CN114974214A - Voice keyword detection method and device, electronic equipment and storage medium - Google Patents
Voice keyword detection method and device, electronic equipment and storage medium Download PDFInfo
- Publication number
- CN114974214A CN114974214A CN202210470313.8A CN202210470313A CN114974214A CN 114974214 A CN114974214 A CN 114974214A CN 202210470313 A CN202210470313 A CN 202210470313A CN 114974214 A CN114974214 A CN 114974214A
- Authority
- CN
- China
- Prior art keywords
- word
- duration
- keyword
- target keyword
- difference
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Machine Translation (AREA)
Abstract
Description
技术领域technical field
本申请涉及语音识别技术领域,尤其涉及一种语音关键词的检测方法、装置、电子设备及存储介质。The present application relates to the technical field of speech recognition, and in particular, to a method, device, electronic device and storage medium for detecting speech keywords.
背景技术Background technique
语音关键词检索技术是一种特殊的语音识别技术,它是在连续语音中辨认和确定一些特定的关键词,或者搜索用户感兴趣的关键词,检索系统返回这些关键词在音频中出现的具体的位置或时间。Voice keyword retrieval technology is a special voice recognition technology, which is to identify and determine some specific keywords in continuous speech, or search for keywords that users are interested in, and the retrieval system returns the specific keywords that appear in the audio. location or time.
目前关于关键词检索技术,均采用机器学习或深度神经网络的方法,输入待检测音频,让机器通过模型自动预测关键词在音频中是否存在和对应的存在位置(起止时间点),但是机器预测结果往往会受环境或者发音不清晰的影响,导致预测结果出现误差。At present, with regard to keyword retrieval technology, the method of machine learning or deep neural network is used to input the audio to be detected, so that the machine can automatically predict whether the keyword exists in the audio and the corresponding existence position (start and end time point) through the model, but the machine predicts The results are often affected by the environment or unclear pronunciation, resulting in errors in the prediction results.
针对上述的问题,目前尚未提出有效的解决方案。For the above problems, no effective solution has been proposed yet.
发明内容SUMMARY OF THE INVENTION
本申请提供了一种语音关键词的检测方法、装置、电子设备及存储介质,以解决相关技术中的关键词检索技术检测结果不准确的问题。The present application provides a method, device, electronic device and storage medium for detecting speech keywords, so as to solve the problem of inaccurate detection results of keyword retrieval technology in the related art.
第一方面,本申请提供了一种语音关键词的检测方法,包括:获取语音检测模型对待检测音频的检测结果,其中,所述检测结果用于表示第一词语的阶段性发音时长特征,所述第一词语是所述语音检测模型从所述待检测音频中识别出的拟为关键词集合中目标关键词的词语,所述关键词集合中保存有预先选定的多个关键词;在所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征匹配的情况下,确定所述第一词语为所述目标关键词。In a first aspect, the present application provides a method for detecting speech keywords, including: acquiring a detection result of the audio to be detected by a speech detection model, wherein the detection result is used to represent the phased pronunciation duration feature of the first word, so The first word is a word recognized by the speech detection model from the audio to be detected and intended to be a target keyword in a keyword set, and the keyword set stores a plurality of pre-selected keywords; When the phased pronunciation duration feature of the first word matches the phased pronunciation duration characteristic of the target keyword, the first word is determined to be the target keyword.
第二方面,本申请提供了一种语音关键词的检测装置,包括:获取单元,用于获取语音检测模型对待检测音频的检测结果,其中,所述检测结果用于表示第一词语的阶段性发音时长特征,所述第一词语是所述语音检测模型从所述待检测音频中识别出的拟为关键词集合中目标关键词的词语,所述关键词集合中保存有预先选定的多个关键词;确定单元,用于在所述第一词语的阶段性发音时长特征与所述目标关键词的阶段性发音时长特征匹配的情况下,确定所述第一词语为所述目标关键词。In a second aspect, the present application provides an apparatus for detecting speech keywords, comprising: an acquisition unit configured to acquire a detection result of the audio to be detected by a speech detection model, wherein the detection result is used to indicate the phase of the first word Pronunciation duration feature, the first word is a word recognized by the speech detection model from the audio to be detected and intended to be a target keyword in a keyword set, and the keyword set stores a number of pre-selected words. A determination unit, configured to determine that the first word is the target keyword when the phased pronunciation duration feature of the first word matches the phased pronunciation duration characteristic of the target keyword .
第三方面,提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;存储器,用于存放计算机程序;处理器,用于执行存储器上所存放的程序时,实现任一种所述的语音关键词的检测方法的步骤。In a third aspect, an electronic device is provided, including a processor, a communication interface, a memory, and a communication bus, wherein the processor, the communication interface, and the memory communicate with each other through the communication bus; the memory is used for storing computer programs; processing The device is used to implement the steps of any one of the voice keyword detection methods when executing the program stored in the memory.
第四方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现任一种所述的语音关键词的检测方法的步骤。In a fourth aspect, a computer-readable storage medium is provided, on which a computer program is stored, and when the computer program is executed by a processor, implements the steps of any one of the voice keyword detection methods.
本申请技术方案可以应用于基于语音识别与处理的深度学习技术领域。本申请实施例提供的上述技术方案与现有技术相比具有如下优点:The technical solution of the present application can be applied to the field of deep learning technology based on speech recognition and processing. Compared with the prior art, the above-mentioned technical solutions provided in the embodiments of the present application have the following advantages:
本申请实施例提供的该方法,首先,获取语音检测模型对待检测音频的检测结果,其中,检测结果用于表示待检测音频中拟为目标关键词的第一词语的阶段性发音时长特征,然后在第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征匹配的情况下,确定第一词语为目标关键词。该方法先采用语音检测模型对待检测音频进行检测,在待检测音频中可能存在目标关键词的情况下,根据拟为目标关键词的第一词语的阶段性发音时长特征判断第一词语是否为目标关键词,本实施例的方法对语音关键词检测进行了二次判断,从而进一步增加检测结果的准确性,进而解决了相关技术中的关键词检索技术检测结果不准确的问题。In the method provided by the embodiment of the present application, first, the detection result of the audio to be detected by the speech detection model is obtained, wherein the detection result is used to represent the staged pronunciation duration feature of the first word in the audio to be detected that is to be the target keyword, and then In the case that the staged pronunciation duration feature of the first word matches the staged pronunciation duration feature of the target keyword, the first word is determined as the target keyword. The method first uses a speech detection model to detect the audio to be detected, and in the case that the target keyword may exist in the audio to be detected, it is judged whether the first word is the target according to the phased pronunciation duration feature of the first word to be the target keyword. keyword, the method of this embodiment performs a secondary judgment on the detection of speech keywords, thereby further increasing the accuracy of the detection result, and further solving the problem of inaccurate detection results of the keyword retrieval technology in the related art.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate embodiments consistent with the invention and together with the description serve to explain the principles of the invention.
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the embodiments of the present invention or the technical solutions in the prior art, the following briefly introduces the accompanying drawings that need to be used in the description of the embodiments or the prior art. In other words, on the premise of no creative labor, other drawings can also be obtained from these drawings.
图1为本申请实施例提供的一种语音关键词的检测方法的流程示意图;1 is a schematic flowchart of a method for detecting a speech keyword according to an embodiment of the present application;
图2至图4为本申请实施例提供的采用深度神经网络获取检测结果的方法的流程示意图;2 to 4 are schematic flowcharts of a method for obtaining a detection result by using a deep neural network according to an embodiment of the present application;
图5为本申请实施例提供的一种语音关键词的检测方法的流程示意图;5 is a schematic flowchart of a method for detecting speech keywords provided by an embodiment of the present application;
图6为本申请实施例提供的一种语音关键词的检测装置的结构示意图;6 is a schematic structural diagram of a device for detecting speech keywords provided by an embodiment of the present application;
图7为本申请实施例提供的一种电子设备的结构示意图。FIG. 7 is a schematic structural diagram of an electronic device according to an embodiment of the present application.
具体实施方式Detailed ways
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请的一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。In order to make the purposes, technical solutions and advantages of the embodiments of the present application clearer, the technical solutions in the embodiments of the present application will be described clearly and completely below with reference to the drawings in the embodiments of the present application. Obviously, the described embodiments It is a part of the embodiments of this application, but not all of the embodiments. Based on the embodiments in the present application, all other embodiments obtained by those of ordinary skill in the art without creative work shall fall within the protection scope of the present application.
根据本申请实施例的一个方面,提供了一种语音关键词的检测方法。可选地,在本实施例中,上述语音关键词的检测方法可以应用于由终端和服务器所构成的硬件环境中。服务器通过网络与终端进行连接,可用于为终端或终端上安装的客户端提供服务,可在服务器上或独立于服务器设置数据库,用于为服务器提供数据存储服务。According to an aspect of the embodiments of the present application, a method for detecting speech keywords is provided. Optionally, in this embodiment, the foregoing method for detecting speech keywords may be applied to a hardware environment composed of a terminal and a server. The server is connected to the terminal through the network, which can be used to provide services for the terminal or the client installed on the terminal, and a database can be set on the server or independent of the server to provide data storage services for the server.
上述网络可以包括但不限于以下至少之一:有线网络,无线网络。上述有线网络可以包括但不限于以下至少之一:广域网,城域网,局域网,上述无线网络可以包括但不限于以下至少之一:WIFI(Wireless Fidelity,无线保真),蓝牙。终端可以并不限定于为PC、手机、平板电脑等。The above network may include, but is not limited to, at least one of the following: wired network, wireless network. The wired network may include but is not limited to at least one of the following: a wide area network, a metropolitan area network, and a local area network, and the wireless network may include but not limited to at least one of the following: WIFI (Wireless Fidelity, wireless fidelity), Bluetooth. The terminal may not be limited to a PC, a mobile phone, a tablet computer, or the like.
本申请实施例的语音关键词的检测方法可以由服务器来执行,也可以由终端来执行,还可以是由服务器和终端共同执行。其中,终端执行本申请实施例的语音关键词的检测方法也可以是由安装在其上的客户端来执行。The method for detecting speech keywords in this embodiment of the present application may be executed by a server, a terminal, or jointly executed by a server and a terminal. Wherein, the terminal executing the voice keyword detection method of the embodiment of the present application may also be executed by a client installed on the terminal.
以由服务器来执行本实施例中的语音关键词的检测方法为例,图1为本申请实施例提供的一种语音关键词的检测方法的流程示意图。如图1所示,该方法包括以下步骤:Taking the method for detecting speech keywords in this embodiment performed by a server as an example, FIG. 1 is a schematic flowchart of a method for detecting speech keywords according to an embodiment of the present application. As shown in Figure 1, the method includes the following steps:
步骤S201,获取语音检测模型对待检测音频的检测结果,其中,上述检测结果用于表示第一词语的阶段性发音时长特征,上述第一词语是上述语音检测模型从上述待检测音频中识别出的拟为关键词集合中目标关键词的词语,上述关键词集合中保存有预先选定的多个关键词;Step S201, obtaining the detection result of the audio to be detected by the voice detection model, wherein the above-mentioned detection result is used to represent the phased pronunciation duration feature of the first word, and the above-mentioned first word is identified by the above-mentioned voice detection model from the above-mentioned audio to be detected. A word intended to be a target keyword in a keyword set, where multiple pre-selected keywords are stored in the keyword set;
在本实施例中,上述阶段性发音时长特征可以是第一词语中每个字的声母时长和韵母时长,例如土豆对应的声韵母为“t-u d-ou”,土豆的阶段性发音时长特征为t的发音时长、u的发音时长、d的发音时长以及ou的发音时长。在实际的应用中,因为人说话的频率不同,同一个词语的声韵母的发音时长可能具有较大差别,但是声韵母时长的比值差别较小,为了进一步提升检测结果的准确性,上述阶段性发音时长特征可以为声母时长和韵母时长的比值,例如t的发音时长和u的发音时长的比值。上述阶段性发音时长特征还可以为归一化后的声母时长和韵母时长,从而缩小因为说话频率不同造成的误差。In this embodiment, the above-mentioned phased pronunciation duration feature may be the duration of initials and finals of each character in the first word. For example, the initials and finals corresponding to potatoes are "t-u d-ou", and the phased pronunciation duration features of potatoes are The pronunciation duration of t, the pronunciation duration of u, the pronunciation duration of d, and the pronunciation duration of ou. In practical applications, due to the different frequencies of people speaking, the pronunciation duration of the initials and finals of the same word may be quite different, but the difference in the ratio of the durations of the initials and finals is small. In order to further improve the accuracy of the detection results, the above phased The pronunciation duration feature may be the ratio of the duration of the initial consonant to the duration of the final, for example, the ratio of the pronunciation duration of t to the pronunciation duration of u. The above-mentioned staged pronunciation duration feature may also be the normalized initial consonant duration and final consonant duration, thereby reducing errors caused by different speaking frequencies.
上述第一词语是上述语音检测模型从上述待检测音频中识别出的拟为关键词集合中目标关键词的词语,表示上述第一词语被语音检测模型识别成目标关键词,但是由于语音检测模型发生了误识别,该第一词语实际上可能不是目标关键词,例如,目标关键词为土豆,第一词语实际为铜豆,但是被语音检测模型识别成土豆。The above-mentioned first word is the word that the above-mentioned speech detection model recognizes from the above-mentioned audio to be detected and is intended to be the target keyword in the keyword set, which means that the above-mentioned first word is recognized as the target keyword by the speech detection model, but due to the speech detection model. Misrecognition occurs, and the first word may not actually be the target keyword. For example, the target keyword is potatoes, and the first word is actually copper beans, but is recognized as potatoes by the speech detection model.
上述关键词集合包括多个关键词,例如打开、关闭、静音等。上述目标关键词可以为一个,也可以为多个。The above keyword set includes a plurality of keywords, such as open, close, mute and so on. The above target keyword may be one or more than one.
步骤S202,在上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征匹配的情况下,确定上述第一词语为上述目标关键词。Step S202, in the case that the phased pronunciation duration feature of the first word matches the phased pronunciation duration feature of the target keyword, determine that the first word is the target keyword.
在本实施例中,上述目标关键词的阶段性发音时长特征可以是每个字的声母时长和韵母时长,也可以是声母时长和韵母时长的比值,还可以是归一化后的声母时长和韵母时长。上述目标关键词的阶段性发音时长特征是通过计算语音数据库中大量标注语音的每类声母时长或每类韵母时长的均值得到的。如果第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征的差别在一定范围内,则说明上述第一词语与上述目标关键词的差别较小,则第一词语为目标关键词。In this embodiment, the staged pronunciation duration feature of the target keyword may be the duration of the initial consonant and the duration of the final consonant of each character, or the ratio of the duration of the initial consonant to the duration of the final vowel, or the normalized duration of the initial consonant and the duration of the final consonant. Rhyme duration. The phased pronunciation duration feature of the above target keyword is obtained by calculating the average duration of each type of initials or the duration of each type of finals of a large number of marked speeches in the speech database. If the difference between the staged pronunciation duration feature of the first word and the staged pronunciation duration feature of the target keyword is within a certain range, it means that the difference between the above-mentioned first word and the above-mentioned target keyword is small, and the first word is the target key. word.
为了快速得到检测结果,在一种实施例中,在上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征匹配的情况下,确定上述第一词语为上述目标关键词,包括:确定上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征的第一差值;根据上述第一差值,确定上述第一词语为上述目标关键词。In order to obtain the detection result quickly, in an embodiment, in the case that the phased pronunciation duration feature of the above-mentioned first word matches the phased pronunciation duration characteristic of the above-mentioned target keyword, the above-mentioned first word is determined to be the above-mentioned target keyword. , comprising: determining a first difference between the staged pronunciation duration feature of the first word and the staged pronunciation duration feature of the target keyword; and determining the first word as the target keyword according to the first difference.
在本实施例中,首先需要确定第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征之间的第一差值,根据第一差值就可以判断第一词语是否为目标关键词,这种检测方法比较简单,不需要复杂的计算过程,从而可以快速得到检测结果。In this embodiment, it is first necessary to determine the first difference between the staged pronunciation duration feature of the first word and the staged pronunciation duration feature of the target keyword, and it can be determined whether the first word is the target according to the first difference Key words, this detection method is relatively simple and does not require complicated calculation process, so that the detection result can be obtained quickly.
在一种实施例中,根据上述第一差值,确定上述第一词语为上述目标关键词,包括:在上述第一差值小于第一预定值的情况下,确定上述第一词语为上述目标关键词;或,将上述第一差值输入至二分类网络中,得到上述第一词语的概率,其中,上述第一词语的概率用于表征上述第一词语为上述目标关键词的概率,上述二分类网络为使用第一样本对初始二分类网络进行训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值进行标注后得到的;在上述第一词语的概率大于第二预定值的情况下,确定上述第一词语为上述目标关键词。In an embodiment, determining the first word as the target keyword according to the first difference value includes: in the case that the first difference value is smaller than a first predetermined value, determining the first word as the target keyword or, inputting the first difference into a two-class network to obtain the probability of the first word, wherein the probability of the first word is used to represent the probability that the first word is the target keyword, the above The two-class network is obtained by using the first sample to train the initial two-class network. The above-mentioned first sample is the phased pronunciation duration feature and reference stage of the words in the speech database to be the target keywords in the keyword set obtained after marking the difference between the sexual pronunciation duration features; when the probability of the first word is greater than the second predetermined value, it is determined that the first word is the target keyword.
在本实施例中,可以直接根据第一差值的大小进行比较,如果第一差值小于第一预定值,表示第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征差别较小,则第一词语为目标关键词。还可以将第一差值输入至二分类网络中,利用二分类网络得到第一词语为目标关键词的概率,当概率大于第二预定值时,上述第一词语为上述目标关键词,从而进一步提升了语音关键词检测结果的准确性。In this embodiment, the comparison can be made directly according to the size of the first difference. If the first difference is smaller than the first predetermined value, it means that the phased pronunciation duration feature of the first word is different from the phased pronunciation duration characteristic of the target keyword. If it is smaller, the first word is the target keyword. It is also possible to input the first difference into a two-class network, and use the two-class network to obtain the probability that the first word is the target keyword. When the probability is greater than the second predetermined value, the above-mentioned first word is the above-mentioned target keyword, thereby further. Improves the accuracy of speech keyword detection results.
上述二分类网络的标注为0和1,分别对应不是关键词和时关键词两类。上述二分类网络一般采用逻辑斯特回归算法(Logistic Regression,简称LR)、支持向量机(SupportVector Machine,简称SVM)等机器学习算法对二次分类网络进行训练。逻辑斯特二分类网络的参数通过第一样本训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值,标注为0和1。The labels of the above two-category network are 0 and 1, which correspond to the two categories of non-keywords and time-keywords, respectively. The above-mentioned binary classification network generally adopts machine learning algorithms such as Logistic Regression (LR), Support Vector Machine (SVM) and the like to train the secondary classification network. The parameters of the Logistic binary classification network are obtained through the training of the first sample, and the above-mentioned first sample is the phased pronunciation duration feature and the reference phased pronunciation of the words in the speech database to be the target keywords in the keyword set The difference between duration features, marked as 0 and 1.
在一种实施例中,确定上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征的第一差值,包括:利用

因为损失函数通常采用均方误差,所以在本实施例中,采用上述公式计算第一词语的声母时长和韵母时长与目标关键词的声母时长和韵母时长的均方误差,这样有利于后续采用模型的方法进行判断。Because the loss function usually adopts the mean square error, in this embodiment, the above formula is used to calculate the mean square error between the initial and final duration of the first word and the initial and final duration of the target keyword, which is conducive to the subsequent adoption of the model method to judge.
例如,目标关键词为土豆,对应声韵母组合为“t-u d-ou”,这四个声韵母的时长均值x,y,z,m,语音检测模型检测出第一词语实际为“铜豆”,对应声韵母组合为“t-ong d-ou”,得到四个声韵母的持续时长a,b,c,d,并计算这四个声韵母的均方误差。For example, if the target keyword is potatoes, the corresponding combination of initials and finals is "t-u d-ou", the average duration of these four initials and finals is x, y, z, m, and the speech detection model detects that the first word is actually "tongdou" , the corresponding combination of consonants and finals is "t-ong d-ou", and the durations a, b, c, and d of the four consonants are obtained, and the mean square error of the four consonants is calculated.
在一种实施例中,确定上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征的第一差值,包括:确定上述第一词语的声母时长和韵母时长的第一比值以及上述目标关键词的声母时长和韵母时长的第二比值;根据上述第一比值和上述第二比值的差值,得到上述第一差值。In one embodiment, determining the first difference between the phased pronunciation duration feature of the first word and the phased pronunciation duration characteristic of the target keyword includes: determining the first difference between the duration of the initials and the duration of the finals of the first word A ratio and a second ratio of the duration of the initial consonant and the duration of the final of the target keyword; the first difference is obtained according to the difference between the first ratio and the second ratio.
如上述内容中提到,人说话的频率不同导致阶段性发音时长特征有较大差异,为了避免这种差异,从而进一步提升检测结果的准确性,本实施例中,计算声母时长与韵母时长的比值,然后根据第一词语的第一比值和目标关键词的第二比值之间的差值来判断。As mentioned in the above content, the different frequencies of people's speech lead to large differences in the characteristics of the stage pronunciation duration. In order to avoid this difference and further improve the accuracy of the detection results, in this embodiment, the difference between the duration of the initial consonant and the duration of the final vowel is calculated. The ratio is then determined according to the difference between the first ratio of the first word and the second ratio of the target keyword.
上述第一词语或目标关键词的声母时长和韵母时长的比值,可以是第一词语或目标关键词中每个字的声母时长之和和韵母时长之和的比值,也可以是每个字的声母时长和韵母时长的比值。如果是每个字的声母时长和韵母时长的比值,会有多个比值,计算第一词语和目标关键词中每个字的比值的误差,然后计算均方误差,就可以得到第一差值。The ratio of the duration of the initial consonant and the duration of the final vowel of the above-mentioned first word or target keyword can be the ratio of the duration of the initial consonant and the duration of the final vowel of each character in the first word or the target keyword, or the ratio of the duration of each character. The ratio of the duration of initials to the duration of finals. If it is the ratio of the duration of the initials to the duration of the finals of each character, there will be multiple ratios. Calculate the error of the ratio between the first word and each character in the target keyword, and then calculate the mean squared error to get the first difference. .
在一种实施例中,获取语音检测模型对待检测音频的检测结果,包括:采用语音识别模型对上述待检测音频进行解码,得到候选字词序列,其中,上述语音识别模型用于将上述待检测音频转换成文本数据;根据上述候选字词序列以及对应的回溯路径和匹配得分生成字词网格;利用上述关键词集合中的多个关键词的拼音对上述字词网格中的字词拼音进行检索,得到上述第一词语;根据上述第一词语的拼音,得到上述第一词语的阶段性发音时长特征。In one embodiment, acquiring the detection result of the audio to be detected by the speech detection model includes: using a speech recognition model to decode the audio to be detected to obtain a sequence of candidate words, wherein the speech recognition model is used to decode the audio to be detected. The audio is converted into text data; the word grid is generated according to the above-mentioned candidate word sequence and the corresponding backtracking path and matching score; Perform retrieval to obtain the above-mentioned first word; according to the pinyin of the above-mentioned first word, obtain the staged pronunciation duration feature of the above-mentioned first word.
在本实施例中,采用语音识别模型先对待检测音频进行解码,得到字词网格,在字词网格上进行快速检索,检索到第一词语和对应的阶段性发音时长特征,这种检测方式准确性较高,但是因为需要解码,所以运行的时间较长。In this embodiment, a speech recognition model is used to first decode the audio to be detected to obtain a word grid, and then perform a quick search on the word grid to retrieve the first word and the corresponding phased pronunciation duration feature. The accuracy of the method is higher, but the running time is longer because of the need for decoding.
在一种实施例中,获取语音检测模型对待检测音频的检测结果,包括:提取上述待检测音频的每帧的语音特征,得到每帧的语音特征向量;将上述每帧的语音特征向量输入至深度神经网络模型中进行分类,得到多个标签以及每个标签的概率,其中,上述标签是从上述待检测音频中识别出的拟为关键词集合中目标关键词或上述目标关键词的部分的词语;在标签的概率大于第三预定值得情况下,确定上述标签为上述第一词语;根据上述第一词语的起始语音帧和结束语音帧,确定上述第一词语的阶段性发音时长特征。In one embodiment, acquiring the detection result of the audio to be detected by the speech detection model includes: extracting the speech feature of each frame of the audio to be detected, and obtaining the speech feature vector of each frame; inputting the speech feature vector of each frame into a Perform classification in the deep neural network model to obtain multiple labels and the probability of each label, wherein the above labels are identified from the above-mentioned audio to be detected and are intended to be the target keywords in the keyword set or the part of the above-mentioned target keywords. word; when the probability of the label is greater than the third predetermined value, the label is determined as the first word; according to the initial speech frame and the end speech frame of the first word, the phased pronunciation duration feature of the first word is determined.
在本实施例中,采用神经网络的方式进行关键词检索,这种方式不需要对待检测音频进行解码,从而减少了运行时的计算时间并减小了内存占用,图2至图4为本申请实施例提供的采用深度神经网络获取检测结果的方法的流程示意图,如图2所示,首先对待检测音频进行特征提取,提取待检测音频的语音特征向量,待检测音频包括关键短语“okay、google”,然后将语音特征向量输入至如图3所示的深度神经网络中,输出3个标签“okay”,“google”和“、filler”,并生成如图4所示的帧级后验概率,后处理模块组合这些概率以提供该窗口的最终置信度分数。In this embodiment, a neural network method is used for keyword retrieval, which does not require decoding of the audio to be detected, thereby reducing the computation time and memory usage during runtime. Figures 2 to 4 are for the application A schematic flowchart of a method for obtaining a detection result by using a deep neural network provided by the embodiment, as shown in FIG. 2 , first, feature extraction is performed on the audio to be detected, and a speech feature vector of the audio to be detected is extracted, and the audio to be detected includes the key phrase "okay, google" ", then input the speech feature vector into the deep neural network as shown in Figure 3,
下文将结合具体实施方式进一步详述本申请的技术方案,如图5所示:The technical solution of the present application will be described in further detail below in conjunction with specific embodiments, as shown in Figure 5:
步骤一,采用语音识别模型对待检测音频进行解码,得到候选字词序列,其中,上述语音识别模型用于将上述待检测音频转换成文本数据,然后根据上述候选字词序列以及对应的回溯路径和匹配得分生成字词网格,之后利用上述关键词集合中的多个关键词的拼音对上述字词网格中的字词拼音进行检索,得到上述第一词语,并根据上述第一词语的拼音,得到上述第一词语中每个字的声母时长和韵母时长。Step 1, using a speech recognition model to decode the audio to be detected to obtain a sequence of candidate words, wherein the speech recognition model is used to convert the audio to be detected into text data, and then according to the sequence of candidate words and the corresponding backtracking path and The matching score generates a word grid, and then uses the pinyin of a plurality of keywords in the above keyword set to retrieve the word pinyin in the above word grid to obtain the above-mentioned first word, and according to the pinyin of the above-mentioned first word , to obtain the duration of the initial consonant and the duration of the final vowel of each character in the first word above.
步骤二,计算语音数据库中大量标注语音的每类声母时长或每类韵母时长的均值,然后找到目标关键词中的每个字的声母时长和韵母时长。Step 2: Calculate the average duration of each type of initials or durations of each type of finals of a large number of marked voices in the speech database, and then find the durations of initials and finals of each character in the target keyword.
步骤三,采用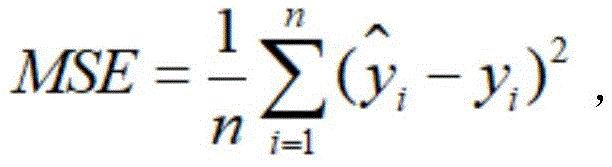
例如,目标关键词为土豆,对应声韵母组合为“t-u d-ou”,这四个声韵母的时长均值x,y,z,m,语音检测模型检测出第一词语实际为“铜豆”,对应声韵母组合为“t-ong d-ou”,得到四个声韵母的持续时长a,b,c,d,并计算这四个声韵母的均方误差。For example, if the target keyword is potatoes, the corresponding combination of initials and finals is "t-u d-ou", the average duration of these four initials and finals is x, y, z, m, and the speech detection model detects that the first word is actually "tongdou" , the corresponding combination of consonants and finals is "t-ong d-ou", and the durations a, b, c, and d of the four consonants are obtained, and the mean square error of the four consonants is calculated.
步骤四,将步骤三中的均方误差输入至二分类模型中,得到第一次词语的概率,上述第一词语的概率用于表征上述第一词语为上述目标关键词的概率。In step 4, the mean square error in
二分类网络的训练过程如下:采用逻辑斯特回归算法(Logistic Regression,简称LR)、支持向量机(Support Vector Machine,简称SVM)等机器学习算法对二次分类网络进行训练。二分类网络的参数通过第一样本训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值,标注为0和1,分别对应不是关键词和是关键词两类。The training process of the binary classification network is as follows: the secondary classification network is trained by using machine learning algorithms such as Logistic Regression (LR) and Support Vector Machine (SVM). The parameters of the two-class network are obtained through the training of the first sample, and the above-mentioned first sample is the difference between the phased pronunciation duration feature and the reference phased pronunciation duration feature of the words in the speech database to be the target keywords in the keyword set. The difference between the values, marked as 0 and 1, corresponds to the two categories of non-keywords and keywords, respectively.
步骤五,根据第一词语的概率进行二次判断,在第一词语的概率大于第二预定值的情况下,确定第一词语为目标关键词。Step 5: Perform a second judgment according to the probability of the first word, and determine the first word as the target keyword when the probability of the first word is greater than the second predetermined value.
图6为本申请实施例提供的一种语音关键词的检测装置的结构示意图。如图6所示,该装置包括:FIG. 6 is a schematic structural diagram of an apparatus for detecting speech keywords according to an embodiment of the present application. As shown in Figure 6, the device includes:
获取单元10,用于获取语音检测模型对待检测音频的检测结果,其中,上述检测结果用于表示第一词语的阶段性发音时长特征,上述第一词语是上述语音检测模型从上述待检测音频中识别出的拟为关键词集合中目标关键词的词语,上述关键词集合中保存有预先选定的多个关键词;The obtaining unit 10 is used to obtain the detection result of the audio to be detected by the voice detection model, wherein the above-mentioned detection result is used to represent the phased pronunciation duration feature of the first word, and the above-mentioned first word is the above-mentioned audio to be detected by the above-mentioned voice detection model. The identified words that are intended to be the target keywords in the keyword set, and the above-mentioned keyword set saves a plurality of pre-selected keywords;
在本实施例中,上述阶段性发音时长特征可以是第一词语中每个字的声母时长和韵母时长,例如土豆对应的声韵母为“t-u d-ou”,土豆的阶段性发音时长特征为t的发音时长、u的发音时长、d的发音时长以及ou的发音时长。在实际的应用中,因为人说话的频率不同,同一个词语的声韵母的发音时长可能具有较大差别,但是声韵母时长的比值差别较小,为了进一步提升检测结果的准确性,上述阶段性发音时长特征可以为声母时长和韵母时长的比值,例如t的发音时长和u的发音时长的比值。上述阶段性发音时长特征还可以为归一化后的声母时长和韵母时长,从而缩小因为说话频率不同造成的误差。In this embodiment, the above-mentioned phased pronunciation duration feature may be the duration of initials and finals of each character in the first word. For example, the initials and finals corresponding to potatoes are "t-u d-ou", and the phased pronunciation duration features of potatoes are The pronunciation duration of t, the pronunciation duration of u, the pronunciation duration of d, and the pronunciation duration of ou. In practical applications, due to the different frequencies of people speaking, the pronunciation duration of the initials and finals of the same word may be quite different, but the difference in the ratio of the durations of the initials and finals is small. In order to further improve the accuracy of the detection results, the above phased The pronunciation duration feature may be the ratio of the duration of the initial consonant to the duration of the final, for example, the ratio of the pronunciation duration of t to the pronunciation duration of u. The above-mentioned staged pronunciation duration feature may also be the normalized initial consonant duration and final consonant duration, thereby reducing errors caused by different speaking frequencies.
上述第一词语是上述语音检测模型从上述待检测音频中识别出的拟为关键词集合中目标关键词的词语,表示上述第一词语被语音检测模型识别成目标关键词,但是由于语音检测模型发生了误识别,该第一词语实际上可能不是目标关键词,例如,目标关键词为土豆,第一词语实际为铜豆,但是被语音检测模型识别成土豆。The above-mentioned first word is the word that the above-mentioned speech detection model recognizes from the above-mentioned audio to be detected and is intended to be the target keyword in the keyword set, which means that the above-mentioned first word is recognized as the target keyword by the speech detection model, but due to the speech detection model. Misrecognition occurs, and the first word may not actually be the target keyword. For example, the target keyword is potatoes, and the first word is actually copper beans, but is recognized as potatoes by the speech detection model.
上述关键词集合包括多个关键词,例如打开、关闭、静音等。上述目标关键词可以为一个,也可以为多个。The above keyword set includes a plurality of keywords, such as open, close, mute and so on. The above target keyword may be one or more than one.
确定单元20,用于在上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征匹配的情况下,确定上述第一词语为上述目标关键词。The determining unit 20 is configured to determine the first word as the target keyword when the phased pronunciation duration feature of the first word matches the phased pronunciation duration characteristic of the target keyword.
在本实施例中,上述目标关键词的阶段性发音时长特征可以是每个字的声母时长和韵母时长,也可以是声母时长和韵母时长的比值,还可以是归一化后的声母时长和韵母时长。上述目标关键词的阶段性发音时长特征是通过计算语音数据库中大量标注语音的每类声母时长或每类韵母时长的均值得到的。如果第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征的差别在一定范围内,则说明上述第一词语与上述目标关键词的差别较小,则第一词语为目标关键词。In this embodiment, the staged pronunciation duration feature of the target keyword may be the duration of the initial consonant and the duration of the final consonant of each character, or the ratio of the duration of the initial consonant to the duration of the final vowel, or the normalized duration of the initial consonant and the duration of the final consonant. Rhyme duration. The phased pronunciation duration feature of the above target keyword is obtained by calculating the average duration of each type of initials or the duration of each type of finals of a large number of marked speeches in the speech database. If the difference between the staged pronunciation duration feature of the first word and the staged pronunciation duration feature of the target keyword is within a certain range, it means that the difference between the above-mentioned first word and the above-mentioned target keyword is small, and the first word is the target key. word.
为了快速得到检测结果,在一种实施例中,上述确定单元包括第一确定模块和第二确定模块,其中,上述第一确定模块用于确定上述第一词语的阶段性发音时长特征与上述目标关键词的阶段性发音时长特征的第一差值;上述第二确定模块用于根据上述第一差值,确定上述第一词语为上述目标关键词。In order to obtain the detection result quickly, in an embodiment, the determining unit includes a first determining module and a second determining module, wherein the first determining module is used to determine the phased pronunciation duration feature of the first word and the target The first difference value of the phased pronunciation duration feature of the keyword; the above-mentioned second determination module is configured to determine the above-mentioned first word as the above-mentioned target keyword according to the above-mentioned first difference value.
在本实施例中,首先需要确定第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征之间的第一差值,根据第一差值就可以判断第一词语是否为目标关键词,这种检测方法比较简单,不需要复杂的计算过程,从而可以快速得到检测结果。In this embodiment, it is first necessary to determine the first difference between the staged pronunciation duration feature of the first word and the staged pronunciation duration feature of the target keyword, and it can be determined whether the first word is the target according to the first difference Key words, this detection method is relatively simple and does not require complicated calculation process, so that the detection result can be obtained quickly.
在一种实施例中,上述第二确定模块包括第一确定子模块、输入子模块和第二确定子模块,其中,上述第一确定子模块用于在上述第一差值小于第一预定值的情况下,确定上述第一词语为上述目标关键词;或,上述输入子模块用于将上述第一差值输入至二分类网络中,得到上述第一词语的概率,其中,上述第一词语的概率用于表征上述第一词语为上述目标关键词的概率,上述二分类网络为使用第一样本对初始二分类网络进行训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值进行标注后得到的;上述第二确定子模块用于在上述第一词语的概率大于第二预定值的情况下,确定上述第一词语为上述目标关键词。In an embodiment, the second determination module includes a first determination sub-module, an input sub-module and a second determination sub-module, wherein the first determination sub-module is configured to be used when the first difference value is smaller than a first predetermined value In the case of , determine that the above-mentioned first word is the above-mentioned target keyword; or, the above-mentioned input sub-module is used to input the above-mentioned first difference into the two-class network to obtain the probability of the above-mentioned first word, wherein the above-mentioned first word The probability of is used to characterize the probability that the first word is the target keyword. The above-mentioned two-class network is obtained by using the first sample to train the initial two-class network, and the above-mentioned first sample is the prediction in the speech database. Obtained after marking the difference between the phased pronunciation duration feature of the words of the target keyword in the keyword set and the reference phased pronunciation duration feature; the above-mentioned second determination sub-module is used when the probability of the above-mentioned first word is greater than that of the first word. In the case of two predetermined values, it is determined that the above-mentioned first word is the above-mentioned target keyword.
在本实施例中,可以直接根据第一差值的大小进行比较,如果第一差值小于第一预定值,表示第一词语的阶段性发音时长特征与目标关键词的阶段性发音时长特征差别较小,则第一词语为目标关键词。还可以将第一差值输入至二分类网络中,利用二分类网络得到第一词语为目标关键词的概率,当概率大于第二预定值时,上述第一词语为上述目标关键词,从而进一步提升了语音关键词检测结果的准确性。In this embodiment, the comparison can be made directly according to the size of the first difference. If the first difference is smaller than the first predetermined value, it means that the phased pronunciation duration feature of the first word is different from the phased pronunciation duration characteristic of the target keyword. If it is smaller, the first word is the target keyword. It is also possible to input the first difference into a two-class network, and use the two-class network to obtain the probability that the first word is the target keyword. When the probability is greater than the second predetermined value, the above-mentioned first word is the above-mentioned target keyword, thereby further. Improves the accuracy of speech keyword detection results.
上述二分类网络的标注为0和1,分别对应不是关键词和时关键词两类。上述二分类网络一般采用逻辑斯特回归算法(Logistic Regression,简称LR)、支持向量机(SupportVector Machine,简称SVM)等机器学习算法对二次分类网络进行训练。逻辑斯特二分类网络的参数通过第一样本训练得到的,上述第一样本为对语音数据库中的拟为关键词集合中目标关键词的词语的阶段性发音时长特征和参考阶段性发音时长特征之间的差值,标注为0和1。The labels of the above two-category network are 0 and 1, which correspond to the two categories of non-keywords and time-keywords, respectively. The above-mentioned binary classification network generally adopts machine learning algorithms such as Logistic Regression (LR), Support Vector Machine (SVM) and the like to train the secondary classification network. The parameters of the Logistic binary classification network are obtained through the training of the first sample, and the above-mentioned first sample is the phased pronunciation duration feature and the reference phased pronunciation of the words in the speech database to be the target keywords in the keyword set The difference between duration features, marked as 0 and 1.
在一种实施例中,上述第一确定模块包括第一计算子模块,其中,上述第一计算子模块用于利用
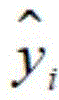
因为损失函数通常采用均方误差,所以在本实施例中,采用上述公式计算第一词语的声母时长和韵母时长与目标关键词的声母时长和韵母时长的均方误差,这样有利于后续采用模型的方法进行判断。Because the loss function usually adopts the mean square error, in this embodiment, the above formula is used to calculate the mean square error between the initial and final duration of the first word and the initial and final duration of the target keyword, which is conducive to the subsequent adoption of the model method to judge.
例如,目标关键词为土豆,对应声韵母组合为“t-u d-ou”,这四个声韵母的时长均值x,y,z,m,语音检测模型检测出第一词语实际为“铜豆”,对应声韵母组合为“t-ong d-ou”,得到四个声韵母的持续时长a,b,c,d,并计算这四个声韵母的均方误差。For example, if the target keyword is potatoes, the corresponding combination of initials and finals is "t-u d-ou", the average duration of these four initials and finals is x, y, z, m, and the speech detection model detects that the first word is actually "tongdou" , the corresponding combination of consonants and finals is "t-ong d-ou", and the durations a, b, c, and d of the four consonants are obtained, and the mean square error of the four consonants is calculated.
在一种实施例中,上述第一确定模块包括第二计算子模块和第三计算子模块,其中,上述第二计算子模块用于确定上述第一词语的声母时长和韵母时长的第一比值以及上述目标关键词的声母时长和韵母时长的第二比值;上述第三计算子模块用于根据上述第一比值和上述第二比值的差值,得到上述第一差值。In an embodiment, the first determination module includes a second calculation submodule and a third calculation submodule, wherein the second calculation submodule is used to determine a first ratio between the duration of the initial consonant and the duration of the final vowel of the first word and the second ratio of the duration of the initial consonant and the duration of the final vowel of the target keyword; the third calculation sub-module is configured to obtain the first difference according to the difference between the first ratio and the second ratio.
如上述内容中提到,人说话的频率不同导致阶段性发音时长特征有较大差异,为了避免这种差异,从而进一步提升检测结果的准确性,本实施例中,计算声母时长与韵母时长的比值,然后根据第一词语的第一比值和目标关键词的第二比值之间的差值来判断。As mentioned in the above content, the different frequencies of people's speech lead to large differences in the characteristics of the stage pronunciation duration. In order to avoid this difference and further improve the accuracy of the detection results, in this embodiment, the difference between the duration of the initial consonant and the duration of the final vowel is calculated. The ratio is then determined according to the difference between the first ratio of the first word and the second ratio of the target keyword.
上述第一词语或目标关键词的声母时长和韵母时长的比值,可以是第一词语或目标关键词中每个字的声母时长之和和韵母时长之和的比值,也可以是每个字的声母时长和韵母时长的比值。如果是每个字的声母时长和韵母时长的比值,会有多个比值,计算第一词语和目标关键词中每个字的比值的误差,然后计算均方误差,就可以得到第一差值。The ratio of the duration of the initial consonant and the duration of the final vowel of the above-mentioned first word or target keyword can be the ratio of the duration of the initial consonant and the duration of the final vowel of each character in the first word or the target keyword, or the ratio of the duration of each character. The ratio of the duration of initials to the duration of finals. If it is the ratio of the duration of the initials to the duration of the finals of each character, there will be multiple ratios. Calculate the error of the ratio between the first word and each character in the target keyword, and then calculate the mean squared error to get the first difference. .
在一种实施例中,上述获取单元包括解码模块、生成模块、检索模块和第三确定模块,其中,上述解码模块用于采用语音识别模型对上述待检测音频进行解码,得到候选字词序列,其中,上述语音识别模型用于将上述待检测音频转换成文本数据;上述生成模块用于根据上述候选字词序列以及对应的回溯路径和匹配得分生成字词网格;上述检索模块用于利用上述关键词集合中的多个关键词的拼音对上述字词网格中的字词拼音进行检索,得到上述第一词语;上述第三确定模块用于根据上述第一词语的拼音,得到上述第一词语的阶段性发音时长特征。In one embodiment, the obtaining unit includes a decoding module, a generating module, a retrieval module and a third determining module, wherein the decoding module is used to decode the audio to be detected by using a speech recognition model to obtain a sequence of candidate words, Wherein, the above-mentioned speech recognition model is used to convert the above-mentioned audio to be detected into text data; the above-mentioned generation module is used to generate a word grid according to the above-mentioned candidate word sequence and the corresponding backtracking path and matching score; the above-mentioned retrieval module is used to use the above-mentioned The pinyin of a plurality of keywords in the keyword set is used to retrieve the pinyin of the words in the word grid to obtain the first word; the third determination module is used for obtaining the first word according to the pinyin of the first word Periodic pronunciation duration characteristics of words.
在本实施例中,采用语音识别模型先对待检测音频进行解码,得到字词网格,在字词网格上进行快速检索,检索到第一词语和对应的阶段性发音时长特征,这种检测方式准确性较高,但是因为需要解码,所以运行的时间较长。In this embodiment, a speech recognition model is used to first decode the audio to be detected to obtain a word grid, and then perform a quick search on the word grid to retrieve the first word and the corresponding phased pronunciation duration feature. The accuracy of the method is higher, but the running time is longer because of the need for decoding.
在一种实施例中,上述获取单元包括提取模块、输入模块、第四确定模块和第五确定模块,其中,上述提取模块用于提取上述待检测音频的每帧的语音特征,得到每帧的语音特征向量;上述输入模块用于将上述每帧的语音特征向量输入至深度神经网络模型中进行分类,得到多个标签以及每个标签的概率,其中,上述标签是从上述待检测音频中识别出的拟为关键词集合中目标关键词或上述目标关键词的部分的词语;上述第四确定模块用于在标签的概率大于第三预定值得情况下,确定上述标签为上述第一词语;上述第五确定模块用于根据上述第一词语的起始语音帧和结束语音帧,确定上述第一词语的阶段性发音时长特征。In one embodiment, the obtaining unit includes an extraction module, an input module, a fourth determination module, and a fifth determination module, wherein the extraction module is used to extract the speech features of each frame of the audio to be detected, and obtain the Speech feature vector; the above-mentioned input module is used to input the above-mentioned speech feature vector of each frame into the deep neural network model for classification, and obtain a plurality of labels and the probability of each label, wherein, the above-mentioned labels are identified from the above-mentioned audio to be detected. The above-mentioned fourth determination module is used to determine that the above-mentioned label is the above-mentioned first word when the probability of the label is greater than the third predetermined value; the above-mentioned The fifth determining module is configured to determine the phased pronunciation duration feature of the first word according to the starting speech frame and the ending speech frame of the first word.
在本实施例中,采用神经网络的方式进行关键词检索,这种方式不需要对待检测音频进行解码,从而减少了运行时的计算时间并减小了内存占用,图2至图4为本申请实施例提供的采用深度神经网络获取检测结果的方法的流程示意图,如图2所示,首先对待检测音频进行特征提取,提取待检测音频的语音特征向量,待检测音频包括关键短语“okay、google”,然后将语音特征向量输入至如图3所示的深度神经网络中,输出3个标签“okay”,“google”和“、filler”,并生成如图4所示的帧级后验概率,后处理模块组合这些概率以提供该窗口的最终置信度分数。In this embodiment, a neural network method is used for keyword retrieval, which does not require decoding of the audio to be detected, thereby reducing the computation time and memory usage during runtime. Figures 2 to 4 are for the application A schematic flowchart of a method for obtaining a detection result by using a deep neural network provided by the embodiment, as shown in FIG. 2 , first, feature extraction is performed on the audio to be detected, and a speech feature vector of the audio to be detected is extracted, and the audio to be detected includes the key phrase "okay, google" ", then input the speech feature vector into the deep neural network as shown in Figure 3,
如图7所示,本申请实施例提供了一种电子设备,包括处理器111、通信接口112、存储器113和通信总线114,其中,处理器111,通信接口112,存储器113通过通信总线114完成相互间的通信,As shown in FIG. 7 , an embodiment of the present application provides an electronic device, including a
存储器113,用于存放计算机程序;a
在本申请一个实施例中,处理器111,用于执行存储器113上所存放的程序时,实现前述任意一个方法实施例提供的语音关键词的检测的控制方法。In an embodiment of the present application, the
本申请实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如前述任意一个方法实施例提供的语音关键词的检测方法的步骤。Embodiments of the present application further provide a computer-readable storage medium on which a computer program is stored, and when the computer program is executed by a processor, implements the steps of the voice keyword detection method provided by any one of the foregoing method embodiments.
需要说明的是,在本文中,诸如“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。It should be noted that, in this document, relational terms such as "first" and "second" etc. are only used to distinguish one entity or operation from another entity or operation, and do not necessarily require or imply these There is no such actual relationship or sequence between entities or operations. Moreover, the terms "comprising", "comprising" or any other variation thereof are intended to encompass a non-exclusive inclusion such that a process, method, article or device that includes a list of elements includes not only those elements, but also includes not explicitly listed or other elements inherent to such a process, method, article or apparatus. Without further limitation, an element qualified by the phrase "comprising a..." does not preclude the presence of additional identical elements in a process, method, article or apparatus that includes the element.
以上所述仅是本发明的具体实施方式,使本领域技术人员能够理解或实现本发明。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所申请的原理和新颖特点相一致的最宽的范围。The above descriptions are only specific embodiments of the present invention, so that those skilled in the art can understand or implement the present invention. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the generic principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the invention. Thus, the present invention is not intended to be limited to the embodiments shown herein, but is to be accorded the widest scope consistent with the principles and novel features claimed herein.
Claims (10)

Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210470313.8A CN114974214A (en) | 2022-04-28 | 2022-04-28 | Voice keyword detection method and device, electronic equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210470313.8A CN114974214A (en) | 2022-04-28 | 2022-04-28 | Voice keyword detection method and device, electronic equipment and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114974214A true CN114974214A (en) | 2022-08-30 |
Family
ID=82979438
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210470313.8A Pending CN114974214A (en) | 2022-04-28 | 2022-04-28 | Voice keyword detection method and device, electronic equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114974214A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115527523A (en) * | 2022-09-23 | 2022-12-27 | 北京世纪好未来教育科技有限公司 | Keyword voice recognition method and device, storage medium and electronic equipment |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103730115A (en) * | 2013-12-27 | 2014-04-16 | 北京捷成世纪科技股份有限公司 | Method and device for detecting keywords in voice |
| CN109192224A (en) * | 2018-09-14 | 2019-01-11 | 科大讯飞股份有限公司 | A kind of speech evaluating method, device, equipment and readable storage medium storing program for executing |
| CN110148427A (en) * | 2018-08-22 | 2019-08-20 | 腾讯数码(天津)有限公司 | Audio-frequency processing method, device, system, storage medium, terminal and server |
| CN111078937A (en) * | 2019-12-27 | 2020-04-28 | 北京世纪好未来教育科技有限公司 | Voice information retrieval method, device, equipment and computer readable storage medium |
| CN113779972A (en) * | 2021-09-10 | 2021-12-10 | 平安科技(深圳)有限公司 | Speech recognition error correction method, system, device and storage medium |
| CN114255739A (en) * | 2020-09-21 | 2022-03-29 | 中国移动通信集团设计院有限公司 | Method and device for recognizing keywords in voice |
-
2022
- 2022-04-28 CN CN202210470313.8A patent/CN114974214A/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103730115A (en) * | 2013-12-27 | 2014-04-16 | 北京捷成世纪科技股份有限公司 | Method and device for detecting keywords in voice |
| CN110148427A (en) * | 2018-08-22 | 2019-08-20 | 腾讯数码(天津)有限公司 | Audio-frequency processing method, device, system, storage medium, terminal and server |
| CN109192224A (en) * | 2018-09-14 | 2019-01-11 | 科大讯飞股份有限公司 | A kind of speech evaluating method, device, equipment and readable storage medium storing program for executing |
| CN111078937A (en) * | 2019-12-27 | 2020-04-28 | 北京世纪好未来教育科技有限公司 | Voice information retrieval method, device, equipment and computer readable storage medium |
| CN114255739A (en) * | 2020-09-21 | 2022-03-29 | 中国移动通信集团设计院有限公司 | Method and device for recognizing keywords in voice |
| CN113779972A (en) * | 2021-09-10 | 2021-12-10 | 平安科技(深圳)有限公司 | Speech recognition error correction method, system, device and storage medium |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115527523A (en) * | 2022-09-23 | 2022-12-27 | 北京世纪好未来教育科技有限公司 | Keyword voice recognition method and device, storage medium and electronic equipment |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11580145B1 (en) | Query rephrasing using encoder neural network and decoder neural network | |
| CN102682763B (en) | Method, device and terminal for correcting named entity vocabularies in voice input text | |
| US20160306783A1 (en) | Method and apparatus for phonetically annotating text | |
| CN112037772B (en) | Response obligation detection method, system and device based on multiple modes | |
| CN111737414B (en) | Song recommendation method and device, server and storage medium | |
| CN106098059A (en) | customizable voice awakening method and system | |
| CN110795913A (en) | Text encoding method and device, storage medium and terminal | |
| CN108538294B (en) | Voice interaction method and device | |
| JP2005165272A (en) | Speech recognition utilizing multitude of speech features | |
| CN108038208B (en) | Training method and device of context information recognition model and storage medium | |
| CN112669842A (en) | Man-machine conversation control method, device, computer equipment and storage medium | |
| CN108536807B (en) | Information processing method and device | |
| US20250037704A1 (en) | Voice recognition method, apparatus, system, electronic device, storage medium, and computer program product | |
| CN113555016A (en) | Voice interaction method, electronic equipment and readable storage medium | |
| CN111209367A (en) | Information searching method, information searching device, electronic equipment and storage medium | |
| US11437043B1 (en) | Presence data determination and utilization | |
| CN114171000A (en) | Audio recognition method based on acoustic model and language model | |
| CN113051384A (en) | User portrait extraction method based on conversation and related device | |
| CN110853669B (en) | Audio identification method, device and equipment | |
| CN109688271A (en) | The method, apparatus and terminal device of contact information input | |
| CN111126084A (en) | Data processing method and device, electronic equipment and storage medium | |
| CN108682415B (en) | Voice search method, device and system | |
| Rose et al. | Integration of utterance verification with statistical language modeling and spoken language understanding | |
| CN119943032B (en) | Speech recognition method, system, equipment and medium based on artificial intelligence | |
| CN114974214A (en) | Voice keyword detection method and device, electronic equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |