CN110222840B - A method and device for cluster resource prediction based on attention mechanism - Google Patents
A method and device for cluster resource prediction based on attention mechanism Download PDFInfo
- Publication number
- CN110222840B CN110222840B CN201910413227.1A CN201910413227A CN110222840B CN 110222840 B CN110222840 B CN 110222840B CN 201910413227 A CN201910413227 A CN 201910413227A CN 110222840 B CN110222840 B CN 110222840B
- Authority
- CN
- China
- Prior art keywords
- attention
- time series
- weight
- state
- hidden layer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
技术领域Technical Field
本发明涉及集群资源管理技术领域,更具体的说是涉及一种基于注意力机制的集群资源预测方法和装置。The present invention relates to the technical field of cluster resource management, and more specifically to a cluster resource prediction method and device based on an attention mechanism.
背景技术Background Art
目前的数据中心的体量越来越大,有效地对数据中心内的集群进行资源管理可以提高硬件资源的利用率,减少运维成本,提高运维的利润。其中一个有效提高资源利用率的方法就是对集群未来的资源需求进行预测,从而提前进行资源规划,减少资源的浪费。The current data center is getting bigger and bigger. Effective resource management of the cluster in the data center can improve the utilization of hardware resources, reduce operation and maintenance costs, and increase operation and maintenance profits. One of the effective ways to improve resource utilization is to predict the future resource demand of the cluster, so as to plan resources in advance and reduce resource waste.
目前进行集群资源需求预测主要是使用集群资源的时间序列数据。而常见的时间序列预测模型有ARIMA(整合移动平均自回归模型),VAR(向量自回归模型),GBRT(梯度提升回归树)LSTM(长短期记忆网络)等,他们都可以直接用于集群内的资源需求预测。Currently, cluster resource demand forecasting mainly uses cluster resource time series data. Common time series forecasting models include ARIMA (Autoregressive Integrated Moving Average), VAR (Vector Autoregressive), GBRT (Gradient Boosted Regression Tree), LSTM (Long Short-Term Memory Network), etc. They can all be directly used for cluster resource demand forecasting.
但是目前集群资源预测方法存在两个主要的问题:1.这些方法主要使用单个时间序列作为特征进行预测的(如ARIMA),几乎没有使用多个时间序列来进行资源需求预测的。预测的准确性依赖于这个时间序列的历史值是否蕴含明显的规律;2.目前虽然已有很多通用的多时间序列预测模型(如VAR),这些模型方法没有考虑数据中心内集群的特点,特别是没有考虑集群内应用负载之间的相关性和相互干扰,上述两个问题都会导致集群资源预测结果不准确。However, there are two main problems with current cluster resource prediction methods: 1. These methods mainly use a single time series as a feature for prediction (such as ARIMA), and almost no methods use multiple time series for resource demand prediction. The accuracy of the prediction depends on whether the historical values of this time series contain obvious rules; 2. Although there are many general multi-time series prediction models (such as VAR), these model methods do not consider the characteristics of clusters in data centers, especially the correlation and mutual interference between application loads in clusters. The above two problems will lead to inaccurate cluster resource prediction results.
因此,如何提供一种集群资源预测结果准确的方法是本领域技术人员亟需解决的问题。Therefore, how to provide a method for accurately predicting cluster resource results is an urgent problem that those skilled in the art need to solve.
发明内容Summary of the invention
有鉴于此,本发明提供了一种基于注意力机制的集群资源预测方法和装置,使用多个资源时间序列来进行未来资源需求量的预测,而且还针对集群内应用负载对资源使用的特点,采用改进的深度学习注意力机制来挖掘多个资源需求时间序列之间的相关性,能够有效提高资源预测的准确率。In view of this, the present invention provides a cluster resource prediction method and device based on an attention mechanism, which uses multiple resource time series to predict future resource demand. In addition, based on the characteristics of resource usage by application loads within the cluster, an improved deep learning attention mechanism is used to mine the correlation between multiple resource demand time series, which can effectively improve the accuracy of resource prediction.
为了实现上述目的,本发明采用如下技术方案:In order to achieve the above object, the present invention adopts the following technical solution:
一种基于注意力机制的集群资源预测方法,包括:A cluster resource prediction method based on an attention mechanism, comprising:
S1:将上一时刻第一隐藏层状态、与目标实例同属于一个部署单元的所有时间序列数据、与目标实例同属于一个主机单元的所有时间序列数据以及历史时刻的目标时序作为输入注意力层的输入,得到第一输入向量;S1: Take the state of the first hidden layer at the previous moment, all time series data belonging to the same deployment unit as the target instance, all time series data belonging to the same host unit as the target instance, and the target time series at the historical moment as the input of the input attention layer to obtain the first input vector;
S2:将所述第一输入向量输入到LSTM编码器,得到当前第一隐藏层状态;S2: Input the first input vector to the LSTM encoder to obtain the current first hidden layer state;
S3:将所述当前第一隐藏层状态和上一时刻第二隐藏层状态输入到时间相关性注意力层,得到上下文向量;S3: Input the current first hidden layer state and the second hidden layer state at the previous moment into the time-dependent attention layer to obtain a context vector;
S4:将所述上下文向量、上一时刻第二隐藏层状态和历史时刻的目标时序输入到LSTM解码器,得到当前第二隐藏层状态;S4: Input the context vector, the second hidden layer state at the previous moment, and the target time sequence at the historical moment into the LSTM decoder to obtain the current second hidden layer state;
S5:将所述当前第二隐藏层状态和所述上下文向量进行线性变换,得到预测值。S5: Perform a linear transformation on the current second hidden layer state and the context vector to obtain a predicted value.
优选的,步骤S1具体包括:Preferably, step S1 specifically includes:
S11:将上一时刻第一隐藏层状态以及与目标实例同属于一个部署单元的所有时间序列数据作为部署单元注意力层的输入,得到部署单元注意力层输出向量;S11: taking the state of the first hidden layer at the previous moment and all time series data belonging to the same deployment unit as the target instance as the input of the deployment unit attention layer, and obtaining the deployment unit attention layer output vector;
S12:将上一时刻第一隐藏层状态以及与目标实例同属于一个主机单元的所有时间序列数据作为主机单元注意力层的输入,得到主机单元注意力输出向量;S12: taking the state of the first hidden layer at the previous moment and all time series data belonging to the same host unit as the target instance as the input of the host unit attention layer, and obtaining the host unit attention output vector;
S13:将上一时刻第一隐藏层状态以及历史时刻的目标时序作为自相关性注意力层的输入,得到自相关性注意力层输出向量;S13: Taking the state of the first hidden layer at the previous moment and the target time sequence at the historical moment as the input of the autocorrelation attention layer, and obtaining the output vector of the autocorrelation attention layer;
S14:将部署单元注意力层输出向量、主机单元注意力输出向量和自相关性注意力层输出向量合并作为第一输入向量。S14: Combine the deployment unit attention layer output vector, the host unit attention output vector and the autocorrelation attention layer output vector as the first input vector.
优选的,步骤S11具体包括:Preferably, step S11 specifically includes:
基于上一时刻第一隐藏层状态和与目标实例同属于一个部署单元的所有时间序列数据计算第一注意力权重;Calculate the first attention weight based on the first hidden layer state at the previous moment and all time series data belonging to the same deployment unit as the target instance;
基于第一注意力权重,使用softmax函数计算出归一化部署单元注意力权重;Based on the first attention weight, the normalized deployment unit attention weight is calculated using the softmax function;
基于上一时刻第一隐藏层状态、与目标实例同属于一个部署单元的所有时间序列数据以及归一化部署单元注意力权重,计算部署单元注意力层输出向量;Calculate the deployment unit attention layer output vector based on the state of the first hidden layer at the previous moment, all time series data belonging to the same deployment unit as the target instance, and the normalized deployment unit attention weight;
步骤S12具体包括:Step S12 specifically includes:
计算与目标实例同属于一个主机单元的每个时间序列数据相对于历史目标时序的一阶时序相关性系数,并得到对应的主机单元内所有时间序列和历史目标时序的静态时间相关性权重;Calculate the first-order time series correlation coefficient of each time series data belonging to the same host unit as the target instance relative to the historical target time series, and obtain the static time correlation weights of all time series in the corresponding host unit and the historical target time series;
基于上一时刻第一隐藏层状态和目标实例同属于一个主机单元的所有时间序列数据计算第二注意力权重;Calculate the second attention weight based on all time series data of the first hidden layer state and the target instance belonging to the same host unit at the previous moment;
基于静态时间相关性权重和第二注意力权重得到主机单元注意力权重,并进行归一化,得到归一化主机单元注意力权重;Obtaining the host unit attention weight based on the static time correlation weight and the second attention weight, and normalizing them to obtain the normalized host unit attention weight;
基于上一时刻第一隐藏层状态、与目标实例同属于一个主机单元的所有时间序列数据、历史时刻的目标时序以及归一化主机单元注意力权重,计算主机单元注意力输出向量;Calculate the host unit attention output vector based on the state of the first hidden layer at the previous moment, all time series data belonging to the same host unit as the target instance, the target time series at the historical moment, and the normalized host unit attention weight;
步骤S13具体包括:Step S13 specifically includes:
计算不同时间窗口内的历史时刻目标时序之间的相关性系数,并得到对应的自相关权重;Calculate the correlation coefficient between the historical moment target time series in different time windows and obtain the corresponding autocorrelation weights;
基于上一时刻第一隐藏层状态和不同历史时刻目标时序计算第三注意力权重;Calculate the third attention weight based on the state of the first hidden layer at the previous moment and the target time sequence at different historical moments;
基于自相关权重和第三注意力权重得到自相关单元注意力权重,并进行归一化,得到归一化自相关单元注意力权重;The autocorrelation unit attention weight is obtained based on the autocorrelation weight and the third attention weight, and normalized to obtain the normalized autocorrelation unit attention weight;
基于上一时刻第一隐藏层状态、历史时刻的目标时序、以及归一化自相关单元注意力权重,计算自相关性注意力层输出向量。Based on the state of the first hidden layer at the previous moment, the target time series at the historical moment, and the normalized autocorrelation unit attention weight, the autocorrelation attention layer output vector is calculated.
优选的,步骤S3具体包括:Preferably, step S3 specifically includes:
基于上一时刻第二隐藏层状态计算时间注意力层权重,并进行归一化,得到归一化后的时间注意力层权重;Calculate the temporal attention layer weight based on the state of the second hidden layer at the previous moment, and normalize it to obtain the normalized temporal attention layer weight;
基于当前第一隐藏层状态和归一化后的时间注意力层权重计算上下文向量。The context vector is calculated based on the current first hidden layer state and the normalized temporal attention layer weights.
一种基于注意力机制的集群资源预测装置,包括:A cluster resource prediction device based on an attention mechanism, comprising:
第一输入向量计算模块,用于将上一时刻第一隐藏层状态、与目标实例同属于一个部署单元的所有时间序列数据、与目标实例同属于一个主机单元的所有时间序列数据以及历史时刻的目标时序作为输入注意力层的输入,得到第一输入向量;A first input vector calculation module is used to use the first hidden layer state at the previous moment, all time series data belonging to a deployment unit with the target instance, all time series data belonging to a host unit with the target instance, and the target time series at the historical moment as inputs to the input attention layer to obtain a first input vector;
第一隐藏层状态计算模块,用于将所述第一输入向量输入到LSTM编码器,得到当前第一隐藏层状态;A first hidden layer state calculation module, used for inputting the first input vector into the LSTM encoder to obtain a current first hidden layer state;
上下文向量计算模块,用于将所述当前第一隐藏层状态和上一时刻第二隐藏层状态输入到时间相关性注意力层,得到上下文向量;A context vector calculation module, used to input the current first hidden layer state and the second hidden layer state at the previous moment into the time correlation attention layer to obtain a context vector;
第二隐藏层状态计算模块,用于将所述上下文向量、上一时刻第二隐藏层状态和历史时刻的目标时序输入到LSTM解码器,得到当前第二隐藏层状态;A second hidden layer state calculation module is used to input the context vector, the second hidden layer state at the previous moment and the target time sequence at the historical moment into the LSTM decoder to obtain the current second hidden layer state;
线性变换模块,用于将所述当前第二隐藏层状态和所述上下文向量进行线性变换,得到预测值。The linear transformation module is used to linearly transform the current second hidden layer state and the context vector to obtain a predicted value.
优选的,所述第一输入向量计算模块具体包括:Preferably, the first input vector calculation module specifically includes:
第一计算单元,用于将上一时刻第一隐藏层状态以及与目标实例同属于一个部署单元的所有时间序列数据作为部署单元注意力层的输入,得到部署单元注意力层输出向量;A first computing unit is used to use the state of the first hidden layer at the previous moment and all time series data belonging to the same deployment unit as the target instance as inputs of the deployment unit attention layer to obtain an output vector of the deployment unit attention layer;
第二计算单元,用于将上一时刻第一隐藏层状态以及与目标实例同属于一个主机单元的所有时间序列数据作为主机单元注意力层的输入,得到主机单元注意力输出向量;The second computing unit is used to use the state of the first hidden layer at the previous moment and all time series data belonging to the same host unit as the target instance as the input of the host unit attention layer to obtain the host unit attention output vector;
第三计算单元,用于将上一时刻第一隐藏层状态以及历史时刻的目标时序作为自相关性注意力层的输入,得到自相关性注意力层输出向量;A third calculation unit is used to use the state of the first hidden layer at the previous moment and the target time sequence at the historical moment as the input of the autocorrelation attention layer to obtain an output vector of the autocorrelation attention layer;
合并单元,用于将部署单元注意力层输出向量、主机单元注意力输出向量和自相关性注意力层输出向量合并作为第一输入向量。A merging unit is used to merge the deployment unit attention layer output vector, the host unit attention output vector and the autocorrelation attention layer output vector as the first input vector.
优选的,所述第一计算单元具体包括:Preferably, the first calculation unit specifically includes:
第一注意力权重计算子单元,用于基于上一时刻第一隐藏层状态和与目标实例同属于一个部署单元的所有时间序列数据计算第一注意力权重;A first attention weight calculation subunit, used to calculate a first attention weight based on the first hidden layer state at the previous moment and all time series data belonging to the same deployment unit as the target instance;
第一归一化权重计算子单元,用于基于第一注意力权重,使用softmax函数计算出归一化部署单元注意力权重;A first normalized weight calculation subunit, used to calculate a normalized deployment unit attention weight using a softmax function based on the first attention weight;
第一注意力层输出向量计算子单元,用于基于上一时刻第一隐藏层状态、与目标实例同属于一个部署单元的所有时间序列数据以及归一化部署单元注意力权重,计算部署单元注意力层输出向量;A first attention layer output vector calculation subunit, used to calculate a deployment unit attention layer output vector based on the first hidden layer state at the previous moment, all time series data belonging to the same deployment unit as the target instance, and a normalized deployment unit attention weight;
所述第二计算单元具体包括:The second calculation unit specifically includes:
静态时间相关性权重计算子单元,用于计算与目标实例同属于一个主机单元的每个时间序列数据相对于历史目标时序的一阶时序相关性系数,并得到对应的主机单元内所有时间序列和历史目标时序的静态时间相关性权重;The static time correlation weight calculation subunit is used to calculate the first-order time correlation coefficient of each time series data belonging to the same host unit as the target instance relative to the historical target time series, and obtain the static time correlation weights of all time series in the corresponding host unit and the historical target time series;
第二注意力权重计算子单元,用于基于上一时刻第一隐藏层状态和目标实例同属于一个主机单元的所有时间序列数据计算第二注意力权重;A second attention weight calculation subunit, used to calculate a second attention weight based on the first hidden layer state at the previous moment and all time series data of the target instance belonging to the same host unit;
第二归一化权重子单元,用于基于静态时间相关性权重和第二注意力权重得到主机单元注意力权重,并进行归一化,得到归一化主机单元注意力权重;A second normalization weight subunit, used to obtain the host unit attention weight based on the static time correlation weight and the second attention weight, and perform normalization to obtain a normalized host unit attention weight;
第二注意力层输出向量计算子单元,用于基于上一时刻第一隐藏层状态、与目标实例同属于一个主机单元的所有时间序列数据、历史时刻的目标时序以及归一化主机单元注意力权重,计算主机单元注意力层输出向量;The second attention layer output vector calculation subunit is used to calculate the host unit attention layer output vector based on the first hidden layer state at the previous moment, all time series data belonging to the same host unit as the target instance, the target time series at the historical moment, and the normalized host unit attention weight;
所述第三计算单元具体包括:The third calculation unit specifically includes:
自相关权重计算子单元,用于计算不同时间窗口内的历史时刻目标时序之间的相关性系数,并得到对应的自相关权重;The autocorrelation weight calculation subunit is used to calculate the correlation coefficient between the historical moment target time series in different time windows and obtain the corresponding autocorrelation weight;
第三注意力权重计算子单元,用于基于上一时刻第一隐藏层状态和不同历史时刻目标时序计算第三注意力权重;A third attention weight calculation subunit, used to calculate a third attention weight based on the state of the first hidden layer at the previous moment and the target time series at different historical moments;
第三归一化权重子单元,用于基于自相关权重和第三注意力权重得到自相关单元注意力权重,并进行归一化,得到归一化自相关单元注意力权重;A third normalization weight subunit, used to obtain an autocorrelation unit attention weight based on the autocorrelation weight and the third attention weight, and perform normalization to obtain a normalized autocorrelation unit attention weight;
第三注意力层输出向量子单元,基于上一时刻第一隐藏层状态、历史时刻的目标时序、以及归一化自相关单元注意力权重,计算自相关性注意力层输出向量。The third attention layer output vector is a quantum unit, which calculates the autocorrelation attention layer output vector based on the state of the first hidden layer at the previous moment, the target time series at the historical moment, and the normalized autocorrelation unit attention weight.
优选的,所述上下文向量计算模块具体包括:Preferably, the context vector calculation module specifically includes:
第四归一化权重子单元,用于基于上一时刻第二隐藏层状态计算时间注意力层权重,并进行归一化,得到归一化后的时间注意力层权重;A fourth normalization weight subunit is used to calculate the temporal attention layer weight based on the state of the second hidden layer at the previous moment, and perform normalization to obtain a normalized temporal attention layer weight;
上下文向量计算子单元,用于基于当前第一隐藏层状态和归一化后的时间注意力层权重计算上下文向量。The context vector calculation subunit is used to calculate the context vector based on the current first hidden layer state and the normalized temporal attention layer weight.
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于注意力机制的集群资源预测方法和装置,采用改进的注意力机制,并将其集成到LSTM中,可以挖掘多个时间序列之间的相关性,并提出使用多个时间序列进行集群内资源需求预测的方案,有效提高了预测的准确率,能更加有效的辅助资源规划,从而提高集群的资源利用率,更有效地降低数据中心的运维成本。It can be seen from the above technical solution that compared with the prior art, the present invention discloses a cluster resource prediction method and device based on the attention mechanism, which adopts an improved attention mechanism and integrates it into LSTM, can mine the correlation between multiple time series, and proposes a solution for using multiple time series to predict resource demand within the cluster, which effectively improves the prediction accuracy and can more effectively assist resource planning, thereby improving the resource utilization of the cluster and more effectively reducing the operation and maintenance costs of the data center.
附图说明BRIEF DESCRIPTION OF THE DRAWINGS
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。In order to more clearly illustrate the embodiments of the present invention or the technical solutions in the prior art, the drawings required for use in the embodiments or the description of the prior art will be briefly introduced below. Obviously, the drawings described below are only embodiments of the present invention. For ordinary technicians in this field, other drawings can be obtained based on the provided drawings without paying creative work.
图1为本发明提供的一种基于注意力机制的集群资源预测方法的流程图;FIG1 is a flow chart of a cluster resource prediction method based on an attention mechanism provided by the present invention;
图2为本发明提供的计算第一输入向量的具体流程图;FIG2 is a specific flow chart of calculating the first input vector provided by the present invention;
图3为本发明提供的一种基于注意力机制的集群资源预测装置的示意图;FIG3 is a schematic diagram of a cluster resource prediction device based on an attention mechanism provided by the present invention;
图4为本发明提供的第一输入向量计算模块的组成示意图;FIG4 is a schematic diagram showing the composition of a first input vector calculation module provided by the present invention;
图5为本发明提供的时间序列采集架构示意图;FIG5 is a schematic diagram of a time series acquisition architecture provided by the present invention;
图6为本发明提供的基于注意力机制的预测模型示意图。FIG6 is a schematic diagram of a prediction model based on an attention mechanism provided by the present invention.
具体实施方式DETAILED DESCRIPTION
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The following will be combined with the drawings in the embodiments of the present invention to clearly and completely describe the technical solutions in the embodiments of the present invention. Obviously, the described embodiments are only part of the embodiments of the present invention, not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by ordinary technicians in this field without creative work are within the scope of protection of the present invention.
参见附图1,本发明实施例公开了一种基于注意力机制的集群资源预测方法,包括:Referring to FIG. 1 , an embodiment of the present invention discloses a cluster resource prediction method based on an attention mechanism, comprising:
S1:将上一时刻第一隐藏层状态、与目标实例同属于一个部署单元的所有时间序列数据、与目标实例同属于一个主机单元的所有时间序列数据以及历史时刻的目标时序作为输入注意力层的输入,得到第一输入向量;S1: Take the state of the first hidden layer at the previous moment, all time series data belonging to the same deployment unit as the target instance, all time series data belonging to the same host unit as the target instance, and the target time series at the historical moment as the input of the input attention layer to obtain the first input vector;
S2:将第一输入向量输入到LSTM编码器,得到当前第一隐藏层状态;S2: Input the first input vector to the LSTM encoder to obtain the current first hidden layer state;
S3:将当前第一隐藏层状态和上一时刻第二隐藏层状态输入到时间相关性注意力层,得到上下文向量;S3: Input the current first hidden layer state and the second hidden layer state at the previous moment into the time-dependent attention layer to obtain a context vector;
S4:将上下文向量、上一时刻第二隐藏层状态和历史时刻的目标时序输入到LSTM解码器,得到当前第二隐藏层状态;S4: Input the context vector, the second hidden layer state at the previous moment, and the target time sequence at the historical moment into the LSTM decoder to obtain the current second hidden layer state;
S5:将当前第二隐藏层状态和上下文向量进行线性变换,得到预测值。S5: Linearly transform the current second hidden layer state and context vector to obtain a predicted value.
本发明在进行资源预测时,使用了多个资源和时间序列而不是一个时间序列来进行预测,此外,还针对集群内应用负载对资源使用的特点,采用改进的深度学习注意力机制来挖掘多个资源时间序列之间的相关性,最终有效的提高资源预测的准确率。When performing resource prediction, the present invention uses multiple resources and time series instead of one time series for prediction. In addition, based on the characteristics of resource usage by application loads within the cluster, an improved deep learning attention mechanism is used to mine the correlation between multiple resource time series, ultimately effectively improving the accuracy of resource prediction.
参见附图2,为了进一步优化上述技术方案,本发明的实施例进一步公开了步骤S1具体包括:Referring to FIG. 2 , in order to further optimize the above technical solution, the embodiment of the present invention further discloses that step S1 specifically includes:
S11:将上一时刻第一隐藏层状态以及与目标实例同属于一个部署单元的所有时间序列数据作为部署单元注意力层的输入,得到部署单元注意力层输出向量;S11: taking the state of the first hidden layer at the previous moment and all time series data belonging to the same deployment unit as the target instance as the input of the deployment unit attention layer, and obtaining the deployment unit attention layer output vector;
S12:将上一时刻第一隐藏层状态以及与目标实例同属于一个主机单元的所有时间序列数据作为主机单元注意力层的输入,得到主机单元注意力输出向量;S12: taking the state of the first hidden layer at the previous moment and all time series data belonging to the same host unit as the target instance as the input of the host unit attention layer, and obtaining the host unit attention output vector;
S13:将上一时刻第一隐藏层状态以及历史时刻的目标时序作为自相关性注意力层的输入,得到自相关性注意力层输出向量;S13: Taking the state of the first hidden layer at the previous moment and the target time sequence at the historical moment as the input of the autocorrelation attention layer, and obtaining the output vector of the autocorrelation attention layer;
S14:将部署单元注意力层输出向量、主机单元注意力输出向量和自相关性注意力层输出向量合并作为第一输入向量。S14: Combine the deployment unit attention layer output vector, the host unit attention output vector and the autocorrelation attention layer output vector as the first input vector.
为了进一步优化上述技术方案,本发明的实施例进一步公开了步骤S11具体包括:In order to further optimize the above technical solution, the embodiment of the present invention further discloses that step S11 specifically includes:
基于上一时刻第一隐藏层状态和与目标实例同属于一个部署单元的所有时间序列数据计算第一注意力权重;Calculate the first attention weight based on the first hidden layer state at the previous moment and all time series data belonging to the same deployment unit as the target instance;
基于第一注意力权重,使用softmax函数计算出归一化部署单元注意力权重;Based on the first attention weight, the normalized deployment unit attention weight is calculated using the softmax function;
基于上一时刻第一隐藏层状态、与目标实例同属于一个部署单元的所有时间序列数据以及归一化部署单元注意力权重,计算部署单元注意力层输出向量;Calculate the deployment unit attention layer output vector based on the state of the first hidden layer at the previous moment, all time series data belonging to the same deployment unit as the target instance, and the normalized deployment unit attention weight;
步骤S12具体包括:Step S12 specifically includes:
计算与目标实例同属于一个主机单元的每个时间序列数据相对于历史目标时序的一阶时序相关性系数,并得到对应的主机单元内所有时间序列和历史目标时序的静态时间相关性权重;Calculate the first-order time series correlation coefficient of each time series data belonging to the same host unit as the target instance relative to the historical target time series, and obtain the static time correlation weights of all time series in the corresponding host unit and the historical target time series;
基于上一时刻第一隐藏层状态和目标实例同属于一个主机单元的所有时间序列数据计算第二注意力权重;Calculate the second attention weight based on all time series data of the first hidden layer state and the target instance belonging to the same host unit at the previous moment;
基于静态时间相关性权重和第二注意力权重得到主机单元注意力权重,并进行归一化,得到归一化主机单元注意力权重;Obtaining the host unit attention weight based on the static time correlation weight and the second attention weight, and normalizing them to obtain the normalized host unit attention weight;
基于上一时刻第一隐藏层状态、与目标实例同属于一个主机单元的所有时间序列数据、历史时刻的目标时序以及归一化主机单元注意力权重,计算主机单元注意力输出向量;Calculate the host unit attention output vector based on the state of the first hidden layer at the previous moment, all time series data belonging to the same host unit as the target instance, the target time series at the historical moment, and the normalized host unit attention weight;
步骤S13具体包括:Step S13 specifically includes:
计算不同时间窗口内的历史时刻目标时序之间的相关性系数,并得到对应的自相关权重;Calculate the correlation coefficient between the historical moment target time series in different time windows and obtain the corresponding autocorrelation weights;
基于上一时刻第一隐藏层状态和不同历史时刻目标时序计算第三注意力权重;Calculate the third attention weight based on the state of the first hidden layer at the previous moment and the target time sequence at different historical moments;
基于自相关权重和第三注意力权重得到自相关单元注意力权重,并进行归一化,得到归一化自相关单元注意力权重;The autocorrelation unit attention weight is obtained based on the autocorrelation weight and the third attention weight, and normalized to obtain the normalized autocorrelation unit attention weight;
基于上一时刻第一隐藏层状态、历史时刻的目标时序、以及归一化自相关单元注意力权重,计算自相关性注意力层输出向量。Based on the state of the first hidden layer at the previous moment, the target time series at the historical moment, and the normalized autocorrelation unit attention weight, the autocorrelation attention layer output vector is calculated.
为了进一步优化上述技术方案,本发明的实施例进一步公开了步骤S3具体包括:In order to further optimize the above technical solution, the embodiment of the present invention further discloses that step S3 specifically includes:
基于上一时刻第二隐藏层状态计算时间注意力层权重,并进行归一化,得到归一化后的时间注意力层权重;Calculate the temporal attention layer weight based on the state of the second hidden layer at the previous moment, and normalize it to obtain the normalized temporal attention layer weight;
基于当前第一隐藏层状态和归一化后的时间注意力层权重计算上下文向量。The context vector is calculated based on the current first hidden layer state and the normalized temporal attention layer weights.
参见附图3,本发明实施例还公开了一种基于注意力机制的集群资源预测装置,包括:Referring to FIG. 3 , an embodiment of the present invention further discloses a cluster resource prediction device based on an attention mechanism, comprising:
第一输入向量计算模块,用于将上一时刻第一隐藏层状态、与目标实例同属于一个部署单元的所有时间序列数据、与目标实例同属于一个主机单元的所有时间序列数据以及历史时刻的目标时序作为输入注意力层的输入,得到第一输入向量;A first input vector calculation module is used to use the first hidden layer state at the previous moment, all time series data belonging to a deployment unit with the target instance, all time series data belonging to a host unit with the target instance, and the target time series at the historical moment as inputs to the input attention layer to obtain a first input vector;
第一隐藏层状态计算模块,用于将第一输入向量输入到LSTM编码器,得到当前第一隐藏层状态;A first hidden layer state calculation module, used for inputting the first input vector into the LSTM encoder to obtain the current first hidden layer state;
上下文向量计算模块,用于将当前第一隐藏层状态和上一时刻第二隐藏层状态输入到时间相关性注意力层,得到上下文向量;A context vector calculation module is used to input the current first hidden layer state and the second hidden layer state at the previous moment into the time correlation attention layer to obtain a context vector;
第二隐藏层状态计算模块,用于将上下文向量、上一时刻第二隐藏层状态和历史时刻的目标时序输入到LSTM解码器,得到当前第二隐藏层状态;The second hidden layer state calculation module is used to input the context vector, the second hidden layer state at the previous moment and the target time sequence at the historical moment into the LSTM decoder to obtain the current second hidden layer state;
线性变换模块,用于将当前第二隐藏层状态和上下文向量进行线性变换,得到预测值。The linear transformation module is used to linearly transform the current second hidden layer state and the context vector to obtain a predicted value.
参见附图4,为了进一步优化上述技术方案,本发明的实施例进一步公开了第一输入向量计算模块具体包括:Referring to FIG. 4 , in order to further optimize the above technical solution, an embodiment of the present invention further discloses that the first input vector calculation module specifically includes:
第一计算单元,用于将上一时刻第一隐藏层状态以及与目标实例同属于一个部署单元的所有时间序列数据作为部署单元注意力层的输入,得到部署单元注意力层输出向量;A first computing unit is used to use the state of the first hidden layer at the previous moment and all time series data belonging to the same deployment unit as the target instance as inputs of the deployment unit attention layer to obtain an output vector of the deployment unit attention layer;
第二计算单元,用于将上一时刻第一隐藏层状态以及与目标实例同属于一个主机单元的所有时间序列数据作为主机单元注意力层的输入,得到主机单元注意力输出向量;The second computing unit is used to use the state of the first hidden layer at the previous moment and all time series data belonging to the same host unit as the target instance as the input of the host unit attention layer to obtain the host unit attention output vector;
第三计算单元,用于将上一时刻第一隐藏层状态以及历史时刻的目标时序作为自相关性注意力层的输入,得到自相关性注意力层输出向量;A third calculation unit is used to use the state of the first hidden layer at the previous moment and the target time sequence at the historical moment as the input of the autocorrelation attention layer to obtain an output vector of the autocorrelation attention layer;
合并单元,用于将部署单元注意力层输出向量、主机单元注意力输出向量和自相关性注意力层输出向量合并作为第一输入向量。A merging unit is used to merge the deployment unit attention layer output vector, the host unit attention output vector and the autocorrelation attention layer output vector as the first input vector.
为了进一步优化上述技术方案,本发明的实施例进一步公开了第一计算单元具体包括:In order to further optimize the above technical solution, an embodiment of the present invention further discloses that the first computing unit specifically includes:
第一注意力权重计算子单元,用于基于上一时刻第一隐藏层状态和与目标实例同属于一个部署单元的所有时间序列数据计算第一注意力权重;A first attention weight calculation subunit, used to calculate a first attention weight based on the first hidden layer state at the previous moment and all time series data belonging to the same deployment unit as the target instance;
第一归一化权重计算子单元,用于基于第一注意力权重,使用softmax函数计算出归一化部署单元注意力权重;A first normalized weight calculation subunit, used to calculate a normalized deployment unit attention weight using a softmax function based on the first attention weight;
第一注意力层输出向量计算子单元,用于基于上一时刻第一隐藏层状态、与目标实例同属于一个部署单元的所有时间序列数据以及归一化部署单元注意力权重,计算部署单元注意力层输出向量;A first attention layer output vector calculation subunit, used to calculate a deployment unit attention layer output vector based on the first hidden layer state at the previous moment, all time series data belonging to the same deployment unit as the target instance, and a normalized deployment unit attention weight;
第二计算单元具体包括:The second computing unit specifically includes:
静态时间相关性权重计算子单元,用于计算与目标实例同属于一个主机单元的每个时间序列数据相对于历史目标时序的一阶时序相关性系数,并得到对应的主机单元内所有时间序列和历史目标时序的静态时间相关性权重;The static time correlation weight calculation subunit is used to calculate the first-order time correlation coefficient of each time series data belonging to the same host unit as the target instance relative to the historical target time series, and obtain the static time correlation weights of all time series in the corresponding host unit and the historical target time series;
第二注意力权重计算子单元,用于基于上一时刻第一隐藏层状态和目标实例同属于一个主机单元的所有时间序列数据计算第二注意力权重;A second attention weight calculation subunit, used to calculate a second attention weight based on the first hidden layer state at the previous moment and all time series data of the target instance belonging to the same host unit;
第二归一化权重子单元,用于基于静态时间相关性权重和第二注意力权重得到主机单元注意力权重,并进行归一化,得到归一化主机单元注意力权重;A second normalization weight subunit, used to obtain the host unit attention weight based on the static time correlation weight and the second attention weight, and perform normalization to obtain a normalized host unit attention weight;
第二注意力层输出向量计算子单元,用于基于上一时刻第一隐藏层状态、与目标实例同属于一个主机单元的所有时间序列数据、历史时刻的目标时序以及归一化主机单元注意力权重,计算主机单元注意力层输出向量;The second attention layer output vector calculation subunit is used to calculate the host unit attention layer output vector based on the first hidden layer state at the previous moment, all time series data belonging to the same host unit as the target instance, the target time series at the historical moment, and the normalized host unit attention weight;
第三计算单元具体包括:The third calculation unit specifically includes:
自相关权重计算子单元,用于计算不同时间窗口内的历史时刻目标时序之间的相关性系数,并得到对应的自相关权重;The autocorrelation weight calculation subunit is used to calculate the correlation coefficient between the historical moment target time series in different time windows and obtain the corresponding autocorrelation weight;
第三注意力权重计算子单元,用于基于上一时刻第一隐藏层状态和不同历史时刻目标时序计算第三注意力权重;A third attention weight calculation subunit, used to calculate a third attention weight based on the state of the first hidden layer at the previous moment and the target time series at different historical moments;
第三归一化权重子单元,用于基于自相关权重和第三注意力权重得到自相关单元注意力权重,并进行归一化,得到归一化自相关单元注意力权重;A third normalization weight subunit, used to obtain an autocorrelation unit attention weight based on the autocorrelation weight and the third attention weight, and perform normalization to obtain a normalized autocorrelation unit attention weight;
第三注意力层输出向量子单元,基于上一时刻第一隐藏层状态、历史时刻的目标时序、以及归一化自相关单元注意力权重,计算自相关性注意力层输出向量。The third attention layer output vector is a quantum unit, which calculates the autocorrelation attention layer output vector based on the state of the first hidden layer at the previous moment, the target time series at the historical moment, and the normalized autocorrelation unit attention weight.
为了进一步优化上述技术方案,本发明的实施例进一步公开了上下文向量计算模块具体包括:In order to further optimize the above technical solution, the embodiment of the present invention further discloses that the context vector calculation module specifically includes:
第四归一化权重子单元,用于基于上一时刻第二隐藏层状态计算时间注意力层权重,并进行归一化,得到归一化后的时间注意力层权重;A fourth normalization weight subunit is used to calculate the temporal attention layer weight based on the state of the second hidden layer at the previous moment, and perform normalization to obtain a normalized temporal attention layer weight;
上下文向量计算子单元,用于基于当前第一隐藏层状态和归一化后的时间注意力层权重计算上下文向量。The context vector calculation subunit is used to calculate the context vector based on the current first hidden layer state and the normalized temporal attention layer weight.
本发明采用的预测方法使用注意力机制,可以挖掘多个具有相关关系的时间序列的相关性,并使用权重来表示这些时间序列对目标时序的相关性,进而利用这些相关关系来对目标时序进行预测,有效提高了预测的准确率。将本发明提供的模型应用在集群资源预测上,可以更加准确的预测集群未来的资源需求,能够更加有效地辅助资源规划,从而提高集群的资源利用率,更有效地降低数据中心的运维成本。The prediction method adopted by the present invention uses an attention mechanism to mine the correlation of multiple time series with correlations, and uses weights to represent the correlation of these time series to the target time series, and then uses these correlations to predict the target time series, effectively improving the prediction accuracy. Applying the model provided by the present invention to cluster resource prediction can more accurately predict the future resource requirements of the cluster, can more effectively assist resource planning, thereby improving the resource utilization of the cluster, and more effectively reducing the operation and maintenance costs of the data center.
下面结合具体实现方法对本发明提供的技术方案做进一步详细说明。The technical solution provided by the present invention is further described in detail below in conjunction with a specific implementation method.
在现代集群内,一个应用一般是由多个应用实例组成的,把这些属于一个应用内的多个应用实例归类为一个部署单元。而这些实例一般会分布在不同的物理主机上,所以每个物理主机上会有多个不同应用实例,把存在于一个物理主机上的应用实例归类为一个主机单元,那么一个部署单元和一个主机单元内的应用实例之间很有可能由相关关系的。所以,对于一个所要预测的目标实例来说,在采集这个目标实例的时间序列数据,也可以同时采集目标实例所在的部署单元的其他应用实例的时间序列数据和目标实例所在的主机单元的其他应用实例的时间序列数据,并最终将这些时序数据都用于目标实例的预测中。In a modern cluster, an application is generally composed of multiple application instances. These multiple application instances belonging to one application are classified as a deployment unit. These instances are generally distributed on different physical hosts, so there will be multiple different application instances on each physical host. If the application instances existing on a physical host are classified as a host unit, then there is a high probability that there is a correlation between a deployment unit and the application instances in a host unit. Therefore, for a target instance to be predicted, when collecting the time series data of this target instance, the time series data of other application instances in the deployment unit where the target instance is located and the time series data of other application instances in the host unit where the target instance is located can also be collected at the same time, and finally all these time series data are used for the prediction of the target instance.
在详细介绍本发明提供的方法之前,先声明本发明中的描述模型的输入和输出所用到的数学符号如下表所示:Before introducing the method provided by the present invention in detail, it is stated that the mathematical symbols used to describe the input and output of the model in the present invention are as shown in the following table:
表1Table 1

首先,如附图5所示,设计一个时间序列数据采集的架构:在每个主机上都部署一个本地时间序列数据数据库,所有主机的本地时间序列数据库可以将数据上传到全局时间序列数据库中。那么对于一个要进行资源预测的目标实例来说,它只需要在本地就可以获取自己的时间数据(目标序列)和与目标实例同属一个主机单元的所有时间序列数据Xi,然后从全局时间序列数据库中查询并获取与目标实例同属一个部署单元的所有时间序列数据Xo。First, as shown in Figure 5, a time series data collection architecture is designed: a local time series data database is deployed on each host, and the local time series databases of all hosts can upload data to the global time series database. Then for a target instance to be used for resource prediction, it only needs to obtain its own time data (target sequence) and all time series data Xi that belong to the same host unit as the target instance locally, and then query and obtain all time series data Xo that belong to the same deployment unit as the target instance from the global time series database.
本发明根据这些数据设计一个基于注意力机制的预测模型,并命名为MLA-LSTM(Multi-level Attention LSTM,具有多层注意力的长短期记忆网络)Based on these data, the present invention designs a prediction model based on the attention mechanism and names it MLA-LSTM (Multi-level Attention LSTM, a long short-term memory network with multi-layer attention).
该模型设置一个大小为T的时间窗口,每个时间序列使用这个窗口内的T个值,然后预测目标实例下一时间点的值,也就是T+1时间点的值,这个过程可以抽象为:
模型中包括两个LSTM:第一个LSTM作为编码器,用于处理输入的多个时间序列,并输出隐藏状态ht;第二个LSTM作为解码器,负责处理第一个LSTM输出的隐藏状态ht,并最终输出预测值,这个模型的示意图如图6所示。The model includes two LSTMs: the first LSTM is used as an encoder to process multiple input time series and output the hidden state h t ; the second LSTM is used as a decoder to process the hidden state h t output by the first LSTM and finally output the predicted value. The schematic diagram of this model is shown in Figure 6.
一、LSTM编码器1. LSTM Encoder
定义LSTM编码器的计算过程为:The calculation process of the LSTM encoder is defined as:

其中,ht是LSTM在时间点t的隐藏状态向量,设它的长度为m,
对于LSTM编码器,合并三个注意力层为一个输入注意力层,来挖掘时间序列之间的相关性,这三个注意力层分别为:For the LSTM encoder, three attention layers are merged into one input attention layer to mine the correlation between time series. The three attention layers are:
(1)使用一种常见的注意力机制挖掘一个部署单元内的多个时间序列Xi的相关性,并将它称为部署单元注意力层。(1) A common attention mechanism is used to mine the correlation of multiple time series Xi within a deployment unit, and it is called the deployment unit attention layer.
(2)使用改进的注意力机制挖掘一个主机单元内的多个时间序列Xo的相关性,并将它称为主机单元注意力层。(2) We use an improved attention mechanism to mine the correlations of multiple time series Xo within a host unit and call it the host unit attention layer.
(3)使用改进的注意力机制挖掘目标实例的时间序列的自相关性,并将它称为自相关性注意力层。(3) An improved attention mechanism is used to mine the autocorrelation of the time series of the target instance, and it is called the autocorrelation attention layer.
1、部署单元注意力层的计算公式如下:1. The calculation formula for the deployment unit attention layer is as follows:

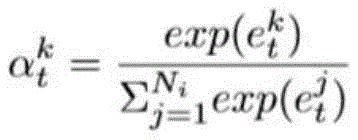

其中,参数说明如下:The parameters are described as follows:


总结来说,部署单元注意力层的输入输出为:In summary, the input and output of the deployment unit attention layer are:

2、主机单元注意力层的计算公式如下:2. The calculation formula of the host unit attention layer is as follows:
(1)首先需要计算每个时间序列相对于目标时序的一阶时序相关性系数CORT(thefirst order temporal correlation coefficient)。(1) First, we need to calculate the first order temporal correlation coefficient (CORT) of each time series relative to the target time series.
以主机单元中第l个时间序列xo,l为例,要计算它与目标时间序列YT的一阶时序相关性系数时,需要对两个序列做一些裁剪处理。Taking the lth time series x o,l in the host unit as an example, to calculate the first-order time series correlation coefficient between it and the target time series Y T , some trimming processing needs to be done on the two series.
首先把xo,l的最后一个值去掉,得到

去掉目标序列在T时刻的滞后值YT的第一个值,得到

然后计算


这个绝对值被当作时序xo,l和目标序列的在时间上的静态时间相关性权重。其中,CORT的计算方法是:This absolute value is taken as the static time correlation weight of the time series x o,l and the target sequence in time. The calculation method of CORT is:

其中S1,S2两个长度为q的时间序列,S1,t,S2,t分别是S1,S2在时刻t的值。Among them, S 1 and S 2 are two time series with length q, S 1,t and S 2,t are the values of S 1 and S 2 at time t respectively.
最后,可以获得主机单元内所有时序和目标时序的静态时间相关性权重,并组合为一个向量Cout:Finally, the static time correlation weights of all timings in the host unit and the target timing can be obtained and combined into a vector C out :

(2)使用常见的注意力机制计算出注意力权重。(2) Use the common attention mechanism to calculate the attention weights.
还是以第l个时间序列xo,l为例,计算这个时间序列的在t时刻的注意力权重:Still taking the lth time series xo ,l as an example, calculate the attention weight of this time series at time t:



则整个主机单元的时间序列在t时刻的注意力权重可以组成一个在t时刻的注意力权重向量gt:
(3)组合上面两个步骤获得的时间相关性权重向量Cout和注意力权重向量gt。组合时通过一个线性变换来完成,变换后得到的新的权重向量θt:(3) Combine the time-correlation weight vector C out and the attention weight vector g t obtained in the above two steps. The combination is completed through a linear transformation, and the new weight vector θ t obtained after the transformation is:


为了使得这个向量的所有元素归一化,再使用一个softmax函数来映射,得到t时刻时主机单元内第l个时间序列的归一化权重值

(4)获得加权后的主机单元时间序列在t时刻的值向量:(4) Obtain the value vector of the weighted host unit time series at time t:
通过上一个步骤获得的归一化权重


总结来说,主机单元注意力层的输入输出为:In summary, the input and output of the host unit attention layer are:

3、自相关性注意力层的计算方法如下:3. The calculation method of the autocorrelation attention layer is as follows:
(1)和主机单元注意力层类似,先计算不同时间窗口内的目标时间序列之间的相关性系数。首先需要计算以时刻r为结尾的目标时间序列Yr和以时刻T为结尾的目标时间序列YT之间的CORT系数Ca,r:(1) Similar to the host unit attention layer, the correlation coefficient between the target time series in different time windows is calculated first. First, the CORT coefficient C a,r between the target time series Y r ending at time r and the target time series Y T ending at time T needs to be calculated:
Ca,T=||CORT(YT,Yr)||C a, T =||CORT(Y T , Y r )||
那么时间窗口T内,每个时刻的对应的目标时间序列的CORT系数可以组成一个长度为T的自相关向量Cauto:Then within the time window T, the CORT coefficient of the corresponding target time series at each moment can form an autocorrelation vector C auto of length T:

(2)使用常见的注意力机制计算出注意力权重。(2) Use the common attention mechanism to calculate the attention weights.

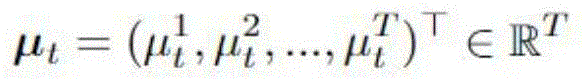


(3)组合上面两个步骤获得的时间相关性权重向量Cauto和注意力权重向量μt。通过线性变换的方法来将两个权重向量转换为一个权重向量φt:(3) Combine the time-correlation weight vector C auto and the attention weight vector μ t obtained in the above two steps. Use linear transformation to convert the two weight vectors into a weight vector φ t :



(4)获得加权后的目标时间序列向量:(4) Obtain the weighted target time series vector:
上一个步骤获得的归一化权重
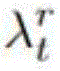



最后,三个注意力层的输出向量合并起来作为编码器LSTM的在t时刻的输入向量,其中

二、解码器LSTM2. Decoder LSTM
定义解码器LSTM为:Define the decoder LSTM as:

设h′t的是作为解码器的LSTM在时刻t的隐藏状态向量,设向量元素个数为n。需要注意的是它与编码器LSTM的隐藏状态向量ht有所区别。我们将这个解码器LSTM按时间维度展开,如图6所示。Let h′t be the hidden state vector of the decoder LSTM at time t, and let the number of vector elements be n. It should be noted that it is different from the hidden state vector ht of the encoder LSTM. We expand this decoder LSTM along the time dimension, as shown in Figure 6.
集成一个时间相关性注意力层到这个LSTM里去,这个时间注意力层的权重计算方法如下:Integrate a time-dependent attention layer into this LSTM. The weight calculation method of this time-dependent attention layer is as follows:




通过上面方法获得的t时刻归一化权重


时刻t的上下文向量ct和目标时间序列值yt合并,并通过一个线性变换,获得时刻t的解码器输入

正如前面所述,

不断循环以上的更新过程,直到T时刻结束,获得T时刻的隐藏状态向量h′T和元胞状态向量cT。The above updating process is repeated until the end of time T, and the hidden state vector h′ T and cell state vector c T at time T are obtained.

最后解码器LSTM输出的T+1时刻的预测值计算方法如下:The calculation method of the predicted value at time T+1 output by the final decoder LSTM is as follows:


总结来说,时间相关性注意力层的输入输出总结如下:In summary, the input and output of the temporal correlation attention layer are summarized as follows:

最后使用MSE(平均平方误差)作为模型的训练准则:
采用梯度下降算法来训练这个模型,确定上述神经网络的权重系数矩阵/向量/偏置的具体值。The gradient descent algorithm is used to train this model and determine the specific values of the weight coefficient matrix/vector/bias of the above neural network.
接下来结合具体实例对本发明的技术方案做进一步阐述。Next, the technical solution of the present invention is further described in conjunction with specific examples.
本实例采用的是阿里巴巴2018年发布的集群数据cluster-trace,随机选取了其中一个容器(id是c_66550)作为一个目标实例,将它的CPU利用率时间序列数据作为该目标实例的资源时序数据。将这个目标实例同属一个部署单元的实例和同属一个主机单元的实例找出,并将这些实例的时序数据提取出来,最后将其分别处理为间隔是300秒的时间序列数据。This example uses cluster-trace, a cluster data released by Alibaba in 2018. It randomly selects one of the containers (id is c_66550) as a target instance and uses its CPU utilization time series data as the resource time series data of the target instance. The instances of the target instance belonging to the same deployment unit and the same host unit are found, and the time series data of these instances are extracted. Finally, they are processed into time series data with an interval of 300 seconds.
最终获取的同一个部署单元的时间序列33个,同属一个主机的23个,以及目标实例的时间序列1个。将这些时间序列按照时间对齐,并统一的划分为三个数据集:训练集,验证集和测试集。其中训练集有10141个时间点,验证集563个时间点,测试集564个时间点。每个数据集都有相同的时间序列个数。Finally, we obtained 33 time series from the same deployment unit, 23 from the same host, and 1 from the target instance. We aligned these time series by time and divided them into three data sets: training set, validation set, and test set. The training set has 10,141 time points, the validation set has 563 time points, and the test set has 564 time points. Each data set has the same number of time series.
模型有多个超参数,设置窗口大小为T={25,35,45,60},编码器和解码器LSTM的隐藏层的隐藏状态向量和元胞状态向量大小为m=n={32,64,128},分别使用MSE和MAE(平均绝对值误差)作为误差准则,并使用批随机梯度下降算法来优化训练模型,其中学习率为5e-4。The model has multiple hyperparameters. The window size is set to T = {25, 35, 45, 60}, the hidden state vector and cell state vector size of the hidden layer of the encoder and decoder LSTM are m = n = {32, 64, 128}, MSE and MAE (mean absolute error) are used as error criteria respectively, and the batch stochastic gradient descent algorithm is used to optimize the training model, with a learning rate of 5e-4.
最后,使用网格搜索的方法训练模型,并取每个模型在验证集上获得最好效果的超参数作为模型的最优参数。然后在测试集中预测,最后用MSE累计测试集中的误差。Finally, the model is trained using the grid search method, and the hyperparameters that achieve the best results on the validation set are taken as the optimal parameters of the model. Then predictions are made on the test set, and finally the MSE is used to accumulate the errors in the test set.
在实验中,为了区分使用单序列和多序列进行预测的LSTM,将使用单序列的记为LSTM-Un,使用多序列的记为LSTM-Mul。In the experiment, in order to distinguish the LSTMs that use single sequence and multiple sequences for prediction, the one that uses a single sequence is denoted as LSTM-Un, and the one that uses multiple sequences is denoted as LSTM-Mul.
实验结果如下表所示:The experimental results are shown in the following table:


实验结果表明,无论是相对于3个单序列的模型还是2个多序列模型,本发明提出的模型的误差都比他们小很多:其中在MSE下,比最好的VAR好98.26%;在MAE下,比最好的VAR好74.40%,具有很高的预测准确度,从而证明了本发明提出的基于注意力机制的多时间序列预测模型的有效性。The experimental results show that the error of the model proposed in the present invention is much smaller than that of the three single-sequence models and the two multi-sequence models: under MSE, it is 98.26% better than the best VAR; under MAE, it is 74.40% better than the best VAR, with high prediction accuracy, thus proving the effectiveness of the multi-time series prediction model based on the attention mechanism proposed in the present invention.
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。In this specification, each embodiment is described in a progressive manner, and each embodiment focuses on the differences from other embodiments. The same or similar parts between the embodiments can be referred to each other. For the device disclosed in the embodiment, since it corresponds to the method disclosed in the embodiment, the description is relatively simple, and the relevant parts can be referred to the method part.
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。The above description of the disclosed embodiments enables one skilled in the art to implement or use the present invention. Various modifications to these embodiments will be apparent to one skilled in the art, and the general principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the present invention. Therefore, the present invention will not be limited to the embodiments shown herein, but rather to the widest scope consistent with the principles and novel features disclosed herein.
Claims (6)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910413227.1A CN110222840B (en) | 2019-05-17 | 2019-05-17 | A method and device for cluster resource prediction based on attention mechanism |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910413227.1A CN110222840B (en) | 2019-05-17 | 2019-05-17 | A method and device for cluster resource prediction based on attention mechanism |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110222840A CN110222840A (en) | 2019-09-10 |
| CN110222840B true CN110222840B (en) | 2023-05-05 |
Family
ID=67821396
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910413227.1A Active CN110222840B (en) | 2019-05-17 | 2019-05-17 | A method and device for cluster resource prediction based on attention mechanism |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110222840B (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110909046B (en) * | 2019-12-02 | 2023-08-11 | 上海舵敏智能科技有限公司 | Time-series abnormality detection method and device, electronic equipment and storage medium |
| CN111638958B (en) * | 2020-06-02 | 2024-04-05 | 中国联合网络通信集团有限公司 | Cloud host load processing method and device, control equipment and storage medium |
| CN112863695B (en) * | 2021-02-22 | 2024-08-02 | 西京学院 | Quantum attention mechanism-based two-way long-short-term memory prediction model and extraction method |
| CN114511458B (en) * | 2022-01-18 | 2025-05-06 | 北京世纪好未来教育科技有限公司 | Image processing method, device, electronic device and storage medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017097693A (en) * | 2015-11-26 | 2017-06-01 | Kddi株式会社 | Data prediction apparatus, information terminal, program and method for performing learning using data of different periodic layers |
| CN107730087A (en) * | 2017-09-20 | 2018-02-23 | 平安科技(深圳)有限公司 | Forecast model training method, data monitoring method, device, equipment and medium |
| CN108182260A (en) * | 2018-01-03 | 2018-06-19 | 华南理工大学 | A kind of Multivariate Time Series sorting technique based on semantic selection |
| CN109685252A (en) * | 2018-11-30 | 2019-04-26 | 西安工程大学 | Building energy consumption prediction technique based on Recognition with Recurrent Neural Network and multi-task learning model |
| CN109740419A (en) * | 2018-11-22 | 2019-05-10 | 东南大学 | A Video Action Recognition Method Based on Attention-LSTM Network |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10565305B2 (en) * | 2016-11-18 | 2020-02-18 | Salesforce.Com, Inc. | Adaptive attention model for image captioning |
| CN110490213B (en) * | 2017-09-11 | 2021-10-29 | 腾讯科技(深圳)有限公司 | Image recognition method, device and storage medium |
| CN108154435A (en) * | 2017-12-26 | 2018-06-12 | 浙江工业大学 | A kind of stock index price expectation method based on Recognition with Recurrent Neural Network |
| CN108090558B (en) * | 2018-01-03 | 2021-06-08 | 华南理工大学 | An automatic filling method for time series missing values based on long short-term memory network |
| CN108491680A (en) * | 2018-03-07 | 2018-09-04 | 安庆师范大学 | Drug relationship abstracting method based on residual error network and attention mechanism |
| CN108804495B (en) * | 2018-04-02 | 2021-10-22 | 华南理工大学 | An Automatic Text Summarization Method Based on Enhanced Semantics |
| CN109697304A (en) * | 2018-11-19 | 2019-04-30 | 天津大学 | A kind of construction method of refrigeration unit multi-sensor data prediction model |
-
2019
- 2019-05-17 CN CN201910413227.1A patent/CN110222840B/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017097693A (en) * | 2015-11-26 | 2017-06-01 | Kddi株式会社 | Data prediction apparatus, information terminal, program and method for performing learning using data of different periodic layers |
| CN107730087A (en) * | 2017-09-20 | 2018-02-23 | 平安科技(深圳)有限公司 | Forecast model training method, data monitoring method, device, equipment and medium |
| CN108182260A (en) * | 2018-01-03 | 2018-06-19 | 华南理工大学 | A kind of Multivariate Time Series sorting technique based on semantic selection |
| CN109740419A (en) * | 2018-11-22 | 2019-05-10 | 东南大学 | A Video Action Recognition Method Based on Attention-LSTM Network |
| CN109685252A (en) * | 2018-11-30 | 2019-04-26 | 西安工程大学 | Building energy consumption prediction technique based on Recognition with Recurrent Neural Network and multi-task learning model |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110222840A (en) | 2019-09-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110222840B (en) | A method and device for cluster resource prediction based on attention mechanism | |
| Wang et al. | DeepSD: Supply-demand prediction for online car-hailing services using deep neural networks | |
| CN110377984A (en) | A kind of industrial equipment remaining useful life prediction technique, system and electronic equipment | |
| CN110928993A (en) | User position prediction method and system based on deep cycle neural network | |
| Said et al. | AI-based solar energy forecasting for smart grid integration | |
| CN112509600A (en) | Model training method and device, voice conversion method and device and storage medium | |
| CN106205126A (en) | Large-scale Traffic Network based on convolutional neural networks is blocked up Forecasting Methodology and device | |
| CN106709588B (en) | Prediction model construction method and device and real-time prediction method and device | |
| CN110474808A (en) | A kind of method for predicting and device | |
| CN112289442A (en) | Method and device for predicting disease endpoint event and electronic equipment | |
| CN113746696A (en) | Network flow prediction method, equipment, storage medium and device | |
| CN116206453B (en) | Traffic flow prediction method and device based on transfer learning and related equipment | |
| CN115240871B (en) | A method for epidemic prediction based on deep embedding clustering meta-learning | |
| CN104010029B (en) | DCE performance prediction method based on laterally longitudinal information integration | |
| CN118630747B (en) | Power load forecasting method, device, equipment and medium | |
| CN116665483A (en) | A Novel Method for Predicting Remaining Parking Spaces | |
| CN118312329A (en) | Intelligent recommendation method for calculating force under heterogeneous calculating force integrated system | |
| CN115269758A (en) | Passenger-guidance-oriented road network passenger flow state deduction method and system | |
| CN114036823A (en) | Power transformer load control method and device based on coding, decoding and memory mechanism | |
| CN118349792A (en) | Multi-scale patch long-term time sequence prediction method based on linear model | |
| CN115294397B (en) | A post-processing method, apparatus, device, and storage medium for a classification task. | |
| CN115689224A (en) | Taxi Demand Forecasting Method Based on Trajectory Semantics and Graph Convolutional Network | |
| CN116561697B (en) | Method and device for long-term prediction of sensor data integrating multiple source factors | |
| CN119474726A (en) | A method for predicting the water level of Poyang Lake based on a large model | |
| CN105701027B (en) | The prediction technique and prediction meanss of data storage capacity |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |