CN116193196A - 虚拟环绕声渲染方法、装置、设备及存储介质 - Google Patents
虚拟环绕声渲染方法、装置、设备及存储介质 Download PDFInfo
- Publication number
- CN116193196A CN116193196A CN202310177960.4A CN202310177960A CN116193196A CN 116193196 A CN116193196 A CN 116193196A CN 202310177960 A CN202310177960 A CN 202310177960A CN 116193196 A CN116193196 A CN 116193196A
- Authority
- CN
- China
- Prior art keywords
- target
- rendered
- head
- multimedia data
- audio
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000009877 rendering Methods 0.000 title claims abstract description 108
- 238000000034 method Methods 0.000 title claims abstract description 84
- 238000005316 response function Methods 0.000 claims description 126
- 230000006870 function Effects 0.000 claims description 45
- 238000004590 computer program Methods 0.000 claims description 19
- 230000008859 change Effects 0.000 claims description 18
- 238000012937 correction Methods 0.000 claims description 16
- 230000004044 response Effects 0.000 claims description 9
- 230000035939 shock Effects 0.000 claims description 4
- 230000009466 transformation Effects 0.000 abstract description 3
- 210000003128 head Anatomy 0.000 description 166
- 238000010586 diagram Methods 0.000 description 38
- 238000005516 engineering process Methods 0.000 description 18
- 230000008569 process Effects 0.000 description 16
- 210000005069 ears Anatomy 0.000 description 15
- 230000000694 effects Effects 0.000 description 14
- 238000004891 communication Methods 0.000 description 11
- 238000012545 processing Methods 0.000 description 9
- 230000005236 sound signal Effects 0.000 description 6
- 238000010521 absorption reaction Methods 0.000 description 5
- 230000003068 static effect Effects 0.000 description 4
- 239000000463 material Substances 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 238000004088 simulation Methods 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 208000025121 Leukoencephalopathy with brain stem and spinal cord involvement-high lactate syndrome Diseases 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 210000000624 ear auricle Anatomy 0.000 description 2
- 239000004973 liquid crystal related substance Substances 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 229920000742 Cotton Polymers 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 210000000613 ear canal Anatomy 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 210000003454 tympanic membrane Anatomy 0.000 description 1
Images














Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/44—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs
- H04N21/44012—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs involving rendering scenes according to scene graphs, e.g. MPEG-4 scene graphs
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/20—Arrangements for obtaining desired frequency or directional characteristics
- H04R1/32—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only
- H04R1/326—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only for microphones
Landscapes
- Engineering & Computer Science (AREA)
- Signal Processing (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Otolaryngology (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Stereophonic System (AREA)
Abstract
本申请实施例提供一种虚拟环绕声渲染方法、装置、设备及存储介质。在本申请实施例中,在确定待渲染多媒体数据的渲染方式时,不仅能够确定待渲染多媒体数据的声道数和影音场景,而且还考虑到待渲染多媒体数据的收听用户的头部转动角度的变换情况,最后基于待渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,使得确定的目标渲染函数与收听用户当前所处的环境、待渲染多媒体数据的声道数以及收听用户的头部转动角度相匹配,这样通过目标渲染函数对待渲染多媒体数据进行渲染得到目标虚拟环绕声,也就能够给收听用户带来更优质的音频体验,而且,该渲染方式充分考虑到了不同场景的差异,也能够应用于更多的场景中。
Description
技术领域
本申请涉及虚拟环绕声技术领域,尤其涉及一种虚拟环绕声渲染方法、装置、设备及存储介质。
背景技术
为满足大多数用户对便携、高品质的移动影音体验的需求,能够利用较简单的设备实现高品质的影音环绕效果的虚拟环绕声技术应运而生。相对于多声道环绕声技术,虚拟环绕声技术通常只需两个声道就可以实现环绕声的效果,这就使得用户希望在重放设备尽量少的情况下仍能享受到“家庭影院”影音效果的愿望得以实现。而如何对现有的虚拟环绕声技术进行改进以将虚拟环绕声技术应用到更广泛的场景中,同时改善收听者音频体验,仍然需要提供进一步的解决方案。
发明内容
本申请的多个方面提供一种虚拟环绕声的渲染方法、装置、设备及存储介质,用以对现有的虚拟环绕声技术进行改进以将虚拟环绕声技术应用到更广泛的场景中,同时改善收听者音频体验。
本申请实施例提供一种虚拟环绕声的渲染方法,包括:确定待渲染多媒体数据的声道数和影音场景;确定所述待渲染多媒体数据的收听用户的头部转动角度;基于所述声道数、所述影音场景以及所述头部转动角度,确定目标渲染函数,以基于所述目标渲染函数对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
本申请实施例还提供一种虚拟环绕声的渲染装置,包括:场景确定模块,用于确定待渲染多媒体数据的声道数和影音场景;角度确定模块,用于确定所述待渲染多媒体数据的收听用户的头部转动角度;资源渲染模块,用于基于所述声道数、所述影音场景以及所述头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
本申请实施例还提供一种电子设备,包括:存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,与所述存储器耦合,用于执行所述计算机程序,以用于:确定待渲染多媒体数据的声道数和影音场景;确定所述待渲染多媒体数据的收听用户的头部转动角度;基于所述声道数、所述影音场景以及所述头部转动角度,确定目标渲染函数,以基于所述目标渲染函数对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
本申请实施例还提供一种存储有计算机程序的计算机可读存储介质,当所述计算机程序被处理器执行时,致使所述处理器实现本申请实施例提供的虚拟环绕声渲染方法中的步骤。
在本申请实施例中,由于能够在确定待渲染多媒体数据的渲染方式时,不仅能够确定待渲染多媒体数据的声道数和影音场景,而且还考虑到待渲染多媒体数据的收听用户的头部转动角度的变换情况,最后基于待渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,使得确定的目标渲染函数与收听用户当前所处的环境、待渲染多媒体数据的声道数以及收听用户的头部转动角度相匹配,这样通过目标渲染函数对待渲染多媒体数据进行渲染得到目标虚拟环绕声,也就能够给收听用户带来更优质的音频体验,而且,该渲染方式充分考虑到了不同场景的差异,也能够应用于更多的场景中。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本申请实施例提供的虚拟环绕声渲染方法实现的系统流程示意图;
图2为本申请示例性实施例提供的一种虚拟环绕声渲染方法的流程示意图;
图3为根据本申请实施例提供的虚拟环绕声渲染方法对收听用户的头部建立三维坐标系的示意图;
图4为根据本申请实施例提供的虚拟环绕声渲染方法将双声道的多媒体数据渲染到收听用户双耳的场景示意图;
图5为根据本申请实施例提供的虚拟环绕声渲染方法将5.1声道的多媒体数据渲染到收听用户双耳的场景示意图;
图6为根据本申请实施例提供的虚拟环绕声渲染方法将7.1声道的多媒体数据渲染到收听用户双耳的场景示意图;
图7为本申请示例性实施例提供的房间模拟的是左耳以及右耳接收5.1声道的虚拟扬声器播放的多媒体数据的场景示意图;
图8为本申请示例性实施例提供的图7所示的影音场景中5.1声道的虚拟扬声器与左耳以及右耳之间的房间相关脉冲响应函数的波形图;
图9为本申请一个实施例根据图像源方法生成目标房间相关脉冲响应函数中声音传播路径的示意图;
图10为本申请一个实施例根据漫射雨射线追踪算法生成目标房间相关脉冲响应函数中声能量射线的传播路径示意图;
图11为本申请一个实施例根据漫射雨射线追踪算法生成目标房间相关脉冲响应函数中接收器收到的一条声能量射线的能量示意图;
图12为本申请示例性实施例提供的以待渲染多媒体数据为5.1声道的多媒体数据为例的渲染过程示意图;
图13为本申请示例性实施例提供的一种虚拟环绕声渲染装置的结构示意图;
图14为本申请示例性实施例提供的一种电子设备的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
首先,对本申请一个或多个实施例涉及的名词术语进行解释。
虚拟环绕声(英文名称为Virtual Surround或者Simulated Surround),是能够把多声道的信号经过处理,在两个平行放置的音箱或者耳机中回放出来,并且能够让人感觉到环绕声的效果的声音。虚拟环绕声系统是在双声道立体声的基础上,不增加声道和音箱,把声场信号通过电路处理后播出,使聆听者感到声音来自多个方位,产生仿真的立体声场。
头部相关传输函数(Head Related Transfer Functions,缩写:HRTF)又称为ATF(anatomical transfer function),是一种音效定位算法。HRTF是一组滤波器,可利用ITD(Interaural Time Delay)、IAD(Interaural Amplitude Difference)和耳廓频率振动等技术产生立体音效,使声音传递至人耳内的耳廓,耳道和鼓膜时,聆听者会有环绕音效之感觉,通过数字信号处理(Digital Signal Processing,DSP),HRTF可实时处理虚拟世界的音源。
单声道音频,是把来自不同方位的音频信号混合后统一由录音器材把它记录下来,再由一只音箱进行播放。单声道音频是指只有一个通道的信号,或者有多个相同但不包含指向信息的通道的信号。单声道音频模式下两只耳机内的音频是一样的。
5.1声道是指中央声道,通俗讲就是五只音箱加上一只低音炮,前置左、右声道,后置左、右环绕声道,一只中置音箱,及所谓的0.1声道重低音声道。5.1声道的一套系统总共可连接6个喇叭。
7.1声道是指环绕立体声,也就是7只音箱加上一只低音炮。环绕其实是虚拟的,实际上只有5个音区(左前方环绕、右前方环绕、中置环绕、左后方环绕、右后方环绕)。剩余2个音区(左环绕、右环绕)是从主音区分配来的。具体来说,7.1声道包括2只前置声道,1只中置声道,2只侧环绕声道,2只后环绕声道和1只低音炮。
如背景技术所述,随着个人电脑,智能手机以及头显等可移动穿戴设备的普及应用,越来越多的用户比如三维空间的游戏爱好者,希望能够轻松便捷地享受到多声道环绕声的效果,同时希望重放设备也能够尽量少,但依然能保持原多声道系统的重放效果,这也对虚拟环绕声的应用范围提出了更高的要求。然而,现有的虚拟环绕声技术大多针对单一场景进行渲染,而且渲染场景通常只局限于静态场景中。
针对此,为对现有的虚拟环绕声技术进行改进以将虚拟环绕声技术应用到更广泛的场景中,同时改善收听者音频体验,本申请实施例提供的方法考虑在确定待渲染多媒体数据的渲染方式时,综合考虑待渲染多媒体数据的声道数和影音场景以及待渲染多媒体数据的收听用户的头部转动角度的变换情况,使得基于确定的渲染方式渲染得到的目标虚拟环绕声,能够给收听用户带来更优质的音频体验,同时,充分考虑到了不同场景的差异,也能够使得该渲染方法应用于更多的场景中。具体地,在本说明书中,提供了虚拟环绕声渲染方法,本说明书同时涉及虚拟环绕声渲染装置,电子设备和计算机可读存储介质,在下面的实施例中逐一进行详细说明。
参见图1,图1为本申请实施例提供的虚拟环绕声渲染方法实现的系统流程示意图。本申请一个实施例中,为了使得渲染得到的虚拟环绕声给收听用户带来更具沉浸式和空间感的音效体验,综合待渲染多媒体数据的声道数、收听用户的体验场景、以及收听用户的头部位置,来确定待渲染多媒体数据的渲染函数。具体地,如图1所示,对待渲染多媒体数据执行S1声道分析,以确定待渲染多媒体数据的声道数,该声道数可包括单声道、双声道、5.1声道和7.1声道,再执行S2确定影音场景,以从提供的录音棚小房间、电影院和音乐厅等场景中确定待渲染多媒体数据的影音场景,接着对收听用户进行头部追踪以执行S3确定头部位置,然后基于待渲染多媒体数据的声道数、影音场景和头部位置执行S4确定渲染函数为目标相关脉冲响应函数,再基于目标相关脉冲响应函数对待渲染多媒体数据的多个声道执行S5进行渲染,得到虚拟环绕声,最后将虚拟环绕声执行S6输入至收听设备中进行播放。
参见图2,图2示出了本申请示例性实施例提供的一种虚拟环绕声渲染方法的流程示意图。如图2所示,该方法可包括:
步骤210,确定待渲染多媒体数据的声道数和影音场景。
其中,待渲染多媒体数据的声道数可对待渲染多媒体数据进行声道分析来确定,例如,待渲染多媒体数据的声道数可携带在待渲染多媒体数据的音频文件中,可通过解析待渲染多媒体数据的音频文件头中的内容获取得到。通常来讲,待渲染多媒体数据的声道数可包括1、2、6和8。当待渲染多媒体数据的声道数为1时,该声道数对应于单声道,由于收听用户用双耳收听,因此可将该带渲染多媒体数据复制到双声道中,即初始情况下到达两个声道中的资源内容是一样的,再通过立体声渲染到收听用户双耳的方案,完成两个声道的待渲染多媒体数据的渲染。当待渲染多媒体数据的声道数为2时,该待渲染多媒体数据为双声道的多媒体数据,当待渲染多媒体数据的声道数为6时,该待渲染多媒体数据可为5.1声道的多媒体数据,当待渲染多媒体数据的声道数为8时,该待渲染多媒体数据可为7.1声道的多媒体数据。
可选地,待渲染多媒体数据的影音场景包括但不限于录音棚小房间、电影院和音乐厅等场景。其中,一个影音场景对应于一个房间冲击响应函数,不同的影音场景对应于不同的房间冲击响应函数,从而基于某一具体的影音场景对应的房间冲击响应函数对待渲染多媒体数据进行渲染,以模拟出该影音场景中待渲染资源的播放效果,增强收听用户收听渲染得到的虚拟环绕声的空间感和临场感。
在一些示例性的实施例中,该影音场景可由收听用户自定义选择,确定待渲染多媒体数据的影音场景,包括:
响应于待渲染多媒体数据的接入请求,向收听用户展示预设的影音场景列表,预设的影音场景列表中包含有多个预设的影音场景,多个预设的影音场景对应于不同的房间冲击响应函数;
响应于收听用户从预设的影音场景列表中对待渲染多媒体数据的影音场景的选择指令,确定待渲染多媒体数据的影音场景。
例如,在收听用户选择播放待渲染多媒体数据时,也即待渲染多媒体数据接入时,可在收听设备上展示预设的影音场景列表供收听用户选择,该预设的影音场景列表中可包括录音棚小房间、电影院和音乐厅等影音场景,收听用户可通过点击等操作从预设的影音场景列表中选择任意一个影音场景模拟待渲染多媒体数据的播放场景。
步骤220,确定待渲染多媒体数据的收听用户的头部转动角度。
应理解,由于渲染函数与声源到双耳的相对位置有关,可能存在较大的个体差异。因此,对于不同的收听用户来说,理想的有效听音域是有限的,而且收听用户头部的轻微转动可能也会造成前后声像的倒置等问题。本申请实施例基于此,在确定待渲染多媒体数据的渲染函数之前,还可通过收听设备的头部追踪模块确定收听用户的头部转动角度。其中,收听设备的头部追踪模块可通过收听设备中的陀螺仪、加速度传感器等模块来实现,收听设备包括但不限于手机、耳机和头显等具备多媒体数据播放功能的移动可穿戴设备。
在一些示例性的实施例中,可对收听用户的头部建立三维坐标系,依据三维坐标系中每个坐标平面的角度变化值来确定收听用户的头部转动角度。具体地,确定待渲染多媒体数据的收听用户的头部转动角度,包括:
建立收听用户的头部三维坐标系;
通过内置在收听用户佩戴的移动设备中的头部追踪模块,获取收听用户的头部关于所述三维坐标系各平面的角度变化值;
基于三维坐标系各平面对应的角度变化值,确定收听用户的头部转动角度。
其中,收听用户的头部三维坐标系包括XOZ平面、ZOY平面和XOY平面;
图3为根据本申请实施例提供的虚拟环绕声渲染方法对收听用户的头部建立三维坐标系的示意图。在图3中,该收听用户的头部三维坐标系的原点可以为第一连线与第二连线之间的交点,其中,第一连线为收听用户两耳尖之间的连线,第二连线为收听用户两眼之间的中心点与后脑勺上与该中心点相对应的点之间的连线,该收听用户的头部三维坐标系由用于指向左右的X坐标系(该X坐标系与第一连线相平行)、用于指向前后的Z坐标系(该Z坐标系与第二连线相平行)和用于指向上下的Y坐标系(该Y坐标系与收听用户的头顶中心点切面垂直的线相平行)组成。其中,X坐标系方向上的偏转角可称为俯仰角、Y坐标系方向上的偏转角可称为偏航角、Z坐标系方向上的偏转角可称为翻滚角。通常情况下,由于各个声道对应的虚拟扬声器是摆放在一个平面上的,在确定收听用户的头部转动角度时,可基于XOZ平面的角度变化值来确定。然而,收听设备由于穿戴在收听用户身上,会随着收听用户头部的转动而转动,因此,并不能保证始终与各个声道对应的虚拟扬声器处于同一平面上。本申请实施例基于此,可根据ZOY平面和XOY平面的角度变化值,对XOZ平面的角度变化值进行修正。
假设φ为从XOZ平面逆时针旋转的方位角,θ为从XOY平面计算出的仰角。则球面坐标(x,y,z)和方位角与仰角之间的转换可通过如下公式(1)~(3)来实现:


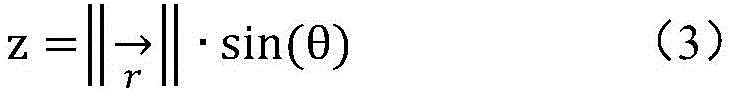
其中,r是球坐标的半径,默认值为1。
步骤230,基于声道数和影音场景以及收听用户的头部转动角度,确定目标渲染函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
其中,目标渲染函数可包括目标头相关脉冲响应函数和目标房间脉冲响应函数。目标头相关脉冲响应函数与收听用户的头部转动角度相关,即目标头相关脉冲响应函数为基于收听用户的头部转动角度确定的,一个目标头相关脉冲响应函数对应于一个时域图,可基于该时域图中的波形对输入至各声道中的待渲染多媒体数据进行滤波处理。不同头部转动角度对应于不同的目标相关脉冲响应函数,也就是说不同头部转动角度对应的目标头相关脉冲响应函数的时域图中的波形是不同的。
目标房间相关脉冲响应函数与待渲染多媒体数据的影音场景相关,即目标房间相关脉冲响应函数为基于待渲染多媒体数据的影音场景确定的,一个目标房间相关脉冲响应函数对应于一个时域图,可基于该时域图中的波形对输入至各声道中的待渲染多媒体数据进行滤波处理。不同影音场景对应于不同的目标房间脉冲响应函数,也就是说不同影音场景对应的目标房间相关脉冲响应函数的时域图中的波形是不同的。
在一些示例性的实施例中,目标渲染函数包括目标头相关脉冲响应函数和目标房间相关脉冲响应函数,基于待渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,确定目标头相关脉冲响应函数和目标房间相关脉冲响应函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声,包括:
基于声道数和影音场景,确定虚拟扬声器与收听用户的头部之间的夹角;
基于收听用户的头部转动角度,更新虚拟扬声器与收听用户的头部之间的夹角;
基于更新后的虚拟扬声器与收听用户的头部之间的夹角以及影音场景,确定目标头相关脉冲响应函数和目标房间相关脉冲响应函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
在一些示例性的实施例中,为消除收听用户头部定位效应,改善声像位置混乱的问题,本申请实施例可在收听用户的头部位置发生变化时,即收听用户的头部角度出现变化时,对各声道对应的虚拟扬声器与收听用户的头部之间的角度进行修正,使得各声道对应的虚拟扬声器与收听用户的头部之间的相对位置不随收听用户的头部位置的变动而发生变化,进而达到消除收听用户头部定位效应,避免声像位置混乱的目的。具体地,基于收听用户的头部转动角度,更新多个虚拟扬声器与收听用户的头部之间的夹角,包括:
确定收听用户的头部转动角度的方向和角度值;
基于收听用户的头部转动角度的方向和角度值,确定虚拟扬声器与所述收听用户的头部之间的夹角的修正方向和修正值;
基于修正方向和修正值,更新虚拟扬声器与收听用户的头部之间的夹角。
比如,收听用户的头部在XOZ平面上以其头部三维坐标系的原点为中心点逆时针转动了90°,则为了消除各声道对应的虚拟扬声器与收听用户的头部出现相对位置改变导致的头部定位效应以及声像位置混乱的问题,各声道对应的虚拟扬声器也可以收听用户头部三维坐标系的原点为中心点逆时针转动90°或顺时针转动270°,从而使得各声道对应的虚拟扬声器与收听用户的头部之间的相对位置不变。
在一些示例性的实施例中,基于更新后的虚拟扬声器与收听用户的头部之间的夹角以及所述影音场景,确定目标头相关脉冲响应函数和目标房间相关脉冲响应函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声,包括:
基于更新后的虚拟扬声器与收听用户的头部之间的夹角,确定虚拟扬声器对应的目标头相关脉冲响应函数和目标房间相关脉冲响应函数;
基于目标头相关脉冲响应函数和目标房间相关脉冲响应函数,对输入至虚拟扬声器的待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
在一些示例性的实施例中,可将各声道对应的目标头相关脉冲响应函数和目标房间相关脉冲响应函数进行叠加后,再对该声道要播放的待渲染多媒体数据进行渲染处理。具体地,基于目标头相关脉冲响应函数和目标房间相关脉冲响应函数,对输入至虚拟扬声器的待渲染多媒体数据进行渲染,得到目标虚拟环绕声,包括:
将目标头相关脉冲响应函数和目标房间相关脉冲响应函数进行叠加,得到叠加后的目标脉冲响应函数;
对叠加后的目标脉冲响应函数与对应的虚拟扬声器的待渲染多媒体数据进行卷积运算;
基于卷积运算的结果,得到目标虚拟环绕声。
下面以单声道、双声道、5.1声道和7.1声道的待渲染多媒体数据的渲染过程为例,对本申请实施例提供的方法进行详细介绍。
对于单声道的待渲染多媒体数据,通常需要将单声道中的多媒体数据内容复制到双声道中,再通过双声道渲染到收听用户双耳的渲染方式完成渲染。参见图4,图4为根据本申请实施例提供的虚拟环绕声渲染方法将双声道的多媒体数据渲染到收听用户双耳的场景示意图。假设该场景中左右两声道对应的虚拟扬声器分别为L和R,虚拟扬声器L和R到使用者双耳的目标相关脉冲响应函数分别为HRL,HLL,HLR,HRR,则收听用户双耳的声压PL,PR则为各虚拟扬声器分别产生的双耳声压的和。其中,PL=HLL*L+HRL*R,PR=HLR*L+HRRR,*表示卷积运算。
对于5.1声道的待渲染多媒体数据,参见图5,图5为根据本申请实施例提供的虚拟环绕声渲染方法将5.1声道的多媒体数据渲染到收听用户双耳的场景示意图。假设5.1声道中各声道对应的虚拟扬声器分别为L、C、R、LR、RS、LFE,虚拟扬声器L、C、R、LS、RS、LFE到使用者双耳的目标相关脉冲响应函数分别为HRL、HLL、HLR、HRR、HCL、HCR、HRSR、HRSL、HLSR、HLSL、HLFER、HLFEL,则收听用户双耳的声压PL、PR为各声道对应的虚拟扬声器分别产生的双耳声压的和。其中,PL=HLL*L+HLR*R+HCL*C+HLSL*LS+HRSL*RS+HLFEL*LFE,PR=HLR*L+HRrr+HCR*C+HLSR*LS+HRSR*RS+HLFER*LFE,*表示卷积运算。
对于7.1声道的待渲染多媒体数据,参见图6,图6为根据本申请实施例提供的虚拟环绕声渲染方法将7.1声道的多媒体数据渲染到收听用户双耳的场景示意图。假设7.1声道中各声道对应的虚拟扬声器分别为L、C、R、LS、RS、LBS、RBS、LFF,虚拟扬声器L、C、R、LS、RS、LBS、RBS、LFE到收听用户双耳的目标相关脉冲响应函数分别为HRL,HLL,HLR,HRR,HCL,HCR,HRSR,HRSL,HLSR,HLSL,HRBSR,HRBSL,HLBSR,HLBSL,HLFER,HLFEL,则双耳的声压PL、PR为各声道对应的虚拟扬声器分别产生的双耳声压的和。其中,PL=HLL*L+HRL*R+HCL*C+HLSL*LS+HRSL*RS+HLBSL*LBS+HRBSL*RBS+HLFEL*LFE,PR=HLR*L+HRR*R+HCR*C+HLSR*LS+HRSR*RS+HLBSR*LBS+HRBSR*RBS++HLFER*LFE,*表示卷积运算。
应理解,在单独考虑收听用户的头部转动角度对虚拟环绕声的影响时,上述目标渲染函数为目标头相关脉冲响应函数,在单独考虑影音场景对虚拟环绕声的影响时,上述目标渲染函数为目标房间相关脉冲响应函数。在综合考虑收听用户的头部转动角度和影音场景对虚拟环绕声的影响时,上述目标渲染函数可以是目标头相关脉冲响应函数和目标房间相关脉冲响应函数叠加处理后的渲染函数。
在考虑影音场景对虚拟环绕声的影响时,可利用roomsim仿真工具,生成图7所示的一个长方形房间,房间的长宽高可以根据需求进行设定,房间的6个平面可以根据反射和吸收系数的不同需求设定为不同的材料。例如,在模拟录音棚小房间时,可选择吸收性较好的吸音棉等材料作为房间的6个平面的材料。图7所示的房间模拟的是左耳以及右耳接收5.1声道的虚拟扬声器播放的多媒体数据的场景示意图。图8为图7所示的影音场景中5.1声道的虚拟扬声器与左耳以及右耳之间的房间相关脉冲响应函数的波形图,该房间相关脉冲响应函数主要包含直达声、早期镜面反射和混响尾等几个感知相关的成分。
作为一种实施方式,上述目标头相关脉冲响应函数和目标房间相关脉冲响应函数可利用图像源方法(英文名称为image-source method)和漫射雨射线追踪算法(diffuserain ray-tracing algorithm)生成。在实际应用中,可预先生成不同影音场景下的目标房间相关脉冲响应函数的波形图、以及不同角度下的目标头相关脉冲响应函数的波形图,在进行虚拟环绕声渲染时,调用对应的影音场景下的目标房间相关脉冲响应函数的波形图、以及对应角度下的目标头相关脉冲响应函数的波形图对输入的影音信号进行滤波处理即可。
以目标房间相关脉冲响应函数的生成过程为例,参见图9,为本申请一个实施例根据图像源方法生成目标房间相关脉冲响应函数中声音传播路径的示意图。在图像源方法中,可通过声源在房间墙面的镜像来创建虚拟图像源,如图9所示,声源为S,声源S在四面墙上的镜像分别为S1~S4,S1~S4为创建的虚拟图像源。从虚拟图像源S1~S4到接收器R的直线对应的是房间中声源S在多个墙面反射到接收器R的声音传播路径。通过获取这些直线的长度和它相交墙面的吸收反射系数,相应的声音传播路径对房间脉冲响应的贡献就可以被计算出来。图像源方法可以精确地找到房间内的所有传播路径,这就使得它非常适合模拟直达声音和低阶反射。然而,该方法对于高阶反射的计算效率较低,因为虚源的数量随着反射阶数的增加而迅速增加,因此,图像源方法通常适合模拟早期镜面反射。
继续以目标房间相关脉冲响应函数的生成过程为例,参见图10,为本申请一个实施例根据漫射雨射线追踪算法生成目标房间相关脉冲响应函数中声能量射线的传播路径示意图。漫射雨射线追踪算法可生成高阶反射、混响尾和漫反射。在漫射雨射线追踪算法中,声能量射线从声源S发射,并在整个房间中跟踪,如图10所示。当声能量射线击中物体表面时,其所携带的声能量可根据物体表面的吸收而降低。接下来,声能量射线对房间脉冲响应的直接贡献可通过从冲击点向接收器R发射第二束射线并记录这束射线的入射角、到达时间和在接收器上的剩余声能量来确定。从声源S发射出的原始第一条射线可从撞击点以随机方向继续发射,并进一步跟踪,直到其声音能量低于预设的能量阈值。所有的声能量射线都可这样处理,而且因为吸收和漫反射都是频率相关的现象,因此,这个过程在所有频带上都可重复。
如图11所示,为本申请一个实施例根据漫射雨射线追踪算法生成目标房间相关脉冲响应函数中接收器收到的一条声能量射线的能量示意图。在接收器R处,一条频率为f的射线以ψ=(θ,φ)的角度在到达时间t时的能量在时频直方图Ei(n,k)中累积。对于每个球仓,时频直方图Ei(n,k)经以下过几步就可以转化为目标房间相关脉冲响应函数。首先,是一个泊松噪声过程,泊松噪声信号的谱图为白色,可按照时频直方图Ei(n,k)进行整形。然后,将整形后的噪声信号与接收器R的冲击响应进行ψ角卷积。最后,将得到的所有球仓信号求和为一个脉冲响应,再叠加在图像源方法的输出上,便可得到完整的目标房间相关脉冲响应函数。
需要说明的是,按照重放设备(即上文所述收听设备)的不同,虚拟环绕声又可以分为基于音箱重放的虚拟环绕声和基于耳机重放的虚拟环绕声。这二者在本质上均是通过双声道信号来实现虚拟环绕声的效果,只需要将上述双耳的声压PL、PR公式中的各声道对应的虚拟扬声器选用与重放设备对应的目标相关脉冲响应函数进行滤波处理就可以实现对应的虚拟环绕声的效果。
此外,为了防止滤波后的信号出现爆音等尖锐噪声,虚拟环绕处理后虚拟环绕声还可使用预设的limiter进行保护,即不管输入电平怎样增加,其最大输出电平均不能大于最大预设输出电平值。具体地,基于声道数和影音场景以及收听用户的头部转动角度,确定目标渲染函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声,包括:
基于声道数和影音场景以及收听用户的头部转动角度,确定目标相关脉冲响应函数;
基于目标渲染函数对待渲染多媒体数据进行渲染,得到渲染后的虚拟环绕声;
将渲染后的虚拟环绕声中大于最大预设输出电平值的电平变换为最大预设输出电平值,得到目标虚拟环绕声。
参见图12,为本申请一示例性的实施例提供的以待渲染多媒体数据为5.1声道的多媒体数据为例的渲染过程示意图。如图12所示,该过程可包括:S121,输入待渲染多媒体数据;S122,对待渲染多媒体数据进行分析,确定待渲染多媒体数据为5.1声道的多媒体数据;S123,确定收听用户选择的目标影音场景;S124,通过收听设备的头部追踪模块获取收听用户的头部转动角度信息;S125,确定与目标影音场景对应的房间相关脉冲响应函数以及与收听用户的头部转动角度信息对应的头相关脉冲响应函数;S126,将房间相关脉冲响应函数以及头相关脉冲响应函数进行叠加得到渲染函数;S127,通过渲染函数将待渲染多媒体数据的多个声道进行渲染,输出至收听设备。
以5.1声道为例,假设从逆时针角度来看,虚拟扬声器L,C,R,LS,RS,LFe与收听用户头部之间的夹角分别是45°,0°,315°,135°,225°,22.5°,且它们都在一个平面上。此时从确定对应夹角位置的头相关脉冲响应函数对各虚拟扬声器的输入信号利用5.1声道中PL、PR的公式进行渲染获得到当前各虚拟扬声器的输出。假设通过头部追踪模块检测到收听用户头部转动逆时针转动了90°角时,则L,C,R,LS,RS,LFE各虚拟扬声器与收听用户头部之间的相对夹角则变为:315°,270°,225°,45°,135°,67.5°。此时需要选择当前角度下的头相关脉冲响应函数对各虚拟扬声器的输入信号利用5.1声道中PL、PR的公式进行渲染获得到当前各虚拟扬声器的输出。也就是说各虚拟扬声器选用的头相关脉冲响应函数需要跟据收听用户头部角度的变化进行实时刷新,从而实现声源不随使用者头部的转动而转动,消除头中定位效应,改善声像位置混乱的问题。
另外,本实施例提供的方法可应用于任何存在虚拟环绕声渲染的应用场景中,都能实时根据带渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,确定用于渲染待渲染多媒体数据的目标渲染函数,使得渲染得到的虚拟环绕声更能贴合实际设备、实际场景和收听用户的头部角度,从而给用户带来更好的音频体验。
在本申请一些实施例提供的虚拟环绕声渲染方法中,由于能够在确定待渲染多媒体数据的渲染方式时,不仅能够确定待渲染多媒体数据的声道数和影音场景,而且还考虑到待渲染多媒体数据的收听用户的头部转动角度的变换情况,最后基于待渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,使得确定的目标渲染函数与收听用户当前所处的环境、待渲染多媒体数据的声道数以及收听用户的头部转动角度相匹配的,这样通过目标渲染函数对待渲染多媒体数据进行渲染得到目标虚拟环绕声,也就能够给收听用户带来更优质的音频体验,而且,该渲染方式充分考虑到了不同场景的差异,也能够应用于更多的场景中。
需要说明的是,上述实施例所提供方法的各步骤的执行主体均可以是同一设备,或者,该方法也由不同设备作为执行主体。比如,步骤210至步骤230的执行主体可以为设备A;又比如,步骤210至步骤220的执行主体可以为设备A,步骤230的执行主体可以为设备B;等等。
另外,在上述实施例及附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如210、220等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。
图13为本申请示例性实施例提供的一种虚拟环绕声渲染装置的结构示意图。如图13所示,该装置包括:场景确定模块1310、角度确定模块1320和资源渲染模块1330,其中:
场景确定模块1310,用于确定待渲染多媒体数据的声道数和影音场景;
角度确定模块1320,用于确定所述待渲染多媒体数据的收听用户的头部转动角度;
资源渲染模块1330,用于基于所述声道数和所述影音场景以及所述收听用户的头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
本申请实施例提供的虚拟环绕声渲染装置,由于能够在确定待渲染多媒体数据的渲染方式时,不仅能够确定待渲染多媒体数据的声道数和影音场景,而且还考虑到待渲染多媒体数据的收听用户的头部转动角度的变换情况,最后基于待渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,使得确定的目标渲染函数与收听用户当前所处的环境、待渲染多媒体数据的声道数以及收听用户的头部转动角度相匹配的,这样通过目标渲染函数对待渲染多媒体数据进行渲染得到的目标虚拟环绕声,也就能够给收听用户带来更优质的音频体验,而且,该渲染方式充分考虑到了不同场景的差异,也能够应用于更多的场景中。
进一步可选地,所述目标渲染函数包括目标头相关脉冲响应函数和目标房间相关脉冲响应函数,所述资源渲染模块1330基于所述和所述影音场景以及所述收听用户的头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声时,具体用于:
基于所述声道数和所述影音场景,确定虚拟扬声器与所述收听用户的头部之间的夹角;
基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角;
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。
进一步可选地,所述资源渲染模块1330基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角时,具体用于:
确定所述收听用户的头部转动角度的方向和角度值;
基于所述收听用户的头部转动角度的方向和角度值,确定所述虚拟扬声器与所述收听用户的头部之间的夹角的修正方向和修正值;
基于所述修正方向和所述修正值,更新所述虚拟扬声器与所述收听用户的头部之间的夹角。
进一步可选地,所述资源渲染模块1330基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声时,具体用于:
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角,确定所述虚拟扬声器对应的目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数;
基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。
进一步可选地,所述资源渲染模块1330基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声时,具体用于:
将所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数进行叠加,得到多个所述叠加后的目标脉冲响应函数;
对所述叠加后的目标脉冲响应函数与对应的所述虚拟扬声器的待渲染多媒体数据进行卷积运算;
基于所述卷积运算的结果,得到所述目标虚拟环绕声。
进一步可选地,所述场景确定模块1310确定待渲染多媒体数据的影音场景时,具体用于:
响应于所述待渲染多媒体数据的接入请求,向所述收听用户展示预设的影音场景列表,所述预设的影音场景列表中包含有多个预设的影音场景,多个所述预设的影音场景对应于不同的房间冲击响应函数;
响应于所述收听用户从预设的影音场景列表中对所述待渲染多媒体数据的影音场景的选择指令,确定所述待渲染多媒体数据的影音场景。
进一步可选地,所述角度确定模块1320确定所述待渲染多媒体数据的收听用户的头部转动角度时,具体用于:
建立所述收听用户的头部三维坐标系;
通过内置在所述收听用户佩戴的移动设备中的头部追踪模块,获取所述收听用户的头部关于所述三维坐标系各平面的角度变化值;
基于所述三维坐标系各平面对应的角度变化值,确定所述收听用户的头部转动角度。
虚拟环绕声渲染装置能够实现图1~图12的方法实施例的方法,具体可参考图1~图12所示实施例的虚拟环绕声渲染方法,不再赘述。
图14为本申请示例性实施例提供的一种电子设备的结构示意图,该电子设备可包括耳机和头显等移动可穿戴设备。如图14所示,该设备包括:存储器141和处理器142。
存储器141,用于存储计算机程序,并可被配置为存储其它各种数据以支持在计算设备上的操作。这些数据的示例包括用于在计算设备上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。
处理器142,与存储器141耦合,用于执行存储器141中的计算机程序,以用于:确定待渲染多媒体数据的声道数和影音场景;确定所述待渲染多媒体数据的收听用户的头部转动角度;基于所述待渲染多媒体数据的声道数和影音场景以及所述收听用户的头部转动角度,确定目标相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
进一步可选地,所述目标渲染函数包括目标头相关脉冲响应函数和目标房间相关脉冲响应函数,所述处理器142基于所述和所述影音场景以及所述收听用户的头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声时,具体用于:
基于所述声道数和所述影音场景,确定虚拟扬声器与所述收听用户的头部之间的夹角;
基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角;
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。
进一步可选地,所述处理器142基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角时,具体用于:
确定所述收听用户的头部转动角度的方向和角度值;
基于所述收听用户的头部转动角度的方向和角度值,确定所述虚拟扬声器与所述收听用户的头部之间的夹角的修正方向和修正值;
基于所述修正方向和所述修正值,更新所述虚拟扬声器与所述收听用户的头部之间的夹角。
进一步可选地,所述处理器142基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声时,具体用于:
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角,确定所述虚拟扬声器对应的目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数;
基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。
进一步可选地,所述处理器142基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声时,具体用于:
将所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数进行叠加,得到多个所述叠加后的目标脉冲响应函数;
对所述叠加后的目标脉冲响应函数与对应的所述虚拟扬声器的待渲染多媒体数据进行卷积运算;
基于所述卷积运算的结果,得到所述目标虚拟环绕声。
进一步可选地,所述处理器142确定待渲染多媒体数据的影音场景时,具体用于:
响应于所述待渲染多媒体数据的接入请求,向所述收听用户展示预设的影音场景列表,所述预设的影音场景列表中包含有多个预设的影音场景,多个所述预设的影音场景对应于不同的房间冲击响应函数;
响应于所述收听用户从预设的影音场景列表中对所述待渲染多媒体数据的影音场景的选择指令,确定所述待渲染多媒体数据的影音场景。
进一步可选地,所述处理器142确定所述待渲染多媒体数据的收听用户的头部转动角度时,具体用于:
建立所述收听用户的头部三维坐标系;
通过内置在所述收听用户佩戴的移动设备中的头部追踪模块,获取所述收听用户的头部关于所述三维坐标系各平面的角度变化值;
基于所述三维坐标系各平面对应的角度变化值,确定所述收听用户的头部转动角度。
进一步,如图14所示,该电子设备还包括:通信组件143、显示器144、电源组件145、音频组件146等其它组件。图14中仅示意性给出部分组件,并不意味着电子设备只包括图14所示组件。另外,根据流量回放设备的实现形态的不同,图14中虚线框内的组件为可选组件,而非必选组件。例如,当电子设备实现为智能手机、平板电脑或台式电脑等终端设备时,可以包括图14中虚线框内的组件;当电子设备实现为常规服务器、云服务器、数据中心或服务器阵列等服务端设备时,可以不包括图14中虚线框内的组件。
相应地,本申请实施例还提供一种存储有计算机程序的计算机可读存储介质,计算机程序被处理器执行时,致使处理器能够实现上述虚拟环绕声渲染方法实施例中的步骤。
上述图14中的通信组件被配置为便于通信组件所在设备和其他设备之间有线或无线方式的通信。通信组件所在设备可以接入基于通信标准的无线网络,如WiFi,2G或3G,或它们的组合。在一个示例性实施例中,通信组件经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,所述通信组件还可以包括近场通信(Near Field Communication,NFC)模块,射频识别(Radio Frequency Identification,RFID)技术,红外数据协会(Infrared Data Association,IrDA)技术,超宽带(Ultra WideBand,UWB)技术,蓝牙(Bluetooth,BT)技术等。
上述图14中的存储器可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(Static Random-Access Memory,SRAM),电可擦除可编程只读存储器(Electrically Erasable Programmable read only memory,EEPROM),可擦除可编程只读存储器(Electrical Programmable Read Only Memory,EPROM),可编程只读存储器(Programmable read-only memory,PROM),只读存储器(Read-Only Memory,ROM),磁存储器,快闪存储器,磁盘或光盘。
上述图14中的显示器包括屏幕,其屏幕可以包括液晶显示器(Liquid CrystalDisplay,LCD)和触摸面板(Touchpanel,TP)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。
上述图14中的电源组件,为电源组件所在设备的各种组件提供电力。电源组件可以包括电源管理系统,一个或多个电源,及其他与为电源组件所在设备生成、管理和分配电力相关联的组件。
上述图14中的音频组件,可被配置为输出和/或输入音频信号。例如,音频组件包括一个麦克风(microphone,MIC),当音频组件所在设备处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器或经由通信组件发送。在一些实施例中,音频组件还包括一个扬声器,用于输出音频信号。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。内存是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(Phase-change memory,PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(Dynamic Random Access Memory,DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(Electrically Erasable Programmable read only memory,EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
Claims (10)
1.一种虚拟环绕声渲染方法,其特征在于,包括:
确定待渲染多媒体数据的声道数和影音场景;
确定所述待渲染多媒体数据的收听用户的头部转动角度;
基于所述声道数、所述影音场景以及所述头部转动角度,确定目标渲染函数,以基于所述目标渲染函数对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
2.如权利要求1所述的方法,其特征在于,所述目标渲染函数包括目标头相关脉冲响应函数和目标房间相关脉冲响应函数,所述基于所述声道数和所述影音场景以及所述头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声,包括:
基于所述声道数和所述影音场景,确定虚拟扬声器与所述收听用户的头部之间的夹角;
基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角;
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。
3.如权利要求2所述的方法,其特征在于,所述基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角,包括:
确定所述收听用户的头部转动角度的方向和角度值;
基于所述收听用户的头部转动角度的方向和角度值,确定所述虚拟扬声器与所述收听用户的头部之间的夹角的修正方向和修正值;
基于所述修正方向和所述修正值,更新所述虚拟扬声器与所述收听用户的头部之间的夹角。
4.如权利要求2或3所述的方法,其特征在于,所述基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声,包括:
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角,确定所述虚拟扬声器对应的目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数;
基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。
5.如权利要求4所述的方法,其特征在于,所述基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声,包括:
将所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数进行叠加,得到多个所述叠加后的目标脉冲响应函数;
对所述叠加后的目标脉冲响应函数与对应的所述虚拟扬声器的待渲染多媒体数据进行卷积运算;
基于所述卷积运算的结果,得到所述目标虚拟环绕声。
6.如权利要求1所述的方法,其特征在于,所述确定待渲染多媒体数据的影音场景,包括:
响应于所述待渲染多媒体数据的接入请求,向所述收听用户展示预设的影音场景列表,所述预设的影音场景列表中包含有多个预设的影音场景,多个所述预设的影音场景对应于不同的房间冲击响应函数;
响应于所述收听用户从预设的影音场景列表中对所述待渲染多媒体数据的影音场景的选择指令,确定所述待渲染多媒体数据的影音场景。
7.如权利要求1所述的方法,其特征在于,所述确定所述待渲染多媒体数据的收听用户的头部转动角度,包括:
建立所述收听用户的头部三维坐标系;
通过内置在所述收听用户佩戴的移动设备中的头部追踪模块,获取所述收听用户的头部关于所述三维坐标系各平面的角度变化值;
基于所述三维坐标系各平面对应的角度变化值,确定所述收听用户的头部转动角度。
8.一种虚拟环绕声渲染装置,其特征在于,包括:
场景确定模块,用于确定待渲染多媒体数据的声道数和影音场景;
角度确定模块,用于确定所述待渲染多媒体数据的收听用户的头部转动角度;
资源渲染模块,用于基于所述声道数、所述影音场景以及所述头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
9.一种电子设备,其特征在于,包括:存储器和处理器;
所述存储器,用于存储计算机程序;
所述处理器,与所述存储器耦合,用于执行所述计算机程序,以用于:
确定待渲染多媒体数据的声道数和影音场景;
确定所述待渲染多媒体数据的收听用户的头部转动角度;
基于所述声道数、所述影音场景以及所述头部转动角度,确定目标渲染函数,以基于所述目标渲染函数对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
10.一种存储有计算机程序的计算机可读存储介质,其特征在于,当所述计算机程序被处理器执行时,致使所述处理器实现权利要求1~7中任一项所述虚拟环绕声渲染方法中的步骤。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310177960.4A CN116193196A (zh) | 2023-02-16 | 2023-02-16 | 虚拟环绕声渲染方法、装置、设备及存储介质 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310177960.4A CN116193196A (zh) | 2023-02-16 | 2023-02-16 | 虚拟环绕声渲染方法、装置、设备及存储介质 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116193196A true CN116193196A (zh) | 2023-05-30 |
Family
ID=86450417
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310177960.4A Pending CN116193196A (zh) | 2023-02-16 | 2023-02-16 | 虚拟环绕声渲染方法、装置、设备及存储介质 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116193196A (zh) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025056002A1 (zh) * | 2023-09-12 | 2025-03-20 | 北京罗克维尔斯科技有限公司 | 声场模拟方法、装置、设备、介质及程序产品 |
| CN120602885A (zh) * | 2025-08-07 | 2025-09-05 | 歌尔股份有限公司 | 音频设备及其控制方法、存储介质 |
| WO2025201411A1 (en) * | 2024-03-29 | 2025-10-02 | Douyin Vision Co., Ltd. | Audio processing method and apparatus, electronic device, computer readable storage medium and computer program product |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060045294A1 (en) * | 2004-09-01 | 2006-03-02 | Smyth Stephen M | Personalized headphone virtualization |
| CN105120421A (zh) * | 2015-08-21 | 2015-12-02 | 北京时代拓灵科技有限公司 | 一种生成虚拟环绕声的方法和装置 |
| CN105376690A (zh) * | 2015-11-04 | 2016-03-02 | 北京时代拓灵科技有限公司 | 生成虚拟环绕声的方法和装置 |
| CN114866950A (zh) * | 2022-05-07 | 2022-08-05 | 安声(重庆)电子科技有限公司 | 音频处理方法、装置、电子设备以及耳机 |
-
2023
- 2023-02-16 CN CN202310177960.4A patent/CN116193196A/zh active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060045294A1 (en) * | 2004-09-01 | 2006-03-02 | Smyth Stephen M | Personalized headphone virtualization |
| CN105120421A (zh) * | 2015-08-21 | 2015-12-02 | 北京时代拓灵科技有限公司 | 一种生成虚拟环绕声的方法和装置 |
| CN105376690A (zh) * | 2015-11-04 | 2016-03-02 | 北京时代拓灵科技有限公司 | 生成虚拟环绕声的方法和装置 |
| CN114866950A (zh) * | 2022-05-07 | 2022-08-05 | 安声(重庆)电子科技有限公司 | 音频处理方法、装置、电子设备以及耳机 |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025056002A1 (zh) * | 2023-09-12 | 2025-03-20 | 北京罗克维尔斯科技有限公司 | 声场模拟方法、装置、设备、介质及程序产品 |
| WO2025201411A1 (en) * | 2024-03-29 | 2025-10-02 | Douyin Vision Co., Ltd. | Audio processing method and apparatus, electronic device, computer readable storage medium and computer program product |
| CN120602885A (zh) * | 2025-08-07 | 2025-09-05 | 歌尔股份有限公司 | 音频设备及其控制方法、存储介质 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9769589B2 (en) | Method of improving externalization of virtual surround sound | |
| JP5955862B2 (ja) | 没入型オーディオ・レンダリング・システム | |
| EP3343349B1 (en) | An apparatus and associated methods in the field of virtual reality | |
| CN109891503B (zh) | 声学场景回放方法和装置 | |
| US11589184B1 (en) | Differential spatial rendering of audio sources | |
| US12156015B2 (en) | System for and method of generating an audio image | |
| CN108781341B (zh) | 音响处理方法及音响处理装置 | |
| CN105325014A (zh) | 基于用户跟踪的声场调节 | |
| CN116193196A (zh) | 虚拟环绕声渲染方法、装置、设备及存储介质 | |
| US11109177B2 (en) | Methods and systems for simulating acoustics of an extended reality world | |
| TW201246060A (en) | Audio spatialization and environment simulation | |
| US20190289418A1 (en) | Method and apparatus for reproducing audio signal based on movement of user in virtual space | |
| US11221821B2 (en) | Audio scene processing | |
| US11102604B2 (en) | Apparatus, method, computer program or system for use in rendering audio | |
| CN111512648A (zh) | 启用空间音频内容的渲染以用于由用户消费 | |
| US9843883B1 (en) | Source independent sound field rotation for virtual and augmented reality applications | |
| CN114816316A (zh) | 音频回放的责任的指示 | |
| KR101111734B1 (ko) | 복수 개의 음원을 구분하여 음향을 출력하는 방법 및 장치 | |
| US20260025630A1 (en) | Methods, devices, and systems for reproducing spatial audio using binaural externalization processing extensions | |
| US20250350898A1 (en) | Object-based Audio Spatializer With Crosstalk Equalization | |
| CN116095594A (zh) | 虚拟环境中渲染实时空间音频的系统和方法 | |
| WO2025218310A9 (zh) | 声学场景回放方法和装置 | |
| WO2025218311A9 (zh) | 声学场景回放方法和装置 | |
| WO2025253637A1 (ja) | 音響信号生成装置、音響信号生成方法、及び音響信号生成プログラム | |
| CN121260169A (zh) | 一种音频处理方法、电子设备、存储介质和芯片 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |