CN114580436A - Social user theme analysis method and system based on semantics and word expansion - Google Patents
Social user theme analysis method and system based on semantics and word expansion Download PDFInfo
- Publication number
- CN114580436A CN114580436A CN202210203458.1A CN202210203458A CN114580436A CN 114580436 A CN114580436 A CN 114580436A CN 202210203458 A CN202210203458 A CN 202210203458A CN 114580436 A CN114580436 A CN 114580436A
- Authority
- CN
- China
- Prior art keywords
- topic
- information
- text
- user
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
- G06F40/35—Discourse or dialogue representation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
技术领域technical field
本发明涉及一种网络用户信息评定技术领域,更具体地说,它涉及一种基于语义和词扩展的社交用户主题分析方法及系统。The invention relates to the technical field of network user information assessment, and more particularly, to a method and system for analyzing social user topics based on semantics and word expansion.
背景技术Background technique
随着互联网的不断发展,网络中的短文本数据呈爆发式增长,人们可以在各种社交平台中发布各种信息。因此,如何从社交平台中分析用户特征是非常有研究价值和实际意义的事情。其中,社交用户的主题特征便是研究重点之一。目前各大社交平台如微博、推特、微信等的信息传播大多都是短文本形式。短文本数据和篇章级的长文本数据不同,短文本数据有着不同的语言规律。而用户又是社交平台中的主体,每位用户可以发布成千的短文本信息。对于企业来讲,针对用户的主题信息进行分析,可以让企业提出具有针对性的方案以此提升用户体验,具有一定的商业价值,对于学者而言,分析用户的主题分布,可以作为社会科学研究成果。With the continuous development of the Internet, the short text data in the network has exploded, and people can publish various information on various social platforms. Therefore, how to analyze user characteristics from social platforms is of great research value and practical significance. Among them, the thematic characteristics of social users is one of the research focuses. At present, most of the information dissemination on major social platforms such as Weibo, Twitter, WeChat, etc. is in the form of short text. Short text data is different from chapter-level long text data, and short text data has different language rules. The user is the main body in the social platform, and each user can publish thousands of short text messages. For enterprises, analyzing the topic information of users can allow enterprises to propose targeted solutions to improve user experience, which has certain commercial value. For scholars, analyzing the topic distribution of users can be used as a social science research tool. results.
当前,针对社交平台用户的主题特征提取常用方法是将同一用户所有的发文整合成一个整体,使其成为一个长文档,再把该长文档输入到主题模型中便得到文档的主题分布,将此分布视为用户的主题分布,这样做虽然可以解决短文本稀疏问题,同时也能获取“用户级”的主题特征。但是,用户的发文间很可能不存在任何上下文关联,甚至讲述的不是同一主题的事物。因此,简单的将同一用户的所有发文合并成伪文档是不合理的。At present, the common method of topic feature extraction for users of social platforms is to integrate all the posted documents of the same user into a whole, making it a long document, and then inputting the long document into the topic model to obtain the topic distribution of the document. The distribution is regarded as the topic distribution of users. Although this can solve the problem of short text sparseness, it can also obtain "user-level" topic features. However, it is very likely that there is no contextual connection between the user's posts, or even about things that are not on the same topic. Therefore, it is unreasonable to simply merge all the posts of the same user into a pseudo-document.
因此,如何使得分析出的用户的主题分布特征更加的合理是目前亟需解决的问题。Therefore, how to make the analyzed topic distribution characteristics of users more reasonable is an urgent problem to be solved at present.
发明内容SUMMARY OF THE INVENTION
本发明的目的是提供一种基于语义和词扩展的社交用户主题分析方法及系统;解决了现有技术主题分析方法得出的主题分布特征的用户发文信息间很可能不存在任何上下文关联,甚至讲述的不是同一主题的事物的问题;本发明改进了传统的短文本主题模型,提出了基于语义和词扩展的短文本主题模型,该模型针对每条社交发文信息进行主题分析,得到主题分布矩阵,再根据每条发文信息的互动信息计算出该条发文信息的权重矩阵,即该条发文信息的重要程度,最后利用主题分布矩阵和权重矩阵计算出用户的主题分布,相较于现有技术的直接构造伪文档的用户主题分析方法,本发明的基于语义和词扩展的社交用户主题分析方法更具优势性。The purpose of the present invention is to provide a social user topic analysis method and system based on semantics and word expansion; it is very likely that there is no contextual correlation between user post information that solves the topic distribution characteristics obtained by the topic analysis method of the prior art, or even The problem of things that are not the same topic is described; the present invention improves the traditional short text topic model, and proposes a short text topic model based on semantics and word expansion. The model performs topic analysis on each social posting information to obtain a topic distribution matrix , and then calculate the weight matrix of the posted information according to the interactive information of each posted information, that is, the importance of the posted information, and finally use the topic distribution matrix and the weight matrix to calculate the user's topic distribution. Compared with the prior art The user topic analysis method for directly constructing pseudo-documents is more advantageous, and the social user topic analysis method based on semantics and word expansion of the present invention is more advantageous.
本发明的上述技术目的是通过以下技术方案得以实现的:The above-mentioned technical purpose of the present invention is achieved through the following technical solutions:
第一方面,提供了一种基于语义和词扩展的社交用户主题分析方法,包括以下步骤:In a first aspect, a method for analyzing social user topics based on semantics and word expansion is provided, including the following steps:
获取用户的发文信息和所述发文信息在社交网络平台中产生的互动信息;Obtaining the post information of the user and the interactive information generated by the post information in the social network platform;
对所述发文信息进行预处理操作,获得发文信息的文本数据;Perform a preprocessing operation on the sent information to obtain text data of the sent information;
根据所述文本数据构建基于语义和词扩展的短文本主题模型;constructing a short text topic model based on semantics and word expansion according to the text data;
将所述发文信息输入所述短文本主题模型进行计算,获得所述发文信息的多个第一主题分布矩阵;Inputting the posting information into the short text topic model for calculation, and obtaining a plurality of first topic distribution matrices of the posting information;
根据所述互动信息计算用户每条所述发文信息的权重矩阵;Calculate the weight matrix of each piece of the posted information of the user according to the interactive information;
根据所述权重矩阵对多个所述第一主题分布矩阵进行加权处理,获得多个第二主题分布矩阵;Perform weighting processing on a plurality of the first topic distribution matrices according to the weight matrix to obtain a plurality of second topic distribution matrices;
对所述多个第二主题分布矩阵进行向量合并和归一化处理,获得用户所述发文信息的主题分布。Perform vector merging and normalization processing on the plurality of second topic distribution matrices to obtain the topic distribution of the user's post information.
与现有技术相比较而言,本发明改进了传统的短文本主题模型,提出了基于语义和词扩展的短文本主题模型,该模型针对每条社交发文信息进行主题分析,得到主题分布矩阵,再根据每条发文信息的互动信息计算出该条发文信息的权重矩阵,即该条发文信息的重要程度,最后利用主题分布矩阵和权重矩阵计算出用户的主题分布,相较于现有技术的直接构造伪文档的用户主题分析方法,本发明的基于语义和词扩展的社交用户主题分析方法更具优势性。Compared with the prior art, the present invention improves the traditional short text topic model, and proposes a short text topic model based on semantics and word expansion. The model performs topic analysis on each piece of social posting information to obtain a topic distribution matrix, Then, according to the interactive information of each post, calculate the weight matrix of the post, that is, the importance of the post, and finally use the subject distribution matrix and the weight matrix to calculate the user's subject distribution, compared with the prior art. The user topic analysis method for directly constructing pseudo-documents, the social user topic analysis method based on semantics and word expansion of the present invention is more advantageous.
进一步的,所述预处理操作包括对所述发文信息进行分词操作、去除所述发文信息的停用词以及去除所述发文信息中的干扰符号。Further, the preprocessing operation includes performing a word segmentation operation on the sent information, removing stop words in the sent information, and removing interference symbols in the sent information.
进一步的,所述根据所述文本数据构建基于语义和词扩展的短文本主题模型的步骤如下:Further, the steps of constructing a short text topic model based on semantics and word expansion according to the text data are as follows:
采用语义依存分析法提取所述文本数据上下文中具有语义关联的第一词对;Extracting the first word pair with semantic association in the context of the text data by using the semantic dependency analysis method;
获取所述文本数据的待扩展关键词,将所述待扩展关键词输入外部语料库中,利用点互信息计算所述待扩展关键词与外部词料库中词的相关性。The keywords to be expanded of the text data are acquired, the keywords to be expanded are input into an external corpus, and the correlation between the keywords to be expanded and words in the external corpus is calculated by using point mutual information.
进一步的,设定所述相关性的判断阈值,若所得所述相关性大于所述判断阈值,则将待扩展关键词与外部语料库中的词组成第二词对。Further, a judgment threshold of the correlation is set, and if the obtained correlation is greater than the judgment threshold, a second word pair is formed between the keyword to be expanded and the word in the external corpus.
进一步的,对所述多个第二主题分布矩阵内所有的向量进行合并,获得用户的主题分布特征向量,利用softmax函数对所述主题分布特征向量进行归一化处理,获得用户所述发文信息的主题分布。Further, merge all the vectors in the plurality of second topic distribution matrices to obtain the user's topic distribution feature vector, and use the softmax function to normalize the topic distribution feature vector to obtain the user's post information. topic distribution.
第二方面,提供了一种基于语义和词扩展的社交用户主题分析系统,包括:In a second aspect, a semantic and word expansion-based social user topic analysis system is provided, including:
信息获取单元,用于获取用户的发文信息和所述发文信息在社交网络平台中产生的互动信息;an information acquisition unit, configured to acquire the post information of the user and the interactive information generated by the post information in the social network platform;
预处理单元,用于对所述发文信息进行预处理操作,获得发文信息的文本数据;a preprocessing unit, configured to perform a preprocessing operation on the sent information to obtain text data of the sent information;
模型构建单元,用于根据所述文本数据构建基于语义和词扩展的短文本主题模型;a model building unit for building a short text topic model based on semantics and word expansion according to the text data;
第一计算单元,用于将所述发文信息输入所述短文本主题模型进行计算,获得所述发文信息的多个第一主题分布矩阵;a first computing unit, configured to input the post information into the short text topic model for calculation, and obtain a plurality of first subject distribution matrices of the post information;
第二计算单元,用于根据所述互动信息计算用户每条所述发文信息的权重矩阵;a second calculation unit, configured to calculate the weight matrix of each piece of the posted information of the user according to the interactive information;
加权处理单元,用于根据所述权重矩阵对多个所述第一主题分布矩阵进行加权处理,获得多个第二主题分布矩阵;a weighting processing unit, configured to perform weighting processing on a plurality of the first topic distribution matrices according to the weight matrix to obtain a plurality of second topic distribution matrices;
合并处理单元,用于对所述多个第二主题分布矩阵进行向量合并和归一化处理,获得用户所述发文信息的主题分布。The merging processing unit is configured to perform vector merging and normalization processing on the plurality of second topic distribution matrices to obtain the topic distribution of the post information of the user.
进一步的,所述预处理单元包括分词单元和去除单元;Further, the preprocessing unit includes a word segmentation unit and a removal unit;
所述分词单元,用于对所述发文信息进行分词操作,所述去除单元,用于去除所述发文信息的停用词以及去除所述发文信息中的干扰符号。The word segmentation unit is configured to perform a word segmentation operation on the posted information, and the removing unit is configured to remove stop words in the posted information and remove interference symbols in the posted information.
进一步的,所述模型构建单元包括语义提取单元和词扩展单元;Further, the model building unit includes a semantic extraction unit and a word expansion unit;
所述语义提取单元,用于采用语义依存分析法提取所述文本数据上下文中具有语义关联的第一词对;The semantic extraction unit is used for extracting the first word pair with semantic association in the context of the text data by using a semantic dependency analysis method;
所述词扩展单元,用于获取所述文本数据的待扩展关键词,将所述待扩展关键词输入外部语料库中,利用点互信息计算所述待扩展关键词与外部词料库中词的相关性。The word expansion unit is used to obtain the keywords to be expanded of the text data, input the keywords to be expanded into an external corpus, and use point mutual information to calculate the relationship between the keywords to be expanded and the words in the external corpus. Correlation.
进一步的,所述词扩展单元还包括判断单元;Further, the word expansion unit also includes a judgment unit;
所述判断单元,用于设定所述相关性的判断阈值,若所得所述相关性大于所述判断阈值,则将待扩展关键词与外部语料库中的词组成第二词对。The judging unit is configured to set a judging threshold for the correlation, and if the obtained correlation is greater than the judging threshold, a second word pair is formed between the keyword to be expanded and the word in the external corpus.
进一步的,所述合并处理单元还包括向量合并单元和处理单元;Further, the merging processing unit also includes a vector merging unit and a processing unit;
所述向量合并单元,用于对所述多个第二主题分布矩阵内所有的向量进行合并,获得用户的主题分布特征向量;The vector merging unit is used for merging all the vectors in the plurality of second topic distribution matrices to obtain the topic distribution feature vector of the user;
所述处理单元,用于利用softmax函数对所述主题分布特征向量进行归一化处理,获得用户所述发文信息的主题分布。The processing unit is configured to use a softmax function to normalize the topic distribution feature vector to obtain the topic distribution of the user's post information.
与现有技术相比,本发明具有以下有益效果:Compared with the prior art, the present invention has the following beneficial effects:
1.本发明的分析方法提出了一种基于语义和词扩展的短文本主题模型,该模型在传统的短文本主题模型基础之上,不仅融合了短文本的语义信息,还通过外部语料知识库进行词对扩展,在解决短文本稀疏问题的同时,增强文本的主题倾向。1. The analysis method of the present invention proposes a short text topic model based on semantics and word expansion. On the basis of the traditional short text topic model, this model not only integrates the semantic information of the short text, but also uses an external corpus knowledge base. The word pair expansion is carried out to enhance the topic tendency of the text while solving the problem of short text sparseness.
2.本发明在基于语义和词扩展的短文本主题模型之上,采用了一种依据用户发文信息之间的互动信息的发文主题加权法,区别发文间的重要程度,从而计算用户的主题分布。相较于传统的主题特征计算方法,更具合理性。2. Based on the short text topic model based on semantics and word expansion, the present invention adopts a topic weighting method based on the interactive information between the messages sent by the users to distinguish the importance of the messages, so as to calculate the topic distribution of users. . Compared with the traditional topic feature calculation method, it is more reasonable.
附图说明Description of drawings
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:The accompanying drawings described herein are used to provide further understanding of the embodiments of the present invention, and constitute a part of the present application, and do not constitute limitations to the embodiments of the present invention. In the attached image:
图1为本发明一实施例提供的社交用户主题分析方法流程示意图;1 is a schematic flowchart of a method for analyzing social user topics provided by an embodiment of the present invention;
图2为现有技术的短文本主题模型词对获取示意图;2 is a schematic diagram of the acquisition of short text topic model word pairs in the prior art;
图3为本发明一实施例提供的基于语义和词扩展的短文本主题模型的词对获取示意图;3 is a schematic diagram of word pair acquisition based on a short text topic model based on semantics and word expansion according to an embodiment of the present invention;
图4为本发明一实施例提供的获取用户主题分布的流程示意图;FIG. 4 is a schematic flowchart of obtaining user topic distribution according to an embodiment of the present invention;
图5为本发明一实施例提供的构建基于语义和词扩展的短文本主题模型的方法流程示意图;5 is a schematic flowchart of a method for constructing a short text topic model based on semantics and word expansion provided by an embodiment of the present invention;
图6为本发明一实施例提供的社交用户主题分析系统结构示意图。FIG. 6 is a schematic structural diagram of a social user topic analysis system provided by an embodiment of the present invention.
具体实施方式Detailed ways
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。In order to make the purpose, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the embodiments and the accompanying drawings. as a limitation of the present invention.
需说明的是,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。It should be noted that the terms "first" and "second" are only used for the purpose of description, and cannot be understood as indicating or implying relative importance or implying the quantity of the indicated technical features. Thus, a feature defined as "first" or "second" may expressly or implicitly include one or more of that feature. In the description of the present invention, "plurality" means two or more, unless otherwise expressly and specifically defined.
实施例一:Example 1:
如图1所示,本申请实施例一提供一种基于语义和词扩展的社交用户主题分析方法,包括以下步骤:As shown in FIG. 1 , Embodiment 1 of the present application provides a method for analyzing social user topics based on semantics and word expansion, including the following steps:
S1,获取用户的发文信息和所述发文信息在社交网络平台中产生的互动信息;S1, obtain the post information of the user and the interactive information generated by the post information in the social network platform;
用户的发文信息包括用户的固定个人信息,如用户ID,以及其原创的作品信息,如文章ID、发文内容等,发文信息主要指的是短文本信息。与每条发文信息产生互动行为的为互动信息,包括转发数量、点赞数量、收藏数量、评论数量、关注数量和分享数量等。要分析社交网络众用户发文的主题分布,本申请以社交网络用户中的所有发文信息作为基础,以及与每篇发文信息产生互动行为的互动信息。The post information of the user includes the fixed personal information of the user, such as the user ID, and the original work information, such as the article ID, post content, etc. The post information mainly refers to short text information. The interactive information that generates interactive behavior with each post information, including the number of forwarding, number of likes, number of favorites, number of comments, number of followers and number of shares, etc. To analyze the topic distribution of posts posted by social network users, this application uses all post information among social network users as a basis, as well as interactive information that generates interactive behaviors with each post information.
S2,对所述发文信息进行预处理操作,获得发文信息的文本数据;S2, performing a preprocessing operation on the sent information to obtain text data of the sent information;
对于发文信息进行预处理操作得到发文信息的文本数据是本领域的常规技术手段,因此不再进行多余的叙述。It is a conventional technical means in the art to perform a preprocessing operation on the sent message to obtain the text data of the sent message, so no redundant description will be given.
S3,根据所述文本数据构建基于语义和词扩展的短文本主题模型;S3, construct a short text topic model based on semantics and word expansion according to the text data;
具体的,如图2所示,图2即是现有技术中的短文本主题模型(简称BTM模型)用来获取短文本的词对信息的方式,但是采用滑动窗口的方式获取词对信息时忽略了词对在短文本中的上下文的语义关联,因此本申请的基于语义和词扩展的短文本主题模型采用语义依存的方法来提取文本中的词对,使得BTM模型能够融合上下文本的语义信息。在现有技术中主要是通过构造伪文档的方式来提取用户的主题特征,其能解决了短文本稀疏问题,因此为使本申请提出的短文本主题模型能够解决短文本稀疏这一问题,提出了基于词关联的词对扩展方法(即词扩展的短文本主题模型),使得BTM模型能够解决短文本的稀疏问题。Specifically, as shown in FIG. 2, FIG. 2 is the method used by the short text topic model (BTM model for short) in the prior art to obtain the word pair information of the short text, but when the word pair information is obtained by using a sliding window The semantic association of the context of word pairs in short texts is ignored, so the short text topic model based on semantics and word expansion of this application adopts the method of semantic dependence to extract word pairs in the text, so that the BTM model can integrate the semantics of the context book. information. In the prior art, the topic features of users are mainly extracted by constructing pseudo-documents, which can solve the problem of sparse short texts. The word pair expansion method based on word association (namely, the short text topic model of word expansion) is proposed, so that the BTM model can solve the sparse problem of short texts.
S4,将所述发文信息输入所述短文本主题模型进行计算,获得所述发文信息的多个第一主题分布矩阵;S4, inputting the post information into the short text topic model for calculation, and obtaining a plurality of first subject distribution matrices of the post information;
将用户所有发文信息输入基于语义和词扩展的短文本主题模型,可获得每条发文信息的第一主题分布矩阵,则每个用户所有发文信息的主题分布实质为一个D*K维的第一主题分布矩阵,D表示用户所有的发文信息,K表示设定的主题数。D*K维的第一主题分布矩阵记为Tuser。Input all the posted information of the user into the short text topic model based on semantics and word expansion, and the first topic distribution matrix of each posted information can be obtained, then the topic distribution of all the posted information of each user is essentially a D*K dimension of the first topic distribution Topic distribution matrix, D represents all the posted information of the user, and K represents the set number of topics. The first topic distribution matrix of D*K dimension is denoted as Tuser.
S5,根据所述互动信息计算用户每条所述发文信息的权重矩阵;S5, calculating the weight matrix of each piece of the posted information of the user according to the interactive information;
每位用户可以获得D*1维度的权重矩阵,D表示用户所有的发文信息,D*1维度的权重矩阵记为Huser。根据互动信息所计算的权重矩阵即为发文信息的“热度”,权重矩阵的值可作为对应发文信息的权重值,权重值表示该条发文信息对于用户的重要程度,值越高表示发文信息的主题分布越重要,影响力越强。Each user can obtain a weight matrix of D*1 dimension, D represents all the post information of the user, and the weight matrix of D*1 dimension is denoted as H user . The weight matrix calculated according to the interactive information is the "hotness" of the posted information. The value of the weight matrix can be used as the weight value of the corresponding posted information. The weight value indicates the importance of the posted information to the user. The more important the topic distribution, the stronger the influence.
S6,根据所述权重矩阵对多个所述第一主题分布矩阵进行加权处理,获得多个第二主题分布矩阵;S6, performing weighting processing on a plurality of the first topic distribution matrices according to the weighting matrix to obtain a plurality of second topic distribution matrices;
在S5中,权重值表示该条发文信息对于用户的重要程度,因此通过互动信息所计算的权重矩阵Huser对发文信息的第一主题分布矩阵进行加权处理Tuser,即可得到用户的第二主题分布矩阵Xuser。由于第一主题分布矩阵是由基于语义和词扩展的短文本主题模型对用户所有的发文信息进行计算而得出的多维矩阵,因此由每条互动信息对所对应的发文信息进行权重添加,从而计算出用户的主题分布。In S5, the weight value represents the importance of the post information to the user. Therefore, the weight matrix H user calculated by the interactive information is used to weight the first topic distribution matrix of the post information Tuser, and the second topic of the user can be obtained. Distribution matrix X user . Since the first topic distribution matrix is a multi-dimensional matrix calculated by the short text topic model based on semantics and word expansion on all the post information of the user, the corresponding post information is weighted by each piece of interactive information, so that Calculate the topic distribution of users.
S7,对所述多个第二主题分布矩阵进行向量合并和归一化处理,获得用户所述发文信息的主题分布。S7: Perform vector merging and normalization processing on the plurality of second topic distribution matrices to obtain the topic distribution of the user's post information.
对于多个第二主题分布矩阵Xuser,需要将多个矩阵内所有的向量进行合并,以表示用户的主题分布,但由于各用户的互动次数不同,导致用户间的主题分布的值存在很大的差异,因此需要进行归一化处理,以降低主题分布的差异性。For multiple second topic distribution matrices X user , all vectors in multiple matrices need to be merged to represent the topic distribution of users, but due to the different number of interactions of each user, the value of topic distribution among users is very large Therefore, normalization is required to reduce the variability of topic distributions.
本申请实施例一的又一个实施例中,所述预处理操作包括对所述发文信息进行分词操作、去除所述发文信息的停用词以及去除所述发文信息中的干扰符号。In yet another embodiment of Embodiment 1 of the present application, the preprocessing operation includes performing a word segmentation operation on the posted information, removing stop words in the posted information, and removing interference symbols in the posted information.
需要说明的是,预处理操作还可包括对发文信息进行词性标注处理,对发文信息进行关键词抽取、主题抽取、摘要、事件抽取和语义抽取,使得其转化的文本数据更加多样性。It should be noted that the preprocessing operation may also include part-of-speech tagging processing for the posted information, and keyword extraction, topic extraction, abstract, event extraction and semantic extraction for the posted information, so that the transformed text data is more diverse.
本申请实施例一的又一个实施例中,如图5所示,所述根据所述文本数据构建基于语义和词扩展的短文本主题模型的步骤如下:In yet another embodiment of Embodiment 1 of the present application, as shown in FIG. 5 , the steps of constructing a short text topic model based on semantics and word expansion according to the text data are as follows:
采用语义依存分析法提取所述文本数据上下文中具有语义关联的第一词对;Extracting the first word pair with semantic association in the context of the text data by using the semantic dependency analysis method;
获取所述文本数据的待扩展关键词,将所述待扩展关键词输入外部语料库中,利用点互信息计算所述待扩展关键词与外部词料库中词的相关性。The keywords to be expanded of the text data are acquired, the keywords to be expanded are input into an external corpus, and the correlation between the keywords to be expanded and words in the external corpus is calculated by using point mutual information.
具体的,基于语义和词扩展的短文本主题模型对传统BTM模型进行改进。如图2所示,传统BTM模型中采用滑动窗口的方式获取词对信息时忽略了词对在文本中的上下文的语义关联。如图3所示,改进后的BTM模型采用语义依存的方法来提取文本中的词对,使得BTM模型融合了文本语义信息,如在传统BTM模型中,以“xx赢得xx国大选成为下届xx国总统”为例,在对发文信息进行预处理操作后,构建词对数据集的过程中,滑动窗口会将“大选”和“成为”构建为一个词对,但是以人对这句话地理解分析,“大选”和“成为”之间没有语法和逻辑上的关联,将两个词组成词对并增强两词同属一个主题的概率是不合理的,“xx”和“总统”两词之间,明显有着语义和逻辑关联,增强它们同属一个主题的概率更加合理,但由于滑动窗口大小的原因,“xx”和“总统”并不会将构成一个词对。而在以语义依存方法提取的第一词对,仍以“xx赢得xx国大选成为下届xx国总统”这句话为例,“xx”与“成为”之间属于主谓关系,“成为”与“总统”之间属于动宾关系,“xx”与“总统”为主宾关系。因此在词对构建中,选择将强关联关系的词组成第一词对,使得组成的第一词对具备在发文信息中的上下文的语义关联。Specifically, the short text topic model based on semantics and word expansion improves the traditional BTM model. As shown in Figure 2, the traditional BTM model uses a sliding window to obtain word pair information, ignoring the contextual semantic association of word pairs in the text. As shown in Figure 3, the improved BTM model uses the semantic dependency method to extract word pairs in the text, so that the BTM model integrates text semantic information. “President of xx country” as an example, after preprocessing the post information, in the process of constructing the word pair data set, the sliding window will construct “election” and “become” into a word pair, but the human opinion of this sentence Geographically understand the analysis, there is no grammatical and logical connection between "election" and "become", it is unreasonable to form two words into word pairs and enhance the probability that the two words belong to the same topic, "xx" and "president" are two words. There are obvious semantic and logical associations between words, and it is more reasonable to enhance the probability that they belong to the same topic, but due to the size of the sliding window, "xx" and "president" will not constitute a word pair. In the first word pair extracted by the semantic dependency method, still take the sentence "xx won the election of xx country to become the next president of xx country" as an example, "xx" and "become" belong to the subject-predicate relationship, "become ” and “President” belong to the relationship of verb and guest, and “xx” and “President” have the relationship of host and guest. Therefore, in the word pair construction, the words with strong correlation are selected to form the first word pair, so that the formed first word pair has the semantic association of the context in the post information.
同时,为了保证该模型可进一步解决发文信息为短文本时的稀疏问题,提出了基于词关联的词对扩展方法,该方法是通过对待扩展关键词x输入到外部语料中,通过点互信息PMI来计算待扩展关键词x与外部语料中词y的相关性。x和y的点互信息记为PMI(x,y),如下式所示:At the same time, in order to ensure that the model can further solve the sparse problem when the text information is short text, a word pair expansion method based on word association is proposed. to calculate the correlation between the keyword x to be expanded and the word y in the external corpus. The point mutual information of x and y is denoted as PMI(x,y), as shown in the following formula:
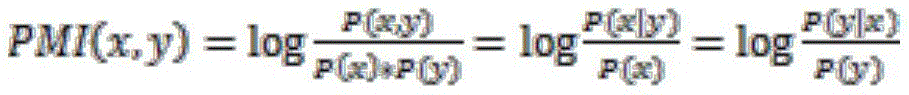
其中,P(x)为关键词x在外部语料库中出现的概率;P(y)为词y在外部语料库中出现的概率。例如以“小米”、“苹果”、“华为”、“电脑”等词为例(假如这些词是从文本中用户发文信息中从提取出来的),在新闻类外部数据集中提取与这些词的PMI值最高的目标词:Among them, P(x) is the probability that the keyword x appears in the external corpus; P(y) is the probability that the word y appears in the external corpus. For example, taking words such as "Xiaomi", "Apple", "Huawei", and "computer" as examples (if these words are extracted from the information posted by users in the text), extract the words related to these words in the external news data set. Target words with the highest PMI values:
表1词扩展计算的结果示例Table 1 Example of the result of word expansion calculation

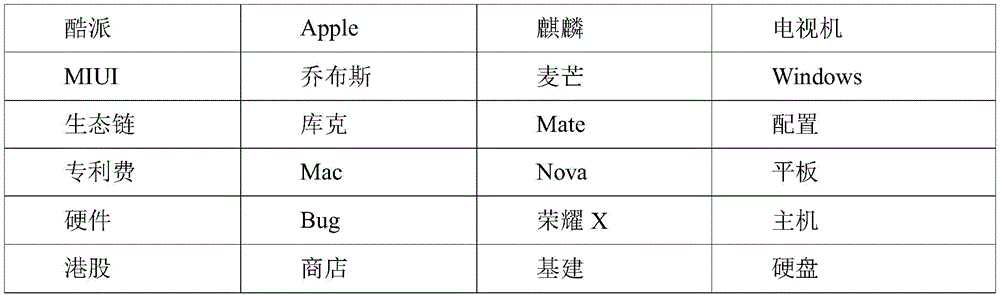
最终可以“小米”一词扩展出的词对为“小米酷派”、“小米MIUI”、“小米生态链”等。“苹果”一词可扩展的词对:“苹果apple”、“苹果乔布斯”、“苹果库克”等,其他词也是类似的词扩展方法。从而解决发文信息为短文本信息时的稀疏问题。In the end, the word pairs that can be expanded from the word "Xiaomi" are "Xiaomi Coolpad", "Xiaomi MIUI", "Xiaomi Ecological Chain" and so on. Word pairs for which the word "apple" can be expanded: "apple apple", "apple jobs", "apple cook", etc. Other words are also similar word expansion methods. Thus, the sparse problem when the sent information is short text information is solved.
本申请实施例一的又一个实施例中,设定所述相关性的判断阈值,若所得所述相关性大于所述判断阈值,则将待扩展关键词与外部语料库中的词组成第二词对。In yet another embodiment of the first embodiment of the present application, a judgment threshold of the correlation is set, and if the obtained correlation is greater than the judgment threshold, the keywords to be expanded and the words in the external corpus are formed into a second word right.
具体的,通过相关性计算所得的相关性值,满足设定的判断阈值,判断阈值一般为200,则认为待扩展关键词与外部语料库中词所具备关联性较强,可以组成第二词对。Specifically, if the correlation value obtained by the correlation calculation satisfies the set judgment threshold, and the judgment threshold is generally 200, it is considered that the keyword to be expanded has a strong correlation with the words in the external corpus, and a second word pair can be formed .
本申请实施例一的又一个实施例中,对所述多个第二主题分布矩阵内所有的向量进行合并,获得用户的主题分布特征向量,利用softmax函数对所述主题分布特征向量进行归一化处理,获得用户所述发文信息的主题分布。In yet another embodiment of Embodiment 1 of the present application, all vectors in the plurality of second topic distribution matrices are combined to obtain the topic distribution feature vector of the user, and the softmax function is used to normalize the topic distribution feature vector process to obtain the topic distribution of the post information described by the user.
具体的,如图4所示,现在已有的技术方案中是将用户所有发文组合成一个长文档后,直接输入传统BTM模型中进行主题分析。而本发明是将用户每一个发文单独进行主题分析后,再将同一用户所有个发文的主题分布合并和归一化处理,以此作为用户的主题特征。归一化处理如下式所示:
综合上述技术方案,本申请实施例一的社交用户主题分析方法,在传统的短文本主题模型基础上,提出了基于语义和词扩展的短文本主题模型,该模型针对每条社交发文信息进行主题分析,得到主题分布矩阵,再根据每条发文信息的互动信息计算出该条发文信息的权重矩阵,即该条发文信息的重要程度,最后利用主题分布矩阵和权重矩阵计算出用户的主题分布,相较于现有技术的直接构造伪文档的用户主题分析方法,本发明的基于语义和词扩展的社交用户主题分析方法更具优势性。Combining the above technical solutions, the social user topic analysis method in Embodiment 1 of the present application proposes a short text topic model based on semantics and word expansion based on the traditional short text topic model. Analysis, get the topic distribution matrix, and then calculate the weight matrix of the posted information according to the interactive information of each posted information, that is, the importance of the posted information, and finally use the topic distribution matrix and the weight matrix to calculate the user's topic distribution, Compared with the user topic analysis method of directly constructing pseudo-documents in the prior art, the social user topic analysis method based on semantics and word expansion of the present invention is more advantageous.
实施例二:Embodiment 2:
基于同一构思,如图6所示,本实施例二在实施例一的基础上提供了一种基于语义和词扩展的社交用户主题分析系统,包括:Based on the same concept, as shown in FIG. 6 , the second embodiment provides a social user topic analysis system based on semantics and word expansion on the basis of the first embodiment, including:
信息获取单元110,用于获取用户的发文信息和所述发文信息在社交网络平台中产生的互动信息;an
预处理单元120,用于对所述发文信息进行预处理操作,获得发文信息的文本数据;a
模型构建单元130,用于根据所述文本数据构建基于语义和词扩展的短文本主题模型;A
第一计算单元140,用于将所述发文信息输入所述短文本主题模型进行计算,获得所述发文信息的多个第一主题分布矩阵;A
第二计算单元150,用于根据所述互动信息计算用户每条所述发文信息的权重矩阵;The
加权处理单元160,用于根据所述权重矩阵对多个所述第一主题分布矩阵进行加权处理,获得多个第二主题分布矩阵;a
合并处理单元170,用于对所述多个第二主题分布矩阵进行向量合并和归一化处理,获得用户所述发文信息的主题分布。The merging
本申请实施例二的社交用户主题分析系统,在传统的短文本主题模型基础上,提出了基于语义和词扩展的短文本主题模型,该模型针对每条社交发文信息进行主题分析,得到主题分布矩阵,再根据每条发文信息的互动信息计算出该条发文信息的权重矩阵,即该条发文信息的重要程度,最后利用主题分布矩阵和权重矩阵计算出用户的主题分布,相较于现有技术的直接构造伪文档的用户主题分析系统,本发明基于语义和词扩展的社交用户主题分析系统更具优势性。The social user topic analysis system in the second embodiment of the present application proposes a short text topic model based on semantics and word expansion on the basis of the traditional short text topic model. The model performs topic analysis on each social posting information to obtain topic distribution. Matrix, and then calculate the weight matrix of the posted information according to the interactive information of each posted information, that is, the importance of the posted information, and finally use the topic distribution matrix and weight matrix to calculate the user's topic distribution. Compared with the existing The technical user topic analysis system for directly constructing pseudo-documents, and the social user topic analysis system based on semantics and word expansion of the present invention is more advantageous.
本申请实施例二的又一个实施例中,所述预处理单元120包括分词单元和去除单元;In yet another embodiment of the second embodiment of the present application, the
所述分词单元,用于对所述发文信息进行分词操作,所述去除单元,用于去除所述发文信息的停用词以及去除所述发文信息中的干扰符号。The word segmentation unit is configured to perform a word segmentation operation on the posted information, and the removing unit is configured to remove stop words in the posted information and remove interference symbols in the posted information.
本申请实施例二的又一个实施例中,所述模型构建单元130包括语义提取单元和词扩展单元;In yet another embodiment of the second embodiment of the present application, the
所述语义提取单元,用于采用语义依存分析法提取所述文本数据上下文中具有语义关联的第一词对;The semantic extraction unit is used for extracting the first word pair with semantic association in the context of the text data by using a semantic dependency analysis method;
所述词扩展单元,用于获取所述文本数据的待扩展关键词,将所述待扩展关键词输入外部语料库中,利用点互信息计算所述待扩展关键词与外部词料库中词的相关性。The word expansion unit is used to obtain the keywords to be expanded of the text data, input the keywords to be expanded into an external corpus, and use point mutual information to calculate the relationship between the keywords to be expanded and the words in the external corpus. Correlation.
本申请实施例二的又一个实施例中,所述词扩展单元还包括判断单元;In yet another embodiment of the second embodiment of the present application, the word expansion unit further includes a judgment unit;
所述判断单元,用于设定所述相关性的判断阈值,若所得所述相关性大于所述判断阈值,则将待扩展关键词与外部语料库中的词组成第二词对。The judging unit is configured to set a judging threshold for the correlation, and if the obtained correlation is greater than the judging threshold, a second word pair is formed between the keyword to be expanded and the word in the external corpus.
本申请实施例二的又一个实施例中,所述合并处理单元170还包括向量合并单元和处理单元;In yet another embodiment of the second embodiment of the present application, the merging
所述向量合并单元,用于对所述多个第二主题分布矩阵内所有的向量进行合并,获得用户的主题分布特征向量;The vector merging unit is used for merging all the vectors in the plurality of second topic distribution matrices to obtain the topic distribution feature vector of the user;
所述处理单元,用于利用softmax函数对所述主题分布特征向量进行归一化处理,获得用户所述发文信息的主题分布。The processing unit is configured to use a softmax function to normalize the topic distribution feature vector to obtain the topic distribution of the user's post information.
需要说明的是,本实施例二中上述各程序单元所执行的方法可参照本发明社交用户主题分析方法中各个实施例,因此不再叙述。It should be noted that, for the methods executed by the above program units in the second embodiment, reference may be made to the various embodiments in the social user topic analysis method of the present invention, and thus will not be described again.
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。The specific embodiments described above further describe the objectives, technical solutions and beneficial effects of the present invention in detail. It should be understood that the above descriptions are only specific embodiments of the present invention, and are not intended to limit the scope of the present invention. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present invention shall be included within the protection scope of the present invention.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210203458.1A CN114580436B (en) | 2022-03-02 | 2022-03-02 | A social user topic analysis method and system based on semantics and word expansion |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210203458.1A CN114580436B (en) | 2022-03-02 | 2022-03-02 | A social user topic analysis method and system based on semantics and word expansion |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114580436A true CN114580436A (en) | 2022-06-03 |
| CN114580436B CN114580436B (en) | 2025-03-18 |
Family
ID=81772000
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210203458.1A Active CN114580436B (en) | 2022-03-02 | 2022-03-02 | A social user topic analysis method and system based on semantics and word expansion |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114580436B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114912448A (en) * | 2022-07-15 | 2022-08-16 | 山东海量信息技术研究院 | Text extension method, device, equipment and medium |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108182176A (en) * | 2017-12-29 | 2018-06-19 | 太原理工大学 | Enhance BTM topic model descriptor semantic dependencies and theme condensation degree method |
| US10459962B1 (en) * | 2018-09-19 | 2019-10-29 | Servicenow, Inc. | Selectively generating word vector and paragraph vector representations of fields for machine learning |
| CN111310467A (en) * | 2020-03-23 | 2020-06-19 | 应豪 | Topic extraction method and system combining semantic inference in long text |
| CN113051932A (en) * | 2021-04-06 | 2021-06-29 | 合肥工业大学 | Method for detecting category of network media event of semantic and knowledge extension topic model |
-
2022
- 2022-03-02 CN CN202210203458.1A patent/CN114580436B/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108182176A (en) * | 2017-12-29 | 2018-06-19 | 太原理工大学 | Enhance BTM topic model descriptor semantic dependencies and theme condensation degree method |
| US10459962B1 (en) * | 2018-09-19 | 2019-10-29 | Servicenow, Inc. | Selectively generating word vector and paragraph vector representations of fields for machine learning |
| CN111310467A (en) * | 2020-03-23 | 2020-06-19 | 应豪 | Topic extraction method and system combining semantic inference in long text |
| CN113051932A (en) * | 2021-04-06 | 2021-06-29 | 合肥工业大学 | Method for detecting category of network media event of semantic and knowledge extension topic model |
Non-Patent Citations (1)
| Title |
|---|
| 李湘东;曹环;丁丛;黄莉;: "利用《知网》和领域关键词集扩展方法的短文本分类研究", 现代图书情报技术, no. 02, 25 February 2015 (2015-02-25), pages 32 - 38 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114912448A (en) * | 2022-07-15 | 2022-08-16 | 山东海量信息技术研究院 | Text extension method, device, equipment and medium |
| CN114912448B (en) * | 2022-07-15 | 2022-12-09 | 山东海量信息技术研究院 | Text extension method, device, equipment and medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114580436B (en) | 2025-03-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Zhao et al. | Cyberbullying detection based on semantic-enhanced marginalized denoising auto-encoder | |
| CN102622338B (en) | Computer-assisted computing method of semantic distance between short texts | |
| CN103559233B (en) | Network neologisms abstracting method and microblog emotional analysis method and system in microblogging | |
| CN105183833B (en) | Microblog text recommendation method and device based on user model | |
| CN104516947B (en) | A kind of Chinese microblog emotional analysis method for merging dominant and recessive character | |
| CN112989208B (en) | Information recommendation method and device, electronic equipment and storage medium | |
| CN104915443B (en) | A kind of abstracting method of Chinese microblogging evaluation object | |
| CN104573057B (en) | It is a kind of to be used for the account association method across UGC website platforms | |
| CN109299277A (en) | Public opinion analysis method, server and computer-readable storage medium | |
| CN108388554A (en) | Text emotion identifying system based on collaborative filtering attention mechanism | |
| CN111651559B (en) | A Method of Extracting User Relations in Social Networks Based on Event Extraction | |
| Qiu et al. | Advanced sentiment classification of tibetan microblogs on smart campuses based on multi-feature fusion | |
| CN111680505A (en) | A Markdown Feature Aware Unsupervised Keyword Extraction Method | |
| CN103631862B (en) | Event characteristic evolution excavation method and system based on microblogs | |
| CN107436877A (en) | Much-talked-about topic method for pushing and device | |
| CN105447144B (en) | Microblogging forwarding visual analysis method and system based on big data analysis technology | |
| CN111626050A (en) | Microblog sentiment analysis method based on expression dictionary and emotional common sense | |
| CN107688630A (en) | A kind of more sentiment dictionary extending methods of Weakly supervised microblogging based on semanteme | |
| Nahar et al. | Sentiment analysis and emotion extraction: A review of research paradigm | |
| CN117150116A (en) | Method for constructing personalized message recommendation system facing user interests | |
| Argueta et al. | Multilingual emotion classifier using unsupervised pattern extraction from microblog data | |
| Zhang et al. | Detecting and analyzing influenza epidemics with social media in China | |
| CN103984731B (en) | Self adaptation topic tracking method and apparatus under microblogging environment | |
| CN116361638A (en) | Question answer search method, device and storage medium | |
| CN114580436A (en) | Social user theme analysis method and system based on semantics and word expansion |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |