人类T细胞的表面上的ICOS胞外结构域的能力。
泛T细胞(CD3细胞)被分离且用CD3/CD28戴诺珠粒(赛默飞世尔)培养3天,以诱导其表面上的ICOS表达。通过两种方法确定STIM001、STIM003和hIgG1杂交对照(HC IgG1)的表面染色,即在直接结合预标记的抗体(抗体直接地与AF647轭合)或间接地经由次级AF647山羊抗人类Fc抗体的使用之后检测。染色的细胞在Attune上运作,且染色强度呈现为荧光强度的平均值(Mean of fluorescence intensity;MFI)。使用GraphPad Prism确定EC50。
结果展示于图14中。一旦活化,泛CD3T细胞就通过STIM001和STIM003hIgG1两者清晰地染色。值得注意的是,与活化T细胞结合的STIM003的饱和度出现在比STIM001的浓度更低的浓度下,表明STIM003对人类ICOS的更高亲和力。STIM003的EC50粗略地比STIM001的EC50低100倍(针对间接结合分析,0.148nM比17nM)。
B.来自非人类灵长类动物的ICOS
在此分析中确认抗ICOS抗体在其原生情形下辨识来自非人类灵长类动物(non-human primates,NHP)的活化原代T细胞的表面上的ICOS胞外结构域的能力。
来自2只毛里求斯猕猴(Wickham Laboratories)的全血的PBMC通过梯度离心分离,且与CD2/CD3/CD28 MACSiBeads(美天旎(Miltenyi))培养3天,以诱导其表面上ICOS表达。在直接结合AF647预标记抗体(80μg到8pg/ml)之后,确定STIM001、STIM003和hIgG1杂交对照(HC IgG1)的表面染色。也用V450-CD3标记细胞以评估T细胞亚群上的染色。染色的细胞在Attune(赛默飞世尔)上运作,且染色强度呈现为平均荧光强度(MFI)。使用GraphPadPrism确定EC50。
结果展示于图28中。一旦活化,T细胞就通过STIM001和STIM003 hIgG1两者清晰地染色。如在与人类T细胞结合的情况下观测到一样,与活化NHP T细胞结合的STIM003的饱和度出现在比STIM001的浓度更低的浓度下,指示STIM0003具有这两种抗体ICOS中的更高亲和力。与NHP ICOS结合的EC50值类似于与人类ICOS结合所获得的那些值。

表E16.计算与活化NHP T细胞上的ICOS结合的抗体的EC50(摩尔)
实例17:肿瘤浸润淋巴细胞和外周T细胞中的T细胞亚群的分析
药效动力学研究揭露,mIgG2a同种型中的抗ICOS抗体STIM001和STIM003明显地减少TReg,增大CD4+效应细胞的百分比且增大肿瘤微环境(TME)内的CD4+效应子/TReg比率以及CD8+/TReg比率。
TME内增大的CD8+/TReg比率和增加数量的CD4+效应细胞可共同地有助于STIM001和STIM003功效研究(实例11)中当这些抗ICOS抗体与抗PDL1抗体共注射时观测到CT26肿瘤清除率。
方法
在携带CT-26小鼠结肠癌细胞(ATCC,CRL-2638)的雌性Balb/c小鼠中执行药效动力学研究。由Charles River UK供应6到8周龄且>18g的Balb/c小鼠并在无特定病原体条件下圈养。在右侧腹皮下注射总共1×10E5 CT-26肿瘤细胞(传代数:P8)。所有CT-26肿瘤携带动物分配到6个组(表E17-1),且个别小鼠用200μg的抗体或生理盐水给予两次(在肿瘤细胞植入后第13天和第15天)。通过FACS在肿瘤细胞植入后第16天分析来自CT-26肿瘤携带动物的CD3+ T细胞。
| 组别 | 动物数量 | 治疗方案(肿瘤细胞植入后第13天和第15天) |
| 1 | 10 | 生理盐水 |
| 2 | 10 | 抗ICOS(STIM001)mIgG1各自200μg |
| 3 | 10 | 抗ICOS(STIM001)mIgG2a各自200μg |
| 4 | 10 | 抗ICOS(STIM003)mIgG1各自200μg |
| 5 | 10 | 抗ICOS(STIM003)mIgG2a各自200μg |
| 6 | 10 | 抗CTLA-4(9H10)各自200μg |
表E17-1:治疗组
结果
用mIgG2a同种型中的STIM001和STIM003治疗的动物当与生理盐水治疗组比较时在肿瘤部位处展示较低百分比的CD4+ CD3+ CD45+细胞(图15A),而STIM001或STIM003治疗对肿瘤部位处的CD8+ CD3+ CD45+细胞百分比具有极边际效果(图15B)。CD4+ T细胞中的减少可归因于用STIM001和STIM003抗体治疗的所有组中T调节性细胞的百分比的影响深远的减少。值得注意的是,用mIgG2a同种型中的STIM001和STIM003治疗的动物展示TME内T-Reg(CD4+Foxp3+CD25+)的显著减少,而mIgG1同种型中的STIM001和STIM003在TME中对T-Reg含量仅具有适度影响。另外,用mIgG2a同种型中的STIM001和STIM003治疗的动物当与用已知减少T-Reg[42]的市售抗CTLA-4(9H10,联想生物科技有限公司目录号106208)抗体治疗的动物比较时在TME中具有减少的T-Reg,但此结果并未达到统计显著性(图15C)。mIgG1或mIgG2a同种型中的STIM001和STIM003对T-Reg隔室的效果在肿瘤浸润淋巴细胞(tumourinfiltrating lymphocyte,TIL)的情况下更具特异性。在外周中未观测到T-reg减少(如先前针对抗CTLA4[43]所描述)(图15D)。T-Reg含量的变化还导致瘤内CD4效应细胞(CD4+Foxp3- CD25-)的百分比显著增大(图15E),类似地,用mIgG2a中的STIM001和STIM003治疗的动物中CD4效应子/T-Reg的比率和CD8/T-Reg比率在TME内也显著地增大(图15F和图15G)。
实例18:抗ICOS抗体对CT26肿瘤和脾脏中的ICOS表达T细胞的含量的影响
在用抗ICOS抗体STIM001或STIM003治疗之后,通过分析肿瘤和脾脏组织中的总免疫细胞来执行分析以定量与脾脏相比肿瘤内的免疫细胞的百分比。STIM001和STIM003mIgG2a各自造成肿瘤内的Treg的显著减少,但不造成脾脏中的减少,从而指示肿瘤选择性效果。此耗减与其它T细胞亚型相比对Treg而言具有选择性。此处所呈现的结果帮助理解STIM抗体对免疫的影响,且确认具有效应子功能启用Fc区域的抗ICOS抗体可强烈耗减TReg。
材料和方法
携带CT26肿瘤的小鼠用STIM001、STIM003或抗CTLA4抗体(9H10)给药两次。由于抗CTLA4抗体先前已显示出选择性地减少肿瘤中的Treg,因此抗CTLA4抗体包括为用于Treg耗减的阳性对照[43]。
在组织解聚集之后通过FACS来分析经过治疗的动物的肿瘤和脾脏内的免疫组织。
这一研究中所用的FACS抗体的细节展示于表E18中。所有FACS抗体以供应商所建议的浓度使用。使用Attune NxT流式细胞测量仪来获取FACS数据且使用FlowJo软件来分析数据。
| 标记物 | 供应商 | 目录号 | 批号 | 荧光团 |
| 存活/死亡 | 生命技术公司 | L-34959 | 1784156 | 可固定黄色 |
| CD45 | 电子生物科学 | 45-0451-82 | E08336-1636 | PerCp-Cy5.5 |
| CD3 | 电子生物科学 | 48-0032-82 | 4278794 | eFlour 450 |
| CD4 | 电子生物科学 | 11-0042-86 | E0084-1633 | FITC |
| CD8 | 电子生物科学 | 12-0081-85 | E01039-1635 | PE |
| Foxp3 | 电子生物科学 | 17-5773-82 | 4291991 | APC |
| CD25 | 电子生物科学 | 47-0251-82 | 4277960 | APC eF 780 |
| ICOS | 电子生物科学 | 25-9942-82 | E17665-103 | PE-CY7 |
| Fc/嵌段 | 电子生物科学 | 16-0161-86 | E06357-1633 | ------------------ |
表E18.FACS抗体。
结果
在CT26肿瘤中和携带肿瘤的动物的脾脏中测定ICOS表达。我们观测到表达ICOS蛋白质的肿瘤浸润性免疫细胞增加的百分比(图20),指示肿瘤中的免疫细胞对ICOS表达比周边的免疫细胞更频繁地呈阳性。未治疗动物的肿瘤中的TReg对ICOS表达几乎全部(>90%)呈阳性,然而肿瘤中的CD8+效应T细胞并非如此(大致60%)。将肿瘤中的T细胞亚群(同样在未治疗小鼠中)与脾脏中的T细胞亚群进行比较,与脾脏中的Treg相比显著更高(p<0.0001)百分比的肿瘤内Treg对ICOS呈阳性,且与脾脏中的CD4+ Teff细胞相比显著更高(p<0.001)百分比的肿瘤内CD4+ Teff细胞对ICOS呈阳性。
此外在治疗前的小鼠中,与脾脏中的免疫细胞相比时,CT26肿瘤微环境中的免疫细胞上的ICOS表达水平高得多(图21)。在肿瘤微环境中分析的所有免疫细胞亚群(CD8 T-效应子、CD4 T-效应子和CD4/FoxP3 Treg细胞)表面上增加ICOS表达。应注意,尽管肿瘤和脾脏中的免疫细胞都表达ICOS,但肿瘤中的免疫细胞(由较高MFI指示,图21)比脾脏中的细胞(由较低MFI指示,图21)表达明显更多的ICOS。重要的是,肿瘤中的TReg表达最高含量的ICOS,如先前所报告[11]。
携带CT26肿瘤的动物用2个剂量的抗体STIM001或STIM003和用抗CTLA-4抗体治疗。当以mIgG1或mIgG2形式使用时,STIM抗体并不影响肿瘤中的CD45阳性细胞(免疫细胞的标记物)的整体百分比。用这些抗体治疗也不显著影响CT26肿瘤中的CD8效应T细胞百分比(图22)。用mIgG2a同种型形式的STIM001治疗导致CD4+效应T细胞的显著(p<0.05)耗减,但STIM001 mIgG1、STIM003 mIgG1和STIM003 mIgG2a中并无一个影响CD4+效应T细胞的百分比。
抗CTLA-4治疗在TME中显著(尽管非统计显著)增加CD45+细胞和CD8+效应T细胞,但并不影响CD4+效应T细胞(图22)。
STIM抗体显著影响肿瘤中的调节性T细胞。如图23中所示,STIM001 mIgG2a和STIM003 mIgG2a显著且选择性地耗减肿瘤微环境中的TReg(ICOS表达很高)。有趣的是,抗CTLA4抗体,尽管在这一实验中包括为用于TReg耗减的阳性对照,也比STIM mIgG2a抗体在耗减TReg上效果小。
TReg的这一选择性耗减使得肿瘤中CD8效应T细胞与TReg的比率增加,和肿瘤中CD4效应T细胞与TReg的比率增加,这两种情况应有利于抗肿瘤免疫反应。比率数据展示于图24中。
与通过STIM001 mIgG2a和STIM003 mIgG2a来耗减肿瘤内Treg相比,在脾脏中的Treg上未观测到此类影响(图25、图26、图27)。这指示在所有组织中抗ICOS抗体对耗减Treg耗减的影响不是全身性的。此类选择性在治疗患者肿瘤时对治疗性抗ICOS抗体可为有利的,这是因为在肿瘤微环境中优先耗减Treg可选择性地减轻对抗肿瘤效应T细胞的抑制,同时使体内其它部位处的副作用降到最低。抗ICOS抗体可由此促进免疫系统中的抗肿瘤反应,其中低风险的不合需要的活化更宽广的T细胞反应可导致治疗限制性自身免疫不良事件。
实例19:抗体稳定性
在储存、冷冻/解冻和纯化期间测试STIM003人类IgG1的稳定性,且发现其在所有已测试条件下保持其稳定性。通过HPLC测定聚集%。
在4℃下储存于缓冲液(10mM,40mM氯化钠,pH 7.0)中3个月后,单体百分比无显著变化(>99%)。
在热变性测试中,所有样品(n=15)具有相同Tm(等分试样之间无显著差异)且具有相当的热变性曲线。
在3个周期的冷冻和解冻之后,Tm(≈70.3℃)、单体百分比或SDS-PAGE上的分布无显著变化。
在室温下储存7天之后,Tm(≈70.3℃)、单体百分比或SDS-PAGE上的分布无显著变化。
蛋白质A纯化后恢复90%。
实例20:抗ICOS Ab针对小鼠中A20肿瘤生长的单药疗法功效
抗ICOS抗体STIM001 mIgG2a和STIM003 mIgG2a在作为活体内单药疗法用于小鼠A20同基因模型中时各自显示较强的抗肿瘤功效。
材料和方法
使用皮下A20网状细胞肉瘤模型(ATCC,TIB-208)在BALB/c小鼠中进行功效研究。A20细胞系是来源于大龄BALB/cAnN小鼠中发现的自发网状细胞肿瘤的BALB/c B细胞淋巴瘤系。这一细胞系已报告为针对ICOSL呈阳性。
由Charles River UK供应>18公克的BALB/c小鼠并在无特定病原体条件下圈养。将总共1×10e5个A20细胞(传代数低于P20)皮下注射到小鼠的右侧腹中。将A20细胞活体外传代,在PBS中洗涤两次且再悬浮于补充有10%胎牛血清的RPMI中。在肿瘤细胞注射时确认细胞存活率高于85%。除非另外说明,否则从肿瘤细胞注射后第8天开始抗体或同种型给药。
STIM001和STIM003抗ICOS抗体以小鼠IgG2a同种型形式产生。小鼠交叉反应性抗PD-L1抗体(AbW)也以相同同种型形式(小鼠IgG2a)产生。从肿瘤细胞植入后第8天(在第8天到第29天之间给药3周)开始腹膜内(IP)给予STIM001、STIM003和抗PD-L1抗体每种抗体200μg一周两次。从肿瘤细胞注射当天开始测量动物重量和肿瘤体积一周3次。通过使用修改后的椭球公式1/2(长度×宽度2)来计算肿瘤体积。持续研究小鼠直到小鼠肿瘤的平均直径达到12mm为止。在肿瘤细胞植入后第43天停止实验。监测肿瘤生长并将其与用同种型对照(mIgG2a)抗体治疗的动物肿瘤进行比较。治疗组展示于下表E20中。
| 组别 | 动物数量 | 治疗方案(每周两次持续3周7次剂量) |
| 1 | 8 | mIgG2a同种型对照200μg/小鼠/每次剂量 |
| 2 | 8 | 抗PD-L1 mIGg2a(AbW)200μg/小鼠/每次剂量 |
| 3 | 8 | 抗ICOS mIgG2a STIM001 200μg/小鼠/每次剂量 |
| 4 | 8 | 抗ICOS mIgG2a STIM003 200μg/小鼠/每次剂量 |
表E20.A20研究的治疗组。
结果
在A20肿瘤模型中单药疗法给药STIM001或STIM003(mIgG2a)产生完全抗肿瘤反应(图32、图33)。所有给药STIM001或STIM003的动物都治愈了疾病。这与同种型对照组和PD-L1 mIgG2a组的结果形成对比(图30、图31)。在罕见情形下,虽然在同种型对照组(自发消退)和抗PDL-1组中观测到一些动物的肿瘤消退,但用抗ICOS抗体治疗产生显著更大的功效。在结束研究时,3/8对照动物和2/8经抗PDL-1治疗的动物无肿瘤。然而,用STIM001或STIM003治疗的所有动物在结束研究时都不含肿瘤(在两个组中8/8小鼠),使用抗ICOS抗体呈现100%治愈。
实例21:在J558骨髓瘤同基因模型中抗ICOS抗体与抗PD-L1抗体的组合的强力活
体内抗肿瘤功效
抗ICOS抗体STIM003 mIgG2a和抗PD-L1抗体AbW mIgG2a在J558肿瘤模型中单独地给予且以组合形式给予。这是骨髓瘤的同基因小鼠模型。发现抗ICOS抗体在作为单药疗法或与抗PD-L1组合给药时抑制肿瘤生长。
材料和方法
使用皮下J558浆细胞瘤:骨髓瘤细胞系(ATCC,TIB-6)在Balb/c小鼠中进行抗肿瘤功效研究。由Charles River UK供应6到8周龄且>18g的Balb/c小鼠并在无特定病原体条件下圈养。将总共1×106个细胞(传代数低于P20)皮下注射(100μl)到小鼠的右侧腹中。除非另外说明,否则在肿瘤细胞注射后第11天,基于肿瘤大小将动物随机分组并开始治疗。J558细胞通过使用TrypLETM表达酶(赛默飞世尔)活体外传代,在PBS中洗涤两次,且再悬浮于补充有10%胎牛血清的DMEM中。在肿瘤细胞注射时确认细胞存活率高于90%。
在肿瘤达到约140mm3的平均体积时开始治疗。随后将具有类似平均肿瘤大小的动物分配到4个组(给药组参见表E-21)。从(肿瘤细胞植入后)第11天给药具有小鼠交叉反应性的两种抗体一周两次持续3周(图38),除非动物由于福利(稀少)或肿瘤大小必须从研究去除。作为对照,在使用生理盐水溶液的同时给药动物组(n=10)。对于组合组,STIM003和抗PDL1抗体两者分别以60μg和200μg(于0.9%生理盐水中)IP并行给药。在37天内监测肿瘤生长,且将其与用生理盐水处理的动物的肿瘤进行比较。从肿瘤细胞注射当天开始测量动物重量和肿瘤体积一周3次。通过使用修改后的椭球公式1/2(长度×宽度2)来计算肿瘤体积。持续研究小鼠,直到小鼠肿瘤达到12mm3的平均直径或在罕见情况下在观测到肿瘤溃疡发生(福利)时为止。

表E21.用于J558功效研究的治疗组
结果
J558同基因肿瘤具有高度侵蚀性,且生理盐水对照组中的所有动物(n=10)由于肿瘤大小截至第21天必须从研究中去除。抗STIM003 mIgG2a和抗PDL1 mIgG2a两者在这一模型中作为单药疗法都展示良好功效,其中分别37.5%和75%的动物治愈疾病。重要的是,两种抗体的组合使得100%的动物截至第37天已排出浆细胞瘤肿瘤。数据展示于图38中。
实例22:给药抗PD1比抗PD-L1抗体更显著增加TIL上的ICOS表达
在携带已形成的CT26肿瘤的动物中进行药效动力学研究,以评估用抗PD-L1或抗PD-1抗体治疗对肿瘤浸润淋巴细胞(TIL)亚群上的ICOS表达的影响。比较以下抗体:
·抗PD-L1 AbW mIgG1[有限效应子功能]
·抗PD-L1 AbW mIgG2a[具有效应子功能]
·抗PD-L1 10F9.G2大鼠IgG2b[具有效应子功能]
·抗PD1抗体RMT1-14大鼠IgG2a[效应子无效]。
将经过治疗的小鼠的肿瘤分离,解离成单个细胞且对CD45、CD3、CD4、CD8、FOXP3和ICOS染色。
材料和方法
大鼠抗PD-1 RMP1-14 IgG2a(BioXCell;目录号:BE0146)、大鼠抗PD-L1 10F9.G2IgG2b(联想生物科技有限公司;目录号:124325)和抗PD-L1 AbW mIgG1和mIgG2a通过在肿瘤细胞植入后第13天和第15天以130μg腹膜内给药来在CT26肿瘤模型中测试。在第16天,将动物挑选出并采集小鼠肿瘤用于FACS分析。使用小鼠肿瘤解离试剂盒(美天旎生物技术公司(Miltenyi Biotec))解离肿瘤并使其均质化。将所得细胞悬浮液通过70μM过滤器澄清,粒化并以2百万个细胞/孔再悬浮于96孔培养板中的FACS缓冲液中。将细胞悬浮液与抗16/32mAb(电子生物科学)一起培育且用对所有从电子生物科学有限公司获得的CD3(17A2)、CD45(30-F11)、CD4(RM4-5)、CD8(53-6.7)和ICOS(7E.17G9)具有特异性的FACS抗体染色。也用LiveDead黄色可固定存活力染料(生命技术公司)将细胞染色。对于Foxp3胞内染色,将样品固定,渗透并用对Foxp3具有特异性的抗体(电子生物科学,FJK-16s)染色。将样品再悬浮于PBS中,且在Attune流式细胞仪(英杰)上获取数据并使用FlowJo V10软件(Treestar)分析数据。
结果
用抗PD1和抗PD-L1抗体治疗仅使得在所测量时间点表达ICOS的CD8细胞和T Reg的百分比呈边际增加。然而,响应于抗PD1大鼠IgG2a,在ICOS+ve CD8细胞表面上观测到ICOS表达的清楚且显著(超过生理盐水处理组)的增加(增加的dMFI)。也注意到CD4效应子和CD4 T Reg细胞上的ICOS表达上调,尽管这并未达到统计显著性。这种抗PD1抗体诱导CD8效应细胞上的ICOS表达的明显增加,这种明显增加在抗PD-L1 mIgG2a的情况下是罕见的。类似地,在比较抗PD-L1抗体的不同形式时,在一些经过治疗的动物中观测到当与具有效应子功能的抗体(mIgG2a和ratIgG2b)比较时,具有最低效应子功能的抗体(mIgG1)与效应子CD8和CD4细胞上的较高ICOS表达相关联,这种情况很罕见。参见图39。
效应子CD8/CD4 T细胞上的ICOS表达的增加可具有使这些细胞对通过抗ICOS抗体进行耗减(例如,对用STIM003 mIgG2a治疗小鼠)更敏感。在效应CD8和CD4 T细胞中呈现较低ICOS诱导的抗体可优选用于与抗ICOS抗体组合使用。来自这一研究的数据指示抗PD-L1效应子阳性抗体可尤其适用于与抗ICOS效应子阳性抗体组合,反映出在将本文中其它实例中所报告的抗PDL1 mIgG2a与STIM003 mIgG2a组合时观测到的抗肿瘤功效。
实例23:在B细胞淋巴瘤同基因模型中活体内单次剂量抗ICOS抗体单药疗法的强
力抗肿瘤功效
这一实验确认STIM003 mIgG2a作为单药疗法的抗肿瘤功效。在短暂暴露STIM003mIgG2a之后展现强力抗肿瘤功效。
材料和方法
使用皮下A20网状细胞肉瘤模型(ATCC编号CRL-TIB-208)在BALB/c小鼠中进行功效研究。由Charles River UK供应6到8周龄且>18g的Balb/c小鼠并在无特定病原体条件下圈养。将总共1×10E5个A20细胞(传代数低于P20)皮下注射到小鼠的右侧腹中。在肿瘤细胞注射后第8天开始治疗,如下表中所示。A20细胞通过使用TrypLETM表达酶(赛默飞世尔)活体外传代,在PBS中洗涤两次,且再悬浮于补充有10%胎牛血清的RPMI中。在肿瘤细胞注射时确认细胞存活率高于85%。将STIM003 mIgG2a以60μg(对于20g动物等效于3mg/kg)的单次剂量(SD)或以60μg的多次剂量(MD,一周两次持续3周)使用。将响应于两个方案所观测到的抗肿瘤功效与用生理盐水(MD,一周两次持续3周)“治疗”的动物的抗肿瘤功效进行比较。以1mg/ml于0.9%生理盐水中腹膜内(IP)给药抗体。从肿瘤细胞注射当天咳嗽测量动物重量和肿瘤体积一周3次。通过使用修改后的椭球公式1/2(长度×宽度2)来计算肿瘤体积。持续研究小鼠,直到小鼠肿瘤达到12mm3的平均直径或罕见地在观测到肿瘤溃疡发生(福利)时为止。
| 组别 | 动物数量 | 治疗方案(IP注射) |
| 1 | 10 | 生理盐水(从第8天开始多次剂量,一周两次持续3周) |
| 2 | 10 | STIM003 mIgG2 A(从第8天开始多次剂量,一周两次持续3周) |
| 3 | 10 | STIM003 mIgG2 A(在第8天单次给药) |
表E23-1.治疗组。
结果
多次剂量和单次剂量的STIM003 mIgG2a两者产生强力且显著的单药疗法抗肿瘤功效,如由在终点(第41天)无肿瘤生长迹象的动物数量所示。SD使得7/10的动物治愈疾病,而用A20B细胞淋巴母细胞注射的多次剂量治愈9/10的动物。生理盐水治疗组中的所有动物截至第40天由于肿瘤大小必须从研究中去除。参见图40。
使用GraphPad Prism V7.0根据卡普兰-迈耶曲线(图41)计算人道终点存活期统计数据。这一方法用于确定治疗是否与改善的存活期相关。风险比(曼特-赫斯则(Mantel-Haenszel))值和其相关P值(对数秩Mantel-Cox)展示于下表中。

表E23-1.对应于图41卡普兰-迈耶曲线的风险比(曼特-赫斯则)值和其相关P值(对数秩Mantel-Cox)。
实例24:抗ICOS抗体在携带CT-26肿瘤的动物中的时间和剂量依赖性效应
这一实例呈现评定抗ICOS抗体对携带CT-26肿瘤的小鼠中的免疫细胞的效应的药效动力学研究结果。在单次给药STIM003 mIgG2a之后通过FACS分析来自不同组织的T细胞和B细胞亚型。
方法
携带CT-26肿瘤的动物在肿瘤细胞植入后第12天用生理盐水或200μg、60μg或6μg的STIM003腹膜内给药。在治疗后第1天、第2天、第3天、第4天和第8天采集肿瘤组织、血液、肿瘤引流淋巴结(TDLN)和脾脏。使用小鼠肿瘤解离试剂盒(美天旎生物技术公司)将肿瘤解离以形成单一细胞悬浮液。使用温和的MACS解离将脾组织解离,使用RBC溶解缓冲液将红血细胞溶解。将肿瘤引流淋巴结机械地解聚以形成单一细胞悬浮液。根据组织通过70μM或40μM过滤器将所得细胞悬浮液澄清,随后将细胞在RMPI完全培养基中洗涤两次且最后再悬浮于冰冷的FACS缓冲液中。将全部血液收集到血浆管中且使用RBC溶解缓冲液溶解红血细胞,将细胞在RMPI完全培养基中洗涤两次且最后再悬浮于冰冷的FACS缓冲液中。将来自所有组织的单一细胞悬浮液分配到96深孔培养板中以用于FACS分析。用Live Dead可固定黄色存活力染料(生命技术公司)将细胞染色。将细胞悬浮液与抗CD16/CD32mAb(电子生物科学)一起培育且用对所有从电子生物科学有限公司获得的CD3(17A2)、CD45(30-F11)、CD4(RM4-5)、CD8(53-6.7)、CD25(PC61.5)、ICOSL(HK5.3)、B220(RA3-6B2)、Ki-67(SolA15)、CD107a(eBio1D4B)、IFN-γ(XMG1.2)、TNF-α(MP6-XT22)、Foxp3(FJK-16s)和ICOS(7E.17G9)具有特异性的FACS抗体染色。对于由FACS读取的细胞因子,将来自肿瘤的单一细胞悬浮液在布雷菲德菌素-A(Brefeldin-A)存在的情况下接种于24孔培养板中4小时。对于胞内染色,将样品固定,渗透并用特异性抗体染色。最后将样品再悬浮于PBS中,且在Attune流式细胞仪(英杰)上获取数据并使用FlowJo V10软件(Treestar)分析数据。
在下文呈现并论述结果。
CT26模型中的肿瘤内T-reg上的ICOS表达较高
当将表达ICOS的肿瘤浸润淋巴细胞(TIL)百分比与脾脏、血液和TDLN中的免疫细胞百分比进行比较时,我们证明了相对于其它组织,CT-26肿瘤微环境中更多免疫细胞表达ICOS。更重要的是,所有组织中和在所有时间点的ICOS阳性T-reg细胞百分比高于对ICOS呈阳性的CD4或CD8效应T细胞百分比。重要的是,ICOS的dMFI(相对表达)也遵循表达的类似排序,其中相对于其它TIL亚型,肿瘤内T-reg对ICOS表达呈高度阳性。引起关注地是,在这一实验的时间帧内ICOS+TIL的百分比无显著变化。类似结果也可见于脾脏和TDLN中。另一方面,在血液中,在实验过程中T效应细胞上的ICOS表达相对稳定但T-reg上的ICOS表达增加。数据完全证明在肿瘤微环境中更多细胞表达ICOS且这些阳性细胞在其表面上也表达更多ICOS分子。更重要的是,TIL中的T reg对ICOS呈高度阳性。参见图42。
响应于STIM003给药极大耗减肿瘤内T-reg细胞
响应于STIM003 mIgG2a抗体,在TME中T-reg细胞(CD4+CD25+Foxp3)耗减极大且快速。由于与其它T细胞亚群相比T-reg具有高度ICOS表达,因此预期具有效应子功能的抗ICOS抗体将优先耗减这些细胞。在STIM003的较低剂量(6μg对应于20g动物的0.3mg/kg)下连续耗减T-reg,且截至第3天从TME中耗减大部分T-reg。引起关注地是,截至第8天,T-reg细胞重建TME随后达到稍微高于生理盐水治疗的动物中所观测到的水平。T-reg细胞在较低剂量下的的重建可归因于在TME中增殖CD4 T细胞的增加,如由观测到的Ki-67+CD4 T细胞的增加所证明。在高于6μg的剂量下在TME中长期耗减T-reg,如由直到这一研究中所分析的最后一个时间点(第8天)为止的完全T Reg耗减所展示。然而在血液中,在所有剂量下短暂耗减T-reg细胞。重要的是,截至第8天,与生理盐水治疗的动物相比,所有经过治疗的动物在血液中具有类似(或对于6μg剂量更高)含量的T-reg细胞。数据展示于图43中。值得注意的是,且类似于先前公布的耗减CTLA-4抗体的数据,脾脏或TDLN组织中的T-reg细胞百分比无显著变化,表明T-reg细胞可免于在这些器官中耗减。
总体而言,TME中T-reg细胞的极大耗减以低至6微克/动物的剂量在CT-26模型中实现。然而,60μg的剂量导致STIM003 mIgG2a注射后长达8天的长期耗减。这无法通过使用较高剂量(200μg)改善。
STIM003 mIgG2a增加CD8:T Reg比率和CD4:T Reg比率
STIM003对T-eff:T-reg比率的影响展示于图44中。
STIM003 mIgG2a增加CD8:T-reg比率以及CD4 eff:T-reg比率。尽管所有治疗剂量都与T-eff与T-reg比率的增加相关,但60μg(等效于20g动物的3mg/kg)的中等剂量在截至治疗后第8天与最高比率相关。
引起关注地是,在6μg剂量下,直到第4天为止比率较高,但在截至治疗后第8天其匹配生理盐水治疗的动物的比率。这可以在截至治疗后第8天通过重建针对这一剂量所观测到的TReg来解释。另一方面,在60μg或200μg的剂量下,Teff与T-reg比率在所有时间点保持较高。这通过在这些剂量下长期耗减Treg来解释。值得注意的是,在较高剂量(200μg)下,不管长期Treg耗减如何,截至第8天比率仅中度改良。这可以通过在STIM003的高浓度下耗减一些ICOSINT效应细胞来解释。
总而言之,数据展示在测试的所有剂量下的TReg耗减和增加的效应子:T reg比率。然而,60μg(约3mg/kg)的最佳剂量实现T-reg的长期耗减以及T-eff与T-reg的最高比率两者,所述比率将与引发抗肿瘤免疫反应的最有利免疫环境相关。引起关注地是,在血液中观测到类似模式,其中60μg的中等剂量与T-eff与T-reg的最高比率相关。重要的是,在血液中,在更早时间点(在第3天与第4天之间)观测到比率的改善。
响应于STIM003活化效应细胞
CD107a在肿瘤浸润性T效应细胞上的表面表达先前被标识为已活化且发挥细胞毒素活性的细胞的可靠标记物[44]。在本研究中,采用这一标记物以确认STIM003除了耗减T-reg以外,还可刺激TME中的效应T细胞的细胞毒素活性。引起关注地是,在治疗后第8天,在STIM003的所有剂量下CD107a在CD4和CD8效应T细胞区室两者上的表面表达都增加。此外,由于以200μg给药未见改善,因此当以60μg给药动物时,CD4和CD8 T细胞两者的表面上CD107a表达的这一上调出现平稳期。
为了进一步展现TME中效应细胞的活化,通过CD4和CD8 TIL进行的细胞因子释放由FACS分析。正如期望且与本文中的更早实例中所呈现的活体外激动作用数据一致,所有剂量下的STIM003 mIgG2a促进通过效应子CD4和CD8 T细胞产生促炎性细胞因子IFN-γ和TNF-α。促炎性细胞因子产生的诱导在60μg的最优剂量下呈现为较高。实际上,60μg的STIM003显著增加通过CD4 T细胞产生的细胞因子。对于在TME中通过效应子CD8 T细胞产生的促炎性细胞因子IFN-γ和TNF-α可见类似趋势。数据展示于图45中。
总体而言,所有剂量下的STIM003在TME中导致T细胞活化,如由(1)脱粒标记物CD107a在其表面上的呈现和(2)通过T细胞产生Th1细胞因子(IFNγ和TNFα)所展示。这指示STIM003很大程度上影响TME中的免疫环境且起到耗减Treg细胞和刺激T效应细胞的杀灭活性的双重作用。
人类剂量估计
基于小鼠中可见的临床前功效数据,可由适合于人类患者的临床剂量作出初始预测,基于对应的生物表面区域(BSA)[45]。
举例来说,考虑到小鼠中最佳抗ICOS IgG剂量为3mg/kg(60μg),且遵循参考[45]的方法,用于人类的对应剂量为0.25mg/kg。
使用莫斯特勒(Mosteller)公式,对于60kg和1.70m的个体,BSA为1.68m2。使以mg/kg为单位的剂量乘以35.7(60/1.68)的因数得出15mg的固定剂量。对于80kg的个体,对应的固定剂量将为20mg。
可针对临床试验中的人类疗法优化剂量以确定安全且有效的治疗方案。
实例25:来自肿瘤样本的数据的生物信息学分析
根据本发明的癌症的一个目标组为与ICOS+免疫抑制性Treg的相对较高水平相关的那些癌症。
为了识别与Treg的高含量相关的癌症类型,从癌症基因组图谱(The CancerGenome Atlas,TCGA)公开数据集获得转录组数据并针对ICOS和FOXP3表达水平分析数据。TCGA为具有积累许多不同类型的癌症的编录基因组和转录组学数据的大规模研究,且包括突变、拷贝数变异、mRNA和miRNA基因表达和DNA甲基化以及大量的样本元数据。
基因集富集分析(Gene Set enrichment analysis,GSEA)如下进行。收集作为TCGA联合体的部分的基因表达RNA序列数据从UCSC Xena功能基因组学浏览器下载作为log2(normalized_count+1)。从数据集去除非肿瘤组织样本,留下来自9732个样本的20530个基因的数据。来自[46]的算法和其在[47]中的计算指定基因集内的基因的富集得分的实施用于将基因水平计数转置到每个样本的基因集得分。所关注的基因集限定为含有ICOS和FOXP3两者。样本通过原发疾病来分组且将每组的ssGSEA得分在33个原发疾病组内进行比较。发现显示最高中位值得分的疾病组是淋巴赘瘤弥漫性大B细胞淋巴瘤、胸腺瘤、头颈部鳞状细胞癌,尽管弥漫性大B细胞淋巴瘤显示具有高计分的子集和计分低于组中位值的剩余部分的得分的多峰分布。
在ICOS和FOXP3表达的最高到最低ssGSEA分值的排序中,前15个癌症类型为:
DLBC(n=48)淋巴赘瘤弥漫性大B细胞淋巴瘤
THYM(n=120)胸腺瘤
HNSC(n=522)头颈部鳞状细胞癌
TGCT(n=156)睾丸生殖细胞肿瘤
STAD(n=415)胃腺癌
SKCM(n=473)皮肤黑素瘤
CESC(n=305)子宫颈鳞状细胞癌和子宫颈内腺癌
LUAD(n=517)肺腺癌
LAML(n=173)急性骨髓性白血病
ESCA(n=185)食道癌
LUSC(n=502)肺鳞状细胞癌
READ(n=95)直肠腺癌
COAD(n=288)结肠腺癌
BRCA(n=1104)乳腺浸润性癌
LIHC(n=373)肝脏肝细胞癌
其中n为TCGA数据集中所述癌症类型的患者样本数量。本文中所描述的抗ICOS抗体可用于治疗这些和其它癌症。
与相对较高水平的ICOS+免疫抑制性Treg相关且进一步表达PD-L1的癌症可对用抗ICOS抗体与抗PD-L1抗体的组合治疗作出尤其良好的反应。出于此目的,恰当的治疗方案和抗体已详述于前述描述中。
使用如前所述的TCGA数据集,ICOS和FOXP3的富集得分使用斯皮尔曼排序相关性(Spearman's rank correlation)与PD-L1的表达水平有关且通过原发疾病适应症来分组。针对每个组计算出P值且将0.05的p值(用邦费罗尼多重比较修正(Bonferroni's multiplecomparison correction))视为统计显著的。。在ICOS/FOXP3与PD-L1表达之间具有最高相关性的疾病组为:
TGCT(n=156)睾丸生殖细胞肿瘤
COAD(n=288)结肠腺癌
READ(n=95)直肠腺癌
BLCA(n=407)膀胱尿道上皮癌
OV(n=308)卵巢浆液性囊腺癌
BRCA(n=1104)乳腺浸润性癌
SKCM(n=473)皮肤黑素瘤
CESC(n=305)子宫颈鳞状细胞癌和子宫颈内腺癌
STAD(n=415)胃腺癌
LUAD(n=517)肺腺癌
可根据分析将患者选用于治疗,所述分析确定患者的癌症与ICOS+免疫抑制性Treg和PD-L1的表达相关。对于癌症类型(其中如上所述存在高相关性得分),其可足够确定ICOS+免疫抑制性Treg和PD-L1表达中的一个存在(例如,高于阈值)。在此上下文中可使用PD-L1免疫组织化学分析。
实例26:评定其它抗ICOS抗体
将实例12中所识别的CL-74570和CL-61091抗体序列合成且以IgG1形式在HEK细胞中表达。
使用类似于实例6中所描述的HTRF分析进行这些抗体的功能特征化,所并进行修改以使分析适用于纯化的IgG1而不是BCT上清液。使用含有从HEK细胞表达的人类IgG1抗体的5μL上清液替代BCT上清液,且总体积使用如前所述的HTRF缓冲液达到20微升/孔。人类IgG1抗体用作阴性对照。两种抗体对于与人类和小鼠ICOS结合都呈现大于5%的效果(如使用等式1计算)且因此确认在这一分析中测试出呈阳性。
这些抗体结合在CHO-S细胞表面上表达的人类和小鼠ICOS的能力使用镜球分析(Mirrorball assay)进一步确认。在这一分析中,将含有抗ICOS IgG1的5μl上清液转移到384镜球黑色培养板(康宁)的每个孔。通过将以0.8mg/ml的浓度稀释于分析缓冲液(PBS+1%BSA+0.1%叠氮化钠)中的10μl山羊抗人类488(杰克逊免疫研究)添加到所有孔中来检测抗ICOS抗体的结合。
对于阳性对照孔,将在分析培养基中稀释到2.2μg/mL的5μL参考抗体添加到培养板中。对于阴性对照孔,将在分析培养基中稀释到2.2μg/mL的5μl杂交对照IgG1添加到培养板中。将10μM的DRAQ5(赛默飞世尔科技公司)添加到再悬浮于分析缓冲液中的0.4×106个/毫升的细胞中且将5μl添加到所有孔中。将培养板在4度下培育2小时。
使用镜球板读取器(TTP莱伯泰科(TTP Labtech))测量荧光强度,从500-700个单一细胞群中测量Alexafluor 488(激发493nm,发射519nm)。分析信号测量为中位值(FL2)平均强度。
使用在2.2μg/mL分析浓度下的参考抗体来限定总结合。使用在2.22μg/mL分析浓度下的杂交对照hIgG1限定非特异性结合。两种抗体呈现大于1%的效果且因此确认在这一分析中测试出呈阳性。

CL-74570和CL-61091中的每一个也展示与在CHO-S细胞上表达的人类和小鼠ICOS的结合,如通过流式细胞测量术所测定。使用类似于实例6中所描述的方法进行FACS筛选,并进行修改以使分析适用于纯化的IgG1而不是BCT上清液。两种抗体呈现超过与hICOS、mICOS和WT CHO细胞结合的阴性对照的几何平均值>10倍的结合。

表E26-1.CL-74570和CL 61091的功能特征化。
参考文献
1 Hutloff A等人.ICOS为与CD28结构上和功能上相关的可诱导T细胞共刺激分子(ICOS is an inducible T-cell co-stimulator structurally and functionallyrelated to CD28).《自然(Nature)》.1999年1月21日;397(6716):263-6。
2 Beier KC等人.人类ICOS的诱导、结合特异性和功能(Induction,bindingspecificity and function of human ICOS).《欧洲免疫学杂志(Eur J Immunol)》.2000年12月;30(12):3707-17。
3 Coyle AJ等人.CD28相关分子ICOS对有效T细胞依赖性免疫反应而言是必需的(The CD28-related molecule ICOS is required for effective T cell-dependentimmune responses).《免疫(Immunity)》.2000年7月;13(1):95-105。
4 Dong C等人.ICOS共刺激受体是T细胞活化和功能所必需的(ICOS co-stimulatory receptor is essential for T-cell activation and function).《自然》.2001年1月4日;409(6816):97-101。
5 Mak TW等人.通过可诱导共刺激分子配体进行共刺激是T细胞依赖性B细胞反应中T辅助细胞功能和B细胞功能都必需的(Costimulation through the induciblecostimulator ligand is essential for both T helper and B cell functions in Tcell-dependent B cell responses).《自然·免疫学(Nat Immunol)》.2003年8月;4(8):765-72。
6 Swallow MM,Wallin JJ,Sha WC.B7h(一种B7.1和B7.2的新颖共刺激同源体)由TNFα诱导(B7h,a novel costimulatory homolog of B7.1and B7.2,is induced byTNFalpha).《免疫》.1999年10月;11(4):423-32。
7 Wang S等人.通过B7-H2(一种结合ICOS的B7样分子)共刺激T细胞(Costimulation of T cells by B7-H2,a B7-like molecule that binds ICOS).《血液(Blood)》.2000年10月15日;96(8):2808-13。
8 Conrad C,Gilliet M.肿瘤微环境中的浆细胞样树突状细胞和调节性T细胞:危险的联系(Plasmacytoid dendritic cells and regulatory T cells in the tumormicroenvironment:Adangerous liaison).《肿瘤免疫学(Oncoimmunology)》.2013年5月1日;2(5):e2388。
9 Simpson等人,肿瘤浸润性调节性T细胞的Fc依赖性耗减共限定抗CTLA-4疗法对黑素瘤的功效(Fc-dependent depletion of tumor-infiltrating regulatory T cellsco-defines the efficacy of anti-CTLA-4 therapy against melanoma).《实验医学杂志(J.Exp.Med.)》.210(9):1695-1710 2013。
10 Fu T,He Q,Sharma P.ICOS/ICOSL路径对由抗CTLA-4疗法介导的最佳抗肿瘤反应而言是必需的(The ICOS/ICOSL pathway is required for optimal antitumorresponses mediated by anti-CTLA-4therapy).《癌症研究(Cancer Res.)》.2011年8月15日;71(16):5445-54。
11 Fan X,Quezada SA,Sepulveda MA,Sharma P,Allison JP.ICOS路径的结合大大增强了CTLA-4阻断在癌症免疫疗法中的功效(Engagement of the ICOS pathwaymarkedly enhances efficacy of CTLA-4 blockade in cancer immunotherapy).《实验医学杂志》.2014年4月7日;211(4):715-25。
12 Carthon,B.C.等人.手术前CTLA-4阻断:在手术前的临床试验环境中的耐受性和免疫监测(Preoperative CTLA-4blockade:Tolerability and immune monitoring inthe setting of a presurgical clinical trial).《临床癌症研究(Clin.CancerRes.)》.16:2861-2871。
13 Liakou CI等人.CTLA-4阻断增加了产生IFNγ的CD4+ICOShi细胞以改变癌症患者中效应子与调节性T细胞的比率(CTLA-4blockade increases IFNgamma-producing CD4+ICOShi cells to shift the ratio of effector to regulatory T cells in cancerpatients).《美国国家科学院院刊(Proc Natl Acad Sci U S A)》.2008年9月30日;105(39):14987-92。
14 Vonderheide,R.H.等人.2010年.在患有晚期乳癌的患者中曲美木单抗(Tremelimumab)与依西美坦(exemestane)组合且对患者T细胞上的可诱导共刺激分子表达进行与治疗相关联的调节(Tremelimumab in combination with exemestane inpatients with advanced breast cancer and treatment-associated modulation ofinducible costimulator expression on patient T cells).《临床癌症研究》.16:3485-3494。
15 Preston CC等人,CD8+ T细胞与CD4+CD25+FOXP3+和FOXP3-T细胞的比率与人类浆液卵巢癌的不良临床结果相关(The ratios of CD8+ T cells to CD4+CD25+FOXP3+and FOXP3-T cells correlate with poor clinical outcome in human serousovarian cancer).《科学公共图书馆综合卷(PLoS One)》11月14日;8(11):e80063。
16 Hodi FS等人,先前已接种疫苗的癌症患者中与细胞毒性T淋巴细胞相关联的抗原4的抗体阻断的免疫和临床效应(Immunologic and clinical effects of antibodyblockade of cytotoxic T lymphocyte-associatedantigen 4in previouslyvaccinated cancer patients).《美国国家科学院院刊(PNAS)》2008年2月26日;105(8):3005-10。
17 Chattopadhyay等人,可诱导共刺激配体功能的结构基础:细胞表面寡聚状态的确定和蛋白质受体结合位点的功能性定位(Structural Basis of InducibleCostimulatory Ligand Function:Determination of the Cell Surface OligomericState and Functional Mapping of the Receptor Binding Site of the Protein),《免疫学杂志(J.Immunol.)》177(6):3920-3929 2006。
18 Lefranc MP,免疫球蛋白和T细胞受体可变结构域和Ig超家族V状结构域的IMGT唯一编号(IMGT unique numbering for immunoglobulin and T cell receptorvariable domains and Ig superfamily V-like domains),《发展与比较免疫学(DevComp Immunol.)》27(1):55-77 2003。
19 Gül等人,“通过巨噬细胞进行的肿瘤细胞的抗体依赖性吞噬作用:癌症的单克隆抗体疗法的有效效应机制(Antibody-Dependent Phagocytosis of Tumor Cells byMacrophages:A Potent Effector Mechanism of Monoclonal Antibody Therapy ofCancer)”,《癌症研究》,75(23),2015年12月1日。
20 Lazar等人,2006,美国国家科学院院刊《(Proc.Natl.Acad.Sci.U.S.A.)》,3月14日;103(11):4005-10。
21 Dall等人,《免疫学》2002;169:5171-5180。
22 Natsume等人,2009,《药物设计、开发和治疗(Drug Des.Devel.Ther.)》,3:7-16或Zhou Q.著,《生物技术与生物工程学(Biotechnol.Bioeng.)》,2008年2月15日,99(3):652-65)。
23 Shields等人,2001,《生物化学杂志(J.Biol.Chem.)》,3月2日;276(9):6591-604)。
24 Idusogie等人,《免疫学杂志》,2001,166:2571-2575。
25 Natsume等人,2008,《癌症研究》,68:3863-3872。
26 Alexandrov LB等人,人类癌症中突变过程的标记(Signatures ofmutational processes in human cancer)。《自然》2013年8月22日;500(7463):415-21。
27 Martin-Orozco等人,黑素瘤细胞表达ICOS配体以促进T-调节性细胞的活化和扩增(Melanoma Cells Express ICOS Ligand to Promote the Activation andExpansion of T-Regulatory Cells),《癌症研究(Cancer Research)》70(23):9581-95902010。
28 Houot等人,CD137免疫调节在淋巴瘤中的治疗作用以及其通过Treg耗减进行的增强(Therapeutic effect of CD137 immunomodulation in lymphoma and itsenhancement by Treg depletion),《血液》114:3431-3438 2009
29 Baruch K.等人,PD-1免疫检查点阻断减少病变且改善阿尔茨海默病小鼠模型的记忆(PD-1immune checkpoint blockade reduces pathology and improves memoryin mouse models of Alzheimer’s disease).《自然医学(Nat Med)》22(2):137-1372016。
30 Curran等人,PD01与CTLA-4组合阻断在B16黑素瘤肿瘤内扩增浸润性T细胞且减少调节性T细胞和骨髓细胞(PD01and CTLA-4combination blockade expandsinfiltrating T cells and reduces regulatory T and myeloid cells within B16melanoma tumours),《美国国家科学院院刊》107(9):4275-4280 2010
31 Sim等人,IL-2疗法促进黑素瘤患者的抑制性ICOS+Treg扩增(IL-2therapypromotes suppressive ICOS+Treg expansion in melanoma patients),《临床研究杂志(J Clin Invest)》2014。
32 Sim等人,IL-2变体避开ICOS+调节性T细胞扩增且促进NK细胞活化(IL-2variant circumvents ICOS+regulatory T cell expansion and promotes NK cellactivation),《癌症免疫学研究(Cancer Immunol Res)》2016
33 Kroemer等人,癌症治疗中的免疫细胞死亡,《免疫学年鉴(Ann RevImmunol.)》31:51-72 2013。
34 Galluzzi,Zitvogel&Kroemer《癌症免疫学研究(Canc.Imm.Res.)》4:895-9022016。
35 Bos等人,短暂调节性T细胞消融阻止致癌基因驱动的乳癌且增强放射线疗法(Transient regulatory T cell ablation deters oncogene-driven breast cancerand enhances radiotherapy),《实验医学杂志》210(11):2434-2446 2013。
36 Sato等人,利用近红外光免疫疗法空间选择性耗减肿瘤相关的调节性T细胞(Spatially selective depletion of tumor-associated regulatory T cells withnear-infrared photoimmunotherapy),《科学转化医学(Science TranslationalMedicine)》8(352)2016。
37 Crotty S.疾病中的T滤泡辅助细胞分化、功能和作用(T follicular helpercell differentiation,function,and roles in disease).《免疫》2014年10月16日;41(4):529-42。
38 Shields等人,(2002)《生物化学杂志(JBC)》277:26733。
39 Lee等人,《自然·生物技术(Nature Biotechnology)》,32:6-363,2014。
40 Yusa K,Zhou L,Li MA,Bradley A,Craig NL.用于哺乳动物应用的活性过高的piggyBac转座酶(A hyperactive piggyBac transposase for mammalianapplications),《美国国家科学院院刊》2011年1月25日。
41 Kilpatrick等人,使用RIMMS快速产生亲和力成熟的单克隆抗体(Rapiddevelopment of affinity matured monoclonal antibodies using RIMMS);《杂交瘤(Hybridoma)》;16(4):381-9 1997年8月。
42 Simpson,T.R.等人,肿瘤浸润性调节性T细胞的Fc依赖性耗减共限定抗CTLA-4疗法对黑素瘤的功效(Fc-dependent depletion of tumor-infiltrating regulatory Tcells co-defines the efficacy of anti-CTLA-4therapy against melanoma).《实验医学杂志(The Journal of experimental medicine)》,210(9):1695-710 2013
43 Selby,M.J.等人,IgG2a同种型的抗CTLA-4抗体通过减少瘤内调节性T细胞提高抗肿瘤活性(Anti-CTLA-4antibodies of IgG2a isotype enhance antitumoractivity through reduction of intratumoral regulatory T cells).《癌症免疫学研究(Cancer immunology research)》,1(1):32-42 2013。
44 Rubio V.等人,肿瘤溶细胞性T细胞的活体外识别、分离和分析(Ex vivoidentification,isolation and analysis of tumor-cytolytic T cells).《自然医学》2003年9月;9(11):1377-82。
45 Nair和Jacob.,在动物与人类之间进行剂量转换的简单操作指南(A simplepractice guide for dose conversion between animals and human).《基础和临床药学杂志(J Basic Clin Pharma)》2016;7:27-31。
46 D.A.Barbie等人,“全身性RNA干扰揭露致癌KRAS驱动的癌症需要TBK1.(Systematic RNA interference reveals that oncogenic KRAS-driven cancersrequire TBK1.)”,《自然》,第462卷,第7269期,第108-12页,2009。
47 S. R.Castelo和J.Guinney,“GSVA:微阵列和RNA-Seq数据的基因集变化分析(GSVA:gene set variation analysis for microarray and RNA-Seq data)”,《BMC生物资讯(BMC Bioinformatics)》,第14卷,第1期,第7页,2013。
R.Castelo和J.Guinney,“GSVA:微阵列和RNA-Seq数据的基因集变化分析(GSVA:gene set variation analysis for microarray and RNA-Seq data)”,《BMC生物资讯(BMC Bioinformatics)》,第14卷,第1期,第7页,2013。
序列
抗体STIM001
VH结构域核苷酸序列:SEQ ID NO:367
CAGGTTCAGGTGGTGCAGTCTGGAGCTGAGGTGAAGAAGCCTGGGGCCTCAGTGAAGGTCTCCTGCAAGGCTTCTGGTTACACCTTTTCCACCTTTGGTATCACCTGGGTGCGACAGGCCCCTGGACAAGGGCTTGAATGGATGGGATGGATCAGCGCTTACAATGGTGACACAAACTATGCACAGAATCTCCAGGGCAGAGTCATCATGACCACAGACACATCCACGAGCACAGCCTACATGGAGCTGAGGAGCCTGAGATCTGACGACACGGCCGTTTATTACTGTGCGAGGAGCAGTGGCCACTACTACTACTACGGTATGGACGTCTGGGGCCAAGGGACCACGGTCACCGTCTCCTCA
VH结构域氨基酸序列:SEQ ID NO:366
QVQVVQSGAEVKKPGASVKVSCKASGYTFSTFGITWVRQAPGQGLEWMGWISAYNGDTNYAQNLQGRVIMTTDTSTSTAYMELRSLRSDDTAVYYCARSSGHYYYYGMDVWGQGTTVTVSS
VH CDR1氨基酸序列:GYTFSTFG SEQ ID NO:363
VH CDR2氨基酸序列:ISAYNGDT SEQ ID NO:364
VH CDR3氨基酸序列:ARSSGHYYYYGMDV SEQ ID NO:365
VL结构域核苷酸序列:SEQ ID NO:374
GATATTGTGATGACTCAGTCTCCACTCTCCCTGCCCGTCACCCCTGGAGAGCCGGCCTCCATCTCCTGCAGGTCTAGTCAGAGCCTCCTGCATAGTAATGAATACAACTATTTGGATTGGTACCTGCAGAAGCCAGGGCAGTCTCCACAGCTCCTGATCTTTTTGGGTTCTAATCGGGCCTCCGGGGTCCCTGACAGGTTCAGTGGCAGTGGATCAGGCACAGATTTTACACTGAAAATCACCAGAGTGGAGGCTGAGGATGTTGGAATTTATTACTGCATGCAATCTCTACAAACTCCGCTCACTTTCGGCGGAGGGACCAAGGTGGAGATCAAA
VL结构域氨基酸序列:SEQ ID NO:373
DIVMTQSPLSLPVTPGEPASISCRSSQSLLHSNEYNYLDWYLQKPGQSPQLLIFLGSNRASGVPDRFSGSGSGTDFTLKITRVEAEDVGIYYCMQSLQTPLTFGGGTKVEIK
VL CDR1氨基酸序列:QSLLHSNEYNY SEQ ID NO:370
VL CDR2氨基酸序列:LGS SEQ ID NO:371
VL CDR3氨基酸序列:MQSLQTPLT SEQ ID NO:372
抗体STIM002
VH结构域核苷酸序列:SEQ ID NO:381
CAGGTTCAACTGGTGCAGTCTGGAGGTGAGGTGAAGAAGCCTGGGGCCTCAGTGAAGGTCTCCTGCAAGGCTTCTGGTTACACCTTTACCAGCTATGGTTTCAGCTGGGTGCGACAGGCCCCTGGACAAGGACTAGAGTGGATGGGATGGATCAGCGCTTACAATGGTAACACAAACTATGCACAGAAGCTCCAGGGCAGAGTCACCATGACCACAGACACATCCACGAGCACAGCCTACATGGAGCTGAGGAGCTTGAGATCTGACGACACGGCCGTGTATTACTGTGCGAGATCTACGTATTTCTATGGTTCGGGGACCCTCTACGGTATGGACGTCTGGGGCCAAGGGACCACGGTCACCGTCTCCTCA
VH结构域氨基酸序列:SEQ ID NO:380
QVQLVQSGGEVKKPGASVKVSCKASGYTFTSYGFSWVRQAPGQGLEWMGWISAYNGNTNYAQKLQGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSTYFYGSGTLYGMDVWGQGTTVTVSS
VH CDR1氨基酸序列:GYTFTSYG SEQ ID NO:377
VH CDR2氨基酸序列:ISAYNGNT SEQ ID NO:378
VH CDR3氨基酸序列:ARSTYFYGSGTLYGMDV SEQ ID NO:379
VL结构域核苷酸序列:388
GATATTGTGATGACTCAGTCTCCACTCTCCCTGCCCGTCACCCCTGGAGAGCCGGCCTCCATCTCCTGCAGGTCTAGTCAGAGCCTCCTGCATAGTGATGGATACAACTGTTTGGATTGGTACCTGCAGAAGCCAGGGCAGTCTCCACAGCTCCTGATCTATTTGGGTTCTACTCGGGCCTCCGGGTTCCCTGACAGGTTCAGTGGCAGTGGATCAGGCACAGATTTTACACTGAAAATCAGCAGAGTGGAGGCTGAGGATGTTGGGGTTTATTACTGCATGCAAGCTCTACAAACTCCGTGCAGTTTTGGCCAGGGGACCAAGCTGGAGATCAAA
经校正的STIM002 VL结构域核苷酸序列:SEQ ID NO:519
GATATTGTGATGACTCAGTCTCCACTCTCCCTGCCCGTCACCCCTGGAGAGCCGGCCTCCATCTCCTGCAGGTCTAGTCAGAGCCTCCTGCATAGTGATGGATACAACTATTTGGATTGGTACCTGCAGAAGCCAGGGCAGTCTCCACAGCTCCTGATCTATTTGGGTTCTACTCGGGCCTCCGGGTTCCCTGACAGGTTCAGTGGCAGTGGATCAGGCACAGATTTTACACTGAAAATCAGCAGAGTGGAGGCTGAGGATGTTGGGGTTTATTACTGCATGCAAGCTCTACAAACTCCGCTCAGTTTTGGCCAGGGGACCAAGCTGGAGATCAAA
VL结构域氨基酸序列:SEQ ID NO:387
DIVMTQSPLSLPVTPGEPASISCRSSQSLLHSDGYNYLDWYLQKPGQSPQLLIYLGSTRASGFPDRFSGSGSGTDFTLKISRVEAEDVGVYYCMQALQTPLSFGQGTKLEIK
VL CDR1氨基酸序列:QSLLHSDGYNY SEQ ID NO:384
VL CDR2氨基酸序列:LGS SEQ ID NO:385
VL CDR3氨基酸序列:MQALQTPLS SEQ ID NO:386
抗体STIM002-B
VH结构域核苷酸序列:SEQ ID NO:395
CAGGTTCAACTGGTGCAGTCTGGAGGTGAGGTGAAGAAGCCTGGGGCCTCAGTGAAGGTCTCCTGCAAGGCTTCTGGTTACACCTTTACCAGCTATGGTTTCAGCTGGGTGCGACAGGCCCCTGGACAAGGACTAGAGTGGATGGGATGGATCAGCGCTTACAATGGTAACACAAACTATGCACAGAAGCTCCAGGGCAGAGTCACCATGACCACAGACACATCCACGAGCACAGCCTACATGGAGCTGAGGAGCTTGAGATCTGACGACACGGCCGTGTATTACTGTGCGAGATCTACGTATTTCTATGGTTCGGGGACCCTCTACGGTATGGACGTCTGGGGCCAAGGGACCACGGTCACCGTCTCCTCA
VH结构域氨基酸序列:SEQ ID NO:394
QVQLVQSGGEVKKPGASVKVSCKASGYTFTSYGFSWVRQAPGQGLEWMGWISAYNGNTNYAQKLQGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSTYFYGSGTLYGMDVWGQGTTVTVSS
VH CDR1氨基酸序列:GYTFTSYG SEQ ID NO:391
VH CDR2氨基酸序列:ISAYNGNT SEQ ID NO:392
VH CDR3氨基酸序列:ARSTYFYGSGTLYGMDV SEQ ID NO:393
VL结构域核苷酸序列:SEQ ID NO:402
GATATTGTGATGACTCAGTCTCCACTCTCCCTGCCCGTCACCCCTGGAGAGCCGGCCTCCATCTCCTGCAGGTCTAGTCAGAGCCTCCTGCATAGTGATGGATACAACTGTTTGGATTGGTACCTGCAGAAGCCAGGGCAGTCTCCACAGCTCCTGATCTATTTGGGTTCTACTCGGGCCTCCGGGTTCCCTGACAGGTTCAGTGGCAGTGGATCAGGCACAGATTTTACACTGAAAATCAGCAGAGTGGAGGCTGAGGATGTTGGGGTTTATTACTGCATGCAAGCTCTACAAACTCCGTGCAGTTTTGGCCAGGGGACCAAGCTGGAGATCAAA
VL结构域氨基酸序列:SEQ ID NO:401
DIVMTQSPLSLPVTPGEPASISCRSSQSLLHSDGYNCLDWYLQKPGQSPQLLIYLGSTRASGFPDRFSGSGSGTDFTLKISRVEAEDVGVYYCMQALQTPCSFGQGTKLEIK
VL CDR1氨基酸序列:QSLLHSDGYNC SEQ ID NO:398
VL CDR2氨基酸序列:LGS SEQ ID NO:399
VL CDR3氨基酸序列:MQALQTPCS SEQ ID NO:400
抗体STIM003
VH结构域核苷酸序列:SEQ ID NO:409
GAGGTGCAGCTGGTGGAGTCTGGGGGAGGTGTGGTACGGCCTGGGGGGTCCCTGAGACTCTCCTGTGTAGCCTCTGGAGTCACCTTTGATGATTATGGCATGAGCTGGGTCCGCCAAGCTCCAGGGAAGGGGCTGGARTGGGTCTCTGGTATTAATTGGAATGGTGGCGACACAGATTATTCAGACTCTGTGAAGGGCCGATTCACCATCTCCAGAGACAACGCCAAGAACTCCCTGTATCTACAAATGAATAGTCTGAGAGCCGAGGACACGGCCTTGTATTACTGTGCGAGGGATTTCTATGGTTCGGGGAGTTATTATCACGTTCCTTTTGACTACTGGGGCCAGGGAATCCTGGTCACCGTCTCCTCA
经校正的STIM003 VH结构域核苷酸序列:SEQ ID NO:521
GAGGTGCAGCTGGTGGAGTCTGGGGGAGGTGTGGTACGGCCTGGGGGGTCCCTGAGACTCTCCTGTGTAGCCTCTGGAGTCACCTTTGATGATTATGGCATGAGCTGGGTCCGCCAAGCTCCAGGGAAGGGGCTGGAGTGGGTCTCTGGTATTAATTGGAATGGTGGCGACACAGATTATTCAGACTCTGTGAAGGGCCGATTCACCATCTCCAGAGACAACGCCAAGAACTCCCTGTATCTACAAATGAATAGTCTGAGAGCCGAGGACACGGCCTTGTATTACTGTGCGAGGGATTTCTATGGTTCGGGGAGTTATTATCACGTTCCTTTTGACTACTGGGGCCAGGGAATCCTGGTCACCGTCTCCTCA
VH结构域氨基酸序列:SEQ ID NO:408
EVQLVESGGGVVRPGGSLRLSCVASGVTFDDYGMSWVRQAPGKGLEWVSGINWNGGDTDYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTALYYCARDFYGSGSYYHVPFDYWGQGILVTVSS
VH CDR1氨基酸序列:GVTFDDYG SEQ ID NO:405
VH CDR2氨基酸序列:INWNGGDT SEQ ID NO:406
VH CDR3氨基酸序列:ARDFYGSGSYYHVPFDY SEQ ID NO:407
VL结构域核苷酸序列:SEQ ID NO:416
GAAATTGTGTTGACGCAGTCTCCAGGGACCCTGTCTTTGTCTCCAGGGGAAAGAGCCACCCTCTCCTGCAGGGCCAGTCAGAGTGTTAGCAGAAGCTACTTAGCCTGGTACCAGCAGAAACGTGGCCAGGCTCCCAGGCTCCTCATCTATGGTGCATCCAGCAGGGCCACTGGCATCCCAGACAGGTTCAGTGGCGATGGGTCTGGGACAGACTTCACTCTCTCCATCAGCAGACTGGAGCCTGAAGATTTTGCAGTGTATTACTGTCACCAGTATGATATGTCACCATTCACTTTCGGCCCTGGGACCAAAGTGGATATCAAA
VL结构域氨基酸序列:SEQ ID NO:415
EIVLTQSPGTLSLSPGERATLSCRASQSVSRSYLAWYQQKRGQAPRLLIYGASSRATGIPDRFSGDGSGTDFTLSISRLEPEDFAVYYCHQYDMSPFTFGPGTKVDIK
VL CDR1氨基酸序列:QSVSRSY SEQ ID NO:412
VL CDR2氨基酸序列:GAS SEQ ID NO:413
VL CDR3氨基酸序列:HQYDMSPFT SEQ ID NO:414
抗体STIM004
VH结构域核苷酸序列:
GAGGTGCAGCTGGTGGAGTCTGGGGGAGGTGTGGTACGGCCTGGGGGGTCCCTGAGACTCTCCTGTGCAGCCTCTGGACTCACCTTTGATGATTATGGCATGAGCTGGGTCCGCCAAGTTCCAGGGAAGGGGCTGGAGTGGGTCTCTGGTATTAATTGGAATGGTGATAACACAGATTATGCAGACTCTGTGAAGGGCCGATTCACCATCTCCAGAGACAACGCCAAGAACTCCCTGTATCTGCAAATGAACAGTCTGAGAGCCGAGGACACGGCCTTGTATTACTGTGCGAGGGATTACTATGGTTCGGGGAGTTATTATAACGTTCCTTTTGACTACTGGGGCCAGGGAACCCTGGTCACCGTCTCCTCASEQ ID NO:423
VH结构域氨基酸序列:
EVQLVESGGGVVRPGGSLRLSCAASGLTFDDYGMSWVRQVPGKGLEWVSGINWNGDNTDYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTALYYCARDYYGSGSYYNVPFDYWGQGTLVTVSS SEQ ID NO:422
VH CDR1氨基酸序列:GLTFDDYG SEQ ID NO:419
VH CDR2氨基酸序列:INWNGDNT SEQ ID NO:420
VH CDR3氨基酸序列:ARDYYGSGSYYNVPFDY SEQ ID NO:421
VL结构域核苷酸序列:SEQ ID NO:431
GAAATTGTGTTGACGCAGTCTCCAGGCACCCTGTCTTTGTCTCCAGGGGAAAGAGCCACCCTCTCCTGCAGGGCCAGTCAGAGTGTTAGCAGCAGCTACTTAGCCTGGTACCAGCAGAAACCTGGCCAGGCTCCCAGGCTCCTCATATATGGTGCATCCAGCAGGGCCACTGGCATCCCAGACAGGTTCAGTGGCAGTGGGTCTGGGACAGACTTCACTCTCACCATCAGAAGACTGGAGCCTGAAGATTTTGCAGTGTATTACTGTCAGCAGTATGGTAGTTCACCATTCACTTCGGCCCTGGGACCAAAGTGGATATCAAA
如由以上VL结构域核苷酸序列编码的VL结构域氨基酸序列。
经校正的VL结构域核苷酸序列:SEQ ID NO:430
GAAATTGTGTTGACGCAGTCTCCAGGCACCCTGTCTTTGTCTCCAGGGGAAAGAGCCACCCTCTCCTGCAGGGCCAGTCAGAGTGTTAGCAGCAGCTACTTAGCCTGGTACCAGCAGAAACCTGGCCAGGCTCCCAGGCTCCTCATATATGGTGCATCCAGCAGGGCCACTGGCATCCCAGACAGGTTCAGTGGCAGTGGGTCTGGGACAGACTTCACTCTCACCATCAGAAGACTGGAGCCTGAAGATTTTGCAGTGTATTACTGTCAGCAGTATGGTAGTTCACCATTCTTCGGCCCTGGGACCAAAGTGGATATCAAA
经校正的VL结构域氨基酸序列:SEQ ID NO:432
EIVLTQSPGTLSLSPGERATLSCRASQSVSSSYLAWYQQKPGQAPRLLIYGASSRATGIPDRFSGSGSGTDFTLTIRRLEPEDFAVYYCQQYGSSPFFGPGTKVDIK
VL CDR1氨基酸序列:QSVSSSY SEQ ID NO:426
VL CDR2氨基酸序列:GAS SEQ ID NO:427
VL CDR3氨基酸序列:QQYGSSPF SEQ ID NO:428
抗体STIM005
VH结构域核苷酸序列:SEQ ID NO:439
CAGGTTCAGTTGGTGCAGTCTGGAGCTGAGGTGAAGAAGCCTGGGGCCTCAGTGAAGGTCTCCTGCAAGGCTTCTGGTTACACCTTTAATAGTTATGGTATCATCTGGGTGCGACAGGCCCCTGGACAAGGGCTTGAGTGGATGGGATGGATCAGCGTTCACAATGGTAACACAAACTGTGCACAGAAGCTCCAGGGTAGAGTCACCATGACCACAGACACATCCACGAGCACAGCCTACATGGAGCTGAGGAGCCTGAGAACTGACGACACGGCCGTGTATTACTGTGCGAGAGCGGGTTACGATATTTTGACTGATTTTTCCGATGCTTTTGATATCTGGGGCCACGGGACAATGGTCACCGTCTCTTCA
VH结构域氨基酸序列:SEQ ID NO:438
QVQLVQSGAEVKKPGASVKVSCKASGYTFNSYGIIWVRQAPGQGLEWMGWISVHNGNTNCAQKLQGRVTMTTDTSTSTAYMELRSLRTDDTAVYYCARAGYDILTDFSDAFDIWGHGTMVTVSS
VH CDR1氨基酸序列:GYTFNSYG SEQ ID NO:435
VH CDR2氨基酸序列:ISVHNGNT SEQ ID NO:436
VH CDR3氨基酸序列:ARAGYDILTDFSDAFDI SEQ ID NO:437
VL结构域核苷酸序列:SEQ ID NO:446
GACATCCAGATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGACAGAGTCACCATCACTTGCCGGGCAAGTCAGAACATTAATAACTTTTTAAATTGGTATCAGCAGAAAGAAGGGAAAGGCCCTAAGCTCCTGATCTATGCAGCATCCAGTTTGCAAAGAGGGATACCATCAACGTTCAGTGGCAGTGGATCTGGGACAGACTTCACTCTCACCATCAGCAGTCTGCAACCTGAAGATTTTGCAACTTACATCTGTCAACAGAGCTACGGTATCCCGTGGGTCGGCCAAGGGACCAAGGTGGAAATCAAA
VL结构域氨基酸序列:SEQ ID NO:445
DIQMTQSPSSLSASVGDRVTITCRASQNINNFLNWYQQKEGKGPKLLIYAASSLQRGIPSTFSGSGSGTDFTLTISSLQPEDFATYICQQSYGIPWVGQGTKVEIK
VL CDR1氨基酸序列:QNINNF SEQ ID NO:442
VL CDR2氨基酸序列:AAS SEQ ID NO:443
VL CDR3氨基酸序列:QQSYGIPW SEQ ID NO:444
抗体STIM006
VH结构域核苷酸序列:SEQ ID NO:453
CAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCAAGCCTGGAGGGTCCCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCTTCAGTGACTACTTCATGAGCTGGATCCGCCAGGCGCCAGGGAAGGGGCTGGAGTGGATTTCATACATTAGTTCTAGTGGTAGTACCATATACTACGCAGACTCTGTGAGGGGCCGATTCACCATCTCCAGGGACAACGCCAAGTACTCACTGTATCTGCAAATGAACAGCCTGAGATCCGAGGACACGGCCGTGTATTACTGTGCGAGAGATCACTACGATGGTTCGGGGATTTATCCCCTCTACTACTATTACGGTTTGGACGTCTGGGGCCAGGGGACCACGGTCACCGTCTCCTCA
VH结构域氨基酸序列:SEQ ID NO:454
QVQLVESGGGLVKPGGSLRLSCAASGFTFSDYFMSWIRQAPGKGLEWISYISSSGSTIYYADSVRGRFTISRDNAKYSLYLQMNSLRSEDTAVYYCARDHYDGSGIYPLYYYYGLDVWGQGTTVTVSS
VH CDR1氨基酸序列:GFTFSDYF SEQ ID NO:449
VH CDR2氨基酸序列:ISSSGSTI SEQ ID NO:450
VH CDR3氨基酸序列:ARDHYDGSGIYPLYYYYGLDV SEQ ID NO:451
VL结构域核苷酸序列:SEQ ID NO:460
ATTGTGATGACTCAGTCTCCACTCTCCCTACCCGTCACCCCTGGAGAGCCGGCCTCCATCTCCTGCAGGTCTAGTCAGAGCCTCCTGCATAGTAATGGATACAACTATTTGGATTATTACCTGCAGAAGCCAGGGCAGTCTCCACAGCTCCTGATCTATTTGGGTTCTTATCGGGCCTCCGGGGTCCCTGACAGGTTCAGTGGCAGTGGATCAGGCACAGATTTTACACTGAAAATCAGCAGAGTGGAGGCTGAGGATGTTGGGGTTTATTACTGCATGCAAGCTCTACAAACTCCTCGCAGTTTTGGCCAGGGGACCACGCTGGAGATCAAA
VL结构域氨基酸序列:SEQ ID NO:459
IVMTQSPLSLPVTPGEPASISCRSSQSLLHSNGYNYLDYYLQKPGQSPQLLIYLGSYRASGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCMQALQTPRSFGQGTTLEIK
VL CDR1氨基酸序列:QSLLHSNGYNY SEQ ID NO:456
VL CDR2氨基酸序列:LGS SEQ ID NO:457
VL CDR3氨基酸序列:MQALQTPRS SEQ ID NO:458
抗体STIM007
VH结构域核苷酸序列:SEQ ID NO:467
CAGATCACCTTGAAGGAGTCTGGTCCTACGCTGGTGAAACCCACACAGACCCTCACGCTGACCTGCACCTTCTCTGGGTTCTCACTCAGCACTACTGGAGTGGGTGTGGGCTGGATCCGTCAGCCCCCAGGAAAGGCCCTGGAGTGGCTTGCAGTCATTTATTGGGATGATGATAAGCGCTACAGCCCATCTCTGAAGAGCAGACTCACCATCACCAAGGACACCTCCAAAAACCAGGTGGTCCTTACAATGACCAACATGGACCCTGTGGACACAGCCACATATTTCTGTACACACGGATATGGTTCGGCGAGTTATTACCACTACGGTATGGACGTCTGGGGCCAAGGGACCACGGTCACCGTCTCCTCA
VH结构域氨基酸序列:SEQ ID NO:466
QITLKESGPTLVKPTQTLTLTCTFSGFSLSTTGVGVGWIRQPPGKALEWLAVIYWDDDKRYSPSLKSRLTITKDTSKNQVVLTMTNMDPVDTATYFCTHGYGSASYYHYGMDVWGQGTTVTVSS
VH CDR1氨基酸序列:GFSLSTTGVG SEQ ID NO:463
VH CDR2氨基酸序列:IYWDDDK SEQ ID NO:464
VH CDR3氨基酸序列:THGYGSASYYHYGMDV SEQ ID NO:465
VL结构域核苷酸序列:SEQ ID NO:474
GAAATTGTATTGACACAGTCTCCAGCCACCCTGTCTTTGTCTCCAGGGGAAAGAGCCACCCTCTCCTGCAGGGCCAGTCAGAGTGTTACCAACTACTTAGCCTGGCACCAACAGAAACCTGGCCAGGCTCCCAGGCTCCTCATCTATGATGCATCCAACAGGGCCACTGGCATCCCAGCCAGGTTCAGTGGCAGTGGGTCTGGGACAGACTTCACTCTCACCATCAGCAGCCTAGAGCCTGAAGATTTTGCAGTTTATTACTGTCAGCACCGTAGCAACTGGCCTCTCACTTTCGGCGGAGGGACCAAGGTGGAGATCAAAC
VL结构域氨基酸序列:SEQ ID NO:473
EIVLTQSPATLSLSPGERATLSCRASQSVTNYLAWHQQKPGQAPRLLIYDASNRATGIPARFSGSGSGTDFTLTISSLEPEDFAVYYCQHRSNWPLTFGGGTKVEIK
VL CDR1氨基酸序列:QSVTNY SEQ ID NO:470
VL CDR2氨基酸序列:DAS SEQ ID NO:471
VL CDR3氨基酸序列:QHRSNWPLT SEQ ID NO:472
抗体STIM008
VH结构域核苷酸序列:SEQ ID NO:481
CAGATCACCTTGAAGGAGTCTGGTCCTACGCTGGTGAAACCCACACAGACCCTCACGCTGACCTGCACCTTCTCTGGGTTCTCACTCAGCACTAGTGGAGTGGGTGTGGGCTGGATCCGTCAGCCCCCAGGAAAGGCCCTGGAGTGGCTTGCAGTCATTTATTGGGATGATGATAAGCGCTACAGCCCATCTCTGAAGAGCAGGCTCACCATCACCAAGGACACCTCCAAAAACCAGGTGGTCCTTACAATGACCAACATGGACCCTGTGGACACAGCCACATATTTCTGTACACACGGATATGGTTCGGCGAGTTATTACCACTACGGTATGGACGTCTGGGGCCAAGGGACCACGGTCACCGTCTCCTCA
VH结构域氨基酸序列:SEQ ID NO:480
QITLKESGPTLVKPTQTLTLTCTFSGFSLSTSGVGVGWIRQPPGKALEWLAVIYWDDDKRYSPSLKSRLTITKDTSKNQVVLTMTNMDPVDTATYFCTHGYGSASYYHYGMDVWGQGTTVTVSS
VH CDR1氨基酸序列:GFSLSTSGVG SEQ ID NO:477
VH CDR2氨基酸序列:IYWDDDK SEQ ID NO:478
VH CDR3氨基酸序列:THGYGSASYYHYGMDV SEQ ID NO:479
VL结构域核苷酸序列:SEQ ID NO:488
GAAATTGTGTTGACACAGTCTCCAGCCACCCTGTCTTTGTCTCCAGGGGAAAGAGCCACCCTCTCCTGCAGGGCCAGTCAGAGTGTTACCAACTACTTAGCCTGGCACCAACAGAAACCTGGCCAGGCTCCCAGGCTCCTCATCTATGATGCATCCAACAGGGCCACTGGCATCCCAGCCAGGTTCAGTGGCAGTGGGTCTGGGACAGACTTCACTCTCACCATCAGCAGCCTAGAGCCTGAAGATTTTGCAGTTTATTACTGTCAGCAGCGTAGCAACTGGCCTCTCACTTTCGGCGGAGGGACCAAGGTGGAGATCAAA
VL结构域氨基酸序列:SEQ ID NO:489
EIVLTQSPATLSLSPGERATLSCRASQSVTNYLAWHQQKPGQAPRLLIYDASNRATGIPARFSGSGSGTDFTLTISSLEPEDFAVYYCQQRSNWPLTFGGGTKVEIK
VL CDR1氨基酸序列:QSVTNY SEQ ID NO:484
VL CDR2氨基酸序列:DAS SEQ ID NO:485
VL CDR3氨基酸序列:QQRSNWPLT SEQ ID NO:486
抗体STIM009
VH结构域核苷酸序列:SEQ ID NO:495
CAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCAAGCCTGGAGGGTCCCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCTTCAGTGACTACTACATGAGCTGGATCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGGTTTCATACATTAGTAGTAGTGGTAGTACCATATACTACGCAGACTCTGTGAAGGGCCGATTCACCATCTCCAGGGACAACGCCAAGAACTCACTGTATCTGCAAATTAACAGCCTGAGAGCCGAGGACACGGCCGTGTATTACTGTGCGAGAGATTTTTACGATATTTTGACTGATAGTCCGTACTTCTACTACGGTGTGGACGTCTGGGGCCAAGGGACCACGGTCACCGTCTCCTCA
VH结构域氨基酸序列:SEQ ID NO:494
QVQLVESGGGLVKPGGSLRLSCAASGFTFSDYYMSWIRQAPGKGLEWVSYISSSGSTIYYADSVKGRFTISRDNAKNSLYLQINSLRAEDTAVYYCARDFYDILTDSPYFYYGVDVWGQGTTVTVSS
VH CDR1氨基酸序列:GFTFSDYY SEQ ID NO:491
VH CDR2氨基酸序列:ISSSGSTI SEQ ID NO:492
VH CDR3氨基酸序列:ARDFYDILTDSPYFYYGVDV SEQ ID NO:493
VL结构域核苷酸序列:SEQ ID NO:502
GATATTGTGATGACTCAGTCTCCACTCTCCCTGCCCGTCACCCCTGGAGAGCCGGCCTCCATCTCCTGCAGGTCTAGTCAGAGCCTCCTGCATAGTAATGGATACAACTATTTGGATTGGTACCTGCAGAAGCCAGGGCAGTCTCCACAGCTCCTGATCTATTTGGGTTCTAATCGGGCCTCCGGGGTCCCTGACAGGTTCAGTGGCAGTGGATCAGGCACAGATTTTACACTGAAAATCAGCAGAGTGGAGGCTGAGGATGTTGGGGTTTATTACTGCATGCAAGCTCTACAAACTCCTCGGACGTTCGGCCAAGGGACCAAGGTGGAAATCAAA
VL结构域氨基酸序列:SEQ ID NO:501
DIVMTQSPLSLPVTPGEPASISCRSSQSLLHSNGYNYLDWYLQKPGQSPQLLIYLGSNRASGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCMQALQTPRTFGQGTKVEIK
VL CDR1氨基酸序列:QSLLHSNGYNY SEQ ID NO:498
VL CDR2氨基酸序列:LGS SEQ ID NO:499
VL CDR3氨基酸序列:MQALQTPRT SEQ ID NO:500
表S1.SEQ ID NOS:1-342

















































表S2.SEQ ID NOS:343-538

































表S3.SEQ ID NOS:539-562





表S4:从额外克隆系获得的抗体重链可变区的序列
根据IMGT限定CDR。




表S5:从额外克隆系获得的抗体轻链可变区的序列
CL-71642中的N端E和5'核苷酸添加以粗体显示。与如图36中所示的相关克隆系相比,这些添加在测序时不恢复但测定为存在于序列中。根据IMGT限定CDR。




SEQUENCE LISTING
<110> 科马布有限公司
<120> 抗ICOS抗体
<130> P54679KST
<150> GB1613683.0
<151> 2016-08-09
<150> GB1615224.1
<151> 2016-09-07
<150> GB1615335.5
<151> 2016-09-09
<150> US15/354,971
<151> 2016-11-17
<150> GB1620414.1
<151> 2016-12-01
<150> GB1621782.0
<151> 2016-12-20
<150> GB1702338.3
<151> 2017-02-13
<150> GB1702339.1
<151> 2017-02-13
<150> GB1703071.9
<151> 2017-02-24
<150> US15/480,525
<151> 2017-04-06
<150> GB1709818.7
<151> 2017-06-20
<150> PCT/GB2017/051794
<151> 2017-06-27
<150> TW106120563
<151> 2017-06-27
<150> PCT/GB2017/051795
<151> 2017-06-27
<150> TW106120562
<151> 2017-06-27
<150> PCT/GB2017/051796
<151> 2017-06-27
<150> TW106120564
<151> 2017-06-27
<160> 610
<170> PatentIn version 3.5
<210> 1
<211> 290
<212> PRT
<213> Homo Sapiens
<400> 1
Met Arg Ile Phe Ala Val Phe Ile Phe Met Thr Tyr Trp His Leu Leu
1 5 10 15
Asn Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr
20 25 30
Gly Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu
35 40 45
Asp Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile
50 55 60
Ile Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser
65 70 75 80
Tyr Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn
85 90 95
Ala Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr
100 105 110
Arg Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val
115 120 125
Lys Val Asn Ala Pro Tyr Asn Lys Ile Asn Gln Arg Ile Leu Val Val
130 135 140
Asp Pro Val Thr Ser Glu His Glu Leu Thr Cys Gln Ala Glu Gly Tyr
145 150 155 160
Pro Lys Ala Glu Val Ile Trp Thr Ser Ser Asp His Gln Val Leu Ser
165 170 175
Gly Lys Thr Thr Thr Thr Asn Ser Lys Arg Glu Glu Lys Leu Phe Asn
180 185 190
Val Thr Ser Thr Leu Arg Ile Asn Thr Thr Thr Asn Glu Ile Phe Tyr
195 200 205
Cys Thr Phe Arg Arg Leu Asp Pro Glu Glu Asn His Thr Ala Glu Leu
210 215 220
Val Ile Pro Glu Leu Pro Leu Ala His Pro Pro Asn Glu Arg Thr His
225 230 235 240
Leu Val Ile Leu Gly Ala Ile Leu Leu Cys Leu Gly Val Ala Leu Thr
245 250 255
Phe Ile Phe Arg Leu Arg Lys Gly Arg Met Met Asp Val Lys Lys Cys
260 265 270
Gly Ile Gln Asp Thr Asn Ser Lys Lys Gln Ser Asp Thr His Leu Glu
275 280 285
Glu Thr
290
<210> 2
<211> 241
<212> PRT
<213> Cynomologus
<400> 2
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Met Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val
20 25 30
Glu Tyr Gly Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys
35 40 45
Gln Leu Asp Leu Thr Ser Leu Ile Val Tyr Trp Glu Met Glu Asp Lys
50 55 60
Asn Ile Ile Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His
65 70 75 80
Ser Asn Tyr Arg Gln Arg Ala Gln Leu Leu Lys Asp Gln Leu Ser Leu
85 90 95
Gly Asn Ala Ala Leu Arg Ile Thr Asp Val Lys Leu Gln Asp Ala Gly
100 105 110
Val Tyr Arg Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile
115 120 125
Thr Val Lys Val Asn Ala Pro Tyr Asn Lys Ile Asn Gln Arg Ile Leu
130 135 140
Val Val Asp Pro Val Thr Ser Glu His Glu Leu Thr Cys Gln Ala Glu
145 150 155 160
Gly Tyr Pro Lys Ala Glu Val Ile Trp Thr Ser Ser Asp His Gln Val
165 170 175
Leu Ser Gly Lys Thr Thr Thr Thr Asn Ser Lys Arg Glu Glu Lys Leu
180 185 190
Leu Asn Val Thr Ser Thr Leu Arg Ile Asn Thr Thr Ala Asn Glu Ile
195 200 205
Phe Tyr Cys Ile Phe Arg Arg Leu Asp Pro Glu Glu Asn His Thr Ala
210 215 220
Glu Leu Val Ile Pro Glu Leu Pro Leu Ala Leu Pro Pro Asn Glu Arg
225 230 235 240
Thr
<210> 3
<211> 245
<212> PRT
<213> Homo Sapiens
<400> 3
Met Arg Ile Phe Ala Val Phe Ile Phe Met Thr Tyr Trp His Leu Leu
1 5 10 15
Asn Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr
20 25 30
Gly Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu
35 40 45
Asp Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile
50 55 60
Ile Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser
65 70 75 80
Tyr Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn
85 90 95
Ala Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr
100 105 110
Arg Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val
115 120 125
Lys Val Asn Ala Pro Tyr Asn Lys Ile Asn Gln Arg Ile Leu Val Val
130 135 140
Asp Pro Val Thr Ser Glu His Glu Leu Thr Cys Gln Ala Glu Gly Tyr
145 150 155 160
Pro Lys Ala Glu Val Ile Trp Thr Ser Ser Asp His Gln Val Leu Ser
165 170 175
Gly Lys Thr Thr Thr Thr Asn Ser Lys Arg Glu Glu Lys Leu Phe Asn
180 185 190
Val Thr Ser Thr Leu Arg Ile Asn Thr Thr Thr Asn Glu Ile Phe Tyr
195 200 205
Cys Thr Phe Arg Arg Leu Asp Pro Glu Glu Asn His Thr Ala Glu Leu
210 215 220
Val Ile Pro Glu Leu Pro Leu Ala His Pro Pro Asn Glu Arg Thr His
225 230 235 240
His His His His His
245
<210> 4
<211> 475
<212> PRT
<213> Homo Sapiens
<400> 4
Met Arg Ile Phe Ala Val Phe Ile Phe Met Thr Tyr Trp His Leu Leu
1 5 10 15
Asn Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr
20 25 30
Gly Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu
35 40 45
Asp Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile
50 55 60
Ile Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser
65 70 75 80
Tyr Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn
85 90 95
Ala Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr
100 105 110
Arg Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val
115 120 125
Lys Val Asn Ala Pro Tyr Asn Lys Ile Asn Gln Arg Ile Leu Val Val
130 135 140
Asp Pro Val Thr Ser Glu His Glu Leu Thr Cys Gln Ala Glu Gly Tyr
145 150 155 160
Pro Lys Ala Glu Val Ile Trp Thr Ser Ser Asp His Gln Val Leu Ser
165 170 175
Gly Lys Thr Thr Thr Thr Asn Ser Lys Arg Glu Glu Lys Leu Phe Asn
180 185 190
Val Thr Ser Thr Leu Arg Ile Asn Thr Thr Thr Asn Glu Ile Phe Tyr
195 200 205
Cys Thr Phe Arg Arg Leu Asp Pro Glu Glu Asn His Thr Ala Glu Leu
210 215 220
Val Ile Pro Glu Leu Pro Leu Ala His Pro Pro Asn Glu Arg Thr Ile
225 230 235 240
Glu Gly Arg Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
245 250 255
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
260 265 270
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
275 280 285
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
290 295 300
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
305 310 315 320
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
325 330 335
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
340 345 350
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
355 360 365
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
370 375 380
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
385 390 395 400
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
405 410 415
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
420 425 430
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
435 440 445
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
450 455 460
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
465 470 475
<210> 5
<211> 249
<212> PRT
<213> Cynomologus
<400> 5
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Met Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val
20 25 30
Glu Tyr Gly Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys
35 40 45
Gln Leu Asp Leu Thr Ser Leu Ile Val Tyr Trp Glu Met Glu Asp Lys
50 55 60
Asn Ile Ile Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His
65 70 75 80
Ser Asn Tyr Arg Gln Arg Ala Gln Leu Leu Lys Asp Gln Leu Ser Leu
85 90 95
Gly Asn Ala Ala Leu Arg Ile Thr Asp Val Lys Leu Gln Asp Ala Gly
100 105 110
Val Tyr Arg Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile
115 120 125
Thr Val Lys Val Asn Ala Pro Tyr Asn Lys Ile Asn Gln Arg Ile Leu
130 135 140
Val Val Asp Pro Val Thr Ser Glu His Glu Leu Thr Cys Gln Ala Glu
145 150 155 160
Gly Tyr Pro Lys Ala Glu Val Ile Trp Thr Ser Ser Asp His Gln Val
165 170 175
Leu Ser Gly Lys Thr Thr Thr Thr Asn Ser Lys Arg Glu Glu Lys Leu
180 185 190
Leu Asn Val Thr Ser Thr Leu Arg Ile Asn Thr Thr Ala Asn Glu Ile
195 200 205
Phe Tyr Cys Ile Phe Arg Arg Leu Asp Pro Glu Glu Asn His Thr Ala
210 215 220
Glu Leu Val Ile Pro Glu Leu Pro Leu Ala Leu Pro Pro Asn Glu Arg
225 230 235 240
Thr Asp Tyr Lys Asp Asp Asp Asp Lys
245
<210> 6
<211> 405
<212> PRT
<213> Homo Sapiens
<400> 6
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Leu Asp Ser Pro Asp Arg Pro Trp Asn Pro Pro Thr Phe
20 25 30
Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp Asn Ala Thr Phe Thr
35 40 45
Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val Leu Asn Trp Tyr Arg
50 55 60
Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala Ala Phe Pro Glu Asp
65 70 75 80
Arg Ser Gln Pro Gly Gln Asp Cys Arg Phe Arg Val Thr Gln Leu Pro
85 90 95
Asn Gly Arg Asp Phe His Met Ser Val Val Arg Ala Arg Arg Asn Asp
100 105 110
Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu Ala Pro Lys Ala Gln
115 120 125
Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val Thr Glu Arg Arg Ala
130 135 140
Glu Val Pro Thr Ala His Pro Ser Pro Ser Pro Arg Pro Ala Gly Gln
145 150 155 160
Lys Leu Glu Asn Leu Tyr Phe Gln Gly Ile Glu Gly Arg Met Asp Glu
165 170 175
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
180 185 190
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
195 200 205
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
210 215 220
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
225 230 235 240
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
245 250 255
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
260 265 270
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
275 280 285
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
290 295 300
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
305 310 315 320
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
325 330 335
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
340 345 350
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
355 360 365
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
370 375 380
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
385 390 395 400
Leu Ser Leu Ser Pro
405
<210> 7
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 7
Gly Phe Thr Phe Asp Asp Tyr Ala
1 5
<210> 8
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 8
Ile Ser Trp Lys Ser Asn Ile Ile
1 5
<210> 9
<211> 15
<212> PRT
<213> Homo Sapiens
<400> 9
Ala Arg Asp Ile Thr Gly Ser Gly Ser Tyr Gly Trp Phe Asp Pro
1 5 10 15
<210> 10
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 10
Asp Tyr Ala Met His
1 5
<210> 11
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 11
Gly Ile Ser Trp Lys Ser Asn Ile Ile Gly Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 12
<211> 13
<212> PRT
<213> Homo Sapiens
<400> 12
Asp Ile Thr Gly Ser Gly Ser Tyr Gly Trp Phe Asp Pro
1 5 10
<210> 13
<211> 122
<212> PRT
<213> Homo Sapiens
<400> 13
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Thr Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Lys Ser Asn Ile Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Thr Gly Ser Gly Ser Tyr Gly Trp Phe Asp Pro Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 14
<211> 508
<212> DNA
<213> Homo Sapiens
<400> 14
caagaaaaag cttgccgcca ccatggagtt tgggctgagc tggattttcc ttttggctat 60
tttaaaaggt gtccagtgtg aagtacaatt ggtggagtcc gggggaggct tggtacagcc 120
tggcaggtcc ctgagactct cctgtgcagc ctctggattc acctttgatg attatgccat 180
gcactgggtc cgacaaactc cagggaaggg cctggagtgg gtctcaggta taagttggaa 240
gagtaatatc ataggctatg cggactctgt gaagggccga ttcaccatct ccagagacaa 300
cgccaagaac tccctgtatc tgcaaatgaa cagtctgaga gctgaggaca cggccttgta 360
ttattgtgca agagatataa cgggttcggg gagttatggc tggttcgacc cctggggcca 420
gggaaccctg gtcaccgtct cctcagccaa aacgacaccc ccatctgtct atccactggc 480
ccctgaatct gctaaaactc agcctccg 508
<210> 15
<211> 449
<212> PRT
<213> Homo Sapiens
<400> 15
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Thr Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Lys Ser Asn Ile Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Arg Asp Ile Thr Gly Ser Gly Ser Tyr Gly Trp Phe Asp Pro Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
Lys
<210> 16
<211> 1356
<212> DNA
<213> Homo Sapiens
<400> 16
gaagtgcagc tggtggaatc tggcggcgga ctggtgcagc ctggcagatc cctgagactg 60
tcttgtgccg cctccggctt caccttcgac gactacgcta tgcactgggt gcgacagacc 120
cctggcaagg gcctggaatg ggtgtccggc atctcctgga agtccaacat catcggctac 180
gccgactccg tgaagggccg gttcaccatc tcccgggaca acgccaagaa ctccctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccctgt actactgcgc cagagacatc 300
accggctccg gctcctacgg atggttcgat ccttggggcc agggcaccct cgtgaccgtg 360
tcctctgcca gcaccaaggg cccctctgtg ttccctctgg ccccttccag caagtccacc 420
tctggcggaa cagccgctct gggctgcctc gtgaaggact acttccccga gcctgtgacc 480
gtgtcctgga actctggcgc tctgaccagc ggagtgcaca ccttccctgc tgtgctgcag 540
tcctccggcc tgtactccct gtcctccgtc gtgaccgtgc cttccagctc tctgggcacc 600
cagacctaca tctgcaacgt gaaccacaag ccctccaaca ccaaggtgga caagaaggtg 660
gaacccaagt cctgcgacaa gacccacacc tgtccccctt gtcctgcccc tgaactgctg 720
ggcggacctt ccgtgttcct gttcccccca aagcccaagg acaccctgat gatctcccgg 780
acccccgaag tgacctgcgt ggtggtggat gtgtcccacg aggaccctga agtgaagttc 840
aattggtacg tggacggcgt ggaagtgcac aacgccaaga ccaagcctag agaggaacag 900
tacaactcca cctaccgggt ggtgtccgtg ctgaccgtgc tgcaccagga ttggctgaac 960
ggcaaagagt acaagtgcaa ggtgtccaac aaggccctgc ctgcccccat cgaaaagacc 1020
atctccaagg ccaagggcca gccccgggaa ccccaggtgt acacactgcc ccctagcagg 1080
gacgagctga ccaagaacca ggtgtccctg acctgtctcg tgaaaggctt ctacccctcc 1140
gatatcgccg tggaatggga gtccaacggc cagcctgaga acaactacaa gaccaccccc 1200
cctgtgctgg actccgacgg ctcattcttc ctgtacagca agctgacagt ggacaagtcc 1260
cggtggcagc agggcaacgt gttctcctgc tccgtgatgc acgaggccct gcacaaccac 1320
tacacccaga agtccctgtc cctgagcccc ggcaag 1356
<210> 17
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 17
Gln Ser Ile Ser Ser Tyr
1 5
<210> 18
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 18
Val Ala Ser
1
<210> 19
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 19
Gln Gln Ser Tyr Ser Asn Pro Ile Thr
1 5
<210> 20
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 20
Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn
1 5 10
<210> 21
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 21
Val Ala Ser Ser Leu Gln Ser
1 5
<210> 22
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 22
Gln Gln Ser Tyr Ser Asn Pro Ile Thr
1 5
<210> 23
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 23
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Pro Leu Ile
35 40 45
Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Ser Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Asn Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105
<210> 24
<211> 321
<212> DNA
<213> Homo Sapiens
<400> 24
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagcccct gatctatgtt gcatccagtt tgcaaagtgg ggtcccatca 180
agtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcaacag agttacagta atccgatcac cttcggccaa 300
gggacacgac tggagatcaa a 321
<210> 25
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 25
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Pro Leu Ile
35 40 45
Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Ser Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Asn Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 26
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 26
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gagcattagc agctatttaa attggtatca gcagaaacca 120
gggaaagccc ctaagcccct gatctatgtt gcatccagtt tgcaaagtgg ggtcccatca 180
agtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcaacag agttacagta atccgatcac cttcggccaa 300
gggacacgac tggagatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 27
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 27
Gly Phe Thr Phe Asp Asp Tyr Ala
1 5
<210> 28
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 28
Ile Ser Trp Ile Arg Thr Gly Ile
1 5
<210> 29
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 29
Ala Lys Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
1 5 10 15
<210> 30
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 30
Asp Tyr Ala Met His
1 5
<210> 31
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 31
Gly Ile Ser Trp Ile Arg Thr Gly Ile Gly Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 32
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 32
Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
1 5 10
<210> 33
<211> 123
<212> PRT
<213> Homo Sapiens
<400> 33
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Ile Arg Thr Gly Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Phe Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 34
<211> 482
<212> DNA
<213> Homo Sapiens
<400> 34
aagcttgccg ccaccatgga gtttgggctg agctggattt tccttttggc tattttaaaa 60
ggtgtccagt gtgaagtgca gctggtggag tctgggggag gcttggtgca gcctggcagg 120
tccctgagac tctcctgtgc agcctctgga ttcacctttg atgattatgc catgcactgg 180
gtccggcaag ttccagggaa gggcctggaa tgggtctcag gcattagttg gattcgtact 240
ggcataggct atgcggactc tgtgaagggc cgattcacca ttttcagaga caacgccaag 300
aattccctgt atctgcaaat gaacagtctg agagctgagg acacggcctt gtattactgt 360
gcaaaagata tgaagggttc ggggacttat ggggggtggt tcgacacctg gggccaggga 420
accctggtca ccgtctcctc agccaaaaca acagccccat cggtctatcc actggcccct 480
gc 482
<210> 35
<211> 450
<212> PRT
<213> Homo Sapiens
<400> 35
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Ile Arg Thr Gly Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Phe Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
195 200 205
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
210 215 220
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
435 440 445
Gly Lys
450
<210> 36
<211> 1359
<212> DNA
<213> Homo Sapiens
<400> 36
gaagtgcagc tggtggaatc tggcggcgga ctggtgcagc ctggcagatc cctgagactg 60
tcttgtgccg cctccggctt caccttcgac gactacgcta tgcactgggt gcgacaggtg 120
ccaggcaagg gcctggaatg ggtgtccggc atctcttgga tccggaccgg catcggctac 180
gccgactctg tgaagggccg gttcaccatc ttccgggaca acgccaagaa ctccctgtac 240
ctgcagatga acagcctgcg ggccgaggac accgccctgt actactgcgc caaggacatg 300
aagggctccg gcacctacgg cggatggttc gatacttggg gccagggcac cctcgtgacc 360
gtgtcctctg ccagcaccaa gggcccctct gtgttccctc tggccccttc cagcaagtcc 420
acctctggcg gaacagccgc tctgggctgc ctcgtgaagg actacttccc cgagcctgtg 480
accgtgtcct ggaactctgg cgctctgacc agcggagtgc acaccttccc tgctgtgctg 540
cagtcctccg gcctgtactc cctgtcctcc gtcgtgaccg tgccttccag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagccctcca acaccaaggt ggacaagaag 660
gtggaaccca agtcctgcga caagacccac acctgtcccc cttgtcctgc ccctgaactg 720
ctgggcggac cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatctcc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaact ccacctaccg ggtggtgtcc gtgctgaccg tgctgcacca ggattggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgaaaag 1020
accatctcca aggccaaggg ccagccccgg gaaccccagg tgtacacact gccccctagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagtccaac ggccagcctg agaacaacta caagaccacc 1200
ccccctgtgc tggactccga cggctcattc ttcctgtaca gcaagctgac agtggacaag 1260
tcccggtggc agcagggcaa cgtgttctcc tgctccgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gtccctgagc cccggcaag 1359
<210> 37
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 37
Gln Ser Ile Ser Ser Tyr
1 5
<210> 38
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 38
Val Ala Ser
1
<210> 39
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 39
Gln Gln Ser Tyr Ser Thr Pro Ile Thr
1 5
<210> 40
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 40
Arg Ala Ser Gln Ser Ile Ser Ser Tyr Leu Asn
1 5 10
<210> 41
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 41
Val Ala Ser Ser Leu Gln Ser
1 5
<210> 42
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 42
Gln Gln Ser Tyr Ser Thr Pro Ile Thr
1 5
<210> 43
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 43
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105
<210> 44
<211> 418
<212> DNA
<213> Homo Sapiens
<400> 44
aaagcttgcc gccaccatga ggctccctgc tcagcttctg gggctcctgc tactctggct 60
ccgaggtgcc agatgtgaca tccagatgac ccagtctcca tcctccctgt ctgcatctgt 120
aggagacaga gtcaccatca cttgccgggc aagtcagagc attagcagct atttaaattg 180
gtatcagcag aaaccaggga aagcccctaa actcctgatc tatgttgcat ccagtttgca 240
aagtggggtc ccatcaaggt tcagtggcag tggatctggg acagatttca ctctcactat 300
cagcagtctg caacctgaag attttgcaac ttactactgt caacagagtt acagtacccc 360
gatcaccttc ggccaaggga cacgtctgga gatcaaacgt acggatgctg caccaact 418
<210> 45
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 45
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 46
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 46
gacatccaga tgacccagtc cccctccagc ctgtctgctt ccgtgggcga cagagtgacc 60
atcacctgtc gggcctccca gtccatctcc tcctacctga actggtatca gcagaagccc 120
ggcaaggccc ccaagctgct gatctacgtg gccagctctc tgcagtccgg cgtgccctct 180
agattctccg gctctggctc tggcaccgac tttaccctga ccatcagctc cctgcagccc 240
gaggacttcg ccacctacta ctgccagcag tcctactcca cccctatcac cttcggccag 300
ggcacccggc tggaaatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 47
<211> 450
<212> PRT
<213> Homo Sapiens
<400> 47
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Ile Arg Thr Gly Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Phe Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
195 200 205
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
210 215 220
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Leu Ala Gly Ala
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
435 440 445
Gly Lys
450
<210> 48
<211> 450
<212> PRT
<213> Homo Sapiens
<400> 48
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Ile Arg Thr Gly Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
195 200 205
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
210 215 220
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Leu Ala Gly Ala
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
435 440 445
Gly Lys
450
<210> 49
<211> 448
<212> PRT
<213> Homo Sapiens
<400> 49
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Ile Arg Thr Gly Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Phe Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
195 200 205
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
210 215 220
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Val Ala Gly Pro Ser
225 230 235 240
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
245 250 255
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
260 265 270
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
275 280 285
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
290 295 300
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
305 310 315 320
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
325 330 335
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
340 345 350
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
355 360 365
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
370 375 380
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
385 390 395 400
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
405 410 415
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
420 425 430
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 50
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 50
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 51
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 51
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Phe Ile
35 40 45
Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 52
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 52
Gly Phe Thr Phe Ser Ser Tyr Trp
1 5
<210> 53
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 53
Ile Lys Glu Asp Gly Ser Glu Lys
1 5
<210> 54
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 54
Ala Arg Asn Arg Leu Tyr Ser Asp Phe Leu Asp Asn
1 5 10
<210> 55
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 55
Ser Tyr Trp Met Ser
1 5
<210> 56
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 56
Asn Ile Lys Glu Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val Lys
1 5 10 15
Gly
<210> 57
<211> 10
<212> PRT
<213> Homo Sapiens
<400> 57
Asn Arg Leu Tyr Ser Asp Phe Leu Asp Asn
1 5 10
<210> 58
<211> 119
<212> PRT
<213> Homo Sapiens
<400> 58
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Glu Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ser Val Tyr Tyr Cys
85 90 95
Ala Arg Asn Arg Leu Tyr Ser Asp Phe Leu Asp Asn Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 59
<211> 358
<212> DNA
<213> Homo Sapiens
<400> 59
gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacgtttagt agctattgga tgagttgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtggccaac atcaaagaag atggaagtga gaaatactat 180
gtcgactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctcactgtat 240
ctgcaaatga acagcctgag agccgaggac acgtctgtgt attactgtgc gagaaatcga 300
ctctacagtg acttccttga caactggggc cagggaaccc tggtcaccgt ctcctcag 358
<210> 60
<211> 449
<212> PRT
<213> Homo Sapiens
<400> 60
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Glu Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ser Val Tyr Tyr Cys
85 90 95
Ala Arg Asn Arg Leu Tyr Ser Asp Phe Leu Asp Asn Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 61
<211> 1347
<212> DNA
<213> Homo Sapiens
<400> 61
gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacgtttagt agctattgga tgagttgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtggccaac atcaaagaag atggaagtga gaaatactat 180
gtcgactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctcactgtat 240
ctgcaaatga acagcctgag agccgaggac acgtctgtgt attactgtgc gagaaatcga 300
ctctacagtg acttccttga caactggggc cagggaaccc tggtcaccgt ctcctcagcc 360
agcaccaagg gcccctctgt gttccctctg gccccttcca gcaagtccac ctctggcgga 420
acagccgctc tgggctgcct cgtgaaggac tacttccccg agcctgtgac cgtgtcctgg 480
aactctggcg ctctgaccag cggagtgcac accttccctg ctgtgctgca gtcctccggc 540
ctgtactccc tgtcctccgt cgtgaccgtg ccttccagct ctctgggcac ccagacctac 600
atctgcaacg tgaaccacaa gccctccaac accaaggtgg acaagaaggt ggaacccaag 660
tcctgcgaca agacccacac ctgtccccct tgtcctgccc ctgaactgct gggcggacct 720
tccgtgttcc tgttcccccc aaagcccaag gacaccctga tgatctcccg gacccccgaa 780
gtgacctgcg tggtggtgga tgtgtcccac gaggaccctg aagtgaagtt caattggtac 840
gtggacggcg tggaagtgca caacgccaag accaagccta gagaggaaca gtacaactcc 900
acctaccggg tggtgtccgt gctgaccgtg ctgcaccagg attggctgaa cggcaaagag 960
tacaagtgca aggtgtccaa caaggccctg cctgccccca tcgaaaagac catctccaag 1020
gccaagggcc agccccggga accccaggtg tacacactgc cccctagcag ggacgagctg 1080
accaagaacc aggtgtccct gacctgtctc gtgaaaggct tctacccctc cgatatcgcc 1140
gtggaatggg agtccaacgg ccagcctgag aacaactaca agaccacccc ccctgtgctg 1200
gactccgacg gctcattctt cctgtacagc aagctgacag tggacaagtc ccggtggcag 1260
cagggcaacg tgttctcctg ctccgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctgt ccctgagccc cggcaag 1347
<210> 62
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 62
Gln Gly Val Ser Ser Trp
1 5
<210> 63
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 63
Gly Ala Ser
1
<210> 64
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 64
Gln Gln Ala Asn Ser Ile Pro Phe Thr
1 5
<210> 65
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 65
Arg Ala Ser Gln Gly Val Ser Ser Trp Leu Ala
1 5 10
<210> 66
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 66
Gly Ala Ser Ser Leu Gln Ser
1 5
<210> 67
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 67
Gln Gln Ala Asn Ser Ile Pro Phe Thr
1 5
<210> 68
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 68
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Val Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Ile Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Ile Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105
<210> 69
<211> 322
<212> DNA
<213> Homo Sapiens
<400> 69
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtcggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtgttagc agctggttag cctggtatca gcagaaatca 120
gggaaagccc ctaagctcct gatctatggt gcatccagtt tgcaaagtgg ggtcccatca 180
agattcagcg gcagtggatc tgggacagag ttcattctca ccatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagta tcccattcac tttcggccct 300
gggaccaaag tggatatcaa ac 322
<210> 70
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 70
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Val Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Ile Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Ile Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 71
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 71
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtcggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtgttagc agctggttag cctggtatca gcagaaatca 120
gggaaagccc ctaagctcct gatctatggt gcatccagtt tgcaaagtgg ggtcccatca 180
agattcagcg gcagtggatc tgggacagag ttcattctca ccatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagta tcccattcac tttcggccct 300
gggaccaaag tggatatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 72
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 72
Gly Phe Thr Phe Ser Ser Tyr Trp
1 5
<210> 73
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 73
Ile Lys Glu Asp Gly Ser Glu Lys
1 5
<210> 74
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 74
Ala Arg Val Arg Leu Tyr Ser Asp Phe Leu Asp Tyr
1 5 10
<210> 75
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 75
Ser Tyr Trp Met Ser
1 5
<210> 76
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 76
Asn Ile Lys Glu Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Leu Lys
1 5 10 15
Gly
<210> 77
<211> 10
<212> PRT
<213> Homo Sapiens
<400> 77
Val Arg Leu Tyr Ser Asp Phe Leu Asp Tyr
1 5 10
<210> 78
<211> 119
<212> PRT
<213> Homo Sapiens
<400> 78
Glu Val Gln Leu Val Asp Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Glu Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Leu
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ser Val Tyr Tyr Cys
85 90 95
Ala Arg Val Arg Leu Tyr Ser Asp Phe Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 79
<211> 358
<212> DNA
<213> Homo Sapiens
<400> 79
gaggtgcagc tggtggactc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacgtttagt agctattgga tgagttgggt ccgccaggct 120
ccaggaaagg ggctggagtg ggtggccaac ataaaagaag atggaagtga gaaatactat 180
gtagactctt tgaagggccg attcaccatc tccagagaca acgccaagaa ctcactgtat 240
ctgcaaatga acagcctgag agccgaggac acgtctgtgt attactgtgc gagagttcga 300
ctctacagtg acttccttga ctactggggc cagggaaccc tggtcaccgt ctcctcag 358
<210> 80
<211> 449
<212> PRT
<213> Homo Sapiens
<400> 80
Glu Val Gln Leu Val Asp Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Glu Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Leu
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ser Val Tyr Tyr Cys
85 90 95
Ala Arg Val Arg Leu Tyr Ser Asp Phe Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 81
<211> 1347
<212> DNA
<213> Homo Sapiens
<400> 81
gaggtgcagc tggtggactc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacgtttagt agctattgga tgagttgggt ccgccaggct 120
ccaggaaagg ggctggagtg ggtggccaac ataaaagaag atggaagtga gaaatactat 180
gtagactctt tgaagggccg attcaccatc tccagagaca acgccaagaa ctcactgtat 240
ctgcaaatga acagcctgag agccgaggac acgtctgtgt attactgtgc gagagttcga 300
ctctacagtg acttccttga ctactggggc cagggaaccc tggtcaccgt ctcctcagcc 360
agcaccaagg gcccctctgt gttccctctg gccccttcca gcaagtccac ctctggcgga 420
acagccgctc tgggctgcct cgtgaaggac tacttccccg agcctgtgac cgtgtcctgg 480
aactctggcg ctctgaccag cggagtgcac accttccctg ctgtgctgca gtcctccggc 540
ctgtactccc tgtcctccgt cgtgaccgtg ccttccagct ctctgggcac ccagacctac 600
atctgcaacg tgaaccacaa gccctccaac accaaggtgg acaagaaggt ggaacccaag 660
tcctgcgaca agacccacac ctgtccccct tgtcctgccc ctgaactgct gggcggacct 720
tccgtgttcc tgttcccccc aaagcccaag gacaccctga tgatctcccg gacccccgaa 780
gtgacctgcg tggtggtgga tgtgtcccac gaggaccctg aagtgaagtt caattggtac 840
gtggacggcg tggaagtgca caacgccaag accaagccta gagaggaaca gtacaactcc 900
acctaccggg tggtgtccgt gctgaccgtg ctgcaccagg attggctgaa cggcaaagag 960
tacaagtgca aggtgtccaa caaggccctg cctgccccca tcgaaaagac catctccaag 1020
gccaagggcc agccccggga accccaggtg tacacactgc cccctagcag ggacgagctg 1080
accaagaacc aggtgtccct gacctgtctc gtgaaaggct tctacccctc cgatatcgcc 1140
gtggaatggg agtccaacgg ccagcctgag aacaactaca agaccacccc ccctgtgctg 1200
gactccgacg gctcattctt cctgtacagc aagctgacag tggacaagtc ccggtggcag 1260
cagggcaacg tgttctcctg ctccgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctgt ccctgagccc cggcaag 1347
<210> 82
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 82
Gln Gly Val Ser Ser Trp
1 5
<210> 83
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 83
Gly Ala Ser
1
<210> 84
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 84
Gln Gln Ala Asn Ser Ile Pro Phe Thr
1 5
<210> 85
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 85
Arg Ala Ser Gln Gly Val Ser Ser Trp Leu Ala
1 5 10
<210> 86
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 86
Gly Ala Ser Ser Leu Gln Ser
1 5
<210> 87
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 87
Gln Gln Ala Asn Ser Ile Pro Phe Thr
1 5
<210> 88
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 88
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Val Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Ile Leu Ser Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Ile Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105
<210> 89
<211> 322
<212> DNA
<213> Homo Sapiens
<400> 89
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtcggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtgttagc agttggttag cctggtatca gcagaaatca 120
gggaaagccc ctaagctcct gatctatggt gcctccagtt tgcaaagtgg ggtcccatca 180
agattcagcg gcagtggatc tgggacagag ttcattctca gcatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagta tcccattcac tttcggccct 300
gggaccaaag tggatatcaa ac 322
<210> 90
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 90
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Val Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Ile Leu Ser Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Ile Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 91
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 91
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtcggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtgttagc agttggttag cctggtatca gcagaaatca 120
gggaaagccc ctaagctcct gatctatggt gcctccagtt tgcaaagtgg ggtcccatca 180
agattcagcg gcagtggatc tgggacagag ttcattctca gcatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagta tcccattcac tttcggccct 300
gggaccaaag tggatatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 92
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 92
Gly Gly Ser Ile Ile Ser Ser Asp Trp
1 5
<210> 93
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 93
Ile Phe His Ser Gly Arg Thr
1 5
<210> 94
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 94
Ala Arg Asp Gly Ser Gly Ser Tyr
1 5
<210> 95
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 95
Ser Ser Asp Trp Trp Asn
1 5
<210> 96
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 96
Glu Ile Phe His Ser Gly Arg Thr Asn Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 97
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 97
Asp Gly Ser Gly Ser Tyr
1 5
<210> 98
<211> 115
<212> PRT
<213> Homo Sapiens
<400> 98
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gly
1 5 10 15
Thr Leu Ser Leu Thr Cys Ile Val Ser Gly Gly Ser Ile Ile Ser Ser
20 25 30
Asp Trp Trp Asn Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Glu Ile Phe His Ser Gly Arg Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Val Thr Ile Ser Ile Asp Lys Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Arg Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Ser Gly Ser Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 99
<211> 346
<212> DNA
<213> Homo Sapiens
<400> 99
caggtgcagc tgcaggagtc gggcccagga ctggtgaagc cttcggggac cctgtccctc 60
acctgcattg tctctggtgg ctccatcatc agtagtgact ggtggaattg ggtccgccag 120
cccccaggga aggggctgga gtggattgga gaaatctttc atagtgggag gaccaactac 180
aacccgtccc tcaagagtcg agtcaccata tcaatagaca agtccaagaa tcagttctcc 240
ctgaggctga gctctgtgac cgccgcggac acggccgtgt attactgtgc gagagatggt 300
tcggggagtt actggggcca gggaaccctg gtcaccgtct cctcag 346
<210> 100
<211> 445
<212> PRT
<213> Homo Sapiens
<400> 100
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gly
1 5 10 15
Thr Leu Ser Leu Thr Cys Ile Val Ser Gly Gly Ser Ile Ile Ser Ser
20 25 30
Asp Trp Trp Asn Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Glu Ile Phe His Ser Gly Arg Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Val Thr Ile Ser Ile Asp Lys Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Arg Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Ser Gly Ser Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
115 120 125
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
130 135 140
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
145 150 155 160
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
165 170 175
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
180 185 190
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
195 200 205
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
210 215 220
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
290 295 300
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 101
<211> 1335
<212> DNA
<213> Homo Sapiens
<400> 101
caggtgcagc tgcaggagtc gggcccagga ctggtgaagc cttcggggac cctgtccctc 60
acctgcattg tctctggtgg ctccatcatc agtagtgact ggtggaattg ggtccgccag 120
cccccaggga aggggctgga gtggattgga gaaatctttc atagtgggag gaccaactac 180
aacccgtccc tcaagagtcg agtcaccata tcaatagaca agtccaagaa tcagttctcc 240
ctgaggctga gctctgtgac cgccgcggac acggccgtgt attactgtgc gagagatggt 300
tcggggagtt actggggcca gggaaccctg gtcaccgtct cctcagccag caccaagggc 360
ccctctgtgt tccctctggc cccttccagc aagtccacct ctggcggaac agccgctctg 420
ggctgcctcg tgaaggacta cttccccgag cctgtgaccg tgtcctggaa ctctggcgct 480
ctgaccagcg gagtgcacac cttccctgct gtgctgcagt cctccggcct gtactccctg 540
tcctccgtcg tgaccgtgcc ttccagctct ctgggcaccc agacctacat ctgcaacgtg 600
aaccacaagc cctccaacac caaggtggac aagaaggtgg aacccaagtc ctgcgacaag 660
acccacacct gtcccccttg tcctgcccct gaactgctgg gcggaccttc cgtgttcctg 720
ttccccccaa agcccaagga caccctgatg atctcccgga cccccgaagt gacctgcgtg 780
gtggtggatg tgtcccacga ggaccctgaa gtgaagttca attggtacgt ggacggcgtg 840
gaagtgcaca acgccaagac caagcctaga gaggaacagt acaactccac ctaccgggtg 900
gtgtccgtgc tgaccgtgct gcaccaggat tggctgaacg gcaaagagta caagtgcaag 960
gtgtccaaca aggccctgcc tgcccccatc gaaaagacca tctccaaggc caagggccag 1020
ccccgggaac cccaggtgta cacactgccc cctagcaggg acgagctgac caagaaccag 1080
gtgtccctga cctgtctcgt gaaaggcttc tacccctccg atatcgccgt ggaatgggag 1140
tccaacggcc agcctgagaa caactacaag accacccccc ctgtgctgga ctccgacggc 1200
tcattcttcc tgtacagcaa gctgacagtg gacaagtccc ggtggcagca gggcaacgtg 1260
ttctcctgct ccgtgatgca cgaggccctg cacaaccact acacccagaa gtccctgtcc 1320
ctgagccccg gcaag 1335
<210> 102
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 102
Gln Ser Val Leu Tyr Ser Ser Asn Asn Lys Asn Tyr
1 5 10
<210> 103
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 103
Trp Ala Ser
1
<210> 104
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 104
Gln Gln Tyr Tyr Ser Asn Arg Ser
1 5
<210> 105
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 105
Lys Ser Ser Gln Ser Val Leu Tyr Ser Ser Asn Asn Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 106
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 106
Trp Ala Ser Thr Arg Glu Ser
1 5
<210> 107
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 107
Gln Gln Tyr Tyr Ser Asn Arg Ser
1 5
<210> 108
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 108
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Ser Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Thr Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Asn Arg Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 109
<211> 337
<212> DNA
<213> Homo Sapiens
<400> 109
gacatcgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtgtttta tacagctcca acaataagaa ttacttagct 120
tggtaccagc agaaatcagg acagcctcct aagttgctca tttactgggc atctacccgg 180
gaatccgggg tccctgaccg attcagtggc agcgggtctg ggacagattt cactctcacc 240
atcagcagcc tgcagactga agatgtggca gtttattact gtcagcaata ttatagtaat 300
cgcagttttg gccaggggac caagctggag atcaaac 337
<210> 110
<211> 219
<212> PRT
<213> Homo Sapiens
<400> 110
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Ser Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Thr Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Asn Arg Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 111
<211> 657
<212> DNA
<213> Homo Sapiens
<400> 111
gacatcgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtgtttta tacagctcca acaataagaa ttacttagct 120
tggtaccagc agaaatcagg acagcctcct aagttgctca tttactgggc atctacccgg 180
gaatccgggg tccctgaccg attcagtggc agcgggtctg ggacagattt cactctcacc 240
atcagcagcc tgcagactga agatgtggca gtttattact gtcagcaata ttatagtaat 300
cgcagttttg gccaggggac caagctggag atcaaacgta cggtggccgc tccctccgtg 360
ttcatcttcc caccttccga cgagcagctg aagtccggca ccgcttctgt cgtgtgcctg 420
ctgaacaact tctacccccg cgaggccaag gtgcagtgga aggtggacaa cgccctgcag 480
tccggcaact cccaggaatc cgtgaccgag caggactcca aggacagcac ctactccctg 540
tcctccaccc tgaccctgtc caaggccgac tacgagaagc acaaggtgta cgcctgcgaa 600
gtgacccacc agggcctgtc tagccccgtg accaagtctt tcaaccgggg cgagtgt 657
<210> 112
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 112
Gly Phe Thr Phe Ser Ser Tyr Trp
1 5
<210> 113
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 113
Ile Lys Glu Asp Gly Ser Glu Lys
1 5
<210> 114
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 114
Ala Arg Asn Arg Leu Tyr Ser Asp Phe Leu Asp Asn
1 5 10
<210> 115
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 115
Ser Tyr Trp Met Ser
1 5
<210> 116
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 116
Asn Ile Lys Glu Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val Lys
1 5 10 15
Gly
<210> 117
<211> 10
<212> PRT
<213> Homo Sapiens
<400> 117
Asn Arg Leu Tyr Ser Asp Phe Leu Asp Asn
1 5 10
<210> 118
<211> 119
<212> PRT
<213> Homo Sapiens
<400> 118
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Glu Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ser Val Tyr Tyr Cys
85 90 95
Ala Arg Asn Arg Leu Tyr Ser Asp Phe Leu Asp Asn Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 119
<211> 358
<212> DNA
<213> Homo Sapiens
<400> 119
gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacgtttagt agctattgga tgagttgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtggccaac atcaaagaag atggaagtga gaaatactat 180
gtcgactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctcactgtat 240
ctgcaaatga acagcctgag agccgaggac acgtctgtgt attactgtgc gagaaatcga 300
ctctacagtg acttccttga caactggggc cagggaaccc tggtcaccgt ctcctcag 358
<210> 120
<211> 449
<212> PRT
<213> Homo Sapiens
<400> 120
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Glu Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ser Val Tyr Tyr Cys
85 90 95
Ala Arg Asn Arg Leu Tyr Ser Asp Phe Leu Asp Asn Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 121
<211> 1347
<212> DNA
<213> Homo Sapiens
<400> 121
gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacgtttagt agctattgga tgagttgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtggccaac atcaaagaag atggaagtga gaaatactat 180
gtcgactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctcactgtat 240
ctgcaaatga acagcctgag agccgaggac acgtctgtgt attactgtgc gagaaatcga 300
ctctacagtg acttccttga caactggggc cagggaaccc tggtcaccgt ctcctcagcc 360
agcaccaagg gcccctctgt gttccctctg gccccttcca gcaagtccac ctctggcgga 420
acagccgctc tgggctgcct cgtgaaggac tacttccccg agcctgtgac cgtgtcctgg 480
aactctggcg ctctgaccag cggagtgcac accttccctg ctgtgctgca gtcctccggc 540
ctgtactccc tgtcctccgt cgtgaccgtg ccttccagct ctctgggcac ccagacctac 600
atctgcaacg tgaaccacaa gccctccaac accaaggtgg acaagaaggt ggaacccaag 660
tcctgcgaca agacccacac ctgtccccct tgtcctgccc ctgaactgct gggcggacct 720
tccgtgttcc tgttcccccc aaagcccaag gacaccctga tgatctcccg gacccccgaa 780
gtgacctgcg tggtggtgga tgtgtcccac gaggaccctg aagtgaagtt caattggtac 840
gtggacggcg tggaagtgca caacgccaag accaagccta gagaggaaca gtacaactcc 900
acctaccggg tggtgtccgt gctgaccgtg ctgcaccagg attggctgaa cggcaaagag 960
tacaagtgca aggtgtccaa caaggccctg cctgccccca tcgaaaagac catctccaag 1020
gccaagggcc agccccggga accccaggtg tacacactgc cccctagcag ggacgagctg 1080
accaagaacc aggtgtccct gacctgtctc gtgaaaggct tctacccctc cgatatcgcc 1140
gtggaatggg agtccaacgg ccagcctgag aacaactaca agaccacccc ccctgtgctg 1200
gactccgacg gctcattctt cctgtacagc aagctgacag tggacaagtc ccggtggcag 1260
cagggcaacg tgttctcctg ctccgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctgt ccctgagccc cggcaag 1347
<210> 122
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 122
Gln Gly Val Ser Ser Trp
1 5
<210> 123
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 123
Gly Ala Ser
1
<210> 124
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 124
Gln Gln Ala Asn Ser Ile Pro Phe Thr
1 5
<210> 125
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 125
Arg Ala Ser Gln Gly Val Ser Ser Trp Leu Ala
1 5 10
<210> 126
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 126
Gly Ala Ser Ser Leu Gln Ser
1 5
<210> 127
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 127
Gln Gln Ala Asn Ser Ile Pro Phe Thr
1 5
<210> 128
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 128
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Val Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Ile Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Ile Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105
<210> 129
<211> 322
<212> DNA
<213> Homo Sapiens
<400> 129
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtcggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtgttagc agctggttag cctggtatca gcagaaatca 120
gggaaagccc ctaagctcct gatctatggt gcatccagtt tgcaaagtgg ggtcccatca 180
agattcagcg gcagtggatc tgggacagag ttcattctca ccatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagta tcccattcac tttcggccct 300
gggaccaaag tggatatcaa ac 322
<210> 130
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 130
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Val Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Ser Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Ile Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Ile Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 131
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 131
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtcggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtgttagc agctggttag cctggtatca gcagaaatca 120
gggaaagccc ctaagctcct gatctatggt gcatccagtt tgcaaagtgg ggtcccatca 180
agattcagcg gcagtggatc tgggacagag ttcattctca ccatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagta tcccattcac tttcggccct 300
gggaccaaag tggatatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 132
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 132
Gly Phe Thr Phe Arg Ile Tyr Gly
1 5
<210> 133
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 133
Ile Trp Tyr Asp Gly Ser Asn Lys
1 5
<210> 134
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 134
Ala Arg Asp Met Asp Tyr Phe Gly Met Asp Val
1 5 10
<210> 135
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 135
Ile Tyr Gly Met His
1 5
<210> 136
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 136
Val Ile Trp Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 137
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 137
Asp Met Asp Tyr Phe Gly Met Asp Val
1 5
<210> 138
<211> 118
<212> PRT
<213> Homo Sapiens
<400> 138
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ile Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Asp Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Met Asp Tyr Phe Gly Met Asp Val Trp Gly Gln Gly Thr
100 105 110
Thr Val Thr Val Ser Ser
115
<210> 139
<211> 355
<212> DNA
<213> Homo Sapiens
<400> 139
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttccgt atttatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atatggtatg atggaagtaa taaatactat 180
gctgactccg tgaagggccg attcaccatc tccagagaca attccgacaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagagatatg 300
gactacttcg gtatggacgt ctggggccaa gggaccacgg tcaccgtctc ctcag 355
<210> 140
<211> 448
<212> PRT
<213> Homo Sapiens
<400> 140
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ile Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Asp Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Met Asp Tyr Phe Gly Met Asp Val Trp Gly Gln Gly Thr
100 105 110
Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro
115 120 125
Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly
130 135 140
Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
145 150 155 160
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln
165 170 175
Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
180 185 190
Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser
195 200 205
Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr
210 215 220
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
225 230 235 240
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
245 250 255
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
260 265 270
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
275 280 285
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
290 295 300
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
305 310 315 320
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
325 330 335
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
340 345 350
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
355 360 365
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
370 375 380
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
385 390 395 400
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
405 410 415
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
420 425 430
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 141
<211> 1344
<212> DNA
<213> Homo Sapiens
<400> 141
caggtgcagc tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cgtctggatt caccttccgt atttatggca tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atatggtatg atggaagtaa taaatactat 180
gctgactccg tgaagggccg attcaccatc tccagagaca attccgacaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagagatatg 300
gactacttcg gtatggacgt ctggggccaa gggaccacgg tcaccgtctc ctcagccagc 360
accaagggcc cctctgtgtt ccctctggcc ccttccagca agtccacctc tggcggaaca 420
gccgctctgg gctgcctcgt gaaggactac ttccccgagc ctgtgaccgt gtcctggaac 480
tctggcgctc tgaccagcgg agtgcacacc ttccctgctg tgctgcagtc ctccggcctg 540
tactccctgt cctccgtcgt gaccgtgcct tccagctctc tgggcaccca gacctacatc 600
tgcaacgtga accacaagcc ctccaacacc aaggtggaca agaaggtgga acccaagtcc 660
tgcgacaaga cccacacctg tcccccttgt cctgcccctg aactgctggg cggaccttcc 720
gtgttcctgt tccccccaaa gcccaaggac accctgatga tctcccggac ccccgaagtg 780
acctgcgtgg tggtggatgt gtcccacgag gaccctgaag tgaagttcaa ttggtacgtg 840
gacggcgtgg aagtgcacaa cgccaagacc aagcctagag aggaacagta caactccacc 900
taccgggtgg tgtccgtgct gaccgtgctg caccaggatt ggctgaacgg caaagagtac 960
aagtgcaagg tgtccaacaa ggccctgcct gcccccatcg aaaagaccat ctccaaggcc 1020
aagggccagc cccgggaacc ccaggtgtac acactgcccc ctagcaggga cgagctgacc 1080
aagaaccagg tgtccctgac ctgtctcgtg aaaggcttct acccctccga tatcgccgtg 1140
gaatgggagt ccaacggcca gcctgagaac aactacaaga ccaccccccc tgtgctggac 1200
tccgacggct cattcttcct gtacagcaag ctgacagtgg acaagtcccg gtggcagcag 1260
ggcaacgtgt tctcctgctc cgtgatgcac gaggccctgc acaaccacta cacccagaag 1320
tccctgtccc tgagccccgg caag 1344
<210> 142
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 142
Gln Gly Ile Arg Asn Asp
1 5
<210> 143
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 143
Ala Ala Ser
1
<210> 144
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 144
Leu Gln His Asn Ser Tyr Pro Arg Thr
1 5
<210> 145
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 145
Arg Ala Ser Gln Gly Ile Arg Asn Asp Leu Gly
1 5 10
<210> 146
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 146
Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 147
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 147
Leu Gln His Asn Ser Tyr Pro Arg Thr
1 5
<210> 148
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 148
Asp Leu Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 149
<211> 322
<212> DNA
<213> Homo Sapiens
<400> 149
gacctccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gggcattaga aatgatttag gctggtatca gcagaaacca 120
gggaaagccc ctaagcgcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagaa ttcactctca caatcagcag cctgcagcct 240
gaagattttg caacttatta ctgtctacag cataatagtt accctcggac gttcggccaa 300
gggaccaagg tggaaatcaa ac 322
<210> 150
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 150
Asp Leu Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Asn Asp
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Arg Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln His Asn Ser Tyr Pro Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 151
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 151
gacctccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gggcattaga aatgatttag gctggtatca gcagaaacca 120
gggaaagccc ctaagcgcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagaa ttcactctca caatcagcag cctgcagcct 240
gaagattttg caacttatta ctgtctacag cataatagtt accctcggac gttcggccaa 300
gggaccaagg tggaaatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 152
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 152
Gly Gly Ser Ile Ser Ser Ser Asp Trp
1 5
<210> 153
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 153
Ile Phe His Ser Gly Asn Thr
1 5
<210> 154
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 154
Val Arg Asp Gly Ser Gly Ser Tyr
1 5
<210> 155
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 155
Ser Ser Asp Trp Trp Ser
1 5
<210> 156
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 156
Glu Ile Phe His Ser Gly Asn Thr Asn Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 157
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 157
Asp Gly Ser Gly Ser Tyr
1 5
<210> 158
<211> 115
<212> PRT
<213> Homo Sapiens
<400> 158
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gly
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Ser Gly Gly Ser Ile Ser Ser Ser
20 25 30
Asp Trp Trp Ser Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Glu Ile Phe His Ser Gly Asn Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Val Thr Ile Ser Val Asp Lys Ser Lys Asn Gln Ile Ser
65 70 75 80
Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Arg Asp Gly Ser Gly Ser Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 159
<211> 346
<212> DNA
<213> Homo Sapiens
<400> 159
caggtgcagc tgcaggagtc gggcccagga ctggtgaagc cttcggggac cctgtccctc 60
acctgcgctg tctctggtgg ctccatcagc agtagtgact ggtggagttg ggtccgccag 120
cccccaggga aggggctgga gtggattggg gaaatctttc atagtgggaa caccaactac 180
aacccgtccc tcaagagtcg agtcaccata tcagtagaca agtccaagaa ccagatctcc 240
ctgaggctga actctgtgac cgccgcggac acggccgtgt attactgtgt gagagatggt 300
tcggggagtt actggggcca gggaaccctg gtcaccgtct cctcag 346
<210> 160
<211> 445
<212> PRT
<213> Homo Sapiens
<400> 160
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gly
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Val Ser Gly Gly Ser Ile Ser Ser Ser
20 25 30
Asp Trp Trp Ser Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Glu Ile Phe His Ser Gly Asn Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Val Thr Ile Ser Val Asp Lys Ser Lys Asn Gln Ile Ser
65 70 75 80
Leu Arg Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Arg Asp Gly Ser Gly Ser Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
115 120 125
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
130 135 140
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
145 150 155 160
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
165 170 175
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
180 185 190
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
195 200 205
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
210 215 220
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
290 295 300
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 161
<211> 1335
<212> DNA
<213> Homo Sapiens
<400> 161
caggtgcagc tgcaggagtc gggcccagga ctggtgaagc cttcggggac cctgtccctc 60
acctgcgctg tctctggtgg ctccatcagc agtagtgact ggtggagttg ggtccgccag 120
cccccaggga aggggctgga gtggattggg gaaatctttc atagtgggaa caccaactac 180
aacccgtccc tcaagagtcg agtcaccata tcagtagaca agtccaagaa ccagatctcc 240
ctgaggctga actctgtgac cgccgcggac acggccgtgt attactgtgt gagagatggt 300
tcggggagtt actggggcca gggaaccctg gtcaccgtct cctcagccag caccaagggc 360
ccctctgtgt tccctctggc cccttccagc aagtccacct ctggcggaac agccgctctg 420
ggctgcctcg tgaaggacta cttccccgag cctgtgaccg tgtcctggaa ctctggcgct 480
ctgaccagcg gagtgcacac cttccctgct gtgctgcagt cctccggcct gtactccctg 540
tcctccgtcg tgaccgtgcc ttccagctct ctgggcaccc agacctacat ctgcaacgtg 600
aaccacaagc cctccaacac caaggtggac aagaaggtgg aacccaagtc ctgcgacaag 660
acccacacct gtcccccttg tcctgcccct gaactgctgg gcggaccttc cgtgttcctg 720
ttccccccaa agcccaagga caccctgatg atctcccgga cccccgaagt gacctgcgtg 780
gtggtggatg tgtcccacga ggaccctgaa gtgaagttca attggtacgt ggacggcgtg 840
gaagtgcaca acgccaagac caagcctaga gaggaacagt acaactccac ctaccgggtg 900
gtgtccgtgc tgaccgtgct gcaccaggat tggctgaacg gcaaagagta caagtgcaag 960
gtgtccaaca aggccctgcc tgcccccatc gaaaagacca tctccaaggc caagggccag 1020
ccccgggaac cccaggtgta cacactgccc cctagcaggg acgagctgac caagaaccag 1080
gtgtccctga cctgtctcgt gaaaggcttc tacccctccg atatcgccgt ggaatgggag 1140
tccaacggcc agcctgagaa caactacaag accacccccc ctgtgctgga ctccgacggc 1200
tcattcttcc tgtacagcaa gctgacagtg gacaagtccc ggtggcagca gggcaacgtg 1260
ttctcctgct ccgtgatgca cgaggccctg cacaaccact acacccagaa gtccctgtcc 1320
ctgagccccg gcaag 1335
<210> 162
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 162
Gln Ser Val Leu Tyr Ser Ser Asn Asn Lys Asn Tyr
1 5 10
<210> 163
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 163
Trp Ala Ser
1
<210> 164
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 164
Gln Gln Tyr Tyr Ser Thr Arg Ser
1 5
<210> 165
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 165
Lys Ser Ser Gln Ser Val Leu Tyr Ser Ser Asn Asn Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 166
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 166
Trp Ala Ser Thr Arg Glu Ser
1 5
<210> 167
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 167
Gln Gln Tyr Tyr Ser Thr Arg Ser
1 5
<210> 168
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 168
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Arg Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 169
<211> 337
<212> DNA
<213> Homo Sapiens
<400> 169
gacatcgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtgtttta tacagctcca acaataagaa ctacttagct 120
tggtaccagc agaaaccagg acagcctcct aaactgctca tttactgggc atctacccgg 180
gaatccgggg tccctgaccg attcagtggc agcgggtctg ggacagattt cactctcacc 240
atcagcagcc tgcaggctga agatgtggca gtttattact gtcagcaata ttatagtact 300
cgcagttttg gccaggggac caagctggag atcaaac 337
<210> 170
<211> 219
<212> PRT
<213> Homo Sapiens
<400> 170
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Arg Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 171
<211> 657
<212> DNA
<213> Homo Sapiens
<400> 171
gacatcgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtgtttta tacagctcca acaataagaa ctacttagct 120
tggtaccagc agaaaccagg acagcctcct aaactgctca tttactgggc atctacccgg 180
gaatccgggg tccctgaccg attcagtggc agcgggtctg ggacagattt cactctcacc 240
atcagcagcc tgcaggctga agatgtggca gtttattact gtcagcaata ttatagtact 300
cgcagttttg gccaggggac caagctggag atcaaacgta cggtggccgc tccctccgtg 360
ttcatcttcc caccttccga cgagcagctg aagtccggca ccgcttctgt cgtgtgcctg 420
ctgaacaact tctacccccg cgaggccaag gtgcagtgga aggtggacaa cgccctgcag 480
tccggcaact cccaggaatc cgtgaccgag caggactcca aggacagcac ctactccctg 540
tcctccaccc tgaccctgtc caaggccgac tacgagaagc acaaggtgta cgcctgcgaa 600
gtgacccacc agggcctgtc tagccccgtg accaagtctt tcaaccgggg cgagtgt 657
<210> 172
<211> 10
<212> PRT
<213> Homo Sapiens
<400> 172
Gly Gly Ser Ile Ser Ser Ser Ser Tyr Tyr
1 5 10
<210> 173
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 173
Ile Tyr Ser Thr Gly Tyr Thr
1 5
<210> 174
<211> 13
<212> PRT
<213> Homo Sapiens
<400> 174
Ala Ile Ser Thr Ala Ala Gly Pro Glu Tyr Phe His Arg
1 5 10
<210> 175
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 175
Ser Ser Ser Tyr Tyr Cys Gly
1 5
<210> 176
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 176
Ser Ile Tyr Ser Thr Gly Tyr Thr Tyr Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 177
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 177
Ser Thr Ala Ala Gly Pro Glu Tyr Phe His Arg
1 5 10
<210> 178
<211> 120
<212> PRT
<213> Homo Sapiens
<400> 178
Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu Thr Leu
1 5 10 15
Ser Leu Thr Cys Thr Val Ser Gly Gly Ser Ile Ser Ser Ser Ser Tyr
20 25 30
Tyr Cys Gly Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Asp Trp Ile
35 40 45
Gly Ser Ile Tyr Ser Thr Gly Tyr Thr Tyr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Ile Asp Thr Ser Lys Asn Gln Phe Ser Cys
65 70 75 80
Leu Ile Leu Thr Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Ser Thr Ala Ala Gly Pro Glu Tyr Phe His Arg Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 179
<211> 361
<212> DNA
<213> Homo Sapiens
<400> 179
cagctgcagg agtcgggccc aggcctggtg aagccttcgg agaccctgtc cctcacctgc 60
actgtctctg gtggctccat cagcagtagt agttattact gcggctggat ccgccagccc 120
cctgggaagg ggctggactg gattgggagt atctattcta ctgggtacac ctactacaac 180
ccgtccctca agagtcgagt caccatttcc atagacacgt ccaagaacca gttctcatgc 240
ctgatactga cctctgtgac cgccgcagac acggctgtgt attactgtgc gataagtaca 300
gcagctggcc ctgaatactt ccatcgctgg ggccagggca ccctggtcac cgtctcctca 360
g 361
<210> 180
<211> 450
<212> PRT
<213> Homo Sapiens
<400> 180
Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu Thr Leu
1 5 10 15
Ser Leu Thr Cys Thr Val Ser Gly Gly Ser Ile Ser Ser Ser Ser Tyr
20 25 30
Tyr Cys Gly Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Asp Trp Ile
35 40 45
Gly Ser Ile Tyr Ser Thr Gly Tyr Thr Tyr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Thr Ile Ser Ile Asp Thr Ser Lys Asn Gln Phe Ser Cys
65 70 75 80
Leu Ile Leu Thr Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Ser Thr Ala Ala Gly Pro Glu Tyr Phe His Arg Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
435 440 445
Gly Lys
450
<210> 181
<211> 1350
<212> DNA
<213> Homo Sapiens
<400> 181
cagctgcagg agtcgggccc aggcctggtg aagccttcgg agaccctgtc cctcacctgc 60
actgtctctg gtggctccat cagcagtagt agttattact gcggctggat ccgccagccc 120
cctgggaagg ggctggactg gattgggagt atctattcta ctgggtacac ctactacaac 180
ccgtccctca agagtcgagt caccatttcc atagacacgt ccaagaacca gttctcatgc 240
ctgatactga cctctgtgac cgccgcagac acggctgtgt attactgtgc gataagtaca 300
gcagctggcc ctgaatactt ccatcgctgg ggccagggca ccctggtcac cgtctcctca 360
gccagcacca agggcccctc tgtgttccct ctggcccctt ccagcaagtc cacctctggc 420
ggaacagccg ctctgggctg cctcgtgaag gactacttcc ccgagcctgt gaccgtgtcc 480
tggaactctg gcgctctgac cagcggagtg cacaccttcc ctgctgtgct gcagtcctcc 540
ggcctgtact ccctgtcctc cgtcgtgacc gtgccttcca gctctctggg cacccagacc 600
tacatctgca acgtgaacca caagccctcc aacaccaagg tggacaagaa ggtggaaccc 660
aagtcctgcg acaagaccca cacctgtccc ccttgtcctg cccctgaact gctgggcgga 720
ccttccgtgt tcctgttccc cccaaagccc aaggacaccc tgatgatctc ccggaccccc 780
gaagtgacct gcgtggtggt ggatgtgtcc cacgaggacc ctgaagtgaa gttcaattgg 840
tacgtggacg gcgtggaagt gcacaacgcc aagaccaagc ctagagagga acagtacaac 900
tccacctacc gggtggtgtc cgtgctgacc gtgctgcacc aggattggct gaacggcaaa 960
gagtacaagt gcaaggtgtc caacaaggcc ctgcctgccc ccatcgaaaa gaccatctcc 1020
aaggccaagg gccagccccg ggaaccccag gtgtacacac tgccccctag cagggacgag 1080
ctgaccaaga accaggtgtc cctgacctgt ctcgtgaaag gcttctaccc ctccgatatc 1140
gccgtggaat gggagtccaa cggccagcct gagaacaact acaagaccac cccccctgtg 1200
ctggactccg acggctcatt cttcctgtac agcaagctga cagtggacaa gtcccggtgg 1260
cagcagggca acgtgttctc ctgctccgtg atgcacgagg ccctgcacaa ccactacacc 1320
cagaagtccc tgtccctgag ccccggcaag 1350
<210> 182
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 182
Gln Ser Val Leu Tyr Ser Ser Asn Ser Lys Asn Phe
1 5 10
<210> 183
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 183
Trp Ala Ser
1
<210> 184
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 184
Gln Gln Tyr Tyr Ser Thr Pro Arg Thr
1 5
<210> 185
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 185
Lys Ser Ser Gln Ser Val Leu Tyr Ser Ser Asn Ser Lys Asn Phe Leu
1 5 10 15
Ala
<210> 186
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 186
Trp Ala Ser Thr Arg Gly Ser
1 5
<210> 187
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 187
Gln Gln Tyr Tyr Ser Thr Pro Arg Thr
1 5
<210> 188
<211> 113
<212> PRT
<213> Homo Sapiens
<400> 188
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Ser Lys Asn Phe Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Phe Ile Tyr Trp Ala Ser Thr Arg Gly Ser Gly Val
50 55 60
Pro Asp Arg Ile Ser Gly Ser Gly Ser Gly Thr Asp Phe Asn Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Pro Arg Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 189
<211> 340
<212> DNA
<213> Homo Sapiens
<400> 189
gacatcgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtgtttta tacagctcca acagtaagaa cttcttagct 120
tggtaccagc agaaaccggg acagcctcct aagctgttca tttactgggc atctacccgg 180
ggatccgggg tccctgaccg aatcagtggc agcgggtctg ggacagattt caatctcacc 240
atcagcagcc tgcaggctga agatgtggca gtttattact gtcaacaata ttatagtact 300
cctcggacgt tcggccaagg gaccaaggtg gagatcaaac 340
<210> 190
<211> 220
<212> PRT
<213> Homo Sapiens
<400> 190
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Val Leu Tyr Ser
20 25 30
Ser Asn Ser Lys Asn Phe Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Phe Ile Tyr Trp Ala Ser Thr Arg Gly Ser Gly Val
50 55 60
Pro Asp Arg Ile Ser Gly Ser Gly Ser Gly Thr Asp Phe Asn Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Thr Pro Arg Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 191
<211> 660
<212> DNA
<213> Homo Sapiens
<400> 191
gacatcgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtgtttta tacagctcca acagtaagaa cttcttagct 120
tggtaccagc agaaaccggg acagcctcct aagctgttca tttactgggc atctacccgg 180
ggatccgggg tccctgaccg aatcagtggc agcgggtctg ggacagattt caatctcacc 240
atcagcagcc tgcaggctga agatgtggca gtttattact gtcaacaata ttatagtact 300
cctcggacgt tcggccaagg gaccaaggtg gagatcaaac gtacggtggc cgctccctcc 360
gtgttcatct tcccaccttc cgacgagcag ctgaagtccg gcaccgcttc tgtcgtgtgc 420
ctgctgaaca acttctaccc ccgcgaggcc aaggtgcagt ggaaggtgga caacgccctg 480
cagtccggca actcccagga atccgtgacc gagcaggact ccaaggacag cacctactcc 540
ctgtcctcca ccctgaccct gtccaaggcc gactacgaga agcacaaggt gtacgcctgc 600
gaagtgaccc accagggcct gtctagcccc gtgaccaagt ctttcaaccg gggcgagtgt 660
<210> 192
<211> 981
<212> DNA
<213> Homo Sapiens
<400> 192
gcttccacca agggcccatc cgtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacagccg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacgaagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagag agttgagtcc 300
aaatatggtc ccccatgccc atcatgccca gcacctgagt tcctgggggg accatcagtc 360
ttcctgttcc ccccaaaacc caaggacact ctcatgatct cccggacccc tgaggtcacg 420
tgcgtggtgg tggacgtgag ccaggaagac cccgaggtcc agttcaactg gtacgtggat 480
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagttcaa cagcacgtac 540
cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaacggcaa ggagtacaag 600
tgcaaggtct ccaacaaagg cctcccgtcc tccatcgaga aaaccatctc caaagccaaa 660
gggcagcccc gagagccaca ggtgtacacc ctgcccccat cccaggagga gatgaccaag 720
aaccaggtca gcctgacctg cctggtcaaa ggcttctacc ccagcgacat cgccgtggag 780
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 840
gacggctcct tcttcctcta cagcaggcta accgtggaca agagcaggtg gcaggagggg 900
aatgtcttct catgctccgt gatgcatgag gctctgcaca accactacac acagaagagc 960
ctctccctgt ctctgggtaa a 981
<210> 193
<211> 327
<212> PRT
<213> Homo Sapiens
<400> 193
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Ser Cys Pro Ala Pro
100 105 110
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 194
<211> 981
<212> DNA
<213> Homo Sapiens
<400> 194
gcttccacca agggcccatc cgtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacagccg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacgaagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagag agttgagtcc 300
aaatatggtc ccccgtgccc atcatgccca gcacctgagt tcctgggggg accatcagtc 360
ttcctgttcc ccccaaaacc caaggacact ctcatgatct cccggacccc tgaggtcacg 420
tgcgtggtgg tggacgtgag ccaggaagac cccgaggtcc agttcaactg gtacgtggat 480
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagttcaa cagcacgtac 540
cgtgtggtca gcgtcctcac cgtcgtgcac caggactggc tgaacggcaa ggagtacaag 600
tgcaaggtct ccaacaaagg cctcccgtcc tccatcgaga aaaccatctc caaagccaaa 660
gggcagcccc gagagccaca ggtgtacacc ctgcccccat cccaggagga gatgaccaag 720
aaccaggtca gcctgacctg cctggtcaaa ggcttctacc ccagcgacat cgccgtggag 780
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 840
gacggctcct tcttcctcta cagcaggcta accgtggaca agagcaggtg gcaggagggg 900
aatgtcttct catgctccgt gatgcatgag gctctgcaca accactacac gcagaagagc 960
ctctccctgt ctctgggtaa a 981
<210> 195
<211> 327
<212> PRT
<213> Homo Sapiens
<400> 195
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Ser Cys Pro Ala Pro
100 105 110
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Val His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 196
<211> 981
<212> DNA
<213> Homo Sapiens
<400> 196
gcttccacca agggcccatc cgtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacagccg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacgaagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagag agttgagtcc 300
aaatatggtc ccccatgccc atcatgccca gcacctgagt tcctgggggg accatcagtc 360
ttcctgttcc ccccaaaacc caaggacact ctcatgatct cccggacccc tgaggtcacg 420
tgcgtggtgg tggacgtgag ccaggaagac cccgaggtcc agttcaactg gtacgtggat 480
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagttcaa cagcacgtac 540
cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaacggcaa ggagtacaag 600
tgcaaggtct ccaacaaagg cctcccgtcc tccatcgaga aaaccatctc caaagccaaa 660
gggcagcccc gagagccaca ggtgtacacc ctgcccccat cccaggagga gatgaccaag 720
aaccaggtca gcctgacctg cctggtcaaa ggcttctacc ccagcgacat cgccgtggag 780
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 840
gacggctcct tcttcctcta cagcaagctc accgtggaca agagcaggtg gcaggagggg 900
aacgtcttct catgctccgt gatgcatgag gctctgcaca accactacac gcagaagagc 960
ctctccctgt ctctgggtaa a 981
<210> 197
<211> 327
<212> PRT
<213> Homo Sapiens
<400> 197
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Ser Cys Pro Ala Pro
100 105 110
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 198
<211> 981
<212> DNA
<213> Homo Sapiens
<400> 198
gcctccacca agggcccatc cgtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacggccg ccctgggctg cctggtcaag gactacttcc ccgaaccagt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacgaagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagag agttgagtcc 300
aaatatggtc ccccatgccc accatgccca gcgcctgaat ttgagggggg accatcagtc 360
ttcctgttcc ccccaaaacc caaggacact ctcatgatct cccggacccc tgaggtcacg 420
tgcgtggtgg tggacgtgag ccaggaagac cccgaggtcc agttcaactg gtacgtggat 480
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagttcaa cagcacgtac 540
cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaacggcaa ggagtacaag 600
tgcaaggtct ccaacaaagg cctcccgtca tcgatcgaga aaaccatctc caaagccaaa 660
gggcagcccc gagagccaca ggtgtacacc ctgcccccat cccaggagga gatgaccaag 720
aaccaggtca gcctgacctg cctggtcaaa ggcttctacc ccagcgacat cgccgtggag 780
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 840
gacggatcct tcttcctcta cagcaggcta accgtggaca agagcaggtg gcaggagggg 900
aatgtcttct catgctccgt gatgcatgag gctctgcaca accactacac acagaagagc 960
ctctccctgt ctctgggtaa a 981
<210> 199
<211> 327
<212> PRT
<213> Homo Sapiens
<400> 199
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
100 105 110
Glu Phe Glu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 200
<211> 981
<212> DNA
<213> Homo Sapiens
<400> 200
gcctccacca agggacctag cgtgttccct ctcgccccct gttccaggtc cacaagcgag 60
tccaccgctg ccctcggctg tctggtgaaa gactactttc ccgagcccgt gaccgtctcc 120
tggaatagcg gagccctgac ctccggcgtg cacacatttc ccgccgtgct gcagagcagc 180
ggactgtata gcctgagcag cgtggtgacc gtgcccagct ccagcctcgg caccaaaacc 240
tacacctgca acgtggacca caagccctcc aacaccaagg tggacaagcg ggtggagagc 300
aagtacggcc ccccttgccc tccttgtcct gcccctgagt tcgagggagg accctccgtg 360
ttcctgtttc cccccaaacc caaggacacc ctgatgatct cccggacacc cgaggtgacc 420
tgtgtggtcg tggacgtcag ccaggaggac cccgaggtgc agttcaactg gtatgtggac 480
ggcgtggagg tgcacaatgc caaaaccaag cccagggagg agcagttcaa ttccacctac 540
agggtggtga gcgtgctgac cgtcctgcat caggattggc tgaacggcaa ggagtacaag 600
tgcaaggtgt ccaacaaggg actgcccagc tccatcgaga agaccatcag caaggctaag 660
ggccagccga gggagcccca ggtgtatacc ctgcctccta gccaggaaga gatgaccaag 720
aaccaagtgt ccctgacctg cctggtgaag ggattctacc cctccgacat cgccgtggag 780
tgggagagca atggccagcc cgagaacaac tacaaaacaa cccctcccgt gctcgatagc 840
gacggcagct tctttctcta cagccggctg acagtggaca agagcaggtg gcaggagggc 900
aacgtgttct cctgttccgt gatgcacgag gccctgcaca atcactacac ccagaagagc 960
ctctccctgt ccctgggcaa g 981
<210> 201
<211> 981
<212> DNA
<213> Homo Sapiens
<400> 201
gccagcacca agggcccttc cgtgttcccc ctggcccctt gcagcaggag cacctccgaa 60
tccacagctg ccctgggctg tctggtgaag gactactttc ccgagcccgt gaccgtgagc 120
tggaacagcg gcgctctgac atccggcgtc cacacctttc ctgccgtcct gcagtcctcc 180
ggcctctact ccctgtcctc cgtggtgacc gtgcctagct cctccctcgg caccaagacc 240
tacacctgta acgtggacca caaaccctcc aacaccaagg tggacaaacg ggtcgagagc 300
aagtacggcc ctccctgccc tccttgtcct gcccccgagt tcgaaggcgg acccagcgtg 360
ttcctgttcc ctcctaagcc caaggacacc ctcatgatca gccggacacc cgaggtgacc 420
tgcgtggtgg tggatgtgag ccaggaggac cctgaggtcc agttcaactg gtatgtggat 480
ggcgtggagg tgcacaacgc caagacaaag ccccgggaag agcagttcaa ctccacctac 540
agggtggtca gcgtgctgac cgtgctgcat caggactggc tgaacggcaa ggagtacaag 600
tgcaaggtca gcaataaggg actgcccagc agcatcgaga agaccatctc caaggctaaa 660
ggccagcccc gggaacctca ggtgtacacc ctgcctccca gccaggagga gatgaccaag 720
aaccaggtga gcctgacctg cctggtgaag ggattctacc cttccgacat cgccgtggag 780
tgggagtcca acggccagcc cgagaacaat tataagacca cccctcccgt cctcgacagc 840
gacggatcct tctttctgta ctccaggctg accgtggata agtccaggtg gcaggaaggc 900
aacgtgttca gctgctccgt gatgcacgag gccctgcaca atcactacac ccagaagtcc 960
ctgagcctgt ccctgggaaa g 981
<210> 202
<211> 981
<212> DNA
<213> Homo Sapiens
<400> 202
gcctccacca agggcccatc cgtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacggccg ccctgggctg cctggtcaag gactacttcc ccgaaccagt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacgaagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagag agttgagtcc 300
aaatatggtc ccccatgccc accatgccca gcgcctccag ttgcgggggg accatcagtc 360
ttcctgttcc ccccaaaacc caaggacact ctcatgatct cccggacccc tgaggtcacg 420
tgcgtggtgg tggacgtgag ccaggaagac cccgaggtcc agttcaactg gtacgtggat 480
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagttcaa cagcacgtac 540
cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaacggcaa ggagtacaag 600
tgcaaggtct ccaacaaagg cctcccgtca tcgatcgaga aaaccatctc caaagccaaa 660
gggcagcccc gagagccaca ggtgtacacc ctgcccccat cccaggagga gatgaccaag 720
aaccaggtca gcctgacctg cctggtcaaa ggcttctacc ccagcgacat cgccgtggag 780
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 840
gacggatcct tcttcctcta cagcaggcta accgtggaca agagcaggtg gcaggagggg 900
aatgtcttct catgctccgt gatgcatgag gctctgcaca accactacac acagaagagc 960
ctctccctgt ctctgggtaa a 981
<210> 203
<211> 327
<212> PRT
<213> Homo Sapiens
<400> 203
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 204
<211> 990
<212> DNA
<213> Homo Sapiens
<400> 204
gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg 60
ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc 240
tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa agtggagccc 300
aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact cgcgggggca 360
ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420
gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 480
tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac 540
agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag 600
gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660
aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggatgag 720
ctgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 780
gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg 840
ctggactccg acggctcctt cttcctctac agcaagctca ccgtggacaa gagcaggtgg 900
cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960
cagaagagcc tctccctgtc tccgggtaaa 990
<210> 205
<211> 330
<212> PRT
<213> Homo Sapiens
<400> 205
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Ala Gly Ala Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 206
<211> 321
<212> DNA
<213> Homo Sapiens
<400> 206
cgtacggtgg ccgctccctc cgtgttcatc ttcccacctt ccgacgagca gctgaagtcc 60
ggcaccgctt ctgtcgtgtg cctgctgaac aacttctacc cccgcgaggc caaggtgcag 120
tggaaggtgg acaacgccct gcagtccggc aactcccagg aatccgtgac cgagcaggac 180
tccaaggaca gcacctactc cctgtcctcc accctgaccc tgtccaaggc cgactacgag 240
aagcacaagg tgtacgcctg cgaagtgacc caccagggcc tgtctagccc cgtgaccaag 300
tctttcaacc ggggcgagtg t 321
<210> 207
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 207
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 208
<211> 321
<212> DNA
<213> Homo Sapiens
<400> 208
cgaactgtgg ctgcaccatc tgtcttcatc ttcccgccat ctgatgagca gttgaaatct 60
ggaactgcct ctgttgtgtg cctgctgaat aacttctatc ccagagaggc caaagtacag 120
tggaaggtgg ataacgccct ccaatcgggt aactcccagg agagtgtcac agagcaggag 180
agcaaggaca gcacctacag cctcagcagc accctgacgc tgagcaaagc agactacgag 240
aaacacaaag tctacgccgg cgaagtcacc catcagggcc tgagctcgcc cgtcacaaag 300
agcttcaaca ggggagagtg t 321
<210> 209
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 209
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Glu Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Gly Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 210
<211> 321
<212> DNA
<213> Homo Sapiens
<400> 210
cgaactgtgg ctgcaccatc tgtcttcatc ttcccgccat ctgatgagca gttgaaatct 60
ggaactgcct ctgttgtgtg cctgctgaat aacttctatc ccagagaggc caaagtacag 120
cggaaggtgg ataacgccct ccaatcgggt aactcccagg agagtgtcac agagcaggag 180
agcaaggaca gcacctacag cctcagcagc accctgacgc tgagcaaagc agactacgag 240
aaacacaaag tctacgcctg cgaagtcacc catcagggcc tgagctcgcc cgtcacaaag 300
agcttcaaca ggggagagtg t 321
<210> 211
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 211
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Arg Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Glu Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 212
<211> 321
<212> DNA
<213> Homo Sapiens
<400> 212
cgaactgtgg ctgcaccatc tgtcttcatc ttcccgccat ctgatgagca gttgaaatct 60
ggaactgcct ctgttgtgtg cctgctgaat aacttctatc ccagagaggc caaagtacag 120
tggaaggtgg ataacgccct ccaatcgggt aactcccagg agagtgtcac agagcaggac 180
agcaaggaca gcacctacag cctcagcagc accctgacgc tgagcaaagc agactacgag 240
aaacacaaac tctacgcctg cgaagtcacc catcagggcc tgagctcgcc cgtcacaaag 300
agcttcaaca ggggagagtg t 321
<210> 213
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 213
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 214
<211> 321
<212> DNA
<213> Homo Sapiens
<400> 214
cgaactgtgg ctgcaccatc tgtcttcatc ttcccgccat ctgatgagca gttgaaatct 60
ggaactgcct ctgttgtgtg cctgctgaat aacttctatc ccagagaggc caaagtacag 120
tggaaggtgg ataacgccct ccaatcgggt aactcccagg agagtgtcac agagcaggac 180
agcaaggaca gcacctacag cctcagcaac accctgacgc tgagcaaagc agactacgag 240
aaacacaaag tctacgcctg cgaagtcacc catcagggcc tgagctcgcc cgtcacaaag 300
agcttcaaca ggggagagtg c 321
<210> 215
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 215
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Asn Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 216
<211> 312
<212> DNA
<213> Homo Sapiens
<400> 216
cccaaggcca accccacggt cactctgttc ccgccctcct ctgaggagct ccaagccaac 60
aaggccacac tagtgtgtct gatcagtgac ttctacccgg gagctgtgac agtggcttgg 120
aaggcagatg gcagccccgt caaggcggga gtggagacga ccaaaccctc caaacagagc 180
aacaacaagt acgcggccag cagctacctg agcctgacgc ccgagcagtg gaagtcccac 240
agaagctaca gctgccaggt cacgcatgaa gggagcaccg tggagaagac agtggcccct 300
acagaatgtt ca 312
<210> 217
<211> 104
<212> PRT
<213> Homo Sapiens
<400> 217
Pro Lys Ala Asn Pro Thr Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
1 5 10 15
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
20 25 30
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Gly Ser Pro Val Lys
35 40 45
Ala Gly Val Glu Thr Thr Lys Pro Ser Lys Gln Ser Asn Asn Lys Tyr
50 55 60
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
65 70 75 80
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
85 90 95
Thr Val Ala Pro Thr Glu Cys Ser
100
<210> 218
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 218
ggtcagccca aggccaaccc cactgtcact ctgttcccgc cctcctctga ggagctccaa 60
gccaacaagg ccacactagt gtgtctgatc agtgacttct acccgggagc tgtgacagtg 120
gcctggaagg cagatggcag ccccgtcaag gcgggagtgg agaccaccaa accctccaaa 180
cagagcaaca acaagtacgc ggccagcagc tacctgagcc tgacgcccga gcagtggaag 240
tcccacagaa gctacagctg ccaggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctacag aatgttca 318
<210> 219
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 219
Gly Gln Pro Lys Ala Asn Pro Thr Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Gly Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Lys Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 220
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 220
ggtcagccca aggccaaccc cactgtcact ctgttcccgc cctcctctga ggagctccaa 60
gccaacaagg ccacactagt gtgtctgatc agtgacttct acccgggagc tgtgacagtg 120
gcctggaagg cagatggcag ccccgtcaag gcgggagtgg agaccaccaa accctccaaa 180
cagagcaaca acaagtacgc ggccagcagc tacctgagcc tgacgcccga gcagtggaag 240
tcccacagaa gctacagctg ccaggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctacag aatgttca 318
<210> 221
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 221
ggccagccta aggccgctcc ttctgtgacc ctgttccccc catcctccga ggaactgcag 60
gctaacaagg ccaccctcgt gtgcctgatc agcgacttct accctggcgc cgtgaccgtg 120
gcctggaagg ctgatagctc tcctgtgaag gccggcgtgg aaaccaccac cccttccaag 180
cagtccaaca acaaatacgc cgcctcctcc tacctgtccc tgacccctga gcagtggaag 240
tcccaccggt cctacagctg ccaagtgacc cacgagggct ccaccgtgga aaagaccgtg 300
gctcctaccg agtgctcc 318
<210> 222
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 222
ggccagccta aagctgcccc cagcgtcacc ctgtttcctc cctccagcga ggagctccag 60
gccaacaagg ccaccctcgt gtgcctgatc tccgacttct atcccggcgc tgtgaccgtg 120
gcttggaaag ccgactccag ccctgtcaaa gccggcgtgg agaccaccac accctccaag 180
cagtccaaca acaagtacgc cgcctccagc tatctctccc tgacccctga gcagtggaag 240
tcccaccggt cctactcctg tcaggtgacc cacgagggct ccaccgtgga aaagaccgtc 300
gcccccaccg agtgctcc 318
<210> 223
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 223
Gly Gln Pro Lys Ala Asn Pro Thr Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Gly Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Lys Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 224
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 224
ggtcagccca aggctgcccc ctcggtcact ctgttcccgc cctcctctga ggagcttcaa 60
gccaacaagg ccacactggt gtgtctcata agtgacttct acccgggagc cgtgacagtg 120
gcctggaagg cagatagcag ccccgtcaag gcgggagtgg agaccaccac accctccaaa 180
caaagcaaca acaagtacgc ggccagcagc tatctgagcc tgacgcctga gcagtggaag 240
tcccacagaa gctacagctg ccaggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctacag aatgttca 318
<210> 225
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 225
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 226
<211> 312
<212> DNA
<213> Homo Sapiens
<400> 226
cccaaggctg ccccctcggt cactctgttc ccaccctcct ctgaggagct tcaagccaac 60
aaggccacac tggtgtgtct cataagtgac ttctacccgg gagccgtgac agttgcctgg 120
aaggcagata gcagccccgt caaggcgggg gtggagacca ccacaccctc caaacaaagc 180
aacaacaagt acgcggccag cagctacctg agcctgacgc ctgagcagtg gaagtcccac 240
aaaagctaca gctgccaggt cacgcatgaa gggagcaccg tggagaagac agttgcccct 300
acggaatgtt ca 312
<210> 227
<211> 104
<212> PRT
<213> Homo Sapiens
<400> 227
Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
1 5 10 15
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
20 25 30
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
35 40 45
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
50 55 60
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
65 70 75 80
Lys Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
85 90 95
Thr Val Ala Pro Thr Glu Cys Ser
100
<210> 228
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 228
ggtcagccca aggctgcccc ctcggtcact ctgttcccac cctcctctga ggagcttcaa 60
gccaacaagg ccacactggt gtgtctcata agtgacttct acccggggcc agtgacagtt 120
gcctggaagg cagatagcag ccccgtcaag gcgggggtgg agaccaccac accctccaaa 180
caaagcaaca acaagtacgc ggccagcagc tacctgagcc tgacgcctga gcagtggaag 240
tcccacaaaa gctacagctg ccaggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctacgg aatgttca 318
<210> 229
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 229
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Pro Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Lys Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 230
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 230
ggtcagccca aggctgcccc ctcggtcact ctgttcccac cctcctctga ggagcttcaa 60
gccaacaagg ccacactggt gtgtctcata agtgacttct acccgggagc cgtgacagtg 120
gcctggaagg cagatagcag ccccgtcaag gcgggagtgg agaccaccac accctccaaa 180
caaagcaaca acaagtacgc ggccagcagc tacctgagcc tgacgcctga gcagtggaag 240
tcccacaaaa gctacagctg ccaggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctacag aatgttca 318
<210> 231
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 231
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Lys Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 232
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 232
ggtcagccca aggctgcccc ctcggtcact ctgttcccgc cctcctctga ggagcttcaa 60
gccaacaagg ccacactggt gtgtctcata agtgacttct acccgggagc cgtgacagtg 120
gcctggaagg cagatagcag ccccgtcaag gcgggagtgg agaccaccac accctccaaa 180
caaagcaaca acaagtacgc ggccagcagc tacctgagcc tgacgcctga gcagtggaag 240
tcccacagaa gctacagctg ccaggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctacag aatgttca 318
<210> 233
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 233
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 234
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 234
ggtcagccca aggctgcccc atcggtcact ctgttcccgc cctcctctga ggagcttcaa 60
gccaacaagg ccacactggt gtgcctgatc agtgacttct acccgggagc tgtgaaagtg 120
gcctggaagg cagatggcag ccccgtcaac acgggagtgg agaccaccac accctccaaa 180
cagagcaaca acaagtacgc ggccagcagc tacctgagcc tgacgcctga gcagtggaag 240
tcccacagaa gctacagctg ccaggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctgcag aatgttca 318
<210> 235
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 235
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Lys Val Ala Trp Lys Ala Asp Gly Ser Pro
35 40 45
Val Asn Thr Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Ala Glu Cys Ser
100 105
<210> 236
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 236
ggtcagccca aggctgcccc atcggtcact ctgttcccac cctcctctga ggagcttcaa 60
gccaacaagg ccacactggt gtgtctcgta agtgacttct acccgggagc cgtgacagtg 120
gcctggaagg cagatggcag ccccgtcaag gtgggagtgg agaccaccaa accctccaaa 180
caaagcaaca acaagtatgc ggccagcagc tacctgagcc tgacgcccga gcagtggaag 240
tcccacagaa gctacagctg ccgggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctgcag aatgctct 318
<210> 237
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 237
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Val Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Gly Ser Pro
35 40 45
Val Lys Val Gly Val Glu Thr Thr Lys Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Arg Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Ala Glu Cys Ser
100 105
<210> 238
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 238
Gly Phe Thr Phe Ser Asp Tyr Tyr
1 5
<210> 239
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 239
Ile Ser Thr Ser Gly Ser Thr Ile
1 5
<210> 240
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 240
Ala Arg Gly Ile Thr Gly Thr Asn Phe Tyr His Tyr Gly Leu Gly Val
1 5 10 15
<210> 241
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 241
Asp Tyr Tyr Met Ser
1 5
<210> 242
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 242
Tyr Ile Ser Thr Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 243
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 243
Gly Ile Thr Gly Thr Asn Phe Tyr His Tyr Gly Leu Gly Val
1 5 10
<210> 244
<211> 123
<212> PRT
<213> Homo Sapiens
<400> 244
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Thr Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Ala Ala Val Tyr His Cys
85 90 95
Ala Arg Gly Ile Thr Gly Thr Asn Phe Tyr His Tyr Gly Leu Gly Val
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 245
<211> 370
<212> DNA
<213> Homo Sapiens
<400> 245
caggtgcagc tggtggagtc tgggggaggc ttggtcaagc ctggagggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt gactactaca tgagctggat ccgccaggtt 120
ccagggaagg ggctggagtg ggtttcatac attagtacta gtggtagtac catatactac 180
gcagactctg tgaagggccg attcaccatc tccagggaca acgccaagaa ctcactgtat 240
ctacaaatga acagcctgag agccgaggac gcggccgtgt atcactgtgc gagaggtata 300
actggaacta acttctacca ctacggtttg ggcgtctggg gccaagggac cacggtcacc 360
gtctcctcag 370
<210> 246
<211> 453
<212> PRT
<213> Homo Sapiens
<400> 246
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Thr Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Ala Ala Val Tyr His Cys
85 90 95
Ala Arg Gly Ile Thr Gly Thr Asn Phe Tyr His Tyr Gly Leu Gly Val
100 105 110
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 247
<211> 1359
<212> DNA
<213> Homo Sapiens
<400> 247
caggtgcagc tggtggagtc tgggggaggc ttggtcaagc ctggagggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt gactactaca tgagctggat ccgccaggtt 120
ccagggaagg ggctggagtg ggtttcatac attagtacta gtggtagtac catatactac 180
gcagactctg tgaagggccg attcaccatc tccagggaca acgccaagaa ctcactgtat 240
ctacaaatga acagcctgag agccgaggac gcggccgtgt atcactgtgc gagaggtata 300
actggaacta acttctacca ctacggtttg ggcgtctggg gccaagggac cacggtcacc 360
gtctcctcag ccagcaccaa gggcccctct gtgttccctc tggccccttc cagcaagtcc 420
acctctggcg gaacagccgc tctgggctgc ctcgtgaagg actacttccc cgagcctgtg 480
accgtgtcct ggaactctgg cgctctgacc agcggagtgc acaccttccc tgctgtgctg 540
cagtcctccg gcctgtactc cctgtcctcc gtcgtgaccg tgccttccag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagccctcca acaccaaggt ggacaagaag 660
gtggaaccca agtcctgcga caagacccac acctgtcccc cttgtcctgc ccctgaactg 720
ctgggcggac cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatctcc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaact ccacctaccg ggtggtgtcc gtgctgaccg tgctgcacca ggattggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgaaaag 1020
accatctcca aggccaaggg ccagccccgg gaaccccagg tgtacacact gccccctagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagtccaac ggccagcctg agaacaacta caagaccacc 1200
ccccctgtgc tggactccga cggctcattc ttcctgtaca gcaagctgac agtggacaag 1260
tcccggtggc agcagggcaa cgtgttctcc tgctccgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gtccctgagc cccggcaag 1359
<210> 248
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 248
Gln Gly Ile Asn Ser Trp
1 5
<210> 249
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 249
Ala Ala Ser
1
<210> 250
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 250
Gln Gln Val Asn Ser Phe Pro Leu Thr
1 5
<210> 251
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 251
Arg Ala Ser Gln Gly Ile Asn Ser Trp Leu Ala
1 5 10
<210> 252
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 252
Ala Ala Ser Thr Leu Gln Ser
1 5
<210> 253
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 253
Gln Gln Val Asn Ser Phe Pro Leu Thr
1 5
<210> 254
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 254
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Asn Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Ala Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Val Asn Ser Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 255
<211> 322
<212> DNA
<213> Homo Sapiens
<400> 255
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtaggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtattaac agctggttag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccactt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtgggtc tggggcagat ttcactctca ccatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gttaacagtt tcccgctcac tttcggcgga 300
gggaccaagg tggagatcaa ac 322
<210> 256
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 256
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Asn Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Ala Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Val Asn Ser Phe Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 257
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 257
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtaggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtattaac agctggttag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccactt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtgggtc tggggcagat ttcactctca ccatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gttaacagtt tcccgctcac tttcggcgga 300
gggaccaagg tggagatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 258
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 258
Gly Phe Thr Phe Ser Tyr Tyr Ala
1 5
<210> 259
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 259
Ile Ser Gly Gly Gly Gly Asn Thr
1 5
<210> 260
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 260
Ala Lys Asp Arg Met Lys Gln Leu Val Arg Ala Tyr Tyr Phe Asp Tyr
1 5 10 15
<210> 261
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 261
Tyr Tyr Ala Met Ser
1 5
<210> 262
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 262
Thr Ile Ser Gly Gly Gly Gly Asn Thr His Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 263
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 263
Asp Arg Met Lys Gln Leu Val Arg Ala Tyr Tyr Phe Asp Tyr
1 5 10
<210> 264
<211> 123
<212> PRT
<213> Homo Sapiens
<400> 264
Glu Val Pro Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Tyr Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Asp Trp Val
35 40 45
Ser Thr Ile Ser Gly Gly Gly Gly Asn Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu His Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Arg Met Lys Gln Leu Val Arg Ala Tyr Tyr Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 265
<211> 370
<212> DNA
<213> Homo Sapiens
<400> 265
gaggtgccgc tggtggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacgtttagc tactatgcca tgagctgggt ccgtcaggct 120
ccagggaagg ggctggactg ggtctcaact attagtggtg gtggtggtaa cacacactac 180
gcagactccg tgaagggccg attcactata tccagagaca attccaagaa cacgctgtat 240
ctgcacatga acagcctgag agccgaagac acggccgtct attactgtgc gaaggatcgg 300
atgaaacagc tcgtccgggc ctactacttt gactactggg gccagggaac cctggtcacc 360
gtctcctcag 370
<210> 266
<211> 453
<212> PRT
<213> Homo Sapiens
<400> 266
Glu Val Pro Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Tyr Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Asp Trp Val
35 40 45
Ser Thr Ile Ser Gly Gly Gly Gly Asn Thr His Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu His Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Arg Met Lys Gln Leu Val Arg Ala Tyr Tyr Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 267
<211> 1359
<212> DNA
<213> Homo Sapiens
<400> 267
gaggtgccgc tggtggagtc tgggggaggc ttggtacagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacgtttagc tactatgcca tgagctgggt ccgtcaggct 120
ccagggaagg ggctggactg ggtctcaact attagtggtg gtggtggtaa cacacactac 180
gcagactccg tgaagggccg attcactata tccagagaca attccaagaa cacgctgtat 240
ctgcacatga acagcctgag agccgaagac acggccgtct attactgtgc gaaggatcgg 300
atgaaacagc tcgtccgggc ctactacttt gactactggg gccagggaac cctggtcacc 360
gtctcctcag ccagcaccaa gggcccctct gtgttccctc tggccccttc cagcaagtcc 420
acctctggcg gaacagccgc tctgggctgc ctcgtgaagg actacttccc cgagcctgtg 480
accgtgtcct ggaactctgg cgctctgacc agcggagtgc acaccttccc tgctgtgctg 540
cagtcctccg gcctgtactc cctgtcctcc gtcgtgaccg tgccttccag ctctctgggc 600
acccagacct acatctgcaa cgtgaaccac aagccctcca acaccaaggt ggacaagaag 660
gtggaaccca agtcctgcga caagacccac acctgtcccc cttgtcctgc ccctgaactg 720
ctgggcggac cttccgtgtt cctgttcccc ccaaagccca aggacaccct gatgatctcc 780
cggacccccg aagtgacctg cgtggtggtg gatgtgtccc acgaggaccc tgaagtgaag 840
ttcaattggt acgtggacgg cgtggaagtg cacaacgcca agaccaagcc tagagaggaa 900
cagtacaact ccacctaccg ggtggtgtcc gtgctgaccg tgctgcacca ggattggctg 960
aacggcaaag agtacaagtg caaggtgtcc aacaaggccc tgcctgcccc catcgaaaag 1020
accatctcca aggccaaggg ccagccccgg gaaccccagg tgtacacact gccccctagc 1080
agggacgagc tgaccaagaa ccaggtgtcc ctgacctgtc tcgtgaaagg cttctacccc 1140
tccgatatcg ccgtggaatg ggagtccaac ggccagcctg agaacaacta caagaccacc 1200
ccccctgtgc tggactccga cggctcattc ttcctgtaca gcaagctgac agtggacaag 1260
tcccggtggc agcagggcaa cgtgttctcc tgctccgtga tgcacgaggc cctgcacaac 1320
cactacaccc agaagtccct gtccctgagc cccggcaag 1359
<210> 268
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 268
Gln Asp Ile Ser Thr Tyr
1 5
<210> 269
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 269
Gly Thr Ser
1
<210> 270
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 270
Gln Gln Leu His Thr Asp Pro Ile Thr
1 5
<210> 271
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 271
Trp Ala Ser Gln Asp Ile Ser Thr Tyr Leu Gly
1 5 10
<210> 272
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 272
Gly Thr Ser Ser Leu Gln Ser
1 5
<210> 273
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 273
Gln Gln Leu His Thr Asp Pro Ile Thr
1 5
<210> 274
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 274
Asp Ile Gln Leu Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Trp Ala Ser Gln Asp Ile Ser Thr Tyr
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Thr Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Leu His Thr Asp Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105
<210> 275
<211> 322
<212> DNA
<213> Homo Sapiens
<400> 275
gacatccagt tgacccagtc tccatccttc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgct gggccagtca ggacattagc acttatttag gctggtatca gcaaaaacca 120
gggaaagccc ctaagctcct gatctatggt acatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagaa ttcactctca caatcagcag cctgcagcct 240
gaagattttg caacttatta ctgtcaacag cttcatactg acccgatcac cttcggccaa 300
gggacacgac tggagatcaa ac 322
<210> 276
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 276
Asp Ile Gln Leu Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Trp Ala Ser Gln Asp Ile Ser Thr Tyr
20 25 30
Leu Gly Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Gly Thr Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Leu His Thr Asp Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 277
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 277
gacatccagt tgacccagtc tccatccttc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgct gggccagtca ggacattagc acttatttag gctggtatca gcaaaaacca 120
gggaaagccc ctaagctcct gatctatggt acatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagaa ttcactctca caatcagcag cctgcagcct 240
gaagattttg caacttatta ctgtcaacag cttcatactg acccgatcac cttcggccaa 300
gggacacgac tggagatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 278
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 278
Gly Phe Thr Phe Ser Ser Tyr Trp
1 5
<210> 279
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 279
Ile Lys Gln Asp Gly Ser Glu Lys
1 5
<210> 280
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 280
Ala Arg Val Arg Gln Trp Ser Asp Tyr Ser Asp Tyr
1 5 10
<210> 281
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 281
Ser Tyr Trp Met Asn
1 5
<210> 282
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 282
Asn Ile Lys Gln Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val Lys
1 5 10 15
Gly
<210> 283
<211> 10
<212> PRT
<213> Homo Sapiens
<400> 283
Val Arg Gln Trp Ser Asp Tyr Ser Asp Tyr
1 5 10
<210> 284
<211> 119
<212> PRT
<213> Homo Sapiens
<400> 284
Glu Val His Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Gln Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Val Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Arg Gln Trp Ser Asp Tyr Ser Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Pro Val Thr Val Ser Ser
115
<210> 285
<211> 358
<212> DNA
<213> Homo Sapiens
<400> 285
gaggtgcacc tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagt agctattgga tgaactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtggccaac ataaagcaag atggaagtga gaaatactat 180
gtggactctg tgaagggccg cttcaccgtc tccagagaca acgccaagaa ctcactgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagagttcga 300
caatggtccg actactctga ctactggggc cagggaaccc cggtcaccgt ctcctcag 358
<210> 286
<211> 449
<212> PRT
<213> Homo Sapiens
<400> 286
Glu Val His Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Lys Gln Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Val Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Arg Gln Trp Ser Asp Tyr Ser Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Pro Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys
210 215 220
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
260 265 270
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440 445
Lys
<210> 287
<211> 1347
<212> DNA
<213> Homo Sapiens
<400> 287
gaggtgcacc tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagt agctattgga tgaactgggt ccgccaggct 120
ccagggaagg ggctggagtg ggtggccaac ataaagcaag atggaagtga gaaatactat 180
gtggactctg tgaagggccg cttcaccgtc tccagagaca acgccaagaa ctcactgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gagagttcga 300
caatggtccg actactctga ctactggggc cagggaaccc cggtcaccgt ctcctcagcc 360
agcaccaagg gcccctctgt gttccctctg gccccttcca gcaagtccac ctctggcgga 420
acagccgctc tgggctgcct cgtgaaggac tacttccccg agcctgtgac cgtgtcctgg 480
aactctggcg ctctgaccag cggagtgcac accttccctg ctgtgctgca gtcctccggc 540
ctgtactccc tgtcctccgt cgtgaccgtg ccttccagct ctctgggcac ccagacctac 600
atctgcaacg tgaaccacaa gccctccaac accaaggtgg acaagaaggt ggaacccaag 660
tcctgcgaca agacccacac ctgtccccct tgtcctgccc ctgaactgct gggcggacct 720
tccgtgttcc tgttcccccc aaagcccaag gacaccctga tgatctcccg gacccccgaa 780
gtgacctgcg tggtggtgga tgtgtcccac gaggaccctg aagtgaagtt caattggtac 840
gtggacggcg tggaagtgca caacgccaag accaagccta gagaggaaca gtacaactcc 900
acctaccggg tggtgtccgt gctgaccgtg ctgcaccagg attggctgaa cggcaaagag 960
tacaagtgca aggtgtccaa caaggccctg cctgccccca tcgaaaagac catctccaag 1020
gccaagggcc agccccggga accccaggtg tacacactgc cccctagcag ggacgagctg 1080
accaagaacc aggtgtccct gacctgtctc gtgaaaggct tctacccctc cgatatcgcc 1140
gtggaatggg agtccaacgg ccagcctgag aacaactaca agaccacccc ccctgtgctg 1200
gactccgacg gctcattctt cctgtacagc aagctgacag tggacaagtc ccggtggcag 1260
cagggcaacg tgttctcctg ctccgtgatg cacgaggccc tgcacaacca ctacacccag 1320
aagtccctgt ccctgagccc cggcaag 1347
<210> 288
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 288
Gln Gly Ile Ser Ser Trp
1 5
<210> 289
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 289
Ala Ala Ser
1
<210> 290
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 290
Gln Gln Ala Asn Ser Phe Pro Phe Thr
1 5
<210> 291
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 291
Arg Ala Ser Gln Gly Ile Ser Ser Trp Leu Ala
1 5 10
<210> 292
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 292
Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 293
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 293
Gln Gln Ala Asn Ser Phe Pro Phe Thr
1 5
<210> 294
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 294
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105
<210> 295
<211> 322
<212> DNA
<213> Homo Sapiens
<400> 295
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtaggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtattagc agctggttag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagat ttcactctca ccatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagtt tcccattcac tttcggccct 300
gggaccaaag tggatatcaa ac 322
<210> 296
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 296
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Ser Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Phe
85 90 95
Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 297
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 297
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtaggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtattagc agctggttag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagat ttcactctca ccatcagcag cctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagtt tcccattcac tttcggccct 300
gggaccaaag tggatatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 298
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 298
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 299
<211> 453
<212> PRT
<213> Homo Sapiens
<400> 299
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Ile Arg Thr Gly Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Phe Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Ala Gly Ala Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 300
<211> 347
<212> PRT
<213> Homo Sapiens
<400> 300
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr
210 215 220
Gln Leu Gln Leu Glu His Leu Leu Leu Asp Leu Gln Met Ile Leu Asn
225 230 235 240
Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu Thr Arg Met Leu Thr Phe
245 250 255
Lys Phe Tyr Met Pro Lys Lys Ala Thr Glu Leu Lys His Leu Gln Cys
260 265 270
Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu Val Leu Asn Leu Ala Gln
275 280 285
Ser Lys Asn Phe His Leu Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn
290 295 300
Val Ile Val Leu Glu Leu Lys Gly Ser Glu Thr Thr Phe Met Cys Glu
305 310 315 320
Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu Phe Leu Asn Arg Trp Ile
325 330 335
Thr Phe Cys Gln Ser Ile Ile Ser Thr Leu Thr
340 345
<210> 301
<211> 133
<212> PRT
<213> Homo Sapiens
<400> 301
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 302
<211> 586
<212> PRT
<213> Homo Sapiens
<400> 302
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Ile Arg Thr Gly Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Phe Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Ala Gly Ala Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln
450 455 460
Leu Gln Leu Glu His Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly
465 470 475 480
Ile Asn Asn Tyr Lys Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys
485 490 495
Phe Tyr Met Pro Lys Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu
500 505 510
Glu Glu Glu Leu Lys Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser
515 520 525
Lys Asn Phe His Leu Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val
530 535 540
Ile Val Leu Glu Leu Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr
545 550 555 560
Ala Asp Glu Thr Ala Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr
565 570 575
Phe Cys Gln Ser Ile Ile Ser Thr Leu Thr
580 585
<210> 303
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 303
Ala Pro Thr Ser Thr Gln Leu Gln Leu Glu Leu Leu Leu Asp
1 5 10
<210> 304
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 304
Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10
<210> 305
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 305
Ala Pro Thr Ser Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu
1 5 10 15
Asp
<210> 306
<211> 19
<212> PRT
<213> Homo Sapiens
<400> 306
Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu
1 5 10 15
Leu Leu Asp
<210> 307
<211> 18
<212> PRT
<213> Homo Sapiens
<400> 307
Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu
1 5 10 15
Leu Asp
<210> 308
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 308
Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu
1 5 10 15
Asp
<210> 309
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 309
Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10 15
<210> 310
<211> 15
<212> PRT
<213> Homo Sapiens
<400> 310
Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10 15
<210> 311
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 311
Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10
<210> 312
<211> 13
<212> PRT
<213> Homo Sapiens
<400> 312
Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10
<210> 313
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 313
Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10
<210> 314
<211> 19
<212> PRT
<213> Homo Sapiens
<400> 314
Ala Pro Thr Ser Ser Ser Thr Lys Thr Gln Leu Gln Leu Glu His Leu
1 5 10 15
Leu Leu Asp
<210> 315
<211> 18
<212> PRT
<213> Homo Sapiens
<400> 315
Ala Pro Thr Ser Ser Ser Thr Thr Gln Leu Gln Leu Glu His Leu Leu
1 5 10 15
Leu Asp
<210> 316
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 316
Ala Pro Thr Ser Ser Ser Thr Gln Leu Gln Leu Glu His Leu Leu Leu
1 5 10 15
Asp
<210> 317
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 317
Ala Pro Thr Ser Ser Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10 15
<210> 318
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 318
Ala Pro Thr Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10
<210> 319
<211> 13
<212> PRT
<213> Homo Sapiens
<400> 319
Ala Pro Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10
<210> 320
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 320
Ala Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10
<210> 321
<211> 15
<212> PRT
<213> Homo Sapiens
<400> 321
Ala Thr Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10 15
<210> 322
<211> 15
<212> PRT
<213> Homo Sapiens
<400> 322
Ala Pro Lys Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10 15
<210> 323
<211> 15
<212> PRT
<213> Homo Sapiens
<400> 323
Ala Pro Thr Lys Thr Gln Leu Gln Leu Glu His Leu Leu Leu Asp
1 5 10 15
<210> 324
<211> 113
<212> PRT
<213> Homo Sapiens
<400> 324
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
1 5 10 15
Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys Lys Ala Thr Glu
20 25 30
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
35 40 45
Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
50 55 60
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
65 70 75 80
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
85 90 95
Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile Ile Ser Thr Leu
100 105 110
Thr
<210> 325
<211> 290
<212> PRT
<213> Mus Musculus
<400> 325
Met Arg Ile Phe Ala Gly Ile Ile Phe Thr Ala Cys Cys His Leu Leu
1 5 10 15
Arg Ala Phe Thr Ile Thr Ala Pro Lys Asp Leu Tyr Val Val Glu Tyr
20 25 30
Gly Ser Asn Val Thr Met Glu Cys Arg Phe Pro Val Glu Arg Glu Leu
35 40 45
Asp Leu Leu Ala Leu Val Val Tyr Trp Glu Lys Glu Asp Glu Gln Val
50 55 60
Ile Gln Phe Val Ala Gly Glu Glu Asp Leu Lys Pro Gln His Ser Asn
65 70 75 80
Phe Arg Gly Arg Ala Ser Leu Pro Lys Asp Gln Leu Leu Lys Gly Asn
85 90 95
Ala Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr
100 105 110
Cys Cys Ile Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Leu
115 120 125
Lys Val Asn Ala Pro Tyr Arg Lys Ile Asn Gln Arg Ile Ser Val Asp
130 135 140
Pro Ala Thr Ser Glu His Glu Leu Ile Cys Gln Ala Glu Gly Tyr Pro
145 150 155 160
Glu Ala Glu Val Ile Trp Thr Asn Ser Asp His Gln Pro Val Ser Gly
165 170 175
Lys Arg Ser Val Thr Thr Ser Arg Thr Glu Gly Met Leu Leu Asn Val
180 185 190
Thr Ser Ser Leu Arg Val Asn Ala Thr Ala Asn Asp Val Phe Tyr Cys
195 200 205
Thr Phe Trp Arg Ser Gln Pro Gly Gln Asn His Thr Ala Glu Leu Ile
210 215 220
Ile Pro Glu Leu Pro Ala Thr His Pro Pro Gln Asn Arg Thr His Trp
225 230 235 240
Val Leu Leu Gly Ser Ile Leu Leu Phe Leu Ile Val Val Ser Thr Val
245 250 255
Leu Leu Phe Leu Arg Lys Gln Val Arg Met Leu Asp Val Glu Lys Cys
260 265 270
Gly Val Glu Asp Thr Ser Ser Lys Asn Arg Asn Asp Thr Gln Phe Glu
275 280 285
Glu Thr
290
<210> 326
<211> 226
<212> PRT
<213> Mus Musculus
<400> 326
Phe Thr Ile Thr Ala Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly Ser
1 5 10 15
Asn Val Thr Met Glu Cys Arg Phe Pro Val Glu Arg Glu Leu Asp Leu
20 25 30
Leu Ala Leu Val Val Tyr Trp Glu Lys Glu Asp Glu Gln Val Ile Gln
35 40 45
Phe Val Ala Gly Glu Glu Asp Leu Lys Pro Gln His Ser Asn Phe Arg
50 55 60
Gly Arg Ala Ser Leu Pro Lys Asp Gln Leu Leu Lys Gly Asn Ala Ala
65 70 75 80
Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Cys Cys
85 90 95
Ile Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Leu Lys Val
100 105 110
Asn Ala Pro Tyr Arg Lys Ile Asn Gln Arg Ile Ser Val Asp Pro Ala
115 120 125
Thr Ser Glu His Glu Leu Ile Cys Gln Ala Glu Gly Tyr Pro Glu Ala
130 135 140
Glu Val Ile Trp Thr Asn Ser Asp His Gln Pro Val Ser Gly Lys Arg
145 150 155 160
Ser Val Thr Thr Ser Arg Thr Glu Gly Met Leu Leu Asn Val Thr Ser
165 170 175
Ser Leu Arg Val Asn Ala Thr Ala Asn Asp Val Phe Tyr Cys Thr Phe
180 185 190
Trp Arg Ser Gln Pro Gly Gln Asn His Thr Ala Glu Leu Ile Ile Pro
195 200 205
Glu Leu Pro Ala Thr His Pro Pro Gln Asn Arg Thr His His His His
210 215 220
His His
225
<210> 327
<211> 251
<212> PRT
<213> Homo Sapiens
<400> 327
Glu Leu Cys Asp Asp Asp Pro Pro Glu Ile Pro His Ala Thr Phe Lys
1 5 10 15
Ala Met Ala Tyr Lys Glu Gly Thr Met Leu Asn Cys Glu Cys Lys Arg
20 25 30
Gly Phe Arg Arg Ile Lys Ser Gly Ser Leu Tyr Met Leu Cys Thr Gly
35 40 45
Asn Ser Ser His Ser Ser Trp Asp Asn Gln Cys Gln Cys Thr Ser Ser
50 55 60
Ala Thr Arg Asn Thr Thr Lys Gln Val Thr Pro Gln Pro Glu Glu Gln
65 70 75 80
Lys Glu Arg Lys Thr Thr Glu Met Gln Ser Pro Met Gln Pro Val Asp
85 90 95
Gln Ala Ser Leu Pro Gly His Cys Arg Glu Pro Pro Pro Trp Glu Asn
100 105 110
Glu Ala Thr Glu Arg Ile Tyr His Phe Val Val Gly Gln Met Val Tyr
115 120 125
Tyr Gln Cys Val Gln Gly Tyr Arg Ala Leu His Arg Gly Pro Ala Glu
130 135 140
Ser Val Cys Lys Met Thr His Gly Lys Thr Arg Trp Thr Gln Pro Gln
145 150 155 160
Leu Ile Cys Thr Gly Glu Met Glu Thr Ser Gln Phe Pro Gly Glu Glu
165 170 175
Lys Pro Gln Ala Ser Pro Glu Gly Arg Pro Glu Ser Glu Thr Ser Cys
180 185 190
Leu Val Thr Thr Thr Asp Phe Gln Ile Gln Thr Glu Met Ala Ala Thr
195 200 205
Met Glu Thr Ser Ile Phe Thr Thr Glu Tyr Gln Val Ala Val Ala Gly
210 215 220
Cys Val Phe Leu Leu Ile Ser Val Leu Leu Leu Ser Gly Leu Thr Trp
225 230 235 240
Gln Arg Arg Gln Arg Lys Ser Arg Arg Thr Ile
245 250
<210> 328
<211> 525
<212> PRT
<213> Homo Sapiens
<400> 328
Ala Val Asn Gly Thr Ser Gln Phe Thr Cys Phe Tyr Asn Ser Arg Ala
1 5 10 15
Asn Ile Ser Cys Val Trp Ser Gln Asp Gly Ala Leu Gln Asp Thr Ser
20 25 30
Cys Gln Val His Ala Trp Pro Asp Arg Arg Arg Trp Asn Gln Thr Cys
35 40 45
Glu Leu Leu Pro Val Ser Gln Ala Ser Trp Ala Cys Asn Leu Ile Leu
50 55 60
Gly Ala Pro Asp Ser Gln Lys Leu Thr Thr Val Asp Ile Val Thr Leu
65 70 75 80
Arg Val Leu Cys Arg Glu Gly Val Arg Trp Arg Val Met Ala Ile Gln
85 90 95
Asp Phe Lys Pro Phe Glu Asn Leu Arg Leu Met Ala Pro Ile Ser Leu
100 105 110
Gln Val Val His Val Glu Thr His Arg Cys Asn Ile Ser Trp Glu Ile
115 120 125
Ser Gln Ala Ser His Tyr Phe Glu Arg His Leu Glu Phe Glu Ala Arg
130 135 140
Thr Leu Ser Pro Gly His Thr Trp Glu Glu Ala Pro Leu Leu Thr Leu
145 150 155 160
Lys Gln Lys Gln Glu Trp Ile Cys Leu Glu Thr Leu Thr Pro Asp Thr
165 170 175
Gln Tyr Glu Phe Gln Val Arg Val Lys Pro Leu Gln Gly Glu Phe Thr
180 185 190
Thr Trp Ser Pro Trp Ser Gln Pro Leu Ala Phe Arg Thr Lys Pro Ala
195 200 205
Ala Leu Gly Lys Asp Thr Ile Pro Trp Leu Gly His Leu Leu Val Gly
210 215 220
Leu Ser Gly Ala Phe Gly Phe Ile Ile Leu Val Tyr Leu Leu Ile Asn
225 230 235 240
Cys Arg Asn Thr Gly Pro Trp Leu Lys Lys Val Leu Lys Cys Asn Thr
245 250 255
Pro Asp Pro Ser Lys Phe Phe Ser Gln Leu Ser Ser Glu His Gly Gly
260 265 270
Asp Val Gln Lys Trp Leu Ser Ser Pro Phe Pro Ser Ser Ser Phe Ser
275 280 285
Pro Gly Gly Leu Ala Pro Glu Ile Ser Pro Leu Glu Val Leu Glu Arg
290 295 300
Asp Lys Val Thr Gln Leu Leu Leu Gln Gln Asp Lys Val Pro Glu Pro
305 310 315 320
Ala Ser Leu Ser Ser Asn His Ser Leu Thr Ser Cys Phe Thr Asn Gln
325 330 335
Gly Tyr Phe Phe Phe His Leu Pro Asp Ala Leu Glu Ile Glu Ala Cys
340 345 350
Gln Val Tyr Phe Thr Tyr Asp Pro Tyr Ser Glu Glu Asp Pro Asp Glu
355 360 365
Gly Val Ala Gly Ala Pro Thr Gly Ser Ser Pro Gln Pro Leu Gln Pro
370 375 380
Leu Ser Gly Glu Asp Asp Ala Tyr Cys Thr Phe Pro Ser Arg Asp Asp
385 390 395 400
Leu Leu Leu Phe Ser Pro Ser Leu Leu Gly Gly Pro Ser Pro Pro Ser
405 410 415
Thr Ala Pro Gly Gly Ser Gly Ala Gly Glu Glu Arg Met Pro Pro Ser
420 425 430
Leu Gln Glu Arg Val Pro Arg Asp Trp Asp Pro Gln Pro Leu Gly Pro
435 440 445
Pro Thr Pro Gly Val Pro Asp Leu Val Asp Phe Gln Pro Pro Pro Glu
450 455 460
Leu Val Leu Arg Glu Ala Gly Glu Glu Val Pro Asp Ala Gly Pro Arg
465 470 475 480
Glu Gly Val Ser Phe Pro Trp Ser Arg Pro Pro Gly Gln Gly Glu Phe
485 490 495
Arg Ala Leu Asn Ala Arg Leu Pro Leu Asn Thr Asp Ala Tyr Leu Ser
500 505 510
Leu Gln Glu Leu Gln Gly Gln Asp Pro Thr His Leu Val
515 520 525
<210> 329
<211> 347
<212> PRT
<213> Homo Sapiens
<400> 329
Leu Asn Thr Thr Ile Leu Thr Pro Asn Gly Asn Glu Asp Thr Thr Ala
1 5 10 15
Asp Phe Phe Leu Thr Thr Met Pro Thr Asp Ser Leu Ser Val Ser Thr
20 25 30
Leu Pro Leu Pro Glu Val Gln Cys Phe Val Phe Asn Val Glu Tyr Met
35 40 45
Asn Cys Thr Trp Asn Ser Ser Ser Glu Pro Gln Pro Thr Asn Leu Thr
50 55 60
Leu His Tyr Trp Tyr Lys Asn Ser Asp Asn Asp Lys Val Gln Lys Cys
65 70 75 80
Ser His Tyr Leu Phe Ser Glu Glu Ile Thr Ser Gly Cys Gln Leu Gln
85 90 95
Lys Lys Glu Ile His Leu Tyr Gln Thr Phe Val Val Gln Leu Gln Asp
100 105 110
Pro Arg Glu Pro Arg Arg Gln Ala Thr Gln Met Leu Lys Leu Gln Asn
115 120 125
Leu Val Ile Pro Trp Ala Pro Glu Asn Leu Thr Leu His Lys Leu Ser
130 135 140
Glu Ser Gln Leu Glu Leu Asn Trp Asn Asn Arg Phe Leu Asn His Cys
145 150 155 160
Leu Glu His Leu Val Gln Tyr Arg Thr Asp Trp Asp His Ser Trp Thr
165 170 175
Glu Gln Ser Val Asp Tyr Arg His Lys Phe Ser Leu Pro Ser Val Asp
180 185 190
Gly Gln Lys Arg Tyr Thr Phe Arg Val Arg Ser Arg Phe Asn Pro Leu
195 200 205
Cys Gly Ser Ala Gln His Trp Ser Glu Trp Ser His Pro Ile His Trp
210 215 220
Gly Ser Asn Thr Ser Lys Glu Asn Pro Phe Leu Phe Ala Leu Glu Ala
225 230 235 240
Val Val Ile Ser Val Gly Ser Met Gly Leu Ile Ile Ser Leu Leu Cys
245 250 255
Val Tyr Phe Trp Leu Glu Arg Thr Met Pro Arg Ile Pro Thr Leu Lys
260 265 270
Asn Leu Glu Asp Leu Val Thr Glu Tyr His Gly Asn Phe Ser Ala Trp
275 280 285
Ser Gly Val Ser Lys Gly Leu Ala Glu Ser Leu Gln Pro Asp Tyr Ser
290 295 300
Glu Arg Leu Cys Leu Val Ser Glu Ile Pro Pro Lys Gly Gly Ala Leu
305 310 315 320
Gly Glu Gly Pro Gly Ala Ser Pro Cys Asn Gln His Ser Pro Tyr Trp
325 330 335
Ala Pro Pro Cys Tyr Thr Leu Lys Pro Glu Thr
340 345
<210> 330
<211> 152
<212> PRT
<213> Homo Sapiens
<400> 330
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His
145 150
<210> 331
<211> 133
<212> PRT
<213> Homo Sapiens
<400> 331
Gly Ile His Val Phe Ile Leu Gly Cys Phe Ser Ala Gly Leu Pro Lys
1 5 10 15
Thr Glu Ala Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu
20 25 30
Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser
35 40 45
Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu
50 55 60
Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp
65 70 75 80
Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn
85 90 95
Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu
100 105 110
Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met
115 120 125
Phe Ile Asn Thr Ser
130
<210> 332
<211> 133
<212> PRT
<213> Homo Sapiens
<400> 332
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser
130
<210> 333
<211> 127
<212> PRT
<213> Homo Sapiens
<400> 333
Ala Pro Ala Arg Ser Pro Ser Pro Ser Thr Gln Pro Trp Glu His Val
1 5 10 15
Asn Ala Ile Gln Glu Ala Arg Arg Leu Leu Asn Leu Ser Arg Asp Thr
20 25 30
Ala Ala Glu Met Asn Glu Thr Val Glu Val Ile Ser Glu Met Phe Asp
35 40 45
Leu Gln Glu Pro Thr Cys Leu Gln Thr Arg Leu Glu Leu Tyr Lys Gln
50 55 60
Gly Leu Arg Gly Ser Leu Thr Lys Leu Lys Gly Pro Leu Thr Met Met
65 70 75 80
Ala Ser His Tyr Lys Gln His Cys Pro Pro Thr Pro Glu Thr Ser Cys
85 90 95
Ala Thr Gln Ile Ile Thr Phe Glu Ser Phe Lys Glu Asn Leu Lys Asp
100 105 110
Phe Leu Leu Val Ile Pro Phe Asp Cys Trp Glu Pro Val Gln Glu
115 120 125
<210> 334
<211> 171
<212> PRT
<213> Homo Sapiens
<400> 334
Cys Asp Leu Pro Gln Asn His Gly Leu Leu Ser Arg Asn Thr Leu Val
1 5 10 15
Leu Leu His Gln Met Arg Arg Ile Ser Pro Phe Leu Cys Leu Lys Asp
20 25 30
Arg Arg Asp Phe Arg Phe Pro Gln Glu Met Val Lys Gly Ser Gln Leu
35 40 45
Gln Lys Ala His Val Met Ser Val Leu His Glu Met Leu Gln Gln Ile
50 55 60
Phe Ser Leu Phe His Thr Glu Arg Ser Ser Ala Ala Trp Asn Met Thr
65 70 75 80
Leu Leu Asp Gln Leu His Thr Glu Leu His Gln Gln Leu Gln His Leu
85 90 95
Glu Thr Cys Leu Leu Gln Val Val Gly Glu Gly Glu Ser Ala Gly Ala
100 105 110
Ile Ser Ser Pro Ala Leu Thr Leu Arg Arg Tyr Phe Gln Gly Ile Arg
115 120 125
Val Tyr Leu Lys Glu Lys Lys Tyr Ser Asp Cys Ala Trp Glu Val Val
130 135 140
Arg Met Glu Ile Met Lys Ser Leu Phe Leu Ser Thr Asn Met Gln Glu
145 150 155 160
Arg Leu Arg Ser Lys Asp Arg Asp Leu Gly Ser
165 170
<210> 335
<211> 177
<212> PRT
<213> Homo Sapiens
<400> 335
Gly Pro Gln Arg Glu Glu Phe Pro Arg Asp Leu Ser Leu Ile Ser Pro
1 5 10 15
Leu Ala Gln Ala Val Arg Ser Ser Ser Arg Thr Pro Ser Asp Lys Pro
20 25 30
Val Ala His Val Val Ala Asn Pro Gln Ala Glu Gly Gln Leu Gln Trp
35 40 45
Leu Asn Arg Arg Ala Asn Ala Leu Leu Ala Asn Gly Val Glu Leu Arg
50 55 60
Asp Asn Gln Leu Val Val Pro Ser Glu Gly Leu Tyr Leu Ile Tyr Ser
65 70 75 80
Gln Val Leu Phe Lys Gly Gln Gly Cys Pro Ser Thr His Val Leu Leu
85 90 95
Thr His Thr Ile Ser Arg Ile Ala Val Ser Tyr Gln Thr Lys Val Asn
100 105 110
Leu Leu Ser Ala Ile Lys Ser Pro Cys Gln Arg Glu Thr Pro Glu Gly
115 120 125
Ala Glu Ala Lys Pro Trp Tyr Glu Pro Ile Tyr Leu Gly Gly Val Phe
130 135 140
Gln Leu Glu Lys Gly Asp Arg Leu Ser Ala Glu Ile Asn Arg Pro Asp
145 150 155 160
Tyr Leu Asp Phe Ala Glu Ser Gly Gln Val Tyr Phe Gly Ile Ile Ala
165 170 175
Leu
<210> 336
<211> 197
<212> PRT
<213> Homo Sapiens
<400> 336
Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe Pro Cys Leu
1 5 10 15
His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met Leu Gln Lys
20 25 30
Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu Glu Ile Asp
35 40 45
His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu Ala Cys Leu
50 55 60
Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser Arg Glu Thr
65 70 75 80
Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys Thr Ser Phe
85 90 95
Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu Lys Met Tyr
100 105 110
Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met Asp Pro Lys
115 120 125
Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile Asp Glu Leu
130 135 140
Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln Lys Ser Ser
145 150 155 160
Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu Cys Ile Leu
165 170 175
Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg Val Met Ser
180 185 190
Tyr Leu Asn Ala Ser
195
<210> 337
<211> 306
<212> PRT
<213> Homo Sapiens
<400> 337
Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp Trp Tyr
1 5 10 15
Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr Pro Glu
20 25 30
Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val Leu Gly
35 40 45
Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp Ala Gly
50 55 60
Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser Leu Leu
65 70 75 80
Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile Leu Lys
85 90 95
Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu Ala Lys
100 105 110
Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile Ser Thr
115 120 125
Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp Pro Gln
130 135 140
Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val Arg Gly
145 150 155 160
Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp Ser Ala
165 170 175
Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val Asp Ala
180 185 190
Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe Ile Arg
195 200 205
Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys Pro Leu
210 215 220
Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp Thr Trp
225 230 235 240
Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln Val Gln
245 250 255
Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp Lys Thr
260 265 270
Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val Arg Ala
275 280 285
Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser Val Pro
290 295 300
Cys Ser
305
<210> 338
<211> 103
<212> PRT
<213> Homo Sapiens
<400> 338
Thr Pro Val Val Arg Lys Gly Arg Cys Ser Cys Ile Ser Thr Asn Gln
1 5 10 15
Gly Thr Ile His Leu Gln Ser Leu Lys Asp Leu Lys Gln Phe Ala Pro
20 25 30
Ser Pro Ser Cys Glu Lys Ile Glu Ile Ile Ala Thr Leu Lys Asn Gly
35 40 45
Val Gln Thr Cys Leu Asn Pro Asp Ser Ala Asp Val Lys Glu Leu Ile
50 55 60
Lys Lys Trp Glu Lys Gln Val Ser Gln Lys Lys Lys Gln Lys Asn Gly
65 70 75 80
Lys Lys His Gln Lys Lys Lys Val Leu Lys Val Arg Lys Ser Gln Arg
85 90 95
Ser Arg Gln Lys Lys Thr Thr
100
<210> 339
<211> 77
<212> PRT
<213> Homo Sapiens
<400> 339
Val Pro Leu Ser Arg Thr Val Arg Cys Thr Cys Ile Ser Ile Ser Asn
1 5 10 15
Gln Pro Val Asn Pro Arg Ser Leu Glu Lys Leu Glu Ile Ile Pro Ala
20 25 30
Ser Gln Phe Cys Pro Arg Val Glu Ile Ile Ala Thr Met Lys Lys Lys
35 40 45
Gly Glu Lys Arg Cys Leu Asn Pro Glu Ser Lys Ala Ile Lys Asn Leu
50 55 60
Leu Lys Ala Val Ser Lys Glu Arg Ser Lys Arg Ser Pro
65 70 75
<210> 340
<211> 330
<212> PRT
<213> Homo Sapiens
<400> 340
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 341
<211> 996
<212> DNA
<213> Homo Sapiens
<400> 341
gccagcacca agggcccctc tgtgttccct ctggcccctt ccagcaagtc cacctctggc 60
ggaacagccg ctctgggctg cctcgtgaag gactacttcc ccgagcctgt gaccgtgtcc 120
tggaactctg gcgctctgac cagcggagtg cacaccttcc ctgctgtgct gcagtcctcc 180
ggcctgtact ccctgtcctc cgtcgtgacc gtgccttcca gctctctggg cacccagacc 240
tacatctgca acgtgaacca caagccctcc aacaccaagg tggacaagaa ggtggaaccc 300
aagtcctgcg acaagaccca cacctgtccc ccttgtcctg cccctgaact gctgggcgga 360
ccttccgtgt tcctgttccc cccaaagccc aaggacaccc tgatgatctc ccggaccccc 420
gaagtgacct gcgtggtggt ggatgtgtcc cacgaggacc ctgaagtgaa gttcaattgg 480
tacgtggacg gcgtggaagt gcacaacgcc aagaccaagc ctagagagga acagtacaac 540
tccacctacc gggtggtgtc cgtgctgacc gtgctgcacc aggattggct gaacggcaaa 600
gagtacaagt gcaaggtgtc caacaaggcc ctgcctgccc ccatcgaaaa gaccatctcc 660
aaggccaagg gccagccccg ggaaccccag gtgtacacac tgccccctag cagggacgag 720
ctgaccaaga accaggtgtc cctgacctgt ctcgtgaaag gcttctaccc ctccgatatc 780
gccgtggaat gggagtccaa cggccagcct gagaacaact acaagaccac cccccctgtg 840
ctggactccg acggctcatt cttcctgtac agcaagctga cagtggacaa gtcccggtgg 900
cagcagggca acgtgttctc ctgctccgtg atgcacgagg ccctgcacaa ccactacacc 960
cagaagtccc tgtccctgag ccccggcaag tgatga 996
<210> 342
<211> 450
<212> PRT
<213> Homo Sapiens
<400> 342
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Ile Arg Thr Gly Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Asp Met Lys Gly Ser Gly Thr Tyr Gly Gly Trp Phe Asp Thr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
195 200 205
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
210 215 220
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Leu Ala Gly Ala
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
435 440 445
Gly Lys
450
<210> 343
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 343
Gly Phe Thr Phe Ser Asn Tyr Ala
1 5
<210> 344
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 344
Ile Ser Phe Ser Gly Gly Thr Thr
1 5
<210> 345
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 345
Ala Lys Asp Glu Ala Pro Ala Gly Ala Thr Phe Phe Asp Ser
1 5 10
<210> 346
<211> 5
<212> PRT
<213> Homo Sapiens
<400> 346
Asn Tyr Ala Met Ser
1 5
<210> 347
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 347
Ala Ile Ser Phe Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 348
<211> 12
<212> PRT
<213> Homo Sapiens
<400> 348
Asp Glu Ala Pro Ala Gly Ala Thr Phe Phe Asp Ser
1 5 10
<210> 349
<211> 121
<212> PRT
<213> Homo Sapiens
<400> 349
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Thr Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Phe Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu His Met Asn Ser Leu Arg Ala Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Glu Ala Pro Ala Gly Ala Thr Phe Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 350
<211> 364
<212> DNA
<213> Homo Sapiens
<400> 350
gaagtgcaac tggcggagtc tgggggaggc ttggtacagc cgggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc aactatgcca tgagttgggt ccgccagact 120
ccaggaaagg ggctggagtg ggtctcagct attagtttta gtggtggtac tacatactac 180
gctgactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ttgcacatga acagcctgag agccgatgac acggccgtat attactgtgc gaaagatgag 300
gcaccagctg gcgcaacctt ctttgactcc tggggccagg gaacgctggt caccgtctcc 360
tcag 364
<210> 351
<211> 448
<212> PRT
<213> Homo Sapiens
<400> 351
Glu Val Gln Leu Ala Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Thr Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Phe Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu His Met Asn Ser Leu Arg Ala Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Glu Ala Pro Ala Gly Ala Thr Phe Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly
210 215 220
Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Glu Gly Gly Pro Ser
225 230 235 240
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
245 250 255
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro
260 265 270
Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
275 280 285
Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val
290 295 300
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
305 310 315 320
Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr
325 330 335
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
340 345 350
Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
355 360 365
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
370 375 380
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
385 390 395 400
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser
405 410 415
Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
420 425 430
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 352
<211> 1344
<212> DNA
<213> Homo Sapiens
<400> 352
gaagtgcaac tggcggagtc tgggggaggc ttggtacagc cgggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttagc aactatgcca tgagttgggt ccgccagact 120
ccaggaaagg ggctggagtg ggtctcagct attagtttta gtggtggtac tacatactac 180
gctgactccg tgaagggccg gttcaccatc tccagagaca attccaagaa cacgctgtat 240
ttgcacatga acagcctgag agccgatgac acggccgtat attactgtgc gaaagatgag 300
gcaccagctg gcgcaacctt ctttgactcc tggggccagg gaacgctggt caccgtctcc 360
tcagccagca ccaagggccc ttccgtgttc cccctggccc cttgcagcag gagcacctcc 420
gaatccacag ctgccctggg ctgtctggtg aaggactact ttcccgagcc cgtgaccgtg 480
agctggaaca gcggcgctct gacatccggc gtccacacct ttcctgccgt cctgcagtcc 540
tccggcctct actccctgtc ctccgtggtg accgtgccta gctcctccct cggcaccaag 600
acctacacct gtaacgtgga ccacaaaccc tccaacacca aggtggacaa acgggtcgag 660
agcaagtacg gccctccctg ccctccttgt cctgcccccg agttcgaagg cggacccagc 720
gtgttcctgt tccctcctaa gcccaaggac accctcatga tcagccggac acccgaggtg 780
acctgcgtgg tggtggatgt gagccaggag gaccctgagg tccagttcaa ctggtatgtg 840
gatggcgtgg aggtgcacaa cgccaagaca aagccccggg aagagcagtt caactccacc 900
tacagggtgg tcagcgtgct gaccgtgctg catcaggact ggctgaacgg caaggagtac 960
aagtgcaagg tcagcaataa gggactgccc agcagcatcg agaagaccat ctccaaggct 1020
aaaggccagc cccgggaacc tcaggtgtac accctgcctc ccagccagga ggagatgacc 1080
aagaaccagg tgagcctgac ctgcctggtg aagggattct acccttccga catcgccgtg 1140
gagtgggagt ccaacggcca gcccgagaac aattataaga ccacccctcc cgtcctcgac 1200
agcgacggat ccttctttct gtactccagg ctgaccgtgg ataagtccag gtggcaggaa 1260
ggcaacgtgt tcagctgctc cgtgatgcac gaggccctgc acaatcacta cacccagaag 1320
tccctgagcc tgtccctggg aaag 1344
<210> 353
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 353
Gln Gly Ile Arg Arg Trp
1 5
<210> 354
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 354
Gly Ala Ser
1
<210> 355
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 355
Gln Gln Ala Asn Ser Phe Pro Ile Thr
1 5
<210> 356
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 356
Arg Ala Ser Gln Gly Ile Arg Arg Trp Leu Ala
1 5 10
<210> 357
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 357
Gly Ala Ser Ser Leu Gln Ser
1 5
<210> 358
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 358
Gln Gln Ala Asn Ser Phe Pro Ile Thr
1 5
<210> 359
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 359
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Arg Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Ser Gly Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Ile Ile Thr Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105
<210> 360
<211> 322
<212> DNA
<213> Homo Sapiens
<400> 360
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtaggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtattagg aggtggttag cctggtatca gcagaaacca 120
gggaaagccc ctaaactcct gatctctggt gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagat ttcactctca tcattaccag tctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagtt tcccgatcac cttcggccaa 300
gggacacgac tggagatcaa ac 322
<210> 361
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 361
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Arg Arg Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Ser Gly Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Ile Ile Thr Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Ile
85 90 95
Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 362
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 362
gacatccaga tgacccagtc tccatcttcc gtgtctgcat ctgtaggaga cagagtcacc 60
atcacttgtc gggcgagtca gggtattagg aggtggttag cctggtatca gcagaaacca 120
gggaaagccc ctaaactcct gatctctggt gcatccagtt tgcaaagtgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagat ttcactctca tcattaccag tctgcagcct 240
gaagattttg caacttacta ttgtcaacag gctaacagtt tcccgatcac cttcggccaa 300
gggacacgac tggagatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 363
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 363
Gly Tyr Thr Phe Ser Thr Phe Gly
1 5
<210> 364
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 364
Ile Ser Ala Tyr Asn Gly Asp Thr
1 5
<210> 365
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 365
Ala Arg Ser Ser Gly His Tyr Tyr Tyr Tyr Gly Met Asp Val
1 5 10
<210> 366
<211> 121
<212> PRT
<213> Homo Sapiens
<400> 366
Gln Val Gln Val Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Thr Phe
20 25 30
Gly Ile Thr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asp Thr Asn Tyr Ala Gln Asn Leu
50 55 60
Gln Gly Arg Val Ile Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Ser Gly His Tyr Tyr Tyr Tyr Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 367
<211> 363
<212> DNA
<213> Homo Sapiens
<400> 367
caggttcagg tggtgcagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta caccttttcc acctttggta tcacctgggt gcgacaggcc 120
cctggacaag ggcttgaatg gatgggatgg atcagcgctt acaatggtga cacaaactat 180
gcacagaatc tccagggcag agtcatcatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcctgag atctgacgac acggccgttt attactgtgc gaggagcagt 300
ggccactact actactacgg tatggacgtc tggggccaag ggaccacggt caccgtctcc 360
tca 363
<210> 368
<211> 451
<212> PRT
<213> Homo Sapiens
<400> 368
Gln Val Gln Val Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Thr Phe
20 25 30
Gly Ile Thr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asp Thr Asn Tyr Ala Gln Asn Leu
50 55 60
Gln Gly Arg Val Ile Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Ser Gly His Tyr Tyr Tyr Tyr Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
130 135 140
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
145 150 155 160
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
165 170 175
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
195 200 205
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
210 215 220
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
225 230 235 240
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
245 250 255
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
260 265 270
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
275 280 285
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
290 295 300
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
305 310 315 320
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
325 330 335
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
340 345 350
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
355 360 365
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
370 375 380
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
385 390 395 400
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
405 410 415
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
420 425 430
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
435 440 445
Pro Gly Lys
450
<210> 369
<211> 1359
<212> DNA
<213> Homo Sapiens
<400> 369
caggttcagg tggtgcagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta caccttttcc acctttggta tcacctgggt gcgacaggcc 120
cctggacaag ggcttgaatg gatgggatgg atcagcgctt acaatggtga cacaaactat 180
gcacagaatc tccagggcag agtcatcatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcctgag atctgacgac acggccgttt attactgtgc gaggagcagt 300
ggccactact actactacgg tatggacgtc tggggccaag ggaccacggt caccgtctcc 360
tcagccagca ccaagggccc ctctgtgttc cctctggccc cttccagcaa gtccacctct 420
ggcggaacag ccgctctggg ctgcctcgtg aaggactact tccccgagcc tgtgaccgtg 480
tcctggaact ctggcgctct gaccagcgga gtgcacacct tccctgctgt gctgcagtcc 540
tccggcctgt actccctgtc ctccgtcgtg accgtgcctt ccagctctct gggcacccag 600
acctacatct gcaacgtgaa ccacaagccc tccaacacca aggtggacaa gaaggtggaa 660
cccaagtcct gcgacaagac ccacacctgt cccccttgtc ctgcccctga actgctgggc 720
ggaccttccg tgttcctgtt ccccccaaag cccaaggaca ccctgatgat ctcccggacc 780
cccgaagtga cctgcgtggt ggtggatgtg tcccacgagg accctgaagt gaagttcaat 840
tggtacgtgg acggcgtgga agtgcacaac gccaagacca agcctagaga ggaacagtac 900
aactccacct accgggtggt gtccgtgctg accgtgctgc accaggattg gctgaacggc 960
aaagagtaca agtgcaaggt gtccaacaag gccctgcctg cccccatcga aaagaccatc 1020
tccaaggcca agggccagcc ccgggaaccc caggtgtaca cactgccccc tagcagggac 1080
gagctgacca agaaccaggt gtccctgacc tgtctcgtga aaggcttcta cccctccgat 1140
atcgccgtgg aatgggagtc caacggccag cctgagaaca actacaagac caccccccct 1200
gtgctggact ccgacggctc attcttcctg tacagcaagc tgacagtgga caagtcccgg 1260
tggcagcagg gcaacgtgtt ctcctgctcc gtgatgcacg aggccctgca caaccactac 1320
acccagaagt ccctgtccct gagccccggc aagtgatga 1359
<210> 370
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 370
Gln Ser Leu Leu His Ser Asn Glu Tyr Asn Tyr
1 5 10
<210> 371
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 371
Leu Gly Ser
1
<210> 372
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 372
Met Gln Ser Leu Gln Thr Pro Leu Thr
1 5
<210> 373
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 373
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Glu Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Phe Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Thr Arg Val Glu Ala Glu Asp Val Gly Ile Tyr Tyr Cys Met Gln Ser
85 90 95
Leu Gln Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 374
<211> 336
<212> DNA
<213> Homo Sapiens
<400> 374
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg aatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct ttttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
accagagtgg aggctgagga tgttggaatt tattactgca tgcaatctct acaaactccg 300
ctcactttcg gcggagggac caaggtggag atcaaa 336
<210> 375
<211> 219
<212> PRT
<213> Homo Sapiens
<400> 375
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Glu Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Phe Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Thr Arg Val Glu Ala Glu Asp Val Gly Ile Tyr Tyr Cys Met Gln Ser
85 90 95
Leu Gln Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 376
<211> 657
<212> DNA
<213> Homo Sapiens
<400> 376
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg aatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct ttttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
accagagtgg aggctgagga tgttggaatt tattactgca tgcaatctct acaaactccg 300
ctcactttcg gcggagggac caaggtggag atcaaacgta cggtggccgc tccctccgtg 360
ttcatcttcc caccttccga cgagcagctg aagtccggca ccgcttctgt cgtgtgcctg 420
ctgaacaact tctacccccg cgaggccaag gtgcagtgga aggtggacaa cgccctgcag 480
tccggcaact cccaggaatc cgtgaccgag caggactcca aggacagcac ctactccctg 540
tcctccaccc tgaccctgtc caaggccgac tacgagaagc acaaggtgta cgcctgcgaa 600
gtgacccacc agggcctgtc tagccccgtg accaagtctt tcaaccgggg cgagtgt 657
<210> 377
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 377
Gly Tyr Thr Phe Thr Ser Tyr Gly
1 5
<210> 378
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 378
Ile Ser Ala Tyr Asn Gly Asn Thr
1 5
<210> 379
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 379
Ala Arg Ser Thr Tyr Phe Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
1 5 10 15
Val
<210> 380
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 380
Gln Val Gln Leu Val Gln Ser Gly Gly Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Phe Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Thr Tyr Phe Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 381
<211> 372
<212> DNA
<213> Homo Sapiens
<400> 381
caggttcaac tggtgcagtc tggaggtgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatggtt tcagctgggt gcgacaggcc 120
cctggacaag gactagagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtcaccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcttgag atctgacgac acggccgtgt attactgtgc gagatctacg 300
tatttctatg gttcggggac cctctacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct ca 372
<210> 382
<211> 454
<212> PRT
<213> Homo Sapiens
<400> 382
Gln Val Gln Leu Val Gln Ser Gly Gly Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Phe Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Thr Tyr Phe Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly Lys
450
<210> 383
<211> 1368
<212> DNA
<213> Homo Sapiens
<400> 383
caggttcaac tggtgcagtc tggaggtgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatggtt tcagctgggt gcgacaggcc 120
cctggacaag gactagagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtcaccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcttgag atctgacgac acggccgtgt attactgtgc gagatctacg 300
tatttctatg gttcggggac cctctacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct cagccagcac caagggcccc tctgtgttcc ctctggcccc ttccagcaag 420
tccacctctg gcggaacagc cgctctgggc tgcctcgtga aggactactt ccccgagcct 480
gtgaccgtgt cctggaactc tggcgctctg accagcggag tgcacacctt ccctgctgtg 540
ctgcagtcct ccggcctgta ctccctgtcc tccgtcgtga ccgtgccttc cagctctctg 600
ggcacccaga cctacatctg caacgtgaac cacaagccct ccaacaccaa ggtggacaag 660
aaggtggaac ccaagtcctg cgacaagacc cacacctgtc ccccttgtcc tgcccctgaa 720
ctgctgggcg gaccttccgt gttcctgttc cccccaaagc ccaaggacac cctgatgatc 780
tcccggaccc ccgaagtgac ctgcgtggtg gtggatgtgt cccacgagga ccctgaagtg 840
aagttcaatt ggtacgtgga cggcgtggaa gtgcacaacg ccaagaccaa gcctagagag 900
gaacagtaca actccaccta ccgggtggtg tccgtgctga ccgtgctgca ccaggattgg 960
ctgaacggca aagagtacaa gtgcaaggtg tccaacaagg ccctgcctgc ccccatcgaa 1020
aagaccatct ccaaggccaa gggccagccc cgggaacccc aggtgtacac actgccccct 1080
agcagggacg agctgaccaa gaaccaggtg tccctgacct gtctcgtgaa aggcttctac 1140
ccctccgata tcgccgtgga atgggagtcc aacggccagc ctgagaacaa ctacaagacc 1200
accccccctg tgctggactc cgacggctca ttcttcctgt acagcaagct gacagtggac 1260
aagtcccggt ggcagcaggg caacgtgttc tcctgctccg tgatgcacga ggccctgcac 1320
aaccactaca cccagaagtc cctgtccctg agccccggca agtgatga 1368
<210> 384
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 384
Gln Ser Leu Leu His Ser Asp Gly Tyr Asn Tyr
1 5 10
<210> 385
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 385
Leu Gly Ser
1
<210> 386
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 386
Met Gln Ala Leu Gln Thr Pro Leu Ser
1 5
<210> 387
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 387
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asp Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Thr Arg Ala Ser Gly Phe Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Leu Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 388
<211> 336
<212> DNA
<213> Homo Sapiens
<400> 388
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtgatg gatacaactg tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
tgcagttttg gccaggggac caagctggag atcaaa 336
<210> 389
<211> 219
<212> PRT
<213> Homo Sapiens
<400> 389
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asp Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Thr Arg Ala Ser Gly Phe Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Leu Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 390
<211> 657
<212> DNA
<213> Homo Sapiens
<400> 390
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtgatg gatacaactg tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
tgcagttttg gccaggggac caagctggag atcaaacgta cggtggccgc tccctccgtg 360
ttcatcttcc caccttccga cgagcagctg aagtccggca ccgcttctgt cgtgtgcctg 420
ctgaacaact tctacccccg cgaggccaag gtgcagtgga aggtggacaa cgccctgcag 480
tccggcaact cccaggaatc cgtgaccgag caggactcca aggacagcac ctactccctg 540
tcctccaccc tgaccctgtc caaggccgac tacgagaagc acaaggtgta cgcctgcgaa 600
gtgacccacc agggcctgtc tagccccgtg accaagtctt tcaaccgggg cgagtgt 657
<210> 391
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 391
Gly Tyr Thr Phe Thr Ser Tyr Gly
1 5
<210> 392
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 392
Ile Ser Ala Tyr Asn Gly Asn Thr
1 5
<210> 393
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 393
Ala Arg Ser Thr Tyr Phe Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
1 5 10 15
Val
<210> 394
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 394
Gln Val Gln Leu Val Gln Ser Gly Gly Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Phe Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Thr Tyr Phe Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 395
<211> 372
<212> DNA
<213> Homo Sapiens
<400> 395
caggttcaac tggtgcagtc tggaggtgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatggtt tcagctgggt gcgacaggcc 120
cctggacaag gactagagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtcaccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcttgag atctgacgac acggccgtgt attactgtgc gagatctacg 300
tatttctatg gttcggggac cctctacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct ca 372
<210> 396
<211> 454
<212> PRT
<213> Homo Sapiens
<400> 396
Gln Val Gln Leu Val Gln Ser Gly Gly Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Phe Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Thr Tyr Phe Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly Lys
450
<210> 397
<211> 1368
<212> DNA
<213> Homo Sapiens
<400> 397
caggttcaac tggtgcagtc tggaggtgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatggtt tcagctgggt gcgacaggcc 120
cctggacaag gactagagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtcaccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcttgag atctgacgac acggccgtgt attactgtgc gagatctacg 300
tatttctatg gttcggggac cctctacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct cagccagcac caagggcccc tctgtgttcc ctctggcccc ttccagcaag 420
tccacctctg gcggaacagc cgctctgggc tgcctcgtga aggactactt ccccgagcct 480
gtgaccgtgt cctggaactc tggcgctctg accagcggag tgcacacctt ccctgctgtg 540
ctgcagtcct ccggcctgta ctccctgtcc tccgtcgtga ccgtgccttc cagctctctg 600
ggcacccaga cctacatctg caacgtgaac cacaagccct ccaacaccaa ggtggacaag 660
aaggtggaac ccaagtcctg cgacaagacc cacacctgtc ccccttgtcc tgcccctgaa 720
ctgctgggcg gaccttccgt gttcctgttc cccccaaagc ccaaggacac cctgatgatc 780
tcccggaccc ccgaagtgac ctgcgtggtg gtggatgtgt cccacgagga ccctgaagtg 840
aagttcaatt ggtacgtgga cggcgtggaa gtgcacaacg ccaagaccaa gcctagagag 900
gaacagtaca actccaccta ccgggtggtg tccgtgctga ccgtgctgca ccaggattgg 960
ctgaacggca aagagtacaa gtgcaaggtg tccaacaagg ccctgcctgc ccccatcgaa 1020
aagaccatct ccaaggccaa gggccagccc cgggaacccc aggtgtacac actgccccct 1080
agcagggacg agctgaccaa gaaccaggtg tccctgacct gtctcgtgaa aggcttctac 1140
ccctccgata tcgccgtgga atgggagtcc aacggccagc ctgagaacaa ctacaagacc 1200
accccccctg tgctggactc cgacggctca ttcttcctgt acagcaagct gacagtggac 1260
aagtcccggt ggcagcaggg caacgtgttc tcctgctccg tgatgcacga ggccctgcac 1320
aaccactaca cccagaagtc cctgtccctg agccccggca agtgatga 1368
<210> 398
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 398
Gln Ser Leu Leu His Ser Asp Gly Tyr Asn Cys
1 5 10
<210> 399
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 399
Leu Gly Ser
1
<210> 400
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 400
Met Gln Ala Leu Gln Thr Pro Cys Ser
1 5
<210> 401
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 401
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asp Gly Tyr Asn Cys Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Thr Arg Ala Ser Gly Phe Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Cys Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 402
<211> 336
<212> DNA
<213> Homo Sapiens
<400> 402
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtgatg gatacaactg tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
tgcagttttg gccaggggac caagctggag atcaaa 336
<210> 403
<211> 219
<212> PRT
<213> Homo Sapiens
<400> 403
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asp Gly Tyr Asn Cys Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Thr Arg Ala Ser Gly Phe Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Cys Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 404
<211> 657
<212> DNA
<213> Homo Sapiens
<400> 404
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtgatg gatacaactg tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
tgcagttttg gccaggggac caagctggag atcaaacgta cggtggccgc tccctccgtg 360
ttcatcttcc caccttccga cgagcagctg aagtccggca ccgcttctgt cgtgtgcctg 420
ctgaacaact tctacccccg cgaggccaag gtgcagtgga aggtggacaa cgccctgcag 480
tccggcaact cccaggaatc cgtgaccgag caggactcca aggacagcac ctactccctg 540
tcctccaccc tgaccctgtc caaggccgac tacgagaagc acaaggtgta cgcctgcgaa 600
gtgacccacc agggcctgtc tagccccgtg accaagtctt tcaaccgggg cgagtgt 657
<210> 405
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 405
Gly Val Thr Phe Asp Asp Tyr Gly
1 5
<210> 406
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 406
Ile Asn Trp Asn Gly Gly Asp Thr
1 5
<210> 407
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 407
Ala Arg Asp Phe Tyr Gly Ser Gly Ser Tyr Tyr His Val Pro Phe Asp
1 5 10 15
Tyr
<210> 408
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 408
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Val Thr Phe Asp Asp Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Trp Asn Gly Gly Asp Thr Asp Tyr Ser Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Arg Asp Phe Tyr Gly Ser Gly Ser Tyr Tyr His Val Pro Phe Asp
100 105 110
Tyr Trp Gly Gln Gly Ile Leu Val Thr Val Ser Ser
115 120
<210> 409
<211> 372
<212> DNA
<213> Homo Sapiens
<400> 409
gaggtgcagc tggtggagtc tgggggaggt gtggtacggc ctggggggtc cctgagactc 60
tcctgtgtag cctctggagt cacctttgat gattatggca tgagctgggt ccgccaagct 120
ccagggaagg ggctggartg ggtctctggt attaattgga atggtggcga cacagattat 180
tcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctccctgtat 240
ctacaaatga atagtctgag agccgaggac acggccttgt attactgtgc gagggatttc 300
tatggttcgg ggagttatta tcacgttcct tttgactact ggggccaggg aatcctggtc 360
accgtctcct ca 372
<210> 410
<211> 454
<212> PRT
<213> Homo Sapiens
<400> 410
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Val Thr Phe Asp Asp Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Trp Asn Gly Gly Asp Thr Asp Tyr Ser Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Arg Asp Phe Tyr Gly Ser Gly Ser Tyr Tyr His Val Pro Phe Asp
100 105 110
Tyr Trp Gly Gln Gly Ile Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly Lys
450
<210> 411
<211> 1368
<212> DNA
<213> Homo Sapiens
<400> 411
gaggtgcagc tggtggagtc tgggggaggt gtggtacggc ctggggggtc cctgagactc 60
tcctgtgtag cctctggagt cacctttgat gattatggca tgagctgggt ccgccaagct 120
ccagggaagg ggctggartg ggtctctggt attaattgga atggtggcga cacagattat 180
tcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctccctgtat 240
ctacaaatga atagtctgag agccgaggac acggccttgt attactgtgc gagggatttc 300
tatggttcgg ggagttatta tcacgttcct tttgactact ggggccaggg aatcctggtc 360
accgtctcct cagccagcac caagggcccc tctgtgttcc ctctggcccc ttccagcaag 420
tccacctctg gcggaacagc cgctctgggc tgcctcgtga aggactactt ccccgagcct 480
gtgaccgtgt cctggaactc tggcgctctg accagcggag tgcacacctt ccctgctgtg 540
ctgcagtcct ccggcctgta ctccctgtcc tccgtcgtga ccgtgccttc cagctctctg 600
ggcacccaga cctacatctg caacgtgaac cacaagccct ccaacaccaa ggtggacaag 660
aaggtggaac ccaagtcctg cgacaagacc cacacctgtc ccccttgtcc tgcccctgaa 720
ctgctgggcg gaccttccgt gttcctgttc cccccaaagc ccaaggacac cctgatgatc 780
tcccggaccc ccgaagtgac ctgcgtggtg gtggatgtgt cccacgagga ccctgaagtg 840
aagttcaatt ggtacgtgga cggcgtggaa gtgcacaacg ccaagaccaa gcctagagag 900
gaacagtaca actccaccta ccgggtggtg tccgtgctga ccgtgctgca ccaggattgg 960
ctgaacggca aagagtacaa gtgcaaggtg tccaacaagg ccctgcctgc ccccatcgaa 1020
aagaccatct ccaaggccaa gggccagccc cgggaacccc aggtgtacac actgccccct 1080
agcagggacg agctgaccaa gaaccaggtg tccctgacct gtctcgtgaa aggcttctac 1140
ccctccgata tcgccgtgga atgggagtcc aacggccagc ctgagaacaa ctacaagacc 1200
accccccctg tgctggactc cgacggctca ttcttcctgt acagcaagct gacagtggac 1260
aagtcccggt ggcagcaggg caacgtgttc tcctgctccg tgatgcacga ggccctgcac 1320
aaccactaca cccagaagtc cctgtccctg agccccggca agtgatga 1368
<210> 412
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 412
Gln Ser Val Ser Arg Ser Tyr
1 5
<210> 413
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 413
Gly Ala Ser
1
<210> 414
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 414
His Gln Tyr Asp Met Ser Pro Phe Thr
1 5
<210> 415
<211> 108
<212> PRT
<213> Homo Sapiens
<400> 415
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Arg Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Arg Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Asp Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys His Gln Tyr Asp Met Ser Pro
85 90 95
Phe Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105
<210> 416
<211> 324
<212> DNA
<213> Homo Sapiens
<400> 416
gaaattgtgt tgacgcagtc tccagggacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agaagctact tagcctggta ccagcagaaa 120
cgtggccagg ctcccaggct cctcatctat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcgatgg gtctgggaca gacttcactc tctccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcac cagtatgata tgtcaccatt cactttcggc 300
cctgggacca aagtggatat caaa 324
<210> 417
<211> 215
<212> PRT
<213> Homo Sapiens
<400> 417
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Arg Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Arg Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Asp Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys His Gln Tyr Asp Met Ser Pro
85 90 95
Phe Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala
100 105 110
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser
115 120 125
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu
130 135 140
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser
145 150 155 160
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu
165 170 175
Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val
180 185 190
Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys
195 200 205
Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 418
<211> 645
<212> DNA
<213> Homo Sapiens
<400> 418
gaaattgtgt tgacgcagtc tccagggacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agaagctact tagcctggta ccagcagaaa 120
cgtggccagg ctcccaggct cctcatctat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcgatgg gtctgggaca gacttcactc tctccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcac cagtatgata tgtcaccatt cactttcggc 300
cctgggacca aagtggatat caaacgtacg gtggccgctc cctccgtgtt catcttccca 360
ccttccgacg agcagctgaa gtccggcacc gcttctgtcg tgtgcctgct gaacaacttc 420
tacccccgcg aggccaaggt gcagtggaag gtggacaacg ccctgcagtc cggcaactcc 480
caggaatccg tgaccgagca ggactccaag gacagcacct actccctgtc ctccaccctg 540
accctgtcca aggccgacta cgagaagcac aaggtgtacg cctgcgaagt gacccaccag 600
ggcctgtcta gccccgtgac caagtctttc aaccggggcg agtgt 645
<210> 419
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 419
Gly Leu Thr Phe Asp Asp Tyr Gly
1 5
<210> 420
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 420
Ile Asn Trp Asn Gly Asp Asn Thr
1 5
<210> 421
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 421
Ala Arg Asp Tyr Tyr Gly Ser Gly Ser Tyr Tyr Asn Val Pro Phe Asp
1 5 10 15
Tyr
<210> 422
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 422
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Leu Thr Phe Asp Asp Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Trp Asn Gly Asp Asn Thr Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Tyr Gly Ser Gly Ser Tyr Tyr Asn Val Pro Phe Asp
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 423
<211> 372
<212> DNA
<213> Homo Sapiens
<400> 423
gaggtgcagc tggtggagtc tgggggaggt gtggtacggc ctggggggtc cctgagactc 60
tcctgtgcag cctctggact cacctttgat gattatggca tgagctgggt ccgccaagtt 120
ccagggaagg ggctggagtg ggtctctggt attaattgga atggtgataa cacagattat 180
gcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctccctgtat 240
ctgcaaatga acagtctgag agccgaggac acggccttgt attactgtgc gagggattac 300
tatggttcgg ggagttatta taacgttcct tttgactact ggggccaggg aaccctggtc 360
accgtctcct ca 372
<210> 424
<211> 454
<212> PRT
<213> Homo Sapiens
<400> 424
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Leu Thr Phe Asp Asp Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Val Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Trp Asn Gly Asp Asn Thr Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Tyr Gly Ser Gly Ser Tyr Tyr Asn Val Pro Phe Asp
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly Lys
450
<210> 425
<211> 1368
<212> DNA
<213> Homo Sapiens
<400> 425
gaggtgcagc tggtggagtc tgggggaggt gtggtacggc ctggggggtc cctgagactc 60
tcctgtgcag cctctggact cacctttgat gattatggca tgagctgggt ccgccaagtt 120
ccagggaagg ggctggagtg ggtctctggt attaattgga atggtgataa cacagattat 180
gcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctccctgtat 240
ctgcaaatga acagtctgag agccgaggac acggccttgt attactgtgc gagggattac 300
tatggttcgg ggagttatta taacgttcct tttgactact ggggccaggg aaccctggtc 360
accgtctcct cagccagcac caagggcccc tctgtgttcc ctctggcccc ttccagcaag 420
tccacctctg gcggaacagc cgctctgggc tgcctcgtga aggactactt ccccgagcct 480
gtgaccgtgt cctggaactc tggcgctctg accagcggag tgcacacctt ccctgctgtg 540
ctgcagtcct ccggcctgta ctccctgtcc tccgtcgtga ccgtgccttc cagctctctg 600
ggcacccaga cctacatctg caacgtgaac cacaagccct ccaacaccaa ggtggacaag 660
aaggtggaac ccaagtcctg cgacaagacc cacacctgtc ccccttgtcc tgcccctgaa 720
ctgctgggcg gaccttccgt gttcctgttc cccccaaagc ccaaggacac cctgatgatc 780
tcccggaccc ccgaagtgac ctgcgtggtg gtggatgtgt cccacgagga ccctgaagtg 840
aagttcaatt ggtacgtgga cggcgtggaa gtgcacaacg ccaagaccaa gcctagagag 900
gaacagtaca actccaccta ccgggtggtg tccgtgctga ccgtgctgca ccaggattgg 960
ctgaacggca aagagtacaa gtgcaaggtg tccaacaagg ccctgcctgc ccccatcgaa 1020
aagaccatct ccaaggccaa gggccagccc cgggaacccc aggtgtacac actgccccct 1080
agcagggacg agctgaccaa gaaccaggtg tccctgacct gtctcgtgaa aggcttctac 1140
ccctccgata tcgccgtgga atgggagtcc aacggccagc ctgagaacaa ctacaagacc 1200
accccccctg tgctggactc cgacggctca ttcttcctgt acagcaagct gacagtggac 1260
aagtcccggt ggcagcaggg caacgtgttc tcctgctccg tgatgcacga ggccctgcac 1320
aaccactaca cccagaagtc cctgtccctg agccccggca agtgatga 1368
<210> 426
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 426
Gln Ser Val Ser Ser Ser Tyr
1 5
<210> 427
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 427
Gly Ala Ser
1
<210> 428
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 428
Gln Gln Tyr Gly Ser Ser Pro Phe
1 5
<210> 429
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 429
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Arg Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Ser Ser Pro
85 90 95
Phe Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105
<210> 430
<211> 321
<212> DNA
<213> Homo Sapiens
<400> 430
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatatat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag aagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagtatggta gttcaccatt cttcggccct 300
gggaccaaag tggatatcaa a 321
<210> 431
<211> 323
<212> DNA
<213> Homo Sapiens
<400> 431
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatatat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag aagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagtatggta gttcaccatt cacttcggcc 300
ctgggaccaa agtggatatc aaa 323
<210> 432
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 432
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Arg Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Ser Ser Pro
85 90 95
Phe Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 433
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 433
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatatat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag aagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagtatggta gttcaccatt cttcggccct 300
gggaccaaag tggatatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 434
<211> 644
<212> DNA
<213> Homo Sapiens
<400> 434
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatatat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag aagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagtatggta gttcaccatt cacttcggcc 300
ctgggaccaa agtggatatc aaacgtacgg tggccgctcc ctccgtgttc atcttcccac 360
cttccgacga gcagctgaag tccggcaccg cttctgtcgt gtgcctgctg aacaacttct 420
acccccgcga ggccaaggtg cagtggaagg tggacaacgc cctgcagtcc ggcaactccc 480
aggaatccgt gaccgagcag gactccaagg acagcaccta ctccctgtcc tccaccctga 540
ccctgtccaa ggccgactac gagaagcaca aggtgtacgc ctgcgaagtg acccaccagg 600
gcctgtctag ccccgtgacc aagtctttca accggggcga gtgt 644
<210> 435
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 435
Gly Tyr Thr Phe Asn Ser Tyr Gly
1 5
<210> 436
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 436
Ile Ser Val His Asn Gly Asn Thr
1 5
<210> 437
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 437
Ala Arg Ala Gly Tyr Asp Ile Leu Thr Asp Phe Ser Asp Ala Phe Asp
1 5 10 15
Ile
<210> 438
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 438
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asn Ser Tyr
20 25 30
Gly Ile Ile Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Val His Asn Gly Asn Thr Asn Cys Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Thr Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Gly Tyr Asp Ile Leu Thr Asp Phe Ser Asp Ala Phe Asp
100 105 110
Ile Trp Gly His Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 439
<211> 372
<212> DNA
<213> Homo Sapiens
<400> 439
caggttcagt tggtgcagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttaat agttatggta tcatctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg atcagcgttc acaatggtaa cacaaactgt 180
gcacagaagc tccagggtag agtcaccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcctgag aactgacgac acggccgtgt attactgtgc gagagcgggt 300
tacgatattt tgactgattt ttccgatgct tttgatatct ggggccacgg gacaatggtc 360
accgtctctt ca 372
<210> 440
<211> 454
<212> PRT
<213> Homo Sapiens
<400> 440
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asn Ser Tyr
20 25 30
Gly Ile Ile Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Val His Asn Gly Asn Thr Asn Cys Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Thr Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Gly Tyr Asp Ile Leu Thr Asp Phe Ser Asp Ala Phe Asp
100 105 110
Ile Trp Gly His Gly Thr Met Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly Lys
450
<210> 441
<211> 1368
<212> DNA
<213> Homo Sapiens
<400> 441
caggttcagt tggtgcagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttaat agttatggta tcatctgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg atcagcgttc acaatggtaa cacaaactgt 180
gcacagaagc tccagggtag agtcaccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcctgag aactgacgac acggccgtgt attactgtgc gagagcgggt 300
tacgatattt tgactgattt ttccgatgct tttgatatct ggggccacgg gacaatggtc 360
accgtctctt cagccagcac caagggcccc tctgtgttcc ctctggcccc ttccagcaag 420
tccacctctg gcggaacagc cgctctgggc tgcctcgtga aggactactt ccccgagcct 480
gtgaccgtgt cctggaactc tggcgctctg accagcggag tgcacacctt ccctgctgtg 540
ctgcagtcct ccggcctgta ctccctgtcc tccgtcgtga ccgtgccttc cagctctctg 600
ggcacccaga cctacatctg caacgtgaac cacaagccct ccaacaccaa ggtggacaag 660
aaggtggaac ccaagtcctg cgacaagacc cacacctgtc ccccttgtcc tgcccctgaa 720
ctgctgggcg gaccttccgt gttcctgttc cccccaaagc ccaaggacac cctgatgatc 780
tcccggaccc ccgaagtgac ctgcgtggtg gtggatgtgt cccacgagga ccctgaagtg 840
aagttcaatt ggtacgtgga cggcgtggaa gtgcacaacg ccaagaccaa gcctagagag 900
gaacagtaca actccaccta ccgggtggtg tccgtgctga ccgtgctgca ccaggattgg 960
ctgaacggca aagagtacaa gtgcaaggtg tccaacaagg ccctgcctgc ccccatcgaa 1020
aagaccatct ccaaggccaa gggccagccc cgggaacccc aggtgtacac actgccccct 1080
agcagggacg agctgaccaa gaaccaggtg tccctgacct gtctcgtgaa aggcttctac 1140
ccctccgata tcgccgtgga atgggagtcc aacggccagc ctgagaacaa ctacaagacc 1200
accccccctg tgctggactc cgacggctca ttcttcctgt acagcaagct gacagtggac 1260
aagtcccggt ggcagcaggg caacgtgttc tcctgctccg tgatgcacga ggccctgcac 1320
aaccactaca cccagaagtc cctgtccctg agccccggca agtgatga 1368
<210> 442
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 442
Gln Asn Ile Asn Asn Phe
1 5
<210> 443
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 443
Ala Ala Ser
1
<210> 444
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 444
Gln Gln Ser Tyr Gly Ile Pro Trp
1 5
<210> 445
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 445
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asn Ile Asn Asn Phe
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Glu Gly Lys Gly Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Arg Gly Ile Pro Ser Thr Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Ile Cys Gln Gln Ser Tyr Gly Ile Pro Trp
85 90 95
Val Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 446
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 446
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gaacattaat aactttttaa attggtatca gcagaaagaa 120
gggaaaggcc ctaagctcct gatctatgca gcatccagtt tgcaaagagg gataccatca 180
acgttcagtg gcagtggatc tgggacagac ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacat ctgtcaacag agctacggta tcccgtgggt cggccaaggg 300
accaaggtgg aaatcaaa 318
<210> 447
<211> 213
<212> PRT
<213> Homo Sapiens
<400> 447
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asn Ile Asn Asn Phe
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Glu Gly Lys Gly Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Ser Leu Gln Arg Gly Ile Pro Ser Thr Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Ile Cys Gln Gln Ser Tyr Gly Ile Pro Trp
85 90 95
Val Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys
210
<210> 448
<211> 639
<212> DNA
<213> Homo Sapiens
<400> 448
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtca gaacattaat aactttttaa attggtatca gcagaaagaa 120
gggaaaggcc ctaagctcct gatctatgca gcatccagtt tgcaaagagg gataccatca 180
acgttcagtg gcagtggatc tgggacagac ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacat ctgtcaacag agctacggta tcccgtgggt cggccaaggg 300
accaaggtgg aaatcaaacg tacggtggcc gctccctccg tgttcatctt cccaccttcc 360
gacgagcagc tgaagtccgg caccgcttct gtcgtgtgcc tgctgaacaa cttctacccc 420
cgcgaggcca aggtgcagtg gaaggtggac aacgccctgc agtccggcaa ctcccaggaa 480
tccgtgaccg agcaggactc caaggacagc acctactccc tgtcctccac cctgaccctg 540
tccaaggccg actacgagaa gcacaaggtg tacgcctgcg aagtgaccca ccagggcctg 600
tctagccccg tgaccaagtc tttcaaccgg ggcgagtgt 639
<210> 449
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 449
Gly Phe Thr Phe Ser Asp Tyr Phe
1 5
<210> 450
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 450
Ile Ser Ser Ser Gly Ser Thr Ile
1 5
<210> 451
<211> 21
<212> PRT
<213> Homo Sapiens
<400> 451
Ala Arg Asp His Tyr Asp Gly Ser Gly Ile Tyr Pro Leu Tyr Tyr Tyr
1 5 10 15
Tyr Gly Leu Asp Val
20
<210> 452
<211> 128
<212> PRT
<213> Homo Sapiens
<400> 452
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Phe Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Tyr Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp His Tyr Asp Gly Ser Gly Ile Tyr Pro Leu Tyr Tyr Tyr
100 105 110
Tyr Gly Leu Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 453
<211> 384
<212> DNA
<213> Homo Sapiens
<400> 453
caggtgcagc tggtggagtc tgggggaggc ttggtcaagc ctggagggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt gactacttca tgagctggat ccgccaggcg 120
ccagggaagg ggctggagtg gatttcatac attagttcta gtggtagtac catatactac 180
gcagactctg tgaggggccg attcaccatc tccagggaca acgccaagta ctcactgtat 240
ctgcaaatga acagcctgag atccgaggac acggccgtgt attactgtgc gagagatcac 300
tacgatggtt cggggattta tcccctctac tactattacg gtttggacgt ctggggccag 360
gggaccacgg tcaccgtctc ctca 384
<210> 454
<211> 458
<212> PRT
<213> Homo Sapiens
<400> 454
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Phe Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Tyr Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp His Tyr Asp Gly Ser Gly Ile Tyr Pro Leu Tyr Tyr Tyr
100 105 110
Tyr Gly Leu Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
130 135 140
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
145 150 155 160
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
165 170 175
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
180 185 190
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
195 200 205
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
210 215 220
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
225 230 235 240
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
245 250 255
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
260 265 270
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
275 280 285
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
290 295 300
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
305 310 315 320
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
325 330 335
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
340 345 350
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
355 360 365
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
370 375 380
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
385 390 395 400
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
405 410 415
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
420 425 430
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
435 440 445
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 455
<211> 1380
<212> DNA
<213> Homo Sapiens
<400> 455
caggtgcagc tggtggagtc tgggggaggc ttggtcaagc ctggagggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt gactacttca tgagctggat ccgccaggcg 120
ccagggaagg ggctggagtg gatttcatac attagttcta gtggtagtac catatactac 180
gcagactctg tgaggggccg attcaccatc tccagggaca acgccaagta ctcactgtat 240
ctgcaaatga acagcctgag atccgaggac acggccgtgt attactgtgc gagagatcac 300
tacgatggtt cggggattta tcccctctac tactattacg gtttggacgt ctggggccag 360
gggaccacgg tcaccgtctc ctcagccagc accaagggcc cctctgtgtt ccctctggcc 420
ccttccagca agtccacctc tggcggaaca gccgctctgg gctgcctcgt gaaggactac 480
ttccccgagc ctgtgaccgt gtcctggaac tctggcgctc tgaccagcgg agtgcacacc 540
ttccctgctg tgctgcagtc ctccggcctg tactccctgt cctccgtcgt gaccgtgcct 600
tccagctctc tgggcaccca gacctacatc tgcaacgtga accacaagcc ctccaacacc 660
aaggtggaca agaaggtgga acccaagtcc tgcgacaaga cccacacctg tcccccttgt 720
cctgcccctg aactgctggg cggaccttcc gtgttcctgt tccccccaaa gcccaaggac 780
accctgatga tctcccggac ccccgaagtg acctgcgtgg tggtggatgt gtcccacgag 840
gaccctgaag tgaagttcaa ttggtacgtg gacggcgtgg aagtgcacaa cgccaagacc 900
aagcctagag aggaacagta caactccacc taccgggtgg tgtccgtgct gaccgtgctg 960
caccaggatt ggctgaacgg caaagagtac aagtgcaagg tgtccaacaa ggccctgcct 1020
gcccccatcg aaaagaccat ctccaaggcc aagggccagc cccgggaacc ccaggtgtac 1080
acactgcccc ctagcaggga cgagctgacc aagaaccagg tgtccctgac ctgtctcgtg 1140
aaaggcttct acccctccga tatcgccgtg gaatgggagt ccaacggcca gcctgagaac 1200
aactacaaga ccaccccccc tgtgctggac tccgacggct cattcttcct gtacagcaag 1260
ctgacagtgg acaagtcccg gtggcagcag ggcaacgtgt tctcctgctc cgtgatgcac 1320
gaggccctgc acaaccacta cacccagaag tccctgtccc tgagccccgg caagtgatga 1380
<210> 456
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 456
Gln Ser Leu Leu His Ser Asn Gly Tyr Asn Tyr
1 5 10
<210> 457
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 457
Leu Gly Ser
1
<210> 458
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 458
Met Gln Ala Leu Gln Thr Pro Arg Ser
1 5
<210> 459
<211> 111
<212> PRT
<213> Homo Sapiens
<400> 459
Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly Glu
1 5 10 15
Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser Asn
20 25 30
Gly Tyr Asn Tyr Leu Asp Tyr Tyr Leu Gln Lys Pro Gly Gln Ser Pro
35 40 45
Gln Leu Leu Ile Tyr Leu Gly Ser Tyr Arg Ala Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser
65 70 75 80
Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala Leu
85 90 95
Gln Thr Pro Arg Ser Phe Gly Gln Gly Thr Thr Leu Glu Ile Lys
100 105 110
<210> 460
<211> 333
<212> DNA
<213> Homo Sapiens
<400> 460
attgtgatga ctcagtctcc actctcccta cccgtcaccc ctggagagcc ggcctccatc 60
tcctgcaggt ctagtcagag cctcctgcat agtaatggat acaactattt ggattattac 120
ctgcagaagc cagggcagtc tccacagctc ctgatctatt tgggttctta tcgggcctcc 180
ggggtccctg acaggttcag tggcagtgga tcaggcacag attttacact gaaaatcagc 240
agagtggagg ctgaggatgt tggggtttat tactgcatgc aagctctaca aactcctcgc 300
agttttggcc aggggaccac gctggagatc aaa 333
<210> 461
<211> 218
<212> PRT
<213> Homo Sapiens
<400> 461
Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly Glu
1 5 10 15
Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser Asn
20 25 30
Gly Tyr Asn Tyr Leu Asp Tyr Tyr Leu Gln Lys Pro Gly Gln Ser Pro
35 40 45
Gln Leu Leu Ile Tyr Leu Gly Ser Tyr Arg Ala Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser
65 70 75 80
Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala Leu
85 90 95
Gln Thr Pro Arg Ser Phe Gly Gln Gly Thr Thr Leu Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 462
<211> 654
<212> DNA
<213> Homo Sapiens
<400> 462
attgtgatga ctcagtctcc actctcccta cccgtcaccc ctggagagcc ggcctccatc 60
tcctgcaggt ctagtcagag cctcctgcat agtaatggat acaactattt ggattattac 120
ctgcagaagc cagggcagtc tccacagctc ctgatctatt tgggttctta tcgggcctcc 180
ggggtccctg acaggttcag tggcagtgga tcaggcacag attttacact gaaaatcagc 240
agagtggagg ctgaggatgt tggggtttat tactgcatgc aagctctaca aactcctcgc 300
agttttggcc aggggaccac gctggagatc aaacgtacgg tggccgctcc ctccgtgttc 360
atcttcccac cttccgacga gcagctgaag tccggcaccg cttctgtcgt gtgcctgctg 420
aacaacttct acccccgcga ggccaaggtg cagtggaagg tggacaacgc cctgcagtcc 480
ggcaactccc aggaatccgt gaccgagcag gactccaagg acagcaccta ctccctgtcc 540
tccaccctga ccctgtccaa ggccgactac gagaagcaca aggtgtacgc ctgcgaagtg 600
acccaccagg gcctgtctag ccccgtgacc aagtctttca accggggcga gtgt 654
<210> 463
<211> 10
<212> PRT
<213> Homo Sapiens
<400> 463
Gly Phe Ser Leu Ser Thr Thr Gly Val Gly
1 5 10
<210> 464
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 464
Ile Tyr Trp Asp Asp Asp Lys
1 5
<210> 465
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 465
Thr His Gly Tyr Gly Ser Ala Ser Tyr Tyr His Tyr Gly Met Asp Val
1 5 10 15
<210> 466
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 466
Gln Ile Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Thr
20 25 30
Gly Val Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala Val Ile Tyr Trp Asp Asp Asp Lys Arg Tyr Ser Pro Ser
50 55 60
Leu Lys Ser Arg Leu Thr Ile Thr Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Thr His Gly Tyr Gly Ser Ala Ser Tyr Tyr His Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 467
<211> 372
<212> DNA
<213> Homo Sapiens
<400> 467
cagatcacct tgaaggagtc tggtcctacg ctggtgaaac ccacacagac cctcacgctg 60
acctgcacct tctctgggtt ctcactcagc actactggag tgggtgtggg ctggatccgt 120
cagcccccag gaaaggccct ggagtggctt gcagtcattt attgggatga tgataagcgc 180
tacagcccat ctctgaagag cagactcacc atcaccaagg acacctccaa aaaccaggtg 240
gtccttacaa tgaccaacat ggaccctgtg gacacagcca catatttctg tacacacgga 300
tatggttcgg cgagttatta ccactacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct ca 372
<210> 468
<211> 454
<212> PRT
<213> Homo Sapiens
<400> 468
Gln Ile Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Thr
20 25 30
Gly Val Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala Val Ile Tyr Trp Asp Asp Asp Lys Arg Tyr Ser Pro Ser
50 55 60
Leu Lys Ser Arg Leu Thr Ile Thr Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Thr His Gly Tyr Gly Ser Ala Ser Tyr Tyr His Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly Lys
450
<210> 469
<211> 1368
<212> DNA
<213> Homo Sapiens
<400> 469
cagatcacct tgaaggagtc tggtcctacg ctggtgaaac ccacacagac cctcacgctg 60
acctgcacct tctctgggtt ctcactcagc actactggag tgggtgtggg ctggatccgt 120
cagcccccag gaaaggccct ggagtggctt gcagtcattt attgggatga tgataagcgc 180
tacagcccat ctctgaagag cagactcacc atcaccaagg acacctccaa aaaccaggtg 240
gtccttacaa tgaccaacat ggaccctgtg gacacagcca catatttctg tacacacgga 300
tatggttcgg cgagttatta ccactacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct cagccagcac caagggcccc tctgtgttcc ctctggcccc ttccagcaag 420
tccacctctg gcggaacagc cgctctgggc tgcctcgtga aggactactt ccccgagcct 480
gtgaccgtgt cctggaactc tggcgctctg accagcggag tgcacacctt ccctgctgtg 540
ctgcagtcct ccggcctgta ctccctgtcc tccgtcgtga ccgtgccttc cagctctctg 600
ggcacccaga cctacatctg caacgtgaac cacaagccct ccaacaccaa ggtggacaag 660
aaggtggaac ccaagtcctg cgacaagacc cacacctgtc ccccttgtcc tgcccctgaa 720
ctgctgggcg gaccttccgt gttcctgttc cccccaaagc ccaaggacac cctgatgatc 780
tcccggaccc ccgaagtgac ctgcgtggtg gtggatgtgt cccacgagga ccctgaagtg 840
aagttcaatt ggtacgtgga cggcgtggaa gtgcacaacg ccaagaccaa gcctagagag 900
gaacagtaca actccaccta ccgggtggtg tccgtgctga ccgtgctgca ccaggattgg 960
ctgaacggca aagagtacaa gtgcaaggtg tccaacaagg ccctgcctgc ccccatcgaa 1020
aagaccatct ccaaggccaa gggccagccc cgggaacccc aggtgtacac actgccccct 1080
agcagggacg agctgaccaa gaaccaggtg tccctgacct gtctcgtgaa aggcttctac 1140
ccctccgata tcgccgtgga atgggagtcc aacggccagc ctgagaacaa ctacaagacc 1200
accccccctg tgctggactc cgacggctca ttcttcctgt acagcaagct gacagtggac 1260
aagtcccggt ggcagcaggg caacgtgttc tcctgctccg tgatgcacga ggccctgcac 1320
aaccactaca cccagaagtc cctgtccctg agccccggca agtgatga 1368
<210> 470
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 470
Gln Ser Val Thr Asn Tyr
1 5
<210> 471
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 471
Asp Ala Ser
1
<210> 472
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 472
Gln His Arg Ser Asn Trp Pro Leu Thr
1 5
<210> 473
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 473
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Asn Tyr
20 25 30
Leu Ala Trp His Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln His Arg Ser Asn Trp Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 474
<211> 322
<212> DNA
<213> Homo Sapiens
<400> 474
gaaattgtat tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttacc aactacttag cctggcacca acagaaacct 120
ggccaggctc ccaggctcct catctatgat gcatccaaca gggccactgg catcccagcc 180
aggttcagtg gcagtgggtc tgggacagac ttcactctca ccatcagcag cctagagcct 240
gaagattttg cagtttatta ctgtcagcac cgtagcaact ggcctctcac tttcggcgga 300
gggaccaagg tggagatcaa ac 322
<210> 475
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 475
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Asn Tyr
20 25 30
Leu Ala Trp His Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln His Arg Ser Asn Trp Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 476
<211> 643
<212> DNA
<213> Homo Sapiens
<400> 476
gaaattgtat tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttacc aactacttag cctggcacca acagaaacct 120
ggccaggctc ccaggctcct catctatgat gcatccaaca gggccactgg catcccagcc 180
aggttcagtg gcagtgggtc tgggacagac ttcactctca ccatcagcag cctagagcct 240
gaagattttg cagtttatta ctgtcagcac cgtagcaact ggcctctcac tttcggcgga 300
gggaccaagg tggagatcaa accgtacggt ggccgctccc tccgtgttca tcttcccacc 360
ttccgacgag cagctgaagt ccggcaccgc ttctgtcgtg tgcctgctga acaacttcta 420
cccccgcgag gccaaggtgc agtggaaggt ggacaacgcc ctgcagtccg gcaactccca 480
ggaatccgtg accgagcagg actccaagga cagcacctac tccctgtcct ccaccctgac 540
cctgtccaag gccgactacg agaagcacaa ggtgtacgcc tgcgaagtga cccaccaggg 600
cctgtctagc cccgtgacca agtctttcaa ccggggcgag tgt 643
<210> 477
<211> 10
<212> PRT
<213> Homo Sapiens
<400> 477
Gly Phe Ser Leu Ser Thr Ser Gly Val Gly
1 5 10
<210> 478
<211> 7
<212> PRT
<213> Homo Sapiens
<400> 478
Ile Tyr Trp Asp Asp Asp Lys
1 5
<210> 479
<211> 16
<212> PRT
<213> Homo Sapiens
<400> 479
Thr His Gly Tyr Gly Ser Ala Ser Tyr Tyr His Tyr Gly Met Asp Val
1 5 10 15
<210> 480
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 480
Gln Ile Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Val Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala Val Ile Tyr Trp Asp Asp Asp Lys Arg Tyr Ser Pro Ser
50 55 60
Leu Lys Ser Arg Leu Thr Ile Thr Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Thr His Gly Tyr Gly Ser Ala Ser Tyr Tyr His Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 481
<211> 372
<212> DNA
<213> Homo Sapiens
<400> 481
cagatcacct tgaaggagtc tggtcctacg ctggtgaaac ccacacagac cctcacgctg 60
acctgcacct tctctgggtt ctcactcagc actagtggag tgggtgtggg ctggatccgt 120
cagcccccag gaaaggccct ggagtggctt gcagtcattt attgggatga tgataagcgc 180
tacagcccat ctctgaagag caggctcacc atcaccaagg acacctccaa aaaccaggtg 240
gtccttacaa tgaccaacat ggaccctgtg gacacagcca catatttctg tacacacgga 300
tatggttcgg cgagttatta ccactacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct ca 372
<210> 482
<211> 454
<212> PRT
<213> Homo Sapiens
<400> 482
Gln Ile Thr Leu Lys Glu Ser Gly Pro Thr Leu Val Lys Pro Thr Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Val Gly Val Gly Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala Val Ile Tyr Trp Asp Asp Asp Lys Arg Tyr Ser Pro Ser
50 55 60
Leu Lys Ser Arg Leu Thr Ile Thr Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Thr His Gly Tyr Gly Ser Ala Ser Tyr Tyr His Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys
115 120 125
Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
130 135 140
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
145 150 155 160
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
165 170 175
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
180 185 190
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
195 200 205
Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
210 215 220
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
225 230 235 240
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
245 250 255
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
260 265 270
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
275 280 285
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
290 295 300
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
305 310 315 320
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
325 330 335
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
340 345 350
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
355 360 365
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
370 375 380
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
385 390 395 400
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
405 410 415
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
420 425 430
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
435 440 445
Ser Leu Ser Pro Gly Lys
450
<210> 483
<211> 1368
<212> DNA
<213> Homo Sapiens
<400> 483
cagatcacct tgaaggagtc tggtcctacg ctggtgaaac ccacacagac cctcacgctg 60
acctgcacct tctctgggtt ctcactcagc actagtggag tgggtgtggg ctggatccgt 120
cagcccccag gaaaggccct ggagtggctt gcagtcattt attgggatga tgataagcgc 180
tacagcccat ctctgaagag caggctcacc atcaccaagg acacctccaa aaaccaggtg 240
gtccttacaa tgaccaacat ggaccctgtg gacacagcca catatttctg tacacacgga 300
tatggttcgg cgagttatta ccactacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct cagccagcac caagggcccc tctgtgttcc ctctggcccc ttccagcaag 420
tccacctctg gcggaacagc cgctctgggc tgcctcgtga aggactactt ccccgagcct 480
gtgaccgtgt cctggaactc tggcgctctg accagcggag tgcacacctt ccctgctgtg 540
ctgcagtcct ccggcctgta ctccctgtcc tccgtcgtga ccgtgccttc cagctctctg 600
ggcacccaga cctacatctg caacgtgaac cacaagccct ccaacaccaa ggtggacaag 660
aaggtggaac ccaagtcctg cgacaagacc cacacctgtc ccccttgtcc tgcccctgaa 720
ctgctgggcg gaccttccgt gttcctgttc cccccaaagc ccaaggacac cctgatgatc 780
tcccggaccc ccgaagtgac ctgcgtggtg gtggatgtgt cccacgagga ccctgaagtg 840
aagttcaatt ggtacgtgga cggcgtggaa gtgcacaacg ccaagaccaa gcctagagag 900
gaacagtaca actccaccta ccgggtggtg tccgtgctga ccgtgctgca ccaggattgg 960
ctgaacggca aagagtacaa gtgcaaggtg tccaacaagg ccctgcctgc ccccatcgaa 1020
aagaccatct ccaaggccaa gggccagccc cgggaacccc aggtgtacac actgccccct 1080
agcagggacg agctgaccaa gaaccaggtg tccctgacct gtctcgtgaa aggcttctac 1140
ccctccgata tcgccgtgga atgggagtcc aacggccagc ctgagaacaa ctacaagacc 1200
accccccctg tgctggactc cgacggctca ttcttcctgt acagcaagct gacagtggac 1260
aagtcccggt ggcagcaggg caacgtgttc tcctgctccg tgatgcacga ggccctgcac 1320
aaccactaca cccagaagtc cctgtccctg agccccggca agtgatga 1368
<210> 484
<211> 6
<212> PRT
<213> Homo Sapiens
<400> 484
Gln Ser Val Thr Asn Tyr
1 5
<210> 485
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 485
Asp Ala Ser
1
<210> 486
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 486
Gln Gln Arg Ser Asn Trp Pro Leu Thr
1 5
<210> 487
<211> 107
<212> PRT
<213> Homo Sapiens
<400> 487
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Asn Tyr
20 25 30
Leu Ala Trp His Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Arg Ser Asn Trp Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 488
<211> 321
<212> DNA
<213> Homo Sapiens
<400> 488
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttacc aactacttag cctggcacca acagaaacct 120
ggccaggctc ccaggctcct catctatgat gcatccaaca gggccactgg catcccagcc 180
aggttcagtg gcagtgggtc tgggacagac ttcactctca ccatcagcag cctagagcct 240
gaagattttg cagtttatta ctgtcagcag cgtagcaact ggcctctcac tttcggcgga 300
gggaccaagg tggagatcaa a 321
<210> 489
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 489
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Thr Asn Tyr
20 25 30
Leu Ala Trp His Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Arg Ser Asn Trp Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 490
<211> 642
<212> DNA
<213> Homo Sapiens
<400> 490
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttacc aactacttag cctggcacca acagaaacct 120
ggccaggctc ccaggctcct catctatgat gcatccaaca gggccactgg catcccagcc 180
aggttcagtg gcagtgggtc tgggacagac ttcactctca ccatcagcag cctagagcct 240
gaagattttg cagtttatta ctgtcagcag cgtagcaact ggcctctcac tttcggcgga 300
gggaccaagg tggagatcaa acgtacggtg gccgctccct ccgtgttcat cttcccacct 360
tccgacgagc agctgaagtc cggcaccgct tctgtcgtgt gcctgctgaa caacttctac 420
ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg caactcccag 480
gaatccgtga ccgagcagga ctccaaggac agcacctact ccctgtcctc caccctgacc 540
ctgtccaagg ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc 600
ctgtctagcc ccgtgaccaa gtctttcaac cggggcgagt gt 642
<210> 491
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 491
Gly Phe Thr Phe Ser Asp Tyr Tyr
1 5
<210> 492
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 492
Ile Ser Ser Ser Gly Ser Thr Ile
1 5
<210> 493
<211> 20
<212> PRT
<213> Homo Sapiens
<400> 493
Ala Arg Asp Phe Tyr Asp Ile Leu Thr Asp Ser Pro Tyr Phe Tyr Tyr
1 5 10 15
Gly Val Asp Val
20
<210> 494
<211> 127
<212> PRT
<213> Homo Sapiens
<400> 494
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Ile Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Phe Tyr Asp Ile Leu Thr Asp Ser Pro Tyr Phe Tyr Tyr
100 105 110
Gly Val Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 495
<211> 381
<212> DNA
<213> Homo Sapiens
<400> 495
caggtgcagc tggtggagtc tgggggaggc ttggtcaagc ctggagggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt gactactaca tgagctggat ccgccaggct 120
ccagggaagg ggctggagtg ggtttcatac attagtagta gtggtagtac catatactac 180
gcagactctg tgaagggccg attcaccatc tccagggaca acgccaagaa ctcactgtat 240
ctgcaaatta acagcctgag agccgaggac acggccgtgt attactgtgc gagagatttt 300
tacgatattt tgactgatag tccgtacttc tactacggtg tggacgtctg gggccaaggg 360
accacggtca ccgtctcctc a 381
<210> 496
<211> 457
<212> PRT
<213> Homo Sapiens
<400> 496
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Ile Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Phe Tyr Asp Ile Leu Thr Asp Ser Pro Tyr Phe Tyr Tyr
100 105 110
Gly Val Asp Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Ala
115 120 125
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser
130 135 140
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe
145 150 155 160
Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly
165 170 175
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu
180 185 190
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr
195 200 205
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys
210 215 220
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
225 230 235 240
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
245 250 255
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
260 265 270
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
275 280 285
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
290 295 300
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
305 310 315 320
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
325 330 335
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
340 345 350
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu
355 360 365
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
370 375 380
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
385 390 395 400
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
405 410 415
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
420 425 430
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
435 440 445
Lys Ser Leu Ser Leu Ser Pro Gly Lys
450 455
<210> 497
<211> 1377
<212> DNA
<213> Homo Sapiens
<400> 497
caggtgcagc tggtggagtc tgggggaggc ttggtcaagc ctggagggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt gactactaca tgagctggat ccgccaggct 120
ccagggaagg ggctggagtg ggtttcatac attagtagta gtggtagtac catatactac 180
gcagactctg tgaagggccg attcaccatc tccagggaca acgccaagaa ctcactgtat 240
ctgcaaatta acagcctgag agccgaggac acggccgtgt attactgtgc gagagatttt 300
tacgatattt tgactgatag tccgtacttc tactacggtg tggacgtctg gggccaaggg 360
accacggtca ccgtctcctc agccagcacc aagggcccct ctgtgttccc tctggcccct 420
tccagcaagt ccacctctgg cggaacagcc gctctgggct gcctcgtgaa ggactacttc 480
cccgagcctg tgaccgtgtc ctggaactct ggcgctctga ccagcggagt gcacaccttc 540
cctgctgtgc tgcagtcctc cggcctgtac tccctgtcct ccgtcgtgac cgtgccttcc 600
agctctctgg gcacccagac ctacatctgc aacgtgaacc acaagccctc caacaccaag 660
gtggacaaga aggtggaacc caagtcctgc gacaagaccc acacctgtcc cccttgtcct 720
gcccctgaac tgctgggcgg accttccgtg ttcctgttcc ccccaaagcc caaggacacc 780
ctgatgatct cccggacccc cgaagtgacc tgcgtggtgg tggatgtgtc ccacgaggac 840
cctgaagtga agttcaattg gtacgtggac ggcgtggaag tgcacaacgc caagaccaag 900
cctagagagg aacagtacaa ctccacctac cgggtggtgt ccgtgctgac cgtgctgcac 960
caggattggc tgaacggcaa agagtacaag tgcaaggtgt ccaacaaggc cctgcctgcc 1020
cccatcgaaa agaccatctc caaggccaag ggccagcccc gggaacccca ggtgtacaca 1080
ctgcccccta gcagggacga gctgaccaag aaccaggtgt ccctgacctg tctcgtgaaa 1140
ggcttctacc cctccgatat cgccgtggaa tgggagtcca acggccagcc tgagaacaac 1200
tacaagacca ccccccctgt gctggactcc gacggctcat tcttcctgta cagcaagctg 1260
acagtggaca agtcccggtg gcagcagggc aacgtgttct cctgctccgt gatgcacgag 1320
gccctgcaca accactacac ccagaagtcc ctgtccctga gccccggcaa gtgatga 1377
<210> 498
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 498
Gln Ser Leu Leu His Ser Asn Gly Tyr Asn Tyr
1 5 10
<210> 499
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 499
Leu Gly Ser
1
<210> 500
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 500
Met Gln Ala Leu Gln Thr Pro Arg Thr
1 5
<210> 501
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 501
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Arg Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 502
<211> 336
<212> DNA
<213> Homo Sapiens
<400> 502
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactcct 300
cggacgttcg gccaagggac caaggtggaa atcaaa 336
<210> 503
<211> 219
<212> PRT
<213> Homo Sapiens
<400> 503
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Arg Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105 110
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
115 120 125
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
130 135 140
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
145 150 155 160
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
165 170 175
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
180 185 190
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
195 200 205
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 504
<211> 657
<212> DNA
<213> Homo Sapiens
<400> 504
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactcct 300
cggacgttcg gccaagggac caaggtggaa atcaaacgta cggtggccgc tccctccgtg 360
ttcatcttcc caccttccga cgagcagctg aagtccggca ccgcttctgt cgtgtgcctg 420
ctgaacaact tctacccccg cgaggccaag gtgcagtgga aggtggacaa cgccctgcag 480
tccggcaact cccaggaatc cgtgaccgag caggactcca aggacagcac ctactccctg 540
tcctccaccc tgaccctgtc caaggccgac tacgagaagc acaaggtgta cgcctgcgaa 600
gtgacccacc agggcctgtc tagccccgtg accaagtctt tcaaccgggg cgagtgt 657
<210> 505
<211> 239
<212> PRT
<213> Homo Sapiens
<400> 505
Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly Ser
1 5 10 15
Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp Leu
20 25 30
Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile Gln
35 40 45
Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr Arg
50 55 60
Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala Ala
65 70 75 80
Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg Cys
85 90 95
Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys Val
100 105 110
Asn Ala Pro Tyr Asn Lys Ile Asn Gln Arg Ile Leu Val Val Asp Pro
115 120 125
Val Thr Ser Glu His Glu Leu Thr Cys Gln Ala Glu Gly Tyr Pro Lys
130 135 140
Ala Glu Val Ile Trp Thr Ser Ser Asp His Gln Val Leu Ser Gly Lys
145 150 155 160
Thr Thr Thr Thr Asn Ser Lys Arg Glu Glu Lys Leu Phe Asn Val Thr
165 170 175
Ser Thr Leu Arg Ile Asn Thr Thr Thr Asn Glu Ile Phe Tyr Cys Thr
180 185 190
Phe Arg Arg Leu Asp Pro Glu Glu Asn His Thr Ala Glu Leu Val Ile
195 200 205
Pro Glu Leu Pro Leu Ala His Pro Pro Asn Glu Arg Thr Ile Glu Gly
210 215 220
Arg Asp Tyr Lys Asp Asp Asp Asp Lys His His His His His His
225 230 235
<210> 506
<211> 179
<212> PRT
<213> Homo Sapiens
<400> 506
Glu Ile Asn Gly Ser Ala Asn Tyr Glu Met Phe Ile Phe His Asn Gly
1 5 10 15
Gly Val Gln Ile Leu Cys Lys Tyr Pro Asp Ile Val Gln Gln Phe Lys
20 25 30
Met Gln Leu Leu Lys Gly Gly Gln Ile Leu Cys Asp Leu Thr Lys Thr
35 40 45
Lys Gly Ser Gly Asn Thr Val Ser Ile Lys Ser Leu Lys Phe Cys His
50 55 60
Ser Gln Leu Ser Asn Asn Ser Val Ser Phe Phe Leu Tyr Asn Leu Asp
65 70 75 80
His Ser His Ala Asn Tyr Tyr Phe Cys Asn Leu Ser Ile Phe Asp Pro
85 90 95
Pro Pro Phe Lys Val Thr Leu Thr Gly Gly Tyr Leu His Ile Tyr Glu
100 105 110
Ser Gln Leu Cys Cys Gln Leu Lys Phe Trp Leu Pro Ile Gly Cys Ala
115 120 125
Ala Phe Val Val Val Cys Ile Leu Gly Cys Ile Leu Ile Cys Trp Leu
130 135 140
Thr Lys Lys Lys Tyr Ser Ser Ser Val His Asp Pro Asn Gly Glu Tyr
145 150 155 160
Met Phe Met Arg Ala Val Asn Thr Ala Lys Lys Ser Arg Leu Thr Asp
165 170 175
Val Thr Leu
<210> 507
<211> 121
<212> PRT
<213> Homo Sapiens
<400> 507
Glu Ile Asn Gly Ser Ala Asn Tyr Glu Met Phe Ile Phe His Asn Gly
1 5 10 15
Gly Val Gln Ile Leu Cys Lys Tyr Pro Asp Ile Val Gln Gln Phe Lys
20 25 30
Met Gln Leu Leu Lys Gly Gly Gln Ile Leu Cys Asp Leu Thr Lys Thr
35 40 45
Lys Gly Ser Gly Asn Thr Val Ser Ile Lys Ser Leu Lys Phe Cys His
50 55 60
Ser Gln Leu Ser Asn Asn Ser Val Ser Phe Phe Leu Tyr Asn Leu Asp
65 70 75 80
His Ser His Ala Asn Tyr Tyr Phe Cys Asn Leu Ser Ile Phe Asp Pro
85 90 95
Pro Pro Phe Lys Val Thr Leu Thr Gly Gly Tyr Leu His Ile Tyr Glu
100 105 110
Ser Gln Leu Cys Cys Gln Leu Lys Phe
115 120
<210> 508
<211> 199
<212> PRT
<213> Homo Sapiens
<400> 508
Met Lys Ser Gly Leu Trp Tyr Phe Phe Leu Phe Cys Leu Arg Ile Lys
1 5 10 15
Val Leu Thr Gly Glu Ile Asn Gly Ser Ala Asn Tyr Glu Met Phe Ile
20 25 30
Phe His Asn Gly Gly Val Gln Ile Leu Cys Lys Tyr Pro Asp Ile Val
35 40 45
Gln Gln Phe Lys Met Gln Leu Leu Lys Gly Gly Gln Ile Leu Cys Asp
50 55 60
Leu Thr Lys Thr Lys Gly Ser Gly Asn Thr Val Ser Ile Lys Ser Leu
65 70 75 80
Lys Phe Cys His Ser Gln Leu Ser Asn Asn Ser Val Ser Phe Phe Leu
85 90 95
Tyr Asn Leu Asp His Ser His Ala Asn Tyr Tyr Phe Cys Asn Leu Ser
100 105 110
Ile Phe Asp Pro Pro Pro Phe Lys Val Thr Leu Thr Gly Gly Tyr Leu
115 120 125
His Ile Tyr Glu Ser Gln Leu Cys Cys Gln Leu Lys Phe Trp Leu Pro
130 135 140
Ile Gly Cys Ala Ala Phe Val Val Val Cys Ile Leu Gly Cys Ile Leu
145 150 155 160
Ile Cys Trp Leu Thr Lys Lys Lys Tyr Ser Ser Ser Val His Asp Pro
165 170 175
Asn Gly Glu Tyr Met Phe Met Arg Ala Val Asn Thr Ala Lys Lys Ser
180 185 190
Arg Leu Thr Asp Val Thr Leu
195
<210> 509
<211> 33
<212> PRT
<213> Homo Sapiens
<400> 509
Lys Tyr Ser Ser Ser Val His Asp Pro Asn Gly Glu Tyr Met Phe Met
1 5 10 15
Arg Ala Val Asn Thr Ala Lys Lys Ser Arg Leu Thr Asp Val Thr Leu
20 25 30
Met
<210> 510
<211> 128
<212> PRT
<213> Mus Musculus
<400> 510
Glu Ile Asn Gly Ser Ala Asp His Arg Met Phe Ser Phe His Asn Gly
1 5 10 15
Gly Val Gln Ile Ser Cys Lys Tyr Pro Glu Thr Val Gln Gln Leu Lys
20 25 30
Met Arg Leu Phe Arg Glu Arg Glu Val Leu Cys Glu Leu Thr Lys Thr
35 40 45
Lys Gly Ser Gly Asn Ala Val Ser Ile Lys Asn Pro Met Leu Cys Leu
50 55 60
Tyr His Leu Ser Asn Asn Ser Val Ser Phe Phe Leu Asn Asn Pro Asp
65 70 75 80
Ser Ser Gln Gly Ser Tyr Tyr Phe Cys Ser Leu Ser Ile Phe Asp Pro
85 90 95
Pro Pro Phe Gln Glu Arg Asn Leu Ser Gly Gly Tyr Leu His Ile Tyr
100 105 110
Glu Ser Gln Leu Cys Cys Gln Leu Lys Ile Val Val Gln Val Thr Glu
115 120 125
<210> 511
<211> 121
<212> PRT
<213> Mus Musculus
<400> 511
Glu Ile Asn Gly Ser Ala Asp His Arg Met Phe Ser Phe His Asn Gly
1 5 10 15
Gly Val Gln Ile Ser Cys Lys Tyr Pro Glu Thr Val Gln Gln Leu Lys
20 25 30
Met Arg Leu Phe Arg Glu Arg Glu Val Leu Cys Glu Leu Thr Lys Thr
35 40 45
Lys Gly Ser Gly Asn Ala Val Ser Ile Lys Asn Pro Met Leu Cys Leu
50 55 60
Tyr His Leu Ser Asn Asn Ser Val Ser Phe Phe Leu Asn Asn Pro Asp
65 70 75 80
Ser Ser Gln Gly Ser Tyr Tyr Phe Cys Ser Leu Ser Ile Phe Asp Pro
85 90 95
Pro Pro Phe Gln Glu Arg Asn Leu Ser Gly Gly Tyr Leu His Ile Tyr
100 105 110
Glu Ser Gln Leu Cys Cys Gln Leu Lys
115 120
<210> 512
<211> 147
<212> PRT
<213> Mus Musculus
<400> 512
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Glu Ile Asn Gly Ser Ala Asp His Arg Met Phe Ser Phe
20 25 30
His Asn Gly Gly Val Gln Ile Ser Cys Lys Tyr Pro Glu Thr Val Gln
35 40 45
Gln Leu Lys Met Arg Leu Phe Arg Glu Arg Glu Val Leu Cys Glu Leu
50 55 60
Thr Lys Thr Lys Gly Ser Gly Asn Ala Val Ser Ile Lys Asn Pro Met
65 70 75 80
Leu Cys Leu Tyr His Leu Ser Asn Asn Ser Val Ser Phe Phe Leu Asn
85 90 95
Asn Pro Asp Ser Ser Gln Gly Ser Tyr Tyr Phe Cys Ser Leu Ser Ile
100 105 110
Phe Asp Pro Pro Pro Phe Gln Glu Arg Asn Leu Ser Gly Gly Tyr Leu
115 120 125
His Ile Tyr Glu Ser Gln Leu Cys Cys Gln Leu Lys Ile Val Val Gln
130 135 140
Val Thr Glu
145
<210> 513
<211> 199
<212> PRT
<213> Cynomologus
<400> 513
Met Lys Ser Gly Leu Trp Tyr Phe Phe Leu Phe Cys Leu His Met Lys
1 5 10 15
Val Leu Thr Gly Glu Ile Asn Gly Ser Ala Asn Tyr Glu Met Phe Ile
20 25 30
Phe His Asn Gly Gly Val Gln Ile Leu Cys Lys Tyr Pro Asp Ile Val
35 40 45
Gln Gln Phe Lys Met Gln Leu Leu Lys Gly Gly Gln Ile Leu Cys Asp
50 55 60
Leu Thr Lys Thr Lys Gly Ser Gly Asn Lys Val Ser Ile Lys Ser Leu
65 70 75 80
Lys Phe Cys His Ser Gln Leu Ser Asn Asn Ser Val Ser Phe Phe Leu
85 90 95
Tyr Asn Leu Asp Arg Ser His Ala Asn Tyr Tyr Phe Cys Asn Leu Ser
100 105 110
Ile Phe Asp Pro Pro Pro Phe Lys Val Thr Leu Thr Gly Gly Tyr Leu
115 120 125
His Ile Tyr Glu Ser Gln Leu Cys Cys Gln Leu Lys Phe Trp Leu Pro
130 135 140
Ile Gly Cys Ala Thr Phe Val Val Val Cys Ile Phe Gly Cys Ile Leu
145 150 155 160
Ile Cys Trp Leu Thr Lys Lys Lys Tyr Ser Ser Thr Val His Asp Pro
165 170 175
Asn Gly Glu Tyr Met Phe Met Arg Ala Val Asn Thr Ala Lys Lys Ser
180 185 190
Arg Leu Thr Gly Thr Thr Pro
195
<210> 514
<211> 120
<212> PRT
<213> Cynomologus
<400> 514
Glu Ile Asn Gly Ser Ala Asn Tyr Glu Met Phe Ile Phe His Asn Gly
1 5 10 15
Gly Val Gln Ile Leu Cys Lys Tyr Pro Asp Ile Val Gln Gln Phe Lys
20 25 30
Met Gln Leu Leu Lys Gly Gly Gln Ile Leu Cys Asp Leu Thr Lys Thr
35 40 45
Lys Gly Ser Gly Asn Lys Val Ser Ile Lys Ser Leu Lys Phe Cys His
50 55 60
Ser Gln Leu Ser Asn Asn Ser Val Ser Phe Phe Leu Tyr Asn Leu Asp
65 70 75 80
Arg Ser His Ala Asn Tyr Tyr Phe Cys Asn Leu Ser Ile Phe Asp Pro
85 90 95
Pro Pro Phe Lys Val Thr Leu Thr Gly Gly Tyr Leu His Ile Tyr Glu
100 105 110
Ser Gln Leu Cys Cys Gln Leu Lys
115 120
<210> 515
<211> 240
<212> PRT
<213> Homo Sapiens
<400> 515
Asp Thr Gln Glu Lys Glu Val Arg Ala Met Val Gly Ser Asp Val Glu
1 5 10 15
Leu Ser Cys Ala Cys Pro Glu Gly Ser Arg Phe Asp Leu Asn Asp Val
20 25 30
Tyr Val Tyr Trp Gln Thr Ser Glu Ser Lys Thr Val Val Thr Tyr His
35 40 45
Ile Pro Gln Asn Ser Ser Leu Glu Asn Val Asp Ser Arg Tyr Arg Asn
50 55 60
Arg Ala Leu Met Ser Pro Ala Gly Met Leu Arg Gly Asp Phe Ser Leu
65 70 75 80
Arg Leu Phe Asn Val Thr Pro Gln Asp Glu Gln Lys Phe His Cys Leu
85 90 95
Val Leu Ser Gln Ser Leu Gly Phe Gln Glu Val Leu Ser Val Glu Val
100 105 110
Thr Leu His Val Ala Ala Asn Phe Ser Val Pro Val Val Ser Ala Pro
115 120 125
His Ser Pro Ser Gln Asp Glu Leu Thr Phe Thr Cys Thr Ser Ile Asn
130 135 140
Gly Tyr Pro Arg Pro Asn Val Tyr Trp Ile Asn Lys Thr Asp Asn Ser
145 150 155 160
Leu Leu Asp Gln Ala Leu Gln Asn Asp Thr Val Phe Leu Asn Met Arg
165 170 175
Gly Leu Tyr Asp Val Val Ser Val Leu Arg Ile Ala Arg Thr Pro Ser
180 185 190
Val Asn Ile Gly Cys Cys Ile Glu Asn Val Leu Leu Gln Gln Asn Leu
195 200 205
Thr Val Gly Ser Gln Thr Gly Asn Asp Ile Gly Glu Arg Asp Lys Ile
210 215 220
Thr Glu Asn Pro Val Ser Thr Gly Glu Lys Asn Ala Ala Thr Trp Ser
225 230 235 240
<210> 516
<211> 302
<212> PRT
<213> Homo Sapiens
<400> 516
Met Arg Leu Gly Ser Pro Gly Leu Leu Phe Leu Leu Phe Ser Ser Leu
1 5 10 15
Arg Ala Asp Thr Gln Glu Lys Glu Val Arg Ala Met Val Gly Ser Asp
20 25 30
Val Glu Leu Ser Cys Ala Cys Pro Glu Gly Ser Arg Phe Asp Leu Asn
35 40 45
Asp Val Tyr Val Tyr Trp Gln Thr Ser Glu Ser Lys Thr Val Val Thr
50 55 60
Tyr His Ile Pro Gln Asn Ser Ser Leu Glu Asn Val Asp Ser Arg Tyr
65 70 75 80
Arg Asn Arg Ala Leu Met Ser Pro Ala Gly Met Leu Arg Gly Asp Phe
85 90 95
Ser Leu Arg Leu Phe Asn Val Thr Pro Gln Asp Glu Gln Lys Phe His
100 105 110
Cys Leu Val Leu Ser Gln Ser Leu Gly Phe Gln Glu Val Leu Ser Val
115 120 125
Glu Val Thr Leu His Val Ala Ala Asn Phe Ser Val Pro Val Val Ser
130 135 140
Ala Pro His Ser Pro Ser Gln Asp Glu Leu Thr Phe Thr Cys Thr Ser
145 150 155 160
Ile Asn Gly Tyr Pro Arg Pro Asn Val Tyr Trp Ile Asn Lys Thr Asp
165 170 175
Asn Ser Leu Leu Asp Gln Ala Leu Gln Asn Asp Thr Val Phe Leu Asn
180 185 190
Met Arg Gly Leu Tyr Asp Val Val Ser Val Leu Arg Ile Ala Arg Thr
195 200 205
Pro Ser Val Asn Ile Gly Cys Cys Ile Glu Asn Val Leu Leu Gln Gln
210 215 220
Asn Leu Thr Val Gly Ser Gln Thr Gly Asn Asp Ile Gly Glu Arg Asp
225 230 235 240
Lys Ile Thr Glu Asn Pro Val Ser Thr Gly Glu Lys Asn Ala Ala Thr
245 250 255
Trp Ser Ile Leu Ala Val Leu Cys Leu Leu Val Val Val Ala Val Ala
260 265 270
Ile Gly Trp Val Cys Arg Asp Arg Cys Leu Gln His Ser Tyr Ala Gly
275 280 285
Ala Trp Ala Val Ser Pro Glu Thr Glu Leu Thr Gly His Val
290 295 300
<210> 517
<211> 113
<212> PRT
<213> Homo Sapiens
<400> 517
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
1 5 10 15
Thr Ala Met Leu Thr Phe Lys Phe Tyr Met Pro Lys Lys Ala Thr Glu
20 25 30
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
35 40 45
Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
50 55 60
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
65 70 75 80
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
85 90 95
Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile Ile Ser Thr Leu
100 105 110
Thr
<210> 518
<211> 113
<212> PRT
<213> Homo Sapiens
<400> 518
Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys Asn Pro Lys Leu
1 5 10 15
Thr Gln Met Leu Thr Phe Lys Phe Tyr Met Pro Lys Lys Ala Thr Glu
20 25 30
Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys Pro Leu Glu Glu
35 40 45
Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu Arg Pro Arg Asp
50 55 60
Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu Lys Gly Ser Glu
65 70 75 80
Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala Thr Ile Val Glu
85 90 95
Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile Ile Ser Thr Leu
100 105 110
Thr
<210> 519
<211> 336
<212> DNA
<213> Homo Sapiens
<400> 519
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtgatg gatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
ctcagttttg gccaggggac caagctggag atcaaa 336
<210> 520
<211> 657
<212> DNA
<213> Homo Sapiens
<400> 520
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtgatg gatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
ctcagttttg gccaggggac caagctggag atcaaacgta cggtggccgc tccctccgtg 360
ttcatcttcc caccttccga cgagcagctg aagtccggca ccgcttctgt cgtgtgcctg 420
ctgaacaact tctacccccg cgaggccaag gtgcagtgga aggtggacaa cgccctgcag 480
tccggcaact cccaggaatc cgtgaccgag caggactcca aggacagcac ctactccctg 540
tcctccaccc tgaccctgtc caaggccgac tacgagaagc acaaggtgta cgcctgcgaa 600
gtgacccacc agggcctgtc tagccccgtg accaagtctt tcaaccgggg cgagtgt 657
<210> 521
<211> 372
<212> DNA
<213> Homo Sapiens
<400> 521
gaggtgcagc tggtggagtc tgggggaggt gtggtacggc ctggggggtc cctgagactc 60
tcctgtgtag cctctggagt cacctttgat gattatggca tgagctgggt ccgccaagct 120
ccagggaagg ggctggagtg ggtctctggt attaattgga atggtggcga cacagattat 180
tcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctccctgtat 240
ctacaaatga atagtctgag agccgaggac acggccttgt attactgtgc gagggatttc 300
tatggttcgg ggagttatta tcacgttcct tttgactact ggggccaggg aatcctggtc 360
accgtctcct ca 372
<210> 522
<211> 1368
<212> DNA
<213> Homo Sapiens
<400> 522
gaggtgcagc tggtggagtc tgggggaggt gtggtacggc ctggggggtc cctgagactc 60
tcctgtgtag cctctggagt cacctttgat gattatggca tgagctgggt ccgccaagct 120
ccagggaagg ggctggagtg ggtctctggt attaattgga atggtggcga cacagattat 180
tcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctccctgtat 240
ctacaaatga atagtctgag agccgaggac acggccttgt attactgtgc gagggatttc 300
tatggttcgg ggagttatta tcacgttcct tttgactact ggggccaggg aatcctggtc 360
accgtctcct cagccagcac caagggcccc tctgtgttcc ctctggcccc ttccagcaag 420
tccacctctg gcggaacagc cgctctgggc tgcctcgtga aggactactt ccccgagcct 480
gtgaccgtgt cctggaactc tggcgctctg accagcggag tgcacacctt ccctgctgtg 540
ctgcagtcct ccggcctgta ctccctgtcc tccgtcgtga ccgtgccttc cagctctctg 600
ggcacccaga cctacatctg caacgtgaac cacaagccct ccaacaccaa ggtggacaag 660
aaggtggaac ccaagtcctg cgacaagacc cacacctgtc ccccttgtcc tgcccctgaa 720
ctgctgggcg gaccttccgt gttcctgttc cccccaaagc ccaaggacac cctgatgatc 780
tcccggaccc ccgaagtgac ctgcgtggtg gtggatgtgt cccacgagga ccctgaagtg 840
aagttcaatt ggtacgtgga cggcgtggaa gtgcacaacg ccaagaccaa gcctagagag 900
gaacagtaca actccaccta ccgggtggtg tccgtgctga ccgtgctgca ccaggattgg 960
ctgaacggca aagagtacaa gtgcaaggtg tccaacaagg ccctgcctgc ccccatcgaa 1020
aagaccatct ccaaggccaa gggccagccc cgggaacccc aggtgtacac actgccccct 1080
agcagggacg agctgaccaa gaaccaggtg tccctgacct gtctcgtgaa aggcttctac 1140
ccctccgata tcgccgtgga atgggagtcc aacggccagc ctgagaacaa ctacaagacc 1200
accccccctg tgctggactc cgacggctca ttcttcctgt acagcaagct gacagtggac 1260
aagtcccggt ggcagcaggg caacgtgttc tcctgctccg tgatgcacga ggccctgcac 1320
aaccactaca cccagaagtc cctgtccctg agccccggca agtgatga 1368
<210> 523
<211> 990
<212> DNA
<213> Homo Sapiens
<400> 523
gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg 60
ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc 240
tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagag agttgagccc 300
aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga 360
ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420
gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 480
tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac 540
agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag 600
gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660
aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag 720
atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 780
gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg 840
ctggactccg acggctcctt cttcctctat agcaagctca ccgtggacaa gagcaggtgg 900
cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960
cagaagagcc tctccctgtc cccgggtaaa 990
<210> 524
<211> 330
<212> PRT
<213> Homo Sapiens
<400> 524
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 525
<211> 990
<212> DNA
<213> Homo Sapiens
<400> 525
gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg 60
ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc 240
tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa agttgagccc 300
aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga 360
ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420
gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 480
tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac 540
agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag 600
gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660
aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggatgag 720
ctgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 780
gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg 840
ctggactccg acggctcctt cttcctctac agcaagctca ccgtggacaa gagcaggtgg 900
cagcagggga acatcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960
cagaagagcc tctccctgtc tccgggtaaa 990
<210> 526
<211> 330
<212> PRT
<213> Homo Sapiens
<400> 526
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Ile Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 527
<211> 978
<212> DNA
<213> Homo Sapiens
<400> 527
gcctccacca agggcccatc ggtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacagccg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgctctgac cagcggcgtg cacaccttcc cagctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcaacttcgg cacccagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagac agttgagcgc 300
aaatgttgtg tcgagtgccc accgtgccca gcaccacctg tggcaggacc gtcagtcttc 360
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacgtgc 420
gtggtggtgg acgtgagcca cgaagacccc gaggtccagt tcaactggta cgtggacggc 480
gtggaggtgc ataatgccaa gacaaagcca cgggaggagc agttcaacag cacgttccgt 540
gtggtcagcg tcctcaccgt tgtgcaccag gactggctga acggcaagga gtacaagtgc 600
aaggtctcca acaaaggcct cccagccccc atcgagaaaa ccatctccaa aaccaaaggg 660
cagccccgag aaccacaggt gtacaccctg cccccatccc gggaggagat gaccaagaac 720
caggtcagcc tgacctgcct ggtcaaaggc ttctacccca gcgacatcgc cgtggagtgg 780
gagagcaatg ggcagccgga gaacaactac aagaccacac ctcccatgct ggactccgac 840
ggctccttct tcctctacag caagctcacc gtggacaaga gcaggtggca gcaggggaac 900
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacgca gaagagcctc 960
tccctgtctc cgggtaaa 978
<210> 528
<211> 326
<212> PRT
<213> Homo Sapiens
<400> 528
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 529
<211> 978
<212> DNA
<213> Homo Sapiens
<400> 529
gcctccacca agggcccatc ggtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgctctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgacctcca gcaacttcgg cacccagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagac agttgagcgc 300
aaatgttgtg tcgagtgccc accgtgccca gcaccacctg tggcaggacc gtcagtcttc 360
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacgtgc 420
gtggtggtgg acgtgagcca cgaagacccc gaggtccagt tcaactggta cgtggacggc 480
atggaggtgc ataatgccaa gacaaagcca cgggaggagc agttcaacag cacgttccgt 540
gtggtcagcg tcctcaccgt cgtgcaccag gactggctga acggcaagga gtacaagtgc 600
aaggtctcca acaaaggcct cccagccccc atcgagaaaa ccatctccaa aaccaaaggg 660
cagccccgag aaccacaggt gtacaccctg cccccatccc gggaggagat gaccaagaac 720
caggtcagcc tgacctgcct ggtcaaaggc ttctacccca gcgacatcgc cgtggagtgg 780
gagagcaatg ggcagccgga gaacaactac aagaccacac ctcccatgct ggactccgac 840
ggctccttct tcctctacag caagctcacc gtggacaaga gcaggtggca gcaggggaac 900
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacaca gaagagcctc 960
tccctgtctc cgggtaaa 978
<210> 530
<211> 326
<212> PRT
<213> Homo Sapiens
<400> 530
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Thr Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Met Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 531
<211> 978
<212> DNA
<213> Homo Sapiens
<400> 531
gcctccacca agggcccatc ggtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgctctgac cagcggcgtg cacaccttcc cagctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagac agttgagcgc 300
aaatgttgtg tcgagtgccc accgtgccca gcaccacctg tggcaggacc gtcagtcttc 360
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacgtgc 420
gtggtggtgg acgtgagcca cgaagacccc gaggtccagt tcaactggta cgtggacggc 480
gtggaggtgc ataatgccaa gacaaagcca cgggaggagc agttcaacag cacgttccgt 540
gtggtcagcg tcctcaccgt tgtgcaccag gactggctga acggcaagga gtacaagtgc 600
aaggtctcca acaaaggcct cccagccccc atcgagaaaa ccatctccaa aaccaaaggg 660
cagccccgag aaccacaggt gtacaccctg cccccatccc gggaggagat gaccaagaac 720
caggtcagcc tgacctgcct ggtcaaaggc ttctacccca gcgacatcgc cgtggagtgg 780
gagagcaatg ggcagccgga gaacaactac aagaccacac ctcccatgct ggactccgac 840
ggctccttct tcctctacag caagctcacc gtggacaaga gcaggtggca gcaggggaac 900
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacgca gaagagcctc 960
tccctgtctc cgggtaaa 978
<210> 532
<211> 326
<212> PRT
<213> Homo Sapiens
<400> 532
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 533
<211> 978
<212> DNA
<213> Homo Sapiens
<400> 533
gcctccacca agggcccatc ggtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgctctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcaacttcgg cacccagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagac agttgagcgc 300
aaatgttgtg tcgagtgccc accgtgccca gcaccacctg tggcaggacc gtcagtcttc 360
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacgtgc 420
gtggtggtgg acgtgagcca cgaagacccc gaggtccagt tcaactggta cgtggacggc 480
gtggaggtgc ataatgccaa gacaaagcca cgggaggagc agttcaacag cacgttccgt 540
gtggtcagcg tcctcaccgt cgtgcaccag gactggctga acggcaagga gtacaagtgc 600
aaggtctcca acaaaggcct cccagccccc atcgagaaaa ccatctccaa aaccaaaggg 660
cagccccgag aaccacaggt gtacaccctg cccccatccc gggaggagat gaccaagaac 720
caggtcagcc tgacctgcct ggtcaaaggc ttctacccca gcgacatctc cgtggagtgg 780
gagagcaatg ggcagccgga gaacaactac aagaccacac ctcccatgct ggactccgac 840
ggctccttct tcctctacag caagctcacc gtggacaaga gcaggtggca gcaggggaac 900
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacaca gaagagcctc 960
tccctgtctc cgggtaaa 978
<210> 534
<211> 326
<212> PRT
<213> Homo Sapiens
<400> 534
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ser Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 535
<211> 318
<212> DNA
<213> Homo Sapiens
<400> 535
ggtcagccca aggctgcccc ctcggtcact ctgttcccac cctcctctga ggagcttcaa 60
gccaacaagg ccacactggt gtgtctcgta agtgacttca acccgggagc cgtgacagtg 120
gcctggaagg cagatggcag ccccgtcaag gtgggagtgg agaccaccaa accctccaaa 180
caaagcaaca acaagtatgc ggccagcagc tacctgagcc tgacgcccga gcagtggaag 240
tcccacagaa gctacagctg ccgggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctgcag aatgctct 318
<210> 536
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 536
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Val Ser Asp
20 25 30
Phe Asn Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Gly Ser Pro
35 40 45
Val Lys Val Gly Val Glu Thr Thr Lys Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Arg Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Ala Glu Cys Ser
100 105
<210> 537
<211> 990
<212> DNA
<213> Homo Sapiens
<400> 537
gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg 60
ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc 240
tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa agttgagccc 300
aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga 360
ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420
gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 480
tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac 540
agcacgtacc gggtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag 600
gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660
aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggatgag 720
ctgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 780
gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg 840
ctggactccg acggctcctt cttcctctac agcaagctca ccgtggacaa gagcaggtgg 900
cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960
cagaagagcc tctccctgtc tccgggtaaa 990
<210> 538
<211> 106
<212> PRT
<213> Homo Sapiens
<400> 538
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 539
<211> 663
<212> PRT
<213> Homo Sapiens
<400> 539
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Glu Thr Val Thr Ile Gln Cys Arg Ala Ser Glu Asp Ile Tyr Ser Gly
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Ser Ser Met Gln Thr
65 70 75 80
Glu Asp Glu Gly Val Tyr Phe Cys Gln Gln Gly Leu Lys Tyr Pro Pro
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly
210 215 220
Leu Thr Gln Pro Gly Lys Ser Leu Lys Leu Ser Cys Glu Ala Ser Gly
225 230 235 240
Phe Thr Phe Ser Ser Phe Thr Met His Trp Val Arg Gln Ser Pro Gly
245 250 255
Lys Gly Leu Glu Trp Val Ala Phe Ile Arg Ser Gly Ser Gly Ile Val
260 265 270
Phe Tyr Ala Asp Ala Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn
275 280 285
Ala Lys Asn Leu Leu Phe Leu Gln Met Asn Asp Leu Lys Ser Glu Asp
290 295 300
Thr Ala Met Tyr Tyr Cys Ala Arg Arg Pro Leu Gly His Asn Thr Phe
305 310 315 320
Asp Ser Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
435 440 445
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
450 455 460
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
485 490 495
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
500 505 510
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
515 520 525
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
530 535 540
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
545 550 555 560
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
565 570 575
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
580 585 590
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
595 600 605
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
610 615 620
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
625 630 635 640
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
645 650 655
Leu Ser Leu Ser Pro Gly Lys
660
<210> 540
<211> 215
<212> PRT
<213> Homo Sapiens
<400> 540
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Phe
20 25 30
Tyr Met Ala Trp Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Tyr Glu Gly Ser Ser Thr Tyr Tyr Gly Asp Ser Val
50 55 60
Met Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Gln Arg Glu Ala Asn Trp Glu Asp Trp Gly Gln Gly Val Met
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val
210 215
<210> 541
<211> 220
<212> PRT
<213> Homo Sapiens
<400> 541
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ala Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Lys Ser Ser Gln Ser Leu Tyr Tyr Ser
20 25 30
Gly Val Lys Glu Asn Leu Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Ile Arg Phe Thr Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr
65 70 75 80
Ile Thr Ser Val Gln Ala Glu Asp Met Gly Gln Tyr Phe Cys Gln Gln
85 90 95
Gly Ile Asn Asn Pro Leu Thr Phe Gly Asp Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 542
<211> 667
<212> PRT
<213> Homo Sapiens
<400> 542
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ala Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Lys Ser Ser Gln Ser Leu Tyr Tyr Ser
20 25 30
Gly Val Lys Glu Asn Leu Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Ile Arg Phe Thr Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr
65 70 75 80
Ile Thr Ser Val Gln Ala Glu Asp Met Gly Gln Tyr Phe Cys Gln Gln
85 90 95
Gly Ile Asn Asn Pro Leu Thr Phe Gly Asp Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu
210 215 220
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg Ser Leu Lys Leu
225 230 235 240
Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Phe Tyr Met Ala Trp
245 250 255
Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val Ala Ser Ile Ser
260 265 270
Tyr Glu Gly Ser Ser Thr Tyr Tyr Gly Asp Ser Val Met Gly Arg Phe
275 280 285
Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr Leu Gln Met Asn
290 295 300
Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys Ala Arg Gln Arg
305 310 315 320
Glu Ala Asn Trp Glu Asp Trp Gly Gln Gly Val Met Val Thr Val Ser
325 330 335
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
340 345 350
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
355 360 365
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
370 375 380
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
385 390 395 400
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
405 410 415
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
420 425 430
Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
435 440 445
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
450 455 460
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
465 470 475 480
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
485 490 495
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
500 505 510
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
515 520 525
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
530 535 540
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
545 550 555 560
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
565 570 575
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
580 585 590
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
595 600 605
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
610 615 620
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
625 630 635 640
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
645 650 655
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 543
<211> 217
<212> PRT
<213> Homo Sapiens
<400> 543
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Thr Gln Pro Gly Lys
1 5 10 15
Ser Leu Lys Leu Ser Cys Glu Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Thr Met His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Phe Ile Arg Ser Gly Ser Gly Ile Val Phe Tyr Ala Asp Ala Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Leu Leu Phe
65 70 75 80
Leu Gln Met Asn Asp Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Arg Pro Leu Gly His Asn Thr Phe Asp Ser Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val
210 215
<210> 544
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 544
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Glu Thr Val Thr Ile Gln Cys Arg Ala Ser Glu Asp Ile Tyr Ser Gly
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Ser Ser Met Gln Thr
65 70 75 80
Glu Asp Glu Gly Val Tyr Phe Cys Gln Gln Gly Leu Lys Tyr Pro Pro
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 545
<211> 663
<212> PRT
<213> Homo Sapiens
<400> 545
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Glu Thr Val Thr Ile Gln Cys Arg Ala Ser Glu Asp Ile Tyr Ser Gly
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Ser Ser Met Gln Thr
65 70 75 80
Glu Asp Glu Gly Val Tyr Phe Cys Gln Gln Gly Leu Lys Tyr Pro Pro
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg Thr Asp Ala Ala
100 105 110
Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln Leu Thr Ser Gly
115 120 125
Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr Pro Lys Asp Ile
130 135 140
Asn Val Lys Trp Lys Ile Asp Gly Ser Glu Arg Gln Asn Gly Val Leu
145 150 155 160
Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp Ser Thr Tyr Ser Met Ser
165 170 175
Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr Glu Arg His Asn Ser Tyr
180 185 190
Thr Cys Glu Ala Thr His Lys Thr Ser Thr Ser Pro Ile Val Lys Ser
195 200 205
Phe Asn Arg Asn Glu Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly
210 215 220
Leu Thr Gln Pro Gly Lys Ser Leu Lys Leu Ser Cys Glu Ala Ser Gly
225 230 235 240
Phe Thr Phe Ser Ser Phe Thr Met His Trp Val Arg Gln Ser Pro Gly
245 250 255
Lys Gly Leu Glu Trp Val Ala Phe Ile Arg Ser Gly Ser Gly Ile Val
260 265 270
Phe Tyr Ala Asp Ala Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn
275 280 285
Ala Lys Asn Leu Leu Phe Leu Gln Met Asn Asp Leu Lys Ser Glu Asp
290 295 300
Thr Ala Met Tyr Tyr Cys Ala Arg Arg Pro Leu Gly His Asn Thr Phe
305 310 315 320
Asp Ser Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Lys Thr
325 330 335
Thr Ala Pro Ser Val Tyr Pro Leu Ala Pro Val Cys Gly Asp Thr Thr
340 345 350
Gly Ser Ser Val Thr Leu Gly Cys Leu Val Lys Gly Tyr Phe Pro Glu
355 360 365
Pro Val Thr Leu Thr Trp Asn Ser Gly Ser Leu Ser Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Asp Leu Tyr Thr Leu Ser Ser Ser
385 390 395 400
Val Thr Val Thr Ser Ser Thr Trp Pro Ser Gln Ser Ile Thr Cys Asn
405 410 415
Val Ala His Pro Ala Ser Ser Thr Lys Val Asp Lys Lys Ile Glu Pro
420 425 430
Arg Gly Pro Thr Ile Lys Pro Cys Pro Pro Cys Lys Cys Pro Ala Pro
435 440 445
Asn Leu Leu Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys
450 455 460
Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn
485 490 495
Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr
500 505 510
Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp
515 520 525
Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu
530 535 540
Pro Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg
545 550 555 560
Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys
565 570 575
Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp
580 585 590
Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys
595 600 605
Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser
610 615 620
Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser
625 630 635 640
Cys Ser Val Val His Glu Gly Leu His Asn His His Thr Thr Lys Ser
645 650 655
Phe Ser Arg Thr Pro Gly Lys
660
<210> 546
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 546
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Phe
20 25 30
Tyr Met Ala Trp Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Tyr Glu Gly Ser Ser Thr Tyr Tyr Gly Asp Ser Val
50 55 60
Met Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Gln Arg Glu Ala Asn Trp Glu Asp Trp Gly Gln Gly Val Met
100 105 110
Val Thr Val Ser Ser Ala Lys Thr Thr Ala Pro Ser Val Tyr Pro Leu
115 120 125
Ala Pro Val Cys Gly Asp Thr Thr Gly Ser Ser Val Thr Leu Gly Cys
130 135 140
Leu Val Lys Gly Tyr Phe Pro Glu Pro Val Thr Leu Thr Trp Asn Ser
145 150 155 160
Gly Ser Leu Ser Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Asp Leu Tyr Thr Leu Ser Ser Ser Val Thr Val Thr Ser Ser Thr Trp
180 185 190
Pro Ser Gln Ser Ile Thr Cys Asn Val Ala His Pro Ala Ser Ser Thr
195 200 205
Lys Val Asp Lys Lys Ile
210
<210> 547
<211> 220
<212> PRT
<213> Homo Sapiens
<400> 547
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ala Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Lys Ser Ser Gln Ser Leu Tyr Tyr Ser
20 25 30
Gly Val Lys Glu Asn Leu Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Ile Arg Phe Thr Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr
65 70 75 80
Ile Thr Ser Val Gln Ala Glu Asp Met Gly Gln Tyr Phe Cys Gln Gln
85 90 95
Gly Ile Asn Asn Pro Leu Thr Phe Gly Asp Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg Thr Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser
115 120 125
Glu Gln Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn
130 135 140
Phe Tyr Pro Lys Asp Ile Asn Val Lys Trp Lys Ile Asp Gly Ser Glu
145 150 155 160
Arg Gln Asn Gly Val Leu Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Met Ser Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr
180 185 190
Glu Arg His Asn Ser Tyr Thr Cys Glu Ala Thr His Lys Thr Ser Thr
195 200 205
Ser Pro Ile Val Lys Ser Phe Asn Arg Asn Glu Cys
210 215 220
<210> 548
<211> 667
<212> PRT
<213> Homo Sapiens
<400> 548
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ala Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Lys Ser Ser Gln Ser Leu Tyr Tyr Ser
20 25 30
Gly Val Lys Glu Asn Leu Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Ile Arg Phe Thr Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr
65 70 75 80
Ile Thr Ser Val Gln Ala Glu Asp Met Gly Gln Tyr Phe Cys Gln Gln
85 90 95
Gly Ile Asn Asn Pro Leu Thr Phe Gly Asp Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg Thr Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser
115 120 125
Glu Gln Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn
130 135 140
Phe Tyr Pro Lys Asp Ile Asn Val Lys Trp Lys Ile Asp Gly Ser Glu
145 150 155 160
Arg Gln Asn Gly Val Leu Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Met Ser Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr
180 185 190
Glu Arg His Asn Ser Tyr Thr Cys Glu Ala Thr His Lys Thr Ser Thr
195 200 205
Ser Pro Ile Val Lys Ser Phe Asn Arg Asn Glu Cys Glu Val Gln Leu
210 215 220
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg Ser Leu Lys Leu
225 230 235 240
Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Phe Tyr Met Ala Trp
245 250 255
Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val Ala Ser Ile Ser
260 265 270
Tyr Glu Gly Ser Ser Thr Tyr Tyr Gly Asp Ser Val Met Gly Arg Phe
275 280 285
Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr Leu Gln Met Asn
290 295 300
Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys Ala Arg Gln Arg
305 310 315 320
Glu Ala Asn Trp Glu Asp Trp Gly Gln Gly Val Met Val Thr Val Ser
325 330 335
Ser Ala Lys Thr Thr Ala Pro Ser Val Tyr Pro Leu Ala Pro Val Cys
340 345 350
Gly Asp Thr Thr Gly Ser Ser Val Thr Leu Gly Cys Leu Val Lys Gly
355 360 365
Tyr Phe Pro Glu Pro Val Thr Leu Thr Trp Asn Ser Gly Ser Leu Ser
370 375 380
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Asp Leu Tyr Thr
385 390 395 400
Leu Ser Ser Ser Val Thr Val Thr Ser Ser Thr Trp Pro Ser Gln Ser
405 410 415
Ile Thr Cys Asn Val Ala His Pro Ala Ser Ser Thr Lys Val Asp Lys
420 425 430
Lys Ile Glu Pro Arg Gly Pro Thr Ile Lys Pro Cys Pro Pro Cys Lys
435 440 445
Cys Pro Ala Pro Asn Leu Leu Gly Gly Pro Ser Val Phe Ile Phe Pro
450 455 460
Pro Lys Ile Lys Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr
465 470 475 480
Cys Val Val Val Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser
485 490 495
Trp Phe Val Asn Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His
500 505 510
Arg Glu Asp Tyr Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile
515 520 525
Gln His Gln Asp Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn
530 535 540
Asn Lys Asp Leu Pro Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys
545 550 555 560
Gly Ser Val Arg Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu
565 570 575
Glu Met Thr Lys Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe
580 585 590
Met Pro Glu Asp Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu
595 600 605
Leu Asn Tyr Lys Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr
610 615 620
Phe Met Tyr Ser Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg
625 630 635 640
Asn Ser Tyr Ser Cys Ser Val Val His Glu Gly Leu His Asn His His
645 650 655
Thr Thr Lys Ser Phe Ser Arg Thr Pro Gly Lys
660 665
<210> 549
<211> 216
<212> PRT
<213> Homo Sapiens
<400> 549
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Thr Gln Pro Gly Lys
1 5 10 15
Ser Leu Lys Leu Ser Cys Glu Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Thr Met His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Phe Ile Arg Ser Gly Ser Gly Ile Val Phe Tyr Ala Asp Ala Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Leu Leu Phe
65 70 75 80
Leu Gln Met Asn Asp Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Arg Pro Leu Gly His Asn Thr Phe Asp Ser Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Lys Thr Thr Ala Pro Ser Val Tyr
115 120 125
Pro Leu Ala Pro Val Cys Gly Asp Thr Thr Gly Ser Ser Val Thr Leu
130 135 140
Gly Cys Leu Val Lys Gly Tyr Phe Pro Glu Pro Val Thr Leu Thr Trp
145 150 155 160
Asn Ser Gly Ser Leu Ser Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Asp Leu Tyr Thr Leu Ser Ser Ser Val Thr Val Thr Ser Ser
180 185 190
Thr Trp Pro Ser Gln Ser Ile Thr Cys Asn Val Ala His Pro Ala Ser
195 200 205
Ser Thr Lys Val Asp Lys Lys Ile
210 215
<210> 550
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 550
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Glu Thr Val Thr Ile Gln Cys Arg Ala Ser Glu Asp Ile Tyr Ser Gly
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Ser Ser Met Gln Thr
65 70 75 80
Glu Asp Glu Gly Val Tyr Phe Cys Gln Gln Gly Leu Lys Tyr Pro Pro
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg Thr Asp Ala Ala
100 105 110
Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu Gln Leu Thr Ser Gly
115 120 125
Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe Tyr Pro Lys Asp Ile
130 135 140
Asn Val Lys Trp Lys Ile Asp Gly Ser Glu Arg Gln Asn Gly Val Leu
145 150 155 160
Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp Ser Thr Tyr Ser Met Ser
165 170 175
Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr Glu Arg His Asn Ser Tyr
180 185 190
Thr Cys Glu Ala Thr His Lys Thr Ser Thr Ser Pro Ile Val Lys Ser
195 200 205
Phe Asn Arg Asn Glu Cys
210
<210> 551
<211> 659
<212> PRT
<213> Homo Sapiens
<400> 551
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Glu Thr Val Thr Ile Gln Cys Arg Ala Ser Glu Asp Ile Tyr Ser Gly
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Ser Ser Met Gln Thr
65 70 75 80
Glu Asp Glu Gly Val Tyr Phe Cys Gln Gln Gly Leu Lys Tyr Pro Pro
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly
210 215 220
Leu Thr Gln Pro Gly Lys Ser Leu Lys Leu Ser Cys Glu Ala Ser Gly
225 230 235 240
Phe Thr Phe Ser Ser Phe Thr Met His Trp Val Arg Gln Ser Pro Gly
245 250 255
Lys Gly Leu Glu Trp Val Ala Phe Ile Arg Ser Gly Ser Gly Ile Val
260 265 270
Phe Tyr Ala Asp Ala Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn
275 280 285
Ala Lys Asn Leu Leu Phe Leu Gln Met Asn Asp Leu Lys Ser Glu Asp
290 295 300
Thr Ala Met Tyr Tyr Cys Ala Arg Arg Pro Leu Gly His Asn Thr Phe
305 310 315 320
Asp Ser Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Asn Leu Leu Gly
435 440 445
Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys Asp Val Leu Met
450 455 460
Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val Asp Val Ser Glu
465 470 475 480
Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn Asn Val Glu Val
485 490 495
His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr Asn Ser Thr Leu
500 505 510
Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp Trp Met Ser Gly
515 520 525
Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu Pro Ala Pro Ile
530 535 540
Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg Ala Pro Gln Val
545 550 555 560
Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys Lys Gln Val Thr
565 570 575
Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp Ile Tyr Val Glu
580 585 590
Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys Asn Thr Glu Pro
595 600 605
Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser Lys Leu Arg Val
610 615 620
Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser Cys Ser Val Val
625 630 635 640
His Glu Gly Leu His Asn His His Thr Thr Lys Ser Phe Ser Arg Thr
645 650 655
Pro Gly Lys
<210> 552
<211> 215
<212> PRT
<213> Homo Sapiens
<400> 552
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Phe
20 25 30
Tyr Met Ala Trp Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Tyr Glu Gly Ser Ser Thr Tyr Tyr Gly Asp Ser Val
50 55 60
Met Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Gln Arg Glu Ala Asn Trp Glu Asp Trp Gly Gln Gly Val Met
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val
210 215
<210> 553
<211> 220
<212> PRT
<213> Homo Sapiens
<400> 553
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ala Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Lys Ser Ser Gln Ser Leu Tyr Tyr Ser
20 25 30
Gly Val Lys Glu Asn Leu Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Ile Arg Phe Thr Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr
65 70 75 80
Ile Thr Ser Val Gln Ala Glu Asp Met Gly Gln Tyr Phe Cys Gln Gln
85 90 95
Gly Ile Asn Asn Pro Leu Thr Phe Gly Asp Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 554
<211> 663
<212> PRT
<213> Homo Sapiens
<400> 554
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ala Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Lys Ser Ser Gln Ser Leu Tyr Tyr Ser
20 25 30
Gly Val Lys Glu Asn Leu Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Ile Arg Phe Thr Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr
65 70 75 80
Ile Thr Ser Val Gln Ala Glu Asp Met Gly Gln Tyr Phe Cys Gln Gln
85 90 95
Gly Ile Asn Asn Pro Leu Thr Phe Gly Asp Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu
210 215 220
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg Ser Leu Lys Leu
225 230 235 240
Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Phe Tyr Met Ala Trp
245 250 255
Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val Ala Ser Ile Ser
260 265 270
Tyr Glu Gly Ser Ser Thr Tyr Tyr Gly Asp Ser Val Met Gly Arg Phe
275 280 285
Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr Leu Gln Met Asn
290 295 300
Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys Ala Arg Gln Arg
305 310 315 320
Glu Ala Asn Trp Glu Asp Trp Gly Gln Gly Val Met Val Thr Val Ser
325 330 335
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
340 345 350
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
355 360 365
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
370 375 380
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
385 390 395 400
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
405 410 415
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
420 425 430
Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
435 440 445
Asn Leu Leu Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys
450 455 460
Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn
485 490 495
Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr
500 505 510
Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp
515 520 525
Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu
530 535 540
Pro Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg
545 550 555 560
Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys
565 570 575
Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp
580 585 590
Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys
595 600 605
Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser
610 615 620
Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser
625 630 635 640
Cys Ser Val Val His Glu Gly Leu His Asn His His Thr Thr Lys Ser
645 650 655
Phe Ser Arg Thr Pro Gly Lys
660
<210> 555
<211> 217
<212> PRT
<213> Homo Sapiens
<400> 555
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Thr Gln Pro Gly Lys
1 5 10 15
Ser Leu Lys Leu Ser Cys Glu Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Thr Met His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Phe Ile Arg Ser Gly Ser Gly Ile Val Phe Tyr Ala Asp Ala Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Leu Leu Phe
65 70 75 80
Leu Gln Met Asn Asp Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Arg Pro Leu Gly His Asn Thr Phe Asp Ser Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val
210 215
<210> 556
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 556
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Glu Thr Val Thr Ile Gln Cys Arg Ala Ser Glu Asp Ile Tyr Ser Gly
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Ser Ser Met Gln Thr
65 70 75 80
Glu Asp Glu Gly Val Tyr Phe Cys Gln Gln Gly Leu Lys Tyr Pro Pro
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 557
<211> 659
<212> PRT
<213> Homo Sapiens
<400> 557
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Glu Thr Val Thr Ile Gln Cys Arg Ala Ser Glu Asp Ile Tyr Ser Gly
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Ser Ser Met Gln Thr
65 70 75 80
Glu Asp Glu Gly Val Tyr Phe Cys Gln Gln Gly Leu Lys Tyr Pro Pro
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly
210 215 220
Leu Thr Gln Pro Gly Lys Ser Leu Lys Leu Ser Cys Glu Ala Ser Gly
225 230 235 240
Phe Thr Phe Ser Ser Phe Thr Met His Trp Val Arg Gln Ser Pro Gly
245 250 255
Lys Gly Leu Glu Trp Val Ala Phe Ile Arg Ser Gly Ser Gly Ile Val
260 265 270
Phe Tyr Ala Asp Ala Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn
275 280 285
Ala Lys Asn Leu Leu Phe Leu Gln Met Asn Asp Leu Lys Ser Glu Asp
290 295 300
Thr Ala Met Tyr Tyr Cys Ala Arg Arg Pro Leu Gly His Asn Thr Phe
305 310 315 320
Asp Ser Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Asn Leu Leu Gly
435 440 445
Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys Asp Val Leu Met
450 455 460
Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val Asp Val Ser Glu
465 470 475 480
Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn Asn Val Glu Val
485 490 495
His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr Asn Ser Thr Leu
500 505 510
Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp Trp Met Ser Gly
515 520 525
Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu Pro Ala Pro Ile
530 535 540
Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg Ala Pro Gln Val
545 550 555 560
Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys Lys Gln Val Thr
565 570 575
Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp Ile Tyr Val Glu
580 585 590
Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys Asn Thr Glu Pro
595 600 605
Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser Lys Leu Arg Val
610 615 620
Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser Cys Ser Val Val
625 630 635 640
His Glu Gly Leu His Asn His His Thr Thr Lys Ser Phe Ser Arg Thr
645 650 655
Pro Gly Lys
<210> 558
<211> 215
<212> PRT
<213> Homo Sapiens
<400> 558
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Phe
20 25 30
Tyr Met Ala Trp Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Tyr Glu Gly Ser Ser Thr Tyr Tyr Gly Asp Ser Val
50 55 60
Met Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Gln Arg Glu Ala Asn Trp Glu Asp Trp Gly Gln Gly Val Met
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Lys Val
210 215
<210> 559
<211> 220
<212> PRT
<213> Homo Sapiens
<400> 559
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ala Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Lys Ser Ser Gln Ser Leu Tyr Tyr Ser
20 25 30
Gly Val Lys Glu Asn Leu Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Ile Arg Phe Thr Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr
65 70 75 80
Ile Thr Ser Val Gln Ala Glu Asp Met Gly Gln Tyr Phe Cys Gln Gln
85 90 95
Gly Ile Asn Asn Pro Leu Thr Phe Gly Asp Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 560
<211> 663
<212> PRT
<213> Homo Sapiens
<400> 560
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ala Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Lys Ser Ser Gln Ser Leu Tyr Tyr Ser
20 25 30
Gly Val Lys Glu Asn Leu Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Ile Arg Phe Thr Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr
65 70 75 80
Ile Thr Ser Val Gln Ala Glu Asp Met Gly Gln Tyr Phe Cys Gln Gln
85 90 95
Gly Ile Asn Asn Pro Leu Thr Phe Gly Asp Gly Thr Lys Leu Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu
210 215 220
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg Ser Leu Lys Leu
225 230 235 240
Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Phe Tyr Met Ala Trp
245 250 255
Val Arg Gln Ala Pro Lys Lys Gly Leu Glu Trp Val Ala Ser Ile Ser
260 265 270
Tyr Glu Gly Ser Ser Thr Tyr Tyr Gly Asp Ser Val Met Gly Arg Phe
275 280 285
Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Leu Tyr Leu Gln Met Asn
290 295 300
Ser Leu Arg Ser Glu Asp Thr Ala Thr Tyr Tyr Cys Ala Arg Gln Arg
305 310 315 320
Glu Ala Asn Trp Glu Asp Trp Gly Gln Gly Val Met Val Thr Val Ser
325 330 335
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
340 345 350
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
355 360 365
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
370 375 380
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
385 390 395 400
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
405 410 415
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
420 425 430
Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
435 440 445
Asn Leu Leu Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys
450 455 460
Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn
485 490 495
Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr
500 505 510
Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp
515 520 525
Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu
530 535 540
Pro Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg
545 550 555 560
Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys
565 570 575
Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp
580 585 590
Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys
595 600 605
Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser
610 615 620
Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser
625 630 635 640
Cys Ser Val Val His Glu Gly Leu His Asn His His Thr Thr Lys Ser
645 650 655
Phe Ser Arg Thr Pro Gly Lys
660
<210> 561
<211> 217
<212> PRT
<213> Homo Sapiens
<400> 561
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Thr Gln Pro Gly Lys
1 5 10 15
Ser Leu Lys Leu Ser Cys Glu Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Thr Met His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Phe Ile Arg Ser Gly Ser Gly Ile Val Phe Tyr Ala Asp Ala Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Leu Leu Phe
65 70 75 80
Leu Gln Met Asn Asp Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Arg Pro Leu Gly His Asn Thr Phe Asp Ser Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Lys Val
210 215
<210> 562
<211> 214
<212> PRT
<213> Homo Sapiens
<400> 562
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Glu Thr Val Thr Ile Gln Cys Arg Ala Ser Glu Asp Ile Tyr Ser Gly
20 25 30
Leu Ala Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Ser Leu Gln Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Ser Ser Met Gln Thr
65 70 75 80
Glu Asp Glu Gly Val Tyr Phe Cys Gln Gln Gly Leu Lys Tyr Pro Pro
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 563
<211> 364
<212> DNA
<213> Homo Sapiens
<400> 563
caggttcaac tgatgcagtc tggaactgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaaga cttctggtta cacctttacc acctatggta tcacttgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatgg atcagcgctt acagtggtga cacagactat 180
gcacagaagt tccagggcag agtcaccgtg acaacagaca catccacgaa cacagcctac 240
atggagttga ggagcctgaa atctgacgac acggccgtgt attattgtgc gagaagtagt 300
ggctggcccc accactacgg tatggacgtc tggggccaag ggaccacggt caccgtctcc 360
tcag 364
<210> 564
<211> 121
<212> PRT
<213> Homo Sapiens
<400> 564
Gln Val Gln Leu Met Gln Ser Gly Thr Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Gly Ile Thr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Ser Gly Asp Thr Asp Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Val Thr Thr Asp Thr Ser Thr Asn Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Lys Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Ser Gly Trp Pro His His Tyr Gly Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 565
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 565
Gly Tyr Thr Phe Thr Thr Tyr Gly
1 5
<210> 566
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 566
Ile Ser Ala Tyr Ser Gly Asp Thr
1 5
<210> 567
<211> 14
<212> PRT
<213> Homo Sapiens
<400> 567
Ala Arg Ser Ser Gly Trp Pro His His Tyr Gly Met Asp Val
1 5 10
<210> 568
<211> 373
<212> DNA
<213> Homo Sapiens
<400> 568
caggttcaac tggtgcagtc tggaggtgag gtgaaaaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatggtt tcagctgggt gcgacaggcc 120
cctggacaag gactagagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtctccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcttgag atctgacgac acggccgtgt atttctgtgc gcgatctacg 300
tcttactatg gttcggggac cctatacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct cag 373
<210> 569
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 569
Gln Val Gln Leu Val Gln Ser Gly Gly Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Phe Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Ser Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser Thr Ser Tyr Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 570
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 570
Ala Arg Ser Thr Ser Tyr Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
1 5 10 15
Val
<210> 571
<211> 373
<212> DNA
<213> Homo Sapiens
<400> 571
caggttcaac tggtgcagtc tggaggtgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatggtt tcagctgggt gcgacaggcc 120
cctggacaag gactagagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtctccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcttgag atctgacgac acggccgtgt attactgtgc gcgatctacg 300
tcttactatg gttcggggac cctctacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct cag 373
<210> 572
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 572
Gln Val Gln Leu Val Gln Ser Gly Gly Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Phe Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Ser Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Thr Ser Tyr Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 573
<211> 373
<212> DNA
<213> Homo Sapiens
<400> 573
caggttcaac tggtgcagtc tggaggtgag gtgaaaaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatggtt tcagctgggt gcgacaggcc 120
cctggacaag gactagagtg gatgggatgg atcagcgctt acaatggtaa cacaaactat 180
gcacagaagc tccagggcag agtctccatg accacagaca catccacgag cacagcctac 240
atggagctga ggagcttgag atctgacgac acggccgtgt atttctgtgc gcgatctacg 300
tcttactatg gttcggggac cctatacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct cag 373
<210> 574
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 574
Gln Val Gln Leu Val Gln Ser Gly Gly Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Gly Phe Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Gly Arg Val Ser Met Thr Thr Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser Thr Ser Tyr Tyr Gly Ser Gly Thr Leu Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 575
<211> 373
<212> DNA
<213> Homo Sapiens
<400> 575
caggttcaac tggtgcagtc tggaggtgag gtgaaaaagc ctcgggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cacctttacc agctatgtgt tcagctgggt gcgacatgcc 120
gctggacaag gactagagtg gatgggatgg atcagcggtt acaatggtaa cacaaactat 180
gcacagaagc tccagtgcgg agtctcgatg accgcagaca catccacgag cacagcctac 240
atggagctga ggagcttgag atctgacgac acggccgtgt atttctgtgc gcgatctacg 300
tcttactatg gtgcggggac cctatacggt atggacgtct ggggccaagg gaccacggtc 360
accgtctcct cag 373
<210> 576
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 576
Gln Val Gln Leu Val Gln Ser Gly Gly Glu Val Lys Lys Pro Arg Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Val Phe Ser Trp Val Arg His Ala Ala Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Ser Gly Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys Leu
50 55 60
Gln Cys Gly Val Ser Met Thr Ala Asp Thr Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser Thr Ser Tyr Tyr Gly Ala Gly Thr Leu Tyr Gly Met Asp
100 105 110
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 577
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 577
Gly Tyr Thr Phe Thr Ser Tyr Val
1 5
<210> 578
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 578
Ile Ser Gly Tyr Asn Gly Asn Thr
1 5
<210> 579
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 579
Ala Arg Ser Thr Ser Tyr Tyr Gly Ala Gly Thr Leu Tyr Gly Met Asp
1 5 10 15
Val
<210> 580
<211> 373
<212> DNA
<213> Homo Sapiens
<400> 580
gaggtgcagc tggtggagtc tgggggaggt gtggtacggc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttgat gattatggca tgagctgggt ccgccaagct 120
ccagggaagg ggctggagtg ggtctctggt attaattgga atggtggtag cacaggttat 180
gcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctccctgtat 240
ctgcaaatga acagtctgag agccgaggac acggccttgt attactgtgc ggccgattac 300
tatggttcgg ggagttatta taacgtcccc tttgactact ggggccaggg aaccctggtc 360
accgtctcct cag 373
<210> 581
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 581
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Asp Tyr Tyr Gly Ser Gly Ser Tyr Tyr Asn Val Pro Phe Asp
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 582
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 582
Gly Phe Thr Phe Asp Asp Tyr Gly
1 5
<210> 583
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 583
Ile Asn Trp Asn Gly Gly Ser Thr
1 5
<210> 584
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 584
Ala Ala Asp Tyr Tyr Gly Ser Gly Ser Tyr Tyr Asn Val Pro Phe Asp
1 5 10 15
Tyr
<210> 585
<211> 373
<212> DNA
<213> Homo Sapiens
<400> 585
gaggtgcagc tggtggagtc tgggggaggt gtgatacggc ctggggggtc cctgagactc 60
tcctgtgcag cctctggatt cacctttgat gattatggca tgagctgggt ccgccaagct 120
ccagggaagg ggctggagtg ggtctctggt attaattgga ttggtgataa cacagattat 180
gcagactctg tgaagggccg attcaccatc tccagagaca acgccaagaa ctccctatat 240
ctgcaaatga acagtctgag agccgaggac acggccttgt attactgtgc gagagattac 300
tttggttcgg ggagttatta taacgttccc tttgactact ggggccaggg aaccctggtc 360
accgtctcct cag 373
<210> 586
<211> 124
<212> PRT
<213> Homo Sapiens
<400> 586
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Ile Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Trp Ile Gly Asp Asn Thr Asp Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Phe Gly Ser Gly Ser Tyr Tyr Asn Val Pro Phe Asp
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 587
<211> 8
<212> PRT
<213> Homo Sapiens
<400> 587
Ile Asn Trp Ile Gly Asp Asn Thr
1 5
<210> 588
<211> 17
<212> PRT
<213> Homo Sapiens
<400> 588
Ala Arg Asp Tyr Phe Gly Ser Gly Ser Tyr Tyr Asn Val Pro Phe Asp
1 5 10 15
Tyr
<210> 589
<211> 337
<212> DNA
<213> Homo Sapiens
<400> 589
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gattcaacta tttcgattgg 120
tacctgcaga agccaggaca gtctccacag ctcctgatct ttttggtttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttgggatt tattactgca tgcaagctct acaaactccg 300
ctcactttcg gcggagggac caaggtggag atcaaac 337
<210> 590
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 590
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Phe Asn Tyr Phe Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Phe Leu Val Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Ile Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 591
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 591
Gln Ser Leu Leu His Ser Asn Gly Phe Asn Tyr
1 5 10
<210> 592
<211> 3
<212> PRT
<213> Homo Sapiens
<400> 592
Leu Val Ser
1
<210> 593
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 593
Met Gln Ala Leu Gln Thr Pro Leu Thr
1 5
<210> 594
<211> 337
<212> DNA
<213> Homo Sapiens
<400> 594
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaactg tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
tgcagttttg gccaggggac caagctggag atcaaac 337
<210> 595
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 595
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Cys Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Thr Arg Ala Ser Gly Phe Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Cys Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 596
<211> 11
<212> PRT
<213> Homo Sapiens
<400> 596
Gln Ser Leu Leu His Ser Asn Gly Tyr Asn Cys
1 5 10
<210> 597
<211> 337
<212> DNA
<213> Homo Sapiens
<400> 597
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaactg tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
tgcagttttg gccaggggac caagctggag atcaaac 337
<210> 598
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 598
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Cys Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Thr Arg Ala Ser Gly Phe Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Cys Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 599
<211> 337
<212> DNA
<213> Homo Sapiens
<400> 599
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaactg tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattctac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
tgcagttttg gccaggggac caagctggag atcaaac 337
<210> 600
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 600
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Cys Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Thr Arg Ala Ser Gly Phe Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Ser Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Cys Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 601
<211> 337
<212> DNA
<213> Homo Sapiens
<400> 601
gatattgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaactg tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc tactcgggcc 180
tccgggttcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttggggtt tattactgca tgcaagctct acaaactccg 300
tgcagttttg gccaggggac caagctggag atcaaac 337
<210> 602
<211> 112
<212> PRT
<213> Homo Sapiens
<400> 602
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Cys Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Thr Arg Ala Ser Gly Phe Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala
85 90 95
Leu Gln Thr Pro Cys Ser Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 603
<211> 325
<212> DNA
<213> Homo Sapiens
<400> 603
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggag 240
cctgaagatt ttgcagtgta ttactgtcag cagtatggta gctcaccttt cactttcggc 300
cctgggacca aagtggatat caaac 325
<210> 604
<211> 108
<212> PRT
<213> Homo Sapiens
<400> 604
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Ser Ser Pro
85 90 95
Phe Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105
<210> 605
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 605
Gln Gln Tyr Gly Ser Ser Pro Phe Thr
1 5
<210> 606
<211> 325
<212> DNA
<213> Homo Sapiens
<400> 606
gaaattgtgt tgacgcagtc tccaggcacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcagctact tagcctggta ccagcagaaa 120
cctggccagg ctcccaggct cctcatctat ggtgcatcca gcagggccac tggcatccca 180
gacaggttca gtggcagtgg gtctgggaca gacttcactc tcaccatcag cagactggaa 240
cctgaagatt ttgcagtata ttactgtcac cagtatggta attcaccatt cactttcggc 300
cctgggacca aagtggatat caaac 325
<210> 607
<211> 108
<212> PRT
<213> Homo Sapiens
<400> 607
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Ser
20 25 30
Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Ala Thr Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys His Gln Tyr Gly Asn Ser Pro
85 90 95
Phe Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105
<210> 608
<211> 9
<212> PRT
<213> Homo Sapiens
<400> 608
His Gln Tyr Gly Asn Ser Pro Phe Thr
1 5
<210> 609
<211> 11
<212> PRT
<213> Homo Sapiens
<220>
<221> MISC_FEATURE
<222> (1)..(1)
<223> X = any amino acid.
<220>
<221> MISC_FEATURE
<222> (5)..(5)
<223> X = any amino acid.
<220>
<221> MISC_FEATURE
<222> (8)..(8)
<223> X = any amino acid.
<220>
<221> MISC_FEATURE
<222> (9)..(9)
<223> X = is either present or absent, and if present, may be any amino
acid.
<400> 609
Xaa Gly Ser Gly Xaa Tyr Gly Xaa Xaa Phe Asp
1 5 10
<210> 610
<211> 478
<212> PRT
<213> Artificial Sequence
<220>
<223> ICOSL-Fc fusion protein
<400> 610
Asp Thr Gln Glu Lys Glu Val Arg Ala Met Val Gly Ser Asp Val Glu
1 5 10 15
Leu Ser Cys Ala Cys Pro Glu Gly Ser Arg Phe Asp Leu Asn Asp Val
20 25 30
Tyr Val Tyr Trp Gln Thr Ser Glu Ser Lys Thr Val Val Thr Tyr His
35 40 45
Ile Pro Gln Asn Ser Ser Leu Glu Asn Val Asp Ser Arg Tyr Arg Asn
50 55 60
Arg Ala Leu Met Ser Pro Ala Gly Met Leu Arg Gly Asp Phe Ser Leu
65 70 75 80
Arg Leu Phe Asn Val Thr Pro Gln Asp Glu Gln Lys Phe His Cys Leu
85 90 95
Val Leu Ser Gln Ser Leu Gly Phe Gln Glu Val Leu Ser Val Glu Val
100 105 110
Thr Leu His Val Ala Ala Asn Phe Ser Val Pro Val Val Ser Ala Pro
115 120 125
His Ser Pro Ser Gln Asp Glu Leu Thr Phe Thr Cys Thr Ser Ile Asn
130 135 140
Gly Tyr Pro Arg Pro Asn Val Tyr Trp Ile Asn Lys Thr Asp Asn Ser
145 150 155 160
Leu Leu Asp Gln Ala Leu Gln Asn Asp Thr Val Phe Leu Asn Met Arg
165 170 175
Gly Leu Tyr Asp Val Val Ser Val Leu Arg Ile Ala Arg Thr Pro Ser
180 185 190
Val Asn Ile Gly Cys Cys Ile Glu Asn Val Leu Leu Gln Gln Asn Leu
195 200 205
Thr Val Gly Ser Gln Thr Gly Asn Asp Ile Gly Glu Arg Asp Lys Ile
210 215 220
Thr Glu Asn Pro Val Ser Thr Gly Glu Lys Asn Ala Ala Thr Trp Ser
225 230 235 240
Asp Ile Glu Gly Arg Met Asp Pro Lys Ser Cys Asp Lys Thr His Thr
245 250 255
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
260 265 270
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
275 280 285
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
290 295 300
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
305 310 315 320
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
325 330 335
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
340 345 350
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
355 360 365
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
370 375 380
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
385 390 395 400
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
405 410 415
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
420 425 430
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
435 440 445
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
450 455 460
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
465 470 475
Claims (36)
1.一种分离抗体,其结合人类和/或小鼠ICOS的胞外结构域,其中所述抗体包含:VH结构域,其具有STIM003 VH结构域SEQ ID NO:408的氨基酸序列;和VL结构域,其具有STIM003VL结构域SEQ ID NO:415的氨基酸序列。
2.根据权利要求1所述的抗体,其中所述VH结构域包含重链互补决定区HCDR集合:HCDR1、HCDR2和HCDR3,其中
HCDR1为具有氨基酸序列SEQ ID NO:405的STIM003 HCDR1,
HCDR2为具有氨基酸序列SEQ ID NO:406的STIM003 HCDR2,
HCDR3为具有氨基酸序列SEQ ID NO:407的STIM003 HCDR3。
3.根据权利要求1所述的抗体,其中所述VL结构域包含轻链互补决定区LCDR集合:LCDR1、LCDR2和LCDR3,其中
LCDR1为具有氨基酸序列SEQ ID NO:412的STIM003 LCDR1,
LCDR2为具有氨基酸序列SEQ ID NO:413的STIM003 LCDR2,
LCDR3为具有氨基酸序列SEQ ID NO:414的STIM003 LCDR3。
4.根据前述权利要求中任一项所述的抗体,其包含抗体恒定区。
5.根据权利要求4所述的抗体,其中所述恒定区包含人类重链恒定区和/或轻链恒定区。
6.根据权利要求5所述的抗体,其中所述恒定区呈Fc效应子阳性。
7.根据权利要求6所述的抗体,其包含具有与原生人类Fc区相比增强的ADCC、ADCP和/或CDC功能的Fc区。
8.根据权利要求6所述的抗体,其中所述抗体为IgG1。
9.根据权利要求1-3中任意一项所述的抗体,其含有SEQ ID NO:410所示的重链氨基酸序列。
10.根据权利要求1-3中任意一项所述的抗体,其含有SEQ ID NO:417所示的轻链氨基酸序列。
11.根据权利要求1-3中任意一项所述的抗体,其含有SEQ ID NO:410所示的重链氨基酸序列和SEQ ID NO:417所示的轻链氨基酸序列。
12.根据权利要求1-3中任一项所述的抗体,其是多特异性抗体。
13.一种根据权利要求1-3中任意一项所述的分离抗体,其以如通过表面等离子共振测定的小于5nM的亲和力结合人类和小鼠ICOS的胞外结构域。
14.根据权利要求13所述的抗体,其中结合人类ICOS的胞外结构域的亲和力在结合小鼠ICOS的胞外结构域的亲和力的10倍内。
15.一种组合物,其包含根据权利要求1-3中任一项所述的分离抗体和药学上可接受的赋形剂。
16.一种组合物,其包含编码根据权利要求1-3中任一项所述的抗体的分离核酸和药学上可接受的赋形剂。
17.权利要求1-14中任意一项所述的抗体在制备用于治疗人类患者癌症的药物中的应用。
18.根据权利要求17所述的应用,其中所述癌症是肾细胞癌、头颈癌、黑素瘤、非小细胞肺癌、食道癌或子宫颈癌。
19.根据权利要求17所述的应用,其中所述癌症为源自抗原呈递细胞的液体血液病肿瘤,其中所述癌症表达ICOS配体。
20.根据权利要求17所述的应用,其中所述癌症为B细胞癌症。
21.根据权利要求20所述的应用,其中所述B细胞癌症为弥漫性大B细胞淋巴瘤。
22.根据权利要求17所述的应用,其中治疗所述癌症包含向患者给予所述抗体和另一治疗剂和/或放射疗法。
23.根据权利要求22所述的应用,其中所述抗体能够介导ADCC、ADCP和/或CDC。
24.根据权利要求22所述的应用,其中所述治疗剂是抗PD-L1抗体。
25.根据权利要求24所述的应用,其中所述抗PD-L1抗体为阿特珠单抗。
26.根据权利要求23所述的应用,其中所述治疗剂是抗PD-L1抗体,其能够介导ADCC、ADCP和/或CDC。
27.根据权利要求24所述的应用,其中所述抗PD-L1抗体包含具有氨基酸序列SEQ IDNO:299的VH结构域和具有氨基酸序列SEQ ID NO:300的VL结构域。
28.根据权利要求26所述的应用,其中抗ICOS抗体是人类IgG1抗体且所述抗PDL1抗体是人类IgG1抗体。
29.根据权利要求22所述的应用,其中所述治疗剂是IL-2。
30.根据权利要求22所述的应用,其中治疗癌症包含在给予所述另一治疗剂和/或放射疗法之后给予所述抗ICOS抗体。
31.一种结合人类ICOS抗体的分离抗体,其中,所述抗体通过以下过程制得:
(i)培养包含一个或多个载体的宿主细胞,所述载体编码包含氨基酸序列SEQ ID NO:408的VH结构域、包含SEQ ID NO:415的VL结构域、以及人类IgG1恒定区,并
(ii)回收抗体。
32.权利要求31所述的分离抗体,其中,所述抗体包含Fc效应子正恒定区。
33.权利要求31所述的分离抗体,其是多特异性抗体。
34.权利要求31所述的分离抗体,其中,所述抗体经无岩藻糖基化。
35.权利要求31所述的分离抗体,其共轭到细胞毒性药物或前药。
36.一种组合物,所述组合物包含权利要求31所述的分离抗体和药学上可接受的赋形剂。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310636091.7A CN116640214A (zh) | 2016-08-09 | 2017-08-09 | 分离抗体及其应用 |
| CN202310348318.8A CN117736325A (zh) | 2016-08-09 | 2017-08-09 | 分离抗体及其应用 |
Applications Claiming Priority (29)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB201613683 | 2016-08-09 | ||
| GB1613683.0 | 2016-08-09 | ||
| GB1615224.1 | 2016-09-07 | ||
| GBGB1615224.1A GB201615224D0 (en) | 2016-09-07 | 2016-09-07 | Antibodies |
| GB1615335.5 | 2016-09-09 | ||
| GBGB1615335.5A GB201615335D0 (en) | 2016-09-09 | 2016-09-09 | Antibodies and immunocytokines |
| US15/354,971 US9617338B1 (en) | 2016-06-20 | 2016-11-17 | Antibodies and immunocytokines |
| US15/354,971 | 2016-11-17 | ||
| GB1620414.1 | 2016-12-01 | ||
| GBGB1620414.1A GB201620414D0 (en) | 2016-12-01 | 2016-12-01 | Antibodies |
| GB1621782.0 | 2016-12-20 | ||
| GBGB1621782.0A GB201621782D0 (en) | 2016-12-20 | 2016-12-20 | Antibodies and immunocytokines PD-L1 specific antibodies and PD-L1 specific immunocytokines |
| GBGB1702339.1A GB201702339D0 (en) | 2017-02-13 | 2017-02-13 | Antibodies and immunocytokines PD-L1 Specific antiboies and PD-L1 Specific immunocytokines |
| GBGB1702338.3A GB201702338D0 (en) | 2017-02-13 | 2017-02-13 | Antibodies and immunocytokines PD-L1 specific antibodies and specific immunocytokines |
| GB1702339.1 | 2017-02-13 | ||
| GB1702338.3 | 2017-02-13 | ||
| GB1703071.9 | 2017-02-24 | ||
| GBGB1703071.9A GB201703071D0 (en) | 2017-02-24 | 2017-02-24 | Antibodies |
| US15/480,525 US10604576B2 (en) | 2016-06-20 | 2017-04-06 | Antibodies and immunocytokines |
| US15/480,525 | 2017-04-06 | ||
| GBPCT/GB2017/051795 | 2017-06-20 | ||
| GBPCT/GB2017/051794 | 2017-06-20 | ||
| GBGB1709818.7A GB201709818D0 (en) | 2017-06-20 | 2017-06-20 | Antibodies |
| GB1709818.7 | 2017-06-20 | ||
| GBPCT/GB2017/051796 | 2017-06-20 | ||
| PCT/GB2017/051795 WO2017220989A1 (en) | 2016-06-20 | 2017-06-20 | Anti-pd-l1 and il-2 cytokines |
| PCT/GB2017/051796 WO2017220990A1 (en) | 2016-06-20 | 2017-06-20 | Anti-pd-l1 antibodies |
| PCT/GB2017/051794 WO2017220988A1 (en) | 2016-06-20 | 2017-06-20 | Multispecific antibodies for immuno-oncology |
| PCT/GB2017/052352 WO2018029474A2 (en) | 2016-08-09 | 2017-08-09 | Anti-icos antibodies |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310348318.8A Division CN117736325A (zh) | 2016-08-09 | 2017-08-09 | 分离抗体及其应用 |
| CN202310636091.7A Division CN116640214A (zh) | 2016-08-09 | 2017-08-09 | 分离抗体及其应用 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109689688A CN109689688A (zh) | 2019-04-26 |
| CN109689688B true CN109689688B (zh) | 2023-06-13 |
Family
ID=62639165
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310636091.7A Pending CN116640214A (zh) | 2016-08-09 | 2017-08-09 | 分离抗体及其应用 |
| CN201780045638.9A Active CN109689688B (zh) | 2016-08-09 | 2017-08-09 | 抗icos抗体 |
| CN202310348318.8A Pending CN117736325A (zh) | 2016-08-09 | 2017-08-09 | 分离抗体及其应用 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310636091.7A Pending CN116640214A (zh) | 2016-08-09 | 2017-08-09 | 分离抗体及其应用 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310348318.8A Pending CN117736325A (zh) | 2016-08-09 | 2017-08-09 | 分离抗体及其应用 |
Country Status (9)
| Country | Link |
|---|---|
| US (4) | US11858996B2 (zh) |
| EP (1) | EP3497128A2 (zh) |
| JP (3) | JP7198752B2 (zh) |
| KR (2) | KR20230044038A (zh) |
| CN (3) | CN116640214A (zh) |
| BR (1) | BR112019002529A2 (zh) |
| CA (1) | CA3032897A1 (zh) |
| RU (1) | RU2764548C2 (zh) |
| TW (1) | TWI760352B (zh) |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3497128A2 (en) | 2016-08-09 | 2019-06-19 | Kymab Limited | Anti-icos antibodies |
| JP7290568B2 (ja) * | 2016-12-20 | 2023-06-13 | カイマブ・リミテッド | 癌免疫療法のための併用療法での多重特異性抗体 |
| EP3728314A1 (en) | 2017-12-19 | 2020-10-28 | Kymab Limited | Bispecific antibody for icos and pd-l1 |
| GB201721338D0 (en) * | 2017-12-19 | 2018-01-31 | Kymab Ltd | Anti-icos Antibodies |
| WO2019222188A1 (en) * | 2018-05-14 | 2019-11-21 | Jounce Therapeutics, Inc. | Methods of treating cancer |
| CA3173134A1 (en) * | 2020-04-20 | 2021-10-28 | Jounce Therapeutics, Inc. | Compositions and methods for vaccination and the treatment of infectious diseases |
| GB202007099D0 (en) * | 2020-05-14 | 2020-07-01 | Kymab Ltd | Tumour biomarkers for immunotherapy |
| TW202313682A (zh) * | 2021-05-18 | 2023-04-01 | 英商凱麥博有限公司 | 抗icos抗體之用途 |
| WO2023102712A1 (zh) * | 2021-12-07 | 2023-06-15 | 深圳市先康达生命科学有限公司 | 一种基因生物制剂及其制备方法和应用 |
| WO2023222854A1 (en) * | 2022-05-18 | 2023-11-23 | Kymab Limited | Uses of anti-icos antibodies |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7794710B2 (en) * | 2001-04-20 | 2010-09-14 | Mayo Foundation For Medical Education And Research | Methods of enhancing T cell responsiveness |
| CN101861168A (zh) * | 2007-05-07 | 2010-10-13 | 米迪缪尼有限公司 | 抗-icos抗体及其在治疗肿瘤、移植和自身免疫病中的应用 |
| WO2016154177A2 (en) * | 2015-03-23 | 2016-09-29 | Jounce Therapeutics, Inc. | Antibodies to icos |
| CN109475603A (zh) * | 2016-06-20 | 2019-03-15 | 科马布有限公司 | 抗pd-l1抗体 |
| CN110914299A (zh) * | 2017-04-07 | 2020-03-24 | 百时美施贵宝公司 | 抗icos促效剂抗体和其用途 |
Family Cites Families (125)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5869046A (en) | 1995-04-14 | 1999-02-09 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US6121022A (en) | 1995-04-14 | 2000-09-19 | Genentech, Inc. | Altered polypeptides with increased half-life |
| NL1003648C2 (nl) | 1996-07-19 | 1998-01-21 | Carino Cornelis Sunderman | Werkwijze en inrichting voor het bevorderen van de rookgasafvoer van een openhaardvuur. |
| JP3521382B2 (ja) | 1997-02-27 | 2004-04-19 | 日本たばこ産業株式会社 | 細胞間接着及びシグナル伝達を媒介する細胞表面分子 |
| US7112655B1 (en) | 1997-02-27 | 2006-09-26 | Japan Tobacco, Inc. | JTT-1 protein and methods of inhibiting lymphocyte activation |
| WO1999015553A2 (de) | 1997-09-23 | 1999-04-01 | Bundesrepublik Deutschland Letztvertreten Durch Den Direktor Des Robert-Koch-Instituts | Ko-stimulierendes polypeptid von t-zellen, monoklonale antikörper sowie die herstellung und deren verwendung |
| DE19821060A1 (de) | 1997-09-23 | 1999-04-15 | Bundesrepublik Deutschland Let | Ko-stimulierendes Polypeptid von T-Zellen, monoklonale Antikörper sowie die Herstellung und deren Verwendung |
| JP4093757B2 (ja) | 1999-08-24 | 2008-06-04 | メダレックス, インコーポレイテッド | ヒトctla−4抗体およびその使用 |
| JP3871503B2 (ja) | 1999-08-30 | 2007-01-24 | 日本たばこ産業株式会社 | 免疫性疾患治療剤 |
| TWI263496B (en) | 1999-12-10 | 2006-10-11 | Novartis Ag | Pharmaceutical combinations and their use in treating gastrointestinal disorders |
| US6579243B2 (en) * | 2000-03-02 | 2003-06-17 | Scimed Life Systems, Inc. | Catheter with thermal sensor for detection of vulnerable plaque |
| AU2001247616B2 (en) | 2000-04-11 | 2007-06-14 | Genentech, Inc. | Multivalent antibodies and uses therefor |
| JP3597140B2 (ja) | 2000-05-18 | 2004-12-02 | 日本たばこ産業株式会社 | 副刺激伝達分子ailimに対するヒトモノクローナル抗体及びその医薬用途 |
| JP4212278B2 (ja) | 2001-03-01 | 2009-01-21 | 日本たばこ産業株式会社 | 移植片拒絶反応抑制剤 |
| US20030124149A1 (en) | 2001-07-06 | 2003-07-03 | Shalaby Shalaby W. | Bioactive absorbable microparticles as therapeutic vaccines |
| WO2003039591A2 (de) | 2001-11-09 | 2003-05-15 | Medigene Aktiengesellschaft | Allogene vakzine enthaltend eine ein costimulatorisches polypeptid exprimierende tumorzelle |
| ES2654064T3 (es) | 2002-07-03 | 2024-03-13 | Ono Pharmaceutical Co | Composiciones inmunopotenciadoras que comprenden anticuerpos anti-PD-L1 |
| EP1740208A2 (en) | 2004-03-23 | 2007-01-10 | Amgen, Inc | Monoclonal antibodies specific for human ox40l (cd134l) |
| JP2008501638A (ja) | 2004-04-23 | 2008-01-24 | ドイツ連邦共和国 | ICOS陽性細胞のinvivo枯渇によるT細胞介在病態の治療方法 |
| WO2006004716A2 (en) | 2004-06-29 | 2006-01-12 | The Johns Hopkins University | Amelioration of drug-induced toxicity |
| TWI309240B (en) | 2004-09-17 | 2009-05-01 | Hoffmann La Roche | Anti-ox40l antibodies |
| PL3428191T3 (pl) | 2004-10-06 | 2025-04-07 | Mayo Foundation For Medical Education And Research | B7-H1 i PD-1 w leczeniu raka nerkowokomórkowego |
| CA2607147C (en) * | 2005-05-09 | 2018-07-17 | Ono Pharmaceutical Co., Ltd. | Human monoclonal antibodies to programmed death 1 (pd-1) and methods for treating cancer using anti-pd-1 antibodies alone or in combination with other immunotherapeutics |
| DK2397156T3 (en) | 2005-06-08 | 2017-01-09 | Dana Farber Cancer Inst Inc | Methods and compositions for the treatment of persistent infektio-tions, and cancer by inhibiting programmed cell death-1 (PD-1) -pathwayen. |
| UA99701C2 (ru) | 2005-07-01 | 2012-09-25 | Медарекс, Инк. | Человеческое моноклональное антитело, которое специфически связывается с лигандом-1 запрограммированной гибели клеток (pd-l1) |
| WO2007133290A2 (en) | 2005-12-16 | 2007-11-22 | Genentech, Inc. | Anti-ox40l antibodies and methods using same |
| WO2007113648A2 (en) | 2006-04-05 | 2007-10-11 | Pfizer Products Inc. | Ctla4 antibody combination therapy |
| AT503889B1 (de) | 2006-07-05 | 2011-12-15 | Star Biotechnologische Forschungs Und Entwicklungsges M B H F | Multivalente immunglobuline |
| NZ600281A (en) | 2006-12-27 | 2013-03-28 | Harvard College | Compositions and methods for the treatment of infections and tumors |
| WO2009070642A1 (en) | 2007-11-28 | 2009-06-04 | Medimmune, Llc | Protein formulation |
| US20090258013A1 (en) | 2008-04-09 | 2009-10-15 | Genentech, Inc. | Novel compositions and methods for the treatment of immune related diseases |
| WO2009141239A1 (en) | 2008-05-20 | 2009-11-26 | F. Hoffmann-La Roche Ag | A pharmaceutical formulation comprising an antibody against ox40l, uses thereof |
| US8552154B2 (en) | 2008-09-26 | 2013-10-08 | Emory University | Anti-PD-L1 antibodies and uses therefor |
| CA2743469C (en) | 2008-11-12 | 2019-01-15 | Medimmune, Llc | Antibody formulation |
| RU2636023C2 (ru) | 2008-12-09 | 2017-11-17 | Дженентек, Инк. | Антитела к pd-l1 и их применение для усиления функции т-клеток |
| JO3672B1 (ar) | 2008-12-15 | 2020-08-27 | Regeneron Pharma | أجسام مضادة بشرية عالية التفاعل الكيماوي بالنسبة لإنزيم سبتيليسين كنفرتيز بروبروتين / كيكسين نوع 9 (pcsk9). |
| EP2393835B1 (en) | 2009-02-09 | 2017-04-05 | Université d'Aix-Marseille | Pd-1 antibodies and pd-l1 antibodies and uses thereof |
| PT2517556E (pt) | 2009-07-08 | 2016-01-20 | Kymab Ltd | Modelos animais e moléculas terapêuticas |
| EP2464661B1 (en) | 2009-08-13 | 2018-01-17 | The Johns Hopkins University | Methods of modulating immune function with anti-b7-h7cr antibodies |
| US8709417B2 (en) * | 2009-09-30 | 2014-04-29 | Memorial Sloan-Kettering Cancer Center | Combination immunotherapy for the treatment of cancer |
| KR101790767B1 (ko) | 2009-11-24 | 2017-10-26 | 메디뮨 리미티드 | B7―h1에 대한 표적화된 결합 물질 |
| SG10201501784YA (en) | 2009-12-07 | 2015-05-28 | Univ Leland Stanford Junior | Methods for enhancing anti-tumor antibody therapy |
| EP3309176A1 (en) | 2009-12-14 | 2018-04-18 | Ablynx N.V. | Immunoglobulin single variable domain antibodies against ox40l, constructs and therapeutic use |
| US9133436B2 (en) | 2010-02-04 | 2015-09-15 | The Trustees Of The University Of Pennsylvania | ICOS critically regulates the expansion and function of inflammatory human Th17 cells |
| NZ605966A (en) | 2010-06-17 | 2015-04-24 | Kymab Ltd | Animal models and therapeutic molecules |
| AU2012233652B2 (en) | 2011-03-31 | 2017-05-18 | Centre Leon Berard | Antibodies directed against ICOS and uses thereof |
| WO2012145493A1 (en) | 2011-04-20 | 2012-10-26 | Amplimmune, Inc. | Antibodies and other molecules that bind b7-h1 and pd-1 |
| US20140170157A1 (en) | 2011-06-15 | 2014-06-19 | Glaxosmithkline Intellectual Property (No.2) Limited | Method of selecting therapeutic indications |
| GB2496375A (en) | 2011-10-28 | 2013-05-15 | Kymab Ltd | A non-human assay vertebrate comprising human antibody loci and human epitope knock-in, and uses thereof |
| HUE051954T2 (hu) | 2011-11-28 | 2021-03-29 | Merck Patent Gmbh | ANTI-PD-L1 ellenanyagok és alkalmazásaik |
| US9253965B2 (en) | 2012-03-28 | 2016-02-09 | Kymab Limited | Animal models and therapeutic molecules |
| BR112014028826B1 (pt) | 2012-05-15 | 2024-04-30 | Bristol-Myers Squibb Company | Uso de nivolumab ou pembrolizumabe |
| US9175082B2 (en) | 2012-05-31 | 2015-11-03 | Sorrento Therapeutics, Inc. | Antigen binding proteins that bind PD-L1 |
| WO2014033327A1 (en) | 2012-09-03 | 2014-03-06 | INSERM (Institut National de la Santé et de la Recherche Médicale) | Antibodies directed against icos for treating graft-versus-host disease |
| AU2013326901B2 (en) | 2012-10-04 | 2018-05-31 | Dana-Farber Cancer Institute, Inc. | Human monoclonal anti-PD-L1 antibodies and methods of use |
| ES2715673T3 (es) | 2012-12-03 | 2019-06-05 | Bristol Myers Squibb Co | Mejora de la actividad anticancerosa de proteínas de fusión FC inmunomoduladoras |
| AR093984A1 (es) | 2012-12-21 | 2015-07-01 | Merck Sharp & Dohme | Anticuerpos que se unen a ligando 1 de muerte programada (pd-l1) humano |
| WO2014116846A2 (en) | 2013-01-23 | 2014-07-31 | Abbvie, Inc. | Methods and compositions for modulating an immune response |
| WO2014165082A2 (en) | 2013-03-13 | 2014-10-09 | Medimmune, Llc | Antibodies and methods of detection |
| ES2644022T3 (es) | 2013-03-14 | 2017-11-27 | Bristol-Myers Squibb Company | Combinación de un agonista de DR5 y un antagonista de anti-PD-1 y métodos de uso |
| FR3006774B1 (fr) | 2013-06-10 | 2015-07-10 | Univ Limoges | Guide d'onde a coeur creux avec un contour optimise |
| GB201316644D0 (en) | 2013-09-19 | 2013-11-06 | Kymab Ltd | Expression vector production & High-Throughput cell screening |
| GB201317622D0 (en) | 2013-10-04 | 2013-11-20 | Star Biotechnology Ltd F | Cancer biomarkers and uses thereof |
| CA2926856A1 (en) | 2013-10-25 | 2015-04-30 | Dana-Farber Cancer Institute, Inc. | Anti-pd-l1 monoclonal antibodies and fragments thereof |
| US10519251B2 (en) | 2013-12-30 | 2019-12-31 | Epimab Biotherapeutics, Inc. | Fabs-in-tandem immunoglobulin and uses thereof |
| HRP20220214T1 (hr) | 2014-01-15 | 2022-04-29 | Kadmon Corporation, Llc | Imunomodulacijska sredstva |
| TWI680138B (zh) | 2014-01-23 | 2019-12-21 | 美商再生元醫藥公司 | 抗pd-l1之人類抗體 |
| TWI681969B (zh) | 2014-01-23 | 2020-01-11 | 美商再生元醫藥公司 | 針對pd-1的人類抗體 |
| JOP20200094A1 (ar) | 2014-01-24 | 2017-06-16 | Dana Farber Cancer Inst Inc | جزيئات جسم مضاد لـ pd-1 واستخداماتها |
| GB201403775D0 (en) | 2014-03-04 | 2014-04-16 | Kymab Ltd | Antibodies, uses & methods |
| WO2015136541A2 (en) | 2014-03-12 | 2015-09-17 | Yeda Research And Development Co. Ltd | Reducing systemic regulatory t cell levels or activity for treatment of disease and injury of the cns |
| US20150307620A1 (en) | 2014-04-16 | 2015-10-29 | University Of Connecticut | Linked immunotherapeutic agonists that costimulate multiple pathways |
| WO2015173267A1 (en) | 2014-05-13 | 2015-11-19 | Medimmune Limited | Anti-b7-h1 and anti-ctla-4 antibodies for treating non-small cell lung cancer |
| WO2015179654A1 (en) | 2014-05-22 | 2015-11-26 | Mayo Foundation For Medical Education And Research | Distinguishing antagonistic and agonistic anti b7-h1 antibodies |
| EP3149042B1 (en) | 2014-05-29 | 2019-08-28 | Spring Bioscience Corporation | Pd-l1 antibodies and uses thereof |
| KR102130600B1 (ko) | 2014-07-03 | 2020-07-08 | 베이진 엘티디 | Pd-l1 항체와 이를 이용한 치료 및 진단 |
| AU2015288232B2 (en) | 2014-07-11 | 2020-10-15 | Ventana Medical Systems, Inc. | Anti-PD-L1 antibodies and diagnostic uses thereof |
| JP6909153B2 (ja) | 2014-08-05 | 2021-07-28 | アポロミクス インコーポレイテッド | 抗pd−l1抗体 |
| CR20170060A (es) | 2014-08-19 | 2017-04-18 | Merck Sharp & Dohme | Anticuerpos anti tigit |
| HRP20200272T1 (hr) | 2014-08-29 | 2020-05-29 | F. Hoffmann - La Roche Ag | Kombinirana terapija za imunocitokine varijante il-2 usmjerene na tumor i protutijela protiv humanog pd-l1 |
| US9988452B2 (en) | 2014-10-14 | 2018-06-05 | Novartis Ag | Antibody molecules to PD-L1 and uses thereof |
| US20160145344A1 (en) | 2014-10-20 | 2016-05-26 | University Of Southern California | Murine and human innate lymphoid cells and lung inflammation |
| GB201419084D0 (en) | 2014-10-27 | 2014-12-10 | Agency Science Tech & Res | Anti-PD-1 antibodies |
| US10259887B2 (en) | 2014-11-26 | 2019-04-16 | Xencor, Inc. | Heterodimeric antibodies that bind CD3 and tumor antigens |
| US10047138B1 (en) | 2014-12-03 | 2018-08-14 | Amgen Inc. | Fusion protein, cells expressing the fusion protein, and uses thereof |
| EA039219B1 (ru) | 2014-12-23 | 2021-12-20 | Бристол-Майерс Сквибб Компани | Антитела к tigit |
| GB201500319D0 (en) | 2015-01-09 | 2015-02-25 | Agency Science Tech & Res | Anti-PD-L1 antibodies |
| MA41414A (fr) | 2015-01-28 | 2017-12-05 | Centre Nat Rech Scient | Protéines de liaison agonistes d' icos |
| WO2016149201A2 (en) | 2015-03-13 | 2016-09-22 | Cytomx Therapeutics, Inc. | Anti-pdl1 antibodies, activatable anti-pdl1 antibodies, and methods of use thereof |
| US10836827B2 (en) | 2015-03-30 | 2020-11-17 | Stcube, Inc. | Antibodies specific to glycosylated PD-L1 and methods of use thereof |
| TWI715587B (zh) | 2015-05-28 | 2021-01-11 | 美商安可美德藥物股份有限公司 | Tigit結合劑和彼之用途 |
| US10696745B2 (en) | 2015-06-11 | 2020-06-30 | Wuxi Biologics (Shanghai) Co. Ltd. | Anti-PD-L1 antibodies |
| CN106397592A (zh) | 2015-07-31 | 2017-02-15 | 苏州康宁杰瑞生物科技有限公司 | 针对程序性死亡配体(pd-l1)的单域抗体及其衍生蛋白 |
| WO2017020291A1 (en) | 2015-08-06 | 2017-02-09 | Wuxi Biologics (Shanghai) Co. Ltd. | Novel anti-pd-l1 antibodies |
| EP3331919A1 (en) | 2015-08-07 | 2018-06-13 | GlaxoSmithKline Intellectual Property Development Limited | Combination therapy comprising anti ctla-4 antibodies |
| JP6976241B2 (ja) | 2015-08-14 | 2021-12-08 | メルク・シャープ・アンド・ドーム・コーポレーションMerck Sharp & Dohme Corp. | 抗tigit抗体 |
| AR105654A1 (es) | 2015-08-24 | 2017-10-25 | Lilly Co Eli | Anticuerpos pd-l1 (ligando 1 de muerte celular programada) |
| EP3344658B1 (en) | 2015-09-02 | 2022-05-11 | Yissum Research Development Company of The Hebrew University of Jerusalem Ltd. | Antibodies specific to human t-cell immunoglobulin and itim domain (tigit) |
| IL319106A (en) | 2015-09-25 | 2025-04-01 | Genentech Inc | Anti-TIGIT antibodies and methods of use |
| SG10201912736UA (en) | 2015-10-01 | 2020-02-27 | Potenza Therapeutics Inc | Anti-tigit antigen-binding proteins and methods of use thereof |
| AU2016342269A1 (en) | 2015-10-22 | 2018-03-29 | Jounce Therapeutics, Inc. | Gene signatures for determining icos expression |
| WO2017087587A1 (en) | 2015-11-18 | 2017-05-26 | Merck Sharp & Dohme Corp. | PD1/CTLA4 Binders |
| WO2017213695A1 (en) | 2016-06-07 | 2017-12-14 | The Brigham And Women's Hospital, Inc. | Compositions and methods relating to t peripheral helper cells in autoantibody-associated conditions |
| US9567399B1 (en) | 2016-06-20 | 2017-02-14 | Kymab Limited | Antibodies and immunocytokines |
| WO2018029474A2 (en) | 2016-08-09 | 2018-02-15 | Kymab Limited | Anti-icos antibodies |
| EP3494140A1 (en) | 2016-08-04 | 2019-06-12 | GlaxoSmithKline Intellectual Property Development Ltd | Anti-icos and anti-pd-1 antibody combination therapy |
| EP3497128A2 (en) | 2016-08-09 | 2019-06-19 | Kymab Limited | Anti-icos antibodies |
| US10793632B2 (en) | 2016-08-30 | 2020-10-06 | Xencor, Inc. | Bispecific immunomodulatory antibodies that bind costimulatory and checkpoint receptors |
| WO2018045110A1 (en) | 2016-08-30 | 2018-03-08 | Xencor, Inc. | Bispecific immunomodulatory antibodies that bind costimulatory and checkpoint receptors |
| AU2017322656B2 (en) | 2016-09-10 | 2024-02-29 | Yeda Research And Development Co. Ltd. | Reducing systemic regulatory T cell levels or activity for treatment of disease and injury of the CNS |
| JP7086066B2 (ja) | 2016-11-02 | 2022-06-17 | ジョンス セラピューティクス, インコーポレイテッド | Pd-1に対する抗体及びその使用 |
| WO2018115859A1 (en) | 2016-12-20 | 2018-06-28 | Kymab Limited | Multispecific antibody with combination therapy for immuno-oncology |
| JP7290568B2 (ja) * | 2016-12-20 | 2023-06-13 | カイマブ・リミテッド | 癌免疫療法のための併用療法での多重特異性抗体 |
| WO2018187191A1 (en) | 2017-04-03 | 2018-10-11 | Jounce Therapeutics, Inc | Compositions and methods for the treatment of cancer |
| JP2020522555A (ja) | 2017-06-09 | 2020-07-30 | グラクソスミスクライン、インテレクチュアル、プロパティー、ディベロップメント、リミテッドGlaxosmithkline Intellectual Property Development Limited | 組み合わせ療法 |
| GB201709808D0 (en) * | 2017-06-20 | 2017-08-02 | Kymab Ltd | Antibodies |
| US10981992B2 (en) | 2017-11-08 | 2021-04-20 | Xencor, Inc. | Bispecific immunomodulatory antibodies that bind costimulatory and checkpoint receptors |
| GB201721338D0 (en) * | 2017-12-19 | 2018-01-31 | Kymab Ltd | Anti-icos Antibodies |
| TW201930355A (zh) | 2017-12-19 | 2019-08-01 | 英商F星貝塔有限公司 | 結合物件(三) |
| EP3728314A1 (en) | 2017-12-19 | 2020-10-28 | Kymab Limited | Bispecific antibody for icos and pd-l1 |
| GB2583352B (en) | 2019-04-24 | 2023-09-06 | Univ Southampton | Antiresonant hollow core fibre, preform therefor and method of fabrication |
| CN110579836B (zh) | 2019-07-31 | 2020-10-02 | 江西师范大学 | 一种多谐振层空芯光纤 |
| WO2021043961A1 (en) | 2019-09-06 | 2021-03-11 | Glaxosmithkline Intellectual Property Development Limited | Dosing regimen for the treatment of cancer with an anti icos agonistic antibody and chemotherapy |
| GB202007099D0 (en) | 2020-05-14 | 2020-07-01 | Kymab Ltd | Tumour biomarkers for immunotherapy |
| TW202313682A (zh) | 2021-05-18 | 2023-04-01 | 英商凱麥博有限公司 | 抗icos抗體之用途 |
-
2017
- 2017-08-09 EP EP17752162.2A patent/EP3497128A2/en active Pending
- 2017-08-09 CN CN202310636091.7A patent/CN116640214A/zh active Pending
- 2017-08-09 BR BR112019002529A patent/BR112019002529A2/pt unknown
- 2017-08-09 RU RU2019104980A patent/RU2764548C2/ru active
- 2017-08-09 KR KR1020237009918A patent/KR20230044038A/ko not_active Ceased
- 2017-08-09 TW TW106126908A patent/TWI760352B/zh active
- 2017-08-09 CN CN201780045638.9A patent/CN109689688B/zh active Active
- 2017-08-09 CN CN202310348318.8A patent/CN117736325A/zh active Pending
- 2017-08-09 KR KR1020197006706A patent/KR102604433B1/ko active Active
- 2017-08-09 US US16/323,980 patent/US11858996B2/en active Active
- 2017-08-09 JP JP2019529699A patent/JP7198752B2/ja active Active
- 2017-08-09 CA CA3032897A patent/CA3032897A1/en active Pending
-
2022
- 2022-04-22 US US17/727,309 patent/US20220403029A1/en active Pending
- 2022-04-22 US US17/727,288 patent/US20220380467A1/en not_active Abandoned
- 2022-06-01 JP JP2022089801A patent/JP7448586B2/ja active Active
-
2023
- 2023-11-01 US US18/499,431 patent/US20240158502A1/en active Pending
- 2023-12-06 JP JP2023205810A patent/JP2024028862A/ja active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7794710B2 (en) * | 2001-04-20 | 2010-09-14 | Mayo Foundation For Medical Education And Research | Methods of enhancing T cell responsiveness |
| CN101861168A (zh) * | 2007-05-07 | 2010-10-13 | 米迪缪尼有限公司 | 抗-icos抗体及其在治疗肿瘤、移植和自身免疫病中的应用 |
| WO2016154177A2 (en) * | 2015-03-23 | 2016-09-29 | Jounce Therapeutics, Inc. | Antibodies to icos |
| CN109475603A (zh) * | 2016-06-20 | 2019-03-15 | 科马布有限公司 | 抗pd-l1抗体 |
| CN109475602A (zh) * | 2016-06-20 | 2019-03-15 | 科马布有限公司 | 抗pd-l1和il-2细胞因子 |
| CN110914299A (zh) * | 2017-04-07 | 2020-03-24 | 百时美施贵宝公司 | 抗icos促效剂抗体和其用途 |
Non-Patent Citations (7)
| Title |
|---|
| An agonist human ICOS monoclonal antibody that induces T cell activation and inhibits proliferation of a myeloma cell line.;Deng ZB, et al.;《Hybrid Hybridomics》;20040601;第23卷(第3期);摘要、第177页材料与方法第2段、右栏末段、第179页左栏第2段 * |
| Engagement of the ICOS pathway markedly enhances efficacy of CTLA-4 blockade in cancer immunotherapy;Fan X, et al.;《J Exp Med.》;20140331;第211卷(第4期);摘要、结果部分、讨论部分 * |
| Follicular B Lymphomas Generate Regulatory T Cells via the ICOS/ICOSL Pathway and Are Susceptible to Treatment by Anti-ICOS/ICOSL Therapy;Le KS et al.;《Cancer Res》;20160531;第76卷(第16期);摘要 * |
| ICOS-ligand expression on plasmacytoid dendritic cells supports breast cancer progression by promoting the accumulation of immunosuppressive CD4+ T cells;Faget J, et al.;《Cancer Res.》;20121201;第72卷(第23期);摘要 * |
| ICOS和PD1共刺激分子的免疫学作用;丁涵露,吴雄飞;《第三军医大学学报》;20050115;全文 * |
| 吴梧桐.单克隆抗体.《生物制药工艺学》.中国医药科技出版社,2015, * |
| 感染免疫中ICOS和PD-1在调节性T细胞上的表达及平衡;李艳华,等;《细胞与分子免疫学杂志》;20121118;第28卷(第11期);全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| RU2764548C2 (ru) | 2022-01-18 |
| CN117736325A (zh) | 2024-03-22 |
| RU2019104980A (ru) | 2020-09-11 |
| US20240158502A1 (en) | 2024-05-16 |
| JP2022116269A (ja) | 2022-08-09 |
| US11858996B2 (en) | 2024-01-02 |
| KR102604433B1 (ko) | 2023-11-24 |
| BR112019002529A2 (pt) | 2019-05-28 |
| US20220380467A1 (en) | 2022-12-01 |
| RU2019104980A3 (zh) | 2020-10-22 |
| JP7448586B2 (ja) | 2024-03-12 |
| JP2024028862A (ja) | 2024-03-05 |
| US20220403029A1 (en) | 2022-12-22 |
| JP2019534892A (ja) | 2019-12-05 |
| KR20230044038A (ko) | 2023-03-31 |
| CN116640214A (zh) | 2023-08-25 |
| US20190330345A1 (en) | 2019-10-31 |
| CN109689688A (zh) | 2019-04-26 |
| CA3032897A1 (en) | 2018-02-15 |
| EP3497128A2 (en) | 2019-06-19 |
| KR20190038618A (ko) | 2019-04-08 |
| TW201811826A (zh) | 2018-04-01 |
| JP7198752B2 (ja) | 2023-01-04 |
| TWI760352B (zh) | 2022-04-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7595618B2 (ja) | 抗pd-l1抗体 | |
| CN109689688B (zh) | 抗icos抗体 | |
| KR102473028B1 (ko) | 항-tim-3 항체 및 조성물 | |
| KR102493282B1 (ko) | Tim3에 대한 항체 및 그의 용도 | |
| CN108137687B (zh) | 抗ox40抗体及其用途 | |
| KR102737715B1 (ko) | Pd-1, tim-3 및 lag-3을 표적화하는 조합 요법 | |
| CN113773388B (zh) | 抗cd73抗体及其用途 | |
| KR20230038311A (ko) | 항-cd73 항체와의 조합 요법 | |
| JP2023055904A (ja) | 癌免疫療法のための併用療法での多重特異性抗体 | |
| KR20200108870A (ko) | Tim3에 대한 항체 및 그의 용도 | |
| KR20230165285A (ko) | Gdf15 신호전달의 치료적 억제제 | |
| KR20240007760A (ko) | 항-icos 항체의 용도 | |
| TW202313110A (zh) | 癌症之治療 | |
| HK40003736B (zh) | 抗icos抗体 | |
| RU2795232C2 (ru) | Комбинированные лекарственные средства, нацеленные на pd-1, tim-3 и lag-3 | |
| HK40082642A (zh) | 靶向pd-1、tim-3及lag-3的组合疗法 | |
| NZ789986A (en) | Antibodies against tim3 and uses thereof | |
| HK40005923B (zh) | 抗pd-l1和il-2细胞因子 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 40003736 Country of ref document: HK |
|
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TG01 | Patent term adjustment | ||
| TG01 | Patent term adjustment |