WO2021088300A1 - Rgb-d multi-mode fusion personnel detection method based on asymmetric double-stream network - Google Patents
Rgb-d multi-mode fusion personnel detection method based on asymmetric double-stream network Download PDFInfo
- Publication number
- WO2021088300A1 WO2021088300A1 PCT/CN2020/080991 CN2020080991W WO2021088300A1 WO 2021088300 A1 WO2021088300 A1 WO 2021088300A1 CN 2020080991 W CN2020080991 W CN 2020080991W WO 2021088300 A1 WO2021088300 A1 WO 2021088300A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- rgb
- depth
- image
- feature
- prediction
- Prior art date
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/30—Noise filtering
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/56—Extraction of image or video features relating to colour
Definitions
- the invention belongs to the field of computer vision and image processing, and in particular relates to an RGB-D multimodal fusion personnel detection method based on an asymmetric dual-stream network.
- personnel detection based on RGB images there are two main methods of personnel detection: personnel detection based on RGB images and personnel detection based on multi-modal image fusion.
- the person detection method based on RGB image is to detect persons only under the RGB image.
- the typical person methods include the person detection method based on RGB face and the person detection method based on RGB whole body.
- the RGB face-based person detection method extracts the general feature representation of the face by calibrating the key points of the face and encoding the features of the face under the RGB image only, and adopts machine learning or deep learning.
- the method trains the face detection model, and selects and locates the face area of the person in the test sample image through the circumscribed rectangular frame predicted by the model, so as to achieve the purpose of person detection.
- the RGB whole-body-based person detection method is different from the face detection.
- the method is to extract the image area containing the whole body of the person or the main body parts with recognizability only under the RGB image for feature representation, and train the person detection based on the whole body image
- the model uses the circumscribed rectangular frame predicted by the model to select and locate the whole body area of the character, so as to achieve the purpose of personnel detection.
- this method is susceptible to the limitation of the scene and the impact of image imaging resolution. Due to the optical imaging principle of the visible light camera, the RGB color image captured by the visible light camera has poor immunity to changes in lighting conditions, especially in low-illumination scenes such as night, rain, snow, and fog.
- the real-time captured image of the camera presents a dark or similar background .
- the foreground and background information that cannot be clearly distinguished from the image will greatly affect the training convergence of the detection model and reduce the accuracy of the detection of people.
- the visible light camera cannot obtain the depth information and thermal radiation information of the objects or people in the scene. Therefore, the captured two-dimensional planar image cannot effectively highlight the key information such as the edge contour and texture of the occluded target to solve the problem of human occlusion, and it is even submerged by similar background information, resulting in a significant drop in the accuracy and recall rate of human detection.
- the person detection method based on multi-modal image fusion is different from the person detection method based on RGB images.
- the input data is images from different image sources in the same detection scene, such as RGB images, depth images, and infrared thermal images. Each image source is captured by different camera equipment, and the image itself has different characteristics.
- the detection method of multi-modal image fusion mainly uses the cross fusion of images of different modalities to achieve feature enhancement and complementary association.
- the RGB color image is more robust to light changes, and can be imaged stably under low illumination conditions such as night, and because the imaging principles of the infrared thermal camera, the depth camera and the visible light camera are different, the two It can better capture auxiliary clues such as the edge contour of the person under partial occlusion, and to a certain extent can alleviate the problem of partial occlusion.
- deep learning methods are often used to realize the feature fusion and associated modeling of multi-modal information.
- the trained model is suitable for personnel detection under multi-constraint and multi-scene conditions (such as low illumination at night, severe occlusion, long-distance shooting, etc.) Better robustness.
- the existing methods for multi-modal image fusion methods mostly use traditional manual extraction of multi-modal feature fusion and use RGBT or RGBD (color image + thermal infrared image, color image + depth image) dual-stream neural network for additional four-channel fusion, single Simple fusion methods such as scale fusion and weighted decision fusion.
- the traditional manual multi-modal fusion method requires human design and extraction of multi-modal features, which relies on subjective experience and is time-consuming and laborious, and cannot achieve end-to-end personnel detection.
- the simple dual-stream neural network multi-modal fusion strategy cannot fully and effectively utilize the fine-grained information such as color and texture of the color image and the semantic information such as edge and depth provided by the depth image to realize the correlation and complementarity between multi-modal data. Even the over-fitting phenomenon occurs due to the high complexity of the model, which causes the accuracy and recall rate of personnel detection to decrease instead of increasing.
- the RGB-T personnel detection has great limitations due to the high cost of the red thermal imaging camera and the high cost in practical applications.
- the present invention provides a pedestrian detection and identity recognition method based on RGBD.
- the method includes: inputting RGB and depth images, preprocessing the images, and converting color channels; and then constructing multi-channel features of RGB and depth images. Specifically, First calculate the horizontal gradient and vertical gradient of the RGB image to construct the RGB gradient direction histogram feature, as well as the horizontal gradient, vertical gradient and depth normal vector direction of the depth image, construct the gradient direction histogram of the depth image, as the multi-channel feature of RGBD; calculate; The scale corresponding to each pixel of the depth image is quantified to obtain the scale list; according to the multi-channel features, the Adaboost algorithm is used to train the pedestrian detection classifier; the detection classifier is used to search the scale space corresponding to the scale list to obtain pedestrian information Circumscribed rectangular frame to complete pedestrian detection
- this method needs to manually extract the gradient direction histogram of the traditional RGBD image as the image feature, which is time-consuming and labor-intensive and takes up a large storage space. It cannot achieve end-to-end pedestrian detection; the gradient direction histogram feature is relatively simple, and it is difficult to extract RGB and depth. Pedestrian detection is performed on the distinguishing features in the image; this method uses the simple fusion of RGB and depth image features, and it is difficult to fully and effectively mine the fine-grained information such as color and texture of the RGB image and the semantic information such as edge and depth provided by the depth image. , To realize the correlation and complementation between multi-modal data, which has great limitations in improving the accuracy of pedestrian detection.
- the present invention provides a RGBD multi-modal fusion personnel detection method based on an asymmetric dual-stream network, but it is not limited to personnel detection, and can also be applied to tasks such as target detection and vehicle detection.
- RGBD multi-modal fusion personnel detection method based on an asymmetric dual-stream network provided by the present invention
- Figure 1 The representative diagram of a RGBD multi-modal fusion personnel detection method based on an asymmetric dual-stream network provided by the present invention is shown in Figure 1, including RGBD image acquisition, depth image preprocessing, RGB feature extraction and Depth feature extraction, and RGB multi-scale fusion Multi-scale fusion with Depth, multi-modal feature channel weighting, and multi-scale personnel prediction, the specific functions of each step are as follows:
- the original RGB image and depth image (hereinafter referred to as Depth image) are obtained by a camera with the function of shooting RGB image and depth image at the same time, and the RGB and Depth images are matched and grouped. Each group of images consists of an RGB image and the same scene.
- the captured Depth image is composed, and the grouped and matched RGB and Depth images are output.
- the original RGB image and Depth image can also be obtained from the public RGBD data set.
- RGB_FP_H, RGB_FP_M, RGB_FP_L which represent the low-level color texture, intermediate edge contour, and high-level semantic feature representation of RGB images
- D_FP_H, D_FP_M, and D_FP_L representing the low-level color texture, intermediate edge contour and high-level semantic features of the Depth image Said.
- the RGB network stream and the Depth network stream have a symmetrical structure, that is, the structure of the RGB network stream and the Depth network stream are exactly the same. However, the features contained in the Depth image are simpler than the RGB image.
- an asymmetric dual-stream convolutional neural network model is designed to extract the features of RGB image and Depth image.
- Figures 2-1 to 2-4 are a specific embodiment structure of the asymmetric dual-stream convolutional neural network model designed by the method, but are not limited to the structures shown in Figures 2-1 to 2-4.
- the DarkNet-53 described in Figure 2-1 and the MiniDepth-30 described in Figure 2-2 respectively represent the RGB network stream and the Depth network stream, and their network structures are asymmetrical.
- RGB feature maps RGB_FP_H, RGB_FP_M, RGB_FP_L input to the RGB multi-scale fusion, first expand the obtained RGB_FP_L to the same size as RGB_FP_M through the upsampling layer, and then merge the channels with RGB_FP_M to realize the advanced semantics of the RGB network deep layer
- the final output of Depth multi-scale fusion is the original input RGB_FP_L, the new feature maps RGB_FP_M and RGB_FP_H after channel merging;
- the output of Depth multi-scale fusion is the original input D_FP_L, the new feature maps D_FP_M and D_FP_H after channel merging.
- RGB_FP_L RGB-FP_M
- RGB_FP_H Depth feature maps D_FP_L, D_FP_M, D_FP_H from Depth multi-scale fusion
- D_FP_L Depth multi-scale fusion
- D_FP_L Depth multi-scale fusion
- channel merging is performed, and the feature map obtained after channel merging is marked as Concat_L; then the channel re-weighting module is applied (Hereinafter referred to as RW_Module) linearly weights the feature channels of Concat_L, assigns a weight to each feature channel, and the re-weighted feature map of the output channel is denoted as RW_L.
- RW_Module the channel re-weighting module linearly weights the feature channels of Concat_L, assigns a weight to each feature channel, and the re-weighted feature map of the output channel is denoted as RW_L.
- the channel weighting of RGB_FP_M and D_FP_M, RGB_FP_H and D_FP_H is done in the same manner as the RGB_FP_L and D_FP_L.
- the final multi-modal feature channel re-weighted output channel re-weighted low-, medium-, and high-resolution feature maps, respectively marked as RW_L,
- Each prediction point on RW_L has a large receptive field, which is used to predict a larger target in the image; each prediction point on RW_M has a medium receptive field, which is used to predict a medium target in the image; each prediction on RW_H Points have smaller receptive fields and are used to predict smaller targets in the image.
- NMS non-maximum suppression
- i represents the ID number of the person
- N is the total number of person detection results retained in the current image. They represent the abscissa of the upper left corner, the ordinate of the upper left corner, the abscissa of the lower right corner, and the ordinate of the lower right corner of the rectangular frame containing all persons.
- the present invention addresses the problem that the traditional symmetrical RGBD dual-stream network (RGB network stream + Depth network stream) is prone to loss of depth characteristics due to the excessive depth of the Depth network.
- the present invention designs an asymmetric RGBD dual-stream convolutional neural network.
- Model the Depth network stream is obtained by effectively model pruning the RGB network stream. While reducing the parameters, it can reduce the risk of model overfitting and improve the detection accuracy.
- the RGB network stream and the Depth network stream are used to extract the high, medium, and low resolution feature maps of RGB and depth images (hereinafter referred to as Depth images), respectively, representing the low-level color texture, intermediate edge contour and high-level semantics of RGB and Depth images.
- Feature representation secondly, a multi-scale fusion structure is designed for the RGB network stream and the Depth network stream to realize the high-level semantic features contained in the low-resolution feature map and the intermediate edge contour and low-level color texture features contained in the medium and high-resolution feature maps.
- the multi-scale information is complementary; then the multi-modal feature channel weighting structure is constructed, RGB and Depth feature maps are combined, and each feature channel after the combination is weighted and assigned, so that the model can automatically learn the contribution proportion, complete feature selection and remove redundancy Remaining functions, so as to realize the multi-modal feature fusion of RGB and Depth features corresponding to high, medium and low resolutions; finally, the use of multi-modal features for personnel classification and border regression, while ensuring real-time performance, improve The accuracy of people detection and the robustness of detection under low illumination at night and under people's obscuration are enhanced.
- Fig. 1 A representative diagram of a RGBD multi-modal fusion personnel detection method based on an asymmetric dual-stream network provided by the present invention
- Figure 2-1 is a structure diagram of an RGB network stream-DarkNet-53
- Figure 2-2 is a structure diagram of a Depth network stream-MiniDepth-30
- Figure 2-3 is a general structure diagram of a convolution block.
- Figure 2-4 is a general structure diagram of a residual convolution block.
- Fig. 3 is a flowchart of a method for RGBD multi-modal fusion personnel detection based on an asymmetric dual-stream network provided by an embodiment of the present invention
- Figure 4 A general structure diagram of a channel reweighting module provided by an embodiment of the present invention
- FIG. 5 A flowchart of the NMS algorithm provided by an embodiment of the present invention
- S1 Use a camera with the function of simultaneously shooting RGB images and depth images to obtain the original RGB image and the depth image, match and group the images, and output the grouped and matched RGB and Depth images.
- Step S110 Obtain the original RGB image by using a camera with the function of simultaneously shooting RGB images and depth images, and the original RGB images can also be obtained from the public RGBD data set.
- Step S120 Acquire the Depth image matching the RGB image synchronously from the step S110, and group the RGB and Depth images.
- Each group of images is composed of an RGB image and a depth image captured in the same scene, and the output group is matched Depth image.
- the original depth image obtained from the step S120 is used as input. First, part of the noise of the Depth image is eliminated, then the hole is filled, and finally the single-channel Depth image is re-encoded into a three-channel image, and the values of the three channels are renormalized to 0 -255, output the Depth image after encoding normalization.
- a 5x5 Gaussian filter is used to remove noise;
- the image repair algorithm proposed in [2] is used for hole repair, and the local normal vector and occlusion boundary in the Depth image are extracted, and then global optimization is applied to fill the hole of the Depth image;
- Depth Image coding adopts HHA coding [3] (horizontal disparity, height above ground, and the angle the pixel), and the three channels are the horizontal disparity, the height above the ground and the angle of the surface normal vector.
- RGB network stream of the asymmetric dual-stream network model adopts DarkNet-53 [4], and the network structure of DarkNet-53 is shown in Figure 2-1.
- the network contains 52 convolutional layers, among which layers L1 ⁇ L10 of the network are used to extract the general features of RGB images and output RGB_FP_C; layers L11 ⁇ L27 are used to extract low-level color texture features of RGB images and output RGB_FP_H; layers L28 ⁇ L44 Used to extract the middle-level edge contour features of RGB images, and output RGB_FP_M; L45 ⁇ L52 layers are used to extract high-level semantic features of RGB images, and output RGB_FP_L.
- the DarkNet-53 model used in this embodiment is only a specific embodiment of the RGB network flow of the asymmetric dual-stream network, and is not limited to the aforementioned DarkNet-53 model. The following only uses DarkNet-53 as an example. Discourse.
- Step S310 Obtain the original RGB image from the S110, extract the general features of the RGB image through the L1 ⁇ L10 layers of the DarkNet-53 network, and downsample the image resolution by K times, and output the RGB general feature map RGB_FP_C, whose size becomes One Kth of the original input size.
- the value of K is 8.
- Layers L1 to L10 can be divided into three sub-sampling layers, L1 to L2, L3 to L5, and L6 to L10. Each sub-sampling layer down-samples the input image resolution from the previous layer by 2 times.
- the first sub-sampling layer includes a standard convolution block with a step length of 1 (denoted as Conv0) and a pooled convolution block with a step length of 2 (denoted as Conv0_pool).
- the general structure of the convolution block is shown in the figure As shown in 2-3, it includes a standard image convolution layer, a batch normalization layer, and a Leaky_ReLU activation layer; the second sub-sampling layer includes a residual convolution block (denoted as Residual_Block_1) and one of the pooling convolution blocks (denoted as Residual_Block_1).
- Is Conv1_pool where the general structure of the residual convolution block is shown in Figure 2-4, including a 1x1xM standard convolution block, a 3x3xN standard convolution block, and an Add that transfers the identity map of the input to the output Module, M represents the number of input feature channels, N represents the number of output feature channels, where the values of M and N are respectively 32;
- the third sub-sampling layer includes 2 of the residual convolution blocks (denoted as Residual_Block_2_1 ⁇ 2_2) and One such pooled convolution block (denoted as Conv2_pool).
- the value of K is 8, and the values of M and N are shown in layers L1 to L10 in Fig. 3-1.
- Step S320 Obtain RGB_FP_C from S310, extract the low-level color texture features of the RGB image through the L11 ⁇ L27 layers of the DarkNet-53 network, and downsample the image resolution by K times, and output the RGB high-resolution feature map RGB_FP_H with its size It becomes one Kth of the original input size.
- L11 to L27 are composed of 8 residual convolution blocks (denoted as Residual_Block_3_1 to 3_8) and one pooling convolution block (Conv3_pool).
- the value of K is 2, and the values of M and N are shown in layers L11 to L27 in Figure 3-1.
- Step S330 Obtain RGB_FP_H from the S320, extract the mid-level edge contour features of the RGB image through the L28 ⁇ L44 layer of the DarkNet-53 network, and downsample the image resolution by K times, and output the RGB mid-resolution feature map RGB_FP_M with its size It becomes one Kth of the original input size.
- L28 to L44 are composed of 8 residual convolution blocks (denoted as Residual_Block_4_1 to 4_8) and one convolution block (Conv4_pool).
- the value of K is 2, and the values of M and N are shown in Layers L28 to L44 in Figure 3-1.
- Step S340 Obtain RGB_FP_M from the S320, extract the high-level semantic features of the RGB image through the L45 ⁇ L52 layers of the DarkNet-53 network, and downsample the image resolution by K times, and output the RGB low-resolution feature map RGB_FP_L, the size of which is changed It is one Kth of the original input size.
- L45 to L52 are composed of 4 of the residual convolution blocks (denoted as Residual_Block_5_1 to 5_4).
- the value of K is 2, and the values of M and N are shown in Layers L45 to L52 in Figure 3-1.
- S3' Obtain the normalized Depth image from the S2, and use the Depth network stream of the asymmetric dual-stream network model to extract the general, low-level, intermediate and high-level features of the Depth image at different network levels, and then output the corresponding general feature map
- the RGB feature maps of high, medium, and low resolutions are denoted as D_FP_C, D_FP_H, D_FP_M, D_FP_L, and D_FP_H, D_FP_M, D_FP_L are input to S4'.
- the Depth network stream of the asymmetric dual-stream network model is obtained by pruning the model on the basis of the RGB network stream DarkNet-53, which is hereinafter referred to as MiniDepth-30 for short.
- the MiniDepth-30 network can extract semantic features such as the edge contour of the depth image more effectively and clearly, and at the same time achieve the effect of reducing network parameters and preventing over-fitting.
- the network structure of MiniDepth-30 is shown in Figure 2-2.
- the network contains a total of 30 convolutional layers, among which the L1 ⁇ L10 layers of the network are used to extract the general features of the Depth image and output D_FP_C; the L11 ⁇ L17 layers are used to extract the low-level color texture features of the Depth image, and the output D_FP_H; L18 ⁇ L24 layers Used to extract the middle-level edge contour features of the Depth image, output D_FP_M; L25 ⁇ L30 layers are used to extract the high-level semantic features of the Depth image, output D_FP_L.
- MiniDepth-30 model used in this embodiment is only a specific embodiment of the Depth network flow of the asymmetric dual-stream network, and is not limited to the aforementioned MiniDepth-30 model.
- Step S310' Obtain the normalized Depth image from the S2, extract the general features of the RGB image through the L1 ⁇ L10 layers of the MiniDepth-30 network, and downsample the image resolution by K times, and output the general Depth feature map D_FP_C, Its size becomes one K of the original input size.
- the L1 to L10 network layers of MiniDepth-30 have the same structure as the L1 to L10 network layers of DarkNet-53 in step S310, and the value of K is 8.
- Step S320' Obtain D_FP_C from the step S310', extract the low-level color texture features of the Depth image through the L11 ⁇ L17 layers of the MiniDepth-30 network, and downsample the image resolution by K times, and output the Depth high-resolution feature map D_FP_H , Its size becomes one K of the original input size.
- L11 to L17 are composed of three of the residual convolution blocks (denoted as Residual_Block_D_3_1 to 3_3) and one of the pooling convolution blocks (Conv3_D_pool).
- the value of K is 2, and the values of M and N are shown in Layers L11 to L17 in Figure 3-2.
- Step S330' Obtain D_FP_H from the step S320', extract the mid-level edge contour features of the Depth image through the L18 ⁇ L24 layers of the MiniDepth-30 network, and downsample the image resolution by K times, and output the Depth mid-resolution feature map D_FP_M , Its size becomes one K of the original input size.
- L18 to L24 are composed of three of the residual convolution blocks (denoted as Residual_Block_D_4_1 to 4_3) and one of the pooling convolution blocks (Conv4_D_pool).
- the value of K is 2, and the values of M and N are shown in layers L18 to L24 in Figure 3-1.
- Step S340' Obtain D_FP_M from the step S330', extract the high-level semantic features of the Depth image through the L25 ⁇ L30 layers of the DarkNet-53 network, and downsample the image resolution by K times, and output the Depth low-resolution feature map D_FP_L, Its size becomes one K of the original input size.
- L25 to L30 are composed of three of the residual convolution blocks (denoted as Residual_Block_D_5_1 to 5_3).
- the value of K is 2, and the values of M and N are shown in Layers L25 to L30 in Figure 3-1.
- S4 Obtain RGB_FP_H, RGB_FP_M and RGB_FP_L from the S3, use upsampling to expand the feature map size, merge the feature channels of the RGB feature maps with the same resolution to achieve feature fusion, and output the feature maps RGB_FP_H, RGB_FP_M and RGB_FP_L after feature fusion to S5.
- Step S410 From the RGB_FP_L obtained in the step S340, it is up-sampled by M times and then merged with the RGB_FP_M obtained in the step S330 to realize the complementary fusion of the high-level semantic features of the deep layer of the RGB network and the middle-level edge contour feature of the middle layer, and output The new feature map RGB_FP_M after feature fusion.
- the specific method of channel merging the number of channels of RGB_FP_L is C1, the number of channels of RGB_FP_M is C2, the two channels are merged C1+C2 to obtain C3, and C3 is the number of channels of the new feature map RGB_FP_M after feature fusion.
- the value of M is 2, and the values of C1, C2, and C3 are 256, 512, and 768, respectively.
- Step S420 Obtain the new feature map RGB_FP_M after the feature fusion from the step S410, and perform channel merging with the RGB_FP_H obtained in the step S320 after up-sampling to realize the deep high-level semantic features of the RGB network and the middle-level edge contour of the middle layer The complementary fusion of features and shallow low-level color texture features, and output the new feature map D_FP_H after feature fusion.
- the specific method of channel merging the number of channels of RGB_FP_M is C1, the number of channels of RGB_FP_H is C2, the two channels are merged C1+C2 to obtain C3, and C3 is the number of channels of the new feature map RGB_FP_H after feature fusion.
- the value of M is 2, and the values of C1, C2, and C3 are 128, 256, and 384, respectively.
- S4' Obtain D_FP_H, D_FP_M, and D_FP_L from the S3', use upsampling to expand the size of the feature map, merge the feature channels of the Depth feature maps with the same resolution to achieve feature fusion, and output the feature maps D_FP_H, D_FP_M, D_FP_M, and D_FP_M after feature fusion.
- D_FP_L to S5.
- Step S410' From the D_FP_L obtained in the step S340', it is up-sampled by M times and then merged with the D_FP_M obtained in the step S330' to realize the complementarity of the deep high-level semantic features of the Depth network and the middle-level edge contour features of the middle layer Fusion, output the new feature map D_FP_M after feature fusion.
- the specific method of channel merging the number of channels of D_FP_L is C1, the number of channels of D_FP_M is C2, the two channels are merged C1+C2 to obtain C3, and C3 is the number of channels of the new feature map D_FP_M after feature fusion.
- the value of M is 2, and the values of C1, C2, and C3 are 256, 512, and 768, respectively.
- Step S420' Obtain the new feature map D_FP_M after the feature fusion from the step S410, and perform channel merging with the D_FP_H obtained in the step S320' after up-sampling to realize the deep high-level semantic features of the Depth network and the intermediate level of the middle layer.
- the complementary fusion of edge contour features and shallow low-level color texture features will output the new feature map D_FP_H after feature fusion.
- the specific method of channel merging the number of channels of D_FP_M is C1, the number of channels of D_FP_H is C2, the two channels are merged C1+C2 to obtain C3, and C3 is the number of channels of the new feature map D_FP_H after feature fusion.
- the value of M is 2, and the values of C1, C2, and C3 are 128, 256, and 384, respectively.
- S5 Obtain new feature maps RGB_FP_H, RGB_FP_M, and RGB_FP_L after feature fusion from S4, and obtain new feature maps D_FP_H, D_FP_M, D_FP_L after feature fusion from S4', and perform feature channel merging at corresponding equal resolutions to obtain channels
- the merged feature maps are marked as Concat_L, Concat_M, and Concat_H respectively, and then the channel weighting module (hereinafter referred to as RW_Module) is applied to linearly weight Concat_L, Concat_M, and Concat_H respectively, and the high, medium, and low resolutions after the channel weighting are output Rate characteristic map, respectively denoted as RW_H, RW_M, RW_L.
- Step S510 Obtain RGB_FP_L and D_FP_L from the S4, first combine the feature channels of RGB_FP_L and D_FP_L to obtain Concat_L, realize the complementary fusion of RGB and Depth in the network deep multi-modal information, and then apply the channel weighting module RW_Module to Concat_L Linear weighting, assign weight to each feature channel, and output the re-weighted feature map RW_L of the channel.
- the channel weighting of RGB_FP_L and D_FP_L as an example, the general structure of a channel weighting module provided in this embodiment is shown in FIG. 4.
- the number of channels of RGB_FP_L is C1
- the number of channels of D_FP_L is C2
- the Concat_L passes through 1 1x1 Ave in turn -Pooling layer, 1 standard convolution layer composed of C3/s (s is the reduction step size) 1x1 convolution kernel, 1 C3 standard convolution layer composed of 1x1 convolution kernel, and 1 Sigmoid layer to obtain C3 weight values ranging from 0 to 1; finally, the obtained C3 weight values are multiplied by the C3 feature channels of the Concat_L, and each feature channel is assigned a weight, and the weighted C3 channels are output.
- the characteristic channel namely RW_L.
- the values of C1, C2, and C3 are 1024, 1024, and 2048 respectively
- the value of the reduction step size s is 16 respectively.
- Step S520 Obtain RGB_FP_M from step S410 and D_FP_M from step S410', first combine the characteristic channels of RGB_FP_M and D_FP_M to obtain Concat_M, to achieve the complementary fusion of RGB and Depth multi-modal information in the middle layer of the network, and then apply The channel re-weighting module RW_Module performs linear weighting on Concat_M, assigns a weight to each feature channel, and outputs the channel re-weighted feature map RW_M.
- the channel weighting method of RGB_FP_M and D_FP_M is consistent with the channel weighting method of RGB_FP_L and D_FP_L in step S510, where the values of C1, C2, and C3 are 512, 512, 1024, respectively, and the step size is reduced.
- the values of are 16 respectively.
- Step S530 Obtain RGB_FP_H from the step S420 and D_FP_H from the step S420', first combine the feature channels of RGB_FP_H and D_FP_H to obtain Concat_H, realize the complementary fusion of RGB and Depth in the network shallow multi-modal information, and then apply The channel re-weighting module RW_Module performs linear weighting on Concat_H, assigns a weight to each feature channel, and outputs the channel re-weighted feature map RW_H.
- the channel weighting method of RGB_FP_H and D_FP_H is consistent with the channel weighting method of RGB_FP_L and D_FP_L in step S510, where the values of C1, C2, and C3 are 256, 256, 512, respectively, which reduces the step size s.
- the values are 16 respectively.
- S6 Obtain the channel-weighted feature maps RW_L, RW_M, RW_H from the S5, and perform classification and frame coordinate regression respectively to obtain prediction results for persons with larger, medium and smaller sizes, and predict the above three different scales
- NMS non-maximum suppression
- i represents the ID number of the person
- N is the total number of person detection results retained in the current image. They represent the abscissa of the upper left corner, the ordinate of the upper left corner, the abscissa of the lower right corner, and the ordinate of the lower right corner of the rectangular frame containing all persons.
- Step S610 Obtain the channel-weighted low-resolution feature map RW_L from the step S510, transmit it to the SoftMax classification layer and the coordinate regression layer, and output the category confidence score for predicting larger-size persons under the low-resolution feature map And the coordinates of the upper left and lower right corners of the rectangular border
- the subscript L represents the prediction result under the low-resolution feature map.
- Step S620 Obtain the channel-weighted low-resolution feature map RW_M from the step S520, transmit it to the SoftMax classification layer and the coordinate regression layer, and output the category confidence score for predicting medium-sized persons under the medium-resolution feature map And the coordinates of the upper left and lower right corners of the rectangular border
- the subscript M represents the prediction result under the medium-resolution feature map.
- Step S630 Obtain the channel-weighted high-resolution feature map RW_H from the step S530, transmit it to the SoftMax classification layer and the coordinate regression layer, and output the category confidence score for predicting the smaller-sized person under the high-resolution feature map And the coordinates of the upper left and lower right corners of the rectangular border
- the subscript H represents the prediction result under the high-resolution feature map.
- Step S640 Obtain the category confidence scores of persons of larger, medium and smaller sizes from the steps S610, S620 and S630 And the upper left and lower right coordinates of the rectangular border
- the flow chart of the NMS algorithm is shown in Figure 5.
- Step S640-1 Obtain the confidence scores of the categories of persons of larger, medium, and smaller sizes from the steps S610, S620, and S630 And the upper left and lower right coordinates of the rectangular border Summarize the prediction results of the three scales, use the confidence threshold to filter the prediction boxes, keep the prediction boxes with category confidence scores greater than the confidence threshold, and add them to the prediction list.
- the confidence threshold is set to 0.3.
- Step S640-2 From the prediction list obtained in step S640-1, the unprocessed prediction frames in the prediction list are sorted in descending order of confidence scores, and the prediction list sorted in descending order is output.
- Step S640-3 Obtain the prediction list in descending order from the step S640-2, select the frame corresponding to the maximum confidence score as the current reference frame, and add the category confidence score and frame coordinates of the current reference frame to the final result list , And remove the reference frame from the prediction list, and calculate the intersection ratio (IoU) for all other predicted frames and the current reference frame.
- Step S640-4 Obtain the prediction list and the IoU values of all the frames in the prediction list and the reference frame from the step S640-3. If the IoU of the current frame is greater than the preset NMS threshold, it is considered to be a duplicate target with the reference frame, and It is removed from the list of predicted bounding boxes, otherwise the current bounding box is kept. Output the filtered prediction list.
- Step S640-5 Obtain the filtered prediction list from the step S640-4. If all frames in the prediction list are processed, that is, the prediction frame is empty, the algorithm ends and the final result list is returned; otherwise, the current prediction list is still If there is an unprocessed frame, return to step S640-2 to repeat the algorithm flow.
- Step S640-6 For the step S640-5, when there is no unprocessed prediction frame in the prediction list, output the final result list as the final retained personnel detection result.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Image Analysis (AREA)
Abstract
The present invention relates to the field of computer vision and image processing, and disclosed in the present invention is an RGB-D multi-mode fusion personnel detection method based on an asymmetric double-stream network. The method comprises the steps of RGBD image collection, depth image preprocessing, RGB feature extraction and Depth feature extraction, RGB multi-scale fusion and Depth multi-scale fusion, multi-mode feature channel reweighting, and multi-scale personnel prediction. According to the present invention, an asymmetric RGBD double-stream convolutional neural network model is designed to solve the problem that traditional symmetric RGBD double-stream networks are prone to causing depth feature loss. Multi-scale fusion structures are respectively designed for RGBD double-stream networks, so that multi-scale information complementation is achieved. A multi-mode reweighting structure is constructed, RGB and Depth feature maps are combined, and weighted assignment is performed on each combined feature channel to implement model automatic learning contribution proportion. Personnel classification and frame regression are performed by using multi-mode features, so that the accuracy of personnel detection is improved while the real-time performance is ensured, and the robustness of detection under low illumination at night and personnel shielding is enhanced.
Description
本发明属于计算机视觉与图像处理领域,具体涉及一种基于非对称双流网络的RGB-D多模态融合人员检测方法。The invention belongs to the field of computer vision and image processing, and in particular relates to an RGB-D multimodal fusion personnel detection method based on an asymmetric dual-stream network.
近年来,智慧家居、智慧建筑以及智能安防等领域得到了飞速发展,视频提取与分析技术的广泛应用成为推动其进步的关键动力,其中人员的检测与统计逐渐成为图像视频分析和人工智能领域的一个热门研究课题。在智慧家居方面,通过检测室内人员可以对人的位置进行定位,记录人员的行为习惯进行记录,进一步调节室内照明、空调等智能设备,为人们提供更为舒适智慧的家庭环境。在智慧建筑方面,人员检测技术可以应用于服务型机器人实现精准避障与办公文件传递,同时依据室内人员位置以及密集程度,可以自动化调节办公区舒适度,提高办公效率。在智能安防方面,安防监控视频中进行的人员检测可以用于身份核验,有效应对陌生人非法闯入,对可疑人员进行跟踪调查和异常行为分析,为智能安防体系提供核心的视频信息支撑。In recent years, the fields of smart homes, smart buildings, and smart security have been rapidly developed. The wide application of video extraction and analysis technology has become a key driving force for their progress. Among them, personnel detection and statistics have gradually become the field of image video analysis and artificial intelligence. A popular research topic. In terms of smart home, by detecting indoor personnel, it is possible to locate people's positions, record their behaviors and habits, and further adjust smart devices such as indoor lighting and air conditioning to provide people with a more comfortable and smart home environment. In terms of smart buildings, personnel detection technology can be applied to service robots to achieve precise obstacle avoidance and office document transfer. At the same time, according to the location and density of indoor personnel, it can automatically adjust the comfort of the office area and improve office efficiency. In terms of smart security, personnel detection in security surveillance videos can be used for identity verification, effectively responding to illegal intrusion by strangers, tracking and investigating suspicious persons and analyzing abnormal behaviors, providing core video information support for the smart security system.
目前人员检测主要有两种方式:基于RGB图像的人员检测和基于多模态图像融合的人员检测。At present, there are two main methods of personnel detection: personnel detection based on RGB images and personnel detection based on multi-modal image fusion.
1)基于RGB图像的人员检测方法是仅在RGB图像下进行人员的检测,典型的人员方法有通过基于RGB人脸的人员检测方法和基于RGB全身的人员检测方法。基于RGB人脸的人员检测方法通过在仅RGB图像下,对人脸所在区域进行人脸关键点标定、人脸特征编码等方式,提取人脸的通用特征表示,并采用机器学习或深度学习的方法训练人脸检测模型,通过模型预测输出的外接矩形框,在测试样本图像中框选并定位人物的人脸区域,从而达到人员检测的目的。基于RGB全身的人员检测方法不同于人脸检测,该方法是仅在RGB图像下,提取包含人物整个身体或具有辨识力的主要身体部位的图像区域进行特征表示,并训练基于全身图像的人员检测模型,通过模型预测输出的外接矩形框,框选并定位人物的全身区域,从而达到人员检测的目的。但该方法易受到场景的限制和图像成像分辨率的影响。由于可见光相机的光学成像原理,可见光相机捕获的RGB彩色图像对于光照条件变化的抗扰动性差,尤其在夜间、雨雪雾天等低照度场景下,相机实时拍摄捕获的图像呈现一片黑暗或相似背景,无法从图像中清 晰地分辨出的前景人员和背景信息,会很大程度上影响检测模型的训练收敛,降低人员检测的精确度。此外在对场景内的多个人物进行检测时,通常会产生人与物体之间的遮挡或者人与人之间的交叉遮挡,可见光相机无法获得场景中物体或人员的深度信息和热辐射信息,因此其捕获二维平面图像无法有效凸显被遮挡目标的边缘轮廓、纹理等解决人员遮挡问题的关键信息,甚至被相似背景信息淹没,导致人员检测的查准率和查全率大幅下降。1) The person detection method based on RGB image is to detect persons only under the RGB image. The typical person methods include the person detection method based on RGB face and the person detection method based on RGB whole body. The RGB face-based person detection method extracts the general feature representation of the face by calibrating the key points of the face and encoding the features of the face under the RGB image only, and adopts machine learning or deep learning. The method trains the face detection model, and selects and locates the face area of the person in the test sample image through the circumscribed rectangular frame predicted by the model, so as to achieve the purpose of person detection. The RGB whole-body-based person detection method is different from the face detection. The method is to extract the image area containing the whole body of the person or the main body parts with recognizability only under the RGB image for feature representation, and train the person detection based on the whole body image The model uses the circumscribed rectangular frame predicted by the model to select and locate the whole body area of the character, so as to achieve the purpose of personnel detection. However, this method is susceptible to the limitation of the scene and the impact of image imaging resolution. Due to the optical imaging principle of the visible light camera, the RGB color image captured by the visible light camera has poor immunity to changes in lighting conditions, especially in low-illumination scenes such as night, rain, snow, and fog. The real-time captured image of the camera presents a dark or similar background , The foreground and background information that cannot be clearly distinguished from the image will greatly affect the training convergence of the detection model and reduce the accuracy of the detection of people. In addition, when detecting multiple people in the scene, there will usually be occlusion between people and objects or cross occlusion between people. The visible light camera cannot obtain the depth information and thermal radiation information of the objects or people in the scene. Therefore, the captured two-dimensional planar image cannot effectively highlight the key information such as the edge contour and texture of the occluded target to solve the problem of human occlusion, and it is even submerged by similar background information, resulting in a significant drop in the accuracy and recall rate of human detection.
2)基于多模态图像融合的人员检测方法不同于基于RGB图像的人员检测方法,其输入数据是来源于同一检测场景下的不同图像源的图像,例如RGB图像、深度图像、红外热图像,每一种图像源通过不同的相机设备捕获,图像本身具备不同的特性。多模态图像融合的检测方法主要是利用不同模态的图像交叉融合,以实现特征强化和互补关联。红外热图像和深度图像相比RGB彩色图像对光照变化的鲁棒性较好,能够在夜间等低照度条件下稳定成像,并且由于红外热相机、深度相机与可见光相机的成像原理不同,二者能够较好地捕获部分遮挡下的人员边缘轮廓等辅助线索,在一定程度上可以缓解部分遮挡的问题。现如今多采用深度学习的方法实现多模态信息的特征融合和关联建模,训练完成的模型对于多约束多场景条件下(例如夜间低照度、严重遮挡、远距离拍摄等)的人员检测具有更好的鲁棒性。但是现存方法对于多模态图像融合方式,多采用传统手工提取多模态特征融合以及利用RGBT或RGBD(彩色图像+热红外图像,彩色图像+深度图像)双流神经网络进行附加四通道融合、单一尺度融合以及加权决策融合等简单融合方式。传统手工多模态融合方法需要人为设计并提取多模态特征,依赖于主观经验且费时费力,无法实现端到端的人员检测。而简单的双流神经网络多模态融合策略,无法充分有效地利用彩色图像的色彩、纹理等细粒度信息和深度图像提供的边缘、深度等语义信息,实现多模态数据之间的关联互补,甚至由于模型复杂度过高而产生过拟合现象,导致人员检测的查准率和查全率不升反降。而RGB-T人员检测由于红热成像相机价格昂贵,在实际应用中由于成本过高具有很大的局限性。2) The person detection method based on multi-modal image fusion is different from the person detection method based on RGB images. The input data is images from different image sources in the same detection scene, such as RGB images, depth images, and infrared thermal images. Each image source is captured by different camera equipment, and the image itself has different characteristics. The detection method of multi-modal image fusion mainly uses the cross fusion of images of different modalities to achieve feature enhancement and complementary association. Compared with the infrared thermal image and the depth image, the RGB color image is more robust to light changes, and can be imaged stably under low illumination conditions such as night, and because the imaging principles of the infrared thermal camera, the depth camera and the visible light camera are different, the two It can better capture auxiliary clues such as the edge contour of the person under partial occlusion, and to a certain extent can alleviate the problem of partial occlusion. Nowadays, deep learning methods are often used to realize the feature fusion and associated modeling of multi-modal information. The trained model is suitable for personnel detection under multi-constraint and multi-scene conditions (such as low illumination at night, severe occlusion, long-distance shooting, etc.) Better robustness. However, the existing methods for multi-modal image fusion methods mostly use traditional manual extraction of multi-modal feature fusion and use RGBT or RGBD (color image + thermal infrared image, color image + depth image) dual-stream neural network for additional four-channel fusion, single Simple fusion methods such as scale fusion and weighted decision fusion. The traditional manual multi-modal fusion method requires human design and extraction of multi-modal features, which relies on subjective experience and is time-consuming and laborious, and cannot achieve end-to-end personnel detection. However, the simple dual-stream neural network multi-modal fusion strategy cannot fully and effectively utilize the fine-grained information such as color and texture of the color image and the semantic information such as edge and depth provided by the depth image to realize the correlation and complementarity between multi-modal data. Even the over-fitting phenomenon occurs due to the high complexity of the model, which causes the accuracy and recall rate of personnel detection to decrease instead of increasing. However, the RGB-T personnel detection has great limitations due to the high cost of the red thermal imaging camera and the high cost in practical applications.
现有代表性技术1项。1 current representative technology.
(1)发明名称:一种基于RGBD的行人检测和身份识别方法及系统(申请号:201710272095)(1) Title of Invention: A method and system for pedestrian detection and identification based on RGBD (application number: 201710272095)
本发明提供了一种基于RGBD的行人检测和身份识别方法,方法包括:输 入RGB和深度图像,并对图像进行预处理,转换颜色通道;然后构建RGB和深度图像的多通道特征,具体的,首先计算RGB图像的水平梯度和垂直梯度构建RGB梯度方向直方图特征,以及深度图像的水平梯度、垂直梯度和深度法向量方向,构建深度图像的梯度方向直方图,作为RGBD的多通道特征;计算深度图像每个像素点对应的尺度,对尺度进行量化,获取尺度列表;根据多通道特征,采用Adaboost算法训练行人检测分类器;采用检测分类器,搜索尺度列表对应的尺度空间,得到包含行人信息的外接矩形框,完成行人检测The present invention provides a pedestrian detection and identity recognition method based on RGBD. The method includes: inputting RGB and depth images, preprocessing the images, and converting color channels; and then constructing multi-channel features of RGB and depth images. Specifically, First calculate the horizontal gradient and vertical gradient of the RGB image to construct the RGB gradient direction histogram feature, as well as the horizontal gradient, vertical gradient and depth normal vector direction of the depth image, construct the gradient direction histogram of the depth image, as the multi-channel feature of RGBD; calculate; The scale corresponding to each pixel of the depth image is quantified to obtain the scale list; according to the multi-channel features, the Adaboost algorithm is used to train the pedestrian detection classifier; the detection classifier is used to search the scale space corresponding to the scale list to obtain pedestrian information Circumscribed rectangular frame to complete pedestrian detection
但此方法需要手工提取传统的RGBD图像的梯度方向直方图作为图像特征,耗时费力且占用较大存储空间,无法端到端的实现行人检测;梯度方向直方图特征较为简单,难以提取RGB和深度图像中具有辨识力的特征进行行人检测;该方法采用RGB和深度图像特征的简单融合,难以充分有效地挖掘利用RGB图像的色彩、纹理等细粒度信息和深度图像提供的边缘、深度等语义信息,实现多模态数据之间的关联互补,在提升行人检测的精确度方面具有很大的局限性。However, this method needs to manually extract the gradient direction histogram of the traditional RGBD image as the image feature, which is time-consuming and labor-intensive and takes up a large storage space. It cannot achieve end-to-end pedestrian detection; the gradient direction histogram feature is relatively simple, and it is difficult to extract RGB and depth. Pedestrian detection is performed on the distinguishing features in the image; this method uses the simple fusion of RGB and depth image features, and it is difficult to fully and effectively mine the fine-grained information such as color and texture of the RGB image and the semantic information such as edge and depth provided by the depth image. , To realize the correlation and complementation between multi-modal data, which has great limitations in improving the accuracy of pedestrian detection.
发明内容Summary of the invention
针对现有技术中的缺陷,本发明提供了一种基于非对称双流网络的RGBD多模态融合人员检测方法,但不限于人员检测,也可以应用于目标检测、车辆检测等任务。Aiming at the defects in the prior art, the present invention provides a RGBD multi-modal fusion personnel detection method based on an asymmetric dual-stream network, but it is not limited to personnel detection, and can also be applied to tasks such as target detection and vehicle detection.
本发明提供的一种基于非对称双流网络的RGBD多模态融合人员检测方法代表图如图1所示,包含RGBD图像采集,深度图像预处理,RGB特征提取和Depth特征提取,RGB多尺度融合和Depth多尺度融合,多模态特征通道重加权以及多尺度人员预测,各步骤的具体功能如下:The representative diagram of a RGBD multi-modal fusion personnel detection method based on an asymmetric dual-stream network provided by the present invention is shown in Figure 1, including RGBD image acquisition, depth image preprocessing, RGB feature extraction and Depth feature extraction, and RGB multi-scale fusion Multi-scale fusion with Depth, multi-modal feature channel weighting, and multi-scale personnel prediction, the specific functions of each step are as follows:
S1 RGBD图像采集;S1 RGBD image collection;
利用具有同时拍摄RGB图像和深度图像功能的相机获取原始RGB图像和深度图像(以下简称为Depth图像),并对RGB和Depth图像进行匹配分组,每组图像由一张RGB图像和同场景下捕获的Depth图像组成,输出分组匹配后的RGB和Depth图像。原始RGB图像和Depth图像也可以从公开RGBD数据集获取。The original RGB image and depth image (hereinafter referred to as Depth image) are obtained by a camera with the function of shooting RGB image and depth image at the same time, and the RGB and Depth images are matched and grouped. Each group of images consists of an RGB image and the same scene. The captured Depth image is composed, and the grouped and matched RGB and Depth images are output. The original RGB image and Depth image can also be obtained from the public RGBD data set.
S2深度图像预处理;S2 depth image preprocessing;
从S1的RGBD图像采集获取分组匹配后的Depth图像,首先消除Depth图像的部分噪声,然后进行空洞填充,最后将单通道Depth图像重新编码为三个通道图像,并将三个通道的图像数值重新规范化到0-255,输出编码规范化后的Depth图像。Obtain the grouped and matched Depth image from the RGBD image of S1. First, remove part of the noise of the Depth image, then fill in the holes, and finally re-encode the single-channel Depth image into three-channel images, and re-encode the image values of the three channels Normalize to 0-255, and output the Depth image after encoding normalization.
S3 RGB特征提取和Depth特征提取;S3 RGB feature extraction and Depth feature extraction;
从所述S1的RGBD图像采集获取原始RGB图像,输入到RGB特征提取(非对称双流网络模型的RGB网络流),进行下采样特征提取,输出RGB图像的高、中、低分辨率特征图,分别记为RGB_FP_H、RGB_FP_M、RGB_FP_L,代表RGB图像的低级色彩纹理、中级边缘轮廓和高级语义特征表示;从深度图像预处理获取编码规范化后的Depth图像,输入到Depth特征提取(非对称双流网络模型的Depth网络流),进行下采样特征提取,输出Depth图像的高、中、低分辨率特征图,分别记为D_FP_H、D_FP_M、D_FP_L,代表Depth图像的低级色彩纹理、中级边缘轮廓和高级语义特征表示。RGB网络流和Depth网络流是对称结构的,即RGB网络流和Depth网络流的结构完全相同。但Depth图像所包含的特征相对于RGB图像更简单,当采用与RGB网络相同深度的卷积网络结构提取Depth特征时,会由于网络传递过深而导致Depth特征消失,同时网络参数增加了过拟合的风险。基于上述原因,设计非对称双流卷积神经网络模型提取RGB图像和Depth图像特征。图2-1至图2-4为本方法设计的非对称双流卷积神经网络模型的一种具体实施例结构,但不限于图2-1至图2-4所示的结构。图2-1所述DarkNet-53和图2-2所述MiniDepth-30分别代表RGB网络流和Depth网络流,二者的网络结构具有非对称的特性。Obtain the original RGB image from the RGBD image collection of the S1, input it to the RGB feature extraction (RGB network stream of the asymmetric dual-stream network model), perform down-sampling feature extraction, and output the high, medium, and low resolution feature maps of the RGB image, Denoted as RGB_FP_H, RGB_FP_M, RGB_FP_L, which represent the low-level color texture, intermediate edge contour, and high-level semantic feature representation of RGB images; the Depth image after encoding and normalization is obtained from the depth image preprocessing, and input to the Depth feature extraction (asymmetric dual-stream network model) Depth network stream), perform down-sampling feature extraction, and output the high, medium, and low resolution feature maps of the Depth image, which are respectively denoted as D_FP_H, D_FP_M, and D_FP_L, representing the low-level color texture, intermediate edge contour and high-level semantic features of the Depth image Said. The RGB network stream and the Depth network stream have a symmetrical structure, that is, the structure of the RGB network stream and the Depth network stream are exactly the same. However, the features contained in the Depth image are simpler than the RGB image. When the Depth feature is extracted using the convolutional network structure with the same depth as the RGB network, the Depth feature will disappear due to the network transmission being too deep, and the network parameters will increase overly. The risk of cooperation. Based on the above reasons, an asymmetric dual-stream convolutional neural network model is designed to extract the features of RGB image and Depth image. Figures 2-1 to 2-4 are a specific embodiment structure of the asymmetric dual-stream convolutional neural network model designed by the method, but are not limited to the structures shown in Figures 2-1 to 2-4. The DarkNet-53 described in Figure 2-1 and the MiniDepth-30 described in Figure 2-2 respectively represent the RGB network stream and the Depth network stream, and their network structures are asymmetrical.
S4 RGB多尺度融合和Depth多尺度融合;S4 RGB multi-scale fusion and Depth multi-scale fusion;
从RGB特征提取获取RGB特征图RGB_FP_H、RGB_FP_M、RGB_FP_L输入到RGB多尺度融合,首先将获取的RGB_FP_L通过上采样层拓展到与RGB_FP_M相同尺寸,然后与RGB_FP_M进行通道合并,实现RGB网络深层的高级语义特征与中间层的中级边缘轮廓特征的互补融合,输出通道合并后的新特征图RGB_FP_M;然后对输出通道合并后的新特征图RGB_FP_M,通过上采样层拓展到与RGB_FP_H相同尺寸,与RGB_FP_H进行通道合并,实现RGB网络深层的高级语义特征、中间层的中级边缘轮廓特征以及浅层的低级色彩纹理特征的互补融合,输出通道合并后的新特征图RGB_FP_H;从Depth特征提取获 取Depth特征图D_FP_H、D_FP_M、D_FP_L输入到Depth多尺度融合,与RGB多尺度融合执行同样的操作。最终Depth多尺度融合的输出为原始输入RGB_FP_L、通道合并后的新特征图RGB_FP_M和RGB_FP_H;Depth多尺度融合的输出为原始输入D_FP_L、通道合并后的新特征图D_FP_M和D_FP_H。S5多模态特征通道重加权;From RGB feature extraction to obtain RGB feature maps RGB_FP_H, RGB_FP_M, RGB_FP_L input to the RGB multi-scale fusion, first expand the obtained RGB_FP_L to the same size as RGB_FP_M through the upsampling layer, and then merge the channels with RGB_FP_M to realize the advanced semantics of the RGB network deep layer The complementary fusion of features and the mid-level edge contour features of the middle layer, the output channel merged new feature map RGB_FP_M; then the new feature map RGB_FP_M after the output channel merged is expanded to the same size as RGB_FP_H through the upsampling layer, and the channel is channeled with RGB_FP_H Merge, realize the complementary fusion of the deep high-level semantic features of the RGB network, the middle-level edge contour features of the middle layer, and the shallow low-level color texture features, and output the new feature map RGB_FP_H after channel merging; obtain the Depth feature map D_FP_H, from the Depth feature extraction, D_FP_M and D_FP_L are input to Depth multi-scale fusion, and perform the same operation as RGB multi-scale fusion. The final output of Depth multi-scale fusion is the original input RGB_FP_L, the new feature maps RGB_FP_M and RGB_FP_H after channel merging; the output of Depth multi-scale fusion is the original input D_FP_L, the new feature maps D_FP_M and D_FP_H after channel merging. S5 multi-modal feature channel re-weighting;
从RGB多尺度融合获取RGB特征图RGB_FP_L、RGB_FP_M、RGB_FP_H和从Depth多尺度融合获取Depth特征图D_FP_L、D_FP_M、D_FP_H,按照分辨率分组输入到多模态特征通道重加权中对应相同分辨率的通道重加权结构中,实现更有效的RGB与Depth的多模态特征融合,提高处理多种限制场景下的检测鲁棒性。具体做法以RGB_FP_L与D_FP_L通道重加权为例,从RGB多尺度融合获取RGB_FP_L以及从Depth多尺度融合获取D_FP_L,首先进行通道合并,获得通道合并后的特征图记为Concat_L;然后应用通道重加权模块(以下简称为RW_Module)对Concat_L的特征通道进行线性加权,为每个特征通道赋予权重,输出通道重加权后的特征图记为RW_L。RGB_FP_M与D_FP_M,RGB_FP_H与D_FP_H的通道重加权采用与所述RGB_FP_L和D_FP_L相同方式完成。最终多模态特征通道重加权输出通道重加权后的低、中、高分辨率特征图,分别记为RW_L,RW_M,RW_H。Obtain RGB feature maps RGB_FP_L, RGB_FP_M, RGB_FP_H from RGB multi-scale fusion and Depth feature maps D_FP_L, D_FP_M, D_FP_H from Depth multi-scale fusion, and enter the channels corresponding to the same resolution in the multi-modal feature channel weighting according to the resolution grouping In the re-weighted structure, a more effective RGB and Depth multi-modal feature fusion is realized, and the detection robustness in processing a variety of restricted scenes is improved. The specific method takes RGB_FP_L and D_FP_L channel weighting as an example. RGB_FP_L is obtained from RGB multi-scale fusion and D_FP_L is obtained from Depth multi-scale fusion. First, channel merging is performed, and the feature map obtained after channel merging is marked as Concat_L; then the channel re-weighting module is applied (Hereinafter referred to as RW_Module) linearly weights the feature channels of Concat_L, assigns a weight to each feature channel, and the re-weighted feature map of the output channel is denoted as RW_L. The channel weighting of RGB_FP_M and D_FP_M, RGB_FP_H and D_FP_H is done in the same manner as the RGB_FP_L and D_FP_L. The final multi-modal feature channel re-weighted output channel re-weighted low-, medium-, and high-resolution feature maps, respectively marked as RW_L, RW_M, RW_H.
S6多尺度人员预测;S6 multi-scale personnel prediction;
从所述S5的多模态特征通道重加权获取通道重加权后的特征图RW_L,RW_M,RW_H,分别输入到多尺度人员预测中对应的预测分支中进行分类和边框坐标回归,获得较大、中等以及较小尺寸人员的预测结果。由于特征图分辨率不同,特征图上每个预测点对应的感受野也不同。RW_L上的每个预测点具有较大感受野,用来预测图像中的较大目标;RW_M上的每个预测点具有中等感受野,用来预测图像中的中等目标;RW_H上的每个预测点具有较小感受野,用来预测图像中的较小目标。对上述三种不同尺度的预测结果进行汇总,采用非极大值抑制(以下简称NMS)算法[1]剔除重叠目标边框,输出最终保留的人员检测结果,即人员的类别置信分数C
i和预测矩形边框
 i=1,2,…,N。在本实施例中,i代表人员的ID编号,N为在当前图像中保留的人员检测结果总数。
i=1,2,…,N。在本实施例中,i代表人员的ID编号,N为在当前图像中保留的人员检测结果总数。
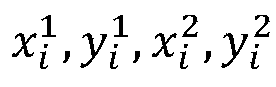 分别代表所有包含人员的矩形边框的左上角横坐标、左上角纵坐标、右下角横坐标以及右下角纵坐标。
Obtain the re-weighted feature maps RW_L, RW_M, and RW_H from the multi-modal feature channel of the S5, and input them into the corresponding prediction branch in the multi-scale human prediction for classification and frame coordinate regression to obtain larger, Predicted results for medium and small size personnel. Because the resolution of the feature map is different, the receptive field corresponding to each prediction point on the feature map is also different. Each prediction point on RW_L has a large receptive field, which is used to predict a larger target in the image; each prediction point on RW_M has a medium receptive field, which is used to predict a medium target in the image; each prediction on RW_H Points have smaller receptive fields and are used to predict smaller targets in the image. The prediction results of the above three different scales are summarized, and the non-maximum suppression (hereinafter referred to as NMS) algorithm [1] is used to eliminate overlapping target borders, and the final retained personnel detection results are output, that is, the category confidence score C i and the prediction of the personnel Rectangular border i=1,2,...,N. In this embodiment, i represents the ID number of the person, and N is the total number of person detection results retained in the current image. They represent the abscissa of the upper left corner, the ordinate of the upper left corner, the abscissa of the lower right corner, and the ordinate of the lower right corner of the rectangular frame containing all persons.
分别代表所有包含人员的矩形边框的左上角横坐标、左上角纵坐标、右下角横坐标以及右下角纵坐标。
Obtain the re-weighted feature maps RW_L, RW_M, and RW_H from the multi-modal feature channel of the S5, and input them into the corresponding prediction branch in the multi-scale human prediction for classification and frame coordinate regression to obtain larger, Predicted results for medium and small size personnel. Because the resolution of the feature map is different, the receptive field corresponding to each prediction point on the feature map is also different. Each prediction point on RW_L has a large receptive field, which is used to predict a larger target in the image; each prediction point on RW_M has a medium receptive field, which is used to predict a medium target in the image; each prediction on RW_H Points have smaller receptive fields and are used to predict smaller targets in the image. The prediction results of the above three different scales are summarized, and the non-maximum suppression (hereinafter referred to as NMS) algorithm [1] is used to eliminate overlapping target borders, and the final retained personnel detection results are output, that is, the category confidence score C i and the prediction of the personnel Rectangular border i=1,2,...,N. In this embodiment, i represents the ID number of the person, and N is the total number of person detection results retained in the current image. They represent the abscissa of the upper left corner, the ordinate of the upper left corner, the abscissa of the lower right corner, and the ordinate of the lower right corner of the rectangular frame containing all persons.
与现有技术相比较,本发明针对传统对称型RGBD双流网络(RGB网络流+Depth网络流)由于Depth网络过深而易导致深度特征流失的问题,本发明设计非对称RGBD双流卷积神经网络模型,Depth网络流通过对RGB网络流进行有效地模型剪枝获得,在降低参数的同时,能够降低模型过拟合的风险,提高检测精度。RGB网络流和Depth网络流分别用于提取RGB和深度图像(以下简称为Depth图像)的高、中、低分辨率特征图,分别代表RGB和Depth图像的低级色彩纹理、中级边缘轮廓和高级语义特征表示;其次对RGB网络流和Depth网络流分别设计多尺度融合结构,实现低分辨率特征图所包含的高级语义特征与中、高分辨率特征图所包含的中级边缘轮廓、低级色彩纹理特征的多尺度信息互补;然后构建多模态特征通道加权结构,合并RGB与Depth特征图,并为合并后的每个特征通道进行加权赋值,使模型能够自动学习贡献比重,完成特征选择和去除冗余的功能,从而实现RGB和Depth特征在对应高、中、低分辨率下的多模态特征融合;最后,利用多模态特征进行人员的分类和边框回归,在保证实时性的同时,提高人员检测的准确性,并增强对夜间低照度以及人员遮挡下检测的鲁棒性。Compared with the prior art, the present invention addresses the problem that the traditional symmetrical RGBD dual-stream network (RGB network stream + Depth network stream) is prone to loss of depth characteristics due to the excessive depth of the Depth network. The present invention designs an asymmetric RGBD dual-stream convolutional neural network. Model, the Depth network stream is obtained by effectively model pruning the RGB network stream. While reducing the parameters, it can reduce the risk of model overfitting and improve the detection accuracy. The RGB network stream and the Depth network stream are used to extract the high, medium, and low resolution feature maps of RGB and depth images (hereinafter referred to as Depth images), respectively, representing the low-level color texture, intermediate edge contour and high-level semantics of RGB and Depth images. Feature representation; secondly, a multi-scale fusion structure is designed for the RGB network stream and the Depth network stream to realize the high-level semantic features contained in the low-resolution feature map and the intermediate edge contour and low-level color texture features contained in the medium and high-resolution feature maps. The multi-scale information is complementary; then the multi-modal feature channel weighting structure is constructed, RGB and Depth feature maps are combined, and each feature channel after the combination is weighted and assigned, so that the model can automatically learn the contribution proportion, complete feature selection and remove redundancy Remaining functions, so as to realize the multi-modal feature fusion of RGB and Depth features corresponding to high, medium and low resolutions; finally, the use of multi-modal features for personnel classification and border regression, while ensuring real-time performance, improve The accuracy of people detection and the robustness of detection under low illumination at night and under people's obscuration are enhanced.
图1本发明提供的一种基于非对称双流网络的RGBD多模态融合人员检测方法的代表图Fig. 1 A representative diagram of a RGBD multi-modal fusion personnel detection method based on an asymmetric dual-stream network provided by the present invention
图2-1为一种RGB网络流——DarkNet-53结构图,图2-2为一种Depth网络流——MiniDepth-30结构图,图2-3为一种卷积块通用结构图,图2-4为一种残差卷积块通用结构图。Figure 2-1 is a structure diagram of an RGB network stream-DarkNet-53, Figure 2-2 is a structure diagram of a Depth network stream-MiniDepth-30, and Figure 2-3 is a general structure diagram of a convolution block. Figure 2-4 is a general structure diagram of a residual convolution block.
图3本发明实施例提供的一种基于非对称双流网络的RGBD多模态融合人员检测方法的流程图Fig. 3 is a flowchart of a method for RGBD multi-modal fusion personnel detection based on an asymmetric dual-stream network provided by an embodiment of the present invention
图4本发明实施例提供的一种通道重加权模块的通用结构图Figure 4 A general structure diagram of a channel reweighting module provided by an embodiment of the present invention
图5本发明实施例提供的NMS算法的流程图Figure 5 A flowchart of the NMS algorithm provided by an embodiment of the present invention
为使本发明实施例的目的、技术方案和有点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。下面通过具体实施例对本发明进行详细说明。本发明的实施例提供的方法示意图如图3所示,包括如下步骤:In order to make the objectives, technical solutions and points of the embodiments of the present invention clearer, the technical solutions in the embodiments of the present invention will be described clearly and completely in conjunction with the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are part of the embodiments of the present invention, rather than all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative work shall fall within the protection scope of the present invention. The present invention will be described in detail below through specific embodiments. The schematic diagram of the method provided by the embodiment of the present invention is shown in FIG. 3, and includes the following steps:
S1:利用具有同时拍摄RGB图像和深度图像功能的相机获取原始RGB图像和深度图像,对图像进行匹配和分组,输出分组匹配后的RGB和Depth图像。S1: Use a camera with the function of simultaneously shooting RGB images and depth images to obtain the original RGB image and the depth image, match and group the images, and output the grouped and matched RGB and Depth images.
步骤S110:利用具有同时拍摄RGB图像和深度图像功能的相机获取原始RGB图像,原始RGB图像也可以从公开RGBD数据集获取。Step S110: Obtain the original RGB image by using a camera with the function of simultaneously shooting RGB images and depth images, and the original RGB images can also be obtained from the public RGBD data set.
步骤S120:从所述步骤S110同步获取与RGB图像匹配的Depth图像,并对RGB和Depth图像进行分组,每组图像由一张RGB图像和同场景下捕获的深度图像组成,输出分组匹配后的Depth图像。Step S120: Acquire the Depth image matching the RGB image synchronously from the step S110, and group the RGB and Depth images. Each group of images is composed of an RGB image and a depth image captured in the same scene, and the output group is matched Depth image.
S2:从所述步骤S120中获取的分组匹配后的Depth图像,对Depth图像进行去噪、空洞修复和编码规范化,输出编码预处理后的Depth图像。S2: Perform denoising, hole repair and coding standardization on the Depth image after group matching obtained in the step S120, and output the preprocessed Depth image after coding.
从所述步骤S120获取的原始深度图像作为输入,首先消除Depth图像的部分噪声,然后进行空洞填充,最后将单通道Depth图像重新编码为三通道图像,并将三个通道的数值重新规范化到0-255,输出编码规范化后的Depth图像。在本实施例中去除噪声采用5x5的高斯滤波器;空洞修复采用[2]提出的图像修复算法,提取Depth图像中的局部法线向量和遮挡边界,然后应用全局优化进行Depth图像空洞填充;Depth图像编码采用HHA编码[3](horizontal disparity,height above ground,and the angle the pixel),三个通道分别为水平视差,高于地面的高度以及表面法向量的角度。The original depth image obtained from the step S120 is used as input. First, part of the noise of the Depth image is eliminated, then the hole is filled, and finally the single-channel Depth image is re-encoded into a three-channel image, and the values of the three channels are renormalized to 0 -255, output the Depth image after encoding normalization. In this embodiment, a 5x5 Gaussian filter is used to remove noise; the image repair algorithm proposed in [2] is used for hole repair, and the local normal vector and occlusion boundary in the Depth image are extracted, and then global optimization is applied to fill the hole of the Depth image; Depth Image coding adopts HHA coding [3] (horizontal disparity, height above ground, and the angle the pixel), and the three channels are the horizontal disparity, the height above the ground and the angle of the surface normal vector.
S3:从所述步骤S110获取原始RGB图像,采用非对称双流网络模型的RGB网络流在不同网络层级分别提取RGB图像的通用、低级、中级和高级特征之后,输出对应通用特征图以及高、中、低三种分辨率的RGB特征图,分别记为RGB_FP_C、RGB_FP_H、RGB_FP_M、RGB_FP_L,并将RGB_FP_H、RGB_FP_M、 RGB_FP_L其输入到S4。在本实施例中,非对称双流网络模型的RGB网络流采用DarkNet-53[4],DarkNet-53的网络结构如图2-1所示。网络共包含52个卷积层,其中网络的L1~L10层用于提取RGB图像的通用特征,输出RGB_FP_C;L11~L27层用于提取RGB图像的低级色彩纹理特征,输出RGB_FP_H;L28~L44层用于提取RGB图像的中级边缘轮廓特征,输出RGB_FP_M;L45~L52层用于提取RGB图像的高级语义特征,输出RGB_FP_L。值得注意的是,本实施例使用的DarkNet-53模型仅为所述非对称双流网络的RGB网络流的一个具体实施例,不限于上述DarkNet-53模型,下文仅以DarkNet-53为例进行方法论述。S3: Obtain the original RGB image from the step S110, and use the RGB network stream of the asymmetric dual-stream network model to extract the general, low-level, intermediate, and high-level features of the RGB image at different network levels, and then output the corresponding general feature map and the high- and middle-level features. The RGB feature maps of the lower three resolutions are respectively marked as RGB_FP_C, RGB_FP_H, RGB_FP_M, RGB_FP_L, and input RGB_FP_H, RGB_FP_M, RGB_FP_L to S4. In this embodiment, the RGB network stream of the asymmetric dual-stream network model adopts DarkNet-53 [4], and the network structure of DarkNet-53 is shown in Figure 2-1. The network contains 52 convolutional layers, among which layers L1~L10 of the network are used to extract the general features of RGB images and output RGB_FP_C; layers L11~L27 are used to extract low-level color texture features of RGB images and output RGB_FP_H; layers L28~L44 Used to extract the middle-level edge contour features of RGB images, and output RGB_FP_M; L45~L52 layers are used to extract high-level semantic features of RGB images, and output RGB_FP_L. It is worth noting that the DarkNet-53 model used in this embodiment is only a specific embodiment of the RGB network flow of the asymmetric dual-stream network, and is not limited to the aforementioned DarkNet-53 model. The following only uses DarkNet-53 as an example. Discourse.
步骤S310:从所述S110获取原始RGB图像,经过DarkNet-53网络的L1~L10层提取RGB图像的通用特征,并将图像分辨率下采样K倍,输出RGB通用特征图RGB_FP_C,其尺寸变为原始输入尺寸的K分之一。在本实施例中,K取值为8。L1~L10层可以划分为L1~L2、L3~L5和L6~L10三个子采样层,每个子采样层将来自上一层的输入图像分辨率下采样2倍。第一子采样层包括1个步长为1的标准卷积块(记为Conv0)和1个步长为2的池化卷积块(记为Conv0_pool),其中卷积块的通用结构如图2-3所示,包括标准图像卷积层、批规范化层和Leaky_ReLU激活层;第二子采样层包括一个残差卷积块(记为Residual_Block_1)和1个所述池化卷积块(记为Conv1_pool),其中残差卷积块的通用结构如图2-4所示,包含一个1x1xM的标准卷积块、一个3x3xN的标准卷积块以及一个将输入的恒等映射传递到输出的Add模块,M代表输入特征通道数,N表示输出特征通道数,此处M,N取值分别为32;第三子采样层包括2个所述残差卷积块(记为Residual_Block_2_1~2_2)和1个所述池化卷积块(记为Conv2_pool)。在本实施例中,K取值为8,M,N的取值见图3-1的L1~L10层。Step S310: Obtain the original RGB image from the S110, extract the general features of the RGB image through the L1~L10 layers of the DarkNet-53 network, and downsample the image resolution by K times, and output the RGB general feature map RGB_FP_C, whose size becomes One Kth of the original input size. In this embodiment, the value of K is 8. Layers L1 to L10 can be divided into three sub-sampling layers, L1 to L2, L3 to L5, and L6 to L10. Each sub-sampling layer down-samples the input image resolution from the previous layer by 2 times. The first sub-sampling layer includes a standard convolution block with a step length of 1 (denoted as Conv0) and a pooled convolution block with a step length of 2 (denoted as Conv0_pool). The general structure of the convolution block is shown in the figure As shown in 2-3, it includes a standard image convolution layer, a batch normalization layer, and a Leaky_ReLU activation layer; the second sub-sampling layer includes a residual convolution block (denoted as Residual_Block_1) and one of the pooling convolution blocks (denoted as Residual_Block_1). Is Conv1_pool), where the general structure of the residual convolution block is shown in Figure 2-4, including a 1x1xM standard convolution block, a 3x3xN standard convolution block, and an Add that transfers the identity map of the input to the output Module, M represents the number of input feature channels, N represents the number of output feature channels, where the values of M and N are respectively 32; the third sub-sampling layer includes 2 of the residual convolution blocks (denoted as Residual_Block_2_1~2_2) and One such pooled convolution block (denoted as Conv2_pool). In this embodiment, the value of K is 8, and the values of M and N are shown in layers L1 to L10 in Fig. 3-1.
步骤S320:从所述S310获取RGB_FP_C,经过DarkNet-53网络的L11~L27层提取RGB图像的低级色彩纹理特征,并将图像分辨率下采样K倍,输出RGB高分辨率特征图RGB_FP_H,其尺寸变为原始输入尺寸的K分之一。在本实施例中,L11~L27由8个所述残差卷积块(记为Residual_Block_3_1~3_8)和1个所述池化卷积块(Conv3_pool)组成。K取值为2,M,N的取值见图3-1的L11~L27层。Step S320: Obtain RGB_FP_C from S310, extract the low-level color texture features of the RGB image through the L11~L27 layers of the DarkNet-53 network, and downsample the image resolution by K times, and output the RGB high-resolution feature map RGB_FP_H with its size It becomes one Kth of the original input size. In this embodiment, L11 to L27 are composed of 8 residual convolution blocks (denoted as Residual_Block_3_1 to 3_8) and one pooling convolution block (Conv3_pool). The value of K is 2, and the values of M and N are shown in layers L11 to L27 in Figure 3-1.
步骤S330:从所述S320获取RGB_FP_H,经过DarkNet-53网络的L28~L44层提取RGB图像的中级边缘轮廓特征,并将图像分辨率下采样K倍,输出RGB 中分辨率特征图RGB_FP_M,其尺寸变为原始输入尺寸的K分之一。在本实施例中,L28~L44由8个所述残差卷积块(记为Residual_Block_4_1~4_8)和1个所述池化卷积块(Conv4_pool)组成。K取值为2,M,N的取值见图3-1的L28~L44层。Step S330: Obtain RGB_FP_H from the S320, extract the mid-level edge contour features of the RGB image through the L28~L44 layer of the DarkNet-53 network, and downsample the image resolution by K times, and output the RGB mid-resolution feature map RGB_FP_M with its size It becomes one Kth of the original input size. In this embodiment, L28 to L44 are composed of 8 residual convolution blocks (denoted as Residual_Block_4_1 to 4_8) and one convolution block (Conv4_pool). The value of K is 2, and the values of M and N are shown in Layers L28 to L44 in Figure 3-1.
步骤S340:从所述S320获取RGB_FP_M,经过DarkNet-53网络的L45~L52层提取RGB图像的高级语义特征,并将图像分辨率下采样K倍,输出RGB低分辨率特征图RGB_FP_L,其尺寸变为原始输入尺寸的K分之一。在本实施例中,L45~L52由4个所述残差卷积块(记为Residual_Block_5_1~5_4)组成。K取值为2,M,N的取值见图3-1的L45~L52层。Step S340: Obtain RGB_FP_M from the S320, extract the high-level semantic features of the RGB image through the L45~L52 layers of the DarkNet-53 network, and downsample the image resolution by K times, and output the RGB low-resolution feature map RGB_FP_L, the size of which is changed It is one Kth of the original input size. In this embodiment, L45 to L52 are composed of 4 of the residual convolution blocks (denoted as Residual_Block_5_1 to 5_4). The value of K is 2, and the values of M and N are shown in Layers L45 to L52 in Figure 3-1.
S3’:从所述S2获取编码规范化后的Depth图像,采用非对称双流网络模型的Depth网络流在不同网络层级上分别提取Depth图像的通用、低级、中级和高级特征之后,输出对应通用特征图以及高、中、低三种分辨率的RGB特征图,分别记为D_FP_C、D_FP_H、D_FP_M、D_FP_L,并将D_FP_H、D_FP_M、D_FP_L输入到S4’。在本实施例中,非对称双流网络模型的Depth网络流是在RGB网络流DarkNet-53的基础上对模型进行剪枝获得,下文简称之为MiniDepth-30。MiniDepth-30网络能更有效更清晰地提取深度图像的边缘轮廓等语义特征,同时达到减少网络参数,防止过拟合的效果。MiniDepth-30的网络结构如图2-2所示。网络共包含30个卷积层,其中网络的L1~L10层用于提取Depth图像的通用特征,输出D_FP_C;L11~L17层用于提取Depth图像的低级色彩纹理特征,输出D_FP_H;L18~L24层用于提取Depth图像的中级边缘轮廓特征,输出D_FP_M;L25~L30层用于提取Depth图像的高级语义特征,输出D_FP_L。值得注意的是,本实施例使用的MiniDepth-30模型仅为所述非对称双流网络的Depth网络流的一个具体实施例,不限于上述MiniDepth-30模型,下文仅以MiniDepth-30为例进行方法论述。S3': Obtain the normalized Depth image from the S2, and use the Depth network stream of the asymmetric dual-stream network model to extract the general, low-level, intermediate and high-level features of the Depth image at different network levels, and then output the corresponding general feature map And the RGB feature maps of high, medium, and low resolutions are denoted as D_FP_C, D_FP_H, D_FP_M, D_FP_L, and D_FP_H, D_FP_M, D_FP_L are input to S4'. In this embodiment, the Depth network stream of the asymmetric dual-stream network model is obtained by pruning the model on the basis of the RGB network stream DarkNet-53, which is hereinafter referred to as MiniDepth-30 for short. The MiniDepth-30 network can extract semantic features such as the edge contour of the depth image more effectively and clearly, and at the same time achieve the effect of reducing network parameters and preventing over-fitting. The network structure of MiniDepth-30 is shown in Figure 2-2. The network contains a total of 30 convolutional layers, among which the L1~L10 layers of the network are used to extract the general features of the Depth image and output D_FP_C; the L11~L17 layers are used to extract the low-level color texture features of the Depth image, and the output D_FP_H; L18~L24 layers Used to extract the middle-level edge contour features of the Depth image, output D_FP_M; L25 ~ L30 layers are used to extract the high-level semantic features of the Depth image, output D_FP_L. It is worth noting that the MiniDepth-30 model used in this embodiment is only a specific embodiment of the Depth network flow of the asymmetric dual-stream network, and is not limited to the aforementioned MiniDepth-30 model. The following only uses MiniDepth-30 as an example for the method. Discourse.
步骤S310’:从所述S2获取编码规范化后的Depth图像,经过MiniDepth-30网络的L1~L10层提取RGB图像的通用特征,并将图像分辨率下采样K倍,输出Depth通用特征图D_FP_C,其尺寸变为原始输入尺寸的K分之一。在本实施例中,MiniDepth-30的L1~L10网络层与步骤S310中DarkNet-53的L1~L10网络层具有相同结构,K取值为8。Step S310': Obtain the normalized Depth image from the S2, extract the general features of the RGB image through the L1~L10 layers of the MiniDepth-30 network, and downsample the image resolution by K times, and output the general Depth feature map D_FP_C, Its size becomes one K of the original input size. In this embodiment, the L1 to L10 network layers of MiniDepth-30 have the same structure as the L1 to L10 network layers of DarkNet-53 in step S310, and the value of K is 8.
步骤S320’:从所述步骤S310’获取D_FP_C,经过MiniDepth-30网络的L11~L17层提取Depth图像的低级色彩纹理特征,并将图像分辨率下采样K倍,输出Depth高分辨率特征图D_FP_H,其尺寸变为原始输入尺寸的K分之一。在本实施例中,L11~L17由3个所述残差卷积块(记为Residual_Block_D_3_1~3_3)和1个所述池化卷积块(Conv3_D_pool)组成。K取值为2,M,N的取值见图3-2的L11~L17层。Step S320': Obtain D_FP_C from the step S310', extract the low-level color texture features of the Depth image through the L11~L17 layers of the MiniDepth-30 network, and downsample the image resolution by K times, and output the Depth high-resolution feature map D_FP_H , Its size becomes one K of the original input size. In this embodiment, L11 to L17 are composed of three of the residual convolution blocks (denoted as Residual_Block_D_3_1 to 3_3) and one of the pooling convolution blocks (Conv3_D_pool). The value of K is 2, and the values of M and N are shown in Layers L11 to L17 in Figure 3-2.
步骤S330’:从所述步骤S320’获取D_FP_H,经过MiniDepth-30网络的L18~L24层提取Depth图像的中级边缘轮廓特征,并将图像分辨率下采样K倍,输出Depth中分辨率特征图D_FP_M,其尺寸变为原始输入尺寸的K分之一。在本实施例中,L18~L24由3个所述残差卷积块(记为Residual_Block_D_4_1~4_3)和1个所述池化卷积块(Conv4_D_pool)组成。K取值为2,M,N的取值见图3-1的L18~L24层。Step S330': Obtain D_FP_H from the step S320', extract the mid-level edge contour features of the Depth image through the L18~L24 layers of the MiniDepth-30 network, and downsample the image resolution by K times, and output the Depth mid-resolution feature map D_FP_M , Its size becomes one K of the original input size. In this embodiment, L18 to L24 are composed of three of the residual convolution blocks (denoted as Residual_Block_D_4_1 to 4_3) and one of the pooling convolution blocks (Conv4_D_pool). The value of K is 2, and the values of M and N are shown in layers L18 to L24 in Figure 3-1.
步骤S340’:从所述步骤S330’获取D_FP_M,经过DarkNet-53网络的L25~L30层提取Depth图像的高级语义特征,并将图像分辨率下采样K倍,输出Depth低分辨率特征图D_FP_L,其尺寸变为原始输入尺寸的K分之一。在本实施例中,L25~L30由3个所述残差卷积块(记为Residual_Block_D_5_1~5_3)组成。K取值为2,M,N的取值见图3-1的L25~L30层。Step S340': Obtain D_FP_M from the step S330', extract the high-level semantic features of the Depth image through the L25~L30 layers of the DarkNet-53 network, and downsample the image resolution by K times, and output the Depth low-resolution feature map D_FP_L, Its size becomes one K of the original input size. In this embodiment, L25 to L30 are composed of three of the residual convolution blocks (denoted as Residual_Block_D_5_1 to 5_3). The value of K is 2, and the values of M and N are shown in Layers L25 to L30 in Figure 3-1.
S4:从所述S3获取RGB_FP_H、RGB_FP_M和RGB_FP_L,利用上采样拓展特征图尺寸,合并具有相同分辨率的RGB特征图的特征通道实现特征融合,输出特征融合之后的特征图RGB_FP_H、RGB_FP_M和RGB_FP_L到S5。S4: Obtain RGB_FP_H, RGB_FP_M and RGB_FP_L from the S3, use upsampling to expand the feature map size, merge the feature channels of the RGB feature maps with the same resolution to achieve feature fusion, and output the feature maps RGB_FP_H, RGB_FP_M and RGB_FP_L after feature fusion to S5.
步骤S410:从所述步骤S340获取的RGB_FP_L,上采样M倍后与所述步骤S330获取的RGB_FP_M进行通道合并,实现RGB网络深层的高级语义特征和中间层的中级边缘轮廓特征的互补融合,输出特征融合后的新特征图RGB_FP_M。通道合并具体做法:RGB_FP_L的通道数为C1,RGB_FP_M的通道数为C2,二者通道合并C1+C2后获得C3,C3为特征融合后新特征图RGB_FP_M的通道数。在本实施例中M取值为2,C1,C2,C3取值分别为256,512,768。Step S410: From the RGB_FP_L obtained in the step S340, it is up-sampled by M times and then merged with the RGB_FP_M obtained in the step S330 to realize the complementary fusion of the high-level semantic features of the deep layer of the RGB network and the middle-level edge contour feature of the middle layer, and output The new feature map RGB_FP_M after feature fusion. The specific method of channel merging: the number of channels of RGB_FP_L is C1, the number of channels of RGB_FP_M is C2, the two channels are merged C1+C2 to obtain C3, and C3 is the number of channels of the new feature map RGB_FP_M after feature fusion. In this embodiment, the value of M is 2, and the values of C1, C2, and C3 are 256, 512, and 768, respectively.
步骤S420:从所述步骤S410获取特征融合后的新特征图RGB_FP_M,上采样M倍后与所述步骤S320获取的RGB_FP_H进行通道合并,实现RGB网络深 层的高级语义特征、中间层的中级边缘轮廓特征以及浅层的低级色彩纹理特征的互补融合,输出特征融合后的新特征图D_FP_H。通道合并具体做法:RGB_FP_M的通道数为C1,RGB_FP_H的通道数为C2,二者通道合并C1+C2后获得C3,C3为特征融合后新特征图RGB_FP_H的通道数。在本实施例中M取值为2,C1,C2,C3取值分别为128,256,384。Step S420: Obtain the new feature map RGB_FP_M after the feature fusion from the step S410, and perform channel merging with the RGB_FP_H obtained in the step S320 after up-sampling to realize the deep high-level semantic features of the RGB network and the middle-level edge contour of the middle layer The complementary fusion of features and shallow low-level color texture features, and output the new feature map D_FP_H after feature fusion. The specific method of channel merging: the number of channels of RGB_FP_M is C1, the number of channels of RGB_FP_H is C2, the two channels are merged C1+C2 to obtain C3, and C3 is the number of channels of the new feature map RGB_FP_H after feature fusion. In this embodiment, the value of M is 2, and the values of C1, C2, and C3 are 128, 256, and 384, respectively.
S4’:从所述S3’获取D_FP_H、D_FP_M、D_FP_L,利用上采样拓展特征图尺寸,合并具有相同分辨率的Depth特征图的特征通道实现特征融合,输出特征融合之后的特征图D_FP_H、D_FP_M、D_FP_L到S5。S4': Obtain D_FP_H, D_FP_M, and D_FP_L from the S3', use upsampling to expand the size of the feature map, merge the feature channels of the Depth feature maps with the same resolution to achieve feature fusion, and output the feature maps D_FP_H, D_FP_M, D_FP_M, and D_FP_M after feature fusion. D_FP_L to S5.
步骤S410’:从所述步骤S340’获取的D_FP_L,上采样M倍后与所述步骤S330’获取的D_FP_M进行通道合并,实现Depth网络深层的高级语义特征和中间层的中级边缘轮廓特征的互补融合,输出特征融合后的新特征图D_FP_M。通道合并具体做法:D_FP_L的通道数为C1,D_FP_M的通道数为C2,二者通道合并C1+C2后获得C3,C3为特征融合后新特征图D_FP_M的通道数。在本实施例中M取值为2,C1,C2,C3取值分别为256,512,768。Step S410': From the D_FP_L obtained in the step S340', it is up-sampled by M times and then merged with the D_FP_M obtained in the step S330' to realize the complementarity of the deep high-level semantic features of the Depth network and the middle-level edge contour features of the middle layer Fusion, output the new feature map D_FP_M after feature fusion. The specific method of channel merging: the number of channels of D_FP_L is C1, the number of channels of D_FP_M is C2, the two channels are merged C1+C2 to obtain C3, and C3 is the number of channels of the new feature map D_FP_M after feature fusion. In this embodiment, the value of M is 2, and the values of C1, C2, and C3 are 256, 512, and 768, respectively.
步骤S420’:从所述步骤S410获取特征融合后的新特征图D_FP_M,上采样M倍后与所述步骤S320’获取的D_FP_H进行通道合并,实现Depth网络深层的高级语义特征、中间层的中级边缘轮廓特征以及浅层的低级色彩纹理特征的互补融合,输出特征融合后的新特征图D_FP_H。通道合并具体做法:D_FP_M的通道数为C1,D_FP_H的通道数为C2,二者通道合并C1+C2后获得C3,C3为特征融合后新特征图D_FP_H的通道数。在本实施例中M取值为2,C1,C2,C3取值分别为128,256,384。Step S420': Obtain the new feature map D_FP_M after the feature fusion from the step S410, and perform channel merging with the D_FP_H obtained in the step S320' after up-sampling to realize the deep high-level semantic features of the Depth network and the intermediate level of the middle layer. The complementary fusion of edge contour features and shallow low-level color texture features will output the new feature map D_FP_H after feature fusion. The specific method of channel merging: the number of channels of D_FP_M is C1, the number of channels of D_FP_H is C2, the two channels are merged C1+C2 to obtain C3, and C3 is the number of channels of the new feature map D_FP_H after feature fusion. In this embodiment, the value of M is 2, and the values of C1, C2, and C3 are 128, 256, and 384, respectively.
S5:从所述S4获取特征融合后新特征图RGB_FP_H、RGB_FP_M和RGB_FP_L,从S4’获取特征融合后新特征图D_FP_H、D_FP_M、D_FP_L,在对应相等的分辨率上分别进行特征通道合并,获得通道合并后的特征图,分别记为Concat_L、Concat_M、Concat_H,然后应用通道重加权模块(以下简称为RW_Module)分别对Concat_L、Concat_M、Concat_H进行线性加权,输出通道重加权后的高、中、低分辨率特征图,分别记为RW_H,RW_M,RW_L。S5: Obtain new feature maps RGB_FP_H, RGB_FP_M, and RGB_FP_L after feature fusion from S4, and obtain new feature maps D_FP_H, D_FP_M, D_FP_L after feature fusion from S4', and perform feature channel merging at corresponding equal resolutions to obtain channels The merged feature maps are marked as Concat_L, Concat_M, and Concat_H respectively, and then the channel weighting module (hereinafter referred to as RW_Module) is applied to linearly weight Concat_L, Concat_M, and Concat_H respectively, and the high, medium, and low resolutions after the channel weighting are output Rate characteristic map, respectively denoted as RW_H, RW_M, RW_L.
步骤S510:从所述S4获取RGB_FP_L和D_FP_L,首先将RGB_FP_L和D_FP_L的特征通道进行合并获得Concat_L,实现RGB和Depth在网络深层多模态信息的互补融合,然后应用通道重加权模块RW_Module对Concat_L进行线性加权,为每个特征通道赋予权重,输出通道重加权后的特征图RW_L。以RGB_FP_L和D_FP_L的通道重加权为例,本实施例提供的一种通道重加权模块的通用结构如图4所示。具体做法,RGB_FP_L的通道数为C1,D_FP_L的通道数为C2,通道合并后的新特征图Concat_L的通道数为C3,其中C3=C1+C2;然后对所述Concat_L依次经过1个1x1的Ave-Pooling层、1个由C3/s(s为缩减步长)个1x1卷积核组成的标准卷积层、1个C3个1x1卷积核组成的标准卷积层和1个Sigmoid层,获取C3个数值范围在0~1之间的权重值;最后将获取的C3个权重值与所述Concat_L的C3个特征通道相乘,为每个特征通道赋予权重,输出通道重加权后的C3个特征通道,即RW_L。在本实施例中,C1、C2、C3的取值分别为1024,1024,2048,缩减步长s的取值分别为16。Step S510: Obtain RGB_FP_L and D_FP_L from the S4, first combine the feature channels of RGB_FP_L and D_FP_L to obtain Concat_L, realize the complementary fusion of RGB and Depth in the network deep multi-modal information, and then apply the channel weighting module RW_Module to Concat_L Linear weighting, assign weight to each feature channel, and output the re-weighted feature map RW_L of the channel. Taking the channel weighting of RGB_FP_L and D_FP_L as an example, the general structure of a channel weighting module provided in this embodiment is shown in FIG. 4. Specifically, the number of channels of RGB_FP_L is C1, the number of channels of D_FP_L is C2, and the number of channels of the new feature map Concat_L after channel merging is C3, where C3=C1+C2; then the Concat_L passes through 1 1x1 Ave in turn -Pooling layer, 1 standard convolution layer composed of C3/s (s is the reduction step size) 1x1 convolution kernel, 1 C3 standard convolution layer composed of 1x1 convolution kernel, and 1 Sigmoid layer to obtain C3 weight values ranging from 0 to 1; finally, the obtained C3 weight values are multiplied by the C3 feature channels of the Concat_L, and each feature channel is assigned a weight, and the weighted C3 channels are output. The characteristic channel, namely RW_L. In this embodiment, the values of C1, C2, and C3 are 1024, 1024, and 2048 respectively, and the value of the reduction step size s is 16 respectively.
步骤S520:从所述步骤S410获取RGB_FP_M和所述步骤S410’获取D_FP_M,首先将RGB_FP_M和D_FP_M的特征通道进行合并获得Concat_M,实现RGB和Depth在网络中间层多模态信息的互补融合,然后应用通道重加权模块RW_Module对Concat_M进行线性加权,为每个特征通道赋予权重,输出通道重加权后的特征图RW_M。在本实施例中,RGB_FP_M和D_FP_M的通道重加权方式与所述步骤S510中RGB_FP_L和D_FP_L的通道重加权方式保持一致,其中C1、C2、C3的取值分别为512,512,1024,缩减步长s的取值分别为16。Step S520: Obtain RGB_FP_M from step S410 and D_FP_M from step S410', first combine the characteristic channels of RGB_FP_M and D_FP_M to obtain Concat_M, to achieve the complementary fusion of RGB and Depth multi-modal information in the middle layer of the network, and then apply The channel re-weighting module RW_Module performs linear weighting on Concat_M, assigns a weight to each feature channel, and outputs the channel re-weighted feature map RW_M. In this embodiment, the channel weighting method of RGB_FP_M and D_FP_M is consistent with the channel weighting method of RGB_FP_L and D_FP_L in step S510, where the values of C1, C2, and C3 are 512, 512, 1024, respectively, and the step size is reduced. The values of are 16 respectively.
步骤S530:从所述步骤S420获取RGB_FP_H和所述步骤S420’获取D_FP_H,首先将RGB_FP_H和D_FP_H的特征通道进行合并获得Concat_H,实现RGB和Depth在网络浅层多模态信息的互补融合,然后应用通道重加权模块RW_Module对Concat_H进行线性加权,为每个特征通道赋予权重,输出通道重加权后的特征图RW_H。在本实施例中,RGB_FP_H和D_FP_H的通道重加权方式与所述步骤S510中RGB_FP_L和D_FP_L的通道重加权方式保持一致,其中,C1、C2、C3的取值分别为256,256,512,缩减步长s的取值分别为16。Step S530: Obtain RGB_FP_H from the step S420 and D_FP_H from the step S420', first combine the feature channels of RGB_FP_H and D_FP_H to obtain Concat_H, realize the complementary fusion of RGB and Depth in the network shallow multi-modal information, and then apply The channel re-weighting module RW_Module performs linear weighting on Concat_H, assigns a weight to each feature channel, and outputs the channel re-weighted feature map RW_H. In this embodiment, the channel weighting method of RGB_FP_H and D_FP_H is consistent with the channel weighting method of RGB_FP_L and D_FP_L in step S510, where the values of C1, C2, and C3 are 256, 256, 512, respectively, which reduces the step size s. The values are 16 respectively.
S6:从所述S5获取通道重加权后的特征图RW_L,RW_M,RW_H,分别进行分类和边框坐标回归,获得较大、中等以及较小尺寸人员的预测结果,对上述三种 不同尺度的预测结果进行汇总,采用非极大值抑制(以下简称NMS)算法剔除重叠目标边框,输出最终保留的人员检测结果,即人员的类别置信分数C
i和预测矩形边框
 i=1,2,…,N。在本实施例中,i代表人员的ID编号,N为在当前图像中保留的人员检测结果总数。
i=1,2,…,N。在本实施例中,i代表人员的ID编号,N为在当前图像中保留的人员检测结果总数。
 分别代表所有包含人员的矩形边框的左上角横坐标、左上角纵坐标、右下角横坐标以及右下角纵坐标。
S6: Obtain the channel-weighted feature maps RW_L, RW_M, RW_H from the S5, and perform classification and frame coordinate regression respectively to obtain prediction results for persons with larger, medium and smaller sizes, and predict the above three different scales The results are summarized, and the non-maximum suppression (hereinafter referred to as NMS) algorithm is used to eliminate overlapping target borders, and the final retained person detection results are output, namely the category confidence score C i of the person and the predicted rectangular frame i=1,2,...,N. In this embodiment, i represents the ID number of the person, and N is the total number of person detection results retained in the current image. They represent the abscissa of the upper left corner, the ordinate of the upper left corner, the abscissa of the lower right corner, and the ordinate of the lower right corner of the rectangular frame containing all persons.
分别代表所有包含人员的矩形边框的左上角横坐标、左上角纵坐标、右下角横坐标以及右下角纵坐标。
S6: Obtain the channel-weighted feature maps RW_L, RW_M, RW_H from the S5, and perform classification and frame coordinate regression respectively to obtain prediction results for persons with larger, medium and smaller sizes, and predict the above three different scales The results are summarized, and the non-maximum suppression (hereinafter referred to as NMS) algorithm is used to eliminate overlapping target borders, and the final retained person detection results are output, namely the category confidence score C i of the person and the predicted rectangular frame i=1,2,...,N. In this embodiment, i represents the ID number of the person, and N is the total number of person detection results retained in the current image. They represent the abscissa of the upper left corner, the ordinate of the upper left corner, the abscissa of the lower right corner, and the ordinate of the lower right corner of the rectangular frame containing all persons.
步骤S610:从所述步骤S510获取通道重加权后的低分辨率特征图RW_L,传输到SoftMax分类层和坐标回归层,输出在低分辨率特征图下预测较大尺寸人员的类别置信分数
 和矩形边框的左上角、右下角坐标
和矩形边框的左上角、右下角坐标
 其中下标L表示在低分辨率特征图下的预测结果。
Step S610: Obtain the channel-weighted low-resolution feature map RW_L from the step S510, transmit it to the SoftMax classification layer and the coordinate regression layer, and output the category confidence score for predicting larger-size persons under the low-resolution feature map And the coordinates of the upper left and lower right corners of the rectangular border The subscript L represents the prediction result under the low-resolution feature map.
其中下标L表示在低分辨率特征图下的预测结果。
Step S610: Obtain the channel-weighted low-resolution feature map RW_L from the step S510, transmit it to the SoftMax classification layer and the coordinate regression layer, and output the category confidence score for predicting larger-size persons under the low-resolution feature map And the coordinates of the upper left and lower right corners of the rectangular border The subscript L represents the prediction result under the low-resolution feature map.
步骤S620:从所述步骤S520获取通道重加权后的低分辨率特征图RW_M,传输到SoftMax分类层和坐标回归层,输出在中分辨率特征图下预测中等尺寸人员的类别置信分数
 和矩形边框的左上角、右下角坐标
和矩形边框的左上角、右下角坐标
 其中下标M表示在中分辨率特征图下的预测结果。
Step S620: Obtain the channel-weighted low-resolution feature map RW_M from the step S520, transmit it to the SoftMax classification layer and the coordinate regression layer, and output the category confidence score for predicting medium-sized persons under the medium-resolution feature map And the coordinates of the upper left and lower right corners of the rectangular border The subscript M represents the prediction result under the medium-resolution feature map.
其中下标M表示在中分辨率特征图下的预测结果。
Step S620: Obtain the channel-weighted low-resolution feature map RW_M from the step S520, transmit it to the SoftMax classification layer and the coordinate regression layer, and output the category confidence score for predicting medium-sized persons under the medium-resolution feature map And the coordinates of the upper left and lower right corners of the rectangular border The subscript M represents the prediction result under the medium-resolution feature map.
步骤S630:从所述步骤S530获取通道重加权后的高分辨率特征图RW_H,传输到SoftMax分类层和坐标回归层,输出在高分辨率特征图下预测较小尺寸人员的类别置信分数
 和矩形边框的左上角、右下角坐标
和矩形边框的左上角、右下角坐标
 其中下标H表示在高分辨率特征图下的预测结果。
Step S630: Obtain the channel-weighted high-resolution feature map RW_H from the step S530, transmit it to the SoftMax classification layer and the coordinate regression layer, and output the category confidence score for predicting the smaller-sized person under the high-resolution feature map And the coordinates of the upper left and lower right corners of the rectangular border The subscript H represents the prediction result under the high-resolution feature map.
其中下标H表示在高分辨率特征图下的预测结果。
Step S630: Obtain the channel-weighted high-resolution feature map RW_H from the step S530, transmit it to the SoftMax classification layer and the coordinate regression layer, and output the category confidence score for predicting the smaller-sized person under the high-resolution feature map And the coordinates of the upper left and lower right corners of the rectangular border The subscript H represents the prediction result under the high-resolution feature map.
步骤S640:从所述步骤S610、S620和S630获取较大、中等和较小尺寸人员的类别置信分数
 和矩形边框左上右下坐标
和矩形边框左上右下坐标

 对三种尺度的预测结果进行汇总,然后采用NMS算法去除重叠的目标边框,输出最终保留的人员检测结果。即人员的类别置信分数C
i和预测矩形边框
对三种尺度的预测结果进行汇总,然后采用NMS算法去除重叠的目标边框,输出最终保留的人员检测结果。即人员的类别置信分数C
i和预测矩形边框
 i=1,2,…,N。NMS算法流程图如图5所示。
Step S640: Obtain the category confidence scores of persons of larger, medium and smaller sizes from the steps S610, S620 and S630 And the upper left and lower right coordinates of the rectangular border The prediction results of the three scales are summarized, and then the NMS algorithm is used to remove the overlapping target frame, and the final retained personnel detection results are output. That is, the category confidence score of the person C i and the predicted rectangular frame i=1,2,...,N. The flow chart of the NMS algorithm is shown in Figure 5.
i=1,2,…,N。NMS算法流程图如图5所示。
Step S640: Obtain the category confidence scores of persons of larger, medium and smaller sizes from the steps S610, S620 and S630 And the upper left and lower right coordinates of the rectangular border The prediction results of the three scales are summarized, and then the NMS algorithm is used to remove the overlapping target frame, and the final retained personnel detection results are output. That is, the category confidence score of the person C i and the predicted rectangular frame i=1,2,...,N. The flow chart of the NMS algorithm is shown in Figure 5.
NMS算法步骤如下:The NMS algorithm steps are as follows:
步骤S640-1:从所述步骤S610、S620和S630获取较大、中等、较小尺寸的人员类别置信分数
 和矩形边框左上右下坐标
和矩形边框左上右下坐标

 对三种尺度的预测结果进行汇总,利用置信阈值对预测框进行筛选,保留类别置信分数大于置信阈值的预测边框,将其加入到预测列表中。在本实施例中置信阈值设置为0.3。
Step S640-1: Obtain the confidence scores of the categories of persons of larger, medium, and smaller sizes from the steps S610, S620, and S630 And the upper left and lower right coordinates of the rectangular border Summarize the prediction results of the three scales, use the confidence threshold to filter the prediction boxes, keep the prediction boxes with category confidence scores greater than the confidence threshold, and add them to the prediction list. In this embodiment, the confidence threshold is set to 0.3.
对三种尺度的预测结果进行汇总,利用置信阈值对预测框进行筛选,保留类别置信分数大于置信阈值的预测边框,将其加入到预测列表中。在本实施例中置信阈值设置为0.3。
Step S640-1: Obtain the confidence scores of the categories of persons of larger, medium, and smaller sizes from the steps S610, S620, and S630 And the upper left and lower right coordinates of the rectangular border Summarize the prediction results of the three scales, use the confidence threshold to filter the prediction boxes, keep the prediction boxes with category confidence scores greater than the confidence threshold, and add them to the prediction list. In this embodiment, the confidence threshold is set to 0.3.
步骤S640-2:从所述步骤S640-1获取的预测列表,对预测列表中未处理的预测边框按照置信分数降序排列,输出降序排列后的预测列表。Step S640-2: From the prediction list obtained in step S640-1, the unprocessed prediction frames in the prediction list are sorted in descending order of confidence scores, and the prediction list sorted in descending order is output.
步骤S640-3:从所述步骤S640-2中获取降序排列后的预测列表,选取最大置信分数对应的边框作为当前基准边框,将当前基准边框的类别置信分数和边框坐标加入到最终结果列表中,并将基准边框从预测列表中剔除,其余所有预测边框与当前基准边框计算交并比(IoU)。Step S640-3: Obtain the prediction list in descending order from the step S640-2, select the frame corresponding to the maximum confidence score as the current reference frame, and add the category confidence score and frame coordinates of the current reference frame to the final result list , And remove the reference frame from the prediction list, and calculate the intersection ratio (IoU) for all other predicted frames and the current reference frame.
步骤S640-4:从所述步骤S640-3获取预测列表以及预测列表中所有边框与基准边框的IoU值,若当前边框的IoU大于预设NMS阈值,则认为其与基准边框为重复目标,将其从预测边框列表中剔除,否则保留当前边框。输出筛选后的预测列表。Step S640-4: Obtain the prediction list and the IoU values of all the frames in the prediction list and the reference frame from the step S640-3. If the IoU of the current frame is greater than the preset NMS threshold, it is considered to be a duplicate target with the reference frame, and It is removed from the list of predicted bounding boxes, otherwise the current bounding box is kept. Output the filtered prediction list.
步骤S640-5:从所述步骤S640-4获取筛选后的预测列表,若预测列表中所有边框都处理完毕即预测边框为空,则算法结束,返回最终结果列表;反之,当前预测列表中仍存在未处理的边框,则返回步骤S640-2重复算法流程。Step S640-5: Obtain the filtered prediction list from the step S640-4. If all frames in the prediction list are processed, that is, the prediction frame is empty, the algorithm ends and the final result list is returned; otherwise, the current prediction list is still If there is an unprocessed frame, return to step S640-2 to repeat the algorithm flow.
步骤S640-6:对所述步骤S640-5,当预测列表中不存在未处理的预测边框时,输出最终结果列表为最终保留的人员检测结果。Step S640-6: For the step S640-5, when there is no unprocessed prediction frame in the prediction list, output the final result list as the final retained personnel detection result.
参考文献:references:
[1]Neubeck A,Gool L V.Efficient Non-Maximum Suppression[C]//International Conference on Pattern Recognition.2006.[1]Neubeck A, Gool L V. Efficient Non-Maximum Suppression[C]//International Conference on Pattern Recognition. 2006.
[2]Zhang Y,Funkhouser T.Deep Depth Completion of a Single RGB-D Image[J].2018.[2]Zhang Y, Funkhouser T. Deep Depth Completion of a Single RGB-D Image[J].2018.
[3]Gupta S,Girshick R,Arbeláez P,et al.Learning Rich Features from RGB-D Images for Object Detection and Segmentation[C]//2014.[3]Gupta S, Girshick R, Arbeláez P, et al. Learning Rich Features from RGB-D Images for Object Detection and Segmentation[C]//2014.
[4]Redmon J,Farhadi A.YOLOv3:An Incremental Improvement[J].2018.[4]Redmon J, Farhadi A.YOLOv3: An Incremental Improvement[J].2018.
Claims (10)
- 一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:包含RGBD图像采集,深度图像预处理,RGB特征提取和Depth特征提取,RGB多尺度融合和Depth多尺度融合,多模态特征通道重加权以及多尺度人员预测。A RGB-D multi-modal fusion method for personnel detection based on an asymmetric dual-stream network, which is characterized by: including RGBD image acquisition, depth image preprocessing, RGB feature extraction and Depth feature extraction, RGB multi-scale fusion and Depth multi-scale fusion , Multi-modal feature channel weighting and multi-scale personnel prediction.
- 根据权利要求1所述的一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:S1RGBD图像采集;An RGB-D multi-modal fusion method for personnel detection based on an asymmetric dual-stream network according to claim 1, characterized in that: S1RGBD image acquisition;利用具有同时拍摄RGB图像和深度图像功能的相机获取原始RGB图像和Depth图像,并对RGB和Depth图像进行匹配分组,每组图像由一张RGB图像和同场景下捕获的Depth图像组成,输出分组匹配后的RGB和Depth图像;原始RGB图像和Depth图像也能够从公开RGBD数据集获取。The original RGB image and Depth image are acquired by a camera with the function of simultaneously shooting RGB images and depth images, and the RGB and Depth images are matched and grouped. Each group of images is composed of an RGB image and a Depth image captured in the same scene, and output Grouped and matched RGB and Depth images; the original RGB image and Depth image can also be obtained from the public RGBD data set.
- 根据权利要求2所述的一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:S2深度图像预处理;The RGB-D multi-modal fusion method for personnel detection based on an asymmetric dual-stream network according to claim 2, characterized in that: S2 depth image preprocessing;从S1的RGBD图像采集获取分组匹配后的Depth图像,首先消除Depth图像的部分噪声,然后进行空洞填充,最后将单通道Depth图像重新编码为三个通道图像,并将三个通道的图像数值重新规范化到0-255,输出编码规范化后的Depth图像。Obtain the grouped and matched Depth image from the RGBD image of S1. First, remove part of the noise of the Depth image, then fill in the holes, and finally re-encode the single-channel Depth image into three-channel images, and re-encode the image values of the three channels Normalize to 0-255, and output the Depth image after encoding normalization.
- 根据权利要求3所述的一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:S3RGB特征提取和Depth特征提取;An RGB-D multi-modal fusion method for personnel detection based on an asymmetric dual-stream network according to claim 3, characterized in that: S3RGB feature extraction and Depth feature extraction;从所述S1的RGBD图像采集获取原始RGB图像,输入到RGB特征提取,进行下采样特征提取,输出RGB图像的高、中、低分辨率特征图,分别记为RGB_FP_H、RGB_FP_M、RGB_FP_L,代表RGB图像的低级色彩纹理、中级边缘轮廓和高级语义特征表示;从深度图像预处理获取编码规范化后的Depth图像,输入到Depth特征提取,进行下采样特征提取,输出Depth图像的高、中、低分辨率特征图,分别记为D_FP_H、D_FP_M、D_FP_L,代表Depth图像的低级色彩纹理、中级边缘轮廓和高级语义特征表示;RGB网络流和Depth网络流是对称结构的,即RGB网络流和Depth网络流的结构完全相同;设计非对称双流卷积神经网络模型提取RGB图像和Depth图像特征;DarkNet-53和MiniDepth-30分别代表RGB网络流和Depth网络流,DarkNet-53和MiniDepth-30的网络结构具有非对称的特性。Obtain the original RGB image from the S1 RGBD image collection, input it to RGB feature extraction, perform down-sampling feature extraction, and output the high, medium, and low resolution feature maps of the RGB image, which are respectively denoted as RGB_FP_H, RGB_FP_M, RGB_FP_L, representing RGB The low-level color texture, middle-level edge contour and high-level semantic feature representation of the image; the Depth image after coding and normalization is obtained from the depth image preprocessing, input to the Depth feature extraction, down-sampling feature extraction, and the high, medium and low resolution of the Depth image are output Rate feature maps, respectively denoted as D_FP_H, D_FP_M, D_FP_L, represent the low-level color texture, intermediate edge contour, and high-level semantic feature representation of the Depth image; the RGB network flow and the Depth network flow are symmetrical, that is, the RGB network flow and the Depth network flow The structure is exactly the same; the asymmetric dual-stream convolutional neural network model is designed to extract the features of the RGB image and the depth image; DarkNet-53 and MiniDepth-30 represent the RGB network stream and the depth network stream, respectively, and the network structure of DarkNet-53 and MiniDepth-30 has Asymmetrical characteristics.
- 根据权利要求4所述的一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:S4RGB多尺度融合和Depth多尺度融合;The RGB-D multi-modal fusion method for personnel detection based on an asymmetric dual-stream network according to claim 4, characterized in that: S4RGB multi-scale fusion and Depth multi-scale fusion;从RGB特征提取获取RGB特征图RGB_FP_H、RGB_FP_M、RGB_FP_L输入到RGB多尺度融合,首先将获取的RGB_FP_L通过上采样层拓展到与RGB_FP_M相同尺寸,然后与RGB_FP_M进行通道合并,实现RGB网络深层的高级语义特征与中间层的中级边缘轮廓特征的互补融合,输出通道合并后的新特征图RGB_FP_M;然后对输出通道合并后的新特征图RGB_FP_M,通过上采样层拓展到与RGB_FP_H相同尺寸,与RGB_FP_H进行通道合并,实现RGB网络深层的高级语义特征、中间层的中级边缘轮廓特征以及浅层的低级色彩纹理特征的互补融合,输出通道合并后的新特征图RGB_FP_H;从Depth特征提取获取Depth特征图D_FP_H、D_FP_M、D_FP_L输入到Depth多尺度融合,与RGB多尺度融合执行同样的操作;最终Depth多尺度融合的输出为原始输入RGB_FP_L、通道合并后的新特征图RGB_FP_M和RGB_FP_H;Depth多尺度融合的输出为原始输入D_FP_L、通道合并后的新特征图D_FP_M和D_FP_H。From RGB feature extraction to obtain RGB feature maps RGB_FP_H, RGB_FP_M, RGB_FP_L input to the RGB multi-scale fusion, first expand the obtained RGB_FP_L to the same size as RGB_FP_M through the upsampling layer, and then merge the channels with RGB_FP_M to realize the advanced semantics of the RGB network deep layer The complementary fusion of features and the mid-level edge contour features of the middle layer, the output channel merged new feature map RGB_FP_M; then the new feature map RGB_FP_M after the output channel merged is expanded to the same size as RGB_FP_H through the upsampling layer, and the channel is channeled with RGB_FP_H Merge, realize the complementary fusion of the deep high-level semantic features of the RGB network, the middle-level edge contour features of the middle layer, and the shallow low-level color texture features, and output the new feature map RGB_FP_H after channel merging; obtain the Depth feature map D_FP_H, from the Depth feature extraction, D_FP_M and D_FP_L are input to Depth multi-scale fusion, and perform the same operation as RGB multi-scale fusion; the final Depth multi-scale fusion output is the original input RGB_FP_L, and the new feature maps after channel merging RGB_FP_M and RGB_FP_H; the output of Depth multi-scale fusion is The original input D_FP_L, the new feature maps D_FP_M and D_FP_H after the channel merge.
- 根据权利要求5所述的一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:S5多模态特征通道重加权;The RGB-D multi-modal fusion method for personnel detection based on an asymmetric dual-stream network according to claim 5, characterized in that: S5 multi-modal feature channels are reweighted;从RGB多尺度融合获取RGB特征图RGB_FP_L、RGB_FP_M、RGB_FP_H和从Depth多尺度融合获取Depth特征图D_FP_L、D_FP_M、D_FP_H,按照分辨率分组输入到多模态特征通道重加权中对应相同分辨率的通道重加权结构中,实现更有效的RGB与Depth的多模态特征融合,提高处理多种限制场景下的检测鲁棒性;具体做法以RGB_FP_L与D_FP_L通道重加权为例,从RGB多尺度融合获取RGB_FP_L以及从Depth多尺度融合获取D_FP_L,首先进行通道合并,获得通道合并后的特征图记为Concat_L;然后应用通道重加权模块简称为RW_Module对Concat_L的特征通道进行线性加权,为每个特征通道赋予权重,输出通道重加权后的特征图记为RW_L;RGB_FP_M与D_FP_M,RGB_FP_H与D_FP_H的通道重加权采用与所述RGB_FP_L和D_FP_L相同方式完成;最终多模态特征通道重加权输出通道重加权后的低、中、高分辨率特征图,分别记为RW_L,RW_M,RW_H。Obtain RGB feature maps RGB_FP_L, RGB_FP_M, RGB_FP_H from RGB multi-scale fusion and Depth feature maps D_FP_L, D_FP_M, D_FP_H from Depth multi-scale fusion, and enter the channels corresponding to the same resolution in the multi-modal feature channel weighting according to the resolution grouping In the re-weighting structure, more effective RGB and Depth multi-modal feature fusion is realized, and the detection robustness in processing a variety of restricted scenes is improved; the specific method is to take the re-weighting of RGB_FP_L and D_FP_L channels as an example, and obtain from RGB multi-scale fusion RGB_FP_L and D_FP_L are obtained from Depth multi-scale fusion. First, channel merging is performed, and the feature map obtained after channel merging is marked as Concat_L; then the channel weighting module is abbreviated as RW_Module to linearly weight the feature channels of Concat_L, and each feature channel is assigned Weight, the re-weighted feature map of the output channel is marked as RW_L; the channel re-weighting of RGB_FP_M and D_FP_M, RGB_FP_H and D_FP_H is done in the same way as the RGB_FP_L and D_FP_L; the final multi-modal feature channel re-weighted output channel re-weighted Low, medium, and high-resolution feature maps are marked as RW_L, RW_M, and RW_H respectively.
- 根据权利要求6所述的一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:S6多尺度人员预测;An RGB-D multi-modal fusion method for personnel detection based on an asymmetric dual-stream network according to claim 6, characterized in that: S6 multi-scale personnel prediction;从所述S5的多模态特征通道重加权获取通道重加权后的特征图RW_L,RW_M,RW_H,分别输入到多尺度人员预测中对应的预测分支中进行分类和边框坐标回归,获得较大、中等以及较小尺寸人员的预测结果;由于特征图分辨率不同,特征图上每个预测点对应的感受野也不同;RW_L上的每个预测点具有较大感受野,用来预测图像中的较大目标;RW_M上的每个预测点具有中等感受野,用来预测图像中的中等目标;RW_H上的每个预测点具有较小感受野,用来预测图像中的较小目标;对上述三种不同尺度的预测结果进行汇总,采用非极大值抑制算法剔除重叠目标边框,输出最终保留的人员检测结果,即人员的类别置信分数C i和预测矩形边框i=1,2,…,N;i代表人员的ID编号,N为在当前图像中保留的人员检测结果总数;
 分别代表所有包含人员的矩形边框的左上角横坐标、左上角纵坐标、右下角横坐标以及右下角纵坐标。 Obtain the re-weighted feature maps RW_L, RW_M, and RW_H from the multi-modal feature channel of the S5, and input them into the corresponding prediction branch in the multi-scale human prediction for classification and frame coordinate regression to obtain larger, The prediction results of medium and small size personnel; due to the different resolution of the feature map, the receptive field corresponding to each prediction point on the feature map is also different; each prediction point on RW_L has a larger receptive field, which is used to predict the image Larger target; each prediction point on RW_M has a medium receptive field, which is used to predict a medium target in the image; each prediction point on RW_H has a small receptive field, which is used to predict a smaller target in the image; The prediction results of three different scales are summarized, and the non-maximum value suppression algorithm is used to eliminate overlapping target frames, and the final retained personnel detection results are output, namely the category confidence score C i of the personnel and the predicted rectangular frame
分别代表所有包含人员的矩形边框的左上角横坐标、左上角纵坐标、右下角横坐标以及右下角纵坐标。 Obtain the re-weighted feature maps RW_L, RW_M, and RW_H from the multi-modal feature channel of the S5, and input them into the corresponding prediction branch in the multi-scale human prediction for classification and frame coordinate regression to obtain larger, The prediction results of medium and small size personnel; due to the different resolution of the feature map, the receptive field corresponding to each prediction point on the feature map is also different; each prediction point on RW_L has a larger receptive field, which is used to predict the image Larger target; each prediction point on RW_M has a medium receptive field, which is used to predict a medium target in the image; each prediction point on RW_H has a small receptive field, which is used to predict a smaller target in the image; The prediction results of three different scales are summarized, and the non-maximum value suppression algorithm is used to eliminate overlapping target frames, and the final retained personnel detection results are output, namely the category confidence score C i of the personnel and the predicted rectangular frame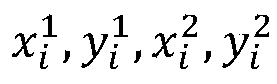 i=1,2,...,N; i represents the ID number of the person, and N is the total number of person detection results retained in the current image;They represent the abscissa of the upper left corner, the ordinate of the upper left corner, the abscissa of the lower right corner, and the ordinate of the lower right corner of the rectangular frame containing all persons.
i=1,2,...,N; i represents the ID number of the person, and N is the total number of person detection results retained in the current image;They represent the abscissa of the upper left corner, the ordinate of the upper left corner, the abscissa of the lower right corner, and the ordinate of the lower right corner of the rectangular frame containing all persons. - 根据权利要求2所述的一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:The RGB-D multi-modal fusion personnel detection method based on an asymmetric dual-stream network according to claim 2, characterized in that:步骤S110:利用具有同时拍摄RGB图像和深度图像功能的相机获取原始RGB图像,原始RGB图像也可以从公开RGBD数据集获取;Step S110: Obtain the original RGB image by using a camera with the function of simultaneously shooting RGB images and depth images, and the original RGB images can also be obtained from the public RGBD data set;步骤S120:从所述步骤S110同步获取与RGB图像匹配的Depth图像,并对RGB和Depth图像进行分组,每组图像由一张RGB图像和同场景下捕获的深度图像组成,输出分组匹配后的Depth图像。Step S120: Acquire the Depth image matching the RGB image synchronously from the step S110, and group the RGB and Depth images. Each group of images is composed of an RGB image and a depth image captured in the same scene, and the output group is matched Depth image.
- 根据权利要求2所述的一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:获取较大、中等和较小尺寸人员的类别置信分数和矩形边框左上右下坐标 The RGB-D multi-modal fusion method for detecting persons based on an asymmetric two-stream network according to claim 2, characterized in that: obtaining category confidence scores of persons of larger, medium and smaller sizes
 And the upper left and lower right coordinates of the rectangular border
And the upper left and lower right coordinates of the rectangular border 对三种尺度的预测结果进行汇总,然后采用NMS算法去除重叠的目标边框,输出最终保留的人员检测结果;即人员的类别置信分数C i和预测矩形边框i=1,2,…,N。 Summarize the prediction results of the three scales, then use the NMS algorithm to remove the overlapping target borders, and output the final retained personnel detection results; namely, the category confidence score C i of the personnel and the predicted rectangular frame
对三种尺度的预测结果进行汇总,然后采用NMS算法去除重叠的目标边框,输出最终保留的人员检测结果;即人员的类别置信分数C i和预测矩形边框i=1,2,…,N。 Summarize the prediction results of the three scales, then use the NMS algorithm to remove the overlapping target borders, and output the final retained personnel detection results; namely, the category confidence score C i of the personnel and the predicted rectangular frame i=1,2,...,N.
i=1,2,...,N. - 根据权利要求9所述的一种基于非对称双流网络的RGB-D多模态融合人员检测方法,其特征在于:The RGB-D multi-modal fusion method for personnel detection based on an asymmetric dual-stream network according to claim 9, characterized in that:NMS算法步骤如下:The NMS algorithm steps are as follows:步骤S640-1:从获取较大、中等、较小尺寸的人员类别置信分数和矩形边框左上右下坐标
 对 三种尺度的预测结果进行汇总,利用置信阈值对预测框进行筛选,保留类别置信分数大于置信阈值的预测边框,将其加入到预测列表中;置信阈值设置为0.3; Step S640-1: Obtain the confidence scores of the categories of persons of larger, medium, and smaller sizes from
对 三种尺度的预测结果进行汇总,利用置信阈值对预测框进行筛选,保留类别置信分数大于置信阈值的预测边框,将其加入到预测列表中;置信阈值设置为0.3; Step S640-1: Obtain the confidence scores of the categories of persons of larger, medium, and smaller sizes from And the upper left and lower right coordinates of the rectangular borderSummarize the prediction results of the three scales, use the confidence threshold to filter the prediction boxes, keep the prediction boxes with category confidence scores greater than the confidence threshold, and add them to the prediction list; set the confidence threshold to 0.3;步骤S640-2:从所述步骤S640-1获取的预测列表,对预测列表中未处理的预测边框按照置信分数降序排列,输出降序排列后的预测列表;Step S640-2: From the prediction list obtained in step S640-1, arrange the unprocessed prediction frames in the prediction list in descending order of confidence scores, and output the prediction list in descending order;步骤S640-3:从所述步骤S640-2中获取降序排列后的预测列表,选取最大置信分数对应的边框作为当前基准边框,将当前基准边框的类别置信分数和边框坐标加入到最终结果列表中,并将基准边框从预测列表中剔除,其余所有预测边框与当前基准边框计算交并比IoU;Step S640-3: Obtain the prediction list in descending order from the step S640-2, select the frame corresponding to the maximum confidence score as the current reference frame, and add the category confidence score and frame coordinates of the current reference frame to the final result list , And remove the reference frame from the prediction list, and calculate the intersection and IoU of all other predicted frames with the current reference frame;步骤S640-4:从所述步骤S640-3获取预测列表以及预测列表中所有边框与基准边框的IoU值,若当前边框的IoU大于预设NMS阈值,则认为其与基准边框为重复目标,将其从预测边框列表中剔除,否则保留当前边框;输出筛选后的预测列表;Step S640-4: Obtain the prediction list and the IoU values of all the frames in the prediction list and the reference frame from the step S640-3. If the IoU of the current frame is greater than the preset NMS threshold, it is considered to be a duplicate target with the reference frame, and Remove it from the prediction frame list, otherwise keep the current frame; output the filtered prediction list;步骤S640-5:从所述步骤S640-4获取筛选后的预测列表,若预测列表中所有边框都处理完毕即预测边框为空,则算法结束,返回最终结果列表;反之,当前预测列表中仍存在未处理的边框,则返回步骤S640-2重复算法流程;Step S640-5: Obtain the filtered prediction list from the step S640-4. If all frames in the prediction list are processed, that is, the prediction frame is empty, the algorithm ends and the final result list is returned; otherwise, the current prediction list is still If there is an unprocessed frame, return to step S640-2 to repeat the algorithm flow;步骤S640-6:对所述步骤S640-5,当预测列表中不存在未处理的预测边框时,输出最终结果列表为最终保留的人员检测结果。Step S640-6: For the step S640-5, when there is no unprocessed prediction frame in the prediction list, output the final result list as the final retained personnel detection result.
And the upper left and lower right coordinates of the rectangular borderSummarize the prediction results of the three scales, use the confidence threshold to filter the prediction boxes, keep the prediction boxes with category confidence scores greater than the confidence threshold, and add them to the prediction list; set the confidence threshold to 0.3;步骤S640-2:从所述步骤S640-1获取的预测列表,对预测列表中未处理的预测边框按照置信分数降序排列,输出降序排列后的预测列表;Step S640-2: From the prediction list obtained in step S640-1, arrange the unprocessed prediction frames in the prediction list in descending order of confidence scores, and output the prediction list in descending order;步骤S640-3:从所述步骤S640-2中获取降序排列后的预测列表,选取最大置信分数对应的边框作为当前基准边框,将当前基准边框的类别置信分数和边框坐标加入到最终结果列表中,并将基准边框从预测列表中剔除,其余所有预测边框与当前基准边框计算交并比IoU;Step S640-3: Obtain the prediction list in descending order from the step S640-2, select the frame corresponding to the maximum confidence score as the current reference frame, and add the category confidence score and frame coordinates of the current reference frame to the final result list , And remove the reference frame from the prediction list, and calculate the intersection and IoU of all other predicted frames with the current reference frame;步骤S640-4:从所述步骤S640-3获取预测列表以及预测列表中所有边框与基准边框的IoU值,若当前边框的IoU大于预设NMS阈值,则认为其与基准边框为重复目标,将其从预测边框列表中剔除,否则保留当前边框;输出筛选后的预测列表;Step S640-4: Obtain the prediction list and the IoU values of all the frames in the prediction list and the reference frame from the step S640-3. If the IoU of the current frame is greater than the preset NMS threshold, it is considered to be a duplicate target with the reference frame, and Remove it from the prediction frame list, otherwise keep the current frame; output the filtered prediction list;步骤S640-5:从所述步骤S640-4获取筛选后的预测列表,若预测列表中所有边框都处理完毕即预测边框为空,则算法结束,返回最终结果列表;反之,当前预测列表中仍存在未处理的边框,则返回步骤S640-2重复算法流程;Step S640-5: Obtain the filtered prediction list from the step S640-4. If all frames in the prediction list are processed, that is, the prediction frame is empty, the algorithm ends and the final result list is returned; otherwise, the current prediction list is still If there is an unprocessed frame, return to step S640-2 to repeat the algorithm flow;步骤S640-6:对所述步骤S640-5,当预测列表中不存在未处理的预测边框时,输出最终结果列表为最终保留的人员检测结果。Step S640-6: For the step S640-5, when there is no unprocessed prediction frame in the prediction list, output the final result list as the final retained personnel detection result.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911090619.5A CN110956094B (en) | 2019-11-09 | 2019-11-09 | RGB-D multi-mode fusion personnel detection method based on asymmetric double-flow network |
| CN201911090619.5 | 2019-11-09 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021088300A1 true WO2021088300A1 (en) | 2021-05-14 |
Family
ID=69977120
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2020/080991 WO2021088300A1 (en) | 2019-11-09 | 2020-03-25 | Rgb-d multi-mode fusion personnel detection method based on asymmetric double-stream network |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN110956094B (en) |
| WO (1) | WO2021088300A1 (en) |
Cited By (51)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113298094A (en) * | 2021-06-10 | 2021-08-24 | 安徽大学 | RGB-T significance target detection method based on modal association and double-perception decoder |
| CN113313688A (en) * | 2021-05-28 | 2021-08-27 | 武汉乾峯智能科技有限公司 | Energetic material medicine barrel identification method and system, electronic equipment and storage medium |
| CN113361466A (en) * | 2021-06-30 | 2021-09-07 | 江南大学 | Multi-modal cross-directed learning-based multi-spectral target detection method |
| CN113362224A (en) * | 2021-05-31 | 2021-09-07 | 维沃移动通信有限公司 | Image processing method and device, electronic equipment and readable storage medium |
| CN113468954A (en) * | 2021-05-20 | 2021-10-01 | 西安电子科技大学 | Face counterfeiting detection method based on local area features under multiple channels |
| CN113486781A (en) * | 2021-07-02 | 2021-10-08 | 国网电力科学研究院有限公司 | Electric power inspection method and device based on deep learning model |
| CN113537326A (en) * | 2021-07-06 | 2021-10-22 | 安徽大学 | A method for salient object detection in RGB-D images |
| CN113538615A (en) * | 2021-06-29 | 2021-10-22 | 中国海洋大学 | Remote sensing image colorization method based on two-stream generator deep convolutional adversarial generative network |
| CN113569723A (en) * | 2021-07-27 | 2021-10-29 | 北京京东尚科信息技术有限公司 | Face detection method and device, electronic equipment and storage medium |
| CN113657521A (en) * | 2021-08-23 | 2021-11-16 | 天津大学 | Method for separating two mutually exclusive components in image |
| CN113658134A (en) * | 2021-08-13 | 2021-11-16 | 安徽大学 | A Multimodal Alignment Calibration Method for Salient Object Detection in RGB-D Images |
| CN113848234A (en) * | 2021-09-16 | 2021-12-28 | 南京航空航天大学 | Method for detecting aviation composite material based on multi-mode information |
| CN113902783A (en) * | 2021-11-19 | 2022-01-07 | 东北大学 | Three-modal image fused saliency target detection system and method |
| CN113989245A (en) * | 2021-10-28 | 2022-01-28 | 杭州中科睿鉴科技有限公司 | Multi-view multi-scale image tampering detection method |
| CN114037938A (en) * | 2021-11-09 | 2022-02-11 | 桂林电子科技大学 | A low-light target detection method based on NFL-Net |
| CN114049508A (en) * | 2022-01-12 | 2022-02-15 | 成都无糖信息技术有限公司 | Fraud website identification method and system based on picture clustering and manual research and judgment |
| CN114119965A (en) * | 2021-11-30 | 2022-03-01 | 齐鲁工业大学 | A road target detection method and system |
| CN114170174A (en) * | 2021-12-02 | 2022-03-11 | 沈阳工业大学 | CLANet steel rail surface defect detection system and method based on RGB-D image |
| CN114202663A (en) * | 2021-12-03 | 2022-03-18 | 大连理工大学宁波研究院 | A saliency detection method based on color image and depth image |
| CN114202646A (en) * | 2021-11-26 | 2022-03-18 | 深圳市朗驰欣创科技股份有限公司 | Infrared image smoking detection method and system based on deep learning |
| CN114219807A (en) * | 2022-02-22 | 2022-03-22 | 成都爱迦飞诗特科技有限公司 | Mammary gland ultrasonic examination image grading method, device, equipment and storage medium |
| CN114359228A (en) * | 2022-01-06 | 2022-04-15 | 深圳思谋信息科技有限公司 | Object surface defect detection method and device, computer equipment and storage medium |
| CN114372986A (en) * | 2021-12-30 | 2022-04-19 | 深圳大学 | Image Semantic Segmentation Method and Device Based on Attention-Guided Multimodal Feature Fusion |
| CN114445442A (en) * | 2022-01-28 | 2022-05-06 | 杭州电子科技大学 | Multispectral image semantic segmentation method based on asymmetric cross fusion |
| CN114663436A (en) * | 2022-05-25 | 2022-06-24 | 南京航空航天大学 | Cross-scale defect detection method based on deep learning |
| CN114708295A (en) * | 2022-04-02 | 2022-07-05 | 华南理工大学 | Logistics package separation method based on Transformer |
| CN114821488A (en) * | 2022-06-30 | 2022-07-29 | 华东交通大学 | Crowd counting method and system based on multi-modal network and computer equipment |
| CN114998826A (en) * | 2022-05-12 | 2022-09-02 | 西北工业大学 | Crowd detection method under dense scene |
| CN115100409A (en) * | 2022-06-30 | 2022-09-23 | 温州大学 | A Video Portrait Segmentation Algorithm Based on Siamese Network |
| CN115273154A (en) * | 2022-09-26 | 2022-11-01 | 哈尔滨工业大学(深圳)(哈尔滨工业大学深圳科技创新研究院) | Thermal infrared pedestrian detection method and system based on edge reconstruction and storage medium |
| CN115641507A (en) * | 2022-11-07 | 2023-01-24 | 哈尔滨工业大学 | Remote sensing image small-scale surface target detection method based on self-adaptive multi-level fusion |
| CN115731473A (en) * | 2022-10-28 | 2023-03-03 | 南开大学 | Remote sensing image analysis method for abnormal changes of farmland plants |
| CN115909182A (en) * | 2022-08-09 | 2023-04-04 | 哈尔滨市科佳通用机电股份有限公司 | An Image Recognition Method for EMU Brake Pad Wear Faults |
| CN115937791A (en) * | 2023-01-10 | 2023-04-07 | 华南农业大学 | Poultry counting method and device suitable for multiple breeding modes |
| CN115984672A (en) * | 2023-03-17 | 2023-04-18 | 成都纵横自动化技术股份有限公司 | Method and device for detecting small target in high-definition image based on deep learning |
| CN116206133A (en) * | 2023-04-25 | 2023-06-02 | 山东科技大学 | RGB-D significance target detection method |
| CN116311077A (en) * | 2023-04-10 | 2023-06-23 | 东北大学 | Pedestrian detection method and device based on multispectral fusion of saliency map |
| CN116343308A (en) * | 2023-04-04 | 2023-06-27 | 湖南交通工程学院 | Fused face image detection method, device, equipment and storage medium |
| CN116519106A (en) * | 2023-06-30 | 2023-08-01 | 中国农业大学 | A method, device, storage medium and equipment for measuring the body weight of live pigs |
| CN116715560A (en) * | 2023-08-10 | 2023-09-08 | 吉林隆源农业服务有限公司 | Intelligent preparation method and system of controlled release fertilizer |
| CN116758117A (en) * | 2023-06-28 | 2023-09-15 | 云南大学 | Target tracking method and system under visible light and infrared images |
| CN116823908A (en) * | 2023-06-26 | 2023-09-29 | 北京邮电大学 | A monocular image depth estimation method based on multi-scale feature correlation enhancement |
| CN117237343A (en) * | 2023-11-13 | 2023-12-15 | 安徽大学 | Semi-supervised RGB-D image mirror detection method, storage medium and computer equipment |
| CN117350926A (en) * | 2023-12-04 | 2024-01-05 | 北京航空航天大学合肥创新研究院 | Multi-mode data enhancement method based on target weight |
| CN117392572A (en) * | 2023-12-11 | 2024-01-12 | 四川能投发展股份有限公司 | Transmission tower bird nest detection method based on unmanned aerial vehicle inspection |
| CN117475182A (en) * | 2023-09-13 | 2024-01-30 | 江南大学 | Stereo matching method based on multi-feature aggregation |
| CN117635953A (en) * | 2024-01-26 | 2024-03-01 | 泉州装备制造研究所 | A real-time semantic segmentation method for power systems based on multi-modal drone aerial photography |
| CN118172615A (en) * | 2024-05-14 | 2024-06-11 | 山西新泰富安新材有限公司 | Method for reducing burn rate of heating furnace |
| CN118553002A (en) * | 2024-07-29 | 2024-08-27 | 浙江幸福轨道交通运营管理有限公司 | Face recognition system and method based on cloud platform four-layer architecture AFC system |
| CN118982488A (en) * | 2024-07-19 | 2024-11-19 | 南京审计大学 | A multi-scale low-light image enhancement method based on full-resolution semantic guidance |
| CN119049091A (en) * | 2024-10-30 | 2024-11-29 | 杭州电子科技大学 | Human body identifier identification method based on dynamic detection reliability update |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111767882B (en) * | 2020-07-06 | 2024-07-19 | 江南大学 | Multi-mode pedestrian detection method based on improved YOLO model |
| CN111968058B (en) * | 2020-08-25 | 2023-08-04 | 北京交通大学 | A Noise Reduction Method for Low Dose CT Image |
| CN111986240A (en) * | 2020-09-01 | 2020-11-24 | 交通运输部水运科学研究所 | Drowning person detection method and system based on visible light and thermal imaging data fusion |
| CN112434654B (en) * | 2020-12-07 | 2022-09-13 | 安徽大学 | Cross-modal pedestrian re-identification method based on symmetric convolutional neural network |
| CN113221659B (en) * | 2021-04-13 | 2022-12-23 | 天津大学 | A dual-light vehicle detection method and device based on uncertain perception network |
| CN113240631B (en) * | 2021-04-22 | 2023-12-12 | 北京中科慧眼科技有限公司 | Road surface detection method and system based on RGB-D fusion information and intelligent terminal |
| CN113360712B (en) * | 2021-05-21 | 2022-12-06 | 北京百度网讯科技有限公司 | Video representation generation method and device and electronic equipment |
| CN113536978B (en) * | 2021-06-28 | 2023-08-18 | 杭州电子科技大学 | A Saliency-Based Camouflaged Target Detection Method |
| CN113887332B (en) * | 2021-09-13 | 2024-04-05 | 华南理工大学 | Skin operation safety monitoring method based on multi-mode fusion |
| CN113902903B (en) * | 2021-09-30 | 2024-08-02 | 北京工业大学 | Downsampling-based double-attention multi-scale fusion method |
| CN113887425B (en) * | 2021-09-30 | 2024-04-12 | 北京工业大学 | Lightweight object detection method and system for low-computation-force computing device |
| CN114581838B (en) * | 2022-04-26 | 2022-08-26 | 阿里巴巴达摩院(杭州)科技有限公司 | Image processing method, device and cloud device |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140107842A1 (en) * | 2012-10-16 | 2014-04-17 | Electronics And Telecommunications Research Institute | Human-tracking method and robot apparatus for performing the same |
| CN107045630A (en) * | 2017-04-24 | 2017-08-15 | 杭州司兰木科技有限公司 | A kind of pedestrian detection and personal identification method and system based on RGBD |
| CN108734210A (en) * | 2018-05-17 | 2018-11-02 | 浙江工业大学 | A kind of method for checking object based on cross-module state multi-scale feature fusion |
| CN109543697A (en) * | 2018-11-16 | 2019-03-29 | 西北工业大学 | A kind of RGBD images steganalysis method based on deep learning |
| CN109598301A (en) * | 2018-11-30 | 2019-04-09 | 腾讯科技(深圳)有限公司 | Detection zone minimizing technology, device, terminal and storage medium |
| WO2019162241A1 (en) * | 2018-02-21 | 2019-08-29 | Robert Bosch Gmbh | Real-time object detection using depth sensors |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105956532B (en) * | 2016-04-25 | 2019-05-21 | 大连理工大学 | A kind of traffic scene classification method based on multiple dimensioned convolutional neural networks |
| CN110309747B (en) * | 2019-06-21 | 2022-09-16 | 大连理工大学 | Support quick degree of depth pedestrian detection model of multiscale |
-
2019
- 2019-11-09 CN CN201911090619.5A patent/CN110956094B/en active Active
-
2020
- 2020-03-25 WO PCT/CN2020/080991 patent/WO2021088300A1/en active Application Filing
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140107842A1 (en) * | 2012-10-16 | 2014-04-17 | Electronics And Telecommunications Research Institute | Human-tracking method and robot apparatus for performing the same |
| CN107045630A (en) * | 2017-04-24 | 2017-08-15 | 杭州司兰木科技有限公司 | A kind of pedestrian detection and personal identification method and system based on RGBD |
| WO2019162241A1 (en) * | 2018-02-21 | 2019-08-29 | Robert Bosch Gmbh | Real-time object detection using depth sensors |
| CN108734210A (en) * | 2018-05-17 | 2018-11-02 | 浙江工业大学 | A kind of method for checking object based on cross-module state multi-scale feature fusion |
| CN109543697A (en) * | 2018-11-16 | 2019-03-29 | 西北工业大学 | A kind of RGBD images steganalysis method based on deep learning |
| CN109598301A (en) * | 2018-11-30 | 2019-04-09 | 腾讯科技(深圳)有限公司 | Detection zone minimizing technology, device, terminal and storage medium |
Cited By (81)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113468954A (en) * | 2021-05-20 | 2021-10-01 | 西安电子科技大学 | Face counterfeiting detection method based on local area features under multiple channels |
| CN113468954B (en) * | 2021-05-20 | 2023-04-18 | 西安电子科技大学 | Face counterfeiting detection method based on local area features under multiple channels |
| CN113313688A (en) * | 2021-05-28 | 2021-08-27 | 武汉乾峯智能科技有限公司 | Energetic material medicine barrel identification method and system, electronic equipment and storage medium |
| CN113313688B (en) * | 2021-05-28 | 2022-08-05 | 武汉乾峯智能科技有限公司 | A method, system, electronic device and storage medium for identifying an energetic material medicine barrel |
| CN113362224A (en) * | 2021-05-31 | 2021-09-07 | 维沃移动通信有限公司 | Image processing method and device, electronic equipment and readable storage medium |
| CN113298094B (en) * | 2021-06-10 | 2022-11-04 | 安徽大学 | An RGB-T Salient Object Detection Method Based on Modality Correlation and Dual Perceptual Decoder |
| CN113298094A (en) * | 2021-06-10 | 2021-08-24 | 安徽大学 | RGB-T significance target detection method based on modal association and double-perception decoder |
| CN113538615B (en) * | 2021-06-29 | 2024-01-09 | 中国海洋大学 | Remote sensing image coloring method based on double-flow generator depth convolution countermeasure generation network |
| CN113538615A (en) * | 2021-06-29 | 2021-10-22 | 中国海洋大学 | Remote sensing image colorization method based on two-stream generator deep convolutional adversarial generative network |
| CN113361466A (en) * | 2021-06-30 | 2021-09-07 | 江南大学 | Multi-modal cross-directed learning-based multi-spectral target detection method |
| CN113361466B (en) * | 2021-06-30 | 2024-03-12 | 江南大学 | Multispectral target detection method based on multi-mode cross guidance learning |
| CN113486781A (en) * | 2021-07-02 | 2021-10-08 | 国网电力科学研究院有限公司 | Electric power inspection method and device based on deep learning model |
| CN113486781B (en) * | 2021-07-02 | 2023-10-24 | 国网电力科学研究院有限公司 | Electric power inspection method and device based on deep learning model |
| CN113537326A (en) * | 2021-07-06 | 2021-10-22 | 安徽大学 | A method for salient object detection in RGB-D images |
| CN113569723A (en) * | 2021-07-27 | 2021-10-29 | 北京京东尚科信息技术有限公司 | Face detection method and device, electronic equipment and storage medium |
| CN113658134A (en) * | 2021-08-13 | 2021-11-16 | 安徽大学 | A Multimodal Alignment Calibration Method for Salient Object Detection in RGB-D Images |
| CN113657521B (en) * | 2021-08-23 | 2023-09-19 | 天津大学 | A way to separate two mutually exclusive components in an image |
| CN113657521A (en) * | 2021-08-23 | 2021-11-16 | 天津大学 | Method for separating two mutually exclusive components in image |
| CN113848234A (en) * | 2021-09-16 | 2021-12-28 | 南京航空航天大学 | Method for detecting aviation composite material based on multi-mode information |
| CN113989245A (en) * | 2021-10-28 | 2022-01-28 | 杭州中科睿鉴科技有限公司 | Multi-view multi-scale image tampering detection method |
| CN113989245B (en) * | 2021-10-28 | 2023-01-24 | 杭州中科睿鉴科技有限公司 | Multi-view multi-scale image tampering detection method |
| CN114037938A (en) * | 2021-11-09 | 2022-02-11 | 桂林电子科技大学 | A low-light target detection method based on NFL-Net |
| CN114037938B (en) * | 2021-11-09 | 2024-03-26 | 桂林电子科技大学 | NFL-Net-based low-illumination target detection method |
| CN113902783B (en) * | 2021-11-19 | 2024-04-30 | 东北大学 | A salient object detection system and method integrating three-modal images |
| CN113902783A (en) * | 2021-11-19 | 2022-01-07 | 东北大学 | Three-modal image fused saliency target detection system and method |
| CN114202646A (en) * | 2021-11-26 | 2022-03-18 | 深圳市朗驰欣创科技股份有限公司 | Infrared image smoking detection method and system based on deep learning |
| CN114119965A (en) * | 2021-11-30 | 2022-03-01 | 齐鲁工业大学 | A road target detection method and system |
| CN114170174A (en) * | 2021-12-02 | 2022-03-11 | 沈阳工业大学 | CLANet steel rail surface defect detection system and method based on RGB-D image |
| CN114170174B (en) * | 2021-12-02 | 2024-01-23 | 沈阳工业大学 | CLANet steel rail surface defect detection system and method based on RGB-D image |
| CN114202663A (en) * | 2021-12-03 | 2022-03-18 | 大连理工大学宁波研究院 | A saliency detection method based on color image and depth image |
| CN114372986A (en) * | 2021-12-30 | 2022-04-19 | 深圳大学 | Image Semantic Segmentation Method and Device Based on Attention-Guided Multimodal Feature Fusion |
| CN114372986B (en) * | 2021-12-30 | 2024-05-24 | 深圳大学 | Image semantic segmentation method and device for attention-guided multi-modal feature fusion |
| CN114359228A (en) * | 2022-01-06 | 2022-04-15 | 深圳思谋信息科技有限公司 | Object surface defect detection method and device, computer equipment and storage medium |
| CN114049508A (en) * | 2022-01-12 | 2022-02-15 | 成都无糖信息技术有限公司 | Fraud website identification method and system based on picture clustering and manual research and judgment |
| CN114049508B (en) * | 2022-01-12 | 2022-04-01 | 成都无糖信息技术有限公司 | Fraud website identification method and system based on picture clustering and manual research and judgment |
| CN114445442B (en) * | 2022-01-28 | 2022-12-02 | 杭州电子科技大学 | Multispectral image semantic segmentation method based on asymmetric cross fusion |
| CN114445442A (en) * | 2022-01-28 | 2022-05-06 | 杭州电子科技大学 | Multispectral image semantic segmentation method based on asymmetric cross fusion |
| CN114219807A (en) * | 2022-02-22 | 2022-03-22 | 成都爱迦飞诗特科技有限公司 | Mammary gland ultrasonic examination image grading method, device, equipment and storage medium |
| CN114708295B (en) * | 2022-04-02 | 2024-04-16 | 华南理工大学 | A logistics package separation method based on Transformer |
| CN114708295A (en) * | 2022-04-02 | 2022-07-05 | 华南理工大学 | Logistics package separation method based on Transformer |
| CN114998826A (en) * | 2022-05-12 | 2022-09-02 | 西北工业大学 | Crowd detection method under dense scene |
| CN114663436A (en) * | 2022-05-25 | 2022-06-24 | 南京航空航天大学 | Cross-scale defect detection method based on deep learning |
| CN115100409B (en) * | 2022-06-30 | 2024-04-26 | 温州大学 | A video portrait segmentation algorithm based on Siamese network |
| CN115100409A (en) * | 2022-06-30 | 2022-09-23 | 温州大学 | A Video Portrait Segmentation Algorithm Based on Siamese Network |
| CN114821488A (en) * | 2022-06-30 | 2022-07-29 | 华东交通大学 | Crowd counting method and system based on multi-modal network and computer equipment |
| CN115909182A (en) * | 2022-08-09 | 2023-04-04 | 哈尔滨市科佳通用机电股份有限公司 | An Image Recognition Method for EMU Brake Pad Wear Faults |
| CN115909182B (en) * | 2022-08-09 | 2023-08-08 | 哈尔滨市科佳通用机电股份有限公司 | Method for identifying abrasion fault image of brake pad of motor train unit |
| CN115273154B (en) * | 2022-09-26 | 2023-01-17 | 哈尔滨工业大学(深圳)(哈尔滨工业大学深圳科技创新研究院) | Thermal infrared pedestrian detection method and system based on edge reconstruction and storage medium |
| CN115273154A (en) * | 2022-09-26 | 2022-11-01 | 哈尔滨工业大学(深圳)(哈尔滨工业大学深圳科技创新研究院) | Thermal infrared pedestrian detection method and system based on edge reconstruction and storage medium |
| CN115731473B (en) * | 2022-10-28 | 2024-05-31 | 南开大学 | Remote sensing image analysis method for farmland plant abnormal change |
| CN115731473A (en) * | 2022-10-28 | 2023-03-03 | 南开大学 | Remote sensing image analysis method for abnormal changes of farmland plants |
| CN115641507A (en) * | 2022-11-07 | 2023-01-24 | 哈尔滨工业大学 | Remote sensing image small-scale surface target detection method based on self-adaptive multi-level fusion |
| CN115937791A (en) * | 2023-01-10 | 2023-04-07 | 华南农业大学 | Poultry counting method and device suitable for multiple breeding modes |
| CN115984672A (en) * | 2023-03-17 | 2023-04-18 | 成都纵横自动化技术股份有限公司 | Method and device for detecting small target in high-definition image based on deep learning |
| CN116343308B (en) * | 2023-04-04 | 2024-02-09 | 湖南交通工程学院 | Fused face image detection method, device, equipment and storage medium |
| CN116343308A (en) * | 2023-04-04 | 2023-06-27 | 湖南交通工程学院 | Fused face image detection method, device, equipment and storage medium |
| CN116311077B (en) * | 2023-04-10 | 2023-11-07 | 东北大学 | Pedestrian detection method and device based on multispectral fusion of saliency map |
| CN116311077A (en) * | 2023-04-10 | 2023-06-23 | 东北大学 | Pedestrian detection method and device based on multispectral fusion of saliency map |
| CN116206133A (en) * | 2023-04-25 | 2023-06-02 | 山东科技大学 | RGB-D significance target detection method |
| CN116206133B (en) * | 2023-04-25 | 2023-09-05 | 山东科技大学 | A RGB-D salient object detection method |
| CN116823908A (en) * | 2023-06-26 | 2023-09-29 | 北京邮电大学 | A monocular image depth estimation method based on multi-scale feature correlation enhancement |
| CN116758117A (en) * | 2023-06-28 | 2023-09-15 | 云南大学 | Target tracking method and system under visible light and infrared images |
| CN116758117B (en) * | 2023-06-28 | 2024-02-09 | 云南大学 | Target tracking method and system under visible light and infrared images |
| CN116519106B (en) * | 2023-06-30 | 2023-09-15 | 中国农业大学 | Method, device, storage medium and equipment for determining weight of live pigs |
| CN116519106A (en) * | 2023-06-30 | 2023-08-01 | 中国农业大学 | A method, device, storage medium and equipment for measuring the body weight of live pigs |
| CN116715560A (en) * | 2023-08-10 | 2023-09-08 | 吉林隆源农业服务有限公司 | Intelligent preparation method and system of controlled release fertilizer |
| CN116715560B (en) * | 2023-08-10 | 2023-11-14 | 吉林隆源农业服务有限公司 | Intelligent preparation method and system of controlled release fertilizer |
| CN117475182B (en) * | 2023-09-13 | 2024-06-04 | 江南大学 | Stereo matching method based on multi-feature aggregation |
| CN117475182A (en) * | 2023-09-13 | 2024-01-30 | 江南大学 | Stereo matching method based on multi-feature aggregation |
| CN117237343B (en) * | 2023-11-13 | 2024-01-30 | 安徽大学 | Semi-supervised RGB-D image mirror detection method, storage media and computer equipment |
| CN117237343A (en) * | 2023-11-13 | 2023-12-15 | 安徽大学 | Semi-supervised RGB-D image mirror detection method, storage medium and computer equipment |
| CN117350926A (en) * | 2023-12-04 | 2024-01-05 | 北京航空航天大学合肥创新研究院 | Multi-mode data enhancement method based on target weight |
| CN117350926B (en) * | 2023-12-04 | 2024-02-13 | 北京航空航天大学合肥创新研究院 | Multi-mode data enhancement method based on target weight |
| CN117392572A (en) * | 2023-12-11 | 2024-01-12 | 四川能投发展股份有限公司 | Transmission tower bird nest detection method based on unmanned aerial vehicle inspection |
| CN117392572B (en) * | 2023-12-11 | 2024-02-27 | 四川能投发展股份有限公司 | Transmission tower bird nest detection method based on unmanned aerial vehicle inspection |
| CN117635953B (en) * | 2024-01-26 | 2024-04-26 | 泉州装备制造研究所 | Multi-mode unmanned aerial vehicle aerial photography-based real-time semantic segmentation method for power system |
| CN117635953A (en) * | 2024-01-26 | 2024-03-01 | 泉州装备制造研究所 | A real-time semantic segmentation method for power systems based on multi-modal drone aerial photography |
| CN118172615A (en) * | 2024-05-14 | 2024-06-11 | 山西新泰富安新材有限公司 | Method for reducing burn rate of heating furnace |
| CN118982488A (en) * | 2024-07-19 | 2024-11-19 | 南京审计大学 | A multi-scale low-light image enhancement method based on full-resolution semantic guidance |
| CN118553002A (en) * | 2024-07-29 | 2024-08-27 | 浙江幸福轨道交通运营管理有限公司 | Face recognition system and method based on cloud platform four-layer architecture AFC system |
| CN119049091A (en) * | 2024-10-30 | 2024-11-29 | 杭州电子科技大学 | Human body identifier identification method based on dynamic detection reliability update |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110956094B (en) | 2023-12-01 |
| CN110956094A (en) | 2020-04-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021088300A1 (en) | Rgb-d multi-mode fusion personnel detection method based on asymmetric double-stream network | |
| CN109819208B (en) | Intensive population security monitoring management method based on artificial intelligence dynamic monitoring | |
| CN107253485B (en) | Foreign matter invades detection method and foreign matter invades detection device | |
| CN112288008B (en) | Mosaic multispectral image disguised target detection method based on deep learning | |
| AU2006252252B2 (en) | Image processing method and apparatus | |
| CN111931684A (en) | A weak and small target detection method based on discriminative features of video satellite data | |
| CN110363140A (en) | A real-time recognition method of human action based on infrared images | |
| CN107622258A (en) | A Fast Pedestrian Detection Method Combining Static Low-level Features and Motion Information | |
| CN110309781A (en) | Remote sensing recognition method for house damage based on multi-scale spectral texture adaptive fusion | |
| Zin et al. | Fusion of infrared and visible images for robust person detection | |
| CN103049751A (en) | Improved weighting region matching high-altitude video pedestrian recognizing method | |
| CN106295636A (en) | Passageway for fire apparatus based on multiple features fusion cascade classifier vehicle checking method | |
| CN117152443B (en) | Image instance segmentation method and system based on semantic lead guidance | |
| CN112926506A (en) | Non-controlled face detection method and system based on convolutional neural network | |
| CN112084928B (en) | Road traffic accident detection method based on visual attention mechanism and ConvLSTM network | |
| CN114119586A (en) | Intelligent detection method for aircraft skin defects based on machine vision | |
| CN111582074A (en) | Monitoring video leaf occlusion detection method based on scene depth information perception | |
| CN105513053A (en) | Background modeling method for video analysis | |
| CN114648714A (en) | YOLO-based workshop normative behavior monitoring method | |
| CN114519819A (en) | Remote sensing image target detection method based on global context awareness | |
| CN113177439B (en) | Pedestrian crossing road guardrail detection method | |
| Zhu et al. | Towards automatic wild animal detection in low quality camera-trap images using two-channeled perceiving residual pyramid networks | |
| CN115376202A (en) | Deep learning-based method for recognizing passenger behaviors in elevator car | |
| CN111274964A (en) | Detection method for analyzing water surface pollutants based on visual saliency of unmanned aerial vehicle | |
| CN107045630B (en) | RGBD-based pedestrian detection and identity recognition method and system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20884981 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20884981 Country of ref document: EP Kind code of ref document: A1 |