CN113150155B - anti-PD-L1 humanized monoclonal antibody and application thereof - Google Patents
anti-PD-L1 humanized monoclonal antibody and application thereof Download PDFInfo
- Publication number
- CN113150155B CN113150155B CN202110436333.9A CN202110436333A CN113150155B CN 113150155 B CN113150155 B CN 113150155B CN 202110436333 A CN202110436333 A CN 202110436333A CN 113150155 B CN113150155 B CN 113150155B
- Authority
- CN
- China
- Prior art keywords
- seq
- cdr
- antibody
- amino acid
- acid sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 14
- 201000011510 cancer Diseases 0.000 claims abstract description 12
- 125000003275 alpha amino acid group Chemical group 0.000 claims abstract 14
- 108010074708 B7-H1 Antigen Proteins 0.000 claims description 17
- 102000008096 B7-H1 Antigen Human genes 0.000 claims description 16
- 239000002773 nucleotide Substances 0.000 claims description 16
- 125000003729 nucleotide group Chemical group 0.000 claims description 16
- 239000003814 drug Substances 0.000 claims description 2
- 239000003937 drug carrier Substances 0.000 claims description 2
- 239000008194 pharmaceutical composition Substances 0.000 claims description 2
- 238000004519 manufacturing process Methods 0.000 claims 1
- 230000001404 mediated effect Effects 0.000 claims 1
- 239000000203 mixture Substances 0.000 claims 1
- 210000004027 cell Anatomy 0.000 abstract description 18
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 abstract description 6
- 102000048776 human CD274 Human genes 0.000 abstract description 6
- 210000002865 immune cell Anatomy 0.000 abstract description 3
- 239000000427 antigen Substances 0.000 description 22
- 102000036639 antigens Human genes 0.000 description 22
- 108091007433 antigens Proteins 0.000 description 22
- 210000001744 T-lymphocyte Anatomy 0.000 description 18
- 150000001413 amino acids Chemical group 0.000 description 12
- 108090000623 proteins and genes Proteins 0.000 description 11
- 108020004414 DNA Proteins 0.000 description 9
- 230000027455 binding Effects 0.000 description 9
- 239000006228 supernatant Substances 0.000 description 7
- 108010074328 Interferon-gamma Proteins 0.000 description 6
- 102000000588 Interleukin-2 Human genes 0.000 description 6
- 108010002350 Interleukin-2 Proteins 0.000 description 6
- 101001117316 Mus musculus Programmed cell death 1 ligand 1 Proteins 0.000 description 6
- 241000699670 Mus sp. Species 0.000 description 6
- 229960003852 atezolizumab Drugs 0.000 description 6
- 108091028043 Nucleic acid sequence Proteins 0.000 description 5
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 5
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 5
- 239000013612 plasmid Substances 0.000 description 5
- 102000004169 proteins and genes Human genes 0.000 description 5
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 4
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 4
- 102100037850 Interferon gamma Human genes 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 238000010828 elution Methods 0.000 description 4
- 210000004408 hybridoma Anatomy 0.000 description 4
- 239000002609 medium Substances 0.000 description 4
- 238000000034 method Methods 0.000 description 4
- 210000001616 monocyte Anatomy 0.000 description 4
- 238000004091 panning Methods 0.000 description 4
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 238000012163 sequencing technique Methods 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 3
- 239000012980 RPMI-1640 medium Substances 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 230000037029 cross reaction Effects 0.000 description 3
- 238000010790 dilution Methods 0.000 description 3
- 239000012895 dilution Substances 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 239000000706 filtrate Substances 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 239000007788 liquid Substances 0.000 description 3
- 239000013642 negative control Substances 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- FEUPVVCGQLNXNP-IRXDYDNUSA-N Gly-Phe-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FEUPVVCGQLNXNP-IRXDYDNUSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 2
- RMNMUUCYTMLWNA-ZPFDUUQYSA-N Ile-Lys-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RMNMUUCYTMLWNA-ZPFDUUQYSA-N 0.000 description 2
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 2
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 2
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 241000699666 Mus <mouse, genus> Species 0.000 description 2
- 206010035226 Plasma cell myeloma Diseases 0.000 description 2
- 239000007983 Tris buffer Substances 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 230000009260 cross reactivity Effects 0.000 description 2
- 210000004748 cultured cell Anatomy 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 238000000684 flow cytometry Methods 0.000 description 2
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 2
- 239000012737 fresh medium Substances 0.000 description 2
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 2
- 108010050848 glycylleucine Proteins 0.000 description 2
- 238000002649 immunization Methods 0.000 description 2
- 230000003053 immunization Effects 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 230000031700 light absorption Effects 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 239000004005 microsphere Substances 0.000 description 2
- 238000007799 mixed lymphocyte reaction assay Methods 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 201000000050 myeloid neoplasm Diseases 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 2
- AVWQQPYHYQKEIZ-UHFFFAOYSA-K trisodium;2-dodecylbenzenesulfonate;3-dodecylbenzenesulfonate;4-dodecylbenzenesulfonate Chemical compound [Na+].[Na+].[Na+].CCCCCCCCCCCCC1=CC=C(S([O-])(=O)=O)C=C1.CCCCCCCCCCCCC1=CC=CC(S([O-])(=O)=O)=C1.CCCCCCCCCCCCC1=CC=CC=C1S([O-])(=O)=O AVWQQPYHYQKEIZ-UHFFFAOYSA-K 0.000 description 2
- 238000000108 ultra-filtration Methods 0.000 description 2
- 239000013598 vector Substances 0.000 description 2
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 1
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 1
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 1
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 1
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 1
- YKBHOXLMMPZPHQ-GMOBBJLQSA-N Arg-Ile-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O YKBHOXLMMPZPHQ-GMOBBJLQSA-N 0.000 description 1
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 1
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 1
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 1
- AYKKKGFJXIDYLX-ACZMJKKPSA-N Asn-Gln-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O AYKKKGFJXIDYLX-ACZMJKKPSA-N 0.000 description 1
- GLWFAWNYGWBMOC-SRVKXCTJSA-N Asn-Leu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GLWFAWNYGWBMOC-SRVKXCTJSA-N 0.000 description 1
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 1
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 1
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 1
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 1
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 1
- 238000011725 BALB/c mouse Methods 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- BVFQOPGFOQVZTE-ACZMJKKPSA-N Cys-Gln-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O BVFQOPGFOQVZTE-ACZMJKKPSA-N 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 238000008157 ELISA kit Methods 0.000 description 1
- 102100029727 Enteropeptidase Human genes 0.000 description 1
- 108010013369 Enteropeptidase Proteins 0.000 description 1
- SHERTACNJPYHAR-ACZMJKKPSA-N Gln-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O SHERTACNJPYHAR-ACZMJKKPSA-N 0.000 description 1
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 1
- GMGKDVVBSVVKCT-NUMRIWBASA-N Gln-Asn-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GMGKDVVBSVVKCT-NUMRIWBASA-N 0.000 description 1
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 1
- IKFZXRLDMYWNBU-YUMQZZPRSA-N Gln-Gly-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N IKFZXRLDMYWNBU-YUMQZZPRSA-N 0.000 description 1
- ININBLZFFVOQIO-JHEQGTHGSA-N Gln-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O ININBLZFFVOQIO-JHEQGTHGSA-N 0.000 description 1
- WIMVKDYAKRAUCG-IHRRRGAJSA-N Gln-Tyr-Glu Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O WIMVKDYAKRAUCG-IHRRRGAJSA-N 0.000 description 1
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 1
- ZOXBSICWUDAOHX-GUBZILKMSA-N Glu-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O ZOXBSICWUDAOHX-GUBZILKMSA-N 0.000 description 1
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 1
- VHPVBPCCWVDGJL-IRIUXVKKSA-N Glu-Thr-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VHPVBPCCWVDGJL-IRIUXVKKSA-N 0.000 description 1
- SOYWRINXUSUWEQ-DLOVCJGASA-N Glu-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O SOYWRINXUSUWEQ-DLOVCJGASA-N 0.000 description 1
- CLODWIOAKCSBAN-BQBZGAKWSA-N Gly-Arg-Asp Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O CLODWIOAKCSBAN-BQBZGAKWSA-N 0.000 description 1
- OCQUNKSFDYDXBG-QXEWZRGKSA-N Gly-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OCQUNKSFDYDXBG-QXEWZRGKSA-N 0.000 description 1
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 1
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 1
- BCZFOHDMCDXPDA-BZSNNMDCSA-N His-Lys-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)O BCZFOHDMCDXPDA-BZSNNMDCSA-N 0.000 description 1
- JSQIXEHORHLQEE-MEYUZBJRSA-N His-Phe-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JSQIXEHORHLQEE-MEYUZBJRSA-N 0.000 description 1
- WZPIKDWQVRTATP-SYWGBEHUSA-N Ile-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 WZPIKDWQVRTATP-SYWGBEHUSA-N 0.000 description 1
- YBGTWSFIGHUWQE-MXAVVETBSA-N Ile-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)CC)CC1=CN=CN1 YBGTWSFIGHUWQE-MXAVVETBSA-N 0.000 description 1
- CAHCWMVNBZJVAW-NAKRPEOUSA-N Ile-Pro-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)O)N CAHCWMVNBZJVAW-NAKRPEOUSA-N 0.000 description 1
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 1
- KUEVMUXNILMJTK-JYJNAYRXSA-N Leu-Gln-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KUEVMUXNILMJTK-JYJNAYRXSA-N 0.000 description 1
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 1
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 1
- PWPBLZXWFXJFHE-RHYQMDGZSA-N Leu-Pro-Thr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O PWPBLZXWFXJFHE-RHYQMDGZSA-N 0.000 description 1
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 1
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 1
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 1
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 1
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 1
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 1
- 108010079364 N-glycylalanine Proteins 0.000 description 1
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 1
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 1
- DBALDZKOTNSBFM-FXQIFTODSA-N Pro-Ala-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DBALDZKOTNSBFM-FXQIFTODSA-N 0.000 description 1
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 1
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 1
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 1
- ZIFYDQAFEMIZII-GUBZILKMSA-N Ser-Leu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZIFYDQAFEMIZII-GUBZILKMSA-N 0.000 description 1
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 1
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 1
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 1
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 1
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 1
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 1
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 1
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 1
- KKPOGALELPLJTL-MEYUZBJRSA-N Thr-Lys-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KKPOGALELPLJTL-MEYUZBJRSA-N 0.000 description 1
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 1
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 1
- RPECVQBNONKZAT-WZLNRYEVSA-N Thr-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H]([C@@H](C)O)N RPECVQBNONKZAT-WZLNRYEVSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- SNWIAPVRCNYFNI-SZMVWBNQSA-N Trp-Met-Arg Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N SNWIAPVRCNYFNI-SZMVWBNQSA-N 0.000 description 1
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 1
- RIJPHPUJRLEOAK-JYJNAYRXSA-N Tyr-Gln-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O RIJPHPUJRLEOAK-JYJNAYRXSA-N 0.000 description 1
- DZKFGCNKEVMXFA-JUKXBJQTSA-N Tyr-Ile-His Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O DZKFGCNKEVMXFA-JUKXBJQTSA-N 0.000 description 1
- LMKKMCGTDANZTR-BZSNNMDCSA-N Tyr-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LMKKMCGTDANZTR-BZSNNMDCSA-N 0.000 description 1
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 1
- QHSSPPHOHJSTML-HOCLYGCPSA-N Val-Trp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N QHSSPPHOHJSTML-HOCLYGCPSA-N 0.000 description 1
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 108010008355 arginyl-glutamine Proteins 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 108010093581 aspartyl-proline Proteins 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000007910 cell fusion Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 239000012916 chromogenic reagent Substances 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000003113 dilution method Methods 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000001976 enzyme digestion Methods 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 238000000227 grinding Methods 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 108010038320 lysylphenylalanine Proteins 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 229940126619 mouse monoclonal antibody Drugs 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 230000007651 self-proliferation Effects 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 210000004989 spleen cell Anatomy 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 108010044292 tryptophyltyrosine Proteins 0.000 description 1
- 108010003137 tyrosyltyrosine Proteins 0.000 description 1
- 108010073969 valyllysine Proteins 0.000 description 1
Images





Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/51—Complete heavy chain or Fd fragment, i.e. VH + CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/515—Complete light chain, i.e. VL + CL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- General Chemical & Material Sciences (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Peptides Or Proteins (AREA)
Abstract
Description
技术领域technical field
本发明涉及免疫学和抗体工程技术领域,具体涉及一种抗PD-L1人源化单克隆抗体及其应用。The invention relates to the technical fields of immunology and antibody engineering, in particular to an anti-PD-L1 humanized monoclonal antibody and an application thereof.
背景技术Background technique
PD-L1,英文全名programmed cell death-Ligand 1,又称细胞程式死亡-配体1。PD-L1蛋白正是PD-1的配体,与免疫系统的抑制有关,可以传导抑制性的信号。PD-1和PD-L1一旦结合便会向T细胞传递一种负向调控信号,诱导T细胞进入静息状态,减低淋巴结CD8+T细胞的增生,让其无法识别癌细胞,并且使T细胞自身增殖减少或凋亡,有效解除机体的免疫反应,因此癌细胞可以肆无忌惮地生长了。本发明提供的抗PD-L1抗体,可以与PD-1蛋白结合,激活T细胞识别并杀死癌细胞。PD-L1, English full name programmed cell death-Ligand 1, also known as programmed cell death-
发明内容SUMMARY OF THE INVENTION
本发明提供一种抗PD-L1单克隆抗体及其制备方法,该抗PD-L1单克隆抗体具有全新序列,能够特异性结合PD-1蛋白,使免疫细胞特异性识别并杀死癌细胞,达到癌症治疗的目的。The present invention provides an anti-PD-L1 monoclonal antibody and a preparation method thereof. The anti-PD-L1 monoclonal antibody has a brand-new sequence and can specifically bind to PD-1 protein, so that immune cells can specifically recognize and kill cancer cells. achieve the purpose of cancer treatment.
本发明是通过以下技术方案实现的:The present invention is achieved through the following technical solutions:
一种抗PD-L1人源化单克隆抗体,所述抗体的重链可变区的CDR-H1为SEQ ID NO:1所示的氨基酸序列,CDR-H2为SEQ ID NO:2所示的氨基酸序列,和CDR-H3为SEQ ID NO:3所示的氨基酸序列;以及所述抗体的轻链可变区的CDR-L1为SEQ ID NO:4所示的氨基酸序列,CDR-L2为SEQ ID NO:5所示的氨基酸序列,和CDR-L3为SEQ ID NO:6所示的氨基酸序列。An anti-PD-L1 humanized monoclonal antibody, the CDR-H1 of the heavy chain variable region of the antibody is the amino acid sequence shown in SEQ ID NO:1, and the CDR-H2 is shown in SEQ ID NO:2 Amino acid sequence, and CDR-H3 is the amino acid sequence shown in SEQ ID NO:3; And the CDR-L1 of the light chain variable region of the antibody is the amino acid sequence shown in SEQ ID NO:4, and CDR-L2 is SEQ ID NO:4 The amino acid sequence shown in ID NO:5, and CDR-L3 is the amino acid sequence shown in SEQ ID NO:6.
优选的,所述抗体的重链可变区的CDR-H1为SEQ ID NO:7所示的核苷酸序列,CDR-H2为SEQ ID NO:8所示的核苷酸序列,和CDR-H3为SEQ ID NO:9所示的核苷酸序列;以及所述抗体的轻链可变区的CDR-L1为SEQ ID NO:10所示的核苷酸序列,CDR-L2为SEQ ID NO:11所示的核苷酸序列,和CDR-L3为SEQ ID NO:12所示的核苷酸序列。Preferably, the CDR-H1 of the heavy chain variable region of the antibody is the nucleotide sequence shown in SEQ ID NO: 7, the CDR-H2 is the nucleotide sequence shown in SEQ ID NO: 8, and the CDR- H3 is the nucleotide sequence shown in SEQ ID NO: 9; and CDR-L1 of the light chain variable region of the antibody is the nucleotide sequence shown in SEQ ID NO: 10, and CDR-L2 is SEQ ID NO : the nucleotide sequence shown in SEQ ID NO: 11, and CDR-L3 is the nucleotide sequence shown in SEQ ID NO: 12.
优选的,所述抗体的重链氨基酸序列如SEQ ID NO:13所示。Preferably, the heavy chain amino acid sequence of the antibody is shown in SEQ ID NO:13.
优选的,所述抗体的轻链氨基酸序列如SEQ ID NO:14所示。Preferably, the amino acid sequence of the light chain of the antibody is shown in SEQ ID NO:14.
优选的,所述抗体的重链核苷酸序列如SEQ ID NO:15所示。Preferably, the heavy chain nucleotide sequence of the antibody is shown in SEQ ID NO:15.
优选的,所述抗体的轻链核苷酸序列如SEQ ID NO:16所示。Preferably, the light chain nucleotide sequence of the antibody is shown in SEQ ID NO:16.
本发明还保护一种药物组合物,该组合物含有上述的抗体和药物学上可接受的载体。The present invention also protects a pharmaceutical composition comprising the above-mentioned antibody and a pharmaceutically acceptable carrier.
本发明还保护上述的抗体在制药中的应用。The present invention also protects the application of the above-mentioned antibodies in pharmacy.
本发明还保护上述的抗体在制备治疗癌症药物中的应用。The present invention also protects the application of the above-mentioned antibody in the preparation of a drug for treating cancer.
本发明的有益效果在于:The beneficial effects of the present invention are:
本发明提供的抗PD-L1单克隆抗体具有全新序列,能够特异性结合人PD-L1蛋白,具有高亲和力,使免疫细胞特异性识别并杀死癌细胞,达到癌症治疗的目的,且该抗体分子细胞水平表现不低于目前在售产品。The anti-PD-L1 monoclonal antibody provided by the present invention has a brand-new sequence, can specifically bind to human PD-L1 protein, has high affinity, enables immune cells to specifically recognize and kill cancer cells, and achieves the purpose of cancer treatment. The molecular and cellular level performance is not lower than the products currently on sale.
附图说明Description of drawings
图1为人源化抗体SA126-C9诱导T细胞分泌IL2结果;Figure 1 shows the results of humanized antibody SA126-C9 inducing T cells to secrete IL2;
图2为人源化抗体SA126-C9诱导T细胞分泌IFN-γ结果;Figure 2 shows the results of humanized antibody SA126-C9 inducing T cells to secrete IFN-γ;
图3为SA126-C9-hIgG1、SA126-G7-hIgG1抗体与人PD-L1抗原的结合活性图;Figure 3 is a graph showing the binding activity of SA126-C9-hIgG1 and SA126-G7-hIgG1 antibodies to human PD-L1 antigen;
图4为SA126-C9-hIgG1、SA126-G7-hIgG1抗体与猴PD-L1抗原的结合活性图;Figure 4 is a graph showing the binding activity of SA126-C9-hIgG1 and SA126-G7-hIgG1 antibodies to monkey PD-L1 antigen;
图5为SA126-C9-hIgG1、SA126-G7-hIgG1抗体与鼠PD-L1抗原的结合活性图。Fig. 5 is a graph showing the binding activity of SA126-C9-hIgG1 and SA126-G7-hIgG1 antibodies to mouse PD-L1 antigen.
具体实施方式Detailed ways
为更好理解本发明,下面结合实施例及附图对本发明作进一步描述,以下实施例仅是对本发明进行说明而非对其加以限定。In order to better understand the present invention, the present invention will be further described below with reference to the embodiments and the accompanying drawings. The following embodiments are only to illustrate the present invention and not to limit it.
以下实施例中所用材料、试剂、仪器和方法,未经特殊说明,均为本领域中的常规材料、试剂、仪器和方法,均可通过商业渠道获得。The materials, reagents, instruments and methods used in the following examples, unless otherwise specified, are conventional materials, reagents, instruments and methods in the art, and can be obtained through commercial channels.
实施例1:PD-L1抗原的制备Example 1: Preparation of PD-L1 antigen
市场购买人肿瘤PD-L1的cDNA。在合成的胞外区PD-L1基因后加上人源IgG1 Fc标签,并在两端引入Xba I,Bam H I两个限制性酶切位点连接到pTT5表达质粒,经测序验证正确。测序完的质粒转染Trans10,挑取单克隆,接种到1升LB液体培养基,至OD600为1时,离心收集菌体,用质粒大提试剂盒提取质粒。Commercially available cDNA of human tumor PD-L1. A human IgG1 Fc tag was added to the synthetic extracellular region PD-L1 gene, and Xba I and Bam HI restriction sites were introduced at both ends to connect to the pTT5 expression plasmid, which was verified to be correct by sequencing. The sequenced plasmids were transfected into Trans10, single clones were picked, and inoculated into 1 liter of LB liquid medium. When the OD 600 was 1, the cells were collected by centrifugation, and the plasmids were extracted with a plasmid extraction kit.
将测序鉴定正确的表达载体转染293F细胞,37℃,5%CO2,130rpm/min培养7天后,离心收集上清。将上清于4000rpm离心10min,再用0.45μm滤膜过滤;滤液加入400mM NaCl;调整pH至8.0。样品经0.2μm滤膜再次过滤后,上样至已用PBS平衡好的5mL HiTrap ProteinA柱;待样品上完后用PBS冲洗,流速5mL/min,紫外监测为水平。1M甘氨酸,pH 3.5洗脱,流速1mL/min,收集流出峰用Tris中和至pH 7.5。用超滤浓缩管浓缩洗脱峰换液至PBS中,由此得到PDL1-Fc抗原融合蛋白。将PDL1-Fc用肠激酶进行酶切,置于37℃12小时,酶切后产物过HiTrap Protein A柱用于吸附切除的Fc标签,收集流出液,即为PD-L1胞外区抗原。The correct expression vector identified by sequencing was transfected into 293F cells, cultured at 37° C., 5% CO 2 , 130 rpm/min for 7 days, and the supernatant was collected by centrifugation. The supernatant was centrifuged at 4000 rpm for 10 min, and then filtered through a 0.45 μm filter; 400 mM NaCl was added to the filtrate; the pH was adjusted to 8.0. After the sample was filtered again through a 0.2 μm filter, the sample was loaded onto a 5 mL HiTrap Protein A column that had been equilibrated with PBS; after the sample was loaded, it was rinsed with PBS at a flow rate of 5 mL/min, and the level was monitored by UV. 1 M glycine, pH 3.5 elution,
实施例2:抗原免疫小鼠和杂交瘤筛选Example 2: Antigen immunized mice and hybridoma screening
本实验选用8周龄雌性BALB/c小鼠3只,采用腹腔注射法,用实施例1制备的PD-L1胞外区抗原与弗氏完全佐剂混合免疫小鼠,每周1次,共3次。最后一次免疫后一周测量小鼠血清效价,满足条件效价大于8K后加强免疫一次,结果显示3只小鼠全部满足效价(大于阴性对照2倍且大于0.25的OD450值对应的稀释度值即为该抗体的效价,效价大于等于8K即满足要求),3天后处死小鼠,取小鼠脾脏,经碾磨后获得脾细胞群。利用流式细胞术(FACS)筛选出抗人肿瘤PD-L1抗体的B细胞,置于RPMI1640培养基中,加入骨髓瘤细胞(SP2/0)混匀,采用50%PEG溶液进行细胞融合。融合后的细胞经过适当稀释,分置于多块96孔培养板中培养,加入HAT选择性培养基,使未融合的B细胞和骨髓瘤细胞死亡,得到杂交瘤细胞。培养2周后收集96孔板细胞培养上清,与铺有PD-L1抗原的96孔酶标板结合1小时,加入抗鼠/HRP二抗孵育1小时,最后加入TMB显色试剂反应10分钟,用酶标仪测定450nm处的光吸收值,选出与PD-L1具有结合活性的杂交瘤细胞。随后进行流式细胞术(FACS)筛选,选出具有PD-1/PD-L1阻断活性的杂交瘤细胞,在进行有限稀释法亚克隆,最终得到一株抗PD-L1鼠源单克隆抗体。In this experiment, three 8-week-old female BALB/c mice were selected, and the mice were immunized with the PD-L1 extracellular domain antigen prepared in Example 1 mixed with Freund's complete adjuvant by intraperitoneal injection, once a week for a total of 3 times. The serum titer of the mice was measured one week after the last immunization, and the titer was more than 8K after the condition was met, and the immunization was boosted once. The results showed that all 3 mice met the titer (2 times greater than the negative control and greater than the dilution value corresponding to the OD450 value of 0.25). That is, the titer of the antibody, and the titer is greater than or equal to 8K to meet the requirements), and the mice were sacrificed after 3 days, and the spleen of the mice was taken, and the spleen cell group was obtained after grinding. B cells with anti-human tumor PD-L1 antibody were screened by flow cytometry (FACS), placed in RPMI1640 medium, myeloma cells (SP2/0) were added and mixed, and 50% PEG solution was used for cell fusion. The fused cells are appropriately diluted and cultured in multiple 96-well culture plates, and HAT selective medium is added to make unfused B cells and myeloma cells die to obtain hybridoma cells. After 2 weeks of culture, collect the cell culture supernatant from the 96-well plate, combine with the 96-well microtiter plate plated with PD-L1 antigen for 1 hour, add anti-mouse/HRP secondary antibody and incubate for 1 hour, and finally add TMB chromogenic reagent to react for 10 minutes , and the light absorption value at 450nm was measured with a microplate reader, and the hybridoma cells with binding activity to PD-L1 were selected. Then, flow cytometry (FACS) screening was performed to select hybridoma cells with PD-1/PD-L1 blocking activity, and subcloning by limiting dilution method to finally obtain an anti-PD-L1 mouse monoclonal antibody .
实施例3:抗PD-L1鼠源抗体可变区基因调取Example 3: Gene transfer of variable region of anti-PD-L1 murine antibody
选取实施例2制备的抗PD-L1鼠源单克隆抗体,采用Trizol方法抽提总RNA,利用抗体亚型(Isotype)特异性引物或者通用引物进行反转录PCR,分别扩增抗体轻链可变区(VL)和重链可变区(VH)基因,随后连接至克隆载体进行DNA测序分析。最终获得完整VL和VH的DNA序列,并翻译成相应的氨基酸序列。The anti-PD-L1 mouse-derived monoclonal antibody prepared in Example 2 was selected, the total RNA was extracted by the Trizol method, and reverse transcription PCR was performed using antibody isotype-specific primers or universal primers to amplify the antibody light chain respectively. The variable region (VL) and heavy chain variable region (VH) genes were then ligated into cloning vectors for DNA sequencing analysis. The complete VL and VH DNA sequences were finally obtained and translated into the corresponding amino acid sequences.
实施例4:抗PD-L1鼠源单抗基因人源化改造及亲和力成熟Example 4: Humanization and Affinity Maturation of Anti-PD-L1 Murine Monoclonal Antibody Gene
分析与小鼠PD-L1抗体的VH基因同源性较高的人种系基因(germline gene),并进行相关人源化改造。The human germline gene with high homology to the VH gene of mouse PD-L1 antibody was analyzed, and related humanization was carried out.
针对抗PD-L1人源化抗体的6个CDR区分别设计了抗体突变体库,突变位点覆盖了所有CDR区的非保守位点。采用SOE-PCR反应获得单链抗体(scFv)基因,经DNA凝胶回收和酶切之后,与酶切后的pCANTAB-5E噬菌体展示载体连接,电转化TG1感受态细菌,获得6个含有CDR突变的单链抗体库。通过感染M13KO7辅助噬菌体,制作重组噬菌体,共进行了三轮淘洗,保留并富集结合能力强的抗体突变体。每轮淘洗分别将重组噬菌体与生物素标记的重组人PD-L1抗原结合2小时,再加入链亲和素磁珠结合30分钟,先后用2%TPBS、1%TPBS和PBS清洗5次,每次5分钟,淘洗之后立刻感染TG1细胞,用于下一轮重组噬菌体制备。挑选三轮淘洗后富集的TG1单克隆,制备重组噬菌体上清,与铺有1ug/mL PD-L1抗原的96孔酶标板结合1小时,加入M13/HRP二抗孵育1小时,最后加入TMB进行显色反应10分钟,用酶标仪测定490nm处的光吸收值。对数据进行分析后,计算含有抗体突变体的相对亲和力,亲和力测定结果如表1,筛选得到1个(SA126-C9)亲和力有明显提高的克隆开展下一步研究。该抗PD-L1人源化抗体亲和力成熟的重链氨基酸和核苷酸序列分别为SEQ ID NO:13和15;其中,重链可变区的CDR-H1、CDR-H2和CDR-H3氨基酸序列分别为SEQ ID NO:1-3,核苷酸序列分别为SEQ IDNO:7-9。抗PD-L1人源化抗体亲和力成熟的轻链氨基酸和核苷酸序列分别为SEQ ID NO:14和16;其中,轻链可变区的CDR-L1、CDR-L2和CDR-L3氨基酸序列分别为SEQ ID NO:4-6,核苷酸序列分别为SEQ ID NO:10-12。An antibody mutant library was designed for the six CDR regions of the anti-PD-L1 humanized antibody, and the mutation sites covered the non-conserved sites of all CDR regions. The single-chain antibody (scFv) gene was obtained by SOE-PCR reaction. After DNA gel recovery and enzyme digestion, it was connected with the digested pCANTAB-5E phage display vector, and TG1 competent bacteria were electrotransformed to obtain 6 CDR mutations. single-chain antibody library. Recombinant phages were made by infecting M13KO7 helper phage, and three rounds of panning were performed to retain and enrich antibody mutants with strong binding ability. In each round of panning, the recombinant phage was combined with biotin-labeled recombinant human PD-L1 antigen for 2 hours, and then streptavidin magnetic beads were added for 30 minutes, and washed with 2% TPBS, 1% TPBS and PBS for 5 times. For 5 minutes each, TG1 cells were infected immediately after panning for the next round of recombinant phage preparation. The TG1 monoclone enriched after three rounds of panning was selected, and the recombinant phage supernatant was prepared, which was combined with a 96-well microtiter plate plated with 1ug/mL PD-L1 antigen for 1 hour, and the M13/HRP secondary antibody was added to incubate for 1 hour. TMB was added to carry out color reaction for 10 minutes, and the light absorption value at 490 nm was measured with a microplate reader. After analyzing the data, the relative affinity of the antibody mutants was calculated. The affinity determination results are shown in Table 1. One clone (SA126-C9) with significantly improved affinity was screened for further research. The heavy chain amino acid and nucleotide sequences of the affinity matured anti-PD-L1 humanized antibody are SEQ ID NOs: 13 and 15, respectively; wherein, the CDR-H1, CDR-H2 and CDR-H3 amino acids of the heavy chain variable region The sequences are SEQ ID NOs: 1-3, respectively, and the nucleotide sequences are SEQ ID NOs: 7-9, respectively. The light chain amino acid and nucleotide sequences of the affinity-matured anti-PD-L1 humanized antibody are SEQ ID NOs: 14 and 16, respectively; wherein, the CDR-L1, CDR-L2 and CDR-L3 amino acid sequences of the light chain variable region They are SEQ ID NOs: 4-6, respectively, and the nucleotide sequences are SEQ ID NOs: 10-12, respectively.
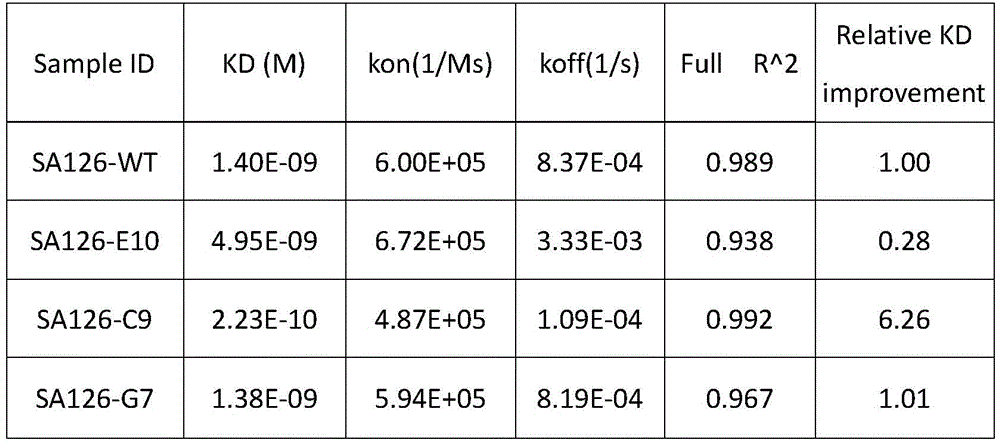
表1亲和力测定结果Table 1 Affinity determination results
实施例5:抗PD-L1人源化抗体的表达与纯化Example 5: Expression and purification of anti-PD-L1 humanized antibody
人工合成抗体的轻链的cDNA,人工合成抗体的重链的cDNA,将合成的cDNA分别克隆到pTT5质粒中,并通过测序确定质粒构建正确。将测序鉴定正确的重链表达载体和轻链表达载体(1:1)共转染到293F细胞中,37℃,5%CO2,130rpm/min培养7天后,离心收集上清。将上清4000rpm离心10min,并用0.45μm滤膜过滤,收集滤液;滤液加入400mM NaCl;调整pH至8.0。样品经0.2μm滤膜再次过滤后,上样至已用PBS平衡好的5mL HiTrap Protein A柱;待样品上完后用PBS冲洗,流速5mL/min,紫外监测为水平。1M甘氨酸,pH 3.5洗脱,流速1mL/min,收集流出峰用Tris中和至pH 7.5。用超滤浓缩管浓缩洗脱峰,用脱盐柱换液至PBS中,由此得到抗体蛋白。The cDNA of the light chain of the antibody was artificially synthesized, and the cDNA of the heavy chain of the antibody was artificially synthesized, and the synthesized cDNAs were cloned into the pTT5 plasmid respectively, and the correct construction of the plasmid was confirmed by sequencing. The correct heavy chain expression vector and light chain expression vector (1:1) identified by sequencing were co-transfected into 293F cells, cultured at 37° C., 5% CO 2 , 130 rpm/min for 7 days, and the supernatant was collected by centrifugation. The supernatant was centrifuged at 4000 rpm for 10 min, and filtered with a 0.45 μm membrane filter to collect the filtrate; 400 mM NaCl was added to the filtrate; the pH was adjusted to 8.0. After the sample was filtered again through a 0.2 μm filter, the sample was loaded onto a 5 mL HiTrap Protein A column that had been equilibrated with PBS; after the sample was loaded, it was rinsed with PBS at a flow rate of 5 mL/min, and the UV level was monitored. 1 M glycine, pH 3.5 elution, flow
实施例6:人源化抗体体外诱导T细胞分泌IL2Example 6: Humanized antibody induces T cells to secrete IL2 in vitro
使用CD14+微球(Miltenyi)从PBMC中分离单核细胞,使用CD4+T细胞分离试剂盒(Miltenyi)从PBMC中分离CD4+T细胞,在液氮中冷冻保存细胞。单核细胞解冻,在RPMI1640培养基中培养6天,产生iDCs。每隔2或3天更换一半培养基,新鲜培养基中添加1000U/mLrhGM CSF和500U/mL rhIL-4。将CD4+T细胞解冻,37℃孵育2-3小时。将CD4+T细胞和iDCs分别以50μL/孔的速度加入到96孔板中,以100μL/孔添加抗体稀释液(浓度分别为10μg/mL、2μg/mL、0.4μg/mL、0.08μg/mL、0.016μg/mL、0.003μg/mL、0μg/mL),加入100μL/孔浓度为10μg/mL的hIgG1作为阴性对照。37℃培养3天后收集上清液,用Luminex仪(购自LifeTechnology公司)和细胞因子IL2检测试剂盒(购自BD Biosciences公司)检测上清IL2的分泌水平。如图1显示抗体均可有效刺激T细胞的功能,分泌IL2,且与抗体浓度有关。在MLR试验中,SA126-C9诱导IL-2分泌的能力略微优于Atezolizumab。Monocytes were isolated from PBMCs using CD14+ microspheres (Miltenyi), CD4+ T cells were isolated from PBMCs using the CD4+ T cell isolation kit (Miltenyi), and cells were cryopreserved in liquid nitrogen. Monocytes were thawed and cultured in RPMI1640 medium for 6 days to generate iDCs. Half of the medium was replaced every 2 or 3 days, and 1000 U/mL rhGM CSF and 500 U/mL rhIL-4 were added to the fresh medium. Thaw CD4+ T cells and incubate at 37°C for 2-3 hours. CD4+ T cells and iDCs were added to the 96-well plate at a rate of 50 μL/well, respectively, and antibody dilution was added at 100 μL/well (concentrations were 10 μg/mL, 2 μg/mL, 0.4 μg/mL, 0.08 μg/mL, respectively. , 0.016 μg/mL, 0.003 μg/mL, 0 μg/mL), and 100 μL/well of hIgG1 with a concentration of 10 μg/mL was added as a negative control. After culturing at 37°C for 3 days, the supernatant was collected, and the secretion level of IL2 in the supernatant was detected with a Luminex instrument (purchased from LifeTechnology) and a cytokine IL2 detection kit (purchased from BD Biosciences). Figure 1 shows that both antibodies can effectively stimulate the function of T cells, secrete IL2, and are related to antibody concentration. SA126-C9 was slightly better than Atezolizumab in its ability to induce IL-2 secretion in the MLR assay.
实施例7:人源化抗体体外诱导T细胞分泌IFN-γExample 7: Humanized antibody induces T cells to secrete IFN-γ in vitro
使用CD14+微球(Miltenyi)从PBMC中分离单核细胞,使用CD4+T细胞分离试剂盒(Miltenyi)从PBMC中分离CD4+T细胞,在液氮中冷冻保存细胞。单核细胞解冻,在RPMI1640培养基中培养6天,产生iDCs。每隔2或3天更换一半培养基,新鲜培养基中添加1000U/mLrhGM CSF和500U/mL rhIL-4。将CD4+T细胞解冻,37℃孵育2-3小时。将CD4+T细胞和iDCs分别以50μL/孔的速度加入到96孔板中,以100μL/孔添加抗体稀释液(浓度分别为10μg/mL、2μg/mL、0.4μg/mL、0.08μg/mL、0.016μg/mL、0.003μg/mL、0μg/mL),加入100μL/孔浓度为10μg/mL的hIgG1作为阴性对照。将细胞于37℃培养5天。5天后,从每份培养物中取出100μL培养基用于细胞因子IFN-γ测量。利用OptEIA ELISA试剂盒(购自BD Biosciences公司)来测定IFN-γ的水平。如图2显示抗体均可有效刺激T细胞的功能分泌细胞因子IFN-γ,且与浓度有关。在MLR试验中,高浓度条件下SA126-C9诱导IFN-γ分泌的能力优于Atezolizumab。Monocytes were isolated from PBMCs using CD14+ microspheres (Miltenyi), CD4+ T cells were isolated from PBMCs using the CD4+ T cell isolation kit (Miltenyi), and cells were cryopreserved in liquid nitrogen. Monocytes were thawed and cultured in RPMI1640 medium for 6 days to generate iDCs. Half of the medium was replaced every 2 or 3 days, and 1000 U/mL rhGM CSF and 500 U/mL rhIL-4 were added to the fresh medium. Thaw CD4+ T cells and incubate at 37°C for 2-3 hours. CD4+ T cells and iDCs were added to the 96-well plate at a rate of 50 μL/well, respectively, and antibody dilution was added at 100 μL/well (concentrations were 10 μg/mL, 2 μg/mL, 0.4 μg/mL, 0.08 μg/mL, respectively. , 0.016 μg/mL, 0.003 μg/mL, 0 μg/mL), and 100 μL/well of hIgG1 with a concentration of 10 μg/mL was added as a negative control. Cells were cultured at 37°C for 5 days. After 5 days, 100 μL of medium was removed from each culture for cytokine IFN-γ measurement. The level of IFN-γ was measured using OptEIA ELISA kit (purchased from BD Biosciences). Figure 2 shows that the antibodies can effectively stimulate the function of T cells to secrete cytokine IFN-γ, and it is related to the concentration. In the MLR assay, SA126-C9 was superior to Atezolizumab in its ability to induce IFN-γ secretion at high concentrations.
实施例8:种属交叉反应Example 8: Species Cross Reaction
将抗体SA126-C9、SA126-G7替换人源IgG1亚型,提高亲和力,检测种属交叉反应。Atezolizumab做对照抗体,cPD-L1、mPD-L1、hPD-L2抗原可购买市售商品化蛋白。购买0.1mgcPD-L1(食蟹猴抗原,R&D公司产)、0.1mg mPD-L1(小鼠抗原,BioLegend公司产)、0.1mghPD-L2(人抗原,BioLegend公司产)待用。The antibodies SA126-C9 and SA126-G7 were replaced with human IgG1 subtype to improve the affinity and detect species cross-reaction. Atezolizumab is used as a control antibody, and commercially available proteins can be purchased for cPD-L1, mPD-L1, and hPD-L2 antigens. 0.1 mg cPD-L1 (cynomolgus monkey antigen, produced by R&D company), 0.1 mg mPD-L1 (mouse antigen, produced by BioLegend company), 0.1 mghPD-L2 (human antigen, produced by BioLegend company) were purchased for use.
用ELISA方法鉴定SA126-C9-hIgG1、SA126-G7-hIgG1待测抗体与三种不同种属PD-L1抗原的结合活性,分别计算IC50值并与对照抗体比较,判断其种属交叉反应特异性。结果如图3-5所示:The binding activities of SA126-C9-hIgG1 and SA126-G7-hIgG1 antibodies to three different species of PD-L1 antigens were identified by ELISA, IC50 values were calculated respectively and compared with the control antibodies to determine their species cross-reactivity specificity . The result is shown in Figure 3-5:
①SA126-C9-hIgG1、SA126-G7-hIgG1抗体与人PD-L1抗原的结合活性(图3)可看出:待测抗体SA126-C9-hIgG和Atezolizumab亲和力大致相同,且均比SA126-G7-hIgG1亲和力更高。①The binding activity of SA126-C9-hIgG1 and SA126-G7-hIgG1 antibodies to human PD-L1 antigen (Fig. 3) can be seen: the tested antibodies SA126-C9-hIgG and Atezolizumab have roughly the same affinity, and both are higher than SA126-G7- hIgG1 affinity is higher.
②SA126-C9-hIgG1、SA126-G7-hIgG1抗体与猴PD-L1抗原的结合活性(图4)可看出:待测抗体SA126-C9-hIgG和SA126-G7-hIgG1亲和力相当,均比Atezolizumab亲和力弱。②The binding activity of SA126-C9-hIgG1 and SA126-G7-hIgG1 antibodies to monkey PD-L1 antigen (Figure 4) can be seen: the tested antibodies SA126-C9-hIgG and SA126-G7-hIgG1 have similar affinities, and both have higher affinity than Atezolizumab weak.
③SA126-C9-hIgG1、SA126-G7-hIgG1抗体与鼠PD-L1抗原的结合活性(图5)可看出:Atezolizumab与鼠PD-L1有较强的亲和力,而待测抗体SA126-C9-hIgG1和SA126-G7-hIgG1均不与鼠PD-L1抗原结合,无交叉反应。③The binding activity of SA126-C9-hIgG1 and SA126-G7-hIgG1 antibodies to mouse PD-L1 antigen (Fig. 5) shows that Atezolizumab has a strong affinity with mouse PD-L1, while the tested antibody SA126-C9-hIgG1 and SA126-G7-hIgG1 did not bind to the mouse PD-L1 antigen and had no cross-reactivity.
综合实验结果表明,SA126-C9与人PD-L1抗原具有较好的亲和力以及与鼠PD-L1抗原无交叉反应,可作为候选抗体进行下一步实验。Comprehensive experimental results show that SA126-C9 has good affinity with human PD-L1 antigen and no cross-reaction with mouse PD-L1 antigen, and can be used as a candidate antibody for further experiments.
虽然本发明已以较佳的实施例公开如上,但其并非用以限定本发明,任何熟悉此技术的人,在不脱离本发明精神和范围内,都可以做各种的改动与修饰,因此,本发明的保护范围应该以权利要求书所界定的为准。Although the present invention has been disclosed above with preferred embodiments, it is not intended to limit the present invention. Anyone who is familiar with this technology can make various changes and modifications without departing from the spirit and scope of the present invention. Therefore, , the protection scope of the present invention should be defined by the claims.
SEQUENCE LISTINGSEQUENCE LISTING
<110> 安徽瀚海博兴生物技术有限公司<110> Anhui Hanhai Boxing Biotechnology Co., Ltd.
<120> 一种抗PD-L1人源化单克隆抗体及其应用<120> An anti-PD-L1 humanized monoclonal antibody and its application
<130> 2021<130> 2021
<160> 16<160> 16
<170> PatentIn version 3.3<170> PatentIn version 3.3
<210> 1<210> 1
<211> 10<211> 10
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 1<400> 1
Gly Phe Phe Ile Lys Asp Thr Tyr Ile HisGly Phe Phe Ile Lys Asp Thr Tyr Ile His
1 5 101 5 10
<210> 2<210> 2
<211> 10<211> 10
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 2<400> 2
Arg Ile Asp Pro Ala Asn Gln Asn Thr LysArg Ile Asp Pro Ala Asn Gln Asn Thr Lys
1 5 101 5 10
<210> 3<210> 3
<211> 9<211> 9
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 3<400> 3
Gly Leu Arg Leu Arg Tyr Phe Asp ValGly Leu Arg Leu Arg Tyr Phe Asp Val
1 51 5
<210> 4<210> 4
<211> 11<211> 11
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 4<400> 4
Gln Ala Ser Gln Asp Ile His Lys Tyr Ile AlaGln Ala Ser Gln Asp Ile His Lys Tyr Ile Ala
1 5 101 5 10
<210> 5<210> 5
<211> 7<211> 7
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 5<400> 5
Phe Thr Ser Thr Leu Gln ThrPhe Thr Ser Thr Leu Gln Thr
1 51 5
<210> 6<210> 6
<211> 9<211> 9
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 6<400> 6
Leu Gln Tyr Glu Asn Leu Leu Pro ThrLeu Gln Tyr Glu Asn Leu Leu Pro Thr
1 51 5
<210> 7<210> 7
<211> 30<211> 30
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 7<400> 7
ggcttcttca tcaaggacac ctacatccac 30ggcttcttca tcaaggacac ctacatccac 30
<210> 8<210> 8
<211> 30<211> 30
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 8<400> 8
aggatcgacc ccgccaacca gaacaccaag 30aggatcgacc ccgccaacca gaacaccaag 30
<210> 9<210> 9
<211> 27<211> 27
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 9<400> 9
ggcctgaggc tgaggtactt cgacgtg 27ggcctgaggc tgaggtactt cgacgtg 27
<210> 10<210> 10
<211> 33<211> 33
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 10<400> 10
caggccagcc aggacatcca caagtacatc gcc 33caggccagcc aggacatcca caagtacatc gcc 33
<210> 11<210> 11
<211> 21<211> 21
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 11<400> 11
ttcaccagca ccctgcagac c 21ttcaccagca ccctgcagac c 21
<210> 12<210> 12
<211> 27<211> 27
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 12<400> 12
ctgcagtacg agaacctgct gcccacc 27ctgcagtacg agaacctgct gcccacc 27
<210> 13<210> 13
<211> 118<211> 118
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 13<400> 13
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Val Lys Pro Gly AlaGln Val Gln Leu Val Gln Ser Gly Ala Glu Val Val Lys Pro Gly Ala
1 5 10 151 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Phe Phe Ile Lys Asp ThrSer Val Lys Leu Ser Cys Lys Ala Ser Gly Phe Phe Ile Lys Asp Thr
20 25 30 20 25 30
Tyr Ile His Trp Met Arg Gln Arg Pro Gly Gln Gly Leu Glu Trp IleTyr Ile His Trp Met Arg Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45 35 40 45
Gly Arg Ile Asp Pro Ala Asn Gln Asn Thr Lys Tyr Ala Gln Lys PheGly Arg Ile Asp Pro Ala Asn Gln Asn Thr Lys Tyr Ala Gln Lys Phe
50 55 60 50 55 60
Gln Gly Arg Ala Thr Val Thr Ala Asp Thr Ser Thr Asn Thr Ala TyrGln Gly Arg Ala Thr Val Thr Ala Asp Thr Ser Thr Asn Thr Ala Tyr
65 70 75 8065 70 75 80
Leu Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr CysLeu Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95 85 90 95
Ala Arg Gly Leu Arg Leu Arg Tyr Phe Asp Val Trp Gly Ala Gly ThrAla Arg Gly Leu Arg Leu Arg Tyr Phe Asp Val Trp Gly Ala Gly Thr
100 105 110 100 105 110
Thr Val Thr Val Ser SerThr Val Thr Val Ser Ser
115 115
<210> 14<210> 14
<211> 107<211> 107
<212> PRT<212> PRT
<213> 人工序列<213> Artificial sequences
<400> 14<400> 14
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val GlyAsp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 151 5 10 15
Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile His Lys TyrAsp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile His Lys Tyr
20 25 30 20 25 30
Ile Ala Trp Tyr Gln His Lys Pro Gly Lys Ala Pro Lys Leu Leu IleIle Ala Trp Tyr Gln His Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45 35 40 45
His Phe Thr Ser Thr Leu Gln Thr Gly Ile Pro Ser Arg Phe Ser GlyHis Phe Thr Ser Thr Leu Gln Thr Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60 50 55 60
Ser Gly Ser Gly Arg Asp Phe Thr Phe Thr Ile Ser Ser Leu Glu ProSer Gly Ser Gly Arg Asp Phe Thr Phe Thr Ile Ser Ser Leu Glu Pro
65 70 75 8065 70 75 80
Glu Asp Ile Glu Thr Tyr Tyr Cys Leu Gln Tyr Glu Asn Leu Leu ProGlu Asp Ile Glu Thr Tyr Tyr Cys Leu Gln Tyr Glu Asn Leu Leu Pro
85 90 95 85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile LysThr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 100 105
<210> 15<210> 15
<211> 354<211> 354
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 15<400> 15
caggtgcagc tggtgcagag cggcgccgag gtggtgaagc ccggcgccag cgtgaagctg 60caggtgcagc tggtgcagag cggcgccgag gtggtgaagc ccggcgccag cgtgaagctg 60
agctgcaagg ccagcggctt cttcatcaag gacacctaca tccactggat gaggcagagg 120agctgcaagg ccagcggctt cttcatcaag gacacctaca tccactggat gaggcagagg 120
cccggccagg gcctggagtg gatcggcagg atcgaccccg ccaaccagaa caccaagtac 180cccggccagg gcctggagtg gatcggcagg atcgaccccg ccaaccagaa caccaagtac 180
gcccagaagt tccagggcag ggccaccgtg accgccgaca ccagcaccaa caccgcctac 240gcccagaagt tccagggcag ggccaccgtg accgccgaca ccagcaccaa caccgcctac 240
ctggagctga gcagcctgag gagcgaggac accgccgtgt actactgcgc caggggcctg 300ctggagctga gcagcctgag gagcgaggac accgccgtgt actactgcgc caggggcctg 300
aggctgaggt acttcgacgt gtggggcgcc ggcaccaccg tgaccgtgag cagc 354aggctgaggt acttcgacgt gtggggcgcc ggcaccaccg tgaccgtgag cagc 354
<210> 16<210> 16
<211> 321<211> 321
<212> DNA<212> DNA
<213> 人工序列<213> Artificial sequences
<400> 16<400> 16
gacatccaga tgacccagag ccccagcagc ctgagcgcca gcgtgggcga cagggtgacc 60gacatccaga tgacccagag ccccagcagc ctgagcgcca gcgtgggcga cagggtgacc 60
atcacctgcc aggccagcca ggacatccac aagtacatcg cctggtacca gcacaagccc 120atcacctgcc aggccagcca ggacatccac aagtacatcg cctggtacca gcacaagccc 120
ggcaaggccc ccaagctgct gatccacttc accagcaccc tgcagaccgg catccccagc 180ggcaaggccc ccaagctgct gatccacttc accagcaccc tgcagaccgg catccccagc 180
aggttcagcg gcagcggcag cggcagggac ttcaccttca ccatcagcag cctggagccc 240aggttcagcg gcagcggcag cggcagggac ttcaccttca ccatcagcag cctggagccc 240
gaggacatcg agacctacta ctgcctgcag tacgagaacc tgctgcccac cttcggcggc 300gaggacatcg agacctacta ctgcctgcag tacgagaacc tgctgcccac cttcggcggc 300
ggcaccaagc tggagatcaa g 321ggcaccaagc tggagatcaa g 321
Claims (8)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110436333.9A CN113150155B (en) | 2021-04-22 | 2021-04-22 | anti-PD-L1 humanized monoclonal antibody and application thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110436333.9A CN113150155B (en) | 2021-04-22 | 2021-04-22 | anti-PD-L1 humanized monoclonal antibody and application thereof |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113150155A CN113150155A (en) | 2021-07-23 |
| CN113150155B true CN113150155B (en) | 2022-04-08 |
Family
ID=76869426
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110436333.9A Active CN113150155B (en) | 2021-04-22 | 2021-04-22 | anti-PD-L1 humanized monoclonal antibody and application thereof |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113150155B (en) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104136610A (en) * | 2011-12-28 | 2014-11-05 | 中外制药株式会社 | Humanized anti-epiregulin antibody, and cancer therapeutic agent comprising said antibody as active ingredient |
| CN105461808A (en) * | 2015-12-24 | 2016-04-06 | 长春金赛药业有限责任公司 | Monoclonal antibody and application thereof |
| CN106110322A (en) * | 2016-07-29 | 2016-11-16 | 安徽瀚海博兴生物技术有限公司 | A kind of pharmaceutical composition and the application in preparation treatment cancer drug thereof |
| CN108250296A (en) * | 2018-01-17 | 2018-07-06 | 长春金赛药业股份有限公司 | Human anti-human PD-L1 monoclonal antibodies and its application |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10208129B2 (en) * | 2010-12-06 | 2019-02-19 | National Research Council Of Canada | Antibodies selective for cells presenting ErbB2 at high density |
| CN110072889B (en) * | 2016-08-05 | 2023-06-13 | Y生物股份有限公司 | Antibodies against programmed cell death ligand 1 (PD-L1) and uses thereof |
-
2021
- 2021-04-22 CN CN202110436333.9A patent/CN113150155B/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104136610A (en) * | 2011-12-28 | 2014-11-05 | 中外制药株式会社 | Humanized anti-epiregulin antibody, and cancer therapeutic agent comprising said antibody as active ingredient |
| CN105461808A (en) * | 2015-12-24 | 2016-04-06 | 长春金赛药业有限责任公司 | Monoclonal antibody and application thereof |
| CN106110322A (en) * | 2016-07-29 | 2016-11-16 | 安徽瀚海博兴生物技术有限公司 | A kind of pharmaceutical composition and the application in preparation treatment cancer drug thereof |
| CN108250296A (en) * | 2018-01-17 | 2018-07-06 | 长春金赛药业股份有限公司 | Human anti-human PD-L1 monoclonal antibodies and its application |
Non-Patent Citations (3)
| Title |
|---|
| "Atezolizumab: A PD-L1-Blocking Antibody for Bladder Cancer";Brant A.Inman et al.;《Clinical Cancer Research》;20161130;第23卷(第8期);第1886-1890页 * |
| "Chain A,IgG1-hDR5-01-Heavy Chain,PDB: 6T3J_A";Overdijk,M.B.et al.;《GenPept》;20201201;第1-2页 * |
| "以PD-1和PD-L1为靶点的肿瘤免疫治疗研究进展";杨占菊 等;《癌症进展》;20200430;第18卷(第8期);第772-777页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113150155A (en) | 2021-07-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7583707B2 (en) | Anti-CD47 antibodies and their applications | |
| CN108026169B (en) | Fully human antibody against human CD137 and its application | |
| CN111018986B (en) | Antibody against phosphatidylinositol proteoglycan-3 and its application | |
| CN105315371B (en) | Anti-human IL-17 monoclonal antibody | |
| CN111518211B (en) | Pharmaceutical application of human interleukin 4receptor alpha monoclonal antibody | |
| CN117024588A (en) | Use of anti-CD19 antibodies in preparing leukemia therapeutic drugs | |
| CN108164600B (en) | anti-GPC 3 antibody, and preparation method and application thereof | |
| CN114262377A (en) | Preparation method of anti-human CD70 nano antibody for blocking combination of CD70 and ligand CD27 thereof and coding sequence thereof | |
| US12258394B2 (en) | IL-5 antibody, antigen binding fragment thereof, and medical application therefor | |
| WO2022247804A1 (en) | Anti-gprc5d antibody, preparation method therefor, and use thereof | |
| CN109776677B (en) | Humanized anti-IL-13 antibody and preparation method and application thereof | |
| CN115536747B (en) | An antibody binding to TROP2 and a bispecific antibody targeting TROP2 and CD3 and preparation method and application thereof | |
| CN110156895A (en) | An anti-PD-L1 antibody or its functional fragment and use thereof | |
| EP3367786A1 (en) | Transgenic rabbit with common light chain | |
| CN115746144B (en) | Anti-TIGIT-PD1 Bispecific Antibody and Its Application | |
| CN113150155B (en) | anti-PD-L1 humanized monoclonal antibody and application thereof | |
| CN111662383B (en) | Anti-PD-L1 antibodies and uses thereof | |
| JP7734856B2 (en) | Bispecific antibodies and uses thereof | |
| CN120865416B (en) | Anti-MICA/B antibodies and their applications | |
| Bao et al. | Isolating human antibody against human hepatocellular carcinoma by guided-selection | |
| CN120865417B (en) | Anti-MICA/B antibodies and their applications | |
| CN119591709A (en) | An anti-CD25 antibody and its application | |
| HK40038467A (en) | Anti-cd47 antibody and application thereof | |
| HK40038037A (en) | Antibodies binding to human il-4r, preparation method therefor and use thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| EE01 | Entry into force of recordation of patent licensing contract | ||
| EE01 | Entry into force of recordation of patent licensing contract |
Application publication date: 20210723 Assignee: Anhui Xingtai Financial Leasing Co.,Ltd. Assignor: ANHUI RUBIOX-VISION BIOTECHNOLOGY Co.,Ltd. Contract record no.: X2024980007355 Denomination of invention: A humanized monoclonal antibody against PD-L1 and its application Granted publication date: 20220408 License type: Exclusive License Record date: 20240620 |
|
| PE01 | Entry into force of the registration of the contract for pledge of patent right |
Denomination of invention: A humanized monoclonal antibody against PD-L1 and its application Granted publication date: 20220408 Pledgee: Anhui Xingtai Financial Leasing Co.,Ltd. Pledgor: ANHUI RUBIOX-VISION BIOTECHNOLOGY Co.,Ltd. Registration number: Y2024980023575 |
|
| PE01 | Entry into force of the registration of the contract for pledge of patent right | ||
| EC01 | Cancellation of recordation of patent licensing contract |
Assignee: Anhui Xingtai Financial Leasing Co.,Ltd. Assignor: ANHUI RUBIOX-VISION BIOTECHNOLOGY Co.,Ltd. Contract record no.: X2024980007355 Date of cancellation: 20250124 |
|
| EC01 | Cancellation of recordation of patent licensing contract | ||
| PC01 | Cancellation of the registration of the contract for pledge of patent right |
Granted publication date: 20220408 Pledgee: Anhui Xingtai Financial Leasing Co.,Ltd. Pledgor: ANHUI RUBIOX-VISION BIOTECHNOLOGY Co.,Ltd. Registration number: Y2024980023575 |
|
| PC01 | Cancellation of the registration of the contract for pledge of patent right |