Android’s defense-in-depth strategy applies not only to the Android OS running on the Application Processor (AP) but also the firmware that runs on devices. We particularly prioritize hardening the cellular baseband given its unique combination of running in an elevated privilege and parsing untrusted inputs that are remotely delivered into the device.
This post covers how to use two high-value sanitizers which can prevent specific classes of vulnerabilities found within the baseband. They are architecture agnostic, suitable for bare-metal deployment, and should be enabled in existing C/C++ code bases to mitigate unknown vulnerabilities. Beyond security, addressing the issues uncovered by these sanitizers improves code health and overall stability, reducing resources spent addressing bugs in the future.
As we outlined previously, security research focused on the baseband has highlighted a consistent lack of exploit mitigations in firmware. Baseband Remote Code Execution (RCE) exploits have their own categorization in well-known third-party marketplaces with a relatively low payout. This suggests baseband bugs may potentially be abundant and/or not too complex to find and exploit, and their prominent inclusion in the marketplace demonstrates that they are useful.
Baseband security and exploitation has been a recurring theme in security conferences for the last decade. Researchers have also made a dent in this area in well-known exploitation contests. Most recently, this area has become prominent enough that it is common to find practical baseband exploitation trainings in top security conferences.
Acknowledging this trend, combined with the severity and apparent abundance of these vulnerabilities, last year we introduced updates to the severity guidelines of Android’s Vulnerability Rewards Program (VRP). For example, we consider vulnerabilities allowing Remote Code Execution (RCE) in the cellular baseband to be of CRITICAL severity.
Common classes of vulnerabilities can be mitigated through the use of sanitizers provided by Clang-based toolchains. These sanitizers insert runtime checks against common classes of vulnerabilities. GCC-based toolchains may also provide some level of support for these flags as well, but will not be considered further in this post. We encourage you to check your toolchain’s documentation.
Two sanitizers included in Undefined Behavior Sanitizer (UBSan) will be our focus – Integer Overflow Sanitizer (IntSan) and BoundsSanitizer (BoundSan). These have been widely deployed in Android userspace for years following a data-driven approach. These two are well suited for bare-metal environments such as the baseband since they do not require support from the OS or specific architecture features, and so are generally supported for all Clang targets.
IntSan causes signed and unsigned integer overflows to abort execution unless the overflow is made explicit. While unsigned integer overflows are technically defined behavior, it can often lead to unintentional behavior and vulnerabilities – especially when they’re used to index into arrays.
As both intentional and unintentional overflows are likely present in most code bases, IntSan may require refactoring and annotating the code base to prevent intentional or benign overflows from trapping (which we consider a false positive for our purposes). Overflows which need to be addressed can be uncovered via testing (see the Deploying Sanitizers section)
BoundSan inserts instrumentation to perform bounds checks around some array accesses. These checks are only added if the compiler cannot prove at compile time that the access will be safe and if the size of the array will be known at runtime, so that it can be checked against. Note that this will not cover all array accesses as the size of the array may not be known at runtime, such as function arguments which are arrays.
As long as the code is correctly written C/C++, BoundSan should produce no false positives. Any violations discovered when first enabling BoundSan is at least a bug, if not a vulnerability. Resolving even those which aren’t exploitable can greatly improve stability and code quality.
Adopting modern mitigations also means adopting (and maintaining) modern toolchains. The benefits of this go beyond utilizing sanitizers however. Maintaining an old toolchain is not free and entails hidden opportunity costs. Toolchains contain bugs which are addressed in subsequent releases. Newer toolchains bring new performance optimizations, valuable in the highly constrained bare-metal environment that basebands operate in. Security issues can even exist in the generated code of out-of-date compilers.
Maintaining a modern up-to-date toolchain for the baseband entails some costs in terms of maintenance, especially at first if the toolchain is particularly old, but over time the benefits, as outlined above, outweigh the costs.
Both BoundSan and IntSan have a measurable performance overhead. Although we were able to significantly reduce this overhead in the past (for example to less than 1% in media codecs), even very small increases in CPU load can have a substantial impact in some environments.
Enabling sanitizers over the entire codebase provides the most benefit, but enabling them in security-critical attack surfaces can serve as a first step in an incremental deployment. For example:
In the particular case of 2G, the best strategy is to disable the stack altogether by supporting Android’s “2G toggle”. However, 2G is still a necessary mobile access technology in certain parts of the world and some users might need to have this legacy protocol enabled.
Having a clear plan for deployment of sanitizers saves a lot of time and effort. We think of the deployment process as having three stages:
We also introduce two modes in which sanitizers should be run: diagnostics mode and trapping mode. These will be discussed in the following sections, but briefly: diagnostics mode recovers from violations and provides valuable debug information, while trapping mode actively mitigates vulnerabilities by trapping execution on violations.
To successfully ship these sanitizers, any benign integer overflows must be made explicit and accidental out-of-bounds accesses must be addressed. These will have to be uncovered through testing. The higher the code coverage your tests provide, the more issues you can uncover at this stage and the easier deployment will be later on.
To diagnose violations uncovered in testing, sanitizers can emit calls to runtime handlers with debug information such as the file, line number, and values leading to the violation. Sanitizers can optionally continue execution after a violation has occurred, allowing multiple violations to be discovered in a single test run. We refer to using the sanitizers in this way as running them in “diagnostics mode”. Diagnostics mode is not intended for production as it provides no security benefits and adds high overhead.
Diagnostics mode for the sanitizers can be set using the following flags:
-fsanitize=signed-integer-overflow,unsigned-integer-overflow,bounds -fsanitize-recover=all
Since Clang does not provide a UBSan runtime for bare-metal targets, a runtime will need to be defined and provided at link time:
// integer overflow handlers __ubsan_handle_add_overflow(OverflowData *data, ValueHandle lhs, ValueHandle rhs) __ubsan_handle_sub_overflow(OverflowData *data, ValueHandle lhs, ValueHandle rhs) __ubsan_handle_mul_overflow(OverflowData *data, ValueHandle lhs, ValueHandle rhs) __ubsan_handle_divrem_overflow(OverflowData *data, ValueHandle lhs, ValueHandle rhs) __ubsan_handle_negate_overflow(OverflowData *data, ValueHandle old_val) // boundsan handler __ubsan_handle_out_of_bounds_overflow(OverflowData *data, ValueHandle old_val)
As an example, see the default Clang implementation; the Linux Kernels implementation may also be illustrative.
With the runtime defined, enable the sanitizer over the entire baseband codebase and run all available tests to uncover and address any violations. Vulnerabilities should be patched, and overflows should either be refactored or made explicit through the use of checked arithmetic builtins which do not trigger sanitizer violations. Certain functions which are expected to have intentional overflows (such as cryptographic functions) can be preemptively excluded from sanitization (see next section).
Aside from uncovering security vulnerabilities, this stage is highly effective at uncovering code quality and stability bugs that could result in instability on user devices.
Once violations have been addressed and tests are no longer uncovering new violations, the next stage can begin.
Once shallow violations have been addressed, benchmarks can be run and the overhead from the sanitizers (performance, code size, memory footprint) can be measured.
Measuring overhead must be done using production flags – namely “trapping mode”, where violations cause execution to abort. The diagnostics runtime used in the first stage carries significant overhead and is not indicative of the actual performance sanitizer overhead.
Trapping mode can be enabled using the following flags:
-fsanitize=signed-integer-overflow,unsigned-integer-overflow,bounds -fsanitize-trap=all
Most of the overhead is likely due to a small handful of “hot functions”, for example those with tight long-running loops. Fine-grained per-function performance metrics (similar to what Simpleperf provides for Android), allows comparing metrics before and after sanitizers and provides the easiest means to identify hot functions. These functions can either be refactored or, after manual inspection to verify that they are safe, have sanitization disabled.
Sanitizers can be disabled either inline in the source or through the use of ignorelists and the -fsanitize-ignorelist flag.
The physical layer code, with its extremely tight performance margins and lower chance of exploitable vulnerabilities, may be a good candidate to disable sanitization wholesale if initial performance seems prohibitive.
With overhead minimized and shallow bugs resolved, the final stage is enabling the sanitizers in trapping mode to mitigate vulnerabilities.
We strongly recommend a long period of internal soak in pre-production with test populations to uncover any remaining violations not discovered in testing. The more thorough the test coverage and length of the soak period, the less risk there will be from undiscovered violations.
As above, the configuration for trapping mode is as follows:
Having infrastructure in place to collect bug reports which result from any undiscovered violations can help minimize the risk they present.
The benefits from deploying sanitizers in your existing code base are tangible, however ultimately they address only the lowest hanging fruit and will not result in a code base free of vulnerabilities. Other classes of memory safety vulnerabilities remain unaddressed by these sanitizers. A longer term solution is to begin transitioning today to memory-safe languages such as Rust.
Rust is ready for bare-metal environments such as the baseband, and we are already using it in other bare-metal components in Android. There is no need to rewrite everything in Rust, as Rust provides a strong C FFI support and easily interfaces with existing C codebases. Just writing new code in Rust can rapidly reduce the number of memory safety vulnerabilities. Rewrites should be limited/prioritized only for the most critical components, such as complex parsers handling untrusted data.
The Android team has developed a Rust training meant to help experienced developers quickly ramp up Rust fundamentals. An entire day for bare-metal Rust is included, and the course has been translated to a number of different languages.
While the Rust compiler may not explicitly support your bare-metal target, because it is a front-end for LLVM, any target supported by LLVM can be supported in Rust through custom target definitions.
As the high-level operating system becomes a more difficult target for attackers to successfully exploit, we expect that lower level components such as the baseband will attract more attention. By using modern toolchains and deploying exploit mitigation technologies, the bar for attacking the baseband can be raised as well. If you have any questions, let us know – we’re here to help!
Systems such as Gmail, YouTube and Google Play rely on text classification models to identify harmful content including phishing attacks, inappropriate comments, and scams. These types of texts are harder for machine learning models to classify because bad actors rely on adversarial text manipulations to actively attempt to evade the classifiers. For example, they will use homoglyphs, invisible characters, and keyword stuffing to bypass defenses.
To help make text classifiers more robust and efficient, we’ve developed a novel, multilingual text vectorizer called RETVec (Resilient & Efficient Text Vectorizer) that helps models achieve state-of-the-art classification performance and drastically reduces computational cost. Today, we’re sharing how RETVec has been used to help protect Gmail inboxes.
Strengthening the Gmail Spam Classifier with RETVec
Figure 1. RETVec-based Gmail Spam filter improvements.
Over the past year, we battle-tested RETVec extensively inside Google to evaluate its usefulness and found it to be highly effective for security and anti-abuse applications. In particular, replacing the Gmail spam classifier’s previous text vectorizer with RETVec allowed us to improve the spam detection rate over the baseline by 38% and reduce the false positive rate by 19.4%. Additionally, using RETVec reduced the TPU usage of the model by 83%, making the RETVec deployment one of the largest defense upgrades in recent years. RETVec achieves these improvements by sporting a very lightweight word embedding model (~200k parameters), allowing us to reduce the Transformer model’s size at equal or better performance, and having the ability to split the computation between the host and TPU in a network and memory efficient manner.
RETVec Benefits
RETVec achieves these improvements by combining a novel, highly-compact character encoder, an augmentation-driven training regime, and the use of metric learning. The architecture details and benchmark evaluations are available in our NeurIPS 2023 paper and we open-source RETVec on Github.
Due to its novel architecture, RETVec works out-of-the-box on every language and all UTF-8 characters without the need for text preprocessing, making it the ideal candidate for on-device, web, and large-scale text classification deployments. Models trained with RETVec exhibit faster inference speed due to its compact representation. Having smaller models reduces computational costs and decreases latency, which is critical for large-scale applications and on-device models.
Figure 1. RETVec architecture diagram.
Models trained with RETVec can be seamlessly converted to TFLite for mobile and edge devices, as a result of a native implementation in TensorFlow Text. For web application model deployment, we provide a TensorflowJS layer implementation that is available on Github and you can check out a demo web page running a RETVec-based model.
Figure 2. Typo resilience of text classification models trained from scratch using different vectorizers.
RETVec is a novel open-source text vectorizer that allows you to build more resilient and efficient server-side and on-device text classifiers. The Gmail spam filter uses it to help protect Gmail inboxes against malicious emails.
If you would like to use RETVec for your own use cases or research, we created a tutorial to help you get started.
This research was conducted by Elie Bursztein, Marina Zhang, Owen Vallis, Xinyu Jia, and Alexey Kurakin. We would like to thank Gengxin Miao, Brunno Attorre, Venkat Sreepati, Lidor Avigad, Dan Givol, Rishabh Seth and Melvin Montenegro and all the Googlers who contributed to the project.
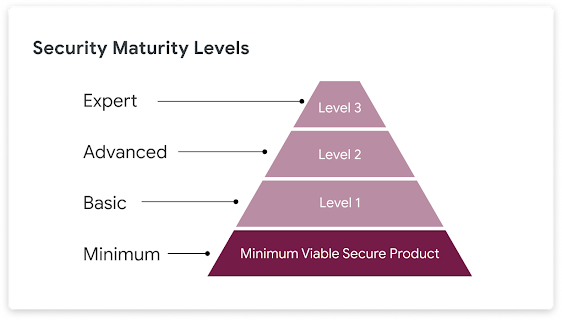
Nearly half of third-parties fail to meet two or more of the Minimum Viable Secure Product controls. Why is this a problem? Because "98% of organizations have a relationship with at least one third-party that has experienced a breach in the last 2 years."
In this post, we're excited to share the latest improvements to the Minimum Viable Secure Product (MVSP) controls. We'll also shed light on how adoption of MVSP has helped Google improve its security processes, and hope this example will help motivate third-parties to increase their adoption of MVSP controls and thus improve product security across the industry.
In October 2021, Google publicly launched MVSP alongside launch partners. Our original goal remains unchanged: to provide a vendor-neutral application security baseline, designed to eliminate overhead, complexity, and confusion in the end-to-end process of onboarding third-party products and services. It covers themes such as procurement, security assessment, and contract negotiation.
Improvements since launch
As part of MVSP’s annual control review, and our core philosophy of evolution over revolution, the working group sought input from the broader security community to ensure MVSP maintains a balance between security and achievability.
As a result of these discussions, we launched updated controls. Key changes include: expanded guidance around external vulnerability reporting to protect bug hunters, and discouraging additional costs for access to basic security features – inline with CISA’s "Secure-by-Design" principles.
In 2022, we developed guidance on build process security based on SLSA, to reflect the importance of supply chain security and integrity.
From an organizational perspective, in the two years since launching, we've seen the community around MVSP continue to expand. The working group has grown to over 20 global members, helping to diversify voices and broaden expertise. We've also had the opportunity to present and discuss the program with a number of key groups, including an invitation to present at the United Nations International Computing Centre – Common Secure Conference.
Google at the UNICC conference in Valencia, Spain
Since its inception, Google has looked to integrate improvements to our own processes using MVSP as a template. Two years later, we can clearly see the impact through faster procurement processes, streamlined contract negotiations, and improved data-driven decision making.
After implementing MVSP into key areas of Google's third-party life-cycle, we've observed a 68% reduction in the time required for third-parties to complete assessment process.
By embedding MVSP into select procurement processes, Google has increased data-driven decision making in earlier phases of the cycle.
Aligning our Information Protection Addendum’s safeguards with MVSP has significantly improved our third-party privacy and security risk management processes.
You use MVSP to enhance your software or procurement processes by reviewing some common use-cases and adopting them into your third-party risk management and/or contracting workflows .
We're invested in helping the industry manage risk posture through continuous improvement, while increasing the minimum bar for product security across the industry.
By making MVSP available to the wider industry, we are helping to create a solid foundation for growing the maturity level of products and services. Google has benefited from driving security and safety improvements through the use of leveled sets of requirements. We expect the same to be true across the wider industry.
We've seen success, but there is still work to be done. Based on initial observations, as mentioned above, 48% of third-parties fail to meet two or more of the Minimum Viable Secure Product controls.
As an industry, we can't stand still when it comes to product security. Help us raise the minimum bar for application security by adopting MVSP and ensuring we as an industry don’t accept anything less than a strong security baseline that works for the wider industry.
Google and the MVSP working group would like to thank those who have supported and contributed since its inception. If you'd like to get involved or provide feedback, please reach out.
Thank you to Chris John Riley, Gabor Acs-Kurucz, Michele Chubirka, Anna Hupa, Dirk Göhmann and Kaan Kivilcim from the Google MVSP Group for their contributions to this post.
The App Defense Alliance (ADA), an industry-leading collaboration launched by Google in 2019 dedicated to ensuring the safety of the app ecosystem, is taking a major step forward. We are proud to announce that the App Defense Alliance is moving under the umbrella of the Linux Foundation, with Meta, Microsoft, and Google as founding steering members.
This strategic migration represents a pivotal moment in the Alliance’s journey, signifying a shared commitment by the members to strengthen app security and related standards across ecosystems. This evolution of the App Defense Alliance will enable us to foster more collaborative implementation of industry standards for app security.
Uniting for App Security
The digital landscape is continually evolving, and so are the threats to user security. With the ever-increasing complexity of mobile apps and the growing importance of data protection, now is the perfect time for this transition. The Linux Foundation is renowned for its dedication to fostering open-source projects that drive innovation, security, and sustainability. By combining forces with additional members under the Linux Foundation, we can adapt and respond more effectively to emerging challenges.
The commitment of the newly structured App Defense Alliance’s founding steering members – Meta, Microsoft, and Google – is pivotal in making this transition a reality. With a member community spanning an additional 16 General and Contributor Members, the Alliance will support industry-wide adoption of app security best practices and guidelines, as well as countermeasures against emerging security risks.
Continuing the Malware Mitigation Program
The App Defense Alliance was formed with the mission of reducing the risk of app-based malware and better protecting Android users. Malware defense remains an important focus for Google and Android, and we will continue to partner closely with the Malware Mitigation Program members – ESET, Lookout, McAfee, Trend Micro, Zimperium – on direct signal sharing. The migration of ADA under the Linux Foundation will enable broader threat intelligence sharing across leading ecosystem partners and researchers.
Looking Ahead and Connecting With the ADA
We invite you to stay connected with the newly structured App Defense Alliance under the Linux foundation umbrella. Join the conversation to help make apps more secure. Together with the steering committee, alliance partners, and the broader ecosystem, we look forward to building more secure and trustworthy app ecosystems.
Since 2018, Google has partnered with ARM and collaborated with many ecosystem partners (SoCs vendors, mobile phone OEMs, etc.) to develop Memory Tagging Extension (MTE) technology. We are now happy to share the growing adoption in the ecosystem. MTE is now available on some OEM devices (as noted in a recent blog post by Project Zero) with Android 14 as a developer option, enabling developers to use MTE to discover memory safety issues in their application easily.
The security landscape is changing dynamically, new attacks are becoming more complex and costly to mitigate. It’s becoming increasingly important to detect and prevent security vulnerabilities early in the software development cycle and also have the capability to mitigate the security attacks at the first moment of exploitation in production.The biggest contributor to security vulnerabilities are memory safety related defects and Google has invested in a set of technologies to help mitigate memory safety risks. These include but are not limited to:
MTE is a hardware based capability that can detect unknown memory safety vulnerabilities in testing and/or mitigate them in production. It works by tagging the pointers and memory regions and comparing the tags to identify mismatches (details). In addition to the security benefits, MTE can also help ensure integrity because memory safety bugs remain one of the major contributors to silent data corruption that not only impact customer trust, but also cause lost productivity for software developers.
At the moment, MTE is supported on some of the latest chipsets:
For both chipsets, this feature can be switched on and off by developers, making it easier to find memory-related bugs during development and after deployment. MTE can help users stay safe while also improving time to market for OEMs.Application developers will be the first to leverage this feature as a way to improve their application security and reliability in the software development lifecycle. MTE can effectively help them to discover hard-to-detect memory safety vulnerabilities (buffer overflows, user-after-free, etc.) with clear & actionable stack trace information in integration testing or pre-production environments. Another benefit of MTE is that the engineering cost of memory-safety testing is drastically reduced because heap bug detection (which is majority of all memory safety bugs) does not require any source or binary changes to leverage MTE, i.e. advanced memory-safety can be achieved with just a simple environment or configuration change.We believe that MTE will play a very important role in detecting and preventing memory safety vulnerabilities and provide a promising path towards improving software security.
ASAN = Address Sanitizer; HWASAN = HW based ASAN;GWP-ASAN = sampling based ASAN ↩
Improving the interoperability of web services is an important and worthy goal. We believe that it should be easier for people to maintain and control their digital identities. And we appreciate that policymakers working on European Union digital certificate legislation, known as eIDAS, are working toward this goal. However, a specific part of the legislation, Article 45, hinders browsers’ ability to enforce certain security requirements on certificates, potentially holding back advances in web security for decades. We and many past and present leaders in the international web community have significant concerns about Article 45's impact on security.
We urge lawmakers to heed the calls of scientists and security experts to revise this part of the legislation rather than erode users’ privacy and security on the web.
Keeping Google Play safe for users and developers remains a top priority for Google. As users increasingly prioritize their digital privacy and security, we continue to invest in our Data Safety section and transparency labeling efforts to help users make more informed choices about the apps they use.
Research shows that transparent security labeling plays a crucial role in consumer risk perception, building trust, and influencing product purchasing decisions. We believe the same principles apply for labeling and badging in the Google Play store. The transparency of an app’s data security and privacy play a key role in a user’s decision to download, trust, and use an app.
Highlighting Independently Security Tested VPN Apps
Last year, App Defense Alliance (ADA) introduced MASA (Mobile App Security Assessment), which allows developers to have their apps independently validated against a global security standard. This signals to users that an independent third-party has validated that the developers designed their apps to meet these industry mobile security and privacy minimum best practices and the developers are going the extra mile to identify and mitigate vulnerabilities. This, in turn, makes it harder for attackers to reach users' devices and improves app quality across the ecosystem. Upon completion of the successful validation, Google Play gives developers the option to declare an “Independent security review” badge in its Data Safety section, as shown in the image below. While certification to baseline security standards does not imply that a product is free of vulnerabilities, the badge associated with these validated apps helps users see at-a-glance that a developer has prioritized security and privacy practices and committed to user safety.
To help give users a simplified view of which apps have undergone an independent security validation, we’re introducing a new Google Play store banner for specific app types, starting with VPN apps. We’ve launched this banner beginning with VPN apps due to the sensitive and significant amount of user data these apps handle. When a user searches for VPN apps, they will now see a banner at the top of Google Play that educates them about the “Independent security review” badge in the Data Safety Section. Users also have the ability to “Learn More”, which redirects them to the App Validation Directory, a centralized place to view all VPN apps that have been independently security reviewed. Users can also discover additional technical assessment details in the App Validation Directory, helping them to make more informed decisions about what VPN apps to download, use, and trust with their data.
Our Commitment to App Security and Privacy Transparency on Google Play
By encouraging independent security testing and displaying security badges for validated apps, we highlight developers who prioritize user safety and data transparency. We also provide developers with app security and privacy best practices – through Play PolicyBytes videos, webinars, blog posts, the Developer Help Community, and other resources – in accordance with our developer policies that help keep Google Play safe. We are continually working on improvements to our app review process, policies, and programs to keep users safe and to help developers navigate our policies with ease. To learn more about how we give developers the tools to succeed while keeping users safe on Google Play, read the Google Safety Center article.
Our efforts to prioritize security and privacy transparency on Google Play are aligned with the needs and expectations we’ve heard from both users and developers. We believe that by prioritizing initiatives that bolster user safety and trust, we can foster a thriving app ecosystem where users can make more informed app decisions and developers are encouraged to uphold the highest standards of security and privacy.
New AI innovations and applications are reaching consumers and businesses on an almost-daily basis. Building AI securely is a paramount concern, and we believe that Google’s Secure AI Framework (SAIF) can help chart a path for creating AI applications that users can trust. Today, we’re highlighting two new ways to make information about AI supply chain security universally discoverable and verifiable, so that AI can be created and used responsibly.
The first principle of SAIF is to ensure that the AI ecosystem has strong security foundations. In particular, the software supply chains for components specific to AI development, such as machine learning models, need to be secured against threats including model tampering, data poisoning, and the production of harmful content.
Even as machine learning and artificial intelligence continue to evolve rapidly, some solutions are now within reach of ML creators. We’re building on our prior work with the Open Source Security Foundation to show how ML model creators can and should protect against ML supply chain attacks by using SLSA and Sigstore.
For supply chain security of conventional software (software that does not use ML), we usually consider questions like:
All of these questions also apply to the hundreds of free ML models that are available for use on the internet. Using an ML model means trusting every part of it, just as you would any other piece of software. This includes concerns such as:
We should treat tampering of ML models with the same severity as we treat injection of malware into conventional software. In fact, since models are programs, many allow the same types of arbitrary code execution exploits that are leveraged for attacks on conventional software. Furthermore, a tampered model could leak or steal data, cause harm from biases, or spread dangerous misinformation.
Inspection of an ML model is insufficient to determine whether bad behaviors were injected. This is similar to trying to reverse engineer an executable to identify malware. To protect supply chains at scale, we need to know how the model or software was created to answer the questions above.
In recent years, we’ve seen how providing public and verifiable information about what happens during different stages of software development is an effective method of protecting conventional software against supply chain attacks. This supply chain transparency offers protection and insights with:
Together, these solutions help combat the enormous uptick in supply chain attacks that have turned every step in the software development lifecycle into a potential target for malicious activity.
We believe transparency throughout the development lifecycle will also help secure ML models, since ML model development follows a similar lifecycle as for regular software artifacts:
Similarities between software development and ML model development
An ML training process can be thought of as a “build:” it transforms some input data to some output data. Similarly, training data can be thought of as a “dependency:” it is data that is used during the build process. Because of the similarity in the development lifecycles, the same software supply chain attack vectors that threaten software development also apply to model development:
Attack vectors on ML through the lens of the ML supply chain
Based on the similarities in development lifecycle and threat vectors, we propose applying the same supply chain solutions from SLSA and Sigstore to ML models to similarly protect them against supply chain attacks.
Code signing is a critical step in supply chain security. It identifies the producer of a piece of software and prevents tampering after publication. But normally code signing is difficult to set up—producers need to manage and rotate keys, set up infrastructure for verification, and instruct consumers on how to verify. Often times secrets are also leaked since security is hard to get right during the process.
We suggest bypassing these challenges by using Sigstore, a collection of tools and services that make code signing secure and easy. Sigstore allows any software producer to sign their software by simply using an OpenID Connect token bound to either a workload or developer identity—all without the need to manage or rotate long-lived secrets.
So how would signing ML models benefit users? By signing models after training, we can assure users that they have the exact model that the builder (aka “trainer”) uploaded. Signing models discourages model hub owners from swapping models, addresses the issue of a model hub compromise, and can help prevent users from being tricked into using a bad model.
Model signatures make attacks similar to PoisonGPT detectable. The tampered models will either fail signature verification or can be directly traced back to the malicious actor. Our current work to encourage this industry standard includes:
Signing with Sigstore provides users with confidence in the models that they are using, but it cannot answer every question they have about the model. SLSA goes a step further to provide more meaning behind those signatures.
SLSA (Supply-chain Levels for Software Artifacts) is a specification for describing how a software artifact was built. SLSA-enabled build platforms implement controls to prevent tampering and output signed provenance describing how the software artifact was produced, including all build inputs. This way, SLSA provides trustworthy metadata about what went into a software artifact.
Applying SLSA to ML could provide similar information about an ML model’s supply chain and address attack vectors not covered by model signing, such as compromised source control, compromised training process, and vulnerability injection. Our vision is to include specific ML information in a SLSA provenance file, which would help users spot an undertrained model or one trained on bad data. Upon detecting a vulnerability in an ML framework, users can quickly identify which models need to be retrained, thus reducing costs.
We don’t need special ML extensions for SLSA. Since an ML training process is a build (shown in the earlier diagram), we can apply the existing SLSA guidelines to ML training. The ML training process should be hardened against tampering and output provenance just like a conventional build process. More work on SLSA is needed to make it fully useful and applicable to ML, particularly around describing dependencies such as datasets and pretrained models. Most of these efforts will also benefit conventional software.
For models training on pipelines that do not require GPUs/TPUs, using an existing, SLSA-enabled build platform is a simple solution. For example, Google Cloud Build, GitHub Actions, or GitLab CI are all generally available SLSA-enabled build platforms. It is possible to run an ML training step on one of these platforms to make all of the built-in supply chain security features available to conventional software.
By incorporating supply chain security into the ML development lifecycle now, while the problem space is still unfolding, we can jumpstart work with the open source community to establish industry standards to solve pressing problems. This effort is already underway and available for testing.
Our repository of tooling for model signing and experimental SLSA provenance support for smaller ML models is available now. Our future ML framework and model hub integrations will be released in this repository as well.
We welcome collaboration with the ML community and are looking forward to reaching consensus on how to best integrate supply chain protection standards into existing tooling (such as Model Cards). If you have feedback or ideas, please feel free to open an issue and let us know.