TW202217000A - Sars-cov-2 mrna domain vaccines - Google Patents
Sars-cov-2 mrna domain vaccines Download PDFInfo
- Publication number
- TW202217000A TW202217000A TW110123289A TW110123289A TW202217000A TW 202217000 A TW202217000 A TW 202217000A TW 110123289 A TW110123289 A TW 110123289A TW 110123289 A TW110123289 A TW 110123289A TW 202217000 A TW202217000 A TW 202217000A
- Authority
- TW
- Taiwan
- Prior art keywords
- mrna
- seq
- amino acid
- mol
- orf
- Prior art date
Links
- 229960005486 vaccine Drugs 0.000 title abstract description 81
- 108020004999 messenger RNA Proteins 0.000 title description 45
- 239000000203 mixture Substances 0.000 claims abstract description 244
- 229920002477 rna polymer Polymers 0.000 claims abstract description 101
- 238000000034 method Methods 0.000 claims abstract description 70
- 102000036639 antigens Human genes 0.000 claims description 363
- 108091007433 antigens Proteins 0.000 claims description 363
- 239000000427 antigen Substances 0.000 claims description 359
- 108700026244 Open Reading Frames Proteins 0.000 claims description 343
- 125000003729 nucleotide group Chemical group 0.000 claims description 241
- 150000002632 lipids Chemical class 0.000 claims description 224
- 239000002773 nucleotide Substances 0.000 claims description 217
- 108090000623 proteins and genes Proteins 0.000 claims description 159
- 102000004169 proteins and genes Human genes 0.000 claims description 144
- 239000002105 nanoparticle Substances 0.000 claims description 127
- 241001678559 COVID-19 virus Species 0.000 claims description 125
- 150000001413 amino acids Chemical class 0.000 claims description 106
- 230000028993 immune response Effects 0.000 claims description 80
- 108020001507 fusion proteins Proteins 0.000 claims description 76
- 102000037865 fusion proteins Human genes 0.000 claims description 76
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 claims description 70
- 101000629318 Severe acute respiratory syndrome coronavirus 2 Spike glycoprotein Proteins 0.000 claims description 68
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 63
- UVBYMVOUBXYSFV-XUTVFYLZSA-N 1-methylpseudouridine Chemical compound O=C1NC(=O)N(C)C=C1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 UVBYMVOUBXYSFV-XUTVFYLZSA-N 0.000 claims description 60
- UVBYMVOUBXYSFV-UHFFFAOYSA-N 1-methylpseudouridine Natural products O=C1NC(=O)N(C)C=C1C1C(O)C(O)C(CO)O1 UVBYMVOUBXYSFV-UHFFFAOYSA-N 0.000 claims description 57
- 229930182558 Sterol Natural products 0.000 claims description 50
- 150000003432 sterols Chemical class 0.000 claims description 50
- 235000003702 sterols Nutrition 0.000 claims description 50
- 230000027455 binding Effects 0.000 claims description 49
- 102100031673 Corneodesmosin Human genes 0.000 claims description 48
- 101710198474 Spike protein Proteins 0.000 claims description 48
- 125000002091 cationic group Chemical group 0.000 claims description 48
- 101710139375 Corneodesmosin Proteins 0.000 claims description 46
- 230000003472 neutralizing effect Effects 0.000 claims description 46
- 229940096437 Protein S Drugs 0.000 claims description 45
- 230000007935 neutral effect Effects 0.000 claims description 42
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 38
- 102000005962 receptors Human genes 0.000 claims description 38
- 108020003175 receptors Proteins 0.000 claims description 38
- NRJAVPSFFCBXDT-HUESYALOSA-N 1,2-distearoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCCCCCC NRJAVPSFFCBXDT-HUESYALOSA-N 0.000 claims description 36
- 235000012000 cholesterol Nutrition 0.000 claims description 35
- -1 cationic lipid Chemical class 0.000 claims description 34
- 229920001223 polyethylene glycol Polymers 0.000 claims description 31
- 229940125904 compound 1 Drugs 0.000 claims description 29
- 101710154606 Hemagglutinin Proteins 0.000 claims description 28
- 101710093908 Outer capsid protein VP4 Proteins 0.000 claims description 28
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 claims description 28
- 101710176177 Protein A56 Proteins 0.000 claims description 28
- 239000000185 hemagglutinin Substances 0.000 claims description 28
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 27
- 108091023045 Untranslated Region Proteins 0.000 claims description 27
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 claims description 27
- 206010022000 influenza Diseases 0.000 claims description 27
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 24
- 230000004927 fusion Effects 0.000 claims description 24
- 239000002202 Polyethylene glycol Substances 0.000 claims description 23
- MTHSVFCYNBDYFN-UHFFFAOYSA-N diethylene glycol Chemical compound OCCOCCO MTHSVFCYNBDYFN-UHFFFAOYSA-N 0.000 claims description 21
- 230000032258 transport Effects 0.000 claims description 18
- 230000005875 antibody response Effects 0.000 claims description 16
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 claims description 13
- 210000004899 c-terminal region Anatomy 0.000 claims description 13
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 claims description 13
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 claims description 13
- 229940045145 uridine Drugs 0.000 claims description 13
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical group NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 claims description 11
- 238000007385 chemical modification Methods 0.000 claims description 11
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 claims description 10
- 210000002540 macrophage Anatomy 0.000 claims description 9
- 210000005220 cytoplasmic tail Anatomy 0.000 claims description 8
- WWZKQHOCKIZLMA-UHFFFAOYSA-N octanoic acid Chemical compound CCCCCCCC(O)=O WWZKQHOCKIZLMA-UHFFFAOYSA-N 0.000 claims description 8
- 101001046686 Homo sapiens Integrin alpha-M Proteins 0.000 claims description 7
- 102100022338 Integrin alpha-M Human genes 0.000 claims description 7
- HVVJCLFLKMGEIY-USYZEHPZSA-N [(2R)-2,3-dioctadecoxypropyl] 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCCCCCCCCCCCCOC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OCCCCCCCCCCCCCCCCCC HVVJCLFLKMGEIY-USYZEHPZSA-N 0.000 claims description 7
- 125000000954 2-hydroxyethyl group Chemical group [H]C([*])([H])C([H])([H])O[H] 0.000 claims description 6
- 150000001412 amines Chemical class 0.000 claims description 6
- 125000004051 hexyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 claims description 6
- 230000011664 signaling Effects 0.000 claims description 6
- 108091026898 Leader sequence (mRNA) Proteins 0.000 claims description 5
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 claims description 5
- 108091036066 Three prime untranslated region Proteins 0.000 claims description 4
- OBETXYAYXDNJHR-UHFFFAOYSA-N alpha-ethylcaproic acid Natural products CCCCC(CC)C(O)=O OBETXYAYXDNJHR-UHFFFAOYSA-N 0.000 claims description 4
- 239000003550 marker Substances 0.000 claims description 4
- 102000006354 HLA-DR Antigens Human genes 0.000 claims description 2
- 108010058597 HLA-DR Antigens Proteins 0.000 claims description 2
- 125000003277 amino group Chemical group 0.000 claims 1
- 241000711573 Coronaviridae Species 0.000 abstract description 67
- 108700021021 mRNA Vaccine Proteins 0.000 abstract description 28
- 229940022005 RNA vaccine Drugs 0.000 abstract description 16
- 125000003275 alpha amino acid group Chemical group 0.000 description 198
- 235000018102 proteins Nutrition 0.000 description 132
- 150000007523 nucleic acids Chemical class 0.000 description 126
- 102000039446 nucleic acids Human genes 0.000 description 124
- 108020004707 nucleic acids Proteins 0.000 description 124
- 108020005345 3' Untranslated Regions Proteins 0.000 description 117
- 108020003589 5' Untranslated Regions Proteins 0.000 description 116
- 210000004027 cell Anatomy 0.000 description 72
- 125000000217 alkyl group Chemical group 0.000 description 63
- 108020004705 Codon Proteins 0.000 description 59
- 125000003342 alkenyl group Chemical group 0.000 description 56
- 239000000126 substance Substances 0.000 description 51
- 235000001014 amino acid Nutrition 0.000 description 49
- 229940024606 amino acid Drugs 0.000 description 47
- 229910052799 carbon Inorganic materials 0.000 description 46
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 45
- 102000004196 processed proteins & peptides Human genes 0.000 description 44
- 241000700605 Viruses Species 0.000 description 39
- 108020004414 DNA Proteins 0.000 description 35
- 102000053602 DNA Human genes 0.000 description 35
- 108091005609 SARS-CoV-2 Spike Subunit S1 Proteins 0.000 description 35
- 150000001875 compounds Chemical class 0.000 description 34
- 125000005647 linker group Chemical group 0.000 description 34
- 239000012528 membrane Substances 0.000 description 34
- 229920001184 polypeptide Polymers 0.000 description 34
- 239000002777 nucleoside Substances 0.000 description 31
- 125000003835 nucleoside group Chemical group 0.000 description 31
- 230000001965 increasing effect Effects 0.000 description 26
- 108091005634 SARS-CoV-2 receptor-binding domains Proteins 0.000 description 25
- 238000008416 Ferritin Methods 0.000 description 24
- 102000008857 Ferritin Human genes 0.000 description 22
- 108050000784 Ferritin Proteins 0.000 description 22
- 230000000890 antigenic effect Effects 0.000 description 22
- 230000006870 function Effects 0.000 description 22
- 102000040430 polynucleotide Human genes 0.000 description 22
- 108091033319 polynucleotide Proteins 0.000 description 22
- 239000002157 polynucleotide Substances 0.000 description 21
- 230000014616 translation Effects 0.000 description 20
- 230000003612 virological effect Effects 0.000 description 20
- 108010033040 Histones Proteins 0.000 description 19
- 210000003719 b-lymphocyte Anatomy 0.000 description 19
- 229910052739 hydrogen Inorganic materials 0.000 description 19
- 108020001580 protein domains Proteins 0.000 description 19
- 241000008904 Betacoronavirus Species 0.000 description 18
- 239000012634 fragment Substances 0.000 description 18
- 238000002965 ELISA Methods 0.000 description 17
- 125000000623 heterocyclic group Chemical group 0.000 description 17
- 238000012217 deletion Methods 0.000 description 16
- 230000037430 deletion Effects 0.000 description 16
- 238000004519 manufacturing process Methods 0.000 description 16
- 230000002163 immunogen Effects 0.000 description 15
- 210000002966 serum Anatomy 0.000 description 15
- 108091006367 SARS-CoV-2 Spike Subunit S2 Proteins 0.000 description 14
- 230000036039 immunity Effects 0.000 description 14
- 238000013519 translation Methods 0.000 description 14
- 108020005176 AU Rich Elements Proteins 0.000 description 13
- 230000001939 inductive effect Effects 0.000 description 13
- 230000001681 protective effect Effects 0.000 description 13
- 208000025721 COVID-19 Diseases 0.000 description 12
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 12
- 238000013461 design Methods 0.000 description 12
- 230000000694 effects Effects 0.000 description 12
- 230000014509 gene expression Effects 0.000 description 12
- 125000001072 heteroaryl group Chemical group 0.000 description 12
- 238000001727 in vivo Methods 0.000 description 12
- 229940126582 mRNA vaccine Drugs 0.000 description 12
- 238000006467 substitution reaction Methods 0.000 description 12
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 11
- 208000015181 infectious disease Diseases 0.000 description 11
- 230000000069 prophylactic effect Effects 0.000 description 11
- 230000004044 response Effects 0.000 description 11
- 235000000346 sugar Nutrition 0.000 description 11
- 238000012360 testing method Methods 0.000 description 11
- RGICCULPCWNRAB-UHFFFAOYSA-N 2-[2-(2-hexoxyethoxy)ethoxy]ethanol Chemical compound CCCCCCOCCOCCOCCO RGICCULPCWNRAB-UHFFFAOYSA-N 0.000 description 10
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 10
- 229940028617 conventional vaccine Drugs 0.000 description 10
- 238000000338 in vitro Methods 0.000 description 10
- 230000004048 modification Effects 0.000 description 10
- 238000012986 modification Methods 0.000 description 10
- 230000035772 mutation Effects 0.000 description 10
- 238000006386 neutralization reaction Methods 0.000 description 10
- 238000012545 processing Methods 0.000 description 10
- 150000003839 salts Chemical class 0.000 description 10
- 210000001519 tissue Anatomy 0.000 description 10
- 238000013518 transcription Methods 0.000 description 10
- 230000035897 transcription Effects 0.000 description 10
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 9
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 9
- 208000001528 Coronaviridae Infections Diseases 0.000 description 9
- 102000002067 Protein Subunits Human genes 0.000 description 9
- 150000004676 glycans Chemical class 0.000 description 9
- 238000003786 synthesis reaction Methods 0.000 description 9
- 102000053723 Angiotensin-converting enzyme 2 Human genes 0.000 description 8
- 108090000975 Angiotensin-converting enzyme 2 Proteins 0.000 description 8
- 241000699670 Mus sp. Species 0.000 description 8
- 108091081024 Start codon Proteins 0.000 description 8
- 239000008186 active pharmaceutical agent Substances 0.000 description 8
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 8
- 125000003118 aryl group Chemical group 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 238000003776 cleavage reaction Methods 0.000 description 8
- 239000003814 drug Substances 0.000 description 8
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 8
- 230000005847 immunogenicity Effects 0.000 description 8
- 238000000746 purification Methods 0.000 description 8
- 230000009467 reduction Effects 0.000 description 8
- 230000007017 scission Effects 0.000 description 8
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 7
- 102000004190 Enzymes Human genes 0.000 description 7
- 108090000790 Enzymes Proteins 0.000 description 7
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 7
- 102100027382 Membrane-bound transcription factor site-2 protease Human genes 0.000 description 7
- 108091034057 RNA (poly(A)) Proteins 0.000 description 7
- 238000004422 calculation algorithm Methods 0.000 description 7
- 238000010790 dilution Methods 0.000 description 7
- 239000012895 dilution Substances 0.000 description 7
- 229940088598 enzyme Drugs 0.000 description 7
- 239000008194 pharmaceutical composition Substances 0.000 description 7
- 239000000546 pharmaceutical excipient Substances 0.000 description 7
- 239000007787 solid Substances 0.000 description 7
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 6
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 6
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 6
- 229960005305 adenosine Drugs 0.000 description 6
- 239000002671 adjuvant Substances 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 125000004429 atom Chemical group 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 210000000170 cell membrane Anatomy 0.000 description 6
- 229940104302 cytosine Drugs 0.000 description 6
- 238000011161 development Methods 0.000 description 6
- 201000010099 disease Diseases 0.000 description 6
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 6
- 229940079593 drug Drugs 0.000 description 6
- 210000001165 lymph node Anatomy 0.000 description 6
- 230000003389 potentiating effect Effects 0.000 description 6
- 230000008569 process Effects 0.000 description 6
- 230000000087 stabilizing effect Effects 0.000 description 6
- 230000008685 targeting Effects 0.000 description 6
- 230000001225 therapeutic effect Effects 0.000 description 6
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 6
- 239000003981 vehicle Substances 0.000 description 6
- 229930024421 Adenine Natural products 0.000 description 5
- 108091036407 Polyadenylation Proteins 0.000 description 5
- 108010001267 Protein Subunits Proteins 0.000 description 5
- 241001112090 Pseudovirus Species 0.000 description 5
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 5
- 241000315672 SARS coronavirus Species 0.000 description 5
- 101710172711 Structural protein Proteins 0.000 description 5
- 230000005867 T cell response Effects 0.000 description 5
- 239000004480 active ingredient Substances 0.000 description 5
- 229960000643 adenine Drugs 0.000 description 5
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 5
- 125000002837 carbocyclic group Chemical group 0.000 description 5
- 230000015556 catabolic process Effects 0.000 description 5
- 230000008859 change Effects 0.000 description 5
- 230000000295 complement effect Effects 0.000 description 5
- 238000006731 degradation reaction Methods 0.000 description 5
- 239000012530 fluid Substances 0.000 description 5
- 238000004128 high performance liquid chromatography Methods 0.000 description 5
- 210000000987 immune system Anatomy 0.000 description 5
- 230000003053 immunization Effects 0.000 description 5
- 230000000670 limiting effect Effects 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 230000034217 membrane fusion Effects 0.000 description 5
- 238000010172 mouse model Methods 0.000 description 5
- 238000005457 optimization Methods 0.000 description 5
- 230000008520 organization Effects 0.000 description 5
- 230000036961 partial effect Effects 0.000 description 5
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 5
- 230000001105 regulatory effect Effects 0.000 description 5
- 238000001890 transfection Methods 0.000 description 5
- 229940035893 uracil Drugs 0.000 description 5
- 238000002255 vaccination Methods 0.000 description 5
- 241000894006 Bacteria Species 0.000 description 4
- 125000000882 C2-C6 alkenyl group Chemical group 0.000 description 4
- 108010061994 Coronavirus Spike Glycoprotein Proteins 0.000 description 4
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 4
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 4
- 102100034235 ELAV-like protein 1 Human genes 0.000 description 4
- 239000004471 Glycine Substances 0.000 description 4
- 102100022823 Histone RNA hairpin-binding protein Human genes 0.000 description 4
- 101000825762 Homo sapiens Histone RNA hairpin-binding protein Proteins 0.000 description 4
- 229930185560 Pseudouridine Natural products 0.000 description 4
- PTJWIQPHWPFNBW-UHFFFAOYSA-N Pseudouridine C Natural products OC1C(O)C(CO)OC1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-UHFFFAOYSA-N 0.000 description 4
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 4
- 108010067390 Viral Proteins Proteins 0.000 description 4
- 125000000539 amino acid group Chemical group 0.000 description 4
- 238000005571 anion exchange chromatography Methods 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- WGDUUQDYDIIBKT-UHFFFAOYSA-N beta-Pseudouridine Natural products OC1OC(CN2C=CC(=O)NC2=O)C(O)C1O WGDUUQDYDIIBKT-UHFFFAOYSA-N 0.000 description 4
- 210000000805 cytoplasm Anatomy 0.000 description 4
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 4
- 239000003937 drug carrier Substances 0.000 description 4
- 230000002708 enhancing effect Effects 0.000 description 4
- 230000002255 enzymatic effect Effects 0.000 description 4
- 210000001808 exosome Anatomy 0.000 description 4
- 238000009472 formulation Methods 0.000 description 4
- 230000036541 health Effects 0.000 description 4
- 125000005842 heteroatom Chemical group 0.000 description 4
- 125000000592 heterocycloalkyl group Chemical group 0.000 description 4
- 239000001257 hydrogen Substances 0.000 description 4
- 238000002649 immunization Methods 0.000 description 4
- 230000006698 induction Effects 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 230000003834 intracellular effect Effects 0.000 description 4
- 239000002609 medium Substances 0.000 description 4
- 239000000178 monomer Substances 0.000 description 4
- 229910052760 oxygen Inorganic materials 0.000 description 4
- 239000002245 particle Substances 0.000 description 4
- 210000002706 plastid Anatomy 0.000 description 4
- 229940023143 protein vaccine Drugs 0.000 description 4
- 230000002829 reductive effect Effects 0.000 description 4
- 238000004007 reversed phase HPLC Methods 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 239000007790 solid phase Substances 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 229910052717 sulfur Inorganic materials 0.000 description 4
- 229940113082 thymine Drugs 0.000 description 4
- 239000005526 vasoconstrictor agent Substances 0.000 description 4
- 125000006273 (C1-C3) alkyl group Chemical group 0.000 description 3
- UHDGCWIWMRVCDJ-UHFFFAOYSA-N 1-beta-D-Xylofuranosyl-NH-Cytosine Natural products O=C1N=C(N)C=CN1C1C(O)C(O)C(CO)O1 UHDGCWIWMRVCDJ-UHFFFAOYSA-N 0.000 description 3
- 101800001779 2'-O-methyltransferase Proteins 0.000 description 3
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical compound OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 3
- ZAYHVCMSTBRABG-UHFFFAOYSA-N 5-Methylcytidine Natural products O=C1N=C(N)C(C)=CN1C1C(O)C(O)C(CO)O1 ZAYHVCMSTBRABG-UHFFFAOYSA-N 0.000 description 3
- 108010068996 6,7-dimethyl-8-ribityllumazine synthase Proteins 0.000 description 3
- UHDGCWIWMRVCDJ-PSQAKQOGSA-N Cytidine Natural products O=C1N=C(N)C=CN1[C@@H]1[C@@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-PSQAKQOGSA-N 0.000 description 3
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 3
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 3
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 3
- 241000127282 Middle East respiratory syndrome-related coronavirus Species 0.000 description 3
- 208000037847 SARS-CoV-2-infection Diseases 0.000 description 3
- 208000036142 Viral infection Diseases 0.000 description 3
- 238000007792 addition Methods 0.000 description 3
- 230000030741 antigen processing and presentation Effects 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 150000001720 carbohydrates Chemical group 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 210000004443 dendritic cell Anatomy 0.000 description 3
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 210000002443 helper t lymphocyte Anatomy 0.000 description 3
- 229940031551 inactivated vaccine Drugs 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 239000007791 liquid phase Substances 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 210000001806 memory b lymphocyte Anatomy 0.000 description 3
- 244000052769 pathogen Species 0.000 description 3
- 230000008488 polyadenylation Effects 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 230000001737 promoting effect Effects 0.000 description 3
- PTJWIQPHWPFNBW-GBNDHIKLSA-N pseudouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-GBNDHIKLSA-N 0.000 description 3
- 230000003248 secreting effect Effects 0.000 description 3
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 3
- 238000011144 upstream manufacturing Methods 0.000 description 3
- 230000007501 viral attachment Effects 0.000 description 3
- 230000009385 viral infection Effects 0.000 description 3
- OILXMJHPFNGGTO-UHFFFAOYSA-N (22E)-(24xi)-24-methylcholesta-5,22-dien-3beta-ol Natural products C1C=C2CC(O)CCC2(C)C2C1C1CCC(C(C)C=CC(C)C(C)C)C1(C)CC2 OILXMJHPFNGGTO-UHFFFAOYSA-N 0.000 description 2
- KILNVBDSWZSGLL-KXQOOQHDSA-N 1,2-dihexadecanoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCCCC KILNVBDSWZSGLL-KXQOOQHDSA-N 0.000 description 2
- KVUXYQHEESDGIJ-UHFFFAOYSA-N 10,13-dimethyl-2,3,4,5,6,7,8,9,11,12,14,15,16,17-tetradecahydro-1h-cyclopenta[a]phenanthrene-3,16-diol Chemical compound C1CC2CC(O)CCC2(C)C2C1C1CC(O)CC1(C)CC2 KVUXYQHEESDGIJ-UHFFFAOYSA-N 0.000 description 2
- HZAXFHJVJLSVMW-UHFFFAOYSA-N 2-Aminoethan-1-ol Chemical compound NCCO HZAXFHJVJLSVMW-UHFFFAOYSA-N 0.000 description 2
- ZAYHVCMSTBRABG-JXOAFFINSA-N 5-methylcytidine Chemical compound O=C1N=C(N)C(C)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 ZAYHVCMSTBRABG-JXOAFFINSA-N 0.000 description 2
- OQMZNAMGEHIHNN-UHFFFAOYSA-N 7-Dehydrostigmasterol Natural products C1C(O)CCC2(C)C(CCC3(C(C(C)C=CC(CC)C(C)C)CCC33)C)C3=CC=C21 OQMZNAMGEHIHNN-UHFFFAOYSA-N 0.000 description 2
- LRFVTYWOQMYALW-UHFFFAOYSA-N 9H-xanthine Chemical compound O=C1NC(=O)NC2=C1NC=N2 LRFVTYWOQMYALW-UHFFFAOYSA-N 0.000 description 2
- 102000002572 Alpha-Globulins Human genes 0.000 description 2
- 108010068307 Alpha-Globulins Proteins 0.000 description 2
- 108091008875 B cell receptors Proteins 0.000 description 2
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 2
- 101100180402 Caenorhabditis elegans jun-1 gene Proteins 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- 101710098119 Chaperonin GroEL 2 Proteins 0.000 description 2
- 238000012286 ELISA Assay Methods 0.000 description 2
- 102000016942 Elastin Human genes 0.000 description 2
- 108010014258 Elastin Proteins 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 108091093094 Glycol nucleic acid Proteins 0.000 description 2
- 102000003886 Glycoproteins Human genes 0.000 description 2
- 108090000288 Glycoproteins Proteins 0.000 description 2
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- 101000899111 Homo sapiens Hemoglobin subunit beta Proteins 0.000 description 2
- 101001045218 Homo sapiens Peroxisomal multifunctional enzyme type 2 Proteins 0.000 description 2
- 108010063738 Interleukins Proteins 0.000 description 2
- 102000015696 Interleukins Human genes 0.000 description 2
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 2
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 2
- 241000713666 Lentivirus Species 0.000 description 2
- 239000005089 Luciferase Substances 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 108091027974 Mature messenger RNA Proteins 0.000 description 2
- 108091093037 Peptide nucleic acid Proteins 0.000 description 2
- AUNGANRZJHBGPY-SCRDCRAPSA-N Riboflavin Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O AUNGANRZJHBGPY-SCRDCRAPSA-N 0.000 description 2
- 102000002278 Ribosomal Proteins Human genes 0.000 description 2
- 108010000605 Ribosomal Proteins Proteins 0.000 description 2
- 102000044437 S1 domains Human genes 0.000 description 2
- 108700036684 S1 domains Proteins 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- 201000003176 Severe Acute Respiratory Syndrome Diseases 0.000 description 2
- 108020004682 Single-Stranded DNA Proteins 0.000 description 2
- 101800000904 Spike protein S1 Proteins 0.000 description 2
- 101800000905 Spike protein S2 Proteins 0.000 description 2
- 230000024932 T cell mediated immunity Effects 0.000 description 2
- 101150114197 TOP gene Proteins 0.000 description 2
- 108091046915 Threose nucleic acid Proteins 0.000 description 2
- 108091026823 U7 small nuclear RNA Proteins 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- 230000010530 Virus Neutralization Effects 0.000 description 2
- 108010031318 Vitronectin Proteins 0.000 description 2
- 241000269370 Xenopus <genus> Species 0.000 description 2
- FHHZHGZBHYYWTG-INFSMZHSSA-N [(2r,3s,4r,5r)-5-(2-amino-7-methyl-6-oxo-3h-purin-9-ium-9-yl)-3,4-dihydroxyoxolan-2-yl]methyl [[[(2r,3s,4r,5r)-5-(2-amino-6-oxo-3h-purin-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-hydroxyphosphoryl] phosphate Chemical compound N1C(N)=NC(=O)C2=C1[N+]([C@H]1[C@@H]([C@H](O)[C@@H](COP([O-])(=O)OP(O)(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](O)[C@@H](O3)N3C4=C(C(N=C(N)N4)=O)N=C3)O)O1)O)=CN2C FHHZHGZBHYYWTG-INFSMZHSSA-N 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 125000003158 alcohol group Chemical group 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 239000011324 bead Substances 0.000 description 2
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 2
- LGJMUZUPVCAVPU-UHFFFAOYSA-N beta-Sitostanol Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(C)CCC(CC)C(C)C)C1(C)CC2 LGJMUZUPVCAVPU-UHFFFAOYSA-N 0.000 description 2
- 210000001124 body fluid Anatomy 0.000 description 2
- 239000010839 body fluid Substances 0.000 description 2
- 125000001369 canonical nucleoside group Chemical group 0.000 description 2
- 238000005251 capillar electrophoresis Methods 0.000 description 2
- 238000001818 capillary gel electrophoresis Methods 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 230000007969 cellular immunity Effects 0.000 description 2
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 210000001268 chyle Anatomy 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 230000008876 conformational transition Effects 0.000 description 2
- 239000000356 contaminant Substances 0.000 description 2
- 238000004132 cross linking Methods 0.000 description 2
- UHDGCWIWMRVCDJ-ZAKLUEHWSA-N cytidine Chemical group O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-ZAKLUEHWSA-N 0.000 description 2
- 230000001086 cytosolic effect Effects 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 230000000779 depleting effect Effects 0.000 description 2
- 125000005265 dialkylamine group Chemical group 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 231100000676 disease causative agent Toxicity 0.000 description 2
- 239000002552 dosage form Substances 0.000 description 2
- 229920002549 elastin Polymers 0.000 description 2
- 108010048367 enhanced green fluorescent protein Proteins 0.000 description 2
- 230000026502 entry into host cell Effects 0.000 description 2
- 150000002148 esters Chemical class 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 210000000285 follicular dendritic cell Anatomy 0.000 description 2
- 229960004956 glycerylphosphorylcholine Drugs 0.000 description 2
- 230000013595 glycosylation Effects 0.000 description 2
- 238000006206 glycosylation reaction Methods 0.000 description 2
- 229940029575 guanosine Drugs 0.000 description 2
- XWSJVWPWQMAZQM-UHFFFAOYSA-N heptadecan-9-yl octanoate Chemical compound CCCCCCCCC(CCCCCCCC)OC(=O)CCCCCCC XWSJVWPWQMAZQM-UHFFFAOYSA-N 0.000 description 2
- 230000005099 host tropism Effects 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 2
- 210000002865 immune cell Anatomy 0.000 description 2
- 238000003018 immunoassay Methods 0.000 description 2
- 230000001976 improved effect Effects 0.000 description 2
- 239000004615 ingredient Substances 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 2
- 229940124590 live attenuated vaccine Drugs 0.000 description 2
- 229940023012 live-attenuated vaccine Drugs 0.000 description 2
- 230000004807 localization Effects 0.000 description 2
- 235000018977 lysine Nutrition 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 229930182817 methionine Natural products 0.000 description 2
- 238000007069 methylation reaction Methods 0.000 description 2
- 230000000813 microbial effect Effects 0.000 description 2
- 244000005700 microbiome Species 0.000 description 2
- 230000005012 migration Effects 0.000 description 2
- 238000013508 migration Methods 0.000 description 2
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 2
- 150000003833 nucleoside derivatives Chemical class 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 230000001717 pathogenic effect Effects 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 2
- 150000008103 phosphatidic acids Chemical class 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 230000002028 premature Effects 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 230000003449 preventive effect Effects 0.000 description 2
- 238000001243 protein synthesis Methods 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- 150000003230 pyrimidines Chemical class 0.000 description 2
- 238000000275 quality assurance Methods 0.000 description 2
- 238000003908 quality control method Methods 0.000 description 2
- 229940126583 recombinant protein vaccine Drugs 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 210000003705 ribosome Anatomy 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 230000000405 serological effect Effects 0.000 description 2
- 230000001568 sexual effect Effects 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 238000012289 standard assay Methods 0.000 description 2
- 230000004936 stimulating effect Effects 0.000 description 2
- 230000000638 stimulation Effects 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 229940031626 subunit vaccine Drugs 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 230000002195 synergetic effect Effects 0.000 description 2
- 238000010189 synthetic method Methods 0.000 description 2
- 229940104230 thymidine Drugs 0.000 description 2
- 238000004448 titration Methods 0.000 description 2
- 230000005030 transcription termination Effects 0.000 description 2
- 230000014621 translational initiation Effects 0.000 description 2
- 238000005829 trimerization reaction Methods 0.000 description 2
- 230000008478 viral entry into host cell Effects 0.000 description 2
- KZJWDPNRJALLNS-VPUBHVLGSA-N (-)-beta-Sitosterol Natural products O[C@@H]1CC=2[C@@](C)([C@@H]3[C@H]([C@H]4[C@@](C)([C@H]([C@H](CC[C@@H](C(C)C)CC)C)CC4)CC3)CC=2)CC1 KZJWDPNRJALLNS-VPUBHVLGSA-N 0.000 description 1
- CSVWWLUMXNHWSU-UHFFFAOYSA-N (22E)-(24xi)-24-ethyl-5alpha-cholest-22-en-3beta-ol Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(C)C=CC(CC)C(C)C)C1(C)CC2 CSVWWLUMXNHWSU-UHFFFAOYSA-N 0.000 description 1
- RQOCXCFLRBRBCS-UHFFFAOYSA-N (22E)-cholesta-5,7,22-trien-3beta-ol Natural products C1C(O)CCC2(C)C(CCC3(C(C(C)C=CCC(C)C)CCC33)C)C3=CC=C21 RQOCXCFLRBRBCS-UHFFFAOYSA-N 0.000 description 1
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- WCGUUGGRBIKTOS-GPOJBZKASA-N (3beta)-3-hydroxyurs-12-en-28-oic acid Chemical compound C1C[C@H](O)C(C)(C)[C@@H]2CC[C@@]3(C)[C@]4(C)CC[C@@]5(C(O)=O)CC[C@@H](C)[C@H](C)[C@H]5C4=CC[C@@H]3[C@]21C WCGUUGGRBIKTOS-GPOJBZKASA-N 0.000 description 1
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 1
- 125000004400 (C1-C12) alkyl group Chemical group 0.000 description 1
- FVXDQWZBHIXIEJ-LNDKUQBDSA-N 1,2-di-[(9Z,12Z)-octadecadienoyl]-sn-glycero-3-phosphocholine Chemical compound CCCCC\C=C/C\C=C/CCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCC\C=C/C\C=C/CCCCC FVXDQWZBHIXIEJ-LNDKUQBDSA-N 0.000 description 1
- DSNRWDQKZIEDDB-SQYFZQSCSA-N 1,2-dioleoyl-sn-glycero-3-phospho-(1'-sn-glycerol) Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@@H](O)CO)OC(=O)CCCCCCC\C=C/CCCCCCCC DSNRWDQKZIEDDB-SQYFZQSCSA-N 0.000 description 1
- SNKAWJBJQDLSFF-NVKMUCNASA-N 1,2-dioleoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCC\C=C/CCCCCCCC SNKAWJBJQDLSFF-NVKMUCNASA-N 0.000 description 1
- PDXQSLIBLQMPJS-FDDDBJFASA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-(methoxymethyl)pyrimidine-2,4-dione Chemical compound O=C1NC(=O)C(COC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 PDXQSLIBLQMPJS-FDDDBJFASA-N 0.000 description 1
- OZNBTMLHSVZFLR-GWTDSMLYSA-N 2-amino-9-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-3h-purin-6-one;6-amino-1h-pyrimidin-2-one Chemical compound NC=1C=CNC(=O)N=1.C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OZNBTMLHSVZFLR-GWTDSMLYSA-N 0.000 description 1
- YCISYUZWCSTBCY-BAYLZEKJSA-N 2-aminoethyl [(2r)-2,3-bis(3,7,11,15-tetramethylhexadecoxy)propyl] hydrogen phosphate Chemical compound CC(C)CCCC(C)CCCC(C)CCCC(C)CCOC[C@H](COP(O)(=O)OCCN)OCCC(C)CCCC(C)CCCC(C)CCCC(C)C YCISYUZWCSTBCY-BAYLZEKJSA-N 0.000 description 1
- SHCCKWGIFIPGNJ-NSUCVBPYSA-N 2-aminoethyl [(2r)-2,3-bis[(z)-octadec-9-enoxy]propyl] hydrogen phosphate Chemical compound CCCCCCCC\C=C/CCCCCCCCOC[C@H](COP(O)(=O)OCCN)OCCCCCCCC\C=C/CCCCCCCC SHCCKWGIFIPGNJ-NSUCVBPYSA-N 0.000 description 1
- KLEXDBGYSOIREE-UHFFFAOYSA-N 24xi-n-propylcholesterol Natural products C1C=C2CC(O)CCC2(C)C2C1C1CCC(C(C)CCC(CCC)C(C)C)C1(C)CC2 KLEXDBGYSOIREE-UHFFFAOYSA-N 0.000 description 1
- 101710176159 32 kDa protein Proteins 0.000 description 1
- IZFJAICCKKWWNM-JXOAFFINSA-N 4-amino-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-methoxypyrimidin-2-one Chemical compound O=C1N=C(N)C(OC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 IZFJAICCKKWWNM-JXOAFFINSA-N 0.000 description 1
- AMMRPAYSYYGRKP-BGZDPUMWSA-N 5-[(2s,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1-ethylpyrimidine-2,4-dione Chemical compound O=C1NC(=O)N(CC)C=C1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 AMMRPAYSYYGRKP-BGZDPUMWSA-N 0.000 description 1
- ZXIATBNUWJBBGT-JXOAFFINSA-N 5-methoxyuridine Chemical compound O=C1NC(=O)C(OC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 ZXIATBNUWJBBGT-JXOAFFINSA-N 0.000 description 1
- SNNBPMAXGYBMHM-JXOAFFINSA-N 5-methyl-2-thiouridine Chemical compound S=C1NC(=O)C(C)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 SNNBPMAXGYBMHM-JXOAFFINSA-N 0.000 description 1
- 102100027573 ATP synthase subunit alpha, mitochondrial Human genes 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 241000180579 Arca Species 0.000 description 1
- 241000203069 Archaea Species 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- 102000006734 Beta-Globulins Human genes 0.000 description 1
- 108010087504 Beta-Globulins Proteins 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 1
- XDUKTQILKJVIMI-HKSQRESASA-N CCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCCOC[C@H](COP(O)(=O)OCCN)OCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC Chemical compound CCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCCOC[C@H](COP(O)(=O)OCCN)OCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC XDUKTQILKJVIMI-HKSQRESASA-N 0.000 description 1
- DRSHXJFUUPIBHX-UHFFFAOYSA-N COc1ccc(cc1)N1N=CC2C=NC(Nc3cc(OC)c(OC)c(OCCCN4CCN(C)CC4)c3)=NC12 Chemical compound COc1ccc(cc1)N1N=CC2C=NC(Nc3cc(OC)c(OC)c(OCCCN4CCN(C)CC4)c3)=NC12 DRSHXJFUUPIBHX-UHFFFAOYSA-N 0.000 description 1
- SGNBVLSWZMBQTH-FGAXOLDCSA-N Campesterol Natural products O[C@@H]1CC=2[C@@](C)([C@@H]3[C@H]([C@H]4[C@@](C)([C@H]([C@H](CC[C@H](C(C)C)C)C)CC4)CC3)CC=2)CC1 SGNBVLSWZMBQTH-FGAXOLDCSA-N 0.000 description 1
- 108090000565 Capsid Proteins Proteins 0.000 description 1
- 102100023321 Ceruloplasmin Human genes 0.000 description 1
- 206010050337 Cerumen impaction Diseases 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- LPZCCMIISIBREI-MTFRKTCUSA-N Citrostadienol Natural products CC=C(CC[C@@H](C)[C@H]1CC[C@H]2C3=CC[C@H]4[C@H](C)[C@@H](O)CC[C@]4(C)[C@H]3CC[C@]12C)C(C)C LPZCCMIISIBREI-MTFRKTCUSA-N 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- MIKUYHXYGGJMLM-GIMIYPNGSA-N Crotonoside Natural products C1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1O MIKUYHXYGGJMLM-GIMIYPNGSA-N 0.000 description 1
- 102100025620 Cytochrome b-245 light chain Human genes 0.000 description 1
- 102000018832 Cytochromes Human genes 0.000 description 1
- 108010052832 Cytochromes Proteins 0.000 description 1
- AUNGANRZJHBGPY-UHFFFAOYSA-N D-Lyxoflavin Natural products OCC(O)C(O)C(O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O AUNGANRZJHBGPY-UHFFFAOYSA-N 0.000 description 1
- NYHBQMYGNKIUIF-UHFFFAOYSA-N D-guanosine Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1O NYHBQMYGNKIUIF-UHFFFAOYSA-N 0.000 description 1
- 102000012410 DNA Ligases Human genes 0.000 description 1
- 108010061982 DNA Ligases Proteins 0.000 description 1
- 101710082494 DNA protection during starvation protein Proteins 0.000 description 1
- ARVGMISWLZPBCH-UHFFFAOYSA-N Dehydro-beta-sitosterol Natural products C1C(O)CCC2(C)C(CCC3(C(C(C)CCC(CC)C(C)C)CCC33)C)C3=CC=C21 ARVGMISWLZPBCH-UHFFFAOYSA-N 0.000 description 1
- 101710088194 Dehydrogenase Proteins 0.000 description 1
- 102000016911 Deoxyribonucleases Human genes 0.000 description 1
- 108010053770 Deoxyribonucleases Proteins 0.000 description 1
- GZDFHIJNHHMENY-UHFFFAOYSA-N Dimethyl dicarbonate Chemical compound COC(=O)OC(=O)OC GZDFHIJNHHMENY-UHFFFAOYSA-N 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 102000016662 ELAV Proteins Human genes 0.000 description 1
- 108010053101 ELAV Proteins Proteins 0.000 description 1
- 238000008157 ELISA kit Methods 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- DNVPQKQSNYMLRS-NXVQYWJNSA-N Ergosterol Natural products CC(C)[C@@H](C)C=C[C@H](C)[C@H]1CC[C@H]2C3=CC=C4C[C@@H](O)CC[C@]4(C)[C@@H]3CC[C@]12C DNVPQKQSNYMLRS-NXVQYWJNSA-N 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 1
- 239000005977 Ethylene Substances 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 102100035233 Furin Human genes 0.000 description 1
- 108090001126 Furin Proteins 0.000 description 1
- 102000048120 Galactokinases Human genes 0.000 description 1
- 108700023157 Galactokinases Proteins 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- JZNWSCPGTDBMEW-UHFFFAOYSA-N Glycerophosphorylethanolamin Natural products NCCOP(O)(=O)OCC(O)CO JZNWSCPGTDBMEW-UHFFFAOYSA-N 0.000 description 1
- 108060003393 Granulin Proteins 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- BTEISVKTSQLKST-UHFFFAOYSA-N Haliclonasterol Natural products CC(C=CC(C)C(C)(C)C)C1CCC2C3=CC=C4CC(O)CCC4(C)C3CCC12C BTEISVKTSQLKST-UHFFFAOYSA-N 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 102000006947 Histones Human genes 0.000 description 1
- 101000936262 Homo sapiens ATP synthase subunit alpha, mitochondrial Proteins 0.000 description 1
- 101000856723 Homo sapiens Cytochrome b-245 light chain Proteins 0.000 description 1
- 101000827703 Homo sapiens Polyphosphoinositide phosphatase Proteins 0.000 description 1
- 101000619564 Homo sapiens Putative testis-specific prion protein Proteins 0.000 description 1
- 101001050288 Homo sapiens Transcription factor Jun Proteins 0.000 description 1
- 244000309467 Human Coronavirus Species 0.000 description 1
- 108010000521 Human Growth Hormone Proteins 0.000 description 1
- 102000002265 Human Growth Hormone Human genes 0.000 description 1
- 239000000854 Human Growth Hormone Substances 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- 102000008100 Human Serum Albumin Human genes 0.000 description 1
- 108010003272 Hyaluronate lyase Proteins 0.000 description 1
- 102000001974 Hyaluronidases Human genes 0.000 description 1
- 102000018251 Hypoxanthine Phosphoribosyltransferase Human genes 0.000 description 1
- 108010091358 Hypoxanthine Phosphoribosyltransferase Proteins 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 1
- 108010090054 Membrane Glycoproteins Proteins 0.000 description 1
- 102000012750 Membrane Glycoproteins Human genes 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 208000025370 Middle East respiratory syndrome Diseases 0.000 description 1
- 108010085220 Multiprotein Complexes Proteins 0.000 description 1
- 102000007474 Multiprotein Complexes Human genes 0.000 description 1
- 241000699666 Mus <mouse, genus> Species 0.000 description 1
- 102000004364 Myogenin Human genes 0.000 description 1
- 108010056785 Myogenin Proteins 0.000 description 1
- 230000004988 N-glycosylation Effects 0.000 description 1
- 125000000729 N-terminal amino-acid group Chemical group 0.000 description 1
- 244000061176 Nicotiana tabacum Species 0.000 description 1
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 1
- 108700001237 Nucleic Acid-Based Vaccines Proteins 0.000 description 1
- 230000004989 O-glycosylation Effects 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- GGZUDCAITXWZKO-VQJSHJPSSA-N PE(O-18:0/O-18:0) Chemical compound CCCCCCCCCCCCCCCCCCOC[C@H](COP(O)(=O)OCCN)OCCCCCCCCCCCCCCCCCC GGZUDCAITXWZKO-VQJSHJPSSA-N 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 102000002508 Peptide Elongation Factors Human genes 0.000 description 1
- 108010068204 Peptide Elongation Factors Proteins 0.000 description 1
- 108010033276 Peptide Fragments Proteins 0.000 description 1
- 102000007079 Peptide Fragments Human genes 0.000 description 1
- 208000005228 Pericardial Effusion Diseases 0.000 description 1
- 102100022587 Peroxisomal multifunctional enzyme type 2 Human genes 0.000 description 1
- 206010035664 Pneumonia Diseases 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 102100023591 Polyphosphoinositide phosphatase Human genes 0.000 description 1
- 206010036790 Productive cough Diseases 0.000 description 1
- 101000933967 Pseudomonas phage KPP25 Major capsid protein Proteins 0.000 description 1
- 102100022208 Putative testis-specific prion protein Human genes 0.000 description 1
- 101710086015 RNA ligase Proteins 0.000 description 1
- 108010065868 RNA polymerase SP6 Proteins 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 206010057190 Respiratory tract infections Diseases 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 230000018199 S phase Effects 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 102000003800 Selectins Human genes 0.000 description 1
- 108090000184 Selectins Proteins 0.000 description 1
- 102000012479 Serine Proteases Human genes 0.000 description 1
- 108010022999 Serine Proteases Proteins 0.000 description 1
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 1
- 101710147732 Small envelope protein Proteins 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- 101710137500 T7 RNA polymerase Proteins 0.000 description 1
- 241000204652 Thermotoga Species 0.000 description 1
- 241000204666 Thermotoga maritima Species 0.000 description 1
- QMGSCYSTMWRURP-UHFFFAOYSA-N Tomatine Natural products CC1CCC2(NC1)OC3CC4C5CCC6CC(CCC6(C)C5CCC4(C)C3C2C)OC7OC(CO)C(OC8OC(CO)C(O)C(OC9OCC(O)C(O)C9OC%10OC(CO)C(O)C(O)C%10O)C8O)C(O)C7O QMGSCYSTMWRURP-UHFFFAOYSA-N 0.000 description 1
- 101001023030 Toxoplasma gondii Myosin-D Proteins 0.000 description 1
- 108700009124 Transcription Initiation Site Proteins 0.000 description 1
- 102100023132 Transcription factor Jun Human genes 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 1
- 108010007780 U7 Small Nuclear Ribonucleoprotein Proteins 0.000 description 1
- HZYXFRGVBOPPNZ-UHFFFAOYSA-N UNPD88870 Natural products C1C=C2CC(O)CCC2(C)C2C1C1CCC(C(C)=CCC(CC)C(C)C)C1(C)CC2 HZYXFRGVBOPPNZ-UHFFFAOYSA-N 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 206010046306 Upper respiratory tract infection Diseases 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 241000710959 Venezuelan equine encephalitis virus Species 0.000 description 1
- 108010003533 Viral Envelope Proteins Proteins 0.000 description 1
- 108010042365 Virus-Like Particle Vaccines Proteins 0.000 description 1
- ZHGJYBCPWWZXOG-OIVUAWODSA-N [(2R)-2,3-bis(docosa-1,3,5,7,9,11-hexaenoxy)propyl] 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCCCCC=CC=CC=CC=CC=CC=COC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC=CC=CC=CC=CC=CC=CCCCCCCCCCC ZHGJYBCPWWZXOG-OIVUAWODSA-N 0.000 description 1
- NJFCSWSRXWCWHV-USYZEHPZSA-N [(2R)-2,3-bis(octadec-1-enoxy)propyl] 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCCCCCCCCCCC=COC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC=CCCCCCCCCCCCCCCCC NJFCSWSRXWCWHV-USYZEHPZSA-N 0.000 description 1
- LABUSINNDYUJLQ-WVAUPCMNSA-N [(2R)-2,3-bis[(9Z,12Z)-octadeca-9,12-dienoxy]propyl] 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCC\C=C/C\C=C/CCCCCCCCOC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OCCCCCCCC\C=C/C\C=C/CCCCC LABUSINNDYUJLQ-WVAUPCMNSA-N 0.000 description 1
- UYWNJNXEHSUWLE-HFWGUVFESA-N [(2R)-3-hexadecanoyloxy-2-[(Z)-octadec-9-enoxy]propyl] 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OCCCCCCCC\C=C/CCCCCCCC UYWNJNXEHSUWLE-HFWGUVFESA-N 0.000 description 1
- RBPWQIKZHBYIEY-PXCYNBOKSA-N [(2r)-2,3-bis[(z)-octadec-9-enoxy]propyl] 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCC\C=C/CCCCCCCCOC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OCCCCCCCC\C=C/CCCCCCCC RBPWQIKZHBYIEY-PXCYNBOKSA-N 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 238000000246 agarose gel electrophoresis Methods 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 150000001335 aliphatic alkanes Chemical class 0.000 description 1
- HMFHBZSHGGEWLO-NEEWWZBLSA-N alpha-L-ribose Chemical compound OC[C@@H]1O[C@@H](O)[C@@H](O)[C@H]1O HMFHBZSHGGEWLO-NEEWWZBLSA-N 0.000 description 1
- QYIXCDOBOSTCEI-UHFFFAOYSA-N alpha-cholestanol Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(C)CCCC(C)C)C1(C)CC2 QYIXCDOBOSTCEI-UHFFFAOYSA-N 0.000 description 1
- 238000003277 amino acid sequence analysis Methods 0.000 description 1
- 210000004381 amniotic fluid Anatomy 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 210000000612 antigen-presenting cell Anatomy 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 210000001742 aqueous humor Anatomy 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 210000003567 ascitic fluid Anatomy 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 230000006472 autoimmune response Effects 0.000 description 1
- 108010028263 bacteriophage T3 RNA polymerase Proteins 0.000 description 1
- HMFHBZSHGGEWLO-TXICZTDVSA-N beta-D-ribose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-TXICZTDVSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- MJVXAPPOFPTTCA-UHFFFAOYSA-N beta-Sistosterol Natural products CCC(CCC(C)C1CCC2C3CC=C4C(C)C(O)CCC4(C)C3CCC12C)C(C)C MJVXAPPOFPTTCA-UHFFFAOYSA-N 0.000 description 1
- 229940017687 beta-d-ribose Drugs 0.000 description 1
- NJKOMDUNNDKEAI-UHFFFAOYSA-N beta-sitosterol Natural products CCC(CCC(C)C1CCC2(C)C3CC=C4CC(O)CCC4C3CCC12C)C(C)C NJKOMDUNNDKEAI-UHFFFAOYSA-N 0.000 description 1
- 210000000941 bile Anatomy 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000006287 biotinylation Effects 0.000 description 1
- 238000007413 biotinylation Methods 0.000 description 1
- 210000002459 blastocyst Anatomy 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 108010006025 bovine growth hormone Proteins 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- SGNBVLSWZMBQTH-PODYLUTMSA-N campesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CC[C@@H](C)C(C)C)[C@@]1(C)CC2 SGNBVLSWZMBQTH-PODYLUTMSA-N 0.000 description 1
- 235000000431 campesterol Nutrition 0.000 description 1
- 210000000234 capsid Anatomy 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 230000005859 cell recognition Effects 0.000 description 1
- 230000005101 cell tropism Effects 0.000 description 1
- 230000033077 cellular process Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 235000010980 cellulose Nutrition 0.000 description 1
- 150000001783 ceramides Chemical class 0.000 description 1
- 210000002939 cerumen Anatomy 0.000 description 1
- 210000003756 cervix mucus Anatomy 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 239000008119 colloidal silica Substances 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 229940001442 combination vaccine Drugs 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- QYIXCDOBOSTCEI-NWKZBHTNSA-N coprostanol Chemical compound C([C@H]1CC2)[C@@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@H](C)CCCC(C)C)[C@@]2(C)CC1 QYIXCDOBOSTCEI-NWKZBHTNSA-N 0.000 description 1
- 239000011258 core-shell material Substances 0.000 description 1
- 108700010904 coronavirus proteins Proteins 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 238000004163 cytometry Methods 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 231100000517 death Toxicity 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 238000000432 density-gradient centrifugation Methods 0.000 description 1
- 239000005549 deoxyribonucleoside Substances 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 150000001982 diacylglycerols Chemical class 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 150000001985 dialkylglycerols Chemical class 0.000 description 1
- 235000005911 diet Nutrition 0.000 description 1
- 230000037213 diet Effects 0.000 description 1
- 238000001085 differential centrifugation Methods 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 241001493065 dsRNA viruses Species 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000007515 enzymatic degradation Effects 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- DNVPQKQSNYMLRS-SOWFXMKYSA-N ergosterol Chemical compound C1[C@@H](O)CC[C@]2(C)[C@H](CC[C@]3([C@H]([C@H](C)/C=C/[C@@H](C)C(C)C)CC[C@H]33)C)C3=CC=C21 DNVPQKQSNYMLRS-SOWFXMKYSA-N 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 210000003722 extracellular fluid Anatomy 0.000 description 1
- 230000002550 fecal effect Effects 0.000 description 1
- 210000004700 fetal blood Anatomy 0.000 description 1
- 239000012091 fetal bovine serum Substances 0.000 description 1
- 238000011049 filling Methods 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 238000007306 functionalization reaction Methods 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 210000001280 germinal center Anatomy 0.000 description 1
- 238000002873 global sequence alignment Methods 0.000 description 1
- PEDCQBHIVMGVHV-UHFFFAOYSA-N glycerol Substances OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 1
- 102000035122 glycosylated proteins Human genes 0.000 description 1
- 108091005608 glycosylated proteins Proteins 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 230000035931 haemagglutination Effects 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 230000005802 health problem Effects 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 244000144980 herd Species 0.000 description 1
- 235000020256 human milk Nutrition 0.000 description 1
- 210000004251 human milk Anatomy 0.000 description 1
- 230000028996 humoral immune response Effects 0.000 description 1
- 229960002773 hyaluronidase Drugs 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 239000012642 immune effector Substances 0.000 description 1
- 238000012151 immunohistochemical method Methods 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 239000003547 immunosorbent Substances 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 230000015788 innate immune response Effects 0.000 description 1
- 239000002054 inoculum Substances 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 230000035990 intercellular signaling Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229940047122 interleukins Drugs 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 229910052742 iron Inorganic materials 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 210000002809 long lived plasma cell Anatomy 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 210000002751 lymph Anatomy 0.000 description 1
- 125000003588 lysine group Chemical class [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- VLBPIWYTPAXCFJ-XMMPIXPASA-N lysophosphatidylcholine O-16:0/0:0 Chemical compound CCCCCCCCCCCCCCCCOC[C@@H](O)COP([O-])(=O)OCC[N+](C)(C)C VLBPIWYTPAXCFJ-XMMPIXPASA-N 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 238000013178 mathematical model Methods 0.000 description 1
- 238000013160 medical therapy Methods 0.000 description 1
- 210000004779 membrane envelope Anatomy 0.000 description 1
- 230000002175 menstrual effect Effects 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 210000003097 mucus Anatomy 0.000 description 1
- 229940031348 multivalent vaccine Drugs 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 238000001821 nucleic acid purification Methods 0.000 description 1
- 229940023146 nucleic acid vaccine Drugs 0.000 description 1
- 229940046166 oligodeoxynucleotide Drugs 0.000 description 1
- 230000014207 opsonization Effects 0.000 description 1
- 150000007530 organic bases Chemical class 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 238000004806 packaging method and process Methods 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 210000001819 pancreatic juice Anatomy 0.000 description 1
- 150000002972 pentoses Chemical class 0.000 description 1
- 210000004912 pericardial fluid Anatomy 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 102000013415 peroxidase activity proteins Human genes 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 239000008177 pharmaceutical agent Substances 0.000 description 1
- 239000008024 pharmaceutical diluent Substances 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 1
- 150000008104 phosphatidylethanolamines Chemical class 0.000 description 1
- 150000004713 phosphodiesters Chemical class 0.000 description 1
- 125000005496 phosphonium group Chemical group 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 230000008884 pinocytosis Effects 0.000 description 1
- 210000002826 placenta Anatomy 0.000 description 1
- 210000002381 plasma Anatomy 0.000 description 1
- 238000007747 plating Methods 0.000 description 1
- 210000004910 pleural fluid Anatomy 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 150000004804 polysaccharides Polymers 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 210000004909 pre-ejaculatory fluid Anatomy 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- AAEVYOVXGOFMJO-UHFFFAOYSA-N prometryn Chemical compound CSC1=NC(NC(C)C)=NC(NC(C)C)=N1 AAEVYOVXGOFMJO-UHFFFAOYSA-N 0.000 description 1
- 210000002307 prostate Anatomy 0.000 description 1
- 210000004908 prostatic fluid Anatomy 0.000 description 1
- 230000018883 protein targeting Effects 0.000 description 1
- 239000013639 protein trimer Substances 0.000 description 1
- 238000001671 psychotherapy Methods 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- 125000000561 purinyl group Chemical group N1=C(N=C2N=CNC2=C1)* 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 210000004915 pus Anatomy 0.000 description 1
- 239000000376 reactant Substances 0.000 description 1
- 238000003753 real-time PCR Methods 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 208000020029 respiratory tract infectious disease Diseases 0.000 description 1
- 230000011506 response to oxidative stress Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000012340 reverse transcriptase PCR Methods 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 235000019192 riboflavin Nutrition 0.000 description 1
- 229960002477 riboflavin Drugs 0.000 description 1
- 239000002151 riboflavin Substances 0.000 description 1
- 239000003161 ribonuclease inhibitor Substances 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 101150026538 rps9 gene Proteins 0.000 description 1
- 101150030614 rpsI gene Proteins 0.000 description 1
- 102220232874 rs1085307493 Human genes 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 210000002374 sebum Anatomy 0.000 description 1
- 238000001338 self-assembly Methods 0.000 description 1
- 210000000582 semen Anatomy 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 238000009589 serological test Methods 0.000 description 1
- 238000007493 shaping process Methods 0.000 description 1
- KZJWDPNRJALLNS-VJSFXXLFSA-N sitosterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CC[C@@H](CC)C(C)C)[C@@]1(C)CC2 KZJWDPNRJALLNS-VJSFXXLFSA-N 0.000 description 1
- 235000015500 sitosterol Nutrition 0.000 description 1
- 229950005143 sitosterol Drugs 0.000 description 1
- NLQLSVXGSXCXFE-UHFFFAOYSA-N sitosterol Natural products CC=C(/CCC(C)C1CC2C3=CCC4C(C)C(O)CCC4(C)C3CCC2(C)C1)C(C)C NLQLSVXGSXCXFE-UHFFFAOYSA-N 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 1
- 159000000000 sodium salts Chemical class 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 210000003802 sputum Anatomy 0.000 description 1
- 208000024794 sputum Diseases 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 229940032091 stigmasterol Drugs 0.000 description 1
- HCXVJBMSMIARIN-PHZDYDNGSA-N stigmasterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)/C=C/[C@@H](CC)C(C)C)[C@@]1(C)CC2 HCXVJBMSMIARIN-PHZDYDNGSA-N 0.000 description 1
- 235000016831 stigmasterol Nutrition 0.000 description 1
- BFDNMXAIBMJLBB-UHFFFAOYSA-N stigmasterol Natural products CCC(C=CC(C)C1CCCC2C3CC=C4CC(O)CCC4(C)C3CCC12C)C(C)C BFDNMXAIBMJLBB-UHFFFAOYSA-N 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 210000004243 sweat Anatomy 0.000 description 1
- 210000001179 synovial fluid Anatomy 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 230000008719 thickening Effects 0.000 description 1
- 239000002562 thickening agent Substances 0.000 description 1
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 238000000954 titration curve Methods 0.000 description 1
- REJLGAUYTKNVJM-SGXCCWNXSA-N tomatine Chemical compound O([C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@@H]1O[C@H]1[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O1)O)O[C@H]1[C@@H](CO)O[C@H]([C@@H]([C@H]1O)O)O[C@@H]1C[C@@H]2CC[C@H]3[C@@H]4C[C@H]5[C@@H]([C@]4(CC[C@@H]3[C@@]2(C)CC1)C)[C@@H]([C@@]1(NC[C@@H](C)CC1)O5)C)[C@@H]1OC[C@@H](O)[C@H](O)[C@H]1O REJLGAUYTKNVJM-SGXCCWNXSA-N 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 238000002054 transplantation Methods 0.000 description 1
- 230000017105 transposition Effects 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- 239000013638 trimer Substances 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- 230000007306 turnover Effects 0.000 description 1
- 108010087967 type I signal peptidase Proteins 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- 238000000870 ultraviolet spectroscopy Methods 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 210000003932 urinary bladder Anatomy 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 229940096998 ursolic acid Drugs 0.000 description 1
- PLSAJKYPRJGMHO-UHFFFAOYSA-N ursolic acid Natural products CC1CCC2(CCC3(C)C(C=CC4C5(C)CCC(O)C(C)(C)C5CCC34C)C2C1C)C(=O)O PLSAJKYPRJGMHO-UHFFFAOYSA-N 0.000 description 1
- 229940125575 vaccine candidate Drugs 0.000 description 1
- 108010027510 vaccinia virus capping enzyme Proteins 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
- 230000007502 viral entry Effects 0.000 description 1
- 229960004854 viral vaccine Drugs 0.000 description 1
- 210000004916 vomit Anatomy 0.000 description 1
- 230000008673 vomiting Effects 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 229940075420 xanthine Drugs 0.000 description 1
- 235000004835 α-tocopherol Nutrition 0.000 description 1
- 150000003772 α-tocopherols Chemical class 0.000 description 1
Images












Landscapes
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
Abstract
Description
人類冠狀病毒係冠狀病毒科之高度接觸傳染性有套膜正單股RNA病毒。已知冠狀病毒科之兩個亞科會引起人類疾病。最重要的是β-冠狀病毒(β-coronaviruses,betacoronaviruses)。β-冠狀病毒係輕度至中度上呼吸道感染之常見致病因子。然而,新型冠狀病毒感染(諸如由最初於2019年12月自中國武漢市鑑別之冠狀病毒引起之感染)之爆發與高死亡率死亡人數相關。此最近鑑別之冠狀病毒(稱為嚴重急性呼吸症候群冠狀病毒2 (SARS-CoV-2),以前稱為「2019新型冠狀病毒」或「2019-nCoV」)已迅速感染數十萬人。SARS-CoV-2病毒引起之大流行病已由世界衛生組織(WHO)命名為COVID-19 (冠狀病毒疾病2019,Coronavirus Disease 2019)。SARS-CoV-2分離株(Wuhan-Hu-1)之第一個基因體序列由位於北京之中國CDC之研究人員在2020年1月10日在Virological發表,該Virological係用於分析及解釋病毒分子進化及流行病學之基於UK之討論論壇。接著將該序列於2020年1月12日保藏在GenBank中,GenBank登錄號為MN908947.1。Human coronavirus is a highly contagious mantle positive single-stranded RNA virus of the family Coronaviridae. Two subfamilies of the coronavirus family are known to cause disease in humans. The most important are beta-coronaviruses (beta-coronaviruses, betacoronaviruses). Beta-coronavirus is a common causative agent of mild to moderate upper respiratory tract infections. However, outbreaks of novel coronavirus infections, such as those caused by a coronavirus originally identified from Wuhan, China in December 2019, are associated with high mortality. This recently identified coronavirus, known as severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), formerly known as "2019 novel coronavirus" or "2019-nCoV", has rapidly infected hundreds of thousands of people. The pandemic caused by the SARS-CoV-2 virus has been named COVID-19 (Coronavirus Disease 2019) by the World Health Organization (WHO). The first genome sequence of the SARS-CoV-2 isolate (Wuhan-Hu-1) was published on January 10, 2020 by researchers at the Chinese CDC in Beijing in Virological, a department for virus analysis and interpretation UK-based discussion forum for molecular evolution and epidemiology. The sequence was then deposited in GenBank on January 12, 2020, with GenBank accession number MN908947.1.
目前,尚無針對COVID-19之特異性治療或針對SARS-CoV-2感染之疫苗。與冠狀病毒感染、特別是SARS-CoV-2大流行相關之持續之健康問題及死亡率在國際上受到極大關注。由SARS-CoV-2引起之公共健康危機加强快速開發針對該等病毒之有效及安全之疫苗候選者的重要性。Currently, there is no specific treatment for COVID-19 or a vaccine against SARS-CoV-2 infection. The ongoing health problems and mortality associated with coronavirus infections, especially the SARS-CoV-2 pandemic, are of great international concern. The public health crisis caused by SARS-CoV-2 reinforces the importance of rapidly developing effective and safe vaccine candidates against these viruses.
在一些實施例中,本文提供包含一或多種信使核糖核酸(mRNA)分子之組合物(例如疫苗),該等信使核糖核酸(mRNA)分子編碼能夠引發針對SARS-CoV-2抗原之強效中和抗體反應之高免疫原性抗原。本文所述之mRNA分子用於表現SARS-CoV-2冠狀病毒刺突(S)蛋白之關鍵中和結構域,當個別地或組合用作免疫原性組合物或疫苗時,其有效誘導保護性免疫,以保護人免於天然病毒感染及/或若感染則減輕症狀。In some embodiments, provided herein are compositions (eg, vaccines) comprising one or more messenger ribonucleic acid (mRNA) molecules encoding a potent medium capable of eliciting an antigen against SARS-CoV-2 Highly immunogenic antigens that react with antibodies. The mRNA molecules described herein are used to express the key neutralizing domain of the SARS-CoV-2 coronavirus spike (S) protein, which is effective in inducing protective properties when used individually or in combination as an immunogenic composition or vaccine Immunization to protect a person from natural viral infection and/or reduce symptoms if infected.
已知β冠狀病毒之套膜S蛋白決定病毒宿主向性及進入宿主細胞,且對於SARS-CoV-2感染係至關重要的。S蛋白之組織在β冠狀病毒(諸如SARS-CoV-2、SARS-CoV、MERS-CoV、HKU1-CoV、MHV-CoV及NL63-CoV (包括兩個次單元S1及S2,其分別介導附著及膜融合))中相似。S1次單元包括N末端結構域(NTD)及受體結合結構域(RBD)。The envelope S protein of betacoronaviruses is known to determine viral host tropism and entry into host cells and is critical for SARS-CoV-2 infection. The organization of the S protein in betacoronaviruses such as SARS-CoV-2, SARS-CoV, MERS-CoV, HKU1-CoV, MHV-CoV and NL63-CoV (including two subunits S1 and S2, which mediate attachment and membrane fusion)). The S1 subunit includes an N-terminal domain (NTD) and a receptor binding domain (RBD).
次單元抗原之表現將免疫反應集中於特定次單元,對與其他相關病毒共有之抗原之其他結構域具有特異性之記憶B及T細胞之刺激最小。本文提供之數據展現,投與編碼膜結合或可溶性SARS-CoV-2 S1次單元抗原之mRNA產生針對SARS-CoV-2 RBD抗原、NTD抗原、野生型全長S蛋白及具有雙脯胺酸突變以穩定融合前構象之S蛋白中之每一者之抗體效價。如本文所示,在所有測試之劑量下,兩劑量方案(亦即,包括加强劑量)有效誘導可識別且結合至SARS-CoV-2 WT S蛋白之抗體。令人驚訝的是,即使在S1次單元中未發現雙脯胺酸突變(雙脯胺酸突變發生在S2中,而在測試之免疫原中不存在S2),當針對雙脯胺酸穩定形式之S蛋白量測時,誘導之效價最高。The presentation of subunit antigens focuses the immune response on specific subunits, with minimal stimulation of memory B and T cells specific for other domains of antigens shared by other related viruses. The data presented herein demonstrate that administration of mRNA encoding a membrane-bound or soluble SARS-CoV-2 S1 subunit antigen produces targeting of the SARS-CoV-2 RBD antigen, NTD antigen, wild-type full-length S protein, and a bisproline mutation to Antibody titers for each of the S proteins that stabilized the prefusion conformation. As shown herein, at all doses tested, the two-dose regimen (ie, including the booster dose) was effective in inducing antibodies that recognize and bind to the SARS-CoV-2 WT S protein. Surprisingly, even though no bisproline mutation was found in the S1 subunit (the bisproline mutation occurred in S2, which was not present in the tested immunogens), when targeting the bisproline stable form When the S protein was measured, the induction titer was the highest.
另外,已知NTD及RBD二者皆係結合中和病毒活性之抗體之位點。在SARS-CoV-2之情形下,RBD係刺突蛋白之受體結合位點,其結合血管收縮肽轉化酶2 (ACE2)。NTD之功能尚未完全瞭解,其似乎在結合糖部分及促進刺突蛋白自融合前構象向融合後構象之構象轉變中起作用。無論如何,NTD及RBD結構域皆誘導如本文所示之高結合抗體及中和抗體效價。In addition, both NTD and RBD are known to be sites of binding of antibodies that neutralize viral activity. In the case of SARS-CoV-2, RBD is the receptor binding site for the spike protein, which binds vasoconstrictor peptide converting enzyme 2 (ACE2). The function of NTD is not fully understood, but it appears to play a role in binding the sugar moiety and promoting the conformational transition of the spike protein from the prefusion to the postfusion conformation. Regardless, both the NTD and RBD domains induce high binding and neutralizing antibody titers as shown herein.
舉例而言,相當令人驚訝的是,本文一些實施例中提供之數據顯示,儘管來自投與編碼膜結合RBD抗原(RBD-TM)或膜結合NTD抗原(NTD-TM)之mRNA之血清顯示對SARS-CoV-2 S1/S2刺突蛋白具有免疫原性,但兩種mRNA (且因此兩種抗原)之50:50組合產生對SARS-CoV-2 S1/S2刺突蛋白出乎意料高之協同中和抗體效價。For example, it is rather surprising that the data presented in some of the examples herein show that although sera from administration of mRNA encoding membrane-bound RBD antigen (RBD-TM) or membrane-bound NTD antigen (NTD-TM) show Immunogenic for the SARS-CoV-2 S1/S2 spike protein, but a 50:50 combination of the two mRNAs (and thus the two antigens) yields unexpectedly high levels of the SARS-CoV-2 S1/S2 spike protein The synergistic neutralizing antibody titer.
因此,本揭示案之一些態樣提供包含編碼SARS-CoV-2 S蛋白之功能結構域之mRNA的組合物,該功能結構域能够誘導針對SARS-CoV-2之免疫反應,例如中和抗體反應。在一些實施例中,mRNA調配於脂質奈米顆粒中。Accordingly, some aspects of the present disclosure provide compositions comprising mRNA encoding a functional domain of the SARS-CoV-2 S protein capable of inducing an immune response, such as a neutralizing antibody response, against SARS-CoV-2 . In some embodiments, the mRNA is formulated in lipid nanoparticles.
在一些態樣中,提供包含編碼SARS-CoV-2刺突蛋白之至少兩個結構域且小於全長刺突蛋白之開放閱讀框(ORF)的mRNA。小於全長刺突蛋白之刺突蛋白係具有比全長刺突蛋白少至少一個胺基酸的刺突蛋白之一或多個結構域及/或次單元,或具有以非天然順序或序列連接在一起之一或多個結構域的融合蛋白。在一些實施例中,兩個結構域中之一者係SARS-CoV-2刺突蛋白之N末端結構域(NTD)。在一些實施例中,兩個結構域中之一者係SARS-CoV-2刺突蛋白之受體結合結構域(RBD)。在一些實施例中,ORF編碼與NTD及/或RBD連接之跨膜結構域(TD)。在一些實施例中,TD係流行性感冒血球凝集素跨膜結構域。在一些實施例中,ORF包含NTD - RBD - TM。在一些實施例中,至少兩個結構域經由可裂解或不可裂解之連接體連接。在一些實施例中,不可裂解之連接體係甘胺酸-絲胺酸(GS)連接體。在一些實施例中,GS連接體係4-15個胺基酸。在一些實施例中,連接體係泛HLA DR結合抗原決定基(pan HLA DR-binding epitope) (PADRE)。在一些實施例中,ORF編碼信號肽。在一些實施例中,信號肽與NTD連接。在一些實施例中,信號肽與RBD連接。在一些實施例中,信號肽與SARS-CoV-2异源。在一些實施例中,至少兩個結構域係可溶的。在一些實施例中,ORF編碼運輸信號結構域。在一些實施例中,運輸信號結構域係巨噬細胞標記物。在一些實施例中,巨噬細胞標記物係CD86及/或CD11b。在一些實施例中,運輸信號結構域係VSV-G胞質尾(VSVGct)。在一些實施例中,兩個結構域中之一者係SARS-CoV-2刺突蛋白之第一重複七肽:HPPHCPC (HR1)。在一些實施例中,兩個結構域中之一者係SARS-CoV-2刺突蛋白之第二重複七肽:HPPHCPC (HR2)。在一些實施例中,ORF編碼與HR1及/或HR2連接之跨膜結構域(TD)。在一些實施例中,TD係流行性感冒血球凝集素跨膜結構域。在一些實施例中,ORF編碼融合肽(FP)。在一些實施例中,ORF編碼CT尾。In some aspects, an mRNA comprising an open reading frame (ORF) that encodes at least two domains of the SARS-CoV-2 spike protein and is smaller than the full-length spike protein is provided. Spike proteins that are smaller than the full-length spike protein are those that have one or more domains and/or subunits of the spike protein that are at least one amino acid fewer than the full-length spike protein, or have a non-native order or sequence linked together A fusion protein of one or more domains. In some embodiments, one of the two domains is the N-terminal domain (NTD) of the SARS-CoV-2 spike protein. In some embodiments, one of the two domains is the receptor binding domain (RBD) of the SARS-CoV-2 spike protein. In some embodiments, the ORF encodes a transmembrane domain (TD) linked to NTD and/or RBD. In some embodiments, the TD is an influenza hemagglutinin transmembrane domain. In some embodiments, the ORF comprises NTD-RBD-TM. In some embodiments, at least two domains are linked via a cleavable or non-cleavable linker. In some embodiments, the non-cleavable linker system glycine-serine (GS) linker. In some embodiments, the GS linkage system is 4-15 amino acids. In some embodiments, the linking system is a pan HLA DR-binding epitope (PADRE). In some embodiments, the ORF encodes a signal peptide. In some embodiments, the signal peptide is linked to the NTD. In some embodiments, the signal peptide is linked to the RBD. In some embodiments, the signal peptide is heterologous to SARS-CoV-2. In some embodiments, at least two domains are soluble. In some embodiments, the ORF encodes a trafficking signaling domain. In some embodiments, the trafficking signaling domain is a macrophage marker. In some embodiments, the macrophage markers are CD86 and/or CD11b. In some embodiments, the trafficking signaling domain is a VSV-G cytoplasmic tail (VSVGct). In some embodiments, one of the two domains is the first repeat heptapeptide of the SARS-CoV-2 spike protein: HPPHCPC (HR1). In some embodiments, one of the two domains is the second repeat heptapeptide of the SARS-CoV-2 spike protein: HPPHCPC (HR2). In some embodiments, the ORF encodes a transmembrane domain (TD) linked to HR1 and/or HR2. In some embodiments, the TD is an influenza hemagglutinin transmembrane domain. In some embodiments, the ORF encodes a fusion peptide (FP). In some embodiments, the ORF encodes a CT tail.
在一些態樣中,提供包含編碼SARS-CoV-2刺突蛋白之受體結合結構域(RBD)之開放閱讀框(ORF)的mRNA。在一些實施例中,RBD係可溶的。在一些實施例中,RBD與跨膜結構域、視情况地流行性感冒血球凝集素跨膜結構域連接。In some aspects, an mRNA comprising an open reading frame (ORF) encoding the receptor binding domain (RBD) of the SARS-CoV-2 spike protein is provided. In some embodiments, the RBD is soluble. In some embodiments, the RBD is linked to a transmembrane domain, optionally an influenza hemagglutinin transmembrane domain.
本發明之一或多個實施例之詳情在以下說明中闡述。自以下附圖及若干實施例之詳細說明以及所附申請專利範圍將明瞭本發明之其他特徵或優點。The details of one or more embodiments of the invention are set forth in the description below. Other features or advantages of the present invention will become apparent from the following drawings and detailed description of several embodiments and appended claims.
相關申请案related applications
本申請案根據35 U.S.C. § 119(e)主張於2020年6月25日提出申請之美國臨時申請案號63/044,330及於2020年8月7日提出申請之美國臨時申請案號63/063,137之權益,每一申請案皆以全文引用之方式併入本文中。This application claims U.S. Provisional Application No. 63/044,330, filed June 25, 2020, and U.S. Provisional Application No. 63/063,137, filed August 7, 2020, under 35 U.S.C. § 119(e) The rights and interests of each application are incorporated herein by reference in their entirety.
嚴重急性呼吸症候群冠狀病毒2 (SARS-CoV-2)係新近出現之高發病率及死亡率之呼吸道病毒。與2002年出現之SARS-CoV及2012年出現之中東呼吸症候群冠狀病毒(MERS-CoV)相比,SARS-CoV-2已經迅速在全世界傳播。世界衛生組織(WHO)報導,截至2020年7月6日,COVID-19之當前爆發在世界範圍內具有幾乎1150萬確診病例,其中有超過530,000例死亡。COVID-19感染之新病例呈上升趨勢,且仍然在迅速增加。因此,開發各種安全且有效之疫苗及藥物來預防及治療COVID-19且减少COVID-19在全世界所具有之嚴重影響係至關重要的。使用多種方式製得之疫苗及藥物以及具有改善之安全性及效能之疫苗係必要的。仍然需要加速針對冠狀病毒疾病2019 (COVID-19)之疫苗及治療藥物之先進設計及開發。Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) is a newly emerged respiratory virus with high morbidity and mortality. Compared with SARS-CoV, which emerged in 2002, and Middle East Respiratory Syndrome Coronavirus (MERS-CoV), which emerged in 2012, SARS-CoV-2 has spread rapidly around the world. The World Health Organization (WHO) reports that as of July 6, 2020, the current outbreak of COVID-19 has nearly 11.5 million confirmed cases worldwide, with more than 530,000 deaths. New cases of COVID-19 infections are on the rise and are still increasing rapidly. Therefore, it is crucial to develop various safe and effective vaccines and drugs to prevent and treat COVID-19 and reduce the severe impact of COVID-19 worldwide. There is a need for vaccines and drugs prepared using a variety of methods, as well as vaccines with improved safety and efficacy. There is still a need to accelerate advanced design and development of vaccines and therapeutics for the coronavirus disease 2019 (COVID-19).
在2020年1月7日,將嚴重急性呼吸症候群冠狀病毒2 (SARS-CoV-2)鑑別為於2019年12月出現在中國湖北省武漢市之新型肺炎之致病因子(Lu H等人,(2020) J Med Virol.四月;92(4):401-402。)。不久,該病毒在中國引起爆發且傳播至世界各地。根據SARS-CoV-2之基因體結構之分析,其屬於β-冠狀病毒(CoV) (Chan等人,2020 Emerg Microbes Infect.; 9(1):221-236)。 On January 7, 2020, severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) was identified as the causative agent of a novel pneumonia that appeared in Wuhan, Hubei Province, China in December 2019 (Lu H et al. (2020) J Med Virol. Apr;92(4):401-402.). Soon, the virus caused an outbreak in China and spread around the world. According to the analysis of the genome structure of SARS-CoV-2, it belongs to beta-coronavirus (CoV) (Chan et al., 2020 Emerg Microbes Infect .; 9(1):221-236).
冠狀病毒表面上之關鍵蛋白係刺突蛋白。已設計大量mRNA構築體且在本文中揭示。當在適當遞送媒劑中調配時,編碼刺突抗原、其次單元及結構域之mRNA能够誘導針對SARS-CoV-2之强免疫反應,從而產生有效且強效之mRNA疫苗。投與編碼各種刺突蛋白抗原、特別是刺突蛋白次單元及結構域抗原之mRNA導致mRNA遞送至免疫系統之免疫組織及細胞,在那裏其快速轉譯成蛋白抗原。其他免疫細胞(例如B細胞及T細胞)接著能够識別及啓動,且免疫反應發展針對編碼之蛋白之免疫反應,且最終產生針對冠狀病毒之持久保護性反應。經由使用本文揭示之編碼刺突蛋白、其次單元及結構域之高效mRNA疫苗避免低免疫原性(由於對免疫系統之呈遞差或抗原之不正確折叠而導致之蛋白疫苗開發之缺點)。The key protein on the surface of the coronavirus is the spike protein. A number of mRNA constructs have been designed and are disclosed herein. When formulated in an appropriate delivery vehicle, mRNA encoding the spike antigen, subunits and domains are capable of inducing a potent immune response against SARS-CoV-2, resulting in an effective and potent mRNA vaccine. Administration of mRNA encoding various Spike antigens, particularly Spike subunit and domain antigens, results in delivery of the mRNA to immune tissues and cells of the immune system, where it is rapidly translated into protein antigens. Other immune cells, such as B cells and T cells, are then able to recognize and initiate, and the immune response develops an immune response against the encoded protein and ultimately a durable protective response against the coronavirus. Low immunogenicity (a disadvantage of protein vaccine development due to poor presentation to the immune system or incorrect folding of the antigen) is avoided by using the highly efficient mRNA vaccines disclosed herein encoding the spike protein, its subunits and domains.
本揭示案提供引發針對冠狀病毒抗原之強效中和抗體之組合物(例如,mRNA疫苗)。在一些實施例中,組合物包括編碼至少一種(例如,一種、兩種或更多種)冠狀病毒抗原(諸如SARS-CoV-2抗原)之mRNA。在一些實施例中,mRNA編碼刺突蛋白結構域,諸如受體結合結構域(RBD)、N末端結構域(NTD)或RBD及NTD之組合。The present disclosure provides compositions (eg, mRNA vaccines) that elicit potent neutralizing antibodies against coronavirus antigens. In some embodiments, the composition includes mRNA encoding at least one (eg, one, two, or more) coronavirus antigens, such as SARS-CoV-2 antigens. In some embodiments, the mRNA encodes a spike protein domain, such as a receptor binding domain (RBD), an N-terminal domain (NTD), or a combination of RBD and NTD.
本揭示案之一些態樣提供包含編碼融合蛋白之開放閱讀框的信使核糖核酸(mRNA),該融合蛋白包含SARS-CoV-2刺突蛋白之受體結合結構域(RBD)及蛋白質跨膜結構域,例如天然存在之或异源之跨膜結構域。Some aspects of the present disclosure provide messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a fusion protein comprising the receptor binding domain (RBD) and protein transmembrane structure of the SARS-CoV-2 spike protein domains, such as naturally occurring or heterologous transmembrane domains.
在一些實施例中,蛋白質跨膜結構域係流行性感冒血球凝集素跨膜結構域。In some embodiments, the protein transmembrane domain is an influenza hemagglutinin transmembrane domain.
在一些實施例中,融合蛋白包含與SEQ ID NO: 77之胺基酸序列具有至少80%一致性的胺基酸序列。In some embodiments, the fusion protein comprises an amino acid sequence that is at least 80% identical to the amino acid sequence of SEQ ID NO: 77.
在一些實施例中,融合蛋白包含與SEQ ID NO: 77之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。In some embodiments, the fusion protein comprises at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% identity to the amino acid sequence of SEQ ID NO: 77 amino acid sequence.
在一些實施例中,融合蛋白包含SEQ ID NO: 77之胺基酸序列。In some embodiments, the fusion protein comprises the amino acid sequence of SEQ ID NO:77.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少70%一致性的核苷酸序列。In some embodiments, the open reading frame comprises a nucleotide sequence that is at least 70% identical to the nucleotide sequence of SEQ ID NO:76.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。In some embodiments, the open reading frame comprises at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or Nucleotide sequences that are at least 99% identical.
在一些實施例中,開放閱讀框包含SEQ ID NO: 76之核苷酸序列。In some embodiments, the open reading frame comprises the nucleotide sequence of SEQ ID NO:76.
本揭示案之其他態樣提供包含編碼融合蛋白之開放閱讀框的信使核糖核酸(mRNA),該融合蛋白包含SARS-CoV-2刺突蛋白之胺基(N)末端結構域及跨膜結構域。Other aspects of the present disclosure provide messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a fusion protein comprising the amino (N) terminal domain and the transmembrane domain of the SARS-CoV-2 spike protein .
在一些實施例中,跨膜結構域係流行性感冒血球凝集素跨膜結構域。In some embodiments, the transmembrane domain is an influenza hemagglutinin transmembrane domain.
在一些實施例中,融合蛋白包含與SEQ ID NO: 47之胺基酸序列具有至少80%一致性的胺基酸序列。In some embodiments, the fusion protein comprises an amino acid sequence that is at least 80% identical to the amino acid sequence of SEQ ID NO: 47.
在一些實施例中,融合蛋白包含與SEQ ID NO: 47之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。In some embodiments, the fusion protein comprises at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% identity to the amino acid sequence of SEQ ID NO: 47 amino acid sequence.
在一些實施例中,融合蛋白包含SEQ ID NO: 47之胺基酸序列。In some embodiments, the fusion protein comprises the amino acid sequence of SEQ ID NO:47.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少70%一致性的核苷酸序列。In some embodiments, the open reading frame comprises a nucleotide sequence that is at least 70% identical to the nucleotide sequence of SEQ ID NO: 46.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。In some embodiments, the open reading frame comprises at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or Nucleotide sequences that are at least 99% identical.
在一些實施例中,開放閱讀框包含SEQ ID NO: 46之核苷酸序列。In some embodiments, the open reading frame comprises the nucleotide sequence of SEQ ID NO:46.
本揭示案之其他態樣提供包含編碼融合蛋白之開放閱讀框的信使核糖核酸(mRNA),該融合蛋白包含視情况地經由連接體與SARS-CoV-2刺突蛋白之胺基(N)末端結構域連接之SARS-CoV-2刺突蛋白的受體結合結構域。Other aspects of the disclosure provide messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a fusion protein comprising, optionally via a linker, the amine (N) terminus of the SARS-CoV-2 spike protein Domain-linked receptor-binding domains of the SARS-CoV-2 spike protein.
在一些實施例中,融合蛋白進一步包含跨膜結構域。In some embodiments, the fusion protein further comprises a transmembrane domain.
在一些實施例中,融合蛋白包含與SEQ ID NO: 92之胺基酸序列具有至少80%一致性的胺基酸序列。In some embodiments, the fusion protein comprises an amino acid sequence that is at least 80% identical to the amino acid sequence of SEQ ID NO: 92.
在一些實施例中,融合蛋白包含與SEQ ID NO: 92之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。In some embodiments, the fusion protein comprises at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% identity to the amino acid sequence of SEQ ID NO: 92 amino acid sequence.
在一些實施例中,融合蛋白包含SEQ ID NO: 92之胺基酸序列。In some embodiments, the fusion protein comprises the amino acid sequence of SEQ ID NO:92.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 91之核苷酸序列具有至少70%一致性的核苷酸序列。In some embodiments, the open reading frame comprises a nucleotide sequence that is at least 70% identical to the nucleotide sequence of SEQ ID NO: 91.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 91之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。In some embodiments, the open reading frame comprises at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or Nucleotide sequences that are at least 99% identical.
在一些實施例中,開放閱讀框包含SEQ ID NO: 91之核苷酸序列。In some embodiments, the open reading frame comprises the nucleotide sequence of SEQ ID NO:91.
在一些實施例中,mRNA進一步包含5'非轉譯區(UTR),該5'非轉譯區視情況地包含SEQ ID NO: 131或2之核苷酸序列。In some embodiments, the mRNA further comprises a 5' untranslated region (UTR) comprising the nucleotide sequence of SEQ ID NO: 131 or 2, as appropriate.
在一些實施例中,mRNA進一步包含3'非轉譯區(UTR),該3'非轉譯區視情況地包含SEQ ID NO: 132或4之核苷酸序列。In some embodiments, the mRNA further comprises a 3' untranslated region (UTR) comprising the nucleotide sequence of SEQ ID NO: 132 or 4, as appropriate.
在一些實施例中,mRNA進一步包含5'端帽,視情況地7mG(5')ppp(5')NlmpNp。In some embodiments, the mRNA further comprises a 5' end cap, optionally 7mG(5')ppp(5')NlmpNp.
在一些實施例中,mRNA進一步包含聚A尾,該聚A尾視情況地具有約100個核苷酸之長度。In some embodiments, the mRNA further comprises a poly-A tail, optionally having a length of about 100 nucleotides.
在一些實施例中,mRNA包含化學修飾,視情況地1-甲基假尿苷。In some embodiments, the mRNA comprises a chemical modification, optionally 1-methylpseudouridine.
本揭示案之一些態樣提供包含前述段落中任一者之mRNA之組合物。Some aspects of the present disclosure provide compositions comprising the mRNA of any of the preceding paragraphs.
本揭示案之其他態樣提供包含前述段落中任一者之至少兩種mRNA之組合物。Other aspects of the present disclosure provide compositions comprising at least two mRNAs of any of the preceding paragraphs.
本揭示案之其他態樣提供組合物,該組合物包含:(a) 包含編碼融合蛋白之開放閱讀框的信使核糖核酸(mRNA),該融合蛋白包含SARS-CoV-2刺突蛋白之受體結合結構域(RBD)及蛋白質跨膜結構域;(b) 包含編碼融合蛋白之開放閱讀框之mRNA,該融合蛋白包含SARS-CoV-2刺突蛋白之胺基(N)末端結構域及跨膜結構域。在一些實施例中,(a)之mRNA對(b)之mRNA之比率為約1:1,例如1:2、1:3、2:1或3:1。在一些實施例中,組合物之至少50%之mRNA係(a)之mRNA。舉例而言,組合物之至少55%、60%、65%、70%、75%、80%、85%、90%或95%之mRNA係(a)之mRNA。在一些實施例中,組合物之至少50%之mRNA係(b)之mRNA。舉例而言,組合物之至少55%、60%、65%、70%、75%、80%、85%、90%或95%之mRNA係(b)之mRNA。Other aspects of the present disclosure provide compositions comprising: (a) messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a fusion protein comprising a receptor for the SARS-CoV-2 spike protein Binding domain (RBD) and protein transmembrane domain; (b) mRNA comprising an open reading frame encoding a fusion protein comprising the amino (N) terminal domain and transmembrane domain of the SARS-CoV-2 spike protein membrane domain. In some embodiments, the ratio of mRNA of (a) to mRNA of (b) is about 1:1, eg, 1:2, 1:3, 2:1, or 3:1. In some embodiments, at least 50% of the mRNA of the composition is the mRNA of (a). For example, at least 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90% or 95% of the mRNA of the composition is the mRNA of (a). In some embodiments, at least 50% of the mRNA of the composition is the mRNA of (b). For example, at least 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90% or 95% of the mRNA of the composition is the mRNA of (b).
在一些實施例中,蛋白質跨膜結構域係流行性感冒血球凝集素跨膜結構域。In some embodiments, the protein transmembrane domain is an influenza hemagglutinin transmembrane domain.
在一些實施例中,(a)之融合蛋白包含與SEQ ID NO: 77之胺基酸序列具有至少80%一致性的胺基酸序列。In some embodiments, the fusion protein of (a) comprises an amino acid sequence that is at least 80% identical to the amino acid sequence of SEQ ID NO: 77.
在一些實施例中,(a)之融合蛋白包含與SEQ ID NO: 77之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。In some embodiments, the fusion protein of (a) comprises at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least the amino acid sequence of SEQ ID NO: 77 99% identical amino acid sequence.
在一些實施例中,(a)之融合蛋白包含SEQ ID NO: 77之胺基酸序列。In some embodiments, the fusion protein of (a) comprises the amino acid sequence of SEQ ID NO:77.
在一些實施例中,(a)之開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少70%一致性的核苷酸序列。In some embodiments, the open reading frame of (a) comprises a nucleotide sequence that is at least 70% identical to the nucleotide sequence of SEQ ID NO: 76.
在一些實施例中,(a)之開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。In some embodiments, the open reading frame of (a) comprises at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, at least 97% of the nucleotide sequence of SEQ ID Nucleotide sequences that are at least 98% or at least 99% identical.
在一些實施例中,(a)之開放閱讀框包含SEQ ID NO: 76之核苷酸序列。In some embodiments, the open reading frame of (a) comprises the nucleotide sequence of SEQ ID NO:76.
在一些實施例中,(b)之融合蛋白包含與SEQ ID NO: 47之胺基酸序列具有至少80%一致性的胺基酸序列。In some embodiments, the fusion protein of (b) comprises an amino acid sequence that is at least 80% identical to the amino acid sequence of SEQ ID NO: 47.
在一些實施例中,(b)之融合蛋白包含與SEQ ID NO: 47之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。In some embodiments, the fusion protein of (b) comprises at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least the amino acid sequence of SEQ ID NO: 47 99% identical amino acid sequence.
在一些實施例中,(b)之融合蛋白包含SEQ ID NO: 47之胺基酸序列。In some embodiments, the fusion protein of (b) comprises the amino acid sequence of SEQ ID NO:47.
在一些實施例中,(b)之開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少70%一致性的核苷酸序列。In some embodiments, the open reading frame of (b) comprises a nucleotide sequence that is at least 70% identical to the nucleotide sequence of SEQ ID NO: 46.
在一些實施例中,(b)之開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。In some embodiments, the open reading frame of (b) comprises at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, at least 97% of the nucleotide sequence of SEQ ID NO: 46, Nucleotide sequences that are at least 98% or at least 99% identical.
在一些實施例中,(b)之開放閱讀框包含SEQ ID NO: 46之核苷酸序列。In some embodiments, the open reading frame of (b) comprises the nucleotide sequence of SEQ ID NO:46.
在一些實施例中,mRNA調配於脂質奈米顆粒中。In some embodiments, the mRNA is formulated in lipid nanoparticles.
在一些實施例中,組合物進一步包含脂質奈米顆粒。In some embodiments, the composition further comprises lipid nanoparticles.
在一些實施例中,(a)之mRNA調配於脂質奈米顆粒中,且(b)之mRNA調配於脂質奈米顆粒中。In some embodiments, the mRNA of (a) is formulated in lipid nanoparticles, and the mRNA of (b) is formulated in lipid nanoparticles.
在一些實施例中,脂質奈米顆粒包含陽離子脂質。In some embodiments, the lipid nanoparticles comprise cationic lipids.
在一些實施例中,脂質奈米顆粒進一步包含中性脂質。In some embodiments, the lipid nanoparticles further comprise neutral lipids.
在一些實施例中,脂質奈米顆粒進一步包含固醇。In some embodiments, the lipid nanoparticle further comprises a sterol.
在一些實施例中,脂質奈米顆粒進一步包含聚乙二醇(PEG)改質之脂質。In some embodiments, the lipid nanoparticles further comprise polyethylene glycol (PEG) modified lipids.
在一些實施例中,脂質奈米顆粒包含可電離之陽離子脂質、中性脂質、固醇及PEG改質之脂質。In some embodiments, lipid nanoparticles comprise ionizable cationic lipids, neutral lipids, sterols, and PEG-modified lipids.
在一些實施例中,可電離之陽離子脂質係8-((2-羥基乙基)(6-側氧基-6-(十一烷基氧基)己基)胺基)辛酸十七烷-9-基酯(化合物1)。In some embodiments, the ionizable cationic lipid is 8-((2-hydroxyethyl)(6-oxy-6-(undecyloxy)hexyl)amino)octanoic acid heptadecan-9 - base ester (compound 1).
在一些實施例中,中性脂質係1,2-二硬脂醯基-sn-甘油-3-磷酸膽鹼(DSPC)。In some embodiments, the neutral lipid is 1,2-distearyl-sn-glycero-3-phosphocholine (DSPC).
在一些實施例中,固醇係膽固醇。In some embodiments, the sterol is cholesterol.
在一些實施例中,PEG改質之脂質係1,2二肉豆蔻醯基-sn-甘油-甲氧基聚乙二醇(PEG2000 DMG)。In some embodiments, the PEG-modified lipid is 1,2 dimyristoyl-sn-glycero-methoxypolyethylene glycol (PEG2000 DMG).
在一些實施例中,脂質奈米顆粒包含20-60 mol%可電離之陽離子脂質、5-25 mol%中性脂質、25-55 mol%固醇及0.5-15 mol% PEG改質之脂質。In some embodiments, the lipid nanoparticles comprise 20-60 mol% ionizable cationic lipids, 5-25 mol% neutral lipids, 25-55 mol% sterols, and 0.5-15 mol% PEG-modified lipids.
在一些實施例中,脂質奈米顆粒包含:47 mol%可電離之陽離子脂質;11.5 mol%中性脂質;38.5 mol%固醇;及3.0 mol% PEG改質之脂質;48 mol%可電離之陽離子脂質;11 mol%中性脂質;38.5 mol%固醇;及2.5 mol% PEG改質之脂質;49 mol%可電離之陽離子脂質;10.5 mol%中性脂質;38.5 mol%固醇;及2.0 mol% PEG改質之脂質;50 mol%可電離之陽離子脂質;10 mol%中性脂質;38.5 mol%固醇;及1.5 mol% PEG改質之脂質;或51 mol%可電離之陽離子脂質;9.5 mol%中性脂質;38.5 mol%固醇;及1.0 mol% PEG改質之脂質。In some embodiments, the lipid nanoparticles comprise: 47 mol% ionizable cationic lipids; 11.5 mol% neutral lipids; 38.5 mol% sterols; and 3.0 mol% PEG-modified lipids; 48 mol% ionizable lipids 11 mol% neutral lipids; 38.5 mol% sterols; and 2.5 mol% PEG-modified lipids; 49 mol% ionizable cationic lipids; 10.5 mol% neutral lipids; 38.5 mol% sterols; and 2.0 mol% PEG-modified lipids; 50 mol% ionizable cationic lipids; 10 mol% neutral lipids; 38.5 mol% sterols; and 1.5 mol% PEG-modified lipids; or 51 mol% ionizable cationic lipids; 9.5 mol% neutral lipids; 38.5 mol% sterols; and 1.0 mol% PEG-modified lipids.
在一些實施例中,脂質奈米顆粒包含47 mol%化合物1;11.5 mol% DSPC;38.5 mol%膽固醇;及3.0 mol% PEG2000 DMG;48 mol%化合物1;11 mol% DSPC;38.5 mol%膽固醇;及2.5 mol% PEG2000 DMG;49 mol%化合物1;10.5 mol% DSPC;38.5 mol%膽固醇;及2.0 mol% PEG2000 DMG;50 mol%化合物1;10 mol% DSPC;38.5 mol%膽固醇;及1.5 mol% PEG2000 DMG;或51 mol%化合物1;9.5 mol% DSPC;38.5 mol%膽固醇;及1.0 mol% PEG2000 DMG。In some embodiments, the lipid nanoparticle comprises 47 mol
本揭示案之其他態樣提供了一種方法,該方法包括向個體投與在個體中有效誘導針對SARS-CoV-2之中和抗體反應之量的後述申請專利範圍中任一項之mRNA或組合物。Other aspects of the present disclosure provide a method comprising administering to an individual an mRNA or combination of any of the following claims in an amount effective to induce a neutralizing antibody response against SARS-CoV-2 in the individual thing.
本揭示案之其他態樣提供了一種方法,該方法包括向個體投與在個體中有效誘導針對SARS-CoV-2之T細胞免疫反應之量的後述申請專利範圍中任一項之mRNA或組合物。Other aspects of the present disclosure provide a method comprising administering to an individual an mRNA or combination of any of the following claims in an amount effective to induce a T cell immune response against SARS-CoV-2 in the individual thing.
本揭示案之一些態樣提供包含開放閱讀框(ORF)之信使核糖核酸(mRNA),該開放閱讀框編碼能夠誘導針對SARS-CoV-2之免疫反應(諸如中和抗體反應)之冠狀病毒抗原,其中抗原包含SARS-CoV-2之蛋白質片段或功能性蛋白質結構域,視情況地其中RNA調配於脂質奈米顆粒中。Some aspects of the present disclosure provide messenger ribonucleic acid (mRNA) comprising an open reading frame (ORF) encoding a coronavirus antigen capable of inducing an immune response (such as a neutralizing antibody response) against SARS-CoV-2 , wherein the antigen comprises a protein fragment or functional protein domain of SARS-CoV-2, optionally wherein the RNA is formulated in lipid nanoparticles.
在一些實施例中,抗原係功能性蛋白質結構域。In some embodiments, the antigen is a functional protein domain.
在一些實施例中,蛋白質結構域係SARS-CoV-2刺突蛋白之N末端結構域(NTD)。In some embodiments, the protein domain is the N-terminal domain (NTD) of the SARS-CoV-2 spike protein.
在一些實施例中,NTD與跨膜結構域、視情况地流行性感冒血球凝集素跨膜結構域連接。In some embodiments, the NTD is linked to a transmembrane domain, optionally an influenza hemagglutinin transmembrane domain.
在一些實施例中,抗原包含與SEQ ID NO: 47之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 47之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of the amino acid sequence of SEQ ID NO: 47 % identical amino acid sequence, optionally wherein the antigen comprises the amino acid sequence of SEQ ID NO:47.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 46之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, A nucleotide sequence that is at least 98% or at least 99% identical, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO: 46.
在一些實施例中,蛋白質結構域係SARS-CoV-2刺突蛋白之受體結合結構域(RBD)。In some embodiments, the protein domain is the receptor binding domain (RBD) of the SARS-CoV-2 spike protein.
在一些實施例中,RBD係可溶的。In some embodiments, the RBD is soluble.
在一些實施例中,抗原包含與SEQ ID NO: 62之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 62之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of the amino acid sequence of SEQ ID NO: 62 % identical amino acid sequence, optionally wherein the antigen comprises the amino acid sequence of SEQ ID NO:62.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 61之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 61之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, A nucleotide sequence that is at least 98% or at least 99% identical, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO: 61.
在一些實施例中,RBD與跨膜結構域、視情况地流行性感冒血球凝集素跨膜結構域連接。In some embodiments, the RBD is linked to a transmembrane domain, optionally an influenza hemagglutinin transmembrane domain.
在一些實施例中,抗原包含與SEQ ID NO: 77之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 77之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of the amino acid sequence of SEQ ID NO: 77 % identical amino acid sequence, optionally wherein the antigen comprises the amino acid sequence of SEQ ID NO:77.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 76之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, A nucleotide sequence that is at least 98% or at least 99% identical, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO:76.
在一些實施例中,NTD與SARS-CoV-2刺突蛋白之RBD連接以形成NTD-RBD融合蛋白。In some embodiments, the NTD is linked to the RBD of the SARS-CoV-2 spike protein to form an NTD-RBD fusion protein.
在一些實施例中,NTD-RBD融合體與跨膜結構域(TM)連接,視情況與流行性感冒血球凝集素跨膜結構域連接,以形成NTD-RBD-TM蛋白。In some embodiments, the NTD-RBD fusion is linked to a transmembrane domain (TM), optionally linked to an influenza hemagglutinin transmembrane domain, to form an NTD-RBD-TM protein.
在一些實施例中,抗原包含與SEQ ID NO: 92之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 92之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of the amino acid sequence of SEQ ID NO: 92 % identical amino acid sequence, optionally wherein the antigen comprises the amino acid sequence of SEQ ID NO:92.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 91之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 91之核苷酸序列。In some embodiments, an open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, A nucleotide sequence that is at least 98% or at least 99% identical, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO: 91.
在一些實施例中,NTD-RBD融合體包含C末端截短。In some embodiments, the NTD-RBD fusion comprises a C-terminal truncation.
在一些實施例中,抗原包含與SEQ ID NO: 107之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 107之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of the amino acid sequence of SEQ ID NO: 107 % identical amino acid sequence, optionally wherein the antigen comprises the amino acid sequence of SEQ ID NO: 107.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 106之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 106之核苷酸序列。In some embodiments, an open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, at least 97%, at least 97%, A nucleotide sequence that is at least 98% or at least 99% identical, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO: 106.
在一些實施例中,NTD及/或RBD包括延伸區。In some embodiments, NTDs and/or RBDs include extension regions.
在一些實施例中,抗原包含與SEQ ID NO: 59、86、89、116、119或122中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 59、86、89、116、119或122中之任一者之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95% of the amino acid sequence of any one of SEQ ID NOs: 59, 86, 89, 116, 119, or 122 , at least 96%, at least 97%, at least 98%, or at least 99% identical amino acid sequences, optionally wherein the antigen comprises any one of SEQ ID NOs: 59, 86, 89, 116, 119 or 122 the amino acid sequence.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 58、85、88、115、118或121中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 58、85、88、115、118或121中之任一者之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 70%, at least 75%, at least 80%, at least the 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical nucleotide sequences, optionally wherein the open reading frame comprises SEQ ID NOs: 58, 85, 88, 115, The nucleotide sequence of any of 118 or 121.
在一些實施例中,蛋白質結構域係SARS-CoV-2刺突蛋白之S1次單元結構域。In some embodiments, the protein domain is the S1 subunit domain of the SARS-CoV-2 spike protein.
在一些實施例中,S1次單元係可溶的。In some embodiments, the S1 subunit is soluble.
在一些實施例中,抗原包含與SEQ ID NO: 5之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 5之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of the amino acid sequence of SEQ ID NO: 5 % identical amino acid sequence, optionally wherein the antigen comprises the amino acid sequence of SEQ ID NO:5.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 3之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 3之核苷酸序列。In some embodiments, an open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, A nucleotide sequence that is at least 98% or at least 99% identical, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO: 3.
在一些實施例中,S1次單元與跨膜結構域、視情况地流行性感冒血球凝集素跨膜結構域連接。In some embodiments, the S1 subunit is linked to a transmembrane domain, optionally an influenza hemagglutinin transmembrane domain.
在一些實施例中,抗原包含與SEQ ID NO: 17之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 17之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of the amino acid sequence of SEQ ID NO: 17 % identical amino acid sequence, optionally wherein the antigen comprises the amino acid sequence of SEQ ID NO: 17.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 16之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 16之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, A nucleotide sequence that is at least 98% or at least 99% identical, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO: 16.
在一些實施例中,S1次單元經修飾以去除S蛋白之RBD或RBD之一部分。In some embodiments, the S1 subunit is modified to remove the RBD or a portion of the RBD of the S protein.
在一些實施例中,抗原包含與SEQ ID NO: 20、23、26、29、32或35中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 20、23、26、29、32或35中之任一者之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95% of the amino acid sequence of any one of SEQ ID NOs: 20, 23, 26, 29, 32, or 35 , at least 96%, at least 97%, at least 98% or at least 99% identical amino acid sequences, optionally wherein the antigen comprises any one of SEQ ID NOs: 20, 23, 26, 29, 32 or 35 the amino acid sequence.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 19、22、25、28、31或34中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 19、22、25、28、31或34中之任一者之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% identical nucleotide sequences, optionally wherein the open reading frame comprises SEQ ID NOs: 19, 22, 25, 28, The nucleotide sequence of any of 31 or 34.
在一些實施例中,S1次單元與S蛋白之S2次單元連接。In some embodiments, the S1 subunit is linked to the S2 subunit of the S protein.
在一些實施例中,S2次單元來自SARS-CoV-2 S蛋白。In some embodiments, the S2 subunit is from the SARS-CoV-2 S protein.
在一些實施例中,S1次單元來自HKU1 S蛋白。In some embodiments, the S1 subunit is from the HKU1 S protein.
在一些實施例中,抗原包含與SEQ ID NO: 38之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 38之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of the amino acid sequence of SEQ ID NO: 38 % identical amino acid sequence, optionally wherein the antigen comprises the amino acid sequence of SEQ ID NO:38.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 37之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 37之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, A nucleotide sequence that is at least 98% or at least 99% identical, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO:37.
在一些實施例中,S1次單元來自OC43 S蛋白。In some embodiments, the S1 subunit is from an OC43 S protein.
在一些實施例中,抗原包含與SEQ ID NO: 41之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 41之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of the amino acid sequence of SEQ ID NO: 41 % identical amino acid sequence, optionally wherein the antigen comprises the amino acid sequence of SEQ ID NO: 41.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 40之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 40之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97%, A nucleotide sequence that is at least 98% or at least 99% identical, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO: 40.
在一些實施例中,抗原進一步包含支架結構域,視情況地選自鐵蛋白、二氧四氫蝶啶(lumazine)合成酶及摺疊子。In some embodiments, the antigen further comprises a scaffold domain, optionally selected from the group consisting of ferritin, lumazine synthetase, and foldon.
在一些實施例中,支架結構域係鐵蛋白。In some embodiments, the scaffold domain is ferritin.
在一些實施例中,抗原包含與SEQ ID NO: 8或65之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 8或65之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or An amino acid sequence of at least 99% identity wherein the antigen comprises the amino acid sequence of SEQ ID NO: 8 or 65, as appropriate.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 7或64之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 7或64之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95%, at least 96%, at least 97% of the nucleotide sequence of SEQ ID NO: 7 or 64 %, at least 98%, or at least 99% identical to a nucleotide sequence, optionally wherein the open reading frame comprises the nucleotide sequence of SEQ ID NO: 7 or 64.
在一些實施例中,支架結構域係二氧四氫蝶啶合成酶。In some embodiments, the scaffold domain is a dioxytetrahydropteridine synthase.
在一些實施例中,抗原包含與SEQ ID NO: 11、14、68或71中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 11、14、68或71中之任一者之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96% of the amino acid sequence of any one of SEQ ID NOs: 11, 14, 68, or 71 , an amino acid sequence of at least 97%, at least 98%, or at least 99% identity, optionally wherein the antigen comprises the amino acid sequence of any one of SEQ ID NOs: 11, 14, 68, or 71.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 10、13、67或70中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 10、13、67或70中之任一者之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least A nucleotide sequence that is 95%, at least 96%, at least 97%, at least 98% or at least 99% identical, optionally wherein the open reading frame comprises any one of SEQ ID NOs: 10, 13, 67 or 70 the nucleotide sequence.
在一些實施例中,支架結構域係摺疊子。In some embodiments, the scaffold domain is a foldon.
在一些實施例中,抗原包含與SEQ ID NO: 44、50、74、80、83、101、104或113中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 44、50、74、80、83、101、104或113中之任一者之胺基酸序列。In some embodiments, the antigen comprises at least 80%, at least 85%, at least 90% of the amino acid sequence of any one of SEQ ID NOs: 44, 50, 74, 80, 83, 101, 104, or 113 , at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% identical amino acid sequences, optionally wherein the antigen comprises SEQ ID NOs: 44, 50, 74, 80, 83, 101, The amino acid sequence of any of 104 or 113.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 43、49、73、79、82、100、103或112中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 43、49、73、79、82、100、103或112中之任一者之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 70%, at least 75%, at least 70%, at least A nucleotide sequence that is 80%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98% or at least 99% identical, optionally wherein the open reading frame comprises SEQ ID NOs: 43, 49, The nucleotide sequence of any of 73, 79, 82, 100, 103 or 112.
在一些實施例中,抗原進一步包含運輸信號,視情況地選自巨噬細胞標記物,視情況地CD86、CD11B及/或VSVGct。In some embodiments, the antigen further comprises a trafficking signal, optionally selected from macrophage markers, optionally CD86, CD11B and/or VSVGct.
在一些實施例中,抗原包含與SEQ ID NO: 95、98或110中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 95、98或110中之任一者之胺基酸序列。In some embodiments the antigen comprises at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least An amino acid sequence that is 97%, at least 98%, or at least 99% identical, as appropriate, wherein the antigen comprises the amino acid sequence of any of SEQ ID NOs: 95, 98, or 110.
在一些實施例中,開放閱讀框包含與SEQ ID NO: 94、97或109中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 94、97或109中之任一者之核苷酸序列。In some embodiments, the open reading frame comprises at least 70%, at least 75%, at least 80%, at least 90%, at least 95% of the nucleotide sequence of any one of SEQ ID NOs: 94, 97, or 109 , a nucleotide sequence of at least 96%, at least 97%, at least 98%, or at least 99% identity, optionally wherein the open reading frame comprises the nucleotides of any one of SEQ ID NOs: 94, 97, or 109 sequence.
在一些實施例中,mRNA調配於脂質奈米顆粒中。In some embodiments, the mRNA is formulated in lipid nanoparticles.
在一些實施例中,脂質奈米顆粒包含陽離子脂質(視情況地可電離之陽離子脂質)、中性脂質、固醇及/或聚乙二醇(PEG)改質之脂質。可電離之陽離子脂質在本文中可與可電離之脂質及陽離子脂質互換使用以指可電離之脂質。在一些實施例中,脂質奈米顆粒包含40-50 mol%可電離之脂質,視情況地45-50 mol%,例如45-46 mol%、46-47 mol%、47-48 mol%、48-49 mol%或49-50 mol%,例如約45 mol%、45.5 mol%、46 mol%、46.5 mol%、47 mol%、47.5 mol%、48 mol%、48.5 mol%、49 mol%或49.5 mol%。在一些實施例中,脂質奈米顆粒包含30-45 mol%固醇,視情況地35-40 mol%,例如30-31 mol%、31-32 mol%、32-33 mol%、33-34 mol%、35-35 mol%、35-36 mol%、36-37 mol%、38-38 mol%、38-39 mol%或39-40 mol%。在一些實施例中,脂質奈米顆粒包含5-15 mol%輔助脂質,視情況地10-12 mol%,例如5-6 mol%、6-7 mol%、7-8 mol%、8-9 mol%、9-10 mol%、10-11 mol%、11-12 mol%、12-13 mol%、13-14 mol%或14-15 mol%。在一些實施例中,脂質奈米顆粒包含1-5% PEG脂質,視情況地1-3 mol%,例如1.5-2.5 mol%、1-2 mol%、2-3 mol%、3-4 mol%或4-5 mol%。In some embodiments, the lipid nanoparticles comprise cationic lipids (optionally ionizable cationic lipids), neutral lipids, sterols, and/or polyethylene glycol (PEG) modified lipids. Ionizable cationic lipids are used interchangeably herein with ionizable lipids and cationic lipids to refer to ionizable lipids. In some embodiments, the lipid nanoparticle comprises 40-50 mol% ionizable lipid, optionally 45-50 mol%, eg, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48 -49 mol% or 49-50 mol%, such as about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol% or 49.5 mol%. In some embodiments, the lipid nanoparticle comprises 30-45 mol% sterol, optionally 35-40 mol%, eg, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol% mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 38-38 mol%, 38-39 mol%, or 39-40 mol%. In some embodiments, the lipid nanoparticle comprises 5-15 mol% helper lipid, optionally 10-12 mol%, eg, 5-6 mol%, 6-7 mol%, 7-8 mol%, 8-9 mol% mol%, 9-10 mol%, 10-11 mol%, 11-12 mol%, 12-13 mol%, 13-14 mol% or 14-15 mol%. In some embodiments, lipid nanoparticles comprise 1-5% PEG lipid, optionally 1-3 mol%, eg, 1.5-2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol% % or 4-5 mol%.
在一些實施例中,可電離之陽離子脂質係8-((2-羥基乙基)(6-側氧基-6-(十一烷基氧基)己基)胺基)辛酸十七烷-9-基酯(化合物1),中性脂質係1,2-二硬脂醯基-sn-甘油-3-磷酸膽鹼(DSPC),固醇係膽固醇,且/或PEG改質之脂質係1,2二肉豆蔻醯基-sn-甘油-甲氧基聚乙二醇(PEG2000 DMG)。In some embodiments, the ionizable cationic lipid is 8-((2-hydroxyethyl)(6-oxy-6-(undecyloxy)hexyl)amino)octanoic acid heptadecan-9 - base ester (compound 1),
在一些實施例中,脂質奈米顆粒包含20-60 mol%可電離之陽離子脂質、5-25 mol%中性脂質、25-55 mol%固醇及0.5-15 mol% PEG改質之脂質。In some embodiments, the lipid nanoparticles comprise 20-60 mol% ionizable cationic lipids, 5-25 mol% neutral lipids, 25-55 mol% sterols, and 0.5-15 mol% PEG-modified lipids.
在一些實施例中,脂質奈米顆粒包含:47 mol%可電離之陽離子脂質;11.5 mol%中性脂質;38.5 mol%固醇;及3.0 mol% PEG改質之脂質;48 mol%可電離之陽離子脂質;11 mol%中性脂質;38.5 mol%固醇;及2.5 mol% PEG改質之脂質;49 mol%可電離之陽離子脂質;10.5 mol%中性脂質;38.5 mol%固醇;及2.0 mol% PEG改質之脂質;50 mol%可電離之陽離子脂質;10 mol%中性脂質;38.5 mol%固醇;及1.5 mol% PEG改質之脂質;或51 mol%可電離之陽離子脂質;9.5 mol%中性脂質;38.5 mol%固醇;及1.0 mol% PEG改質之脂質。In some embodiments, the lipid nanoparticles comprise: 47 mol% ionizable cationic lipids; 11.5 mol% neutral lipids; 38.5 mol% sterols; and 3.0 mol% PEG-modified lipids; 48 mol% ionizable lipids 11 mol% neutral lipids; 38.5 mol% sterols; and 2.5 mol% PEG-modified lipids; 49 mol% ionizable cationic lipids; 10.5 mol% neutral lipids; 38.5 mol% sterols; and 2.0 mol% PEG-modified lipids; 50 mol% ionizable cationic lipids; 10 mol% neutral lipids; 38.5 mol% sterols; and 1.5 mol% PEG-modified lipids; or 51 mol% ionizable cationic lipids; 9.5 mol% neutral lipids; 38.5 mol% sterols; and 1.0 mol% PEG-modified lipids.
在一些實施例中,脂質奈米顆粒包含47 mol%化合物1;11.5 mol% DSPC;38.5 mol%膽固醇;及3.0 mol% PEG2000 DMG;48 mol%化合物1;11 mol% DSPC;38.5 mol%膽固醇;及2.5 mol% PEG2000 DMG;49 mol%化合物1;10.5 mol% DSPC;38.5 mol%膽固醇;及2.0 mol% PEG2000 DMG;50 mol%化合物1;10 mol% DSPC;38.5 mol%膽固醇;及1.5 mol% PEG2000 DMG;或51 mol%化合物1;9.5 mol% DSPC;38.5 mol%膽固醇;及1.0 mol% PEG2000 DMG。In some embodiments, the lipid nanoparticle comprises 47 mol
國際申請案號PCT/US2016/058327 (公開案號WO2017/070626)及國際申請案號PCT/US2018/022777 (公開案號WO2018/170347)之全部內容以引用方式併入本文中。 SARS-Cov-2 The entire contents of International Application No. PCT/US2016/058327 (Publication No. WO2017/070626) and International Application No. PCT/US2018/022777 (Publication No. WO2018/170347) are incorporated herein by reference. SARS-Cov-2
SARS-CoV-2之基因體係單股正義RNA (+ssRNA),大小為29.8-30 kb,編碼約9860個胺基酸(Chan等人,2000,同上;Kim等人,2020 Cell,5月14日;181(4):914-921,e10)。SARS-CoV-2係具有5'-端帽及3'-聚A尾之多順反子mRNA。將SARS-CoV-2基因體組織成編碼結構蛋白及非結構蛋白(Nsp)之特定基因。結構蛋白在基因體中之順序係5'-複製酶(開放閱讀框(ORF)1/ab)-結構蛋白[刺突(S)-套膜(E)-膜(M)-核酸蛋白殼(N)]-3'。冠狀病毒之基因體包括可變數量之編碼輔助蛋白、非結構蛋白及結構蛋白之開放閱讀框(Song等人,2019 Viruses;11(1):第59頁)。大部分抗原性肽位於結構蛋白中(Cui等人,2019 Nat. Rev. Microbiol.;17(3):181-192)。刺突表面醣蛋白(S)、小套膜蛋白(E)、基質蛋白(M)及核酸蛋白殼蛋白(N)係四種主要之結構蛋白。由於S-蛋白有助於細胞向性,其能够誘導中和抗體(NAb)及保護性免疫,故可將其視為所有其他結構蛋白中冠狀病毒疫苗開發中最重要之靶標之一。此外,胺基酸序列分析顯示S-蛋白含有冠狀病毒中之保守區,此可為開發通用疫苗之基礎。 抗原 The genetic system of SARS-CoV-2 single-stranded positive-sense RNA (+ssRNA), 29.8-30 kb in size, encodes about 9860 amino acids (Chan et al., 2000, supra; Kim et al., 2020 Cell, May 14 Sun;181(4):914-921, e10). SARS-CoV-2 is a polycistronic mRNA with a 5'-end cap and a 3'-poly A tail. The SARS-CoV-2 genome is organized into specific genes encoding structural and nonstructural proteins (Nsp). The sequence of structural proteins in the genome is 5'-replicase (open reading frame (ORF) 1/ab)-structural protein [spike (S)-mantle (E)-membrane (M)-nucleoprotein shell ( N)]-3'. The genome of coronaviruses includes a variable number of open reading frames encoding accessory, nonstructural, and structural proteins (Song et al., 2019 Viruses; 11(1): p. 59). Most antigenic peptides are located in structural proteins (Cui et al., 2019 Nat. Rev. Microbiol.; 17(3):181-192). Spike surface glycoprotein (S), small envelope protein (E), matrix protein (M) and nucleic acid protein capsid protein (N) are four major structural proteins. Since the S-protein contributes to cell tropism, its ability to induce neutralizing antibodies (NAbs) and protective immunity, it can be regarded as one of the most important targets in coronavirus vaccine development among all other structural proteins. In addition, amino acid sequence analysis showed that the S-protein contains a conserved region in coronaviruses, which can be the basis for the development of a universal vaccine. antigen
本發明之組合物(例如疫苗組合物)之特徵在於設計用於編碼相關抗原(例如,源自β冠狀病毒結構蛋白之抗原,特別是源自SARS-CoV-2刺突蛋白之抗原)之核酸,特別是mRNA。本發明之組合物(例如疫苗組合物)不包含抗原本身,而是包含一旦遞送至細胞、組織或個體即編碼抗原或抗原性序列之核酸,特別是mRNA。核酸分子(特別是mRNA)之遞送係藉由將該等核酸分子調配於適當載劑或遞送媒劑(例如,脂質奈米顆粒)中來實現,使得在投與至細胞、組織或個體後,核酸由細胞攝取,該等細胞進而表現由核酸(例如mRNA)編碼之蛋白質。如本文所用之術語「抗原」係指諸如蛋白質(例如醣蛋白)、多肽、肽或諸如此類等物質,其引發免疫反應,例如當存在於個體中時(例如,當存在於人類或哺乳動物個體中時)引發免疫反應。本發明至少部分基於以下理解:當mRNA編碼之抗原自投與至細胞或個體之mRNA表現時,可引起免疫系統產生針對表現之抗原之免疫反應,例如可觸發針對表現抗原之抗體(例如結合及/或中和抗體)之產生,可觸發對表現之抗原特異性之B細胞及或T細胞反應,且最終可引起針對隨後遇到抗原或與抗原相關之病原體之保護性或預防性反應。較佳mRNA編碼之抗原係「病毒抗原」。如本文所用之術語「病毒抗原」係指源自病毒、例如源自致病病毒之抗原。如本文所用之術語抗原可指全長蛋白,例如全長病毒蛋白,或可指蛋白之片段(例如多肽或肽片段)、次單元或結構域,例如病毒蛋白次單元或結構域。Compositions (eg vaccine compositions) of the invention are characterized by nucleic acids designed to encode relevant antigens (eg, antigens derived from betacoronavirus structural proteins, particularly antigens derived from the SARS-CoV-2 spike protein) , especially mRNA. The compositions (eg vaccine compositions) of the invention do not comprise the antigen itself, but rather comprise nucleic acid, particularly mRNA, that encodes the antigen or antigenic sequence once delivered to a cell, tissue or individual. Delivery of nucleic acid molecules, particularly mRNA, is accomplished by formulating the nucleic acid molecules in a suitable carrier or delivery vehicle (eg, lipid nanoparticles) such that upon administration to a cell, tissue or individual, Nucleic acids are taken up by cells, which in turn express proteins encoded by nucleic acids (eg, mRNA). The term "antigen" as used herein refers to substances such as proteins (eg, glycoproteins), polypeptides, peptides, or the like, which elicit an immune response, eg, when present in an individual (eg, when present in a human or mammalian individual). time) triggers an immune response. The invention is based, at least in part, on the understanding that, when an mRNA-encoded antigen is self-administered to the expression of the mRNA in a cell or individual, the immune system can be induced to mount an immune response against the expressed antigen, for example, antibodies to the expressed antigen can be triggered (e.g., binding and The production of neutralizing antibodies) can trigger a B-cell and or T-cell response specific for the presented antigen and, ultimately, can elicit a protective or preventive response against subsequently encountered antigen or antigen-related pathogens. A preferred mRNA-encoded antigen is a "viral antigen". The term "viral antigen" as used herein refers to an antigen derived from a virus, eg, from a pathogenic virus. The term antigen as used herein may refer to a full-length protein, eg, a full-length viral protein, or may refer to a fragment (eg, a polypeptide or peptide fragment), subunit or domain of a protein, eg, a viral protein subunit or domain.
許多蛋白質具有四級或三維結構,其由一個以上多肽或若干締合成寡聚分子之多肽鏈組成。如本文所用之術語「次單元」係指單一蛋白質分子,例如,由處理新生蛋白質分子產生之多肽或多肽鏈,該次單元與其他蛋白質分子(例如次單元或鏈)組裝(或「共組裝」)形成蛋白質複合體。蛋白質可具有相對小數目之次單元,且因此闡述為「寡聚的」,或可由大數目之次單元組成且因此闡述為「多聚的」。寡聚或多聚蛋白質之次單元可為相同的、同源的或完全不相似的,且專用於不同之任務。Many proteins have a quaternary or three-dimensional structure consisting of more than one polypeptide or several polypeptide chains associated into oligomeric molecules. The term "subunit" as used herein refers to a single protein molecule, eg, a polypeptide or polypeptide chain resulting from processing a nascent protein molecule, that assembles (or "co-assembles" with other protein molecules (eg, subunits or chains) ) to form protein complexes. A protein may have a relatively small number of subunits and thus be described as "oligomeric", or may consist of a large number of subunits and thus be described as "polymeric". Subunits of oligomeric or multimeric proteins can be identical, homologous or completely dissimilar, and dedicated to different tasks.
蛋白質或蛋白質次單元可進一步包含結構域。如本文所用之術語「結構域」係指蛋白質內不同之功能及/或結構單元。通常,「結構域」負責特定功能或相互作用,從而有助於蛋白質之總體作用。結構域可存在於各種生物環境中。相似結構域(亦即,共享結構、功能及/或序列同源性之結構域)可存在於單一蛋白質內或可存在於具有相似或不同功能之不同蛋白質內。蛋白質結構域通常係給定蛋白質三級結構或序列之保守部分,其可獨立於蛋白質或其次單元之其餘部分起作用及存在。The protein or protein subunit may further comprise domains. The term "domain" as used herein refers to distinct functional and/or structural units within a protein. Typically, "domains" are responsible for specific functions or interactions that contribute to the overall functioning of the protein. Domains can exist in a variety of biological contexts. Similar domains (ie, domains that share structural, functional and/or sequence homology) may exist within a single protein or may exist within different proteins with similar or different functions. A protein domain is typically a conserved portion of a given protein's tertiary structure or sequence that can function and exist independently of the rest of the protein or its subunits.
在結構及分子生物學中,相同、同源或相似之次單元或結構域可幫助對新近鑑別或新穎蛋白質進行分類,正如在SARS-CoV-2病毒基因體序列公佈後立即進行之那樣。In structural and molecular biology, identical, homologous, or similar subunits or domains can aid in the classification of newly identified or novel proteins, as was done immediately after the publication of the SARS-CoV-2 viral genome sequence.
如本文所用之術語抗原不同於術語「抗原決定基」,該抗原決定基係抗原之亞結構,例如多肽或碳水化合物結構,其可由抗原結合位點識別,但不足以誘導免疫反應。業內闡述以分離形式遞送至個體或免疫細胞之蛋白抗原,例如分離之蛋白質、多肽或肽抗原,然而,蛋白抗原之設計、測試、驗證及產生可為昂貴且耗時的,尤其當大規模產生蛋白時。相反,mRNA技術可用於快速設計及測試編碼各種抗原之mRNA構築體。此外,結合調配於適當遞送媒劑(例如,脂質奈米顆粒)中之mRNA之快速產生可快速進行且可快速大規模產生mRNA疫苗。潜在益處亦來自於以下事實:由本發明之mRNA編碼之抗原由個體之細胞表現,例如由人體表現,且因此,個體(例如人體)用作「工廠」以產生抗原,其進而引發期望免疫反應。The term antigen as used herein differs from the term "epitope," which is a substructure of an antigen, such as a polypeptide or carbohydrate structure, that is recognized by the antigen binding site, but is not sufficient to induce an immune response. Protein antigens, such as isolated protein, polypeptide or peptide antigens, are described in the art for delivery to an individual or immune cell in isolated form, however, the design, testing, validation and production of protein antigens can be expensive and time consuming, especially when produced on a large scale protein time. In contrast, mRNA technology can be used to rapidly design and test mRNA constructs encoding various antigens. In addition, rapid production of mRNA in combination with formulated in an appropriate delivery vehicle (eg, lipid nanoparticles) can be performed rapidly and mRNA vaccines can be produced rapidly on a large scale. Potential benefits also arise from the fact that the antigens encoded by the mRNAs of the invention are expressed by cells of the individual, eg, by the human body, and thus, the individual (eg, the human body) acts as a "factory" to generate antigens, which in turn elicit the desired immune response.
在較佳態樣中,抗原係能够誘導免疫反應(例如,引起免疫系統產生針對抗原之抗體)之蛋白質。在本文中,除非另有說明,否則術語「抗原」之使用包括免疫原性蛋白以及衍生自免疫原性蛋白之多肽或肽,例如免疫原性片段(誘導(或能够誘導)對抗原之免疫反應之免疫原性片段)。應理解,術語「蛋白質」涵蓋多肽及肽,且術語「抗原」涵蓋抗原性片段。其他分子可為抗原性的,諸如細菌多醣或蛋白及多醣結構之組合,但對於本文包括之病毒疫苗,源自β冠狀病毒SARS-CoV-2之病毒蛋白、病毒蛋白片段及設計及/或突變之蛋白係本文特徵性之抗原。 核酸 /mRNA In preferred aspects, the antigen is a protein capable of inducing an immune response (eg, causing the immune system to produce antibodies against the antigen). As used herein, unless otherwise stated, the use of the term "antigen" includes immunogenic proteins as well as polypeptides or peptides derived from immunogenic proteins, such as immunogenic fragments that induce (or are capable of inducing) an immune response to the antigen the immunogenic fragment). It is to be understood that the term "protein" encompasses polypeptides and peptides, and the term "antigen" encompasses antigenic fragments. Other molecules may be antigenic, such as bacterial polysaccharides or combinations of proteins and polysaccharide structures, but for viral vaccines included herein, viral proteins, viral protein fragments and designs and/or mutations derived from betacoronavirus SARS-CoV-2 The protein is the antigen characterized herein. Nucleic acid /mRNA
本文所述之疫苗技術之特徵在於設計用於編碼相關抗原(例如β冠狀病毒刺突蛋白抗原、其次單元、結構域或片段(例如抗原性片段))之核酸,特別是信使RNA (mRNA)。本發明之核酸(例如mRNA)較佳調配於適當載劑或遞送媒劑(例如,脂質奈米顆粒)中,使得核酸(例如mRNA)適於活體內使用。核酸(例如mRNA)當經適當調配時能够遞送至個體(例如人類個體)內之細胞及/或組織,以完成由該等核酸編碼之蛋白質之轉譯。The vaccine technologies described herein feature nucleic acids, particularly messenger RNA (mRNA), designed to encode relevant antigens (eg, betacoronavirus spike protein antigens, subunits, domains or fragments (eg, antigenic fragments)). The nucleic acid (eg, mRNA) of the present invention is preferably formulated in a suitable carrier or delivery vehicle (eg, lipid nanoparticle), making the nucleic acid (eg, mRNA) suitable for in vivo use. Nucleic acids (eg, mRNAs), when appropriately formulated, can be delivered to cells and/or tissues within an individual (eg, a human individual) to accomplish translation of the proteins encoded by the nucleic acids.
核酸分子係由携帶遺傳資訊之連接核苷酸構成之大分子,且藉由指導蛋白質合成過程,指導大部分(若並非全部)細胞功能。核酸包含核苷酸(核苷酸單體)之聚合物。因此,核酸亦稱為聚核苷酸(亦稱為聚核苷酸鏈)。核酸之兩個主要類別係去氧核糖核酸(DNA)及核糖核酸(RNA)。DNA構成所有自由生活之生物體及大部分病毒中之遺傳物質。RNA係某些病毒之遺傳物質,但亦在所有活細胞中發現,在該等活細胞中,RNA在細胞過程中、最顯著的是在蛋白質之製備中起重要作用。Nucleic acid molecules are macromolecules composed of linked nucleotides that carry genetic information and direct most, if not all, cellular functions by directing the process of protein synthesis. Nucleic acids comprise polymers of nucleotides (nucleotide monomers). Accordingly, nucleic acids are also known as polynucleotides (also known as polynucleotide chains). The two main classes of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA constitutes the genetic material in all free-living organisms and in most viruses. RNA is the genetic material of some viruses, but is also found in all living cells where it plays an important role in cellular processes, most notably in the production of proteins.
核苷係核酸(諸如DNA及RNA)之結構次單元。核苷由共價附接至五碳碳水化合物核糖或「糖」(其為核糖或去氧核糖)之含氮鹼基(核鹼基)、通常為嘧啶(胞嘧啶、胸腺嘧啶或尿嘧啶)或嘌呤(腺嘌呤或鳥嘌呤)構成。核苷酸由含氮鹼基、糖(核糖或去氧核糖)及一至三個磷酸基團組成。本質上,核苷酸僅僅係具有一或多個額外磷酸基團之核苷。Nucleosides are structural subunits of nucleic acids such as DNA and RNA. Nucleosides consist of a nitrogenous base (nucleobase), usually a pyrimidine (cytosine, thymine, or uracil), covalently attached to the five-carbon carbohydrate ribose or "sugar" (which is ribose or deoxyribose) or purine (adenine or guanine). Nucleotides consist of a nitrogenous base, a sugar (ribose or deoxyribose), and one to three phosphate groups. Essentially, nucleotides are simply nucleosides with one or more additional phosphate groups.
核酸分子(DNA及RNA)由在一個核苷酸之糖鹼基與相鄰核苷酸之磷酸基團之間藉由化學鍵(稱為酯鍵)在鏈中彼此連接的核苷酸構成。糖在每個核苷酸之3'端,且磷酸在每個核苷酸之5'端。附接至一個核苷酸上之糖之5'碳之磷酸基團與下一個核苷酸之3'碳上之游離羥基形成酯鍵。該等鍵稱為磷酸二酯鍵,且當合成分子時,糖-磷酸主鏈闡述為在5'至3'方向上延伸或生長。Nucleic acid molecules (DNA and RNA) are composed of nucleotides linked to each other in a chain by chemical bonds (called ester bonds) between the sugar bases of one nucleotide and the phosphate groups of adjacent nucleotides. The sugar is at the 3' end of each nucleotide and the phosphate is at the 5' end of each nucleotide. The phosphate group attached to the 5' carbon of the sugar on one nucleotide forms an ester bond with the free hydroxyl group on the 3' carbon of the next nucleotide. These bonds are called phosphodiester bonds, and when synthesizing the molecule, the sugar-phosphate backbone is illustrated as extending or growing in the 5' to 3' direction.
核酸之核鹼基部分之特徵在於嘌呤鹼基:腺嘌呤(A)及鳥嘌呤(G);及嘧啶鹼基:胞嘧啶(C)、DNA中之胸腺嘧啶(T)及RNA中之尿嘧啶(U)。核酸之糖部分之特徵在於DNA中之去氧核糖、RNA中之核糖。五個核苷通常分別縮寫為其單字母代碼A、G、C、T及U。然而,胸苷更通常地寫為「dT」 (「d」代表「去氧」),此乃因其含有2'-去氧呋喃核糖部分而非尿苷中發現之呋喃核糖環。此係由於胸苷在去氧核糖核酸(DNA)而非核糖核酸(RNA)中發現。相反,尿苷在RNA中而非DNA中發現。其餘三個核苷可在RNA及DNA二者中發現。在RNA中,其將表示為A、C及G,而在DNA中,其將表示為dA、dC及dG。The nucleobase portion of nucleic acids is characterized by the purine bases: adenine (A) and guanine (G); and the pyrimidine bases: cytosine (C), thymine (T) in DNA, and uracil in RNA (U). The sugar moiety of nucleic acids is characterized by deoxyribose in DNA and ribose in RNA. The five nucleosides are commonly abbreviated by their one-letter codes A, G, C, T, and U, respectively. However, thymidine is more commonly written as "dT" ("d" stands for "deoxy") because it contains a 2'-deoxyribofuranose moiety rather than the ribofuranose ring found in uridine. This is due to the fact that thymidine is found in deoxyribonucleic acid (DNA) rather than ribonucleic acid (RNA). In contrast, uridine is found in RNA rather than DNA. The remaining three nucleosides can be found in both RNA and DNA. In RNA it will be denoted A, C and G, and in DNA it will be denoted dA, dC and dG.
熟習此項技術者理解,除非另有說明,否則本申請案中所闡釋之核酸序列可在代表性DNA序列中列舉「T」,但在序列表示mRNA之情況下,「T」將被取代為「U」。因此,所揭示及由本文特定序列識別號鑑別之任何DNA亦揭示與DNA互補之相應mRNA序列,其中DNA序列之每個「T」經「U」取代。It will be understood by those skilled in the art that unless otherwise stated, the nucleic acid sequences illustrated in this application may recite a "T" in a representative DNA sequence, but where the sequence represents mRNA, the "T" will be replaced by "U". Thus, any DNA disclosed and identified by a specific sequence identification number herein also discloses the corresponding mRNA sequence complementary to the DNA, wherein each "T" of the DNA sequence is substituted with a "U".
核酸可為或可包括(例如)去氧核糖核酸(DNA)、核糖核酸(RNA) (例如mRNA)、蘇糖核酸(TNA)、二醇核酸(GNA)、肽核酸(PNA)、鎖核酸(LNA,包括具有β-D-核糖組態之LNA、具有α-L-核糖組態之α-LNA (LNA之非鏡像异構物)、具有2'-胺基官能化之2'-胺基-LNA及具有2'-胺基官能化之2'-胺基-α-LNA)、乙烯核酸(ENA)、環己烯基核酸(CeNA)及/或其嵌合體及/或組合。Nucleic acids can be or can include, for example, deoxyribonucleic acid (DNA), ribonucleic acid (RNA) (eg, mRNA), threose nucleic acid (TNA), glycol nucleic acid (GNA), peptide nucleic acid (PNA), locked nucleic acid ( LNAs, including LNAs with a β-D-ribose configuration, α-LNAs with an α-L-ribose configuration (a mirror isomer of LNA), 2'-amine functionalized with a 2'-amine group -LNA and 2'-amino-α-LNA with 2'-amino functionalization), ethylene nucleic acid (ENA), cyclohexenyl nucleic acid (CeNA) and/or chimeras and/or combinations thereof.
本發明之特徵在於信使RNA (mRNA),特別是設計用於編碼相關抗原(例如β冠狀病毒刺突蛋白抗原、其次單元、結構域或片段(例如抗原性片段))之mRNA。信使RNA (mRNA) (一種RNA亞型)係對應於基因之遺傳序列之單股RNA分子。在轉錄過程中產生mRNA,其中單股DNA藉由RNA聚合酶解碼,且合成、亦即轉錄mRNA。mRNA在合成蛋白質、亦即轉譯之過程中由核糖體讀取。因此,信使RNA (mRNA)係編碼(至少一種)蛋白質(天然存在的、非天然存在的或經改質之胺基酸聚合物)的RNA,且可經轉譯以在活體外、活體內、原位或離體産生編碼之蛋白質。The invention features messenger RNA (mRNA), particularly mRNA designed to encode a relevant antigen (eg, betacoronavirus spike protein antigen, subunits, domains or fragments (eg, antigenic fragments)). Messenger RNA (mRNA), a subtype of RNA, is a single-stranded RNA molecule that corresponds to the genetic sequence of a gene. mRNA is produced during transcription, in which single-stranded DNA is decoded by RNA polymerase, and mRNA is synthesized, ie, transcribed. mRNA is read by ribosomes during protein synthesis, ie, translation. Thus, messenger RNA (mRNA) is RNA that encodes (at least one) protein (naturally-occurring, non-naturally-occurring or modified amino acid polymer), and can be translated for in vitro, in vivo, original The encoded protein is produced in situ or ex vivo.
本揭示案之組合物包含(至少一種)具有編碼冠狀病毒抗原之開放閱讀框(ORF)之mRNA。在一些實施例中,mRNA進一步包含5ꞌ UTR、3ꞌ UTR、聚(A)尾及/或5ꞌ端帽或端帽類似物。開放閱讀框(ORF)係一段連續之DNA或RNA,以起始密碼子(例如,甲硫胺酸(ATG或AUG))開始且以終止密碼子(例如TAA、TAG或TGA,或UAA、UAG或UGA)結束。ORF通常編碼蛋白質。應理解,本文揭示之序列可進一步包含額外元件,例如5'及3' UTR,但與ORF不同,彼等元件不一定存在於本揭示案之mRNA中。亦應理解,本發明之mRNA (例如本揭示案之β冠狀病毒疫苗中特徵性之mRNA)可包括任何5'非轉譯區(UTR)及/或任何3' UTR。示例性UTR序列提供於序列表中(例如,SEQ ID NO: 2、4、131及132);然而,其他UTR序列可使用或替換本文所述之任何UTR序列。亦可自本文提供之mRNA省略UTR。Compositions of the present disclosure comprise (at least one) mRNA having an open reading frame (ORF) encoding a coronavirus antigen. In some embodiments, the mRNA further comprises a 5ꞌ UTR, a 3ꞌ UTR, a poly(A) tail, and/or a 5ꞌ end cap or end cap analog. An open reading frame (ORF) is a continuous stretch of DNA or RNA that begins with a start codon (eg, methionine (ATG or AUG)) and ends with a stop codon (eg, TAA, TAG, or TGA, or UAA, UAG) or UGA) ends. ORFs usually encode proteins. It is understood that the sequences disclosed herein may further comprise additional elements, such as 5' and 3' UTRs, but unlike ORFs, these elements are not necessarily present in the mRNAs of the present disclosure. It should also be understood that the mRNAs of the present invention (eg, mRNAs characterized in the betacoronavirus vaccines of the present disclosure) may include any 5' untranslated region (UTR) and/or any 3' UTR. Exemplary UTR sequences are provided in the Sequence Listing (eg, SEQ ID NOs: 2, 4, 131, and 132); however, other UTR sequences may use or replace any of the UTR sequences described herein. UTRs can also be omitted from the mRNAs provided herein.
在一些實施例中,組合物包含mRNA,該mRNA包含與SEQ ID NO: 45、75或90中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%或100%一致性的核苷酸序列。在一些實施例中,組合物包含mRNA,該mRNA包含與表1至15中之序列中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%或100%一致性的核苷酸序列。In some embodiments, the composition comprises mRNA comprising at least 70%, at least 75%, at least 80%, at least 85% of the nucleotide sequence of any one of SEQ ID NOs: 45, 75 or 90 , at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical nucleotide sequences. In some embodiments, the composition comprises mRNA comprising at least 70%, at least 75%, at least 80%, at least 85%, at least 70%, at least 75%, at least 80%, at least 85%, at least a nucleotide sequence of any of the sequences in Tables 1-15 Nucleotide sequences that are 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99% or 100% identical.
在一些實施例中,組合物包含mRNA,該mRNA包含與SEQ ID NO: 46、76或91中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%或100%一致性的ORF。在一些實施例中,組合物包含mRNA,該mRNA包含與表1至15中之序列中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%或100%一致性的ORF。In some embodiments, the composition comprises mRNA comprising at least 70%, at least 75%, at least 80%, at least 85% of the nucleotide sequence of any one of SEQ ID NOs: 46, 76, or 91 , at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical ORFs. In some embodiments, the composition comprises mRNA comprising at least 70%, at least 75%, at least 80%, at least 85%, at least 70%, at least 75%, at least 80%, at least 85%, at least a nucleotide sequence of any of the sequences in Tables 1-15 ORFs of 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identity.
表1至15中提供本揭示案之組合物之冠狀病毒抗原及編碼冠狀病毒抗原之mRNA之示例性序列。Exemplary sequences of coronavirus antigens and mRNA encoding coronavirus antigens of the compositions of the present disclosure are provided in Tables 1-15.
應理解,本文所述mRNA編碼之任何一種抗原可包含或不包含信號序列。 編碼之冠狀病毒刺突 (S) 蛋白抗原 It will be appreciated that any of the antigens encoded by the mRNAs described herein may or may not contain a signal sequence. Encoded coronavirus spike (S) protein antigen
已知之β-冠狀病毒之套膜刺突(S)蛋白决定病毒宿主向性及進入宿主細胞。冠狀病毒刺突(S)蛋白係疫苗設計之選擇抗原,此乃因其可誘導中和抗體及保護性免疫。S蛋白對於SARS-CoV-2感染至關重要。S蛋白之組織在β-冠狀病毒(諸如SARS-CoV-2、SARS-CoV、MERS-CoV、HKU1-CoV、MHV-CoV及NL63-CoV)中係相似的。The known mantle spike (S) protein of betacoronaviruses determines viral host tropism and entry into host cells. The coronavirus spike (S) protein is the antigen of choice for vaccine design because it induces neutralizing antibodies and protective immunity. The S protein is essential for SARS-CoV-2 infection. The organization of the S protein is similar in betacoronaviruses such as SARS-CoV-2, SARS-CoV, MERS-CoV, HKU1-CoV, MHV-CoV and NL63-CoV.
如本文所用之術語「刺突蛋白」係指形成自病毒(包括β冠狀病毒)之套膜(病毒表面)突出之同三聚體的醣蛋白。三聚化刺突蛋白藉由與宿主細胞表面上之受體結合、之後融合病毒及宿主細胞膜而促進病毒粒子進入宿主細胞。S蛋白係高度醣基化之大的I型跨膜融合蛋白,其由1,160至1,400個胺基酸組成,此取决於病毒之類型。β冠狀病毒刺突蛋白包含約1100至1500個胺基酸,且包含如 圖 1所闡釋之結構(亦即,結構域組成及組織)。SARS-CoV-2刺突(S)蛋白係疫苗設計之選擇抗原,此乃因其可誘導中和抗體及保護性免疫。本發明之mRNA經設計用於產生SARS-CoV-2刺突蛋白(亦即,編碼刺突蛋白,使得當mRNA遞送至細胞或組織(例如個體之細胞或組織)時刺突蛋白表現),以及其抗原性變異體。熟習此項技術者將理解,儘管基本上全長或完整刺突蛋白對於病毒(例如β冠狀病毒)實施其促進病毒進入宿主細胞之預期功能可為必需的,但當主要尋求引發針對刺突蛋白之免疫反應時,可耐受刺突蛋白結構及/或序列之一定量之變化。舉例而言,可耐受例如自編碼之刺突蛋白(例如編碼之刺突蛋白抗原)之N末端或C末端之一個至幾個、可能至多5個或至多10個胺基酸之少量截短,而不改變蛋白質之抗原性質。同樣,可耐受編碼之刺突蛋白(例如編碼之刺突蛋白抗原)之一個至幾個、可能至多5個或至多10個胺基酸(或更多)之變化(例如保守取代),而不改變蛋白質之抗原性質。在示例性實施例中,刺突蛋白(例如編碼之刺突蛋白抗原)具有表1-15之序列中之任一者中所闡釋之胺基酸序列(例如,源自如SEQ ID NO: 125所闡釋之胺基酸序列)。在其他實施例中,與具有表1-15之序列中之任一者中所闡釋之胺基酸序列(例如,源自如SEQ ID NO: 125所闡釋之胺基酸序列)之刺突蛋白相比(當與其比對時),刺突蛋白(例如編碼之刺突蛋白抗原)具有不大於100、不大於90、不大於80、不大於70、不大於60、不大於50、不大於40、不大於30、不大於20、不大於10或不大於5個胺基酸取代及/或缺失。在編碼之刺突蛋白序列中進行微小變化之情況下,變異體較佳具有與參考刺突蛋白序列相同之活性及/或具有與參考刺突蛋白相同之免疫特異性,如例如在免疫分析(例如酶聯免疫吸附分析(ELISA分析))中所測定。 The term "spike protein" as used herein refers to a glycoprotein that forms a homotrimer protruding from the envelope (viral surface) of viruses, including betacoronaviruses. Trimeric spike proteins facilitate viral entry into host cells by binding to receptors on the host cell surface, followed by fusion of the viral and host cell membranes. The S protein is a large, highly glycosylated type I transmembrane fusion protein consisting of 1,160 to 1,400 amino acids, depending on the type of virus. Betacoronavirus spike proteins comprise approximately 1100 to 1500 amino acids and comprise the structure (i.e., domain composition and organization) as illustrated in Figure 1 . The SARS-CoV-2 spike (S) protein is the antigen of choice for vaccine design because of its ability to induce neutralizing antibodies and protective immunity. The mRNA of the invention is designed to produce the SARS-CoV-2 spike protein (ie, encodes the spike protein such that the spike protein behaves when the mRNA is delivered to a cell or tissue (eg, a cell or tissue of an individual)), and its antigenic variants. Those skilled in the art will appreciate that although substantially full-length or intact spike proteins may be necessary for a virus (eg, betacoronavirus) to perform its intended function of facilitating viral entry into host cells, when primary elicitation of targeting of the spike protein is sought. A quantitative change in the structure and/or sequence of the spike protein is tolerated during an immune response. For example, minor truncations such as one to several, possibly up to 5 or up to 10 amino acids from the N-terminus or C-terminus of the encoded spike protein (eg, the encoded spike protein antigen) can be tolerated , without changing the antigenic properties of the protein. Likewise, one to several, possibly up to 5 or up to 10 amino acid (or more) changes (eg, conservative substitutions) in the encoded spike protein (eg, the encoded spike protein antigen) are tolerated, while Does not alter the antigenic properties of the protein. In exemplary embodiments, the spike protein (eg, the encoded spike protein antigen) has the amino acid sequence (eg, derived from, eg, SEQ ID NO: 125) as set forth in any of the sequences of Tables 1-15 the amino acid sequence explained). In other embodiments, with a spike protein having the amino acid sequence set forth in any of the sequences of Tables 1-15 (eg, derived from the amino acid sequence set forth as SEQ ID NO: 125) Compared (when aligned to) the spike protein (eg, the encoded spike protein antigen) has no greater than 100, no greater than 90, no greater than 80, no greater than 70, no greater than 60, no greater than 50, no greater than 40 , no more than 30, no more than 20, no more than 10, or no more than 5 amino acid substitutions and/or deletions. Where minor changes are made in the encoded spike protein sequence, the variant preferably has the same activity and/or the same immunospecificity as the reference spike protein sequence, as for example in an immunoassay ( For example, as determined in an enzyme-linked immunosorbent assay (ELISA assay).
冠狀病毒之S蛋白可分為兩個重要之功能次單元,其中包括N末端S1次單元,其形成S蛋白之球狀頭部;及C末端S2區,其形成蛋白之莖且直接嵌入病毒套膜中。在與潜在宿主細胞相互作用時,S1次單元將識別且結合至宿主細胞上之受體,尤其是血管收縮肽轉化酶2 (ACE2)受體,而作為S蛋白之最保守組分之S2次單元將負責將病毒之套膜與宿主細胞膜融合。(參見例如Shang等人,PLoS Pathog. 2020年3月;16(3):e1008392。)。三聚化S蛋白三聚體之每個單體含有兩個次單元S1及S2,分別介導附著及膜融合。參見例如 圖 1。作為活體內感染過程之一部分,兩個次單元藉由酶裂解過程彼此分離。S蛋白首先藉由弗林蛋白酶(furin)介導之裂解在感染細胞中在S1/S2位點進行裂解,在活體內,隨後在S1內之S2'位點發生絲胺酸蛋白酶介導之裂解事件。在SARS-CoV2中,S1/S2裂解位點在胺基酸676 - TQTNSPRRAR/SVA - 688 (參考SEQ ID NO: 127)。S2'裂解位點在胺基酸811 - KPSKR/SFI - 818 (參考SEQ ID NO: 126)。 The S protein of coronavirus can be divided into two important functional subunits, including the N-terminal S1 subunit, which forms the globular head of the S protein; and the C-terminal S2 region, which forms the stem of the protein and directly embeds the viral jacket in the membrane. When interacting with a potential host cell, the S1 subunit will recognize and bind to receptors on the host cell, especially the vasoconstrictor peptide-converting enzyme 2 (ACE2) receptor, while the S2 subunit, the most conserved component of the S protein The unit will be responsible for fusing the viral envelope with the host cell membrane. (See eg, Shang et al., PLoS Pathog. 2020 Mar;16(3):e1008392.). Each monomer of the trimerized S protein trimer contains two subunits, S1 and S2, which mediate attachment and membrane fusion, respectively. See e.g. Figure 1 . As part of the in vivo infection process, the two subunits are separated from each other by an enzymatic cleavage process. The S protein is first cleaved at the S1/S2 site in infected cells by furin-mediated cleavage, followed by serine protease-mediated cleavage at the S2' site within S1 in vivo event. In SARS-CoV2, the S1/S2 cleavage site is at amino acid 676 - TQTNSPRRAR/SVA - 688 (refer to SEQ ID NO: 127). The S2' cleavage site is at amino acid 811 - KPSKR/SFI - 818 (refer to SEQ ID NO: 126).
如本文所用,例如在設計由本發明之核酸(例如mRNA)編碼之SARS-CoV-2 S蛋白抗原之情况下,術語「S1次單元」(例如,S1次單元抗原)係指刺突蛋白之N末端次單元,以S蛋白N末端開始且以S1/S2裂解位點結束,而術語「S2次單元」 (例如,S2次單元抗原)係指刺突蛋白之C末端次單元,以S1/S2裂解位點開始且以刺突蛋白之C末端結束。如上文所述,熟習此項技術者將理解,儘管基本上全長或完整刺突蛋白S1或S2次單元可分別為受體結合或膜融合所必需的,但當主要尋求引發針對刺突蛋白次單元之免疫反應時,可耐受S1或S2結構及/或序列之一定量之變化。舉例而言,可耐受例如自編碼之次單元(例如編碼之S1或S2蛋白抗原)之N或C末端一個至幾個、可能至多4、5、6、7、8、9或10個胺基酸之少量截短,而不改變蛋白質之抗原性質。同樣,可耐受編碼之刺突蛋白次單元(例如編碼之S1或S2蛋白抗原)之一個至幾個、可能至多4、5、6、7、8、9或10個胺基酸(或更多)之變化(例如保守取代),而不改變蛋白質之抗原性質。在示例性實施例中,刺突蛋白(例如編碼之刺突蛋白抗原)具有表1-15之序列中之任一者中所闡釋之胺基酸序列(例如,源自如SEQ ID NO: 125所闡釋之胺基酸序列)。在其他實施例中,與包含具有如SEQ ID NO: 125所闡釋之胺基酸序列之刺突蛋白之胺基酸1-685或由胺基酸1-685組成之刺突蛋白S1次單元或包含胺基酸686-1273或由胺基酸686-1273組成的刺突蛋白S2次單元相比(當與其比對時),刺突蛋白次單元(例如編碼之S1或S2蛋白抗原)具有不大於50、不大於40、不大於30、不大於20、不大於10或不大於5個胺基酸取代及/或缺失。當在編碼之刺突蛋白次單元序列中進行微小變化時,變異體較佳具有與參考刺突蛋白次單元序列相同之活性及/或具有與參考刺突蛋白次單元相同之免疫特異性,如例如在免疫分析(例如酶聯免疫吸附分析(ELISA分析))中所測定。As used herein, eg, in the context of designing a SARS-CoV-2 S protein antigen encoded by a nucleic acid (eg, mRNA) of the invention, the term "S1 subunit" (eg, S1 subunit antigen) refers to the N of the spike protein The terminal subunit, starting at the N-terminus of the S protein and ending with the S1/S2 cleavage site, and the term "S2 subunit" (e.g., the S2 subunit antigen) refers to the C-terminal subunit of the spike protein, beginning with S1/S2 The cleavage site begins and ends with the C-terminus of the spike protein. As noted above, those skilled in the art will appreciate that while substantially full-length or complete Spike protein S1 or S2 subunits may be required for receptor binding or membrane fusion, respectively, when the primary goal is to elicit targeting of the Spike protein subunits Quantitative changes in S1 or S2 structure and/or sequence are tolerated during the immune response of the unit. For example, one to several, possibly up to 4, 5, 6, 7, 8, 9 or 10 amines can be tolerated, eg, from the N or C terminus of the encoded subunit (eg, the encoded S1 or S2 protein antigen) Minor truncations of amino acids without altering the antigenic properties of the protein. Likewise, one to several, possibly up to 4, 5, 6, 7, 8, 9, or 10 amino acids (or more) of the encoded spike protein subunit (eg, the encoded S1 or S2 protein antigen) may be tolerated. multiple) changes (such as conservative substitutions) without changing the antigenic properties of the protein. In exemplary embodiments, the spike protein (eg, the encoded spike protein antigen) has the amino acid sequence (eg, derived from, eg, SEQ ID NO: 125) as set forth in any of the sequences of Tables 1-15 the amino acid sequence explained). In other embodiments, with a spike protein S1 subunit comprising or consisting of amino acids 1-685 of a spike protein having the amino acid sequence set forth in SEQ ID NO: 125 or Spike protein subunits (eg, the encoded S1 or S2 protein antigens) have different properties compared to (when aligned with) the spike protein S2 subunits comprising or consisting of amino acids 686-1273. More than 50, no more than 40, no more than 30, no more than 20, no more than 10, or no more than 5 amino acid substitutions and/or deletions. When minor changes are made in the encoded Spike subunit sequence, the variant preferably has the same activity and/or the same immunospecificity as the reference Spike subunit sequence, such as For example, as determined in an immunoassay, such as an enzyme-linked immunosorbent assay (ELISA assay).
SARS-CoV-2刺突蛋白之S1及S2次單元進一步包括藉由結構及功能容易辨別之結構域,其特徵又在於設計由核酸疫苗(特別是本發明之mRNA疫苗)編碼之抗原。在S1次單元內,結構域包括N末端結構域(NTD)及受體結合結構域(RBD),該RBD結構域進一步包括受體結合基元(RBM)。野生型S1次單元亦包括在NTD結構域之N末端之信號肽(SD)以及第一子結構域(SD1)及第二子結構域(SD2)。在S2次單元內,結構域包括融合肽(FP)、七肽重複區1 (HR1)、七肽重複區2 (HR2)、跨膜結構域(TM)及細胞質結構域,亦稱為胞質尾區(CT) (Lu R.等人,同上;Wan等人, J. Virol.2020年3月, 94 (7) e00127-20)。HR1及HR2結構域可稱為SARS-CoV-2之「融合核心區」 (Xia等人,2020 Cell Mol Immunol.1月; 17(1):1-12。)。 圖 1繪示SARS-CoV-2刺突蛋白中之結構域架構。S1次單元包括N末端結構域(NTD)、連接體區、受體結合結構域(RBD)、第一子結構域(SD1)及第二子結構域(SD2)。S1次單元可經修飾以添加C末端跨膜結構域(TM),或者其可為可溶的。S2次單元尤其包括第一七肽重複區(HR1)、第二七肽重複區(HR2)、跨膜結構域(TM)及胞質尾區。可溶性S2次單元可在沒有TM結構域之情况下產生。 The S1 and S2 subunits of the SARS-CoV-2 spike protein further include domains that are easily discernible by structure and function, and are further characterized by designing antigens encoded by nucleic acid vaccines, especially mRNA vaccines of the present invention. Within the S1 subunit, the domains include an N-terminal domain (NTD) and a receptor binding domain (RBD), which further includes a receptor binding motif (RBM). The wild-type S1 subunit also includes a signal peptide (SD) at the N-terminus of the NTD domain and a first subdomain (SD1) and a second subdomain (SD2). Within the S2 subunit, the domains include fusion peptide (FP), heptapeptide repeat 1 (HR1), heptapeptide repeat 2 (HR2), transmembrane domain (TM), and the cytoplasmic domain, also known as the cytoplasmic domain Tail region (CT) (Lu R. et al, supra; Wan et al, J. Virol. Mar 2020, 94(7) e00127-20). The HR1 and HR2 domains may be referred to as the "fusion core region" of SARS-CoV-2 (Xia et al., 2020 Cell Mol Immunol. Jan; 17(1): 1-12.). Figure 1 depicts the domain architecture in the SARS-CoV-2 spike protein. The S1 subunit includes an N-terminal domain (NTD), a linker region, a receptor binding domain (RBD), a first subdomain (SD1), and a second subdomain (SD2). The S1 subunit can be modified to add a C-terminal transmembrane domain (TM), or it can be soluble. The S2 subunit includes, inter alia, the first heptapeptide repeat region (HR1), the second heptapeptide repeat region (HR2), the transmembrane domain (TM), and the cytoplasmic tail region. Soluble S2 subunits can be produced without the TM domain.
S1之NTD及RBD係用於本發明之疫苗設計方法之良好抗原,此乃因該等結構域已顯示係β冠狀病毒感染個體中之中和抗體之靶標。如本文所用,例如,在抗原設計(該抗原由本發明之mRNA編碼且例如由本發明之mRNA疫苗表現)之背景下,術語「N末端結構域」或「NTD」係指SARS-CoV-2 S1次單元內之結構域,其包含約290個胺基酸長度,與具有如SEQ ID NO: 125所闡釋之胺基酸序列之刺突蛋白之S1次單元的胺基酸1-290具有一致性。如本文所用,例如,在抗原設計(該抗原由本發明之mRNA編碼且例如由本發明之mRNA疫苗表現)之背景下,術語「受體結合結構域」或「RBD」係指SARS-CoV-2之S1次單元內之結構域,其包含約175-225個胺基酸長度,與具有如SEQ ID NO: 125所闡釋之胺基酸序列之刺突蛋白之S1次單元的胺基酸316-517具有一致性。如本文所用之術語「受體結合基元」係指RBD中直接接觸ACE2受體之部分。預測表現之RBD特異性結合至血管收縮肽轉化酶2 (ACE2)作為其受體及/或與RBD結合及/或中和抗體(例如CR3022)特異性反應。The NTD and RBD of S1 are good antigens for use in the vaccine design methods of the present invention, as these domains have been shown to be targets for neutralizing antibodies in betacoronavirus-infected individuals. As used herein, for example, in the context of antigen design (the antigen is encoded by the mRNA of the invention and expressed, for example, by the mRNA vaccine of the invention), the term "N-terminal domain" or "NTD" refers to SARS-CoV-2 S1 time The domain within the unit, comprising about 290 amino acids in length, is identical to amino acids 1-290 of the S1 subunit of the spike protein having the amino acid sequence set forth in SEQ ID NO: 125. As used herein, eg, in the context of antigen design (the antigen is encoded by the mRNA of the invention and expressed, eg, by the mRNA vaccine of the invention), the term "receptor binding domain" or "RBD" refers to the A domain within the S1 subunit comprising about 175-225 amino acids in length with amino acids 316-517 of the S1 subunit of the spike protein having the amino acid sequence set forth in SEQ ID NO: 125 Consistent. The term "receptor binding motif" as used herein refers to the portion of the RBD that directly contacts the ACE2 receptor. The RBDs predicted to appear specifically bind to vasoconstrictor peptide converting enzyme 2 (ACE2) as its receptor and/or react specifically with RBD binding and/or neutralizing antibodies (eg, CR3022).
本文提供之組合物包括mRNA,其可編碼任一或多個全長或部分(截短或其他序列缺失) S蛋白次單元(例如,S1或S2次單元)、S蛋白次單元之一或多個結構域或結構域之組合(例如,NTD、RBD或NTD-RBD融合體,有或無SD1及/或SD2)或全長或部分S1及S2蛋白次單元之嵌合體。本文考慮其他S蛋白次單元及/或結構域組態。Compositions provided herein include mRNAs that can encode any or more full-length or partial (truncated or other sequence deletions) S protein subunits (eg, S1 or S2 subunits), one or more of S protein subunits Domains or combinations of domains (eg, NTD, RBD or NTD-RBD fusions, with or without SD1 and/or SD2) or chimeras of full or partial S1 and S2 protein subunits. Other S protein subunit and/or domain configurations are contemplated herein.
圖 2 及圖 6繪示源自SARS-CoV-2刺突蛋白之示例性結構域及次單元抗原。圖2A及圖2B分別繪示可溶性及跨膜RBD抗原。跨膜NTD抗原示於圖2C中。圖2D-圖2F及圖2I中所示之結構域抗原表示NTD及RBD之示例性融合蛋白,每種具有SP及TM結構域。構築體中之兩者亦具有末端運輸結構域(CD86及/或CD11b)。結構域經由連接體、特別是GS連接體或PADRE連接體(圖2I)連接。具有在NTD結構域之N末端之RBD結構域的結構域構築體繪示於圖2G及圖2H中。每個構築體亦可包括SP及/或TM結構域。 編碼之次單元抗原 2 and 6 depict exemplary domains and subunit antigens derived from the SARS - CoV-2 spike protein. 2A and 2B depict soluble and transmembrane RBD antigens, respectively. Transmembrane NTD antigens are shown in Figure 2C. The domain antigens shown in Figures 2D-2F and 2I represent exemplary fusion proteins of NTD and RBD, each with SP and TM domains. Both of the constructs also have terminal trafficking domains (CD86 and/or CD11b). The domains are linked via linkers, in particular GS linkers or PADRE linkers (Figure 2I). Domain constructs with the RBD domain at the N-terminus of the NTD domain are depicted in Figures 2G and 2H. Each construct may also include SP and/or TM domains. encoded subunit antigen
本揭示案之一些態樣提供包含編碼SARS-CoV-2 S蛋白之(至少一個)次單元之mRNA的組合物。在一些實施例中,mRNA編碼S1次單元(例如全長或部分)。在其他實施例中,mRNA編碼S2次單元(例如全長或部分)。在其他實施例中,mRNA編碼嵌合S1-S2蛋白,其中一個次單元來自SARS-CoV-2 S蛋白,而另一次單元來自另一生物體,例如病毒,諸如流行性感冒病毒。由本揭示案之mRNA編碼之SARS-CoV-2次單元(S1及/或S2)可為可溶的或膜結合的(例如,與跨膜結構域連接)。基於S2之示例性抗原設計示於圖6中。圖6A繪示全長S2,包括FP、HR1、HR2、TM及CT結構域。由次單元之間之連接體構成之一種形式之S2示於圖6B中。無CT結構域之結構域抗原示於圖6C及圖6D中。 可溶性次單元抗原 Some aspects of the present disclosure provide compositions comprising mRNA encoding (at least one) subunit of the SARS-CoV-2 S protein. In some embodiments, the mRNA encodes the S1 subunit (eg, full-length or partial). In other embodiments, the mRNA encodes the S2 subunit (eg, full-length or partial). In other embodiments, the mRNA encodes a chimeric S1-S2 protein, wherein one subunit is from the SARS-CoV-2 S protein and the other subunit is from another organism, eg, a virus, such as influenza virus. The SARS-CoV-2 subunits (S1 and/or S2) encoded by the mRNAs of the present disclosure may be soluble or membrane bound (eg, linked to a transmembrane domain). An exemplary antigen design based on S2 is shown in FIG. 6 . Figure 6A depicts full-length S2, including FP, HRl, HR2, TM and CT domains. One form of S2 consisting of links between subunits is shown in Figure 6B. Domain antigens without the CT domain are shown in Figures 6C and 6D. soluble subunit antigen
可溶性蛋白存在於細胞之細胞質中或自細胞分泌(例如,不結合膜)。細胞分泌之可溶性抗原可由補體調理,且由淋巴結中之濾泡樹突細胞捕獲,在這裏其可由對表現之蛋白質上存在之抗原決定基特異性之B細胞識別。次單元抗原之表現進一步允許將免疫反應集中於特定次單元,且對與其他相關病毒共有之抗原之其他結構域具有特異性之記憶B及T細胞之刺激最小。不受限於理論,據信SARS-CoV-2 S1次單元(包括NTD、RBD及在一些情况下SARS-CoV-2 S1次單元之插入多肽)以可溶形式之呈遞,產生S1次單元特異性免疫反應。因此,在一些實施例中,本文提供之mRNA編碼可溶性SARS-CoV-2 S1次單元抗原及/或可溶性SARS-CoV-2 S2次單元抗原。可溶性SARS-CoV-2 S1次單元抗原及編碼其之mRNA之非限制性實例提供於下文
表 1A及
表 1B中。本文提供可溶性SARS-CoV-2次單元抗原之其他實例。
表 1A. 可溶性次單元抗原
膜結合之蛋白錨定在細胞膜中(不可溶的)。不受限於理論,據信抗原呈遞細胞將嵌入之抗原攜帶至引流淋巴結以產生強烈免疫反應。引流淋巴結中出現之生發中心反應包括CD4
+TFH 細胞與B細胞之間之延長接觸,允許共刺激及局部細胞介素信號,諸如IL-4及IL-21,其有利於對所呈遞抗原特異之B細胞之複製及類別轉換至IgG1之產生,其各自可促進長壽命之漿細胞及記憶B細胞之產生。因此,在一些實施例中,mRNA編碼膜結合之SARS-CoV-2 S1次單元抗原及/或膜結合之SARS-CoV-2 S2次單元抗原。在一些實施例中,膜結合抗原(例如,S1次單元、S2次單元、NTD、RBD或其任何組合)與跨膜結構域(例如天然存在之跨膜結構域或異源跨膜結構域(源自異源蛋白質),其負責將蛋白質錨定在細胞膜中)連接。膜結合之SARS-CoV-2 S1次單元抗原及SARS-CoV-2 S2次單元抗原及編碼其之mRNA的非限制性實例提供於下文
表 2A及
表 2B中。本文考慮其他膜結合之SARS-CoV-2 S1次單元抗原。
表 2A. 膜結合之次單元抗原
在一些實施例中,組合物包含編碼已經修飾以去除RBD或RBD之一部分之S1次單元的mRNA。S1次單元之截短為免疫系統提供較少之抗原決定基來識別,從而使免疫反應偏向於其餘抗原決定基,此可選擇針對對於病毒中和重要之特定抗原決定基之抗體。RBD之截短或部分缺失可防止表現之蛋白質或携帶其之細胞與受體ACE2相互作用,使其更可能到達淋巴結且刺激期望免疫反應。此外,去除RBD可防止以前針對相關病毒產生之交叉反應性抗體造成之抗原決定基掩蔽,且因此將引發之免疫反應特異性地集中於期望抗原。另外,去除RBD可改變表現之次單元之構象,允許對該等替代構象抗原決定基特異之B細胞攝取綫性肽且將綫性肽呈遞給T細胞,從而間接增强CD4 +T細胞對仍以天然構象存在之彼等抗原決定基之反應。 In some embodiments, the composition comprises an mRNA encoding an S1 subunit that has been modified to remove an RBD or a portion of an RBD. Truncation of the S1 subunit provides the immune system with fewer epitopes to recognize, thereby biasing the immune response to the remaining epitopes, which select antibodies against specific epitopes important for virus neutralization. Truncation or partial deletion of the RBD prevents the expressed protein or cells carrying it from interacting with the receptor ACE2, making it more likely to reach lymph nodes and stimulate the desired immune response. In addition, removal of RBD prevents epitope masking by cross-reactive antibodies previously raised against related viruses, and thus focuses the elicited immune response specifically to the desired antigen. In addition, removal of RBD alters the conformation of the expressed subunit, allowing B cells specific for these alternative conformational epitopes to uptake and present linear peptides to T cells, thereby indirectly enhancing the ability of CD4 + T cells to remain viable. The reaction of those epitopes in their native conformation.
在一些實施例中,組合物包含編碼S1次單元之mRNA,該S1次單元已經修飾以去除RBD或RBD之一部分,其中S2次單元含有聚醣。聚醣藉由經由天冬醯胺殘基之N-連接醣基化或絲胺酸或蘇胺酸殘基上之O-連接醣基化與蛋白質附接。在蛋白質之一些組分上存在聚醣屏蔽物可掩蔽肽抗原決定基,從而將抗體反應集中於其他暴露之肽抗原決定基。此外,醣基化蛋白亦引發識別包被聚醣之抗體。識別聚醣抗原決定基之B細胞將攝取綫性肽抗原決定基且將其呈遞給CD4 +T細胞,從而加強CD4 +T細胞對遍及蛋白發現之綫性抗原決定基之反應。 In some embodiments, the composition comprises mRNA encoding an S1 subunit that has been modified to remove an RBD or a portion of an RBD, wherein the S2 subunit contains a glycan. Glycans are attached to proteins by N-linked glycosylation via asparagine residues or O-linked glycosylation on serine or threonine residues. The presence of glycan shields on some components of a protein can mask peptide epitopes, thereby focusing antibody responses on other exposed peptide epitopes. In addition, glycosylated proteins also elicit antibodies that recognize coated glycans. B cells recognizing the glycan epitope will take up the linear peptide epitope and present it to CD4 + T cells, thereby enhancing the CD4 + T cell response to the linear epitope found on ubiquitin.
截短之SARS-CoV-2 S1次單元抗原及編碼其之mRNA之非限制性實例提供於下文 表 3A及 表 3B中。 Non-limiting examples of truncated SARS-CoV-2 S1 subunit antigens and mRNAs encoding them are provided in Tables 3A and 3B below .
具有RBD缺失之SARS-CoV-2 S1次單元及編碼其之mRNA之非限制性實例提供於下文
表 4A及
表 4B中。
表 3A. 次單元抗原截短
在一些實施例中,組合物包含編碼嵌合蛋白(例如具有來自一種病毒之S蛋白之S1次單元及來自另一種不同病毒之S蛋白之S2次單元之嵌合S1-S2蛋白)之mRNA。舉例而言,S2次單元可來自SARS-CoV-2,而S1次單元可來自HKU1。作為另一實例,S2次單元可來自SARS-CoV-2,而S1次單元可來自OC43。該等嵌合蛋白可能由藉由先前暴露而產生之對HKU1或OC43之S1次單元特異之循環抗體調理,促進巨噬細胞及樹突細胞有效地攝取SARS-CoV-2 S2次單元肽且將其交叉呈遞給CD4
+T細胞。藉由循環抗體之調理作用亦促進由濾泡樹突細胞之捕獲,用於呈遞給具有對SARS-CoV-2 S2次單元抗原決定基特異之受體的B細胞。嵌合S1/S2次單元構築體及編碼其之mRNA之非限制性實例提供於下文
表 5A及
表 5B中。
表 5A. 嵌合 S1 次單元 -S2 次單元抗原
本揭示案之其他態樣提供包含編碼S蛋白之SARS-CoV-2 S1次單元之(至少一個)子結構域之mRNA的組合物。子結構域可為N末端結構域(NTD)或受體結合結構域(RBD)(有或無SD1及/或SD2)。在一些實施例中,mRNA編碼NTD及RBD (有或無SD1及/或SD2)之組合(例如,非天然組合)。在一些實施例中,NTD及/或RBD與跨膜結構域(有或無SD1及/或SD2)連接。在一些實施例中,mRNA編碼S蛋白之SARS-CoV-2 S1次單元之兩個子結構域(NTD及RBD),其經突變以包含半胱胺酸殘基。在一些實施例中,該等突變導致二硫鍵之形成。作為實例,mRNA可編碼包含F43C突變之NTD及包含Q563C突變之RBD,最終產生經由二硫鍵與RBD連接之NTD。 N 末端結構域 (NTD) 構築體 Other aspects of the disclosure provide compositions comprising mRNA encoding a (at least one) subdomain of the SARS-CoV-2 S1 subunit of the S protein. A subdomain can be an N-terminal domain (NTD) or a receptor binding domain (RBD) (with or without SD1 and/or SD2). In some embodiments, the mRNA encodes a combination (eg, a non-natural combination) of NTD and RBD (with or without SD1 and/or SD2). In some embodiments, the NTD and/or RBD is linked to the transmembrane domain (with or without SD1 and/or SD2). In some embodiments, the mRNA encodes two subdomains (NTD and RBD) of the SARS-CoV-2 S1 subunit of the S protein, which are mutated to include cysteine residues. In some embodiments, the mutations result in the formation of disulfide bonds. As an example, an mRNA can encode an NTD comprising the F43C mutation and an RBD comprising the Q563C mutation, ultimately resulting in an NTD linked to the RBD via a disulfide bond. N -terminal domain (NTD) construct
在一些實施例中,本文提供之mRNA編碼SARS-CoV-2 S蛋白之S1次單元之NTD。某些β冠狀病毒之NTD會引發保護性位準之抗體。對其他β冠狀病毒(諸如MERS)之NTD特異之抗體藉由防止膜融合及病毒進入起作用(Zhou H等人,
Nat Commun.2019; 3068),提供不同於防止病毒附著至ACE2之第二種中和機制。由本揭示案之mRNA編碼之SARS-CoV-2 NTD可為可溶的或膜結合的。膜結合之SARS-CoV-2 NTD抗原及編碼其之mRNA之非限制性實例提供於下文
表 6A及
表 6B中。
表 6A. 膜結合之 NTD 抗原
在其他實施例中,本文提供之mRNA編碼SARS-CoV-2 S蛋白之S1次單元之RBD。RBD結合宿主細胞上之ACE2受體,此介導病毒附著至細胞。附著對於病毒進入細胞及複製係必需的。因此,阻斷病毒附著至細胞中之RBD靶向抗體反應有效地中和細胞外病毒顆粒,從而防止增殖且促進對中和之病毒顆粒之其他組分之進一步免疫反應。由本揭示案之mRNA編碼之SARS-CoV-2 RBD可為可溶的或膜結合的(例如,與跨膜結構域連接)。 可溶性 RBD 抗原 In other embodiments, the mRNA provided herein encodes the RBD of the S1 subunit of the SARS-CoV-2 S protein. RBD binds to ACE2 receptors on host cells, which mediate viral attachment to cells. Attachment is necessary for virus entry into cells and replication lines. Thus, RBD-targeted antibody responses that block viral attachment into cells effectively neutralize extracellular viral particles, preventing proliferation and promoting further immune responses to other components of the neutralized viral particles. The SARS-CoV-2 RBD encoded by the mRNA of the present disclosure can be soluble or membrane bound (eg, linked to a transmembrane domain). soluble RBD antigen
在一些實施例中,mRNA編碼可溶性SARS-CoV-2 RBD。樹突細胞藉由胞飲作用對可溶性蛋白進行取樣,且在遷移至引流淋巴結時,將包含取樣之蛋白質之綫性肽呈遞至CD4
+T細胞。該等CD4
+T細胞向已經識別、攝取及呈遞來自RBD之抗原決定基之B細胞提供增殖信號,因此投與特异性RBD而沒有SARS-CoV-2刺突蛋白之其他組分預計將免疫反應集中於RBD中存在之抗原決定基。可溶性SARS-CoV-2 RBD及編碼其之mRNA之非限制性實例提供於下文
表 7A及
表 7B中。
表 7. 可溶性 RBD 抗原
在一些實施例中,mRNA編碼膜結合之SARS-CoV-2 RBD。預計表現膜結合之RBD之細胞將該等膜結合之抗原攜帶至引流淋巴結,且促進RBD特異性B細胞對抗原決定基之有效識別。由於B細胞表面含有許多表面結合之抗體且表現細胞含有許多膜結合之RBD之拷貝,故預計B細胞最初識別抗原後會發生B細胞受體之交聯,從而經由親合效應刺激強反應。膜結合之SARS-CoV-2 RBD及編碼其之mRNA之非限制性實例提供於下文
表 8A及
表 8B中。
表 8A. 膜結合之 RBD 抗原
在其他實施例中,本文提供之mRNA編碼SARS-CoV-2 NTD-RBD融合蛋白。舉例而言,S蛋白之SARS-CoV-2 S1次單元之NTD及RBD可經由連接體(諸如短胺基酸(例如,甘胺酸-絲胺酸)連接體)彼此連接,以允許結構域之間之撓性/鉸接及空間。在另一實施例中,可使用包含抗原性抗原決定基(例如II類通用T細胞抗原決定基,諸如PADRE)之連接體。在一些實施例中,跨膜區例如經由另一短胺基酸(例如,甘胺酸-絲胺酸或PADRE)連接體與NTD-RBD融合體連接以獲得撓性且允許膜與抗原之間存在合理距離。不受限於理論,據信此種膜結合之串聯組態在一個開放閱讀框中呈遞大部分(若並非全部)已知中和抗原決定基及保護性抗原決定基。投與該融合蛋白接著應將免疫反應集中於已知保護性抗原決定基,且减少對非保護性抗原決定基特異之抗體及T細胞之不必要產生。此外,針對不同結構域之抗體可經由不同機制、例如藉由阻斷與宿主細胞之附著或防止結合之病毒經歷膜融合且進入宿主細胞來中和病毒顆粒。因此,由包含不同結構域之融合蛋白引發之廣泛反應在進化上可能更强,需要多個不同突變來逃避疫苗誘導之免疫。SARS-CoV-2 NTD-RBD融合蛋白及編碼其之mRNA之非限制性實例提供於下文 表 9A及 表 9B中。 連接體 In other embodiments, the mRNA provided herein encodes a SARS-CoV-2 NTD-RBD fusion protein. For example, the NTD and RBD of the SARS-CoV-2 S1 subunit of the S protein can be linked to each other via a linker, such as a short amino acid (eg, glycine-serine) linker, to allow the domains Flexibility/hinged and space between. In another embodiment, linkers comprising antigenic epitopes (eg, class II universal T cell epitopes such as PADRE) can be used. In some embodiments, the transmembrane region is linked to the NTD-RBD fusion, eg, via another short amino acid (eg, glycine-serine or PADRE) linker to obtain flexibility and allow for the separation between the membrane and the antigen A reasonable distance exists. Without being bound by theory, it is believed that this membrane-bound tandem configuration presents most, if not all, known neutralizing and protective epitopes in one open reading frame. Administration of the fusion protein should then focus the immune response on known protective epitopes and reduce unwanted production of antibodies and T cells specific for non-protective epitopes. In addition, antibodies directed against different domains can neutralize viral particles through different mechanisms, such as by blocking attachment to the host cell or preventing the bound virus from undergoing membrane fusion and entering the host cell. Thus, the broad response elicited by fusion proteins comprising different domains may be evolutionarily stronger, requiring multiple distinct mutations to evade vaccine-induced immunity. Non-limiting examples of SARS-CoV-2 NTD-RBD fusion proteins and mRNAs encoding them are provided in Table 9A and Table 9B below. linker
根據本揭示案可使用多種連接體。如本文提供之連接體僅僅係將兩個其他胺基酸序列人工連接在一起之胺基酸序列。本文所用之連接體可為可裂解的或不可裂解的。可裂解之連接體允許將mRNA轉譯成多肽,之後裂解連接體,允許獨立地釋放每一個別組分。不可裂解之連接體保持連接一或多個蛋白質次單元,允許整個蛋白質執行需要組分次單元緊密接近之功能。該等連接體之非限制性實例包括甘胺酸-絲胺酸(GS)連接體(不可裂解的);以及F2A連接體、P2A連接體、T2A連接體及E2A連接體(可裂解的)。本文可使用其他連接法。A variety of linkers can be used in accordance with the present disclosure. Linkers as provided herein are simply amino acid sequences that artificially link together two other amino acid sequences. Linkers as used herein can be cleavable or non-cleavable. The cleavable linker allows translation of the mRNA into a polypeptide, followed by cleavage of the linker, allowing each individual component to be released independently. Non-cleavable linkers remain linked to one or more protein subunits, allowing the entire protein to perform functions that require close proximity of the subunits. Non-limiting examples of such linkers include glycine-serine (GS) linkers (non-cleavable); and F2A linkers, P2A linkers, T2A linkers, and E2A linkers (cleavable). Other connection methods may be used in this article.
在一些實施例中,連接體係GS連接體。GS連接體係包括甘胺酸及絲胺酸胺基酸重複之多肽連接體。其等包含撓性及親水性殘基,且可用於實施蛋白質次單元之融合,而不干擾蛋白質結構域之摺疊及功能,且不形成二級結構。在一些實施例中,mRNA編碼包含3至20個胺基酸長之GS連接體之融合蛋白。舉例而言,GS連接體可具有之長度為(或具有之長度至少為)3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20個胺基酸。在一些實施例中,GS連接體係(或至少係) 15個胺基酸長(例如,GGSGGSGGSGGSGGG (SEQ ID NO: 133))。在一些實施例中,GS連接體係(或至少係) 8個胺基酸長(例如,GGGSGGGS (SEQ ID NO: 134))。在一些實施例中,GS連接體係(或至少係) 7個胺基酸長(例如,GGGSGGG (SEQ ID NO: 135))。在一些實施例中,GS連接體係(或至少係) 4個胺基酸長(例如,GGGS (SEQ ID NO: 136))。在一些實施例中,GS連接體包含(GGGS)n (SEQ ID NO: 136),其中n為1-5之任一整數。在一些實施例中,GS連接體係(或至少係) 4個胺基酸長(例如,GSGG (SEQ ID NO: 152))。在一些實施例中,GS連接體包含(GSGG)n (SEQ ID NO: 152),其中n為1-5之任一整數。In some embodiments, the ligation system is a GS linker. The GS linker system includes polypeptide linkers of glycine and serine amino acid repeats. These contain flexible and hydrophilic residues and can be used to effect fusion of protein subunits without interfering with the folding and function of the protein domains and without forming secondary structures. In some embodiments, the mRNA encodes a fusion protein comprising a 3 to 20 amino acid long GS linker. For example, a GS linker can have a length of (or have a length of at least) 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 or 20 amino acids. In some embodiments, the GS linker is (or at least is) 15 amino acids long (eg, GGSGGSGGSGGSGGGG (SEQ ID NO: 133)). In some embodiments, the GS linker is (or at least is) 8 amino acids long (eg, GGGSGGGS (SEQ ID NO: 134)). In some embodiments, the GS linker is (or at least is) 7 amino acids long (eg, GGGSGGG (SEQ ID NO: 135)). In some embodiments, the GS linker is (or at least is) 4 amino acids long (eg, GGGS (SEQ ID NO: 136)). In some embodiments, the GS linker comprises (GGGS)n (SEQ ID NO: 136), wherein n is any integer from 1-5. In some embodiments, the GS linker is (or at least is) 4 amino acids long (eg, GSGG (SEQ ID NO: 152)). In some embodiments, the GS linker comprises (GSGG)n (SEQ ID NO: 152), wherein n is any integer from 1-5.
在一些實施例中,連接體係甘胺酸連接體,例如具有3個胺基酸之長度(或至少3個胺基酸之長度) (例如,GGG)。In some embodiments, the linking system is a glycine linker, eg, having a length of 3 amino acids (or at least 3 amino acids in length) (eg, GGG).
在一些實施例中,由mRNA疫苗編碼之蛋白質包括一個以上連接體,其可彼此相同或不同(例如,在同一S蛋白構築體中之GGGSGGG (SEQ ID NO: 135)及GGGS (SEQ ID NO: 136))。In some embodiments, the protein encoded by the mRNA vaccine includes more than one linker, which may be the same or different from each other (e.g., GGGSGGG (SEQ ID NO: 135) and GGGS (SEQ ID NO: 135) in the same S protein construct 136)).
在一些實施例中,連接體包含編碼泛HLA DR結合抗原決定基(PADRE)之mRNA (例如,AKFVAAWTLKAAA (SEQ ID NO: 148))。PADRE係免疫顯性輔助CD4 T細胞抗原決定基及强效免疫原(參見,例如Alexander J.等人,J of Immuno. 164(3): 1625-33,以引用方式併入本文中)。
表 9A. 結構域融合抗原
在一些實施例中,mRNA編碼與高爾基體(Golgi)運輸信號連接之SARS-CoV-2 S蛋白結構域(例如,NTD、RBD或NTD-RBD融合體)。該等信號之非限制性實例包括巨噬細胞標記物,諸如CD86及/或CD11b,其係高度表現的,且細胞內區可控制自高爾基體至細胞表面之有效輸出。本文可使用其他細胞運輸信號(序列),例如VSV-G胞質尾(VSVGct)。預計將編碼之蛋白質更有效地運輸至細胞表面會增加B細胞對抗原之識別,且因此促進產生針對編碼之SARS-CoV-2 S蛋白結構域之抗體。與運輸信號連接之SARS-CoV-2抗原及編碼其之mRNA之非限制性實例提供於下文
表 10A及
表 10B中。
表 10A. 與運輸信號連接之結構域融合抗原
在其他實施例中,本文提供之mRNA編碼SARS-CoV-2 NTD-RBD融合蛋白,其中C末端結構域之某一部分已經截短/缺失。在一個實施例中,NTD-RBD融合蛋白之C末端結構域缺失13個(或至少13個)胺基酸。預計該等胺基酸之缺失會增加抗原決定基於抗體中之暴露,從而刺激對NTD及RBD結構域上存在之保護性抗原決定基之更强之免疫反應。In other embodiments, the mRNA provided herein encodes a SARS-CoV-2 NTD-RBD fusion protein in which a certain portion of the C-terminal domain has been truncated/deleted. In one embodiment, 13 (or at least 13) amino acids are deleted from the C-terminal domain of the NTD-RBD fusion protein. Deletion of these amino acids is expected to increase epitope exposure in the antibody, thereby stimulating a stronger immune response to the protective epitopes present on the NTD and RBD domains.
具有C末端截短之SARS-CoV-2結構域融合抗原及編碼其之mRNA之非限制性實例提供於下文
表 11A及
表 11B中。
表 11A. 結構域融合 C 末端截短
在一些實施例中,SARS-CoV-2 S蛋白結構域抗原包括「延伸」區,其包括與本業內理解之NTD結構域或RBD結構域相鄰及/或側接之序列。RBD_EXT系列涵蓋SD1 (子結構域1)。NTD_EXT系列涵蓋NTD中之C末端螺旋。一些B細胞及抗體識別僅在正確摺疊而非變性形式之SARS-CoV-2 S蛋白NTD及RBD中發現之構象抗原決定基。包括與NTD及RBD結構域相鄰及/或側接之序列不僅可為抗原提供額外B細胞抗原決定基,且可潜在地達成彼等結構域之更優化摺疊,且用對可在任一結構域邊緣上發現之抗原決定基特異之抗體刺激B細胞。此外,包括該等延伸序列可因此增加NTD或RBD與表現細胞膜之間之距離,從而增加兩個結構域於抗體中之暴露,若表現之蛋白質太靠近細胞表面,則抗體結合效率較低。最後,包括延伸序列會增加肽之集合,該等肽可潜在地由識別NTD或RBD抗原決定基之B細胞呈遞給CD4
+T細胞,接著加工完整蛋白用於抗原呈遞,從而增加NTD或RBD特異性B細胞接受足够T細胞輔助之機會。SARS-CoV-2結構域延伸及編碼其之mRNA之非限制性實例提供於下文
表 12A及
表 12B中。
表 12. 結構域延伸
在一些態樣中,本揭示案提供包含編碼SARS-CoV-2 S蛋白子結構域之mRNA之混合物的組合物。在一個實例中,組合物包含編碼NTD (有或無SD1、SD2及/或跨膜結構域)之mRNA及編碼RBD (有或無SD1、SD2及/或跨膜結構域)之mRNA之混合物。在一些實施例中,組合物包含編碼與跨膜結構域連接之NTD (例如SEQ ID NO: 47)之mRNA (例如SEQ ID NO: 45或46)及編碼與跨膜結構域連接之RBD (例如SEQ ID NO: 77)之mRNA (例如SEQ ID NO: 75或76)。In some aspects, the present disclosure provides compositions comprising mixtures of mRNAs encoding SARS-CoV-2 S protein subdomains. In one example, the composition comprises a mixture of mRNA encoding NTD (with or without SD1, SD2 and/or transmembrane domains) and mRNA encoding RBD (with or without SD1, SD2 and/or transmembrane domains). In some embodiments, the composition comprises an mRNA (e.g., SEQ ID NO: 45 or 46) encoding an NTD (e.g., SEQ ID NO: 47) linked to a transmembrane domain and an RBD (e.g., SEQ ID NO: 45 or 46) encoding a transmembrane domain SEQ ID NO: 77) mRNA (eg, SEQ ID NO: 75 or 76).
組合物中一種mRNA對另一種mRNA之濃度之比率可為1:1 (50:50)、1:2、1:3、1:4或1:5。在一些實施例中,該比率為1:1。舉例而言,組合物可包含1:1比率之編碼與跨膜結構域連接之NTD (例如SEQ ID NO: 47)之mRNA (例如SEQ ID NO: 45或46)對編碼與跨膜結構域連接之RBD (例如SEQ ID NO: 77)之mRNA (例如SEQ ID NO: 75或76)。在一些實施例中,該比率為1:2。舉例而言,組合物可包含1:2比率之編碼與跨膜結構域連接之NTD (例如SEQ ID NO: 47)之mRNA (例如SEQ ID NO: 45或46)對編碼與跨膜結構域連接之RBD (例如SEQ ID NO: 77)之mRNA (例如SEQ ID NO: 75或76)。作為另一實例,組合物可包含1:2比率之編碼與跨膜結構域連接之RBD (例如,SEQ ID NO: 77)之mRNA (例如SEQ ID NO: 75或76)對編碼與跨膜結構域連接之NTD (例如,SEQ ID NO: 47)之mRNA(例如,SEQ ID NO: 45或46)。編碼不同抗原之不同mRNA可刺激不同強度之免疫反應(Magini D等人,PLoS ONE.2016; 11:e0161193),且投與等莫耳比率之編碼兩種不同抗原之兩種mRNA可引起對一者而非另一者之免疫反應(John S等人, Vaccine.2018; 36:1689-1699)。對共遞送之mRNA之比率之操縱可用於引發以相等功效靶向期望抗原之廣泛免疫反應。 編碼之奈米顆粒抗原 The ratio of the concentration of one mRNA to the other mRNA in the composition may be 1:1 (50:50), 1:2, 1:3, 1:4 or 1:5. In some embodiments, the ratio is 1:1. For example, a composition may comprise a 1:1 ratio of mRNA (eg, SEQ ID NO: 45 or 46) encoding an NTD linked to a transmembrane domain (eg, SEQ ID NO: 47) to a pair encoding the NTD linked to the transmembrane domain mRNA (eg, SEQ ID NO: 75 or 76) of the RBD (eg, SEQ ID NO: 77). In some embodiments, the ratio is 1:2. For example, a composition may comprise a 1:2 ratio of mRNA (eg, SEQ ID NO: 45 or 46) encoding an NTD linked to a transmembrane domain (eg, SEQ ID NO: 47) to a pair encoding the NTD linked to the transmembrane domain mRNA (eg, SEQ ID NO: 75 or 76) of the RBD (eg, SEQ ID NO: 77). As another example, a composition may comprise a 1:2 ratio of mRNA (e.g., SEQ ID NO: 75 or 76) encoding an RBD (e.g., SEQ ID NO: 77) linked to the transmembrane domain to the encoding and transmembrane structure mRNA (eg, SEQ ID NO: 45 or 46) of a domain-linked NTD (eg, SEQ ID NO: 47). Different mRNAs encoding different antigens can stimulate immune responses of different strengths (Magini D et al., PLoS ONE. 2016; 11:e0161193), and administration of two mRNAs encoding two different antigens in equimolar ratios can elicit a one-to-one response immune response to one but not the other (John S et al., Vaccine. 2018; 36:1689-1699). Manipulation of the ratio of co-delivered mRNAs can be used to elicit a broad immune response targeting the desired antigen with equal efficacy. Encoded Nanoparticle Antigen
在一些實施例中,本文提供之mRNA疫苗編碼包含與支架結構域連接之冠狀病毒抗原之融合蛋白。在一些實施例中,支架結構域賦予由本揭示案之mRNA編碼之抗原期望之性質。舉例而言,支架結構域可例如藉由改變抗原之結構、改變抗原之攝取及加工及/或使抗原結合至另一分子來改善抗原之免疫原性。在一些實施例中,與抗原連接之支架結構域促進抗原自組裝成病毒奈米顆粒或更大之蛋白質摺疊免疫原。可如本文提供使用之支架結構域之非限制性實例包括鐵蛋白結構域、二氧四氫蝶啶合成酶結構域、摺疊子結構域及包封蛋白(encapsulin)結構域。可使用其他支架結構域。 鐵蛋白 In some embodiments, the mRNA vaccines provided herein encode fusion proteins comprising a coronavirus antigen linked to a scaffold domain. In some embodiments, the scaffold domain confers desirable properties to the antigen encoded by the mRNA of the present disclosure. For example, scaffold domains can improve the immunogenicity of an antigen, eg, by altering the structure of the antigen, altering the uptake and processing of the antigen, and/or binding the antigen to another molecule. In some embodiments, the scaffold domain linked to the antigen promotes self-assembly of the antigen into viral nanoparticles or larger protein-folded immunogens. Non-limiting examples of scaffold domains that can be used as provided herein include ferritin domains, dioxytetrahydropteridine synthase domains, foldon domains, and encapsulin domains. Other scaffold domains can be used. Ferritin
在一些實施例中,鐵蛋白結構域用作支架結構域。鐵蛋白係主要功能為在細胞內儲存鐵之蛋白質。鐵蛋白由二十四(24)個次單元組成,每個次單元由自組裝成具有八面體對稱性之四級結構之四α螺旋束構成(Cho K. J.等人, J Mol Biol.2009;390: 83-98;Granier T.等人, J Biol Inorg Chem.2003;8: 105-111;及Lawson D.M.等人, Nature.1991;349: 541-544)。鐵蛋白自組裝成具有强的熱穩定性及化學穩定性之奈米顆粒。預計以此方式將抗原包封在鐵蛋白奈米顆粒內既會延遲抗原之降解亦會聚集個別抗原,其中每個奈米顆粒含有二十四(24)個抗原次單元。相同抗原之多個拷貝之聚集增强由樹突細胞之抗原攝取及遷移,以及更强之CD4 +及CD8 +T細胞反應(Kastenmüller K等人, J Clin Invest.2011; 121(5):1782-96)。因此,鐵蛋白奈米顆粒係非常適合抗原呈遞及疫苗開發之平臺。 In some embodiments, a ferritin domain is used as a scaffold domain. Ferritin is a protein whose main function is to store iron in cells. Ferritin consists of twenty-four (24) subunits, each consisting of four alpha helical bundles that self-assemble into a quaternary structure with octahedral symmetry (Cho KJ et al., J Mol Biol. 2009; 390: 83-98; Granier T. et al, J Biol Inorg Chem. 2003; 8: 105-111; and Lawson DM et al, Nature. 1991; 349: 541-544). Ferritin self-assembles into nanoparticles with strong thermal and chemical stability. Encapsulation of antigens within ferritin nanoparticles in this manner is expected to both delay degradation of the antigens and aggregate individual antigens, each nanoparticle containing twenty-four (24) antigenic subunits. Aggregation of multiple copies of the same antigen enhances antigen uptake and migration by dendritic cells, and stronger CD4 + and CD8 + T cell responses (Kastenmüller K et al, J Clin Invest. 2011; 121(5):1782-96 ). Therefore, ferritin nanoparticles are very suitable platforms for antigen presentation and vaccine development.
在一些實施例中,本文提供之mRNA編碼例如經由甘胺酸(例如,GGG)連接體結構域與鐵蛋白結構域連接之RBD。可使用其他連接體。In some embodiments, the mRNA provided herein encodes an RBD linked to a ferritin domain, eg, via a glycine (eg, GGG) linker domain. Other linkers can be used.
在其他實施例中,本文提供之mRNA編碼例如經由甘胺酸(例如,GGG)連接體與鐵蛋白結構域連接之S蛋白之S1結構域。如本文中別處指示,可使用其他連接體。In other embodiments, the mRNA provided herein encodes the S1 domain of the S protein, eg, linked to the ferritin domain via a glycine (eg, GGG) linker. Other linkers can be used as indicated elsewhere herein.
與鐵蛋白結構域連接之SARS-CoV-2抗原及編碼其之mRNA之非限制性實例提供於下文
表 13A及
表 13B中。
表 13A. 與鐵蛋白結構域連接之抗原
在一些實施例中,二氧四氫蝶啶合成酶結構域用作支架結構域。二氧四氫蝶啶合成酶係一種在多種生物體(包括古細菌、細菌、真菌、植物及真細菌)中負責核黃素生物合成之倒數第二個催化步驟之酶。二氧四氫蝶啶合成酶由同寡聚體構成,該等同寡聚體根據其來源之種類而大小及次單元數不同,包括五聚體、十聚體及二十面六十聚體(icosahedral sixty-mer)。二氧四氫蝶啶合成酶單體長度為150個胺基酸,且包括具有側翼串聯α-螺旋之β-摺疊。已報導二氧四氫蝶啶合成酶之不同四級結構,闡釋其形態多樣性:自同五聚體至形成150 Å直徑之衣殼之十二(12)個五聚體之對稱裝配。在二氧四氫蝶啶合成酶表面之抗原呈遞導致以有序陣列展示之抗原之高局部濃度。該等重複結構使得B細胞受體能够交聯,且經由親合效應導致强免疫反應。In some embodiments, a dioxytetrahydropteridine synthase domain is used as a scaffold domain. Dioxytetrahydropteridine synthase is an enzyme responsible for the penultimate catalytic step of riboflavin biosynthesis in a variety of organisms including archaea, bacteria, fungi, plants and eubacteria. Dioxytetrahydropteridine synthase is composed of homo-oligomers that vary in size and number of subunits according to the type of source, including pentamers, decamers, and icosahedral hexamers ( icosahedral sixty-mer). The dioxytetrahydropteridine synthase monomer is 150 amino acids in length and includes a β-sheet with flanking tandem α-helices. Different quaternary structures of dioxytetrahydropteridine synthases have been reported, illustrating their morphological diversity: symmetrical assembly of twelve (12) pentamers ranging from homopentamers to form 150 Å diameter capsids. Antigen presentation on the surface of dioxytetrahydropteridine synthase results in high local concentrations of antigen displayed in ordered arrays. These repeating structures enable cross-linking of B cell receptors and lead to strong immune responses via affinity effects.
在一些實施例中,本文提供之mRNA編碼(例如)經由甘胺酸-絲胺酸(例如,GGS)與二氧四氫蝶啶合成酶結構域連接之RBD。可使用其他連接體。In some embodiments, the mRNA provided herein encodes an RBD linked to a dioxytetrahydropteridine synthase domain, eg, via a glycine-serine (eg, GGS). Other linkers can be used.
在其他實施例中,本文提供之mRNA編碼(例如)經由甘胺酸-絲胺酸(例如,GGS)連接體與二氧四氫蝶啶合成酶結構域連接之S蛋白之S1結構域。如本文中別處指示,可使用其他連接體。In other embodiments, the mRNA provided herein encodes the S1 domain of the S protein linked, eg, via a glycine-serine (eg, GGS) linker to a dioxytetrahydropteridine synthase domain. Other linkers can be used as indicated elsewhere herein.
與摺疊子結構域連接之SARS-CoV-2抗原及編碼其之mRNA之非限制性實例提供於下文
表 14A及
表 14B中。
表 14A. 與二氧四氫蝶啶合成酶結構域連接之抗原
在一些實施例中,摺疊子結構域用作支架結構域。T4彈力素之C末端結構域(摺疊子)對於形成彈力素三聚體結構係必需的,且可用作人工三聚化結構域(參見例如Meier S.等人,
Journal of Molecular Biology2004年12月3日;344(4): 1051-1069;Tao Y等人,
Structure1997年6月15日;5(6):789-98)。當與S蛋白胞外結構域融合時,摺疊子結構域促進S蛋白之正確三聚化,從而避免蛋白質之錯誤摺疊。導致S蛋白融合前構象產生之該過程導致表現、構象均質性增加,且引發強效中和抗體反應。
In some embodiments, the Foldon domain is used as a scaffold domain. The C-terminal domain (foldon) of T4 elastin is necessary for the formation of the elastin trimer structure and can be used as an artificial trimerization domain (see eg Meier S. et al, Journal of Molecular Biology 2004 12
不受限於理論,認為此組態將導致摺疊子在蛋白質之細胞內區上在很大程度上免疫原性沈默。與摺疊子結構域連接之SARS-CoV-2抗原及編碼其之mRNA之非限制性實例提供於下文
表 15A及
表 15B中。
表 15A. 與摺疊子結構域連接之抗原
在一些實施例中,包封蛋白結構域用作支架結構域。包封蛋白係自適溫性海栖熱袍菌( Thermotoga maritima)分離之蛋白質籠形奈米顆粒。包封蛋白由相同31 kDa單體之60個拷貝組裝而成,該等單體具有薄的二十面體T = 1對稱之籠形結構,其內徑及外徑分別為20 nm及24 nm (Sutter M.等人, Nat Struct Mol Biol.2008;15: 939-947)。儘管包封蛋白在海栖熱袍菌中之確切功能尚未清楚地為人們所瞭解,但最近其晶體結構已得以解决,且其功能假定為包封諸如DyP (染料脫色過氧化物酶)及Flp (鐵蛋白樣蛋白)等蛋白質之細胞隔室,該等蛋白質參與氧化應激反應30 (Rahmanpour R.等人, FEBS J.2013;280: 2097-2104)。使用包封蛋白進行奈米顆粒構築使得蛋白質抗原能够在奈米顆粒表面上展示,且能够將諸如mRNA等貨物包封在奈米顆粒本身內。以前之基於包封蛋白奈米顆粒之疫苗已引發對表面展示抗原及貨物蛋白本身之强免疫反應(Lagoutte P.等人, Vaccine.2018;36(25): 3622-3628)。 In some embodiments, an encapsulated protein domain is used as a scaffold domain. The encapsulated protein is a protein cage-shaped nanoparticle isolated from thermotoga maritima . The encapsulated protein is assembled from 60 copies of the same 31 kDa monomer with a thin icosahedral T=1 symmetric cage with inner and outer diameters of 20 nm and 24 nm, respectively (Sutter M. et al., Nat Struct Mol Biol. 2008; 15: 939-947). Although the exact function of the encapsulating protein in Thermotoga maris is not clearly understood, its crystal structure has recently been solved and its function is postulated to encapsulate enzymes such as DyP (dye depigmenting peroxidase) and Flp (ferritin-like protein) and other proteins involved in the oxidative stress response 30 (Rahmanpour R. et al., FEBS J. 2013; 280: 2097-2104). Nanoparticle construction using encapsulated proteins enables protein antigens to be displayed on the nanoparticle surface and to encapsulate cargoes such as mRNA within the nanoparticles themselves. Previous vaccines based on encapsulated protein nanoparticles have elicited strong immune responses to surface displayed antigens and the cargo protein itself (Lagoutte P. et al., Vaccine. 2018;36(25):3622-3628).
在一些實施例中,本文提供之mRNA編碼與包封蛋白結構域連接之S蛋白結構域(例如,S1、S2、RBD及/或NTD)。 融合蛋白 In some embodiments, the mRNA provided herein encodes a S protein domain (eg, S1, S2, RBD, and/or NTD) linked to an encapsulate protein domain. fusion protein
在一些實施例中,本揭示案之組合物包括編碼抗原性融合蛋白之mRNA。因此,編碼之一或多種抗原可包括接合在一起之兩種或更多種蛋白質(例如,蛋白質及/或蛋白質片段)。或者,與蛋白抗原融合之蛋白質不促進對其自身之强免疫反應,而是促進對冠狀病毒抗原之强免疫反應。在一些實施例中,抗原性融合蛋白保留來自每一原始蛋白質之功能性質。In some embodiments, the compositions of the present disclosure include mRNA encoding an antigenic fusion protein. Thus, encoding one or more antigens can include two or more proteins (eg, proteins and/or protein fragments) joined together. Alternatively, the protein fused to the protein antigen does not promote a strong immune response to itself, but rather a strong immune response to the coronavirus antigen. In some embodiments, the antigenic fusion proteins retain functional properties from each original protein.
在一些實施例中,融合蛋白包含來自SARS-CoV-2刺突蛋白之受體結合結構域。In some embodiments, the fusion protein comprises a receptor binding domain from the SARS-CoV-2 spike protein.
在一些實施例中,融合蛋白包含來自SARS-CoV-2刺突蛋白之N末端結構域。In some embodiments, the fusion protein comprises the N-terminal domain from the SARS-CoV-2 spike protein.
在一些實施例中,融合蛋白包含跨膜結構域。在一些實施例中,跨膜結構域可來自不為SARS-CoV-2之病毒。舉例而言,跨膜結構域可來自流行性感冒血球凝集素跨膜結構域,其已展現有效地將蛋白質錨定在細胞表面。 變異體 In some embodiments, the fusion protein comprises a transmembrane domain. In some embodiments, the transmembrane domain can be from a virus other than SARS-CoV-2. For example, the transmembrane domain can be derived from the influenza hemagglutinin transmembrane domain, which has been shown to efficiently anchor proteins to the cell surface. variant
在一些實施例中,本揭示案之組合物包括編碼冠狀病毒抗原變異體之RNA。抗原變異體或其他多肽變異體係指其胺基酸序列與野生型、天然或參照序列不同之分子。與天然或參照序列相比,抗原/多肽變異體可在胺基酸序列內之某些位置處具有取代、缺失及/或插入。通常,變異體與野生型、天然或參照序列具有至少50%之一致性。在一些實施例中,變異體與野生型、天然或參照序列共享至少80%或至少90%之一致性。In some embodiments, the compositions of the present disclosure include RNA encoding a coronavirus antigenic variant. An antigenic variant or other system of polypeptide variation refers to a molecule whose amino acid sequence differs from the wild-type, native, or reference sequence. Antigen/polypeptide variants may have substitutions, deletions and/or insertions at certain positions within the amino acid sequence compared to the native or reference sequence. Typically, the variant is at least 50% identical to the wild-type, native, or reference sequence. In some embodiments, the variant shares at least 80% or at least 90% identity with the wild-type, native or reference sequence.
由本揭示案之核酸編碼之變異體抗原/多肽可含有賦予多種期望性質中之任一者之胺基酸變化,例如,在個體中增强其免疫原性、增强其表現及/或改善其穩定性或PK/PD性質。變異體抗原/多肽可使用常規誘變技術製備,且適當地進行分析以確定其是否具有期望性質。用以測定表現水準及免疫原性之分析為業內所熟知,且示例性之此類分析在實例部分中闡釋。類似地,可使用業內公認之技術、例如藉由測定抗原在接種之個體中隨時間推移之表現及/或藉由觀察誘導之免疫反應之耐久性,來量測蛋白質變異體之PK/PD性質。由變異體核酸編碼之蛋白質之穩定性可藉由分析熱穩定性或尿素變性時之穩定性來量測,或可使用電腦預測來量測。用於該等實驗及電腦測定之方法為業內已知。The variant antigens/polypeptides encoded by the nucleic acids of the present disclosure may contain amino acid changes that confer any of a variety of desirable properties, eg, enhancing their immunogenicity, enhancing their performance, and/or improving their stability in an individual or PK/PD properties. Variant antigens/polypeptides can be prepared using conventional mutagenesis techniques and suitably analyzed to determine whether they have the desired properties. Assays to determine expression levels and immunogenicity are well known in the art, and exemplary such assays are illustrated in the Examples section. Similarly, the PK/PD properties of protein variants can be measured using art-recognized techniques, such as by measuring the performance of the antigen in vaccinated individuals over time and/or by observing the durability of the induced immune response . The stability of the protein encoded by the variant nucleic acid can be measured by analyzing thermal stability or stability upon urea denaturation, or can be measured using computer prediction. The methods used for these experiments and computer assays are known in the art.
在一些實施例中,組合物包含mRNA或mRNA ORF,其包含本文提供之序列中之任一者之核苷酸序列(參見,例如,序列表),或包含與本文提供之序列中之任一者之核苷酸序列至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致的核苷酸序列。In some embodiments, the composition comprises an mRNA or mRNA ORF comprising the nucleotide sequence of any of the sequences provided herein (see, eg, the Sequence Listing), or comprising any of the sequences provided herein The nucleotide sequences of these are at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% identical.
術語「一致性」係指如藉由比較序列確定之兩種或更多種多肽(例如抗原)或聚核苷酸(核酸)之序列之間之關係。一致性亦係指如藉由兩個或更多個胺基酸殘基或核酸殘基之串之間之匹配數確定的序列之間或之中之序列相關性程度。一致性度量由特定數學模型或電腦程式(例如,「算法」)處理之具有空位比對(若有的話)之兩個或更多個序列中之較小者間之一致性匹配百分比。相關抗原或核酸之一致性可容易地藉由已知方法計算。「一致性百分比(%)」當應用於多肽或聚核苷酸序列時,定義為在比對序列且引入空位(若需要)以實現最大一致性百分比之後,候選胺基酸或核酸序列中與第二序列之胺基酸序列或核酸序列中之殘基(胺基酸殘基或核酸殘基)一致之殘基之百分數。用於比對之方法及電腦程式為業內所熟知。應理解,一致性取决於一致性百分比之計算,但由於計算中引入之空位及罰分,一致性之值可能不同。通常,特定聚核苷酸或多肽(例如抗原)之變異體與該特定參照聚核苷酸或多肽具有如藉由本文所述及熟習此項技術者已知之序列比對程式及參數所確定之至少40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%但小於100%之序列一致性。用於比對之該等工具包括BLAST套件之彼等工具(Stephen F. Altschul等人(1997),「Gapped BLAST and PSI-BLAST: a new generation of protein database search programs」,Nucleic Acids Res. 25:3389-3402)。另一種常用局部比對技術係基於Smith-Waterman算法(Smith, T.F.及Waterman, M.S. (1981) 「Identification of common molecular subsequences.」J. Mol. Biol. 147:195-197)。基於動態規劃之一般全局比對技術係Needleman-Wunsch算法(Needleman, S.B.及Wunsch, C.D. (1970) 「A general method applicable to the search for similarities in the amino acid sequences of two proteins.」J. Mol. Biol. 48:443-453)。最近,已開發一種快速最佳全局序列比對算法(FOGSAA),據稱其比其他最佳全局比對方法(包括Needleman-Wunsch算法)更快地產生核苷酸及蛋白質序列之全局比對。The term "identity" refers to the relationship between the sequences of two or more polypeptides (eg, antigens) or polynucleotides (nucleic acids) as determined by comparing the sequences. Identity also refers to the degree of sequence relatedness between or among sequences as determined by the number of matches between strings of two or more amino acid residues or nucleic acid residues. A measure of identity is the percent identity match between the smaller of two or more sequences with gapped alignments, if any, processed by a particular mathematical model or computer program (eg, an "algorithm"). The identity of related antigens or nucleic acids can be readily calculated by known methods. "Percent identity (%)", when applied to polypeptide or polynucleotide sequences, is defined as the difference in the candidate amino acid or nucleic acid sequence with the The percentage of residues in which the amino acid sequence of the second sequence or the residues (amino acid residues or nucleic acid residues) in the nucleic acid sequence are identical. Methods and computer programs for alignment are well known in the art. It should be understood that agreement depends on the calculation of percent agreement, but the value of agreement may vary due to gaps and penalties introduced in the calculation. Typically, a variant of a particular polynucleotide or polypeptide (eg, an antigen) has the properties as determined by sequence alignment programs and parameters known to those skilled in the art as described herein and to that particular reference polynucleotide or polypeptide. At least 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96 %, 97%, 98%, 99% but less than 100% sequence identity. Such tools for alignment include those of the BLAST suite (Stephen F. Altschul et al. (1997), "Gapped BLAST and PSI-BLAST: a new generation of protein database search programs", Nucleic Acids Res. 25: 3389-3402). Another commonly used local alignment technique is based on the Smith-Waterman algorithm (Smith, T.F. and Waterman, M.S. (1981) "Identification of common molecular subsequences." J. Mol. Biol. 147:195-197). A general global alignment technique based on dynamic programming is the Needleman-Wunsch algorithm (Needleman, S.B. and Wunsch, C.D. (1970) "A general method applicable to the search for similarities in the amino acid sequences of two proteins." J. Mol. Biol 48:443-453). Recently, a Fast Optimal Global Sequence Alignment Algorithm (FOGSAA) has been developed which is said to produce global alignments of nucleotide and protein sequences faster than other optimal global alignment methods, including the Needleman-Wunsch algorithm.
因此,編碼相對於參照序列、特別是本文揭示之多肽(例如抗原)序列含有取代、插入及/或添加、缺失及共價修飾之肽或多肽的聚核苷酸包括在本揭示案之範圍內。舉例而言,序列標籤或胺基酸(諸如一或多個離胺酸)可添加至肽序列中(例如,在N末端或C末端)。序列標籤可用於肽偵測、純化或定位。離胺酸可用於增加肽之溶解度或允許生物素化。或者,位於肽或蛋白質之胺基酸序列之羧基及胺基末端區之胺基酸殘基可視情况地缺失,以提供截短之序列。根據序列之用途,例如作為可溶或連接至固體載體之更大序列之一部分之序列之表現,某些胺基酸(例如,C末端或N末端殘基)可或者缺失。在一些實施例中,信號序列、終止序列、跨膜結構域、連接體、多聚化結構域(諸如,摺疊子區)及諸如此類(或編碼其)之序列可用實現相同或相似功能之替代序列取代。在一些實施例中,可例如藉由引入更大之胺基酸填充蛋白質核心中之空腔以改善穩定性。在其他實施例中,可用疏水性殘基置換包埋之氫鍵網路以改善穩定性。在其他實施例中,可去除醣基化位點且用適當殘基置換。熟習此項技術者可容易地鑑別該等序列。亦應理解,本文提供之一些序列含有可在例如用於製備mRNA疫苗之前缺失之序列標籤或末端肽序列(例如,在N末端或C末端)。Accordingly, polynucleotides encoding peptides or polypeptides containing substitutions, insertions and/or additions, deletions, and covalent modifications relative to a reference sequence, particularly a polypeptide (eg, antigen) sequence disclosed herein are included within the scope of the present disclosure . For example, sequence tags or amino acids such as one or more lysines can be added to the peptide sequence (eg, at the N-terminus or C-terminus). Sequence tags can be used for peptide detection, purification or localization. Lysine can be used to increase the solubility of peptides or to allow biotinylation. Alternatively, amino acid residues located in the carboxyl and amino terminal regions of the amino acid sequence of a peptide or protein can optionally be deleted to provide a truncated sequence. Certain amino acids (eg, C-terminal or N-terminal residues) may or may not be deleted depending on the use of the sequence, eg, the representation of the sequence as part of a larger sequence that is soluble or linked to a solid support. In some embodiments, signal sequences, termination sequences, transmembrane domains, linkers, multimerization domains (such as foldon regions), and the like (or sequences encoding the same) may be used as alternative sequences that perform the same or similar functions replace. In some embodiments, stability can be improved by filling cavities in the protein core, eg, by introducing larger amino acids. In other embodiments, the embedded hydrogen bonding network can be replaced with hydrophobic residues to improve stability. In other embodiments, glycosylation sites can be removed and replaced with appropriate residues. Those skilled in the art can readily identify such sequences. It will also be understood that some of the sequences provided herein contain sequence tags or terminal peptide sequences (eg, at the N-terminus or C-terminus) that may be deleted, eg, prior to use in the preparation of mRNA vaccines.
如由熟習此項技術者認識到,亦將蛋白質片段、功能蛋白質結構域及同源蛋白質視為在相關冠狀病毒抗原之範圍內。舉例而言,本文提供參照蛋白質之任何蛋白質片段(意指比參照抗原序列短至少一個胺基酸殘基、但在其他方面相同之多肽序列),條件係該片段係免疫原性的且賦予針對冠狀病毒之保護性免疫反應。除了與參照蛋白質相同但截短之變異體之外,在一些實施例中,如本文提供或參考之任何序列中所示,抗原包括2、3、4、5、6、7、8、9、10或更多個突變。抗原/抗原性多肽之長度範圍可為約4、6或8個胺基酸至全長蛋白質。 穩定元件 As recognized by those skilled in the art, protein fragments, functional protein domains and homologous proteins are also considered to be within the scope of relevant coronavirus antigens. For example, provided herein is any protein fragment (meaning a polypeptide sequence that is at least one amino acid residue shorter than a reference antigen sequence, but otherwise identical) of a reference protein, provided that the fragment is immunogenic and confers a target to Protective immune response to coronavirus. In addition to identical but truncated variants of the reference protein, in some embodiments, as shown in any of the sequences provided or referenced herein, the antigens include 2, 3, 4, 5, 6, 7, 8, 9, 10 or more mutations. Antigens/antigenic polypeptides can range in length from about 4, 6 or 8 amino acids to full length proteins. Stabilizing element
天然存在之真核mRNA分子除了諸如5'-端帽結構或3'-聚(A)尾等其他結構特徵之外,亦可含有穩定元件,包括但不限於在其5'端(5' UTR)及/或在其3'端(3 ' UTR)之非轉譯區(UTR)。5' UTR及3' UTR二者皆通常係自基因體DNA轉錄且係成熟前mRNA之元件。通常在mRNA加工期間向轉錄之(成熟前) mRNA中添加成熟mRNA之特徵性結構特徵(諸如5'-端帽及3'-聚(A)尾)。Naturally occurring eukaryotic mRNA molecules may also contain stabilizing elements, including but not limited to, at their 5' end (5' UTR ) and/or the untranslated region (UTR) at its 3' end (3' UTR). Both the 5' UTR and the 3' UTR are typically transcribed from genomic DNA and are elements of pre-mature mRNA. Structural features characteristic of mature mRNAs (such as 5'-end caps and 3'-poly(A) tails) are typically added to transcribed (pre-mature) mRNAs during mRNA processing.
在一些實施例中,組合物包括具有編碼至少一種具有至少一個修飾之抗原性多肽之開放閱讀框、至少一個5'末端端帽之mRNA,且調配在脂質奈米顆粒內。聚核苷酸之5'-加端帽可根據製造商之方案在活體外轉錄反應期間使用以下化學RNA端帽類似物同時完成,以產生5'-鳥苷端帽結構:3´-O-Me-m7G(5')ppp(5') G [ARCA端帽];G(5')ppp(5')A;G(5')ppp(5')G;m7G(5')ppp(5')A;m7G(5')ppp(5')G (New England BioLabs, Ipswich, MA)。經修飾之RNA之5'-加端帽可在轉錄後使用牛痘病毒加端帽酶完成,以產生「端帽0」結構:m7G(5')ppp(5')G (New England BioLabs, Ipswich, MA)。端帽1結構可使用牛痘病毒加端帽酶及2'-O甲基轉移酶產生,以產生:m7G(5')ppp(5')G-2′-O-甲基。端帽2結構可自端帽1結構、隨後使用2'-O甲基轉移酶對5'-倒數第三個核苷酸進行2'-O-甲基化來產生。端帽3結構可自端帽2結構、隨後使用2'-O甲基轉移酶對5'-倒數第四個核苷酸進行2'-O-甲基化來產生。酶可源自重組來源。In some embodiments, the composition includes an mRNA having an open reading frame encoding at least one antigenic polypeptide with at least one modification, at least one 5' end cap, and formulated within a lipid nanoparticle. 5'-end capping of polynucleotides can be accomplished simultaneously during in vitro transcription reactions according to the manufacturer's protocol using the following chemical RNA end cap analogs to generate 5'-guanosine end cap structures: 3´-O- Me-m7G(5')ppp(5')G [ARCA end caps]; G(5')ppp(5')A; G(5')ppp(5')G; m7G(5')ppp( 5')A; m7G(5')ppp(5')G (New England BioLabs, Ipswich, MA). 5'-end capping of the modified RNA can be accomplished post-transcriptionally using the vaccinia virus capping enzyme to generate the "
3'-聚(A)尾通常係添加至轉錄之mRNA之3'端之一段腺嘌呤核苷酸。在一些情况下,其可包含高達約400個腺嘌呤核苷酸。在一些實施例中,3'-聚(A)尾之長度對於個別mRNA之穩定性可為必需之要素。The 3'-poly(A) tail is usually a stretch of adenine nucleotides added to the 3' end of the transcribed mRNA. In some cases, it may contain up to about 400 adenine nucleotides. In some embodiments, the length of the 3'-poly(A) tail may be an essential element for the stability of the individual mRNA.
在一些實施例中,組合物包括穩定元件。穩定元件可包括例如組蛋白莖環。已鑑別莖環結合蛋白(SLBP),一種32 kDa之蛋白質。其與細胞核及細胞質二者中組蛋白信使3'端之組蛋白莖環結合。其表現水準受細胞週期之調控;其在S期達到峰值,此時組蛋白mRNA水準亦升高。已顯示該蛋白質對於U7 snRNP對組蛋白前mRNA之有效3'端加工係至關重要的。SLBP在加工後繼續與莖環結合,且接著刺激成熟組蛋白mRNA在細胞質中轉譯成組蛋白。SLBP之RNA結合結構域在後生動物及原生動物中係保守的;其與組蛋白莖環之結合取决於環之結構。最小結合位點包括相對於莖環之5'之至少三個核苷酸及3'之兩個核苷酸。In some embodiments, the composition includes a stabilizing element. Stabilizing elements may include, for example, histone stem-loops. Stem-loop binding protein (SLBP), a 32 kDa protein, has been identified. It binds to the histone stem-loop at the 3' end of histone messengers in both the nucleus and cytoplasm. Its level of expression is regulated by the cell cycle; it peaks in S phase, when histone mRNA levels are also elevated. This protein has been shown to be critical for efficient 3' end processing of histone pre-mRNA by U7 snRNP. SLBP continues to bind to the stem-loop after processing and then stimulates the translation of mature histone mRNA into histones in the cytoplasm. The RNA binding domain of SLBP is conserved in metazoans and protozoa; its binding to the histone stem-loop depends on the structure of the loop. The minimal binding site includes at least three nucleotides 5' and two nucleotides 3' relative to the stem loop.
在一些實施例中,mRNA包括編碼區、至少一個組蛋白莖環及視情况選用之聚(A)序列或聚腺苷酸化信號。聚(A)序列或聚腺苷酸化信號通常應增强編碼之蛋白質之表現水準。在一些實施例中,編碼之蛋白質不為組蛋白、報導基因蛋白(例如螢光素酶、GFP、EGFP、β-半乳糖苷酶、EGFP)或標記物或選擇蛋白(例如α-球蛋白、半乳糖激酶及黃嘌呤:鳥嘌呤磷酸核糖基轉移酶(GPT))。In some embodiments, the mRNA includes a coding region, at least one histone stem-loop, and optionally a poly(A) sequence or a polyadenylation signal. The poly(A) sequence or polyadenylation signal should generally enhance the level of expression of the encoded protein. In some embodiments, the encoded protein is not a histone, reporter protein (eg, luciferase, GFP, EGFP, β-galactosidase, EGFP) or marker or selectin (eg, α-globulin, Galactokinase and xanthine:guanine phosphoribosyltransferase (GPT)).
在一些實施例中,mRNA包括聚(A)序列或聚腺苷酸化信號與至少一個組蛋白莖環之組合,即使二者在性質上代表替代機制,但協同地作用以增加蛋白質表現超過用任一個別元件觀察到之水準。聚(A)及至少一種組蛋白莖環之組合之協同效應不依賴於元件之順序或聚(A)序列之長度。In some embodiments, the mRNA includes a poly(A) sequence or a polyadenylation signal in combination with at least one histone stem-loop, even though the two represent alternative mechanisms in nature, but act synergistically to increase protein expression over using either A level observed by another component. The synergistic effect of the combination of poly(A) and at least one histone stem-loop is independent of the order of the elements or the length of the poly(A) sequence.
在一些實施例中,mRNA不包括組蛋白下游元件(HDE)。「組蛋白下游元件」 (HDE)包括在天然存在之莖環之3'之大約15至20個核苷酸之富含嘌呤之聚核苷酸段,其代表U7 snRNA之結合位點,該U7 snRNA參與組蛋白前mRNA加工成成熟組蛋白mRNA。在一些實施例中,核酸不包括內含子。In some embodiments, the mRNA does not include histone downstream elements (HDEs). "Histone Downstream Elements" (HDEs) include stretches of purine-rich polynucleotides of approximately 15 to 20 nucleotides 3' to naturally occurring stem loops that represent the binding site for U7 snRNA, the U7 snRNA is involved in the processing of histone pre-mRNA into mature histone mRNA. In some embodiments, the nucleic acid does not include introns.
mRNA可含有或可不含有增强子及/或啓動子序列,其可經修飾或未經修飾,或者其可經活化或未經活化。在一些實施例中,組蛋白莖環通常源自組蛋白基因,且包括由間隔體分開之兩個相鄰之部分或完全反向互補序列之分子內鹼基配對,該間隔體由形成結構之環之短序列組成。未配對之環區通常不能與莖環元件中之任一者鹼基配對。其由於係許多RNA二級結構之關鍵組分而更經常地出現於RNA中,但亦可存在於單股DNA中。莖環結構之穩定性通常取决於長度、失配或膨出部之數目及配對區之鹼基組成。在一些實施例中,搖擺鹼基配對(非沃森-克裏克鹼基配對(non-Watson-Crick base pairing))可產生。在一些實施例中,至少一種組蛋白莖環序列包含15至45個核苷酸之長度。mRNA may or may not contain enhancer and/or promoter sequences, which may or may not be modified, or which may or may not be activated. In some embodiments, a histone stem-loop is typically derived from a histone gene and includes intramolecular base pairing of two adjacent partially or fully reverse complementary sequences separated by a spacer formed by a structural A short sequence of loops. Unpaired loop regions are generally unable to base pair with any of the stem-loop elements. It occurs more frequently in RNA as it is a key component of many RNA secondary structures, but can also be found in single-stranded DNA. The stability of the stem-loop structure generally depends on the length, the number of mismatches or bulges, and the base composition of the paired regions. In some embodiments, rocking base pairing (non-Watson-Crick base pairing) can be generated. In some embodiments, the at least one histone stem-loop sequence comprises a length of 15 to 45 nucleotides.
在一些實施例中,mRNA去除一或多個富含AU之序列。有時稱為AURES之該等序列係在3'UTR中發現之不穩定序列。AURES可自RNA疫苗去除。或者,AURES可保留在RNA疫苗中。 信號肽 In some embodiments, the mRNA removes one or more AU-rich sequences. These sequences, sometimes referred to as AURES, are unstable sequences found in the 3'UTR. AURES can be removed from RNA vaccines. Alternatively, AURES can be retained in the RNA vaccine. signal peptide
在一些實施例中,組合物包含具有ORF之mRNA,該ORF編碼與冠狀病毒抗原融合之信號肽。包含蛋白質N末端15-60個胺基酸之信號肽通常係分泌路徑上跨膜易位所需要的,且因此,普遍控制真核及原核生物中大部分蛋白質進入分泌路徑。在真核生物中,新生前體蛋白(先驅蛋白)之信號肽將核糖體引導至粗內質網(ER)膜,且起始生長之肽鏈穿過其轉運以進行加工。ER加工產生成熟蛋白質,其中信號肽通常藉由宿主細胞之ER駐留信號肽酶自前體蛋白裂解,或者其保持未裂解且作為膜錨起作用。信號肽亦可促進蛋白質靶向細胞膜。In some embodiments, the composition comprises mRNA with an ORF encoding a signal peptide fused to a coronavirus antigen. Signal peptides comprising the N-terminal 15-60 amino acids of proteins are generally required for transmembrane translocation on the secretory pathway, and thus, generally control the entry of most proteins into the secretory pathway in eukaryotes and prokaryotes. In eukaryotes, the signal peptide of a nascent precursor protein (pioneer protein) guides ribosomes to the crude endoplasmic reticulum (ER) membrane, and the growth-initiating peptide chain is transported across it for processing. ER processing produces mature proteins in which the signal peptide is typically cleaved from the precursor protein by the host cell's ER-resident signal peptidase, or it remains uncleaved and functions as a membrane anchor. Signal peptides can also facilitate protein targeting to the cell membrane.
信號肽之長度可為15-60個胺基酸。舉例而言,信號肽之長度可為15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59或60個胺基酸。在一些實施例中,信號肽之長度為20-60、25-60、30-60、35-60、40-60、45- 60、50-60、55-60、15-55、20-55、25-55、30-55、35-55、40-55、45-55、50-55、15-50、20-50、25-50、30-50、35-50、40-50、45-50、15-45、20-45、25-45、30-45、35-45、40-45、15-40、20-40、25-40、30-40、35-40、15-35、20-35、25-35、30-35、15-30、20-30、25-30、15-25、20-25或15-20個胺基酸。The signal peptide can be 15-60 amino acids in length. For example, the length of the signal peptide can be 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59 or 60 amino acids. In some embodiments, the length of the signal peptide is 20-60, 25-60, 30-60, 35-60, 40-60, 45-60, 50-60, 55-60, 15-55, 20-55 , 25-55, 30-55, 35-55, 40-55, 45-55, 50-55, 15-50, 20-50, 25-50, 30-50, 35-50, 40-50, 45 -50, 15-45, 20-45, 25-45, 30-45, 35-45, 40-45, 15-40, 20-40, 25-40, 30-40, 35-40, 15-35 , 20-35, 25-35, 30-35, 15-30, 20-30, 25-30, 15-25, 20-25, or 15-20 amino acids.
來自異源基因之信號肽(其調控自然界中除冠狀病毒抗原外之基因之表現)為業內已知,且可測試其期望性質,且接著納入本揭示案之核酸中。 序列最佳化 Signal peptides from heterologous genes that regulate the expression of genes other than coronavirus antigens in nature are known in the art and can be tested for their desired properties and then incorporated into the nucleic acids of the present disclosure. sequence optimization
在一些實施例中,對編碼本揭示案之抗原之ORF進行密碼子最佳化。密碼子最佳化方法為業內已知。舉例而言,本文提供之任何一或多個序列之ORF可為密碼子最佳化的。在一些實施例中,密碼子最佳化可用於匹配靶及宿主生物體中之密碼子頻率以確保正確摺疊;偏向GC含量以增加mRNA穩定性或减少二級結構;最小化可損害基因構築或表現之串聯重複密碼子或鹼基串(base run);定制轉錄及轉譯控制區;插入或去除蛋白質運輸序列;在編碼之蛋白質中去除/添加轉譯後修飾位點(例如,醣基化位點);添加、去除或改組蛋白結構域;插入或缺失限制性位點;修飾核糖體結合位點及mRNA降解位點;調整轉譯率以允許蛋白質之各種結構域正確摺疊;或减少或消除聚核苷酸內之問題二級結構。密碼子最佳化工具、算法及服務為業內已知-非限制性實例包括來自GeneArt (Life Technologies)、DNA2.0 (Menlo Park CA)及/或專有方法之服務。在一些實施例中,使用最佳化算法最佳化開放閱讀框(ORF)序列。In some embodiments, ORFs encoding antigens of the present disclosure are codon-optimized. Codon optimization methods are known in the art. For example, the ORF of any one or more of the sequences provided herein may be codon-optimized. In some embodiments, codon optimization can be used to match codon frequencies in the target and host organisms to ensure correct folding; bias toward GC content to increase mRNA stability or reduce secondary structure; minimize damage to gene architecture or Representation of tandem repeat codons or base runs; custom transcription and translation control regions; insertion or removal of protein trafficking sequences; removal/addition of post-translational modification sites (eg, glycosylation sites) in the encoded protein ); add, remove, or shuffle protein domains; insert or delete restriction sites; modify ribosome binding sites and mRNA degradation sites; adjust translation rates to allow correct folding of various domains of the protein; or reduce or eliminate polynucleation Problematic secondary structure within nucleotides. Codon optimization tools, algorithms and services are known in the art - non-limiting examples include services from GeneArt (Life Technologies), DNA2.0 (Menlo Park CA) and/or proprietary methods. In some embodiments, an optimization algorithm is used to optimize open reading frame (ORF) sequences.
在一些實施例中,密碼子最佳化之序列與天然存在或野生型序列ORF (例如,編碼冠狀病毒抗原之天然存在或野生型mRNA序列)共享小於95%之序列一致性。在一些實施例中,密碼子最佳化之序列與天然存在或野生型序列(例如,編碼冠狀病毒抗原之天然存在或野生型mRNA序列)共享小於90%之序列一致性。在一些實施例中,密碼子最佳化之序列與天然存在或野生型序列(例如,編碼冠狀病毒抗原之天然存在或野生型mRNA序列)共享小於85%之序列一致性。在一些實施例中,密碼子最佳化之序列與天然存在或野生型序列(例如,編碼冠狀病毒抗原之天然存在或野生型mRNA序列)共享小於80%之序列一致性。在一些實施例中,密碼子最佳化之序列與天然存在或野生型序列(例如,編碼冠狀病毒抗原之天然存在或野生型mRNA序列)共享小於75%之序列一致性。In some embodiments, the codon-optimized sequence shares less than 95% sequence identity with a naturally-occurring or wild-type sequence ORF (eg, a naturally-occurring or wild-type mRNA sequence encoding a coronavirus antigen). In some embodiments, the codon-optimized sequence shares less than 90% sequence identity with a naturally-occurring or wild-type sequence (eg, a naturally-occurring or wild-type mRNA sequence encoding a coronavirus antigen). In some embodiments, the codon-optimized sequence shares less than 85% sequence identity with a naturally-occurring or wild-type sequence (eg, a naturally-occurring or wild-type mRNA sequence encoding a coronavirus antigen). In some embodiments, the codon-optimized sequence shares less than 80% sequence identity with a naturally-occurring or wild-type sequence (eg, a naturally-occurring or wild-type mRNA sequence encoding a coronavirus antigen). In some embodiments, the codon-optimized sequence shares less than 75% sequence identity with a naturally-occurring or wild-type sequence (eg, a naturally-occurring or wild-type mRNA sequence encoding a coronavirus antigen).
在一些實施例中,密碼子最佳化之序列與天然存在或野生型序列(例如,編碼冠狀病毒抗原之天然存在或野生型mRNA序列)共享介於65%與85%之間(例如,介於約67%與約85%之間或介於約67%與約80%之間)之序列一致性。在一些實施例中,密碼子最佳化之序列與天然存在或野生型序列(例如,編碼冠狀病毒抗原之天然存在或野生型mRNA序列)共享介於65%與75%或約80%之間之序列一致性。In some embodiments, the codon-optimized sequence shares between 65% and 85% (eg, between 65% and 85%) with a naturally occurring or wild-type sequence (eg, a naturally occurring or wild-type mRNA sequence encoding a coronavirus antigen). between about 67% and about 85% or between about 67% and about 80%) sequence identity. In some embodiments, the codon-optimized sequence shares between 65% and 75% or about 80% with a naturally occurring or wild-type sequence (eg, a naturally occurring or wild-type mRNA sequence encoding a coronavirus antigen) sequence consistency.
在一些實施例中,密碼子最佳化之序列編碼之抗原與由非密碼子最佳化之序列編碼之冠狀病毒抗原之免疫原性一樣,或比其免疫原性更高(例如,高至少10%、至少20%、至少30%、至少40%、至少50%、至少100%或至少200%)。In some embodiments, the antigen encoded by the codon-optimized sequence is as immunogenic as, or more immunogenic (eg, at least higher than the coronavirus antigen encoded by the non-codon-optimized sequence) 10%, at least 20%, at least 30%, at least 40%, at least 50%, at least 100%, or at least 200%).
經修飾之mRNA在轉染至哺乳動物宿主細胞中時具有12-18小時之間或大於18小時、例如24小時、36小時、48小時、60小時、72小時或大於72小時之穩定性,且能够由哺乳動物宿主細胞表現。The modified mRNA is stable when transfected into a mammalian host cell for between 12-18 hours or greater than 18 hours, such as 24 hours, 36 hours, 48 hours, 60 hours, 72 hours or greater than 72 hours, and Can be expressed by mammalian host cells.
在一些實施例中,密碼子最佳化之RNA可為其中G/C之水準增加之RNA。核酸分子(例如mRNA)之G/C含量可影響RNA之穩定性。具有增加量之鳥嘌呤(G)及/或胞嘧啶(C)殘基之RNA可在功能上比含有大量腺嘌呤(A)及胸腺嘧啶(T)或尿嘧啶(U)核苷酸之mRNA更穩定。作為實例,WO02/098443揭示一種醫藥組合物,含有藉由轉譯區中之序列修飾而穩定之mRNA。由於遺傳密碼之簡併性,修飾藉由用促進更大RNA穩定性而不改變所得胺基酸之彼等密碼子取代現有密碼子來起作用。該方法限於RNA之編碼區。 化學上未經修飾之核苷酸 In some embodiments, the codon-optimized RNA can be an RNA in which the level of G/C is increased. The G/C content of a nucleic acid molecule (eg, mRNA) can affect RNA stability. RNAs with increased amounts of guanine (G) and/or cytosine (C) residues are functionally more functional than mRNAs that contain larger amounts of adenine (A) and thymine (T) or uracil (U) nucleotides more stable. As an example, WO02/098443 discloses a pharmaceutical composition containing mRNA stabilized by sequence modifications in the translation region. Due to the degeneracy of the genetic code, modifications work by replacing existing codons with those that promote greater RNA stability without altering the resulting amino acid. This method is limited to the coding region of RNA. Chemically unmodified nucleotides
在一些實施例中,mRNA未經化學修飾,且包含由腺苷、鳥苷、胞嘧啶及尿苷組成之標準核糖核苷酸。在一些實施例中,本揭示案之核苷酸及核苷包含標準核苷殘基,諸如存在於轉錄之RNA中之彼等核苷殘基(例如A、G、C或U)。在一些實施例中,本揭示案之核苷酸及核苷包含標準去氧核糖核苷,例如存在於DNA中之彼等去氧核糖核苷(例如dA、dG、dC或dT)。 化學修飾 In some embodiments, the mRNA is not chemically modified and comprises standard ribonucleotides consisting of adenosine, guanosine, cytosine, and uridine. In some embodiments, the nucleotides and nucleosides of the present disclosure comprise standard nucleoside residues, such as those found in transcribed RNA (eg, A, G, C, or U). In some embodiments, the nucleotides and nucleosides of the present disclosure comprise standard deoxyribonucleosides, such as those found in DNA (eg, dA, dG, dC, or dT). chemical modification
在一些實施例中,本揭示案之組合物包含具有編碼冠狀病毒抗原之開放閱讀框之mRNA,其中核酸包含可為標準之(未經修飾之)或如業內已知修飾之核苷酸及/或核苷。在一些實施例中,本揭示案之核苷酸及核苷包含經修飾之核苷酸或核苷。該等經修飾之核苷酸及核苷可為天然存在之經修飾之核苷酸及核苷或非天然存在之經修飾之核苷酸及核苷。該等修飾可包括如業內所公認之在核苷酸及/或核苷之糖、主鏈或核鹼基部分之彼等修飾。In some embodiments, the compositions of the present disclosure comprise mRNA having an open reading frame encoding a coronavirus antigen, wherein the nucleic acid comprises nucleotides that may be standard (unmodified) or modified as known in the art and/or or nucleosides. In some embodiments, the nucleotides and nucleosides of the present disclosure comprise modified nucleotides or nucleosides. Such modified nucleotides and nucleosides can be naturally occurring modified nucleotides and nucleosides or non-naturally occurring modified nucleotides and nucleosides. Such modifications may include such modifications in the sugar, backbone or nucleobase moieties of nucleotides and/or nucleosides, as recognized in the art.
在一些實施例中,本揭示案之天然存在之經修飾之核苷酸或核苷係業內通常已知或公認之核苷酸或核苷。該等天然存在之經修飾之核苷酸及核苷之非限制性實例尤其可在廣泛公認之MODOMICS數據庫中發現。In some embodiments, the naturally-occurring modified nucleotides or nucleosides of the present disclosure are nucleotides or nucleosides generally known or recognized in the art. Non-limiting examples of such naturally occurring modified nucleotides and nucleosides can be found, inter alia, in the widely recognized MODOMICS database.
在一些實施例中,本揭示案之非天然存在之經修飾之核苷酸或核苷係業內通常已知或公認之核苷酸或核苷。該等非天然存在之經修飾之核苷酸及核苷之非限制性實例尤其可參見公開之美國申請案號 PCT/US2012/058519;PCT/US2013/075177;PCT/US2014/058897;PCT/US2014/058891;PCT/US2014/070413;PCT/US2015/36773;PCT/US2015/36759;PCT/US2015/36771;或PCT/IB2017/051367,所有該等申請案皆以引用方式併入本文中。In some embodiments, the non-naturally occurring modified nucleotides or nucleosides of the present disclosure are nucleotides or nucleosides generally known or recognized in the art. Non-limiting examples of such non-naturally occurring modified nucleotides and nucleosides can be found in, inter alia, Published US Application Nos. PCT/US2012/058519; PCT/US2013/075177; PCT/US2014/058897; PCT/US2014 /058891; PCT/US2014/070413; PCT/US2015/36773; PCT/US2015/36759; PCT/US2015/36771; or PCT/IB2017/051367, all of which are incorporated herein by reference.
因此,本揭示案之核酸(例如,DNA核酸及RNA核酸,諸如mRNA核酸)可包含標準核苷酸及核苷、天然存在之核苷酸及核苷、非天然存在之核苷酸及核苷或其任一組合。Accordingly, nucleic acids (eg, DNA nucleic acids and RNA nucleic acids, such as mRNA nucleic acids) of the present disclosure can include standard nucleotides and nucleosides, naturally occurring nucleotides and nucleosides, non-naturally occurring nucleotides and nucleosides or any combination thereof.
在一些實施例中,本揭示案之核酸(例如,DNA核酸及RNA核酸,諸如mRNA核酸)包含多種(一種以上)不同類型之標準及/或經修飾之核苷酸及核苷。在一些實施例中,核酸之特定區含有一種、兩種或更多種(視情况地不同)類型之標準及/或經修飾之核苷酸及核苷。In some embodiments, nucleic acids (eg, DNA nucleic acids and RNA nucleic acids, such as mRNA nucleic acids) of the present disclosure comprise multiple (more than one) different types of standard and/or modified nucleotides and nucleosides. In some embodiments, a particular region of a nucleic acid contains one, two or more (as appropriate) types of standard and/or modified nucleotides and nucleosides.
在一些實施例中,相對於包含標準核苷酸及核苷之未經修飾之核酸,引入細胞或生物體之經修飾之RNA核酸(例如,經修飾之mRNA核酸)分別在細胞或生物體中展現降低之降解。In some embodiments, the modified RNA nucleic acid (eg, modified mRNA nucleic acid) introduced into the cell or organism is in the cell or organism, respectively, relative to the unmodified nucleic acid comprising standard nucleotides and nucleosides Shows reduced degradation.
在一些實施例中,相對於包含標準核苷酸及核苷之未經修飾之核酸,引入細胞或生物體中之經修飾之RNA核酸(例如,經修飾之mRNA核酸)可分別在細胞或生物體中展現降低之免疫原性(例如,降低之先天反應)。In some embodiments, a modified RNA nucleic acid (eg, a modified mRNA nucleic acid) introduced into a cell or organism, relative to an unmodified nucleic acid comprising standard nucleotides and nucleosides, can be used in the cell or organism, respectively. A reduced immunogenicity is exhibited in vivo (eg, a reduced innate response).
在一些實施例中,核酸(例如RNA核酸,諸如mRNA核酸)包含非天然修飾之核苷酸,其在核酸之合成或合成後引入以實現期望功能或性質。修飾可存在於核苷酸間鍵聯、嘌呤或嘧啶鹼基或糖上。修飾可用化學合成或用聚合酶在鏈之末端或鏈中之任何其他地方引入。核酸之任何區可經化學修飾。In some embodiments, nucleic acids (eg, RNA nucleic acids, such as mRNA nucleic acids) comprise non-naturally modified nucleotides that are introduced during or after synthesis of the nucleic acid to achieve a desired function or property. Modifications can exist on internucleotide linkages, purine or pyrimidine bases, or sugars. Modifications can be introduced at the end of the chain or anywhere else in the chain by chemical synthesis or with a polymerase. Any region of a nucleic acid can be chemically modified.
本揭示案提供核酸(例如RNA核酸,諸如mRNA核酸)之經修飾之核苷及核苷酸。「核苷」係指含有糖分子(例如戊醣或核糖)或其衍生物與有機鹼基(例如嘌呤或嘧啶)或其衍生物(在本文中亦稱為「核鹼基」)組合之化合物。「核苷酸」係指包括磷酸基團之核苷。經修飾之核苷酸可藉由任何有用之方法、例如化學、酶促或重組方法合成,以包括一或多個經修飾之或非天然之核苷。核酸可包含連接之核苷之一或多個區。該等區可具有可變之主鏈鍵聯。鍵聯可為標準磷酸二酯鍵聯,在該情形下,核酸將包含核苷酸之區。The present disclosure provides modified nucleosides and nucleotides of nucleic acids (eg, RNA nucleic acids, such as mRNA nucleic acids). "Nucleoside" refers to a compound containing a sugar molecule (eg, pentose or ribose) or a derivative thereof in combination with an organic base (eg, purine or pyrimidine) or a derivative thereof (also referred to herein as a "nucleobase") . "Nucleotide" refers to a nucleoside that includes a phosphate group. Modified nucleotides can be synthesized by any useful method, such as chemical, enzymatic or recombinant methods, to include one or more modified or non-natural nucleosides. Nucleic acids may comprise one or more regions of linked nucleosides. The regions may have variable backbone linkages. The linkage can be a standard phosphodiester linkage, in which case the nucleic acid will comprise a region of nucleotides.
經修飾之核苷酸鹼基配對不僅涵蓋標準腺苷-胸腺嘧啶、腺苷-尿嘧啶或鳥苷-胞嘧啶鹼基對,且亦包括在核苷酸及/或包含非標準或經修飾之鹼基之經修飾之核苷酸之間形成之鹼基對,其中氫鍵供體及氫鍵受體之排列允許在非標準鹼基與標準鹼基之間或在兩個互補非標準鹼基結構之間、例如在具有至少一個化學修飾之彼等核酸中之氫鍵。該非標準鹼基配對之一個實例係經修飾之核苷酸肌苷與腺嘌呤、胞嘧啶或尿嘧啶之間之鹼基配對。鹼基/糖或連接體之任何組合可納入本揭示案之核酸中。Modified nucleotide base pairings encompass not only standard adenosine-thymine, adenosine-uracil, or guanosine-cytosine base pairs, but also include nucleotides and/or include non-standard or modified base pairs. A base pair formed between modified nucleotides of bases in which the hydrogen bond donor and hydrogen bond acceptor are arranged to allow between a non-standard base and a standard base or between two complementary non-standard bases Hydrogen bonds between structures, such as in those nucleic acids with at least one chemical modification. An example of such non-standard base pairing is the base pairing between the modified nucleotides inosine and adenine, cytosine or uracil. Any combination of bases/sugars or linkers can be incorporated into the nucleic acids of the present disclosure.
在一些實施例中,核酸(例如RNA核酸,諸如mRNA核酸)中經修飾之核鹼基包含1-甲基-假尿苷(m1ψ)、1-乙基-假尿苷(e1ψ)、5-甲氧基-尿苷(mo5U)、5-甲基-胞苷(m5C)及/或假尿苷(ψ)。在一些實施例中,核酸(例如RNA核酸,諸如mRNA核酸)中之經修飾之核鹼基包含5-甲氧基甲基尿苷、5-甲硫基尿苷、1-甲氧基甲基假尿苷、5-甲基胞苷及/或5-甲氧基胞苷。在一些實施例中,多核糖核苷酸包括至少兩種(例如,2、3、4或更多種)任何上文所提及之經修飾之核鹼基之組合,包括但不限於化學修飾。In some embodiments, the modified nucleobases in nucleic acids (eg, RNA nucleic acids, such as mRNA nucleic acids) comprise 1-methyl-pseudouridine (m1ψ), 1-ethyl-pseudouridine (e1ψ), 5- Methoxy-uridine (mo5U), 5-methyl-cytidine (m5C) and/or pseudouridine (ψ). In some embodiments, the modified nucleobases in nucleic acids (eg, RNA nucleic acids, such as mRNA nucleic acids) comprise 5-methoxymethyluridine, 5-methylthiouridine, 1-methoxymethyl Pseudouridine, 5-methylcytidine and/or 5-methoxycytidine. In some embodiments, the polyribonucleotide includes a combination of at least two (eg, 2, 3, 4, or more) any of the above-mentioned modified nucleobases, including but not limited to chemical modifications .
在一些實施例中,本揭示案之mRNA包含在核酸之一或多個或所有尿苷位置之1-甲基-假尿苷(m1ψ)取代。In some embodiments, the mRNA of the present disclosure comprises a 1-methyl-pseudouridine (m1ψ) substitution at one or more or all uridine positions of the nucleic acid.
在一些實施例中,本揭示案之mRNA包含在核酸之一或多個或所有尿苷位置之1-甲基-假尿苷(m1ψ)取代及在核酸之一或多個或所有胞苷位置之5-甲基胞苷取代。In some embodiments, the mRNA of the present disclosure comprises a 1-methyl-pseudouridine (m1ψ) substitution at one or more or all uridine positions of the nucleic acid and at one or more or all cytidine positions of the nucleic acid 5-methylcytidine substitution.
在一些實施例中,本揭示案之mRNA包含在核酸之一或多個或所有尿苷位置之假尿苷(ψ)取代。In some embodiments, the mRNAs of the present disclosure comprise pseudouridine (ψ) substitutions at one or more or all uridine positions of the nucleic acid.
在一些實施例中,本揭示案之mRNA包含在核酸之一或多個或所有尿苷位置之假尿苷(ψ)取代及在核酸之一或多個或所有胞苷位置之5-甲基胞苷取代。In some embodiments, mRNAs of the present disclosure comprise pseudouridine (ψ) substitutions at one or more or all uridine positions of the nucleic acid and a 5-methyl group at one or more or all cytidine positions of the nucleic acid Cytidine substitution.
在一些實施例中,本揭示案之mRNA包含在核酸之一或多個或所有尿苷位置之尿苷。In some embodiments, the mRNA of the present disclosure comprises uridine at one or more or all uridine positions of the nucleic acid.
在一些實施例中,對於特定修飾,對mRNA進行均勻修飾(例如,完全修飾、在整個序列中修飾)。舉例而言,核酸可用1-甲基-假尿苷均勻修飾,此意味著mRNA序列中之所有尿苷殘基皆用1-甲基-假尿苷置換。類似地,藉由用經修飾之殘基(諸如上文所闡釋之彼等殘基)置換,可針對序列中存在之任何類型之核苷殘基對核酸進行均勻修飾。In some embodiments, for a particular modification, the mRNA is modified uniformly (eg, fully modified, modified throughout the sequence). For example, nucleic acids can be uniformly modified with 1-methyl-pseudouridine, which means that all uridine residues in the mRNA sequence are replaced with 1-methyl-pseudouridine. Similarly, nucleic acids can be uniformly modified for any type of nucleoside residue present in the sequence by replacement with modified residues, such as those explained above.
本揭示案之核酸可沿著分子之整個長度經部分或完全修飾。舉例而言,在本揭示案之核酸中,或在其預定序列區中(例如,在包括或不包括聚(A)尾之mRNA中),可均勻地修飾一或多種或所有或給定類型之核苷酸(例如,嘌呤或嘧啶,或任一或多種或所有A、G、U、C)。在一些實施例中,本揭示案之核酸中(或其序列區中)之所有核苷酸X皆係經修飾之核苷酸,其中X可為核苷酸A、G、U、C中之任一者,或組合A+G、A+U、A+C、G+U、G+C、U+C、A+G+U、A+G+C、G+U+C或A+G+C中之任一者。Nucleic acids of the present disclosure can be partially or fully modified along the entire length of the molecule. For example, in a nucleic acid of the present disclosure, or in a predetermined sequence region thereof (eg, in an mRNA that includes or does not include a poly(A) tail), one or more or all or a given type can be modified uniformly nucleotides (eg, purines or pyrimidines, or any or more or all of A, G, U, C). In some embodiments, all nucleotides X in the nucleic acids of the present disclosure (or in their sequence regions) are modified nucleotides, wherein X can be one of nucleotides A, G, U, C Any, or a combination of A+G, A+U, A+C, G+U, G+C, U+C, A+G+U, A+G+C, G+U+C, or A+ Any of G+C.
核酸可含有約1%至約100%之經修飾之核苷酸(相對於總核苷酸含量,或相對於一或多種類型之核苷酸,亦即A、G、U或C中之任一或多者)或任何居間百分比(例如,1%至20%、1%至25%、1%至50%、1%至60%、1%至70%、1%至80%、1%至90%、1%至95%、10%至20%、10%至25%、10%至50%、10%至60%、10%至70%、10%至80%、10%至90%、10%至95%、10%至100%、20%至25%、20%至50%、20%至60%、20%至70%、20%至80%、20%至90%、20%至95%、20%至100%、50%至60%、50%至70%、50%至80%、50%至90%、50%至95%、50%至100%、70%至80%、70%至90%、70%至95%、70%至100%、80%至90%、80%至95%、80%至100%、90%至95%、90%至100%及95%至100%)。應理解,未經修飾之A、G、U或C之存在佔任何其餘百分數。Nucleic acids may contain from about 1% to about 100% modified nucleotides (relative to total nucleotide content, or to one or more types of nucleotides, ie, any of A, G, U, or C). one or more) or any intermediate percentage (eg, 1% to 20%, 1% to 25%, 1% to 50%, 1% to 60%, 1% to 70%, 1% to 80%, 1% to 90%, 1% to 95%, 10% to 20%, 10% to 25%, 10% to 50%, 10% to 60%, 10% to 70%, 10% to 80%, 10% to 90% %, 10% to 95%, 10% to 100%, 20% to 25%, 20% to 50%, 20% to 60%, 20% to 70%, 20% to 80%, 20% to 90%, 20% to 95%, 20% to 100%, 50% to 60%, 50% to 70%, 50% to 80%, 50% to 90%, 50% to 95%, 50% to 100%, 70% to 80%, 70% to 90%, 70% to 95%, 70% to 100%, 80% to 90%, 80% to 95%, 80% to 100%, 90% to 95%, 90% to 100 % and 95% to 100%). It should be understood that the presence of unmodified A, G, U or C accounts for any remaining percentages.
mRNA可含有最少1%且最多100%之經修飾之核苷酸或任何居間百分數,諸如至少5%之經修飾之核苷酸、至少10%之經修飾之核苷酸、至少25%之經修飾之核苷酸、至少50%之經修飾之核苷酸、至少80%之經修飾之核苷酸或至少90%之經修飾之核苷酸。舉例而言,核酸可含有經修飾之嘧啶,諸如經修飾之尿嘧啶或胞嘧啶。在一些實施例中,核酸中至少5%、至少10%、至少25%、至少50%、至少80%、至少90%或100%之尿嘧啶由經修飾之尿嘧啶(例如5-取代之尿嘧啶)置換。經修飾之尿嘧啶可由具有單一獨特結構之化合物置換,或可由具有不同結構(例如,2、3、4或更多種獨特結構)之複數種化合物置換。在一些實施例中,核酸中至少5%、至少10%、至少25%、至少50%、至少80%、至少90%或100%之胞嘧啶由經修飾之胞嘧啶(例如5-取代之胞嘧啶)置換。經修飾之胞嘧啶可由具有單一獨特結構之化合物置換,或可由具有不同結構(例如,2、3、4或更多種獨特結構)之複數種化合物置換。 非轉譯區 (UTR) mRNA may contain a minimum of 1% and a maximum of 100% modified nucleotides or any intermediate percentages, such as at least 5% modified nucleotides, at least 10% modified nucleotides, at least 25% modified nucleotides Modified nucleotides, at least 50% modified nucleotides, at least 80% modified nucleotides, or at least 90% modified nucleotides. For example, nucleic acids can contain modified pyrimidines, such as modified uracil or cytosine. In some embodiments, at least 5%, at least 10%, at least 25%, at least 50%, at least 80%, at least 90%, or 100% of the uracils in the nucleic acid consist of modified uracils (eg, 5-substituted uracils pyrimidine) replacement. The modified uracil can be replaced by a compound having a single unique structure, or can be replaced by a plurality of compounds having different structures (eg, 2, 3, 4, or more unique structures). In some embodiments, at least 5%, at least 10%, at least 25%, at least 50%, at least 80%, at least 90%, or 100% of the cytosines in the nucleic acid are modified cytosines (eg, 5-substituted cytosines) pyrimidine) replacement. Modified cytosines can be replaced by compounds with a single unique structure, or can be replaced by multiple compounds with different structures (eg, 2, 3, 4, or more unique structures). Untranslated Region (UTR)
本揭示案之mRNA可包含一或多個充當或用作非轉譯區之區或部分。當mRNA經設計為編碼至少一種相關抗原時,核酸可包含該等非轉譯區(UTR)中之一或多者。核酸之野生型非轉譯區經轉錄,而非經轉譯。在mRNA中,5' UTR在轉錄起始位點開始,且繼續至起始密碼子,但不包括起始密碼子;而3' UTR在終止密碼子之後立即開始,且繼續至轉錄終止信號。愈來愈多之證據表明UTR在核酸分子之穩定性及轉譯方面所起之調控作用。UTR之調控特徵可納入本揭示案之聚核苷酸中,以尤其增强分子之穩定性。亦可納入特定特徵以確保在轉錄物被錯誤導向不期望器官部位之情形下轉錄物之受控下調。多種5' UTR及3' UTR序列為業內已知及可獲得的。The mRNAs of the present disclosure may comprise one or more regions or portions that serve or function as untranslated regions. When the mRNA is designed to encode at least one relevant antigen, the nucleic acid may comprise one or more of these untranslated regions (UTRs). The wild-type untranslated region of the nucleic acid is transcribed, not translated. In mRNA, the 5'UTR begins at the transcription initiation site and continues to, but not including, the initiation codon; while the 3'UTR begins immediately after the stop codon and continues to the transcription termination signal. There is increasing evidence that UTRs play a regulatory role in the stability and translation of nucleic acid molecules. Regulatory features of UTRs can be incorporated into the polynucleotides of the present disclosure to, inter alia, enhance the stability of the molecule. Specific features may also be incorporated to ensure controlled downregulation of transcripts in the event that they are misdirected to undesired organ sites. Various 5'UTR and 3'UTR sequences are known and available in the art.
5ꞌ UTR係mRNA之直接在起始密碼子(核糖體轉譯之mRNA轉錄物之第一個密碼子)上游(5ꞌ)之區。5ꞌ UTR不編碼蛋白質(係非編碼的)。天然5' UTR具有在轉譯起始中起作用之特徵。其具有如Kozak序列之記號,通常已知Kozak序列參與核糖體起始許多基因轉譯之過程。Kozak序列具有共有CCR(A/G)CCAUGG (SEQ ID NO: 128),其中R係起始密碼子(AUG)上游三個鹼基處之嘌呤(腺嘌呤或鳥嘌呤),起始密碼子(AUG)後接另一『G』。亦已知5' UTR形成參與延伸因子結合之二級結構。The 5ꞌ UTR is the region of the mRNA immediately upstream (5ꞌ) of the initiation codon (the first codon of the ribosome-translated mRNA transcript). 5ꞌ UTR does not encode protein (it is non-coding). The native 5'UTR is characterized by a role in translation initiation. It has a signature like the Kozak sequence, which is generally known to be involved in the process by which the ribosome initiates the translation of many genes. The Kozak sequence has a consensus CCR(A/G)CCAUGG (SEQ ID NO: 128), where R is a purine (adenine or guanine) three bases upstream of the initiation codon (AUG), and the initiation codon ( AUG) followed by another "G". The 5'UTR is also known to form secondary structures involved in elongation factor binding.
在本揭示案之一些實施例中,5' UTR係異源UTR,亦即,係在自然界中發現之與不同ORF相關之UTR。在另一實施例中,5' UTR係合成UTR,亦即,自然界中不出現。合成之UTR包括已經突變以改善其性質之UTR,例如,增加基因表現之UTR,以及完全合成之UTR。示例性5' UTR包括非洲爪蟾屬(Xenopus)或人類源a-球蛋白或b-球蛋白(8278063;9012219)、人類細胞色素b-245a多肽及羥基類固醇(17b)去氫酶及烟草蝕紋病毒(US8278063, 9012219)。亦可使用CMV立即早期1 (IE1)基因(US20140206753、WO2013/185069)、序列GGGAUCCUACC (SEQ ID NO: 129) (WO2014144196)。在另一實施例中,TOP基因之5' UTR係缺乏5' TOP基元(寡嘧啶束)之TOP基因之5' UTR (例如,WO/2015101414、WO2015101415、WO/2015/062738、WO2015024667、WO2015024667);可使用源自核糖體蛋白大32 (L32)基因之5' UTR元件(WO/2015101414、WO2015101415、WO/2015/062738)、源自羥基類固醇(17-β)去氫酶4基因(HSD17B4)之5'UTR之5' UTR元件(WO2015024667)或源自ATP5A1之5' UTR之5' UTR元件(WO2015024667)。在一些實施例中,使用內部核糖體進入位點(IRES)代替5' UTR。In some embodiments of the present disclosure, the 5' UTR is a heterologous UTR, ie, a UTR that is found in nature to be associated with a different ORF. In another embodiment, the 5' UTR is a synthetic UTR, ie, does not occur in nature. Synthetic UTRs include UTRs that have been mutated to improve their properties, eg, UTRs that increase gene expression, as well as fully synthetic UTRs. Exemplary 5' UTRs include Xenopus or human derived a-globulin or b-globin (8278063; 9012219), human cytochrome b-245a polypeptide and hydroxysteroid (17b) dehydrogenase and tobacco etch Streak virus (US8278063, 9012219). The CMV immediate early 1 (IE1) gene (US20140206753, WO2013/185069), sequence GGGAUCCUACC (SEQ ID NO: 129) (WO2014144196) can also be used. In another embodiment, the 5' UTR of the TOP gene is the 5' UTR of the TOP gene lacking the 5' TOP motif (oligopyrimidine tract) (eg, WO/2015101414, WO2015101415, WO/2015/062738, WO2015024667, WO2015024667 ); the 5' UTR element derived from the ribosomal protein large 32 (L32) gene (WO/2015101414, WO2015101415, WO/2015/062738), the hydroxysteroid (17-beta)
在一些實施例中,本揭示案之5' UTR包含選自SEQ ID NO: 131及SEQ ID NO: 2之序列。In some embodiments, the 5' UTR of the present disclosure comprises a sequence selected from the group consisting of SEQ ID NO: 131 and SEQ ID NO: 2.
3ꞌ UTR係mRNA之直接在終止密碼子(mRNA轉錄物之發出轉譯終止信號之密碼子)下游(3ꞌ)之區。3ꞌ UTR不編碼蛋白質(係非編碼的)。已知天然或野生型3 ' UTR具有嵌入其中之腺苷及尿苷之段。該等富AU之記號在具有高周轉率之基因中特別普遍。富AU之元件(ARE)基於其序列特徵及功能特性可分成三類(Chen等人,1995):I類ARE在富U之區內含有AUUUA基元之若干分散之拷貝。C-Myc及MyoD含有I類ARE。II類ARE具有兩個或更多個重疊UUAUUUA(U/A)(U/A) (SEQ ID NO: 130)九聚體。含有此種類型之ARE之分子包括GM-CSF及TNF-α。III類ARE定義不太明確。該等富U之區不含AUUUA基元。c-Jun及肌細胞生成素係此類別之兩個充分研究之實例。已知大多數結合至ARE之蛋白質使信使不穩定,而據記載ELAV家族之成員(最著名的是HuR)增加mRNA之穩定性。HuR結合至所有三個類別之ARE。將HuR特異性結合位點改造至核酸分子之3 'UTR中將導致HuR結合,且因此導致活體內信使之穩定。The 3ꞌ UTR is the region of the mRNA immediately downstream (3ꞌ) of the stop codon (the codon that signals the termination of translation of the mRNA transcript). 3ꞌ UTRs do not encode proteins (are non-coding). Natural or wild-type 3'UTRs are known to have stretches of adenosine and uridine embedded therein. These AU-rich markers are particularly prevalent in genes with high turnover. AU-rich elements (AREs) can be divided into three classes based on their sequence characteristics and functional properties (Chen et al., 1995): Class I AREs contain scattered copies of the AUUUA motif within the U-rich region. C-Myc and MyoD contain class I AREs. Class II AREs have two or more overlapping UUAUUUA(U/A)(U/A) (SEQ ID NO: 130) nonamers. Molecules containing AREs of this type include GM-CSF and TNF-alpha. Class III AREs are less well-defined. These U-rich regions do not contain AUUUA primitives. c-Jun and myogenin are two well-studied examples of this class. Most proteins that bind to AREs are known to destabilize messengers, while members of the ELAV family, most notably HuR, have been documented to increase mRNA stability. HuR binds to all three classes of AREs. Engineering a HuR-specific binding site into the 3'UTR of a nucleic acid molecule will result in HuR binding and thus in vivo messenger stabilization.
3' UTR富AU元件(ARE)之引入、去除或修飾可用於調節本揭示案之核酸(例如RNA)之穩定性。當工程改造特定核酸時,可引入ARE之一或多個拷貝以使本揭示案之核酸更不穩定,從而縮減轉譯且减少所得蛋白質之產生。同樣,可鑑別及去除或突變ARE以增加細胞內穩定性,從而增加所得蛋白質之轉譯及產生。可在相關細胞株中使用本揭示案之核酸執行轉染實驗,且可在轉染後之不同時間點分析蛋白質產生。舉例而言,可用不同ARE工程改造分子,且藉由對相關蛋白質使用ELISA套組且分析在轉染後6小時、12小時、24小時、48小時及7天產生之蛋白質,來轉染細胞。Introduction, removal or modification of 3'UTR AU-rich elements (AREs) can be used to modulate the stability of nucleic acids (eg, RNAs) of the present disclosure. When engineering a particular nucleic acid, one or more copies of the ARE can be introduced to make the nucleic acid of the present disclosure more unstable, thereby curtailing translation and reducing the production of the resulting protein. Likewise, AREs can be identified and removed or mutated to increase intracellular stability, thereby increasing translation and production of the resulting protein. Transfection experiments using the nucleic acids of the present disclosure can be performed in relevant cell lines, and protein production can be analyzed at various time points after transfection. For example, the molecules can be engineered with different AREs and cells can be transfected by using an ELISA kit for the relevant protein and analyzing the protein produced at 6 hours, 12 hours, 24 hours, 48 hours and 7 days after transfection.
3' UTR可為異源的或合成的。關於3' UTR,球蛋白UTR (包括非洲爪蟾屬β-球蛋白UTR及人類β-球蛋白UTR)為業內已知(8278063、9012219、US20110086907)。藉由首尾相連地選殖兩個連續之人類β-球蛋白3' UTR,已開發在一些細胞類型中具有增强之穩定性之經修飾之β-球蛋白構築體,且其為業內所熟知(US2012/0195936、WO2014/071963)。另外,a2-球蛋白、a1-球蛋白、UTR及其突變體亦為業內已知(WO2015101415、WO2015024667)。在非專利文獻中mRNA構築體中闡述之其他3' UTR包括CYBA (Ferizi等人,2015)及白蛋白(Thess等人,2015)。其他示例性3' UTR包括牛或人類生長激素(野生型或經修飾) (WO2013/185069、US20140206753、WO2014152774)、兔β球蛋白及B型肝炎病毒(HBV)之3′ UTR,α-球蛋白3' UTR及病毒VEEV 3' UTR序列亦為業內已知。在一些實施例中,使用序列UUUGAAUU (WO2014144196)。在一些實施例中,使用人類及小鼠核糖體蛋白之3 'UTR。其他實例包括rps9 3'UTR (WO2015101414)、FIG4 (WO2015101415)及人類白蛋白7 (WO2015101415)。The 3' UTR can be heterologous or synthetic. Regarding 3' UTRs, globulin UTRs (including Xenopus β-globin UTR and human β-globin UTR) are known in the art (8278063, 9012219, US20110086907). By colonizing two consecutive human β-globin 3' UTRs end-to-end, modified β-globin constructs with enhanced stability in some cell types have been developed and are well known in the art ( US2012/0195936, WO2014/071963). In addition, a2-globulin, a1-globulin, UTR and mutants thereof are also known in the art (WO2015101415, WO2015024667). Other 3' UTRs described in mRNA constructs in the non-patent literature include CYBA (Ferizi et al., 2015) and albumin (Thess et al., 2015). Other exemplary 3' UTRs include bovine or human growth hormone (wild type or modified) (WO2013/185069, US20140206753, WO2014152774), rabbit beta globulin and the 3' UTR of hepatitis B virus (HBV), alpha-globulin 3' UTR and viral VEEV 3' UTR sequences are also known in the art. In some embodiments, the sequence UUUGAAUU (WO2014144196) is used. In some embodiments, the 3'UTRs of human and mouse ribosomal proteins are used. Other examples include rps9 3'UTR (WO2015101414), FIG4 (WO2015101415) and human albumin 7 (WO2015101415).
在一些實施例中,本揭示案之3ꞌ UTR包含選自SEQ ID NO: 132及SEQ ID NO: 4之序列。In some embodiments, the 3ꞌ UTR of the present disclosure comprises a sequence selected from the group consisting of SEQ ID NO: 132 and SEQ ID NO: 4.
熟習此項技術者將理解,異源或合成之5' UTR可與任何期望之3' UTR序列一起使用。舉例而言,異源5' UTR可與合成3' UTR或異源3'' UTR一起使用。Those skilled in the art will understand that a heterologous or synthetic 5'UTR can be used with any desired 3'UTR sequence. For example, a heterologous 5' UTR can be used with a synthetic 3' UTR or a heterologous 3' UTR.
非UTR序列亦可用作核酸內之區或亞區。舉例而言,內含子或一部分內含子序列可納入本揭示案之核酸之區中。納入內含子序列可增加蛋白質產生及核酸含量。Non-UTR sequences can also be used as regions or subregions within a nucleic acid. For example, introns or portions of intron sequences can be incorporated into regions of the nucleic acids of the present disclosure. Incorporation of intron sequences can increase protein production and nucleic acid content.
特徵之組合可包括在側翼區中且可包含在其他特徵內。舉例而言,ORF可以側接5' UTR,其可含有强Kozak轉譯起始信號;及/或3' UTR,其可包括用於作為模板添加聚A尾之寡(dT)序列。5' UTR可包含來自相同及/或不同基因之第一聚核苷酸片段及第二聚核苷酸片段,諸如美國專利申請公開案號20100293625及PCT/US2014/069155中所述之5' UTR,該等公開案以全文引用之方式併入本文中。Combinations of features may be included in flanking regions and may be included within other features. For example, the ORF can be flanked by a 5' UTR, which can contain a strong Kozak translation initiation signal; and/or a 3' UTR, which can include an oligo (dT) sequence for adding a poly-A tail as a template. The 5'UTR may comprise a first polynucleotide fragment and a second polynucleotide fragment from the same and/or different genes, such as the 5'UTRs described in US Patent Application Publication No. 20100293625 and PCT/US2014/069155 , these publications are incorporated herein by reference in their entirety.
應理解,來自任何基因之任何UTR均可納入核酸之區中。此外,可利用任何已知基因之多個野生型UTR。本揭示案之範圍內亦提供不為野生型區之變異體之人工UTR。該等UTR或其部分可以與選出該等UTR之轉錄物相同之方向放置,或可改變方向或位置。因此,5'或3' UTR可倒置、縮短、延長,與一或多個其他5' UTR或3' UTR一起製備。如本文之術語「改變之」用在關於UTR序列時,意指相對於參考序列,UTR已經以某種方式改變。舉例而言,3′ UTR或5′ UTR可藉由如上文教示之方向或位置之改變而相對於野生型或天然UTR改變,或可藉由包括額外核苷酸、缺失核苷酸、交換或轉座核苷酸而改變。產生「改變之」UTR (無論3'或5 ')之該等改變中之任一者包含變異體UTR。It is understood that any UTR from any gene can be incorporated into a region of nucleic acid. In addition, multiple wild-type UTRs for any known gene can be utilized. Artificial UTRs that are not variants of the wild-type region are also provided within the scope of this disclosure. The UTRs or portions thereof may be placed in the same orientation as the transcripts from which the UTRs were selected, or the orientation or position may be altered. Thus, a 5' or 3' UTR can be inverted, shortened, elongated, and prepared with one or more other 5' UTRs or 3' UTRs. The term "altered" as used herein in reference to a UTR sequence means that the UTR has been altered in some way relative to the reference sequence. For example, a 3' UTR or 5' UTR can be altered relative to a wild-type or native UTR by a change in orientation or position as taught above, or by the inclusion of additional nucleotides, deletions of nucleotides, exchanges or change by transposition of nucleotides. Any of these changes that result in an "altered" UTR (whether 3' or 5') comprises a variant UTR.
在一些實施例中,可使用雙重、三重或四重UTR,例如5' UTR或3' UTR。如本文所用之「雙重」UTR係其中串聯或實質上串聯編碼相同UTR之兩個拷貝之UTR。舉例而言,可使用雙重β-球蛋白3' UTR,如美國專利公開案20100129877中所述,該專利之全部內容以引用方式併入本文中。In some embodiments, double, triple or quadruple UTRs may be used, eg, 5' UTRs or 3' UTRs. A "double" UTR as used herein is a UTR in which two copies of the same UTR are encoded in tandem or substantially in tandem. For example, dual beta-globin 3' UTRs can be used, as described in US Patent Publication 20100129877, which is incorporated herein by reference in its entirety.
具有模式化UTR亦在本揭示案之範圍內。如本文所用之「模式化UTR」係反映重複或交替模式之彼等UTR,諸如重複一次、兩次或超過3次之ABABAB或AABBAABBAABB或ABCABCABC或其變異體。在該等模式中,每個字母A、B或C代表核苷酸水準之不同UTR。It is also within the scope of this disclosure to have a patterned UTR. As used herein, "patterned UTRs" reflect repeating or alternating patterns of those UTRs, such as ABABAB or AABBAABBAABB or ABCABCABC or variants thereof repeated once, twice, or more than three times. In these patterns, each letter A, B or C represents a different UTR at the nucleotide level.
在一些實施例中,側翼區選自其蛋白質共享共同功能、結構、特徵或性質之轉錄物家族。舉例而言,相關多肽可屬於在特定細胞、組織中或在發育期間之某個時間表現之蛋白質家族。來自該等基因中之任一者之UTR可交換為相同或不同蛋白質家族之任何其他UTR,以產生新的聚核苷酸。如本文所用之「蛋白質家族」以最廣泛之意義使用,指共享至少一種功能、結構、特徵、定位、起源或表現模式之一組兩種或更多種相關多肽。In some embodiments, the flanking regions are selected from a family of transcripts whose proteins share a common function, structure, characteristic or property. For example, related polypeptides may belong to a family of proteins that are expressed in a particular cell, tissue, or at some point during development. UTRs from any of these genes can be exchanged for any other UTRs of the same or different protein families to generate new polynucleotides. A "family of proteins" as used herein is used in the broadest sense to refer to a group of two or more related polypeptides that share at least one function, structure, characteristic, localization, origin, or mode of expression.
非轉譯區亦可包括轉譯增强子元件(TEE)。作為非限制性實例,TEE可包括美國申請案號20090226470中闡述之彼等TEE及業內已知之彼等TEE,該專利之全文以引用方式併入本文中。 RNA 之活體外轉錄 Untranslated regions may also include translational enhancer elements (TEEs). By way of non-limiting example, TEEs may include those TEEs set forth in US Application No. 20090226470 and those TEEs known in the art, incorporated herein by reference in its entirety. In vitro transcription of RNA
編碼本文所述之聚核苷酸之cDNA可使用活體外轉錄(IVT)系統轉錄。RNA之活體外轉錄為業內已知,且闡述於國際公開案WO 2014/152027中,該公開案之全文以引用方式併入本文中。在一些實施例中,本揭示案之RNA係根據WO 2018/053209及WO 2019/036682中闡述之任一或多種方法製備,該等專利各自以引用方式併入本文中。cDNAs encoding the polynucleotides described herein can be transcribed using an in vitro transcription (IVT) system. In vitro transcription of RNA is known in the art and described in International Publication WO 2014/152027, which is incorporated herein by reference in its entirety. In some embodiments, the RNAs of the present disclosure are prepared according to any one or more of the methods set forth in WO 2018/053209 and WO 2019/036682, each of which is incorporated herein by reference.
在一些實施例中,RNA轉錄物係使用非擴增之綫性化DNA模板在活體外轉錄反應中產生,以產生RNA轉錄物。在一些實施例中,模板DNA係分離之DNA。在一些實施例中,模板DNA係cDNA。在一些實施例中,cDNA藉由mRNA (例如但不限於冠狀病毒mRNA)之反轉錄形成。在一些實施例中,用質體DNA模板轉染細胞,例如細菌細胞,例如大腸杆菌,例如DH-1細胞。在一些實施例中,培養轉染之細胞以複製質體DNA,接著分離及純化該質體DNA。在一些實施例中,DNA模板包括RNA聚合酶啓動子,例如位於相關基因5'且與其可操作連接之T7啓動子。In some embodiments, RNA transcripts are produced in an in vitro transcription reaction using a non-amplified linearized DNA template to generate RNA transcripts. In some embodiments, the template DNA is isolated DNA. In some embodiments, the template DNA is cDNA. In some embodiments, cDNA is formed by reverse transcription of mRNA, such as, but not limited to, coronavirus mRNA. In some embodiments, cells, eg, bacterial cells, eg, E. coli, eg, DH-1 cells, are transfected with a plastid DNA template. In some embodiments, the transfected cells are cultured to replicate plastid DNA, followed by isolation and purification of the plastid DNA. In some embodiments, the DNA template includes an RNA polymerase promoter, such as the T7 promoter located 5' to and operably linked to the gene of interest.
在一些實施例中,活體外轉錄模板編碼5'非轉譯(UTR)區,含有開放閱讀框,且編碼3' UTR及聚(A)尾。活體外轉錄模板之特定核酸序列組成及長度將取决於模板編碼之mRNA。In some embodiments, the in vitro transcription template encodes a 5' untranslated (UTR) region, contains an open reading frame, and encodes a 3' UTR and a poly(A) tail. The specific nucleic acid sequence composition and length of an in vitro transcribed template will depend on the mRNA encoded by the template.
「5'非轉譯區」 (UTR)係指不編碼多肽之mRNA之直接位於起始密碼子(亦即,核糖體轉譯之mRNA轉錄物之第一個密碼子)上游(亦即,5')之區。當產生RNA轉錄物時,5' UTR可包含啓動子序列。該等啓動子序列為業內已知。應理解,該等啓動子序列將不存在於本揭示案之疫苗中。A "5' untranslated region" (UTR) refers to the mRNA that does not encode a polypeptide that is directly upstream (ie, 5') of the initiation codon (ie, the first codon of a ribosome-translated mRNA transcript). area. When producing RNA transcripts, the 5' UTR may contain a promoter sequence. Such promoter sequences are known in the art. It will be understood that such promoter sequences will not be present in the vaccines of the present disclosure.
「3'非轉譯區」 (UTR)係指不編碼多肽之mRNA之直接位於終止密碼子(亦即,發出轉譯終止信號之mRNA轉錄物之密碼子)下游(亦即,3')之區。A "3' untranslated region" (UTR) refers to the region of an mRNA that does not encode a polypeptide that is immediately downstream (ie, 3') of a stop codon (ie, the codon of the mRNA transcript that signals translation termination).
「開放閱讀框」係以起始密碼子(例如,甲硫胺酸(ATG))開始且以終止密碼子(例如,TAA、TAG或TGA)結束之DNA之連續段,且編碼多肽。An "open reading frame" is a contiguous stretch of DNA that begins with a start codon (eg, methionine (ATG)) and ends with a stop codon (eg, TAA, TAG, or TGA), and encodes a polypeptide.
「聚(A)尾」係mRNA之位於含有多個連續單磷酸腺苷之3' UTR之下游、例如直接下游(亦即,3')的區。聚A尾可含有10至300個單磷酸腺苷。舉例而言,聚(A)尾可含有10、20、30、40、50、60、70、80、90、100、110、120、130、140、150、160、170、180、190、200、210、220、230、240、250、260、270、280、290或300個單磷酸腺苷。在一些實施例中,聚(A)尾含有50至250個單磷酸腺苷。在相關生物學環境中(例如,在細胞中,活體內),聚(A)尾用於保護mRNA免於例如在細胞質中之酶促降解,且幫助轉錄終止,及/或mRNA自細胞核輸出及轉譯。A "poly(A) tail" is a region of an mRNA that is located downstream, eg, immediately downstream (ie, 3') of the 3' UTR containing multiple consecutive adenosine monophosphates. Poly A tails can contain from 10 to 300 adenosine monophosphates. For example, poly(A) tails can contain 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200 , 210, 220, 230, 240, 250, 260, 270, 280, 290 or 300 adenosine monophosphates. In some embodiments, the poly(A) tail contains 50 to 250 adenosine monophosphates. In relevant biological contexts (eg, in cells, in vivo), poly(A) tails are used to protect mRNA from enzymatic degradation, eg, in the cytoplasm, and to aid in transcription termination, and/or mRNA export from the nucleus and translate.
在一些實施例中,核酸包括200至3,000個核苷酸。舉例而言,核酸可包括200至500、200至1000、200至1500、200至3000、500至1000、500至1500、500至2000、500至3000、1000至1500、1000至2000、1000至3000、1500至3000或2000至3000個核苷酸。In some embodiments, the nucleic acid includes 200 to 3,000 nucleotides. For example, the nucleic acid can include 200 to 500, 200 to 1000, 200 to 1500, 200 to 3000, 500 to 1000, 500 to 1500, 500 to 2000, 500 to 3000, 1000 to 1500, 1000 to 2000, 1000 to 3000 , 1500 to 3000 or 2000 to 3000 nucleotides.
活體外轉錄系統通常包括轉錄緩衝液、核苷酸三磷酸(NTP)、RNA酶抑制劑及聚合酶。In vitro transcription systems typically include transcription buffers, nucleotide triphosphates (NTPs), RNase inhibitors, and polymerases.
NTP可在內部製造,可選自供應商,或可如本文所述合成。NTP可選自但不限於本文所述之彼等NTP,包括天然及非天然(經修飾之) NTP。NTPs can be manufactured in-house, can be selected from suppliers, or can be synthesized as described herein. NTPs can be selected from, but are not limited to, those NTPs described herein, including natural and non-natural (modified) NTPs.
任何數量之RNA聚合酶或變異體可用於本揭示案之方法中。聚合酶可選自但不限於噬菌體RNA聚合酶,例如T7 RNA聚合酶、T3 RNA聚合酶、SP6 RNA聚合酶及/或突變型聚合酶,諸如但不限於能够納入經修飾之核酸及/或經修飾之核苷酸(包括化學修飾之核酸及/或核苷酸)之聚合酶。一些實施例排除使用DNA酶。Any number of RNA polymerases or variants can be used in the methods of the present disclosure. The polymerase may be selected from, but not limited to, bacteriophage RNA polymerases, such as T7 RNA polymerase, T3 RNA polymerase, SP6 RNA polymerase, and/or mutant polymerases, such as, but not limited to, capable of incorporating modified nucleic acids and/or modified nucleic acids. Polymerases of modified nucleotides, including chemically modified nucleic acids and/or nucleotides. Some embodiments exclude the use of DNase.
在一些實施例中,RNA轉錄物藉由酶促加端帽來加端帽。在一些實施例中,RNA包含5'末端端帽,例如7mG(5')ppp(5')NlmpNp。 化學合成 In some embodiments, RNA transcripts are end-capped by enzymatic end-capping. In some embodiments, the RNA comprises a 5' end cap, eg, 7mG(5')ppp(5')NlmpNp. chemical synthesis
固相化學合成。本揭示案之核酸可使用固相技術全部或部分地製造。核酸之固相化學合成係一種自動化方法,其中分子固定於固體載體上,且在反應物溶液中逐步合成。固相合成可用於在核酸序列中位點特異性引入化學修飾。Solid-phase chemical synthesis. Nucleic acids of the present disclosure can be produced in whole or in part using solid phase techniques. Solid-phase chemical synthesis of nucleic acids is an automated method in which molecules are immobilized on solid supports and synthesized stepwise in reactant solutions. Solid phase synthesis can be used to site-specifically introduce chemical modifications in nucleic acid sequences.
液相化學合成。藉由順序添加單體結構單元合成本揭示案之核酸可在液相中實施。 Liquid phase chemical synthesis. Synthesis of nucleic acids of the present disclosure by sequential addition of monomeric building blocks can be performed in the liquid phase.
合成方法之組合。上文論述之合成方法各自具有其自身之優點及限制。已嘗試組合該等方法以克服該等限制。該等方法之組合在本揭示案之範圍內。固相或液相化學合成與酶促連接之組合使用提供產生不能藉由單獨化學合成獲得之長鏈核酸之有效方式。 核酸區或亞區之連接 A combination of synthetic methods. The synthetic methods discussed above each have their own advantages and limitations. Attempts have been made to combine these approaches to overcome these limitations. Combinations of these methods are within the scope of this disclosure. The combined use of solid-phase or liquid-phase chemical synthesis and enzymatic ligation provides an efficient way to generate long-chain nucleic acids that cannot be obtained by chemical synthesis alone. Linking nucleic acid regions or subregions
亦可使用藉由連接酶裝配核酸。DNA或RNA連接酶經由磷酸二酯鍵之形成促進聚核苷酸鏈之5'及3'端之分子間連接。核酸(諸如嵌合聚核苷酸及/或環狀核酸)可藉由一或多個區或亞區之連接來製備。DNA片段可藉由連接酶催化之反應連接,以產生具有不同功能之重組DNA。兩個寡去氧核苷酸(一個具有5'磷醯基,且另一個具有游離之3'羥基)用作DNA連接酶之受質。 純化 Assembly of nucleic acids by ligases can also be used. DNA or RNA ligase facilitates the intermolecular ligation of the 5' and 3' ends of polynucleotide chains through the formation of phosphodiester bonds. Nucleic acids, such as chimeric polynucleotides and/or circular nucleic acids, can be prepared by linking one or more regions or subregions. DNA fragments can be joined by ligase-catalyzed reactions to generate recombinant DNA with different functions. Two oligodeoxynucleotides (one with a 5' phosphonium group and the other with a free 3' hydroxyl group) were used as substrates for DNA ligase. purification
本文所述之核酸之純化可包括但不限於核酸淨化、品質保證及品質控制。淨化可藉由業內已知之方法實施,該等方法例如但不限於AGENCOURT®珠粒(Beckman Coulter Genomics, Danvers, MA)、聚-T珠粒、LNATM寡-T捕獲探針(EXIQON®公司, Vedbaek, Denmark)或基於HPLC之純化方法,諸如但不限於强陰離子交換HPLC、弱陰離子交換HPLC、反相HPLC (RP-HPLC)及疏水相互作用HPLC (HIC-HPLC)。術語「純化之」當關於核酸使用時,諸如「純化之核酸」,係指與至少一種污染物分離之核酸。「污染物」係使另一種物質不適合、不純或劣質之任何物質。因此,純化之核酸(例如,DNA及RNA)以不同於其在自然界中發現之形式或環境存在,或以不同於其在進行處理或純化方法之前存在之形式或環境存在。Purification of nucleic acids described herein can include, but is not limited to, nucleic acid purification, quality assurance, and quality control. Purification can be performed by methods known in the art such as, but not limited to, AGENCOURT® beads (Beckman Coulter Genomics, Danvers, MA), poly-T beads, LNATM oligo-T capture probes (EXIQON® Corporation, Vedbaek , Denmark) or HPLC-based purification methods such as but not limited to strong anion exchange HPLC, weak anion exchange HPLC, reverse phase HPLC (RP-HPLC) and hydrophobic interaction HPLC (HIC-HPLC). The term "purified" when used in reference to nucleic acid, such as "purified nucleic acid," refers to nucleic acid that has been separated from at least one contaminant. A "contaminant" is any substance that renders another substance unsuitable, impure or inferior. Thus, purified nucleic acids (eg, DNA and RNA) exist in a form or environment different from the form or environment in which they are found in nature, or in a form or environment different from the form or environment in which they existed prior to processing or purification methods.
品質保證及/或品質控制檢查可使用諸如但不限於凝膠電泳、UV吸光度或分析型HPLC之方法執行。Quality assurance and/or quality control checks can be performed using methods such as, but not limited to, gel electrophoresis, UV absorbance, or analytical HPLC.
在一些實施例中,核酸可藉由包括但不限於反轉錄酶-PCR之方法測序。 定量 In some embodiments, nucleic acids can be sequenced by methods including, but not limited to, reverse transcriptase-PCR. Quantitative
在一些實施例中,本揭示案之核酸可在外來體中或當衍生自一或多種體液時定量。體液包括外周血、血清、血漿、腹水、尿液、腦脊髓液(CSF)、痰、唾液、骨髓、滑液、房水、羊水、耳垢、母乳、支氣管肺泡灌洗液、精液、前列腺液、考珀液(cowper's fluid)或預射精液、汗液、排泄物、毛髮、淚液、囊腫液、胸膜液及腹膜液、心包液、淋巴、食糜、乳糜、膽汁、間質液、經血、膿液、皮脂、嘔吐物、陰道分泌物、黏膜分泌物、糞便水、胰液、竇腔灌洗液、支氣管肺抽吸物、囊胚腔液及臍帶血。或者,外來體可自選自由以下組成之群之器官回收:肺、心臟、胰臟、胃、腸、膀胱、腎、卵巢、睪丸、皮膚、結腸、乳房、前列腺、腦、食管、肝及胎盤。In some embodiments, nucleic acids of the present disclosure can be quantified in exosomes or when derived from one or more body fluids. Body fluids include peripheral blood, serum, plasma, ascites, urine, cerebrospinal fluid (CSF), sputum, saliva, bone marrow, synovial fluid, aqueous humor, amniotic fluid, ear wax, breast milk, bronchoalveolar lavage fluid, semen, prostatic fluid, Cowper's fluid or pre-ejaculate fluid, sweat, excrement, hair, tears, cystic fluid, pleural and peritoneal fluid, pericardial fluid, lymph, chyle, chyle, bile, interstitial fluid, menstrual blood, pus , sebum, vomit, vaginal secretions, mucosal secretions, fecal water, pancreatic juice, sinus lavage fluid, bronchopulmonary aspirates, blastocyst fluid and umbilical cord blood. Alternatively, the exosomes can be recovered from an organ selected from the group consisting of lung, heart, pancreas, stomach, intestine, bladder, kidney, ovary, testis, skin, colon, breast, prostate, brain, esophagus, liver and placenta.
可使用構築體特異性探針、細胞計量術、qRT-PCR、即時PCR、PCR、流式細胞術、電泳、質譜或其組合來實施分析,而可使用免疫組織化學方法(諸如酶聯免疫吸附分析(ELISA))方法分離外來體。外來體亦可藉由粒徑篩析層析、密度梯度離心、差速離心、奈米膜超濾、免疫吸附捕獲、親和純化、微流體分離或其組合來分離。Analysis can be performed using construct-specific probes, cytometry, qRT-PCR, real-time PCR, PCR, flow cytometry, electrophoresis, mass spectrometry, or a combination thereof, while immunohistochemical methods such as enzyme-linked immunosorbent assay can be used. assay (ELISA)) method to isolate exosomes. Exosomes can also be isolated by particle size chromatography, density gradient centrifugation, differential centrifugation, nanomembrane ultrafiltration, immunosorbent capture, affinity purification, microfluidic separation, or a combination thereof.
該等方法使研究者能够實時監測剩餘或遞送之核酸水準。由於在一些實施例中,本揭示案之核酸由於結構或化學修飾而不同於內源形式,故此係可能的。These methods allow researchers to monitor the level of nucleic acid remaining or delivered in real time. This is possible because, in some embodiments, the nucleic acids of the present disclosure differ from the endogenous form due to structural or chemical modifications.
在一些實施例中,核酸可使用諸如但不限於紫外可見光譜(UV/Vis)之方法來定量。UV/Vis光譜儀之非限制性實例係NANODROP®光譜儀(ThermoFisher, Waltham, MA)。可分析定量之核酸,以確定核酸是否具有正確大小、檢查核酸未發生降解。核酸之降解可藉由以下方法檢查,諸如但不限於瓊脂糖凝膠電泳;基於HPLC之純化方法,諸如但不限於强陰離子交換HPLC、弱陰離子交換HPLC、反相HPLC (RP-HPLC)及疏水相互作用HPLC (HIC-HPLC);液相層析-質譜(LCMS)、毛細管電泳(CE)及毛細管凝膠電泳(CGE)。 脂質奈米顆粒 (LNP) In some embodiments, nucleic acids can be quantified using methods such as, but not limited to, ultraviolet visible spectroscopy (UV/Vis). A non-limiting example of a UV/Vis spectrometer is the NANODROP® spectrometer (ThermoFisher, Waltham, MA). The quantified nucleic acid can be analyzed to determine if the nucleic acid is of the correct size and to check that the nucleic acid has not been degraded. Degradation of nucleic acids can be checked by methods such as but not limited to agarose gel electrophoresis; HPLC based purification methods such as but not limited to strong anion exchange HPLC, weak anion exchange HPLC, reverse phase HPLC (RP-HPLC) and hydrophobic Interaction HPLC (HIC-HPLC); Liquid Chromatography-Mass Spectrometry (LCMS), Capillary Electrophoresis (CE) and Capillary Gel Electrophoresis (CGE). Lipid Nanoparticles (LNPs)
在一些實施例中,本揭示案之mRNA調配於脂質奈米顆粒(LNP)中。脂質奈米顆粒通常包含可電離之陽離子脂質、非陽離子脂質、固醇及PEG脂質組分以及相關核酸貨物。本揭示案之脂質奈米顆粒可使用業內通常已知之組分、組合物及方法產生,例如,參見PCT/US2016/052352;PCT/US2016/068300;PCT/US2017/037551;PCT/US2015/027400;PCT/US2016/047406;PCT/US2016000129;PCT/US2016/014280;PCT/US2016/014280;PCT/US2017/038426;PCT/US2014/027077;PCT/US2014/055394;PCT/US2016/52117;PCT/US2012/069610;PCT/US2017/027492;PCT/US2016/059575及PCT/US2016/069491,所有該等專利之全文皆以引用方式併入本文中。In some embodiments, the mRNAs of the present disclosure are formulated in lipid nanoparticles (LNPs). Lipid nanoparticles typically contain ionizable cationic lipids, non-cationic lipids, sterol and PEG lipid components, and related nucleic acid cargoes. The lipid nanoparticles of the present disclosure can be produced using components, compositions and methods generally known in the art, eg, see PCT/US2016/052352; PCT/US2016/068300; PCT/US2017/037551; PCT/US2015/027400; PCT/US2016/047406; PCT/US2016000129; PCT/US2016/014280; PCT/US2016/014280; PCT/US2017/038426; 069610; PCT/US2017/027492; PCT/US2016/059575 and PCT/US2016/069491, all of which are incorporated herein by reference in their entirety.
本揭示案之疫苗通常調配於脂質奈米顆粒中。在一些實施例中,脂質奈米顆粒包含至少一種可電離之陽離子脂質、至少一種非陽離子脂質、至少一種固醇及/或至少一種聚乙二醇(PEG)改質之脂質。The vaccines of the present disclosure are typically formulated in lipid nanoparticles. In some embodiments, the lipid nanoparticles comprise at least one ionizable cationic lipid, at least one non-cationic lipid, at least one sterol, and/or at least one polyethylene glycol (PEG)-modified lipid.
在一些實施例中,脂質奈米顆粒包含40-50 mol%可電離之脂質,視情況地45-50 mol%,例如45-46 mol%、46-47 mol%、47-48 mol%、48-49 mol%或49-50 mol%,例如約45 mol%、45.5 mol%、46 mol%、46.5 mol%、47 mol%、47.5 mol%、48 mol%、48.5 mol%、49 mol%或49.5 mol%。In some embodiments, the lipid nanoparticle comprises 40-50 mol% ionizable lipid, optionally 45-50 mol%, eg, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48 -49 mol% or 49-50 mol%, such as about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol% or 49.5 mol%.
在一些實施例中,脂質奈米顆粒包含30-45 mol%固醇,視情況地35-40 mol%,例如30-31 mol%、31-32 mol%、32-33 mol%、33-34 mol%、35-35 mol%、35-36 mol%、36-37 mol%、38-38 mol%、38-39 mol%或39-40 mol%。In some embodiments, the lipid nanoparticle comprises 30-45 mol% sterol, optionally 35-40 mol%, eg, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol% mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 38-38 mol%, 38-39 mol%, or 39-40 mol%.
在一些實施例中,脂質奈米顆粒包含5-15 mol%輔助脂質,視情況地10-12 mol%,例如5-6 mol%、6-7 mol%、7-8 mol%、8-9 mol%、9-10 mol%、10-11 mol%、11-12 mol%、12-13 mol%、13-14 mol%或14-15 mol%。In some embodiments, the lipid nanoparticle comprises 5-15 mol% helper lipid, optionally 10-12 mol%, eg, 5-6 mol%, 6-7 mol%, 7-8 mol%, 8-9 mol% mol%, 9-10 mol%, 10-11 mol%, 11-12 mol%, 12-13 mol%, 13-14 mol% or 14-15 mol%.
在一些實施例中,脂質奈米顆粒包含1-5% PEG脂質,視情況地1-3 mol%,例如1.5-2.5 mol%、1-2 mol%、2-3 mol%、3-4 mol%或4-5 mol%。In some embodiments, lipid nanoparticles comprise 1-5% PEG lipid, optionally 1-3 mol%, eg, 1.5-2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol% % or 4-5 mol%.
在一些實施例中,脂質奈米顆粒包含20-60 mol%可電離之陽離子脂質。舉例而言,脂質奈米顆粒可包含20-50 mol%、20-40 mol%、20-30 mol%、30-60 mol%、30-50 mol%、30-40 mol%、40-60 mol%、40-50 mol%或50-60 mol%可電離之陽離子脂質。在一些實施例中,脂質奈米顆粒包含20 mol%、30 mol%、40 mol%、50 mol%或60 mol%可電離之陽離子脂質。在一些實施例中,脂質奈米顆粒包含 35 mol%、36 mol%、37 mol%、38 mol%、39 mol%、40 mol%、41 mol%、42 mol%、43 mol%、44 mol%、45 mol% %、46 mol%、47 mol%、48 mol%、49 mol%、50 mol%、51 mol%、52 mol%、53 mol%、54 mol%或55 mol%可電離之陽離子脂質。In some embodiments, the lipid nanoparticles comprise 20-60 mol% ionizable cationic lipids. For example, lipid nanoparticles can comprise 20-50 mol%, 20-40 mol%, 20-30 mol%, 30-60 mol%, 30-50 mol%, 30-40 mol%, 40-60 mol% %, 40-50 mol% or 50-60 mol% ionizable cationic lipids. In some embodiments, the lipid nanoparticles comprise 20 mol %, 30 mol %, 40 mol %, 50 mol %, or 60 mol % of ionizable cationic lipids. In some embodiments, the lipid nanoparticles comprise 35 mol%, 36 mol%, 37 mol%, 38 mol%, 39 mol%, 40 mol%, 41 mol%, 42 mol%, 43 mol%, 44 mol% , 45 mol%, 46 mol%, 47 mol%, 48 mol%, 49 mol%, 50 mol%, 51 mol%, 52 mol%, 53 mol%, 54 mol%, or 55 mol% of ionizable cationic lipids .
在一些實施例中,脂質奈米顆粒包含5-25 mol%非陽離子脂質。舉例而言,脂質奈米顆粒可包含 5-20 mol%、5-15 mol%、5-10 mol%、10-25 mol%、10-20 mol%、10-25 mol%、15-25 mol%、15-20 mol% 或 20-25 mol%非陽離子脂質。在一些實施例中,脂質奈米顆粒包含5 mol%、10 mol%、15 mol%、20 mol%或25 mol%非陽離子脂質。In some embodiments, the lipid nanoparticles comprise 5-25 mol% non-cationic lipids. For example, lipid nanoparticles can comprise 5-20 mol%, 5-15 mol%, 5-10 mol%, 10-25 mol%, 10-20 mol%, 10-25 mol%, 15-25 mol% %, 15-20 mol% or 20-25 mol% non-cationic lipids. In some embodiments, the lipid nanoparticle comprises 5 mol%, 10 mol%, 15 mol%, 20 mol%, or 25 mol% non-cationic lipid.
在一些實施例中,脂質奈米顆粒包含25-55 mol%固醇。舉例而言,脂質奈米顆粒可包含25-50 mol%、25-45 mol%、25-40 mol%、25-35 mol%、25-30 mol%、30-55 mol%、30-50 mol%、30-45 mol%、30-40 mol%、30-35 mol%、35-55 mol%、35-50 mol%、35-45 mol%、35-40 mol%、40-55 mol%、40-50 mol%、40-45 mol%、45-55 mol%、45-50 mol%或50-55 mol%固醇。在一些實施例中,脂質奈米顆粒包含25 mol%、30 mol%、35 mol%、40 mol%、45 mol%、50 mol%或55 mol%固醇。In some embodiments, the lipid nanoparticles comprise 25-55 mol% sterols. For example, lipid nanoparticles can comprise 25-50 mol%, 25-45 mol%, 25-40 mol%, 25-35 mol%, 25-30 mol%, 30-55 mol%, 30-50 mol% %, 30-45 mol%, 30-40 mol%, 30-35 mol%, 35-55 mol%, 35-50 mol%, 35-45 mol%, 35-40 mol%, 40-55 mol%, 40-50 mol%, 40-45 mol%, 45-55 mol%, 45-50 mol% or 50-55 mol% sterol. In some embodiments, the lipid nanoparticles comprise 25 mol%, 30 mol%, 35 mol%, 40 mol%, 45 mol%, 50 mol%, or 55 mol% sterols.
在一些實施例中,脂質奈米顆粒包含0.5-15 mol% PEG改質之脂質。舉例而言,脂質奈米顆粒可包含0.5-10 mol%、0.5-5 mol%、1-15 mol%、1-10 mol%、1-5 mol%、2-15 mol%、2-10 mol%、2-5 mol%、5-15 mol%、5-10 mol%或10-15 mol%。在一些實施例中,脂質奈米顆粒包含0.5 mol%、1 mol%、2 mol%、3 mol%、4 mol%、5 mol%、6 mol%、7 mol%、8 mol%、9 mol%、10 mol% %、11 mol%、12 mol%、13 mol%、14 mol%或15 mol% PEG改質之脂質。In some embodiments, the lipid nanoparticles comprise 0.5-15 mol% PEG-modified lipids. For example, lipid nanoparticles can comprise 0.5-10 mol%, 0.5-5 mol%, 1-15 mol%, 1-10 mol%, 1-5 mol%, 2-15 mol%, 2-10 mol% %, 2-5 mol%, 5-15 mol%, 5-10 mol% or 10-15 mol%. In some embodiments, the lipid nanoparticles comprise 0.5 mol%, 1 mol%, 2 mol%, 3 mol%, 4 mol%, 5 mol%, 6 mol%, 7 mol%, 8 mol%, 9 mol% , 10 mol%, 11 mol%, 12 mol%, 13 mol%, 14 mol% or 15 mol% PEG-modified lipids.
在一些實施例中,脂質奈米顆粒包含20-60 mol%可電離之陽離子脂質、5-25 mol%非陽離子脂質、25-55 mol%固醇及0.5-15 mol% PEG改質之脂質。In some embodiments, the lipid nanoparticles comprise 20-60 mol% ionizable cationic lipids, 5-25 mol% non-cationic lipids, 25-55 mol% sterols, and 0.5-15 mol% PEG-modified lipids.
在一些實施例中,本揭示案之可電離之陽離子脂質包含式(I)化合物:

在一些實施例中,式(I)化合物之亞組包括以下之彼等化合物:其中當R 4係-(CH 2) nQ、-(CH 2) nCHQR、-CHQR或-CQ(R) 2時,則(i) 當n為1、2、3、4或5時,Q不為-N(R) 2,或(ii) 當n為1或2時,Q不為5員、6員或7員雜環烷基。 In some embodiments, the subgroup of compounds of formula (I) includes those compounds wherein when R4 is - ( CH2 )nQ, -( CH2 ) nCHQR , -CHQR or -CQ(R) 2 , then (i) when n is 1, 2, 3, 4, or 5, Q is not -N(R) 2 , or (ii) when n is 1 or 2, Q is not 5-membered, 6-membered or 7-membered heterocycloalkyl.
在一些實施例中,式(I)化合物之另一亞組包括以下之彼等化合物:其中 R 1選自由C 5-30烷基、C 5-20烯基、-R*YR''、-YR''及-R''M'R'組成之群; R 2及R 3獨立地選自由H、C 1-14烷基、C 2-14烯基、-R*YR''、-YR''及-R*OR''組成之群,或R 2及R 3與其所附接之原子一起形成雜環或碳環; R 4選自由C 3-6碳環、-(CH 2) nQ、-(CH 2) nCHQR、-CHQR、-CQ(R) 2及未經取代之C 1-6烷基組成之群,其中Q選自C 3-6碳環、具有一或多個選自N、O及S之雜原子之5至14員雜芳基、-OR、-O(CH 2) nN(R) 2、-C(O)OR、-OC(O)R、-CX 3、-CX 2H、-CXH 2、-CN、-C(O)N(R) 2、-N(R)C(O)R、-N(R)S(O) 2R、-N(R)C(O)N(R) 2、-N(R)C(S)N(R) 2、-CRN(R) 2C(O)OR、-N(R)R 8、-O(CH 2) nOR、-N(R)C(=NR 9)N(R) 2、-N(R)C(=CHR 9)N(R) 2、-OC(O)N(R) 2、-N(R)C(O)OR、-N(OR)C(O)R、-N(OR)S(O) 2R、-N(OR)C(O)OR、-N(OR)C(O)N(R) 2、-N(OR)C(S)N(R) 2、-N(OR)C(=NR 9)N(R) 2、-N(OR)C(=CHR 9)N(R) 2、-C(=NR 9)N(R) 2、-C(=NR 9)R、-C(O)N(R)OR及具有一或多個選自N、O及S之雜原子之5至14員雜環烷基,經一或多個選自以下之取代基取代:側氧基(=O)、OH、胺基、單烷基胺基或二烷基胺基及C 1-3烷基,且每一n獨立地選自1、2、3、4及5; 每一R 5獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R 6獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; M及M'獨立地選自-C(O)O-、-OC(O)-、-C(O)N(R')-、-N(R')C(O)-、-C(O)-、-C(S)-、-C(S)S-、-SC(S)-、-CH(OH)-、-P(O)(OR')O-、-S(O) 2-、-S-S-、芳基及雜芳基; R 7選自由C 1-3烷基、C 2-3烯基及H組成之群; R 8選自由C 3-6碳環及雜環組成之群; R 9選自由H、CN、NO 2、C 1-6烷基、-OR、-S(O) 2R、-S(O) 2N(R) 2、C 2-6烯基、C 3-6碳環及雜環組成之群; 每一R獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R'獨立地選自由C 1-18烷基、C 2-18烯基、-R*YR''、-YR''及H組成之群; 每一R''獨立地選自由C 3-14烷基及C 3-14烯基組成之群; 每一R*獨立地選自由C 1-12烷基及C 2-12烯基組成之群; 每一Y獨立地係C 3-6碳環; 每一X獨立地選自由F、Cl、Br及I組成之群;且 m選自5、6、7、8、9、10、11、12及13, 或其鹽或異構物。 In some embodiments, another subset of compounds of formula (I) includes those compounds wherein R 1 is selected from C 5-30 alkyl, C 5-20 alkenyl, -R*YR'', - The group consisting of YR'' and -R''M'R'; R 2 and R 3 are independently selected from H, C 1-14 alkyl, C 2-14 alkenyl, -R*YR'', -YR '' and -R*OR'', or R 2 and R 3 together with the atoms to which they are attached form a heterocycle or carbocycle; R 4 is selected from C 3-6 carbocycle, -(CH 2 ) n The group consisting of Q, -(CH 2 ) n CHQR, -CHQR, -CQ(R) 2 and unsubstituted C 1-6 alkyl, wherein Q is selected from C 3-6 carbocyclic ring, having one or more 5- to 14-membered heteroaryl selected from heteroatoms of N, O and S, -OR, -O( CH2 ) nN (R) 2 , -C(O)OR, -OC(O)R, - CX 3 , -CX 2 H, -CXH 2 , -CN, -C(O)N(R) 2 , -N(R)C(O)R, -N(R)S(O) 2 R, - N(R)C(O)N(R) 2 , -N(R)C(S)N(R) 2 , -CRN(R) 2 C(O)OR, -N(R)R 8 , - O(CH 2 ) n OR, -N(R)C(=NR 9 )N(R) 2 , -N(R)C(=CHR 9 )N(R) 2 , -OC(O)N(R ) 2 , -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O) 2 R, -N(OR)C(O)OR, -N (OR)C(O)N(R) 2 , -N(OR)C(S)N(R) 2 , -N(OR)C(=NR 9 )N(R) 2 , -N(OR) C(=CHR 9 )N(R) 2 , -C(=NR 9 )N(R) 2 , -C(=NR 9 )R, -C(O)N(R)OR and having one or more 5- to 14-membered heterocycloalkyl of heteroatoms selected from N, O and S, substituted with one or more substituents selected from: pendant oxy (=O), OH, amine, monoalkylamine group or dialkylamine group and C 1-3 alkyl group, and each n is independently selected from 1, 2, 3, 4 and 5; each R 5 is independently selected from C 1-3 alkyl group, C 2 The group consisting of -3 alkenyl and H ; each R is independently selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl and H; M and M' are independently selected from -C(O) O-, -OC(O)-, -C(O)N(R')-, -N(R')C(O)-, -C(O)-, -C(S)-, -C (S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR')O-, -S(O) 2- , -SS-, aryl and heteroaryl ; R 7 is chosen from C The group consisting of 1-3 alkyl, C 2-3 alkenyl and H; R 8 is selected from the group consisting of C 3-6 carbocycle and heterocycle; R 9 is selected from H, CN, NO 2 , C 1-6 The group consisting of alkyl, -OR, -S(O) 2 R, -S(O) 2 N(R) 2 , C 2-6 alkenyl, C 3-6 carbocycle and heterocycle; each R independently is selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl, and H; each R' is independently selected from C 1-18 alkyl, C 2-18 alkenyl, -R*YR'' , -YR'' and H; each R'' is independently selected from the group consisting of C 3-14 alkyl and C 3-14 alkenyl; each R* is independently selected from C 1-12 alkane each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6 , 7, 8, 9, 10, 11, 12 and 13, or salts or isomers thereof.
在一些實施例中,式(I)化合物之另一亞組包括以下之彼等化合物:其中 R 1選自由C 5-30烷基、C 5-20烯基、-R*YR''、-YR''及-R''M'R'組成之群; R 2及R 3獨立地選自由H、C 1-14烷基、C 2-14烯基、-R*YR''、-YR''及-R*OR''組成之群,或R 2及R 3與其所附接之原子一起形成雜環或碳環; R 4選自由C 3-6碳環、-(CH 2) nQ、-(CH 2) nCHQR、-CHQR、-CQ(R) 2及未經取代之C 1-6烷基組成之群,其中Q選自C 3-6碳環、具有一或多個選自N、O及S之雜原子之5至14員雜環、-OR、-O(CH 2) nN(R) 2、-C(O)OR、-OC(O)R、-CX 3、-CX 2H、-CXH 2、-CN、-C(O)N(R) 2、-N(R)C(O)R、-N(R)S(O) 2R、-N(R)C(O)N(R) 2、-N(R)C(S)N(R) 2、-CRN(R) 2C(O)OR、-N(R)R 8、-O(CH 2) nOR、-N(R)C(=NR 9)N(R) 2、-N(R)C(=CHR 9)N(R) 2、-OC(O)N(R) 2、-N(R)C(O)OR、-N(OR)C(O)R、-N(OR)S(O) 2R、-N(OR)C(O)OR、-N(OR)C(O)N(R) 2、-N(OR)C(S)N(R) 2、-N(OR)C(=NR 9)N(R) 2、-N(OR)C(=CHR 9)N(R) 2、-C(=NR 9)R、-C(O)N(R)OR及-C(=NR 9)N(R) 2,且每一n獨立地選自1、2、3、4及5;且當Q係5至14員雜環且(i) R 4係-(CH 2) nQ,其中n為1或2,或(ii) R 4係-(CH 2) nCHQR,其中n為1,或(iii) R 4係-CHQR及-CQ(R) 2時,則Q係5至14員雜芳基或8至14員雜環烷基; 每一R 5獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R 6獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; M及M'獨立地選自-C(O)O-、-OC(O)-、-C(O)N(R')-、-N(R')C(O)-、-C(O)-、-C(S)-、-C(S)S-、-SC(S)-、-CH(OH)-、-P(O)(OR')O-、-S(O) 2-、-S-S-、芳基及雜芳基; R 7選自由C 1-3烷基、C 2-3烯基及H組成之群; R 8選自由C 3-6碳環及雜環組成之群; R 9選自由H、CN、NO 2、C 1-6烷基、-OR、-S(O) 2R、-S(O) 2N(R) 2、C 2-6烯基、C 3-6碳環及雜環組成之群; 每一R獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R'獨立地選自由C 1-18烷基、C 2-18烯基、-R*YR''、-YR''及H組成之群; 每一R''獨立地選自由C 3-14烷基及C 3-14烯基組成之群; 每一R*獨立地選自由C 1-12烷基及C 2-12烯基組成之群; 每一Y獨立地係C 3-6碳環; 每一X獨立地選自由F、Cl、Br及I組成之群;且 m選自5、6、7、8、9、10、11、12及13, 或其鹽或異構物。 In some embodiments, another subgroup of compounds of formula (I) includes those compounds wherein R 1 is selected from C 5-30 alkyl, C 5-20 alkenyl, -R*YR'', - The group consisting of YR'' and -R''M'R'; R 2 and R 3 are independently selected from H, C 1-14 alkyl, C 2-14 alkenyl, -R*YR'', -YR '' and -R*OR'', or R 2 and R 3 together with the atoms to which they are attached form a heterocycle or carbocycle; R 4 is selected from C 3-6 carbocycle, -(CH 2 ) n The group consisting of Q, -(CH 2 ) n CHQR, -CHQR, -CQ(R) 2 and unsubstituted C 1-6 alkyl, wherein Q is selected from C 3-6 carbocyclic ring, having one or more 5- to 14-membered heterocycle of heteroatoms selected from N, O and S, -OR, -O( CH2 ) nN (R) 2 , -C(O)OR, -OC(O)R, -CX 3 , -CX 2 H, -CXH 2 , -CN, -C(O)N(R) 2 , -N(R)C(O)R, -N(R)S(O) 2 R, -N (R)C(O)N(R) 2 , -N(R)C(S)N(R) 2 , -CRN(R) 2 C(O)OR, -N(R)R 8 , -O (CH 2 ) n OR, -N(R)C(=NR 9 )N(R) 2 , -N(R)C(=CHR 9 )N(R) 2 , -OC(O)N(R) 2 , -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O) 2 R, -N(OR)C(O)OR, -N( OR)C(O)N(R) 2 , -N(OR)C(S)N(R) 2 , -N(OR)C(=NR 9 )N(R) 2 , -N(OR)C (=CHR 9 )N(R) 2 , -C(=NR 9 )R, -C(O)N(R)OR, and -C(=NR 9 )N(R) 2 , and each n independently is selected from 1, 2, 3, 4, and 5; and when Q is a 5- to 14-membered heterocycle and (i) R4 is - ( CH2 )nQ, wherein n is 1 or 2 , or (ii) R4 is -(CH 2 ) n CHQR, wherein n is 1, or (iii) R 4 is -CHQR and -CQ(R) 2 , then Q is a 5- to 14-membered heteroaryl or an 8- to 14-membered heterocycloalkane each R 5 is independently selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl and H; each R 6 is independently selected from C 1-3 alkyl, C 2-3 alkenyl and the group consisting of H; M and M' are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R')-, -N(R')C(O )-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR')O-, -S(O) 2 -, -SS-, aryl and heteroaryl; R 7 is selected from C 1-3 alkyl, C 2-3 alkenyl and H The group consisting of; R 8 is selected from the group consisting of C 3-6 carbocycles and heterocycles; R 9 is selected from H, CN, NO 2 , C 1-6 alkyl, -OR, -S(O) 2 R, -S(O) 2 N(R) 2 , C 2-6 alkenyl, C 3-6 carbocycle and heterocycle; each R is independently selected from C 1-3 alkyl, C 2-3 the group consisting of alkenyl and H; each R' is independently selected from the group consisting of C 1-18 alkyl, C 2-18 alkenyl, -R*YR'', -YR'', and H; each R '' is independently selected from the group consisting of C 3-14 alkyl and C 3-14 alkenyl; each R* is independently selected from the group consisting of C 1-12 alkyl and C 2-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13 , or its salts or isomers.
在一些實施例中,式(I)化合物之另一亞組包括以下之彼等化合物:其中 R 1選自由C 5-30烷基、C 5-20烯基、-R*YR''、-YR''及-R''M'R'組成之群; R 2及R 3獨立地選自由H、C 1-14烷基、C 2-14烯基、-R*YR''、-YR''及-R*OR''組成之群,或R 2及R 3與其所附接之原子一起形成雜環或碳環; R 4選自由C 3-6碳環、-(CH 2) nQ、-(CH 2) nCHQR、-CHQR、-CQ(R) 2及未經取代之C 1-6烷基組成之群,其中Q選自C 3-6碳環、具有一或多個選自N、O及S之雜原子5至14員雜芳基、-OR、-O(CH 2) nN(R) 2、-C(O)OR、-OC(O)R、-CX 3、-CX 2H、-CXH 2、-CN、-C(O)N(R) 2、-N(R)C(O)R、-N(R)S(O) 2R、-N(R)C(O)N(R) 2、-N(R)C(S)N(R) 2、-CRN(R) 2C(O)OR、-N(R)R 8、-O(CH 2) nOR、-N(R)C(=NR 9)N(R) 2、-N(R)C(=CHR 9)N(R) 2、-OC(O)N(R) 2、-N(R)C(O)OR、-N(OR)C(O)R、-N(OR)S(O) 2R、-N(OR)C(O)OR、-N(OR)C(O)N(R) 2、-N(OR)C(S)N(R) 2、-N(OR)C(=NR 9)N(R) 2、-N(OR)C(=CHR 9)N(R) 2、-C(=NR 9)R、-C(O)N(R)OR及-C(=NR 9)N(R) 2,且每一n獨立地選自1、2、3、4及5; 每一R 5獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R 6獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; M及M'獨立地選自-C(O)O-、-OC(O)-、-C(O)N(R')-、-N(R')C(O)-、-C(O)-、-C(S)-、-C(S)S-、-SC(S)-、-CH(OH)-、-P(O)(OR')O-、-S(O) 2-、-S-S-、芳基及雜芳基; R 7選自由C 1-3烷基、C 2-3烯基及H組成之群; R 8選自由C 3-6碳環及雜環組成之群; R 9選自由H、CN、NO 2、C 1-6烷基、-OR、-S(O) 2R、-S(O) 2N(R) 2、C 2-6烯基、C 3-6碳環及雜環組成之群; 每一R獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R'獨立地選自由C 1-18烷基、C 2-18烯基、-R*YR''、-YR''及H組成之群; 每一R''獨立地選自由C 3-14烷基及C 3-14烯基組成之群; 每一R*獨立地選自由C 1-12烷基及C 2-12烯基組成之群; 每一Y獨立地係C 3-6碳環; 每一X獨立地選自由F、Cl、Br及I組成之群;且 m選自5、6、7、8、9、10、11、12及13, 或其鹽或異構物。 In some embodiments, another subgroup of compounds of formula (I) includes those compounds wherein R 1 is selected from C 5-30 alkyl, C 5-20 alkenyl, -R*YR'', - The group consisting of YR'' and -R''M'R'; R 2 and R 3 are independently selected from H, C 1-14 alkyl, C 2-14 alkenyl, -R*YR'', -YR '' and -R*OR'', or R 2 and R 3 together with the atoms to which they are attached form a heterocycle or carbocycle; R 4 is selected from C 3-6 carbocycle, -(CH 2 ) n The group consisting of Q, -(CH 2 ) n CHQR, -CHQR, -CQ(R) 2 and unsubstituted C 1-6 alkyl, wherein Q is selected from C 3-6 carbocyclic ring, having one or more Heteroatom 5- to 14-membered heteroaryl selected from N, O and S, -OR, -O(CH 2 ) n N(R) 2 , -C(O)OR, -OC(O)R, -CX 3 , -CX 2 H, -CXH 2 , -CN, -C(O)N(R) 2 , -N(R)C(O)R, -N(R)S(O) 2 R, -N (R)C(O)N(R) 2 , -N(R)C(S)N(R) 2 , -CRN(R) 2 C(O)OR, -N(R)R 8 , -O (CH 2 ) n OR, -N(R)C(=NR 9 )N(R) 2 , -N(R)C(=CHR 9 )N(R) 2 , -OC(O)N(R) 2 , -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O) 2 R, -N(OR)C(O)OR, -N( OR)C(O)N(R) 2 , -N(OR)C(S)N(R) 2 , -N(OR)C(=NR 9 )N(R) 2 , -N(OR)C (=CHR 9 )N(R) 2 , -C(=NR 9 )R, -C(O)N(R)OR, and -C(=NR 9 )N(R) 2 , and each n independently selected from 1, 2, 3, 4, and 5 ; each R is independently selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl, and H ; each R is independently selected from C 1- The group consisting of 3 alkyl, C 2-3 alkenyl and H; M and M' are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R')- , -N(R')C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, - P(O)(OR')O-, -S(O) 2 -, -SS-, aryl and heteroaryl; R 7 is selected from C 1-3 alkyl, C 2-3 alkenyl and H group; R 8 is selected from the group consisting of C 3-6 carbocycle and heterocycle; R 9 is selected from H, CN, NO 2 , C 1-6 alkyl, -OR, -S(O) 2 R, -S(O) 2 N(R) 2 , the group consisting of C 2-6 alkenyl, C 3-6 carbocycle and heterocycle; each R is independently selected from C 1-3 alkyl, C The group consisting of 2-3 alkenyl and H; each R' is independently selected from the group consisting of C 1-18 alkyl, C 2-18 alkenyl, -R*YR'', -YR'' and H; Each R'' is independently selected from the group consisting of C 3-14 alkyl and C 3-14 alkenyl; each R* is independently selected from the group consisting of C 1-12 alkyl and C 2-12 alkenyl each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12 and 13, or their salts or isomers.
在一些實施例中,式(I)化合物之另一亞組包括以下之彼等化合物:其中 R 1選自由C 5-30烷基、C 5-20烯基、-R*YR''、-YR''及-R''M'R'組成之群; R 2及R 3獨立地選自由H、C 2-14烷基、C 2-14烯基、-R*YR''、-YR''及-R*OR''組成之群,或R 2及R 3與其所附接之原子一起形成雜環或碳環; R 4係-(CH 2) nQ或-(CH 2) nCHQR,其中Q係-N(R) 2,且n選自3、4及5; 每一R 5獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R 6獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; M及M'獨立地選自-C(O)O-、-OC(O)-、-C(O)N(R')-、-N(R')C(O)-、-C(O)-、-C(S)-、-C(S)S-、-SC(S)-、-CH(OH)-、-P(O)(OR')O-、-S(O) 2-、-S-S-、芳基及雜芳基; R 7選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R'獨立地選自由C 1-18烷基、C 2-18烯基、-R*YR''、-YR''及H組成之群; 每一R''獨立地選自由C 3-14烷基及C 3-14烯基組成之群; 每一R*獨立地選自由C 1-12烷基及C 1-12烯基組成之群; 每一Y獨立地係C 3-6碳環; 每一X獨立地選自由F、Cl、Br及I組成之群;且 m選自5、6、7、8、9、10、11、12及13, 或其鹽或異構物。 In some embodiments, another subgroup of compounds of formula (I) includes those compounds wherein R 1 is selected from C 5-30 alkyl, C 5-20 alkenyl, -R*YR'', - The group consisting of YR'' and -R''M'R'; R 2 and R 3 are independently selected from H, C 2-14 alkyl, C 2-14 alkenyl, -R*YR'', -YR '' and -R*OR'', or R 2 and R 3 together with the atoms to which they are attached form a heterocyclic or carbocyclic ring; R 4 is -(CH 2 ) n Q or -(CH 2 ) n CHQR, wherein Q is -N(R) 2 , and n is selected from 3, 4, and 5; each R 5 is independently selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl, and H; each - R 6 is independently selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl and H; M and M' are independently selected from -C(O)O-, -OC(O)-, - C(O)N(R')-, -N(R')C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S) -, -CH(OH)-, -P(O)(OR')O-, -S(O) 2 -, -SS-, aryl and heteroaryl; R 7 is selected from C 1-3 alkyl , C 2-3 alkenyl and the group consisting of H; each R is independently selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl and H; each R' is independently selected from C 1- The group consisting of 18 alkyl, C 2-18 alkenyl, -R*YR'', -YR'' and H; each R'' is independently selected from C 3-14 alkyl and C 3-14 alkenyl the group consisting of; each R* is independently selected from the group consisting of C 1-12 alkyl and C 1-12 alkenyl; each Y is independently C 3-6 carbocycle; each X is independently selected from F , Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or a salt or isomer thereof.
在一些實施例中,式(I)化合物之另一亞組包括以下之彼等化合物:其中 R 1選自由C 5-30烷基、C 5-20烯基、-R*YR''、-YR''及-R''M'R'組成之群; R 2及R 3獨立地選自由C 1-14烷基、C 2-14烯基、-R*YR''、-YR''及-R*OR''組成之群,或R 2及R 3與其所附接之原子一起形成雜環或碳環; R 4選自由-(CH 2) nQ、-(CH 2) nCHQR、-CHQR及-CQ(R) 2組成之群,其中Q係-N(R) 2,且n選自1、2、3、4及5; 每一R 5獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R 6獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; M及M'獨立地選自-C(O)O-、-OC(O)-、-C(O)N(R')-、-N(R')C(O)-、-C(O)-、-C(S)-、-C(S)S-、-SC(S)-、-CH(OH)-、-P(O)(OR')O-、-S(O) 2-、-S-S-、芳基及雜芳基; R 7選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R獨立地選自由C 1-3烷基、C 2-3烯基及H組成之群; 每一R'獨立地選自由C 1-18烷基、C 2-18烯基、-R*YR''、-YR''及H組成之群; 每一R''獨立地選自由C 3-14烷基及C 3-14烯基組成之群; 每一R*獨立地選自由C 1-12烷基及C 1-12烯基組成之群; 每一Y獨立地係C 3-6碳環; 每一X獨立地選自由F、Cl、Br及I組成之群;且 m選自5、6、7、8、9、10、11、12及13, 或其鹽或異構物。 In some embodiments, another subgroup of compounds of formula (I) includes those compounds wherein R 1 is selected from C 5-30 alkyl, C 5-20 alkenyl, -R*YR'', - The group consisting of YR'' and -R''M'R'; R 2 and R 3 are independently selected from C 1-14 alkyl, C 2-14 alkenyl, -R*YR'', -YR'' and -R*OR'', or R 2 and R 3 together with the atoms to which they are attached form a heterocyclic or carbocyclic ring; R 4 is selected from -(CH 2 ) n Q, -(CH 2 ) n CHQR The group consisting of , -CHQR and -CQ(R) 2 , wherein Q is -N(R) 2 , and n is selected from 1, 2, 3, 4, and 5; each R 5 is independently selected from C 1-3 The group consisting of alkyl, C 2-3 alkenyl and H; each R 6 is independently selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl and H; M and M' are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R')-, -N(R')C(O)-, -C(O)-, -C(S )-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR')O-, -S(O) 2 -, -SS-, aromatic R is selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl and H; each R is independently selected from C 1-3 alkyl, C 2-3 alkenyl and The group consisting of H; each R' is independently selected from the group consisting of C 1-18 alkyl, C 2-18 alkenyl, -R*YR'', -YR'' and H; each R'' is independently is selected from the group consisting of C 3-14 alkyl and C 3-14 alkenyl; each R* is independently selected from the group consisting of C 1-12 alkyl and C 1-12 alkenyl; each Y is independently is a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salt or isomer.
在一些實施例中,式(I)化合物之亞組包括式(IA)化合物:

在一些實施例中,式(I)化合物之亞組包括式(II)化合物:

在一些實施例中,式(I)化合物之亞組包括式(IIa)、(IIb)、(IIc)或(IIe)之化合物:


在一些實施例中,式(I)化合物之亞組包括式(IId)化合物:

在一些實施例中,本揭示案之可電離之陽離子脂質包含具有以下結構之化合物:

在一些實施例中,本揭示案之可電離之陽離子脂質包含具有以下結構之化合物:

在一些實施例中,本揭示案之非陽離子脂質包含1,2-二硬脂醯基-sn-甘油-3-磷酸膽鹼(DSPC)、1,2-二油醯基-sn-甘油-3-磷酸乙醇胺(DOPE)、1,2-二亞油醯基-sn-甘油-3-磷酸膽鹼(DLPC)、1,2-二肉豆蔻醯基-sn-甘油-磷酸膽鹼(DMPC)、1,2-二油醯基-sn-甘油-3-磷酸膽鹼(DOPC)、1,2-二棕櫚醯基-sn-甘油-3-磷酸膽鹼(DPPC)、1,2-二-十一烷醯基-sn-甘油-磷酸膽鹼(DUPC)、1-棕櫚醯基-2-油醯基-sn-甘油-3-磷酸膽鹼(POPC)、1,2-二-O-十八碳烯基-sn-甘油-3-磷酸膽鹼(18:0二醚PC)、1-油醯基-2 膽固醇基半琥珀醯基-sn-甘油-3-磷酸膽鹼(OChemsPC)、1-十六烷基-sn-甘油-3-磷酸膽鹼(C16 Lyso PC)、1,2-二亞麻醯基-sn-甘油-3-磷酸膽鹼、1,2-二花生四烯醯基-sn-甘油-3-磷酸膽鹼、1,2-二-二十二碳六烯醯基-sn-甘油-3-磷酸膽鹼、1,2-二植烷醯基-sn-甘油-3-磷酸乙醇胺(ME 16.0 PE)、1,2-二硬脂醯基-sn-甘油-3-磷酸乙醇胺、1,2-二亞油醯基-sn-甘油-3-磷酸乙醇胺、1,2-二亞麻醯基-sn-甘油-3-磷酸乙醇胺、1,2-二花生四烯醯基-sn-甘油-3-磷酸乙醇胺、1,2-二-二十二碳六烯醯基-sn-甘油-3-磷酸乙醇胺、1,2-二油醯基-sn-甘油-3-磷酸-外消旋-(1-甘油)鈉鹽(DOPG)、鞘磷脂及其混合物。In some embodiments, the non-cationic lipids of the present disclosure comprise 1,2-distearyl-sn-glycero-3-phosphocholine (DSPC), 1,2-dioleyl-sn-glycero- 3-Phosphoethanolamine (DOPE), 1,2-Dilinoleyl-sn-glycero-3-phosphocholine (DLPC), 1,2-Dimyristyl-sn-glycero-phosphocholine (DMPC) ), 1,2-dioleyl-sn-glycero-3-phosphocholine (DOPC), 1,2-dipalmitoyl-sn-glycero-3-phosphocholine (DPPC), 1,2- Di-undecanyl-sn-glycero-phosphocholine (DUPC), 1-palmitoyl-2-oleyl-sn-glycero-3-phosphocholine (POPC), 1,2-di- O-octadecenyl-sn-glycero-3-phosphocholine (18:0 diether PC), 1-oleyl-2-cholesterylhemisuccinoyl-sn-glycero-3-phosphocholine ( OChemsPC), 1-hexadecyl-sn-glycero-3-phosphocholine (C16 Lyso PC), 1,2-dilinanoyl-sn-glycero-3-phosphocholine, 1,2-diarachis Tetraenyl-sn-glycero-3-phosphocholine, 1,2-di-docosahexaenyl-sn-glycero-3-phosphocholine, 1,2-diphytanyl- sn-glycero-3-phosphoethanolamine (ME 16.0 PE), 1,2-distearyl-sn-glycero-3-phosphoethanolamine, 1,2-dilinoleo-sn-glycero-3-phosphate Ethanolamine, 1,2-Dilinanoyl-sn-glycero-3-phosphoethanolamine, 1,2-Diarachidonyl-sn-glycero-3-phosphoethanolamine, 1,2-di-docosyl Hexenyl-sn-glycero-3-phosphoethanolamine, 1,2-dioleyl-sn-glycero-3-phosphate-racemic-(1-glycerol) sodium salt (DOPG), sphingomyelin and its mixture.
在一些實施例中,本揭示案之PEG改質之脂質包含PEG改質之磷脂醯乙醇胺、PEG改質之磷脂酸、PEG改質之神經醯胺、PEG改質之二烷基胺、PEG改質之二醯基甘油、PEG改質之二烷基甘油及其混合物。在一些實施例中,PEG改質之脂質係DMG-PEG、PEG-c-DOMG (亦稱為PEG-DOMG)、PEG-DSG及/或PEG-DPG。In some embodiments, the PEG-modified lipids of the present disclosure comprise PEG-modified phosphatidylethanolamine, PEG-modified phosphatidic acid, PEG-modified ceramide, PEG-modified dialkylamine, PEG-modified phosphatidic acid, Quality diacylglycerol, PEG-modified dialkylglycerol and mixtures thereof. In some embodiments, the PEG-modified lipids are DMG-PEG, PEG-c-DOMG (also known as PEG-DOMG), PEG-DSG, and/or PEG-DPG.
在一些實施例中,本揭示案之固醇包含膽固醇、糞生固醇、谷固醇、麥角固醇、菜油固醇、豆固醇、蕓苔固醇、番茄鹼、熊果酸、α-生育酚及其混合物。In some embodiments, the sterols of the present disclosure comprise cholesterol, coprosterol, sitosterol, ergosterol, campesterol, stigmasterol, brassosterol, tomatine, ursolic acid, alpha - Tocopherols and mixtures thereof.
在一些實施例中,本揭示案之LNP包含化合物1之可電離之陽離子脂質,其中非陽離子脂質係DSPC,結構脂質係膽固醇,且PEG脂質係DMG-PEG。In some embodiments, the LNPs of the present disclosure comprise the ionizable cationic lipid of
在一些實施例中,脂質奈米顆粒包含45-55莫耳百分比(mol%)之可電離之陽離子脂質。舉例而言,脂質奈米顆粒可包含45 mol%、46 mol%、47 mol%、48 mol%、49 mol%、50 mol%、51 mol%、52 mol%、53 mol%、54 mol%或55 mol%可電離之陽離子脂質。In some embodiments, the lipid nanoparticles comprise 45-55 mole percent (mol %) of ionizable cationic lipids. For example, the lipid nanoparticle may comprise 45 mol%, 46 mol%, 47 mol%, 48 mol%, 49 mol%, 50 mol%, 51 mol%, 52 mol%, 53 mol%, 54 mol%, or 55 mol% ionizable cationic lipid.
在一些實施例中,脂質奈米顆粒包含5-15 mol%、5-10 mol%或10-15 mol% DSPC。舉例而言,脂質奈米顆粒可包含5 mol%、6 mol%、7 mol%、8 mol%、9 mol%、10 mol%、11 mol%、12 mol%、13 mol%、14 mol%或15 mol% DSPC。In some embodiments, the lipid nanoparticles comprise 5-15 mol%, 5-10 mol%, or 10-15 mol% DSPC. For example, the lipid nanoparticle can comprise 5 mol%, 6 mol%, 7 mol%, 8 mol%, 9 mol%, 10 mol%, 11 mol%, 12 mol%, 13 mol%, 14 mol% or 15 mol% DSPC.
在一些實施例中,脂質奈米顆粒包含35-40 mol%膽固醇。舉例而言,脂質奈米顆粒可包含35 mol%、35.5 mol%、36 mol%、36.5 mol%、37 mol%、37.5 mol%、38 mol%、38.5 mol%、39 mol%、39.5 mol%或40 mol%膽固醇。In some embodiments, the lipid nanoparticles comprise 35-40 mol% cholesterol. For example, the lipid nanoparticle can comprise 35 mol%, 35.5 mol%, 36 mol%, 36.5 mol%, 37 mol%, 37.5 mol%, 38 mol%, 38.5 mol%, 39 mol%, 39.5 mol%, or 40 mol% cholesterol.
在一些實施例中,脂質奈米顆粒包含1-2 mol%、1-3 mol%、1-4 mol%或1-5 mol% DMG-PEG。舉例而言,脂質奈米顆粒可包含1 mol%、1.5 mol%、2 mol%、2.5 mol%、3 mol%或3.5 mol% DMG-PEG。In some embodiments, the lipid nanoparticles comprise 1-2 mol%, 1-3 mol%, 1-4 mol%, or 1-5 mol% DMG-PEG. For example, lipid nanoparticles can comprise 1 mol%, 1.5 mol%, 2 mol%, 2.5 mol%, 3 mol%, or 3.5 mol% DMG-PEG.
在一些實施例中,脂質奈米顆粒包含50 mol%可電離之陽離子脂質、10 mol% DSPC、38.5 mol%膽固醇及1.5 mol% DMG-PEG。In some embodiments, the lipid nanoparticles comprise 50 mol% ionizable cationic lipid, 10 mol% DSPC, 38.5 mol% cholesterol, and 1.5 mol% DMG-PEG.
在一些實施例中,脂質奈米顆粒包含49 mol%可電離之陽離子脂質、10 mol% DSPC、38.5 mol%膽固醇及2.5 mol% DMG-PEG。In some embodiments, the lipid nanoparticles comprise 49 mol% ionizable cationic lipids, 10 mol% DSPC, 38.5 mol% cholesterol, and 2.5 mol% DMG-PEG.
在一些實施例中,脂質奈米顆粒包含49 mol%可電離之陽離子脂質、11 mol% DSPC、38.5 mol%膽固醇及1.5 mol% DMG-PEG。In some embodiments, the lipid nanoparticles comprise 49 mol% ionizable cationic lipids, 11 mol% DSPC, 38.5 mol% cholesterol, and 1.5 mol% DMG-PEG.
在一些實施例中,脂質奈米顆粒包含48 mol%可電離之陽離子脂質、11 mol% DSPC、38.5 mol%膽固醇及2.5 mol% DMG-PEG。In some embodiments, the lipid nanoparticles comprise 48 mol% ionizable cationic lipids, 11 mol% DSPC, 38.5 mol% cholesterol, and 2.5 mol% DMG-PEG.
在一些實施例中,本揭示案之LNP包含約2:1至約30:1之N:P比。In some embodiments, the LNPs of the present disclosure comprise an N:P ratio of about 2:1 to about 30:1.
在一些實施例中,本揭示案之LNP包含約6:1之N:P比。In some embodiments, the LNPs of the present disclosure comprise an N:P ratio of about 6:1.
在一些實施例中,本揭示案之LNP包含約3:1之N:P比。In some embodiments, the LNPs of the present disclosure comprise an N:P ratio of about 3:1.
在一些實施例中,本揭示案之LNP包含約10:1至約100:1之可電離之陽離子脂質組分對RNA之重量/重量比。In some embodiments, the LNPs of the present disclosure comprise a weight/weight ratio of ionizable cationic lipid component to RNA of about 10:1 to about 100:1.
在一些實施例中,本揭示案之LNP包含約20:1之可電離之陽離子脂質組分對RNA之重量/重量比。In some embodiments, the LNPs of the present disclosure comprise a weight/weight ratio of ionizable cationic lipid component to RNA of about 20:1.
在一些實施例中,本揭示案之LNP包含約10:1之可電離之陽離子脂質組分對RNA之重量/重量比。In some embodiments, the LNPs of the present disclosure comprise a weight/weight ratio of ionizable cationic lipid component to RNA of about 10:1.
在一些實施例中,本揭示案之LNP具有約50 nm至約150 nm之平均直徑。In some embodiments, the LNPs of the present disclosure have an average diameter of about 50 nm to about 150 nm.
在一些實施例中,本揭示案之LNP具有約70 nm至約120 nm之平均直徑。 多價疫苗 In some embodiments, the LNPs of the present disclosure have an average diameter of about 70 nm to about 120 nm. polyvalent vaccine
如本文提供之組合物可包括編碼相同或不同種類之兩種或更多種抗原之RNA或多種RNA。在一些實施例中,組合物包括編碼兩種或更多種冠狀病毒抗原之mRNA或多種mRNA。在一些實施例中,RNA可編碼1種、2種、3種、4種、5種、6種、7種、8種、9種、10種、11種、12種或更多種冠狀病毒抗原。Compositions as provided herein can include RNA or RNAs encoding two or more antigens of the same or different species. In some embodiments, the composition includes mRNA or mRNAs encoding two or more coronavirus antigens. In some embodiments, the RNA can encode 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 or more coronaviruses antigen.
在一些實施例中,可將兩種或更多種不同的編碼抗原之mRNA調配於相同脂質奈米顆粒中。在其他實施例中,可將兩種或更多種不同之編碼抗原之RNA調配於單獨脂質奈米顆粒中(每一RNA調配於單一脂質奈米顆粒中)。接著,可組合脂質奈米顆粒且作為單一疫苗組合物(例如,包含編碼多種抗原之多種RNA)投與,或可單獨投與。 組合疫苗 In some embodiments, two or more different antigen-encoding mRNAs can be formulated in the same lipid nanoparticle. In other embodiments, two or more different antigen-encoding RNAs can be formulated into separate lipid nanoparticles (each RNA is formulated into a single lipid nanoparticle). The lipid nanoparticles can then be combined and administered as a single vaccine composition (eg, comprising multiple RNAs encoding multiple antigens), or can be administered separately. combination vaccine
如本文提供之組合物可包括編碼相同或不同病毒株之兩種或更多種抗原之mRNA或多種RNA。本文亦提供了包含編碼一或多種冠狀病毒及不同生物體之一或多種抗原之RNA的組合疫苗。因此,本揭示案之疫苗可為靶向相同株/種類之一或多種抗原或不同株/種類之一或多種抗原之組合疫苗,例如誘導對在冠狀病毒感染風險高之相同地理區域發現之生物體或當暴露於冠狀病毒時個體可能暴露於之生物體之免疫的抗原。 醫藥調配物 Compositions as provided herein can include mRNA or multiple RNAs encoding two or more antigens of the same or different virus strains. Also provided herein are combination vaccines comprising RNA encoding one or more coronaviruses and one or more antigens from different organisms. Thus, the vaccines of the present disclosure may be combination vaccines targeting one or more antigens of the same strain/species or one or more antigens of different strains/species, eg to induce response to organisms found in the same geographic area with a high risk of coronavirus infection Antigens of immunity of an organism or an organism to which an individual may be exposed when exposed to the coronavirus. Pharmaceutical formulations
本文提供用於預防或治療例如人類及其他哺乳動物之冠狀病毒之組合物(例如醫藥組合物)、方法、套組及試劑。本文提供之組合物可用作治療劑或預防劑。其可在醫藥中用於預防及/或治療冠狀病毒感染。Provided herein are compositions (eg, pharmaceutical compositions), methods, kits, and reagents for the prevention or treatment of, eg, human and other mammalian coronaviruses. The compositions provided herein can be used as therapeutic or prophylactic agents. It can be used in medicine to prevent and/or treat coronavirus infection.
在一些實施例中,可將如本文所述之含有RNA之冠狀病毒疫苗投與給個體(例如哺乳動物個體,諸如人類個體),且mRNA在活體內轉譯以產生抗原性多肽(抗原)。In some embodiments, an RNA-containing coronavirus vaccine as described herein can be administered to an individual (eg, a mammalian individual, such as a human individual), and the mRNA is translated in vivo to produce an antigenic polypeptide (antigen).
組合物(例如,包含RNA)之「有效量」至少部分基於靶組織、靶細胞類型、投與方式、RNA之物理特徵(例如,長度、核苷酸組成及/或修飾之核苷之程度)、疫苗之其他組分及其他决定因素,諸如個體之年齡、體重、身高、性別及一般健康狀况。通常,有效量之組合物提供誘導或增强之免疫反應,作為個體細胞中之抗原產生之函數。在一些實施例中,有效量之含有具有至少一個化學修飾之mRNA之組合物比含有編碼相同抗原或肽抗原之相應未經修飾之聚核苷酸之組合物更有效。抗原產生增加可藉由細胞轉染(用RNA疫苗轉染之細胞之百分數)增加、自聚核苷酸之蛋白質轉譯及/或表現增加、核酸降解减少(例如,如藉由自經修飾之聚核苷酸之蛋白質轉譯之持續時間增加)或宿主細胞之抗原特異性免疫反應之改變來證明。An "effective amount" of a composition (e.g., comprising RNA) is based, at least in part, on the target tissue, target cell type, mode of administration, physical characteristics of the RNA (e.g., length, nucleotide composition, and/or degree of modified nucleosides) , other components of the vaccine and other determinants such as the age, weight, height, sex and general health of the individual. Typically, an effective amount of the composition provides for induction or enhancement of an immune response as a function of antigen production in the cells of the individual. In some embodiments, an effective amount of a composition containing mRNA with at least one chemical modification is more effective than a composition containing the corresponding unmodified polynucleotide encoding the same antigen or peptide antigen. Increased antigen production can be achieved by increased cell transfection (percentage of cells transfected with RNA vaccine), increased protein translation and/or expression from polynucleotides, decreased nucleic acid degradation (eg, as by modified polynucleotides). This is evidenced by an increase in the duration of protein translation of nucleotides) or by changes in the antigen-specific immune response of the host cell.
術語「醫藥組合物」係指活性劑與惰性或活性載劑之組合,使得組合物特別適用於活體內或離體診斷或治療用途。「醫藥學上可接受之載劑」在投與給個體後或在投與給個體時不會引起不期望之生理效應。醫藥組合物中之載劑自其與活性成分相容且能够穩定活性成分之意義上必須亦係「可接受的」。一或多種增溶劑可用作遞送活性劑之醫藥載劑。醫藥學上可接受之載劑之實例包括(但不限於)生物相容性媒劑、佐劑、添加劑及稀釋劑,以獲得可用作劑型之組合物。其他載劑之實例包括膠態氧化矽、硬脂酸鎂、纖維素及月桂基硫酸鈉。額外適宜醫藥載劑及稀釋劑以及使用其之醫藥必需品闡述於Remington's Pharmaceutical Sciences中。The term "pharmaceutical composition" refers to a combination of an active agent and an inert or active carrier that makes the composition particularly suitable for in vivo or ex vivo diagnostic or therapeutic use. A "pharmaceutically acceptable carrier" does not cause undesired physiological effects after or when administered to a subject. A carrier in a pharmaceutical composition must also be "acceptable" in the sense that it is compatible with and capable of stabilizing the active ingredient. One or more solubilizers can be used as pharmaceutical carriers for delivery of active agents. Examples of pharmaceutically acceptable carriers include, but are not limited to, biocompatible vehicles, adjuvants, additives, and diluents to obtain compositions useful as dosage forms. Examples of other carriers include colloidal silica, magnesium stearate, cellulose and sodium lauryl sulfate. Additional suitable pharmaceutical carriers and diluents and the medical necessities for their use are described in Remington's Pharmaceutical Sciences.
在一些實施例中,根據本揭示案之組合物(包含聚核苷酸及其編碼之多肽)可用於治療或預防冠狀病毒感染。組合物可作為主動免疫方案之一部分預防性或治療性地投與給健康個體或在潜伏期(incubation phase)期間或在症狀發作後之活動性感染期間之感染早期投與。在一些實施例中,提供給細胞、組織或個體之RNA之量可為有效用於免疫預防之量。In some embodiments, compositions according to the present disclosure (including polynucleotides and their encoded polypeptides) can be used to treat or prevent coronavirus infection. The compositions may be administered prophylactically or therapeutically to healthy individuals as part of an active immunization regimen or early in infection during the incubation phase or during active infection following the onset of symptoms. In some embodiments, the amount of RNA provided to the cell, tissue or individual may be an amount effective for immunoprophylaxis.
組合物可與其他預防性或治療性化合物一起投與。作為非限制性實例,預防性或治療性化合物可為佐劑或加强劑。如本文所用,當提及預防性組合物(諸如疫苗)時,術語「加强劑」係指額外投與預防性(疫苗)組合物。加强劑(或加强疫苗)可在較早投與預防性組合物之後給予。初始投與預防性組合物與加强劑之間之投與時間可為(但不限於) 1分鐘、2分鐘、3分鐘、4分鐘、5分鐘、6分鐘、7分鐘、8分鐘、9分鐘、10分鐘、15分鐘、20分鐘、35分鐘、40分鐘、45分鐘、50分鐘、55分鐘、1小時、2小時、3小時、4小時、5小時、6小時、7小時、8小時、9小時、10小時、11小時、12小時、13小時、14小時、15小時、16小時、17小時、18小時、19小時、20小時、21小時、22小時、23小時、1天、36小時、2天、3天、4天、5天、6天、1週、10天、2週、3週、1個月、2個月、3個月、4個月、5個月、6個月、7個月、8個月、9個月、10個月、11個月、1年、18個月、2年、3年、4年、5年、6年、7年、8年、9年、10年、11年、12年、13年、14年、15年、16年、17年、18年、19年、20年、25年、30年、35年、40年、45年、50年、55年、60年、65年、70年、75年、80年、85年、90年、95年或超過99年。在示例性實施例中,初始投與預防性組合物與加强劑之間之投與時間可為(但不限於) 1週、2週、3週、1個月、2個月、3個月、6個月或1年。The compositions can be administered with other prophylactic or therapeutic compounds. By way of non-limiting example, a prophylactic or therapeutic compound can be an adjuvant or booster. As used herein, when referring to a prophylactic composition (such as a vaccine), the term "booster" refers to the additional administration of the prophylactic (vaccine) composition. A booster (or booster vaccine) can be administered after an earlier administration of the prophylactic composition. The administration time between the initial administration of the prophylactic composition and the booster can be, but is not limited to, 1 minute, 2 minutes, 3 minutes, 4 minutes, 5 minutes, 6 minutes, 7 minutes, 8 minutes, 9 minutes, 10 minutes, 15 minutes, 20 minutes, 35 minutes, 40 minutes, 45 minutes, 50 minutes, 55 minutes, 1 hour, 2 hours, 3 hours, 4 hours, 5 hours, 6 hours, 7 hours, 8 hours, 9 hours , 10 hours, 11 hours, 12 hours, 13 hours, 14 hours, 15 hours, 16 hours, 17 hours, 18 hours, 19 hours, 20 hours, 21 hours, 22 hours, 23 hours, 1 day, 36 hours, 2 days, 3 days, 4 days, 5 days, 6 days, 1 week, 10 days, 2 weeks, 3 weeks, 1 month, 2 months, 3 months, 4 months, 5 months, 6 months, 7 months, 8 months, 9 months, 10 months, 11 months, 1 year, 18 months, 2 years, 3 years, 4 years, 5 years, 6 years, 7 years, 8 years, 9 years , 10 years, 11 years, 12 years, 13 years, 14 years, 15 years, 16 years, 17 years, 18 years, 19 years, 20 years, 25 years, 30 years, 35 years, 40 years, 45 years, 50 years years, 55 years, 60 years, 65 years, 70 years, 75 years, 80 years, 85 years, 90 years, 95 years or more than 99 years. In exemplary embodiments, the administration time between the initial administration of the prophylactic composition and the booster can be, but is not limited to, 1 week, 2 weeks, 3 weeks, 1 month, 2 months, 3 months , 6 months or 1 year.
在一些實施例中,組合物可經肌內、鼻內或真皮內投與,類似於業內已知之滅活疫苗之投與。In some embodiments, the composition may be administered intramuscularly, intranasally, or intradermally, similar to the administration of inactivated vaccines known in the art.
根據感染之盛行率或未滿足之醫療需要之程度或水準,組合物可用於各種環境。作為非限制性實例,RNA疫苗可用於治療及/或預防多種傳染病。RNA疫苗具有優越的性質,此乃因其比可商購獲得之疫苗產生大得多之抗體效價、更佳之中和免疫性、產生更耐久之免疫反應及/或更早產生反應。The compositions can be used in a variety of settings depending on the prevalence of infection or the degree or level of unmet medical need. By way of non-limiting example, RNA vaccines can be used to treat and/or prevent a variety of infectious diseases. RNA vaccines have superior properties because they generate much larger antibody titers, better neutralize immunity, generate more durable immune responses, and/or generate responses earlier than commercially available vaccines.
本文提供醫藥組合物,其包括RNA及/或複合體,視情况地與一或多種醫藥學上可接受之賦形劑組合。Provided herein are pharmaceutical compositions comprising RNA and/or complexes, optionally in combination with one or more pharmaceutically acceptable excipients.
RNA可單獨調配或投與,或與一或多種其他組分聯合調配或投與。舉例而言,組合物可包含其他組分,包括但不限於佐劑。RNA can be formulated or administered alone, or in combination with one or more other components. For example, the composition may contain other components including, but not limited to, adjuvants.
在一些實施例中,組合物不包含佐劑(其不含佐劑)。In some embodiments, the composition does not contain an adjuvant (it does not contain an adjuvant).
RNA可與一或多種醫藥學上可接受之賦形劑組合調配或投與。在一些實施例中,疫苗組合物包含至少一種額外活性物質,例如治療活性物質、預防活性物質或兩者之組合。疫苗組合物可為無菌的、無熱原的,或無菌及無熱原的。在醫藥劑(諸如疫苗組合物)之調配及/或製造中之一般考慮因素可參見(例如) Remington: The Science and Practice of Pharmacy,第21版,Lippincott Williams & Wilkins, 2005 (其全部內容以引用方式併入本文中)。RNA can be formulated or administered in combination with one or more pharmaceutically acceptable excipients. In some embodiments, the vaccine composition comprises at least one additional active, eg, a therapeutic active, a prophylactic active, or a combination of the two. Vaccine compositions can be sterile, pyrogen-free, or sterile and pyrogen-free. General considerations in the formulation and/or manufacture of pharmaceutical agents such as vaccine compositions can be found, for example, in Remington: The Science and Practice of Pharmacy, 21st Ed. Lippincott Williams & Wilkins, 2005 (incorporated by reference in its entirety). manner is incorporated herein).
在一些實施例中,將組合物投與給人類、人類患者或個體。出於本揭示案之目的,片語「活性成分」通常係指RNA疫苗或其中含有之聚核苷酸,例如編碼抗原之mRNA。In some embodiments, the composition is administered to a human, human patient or individual. For the purposes of this disclosure, the phrase "active ingredient" generally refers to an RNA vaccine or a polynucleotide contained therein, such as mRNA encoding an antigen.
本文所述之疫苗組合物之調配物可藉由藥理學領域中已知或以後開發之任何方法來製備。一般而言,該等製備方法包括使活性成分(例如mRNA)與賦形劑及/或一或多種其他輔助成分締合且接著若必要及/或期望,將產品分割、成型及/或包裝成期望單劑量或多劑量單位之步驟。Formulations of the vaccine compositions described herein can be prepared by any method known or later developed in the art of pharmacology. In general, such methods of preparation include associating the active ingredient (eg, mRNA) with excipients and/or one or more other auxiliary ingredients and then, if necessary and/or desired, dividing, shaping and/or packaging the product into a Single-dose or multiple-dose unit procedures are desired.
本揭示案之醫藥組合物中之活性成分、醫藥學上可接受之賦形劑及/或任何額外成分之相對量將根據所治療之個體之身份、大小及/或狀况且進一步根據組合物欲投與之途徑而變化。舉例而言,組合物可包含介於0.1%與100%之間、例如介於0.5%與50%之間、介於1%與30%之間、介於5%與80%之間、至少80% (w/w)之活性成分。The relative amounts of active ingredients, pharmaceutically acceptable excipients and/or any additional ingredients in the pharmaceutical compositions of the present disclosure will depend on the identity, size and/or condition of the individual being treated and further on the composition to be administered change with the way. For example, the composition may comprise between 0.1% and 100%, such as between 0.5% and 50%, between 1% and 30%, between 5% and 80%, at least 80% (w/w) active ingredient.
在一些實施例中,使用一或多種賦形劑調配mRNA以:(1)增加穩定性;(2)增加細胞轉染;(3)允許持續或延遲釋放(例如,自貯庫調配物);(4)改變生物分佈(例如,靶向特定組織或細胞類型);(5)增加編碼之蛋白質在活體內之轉譯;及/或(6)改變編碼之蛋白質(抗原)在活體內之釋放曲綫。除了傳統賦形劑(諸如任何及所有溶劑、分散介質、稀釋劑或其他液體媒劑、分散或懸浮助劑、表面活性劑、等滲劑、增稠劑或乳化劑、防腐劑)之外,賦形劑亦可包括(但不限於)類脂質、脂質體、脂質奈米顆粒、聚合物、脂質複合體、核-殼奈米顆粒、肽、蛋白質、用RNA轉染之細胞(例如,用於移植至個體中)、玻尿酸酶、奈米顆粒模擬物及其組合。 投藥 / 投與 In some embodiments, mRNA is formulated with one or more excipients to: (1) increase stability; (2) increase cell transfection; (3) allow sustained or delayed release (eg, from a depot formulation); (4) alter biodistribution (eg, target specific tissues or cell types); (5) increase translation of the encoded protein in vivo; and/or (6) alter the release profile of the encoded protein (antigen) in vivo . In addition to conventional excipients such as any and all solvents, dispersion media, diluents or other liquid vehicles, dispersing or suspending aids, surfactants, isotonic, thickening or emulsifying agents, preservatives, Excipients may also include, but are not limited to, lipidoids, liposomes, lipid nanoparticles, polymers, lipid complexes, core-shell nanoparticles, peptides, proteins, cells transfected with RNA (e.g., with transplantation into an individual), hyaluronidase, nanoparticle mimics, and combinations thereof. dosing / administration
本文提供用於預防及/或治療人類及其他哺乳動物之冠狀病毒感染之組合物(例如,RNA疫苗)、方法、套組及試劑。免疫組合物可用作治療劑或預防劑。在一些實施例中,組合物用於提供對冠狀病毒感染之預防性保護。在一些實施例中,組合物用於治療冠狀病毒感染。在一些實施例中,組合物用於引發免疫效應細胞,例如離體活化外周血單核細胞(PBMC),接著將其輸注(再輸注)至個體中。Provided herein are compositions (eg, RNA vaccines), methods, kits and reagents for preventing and/or treating coronavirus infections in humans and other mammals. Immunological compositions can be used as therapeutic or prophylactic agents. In some embodiments, the compositions are used to provide prophylactic protection against coronavirus infection. In some embodiments, the composition is used to treat a coronavirus infection. In some embodiments, the compositions are used to elicit immune effector cells, eg, ex vivo activated peripheral blood mononuclear cells (PBMCs), which are then infused (re-infused) into an individual.
個體可為任何哺乳動物,包括非人靈長類及人類個體。通常,個體為人類個體。The subject can be any mammal, including non-human primates and human subjects. Typically, the individual is a human individual.
在一些實施例中,將組合物(例如,RNA疫苗)以有效誘導抗原特異性免疫反應之量投與給個體(例如,哺乳動物個體,諸如人類個體)。編碼冠狀病毒抗原之RNA在活體內表現及轉譯以產生抗原,此接著刺激個體之免疫反應。In some embodiments, a composition (eg, an RNA vaccine) is administered to an individual (eg, a mammalian individual, such as a human individual) in an amount effective to induce an antigen-specific immune response. The RNA encoding the coronavirus antigen is expressed and translated in vivo to produce the antigen, which in turn stimulates an immune response in the individual.
在投與本揭示案之組合物之後,可實現對冠狀病毒之預防性保護。免疫組合物可投與一次、兩次、三次、四次或更多次,但可能投與一次疫苗即足矣(視情况地隨後進行單次加强)。儘管不太期望,但可將組合物投與給感染之個體以實現治療反應。可能需要相應地調整投藥。Preventive protection against coronaviruses can be achieved following administration of the compositions of the present disclosure. The immunizing composition may be administered once, twice, three times, four times or more, although one administration of the vaccine may suffice (optionally followed by a single boost). Although less desirable, the composition can be administered to an infected individual to achieve a therapeutic response. Dosing may need to be adjusted accordingly.
在本揭示案之態樣中,提供在個體中引發針對冠狀病毒抗原(或多種抗原)之免疫反應之方法。在一些實施例中,方法包括向個體投與包含具有編碼冠狀病毒抗原之開放閱讀框之mRNA的組合物,從而在個體中誘導對冠狀病毒抗原特異性之免疫反應,其中相對於用預防有效劑量之針對該抗原之傳統疫苗接種之個體中之抗抗原抗體效價,疫苗接種後個體中之抗抗原抗體效價增加。「抗抗原抗體」係特異性結合至抗原之血清抗體。In aspects of the present disclosure, methods of eliciting an immune response against a coronavirus antigen (or antigens) in an individual are provided. In some embodiments, the method comprises administering to the individual a composition comprising mRNA having an open reading frame encoding a coronavirus antigen, thereby inducing in the individual an immune response specific for the coronavirus antigen, wherein relative to using a prophylactically effective dose The anti-antigen antibody titers in individuals traditionally vaccinated against the antigen increased after vaccination. "Anti-antigen antibodies" are serum antibodies that specifically bind to an antigen.
預防有效劑量係在臨床上可接受之水準上預防病毒感染之有效劑量。在一些實施例中,有效劑量係疫苗之包裝插頁中列出之劑量。如本文所用,傳統疫苗係指除本揭示案之mRNA疫苗之外之疫苗。例如,傳統疫苗包括(但不限於)活微生物疫苗、殺死之微生物疫苗、次單元疫苗、蛋白質抗原疫苗、DNA疫苗、類病毒顆粒(VLP)疫苗等。在示例性實施例中,傳統疫苗係已經獲得監管部門批准及/或在國家藥物監管機構(例如美國食品藥品管理局(FDA)或歐洲藥物管理局(EMA))註册之疫苗。A prophylactically effective dose is a dose effective at a clinically acceptable level to prevent viral infection. In some embodiments, the effective dose is the dose listed on the package insert of the vaccine. As used herein, traditional vaccines refer to vaccines other than the mRNA vaccines of the present disclosure. For example, conventional vaccines include, but are not limited to, live microbial vaccines, killed microbial vaccines, subunit vaccines, protein antigen vaccines, DNA vaccines, virus-like particle (VLP) vaccines, and the like. In exemplary embodiments, conventional vaccines are vaccines that have been approved by regulatory authorities and/or registered with a national drug regulatory agency, such as the US Food and Drug Administration (FDA) or the European Medicines Agency (EMA).
在一些實施例中,相對於用預防有效劑量之針對冠狀病毒之傳統疫苗接種之個體或未接種疫苗之個體中之抗抗原抗體效價,疫苗接種後之個體中之抗抗原抗體效價增加1 log至10 log。在一些實施例中,相對於用預防有效劑量之針對冠狀病毒之傳統疫苗接種之個體或未接種疫苗之個體中之抗抗原抗體效價,疫苗接種後之個體中之抗抗原抗體效價增加1 log、2 log、3 log、4 log、5 log或10 log。In some embodiments, the anti-antigen antibody titer in a vaccinated individual increases by 1 relative to the anti-antigen antibody titer in an individual vaccinated with a prophylactically effective dose of traditional vaccine against coronavirus or an unvaccinated individual log to 10 log. In some embodiments, the anti-antigen antibody titer in a vaccinated individual increases by 1 relative to the anti-antigen antibody titer in an individual vaccinated with a prophylactically effective dose of traditional vaccine against coronavirus or an unvaccinated individual log, 2 log, 3 log, 4 log, 5 log or 10 log.
在本揭示案之其他態樣中,提供在個體中引發針對冠狀病毒之免疫反應之方法。該方法包括向個體投與包含含有編碼冠狀病毒抗原之開放閱讀框之mRNA的組合物,從而在個體中誘導對冠狀病毒特異性之免疫反應,其中個體中之免疫反應等同於以相對於組合物2倍至100倍劑量水準用針對冠狀病毒之傳統疫苗接種之個體中之免疫反應。In other aspects of the present disclosure, methods of eliciting an immune response against a coronavirus in an individual are provided. The method comprises administering to an individual a composition comprising mRNA comprising an open reading frame encoding a coronavirus antigen, thereby inducing in the individual an immune response specific to the coronavirus, wherein the immune response in the individual is equivalent to that relative to the composition Immune responses in individuals vaccinated with conventional vaccines against coronavirus at 2-fold to 100-fold dose levels.
在一些實施例中,個體中之免疫反應等同於以相對於本揭示案之組合物兩倍之劑量水準用傳統疫苗接種之個體中之免疫反應。在一些實施例中,個體中之免疫反應等同於以相對於本揭示案之組合物三倍之劑量水準用傳統疫苗接種之個體中之免疫反應。在一些實施例中,個體中之免疫反應等同於以相對於本揭示案之組合物4倍、5倍、10倍、50倍或100倍之劑量水準用傳統疫苗接種之個體中之免疫反應。在一些實施例中,個體中之免疫反應等同於以相對於本揭示案之組合物10倍至1000倍之劑量水準用傳統疫苗接種之個體中之免疫反應。在一些實施例中,個體中之免疫反應等同於以相對於本揭示案之組合物100倍至1000倍之劑量水準用傳統疫苗接種之個體中之免疫反應。In some embodiments, the immune response in an individual is equivalent to that in an individual vaccinated with conventional vaccines at dose levels that are twice relative to the compositions of the present disclosure. In some embodiments, the immune response in an individual is equivalent to that in an individual vaccinated with conventional vaccines at dose levels three times relative to the compositions of the present disclosure. In some embodiments, the immune response in an individual is equivalent to that in an individual vaccinated with conventional vaccines at dose levels 4-, 5-, 10-, 50-, or 100-fold relative to the compositions of the present disclosure. In some embodiments, the immune response in an individual is equivalent to that in an individual vaccinated with conventional vaccines at dose levels 10- to 1000-fold relative to the compositions of the present disclosure. In some embodiments, the immune response in an individual is equivalent to that in an individual vaccinated with conventional vaccines at dose levels 100- to 1000-fold relative to the compositions of the present disclosure.
在其他實施例中,藉由測定個體中之[蛋白]抗體效價來評價免疫反應。在其他實施例中,測試來自經免疫個體之血清或抗體中和病毒攝取或减少人類B淋巴球之冠狀病毒轉型之能力。在其他實施例中,使用業內公認之技術來量測促進强T細胞反應之能力。In other embodiments, the immune response is assessed by measuring [protein] antibody titers in the individual. In other embodiments, sera or antibodies from immunized individuals are tested for their ability to neutralize viral uptake or reduce coronavirus transformation of human B lymphocytes. In other embodiments, the ability to promote a strong T cell response is measured using art-recognized techniques.
本揭示案之其他態樣提供藉由向個體投與包含具有編碼冠狀病毒抗原之開放閱讀框之mRNA之組合物,從而在個體中誘導對冠狀病毒抗原特異性之免疫反應,而在個體中引發針對冠狀病毒之免疫反應的方法,其中相對於在用預防有效劑量之針對冠狀病毒之傳統疫苗接種之個體中誘導之免疫反應,該個體中誘導之免疫反應早2天至10週。在一些實施例中,在以相對於本揭示案之組合物2倍至100倍之劑量水準用預防有效劑量之傳統疫苗接種之個體中,誘導該個體中之免疫反應。Other aspects of the present disclosure provide for inducing an immune response specific to a coronavirus antigen in an individual by administering to the individual a composition comprising mRNA having an open reading frame encoding a coronavirus antigen, eliciting in an individual A method of an immune response against a coronavirus wherein the immune response is induced in an individual 2 days to 10 weeks earlier than that induced in an individual vaccinated with a prophylactically effective dose of a conventional vaccine against the coronavirus. In some embodiments, an immune response in an individual is induced in an individual vaccinated with a prophylactically effective dose of a conventional vaccine at a dose level of 2- to 100-fold relative to a composition of the present disclosure.
在一些實施例中,相對於在用預防有效劑量之傳統疫苗接種之個體中誘導之免疫反應,該個體中誘導之免疫反應早2天、3天、1週、2週、3週、5週或10週。In some embodiments, the immune response is induced in an individual 2 days, 3 days, 1 week, 2 weeks, 3 weeks, 5 weeks earlier than the immune response induced in the individual vaccinated with a prophylactically effective dose of the traditional vaccine or 10 weeks.
本文亦提供藉由向個體投與具有編碼第一抗原之開放閱讀框之mRNA而在個體中引發針對冠狀病毒之免疫反應的方法,其中RNA不包括穩定元件,且其中佐劑不與疫苗共調配或共投與。Also provided herein are methods of eliciting an immune response against a coronavirus in an individual by administering to the individual mRNA having an open reading frame encoding a first antigen, wherein the RNA does not include stabilizing elements, and wherein the adjuvant is not co-formulated with the vaccine or co-investment.
組合物可藉由任何產生治療有效結果之途徑投與。該等途徑包括(但不限於)真皮內、肌內、鼻內及/或皮下投與。本揭示案提供包括向有需要之個體投與RNA疫苗之方法。所需之確切量將因個體而異,此取决於個體之物種、年齡及一般狀况、疾病之嚴重程度、特定組合物、其投與模式、其活性模式及諸如此類。RNA通常調配成劑量單位形式以便於投與及劑量之均勻性。然而,應理解,RNA之總日用量可由主治醫師在合理之醫學判斷範圍內决定。對於任何特定患者之具體治療有效、預防有效或適當之成像劑量水準將取决於多種因素,包括所治療之病症及病症之嚴重程度;所採用之具體化合物之活性;所採用之具體組合物;患者之年齡、體重、一般健康狀况、性別及飲食;投與時間、投與途徑及所採用之具體化合物之排泄速率;治療之持續時間;與所採用之具體化合物組合或同時使用之藥物;以及醫學領域熟知之類似因素。The compositions can be administered by any route that produces therapeutically effective results. Such routes include, but are not limited to, intradermal, intramuscular, intranasal and/or subcutaneous administration. The present disclosure provides methods comprising administering RNA vaccines to individuals in need. The exact amount required will vary from individual to individual, depending on the individual's species, age and general condition, the severity of the disease, the particular composition, its mode of administration, its mode of activity, and the like. RNA is usually formulated in dosage unit form for ease of administration and uniformity of dosage. It should be understood, however, that the total daily amount of RNA can be determined by the attending physician within the scope of sound medical judgment. The particular therapeutically, prophylactically, or appropriate imaging dose level for any particular patient will depend on a variety of factors, including the condition being treated and the severity of the condition; the activity of the particular compound employed; the particular composition employed; the patient age, weight, general health, sex, and diet; time of administration, route of administration, and rate of excretion of the particular compound employed; duration of treatment; drugs used in combination or concomitantly with the particular compound employed; and Similar factors are well known in the medical field.
如本文提供之RNA之有效量可低至20 μg,例如以單一劑量或兩個10 μg劑量投與。在一些實施例中,有效量為20 µg-300 µg或25 µg-300 µg之總劑量。舉例而言,有效量可為20 µg、25 µg、30 µg、35 µg、40 µg、45 µg、50 µg、55 µg、60 µg、65 µg、70 µg、75 µg、80 µg、85 µg、90 µg、95 µg、100 µg、110 µg、120 µg、130 µg、140 µg、150 µg、160 µg、170 µg、180 µg、190 µg、200 µg、250 µg或300 µg之總劑量。在一些實施例中,有效量為20 μg之總劑量。在一些實施例中,有效量為25 μg之總劑量。在一些實施例中,有效量為50 μg之總劑量。在一些實施例中,有效量為75 μg之總劑量。在一些實施例中,有效量為100 μg之總劑量。在一些實施例中,有效量為150 μg之總劑量。在一些實施例中,有效量為200 μg之總劑量。在一些實施例中,有效量為250 μg之總劑量。在一些實施例中,有效量為300 μg之總劑量。An effective amount of RNA as provided herein can be as low as 20 μg, eg, administered in a single dose or in two 10 μg doses. In some embodiments, the effective amount is a total dose of 20 μg-300 μg or 25 μg-300 μg. For example, an effective amount can be 20 µg, 25 µg, 30 µg, 35 µg, 40 µg, 45 µg, 50 µg, 55 µg, 60 µg, 65 µg, 70 µg, 75 µg, 80 µg, 85 µg, Total dose of 90 µg, 95 µg, 100 µg, 110 µg, 120 µg, 130 µg, 140 µg, 150 µg, 160 µg, 170 µg, 180 µg, 190 µg, 200 µg, 250 µg or 300 µg. In some embodiments, the effective amount is a total dose of 20 μg. In some embodiments, the effective amount is a total dose of 25 μg. In some embodiments, the effective amount is a total dose of 50 μg. In some embodiments, the effective amount is a total dose of 75 μg. In some embodiments, the effective amount is a total dose of 100 μg. In some embodiments, the effective amount is a total dose of 150 μg. In some embodiments, the effective amount is a total dose of 200 μg. In some embodiments, the effective amount is a total dose of 250 μg. In some embodiments, the effective amount is a total dose of 300 μg.
本文所述之RNA可調配成本文所述之劑型,諸如鼻內、氣管內或可注射(例如,靜脉內、眼內、玻璃體內、肌內、真皮內、心內、腹膜內及皮下)。 疫苗效能 The RNAs described herein can be formulated into dosage forms described herein, such as intranasal, intratracheal, or injectable (eg, intravenous, intraocular, intravitreal, intramuscular, intradermal, intracardiac, intraperitoneal, and subcutaneous). vaccine efficacy
本揭示案之一些態樣提供組合物(例如,RNA疫苗)之調配物,其中以有效量調配RNA以在個體中產生抗原特異性免疫反應(例如,產生對冠狀病毒抗原特異性之抗體)。「有效量」係有效產生抗原特異性免疫反應之RNA之劑量。本文亦提供在個體中誘導抗原特異性免疫反應之方法。Some aspects of the present disclosure provide formulations of compositions (eg, RNA vaccines) in which the RNA is formulated in an effective amount to generate an antigen-specific immune response (eg, to generate antibodies specific to a coronavirus antigen) in an individual. An "effective amount" is an amount of RNA effective to generate an antigen-specific immune response. Also provided herein are methods of inducing an antigen-specific immune response in an individual.
如本文所用,對本揭示案之疫苗或LNP之免疫反應係在個體中產生對疫苗中存在之(一或多種)冠狀病毒蛋白之體液及/或細胞免疫反應。出於本揭示案之目的,「體液」免疫反應係指由抗體分子(包括例如分泌性(IgA)或IgG分子)介導之免疫反應,而「細胞」免疫反應係由T淋巴球(例如,CD4 +輔助細胞及/或CD8 +T細胞(例如CTL))及/或其他白血球介導之免疫反應。細胞免疫之一個重要態樣包括由細胞溶解性T細胞(CTL)引起之抗原特異性反應。CTL對與主要組織相容性複合體(MHC)編碼之蛋白質締合呈遞且在細胞表面上表現之肽抗原具有特異性。CTL幫助誘導及促進細胞內微生物之破壞或感染該等微生物之細胞之溶解。細胞免疫之另一態樣包括由輔助T細胞引起之抗原特異性反應。輔助T細胞用於幫助刺激功能且使非特異性效應細胞之活性集中於在表面上展示與MHC分子締合之肽抗原的细胞。細胞免疫反應亦導致產生細胞介素、趨化介素及由活化T細胞及/或其他白血球產生之其他該等分子(包括源自CD4 +及CD8 +T細胞者)。 As used herein, an immune response to a vaccine or LNP of the present disclosure is the production of a humoral and/or cellular immune response in an individual to the coronavirus protein(s) present in the vaccine. For the purposes of this disclosure, a "humoral" immune response refers to an immune response mediated by antibody molecules, including, for example, secretory (IgA) or IgG molecules, while a "cellular" immune response is one mediated by T lymphocytes (eg, CD4 + helper cells and/or CD8 + T cells (eg CTL)) and/or other leukocyte-mediated immune responses. An important aspect of cellular immunity involves antigen-specific responses elicited by cytolytic T cells (CTLs). CTLs are specific for peptide antigens presented in association with proteins encoded by the major histocompatibility complex (MHC) and expressed on the cell surface. CTLs help to induce and promote the destruction of intracellular microorganisms or the lysis of cells infected with such microorganisms. Another aspect of cellular immunity involves antigen-specific responses elicited by helper T cells. Helper T cells are used to help stimulate function and focus the activity of nonspecific effector cells on cells displaying peptide antigens associated with MHC molecules on their surface. The cellular immune response also results in the production of interleukins, chemokines, and other such molecules (including those derived from CD4 + and CD8 + T cells) produced by activated T cells and/or other white blood cells.
在一些實施例中,抗原特異性免疫反應藉由量測在投與如本文提供之組合物之個體中產生之抗冠狀病毒抗原抗體效價來表徵。抗體效價係個體內抗體(例如,對特定抗原或抗原之抗原決定基特異性之抗體)之量之量度。抗體效價通常表示為提供陽性結果之最大稀釋度之倒數。例如,酶聯免疫吸附分析(ELISA)係用於測定抗體效價之常見分析。In some embodiments, an antigen-specific immune response is characterized by measuring the anti-coronavirus antigen antibody titers produced in an individual administered a composition as provided herein. Antibody titer is a measure of the amount of antibody (eg, antibody specific for a particular antigen or epitope of an antigen) in an individual. Antibody titers are usually expressed as the reciprocal of the largest dilution that gave a positive result. For example, enzyme-linked immunosorbent assay (ELISA) is a common assay used to determine antibody titers.
可使用多種血清學測試來量測針對編碼之相關抗原之抗體,例如SAR-CoV-2病毒或SAR-CoV-2病毒抗原,例如SAR-CoV-2刺突或S蛋白,或其結構域。該等測試包括血球凝集抑制測試、補體結合測試、螢光抗體測試、酶聯免疫吸附分析(ELISA)及噬斑减少中和測試(PRNT)。該等測試中之每一者皆量測不同抗體活性。在示例性實施例中,噬斑减少中和測試或PRNT (例如PRNT50或PRNT90)用作保護之血清學相關物。PRNT量測活體外病毒中和之生物學參數,且係某些類別之病毒中最具血清學病毒特異性之測試,與病毒感染之保護之血清水準密切相關。A variety of serological tests can be used to measure antibodies against encoded relevant antigens, such as SAR-CoV-2 virus or SAR-CoV-2 viral antigens, such as the SAR-CoV-2 spike or S protein, or domains thereof. Such tests include hemagglutination inhibition test, complement fixation test, fluorescent antibody test, enzyme-linked immunosorbent assay (ELISA) and plaque reduction neutralization test (PRNT). Each of these tests measures a different antibody activity. In exemplary embodiments, plaque reduction neutralization tests or PRNTs (eg, PRNT50 or PRNT90) are used as serological correlates of protection. PRNT measures the biological parameter of virus neutralization in vitro and is the most serological virus-specific test among certain classes of viruses, and is closely related to the serum level of protection against viral infection.
PRNT之基本設計允許在試管或微量滴定板中發生病毒-抗體相互作用,且接著藉由將混合物平鋪在病毒易感性細胞、較佳哺乳動物來源之細胞上來量測抗體對病毒感染性之效應。用限制後代病毒傳播之半固體培養基覆蓋細胞。引發生產性感染之每一病毒產生局部感染區域(噬斑),其可以多種方式偵測。對噬斑計數且與病毒之起始濃度進行比較以確定總病毒感染性之降低百分比。在PRNT中,通常在與標準量之病毒混合之前,將所測試之血清樣品進行連續稀釋。病毒之濃度保持恒定,使得當添加至易感細胞中且用半固體培養基覆蓋時,可辨別且計數個別噬斑。以此方式,可在任何選擇之病毒活性降低百分比下計算每一血清樣品之PRNT終點效價。The basic design of PRNT allows for virus-antibody interactions to take place in test tubes or microtiter plates, and then to measure the effect of the antibody on virus infectivity by plating the mixture on virus susceptible cells, preferably cells of mammalian origin . Cells were overlaid with semi-solid medium that would limit transmission of progeny virus. Each virus that causes a productive infection produces localized areas of infection (plaques) that can be detected in a variety of ways. Plaques were counted and compared to the starting concentration of virus to determine the percent reduction in total virus infectivity. In PRNT, serial dilutions of the tested serum samples are typically made before mixing with a standard amount of virus. The concentration of virus is kept constant so that when added to susceptible cells and covered with semi-solid medium, individual plaques can be identified and counted. In this manner, the PRNT endpoint titer for each serum sample can be calculated at any selected percent reduction in viral activity.
在意欲評價疫苗免疫原性之功能分析中,用於抗體滴定之血清樣品稀釋系列理想地應在低於「血清保護性」臨限值效價下開始。關於SARS-CoV-2中和抗體,「血清保護性」臨限值效價仍然未知;但在某些實施例中,1:10之血清陽性臨限值可被認為係血清保護臨限值。In functional assays intended to assess vaccine immunogenicity, dilution series of serum samples for antibody titration should ideally begin at titers below the "seroprotective" threshold value. With respect to SARS-CoV-2 neutralizing antibodies, the "seroprotective" threshold titer is still unknown; however, in certain embodiments, a seropositivity threshold of 1:10 may be considered a seroprotective threshold.
PRNT終點效價表示為顯示所需之噬斑計數减少百分比之最後血清稀釋度之倒數。PRNT效價可基於50%或更大之噬斑計數减少來計算(PRNT50)。對於疫苗血清,PRNT50效價比使用較高截止值(例如,PRNT90)之效價更佳,自滴定曲綫之綫性部分提供更準確之結果。PRNT endpoint titers are expressed as the reciprocal of the final serum dilution showing the desired percent reduction in plaque counts. PRNT titers can be calculated based on a 50% or greater reduction in plaque count (PRNT50). For vaccine sera, PRNT50 titers are better than those using higher cutoffs (eg, PRNT90), providing more accurate results from the linear portion of the titration curve.
存在用以計算PRNT效價之若干方式。計算效價之最簡單及最廣泛使用之方式係對噬斑計數,且將效價報告為基於輸入噬斑之反滴定,顯示輸入噬斑計數减少>50%之最後血清稀釋度之倒數。使用來自若干血清稀釋之曲綫擬合方法可允許計算更精確之結果。存在多種電腦分析程式可用於該目的(例如,SPSS或GraphPad Prism)。There are several ways to calculate PRNT titers. The simplest and most widely used way to calculate titers is to count plaques, and to report titers as the reciprocal of the final serum dilution based on a back-titration of input plaques showing a >50% reduction in input plaque counts. Using a curve fitting method from several serum dilutions may allow more accurate results to be calculated. Various computer analysis programs exist for this purpose (eg, SPSS or GraphPad Prism).
在一些實施例中,抗體效價用於評價個體是否已經感染或確定是否需要免疫。在一些實施例中,抗體效價用於確定自體免疫反應之强度,確定是否需要加强免疫,確定先前之疫苗是否有效,以及鑑別任何最近或先前之感染。根據本揭示案,抗體效價可用於確定由組合物(例如,RNA疫苗)在個體中誘導之免疫反應之强度。In some embodiments, antibody titers are used to assess whether an individual is already infected or to determine whether immunization is required. In some embodiments, antibody titers are used to determine the strength of an autoimmune response, to determine the need for booster immunization, to determine whether previous vaccines are effective, and to identify any recent or previous infection. According to the present disclosure, antibody titers can be used to determine the strength of an immune response induced in an individual by a composition (eg, an RNA vaccine).
在一些實施例中,個體中產生之抗冠狀病毒抗原抗體效價相對於對照增加至少1 log。舉例而言,個體中產生之抗冠狀病毒抗原抗體效價相對於對照可增加至少1.5、至少2、至少2.5或至少3 log。在一些實施例中,個體中產生之抗冠狀病毒抗原抗體效價相對於對照增加1、1.5、2、2.5或3 log。在一些實施例中,個體中產生之抗冠狀病毒抗原抗體效價相對於對照增加1-3 log。舉例而言,個體中產生之抗冠狀病毒抗原抗體效價相對於對照可增加1-1.5、1-2、1-2.5、1-3、1.5-2、1.5-2.5、1.5-3、2-2.5、2-3或2.5-3 log。In some embodiments, the anti-coronavirus antigen antibody titer produced in the individual is increased by at least 1 log relative to a control. For example, the anti-coronavirus antigen antibody titer produced in an individual can be increased by at least 1.5, at least 2, at least 2.5, or at least 3 logs relative to a control. In some embodiments, the anti-coronavirus antigen antibody titer produced in the individual is increased by 1, 1.5, 2, 2.5, or 3 logs relative to a control. In some embodiments, the anti-coronavirus antigen antibody titers produced in the individual are increased by 1-3 logs relative to a control. For example, the anti-coronavirus antigen antibody titer produced in an individual can be increased by 1-1.5, 1-2, 1-2.5, 1-3, 1.5-2, 1.5-2.5, 1.5-3, 2- 2.5, 2-3 or 2.5-3 log.
在一些實施例中,個體中產生之抗冠狀病毒抗原抗體效價相對於對照增加至少2倍。舉例而言,個體中產生之抗冠狀病毒抗原抗體效價可相對於對照增加至少3倍、至少4倍、至少5倍、至少6倍、至少7倍、至少8倍、至少9倍或至少10倍。在一些實施例中,個體中產生之抗冠狀病毒抗原抗體效價相對於對照增加2、3、4、5、6、7、8、9或10倍。在一些實施例中,個體中產生之抗冠狀病毒抗原抗體效價相對於對照增加2-10倍。舉例而言,個體中產生之抗冠狀病毒抗原抗體效價相對於對照可增加2-10、2-9、2-8、2-7、2-6、2-5、2-4、2-3、3-10、3-9、3-8、3-7、3-6、3-5、3-4、4-10、4-9、4-8、4-7、4-6、4-5、5-10、5-9、5-8、5-7、5-6、6-10、6-9、6-8、6-7、7-10、7-9、7-8、8-10、8-9或9-10倍。In some embodiments, the anti-coronavirus antigen antibody titer produced in the individual is increased by at least 2-fold relative to a control. For example, the anti-coronavirus antigen antibody titer produced in the individual can be increased by at least 3-fold, at least 4-fold, at least 5-fold, at least 6-fold, at least 7-fold, at least 8-fold, at least 9-fold, or at least 10-fold relative to a control times. In some embodiments, the anti-coronavirus antigen antibody titer produced in the individual is increased by 2, 3, 4, 5, 6, 7, 8, 9, or 10-fold relative to a control. In some embodiments, the anti-coronavirus antigen antibody titer produced in the individual is increased by 2-10 fold relative to the control. For example, the anti-coronavirus antigen antibody titer produced in an individual can be increased by 2-10, 2-9, 2-8, 2-7, 2-6, 2-5, 2-4, 2- 3, 3-10, 3-9, 3-8, 3-7, 3-6, 3-5, 3-4, 4-10, 4-9, 4-8, 4-7, 4-6, 4-5, 5-10, 5-9, 5-8, 5-7, 5-6, 6-10, 6-9, 6-8, 6-7, 7-10, 7-9, 7- 8, 8-10, 8-9 or 9-10 times.
在一些實施例中,抗原特異性免疫反應量測為冠狀病毒血清中和抗體效價之幾何平均效價(GMT)之比率,稱為幾何平均比率(GMR)。幾何平均效價(GMT)係藉由將所有值相乘且取該數之 n次根來計算之一組個體之平均抗體效價,其中 n係具有可用數據之個體之數目。 In some embodiments, the antigen-specific immune response is measured as the ratio of the geometric mean titers (GMT) of the titers of coronavirus serum neutralizing antibodies, referred to as the geometric mean ratio (GMR). Geometric mean titers (GMT) are calculated by multiplying all values together and taking the n root of the number, where n is the number of individuals with available data.
在一些實施例中,對照係在未投與組合物(例如RNA疫苗)之個體中產生之抗冠狀病毒抗原抗體效價。在一些實施例中,對照係在投與重組或純化之蛋白疫苗之個體中產生之抗冠狀病毒抗原抗體效價。重組蛋白疫苗通常包括在異源表現系統(例如細菌或酵母)中產生或自大量病原生物體中純化之蛋白抗原。In some embodiments, the control is an anti-coronavirus antigen antibody titer produced in individuals not administered the composition (eg, RNA vaccine). In some embodiments, the control is an anti-coronavirus antigen antibody titer produced in an individual administered a recombinant or purified protein vaccine. Recombinant protein vaccines typically include protein antigens produced in heterologous expression systems (eg, bacteria or yeast) or purified from a number of pathogenic organisms.
在一些實施例中,在鼠類模型中量測組合物(例如RNA疫苗)有效之能力。舉例而言,可將組合物投與給鼠類模型,且分析鼠類模型之中和抗體效價之誘導。病毒攻擊研究亦可用於評價本揭示案之疫苗之效能。舉例而言,可將組合物投與給鼠類模型,用病毒攻擊鼠類模型,且分析鼠類模型之存活及/或免疫反應(例如中和抗體反應、T細胞反應(例如細胞介素反應))。In some embodiments, the ability of a composition (eg, an RNA vaccine) to be effective is measured in a murine model. For example, the composition can be administered to a murine model and assayed for the induction of neutralizing antibody titers in the murine model. Viral challenge studies can also be used to evaluate the efficacy of the vaccines of the present disclosure. For example, the composition can be administered to a murine model, challenged with a virus, and the murine model analyzed for survival and/or immune responses (eg, neutralizing antibody responses, T cell responses (eg, interleukin responses) )).
在一些實施例中,組合物(例如,RNA疫苗)之有效量係與重組蛋白疫苗之標準護理劑量相比减少之劑量。如本文所提供之「標準護理」係指醫學或心理治療指南,且可為一般性的或特異性的。「標準護理」基於科學證據及參與給定疾患之治療之醫學專業人士之間之合作來指定適當治療。其係醫師/臨床醫師對於某種類型之患者、疾病或臨床情况應遵循之診斷及治療過程。本文提供之「標準護理劑量」係指醫師/臨床醫師或其他醫學專業人士在遵循用於治療或預防冠狀病毒感染或相關疾患之標準護理指南的同時,將投與給個體以治療或預防冠狀病毒感染或相關疾患之重組或純化蛋白疫苗、或活的减毒或滅活疫苗、或VLP疫苗的劑量。In some embodiments, an effective amount of a composition (eg, an RNA vaccine) is a reduced dose compared to a standard-of-care dose of a recombinant protein vaccine. "Standard of care" as provided herein refers to medical or psychotherapy guidelines, and can be general or specific. "Standard Care" prescribes appropriate treatment based on scientific evidence and collaboration between medical professionals involved in the treatment of a given condition. It is the process of diagnosis and treatment that a physician/clinician should follow for a certain type of patient, disease or clinical condition. "Standard of Care Dosage" provided herein refers to the amount that a physician/clinician or other medical professional would administer to an individual to treat or prevent coronavirus while following standard of care guidelines for the treatment or prevention of coronavirus infection or related conditions Doses of recombinant or purified protein vaccines, or live attenuated or inactivated vaccines, or VLP vaccines for infections or related conditions.
在一些實施例中,在投與有效量之組合物之個體中產生之抗冠狀病毒抗原抗體效價等同於在投與標準護理劑量之重組或純化蛋白疫苗、或活的减毒或滅活疫苗、或VLP疫苗之對照個體中產生的抗冠狀病毒抗原抗體效價。In some embodiments, the anti-coronavirus antigen antibody titers produced in an individual administered an effective amount of the composition are equivalent to those administered a standard-of-care dose of recombinant or purified protein vaccines, or live attenuated or inactivated vaccines , or the anti-coronavirus antigen antibody titers produced in control individuals of VLP vaccine.
疫苗效能可使用標準分析來評價(例如,參見Weinberg等人,J Infect Dis. 2010年6月1日;201(11):1607-10)。舉例而言,疫苗效能可藉由雙盲、隨機化、臨床對照試驗來量測。疫苗效能可表示為未接種疫苗(ARU)及接種疫苗(ARV)之研究同類群組之間疾病罹患率(AR)之成比例降低,且可使用下式自接種疫苗組中疾病之相對風險(RR)計算:
效能 = (ARU - ARV)/ARU × 100;且
效能 = (1-RR) × 100。
Vaccine efficacy can be assessed using standard assays (see, eg, Weinberg et al., J Infect Dis. 2010
同樣,疫苗有效性可使用標準分析來評估(例如,參見Weinberg等人,J Infect Dis. 2010年6月1日;201(11):1607-10)。疫苗有效性係評價疫苗(其可能已經證明具有高疫苗效能)如何减少群體中之疾病。此量度可評價在自然現場條件下而非在受控臨床試驗中,疫苗接種程式而不僅僅疫苗本身之益處及不利效應之淨平衡。疫苗有效性與疫苗效能(功效)成正比,但亦受群體中之靶群體免疫之程度以及影響住院治療、流動就診或花費之「真實世界」結果之其他非疫苗相關因素影響。舉例而言,可使用回溯性病例對照分析,其中比較一組感染病例及適當對照之間之疫苗接種率。疫苗有效性可表示為比率差異,使用勝算比(OR)用於儘管接種但亦發生感染:
有效性 = (1 - OR) × 100。
Likewise, vaccine efficacy can be assessed using standard assays (eg, see Weinberg et al., J Infect Dis. 2010
在一些實施例中,相對於未接種疫苗之對照個體,組合物(例如,RNA疫苗)之效能為至少60%。舉例而言,相對於未接種疫苗之對照個體,組合物之效能可為至少65%、至少70%、至少75%、至少80%、至少85%、至少95%、至少98%或100%。In some embodiments, the efficacy of the composition (eg, RNA vaccine) is at least 60% relative to unvaccinated control individuals. For example, the efficacy of the composition can be at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 95%, at least 98%, or 100% relative to unvaccinated control individuals.
消除性免疫性 .消除性免疫性係指防止病原體有效感染至宿主中之獨特免疫狀態。在一些實施例中,有效量之本揭示案之組合物足以在個體中提供消除性免疫性至少1年。舉例而言,有效量之本揭示案之組合物足以在個體中提供消除性免疫性至少2年、至少3年、至少4年或至少5年。在一些實施例中,有效量之本揭示案之組合物足以在個體中以相對於對照低至少5倍之劑量提供消除性免疫性。舉例而言,有效量可足以在個體中以相對於對照低至少10倍、15倍或20倍之劑量提供消除性免疫性。 Eliminating immunity . Eliminating immunity refers to a unique immune state that prevents efficient infection of a pathogen into a host. In some embodiments, an effective amount of a composition of the present disclosure is sufficient to provide eliminating immunity in an individual for at least 1 year. For example, an effective amount of a composition of the present disclosure is sufficient to provide eliminating immunity in an individual for at least 2 years, at least 3 years, at least 4 years, or at least 5 years. In some embodiments, an effective amount of a composition of the present disclosure is sufficient to provide depleting immunity in an individual at a dose that is at least 5-fold lower relative to a control. For example, an effective amount can be sufficient to provide depleting immunity in an individual at a dose that is at least 10-fold, 15-fold or 20-fold lower relative to a control.
可偵測抗原 .在一些實施例中,有效量之本揭示案之組合物足以產生可偵測水準之冠狀病毒抗原,如在投與後1-72小時在個體之血清中所量測。 Detectable antigens . In some embodiments, an effective amount of a composition of the present disclosure is sufficient to produce detectable levels of coronavirus antigens, as measured in the serum of an individual 1-72 hours after administration.
效價 .抗體效價係個體內抗體(例如,對特定抗原(例如,抗冠狀病毒抗原)特異性之抗體)之數量之量度。抗體效價通常表示為提供陽性結果之最大稀釋度之倒數。例如,酶聯免疫吸附分析(ELISA)係用於測定抗體效價之常見分析。 Titer . Antibody titer is a measure of the number of antibodies (eg, antibodies specific for a particular antigen (eg, an anti-coronavirus antigen)) in an individual. Antibody titers are usually expressed as the reciprocal of the largest dilution that gave a positive result. For example, enzyme-linked immunosorbent assay (ELISA) is a common assay used to determine antibody titers.
在一些實施例中,有效量之本揭示案之組合物足以產生由針對冠狀病毒抗原之中和抗體產生之1,000-10,000中和抗體效價,如在投與後1-72小時在個體之血清中所量測。在一些實施例中,有效量之本揭示案之組合物足以產生由針對冠狀病毒抗原之中和抗體產生之1,000-5,000中和抗體效價,如在投與後1-72小時在個體之血清中所量測。在一些實施例中,有效量足以產生由針對冠狀病毒抗原之中和抗體產生之5,000-10,000中和抗體效價,如在投與後1-72小時在個體之血清中所量測。In some embodiments, an effective amount of a composition of the present disclosure is sufficient to produce 1,000-10,000 neutralizing antibody titers produced by neutralizing antibodies directed against a coronavirus antigen, such as in the serum of an individual 1-72 hours after administration Measured in. In some embodiments, an effective amount of a composition of the present disclosure is sufficient to generate 1,000-5,000 neutralizing antibody titers produced by neutralizing antibodies directed against a coronavirus antigen, such as in the serum of an individual 1-72 hours after administration Measured in. In some embodiments, the effective amount is sufficient to generate a titer of 5,000-10,000 neutralizing antibodies produced by neutralizing antibodies directed against a coronavirus antigen, as measured in the serum of the individual 1-72 hours after administration.
在一些實施例中,中和抗體效價係至少100 NT 50。舉例而言,中和抗體效價可為至少200、300、400、500、600、700、800、900或1000 NT 50。在一些實施例中,中和抗體效價係至少10,000 NT 50。 In some embodiments, the neutralizing antibody titer is at least 100 NT 50 . For example, the neutralizing antibody titer can be at least 200, 300, 400, 500 , 600, 700, 800, 900, or 1000 NT50. In some embodiments, the neutralizing antibody titer is at least 10,000 NT50 .
在一些實施例中,中和抗體效價係至少100個中和單位/毫升(NU/mL)。舉例而言,中和抗體效價可為至少200、300、400、500、600、700、800、900或1000 NU/mL。在一些實施例中,中和抗體效價係至少10,000 NU/mL。In some embodiments, the neutralizing antibody titer is at least 100 neutralizing units per milliliter (NU/mL). For example, the neutralizing antibody titer can be at least 200, 300, 400, 500, 600, 700, 800, 900, or 1000 NU/mL. In some embodiments, the neutralizing antibody titer is at least 10,000 NU/mL.
在一些實施例中,個體中產生之抗冠狀病毒抗原抗體效價相對於對照增加至少1 log。舉例而言,個體中產生之抗冠狀病毒抗原抗體效價相對於對照可增加至少2、3、4、5、6、7、8、9或10 log。In some embodiments, the anti-coronavirus antigen antibody titer produced in the individual is increased by at least 1 log relative to a control. For example, the anti-coronavirus antigen antibody titer produced in an individual can be increased by at least 2, 3, 4, 5, 6, 7, 8, 9, or 10 logs relative to a control.
在一些實施例中,個體中產生之抗冠狀病毒抗原抗體效價相對於對照增加至少2倍。舉例而言,個體中產生之抗冠狀病毒抗原抗體效價相對於對照增加至少3、4、5、6、7、8、9或10倍。In some embodiments, the anti-coronavirus antigen antibody titer produced in the individual is increased by at least 2-fold relative to a control. For example, the anti-coronavirus antigen antibody titer produced in the individual is increased by at least 3, 4, 5, 6, 7, 8, 9 or 10 fold relative to the control.
在一些實施例中,幾何平均值,即n個數之乘積之n次根,通常用於闡述成比例生長。在一些實施例中,幾何平均值用於描述個體中產生之抗體效價。In some embodiments, the geometric mean, the nth root of the product of n numbers, is often used to describe proportional growth. In some embodiments, the geometric mean is used to describe the antibody titer produced in an individual.
對照可為例如未接種疫苗之個體,或投與活的减毒病毒疫苗、滅活病毒疫苗或蛋白質次單元疫苗之個體。 額外實施例 Controls can be, for example, unvaccinated individuals, or individuals administered a live attenuated virus vaccine, an inactivated virus vaccine, or a protein subunit vaccine. Additional Embodiments
以下編號之段落涵蓋本揭示案之額外實施例:
1. 一種信使核糖核酸(mRNA),其包含編碼融合蛋白之開放閱讀框,該融合蛋白包含SARS-CoV-2刺突蛋白之受體結合結構域(RBD)及蛋白質跨膜結構域。
2. 如段落1之mRNA,其中該蛋白質跨膜結構域係流行性感冒血球凝集素跨膜結構域。
3. 如段落2之mRNA,其中該融合蛋白包含與SEQ ID NO: 77之胺基酸序列具有至少80%一致性的胺基酸序列。
4. 如段落3之mRNA,其中該融合蛋白包含與SEQ ID NO: 77之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。
5. 如段落4之mRNA,其中該融合蛋白包含SEQ ID NO: 77之胺基酸序列。
6. 如前述段落中任一者之mRNA,其中該開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少70%一致性的核苷酸序列。
7. 如段落6之mRNA,其中該開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。
8. 如段落7之mRNA,其中該開放閱讀框包含SEQ ID NO: 76之核苷酸序列。
9. 一種信使核糖核酸(mRNA),其包含編碼融合蛋白之開放閱讀框,該融合蛋白包含SARS-CoV-2刺突蛋白之胺基(N)末端結構域及跨膜結構域。
10. 如段落9之mRNA,其中該跨膜結構域係流行性感冒血球凝集素跨膜結構域。
11. 如段落10之mRNA,其中該融合蛋白包含與SEQ ID NO: 47之胺基酸序列具有至少80%一致性的胺基酸序列。
12. 如段落11之mRNA,其中該融合蛋白包含與SEQ ID NO: 47之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。
13. 如段落12之mRNA,其中該融合蛋白包含SEQ ID NO: 47之胺基酸序列。
14. 如前述段落中任一者之mRNA,其中該開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少70%一致性的核苷酸序列。
15. 如段落14之mRNA,其中該開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。
16. 如段落15之mRNA,其中該開放閱讀框包含SEQ ID NO: 46之核苷酸序列。
17. 一種信使核糖核酸(mRNA),其包含編碼融合蛋白之開放閱讀框,該融合蛋白包含與SARS-CoV-2刺突蛋白的受體結合結構域連接之SARS-CoV-2刺突蛋白之胺基(N)末端結構域。
18. 如段落17之mRNA,其中該融合蛋白進一步包含跨膜結構域。
19. 如段落18之mRNA,其中該融合蛋白包含與SEQ ID NO: 92之胺基酸序列具有至少80%一致性的胺基酸序列。
20. 如段落18之mRNA,其中該融合蛋白包含與SEQ ID NO: 92之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。
21. 如段落20之mRNA,其中該融合蛋白包含SEQ ID NO: 92之胺基酸序列。
22. 如前述段落中任一者之mRNA,其中該開放閱讀框包含與SEQ ID NO: 91之核苷酸序列具有至少70%一致性的核苷酸序列。
23. 如段落22之mRNA,其中該開放閱讀框包含與SEQ ID NO: 91之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。
24. 如段落23之mRNA,其中該開放閱讀框包含SEQ ID NO: 91之核苷酸序列。
25. 如前述段落中任一者之mRNA,進一步包含5'非轉譯區(UTR),該5'非轉譯區視情況地包含SEQ ID NO: 131或2之核苷酸序列。
26. 如前述段落中任一者之mRNA,進一步包含3'非轉譯區(UTR),該3'非轉譯區視情況地包含SEQ ID NO: 132或4之核苷酸序列。
27. 如前述段落中任一者之mRNA,進一步包含5'端帽,視情況地7mG(5')ppp(5')NlmpNp。
28.如前述段落中任一者之mRNA,進一步包含聚A尾,該聚A尾視情況地具有約100個核苷酸之長度。
29. 如前述段落中任一者之mRNA,其中該mRNA包含化學修飾,視情況地1-甲基假尿苷。
30. 一種組合物,其包含如段落1至29中任一者之mRNA。
31. 一種組合物,其包含如段落1至8中任一者之mRNA及如段落9至16中任一者之mRNA。
32. 一種組合物,其包含如段落17至29中任一者之mRNA。
33. 一種組合物,其包含:
(a) 包含編碼融合蛋白之開放閱讀框的信使核糖核酸(mRNA),該融合蛋白包含SARS-CoV-2刺突蛋白之受體結合結構域(RBD)及蛋白質跨膜結構域;及
(b) 包含編碼融合蛋白之開放閱讀框之mRNA,該融合蛋白包含SARS-CoV-2刺突蛋白之胺基(N)末端結構域及跨膜結構域。
34. 如段落33之組合物,其中該蛋白質跨膜結構域係流行性感冒血球凝集素跨膜結構域。
35. 如段落34之組合物,其中(a)之融合蛋白包含與SEQ ID NO: 77之胺基酸序列具有至少80%一致性的胺基酸序列。
36. 如段落35之組合物,其中(a)之融合蛋白包含與SEQ ID NO: 77之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。
37. 如段落36之組合物,其中(a)之融合蛋白包含SEQ ID NO: 77之胺基酸序列。
38. 如段落34至37中任一者之組合物,其中(a)之開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少70%一致性的核苷酸序列。
39. 如段落38之組合物,其中(a)之開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。
40. 如段落39之組合物,其中(a)之開放閱讀框包含SEQ ID NO: 76之核苷酸序列。
41. 如段落34至40中任一者之組合物,其中(b)之融合蛋白包含與SEQ ID NO: 47之胺基酸序列具有至少80%一致性的胺基酸序列。
42. 如段落41之組合物,其中(b)之融合蛋白包含與SEQ ID NO: 47之胺基酸序列具有至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列。
43. 如段落42之組合物,其中(b)之融合蛋白包含SEQ ID NO: 47之胺基酸序列。
44. 如段落34至43中任一者之組合物,其中(b)之開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少70%一致性的核苷酸序列。
45. 如段落44之組合物,其中(b)之開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列。
46. 如段落45之組合物,其中(b)之開放閱讀框包含SEQ ID NO: 46之核苷酸序列。
47. 如段落33至46中任一者之組合物,其中(a)之mRNA對(b)之mRNA之比率為約1:1。
48. 如段落1至29中任一者之組合物,其調配於脂質奈米顆粒中。
49. 如段落30至47中任一者之組合物,其進一步包含脂質奈米顆粒。
50. 如段落49之組合物,其中該mRNA調配於脂質奈米顆粒中。
51. 如段落33至47中任一者之組合物,其中(a)之mRNA調配於脂質奈米顆粒中,且(b)之mRNA調配於脂質奈米顆粒中。
52. 如段落51之組合物,其中(a)及(b)之mRNA於相同脂質奈米顆粒中,或其中(a)及(b)之mRNA相對於彼此各自調配於單獨奈米顆粒中。
53. 如段落48之mRNA或如段落49至52中任一者之組合物,其中該脂質奈米顆粒包含陽離子脂質。
54. 如段落53之mRNA或組合物,其中該脂質奈米顆粒進一步包含中性脂質。
55. 如段落53或54之mRNA或組合物,其中該脂質奈米顆粒進一步包含固醇。
56. 如段落53至55中任一者之mRNA或組合物,其中該脂質奈米顆粒進一步包含聚乙二醇(PEG)改質之脂質。
57. 如段落53至56中任一者之mRNA或組合物,其中該脂質奈米顆粒包含可電離之陽離子脂質、中性脂質、固醇及PEG改質之脂質。
58. 如段落57之mRNA或組合物,其中該可電離之陽離子脂質係8-((2-羥基乙基)(6-側氧基-6-(十一烷基氧基)己基)胺基)辛酸十七烷-9-基酯(化合物1)。
59. 如段落57或58之mRNA或組合物,其中該中性脂質係1,2-二硬脂醯基-sn-甘油-3-磷酸膽鹼(DSPC)。
60. 如段落57至59中任一者之mRNA或組合物,其中該固醇係膽固醇。
61. 如段落57至60中任一者之mRNA或組合物,其中該PEG改質之脂質係1,2二肉豆蔻醯基-sn-甘油-甲氧基聚乙二醇(PEG2000 DMG)。
62. 如段落57至61中任一者之mRNA或組合物,其中該脂質奈米顆粒包含20-60 mol%可電離之陽離子脂質、5-25 mol%中性脂質、25-55 mol%固醇及0.5-15 mol% PEG改質之脂質。
63. 如段落62之mRNA或組合物,其中該脂質奈米顆粒包含:
47 mol%可電離之脂質;11.5 mol%中性脂質;38.5 mol%固醇;及3.0 mol% PEG改質之脂質;
48 mol%可電離之脂質;11 mol%中性脂質;38.5 mol%固醇;及2.5 mol% PEG改質之脂質;
49 mol%可電離之脂質;10.5 mol%中性脂質;38.5 mol%固醇;及2.0 mol% PEG改質之脂質;
50 mol%可電離之脂質;10 mol%中性脂質;38.5 mol%固醇;及1.5 mol% PEG改質之脂質;或
51 mol%可電離之脂質;9.5 mol%中性脂質;38.5 mol%固醇;及1.0 mol% PEG改質之脂質。
64. 如段落63之mRNA或組合物,其中該脂質奈米顆粒包含:
47 mol%化合物1;11.5 mol% DSPC;38.5 mol%膽固醇;及3.0% PEG2000DMG;
48 mol%化合物1;11.5 mol% DSPC;38.5 mol%膽固醇;及2.5% PEG2000DMG;
49 mol%化合物1;11.5 mol% DSPC;38.5 mol%膽固醇;及2.0% PEG2000DMG;
50 mol%化合物1;11.5 mol% DSPC;38.5 mol%膽固醇;及1.5% PEG2000DMG;或
51 mol%化合物1;11.5 mol% DSPC;38.5 mol%膽固醇;及1.0% PEG2000DMG。
65. 一種方法,該方法包括向個體投與有效地在該個體中誘導針對SARS-CoV-2之中和抗體反應之量的如前述段落中任一者之mRNA或組合物。
66. 一種方法,該方法包括向個體投與有效地在該個體中誘導針對SARS-CoV-2之T細胞免疫反應之量的如前述段落中任一者之mRNA或組合物。
67. 一種信使核糖核酸(mRNA),其包含編碼冠狀病毒抗原之開放閱讀框(ORF),該冠狀病毒抗原能夠誘導針對SARS-CoV-2之免疫反應(諸如中和抗體反應),其中該抗原包含SARS-CoV-2之蛋白質片段或功能性蛋白質結構域,視情況地其中RNA調配於脂質奈米顆粒中。
68. 如段落67之mRNA,其中該抗原為功能性蛋白質結構域。
69. 如段落68之mRNA,其中該蛋白質結構域係SARS-CoV-2刺突蛋白之N末端結構域(NTD)。
70. 如段落69之mRNA,其中該NTD與跨膜結構域、視情况地流行性感冒血球凝集素跨膜結構域連接。
71. 如段落70之mRNA,其中該抗原包含與SEQ ID NO: 47之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 47之胺基酸序列。
72. 如段落70或71之mRNA,其中該開放閱讀框包含與SEQ ID NO: 46之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 46之核苷酸序列。
73. 如段落68之mRNA,其中該蛋白質結構域係SARS-CoV-2刺突蛋白之受體結合結構域(RBD)。
74. 如段落73之mRNA,其中該RBD係可溶的。
75. 如段落74之mRNA,其中該抗原包含與SEQ ID NO: 62之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 62之胺基酸序列。
76. 如段落74或75之mRNA,其中該開放閱讀框包含與SEQ ID NO: 61之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 61之核苷酸序列。
77. 如段落73之mRNA,其中該RBD與跨膜結構域、視情况地流行性感冒血球凝集素跨膜結構域連接。
78. 如段落77之mRNA,其中該抗原包含與SEQ ID NO: 77之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 77之胺基酸序列。
79. 如段落77或78之mRNA,其中該開放閱讀框包含與SEQ ID NO: 76之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 76之核苷酸序列。
80. 如段落69之mRNA,其中該NTD與SARS-CoV-2刺突蛋白之RBD連接以形成NTD-RBD融合蛋白。
81. 如段落80之mRNA,其中該NTD-RBD融合體與跨膜結構域(TM)連接,視情況與流行性感冒血球凝集素跨膜結構域連接,以形成NTD-RBD-TM蛋白。
82. 如段落81之mRNA,其中該抗原包含與SEQ ID NO: 92之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 92之胺基酸序列。
83. 如段落81或82之mRNA,其中該開放閱讀框包含與SEQ ID NO: 91之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 91之核苷酸序列。
84. 如段落80之mRNA,其中該NTD-RBD融合體包含C末端截短。
85. 如段落84之mRNA,其中該抗原包含與SEQ ID NO: 107之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 107之胺基酸序列。
86. 如段落84或85之mRNA,其中該開放閱讀框包含與SEQ ID NO: 106之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 106之核苷酸序列。
87. 如前述段落中任一者之mRNA,其中該NTD及/或RBD包括延伸區。
88. 如段落87之mRNA,其中該抗原包含與SEQ ID NO: 59、86、89、116、119或122中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 59、86、89、116、119或122中之任一者之胺基酸序列。
89. 如段落87或88之mRNA,其中該開放閱讀框包含與SEQ ID NO: 58、85、88、115、118或121中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 58、85、88、115、118或121中之任一者之核苷酸序列。
90. 如段落68之mRNA,其中該蛋白質結構域係SARS-CoV-2刺突蛋白之S1次單元結構域。
91. 如段落90之mRNA,其中該S1次單元係可溶的。
92. 如段落91之mRNA,其中該抗原包含與SEQ ID NO: 5之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 5之胺基酸序列。
93. 如段落91或92之mRNA,其中該開放閱讀框包含與SEQ ID NO: 3之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 3之核苷酸序列。
94. 如段落90之mRNA,其中該S1次單元與跨膜結構域、視情况地流行性感冒血球凝集素跨膜結構域連接。
95. 如段落94之mRNA,其中該抗原包含與SEQ ID NO: 17之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 17之胺基酸序列。
96. 如段落94或95之mRNA,其中該開放閱讀框包含與SEQ ID NO: 16之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 16之核苷酸序列。
97. 如段落90之mRNA,其中該S1次單元經修飾以去除S蛋白之RBD或RBD之一部分。
98. 如段落97之mRNA,其中該抗原包含與SEQ ID NO: 20、23、26、29、32或35中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 20、23、26、29、32或35中之任一者之胺基酸序列。
99. 如段落97或98之mRNA,其中該開放閱讀框包含與SEQ ID NO: 19、22、25、28、31或34中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 19、22、25、28、31或34中之任一者之核苷酸序列。
100. 如段落90之mRNA,其中該S1次單元與S蛋白之S2次單元連接。
101. 如段落100之mRNA,其中該S2次單元來自SARS-CoV-2 S蛋白,且在一些實施例中其中該S2次單元包含開放閱讀框,該開放閱讀框包含與SEQ ID NO:145之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中該開放閱讀框包含SEQ ID NO: 145之核苷酸序列。
102. 如段落101之mRNA,其中該S1次單元來自HKU1 S蛋白。
103. 如段落102之mRNA,其中該抗原包含與SEQ ID NO: 38之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 38之胺基酸序列。
104. 如段落102或103之mRNA,其中該開放閱讀框包含與SEQ ID NO: 37之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 37之核苷酸序列。
105. 如段落101之mRNA,其中該S1次單元來自OC43 S蛋白。
106. 如段落105之mRNA,其中該抗原包含與SEQ ID NO: 41之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 41之胺基酸序列。
107. 如段落105或106之mRNA,其中該開放閱讀框包含與SEQ ID NO: 40之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 40之核苷酸序列。
108. 如前述段落中任一者之mRNA,其中該抗原進一步包含支架結構域,視情況地選自鐵蛋白、二氧四氫蝶啶(lumazine)合成酶及摺疊子。
109. 如段落108之mRNA,其中該支架結構域係鐵蛋白。
110. 如段落109之mRNA,其中該抗原包含與SEQ ID NO: 8或65之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 8或65之胺基酸序列。
111. 如段落109或110之mRNA,其中該開放閱讀框包含與SEQ ID NO: 7或64之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 7或64之核苷酸序列。
112. 如段落108之mRNA,其中該支架結構域係二氧四氫蝶啶(lumazine)合成酶。
113. 如段落112之mRNA,其中該抗原包含與SEQ ID NO: 11、14、68或71中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 11、14、68或71中之任一者之胺基酸序列。
114. 如段落112或113之mRNA,其中該開放閱讀框包含與SEQ ID NO: 10、13、67或70中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 10、13、67或70中之任一者之核苷酸序列。
115. 如段落108之mRNA,其中該支架結構域係摺疊子。
116. 如段落115之mRNA,其中該抗原包含與SEQ ID NO: 44、50、74、80、83、101、104或113中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 44、50、74、80、83、101、104或113中之任一者之胺基酸序列。
117. 如段落115或116之mRNA,其中該開放閱讀框包含與SEQ ID NO: 43、49、73、79、82、100、103或112中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 43、49、73、79、82、100、103或112中之任一者之核苷酸序列。
118. 如前述段落中任一者之mRNA,其中該抗原進一步包含運輸信號,視情況地選自巨噬細胞標記物,視情況地CD86、CD11B及/或VSVGct。
119. 如段落118之mRNA,其中該抗原包含與SEQ ID NO: 95、98或110中之任一者之胺基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的胺基酸序列,視情況地其中抗原包含SEQ ID NO: 95、98或110中之任一者之胺基酸序列。
120. 如段落118或119之mRNA,其中該開放閱讀框包含與SEQ ID NO: 94、97或109中之任一者之核苷酸序列具有至少70%、至少75%、至少80%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%一致性的核苷酸序列,視情況地其中開放閱讀框包含SEQ ID NO: 94、97或109中之任一者之核苷酸序列。
121. 如段落67至120中任一者之mRNA,其調配於脂質奈米顆粒中。
122. 如段落121之mRNA,其中該脂質奈米顆粒包含陽離子脂質(視情況地可電離之陽離子脂質)、中性脂質、固醇及/或聚乙二醇(PEG)改質之脂質。
123. 如段落108之mRNA或組合物,其中該可電離之陽離子脂質係8-((2-羥基乙基)(6-側氧基-6-(十一烷基氧基)己基)胺基)辛酸十七烷-9-基酯(化合物1),中性脂質係1,2-二硬脂醯基-sn-甘油-3-磷酸膽鹼(DSPC),固醇係膽固醇,及/或PEG改質之脂質係1,2二肉豆蔻醯基-sn-甘油-甲氧基聚乙二醇(PEG2000 DMG)。
124. 如段落121至123中任一者之mRNA或組合物,其中該脂質奈米顆粒包含20-60 mol%可電離之陽離子脂質、5-25 mol%中性脂質、25-55 mol%固醇及0.5-15 mol% PEG改質之脂質。
125. 如段落124之mRNA或組合物,其中該脂質奈米顆粒包含:
47 mol%可電離之陽離子脂質;11.5 mol%中性脂質;38.5 mol%固醇;及3.0 mol% PEG改質之脂質;
48 mol%可電離之陽離子脂質;11 mol%中性脂質;38.5 mol%固醇;及2.5 mol% PEG改質之脂質;
49 mol%可電離之陽離子脂質;10.5 mol%中性脂質;38.5 mol%固醇;及2.0 mol% PEG改質之脂質;
50 mol%可電離之陽離子脂質;10 mol%中性脂質;38.5 mol%固醇;及1.5 mol% PEG改質之脂質;或
51 mol%可電離之陽離子脂質;9.5 mol%中性脂質;38.5 mol%固醇;及1.0 mol% PEG改質之脂質。
126. 如段落125之mRNA或組合物,其中該脂質奈米顆粒包含:
47 mol%化合物1;11.5 mol% DSPC;38.5 mol%膽固醇;及3.0 mol% PEG2000 DMG;
48 mol%化合物1;11 mol% DSPC;38.5 mol%膽固醇;及2.5 mol% PEG2000 DMG;
49 mol%化合物1;10.5 mol% DSPC;38.5 mol%膽固醇;及2.0 mol% PEG2000 DMG;
50 mol%化合物1;10 mol% DSPC;38.5 mol%膽固醇;及1.5 mol% PEG2000 DMG;或
51 mol%化合物1;9.5 mol% DSPC;38.5 mol%膽固醇;及1.0 mol% PEG2000 DMG。
127. 一種方法,該方法包括向個體投與有效地在該個體中誘導針對SARS-CoV-2之中和抗體反應之量的如段落67至126中任一者之mRNA。
128. 一種方法,該方法包括向個體投與有效地在該個體中誘導針對SARS-CoV-2之T細胞免疫反應之量的如段落67至126中任一者之mRNA或組合物。
實例 實例 1. 表現數據 The following numbered paragraphs cover additional embodiments of the present disclosure: 1. A messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a fusion protein comprising the receptor binding structure of the SARS-CoV-2 spike protein domain (RBD) and protein transmembrane domain. 2. The mRNA of
本研究中使用之mRNA用於表現SARS-CoV-2冠狀病毒刺突(S)蛋白之關鍵中和結構域,且評價該等中和蛋白結構域在個別地或組合用作免疫原性組合物或疫苗以保護人免受活的及傳播之天然病毒感染時是否可更有效地誘導保護性免疫性。由mRNA編碼之蛋白質之綫性設計如 圖 2中所示。蛋白質亦皆含有源自流行性感冒之血球凝集素(HA)之羧基(C)末端跨膜結構域(TM)。 The mRNA used in this study was used to express the key neutralizing domains of the SARS-CoV-2 coronavirus spike (S) protein, and these neutralizing protein domains were evaluated individually or in combination as immunogenic compositions Or vaccines to protect people from live and circulating natural viruses are more effective in inducing protective immunity. The linear design of the protein encoded by the mRNA is shown in Figure 2 . The proteins also all contain the carboxy (C) terminal transmembrane domain (TM) of the influenza-derived hemagglutinin (HA).
已知NTD及RBD二者皆係結合表現中和病毒活性之抗體之位點。在SARS-CoV-2之情形下,RBD係刺突蛋白之受體結合位點,且結合血管收縮肽轉化酶2 (ACE2)。胺基(N)末端結構域NTD之功能尚未完全瞭解,似乎在結合糖部分及促進刺突蛋白自融合前構象向融合後構象之構象轉變中起作用。參見Zhou H, Chen Y, Zhang S等人, Nat Commun.2019;10(1): 3068。無論如何,NTD及RBD結構域二者皆誘導如下文論述之高結合抗體及中和抗體效價。 Both NTD and RBD are known to bind to the site of antibodies that exhibit virus-neutralizing activity. In the case of SARS-CoV-2, RBD is the receptor binding site for the spike protein and binds vasoconstrictor peptide converting enzyme 2 (ACE2). The function of the amine (N) terminal domain, NTD, is not fully understood and appears to play a role in binding the carbohydrate moiety and promoting the conformational transition of the spike protein from the prefusion to the postfusion conformation. See Zhou H, Chen Y, Zhang S et al., Nat Commun. 2019;10(1):3068. Regardless, both the NTD and RBD domains induce high binding and neutralizing antibody titers as discussed below.
使用對SARS-CoV-2刺突蛋白之受體結合結構域(RBD) (mAb1)及SARS-CoV-2刺突蛋白之N末端結構域(NTD) (Ab2)特異性之抗體,在
表 16 及 17中顯示mRNA RBD-TM疫苗(「SARS-CoV-2 RBD-TM」;SEQ ID NO: 75-77)、mRNA NTD-TM疫苗(「SARS-CoV-2 NTD-TM」;SEQ ID NO: 45-47)及mRNA NTD-RBD-TM (「SARS-CoV-1 NTD-RBD-TM」;SEQ ID NO: 90-92)疫苗之表現數據。
表 16顯示在24小時(hr)、48 hr及72 hr時,與WT SARS-CoV-2刺突蛋白mRNA相比,MFI * Freq之平均倍數差異(在稀釋範圍內) (
表 16)。
表 16.與S2P蛋白相比之總抗原表現(MFI * Freq)之倍數變化
以如下劑量向小鼠投與mRNA NTD-TM及mRNA RBD-TM (闡述於
實例 1中):0.001 μg、0.01 μg、0.1 μg或1 μg (N=8)。以如下劑量向小鼠投與mRNA NTD-RBD-TM (闡述於
實例 1中):0.1 μg或1 μg (N=8)。向小鼠投與mRNA NTD-TM及mRNA RBD-TM之50:50混合物,其含有0.1 μg每一mRNA,總共0.2 μg mRNA,或1 μg每一mRNA,總共2 μg mRNA (N=8)。接著在疫苗接種後第21天藉由ELISA量測SARS-CoV-2刺突蛋白特異性IgG效價(
表 17)、SARS-CoV-2 RBD特異性IgG效價(
表 18)及SARS-CoV-2 NTD特異性IgG效價(
表 19)。數據提供於
表 17-19中。0.1 μg劑量之mRNA NTD-RBD-TM及0.2 μg劑量之mRNA NTD-TM及mRNA RBD-TM組合物之50:50混合物引發可觀察到之NTD特異性及RBD特異性IgG效價,且0.1 μg劑量之RBD-TM及NTD-TM分別引發可量測之針對RBD及NTD抗原之IgG效價。
表 17.SARS-CoV-2 S1/S2刺突蛋白特異性IgG效價 - 平均值
量測來自用1 μg劑量之RBD-TM及NTD-RBD-TM組合物及2 μg劑量之NTD-TM及RBD-TM組合物之50:50混合物接種之小鼠之血清之中和效價,且分析ELISA效價與中和效價之間之相關性( 圖 7)。 Neutralization titers of sera from mice vaccinated with a 1 μg dose of the RBD-TM and NTD-RBD-TM composition and a 50:50 mixture of the NTD-TM and RBD-TM composition at a 2 μg dose were measured, And the correlation between ELISA titer and neutralization titer was analyzed ( Fig. 7 ).
由1 μg劑量之NTD-RBD-TM組合物或2 μg之NTD-TM及RBD-TM組合物之50:50混合物引發之效價大於由1 μg劑量之RBD-TM組合物引發之彼等效價(
表 20)。在刺突特異性IgG、RBD特異性IgG及NTD特異性IgG之中和效價及ELISA效價之間存在顯著之相關性(
圖 7)。
表 20.中和效價 - 平均值
將密碼子最佳化之野生型或D614G刺突基因(Wuhan-Hu-1株;NC_045512.2)選殖至pCAGGS載體中。為了產生基於VSVΔG之SARS-CoV-2假病毒,如先前所述(Whitt, 2010),用刺突表現質體及感染之VSVΔG-螢火蟲-螢光素酶轉染BHK-21/WI-2細胞。使用A549-hACE2-TMPRSS2細胞作為基於VSV∆G之SARS-CoV-2假病毒中和分析之靶細胞。製備編碼hACE2-P2A-TMPRSS2之慢病毒屬,以產生A549-hACE2-TMPRSS2細胞,將其維持在補充有10%胎牛血清及1 μg/mL嘌呤黴素(puromycin)之DMEM中。在37℃下用假病毒感染A549-hACE2-TMPRSS2細胞1小時。感染後除去接種病毒或病毒-抗體混合物。18小時後,將等體積之One-Glo試劑(Promega;E6120)添加至培養基中,使用BMG PHERastar-FS讀板儀讀數。中和程序及數據分析與上述基於慢病毒屬之假病毒中和分析中之相同。參見Whitt, M.A. (2010).
Journal of Virological Methods 169, 365-374。
實例 3. 兩個劑量後第 36 天之免疫原性數據 The codon-optimized wild-type or D614G spike gene (strain Wuhan-Hu-1; NC_045512.2) was cloned into the pCAGGS vector. To generate VSVΔG-based SARS-CoV-2 pseudoviruses, BHK-21/WI-2 cells were transfected with spike-expressing plastids and infected VSVΔG-firefly-luciferase as previously described (Whitt, 2010). . A549-hACE2-TMPRSS2 cells were used as target cells for the VSVΔG-based SARS-CoV-2 pseudovirus neutralization assay. A lentivirus encoding hACE2-P2A-TMPRSS2 was prepared to generate A549-hACE2-TMPRSS2 cells, which were maintained in DMEM supplemented with 10% fetal bovine serum and 1 μg/mL puromycin. A549-hACE2-TMPRSS2 cells were infected with pseudovirus for 1 hour at 37°C. The inoculum virus or virus-antibody mixture is removed after infection. After 18 hours, an equal volume of One-Glo reagent (Promega; E6120) was added to the medium and read using a BMG PHERastar-FS plate reader. The neutralization procedure and data analysis were the same as in the above-described lentivirus-based pseudovirus neutralization analysis. See Whitt, MA (2010). Journal of Virological Methods 169 , 365-374. Example 3. Immunogenicity data at
接種疫苗第一劑量後第22天,再次將
實例 2中所述之相同劑量之mRNA疫苗作為加强劑量投與給小鼠。自第36天血清藉由ELISA量測在加强劑量後產生之針對RBD抗原、NTD抗原、野生型(WT)刺突(S)蛋白及S2P蛋白(具有雙脯胺酸突變以穩定融合前構象之S蛋白)中之每一者之抗體之效價,且顯示如下。將由LNP中之mRNA編碼之RBD-TM及NTD-TM之兩種免疫原性組合物之50:50混合物在第22天以2 μg或0.2 μg總mRNA作為加强劑量投與給小鼠,且在第36天測定效價。參見
表 21。
On day 22 after the first dose of the vaccine, the same dose of mRNA vaccine described in Example 2 was again administered to the mice as a booster dose. Serum from
表 21中顯示之用由LNP中之mRNA編碼之RBD-TM、NTD-TM或NTD-RBD-TM免疫之小鼠之WT S蛋白效價指示,在誘導可識別且結合至SARS-CoV-2 WT S蛋白之抗體方面,兩個劑量在所有測試之劑量下皆係優異的。
表 21.SARS-CoV-2 WT S特異性IgG效價 - 幾何平均值
進一步分析來自用兩個劑量之由LNP中之mRNA編碼之RBD-TM、NTD-TM或NTD-RBD-TM免疫之小鼠之血清的抗體識別及結合SARS-CoV-2 S2P蛋白之能力。藉由ELISA使用S2P作為板上之抗原測定SARS-CoV-2 S2P蛋白之效價,且其示於下
表 22中。當S2P為抗原時,該等免疫原中之每一者誘導比當WT S蛋白為ELISA抗原時高得多之抗體效價。比較
表 21及
表 22。
表 22.SARS-CoV-2 S2P特異性IgG效價 - 幾何平均值
在
表 23中,免疫原係由LNP中之mRNA編碼之RBD-TM及NTD-TM之50:50混合物,且在一個劑量(第21天)及兩個劑量(第36天)後測定對WT S、RBD、NTD及S2P之效價。該等結果顯示,當免疫原係RBD-TM及NTD-TM以50:50混合之組合時,與相同劑量之個別抗原誘導之抗體效價相比,效價顯著增加。50:50混合物誘導對免疫抗原之良好效價,但令人驚訝的是,對WT S蛋白之效價甚至更佳且對S2P蛋白之效價極高。參見
表 23。
表 23.SARS-CoV-2抗原特異性IgG效價 - 幾何平均值
表 24顯示用RBD-TM及NTD-TM中之每一者作為編碼彼等抗原之mRNA進行免疫之結果。使用由mRNA免疫原編碼之蛋白質作為ELISA板上之抗原,量測每組8隻小鼠之幾何平均效價。同樣,當抗原作為調配於LNP中之mRNA投與時,兩種免疫原性組合物皆誘導對免疫抗原之高效價。在此情形中,兩個劑量在所有濃度下皆產生優異之抗體反應。然而,以每微克(μg)計,該等抗原之50:50混合物誘導之抗體反應係單獨投與抗原時之約10倍。比較
表 23及
表 24。
表 24.SARS-CoV-2 RBD及NTD結構域特異性IgG效價 - 幾何平均值
在第1天及第21天,以0.1及1 μg劑量將包含與RBD連接且由LNP中之mRNA編碼之NTD之融合蛋白作為免疫原性組合物投與給8隻小鼠之組。參見下
表 25。甚至編碼NTD-RBD-TM之融合蛋白形式之mRNA對個別結構域亦誘導極佳效價,該等效價高於當單一結構域為免疫抗原時之效價。對S2P蛋白之效價係對WT S蛋白之效價之約8倍。參見
表 25。
表 25.SARS-CoV-2 NTD-RBD-TM結構域特異性IgG 效價 - 幾何平均值
中和數據示於
表 26中。由mRNA編碼之S1-666-TM係使用S1子結構域之抗原,特別是SARS-CoV-2刺突蛋白之附接至跨膜結構域之殘基1-666。
表 26.第1天及第22天兩次免疫後第36天之平均中和效價.
將由LNP中之mRNA編碼之S1-666-TM (或刺突蛋白S之S1殘基1-666)在第1天作為初免免疫投與給小鼠,且在第22天作為加强劑量投與0.01 μg及0.1 μg (N =8)組。自第21天(加强前)及第36天(加强後)血清藉由ELISA量測加强劑量後產生之針對mRNA RBD、mRNA NTD及mRNA野生型(WT)刺突(S)蛋白(
圖 1)中每一者之抗體效價,且示於下
表 27中。
S1-666-TM (or S1 residues 1-666 of Spike protein S) encoded by mRNA in LNP was administered to mice as a prime immunization on
表 27中顯示之用由LNP中之mRNA編碼之S1-666-TM免疫之小鼠之WT S蛋白效價指示,在誘導可識別且結合至SARS-CoV-2 WT S蛋白之抗體方面,兩個劑量在所有測試之劑量下皆係優異的。令人驚訝的是,即使在S1中未發現2P突變(這是因為2P突變發生在S2中,而免疫原中不存在S2),當針對刺突蛋白之S2P形式量測時,誘導之效價亦最高。與其他構築體相似,NTD效價需要第二劑量升高。
表 27.SARS-CoV-2抗原特異性IgG效價 - 幾何平均值
在該重複實驗中,在接種第一劑量後第22天,再次向小鼠投與上述實例中所述相同劑量之mRNA疫苗作為加强劑量。接著在接種第一劑量後第36天藉由ELISA量測SARS-CoV-2刺突蛋白特異性IgG效價、SARS-CoV-2 S2P蛋白特異性IgG效價、SARS-CoV-2 RBD特異性IgG效價及SARS-CoV-2 NTD特異性IgG效價。In this replicate experiment, on day 22 after the first dose, mice were again administered the same dose of mRNA vaccine as described in the above example as a booster dose. The SARS-CoV-2 spike protein-specific IgG titers, SARS-CoV-2 S2P protein-specific IgG titers, SARS-CoV-2 RBD-specific IgG titers were then measured by ELISA on
結果顯示1 μg及0.1 μg劑量之mRNA RBD-TM、mRNA NTD-TM、mRNA NTD-RBD-TM組合物及含有1 μg或0.1 μg mRNA RBD-TM及mRNA NTD-TM組合物中之每一者之50:50混合物引發針對SARS-CoV-2刺突或SARS-CoV-2 S2P蛋白之高ELISA效價。 實例 6. 免疫原性研究 The results show 1 μg and 0.1 μg doses of mRNA RBD-TM, mRNA NTD-TM, mRNA NTD-RBD-TM compositions and compositions containing 1 μg or 0.1 μg of each of mRNA RBD-TM and mRNA NTD-TM The 50:50 mixture elicited high ELISA titers against the SARS-CoV-2 spike or the SARS-CoV-2 S2P protein. Example 6. Immunogenicity studies
將mRNA NTD-TM及mRNA RBD-TM之50:50混合物之免疫原性以如下劑量投與給小鼠:0.2 μg或2 μg總mRNA (0.1 μg或1 μg每一mRNA) (N=8)。在第1天投與初免劑量,且在第22天投與加强劑量。在第36天,使用ELISA來評價抗體與SARS-CoV-2穩定之融合前刺突蛋白(SARS-CoV-2 pre-S)之結合。將包括mRNA NTD-RBD-TM、mRNA RBD-TM及mRNA NTD-TM之以下疫苗組合物以如下劑量投與給小鼠:0.1 μg及0.01 μg (N=8)。測定GMT數據且示於下
表 28中。
表 28.S蛋白結構域融合及組合誘導之SARS-CoV-2刺突效價
將NTD-RBD-TM、mRNA NTD-RBD-TM之組合物以如下劑量投與給小鼠:0.1 μg及1 μg。在第1天投與初免劑量,且在第22天投與加强劑量。在第36天,評價S2P特異性IgG1及IgG2a之效價。參見
圖 8A-8C。截至第36天,在兩個劑量水準下,IgG2a之效價皆高於IgG1之量。參見
圖 8A。為了確定T細胞反應是否偏向Th1或Th2型反應,吾人繪製在第36天時間點之IgG2a/IgG1之比率。如
圖 8B中所示,NTD-RBD-TM組合物誘導抗體免疫反應,該抗體免疫反應明確地在Th1型反應中。Th2型反應在疫苗開發中係不利的,此乃因其與驅動疾病增强有關。
實例 8. 免疫原性研究 The composition of NTD-RBD-TM, mRNA NTD-RBD-TM was administered to mice at the following doses: 0.1 μg and 1 μg. The prime dose was administered on
將
表 29中列出之mRNA以如下劑量投與給小鼠:0.1 μg及1 μg (N =8)。在第1天投與初免劑量,且在第22天投與加强劑量。第21天及第36天在S2P包被之板上分析血清IgG效價。結果示於
表 29中。
表 29.
應理解,本文所述之任何mRNA序列可包括5' UTR及/或3' UTR。UTR序列可選自以下序列,或可使用其他已知UTR序列。亦應理解,本文所述之任何mRNA構築體可進一步包含聚(A)尾及/或端帽(例如,7mG(5')ppp(5')NlmpNp)。此外,儘管本文所述之許多mRNA及編碼之抗原序列包括信號肽及/或肽標籤(例如,C末端His標籤),但應理解,所指示之信號肽及/或肽標籤可用不同信號肽及/或肽標籤取代,或者可省略信號肽及/或肽標籤。

亦應理解,本文所述之開放閱讀框及/或相應胺基酸序列中之任一者可包括或排除信號序列。It is also understood that any of the open reading frames and/or corresponding amino acid sequences described herein may include or exclude signal sequences.
本文揭示之所有參考文獻、專利及專利申請皆關於其每一者所列舉之標的物以引用方式併入,其在一些情形下可涵蓋整個文件。All references, patents, and patent applications disclosed herein are incorporated by reference, which in some cases may cover the entire document, with respect to the subject matter recited in each of them.
除非明確指示相反含義,否則如本說明書及申請專利範圍中所用之不定冠詞「一(a及an)」應理解為意指「至少一個」。The indefinite articles "a (a and an)" as used in this specification and the scope of the claims should be understood to mean "at least one" unless the contrary meaning is expressly indicated.
亦應理解,除非明確指示相反含義,否則在本文所主張之包括一個以上步驟或動作之任何方法中,該方法之步驟或動作之順序不必受限於列舉該方法之步驟或動作之順序。It should also be understood that in any method claimed herein that includes more than one step or action, the order of the steps or actions of the method is not necessarily limited to the order in which the steps or actions of the method are listed, unless expressly indicated to the contrary.
在申請專利範圍中以及在上文說明書中,所有過渡片語(諸如「包含」、「包括」、「携載」、「具有」、「含有」、「涉及」、「容納」、「由...構成」及諸如此類)應理解爲係開放式的,亦即,意指包括但不限於。如美國專利局專利審查規程手册(United States Patent Office Manual of Patent Examining Procedures)第2111.03節所述,僅過渡片語「由……組成」及「基本上由……組成」分別應當係封閉式或半封閉式過渡片語。In the scope of the patent application and in the above specification, all transitional phrases (such as "comprising", "including", "carrying", "having", "containing", "involving", "containing", "by. .. constitutes" and the like) shall be construed as open ended, that is, meant to include, but not be limited to. As stated in Section 2111.03 of the United States Patent Office Manual of Patent Examining Procedures, only the transitional phrases "consisting of" and "consisting essentially of" should be closed or closed, respectively. Semi-closed transitional phrase.
在數值之前之術語「約」及「實質上」意指所列舉之數值之±10%。The terms "about" and "substantially" preceding a numerical value mean ±10% of the recited numerical value.
在提供值之範圍之情况下,本文具體考慮及闡述該範圍之上端及下端之間之每一值。Where a range of values is provided, each value between the upper and lower end of the range is specifically considered and set forth herein.
國際申請案號PCT/US2015/02740、PCT/US2016/043348、PCT/US2016/043332、PCT/US2016/058327、PCT/US2016/058324、PCT/US2016/058314、PCT/US2016/058310、PCT/US2016/058321、PCT/US2016/058297、PCT/US2016/058319及PCT/US2016/058314之整個內容以引用方式併入本文中。International application case numbers PCT/US2015/02740, PCT/US2016/043348, PCT/US2016/043332, PCT/US2016/058327, PCT/US2016/058324, PCT/US2016/058314, PCT/US2016/058310, PCT/US2016/ 058321, PCT/US2016/058297, PCT/US2016/058319, and PCT/US2016/058314 are incorporated herein by reference in their entirety.
圖 1由本發明之mRNA編碼之野生型及2P刺突蛋白抗原之示意圖;信號肽(SP),無填充;N末端結構域(NTD),有點的;受體結合結構域(RBD),向下對角條帶;子結構域1 (SD1),水平條帶;子結構域2 (SD2),波形;融合肽(FP),向上對角條帶;七肽重複區1 (HR1),編織形;七肽重複區2 (HR2),對角磚形;(TM),垂直條帶;及胞質尾區(CT),磚形。
圖 2A- 圖 2I顯示由實例1-3中所述之mRNA編碼之抗原之示例性綫性設計。
圖 3顯示圖2中繪示之抗原之序列比對。
圖 4顯示由實例4-6中所述之mRNA編碼之抗原之示例性綫性設計。
圖 5顯示本文所述之各種S1次單元抗原之序列比對。
圖 6A- 圖 6D顯示由實例7及8中所述之mRNA編碼之抗原之示例性綫性設計。
圖 7顯示中和與ELISA效價之相關性。
圖 8A- 圖 8C顯示用LNP中之編碼NTD-RBD-TM之mRNA對小鼠進行第1天初免及第21天加强劑量後第36天之血清IgG1效價及IgG2a效價。
Figure 1 Schematic representation of wild-type and 2P spike protein antigens encoded by mRNAs of the invention; signal peptide (SP), unfilled; N-terminal domain (NTD), dotted; receptor binding domain (RBD), down Diagonal band; subdomain 1 (SD1), horizontal band; subdomain 2 (SD2), vimentum; fusion peptide (FP), upward diagonal band; heptapeptide repeat 1 (HR1), braided ; heptapeptide repeat 2 (HR2), diagonal brick; (TM), vertical bars; and cytoplasmic tail (CT), brick. Figures 2A - 2I show exemplary linear designs of antigens encoded by mRNAs described in Examples 1-3. FIG. 3 shows a sequence alignment of the antigens depicted in FIG. 2 . Figure 4 shows an exemplary linear design of the antigens encoded by the mRNAs described in Examples 4-6. Figure 5 shows a sequence alignment of the various S1 subunit antigens described herein. 6A - 6D show exemplary linear designs of antigens encoded by mRNAs described in Examples 7 and 8. Figure 7 shows the correlation of neutralization with ELISA titers. Figures 8A - 8C show serum IgGl titers and IgG2a titers at
<![CDATA[<110> 美商現代公司(ModernaTX, Inc.)]]>
<![CDATA[<120> SARS-COV-2 MRNA結構域疫苗]]>
<![CDATA[<130> M1378.70157]]>
<![CDATA[<140> TW 110123289]]>
<![CDATA[<141> 2021-06-25]]>
<![CDATA[<150> US 63/063,137]]>
<![CDATA[<151> 2020-08-07]]>
<![CDATA[<150> US 63/044,330]]>
<![CDATA[<151> 2020-06-25]]>
<![CDATA[<160> 152]]>
<![CDATA[<170> PatentIn 3.5版]]>
<![CDATA[<210> 1]]>
<![CDATA[<211> 2216]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 1]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucauga 2100
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccucccc ccagccccuc 2160
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 2216
<![CDATA[<210> 2]]>
<![CDATA[<211> 57]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 2]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccacc 57
<![CDATA[<210> 3]]>
<![CDATA[<211> 2040]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 3]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
<![CDATA[<210> 4]]>
<![CDATA[<211> 119]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 4]]>
ugauaauagg cuggagccuc gguggccuag cuucuugccc cuugggccuc cccccagccc 60
cuccuccccu uccugcaccc guacccccgu ggucuuugaa uaaagucuga gugggcggc 119
<![CDATA[<210> 5]]>
<![CDATA[<211> 680]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 5]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser
675 680
<![CDATA[<210> 6]]>
<![CDATA[<211> 2729]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 6]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucagga 2100
ggaggcagcg gcggcgauau caucaagcuu cugaacgagc aaguuaacaa ggaaaugcag 2160
agcaguaauc ucuacaugag caugagcagc uggugcuaca cccacucccu ggacggagca 2220
ggccucuucc uguucgacca cgcagccgag gaguacgagc acgcuaagaa guugaucauu 2280
uucuugaacg agaacaacgu gcccgugcag cuaacgucaa ucagcgcacc ugagcacaag 2340
uucgagggcc ugacccagau cuuccagaag gccuacgaac acgaacagca caucuccgag 2400
agcaucaaca auauugugga ucacgcuauc aaguccaagg accacgcuac cuucaacuuc 2460
cugcaguggu acguggccga gcaacaugag gaggaggugc uguucaagga cauccuggac 2520
aagaucgagc ugaucgguaa ugagaaucac ggccuguacc uggccgacca guacgugaag 2580
ggcaucgcca agagccggaa gucaggcuca ugauaauagg cuggagccuc gguggccuag 2640
cuucuugccc cuugggccuc cccccagccc cuccuccccu uccugcaccc guacccccgu 2700
ggucuuugaa uaaagucuga gugggcggc 2729
<![CDATA[<210> 7]]>
<![CDATA[<211> 2553]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 7]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
ggaggaggca gcggcggcga uaucaucaag cuucugaacg agcaaguuaa caaggaaaug 2100
cagagcagua aucucuacau gagcaugagc agcuggugcu acacccacuc ccuggacgga 2160
gcaggccucu uccuguucga ccacgcagcc gaggaguacg agcacgcuaa gaaguugauc 2220
auuuucuuga acgagaacaa cgugcccgug cagcuaacgu caaucagcgc accugagcac 2280
aaguucgagg gccugaccca gaucuuccag aaggccuacg aacacgaaca gcacaucucc 2340
gagagcauca acaauauugu ggaucacgcu aucaagucca aggaccacgc uaccuucaac 2400
uuccugcagu gguacguggc cgagcaacau gaggaggagg ugcuguucaa ggacauccug 2460
gacaagaucg agcugaucgg uaaugagaau cacggccugu accuggccga ccaguacgug 2520
aagggcaucg ccaagagccg gaagucaggc uca 2553
<![CDATA[<210> 8]]>
<![CDATA[<211> 851]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 8]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Gly Gly Gly Ser Gly Gly Asp Ile
675 680 685
Ile Lys Leu Leu Asn Glu Gln Val Asn Lys Glu Met Gln Ser Ser Asn
690 695 700
Leu Tyr Met Ser Met Ser Ser Trp Cys Tyr Thr His Ser Leu Asp Gly
705 710 715 720
Ala Gly Leu Phe Leu Phe Asp His Ala Ala Glu Glu Tyr Glu His Ala
725 730 735
Lys Lys Leu Ile Ile Phe Leu Asn Glu Asn Asn Val Pro Val Gln Leu
740 745 750
Thr Ser Ile Ser Ala Pro Glu His Lys Phe Glu Gly Leu Thr Gln Ile
755 760 765
Phe Gln Lys Ala Tyr Glu His Glu Gln His Ile Ser Glu Ser Ile Asn
770 775 780
Asn Ile Val Asp His Ala Ile Lys Ser Lys Asp His Ala Thr Phe Asn
785 790 795 800
Phe Leu Gln Trp Tyr Val Ala Glu Gln His Glu Glu Glu Val Leu Phe
805 810 815
Lys Asp Ile Leu Asp Lys Ile Glu Leu Ile Gly Asn Glu Asn His Gly
820 825 830
Leu Tyr Leu Ala Asp Gln Tyr Val Lys Gly Ile Ala Lys Ser Arg Lys
835 840 845
Ser Gly Ser
850
<![CDATA[<210> 9]]>
<![CDATA[<211> 2762]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 9]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
ggcauccugc ccagcccugg caugcccgcu cugcugagcc uggugagccu gcugagcgug 120
cugcugaugg gcugcguggc ugagaccggc augcagaucu acgagggcaa gcugaccgca 180
gagggccugc gguucggcau cguggccagc cgcgccaacc acgcucuggu ggaccggcuu 240
guggagggcg cuaucgacgc caucgugaga cacggcggcc gggaagagga caucacccug 300
gugcgggugu gcggcagcug ggagauuccc gucgccgccg gagaacuggc ccggaaggag 360
gacaucgacg ccgugaucgc caucggcgug cugugcagag gcgccacgcc cagcuucgac 420
uacaucgcca gcgaggugag caagggccug gccgaccuga gccuggagcu gcggaagccc 480
aucaccuucg gcgugaucac cgccgacacc cuggagcagg ccaucgaggc cgcaggcacc 540
ugccacggca acaagggcug ggaagccgcc cugugcgcca ucgagauggc caaccuguuc 600
aagagccugc ggggcggaag uggaggcucu gguggcagcg gaggaucugg cggcggcacc 660
acccggaccc agcugccacc agccuacacc aacagcuuca cccggggcgu cuacuacccc 720
gacaaggugu uccggagcag cguccugcac agcacccagg accuguuccu gcccuucuuc 780
agcaacguga ccugguucca cgccauccac gugagcggca ccaacggcac caagcgguuc 840
gacaaccccg ugcugcccuu caacgacggc guguacuucg ccagcaccga gaagagcaac 900
aucauccggg gcuggaucuu cggcaccacc cuggacagca agacccagag ccugcugauc 960
gugaauaacg ccaccaacgu ggugaucaag gugugcgagu uccaguucug caacgacccc 1020
uuccugggcg uguacuacca caagaacaac aagagcugga uggagagcga guuccgggug 1080
uacagcagcg ccaacaacug caccuucgag uacgugagcc agcccuuccu gauggaccug 1140
gagggcaagc agggcaacuu caagaaccug cgggaguucg uguucaagaa caucgacggc 1200
uacuucaaga ucuacagcaa gcacacccca aucaaccugg ugcgggaucu gccccagggc 1260
uucucagccc uggagccccu gguggaccug cccaucggca ucaacaucac ccgguuccag 1320
acccugcugg cccugcaccg gagcuaccug accccaggcg acagcagcag cggguggaca 1380
gcaggcgcgg cugcuuacua cgugggcuac cugcagcccc ggaccuuccu gcugaaguac 1440
aacgagaacg gcaccaucac cgacgccgug gacugcgccc uggacccucu gagcgagacc 1500
aagugcaccc ugaagagcuu caccguggag aagggcaucu accagaccag caacuuccgg 1560
gugcagccca ccgagagcau cgugcgguuc cccaacauca ccaaccugug ccccuucggc 1620
gagguguuca acgccacccg guucgccagc guguacgccu ggaaccggaa gcggaucagc 1680
aacugcgugg ccgacuacag cgugcuguac aacagcgcca gcuucagcac cuucaagugc 1740
uacggcguga gccccaccaa gcugaacgac cugugcuuca ccaacgugua cgccgacagc 1800
uucgugaucc guggcgacga ggugcggcag aucgcacccg gccagacagg caagaucgcc 1860
gacuacaacu acaagcugcc cgacgacuuc accggcugcg ugaucgccug gaacagcaac 1920
aaccucgaca gcaagguggg cggcaacuac aacuaccugu accggcuguu ccggaagagc 1980
aaccugaagc ccuucgagcg ggacaucagc accgagaucu accaagccgg cuccaccccu 2040
ugcaacggcg uggagggcuu caacugcuac uucccucugc agagcuacgg cuuccagccc 2100
accaacggcg ugggcuacca gcccuaccgg gugguggugc ugagcuucga gcugcugcac 2160
gccccagcca ccgugugugg ccccaagaag agcaccaacc uggugaagaa caagugcgug 2220
aacuucaacu ucaacggccu uaccggcacc ggcgugcuga ccgagagcaa caagaaauuc 2280
cugcccuuuc agcaguucgg ccgggacauc gccgacacca ccgacgcugu gcgggauccc 2340
cagacccugg agauccugga caucaccccu ugcagcuucg gcggcgugag cgugaucacc 2400
ccaggcacca acaccagcaa ccagguggcc gugcuguacc aggacgugaa cugcaccgag 2460
gugcccgugg ccauccacgc cgaccagcug acacccaccu ggcgggucua cagcaccggc 2520
agcaacgugu uccagacccg ggccgguugc cugaucggcg ccgagcacgu gaacaacagc 2580
uacgagugcg acauccccau cggcgccggc aucugugcca gcuaccagac ccagaccaau 2640
ucaugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 2700
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 2760
gc 2762
<![CDATA[<210> 10]]>
<![CDATA[<211> 2586]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 10]]>
augggcaucc ugcccagccc uggcaugccc gcucugcuga gccuggugag ccugcugagc 60
gugcugcuga ugggcugcgu ggcugagacc ggcaugcaga ucuacgaggg caagcugacc 120
gcagagggcc ugcgguucgg caucguggcc agccgcgcca accacgcucu gguggaccgg 180
cuuguggagg gcgcuaucga cgccaucgug agacacggcg gccgggaaga ggacaucacc 240
cuggugcggg ugugcggcag cugggagauu cccgucgccg ccggagaacu ggcccggaag 300
gaggacaucg acgccgugau cgccaucggc gugcugugca gaggcgccac gcccagcuuc 360
gacuacaucg ccagcgaggu gagcaagggc cuggccgacc ugagccugga gcugcggaag 420
cccaucaccu ucggcgugau caccgccgac acccuggagc aggccaucga ggccgcaggc 480
accugccacg gcaacaaggg cugggaagcc gcccugugcg ccaucgagau ggccaaccug 540
uucaagagcc ugcggggcgg aaguggaggc ucugguggca gcggaggauc uggcggcggc 600
accacccgga cccagcugcc accagccuac accaacagcu ucacccgggg cgucuacuac 660
cccgacaagg uguuccggag cagcguccug cacagcaccc aggaccuguu ccugcccuuc 720
uucagcaacg ugaccugguu ccacgccauc cacgugagcg gcaccaacgg caccaagcgg 780
uucgacaacc ccgugcugcc cuucaacgac ggcguguacu ucgccagcac cgagaagagc 840
aacaucaucc ggggcuggau cuucggcacc acccuggaca gcaagaccca gagccugcug 900
aucgugaaua acgccaccaa cguggugauc aaggugugcg aguuccaguu cugcaacgac 960
cccuuccugg gcguguacua ccacaagaac aacaagagcu ggauggagag cgaguuccgg 1020
guguacagca gcgccaacaa cugcaccuuc gaguacguga gccagcccuu ccugauggac 1080
cuggagggca agcagggcaa cuucaagaac cugcgggagu ucguguucaa gaacaucgac 1140
ggcuacuuca agaucuacag caagcacacc ccaaucaacc uggugcggga ucugccccag 1200
ggcuucucag cccuggagcc ccugguggac cugcccaucg gcaucaacau cacccgguuc 1260
cagacccugc uggcccugca ccggagcuac cugaccccag gcgacagcag cagcgggugg 1320
acagcaggcg cggcugcuua cuacgugggc uaccugcagc cccggaccuu ccugcugaag 1380
uacaacgaga acggcaccau caccgacgcc guggacugcg cccuggaccc ucugagcgag 1440
accaagugca cccugaagag cuucaccgug gagaagggca ucuaccagac cagcaacuuc 1500
cgggugcagc ccaccgagag caucgugcgg uuccccaaca ucaccaaccu gugccccuuc 1560
ggcgaggugu ucaacgccac ccgguucgcc agcguguacg ccuggaaccg gaagcggauc 1620
agcaacugcg uggccgacua cagcgugcug uacaacagcg ccagcuucag caccuucaag 1680
ugcuacggcg ugagccccac caagcugaac gaccugugcu ucaccaacgu guacgccgac 1740
agcuucguga uccguggcga cgaggugcgg cagaucgcac ccggccagac aggcaagauc 1800
gccgacuaca acuacaagcu gcccgacgac uucaccggcu gcgugaucgc cuggaacagc 1860
aacaaccucg acagcaaggu gggcggcaac uacaacuacc uguaccggcu guuccggaag 1920
agcaaccuga agcccuucga gcgggacauc agcaccgaga ucuaccaagc cggcuccacc 1980
ccuugcaacg gcguggaggg cuucaacugc uacuucccuc ugcagagcua cggcuuccag 2040
cccaccaacg gcgugggcua ccagcccuac cggguggugg ugcugagcuu cgagcugcug 2100
cacgccccag ccaccgugug uggccccaag aagagcacca accuggugaa gaacaagugc 2160
gugaacuuca acuucaacgg ccuuaccggc accggcgugc ugaccgagag caacaagaaa 2220
uuccugcccu uucagcaguu cggccgggac aucgccgaca ccaccgacgc ugugcgggau 2280
ccccagaccc uggagauccu ggacaucacc ccuugcagcu ucggcggcgu gagcgugauc 2340
accccaggca ccaacaccag caaccaggug gccgugcugu accaggacgu gaacugcacc 2400
gaggugcccg uggccaucca cgccgaccag cugacaccca ccuggcgggu cuacagcacc 2460
ggcagcaacg uguuccagac ccgggccggu ugccugaucg gcgccgagca cgugaacaac 2520
agcuacgagu gcgacauccc caucggcgcc ggcaucugug ccagcuacca gacccagacc 2580
aauuca 2586
<![CDATA[<210> 11]]>
<![CDATA[<211> 862]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 11]]>
Met Gly Ile Leu Pro Ser Pro Gly Met Pro Ala Leu Leu Ser Leu Val
1 5 10 15
Ser Leu Leu Ser Val Leu Leu Met Gly Cys Val Ala Glu Thr Gly Met
20 25 30
Gln Ile Tyr Glu Gly Lys Leu Thr Ala Glu Gly Leu Arg Phe Gly Ile
35 40 45
Val Ala Ser Arg Ala Asn His Ala Leu Val Asp Arg Leu Val Glu Gly
50 55 60
Ala Ile Asp Ala Ile Val Arg His Gly Gly Arg Glu Glu Asp Ile Thr
65 70 75 80
Leu Val Arg Val Cys Gly Ser Trp Glu Ile Pro Val Ala Ala Gly Glu
85 90 95
Leu Ala Arg Lys Glu Asp Ile Asp Ala Val Ile Ala Ile Gly Val Leu
100 105 110
Cys Arg Gly Ala Thr Pro Ser Phe Asp Tyr Ile Ala Ser Glu Val Ser
115 120 125
Lys Gly Leu Ala Asp Leu Ser Leu Glu Leu Arg Lys Pro Ile Thr Phe
130 135 140
Gly Val Ile Thr Ala Asp Thr Leu Glu Gln Ala Ile Glu Ala Ala Gly
145 150 155 160
Thr Cys His Gly Asn Lys Gly Trp Glu Ala Ala Leu Cys Ala Ile Glu
165 170 175
Met Ala Asn Leu Phe Lys Ser Leu Arg Gly Gly Ser Gly Gly Ser Gly
180 185 190
Gly Ser Gly Gly Ser Gly Gly Gly Thr Thr Arg Thr Gln Leu Pro Pro
195 200 205
Ala Tyr Thr Asn Ser Phe Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val
210 215 220
Phe Arg Ser Ser Val Leu His Ser Thr Gln Asp Leu Phe Leu Pro Phe
225 230 235 240
Phe Ser Asn Val Thr Trp Phe His Ala Ile His Val Ser Gly Thr Asn
245 250 255
Gly Thr Lys Arg Phe Asp Asn Pro Val Leu Pro Phe Asn Asp Gly Val
260 265 270
Tyr Phe Ala Ser Thr Glu Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe
275 280 285
Gly Thr Thr Leu Asp Ser Lys Thr Gln Ser Leu Leu Ile Val Asn Asn
290 295 300
Ala Thr Asn Val Val Ile Lys Val Cys Glu Phe Gln Phe Cys Asn Asp
305 310 315 320
Pro Phe Leu Gly Val Tyr Tyr His Lys Asn Asn Lys Ser Trp Met Glu
325 330 335
Ser Glu Phe Arg Val Tyr Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr
340 345 350
Val Ser Gln Pro Phe Leu Met Asp Leu Glu Gly Lys Gln Gly Asn Phe
355 360 365
Lys Asn Leu Arg Glu Phe Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys
370 375 380
Ile Tyr Ser Lys His Thr Pro Ile Asn Leu Val Arg Asp Leu Pro Gln
385 390 395 400
Gly Phe Ser Ala Leu Glu Pro Leu Val Asp Leu Pro Ile Gly Ile Asn
405 410 415
Ile Thr Arg Phe Gln Thr Leu Leu Ala Leu His Arg Ser Tyr Leu Thr
420 425 430
Pro Gly Asp Ser Ser Ser Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr
435 440 445
Val Gly Tyr Leu Gln Pro Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn
450 455 460
Gly Thr Ile Thr Asp Ala Val Asp Cys Ala Leu Asp Pro Leu Ser Glu
465 470 475 480
Thr Lys Cys Thr Leu Lys Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln
485 490 495
Thr Ser Asn Phe Arg Val Gln Pro Thr Glu Ser Ile Val Arg Phe Pro
500 505 510
Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala Thr Arg
515 520 525
Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn Cys Val
530 535 540
Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys
545 550 555 560
Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn
565 570 575
Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg Gln Ile
580 585 590
Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro
595 600 605
Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn Leu Asp
610 615 620
Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys
625 630 635 640
Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln
645 650 655
Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe
660 665 670
Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln
675 680 685
Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala Pro Ala
690 695 700
Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn Lys Cys
705 710 715 720
Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu Thr Glu
725 730 735
Ser Asn Lys Lys Phe Leu Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala
740 745 750
Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp
755 760 765
Ile Thr Pro Cys Ser Phe Gly Gly Val Ser Val Ile Thr Pro Gly Thr
770 775 780
Asn Thr Ser Asn Gln Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr
785 790 795 800
Glu Val Pro Val Ala Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg
805 810 815
Val Tyr Ser Thr Gly Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu
820 825 830
Ile Gly Ala Glu His Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile
835 840 845
Gly Ala Gly Ile Cys Ala Ser Tyr Gln Thr Gln Thr Asn Ser
850 855 860
<![CDATA[<210> 12]]>
<![CDATA[<211> 2714]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 12]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucagga 2100
ggaggcuccg gaggcgguag cgcugagacc ggcaugcaga ucuacgaggg caagcugacc 2160
gcagagggcc ugcgguucgg caucguggcc agccgcgcca accacgcucu gguggaccgg 2220
cuuguggagg gcgcuaucga cgccaucgug agacacggcg gccgggaaga ggacaucacc 2280
cuggugcggg ugugcggcag cugggagauu cccgucgccg ccggagaacu ggcccggaag 2340
gaggacaucg acgccgugau cgccaucggc gugcugugca gaggcgccac gcccagcuuc 2400
gacuacaucg ccagcgaggu gagcaagggc cuggccgacc ugagccugga gcugcggaag 2460
cccaucaccu ucggcgugau caccgccgac acccuggagc aggccaucga ggccgcaggc 2520
accugccacg gcaacaaggg cugggaagcc gcccugugcg ccaucgagau ggccaaccug 2580
uucaagagcc ugcggugaua auaggcugga gccucggugg ccuagcuucu ugccccuugg 2640
gccucccccc agccccuccu ccccuuccug cacccguacc cccguggucu uugaauaaag 2700
ucugaguggg cggc 2714
<![CDATA[<210> 13]]>
<![CDATA[<211> 2538]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 13]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
ggaggaggcu ccggaggcgg uagcgcugag accggcaugc agaucuacga gggcaagcug 2100
accgcagagg gccugcgguu cggcaucgug gccagccgcg ccaaccacgc ucugguggac 2160
cggcuugugg agggcgcuau cgacgccauc gugagacacg gcggccggga agaggacauc 2220
acccuggugc gggugugcgg cagcugggag auucccgucg ccgccggaga acuggcccgg 2280
aaggaggaca ucgacgccgu gaucgccauc ggcgugcugu gcagaggcgc cacgcccagc 2340
uucgacuaca ucgccagcga ggugagcaag ggccuggccg accugagccu ggagcugcgg 2400
aagcccauca ccuucggcgu gaucaccgcc gacacccugg agcaggccau cgaggccgca 2460
ggcaccugcc acggcaacaa gggcugggaa gccgcccugu gcgccaucga gauggccaac 2520
cuguucaaga gccugcgg 2538
<![CDATA[<210> 14]]>
<![CDATA[<211> 846]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 14]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Gly Gly Gly Ser Gly Gly Gly Ser
675 680 685
Ala Glu Thr Gly Met Gln Ile Tyr Glu Gly Lys Leu Thr Ala Glu Gly
690 695 700
Leu Arg Phe Gly Ile Val Ala Ser Arg Ala Asn His Ala Leu Val Asp
705 710 715 720
Arg Leu Val Glu Gly Ala Ile Asp Ala Ile Val Arg His Gly Gly Arg
725 730 735
Glu Glu Asp Ile Thr Leu Val Arg Val Cys Gly Ser Trp Glu Ile Pro
740 745 750
Val Ala Ala Gly Glu Leu Ala Arg Lys Glu Asp Ile Asp Ala Val Ile
755 760 765
Ala Ile Gly Val Leu Cys Arg Gly Ala Thr Pro Ser Phe Asp Tyr Ile
770 775 780
Ala Ser Glu Val Ser Lys Gly Leu Ala Asp Leu Ser Leu Glu Leu Arg
785 790 795 800
Lys Pro Ile Thr Phe Gly Val Ile Thr Ala Asp Thr Leu Glu Gln Ala
805 810 815
Ile Glu Ala Ala Gly Thr Cys His Gly Asn Lys Gly Trp Glu Ala Ala
820 825 830
Leu Cys Ala Ile Glu Met Ala Asn Leu Phe Lys Ser Leu Arg
835 840 845
<![CDATA[<210> 15]]>
<![CDATA[<211> 2300]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 15]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucaucu 2100
ggcggaggca gcauccuggc caucuacagc accguggcca gcagccuggu gcugcuggug 2160
agccugggcg ccaucagcuu cugauaauag gcuggagccu cgguggccua gcuucuugcc 2220
ccuugggccu ccccccagcc ccuccucccc uuccugcacc cguacccccg uggucuuuga 2280
auaaagucug agugggcggc 2300
<![CDATA[<210> 16]]>
<![CDATA[<211> 2124]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 16]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
ucuggcggag gcagcauccu ggccaucuac agcaccgugg ccagcagccu ggugcugcug 2100
gugagccugg gcgccaucag cuuc 2124
<![CDATA[<210> 17]]>
<![CDATA[<211> 707]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 17]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Gly Gly Gly Ser Ile Leu Ala Ile
675 680 685
Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala
690 695 700
Ile Ser Phe
705
<![CDATA[<210> 18]]>
<![CDATA[<211> 1853]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 18]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc ucuggcggag gcagcauccu ggccaucuac 1680
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuucugauaa 1740
uaggcuggag ccucgguggc cuagcuucuu gccccuuggg ccucccccca gccccuccuc 1800
cccuuccugc acccguaccc ccguggucuu ugaauaaagu cugagugggc ggc 1853
<![CDATA[<210> 19]]>
<![CDATA[<211> 1677]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 19]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accucuggcg gaggcagcau ccuggccauc 1620
uacagcaccg uggccagcag ccuggugcug cuggugagcc ugggcgccau cagcuuc 1677
<![CDATA[<210> 20]]>
<![CDATA[<211> 559]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 20]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val
530 535 540
Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
545 550 555
<![CDATA[<210> 21]]>
<![CDATA[<211> 2042]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 21]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcu cuggcggagg cagcauccug 1860
gccaucuaca gcaccguggc cagcagccug gugcugcugg ugagccuggg cgccaucagc 1920
uucugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 1980
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 2040
gc 2042
<![CDATA[<210> 22]]>
<![CDATA[<211> 1866]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 22]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcucuggcgg aggcagcauc 1800
cuggccaucu acagcaccgu ggccagcagc cuggugcugc uggugagccu gggcgccauc 1860
agcuuc 1866
<![CDATA[<210> 23]]>
<![CDATA[<211> 622]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 23]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala
595 600 605
Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
610 615 620
<![CDATA[<210> 24]]>
<![CDATA[<211> 2066]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 24]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu gggcagcggc ggcggcagcg gcggaggcag cggaggaggc 1020
agcggcggag gcaguggagg ccagcccacc gagagcaucg ugcgguuccc caacaucacc 1080
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1140
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1200
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1260
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1320
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1380
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1440
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1500
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1560
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1620
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagaagag caccaaccug 1680
gugaagaaca agugcgugaa cuucaacuuc aacggccuua ccggcaccgg cgugcugacc 1740
gagagcaaca agaaauuccu gcccuuucag caguucggcc gggacaucgc cgacaccacc 1800
gacgcugugc gggaucccca gacccuggag auccuggaca ucaccccuug cagcuucggc 1860
ggcucuggcg gaggcagcau ccuggccauc uacagcaccg uggccagcag ccuggugcug 1920
cuggugagcc ugggcgccau cagcuucuga uaauaggcug gagccucggu ggccuagcuu 1980
cuugccccuu gggccucccc ccagccccuc cuccccuucc ugcacccgua cccccguggu 2040
cuuugaauaa agucugagug ggcggc 2066
<![CDATA[<210> 25]]>
<![CDATA[<211> 1890]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 25]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cgugggcagc ggcggcggca gcggcggagg cagcggagga 960
ggcagcggcg gaggcagugg aggccagccc accgagagca ucgugcgguu ccccaacauc 1020
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 1080
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1140
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1200
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1260
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1320
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1380
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1440
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1500
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1560
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaagaa gagcaccaac 1620
cuggugaaga acaagugcgu gaacuucaac uucaacggcc uuaccggcac cggcgugcug 1680
accgagagca acaagaaauu ccugcccuuu cagcaguucg gccgggacau cgccgacacc 1740
accgacgcug ugcgggaucc ccagacccug gagauccugg acaucacccc uugcagcuuc 1800
ggcggcucug gcggaggcag cauccuggcc aucuacagca ccguggccag cagccuggug 1860
cugcugguga gccugggcgc caucagcuuc 1890
<![CDATA[<210> 26]]>
<![CDATA[<211> 630]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 26]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly
305 310 315 320
Gly Ser Gly Gly Gly Ser Gly Gly Gln Pro Thr Glu Ser Ile Val Arg
325 330 335
Phe Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala
340 345 350
Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn
355 360 365
Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr
370 375 380
Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe
385 390 395 400
Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg
405 410 415
Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys
420 425 430
Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn
435 440 445
Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe
450 455 460
Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile
465 470 475 480
Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys
485 490 495
Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly
500 505 510
Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala
515 520 525
Pro Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn
530 535 540
Lys Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu
545 550 555 560
Thr Glu Ser Asn Lys Lys Phe Leu Pro Phe Gln Gln Phe Gly Arg Asp
565 570 575
Ile Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile
580 585 590
Leu Asp Ile Thr Pro Cys Ser Phe Gly Gly Ser Gly Gly Gly Ser Ile
595 600 605
Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser
610 615 620
Leu Gly Ala Ile Ser Phe
625 630
<![CDATA[<210> 27]]>
<![CDATA[<211> 2066]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 27]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
gugugccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu gggcagcggc ggcggcagcg gcggaggcag cggaggaggc 1020
agcggcggag gcaguggagg ccagcccacc gagagcaucg ugcgguuccc caacaucacc 1080
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1140
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1200
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1260
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1320
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1380
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1440
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1500
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1560
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1620
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagaagag caccaaccug 1680
gugaagaaca agugcgugaa cuucaacuuc aacggccuua ccggcaccgg cgugcugacc 1740
gagagcaaca agaaauuccu gcccuuuugc caguucggcc gggacaucgc cgacaccacc 1800
gacgcugugc gggaucccca gacccuggag auccuggaca ucaccccuug cagcuucggc 1860
ggcucuggcg gaggcagcau ccuggccauc uacagcaccg uggccagcag ccuggugcug 1920
cuggugagcc ugggcgccau cagcuucuga uaauaggcug gagccucggu ggccuagcuu 1980
cuugccccuu gggccucccc ccagccccuc cuccccuucc ugcacccgua cccccguggu 2040
cuuugaauaa agucugagug ggcggc 2066
<![CDATA[<210> 28]]>
<![CDATA[<211> 1890]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 28]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aaggugugcc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cgugggcagc ggcggcggca gcggcggagg cagcggagga 960
ggcagcggcg gaggcagugg aggccagccc accgagagca ucgugcgguu ccccaacauc 1020
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 1080
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1140
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1200
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1260
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1320
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1380
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1440
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1500
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1560
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaagaa gagcaccaac 1620
cuggugaaga acaagugcgu gaacuucaac uucaacggcc uuaccggcac cggcgugcug 1680
accgagagca acaagaaauu ccugcccuuu ugccaguucg gccgggacau cgccgacacc 1740
accgacgcug ugcgggaucc ccagacccug gagauccugg acaucacccc uugcagcuuc 1800
ggcggcucug gcggaggcag cauccuggcc aucuacagca ccguggccag cagccuggug 1860
cugcugguga gccugggcgc caucagcuuc 1890
<![CDATA[<210> 29]]>
<![CDATA[<211> 630]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 29]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Cys Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly
305 310 315 320
Gly Ser Gly Gly Gly Ser Gly Gly Gln Pro Thr Glu Ser Ile Val Arg
325 330 335
Phe Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala
340 345 350
Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn
355 360 365
Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr
370 375 380
Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe
385 390 395 400
Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg
405 410 415
Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys
420 425 430
Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn
435 440 445
Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe
450 455 460
Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile
465 470 475 480
Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys
485 490 495
Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly
500 505 510
Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala
515 520 525
Pro Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn
530 535 540
Lys Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu
545 550 555 560
Thr Glu Ser Asn Lys Lys Phe Leu Pro Phe Cys Gln Phe Gly Arg Asp
565 570 575
Ile Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile
580 585 590
Leu Asp Ile Thr Pro Cys Ser Phe Gly Gly Ser Gly Gly Gly Ser Ile
595 600 605
Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser
610 615 620
Leu Gly Ala Ile Ser Phe
625 630
<![CDATA[<210> 30]]>
<![CDATA[<211> 3182]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 30]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu cggcggcagc 1020
ggcggcguga gcgugaucac cccaggcacc aacaccagca accagguggc cgugcuguac 1080
caggacguga acugcaccga ggugcccgug gccauccacg ccgaccagcu gacacccacc 1140
uggcgggucu acagcaccgg cagcaacgug uuccagaccc gggccgguug ccugaucggc 1200
gccgagcacg ugaacaacag cuacgagugc gacaucccca ucggcgccgg caucugugcc 1260
agcuaccaga cccagaccaa uucaccccgg agggcaagga gcguggccag ccagagcauc 1320
aucgccuaca ccaugagccu gggcgccgag aacagcgugg ccuacagcaa caacagcauc 1380
gccaucccca ccaacuucac caucagcgug accaccgaga uucugcccgu gagcaugacc 1440
aagaccagcg uggacugcac cauguacauc ugcggcgaca gcaccgagug cagcaaccug 1500
cugcugcagu acggcagcuu cugcacccag cugaaccggg cccugaccgg caucgccgug 1560
gagcaggaca agaacaccca ggagguguuc gcccagguga agcagaucua caagaccccu 1620
cccaucaagg acuucggcgg cuucaacuuc agccagaucc ugcccgaccc cagcaagccc 1680
agcaagcgga gcuucaucga ggaccugcug uucaacaagg ugacccuagc cgacgccggc 1740
uucaucaagc aguacggcga cugccucggc gacauagccg cccgggaccu gaucugcgcc 1800
cagaaguuca acggccugac cgugcugccu ccccugcuga ccgacgagau gaucgcccag 1860
uacaccagcg cccuguuagc cggaaccauc accagcggcu ggacuuucgg cgcuggagcc 1920
gcucugcaga uccccuucgc caugcagaug gccuaccggu ucaacggcau cggcgugacc 1980
cagaacgugc uguacgagaa ccagaagcug aucgccaacc aguucaacag cgccaucggc 2040
aagauccagg acagccugag cagcaccgcu agcgcccugg gcaagcugca ggacguggug 2100
aaccagaacg cccaggcccu gaacacccug gugaagcagc ugagcagcaa cuucggcgcc 2160
aucagcagcg ugcugaacga cauccugagc cggcuggacc cucccaacgc caccgugcag 2220
aucgaccggc ugaucacugg ccggcugcag agccugcaga ccuacgugac ccagcagcug 2280
auccgggccg ccgagauucg ggccagcgcc aaccuggccg ccaccaagau gagcgagugc 2340
gugcugggcc agagcaagcg gguggacuuc ugcggcaagg gcuaccaccu gaugagcuuu 2400
ccccagagcg caccccacgg agugguguuc cugcacguga ccuacgugcc cgcccaggag 2460
aagaacuuca ccaccgcccc agccaucugc cacgacggca aggcccacuu uccccgggag 2520
ggcguguucg ugagcaacgg cacccacugg uucgugaccc agcggaacuu cuacgagccc 2580
cagaucauca ccaccgacaa caccuucgug agcggcaacu gcgacguggu gaucggcauc 2640
gugaacaaca ccguguacga uccccugcag cccgagcugg acagcuucaa ggaggagcug 2700
gacaaguacu ucaagaauca caccagcccc gacguggacc ugggcgacau cagcggcauc 2760
aacgccagcg uggugaacau ccagaaggag aucgaucggc ugaacgaggu ggccaagaac 2820
cugaacgaga gccugaucga ccugcaggag cugggcaagu acgagcagua caucaagugg 2880
cccugguaca ucuggcuggg cuucaucgcc ggccugaucg ccaucgugau ggugaccauc 2940
augcugugcu gcaugaccag cugcugcagc ugccugaagg gcuguugcag cugcggcagc 3000
ugcugcaagu ucgacgagga cgacagcgag cccgugcuga agggcgugaa gcugcacuac 3060
accugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 3120
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 3180
gc 3182
<![CDATA[<210> 31]]>
<![CDATA[<211> 3006]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 31]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuucggcggc 960
agcggcggcg ugagcgugau caccccaggc accaacacca gcaaccaggu ggccgugcug 1020
uaccaggacg ugaacugcac cgaggugccc guggccaucc acgccgacca gcugacaccc 1080
accuggcggg ucuacagcac cggcagcaac guguuccaga cccgggccgg uugccugauc 1140
ggcgccgagc acgugaacaa cagcuacgag ugcgacaucc ccaucggcgc cggcaucugu 1200
gccagcuacc agacccagac caauucaccc cggagggcaa ggagcguggc cagccagagc 1260
aucaucgccu acaccaugag ccugggcgcc gagaacagcg uggccuacag caacaacagc 1320
aucgccaucc ccaccaacuu caccaucagc gugaccaccg agauucugcc cgugagcaug 1380
accaagacca gcguggacug caccauguac aucugcggcg acagcaccga gugcagcaac 1440
cugcugcugc aguacggcag cuucugcacc cagcugaacc gggcccugac cggcaucgcc 1500
guggagcagg acaagaacac ccaggaggug uucgcccagg ugaagcagau cuacaagacc 1560
ccucccauca aggacuucgg cggcuucaac uucagccaga uccugcccga ccccagcaag 1620
cccagcaagc ggagcuucau cgaggaccug cuguucaaca aggugacccu agccgacgcc 1680
ggcuucauca agcaguacgg cgacugccuc ggcgacauag ccgcccggga ccugaucugc 1740
gcccagaagu ucaacggccu gaccgugcug ccuccccugc ugaccgacga gaugaucgcc 1800
caguacacca gcgcccuguu agccggaacc aucaccagcg gcuggacuuu cggcgcugga 1860
gccgcucugc agauccccuu cgccaugcag auggccuacc gguucaacgg caucggcgug 1920
acccagaacg ugcuguacga gaaccagaag cugaucgcca accaguucaa cagcgccauc 1980
ggcaagaucc aggacagccu gagcagcacc gcuagcgccc ugggcaagcu gcaggacgug 2040
gugaaccaga acgcccaggc ccugaacacc cuggugaagc agcugagcag caacuucggc 2100
gccaucagca gcgugcugaa cgacauccug agccggcugg acccucccaa cgccaccgug 2160
cagaucgacc ggcugaucac uggccggcug cagagccugc agaccuacgu gacccagcag 2220
cugauccggg ccgccgagau ucgggccagc gccaaccugg ccgccaccaa gaugagcgag 2280
ugcgugcugg gccagagcaa gcggguggac uucugcggca agggcuacca ccugaugagc 2340
uuuccccaga gcgcacccca cggaguggug uuccugcacg ugaccuacgu gcccgcccag 2400
gagaagaacu ucaccaccgc cccagccauc ugccacgacg gcaaggccca cuuuccccgg 2460
gagggcgugu ucgugagcaa cggcacccac ugguucguga cccagcggaa cuucuacgag 2520
ccccagauca ucaccaccga caacaccuuc gugagcggca acugcgacgu ggugaucggc 2580
aucgugaaca acaccgugua cgauccccug cagcccgagc uggacagcuu caaggaggag 2640
cuggacaagu acuucaagaa ucacaccagc cccgacgugg accugggcga caucagcggc 2700
aucaacgcca gcguggugaa cauccagaag gagaucgauc ggcugaacga gguggccaag 2760
aaccugaacg agagccugau cgaccugcag gagcugggca aguacgagca guacaucaag 2820
uggcccuggu acaucuggcu gggcuucauc gccggccuga ucgccaucgu gauggugacc 2880
aucaugcugu gcugcaugac cagcugcugc agcugccuga agggcuguug cagcugcggc 2940
agcugcugca aguucgacga ggacgacagc gagcccgugc ugaagggcgu gaagcugcac 3000
uacacc 3006
<![CDATA[<210> 32]]>
<![CDATA[<211> 1002]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 32]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Gly Gly
305 310 315 320
Ser Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln
325 330 335
Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala
340 345 350
Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly
355 360 365
Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His
370 375 380
Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys
385 390 395 400
Ala Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg Ala Arg Ser Val
405 410 415
Ala Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly Ala Glu Asn
420 425 430
Ser Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr Asn Phe Thr
435 440 445
Ile Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr Lys Thr Ser
450 455 460
Val Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu Cys Ser Asn
465 470 475 480
Leu Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn Arg Ala Leu
485 490 495
Thr Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu Val Phe Ala
500 505 510
Gln Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp Phe Gly Gly
515 520 525
Phe Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro Ser Lys Arg
530 535 540
Ser Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu Ala Asp Ala
545 550 555 560
Gly Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile Ala Ala Arg
565 570 575
Asp Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val Leu Pro Pro
580 585 590
Leu Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala Leu Leu Ala
595 600 605
Gly Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala Ala Leu Gln
610 615 620
Ile Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly Ile Gly Val
625 630 635 640
Thr Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala Asn Gln Phe
645 650 655
Asn Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser Ser Thr Ala Ser
660 665 670
Ala Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn Ala Gln Ala Leu
675 680 685
Asn Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly Ala Ile Ser Ser
690 695 700
Val Leu Asn Asp Ile Leu Ser Arg Leu Asp Pro Pro Asn Ala Thr Val
705 710 715 720
Gln Ile Asp Arg Leu Ile Thr Gly Arg Leu Gln Ser Leu Gln Thr Tyr
725 730 735
Val Thr Gln Gln Leu Ile Arg Ala Ala Glu Ile Arg Ala Ser Ala Asn
740 745 750
Leu Ala Ala Thr Lys Met Ser Glu Cys Val Leu Gly Gln Ser Lys Arg
755 760 765
Val Asp Phe Cys Gly Lys Gly Tyr His Leu Met Ser Phe Pro Gln Ser
770 775 780
Ala Pro His Gly Val Val Phe Leu His Val Thr Tyr Val Pro Ala Gln
785 790 795 800
Glu Lys Asn Phe Thr Thr Ala Pro Ala Ile Cys His Asp Gly Lys Ala
805 810 815
His Phe Pro Arg Glu Gly Val Phe Val Ser Asn Gly Thr His Trp Phe
820 825 830
Val Thr Gln Arg Asn Phe Tyr Glu Pro Gln Ile Ile Thr Thr Asp Asn
835 840 845
Thr Phe Val Ser Gly Asn Cys Asp Val Val Ile Gly Ile Val Asn Asn
850 855 860
Thr Val Tyr Asp Pro Leu Gln Pro Glu Leu Asp Ser Phe Lys Glu Glu
865 870 875 880
Leu Asp Lys Tyr Phe Lys Asn His Thr Ser Pro Asp Val Asp Leu Gly
885 890 895
Asp Ile Ser Gly Ile Asn Ala Ser Val Val Asn Ile Gln Lys Glu Ile
900 905 910
Asp Arg Leu Asn Glu Val Ala Lys Asn Leu Asn Glu Ser Leu Ile Asp
915 920 925
Leu Gln Glu Leu Gly Lys Tyr Glu Gln Tyr Ile Lys Trp Pro Trp Tyr
930 935 940
Ile Trp Leu Gly Phe Ile Ala Gly Leu Ile Ala Ile Val Met Val Thr
945 950 955 960
Ile Met Leu Cys Cys Met Thr Ser Cys Cys Ser Cys Leu Lys Gly Cys
965 970 975
Cys Ser Cys Gly Ser Cys Cys Lys Phe Asp Glu Asp Asp Ser Glu Pro
980 985 990
Val Leu Lys Gly Val Lys Leu His Tyr Thr
995 1000
<![CDATA[<210> 33]]>
<![CDATA[<211> 2378]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 33]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagg gcaccaucac cgacgccgug 120
gacugcgccc uggacccucu gagcgagacc aagugcaccc ugaagagcuu caccguggag 180
aagggcaucu accagaccag caacuucggc ggcagcggcg gcgugagcgu gaucacccca 240
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 300
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 360
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 420
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 480
ccccggaggg caaggagcgu ggccagccag agcaucaucg ccuacaccau gagccugggc 540
gccgagaaca gcguggccua cagcaacaac agcaucgcca uccccaccaa cuucaccauc 600
agcgugacca ccgagauucu gcccgugagc augaccaaga ccagcgugga cugcaccaug 660
uacaucugcg gcgacagcac cgagugcagc aaccugcugc ugaacuacac cagcuucugc 720
acccagcuga accgggcccu gaccggcauc gccguggagc aggacaagaa cacccaggag 780
guguucgccc aggugaagca gaucuacaag accccuccca ucaaggacuu cggcggcuuc 840
aacuucagcc agauccugcc cgaccccagc aagcccagca agcggagcuu caucgaggac 900
cugcuguuca acaaggugac ccuagccgac gccggcuuca ucaagcagua cggcgacugc 960
cucggcgaca uagccgcccg ggaccugauc ugcgcccaga aguucaacgg ccugaccgug 1020
cugccucccc ugcugaccga cgagaugauc gcccaguaca ccagcgcccu guuagccgga 1080
accaucacca gcggcuggac uuucggcgcu ggagccgcuc ugcagauccc cuucgccaug 1140
cagauggccu accgguucaa cggcaucggc gugacccaga acgugcugua cgagaaccag 1200
aagcugaucg ccaaccaguu caacagcgcc aucggcaaga uccaggacag ccugagcagc 1260
accgcuagcg cccugggcaa gcugcaggac guggugaacc agaacgccca ggcccugaac 1320
acccugguga agcagcugag cagcaacuuc ggcgccauca gcagcgugcu gaacgacauc 1380
cugagccggc uggacccucc caacgccacc gugcagaucg accggcugau cacuggccgg 1440
cugcagagcc ugcagaccua cgugacccag cagcugaucc gggccgccga gauucgggcc 1500
agcgccaacc uggccgccac caagaugagc gagugcgugc ugggccagag caagcgggug 1560
gacuucugcg gcaagggcua ccaccugaug agcuuucccc agagcgcacc ccacggagug 1620
guguuccugc acgugaccua cgugcccgcc caggagaaga acuucaccac cgccccagcc 1680
aucugccacg acggcaaggc ccacuuuccc cgggagggcg uguucgugag caacggcacc 1740
cacugguucg ugacccagcg gaacuucuac gagccccaga ucaucaccac cgacaacacc 1800
uucgugagcg gcaacugcga cguggugauc ggcaucguga acaacaccgu guacgauccc 1860
cugcagcccg agcuggacag cuucaaggag gagcuggaca aguacuucaa gaaucacacc 1920
agccccgacg uggaccuggg cgacaucagc ggcaucaacg ccagcguggu gaacauccag 1980
aaggagaucg aucggcugaa cgagguggcc aagaaccuga acgagagccu gaucgaccug 2040
caggagcugg gcaaguacga gcaguacauc aaguggcccu gguacaucug gcugggcuuc 2100
aucgccggcc ugaucgccau cgugauggug accaucaugc ugugcugcau gaccagcugc 2160
ugcagcugcc ugaagggcug uugcagcugc ggcagcugcu gcaaguucga cgaggacgac 2220
agcgagcccg ugcugaaggg cgugaagcug cacuacaccu gauaauaggc uggagccucg 2280
guggccuagc uucuugcccc uugggccucc ccccagcccc uccuccccuu ccugcacccg 2340
uacccccgug gucuuugaau aaagucugag ugggcggc 2378
<![CDATA[<210> 34]]>
<![CDATA[<211> 2202]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 34]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agggcaccau caccgacgcc 60
guggacugcg cccuggaccc ucugagcgag accaagugca cccugaagag cuucaccgug 120
gagaagggca ucuaccagac cagcaacuuc ggcggcagcg gcggcgugag cgugaucacc 180
ccaggcacca acaccagcaa ccagguggcc gugcuguacc aggacgugaa cugcaccgag 240
gugcccgugg ccauccacgc cgaccagcug acacccaccu ggcgggucua cagcaccggc 300
agcaacgugu uccagacccg ggccgguugc cugaucggcg ccgagcacgu gaacaacagc 360
uacgagugcg acauccccau cggcgccggc aucugugcca gcuaccagac ccagaccaau 420
ucaccccgga gggcaaggag cguggccagc cagagcauca ucgccuacac caugagccug 480
ggcgccgaga acagcguggc cuacagcaac aacagcaucg ccauccccac caacuucacc 540
aucagcguga ccaccgagau ucugcccgug agcaugacca agaccagcgu ggacugcacc 600
auguacaucu gcggcgacag caccgagugc agcaaccugc ugcugaacua caccagcuuc 660
ugcacccagc ugaaccgggc ccugaccggc aucgccgugg agcaggacaa gaacacccag 720
gagguguucg cccaggugaa gcagaucuac aagaccccuc ccaucaagga cuucggcggc 780
uucaacuuca gccagauccu gcccgacccc agcaagccca gcaagcggag cuucaucgag 840
gaccugcugu ucaacaaggu gacccuagcc gacgccggcu ucaucaagca guacggcgac 900
ugccucggcg acauagccgc ccgggaccug aucugcgccc agaaguucaa cggccugacc 960
gugcugccuc cccugcugac cgacgagaug aucgcccagu acaccagcgc ccuguuagcc 1020
ggaaccauca ccagcggcug gacuuucggc gcuggagccg cucugcagau ccccuucgcc 1080
augcagaugg ccuaccgguu caacggcauc ggcgugaccc agaacgugcu guacgagaac 1140
cagaagcuga ucgccaacca guucaacagc gccaucggca agauccagga cagccugagc 1200
agcaccgcua gcgcccuggg caagcugcag gacgugguga accagaacgc ccaggcccug 1260
aacacccugg ugaagcagcu gagcagcaac uucggcgcca ucagcagcgu gcugaacgac 1320
auccugagcc ggcuggaccc ucccaacgcc accgugcaga ucgaccggcu gaucacuggc 1380
cggcugcaga gccugcagac cuacgugacc cagcagcuga uccgggccgc cgagauucgg 1440
gccagcgcca accuggccgc caccaagaug agcgagugcg ugcugggcca gagcaagcgg 1500
guggacuucu gcggcaaggg cuaccaccug augagcuuuc cccagagcgc accccacgga 1560
gugguguucc ugcacgugac cuacgugccc gcccaggaga agaacuucac caccgcccca 1620
gccaucugcc acgacggcaa ggcccacuuu ccccgggagg gcguguucgu gagcaacggc 1680
acccacuggu ucgugaccca gcggaacuuc uacgagcccc agaucaucac caccgacaac 1740
accuucguga gcggcaacug cgacguggug aucggcaucg ugaacaacac cguguacgau 1800
ccccugcagc ccgagcugga cagcuucaag gaggagcugg acaaguacuu caagaaucac 1860
accagccccg acguggaccu gggcgacauc agcggcauca acgccagcgu ggugaacauc 1920
cagaaggaga ucgaucggcu gaacgaggug gccaagaacc ugaacgagag ccugaucgac 1980
cugcaggagc ugggcaagua cgagcaguac aucaaguggc ccugguacau cuggcugggc 2040
uucaucgccg gccugaucgc caucgugaug gugaccauca ugcugugcug caugaccagc 2100
ugcugcagcu gccugaaggg cuguugcagc ugcggcagcu gcugcaaguu cgacgaggac 2160
gacagcgagc ccgugcugaa gggcgugaag cugcacuaca cc 2202
<![CDATA[<210> 35]]>
<![CDATA[<211> 734]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 35]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Gly Thr
1 5 10 15
Ile Thr Asp Ala Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys
20 25 30
Cys Thr Leu Lys Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser
35 40 45
Asn Phe Gly Gly Ser Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn
50 55 60
Thr Ser Asn Gln Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu
65 70 75 80
Val Pro Val Ala Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val
85 90 95
Tyr Ser Thr Gly Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile
100 105 110
Gly Ala Glu His Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly
115 120 125
Ala Gly Ile Cys Ala Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg
130 135 140
Ala Arg Ser Val Ala Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu
145 150 155 160
Gly Ala Glu Asn Ser Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro
165 170 175
Thr Asn Phe Thr Ile Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met
180 185 190
Thr Lys Thr Ser Val Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr
195 200 205
Glu Cys Ser Asn Leu Leu Leu Asn Tyr Thr Ser Phe Cys Thr Gln Leu
210 215 220
Asn Arg Ala Leu Thr Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln
225 230 235 240
Glu Val Phe Ala Gln Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys
245 250 255
Asp Phe Gly Gly Phe Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys
260 265 270
Pro Ser Lys Arg Ser Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr
275 280 285
Leu Ala Asp Ala Gly Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp
290 295 300
Ile Ala Ala Arg Asp Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr
305 310 315 320
Val Leu Pro Pro Leu Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser
325 330 335
Ala Leu Leu Ala Gly Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly
340 345 350
Ala Ala Leu Gln Ile Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn
355 360 365
Gly Ile Gly Val Thr Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile
370 375 380
Ala Asn Gln Phe Asn Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser
385 390 395 400
Ser Thr Ala Ser Ala Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn
405 410 415
Ala Gln Ala Leu Asn Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly
420 425 430
Ala Ile Ser Ser Val Leu Asn Asp Ile Leu Ser Arg Leu Asp Pro Pro
435 440 445
Asn Ala Thr Val Gln Ile Asp Arg Leu Ile Thr Gly Arg Leu Gln Ser
450 455 460
Leu Gln Thr Tyr Val Thr Gln Gln Leu Ile Arg Ala Ala Glu Ile Arg
465 470 475 480
Ala Ser Ala Asn Leu Ala Ala Thr Lys Met Ser Glu Cys Val Leu Gly
485 490 495
Gln Ser Lys Arg Val Asp Phe Cys Gly Lys Gly Tyr His Leu Met Ser
500 505 510
Phe Pro Gln Ser Ala Pro His Gly Val Val Phe Leu His Val Thr Tyr
515 520 525
Val Pro Ala Gln Glu Lys Asn Phe Thr Thr Ala Pro Ala Ile Cys His
530 535 540
Asp Gly Lys Ala His Phe Pro Arg Glu Gly Val Phe Val Ser Asn Gly
545 550 555 560
Thr His Trp Phe Val Thr Gln Arg Asn Phe Tyr Glu Pro Gln Ile Ile
565 570 575
Thr Thr Asp Asn Thr Phe Val Ser Gly Asn Cys Asp Val Val Ile Gly
580 585 590
Ile Val Asn Asn Thr Val Tyr Asp Pro Leu Gln Pro Glu Leu Asp Ser
595 600 605
Phe Lys Glu Glu Leu Asp Lys Tyr Phe Lys Asn His Thr Ser Pro Asp
610 615 620
Val Asp Leu Gly Asp Ile Ser Gly Ile Asn Ala Ser Val Val Asn Ile
625 630 635 640
Gln Lys Glu Ile Asp Arg Leu Asn Glu Val Ala Lys Asn Leu Asn Glu
645 650 655
Ser Leu Ile Asp Leu Gln Glu Leu Gly Lys Tyr Glu Gln Tyr Ile Lys
660 665 670
Trp Pro Trp Tyr Ile Trp Leu Gly Phe Ile Ala Gly Leu Ile Ala Ile
675 680 685
Val Met Val Thr Ile Met Leu Cys Cys Met Thr Ser Cys Cys Ser Cys
690 695 700
Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys Lys Phe Asp Glu Asp
705 710 715 720
Asp Ser Glu Pro Val Leu Lys Gly Val Lys Leu His Tyr Thr
725 730
<![CDATA[<210> 36]]>
<![CDATA[<211> 4241]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 36]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uuccugauca ucuucauccu gcccaccacc cuggccguga ucggcgacuu caacugcacc 120
aacagcuuca ucaacgacua caacaagacc aucccucgga ucagcgaaga cgugguggac 180
gugucccugg gccugggcac cuacuacgug cugaaccggg uguaccugaa caccacacug 240
cuguucaccg gcuacuuccc caagagcggc gccaacuucc gggaccuggc ccugaagggc 300
agcaucuacc ugagcaccuu gugguacaag ccucccuucc ugagcgacuu caauaacggc 360
aucuucucua aggugaagaa caccaagcug uacguaaaca acacccugua cagcgaguuc 420
agcaccaucg ugaucggcag cguguucguc aacaccagcu acaccaucgu ggugcagccc 480
cacaacggca uccuggagau caccgccugc caguacacca ugugcgagua cccucacacc 540
gugugcaaga gcaagggcuc cauccggaac gagagcuggc acaucgacag cagcgagccg 600
cugugccugu ucaagaagaa cuucaccuac aacgugagcg ccgacuggcu guacuuccac 660
uucuaccagg agcggggcgu guucuacgcc uacuacgccg acgugggcau gccaaccacc 720
uuccuguuca gccuguaccu gggcaccauc cugagccacu acuacgugau gccccugacc 780
ugcaacgcca ucagcucaaa caccgacaac gagacccugg aguacugggu gacuccacug 840
agccggcggc aguaccugcu gaacuucgac gagcacggcg ugaucaccaa cgccguggac 900
ugcgcccugg acccucugag cgagaccaag ugcacccuga agagcuucac cguggagaag 960
ggcaucuacc agaccagcgg cuucaccgug aagcccguag ccaccgugua ccggcggauc 1020
cccaaccugc ccgacugcga caucgacaac uggcugaaca acgucagcgu gcccagccca 1080
cugaacuggg agcggcggau cuucagcaac ugcaacuuca aucugagcac ccugcugcgg 1140
cuggugcacg uggacagcuu cagcugcaac aaccuggaca agagcaagau cuucgguagc 1200
ugcuucaaca gcaucaccgu ggacaaguuc gccaucccua accggcggcg ggacgaucug 1260
cagcugggca gcagcggcuu ccugcagagc agcaacuaca agaucgacau cagcagcuca 1320
agcugccagc uguacuacag ccugccccug gugaacguga ccaucaacaa cuucaacccc 1380
agcagcugga accggcggua cggcuucggc agcuucaacc ugagcagcua cgacguggug 1440
uacagcgacc acugcuucag cgugaacagc gacuucugcc ccugugccga cccuagcgug 1500
gugaacagcu gcgccaagag caagccuccc agcgccauuu gccccgccgg caccaaguac 1560
cggcacugcg accuggacac cacccuguac gugaagaacu ggugccggug cagcugccug 1620
cccgacccca ucagcaccua cagccccaac accugucccc agaagaaggu gguggugggu 1680
aucggcgagc acugucccgg ccugggcauc aacgaggaga agugcggcac ccagcugaac 1740
cacagcagcu gcuucuguag ccccgacgcc uuccugggcu ggagcuucga cagcugcauc 1800
agcaacaacc ggugcaacau cuuuagcaac uucaucuuca acggaaucaa cagcggcacc 1860
accugcagca acgaccugcu guauagcaac accgagauca gcaccggcgu gugcgugaac 1920
uacgaccugu acggcaucac cggccagggc aucuucaagg aggugagcgc cgccuacuac 1980
aacaacuggc agaaccugcu guacgacagc aacggcaaca ucaucggcuu caaggacuuu 2040
cugaccaaca agaccuacac cauccugccc ugcuacagcg gcggcgugag cgugaucacc 2100
ccaggcacca acaccagcaa ccagguggcc gugcuguacc aggacgugaa cugcaccgag 2160
gugcccgugg ccauccacgc cgaccagcug acacccaccu ggcgggucua cagcaccggc 2220
agcaacgugu uccagacccg ggccgguugc cugaucggcg ccgagcacgu gaacaacagc 2280
uacgagugcg acauccccau cggcgccggc aucugugcca gcuaccagac ccagaccaau 2340
ucaccccgga gggcaaggag cguggccagc cagagcauca ucgccuacac caugagccug 2400
ggcgccgaga acagcguggc cuacagcaac aacagcaucg ccauccccac caacuucacc 2460
aucagcguga ccaccgagau ucugcccgug agcaugacca agaccagcgu ggacugcacc 2520
auguacaucu gcggcgacag caccgagugc agcaaccugc ugcugcagua cggcagcuuc 2580
ugcacccagc ugaaccgggc ccugaccggc aucgccgugg agcaggacaa gaacacccag 2640
gagguguucg cccaggugaa gcagaucuac aagaccccuc ccaucaagga cuucggcggc 2700
uucaacuuca gccagauccu gcccgacccc agcaagccca gcaagcggag cuucaucgag 2760
gaccugcugu ucaacaaggu gacccuagcc gacgccggcu ucaucaagca guacggcgac 2820
ugccucggcg acauagccgc ccgggaccug aucugcgccc agaaguucaa cggccugacc 2880
gugcugccuc cccugcugac cgacgagaug aucgcccagu acaccagcgc ccuguuagcc 2940
ggaaccauca ccagcggcug gacuuucggc gcuggagccg cucugcagau ccccuucgcc 3000
augcagaugg ccuaccgguu caacggcauc ggcgugaccc agaacgugcu guacgagaac 3060
cagaagcuga ucgccaacca guucaacagc gccaucggca agauccagga cagccugagc 3120
agcaccgcua gcgcccuggg caagcugcag gacgugguga accagaacgc ccaggcccug 3180
aacacccugg ugaagcagcu gagcagcaac uucggcgcca ucagcagcgu gcugaacgac 3240
auccugagcc ggcuggaccc ucccgaggcc gaggugcaga ucgaccggcu gaucacuggc 3300
cggcugcaga gccugcagac cuacgugacc cagcagcuga uccgggccgc cgagauucgg 3360
gccagcgcca accuggccgc caccaagaug agcgagugcg ugcugggcca gagcaagcgg 3420
guggacuucu gcggcaaggg cuaccaccug augagcuuuc cccagagcgc accccacgga 3480
gugguguucc ugcacgugac cuacgugccc gcccaggaga agaacuucac caccgcccca 3540
gccaucugcc acgacggcaa ggcccacuuu ccccgggagg gcguguucgu gagcaacggc 3600
acccacuggu ucgugaccca gcggaacuuc uacgagcccc agaucaucac caccgacaac 3660
accuucguga gcggcaacug cgacguggug aucggcaucg ugaacaacac cguguacgau 3720
ccccugcagc ccgagcugga cagcuucaag gaggagcugg acaaguacuu caagaaucac 3780
accagccccg acguggaccu gggcgacauc agcggcauca acgccagcgu ggugaacauc 3840
cagaaggaga ucgaucggcu gaacgaggug gccaagaacc ugaacgagag ccugaucgac 3900
cugcaggagc ugggcaagua cgagcaguac aucaaguggc ccugguacau cuggcugggc 3960
uucaucgccg gccugaucgc caucgugaug gugaccauca ugcugugcug caugaccagc 4020
ugcugcagcu gccugaaggg cuguugcagc ugcggcagcu gcugcaaguu cgacgaggac 4080
gacagcgagc ccgugcugaa gggcgugaag cugcacuaca ccugauaaua ggcuggagcc 4140
ucgguggccu agcuucuugc cccuugggcc uccccccagc cccuccuccc cuuccugcac 4200
ccguaccccc guggucuuug aauaaagucu gagugggcgg c 4241
<![CDATA[<210> 37]]>
<![CDATA[<211> 4065]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 37]]>
auguuccuga ucaucuucau ccugcccacc acccuggccg ugaucggcga cuucaacugc 60
accaacagcu ucaucaacga cuacaacaag accaucccuc ggaucagcga agacguggug 120
gacguguccc ugggccuggg caccuacuac gugcugaacc ggguguaccu gaacaccaca 180
cugcuguuca ccggcuacuu ccccaagagc ggcgccaacu uccgggaccu ggcccugaag 240
ggcagcaucu accugagcac cuugugguac aagccucccu uccugagcga cuucaauaac 300
ggcaucuucu cuaaggugaa gaacaccaag cuguacguaa acaacacccu guacagcgag 360
uucagcacca ucgugaucgg cagcguguuc gucaacacca gcuacaccau cguggugcag 420
ccccacaacg gcauccugga gaucaccgcc ugccaguaca ccaugugcga guacccucac 480
accgugugca agagcaaggg cuccauccgg aacgagagcu ggcacaucga cagcagcgag 540
ccgcugugcc uguucaagaa gaacuucacc uacaacguga gcgccgacug gcuguacuuc 600
cacuucuacc aggagcgggg cguguucuac gccuacuacg ccgacguggg caugccaacc 660
accuuccugu ucagccugua ccugggcacc auccugagcc acuacuacgu gaugccccug 720
accugcaacg ccaucagcuc aaacaccgac aacgagaccc uggaguacug ggugacucca 780
cugagccggc ggcaguaccu gcugaacuuc gacgagcacg gcgugaucac caacgccgug 840
gacugcgccc uggacccucu gagcgagacc aagugcaccc ugaagagcuu caccguggag 900
aagggcaucu accagaccag cggcuucacc gugaagcccg uagccaccgu guaccggcgg 960
auccccaacc ugcccgacug cgacaucgac aacuggcuga acaacgucag cgugcccagc 1020
ccacugaacu gggagcggcg gaucuucagc aacugcaacu ucaaucugag cacccugcug 1080
cggcuggugc acguggacag cuucagcugc aacaaccugg acaagagcaa gaucuucggu 1140
agcugcuuca acagcaucac cguggacaag uucgccaucc cuaaccggcg gcgggacgau 1200
cugcagcugg gcagcagcgg cuuccugcag agcagcaacu acaagaucga caucagcagc 1260
ucaagcugcc agcuguacua cagccugccc cuggugaacg ugaccaucaa caacuucaac 1320
cccagcagcu ggaaccggcg guacggcuuc ggcagcuuca accugagcag cuacgacgug 1380
guguacagcg accacugcuu cagcgugaac agcgacuucu gccccugugc cgacccuagc 1440
guggugaaca gcugcgccaa gagcaagccu cccagcgcca uuugccccgc cggcaccaag 1500
uaccggcacu gcgaccugga caccacccug uacgugaaga acuggugccg gugcagcugc 1560
cugcccgacc ccaucagcac cuacagcccc aacaccuguc cccagaagaa ggugguggug 1620
gguaucggcg agcacugucc cggccugggc aucaacgagg agaagugcgg cacccagcug 1680
aaccacagca gcugcuucug uagccccgac gccuuccugg gcuggagcuu cgacagcugc 1740
aucagcaaca accggugcaa caucuuuagc aacuucaucu ucaacggaau caacagcggc 1800
accaccugca gcaacgaccu gcuguauagc aacaccgaga ucagcaccgg cgugugcgug 1860
aacuacgacc uguacggcau caccggccag ggcaucuuca aggaggugag cgccgccuac 1920
uacaacaacu ggcagaaccu gcuguacgac agcaacggca acaucaucgg cuucaaggac 1980
uuucugacca acaagaccua caccauccug cccugcuaca gcggcggcgu gagcgugauc 2040
accccaggca ccaacaccag caaccaggug gccgugcugu accaggacgu gaacugcacc 2100
gaggugcccg uggccaucca cgccgaccag cugacaccca ccuggcgggu cuacagcacc 2160
ggcagcaacg uguuccagac ccgggccggu ugccugaucg gcgccgagca cgugaacaac 2220
agcuacgagu gcgacauccc caucggcgcc ggcaucugug ccagcuacca gacccagacc 2280
aauucacccc ggagggcaag gagcguggcc agccagagca ucaucgccua caccaugagc 2340
cugggcgccg agaacagcgu ggccuacagc aacaacagca ucgccauccc caccaacuuc 2400
accaucagcg ugaccaccga gauucugccc gugagcauga ccaagaccag cguggacugc 2460
accauguaca ucugcggcga cagcaccgag ugcagcaacc ugcugcugca guacggcagc 2520
uucugcaccc agcugaaccg ggcccugacc ggcaucgccg uggagcagga caagaacacc 2580
caggaggugu ucgcccaggu gaagcagauc uacaagaccc cucccaucaa ggacuucggc 2640
ggcuucaacu ucagccagau ccugcccgac cccagcaagc ccagcaagcg gagcuucauc 2700
gaggaccugc uguucaacaa ggugacccua gccgacgccg gcuucaucaa gcaguacggc 2760
gacugccucg gcgacauagc cgcccgggac cugaucugcg cccagaaguu caacggccug 2820
accgugcugc cuccccugcu gaccgacgag augaucgccc aguacaccag cgcccuguua 2880
gccggaacca ucaccagcgg cuggacuuuc ggcgcuggag ccgcucugca gauccccuuc 2940
gccaugcaga uggccuaccg guucaacggc aucggcguga cccagaacgu gcuguacgag 3000
aaccagaagc ugaucgccaa ccaguucaac agcgccaucg gcaagaucca ggacagccug 3060
agcagcaccg cuagcgcccu gggcaagcug caggacgugg ugaaccagaa cgcccaggcc 3120
cugaacaccc uggugaagca gcugagcagc aacuucggcg ccaucagcag cgugcugaac 3180
gacauccuga gccggcugga cccucccgag gccgaggugc agaucgaccg gcugaucacu 3240
ggccggcugc agagccugca gaccuacgug acccagcagc ugauccgggc cgccgagauu 3300
cgggccagcg ccaaccuggc cgccaccaag augagcgagu gcgugcuggg ccagagcaag 3360
cggguggacu ucugcggcaa gggcuaccac cugaugagcu uuccccagag cgcaccccac 3420
ggaguggugu uccugcacgu gaccuacgug cccgcccagg agaagaacuu caccaccgcc 3480
ccagccaucu gccacgacgg caaggcccac uuuccccggg agggcguguu cgugagcaac 3540
ggcacccacu gguucgugac ccagcggaac uucuacgagc cccagaucau caccaccgac 3600
aacaccuucg ugagcggcaa cugcgacgug gugaucggca ucgugaacaa caccguguac 3660
gauccccugc agcccgagcu ggacagcuuc aaggaggagc uggacaagua cuucaagaau 3720
cacaccagcc ccgacgugga ccugggcgac aucagcggca ucaacgccag cguggugaac 3780
auccagaagg agaucgaucg gcugaacgag guggccaaga accugaacga gagccugauc 3840
gaccugcagg agcugggcaa guacgagcag uacaucaagu ggcccuggua caucuggcug 3900
ggcuucaucg ccggccugau cgccaucgug auggugacca ucaugcugug cugcaugacc 3960
agcugcugca gcugccugaa gggcuguugc agcugcggca gcugcugcaa guucgacgag 4020
gacgacagcg agcccgugcu gaagggcgug aagcugcacu acacc 4065
<![CDATA[<210> 38]]>
<![CDATA[<211> 1355]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 38]]>
Met Phe Leu Ile Ile Phe Ile Leu Pro Thr Thr Leu Ala Val Ile Gly
1 5 10 15
Asp Phe Asn Cys Thr Asn Ser Phe Ile Asn Asp Tyr Asn Lys Thr Ile
20 25 30
Pro Arg Ile Ser Glu Asp Val Val Asp Val Ser Leu Gly Leu Gly Thr
35 40 45
Tyr Tyr Val Leu Asn Arg Val Tyr Leu Asn Thr Thr Leu Leu Phe Thr
50 55 60
Gly Tyr Phe Pro Lys Ser Gly Ala Asn Phe Arg Asp Leu Ala Leu Lys
65 70 75 80
Gly Ser Ile Tyr Leu Ser Thr Leu Trp Tyr Lys Pro Pro Phe Leu Ser
85 90 95
Asp Phe Asn Asn Gly Ile Phe Ser Lys Val Lys Asn Thr Lys Leu Tyr
100 105 110
Val Asn Asn Thr Leu Tyr Ser Glu Phe Ser Thr Ile Val Ile Gly Ser
115 120 125
Val Phe Val Asn Thr Ser Tyr Thr Ile Val Val Gln Pro His Asn Gly
130 135 140
Ile Leu Glu Ile Thr Ala Cys Gln Tyr Thr Met Cys Glu Tyr Pro His
145 150 155 160
Thr Val Cys Lys Ser Lys Gly Ser Ile Arg Asn Glu Ser Trp His Ile
165 170 175
Asp Ser Ser Glu Pro Leu Cys Leu Phe Lys Lys Asn Phe Thr Tyr Asn
180 185 190
Val Ser Ala Asp Trp Leu Tyr Phe His Phe Tyr Gln Glu Arg Gly Val
195 200 205
Phe Tyr Ala Tyr Tyr Ala Asp Val Gly Met Pro Thr Thr Phe Leu Phe
210 215 220
Ser Leu Tyr Leu Gly Thr Ile Leu Ser His Tyr Tyr Val Met Pro Leu
225 230 235 240
Thr Cys Asn Ala Ile Ser Ser Asn Thr Asp Asn Glu Thr Leu Glu Tyr
245 250 255
Trp Val Thr Pro Leu Ser Arg Arg Gln Tyr Leu Leu Asn Phe Asp Glu
260 265 270
His Gly Val Ile Thr Asn Ala Val Asp Cys Ala Leu Asp Pro Leu Ser
275 280 285
Glu Thr Lys Cys Thr Leu Lys Ser Phe Thr Val Glu Lys Gly Ile Tyr
290 295 300
Gln Thr Ser Gly Phe Thr Val Lys Pro Val Ala Thr Val Tyr Arg Arg
305 310 315 320
Ile Pro Asn Leu Pro Asp Cys Asp Ile Asp Asn Trp Leu Asn Asn Val
325 330 335
Ser Val Pro Ser Pro Leu Asn Trp Glu Arg Arg Ile Phe Ser Asn Cys
340 345 350
Asn Phe Asn Leu Ser Thr Leu Leu Arg Leu Val His Val Asp Ser Phe
355 360 365
Ser Cys Asn Asn Leu Asp Lys Ser Lys Ile Phe Gly Ser Cys Phe Asn
370 375 380
Ser Ile Thr Val Asp Lys Phe Ala Ile Pro Asn Arg Arg Arg Asp Asp
385 390 395 400
Leu Gln Leu Gly Ser Ser Gly Phe Leu Gln Ser Ser Asn Tyr Lys Ile
405 410 415
Asp Ile Ser Ser Ser Ser Cys Gln Leu Tyr Tyr Ser Leu Pro Leu Val
420 425 430
Asn Val Thr Ile Asn Asn Phe Asn Pro Ser Ser Trp Asn Arg Arg Tyr
435 440 445
Gly Phe Gly Ser Phe Asn Leu Ser Ser Tyr Asp Val Val Tyr Ser Asp
450 455 460
His Cys Phe Ser Val Asn Ser Asp Phe Cys Pro Cys Ala Asp Pro Ser
465 470 475 480
Val Val Asn Ser Cys Ala Lys Ser Lys Pro Pro Ser Ala Ile Cys Pro
485 490 495
Ala Gly Thr Lys Tyr Arg His Cys Asp Leu Asp Thr Thr Leu Tyr Val
500 505 510
Lys Asn Trp Cys Arg Cys Ser Cys Leu Pro Asp Pro Ile Ser Thr Tyr
515 520 525
Ser Pro Asn Thr Cys Pro Gln Lys Lys Val Val Val Gly Ile Gly Glu
530 535 540
His Cys Pro Gly Leu Gly Ile Asn Glu Glu Lys Cys Gly Thr Gln Leu
545 550 555 560
Asn His Ser Ser Cys Phe Cys Ser Pro Asp Ala Phe Leu Gly Trp Ser
565 570 575
Phe Asp Ser Cys Ile Ser Asn Asn Arg Cys Asn Ile Phe Ser Asn Phe
580 585 590
Ile Phe Asn Gly Ile Asn Ser Gly Thr Thr Cys Ser Asn Asp Leu Leu
595 600 605
Tyr Ser Asn Thr Glu Ile Ser Thr Gly Val Cys Val Asn Tyr Asp Leu
610 615 620
Tyr Gly Ile Thr Gly Gln Gly Ile Phe Lys Glu Val Ser Ala Ala Tyr
625 630 635 640
Tyr Asn Asn Trp Gln Asn Leu Leu Tyr Asp Ser Asn Gly Asn Ile Ile
645 650 655
Gly Phe Lys Asp Phe Leu Thr Asn Lys Thr Tyr Thr Ile Leu Pro Cys
660 665 670
Tyr Ser Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn
675 680 685
Gln Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val
690 695 700
Ala Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr
705 710 715 720
Gly Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu
725 730 735
His Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile
740 745 750
Cys Ala Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg Ala Arg Ser
755 760 765
Val Ala Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly Ala Glu
770 775 780
Asn Ser Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr Asn Phe
785 790 795 800
Thr Ile Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr Lys Thr
805 810 815
Ser Val Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu Cys Ser
820 825 830
Asn Leu Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn Arg Ala
835 840 845
Leu Thr Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu Val Phe
850 855 860
Ala Gln Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp Phe Gly
865 870 875 880
Gly Phe Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro Ser Lys
885 890 895
Arg Ser Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu Ala Asp
900 905 910
Ala Gly Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile Ala Ala
915 920 925
Arg Asp Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val Leu Pro
930 935 940
Pro Leu Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala Leu Leu
945 950 955 960
Ala Gly Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala Ala Leu
965 970 975
Gln Ile Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly Ile Gly
980 985 990
Val Thr Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala Asn Gln
995 1000 1005
Phe Asn Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser Ser Thr
1010 1015 1020
Ala Ser Ala Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn Ala
1025 1030 1035
Gln Ala Leu Asn Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly
1040 1045 1050
Ala Ile Ser Ser Val Leu Asn Asp Ile Leu Ser Arg Leu Asp Pro
1055 1060 1065
Pro Glu Ala Glu Val Gln Ile Asp Arg Leu Ile Thr Gly Arg Leu
1070 1075 1080
Gln Ser Leu Gln Thr Tyr Val Thr Gln Gln Leu Ile Arg Ala Ala
1085 1090 1095
Glu Ile Arg Ala Ser Ala Asn Leu Ala Ala Thr Lys Met Ser Glu
1100 1105 1110
Cys Val Leu Gly Gln Ser Lys Arg Val Asp Phe Cys Gly Lys Gly
1115 1120 1125
Tyr His Leu Met Ser Phe Pro Gln Ser Ala Pro His Gly Val Val
1130 1135 1140
Phe Leu His Val Thr Tyr Val Pro Ala Gln Glu Lys Asn Phe Thr
1145 1150 1155
Thr Ala Pro Ala Ile Cys His Asp Gly Lys Ala His Phe Pro Arg
1160 1165 1170
Glu Gly Val Phe Val Ser Asn Gly Thr His Trp Phe Val Thr Gln
1175 1180 1185
Arg Asn Phe Tyr Glu Pro Gln Ile Ile Thr Thr Asp Asn Thr Phe
1190 1195 1200
Val Ser Gly Asn Cys Asp Val Val Ile Gly Ile Val Asn Asn Thr
1205 1210 1215
Val Tyr Asp Pro Leu Gln Pro Glu Leu Asp Ser Phe Lys Glu Glu
1220 1225 1230
Leu Asp Lys Tyr Phe Lys Asn His Thr Ser Pro Asp Val Asp Leu
1235 1240 1245
Gly Asp Ile Ser Gly Ile Asn Ala Ser Val Val Asn Ile Gln Lys
1250 1255 1260
Glu Ile Asp Arg Leu Asn Glu Val Ala Lys Asn Leu Asn Glu Ser
1265 1270 1275
Leu Ile Asp Leu Gln Glu Leu Gly Lys Tyr Glu Gln Tyr Ile Lys
1280 1285 1290
Trp Pro Trp Tyr Ile Trp Leu Gly Phe Ile Ala Gly Leu Ile Ala
1295 1300 1305
Ile Val Met Val Thr Ile Met Leu Cys Cys Met Thr Ser Cys Cys
1310 1315 1320
Ser Cys Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys Lys Phe
1325 1330 1335
Asp Glu Asp Asp Ser Glu Pro Val Leu Lys Gly Val Lys Leu His
1340 1345 1350
Tyr Thr
1355
<![CDATA[<210> 39]]>
<![CDATA[<211> 4247]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 39]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uuccugaucc ugcugaucag ccugcccacc gccuucgccg ugaucggcga ccugaagugc 120
accagcgaca acaucaacga caaggacacc ggcccaccac ccaucagcac cgacaccgug 180
gacgugacca acggccuggg caccuacuac gugcuggacc ggguguaccu gaacaccacc 240
cuguuccuga acggcuacua ccccaccagc ggcagcaccu accggaauau ggcccugaag 300
ggcagcgugc ugcugagccg gcugugguuc aagccaccau uccugagcga cuucaucaac 360
ggaaucuucg ccaaggugaa gaacaccaag gugaucaagg accgggugau guacagcgag 420
uuccccgcca ucaccauugg caguaccuuc gugaacacca gcuacagcgu gguggugcag 480
ccccggacca ucaacagcac ccaggacggc gacaacaagc ugcagggccu gcuggaggug 540
agcgugugcc aguacaacau gugcgaguac ccucagacca ucugccaccc caaccugggc 600
aaccaccgga aggagcugug gcaccuggac accggcgugg ugagcugccu guacaagcgg 660
aacuucaccu acgacguaaa cgccgacuac cuguacuucc acuucuacca ggagggcggc 720
accuucuacg ccuacuucac cgacacgggc guggugacca aguuccuguu caacguguac 780
cugggcaugg cccugagcca cuacuacgug augccccuga ccuguaacag caagcugacc 840
cuggaguacu gggugacccc ucugaccagc cggcaguacc ugcuggccuu caaccaggac 900
ggcaucaucu ucaacgccgu ggacugcgcc cuggacccuc ugagcgagac caagugcacc 960
cugaagagcu ucaccgugga gaagggcauc uaccagacca acggcuacac cgugcagccc 1020
aucgccgacg uguaccggcg gaagcccaac cugcccaacu gcaacaucga ggccuggcug 1080
aacgacaaga gcgugcccuc gccccugaac ugggagcgga agaccuucag caacugcaac 1140
uucaacauga gcagucugau gagcuucauc caggccgaca gcuucaccug caacaacauc 1200
gacgccgcca agaucuacgg caugugcuuc agcagcauca ccaucgacaa guuugccauc 1260
cccaacggcc ggaaggugga ccugcagcug ggcaaccugg gcuaccugca gagcuucaac 1320
uaccggaucg acaccaccgc caccucuugc cagcuguacu acaaccugcc cgccgccaac 1380
gugagcguga gccgguucaa ccccagcacc uggaacaagc gguucggcuu cauugaggac 1440
agcguguuca aaccccggcc cgcaggagua cugaccaacc acgacguggu guacgcccag 1500
cacugcuuca aggcacccaa gaacuucugc cccugcaagc ugaacggcag cugugugggc 1560
ucuggccccg guaagaacaa cggcauaggg acuugcccgg cagggaccaa cuaccugacc 1620
ugcgacaacc ugugcacacc cgaccccauc accuucaccg gcaccuacaa guguccccag 1680
accaagagcc uggugggcau cggcgagcac ugcagcggcc uggccgugaa gagcgacuac 1740
ugcggcggca acagcugcac cugucggccc caggccuucc ugggcuggag cgccgacagc 1800
ugccugcagg gcgacaagug caacaucuuu gccaacuuca uccugcacga cgugaacagc 1860
ggccugaccu gcagcaccga ccugcagaag gccaacaccg acaucauccu gggcgugugc 1920
gugaacuacg acuuguacgg cauccugggc cagggcaucu ucguggaggu gaacgccacc 1980
uacuacaaca gcuggcagaa ccugcuguac gacagcaacg gcaaccugua cggcuuccgg 2040
gacuacauca ucaaccggac cuucaugauc cggagcugcu acagcggcgg cgugagcgug 2100
aucaccccag gcaccaacac cagcaaccag guggccgugc uguaccagga cgugaacugc 2160
accgaggugc ccguggccau ccacgccgac cagcugacac ccaccuggcg ggucuacagc 2220
accggcagca acguguucca gacccgggcc gguugccuga ucggcgccga gcacgugaac 2280
aacagcuacg agugcgacau ccccaucggc gccggcaucu gugccagcua ccagacccag 2340
accaauucac cccggagggc aaggagcgug gccagccaga gcaucaucgc cuacaccaug 2400
agccugggcg ccgagaacag cguggccuac agcaacaaca gcaucgccau ccccaccaac 2460
uucaccauca gcgugaccac cgagauucug cccgugagca ugaccaagac cagcguggac 2520
ugcaccaugu acaucugcgg cgacagcacc gagugcagca accugcugcu gcaguacggc 2580
agcuucugca cccagcugaa ccgggcccug accggcaucg ccguggagca ggacaagaac 2640
acccaggagg uguucgccca ggugaagcag aucuacaaga ccccucccau caaggacuuc 2700
ggcggcuuca acuucagcca gauccugccc gaccccagca agcccagcaa gcggagcuuc 2760
aucgaggacc ugcuguucaa caaggugacc cuagccgacg ccggcuucau caagcaguac 2820
ggcgacugcc ucggcgacau agccgcccgg gaccugaucu gcgcccagaa guucaacggc 2880
cugaccgugc ugccuccccu gcugaccgac gagaugaucg cccaguacac cagcgcccug 2940
uuagccggaa ccaucaccag cggcuggacu uucggcgcug gagccgcucu gcagaucccc 3000
uucgccaugc agauggccua ccgguucaac ggcaucggcg ugacccagaa cgugcuguac 3060
gagaaccaga agcugaucgc caaccaguuc aacagcgcca ucggcaagau ccaggacagc 3120
cugagcagca ccgcuagcgc ccugggcaag cugcaggacg uggugaacca gaacgcccag 3180
gcccugaaca cccuggugaa gcagcugagc agcaacuucg gcgccaucag cagcgugcug 3240
aacgacaucc ugagccggcu ggacccuccc gaggccgagg ugcagaucga ccggcugauc 3300
acuggccggc ugcagagccu gcagaccuac gugacccagc agcugauccg ggccgccgag 3360
auucgggcca gcgccaaccu ggccgccacc aagaugagcg agugcgugcu gggccagagc 3420
aagcgggugg acuucugcgg caagggcuac caccugauga gcuuucccca gagcgcaccc 3480
cacggagugg uguuccugca cgugaccuac gugcccgccc aggagaagaa cuucaccacc 3540
gccccagcca ucugccacga cggcaaggcc cacuuucccc gggagggcgu guucgugagc 3600
aacggcaccc acugguucgu gacccagcgg aacuucuacg agccccagau caucaccacc 3660
gacaacaccu ucgugagcgg caacugcgac guggugaucg gcaucgugaa caacaccgug 3720
uacgaucccc ugcagcccga gcuggacagc uucaaggagg agcuggacaa guacuucaag 3780
aaucacacca gccccgacgu ggaccugggc gacaucagcg gcaucaacgc cagcguggug 3840
aacauccaga aggagaucga ucggcugaac gagguggcca agaaccugaa cgagagccug 3900
aucgaccugc aggagcuggg caaguacgag caguacauca aguggcccug guacaucugg 3960
cugggcuuca ucgccggccu gaucgccauc gugaugguga ccaucaugcu gugcugcaug 4020
accagcugcu gcagcugccu gaagggcugu ugcagcugcg gcagcugcug caaguucgac 4080
gaggacgaca gcgagcccgu gcugaagggc gugaagcugc acuacaccug auaauaggcu 4140
ggagccucgg uggccuagcu ucuugccccu ugggccuccc cccagccccu ccuccccuuc 4200
cugcacccgu acccccgugg ucuuugaaua aagucugagu gggcggc 4247
<![CDATA[<210> 40]]>
<![CDATA[<211> 4071]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 40]]>
auguuccuga uccugcugau cagccugccc accgccuucg ccgugaucgg cgaccugaag 60
ugcaccagcg acaacaucaa cgacaaggac accggcccac cacccaucag caccgacacc 120
guggacguga ccaacggccu gggcaccuac uacgugcugg accgggugua ccugaacacc 180
acccuguucc ugaacggcua cuaccccacc agcggcagca ccuaccggaa uauggcccug 240
aagggcagcg ugcugcugag ccggcugugg uucaagccac cauuccugag cgacuucauc 300
aacggaaucu ucgccaaggu gaagaacacc aaggugauca aggaccgggu gauguacagc 360
gaguuccccg ccaucaccau uggcaguacc uucgugaaca ccagcuacag cgugguggug 420
cagccccgga ccaucaacag cacccaggac ggcgacaaca agcugcaggg ccugcuggag 480
gugagcgugu gccaguacaa caugugcgag uacccucaga ccaucugcca ccccaaccug 540
ggcaaccacc ggaaggagcu guggcaccug gacaccggcg uggugagcug ccuguacaag 600
cggaacuuca ccuacgacgu aaacgccgac uaccuguacu uccacuucua ccaggagggc 660
ggcaccuucu acgccuacuu caccgacacg ggcgugguga ccaaguuccu guucaacgug 720
uaccugggca uggcccugag ccacuacuac gugaugcccc ugaccuguaa cagcaagcug 780
acccuggagu acugggugac cccucugacc agccggcagu accugcuggc cuucaaccag 840
gacggcauca ucuucaacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 900
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccaacggcua caccgugcag 960
cccaucgccg acguguaccg gcggaagccc aaccugccca acugcaacau cgaggccugg 1020
cugaacgaca agagcgugcc cucgccccug aacugggagc ggaagaccuu cagcaacugc 1080
aacuucaaca ugagcagucu gaugagcuuc auccaggccg acagcuucac cugcaacaac 1140
aucgacgccg ccaagaucua cggcaugugc uucagcagca ucaccaucga caaguuugcc 1200
auccccaacg gccggaaggu ggaccugcag cugggcaacc ugggcuaccu gcagagcuuc 1260
aacuaccgga ucgacaccac cgccaccucu ugccagcugu acuacaaccu gcccgccgcc 1320
aacgugagcg ugagccgguu caaccccagc accuggaaca agcgguucgg cuucauugag 1380
gacagcgugu ucaaaccccg gcccgcagga guacugacca accacgacgu gguguacgcc 1440
cagcacugcu ucaaggcacc caagaacuuc ugccccugca agcugaacgg cagcugugug 1500
ggcucuggcc ccgguaagaa caacggcaua gggacuugcc cggcagggac caacuaccug 1560
accugcgaca accugugcac acccgacccc aucaccuuca ccggcaccua caaguguccc 1620
cagaccaaga gccugguggg caucggcgag cacugcagcg gccuggccgu gaagagcgac 1680
uacugcggcg gcaacagcug caccugucgg ccccaggccu uccugggcug gagcgccgac 1740
agcugccugc agggcgacaa gugcaacauc uuugccaacu ucauccugca cgacgugaac 1800
agcggccuga ccugcagcac cgaccugcag aaggccaaca ccgacaucau ccugggcgug 1860
ugcgugaacu acgacuugua cggcauccug ggccagggca ucuucgugga ggugaacgcc 1920
accuacuaca acagcuggca gaaccugcug uacgacagca acggcaaccu guacggcuuc 1980
cgggacuaca ucaucaaccg gaccuucaug auccggagcu gcuacagcgg cggcgugagc 2040
gugaucaccc caggcaccaa caccagcaac cagguggccg ugcuguacca ggacgugaac 2100
ugcaccgagg ugcccguggc cauccacgcc gaccagcuga cacccaccug gcgggucuac 2160
agcaccggca gcaacguguu ccagacccgg gccgguugcc ugaucggcgc cgagcacgug 2220
aacaacagcu acgagugcga cauccccauc ggcgccggca ucugugccag cuaccagacc 2280
cagaccaauu caccccggag ggcaaggagc guggccagcc agagcaucau cgccuacacc 2340
augagccugg gcgccgagaa cagcguggcc uacagcaaca acagcaucgc cauccccacc 2400
aacuucacca ucagcgugac caccgagauu cugcccguga gcaugaccaa gaccagcgug 2460
gacugcacca uguacaucug cggcgacagc accgagugca gcaaccugcu gcugcaguac 2520
ggcagcuucu gcacccagcu gaaccgggcc cugaccggca ucgccgugga gcaggacaag 2580
aacacccagg agguguucgc ccaggugaag cagaucuaca agaccccucc caucaaggac 2640
uucggcggcu ucaacuucag ccagauccug cccgacccca gcaagcccag caagcggagc 2700
uucaucgagg accugcuguu caacaaggug acccuagccg acgccggcuu caucaagcag 2760
uacggcgacu gccucggcga cauagccgcc cgggaccuga ucugcgccca gaaguucaac 2820
ggccugaccg ugcugccucc ccugcugacc gacgagauga ucgcccagua caccagcgcc 2880
cuguuagccg gaaccaucac cagcggcugg acuuucggcg cuggagccgc ucugcagauc 2940
cccuucgcca ugcagauggc cuaccgguuc aacggcaucg gcgugaccca gaacgugcug 3000
uacgagaacc agaagcugau cgccaaccag uucaacagcg ccaucggcaa gauccaggac 3060
agccugagca gcaccgcuag cgcccugggc aagcugcagg acguggugaa ccagaacgcc 3120
caggcccuga acacccuggu gaagcagcug agcagcaacu ucggcgccau cagcagcgug 3180
cugaacgaca uccugagccg gcuggacccu cccgaggccg aggugcagau cgaccggcug 3240
aucacuggcc ggcugcagag ccugcagacc uacgugaccc agcagcugau ccgggccgcc 3300
gagauucggg ccagcgccaa ccuggccgcc accaagauga gcgagugcgu gcugggccag 3360
agcaagcggg uggacuucug cggcaagggc uaccaccuga ugagcuuucc ccagagcgca 3420
ccccacggag ugguguuccu gcacgugacc uacgugcccg cccaggagaa gaacuucacc 3480
accgccccag ccaucugcca cgacggcaag gcccacuuuc cccgggaggg cguguucgug 3540
agcaacggca cccacugguu cgugacccag cggaacuucu acgagcccca gaucaucacc 3600
accgacaaca ccuucgugag cggcaacugc gacgugguga ucggcaucgu gaacaacacc 3660
guguacgauc cccugcagcc cgagcuggac agcuucaagg aggagcugga caaguacuuc 3720
aagaaucaca ccagccccga cguggaccug ggcgacauca gcggcaucaa cgccagcgug 3780
gugaacaucc agaaggagau cgaucggcug aacgaggugg ccaagaaccu gaacgagagc 3840
cugaucgacc ugcaggagcu gggcaaguac gagcaguaca ucaaguggcc cugguacauc 3900
uggcugggcu ucaucgccgg ccugaucgcc aucgugaugg ugaccaucau gcugugcugc 3960
augaccagcu gcugcagcug ccugaagggc uguugcagcu gcggcagcug cugcaaguuc 4020
gacgaggacg acagcgagcc cgugcugaag ggcgugaagc ugcacuacac c 4071
<![CDATA[<210> 41]]>
<![CDATA[<211> 1357]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 41]]>
Met Phe Leu Ile Leu Leu Ile Ser Leu Pro Thr Ala Phe Ala Val Ile
1 5 10 15
Gly Asp Leu Lys Cys Thr Ser Asp Asn Ile Asn Asp Lys Asp Thr Gly
20 25 30
Pro Pro Pro Ile Ser Thr Asp Thr Val Asp Val Thr Asn Gly Leu Gly
35 40 45
Thr Tyr Tyr Val Leu Asp Arg Val Tyr Leu Asn Thr Thr Leu Phe Leu
50 55 60
Asn Gly Tyr Tyr Pro Thr Ser Gly Ser Thr Tyr Arg Asn Met Ala Leu
65 70 75 80
Lys Gly Ser Val Leu Leu Ser Arg Leu Trp Phe Lys Pro Pro Phe Leu
85 90 95
Ser Asp Phe Ile Asn Gly Ile Phe Ala Lys Val Lys Asn Thr Lys Val
100 105 110
Ile Lys Asp Arg Val Met Tyr Ser Glu Phe Pro Ala Ile Thr Ile Gly
115 120 125
Ser Thr Phe Val Asn Thr Ser Tyr Ser Val Val Val Gln Pro Arg Thr
130 135 140
Ile Asn Ser Thr Gln Asp Gly Asp Asn Lys Leu Gln Gly Leu Leu Glu
145 150 155 160
Val Ser Val Cys Gln Tyr Asn Met Cys Glu Tyr Pro Gln Thr Ile Cys
165 170 175
His Pro Asn Leu Gly Asn His Arg Lys Glu Leu Trp His Leu Asp Thr
180 185 190
Gly Val Val Ser Cys Leu Tyr Lys Arg Asn Phe Thr Tyr Asp Val Asn
195 200 205
Ala Asp Tyr Leu Tyr Phe His Phe Tyr Gln Glu Gly Gly Thr Phe Tyr
210 215 220
Ala Tyr Phe Thr Asp Thr Gly Val Val Thr Lys Phe Leu Phe Asn Val
225 230 235 240
Tyr Leu Gly Met Ala Leu Ser His Tyr Tyr Val Met Pro Leu Thr Cys
245 250 255
Asn Ser Lys Leu Thr Leu Glu Tyr Trp Val Thr Pro Leu Thr Ser Arg
260 265 270
Gln Tyr Leu Leu Ala Phe Asn Gln Asp Gly Ile Ile Phe Asn Ala Val
275 280 285
Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys Ser
290 295 300
Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Asn Gly Tyr Thr Val Gln
305 310 315 320
Pro Ile Ala Asp Val Tyr Arg Arg Lys Pro Asn Leu Pro Asn Cys Asn
325 330 335
Ile Glu Ala Trp Leu Asn Asp Lys Ser Val Pro Ser Pro Leu Asn Trp
340 345 350
Glu Arg Lys Thr Phe Ser Asn Cys Asn Phe Asn Met Ser Ser Leu Met
355 360 365
Ser Phe Ile Gln Ala Asp Ser Phe Thr Cys Asn Asn Ile Asp Ala Ala
370 375 380
Lys Ile Tyr Gly Met Cys Phe Ser Ser Ile Thr Ile Asp Lys Phe Ala
385 390 395 400
Ile Pro Asn Gly Arg Lys Val Asp Leu Gln Leu Gly Asn Leu Gly Tyr
405 410 415
Leu Gln Ser Phe Asn Tyr Arg Ile Asp Thr Thr Ala Thr Ser Cys Gln
420 425 430
Leu Tyr Tyr Asn Leu Pro Ala Ala Asn Val Ser Val Ser Arg Phe Asn
435 440 445
Pro Ser Thr Trp Asn Lys Arg Phe Gly Phe Ile Glu Asp Ser Val Phe
450 455 460
Lys Pro Arg Pro Ala Gly Val Leu Thr Asn His Asp Val Val Tyr Ala
465 470 475 480
Gln His Cys Phe Lys Ala Pro Lys Asn Phe Cys Pro Cys Lys Leu Asn
485 490 495
Gly Ser Cys Val Gly Ser Gly Pro Gly Lys Asn Asn Gly Ile Gly Thr
500 505 510
Cys Pro Ala Gly Thr Asn Tyr Leu Thr Cys Asp Asn Leu Cys Thr Pro
515 520 525
Asp Pro Ile Thr Phe Thr Gly Thr Tyr Lys Cys Pro Gln Thr Lys Ser
530 535 540
Leu Val Gly Ile Gly Glu His Cys Ser Gly Leu Ala Val Lys Ser Asp
545 550 555 560
Tyr Cys Gly Gly Asn Ser Cys Thr Cys Arg Pro Gln Ala Phe Leu Gly
565 570 575
Trp Ser Ala Asp Ser Cys Leu Gln Gly Asp Lys Cys Asn Ile Phe Ala
580 585 590
Asn Phe Ile Leu His Asp Val Asn Ser Gly Leu Thr Cys Ser Thr Asp
595 600 605
Leu Gln Lys Ala Asn Thr Asp Ile Ile Leu Gly Val Cys Val Asn Tyr
610 615 620
Asp Leu Tyr Gly Ile Leu Gly Gln Gly Ile Phe Val Glu Val Asn Ala
625 630 635 640
Thr Tyr Tyr Asn Ser Trp Gln Asn Leu Leu Tyr Asp Ser Asn Gly Asn
645 650 655
Leu Tyr Gly Phe Arg Asp Tyr Ile Ile Asn Arg Thr Phe Met Ile Arg
660 665 670
Ser Cys Tyr Ser Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr
675 680 685
Ser Asn Gln Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val
690 695 700
Pro Val Ala Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr
705 710 715 720
Ser Thr Gly Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly
725 730 735
Ala Glu His Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala
740 745 750
Gly Ile Cys Ala Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg Ala
755 760 765
Arg Ser Val Ala Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly
770 775 780
Ala Glu Asn Ser Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr
785 790 795 800
Asn Phe Thr Ile Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr
805 810 815
Lys Thr Ser Val Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu
820 825 830
Cys Ser Asn Leu Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn
835 840 845
Arg Ala Leu Thr Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu
850 855 860
Val Phe Ala Gln Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp
865 870 875 880
Phe Gly Gly Phe Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro
885 890 895
Ser Lys Arg Ser Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu
900 905 910
Ala Asp Ala Gly Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile
915 920 925
Ala Ala Arg Asp Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val
930 935 940
Leu Pro Pro Leu Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala
945 950 955 960
Leu Leu Ala Gly Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala
965 970 975
Ala Leu Gln Ile Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly
980 985 990
Ile Gly Val Thr Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala
995 1000 1005
Asn Gln Phe Asn Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser
1010 1015 1020
Ser Thr Ala Ser Ala Leu Gly Lys Leu Gln Asp Val Val Asn Gln
1025 1030 1035
Asn Ala Gln Ala Leu Asn Thr Leu Val Lys Gln Leu Ser Ser Asn
1040 1045 1050
Phe Gly Ala Ile Ser Ser Val Leu Asn Asp Ile Leu Ser Arg Leu
1055 1060 1065
Asp Pro Pro Glu Ala Glu Val Gln Ile Asp Arg Leu Ile Thr Gly
1070 1075 1080
Arg Leu Gln Ser Leu Gln Thr Tyr Val Thr Gln Gln Leu Ile Arg
1085 1090 1095
Ala Ala Glu Ile Arg Ala Ser Ala Asn Leu Ala Ala Thr Lys Met
1100 1105 1110
Ser Glu Cys Val Leu Gly Gln Ser Lys Arg Val Asp Phe Cys Gly
1115 1120 1125
Lys Gly Tyr His Leu Met Ser Phe Pro Gln Ser Ala Pro His Gly
1130 1135 1140
Val Val Phe Leu His Val Thr Tyr Val Pro Ala Gln Glu Lys Asn
1145 1150 1155
Phe Thr Thr Ala Pro Ala Ile Cys His Asp Gly Lys Ala His Phe
1160 1165 1170
Pro Arg Glu Gly Val Phe Val Ser Asn Gly Thr His Trp Phe Val
1175 1180 1185
Thr Gln Arg Asn Phe Tyr Glu Pro Gln Ile Ile Thr Thr Asp Asn
1190 1195 1200
Thr Phe Val Ser Gly Asn Cys Asp Val Val Ile Gly Ile Val Asn
1205 1210 1215
Asn Thr Val Tyr Asp Pro Leu Gln Pro Glu Leu Asp Ser Phe Lys
1220 1225 1230
Glu Glu Leu Asp Lys Tyr Phe Lys Asn His Thr Ser Pro Asp Val
1235 1240 1245
Asp Leu Gly Asp Ile Ser Gly Ile Asn Ala Ser Val Val Asn Ile
1250 1255 1260
Gln Lys Glu Ile Asp Arg Leu Asn Glu Val Ala Lys Asn Leu Asn
1265 1270 1275
Glu Ser Leu Ile Asp Leu Gln Glu Leu Gly Lys Tyr Glu Gln Tyr
1280 1285 1290
Ile Lys Trp Pro Trp Tyr Ile Trp Leu Gly Phe Ile Ala Gly Leu
1295 1300 1305
Ile Ala Ile Val Met Val Thr Ile Met Leu Cys Cys Met Thr Ser
1310 1315 1320
Cys Cys Ser Cys Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys
1325 1330 1335
Lys Phe Asp Glu Asp Asp Ser Glu Pro Val Leu Lys Gly Val Lys
1340 1345 1350
Leu His Tyr Thr
1355
<![CDATA[<210> 42]]>
<![CDATA[<211> 1157]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 42]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacucu ggcggaggcg gcagcgccau cggcggcuac 960
auccccgagg ccccuagaga cggccaggcc uacgugcgga aggacggcga gugggugcug 1020
cugagcaccu uccugggcug auaauaggcu ggagccucgg uggccuagcu ucuugccccu 1080
ugggccuccc cccagccccu ccuccccuuc cugcacccgu acccccgugg ucuuugaaua 1140
aagucugagu gggcggc 1157
<![CDATA[<210> 43]]>
<![CDATA[<211> 981]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 43]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ucuggcggag gcggcagcgc caucggcggc 900
uacauccccg aggccccuag agacggccag gccuacgugc ggaaggacgg cgagugggug 960
cugcugagca ccuuccuggg c 981
<![CDATA[<210> 44]]>
<![CDATA[<211> 327]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 44]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Ser Gly Gly Gly Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu
290 295 300
Ala Pro Arg Asp Gly Gln Ala Tyr Val Arg Lys Asp Gly Glu Trp Val
305 310 315 320
Leu Leu Ser Thr Phe Leu Gly
325
<![CDATA[<210> 45]]>
<![CDATA[<211> 1130]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 45]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacucu ggcggaggca gcauccuggc caucuacagc 960
accguggcca gcagccuggu gcugcuggug agccugggcg ccaucagcuu cugauaauag 1020
gcuggagccu cgguggccua gcuucuugcc ccuugggccu ccccccagcc ccuccucccc 1080
uuccugcacc cguacccccg uggucuuuga auaaagucug agugggcggc 1130
<![CDATA[<210> 46]]>
<![CDATA[<211> 954]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 46]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ucuggcggag gcagcauccu ggccaucuac 900
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuuc 954
<![CDATA[<210> 47]]>
<![CDATA[<211> 318]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 47]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala
290 295 300
Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
305 310 315
<![CDATA[<210> 48]]>
<![CDATA[<211> 1238]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 48]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacucu ggcggaggca gcauccuggc caucuacagc 960
accguggcca gcagccuggu gcugcuggug agccugggcg ccaucagcuu cggcggaggc 1020
agcgccaucg gcggcuacau ccccgaggcc ccuagagacg gccaggccua cgugcggaag 1080
gacggcgagu gggugcugcu gagcaccuuc cugggcaagu gauaauaggc uggagccucg 1140
guggccuagc uucuugcccc uugggccucc ccccagcccc uccuccccuu ccugcacccg 1200
uacccccgug gucuuugaau aaagucugag ugggcggc 1238
<![CDATA[<210> 49]]>
<![CDATA[<211> 1062]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 49]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ucuggcggag gcagcauccu ggccaucuac 900
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuucggcgga 960
ggcagcgcca ucggcggcua cauccccgag gccccuagag acggccaggc cuacgugcgg 1020
aaggacggcg agugggugcu gcugagcacc uuccugggca ag 1062
<![CDATA[<210> 50]]>
<![CDATA[<211> 354]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 50]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala
290 295 300
Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe Gly Gly
305 310 315 320
Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln
325 330 335
Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu Ser Thr Phe Leu
340 345 350
Gly Lys
<![CDATA[<210> 51]]>
<![CDATA[<211> 1130]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 51]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
gugugccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacucu ggcggaggca gcauccuggc caucuacagc 960
accguggcca gcagccuggu gcugcuggug agccugggcg ccaucagcuu cugauaauag 1020
gcuggagccu cgguggccua gcuucuugcc ccuugggccu ccccccagcc ccuccucccc 1080
uuccugcacc cguacccccg uggucuuuga auaaagucug agugggcggc 1130
<![CDATA[<210> 52]]>
<![CDATA[<211> 954]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 52]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aaggugugcc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ucuggcggag gcagcauccu ggccaucuac 900
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuuc 954
<![CDATA[<210> 53]]>
<![CDATA[<211> 318]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 53]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Cys Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala
290 295 300
Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
305 310 315
<![CDATA[<210> 54]]>
<![CDATA[<211> 1181]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 54]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
gugugccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccuc uggcggaggc agcauccugg ccaucuacag caccguggcc 1020
agcagccugg ugcugcuggu gagccugggc gccaucagcu ucugauaaua ggcuggagcc 1080
ucgguggccu agcuucuugc cccuugggcc uccccccagc cccuccuccc cuuccugcac 1140
ccguaccccc guggucuuug aauaaagucu gagugggcgg c 1181
<![CDATA[<210> 55]]>
<![CDATA[<211> 1005]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 55]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aaggugugcc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cucuggcgga ggcagcaucc uggccaucua cagcaccgug 960
gccagcagcc uggugcugcu ggugagccug ggcgccauca gcuuc 1005
<![CDATA[<210> 56]]>
<![CDATA[<211> 335]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 56]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Cys Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val
305 310 315 320
Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
325 330 335
<![CDATA[<210> 57]]>
<![CDATA[<211> 1181]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 57]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccuc uggcggaggc agcauccugg ccaucuacag caccguggcc 1020
agcagccugg ugcugcuggu gagccugggc gccaucagcu ucugauaaua ggcuggagcc 1080
ucgguggccu agcuucuugc cccuugggcc uccccccagc cccuccuccc cuuccugcac 1140
ccguaccccc guggucuuug aauaaagucu gagugggcgg c 1181
<![CDATA[<210> 58]]>
<![CDATA[<211> 1005]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 58]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cucuggcgga ggcagcaucc uggccaucua cagcaccgug 960
gccagcagcc uggugcugcu ggugagccug ggcgccauca gcuuc 1005
<![CDATA[<210> 59]]>
<![CDATA[<211> 335]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 59]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val
305 310 315 320
Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
325 330 335
<![CDATA[<210> 60]]>
<![CDATA[<211> 836]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 60]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaaguga 720
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccucccc ccagccccuc 780
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 836
<![CDATA[<210> 61]]>
<![CDATA[<211> 660]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 61]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
<![CDATA[<210> 62]]>
<![CDATA[<211> 220]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 62]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
210 215 220
<![CDATA[<210> 63]]>
<![CDATA[<211> 1349]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 63]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaaggga 720
ggaggcagcg gcggcgauau caucaagcuu cugaacgagc aaguuaacaa ggaaaugcag 780
agcaguaauc ucuacaugag caugagcagc uggugcuaca cccacucccu ggacggagca 840
ggccucuucc uguucgacca cgcagccgag gaguacgagc acgcuaagaa guugaucauu 900
uucuugaacg agaacaacgu gcccgugcag cuaacgucaa ucagcgcacc ugagcacaag 960
uucgagggcc ugacccagau cuuccagaag gccuacgaac acgaacagca caucuccgag 1020
agcaucaaca auauugugga ucacgcuauc aaguccaagg accacgcuac cuucaacuuc 1080
cugcaguggu acguggccga gcaacaugag gaggaggugc uguucaagga cauccuggac 1140
aagaucgagc ugaucgguaa ugagaaucac ggccuguacc uggccgacca guacgugaag 1200
ggcaucgcca agagccggaa gucaggcuca ugauaauagg cuggagccuc gguggccuag 1260
cuucuugccc cuugggccuc cccccagccc cuccuccccu uccugcaccc guacccccgu 1320
ggucuuugaa uaaagucuga gugggcggc 1349
<![CDATA[<210> 64]]>
<![CDATA[<211> 1173]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 64]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ggaggaggca gcggcggcga uaucaucaag cuucugaacg agcaaguuaa caaggaaaug 720
cagagcagua aucucuacau gagcaugagc agcuggugcu acacccacuc ccuggacgga 780
gcaggccucu uccuguucga ccacgcagcc gaggaguacg agcacgcuaa gaaguugauc 840
auuuucuuga acgagaacaa cgugcccgug cagcuaacgu caaucagcgc accugagcac 900
aaguucgagg gccugaccca gaucuuccag aaggccuacg aacacgaaca gcacaucucc 960
gagagcauca acaauauugu ggaucacgcu aucaagucca aggaccacgc uaccuucaac 1020
uuccugcagu gguacguggc cgagcaacau gaggaggagg ugcuguucaa ggacauccug 1080
gacaagaucg agcugaucgg uaaugagaau cacggccugu accuggccga ccaguacgug 1140
aagggcaucg ccaagagccg gaagucaggc uca 1173
<![CDATA[<210> 65]]>
<![CDATA[<211> 391]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 65]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Gly Gly Gly Ser
210 215 220
Gly Gly Asp Ile Ile Lys Leu Leu Asn Glu Gln Val Asn Lys Glu Met
225 230 235 240
Gln Ser Ser Asn Leu Tyr Met Ser Met Ser Ser Trp Cys Tyr Thr His
245 250 255
Ser Leu Asp Gly Ala Gly Leu Phe Leu Phe Asp His Ala Ala Glu Glu
260 265 270
Tyr Glu His Ala Lys Lys Leu Ile Ile Phe Leu Asn Glu Asn Asn Val
275 280 285
Pro Val Gln Leu Thr Ser Ile Ser Ala Pro Glu His Lys Phe Glu Gly
290 295 300
Leu Thr Gln Ile Phe Gln Lys Ala Tyr Glu His Glu Gln His Ile Ser
305 310 315 320
Glu Ser Ile Asn Asn Ile Val Asp His Ala Ile Lys Ser Lys Asp His
325 330 335
Ala Thr Phe Asn Phe Leu Gln Trp Tyr Val Ala Glu Gln His Glu Glu
340 345 350
Glu Val Leu Phe Lys Asp Ile Leu Asp Lys Ile Glu Leu Ile Gly Asn
355 360 365
Glu Asn His Gly Leu Tyr Leu Ala Asp Gln Tyr Val Lys Gly Ile Ala
370 375 380
Lys Ser Arg Lys Ser Gly Ser
385 390
<![CDATA[<210> 66]]>
<![CDATA[<211> 1376]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 66]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
ggcauccugc ccagcccugg caugcccgcu cugcugagcc uggugagccu gcugagcgug 120
cugcugaugg gcugcguggc ugagaccggc augcagaucu acgagggcaa gcugaccgca 180
gagggccugc gguucggcau cguggccagc cgcgccaacc acgcucuggu ggaccggcuu 240
guggagggcg cuaucgacgc caucgugaga cacggcggcc gggaagagga caucacccug 300
gugcgggugu gcggcagcug ggagauuccc gucgccgccg gagaacuggc ccggaaggag 360
gacaucgacg ccgugaucgc caucggcgug cugugcagag gcgccacgcc cagcuucgac 420
uacaucgcca gcgaggugag caagggccug gccgaccuga gccuggagcu gcggaagccc 480
aucaccuucg gcgugaucac cgccgacacc cuggagcagg ccaucgaggc cgcaggcacc 540
ugccacggca acaagggcug ggaagccgcc cugugcgcca ucgagauggc caaccuguuc 600
aagagccugc ggggcggaag uggaggcucu gguggcagcg gaggaucugg cggcggccag 660
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 720
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 780
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 840
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 900
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 960
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 1020
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 1080
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 1140
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 1200
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaaguga 1260
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccucccc ccagccccuc 1320
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 1376
<![CDATA[<210> 67]]>
<![CDATA[<211> 1200]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 67]]>
augggcaucc ugcccagccc uggcaugccc gcucugcuga gccuggugag ccugcugagc 60
gugcugcuga ugggcugcgu ggcugagacc ggcaugcaga ucuacgaggg caagcugacc 120
gcagagggcc ugcgguucgg caucguggcc agccgcgcca accacgcucu gguggaccgg 180
cuuguggagg gcgcuaucga cgccaucgug agacacggcg gccgggaaga ggacaucacc 240
cuggugcggg ugugcggcag cugggagauu cccgucgccg ccggagaacu ggcccggaag 300
gaggacaucg acgccgugau cgccaucggc gugcugugca gaggcgccac gcccagcuuc 360
gacuacaucg ccagcgaggu gagcaagggc cuggccgacc ugagccugga gcugcggaag 420
cccaucaccu ucggcgugau caccgccgac acccuggagc aggccaucga ggccgcaggc 480
accugccacg gcaacaaggg cugggaagcc gcccugugcg ccaucgagau ggccaaccug 540
uucaagagcc ugcggggcgg aaguggaggc ucugguggca gcggaggauc uggcggcggc 600
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 660
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 720
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 780
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 840
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 900
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 960
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 1020
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 1080
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 1140
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 1200
<![CDATA[<210> 68]]>
<![CDATA[<211> 400]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 68]]>
Met Gly Ile Leu Pro Ser Pro Gly Met Pro Ala Leu Leu Ser Leu Val
1 5 10 15
Ser Leu Leu Ser Val Leu Leu Met Gly Cys Val Ala Glu Thr Gly Met
20 25 30
Gln Ile Tyr Glu Gly Lys Leu Thr Ala Glu Gly Leu Arg Phe Gly Ile
35 40 45
Val Ala Ser Arg Ala Asn His Ala Leu Val Asp Arg Leu Val Glu Gly
50 55 60
Ala Ile Asp Ala Ile Val Arg His Gly Gly Arg Glu Glu Asp Ile Thr
65 70 75 80
Leu Val Arg Val Cys Gly Ser Trp Glu Ile Pro Val Ala Ala Gly Glu
85 90 95
Leu Ala Arg Lys Glu Asp Ile Asp Ala Val Ile Ala Ile Gly Val Leu
100 105 110
Cys Arg Gly Ala Thr Pro Ser Phe Asp Tyr Ile Ala Ser Glu Val Ser
115 120 125
Lys Gly Leu Ala Asp Leu Ser Leu Glu Leu Arg Lys Pro Ile Thr Phe
130 135 140
Gly Val Ile Thr Ala Asp Thr Leu Glu Gln Ala Ile Glu Ala Ala Gly
145 150 155 160
Thr Cys His Gly Asn Lys Gly Trp Glu Ala Ala Leu Cys Ala Ile Glu
165 170 175
Met Ala Asn Leu Phe Lys Ser Leu Arg Gly Gly Ser Gly Gly Ser Gly
180 185 190
Gly Ser Gly Gly Ser Gly Gly Gly Gln Pro Asn Ile Thr Asn Leu Cys
195 200 205
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
210 215 220
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
225 230 235 240
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
245 250 255
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
260 265 270
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
275 280 285
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
290 295 300
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
305 310 315 320
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
325 330 335
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
340 345 350
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
355 360 365
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
370 375 380
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
385 390 395 400
<![CDATA[<210> 69]]>
<![CDATA[<211> 1334]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 69]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaaggga 720
ggaggcuccg gaggcgguag cgcugagacc ggcaugcaga ucuacgaggg caagcugacc 780
gcagagggcc ugcgguucgg caucguggcc agccgcgcca accacgcucu gguggaccgg 840
cuuguggagg gcgcuaucga cgccaucgug agacacggcg gccgggaaga ggacaucacc 900
cuggugcggg ugugcggcag cugggagauu cccgucgccg ccggagaacu ggcccggaag 960
gaggacaucg acgccgugau cgccaucggc gugcugugca gaggcgccac gcccagcuuc 1020
gacuacaucg ccagcgaggu gagcaagggc cuggccgacc ugagccugga gcugcggaag 1080
cccaucaccu ucggcgugau caccgccgac acccuggagc aggccaucga ggccgcaggc 1140
accugccacg gcaacaaggg cugggaagcc gcccugugcg ccaucgagau ggccaaccug 1200
uucaagagcc ugcggugaua auaggcugga gccucggugg ccuagcuucu ugccccuugg 1260
gccucccccc agccccuccu ccccuuccug cacccguacc cccguggucu uugaauaaag 1320
ucugaguggg cggc 1334
<![CDATA[<210> 70]]>
<![CDATA[<211> 1158]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 70]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ggaggaggcu ccggaggcgg uagcgcugag accggcaugc agaucuacga gggcaagcug 720
accgcagagg gccugcgguu cggcaucgug gccagccgcg ccaaccacgc ucugguggac 780
cggcuugugg agggcgcuau cgacgccauc gugagacacg gcggccggga agaggacauc 840
acccuggugc gggugugcgg cagcugggag auucccgucg ccgccggaga acuggcccgg 900
aaggaggaca ucgacgccgu gaucgccauc ggcgugcugu gcagaggcgc cacgcccagc 960
uucgacuaca ucgccagcga ggugagcaag ggccuggccg accugagccu ggagcugcgg 1020
aagcccauca ccuucggcgu gaucaccgcc gacacccugg agcaggccau cgaggccgca 1080
ggcaccugcc acggcaacaa gggcugggaa gccgcccugu gcgccaucga gauggccaac 1140
cuguucaaga gccugcgg 1158
<![CDATA[<210> 71]]>
<![CDATA[<211> 386]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 71]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Gly Gly Gly Ser
210 215 220
Gly Gly Gly Ser Ala Glu Thr Gly Met Gln Ile Tyr Glu Gly Lys Leu
225 230 235 240
Thr Ala Glu Gly Leu Arg Phe Gly Ile Val Ala Ser Arg Ala Asn His
245 250 255
Ala Leu Val Asp Arg Leu Val Glu Gly Ala Ile Asp Ala Ile Val Arg
260 265 270
His Gly Gly Arg Glu Glu Asp Ile Thr Leu Val Arg Val Cys Gly Ser
275 280 285
Trp Glu Ile Pro Val Ala Ala Gly Glu Leu Ala Arg Lys Glu Asp Ile
290 295 300
Asp Ala Val Ile Ala Ile Gly Val Leu Cys Arg Gly Ala Thr Pro Ser
305 310 315 320
Phe Asp Tyr Ile Ala Ser Glu Val Ser Lys Gly Leu Ala Asp Leu Ser
325 330 335
Leu Glu Leu Arg Lys Pro Ile Thr Phe Gly Val Ile Thr Ala Asp Thr
340 345 350
Leu Glu Gln Ala Ile Glu Ala Ala Gly Thr Cys His Gly Asn Lys Gly
355 360 365
Trp Glu Ala Ala Leu Cys Ala Ile Glu Met Ala Asn Leu Phe Lys Ser
370 375 380
Leu Arg
385
<![CDATA[<210> 72]]>
<![CDATA[<211> 947]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 72]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggcg gcagcgccau cggcggcuac auccccgagg ccccuagaga cggccaggcc 780
uacgugcgga aggacggcga gugggugcug cugagcaccu uccugggcug auaauaggcu 840
ggagccucgg uggccuagcu ucuugccccu ugggccuccc cccagccccu ccuccccuuc 900
cugcacccgu acccccgugg ucuuugaaua aagucugagu gggcggc 947
<![CDATA[<210> 73]]>
<![CDATA[<211> 771]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 73]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcggcagcgc caucggcggc uacauccccg aggccccuag agacggccag 720
gccuacgugc ggaaggacgg cgagugggug cugcugagca ccuuccuggg c 771
<![CDATA[<210> 74]]>
<![CDATA[<211> 257]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 74]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln
225 230 235 240
Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu Ser Thr Phe Leu
245 250 255
Gly
<![CDATA[<210> 75]]>
<![CDATA[<211> 920]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 75]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggca gcauccuggc caucuacagc accguggcca gcagccuggu gcugcuggug 780
agccugggcg ccaucagcuu cugauaauag gcuggagccu cgguggccua gcuucuugcc 840
ccuugggccu ccccccagcc ccuccucccc uuccugcacc cguacccccg uggucuuuga 900
auaaagucug agugggcggc 920
<![CDATA[<210> 76]]>
<![CDATA[<211> 744]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 76]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcagcauccu ggccaucuac agcaccgugg ccagcagccu ggugcugcug 720
gugagccugg gcgccaucag cuuc 744
<![CDATA[<210> 77]]>
<![CDATA[<211> 248]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 77]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu
225 230 235 240
Val Ser Leu Gly Ala Ile Ser Phe
245
<![CDATA[<210> 78]]>
<![CDATA[<211> 1025]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 78]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggcg gcagcgccau cggcggcuac auccccgagg ccccuagaga cggccaggcc 780
uacgugcgga aggacggcga gugggugcug cugagcaccu uccugggcgg aggcagcauc 840
cuggccaucu acagcaccgu ggccagcagc cuggugcugc uggugagccu gggcgccauc 900
agcuucugau aauaggcugg agccucggug gccuagcuuc uugccccuug ggccuccccc 960
cagccccucc uccccuuccu gcacccguac ccccgugguc uuugaauaaa gucugagugg 1020
gcggc 1025
<![CDATA[<210> 79]]>
<![CDATA[<211> 849]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 79]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcggcagcgc caucggcggc uacauccccg aggccccuag agacggccag 720
gccuacgugc ggaaggacgg cgagugggug cugcugagca ccuuccuggg cggaggcagc 780
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 840
aucagcuuc 849
<![CDATA[<210> 80]]>
<![CDATA[<211> 283]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 80]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln
225 230 235 240
Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu Ser Thr Phe Leu
245 250 255
Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu
260 265 270
Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
275 280
<![CDATA[<210> 81]]>
<![CDATA[<211> 1028]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 81]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggca gcauccuggc caucuacagc accguggcca gcagccuggu gcugcuggug 780
agccugggcg ccaucagcuu cggcggaggc agcgccaucg gcggcuacau ccccgaggcc 840
ccuagagacg gccaggccua cgugcggaag gacggcgagu gggugcugcu gagcaccuuc 900
cugggcaagu gauaauaggc uggagccucg guggccuagc uucuugcccc uugggccucc 960
ccccagcccc uccuccccuu ccugcacccg uacccccgug gucuuugaau aaagucugag 1020
ugggcggc 1028
<![CDATA[<210> 82]]>
<![CDATA[<211> 852]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 82]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcagcauccu ggccaucuac agcaccgugg ccagcagccu ggugcugcug 720
gugagccugg gcgccaucag cuucggcgga ggcagcgcca ucggcggcua cauccccgag 780
gccccuagag acggccaggc cuacgugcgg aaggacggcg agugggugcu gcugagcacc 840
uuccugggca ag 852
<![CDATA[<210> 83]]>
<![CDATA[<211> 284]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 83]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu
225 230 235 240
Val Ser Leu Gly Ala Ile Ser Phe Gly Gly Gly Ser Ala Ile Gly Gly
245 250 255
Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln Ala Tyr Val Arg Lys Asp
260 265 270
Gly Glu Trp Val Leu Leu Ser Thr Phe Leu Gly Lys
275 280
<![CDATA[<210> 84]]>
<![CDATA[<211> 1142]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 84]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cgggugcagc ccaccgagag caucgugcgg uuccccaaca ucaccaaccu gugccccuuc 180
ggcgaggugu ucaacgccac ccgguucgcc agcguguacg ccuggaaccg gaagcggauc 240
agcaacugcg uggccgacua cagcgugcug uacaacagcg ccagcuucag caccuucaag 300
ugcuacggcg ugagccccac caagcugaac gaccugugcu ucaccaacgu guacgccgac 360
agcuucguga uccguggcga cgaggugcgg cagaucgcac ccggccagac aggcaagauc 420
gccgacuaca acuacaagcu gcccgacgac uucaccggcu gcgugaucgc cuggaacagc 480
aacaaccucg acagcaaggu gggcggcaac uacaacuacc uguaccggcu guuccggaag 540
agcaaccuga agcccuucga gcgggacauc agcaccgaga ucuaccaagc cggcuccacc 600
ccuugcaacg gcguggaggg cuucaacugc uacuucccuc ugcagagcua cggcuuccag 660
cccaccaacg gcgugggcua ccagcccuac cggguggugg ugcugagcuu cgagcugcug 720
cacgccccag ccaccgugug uggccccaag aagagcacca accuggugaa gaacaagugc 780
gugaacuuca acuucaacgg ccuuaccggc accggcgugc ugaccgagag caacaagaaa 840
uuccugcccu uucagcaguu cggccgggac aucgccgaca ccaccgacgc ugugcgggau 900
ccccagaccc uggagauccu ggacaucacc ccuugcagcu cuggcggagg cagcauccug 960
gccaucuaca gcaccguggc cagcagccug gugcugcugg ugagccuggg cgccaucagc 1020
uucugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 1080
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 1140
gc 1142
<![CDATA[<210> 85]]>
<![CDATA[<211> 966]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 85]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcgggugc agcccaccga gagcaucgug cgguucccca acaucaccaa ccugugcccc 120
uucggcgagg uguucaacgc cacccgguuc gccagcgugu acgccuggaa ccggaagcgg 180
aucagcaacu gcguggccga cuacagcgug cuguacaaca gcgccagcuu cagcaccuuc 240
aagugcuacg gcgugagccc caccaagcug aacgaccugu gcuucaccaa cguguacgcc 300
gacagcuucg ugauccgugg cgacgaggug cggcagaucg cacccggcca gacaggcaag 360
aucgccgacu acaacuacaa gcugcccgac gacuucaccg gcugcgugau cgccuggaac 420
agcaacaacc ucgacagcaa ggugggcggc aacuacaacu accuguaccg gcuguuccgg 480
aagagcaacc ugaagcccuu cgagcgggac aucagcaccg agaucuacca agccggcucc 540
accccuugca acggcgugga gggcuucaac ugcuacuucc cucugcagag cuacggcuuc 600
cagcccacca acggcguggg cuaccagccc uaccgggugg uggugcugag cuucgagcug 660
cugcacgccc cagccaccgu guguggcccc aagaagagca ccaaccuggu gaagaacaag 720
ugcgugaacu ucaacuucaa cggccuuacc ggcaccggcg ugcugaccga gagcaacaag 780
aaauuccugc ccuuucagca guucggccgg gacaucgccg acaccaccga cgcugugcgg 840
gauccccaga cccuggagau ccuggacauc accccuugca gcucuggcgg aggcagcauc 900
cuggccaucu acagcaccgu ggccagcagc cuggugcugc uggugagccu gggcgccauc 960
agcuuc 966
<![CDATA[<210> 86]]>
<![CDATA[<211> 322]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 86]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Arg Val Gln Pro Thr Glu Ser Ile Val Arg Phe
20 25 30
Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala Thr
35 40 45
Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn Cys
50 55 60
Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr Phe
65 70 75 80
Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe Thr
85 90 95
Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg Gln
100 105 110
Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys Leu
115 120 125
Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn Leu
130 135 140
Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg
145 150 155 160
Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile Tyr
165 170 175
Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys Tyr
180 185 190
Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly Tyr
195 200 205
Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala Pro
210 215 220
Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn Lys
225 230 235 240
Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu Thr
245 250 255
Glu Ser Asn Lys Lys Phe Leu Pro Phe Gln Gln Phe Gly Arg Asp Ile
260 265 270
Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile Leu
275 280 285
Asp Ile Thr Pro Cys Ser Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr
290 295 300
Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile
305 310 315 320
Ser Phe
<![CDATA[<210> 87]]>
<![CDATA[<211> 1142]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 87]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cgggugcagc ccaccgagag caucgugcgg uuccccaaca ucaccaaccu gugccccuuc 180
ggcgaggugu ucaacgccac ccgguucgcc agcguguacg ccuggaaccg gaagcggauc 240
agcaacugcg uggccgacua cagcgugcug uacaacagcg ccagcuucag caccuucaag 300
ugcuacggcg ugagccccac caagcugaac gaccugugcu ucaccaacgu guacgccgac 360
agcuucguga uccguggcga cgaggugcgg cagaucgcac ccggccagac aggcaagauc 420
gccgacuaca acuacaagcu gcccgacgac uucaccggcu gcgugaucgc cuggaacagc 480
aacaaccucg acagcaaggu gggcggcaac uacaacuacc uguaccggcu guuccggaag 540
agcaaccuga agcccuucga gcgggacauc agcaccgaga ucuaccaagc cggcuccacc 600
ccuugcaacg gcguggaggg cuucaacugc uacuucccuc ugcagagcua cggcuuccag 660
cccaccaacg gcgugggcua ccagcccuac cggguggugg ugcugagcuu cgagcugcug 720
cacgccccag ccaccgugug uggccccaag aagagcacca accuggugaa gaacaagugc 780
gugaacuuca acuucaacgg ccuuaccggc accggcgugc ugaccgagag caacaagaaa 840
uuccugcccu uuugccaguu cggccgggac aucgccgaca ccaccgacgc ugugcgggau 900
ccccagaccc uggagauccu ggacaucacc ccuugcagcu cuggcggagg cagcauccug 960
gccaucuaca gcaccguggc cagcagccug gugcugcugg ugagccuggg cgccaucagc 1020
uucugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 1080
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 1140
gc 1142
<![CDATA[<210> 88]]>
<![CDATA[<211> 966]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 88]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcgggugc agcccaccga gagcaucgug cgguucccca acaucaccaa ccugugcccc 120
uucggcgagg uguucaacgc cacccgguuc gccagcgugu acgccuggaa ccggaagcgg 180
aucagcaacu gcguggccga cuacagcgug cuguacaaca gcgccagcuu cagcaccuuc 240
aagugcuacg gcgugagccc caccaagcug aacgaccugu gcuucaccaa cguguacgcc 300
gacagcuucg ugauccgugg cgacgaggug cggcagaucg cacccggcca gacaggcaag 360
aucgccgacu acaacuacaa gcugcccgac gacuucaccg gcugcgugau cgccuggaac 420
agcaacaacc ucgacagcaa ggugggcggc aacuacaacu accuguaccg gcuguuccgg 480
aagagcaacc ugaagcccuu cgagcgggac aucagcaccg agaucuacca agccggcucc 540
accccuugca acggcgugga gggcuucaac ugcuacuucc cucugcagag cuacggcuuc 600
cagcccacca acggcguggg cuaccagccc uaccgggugg uggugcugag cuucgagcug 660
cugcacgccc cagccaccgu guguggcccc aagaagagca ccaaccuggu gaagaacaag 720
ugcgugaacu ucaacuucaa cggccuuacc ggcaccggcg ugcugaccga gagcaacaag 780
aaauuccugc ccuuuugcca guucggccgg gacaucgccg acaccaccga cgcugugcgg 840
gauccccaga cccuggagau ccuggacauc accccuugca gcucuggcgg aggcagcauc 900
cuggccaucu acagcaccgu ggccagcagc cuggugcugc uggugagccu gggcgccauc 960
agcuuc 966
<![CDATA[<210> 89]]>
<![CDATA[<211> 322]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 89]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Arg Val Gln Pro Thr Glu Ser Ile Val Arg Phe
20 25 30
Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala Thr
35 40 45
Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn Cys
50 55 60
Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr Phe
65 70 75 80
Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe Thr
85 90 95
Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg Gln
100 105 110
Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys Leu
115 120 125
Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn Leu
130 135 140
Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg
145 150 155 160
Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile Tyr
165 170 175
Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys Tyr
180 185 190
Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly Tyr
195 200 205
Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala Pro
210 215 220
Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn Lys
225 230 235 240
Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu Thr
245 250 255
Glu Ser Asn Lys Lys Phe Leu Pro Phe Cys Gln Phe Gly Arg Asp Ile
260 265 270
Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile Leu
275 280 285
Asp Ile Thr Pro Cys Ser Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr
290 295 300
Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile
305 310 315 320
Ser Phe
<![CDATA[<210> 90]]>
<![CDATA[<211> 1748]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 90]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 1620
aucagcuucu gauaauaggc uggagccucg guggccuagc uucuugcccc uugggccucc 1680
ccccagcccc uccuccccuu ccugcacccg uacccccgug gucuuugaau aaagucugag 1740
ugggcggc 1748
<![CDATA[<210> 91]]>
<![CDATA[<211> 1572]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 91]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag caccguggcc agcagccugg ugcugcuggu gagccugggc 1560
gccaucagcu uc 1572
<![CDATA[<210> 92]]>
<![CDATA[<211> 524]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 92]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser
500 505 510
Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
515 520
<![CDATA[<210> 93]]>
<![CDATA[<211> 1925]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 93]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 1620
aucagcuuca agaagaagaa gcggccacgg aacuccuaca agugcggcac caacaccaug 1680
gagcgggagg agagcgagca gaccaagaag cgggagaaga uccacauucc ugaacggucc 1740
gacgaagccc agcggguguu caagagcagc aagaccagca gcugcgacaa gagcgacacc 1800
ugcuucugau aauaggcugg agccucggug gccuagcuuc uugccccuug ggccuccccc 1860
cagccccucc uccccuuccu gcacccguac ccccgugguc uuugaauaaa gucugagugg 1920
gcggc 1925
<![CDATA[<210> 94]]>
<![CDATA[<211> 1749]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 94]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag caccguggcc agcagccugg ugcugcuggu gagccugggc 1560
gccaucagcu ucaagaagaa gaagcggcca cggaacuccu acaagugcgg caccaacacc 1620
auggagcggg aggagagcga gcagaccaag aagcgggaga agauccacau uccugaacgg 1680
uccgacgaag cccagcgggu guucaagagc agcaagacca gcagcugcga caagagcgac 1740
accugcuuc 1749
<![CDATA[<210> 95]]>
<![CDATA[<211> 583]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 95]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser
500 505 510
Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe Lys Lys Lys Lys
515 520 525
Arg Pro Arg Asn Ser Tyr Lys Cys Gly Thr Asn Thr Met Glu Arg Glu
530 535 540
Glu Ser Glu Gln Thr Lys Lys Arg Glu Lys Ile His Ile Pro Glu Arg
545 550 555 560
Ser Asp Glu Ala Gln Arg Val Phe Lys Ser Ser Lys Thr Ser Ser Cys
565 570 575
Asp Lys Ser Asp Thr Cys Phe
580
<![CDATA[<210> 96]]>
<![CDATA[<211> 1805]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 96]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 1620
aucagcuuca agcggcagua caaggacaug augagcgagg gaggaccacc uggcgcugag 1680
ccacagugau aauaggcugg agccucggug gccuagcuuc uugccccuug ggccuccccc 1740
cagccccucc uccccuuccu gcacccguac ccccgugguc uuugaauaaa gucugagugg 1800
gcggc 1805
<![CDATA[<210> 97]]>
<![CDATA[<211> 1629]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 97]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag caccguggcc agcagccugg ugcugcuggu gagccugggc 1560
gccaucagcu ucaagcggca guacaaggac augaugagcg agggaggacc accuggcgcu 1620
gagccacag 1629
<![CDATA[<210> 98]]>
<![CDATA[<211> 543]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 98]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser
500 505 510
Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe Lys Arg Gln Tyr
515 520 525
Lys Asp Met Met Ser Glu Gly Gly Pro Pro Gly Ala Glu Pro Gln
530 535 540
<![CDATA[<210> 99]]>
<![CDATA[<211> 1853]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 99]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcggc 1560
agcgccaucg gcggcuacau ccccgaggcc ccuagagacg gccaggccua cgugcggaag 1620
gacggcgagu gggugcugcu gagcaccuuc cugggcggag gcagcauccu ggccaucuac 1680
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuucugauaa 1740
uaggcuggag ccucgguggc cuagcuucuu gccccuuggg ccucccccca gccccuccuc 1800
cccuuccugc acccguaccc ccguggucuu ugaauaaagu cugagugggc ggc 1853
<![CDATA[<210> 100]]>
<![CDATA[<211> 1677]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 100]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
ggcagcgcca ucggcggcua cauccccgag gccccuagag acggccaggc cuacgugcgg 1560
aaggacggcg agugggugcu gcugagcacc uuccugggcg gaggcagcau ccuggccauc 1620
uacagcaccg uggccagcag ccuggugcug cuggugagcc ugggcgccau cagcuuc 1677
<![CDATA[<210> 101]]>
<![CDATA[<211> 559]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 101]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro
500 505 510
Arg Asp Gly Gln Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu
515 520 525
Ser Thr Phe Leu Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val
530 535 540
Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
545 550 555
<![CDATA[<210> 102]]>
<![CDATA[<211> 1856]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 102]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 1620
aucagcuucg gcggaggcag cgccaucggc ggcuacaucc ccgaggcccc uagagacggc 1680
caggccuacg ugcggaagga cggcgagugg gugcugcuga gcaccuuccu gggcaaguga 1740
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccucccc ccagccccuc 1800
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 1856
<![CDATA[<210> 103]]>
<![CDATA[<211> 1680]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 103]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag caccguggcc agcagccugg ugcugcuggu gagccugggc 1560
gccaucagcu ucggcggagg cagcgccauc ggcggcuaca uccccgaggc cccuagagac 1620
ggccaggccu acgugcggaa ggacggcgag ugggugcugc ugagcaccuu ccugggcaag 1680
<![CDATA[<210> 104]]>
<![CDATA[<211> 560]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 104]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser
500 505 510
Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe Gly Gly Gly Ser
515 520 525
Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln Ala Tyr
530 535 540
Val Arg Lys Asp Gly Glu Trp Val Leu Leu Ser Thr Phe Leu Gly Lys
545 550 555 560
<![CDATA[<210> 105]]>
<![CDATA[<211> 1826]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 105]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagccu gggcuucauc gccggccuga ucgccaucgu gauggugacc 1620
aucaugcugu gcugcaugac cagcugcugc agcugccuga agggcuguug cagcugcggc 1680
agcugcugca aguucgacga ggacgacuga uaauaggcug gagccucggu ggccuagcuu 1740
cuugccccuu gggccucccc ccagccccuc cuccccuucc ugcacccgua cccccguggu 1800
cuuugaauaa agucugagug ggcggc 1826
<![CDATA[<210> 106]]>
<![CDATA[<211> 1650]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 106]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag ccugggcuuc aucgccggcc ugaucgccau cgugauggug 1560
accaucaugc ugugcugcau gaccagcugc ugcagcugcc ugaagggcug uugcagcugc 1620
ggcagcugcu gcaaguucga cgaggacgac 1650
<![CDATA[<210> 107]]>
<![CDATA[<211> 550]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 107]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Leu Gly Phe Ile Ala
500 505 510
Gly Leu Ile Ala Ile Val Met Val Thr Ile Met Leu Cys Cys Met Thr
515 520 525
Ser Cys Cys Ser Cys Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys
530 535 540
Lys Phe Asp Glu Asp Asp
545 550
<![CDATA[<210> 108]]>
<![CDATA[<211> 1826]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 108]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
agcagcaucg ccagcuucuu cuucaucauc gggcugauca ucggccucuu ccuggugcug 1620
cgggugggca uccaccugug caucaagcug aagcacacca agaagagaca gaucuacacc 1680
gacaucgaga ugaaccggcu gggcaaguga uaauaggcug gagccucggu ggccuagcuu 1740
cuugccccuu gggccucccc ccagccccuc cuccccuucc ugcacccgua cccccguggu 1800
cuuugaauaa agucugagug ggcggc 1826
<![CDATA[<210> 109]]>
<![CDATA[<211> 1650]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 109]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcagcagca ucgccagcuu cuucuucauc aucgggcuga ucaucggccu cuuccuggug 1560
cugcgggugg gcauccaccu gugcaucaag cugaagcaca ccaagaagag acagaucuac 1620
accgacaucg agaugaaccg gcugggcaag 1650
<![CDATA[<210> 110]]>
<![CDATA[<211> 550]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 110]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ser Ser Ile Ala Ser Phe Phe Phe Ile Ile Gly
500 505 510
Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile His Leu Cys
515 520 525
Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr Asp Ile Glu
530 535 540
Met Asn Arg Leu Gly Lys
545 550
<![CDATA[<210> 111]]>
<![CDATA[<211> 1775]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 111]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcggc 1560
agcgccaucg gcggcuacau ccccgaggcc ccuagagacg gccaggccua cgugcggaag 1620
gacggcgagu gggugcugcu gagcaccuuc cugggcugau aauaggcugg agccucggug 1680
gccuagcuuc uugccccuug ggccuccccc cagccccucc uccccuuccu gcacccguac 1740
ccccgugguc uuugaauaaa gucugagugg gcggc 1775
<![CDATA[<210> 112]]>
<![CDATA[<211> 1599]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 112]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
ggcagcgcca ucggcggcua cauccccgag gccccuagag acggccaggc cuacgugcgg 1560
aaggacggcg agugggugcu gcugagcacc uuccugggc 1599
<![CDATA[<210> 113]]>
<![CDATA[<211> 533]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 113]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro
500 505 510
Arg Asp Gly Gln Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu
515 520 525
Ser Thr Phe Leu Gly
530
<![CDATA[<210> 114]]>
<![CDATA[<211> 1973]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 114]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggaca gcgggugcag 960
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1020
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1080
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1140
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1200
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1260
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1320
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1380
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1440
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1500
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1560
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1620
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1680
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1740
cuggagaucc uggacaucac cccuugcagc ucuggcggag gcagcauccu ggccaucuac 1800
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuucugauaa 1860
uaggcuggag ccucgguggc cuagcuucuu gccccuuggg ccucccccca gccccuccuc 1920
cccuuccugc acccguaccc ccguggucuu ugaauaaagu cugagugggc ggc 1973
<![CDATA[<210> 115]]>
<![CDATA[<211> 1797]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 115]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acagcgggug 900
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 960
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1020
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1080
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1140
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1200
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1260
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1320
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1380
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1440
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1500
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1560
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1620
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1680
acccuggaga uccuggacau caccccuugc agcucuggcg gaggcagcau ccuggccauc 1740
uacagcaccg uggccagcag ccuggugcug cuggugagcc ugggcgccau cagcuuc 1797
<![CDATA[<210> 116]]>
<![CDATA[<211> 599]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 116]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Gln Arg Val Gln Pro Thr Glu
290 295 300
Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
305 310 315 320
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
325 330 335
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
340 345 350
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
355 360 365
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
370 375 380
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
385 390 395 400
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
405 410 415
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
420 425 430
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
435 440 445
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
450 455 460
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
465 470 475 480
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
485 490 495
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn
500 505 510
Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly
515 520 525
Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu Pro Phe Gln Gln
530 535 540
Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln
545 550 555 560
Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Ser Gly Gly Gly Ser
565 570 575
Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val
580 585 590
Ser Leu Gly Ala Ile Ser Phe
595
<![CDATA[<210> 117]]>
<![CDATA[<211> 1799]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 117]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgg aggcggaucg ggaggcggac ccaacaucac caaccugugc 1020
cccuucggcg agguguucaa cgccacccgg uucgccagcg uguacgccug gaaccggaag 1080
cggaucagca acugcguggc cgacuacagc gugcuguaca acagcgccag cuucagcacc 1140
uucaagugcu acggcgugag ccccaccaag cugaacgacc ugugcuucac caacguguac 1200
gccgacagcu ucgugauccg uggcgacgag gugcggcaga ucgcacccgg ccagacaggc 1260
aagaucgccg acuacaacua caagcugccc gacgacuuca ccggcugcgu gaucgccugg 1320
aacagcaaca accucgacag caaggugggc ggcaacuaca acuaccugua ccggcuguuc 1380
cggaagagca accugaagcc cuucgagcgg gacaucagca ccgagaucua ccaagccggc 1440
uccaccccuu gcaacggcgu ggagggcuuc aacugcuacu ucccucugca gagcuacggc 1500
uuccagccca ccaacggcgu gggcuaccag cccuaccggg ugguggugcu gagcuucgag 1560
cugcugcacg ccccagccac cguguguggc cccaagucug gcggaggcag cauccuggcc 1620
aucuacagca ccguggccag cagccuggug cugcugguga gccugggcgc caucagcuuc 1680
ugauaauagg cuggagccuc gguggccuag cuucuugccc cuugggccuc cccccagccc 1740
cuccuccccu uccugcaccc guacccccgu ggucuuugaa uaaagucuga gugggcggc 1799
<![CDATA[<210> 118]]>
<![CDATA[<211> 1623]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 118]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cggaggcgga ucgggaggcg gacccaacau caccaaccug 960
ugccccuucg gcgagguguu caacgccacc cgguucgcca gcguguacgc cuggaaccgg 1020
aagcggauca gcaacugcgu ggccgacuac agcgugcugu acaacagcgc cagcuucagc 1080
accuucaagu gcuacggcgu gagccccacc aagcugaacg accugugcuu caccaacgug 1140
uacgccgaca gcuucgugau ccguggcgac gaggugcggc agaucgcacc cggccagaca 1200
ggcaagaucg ccgacuacaa cuacaagcug cccgacgacu ucaccggcug cgugaucgcc 1260
uggaacagca acaaccucga cagcaaggug ggcggcaacu acaacuaccu guaccggcug 1320
uuccggaaga gcaaccugaa gcccuucgag cgggacauca gcaccgagau cuaccaagcc 1380
ggcuccaccc cuugcaacgg cguggagggc uucaacugcu acuucccucu gcagagcuac 1440
ggcuuccagc ccaccaacgg cgugggcuac cagcccuacc gggugguggu gcugagcuuc 1500
gagcugcugc acgccccagc caccgugugu ggccccaagu cuggcggagg cagcauccug 1560
gccaucuaca gcaccguggc cagcagccug gugcugcugg ugagccuggg cgccaucagc 1620
uuc 1623
<![CDATA[<210> 119]]>
<![CDATA[<211> 541]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 119]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu
305 310 315 320
Cys Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr
325 330 335
Ala Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val
340 345 350
Leu Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser
355 360 365
Pro Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser
370 375 380
Phe Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr
385 390 395 400
Gly Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly
405 410 415
Cys Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly
420 425 430
Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro
435 440 445
Phe Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro
450 455 460
Cys Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr
465 470 475 480
Gly Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val
485 490 495
Val Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro
500 505 510
Lys Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser
515 520 525
Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
530 535 540
<![CDATA[<210> 120]]>
<![CDATA[<211> 2024]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 120]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgg aggcggaucg ggaggcggac agcgggugca gcccaccgag 1020
agcaucgugc gguuccccaa caucaccaac cugugccccu ucggcgaggu guucaacgcc 1080
acccgguucg ccagcgugua cgccuggaac cggaagcgga ucagcaacug cguggccgac 1140
uacagcgugc uguacaacag cgccagcuuc agcaccuuca agugcuacgg cgugagcccc 1200
accaagcuga acgaccugug cuucaccaac guguacgccg acagcuucgu gauccguggc 1260
gacgaggugc ggcagaucgc acccggccag acaggcaaga ucgccgacua caacuacaag 1320
cugcccgacg acuucaccgg cugcgugauc gccuggaaca gcaacaaccu cgacagcaag 1380
gugggcggca acuacaacua ccuguaccgg cuguuccgga agagcaaccu gaagcccuuc 1440
gagcgggaca ucagcaccga gaucuaccaa gccggcucca ccccuugcaa cggcguggag 1500
ggcuucaacu gcuacuuccc ucugcagagc uacggcuucc agcccaccaa cggcgugggc 1560
uaccagcccu accggguggu ggugcugagc uucgagcugc ugcacgcccc agccaccgug 1620
uguggcccca agaagagcac caaccuggug aagaacaagu gcgugaacuu caacuucaac 1680
ggccuuaccg gcaccggcgu gcugaccgag agcaacaaga aauuccugcc cuuucagcag 1740
uucggccggg acaucgccga caccaccgac gcugugcggg auccccagac ccuggagauc 1800
cuggacauca ccccuugcag cucuggcgga ggcagcaucc uggccaucua cagcaccgug 1860
gccagcagcc uggugcugcu ggugagccug ggcgccauca gcuucugaua auaggcugga 1920
gccucggugg ccuagcuucu ugccccuugg gccucccccc agccccuccu ccccuuccug 1980
cacccguacc cccguggucu uugaauaaag ucugaguggg cggc 2024
<![CDATA[<210> 121]]>
<![CDATA[<211> 1848]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 121]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cggaggcgga ucgggaggcg gacagcgggu gcagcccacc 960
gagagcaucg ugcgguuccc caacaucacc aaccugugcc ccuucggcga gguguucaac 1020
gccacccggu ucgccagcgu guacgccugg aaccggaagc ggaucagcaa cugcguggcc 1080
gacuacagcg ugcuguacaa cagcgccagc uucagcaccu ucaagugcua cggcgugagc 1140
cccaccaagc ugaacgaccu gugcuucacc aacguguacg ccgacagcuu cgugauccgu 1200
ggcgacgagg ugcggcagau cgcacccggc cagacaggca agaucgccga cuacaacuac 1260
aagcugcccg acgacuucac cggcugcgug aucgccugga acagcaacaa ccucgacagc 1320
aaggugggcg gcaacuacaa cuaccuguac cggcuguucc ggaagagcaa ccugaagccc 1380
uucgagcggg acaucagcac cgagaucuac caagccggcu ccaccccuug caacggcgug 1440
gagggcuuca acugcuacuu cccucugcag agcuacggcu uccagcccac caacggcgug 1500
ggcuaccagc ccuaccgggu gguggugcug agcuucgagc ugcugcacgc cccagccacc 1560
guguguggcc ccaagaagag caccaaccug gugaagaaca agugcgugaa cuucaacuuc 1620
aacggccuua ccggcaccgg cgugcugacc gagagcaaca agaaauuccu gcccuuucag 1680
caguucggcc gggacaucgc cgacaccacc gacgcugugc gggaucccca gacccuggag 1740
auccuggaca ucaccccuug cagcucuggc ggaggcagca uccuggccau cuacagcacc 1800
guggccagca gccuggugcu gcuggugagc cugggcgcca ucagcuuc 1848
<![CDATA[<210> 122]]>
<![CDATA[<211> 616]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 122]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Gly Gly Gly Ser Gly Gly Gly Gln Arg Val Gln Pro Thr
305 310 315 320
Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly
325 330 335
Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg
340 345 350
Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser
355 360 365
Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu
370 375 380
Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg
385 390 395 400
Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala
405 410 415
Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala
420 425 430
Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr
435 440 445
Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp
450 455 460
Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val
465 470 475 480
Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro
485 490 495
Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe
500 505 510
Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Lys Ser Thr
515 520 525
Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn Gly Leu Thr
530 535 540
Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu Pro Phe Gln
545 550 555 560
Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val Arg Asp Pro
565 570 575
Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Ser Gly Gly Gly
580 585 590
Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu
595 600 605
Val Ser Leu Gly Ala Ile Ser Phe
610 615
<![CDATA[<210> 123]]>
<![CDATA[<211> 3995]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 123]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucaccc 2100
cggagggcaa ggagcguggc cagccagagc aucaucgccu acaccaugag ccugggcgcc 2160
gagaacagcg uggccuacag caacaacagc aucgccaucc ccaccaacuu caccaucagc 2220
gugaccaccg agauucugcc cgugagcaug accaagacca gcguggacug caccauguac 2280
aucugcggcg acagcaccga gugcagcaac cugcugcugc aguacggcag cuucugcacc 2340
cagcugaacc gggcccugac cggcaucgcc guggagcagg acaagaacac ccaggaggug 2400
uucgcccagg ugaagcagau cuacaagacc ccucccauca aggacuucgg cggcuucaac 2460
uucagccaga uccugcccga ccccagcaag cccagcaagc ggagcuucau cgaggaccug 2520
cuguucaaca aggugacccu agccgacgcc ggcuucauca agcaguacgg cgacugccuc 2580
ggcgacauag ccgcccggga ccugaucugc gcccagaagu ucaacggccu gaccgugcug 2640
ccuccccugc ugaccgacga gaugaucgcc caguacacca gcgcccuguu agccggaacc 2700
aucaccagcg gcuggacuuu cggcgcugga gccgcucugc agauccccuu cgccaugcag 2760
auggccuacc gguucaacgg caucggcgug acccagaacg ugcuguacga gaaccagaag 2820
cugaucgcca accaguucaa cagcgccauc ggcaagaucc aggacagccu gagcagcacc 2880
gcuagcgccc ugggcaagcu gcaggacgug gugaaccaga acgcccaggc ccugaacacc 2940
cuggugaagc agcugagcag caacuucggc gccaucagca gcgugcugaa cgacauccug 3000
agccggcugg acaaggugga ggccgaggug cagaucgacc ggcugaucac uggccggcug 3060
cagagccugc agaccuacgu gacccagcag cugauccggg ccgccgagau ucgggccagc 3120
gccaaccugg ccgccaccaa gaugagcgag ugcgugcugg gccagagcaa gcggguggac 3180
uucugcggca agggcuacca ccugaugagc uuuccccaga gcgcacccca cggaguggug 3240
uuccugcacg ugaccuacgu gcccgcccag gagaagaacu ucaccaccgc cccagccauc 3300
ugccacgacg gcaaggccca cuuuccccgg gagggcgugu ucgugagcaa cggcacccac 3360
ugguucguga cccagcggaa cuucuacgag ccccagauca ucaccaccga caacaccuuc 3420
gugagcggca acugcgacgu ggugaucggc aucgugaaca acaccgugua cgauccccug 3480
cagcccgagc uggacagcuu caaggaggag cuggacaagu acuucaagaa ucacaccagc 3540
cccgacgugg accugggcga caucagcggc aucaacgcca gcguggugaa cauccagaag 3600
gagaucgauc ggcugaacga gguggccaag aaccugaacg agagccugau cgaccugcag 3660
gagcugggca aguacgagca guacaucaag uggcccuggu acaucuggcu gggcuucauc 3720
gccggccuga ucgccaucgu gauggugacc aucaugcugu gcugcaugac cagcugcugc 3780
agcugccuga agggcuguug cagcugcggc agcugcugca aguucgacga ggacgacagc 3840
gagcccgugc ugaagggcgu gaagcugcac uacaccugau aauaggcugg agccucggug 3900
gccuagcuuc uugccccuug ggccuccccc cagccccucc uccccuuccu gcacccguac 3960
ccccgugguc uuugaauaaa gucugagugg gcggc 3995
<![CDATA[<210> 124]]>
<![CDATA[<211> 3819]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 124]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
ccccggaggg caaggagcgu ggccagccag agcaucaucg ccuacaccau gagccugggc 2100
gccgagaaca gcguggccua cagcaacaac agcaucgcca uccccaccaa cuucaccauc 2160
agcgugacca ccgagauucu gcccgugagc augaccaaga ccagcgugga cugcaccaug 2220
uacaucugcg gcgacagcac cgagugcagc aaccugcugc ugcaguacgg cagcuucugc 2280
acccagcuga accgggcccu gaccggcauc gccguggagc aggacaagaa cacccaggag 2340
guguucgccc aggugaagca gaucuacaag accccuccca ucaaggacuu cggcggcuuc 2400
aacuucagcc agauccugcc cgaccccagc aagcccagca agcggagcuu caucgaggac 2460
cugcuguuca acaaggugac ccuagccgac gccggcuuca ucaagcagua cggcgacugc 2520
cucggcgaca uagccgcccg ggaccugauc ugcgcccaga aguucaacgg ccugaccgug 2580
cugccucccc ugcugaccga cgagaugauc gcccaguaca ccagcgcccu guuagccgga 2640
accaucacca gcggcuggac uuucggcgcu ggagccgcuc ugcagauccc cuucgccaug 2700
cagauggccu accgguucaa cggcaucggc gugacccaga acgugcugua cgagaaccag 2760
aagcugaucg ccaaccaguu caacagcgcc aucggcaaga uccaggacag ccugagcagc 2820
accgcuagcg cccugggcaa gcugcaggac guggugaacc agaacgccca ggcccugaac 2880
acccugguga agcagcugag cagcaacuuc ggcgccauca gcagcgugcu gaacgacauc 2940
cugagccggc uggacaaggu ggaggccgag gugcagaucg accggcugau cacuggccgg 3000
cugcagagcc ugcagaccua cgugacccag cagcugaucc gggccgccga gauucgggcc 3060
agcgccaacc uggccgccac caagaugagc gagugcgugc ugggccagag caagcgggug 3120
gacuucugcg gcaagggcua ccaccugaug agcuuucccc agagcgcacc ccacggagug 3180
guguuccugc acgugaccua cgugcccgcc caggagaaga acuucaccac cgccccagcc 3240
aucugccacg acggcaaggc ccacuuuccc cgggagggcg uguucgugag caacggcacc 3300
cacugguucg ugacccagcg gaacuucuac gagccccaga ucaucaccac cgacaacacc 3360
uucgugagcg gcaacugcga cguggugauc ggcaucguga acaacaccgu guacgauccc 3420
cugcagcccg agcuggacag cuucaaggag gagcuggaca aguacuucaa gaaucacacc 3480
agccccgacg uggaccuggg cgacaucagc ggcaucaacg ccagcguggu gaacauccag 3540
aaggagaucg aucggcugaa cgagguggcc aagaaccuga acgagagccu gaucgaccug 3600
caggagcugg gcaaguacga gcaguacauc aaguggcccu gguacaucug gcugggcuuc 3660
aucgccggcc ugaucgccau cgugauggug accaucaugc ugugcugcau gaccagcugc 3720
ugcagcugcc ugaagggcug uugcagcugc ggcagcugcu gcaaguucga cgaggacgac 3780
agcgagcccg ugcugaaggg cgugaagcug cacuacacc 3819
<![CDATA[<210> 125]]>
<![CDATA[<211> 1273]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 125]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg Ala Arg Ser Val Ala
675 680 685
Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly Ala Glu Asn Ser
690 695 700
Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr Asn Phe Thr Ile
705 710 715 720
Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr Lys Thr Ser Val
725 730 735
Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu Cys Ser Asn Leu
740 745 750
Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn Arg Ala Leu Thr
755 760 765
Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu Val Phe Ala Gln
770 775 780
Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp Phe Gly Gly Phe
785 790 795 800
Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro Ser Lys Arg Ser
805 810 815
Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu Ala Asp Ala Gly
820 825 830
Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile Ala Ala Arg Asp
835 840 845
Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val Leu Pro Pro Leu
850 855 860
Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala Leu Leu Ala Gly
865 870 875 880
Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala Ala Leu Gln Ile
885 890 895
Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly Ile Gly Val Thr
900 905 910
Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala Asn Gln Phe Asn
915 920 925
Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser Ser Thr Ala Ser Ala
930 935 940
Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn Ala Gln Ala Leu Asn
945 950 955 960
Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly Ala Ile Ser Ser Val
965 970 975
Leu Asn Asp Ile Leu Ser Arg Leu Asp Lys Val Glu Ala Glu Val Gln
980 985 990
Ile Asp Arg Leu Ile Thr Gly Arg Leu Gln Ser Leu Gln Thr Tyr Val
995 1000 1005
Thr Gln Gln Leu Ile Arg Ala Ala Glu Ile Arg Ala Ser Ala Asn
1010 1015 1020
Leu Ala Ala Thr Lys Met Ser Glu Cys Val Leu Gly Gln Ser Lys
1025 1030 1035
Arg Val Asp Phe Cys Gly Lys Gly Tyr His Leu Met Ser Phe Pro
1040 1045 1050
Gln Ser Ala Pro His Gly Val Val Phe Leu His Val Thr Tyr Val
1055 1060 1065
Pro Ala Gln Glu Lys Asn Phe Thr Thr Ala Pro Ala Ile Cys His
1070 1075 1080
Asp Gly Lys Ala His Phe Pro Arg Glu Gly Val Phe Val Ser Asn
1085 1090 1095
Gly Thr His Trp Phe Val Thr Gln Arg Asn Phe Tyr Glu Pro Gln
1100 1105 1110
Ile Ile Thr Thr Asp Asn Thr Phe Val Ser Gly Asn Cys Asp Val
1115 1120 1125
Val Ile Gly Ile Val Asn Asn Thr Val Tyr Asp Pro Leu Gln Pro
1130 1135 1140
Glu Leu Asp Ser Phe Lys Glu Glu Leu Asp Lys Tyr Phe Lys Asn
1145 1150 1155
His Thr Ser Pro Asp Val Asp Leu Gly Asp Ile Ser Gly Ile Asn
1160 1165 1170
Ala Ser Val Val Asn Ile Gln Lys Glu Ile Asp Arg Leu Asn Glu
1175 1180 1185
Val Ala Lys Asn Leu Asn Glu Ser Leu Ile Asp Leu Gln Glu Leu
1190 1195 1200
Gly Lys Tyr Glu Gln Tyr Ile Lys Trp Pro Trp Tyr Ile Trp Leu
1205 1210 1215
Gly Phe Ile Ala Gly Leu Ile Ala Ile Val Met Val Thr Ile Met
1220 1225 1230
Leu Cys Cys Met Thr Ser Cys Cys Ser Cys Leu Lys Gly Cys Cys
1235 1240 1245
Ser Cys Gly Ser Cys Cys Lys Phe Asp Glu Asp Asp Ser Glu Pro
1250 1255 1260
Val Leu Lys Gly Val Lys Leu His Tyr Thr
1265 1270
<![CDATA[<210> 126]]>
<![CDATA[<211> 8]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 126]]>
Lys Pro Ser Lys Arg Ser Phe Ile
1 5
<![CDATA[<210> 127]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 127]]>
Thr Gln Thr Asn Ser Pro Arg Arg Ala Arg Ser Val Ala
1 5 10
<![CDATA[<210> 128]]>
<![CDATA[<211> 9]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 128]]>
ccrccaugg 9
<![CDATA[<210> 129]]>
<![CDATA[<211> 11]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 129]]>
gggauccuac c 11
<![CDATA[<210> 130]]>
<![CDATA[<211> 9]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 130]]>
uuauuuaww 9
<![CDATA[<210> 131]]>
<![CDATA[<211> 47]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 131]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag agccacc 47
<![CDATA[<210> 132]]>
<![CDATA[<211> 119]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 132]]>
ugauaauagg cuggagccuc gguggccaug cuucuugccc cuugggccuc cccccagccc 60
cuccuccccu uccugcaccc guacccccgu ggucuuugaa uaaagucuga gugggcggc 119
<![CDATA[<210> 133]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 133]]>
Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Gly
1 5 10 15
<![CDATA[<210> 134]]>
<![CDATA[<211> 8]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 134]]>
Gly Gly Gly Ser Gly Gly Gly Ser
1 5
<![CDATA[<210> 135]]>
<![CDATA[<211> 7]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 135]]>
Gly Gly Gly Ser Gly Gly Gly
1 5
<![CDATA[<210> 136]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 136]]>
Gly Gly Gly Ser
1
<![CDATA[<210> 137]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 137]]>
Ser Gly Gly Ser
1
<![CDATA[<210> 138]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 138]]>
Ser Gly Gly Gly Ser
1 5
<![CDATA[<210> 139]]>
<![CDATA[<211> 1602]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 139]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcagcggagg cggaagccag ugcgugaacc ugaccacccg gacccagcug 720
ccaccagccu acaccaacag cuucacccgg ggcgucuacu accccgacaa gguguuccgg 780
agcagcgucc ugcacagcac ccaggaccug uuccugcccu ucuucagcaa cgugaccugg 840
uuccacgcca uccacgugag cggcaccaac ggcaccaagc gguucgacaa ccccgugcug 900
cccuucaacg acggcgugua cuucgccagc accgagaaga gcaacaucau ccggggcugg 960
aucuucggca ccacccugga cagcaagacc cagagccugc ugaucgugaa uaacgccacc 1020
aacgugguga ucaaggugug cgaguuccag uucugcaacg accccuuccu gggcguguac 1080
uaccacaaga acaacaagag cuggauggag agcgaguucc ggguguacag cagcgccaac 1140
aacugcaccu ucgaguacgu gagccagccc uuccugaugg accuggaggg caagcagggc 1200
aacuucaaga accugcggga guucguguuc aagaacaucg acggcuacuu caagaucuac 1260
agcaagcaca ccccaaucaa ccuggugcgg gaucugcccc agggcuucuc agcccuggag 1320
ccccuggugg accugcccau cggcaucaac aucacccggu uccagacccu gcuggcccug 1380
caccggagcu accugacccc aggcgacagc agcagcgggu ggacagcagg cgcggcugcu 1440
uacuacgugg gcuaccugca gccccggacc uuccugcuga aguacaacga gaacggcacc 1500
aucaccgacg ccguggacuc uggcggaggc agcauccugg ccaucuacag caccguggcc 1560
agcagccugg ugcugcuggu gagccugggc gccaucagcu uc 1602
<![CDATA[<210> 140]]>
<![CDATA[<211> 534]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 140]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Ser Gly Gly Gly Ser Gln Cys Val Asn Leu Thr Thr Arg Thr Gln Leu
225 230 235 240
Pro Pro Ala Tyr Thr Asn Ser Phe Thr Arg Gly Val Tyr Tyr Pro Asp
245 250 255
Lys Val Phe Arg Ser Ser Val Leu His Ser Thr Gln Asp Leu Phe Leu
260 265 270
Pro Phe Phe Ser Asn Val Thr Trp Phe His Ala Ile His Val Ser Gly
275 280 285
Thr Asn Gly Thr Lys Arg Phe Asp Asn Pro Val Leu Pro Phe Asn Asp
290 295 300
Gly Val Tyr Phe Ala Ser Thr Glu Lys Ser Asn Ile Ile Arg Gly Trp
305 310 315 320
Ile Phe Gly Thr Thr Leu Asp Ser Lys Thr Gln Ser Leu Leu Ile Val
325 330 335
Asn Asn Ala Thr Asn Val Val Ile Lys Val Cys Glu Phe Gln Phe Cys
340 345 350
Asn Asp Pro Phe Leu Gly Val Tyr Tyr His Lys Asn Asn Lys Ser Trp
355 360 365
Met Glu Ser Glu Phe Arg Val Tyr Ser Ser Ala Asn Asn Cys Thr Phe
370 375 380
Glu Tyr Val Ser Gln Pro Phe Leu Met Asp Leu Glu Gly Lys Gln Gly
385 390 395 400
Asn Phe Lys Asn Leu Arg Glu Phe Val Phe Lys Asn Ile Asp Gly Tyr
405 410 415
Phe Lys Ile Tyr Ser Lys His Thr Pro Ile Asn Leu Val Arg Asp Leu
420 425 430
Pro Gln Gly Phe Ser Ala Leu Glu Pro Leu Val Asp Leu Pro Ile Gly
435 440 445
Ile Asn Ile Thr Arg Phe Gln Thr Leu Leu Ala Leu His Arg Ser Tyr
450 455 460
Leu Thr Pro Gly Asp Ser Ser Ser Gly Trp Thr Ala Gly Ala Ala Ala
465 470 475 480
Tyr Tyr Val Gly Tyr Leu Gln Pro Arg Thr Phe Leu Leu Lys Tyr Asn
485 490 495
Glu Asn Gly Thr Ile Thr Asp Ala Val Asp Ser Gly Gly Gly Ser Ile
500 505 510
Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser
515 520 525
Leu Gly Ala Ile Ser Phe
530
<![CDATA[<210> 141]]>
<![CDATA[<211> 1778]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 141]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggca gcggaggcgg aagccagugc gugaaccuga ccacccggac ccagcugcca 780
ccagccuaca ccaacagcuu cacccggggc gucuacuacc ccgacaaggu guuccggagc 840
agcguccugc acagcaccca ggaccuguuc cugcccuucu ucagcaacgu gaccugguuc 900
cacgccaucc acgugagcgg caccaacggc accaagcggu ucgacaaccc cgugcugccc 960
uucaacgacg gcguguacuu cgccagcacc gagaagagca acaucauccg gggcuggauc 1020
uucggcacca cccuggacag caagacccag agccugcuga ucgugaauaa cgccaccaac 1080
guggugauca aggugugcga guuccaguuc ugcaacgacc ccuuccuggg cguguacuac 1140
cacaagaaca acaagagcug gauggagagc gaguuccggg uguacagcag cgccaacaac 1200
ugcaccuucg aguacgugag ccagcccuuc cugauggacc uggagggcaa gcagggcaac 1260
uucaagaacc ugcgggaguu cguguucaag aacaucgacg gcuacuucaa gaucuacagc 1320
aagcacaccc caaucaaccu ggugcgggau cugccccagg gcuucucagc ccuggagccc 1380
cugguggacc ugcccaucgg caucaacauc acccgguucc agacccugcu ggcccugcac 1440
cggagcuacc ugaccccagg cgacagcagc agcgggugga cagcaggcgc ggcugcuuac 1500
uacgugggcu accugcagcc ccggaccuuc cugcugaagu acaacgagaa cggcaccauc 1560
accgacgccg uggacucugg cggaggcagc auccuggcca ucuacagcac cguggccagc 1620
agccuggugc ugcuggugag ccugggcgcc aucagcuucu gauaauaggc uggagccucg 1680
guggccuagc uucuugcccc uugggccucc ccccagcccc uccuccccuu ccugcacccg 1740
uacccccgug gucuuugaau aaagucugag ugggcggc 1778
<![CDATA[<210> 142]]>
<![CDATA[<211> 1602]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 142]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcgcca aguucguggc cgccuggacu 900
cugaaggccg cagccggcgg acccaacauc accaaccugu gccccuucgg cgagguguuc 960
aacgccaccc gguucgccag cguguacgcc uggaaccgga agcggaucag caacugcgug 1020
gccgacuaca gcgugcugua caacagcgcc agcuucagca ccuucaagug cuacggcgug 1080
agccccacca agcugaacga ccugugcuuc accaacgugu acgccgacag cuucgugauc 1140
cguggcgacg aggugcggca gaucgcaccc ggccagacag gcaagaucgc cgacuacaac 1200
uacaagcugc ccgacgacuu caccggcugc gugaucgccu ggaacagcaa caaccucgac 1260
agcaaggugg gcggcaacua caacuaccug uaccggcugu uccggaagag caaccugaag 1320
cccuucgagc gggacaucag caccgagauc uaccaagccg gcuccacccc uugcaacggc 1380
guggagggcu ucaacugcua cuucccucug cagagcuacg gcuuccagcc caccaacggc 1440
gugggcuacc agcccuaccg ggugguggug cugagcuucg agcugcugca cgccccagcc 1500
accgugugug gccccaaguc uggcggaggc agcauccugg ccaucuacag caccguggcc 1560
agcagccugg ugcugcuggu gagccugggc gccaucagcu uc 1602
<![CDATA[<210> 143]]>
<![CDATA[<211> 534]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 143]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Ala Lys Phe Val Ala Ala Trp Thr Leu Lys Ala Ala
290 295 300
Ala Gly Gly Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe
305 310 315 320
Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile
325 330 335
Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe
340 345 350
Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu
355 360 365
Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu
370 375 380
Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn
385 390 395 400
Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser
405 410 415
Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg
420 425 430
Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr
435 440 445
Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe
450 455 460
Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly
465 470 475 480
Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu
485 490 495
His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly Ser Ile
500 505 510
Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser
515 520 525
Leu Gly Ala Ile Ser Phe
530
<![CDATA[<210> 144]]>
<![CDATA[<211> 1778]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 144]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcgccaagu ucguggccgc cuggacucug 960
aaggccgcag ccggcggacc caacaucacc aaccugugcc ccuucggcga gguguucaac 1020
gccacccggu ucgccagcgu guacgccugg aaccggaagc ggaucagcaa cugcguggcc 1080
gacuacagcg ugcuguacaa cagcgccagc uucagcaccu ucaagugcua cggcgugagc 1140
cccaccaagc ugaacgaccu gugcuucacc aacguguacg ccgacagcuu cgugauccgu 1200
ggcgacgagg ugcggcagau cgcacccggc cagacaggca agaucgccga cuacaacuac 1260
aagcugcccg acgacuucac cggcugcgug aucgccugga acagcaacaa ccucgacagc 1320
aaggugggcg gcaacuacaa cuaccuguac cggcuguucc ggaagagcaa ccugaagccc 1380
uucgagcggg acaucagcac cgagaucuac caagccggcu ccaccccuug caacggcgug 1440
gagggcuuca acugcuacuu cccucugcag agcuacggcu uccagcccac caacggcgug 1500
ggcuaccagc ccuaccgggu gguggugcug agcuucgagc ugcugcacgc cccagccacc 1560
guguguggcc ccaagucugg cggaggcagc auccuggcca ucuacagcac cguggccagc 1620
agccuggugc ugcuggugag ccugggcgcc aucagcuucu gauaauaggc uggagccucg 1680
guggccuagc uucuugcccc uugggccucc ccccagcccc uccuccccuu ccugcacccg 1740
uacccccgug gucuuugaau aaagucugag ugggcggc 1778
<![CDATA[<210> 145]]>
<![CDATA[<211> 1785]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 145]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagggcgccg agaacagcgu ggccuacagc aacaacagca ucgccauccc caccaacuuc 120
accaucagcg ugaccaccga gauucugccc gugagcauga ccaagaccag cguggacugc 180
accauguaca ucugcggcga cagcaccgag ugcagcaacc ugcugcugca guacggcagc 240
uucugcaccc agcugaaccg ggcccugacc ggcaucgccg uggagcagga caagaacacc 300
caggaggugu ucgcccaggu gaagcagauc uacaagaccc cucccaucaa ggacuucggc 360
ggcuucaacu ucagccagau ccugcccgac cccagcaagc ccagcaagcg gagcuucauc 420
gaggaccugc uguucaacaa ggugacccua gccgacgccg gcuucaucaa gcaguacggc 480
gacugccucg gcgacauagc cgcccgggac cugaucugcg cccagaaguu caacggccug 540
accgugcugc cuccccugcu gaccgacgag augaucgccc aguacaccag cgcccuguua 600
gccggaacca ucaccagcgg cuggacuuuc ggcgcuggag ccgcucugca gauccccuuc 660
gccaugcaga uggccuaccg guucaacggc aucggcguga cccagaacgu gcuguacgag 720
aaccagaagc ugaucgccaa ccaguucaac agcgccaucg gcaagaucca ggacagccug 780
agcagcaccg cuagcgcccu gggcaagcug caggacgugg ugaaccagaa cgcccaggcc 840
cugaacaccc uggugaagca gcugagcagc aacuucggcg ccaucagcag cgugcugaac 900
gacauccuga gccggcugga cccucccgag gccgaggugc agaucgaccg gcugaucacu 960
ggccggcugc agagccugca gaccuacgug acccagcagc ugauccgggc cgccgagauu 1020
cgggccagcg ccaaccuggc cgccaccaag augagcgagu gcgugcuggg ccagagcaag 1080
cggguggacu ucugcggcaa gggcuaccac cugaugagcu uuccccagag cgcaccccac 1140
ggaguggugu uccugcacgu gaccuacgug cccgcccagg agaagaacuu caccaccgcc 1200
ccagccaucu gccacgacgg caaggcccac uuuccccggg agggcguguu cgugagcaac 1260
ggcacccacu gguucgugac ccagcggaac uucuacgagc cccagaucau caccaccgac 1320
aacaccuucg ugagcggcaa cugcgacgug gugaucggca ucgugaacaa caccguguac 1380
gauccccugc agcccgagcu ggacagcuuc aaggaggagc uggacaagua cuucaagaau 1440
cacaccagcc ccgacgugga ccugggcgac aucagcggca ucaacgccag cguggugaac 1500
auccagaagg agaucgaucg gcugaacgag guggccaaga accugaacga gagccugauc 1560
gaccugcagg agcugggcaa guacgagcag uacaucaagu ggcccuggua caucuggcug 1620
ggcuucaucg ccggccugau cgccaucgug auggugacca ucaugcugug cugcaugacc 1680
agcugcugca gcugccugaa gggcuguugc agcugcggca gcugcugcaa guucgacgag 1740
gacgacagcg agcccgugcu gaagggcgug aagcugcacu acacc 1785
<![CDATA[<210> 146]]>
<![CDATA[<211> 595]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 146]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Gly Ala Glu Asn Ser Val Ala Tyr Ser Asn Asn
20 25 30
Ser Ile Ala Ile Pro Thr Asn Phe Thr Ile Ser Val Thr Thr Glu Ile
35 40 45
Leu Pro Val Ser Met Thr Lys Thr Ser Val Asp Cys Thr Met Tyr Ile
50 55 60
Cys Gly Asp Ser Thr Glu Cys Ser Asn Leu Leu Leu Gln Tyr Gly Ser
65 70 75 80
Phe Cys Thr Gln Leu Asn Arg Ala Leu Thr Gly Ile Ala Val Glu Gln
85 90 95
Asp Lys Asn Thr Gln Glu Val Phe Ala Gln Val Lys Gln Ile Tyr Lys
100 105 110
Thr Pro Pro Ile Lys Asp Phe Gly Gly Phe Asn Phe Ser Gln Ile Leu
115 120 125
Pro Asp Pro Ser Lys Pro Ser Lys Arg Ser Phe Ile Glu Asp Leu Leu
130 135 140
Phe Asn Lys Val Thr Leu Ala Asp Ala Gly Phe Ile Lys Gln Tyr Gly
145 150 155 160
Asp Cys Leu Gly Asp Ile Ala Ala Arg Asp Leu Ile Cys Ala Gln Lys
165 170 175
Phe Asn Gly Leu Thr Val Leu Pro Pro Leu Leu Thr Asp Glu Met Ile
180 185 190
Ala Gln Tyr Thr Ser Ala Leu Leu Ala Gly Thr Ile Thr Ser Gly Trp
195 200 205
Thr Phe Gly Ala Gly Ala Ala Leu Gln Ile Pro Phe Ala Met Gln Met
210 215 220
Ala Tyr Arg Phe Asn Gly Ile Gly Val Thr Gln Asn Val Leu Tyr Glu
225 230 235 240
Asn Gln Lys Leu Ile Ala Asn Gln Phe Asn Ser Ala Ile Gly Lys Ile
245 250 255
Gln Asp Ser Leu Ser Ser Thr Ala Ser Ala Leu Gly Lys Leu Gln Asp
260 265 270
Val Val Asn Gln Asn Ala Gln Ala Leu Asn Thr Leu Val Lys Gln Leu
275 280 285
Ser Ser Asn Phe Gly Ala Ile Ser Ser Val Leu Asn Asp Ile Leu Ser
290 295 300
Arg Leu Asp Pro Pro Glu Ala Glu Val Gln Ile Asp Arg Leu Ile Thr
305 310 315 320
Gly Arg Leu Gln Ser Leu Gln Thr Tyr Val Thr Gln Gln Leu Ile Arg
325 330 335
Ala Ala Glu Ile Arg Ala Ser Ala Asn Leu Ala Ala Thr Lys Met Ser
340 345 350
Glu Cys Val Leu Gly Gln Ser Lys Arg Val Asp Phe Cys Gly Lys Gly
355 360 365
Tyr His Leu Met Ser Phe Pro Gln Ser Ala Pro His Gly Val Val Phe
370 375 380
Leu His Val Thr Tyr Val Pro Ala Gln Glu Lys Asn Phe Thr Thr Ala
385 390 395 400
Pro Ala Ile Cys His Asp Gly Lys Ala His Phe Pro Arg Glu Gly Val
405 410 415
Phe Val Ser Asn Gly Thr His Trp Phe Val Thr Gln Arg Asn Phe Tyr
420 425 430
Glu Pro Gln Ile Ile Thr Thr Asp Asn Thr Phe Val Ser Gly Asn Cys
435 440 445
Asp Val Val Ile Gly Ile Val Asn Asn Thr Val Tyr Asp Pro Leu Gln
450 455 460
Pro Glu Leu Asp Ser Phe Lys Glu Glu Leu Asp Lys Tyr Phe Lys Asn
465 470 475 480
His Thr Ser Pro Asp Val Asp Leu Gly Asp Ile Ser Gly Ile Asn Ala
485 490 495
Ser Val Val Asn Ile Gln Lys Glu Ile Asp Arg Leu Asn Glu Val Ala
500 505 510
Lys Asn Leu Asn Glu Ser Leu Ile Asp Leu Gln Glu Leu Gly Lys Tyr
515 520 525
Glu Gln Tyr Ile Lys Trp Pro Trp Tyr Ile Trp Leu Gly Phe Ile Ala
530 535 540
Gly Leu Ile Ala Ile Val Met Val Thr Ile Met Leu Cys Cys Met Thr
545 550 555 560
Ser Cys Cys Ser Cys Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys
565 570 575
Lys Phe Asp Glu Asp Asp Ser Glu Pro Val Leu Lys Gly Val Lys Leu
580 585 590
His Tyr Thr
595
<![CDATA[<210> 147]]>
<![CDATA[<211> 1961]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 147]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
ggcgccgaga acagcguggc cuacagcaac aacagcaucg ccauccccac caacuucacc 180
aucagcguga ccaccgagau ucugcccgug agcaugacca agaccagcgu ggacugcacc 240
auguacaucu gcggcgacag caccgagugc agcaaccugc ugcugcagua cggcagcuuc 300
ugcacccagc ugaaccgggc ccugaccggc aucgccgugg agcaggacaa gaacacccag 360
gagguguucg cccaggugaa gcagaucuac aagaccccuc ccaucaagga cuucggcggc 420
uucaacuuca gccagauccu gcccgacccc agcaagccca gcaagcggag cuucaucgag 480
gaccugcugu ucaacaaggu gacccuagcc gacgccggcu ucaucaagca guacggcgac 540
ugccucggcg acauagccgc ccgggaccug aucugcgccc agaaguucaa cggccugacc 600
gugcugccuc cccugcugac cgacgagaug aucgcccagu acaccagcgc ccuguuagcc 660
ggaaccauca ccagcggcug gacuuucggc gcuggagccg cucugcagau ccccuucgcc 720
augcagaugg ccuaccgguu caacggcauc ggcgugaccc agaacgugcu guacgagaac 780
cagaagcuga ucgccaacca guucaacagc gccaucggca agauccagga cagccugagc 840
agcaccgcua gcgcccuggg caagcugcag gacgugguga accagaacgc ccaggcccug 900
aacacccugg ugaagcagcu gagcagcaac uucggcgcca ucagcagcgu gcugaacgac 960
auccugagcc ggcuggaccc ucccgaggcc gaggugcaga ucgaccggcu gaucacuggc 1020
cggcugcaga gccugcagac cuacgugacc cagcagcuga uccgggccgc cgagauucgg 1080
gccagcgcca accuggccgc caccaagaug agcgagugcg ugcugggcca gagcaagcgg 1140
guggacuucu gcggcaaggg cuaccaccug augagcuuuc cccagagcgc accccacgga 1200
gugguguucc ugcacgugac cuacgugccc gcccaggaga agaacuucac caccgcccca 1260
gccaucugcc acgacggcaa ggcccacuuu ccccgggagg gcguguucgu gagcaacggc 1320
acccacuggu ucgugaccca gcggaacuuc uacgagcccc agaucaucac caccgacaac 1380
accuucguga gcggcaacug cgacguggug aucggcaucg ugaacaacac cguguacgau 1440
ccccugcagc ccgagcugga cagcuucaag gaggagcugg acaaguacuu caagaaucac 1500
accagccccg acguggaccu gggcgacauc agcggcauca acgccagcgu ggugaacauc 1560
cagaaggaga ucgaucggcu gaacgaggug gccaagaacc ugaacgagag ccugaucgac 1620
cugcaggagc ugggcaagua cgagcaguac aucaaguggc ccugguacau cuggcugggc 1680
uucaucgccg gccugaucgc caucgugaug gugaccauca ugcugugcug caugaccagc 1740
ugcugcagcu gccugaaggg cuguugcagc ugcggcagcu gcugcaaguu cgacgaggac 1800
gacagcgagc ccgugcugaa gggcgugaag cugcacuaca ccugauaaua ggcuggagcc 1860
ucgguggccu agcuucuugc cccuugggcc uccccccagc cccuccuccc cuuccugcac 1920
ccguaccccc guggucuuug aauaaagucu gagugggcgg c 1961
<![CDATA[<210> 148]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 148]]>
Ala Lys Phe Val Ala Ala Trp Thr Leu Lys Ala Ala Ala
1 5 10
<![CDATA[<210> 149]]>
<![CDATA[<211> 2216]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 149]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucauga 2100
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccucccc ccagccccuc 2160
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 2216
<![CDATA[<210> 150]]>
<![CDATA[<211> 2040]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 150]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
<![CDATA[<210> 151]]>
<![CDATA[<211> 680]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 151]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser
675 680
<![CDATA[<210> 152]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列(Artificial Sequence)]]>
<![CDATA[<220>]]>
<![CDATA[<223> 合成]]>
<![CDATA[<400> 152]]>
Gly Ser Gly Gly
1
<![CDATA[ <110> ModernaTX, Inc.]]>
<![CDATA[ <120> SARS-COV-2 mRNA domain vaccine]]>
<![CDATA[ <130> M1378.70157]]>
<![CDATA[ <140>TW 110123289]]>
<![CDATA[ <141> 2021-06-25]]>
<![CDATA[ <150> US 63/063,137]]>
<![CDATA[ <151> 2020-08-07]]>
<![CDATA[ <150> US 63/044,330]]>
<![CDATA[ <151> 2020-06-25]]>
<![CDATA[ <160> 152]]>
<![CDATA[ <170> PatentIn Version 3.5]]>
<![CDATA[ <210> 1]]>
<![CDATA[ <211> 2216]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 1]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucauga 2100
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccucccc ccagccccuc 2160
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 2216
<![CDATA[ <210> 2]]>
<![CDATA[ <211> 57]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 2]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccacc 57
<![CDATA[ <210> 3]]>
<![CDATA[ <211> 2040]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 3]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
<![CDATA[ <210> 4]]>
<![CDATA[ <211> 119]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 4]]>
ugauaauagg cuggagccuc gguggccuag cuucuugccc cuugggccuc cccccagccc 60
cuccuccccu uccugcaccc guacccccgu ggucuuugaa uaaagucuga gugggcggc 119
<![CDATA[ <210> 5]]>
<![CDATA[ <211> 680]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 5]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser
675 680
<![CDATA[ <210> 6]]>
<![CDATA[ <211> 2729]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 6]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucagga 2100
ggaggcagcg gcggcgauau caucaagcuu cugaacgagc aaguuaacaa ggaaaugcag 2160
agcaguaauc ucuacaugag caugagcagc uggugcuaca cccacucccu ggacggagca 2220
ggccucuucc uguucgacca cgcagccgag gaguacgagc acgcuaagaa guugaucauu 2280
uucuugaacg agaacaacgu gcccgugcag cuaacgucaa ucagcgcacc ugagcacaag 2340
uucgagggcc ugacccagau cuuccagaag gccuacgaac acgaacagca caucuccgag 2400
agcaucaaca auauugugga ucacgcuauc aaguccaagg accacgcuac cuucaacuuc 2460
cugcaguggu acguggccga gcaacaugag gaggaggugc uguucaagga cauccuggac 2520
aagaucgagc ugaucgguaa ugagaaucac ggccuguacc uggccgacca guacgugaag 2580
ggcaucgcca agagccggaa gucaggcuca ugauaauagg cuggagccuc gguggccuag 2640
cuucuugccc cuugggccuc cccccagccc cuccuccccu uccugcaccc guacccccgu 2700
ggucuuugaa uaaagucuga gugggcggc 2729
<![CDATA[ <210> 7]]>
<![CDATA[ <211> 2553]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 7]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
ggaggaggca gcggcggcga uaucaucaag cuucugaacg agcaaguuaa caaggaaaug 2100
cagagcagua aucucuacau gagcaugagc agcuggugcu acacccacuc ccuggacgga 2160
gcaggccucu uccuguucga ccacgcagcc gaggaguacg agcacgcuaa gaaguugauc 2220
auuuucuuga acgagaacaa cgugcccgug cagcuaacgu caaucagcgc accugagcac 2280
aaguucgagg gccugaccca gaucuuccag aaggccuacg aacacgaaca gcacaucucc 2340
gagagcauca acaauauugu ggaucacgcu aucaagucca aggaccacgc uaccuucaac 2400
uuccugcagu gguacguggc cgagcaacau gaggaggagg ugcuguucaa ggacauccug 2460
gacaagaucg agcugaucgg uaaugagaau cacggccugu accuggccga ccaguacgug 2520
aagggcaucg ccaagagccg gaagucaggc uca 2553
<![CDATA[ <210> 8]]>
<![CDATA[ <211> 851]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 8]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Gly Gly Gly Ser Gly Gly Asp Ile
675 680 685
Ile Lys Leu Leu Asn Glu Gln Val Asn Lys Glu Met Gln Ser Ser Asn
690 695 700
Leu Tyr Met Ser Met Ser Ser Trp Cys Tyr Thr His Ser Leu Asp Gly
705 710 715 720
Ala Gly Leu Phe Leu Phe Asp His Ala Ala Glu Glu Tyr Glu His Ala
725 730 735
Lys Lys Leu Ile Ile Phe Leu Asn Glu Asn Asn Val Pro Val Gln Leu
740 745 750
Thr Ser Ile Ser Ala Pro Glu His Lys Phe Glu Gly Leu Thr Gln Ile
755 760 765
Phe Gln Lys Ala Tyr Glu His Glu Gln His Ile Ser Glu Ser Ile Asn
770 775 780
Asn Ile Val Asp His Ala Ile Lys Ser Lys Asp His Ala Thr Phe Asn
785 790 795 800
Phe Leu Gln Trp Tyr Val Ala Glu Gln His Glu Glu Glu Val Leu Phe
805 810 815
Lys Asp Ile Leu Asp Lys Ile Glu Leu Ile Gly Asn Glu Asn His Gly
820 825 830
Leu Tyr Leu Ala Asp Gln Tyr Val Lys Gly Ile Ala Lys Ser Arg Lys
835 840 845
Ser Gly Ser
850
<![CDATA[ <210> 9]]>
<![CDATA[ <211> 2762]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 9]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
ggcauccugc ccagcccugg caugcccgcu cugcugagcc uggugagccu gcugagcgug 120
cugcugaugg gcugcguggc ugagaccggc augcagaucu acgagggcaa gcugaccgca 180
gagggccugc gguucggcau cguggccagc cgcgccaacc acgcucuggu ggaccggcuu 240
guggagggcg cuaucgacgc caucgugaga cacggcggcc gggaagagga caucacccug 300
gugcgggugu gcggcagcug ggagauuccc gucgccgccg gagaacuggc ccggaaggag 360
gacaucgacg ccgugaucgc caucggcgug cugugcagag gcgccacgcc cagcuucgac 420
uacaucgcca gcgaggugag caagggccug gccgaccuga gccuggagcu gcggaagccc 480
aucaccuucg gcgugaucac cgccgacacc cuggagcagg ccaucgaggc cgcaggcacc 540
ugccacggca acaagggcug ggaagccgcc cugugcgcca ucgagauggc caaccuguuc 600
aagagccugc ggggcggaag uggaggcucu gguggcagcg gaggaucugg cggcggcacc 660
acccggaccc agcugccacc agccuacacc aacagcuuca cccggggcgu cuacuacccc 720
gacaaggugu uccggagcag cguccugcac agcacccagg accuguuccu gcccuucuuc 780
agcaacguga ccugguucca cgccauccac gugagcggca ccaacggcac caagcgguuc 840
gacaaccccg ugcugcccuu caacgacggc guguacuucg ccagcaccga gaagagcaac 900
aucauccggg gcuggaucuu cggcaccacc cuggacagca agacccagag ccugcugauc 960
gugaauaacg ccaccaacgu ggugaucaag gugugcgagu uccaguucug caacgacccc 1020
uuccugggcg uguacuacca caagaacaac aagagcugga uggagagcga guuccgggug 1080
uacagcagcg ccaacaacug caccuucgag uacgugagcc agcccuuccu gauggaccug 1140
gagggcaagc agggcaacuu caagaaccug cgggaguucg uguucaagaa caucgacggc 1200
uacuucaaga ucuacagcaa gcacacccca aucaaccugg ugcgggaucu gccccagggc 1260
uucucagccc uggagccccu gguggaccug cccaucggca ucaacaucac ccgguuccag 1320
acccugcugg cccugcaccg gagcuaccug accccaggcg acagcagcag cggguggaca 1380
gcaggcgcgg cugcuuacua cgugggcuac cugcagcccc ggaccuuccu gcugaaguac 1440
aacgagaacg gcaccaucac cgacgccgug gacugcgccc uggacccucu gagcgagacc 1500
aagugcaccc ugaagagcuu caccguggag aagggcaucu accagaccag caacuuccgg 1560
gugcagccca ccgagagcau cgugcgguuc cccaacauca ccaaccugug ccccuucggc 1620
gagguguuca acgccacccg guucgccagc guguacgccu ggaaccggaa gcggaucagc 1680
aacugcgugg ccgacuacag cgugcuguac aacagcgcca gcuucagcac cuucaagugc 1740
uacggcguga gccccaccaa gcugaacgac cugugcuuca ccaacgugua cgccgacagc 1800
uucgugaucc guggcgacga ggugcggcag aucgcacccg gccagacagg caagaucgcc 1860
gacuacaacu acaagcugcc cgacgacuuc accggcugcg ugaucgccug gaacagcaac 1920
aaccucgaca gcaagguggg cggcaacuac aacuaccugu accggcuguu ccggaagagc 1980
aaccugaagc ccuucgagcg ggacaucagc accgagaucu accaagccgg cuccaccccu 2040
ugcaacggcg uggagggcuu caacugcuac uucccucugc agagcuacgg cuuccagccc 2100
accaacggcg ugggcuacca gcccuaccgg gugguggugc ugagcuucga gcugcugcac 2160
gccccagcca ccgugugugg ccccaagaag agcaccaacc uggugaagaa caagugcgug 2220
aacuucaacu ucaacggccu uaccggcacc ggcgugcuga ccgagagcaa caagaaauuc 2280
cugcccuuuc agcaguucgg ccgggacauc gccgacacca ccgacgcugu gcgggauccc 2340
cagacccugg agauccugga caucaccccu ugcagcuucg gcggcgugag cgugaucacc 2400
ccaggcacca acaccagcaa ccagguggcc gugcuguacc aggacgugaa cugcaccgag 2460
gugcccgugg ccauccacgc cgaccagcug acacccaccu ggcgggucua cagcaccggc 2520
agcaacgugu uccagacccg ggccgguugc cugaucggcg ccgagcacgu gaacaacagc 2580
uacgagugcg acauccccau cggcgccggc aucugugcca gcuaccagac ccagaccaau 2640
ucaugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 2700
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 2760
gc 2762
<![CDATA[ <210> 10]]>
<![CDATA[ <211> 2586]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 10]]>
augggcaucc ugcccagccc uggcaugccc gcucugcuga gccuggugag ccugcugagc 60
gugcugcuga ugggcugcgu ggcugagacc ggcaugcaga ucuacgaggg caagcugacc 120
gcagagggcc ugcgguucgg caucguggcc agccgcgcca accacgcucu gguggaccgg 180
cuuguggagg gcgcuaucga cgccaucgug agacacggcg gccgggaaga ggacaucacc 240
cuggugcggg ugugcggcag cugggagauu cccgucgccg ccggagaacu ggcccggaag 300
gaggacaucg acgccgugau cgccaucggc gugcugugca gaggcgccac gcccagcuuc 360
gacuacaucg ccagcgaggu gagcaagggc cuggccgacc ugagccugga gcugcggaag 420
cccaucaccu ucggcgugau caccgccgac acccuggagc aggccaucga ggccgcaggc 480
accugccacg gcaacaaggg cugggaagcc gcccugugcg ccaucgagau ggccaaccug 540
uucaagagcc ugcggggcgg aaguggaggc ucugguggca gcggaggauc uggcggcggc 600
accacccgga cccagcugcc accagccuac accaacagcu ucacccgggg cgucuacuac 660
cccgacaagg uguuccggag cagcguccug cacagcaccc aggaccuguu ccugcccuuc 720
uucagcaacg ugaccugguu ccacgccauc cacgugagcg gcaccaacgg caccaagcgg 780
uucgacaacc ccgugcugcc cuucaacgac ggcguguacu ucgccagcac cgagaagagc 840
aacaucaucc ggggcuggau cuucggcacc acccuggaca gcaagaccca gagccugcug 900
aucgugaaua acgccaccaa cguggugauc aaggugugcg aguuccaguu cugcaacgac 960
cccuuccugg gcguguacua ccacaagaac aacaagagcu ggauggagag cgaguuccgg 1020
guguacagca gcgccaacaa cugcaccuuc gaguacguga gccagcccuu ccugauggac 1080
cuggagggca agcagggcaa cuucaagaac cugcgggagu ucguguucaa gaacaucgac 1140
ggcuacuuca agaucuacag caagcacacc ccaaucaacc uggugcggga ucugccccag 1200
ggcuucucag cccuggagcc ccugguggac cugcccaucg gcaucaacau cacccgguuc 1260
cagacccugc uggcccugca ccggagcuac cugaccccag gcgacagcag cagcgggugg 1320
acagcaggcg cggcugcuua cuacgugggc uaccugcagc cccggaccuu ccugcugaag 1380
uacaacgaga acggcaccau caccgacgcc guggacugcg cccuggaccc ucugagcgag 1440
accaagugca cccugaagag cuucaccgug gagaagggca ucuaccagac cagcaacuuc 1500
cgggugcagc ccaccgagag caucgugcgg uuccccaaca ucaccaaccu gugccccuuc 1560
ggcgaggugu ucaacgccac ccgguucgcc agcguguacg ccuggaaccg gaagcggauc 1620
agcaacugcg uggccgacua cagcgugcug uacaacagcg ccagcuucag caccuucaag 1680
ugcuacggcg ugagccccac caagcugaac gaccugugcu ucaccaacgu guacgccgac 1740
agcuucguga uccguggcga cgaggugcgg cagaucgcac ccggccagac aggcaagauc 1800
gccgacuaca acuacaagcu gcccgacgac uucaccggcu gcgugaucgc cuggaacagc 1860
aacaaccucg acagcaaggu gggcggcaac uacaacuacc uguaccggcu guuccggaag 1920
agcaaccuga agcccuucga gcgggacauc agcaccgaga ucuaccaagc cggcuccacc 1980
ccuugcaacg gcguggaggg cuucaacugc uacuucccuc ugcagagcua cggcuuccag 2040
cccaccaacg gcgugggcua ccagcccuac cggguggugg ugcugagcuu cgagcugcug 2100
cacgccccag ccaccgugug uggccccaag aagagcacca accuggugaa gaacaagugc 2160
gugaacuuca acuucaacgg ccuuaccggc accggcgugc ugaccgagag caacaagaaa 2220
uuccugcccu uucagcaguu cggccgggac aucgccgaca ccaccgacgc ugugcgggau 2280
ccccagaccc uggagauccu ggacaucacc ccuugcagcu ucggcggcgu gagcgugauc 2340
accccaggca ccaacaccag caaccaggug gccgugcugu accaggacgu gaacugcacc 2400
gaggugcccg uggccaucca cgccgaccag cugacaccca ccuggcgggu cuacagcacc 2460
ggcagcaacg uguuccagac ccgggccggu ugccugaucg gcgccgagca cgugaacaac 2520
agcuacgagu gcgacauccc caucggcgcc ggcaucugug ccagcuacca gacccagacc 2580
aauuca 2586
<![CDATA[ <210> 11]]>
<![CDATA[ <211> 862]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 11]]>
Met Gly Ile Leu Pro Ser Pro Gly Met Pro Ala Leu Leu Ser Leu Val
1 5 10 15
Ser Leu Leu Ser Val Leu Leu Met Gly Cys Val Ala Glu Thr Gly Met
20 25 30
Gln Ile Tyr Glu Gly Lys Leu Thr Ala Glu Gly Leu Arg Phe Gly Ile
35 40 45
Val Ala Ser Arg Ala Asn His Ala Leu Val Asp Arg Leu Val Glu Gly
50 55 60
Ala Ile Asp Ala Ile Val Arg His Gly Gly Arg Glu Glu Asp Ile Thr
65 70 75 80
Leu Val Arg Val Cys Gly Ser Trp Glu Ile Pro Val Ala Ala Gly Glu
85 90 95
Leu Ala Arg Lys Glu Asp Ile Asp Ala Val Ile Ala Ile Gly Val Leu
100 105 110
Cys Arg Gly Ala Thr Pro Ser Phe Asp Tyr Ile Ala Ser Glu Val Ser
115 120 125
Lys Gly Leu Ala Asp Leu Ser Leu Glu Leu Arg Lys Pro Ile Thr Phe
130 135 140
Gly Val Ile Thr Ala Asp Thr Leu Glu Gln Ala Ile Glu Ala Ala Gly
145 150 155 160
Thr Cys His Gly Asn Lys Gly Trp Glu Ala Ala Leu Cys Ala Ile Glu
165 170 175
Met Ala Asn Leu Phe Lys Ser Leu Arg Gly Gly Ser Gly Gly Ser Gly
180 185 190
Gly Ser Gly Gly Ser Gly Gly Gly Thr Thr Arg Thr Gln Leu Pro Pro
195 200 205
Ala Tyr Thr Asn Ser Phe Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val
210 215 220
Phe Arg Ser Ser Val Leu His Ser Thr Gln Asp Leu Phe Leu Pro Phe
225 230 235 240
Phe Ser Asn Val Thr Trp Phe His Ala Ile His Val Ser Gly Thr Asn
245 250 255
Gly Thr Lys Arg Phe Asp Asn Pro Val Leu Pro Phe Asn Asp Gly Val
260 265 270
Tyr Phe Ala Ser Thr Glu Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe
275 280 285
Gly Thr Thr Leu Asp Ser Lys Thr Gln Ser Leu Leu Ile Val Asn Asn
290 295 300
Ala Thr Asn Val Val Ile Lys Val Cys Glu Phe Gln Phe Cys Asn Asp
305 310 315 320
Pro Phe Leu Gly Val Tyr Tyr His Lys Asn Asn Lys Ser Trp Met Glu
325 330 335
Ser Glu Phe Arg Val Tyr Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr
340 345 350
Val Ser Gln Pro Phe Leu Met Asp Leu Glu Gly Lys Gln Gly Asn Phe
355 360 365
Lys Asn Leu Arg Glu Phe Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys
370 375 380
Ile Tyr Ser Lys His Thr Pro Ile Asn Leu Val Arg Asp Leu Pro Gln
385 390 395 400
Gly Phe Ser Ala Leu Glu Pro Leu Val Asp Leu Pro Ile Gly Ile Asn
405 410 415
Ile Thr Arg Phe Gln Thr Leu Leu Ala Leu His Arg Ser Tyr Leu Thr
420 425 430
Pro Gly Asp Ser Ser Ser Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr
435 440 445
Val Gly Tyr Leu Gln Pro Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn
450 455 460
Gly Thr Ile Thr Asp Ala Val Asp Cys Ala Leu Asp Pro Leu Ser Glu
465 470 475 480
Thr Lys Cys Thr Leu Lys Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln
485 490 495
Thr Ser Asn Phe Arg Val Gln Pro Thr Glu Ser Ile Val Arg Phe Pro
500 505 510
Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala Thr Arg
515 520 525
Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn Cys Val
530 535 540
Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys
545 550 555 560
Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn
565 570 575
Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg Gln Ile
580 585 590
Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro
595 600 605
Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn Leu Asp
610 615 620
Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys
625 630 635 640
Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln
645 650 655
Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe
660 665 670
Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln
675 680 685
Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala Pro Ala
690 695 700
Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn Lys Cys
705 710 715 720
Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu Thr Glu
725 730 735
Ser Asn Lys Lys Phe Leu Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala
740 745 750
Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp
755 760 765
Ile Thr Pro Cys Ser Phe Gly Gly Val Ser Val Ile Thr Pro Gly Thr
770 775 780
Asn Thr Ser Asn Gln Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr
785 790 795 800
Glu Val Pro Val Ala Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg
805 810 815
Val Tyr Ser Thr Gly Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu
820 825 830
Ile Gly Ala Glu His Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile
835 840 845
Gly Ala Gly Ile Cys Ala Ser Tyr Gln Thr Gln Thr Asn Ser
850 855 860
<![CDATA[ <210> 12]]>
<![CDATA[ <211> 2714]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 12]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucagga 2100
ggaggcuccg gaggcgguag cgcugagacc ggcaugcaga ucuacgaggg caagcugacc 2160
gcagagggcc ugcgguucgg caucguggcc agccgcgcca accacgcucu gguggaccgg 2220
cuuguggagg gcgcuaucga cgccaucgug agacacggcg gccgggaaga ggacaucacc 2280
cuggugcggg ugugcggcag cugggagauu cccgucgccg ccggagaacu ggcccggaag 2340
gaggacaucg acgccgugau cgccaucggc gugcugugca gaggcgccac gcccagcuuc 2400
gacuacaucg ccagcgaggu gagcaagggc cuggccgacc ugagccugga gcugcggaag 2460
cccaucaccu ucggcgugau caccgccgac acccuggagc aggccaucga ggccgcaggc 2520
accugccacg gcaacaaggg cugggaagcc gcccugugcg ccaucgagau ggccaaccug 2580
uucaagagcc ugcggugaua auaggcugga gccucggugg ccuagcuucu ugccccuugg 2640
gccuccccccc agccccuccu ccccuuccug cacccguacc cccguggucu uugaauaaag 2700
ucugaguggg cggc 2714
<![CDATA[ <210> 13]]>
<![CDATA[ <211> 2538]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 13]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
ggaggaggcu ccggaggcgg uagcgcugag accggcaugc agaucuacga gggcaagcug 2100
accgcagagg gccugcgguu cggcaucgug gccagccgcg ccaaccacgc ucugguggac 2160
cggcuugugg agggcgcuau cgacgccauc gugagacacg gcggccggga agaggacauc 2220
acccuggugc gggugugcgg cagcugggag auucccgucg ccgccggaga acuggcccgg 2280
aaggaggaca ucgacgccgu gaucgccauc ggcgugcugu gcagaggcgc cacgcccagc 2340
uucgacuaca ucgccagcga ggugagcaag ggccuggccg accugagccu ggagcugcgg 2400
aagcccauca ccuucggcgu gaucaccgcc gacacccugg agcaggccau cgaggccgca 2460
ggcaccugcc acggcaacaa gggcugggaa gccgcccugu gcgccaucga gauggccaac 2520
cuguucaaga gccugcgg 2538
<![CDATA[ <210> 14]]>
<![CDATA[ <211> 846]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 14]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Gly Gly Gly Ser Gly Gly Gly Ser
675 680 685
Ala Glu Thr Gly Met Gln Ile Tyr Glu Gly Lys Leu Thr Ala Glu Gly
690 695 700
Leu Arg Phe Gly Ile Val Ala Ser Arg Ala Asn His Ala Leu Val Asp
705 710 715 720
Arg Leu Val Glu Gly Ala Ile Asp Ala Ile Val Arg His Gly Gly Arg
725 730 735
Glu Glu Asp Ile Thr Leu Val Arg Val Cys Gly Ser Trp Glu Ile Pro
740 745 750
Val Ala Ala Gly Glu Leu Ala Arg Lys Glu Asp Ile Asp Ala Val Ile
755 760 765
Ala Ile Gly Val Leu Cys Arg Gly Ala Thr Pro Ser Phe Asp Tyr Ile
770 775 780
Ala Ser Glu Val Ser Lys Gly Leu Ala Asp Leu Ser Leu Glu Leu Arg
785 790 795 800
Lys Pro Ile Thr Phe Gly Val Ile Thr Ala Asp Thr Leu Glu Gln Ala
805 810 815
Ile Glu Ala Ala Gly Thr Cys His Gly Asn Lys Gly Trp Glu Ala Ala
820 825 830
Leu Cys Ala Ile Glu Met Ala Asn Leu Phe Lys Ser Leu Arg
835 840 845
<![CDATA[ <210> 15]]>
<![CDATA[ <211> 2300]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 15]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucaucu 2100
ggcggaggca gcauccuggc caucuacagc accguggcca gcagccuggu gcugcuggug 2160
agccugggcg ccaucagcuu cugauaauag gcuggagccu cgguggccua gcuucuugcc 2220
ccuugggccu ccccccagcc ccuccucccc uuccugcacc cguacccccg uggucuuuga 2280
auaaagucug agugggcggc 2300
<![CDATA[ <210> 16]]>
<![CDATA[ <211> 2124]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 16]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
ucuggcggag gcagcauccu ggccaucuac agcaccgugg ccagcagccu ggugcugcug 2100
gugagccugg gcgccaucag cuuc 2124
<![CDATA[ <210> 17]]>
<![CDATA[ <211> 707]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 17]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Gly Gly Gly Ser Ile Leu Ala Ile
675 680 685
Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala
690 695 700
Ile Ser Phe
705
<![CDATA[ <210> 18]]>
<![CDATA[ <211> 1853]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 18]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc ucuggcggag gcagcauccu ggccaucuac 1680
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuucugauaa 1740
uaggcuggag ccucgguggc cuagcuucuu gccccuuggg ccucccccca gccccucccuc 1800
cccuuccugc acccguaccc ccguggucuu ugaauaaagu cugagugggc ggc 1853
<![CDATA[ <210> 19]]>
<![CDATA[ <211> 1677]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 19]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accucuggcg gaggcagcau ccuggccauc 1620
uacagcaccg uggccagcag ccuggugcug cuggugagcc ugggcgccau cagcuuc 1677
<![CDATA[ <210> 20]]>
<![CDATA[ <211> 559]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 20]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val
530 535 540
Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
545 550 555
<![CDATA[ <210> 21]]>
<![CDATA[ <211> 2042]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 21]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcu cuggcggagg cagcauccug 1860
gccaucuaca gcaccguggc cagcagccug gugcugcugg ugagccuggg cgccaucagc 1920
uucugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 1980
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 2040
gc 2042
<![CDATA[ <210> 22]]>
<![CDATA[ <211> 1866]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 22]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcucuggcgg aggcagcauc 1800
cuggccaucu acagcaccgu ggccagcagc cuggugcugc uggugagccu gggcgccauc 1860
agcuuc 1866
<![CDATA[ <210> 23]]>
<![CDATA[ <211> 622]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 23]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala
595 600 605
Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
610 615 620
<![CDATA[ <210> 24]]>
<![CDATA[ <211> 2066]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 24]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu gggcagcggc ggcggcagcg gcggaggcag cggaggaggc 1020
agcggcggag gcaguggagg ccagcccacc gagagcaucg ugcgguuccc caacaucacc 1080
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1140
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1200
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1260
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1320
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1380
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1440
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1500
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1560
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1620
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagaagag caccaaccug 1680
gugaagaaca agugcgugaa cuucaacuuc aacggccuua ccggcaccgg cgugcugacc 1740
gagagcaaca agaaauuccu gcccuuucag caguucggcc gggacaucgc cgacaccacc 1800
gacgcugugc gggaucccca gacccuggag auccuggaca ucaccccuug cagcuucggc 1860
ggcucuggcg gaggcagcau ccuggccauc uacagcaccg uggccagcag ccuggugcug 1920
cuggugagcc ugggcgccau cagcuucuga uaauaggcug gagccucggu ggccuagcuu 1980
cuugccccuu gggccucccc ccagccccuc cuccccuucc ugcacccgua cccccguggu 2040
cuuugaauaa agucugagug ggcggc 2066
<![CDATA[ <210> 25]]>
<![CDATA[ <211> 1890]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 25]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cgugggcagc ggcggcggca gcggcggagg cagcggagga 960
ggcagcggcg gaggcagugg aggccagccc accgagagca ucgugcgguu ccccaacauc 1020
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 1080
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1140
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1200
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1260
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1320
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1380
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1440
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1500
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1560
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaagaa gagcaccaac 1620
cuggugaaga acaagugcgu gaacuucaac uucaacggcc uuaccggcac cggcgugcug 1680
accgagagca acaagaaauu ccugcccuuu cagcaguucg gccgggacau cgccgacacc 1740
accgacgcug ugcgggaucc ccagacccug gagauccugg acaucacccc uugcagcuuc 1800
ggcggcucug gcggaggcag cauccuggcc aucuacagca ccguggccag cagccuggug 1860
cugcugguga gccugggcgc caucagcuuc 1890
<![CDATA[ <210> 26]]>
<![CDATA[ <211> 630]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 26]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly
305 310 315 320
Gly Ser Gly Gly Gly Ser Gly Gly Gln Pro Thr Glu Ser Ile Val Arg
325 330 335
Phe Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala
340 345 350
Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn
355 360 365
Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr
370 375 380
Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe
385 390 395 400
Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg
405 410 415
Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys
420 425 430
Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn
435 440 445
Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe
450 455 460
Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile
465 470 475 480
Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys
485 490 495
Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly
500 505 510
Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala
515 520 525
Pro Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn
530 535 540
Lys Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu
545 550 555 560
Thr Glu Ser Asn Lys Lys Phe Leu Pro Phe Gln Gln Phe Gly Arg Asp
565 570 575
Ile Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile
580 585 590
Leu Asp Ile Thr Pro Cys Ser Phe Gly Gly Ser Gly Gly Gly Ser Ile
595 600 605
Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser
610 615 620
Leu Gly Ala Ile Ser Phe
625 630
<![CDATA[ <210> 27]]>
<![CDATA[ <211> 2066]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 27]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
gugugccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu gggcagcggc ggcggcagcg gcggaggcag cggaggaggc 1020
agcggcggag gcaguggagg ccagcccacc gagagcaucg ugcgguuccc caacaucacc 1080
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1140
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1200
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1260
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1320
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1380
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1440
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1500
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1560
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1620
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagaagag caccaaccug 1680
gugaagaaca agugcgugaa cuucaacuuc aacggccuua ccggcaccgg cgugcugacc 1740
gagagcaaca agaaauuccu gcccuuuugc caguucggcc gggacaucgc cgacaccacc 1800
gacgcugugc gggaucccca gacccuggag auccuggaca ucaccccuug cagcuucggc 1860
ggcucuggcg gaggcagcau ccuggccauc uacagcaccg uggccagcag ccuggugcug 1920
cuggugagcc ugggcgccau cagcuucuga uaauaggcug gagccucggu ggccuagcuu 1980
cuugccccuu gggccucccc ccagccccuc cuccccuucc ugcacccgua cccccguggu 2040
cuuugaauaa agucugagug ggcggc 2066
<![CDATA[ <210> 28]]>
<![CDATA[ <211> 1890]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 28]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aaggugugcc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cgugggcagc ggcggcggca gcggcggagg cagcggagga 960
ggcagcggcg gaggcagugg aggccagccc accgagagca ucgugcgguu ccccaacauc 1020
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 1080
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1140
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1200
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1260
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1320
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1380
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1440
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1500
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1560
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaagaa gagcaccaac 1620
cuggugaaga acaagugcgu gaacuucaac uucaacggcc uuaccggcac cggcgugcug 1680
accgagagca acaagaaauu ccugcccuuu ugccaguucg gccgggacau cgccgacacc 1740
accgacgcug ugcgggaucc ccagacccug gagauccugg acaucacccc uugcagcuuc 1800
ggcggcucug gcggaggcag cauccuggcc aucuacagca ccguggccag cagccuggug 1860
cugcugguga gccugggcgc caucagcuuc 1890
<![CDATA[ <210> 29]]>
<![CDATA[ <211> 630]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 29]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Cys Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly
305 310 315 320
Gly Ser Gly Gly Gly Ser Gly Gly Gln Pro Thr Glu Ser Ile Val Arg
325 330 335
Phe Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala
340 345 350
Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn
355 360 365
Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr
370 375 380
Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe
385 390 395 400
Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg
405 410 415
Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys
420 425 430
Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn
435 440 445
Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe
450 455 460
Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile
465 470 475 480
Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys
485 490 495
Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly
500 505 510
Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala
515 520 525
Pro Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn
530 535 540
Lys Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu
545 550 555 560
Thr Glu Ser Asn Lys Lys Phe Leu Pro Phe Cys Gln Phe Gly Arg Asp
565 570 575
Ile Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile
580 585 590
Leu Asp Ile Thr Pro Cys Ser Phe Gly Gly Ser Gly Gly Gly Ser Ile
595 600 605
Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser
610 615 620
Leu Gly Ala Ile Ser Phe
625 630
<![CDATA[ <210> 30]]>
<![CDATA[ <211> 3182]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 30]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu cggcggcagc 1020
ggcggcguga gcgugaucac cccaggcacc aacaccagca accagguggc cgugcuguac 1080
caggacguga acugcaccga ggugcccgug gccauccacg ccgaccagcu gacacccacc 1140
uggcgggucu acagcaccgg cagcaacgug uuccagaccc gggccgguug ccugaucggc 1200
gccgagcacg ugaacaacag cuacgagugc gacaucccca ucggcgccgg caucugugcc 1260
agcuaccaga cccagaccaa uucaccccgg agggcaagga gcguggccag ccagagcauc 1320
aucgccuaca ccaugagccu gggcgccgag aacagcgugg ccuacagcaa caacagcauc 1380
gccaucccca ccaacuucac caucagcgug accaccgaga uucugcccgu gagcaugacc 1440
aagaccagcg uggacugcac cauguacauc ugcggcgaca gcaccgagug cagcaaccug 1500
cugcugcagu acggcagcuu cugcacccag cugaaccggg cccugaccgg caucgccgug 1560
gagcaggaca agaacaccca ggagguguuc gcccagguga agcagaucua caagaccccu 1620
cccaucaagg acuucggcgg cuucaacuuc agccagaucc ugcccgaccc cagcaagccc 1680
agcaagcgga gcuucaucga ggaccugcug uucaacaagg ugacccuagc cgacgccggc 1740
uucaucaagc aguacggcga cugccucggc gacauagccg cccgggaccu gaucugcgcc 1800
cagaaguuca acggccugac cgugcugccu ccccugcuga ccgacgagau gaucgcccag 1860
uacaccagcg cccuguuagc cggaaccauc accagcggcu ggacuuucgg cgcuggagcc 1920
gcucugcaga uccccuucgc caugcagaug gccuaccggu ucaacggcau cggcgugacc 1980
cagaacgugc uguacgagaa ccagaagcug aucgccaacc aguucaacag cgccaucggc 2040
aagauccagg acagccugag cagcaccgcu agcgcccugg gcaagcugca ggacguggug 2100
aaccagaacg cccaggcccu gaacacccug gugaagcagc ugagcagcaa cuucggcgcc 2160
aucagcagcg ugcugaacga cauccugagc cggcuggacc cucccaacgc caccgugcag 2220
aucgaccggc ugaucacugg ccggcugcag agccugcaga ccuacgugac ccagcagcug 2280
auccgggccg ccgagauucg ggccagcgcc aaccuggccg ccaccaagau gagcgagugc 2340
gugcugggcc agagcaagcg gguggacuuc ugcggcaagg gcuaccaccu gaugagcuuu 2400
ccccagagcg caccccacgg agugguguuc cugcacguga ccuacgugcc cgcccaggag 2460
aagaacuuca ccaccgcccc agccaucugc cacgacggca aggcccacuu uccccgggag 2520
ggcguguucg ugagcaacgg cacccacugg uucgugaccc agcggaacuu cuacgagccc 2580
cagaucauca ccaccgacaa caccuucgug agcggcaacu gcgacguggu gaucggcauc 2640
gugaacaaca ccguguacga uccccugcag cccgagcugg acagcuucaa ggaggagcug 2700
gacaaguacu ucaagaauca caccagcccc gacguggacc ugggcgacau cagcggcauc 2760
aacgccagcg uggugaacau ccagaaggag aucgaucggc ugaacgaggu ggccaagaac 2820
cugaacgaga gccugaucga ccugcaggag cugggcaagu acgagcagua caucaagugg 2880
cccugguaca ucuggcuggg cuucaucgcc ggccugaucg ccaucgugau ggugaccauc 2940
augcugugcu gcaugaccag cugcugcagc ugccugaagg gcuguugcag cugcggcagc 3000
ugcugcaagu ucgacgagga cgacagcgag cccgugcuga agggcgugaa gcugcacuac 3060
accugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 3120
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 3180
gc 3182
<![CDATA[ <210> 31]]>
<![CDATA[ <211> 3006]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 31]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuucggcggc 960
agcggcggcg ugagcgugau caccccaggc accaacacca gcaaccaggu ggccgugcug 1020
uaccaggacg ugaacugcac cgaggugccc guggccaucc acgccgacca gcugacaccc 1080
accuggcggg ucuacagcac cggcagcaac guguuccaga cccgggccgg uugccugauc 1140
ggcgccgagc acgugaacaa cagcuacgag ugcgacaucc ccaucggcgc cggcaucugu 1200
gccagcuacc agacccagac caauucaccc cggagggcaa ggagcguggc cagccagagc 1260
aucaucgccu acaccaugag ccugggcgcc gagaacagcg uggccuacag caacaacagc 1320
aucgccaucc ccaccaacuu caccaucagc gugaccaccg agauucugcc cgugagcaug 1380
accaagacca gcguggacug caccauguac aucugcggcg acagcaccga gugcagcaac 1440
cugcugcugc aguacggcag cuucugcacc cagcugaacc gggcccugac cggcaucgcc 1500
guggagcagg acaagaacac ccaggaggug uucgcccagg ugaagcagau cuacaagacc 1560
ccucccauca aggacuucgg cggcuucaac uucagccaga uccugcccga ccccagcaag 1620
cccagcaagc ggagcuucau cgaggaccug cuguucaaca aggugacccu agccgacgcc 1680
ggcuucauca agcaguacgg cgacugccuc ggcgacauag ccgcccggga ccugaucugc 1740
gcccagaagu ucaacggccu gaccgugcug ccuccccugc ugaccgacga gaugaucgcc 1800
caguacacca gcgcccuguu agccggaacc aucaccagcg gcuggacuuu cggcgcugga 1860
gccgcucugc agauccccuu cgccaugcag auggccuacc gguucaacgg caucggcgug 1920
acccagaacg ugcuguacga gaaccagaag cugaucgcca accaguucaa cagcgccauc 1980
ggcaagaucc aggacagccu gagcagcacc gcuagcgccc ugggcaagcu gcaggacgug 2040
gugaaccaga acgcccaggc ccugaacacc cuggugaagc agcugagcag caacuucggc 2100
gccaucagca gcgugcugaa cgacauccug agccggcugg acccucccaa cgccaccgug 2160
cagaucgacc ggcugaucac uggccggcug cagagccugc agaccuacgu gacccagcag 2220
cugauccggg ccgccgagau ucgggccagc gccaaccugg ccgccaccaa gaugagcgag 2280
ugcgugcugg gccagagcaa gcggguggac uucugcggca agggcuacca ccugaugagc 2340
uuuccccaga gcgcacccca cggaguggug uuccugcacg ugaccuacgu gcccgcccag 2400
gagaagaacu ucaccaccgc cccagccauc ugccacgacg gcaaggccca cuuuccccgg 2460
gagggcgugu ucgugagcaa cggcacccac ugguucguga cccagcggaa cuucuacgag 2520
ccccagauca ucaccaccga caacaccuuc gugagcggca acugcgacgu ggugaucggc 2580
aucgugaaca acaccgugua cgauccccug cagcccgagc uggacagcuu caaggaggag 2640
cuggacaagu acuucaagaa ucacaccagc cccgacgugg accugggcga caucagcggc 2700
aucaacgcca gcguggugaa cauccagaag gagaucgauc ggcugaacga gguggccaag 2760
aaccugaacg agagccugau cgaccugcag gagcugggca aguacgagca guacaucaag 2820
uggcccuggu acaucuggcu gggcuucauc gccggccuga ucgccaucgu gauggugacc 2880
aucaugcugu gcugcaugac cagcugcugc agcugccuga agggcuguug cagcugcggc 2940
agcugcugca aguucgacga ggacgacagc gagcccgugc ugaagggcgu gaagcugcac 3000
uacacc 3006
<![CDATA[ <210> 32]]>
<![CDATA[ <211> 1002]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 32]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Gly Gly
305 310 315 320
Ser Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln
325 330 335
Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala
340 345 350
Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly
355 360 365
Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His
370 375 380
Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys
385 390 395 400
Ala Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg Ala Arg Ser Val
405 410 415
Ala Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly Ala Glu Asn
420 425 430
Ser Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr Asn Phe Thr
435 440 445
Ile Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr Lys Thr Ser
450 455 460
Val Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu Cys Ser Asn
465 470 475 480
Leu Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn Arg Ala Leu
485 490 495
Thr Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu Val Phe Ala
500 505 510
Gln Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp Phe Gly Gly
515 520 525
Phe Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro Ser Lys Arg
530 535 540
Ser Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu Ala Asp Ala
545 550 555 560
Gly Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile Ala Ala Arg
565 570 575
Asp Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val Leu Pro Pro
580 585 590
Leu Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala Leu Leu Ala
595 600 605
Gly Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala Ala Leu Gln
610 615 620
Ile Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly Ile Gly Val
625 630 635 640
Thr Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala Asn Gln Phe
645 650 655
Asn Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser Ser Thr Ala Ser
660 665 670
Ala Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn Ala Gln Ala Leu
675 680 685
Asn Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly Ala Ile Ser Ser
690 695 700
Val Leu Asn Asp Ile Leu Ser Arg Leu Asp Pro Pro Asn Ala Thr Val
705 710 715 720
Gln Ile Asp Arg Leu Ile Thr Gly Arg Leu Gln Ser Leu Gln Thr Tyr
725 730 735
Val Thr Gln Gln Leu Ile Arg Ala Ala Glu Ile Arg Ala Ser Ala Asn
740 745 750
Leu Ala Ala Thr Lys Met Ser Glu Cys Val Leu Gly Gln Ser Lys Arg
755 760 765
Val Asp Phe Cys Gly Lys Gly Tyr His Leu Met Ser Phe Pro Gln Ser
770 775 780
Ala Pro His Gly Val Val Phe Leu His Val Thr Tyr Val Pro Ala Gln
785 790 795 800
Glu Lys Asn Phe Thr Thr Ala Pro Ala Ile Cys His Asp Gly Lys Ala
805 810 815
His Phe Pro Arg Glu Gly Val Phe Val Ser Asn Gly Thr His Trp Phe
820 825 830
Val Thr Gln Arg Asn Phe Tyr Glu Pro Gln Ile Ile Thr Thr Asp Asn
835 840 845
Thr Phe Val Ser Gly Asn Cys Asp Val Val Ile Gly Ile Val Asn Asn
850 855 860
Thr Val Tyr Asp Pro Leu Gln Pro Glu Leu Asp Ser Phe Lys Glu Glu
865 870 875 880
Leu Asp Lys Tyr Phe Lys Asn His Thr Ser Pro Asp Val Asp Leu Gly
885 890 895
Asp Ile Ser Gly Ile Asn Ala Ser Val Val Asn Ile Gln Lys Glu Ile
900 905 910
Asp Arg Leu Asn Glu Val Ala Lys Asn Leu Asn Glu Ser Leu Ile Asp
915 920 925
Leu Gln Glu Leu Gly Lys Tyr Glu Gln Tyr Ile Lys Trp Pro Trp Tyr
930 935 940
Ile Trp Leu Gly Phe Ile Ala Gly Leu Ile Ala Ile Val Met Val Thr
945 950 955 960
Ile Met Leu Cys Cys Met Thr Ser Cys Cys Ser Cys Leu Lys Gly Cys
965 970 975
Cys Ser Cys Gly Ser Cys Cys Lys Phe Asp Glu Asp Asp Ser Glu Pro
980 985 990
Val Leu Lys Gly Val Lys Leu His Tyr Thr
995 1000
<![CDATA[ <210> 33]]>
<![CDATA[ <211> 2378]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 33]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagg gcaccaucac cgacgccgug 120
gacugcgccc uggacccucu gagcgagacc aagugcaccc ugaagagcuu caccguggag 180
aagggcaucu accagaccag caacuucggc ggcagcggcg gcgugagcgu gaucacccca 240
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 300
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 360
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 420
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 480
ccccggaggg caaggagcgu ggccagccag agcaucaucg ccuacaccau gagccugggc 540
gccgagaaca gcguggccua cagcaacaac agcaucgcca uccccaccaa cuucaccauc 600
agcgugacca ccgagauucu gcccgugagc augaccaaga ccagcgugga cugcaccaug 660
uacaucugcg gcgacagcac cgagugcagc aaccugcugc ugaacuacac cagcuucugc 720
acccagcuga accgggcccu gaccggcauc gccguggagc aggacaagaa cacccaggag 780
guguucgccc aggugaagca gaucuacaag accccuccca ucaaggacuu cggcggcuuc 840
aacuucagcc agauccugcc cgaccccagc aagcccagca agcggagcuu caucgaggac 900
cugcuguuca acaaggugac ccuagccgac gccggcuuca ucaagcagua cggcgacugc 960
cucggcgaca uagccgcccg ggaccugauc ugcgcccaga aguucaacgg ccugaccgug 1020
cugccuccccc ugcugaccga cgagaugauc gcccaguaca ccagcgcccu guuagccgga 1080
accaucacca gcggcuggac uuucggcgcu ggagccgcuc ugcagauccc cuucgccaug 1140
cagauggccu accgguucaa cggcaucggc gugacccaga acgugcugua cgagaaccag 1200
aagcugaucg ccaaccaguu caacagcgcc aucggcaaga uccaggacag ccugagcagc 1260
accgcuagcg cccugggcaa gcugcaggac guggugaacc agaacgccca ggcccugaac 1320
acccugguga agcagcugag cagcaacuuc ggcgccauca gcagcgugcu gaacgacauc 1380
cugagccggc uggacccucc caacgccacc gugcagaucg accggcugau cacuggccgg 1440
cugcagagcc ugcagaccua cgugacccag cagcugaucc gggccgccga gauucgggcc 1500
agcgccaacc uggccgccac caagaugagc gagugcgugc ugggccagag caagcgggug 1560
gacuucugcg gcaagggcua ccaccugaug agcuuucccc agagcgcacc ccacggagug 1620
guguuccugc acgugaccua cgugcccgcc caggagaaga acuucaccac cgccccagcc 1680
aucugccacg acggcaaggc ccacuuuccc cgggagggcg uguucgugag caacggcacc 1740
cacugguucg ugacccagcg gaacuucuac gagccccaga ucaucaccac cgacaacacc 1800
uucgugagcg gcaacugcga cguggugauc ggcaucguga acaacaccgu guacgauccc 1860
cugcagcccg agcuggacag cuucaaggag gagcuggaca aguacuucaa gaaucacacc 1920
agccccgacg uggaccuggg cgacaucagc ggcaucaacg ccagcguggu gaacauccag 1980
aaggagaucg aucggcugaa cgagguggcc aagaaccuga acgagagccu gaucgaccug 2040
caggagcugg gcaaguacga gcaguacauc aaguggcccu gguacaucug gcugggcuuc 2100
aucgccggcc ugaucgccau cgugauggug accaucaugc ugugcugcau gaccagcugc 2160
ugcagcugcc ugaagggcug uugcagcugc ggcagcugcu gcaaguucga cgaggacgac 2220
agcgagcccg ugcugaaggg cgugaagcug cacuacaccu gauaauaggc uggagccucg 2280
guggccuagc uucuugcccc uugggccucc ccccagcccc uccuccccuu ccugcacccg 2340
uacccccgug gucuuugaau aaagucugag ugggcggc 2378
<![CDATA[ <210> 34]]>
<![CDATA[ <211> 2202]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 34]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agggcaccau caccgacgcc 60
guggacugcg cccuggaccc ucugagcgag accaagugca cccugaagag cuucaccgug 120
gagaagggca ucuaccagac cagcaacuuc ggcggcagcg gcggcgugag cgugaucacc 180
ccaggcacca acaccagcaa ccagguggcc gugcuguacc aggacgugaa cugcaccgag 240
gugcccgugg ccauccacgc cgaccagcug acacccaccu ggcgggucua cagcaccggc 300
agcaacgugu uccagacccg ggccgguugc cugaucggcg ccgagcacgu gaacaacagc 360
uacgagugcg acauccccau cggcgccggc aucugugcca gcuaccagac ccagaccaau 420
ucaccccgga gggcaaggag cguggccagc cagagcauca ucgccuacac caugagccug 480
ggcgccgaga acagcguggc cuacagcaac aacagcaucg ccauccccac caacuucacc 540
aucagcguga ccaccgagau ucugcccgug agcaugacca agaccagcgu ggacugcacc 600
auguacaucu gcggcgacag caccgagugc agcaaccugc ugcugaacua caccagcuuc 660
ugcacccagc ugaaccgggc ccugaccggc aucgccgugg agcaggacaa gaacacccag 720
gagguguucg cccaggugaa gcagaucuac aagaccccuc ccaucaagga cuucggcggc 780
uucaacuuca gccagauccu gcccgacccc agcaagccca gcaagcggag cuucaucgag 840
gaccugcugu ucaacaaggu gacccuagcc gacgccggcu ucaucaagca guacggcgac 900
ugccucggcg acauagccgc ccgggaccug aucugcgccc agaaguucaa cggccugacc 960
gugcugccuc cccugcugac cgacgagaug aucgcccagu acaccagcgc ccuguuagcc 1020
ggaaccauca ccagcggcug gacuuucggc gcuggagccg cucugcagau ccccuucgcc 1080
augcagaugg ccuaccgguu caacggcauc ggcgugaccc agaacgugcu guacgagaac 1140
cagaagcuga ucgccaacca guucaacagc gccaucggca agauccagga cagccugagc 1200
agcaccgcua gcgcccuggg caagcugcag gacgugguga accagaacgc ccaggcccug 1260
aacacccugg ugaagcagcu gagcagcaac uucggcgcca ucagcagcgu gcugaacgac 1320
auccugagcc ggcuggaccc ucccaacgcc accgugcaga ucgaccggcu gaucacuggc 1380
cggcugcaga gccugcagac cuacgugacc cagcagcuga uccgggccgc cgagauucgg 1440
gccagcgcca accuggccgc caccaagaug agcgagugcg ugcugggcca gagcaagcgg 1500
guggacuucu gcggcaaggg cuaccaccug augagcuuuc cccagagcgc accccacgga 1560
gugguguucc ugcacgugac cuacgugccc gcccaggaga agaacuucac caccgcccca 1620
gccaucugcc acgacggcaa ggcccacuuu ccccgggagg gcguguucgu gagcaacggc 1680
acccacuggu ucgugaccca gcggaacuuc uacgagcccc agaucaucac caccgacaac 1740
accuucguga gcggcaacug cgacguggug aucggcaucg ugaacaacac cguguacgau 1800
ccccugcagc ccgagcugga cagcuucaag gaggagcugg acaaguacuu caagaaucac 1860
accagccccg acguggaccu gggcgacauc agcggcauca acgccagcgu ggugaacauc 1920
cagaaggaga ucgaucggcu gaacgaggug gccaagaacc ugaacgagag ccugaucgac 1980
cugcaggagc ugggcaagua cgagcaguac aucaaguggc ccugguacau cuggcugggc 2040
uucaucgccg gccugaucgc caucgugaug gugaccauca ugcugugcug caugaccagc 2100
ugcugcagcu gccugaaggg cuguugcagc ugcggcagcu gcugcaaguu cgacgaggac 2160
gacagcgagc ccgugcugaa gggcgugaag cugcacuaca cc 2202
<![CDATA[ <210> 35]]>
<![CDATA[ <211> 734]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 35]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Gly Thr
1 5 10 15
Ile Thr Asp Ala Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys
20 25 30
Cys Thr Leu Lys Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser
35 40 45
Asn Phe Gly Gly Ser Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn
50 55 60
Thr Ser Asn Gln Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu
65 70 75 80
Val Pro Val Ala Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val
85 90 95
Tyr Ser Thr Gly Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile
100 105 110
Gly Ala Glu His Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly
115 120 125
Ala Gly Ile Cys Ala Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg
130 135 140
Ala Arg Ser Val Ala Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu
145 150 155 160
Gly Ala Glu Asn Ser Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro
165 170 175
Thr Asn Phe Thr Ile Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met
180 185 190
Thr Lys Thr Ser Val Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr
195 200 205
Glu Cys Ser Asn Leu Leu Leu Asn Tyr Thr Ser Phe Cys Thr Gln Leu
210 215 220
Asn Arg Ala Leu Thr Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln
225 230 235 240
Glu Val Phe Ala Gln Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys
245 250 255
Asp Phe Gly Gly Phe Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys
260 265 270
Pro Ser Lys Arg Ser Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr
275 280 285
Leu Ala Asp Ala Gly Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp
290 295 300
Ile Ala Ala Arg Asp Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr
305 310 315 320
Val Leu Pro Pro Leu Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser
325 330 335
Ala Leu Leu Ala Gly Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly
340 345 350
Ala Ala Leu Gln Ile Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn
355 360 365
Gly Ile Gly Val Thr Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile
370 375 380
Ala Asn Gln Phe Asn Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser
385 390 395 400
Ser Thr Ala Ser Ala Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn
405 410 415
Ala Gln Ala Leu Asn Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly
420 425 430
Ala Ile Ser Ser Val Leu Asn Asp Ile Leu Ser Arg Leu Asp Pro Pro
435 440 445
Asn Ala Thr Val Gln Ile Asp Arg Leu Ile Thr Gly Arg Leu Gln Ser
450 455 460
Leu Gln Thr Tyr Val Thr Gln Gln Leu Ile Arg Ala Ala Glu Ile Arg
465 470 475 480
Ala Ser Ala Asn Leu Ala Ala Thr Lys Met Ser Glu Cys Val Leu Gly
485 490 495
Gln Ser Lys Arg Val Asp Phe Cys Gly Lys Gly Tyr His Leu Met Ser
500 505 510
Phe Pro Gln Ser Ala Pro His Gly Val Val Phe Leu His Val Thr Tyr
515 520 525
Val Pro Ala Gln Glu Lys Asn Phe Thr Thr Ala Pro Ala Ile Cys His
530 535 540
Asp Gly Lys Ala His Phe Pro Arg Glu Gly Val Phe Val Ser Asn Gly
545 550 555 560
Thr His Trp Phe Val Thr Gln Arg Asn Phe Tyr Glu Pro Gln Ile Ile
565 570 575
Thr Thr Asp Asn Thr Phe Val Ser Gly Asn Cys Asp Val Val Ile Gly
580 585 590
Ile Val Asn Asn Thr Val Tyr Asp Pro Leu Gln Pro Glu Leu Asp Ser
595 600 605
Phe Lys Glu Glu Leu Asp Lys Tyr Phe Lys Asn His Thr Ser Pro Asp
610 615 620
Val Asp Leu Gly Asp Ile Ser Gly Ile Asn Ala Ser Val Val Asn Ile
625 630 635 640
Gln Lys Glu Ile Asp Arg Leu Asn Glu Val Ala Lys Asn Leu Asn Glu
645 650 655
Ser Leu Ile Asp Leu Gln Glu Leu Gly Lys Tyr Glu Gln Tyr Ile Lys
660 665 670
Trp Pro Trp Tyr Ile Trp Leu Gly Phe Ile Ala Gly Leu Ile Ala Ile
675 680 685
Val Met Val Thr Ile Met Leu Cys Cys Met Thr Ser Cys Cys Ser Cys
690 695 700
Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys Lys Phe Asp Glu Asp
705 710 715 720
Asp Ser Glu Pro Val Leu Lys Gly Val Lys Leu His Tyr Thr
725 730
<![CDATA[ <210> 36]]>
<![CDATA[ <211> 4241]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 36]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uuccugauca ucuucauccu gcccaccacc cuggccguga ucggcgacuu caacugcacc 120
aacagcuuca ucaacgacua caacaagacc aucccucgga ucagcgaaga cgugguggac 180
gugucccugg gccugggcac cuacuacgug cugaaccggg uguaccugaa caccacacug 240
cuguucaccg gcuacuuccc caagagcggc gccaacuucc gggaccuggc ccugaagggc 300
agcaucuacc ugagcaccuu gugguacaag ccucccuucc ugagcgacuu caauaacggc 360
aucuucucua aggugaagaa caccaagcug uacguaaaca acacccugua cagcgaguuc 420
agcaccaucg ugaucggcag cguguucguc aacaccagcu acaccaucgu ggugcagccc 480
cacaacggca uccuggagau caccgccugc caguacacca ugugcgagua cccucacacc 540
gugugcaaga gcaagggcuc cauccggaac gagagcuggc acaucgacag cagcgagccg 600
cugugccugu ucaagaagaa cuucaccuac aacgugagcg ccgacuggcu guacuuccac 660
uucuaccagg agcggggcgu guucuacgcc uacuacgccg acgugggcau gccaaccacc 720
uuccuguuca gccuguaccu gggcaccauc cugagccacu acuacgugau gccccugacc 780
ugcaacgcca ucagcucaaa caccgacaac gagacccugg aguacugggu gacuccacug 840
agccggcggc aguaccugcu gaacuucgac gagcacggcg ugaucaccaa cgccguggac 900
ugcgcccugg acccucugag cgagaccaag ugcacccuga agagcuucac cguggagaag 960
ggcaucuacc agaccagcgg cuucaccgug aagcccguag ccaccgugua ccggcggauc 1020
cccaaccugc ccgacugcga caucgacaac uggcugaaca acgucagcgu gcccagccca 1080
cugaacuggg agcggcggau cuucagcaac ugcaacuuca aucugagcac ccugcugcgg 1140
cuggugcacg uggacagcuu cagcugcaac aaccuggaca agagcaagau cuucgguagc 1200
ugcuucaaca gcaucaccgu ggacaaguuc gccaucccua accggcggcg ggacgaucug 1260
cagcugggca gcagcggcuu ccugcagagc agcaacuaca agaucgacau cagcagcuca 1320
agcugccagc uguacuacag ccugccccug gugaacguga ccaucaacaa cuucaacccc 1380
agcagcugga accggcggua cggcuucggc agcuucaacc ugagcagcua cgacguggug 1440
uacagcgacc acugcuucag cgugaacagc gacuucugcc ccugugccga cccuagcgug 1500
gugaacagcu gcgccaagag caagccuccc agcgccauuu gccccgccgg caccaaguac 1560
cggcacugcg accuggacac cacccuguac gugaagaacu ggugccggug cagcugccug 1620
cccgacccca ucagcaccua cagccccaac accugucccc agaagaaggu gguggugggu 1680
aucggcgagc acugucccgg ccugggcauc aacgaggaga agugcggcac ccagcugaac 1740
cacagcagcu gcuucuguag ccccgacgcc uuccugggcu ggagcuucga cagcugcauc 1800
agcaacaacc ggugcaacau cuuuagcaac uucaucuuca acggaaucaa cagcggcacc 1860
accugcagca acgaccugcu guauagcaac accgagauca gcaccggcgu gugcgugaac 1920
uacgaccugu acggcaucac cggccagggc aucuucaagg aggugagcgc cgccuacuac 1980
aacaacuggc agaaccugcu guacgacagc aacggcaaca ucaucggcuu caaggacuuu 2040
cugaccaaca agaccuacac cauccugccc ugcuacagcg gcggcgugag cgugaucacc 2100
ccaggcacca acaccagcaa ccagguggcc gugcuguacc aggacgugaa cugcaccgag 2160
gugcccgugg ccauccacgc cgaccagcug acacccaccu ggcgggucua cagcaccggc 2220
agcaacgugu uccagacccg ggccgguugc cugaucggcg ccgagcacgu gaacaacagc 2280
uacgagugcg acauccccau cggcgccggc aucugugcca gcuaccagac ccagaccaau 2340
ucaccccgga gggcaaggag cguggccagc cagagcauca ucgccuacac caugagccug 2400
ggcgccgaga acagcguggc cuacagcaac aacagcaucg ccauccccac caacuucacc 2460
aucagcguga ccaccgagau ucugcccgug agcaugacca agaccagcgu ggacugcacc 2520
auguacaucu gcggcgacag caccgagugc agcaaccugc ugcugcagua cggcagcuuc 2580
ugcacccagc ugaaccgggc ccugaccggc aucgccgugg agcaggacaa gaacacccag 2640
gagguguucg cccaggugaa gcagaucuac aagaccccuc ccaucaagga cuucggcggc 2700
uucaacuuca gccagauccu gcccgacccc agcaagccca gcaagcggag cuucaucgag 2760
gaccugcugu ucaacaaggu gacccuagcc gacgccggcu ucaucaagca guacggcgac 2820
ugccucggcg acauagccgc ccgggaccug aucugcgccc agaaguucaa cggccugacc 2880
gugcugccuc cccugcugac cgacgagaug aucgcccagu acaccagcgc ccuguuagcc 2940
ggaaccauca ccagcggcug gacuuucggc gcuggagccg cucugcagau ccccuucgcc 3000
augcagaugg ccuaccgguu caacggcauc ggcgugaccc agaacgugcu guacgagaac 3060
cagaagcuga ucgccaacca guucaacagc gccaucggca agauccagga cagccugagc 3120
agcaccgcua gcgcccuggg caagcugcag gacgugguga accagaacgc ccaggcccug 3180
aacacccugg ugaagcagcu gagcagcaac uucggcgcca ucagcagcgu gcugaacgac 3240
auccugagcc ggcuggaccc ucccgaggcc gaggugcaga ucgaccggcu gaucacuggc 3300
cggcugcaga gccugcagac cuacgugacc cagcagcuga uccgggccgc cgagauucgg 3360
gccagcgcca accuggccgc caccaagaug agcgagugcg ugcugggcca gagcaagcgg 3420
guggacuucu gcggcaaggg cuaccaccug augagcuuuc cccagagcgc accccacgga 3480
gugguguucc ugcacgugac cuacgugccc gcccaggaga agaacuucac caccgcccca 3540
gccaucugcc acgacggcaa ggcccacuuu ccccgggagg gcguguucgu gagcaacggc 3600
acccacuggu ucgugaccca gcggaacuuc uacgagcccc agaucaucac caccgacaac 3660
accuucguga gcggcaacug cgacguggug aucggcaucg ugaacaacac cguguacgau 3720
ccccugcagc ccgagcugga cagcuucaag gaggagcugg acaaguacuu caagaaucac 3780
accagccccg acguggaccu gggcgacauc agcggcauca acgccagcgu ggugaacauc 3840
cagaaggaga ucgaucggcu gaacgaggug gccaagaacc ugaacgagag ccugaucgac 3900
cugcaggagc ugggcaagua cgagcaguac aucaaguggc ccugguacau cuggcugggc 3960
uucaucgccg gccugaucgc caucgugaug gugaccauca ugcugugcug caugaccagc 4020
ugcugcagcu gccugaaggg cuguugcagc ugcggcagcu gcugcaaguu cgacgaggac 4080
gacagcgagc ccgugcugaa gggcgugaag cugcacuaca ccugauaaua ggcuggagcc 4140
ucgguggccu agcuucuugc cccuugggcc uccccccagc cccuccuccc cuuccugcac 4200
ccguaccccc guggucuuug aauaaagucu gagugggcgg c 4241
<![CDATA[ <210> 37]]>
<![CDATA[ <211> 4065]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 37]]>
auguuccuga ucaucuucau ccugcccacc acccuggccg ugaucggcga cuucaacugc 60
accaacagcu ucaucaacga cuacaacaag accaucccuc ggaucagcga agacguggug 120
gacguguccc ugggccuggg caccuacuac gugcugaacc ggguguaccu gaacaccaca 180
cugcuguuca ccggcuacuu ccccaagagc ggcgccaacu uccgggaccu ggcccugaag 240
ggcagcaucu accugagcac cuugugguac aagccucccu uccugagcga cuucaauaac 300
ggcaucuucu cuaaggugaa gaacaccaag cuguacguaa acaacacccu guacagcgag 360
uucagcacca ucgugaucgg cagcguguuc gucaacacca gcuacaccau cguggugcag 420
ccccacaacg gcauccugga gaucaccgcc ugccaguaca ccaugugcga guacccucac 480
accgugugca agagcaaggg cuccauccgg aacgagagcu ggcacaucga cagcagcgag 540
ccgcugugcc uguucaagaa gaacuucacc uacaacguga gcgccgacug gcuguacuuc 600
cacuucuacc aggagcgggg cguguucuac gccuacuacg ccgacguggg caugccaacc 660
accuuccugu ucagccugua ccugggcacc auccugagcc acuacuacgu gaugccccug 720
accugcaacg ccaucagcuc aaacaccgac aacgagaccc uggaguacug ggugacucca 780
cugagccggc ggcaguaccu gcugaacuuc gacgagcacg gcgugaucac caacgccgug 840
gacugcgccc uggacccucu gagcgagacc aagugcaccc ugaagagcuu caccguggag 900
aagggcaucu accagaccag cggcuucacc gugaagcccg uagccaccgu guaccggcgg 960
auccccaacc ugcccgacug cgacaucgac aacuggcuga acaacgucag cgugcccagc 1020
ccacugaacu gggagcggcg gaucuucagc aacugcaacu ucaaucugag cacccugcug 1080
cggcuggugc acguggacag cuucagcugc aacaaccugg acaagagcaa gaucuucggu 1140
agcugcuuca acagcaucac cguggacaag uucgccaucc cuaaccggcg gcgggacgau 1200
cugcagcugg gcagcagcgg cuuccugcag agcagcaacu acaagaucga caucagcagc 1260
ucaagcugcc agcuguacua cagccugccc cuggugaacg ugaccaucaa caacuucaac 1320
cccagcagcu ggaaccggcg guacggcuuc ggcagcuuca accugagcag cuacgacgug 1380
guguacagcg accacugcuu cagcgugaac agcgacuucu gccccugugc cgacccuagc 1440
guggugaaca gcugcgccaa gagcaagccu cccagcgcca uuugccccgc cggcaccaag 1500
uaccggcacu gcgaccugga caccacccug uacgugaaga acuggugccg gugcagcugc 1560
cugcccgacc ccaucagcac cuacagcccc aacaccuguc cccagaagaa ggugguggug 1620
gguaucggcg agcacugucc cggccugggc aucaacgagg agaagugcgg cacccagcug 1680
aaccacagca gcugcuucug uagccccgac gccuuccugg gcuggagcuu cgacagcugc 1740
aucagcaaca accggugcaa caucuuuagc aacuucaucu ucaacggaau caacagcggc 1800
accaccugca gcaacgaccu gcuguauagc aacaccgaga ucagcaccgg cgugugcgug 1860
aacuacgacc uguacggcau caccggccag ggcaucuuca aggaggugag cgccgccuac 1920
uacaacaacu ggcagaaccu gcuguacgac agcaacggca acaucaucgg cuucaaggac 1980
uuucugacca acaagaccua caccauccug cccugcuaca gcggcggcgu gagcgugauc 2040
accccaggca ccaacaccag caaccaggug gccgugcugu accaggacgu gaacugcacc 2100
gaggugcccg uggccaucca cgccgaccag cugacaccca ccuggcgggu cuacagcacc 2160
ggcagcaacg uguuccagac ccgggccggu ugccugaucg gcgccgagca cgugaacaac 2220
agcuacgagu gcgacauccc caucggcgcc ggcaucugug ccagcuacca gacccagacc 2280
aauucacccc ggagggcaag gagcguggcc agccagagca ucaucgccua caccaugagc 2340
cugggcgccg agaacagcgu ggccuacagc aacaacagca ucgccauccc caccaacuuc 2400
accaucagcg ugaccaccga gauucugccc gugagcauga ccaagaccag cguggacugc 2460
accauguaca ucugcggcga cagcaccgag ugcagcaacc ugcugcugca guacggcagc 2520
uucugcaccc agcugaaccg ggcccugacc ggcaucgccg uggagcagga caagaacacc 2580
caggaggugu ucgcccaggu gaagcagauc uacaagaccc cucccaucaa ggacuucggc 2640
ggcuucaacu ucagccagau ccugcccgac cccagcaagc ccagcaagcg gagcuucauc 2700
gaggaccugc uguucaacaa ggugacccua gccgacgccg gcuucaucaa gcaguacggc 2760
gacugccucg gcgacauagc cgcccgggac cugaucugcg cccagaaguu caacggccug 2820
accgugcugc cuccccugcu gaccgacgag augaucgccc aguacaccag cgcccuguua 2880
gccggaacca ucaccagcgg cuggacuuuc ggcgcuggag ccgcucugca gauccccuuc 2940
gccaugcaga uggccuaccg guucaacggc aucggcguga cccagaacgu gcuguacgag 3000
aaccagaagc ugaucgccaa ccaguucaac agcgccaucg gcaagaucca ggacagccug 3060
agcagcaccg cuagcgcccu gggcaagcug caggacgugg ugaaccagaa cgcccaggcc 3120
cugaacaccc uggugaagca gcugagcagc aacuucggcg ccaucagcag cgugcugaac 3180
gacauccuga gccggcugga cccucccgag gccgaggugc agaucgaccg gcugaucacu 3240
ggccggcugc agagccugca gaccuacgug acccagcagc ugauccgggc cgccgagauu 3300
cgggccagcg ccaaccuggc cgccaccaag augagcgagu gcgugcuggg ccagagcaag 3360
cgggguggacu ucugcggcaa gggcuaccac cugaugagcu uuccccagag cgcaccccac 3420
ggaguggugu uccugcacgu gaccuacgug cccgcccagg agaagaacuu caccaccgcc 3480
ccagccaucu gccacgacgg caaggcccac uuuccccggg agggcguguu cgugagcaac 3540
ggcacccacu gguucgugac ccagcggaac uucuacgagc cccagaucau caccaccgac 3600
aacaccuucg ugagcggcaa cugcgacgug gugaucggca ucgugaacaa caccguguac 3660
gauccccugc agcccgagcu ggacagcuuc aaggaggagc uggacaagua cuucaagaau 3720
cacaccagcc ccgacgugga ccugggcgac aucagcggca ucaacgccag cguggugaac 3780
auccagaagg agaucgaucg gcugaacgag guggccaaga accugaacga gagccugauc 3840
gaccugcagg agcugggcaa guacgagcag uacaucaagu ggcccuggua caucuggcug 3900
ggcuucaucg ccggccugau cgccaucgug auggugacca ucaugcugug cugcaugacc 3960
agcugcugca gcugccugaa gggcuguugc agcugcggca gcugcugcaa guucgacgag 4020
gacgacagcg agcccgugcu gaagggcgug aagcugcacu acacc 4065
<![CDATA[ <210> 38]]>
<![CDATA[ <211> 1355]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 38]]>
Met Phe Leu Ile Ile Phe Ile Leu Pro Thr Thr Leu Ala Val Ile Gly
1 5 10 15
Asp Phe Asn Cys Thr Asn Ser Phe Ile Asn Asp Tyr Asn Lys Thr Ile
20 25 30
Pro Arg Ile Ser Glu Asp Val Val Asp Val Ser Leu Gly Leu Gly Thr
35 40 45
Tyr Tyr Val Leu Asn Arg Val Tyr Leu Asn Thr Thr Leu Leu Phe Thr
50 55 60
Gly Tyr Phe Pro Lys Ser Gly Ala Asn Phe Arg Asp Leu Ala Leu Lys
65 70 75 80
Gly Ser Ile Tyr Leu Ser Thr Leu Trp Tyr Lys Pro Pro Phe Leu Ser
85 90 95
Asp Phe Asn Asn Gly Ile Phe Ser Lys Val Lys Asn Thr Lys Leu Tyr
100 105 110
Val Asn Asn Thr Leu Tyr Ser Glu Phe Ser Thr Ile Val Ile Gly Ser
115 120 125
Val Phe Val Asn Thr Ser Tyr Thr Ile Val Val Gln Pro His Asn Gly
130 135 140
Ile Leu Glu Ile Thr Ala Cys Gln Tyr Thr Met Cys Glu Tyr Pro His
145 150 155 160
Thr Val Cys Lys Ser Lys Gly Ser Ile Arg Asn Glu Ser Trp His Ile
165 170 175
Asp Ser Ser Glu Pro Leu Cys Leu Phe Lys Lys Asn Phe Thr Tyr Asn
180 185 190
Val Ser Ala Asp Trp Leu Tyr Phe His Phe Tyr Gln Glu Arg Gly Val
195 200 205
Phe Tyr Ala Tyr Tyr Ala Asp Val Gly Met Pro Thr Thr Phe Leu Phe
210 215 220
Ser Leu Tyr Leu Gly Thr Ile Leu Ser His Tyr Tyr Val Met Pro Leu
225 230 235 240
Thr Cys Asn Ala Ile Ser Ser Asn Thr Asp Asn Glu Thr Leu Glu Tyr
245 250 255
Trp Val Thr Pro Leu Ser Arg Arg Gln Tyr Leu Leu Asn Phe Asp Glu
260 265 270
His Gly Val Ile Thr Asn Ala Val Asp Cys Ala Leu Asp Pro Leu Ser
275 280 285
Glu Thr Lys Cys Thr Leu Lys Ser Phe Thr Val Glu Lys Gly Ile Tyr
290 295 300
Gln Thr Ser Gly Phe Thr Val Lys Pro Val Ala Thr Val Tyr Arg Arg
305 310 315 320
Ile Pro Asn Leu Pro Asp Cys Asp Ile Asp Asn Trp Leu Asn Asn Val
325 330 335
Ser Val Pro Ser Pro Leu Asn Trp Glu Arg Arg Ile Phe Ser Asn Cys
340 345 350
Asn Phe Asn Leu Ser Thr Leu Leu Arg Leu Val His Val Asp Ser Phe
355 360 365
Ser Cys Asn Asn Leu Asp Lys Ser Lys Ile Phe Gly Ser Cys Phe Asn
370 375 380
Ser Ile Thr Val Asp Lys Phe Ala Ile Pro Asn Arg Arg Arg Asp Asp
385 390 395 400
Leu Gln Leu Gly Ser Ser Gly Phe Leu Gln Ser Ser Asn Tyr Lys Ile
405 410 415
Asp Ile Ser Ser Ser Ser Cys Gln Leu Tyr Tyr Ser Leu Pro Leu Val
420 425 430
Asn Val Thr Ile Asn Asn Phe Asn Pro Ser Ser Trp Asn Arg Arg Tyr
435 440 445
Gly Phe Gly Ser Phe Asn Leu Ser Ser Tyr Asp Val Val Tyr Ser Asp
450 455 460
His Cys Phe Ser Val Asn Ser Asp Phe Cys Pro Cys Ala Asp Pro Ser
465 470 475 480
Val Val Asn Ser Cys Ala Lys Ser Lys Pro Pro Ser Ala Ile Cys Pro
485 490 495
Ala Gly Thr Lys Tyr Arg His Cys Asp Leu Asp Thr Thr Leu Tyr Val
500 505 510
Lys Asn Trp Cys Arg Cys Ser Cys Leu Pro Asp Pro Ile Ser Thr Tyr
515 520 525
Ser Pro Asn Thr Cys Pro Gln Lys Lys Val Val Val Gly Ile Gly Glu
530 535 540
His Cys Pro Gly Leu Gly Ile Asn Glu Glu Lys Cys Gly Thr Gln Leu
545 550 555 560
Asn His Ser Ser Cys Phe Cys Ser Pro Asp Ala Phe Leu Gly Trp Ser
565 570 575
Phe Asp Ser Cys Ile Ser Asn Asn Arg Cys Asn Ile Phe Ser Asn Phe
580 585 590
Ile Phe Asn Gly Ile Asn Ser Gly Thr Thr Cys Ser Asn Asp Leu Leu
595 600 605
Tyr Ser Asn Thr Glu Ile Ser Thr Gly Val Cys Val Asn Tyr Asp Leu
610 615 620
Tyr Gly Ile Thr Gly Gln Gly Ile Phe Lys Glu Val Ser Ala Ala Tyr
625 630 635 640
Tyr Asn Asn Trp Gln Asn Leu Leu Tyr Asp Ser Asn Gly Asn Ile Ile
645 650 655
Gly Phe Lys Asp Phe Leu Thr Asn Lys Thr Tyr Thr Ile Leu Pro Cys
660 665 670
Tyr Ser Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn
675 680 685
Gln Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val
690 695 700
Ala Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr
705 710 715 720
Gly Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu
725 730 735
His Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile
740 745 750
Cys Ala Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg Ala Arg Ser
755 760 765
Val Ala Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly Ala Glu
770 775 780
Asn Ser Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr Asn Phe
785 790 795 800
Thr Ile Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr Lys Thr
805 810 815
Ser Val Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu Cys Ser
820 825 830
Asn Leu Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn Arg Ala
835 840 845
Leu Thr Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu Val Phe
850 855 860
Ala Gln Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp Phe Gly
865 870 875 880
Gly Phe Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro Ser Lys
885 890 895
Arg Ser Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu Ala Asp
900 905 910
Ala Gly Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile Ala Ala
915 920 925
Arg Asp Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val Leu Pro
930 935 940
Pro Leu Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala Leu Leu
945 950 955 960
Ala Gly Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala Ala Leu
965 970 975
Gln Ile Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly Ile Gly
980 985 990
Val Thr Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala Asn Gln
995 1000 1005
Phe Asn Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser Ser Thr
1010 1015 1020
Ala Ser Ala Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn Ala
1025 1030 1035
Gln Ala Leu Asn Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly
1040 1045 1050
Ala Ile Ser Ser Val Leu Asn Asp Ile Leu Ser Arg Leu Asp Pro
1055 1060 1065
Pro Glu Ala Glu Val Gln Ile Asp Arg Leu Ile Thr Gly Arg Leu
1070 1075 1080
Gln Ser Leu Gln Thr Tyr Val Thr Gln Gln Leu Ile Arg Ala Ala
1085 1090 1095
Glu Ile Arg Ala Ser Ala Asn Leu Ala Ala Thr Lys Met Ser Glu
1100 1105 1110
Cys Val Leu Gly Gln Ser Lys Arg Val Asp Phe Cys Gly Lys Gly
1115 1120 1125
Tyr His Leu Met Ser Phe Pro Gln Ser Ala Pro His Gly Val Val
1130 1135 1140
Phe Leu His Val Thr Tyr Val Pro Ala Gln Glu Lys Asn Phe Thr
1145 1150 1155
Thr Ala Pro Ala Ile Cys His Asp Gly Lys Ala His Phe Pro Arg
1160 1165 1170
Glu Gly Val Phe Val Ser Asn Gly Thr His Trp Phe Val Thr Gln
1175 1180 1185
Arg Asn Phe Tyr Glu Pro Gln Ile Ile Thr Thr Asp Asn Thr Phe
1190 1195 1200
Val Ser Gly Asn Cys Asp Val Val Ile Gly Ile Val Asn Asn Thr
1205 1210 1215
Val Tyr Asp Pro Leu Gln Pro Glu Leu Asp Ser Phe Lys Glu Glu
1220 1225 1230
Leu Asp Lys Tyr Phe Lys Asn His Thr Ser Pro Asp Val Asp Leu
1235 1240 1245
Gly Asp Ile Ser Gly Ile Asn Ala Ser Val Val Asn Ile Gln Lys
1250 1255 1260
Glu Ile Asp Arg Leu Asn Glu Val Ala Lys Asn Leu Asn Glu Ser
1265 1270 1275
Leu Ile Asp Leu Gln Glu Leu Gly Lys Tyr Glu Gln Tyr Ile Lys
1280 1285 1290
Trp Pro Trp Tyr Ile Trp Leu Gly Phe Ile Ala Gly Leu Ile Ala
1295 1300 1305
Ile Val Met Val Thr Ile Met Leu Cys Cys Met Thr Ser Cys Cys
1310 1315 1320
Ser Cys Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys Lys Phe
1325 1330 1335
Asp Glu Asp Asp Ser Glu Pro Val Leu Lys Gly Val Lys Leu His
1340 1345 1350
Tyr Thr
1355
<![CDATA[ <210> 39]]>
<![CDATA[ <211> 4247]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 39]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uuccugaucc ugcugaucag ccugcccacc gccuucgccg ugaucggcga ccugaagugc 120
accagcgaca acaucaacga caaggacacc ggcccaccac ccaucagcac cgacaccgug 180
gacgugacca acggccuggg caccuacuac gugcuggacc ggguguaccu gaacaccacc 240
cuguuccuga acggcuacua ccccaccagc ggcagcaccu accggaauau ggcccugaag 300
ggcagcgugc ugcugagccg gcugugguuc aagccaccau uccugagcga cuucaucaac 360
ggaaucuucg ccaaggugaa gaacaccaag gugaucaagg accgggugau guacagcgag 420
uuccccgcca ucaccauugg caguaccuuc gugaacacca gcuacagcgu gguggugcag 480
ccccggacca ucaacagcac ccaggacggc gacaacaagc ugcagggccu gcuggaggug 540
agcgugugcc aguacaacau gugcgaguac ccucagacca ucugccaccc caaccugggc 600
aaccaccgga aggagcugug gcaccuggac accggcgugg ugagcugccu guacaagcgg 660
aacuucaccu acgacguaaa cgccgacuac cuguacuucc acuucuacca ggagggcggc 720
accuucuacg ccuacuucac cgacacgggc guggugacca aguuccuguu caacguguac 780
cugggcaugg cccugagcca cuacuacgug augccccuga ccuguaacag caagcugacc 840
cuggaguacu gggugacccc ucugaccagc cggcaguacc ugcuggccuu caaccaggac 900
ggcaucaucu ucaacgccgu ggacugcgcc cuggacccuc ugagcgagac caagugcacc 960
cugaagagcu ucaccgugga gaagggcauc uaccagacca acggcuacac cgugcagccc 1020
aucgccgacg uguaccggcg gaagcccaac cugcccaacu gcaacaucga ggccuggcug 1080
aacgacaaga gcgugcccuc gccccugaac ugggagcgga agaccuucag caacugcaac 1140
uucaacauga gcagucugau gagcuucauc caggccgaca gcuucaccug caacaacauc 1200
gacgccgcca agaucuacgg caugugcuuc agcagcauca ccaucgacaa guuugccauc 1260
cccaacggcc ggaaggugga ccugcagcug ggcaaccugg gcuaccugca gagcuucaac 1320
uaccggaucg acaccaccgc caccucuugc cagcuguacu acaaccugcc cgccgccaac 1380
gugagcguga gccgguucaa ccccagcacc uggaacaagc gguucggcuu cauugaggac 1440
agcguguuca aaccccggcc cgcaggagua cugaccaacc acgacguggu guacgcccag 1500
cacugcuuca aggcacccaa gaacuucugc cccugcaagc ugaacggcag cugugugggc 1560
ucuggccccg guaagaacaa cggcauaggg acuugcccgg cagggaccaa cuaccugacc 1620
ugcgacaacc ugugcacacc cgaccccauc accuucaccg gcaccuacaa guguccccag 1680
accaagagcc uggugggcau cggcgagcac ugcagcggcc uggccgugaa gagcgacuac 1740
ugcggcggca acagcugcac cugucggccc caggccuucc ugggcuggag cgccgacagc 1800
ugccugcagg gcgacaagug caacaucuuu gccaacuuca uccugcacga cgugaacagc 1860
ggccugaccu gcagcaccga ccugcagaag gccaacaccg acaucauccu gggcgugugc 1920
gugaacuacg acuuguacgg cauccugggc cagggcaucu ucguggaggu gaacgccacc 1980
uacuacaaca gcuggcagaa ccugcuguac gacagcaacg gcaaccugua cggcuuccgg 2040
gacuacauca ucaaccggac cuucaugauc cggagcugcu acagcggcgg cgugagcgug 2100
aucaccccag gcaccaacac cagcaaccag guggccgugc uguaccagga cgugaacugc 2160
accgaggugc ccguggccau ccacgccgac cagcugacac ccaccuggcg ggucuacagc 2220
accggcagca acguguucca gacccgggcc gguugccuga ucggcgccga gcacgugaac 2280
aacagcuacg agugcgacau ccccaucggc gccggcaucu gugccagcua ccagacccag 2340
accaauucac cccggagggc aaggagcgug gccagccaga gcaucaucgc cuacaccaug 2400
agccugggcg ccgagaacag cguggccuac agcaacaaca gcaucgccau ccccaccaac 2460
uucaccauca gcgugaccac cgagauucug cccgugagca ugaccaagac cagcguggac 2520
ugcaccaugu acaucugcgg cgacagcacc gagugcagca accugcugcu gcaguacggc 2580
agcuucugca cccagcugaa ccgggcccug accggcaucg ccguggagca ggacaagaac 2640
acccaggagg uguucgccca ggugaagcag aucuacaaga ccccucccau caaggacuuc 2700
ggcggcuuca acuucagcca gauccugccc gaccccagca agcccagcaa gcggagcuuc 2760
aucgaggacc ugcuguucaa caaggugacc cuagccgacg ccggcuucau caagcaguac 2820
ggcgacugcc ucggcgacau agccgcccgg gaccugaucu gcgcccagaa guucaacggc 2880
cugaccgugc ugccuccccu gcugaccgac gagaugaucg cccaguacac cagcgcccug 2940
uuagccggaa ccaucaccag cggcuggacu uucggcgcug gagccgcucu gcagaucccc 3000
uucgccaugc agauggccua ccgguucaac ggcaucggcg ugacccagaa cgugcuguac 3060
gagaaccaga agcugaucgc caaccaguuc aacagcgcca ucggcaagau ccaggacagc 3120
cugagcagca ccgcuagcgc ccugggcaag cugcaggacg uggugaacca gaacgcccag 3180
gcccugaaca cccuggugaa gcagcugagc agcaacuucg gcgccaucag cagcgugcug 3240
aacgacaucc ugagccggcu ggacccuccc gaggccgagg ugcagaucga ccggcugauc 3300
acuggccggc ugcagagccu gcagaccuac gugacccagc agcugauccg ggccgccgag 3360
auucgggcca gcgccaaccu ggccgccacc aagaugagcg agugcgugcu gggccagagc 3420
aagcgggugg acuucugcgg caagggcuac caccugauga gcuuucccca gagcgcaccc 3480
cacggagugg uguuccugca cgugaccuac gugcccgccc aggagaagaa cuucaccacc 3540
gccccagcca ucugccacga cggcaaggcc cacuuucccc gggagggcgu guucgugagc 3600
aacggcaccc acugguucgu gacccagcgg aacuucuacg agccccagau caucaccacc 3660
gacaacaccu ucgugagcgg caacugcgac guggugaucg gcaucgugaa caacaccgug 3720
uacgaucccc ugcagcccga gcuggacagc uucaaggagg agcuggacaa guacuucaag 3780
aaucacacca gccccgacgu ggaccugggc gacaucagcg gcaucaacgc cagcguggug 3840
aacauccaga aggagaucga ucggcugaac gagguggcca agaaccugaa cgagagccug 3900
aucgaccugc aggagcuggg caaguacgag caguacauca aguggcccug guacaucugg 3960
cugggcuuca ucgccggccu gaucgccauc gugaugguga ccaucaugcu gugcugcaug 4020
accagcugcu gcagcugccu gaagggcugu ugcagcugcg gcagcugcug caaguucgac 4080
gaggacgaca gcgagcccgu gcugaagggc gugaagcugc acuacaccug auaauaggcu 4140
ggagccucgg uggccuagcu ucuugccccu ugggccuccc cccagccccu ccuccccuuc 4200
cugcacccgu acccccgugg ucuuugaaua aagucugagu gggcggc 4247
<![CDATA[ <210> 40]]>
<![CDATA[ <211> 4071]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 40]]>
auguuccuga uccugcugau cagccugccc accgccuucg ccgugaucgg cgaccugaag 60
ugcaccagcg acaacaucaa cgacaaggac accggcccac cacccaucag caccgacacc 120
guggacguga ccaacggccu gggcaccuac uacgugcugg accgggugua ccugaacacc 180
acccuguucc ugaacggcua cuaccccacc agcggcagca ccuaccggaa uauggcccug 240
aagggcagcg ugcugcugag ccggcugugg uucaagccac cauuccugag cgacuucauc 300
aacggaaucu ucgccaaggu gaagaacacc aagugauca aggaccgggu gauguacagc 360
gaguuccccg ccaucaccau uggcaguacc uucgugaaca ccagcuacag cgugguggug 420
cagccccgga ccaucaacag cacccaggac ggcgacaaca agcugcaggg ccugcuggag 480
gugagcgugu gccaguacaa caugugcgag uacccucaga ccaucugcca ccccaaccug 540
ggcaaccacc ggaaggagcu guggcaccug gacaccggcg uggugagcug ccuguacaag 600
cggaacuuca ccuacgacgu aaacgccgac uaccuguacu uccacuucua ccaggagggc 660
ggcaccuucu acgccuacuu caccgacacg ggcgugguga ccaaguuccu guucaacgug 720
uaccugggca uggcccugag ccacuacuac gugaugcccc ugaccuguaa cagcaagcug 780
acccuggagu acugggugac cccucugacc agccggcagu accugcuggc cuucaaccag 840
gacggcauca ucuucaacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 900
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccaacggcua caccgugcag 960
cccaucgccg acguguaccg gcggaagccc aaccugccca acugcaacau cgaggccugg 1020
cugaacgaca agagcgugcc cucgccccug aacugggagc ggaagaccuu cagcaacugc 1080
aacuucaaca ugagcagucu gaugagcuuc auccaggccg acagcuucac cugcaacaac 1140
aucgacgccg ccaagaucua cggcaugugc uucagcagca ucaccaucga caaguuugcc 1200
auccccaacg gccggaaggu ggaccugcag cugggcaacc ugggcuaccu gcagagcuuc 1260
aacuaccgga ucgacaccac cgccaccucu ugccagcugu acuacaaccu gcccgccgcc 1320
aacgugagcg ugagccgguu caaccccagc accuggaaca agcgguucgg cuucauugag 1380
gacagcgugu ucaaaccccg gcccgcagga guacugacca accacgacgu gguguacgcc 1440
cagcacugcu ucaaggcacc caagaacuuc ugccccugca agcugaacgg cagcugugug 1500
ggcucuggcc ccgguaagaa caacggcaua gggacuugcc cggcagggac caacuaccug 1560
accugcgaca accugugcac acccgacccc aucaccuuca ccggcaccua caaguguccc 1620
cagaccaaga gccugguggg caucggcgag cacugcagcg gccuggccgu gaagagcgac 1680
uacugcggcg gcaacagcug caccugucgg ccccaggccu uccugggcug gagcgccgac 1740
agcugccugc agggcgacaa gugcaacauc uuugccaacu ucauccugca cgacgugaac 1800
agcggccuga ccugcagcac cgaccugcag aaggccaaca ccgacaucau ccugggcgug 1860
ugcgugaacu acgacuugua cggcauccug ggccagggca ucuucgugga ggugaacgcc 1920
accuacuaca acagcuggca gaaccugcug uacgacagca acggcaaccu guacggcuuc 1980
cgggacuaca ucaucaaccg gaccuucaug auccggagcu gcuacagcgg cggcgugagc 2040
gugaucaccc caggcaccaa caccagcaac cagguggccg ugcuguacca ggacgugaac 2100
ugcaccgagg ugcccguggc cauccacgcc gaccagcuga cacccaccug gcgggucuac 2160
agcaccggca gcaacguguu ccagacccgg gccgguugcc ugaucggcgc cgagcacgug 2220
aacaacagcu acgagugcga cauccccauc ggcgccggca ucugugccag cuaccagacc 2280
cagaccaauu caccccggag ggcaaggagc guggccagcc agagcaucau cgccuacacc 2340
augagccugg gcgccgagaa cagcguggcc uacagcaaca acagcaucgc cauccccacc 2400
aacuucacca ucagcgugac caccgagauu cugcccgug gcaugaccaa gaccagcgug 2460
gacugcacca uguacaucug cggcgacagc accgagugca gcaaccugcu gcugcaguac 2520
ggcagcuucu gcacccagcu gaaccgggcc cugaccggca ucgccgugga gcaggacaag 2580
aacacccagg agguguucgc ccaggugaag cagaucuaca agaccccucc caucaaggac 2640
uucggcggcu ucaacuucag ccagauccug cccgacccca gcaagcccag caagcggagc 2700
uucaucgagg accugcuguu caacaaggug acccuagccg acgccggcuu caucaagcag 2760
uacggcgacu gccucggcga cauagccgcc cgggaccuga ucugcgccca gaaguucaac 2820
ggccugaccg ugcugccucc ccugcugacc gacgagauga ucgcccagua caccagcgcc 2880
cuguuagccg gaaccaucac cagcggcugg acuuucggcg cuggagccgc ucugcagauc 2940
cccuucgcca ugcagauggc cuaccgguuc aacggcaucg gcgugaccca gaacgugcug 3000
uacgagaacc agaagcugau cgccaaccag uucaacagcg ccaucggcaa gauccaggac 3060
agccugagca gcaccgcuag cgcccugggc aagcugcagg acguggugaa ccagaacgcc 3120
caggcccuga acacccuggu gaagcagcug agcagcaacu ucggcgccau cagcagcgug 3180
cugaacgaca uccugagccg gcuggacccu cccgaggccg aggugcagau cgaccggcug 3240
aucacuggcc ggcugcagag ccugcagacc uacgugaccc agcagcugau ccgggccgcc 3300
gagauucggg ccagcgccaa ccuggccgcc accaagauga gcgagugcgu gcugggccag 3360
agcaagcggg uggacuucug cggcaagggc uaccaccuga ugagcuuucc ccagagcgca 3420
ccccacggag ugguguuccu gcacgugacc uacgugcccg cccaggagaa gaacuucacc 3480
accgccccag ccaucugcca cgacggcaag gcccacuuuc cccgggaggg cguguucgug 3540
agcaacggca cccacugguu cgugacccag cggaacuucu acgagcccca gaucaucacc 3600
accgacaaca ccuucgugag cggcaacugc gacgugguga ucggcaucgu gaacaacacc 3660
guguacgauc cccugcagcc cgagcuggac agcuucaagg aggagcugga caaguacuuc 3720
aagaaucaca ccagccccga cguggaccug ggcgacauca gcggcaucaa cgccagcgug 3780
gugaacaucc agaaggagau cgaucggcug aacgaggugg ccaagaaccu gaacgagagc 3840
cugaucgacc ugcaggagcu gggcaaguac gagcaguaca ucaaguggcc cugguacauc 3900
uggcugggcu ucaucgccgg ccugaucgcc aucgugaugg ugaccaucau gcugugcugc 3960
augaccagcu gcugcagcug ccugaagggc uguugcagcu gcggcagcug cugcaaguuc 4020
gacgaggacg acagcgagcc cgugcugaag ggcgugaagc ugcacuacac c 4071
<![CDATA[ <210> 41]]>
<![CDATA[ <211> 1357]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 41]]>
Met Phe Leu Ile Leu Leu Ile Ser Leu Pro Thr Ala Phe Ala Val Ile
1 5 10 15
Gly Asp Leu Lys Cys Thr Ser Asp Asn Ile Asn Asp Lys Asp Thr Gly
20 25 30
Pro Pro Pro Ile Ser Thr Asp Thr Val Asp Val Thr Asn Gly Leu Gly
35 40 45
Thr Tyr Tyr Val Leu Asp Arg Val Tyr Leu Asn Thr Thr Leu Phe Leu
50 55 60
Asn Gly Tyr Tyr Pro Thr Ser Gly Ser Thr Tyr Arg Asn Met Ala Leu
65 70 75 80
Lys Gly Ser Val Leu Leu Ser Arg Leu Trp Phe Lys Pro Pro Phe Leu
85 90 95
Ser Asp Phe Ile Asn Gly Ile Phe Ala Lys Val Lys Asn Thr Lys Val
100 105 110
Ile Lys Asp Arg Val Met Tyr Ser Glu Phe Pro Ala Ile Thr Ile Gly
115 120 125
Ser Thr Phe Val Asn Thr Ser Tyr Ser Val Val Val Gln Pro Arg Thr
130 135 140
Ile Asn Ser Thr Gln Asp Gly Asp Asn Lys Leu Gln Gly Leu Leu Glu
145 150 155 160
Val Ser Val Cys Gln Tyr Asn Met Cys Glu Tyr Pro Gln Thr Ile Cys
165 170 175
His Pro Asn Leu Gly Asn His Arg Lys Glu Leu Trp His Leu Asp Thr
180 185 190
Gly Val Val Ser Cys Leu Tyr Lys Arg Asn Phe Thr Tyr Asp Val Asn
195 200 205
Ala Asp Tyr Leu Tyr Phe His Phe Tyr Gln Glu Gly Gly Thr Phe Tyr
210 215 220
Ala Tyr Phe Thr Asp Thr Gly Val Val Thr Lys Phe Leu Phe Asn Val
225 230 235 240
Tyr Leu Gly Met Ala Leu Ser His Tyr Tyr Val Met Pro Leu Thr Cys
245 250 255
Asn Ser Lys Leu Thr Leu Glu Tyr Trp Val Thr Pro Leu Thr Ser Arg
260 265 270
Gln Tyr Leu Leu Ala Phe Asn Gln Asp Gly Ile Ile Phe Asn Ala Val
275 280 285
Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys Ser
290 295 300
Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Asn Gly Tyr Thr Val Gln
305 310 315 320
Pro Ile Ala Asp Val Tyr Arg Arg Lys Pro Asn Leu Pro Asn Cys Asn
325 330 335
Ile Glu Ala Trp Leu Asn Asp Lys Ser Val Pro Ser Pro Leu Asn Trp
340 345 350
Glu Arg Lys Thr Phe Ser Asn Cys Asn Phe Asn Met Ser Ser Leu Met
355 360 365
Ser Phe Ile Gln Ala Asp Ser Phe Thr Cys Asn Asn Ile Asp Ala Ala
370 375 380
Lys Ile Tyr Gly Met Cys Phe Ser Ser Ile Thr Ile Asp Lys Phe Ala
385 390 395 400
Ile Pro Asn Gly Arg Lys Val Asp Leu Gln Leu Gly Asn Leu Gly Tyr
405 410 415
Leu Gln Ser Phe Asn Tyr Arg Ile Asp Thr Thr Ala Thr Ser Cys Gln
420 425 430
Leu Tyr Tyr Asn Leu Pro Ala Ala Asn Val Ser Val Ser Arg Phe Asn
435 440 445
Pro Ser Thr Trp Asn Lys Arg Phe Gly Phe Ile Glu Asp Ser Val Phe
450 455 460
Lys Pro Arg Pro Ala Gly Val Leu Thr Asn His Asp Val Val Tyr Ala
465 470 475 480
Gln His Cys Phe Lys Ala Pro Lys Asn Phe Cys Pro Cys Lys Leu Asn
485 490 495
Gly Ser Cys Val Gly Ser Gly Pro Gly Lys Asn Asn Gly Ile Gly Thr
500 505 510
Cys Pro Ala Gly Thr Asn Tyr Leu Thr Cys Asp Asn Leu Cys Thr Pro
515 520 525
Asp Pro Ile Thr Phe Thr Gly Thr Tyr Lys Cys Pro Gln Thr Lys Ser
530 535 540
Leu Val Gly Ile Gly Glu His Cys Ser Gly Leu Ala Val Lys Ser Asp
545 550 555 560
Tyr Cys Gly Gly Asn Ser Cys Thr Cys Arg Pro Gln Ala Phe Leu Gly
565 570 575
Trp Ser Ala Asp Ser Cys Leu Gln Gly Asp Lys Cys Asn Ile Phe Ala
580 585 590
Asn Phe Ile Leu His Asp Val Asn Ser Gly Leu Thr Cys Ser Thr Asp
595 600 605
Leu Gln Lys Ala Asn Thr Asp Ile Ile Leu Gly Val Cys Val Asn Tyr
610 615 620
Asp Leu Tyr Gly Ile Leu Gly Gln Gly Ile Phe Val Glu Val Asn Ala
625 630 635 640
Thr Tyr Tyr Asn Ser Trp Gln Asn Leu Leu Tyr Asp Ser Asn Gly Asn
645 650 655
Leu Tyr Gly Phe Arg Asp Tyr Ile Ile Asn Arg Thr Phe Met Ile Arg
660 665 670
Ser Cys Tyr Ser Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr
675 680 685
Ser Asn Gln Val Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val
690 695 700
Pro Val Ala Ile His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr
705 710 715 720
Ser Thr Gly Ser Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly
725 730 735
Ala Glu His Val Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala
740 745 750
Gly Ile Cys Ala Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg Ala
755 760 765
Arg Ser Val Ala Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly
770 775 780
Ala Glu Asn Ser Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr
785 790 795 800
Asn Phe Thr Ile Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr
805 810 815
Lys Thr Ser Val Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu
820 825 830
Cys Ser Asn Leu Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn
835 840 845
Arg Ala Leu Thr Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu
850 855 860
Val Phe Ala Gln Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp
865 870 875 880
Phe Gly Gly Phe Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro
885 890 895
Ser Lys Arg Ser Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu
900 905 910
Ala Asp Ala Gly Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile
915 920 925
Ala Ala Arg Asp Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val
930 935 940
Leu Pro Pro Leu Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala
945 950 955 960
Leu Leu Ala Gly Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala
965 970 975
Ala Leu Gln Ile Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly
980 985 990
Ile Gly Val Thr Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala
995 1000 1005
Asn Gln Phe Asn Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser
1010 1015 1020
Ser Thr Ala Ser Ala Leu Gly Lys Leu Gln Asp Val Val Asn Gln
1025 1030 1035
Asn Ala Gln Ala Leu Asn Thr Leu Val Lys Gln Leu Ser Ser Asn
1040 1045 1050
Phe Gly Ala Ile Ser Ser Val Leu Asn Asp Ile Leu Ser Arg Leu
1055 1060 1065
Asp Pro Pro Glu Ala Glu Val Gln Ile Asp Arg Leu Ile Thr Gly
1070 1075 1080
Arg Leu Gln Ser Leu Gln Thr Tyr Val Thr Gln Gln Leu Ile Arg
1085 1090 1095
Ala Ala Glu Ile Arg Ala Ser Ala Asn Leu Ala Ala Thr Lys Met
1100 1105 1110
Ser Glu Cys Val Leu Gly Gln Ser Lys Arg Val Asp Phe Cys Gly
1115 1120 1125
Lys Gly Tyr His Leu Met Ser Phe Pro Gln Ser Ala Pro His Gly
1130 1135 1140
Val Val Phe Leu His Val Thr Tyr Val Pro Ala Gln Glu Lys Asn
1145 1150 1155
Phe Thr Thr Ala Pro Ala Ile Cys His Asp Gly Lys Ala His Phe
1160 1165 1170
Pro Arg Glu Gly Val Phe Val Ser Asn Gly Thr His Trp Phe Val
1175 1180 1185
Thr Gln Arg Asn Phe Tyr Glu Pro Gln Ile Ile Thr Thr Asp Asn
1190 1195 1200
Thr Phe Val Ser Gly Asn Cys Asp Val Val Ile Gly Ile Val Asn
1205 1210 1215
Asn Thr Val Tyr Asp Pro Leu Gln Pro Glu Leu Asp Ser Phe Lys
1220 1225 1230
Glu Glu Leu Asp Lys Tyr Phe Lys Asn His Thr Ser Pro Asp Val
1235 1240 1245
Asp Leu Gly Asp Ile Ser Gly Ile Asn Ala Ser Val Val Asn Ile
1250 1255 1260
Gln Lys Glu Ile Asp Arg Leu Asn Glu Val Ala Lys Asn Leu Asn
1265 1270 1275
Glu Ser Leu Ile Asp Leu Gln Glu Leu Gly Lys Tyr Glu Gln Tyr
1280 1285 1290
Ile Lys Trp Pro Trp Tyr Ile Trp Leu Gly Phe Ile Ala Gly Leu
1295 1300 1305
Ile Ala Ile Val Met Val Thr Ile Met Leu Cys Cys Met Thr Ser
1310 1315 1320
Cys Cys Ser Cys Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys
1325 1330 1335
Lys Phe Asp Glu Asp Asp Ser Glu Pro Val Leu Lys Gly Val Lys
1340 1345 1350
Leu His Tyr Thr
1355
<![CDATA[ <210> 42]]>
<![CDATA[ <211> 1157]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 42]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacucu ggcggaggcg gcagcgccau cggcggcuac 960
auccccgagg ccccuagaga cggccaggcc uacgugcgga aggacggcga gugggugcug 1020
cugagcaccu uccugggcug auaauaggcu ggagccucgg uggccuagcu ucuugccccu 1080
ugggccuccc cccagccccu ccuccccuuc cugcacccgu acccccgugg ucuuugaaua 1140
aagucugagu gggcggc 1157
<![CDATA[ <210> 43]]>
<![CDATA[ <211> 981]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 43]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ucuggcggag gcggcagcgc caucggcggc 900
uacauccccg aggccccuag agacggccag gccuacgugc ggaaggacgg cgagugggug 960
cugcugagca ccuuccuggg c 981
<![CDATA[ <210> 44]]>
<![CDATA[ <211> 327]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 44]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Ser Gly Gly Gly Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu
290 295 300
Ala Pro Arg Asp Gly Gln Ala Tyr Val Arg Lys Asp Gly Glu Trp Val
305 310 315 320
Leu Leu Ser Thr Phe Leu Gly
325
<![CDATA[ <210> 45]]>
<![CDATA[ <211> 1130]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 45]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuucuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacucu ggcggaggca gcauccuggc caucuacagc 960
accguggcca gcagccuggu gcugcuggug agccugggcg ccaucagcuu cugauaauag 1020
gcuggagccu cgguggccua gcuucuugcc ccuugggccu ccccccagcc ccuccucccc 1080
uuccugcacc cguacccccg uggucuuuga auaaagucug agugggcggc 1130
<![CDATA[ <210> 46]]>
<![CDATA[ <211> 954]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 46]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ucuggcggag gcagcauccu ggccaucuac 900
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuuc 954
<![CDATA[ <210> 47]]>
<![CDATA[ <211> 318]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 47]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala
290 295 300
Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
305 310 315
<![CDATA[ <210> 48]]>
<![CDATA[ <211> 1238]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 48]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacucu ggcggaggca gcauccuggc caucuacagc 960
accguggcca gcagccuggu gcugcuggug agccugggcg ccaucagcuu cggcggaggc 1020
agcgccaucg gcggcuacau ccccgaggcc ccuagagacg gccaggccua cgugcggaag 1080
gacggcgagu gggugcugcu gagcaccuuc cugggcaagu gauaauaggc uggagccucg 1140
guggccuagc uucuugcccc uugggccucc ccccagcccc uccuccccuu ccugcacccg 1200
uacccccgug gucuuugaau aaagucugag ugggcggc 1238
<![CDATA[ <210> 49]]>
<![CDATA[ <211> 1062]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 49]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ucuggcggag gcagcauccu ggccaucuac 900
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuucggcgga 960
ggcagcgcca ucggcggcua cauccccgag gccccuagag acggccaggc cuacgugcgg 1020
aaggacggcg agugggugcu gcugagcacc uuccugggca ag 1062
<![CDATA[ <210> 50]]>
<![CDATA[ <211> 354]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 50]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala
290 295 300
Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe Gly Gly
305 310 315 320
Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln
325 330 335
Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu Ser Thr Phe Leu
340 345 350
Gly Lys
<![CDATA[ <210> 51]]>
<![CDATA[ <211> 1130]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 51]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
gugugccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacucu ggcggaggca gcauccuggc caucuacagc 960
accguggcca gcagccuggu gcugcuggug agccugggcg ccaucagcuu cugauaauag 1020
gcuggagccu cgguggccua gcuucuugcc ccuugggccu ccccccagcc ccuccucccc 1080
uuccugcacc cguacccccg uggucuuuga auaaagucug agugggcggc 1130
<![CDATA[ <210> 52]]>
<![CDATA[ <211> 954]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 52]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aaggugugcc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ucuggcggag gcagcauccu ggccaucuac 900
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuuc 954
<![CDATA[ <210> 53]]>
<![CDATA[ <211> 318]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 53]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Cys Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala
290 295 300
Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
305 310 315
<![CDATA[ <210> 54]]>
<![CDATA[ <211> 1181]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 54]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
gugugccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccuc uggcggaggc agcauccugg ccaucuacag caccguggcc 1020
agcagccugg ugcugcuggu gagccugggc gccaucagcu ucugauaaua ggcuggagcc 1080
ucgguggccu agcuucuugc cccuugggcc uccccccagc cccuccuccc cuuccugcac 1140
ccguaccccc guggucuuug aauaaagucu gagugggcgg c 1181
<![CDATA[ <210> 55]]>
<![CDATA[ <211> 1005]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 55]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aaggugugcc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cucuggcgga ggcagcaucc uggccaucua cagcaccgug 960
gccagcagcc uggugcugcu ggugagccug ggcgccauca gcuuc 1005
<![CDATA[ <210> 56]]>
<![CDATA[ <211> 335]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 56]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Cys Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val
305 310 315 320
Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
325 330 335
<![CDATA[ <210> 57]]>
<![CDATA[ <211> 1181]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 57]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccuc uggcggaggc agcauccugg ccaucuacag caccguggcc 1020
agcagccugg ugcugcuggu gagccugggc gccaucagcu ucugauaaua ggcuggagcc 1080
ucgguggccu agcuucuugc cccuugggcc uccccccagc cccuccuccc cuuccugcac 1140
ccguaccccc guggucuuug aauaaagucu gagugggcgg c 1181
<![CDATA[ <210> 58]]>
<![CDATA[ <211> 1005]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 58]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cucuggcgga ggcagcaucc uggccaucua cagcaccgug 960
gccagcagcc uggugcugcu ggugagccug ggcgccauca gcuuc 1005
<![CDATA[ <210> 59]]>
<![CDATA[ <211> 335]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 59]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val
305 310 315 320
Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
325 330 335
<![CDATA[ <210> 60]]>
<![CDATA[ <211> 836]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 60]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaaguga 720
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccuccccc ccagccccuc 780
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 836
<![CDATA[ <210> 61]]>
<![CDATA[ <211> 660]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 61]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
<![CDATA[ <210> 62]]>
<![CDATA[ <211> 220]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 62]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
210 215 220
<![CDATA[ <210> 63]]>
<![CDATA[ <211> 1349]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 63]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaaggga 720
ggaggcagcg gcggcgauau caucaagcuu cugaacgagc aaguuaacaa ggaaaugcag 780
agcaguaauc ucuacaugag caugagcagc uggugcuaca cccacucccu ggacggagca 840
ggccucuucc uguucgacca cgcagccgag gaguacgagc acgcuaagaa guugaucauu 900
uucuugaacg agaacaacgu gcccgugcag cuaacgucaa ucagcgcacc ugagcacaag 960
uucgagggcc ugacccagau cuuccagaag gccuacgaac acgaacagca caucuccgag 1020
agcaucaaca auauugugga ucacgcuauc aaguccaagg accacgcuac cuucaacuuc 1080
cugcaguggu acguggccga gcaacaugag gaggaggugc uguucaagga cauccuggac 1140
aagaucgagc ugaucgguaa ugagaaucac ggccuguacc uggccgacca guacgugaag 1200
ggcaucgcca agagccggaa gucaggcuca ugauaauagg cuggagccuc gguggccuag 1260
cuucuugccc cuugggccuc cccccagccc cuccuccccu uccugcaccc guacccccgu 1320
ggucuuugaa uaaagucuga gugggcggc 1349
<![CDATA[ <210> 64]]>
<![CDATA[ <211> 1173]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 64]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ggaggaggca gcggcggcga uaucaucaag cuucugaacg agcaaguuaa caaggaaaug 720
cagagcagua aucucuacau gagcaugagc agcuggugcu acacccacuc ccuggacgga 780
gcaggccucu uccuguucga ccacgcagcc gaggaguacg agcacgcuaa gaaguugauc 840
auuuucuuga acgagaacaa cgugcccgug cagcuaacgu caaucagcgc accugagcac 900
aaguucgagg gccugaccca gaucuuccag aaggccuacg aacacgaaca gcacaucucc 960
gagagcauca acaauauugu ggaucacgcu aucaagucca aggaccacgc uaccuucaac 1020
uuccugcagu gguacguggc cgagcaacau gaggaggagg ugcuguucaa ggacauccug 1080
gacaagaucg agcugaucgg uaaugagaau cacggccugu accuggccga ccaguacgug 1140
aagggcaucg ccaagagccg gaaguccaggc uca 1173
<![CDATA[ <210> 65]]>
<![CDATA[ <211> 391]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 65]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Gly Gly Gly Ser
210 215 220
Gly Gly Asp Ile Ile Lys Leu Leu Asn Glu Gln Val Asn Lys Glu Met
225 230 235 240
Gln Ser Ser Asn Leu Tyr Met Ser Met Ser Ser Trp Cys Tyr Thr His
245 250 255
Ser Leu Asp Gly Ala Gly Leu Phe Leu Phe Asp His Ala Ala Glu Glu
260 265 270
Tyr Glu His Ala Lys Lys Leu Ile Ile Phe Leu Asn Glu Asn Asn Val
275 280 285
Pro Val Gln Leu Thr Ser Ile Ser Ala Pro Glu His Lys Phe Glu Gly
290 295 300
Leu Thr Gln Ile Phe Gln Lys Ala Tyr Glu His Glu Gln His Ile Ser
305 310 315 320
Glu Ser Ile Asn Asn Ile Val Asp His Ala Ile Lys Ser Lys Asp His
325 330 335
Ala Thr Phe Asn Phe Leu Gln Trp Tyr Val Ala Glu Gln His Glu Glu
340 345 350
Glu Val Leu Phe Lys Asp Ile Leu Asp Lys Ile Glu Leu Ile Gly Asn
355 360 365
Glu Asn His Gly Leu Tyr Leu Ala Asp Gln Tyr Val Lys Gly Ile Ala
370 375 380
Lys Ser Arg Lys Ser Gly Ser
385 390
<![CDATA[ <210> 66]]>
<![CDATA[ <211> 1376]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 66]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
ggcauccugc ccagcccugg caugcccgcu cugcugagcc uggugagccu gcugagcgug 120
cugcugaugg gcugcguggc ugagaccggc augcagaucu acgagggcaa gcugaccgca 180
gagggccugc gguucggcau cguggccagc cgcgccaacc acgcucuggu ggaccggcuu 240
guggagggcg cuaucgacgc caucgugaga cacggcggcc gggaagagga caucacccug 300
gugcgggugu gcggcagcug ggagauuccc gucgccgccg gagaacuggc ccggaaggag 360
gacaucgacg ccgugaucgc caucggcgug cugugcagag gcgccacgcc cagcuucgac 420
uacaucgcca gcgaggugag caagggccug gccgaccuga gccuggagcu gcggaagccc 480
aucaccuucg gcgugaucac cgccgacacc cuggagcagg ccaucgaggc cgcaggcacc 540
ugccacggca acaagggcug ggaagccgcc cugugcgcca ucgagauggc caaccuguuc 600
aagagccugc ggggcggaag uggaggcucu gguggcagcg gaggaucugg cggcggccag 660
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 720
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 780
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 840
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 900
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 960
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 1020
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 1080
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 1140
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 1200
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaaguga 1260
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccucccc ccagccccuc 1320
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 1376
<![CDATA[ <210> 67]]>
<![CDATA[ <211> 1200]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 67]]>
augggcaucc ugcccagccc uggcaugccc gcucugcuga gccuggugag ccugcugagc 60
gugcugcuga ugggcugcgu ggcugagacc ggcaugcaga ucuacgaggg caagcugacc 120
gcagagggcc ugcgguucgg caucguggcc agccgcgcca accacgcucu gguggaccgg 180
cuuguggagg gcgcuaucga cgccaucgug agacacggcg gccgggaaga ggacaucacc 240
cuggugcggg ugugcggcag cugggagauu cccgucgccg ccggagaacu ggcccggaag 300
gaggacaucg acgccgugau cgccaucggc gugcugugca gaggcgccac gcccagcuuc 360
gacuacaucg ccagcgaggu gagcaagggc cuggccgacc ugagccugga gcugcggaag 420
cccaucaccu ucggcgugau caccgccgac acccuggagc aggccaucga ggccgcaggc 480
accugccacg gcaacaaggg cugggaagcc gcccugugcg ccaucgagau ggccaaccug 540
uucaagagcc ugcggggcgg aaguggaggc ucugguggca gcggaggauc uggcggcggc 600
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 660
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 720
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 780
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 840
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 900
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 960
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 1020
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 1080
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 1140
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 1200
<![CDATA[ <210> 68]]>
<![CDATA[ <211> 400]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 68]]>
Met Gly Ile Leu Pro Ser Pro Gly Met Pro Ala Leu Leu Ser Leu Val
1 5 10 15
Ser Leu Leu Ser Val Leu Leu Met Gly Cys Val Ala Glu Thr Gly Met
20 25 30
Gln Ile Tyr Glu Gly Lys Leu Thr Ala Glu Gly Leu Arg Phe Gly Ile
35 40 45
Val Ala Ser Arg Ala Asn His Ala Leu Val Asp Arg Leu Val Glu Gly
50 55 60
Ala Ile Asp Ala Ile Val Arg His Gly Gly Arg Glu Glu Asp Ile Thr
65 70 75 80
Leu Val Arg Val Cys Gly Ser Trp Glu Ile Pro Val Ala Ala Gly Glu
85 90 95
Leu Ala Arg Lys Glu Asp Ile Asp Ala Val Ile Ala Ile Gly Val Leu
100 105 110
Cys Arg Gly Ala Thr Pro Ser Phe Asp Tyr Ile Ala Ser Glu Val Ser
115 120 125
Lys Gly Leu Ala Asp Leu Ser Leu Glu Leu Arg Lys Pro Ile Thr Phe
130 135 140
Gly Val Ile Thr Ala Asp Thr Leu Glu Gln Ala Ile Glu Ala Ala Gly
145 150 155 160
Thr Cys His Gly Asn Lys Gly Trp Glu Ala Ala Leu Cys Ala Ile Glu
165 170 175
Met Ala Asn Leu Phe Lys Ser Leu Arg Gly Gly Ser Gly Gly Ser Gly
180 185 190
Gly Ser Gly Gly Ser Gly Gly Gly Gln Pro Asn Ile Thr Asn Leu Cys
195 200 205
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
210 215 220
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
225 230 235 240
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
245 250 255
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
260 265 270
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
275 280 285
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
290 295 300
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
305 310 315 320
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
325 330 335
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
340 345 350
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
355 360 365
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
370 375 380
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
385 390 395 400
<![CDATA[ <210> 69]]>
<![CDATA[ <211> 1334]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 69]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaaggga 720
ggaggcuccg gaggcgguag cgcugagacc ggcaugcaga ucuacgaggg caagcugacc 780
gcagagggcc ugcgguucgg caucguggcc agccgcgcca accacgcucu gguggaccgg 840
cuuguggagg gcgcuaucga cgccaucgug agacacggcg gccgggaaga ggacaucacc 900
cuggugcggg ugugcggcag cugggagauu cccgucgccg ccggagaacu ggcccggaag 960
gaggacaucg acgccgugau cgccaucggc gugcugugca gaggcgccac gcccagcuuc 1020
gacuacaucg ccagcgaggu gagcaagggc cuggccgacc ugagccugga gcugcggaag 1080
cccaucaccu ucggcgugau caccgccgac acccuggagc aggccaucga ggccgcaggc 1140
accugccacg gcaacaaggg cugggaagcc gcccugugcg ccaucgagau ggccaaccug 1200
uucaagagcc ugcggugaua auaggcugga gccucggugg ccuagcuucu ugccccuugg 1260
gccuccicccc agccccuccu ccccuuccug cacccguacc cccguggucu uugaauaaag 1320
ucugaguggg cggc 1334
<![CDATA[ <210> 70]]>
<![CDATA[ <211> 1158]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 70]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ggaggaggcu ccggaggcgg uagcgcugag accggcaugc agaucuacga gggcaagcug 720
accgcagagg gccugcgguu cggcaucgug gccagccgcg ccaaccacgc ucugguggac 780
cggcuugugg agggcgcuau cgacgccauc gugagacacg gcggccggga agaggacauc 840
acccuggugc gggugugcgg cagcugggag auucccgucg ccgccggaga acuggcccgg 900
aaggaggaca ucgacgccgu gaucgccauc ggcgugcugu gcagaggcgc cacgcccagc 960
uucgacuaca ucgccagcga ggugagcaag ggccuggccg accugagccu ggagcugcgg 1020
aagcccauca ccuucggcgu gaucaccgcc gacacccugg agcaggccau cgaggccgca 1080
ggcaccugcc acggcaacaa gggcugggaa gccgcccugu gcgccaucga gauggccaac 1140
cuguucaaga gccugcgg 1158
<![CDATA[ <210> 71]]>
<![CDATA[ <211> 386]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 71]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Gly Gly Gly Ser
210 215 220
Gly Gly Gly Ser Ala Glu Thr Gly Met Gln Ile Tyr Glu Gly Lys Leu
225 230 235 240
Thr Ala Glu Gly Leu Arg Phe Gly Ile Val Ala Ser Arg Ala Asn His
245 250 255
Ala Leu Val Asp Arg Leu Val Glu Gly Ala Ile Asp Ala Ile Val Arg
260 265 270
His Gly Gly Arg Glu Glu Asp Ile Thr Leu Val Arg Val Cys Gly Ser
275 280 285
Trp Glu Ile Pro Val Ala Ala Gly Glu Leu Ala Arg Lys Glu Asp Ile
290 295 300
Asp Ala Val Ile Ala Ile Gly Val Leu Cys Arg Gly Ala Thr Pro Ser
305 310 315 320
Phe Asp Tyr Ile Ala Ser Glu Val Ser Lys Gly Leu Ala Asp Leu Ser
325 330 335
Leu Glu Leu Arg Lys Pro Ile Thr Phe Gly Val Ile Thr Ala Asp Thr
340 345 350
Leu Glu Gln Ala Ile Glu Ala Ala Gly Thr Cys His Gly Asn Lys Gly
355 360 365
Trp Glu Ala Ala Leu Cys Ala Ile Glu Met Ala Asn Leu Phe Lys Ser
370 375 380
Leu Arg
385
<![CDATA[ <210> 72]]>
<![CDATA[ <211> 947]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 72]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggcg gcagcgccau cggcggcuac auccccgagg ccccuagaga cggccaggcc 780
uacgugcgga aggacggcga gugggugcug cugagcaccu uccugggcug auaauaggcu 840
ggagccucgg uggccuagcu ucuugccccu ugggccuccc cccagccccu ccuccccuuc 900
cugcacccgu acccccgugg ucuuugaaua aagucugagu gggcggc 947
<![CDATA[ <210> 73]]>
<![CDATA[ <211> 771]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 73]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcggcagcgc caucggcggc uacauccccg aggccccuag agacggccag 720
gccuacgugc ggaaggacgg cgagugggug cugcugagca ccuuccuggg c 771
<![CDATA[ <210> 74]]>
<![CDATA[ <211> 257]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 74]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln
225 230 235 240
Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu Ser Thr Phe Leu
245 250 255
Gly
<![CDATA[ <210> 75]]>
<![CDATA[ <211> 920]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 75]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggca gcauccuggc caucuacagc accguggcca gcagccuggu gcugcuggug 780
agccugggcg ccaucagcuu cugauaauag gcuggagccu cgguggccua gcuucuugcc 840
ccuugggccu ccccccagcc ccuccucccc uuccugcacc cguacccccg uggucuuuga 900
auaaagucug agugggcggc 920
<![CDATA[ <210> 76]]>
<![CDATA[ <211> 744]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 76]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcagcauccu ggccaucuac agcaccgugg ccagcagccu ggugcugcug 720
gugagccugg gcgccaucag cuuc 744
<![CDATA[ <210> 77]]>
<![CDATA[ <211> 248]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 77]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu
225 230 235 240
Val Ser Leu Gly Ala Ile Ser Phe
245
<![CDATA[ <210> 78]]>
<![CDATA[ <211> 1025]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 78]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggcg gcagcgccau cggcggcuac auccccgagg ccccuagaga cggccaggcc 780
uacgugcgga aggacggcga gugggugcug cugagcaccu uccugggcgg aggcagcauc 840
cuggccaucu acagcaccgu ggccagcagc cuggugcugc uggugagccu gggcgccauc 900
agcuucugau aauaggcugg agccucggug gccuagcuuc uugccccuug ggccuccccc 960
cagccccuccc uccccuuccu gcacccguac ccccgugguc uuugaauaaa gucugagugg 1020
gcggc 1025
<![CDATA[ <210> 79]]>
<![CDATA[ <211> 849]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 79]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcggcagcgc caucggcggc uacauccccg aggccccuag agacggccag 720
gccuacgugc ggaaggacgg cgagugggug cugcugagca ccuuccuggg cggaggcagc 780
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 840
aucagcuuc 849
<![CDATA[ <210> 80]]>
<![CDATA[ <211> 283]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 80]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln
225 230 235 240
Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu Ser Thr Phe Leu
245 250 255
Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu
260 265 270
Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
275 280
<![CDATA[ <210> 81]]>
<![CDATA[ <211> 1028]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 81]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggca gcauccuggc caucuacagc accguggcca gcagccuggu gcugcuggug 780
agccugggcg ccaucagcuu cggcggaggc agcgccaucg gcggcuacau ccccgaggcc 840
ccuagagacg gccaggccua cgugcggaag gacggcgagu gggugcugcu gagcaccuuc 900
cugggcaagu gauaauaggc uggagccucg guggccuagc uucuugcccc uugggccucc 960
ccccagcccc uccuccccuu ccugcacccg uacccccgug gucuuugaau aaagucugag 1020
ugggcggc 1028
<![CDATA[ <210> 82]]>
<![CDATA[ <211> 852]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 82]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcagcauccu ggccaucuac agcaccgugg ccagcagccu ggugcugcug 720
gugagccugg gcgccaucag cuucggcgga ggcagcgcca ucggcggcua cauccccgag 780
gccccuagag acggccaggc cuacgugcgg aaggacggcg agugggugcu gcugagcacc 840
uuccugggca ag 852
<![CDATA[ <210> 83]]>
<![CDATA[ <211> 284]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 83]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu
225 230 235 240
Val Ser Leu Gly Ala Ile Ser Phe Gly Gly Gly Ser Ala Ile Gly Gly
245 250 255
Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln Ala Tyr Val Arg Lys Asp
260 265 270
Gly Glu Trp Val Leu Leu Ser Thr Phe Leu Gly Lys
275 280
<![CDATA[ <210> 84]]>
<![CDATA[ <211> 1142]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 84]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cgggugcagc ccaccgagag caucgugcgg uuccccaaca ucaccaaccu gugccccuuc 180
ggcgaggugu ucaacgccac ccgguucgcc agcguguacg ccuggaaccg gaagcggauc 240
agcaacugcg uggccgacua cagcgugcug uacaacagcg ccagcuucag caccuucaag 300
ugcuacggcg ugagccccac caagcugaac gaccugugcu ucaccaacgu guacgccgac 360
agcuucguga uccguggcga cgaggugcgg cagaucgcac ccggccagac aggcaagauc 420
gccgacuaca acuacaagcu gcccgacgac uucaccggcu gcgugaucgc cuggaacagc 480
aacaaccucg acagcaaggu gggcggcaac uacaacuacc uguaccggcu guuccggaag 540
agcaaccuga agcccuucga gcgggacauc agcaccgaga ucuaccaagc cggcuccacc 600
ccuugcaacg gcguggaggg cuucaacugc uacuucccuc ugcagagcua cggcuuccag 660
cccaccaacg gcgugggcua ccagcccuac cggguggugg ugcugagcuu cgagcugcug 720
cacgccccag ccaccgugug uggccccaag aagagcacca accuggugaa gaacaagugc 780
gugaacuuca acuucaacgg ccuuaccggc accggcgugc ugaccgagag caacaagaaa 840
uuccugcccu uucagcaguu cggccgggac aucgccgaca ccaccgacgc ugugcgggau 900
ccccagaccc uggagauccu ggacaucacc ccuugcagcu cuggcggagg cagcauccug 960
gccaucuaca gcaccguggc cagcagccug gugcugcugg ugagccuggg cgccaucagc 1020
uucugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 1080
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 1140
gc 1142
<![CDATA[ <210> 85]]>
<![CDATA[ <211> 966]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 85]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcgggugc agcccaccga gagcaucgug cgguucccca acaucaccaa ccugugcccc 120
uucggcgagg uguucaacgc cacccgguuc gccagcgugu acgccuggaa ccggaagcgg 180
aucagcaacu gcguggccga cuacagcgug cuguacaaca gcgccagcuu cagcaccuuc 240
aagugcuacg gcgugagccc caccaagcug aacgaccugu gcuucaccaa cguguacgcc 300
gacagcuucg ugauccgugg cgacgaggug cggcagaucg cacccggcca gacaggcaag 360
aucgccgacu acaacuacaa gcugcccgac gacuucaccg gcugcgugau cgccuggaac 420
agcaacaacc ucgacagcaa ggugggcggc aacuacaacu accuguaccg gcuguuccgg 480
aagagcaacc ugaagcccuu cgagcgggac aucagcaccg agaucuacca agccggcucc 540
accccuugca acggcgugga gggcuucaac ugcuacuucc cucugcagag cuacggcuuc 600
cagcccacca acggcguggg cuaccagccc uaccgggugg uggugcugag cuucgagcug 660
cugcacgccc cagccaccgu guguggcccc aagaagagca ccaaccuggu gaagaacaag 720
ugcgugaacu ucaacuucaa cggccuuacc ggcaccggcg ugcugaccga gagcaacaag 780
aaauuccugc ccuuucagca guucggccgg gacaucgccg acaccaccga cgcugugcgg 840
gauccccaga cccuggagau ccuggacauc accccuugca gcucuggcgg aggcagcauc 900
cuggccaucu acagcaccgu ggccagcagc cuggugcugc uggugagccu gggcgccauc 960
agcuuc 966
<![CDATA[ <210> 86]]>
<![CDATA[ <211> 322]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 86]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Arg Val Gln Pro Thr Glu Ser Ile Val Arg Phe
20 25 30
Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala Thr
35 40 45
Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn Cys
50 55 60
Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr Phe
65 70 75 80
Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe Thr
85 90 95
Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg Gln
100 105 110
Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys Leu
115 120 125
Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn Leu
130 135 140
Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg
145 150 155 160
Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile Tyr
165 170 175
Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys Tyr
180 185 190
Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly Tyr
195 200 205
Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala Pro
210 215 220
Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn Lys
225 230 235 240
Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu Thr
245 250 255
Glu Ser Asn Lys Lys Phe Leu Pro Phe Gln Gln Phe Gly Arg Asp Ile
260 265 270
Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile Leu
275 280 285
Asp Ile Thr Pro Cys Ser Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr
290 295 300
Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile
305 310 315 320
Ser Phe
<![CDATA[ <210> 87]]>
<![CDATA[ <211> 1142]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 87]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cgggugcagc ccaccgagag caucgugcgg uuccccaaca ucaccaaccu gugccccuuc 180
ggcgaggugu ucaacgccac ccgguucgcc agcguguacg ccuggaaccg gaagcggauc 240
agcaacugcg uggccgacua cagcgugcug uacaacagcg ccagcuucag caccuucaag 300
ugcuacggcg ugagccccac caagcugaac gaccugugcu ucaccaacgu guacgccgac 360
agcuucguga uccguggcga cgaggugcgg cagaucgcac ccggccagac aggcaagauc 420
gccgacuaca acuacaagcu gcccgacgac uucaccggcu gcgugaucgc cuggaacagc 480
aacaaccucg acagcaaggu gggcggcaac uacaacuacc uguaccggcu guuccggaag 540
agcaaccuga agcccuucga gcgggacauc agcaccgaga ucuaccaagc cggcuccacc 600
ccuugcaacg gcguggaggg cuucaacugc uacuucccuc ugcagagcua cggcuuccag 660
cccaccaacg gcgugggcua ccagcccuac cggguggugg ugcugagcuu cgagcugcug 720
cacgccccag ccaccgugug uggccccaag aagagcacca accuggugaa gaacaagugc 780
gugaacuuca acuucaacgg ccuuaccggc accggcgugc ugaccgagag caacaagaaa 840
uuccugcccu uuugccaguu cggccgggac aucgccgaca ccaccgacgc ugugcgggau 900
ccccagaccc uggagauccu ggacaucacc ccuugcagcu cuggcggagg cagcauccug 960
gccaucuaca gcaccguggc cagcagccug gugcugcugg ugagccuggg cgccaucagc 1020
uucugauaau aggcuggagc cucgguggcc uagcuucuug ccccuugggc cuccccccag 1080
ccccuccucc ccuuccugca cccguacccc cguggucuuu gaauaaaguc ugagugggcg 1140
gc 1142
<![CDATA[ <210> 88]]>
<![CDATA[ <211> 966]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 88]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcgggugc agcccaccga gagcaucgug cgguucccca acaucaccaa ccugugcccc 120
uucggcgagg uguucaacgc cacccgguuc gccagcgugu acgccuggaa ccggaagcgg 180
aucagcaacu gcguggccga cuacagcgug cuguacaaca gcgccagcuu cagcaccuuc 240
aagugcuacg gcgugagccc caccaagcug aacgaccugu gcuucaccaa cguguacgcc 300
gacagcuucg ugauccgugg cgacgaggug cggcagaucg cacccggcca gacaggcaag 360
aucgccgacu acaacuacaa gcugcccgac gacuucaccg gcugcgugau cgccuggaac 420
agcaacaacc ucgacagcaa ggugggcggc aacuacaacu accuguaccg gcuguuccgg 480
aagagcaacc ugaagcccuu cgagcgggac aucagcaccg agaucuacca agccggcucc 540
accccuugca acggcgugga gggcuucaac ugcuacuucc cucugcagag cuacggcuuc 600
cagcccacca acggcguggg cuaccagccc uaccgggugg uggugcugag cuucgagcug 660
cugcacgccc cagccaccgu guguggcccc aagaagagca ccaaccuggu gaagaacaag 720
ugcgugaacu ucaacuucaa cggccuuacc ggcaccggcg ugcugaccga gagcaacaag 780
aaauuccugc ccuuuugcca guucggccgg gacaucgccg acaccaccga cgcugugcgg 840
gauccccaga cccuggagau ccuggacauc accccuugca gcucuggcgg aggcagcauc 900
cuggccaucu acagcaccgu ggccagcagc cuggugcugc uggugagccu gggcgccauc 960
agcuuc 966
<![CDATA[ <210> 89]]>
<![CDATA[ <211> 322]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 89]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Arg Val Gln Pro Thr Glu Ser Ile Val Arg Phe
20 25 30
Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe Asn Ala Thr
35 40 45
Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile Ser Asn Cys
50 55 60
Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe Ser Thr Phe
65 70 75 80
Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu Cys Phe Thr
85 90 95
Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu Val Arg Gln
100 105 110
Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn Tyr Lys Leu
115 120 125
Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser Asn Asn Leu
130 135 140
Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg
145 150 155 160
Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr Glu Ile Tyr
165 170 175
Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe Asn Cys Tyr
180 185 190
Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly Val Gly Tyr
195 200 205
Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu His Ala Pro
210 215 220
Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn Leu Val Lys Asn Lys
225 230 235 240
Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly Thr Gly Val Leu Thr
245 250 255
Glu Ser Asn Lys Lys Phe Leu Pro Phe Cys Gln Phe Gly Arg Asp Ile
260 265 270
Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln Thr Leu Glu Ile Leu
275 280 285
Asp Ile Thr Pro Cys Ser Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr
290 295 300
Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile
305 310 315 320
Ser Phe
<![CDATA[ <210> 90]]>
<![CDATA[ <211> 1748]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 90]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 1620
aucagcuucu gauaauaggc uggagccucg guggccuagc uucuugcccc uugggccucc 1680
ccccagcccc uccuccccuu ccugcacccg uacccccgug gucuuugaau aaagucugag 1740
ugggcggc 1748
<![CDATA[ <210> 91]]>
<![CDATA[ <211> 1572]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 91]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag caccguggcc agcagccugg ugcugcuggu gagccugggc 1560
gccaucagcu uc 1572
<![CDATA[ <210> 92]]>
<![CDATA[ <211> 524]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 92]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser
500 505 510
Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
515 520
<![CDATA[ <210> 93]]>
<![CDATA[ <211> 1925]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 93]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 1620
aucagcuuca agaagaagaa gcggccacgg aacuccuaca agugcggcac caacaccaug 1680
gagcgggagg agagcgagca gaccaagaag cgggagaaga uccacauucc ugaacggucc 1740
gacgaagccc agcggguguu caagagcagc aagaccagca gcugcgacaa gagcgacacc 1800
ugcuucugau aauaggcugg agccucggug gccuagcuuc uugccccuug ggccuccccc 1860
cagccccuccc uccccuuccu gcacccguac ccccgugguc uuugaauaaa gucugagugg 1920
gcggc 1925
<![CDATA[ <210> 94]]>
<![CDATA[ <211> 1749]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 94]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag caccguggcc agcagccugg ugcugcuggu gagccugggc 1560
gccaucagcu ucaagaagaa gaagcggcca cggaacuccu acaagugcgg caccaacacc 1620
auggagcggg aggagagcga gcagaccaag aagcgggaga agauccacau uccugaacgg 1680
uccgacgaag cccagcgggu guucaagagc agcaagacca gcagcugcga caagagcgac 1740
accugcuuc 1749
<![CDATA[ <210> 95]]>
<![CDATA[ <211> 583]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 95]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser
500 505 510
Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe Lys Lys Lys Lys
515 520 525
Arg Pro Arg Asn Ser Tyr Lys Cys Gly Thr Asn Thr Met Glu Arg Glu
530 535 540
Glu Ser Glu Gln Thr Lys Lys Arg Glu Lys Ile His Ile Pro Glu Arg
545 550 555 560
Ser Asp Glu Ala Gln Arg Val Phe Lys Ser Ser Lys Thr Ser Ser Cys
565 570 575
Asp Lys Ser Asp Thr Cys Phe
580
<![CDATA[ <210> 96]]>
<![CDATA[ <211> 1805]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 96]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 1620
aucagcuuca agcggcagua caaggacaug augagcgagg gaggaccacc uggcgcugag 1680
ccacagugau aauaggcugg agccucggug gccuagcuuc uugccccuug ggccuccccc 1740
cagccccuccc uccccuuccu gcacccguac ccccgugguc uuugaauaaa gucugagugg 1800
gcggc 1805
<![CDATA[ <210> 97]]>
<![CDATA[ <211> 1629]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 97]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag caccguggcc agcagccugg ugcugcuggu gagccugggc 1560
gccaucagcu ucaagcggca guacaaggac augaugagcg agggaggacc accuggcgcu 1620
gagccacag 1629
<![CDATA[ <210> 98]]>
<![CDATA[ <211> 543]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 98]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser
500 505 510
Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe Lys Arg Gln Tyr
515 520 525
Lys Asp Met Met Ser Glu Gly Gly Pro Gly Ala Glu Pro Gln
530 535 540
<![CDATA[ <210> 99]]>
<![CDATA[ <211> 1853]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 99]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcggc 1560
agcgccaucg gcggcuacau ccccgaggcc ccuagagacg gccaggccua cgugcggaag 1620
gacggcgagu gggugcugcu gagcaccuuc cugggcggag gcagcauccu ggccaucuac 1680
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuucugauaa 1740
uaggcuggag ccucgguggc cuagcuucuu gccccuuggg ccucccccca gccccucccuc 1800
cccuuccugc acccguaccc ccguggucuu ugaauaaagu cugagugggc ggc 1853
<![CDATA[ <210> 100]]>
<![CDATA[ <211> 1677]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 100]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
ggcagcgcca ucggcggcua cauccccgag gccccuagag acggccaggc cuacgugcgg 1560
aaggacggcg agugggugcu gcugagcacc uuccugggcg gaggcagcau ccuggccauc 1620
uacagcaccg uggccagcag ccuggugcug cuggugagcc ugggcgccau cagcuuc 1677
<![CDATA[ <210> 101]]>
<![CDATA[ <211> 559]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 101]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro
500 505 510
Arg Asp Gly Gln Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu
515 520 525
Ser Thr Phe Leu Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val
530 535 540
Ala Ser Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
545 550 555
<![CDATA[ <210> 102]]>
<![CDATA[ <211> 1856]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 102]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagcac cguggccagc agccuggugc ugcuggugag ccugggcgcc 1620
aucagcuucg gcggaggcag cgccaucggc ggcuacaucc ccgaggcccc uagagacggc 1680
caggccuacg ugcggaagga cggcgagugg gugcugcuga gcaccuuccu gggcaaguga 1740
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccuccccc ccagccccuc 1800
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 1856
<![CDATA[ <210> 103]]>
<![CDATA[ <211> 1680]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 103]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag caccguggcc agcagccugg ugcugcuggu gagccugggc 1560
gccaucagcu ucggcggagg cagcgccauc ggcggcuaca uccccgaggc cccuagagac 1620
ggccaggccu acgugcggaa ggacggcgag ugggugcugc ugagcaccuu ccugggcaag 1680
<![CDATA[ <210> 104]]>
<![CDATA[ <211> 560]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 104]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser
500 505 510
Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe Gly Gly Gly Ser
515 520 525
Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro Arg Asp Gly Gln Ala Tyr
530 535 540
Val Arg Lys Asp Gly Glu Trp Val Leu Leu Ser Thr Phe Leu Gly Lys
545 550 555 560
<![CDATA[ <210> 105]]>
<![CDATA[ <211> 1826]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 105]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
auccuggcca ucuacagccu gggcuucauc gccggccuga ucgccaucgu gauggugacc 1620
aucaugcugu gcugcaugac cagcugcugc agcugccuga agggcuguug cagcugcggc 1680
agcugcugca aguucgacga ggacgacuga uaauaggcug gagccucggu ggccuagcuu 1740
cuugccccuu gggccuccccc ccagccccuc cuccccuucc ugcacccgua cccccguggu 1800
cuuugaauaa agucugagug ggcggc 1826
<![CDATA[ <210> 106]]>
<![CDATA[ <211> 1650]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 106]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcauccugg ccaucuacag ccugggcuuc aucgccggcc ugaucgccau cgugauggug 1560
accaucaugc ugugcugcau gaccagcugc ugcagcugcc ugaagggcug uugcagcugc 1620
ggcagcugcu gcaaguucga cgaggacgac 1650
<![CDATA[ <210> 107]]>
<![CDATA[ <211> 550]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 107]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Leu Gly Phe Ile Ala
500 505 510
Gly Leu Ile Ala Ile Val Met Val Thr Ile Met Leu Cys Cys Met Thr
515 520 525
Ser Cys Cys Ser Cys Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys
530 535 540
Lys Phe Asp Glu Asp Asp
545 550
<![CDATA[ <210> 108]]>
<![CDATA[ <211> 1826]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 108]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcagc 1560
agcagcaucg ccagcuucuu cuucaucauc gggcugauca ucggccucuu ccuggugcug 1620
cgggugggca uccaccugug caucaagcug aagcacacca agaagagaca gaucuacacc 1680
gacaucgaga ugaaccggcu gggcaaguga uaauaggcug gagccucggu ggccuagcuu 1740
cuugccccuu gggccuccccc ccagccccuc cuccccuucc ugcacccgua cccccguggu 1800
cuuugaauaa agucugagug ggcggc 1826
<![CDATA[ <210> 109]]>
<![CDATA[ <211> 1650]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 109]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
agcagcagca ucgccagcuu cuucuucauc aucgggcuga ucaucggccu cuuccuggug 1560
cugcgggugg gcauccaccu gugcaucaag cugaagcaca ccaagaagag acagaucuac 1620
accgacaucg agaugaaccg gcugggcaag 1650
<![CDATA[ <210> 110]]>
<![CDATA[ <211> 550]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 110]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Ser Ser Ser Ile Ala Ser Phe Phe Phe Ile Ile Gly
500 505 510
Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile His Leu Cys
515 520 525
Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr Asp Ile Glu
530 535 540
Met Asn Arg Leu Gly Lys
545 550
<![CDATA[ <210> 111]]>
<![CDATA[ <211> 1775]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 111]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggacc caacaucacc 960
aaccugugcc ccuucggcga gguguucaac gccacccggu ucgccagcgu guacgccugg 1020
aaccggaagc ggaucagcaa cugcguggcc gacuacagcg ugcuguacaa cagcgccagc 1080
uucagcaccu ucaagugcua cggcgugagc cccaccaagc ugaacgaccu gugcuucacc 1140
aacguguacg ccgacagcuu cgugauccgu ggcgacgagg ugcggcagau cgcacccggc 1200
cagacaggca agaucgccga cuacaacuac aagcugcccg acgacuucac cggcugcgug 1260
aucgccugga acagcaacaa ccucgacagc aaggugggcg gcaacuacaa cuaccuguac 1320
cggcuguucc ggaagagcaa ccugaagccc uucgagcggg acaucagcac cgagaucuac 1380
caagccggcu ccaccccuug caacggcgug gagggcuuca acugcuacuu cccucugcag 1440
agcuacggcu uccagcccac caacggcgug ggcuaccagc ccuaccgggu gguggugcug 1500
agcuucgagc ugcugcacgc cccagccacc guguguggcc ccaagucugg cggaggcggc 1560
agcgccaucg gcggcuacau ccccgaggcc ccuagagacg gccaggccua cgugcggaag 1620
gacggcgagu gggugcugcu gagcaccuuc cugggcugau aauaggcugg agccucggug 1680
gccuagcuuc uugccccuug ggccuccccc cagccccuccc uccccuuccu gcacccguac 1740
ccccgugguc uuugaauaaa gucugagugg gcggc 1775
<![CDATA[ <210> 112]]>
<![CDATA[ <211> 1599]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 112]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acccaacauc 900
accaaccugu gccccuucgg cgagguguuc aacgccaccc gguucgccag cguguacgcc 960
uggaaccgga agcggaucag caacugcgug gccgacuaca gcgugcugua caacagcgcc 1020
agcuucagca ccuucaagug cuacggcgug agccccacca agcugaacga ccugugcuuc 1080
accaacgugu acgccgacag cuucgugauc cguggcgacg aggugcggca gaucgcaccc 1140
ggccagacag gcaagaucgc cgacuacaac uacaagcugc ccgacgacuu caccggcugc 1200
gugaucgccu ggaacagcaa caaccucgac agcaaggugg gcggcaacua caacuaccug 1260
uaccggcugu uccggaagag caaccugaag cccuucgagc gggacaucag caccgagauc 1320
uaccaagccg gcuccacccc uugcaacggc guggagggcu ucaacugcua cuucccucug 1380
cagagcuacg gcuuccagcc caccaacggc gugggcuacc agcccuaccg ggugguggug 1440
cugagcuucg agcugcugca cgccccagcc accgugugug gccccaaguc uggcggaggc 1500
ggcagcgcca ucggcggcua cauccccgag gccccuagag acggccaggc cuacgugcgg 1560
aaggacggcg agugggugcu gcugagcacc uuccugggc 1599
<![CDATA[ <210> 113]]>
<![CDATA[ <211> 533]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 113]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu Cys
290 295 300
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
305 310 315 320
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
325 330 335
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
340 345 350
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
355 360 365
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
370 375 380
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
385 390 395 400
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
405 410 415
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
420 425 430
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
435 440 445
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
450 455 460
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
465 470 475 480
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
485 490 495
Ser Gly Gly Gly Gly Ser Ala Ile Gly Gly Tyr Ile Pro Glu Ala Pro
500 505 510
Arg Asp Gly Gln Ala Tyr Val Arg Lys Asp Gly Glu Trp Val Leu Leu
515 520 525
Ser Thr Phe Leu Gly
530
<![CDATA[ <210> 114]]>
<![CDATA[ <211> 1973]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 114]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcggaucgg gaggcggaca gcgggugcag 960
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1020
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1080
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1140
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1200
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1260
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1320
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1380
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1440
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1500
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1560
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1620
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1680
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1740
cuggagaucc uggacaucac cccuugcagc ucuggcggag gcagcauccu ggccaucuac 1800
agcaccgugg ccagcagccu ggugcugcug gugagccugg gcgccaucag cuucugauaa 1860
uaggcuggag ccucgguggc cuagcuucuu gccccuuggg ccucccccca gccccuccuc 1920
cccuuccugc acccguaccc ccguggucuu ugaauaaagu cugagugggc ggc 1973
<![CDATA[ <210> 115]]>
<![CDATA[ <211> 1797]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 115]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcggau cgggaggcgg acagcgggug 900
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 960
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1020
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1080
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1140
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1200
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1260
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1320
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1380
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1440
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1500
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1560
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1620
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1680
acccuggaga uccuggacau caccccuugc agcucuggcg gaggcagcau ccuggccauc 1740
uacagcaccg uggccagcag ccuggugcug cuggugagcc ugggcgccau cagcuuc 1797
<![CDATA[ <210> 116]]>
<![CDATA[ <211> 599]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 116]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Gly Ser Gly Gly Gly Gln Arg Val Gln Pro Thr Glu
290 295 300
Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
305 310 315 320
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
325 330 335
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
340 345 350
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
355 360 365
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
370 375 380
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
385 390 395 400
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
405 410 415
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
420 425 430
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
435 440 445
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
450 455 460
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
465 470 475 480
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
485 490 495
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Lys Ser Thr Asn
500 505 510
Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn Gly Leu Thr Gly
515 520 525
Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu Pro Phe Gln Gln
530 535 540
Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val Arg Asp Pro Gln
545 550 555 560
Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Ser Gly Gly Gly Ser
565 570 575
Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val
580 585 590
Ser Leu Gly Ala Ile Ser Phe
595
<![CDATA[ <210> 117]]>
<![CDATA[ <211> 1799]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 117]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgg aggcggaucg ggaggcggac ccaacaucac caaccugugc 1020
cccuucggcg agguguucaa cgccacccgg uucgccagcg uguacgccug gaaccggaag 1080
cggaucagca acugcguggc cgacuacagc gugcuguaca acagcgccag cuucagcacc 1140
uucaagugcu acggcgugag ccccaccaag cugaacgacc ugugcuucac caacguguac 1200
gccgacagcu ucgugauccg uggcgacgag gugcggcaga ucgcacccgg ccagacaggc 1260
aagaucgccg acuacaacua caagcugccc gacgacuuca ccggcugcgu gaucgccugg 1320
aacagcaaca accucgacag caaggugggc ggcaacuaca acuaccugua ccggcuguuc 1380
cggaagagca accugaagcc cuucgagcgg gacaucagca ccgagaucua ccaagccggc 1440
uccaccccuu gcaacggcgu ggagggcuuc aacugcuacu ucccucugca gagcuacggc 1500
uuccagccca ccaacggcgu gggcuaccag cccuaccggg ugguggugcu gagcuucgag 1560
cugcugcacg ccccagccac cguguguggc cccaagucug gcggaggcag cauccuggcc 1620
aucuacagca ccguggccag cagccuggug cugcugguga gccugggcgc caucagcuuc 1680
ugauaauagg cuggagccuc gguggccuag cuucuugccc cuugggccuc cccccagccc 1740
cuccuccccu uccugcaccc guacccccgu ggucuuugaa uaaagucuga gugggcggc 1799
<![CDATA[ <210> 118]]>
<![CDATA[ <211> 1623]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 118]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cggaggcgga ucgggaggcg gacccaacau caccaaccug 960
ugccccuucg gcgagguguu caacgccacc cgguucgcca gcguguacgc cuggaaccgg 1020
aagcggauca gcaacugcgu ggccgacuac agcgugcugu acaacagcgc cagcuucagc 1080
accuucaagu gcuacggcgu gagccccacc aagcugaacg accugugcuu caccaacgug 1140
uacgccgaca gcuucgugau ccguggcgac gaggugcggc agaucgcacc cggccagaca 1200
ggcaagaucg ccgacuacaa cuacaagcug cccgacgacu ucaccggcug cgugaucgcc 1260
uggaacagca acaaccucga cagcaaggug ggcggcaacu acaacuaccu guaccggcug 1320
uuccggaaga gcaaccugaa gcccuucgag cgggacauca gcaccgagau cuaccaagcc 1380
ggcuccaccc cuugcaacgg cguggagggc uucaacugcu acuucccucu gcagagcuac 1440
ggcuuccagc ccaccaacgg cgugggcuac cagcccuacc gggugguggu gcugagcuuc 1500
gagcugcugc acgccccagc caccgugugu ggccccaagu cuggcggagg cagcauccug 1560
gccaucuaca gcaccguggc cagcagccug gugcugcugg ugagccuggg cgccaucagc 1620
uuc 1623
<![CDATA[ <210> 119]]>
<![CDATA[ <211> 541]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 119]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Gly Gly Gly Ser Gly Gly Gly Pro Asn Ile Thr Asn Leu
305 310 315 320
Cys Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr
325 330 335
Ala Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val
340 345 350
Leu Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser
355 360 365
Pro Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser
370 375 380
Phe Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr
385 390 395 400
Gly Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly
405 410 415
Cys Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly
420 425 430
Asn Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro
435 440 445
Phe Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro
450 455 460
Cys Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr
465 470 475 480
Gly Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val
485 490 495
Val Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro
500 505 510
Lys Ser Gly Gly Gly Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser
515 520 525
Ser Leu Val Leu Leu Val Ser Leu Gly Ala Ile Ser Phe
530 535 540
<![CDATA[ <210> 120]]>
<![CDATA[ <211> 2024]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 120]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgg aggcggaucg ggaggcggac agcgggugca gcccaccgag 1020
agcaucgugc gguuccccaa caucaccaac cugugccccu ucggcgaggu guucaacgcc 1080
acccgguucg ccagcgugua cgccuggaac cggaagcgga ucagcaacug cguggccgac 1140
uacagcgugc uguacaacag cgccagcuuc agcaccuuca agugcuacgg cgugagcccc 1200
accaagcuga acgaccugug cuucaccaac guguacgccg acagcuucgu gauccguggc 1260
gacgaggugc ggcagaucgc acccggccag acaggcaaga ucgccgacua caacuacaag 1320
cugcccgacg acuucaccgg cugcgugauc gccuggaaca gcaacaaccu cgacagcaag 1380
gugggcggca acuacaacua ccuguaccgg cuguuccgga agagcaaccu gaagcccuuc 1440
gagcgggaca ucagcaccga gaucuaccaa gccggcucca ccccuugcaa cggcguggag 1500
ggcuucaacu gcuacuuccc ucugcagagc uacggcuucc agcccaccaa cggcgugggc 1560
uaccagcccu accggguggu ggugcugagc uucgagcugc ugcacgcccc agccaccgug 1620
uguggcccca agaagagcac caaccuggug aagaacaagu gcgugaacuu caacuucaac 1680
ggccuuaccg gcaccggcgu gcugaccgag agcaacaaga aauuccugcc cuuucagcag 1740
uucggccggg acaucgccga caccaccgac gcugugcggg auccccagac ccuggagauc 1800
cuggacauca ccccuugcag cucuggcgga ggcagcaucc uggccaucua cagcaccgug 1860
gccagcagcc uggugcugcu ggugagccug ggcgccauca gcuucugaua auaggcugga 1920
gccucggugg ccuagcuucu ugccccuugg gccucccccc agccccuccu ccccuuccug 1980
cacccguacc cccguggucu uugaauaaag ucugaguggg cggc 2024
<![CDATA[ <210> 121]]>
<![CDATA[ <211> 1848]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 121]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cggaggcgga ucgggaggcg gacagcgggu gcagcccacc 960
gagagcaucg ugcgguuccc caacaucacc aaccugugcc ccuucggcga gguguucaac 1020
gccacccggu ucgccagcgu guacgccugg aaccggaagc ggaucagcaa cugcguggcc 1080
gacuacagcg ugcuguacaa cagcgccagc uucagcaccu ucaagugcua cggcgugagc 1140
cccaccaagc ugaacgaccu gugcuucacc aacguguacg ccgacagcuu cgugauccgu 1200
ggcgacgagg ugcggcagau cgcacccggc cagacaggca agaucgccga cuacaacuac 1260
aagcugcccg acgacuucac cggcugcgug aucgccugga acagcaacaa ccucgacagc 1320
aaggugggcg gcaacuacaa cuaccuguac cggcuguucc ggaagagcaa ccugaagccc 1380
uucgagcggg acaucagcac cgagaucuac caagccggcu ccaccccuug caacggcgug 1440
gagggcuuca acugcuacuu cccucugcag agcuacggcu uccagcccac caacggcgug 1500
ggcuaccagc ccuaccgggu gguggugcug agcuucgagc ugcugcacgc cccagccacc 1560
guguguggcc ccaagaagag caccaaccug gugaagaaca agugcgugaa cuucaacuuc 1620
aacggccuua ccggcaccgg cgugcugacc gagagcaaca agaaauuccu gcccuuucag 1680
caguucggcc gggacaucgc cgacaccacc gacgcugugc gggaucccca gacccuggag 1740
auccuggaca ucaccccuug cagcucuggc ggaggcagca uccuggccau cuacagcacc 1800
guggccagca gccuggugcu gcuggugagc cugggcgcca ucagcuuc 1848
<![CDATA[ <210> 122]]>
<![CDATA[ <211> 616]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 122]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Gly Gly Gly Ser Gly Gly Gly Gln Arg Val Gln Pro Thr
305 310 315 320
Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly
325 330 335
Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg
340 345 350
Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser
355 360 365
Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu
370 375 380
Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg
385 390 395 400
Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala
405 410 415
Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala
420 425 430
Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr
435 440 445
Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp
450 455 460
Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val
465 470 475 480
Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro
485 490 495
Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe
500 505 510
Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Lys Ser Thr
515 520 525
Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn Gly Leu Thr
530 535 540
Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu Pro Phe Gln
545 550 555 560
Gln Phe Gly Arg Asp Ile Ala Asp Thr Asp Ala Val Arg Asp Pro
565 570 575
Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Ser Gly Gly Gly
580 585 590
Ser Ile Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu
595 600 605
Val Ser Leu Gly Ala Ile Ser Phe
610 615
<![CDATA[ <210> 123]]>
<![CDATA[ <211> 3995]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 123]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucaccc 2100
cggagggcaa ggagcguggc cagccagagc aucaucgccu acaccaugag ccugggcgcc 2160
gagaacagcg uggccuacag caacaacagc aucgccaucc ccaccaacuu caccaucagc 2220
gugaccaccg agauucugcc cgugagcaug accaagacca gcguggacug caccauguac 2280
aucugcggcg acagcaccga gugcagcaac cugcugcugc aguacggcag cuucugcacc 2340
cagcugaacc gggcccugac cggcaucgcc guggagcagg acaagaacac ccaggaggug 2400
uucgcccagg ugaagcagau cuacaagacc ccucccauca aggacuucgg cggcuucaac 2460
uucagccaga uccugcccga ccccagcaag cccagcaagc ggagcuucau cgaggaccug 2520
cuguucaaca aggugacccu agccgacgcc ggcuucauca agcaguacgg cgacugccuc 2580
ggcgacauag ccgcccggga ccugaucugc gcccagaagu ucaacggccu gaccgugcug 2640
ccuccccugc ugaccgacga gaugaucgcc caguacacca gcgcccuguu agccggaacc 2700
aucaccagcg gcuggacuuu cggcgcugga gccgcucugc agauccccuu cgccaugcag 2760
auggccuacc gguucaacgg caucggcgug acccagaacg ugcuguacga gaaccagaag 2820
cugaucgcca accaguucaa cagcgccauc ggcaagaucc aggacagccu gagcagcacc 2880
gcuagcgccc ugggcaagcu gcaggacgug gugaaccaga acgcccaggc ccugaacacc 2940
cuggugaagc agcugagcag caacuucggc gccaucagca gcgugcugaa cgacauccug 3000
agccggcugg acaaggugga ggccgaggug cagaucgacc ggcugaucac uggccggcug 3060
cagagccugc agaccuacgu gacccagcag cugauccggg ccgccgagau ucgggccagc 3120
gccaaccugg ccgccaccaa gaugagcgag ugcgugcugg gccagagcaa gcggguggac 3180
uucugcggca agggcuacca ccugaugagc uuuccccaga gcgcacccca cggaguggug 3240
uuccugcacg ugaccuacgu gcccgcccag gagaagaacu ucaccaccgc cccagccauc 3300
ugccacgacg gcaaggccca cuuuccccgg gagggcgugu ucgugagcaa cggcacccac 3360
ugguucguga cccagcggaa cuucuacgag ccccagauca ucaccaccga caacaccuuc 3420
gugagcggca acugcgacgu ggugaucggc aucgugaaca acaccgugua cgauccccug 3480
cagcccgagc uggacagcuu caaggaggag cuggacaagu acuucaagaa ucacaccagc 3540
cccgacgugg accugggcga caucagcggc aucaacgcca gcguggugaa cauccagaag 3600
gagaucgauc ggcugaacga gguggccaag aaccugaacg agagccugau cgaccugcag 3660
gagcugggca aguacgagca guacaucaag uggcccuggu acaucuggcu gggcuucauc 3720
gccggccuga ucgccaucgu gauggugacc aucaugcugu gcugcaugac cagcugcugc 3780
agcugccuga agggcuguug cagcugcggc agcugcugca aguucgacga ggacgacagc 3840
gagcccgugc ugaagggcgu gaagcugcac uacaccugau aauaggcugg agccucggug 3900
gccuagcuuc uugccccuug ggccuccccc cagccccuccc uccccuuccu gcacccguac 3960
ccccgugguc uuugaauaaa gucugagugg gcggc 3995
<![CDATA[ <210> 124]]>
<![CDATA[ <211> 3819]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 124]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
ccccggaggg caaggagcgu ggccagccag agcaucaucg ccuacaccau gagccugggc 2100
gccgagaaca gcguggccua cagcaacaac agcaucgcca uccccaccaa cuucaccauc 2160
agcgugacca ccgagauucu gcccgugagc augaccaaga ccagcgugga cugcaccaug 2220
uacaucugcg gcgacagcac cgagugcagc aaccugcugc ugcaguacgg cagcuucugc 2280
acccagcuga accgggcccu gaccggcauc gccguggagc aggacaagaa cacccaggag 2340
guguucgccc aggugaagca gaucuacaag accccuccca ucaaggacuu cggcggcuuc 2400
aacuucagcc agauccugcc cgaccccagc aagcccagca agcggagcuu caucgaggac 2460
cugcuguuca acaaggugac ccuagccgac gccggcuuca ucaagcagua cggcgacugc 2520
cucggcgaca uagccgcccg ggaccugauc ugcgcccaga aguucaacgg ccugaccgug 2580
cugccuccccc ugcugaccga cgagaugauc gcccaguaca ccagcgcccu guuagccgga 2640
accaucacca gcggcuggac uuucggcgcu ggagccgcuc ugcagauccc cuucgccaug 2700
cagauggccu accgguucaa cggcaucggc gugacccaga acgugcugua cgagaaccag 2760
aagcugaucg ccaaccaguu caacagcgcc aucggcaaga uccaggacag ccugagcagc 2820
accgcuagcg cccugggcaa gcugcaggac guggugaacc agaacgccca ggcccugaac 2880
acccugguga agcagcugag cagcaacuuc ggcgccauca gcagcgugcu gaacgacauc 2940
cugagccggc uggacaaggu ggaggccgag gugcagaucg accggcugau cacuggccgg 3000
cugcagagcc ugcagaccua cgugacccag cagcugaucc gggccgccga gauucgggcc 3060
agcgccaacc uggccgccac caagaugagc gagugcgugc ugggccagag caagcgggug 3120
gacuucugcg gcaagggcua ccaccugaug agcuuucccc agagcgcacc ccacggagug 3180
guguuccugc acgugaccua cgugcccgcc caggagaaga acuucaccac cgccccagcc 3240
aucugccacg acggcaaggc ccacuuuccc cgggagggcg uguucgugag caacggcacc 3300
cacugguucg ugacccagcg gaacuucuac gagccccaga ucaucaccac cgacaacacc 3360
uucgugagcg gcaacugcga cguggugauc ggcaucguga acaacaccgu guacgauccc 3420
cugcagcccg agcuggacag cuucaaggag gagcuggaca aguacuucaa gaaucacacc 3480
agccccgacg uggaccuggg cgacaucagc ggcaucaacg ccagcguggu gaacauccag 3540
aaggagaucg aucggcugaa cgagguggcc aagaaccuga acgagagccu gaucgaccug 3600
caggagcugg gcaaguacga gcaguacauc aaguggcccu gguacaucug gcugggcuuc 3660
aucgccggcc ugaucgccau cgugauggug accaucaugc ugugcugcau gaccagcugc 3720
ugcagcugcc ugaagggcug uugcagcugc ggcagcugcu gcaaguucga cgaggacgac 3780
agcgagcccg ugcugaaggg cgugaagcug cacuacacc 3819
<![CDATA[ <210> 125]]>
<![CDATA[ <211> 1273]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 125]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg Ala Arg Ser Val Ala
675 680 685
Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly Ala Glu Asn Ser
690 695 700
Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr Asn Phe Thr Ile
705 710 715 720
Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr Lys Thr Ser Val
725 730 735
Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu Cys Ser Asn Leu
740 745 750
Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn Arg Ala Leu Thr
755 760 765
Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu Val Phe Ala Gln
770 775 780
Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp Phe Gly Gly Phe
785 790 795 800
Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro Ser Lys Arg Ser
805 810 815
Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu Ala Asp Ala Gly
820 825 830
Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile Ala Ala Arg Asp
835 840 845
Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val Leu Pro Pro Leu
850 855 860
Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala Leu Leu Ala Gly
865 870 875 880
Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala Ala Leu Gln Ile
885 890 895
Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly Ile Gly Val Thr
900 905 910
Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala Asn Gln Phe Asn
915 920 925
Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser Ser Thr Ala Ser Ala
930 935 940
Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn Ala Gln Ala Leu Asn
945 950 955 960
Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly Ala Ile Ser Ser Val
965 970 975
Leu Asn Asp Ile Leu Ser Arg Leu Asp Lys Val Glu Ala Glu Val Gln
980 985 990
Ile Asp Arg Leu Ile Thr Gly Arg Leu Gln Ser Leu Gln Thr Tyr Val
995 1000 1005
Thr Gln Gln Leu Ile Arg Ala Ala Glu Ile Arg Ala Ser Ala Asn
1010 1015 1020
Leu Ala Ala Thr Lys Met Ser Glu Cys Val Leu Gly Gln Ser Lys
1025 1030 1035
Arg Val Asp Phe Cys Gly Lys Gly Tyr His Leu Met Ser Phe Pro
1040 1045 1050
Gln Ser Ala Pro His Gly Val Val Phe Leu His Val Thr Tyr Val
1055 1060 1065
Pro Ala Gln Glu Lys Asn Phe Thr Thr Ala Pro Ala Ile Cys His
1070 1075 1080
Asp Gly Lys Ala His Phe Pro Arg Glu Gly Val Phe Val Ser Asn
1085 1090 1095
Gly Thr His Trp Phe Val Thr Gln Arg Asn Phe Tyr Glu Pro Gln
1100 1105 1110
Ile Ile Thr Thr Asp Asn Thr Phe Val Ser Gly Asn Cys Asp Val
1115 1120 1125
Val Ile Gly Ile Val Asn Asn Thr Val Tyr Asp Pro Leu Gln Pro
1130 1135 1140
Glu Leu Asp Ser Phe Lys Glu Glu Leu Asp Lys Tyr Phe Lys Asn
1145 1150 1155
His Thr Ser Pro Asp Val Asp Leu Gly Asp Ile Ser Gly Ile Asn
1160 1165 1170
Ala Ser Val Val Asn Ile Gln Lys Glu Ile Asp Arg Leu Asn Glu
1175 1180 1185
Val Ala Lys Asn Leu Asn Glu Ser Leu Ile Asp Leu Gln Glu Leu
1190 1195 1200
Gly Lys Tyr Glu Gln Tyr Ile Lys Trp Pro Trp Tyr Ile Trp Leu
1205 1210 1215
Gly Phe Ile Ala Gly Leu Ile Ala Ile Val Met Val Thr Ile Met
1220 1225 1230
Leu Cys Cys Met Thr Ser Cys Cys Ser Cys Leu Lys Gly Cys Cys
1235 1240 1245
Ser Cys Gly Ser Cys Cys Lys Phe Asp Glu Asp Asp Ser Glu Pro
1250 1255 1260
Val Leu Lys Gly Val Lys Leu His Tyr Thr
1265 1270
<![CDATA[ <210> 126]]>
<![CDATA[ <211> 8]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 126]]>
Lys Pro Ser Lys Arg Ser Phe Ile
1 5
<![CDATA[ <210> 127]]>
<![CDATA[ <211> 13]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 127]]>
Thr Gln Thr Asn Ser Pro Arg Arg Ala Arg Ser Val Ala
1 5 10
<![CDATA[ <210> 128]]>
<![CDATA[ <211> 9]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 128]]>
ccrccaugg 9
<![CDATA[ <210> 129]]>
<![CDATA[ <211> 11]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 129]]>
gggauccuac c 11
<![CDATA[ <210> 130]]>
<![CDATA[ <211> 9]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 130]]>
uuauuuaww 9
<![CDATA[ <210> 131]]>
<![CDATA[ <211> 47]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 131]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag agccacc 47
<![CDATA[ <210> 132]]>
<![CDATA[ <211> 119]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 132]]>
ugauaauagg cuggagccuc gguggccaug cuucuugccc cuugggccuc cccccagccc 60
cuccuccccu uccugcaccc guacccccgu ggucuuugaa uaaagucuga gugggcggc 119
<![CDATA[ <210> 133]]>
<![CDATA[ <211> 15]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 133]]>
Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Gly
1 5 10 15
<![CDATA[ <210> 134]]>
<![CDATA[ <211> 8]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 134]]>
Gly Gly Gly Ser Gly Gly Gly Ser
1 5
<![CDATA[ <210> 135]]>
<![CDATA[ <211> 7]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 135]]>
Gly Gly Gly Ser Gly Gly Gly
1 5
<![CDATA[ <210> 136]]>
<![CDATA[ <211> 4]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 136]]>
Gly Gly Gly Ser
1
<![CDATA[ <210> 137]]>
<![CDATA[ <211> 4]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 137]]>
Ser Gly Gly Ser
1
<![CDATA[ <210> 138]]>
<![CDATA[ <211> 5]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 138]]>
Ser Gly Gly Gly Ser
1 5
<![CDATA[ <210> 139]]>
<![CDATA[ <211> 1602]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 139]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagcccaaca ucaccaaccu gugccccuuc ggcgaggugu ucaacgccac ccgguucgcc 120
agcguguacg ccuggaaccg gaagcggauc agcaacugcg uggccgacua cagcgugcug 180
uacaacagcg ccagcuucag caccuucaag ugcuacggcg ugagccccac caagcugaac 240
gaccugugcu ucaccaacgu guacgccgac agcuucguga uccguggcga cgaggugcgg 300
cagaucgcac ccggccagac aggcaagauc gccgacuaca acuacaagcu gcccgacgac 360
uucaccggcu gcgugaucgc cuggaacagc aacaaccucg acagcaaggu gggcggcaac 420
uacaacuacc uguaccggcu guuccggaag agcaaccuga agcccuucga gcgggacauc 480
agcaccgaga ucuaccaagc cggcuccacc ccuugcaacg gcguggaggg cuucaacugc 540
uacuucccuc ugcagagcua cggcuuccag cccaccaacg gcgugggcua ccagcccuac 600
cggguggugg ugcugagcuu cgagcugcug cacgccccag ccaccgugug uggccccaag 660
ucuggcggag gcagcggagg cggaagccag ugcgugaacc ugaccacccg gacccagcug 720
ccaccagccu acaccaacag cuucacccgg ggcgucuacu accccgacaa gguguuccgg 780
agcagcgucc ugcacagcac ccaggaccug uuccugcccu ucuucagcaa cgugaccugg 840
uuccacgcca uccacgugag cggcaccaac ggcaccaagc gguucgacaa ccccgugcug 900
cccuucaacg acggcgugua cuucgccagc accgagaaga gcaacaucau ccggggcugg 960
aucuucggca ccacccugga cagcaagacc cagagccugc ugaucgugaa uaacgccacc 1020
aacgugguga ucaaggugug cgaguuccag uucugcaacg accccuuccu gggcguguac 1080
uaccacaaga acaacaagag cuggauggag agcgaguucc ggguguacag cagcgccaac 1140
aacugcaccu ucgaguacgu gagccagccc uuccugaugg accuggaggg caagcagggc 1200
aacuucaaga accugcggga guucguguuc aagaacaucg acggcuacuu caagaucuac 1260
agcaagcaca ccccaaucaa ccuggugcgg gaucugcccc agggcuucuc agcccuggag 1320
ccccuggugg accugcccau cggcaucaac aucacccggu uccagacccu gcuggcccug 1380
caccggagcu accugacccc aggcgacagc agcagcgggu ggacagcagg cgcggcugcu 1440
uacuacgugg gcuaccugca gccccggacc uuccugcuga aguacaacga gaacggcacc 1500
aucaccgacg ccguggacuc uggcggaggc agcauccugg ccaucuacag caccguggcc 1560
agcagccugg ugcugcuggu gagccugggc gccaucagcu uc 1602
<![CDATA[ <210> 140]]>
<![CDATA[ <211> 534]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 140]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu
20 25 30
Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys
35 40 45
Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala
50 55 60
Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn
65 70 75 80
Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly
85 90 95
Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp
100 105 110
Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp
115 120 125
Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu
130 135 140
Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile
145 150 155 160
Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu
165 170 175
Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr
180 185 190
Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu
195 200 205
Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly
210 215 220
Ser Gly Gly Gly Ser Gln Cys Val Asn Leu Thr Thr Arg Thr Gln Leu
225 230 235 240
Pro Pro Ala Tyr Thr Asn Ser Phe Thr Arg Gly Val Tyr Tyr Pro Asp
245 250 255
Lys Val Phe Arg Ser Ser Val Leu His Ser Thr Gln Asp Leu Phe Leu
260 265 270
Pro Phe Phe Ser Asn Val Thr Trp Phe His Ala Ile His Val Ser Gly
275 280 285
Thr Asn Gly Thr Lys Arg Phe Asp Asn Pro Val Leu Pro Phe Asn Asp
290 295 300
Gly Val Tyr Phe Ala Ser Thr Glu Lys Ser Asn Ile Ile Arg Gly Trp
305 310 315 320
Ile Phe Gly Thr Thr Leu Asp Ser Lys Thr Gln Ser Leu Leu Ile Val
325 330 335
Asn Asn Ala Thr Asn Val Val Ile Lys Val Cys Glu Phe Gln Phe Cys
340 345 350
Asn Asp Pro Phe Leu Gly Val Tyr Tyr His Lys Asn Asn Lys Ser Trp
355 360 365
Met Glu Ser Glu Phe Arg Val Tyr Ser Ser Ala Asn Asn Cys Thr Phe
370 375 380
Glu Tyr Val Ser Gln Pro Phe Leu Met Asp Leu Glu Gly Lys Gln Gly
385 390 395 400
Asn Phe Lys Asn Leu Arg Glu Phe Val Phe Lys Asn Ile Asp Gly Tyr
405 410 415
Phe Lys Ile Tyr Ser Lys His Thr Pro Ile Asn Leu Val Arg Asp Leu
420 425 430
Pro Gln Gly Phe Ser Ala Leu Glu Pro Leu Val Asp Leu Pro Ile Gly
435 440 445
Ile Asn Ile Thr Arg Phe Gln Thr Leu Leu Ala Leu His Arg Ser Tyr
450 455 460
Leu Thr Pro Gly Asp Ser Ser Ser Gly Trp Thr Ala Gly Ala Ala Ala
465 470 475 480
Tyr Tyr Val Gly Tyr Leu Gln Pro Arg Thr Phe Leu Leu Lys Tyr Asn
485 490 495
Glu Asn Gly Thr Ile Thr Asp Ala Val Asp Ser Gly Gly Gly Ser Ile
500 505 510
Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser
515 520 525
Leu Gly Ala Ile Ser Phe
530
<![CDATA[ <210> 141]]>
<![CDATA[ <211> 1778]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 141]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
cccaacauca ccaaccugug ccccuucggc gagguguuca acgccacccg guucgccagc 180
guguacgccu ggaaccggaa gcggaucagc aacugcgugg ccgacuacag cgugcuguac 240
aacagcgcca gcuucagcac cuucaagugc uacggcguga gccccaccaa gcugaacgac 300
cugugcuuca ccaacgugua cgccgacagc uucgugaucc guggcgacga ggugcggcag 360
aucgcacccg gccagacagg caagaucgcc gacuacaacu acaagcugcc cgacgacuuc 420
accggcugcg ugaucgccug gaacagcaac aaccucgaca gcaagguggg cggcaacuac 480
aacuaccugu accggcuguu ccggaagagc aaccugaagc ccuucgagcg ggacaucagc 540
accgagaucu accaagccgg cuccaccccu ugcaacggcg uggagggcuu caacugcuac 600
uucccucugc agagcuacgg cuuccagccc accaacggcg ugggcuacca gcccuaccgg 660
gugguggugc ugagcuucga gcugcugcac gccccagcca ccgugugugg ccccaagucu 720
ggcggaggca gcggaggcgg aagccagugc gugaaccuga ccacccggac ccagcugcca 780
ccagccuaca ccaacagcuu cacccggggc gucuacuacc ccgacaaggu guuccggagc 840
agcguccugc acagcaccca ggaccuguuc cugcccuucu ucagcaacgu gaccugguuc 900
cacgccaucc acgugagcgg caccaacggc accaagcggu ucgacaaccc cgugcugccc 960
uucaacgacg gcguguacuu cgccagcacc gagaagagca acaucauccg gggcuggauc 1020
uucggcacca cccuggacag caagacccag agccugcuga ucgugaauaa cgccaccaac 1080
guggugauca aggugugcga guuccaguuc ugcaacgacc ccuuccuggg cguguacuac 1140
cacaagaaca acaagagcug gauggagagc gaguuccggg uguacagcag cgccaacaac 1200
ugcaccuucg aguacgugag ccagcccuuc cugauggacc uggagggcaa gcagggcaac 1260
uucaagaacc ugcgggaguu cguguucaag aacaucgacg gcuacuucaa gaucuacagc 1320
aagcacaccc caaucaaccu ggugcgggau cugccccagg gcuucucagc ccuggagccc 1380
cugguggacc ugcccaucgg caucaacauc acccgguucc agacccugcu ggcccugcac 1440
cggagcuacc ugaccccagg cgacagcagc agcgggugga cagcaggcgc ggcugcuuac 1500
uacgugggcu accugcagcc ccggaccuuc cugcugaagu acaacgagaa cggcaccauc 1560
accgacgccg uggacucugg cggaggcagc auccuggcca ucuacagcac cguggccagc 1620
agccuggugc ugcuggugag ccugggcgcc aucagcuucu gauaauaggc uggagccucg 1680
guggccuagc uucuugcccc uugggccucc ccccagcccc uccuccccuu ccugcacccg 1740
uacccccgug gucuuugaau aaagucugag ugggcggc 1778
<![CDATA[ <210> 142]]>
<![CDATA[ <211> 1602]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 142]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ggaggcgcca aguucguggc cgccuggacu 900
cugaaggccg cagccggcgg acccaacauc accaaccugu gccccuucgg cgagguguuc 960
aacgccaccc gguucgccag cguguacgcc uggaaccgga agcggaucag caacugcgug 1020
gccgacuaca gcgugcugua caacagcgcc agcuucagca ccuucaagug cuacggcgug 1080
agccccacca agcugaacga ccugugcuuc accaacgugu acgccgacag cuucgugauc 1140
cguggcgacg aggugcggca gaucgcaccc ggccagacag gcaagaucgc cgacuacaac 1200
uacaagcugc ccgacgacuu caccggcugc gugaucgccu ggaacagcaa caaccucgac 1260
agcaaggugg gcggcaacua caacuaccug uaccggcugu uccggaagag caaccugaag 1320
cccuucgagc gggacaucag caccgagauc uaccaagccg gcuccacccc uugcaacggc 1380
guggagggcu ucaacugcua cuucccucug cagagcuacg gcuuccagcc caccaacggc 1440
gugggcuacc agcccuaccg ggugguggug cugagcuucg agcugcugca cgccccagcc 1500
accgugugug gccccaaguc uggcggaggc agcauccugg ccaucuacag caccguggcc 1560
agcagccugg ugcugcuggu gagccugggc gccaucagcu uc 1602
<![CDATA[ <210> 143]]>
<![CDATA[ <211> 534]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 143]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Gly Gly Ala Lys Phe Val Ala Ala Trp Thr Leu Lys Ala Ala
290 295 300
Ala Gly Gly Pro Asn Ile Thr Asn Leu Cys Pro Phe Gly Glu Val Phe
305 310 315 320
Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala Trp Asn Arg Lys Arg Ile
325 330 335
Ser Asn Cys Val Ala Asp Tyr Ser Val Leu Tyr Asn Ser Ala Ser Phe
340 345 350
Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro Thr Lys Leu Asn Asp Leu
355 360 365
Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe Val Ile Arg Gly Asp Glu
370 375 380
Val Arg Gln Ile Ala Pro Gly Gln Thr Gly Lys Ile Ala Asp Tyr Asn
385 390 395 400
Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys Val Ile Ala Trp Asn Ser
405 410 415
Asn Asn Leu Asp Ser Lys Val Gly Gly Asn Tyr Asn Tyr Leu Tyr Arg
420 425 430
Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe Glu Arg Asp Ile Ser Thr
435 440 445
Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys Asn Gly Val Glu Gly Phe
450 455 460
Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly Phe Gln Pro Thr Asn Gly
465 470 475 480
Val Gly Tyr Gln Pro Tyr Arg Val Val Val Leu Ser Phe Glu Leu Leu
485 490 495
His Ala Pro Ala Thr Val Cys Gly Pro Lys Ser Gly Gly Gly Gly Ser Ile
500 505 510
Leu Ala Ile Tyr Ser Thr Val Ala Ser Ser Leu Val Leu Leu Val Ser
515 520 525
Leu Gly Ala Ile Ser Phe
530
<![CDATA[ <210> 144]]>
<![CDATA[ <211> 1778]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 144]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacgga ggcgccaagu ucguggccgc cuggacucug 960
aaggccgcag ccggcggacc caacaucacc aaccugugcc ccuucggcga gguguucaac 1020
gccacccggu ucgccagcgu guacgccugg aaccggaagc ggaucagcaa cugcguggcc 1080
gacuacagcg ugcuguacaa cagcgccagc uucagcaccu ucaagugcua cggcgugagc 1140
cccaccaagc ugaacgaccu gugcuucacc aacguguacg ccgacagcuu cgugauccgu 1200
ggcgacgagg ugcggcagau cgcacccggc cagacaggca agaucgccga cuacaacuac 1260
aagcugcccg acgacuucac cggcugcgug aucgccugga acagcaacaa ccucgacagc 1320
aaggugggcg gcaacuacaa cuaccuguac cggcuguucc ggaagagcaa ccugaagccc 1380
uucgagcggg acaucagcac cgagaucuac caagccggcu ccaccccuug caacggcgug 1440
gagggcuuca acugcuacuu cccucugcag agcuacggcu uccagcccac caacggcgug 1500
ggcuaccagc ccuaccgggu gguggugcug agcuucgagc ugcugcacgc cccagccacc 1560
guguguggcc ccaagucugg cggaggcagc auccuggcca ucuacagcac cguggccagc 1620
agccuggugc ugcuggugag ccugggcgcc aucagcuucu gauaauaggc uggagccucg 1680
guggccuagc uucuugcccc uugggccucc ccccagcccc uccuccccuu ccugcacccg 1740
uacccccgug gucuuugaau aaagucugag ugggcggc 1778
<![CDATA[ <210> 145]]>
<![CDATA[ <211> 1785]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 145]]>
auguacagca ugcagcuggc uagcugcgug acccugaccc uggugcugcu ggugaacagc 60
cagggcgccg agaacagcgu ggccuacagc aacaacagca ucgccauccc caccaacuuc 120
accaucagcg ugaccaccga gauucugccc gugagcauga ccaagaccag cguggacugc 180
accauguaca ucugcggcga cagcaccgag ugcagcaacc ugcugcugca guacggcagc 240
uucugcaccc agcugaaccg ggcccugacc ggcaucgccg uggagcagga caagaacacc 300
caggaggugu ucgcccaggu gaagcagauc uacaagaccc cucccaucaa ggacuucggc 360
ggcuucaacu ucagccagau ccugcccgac cccagcaagc ccagcaagcg gagcuucauc 420
gaggaccugc uguucaacaa ggugacccua gccgacgccg gcuucaucaa gcaguacggc 480
gacugccucg gcgacauagc cgcccgggac cugaucugcg cccagaaguu caacggccug 540
accgugcugc cuccccugcu gaccgacgag augaucgccc aguacaccag cgcccuguua 600
gccggaacca ucaccagcgg cuggacuuuc ggcgcuggag ccgcucugca gauccccuuc 660
gccaugcaga uggccuaccg guucaacggc aucggcguga cccagaacgu gcuguacgag 720
aaccagaagc ugaucgccaa ccaguucaac agcgccaucg gcaagaucca ggacagccug 780
agcagcaccg cuagcgcccu gggcaagcug caggacgugg ugaaccagaa cgcccaggcc 840
cugaacaccc uggugaagca gcugagcagc aacuucggcg ccaucagcag cgugcugaac 900
gacauccuga gccggcugga cccucccgag gccgaggugc agaucgaccg gcugaucacu 960
ggccggcugc agagccugca gaccuacgug acccagcagc ugauccgggc cgccgagauu 1020
cgggccagcg ccaaccuggc cgccaccaag augagcgagu gcgugcuggg ccagagcaag 1080
cgggguggacu ucugcggcaa gggcuaccac cugaugagcu uuccccagag cgcaccccac 1140
ggaguggugu uccugcacgu gaccuacgug cccgcccagg agaagaacuu caccaccgcc 1200
ccagccaucu gccacgacgg caaggcccac uuuccccggg agggcguguu cgugagcaac 1260
ggcacccacu gguucgugac ccagcggaac uucuacgagc cccagaucau caccaccgac 1320
aacaccuucg ugagcggcaa cugcgacgug gugaucggca ucgugaacaa caccguguac 1380
gauccccugc agcccgagcu ggacagcuuc aaggaggagc uggacaagua cuucaagaau 1440
cacaccagcc ccgacgugga ccugggcgac aucagcggca ucaacgccag cguggugaac 1500
auccagaagg agaucgaucg gcugaacgag guggccaaga accugaacga gagccugauc 1560
gaccugcagg agcugggcaa guacgagcag uacaucaagu ggcccuggua caucuggcug 1620
ggcuucaucg ccggccugau cgccaucgug auggugacca ucaugcugug cugcaugacc 1680
agcugcugca gcugccugaa gggcuguugc agcugcggca gcugcugcaa guucgacgag 1740
gacgacagcg agcccgugcu gaagggcgug aagcugcacu acacc 1785
<![CDATA[ <210> 146]]>
<![CDATA[ <211> 595]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 146]]>
Met Tyr Ser Met Gln Leu Ala Ser Cys Val Thr Leu Thr Leu Val Leu
1 5 10 15
Leu Val Asn Ser Gln Gly Ala Glu Asn Ser Val Ala Tyr Ser Asn Asn
20 25 30
Ser Ile Ala Ile Pro Thr Asn Phe Thr Ile Ser Val Thr Glu Ile
35 40 45
Leu Pro Val Ser Met Thr Lys Thr Ser Val Asp Cys Thr Met Tyr Ile
50 55 60
Cys Gly Asp Ser Thr Glu Cys Ser Asn Leu Leu Leu Gln Tyr Gly Ser
65 70 75 80
Phe Cys Thr Gln Leu Asn Arg Ala Leu Thr Gly Ile Ala Val Glu Gln
85 90 95
Asp Lys Asn Thr Gln Glu Val Phe Ala Gln Val Lys Gln Ile Tyr Lys
100 105 110
Thr Pro Pro Ile Lys Asp Phe Gly Gly Phe Asn Phe Ser Gln Ile Leu
115 120 125
Pro Asp Pro Ser Lys Pro Ser Lys Arg Ser Phe Ile Glu Asp Leu Leu
130 135 140
Phe Asn Lys Val Thr Leu Ala Asp Ala Gly Phe Ile Lys Gln Tyr Gly
145 150 155 160
Asp Cys Leu Gly Asp Ile Ala Ala Arg Asp Leu Ile Cys Ala Gln Lys
165 170 175
Phe Asn Gly Leu Thr Val Leu Pro Pro Leu Leu Thr Asp Glu Met Ile
180 185 190
Ala Gln Tyr Thr Ser Ala Leu Leu Ala Gly Thr Ile Thr Ser Gly Trp
195 200 205
Thr Phe Gly Ala Gly Ala Ala Leu Gln Ile Pro Phe Ala Met Gln Met
210 215 220
Ala Tyr Arg Phe Asn Gly Ile Gly Val Thr Gln Asn Val Leu Tyr Glu
225 230 235 240
Asn Gln Lys Leu Ile Ala Asn Gln Phe Asn Ser Ala Ile Gly Lys Ile
245 250 255
Gln Asp Ser Leu Ser Ser Thr Ala Ser Ala Leu Gly Lys Leu Gln Asp
260 265 270
Val Val Asn Gln Asn Ala Gln Ala Leu Asn Thr Leu Val Lys Gln Leu
275 280 285
Ser Ser Asn Phe Gly Ala Ile Ser Ser Val Leu Asn Asp Ile Leu Ser
290 295 300
Arg Leu Asp Pro Pro Glu Ala Glu Val Gln Ile Asp Arg Leu Ile Thr
305 310 315 320
Gly Arg Leu Gln Ser Leu Gln Thr Tyr Val Thr Gln Gln Leu Ile Arg
325 330 335
Ala Ala Glu Ile Arg Ala Ser Ala Asn Leu Ala Ala Thr Lys Met Ser
340 345 350
Glu Cys Val Leu Gly Gln Ser Lys Arg Val Asp Phe Cys Gly Lys Gly
355 360 365
Tyr His Leu Met Ser Phe Pro Gln Ser Ala Pro His Gly Val Val Phe
370 375 380
Leu His Val Thr Tyr Val Pro Ala Gln Glu Lys Asn Phe Thr Thr Ala
385 390 395 400
Pro Ala Ile Cys His Asp Gly Lys Ala His Phe Pro Arg Glu Gly Val
405 410 415
Phe Val Ser Asn Gly Thr His Trp Phe Val Thr Gln Arg Asn Phe Tyr
420 425 430
Glu Pro Gln Ile Ile Thr Thr Asp Asn Thr Phe Val Ser Gly Asn Cys
435 440 445
Asp Val Val Ile Gly Ile Val Asn Asn Thr Val Tyr Asp Pro Leu Gln
450 455 460
Pro Glu Leu Asp Ser Phe Lys Glu Glu Leu Asp Lys Tyr Phe Lys Asn
465 470 475 480
His Thr Ser Pro Asp Val Asp Leu Gly Asp Ile Ser Gly Ile Asn Ala
485 490 495
Ser Val Val Asn Ile Gln Lys Glu Ile Asp Arg Leu Asn Glu Val Ala
500 505 510
Lys Asn Leu Asn Glu Ser Leu Ile Asp Leu Gln Glu Leu Gly Lys Tyr
515 520 525
Glu Gln Tyr Ile Lys Trp Pro Trp Tyr Ile Trp Leu Gly Phe Ile Ala
530 535 540
Gly Leu Ile Ala Ile Val Met Val Thr Ile Met Leu Cys Cys Met Thr
545 550 555 560
Ser Cys Cys Ser Cys Leu Lys Gly Cys Cys Ser Cys Gly Ser Cys Cys
565 570 575
Lys Phe Asp Glu Asp Asp Ser Glu Pro Val Leu Lys Gly Val Lys Leu
580 585 590
His Tyr Thr
595
<![CDATA[ <210> 147]]>
<![CDATA[ <211> 1961]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 147]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uacagcaugc agcuggcuag cugcgugacc cugacccugg ugcugcuggu gaacagccag 120
ggcgccgaga acagcguggc cuacagcaac aacagcaucg ccauccccac caacuucacc 180
aucagcguga ccaccgagau ucugcccgug agcaugacca agaccagcgu ggacugcacc 240
auguacaucu gcggcgacag caccgagugc agcaaccugc ugcugcagua cggcagcuuc 300
ugcacccagc ugaaccgggc ccugaccggc aucgccgugg agcaggacaa gaacacccag 360
gagguguucg cccaggugaa gcagaucuac aagaccccuc ccaucaagga cuucggcggc 420
uucaacuuca gccagauccu gcccgacccc agcaagccca gcaagcggag cuucaucgag 480
gaccugcugu ucaacaaggu gacccuagcc gacgccggcu ucaucaagca guacggcgac 540
ugccucggcg acauagccgc ccgggaccug aucugcgccc agaaguucaa cggccugacc 600
gugcugccuc cccugcugac cgacgagaug aucgcccagu acaccagcgc ccuguuagcc 660
ggaaccauca ccagcggcug gacuuucggc gcuggagccg cucugcagau ccccuucgcc 720
augcagaugg ccuaccgguu caacggcauc ggcgugaccc agaacgugcu guacgagaac 780
cagaagcuga ucgccaacca guucaacagc gccaucggca agauccagga cagccugagc 840
agcaccgcua gcgcccuggg caagcugcag gacgugguga accagaacgc ccaggcccug 900
aacacccugg ugaagcagcu gagcagcaac uucggcgcca ucagcagcgu gcugaacgac 960
auccugagcc ggcuggaccc ucccgaggcc gaggugcaga ucgaccggcu gaucacuggc 1020
cggcugcaga gccugcagac cuacgugacc cagcagcuga uccgggccgc cgagauucgg 1080
gccagcgcca accuggccgc caccaagaug agcgagugcg ugcugggcca gagcaagcgg 1140
guggacuucu gcggcaaggg cuaccaccug augagcuuuc cccagagcgc accccacgga 1200
gugguguucc ugcacgugac cuacgugccc gcccaggaga agaacuucac caccgcccca 1260
gccaucugcc acgacggcaa ggcccacuuu ccccgggagg gcguguucgu gagcaacggc 1320
acccacuggu ucgugaccca gcggaacuuc uacgagcccc agaucaucac caccgacaac 1380
accuucguga gcggcaacug cgacguggug aucggcaucg ugaacaacac cguguacgau 1440
ccccugcagc ccgagcugga cagcuucaag gaggagcugg acaaguacuu caagaaucac 1500
accagccccg acguggaccu gggcgacauc agcggcauca acgccagcgu ggugaacauc 1560
cagaaggaga ucgaucggcu gaacgaggug gccaagaacc ugaacgagag ccugaucgac 1620
cugcaggagc ugggcaagua cgagcaguac aucaaguggc ccugguacau cuggcugggc 1680
uucaucgccg gccugaucgc caucgugaug gugaccauca ugcugugcug caugaccagc 1740
ugcugcagcu gccugaaggg cuguugcagc ugcggcagcu gcugcaaguu cgacgaggac 1800
gacagcgagc ccgugcugaa gggcgugaag cugcacuaca ccugauaaua ggcuggagcc 1860
ucgguggccu agcuucuugc cccuugggcc uccccccagc cccuccuccc cuuccugcac 1920
ccguaccccc guggucuuug aauaaagucu gagugggcgg c 1961
<![CDATA[ <210> 148]]>
<![CDATA[ <211> 13]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 148]]>
Ala Lys Phe Val Ala Ala Trp Thr Leu Lys Ala Ala Ala
1 5 10
<![CDATA[ <210> 149]]>
<![CDATA[ <211> 2216]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 149]]>
gggaaauaag agagaaaaga agaguaagaa gaaauauaag accccggcgc cgccaccaug 60
uucguguucc uggugcugcu gccccuggug agcagccagu gcgugaaccu gaccacccgg 120
acccagcugc caccagccua caccaacagc uucacccggg gcgucuacua ccccgacaag 180
guguuccgga gcagcguccu gcacagcacc caggaccugu uccugcccuu cuucagcaac 240
gugaccuggu uccacgccau ccacgugagc ggcaccaacg gcaccaagcg guucgacaac 300
cccgugcugc ccuucaacga cggcguguac uucgccagca ccgagaagag caacaucauc 360
cggggcugga ucuucggcac cacccuggac agcaagaccc agagccugcu gaucgugaau 420
aacgccacca acguggugau caaggugugc gaguuccagu ucugcaacga ccccuuccug 480
ggcguguacu accacaagaa caacaagagc uggauggaga gcgaguuccg gguguacagc 540
agcgccaaca acugcaccuu cgaguacgug agccagcccu uccugaugga ccuggagggc 600
aagcagggca acuucaagaa ccugcgggag uucguguuca agaacaucga cggcuacuuc 660
aagaucuaca gcaagcacac cccaaucaac cuggugcggg aucugcccca gggcuuca 720
gcccuggagc cccuggugga ccugcccauc ggcaucaaca ucacccgguu ccagacccug 780
cuggcccugc accggagcua ccugacccca ggcgacagca gcagcgggug gacagcaggc 840
gcggcugcuu acuacguggg cuaccugcag ccccggaccu uccugcugaa guacaacgag 900
aacggcacca ucaccgacgc cguggacugc gcccuggacc cucugagcga gaccaagugc 960
acccugaaga gcuucaccgu ggagaagggc aucuaccaga ccagcaacuu ccgggugcag 1020
cccaccgaga gcaucgugcg guuccccaac aucaccaacc ugugccccuu cggcgaggug 1080
uucaacgcca cccgguucgc cagcguguac gccuggaacc ggaagcggau cagcaacugc 1140
guggccgacu acagcgugcu guacaacagc gccagcuuca gcaccuucaa gugcuacggc 1200
gugagcccca ccaagcugaa cgaccugugc uucaccaacg uguacgccga cagcuucgug 1260
auccguggcg acgaggugcg gcagaucgca cccggccaga caggcaagau cgccgacuac 1320
aacuacaagc ugcccgacga cuucaccggc ugcgugaucg ccuggaacag caacaaccuc 1380
gacagcaagg ugggcggcaa cuacaacuac cuguaccggc uguuccggaa gagcaaccug 1440
aagcccuucg agcgggacau cagcaccgag aucuaccaag ccggcuccac cccuugcaac 1500
ggcguggagg gcuucaacug cuacuucccu cugcagagcu acggcuucca gcccaccaac 1560
ggcgugggcu accagcccua ccggguggug gugcugagcu ucgagcugcu gcacgcccca 1620
gccaccgugu guggccccaa gaagagcacc aaccugguga agaacaagug cgugaacuuc 1680
aacuucaacg gccuuaccgg caccggcgug cugaccgaga gcaacaagaa auuccugccc 1740
uuucagcagu ucggccggga caucgccgac accaccgacg cugugcggga uccccagacc 1800
cuggagaucc uggacaucac cccuugcagc uucggcggcg ugagcgugau caccccaggc 1860
accaacacca gcaaccaggu ggccgugcug uaccaggacg ugaacugcac cgaggugccc 1920
guggccaucc acgccgacca gcugacaccc accuggcggg ucuacagcac cggcagcaac 1980
guguuccaga cccgggccgg uugccugauc ggcgccgagc acgugaacaa cagcuacgag 2040
ugcgacaucc ccaucggcgc cggcaucugu gccagcuacc agacccagac caauucauga 2100
uaauaggcug gagccucggu ggccuagcuu cuugccccuu gggccucccc ccagccccuc 2160
cuccccuucc ugcacccgua cccccguggu cuuugaauaa agucugagug ggcggc 2216
<![CDATA[ <210> 150]]>
<![CDATA[ <211> 2040]]>
<![CDATA[ <212> RNA]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 150]]>
auguucgugu uccuggugcu gcugccccug gugagcagcc agugcgugaa ccugaccacc 60
cggacccagc ugccaccagc cuacaccaac agcuucaccc ggggcgucua cuaccccgac 120
aagguguucc ggagcagcgu ccugcacagc acccaggacc uguuccugcc cuucuucagc 180
aacgugaccu gguuccacgc cauccacgug agcggcacca acggcaccaa gcgguucgac 240
aaccccgugc ugcccuucaa cgacggcgug uacuucgcca gcaccgagaa gagcaacauc 300
auccggggcu ggaucuucgg caccacccug gacagcaaga cccagagccu gcugaucgug 360
aauaacgcca ccaacguggu gaucaaggug ugcgaguucc aguucugcaa cgaccccuuc 420
cugggcgugu acuaccacaa gaacaacaag agcuggaugg agagcgaguu ccggguguac 480
agcagcgcca acaacugcac cuucgaguac gugagccagc ccuuccugau ggaccuggag 540
ggcaagcagg gcaacuucaa gaaccugcgg gaguucgugu ucaagaacau cgacggcuac 600
uucaagaucu acagcaagca caccccaauc aaccuggugc gggaucugcc ccagggcuuc 660
ucagcccugg agccccuggu ggaccugccc aucggcauca acaucacccg guuccagacc 720
cugcuggccc ugcaccggag cuaccugacc ccaggcgaca gcagcagcgg guggacagca 780
ggcgcggcug cuuacuacgu gggcuaccug cagccccgga ccuuccugcu gaaguacaac 840
gagaacggca ccaucaccga cgccguggac ugcgcccugg acccucugag cgagaccaag 900
ugcacccuga agagcuucac cguggagaag ggcaucuacc agaccagcaa cuuccgggug 960
cagcccaccg agagcaucgu gcgguucccc aacaucacca accugugccc cuucggcgag 1020
guguucaacg ccacccgguu cgccagcgug uacgccugga accggaagcg gaucagcaac 1080
ugcguggccg acuacagcgu gcuguacaac agcgccagcu ucagcaccuu caagugcuac 1140
ggcgugagcc ccaccaagcu gaacgaccug ugcuucacca acguguacgc cgacagcuuc 1200
gugauccgug gcgacgaggu gcggcagauc gcacccggcc agacaggcaa gaucgccgac 1260
uacaacuaca agcugcccga cgacuucacc ggcugcguga ucgccuggaa cagcaacaac 1320
cucgacagca aggugggcgg caacuacaac uaccuguacc ggcuguuccg gaagagcaac 1380
cugaagcccu ucgagcggga caucagcacc gagaucuacc aagccggcuc caccccuugc 1440
aacggcgugg agggcuucaa cugcuacuuc ccucugcaga gcuacggcuu ccagcccacc 1500
aacggcgugg gcuaccagcc cuaccgggug guggugcuga gcuucgagcu gcugcacgcc 1560
ccagccaccg uguguggccc caagaagagc accaaccugg ugaagaacaa gugcgugaac 1620
uucaacuuca acggccuuac cggcaccggc gugcugaccg agagcaacaa gaaauuccug 1680
cccuuucagc aguucggccg ggacaucgcc gacaccaccg acgcugugcg ggauccccag 1740
acccuggaga uccuggacau caccccuugc agcuucggcg gcgugagcgu gaucacccca 1800
ggcaccaaca ccagcaacca gguggccgug cuguaccagg acgugaacug caccgaggug 1860
cccguggcca uccacgccga ccagcugaca cccaccuggc gggucuacag caccggcagc 1920
aacguguucc agacccgggc cgguugccug aucggcgccg agcacgugaa caacagcuac 1980
gagugcgaca uccccaucgg cgccggcauc ugugccagcu accagaccca gaccaauuca 2040
<![CDATA[ <210> 151]]>
<![CDATA[ <211> 680]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 151]]>
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser
675 680
<![CDATA[ <210> 152]]>
<![CDATA[ <211> 4]]>
<![CDATA[ <212> PRT]]>
<![CDATA[ <213> Artificial Sequence]]>
<![CDATA[ <220>]]>
<![CDATA[ <223> Synthesis]]>
<![CDATA[ <400> 152]]>
Gly Ser Gly Gly
1


























































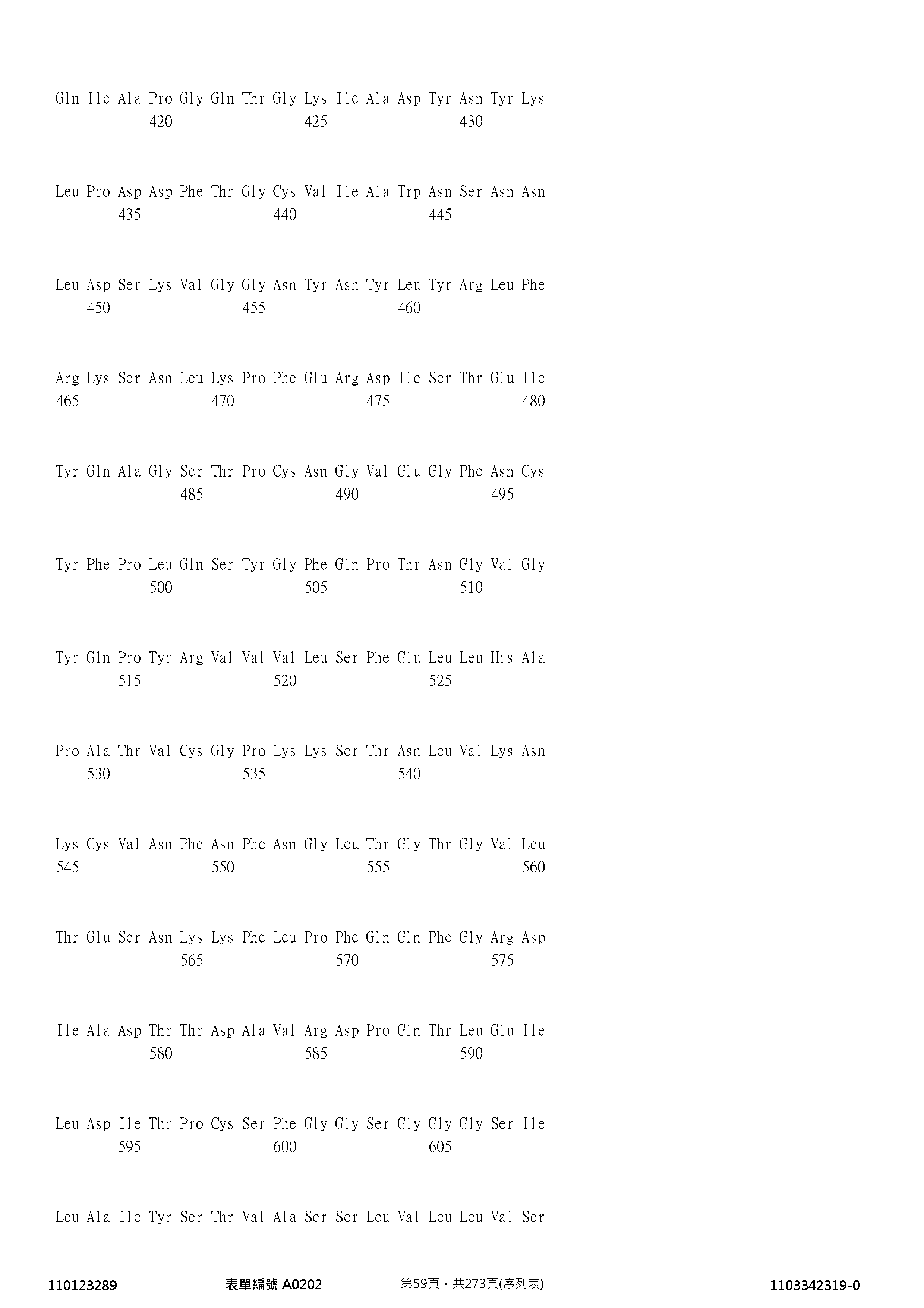






















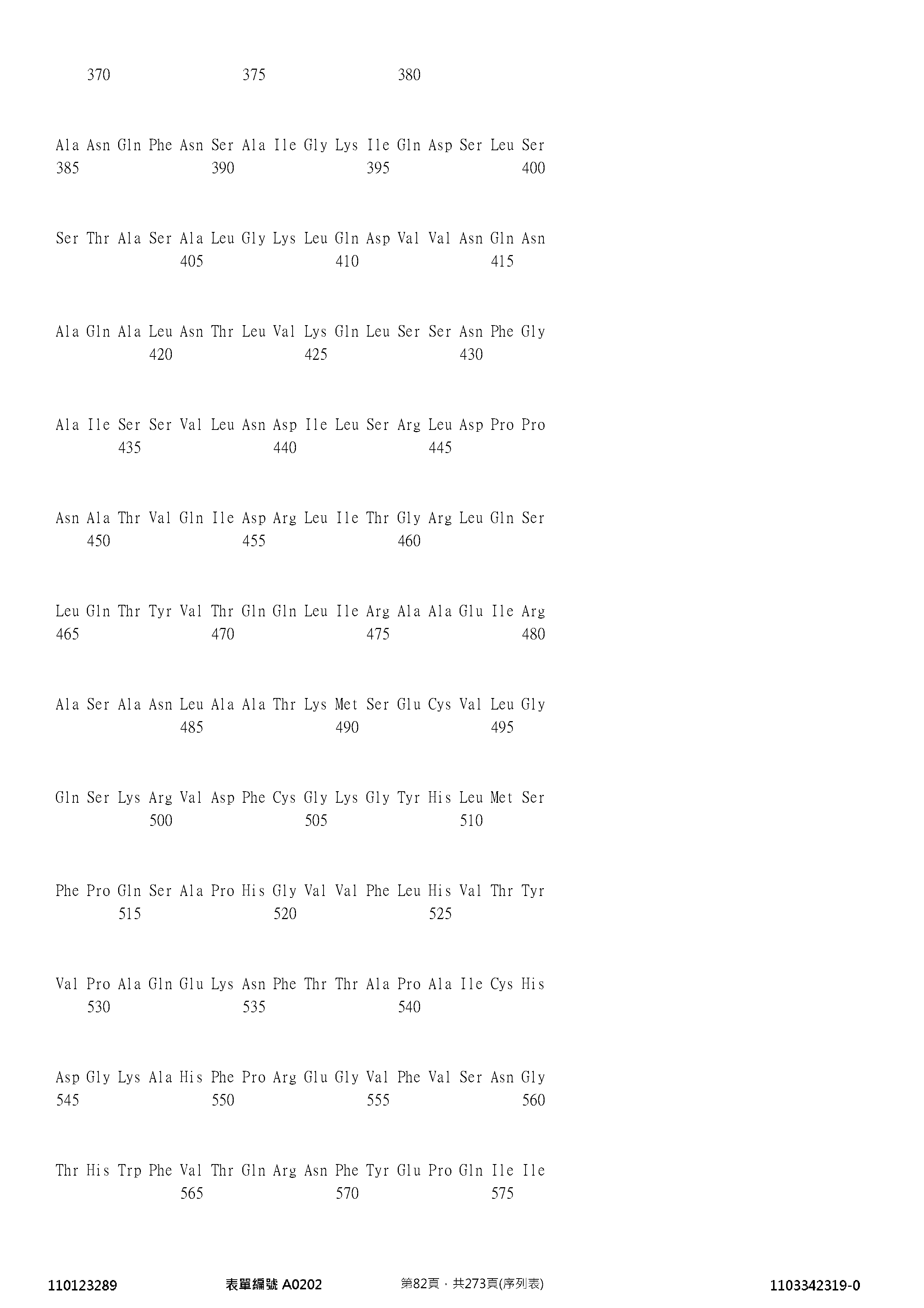





























































































































































































Claims (154)
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063044330P | 2020-06-25 | 2020-06-25 | |
| US63/044,330 | 2020-06-25 | ||
| US202063063137P | 2020-08-07 | 2020-08-07 | |
| US63/063,137 | 2020-08-07 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| TW202217000A true TW202217000A (en) | 2022-05-01 |
Family
ID=82558760
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| TW110123289A TW202217000A (en) | 2020-06-25 | 2021-06-25 | Sars-cov-2 mrna domain vaccines |
Country Status (1)
| Country | Link |
|---|---|
| TW (1) | TW202217000A (en) |
-
2021
- 2021-06-25 TW TW110123289A patent/TW202217000A/en unknown
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7443608B2 (en) | SARS-COV-2 mRNA domain vaccine | |
| US20240299531A1 (en) | Therapeutic use of sars-cov-2 mrna domain vaccines | |
| US20240293534A1 (en) | Coronavirus glycosylation variant vaccines | |
| US20240358819A1 (en) | Pan-human coronavirus domain vaccines | |
| US20240285754A1 (en) | Mrna vaccines encoding flexible coronavirus spike proteins | |
| US20240382581A1 (en) | Pan-human coronavirus vaccines | |
| US20230355743A1 (en) | Multi-proline-substituted coronavirus spike protein vaccines | |
| US20230108894A1 (en) | Coronavirus rna vaccines | |
| JP2024503699A (en) | Variant strain-based coronavirus vaccines | |
| JP2024503698A (en) | Mutant strain-based coronavirus vaccine | |
| WO2023283642A2 (en) | Pan-human coronavirus concatemeric vaccines | |
| WO2021159130A2 (en) | Coronavirus rna vaccines and methods of use | |
| CA3216490A1 (en) | Epstein-barr virus mrna vaccines | |
| WO2023092069A1 (en) | Sars-cov-2 mrna domain vaccines and methods of use | |
| TW202217000A (en) | Sars-cov-2 mrna domain vaccines | |
| WO2025149032A1 (en) | Respiratory syncytial virus vaccine compositions and their use |