CN114974214A - 语音关键词的检测方法、装置、电子设备及存储介质 - Google Patents
语音关键词的检测方法、装置、电子设备及存储介质 Download PDFInfo
- Publication number
- CN114974214A CN114974214A CN202210470313.8A CN202210470313A CN114974214A CN 114974214 A CN114974214 A CN 114974214A CN 202210470313 A CN202210470313 A CN 202210470313A CN 114974214 A CN114974214 A CN 114974214A
- Authority
- CN
- China
- Prior art keywords
- word
- duration
- keyword
- target keyword
- difference
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Machine Translation (AREA)
Abstract
本申请涉及一种语音关键词的检测方法、装置、电子设备及存储介质。该方法包括:获取语音检测模型对待检测音频的检测结果,其中,检测结果用于表示第一词语的阶段性发音时长特征,第一词语是语音检测模型从待检测音频中识别出的拟为关键词集合中目标关键词的词语,关键词集合中保存有预先选定的多个关键词;在第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征匹配的情况下,确定第一词语为目标关键词。该方法在待检测音频中可能存在目标关键词的情况下,根据拟为目标关键词的第一词语的阶段性发音时长特征进行了二次判断,从而进一步增加检测结果的准确性,进而解决了相关技术中的关键词检索技术检测结果不准确的问题。
Description
技术领域
本申请涉及语音识别技术领域,尤其涉及一种语音关键词的检测方法、装置、电子设备及存储介质。
背景技术
语音关键词检索技术是一种特殊的语音识别技术,它是在连续语音中辨认和确定一些特定的关键词,或者搜索用户感兴趣的关键词,检索系统返回这些关键词在音频中出现的具体的位置或时间。
目前关于关键词检索技术,均采用机器学习或深度神经网络的方法,输入待检测音频,让机器通过模型自动预测关键词在音频中是否存在和对应的存在位置(起止时间点),但是机器预测结果往往会受环境或者发音不清晰的影响,导致预测结果出现误差。
针对上述的问题,目前尚未提出有效的解决方案。
发明内容
本申请提供了一种语音关键词的检测方法、装置、电子设备及存储介质,以解决相关技术中的关键词检索技术检测结果不准确的问题。
第一方面,本申请提供了一种语音关键词的检测方法,包括:获取语音检测模型对待检测音频的检测结果,其中,所述检测结果用于表示第一词语的阶段性发音时长特征,所述第一词语是所述语音检测模型从所述待检测音频中识别出的拟为关键词集合中目标关键词的词语,所述关键词集合中保存有预先选定的多个关键词;在所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征匹配的情况下,确定所述第一词语为所述目标关键词。
第二方面,本申请提供了一种语音关键词的检测装置,包括:获取单元,用于获取语音检测模型对待检测音频的检测结果,其中,所述检测结果用于表示第一词语的阶段性发音时长特征,所述第一词语是所述语音检测模型从所述待检测音频中识别出的拟为关键词集合中目标关键词的词语,所述关键词集合中保存有预先选定的多个关键词;确定单元,用于在所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征匹配的情况下,确定所述第一词语为所述目标关键词。
第三方面,提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;存储器,用于存放计算机程序;处理器,用于执行存储器上所存放的程序时,实现任一种所述的语音关键词的检测方法的步骤。
第四方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现任一种所述的语音关键词的检测方法的步骤。
本申请技术方案可以应用于基于语音识别与处理的深度学习技术领域。本申请实施例提供的上述技术方案与现有技术相比具有如下优点:
本申请实施例提供的该方法,首先,获取语音检测模型对待检测音频的检测结果,其中,检测结果用于表示待检测音频中拟为目标关键词的第一词语的阶段性发音时长特征,然后在第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征匹配的情况下,确定第一词语为目标关键词。该方法先采用语音检测模型对待检测音频进行检测,在待检测音频中可能存在目标关键词的情况下,根据拟为目标关键词的第一词语的阶段性发音时长特征判断第一词语是否为目标关键词,本实施例的方法对语音关键词检测进行了二次判断,从而进一步增加检测结果的准确性,进而解决了相关技术中的关键词检索技术检测结果不准确的问题。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种语音关键词的检测方法的流程示意图;
图2至图4为本申请实施例提供的采用深度神经网络获取检测结果的方法的流程示意图;
图5为本申请实施例提供的一种语音关键词的检测方法的流程示意图;
图6为本申请实施例提供的一种语音关键词的检测装置的结构示意图;
图7为本申请实施例提供的一种电子设备的结构示意图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请的一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。
根据本申请实施例的一个方面,提供了一种语音关键词的检测方法。可选地,在本实施例中,上述语音关键词的检测方法可以应用于由终端和服务器所构成的硬件环境中。服务器通过网络与终端进行连接,可用于为终端或终端上安装的客户端提供服务,可在服务器上或独立于服务器设置数据库,用于为服务器提供数据存储服务。
上述网络可以包括但不限于以下至少之一:有线网络,无线网络。上述有线网络可以包括但不限于以下至少之一:广域网,城域网,局域网,上述无线网络可以包括但不限于以下至少之一:WIFI(Wireless Fidelity,无线保真),蓝牙。终端可以并不限定于为PC、手机、平板电脑等。
本申请实施例的语音关键词的检测方法可以由服务器来执行,也可以由终端来执行,还可以是由服务器和终端共同执行。其中,终端执行本申请实施例的语音关键词的检测方法也可以是由安装在其上的客户端来执行。
以由服务器来执行本实施例中的语音关键词的检测方法为例,图1为本申请实施例提供的一种语音关键词的检测方法的流程示意图。如图1所示,该方法包括以下步骤:
步骤S201,获取语音检测模型对待检测音频的检测结果,其中,上述检测结果用于表示第一词语的阶段性发音时长特征,上述第一词语是上述语音检测模型从上述待检测音频中识别出的拟为关键词集合中目标关键词的词语,上述关键词集合中保存有预先选定的多个关键词;
在本实施例中,上述阶段性发音时长特征可以是第一词语中每个字的声母时长和韵母时长,例如土豆对应的声韵母为“t-u d-ou”,土豆的阶段性发音时长特征为t的发音时长、u的发音时长、d的发音时长以及ou的发音时长。在实际的应用中,因为人说话的频率不同,同一个词语的声韵母的发音时长可能具有较大差别,但是声韵母时长的比值差别较小,为了进一步提升检测结果的准确性,上述阶段性发音时长特征可以为声母时长和韵母时长的比值,例如t的发音时长和u的发音时长的比值。上述阶段性发音时长特征还可以为归一化后的声母时长和韵母时长,从而缩小因为说话频率不同造成的误差。
上述第一词语是上述语音检测模型从上述待检测音频中识别出的拟为关键词集合中目标关键词的词语,表示上述第一词语被语音检测模型识别成目标关键词,但是由于语音检测模型发生了误识别,该第一词语实际上可能不是目标关键词,例如,目标关键词为土豆,第一词语实际为铜豆,但是被语音检测模型识别成土豆。
上述关键词集合包括多个关键词,例如打开、关闭、静音等。上述目标关键词可以为一个,也可以为多个。
步骤S202,在上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征匹配的情况下,确定上述第一词语为上述目标关键词。
在本实施例中,上述目标关键词的阶段性发音时长特征可以是每个字的声母时长和韵母时长,也可以是声母时长和韵母时长的比值,还可以是归一化后的声母时长和韵母时长。上述目标关键词的阶段性发音时长特征是通过计算语音数据库中大量标注语音的每类声母时长或每类韵母时长的均值得到的。如果第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征的差别在一定范围内,则说明上述第一词语与上述目标关键词的差别较小,则第一词语为目标关键词。
为了快速得到检测结果,在一种实施例中,在上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征匹配的情况下,确定上述第一词语为上述目标关键词,包括:确定上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征的第一差值;根据上述第一差值,确定上述第一词语为上述目标关键词。
在本实施例中,首先需要确定第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征之间的第一差值,根据第一差值就可以判断第一词语是否为目标关键词,这种检测方法比较简单,不需要复杂的计算过程,从而可以快速得到检测结果。
在一种实施例中,根据上述第一差值,确定上述第一词语为上述目标关键词,包括:在上述第一差值小于第一预定值的情况下,确定上述第一词语为上述目标关键词;或,将上述第一差值输入至二分类网络中,得到上述第一词语的概率,其中,上述第一词语的概率用于表征上述第一词语为上述目标关键词的概率,上述二分类网络为使用第一样本对初始二分类网络进行训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值进行标注后得到的;在上述第一词语的概率大于第二预定值的情况下,确定上述第一词语为上述目标关键词。
在本实施例中,可以直接根据第一差值的大小进行比较,如果第一差值小于第一预定值,表示第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征差别较小,则第一词语为目标关键词。还可以将第一差值输入至二分类网络中,利用二分类网络得到第一词语为目标关键词的概率,当概率大于第二预定值时,上述第一词语为上述目标关键词,从而进一步提升了语音关键词检测结果的准确性。
上述二分类网络的标注为0和1,分别对应不是关键词和时关键词两类。上述二分类网络一般采用逻辑斯特回归算法(Logistic Regression,简称LR)、支持向量机(SupportVector Machine,简称SVM)等机器学习算法对二次分类网络进行训练。逻辑斯特二分类网络的参数通过第一样本训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值,标注为0和1。
在一种实施例中,确定上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征的第一差值,包括:利用 得到上述第一差值,其中,MSE表示上述第一差值,
得到上述第一差值,其中,MSE表示上述第一差值, 表示上述目标关键词的声母时长均值或韵母时长均值,yi表示上述第一词语的声母时长或韵母时长,n表示上述第一词语的声母数量和韵母数量之和,i为大于等于1且小于等于n的整数。
表示上述目标关键词的声母时长均值或韵母时长均值,yi表示上述第一词语的声母时长或韵母时长,n表示上述第一词语的声母数量和韵母数量之和,i为大于等于1且小于等于n的整数。
因为损失函数通常采用均方误差,所以在本实施例中,采用上述公式计算第一词语的声母时长和韵母时长与目标关键词的声母时长和韵母时长的均方误差,这样有利于后续采用模型的方法进行判断。
例如,目标关键词为土豆,对应声韵母组合为“t-u d-ou”,这四个声韵母的时长均值x,y,z,m,语音检测模型检测出第一词语实际为“铜豆”,对应声韵母组合为“t-ong d-ou”,得到四个声韵母的持续时长a,b,c,d,并计算这四个声韵母的均方误差。
在一种实施例中,确定上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征的第一差值,包括:确定上述第一词语的声母时长和韵母时长的第一比值以及上述目标关键词的声母时长和韵母时长的第二比值;根据上述第一比值和上述第二比值的差值,得到上述第一差值。
如上述内容中提到,人说话的频率不同导致阶段性发音时长特征有较大差异,为了避免这种差异,从而进一步提升检测结果的准确性,本实施例中,计算声母时长与韵母时长的比值,然后根据第一词语的第一比值和目标关键词的第二比值之间的差值来判断。
上述第一词语或目标关键词的声母时长和韵母时长的比值,可以是第一词语或目标关键词中每个字的声母时长之和和韵母时长之和的比值,也可以是每个字的声母时长和韵母时长的比值。如果是每个字的声母时长和韵母时长的比值,会有多个比值,计算第一词语和目标关键词中每个字的比值的误差,然后计算均方误差,就可以得到第一差值。
在一种实施例中,获取语音检测模型对待检测音频的检测结果,包括:采用语音识别模型对上述待检测音频进行解码,得到候选字词序列,其中,上述语音识别模型用于将上述待检测音频转换成文本数据;根据上述候选字词序列以及对应的回溯路径和匹配得分生成字词网格;利用上述关键词集合中的多个关键词的拼音对上述字词网格中的字词拼音进行检索,得到上述第一词语;根据上述第一词语的拼音,得到上述第一词语的阶段性发音时长特征。
在本实施例中,采用语音识别模型先对待检测音频进行解码,得到字词网格,在字词网格上进行快速检索,检索到第一词语和对应的阶段性发音时长特征,这种检测方式准确性较高,但是因为需要解码,所以运行的时间较长。
在一种实施例中,获取语音检测模型对待检测音频的检测结果,包括:提取上述待检测音频的每帧的语音特征,得到每帧的语音特征向量;将上述每帧的语音特征向量输入至深度神经网络模型中进行分类,得到多个标签以及每个标签的概率,其中,上述标签是从上述待检测音频中识别出的拟为关键词集合中目标关键词或上述目标关键词的部分的词语;在标签的概率大于第三预定值得情况下,确定上述标签为上述第一词语;根据上述第一词语的起始语音帧和结束语音帧,确定上述第一词语的阶段性发音时长特征。
在本实施例中,采用神经网络的方式进行关键词检索,这种方式不需要对待检测音频进行解码,从而减少了运行时的计算时间并减小了内存占用,图2至图4为本申请实施例提供的采用深度神经网络获取检测结果的方法的流程示意图,如图2所示,首先对待检测音频进行特征提取,提取待检测音频的语音特征向量,待检测音频包括关键短语“okay、google”,然后将语音特征向量输入至如图3所示的深度神经网络中,输出3个标签“okay”,“google”和“、filler”,并生成如图4所示的帧级后验概率,后处理模块组合这些概率以提供该窗口的最终置信度分数。
下文将结合具体实施方式进一步详述本申请的技术方案,如图5所示:
步骤一,采用语音识别模型对待检测音频进行解码,得到候选字词序列,其中,上述语音识别模型用于将上述待检测音频转换成文本数据,然后根据上述候选字词序列以及对应的回溯路径和匹配得分生成字词网格,之后利用上述关键词集合中的多个关键词的拼音对上述字词网格中的字词拼音进行检索,得到上述第一词语,并根据上述第一词语的拼音,得到上述第一词语中每个字的声母时长和韵母时长。
步骤二,计算语音数据库中大量标注语音的每类声母时长或每类韵母时长的均值,然后找到目标关键词中的每个字的声母时长和韵母时长。
步骤三,采用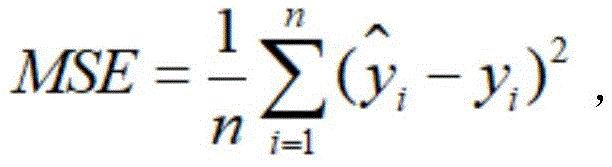 计算第一词语中的声母时长和韵母时长与目标关键词的声母时长和韵母时长的均方误差。
计算第一词语中的声母时长和韵母时长与目标关键词的声母时长和韵母时长的均方误差。
例如,目标关键词为土豆,对应声韵母组合为“t-u d-ou”,这四个声韵母的时长均值x,y,z,m,语音检测模型检测出第一词语实际为“铜豆”,对应声韵母组合为“t-ong d-ou”,得到四个声韵母的持续时长a,b,c,d,并计算这四个声韵母的均方误差。
步骤四,将步骤三中的均方误差输入至二分类模型中,得到第一次词语的概率,上述第一词语的概率用于表征上述第一词语为上述目标关键词的概率。
二分类网络的训练过程如下:采用逻辑斯特回归算法(Logistic Regression,简称LR)、支持向量机(Support Vector Machine,简称SVM)等机器学习算法对二次分类网络进行训练。二分类网络的参数通过第一样本训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值,标注为0和1,分别对应不是关键词和是关键词两类。
步骤五,根据第一词语的概率进行二次判断,在第一词语的概率大于第二预定值的情况下,确定第一词语为目标关键词。
图6为本申请实施例提供的一种语音关键词的检测装置的结构示意图。如图6所示,该装置包括:
获取单元10,用于获取语音检测模型对待检测音频的检测结果,其中,上述检测结果用于表示第一词语的阶段性发音时长特征,上述第一词语是上述语音检测模型从上述待检测音频中识别出的拟为关键词集合中目标关键词的词语,上述关键词集合中保存有预先选定的多个关键词;
在本实施例中,上述阶段性发音时长特征可以是第一词语中每个字的声母时长和韵母时长,例如土豆对应的声韵母为“t-u d-ou”,土豆的阶段性发音时长特征为t的发音时长、u的发音时长、d的发音时长以及ou的发音时长。在实际的应用中,因为人说话的频率不同,同一个词语的声韵母的发音时长可能具有较大差别,但是声韵母时长的比值差别较小,为了进一步提升检测结果的准确性,上述阶段性发音时长特征可以为声母时长和韵母时长的比值,例如t的发音时长和u的发音时长的比值。上述阶段性发音时长特征还可以为归一化后的声母时长和韵母时长,从而缩小因为说话频率不同造成的误差。
上述第一词语是上述语音检测模型从上述待检测音频中识别出的拟为关键词集合中目标关键词的词语,表示上述第一词语被语音检测模型识别成目标关键词,但是由于语音检测模型发生了误识别,该第一词语实际上可能不是目标关键词,例如,目标关键词为土豆,第一词语实际为铜豆,但是被语音检测模型识别成土豆。
上述关键词集合包括多个关键词,例如打开、关闭、静音等。上述目标关键词可以为一个,也可以为多个。
确定单元20,用于在上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征匹配的情况下,确定上述第一词语为上述目标关键词。
在本实施例中,上述目标关键词的阶段性发音时长特征可以是每个字的声母时长和韵母时长,也可以是声母时长和韵母时长的比值,还可以是归一化后的声母时长和韵母时长。上述目标关键词的阶段性发音时长特征是通过计算语音数据库中大量标注语音的每类声母时长或每类韵母时长的均值得到的。如果第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征的差别在一定范围内,则说明上述第一词语与上述目标关键词的差别较小,则第一词语为目标关键词。
为了快速得到检测结果,在一种实施例中,上述确定单元包括第一确定模块和第二确定模块,其中,上述第一确定模块用于确定上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征的第一差值;上述第二确定模块用于根据上述第一差值,确定上述第一词语为上述目标关键词。
在本实施例中,首先需要确定第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征之间的第一差值,根据第一差值就可以判断第一词语是否为目标关键词,这种检测方法比较简单,不需要复杂的计算过程,从而可以快速得到检测结果。
在一种实施例中,上述第二确定模块包括第一确定子模块、输入子模块和第二确定子模块,其中,上述第一确定子模块用于在上述第一差值小于第一预定值的情况下,确定上述第一词语为上述目标关键词;或,上述输入子模块用于将上述第一差值输入至二分类网络中,得到上述第一词语的概率,其中,上述第一词语的概率用于表征上述第一词语为上述目标关键词的概率,上述二分类网络为使用第一样本对初始二分类网络进行训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值进行标注后得到的;上述第二确定子模块用于在上述第一词语的概率大于第二预定值的情况下,确定上述第一词语为上述目标关键词。
在本实施例中,可以直接根据第一差值的大小进行比较,如果第一差值小于第一预定值,表示第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征差别较小,则第一词语为目标关键词。还可以将第一差值输入至二分类网络中,利用二分类网络得到第一词语为目标关键词的概率,当概率大于第二预定值时,上述第一词语为上述目标关键词,从而进一步提升了语音关键词检测结果的准确性。
上述二分类网络的标注为0和1,分别对应不是关键词和时关键词两类。上述二分类网络一般采用逻辑斯特回归算法(Logistic Regression,简称LR)、支持向量机(SupportVector Machine,简称SVM)等机器学习算法对二次分类网络进行训练。逻辑斯特二分类网络的参数通过第一样本训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值,标注为0和1。
在一种实施例中,上述第一确定模块包括第一计算子模块,其中,上述第一计算子模块用于利用 得到上述第一差值,其中,MSE表示上述第一差值,
得到上述第一差值,其中,MSE表示上述第一差值,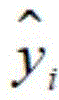 表示上述目标关键词的声母时长均值或韵母时长均值,yi表示上述第一词语的声母时长或韵母时长,n表示上述第一词语的声母数量和韵母数量之和,i为大于等于1且小于等于n的整数。
表示上述目标关键词的声母时长均值或韵母时长均值,yi表示上述第一词语的声母时长或韵母时长,n表示上述第一词语的声母数量和韵母数量之和,i为大于等于1且小于等于n的整数。
因为损失函数通常采用均方误差,所以在本实施例中,采用上述公式计算第一词语的声母时长和韵母时长与目标关键词的声母时长和韵母时长的均方误差,这样有利于后续采用模型的方法进行判断。
例如,目标关键词为土豆,对应声韵母组合为“t-u d-ou”,这四个声韵母的时长均值x,y,z,m,语音检测模型检测出第一词语实际为“铜豆”,对应声韵母组合为“t-ong d-ou”,得到四个声韵母的持续时长a,b,c,d,并计算这四个声韵母的均方误差。
在一种实施例中,上述第一确定模块包括第二计算子模块和第三计算子模块,其中,上述第二计算子模块用于确定上述第一词语的声母时长和韵母时长的第一比值以及上述目标关键词的声母时长和韵母时长的第二比值;上述第三计算子模块用于根据上述第一比值和上述第二比值的差值,得到上述第一差值。
如上述内容中提到,人说话的频率不同导致阶段性发音时长特征有较大差异,为了避免这种差异,从而进一步提升检测结果的准确性,本实施例中,计算声母时长与韵母时长的比值,然后根据第一词语的第一比值和目标关键词的第二比值之间的差值来判断。
上述第一词语或目标关键词的声母时长和韵母时长的比值,可以是第一词语或目标关键词中每个字的声母时长之和和韵母时长之和的比值,也可以是每个字的声母时长和韵母时长的比值。如果是每个字的声母时长和韵母时长的比值,会有多个比值,计算第一词语和目标关键词中每个字的比值的误差,然后计算均方误差,就可以得到第一差值。
在一种实施例中,上述获取单元包括解码模块、生成模块、检索模块和第三确定模块,其中,上述解码模块用于采用语音识别模型对上述待检测音频进行解码,得到候选字词序列,其中,上述语音识别模型用于将上述待检测音频转换成文本数据;上述生成模块用于根据上述候选字词序列以及对应的回溯路径和匹配得分生成字词网格;上述检索模块用于利用上述关键词集合中的多个关键词的拼音对上述字词网格中的字词拼音进行检索,得到上述第一词语;上述第三确定模块用于根据上述第一词语的拼音,得到上述第一词语的阶段性发音时长特征。
在本实施例中,采用语音识别模型先对待检测音频进行解码,得到字词网格,在字词网格上进行快速检索,检索到第一词语和对应的阶段性发音时长特征,这种检测方式准确性较高,但是因为需要解码,所以运行的时间较长。
在一种实施例中,上述获取单元包括提取模块、输入模块、第四确定模块和第五确定模块,其中,上述提取模块用于提取上述待检测音频的每帧的语音特征,得到每帧的语音特征向量;上述输入模块用于将上述每帧的语音特征向量输入至深度神经网络模型中进行分类,得到多个标签以及每个标签的概率,其中,上述标签是从上述待检测音频中识别出的拟为关键词集合中目标关键词或上述目标关键词的部分的词语;上述第四确定模块用于在标签的概率大于第三预定值得情况下,确定上述标签为上述第一词语;上述第五确定模块用于根据上述第一词语的起始语音帧和结束语音帧,确定上述第一词语的阶段性发音时长特征。
在本实施例中,采用神经网络的方式进行关键词检索,这种方式不需要对待检测音频进行解码,从而减少了运行时的计算时间并减小了内存占用,图2至图4为本申请实施例提供的采用深度神经网络获取检测结果的方法的流程示意图,如图2所示,首先对待检测音频进行特征提取,提取待检测音频的语音特征向量,待检测音频包括关键短语“okay、google”,然后将语音特征向量输入至如图3所示的深度神经网络中,输出3个标签“okay”,“google”和“、filler”,并生成如图4所示的帧级后验概率,后处理模块组合这些概率以提供该窗口的最终置信度分数。
如图7所示,本申请实施例提供了一种电子设备,包括处理器111、通信接口112、存储器113和通信总线114,其中,处理器111,通信接口112,存储器113通过通信总线114完成相互间的通信,
存储器113,用于存放计算机程序;
在本申请一个实施例中,处理器111,用于执行存储器113上所存放的程序时,实现前述任意一个方法实施例提供的语音关键词的检测的控制方法。
本申请实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如前述任意一个方法实施例提供的语音关键词的检测方法的步骤。
需要说明的是,在本文中,诸如“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上所述仅是本发明的具体实施方式,使本领域技术人员能够理解或实现本发明。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所申请的原理和新颖特点相一致的最宽的范围。
Claims (10)
1.一种语音关键词的检测方法,其特征在于,包括:
获取语音检测模型对待检测音频的检测结果,其中,所述检测结果用于表示第一词语的阶段性发音时长特征,所述第一词语是所述语音检测模型从所述待检测音频中识别出的拟为关键词集合中目标关键词的词语,所述关键词集合中保存有预先选定的多个关键词;
在所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征匹配的情况下,确定所述第一词语为所述目标关键词。
2.根据权利要求1所述的方法,其特征在于,在所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征匹配的情况下,确定所述第一词语为所述目标关键词,包括:
确定所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征的第一差值;
根据所述第一差值,确定所述第一词语为所述目标关键词。
3.根据权利要求2所述的方法,其特征在于,根据所述第一差值,确定所述第一词语为所述目标关键词,包括:
在所述第一差值小于第一预定值的情况下,确定所述第一词语为所述目标关键词;或,
将所述第一差值输入至二分类网络中,得到所述第一词语的概率,其中,所述第一词语的概率用于表征所述第一词语为所述目标关键词的概率,所述二分类网络为使用第一样本对初始二分类网络进行训练得到的,所述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值进行标注后得到的;在所述第一词语的概率大于第二预定值的情况下,确定所述第一词语为所述目标关键词。
4.根据权利要求2所述的方法,其特征在于,确定所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征的第一差值,包括:
利用 得到所述第一差值,其中,MSE表示所述第一差值,
得到所述第一差值,其中,MSE表示所述第一差值,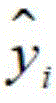 表示所述目标关键词的声母时长均值或韵母时长均值,yi表示所述第一词语的声母时长或韵母时长,n表示所述第一词语的声母数量和韵母数量之和,i为大于等于1且小于等于n的整数。
表示所述目标关键词的声母时长均值或韵母时长均值,yi表示所述第一词语的声母时长或韵母时长,n表示所述第一词语的声母数量和韵母数量之和,i为大于等于1且小于等于n的整数。
5.根据权利要求2所述的方法,其特征在于,确定所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征的第一差值,包括:
确定所述第一词语的声母时长和韵母时长的第一比值以及所述目标关键词的声母时长和韵母时长的第二比值;
根据所述第一比值和所述第二比值的差值,得到所述第一差值。
6.根据权利要求1所述的方法,其特征在于,获取语音检测模型对待检测音频的检测结果,包括:
采用语音识别模型对所述待检测音频进行解码,得到候选字词序列,其中,所述语音识别模型用于将所述待检测音频转换成文本数据;
根据所述候选字词序列以及对应的回溯路径和匹配得分生成字词网格;
利用所述关键词集合中的多个关键词的拼音对所述字词网格中的字词拼音进行检索,得到所述第一词语;
根据所述第一词语的拼音,得到所述第一词语的阶段性发音时长特征。
7.根据权利要求1所述的方法,其特征在于,获取语音检测模型对待检测音频的检测结果,包括:
提取所述待检测音频的每帧的语音特征,得到每帧的语音特征向量;
将所述每帧的语音特征向量输入至深度神经网络模型中进行分类,得到多个标签以及每个标签的概率,其中,所述标签是从所述待检测音频中识别出的拟为关键词集合中目标关键词或所述目标关键词的部分的词语;
在标签的概率大于第三预定值得情况下,确定所述标签为所述第一词语;
根据所述第一词语的起始语音帧和结束语音帧,确定所述第一词语的阶段性发音时长特征。
8.一种语音关键词的检测装置,其特征在于,包括:
获取单元,用于获取语音检测模型对待检测音频的检测结果,其中,所述检测结果用于表示第一词语的阶段性发音时长特征,所述第一词语是所述语音检测模型从所述待检测音频中识别出的拟为关键词集合中目标关键词的词语,所述关键词集合中保存有预先选定的多个关键词;
确定单元,用于在所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征匹配的情况下,确定所述第一词语为所述目标关键词。
9.一种电子设备,其特征在于,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
存储器,用于存放计算机程序;
处理器,用于执行存储器上所存放的程序时,实现权利要求1-7中任一项所述的语音关键词的检测方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-7中任一项所述的语音关键词的检测方法的步骤。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210470313.8A CN114974214A (zh) | 2022-04-28 | 2022-04-28 | 语音关键词的检测方法、装置、电子设备及存储介质 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210470313.8A CN114974214A (zh) | 2022-04-28 | 2022-04-28 | 语音关键词的检测方法、装置、电子设备及存储介质 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114974214A true CN114974214A (zh) | 2022-08-30 |
Family
ID=82979438
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210470313.8A Pending CN114974214A (zh) | 2022-04-28 | 2022-04-28 | 语音关键词的检测方法、装置、电子设备及存储介质 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114974214A (zh) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115527523A (zh) * | 2022-09-23 | 2022-12-27 | 北京世纪好未来教育科技有限公司 | 关键词语音识别方法、装置、存储介质和电子设备 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103730115A (zh) * | 2013-12-27 | 2014-04-16 | 北京捷成世纪科技股份有限公司 | 一种语音中检测关键词的方法和装置 |
| CN109192224A (zh) * | 2018-09-14 | 2019-01-11 | 科大讯飞股份有限公司 | 一种语音评测方法、装置、设备及可读存储介质 |
| CN110148427A (zh) * | 2018-08-22 | 2019-08-20 | 腾讯数码(天津)有限公司 | 音频处理方法、装置、系统、存储介质、终端及服务器 |
| CN111078937A (zh) * | 2019-12-27 | 2020-04-28 | 北京世纪好未来教育科技有限公司 | 语音信息检索方法、装置、设备和计算机可读存储介质 |
| CN113779972A (zh) * | 2021-09-10 | 2021-12-10 | 平安科技(深圳)有限公司 | 语音识别纠错方法、系统、装置及存储介质 |
| CN114255739A (zh) * | 2020-09-21 | 2022-03-29 | 中国移动通信集团设计院有限公司 | 识别语音中关键词的方法及装置 |
-
2022
- 2022-04-28 CN CN202210470313.8A patent/CN114974214A/zh active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103730115A (zh) * | 2013-12-27 | 2014-04-16 | 北京捷成世纪科技股份有限公司 | 一种语音中检测关键词的方法和装置 |
| CN110148427A (zh) * | 2018-08-22 | 2019-08-20 | 腾讯数码(天津)有限公司 | 音频处理方法、装置、系统、存储介质、终端及服务器 |
| CN109192224A (zh) * | 2018-09-14 | 2019-01-11 | 科大讯飞股份有限公司 | 一种语音评测方法、装置、设备及可读存储介质 |
| CN111078937A (zh) * | 2019-12-27 | 2020-04-28 | 北京世纪好未来教育科技有限公司 | 语音信息检索方法、装置、设备和计算机可读存储介质 |
| CN114255739A (zh) * | 2020-09-21 | 2022-03-29 | 中国移动通信集团设计院有限公司 | 识别语音中关键词的方法及装置 |
| CN113779972A (zh) * | 2021-09-10 | 2021-12-10 | 平安科技(深圳)有限公司 | 语音识别纠错方法、系统、装置及存储介质 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115527523A (zh) * | 2022-09-23 | 2022-12-27 | 北京世纪好未来教育科技有限公司 | 关键词语音识别方法、装置、存储介质和电子设备 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11580145B1 (en) | Query rephrasing using encoder neural network and decoder neural network | |
| CN102682763B (zh) | 修正语音输入文本中命名实体词汇的方法、装置及终端 | |
| US20160306783A1 (en) | Method and apparatus for phonetically annotating text | |
| CN112037772B (zh) | 基于多模态的响应义务检测方法、系统及装置 | |
| CN111737414B (zh) | 一种歌曲推荐方法及装置、服务器、存储介质 | |
| CN106098059A (zh) | 可定制语音唤醒方法及系统 | |
| CN110795913A (zh) | 一种文本编码方法、装置、存储介质及终端 | |
| CN108538294B (zh) | 一种语音交互方法及装置 | |
| JP2005165272A (ja) | 多数の音声特徴を利用する音声認識 | |
| CN108038208B (zh) | 上下文信息识别模型的训练方法、装置和存储介质 | |
| CN112669842A (zh) | 人机对话控制方法、装置、计算机设备及存储介质 | |
| CN108536807B (zh) | 一种信息处理方法及装置 | |
| US20250037704A1 (en) | Voice recognition method, apparatus, system, electronic device, storage medium, and computer program product | |
| CN113555016A (zh) | 语音交互方法、电子设备及可读存储介质 | |
| CN111209367A (zh) | 信息查找方法、信息查找装置、电子设备及存储介质 | |
| US11437043B1 (en) | Presence data determination and utilization | |
| CN114171000A (zh) | 一种基于声学模型和语言模型的音频识别方法 | |
| CN113051384A (zh) | 基于对话的用户画像抽取方法及相关装置 | |
| CN110853669B (zh) | 音频识别方法、装置及设备 | |
| CN109688271A (zh) | 联系人信息输入的方法、装置及终端设备 | |
| CN111126084A (zh) | 数据处理方法、装置、电子设备和存储介质 | |
| CN108682415B (zh) | 语音搜索方法、装置和系统 | |
| Rose et al. | Integration of utterance verification with statistical language modeling and spoken language understanding | |
| CN119943032B (zh) | 基于人工智能的语音识别方法、系统、设备及介质 | |
| CN114974214A (zh) | 语音关键词的检测方法、装置、电子设备及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |