CN114912448A - Text extension method, device, equipment and medium - Google Patents
Text extension method, device, equipment and medium Download PDFInfo
- Publication number
- CN114912448A CN114912448A CN202210829003.0A CN202210829003A CN114912448A CN 114912448 A CN114912448 A CN 114912448A CN 202210829003 A CN202210829003 A CN 202210829003A CN 114912448 A CN114912448 A CN 114912448A
- Authority
- CN
- China
- Prior art keywords
- text
- target
- expanded
- expansion
- preset
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/194—Calculation of difference between files
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
The application discloses a text extension method, a text extension device, text extension equipment and a text extension medium, which relate to the field of short text extension, and the method comprises the following steps: determining a text to be expanded and determining a target noun in the text to be expanded; performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics; combining the target expansion entity and the target expansion semantics pairwise, and calculating a corresponding relevance score of each combination; inputting a combination of a text to be expanded and a correlation score meeting a first preset condition into a preset text generation model to obtain an expanded text; and evaluating the semantic similarity between the expanded text and the text to be expanded by using a preset text semantic similarity evaluation model, and determining the expanded text of which the semantic similarity meets a preset similarity condition from the expanded text as a target expanded text to be output. The method can expand the short text into the long text with rich semantics and consistent emotion, and improves the accuracy of text expansion.
Description
Technical Field
The present invention relates to the field of short text extension, and in particular, to a text extension method, apparatus, device, and medium.
Background
The purpose of the short text semantic expansion is to expand a short text with limited semantic information into a long text with richer semantic information, and the short text semantic expansion can be applied to various text rewriting tasks, automatic text generation tasks, data enhancement tasks, text classification tasks and other scenes. The existing short text expansion method mainly aims at expanding the feature words in the short text. For example, the microblog short text "friends of a whole family" may be expanded to long text "i am and my puppies pleasantly play with each day, we are always good friends" or "girlfriends" may be expanded to "i am and girlfriends, we are friends of a whole family".
The task similar to the short text extension is text extension which mainly extends a small amount of text to a large amount of similar text with various sentence patterns and semantic fidelity, and short text extension which extends the limited semantic features of the short text to more dimensions. The three tasks all belong to text enhancement tasks, and the main methods include manual labeling, word replacement, syntax trees, retranslation, neural networks and the like. The manual labeling method is a main way of early corpus expansion, and the expanded corpus has high quality, but has long working period and high cost. The word replacement method realizes the expansion of the text corpus by replacing non-core words in the text with synonyms, inserting and deleting virtual words, assisting words and other modes, and the mode is rapid and convenient, but the expanded text sentence pattern is single. The retroversion method is a text enhancement method which is used more in recent years, and constructs enhanced data of a source language in a mode of translating a source language into another language and translating a sentence of the obtained another language back to the source language; although the translation method can generate corpora of different sentence patterns, when the text contains spoken words, wrongly written words, or domain specialized words, the method easily causes semantic changes of the generated sentences. The syntax tree method mainly analyzes the syntactic dependency and semantic role of the text and changes sentence patterns through the compiled transformation rules.
Therefore, in the short text extension process, how to avoid the situation that the semantic change of the extended text is not rich enough and the semantic information is easy to change is a problem to be solved in the field.
Disclosure of Invention
In view of the above, the present invention provides a text extension method, apparatus, device and medium, which can extend a short text into a long text with rich semantics and consistent emotion. The specific scheme is as follows:
in a first aspect, the present application discloses a text extension method, including:
determining a text to be expanded, and determining a target noun from the text to be expanded;
performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics;
combining the target extended entities and the target extended semantics pairwise, and calculating a correlation score between the corresponding target extended entities and the target extended semantics in each combination;
inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model to obtain an expanded text output by the preset text generation model;
and evaluating the semantic similarity between the expanded text and the text to be expanded by using a preset text semantic similarity evaluation model, and determining the expanded text of which the semantic similarity meets a preset similarity condition from the expanded text as a target expanded text to be output.
Optionally, the determining a target noun from the text to be expanded includes:
performing part-of-speech tagging on the text to be expanded by using a preset part-of-speech tagging tool to obtain the text to be expanded with part-of-speech tags;
and determining a word group with a part-of-speech tag as a part-of-speech of the noun from the text to be expanded with the part-of-speech tag as a target noun.
Optionally, the performing part-of-speech tagging on the text to be expanded by using a preset part-of-speech tagging tool to obtain the text to be expanded with a part-of-speech tag includes:
and performing part-of-speech tagging on the text to be expanded by utilizing stanza to obtain the text to be expanded with part-of-speech tags.
Optionally, the determining a text to be expanded and determining a target noun from the text to be expanded includes:
determining a text to be expanded, and determining a target noun from the text to be expanded to generate a noun list;
correspondingly, the performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics includes:
and performing entity expansion and semantic expansion on the target nouns in the noun list to determine target expansion entities and target expansion semantics.
Optionally, after determining the target expansion entity and the target expansion semantics, the method further includes:
determining a superior-inferior relation list of the target noun by using a knowledge graph;
generating an entity extension list based on the superior-inferior relation list and the target extension entity;
and generating a semantic extension list based on the upper and lower relation list and the target extension semantics.
Optionally, the determining the top-bottom relation list of the target noun by using the knowledge graph includes:
and searching the upper and lower relation of the target noun by using a searching interface of the conceptNet to determine an upper and lower relation list of the target noun.
Optionally, the generating an entity extension list based on the context list and the target extension entity, and generating a semantic extension list based on the context list and the target extension semantic, includes:
extracting tail entities with the relationship of a preset first relationship in the upper and lower relationship list to form an entity expansion list;
and extracting tail entities with the relationship of a preset second relationship in the upper and lower relationship list to form a semantic expansion list.
Optionally, before determining the text to be expanded and determining the target noun from the text to be expanded, the method further includes:
collecting texts from a preset social platform, and classifying the texts into short texts and long texts by using a preset classification rule;
correspondingly, the determining the text to be expanded includes:
and determining the short text as the text to be expanded.
Optionally, before pairwise combining the target extended entity and the target extended semantic, and calculating a correlation score between the corresponding target extended entity and the target extended semantic in each combination, the method further includes:
performing part-of-speech tagging on the long text by using a preset part-of-speech tagging tool to obtain the long text with part-of-speech tags, and then determining the part-of-speech tags as word groups of verb parts-of-speech and noun parts-of-speech from the long text with part-of-speech tags;
determining verb phrases and noun phrases in the same long text as phrases with correlation, inputting the phrases with correlation as training data into a preset language representation model for training to obtain a trained model.
Optionally, the pairwise combining the target extended entity and the target extended semantic, and calculating a correlation score between the corresponding target extended entity and the target extended semantic in each combination includes:
combining the target expansion entity and the target expansion semantics pairwise and inputting the combination into the trained model;
and acquiring a correlation score between the corresponding target expansion entity and the target expansion semantic in each combination of the output of the trained model.
Optionally, the inputting the combination of the text to be expanded and the relevance score meeting the first preset condition into a preset text generation model includes:
determining the relevance scores of all combinations of the target expansion entities and the target expansion semantics, and sequencing all combinations according to the relevance scores;
respectively determining the combination of the relevance scores corresponding to each target extension entity, wherein the scores are sorted into a front preset number group;
and sorting the scores corresponding to each target expansion entity into a combination of a preset number group and the text to be expanded, and inputting the combination and the text to be expanded into a preset text generation model.
Optionally, the inputting the combination of the text to be expanded and the relevance score meeting the first preset condition into a preset text generation model includes:
splicing the text to be expanded and the combination of which the correlation score meets a first preset condition by using a preset splicing method to generate a spliced sequence;
and inputting the spliced sequence into a preset text generation model.
In a second aspect, the present application discloses a text extension apparatus, comprising:
the target noun determining module is used for determining a text to be expanded and determining a target noun from the text to be expanded;
the entity semantic expansion module is used for performing entity expansion and semantic expansion on the target nouns so as to determine a target expansion entity and target expansion semantics;
the entity semantic combination module is used for combining the target expansion entities and the target expansion semantics in pairs and calculating the correlation score between the corresponding target expansion entities and the target expansion semantics in each combination;
the text expansion module is used for inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model so as to obtain an expanded text output by the preset text generation model;
and the target expanded text output module is used for evaluating the semantic similarity between the expanded text and the text to be expanded by utilizing a preset text semantic similarity evaluation model, and determining an expanded text of which the semantic similarity meets a preset similarity condition from the expanded text to serve as the target expanded text for output.
In a third aspect, the present application discloses an electronic device, comprising:
a memory for storing a computer program;
a processor for executing the computer program to implement the text extension method as described above.
In a fourth aspect, the present application discloses a computer storage medium for storing a computer program; wherein the computer program realizes the steps of the text extension method disclosed in the foregoing when being executed by a processor.
In the application, firstly, by determining the text to be expanded and determining the target noun from the text to be expanded, performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and a target expansion semantic, combining the target expansion entity and the target expansion semantic two by two, calculating a correlation score between the corresponding target expansion entity and the target expansion semantic in each combination, inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model, obtaining an expanded text output by the preset text generation model, evaluating the semantic similarity between the expanded text and the text to be expanded by utilizing a preset text semantic similarity evaluation model, and determining an expanded text with semantic similarity meeting a preset similar condition from the expanded text, and outputting the expanded text serving as a target expanded text. Therefore, the method and the device realize the accurate expansion of the short text to be expanded by utilizing the entity expansion and the semantic expansion, and also utilize the preset text generation model and the preset text semantic similarity evaluation model to evaluate the text generation and text similarity, thereby improving the efficiency of text expansion, solving the problems of insufficient semantic richness and semantic change during the short text expansion, ensuring the semantic richness, simultaneously ensuring the semantic consistency and improving the accuracy of text expansion.
Drawings
In order to more clearly illustrate the embodiments of the present invention or the technical solutions in the prior art, the drawings used in the description of the embodiments or the prior art will be briefly described below, it is obvious that the drawings in the following description are only embodiments of the present invention, and for those skilled in the art, other drawings can be obtained according to the provided drawings without creative efforts.
FIG. 1 is a flow chart of a text expansion method provided by the present application;
FIG. 2 is a flowchart of a specific text extension method provided in the present application;
FIG. 3 is a schematic flow chart of a method provided herein;
FIG. 4 is a flowchart of a specific text extension method provided in the present application;
FIG. 5 is a system framework diagram provided herein;
FIG. 6 is a schematic structural diagram of a text expansion apparatus according to the present application;
fig. 7 is a block diagram of an electronic device provided in the present application.
Detailed Description
The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the drawings in the embodiments of the present invention, and it is obvious that the described embodiments are only a part of the embodiments of the present invention, and not all of the embodiments. All other embodiments, which can be obtained by a person skilled in the art without making any creative effort based on the embodiments in the present invention, belong to the protection scope of the present invention.
In the prior art, in the short text extension process, the semantic change of the extended text is not rich enough, and the semantic information is easy to change. In the application, the short text can be expanded into the long text with rich semantics and consistent emotion, the consistency of the semantics can be ensured while the rich semantics are ensured, and the accuracy of text expansion is further improved.
The embodiment of the invention discloses a text extension method, which is described with reference to FIG. 1 and comprises the following steps:
step S11: determining a text to be expanded, and determining a target noun from the text to be expanded.
In this embodiment, after the text T to be expanded is determined, the target noun is determined from the text T to be expanded. Wherein the determining of the target noun from the text to be expanded comprises: performing part-of-speech tagging on the text to be expanded by using a preset part-of-speech tagging tool to obtain the text to be expanded with part-of-speech tags; and determining a word group with a part-of-speech tag as a part-of-speech of the noun from the text to be expanded with the part-of-speech tag as a target noun. In a specific embodiment, a part-of-speech tagging tool stanza may be used to perform part-of-speech analysis on the text T to be expanded, and extract all nouns labeled as NN or NNP as target nouns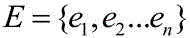 。
。
The determining a text to be expanded and determining a target noun from the text to be expanded includes: determining a text to be expanded, and determining a target noun from the text to be expanded to generate a noun list; correspondingly, the performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics includes: and performing entity expansion and semantic expansion on the target nouns in the noun list to determine target expansion entities and target expansion semantics. It can be understood that the target nouns determined from the text to be expanded can be stored in the noun list, and accordingly, when the target nouns are expanded, the target nouns can be extracted from the noun list and then expanded.
Step S12: and performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics.
In this step, the target noun is expanded in two aspects of entity expansion and semantic expansion. In some embodiments, if the target noun is "friend," the target expanded entities that may be generated are: pets, dogs, girls, buddies, acquaintances; the target extension semantics that may be generated are: chat, rely on, play games.
Step S13: and combining the target extended entities and the target extended semantics pairwise, and calculating a correlation score between the corresponding target extended entities and the target extended semantics in each combination.
In this embodiment, the target extension entities and the target extension semantics are combined pairwise, and a correlation score between the target extension entities and the target extension semantics in each combination is calculated. In some embodiments, a relevance score for each group may be calculated using a trained artificial intelligence model.
In this embodiment, after calculating the correlation score between the corresponding target expansion entity and the target expansion semantic in each combination, the method may further include: and sorting the relevance scores in a descending order, and selecting the preset front N groups as a splicing sequence of a next input preset text generation model.
Step S14: and inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model so as to obtain an expanded text output by the preset text generation model.
The step of inputting the combination of the text to be expanded and the relevance score meeting a first preset condition into a preset text generation model comprises the following steps: splicing the text to be expanded and the combination of which the correlation score meets a first preset condition by using a preset splicing method to generate a spliced sequence; and inputting the spliced sequence into a preset text generation model. It can be understood that, in this embodiment, the text to be expanded is spliced with the combination obtained in the previous step to generate a spliced sequence, and then the spliced sequence is input into the text generation model that has been pre-trained to obtain a long text that is generated by the model and has richer semantics, that is, the expanded text. In some embodiments, the predetermined text generation model includes, but is not limited to, the GPT3 model (i.e., generated Pre-trained Transformer 3, auto-regressive language model).
Step S15: and evaluating the semantic similarity between the expanded text and the text to be expanded by using a preset text semantic similarity evaluation model, and determining the expanded text of which the semantic similarity meets a preset similarity condition from the expanded text as a target expanded text to be output.
After the expanded text generated by the preset text generation model is obtained, the semantic similarity between the expanded text and the text to be expanded can be calculated through the preset text semantic similarity evaluation model, and then N expanded texts before sequencing can be selected as the finally output long text, wherein N is a positive integer and can be set or changed at will according to the requirements of users. In some specific embodiments, the preset text Semantic similarity evaluation Model includes, but is not limited to, a DSSM (Deep Structured Semantic Model) Model.
In the embodiment, firstly, by determining the text to be expanded and determining the target noun from the text to be expanded, performing entity expansion and semantic expansion on the target nouns to determine target expansion entities and target expansion semantics, combining the target expansion entities and the target expansion semantics in pairs, calculating a correlation score between the corresponding target expansion entity and the target expansion semantic in each combination, inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model, obtaining an expanded text output by the preset text generation model, evaluating the semantic similarity between the expanded text and the text to be expanded by utilizing a preset text semantic similarity evaluation model, and determining an expanded text with semantic similarity meeting a preset similar condition from the expanded text, and outputting the expanded text serving as a target expanded text. Therefore, the method and the device realize the accurate expansion of the short text to be expanded by utilizing the entity expansion and the semantic expansion, and also utilize the preset text generation model and the preset text semantic similarity evaluation model to evaluate the text generation and text similarity, thereby improving the efficiency of text expansion, solving the problems of insufficient semantic richness and semantic change during the short text expansion, ensuring the semantic richness, simultaneously ensuring the semantic consistency and improving the accuracy of text expansion.
Fig. 2 is a flowchart of a specific text extension method provided in an embodiment of the present application. Referring to fig. 2, the method includes:
step S21: determining a text to be expanded, performing part-of-speech tagging on the text to be expanded by using stanza to obtain the text to be expanded with part-of-speech tags, and then determining a word group with the part-of-speech tags as noun parts-of-speech from the text to be expanded with the part-of-speech tags as a target noun.
In some embodiments of this embodiment, a part-of-speech tagging tool stanza may be used to tag the part-of-speech of the text to be expanded.
Step S22: and performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics.
For a more specific processing procedure of step S22, reference may be made to corresponding contents disclosed in the foregoing embodiments, and details are not repeated here.
Step S23: and determining a superior-inferior relation list of the target noun by using a knowledge graph, generating an entity expansion list based on the superior-inferior relation list and the target expansion entity, and generating a semantic expansion list based on the superior-inferior relation list and the target expansion semantics.
The determining the upper and lower relation list of the target noun by using the knowledge graph comprises the following steps: and searching the upper and lower relation of the target noun by using a searching interface of the conceptNet to determine an upper and lower relation list of the target noun.
Generating an entity extension list based on the superior-inferior relationship list and the target extension entity, and generating a semantic extension list based on the superior-inferior relationship list and the target extension semantic, including: extracting tail entities with the relationship of a preset first relationship in the upper and lower relationship list to form an entity expansion list; and extracting tail entities with the relationship of a preset second relationship in the upper and lower relationship list to form a semantic expansion list.
In this embodiment, each noun in the noun list may be queried through a retrieval API (Application Programming Interface) of the ConceptNet to obtain a list of top and bottom relationships of all nouns, and then tail entities of five Types of relationships "is a subclaves of (about.)", "Types of (a.)," Parts of (a.), "Symbols of (a.)"), and "is a type of (a.)," are in the top and bottom relationship list may be extracted to form an entity extension list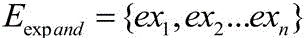 For example, the entities of "friends" in the concept graph that meet the five relationships are { pet, dog, girl friend, buddy, acquaintance, cat … }; the tail entities and relationships in the upper and lower relationship list, namely "topics of" (bring up), "is capable of" (enable), "reasons moved by" (driven to do), "Location of" (place), "places" (want), "is moved by" (driven), "reasons mause of" (let you need), "reasons of" (let you want to do), and "keys you way …" (let you want to do), are also required to be extracted to form a semantic extension list
For example, the entities of "friends" in the concept graph that meet the five relationships are { pet, dog, girl friend, buddy, acquaintance, cat … }; the tail entities and relationships in the upper and lower relationship list, namely "topics of" (bring up), "is capable of" (enable), "reasons moved by" (driven to do), "Location of" (place), "places" (want), "is moved by" (driven), "reasons mause of" (let you need), "reasons of" (let you want to do), and "keys you way …" (let you want to do), are also required to be extracted to form a semantic extension list For example, the semantics of "friends" in the concept graph that meet the above eight relationships are { "chat", "rely on", "play" … }.
For example, the semantics of "friends" in the concept graph that meet the above eight relationships are { "chat", "rely on", "play" … }.
Step S24: and combining the target extended entities and the target extended semantics pairwise, and calculating a correlation score between the corresponding target extended entities and the target extended semantics in each combination.
For a more specific processing procedure of step S24, reference may be made to corresponding contents disclosed in the foregoing embodiments, and details are not repeated here.
Step S25: and inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model so as to obtain an expanded text output by the preset text generation model.
For a more specific processing procedure of step S25, reference may be made to corresponding contents disclosed in the foregoing embodiments, and details are not repeated here.
Step S26: and evaluating the semantic similarity between the expanded text and the text to be expanded by using a preset text semantic similarity evaluation model, and determining the expanded text of which the semantic similarity meets a preset similarity condition from the expanded text as a target expanded text to be output.
For a more specific processing procedure of step S26, reference may be made to corresponding contents disclosed in the foregoing embodiments, and details are not repeated here.
Fig. 3 is a schematic flow chart of a method provided in this embodiment, first, entity expansion and semantic expansion are performed on a target noun by using concept net, then, correlation between the expanded entity and the expanded semantic is calculated, a combination with a correlation score satisfying a first preset condition is input into a preset text generation model to generate a long text, then, a text similarity model is used to score the output long text, and sorting is performed according to the score to finally determine the output displayed long text.
In the embodiment, a text to be expanded is determined, part-of-speech tagging is performed on the text to be expanded by using stanza to obtain the text to be expanded with part-of-speech tags, and then a phrase with the part-of-speech tags as noun parts-of-speech is determined from the text to be expanded with the part-of-speech tags to be used as a target noun. And then, performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics. And then, determining a superior-inferior relation list of the target noun by using a knowledge graph, generating an entity expansion list based on the superior-inferior relation list and the target expansion entity, and generating a semantic expansion list based on the superior-inferior relation list and the target expansion semantic. And combining the target extended entities and the target extended semantics pairwise, and calculating a correlation score between the corresponding target extended entities and the target extended semantics in each combination. And inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model so as to obtain an expanded text output by the preset text generation model. And finally, evaluating the semantic similarity between the expanded text and the text to be expanded by using a preset text semantic similarity evaluation model, and determining the expanded text of which the semantic similarity meets a preset similarity condition from the expanded text as a target expanded text to be output. In this embodiment, a context list of a target noun is determined by a knowledge graph, an entity expansion list is generated based on the context list and the target expansion entity, and a semantic expansion list is generated based on the context list and the target expansion semantics. The method for extracting the related entities and semantics by using the concept map as the candidate expansion and scoring the finally generated long text by using the semantic correlation evaluation model can ensure the semantic and emotion consistency of the expanded long text and improve the accuracy of text expansion.
Fig. 4 is a flowchart of a specific text expansion method provided in an embodiment of the present application. Referring to fig. 4, the method includes:
step S31: collecting texts from a preset social platform, classifying the texts into short texts and long texts by using a preset classification rule, determining the short texts as texts to be expanded, and determining target nouns from the texts to be expanded.
In this embodiment, texts may be collected in a preset social platform, a text with a chinese character length of 10 or less is defined as a short text, a text with a chinese character length of 10 or more is defined as a long text, then the short text is used as a text to be expanded, and a target noun is determined from the text to be expanded. In this embodiment, the preset social platform includes, but is not limited to, a microblog.
Step S32: and performing entity expansion and semantic expansion on the target nouns to determine a target expansion entity and target expansion semantics.
For a more specific processing procedure of step S32, reference may be made to corresponding contents disclosed in the foregoing embodiments, and details are not repeated here.
Step S33: and performing part-of-speech tagging on the long text by using a preset part-of-speech tagging tool to obtain the long text with part-of-speech tags, and then determining the part-of-speech tags as word groups of verb parts-of-speech and noun parts-of-speech from the long text with part-of-speech tags.
In this embodiment, a preset part-of-speech tagging tool may be used to perform part-of-speech tagging on the long text to obtain the long text with part-of-speech tags, and then determine that the part-of-speech tags are word groups of verb parts-of-speech and noun parts-of-speech from the long text with part-of-speech tags.
Step S34: and determining verb phrases and noun phrases in the same long text as phrases with correlation, and inputting the phrases with correlation as training data into a preset language representation model for training to obtain a trained model.
In this embodiment, the correlation between verbs and nouns appearing in the same text may be determined as 1, otherwise, the correlation is 0, and then the phrase with the correlation is input into a BERT (i.e., a pre-trained language Representation model) model as training data to be trained, so as to obtain a correlation calculation model 。
。
Step S35: and combining the target extension entities and the target extension semantics in pairs and inputting the combinations into the trained model, and acquiring the correlation score between the corresponding target extension entities and the target extension semantics in each combination output by the trained model.
In this step, the target extension entity and the target extension semantics can be input into the trained correlation calculation model in a pairwise combination manner And obtaining the correlation calculation model
And obtaining the correlation calculation model And outputting a correlation score between the target expansion entity and the target expansion semantics in each combination.
And outputting a correlation score between the target expansion entity and the target expansion semantics in each combination.
Step S36: and inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model so as to obtain an expanded text output by the preset text generation model.
The step of inputting the combination of the text to be expanded and the relevance score meeting a first preset condition into a preset text generation model comprises the following steps: determining the relevance scores of all combinations of the target expansion entities and the target expansion semantics, and sequencing all combinations according to the relevance scores; respectively determining the combination of the relevance scores corresponding to each target extension entity, wherein the scores are sorted into a front preset number group; and sorting the scores corresponding to each target expansion entity into a combination of a preset number group and the text to be expanded, and inputting the combination and the text to be expanded into a preset text generation model.
In some embodiments, all the relevance scores corresponding to the same target extension entity may be sorted, and a combination of top ten relevance scores may be selected And splicing the text to be expanded to obtain a spliced sequence
And splicing the text to be expanded to obtain a spliced sequence Inputting the spliced sequence into a preset text generation model GPT-3 to obtain the output lengthText T ̀. It can be understood that the preset number in this step can be optionally set and changed according to the user requirement.
Inputting the spliced sequence into a preset text generation model GPT-3 to obtain the output lengthText T ̀. It can be understood that the preset number in this step can be optionally set and changed according to the user requirement.
Step S37: and evaluating the semantic similarity between the expanded text and the text to be expanded by using a preset text semantic similarity evaluation model, and determining the expanded text of which the semantic similarity meets a preset similarity condition from the expanded text as a target expanded text to be output.
In this step, the text T to be expanded and the expanded text T ̀ generated in step S36 may be input into a text similarity calculation model DSSM model, so as to obtain a similarity score between the text to be expanded and each expanded text to date, and then a preset number of texts to be expanded may be selected as a final target expanded text for output. It can be understood that the preset number in this step can be optionally set and changed according to the wishes of the user.
Fig. 5 is a system framework diagram provided in this embodiment, in which a preset language representation model is trained by using a long text, and a correlation score between a target expansion entity of a text to be expanded and a target expansion semantic is evaluated by using the trained model. Firstly, part-of-speech tagging of nouns and verbs is carried out on an acquired long text, after the relevance between the verbs and the nouns is determined, a preset model is trained, and a trained relevance model is acquired . After the short text is obtained, an entity set containing target nouns is determined, then entity expansion and semantic expansion are carried out on the target nouns based on a conceptual diagram in a knowledge graph technology, and the entity expansion and the semantic expansion are input into the correlation model
. After the short text is obtained, an entity set containing target nouns is determined, then entity expansion and semantic expansion are carried out on the target nouns based on a conceptual diagram in a knowledge graph technology, and the entity expansion and the semantic expansion are input into the correlation model After the scores are sorted, the sorted entity semantic combinations are input into a preset text generation model GPT3, and then the relevance scores of the combination of each entity and the semantics are obtainedAnd finally, the similarity ranking is carried out on the long text output by the GPT3 and the long text output by the GPT3 by utilizing a DSSM model, and the long text at the top 5 of the ranking is finally determined.
After the scores are sorted, the sorted entity semantic combinations are input into a preset text generation model GPT3, and then the relevance scores of the combination of each entity and the semantics are obtainedAnd finally, the similarity ranking is carried out on the long text output by the GPT3 and the long text output by the GPT3 by utilizing a DSSM model, and the long text at the top 5 of the ranking is finally determined.
In this embodiment, a text is collected from a preset social platform, the text is classified into a short text and a long text by using a preset classification rule, then the short text is determined as a text to be expanded, a target noun is determined from the text to be expanded, and entity expansion and semantic expansion are performed on the target noun to determine a target expanded entity and target expanded semantics. And then, performing part-of-speech tagging on the long text by using a preset part-of-speech tagging tool to obtain the long text with part-of-speech tags, and then determining that the part-of-speech tags are word groups of verb parts-of-speech and noun parts-of-speech from the long text with part-of-speech tags. And then determining verb phrases and noun phrases in the same long text as phrases with correlation, and inputting the phrases with correlation as training data into a preset language representation model for training to obtain a trained model. And then combining the target extension entities and the target extension semantics in pairs and inputting the combinations into the trained model, and acquiring the correlation score between the corresponding target extension entities and the target extension semantics in each combination output by the trained model. And finally, inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model so as to obtain the expanded text output by the preset text generation model. By the text extension method provided by the embodiment, the long text acquired from the preset social platform can be used for training the preset language representation model, and the trained model is used for evaluating the relevance score between the target extension entity of the text to be extended and the target extension semantics, so that the applicability of the method is improved. In addition, in the process of expanding the short text, the consistency of semantics can be ensured while ensuring rich semantics, and the accuracy of text expansion is improved.
Referring to fig. 6, an embodiment of the present application discloses a text extension apparatus, which may specifically include:
the target noun determining module 11 is configured to determine a text to be expanded, and determine a target noun from the text to be expanded;
an entity semantic expansion module 12, configured to perform entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics;
an entity semantic combination module 13, configured to combine the target extended entity and the target extended semantic two by two, and calculate a relevance score between the corresponding target extended entity and the target extended semantic in each combination;
the text expansion module 14 is configured to input a combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model, so as to obtain an expanded text output by the preset text generation model;
and the target expanded text output module 15 is configured to evaluate the semantic similarity between the expanded text and the text to be expanded by using a preset text semantic similarity evaluation model, and determine an expanded text with semantic similarity meeting a preset similarity condition from the expanded text, and output the expanded text as a target expanded text.
In the application, firstly, by determining the text to be expanded and determining the target noun from the text to be expanded, performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and a target expansion semantic, combining the target expansion entity and the target expansion semantic two by two, calculating a correlation score between the corresponding target expansion entity and the target expansion semantic in each combination, inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model, obtaining an expanded text output by the preset text generation model, evaluating the semantic similarity between the expanded text and the text to be expanded by utilizing a preset text semantic similarity evaluation model, and determining an expanded text with semantic similarity meeting a preset similar condition from the expanded text, and outputting the expanded text serving as a target expanded text. Therefore, the method and the device realize the accurate expansion of the short text to be expanded by utilizing the entity expansion and the semantic expansion, and also utilize the preset text generation model and the preset text semantic similarity evaluation model to evaluate the text generation and text similarity, thereby improving the efficiency of text expansion, solving the problems of insufficient semantic richness and semantic change during the short text expansion, ensuring the semantic richness, ensuring the semantic consistency and improving the accuracy of text expansion.
In some embodiments, the target noun determination module 11 may include:
the first part-of-speech tagging unit is used for tagging the part-of-speech of the text to be expanded by using a preset part-of-speech tagging tool so as to acquire the text to be expanded with a part-of-speech tag;
and the target noun extracting unit is used for determining a word group with a part-of-speech tag as a noun part-of-speech from the text to be expanded with the part-of-speech tag as a target noun.
In some embodiments, the first part-of-speech tagging unit includes:
and the part-of-speech tagging tool application unit is used for performing part-of-speech tagging on the text to be expanded by using stanza so as to obtain the text to be expanded with part-of-speech tags.
In some embodiments, the target noun determination module 11 includes:
the noun list generating unit is used for determining a text to be expanded and determining a target noun from the text to be expanded so as to generate a noun list;
correspondingly, the entity semantic extension module 12 includes:
and the entity semantic expansion unit is used for performing entity expansion and semantic expansion on the target nouns in the noun list so as to determine target expansion entities and target expansion semantics.
In some specific embodiments, the text expansion apparatus further includes:
a list determining unit for determining a top and bottom relation list of the target nouns by using a knowledge graph;
a first list generating unit, configured to generate an entity extension list based on the context relationship list and the target extension entity;
and the second list generating unit is used for generating a semantic extended list based on the upper and lower relation list and the target extended semantics.
In some embodiments, the list determining unit includes:
and the noun retrieval unit is used for retrieving the superior and inferior relations of the target nouns by using a retrieval interface of the ConceptNet so as to determine a superior and inferior relation list of the target nouns.
In some specific embodiments, the first list generating unit and the second list generating unit include:
a first tail entity extracting unit, configured to extract a tail entity whose relationship in the upper and lower relationship list is a preset first relationship, so as to form an entity extension list;
and the second tail entity extraction unit is used for extracting tail entities with preset second relations in the upper and lower relation lists so as to form a semantic expansion list.
In some specific embodiments, the text expansion apparatus further includes:
the system comprises a text collection unit, a text classification unit and a text classification unit, wherein the text collection unit is used for collecting texts from a preset social platform and classifying the texts into short texts and long texts by using a preset classification rule;
accordingly, the target noun determination module 11 includes:
and the short text determining unit is used for determining the short text as the text to be expanded.
In some specific embodiments, the text expansion apparatus further includes:
the long text labeling unit is used for performing part-of-speech labeling on the long text by using a preset part-of-speech labeling tool to obtain the long text with part-of-speech labels, and then determining the part-of-speech labels as word groups of verb parts-of-speech and noun parts-of-speech from the long text with part-of-speech labels;
and the model training unit is used for determining verb phrases and noun phrases in the same long text as phrases with correlation, inputting the phrases with correlation as training data into a preset language representation model for training to obtain a trained model.
In some specific embodiments, the text expansion apparatus further includes:
combining the target expansion entity and the target expansion semantics pairwise and inputting the combination into the trained model;
and acquiring a correlation score between the corresponding target expansion entity and the target expansion semantic in each combination of the output of the trained model.
In some specific embodiments, the entity semantic combination module 13 further includes:
the first text input unit is used for combining and inputting the target expansion entity and the target expansion semantic into the trained model;
and the score output unit is used for acquiring a correlation score between the corresponding target expansion entity and the target expansion semantic in each combination of the output of the model after training.
In some specific embodiments, the text extension module 14 includes:
the score sorting unit is used for determining the relevance scores of all combinations of the target expansion entities and the target expansion semantics and sorting all the combinations according to the relevance scores;
the combination determining unit is used for respectively determining the combination of the relevance scores corresponding to each target extension entity, wherein the scores of the relevance scores are sorted into a preset number group;
and the second text input unit is used for sorting the scores corresponding to each target expansion entity into a combination of a preset number group and inputting the text to be expanded into a preset text generation model.
In some specific embodiments, the text extension module 14 includes:
the sequence splicing unit is used for splicing the text to be expanded and the combination with the correlation score meeting a first preset condition by using a preset splicing method so as to generate a spliced sequence;
and the sequence input unit is used for inputting the spliced sequence into a preset text generation model.
Further, an electronic device is also disclosed in the embodiments of the present application, fig. 7 is a block diagram of the electronic device 20 shown in the exemplary embodiments, and the content in the diagram cannot be considered as any limitation to the scope of the application.
Fig. 7 is a schematic structural diagram of an electronic device 20 according to an embodiment of the present disclosure. The electronic device 20 may specifically include: at least one processor 21, at least one memory 22, a power supply 23, a display 24, an input-output interface 25, a communication interface 26, and a communication bus 27. Wherein the memory 22 is used for storing a computer program, which is loaded and executed by the processor 21 to implement the relevant steps in the text extension method disclosed in any of the foregoing embodiments. In addition, the electronic device 20 in the present embodiment may be specifically an electronic computer.
In this embodiment, the power supply 23 is configured to provide an operating voltage for each hardware device on the electronic device 20; the communication interface 26 can create a data transmission channel between the electronic device 20 and an external device, and the communication protocol followed by the communication interface is any communication protocol that can be applied to the technical solution of the present application, and is not specifically limited herein; the input/output interface 25 is configured to obtain external input data or output data to the outside, and a specific interface type thereof may be selected according to specific application requirements, which is not specifically limited herein.
In addition, the storage 22 is used as a carrier for storing resources, and may be a read-only memory, a random access memory, a magnetic disk, an optical disk, or the like, the resources stored thereon may include an operating system 221, a computer program 222, virtual machine data 223, and the like, and the virtual machine data 223 may include various data. The storage means may be a transient storage or a permanent storage.
The operating system 221 is used for managing and controlling each hardware device on the electronic device 20 and the computer program 222, and may be Windows Server, Netware, Unix, Linux, or the like. The computer program 222 may further include a computer program that can be used to perform other specific tasks in addition to the computer program that can be used to perform the text extension method disclosed by any of the foregoing embodiments and executed by the electronic device 20.
Further, the present application discloses a computer-readable storage medium, wherein the computer-readable storage medium includes a Random Access Memory (RAM), a Memory, a Read-Only Memory (ROM), an electrically programmable ROM, an electrically erasable programmable ROM, a register, a hard disk, a magnetic disk, or an optical disk or any other form of storage medium known in the art. Wherein the computer program when executed by a processor implements the text extension method of the preceding disclosure. For the specific steps of the method, reference may be made to the corresponding contents disclosed in the foregoing embodiments, which are not described herein again.
The embodiments are described in a progressive manner, each embodiment focuses on differences from other embodiments, and the same or similar parts among the embodiments are referred to each other. The device disclosed by the embodiment corresponds to the method disclosed by the embodiment, so that the description is simple, and the relevant points can be referred to the method part for description. Those of skill would further appreciate that the various illustrative elements and algorithm steps described in connection with the embodiments disclosed herein may be implemented as electronic hardware, computer software, or combinations of both, and that the various illustrative components and steps have been described above generally in terms of their functionality in order to clearly illustrate this interchangeability of hardware and software. Whether such functionality is implemented as hardware or software depends upon the particular application and design constraints imposed on the implementation. Skilled artisans may implement the described functionality in varying ways for each particular application, but such implementation decisions should not be interpreted as causing a departure from the scope of the present application.
The steps of a method or algorithm described in connection with the embodiments disclosed herein may be embodied directly in hardware, in a software module executed by a processor, or in a combination of the two. A software module may reside in Random Access Memory (RAM), memory, Read Only Memory (ROM), electrically programmable ROM, electrically erasable programmable ROM, registers, hard disk, a removable disk, a CD-ROM, or any other form of storage medium known in the art.
Finally, it should also be noted that, herein, relational terms such as first and second, and the like may be used solely to distinguish one entity or action from another entity or action without necessarily requiring or implying any actual such relationship or order between such entities or actions. Also, the terms "comprises," "comprising," or any other variation thereof, are intended to cover a non-exclusive inclusion, such that a process, method, article, or apparatus that comprises a list of elements does not include only those elements but may include other elements not expressly listed or inherent to such process, method, article, or apparatus. Without further limitation, an element defined by the phrase "comprising an … …" does not exclude the presence of other identical elements in a process, method, article, or apparatus that comprises the element.
The text extension method, apparatus, device, and storage medium provided by the present invention are described in detail above, and a specific example is applied in the text to explain the principle and the implementation of the present invention, and the description of the above embodiment is only used to help understand the method and the core idea of the present invention; meanwhile, for a person skilled in the art, according to the idea of the present invention, there may be variations in the specific embodiments and the application scope, and in summary, the content of the present specification should not be construed as a limitation to the present invention.
Claims (15)
1. A text extension method, comprising:
determining a text to be expanded, and determining a target noun from the text to be expanded;
performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics;
combining the target extended entities and the target extended semantics pairwise, and calculating a correlation score between the corresponding target extended entities and the target extended semantics in each combination;
inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model to obtain an expanded text output by the preset text generation model;
and evaluating the semantic similarity between the expanded text and the text to be expanded by using a preset text semantic similarity evaluation model, and determining the expanded text of which the semantic similarity meets a preset similarity condition from the expanded text as a target expanded text to be output.
2. The text expansion method of claim 1, wherein the determining a target noun from the text to be expanded comprises:
performing part-of-speech tagging on the text to be expanded by using a preset part-of-speech tagging tool to obtain the text to be expanded with part-of-speech tags;
and determining a word group with a part-of-speech tag as a part-of-speech of the noun from the text to be expanded with the part-of-speech tag as a target noun.
3. The text extension method of claim 2, wherein the obtaining of the text to be extended with part-of-speech tags by performing part-of-speech tagging on the text to be extended by using a preset part-of-speech tagging tool comprises:
and performing part-of-speech tagging on the text to be expanded by utilizing stanza to obtain the text to be expanded with part-of-speech tags.
4. The text expansion method according to claim 1, wherein the determining a text to be expanded and determining a target noun from the text to be expanded comprises:
determining a text to be expanded, and determining a target noun from the text to be expanded to generate a noun list;
correspondingly, the performing entity expansion and semantic expansion on the target noun to determine a target expansion entity and target expansion semantics includes:
and performing entity expansion and semantic expansion on the target nouns in the noun list to determine target expansion entities and target expansion semantics.
5. The text extension method of claim 4, wherein after determining the target extension entity and the target extension semantics, further comprising:
determining a superior-inferior relation list of the target noun by using a knowledge graph;
generating an entity extension list based on the superior-inferior relation list and the target extension entity;
and generating a semantic extension list based on the upper and lower relation list and the target extension semantics.
6. The text expansion method of claim 5, wherein the determining the top-bottom relation list of the target noun by using the knowledge graph comprises:
and searching the upper and lower relation of the target noun by using a searching interface of the conceptNet to determine an upper and lower relation list of the target noun.
7. The text expansion method of claim 5, wherein the generating an entity expansion list based on the context list and the target expansion entity and generating a semantic expansion list based on the context list and the target expansion semantics comprises:
extracting tail entities with a preset first relationship in the upper and lower relationship list to form an entity extension list;
and extracting tail entities with the relationship of a preset second relationship in the upper and lower relationship list to form a semantic expansion list.
8. The text expansion method according to claim 1, wherein before determining the text to be expanded and determining the target noun from the text to be expanded, the method further comprises:
collecting texts from a preset social platform, and classifying the texts into short texts and long texts by using a preset classification rule;
correspondingly, the determining the text to be expanded includes:
and determining the short text as the text to be expanded.
9. The text expansion method of claim 8, wherein before combining the target expansion entities and the target expansion semantics two by two and calculating a relevance score between the corresponding target expansion entities and the target expansion semantics in each combination, further comprising:
performing part-of-speech tagging on the long text by using a preset part-of-speech tagging tool to obtain the long text with part-of-speech tags, and then determining the part-of-speech tags as word groups of verb parts-of-speech and noun parts-of-speech from the long text with part-of-speech tags;
and determining verb phrases and noun phrases in the same long text as phrases with correlation, and inputting the phrases with correlation as training data into a preset language representation model for training to obtain a trained model.
10. The text extension method of claim 9, wherein combining the target extension entities and the target extension semantics two by two and calculating a relevance score between the corresponding target extension entities and the target extension semantics in each combination comprises:
combining and inputting the target extension entity and the target extension semantics into the trained model;
obtaining a relevance score between the corresponding target extension entity and the target extension semantics in each combination of the trained model output.
11. The text expansion method according to claim 1, wherein the inputting of the combination of the text to be expanded and the relevance score satisfying a first preset condition into a preset text generation model comprises:
determining the relevance scores of all combinations of the target expansion entities and the target expansion semantics, and sequencing all combinations according to the relevance scores;
respectively determining the combination of the relevance scores corresponding to each target extension entity, wherein the scores are sorted into a front preset number group;
and sorting the scores corresponding to each target expansion entity into a combination of a preset number group and the text to be expanded, and inputting the combination and the text to be expanded into a preset text generation model.
12. The text expansion method according to any one of claims 1 to 11, wherein the inputting of the combination of the text to be expanded and the relevance score satisfying a first preset condition into a preset text generation model comprises:
splicing the text to be expanded and the combination of which the correlation score meets a first preset condition by using a preset splicing method to generate a spliced sequence;
and inputting the spliced sequence into a preset text generation model.
13. A text extension apparatus, comprising:
the target noun determining module is used for determining a text to be expanded and determining a target noun from the text to be expanded;
the entity semantic expansion module is used for performing entity expansion and semantic expansion on the target nouns so as to determine a target expansion entity and target expansion semantics;
the entity semantic combination module is used for combining the target expansion entities and the target expansion semantics in pairs and calculating the correlation score between the corresponding target expansion entities and the target expansion semantics in each combination;
the text expansion module is used for inputting the combination of the text to be expanded and the correlation score meeting a first preset condition into a preset text generation model so as to obtain an expanded text output by the preset text generation model;
and the target expanded text output module is used for evaluating the semantic similarity between the expanded text and the text to be expanded by utilizing a preset text semantic similarity evaluation model, and determining an expanded text of which the semantic similarity meets a preset similarity condition from the expanded text to serve as the target expanded text for output.
14. An electronic device comprising a processor and a memory; wherein the processor, when executing the computer program stored in the memory, implements the text extension method of any of claims 1 to 12.
15. A computer-readable storage medium for storing a computer program; wherein the computer program when executed by a processor implements the text extension method of any of claims 1 to 12.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210829003.0A CN114912448B (en) | 2022-07-15 | 2022-07-15 | Text extension method, device, equipment and medium |
| PCT/CN2022/134086 WO2024011813A1 (en) | 2022-07-15 | 2022-11-24 | Text expansion method and apparatus, device, and medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210829003.0A CN114912448B (en) | 2022-07-15 | 2022-07-15 | Text extension method, device, equipment and medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114912448A true CN114912448A (en) | 2022-08-16 |
| CN114912448B CN114912448B (en) | 2022-12-09 |
Family
ID=82771900
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210829003.0A Active CN114912448B (en) | 2022-07-15 | 2022-07-15 | Text extension method, device, equipment and medium |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN114912448B (en) |
| WO (1) | WO2024011813A1 (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115392214A (en) * | 2022-08-26 | 2022-11-25 | 山东省计算中心(国家超级计算济南中心) | Data enhancement method and system based on text generation and storage medium |
| CN115964487A (en) * | 2022-12-22 | 2023-04-14 | 南阳理工学院 | Thesis label supplementing method and device based on natural language and storage medium |
| CN116738250A (en) * | 2023-06-15 | 2023-09-12 | 广州虎牙科技有限公司 | Prompt text expansion methods, devices, electronic devices and storage media |
| WO2024011813A1 (en) * | 2022-07-15 | 2024-01-18 | 山东海量信息技术研究院 | Text expansion method and apparatus, device, and medium |
| CN117540730A (en) * | 2023-10-10 | 2024-02-09 | 鹏城实验室 | Text labeling method and device, computer equipment and storage medium |
| WO2024077906A1 (en) * | 2022-10-09 | 2024-04-18 | 京东科技信息技术有限公司 | Speech text generation method and apparatus, and training method and apparatus for speech text generation model |
| CN118396126A (en) * | 2024-06-28 | 2024-07-26 | 山东海量信息技术研究院 | Text processing method, product, equipment and medium |
| CN119783679A (en) * | 2024-12-17 | 2025-04-08 | 中国联合网络通信集团有限公司 | Method, device, equipment and medium for generating text data based on user needs |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN118673161B (en) * | 2024-08-23 | 2024-11-12 | 江西农业大学 | A big data analysis method for online course quality evaluation based on knowledge graph |
| CN119150881B (en) * | 2024-11-14 | 2025-03-11 | 一网互通(北京)科技有限公司 | Keyword expansion method and device based on pre-training model |
| CN119724187B (en) * | 2024-12-31 | 2025-08-22 | 合肥智能语音创新发展有限公司 | A speech recognition method and related device |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150242493A1 (en) * | 2014-02-27 | 2015-08-27 | Accenture Global Services Limited | User-guided search query expansion |
| US20170024461A1 (en) * | 2015-07-23 | 2017-01-26 | International Business Machines Corporation | Context sensitive query expansion |
| CN107180026A (en) * | 2017-05-02 | 2017-09-19 | 苏州大学 | The event phrase learning method and device of a kind of word-based embedded Semantic mapping |
| CN109271514A (en) * | 2018-09-14 | 2019-01-25 | 华南师范大学 | Generation method, classification method, device and the storage medium of short text disaggregated model |
| CN112487827A (en) * | 2020-12-28 | 2021-03-12 | 科大讯飞华南人工智能研究院(广州)有限公司 | Question answering method, electronic equipment and storage device |
| CN112651235A (en) * | 2020-12-24 | 2021-04-13 | 北京搜狗科技发展有限公司 | Poetry generation method and related device |
| CN113392647A (en) * | 2020-11-25 | 2021-09-14 | 腾讯科技(深圳)有限公司 | Corpus generation method, related device, computer equipment and storage medium |
| CN114580436A (en) * | 2022-03-02 | 2022-06-03 | 重庆邮电大学 | Social user theme analysis method and system based on semantics and word expansion |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102567290B (en) * | 2010-12-30 | 2015-01-14 | 百度在线网络技术(北京)有限公司 | Method, device and equipment for expanding short text to be processed |
| WO2016117920A1 (en) * | 2015-01-20 | 2016-07-28 | 한국과학기술원 | Knowledge represention expansion method and apparatus |
| JP6531025B2 (en) * | 2015-10-19 | 2019-06-12 | 日本電信電話株式会社 | Word expansion device, classification device, machine learning device, method, and program |
| KR102630668B1 (en) * | 2016-12-06 | 2024-01-30 | 한국전자통신연구원 | System and method for expanding input text automatically |
| CN110222707A (en) * | 2019-04-28 | 2019-09-10 | 平安科技(深圳)有限公司 | A kind of text data Enhancement Method and device, electronic equipment |
| CN111027312B (en) * | 2019-12-12 | 2024-04-19 | 中金智汇科技有限责任公司 | Text expansion method and device, electronic equipment and readable storage medium |
| CN111930891B (en) * | 2020-07-31 | 2024-02-02 | 中国平安人寿保险股份有限公司 | Knowledge graph-based search text expansion method and related device |
| CN114385791B (en) * | 2022-01-14 | 2025-12-02 | 平安科技(深圳)有限公司 | Artificial intelligence-based text augmentation methods, devices, equipment, and storage media |
| CN114912448B (en) * | 2022-07-15 | 2022-12-09 | 山东海量信息技术研究院 | Text extension method, device, equipment and medium |
-
2022
- 2022-07-15 CN CN202210829003.0A patent/CN114912448B/en active Active
- 2022-11-24 WO PCT/CN2022/134086 patent/WO2024011813A1/en not_active Ceased
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150242493A1 (en) * | 2014-02-27 | 2015-08-27 | Accenture Global Services Limited | User-guided search query expansion |
| US20170024461A1 (en) * | 2015-07-23 | 2017-01-26 | International Business Machines Corporation | Context sensitive query expansion |
| CN107180026A (en) * | 2017-05-02 | 2017-09-19 | 苏州大学 | The event phrase learning method and device of a kind of word-based embedded Semantic mapping |
| CN109271514A (en) * | 2018-09-14 | 2019-01-25 | 华南师范大学 | Generation method, classification method, device and the storage medium of short text disaggregated model |
| CN113392647A (en) * | 2020-11-25 | 2021-09-14 | 腾讯科技(深圳)有限公司 | Corpus generation method, related device, computer equipment and storage medium |
| CN112651235A (en) * | 2020-12-24 | 2021-04-13 | 北京搜狗科技发展有限公司 | Poetry generation method and related device |
| CN112487827A (en) * | 2020-12-28 | 2021-03-12 | 科大讯飞华南人工智能研究院(广州)有限公司 | Question answering method, electronic equipment and storage device |
| CN114580436A (en) * | 2022-03-02 | 2022-06-03 | 重庆邮电大学 | Social user theme analysis method and system based on semantics and word expansion |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024011813A1 (en) * | 2022-07-15 | 2024-01-18 | 山东海量信息技术研究院 | Text expansion method and apparatus, device, and medium |
| CN115392214A (en) * | 2022-08-26 | 2022-11-25 | 山东省计算中心(国家超级计算济南中心) | Data enhancement method and system based on text generation and storage medium |
| WO2024077906A1 (en) * | 2022-10-09 | 2024-04-18 | 京东科技信息技术有限公司 | Speech text generation method and apparatus, and training method and apparatus for speech text generation model |
| CN115964487A (en) * | 2022-12-22 | 2023-04-14 | 南阳理工学院 | Thesis label supplementing method and device based on natural language and storage medium |
| CN116738250A (en) * | 2023-06-15 | 2023-09-12 | 广州虎牙科技有限公司 | Prompt text expansion methods, devices, electronic devices and storage media |
| CN117540730A (en) * | 2023-10-10 | 2024-02-09 | 鹏城实验室 | Text labeling method and device, computer equipment and storage medium |
| CN118396126A (en) * | 2024-06-28 | 2024-07-26 | 山东海量信息技术研究院 | Text processing method, product, equipment and medium |
| CN119783679A (en) * | 2024-12-17 | 2025-04-08 | 中国联合网络通信集团有限公司 | Method, device, equipment and medium for generating text data based on user needs |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2024011813A1 (en) | 2024-01-18 |
| CN114912448B (en) | 2022-12-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114912448B (en) | Text extension method, device, equipment and medium | |
| CN114020862B (en) | Search type intelligent question-answering system and method for coal mine safety regulations | |
| US10642938B2 (en) | Artificial intelligence based method and apparatus for constructing comment graph | |
| CN115292457B (en) | Knowledge question answering method and device, computer readable medium and electronic equipment | |
| CN111475623A (en) | Case information semantic retrieval method and device based on knowledge graph | |
| CN110457708B (en) | Vocabulary mining method and device based on artificial intelligence, server and storage medium | |
| CN110427614B (en) | Construction method and device of paragraph level, electronic equipment and storage medium | |
| CN117149984B (en) | Customization training method and device based on large model thinking chain | |
| CN113887244B (en) | Text processing method and device | |
| Mirkovic et al. | Where does gender come from? Evidence from a complex inflectional system | |
| US12190753B2 (en) | Methods, systems, devices, and software for managing and conveying knowledge | |
| JP2003196280A (en) | Text generating method and text generating device | |
| Hsu et al. | A hybrid Latent Dirichlet Allocation approach for topic classification | |
| CN116227466A (en) | A method, device and equipment for generating sentences with different semantics and similar wording | |
| CN105786971A (en) | International Chinese-teaching oriented grammar point identification method | |
| JP7782574B2 (en) | Information processing device, information processing method, and information processing program | |
| JP6895037B2 (en) | Speech recognition methods, computer programs and equipment | |
| Ivanova et al. | Comparing annotated datasets for named entity recognition in english literature | |
| CN118966343A (en) | Question and answer knowledge base construction method, device, equipment and storage medium | |
| Sarmento et al. | Corpógrafo v3: From terminological aid to semi-automatic knowledge engine | |
| Talita et al. | Challenges in building domain ontology for minority languages | |
| CN120353940B (en) | Knowledge graph construction method, device, equipment and product | |
| CN120030128B (en) | An extraction-based retrieval question-answering method, apparatus, equipment, and medium | |
| Borg | Automatic definition extraction using evolutionary algorithms | |
| Van Gompel | Phrase-based memory-based machine translation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |