CN116193196A - Virtual surround sound rendering method, device, equipment and storage medium - Google Patents
Virtual surround sound rendering method, device, equipment and storage medium Download PDFInfo
- Publication number
- CN116193196A CN116193196A CN202310177960.4A CN202310177960A CN116193196A CN 116193196 A CN116193196 A CN 116193196A CN 202310177960 A CN202310177960 A CN 202310177960A CN 116193196 A CN116193196 A CN 116193196A
- Authority
- CN
- China
- Prior art keywords
- target
- rendered
- head
- multimedia data
- audio
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000009877 rendering Methods 0.000 title claims abstract description 108
- 238000000034 method Methods 0.000 title claims abstract description 84
- 238000005316 response function Methods 0.000 claims description 126
- 230000006870 function Effects 0.000 claims description 45
- 238000004590 computer program Methods 0.000 claims description 19
- 230000008859 change Effects 0.000 claims description 18
- 238000012937 correction Methods 0.000 claims description 16
- 230000004044 response Effects 0.000 claims description 9
- 230000035939 shock Effects 0.000 claims description 4
- 230000009466 transformation Effects 0.000 abstract description 3
- 210000003128 head Anatomy 0.000 description 166
- 238000010586 diagram Methods 0.000 description 38
- 238000005516 engineering process Methods 0.000 description 18
- 230000008569 process Effects 0.000 description 16
- 210000005069 ears Anatomy 0.000 description 15
- 230000000694 effects Effects 0.000 description 14
- 238000004891 communication Methods 0.000 description 11
- 238000012545 processing Methods 0.000 description 9
- 230000005236 sound signal Effects 0.000 description 6
- 238000010521 absorption reaction Methods 0.000 description 5
- 230000003068 static effect Effects 0.000 description 4
- 239000000463 material Substances 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 238000004088 simulation Methods 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 208000025121 Leukoencephalopathy with brain stem and spinal cord involvement-high lactate syndrome Diseases 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 210000000624 ear auricle Anatomy 0.000 description 2
- 239000004973 liquid crystal related substance Substances 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 229920000742 Cotton Polymers 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 210000000613 ear canal Anatomy 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 210000003454 tympanic membrane Anatomy 0.000 description 1
Images














Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/44—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs
- H04N21/44012—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs involving rendering scenes according to scene graphs, e.g. MPEG-4 scene graphs
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/20—Arrangements for obtaining desired frequency or directional characteristics
- H04R1/32—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only
- H04R1/326—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only for microphones
Landscapes
- Engineering & Computer Science (AREA)
- Signal Processing (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Otolaryngology (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Stereophonic System (AREA)
Abstract
Description
技术领域technical field
本申请涉及虚拟环绕声技术领域,尤其涉及一种虚拟环绕声渲染方法、装置、设备及存储介质。The present application relates to the technical field of virtual surround sound, and in particular to a virtual surround sound rendering method, device, device and storage medium.
背景技术Background technique
为满足大多数用户对便携、高品质的移动影音体验的需求,能够利用较简单的设备实现高品质的影音环绕效果的虚拟环绕声技术应运而生。相对于多声道环绕声技术,虚拟环绕声技术通常只需两个声道就可以实现环绕声的效果,这就使得用户希望在重放设备尽量少的情况下仍能享受到“家庭影院”影音效果的愿望得以实现。而如何对现有的虚拟环绕声技术进行改进以将虚拟环绕声技术应用到更广泛的场景中,同时改善收听者音频体验,仍然需要提供进一步的解决方案。In order to meet the needs of most users for portable and high-quality mobile audio-visual experience, virtual surround sound technology, which can realize high-quality audio-visual surround effects with relatively simple equipment, has emerged as the times require. Compared with multi-channel surround sound technology, virtual surround sound technology usually only needs two channels to achieve the effect of surround sound, which makes users hope that they can still enjoy "home theater" with as few playback devices as possible. The wish of audio-visual effect is realized. However, how to improve the existing virtual surround sound technology so as to apply the virtual surround sound technology to a wider range of scenarios and improve the audio experience of listeners still needs to provide further solutions.
发明内容Contents of the invention
本申请的多个方面提供一种虚拟环绕声的渲染方法、装置、设备及存储介质,用以对现有的虚拟环绕声技术进行改进以将虚拟环绕声技术应用到更广泛的场景中,同时改善收听者音频体验。Various aspects of the present application provide a virtual surround sound rendering method, device, device, and storage medium, which are used to improve the existing virtual surround sound technology so as to apply the virtual surround sound technology to a wider range of scenarios, and at the same time Improve the listener audio experience.
本申请实施例提供一种虚拟环绕声的渲染方法,包括:确定待渲染多媒体数据的声道数和影音场景;确定所述待渲染多媒体数据的收听用户的头部转动角度;基于所述声道数、所述影音场景以及所述头部转动角度,确定目标渲染函数,以基于所述目标渲染函数对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。An embodiment of the present application provides a virtual surround sound rendering method, including: determining the number of channels of the multimedia data to be rendered and the audio-visual scene; determining the head rotation angle of the user listening to the multimedia data to be rendered; data, the audio-visual scene, and the head rotation angle, determine a target rendering function, so as to render the multimedia data to be rendered based on the target rendering function, and obtain target virtual surround sound.
本申请实施例还提供一种虚拟环绕声的渲染装置,包括:场景确定模块,用于确定待渲染多媒体数据的声道数和影音场景;角度确定模块,用于确定所述待渲染多媒体数据的收听用户的头部转动角度;资源渲染模块,用于基于所述声道数、所述影音场景以及所述头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。The embodiment of the present application also provides a virtual surround sound rendering device, including: a scene determination module, used to determine the number of channels and video and audio scenes of the multimedia data to be rendered; an angle determination module, used to determine the angle of the multimedia data to be rendered Listen to the user's head rotation angle; the resource rendering module is used to determine the target rendering function based on the number of channels, the audio-visual scene and the head rotation angle to render the multimedia data to be rendered to obtain the target Virtual surround sound.
本申请实施例还提供一种电子设备,包括:存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,与所述存储器耦合,用于执行所述计算机程序,以用于:确定待渲染多媒体数据的声道数和影音场景;确定所述待渲染多媒体数据的收听用户的头部转动角度;基于所述声道数、所述影音场景以及所述头部转动角度,确定目标渲染函数,以基于所述目标渲染函数对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。The embodiment of the present application also provides an electronic device, including: a memory and a processor; the memory is used to store a computer program; the processor is coupled to the memory and used to execute the computer program for : determine the number of channels and audiovisual scenes of the multimedia data to be rendered; determine the head rotation angle of the listening user of the multimedia data to be rendered; determine based on the number of channels, the audiovisual scenes and the head rotation angle A target rendering function, for rendering the multimedia data to be rendered based on the target rendering function to obtain target virtual surround sound.
本申请实施例还提供一种存储有计算机程序的计算机可读存储介质,当所述计算机程序被处理器执行时,致使所述处理器实现本申请实施例提供的虚拟环绕声渲染方法中的步骤。The embodiment of the present application also provides a computer-readable storage medium storing a computer program. When the computer program is executed by a processor, the processor is caused to implement the steps in the virtual surround sound rendering method provided in the embodiment of the present application. .
在本申请实施例中,由于能够在确定待渲染多媒体数据的渲染方式时,不仅能够确定待渲染多媒体数据的声道数和影音场景,而且还考虑到待渲染多媒体数据的收听用户的头部转动角度的变换情况,最后基于待渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,使得确定的目标渲染函数与收听用户当前所处的环境、待渲染多媒体数据的声道数以及收听用户的头部转动角度相匹配,这样通过目标渲染函数对待渲染多媒体数据进行渲染得到目标虚拟环绕声,也就能够给收听用户带来更优质的音频体验,而且,该渲染方式充分考虑到了不同场景的差异,也能够应用于更多的场景中。In the embodiment of the present application, when determining the rendering method of the multimedia data to be rendered, not only the number of channels and the audio-visual scene of the multimedia data to be rendered can be determined, but also the head rotation of the listening user of the multimedia data to be rendered can be considered Angle transformation, finally, based on the number of channels of the multimedia data to be rendered, the audio-visual scene and the head rotation angle of the listening user, the determined target rendering function is compatible with the current environment of the listening user and the number of channels of the multimedia data to be rendered and the head rotation angle of the listening user, so that the target virtual surround sound can be obtained by rendering the multimedia data to be rendered through the target rendering function, which can also bring a better audio experience to the listening user. Moreover, this rendering method fully takes into account Differences in different scenarios can also be applied to more scenarios.
附图说明Description of drawings
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:The drawings described here are used to provide a further understanding of the application and constitute a part of the application. The schematic embodiments and descriptions of the application are used to explain the application and do not constitute an improper limitation to the application. In the attached picture:
图1为本申请实施例提供的虚拟环绕声渲染方法实现的系统流程示意图;FIG. 1 is a schematic flowchart of a system implemented by a virtual surround sound rendering method provided in an embodiment of the present application;
图2为本申请示例性实施例提供的一种虚拟环绕声渲染方法的流程示意图;FIG. 2 is a schematic flowchart of a virtual surround sound rendering method provided by an exemplary embodiment of the present application;
图3为根据本申请实施例提供的虚拟环绕声渲染方法对收听用户的头部建立三维坐标系的示意图;3 is a schematic diagram of establishing a three-dimensional coordinate system for the head of the listening user according to the virtual surround sound rendering method provided by the embodiment of the present application;
图4为根据本申请实施例提供的虚拟环绕声渲染方法将双声道的多媒体数据渲染到收听用户双耳的场景示意图;FIG. 4 is a schematic diagram of a scene where binaural multimedia data is rendered to both ears of a listening user according to a virtual surround sound rendering method provided by an embodiment of the present application;
图5为根据本申请实施例提供的虚拟环绕声渲染方法将5.1声道的多媒体数据渲染到收听用户双耳的场景示意图;FIG. 5 is a schematic diagram of a scene where 5.1-channel multimedia data is rendered to both ears of a listening user according to a virtual surround sound rendering method provided by an embodiment of the present application;
图6为根据本申请实施例提供的虚拟环绕声渲染方法将7.1声道的多媒体数据渲染到收听用户双耳的场景示意图;FIG. 6 is a schematic diagram of a scene where 7.1-channel multimedia data is rendered to both ears of a listening user according to a virtual surround sound rendering method provided by an embodiment of the present application;
图7为本申请示例性实施例提供的房间模拟的是左耳以及右耳接收5.1声道的虚拟扬声器播放的多媒体数据的场景示意图;FIG. 7 is a schematic diagram of a scene where the room simulation provided by the exemplary embodiment of the present application is that the left ear and the right ear receive multimedia data played by a 5.1-channel virtual speaker;
图8为本申请示例性实施例提供的图7所示的影音场景中5.1声道的虚拟扬声器与左耳以及右耳之间的房间相关脉冲响应函数的波形图;FIG. 8 is a waveform diagram of the room-related impulse response function between the 5.1-channel virtual speaker and the left ear and the right ear in the audio-visual scene shown in FIG. 7 provided by an exemplary embodiment of the present application;
图9为本申请一个实施例根据图像源方法生成目标房间相关脉冲响应函数中声音传播路径的示意图;FIG. 9 is a schematic diagram of the sound propagation path generated in the target room-related impulse response function according to an embodiment of the present application according to the image source method;
图10为本申请一个实施例根据漫射雨射线追踪算法生成目标房间相关脉冲响应函数中声能量射线的传播路径示意图;FIG. 10 is a schematic diagram of the propagation path of acoustic energy rays in the target room-related impulse response function generated according to the diffuse rain ray tracing algorithm according to an embodiment of the present application;
图11为本申请一个实施例根据漫射雨射线追踪算法生成目标房间相关脉冲响应函数中接收器收到的一条声能量射线的能量示意图;Fig. 11 is an energy schematic diagram of an acoustic energy ray received by the receiver in the target room-related impulse response function generated according to the diffuse rain ray tracing algorithm according to an embodiment of the present application;
图12为本申请示例性实施例提供的以待渲染多媒体数据为5.1声道的多媒体数据为例的渲染过程示意图;FIG. 12 is a schematic diagram of a rendering process provided by an exemplary embodiment of the present application, where the multimedia data to be rendered is 5.1-channel multimedia data as an example;
图13为本申请示例性实施例提供的一种虚拟环绕声渲染装置的结构示意图;Fig. 13 is a schematic structural diagram of a virtual surround sound rendering device provided by an exemplary embodiment of the present application;
图14为本申请示例性实施例提供的一种电子设备的结构示意图。Fig. 14 is a schematic structural diagram of an electronic device provided by an exemplary embodiment of the present application.
具体实施方式Detailed ways
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。In order to make the purpose, technical solution and advantages of the present application clearer, the technical solution of the present application will be clearly and completely described below in conjunction with specific embodiments of the present application and corresponding drawings. Apparently, the described embodiments are only some of the embodiments of the present application, rather than all the embodiments. Based on the embodiments in this application, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the scope of protection of this application.
首先,对本申请一个或多个实施例涉及的名词术语进行解释。First, terms and terms involved in one or more embodiments of the present application are explained.
虚拟环绕声(英文名称为Virtual Surround或者Simulated Surround),是能够把多声道的信号经过处理,在两个平行放置的音箱或者耳机中回放出来,并且能够让人感觉到环绕声的效果的声音。虚拟环绕声系统是在双声道立体声的基础上,不增加声道和音箱,把声场信号通过电路处理后播出,使聆听者感到声音来自多个方位,产生仿真的立体声场。Virtual surround sound (English name is Virtual Surround or Simulated Surround), is a sound that can process multi-channel signals and play them back in two parallel speakers or headphones, and can make people feel the effect of surround sound . The virtual surround sound system is based on two-channel stereo, without adding channels and speakers, and broadcasting the sound field signal after being processed by the circuit, so that the listener feels that the sound comes from multiple directions and generates a simulated stereo field.
头部相关传输函数(Head Related Transfer Functions,缩写:HRTF)又称为ATF(anatomical transfer function),是一种音效定位算法。HRTF是一组滤波器,可利用ITD(Interaural Time Delay)、IAD(Interaural Amplitude Difference)和耳廓频率振动等技术产生立体音效,使声音传递至人耳内的耳廓,耳道和鼓膜时,聆听者会有环绕音效之感觉,通过数字信号处理(Digital Signal Processing,DSP),HRTF可实时处理虚拟世界的音源。Head Related Transfer Functions (Head Related Transfer Functions, abbreviation: HRTF), also known as ATF (anatomical transfer function), is a sound localization algorithm. HRTF is a set of filters that can use technologies such as ITD (Interaural Time Delay), IAD (Interaural Amplitude Difference) and pinna frequency vibration to produce stereo sound effects, so that when the sound is transmitted to the pinna, ear canal and tympanic membrane in the human ear, The listener will have the feeling of surround sound effect. Through digital signal processing (Digital Signal Processing, DSP), HRTF can process the sound source of the virtual world in real time.
单声道音频,是把来自不同方位的音频信号混合后统一由录音器材把它记录下来,再由一只音箱进行播放。单声道音频是指只有一个通道的信号,或者有多个相同但不包含指向信息的通道的信号。单声道音频模式下两只耳机内的音频是一样的。Mono audio is to mix audio signals from different directions and record it uniformly by recording equipment, and then play it by a speaker. Mono audio refers to a signal with only one channel, or multiple identical channels that contain no directional information. The audio in both earphones is the same in mono audio mode.
5.1声道是指中央声道,通俗讲就是五只音箱加上一只低音炮,前置左、右声道,后置左、右环绕声道,一只中置音箱,及所谓的0.1声道重低音声道。5.1声道的一套系统总共可连接6个喇叭。5.1 channel refers to the center channel, in layman’s terms, five speakers plus a subwoofer, front left and right channels, rear left and right surround channels, a center speaker, and the so-called 0.1 sound channel subwoofer channel. A total of 6 speakers can be connected to a 5.1-channel system.
7.1声道是指环绕立体声,也就是7只音箱加上一只低音炮。环绕其实是虚拟的,实际上只有5个音区(左前方环绕、右前方环绕、中置环绕、左后方环绕、右后方环绕)。剩余2个音区(左环绕、右环绕)是从主音区分配来的。具体来说,7.1声道包括2只前置声道,1只中置声道,2只侧环绕声道,2只后环绕声道和1只低音炮。7.1 channel refers to surround sound, that is, 7 speakers plus a subwoofer. The surround is actually virtual, and there are actually only 5 sound zones (left front surround, right front surround, center surround, left rear surround, right rear surround). The remaining 2 sound zones (left surround, right surround) are allocated from the main sound zone. Specifically, 7.1 channels include 2 front channels, 1 center channel, 2 side surround channels, 2 rear surround channels and 1 subwoofer.
如背景技术所述,随着个人电脑,智能手机以及头显等可移动穿戴设备的普及应用,越来越多的用户比如三维空间的游戏爱好者,希望能够轻松便捷地享受到多声道环绕声的效果,同时希望重放设备也能够尽量少,但依然能保持原多声道系统的重放效果,这也对虚拟环绕声的应用范围提出了更高的要求。然而,现有的虚拟环绕声技术大多针对单一场景进行渲染,而且渲染场景通常只局限于静态场景中。As mentioned in the background technology, with the popularization and application of mobile wearable devices such as personal computers, smart phones, and head-mounted displays, more and more users, such as game lovers in three-dimensional space, hope to enjoy multi-channel surround sound easily and conveniently. At the same time, it is hoped that there will be as few playback devices as possible, but the playback effect of the original multi-channel system can still be maintained, which also puts forward higher requirements for the application range of virtual surround sound. However, most of the existing virtual surround sound technologies are rendered for a single scene, and the rendered scene is usually limited to a static scene.
针对此,为对现有的虚拟环绕声技术进行改进以将虚拟环绕声技术应用到更广泛的场景中,同时改善收听者音频体验,本申请实施例提供的方法考虑在确定待渲染多媒体数据的渲染方式时,综合考虑待渲染多媒体数据的声道数和影音场景以及待渲染多媒体数据的收听用户的头部转动角度的变换情况,使得基于确定的渲染方式渲染得到的目标虚拟环绕声,能够给收听用户带来更优质的音频体验,同时,充分考虑到了不同场景的差异,也能够使得该渲染方法应用于更多的场景中。具体地,在本说明书中,提供了虚拟环绕声渲染方法,本说明书同时涉及虚拟环绕声渲染装置,电子设备和计算机可读存储介质,在下面的实施例中逐一进行详细说明。In view of this, in order to improve the existing virtual surround sound technology so as to apply the virtual surround sound technology to a wider range of scenarios and improve the audio experience of the listener, the method provided in the embodiment of the present application considers determining the multimedia data to be rendered In the rendering method, the number of channels of the multimedia data to be rendered, the video and audio scene, and the change of the head rotation angle of the user listening to the multimedia data to be rendered are considered comprehensively, so that the target virtual surround sound rendered based on the determined rendering method can give Listening users can bring a better audio experience, and at the same time, taking into account the differences of different scenes, this rendering method can also be applied to more scenes. Specifically, in this specification, a virtual surround sound rendering method is provided. This specification also relates to a virtual surround sound rendering device, an electronic device, and a computer-readable storage medium, which will be described in detail in the following embodiments one by one.
参见图1,图1为本申请实施例提供的虚拟环绕声渲染方法实现的系统流程示意图。本申请一个实施例中,为了使得渲染得到的虚拟环绕声给收听用户带来更具沉浸式和空间感的音效体验,综合待渲染多媒体数据的声道数、收听用户的体验场景、以及收听用户的头部位置,来确定待渲染多媒体数据的渲染函数。具体地,如图1所示,对待渲染多媒体数据执行S1声道分析,以确定待渲染多媒体数据的声道数,该声道数可包括单声道、双声道、5.1声道和7.1声道,再执行S2确定影音场景,以从提供的录音棚小房间、电影院和音乐厅等场景中确定待渲染多媒体数据的影音场景,接着对收听用户进行头部追踪以执行S3确定头部位置,然后基于待渲染多媒体数据的声道数、影音场景和头部位置执行S4确定渲染函数为目标相关脉冲响应函数,再基于目标相关脉冲响应函数对待渲染多媒体数据的多个声道执行S5进行渲染,得到虚拟环绕声,最后将虚拟环绕声执行S6输入至收听设备中进行播放。Referring to FIG. 1 , FIG. 1 is a schematic flowchart of a system implementing a virtual surround sound rendering method provided by an embodiment of the present application. In one embodiment of the present application, in order to make the rendered virtual surround sound bring more immersive and spatial sound experience to the listening user, the number of channels of the multimedia data to be rendered, the listening user's experience scene, and the listening user's head position to determine the rendering function of the multimedia data to be rendered. Specifically, as shown in FIG. 1 , S1 channel analysis is performed on the multimedia data to be rendered to determine the number of channels of the multimedia data to be rendered. The number of channels may include monophonic, dual-channel, 5.1-channel and 7.1-channel Then execute S2 to determine the audio-visual scene, so as to determine the audio-visual scene of the multimedia data to be rendered from the provided recording studio small room, movie theater and concert hall, etc., and then perform head tracking on the listening user to execute S3 to determine the head position, Then execute S4 based on the number of channels of the multimedia data to be rendered, the audio-visual scene and the head position to determine that the rendering function is a target-related impulse response function, and then execute S5 to render based on the multiple channels of the multimedia data to be rendered based on the target-related impulse response function, The virtual surround sound is obtained, and finally the virtual surround sound execution S6 is input to the listening device for playback.
参见图2,图2示出了本申请示例性实施例提供的一种虚拟环绕声渲染方法的流程示意图。如图2所示,该方法可包括:Referring to FIG. 2 , FIG. 2 shows a schematic flowchart of a virtual surround sound rendering method provided by an exemplary embodiment of the present application. As shown in Figure 2, the method may include:
步骤210,确定待渲染多媒体数据的声道数和影音场景。
其中,待渲染多媒体数据的声道数可对待渲染多媒体数据进行声道分析来确定,例如,待渲染多媒体数据的声道数可携带在待渲染多媒体数据的音频文件中,可通过解析待渲染多媒体数据的音频文件头中的内容获取得到。通常来讲,待渲染多媒体数据的声道数可包括1、2、6和8。当待渲染多媒体数据的声道数为1时,该声道数对应于单声道,由于收听用户用双耳收听,因此可将该带渲染多媒体数据复制到双声道中,即初始情况下到达两个声道中的资源内容是一样的,再通过立体声渲染到收听用户双耳的方案,完成两个声道的待渲染多媒体数据的渲染。当待渲染多媒体数据的声道数为2时,该待渲染多媒体数据为双声道的多媒体数据,当待渲染多媒体数据的声道数为6时,该待渲染多媒体数据可为5.1声道的多媒体数据,当待渲染多媒体数据的声道数为8时,该待渲染多媒体数据可为7.1声道的多媒体数据。Among them, the number of channels of the multimedia data to be rendered can be determined by analyzing the channels of the multimedia data to be rendered. For example, the number of channels of the multimedia data to be rendered can be carried in the audio file of the multimedia data to be rendered. The content in the audio file header of the data is obtained. Generally speaking, the number of channels of the multimedia data to be rendered may include 1, 2, 6 and 8. When the channel number of the multimedia data to be rendered is 1, the channel number corresponds to monophonic. Since the listening user listens with both ears, the rendered multimedia data can be copied to the dual channel, that is, in the initial case The content of the resources arriving in the two channels is the same, and then through stereo rendering to the listening user's ears, the rendering of the multimedia data to be rendered in the two channels is completed. When the number of channels of the multimedia data to be rendered is 2, the multimedia data to be rendered is two-channel multimedia data; when the number of channels of the multimedia data to be rendered is 6, the multimedia data to be rendered can be 5.1 channels For multimedia data, when the number of channels of the multimedia data to be rendered is 8, the multimedia data to be rendered may be 7.1-channel multimedia data.
可选地,待渲染多媒体数据的影音场景包括但不限于录音棚小房间、电影院和音乐厅等场景。其中,一个影音场景对应于一个房间冲击响应函数,不同的影音场景对应于不同的房间冲击响应函数,从而基于某一具体的影音场景对应的房间冲击响应函数对待渲染多媒体数据进行渲染,以模拟出该影音场景中待渲染资源的播放效果,增强收听用户收听渲染得到的虚拟环绕声的空间感和临场感。Optionally, the video and audio scenes to be rendered multimedia data include but not limited to small rooms in recording studios, movie theaters, and concert halls. Among them, one audio-visual scene corresponds to one room impact response function, and different audio-visual scenes correspond to different room impact response functions, so that the multimedia data to be rendered is rendered based on the room impact response function corresponding to a specific audio-visual scene to simulate the The playback effect of the resources to be rendered in the audio-visual scene enhances the sense of space and presence of the listening user listening to the rendered virtual surround sound.
在一些示例性的实施例中,该影音场景可由收听用户自定义选择,确定待渲染多媒体数据的影音场景,包括:In some exemplary embodiments, the audiovisual scene can be customized by the listening user to determine the audiovisual scene of the multimedia data to be rendered, including:
响应于待渲染多媒体数据的接入请求,向收听用户展示预设的影音场景列表,预设的影音场景列表中包含有多个预设的影音场景,多个预设的影音场景对应于不同的房间冲击响应函数;In response to an access request for multimedia data to be rendered, display a list of preset audio-visual scenes to the listening user. Room shock response function;
响应于收听用户从预设的影音场景列表中对待渲染多媒体数据的影音场景的选择指令,确定待渲染多媒体数据的影音场景。In response to listening to the user's selection instruction from the preset audio-visual scene list, the audio-visual scene of the multimedia data to be rendered is determined.
例如,在收听用户选择播放待渲染多媒体数据时,也即待渲染多媒体数据接入时,可在收听设备上展示预设的影音场景列表供收听用户选择,该预设的影音场景列表中可包括录音棚小房间、电影院和音乐厅等影音场景,收听用户可通过点击等操作从预设的影音场景列表中选择任意一个影音场景模拟待渲染多媒体数据的播放场景。For example, when the listening user chooses to play the multimedia data to be rendered, that is, when the multimedia data to be rendered is accessed, a preset audio-visual scene list may be displayed on the listening device for the listening user to select. The preset audio-visual scene list may include For audio-visual scenes such as small rooms in recording studios, cinemas, and concert halls, users can select any audio-visual scene from the preset audio-visual scene list to simulate the playback scene of multimedia data to be rendered by clicking and other operations.
步骤220,确定待渲染多媒体数据的收听用户的头部转动角度。
应理解,由于渲染函数与声源到双耳的相对位置有关,可能存在较大的个体差异。因此,对于不同的收听用户来说,理想的有效听音域是有限的,而且收听用户头部的轻微转动可能也会造成前后声像的倒置等问题。本申请实施例基于此,在确定待渲染多媒体数据的渲染函数之前,还可通过收听设备的头部追踪模块确定收听用户的头部转动角度。其中,收听设备的头部追踪模块可通过收听设备中的陀螺仪、加速度传感器等模块来实现,收听设备包括但不限于手机、耳机和头显等具备多媒体数据播放功能的移动可穿戴设备。It should be understood that since the rendering function is related to the relative position of the sound source to the ears, there may be large individual differences. Therefore, for different listening users, the ideal effective listening range is limited, and a slight rotation of the listening user's head may also cause problems such as inversion of the front and rear sound images. The embodiment of the present application is based on this, before determining the rendering function of the multimedia data to be rendered, the head-tracking module of the listening device may also be used to determine the head rotation angle of the listening user. Among them, the head tracking module of the listening device can be realized by modules such as gyroscopes and acceleration sensors in the listening device, and the listening device includes but is not limited to mobile wearable devices with multimedia data playback functions such as mobile phones, earphones, and head-mounted displays.
在一些示例性的实施例中,可对收听用户的头部建立三维坐标系,依据三维坐标系中每个坐标平面的角度变化值来确定收听用户的头部转动角度。具体地,确定待渲染多媒体数据的收听用户的头部转动角度,包括:In some exemplary embodiments, a three-dimensional coordinate system may be established for the listening user's head, and the head rotation angle of the listening user may be determined according to the angle change value of each coordinate plane in the three-dimensional coordinate system. Specifically, determining the head rotation angle of the user listening to the multimedia data to be rendered includes:
建立收听用户的头部三维坐标系;Establish a three-dimensional coordinate system of the listening user's head;
通过内置在收听用户佩戴的移动设备中的头部追踪模块,获取收听用户的头部关于所述三维坐标系各平面的角度变化值;Obtain the angle change value of the head of the listening user with respect to each plane of the three-dimensional coordinate system through the head tracking module built in the mobile device worn by the listening user;
基于三维坐标系各平面对应的角度变化值,确定收听用户的头部转动角度。Based on the angle change values corresponding to the planes of the three-dimensional coordinate system, the head rotation angle of the listening user is determined.
其中,收听用户的头部三维坐标系包括XOZ平面、ZOY平面和XOY平面;Wherein, the three-dimensional coordinate system of the listening user's head includes XOZ plane, ZOY plane and XOY plane;
图3为根据本申请实施例提供的虚拟环绕声渲染方法对收听用户的头部建立三维坐标系的示意图。在图3中,该收听用户的头部三维坐标系的原点可以为第一连线与第二连线之间的交点,其中,第一连线为收听用户两耳尖之间的连线,第二连线为收听用户两眼之间的中心点与后脑勺上与该中心点相对应的点之间的连线,该收听用户的头部三维坐标系由用于指向左右的X坐标系(该X坐标系与第一连线相平行)、用于指向前后的Z坐标系(该Z坐标系与第二连线相平行)和用于指向上下的Y坐标系(该Y坐标系与收听用户的头顶中心点切面垂直的线相平行)组成。其中,X坐标系方向上的偏转角可称为俯仰角、Y坐标系方向上的偏转角可称为偏航角、Z坐标系方向上的偏转角可称为翻滚角。通常情况下,由于各个声道对应的虚拟扬声器是摆放在一个平面上的,在确定收听用户的头部转动角度时,可基于XOZ平面的角度变化值来确定。然而,收听设备由于穿戴在收听用户身上,会随着收听用户头部的转动而转动,因此,并不能保证始终与各个声道对应的虚拟扬声器处于同一平面上。本申请实施例基于此,可根据ZOY平面和XOY平面的角度变化值,对XOZ平面的角度变化值进行修正。FIG. 3 is a schematic diagram of establishing a three-dimensional coordinate system for a listening user's head according to a virtual surround sound rendering method provided by an embodiment of the present application. In Fig. 3, the origin of the three-dimensional coordinate system of the listening user's head may be the intersection point between the first connecting line and the second connecting line, wherein the first connecting line is the connecting line between the two ear tips of the listening user, and the second connecting line The two connecting lines are the connecting line between the central point between the eyes of the listening user and the point corresponding to the central point on the back of the head. The three-dimensional coordinate system of the head of the listening user is composed of the X coordinate system for pointing to the left and right (the The X coordinate system is parallel to the first connecting line), the Z coordinate system for pointing forward and backward (the Z coordinate system is parallel to the second connecting line), and the Y coordinate system for pointing up and down (the Y coordinate system is related to the listening user The lines perpendicular to the tangential plane of the center point of the top of the head are parallel to each other). Wherein, the deflection angle in the direction of the X coordinate system may be called a pitch angle, the deflection angle in the direction of the Y coordinate system may be called a yaw angle, and the deflection angle in the direction of the Z coordinate system may be called a roll angle. Usually, since the virtual speakers corresponding to each channel are placed on a plane, when determining the head rotation angle of the listening user, it can be determined based on the angle change value of the XOZ plane. However, since the listening device is worn on the listening user, it will rotate with the rotation of the listening user's head. Therefore, it cannot be guaranteed that the virtual speakers corresponding to each channel are always on the same plane. Based on this, the embodiment of the present application can correct the angle change value of the XOZ plane according to the angle change values of the ZOY plane and the XOY plane.
假设φ为从XOZ平面逆时针旋转的方位角,θ为从XOY平面计算出的仰角。则球面坐标(x,y,z)和方位角与仰角之间的转换可通过如下公式(1)~(3)来实现:Suppose φ is the azimuth angle rotated counterclockwise from the XOZ plane, and θ is the elevation angle calculated from the XOY plane. Then the conversion between the spherical coordinates (x, y, z) and the azimuth angle and elevation angle can be realized by the following formulas (1)~(3):


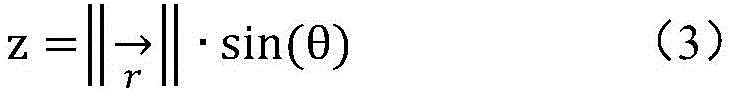
其中,r是球坐标的半径,默认值为1。Among them, r is the radius of the spherical coordinates, and the default value is 1.
步骤230,基于声道数和影音场景以及收听用户的头部转动角度,确定目标渲染函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声。
其中,目标渲染函数可包括目标头相关脉冲响应函数和目标房间脉冲响应函数。目标头相关脉冲响应函数与收听用户的头部转动角度相关,即目标头相关脉冲响应函数为基于收听用户的头部转动角度确定的,一个目标头相关脉冲响应函数对应于一个时域图,可基于该时域图中的波形对输入至各声道中的待渲染多媒体数据进行滤波处理。不同头部转动角度对应于不同的目标相关脉冲响应函数,也就是说不同头部转动角度对应的目标头相关脉冲响应函数的时域图中的波形是不同的。Wherein, the target rendering function may include a target head-related impulse response function and a target room impulse response function. The target head-related impulse response function is related to the listening user's head rotation angle, that is, the target head-related impulse response function is determined based on the listening user's head rotation angle, and a target head-related impulse response function corresponds to a time-domain diagram, which can be Based on the waveform in the time domain diagram, the multimedia data to be rendered input into each channel is filtered. Different head rotation angles correspond to different target-related impulse response functions, that is to say, the waveforms in the time-domain diagrams of the target head-related impulse response functions corresponding to different head rotation angles are different.
目标房间相关脉冲响应函数与待渲染多媒体数据的影音场景相关,即目标房间相关脉冲响应函数为基于待渲染多媒体数据的影音场景确定的,一个目标房间相关脉冲响应函数对应于一个时域图,可基于该时域图中的波形对输入至各声道中的待渲染多媒体数据进行滤波处理。不同影音场景对应于不同的目标房间脉冲响应函数,也就是说不同影音场景对应的目标房间相关脉冲响应函数的时域图中的波形是不同的。The target room-related impulse response function is related to the audio-visual scene of the multimedia data to be rendered, that is, the target room-related impulse response function is determined based on the audio-visual scene of the multimedia data to be rendered, and a target room-related impulse response function corresponds to a time-domain graph, which can be Based on the waveform in the time domain diagram, the multimedia data to be rendered input into each channel is filtered. Different audio-visual scenes correspond to different target room impulse response functions, that is to say, the waveforms in the time-domain diagrams of the target room-related impulse response functions corresponding to different audio-visual scenes are different.
在一些示例性的实施例中,目标渲染函数包括目标头相关脉冲响应函数和目标房间相关脉冲响应函数,基于待渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,确定目标头相关脉冲响应函数和目标房间相关脉冲响应函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声,包括:In some exemplary embodiments, the target rendering function includes a target head-related impulse response function and a target room-related impulse response function, and the target is determined based on the number of channels of the multimedia data to be rendered, the audio-visual scene and the head rotation angle of the listening user. The head-related impulse response function and the target room-related impulse response function are used to render the multimedia data to be rendered to obtain the target virtual surround sound, including:
基于声道数和影音场景,确定虚拟扬声器与收听用户的头部之间的夹角;Determine the angle between the virtual speaker and the listening user's head based on the number of channels and the audiovisual scene;
基于收听用户的头部转动角度,更新虚拟扬声器与收听用户的头部之间的夹角;updating the angle between the virtual speaker and the head of the listening user based on the head rotation angle of the listening user;
基于更新后的虚拟扬声器与收听用户的头部之间的夹角以及影音场景,确定目标头相关脉冲响应函数和目标房间相关脉冲响应函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声。Based on the updated angle between the virtual speaker and the listening user's head and the audio-visual scene, the target head-related impulse response function and the target room-related impulse response function are determined to render the multimedia data to be rendered to obtain the target virtual surround sound.
在一些示例性的实施例中,为消除收听用户头部定位效应,改善声像位置混乱的问题,本申请实施例可在收听用户的头部位置发生变化时,即收听用户的头部角度出现变化时,对各声道对应的虚拟扬声器与收听用户的头部之间的角度进行修正,使得各声道对应的虚拟扬声器与收听用户的头部之间的相对位置不随收听用户的头部位置的变动而发生变化,进而达到消除收听用户头部定位效应,避免声像位置混乱的目的。具体地,基于收听用户的头部转动角度,更新多个虚拟扬声器与收听用户的头部之间的夹角,包括:In some exemplary embodiments, in order to eliminate the head positioning effect of the listening user and improve the problem of sound image position confusion, the embodiments of the present application may change the listening user's head position, that is, the listening user's head angle appears When changing, correct the angle between the virtual speaker corresponding to each channel and the listening user's head, so that the relative position between the virtual speaker corresponding to each channel and the listening user's head does not change with the listening user's head position Changes due to changes, thereby eliminating the head positioning effect of the listening user and avoiding confusion in the sound and image positions. Specifically, based on the head rotation angle of the listening user, the included angles between the plurality of virtual speakers and the listening user's head are updated, including:
确定收听用户的头部转动角度的方向和角度值;Determine the direction and angle values of the listening user's head rotation angle;
基于收听用户的头部转动角度的方向和角度值,确定虚拟扬声器与所述收听用户的头部之间的夹角的修正方向和修正值;Based on the direction and angle value of the listening user's head rotation angle, determine the correction direction and correction value of the included angle between the virtual speaker and the listening user's head;
基于修正方向和修正值,更新虚拟扬声器与收听用户的头部之间的夹角。Based on the correction direction and the correction value, the angle between the virtual speaker and the listening user's head is updated.
比如,收听用户的头部在XOZ平面上以其头部三维坐标系的原点为中心点逆时针转动了90°,则为了消除各声道对应的虚拟扬声器与收听用户的头部出现相对位置改变导致的头部定位效应以及声像位置混乱的问题,各声道对应的虚拟扬声器也可以收听用户头部三维坐标系的原点为中心点逆时针转动90°或顺时针转动270°,从而使得各声道对应的虚拟扬声器与收听用户的头部之间的相对位置不变。For example, if the head of the listening user rotates 90° counterclockwise on the XOZ plane with the origin of the three-dimensional coordinate system of the head as the center point, in order to eliminate the relative position change between the virtual speakers corresponding to each channel and the head of the listening user Due to the head positioning effect and the confusion of the sound image position, the virtual speakers corresponding to each channel can also listen to the user's head with the origin of the three-dimensional coordinate system as the center point and rotate 90° counterclockwise or 270° clockwise, so that each The relative position between the virtual speaker corresponding to the channel and the listening user's head remains unchanged.
在一些示例性的实施例中,基于更新后的虚拟扬声器与收听用户的头部之间的夹角以及所述影音场景,确定目标头相关脉冲响应函数和目标房间相关脉冲响应函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声,包括:In some exemplary embodiments, based on the angle between the updated virtual speaker and the listening user's head and the audiovisual scene, the target head-related impulse response function and the target room-related impulse response function are determined for the multimedia to be rendered The data is rendered to obtain the target virtual surround sound, including:
基于更新后的虚拟扬声器与收听用户的头部之间的夹角,确定虚拟扬声器对应的目标头相关脉冲响应函数和目标房间相关脉冲响应函数;Based on the angle between the updated virtual speaker and the head of the listening user, determine a target head-related impulse response function and a target room-related impulse response function corresponding to the virtual speaker;
基于目标头相关脉冲响应函数和目标房间相关脉冲响应函数,对输入至虚拟扬声器的待渲染多媒体数据进行渲染,得到目标虚拟环绕声。Based on the target head-related impulse response function and the target room-related impulse response function, the multimedia data to be rendered input to the virtual speaker is rendered to obtain the target virtual surround sound.
在一些示例性的实施例中,可将各声道对应的目标头相关脉冲响应函数和目标房间相关脉冲响应函数进行叠加后,再对该声道要播放的待渲染多媒体数据进行渲染处理。具体地,基于目标头相关脉冲响应函数和目标房间相关脉冲响应函数,对输入至虚拟扬声器的待渲染多媒体数据进行渲染,得到目标虚拟环绕声,包括:In some exemplary embodiments, after the target head-related impulse response function and the target room-related impulse response function corresponding to each channel are superimposed, rendering processing is performed on the multimedia data to be rendered to be played by the channel. Specifically, based on the target head-related impulse response function and the target room-related impulse response function, the multimedia data to be rendered input to the virtual speaker is rendered to obtain the target virtual surround sound, including:
将目标头相关脉冲响应函数和目标房间相关脉冲响应函数进行叠加,得到叠加后的目标脉冲响应函数;The target head-related impulse response function and the target room-related impulse response function are superimposed to obtain the superimposed target impulse response function;
对叠加后的目标脉冲响应函数与对应的虚拟扬声器的待渲染多媒体数据进行卷积运算;Perform convolution operation on the superimposed target impulse response function and the multimedia data to be rendered corresponding to the virtual speaker;
基于卷积运算的结果,得到目标虚拟环绕声。Based on the result of the convolution operation, the target virtual surround sound is obtained.
下面以单声道、双声道、5.1声道和7.1声道的待渲染多媒体数据的渲染过程为例,对本申请实施例提供的方法进行详细介绍。The method provided in the embodiment of the present application will be described in detail below by taking the rendering process of multimedia data to be rendered in monophonic, dual-channel, 5.1-channel and 7.1-channel as examples.
对于单声道的待渲染多媒体数据,通常需要将单声道中的多媒体数据内容复制到双声道中,再通过双声道渲染到收听用户双耳的渲染方式完成渲染。参见图4,图4为根据本申请实施例提供的虚拟环绕声渲染方法将双声道的多媒体数据渲染到收听用户双耳的场景示意图。假设该场景中左右两声道对应的虚拟扬声器分别为L和R,虚拟扬声器L和R到使用者双耳的目标相关脉冲响应函数分别为HRL,HLL,HLR,HRR,则收听用户双耳的声压PL,PR则为各虚拟扬声器分别产生的双耳声压的和。其中,PL=HLL*L+HRL*R,PR=HLR*L+HRRR,*表示卷积运算。For the monophonic multimedia data to be rendered, it is usually necessary to copy the multimedia data content in the monophonic to the dual-channel, and then render to the listening user’s ears through the dual-channel rendering to complete the rendering. Referring to FIG. 4 , FIG. 4 is a schematic diagram of a scene where binaural multimedia data is rendered to both ears of a listening user according to a virtual surround sound rendering method provided by an embodiment of the present application. Assuming that the virtual speakers corresponding to the left and right channels in this scene are L and R respectively, and the target-related impulse response functions of the virtual speakers L and R to the user's ears are H RL , H LL , H LR , H RR , then listen to The sound pressures PL and P R of the user's ears are the sum of the sound pressures of the ears generated by the virtual speakers respectively. Wherein, P L =H LL *L+H RL *R, P R =H LR *L+H RR R, and * represents a convolution operation.
对于5.1声道的待渲染多媒体数据,参见图5,图5为根据本申请实施例提供的虚拟环绕声渲染方法将5.1声道的多媒体数据渲染到收听用户双耳的场景示意图。假设5.1声道中各声道对应的虚拟扬声器分别为L、C、R、LR、RS、LFE,虚拟扬声器L、C、R、LS、RS、LFE到使用者双耳的目标相关脉冲响应函数分别为HRL、HLL、HLR、HRR、HCL、HCR、HRSR、HRSL、HLSR、HLSL、HLFER、HLFEL,则收听用户双耳的声压PL、PR为各声道对应的虚拟扬声器分别产生的双耳声压的和。其中,PL=HLL*L+HLR*R+HCL*C+HLSL*LS+HRSL*RS+HLFEL*LFE,PR=HLR*L+HRrr+HCR*C+HLSR*LS+HRSR*RS+HLFER*LFE,*表示卷积运算。For 5.1-channel multimedia data to be rendered, refer to FIG. 5 , which is a schematic diagram of rendering 5.1-channel multimedia data to the ears of a listening user according to a virtual surround sound rendering method provided in an embodiment of the present application. Assuming that the virtual speakers corresponding to each channel in the 5.1 channel are L, C, R, LR, RS, LFE respectively, the target-related impulse response function of the virtual speakers L, C, R, LS, RS, LFE to the user's ears H RL , H LL , H LR , H RR , H CL , H CR , H RSR , H RSL , H LSR , H LSL , H LFER , H LFEL , then listen to the sound pressure PL and P R is the sum of the binaural sound pressures produced by the virtual speakers corresponding to each channel. Among them, P L =H LL *L+H LR *R+H CL *C+H LSL *LS+H RSL *RS+H LFEL *LFE, P R =H LR *L+H Rr r+H CR * C+H LSR *LS+H RSR *RS+H LFER *LFE, * means convolution operation.
对于7.1声道的待渲染多媒体数据,参见图6,图6为根据本申请实施例提供的虚拟环绕声渲染方法将7.1声道的多媒体数据渲染到收听用户双耳的场景示意图。假设7.1声道中各声道对应的虚拟扬声器分别为L、C、R、LS、RS、LBS、RBS、LFF,虚拟扬声器L、C、R、LS、RS、LBS、RBS、LFE到收听用户双耳的目标相关脉冲响应函数分别为HRL,HLL,HLR,HRR,HCL,HCR,HRSR,HRSL,HLSR,HLSL,HRBSR,HRBSL,HLBSR,HLBSL,HLFER,HLFEL,则双耳的声压PL、PR为各声道对应的虚拟扬声器分别产生的双耳声压的和。其中,PL=HLL*L+HRL*R+HCL*C+HLSL*LS+HRSL*RS+HLBSL*LBS+HRBSL*RBS+HLFEL*LFE,PR=HLR*L+HRR*R+HCR*C+HLSR*LS+HRSR*RS+HLBSR*LBS+HRBSR*RBS++HLFER*LFE,*表示卷积运算。For 7.1-channel multimedia data to be rendered, refer to FIG. 6 , which is a schematic diagram of rendering 7.1-channel multimedia data to the ears of a listening user according to a virtual surround sound rendering method provided by an embodiment of the present application. Assume that the virtual speakers corresponding to each channel in the 7.1 channel are L, C, R, LS, RS, LBS, RBS, LFF, and the virtual speakers L, C, R, LS, RS, LBS, RBS, LFE to the listening user The target-related impulse response functions of both ears are H RL , H LL , H LR , H RR , H CL , H CR , H RSR , H RSL , H LSR , H LSL , H RBSR , H RBSL , H LBSR , H LBSL , H LFER , H LFEL , then the binaural sound pressures PL and PR are the sum of the binaural sound pressures produced by the virtual speakers corresponding to each channel. Among them, P L =H LL *L+H RL *R+H CL *C+H LSL *LS+H RSL *RS+H LBSL *LBS+H RBSL *RBS+H LFEL *LFE, P R =H LR *L+H RR *R+H CR *C+H LSR *LS+H RSR *RS+H LBSR *LBS+H RBSR *RBS++H LFER *LFE, * means convolution operation.
应理解,在单独考虑收听用户的头部转动角度对虚拟环绕声的影响时,上述目标渲染函数为目标头相关脉冲响应函数,在单独考虑影音场景对虚拟环绕声的影响时,上述目标渲染函数为目标房间相关脉冲响应函数。在综合考虑收听用户的头部转动角度和影音场景对虚拟环绕声的影响时,上述目标渲染函数可以是目标头相关脉冲响应函数和目标房间相关脉冲响应函数叠加处理后的渲染函数。It should be understood that when the influence of the listening user's head rotation angle on the virtual surround sound is considered separately, the above-mentioned target rendering function is the target head-related impulse response function; is the target room-related impulse response function. When comprehensively considering the listening user's head rotation angle and the influence of the audio-visual scene on the virtual surround sound, the above-mentioned target rendering function may be a rendering function obtained by superimposing the target head-related impulse response function and the target room-related impulse response function.
在考虑影音场景对虚拟环绕声的影响时,可利用roomsim仿真工具,生成图7所示的一个长方形房间,房间的长宽高可以根据需求进行设定,房间的6个平面可以根据反射和吸收系数的不同需求设定为不同的材料。例如,在模拟录音棚小房间时,可选择吸收性较好的吸音棉等材料作为房间的6个平面的材料。图7所示的房间模拟的是左耳以及右耳接收5.1声道的虚拟扬声器播放的多媒体数据的场景示意图。图8为图7所示的影音场景中5.1声道的虚拟扬声器与左耳以及右耳之间的房间相关脉冲响应函数的波形图,该房间相关脉冲响应函数主要包含直达声、早期镜面反射和混响尾等几个感知相关的成分。When considering the impact of audio-visual scenes on virtual surround sound, the roomsim simulation tool can be used to generate a rectangular room as shown in Figure 7. The length, width and height of the room can be set according to requirements, and the six planes of the room can be adjusted according to reflection and absorption. The different needs of the coefficients are set for different materials. For example, when simulating a small room in a recording studio, materials such as sound-absorbing cotton with better absorption can be selected as the materials for the six planes of the room. The room simulation shown in FIG. 7 is a schematic diagram of a scenario in which the left ear and the right ear receive multimedia data played by a 5.1-channel virtual speaker. Fig. 8 is the oscillogram of the room-related impulse response function between the 5.1-channel virtual loudspeaker and the left ear and the right ear in the audio-visual scene shown in Fig. 7, and the room-related impulse response function mainly includes direct sound, early specular reflection and Reverb tail and several other perceptually relevant components.
作为一种实施方式,上述目标头相关脉冲响应函数和目标房间相关脉冲响应函数可利用图像源方法(英文名称为image-source method)和漫射雨射线追踪算法(diffuserain ray-tracing algorithm)生成。在实际应用中,可预先生成不同影音场景下的目标房间相关脉冲响应函数的波形图、以及不同角度下的目标头相关脉冲响应函数的波形图,在进行虚拟环绕声渲染时,调用对应的影音场景下的目标房间相关脉冲响应函数的波形图、以及对应角度下的目标头相关脉冲响应函数的波形图对输入的影音信号进行滤波处理即可。As an implementation manner, the above-mentioned target head-related impulse response function and target room-related impulse response function can be generated using an image-source method (image-source method in English) and a diffuse rain ray-tracing algorithm (diffuserain ray-tracing algorithm). In practical applications, waveform diagrams of target room-related impulse response functions under different audio-visual scenes and waveform diagrams of target head-related impulse response functions under different angles can be generated in advance. When performing virtual surround sound rendering, the corresponding audio-visual The waveform diagram of the target room-related impulse response function in the scene and the waveform diagram of the target head-related impulse response function in the corresponding angle can be filtered for the input video and audio signals.
以目标房间相关脉冲响应函数的生成过程为例,参见图9,为本申请一个实施例根据图像源方法生成目标房间相关脉冲响应函数中声音传播路径的示意图。在图像源方法中,可通过声源在房间墙面的镜像来创建虚拟图像源,如图9所示,声源为S,声源S在四面墙上的镜像分别为S1~S4,S1~S4为创建的虚拟图像源。从虚拟图像源S1~S4到接收器R的直线对应的是房间中声源S在多个墙面反射到接收器R的声音传播路径。通过获取这些直线的长度和它相交墙面的吸收反射系数,相应的声音传播路径对房间脉冲响应的贡献就可以被计算出来。图像源方法可以精确地找到房间内的所有传播路径,这就使得它非常适合模拟直达声音和低阶反射。然而,该方法对于高阶反射的计算效率较低,因为虚源的数量随着反射阶数的增加而迅速增加,因此,图像源方法通常适合模拟早期镜面反射。Taking the generation process of the target room-related impulse response function as an example, see FIG. 9 , which is a schematic diagram of the sound propagation path in the generation of the target room-related impulse response function according to the image source method according to an embodiment of the present application. In the image source method, a virtual image source can be created by mirroring the sound source on the wall of the room. As shown in Figure 9, the sound source is S, and the mirror images of the sound source S on the four walls are S1~S4, S1~ S4 is the created virtual image source. The straight line from the virtual image sources S1-S4 to the receiver R corresponds to the sound propagation path from the sound source S reflected on multiple walls to the receiver R in the room. By taking the length of these lines and the absorption and reflection coefficients of the walls it intersects, the contribution of the corresponding sound propagation path to the impulse response of the room can be calculated. The image source method can accurately find all propagation paths in a room, which makes it ideal for simulating direct sound and low-order reflections. However, this method is computationally inefficient for higher-order reflections because the number of virtual sources increases rapidly with the reflection order, so the image source method is usually suitable for simulating early specular reflections.
继续以目标房间相关脉冲响应函数的生成过程为例,参见图10,为本申请一个实施例根据漫射雨射线追踪算法生成目标房间相关脉冲响应函数中声能量射线的传播路径示意图。漫射雨射线追踪算法可生成高阶反射、混响尾和漫反射。在漫射雨射线追踪算法中,声能量射线从声源S发射,并在整个房间中跟踪,如图10所示。当声能量射线击中物体表面时,其所携带的声能量可根据物体表面的吸收而降低。接下来,声能量射线对房间脉冲响应的直接贡献可通过从冲击点向接收器R发射第二束射线并记录这束射线的入射角、到达时间和在接收器上的剩余声能量来确定。从声源S发射出的原始第一条射线可从撞击点以随机方向继续发射,并进一步跟踪,直到其声音能量低于预设的能量阈值。所有的声能量射线都可这样处理,而且因为吸收和漫反射都是频率相关的现象,因此,这个过程在所有频带上都可重复。Continuing to take the generation process of the target room-related impulse response function as an example, see FIG. 10 , which is a schematic diagram of the propagation path of acoustic energy rays in the target room-related impulse response function generated according to the diffuse rain ray tracing algorithm according to an embodiment of the present application. The diffuse rain ray tracing algorithm generates higher order reflections, reverb tails and diffuse reflections. In the diffuse rain ray tracing algorithm, a ray of acoustic energy is emitted from a sound source S and traced throughout the room, as shown in Figure 10. When the sound energy ray hits the surface of the object, the sound energy carried by it can be reduced according to the absorption of the surface of the object. Next, the direct contribution of the acoustic energy ray to the room impulse response can be determined by launching a second ray from the point of impact to the receiver R and recording the angle of incidence, time of arrival, and residual acoustic energy at the receiver for this ray. The original first ray emitted from the sound source S can continue to be emitted in random directions from the point of impact and tracked further until its sound energy falls below a preset energy threshold. All rays of acoustic energy can be treated in this way, and since both absorption and diffuse reflection are frequency-dependent phenomena, the process is repeatable across all frequency bands.
如图11所示,为本申请一个实施例根据漫射雨射线追踪算法生成目标房间相关脉冲响应函数中接收器收到的一条声能量射线的能量示意图。在接收器R处,一条频率为f的射线以ψ=(θ,φ)的角度在到达时间t时的能量在时频直方图Ei(n,k)中累积。对于每个球仓,时频直方图Ei(n,k)经以下过几步就可以转化为目标房间相关脉冲响应函数。首先,是一个泊松噪声过程,泊松噪声信号的谱图为白色,可按照时频直方图Ei(n,k)进行整形。然后,将整形后的噪声信号与接收器R的冲击响应进行ψ角卷积。最后,将得到的所有球仓信号求和为一个脉冲响应,再叠加在图像源方法的输出上,便可得到完整的目标房间相关脉冲响应函数。As shown in FIG. 11 , it is an energy schematic diagram of an acoustic energy ray received by a receiver in a target room-related impulse response function generated according to a diffuse rain ray tracing algorithm according to an embodiment of the present application. At receiver R, the energy of a ray with frequency f at arrival time t at angle ψ=(θ, φ) is accumulated in the time-frequency histogram Ei(n,k). For each spherical bin, the time-frequency histogram Ei(n,k) can be transformed into the target room-related impulse response function through the following steps. First, it is a Poisson noise process. The spectrogram of the Poisson noise signal is white and can be shaped according to the time-frequency histogram Ei(n,k). Then, the shaped noise signal is convolved with the impulse response of the receiver R with a ψ angle. Finally, the sum of all the spherical bin signals obtained is an impulse response, and then superimposed on the output of the image source method, the complete target room-related impulse response function can be obtained.
需要说明的是,按照重放设备(即上文所述收听设备)的不同,虚拟环绕声又可以分为基于音箱重放的虚拟环绕声和基于耳机重放的虚拟环绕声。这二者在本质上均是通过双声道信号来实现虚拟环绕声的效果,只需要将上述双耳的声压PL、PR公式中的各声道对应的虚拟扬声器选用与重放设备对应的目标相关脉冲响应函数进行滤波处理就可以实现对应的虚拟环绕声的效果。It should be noted that, according to different playback devices (that is, the above-mentioned listening devices), virtual surround sound can be divided into virtual surround sound based on speaker playback and virtual surround sound based on earphone playback. In essence, both of them use binaural signals to realize the effect of virtual surround sound. It is only necessary to select the virtual speakers corresponding to each channel in the above-mentioned binaural sound pressure PL , PR formulas and playback equipment. The corresponding virtual surround sound effect can be realized by performing filtering processing on the corresponding target-related impulse response function.
此外,为了防止滤波后的信号出现爆音等尖锐噪声,虚拟环绕处理后虚拟环绕声还可使用预设的limiter进行保护,即不管输入电平怎样增加,其最大输出电平均不能大于最大预设输出电平值。具体地,基于声道数和影音场景以及收听用户的头部转动角度,确定目标渲染函数以对待渲染多媒体数据进行渲染,得到目标虚拟环绕声,包括:In addition, in order to prevent the filtered signal from popping and other sharp noises, the virtual surround sound after virtual surround processing can also be protected by a preset limiter, that is, no matter how the input level increases, its maximum output level cannot be greater than the maximum preset output level value. Specifically, based on the number of channels, the audio-visual scene and the listening user's head rotation angle, the target rendering function is determined to render the multimedia data to be rendered, and the target virtual surround sound is obtained, including:
基于声道数和影音场景以及收听用户的头部转动角度,确定目标相关脉冲响应函数;Determine the target-related impulse response function based on the number of channels, the audio-visual scene and the head rotation angle of the listening user;
基于目标渲染函数对待渲染多媒体数据进行渲染,得到渲染后的虚拟环绕声;Render the multimedia data to be rendered based on the target rendering function to obtain the rendered virtual surround sound;
将渲染后的虚拟环绕声中大于最大预设输出电平值的电平变换为最大预设输出电平值,得到目标虚拟环绕声。Converting the level in the rendered virtual surround sound greater than the maximum preset output level value to the maximum preset output level value to obtain the target virtual surround sound.
参见图12,为本申请一示例性的实施例提供的以待渲染多媒体数据为5.1声道的多媒体数据为例的渲染过程示意图。如图12所示,该过程可包括:S121,输入待渲染多媒体数据;S122,对待渲染多媒体数据进行分析,确定待渲染多媒体数据为5.1声道的多媒体数据;S123,确定收听用户选择的目标影音场景;S124,通过收听设备的头部追踪模块获取收听用户的头部转动角度信息;S125,确定与目标影音场景对应的房间相关脉冲响应函数以及与收听用户的头部转动角度信息对应的头相关脉冲响应函数;S126,将房间相关脉冲响应函数以及头相关脉冲响应函数进行叠加得到渲染函数;S127,通过渲染函数将待渲染多媒体数据的多个声道进行渲染,输出至收听设备。Referring to FIG. 12 , it is a schematic diagram of a rendering process provided by an exemplary embodiment of the present application, where the multimedia data to be rendered is 5.1-channel multimedia data as an example. As shown in Figure 12, the process may include: S121, inputting the multimedia data to be rendered; S122, analyzing the multimedia data to be rendered, and determining that the multimedia data to be rendered is 5.1-channel multimedia data; S123, determining to listen to the target audio and video selected by the user Scene; S124, obtain the head rotation angle information of the listening user through the head tracking module of the listening device; S125, determine the room-related impulse response function corresponding to the target audio-visual scene and the head correlation corresponding to the head rotation angle information of the listening user Impulse response function; S126, superimpose the room-related impulse response function and the head-related impulse response function to obtain a rendering function; S127, use the rendering function to render multiple channels of the multimedia data to be rendered, and output to the listening device.
以5.1声道为例,假设从逆时针角度来看,虚拟扬声器L,C,R,LS,RS,LFe与收听用户头部之间的夹角分别是45°,0°,315°,135°,225°,22.5°,且它们都在一个平面上。此时从确定对应夹角位置的头相关脉冲响应函数对各虚拟扬声器的输入信号利用5.1声道中PL、PR的公式进行渲染获得到当前各虚拟扬声器的输出。假设通过头部追踪模块检测到收听用户头部转动逆时针转动了90°角时,则L,C,R,LS,RS,LFE各虚拟扬声器与收听用户头部之间的相对夹角则变为:315°,270°,225°,45°,135°,67.5°。此时需要选择当前角度下的头相关脉冲响应函数对各虚拟扬声器的输入信号利用5.1声道中PL、PR的公式进行渲染获得到当前各虚拟扬声器的输出。也就是说各虚拟扬声器选用的头相关脉冲响应函数需要跟据收听用户头部角度的变化进行实时刷新,从而实现声源不随使用者头部的转动而转动,消除头中定位效应,改善声像位置混乱的问题。Taking the 5.1 channel as an example, assuming that from a counterclockwise perspective, the angles between the virtual speakers L, C, R, LS, RS, LFe and the listening user's head are 45°, 0°, 315°, 135°, respectively. °, 225°, 22.5°, and they are all on the same plane. At this time, from the head-related impulse response function that determines the corresponding angle position, the input signal of each virtual speaker is rendered using the formulas of PL and PR in the 5.1 channel to obtain the current output of each virtual speaker. Assuming that when the head tracking module detects that the head of the listening user rotates counterclockwise by 90°, the relative angles between the virtual speakers of L, C, R, LS, RS, and LFE and the head of the listening user change. For: 315°, 270°, 225°, 45°, 135°, 67.5°. At this time, it is necessary to select the head-related impulse response function at the current angle to render the input signals of each virtual speaker using the formulas of PL and PR in the 5.1 channel to obtain the output to the current virtual speakers. That is to say, the head-related impulse response function selected by each virtual speaker needs to be refreshed in real time according to the change of the listening user's head angle, so that the sound source does not rotate with the rotation of the user's head, eliminates the positioning effect in the head, and improves the sound image The problem of location confusion.
另外,本实施例提供的方法可应用于任何存在虚拟环绕声渲染的应用场景中,都能实时根据带渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,确定用于渲染待渲染多媒体数据的目标渲染函数,使得渲染得到的虚拟环绕声更能贴合实际设备、实际场景和收听用户的头部角度,从而给用户带来更好的音频体验。In addition, the method provided by this embodiment can be applied to any application scene where there is virtual surround sound rendering, and can determine the audio frequency for rendering in real time according to the number of channels with rendered multimedia data, the audio-visual scene, and the head rotation angle of the listening user. The target rendering function of the multimedia data to be rendered makes the rendered virtual surround sound more suitable for the actual device, the actual scene and the head angle of the listening user, thereby bringing a better audio experience to the user.
在本申请一些实施例提供的虚拟环绕声渲染方法中,由于能够在确定待渲染多媒体数据的渲染方式时,不仅能够确定待渲染多媒体数据的声道数和影音场景,而且还考虑到待渲染多媒体数据的收听用户的头部转动角度的变换情况,最后基于待渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,使得确定的目标渲染函数与收听用户当前所处的环境、待渲染多媒体数据的声道数以及收听用户的头部转动角度相匹配的,这样通过目标渲染函数对待渲染多媒体数据进行渲染得到目标虚拟环绕声,也就能够给收听用户带来更优质的音频体验,而且,该渲染方式充分考虑到了不同场景的差异,也能够应用于更多的场景中。In the virtual surround sound rendering method provided by some embodiments of the present application, when determining the rendering method of the multimedia data to be rendered, not only the number of channels of the multimedia data to be rendered and the audio-visual scene can be determined, but also the multimedia data to be rendered can be considered The conversion of the head rotation angle of the user listening to the data, and finally based on the number of channels of the multimedia data to be rendered, the audio-visual scene and the head rotation angle of the listening user, so that the determined target rendering function is consistent with the current environment of the listening user, The number of channels of the multimedia data to be rendered matches the head rotation angle of the listening user, so that the target virtual surround sound can be obtained by rendering the multimedia data to be rendered through the target rendering function, which can also bring a better audio experience to the listening user , Moreover, this rendering method fully takes into account the differences of different scenes, and can also be applied to more scenes.
需要说明的是,上述实施例所提供方法的各步骤的执行主体均可以是同一设备,或者,该方法也由不同设备作为执行主体。比如,步骤210至步骤230的执行主体可以为设备A;又比如,步骤210至步骤220的执行主体可以为设备A,步骤230的执行主体可以为设备B;等等。It should be noted that the subject of execution of each step of the method provided in the foregoing embodiments may be the same device, or the method may also be executed by different devices. For example, the execution subject of
另外,在上述实施例及附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如210、220等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。In addition, in some of the processes described in the above embodiments and accompanying drawings, multiple operations appearing in a specific order are included, but it should be clearly understood that these operations may not be executed in the order in which they appear herein or executed in parallel , the sequence numbers of the operations, such as 210, 220, etc., are only used to distinguish different operations, and the sequence numbers themselves do not represent any execution sequence. Additionally, the processes may include more or fewer operations, and the operations may be performed sequentially or in parallel. It should be noted that the descriptions of "first" and "second" in this article are used to distinguish different messages, devices, modules, etc. are different types.
图13为本申请示例性实施例提供的一种虚拟环绕声渲染装置的结构示意图。如图13所示,该装置包括:场景确定模块1310、角度确定模块1320和资源渲染模块1330,其中:Fig. 13 is a schematic structural diagram of a virtual surround sound rendering device provided by an exemplary embodiment of the present application. As shown in Figure 13, the device includes: a
场景确定模块1310,用于确定待渲染多媒体数据的声道数和影音场景;
角度确定模块1320,用于确定所述待渲染多媒体数据的收听用户的头部转动角度;An
资源渲染模块1330,用于基于所述声道数和所述影音场景以及所述收听用户的头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。The
本申请实施例提供的虚拟环绕声渲染装置,由于能够在确定待渲染多媒体数据的渲染方式时,不仅能够确定待渲染多媒体数据的声道数和影音场景,而且还考虑到待渲染多媒体数据的收听用户的头部转动角度的变换情况,最后基于待渲染多媒体数据的声道数和影音场景以及收听用户的头部转动角度,使得确定的目标渲染函数与收听用户当前所处的环境、待渲染多媒体数据的声道数以及收听用户的头部转动角度相匹配的,这样通过目标渲染函数对待渲染多媒体数据进行渲染得到的目标虚拟环绕声,也就能够给收听用户带来更优质的音频体验,而且,该渲染方式充分考虑到了不同场景的差异,也能够应用于更多的场景中。The virtual surround sound rendering device provided by the embodiment of the present application can not only determine the number of channels and audio-visual scenes of the multimedia data to be rendered, but also consider the listening of the multimedia data to be rendered when determining the rendering method of the multimedia data to be rendered. The transformation of the user's head rotation angle, finally based on the number of channels of the multimedia data to be rendered, the audio-visual scene and the listening user's head rotation angle, so that the determined target rendering function is consistent with the listening user's current environment, the multimedia to be rendered The number of channels of the data and the head rotation angle of the listening user match, so that the target virtual surround sound obtained by rendering the multimedia data to be rendered through the target rendering function can bring a better audio experience to the listening user, and , this rendering method fully takes into account the differences of different scenes, and can also be applied to more scenes.
进一步可选地,所述目标渲染函数包括目标头相关脉冲响应函数和目标房间相关脉冲响应函数,所述资源渲染模块1330基于所述和所述影音场景以及所述收听用户的头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声时,具体用于:Further optionally, the target rendering function includes a target head-related impulse response function and a target room-related impulse response function, and the
基于所述声道数和所述影音场景,确定虚拟扬声器与所述收听用户的头部之间的夹角;Based on the number of channels and the audio-visual scene, determine the angle between the virtual speaker and the head of the listening user;
基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角;updating an angle between the virtual speaker and the listening user's head based on the head rotation angle;
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。Based on the updated angle between the virtual speaker and the listening user's head and the audio-visual scene, determine the target head-related impulse response function and the target room-related impulse response function to treat the target The multimedia data is rendered for rendering to obtain the target virtual surround sound.
进一步可选地,所述资源渲染模块1330基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角时,具体用于:Further optionally, when the
确定所述收听用户的头部转动角度的方向和角度值;determining the direction and angle value of the head rotation angle of the listening user;
基于所述收听用户的头部转动角度的方向和角度值,确定所述虚拟扬声器与所述收听用户的头部之间的夹角的修正方向和修正值;determining a correction direction and a correction value of an included angle between the virtual speaker and the listening user's head based on the direction and angle value of the listening user's head rotation angle;
基于所述修正方向和所述修正值,更新所述虚拟扬声器与所述收听用户的头部之间的夹角。Based on the correction direction and the correction value, the angle between the virtual speaker and the listening user's head is updated.
进一步可选地,所述资源渲染模块1330基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声时,具体用于:Further optionally, the
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角,确定所述虚拟扬声器对应的目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数;determining a target head-related impulse response function and a target room-related impulse response function corresponding to the virtual speaker based on the updated angle between the virtual speaker and the head of the listening user;
基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。Based on the target head-related impulse response function and the target room-related impulse response function, the multimedia data to be rendered input to the virtual speaker is rendered to obtain the target virtual surround sound.
进一步可选地,所述资源渲染模块1330基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声时,具体用于:Further optionally, the
将所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数进行叠加,得到多个所述叠加后的目标脉冲响应函数;superimposing the target head-related impulse response function and the target room-related impulse response function to obtain a plurality of superimposed target impulse response functions;
对所述叠加后的目标脉冲响应函数与对应的所述虚拟扬声器的待渲染多媒体数据进行卷积运算;performing a convolution operation on the superimposed target impulse response function and the corresponding multimedia data to be rendered of the virtual speaker;
基于所述卷积运算的结果,得到所述目标虚拟环绕声。Based on the result of the convolution operation, the target virtual surround sound is obtained.
进一步可选地,所述场景确定模块1310确定待渲染多媒体数据的影音场景时,具体用于:Further optionally, when the
响应于所述待渲染多媒体数据的接入请求,向所述收听用户展示预设的影音场景列表,所述预设的影音场景列表中包含有多个预设的影音场景,多个所述预设的影音场景对应于不同的房间冲击响应函数;Responding to the access request of the multimedia data to be rendered, displaying a preset audio-visual scene list to the listening user, the preset audio-visual scene list includes a plurality of preset audio-visual scenes, a plurality of the preset audio-visual scenes The assumed audio-visual scenes correspond to different room shock response functions;
响应于所述收听用户从预设的影音场景列表中对所述待渲染多媒体数据的影音场景的选择指令,确定所述待渲染多媒体数据的影音场景。In response to the listening user's instruction to select the audio-visual scene of the multimedia data to be rendered from a list of preset audio-visual scenes, the audio-visual scene of the multimedia data to be rendered is determined.
进一步可选地,所述角度确定模块1320确定所述待渲染多媒体数据的收听用户的头部转动角度时,具体用于:Further optionally, when the
建立所述收听用户的头部三维坐标系;Establishing the three-dimensional coordinate system of the head of the listening user;
通过内置在所述收听用户佩戴的移动设备中的头部追踪模块,获取所述收听用户的头部关于所述三维坐标系各平面的角度变化值;Obtain the angle change value of the head of the listening user with respect to each plane of the three-dimensional coordinate system through a head tracking module built in the mobile device worn by the listening user;
基于所述三维坐标系各平面对应的角度变化值,确定所述收听用户的头部转动角度。Based on the angle change values corresponding to the planes of the three-dimensional coordinate system, the head rotation angle of the listening user is determined.
虚拟环绕声渲染装置能够实现图1~图12的方法实施例的方法,具体可参考图1~图12所示实施例的虚拟环绕声渲染方法,不再赘述。The virtual surround sound rendering device can implement the methods in the method embodiments shown in FIGS. 1 to 12 . For details, reference may be made to the virtual surround sound rendering method in the embodiments shown in FIGS. 1 to 12 , which will not be repeated here.
图14为本申请示例性实施例提供的一种电子设备的结构示意图,该电子设备可包括耳机和头显等移动可穿戴设备。如图14所示,该设备包括:存储器141和处理器142。Fig. 14 is a schematic structural diagram of an electronic device provided by an exemplary embodiment of the present application, and the electronic device may include mobile wearable devices such as earphones and head-mounted displays. As shown in FIG. 14 , the device includes: a
存储器141,用于存储计算机程序,并可被配置为存储其它各种数据以支持在计算设备上的操作。这些数据的示例包括用于在计算设备上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。The
处理器142,与存储器141耦合,用于执行存储器141中的计算机程序,以用于:确定待渲染多媒体数据的声道数和影音场景;确定所述待渲染多媒体数据的收听用户的头部转动角度;基于所述待渲染多媒体数据的声道数和影音场景以及所述收听用户的头部转动角度,确定目标相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声。The
进一步可选地,所述目标渲染函数包括目标头相关脉冲响应函数和目标房间相关脉冲响应函数,所述处理器142基于所述和所述影音场景以及所述收听用户的头部转动角度,确定目标渲染函数以对所述待渲染多媒体数据进行渲染,得到目标虚拟环绕声时,具体用于:Further optionally, the target rendering function includes a target head-related impulse response function and a target room-related impulse response function, and the
基于所述声道数和所述影音场景,确定虚拟扬声器与所述收听用户的头部之间的夹角;Based on the number of channels and the audio-visual scene, determine the angle between the virtual speaker and the head of the listening user;
基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角;updating an angle between the virtual speaker and the listening user's head based on the head rotation angle;
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。Based on the updated angle between the virtual speaker and the listening user's head and the audio-visual scene, determine the target head-related impulse response function and the target room-related impulse response function to treat the target Render the multimedia data to obtain the target virtual surround sound.
进一步可选地,所述处理器142基于所述头部转动角度,更新所述虚拟扬声器与所述收听用户的头部之间的夹角时,具体用于:Further optionally, when the
确定所述收听用户的头部转动角度的方向和角度值;determining the direction and angle value of the head rotation angle of the listening user;
基于所述收听用户的头部转动角度的方向和角度值,确定所述虚拟扬声器与所述收听用户的头部之间的夹角的修正方向和修正值;determining a correction direction and a correction value of an included angle between the virtual speaker and the listening user's head based on the direction and angle value of the listening user's head rotation angle;
基于所述修正方向和所述修正值,更新所述虚拟扬声器与所述收听用户的头部之间的夹角。Based on the correction direction and the correction value, the angle between the virtual speaker and the listening user's head is updated.
进一步可选地,所述处理器142基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角以及所述影音场景,确定所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数以对所述待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声时,具体用于:Further optionally, the
基于更新后的所述虚拟扬声器与所述收听用户的头部之间的夹角,确定所述虚拟扬声器对应的目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数;determining a target head-related impulse response function and a target room-related impulse response function corresponding to the virtual speaker based on the updated angle between the virtual speaker and the head of the listening user;
基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声。Based on the target head-related impulse response function and the target room-related impulse response function, the multimedia data to be rendered input to the virtual speaker is rendered to obtain the target virtual surround sound.
进一步可选地,所述处理器142基于所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数,对输入至所述虚拟扬声器的待渲染多媒体数据进行渲染,得到所述目标虚拟环绕声时,具体用于:Further optionally, the
将所述目标头相关脉冲响应函数和所述目标房间相关脉冲响应函数进行叠加,得到多个所述叠加后的目标脉冲响应函数;superimposing the target head-related impulse response function and the target room-related impulse response function to obtain a plurality of superimposed target impulse response functions;
对所述叠加后的目标脉冲响应函数与对应的所述虚拟扬声器的待渲染多媒体数据进行卷积运算;performing a convolution operation on the superimposed target impulse response function and the corresponding multimedia data to be rendered of the virtual speaker;
基于所述卷积运算的结果,得到所述目标虚拟环绕声。Based on the result of the convolution operation, the target virtual surround sound is obtained.
进一步可选地,所述处理器142确定待渲染多媒体数据的影音场景时,具体用于:Further optionally, when the
响应于所述待渲染多媒体数据的接入请求,向所述收听用户展示预设的影音场景列表,所述预设的影音场景列表中包含有多个预设的影音场景,多个所述预设的影音场景对应于不同的房间冲击响应函数;Responding to the access request of the multimedia data to be rendered, displaying a preset audio-visual scene list to the listening user, the preset audio-visual scene list includes a plurality of preset audio-visual scenes, a plurality of the preset audio-visual scenes The assumed audio-visual scenes correspond to different room shock response functions;
响应于所述收听用户从预设的影音场景列表中对所述待渲染多媒体数据的影音场景的选择指令,确定所述待渲染多媒体数据的影音场景。In response to the listening user's instruction to select the audio-visual scene of the multimedia data to be rendered from a list of preset audio-visual scenes, the audio-visual scene of the multimedia data to be rendered is determined.
进一步可选地,所述处理器142确定所述待渲染多媒体数据的收听用户的头部转动角度时,具体用于:Further optionally, when the
建立所述收听用户的头部三维坐标系;Establishing the three-dimensional coordinate system of the head of the listening user;
通过内置在所述收听用户佩戴的移动设备中的头部追踪模块,获取所述收听用户的头部关于所述三维坐标系各平面的角度变化值;Obtain the angle change value of the head of the listening user with respect to each plane of the three-dimensional coordinate system through a head tracking module built in the mobile device worn by the listening user;
基于所述三维坐标系各平面对应的角度变化值,确定所述收听用户的头部转动角度。Based on the angle change values corresponding to the planes of the three-dimensional coordinate system, the head rotation angle of the listening user is determined.
进一步,如图14所示,该电子设备还包括:通信组件143、显示器144、电源组件145、音频组件146等其它组件。图14中仅示意性给出部分组件,并不意味着电子设备只包括图14所示组件。另外,根据流量回放设备的实现形态的不同,图14中虚线框内的组件为可选组件,而非必选组件。例如,当电子设备实现为智能手机、平板电脑或台式电脑等终端设备时,可以包括图14中虚线框内的组件;当电子设备实现为常规服务器、云服务器、数据中心或服务器阵列等服务端设备时,可以不包括图14中虚线框内的组件。Further, as shown in FIG. 14 , the electronic device further includes: a
相应地,本申请实施例还提供一种存储有计算机程序的计算机可读存储介质,计算机程序被处理器执行时,致使处理器能够实现上述虚拟环绕声渲染方法实施例中的步骤。Correspondingly, the embodiment of the present application also provides a computer-readable storage medium storing a computer program, and when the computer program is executed by a processor, the processor can implement the steps in the above-mentioned embodiment of the virtual surround sound rendering method.
上述图14中的通信组件被配置为便于通信组件所在设备和其他设备之间有线或无线方式的通信。通信组件所在设备可以接入基于通信标准的无线网络,如WiFi,2G或3G,或它们的组合。在一个示例性实施例中,通信组件经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,所述通信组件还可以包括近场通信(Near Field Communication,NFC)模块,射频识别(Radio Frequency Identification,RFID)技术,红外数据协会(Infrared Data Association,IrDA)技术,超宽带(Ultra WideBand,UWB)技术,蓝牙(Bluetooth,BT)技术等。The above-mentioned communication component in FIG. 14 is configured to facilitate wired or wireless communication between the device where the communication component is located and other devices. The device where the communication component is located can access a wireless network based on communication standards, such as WiFi, 2G or 3G, or a combination thereof. In one exemplary embodiment, the communication component receives a broadcast signal or broadcast related information from an external broadcast management system via a broadcast channel. In an exemplary embodiment, the communication component may further include a near field communication (Near Field Communication, NFC) module, a radio frequency identification (Radio Frequency Identification, RFID) technology, an infrared data association (Infrared Data Association, IrDA) technology, Ultra Wideband (Ultra WideBand, UWB) technology, Bluetooth (Bluetooth, BT) technology, etc.
上述图14中的存储器可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(Static Random-Access Memory,SRAM),电可擦除可编程只读存储器(Electrically Erasable Programmable read only memory,EEPROM),可擦除可编程只读存储器(Electrical Programmable Read Only Memory,EPROM),可编程只读存储器(Programmable read-only memory,PROM),只读存储器(Read-Only Memory,ROM),磁存储器,快闪存储器,磁盘或光盘。The above memory in FIG. 14 can be realized by any type of volatile or non-volatile storage device or their combination, such as Static Random-Access Memory (Static Random-Access Memory, SRAM), Electrically Erasable and Programmable Only Electrically Erasable Programmable read only memory (EEPROM), Electrically Erasable Programmable Read Only Memory (EPROM), Programmable read-only memory (PROM), read-only memory ( Read-Only Memory, ROM), magnetic memory, flash memory, magnetic disk or optical disk.
上述图14中的显示器包括屏幕,其屏幕可以包括液晶显示器(Liquid CrystalDisplay,LCD)和触摸面板(Touchpanel,TP)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。The above-mentioned display in FIG. 14 includes a screen, and the screen may include a liquid crystal display (Liquid Crystal Display, LCD) and a touch panel (Touchpanel, TP). If the screen includes a touch panel, the screen may be implemented as a touch screen to receive input signals from a user. The touch panel includes one or more touch sensors to sense touches, swipes, and gestures on the touch panel. The touch sensor may not only sense a boundary of a touch or swipe action, but also detect duration and pressure associated with the touch or swipe action.
上述图14中的电源组件,为电源组件所在设备的各种组件提供电力。电源组件可以包括电源管理系统,一个或多个电源,及其他与为电源组件所在设备生成、管理和分配电力相关联的组件。The above-mentioned power supply component in FIG. 14 provides power for various components of the device where the power supply component is located. A power supply component may include a power management system, one or more power supplies, and other components associated with generating, managing, and distributing power to the device in which the power supply component resides.
上述图14中的音频组件,可被配置为输出和/或输入音频信号。例如,音频组件包括一个麦克风(microphone,MIC),当音频组件所在设备处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器或经由通信组件发送。在一些实施例中,音频组件还包括一个扬声器,用于输出音频信号。The above-mentioned audio components in FIG. 14 may be configured to output and/or input audio signals. For example, the audio component includes a microphone (microphone, MIC). When the device where the audio component is located is in an operation mode, such as a calling mode, a recording mode, and a speech recognition mode, the microphone is configured to receive an external audio signal. The received audio signal may be further stored in a memory or sent via a communication component. In some embodiments, the audio component further includes a speaker for outputting audio signals.
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。Those skilled in the art should understand that the embodiments of the present application may be provided as methods, systems, or computer program products. Accordingly, the present application may take the form of an entirely hardware embodiment, an entirely software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present application may take the form of a computer program product embodied on one or more computer-usable storage media (including but not limited to disk storage, CD-ROM, optical storage, etc.) having computer-usable program code embodied therein.
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present application is described with reference to flowcharts and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the present application. It should be understood that each procedure and/or block in the flowchart and/or block diagram, and a combination of procedures and/or blocks in the flowchart and/or block diagram can be realized by computer program instructions. These computer program instructions may be provided to a general purpose computer, special purpose computer, embedded processor, or processor of other programmable data processing equipment to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing equipment produce a An apparatus for realizing the functions specified in one or more procedures of the flowchart and/or one or more blocks of the block diagram.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to operate in a specific manner, such that the instructions stored in the computer-readable memory produce an article of manufacture comprising instruction means, the instructions The device realizes the function specified in one or more procedures of the flowchart and/or one or more blocks of the block diagram.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded onto a computer or other programmable data processing device, causing a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process, thereby The instructions provide steps for implementing the functions specified in the flow chart or blocks of the flowchart and/or the block or blocks of the block diagrams.
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。In a typical configuration, a computing device includes one or more processors (CPUs), input/output interfaces, network interfaces, and memory.
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。内存是计算机可读介质的示例。Memory may include non-permanent storage in computer readable media, in the form of random access memory (RAM) and/or nonvolatile memory such as read only memory (ROM) or flash RAM. Memory is an example of computer readable media.
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(Phase-change memory,PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(Dynamic Random Access Memory,DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(Electrically Erasable Programmable read only memory,EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。Computer-readable media, including both permanent and non-permanent, removable and non-removable media, can be implemented by any method or technology for storage of information. Information may be computer readable instructions, data structures, modules of a program, or other data. Examples of computer storage media include, but are not limited to, phase-change memory (Phase-change memory, PRAM), static random access memory (SRAM), dynamic random access memory (Dynamic Random Access Memory, DRAM), other types of random Access memory (RAM), read-only memory (ROM), electrically erasable programmable read-only memory (EEPROM), flash memory or other memory technologies, CD-ROM ROM ( CD-ROM), digital versatile disc (DVD) or other optical storage, magnetic tape cartridge, magnetic tape magnetic disk storage or other magnetic storage device, or any other non-transmission medium that can be used to store information that can be accessed by a computing device. As defined herein, computer-readable media excludes transitory computer-readable media, such as modulated data signals and carrier waves.
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。It should also be noted that the term "comprises", "comprises" or any other variation thereof is intended to cover a non-exclusive inclusion such that a process, method, article, or apparatus comprising a set of elements includes not only those elements, but also includes Other elements not expressly listed, or elements inherent in the process, method, commodity, or apparatus are also included. Without further limitations, an element defined by the phrase "comprising a ..." does not exclude the presence of additional identical elements in the process, method, article or apparatus comprising said element.
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。The above descriptions are only examples of the present application, and are not intended to limit the present application. For those skilled in the art, various modifications and changes may occur in this application. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present application shall be included within the scope of the claims of the present application.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310177960.4A CN116193196A (en) | 2023-02-16 | 2023-02-16 | Virtual surround sound rendering method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310177960.4A CN116193196A (en) | 2023-02-16 | 2023-02-16 | Virtual surround sound rendering method, device, equipment and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116193196A true CN116193196A (en) | 2023-05-30 |
Family
ID=86450417
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310177960.4A Pending CN116193196A (en) | 2023-02-16 | 2023-02-16 | Virtual surround sound rendering method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116193196A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025056002A1 (en) * | 2023-09-12 | 2025-03-20 | 北京罗克维尔斯科技有限公司 | Sound field simulation method and apparatus, device, medium, and program product |
| CN120602885A (en) * | 2025-08-07 | 2025-09-05 | 歌尔股份有限公司 | Audio device, control method thereof, and storage medium |
| WO2025201411A1 (en) * | 2024-03-29 | 2025-10-02 | Douyin Vision Co., Ltd. | Audio processing method and apparatus, electronic device, computer readable storage medium and computer program product |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060045294A1 (en) * | 2004-09-01 | 2006-03-02 | Smyth Stephen M | Personalized headphone virtualization |
| CN105120421A (en) * | 2015-08-21 | 2015-12-02 | 北京时代拓灵科技有限公司 | Method and apparatus of generating virtual surround sound |
| CN105376690A (en) * | 2015-11-04 | 2016-03-02 | 北京时代拓灵科技有限公司 | Method and device of generating virtual surround sound |
| CN114866950A (en) * | 2022-05-07 | 2022-08-05 | 安声(重庆)电子科技有限公司 | Audio processing method, device, electronic device, and earphone |
-
2023
- 2023-02-16 CN CN202310177960.4A patent/CN116193196A/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060045294A1 (en) * | 2004-09-01 | 2006-03-02 | Smyth Stephen M | Personalized headphone virtualization |
| CN105120421A (en) * | 2015-08-21 | 2015-12-02 | 北京时代拓灵科技有限公司 | Method and apparatus of generating virtual surround sound |
| CN105376690A (en) * | 2015-11-04 | 2016-03-02 | 北京时代拓灵科技有限公司 | Method and device of generating virtual surround sound |
| CN114866950A (en) * | 2022-05-07 | 2022-08-05 | 安声(重庆)电子科技有限公司 | Audio processing method, device, electronic device, and earphone |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025056002A1 (en) * | 2023-09-12 | 2025-03-20 | 北京罗克维尔斯科技有限公司 | Sound field simulation method and apparatus, device, medium, and program product |
| WO2025201411A1 (en) * | 2024-03-29 | 2025-10-02 | Douyin Vision Co., Ltd. | Audio processing method and apparatus, electronic device, computer readable storage medium and computer program product |
| CN120602885A (en) * | 2025-08-07 | 2025-09-05 | 歌尔股份有限公司 | Audio device, control method thereof, and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9769589B2 (en) | Method of improving externalization of virtual surround sound | |
| JP5955862B2 (en) | Immersive audio rendering system | |
| EP3343349B1 (en) | An apparatus and associated methods in the field of virtual reality | |
| CN109891503B (en) | Acoustic scene playback method and device | |
| US11589184B1 (en) | Differential spatial rendering of audio sources | |
| US12156015B2 (en) | System for and method of generating an audio image | |
| CN108781341B (en) | Sound processing method and sound processing device | |
| CN105325014A (en) | Sound field adjustment based on user tracking | |
| CN116193196A (en) | Virtual surround sound rendering method, device, equipment and storage medium | |
| US11109177B2 (en) | Methods and systems for simulating acoustics of an extended reality world | |
| TW201246060A (en) | Audio spatialization and environment simulation | |
| US20190289418A1 (en) | Method and apparatus for reproducing audio signal based on movement of user in virtual space | |
| US11221821B2 (en) | Audio scene processing | |
| US11102604B2 (en) | Apparatus, method, computer program or system for use in rendering audio | |
| CN111512648A (en) | Enables rendering of spatial audio content for consumption by the user | |
| US9843883B1 (en) | Source independent sound field rotation for virtual and augmented reality applications | |
| CN114816316A (en) | Indication of responsibility for audio playback | |
| KR101111734B1 (en) | Method and apparatus for outputting sound by classifying a plurality of sound sources | |
| US20260025630A1 (en) | Methods, devices, and systems for reproducing spatial audio using binaural externalization processing extensions | |
| US20250350898A1 (en) | Object-based Audio Spatializer With Crosstalk Equalization | |
| CN116095594A (en) | System and method for rendering real-time spatial audio in a virtual environment | |
| WO2025218310A9 (en) | Acoustic scene playback method and apparatus | |
| WO2025218311A9 (en) | Acoustic scene playback method and apparatus | |
| WO2025253637A1 (en) | Acoustic signal generation device, acoustic signal generation method, and acoustic signal generation program | |
| CN121260169A (en) | An audio processing method, an electronic device, a storage medium, and a chip |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |