CN114457024A - A pluripotent stem cell expressing IL-4Rα blocker or its derivative and application - Google Patents
A pluripotent stem cell expressing IL-4Rα blocker or its derivative and application Download PDFInfo
- Publication number
- CN114457024A CN114457024A CN202011186002.6A CN202011186002A CN114457024A CN 114457024 A CN114457024 A CN 114457024A CN 202011186002 A CN202011186002 A CN 202011186002A CN 114457024 A CN114457024 A CN 114457024A
- Authority
- CN
- China
- Prior art keywords
- shrna
- hla
- seq
- pluripotent stem
- mir
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images











Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0603—Embryonic cells ; Embryoid bodies
- C12N5/0606—Pluripotent embryonic cells, e.g. embryonic stem cells [ES]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/28—Bone marrow; Haematopoietic stem cells; Mesenchymal stem cells of any origin, e.g. adipose-derived stem cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/30—Nerves; Brain; Eyes; Corneal cells; Cerebrospinal fluid; Neuronal stem cells; Neuronal precursor cells; Glial cells; Oligodendrocytes; Schwann cells; Astroglia; Astrocytes; Choroid plexus; Spinal cord tissue
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/48—Reproductive organs
- A61K35/54—Ovaries; Ova; Ovules; Embryos; Foetal cells; Germ cells
- A61K35/545—Embryonic stem cells; Pluripotent stem cells; Induced pluripotent stem cells; Uncharacterised stem cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
- A61P11/06—Antiasthmatics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/08—Antiallergic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2866—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for cytokines, lymphokines, interferons
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0608—Germ cells
- C12N5/0611—Primordial germ cells, e.g. embryonic germ cells [EG]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0618—Cells of the nervous system
- C12N5/0623—Stem cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0652—Cells of skeletal and connective tissues; Mesenchyme
- C12N5/0662—Stem cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0696—Artificially induced pluripotent stem cells, e.g. iPS
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/51—Complete heavy chain or Fd fragment, i.e. VH + CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/515—Complete light chain, i.e. VL + CL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Biomedical Technology (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Developmental Biology & Embryology (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- General Health & Medical Sciences (AREA)
- Cell Biology (AREA)
- Genetics & Genomics (AREA)
- Wood Science & Technology (AREA)
- Medicinal Chemistry (AREA)
- Immunology (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- General Engineering & Computer Science (AREA)
- Reproductive Health (AREA)
- Epidemiology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Pulmonology (AREA)
- Gynecology & Obstetrics (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Virology (AREA)
- Neurology (AREA)
- Neurosurgery (AREA)
- Dermatology (AREA)
- Mycology (AREA)
- Rheumatology (AREA)
- Hematology (AREA)
- Endocrinology (AREA)
- Transplantation (AREA)
- Biophysics (AREA)
Abstract
Description
技术领域technical field
本发明属于基因工程技术领域,具体涉及一种表达IL-4Rα阻断物的多能干细胞或其衍生物及应用。The invention belongs to the technical field of genetic engineering, and in particular relates to a pluripotent stem cell expressing an IL-4Rα blocker or a derivative thereof and application thereof.
背景技术Background technique
IL-4最初由于具有促进B淋巴细胞增殖的作用而被命名为B细胞生长因子-1。有的实验室则称之为B细胞刺激因子-1、T细胞生长因子-2等。后来基因克隆成功才统一将其命名为白细胞介素4(Interleukin-4,IL-4)。人IL-4的基因的染色体定位于5q31,成熟人IL-4由129个氨基酸残基组成的,分子质量为18~19kDa。IL-4主要由活化的T细胞Th2亚群产生,另外一些其他细胞如肥大细胞、嗜酸性粒细胞、嗜酸性粒细胞等也可分泌少量IL-4,并诱导初始CD4+T细胞向Th2亚群分化。IL-4与IL-13在支气管哮喘的炎症方面有重要的作用,同时,IL-13与IL-4还在过敏、特性性皮炎等方面有重要作用,但他们必须与靶细胞上的受体复合物结合才可以发挥其生物活性。IL-4受体(IL-4Receptor,IL-4R)分为I型IL-4受体和Ⅱ型IL-4受体两种亚型。I型IL-4R由IL-4Rα(IL-4Receptorα)链(CD124)和γc链(CD132)组成;Ⅱ型IL-4R由IL4Rα链(CD124)和IL-13Rα1链(CD213α1)组成,因此IL-13与IL-4共享Ⅱ型IL-4R受体即IL-4Rα进行信号传导。因此,IL-4Rα已成为治疗过敏、哮喘、特应性皮炎的新靶点,IL-4Rα阻断物(抗IL-4Rα抗体)可作为过敏、哮喘治疗药物。目前,处于临床阶段的IL-4Rα抗体有Dupixent、苏州康乃德生物的IL-4Rα抗体CBP-201等。然而,抗IL-4Rα抗体的作用时间短,需要长期进行注射,对于病人来说需要花费高昂的费用。IL-4 was originally named B cell growth factor-1 due to its role in promoting the proliferation of B lymphocytes. Some laboratories call it B cell stimulating factor-1, T cell growth factor-2, etc. After the successful gene cloning, it was uniformly named as interleukin-4 (Interleukin-4, IL-4). The chromosomal location of the human IL-4 gene is at 5q31. Mature human IL-4 consists of 129 amino acid residues and has a molecular mass of 18-19 kDa. IL-4 is mainly produced by activated T cell Th2 subsets, and some other cells such as mast cells, eosinophils, eosinophils, etc. can also secrete a small amount of IL-4, and induce naive CD4+ T cells to Th2 subsets. group differentiation. IL-4 and IL-13 play an important role in the inflammation of bronchial asthma. At the same time, IL-13 and IL-4 also play an important role in allergy, atopic dermatitis, etc., but they must interact with receptors on target cells. Only when the complex is combined can it exert its biological activity. IL-4 receptor (IL-4Receptor, IL-4R) is divided into two subtypes of type I IL-4 receptor and type II IL-4 receptor. Type I IL-4R is composed of IL-4Rα (IL-4Receptorα) chain (CD124) and γc chain (CD132); type II IL-4R is composed of IL4Rα chain (CD124) and IL-13Rα1 chain (CD213α1), so IL- 13 shares the type II IL-4R receptor, IL-4Rα, with IL-4 for signaling. Therefore, IL-4Rα has become a new target for the treatment of allergy, asthma and atopic dermatitis, and IL-4Rα blocker (anti-IL-4Rα antibody) can be used as a drug for allergy and asthma. At present, IL-4Rα antibodies in clinical stage include Dupixent, IL-4Rα antibody CBP-201 of Suzhou Connect Biotechnology, etc. However, the anti-IL-4Rα antibody has a short duration of action, requires long-term injection, and is expensive for patients.
干细胞是一类具备自我更新能力及向特定功能体细胞分化能力的“种子”细胞,具有再生为各种组织器官和人体的潜力,在免疫应答、衰老、肿瘤发生等重大生物学活动中发挥着核心且不可替代的作用。依据干细胞特性的程度差异,主要将干细胞分为:全能干细胞(Totipotent stem cells)、多能干细胞(Pluripotent stem cells,PSCs)和成体干细胞(adult stem cell)。其中,多能干细胞PSCs具备几近无限的自我更新能力,以及在正常发育条件下向胚内所有胚层的器官、组织、细胞发育分化的潜能,典型的PSCs主要包括胚胎干细胞(embryonic stem cells,ESCs)、胚胎生殖细胞(embryonic germ cells,EGCs)、胚胎癌细胞(embryonic carcinoma cells,ECCs),以及诱导多能干细胞(induced pluripotentstem cells,iPSCs)等,这类细胞由于其强大的功能,并且可以一定程度地通过伦理限制,因此具有十分深远和广泛的应用前景。Stem cells are a type of "seed" cells that have the ability to self-renew and differentiate into specific functional somatic cells. They have the potential to regenerate into various tissues and organs and the human body. core and irreplaceable role. According to the degree of stem cell characteristics, stem cells are mainly divided into: totipotent stem cells (Totipotent stem cells), pluripotent stem cells (PSCs) and adult stem cells (adult stem cells). Among them, pluripotent stem cells (PSCs) have almost unlimited self-renewal ability and the potential to develop and differentiate into organs, tissues and cells of all germ layers in the embryo under normal developmental conditions. Typical PSCs mainly include embryonic stem cells (ESCs). ), embryonic germ cells (EGCs), embryonic carcinoma cells (ECCs), and induced pluripotentstem cells (iPSCs). It can pass ethical restrictions to a certain extent, so it has a very far-reaching and wide-ranging application prospect.
因此,开发一种可以在人体中表达IL-4Rα阻断物的多能干细胞或其衍生物具有重要意义。Therefore, it is of great significance to develop a pluripotent stem cell or its derivative that can express an IL-4Rα blocker in humans.
但是,无论是自体iPSCs细胞库,还是免疫配型PSCs细胞库的构思或建立都需要花费极大的财力、物力和人力。同种异基因供受体的器官、组织或细胞移植的分子免疫学基础主要是基于经典的主要组织相容性复合体MHC-I和MHC-II(人又作HLA-I、HLA-II)的配型。截至2019年6月,已鉴定和命名的HLA系统等位基因已超过20000个,仅经典的HLA-A、B、C的等位基因数分别都超过5000个,这些经典的HLA-I/II型等位基因各种可能的随机组合将是天文数字,并且随着新的等位基因的发现组合数随之增加,给器官、组织、细胞移植前的组织配型及供体选择带来极大的障碍,也给构建覆盖人群免疫配型PSCs细胞库带来巨大的困难。However, the conception or establishment of an autologous iPSCs cell bank or an immune-matched PSCs cell bank requires enormous financial, material and human resources. The molecular immunological basis of organ, tissue or cell transplantation of allogeneic donors and recipients is mainly based on the classical major histocompatibility complex MHC-I and MHC-II (also known as HLA-I, HLA-II in humans) 's matching. As of June 2019, more than 20,000 HLA system alleles have been identified and named, and only classical HLA-A, B, and C alleles have more than 5,000 alleles. These classical HLA-I/II The number of possible random combinations of alleles will be astronomical, and the number of combinations will increase with the discovery of new alleles, bringing great importance to the tissue matching and donor selection of organs, tissues, and cells before transplantation. This is a huge obstacle, and it also brings huge difficulties to the construction of a population-covering immune-matched PSCs cell bank.
于是,构建同种异体免疫兼容的通用型PSCs迫在眉睫。近年已有许多报道通过敲除B2M、CIITA等基因,实现HLA-I和HLA-II细胞表面或本身基因的缺失表达,进而使细胞具备免疫耐受或逃逸T/B细胞特异性免疫应答,产生免疫兼容的通用型PSCs,为更广泛的通用型PSCs源细胞、组织、器官应用奠定了重要的基础。也有报道细胞过表达CTLA4-Ig、PD-L1从而抑制同种异的免疫排斥。最近又有报道,在敲除B2M、CIITA的同时,敲入CD47,从而使细胞获得了逃逸除特异性免疫应答外,还具备免疫耐受或逃逸NK等细胞的固有免疫应答,从而使细胞具备了更加全面更强的免疫兼容特性。然而,这些方案要么免疫兼容不彻底,仍有通过其他途径发生同种异体的免疫排斥;要么彻底消除同种异体免疫排斥应答,但使供体源移植物的细胞本身同时丧失了抗原提呈的能力,这给受体带来了极大的致瘤性和病毒感染等疾病的风险。Therefore, the construction of alloimmune compatible universal PSCs is imminent. In recent years, there have been many reports that by knocking out B2M, CIITA and other genes, the expression of HLA-I and HLA-II cells surface or their own genes is lost, so that cells have immune tolerance or escape T/B cell-specific immune responses, resulting in The immune-compatible universal PSCs have laid an important foundation for the wider application of universal PSC-derived cells, tissues and organs. It has also been reported that cells overexpress CTLA4-Ig and PD-L1 to inhibit allogeneic immune rejection. Recently, it has been reported that while knocking out B2M and CIITA, CD47 is knocked in, so that the cells can escape from the specific immune response, but also have immune tolerance or escape the innate immune response of NK cells, so that the cells have More comprehensive and stronger immune compatibility features. However, these regimens are either not fully immune compatible, and allogeneic immune rejection still occurs through other means; or they completely eliminate the allogeneic immune rejection response, but the cells of the donor-derived graft lose their antigen-presenting ability at the same time. capacity, which poses a great risk to the receptor for diseases such as tumorigenicity and viral infection.
为此,也有报道,不直接敲除B2M,而敲除HLA-A、HLA-B或一并敲除CIITA的同时,保留HLA-C,并构建12个覆盖人群超过90%的HLA-C免疫配型抗原,以此达到移植物的细胞仍具备一定程度的抗原提呈功能,并且同时能够通过HLA-C抑制NK细胞的固有免疫应答。但这类细胞,一来,HLA-I类抗原提呈的抗原类型缩小了三分之二以上,能够提呈的抗原完整性极大地不可逆的缩小,对于各种肿瘤、病毒以及其他疾病抗原的提呈具有极大的偏向性,仍然保留了相当程度的致瘤和病毒感染等疾病的风险,在CIITA同时敲除的情况下其致病风险更高;二来,12种高频率免疫配型的HLA-C抗原种族差异很大,通过我们核实计算部分地区仅能占到70%的比例,而中国、印度等人口大国目前尚未有权威的大样本量的HLA数据展示,这样制备出来的通用型PSCs使用仍受到巨大的配型空缺考验;第三,这种方法会经历数次反复的基因编辑工作,按每次基因编辑至少两轮单细胞分离培养计,整个过程至少需要六轮以上的单细胞分离培养,这些流程不可避免且极大概率地因多次基因编辑脱靶或染色质不稳定或因大量单细胞传代增殖造成细胞各种不可预测的突变,进而诱发致癌、代谢疾病等各种问题。由此可见,这类免疫兼容方案亦为“过渡时期”的权宜之计,仍有许多问题没有更好的解决。For this reason, it has also been reported that, instead of directly knocking out B2M, HLA-A, HLA-B or CIITA are knocked out together, while retaining HLA-C, and constructing 12 HLA-C immune systems that cover more than 90% of the population. Matching antigens, so that the transplanted cells still have a certain degree of antigen presentation function, and at the same time can inhibit the innate immune response of NK cells through HLA-C. However, the types of antigens presented by HLA-I antigens have been reduced by more than two-thirds, and the integrity of the antigens that can be presented has been greatly and irreversibly reduced. For various tumors, viruses and other disease antigens The presentation is highly biased, and still retains a considerable degree of risk of tumorigenicity and viral infection, and its pathogenic risk is higher when CIITA is knocked out at the same time; secondly, 12 high-frequency immune matching The ethnic differences of HLA-C antigens are very large. Through our verification and calculation, some regions can only account for 70% of the proportion. However, China, India and other populous countries currently do not have authoritative large-scale HLA data display. The use of type PSCs is still subject to the huge matching vacancy test; thirdly, this method will undergo several iterations of gene editing work. Based on at least two rounds of single-cell isolation and culture for each gene editing, the whole process requires at least more than six rounds of single-cell isolation and culture. Cell isolation and culture, these processes are inevitably and highly likely to cause various unpredictable mutations in cells due to multiple off-target gene editing or chromatin instability or due to a large number of single-cell passages and proliferations, and then induce various problems such as carcinogenesis and metabolic diseases . It can be seen that this type of immunocompatibility program is also an expedient measure in the "transition period", and there are still many problems that have not been better resolved.
此外,还有人设计通过诱导自杀基因在供体组织、细胞致病后诱导杀死,这样做的后果将产生严重的组织坏死、细胞因子风暴等不可预知的疾病风险问题,并且这类设计的细胞杀死后将不复存在合适的供体细胞、组织和器官又是一大难题。In addition, some people have designed suicide genes to induce killing after the donor tissue and cells become diseased. The consequences of doing so will cause severe tissue necrosis, cytokine storms and other unpredictable disease risk problems, and such designed cells Another problem is that after killing, there will be no suitable donor cells, tissues and organs.
发明内容SUMMARY OF THE INVENTION
为了克服现有技术所存在的不足,本发明的第一方面的目的,在于提供一种表达IL-4Rα阻断物的多能干细胞或其衍生物,包括表达IL-4Rα阻断物的非免疫兼容的多能干细胞或其衍生物、表达IL-4Rα阻断物的免疫兼容的多能干细胞或其衍生物、表达IL-4Rα阻断物的免疫兼容可逆的多能干细胞或其衍生物中的至少一种;其中,表达IL-4Rα阻断物的免疫兼容的多能干细胞或其衍生物可以通过如下方案实现:将多能干细胞或其衍生物基因组中的B2M和/或CIITA基因敲除和/或在多能干细胞或其衍生物的基因组导入免疫兼容分子的表达序列;表达IL-4Rα阻断物的免疫兼容可逆的多能干细胞或其衍生物通过如下方案实现:在多能干细胞或其衍生物的基因组导入免疫兼容分子及诱导型基因表达系统,多能干细胞或其衍生物基因组中导入的免疫兼容分子的表达通过诱导型基因表达系统调控,而诱导型基因表达系统的开启与关闭受外源诱导物的调控;当免疫兼容分子正常表达时,多能干细胞或其衍生物中与免疫应答相关的基因的表达被抑制或过表达,可以消除或降低供体细胞和受体之间的同种异体免疫排斥应答;而当供体细胞发生病变时,可通过外源诱导物诱导关闭免疫兼容分子的表达,恢复供体细胞的抗原提呈能力,使受体能够清除病变的供体细胞。In order to overcome the deficiencies in the prior art, the first aspect of the present invention aims to provide a pluripotent stem cell or its derivatives expressing an IL-4Rα blocker, including non-immune cells expressing an IL-4Rα blocker. Compatible pluripotent stem cells or derivatives thereof, immunocompatible pluripotent stem cells or derivatives thereof expressing IL-4Rα blockers, immunocompatible reversible pluripotent stem cells or derivatives thereof expressing IL-4Rα blockers At least one; wherein, immune-compatible pluripotent stem cells or derivatives thereof expressing IL-4Rα blocker can be achieved by the following scheme: knocking out B2M and/or CIITA genes in the genome of pluripotent stem cells or derivatives thereof and / or introduce the expression sequence of immune-compatible molecules into the genome of pluripotent stem cells or their derivatives; the immune-compatible and reversible pluripotent stem cells or their derivatives expressing IL-4Rα blocker are achieved by the following scheme: in pluripotent stem cells or their derivatives The genome of derivatives is introduced into immune-compatible molecules and inducible gene expression systems. The expression of immune-compatible molecules introduced into the genomes of pluripotent stem cells or their derivatives is regulated by the inducible gene expression system, and the opening and closing of the inducible gene expression system is controlled by Regulation of exogenous inducers; when immune-compatible molecules are normally expressed, the expression of genes related to immune response in pluripotent stem cells or their derivatives is inhibited or overexpressed, which can eliminate or reduce the interaction between donor cells and recipients. Allogeneic immune rejection response; and when the donor cells are diseased, the expression of immune-compatible molecules can be induced to shut down by exogenous inducers, restoring the antigen-presenting ability of the donor cells, and enabling the recipient to clear the diseased donor cells. .
本发明的第二个方面的目的,在于提供上述多能干细胞或其衍生物在制备抗过敏、特应性皮炎和/或抗哮喘治疗药物中的应用。The purpose of the second aspect of the present invention is to provide the application of the above-mentioned pluripotent stem cells or derivatives thereof in the preparation of anti-allergy, atopic dermatitis and/or anti-asthma therapeutic drugs.
本发明的第三个方面的目的,在于提供一种制剂,包含上述多能干细胞或其衍生物。The object of the third aspect of the present invention is to provide a preparation comprising the above-mentioned pluripotent stem cells or derivatives thereof.
为了实现上述目的,本发明所采取的技术方案是:In order to achieve the above object, the technical scheme adopted by the present invention is:
本发明的第一个方面,提供一种表达IL-4Rα阻断物的多能干细胞或其衍生物,所述多能干细胞或其衍生物的基因组导入有IL-4Rα阻断物的表达序列,所述IL-4Rα阻断物为抗IL-4Rα抗体。In a first aspect of the present invention, there is provided a pluripotent stem cell or a derivative thereof expressing an IL-4Rα blocker, the genome of the pluripotent stem cell or its derivative is introduced with an expression sequence of the IL-4Rα blocker, The IL-4Rα blocker is an anti-IL-4Rα antibody.
所述抗IL-4Rα抗体的重链序列如SEQ ID NO.1所示,轻链序列如SEQ ID NO.2所示。The heavy chain sequence of the anti-IL-4Rα antibody is shown in SEQ ID NO.1, and the light chain sequence is shown in SEQ ID NO.2.
所述抗IL-4Rα抗体优选为分泌型抗体。The anti-IL-4Rα antibody is preferably a secretory antibody.
所述IL-4Rα阻断物的表达序列的导入位点为多能干细胞或其衍生物的基因组安全位点。The introduction site of the expression sequence of the IL-4Rα blocker is the genomic safety site of the pluripotent stem cell or its derivative.
所述基因组安全位点包括AAVS1安全位点、eGSH安全位点、H11安全位点中的一种或多种。The genomic safety site includes one or more of the AAVS1 safety site, the eGSH safety site, and the H11 safety site.
作为本发明的另一个技术方案:所述多能干细胞或其衍生物的B2M和/或CIITA基因被敲除,从而得到一种表达IL-4Rα阻断物的免疫兼容的多能干细胞或其衍生物。As another technical solution of the present invention: the B2M and/or CIITA genes of the pluripotent stem cells or derivatives thereof are knocked out, thereby obtaining an immune-compatible pluripotent stem cell or its derivatives expressing an IL-4Rα blocker thing.
作为本发明的另一个技术方案:所述多能干细胞或其衍生物的基因组还导入一种或多种免疫兼容分子表达序列,所述免疫兼容分子用于调控多能干细胞细胞或其衍生物中与免疫应答(同种异体免疫排斥)相关的基因的表达,从而得到一种表达IL-4Rα阻断物的免疫兼容的多能干细胞或其衍生物。As another technical solution of the present invention: the genome of the pluripotent stem cells or their derivatives is further introduced with one or more immune-compatible molecule expression sequences, and the immune-compatible molecules are used to regulate the pluripotent stem cells or their derivatives. Expression of genes associated with immune response (allogeneic immune rejection), resulting in an immune-compatible pluripotent stem cell or derivative thereof expressing an IL-4Rα blocker.
所述与免疫应答相关的基因包括:The genes associated with the immune response include:
(1)主要组织相容性复合体基因,包括HLA-A、HLA-B、HLA-C、HLA-DRA、HLA-DRB1、HLA-DRB3、HLA-DRB4、HLA-DRB5、HLA-DQA1、HLA-DQB1、HLA-DPA1和HLA-DPB1中的至少一种;(1) Major histocompatibility complex genes, including HLA-A, HLA-B, HLA-C, HLA-DRA, HLA-DRB1, HLA-DRB3, HLA-DRB4, HLA-DRB5, HLA-DQA1, HLA - at least one of DQB1, HLA-DPAl and HLA-DPB1;
(2)主要组织相容性复合体相关基因,包括B2M和CIITA中的至少一种。(2) Major histocompatibility complex-related genes, including at least one of B2M and CIITA.
所述免疫兼容分子表达序列的导入位点为多能干细胞或其衍生物的基因组安全位点。The introduction site of the immunocompatible molecule expression sequence is the genome safety site of the pluripotent stem cell or its derivative.
所述基因组安全位点包括AAVS1安全位点、eGSH安全位点、H11安全位点中的一种或多种。The genomic safety site includes one or more of the AAVS1 safety site, the eGSH safety site, and the H11 safety site.
所述免疫兼容分子包括以下的任一种或多种:The immunocompatible molecule includes any one or more of the following:
(1)免疫耐受相关基因,包括CD47或HLA-G;(1) Immune tolerance-related genes, including CD47 or HLA-G;
(2)HLA-C类分子,包括人群中比例合计超过90%的HLA-C复等位基因,或者超过90%的HLA-C复等位基因与B2M构成的融合蛋白基因;(2) HLA-C class molecules, including HLA-C multiple alleles with a proportion of more than 90% in the population, or fusion protein genes composed of more than 90% of HLA-C multiple alleles and B2M;
(3)主要组织相容性复合体基因的shRNA和/或shRNA-miR,所述主要组织相容性复合体基因包括HLA-A、HLA-B、HLA-C、HLA-DRA、HLA-DRB1、HLA-DRB3、HLA-DRB4、HLA-DRB5、HLA-DQA1、HLA-DQB1、HLA-DPA1和HLA-DPB1中的至少一种;(3) shRNA and/or shRNA-miR of major histocompatibility complex genes, the major histocompatibility complex genes include HLA-A, HLA-B, HLA-C, HLA-DRA, HLA-DRB1 , at least one of HLA-DRB3, HLA-DRB4, HLA-DRB5, HLA-DQA1, HLA-DQB1, HLA-DPA1 and HLA-DPB1;
(4)主要组织相容性复合体相关基因的shRNA和/或shRNA-miR,所述主要组织相容性复合体相关基因包括B2M和CIITA中的至少一种。(4) shRNA and/or shRNA-miR of a major histocompatibility complex-related gene, the major histocompatibility complex-related gene including at least one of B2M and CIITA.
所述B2M的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.3~SEQ ID NO.5中的至少一种;The target sequence of the B2M shRNA and/or shRNA-miR is at least one of SEQ ID NO.3 to SEQ ID NO.5;
所述CIITA的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.6~SEQ ID NO.15中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the CIITA is at least one of SEQ ID NO.6 to SEQ ID NO.15;
所述HLA-A的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.16~SEQ ID NO.18中的至少一种;The target sequence of the HLA-A shRNA and/or shRNA-miR is at least one of SEQ ID NO.16 to SEQ ID NO.18;
所述HLA-B的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.19~SEQ ID NO.24中的至少一种;The target sequence of the HLA-B shRNA and/or shRNA-miR is at least one of SEQ ID NO.19-SEQ ID NO.24;
所述HLA-C的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.25~SEQ ID NO.30中的至少一种;The target sequence of the HLA-C shRNA and/or shRNA-miR is at least one of SEQ ID NO.25-SEQ ID NO.30;
所述HLA-DRA的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.31~SEQ ID NO.40中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the HLA-DRA is at least one of SEQ ID NO.31-SEQ ID NO.40;
所述HLA-DRB1的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.41~SEQ ID NO.45中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the HLA-DRB1 is at least one of SEQ ID NO.41-SEQ ID NO.45;
所述HLA-DRB3的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.46~SEQ ID NO.47中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the HLA-DRB3 is at least one of SEQ ID NO.46-SEQ ID NO.47;
所述HLA-DRB4的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.48~SEQ ID NO.57中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the HLA-DRB4 is at least one of SEQ ID NO.48-SEQ ID NO.57;
所述HLA-DRB5的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.58~SEQ ID NO.66中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the HLA-DRB5 is at least one of SEQ ID NO.58-SEQ ID NO.66;
所述HLA-DQA1的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.67~SEQ ID NO.73中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the HLA-DQA1 is at least one of SEQ ID NO.67-SEQ ID NO.73;
所述HLA-DQB1的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.74~SEQ ID NO.83中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the HLA-DQB1 is at least one of SEQ ID NO.74-SEQ ID NO.83;
所述HLA-DPA1的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.84~SEQ ID NO.93中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the HLA-DPA1 is at least one of SEQ ID NO.84-SEQ ID NO.93;
所述HLA-DPB1的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.94~SEQ IDNO.103中的至少一种。The target sequence of the shRNA and/or shRNA-miR of the HLA-DPB1 is at least one of SEQ ID NO.94-SEQ ID NO.103.
所述多能干细胞或其衍生物的基因组中还导入shRNA和/或miRNA加工复合体相关基因和/或抗干扰素效应分子。shRNA and/or miRNA processing complex-related genes and/or anti-interferon effector molecules are also introduced into the genome of the pluripotent stem cells or derivatives thereof.
所述shRNA和/或miRNA加工复合体相关基因包括Drosha、Ago1、Ago2、Dicer1、Exportin-5、TRBP(TARBP2)、PACT(PRKRA)、DGCR8中的至少一种;所述抗干扰素效应分子为PKR、2-5As、IRF-3和IRF-7中的至少一种的shRNA和/或shRNA-miR。The shRNA and/or miRNA processing complex-related genes include at least one of Drosha, Ago1, Ago2, Dicer1, Exportin-5, TRBP (TARBP2), PACT (PRKRA), and DGCR8; the anti-interferon effector molecule is shRNA and/or shRNA-miR of at least one of PKR, 2-5As, IRF-3, and IRF-7.
所述shRNA和/或miRNA加工复合体相关基因和/或抗干扰素效应分子的导入位点为多能干细胞或其衍生物的基因组安全位点。The introduction site of the shRNA and/or miRNA processing complex-related gene and/or the anti-interferon effector molecule is the genomic safety site of the pluripotent stem cell or its derivative.
所述基因组安全位点包括AAVS1安全位点、eGSH安全位点、H11安全位点中的一种或多种。The genomic safety site includes one or more of the AAVS1 safety site, the eGSH safety site, and the H11 safety site.
所述PKR的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.104~SEQ ID NO.113中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the PKR is at least one of SEQ ID NO.104-SEQ ID NO.113;
所述2-5As的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.114~SEQ ID NO.143中的至少一种;The target sequence of the 2-5As shRNA and/or shRNA-miR is at least one of SEQ ID NO.114-SEQ ID NO.143;
所述IRF-3的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.144~SEQ ID NO.153中的至少一种;The target sequence of the shRNA and/or shRNA-miR of the IRF-3 is at least one of SEQ ID NO.144-SEQ ID NO.153;
所述IRF-7的shRNA和/或shRNA-miR的靶序列为SEQ ID NO.154~SEQ ID NO.163中的至少一种。The target sequence of the shRNA and/or shRNA-miR of IRF-7 is at least one of SEQ ID NO.154-SEQ ID NO.163.
所述主要组织相容性复合体基因、主要组织相容性复合体相关基因、PKR、2-5As、IRF-3或IRF-7的shRNA和/或shRNA-miR的表达框架如下所示:The expression framework of the major histocompatibility complex gene, major histocompatibility complex-related gene, PKR, 2-5As, IRF-3 or IRF-7 shRNA and/or shRNA-miR is as follows:
(1)shRNA表达框架:由5’到3’依次包括shRNA靶序列、茎环序列、shRNA靶序列的反向互补序列、Poly T;两个反向互补靶序列由中间一茎环序列分隔组成发夹结构,最后连上Poly T作为RNA聚合酶III的转录终止子;(1) shRNA expression framework: from 5' to 3', it includes the shRNA target sequence, the stem-loop sequence, the reverse complement of the shRNA target sequence, and Poly T; the two reverse complement target sequences are separated by a stem-loop sequence in the middle. Hairpin structure, finally connected with Poly T as the transcription terminator of RNA polymerase III;
(2)shRNA-miR表达框架:使用上述主要组织相容性复合体基因、主要组织相容性复合体相关基因、PKR、2-5As、IRF-3或IRF-7的shRNA-miR靶序列替换microRNA-30或者microRNA-155中的靶序列得到。(2) shRNA-miR expression framework: use the above-mentioned major histocompatibility complex gene, major histocompatibility complex-related gene, PKR, 2-5As, IRF-3 or IRF-7 shRNA-miR target sequence replacement Target sequences in microRNA-30 or microRNA-155 were obtained.
所述shRNA表达框架中的茎环序列长度为3~9个碱基;所述Poly T长度为5~6个碱基。The length of the stem-loop sequence in the shRNA expression framework is 3-9 bases; the length of the Poly T is 5-6 bases.
上述表达框架可根据需要在5’端加上组成型启动子或诱导型启动子,例如U6启动子、H1启动子,以及配套的启动子调控元件。The above-mentioned expression framework can add a constitutive promoter or an inducible promoter at the 5' end as required, such as U6 promoter, H1 promoter, and matching promoter regulatory elements.
作为本发明的另一个技术方案:所述多能干细胞或其衍生物的基因组中还导入诱导型基因表达系统,用于调控免疫兼容分子的表达,从而得到一种免疫兼容可逆的表达IL-4Rα阻断物的多能干细胞或其衍生物。As another technical solution of the present invention: an inducible gene expression system is also introduced into the genome of the pluripotent stem cells or their derivatives for regulating the expression of immune-compatible molecules, thereby obtaining an immune-compatible and reversible expression of IL-4Rα Blocker of pluripotent stem cells or derivatives thereof.
所述诱导型基因表达系统为Tet-Off系统、二聚体诱导表达系统中的至少一种。The inducible gene expression system is at least one of Tet-Off system and dimer inducible expression system.
所述诱导型基因表达系统的导入位点为多能干细胞或其衍生物的基因组安全位点。The introduction site of the inducible gene expression system is the genomic safety site of pluripotent stem cells or derivatives thereof.
所述基因组安全位点包括AAVS1安全位点、eGSH安全位点、H11安全位点中的一种或多种。The genomic safety site includes one or more of the AAVS1 safety site, the eGSH safety site, and the H11 safety site.
以上所述IL-4Rα阻断物的表达序列、免疫兼容分子的表达序列、shRNA和/或miRNA加工复合体相关基因、抗干扰素效应分子、诱导型基因表达系统的导入采用病毒载体干扰、非病毒载体转染或基因编辑的方法。The expression sequences of the above-mentioned IL-4Rα blockers, the expression sequences of immune-compatible molecules, shRNA and/or miRNA processing complex-related genes, anti-interferon effector molecules, and inducible gene expression systems were introduced using viral vector interference, non- Methods for viral vector transfection or gene editing.
所述基因编辑的方法包括基因敲入。The method of gene editing includes gene knock-in.
以上所述多能干细胞包括胚胎干细胞、胚胎生殖细胞、胚胎癌细胞、或者诱导多能干细胞;所述多能干细胞衍生物包括多能干细胞所分化的成体干细胞、各胚层细胞或组织。The pluripotent stem cells described above include embryonic stem cells, embryonic germ cells, embryonic cancer cells, or induced pluripotent stem cells; the pluripotent stem cell derivatives include adult stem cells, cells or tissues of various germ layers differentiated from pluripotent stem cells.
所述成体干细胞包括间充质干细胞、神经干细胞。The adult stem cells include mesenchymal stem cells and neural stem cells.
本发明的第二个方面,提供上述多能干细胞或其衍生物在制备抗过敏、特应性皮炎和/或抗哮喘治疗药物中的应用。The second aspect of the present invention provides the use of the above-mentioned pluripotent stem cells or derivatives thereof in the preparation of anti-allergy, atopic dermatitis and/or anti-asthma therapeutic drugs.
本发明的第三个方面,提供一种制剂,包含上述多能干细胞或其衍生物。A third aspect of the present invention provides a preparation comprising the above-mentioned pluripotent stem cells or derivatives thereof.
所述制剂还包含药学上可接受的载体、稀释剂或赋形剂。The formulation also includes a pharmaceutically acceptable carrier, diluent or excipient.
本发明的有益效果是:The beneficial effects of the present invention are:
本发明提供的表达IL-4Rα阻断物的多能干细胞或其衍生物,可用于自体细胞诱导iPSCs或分化成MSCs这类低免疫源性细胞进行运用,其可在体内持续表达IL-4Rα阻断物,用于治疗过敏、特应性皮炎和/或哮喘及相关疾病。The pluripotent stem cells or derivatives thereof expressing IL-4Rα blocker provided by the present invention can be used for autologous cells to induce iPSCs or differentiate into low-immunogenic cells such as MSCs, and they can continuously express IL-4Rα blocker in vivo. Drugs for the treatment of allergies, atopic dermatitis and/or asthma and related conditions.
本发明提供的表达IL-4Rα阻断物的免疫兼容的多能干细胞或其衍生物,由于多能干细胞或其衍生物中的B2M、CIITA基因被敲除,或者其基因组中导入了免疫兼容分子表达序列,因而此类多能干细胞或其衍生物的免疫源性低,将其移植到受体中时,可以克服供体细胞和受体之间的同种异体免疫排斥问题,使得供体细胞能够在受体内长时间持续表达IL-4Rα阻断物。The immune-compatible pluripotent stem cells or derivatives thereof expressing the IL-4Rα blocker provided by the present invention are due to the knockout of B2M and CIITA genes in the pluripotent stem cells or their derivatives, or the introduction of immune-compatible molecules into their genomes. Expression sequences, so that such pluripotent stem cells or their derivatives are of low immunogenicity, and when transplanted into recipients, can overcome the problem of allogeneic immune rejection between donor cells and recipients, allowing the donor cells to The IL-4Rα blocker can be expressed continuously in the receptor for a long time.
本发明提供的表达IL-4Rα阻断物的免疫兼容可逆的多能干细胞或其衍生物的基因组中导入诱导型基因表达系统以及免疫兼容分子表达序列。诱导型基因表达系统受外源诱导物的调控,通过调整外源诱导物的添加量、持续作用时间、种类来控制诱导型基因表达系统的开启与关闭,从而控制疫兼容分子表达序列的表达量。而免疫兼容分子可调控多能干细胞细胞或其衍生物中与免疫应答相关的基因的表达。当免疫兼容分子正常表达时,多能干细胞或其衍生物中与免疫应答相关的基因的表达被抑制或过表达,可以消除或降低供体细胞和受体之间的同种异体免疫排斥应答,使得供体细胞能够长时间在受体中持续表达IL-4Rα阻断物。而当供体细胞发生病变时,可通过外源诱导物诱导关闭免疫兼容分子的表达,从而可逆地使供体细胞表面重新表达HLA Ⅰ类分子,恢复供体细胞的抗原提呈能力,使受体能够清除病变的细胞,从而提高了这类通用型多能干细胞或其衍生物的临床安全性,极大地扩展其在临床应用的价值。An inducible gene expression system and an immune-compatible molecular expression sequence are introduced into the genome of the immune-compatible and reversible pluripotent stem cells or derivatives thereof expressing the IL-4Rα blocker provided by the present invention. The inducible gene expression system is regulated by exogenous inducers. By adjusting the addition amount, duration and type of exogenous inducers, the inducible gene expression system can be turned on and off, thereby controlling the expression of immune-compatible molecular expression sequences. . And immune-compatible molecules can regulate the expression of immune response-related genes in pluripotent stem cells or their derivatives. When immune-compatible molecules are normally expressed, the expression of genes related to immune response in pluripotent stem cells or their derivatives is inhibited or overexpressed, which can eliminate or reduce the allogeneic immune rejection response between donor cells and recipients, This allows the donor cells to continue expressing the IL-4Rα blocker in the recipient for a long time. When the donor cell becomes diseased, the expression of immune-compatible molecules can be induced to shut down by exogenous inducers, thereby reversibly re-expressing HLA class I molecules on the surface of the donor cell, restoring the antigen-presenting ability of the donor cell, and making the recipient cell. The body can clear the diseased cells, thereby improving the clinical safety of such universal pluripotent stem cells or their derivatives, and greatly expanding their value in clinical applications.
此外,还可以通过调整外源诱导物的添加量、持续作用时间,让移植物逐步表达低浓度的HLA分子来刺激受体,使得受体对移植物逐步产生耐受,最终达到稳定的耐受。此时,即使移植物细胞表面表达不匹配的HLA Ⅰ类分子,也能够被受体免疫系统兼容,这样可以使得在诱导关闭移植物细胞中免疫兼容分子的表达后,受体免疫系统一方面能够重新识别移植物中HLA Ⅰ类分子提呈的有基因突变的细胞,清除病变细胞;另一方面,未发生突变的部分由于被上述诱导物训练产生同种异体HLA Ⅰ类分子耐受而不会被受体免疫系统清除。从而使受体免疫系统仅清除有害突变的移植物,保留正常功能的移植物,当有害的移植物清除后,又可以转入移植物细胞表面HLAⅠ类分子沉默的模式。由外源诱导物介导的移植物免疫耐受程序还可以在受体彻底耐受后,植入无诱导或其他方式诱导开启或关闭HLAⅠ类分子表面表达的移植物。In addition, by adjusting the amount of exogenous inducer and the duration of action, the graft can gradually express low concentrations of HLA molecules to stimulate the recipient, so that the recipient can gradually develop tolerance to the graft, and finally achieve a stable tolerance. . At this time, even if the unmatched HLA class I molecules expressed on the surface of the transplanted cells can be compatible with the recipient immune system, so that after inducing and shutting down the expression of immune compatible molecules in the transplanted cells, the recipient immune system can, on the one hand, be able to Re-identify the cells with genetic mutations presented by HLA class I molecules in the transplant, and remove the diseased cells; Cleared by the recipient's immune system. Thus, the recipient's immune system only removes the harmful mutation of the graft, and retains the normal function of the graft. The graft immune tolerance program mediated by exogenous inducers can also be implanted after the recipient is completely tolerated, without induction or other ways to induce the on or off surface expression of HLA class I molecules.
附图说明Description of drawings
图1是AAVS1 KI(Knock-in,下同)Vector(shRNA,组成型)质粒图谱。Figure 1 is a map of AAVS1 KI (Knock-in, the same below) Vector (shRNA, constitutive) plasmid.
图2是AAVS1 KI Vector(shRNA,诱导型)质粒图谱。Figure 2 is the AAVS1 KI Vector (shRNA, inducible) plasmid map.
图3是AAVS1 KI Vector(shRNA-miR,组成型)质粒图谱。Figure 3 is the AAVS1 KI Vector (shRNA-miR, constitutive) plasmid map.
图4是AAVS1 KI Vector(shRNA-miR,诱导型)质粒图谱。Figure 4 is the AAVS1 KI Vector (shRNA-miR, inducible) plasmid map.
图5是sgRNA clone B2M-1质粒图谱。Figure 5 is the sgRNA clone B2M-1 plasmid map.
图6是sgRNA clone B2M-2质粒图谱。Figure 6 is the sgRNA clone B2M-2 plasmid map.
图7是sgRNA clone CIITA-1质粒图谱。Figure 7 is the sgRNA clone CIITA-1 plasmid map.
图8是sgRNA clone CIITA-2质粒图谱。Figure 8 is a map of the sgRNA clone CIITA-2 plasmid.
图9是Cas9(D10A)质粒图谱。Figure 9 is a map of the Cas9 (D10A) plasmid.
图10是sgRNA Clone AAVS1-1质粒图谱。Figure 10 is the sgRNA Clone AAVS1-1 plasmid map.
图11是sgRNA Clone AAVS1-2质粒图谱。Figure 11 is the sgRNA Clone AAVS1-2 plasmid map.
具体实施方式Detailed ways
以下结合具体的实施例及附图对本发明的内容作进一步详细的说明。The content of the present invention will be described in further detail below with reference to specific embodiments and accompanying drawings.
应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。It should be understood that these examples are only used to illustrate the present invention and not to limit the scope of the present invention.
下列实施例中未注明具体条件的实验方法,通常按照常规条件,例如Sambrook等人,分子克隆:实验室手册(New York:Cold Spring Harbor Laboratory Press,1989)中所述的条件,或按照制造厂商所建议的条件。实施例中所用到的各种常用化学试剂,均为市售产品。The experimental method of unreceipted specific conditions in the following examples, usually according to normal conditions, such as people such as Sambrook, molecular cloning: the conditions described in laboratory manual (New York:Cold Spring Harbor Laboratory Press, 1989), or according to manufacture conditions recommended by the manufacturer. Various common chemical reagents used in the examples are all commercially available products.
1实验材料与方法1 Experimental materials and methods
1.1IL-4Rα阻断物1.1 IL-4Rα blocker
抗IL-4Rα抗体的重链(HC)序列如SEQ ID NO.1所示,轻链(LC)序列如SEQ ID NO.2所示。The heavy chain (HC) sequence of the anti-IL-4Rα antibody is shown in SEQ ID NO.1, and the light chain (LC) sequence is shown in SEQ ID NO.2.
1.2多能干细胞或其衍生物1.2 Pluripotent stem cells or their derivatives
多能干细胞可选自胚胎干细胞(ESCs)、诱导多能干细胞(iPSCs)以及其他形式的多能干细胞,例如hPSCs-MSCs、NSCs、EBs细胞。其中:Pluripotent stem cells can be selected from embryonic stem cells (ESCs), induced pluripotent stem cells (iPSCs), and other forms of pluripotent stem cells, such as hPSCs-MSCs, NSCs, EBs cells. in:
ESCs:可选用HN4细胞,购自上海中科院。ESCs: HN4 cells can be used, purchased from Shanghai Chinese Academy of Sciences.
iPSCs:使用我们所建立的第三代高效安全的episomal-iPSCs诱导系统(6F/BM1-4C),pE3.1-OG--KS和pE3.1-L-Myc--hmiR302 cluster经电转进入体细胞中,RM1培养2天,含2uM Parnate的BioCISO-BM1培养2天,含2uM Parnate、0.25mM sodium butyrate、3uMCHIR99021和0.5uM PD03254901的BioCISO-BM1培养2天,在用干细胞培养基BioCISO培养到17天左右即可挑取iPSCs克隆,所挑取的iPSCs克隆经纯化、消化、传代以获得稳定的iPSCs。具体构建方法参见:Stem Cell Res Ther.2017 Nov 2;8(1):245。iPSCs: Using our third-generation efficient and safe episomal-iPSCs induction system (6F/BM1-4C), pE3.1-OG--KS and pE3.1-L-Myc--hmiR302 cluster were electroporated into the body In cells, RM1 was cultured for 2 days, BioCISO-BM1 containing 2uM Parnate was cultured for 2 days, BioCISO-BM1 containing 2uM Parnate, 0.25mM sodium butyrate, 3uMCHIR99021 and 0.5uM PD03254901 was cultured for 2 days, and the stem cell medium BioCISO was cultured to 17 The iPSCs clones can be picked in about a day, and the picked iPSCs clones are purified, digested, and passaged to obtain stable iPSCs. For the specific construction method, see: Stem Cell Res Ther. 2017
hPSCs-MSCs:将iPSCs使用干细胞培养基(BioCISO,含10uM TGFβ抑制剂SB431542)培养25天,期间80-90汇合度进行消化传代(2mg/mL Dispase消化),1:3传代到Matrigel包被的培养板中,接着ESC-MSC培养基(knockout DMEM培养基,含10%KSR、NEAA、双抗、谷氨酰胺、β-巯基乙醇、10ng/mL bFGF和SB-431542)进行培养,每天换液,80-90汇合度进行传代(1:3传代),连续培养20天即可。具体构建方法参见:Proc Natl Acad Sci U S A.2015;112(2):530-535。hPSCs-MSCs: iPSCs were cultured in stem cell medium (BioCISO, containing 10uM TGFβ inhibitor SB431542) for 25 days, digested and passaged at 80-90 confluency (2mg/mL Dispase digestion), and passaged 1:3 into Matrigel-coated cells In the culture plate, then ESC-MSC medium (knockout DMEM medium, containing 10% KSR, NEAA, double antibody, glutamine, β-mercaptoethanol, 10ng/mL bFGF and SB-431542) was cultured, and the medium was changed every day , 80-90 confluency for passage (1:3 passage), continuous culture for 20 days. For the specific construction method, please refer to: Proc Natl Acad Sci US A. 2015; 112(2):530-535.
NSCs:将iPSCs使用诱导培养基(knockout DMEM培养基,含10%KSR,含TGF-β抑制剂,BMP4抑制剂)培养14天,挑取玫瑰花环状的神经细胞到低粘附培养板中进行培养,培养基使用比例为1:1的DMEM/F12(含1%N2,Invitrogen)和Neurobasal培养基(含2%B27,Invitrogen),还含有20ng/ml bFGF和20ng/ml EGF,进行培养,消化使用Accutase进行消化传代即可。具体构建方法参见:FASEB J.2014;28(11):4642-4656。NSCs: iPSCs were cultured in induction medium (knockout DMEM medium, containing 10% KSR, containing TGF-β inhibitor, BMP4 inhibitor) for 14 days, and rosette-shaped neurons were picked into low-adherence culture plates Cultivated in a 1:1 ratio of DMEM/F12 (containing 1% N2, Invitrogen) and Neurobasal medium (containing 2% B27, Invitrogen), and also containing 20ng/ml bFGF and 20ng/ml EGF, for culture , Digestion using Accutase for digestion and passage. For the specific construction method, please refer to: FASEB J. 2014; 28(11): 4642-4656.
EBs细胞:将汇合度达到95%的iPSCs使用BioC-PDE1消化6min后使用机械刮传法将细胞刮成块状,沉降降细胞团块,沉降的细胞团块转移到低粘附培养板中使用BioCISO-EB1培养7天,隔天换液。7天后转移到Matrigel包被的培养板中继续使用BioCISO进行贴壁培养,7天后即可获得具有内、中、外三胚层结构的拟胚体(EBs)。具体构建方法参见:StemCell Res Ther.2017 Nov 2;8(1):245。EBs cells: iPSCs with a confluency of 95% were digested with BioC-PDE1 for 6 min, and then scraped into a block using a mechanical scraping method, settled down to the cell mass, and the settled cell mass was transferred to a low-adherence culture plate for use BioCISO-EB1 was cultured for 7 days, and the medium was changed every other day. After 7 days, the cells were transferred to Matrigel-coated culture plates to continue adherent culture with BioCISO. After 7 days, embryoid bodies (EBs) with inner, middle and outer germ layers were obtained. For the specific construction method, please refer to: StemCell Res Ther. 2017
所述多能干细胞衍生物还包括多能干细胞所分化的成体干细胞、各胚层细胞或组织、器官;所述成体干细胞包括间充质干细胞或者神经干细胞。The pluripotent stem cell derivatives also include adult stem cells differentiated from pluripotent stem cells, cells of each germ layer, tissues, and organs; and the adult stem cells include mesenchymal stem cells or neural stem cells.
1.3基因组安全位点1.3 Genome Safety Sites
本发明技术方案中,基因敲入的基因组安全位点可选自AAVS1安全位点、eGSH安全位点,或者其它安全位点:In the technical solution of the present invention, the genomic safety site for gene knock-in can be selected from the AAVS1 safety site, the eGSH safety site, or other safety sites:
(1)AAVS1安全位点(1) AAVS1 safety site
AAVS1位点(别名“PPP1R2C位点”)位于人类基因组第19号染色体上,是一个经过验证、能够确保转入DNA片段预期功能的“安全港”位点。该位点是一个开放的染色体结构,能保证转入基因能被正常转录,且该位点插入外源目的片段对细胞无已知的副作用。The AAVS1 locus (alias "PPP1R2C locus") is located on chromosome 19 of the human genome and is a validated "safe harbor" site that ensures the intended function of the transferred DNA fragment. This site is an open chromosomal structure, which can ensure that the transferred gene can be transcribed normally, and the insertion of exogenous target fragments at this site has no known side effects on cells.
(2)eGSH安全位点(2) eGSH safety site
eGSH安全位点位于人类基因组第1号染色体上,是一个经过论文验证、能够确保转入DNA片段预期功能的另一个“安全港”位点。The eGSH safety site is located on
(3)其它安全位点(3) Other security sites
H11安全位点(也叫Hipp11),位于人的22号染色体,是Eif4enif1与Drg1这两个基因之间的一个位点,由Simon Hippenmeyer于2010年发现并命名,由于H11位点位于两个基因之间,故外源基因插入后影响內源基因表达的风险很小。H11位点被验证是一个基因间的安全的转录激活区域,是AAVS1、eGSH位点之外的一个新的“安全港”位点。The H11 safety site (also called Hipp11), located on human chromosome 22, is a site between the two genes Eif4enif1 and Drg1. It was discovered and named by Simon Hippenmeyer in 2010. Since the H11 site is located in two genes Therefore, the risk of affecting the expression of the endogenous gene after the insertion of the exogenous gene is very small. The H11 locus was verified to be a safe transcriptional activation region between genes and a new "safe harbor" site besides the AAVS1 and eGSH loci.
1.4诱导型基因表达系统1.4 Inducible gene expression system
诱导型基因表达系统选自:tet-Off系统或者二聚体关闭表达系统:The inducible gene expression system is selected from: tet-Off system or dimer off expression system:
(1)tet-Off系统(1) tet-Off system
在没有四环素存在时,tTA蛋白持续作用在tet启动子上,使基因持续表达。在需要转基因保持在一个持续表达状态下,该系统是非常有用。加入四环素时,四环素可使tTA蛋白的结构变化,使其不能与启动子结合,从而使其驱动的基因表达水平下降。为了使该系统保持“关闭”状态,必须连续添加四环素。In the absence of tetracycline, the tTA protein continues to act on the tet promoter, allowing the gene to continue to be expressed. This system is very useful where transgenes need to be maintained in a state of continuous expression. When tetracycline is added, tetracycline can change the structure of the tTA protein so that it cannot bind to the promoter, thereby reducing the level of gene expression it drives. To keep this system "off", tetracycline must be added continuously.
本发明将tet-Off系统以及一种或多种免疫兼容分子的序列敲入多能干细胞的基因组安全位点处,通过四环素的添加与否精准开启或关闭免疫兼容分子的表达,从而可逆调控多能干细胞或其衍生物中主要组织相容性复合体相关基因的表达。In the present invention, the sequences of the tet-Off system and one or more immune-compatible molecules are knocked into the genome safety site of pluripotent stem cells, and the expression of immune-compatible molecules can be accurately turned on or off by adding tetracycline, thereby reversibly regulating the expression of immune-compatible molecules. Expression of major histocompatibility complex-related genes in competent stem cells or their derivatives.
(2)二聚体关闭表达系统(2) Dimer shutdown expression system
二聚体介导的基因表达调控系统:化学调控靶基因转录的方法有很多种,最常见的是利用影响转录因子活性的别构调节物进行调控。其中的一个方法是运用二聚化的诱导剂或者二聚体在无活性的融合蛋白上重组有活性的转录因子。最常用的体系是将天然产物雷帕霉素(rapamydn)或者无生物活性的类似物作为二聚化的药物。雷帕霉素(或类似物)同胞质蛋白FKBP12(FKBP与FK506结合的蛋白)和一种大的丝-苏氨酸蛋白激酶,称为FRAP【FRBP-雷帕霉素相关蛋白,即mTOR(哺乳动物的雷帕霉素靶点)】有高度亲和性,又与这两种蛋白质相结合的功能,因此作为异源性二聚体将这两种蛋白质聚到一起。为调控靶基因转录,将DNA结合区域融合到一个或多个FKBP结构域,将转录抑制域融合到FRAP的93位氨基酸部位,称为FRB,这样足以结合FKBP-雷帕霉素复合物。只有在雷帕霉素存在的情况下,这两种融合蛋白才能发生二聚化。因而抑制具有与DNA结合区域相结合的位点的基因进行转录。Dimer-mediated gene expression regulation system: There are many ways to chemically regulate the transcription of target genes, the most common is the use of allosteric regulators that affect the activity of transcription factors. One such approach is to use dimerization inducers or dimers to reconstitute active transcription factors on inactive fusion proteins. The most commonly used system uses the natural product rapamydn or a biologically inactive analog as the dimerized drug. Rapamycin (or analog) homoplasmic protein FKBP12 (the protein that FKBP binds to FK506) and a large serine-threonine protein kinase called FRAP [FRBP-rapamycin-related protein, or mTOR ( Mammalian target of rapamycin)] has high affinity and the function of binding with these two proteins, so these two proteins are brought together as a heterodimer. To regulate target gene transcription, a DNA binding domain is fused to one or more FKBP domains, and a transcriptional repression domain is fused to amino acid 93 of FRAP, called FRB, which is sufficient to bind the FKBP-rapamycin complex. The two fusion proteins dimerized only in the presence of rapamycin. Transcription of genes with sites that bind to the DNA binding region is thus inhibited.
1.5免疫兼容分子1.5 Immunocompatible molecules
所述免疫兼容分子可以调控多能干细胞或其衍生物中同种异体免疫排斥相关基因的表达。The immune compatible molecule can regulate the expression of allogeneic immune rejection-related genes in pluripotent stem cells or derivatives thereof.
具体免疫兼容分子的种类及序列如表1所示。The types and sequences of specific immunocompatible molecules are shown in Table 1.
表1免疫兼容分子Table 1 Immunocompatible molecules



以上shRNA或shRNA-miR免疫兼容分子的靶序列如表2所示。The target sequences of the above shRNA or shRNA-miR immune-compatible molecules are shown in Table 2.
表2 shRNA或shRNA-miR的靶序列Table 2 Target sequences of shRNA or shRNA-miR



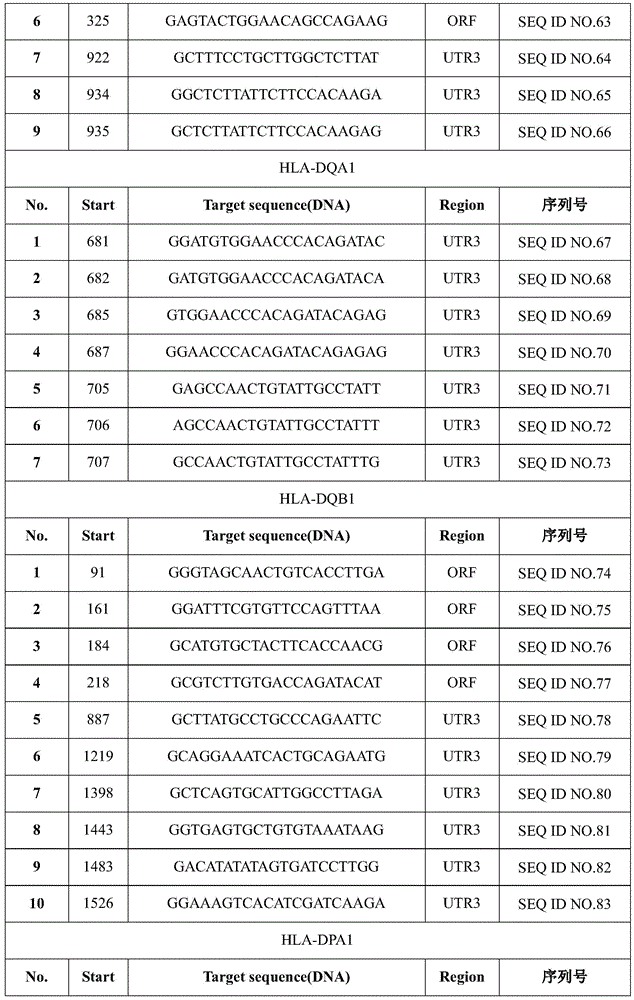
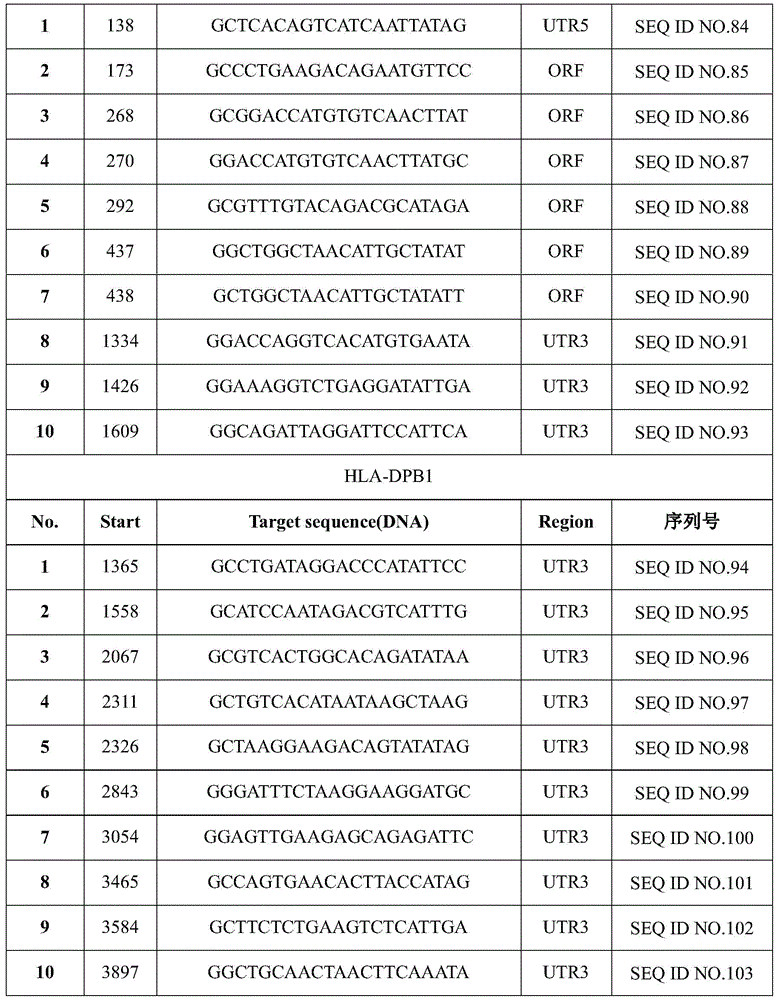
下面表5-表6的免疫兼容分子敲入方案中,各实验组别的shRNA或shRNA-miR序列均为采用表2中的靶序列1构建得到的shRNA或shRNA-miR免疫兼容分子。本领域的技术人员可以理解:以其他靶序列构建得到的shRNA或shRNA-miR免疫兼容分子同样可以实现本发明的技术效果,均落入本发明权利要求的保护范围。In the immune-compatible molecular knock-in schemes in Tables 5-6 below, the shRNA or shRNA-miR sequences of each experimental group were the shRNA or shRNA-miR immune-compatible molecules constructed by using the
1.6shRNA/miRNA加工复合体基因和抗干扰素效应分子1.6 shRNA/miRNA processing complex genes and anti-interferon effector molecules
在细胞核内的初级miRNA(pri-miRNA)经过复合物Drosha-DGCR8进行微处理,将pri-miRNA裂解成前体miRNA(pre-miRNA),这时会形成发夹结构。接着,经Exportin-5-Ran-GTP复合物将pre-miRNA转运出核。在胞浆中与双链RNA结合蛋白TRBP(TARBP2)结合的RNaseDicer酶将pre-miRNA分解成成熟的长度,miRNA在这时还处于双链状态。最后被转运进AGO2,形成RISC(RNA诱导沉默复合体)。最终miRNA双链的一条链保留在RISC复合物中,另外一条则排出被迅速降解掉。而DGCR8作为Drosha的主要结合蛋白,可以通过其C末端的两个双链RNA结合区域与pri-miRNA结合,招募并指导Drosha在pri-miRNA的正确位置剪切,生产pre-miRNA,pre-miRNA进一步被Dicer和TRBP/PACT加工剪切,形成成熟的miRNA。DGCR8的缺失或异常表达会影响Drosha的剪切活性,进而影响miRNA的活性,导致疾病的发生。TRBP能够招募Dicer复合体miRNA形成RISC Ago2。The primary miRNA (pri-miRNA) in the nucleus is micro-processed by the complex Drosha-DGCR8, and the pri-miRNA is cleaved into the precursor miRNA (pre-miRNA), which will form a hairpin structure. Next, the pre-miRNA is transported out of the nucleus via the Exportin-5-Ran-GTP complex. The RNaseDicer enzyme, which binds to the double-stranded RNA-binding protein TRBP (TARBP2) in the cytoplasm, cleaves pre-miRNAs to their mature lengths, while the miRNAs are still double-stranded. Finally, it is transported into AGO2 to form RISC (RNA-induced silencing complex). One strand of the final miRNA duplex remains in the RISC complex, while the other is excreted and rapidly degraded. As the main binding protein of Drosha, DGCR8 can bind to pri-miRNA through its two double-stranded RNA binding regions at the C-terminus, recruit and guide Drosha to cleave at the correct position of pri-miRNA to produce pre-miRNA, pre-miRNA It is further processed and cleaved by Dicer and TRBP/PACT to form mature miRNA. The deletion or abnormal expression of DGCR8 can affect the splicing activity of Drosha, which in turn affects the activity of miRNAs, leading to the occurrence of diseases. TRBP can recruit Dicer complex miRNAs to form RISC Ago2.
本发明利用基因敲入技术,在基因组安全位点敲入可诱导关闭表达的针对HLA I类分子和HLA II类分子等的shRNA-miR表达序列时,优选同时敲入可诱导关闭表达的shRNA和/或miRNA加工机器包括Drosha(Accession number:NM_001100412)、Ago1(Accessionnumber:NM_012199)、Ago2(Accession number:NM_001164623)、Dicer1(Accessionnumber:NM_001195573)、Exportin-5(Accession number:NM_020750)、TRBP(Accessionnumber:NM_134323)、PACT(Accession number:NM_003690)和DGCR8(Accession number:NM_022720),以便细胞不占用其他miRNA的加工,影响细胞功能。The present invention utilizes the gene knock-in technology to knock-in the shRNA-miR expression sequences for HLA class I molecules and HLA class II molecules that can be inducible to shut down the expression at the safe site of the genome, preferably, the shRNA that can be inducible to shut down the expression and / or miRNA processing machines include Drosha (Accession number: NM_001100412), Ago1 (Accession number: NM_012199), Ago2 (Accession number: NM_001164623), Dicer1 (Accession number: NM_001195573), Exportin-5 (Accession number: NM_020750), TRBP (Accession number: NM_134323), PACT (Accession number: NM_003690) and DGCR8 (Accession number: NM_022720), so that cells do not occupy the processing of other miRNAs and affect cell function.
此外,在IFN诱生的过程中,双链RNA所依赖的蛋白激酶(double-stranded RNA-dependent Protein Kinase,PKR),它是整个细胞信号转导通路的关键因子,同时还有2’,5’寡腺苷酸合成酶(2,5-Oligoadenylate Synthetase,2-5As),这两种酶与dsRNA诱生IFN密切相关。PKR能通过磷酸化真核细胞转录因子,从而抑制蛋白质合成,使细胞停滞于G0/G1和G2/M期,并诱导凋亡,而dsRNA可以促进2-5As合成,结果导致RNase即RNaseL的非特异性活化,降解细胞内所有的mRNA,致细胞死亡。I型干扰素的诱导特异性是通过IRF转录因子家族成员实现的,在细胞缺乏IRF-3和IRF-7的表达下,在很多病毒感染情况下I型干扰素是不能被诱导分泌的。缺乏IFN的应答,要使其恢复,需要上述两种蛋白质的共表达才行。In addition, in the process of IFN induction, double-stranded RNA-dependent Protein Kinase (PKR), which is a key factor in the entire cell signal transduction pathway, also has 2',5 'Oligoadenylate synthase (2,5-Oligoadenylate Synthetase, 2-5As), these two enzymes are closely related to dsRNA-induced IFN. PKR can inhibit protein synthesis by phosphorylating eukaryotic transcription factors, make cells stagnate in G0/G1 and G2/M phases, and induce apoptosis, while dsRNA can promote 2-5As synthesis, resulting in non-specific RNase, RNaseL. Heterogeneous activation, degrades all mRNA in cells, and causes cell death. The induction specificity of type I interferon is achieved by members of the IRF transcription factor family. In the absence of the expression of IRF-3 and IRF-7 in cells, type I interferon cannot be induced and secreted in many viral infections. In the absence of an IFN response, co-expression of the two proteins is required to restore it.
本发明利用基因敲入技术,在基因组安全位点处敲入免疫兼容分子shRNA-miR表达序列时,优选同时敲入可诱导关闭表达的针对抑制PKR、2-5As、IRF-3和IRF-7基因的shRNA和/或shRNA-miR表达序列,降低dsRNA诱发的干扰素反应,从而避免产生细胞毒性。The present invention utilizes gene knock-in technology to knock-in the expression sequence of immune compatible molecule shRNA-miR at the safe site of the genome, preferably simultaneously knock-in inducible shut-down expression for inhibiting PKR, 2-5As, IRF-3 and IRF-7 Gene shRNA and/or shRNA-miR expression sequences that reduce dsRNA-induced interferon responses, thereby avoiding cytotoxicity.
shRNA/miRNA加工复合体相关基因、抗干扰素效应分子、免疫兼容分子在基因组安全位点的插入位置顺序没有限定,它们之间可以以任何次序排列,而不会相互干扰或者影响基因组其它基因的结构和功能。There is no restriction on the insertion positions of shRNA/miRNA processing complex-related genes, anti-interferon effector molecules, and immune-compatible molecules in the safe sites of the genome, and they can be arranged in any order without interfering with each other or affecting other genes in the genome. structure and function.
具体的抗干扰素效应分子的靶序列如表3所示。The target sequences of specific anti-interferon effector molecules are shown in Table 3.
表3抗干扰素效应分子的靶序列Table 3 Target sequences of anti-interferon effector molecules
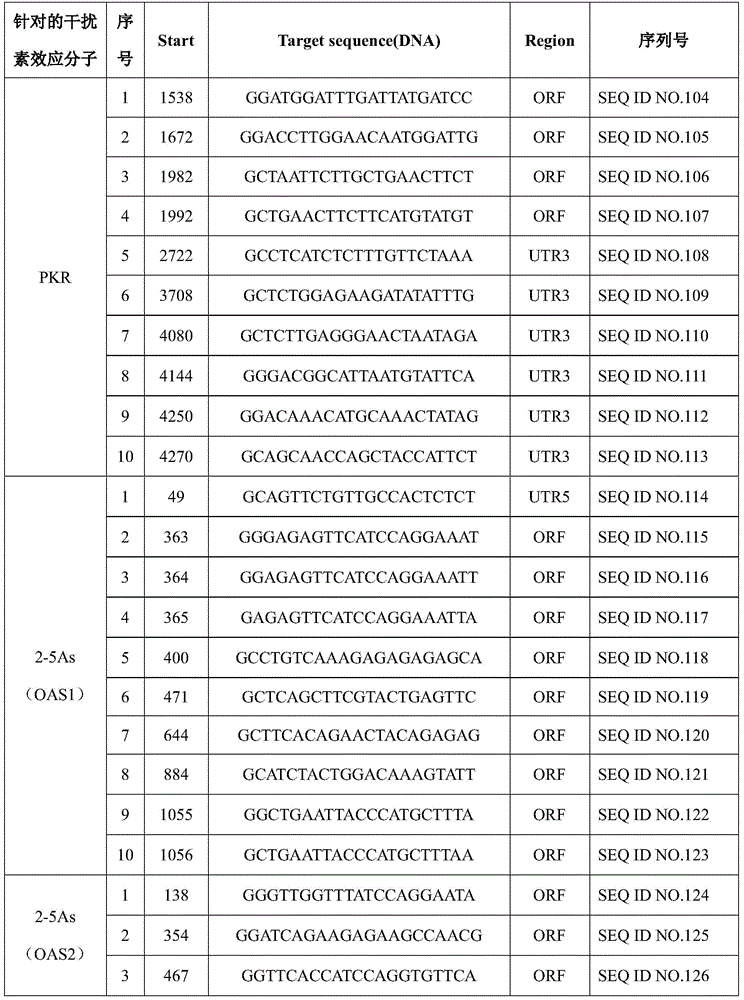


下面表5-表6的抗干扰素效应分子敲入方案中,各实验组别的抗干扰素效应分子的靶序列均为采用表3中的靶序列1构建得到的抗干扰素效应分子。本领域的技术人员可以理解:以其他靶序列构建得到的抗干扰素效应分子同样可以实现本发明的技术效果,均落入本发明权利要求的保护范围。In the anti-interferon effector molecule knock-in scheme in Tables 5 to 6 below, the target sequences of the anti-interferon effector molecules of each experimental group are the anti-interferon effector molecules constructed by using the
1.7免疫兼容分子、抗干扰素效应分子的shRNA或shRNA-miR的通用框架1.7 General framework for immune-compatible molecules, shRNAs against interferon effector molecules, or shRNA-miRs
免疫兼容分子、抗干扰素效应分子的shRNA或shRNA-miR的通用框架序列如下所示:The general framework sequences of immunocompatible molecules, anti-interferon effector shRNAs or shRNA-miRs are shown below:
(1)shRNA组成型表达框架为:(1) The shRNA constitutive expression framework is:
GAGGGCCTATTTCCCATGATTCCTTCATATTTGCATATACGATACAAGGCTGTTAGAGAGATAATTGGAATTAATTTGACTGTAAACACAAAGATATTAGTACAAAATACGTGACGTAGAAAGTAATAATTTCTTGGGTAGTTTGCAGTTTTAAAATTATGTTTTAAAATGGACTATCATATGCTTACCGTAACTTGAAAGTATTTCGATTTCTTGGCTTTATATATCTTGTGGAAAGGACGCTAGCGCCACC(SEQ ID NO.164)N1...N21TTCAAGAGA(SEQ IDNO.165)N22...N42TTTTTT;GAGGGCCTATTTCCCATGATTCCTTCATATTTGCATATACGATACAAGGCTGTTAGAGAGATAATTGGAATTAATTTGACTGTAAACACAAAGATATTAGTACAAAATACGTGACGTAGAAAGTAATAATTTCTTGGGTAGTTTGCAGTTTTAAAATTATGTTTTAAAATGGACTATCATATGCTTACCGTAACTTGAAAGTATTTCGATTTCTTGGCTTTATATATCTTGTGGAAAGGACGCTAGCGCCACC(SEQ ID NO.164)N 1 ...N 21 TTCAAGAGA(SEQ IDNO.165)N 22 ...N 42 TTTTTT;
其中:in:
a、N1...N21为对应基因的shRNA靶序列,N22...N42为对应基因的shRNA靶序列的反向互补序列; a . N1... N21 is the shRNA target sequence of the corresponding gene, and N22 ... N42 is the reverse complementary sequence of the shRNA target sequence of the corresponding gene;
b、如果质粒需要表达多个基因的shRNA,则每个基因分对应一个shRNA表达框架,然后无缝连接起来;b. If the plasmid needs to express shRNA of multiple genes, each gene corresponds to a shRNA expression frame, and then they are seamlessly connected;
c、带不同抗性基因的组成型shRNA质粒,只有抗性基因不同,其它序列一样;c. Constitutive shRNA plasmids with different resistance genes, only the resistance genes are different, and other sequences are the same;
d、N表示A、T、G、C碱基;d, N represent A, T, G, C bases;
e、SEQ ID NO.164为U6启动子序列;e, SEQ ID NO.164 is the U6 promoter sequence;
f、SEQ ID NO.165为茎环序列。f. SEQ ID NO. 165 is the stem-loop sequence.
(2)shRNA诱导型表达框架为:(2) The shRNA-inducible expression framework is:
GAGGGCCTATTTCCCATGATTCCTTCATATTTGCATATACGATACAAGGCTGTTAGAGAGATAATTGGAATTAATTTGACTGTAAACACAAAGATATTAGTACAAAATACGTGACGTAGAAAGTAATAATTTCTTGGGTAGTTTGCAGTTTTAAAATTATGTTTTAAAATGGACTATCATATGCTTACCGTAACTTGAAAGTATTTCGATTTCTTGGCTTTATATATCTTGTGGAAAGGACTTTACCACTCCCTATCAGTGATAGAGAAAAGTGAAAGTCGAGTTTACCACTCCCTATCAGTGATAGAGAAAAGTGAAAGTCGAGTTTACCACTCCCTATCAGTGATAGAGAAAAGTGAAAGTCGAGTTTACCACTCCCTATCAGTGATAGAGAAAAGTGAAAGTCGAGTTTACCACTCCCTATCAGTGATAGAGAAAAGTGAAAGTCGAGTTTACCACTCCCTATCAGTGATAGAGAAAAGTGAAAGTCGAGTTTACCACTCCCTATCAGTGATAGAGAAAAGTGAAAGTCGAGCTCGGTACCCGGGTCGAGGTAGGCGTGTACGGTGGGAGGCCTATATAAGCAGAGCTCGTTTAGTGAACCGTCAGATCGCCTGGAGACGCCATCCACGCTGTTTTGACCTCCATAGAAGACACCGGGACCGATCCAGCCTGCTAGCGCCACC(SEQ ID NO.166)N1...N21TTCAAGAGA(SEQ ID NO.165)N22...N42TTTTTT;(SEQ ID NO. 166) N 1 ... N 21 TTCAAGAGA (SEQ ID NO. 165) N 22 ... N 42 TTTTTT;
其中:in:
a、N1...N21为对应基因的shRNA靶序列,N22...N42为对应基因的shRNA靶序列的反向互补序列; a . N1... N21 is the shRNA target sequence of the corresponding gene, and N22 ... N42 is the reverse complementary sequence of the shRNA target sequence of the corresponding gene;
b、如果质粒需要表达多个基因的shRNA,则每个基因分对应一个shRNA表达框架,然后无缝连接起来;b. If the plasmid needs to express shRNA of multiple genes, each gene corresponds to a shRNA expression frame, and then they are seamlessly connected;
c、带不同抗性基因的组成型shRNA质粒,只有抗性基因不同,其它序列一样;c. Constitutive shRNA plasmids with different resistance genes, only the resistance genes are different, and other sequences are the same;
d、N表示A、T、G、C碱基;d, N represent A, T, G, C bases;
e、SEQ ID NO.166为H1 TO启动子序列;e, SEQ ID NO.166 is the H1 TO promoter sequence;
f、SEQ ID NO.165为茎环序列。f. SEQ ID NO. 165 is the stem-loop sequence.
(3)shRNA-miR组成型或诱导型表达框架为:(3) The shRNA-miR constitutive or inducible expression framework is:
以shRNA-miR靶序列替换microRNA-30中的靶序列得到,具体序列如下:Obtained by replacing the target sequence in microRNA-30 with the shRNA-miR target sequence, the specific sequence is as follows:
GAGGCTTCAGTACTTTACAGAATCGTTGCCTGCACATCTTGGAAACACTTGCTGGGATTACTTCTTCAGGTTAACCCAACAGAAGGCTAAAGAAGGTATATTGCTGTTGACAGTGAGCG(SEQ ID NO.167)M1N1...N21TAGTGAAGCCACAGATGTA(SEQ ID NO.168)GAGGCTTCAGTACTTTACAGAATCGTTGCCTGCACATCTTGGAAACACTTGCTGGGATTACTTCTTCAGGTTAACCCAACAGAAGGCTAAAGAAGGTATATTGCTGTTGACAGTGAGCG (SEQ ID NO. 167) M 1 N 1 ...N 21 TAGTGAAGCCACAGATGTA (SEQ ID NO. 168)
N22...N42M2TGCCTACTGCCTCGGACTTCAAGGGGCTACTTTAGGAGCAATTATCTTGTTTACTAAAACTGAATACCTTGCTATCTCTTTGATACATTTTTACAAAGCTGAATTAAAATGGTATAAAT(SEQ ID NO.169);N 22 ... N 42 M 2 TGCCTACTGCCTCGGACTTCAAGGGGCTACTTTAGGAGCAATTATCTTGTTTACTAAAACTGAATACCTTGCTATCTCTTTGATACATTTTTACAAAGCTGAATTAAAATGGTATAAAT (SEQ ID NO. 169);
其中:in:
a、N1...N21为对应基因的shRNA-miR靶序列,N22...N42为对应基因的shRNA-miR靶序列的反向互补序列; a . N1... N21 is the shRNA-miR target sequence of the corresponding gene, and N22 ... N42 is the reverse complementary sequence of the shRNA-miR target sequence of the corresponding gene;
b、如果质粒需要表达多个基因的shRNA-miR,则每个基因分对应一个shRNA-miR表达框架,然后无缝连接起来;b. If the plasmid needs to express shRNA-miR of multiple genes, each gene corresponds to a shRNA-miR expression frame, and then seamlessly connected;
c、带不同抗性基因的组成型shRNA-miR质粒,只有抗性基因不同,其它序列一样;c. Constitutive shRNA-miR plasmids with different resistance genes, only the resistance genes are different, and other sequences are the same;
d、M碱基表示A或C碱基,N表示A、T、G、C碱基;d, M base represents A or C base, N represents A, T, G, C base;
e、如果N1为G碱基,则M1为A碱基;否则M1为C碱基;e. If N 1 is a G base, then M 1 is an A base; otherwise, M 1 is a C base;
f、M1碱基与M2碱基互补。 f . M1 base is complementary to M2 base.
1.8基因编辑系统、基因编辑方法及检验方法1.8 Gene editing system, gene editing method and testing method
1.8.1基因编辑系统1.8.1 Gene editing system
本专利的基因编辑技术采用CRISPR-Cas9基因编辑系统。使用的Cas 9蛋白为Cas9(D10A),Cas 9(D10A)与sgRNA结合,sgRNA负责特异识别靶序列(基因组DNA),然后Cas9(D10A)对该靶序列进行单链切割。基因组DNA发生双链断裂(DNA Double Strand Break,DSB),必须有两组Cas 9(D10A)/sgRNA分别对基因组DNA的两条链进行切割,且切割的距离不能太远。Cas 9(D10A)/sgRNA方案与Cas 9/sgRNA方案相比,优点是特异性更高,脱靶的概率更低。本基因编辑系统使用的质粒或Donor片段分别为:Cas9(D10A)质粒、sgRNA clone质粒、Donor片段。The gene editing technology of this patent adopts the CRISPR-Cas9 gene editing system. The Cas 9 protein used is Cas9(D10A), Cas 9(D10A) binds to sgRNA, sgRNA is responsible for specific recognition of the target sequence (genomic DNA), and then Cas9(D10A) performs single-stranded cleavage of the target sequence. Genomic DNA double-strand break (DNA Double Strand Break, DSB), there must be two sets of Cas 9 (D10A)/sgRNA to cut the two strands of genomic DNA, and the cutting distance should not be too far. The advantages of Cas 9(D10A)/sgRNA protocol compared with Cas 9/sgRNA protocol are higher specificity and lower probability of off-target. The plasmids or Donor fragments used in this gene editing system are: Cas9 (D10A) plasmid, sgRNA clone plasmid, and Donor fragment, respectively.
(1)Cas9(D10A)质粒:表达Cas 9(D10A)蛋白的质粒,在sgRNA的引导下特异性单链切割基因组DNA。(1) Cas9 (D10A) plasmid: a plasmid expressing Cas 9 (D10A) protein, which specifically cuts genomic DNA under the guidance of sgRNA.
(2)sgRNA质粒:表达sgRNA的质粒,sgRNA(small guide RNA)是向导RNA(guideRNA,gRNA),在基因编辑负责引导表达Cas 9(D10A)蛋白的靶向切割。(2) sgRNA plasmid: a plasmid expressing sgRNA, sgRNA (small guide RNA) is a guide RNA (guideRNA, gRNA), which is responsible for guiding the targeted cleavage of the expressed Cas 9 (D10A) protein in gene editing.
(3)Donor片段:两头含有重组臂,分别位于基因组DNA断裂位置的左右两边,中间含有需要插入的基因、片段或者表达元件。在Donor片段存在的情况下,细胞在基因组断裂的位置发生同源重组(Homologous recombination,HR)反应。如果不添加Donor片段,细胞的基因组断裂位置发生非同源末端连接(Non-homologous End Joining-NHEJ)反应。该片段由KI(Knock-in,下同)Vector质粒酶切后回收获取。(3) Donor fragment: the two ends contain recombination arms, which are located on the left and right sides of the genomic DNA break position, and the middle contains the gene, fragment or expression element to be inserted. In the presence of Donor fragments, cells undergo a homologous recombination (HR) reaction at the site of genome breakage. If the Donor fragment is not added, the non-homologous end joining (NHEJ) reaction occurs at the genomic break site of the cell. The fragment was recovered by KI (Knock-in, the same below) vector plasmid digestion.
1.8.2组成型质粒和诱导型质粒1.8.2 Constitutive and inducible plasmids
组成型质粒:从组成型质粒获取的Donor片段,敲入基因组DNA后,该片段的表达功能不可以进行调控。Constitutive plasmid: Donor fragment obtained from constitutive plasmid, after knocking in genomic DNA, the expression function of this fragment cannot be regulated.
诱导型质粒:从诱导型质粒获取的Donor片段,敲入基因组DNA后,该片段的表达功能可以通过添加诱导物的方法来调控,相当于对表达功能添加了一个开启或者关闭的开关。Inducible plasmid: After the Donor fragment obtained from the inducible plasmid is knocked into the genomic DNA, the expression function of the fragment can be regulated by adding an inducer, which is equivalent to adding an on or off switch to the expression function.
1.8.3质粒构建方法1.8.3 Plasmid construction method
(1)Cas9(D10A)质粒:该质粒不再需要构建,直接从Addgene(Plasmid 41816,Addgene)订购。(1) Cas9 (D10A) plasmid: This plasmid no longer needs to be constructed, and is directly ordered from Addgene (Plasmid 41816, Addgene).
(2)sgRNA质粒:原始的空白质粒从Addgene(Plasmid 41824,Addgene)订购,然后在网站(URL:https://cctop.cos.uni-heidelberg.de)输入DNA序列设计靶序列,最后把不同的靶序列分别放入空白的sgRNA质粒完成构建。(2) sgRNA plasmid: The original blank plasmid was ordered from Addgene (Plasmid 41824, Addgene), and then the DNA sequence was entered on the website (URL: https://cctop.cos.uni-heidelberg.de) to design the target sequence, and finally the different The target sequences were put into blank sgRNA plasmids to complete the construction.
(3)KI Vector质粒:(3)KI Vector plasmid:
a.Amp(R)-pUC origin片段的获取:设计PCR引物,以pUC18质粒为模板使用高保真酶(南京诺唯赞生物,P505-d1)通过PCR的方法,把该片段扩增出来并回收;a. Acquisition of Amp(R)-pUC origin fragment: Design PCR primers, and use high-fidelity enzyme (Nanjing Novozymes, P505-d1) to amplify and recover the fragment by PCR with pUC18 plasmid as template ;
b.AAVS1或者eGSH重组臂的获取:提取人细胞的基因组DNA并设计对应的引物,然后以人的基因组DNA为模板使用高保真酶(南京诺唯赞生物,P505-d1)通过PCR的方法,把这类片段扩增出来并回收;b. Acquisition of AAVS1 or eGSH recombination arm: extract the genomic DNA of human cells and design corresponding primers, and then use the human genomic DNA as a template to use a high-fidelity enzyme (Nanjing Novozymes, P505-d1) to pass the PCR method, Amplify and recover such fragments;
c.各个质粒元件的获取:设计各元件的PCR扩增引物,然后以含该元件的质粒为模板使用高保真酶(南京诺唯赞生物,P505-d1)通过PCR的方法,分别把各个质粒元件扩增出来并回收;c. Acquisition of each plasmid element: Design the PCR amplification primers of each element, and then use the plasmid containing the element as a template and use a high-fidelity enzyme (Nanjing Novozyme, P505-d1) to separate each plasmid by PCR method. Elements are amplified and recovered;
d.组装成完整质粒:使用多片段重组酶(南京诺唯赞生物,C113-02)把前面步骤获取的片段连接起来,形成一个完整的质粒。d. Assemble into a complete plasmid: Use multi-fragment recombinase (Nanjing Novozymes, C113-02) to connect the fragments obtained in the previous steps to form a complete plasmid.
1.8.4基因编辑过程1.8.4 Gene editing process
一、AAVS1基因敲入的单细胞克隆操作步骤1. Single-cell cloning operation steps of AAVS1 gene knock-in
(1)电转程序:(1) Electric transfer procedure:
供体细胞准备:人多能干细胞。Donor cell preparation: Human pluripotent stem cells.
试剂盒:Human Stem Cell
仪器:电转仪。Instrument: electroporator.
培养基:BioCISO。Medium: BioCISO.
诱导质粒:Cas9D10A、sgRNA clone AAVS1-1、sgRNA clone AAVS1-2、AAVS1 neoVectoⅠ、AAVS1 neo VectorⅡ。Induction plasmids: Cas9D10A, sgRNA clone AAVS1-1, sgRNA clone AAVS1-2, AAVS1 neoVectoⅠ, AAVS1 neo VectorⅡ.
注:eGSH基因敲入使用的诱导质粒:Cas9D10A、sgRNA clone eGSH-1、sgRNA cloneeGSH-2、eGSH-neo/eGSH-puro(donor)这里的donor质粒与AAVS1的比较,只有左右重组臂不一样,其它元件都一样。由于eGSH的基因编辑过程与AAVS1的相同,后面就不再重复列举。Note: The induction plasmids used for eGSH gene knock-in: Cas9D10A, sgRNA clone eGSH-1, sgRNA clone eGSH-2, eGSH-neo/eGSH-puro(donor) The donor plasmid here is compared with AAVS1, only the left and right recombination arms are different. All other components are the same. Since the gene editing process of eGSH is the same as that of AAVS1, it will not be repeated later.
(2)电转后的人多能干细胞进行含G418和puro的双抗生素培养基进行筛选。(2) The electrotransformed human pluripotent stem cells were screened in double antibiotic medium containing G418 and puro.
(3)进行单细胞克隆筛选及培养,获得单细胞克隆株。(3) Screening and culturing single-cell clones to obtain single-cell clones.
二、AAVS1基因敲入的单细胞克隆株培养试剂2. Culture reagents for single-cell clones with AAVS1 gene knock-in
(1)培养基:BioCISO+300μg/mL G418+0.5μg/mL puro(应提前置于室温,避光条件放置30~60分钟,直至恢复到室温。注意:不应将BioCISO置于37℃进行预热,避免生物分子活性降低。)。(1) Culture medium: BioCISO + 300μg/mL G418 + 0.5μg/mL puro (should be placed at room temperature in advance and placed in the dark for 30 to 60 minutes until it returns to room temperature. Note: BioCISO should not be placed at 37°C for Preheat to avoid reduced biomolecular activity.).
(2)基质胶:hESC级Matrigel(传代或复苏细胞前,将Matrigel工作液加入细胞培养瓶皿中并摇匀,确保Matrigel完全没过培养瓶皿底部,且在使用前任意一处Matrigel都不能干掉。为保证细胞能够更好的贴壁和存活,Matrigel放入37℃培养箱包被时间:1:100XMatrigel不能低于0.5小时;1:200X Matrigel不能低于2小时。)。(2) Matrigel: hESC-grade Matrigel (before passage or resuscitation of cells, add the Matrigel working solution to the cell culture flask and shake well to ensure that the Matrigel completely covers the bottom of the culture flask, and the Matrigel cannot be placed anywhere before use. Dry. In order to ensure better adherence and survival of cells, Matrigel should be placed in a 37°C incubator for coating time: 1:100X Matrigel should not be less than 0.5 hours; 1:200X Matrigel should not be less than 2 hours.).
(3)消化液:使用DPBS溶解EDTA至终浓度为0.5mM,pH7.4(注意:EDTA不能使用水稀释,否则细胞会因渗透压降低而死亡。)。(3) Digestion solution: Use DPBS to dissolve EDTA to a final concentration of 0.5mM, pH 7.4 (Note: EDTA cannot be diluted with water, otherwise cells will die due to reduced osmotic pressure.).
(4)冻存液:60%BioCISO+30%ESCs级FBS+10%DMSO(冻存液最好现配现用。)。(4) Cryopreservation solution: 60% BioCISO+30% ESCs grade FBS+10% DMSO (the cryopreservation solution is best prepared and used immediately).
三、常规维持传代培养过程3. Routine maintenance subculture process
(1)传代的最佳时刻以及传代比例(1) The best time for passage and passage ratio
a.传代最佳时刻:细胞整体汇合度达80%~90%;a. The best time for passage: the overall confluence of cells reaches 80% to 90%;
b.传代最佳比例:1:4~1:7传代,次日最佳汇合度应维持在20%~30%。b. The optimal ratio of passage: 1:4~1:7 passage, and the best confluence the next day should be maintained at 20%~30%.
(2)传代过程(2) Passaging process
a.事先将包被好的细胞培养瓶皿中的Matrigel吸走弃掉,加入适量培养基(BioCISO+300μg/mL G418+0.5μg/mL puro),并放入37℃、5%CO2培养箱中孵育;a. Aspirate and discard the Matrigel in the coated cell culture flask in advance, add an appropriate amount of medium (BioCISO+300μg/mL G418+0.5μg/mL puro), and put it into 37°C, 5% CO 2 for culture incubation in the box;
b.待细胞符合传代的要求,吸掉培养基上清,加入适量的0.5mM EDTA消化液到细胞瓶皿中;b. When the cells meet the requirements of passage, aspirate the medium supernatant, and add an appropriate amount of 0.5mM EDTA digestion solution to the cell flask dish;
c.将细胞放入37℃、5%CO2培养箱中孵育5~10分钟(消化至镜下观察到大部分细胞收缩变圆但还未漂浮即可,轻柔吹打细胞使其从壁上脱离,将细胞悬液吸到离心管内,200g离心5分钟;c. Incubate the cells in a 37°C, 5% CO 2 incubator for 5-10 minutes (digest until most cells shrink and become rounded but not floating under the microscope, gently pipette the cells to detach from the wall , suck the cell suspension into a centrifuge tube and centrifuge at 200g for 5 minutes;
d.离心后,弃上清,用培养基重悬细胞,轻柔反复吹打细胞数次至混匀,然后将细胞转移至事先准备好包被Matrigel的瓶皿中;d. After centrifugation, discard the supernatant, resuspend the cells with medium, gently pipette the cells several times to mix well, and then transfer the cells to a bottle prepared to be coated with Matrigel;
e.细胞转移至细胞瓶皿后,前后左右水平摇匀,镜下观察无异常后,摇匀置于37℃、5%CO2培养箱中进行培养;e. After the cells are transferred to the cell flask dish, shake them horizontally from front to back and left and right. After no abnormality is observed under the microscope, shake well and place them in a 37°C, 5% CO 2 incubator for culture;
f.次日观察细胞贴壁存活状态,吸掉培养基每天正常按时换液。f. Observe the cell adherent survival state the next day, aspirate the medium and change the medium on time every day.
四、细胞冻存4. Cell cryopreservation
(1)按照常规传代的操作步骤,使用0.5mM EDTA消化细胞至大部分细胞收缩变圆但尚未漂浮,轻柔吹打细胞,收集细胞悬液,200g离心5分钟,弃上清,加入适量冻存液重悬细胞,将细胞转移至冻存管(建议六孔板汇合度80%冻存一支,冻存液体积为0.5mL/支);(1) According to the routine passaging procedure, digest the cells with 0.5mM EDTA until most of the cells shrink and become round but have not floated, gently pipet the cells, collect the cell suspension, centrifuge at 200g for 5 minutes, discard the supernatant, and add an appropriate amount of freezing solution Resuspend the cells and transfer the cells to a cryopreservation tube (it is recommended to freeze one tube at a confluence of 80% of the six-well plate, and the volume of the freezing solution is 0.5mL/tube);
(2)将冻存管置于程序降温盒中,立即放入-80℃过夜(需保证冻存管每分钟温度下降1℃);(2) Place the cryovials in a programmed cooling box, and immediately put them at -80°C overnight (the temperature of the cryopreservation tube must be lowered by 1°C per minute);
(3)次日立即将细胞转移入液氮。(3) The cells were immediately transferred into liquid nitrogen the next day.
五、细胞复苏5. Cell recovery
(1)提前准备好Matrigel包被的细胞瓶皿,复苏细胞前,吸掉Matrigel,向细胞瓶皿中加入适量的BioCISO,置于37℃、5%CO2培养箱中孵育;(1) Prepare the Matrigel-coated cell flask dish in advance. Before resuscitating the cells, aspirate the Matrigel, add an appropriate amount of BioCISO to the cell flask dish, and incubate in a 37°C, 5% CO 2 incubator;
(2)将冻存管从液氮中快速取出,立即放入37℃水浴锅中快速摇晃,使细胞快速融解,仔细观察待冰晶完全消失停止摇晃,将细胞转移至生物安全柜;(2) Quickly take out the cryopreservation tube from the liquid nitrogen, and immediately put it into a 37°C water bath and shake it quickly to thaw the cells quickly. After careful observation, stop shaking when the ice crystals completely disappear, and transfer the cells to a biological safety cabinet;
(3)提前加入10mL DMEM/F12(1:1)基础培养基至15mL离心管,并平衡至室温,使用巴氏吸管吸取1mL DMEM/F12(1:1)缓慢加入冻存管中,轻柔混匀,将细胞悬液转移到准备好的含有DMEM/F12(1:1)的15mL离心管中,200g离心5分钟;(3) Add 10 mL of DMEM/F12 (1:1) basal medium to a 15 mL centrifuge tube in advance, and equilibrate to room temperature. Use a Pasteur pipette to
(4)小心弃掉上清,加入适量BioCISO,轻轻混匀细胞,种到提前准备好的细胞瓶皿中,水平前后左右摇匀后,镜下观察无异常后,摇匀置于37℃、5%CO2培养箱中培养;(4) Carefully discard the supernatant, add an appropriate amount of BioCISO, gently mix the cells, and plant them in the prepared cell flask dish. , 5% CO 2 incubator;
(5)次日观察细胞贴壁存活状态,每天正常按时换液。若贴壁良好,则BioCISO更换为BioCISO+300μg/mL G418+0.5μg/mL puro。(5) Observe the cell adherent survival state the next day, and change the medium regularly every day. If the adherence is good, replace BioCISO with BioCISO+300μg/mL G418+0.5μg/mL puro.
1.8.5AAVS1基因敲入检测方法1.8.5 AAVS1 gene knock-in detection method
一、单细胞克隆AAVS1基因敲入检测1. Single-cell clone AAVS1 gene knock-in detection
(1)AAVS1基因敲入检测说明(1) Description of AAVS1 gene knock-in detection
a.试验目的:PCR检测经过基因敲入处理的细胞,测试该细胞是否为纯合子;由于两个Donor片段只有抗性基因的序列具有差异性,因此要判断该细胞是否为纯合子(两条染色体分别敲入不同抗性基因的Donor片段),就需要检测该细胞的基因组是否含有两种抗性基因的Donor片段,只有双敲入的细胞才有可能是正确的纯合子;a. Purpose of the test: PCR detects the cells that have undergone gene knock-in treatment to test whether the cells are homozygous; since the two Donor fragments only have differences in the sequence of the resistance gene, it is necessary to determine whether the cells are homozygous (two Donor fragments). Chromosome knock-in Donor fragments of different resistance genes respectively), it is necessary to detect whether the genome of the cell contains Donor fragments of two resistance genes, only double-knock-in cells may be correct homozygotes;
b.试验方法:首先在Donor质粒内部(非重组臂部分)设计一条引物,然后在基因组PPP1R12C(非重组臂部分)设计另一条引物;如果Donor片段在基因组能够正确插入,就会有目的条带出现,否则无目的条带出现);b. Test method: first design a primer inside the Donor plasmid (non-recombination arm part), and then design another primer in the genome PPP1R12C (non-recombination arm part); if the Donor fragment can be inserted correctly in the genome, there will be a target band appears, otherwise no purposeful bands appear);
c.试验方案引物序列及PCR方案如表4所示。c. Test protocol The primer sequences and PCR protocol are shown in Table 4.
表4试验方案引物序列及PCR方案Table 4 Test protocol primer sequences and PCR protocol

二、eGSH基因敲入的检测方法跟AAVS1基因敲入检测原理和方法一样,这里不再描述。2. The detection method of eGSH gene knock-in is the same as that of AAVS1 gene knock-in detection, and will not be described here.
1.8.6在基因组安全位点敲入基因方法的检验方法1.8.6 Test methods for knock-in gene methods at safe genomic sites
(1)试验目的:PCR检测经过基因敲入处理的细胞,测试该细胞是否为纯合子。由于两个Donor片段只有抗性基因的序列具有差异性,因此要判断该细胞是否为纯合子(两条染色体分别敲入不同抗性基因的Donor片段),就需要检测该细胞的基因组是否含有两种抗性基因的Donor片段,只有双敲入的细胞才有可能是正确的纯合子。(1) Test purpose: PCR detection of gene knock-in-treated cells to test whether the cells are homozygous. Since the two Donor fragments only have differences in the sequence of the resistance gene, to determine whether the cell is homozygous (two chromosomes knock-in the Donor fragments of different resistance genes respectively), it is necessary to detect whether the genome of the cell contains two genes. The Donor fragment of the resistance gene, only double knock-in cells may be correct homozygous.
(2)试验方法:首先在Donor质粒内部(非重组臂部分)设计一条引物,然后在基因组(非重组臂部分)设计另一条引物。如果Donor片段在基因组能够正确插入,就会有目的条带出现,否则无目的条带出现。(2) Test method: First design a primer inside the Donor plasmid (non-recombination arm part), and then design another primer in the genome (non-recombination arm part). If the Donor fragment can be inserted correctly in the genome, there will be a target band, otherwise no target band will appear.
1.9多能干细胞或其衍生物表达IL-4Rα阻断物的测定方法1.9 Determination method of pluripotent stem cells or their derivatives expressing IL-4Rα blocker
使用ELISA(竞争法)对多能干细胞或其衍生物表达的抗IL-4Rα抗体进行检测。收集表达抗IL-4Rα抗体的多能干细胞或其衍生物培养上清,加样品稀释液稀释5倍,并与酶标的抗IL-4Rα抗体混合(1:1),再在已经包被IL-4Rα抗原的酶标板上进行上样,对照组则加不表达抗IL-4Rα抗体的多能干细胞或其衍生物培养上清,轻轻混匀。封板后置于37℃温育30min,洗涤5次后加入显色液显色15min,加入终止液50uL读数测量450nm吸光度值(抗IL-4Rα抗体的表达量与颜色深浅成负相关)。Anti-IL-4Rα antibody expressed by pluripotent stem cells or derivatives thereof was detected by ELISA (competitive method). Collect the culture supernatant of pluripotent stem cells or their derivatives expressing anti-IL-4Rα antibody, add sample diluent to dilute 5 times, and mix with enzyme-labeled anti-IL-4Rα antibody (1:1), and then add IL- 4Rα antigen was loaded on the ELISA plate, and the control group was added with the culture supernatant of pluripotent stem cells or their derivatives that do not express anti-IL-4Rα antibody, and mixed gently. After sealing, the plates were incubated at 37°C for 30 min, washed for 5 times, and then added with color developing solution for 15 min. Add 50 uL of stop solution to measure the absorbance at 450 nm (the expression of anti-IL-4Rα antibody is negatively correlated with the color depth).
1.10小鼠过敏性哮喘模型的治疗方法1.10 Therapeutic method of mouse allergic asthma model
在人源化NSG小鼠(The Jackson Laboratory(JAX))中,注射同一供体的人免疫细胞来重建小鼠的免疫系统,2周后建立由氢氧化铝凝胶佐剂和鸡卵白蛋白诱导的小鼠过敏性哮喘模型。待小鼠的IgE明显增加后再进行治疗测试,进行尾静脉注射200uLPBS(含人免疫细胞和1×106的表达IL-4Rα阻断物的多能干细胞或其衍生物)进行过敏性哮喘治疗,其中只注射含人免疫细胞的组作为对照组。Th2细胞因子水平增高是哮喘的重要特征之一,因此我们可以通过检测Th2细胞因子(IL-4、IL-5、IL-13)水平来判断哮喘的治疗效果。In humanized NSG mice (The Jackson Laboratory (JAX)), the immune system of mice was reconstituted by injection of human immune cells from the same donor, and establishment was induced 2 weeks later by aluminum hydroxide gel adjuvant and chicken ovalbumin mouse model of allergic asthma. After the IgE of the mice increased significantly, the treatment test was performed, and 200uL PBS (containing human immune cells and 1×10 6 IL-4Rα blocker-expressing pluripotent stem cells or their derivatives) was injected into the tail vein for allergic asthma treatment. , in which only the group containing human immune cells was injected as a control group. The increased level of Th2 cytokines is one of the important characteristics of asthma, so we can judge the therapeutic effect of asthma by detecting the levels of Th2 cytokines (IL-4, IL-5, IL-13).
1.11小鼠特应性皮炎模型的治疗方法1.11 Therapeutic method of mouse model of atopic dermatitis
在人源化NSG小鼠(The Jackson Laboratory(JAX))中,注射同一供体的人免疫细胞来重建小鼠的免疫系统,2周后建立由2,4-二硝基氟苯(DNFB)对小鼠进行皮肤致敏产生的特应性皮炎模型小鼠。待小鼠的IgE明显增加后再进行治疗测试,进行尾静脉注射200uLPBS(含人免疫细胞和1×106的表达IL-4Rα阻断物的多能干细胞衍生物)进行特应性皮炎治疗。In humanized NSG mice (The Jackson Laboratory (JAX)), the immune system of the mice was reconstituted by injection of human immune cells from the same donor, which was established 2 weeks later by 2,4-dinitrofluorobenzene (DNFB) Atopic dermatitis model mice produced by skin sensitization of mice. The treatment test was performed after the IgE of the mice was significantly increased, and 200uL PBS (containing human immune cells and 1×10 6 IL-4Rα blocker-expressing pluripotent stem cell derivatives) was injected into the tail vein for atopic dermatitis treatment.
2.实验方案2. Experimental protocol
将表达IL-4Rα阻断物的基因、一个或多个免疫兼容分子、shRNA和/或miRNA加工复合体相关基因、抗干扰素效应分子敲入到多能干细胞基因组安全位点的实验方案如表5-表6所示,其中,“+”号表示基因或核酸序列的敲入,“-”号表示基因敲除。The experimental protocol for knocking-in genes expressing IL-4Rα blocker, one or more immune-compatible molecules, shRNA and/or miRNA processing complex-related genes, and anti-interferon effector molecules into safe sites in the genome of pluripotent stem cells is shown in the table below. 5-Table 6, where "+" indicates gene or nucleic acid sequence knock-in, and "-" indicates gene knock-out.
表5组成型表达实验方案Table 5 Experimental protocol for constitutive expression

选取的质粒以及具体的敲入位置情况如下:The selected plasmids and the specific knock-in positions are as follows:
总体原则:General principles:
抗IL-4Rα抗体为分泌型抗体,其结构为:IL-2sig信号肽(SEQ ID NO.183)+轻链(轻链的序列的末端添加终止密码子TGA)+EMCV IRESwt(SEQ ID NO.178)+IL-2sig信号肽+重链(重链的序列的末端添加终止密码子TGA)。Anti-IL-4Rα antibody is secretory antibody, and its structure is: IL-2sig signal peptide (SEQ ID NO.183)+light chain (the end of the sequence of light chain adds stop codon TGA)+EMCV IRESwt (SEQ ID NO.183)+EMV IRESwt (SEQ ID NO. 178)+IL-2sig signal peptide+heavy chain (stop codon TGA is added to the end of the sequence of the heavy chain).
抗IL-4Rα抗体序列放入对应质粒的MCS2的位置(抗体的LC轻链、HC重链的前面均添加IL-2sig信号肽,抗体的LC轻链和HC重链序列中间使用EMCV IRESwt连接起来,排序顺序如下:LC轻链,EMCV IRESwt,HC重链),shRNA放入对应质粒的shRNA表达框架内,shRNA-miR放入对应质粒的shRNA-miR表达框架内,其它基因放入对应质粒的MCS1的位置。各质粒的图谱如图1-图11所示。The anti-IL-4Rα antibody sequence was placed in the position of MCS2 of the corresponding plasmid (the LC light chain and HC heavy chain of the antibody were added in front of the IL-2sig signal peptide, and the LC light chain and HC heavy chain sequences of the antibody were connected using EMCV IRESwt. , the sorting order is as follows: LC light chain, EMCV IRESwt, HC heavy chain), shRNA is put into the shRNA expression frame of the corresponding plasmid, shRNA-miR is put into the shRNA-miR expression frame of the corresponding plasmid, and other genes are put into the shRNA-miR expression frame of the corresponding plasmid. Location of MCS1. The maps of each plasmid are shown in Figures 1-11.
注:sgRNA clone B2M质粒包含sgRNA clone B2M-1和sgRNA clone B2M-2质粒。sgRNA clone CIITA质粒包含sgRNA clone CIITA-1和sgRNA clone CIITA-2质粒。Note: sgRNA clone B2M plasmid contains sgRNA clone B2M-1 and sgRNA clone B2M-2 plasmids. The sgRNA clone CIITA plasmid contains the sgRNA clone CIITA-1 and sgRNA clone CIITA-2 plasmids.
(1)A1分组(1) Group A1
AAVS1 KI Vector(shRNA,组成型)质粒的MCS2放入IL-4Rα抗体序列。The MCS2 of the AAVS1 KI Vector (shRNA, constitutive) plasmid was placed into the IL-4Rα antibody sequence.
(2)A2分组(2) A2 grouping
AAVS1 KI Vector(shRNA,组成型)质粒的MCS2放入IL-4Rα抗体序列。shRNA表达框架放入shRNA靶序列(若存在多个shRNA则无缝连接起来)。MCS1放入基因序列(若存在多个基因则使用EMCV IRESwt连接起来)。The MCS2 of the AAVS1 KI Vector (shRNA, constitutive) plasmid was placed into the IL-4Rα antibody sequence. The shRNA expression framework is placed into the shRNA target sequence (seamlessly linked if multiple shRNAs are present). MCS1 was placed into the gene sequence (connected using EMCV IRESwt if multiple genes were present).
(3)A3分组(3) A3 grouping
AAVS1 KI Vector(shRNA-miR,组成型)质粒的MCS2放入IL-4Rα抗体序列。shRNA-miR表达框架放入shRNA-miR靶序列(若存在多个shRNA-miR则无缝连接起来)。MCS1放入基因序列(若存在多个基因则使用EMCV IRESwt连接起来)。MCS2 of AAVS1 KI Vector (shRNA-miR, constitutive) plasmid was put into IL-4Rα antibody sequence. The shRNA-miR expression framework is placed into the shRNA-miR target sequence (seamlessly linked if multiple shRNA-miRs are present). MCS1 was placed into the gene sequence (connected using EMCV IRESwt if multiple genes were present).
(4)A4分组(4) A4 grouping
AAVS1 KI Vector(shRNA,组成型)质粒的MCS2放入IL-4Rα抗体序列,sgRNA cloneB2M质粒的靶序列放入B2M的sgRNA靶序列(SEQ ID NO.179和SEQ ID NO.180),sgRNA cloneCIITA质粒的靶序列放入CIITA的sgRNA靶序列(SEQ ID NO.181和SEQ ID NO.182)。MCS1放入基因序列(若存在多个基因则使用EMCV IRESwt连接起来)。The MCS2 of the AAVS1 KI Vector (shRNA, constitutive) plasmid was put into the IL-4Rα antibody sequence, the target sequence of the sgRNA cloneB2M plasmid was put into the sgRNA target sequence of B2M (SEQ ID NO.179 and SEQ ID NO.180), the sgRNA cloneCIITA plasmid The target sequence was placed into the sgRNA target sequence of CIITA (SEQ ID NO. 181 and SEQ ID NO. 182). MCS1 was placed into the gene sequence (connected using EMCV IRESwt if multiple genes were present).
(5)A5分组(5) A5 grouping
同A2分组的方法。The method of grouping with A2.
(6)A6分组(6) A6 grouping
同A3分组的方法。The method of grouping with A3.
表6诱导型表达(免疫兼容可逆)实验方案Table 6 Inducible expression (immunocompatible and reversible) experimental protocol


(1)B1分组:(1) Group B1:
AAVS1 KI Vector(shRNA,诱导型)质粒的MCS2放入IL-4Rα抗体序列。shRNA表达框架放入shRNA靶序列(若存在多个shRNA则无缝连接起来)。MCS1放入基因序列(若存在多个基因则使用EMCV IRESwt连接起来)。MCS2 of AAVS1 KI Vector (shRNA, inducible) plasmid was put into IL-4Rα antibody sequence. The shRNA expression framework is placed into the shRNA target sequence (seamlessly linked if multiple shRNAs are present). MCS1 was placed into the gene sequence (connected using EMCV IRESwt if multiple genes were present).
(2)B2分组:(2) Group B2:
AAVS1 KI Vector(shRNA-miR,诱导型)质粒的MCS2放入IL-4Rα抗体序列。shRNA-miR表达框架放入shRNA-miR靶序列(若存在多个shRNA-miR则无缝连接起来)。MCS1放入基因序列(若存在多个基因则使用EMCV IRESwt连接起来)。The MCS2 of the AAVS1 KI Vector (shRNA-miR, inducible) plasmid was put into the IL-4Rα antibody sequence. The shRNA-miR expression framework is placed into the shRNA-miR target sequence (seamlessly linked if multiple shRNA-miRs are present). MCS1 was placed into the gene sequence (connected using EMCV IRESwt if multiple genes were present).
(3)B3分组:(3) Group B3:
同B1分组的方法。The method of grouping with B1.
(4)B4分组:(4) Group B4:
同B2分组的方法。The method of grouping with B2.
3.实验结果3. Experimental results
3.1多能干细胞或其衍生物表达的IL-4Rα阻断物的阻断效果检测3.1 Detection of blocking effect of IL-4Rα blocker expressed by pluripotent stem cells or their derivatives
将表5和表6各实验组方案敲入iPSCs、MSCs、EBs、NSCs的基因组安全位点AAVS1,37℃,0.5%CO2培养箱培养,收集培养基上清,加样品稀释液稀释5倍,并与酶标的抗IL-4Rα抗体混合(1:1)(对照组则加不表达抗IL-4Rα抗体的多能干细胞或其衍生物培养上清,轻轻混匀),再在已经包被IL-4Rα抗原的酶标板上进行上样。封板后置于37℃温育30min,洗涤5次后加入显色液显色15min,加入终止液50uL,读数测量450nm吸光度值。各实验组的检测结果如表7所示。Knock into the genomic safety site AAVS1 of iPSCs, MSCs, EBs, and NSCs according to the protocols of each experimental group in Table 5 and Table 6, culture at 37 °C, 0.5% CO 2 incubator, collect the supernatant of the medium, add sample diluent to dilute 5 times , and mixed with enzyme-labeled anti-IL-4Rα antibody (1:1) (for the control group, add the culture supernatant of pluripotent stem cells or their derivatives that do not express anti-IL-4Rα antibody, and mix gently), Loaded on a microtiter plate with IL-4Rα antigen. After sealing, the plates were incubated at 37 °C for 30 min, washed 5 times, and then added with color developing solution for 15 min, added with 50 uL of stop solution, and read to measure the absorbance value at 450 nm. The test results of each experimental group are shown in Table 7.
表7各实验组表达的IL-4Rα抗体对IL-4Rα的阻断效果Table 7 The blocking effect of IL-4Rα antibodies expressed in each experimental group on IL-4Rα


从上表可以看出,本发明的多能干细胞或其衍生物所表达的抗IL-4Rα抗体能够有效阻断酶标的抗IL-4Rα抗体与细胞表面IL-4Rα的结合。而且其表达量在各组中表达相对恒定,所以多能干细胞或其衍生物所表达的IL-4Rα抗体不受细胞分化形态及其他外源基因(免疫兼容改造)所影响。It can be seen from the above table that the anti-IL-4Rα antibody expressed by the pluripotent stem cells or derivatives thereof of the present invention can effectively block the binding of the enzyme-labeled anti-IL-4Rα antibody to the cell surface IL-4Rα. And its expression level is relatively constant in each group, so the IL-4Rα antibody expressed by pluripotent stem cells or their derivatives is not affected by cell differentiation morphology and other exogenous genes (immunocompatible transformation).
3.2表达IL-4Rα阻断物的多能干细胞或其衍生物在治疗过敏性哮喘中的效果3.2 The effect of pluripotent stem cells or their derivatives expressing IL-4Rα blocker in the treatment of allergic asthma
我们选择表达阻断物方案组(A1)的细胞(iPSCs、MSCs、EBs、NSCs)中进行测试。在人源化NSG小鼠过敏性哮喘模型中,我们对其进行注射能够表达IL-4Rα抗体的hPSCs及hPSCs源衍生物(iPSCs、hPSCs-MSCs、hPSCs-NSCs、hPSCs-EBs),通过检测支气管肺泡灌洗液中细胞因子水平(pg/ml)来观察其治疗过敏性哮喘的效果。注:为避免免疫兼容问题,我们所使用的免疫细胞与hPSCs及hPSCs源衍生物均来源于同一人的。实验结果如8所示。We selected cells (iPSCs, MSCs, EBs, NSCs) expressing the blocker protocol group (A1) for testing. In the humanized NSG mouse model of allergic asthma, we injected hPSCs and hPSCs-derived derivatives (iPSCs, hPSCs-MSCs, hPSCs-NSCs, hPSCs-EBs) capable of expressing IL-4Rα antibody. Cytokine level (pg/ml) in bronchoalveolar lavage fluid to observe its effect on allergic asthma. Note: To avoid immunocompatibility issues, the immune cells we use are derived from the same human as hPSCs and hPSCs-derived derivatives. The experimental results are shown in 8.
表8表达IL-4Rα抗体的多能干细胞或其衍生物的过敏性哮喘治疗效果Table 8 Therapeutic effect of allergic asthma by pluripotent stem cells or derivatives thereof expressing IL-4Rα antibody

注:对照组是指未注射表达IL-4Rα抗体的hPSCs或hPSCs源衍生物的NSG小鼠过敏性哮喘模型。Note: The control group refers to the allergic asthma model of NSG mice without injection of hPSCs or hPSCs-derived derivatives expressing IL-4Rα antibody.
通过以上实验,可以证明本发明制备的表达IL-4Rα阻断物的干细胞或其衍生物在治疗过敏性哮喘模型的小鼠中,Th2细胞因子(IL-4、IL-5、IL-13)水平有所下降。因此注射表达IL-4Rα阻断物的hPSCs或hPSCs源衍生物能够起到治疗过敏性哮喘的作用。Through the above experiments, it can be proved that the stem cells or their derivatives expressing the IL-4Rα blocker prepared by the present invention are effective in treating allergic asthma model mice, Th2 cytokines (IL-4, IL-5, IL-13) level has declined. Therefore, injection of hPSCs or hPSCs-derived derivatives expressing IL-4Rα blocker can play a role in the treatment of allergic asthma.
3.3表达IL-4Rα阻断物的多能干细胞或其衍生物在治疗特应性皮炎中的效果3.3 The effect of pluripotent stem cells or their derivatives expressing IL-4Rα blocker in the treatment of atopic dermatitis
我们选择表达阻断物方案组(A1)的细胞(iPSCs、MSCs、EBs、NSCs)中进行测试。在人源化NSG小鼠特应性皮炎模型中,我们对其进行注射能够表达IL-4Rα抗体的hPSCs及hPSCs源衍生物(iPSCs、hPSCs-MSCs、hPSCs-NSCs、hPSCs-EBs),通过血液中IgE水平进行检测来观察其治疗特应性皮炎的效果。注:为避免免疫兼容问题,我们所使用的免疫细胞与hPSCs及hPSCs源衍生物均来源于同一人的。实验结果如9所示。We selected cells (iPSCs, MSCs, EBs, NSCs) expressing the blocker protocol group (A1) for testing. In a humanized NSG mouse model of atopic dermatitis, we injected hPSCs and hPSCs-derived derivatives (iPSCs, hPSCs-MSCs, hPSCs-NSCs, hPSCs-EBs) capable of expressing IL-4Rα antibody through blood The level of IgE was detected to observe its effect on atopic dermatitis. Note: To avoid immunocompatibility issues, the immune cells we use are derived from the same human as hPSCs and hPSCs-derived derivatives. The experimental results are shown in 9.
表9表达IL-4Rα抗体的多能干细胞或其衍生物的特应性皮炎治疗效果Table 9 Therapeutic effect of atopic dermatitis by pluripotent stem cells or derivatives thereof expressing IL-4Rα antibody

注:对照组是指未注射表达IL-4Rα抗体的hPSCs或hPSCs源衍生物的NSG小鼠特应性皮炎模型。Note: The control group refers to the NSG mouse model of atopic dermatitis without injection of hPSCs or hPSCs-derived derivatives expressing IL-4Rα antibody.
通过以上实验,可以证明本发明制备的表达IL-4Rα阻断物的干细胞或其衍生物在治疗特应性皮炎模型的小鼠中,血液中IgE水平有所下降。因此注射表达IL-4Rα阻断物的hPSCs或hPSCs源衍生物能够起到治疗特应性皮炎的作用。Through the above experiments, it can be proved that the IL-4Rα blocker-expressing stem cells or their derivatives prepared by the present invention have decreased blood IgE levels in mice treated with atopic dermatitis model. Therefore, injection of hPSCs or hPSCs-derived derivatives expressing IL-4Rα blocker can play a role in the treatment of atopic dermatitis.
3.4免疫兼容分子诱导型表达组的可逆性表达测试3.4 Reversible expression test of immune-compatible molecular-inducible expression panel
通过上述实施例,表达IL-4Rα阻断物的hPSCs或hPSCs源衍生物能有效阻断IL-4Rα而起到治疗过敏性哮喘的作用。我们还必须考虑hPSCs或hPSCs源衍生物的免疫兼容问题。因此我们选取一个合适的组合对免疫兼容进行测试。Through the above examples, hPSCs or hPSCs-derived derivatives expressing IL-4Rα blocker can effectively block IL-4Rα and play a role in the treatment of allergic asthma. We must also consider the immunocompatibility of hPSCs or hPSCs-derived derivatives. Therefore, we selected a suitable combination to test the immune compatibility.
我们利用MSCs的低免疫源性的特点,在人源化NSG小鼠疾病(过敏性哮喘)模型中,对其进行注射能够表达IL-4Rα阻断物(抗IL-4Rα抗体)的hPSCs源免疫兼容MSCs,通过检测支气管肺泡灌洗液中细胞因子水平(IL-13,pg/mL)来观察其治疗过敏性哮喘的效果。注:所使用的免疫细胞与hPSCs源MSCs来源于为非同一人。Taking advantage of the low immunogenicity of MSCs, in a humanized NSG mouse model of disease (allergic asthma), we injected them with hPSCs that express an IL-4Rα blocker (anti-IL-4Rα antibody) for immunization. Compatible with MSCs, the effect of treating allergic asthma was observed by detecting cytokine levels (IL-13, pg/mL) in bronchoalveolar lavage fluid. Note: The immune cells and hPSCs-derived MSCs used are not from the same person.
对照组是指未注射MSCs细胞的NSG小鼠疾病(过敏性哮喘)模型。The control group refers to the NSG mouse disease (allergic asthma) model without injection of MSCs cells.
加Dox组别的处理是:在小鼠饮食中添加0.5mg/mL的Dox,进行饲养小鼠,从注射表达阻断物细胞开始,一直使用,直到试验结束。结果如表10所示。The treatment of the Dox-added group was as follows: 0.5 mg/mL of Dox was added to the mouse diet, and the mice were fed, starting from the injection of the cells expressing the blocker, and used until the end of the experiment. The results are shown in Table 10.
表10免疫兼容分子诱导型表达组的可逆性表达测试结果Table 10 The reversible expression test results of the immune-compatible molecule-inducible expression group

以上实验表明:在进行治疗过敏性哮喘中,仅表达阻断物的MSCs(组2),其具有低免疫源性,可以在异体内存在一定时间,所以其能够发挥一定的治疗效果,而进行免疫兼容改造的(组3-11,包括组成型和可逆诱导型免疫兼容),其免疫兼容效果更佳,比没有经免疫兼容改造的MSCs在体内存在时间更长(或能做到长期共存),其发挥治疗效果更佳,而组5为B2M和CIITA基因敲除组,其完全消除HLA-I和HLA-II类分子产生的影响,因此其治疗效果最佳。但由于其组成型免疫兼容改造(基因敲入/敲除),无法在移植物产生变异或不需要时进行清除,从而有组8-15方案设定。组12-15中在进行注射表达阻断物细胞进入小鼠的同时,对小鼠使用Dox诱导剂(一直使用),注射表达阻断物细胞的小鼠的免疫兼容效果将被消除,其在体内存在时间与未经免疫兼容改造的MSCs相当,其疗效果也与未经免疫兼容改造的MSCs相当。The above experiments show that: in the treatment of allergic asthma, only the MSCs (group 2) expressing the blocker have low immunogenicity and can exist in the allogene for a certain period of time, so they can exert a certain therapeutic effect. Immunocompatibility engineered (groups 3-11, including constitutive and reversible inducible immunocompatibility) have better immunocompatibility and persist in vivo for longer (or long-term coexistence) than MSCs without immunocompatibility engineered , it has better therapeutic effect, and group 5 is the B2M and CIITA gene knockout group, which completely eliminates the effects of HLA-I and HLA-II molecules, so its therapeutic effect is the best. However, due to its constitutive immune-compatible modification (gene knock-in/knock-out), it cannot be cleared when the graft is mutated or not needed, so there is a group 8-15 protocol setting. In Groups 12-15, the Dox inducer (always used) was administered to the mice at the same time as the injection of the blocker-expressing cells into the mice. The existence time in vivo is comparable to that of MSCs without immune-compatibility modification, and its therapeutic effect is also comparable to that of MSCs without immune-compatibility modification.
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。The above-mentioned embodiments are preferred embodiments of the present invention, but the embodiments of the present invention are not limited by the above-mentioned embodiments, and any other changes, modifications, substitutions, combinations, The simplification should be equivalent replacement manners, which are all included in the protection scope of the present invention.
SEQUENCE LISTINGSEQUENCE LISTING
<110> 未来智人再生医学研究院(广州)有限公司;王淋立<110> Future Homo sapiens Regenerative Medicine Research Institute (Guangzhou) Co., Ltd.; Wang Linli
<120> 一种表达IL-4Rα阻断物的多能干细胞或其衍生物及应用<120> A pluripotent stem cell expressing IL-4Rα blocker or its derivative and application
<130><130>
<160> 183<160> 183
<170> PatentIn version 3.5<170> PatentIn version 3.5
<210> 1<210> 1
<211> 1353<211> 1353
<212> DNA<212> DNA
<213> human<213> human
<400> 1<400> 1
gaggtgcagc tggtggagag cggcggcggc ctggagcagc ccggcggcag cctgaggctg 60gaggtgcagc tggtggagag cggcggcggc ctggagcagc ccggcggcag cctgaggctg 60
agctgcgccg gcagcggctt caccttcagg gactacgcca tgacctgggt gaggcaggcc 120agctgcgccg gcagcggctt caccttcagg gactacgcca tgacctgggt gaggcaggcc 120
cccggcaagg gcctggagtg ggtgagcagc atcagcggca gcggcggcaa cacctactac 180cccggcaagg gcctggagtg ggtgagcagc atcagcggca gcggcggcaa cacctactac 180
gccgacagcg tgaagggcag gttcaccatc agcagggaca acagcaagaa caccctgtac 240gccgacagcg tgaagggcag gttcaccatc agcagggaca acagcaagaa caccctgtac 240
ctgcagatga acagcctgag ggccgaggac accgccgtgt actactgcgc caaggacagg 300ctgcagatga acagcctgag ggccgaggac accgccgtgt actactgcgc caaggacagg 300
ctgagcatca ccatcaggcc caggtactac ggcctggacg tgtggggcca gggcaccacc 360ctgagcatca ccatcaggcc caggtactac ggcctggacg tgtggggcca gggcaccacc 360
gtgaccgtga gcagcgccag caccaagggc cccagcgtgt tccccctggc cccctgcagc 420gtgaccgtga gcagcgccag caccaagggc cccagcgtgt tccccctggc cccctgcagc 420
aggagcacca gcgagagcac cgccgccctg ggctgcctgg tgaaggacta cttccccgag 480aggagcacca gcgagagcac cgccgccctg ggctgcctgg tgaaggacta cttccccgag 480
cccgtgaccg tgagctggaa cagcggcgcc ctgaccagcg gcgtgcacac cttccccgcc 540cccgtgaccg tgagctggaa cagcggcgcc ctgaccagcg gcgtgcacac cttccccgcc 540
gtgctgcaga gcagcggcct gtacagcctg agcagcgtgg tgaccgtgcc cagcagcagc 600gtgctgcaga gcagcggcct gtacagcctg agcagcgtgg tgaccgtgcc cagcagcagc 600
ctgggcacca agacctacac ctgcaacgtg gaccacaagc ccagcaacac caaggtggac 660ctgggcacca agacctacac ctgcaacgtg gaccacaagc ccagcaacac caaggtggac 660
aagagggtgg agagcaagta cggccccccc tgccccccct gccccgcccc cgagttcctg 720aagagggtgg agagcaagta cggcccccccc tgccccccct gccccgcccc cgagttcctg 720
ggcggcccca gcgtgttcct gttccccccc aagcccaagg acaccctgat gatcagcagg 780ggcggcccca gcgtgttcct gttcccccccc aagcccaagg acaccctgat gatcagcagg 780
acccccgagg tgacctgcgt ggtggtggac gtgagccagg aggaccccga ggtgcagttc 840acccccgagg tgacctgcgt ggtggtggac gtgagccagg aggaccccga ggtgcagttc 840
aactggtacg tggacggcgt ggaggtgcac aacgccaaga ccaagcccag ggaggagcag 900aactggtacg tggacggcgt ggaggtgcac aacgccaaga ccaagcccag ggaggagcag 900
ttcaacagca cctacagggt ggtgagcgtg ctgaccgtgc tgcaccagga ctggctgaac 960ttcaacagca cctacagggt ggtgagcgtg ctgaccgtgc tgcaccagga ctggctgaac 960
ggcaaggagt acaagtgcaa ggtgagcaac aagggcctgc ccagcagcat cgagaagacc 1020ggcaaggagt acaagtgcaa ggtgagcaac aagggcctgc ccagcagcat cgagaagacc 1020
atcagcaagg ccaagggcca gcccagggag ccccaggtgt acaccctgcc ccccagccag 1080atcagcaagg ccaagggcca gcccagggag ccccaggtgt acaccctgcc ccccagccag 1080
gaggagatga ccaagaacca ggtgagcctg acctgcctgg tgaagggctt ctaccccagc 1140gaggagatga ccaagaacca ggtgagcctg acctgcctgg tgaagggctt ctaccccagc 1140
gacatcgccg tggagtggga gagcaacggc cagcccgaga acaactacaa gaccaccccc 1200gacatcgccg tggagtggga gagcaacggc cagcccgaga acaactacaa gaccaccccc 1200
cccgtgctgg acagcgacgg cagcttcttc ctgtacagca ggctgaccgt ggacaagagc 1260cccgtgctgg acagcgacgg cagcttcttc ctgtacagca ggctgaccgt ggacaagagc 1260
aggtggcagg agggcaacgt gttcagctgc agcgtgatgc acgaggccct gcacaaccac 1320aggtggcagg agggcaacgt gttcagctgc agcgtgatgc acgaggccct gcacaaccac 1320
tacacccaga agagcctgag cctgagcctg ggc 1353tacacccaga agagcctgag cctgagcctg ggc 1353
<210> 2<210> 2
<211> 657<211> 657
<212> DNA<212> DNA
<213> human<213> human
<400> 2<400> 2
gacatcgtga tgacccagag ccccctgagc ctgcccgtga cccccggcga gcccgccagc 60gacatcgtga tgacccagag ccccctgagc ctgcccgtga cccccggcga gcccgccagc 60
atcagctgca ggagcagcca gagcctgctg tacagcatcg gctacaacta cctggactgg 120atcagctgca ggagcagcca gagcctgctg tacagcatcg gctacaacta cctggactgg 120
tacctgcaga agagcggcca gagcccccag ctgctgatct acctgggcag caacagggcc 180tacctgcaga agagcggcca gagcccccag ctgctgatct acctgggcag caacagggcc 180
agcggcgtgc ccgacaggtt cagcggcagc ggcagcggca ccgacttcac cctgaagatc 240agcggcgtgc ccgacaggtt cagcggcagc ggcagcggca ccgacttcac cctgaagatc 240
agcagggtgg aggccgagga cgtgggcttc tactactgca tgcaggccct gcagaccccc 300agcagggtgg aggccgagga cgtgggcttc tactactgca tgcaggccct gcagaccccc 300
tacaccttcg gccagggcac caagctggag atcaagagga ccgtggccgc ccccagcgtg 360tacaccttcg gccagggcac caagctggag atcaagagga ccgtggccgc ccccagcgtg 360
ttcatcttcc cccccagcga cgagcagctg aagagcggca ccgccagcgt ggtgtgcctg 420ttcatcttcc cccccagcga cgagcagctg aagagcggca ccgccagcgt ggtgtgcctg 420
ctgaacaact tctaccccag ggaggccaag gtgcagtgga aggtggacaa cgccctgcag 480ctgaacaact tctaccccag ggaggccaag gtgcagtgga aggtggacaa cgccctgcag 480
agcggcaaca gccaggagag cgtgaccgag caggacagca aggacagcac ctacagcctg 540agcggcaaca gccaggagag cgtgaccgag caggacagca aggacagcac ctacagcctg 540
agcagcaccc tgaccctgag caaggccgac tacgagaagc acaaggtgta cgcctgcgag 600agcagcaccc tgaccctgag caaggccgac tacgagaagc acaaggtgta cgcctgcgag 600
gtgacccacc agggcctgag cagccccgtg accaagagct tcaacagggg cgagtgc 657gtgacccacc agggcctgag cagccccgtg accaagagct tcaacagggg cgagtgc 657
<210> 3<210> 3
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 3<400> 3
gggagcagag aattctctta t 21gggagcagag aattctctta t 21
<210> 4<210> 4
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 4<400> 4
ggagcagaga attctcttat c 21ggagcagaga attctcttat c 21
<210> 5<210> 5
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 5<400> 5
gagcagagaa ttctcttatc c 21gagcagagaa ttctcttatc c 21
<210> 6<210> 6
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 6<400> 6
gctacctgga gcttcttaac a 21gctacctgga gcttcttaac a 21
<210> 7<210> 7
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 7<400> 7
ggagcttctt aacagcgatg c 21ggagcttctt aacagcgatg c 21
<210> 8<210> 8
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 8<400> 8
gggtctccag tatattcatc t 21gggtctccag tatattcatc t 21
<210> 9<210> 9
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 9<400> 9
gcctcctgat gcacatgtac t 21gcctcctgat gcacatgtac t 21
<210> 10<210> 10
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 10<400> 10
ggaagacctg ggaaagcttg t 21ggaagacctg ggaaagcttg t 21
<210> 11<210> 11
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 11<400> 11
ggctaagctt gtacaataac t 21ggctaagctt gtacaataac t 21
<210> 12<210> 12
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 12<400> 12
gcggaatgaa ccacatcttg c 21gcggaatgaa ccacatcttg c 21
<210> 13<210> 13
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 13<400> 13
ggccttctct gaaggacatt g 21ggccttctct gaaggacatt g 21
<210> 14<210> 14
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 14<400> 14
ggactcaatg cactgacatt g 21ggactcaatg cactgacatt g 21
<210> 15<210> 15
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 15<400> 15
ggtacccact gctctggtta t 21ggtacccact gctctggtta t 21
<210> 16<210> 16
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 16<400> 16
gctcccactc catgaggtat t 21gctcccactc catgaggtat t 21
<210> 17<210> 17
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 17<400> 17
ggtatttctt cacatccgtg t 21ggtatttctt cacatccgtg t 21
<210> 18<210> 18
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 18<400> 18
aggagacacg gaatgtgaag g 21aggagacacg gaatgtgaag g 21
<210> 19<210> 19
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 19<400> 19
gctcccactc catgaggtat t 21gctcccactc catgaggtat t 21
<210> 20<210> 20
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 20<400> 20
ggtatttcta cacctccgtg t 21ggtatttcta cacctccgtg t 21
<210> 21<210> 21
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 21<400> 21
ggaccggaac acacagatct a 21ggaccggaac acacagatct a 21
<210> 22<210> 22
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 22<400> 22
accggaacac acagatctac a 21accggaacac acagatctac a 21
<210> 23<210> 23
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 23<400> 23
ggaacacaca gatctacaag g 21ggaacacaca gatctacaag g 21
<210> 24<210> 24
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 24<400> 24
gaacacacag atctacaagg c 21gaacacacag atctacaagg c 21
<210> 25<210> 25
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 25<400> 25
ttcttacttc cctaatgaag t 21ttcttacttc cctaatgaag t 21
<210> 26<210> 26
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 26<400> 26
aagttaagaa cctgaatata a 21aagttaagaa cctgaatata a 21
<210> 27<210> 27
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 27<400> 27
aacctgaata taaatttgtg t 21aacctgaata taaatttgtg t 21
<210> 28<210> 28
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 28<400> 28
acctgaatat aaatttgtgt t 21acctgaatat aaatttgtgt t 21
<210> 29<210> 29
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 29<400> 29
aagcgttgat ggattaatta a 21aagcgttgat ggattaatta a 21
<210> 30<210> 30
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 30<400> 30
agcgttgatg gattaattaa a 21agcgttgatg gattaattaa a 21
<210> 31<210> 31
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 31<400> 31
gggtctggtg ggcatcatta t 21gggtctggtg ggcatcatta t 21
<210> 32<210> 32
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 32<400> 32
ggtctggtgg gcatcattat t 21ggtctggtgg gcatcattat t 21
<210> 33<210> 33
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 33<400> 33
gcatcattat tgggaccatc t 21gcatcattat tgggaccatc t 21
<210> 34<210> 34
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 34<400> 34
gcacatggag gtgatggtgt t 21gcacatggag gtgatggtgt t 21
<210> 35<210> 35
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 35<400> 35
ggaggtgatg gtgtttctta g 21ggaggtgatg gtgtttctta g 21
<210> 36<210> 36
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 36<400> 36
gagaagatca ctgaagaaac t 21gagaagatca ctgaagaaac t 21
<210> 37<210> 37
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 37<400> 37
gctttaatgg ctttacaaag c 21gctttaatgg ctttacaaag c 21
<210> 38<210> 38
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 38<400> 38
ggctttacaa agctggcaat a 21ggctttacaa agctggcaat a 21
<210> 39<210> 39
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 39<400> 39
gctttacaaa gctggcaata t 21gctttacaaa gctggcaata t 21
<210> 40<210> 40
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 40<400> 40
gctccgtact ctaacatcta g 21gctccgtact ctaacatcta g 21
<210> 41<210> 41
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 41<400> 41
gatgaccaca ttcaaggaag a 21gatgaccaca ttcaaggaag a 21
<210> 42<210> 42
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 42<400> 42
gaccacattc aaggaagaac t 21gaccacattc aaggaagaac t 21
<210> 43<210> 43
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 43<400> 43
gctttcctgc ttggcagtta t 21gctttcctgc ttggcagtta t 21
<210> 44<210> 44
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 44<400> 44
ggcagttatt cttccacaag a 21ggcagttatt cttccacaag a 21
<210> 45<210> 45
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 45<400> 45
gcagttattc ttccacaaga g 21gcagttattc ttccacaaga g 21
<210> 46<210> 46
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 46<400> 46
gcgtaagtct gagtgtcatt t 21gcgtaagtct gagtgtcatt t 21
<210> 47<210> 47
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 47<400> 47
gacaatttaa ggaagaatct t 21gacaatttaa ggaagaatct t 21
<210> 48<210> 48
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 48<400> 48
ggccatagtt ctccctgatt g 21ggccatagtt ctccctgatt g 21
<210> 49<210> 49
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 49<400> 49
gccatagttc tccctgattg a 21gccatagttc tccctgattg a 21
<210> 50<210> 50
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 50<400> 50
gcagatgacc acattcaagg a 21gcagatgacc acattcaagg a 21
<210> 51<210> 51
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 51<400> 51
gatgaccaca ttcaaggaag a 21gatgaccaca ttcaaggaag a 21
<210> 52<210> 52
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 52<400> 52
gaccacattc aaggaagaac c 21gaccacattc aaggaagaac c 21
<210> 53<210> 53
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 53<400> 53
gctttgtcag gaccaggttg t 21gctttgtcag gaccaggttg t 21
<210> 54<210> 54
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 54<400> 54
gaccaggttg ttactggttc a 21gaccaggttg ttactggttc a 21
<210> 55<210> 55
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 55<400> 55
gaagcctcac agctttgatg g 21gaagcctcac agctttgatg g 21
<210> 56<210> 56
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 56<400> 56
gatggcagtg cctcatcttc a 21gatggcagtg cctcatcttc a 21
<210> 57<210> 57
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 57<400> 57
ggcagtgcct catcttcaac t 21ggcagtgcct catcttcaac t 21
<210> 58<210> 58
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 58<400> 58
gcagcaggat aagtatgagt g 21gcagcaggat aagtatgagt g 21
<210> 59<210> 59
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 59<400> 59
gcaggataag tatgagtgtc a 21gcaggataag tatgagtgtc a 21
<210> 60<210> 60
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 60<400> 60
ggttcctgca cagagacatc t 21ggttcctgca cagagacatc t 21
<210> 61<210> 61
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 61<400> 61
gcacagagac atctataacc a 21gcacaagagac atctataacc a 21
<210> 62<210> 62
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 62<400> 62
gagacatcta taaccaagag g 21gagacatcta taaccaagag g 21
<210> 63<210> 63
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 63<400> 63
gagtactgga acagccagaa g 21gagtactgga acagccagaa g 21
<210> 64<210> 64
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 64<400> 64
gctttcctgc ttggctctta t 21gctttcctgc ttggctctta t 21
<210> 65<210> 65
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 65<400> 65
ggctcttatt cttccacaag a 21ggctcttatt cttccacaag a 21
<210> 66<210> 66
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 66<400> 66
gctcttattc ttccacaaga g 21gctcttattc ttccacaaga g 21
<210> 67<210> 67
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 67<400> 67
ggatgtggaa cccacagata c 21ggatgtggaa cccacagata c 21
<210> 68<210> 68
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 68<400> 68
gatgtggaac ccacagatac a 21gatgtggaac ccacagatac a 21
<210> 69<210> 69
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 69<400> 69
gtggaaccca cagatacaga g 21gtggaaccca cagatacaga g 21
<210> 70<210> 70
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 70<400> 70
ggaacccaca gatacagaga g 21ggaacccaca gatacagaga g 21
<210> 71<210> 71
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 71<400> 71
gagccaactg tattgcctat t 21gagccaactg tattgcctat t 21
<210> 72<210> 72
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 72<400> 72
agccaactgt attgcctatt t 21agccaactgt attgcctatt t 21
<210> 73<210> 73
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 73<400> 73
gccaactgta ttgcctattt g 21gccaactgta ttgcctattt g 21
<210> 74<210> 74
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 74<400> 74
gggtagcaac tgtcaccttg a 21gggtagcaac tgtcaccttg a 21
<210> 75<210> 75
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 75<400> 75
ggatttcgtg ttccagttta a 21ggatttcgtg ttccagttta a 21
<210> 76<210> 76
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 76<400> 76
gcatgtgcta cttcaccaac g 21gcatgtgcta cttcaccaac g 21
<210> 77<210> 77
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 77<400> 77
gcgtcttgtg accagataca t 21gcgtcttgtg accagataca t 21
<210> 78<210> 78
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 78<400> 78
gcttatgcct gcccagaatt c 21gcttatgcct gcccagaatt c 21
<210> 79<210> 79
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 79<400> 79
gcaggaaatc actgcagaat g 21gcaggaaatc actgcagaat g 21
<210> 80<210> 80
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 80<400> 80
gctcagtgca ttggccttag a 21gctcagtgca ttggccttag a 21
<210> 81<210> 81
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 81<400> 81
ggtgagtgct gtgtaaataa g 21ggtgagtgct gtgtaaataa g 21
<210> 82<210> 82
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 82<400> 82
gacatatata gtgatccttg g 21gacatatata gtgatccttg g 21
<210> 83<210> 83
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 83<400> 83
ggaaagtcac atcgatcaag a 21ggaaagtcac atcgatcaag a 21
<210> 84<210> 84
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 84<400> 84
gctcacagtc atcaattata g 21gctcacagtc atcaattata g 21
<210> 85<210> 85
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 85<400> 85
gccctgaaga cagaatgttc c 21gccctgaaga cagaatgttc c 21
<210> 86<210> 86
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 86<400> 86
gcggaccatg tgtcaactta t 21gcggaccatg tgtcaactta t 21
<210> 87<210> 87
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 87<400> 87
ggaccatgtg tcaacttatg c 21ggaccatgtg tcaacttatg c 21
<210> 88<210> 88
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 88<400> 88
gcgtttgtac agacgcatag a 21gcgtttgtac agacgcatag a 21
<210> 89<210> 89
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 89<400> 89
ggctggctaa cattgctata t 21ggctggctaa cattgctata t 21
<210> 90<210> 90
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 90<400> 90
gctggctaac attgctatat t 21gctggctaac attgctatat t 21
<210> 91<210> 91
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 91<400> 91
ggaccaggtc acatgtgaat a 21ggaccaggtc acatgtgaat a 21
<210> 92<210> 92
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 92<400> 92
ggaaaggtct gaggatattg a 21ggaaaggtct gaggatattg a 21
<210> 93<210> 93
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 93<400> 93
ggcagattag gattccattc a 21ggcagattag gattccattc a 21
<210> 94<210> 94
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 94<400> 94
gcctgatagg acccatattc c 21gcctgatagg acccatattc c 21
<210> 95<210> 95
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 95<400> 95
gcatccaata gacgtcattt g 21gcatccaata gacgtcattt g 21
<210> 96<210> 96
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 96<400> 96
gcgtcactgg cacagatata a 21gcgtcactgg cacagatata a 21
<210> 97<210> 97
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 97<400> 97
gctgtcacat aataagctaa g 21gctgtcacat aataagctaa g 21
<210> 98<210> 98
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 98<400> 98
gctaaggaag acagtatata g 21gctaaggaag acagtatata g 21
<210> 99<210> 99
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 99<400> 99
gggatttcta aggaaggatg c 21gggatttcta aggaaggatg c 21
<210> 100<210> 100
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 100<400> 100
ggagttgaag agcagagatt c 21ggagttgaag agcagagatt c 21
<210> 101<210> 101
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 101<400> 101
gccagtgaac acttaccata g 21gccagtgaac acttaccata g 21
<210> 102<210> 102
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 102<400> 102
gcttctctga agtctcattg a 21gcttctctga agtctcattg a 21
<210> 103<210> 103
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 103<400> 103
ggctgcaact aacttcaaat a 21ggctgcaact aacttcaaat a 21
<210> 104<210> 104
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 104<400> 104
ggatggattt gattatgatc c 21ggatggattt gattatgatc c 21
<210> 105<210> 105
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 105<400> 105
ggaccttgga acaatggatt g 21ggaccttgga acaatggatt g 21
<210> 106<210> 106
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 106<400> 106
gctaattctt gctgaacttc t 21gctaattctt gctgaacttc t 21
<210> 107<210> 107
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 107<400> 107
gctgaacttc ttcatgtatg t 21gctgaacttc ttcatgtatg t 21
<210> 108<210> 108
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 108<400> 108
gcctcatctc tttgttctaa a 21gcctcatctc tttgttctaa a 21
<210> 109<210> 109
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 109<400> 109
gctctggaga agatatattt g 21gctctggaga agatatattt g 21
<210> 110<210> 110
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 110<400> 110
gctcttgagg gaactaatag a 21gctcttgagg gaactaatag a 21
<210> 111<210> 111
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 111<400> 111
gggacggcat taatgtattc a 21gggacggcat taatgtattc a 21
<210> 112<210> 112
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 112<400> 112
ggacaaacat gcaaactata g 21ggacaaacat gcaaactata g 21
<210> 113<210> 113
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 113<400> 113
gcagcaacca gctaccattc t 21gcagcaacca gctaccattc t 21
<210> 114<210> 114
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 114<400> 114
gcagttctgt tgccactctc t 21gcagttctgt tgccactctc t 21
<210> 115<210> 115
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 115<400> 115
gggagagttc atccaggaaa t 21gggagagttc atccaggaaa t 21
<210> 116<210> 116
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 116<400> 116
ggagagttca tccaggaaat t 21ggagagttca tccaggaaat t 21
<210> 117<210> 117
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 117<400> 117
gagagttcat ccaggaaatt a 21gagagttcat ccaggaaatt a 21
<210> 118<210> 118
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 118<400> 118
gcctgtcaaa gagagagagc a 21gcctgtcaaa gagagagagc a 21
<210> 119<210> 119
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 119<400> 119
gctcagcttc gtactgagtt c 21gctcagcttc gtactgagtt c 21
<210> 120<210> 120
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 120<400> 120
gcttcacaga actacagaga g 21gcttcacaga actacagaga g 21
<210> 121<210> 121
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 121<400> 121
gcatctactg gacaaagtat t 21gcatctactg gacaaagtat t 21
<210> 122<210> 122
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 122<400> 122
ggctgaatta cccatgcttt a 21ggctgaatta cccatgcttt a 21
<210> 123<210> 123
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 123<400> 123
gctgaattac ccatgcttta a 21gctgaattac ccatgcttta a 21
<210> 124<210> 124
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 124<400> 124
gggttggttt atccaggaat a 21gggttggttt atccaggaat a 21
<210> 125<210> 125
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 125<400> 125
ggatcagaag agaagccaac g 21ggatcagaag agaagccaac g 21
<210> 126<210> 126
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 126<400> 126
ggttcaccat ccaggtgttc a 21ggttcaccat ccaggtgttc a 21
<210> 127<210> 127
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 127<400> 127
gctctcttct ctggaactaa c 21gctctcttct ctggaactaa c 21
<210> 128<210> 128
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 128<400> 128
gctagagtga ctccatctta a 21gctagagtga ctccatctta a 21
<210> 129<210> 129
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 129<400> 129
gctgaccacc aattataatt g 21gctgaccacc aattataatt g 21
<210> 130<210> 130
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 130<400> 130
gcagaatatt taaggccata c 21gcagaatatt taaggccata c 21
<210> 131<210> 131
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 131<400> 131
gcccacttaa aggcagcatt a 21gcccacttaa aggcagcatt a 21
<210> 132<210> 132
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 132<400> 132
ggtcatcaat accactgtta a 21ggtcatcaat accactgtta a 21
<210> 133<210> 133
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 133<400> 133
gcattcctcc ttctcctttc t 21gcattcctcc ttctcctttc t 21
<210> 134<210> 134
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 134<400> 134
ggaggaactt tgtgaacatt c 21ggaggaactt tgtgaacatt c 21
<210> 135<210> 135
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 135<400> 135
gctgtaagaa ggatgctttc a 21gctgtaagaa ggatgctttc a 21
<210> 136<210> 136
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 136<400> 136
gctgcaggca ggattgtttc a 21gctgcaggca ggattgtttc a 21
<210> 137<210> 137
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 137<400> 137
gcagttcgag gtcaagtttg a 21gcagttcgag gtcaagtttg a 21
<210> 138<210> 138
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 138<400> 138
gccaattagc tgagaagaat t 21gccaattagc tgagaagaat t 21
<210> 139<210> 139
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 139<400> 139
gcaggtttac agtgtatatg t 21gcaggtttac agtgtatatg t 21
<210> 140<210> 140
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 140<400> 140
gcctacagag actagagtag g 21gcctacagag actagagtag g 21
<210> 141<210> 141
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 141<400> 141
gcagttgggt accttccatt c 21gcagttgggt accttccatt c 21
<210> 142<210> 142
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 142<400> 142
gcaactcagg tgcatgatac a 21gcaactcagg tgcatgatac a 21
<210> 143<210> 143
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 143<400> 143
gcatggcgct ggtacgtaaa t 21gcatggcgct ggtacgtaaa t 21
<210> 144<210> 144
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 144<400> 144
gcctcgagtt tgagagcta 19gcctcgagtt tgagagcta 19
<210> 145<210> 145
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 145<400> 145
agacattctg gatgagtta 19agacattctg gatgagtta 19
<210> 146<210> 146
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 146<400> 146
gggtctgtta cccaaagaa 19gggtctgtta cccaaagaa 19
<210> 147<210> 147
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 147<400> 147
ggtctgttac ccaaagaat 19ggtctgttac ccaaagaat 19
<210> 148<210> 148
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 148<400> 148
ggaaggaagc ggacgctca 19ggaaggaagc ggacgctca 19
<210> 149<210> 149
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 149<400> 149
ggaggcagta cttctgata 19ggaggcagta cttctgata 19
<210> 150<210> 150
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 150<400> 150
cgctctagag ctcagctga 19cgctctagag ctcagctga 19
<210> 151<210> 151
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 151<400> 151
ccaccacctc aaccaataa 19ccaccacctc aaccaataa 19
<210> 152<210> 152
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 152<400> 152
atttcaagaa gtcgatcaa 19atttcaagaa gtcgatcaa 19
<210> 153<210> 153
<211> 19<211> 19
<212> DNA<212> DNA
<213> human<213> human
<400> 153<400> 153
gaagatctga ttaccttca 19gaagatctga ttaccttca 19
<210> 154<210> 154
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 154<400> 154
ggacactggt tcaacacctg t 21ggacactggt tcaacacctg t 21
<210> 155<210> 155
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 155<400> 155
ggttcaacac ctgtgacttc a 21ggttcaacac ctgtgacttc a 21
<210> 156<210> 156
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 156<400> 156
acctgtgact tcatgtgtgc g 21acctgtgact tcatgtgtgc g 21
<210> 157<210> 157
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 157<400> 157
gctggacgtg accatcatgt a 21gctggacgtg accatcatgt a 21
<210> 158<210> 158
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 158<400> 158
ggacgtgacc atcatgtaca a 21ggacgtgacc atcatgtaca a 21
<210> 159<210> 159
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 159<400> 159
gacgtgacca tcatgtacaa g 21gacgtgacca tcatgtacaa g 21
<210> 160<210> 160
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 160<400> 160
acgtgaccat catgtacaag g 21acgtgaccat catgtacaag g 21
<210> 161<210> 161
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 161<400> 161
acgctatacc atctacctgg g 21acgctatacc atctacctgg g 21
<210> 162<210> 162
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 162<400> 162
gcctctatga cgacatcgag t 21gcctctatga cgacatcgag t 21
<210> 163<210> 163
<211> 21<211> 21
<212> DNA<212> DNA
<213> human<213> human
<400> 163<400> 163
gacatcgagt gcttccttat g 21gacatcgagt gcttccttat g 21
<210> 164<210> 164
<211> 253<211> 253
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 164<400> 164
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgctagcgcc acc 253cgctagcgcc acc 253
<210> 165<210> 165
<211> 9<211> 9
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 165<400> 165
ttcaagaga 9ttcaagaga 9
<210> 166<210> 166
<211> 686<211> 686
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 166<400> 166
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
ctttaccact ccctatcagt gatagagaaa agtgaaagtc gagtttacca ctccctatca 300ctttaccact ccctatcagt gatagagaaa agtgaaagtc gagtttacca ctccctatca 300
gtgatagaga aaagtgaaag tcgagtttac cactccctat cagtgataga gaaaagtgaa 360gtgatagaga aaagtgaaag tcgagtttac cactccctat cagtgataga gaaaagtgaa 360
agtcgagttt accactccct atcagtgata gagaaaagtg aaagtcgagt ttaccactcc 420agtcgagttt accactccct atcagtgata gagaaaagtg aaagtcgagt ttaccactcc 420
ctatcagtga tagagaaaag tgaaagtcga gtttaccact ccctatcagt gatagagaaa 480ctatcagtga tagagaaaag tgaaagtcga gtttaccact ccctatcagt gatagagaaa 480
agtgaaagtc gagtttacca ctccctatca gtgatagaga aaagtgaaag tcgagctcgg 540agtgaaagtc gagtttacca ctccctatca gtgatagaga aaagtgaaag tcgagctcgg 540
tacccgggtc gaggtaggcg tgtacggtgg gaggcctata taagcagagc tcgtttagtg 600tacccgggtc gaggtaggcg tgtacggtgg gaggcctata taagcagagc tcgtttagtg 600
aaccgtcaga tcgcctggag acgccatcca cgctgttttg acctccatag aagacaccgg 660aaccgtcaga tcgcctggag acgccatcca cgctgttttg acctccatag aagacaccgg 660
gaccgatcca gcctgctagc gccacc 686gaccgatcca gcctgctagc gccacc 686
<210> 167<210> 167
<211> 119<211> 119
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 167<400> 167
gaggcttcag tactttacag aatcgttgcc tgcacatctt ggaaacactt gctgggatta 60gaggcttcag tactttacag aatcgttgcc tgcacatctt ggaaacactt gctgggatta 60
cttcttcagg ttaacccaac agaaggctaa agaaggtata ttgctgttga cagtgagcg 119cttcttcagg ttaacccaac agaaggctaa agaaggtata ttgctgttga cagtgagcg 119
<210> 168<210> 168
<211> 19<211> 19
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 168<400> 168
tagtgaagcc acagatgta 19tagtgaagcc acagatgta 19
<210> 169<210> 169
<211> 119<211> 119
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 169<400> 169
tgcctactgc ctcggacttc aaggggctac tttaggagca attatcttgt ttactaaaac 60tgcctactgc ctcggacttc aaggggctac tttaggagca attatcttgt ttactaaaac 60
tgaatacctt gctatctctt tgatacattt ttacaaagct gaattaaaat ggtataaat 119tgaatacctt gctatctctt tgatacattt ttacaaagct gaattaaaat ggtataaat 119
<210> 170<210> 170
<211> 22<211> 22
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 170<400> 170
ccatagctca gtctggtcta tc 22ccatagctca gtctggtcta tc 22
<210> 171<210> 171
<211> 22<211> 22
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 171<400> 171
tcaggatgat ctggacgaag ag 22tcaggatgat ctggacgaag ag 22
<210> 172<210> 172
<211> 20<211> 20
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 172<400> 172
ccggtcctgg actttgtctc 20ccggtcctgg actttgtctc 20
<210> 173<210> 173
<211> 20<211> 20
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 173<400> 173
ctcgacatcg gcaaggtgtg 20ctcgacatcg gcaaggtgtg 20
<210> 174<210> 174
<211> 20<211> 20
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 174<400> 174
cgcattggag tcgctttaac 20cgcattggag tcgctttaac 20
<210> 175<210> 175
<211> 24<211> 24
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 175<400> 175
cgagctgcaa gaactcttcc tcac 24cgagctgcaa gaactcttcc tcac 24
<210> 176<210> 176
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 176<400> 176
cacggcactt acctgtgttc tgg 23cacggcactt acctgtgttc tgg 23
<210> 177<210> 177
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 177<400> 177
cagtacaggc atccctgtga aag 23cagtacaggc atccctgtga aag 23
<210> 178<210> 178
<211> 590<211> 590
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 178<400> 178
cccctctccc tccccccccc ctaacgttac tggccgaagc cgcttggaat aaggccggtg 60cccctctccc tccccccccc ctaacgttac tggccgaagc cgcttggaat aaggccggtg 60
tgcgtttgtc tatatgttat tttccaccat attgccgtct tttggcaatg tgagggcccg 120tgcgtttgtc tatatgttat tttccaccat attgccgtct tttggcaatg tgagggcccg 120
gaaacctggc cctgtcttct tgacgagcat tcctaggggt ctttcccctc tcgccaaagg 180gaaacctggc cctgtcttct tgacgagcat tcctaggggt ctttcccctc tcgccaaagg 180
aatgcaaggt ctgttgaatg tcgtgaagga agcagttcct ctggaagctt cttgaagaca 240aatgcaaggt ctgttgaatg tcgtgaagga agcagttcct ctggaagctt cttgaagaca 240
aacaacgtct gtagcgaccc tttgcaggca gcggaacccc ccacctggcg acaggtgcct 300aacaacgtct gtagcgaccc tttgcaggca gcggaacccc ccacctggcg acaggtgcct 300
ctgcggccaa aagccacgtg tataagatac acctgcaaag gcggcacaac cccagtgcca 360ctgcggccaa aagccacgtg tataagatac acctgcaaag gcggcacaac cccagtgcca 360
cgttgtgagt tggatagttg tggaaagagt caaatggctc tcctcaagcg tattcaacaa 420cgttgtgagt tggatagttg tggaaagagt caaatggctc tcctcaagcg tattcaacaa 420
ggggctgaag gatgcccaga aggtacccca ttgtatggga tctgatctgg ggcctcggtg 480ggggctgaag gatgcccaga aggtacccca ttgtatggga tctgatctgg ggcctcggtg 480
cacatgcttt acatgtgttt agtcgaggtt aaaaaaacgt ctaggccccc cgaaccacgg 540cacatgcttt acatgtgttt agtcgaggtt aaaaaaacgt ctaggccccc cgaaccacgg 540
ggacgtggtt ttcctttgaa aaacacgatg ataatatggc cacaaccatg 590ggacgtggtt ttcctttgaa aaacacgatg ataatatggc cacaaccatg 590
<210> 179<210> 179
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 179<400> 179
cgcgagcaca gctaaggcca cgg 23cgcgagcaca gctaaggcca cgg 23
<210> 180<210> 180
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 180<400> 180
actctctctt tctggcctgg agg 23actctctctt tctggcctgg agg 23
<210> 181<210> 181
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 181<400> 181
acccagcagg gcgtggagcc agg 23acccagcagg gcgtggagcc agg 23
<210> 182<210> 182
<211> 23<211> 23
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 182<400> 182
gtcagagccc caaggtaaaa agg 23gtcagagccc caaggtaaaa agg 23
<210> 183<210> 183
<211> 60<211> 60
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 183<400> 183
atgtacagga tgcaactcct gtcttgcatt gcactaagtc ttgcacttgt cacgaattcg 60atgtacagga tgcaactcct gtcttgcatt gcactaagtc ttgcacttgt cacgaattcg 60
Claims (20)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011186002.6A CN114457024A (en) | 2020-10-30 | 2020-10-30 | A pluripotent stem cell expressing IL-4Rα blocker or its derivative and application |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011186002.6A CN114457024A (en) | 2020-10-30 | 2020-10-30 | A pluripotent stem cell expressing IL-4Rα blocker or its derivative and application |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114457024A true CN114457024A (en) | 2022-05-10 |
Family
ID=81403991
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011186002.6A Pending CN114457024A (en) | 2020-10-30 | 2020-10-30 | A pluripotent stem cell expressing IL-4Rα blocker or its derivative and application |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114457024A (en) |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150056225A1 (en) * | 2012-04-17 | 2015-02-26 | University Of Washington Through Its Center For Commercialization | HLA Class II Deficient Cells, HLA Class I Deficient Cells Capable of Expressing HLA Class II Proteins, and Uses Thereof |
| CN105764926A (en) * | 2013-09-24 | 2016-07-13 | 梅迪塞纳医疗股份有限公司 | Interleukin-4 receptor binding fusion protein and application thereof |
| CN108368520A (en) * | 2015-11-04 | 2018-08-03 | 菲特治疗公司 | Genome engineering of pluripotent cells |
| CN110249045A (en) * | 2016-11-24 | 2019-09-17 | 剑桥企业有限公司 | controlled transcription |
| CN110637083A (en) * | 2017-03-20 | 2019-12-31 | 华盛顿大学 | Cells and methods for their use and preparation |
| CN110819592A (en) * | 2018-08-13 | 2020-02-21 | 赛元生物科技(杭州)有限公司 | Universal donor stem cell and preparation method thereof |
| CN110951693A (en) * | 2019-12-05 | 2020-04-03 | 北京兴元和济生命医学科技有限公司 | Method for knocking in exogenous gene into mesenchymal stem cells at fixed point by using CRISPR-Cas9 system |
| CN110996975A (en) * | 2017-04-13 | 2020-04-10 | 森迪生物科学公司 | Combination Cancer Immunotherapy |
| CN111386123A (en) * | 2017-11-22 | 2020-07-07 | 布里格姆及妇女医院股份有限公司 | MSC-expressed immunomodulators combined with CAR-T for cancer therapy |
| WO2020168317A2 (en) * | 2019-02-15 | 2020-08-20 | President And Fellows Of Harvard College | Universal donor stem cells and related methods |
| CN111647082A (en) * | 2018-12-27 | 2020-09-11 | 中山康方生物医药有限公司 | Antibody against human IL-4RA and use thereof |
| CN114657133A (en) * | 2020-12-22 | 2022-06-24 | 未来智人再生医学研究院(广州)有限公司 | A pluripotent stem cell expressing shRNA and/or shRNA-miR targeting IL-4Rα |
-
2020
- 2020-10-30 CN CN202011186002.6A patent/CN114457024A/en active Pending
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150056225A1 (en) * | 2012-04-17 | 2015-02-26 | University Of Washington Through Its Center For Commercialization | HLA Class II Deficient Cells, HLA Class I Deficient Cells Capable of Expressing HLA Class II Proteins, and Uses Thereof |
| CN105764926A (en) * | 2013-09-24 | 2016-07-13 | 梅迪塞纳医疗股份有限公司 | Interleukin-4 receptor binding fusion protein and application thereof |
| CN108368520A (en) * | 2015-11-04 | 2018-08-03 | 菲特治疗公司 | Genome engineering of pluripotent cells |
| CN110249045A (en) * | 2016-11-24 | 2019-09-17 | 剑桥企业有限公司 | controlled transcription |
| CN110637083A (en) * | 2017-03-20 | 2019-12-31 | 华盛顿大学 | Cells and methods for their use and preparation |
| CN110996975A (en) * | 2017-04-13 | 2020-04-10 | 森迪生物科学公司 | Combination Cancer Immunotherapy |
| CN111386123A (en) * | 2017-11-22 | 2020-07-07 | 布里格姆及妇女医院股份有限公司 | MSC-expressed immunomodulators combined with CAR-T for cancer therapy |
| CN110819592A (en) * | 2018-08-13 | 2020-02-21 | 赛元生物科技(杭州)有限公司 | Universal donor stem cell and preparation method thereof |
| CN111647082A (en) * | 2018-12-27 | 2020-09-11 | 中山康方生物医药有限公司 | Antibody against human IL-4RA and use thereof |
| WO2020168317A2 (en) * | 2019-02-15 | 2020-08-20 | President And Fellows Of Harvard College | Universal donor stem cells and related methods |
| CN110951693A (en) * | 2019-12-05 | 2020-04-03 | 北京兴元和济生命医学科技有限公司 | Method for knocking in exogenous gene into mesenchymal stem cells at fixed point by using CRISPR-Cas9 system |
| CN114657133A (en) * | 2020-12-22 | 2022-06-24 | 未来智人再生医学研究院(广州)有限公司 | A pluripotent stem cell expressing shRNA and/or shRNA-miR targeting IL-4Rα |
Non-Patent Citations (5)
| Title |
|---|
| AKKOÇ T ET AL: "Asthma immunotherapy and treatment approaches with mesenchymal stem cells", IMMUNOTHERAPY, vol. 12, no. 9, 3 July 2020 (2020-07-03) * |
| RICHARD T. FRANK ET AL: "Concise Review: Stem Cells As an Emerging Platform for Antibody Therapy of Cancer", STEM CELLS, vol. 18, no. 11, 30 November 2010 (2010-11-30), pages 1 - 2 * |
| SANTINI G ET AL: "Dupilumab for the treatment of asthma", EXPERT OPINION ON INVESTIGATIONAL DRUGS, vol. 26, no. 3, 4 September 2014 (2014-09-04) * |
| 余刚: "hIL-37基因修饰的骨髓间充质干细胞对哮喘治疗作用的研究 余刚", 万方数据, 29 December 2015 (2015-12-29) * |
| 黄世杰: "dupilumab长期治疗中重度特应性皮炎的Ⅲ期临床试验获阳性资料", 国际药学研究杂志, vol. 44, no. 4, 30 April 2017 (2017-04-30), pages 365 * |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2022037481A1 (en) | Immunologically compatible and reversible universal pluripotent stem cell and application thereof | |
| CN114657133A (en) | A pluripotent stem cell expressing shRNA and/or shRNA-miR targeting IL-4Rα | |
| KR20240170824A (en) | Method and composition for producing granulosa-like cells | |
| CN114107211B (en) | A pluripotent stem cell and its derivatives | |
| CN114426953A (en) | Pluripotent stem cell derivative for expressing IL-12 and application thereof | |
| CN114457024A (en) | A pluripotent stem cell expressing IL-4Rα blocker or its derivative and application | |
| CN114657131A (en) | Pluripotent stem cell expressing urate oxidase or derivative thereof | |
| CN114657136A (en) | Pluripotent stem cell expressing shRNA and/or shRNA-miR of target PCSK9 or derivative thereof | |
| CN114525255A (en) | Pluripotent stem cell derivative for expressing IL-11 and application thereof | |
| CN114645021A (en) | Pluripotent stem cell expressing targeted CD47 inhibitory factor, derivative and application thereof | |
| CN114657135A (en) | Pluripotent stem cell expressing Tim-3 targeted inhibitory factor, derivative and application thereof | |
| CN114457034A (en) | Pluripotent stem cell derivative for expressing IL-1 blocker and application thereof | |
| CN114457030A (en) | A kind of pluripotent stem cell expressing IgE blocker or its derivative and application | |
| CN114507643A (en) | Pluripotent stem cell derivative for expressing IL-2 and application thereof | |
| CN114657134A (en) | A pluripotent stem cell or a derivative thereof expressing shRNA and/or shRNA-miR targeting IgE | |
| CN114457026A (en) | A pluripotent stem cell expressing 4-1BB activating antibody and its derivatives and applications | |
| CN114517184A (en) | Pluripotent stem cell expressing adipsin or derivative thereof and application thereof | |
| CN114457031A (en) | Pluripotent stem cell expressing B7-H5 blocking substance or derivative thereof and application | |
| CN114525254A (en) | FGF-21-expressing pluripotent stem cell or derivative thereof and application | |
| CN114457029A (en) | Pluripotent stem cell expressing VEGF-A blocking substance or derivative thereof and application | |
| CN114717193A (en) | Pluripotent stem cell expressing shRNA and/or shRNA-miR targeting B7-H5 or derivative thereof | |
| CN114350611A (en) | Pluripotent stem cells expressing effector RNA molecules targeting PD-1/PD-L1 and derivatives thereof | |
| CN114657137A (en) | A pluripotent stem cell or a derivative thereof expressing shRNA and/or shRNA-miR targeting BTLA | |
| CN114457035A (en) | Pluripotent stem cell expressing LAG-3 blocking substance or derivative thereof and application | |
| CN114457032A (en) | A pluripotent stem cell expressing B7-H4 blocker or its derivative and application |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |