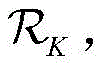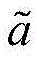Disclosure of Invention
The present application is directed to solving at least the problems of the prior art, and based on the inventors' knowledge and understanding of the following facts and problems, the design of a reward function requires much effort when solving a decision problem with reinforcement learning. Complex decision problems have many constraints, and except that the reward after the task is executed is easy to judge, the reward in the middle process is difficult to design in detail. If the design is not proper, the intelligent agent learns wrong knowledge so that the task is executed unsuccessfully, and irreparable results appear in the serious condition. For such a problem of sparse reward, a large amount of invalid searches are performed in the early learning stage, feedback of a reward function cannot be obtained even if many wrong strategies are tried, and learning efficiency is extremely low. Thus, an action filter established based on expert knowledge effectively filters the generated actions, and converts illegal actions into legal actions, which is an effective means for solving the problem. At present, the problem of reinforcement learning aiming at sparse rewards is still a difficult point.
In view of the above, the present disclosure provides an agent reinforcement learning decision method, an agent reinforcement learning decision device, an electronic device, and a storage medium thereof, so as to implement a reinforcement learning decision method based on confidence action filtering, in which expert knowledge data is used to fill a Replay Buffer in a reinforcement learning algorithm, expert knowledge is used to filter learned actions to obtain an effective action, whether the expert action is adopted is determined according to a confidence degree, and an important technical problem that efficient learning cannot be performed in reinforcement learning based on sparse reward is solved.
According to a first aspect of the present disclosure, an agent reinforcement learning decision method is provided, including:
step 1, constructing an expert knowledge data set for an intelligent agent reinforcement learning decision;
step 2, constructing a playback buffer module of the reinforcement learning network;
step 3, training the reinforcement learning network to obtain an intelligent agent preliminary strategy and action;
and 4, setting an action filtering module, filtering the initial strategy of the intelligent agent, and determining the final action of the intelligent agent by using a confidence function.
The disclosure is a reinforcement learning decision method under the condition of solving sparse reward. Compared with the existing method, the method has good universality and easy operability for solving the problem of complex scenes. The method mainly comprises two aspects, wherein when the expert training data set is constructed, the scene is simplified into a linear programming or dynamic programming solution, and then a reward function is added to the solution to form the expert training data set. And secondly, when the final action of the intelligent agent is selected, a simple confidence coefficient method is added to ensure that the intelligent agent selects the optimal action which meets the conditions.
Optionally, the constructing an expert knowledge data set for an agent reinforcement learning decision includes:
(1) for a scene in which a target equation and a constraint equation are linearly expressed, acquiring action information and state information of the intelligent agent by adopting a linear programming method, and for a scene needing iterative solution, acquiring the action information and the state information of the intelligent agent by adopting a dynamic programming method;
(2) obtaining the current state information s, the action information a, the state information s' of the agent at the next moment and the mark d for judging whether the task is terminated under N different simple scenes according to a linear programming or dynamic programming method, and forming a knowledge data set by the information
Wherein i represents the relevant information of the agent decision in the ith scene;
(3) for the knowledge data set
Each item of data sets a reward function r
i;
(4) The reward function r is set
iAnd the set
Merging and constructing to obtain an expert knowledge data set for the reinforcement learning decision of the intelligent agent
Optionally, a playback buffer module of the reinforcement learning network
Comprises two parts, the first part is a fixed list
The first part is used for storing expert knowledge data, accounts for 30% of the length of the playback buffer module, and is called an expert data playback buffer zone; the second part is a first-in first-out queue
The system is used for storing samples collected by the intelligent agent from the environment and is called an environment data playback buffer zone; the queue is empty during initialization, and is updated according to a first-in first-out algorithm after the queue is full.
Optionally, the training of the reinforcement learning network to obtain an agent preliminary strategy and action includes the following steps:
(1) in the complex environment problem, the intelligent agent collects samples from the environment for multiple times, obtains at least one batch of environment data with the quantity of B, and stores the environment data into the first-in first-out queue
Performing the following steps;
(2) respectively from the fixed list
And a first-in first-out queue
The training samples are randomly drawn to form training data with a batch number B, and 30% of the training data is from
70% from
Inputting training data into reinforcement learning algorithm, outputting intelligent agent preliminary strategy by reinforcement learning algorithm
And agent preliminary actions
Wherein
Is a probability distribution about the agent's preliminary actions,
optionally, the setting an action filtering module filters the preliminary policy of the agent, and determines the final action of the agent by using a confidence function, including:
(1) setting a motion filtering module F
afThe action filtering module expresses the limiting conditions of the complex environment problem as an inequality equation set and the intelligent agent preliminary strategy
The output is used as the input of the action filtering module to obtain the filtering action of the intelligent agent
(2) Setting a confidence function fc:
Preliminary actions from the agent
With filtering actions by agent
Selecting a final action a of the agent, and training a subsequent network by using the final action;
(3) setting a loss function L, training the reinforcement learning network by using an Adam algorithm with the aim of minimizing the loss function until the loss function is converged to obtain the trained reinforcement learning network;
wherein beta is a hyperparameter, FafThe motion filtering module, | ·| non-woven phosphor2Is a two-norm, i is the serial number of the training data, B is the B pieces of data of the batch, and L 'is the loss function of the initial reinforcement learning algorithm and is defined as L' ((r + gamma. max (Q (s ', a'))) -Q (s, a))2Wherein s, a, r represent the current state information, action information and reward function of the agent, s ', a' represent the state information and action information of the agent at the next time, γ ═ 0.9, Q (s, a) is a variable related to the state information and action information, and is generated by the neural network, (·)2Is a square operator;
(4) and taking the state information of each step in the task as the input of the trained reinforcement learning network to obtain the final action of the intelligent agent.
According to the second aspect of the present disclosure, an intelligent agent reinforcement learning decision device is further provided, including:
the expert knowledge data set construction module is used for constructing an expert knowledge data set for an intelligent agent reinforcement learning decision;
constructing a playback buffer module for constructing a playback buffer module of the reinforcement learning network,
the intelligent agent preliminary action generation module is used for training the reinforcement learning network to obtain an intelligent agent preliminary strategy and action;
and the intelligent agent final action generating module is used for setting an action filtering module, filtering the intelligent agent preliminary strategy and determining the intelligent agent final action by utilizing the confidence function.
According to a third aspect of the present disclosure, an electronic device is presented, comprising:
a memory for storing processor-executable instructions;
a processor configured to perform any of the agent reinforcement learning decision methods of claims 1-5.
According to a fourth aspect of the present disclosure, a computer-readable storage medium is proposed, having stored thereon a computer program for causing a computer to execute:
constructing an expert knowledge data set for an agent reinforcement learning decision;
constructing a playback buffer module of the reinforcement learning network,
training the reinforcement learning network to obtain an intelligent agent preliminary strategy and action;
and setting an action filtering module, filtering the initial strategy of the intelligent agent, and determining the final action of the intelligent agent by using a confidence function.
According to a fourth invention of the present invention, there is provided a computer-readable storage medium having stored thereon a computer program for causing a computer to execute:
constructing an expert knowledge data set for an agent reinforcement learning decision;
constructing a playback buffer module of the reinforcement learning network,
training the reinforcement learning network to obtain an intelligent agent preliminary strategy and action;
and setting an action filtering module, filtering the initial strategy of the intelligent agent, and determining the final action of the intelligent agent by using a confidence function.
A method for constructing a demonstration data set is generally adopted when the problem of sparse rewarding reinforcement learning in a complex scene is solved, and the demonstration data set is also an expert knowledge data set. The main idea of constructing the data set is to collect track information formed by a series of complete state information and action information required by the agent to complete the task. The expert knowledge data set does not need a plurality of pieces of complete track information, and mainly adopts the results of linear programming and dynamic programming as the expert knowledge data after simplifying complex scenes, so that the process of data set acquisition is more efficient and convenient. In addition, the optimality of the planning result has theoretical guarantee, and the design of the reward function becomes very simple. The method also introduces a confidence function, compares the initial action of the intelligent agent generated by the reinforcement learning neural network with the filtering action of the intelligent agent generated by the action filtering module, and determines the final action of the intelligent agent. Other algorithms consider agent filtering actions to be optimal, but reinforcement learning may learn agent preliminary actions that are better than agent filtering actions after multiple explorations. Thus, the confidence function may select the best strategy for the agent for the corresponding task.
Additional aspects and advantages of the disclosure will be set forth in part in the description which follows and, in part, will be obvious from the description, or may be learned by practice of the disclosure.
Detailed Description
The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the drawings in the embodiments of the present application, and it is obvious that the described embodiments are only a part of the embodiments of the present application, and not all of the embodiments. All other embodiments, which can be derived by a person skilled in the art from the embodiments given herein without making any creative effort, shall fall within the protection scope of the present application.
Fig. 1 is a schematic flow chart of an intelligent agent reinforcement learning decision method according to an embodiment of the present disclosure, which may be applied to a user device, such as a mobile phone, a tablet computer, and the like.
As shown in fig. 1 and fig. 2, the intelligent agent reinforcement learning decision method may include the following steps:
in step 1, an expert knowledge data set for an agent reinforcement learning decision is constructed.
In a specific embodiment, the constructing of the expert knowledge data set for the reinforcement learning decision of the agent, the constructing of the expert knowledge data set by using the action information and the state information in the simple scene and the manually set reward function, includes:
(1) for a scene in which a target equation and a constraint equation are linearly expressed, acquiring action information and state information of the intelligent agent by adopting a linear programming method, and for a scene needing iterative solution, acquiring the action information and the state information of the intelligent agent by adopting a dynamic programming method;
(2) obtaining the current state information s, the action information a, the state information s' of the agent at the next moment and the mark d for judging whether the task is terminated under N different simple scenes according to a linear programming or dynamic programming method, and using the above stepsInformation is combined into a knowledge data set
Wherein i represents the relevant information of the agent decision in the ith scene;
(3) for the knowledge data set
Each item of data sets a reward function r
i;
(4) The reward function r is set
iAnd the set
Merging and constructing to obtain an expert knowledge data set for the reinforcement learning decision of the intelligent agent
In step 2, a playback buffer module of the reinforcement learning network is constructed, wherein one part of the module stores the expert knowledge data set, and the other part stores data of samples collected by the intelligent agent from the environment during network training.
In one embodiment, the playback buffer module of the reinforcement learning network
The (replay buffer) includes two parts, the first part being a fixed list
The first part is used for storing expert knowledge data, accounts for 30% of the length of the playback buffer module, and is called an expert data playback buffer zone; the second part is a first-in first-out queue
The system is used for storing samples collected by the intelligent agent from the environment and is called an environment data playback buffer zone; the queue is empty during initialization, and is updated according to a first-in first-out algorithm after the queue is full.
And step 3, training the reinforcement learning network to obtain the initial strategy and action of the intelligent agent.
In one embodiment, the training of the reinforcement learning network to obtain the initial strategy and action of the agent includes the following steps:
(1) in the complex environment problem, the intelligent agent collects samples from the environment for multiple times, obtains at least one batch of environment data with the quantity of B, and stores the environment data into the first-in first-out queue
Performing the following steps;
(2) respectively from the fixed list
And a first-in first-out queue
The training samples are randomly drawn to form training data with a batch number B, and 30% of the training data is from
70% from
Inputting training data into reinforcement learning algorithm, outputting intelligent agent preliminary strategy by reinforcement learning algorithm
And agent preliminary actions
Wherein
Is a probability distribution about the agent's preliminary actions,
x
0argmax (f (x)) is expressed when x is x
0The value of the function f (x) is maximized.
And 4, setting an action filtering module, filtering the initial strategy of the intelligent agent according to the constraint in the decision task required by the intelligent agent to obtain the filtering action of the intelligent agent, and determining the final action of the intelligent agent by using a confidence function.
In one embodiment, the action setting and filtering module filters the preliminary policy of the agent and determines the final action of the agent by using a confidence function, and the action setting and filtering module includes:
(1) setting a motion filtering module F
afThe action filtering module expresses the limiting conditions of the complex environment problem as an inequality equation set and the intelligent agent preliminary strategy
The output is used as the input of the action filtering module to obtain the filtering action of the intelligent agent
(2) Setting a confidence function fc:
Wherein p (-) represents the probability, α is the artificially set significance level,
in order not to violate system constraints
Ratio of
A better performing set of agent actions;
preliminary actions from the agent
With filtering actions by agent
Selecting a final action a of the agent, and training a subsequent network by using the final action;
(3) a loss function L is set up which is,
training the reinforcement learning network by using an Adam algorithm with a minimum loss function as a target until the loss function is converged to obtain the trained reinforcement learning network;
wherein beta is a hyperparameter which can be adaptively changed in the training process of the learning algorithm, FafThe motion filtering module, | ·| non-woven phosphor2Is a two-norm, i is the serial number of the training data, B is the B pieces of data of the batch, and L 'is the loss function of the initial reinforcement learning algorithm and is defined as L' ((r + gamma. max (Q (s ', a'))) -Q (s, a))2Wherein s, a, r represent the current state information, action information and reward function of the agent, s ', a' represent the state information and action information of the agent at the next time, γ ═ 0.9, Q (s, a) is a variable related to the state information and action information, and is generated by the neural network, (·)2Is a square operator;
(4) and taking the state information of each step in the task as the input of the trained reinforcement learning network to obtain the final action of the intelligent agent.
The disclosure is a reinforcement learning decision method under the condition of solving sparse reward. Compared with the existing method, the method has good universality and easy operability for solving the problem of complex scenes. The method mainly comprises two aspects, wherein when the expert training data set is constructed, the scene is simplified into a linear programming or dynamic programming solution, and then a reward function is added to the solution to form the expert training data set. And secondly, when the final action of the intelligent agent is selected, a simple confidence coefficient method is added to ensure that the intelligent agent selects the optimal action which meets the conditions.
Corresponding to the intelligent agent reinforcement learning decision method, the intelligent agent reinforcement learning decision device is further provided by the disclosure.
Fig. 3 is a schematic diagram of an intelligent agent reinforcement learning decision device according to an embodiment of the present disclosure, and as shown in fig. 3, the intelligent agent reinforcement learning decision device includes:
the expert knowledge data set construction module is used for constructing an expert knowledge data set for an intelligent agent reinforcement learning decision;
constructing a playback buffer module for constructing a playback buffer module of the reinforcement learning network,
the intelligent agent preliminary action generation module is used for training the reinforcement learning network to obtain an intelligent agent preliminary strategy and action;
and the intelligent agent final action generating module is used for setting an action filtering module, filtering the intelligent agent preliminary strategy according to the constraint in the decision task required by the intelligent agent to obtain the intelligent agent filtering action, and determining the intelligent agent final action by utilizing the confidence function.
An embodiment of the present disclosure also provides an electronic device, including:
a memory for storing processor-executable instructions;
a processor configured to perform:
constructing an expert knowledge data set for an agent reinforcement learning decision;
constructing a playback buffer module of the reinforcement learning network,
training the reinforcement learning network to obtain an intelligent agent preliminary strategy and action;
and setting an action filtering module, filtering the initial strategy of the intelligent agent, and determining the final action of the intelligent agent by using a confidence function.
Embodiments of the present disclosure also provide a computer-readable storage medium having stored thereon a computer program for causing a computer to execute:
constructing an expert knowledge data set for an agent reinforcement learning decision;
constructing a playback buffer module of the reinforcement learning network,
training the reinforcement learning network to obtain an intelligent agent preliminary strategy and action;
and setting an action filtering module, filtering the initial strategy of the intelligent agent, and determining the final action of the intelligent agent by using a confidence function.
A method for constructing a demonstration data set is generally adopted when the problem of sparse rewarding reinforcement learning in a complex scene is solved, and the demonstration data set is also an expert knowledge data set. The main idea of constructing the data set is to collect track information formed by a series of complete state information and action information required by the agent to complete the task. The expert knowledge data set does not need a plurality of pieces of complete track information, and mainly adopts the results of linear programming and dynamic programming as the expert knowledge data after simplifying complex scenes, so that the process of data set acquisition is more efficient and convenient. In addition, the optimality of the planning result has theoretical guarantee, and the design of the reward function becomes very simple. The method also introduces a confidence function, compares the initial action of the intelligent agent generated by the reinforcement learning neural network with the filtering action of the intelligent agent generated by the action filtering module, and determines the final action of the intelligent agent. Other algorithms consider agent filtering actions to be optimal, but reinforcement learning may learn agent preliminary actions that are better than agent filtering actions after multiple explorations. Thus, the confidence function may select the best strategy for the agent for the corresponding task.
It should be noted that, in the embodiment of the present disclosure, the Processor may be a Central Processing Unit (CPU), or may be other general-purpose processors, Digital Signal Processors (DSPs), Application Specific Integrated Circuits (ASICs), Field Programmable Gate Arrays (FPGAs) or other programmable logic devices, discrete Gate or transistor logic devices, discrete hardware components, and the like. The general-purpose processor may be a microprocessor or the processor may be any conventional processor or the like, the memory may be used for storing the computer program and/or the module, and the processor may realize various functions of the automobile accessory picture dataset making apparatus by executing or executing the computer program and/or the module stored in the memory and calling data stored in the memory. The memory may mainly include a storage program area and a storage data area, wherein the storage program area may store an operating system, an application program required by at least one function (such as a sound playing function, an image playing function, etc.), and the like; the storage data area may store data (such as audio data, a phonebook, etc.) created according to the use of the cellular phone, and the like. In addition, the memory may include high speed random access memory, and may also include non-volatile memory, such as a hard disk, a memory, a plug-in hard disk, a Smart Media Card (SMC), a Secure Digital (SD) Card, a Flash memory Card (Flash Card), at least one magnetic disk storage device, a Flash memory device, or other volatile solid state storage device. If the modules/units of the construction device of the wind power system operation stability domain are realized in the form of software functional units and sold or used as independent products, the modules/units can be stored in a computer readable storage medium. Based on such understanding, all or part of the flow of the method of the embodiments described above can be realized by the present disclosure, and the method can also be realized by the relevant hardware instructed by a computer program, which can be stored in a computer readable storage medium, and when the computer program is executed by a processor, the steps of the method embodiments described above can be realized. Wherein the computer program comprises computer program code, which may be in the form of source code, object code, an executable file or some intermediate form, etc. The computer-readable medium may include: any entity or device capable of carrying the computer program code, recording medium, usb disk, removable hard disk, magnetic disk, optical disk, computer Memory, Read Only Memory (ROM), Random Access Memory (RAM), electrical carrier wave signals, telecommunications signals, software distribution medium, etc. It should be noted that the above-described device embodiments are merely illustrative, where the units described as separate parts may or may not be physically separate, and the parts displayed as units may or may not be physical units, may be located in one place, or may be distributed on multiple network units. Some or all of the modules may be selected according to actual needs to achieve the purpose of the solution of the present embodiment. In addition, in the drawings of the embodiment of the device provided by the present disclosure, the connection relationship between the modules indicates that there is a communication connection between them, and may be specifically implemented as one or more communication buses or signal lines. One of ordinary skill in the art can understand and implement it without inventive effort.
The present disclosure is described in detail below with reference to the drawings and examples.
The method is used for verifying a decision method based on expert knowledge driving for sparse reward problems in deep reinforcement learning by taking a game for defending aircraft attack as an object.
An expert knowledge-driven decision flow chart for the sparse reward problem in deep reinforcement learning is shown in fig. 1, and mainly includes:
(1) and constructing an expert knowledge data set, and simplifying the intelligent agent defense problem of the complex scene that the airplane can randomly fly into a linear programming problem of the airplane linear flight or a dynamic programming problem of the sectional flight. Knowledge data sets can be determined from the planning algorithm
And endowing each piece of data in the knowledge data set with a reward function r according to artificial experience
iThe knowledge data set becomes an expert knowledge data set
(2) The method comprises the steps that an improved playback buffer module is obtained, data of all expert knowledge data sets are placed into an expert data playback buffer area, and sample data collected by an agent from the environment are placed into an environment data playback buffer area;
(3) and acquiring the initial action of the intelligent agent, and randomly drawing 128 samples from the playback buffer module to serve as training data, wherein 30% of the training data are expert knowledge data, and 70% of the training data are environmental data. Taking the sample as the input of a DDQN network to obtain an intelligent agent preliminary strategy and intelligent agent preliminary action;
(4) and acquiring the final action of the intelligent agent, and constructing an action filtering module according to the constraint conditions of weapon shot size, weapon shooting range and the like of the defense system. And taking the initial strategy of the intelligent agent as the input of the action filtering module to obtain the filtering action of the intelligent agent. In the learning process, an intelligent agent action set which is better than the intelligent agent filtering action in performance of the intelligent agent preliminary action when the system constraint is not violated is continuously constructed, and the final action of the intelligent agent is determined by utilizing a confidence function.
Acquiring the defense target state comprises the following steps: coordinates of a defended target;
acquiring the state of the defensive weapon comprises the following steps: coordinates of three weapons, the amount of residual charge in each weapon, and the weapon firing range, wherein the relationship between the defensive target and the weapon is shown in fig. 4 and 5.
Acquiring the aircraft state comprises: all the airplanes fly linearly or along a curve fixed in sections according to the current positions and the current headings of all the airplanes.
Calculating weapon launching moments when a plurality of airplanes are in direct flight at different initial positions according to linear programming or dynamic programming, putting the result in an Ex-replay-buffer as expert knowledge data in cooperation with a designed reward function, filtering actions generated by interaction between an agent and the environment through a filtering function generated by an expert system, storing the data in the Ex-replay-buffer after the actions of the weapons interact with the environment, randomly sampling the data in proportion from the Ex-replay-buffer during training to obtain batch training data, and inputting the training data into a reinforcement learning neural network to obtain the initial actions of the weapons.
And constructing an action filtering module according to constraints such as weapon range and the like, inputting the preliminary action into the action filtering module to obtain a filtering action, and determining a final action by using a confidence function.
When there are 12 planes attacking in any way, with 4 rounds per defensive weapon, the training results are shown in fig. 6, and the system converges only over 30 cycles. And the legal action remains 1 at all times. The test data is shown in fig. 7, and the test accuracy is as high as 97.3%.