CN109660297B - A Machine Learning-Based Physical Layer Visible Light Communication Method - Google Patents
A Machine Learning-Based Physical Layer Visible Light Communication Method Download PDFInfo
- Publication number
- CN109660297B CN109660297B CN201811554831.8A CN201811554831A CN109660297B CN 109660297 B CN109660297 B CN 109660297B CN 201811554831 A CN201811554831 A CN 201811554831A CN 109660297 B CN109660297 B CN 109660297B
- Authority
- CN
- China
- Prior art keywords
- layer
- rbm
- signal
- label
- classifier
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images














Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04B—TRANSMISSION
- H04B10/00—Transmission systems employing electromagnetic waves other than radio-waves, e.g. infrared, visible or ultraviolet light, or employing corpuscular radiation, e.g. quantum communication
- H04B10/11—Arrangements specific to free-space transmission, i.e. transmission through air or vacuum
- H04B10/114—Indoor or close-range type systems
- H04B10/116—Visible light communication
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Electromagnetism (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Digital Transmission Methods That Use Modulated Carrier Waves (AREA)
- Error Detection And Correction (AREA)
Abstract
本发明公开了一种基于机器学习(machine learning,ML)的物理层可见光通信方法,建立了端到端的可见光通信系统,传输距离为0cm~140cm。在此基础上,将接收到的数据采样后转换为向量,并收集到数据集中。研究了基于ML的解调方法,包括卷积神经网络(CNN)、深置信网络(DBN)、自适应增强(AdaBoost)的性能。特别地,本发明提出了一种用二维图像表示调制信号的方法。此外,还研究了调制方式、数据矢量维数和训练集大小对性能的影响。最后计算了不同调制方案的有效速率,结果表明应根据信噪比选择不同的调制方案。
The invention discloses a physical layer visible light communication method based on machine learning (ML), establishes an end-to-end visible light communication system, and has a transmission distance of 0 cm to 140 cm. On this basis, the received data is sampled and converted into a vector and collected into the dataset. The performance of ML-based demodulation methods, including Convolutional Neural Networks (CNN), Deep Belief Networks (DBN), and Adaptive Boosting (AdaBoost), is investigated. In particular, the present invention proposes a method for representing modulated signals with a two-dimensional image. In addition, the effects of modulation method, data vector dimension and training set size on performance are also investigated. Finally, the effective rates of different modulation schemes are calculated, and the results show that different modulation schemes should be selected according to the signal-to-noise ratio.
Description
技术领域technical field
本发明涉及可见光通信领域,尤其涉及一种基于机器学习(machine learning,ML)的物理层可见光通信方法。The present invention relates to the field of visible light communication, in particular to a physical layer visible light communication method based on machine learning (ML).
背景技术Background technique
随着移动数字设备与无线数据业务的快速发展,对高速无线传输的需求呈指数级增长。传统的射频(Radio Frequency,RF)系统正面临着过于拥挤的频谱挑战,提升网络容量遭遇了瓶颈(参考文献[1])。可见光通信(Visible Light Communication,VLC)以其拥有巨量未被管理的频谱、数据速率高、安全性强、抗电磁干扰能力强等优点,已经作为一种短距离无线通信的潜在解决方案而引起了广泛的关注(参考文献[2])。通过发光二极管(LED)的大规模部署,VLC采用强度调制和直接检测技术来实现双重目的:照明和数据传输(参考文献[3]-[7])。With the rapid development of mobile digital devices and wireless data services, the demand for high-speed wireless transmission has grown exponentially. The traditional radio frequency (Radio Frequency, RF) system is facing the challenge of overcrowded spectrum, and the enhancement of network capacity has encountered a bottleneck (Reference [1]). Visible Light Communication (VLC) has emerged as a potential solution for short-range wireless communication due to its advantages of huge unmanaged spectrum, high data rate, strong security, and strong anti-electromagnetic interference capability. has received extensive attention (Ref. [2]). With the large-scale deployment of light-emitting diodes (LEDs), VLCs employ intensity modulation and direct detection techniques for a dual purpose: illumination and data transmission (refs [3]–[7]).
无线信号的调制和解调在VLC系统中起着基础性的作用。在现有的绝大多数研究中,VLC信道被假定为有着加性高斯白噪声(AWGN)的直射信道(参考文献[8]-[10])。然而,实际的VLC信道要面临着商用LED的非线性、多径色散、脉冲噪声、杂散或连续干扰以及光电探测器的灵敏度低等诸多挑战。这些挑战在实际中总是同时存在并相互作用,这使得解调问题变得具有挑战性。The modulation and demodulation of wireless signals play a fundamental role in the VLC system. In most existing studies, the VLC channel is assumed to be a direct channel with additive white Gaussian noise (AWGN) (References [8]-[10]). However, practical VLC channels face the challenges of non-linearity, multipath dispersion, impulse noise, spurious or continuous interference, and low sensitivity of photodetectors of commercial LEDs. These challenges always coexist and interact in practice, making the demodulation problem challenging.
截至目前,已有很多工作将ML应用于各种通信领域,例如信道估计(参考文献[13]、[14])、介质访问控制(参考文献[15]、[16])、自动调制分类(参考文献[17]、[18]),干扰管理(参考文献[19])、导频分配(参考文献[20])、天线选择(参考文献[21])、信道解码(参考文献[22]))。最近的文献[23]提出将端到端通信系统解释为自动编码器的概念,并在文献[24]中使用软件无线电验证了其可行性。从那时起,深度学习(DL)在物理层上的潜在应用也日益受到重视,其主要原因在于未来通信的新特征,例如具有未知信道模型的复杂场景(参考文献[25])、高速和精确的处理要求。So far, many works have applied ML to various communication domains, such as channel estimation (refs [13], [14]), medium access control (refs [15], [16]), automatic modulation classification ( [17], [18]), interference management (ref. [19]), pilot allocation (ref. [20]), antenna selection (ref. [21]), channel decoding (ref. [22] )). A recent literature [23] proposes the concept of interpreting an end-to-end communication system as an autoencoder, and its feasibility is verified using software-defined radio in literature [24]. Since then, potential applications of deep learning (DL) at the physical layer have also received increasing attention, mainly due to the new features of future communications, such as complex scenarios with unknown channel models (ref. [25]), high-speed and Precise handling requirements.
在文献[26]中,作者使用人工神经网络作为解调器来解调16-QAM信号,实验证明该解调器性能优于使用线性滤波器的传统方法。在文献[27]中,针对频移键控(FSK)信号,作者提出了一种基于人工神经网络(ANN)的解调器。与传统接收机相比,该解调器具有更好的抗干扰能力。通过利用一维卷积神经网络(1-D CNN),文献[28]提出了一种二进制相移键控解调器来处理载波频率偏移和采样频率误差。文献[29]提出了一种深度卷积网络(DCNN)解调器来分别从混合信号中解调符号序列。在文献[30]中,作者证明了DCNN在解调瑞利衰减信号方面的优异性能。基于深度置信网络(DBN)的特征提取方法也被用于解决这个有挑战性的问题。在文献[31]中,提出了一种基于DBN的方法,用于不同类型通信信道中的信号解调。作者证明了基于DBN的解调器可用于具有一定信道脉冲响应的AWGN信道和瑞利非频率选择性平坦衰落信道。在文献[32]中,提出了一种基于DL(深度学习,Deep Learning)的短距离多径信道信号解调方法。在文献[33]中提出了一种基于神经网络的软件无线电接收机来处理未知信道上的解调信号。然而,这些工作是基于模拟数据集而不是真实的数据集。In [26], the authors used an artificial neural network as a demodulator to demodulate 16-QAM signals, and experiments proved that the demodulator outperformed the traditional method using linear filters. In [27], the authors propose an artificial neural network (ANN) based demodulator for frequency shift keying (FSK) signals. Compared with the traditional receiver, the demodulator has better anti-interference ability. By utilizing one-dimensional convolutional neural network (1-D CNN), literature [28] proposed a binary phase shift keying demodulator to deal with carrier frequency offset and sampling frequency error. In [29], a deep convolutional network (DCNN) demodulator was proposed to demodulate the sequence of symbols separately from the mixed signal. In [30], the authors demonstrate the excellent performance of DCNN in demodulating Rayleigh decayed signals. Feature extraction methods based on Deep Belief Network (DBN) are also used to solve this challenging problem. In [31], a DBN-based method is proposed for signal demodulation in different types of communication channels. The authors demonstrate that the DBN-based demodulator can be used for AWGN channels with a certain channel impulse response and for Rayleigh non-frequency selective flat fading channels. In [32], a short-distance multipath channel signal demodulation method based on DL (Deep Learning) is proposed. In [33], a neural network-based software radio receiver is proposed to process demodulated signals on unknown channels. However, these works are based on simulated datasets rather than real datasets.
DL在VLC系统中有一定的应用。文献[34]采用了一种无监督的基于DL的自编码器来设计多色VLC系统的收发机,它在平均符号错误率方面优于现有技术。文献[35]将基于DL方法的自动编码器用于对抗调光控制和信道缺陷的复杂光学特性。然而,VLC系统中有关基于ML的解调器的研究尚不充分,并且没有开放的实测数据集。DL has certain applications in the VLC system. Reference [34] adopts an unsupervised DL-based autoencoder to design the transceiver for multicolor VLC system, which outperforms the state-of-the-art in terms of average symbol error rate. In [35], an autoencoder based on a DL method is used to combat the complex optical properties of dimming control and channel imperfections. However, research on ML-based demodulators in VLC systems is insufficient, and there are no open measured datasets.
参考文献:references:
[1]V.Chandrasekhar,J.Andrews,and A.Gatherer,“Femtocell networks:asurvey,”IEEE Commun.Mag.,vol.46,no.9,pp.59–67,Sep.2008.[1] V. Chandrasekhar, J. Andrews, and A. Gatherer, "Femtocell networks: asurvey," IEEE Commun. Mag., vol. 46, no. 9, pp. 59–67, Sep. 2008.
[2]“IEEE standard for local and metropolitan area networks–part 15.7:Short-range wireless optical communication using visible light,”IEEE Std802.15.7-2011,pp.1–309,Sep.2011.[2] “IEEE standard for local and metropolitan area networks–part 15.7:Short-range wireless optical communication using visible light,” IEEE Std802.15.7-2011, pp.1–309, Sep.2011.
[3]T.Komine and M.Nakagawa,“Fundamental analysis for visible-lightcommunication system using LED lights,”IEEE Trans.Consum.Electron.,vol.50,no.1,pp.100–107,Feb.2004.[3] T.Komine and M.Nakagawa, "Fundamental analysis for visible-lightcommunication system using LED lights," IEEE Trans.Consum.Electron.,vol.50,no.1,pp.100–107,Feb.2004.
[4]H.Elgala,R.Mesleh,and H.Haas,“Indoor optical wirelesscommunication:Potential and state-of-the-art,”IEEE Commun.Mag.,vol.49,no.9,pp.56–62,Dec.2011.[4] H. Elgala, R. Mesleh, and H. Haas, "Indoor optical wireless communication: Potential and state-of-the-art," IEEE Commun. Mag., vol. 49, no. 9, pp. 56– 62, Dec. 2011.
[5]S.Arnon,J.Barry,G.Karagiannidis,R.Schober,and M.Uysal,AdvancedOptical Wireless Communication Systems,1st ed,Cambridge,U.K.:Cambridge Univ,2012.[5] S. Arnon, J. Barry, G. Karagiannidis, R. Schober, and M. Uysal, Advanced Optical Wireless Communication Systems, 1st ed, Cambridge, U.K.: Cambridge Univ, 2012.
[6]A.Jovicic,J.Li,and T.Richardson,“Visible light communication:opportunities,challenges and the path to market,”IEEE Commun.Mag.,vol.51,no.12,pp.26–32,Dec.2013.[6] A. Jovicic, J. Li, and T. Richardson, “Visible light communication: opportunities, challenges and the path to market,” IEEE Commun. Mag., vol. 51, no. 12, pp. 26–32 , Dec.2013.
[7]P.H.Pathak,X.Feng,P.Hu,and P.Mohapatra,“Visible lightcommunication,networking,and sensing:a survey,potential and challenges,”IEEECommun.Surveys Tuts.,vol.17,no.4,pp.2047–2077,Sep.2015.[7] P.H.Pathak, X.Feng, P.Hu, and P.Mohapatra, "Visible lightcommunication, networking, and sensing: a survey, potential and challenges," IEEECommun.Surveys Tuts.,vol.17,no.4, pp. 2047–2077, Sep. 2015.
[8]T.Fath and H.Haas,“Performance comparison of MIMO techniques foroptical wireless communications in indoor environments,”IEEE Trans.Commun.,vol.61,no.2,pp.733–742,Feb.2013.[8] T.Fath and H.Haas, "Performance comparison of MIMO techniques for optical wireless communications in indoor environments," IEEE Trans. Commun., vol. 61, no. 2, pp. 733–742, Feb. 2013.
[9]T.Q.Wang,Y.A.Sekercioglu,and J.Armstrong,“Analysis of an opticalwireless receiver using a hemispherical lens with application in MIMO visiblelight communications,”J.Lightw.Technol.,vol.31,no.11,pp.1744–1754,Jun.2013.[10]K.Ying,H.Qian,R.J.Baxley,and S.Yao,“Joint optimization of precoder andequalizer in MIMO VLC systems,”IEEE J.Sel.Areas in Comm.,vol.33,no.9,pp.1949–1958,Sep.2015[9] T.Q.Wang, Y.A.Sekercioglu, and J.Armstrong, "Analysis of an opticalwireless receiver using a hemispherical lens with application in MIMO visiblelight communications," J.Lightw.Technol., vol.31, no.11, pp.1744 –1754, Jun. 2013. [10] K. Ying, H. Qian, R. J. Baxley, and S. Yao, “Joint optimization of precoder and equalizer in MIMO VLC systems,” IEEE J. Sel. Areas in Comm., vol. 33, no.9, pp.1949–1958, Sep.2015
[11]T.Mitchell,B.Buchanan,G.Dejong,T.Dietterich,P.Rosenbloom,andA.Waibel,Machine Learning,China Machine Press,2003.[11] T. Mitchell, B. Buchanan, G. Dejong, T. Dietterich, P. Rosenbloom, and A. Waibel, Machine Learning, China Machine Press, 2003.
[12]K.Hornik,M.Stinchcombe,and H.White,“Multilayer feedforwardnetworks are universal approximators,”Neural Networks,vol.2,no.5,pp.359–366,Jul.1989.[12] K. Hornik, M. Stinchcombe, and H. White, "Multilayer feedforward networks are universal approximators," Neural Networks, vol. 2, no. 5, pp. 359–366, Jul. 1989.
[13]M.N.Seyman and N.Tapnar,“Channel estimation based on neuralnetwork in space time block coded MIMO-OFDM system,”Digital Signal Process.,vol.23,no.1,pp.275–280,Jan.2013.[13] M.N.Seyman and N.Tapnar, "Channel estimation based on neuralnetwork in space time block coded MIMO-OFDM system," Digital Signal Process., vol.23, no.1, pp.275–280, Jan.2013.
[14]H.Ye,G.Y.Li,and B.H.Juang,“Power of deep learning for channelestimation and signal detection in OFDM systems,”IEEE Wireless Commun.Lett.,vol.7,no.1,pp.114–117,Apr.2018.[14] H.Ye, G.Y.Li, and B.H.Juang, “Power of deep learning for channelestimation and signal detection in OFDM systems,” IEEE Wireless Commun.Lett., vol.7, no.1, pp.114–117, Apr.2018.
[15]S.Hu,Y.Yao,and Z.Yang,“Mac protocol identification using supportvector machines for cognitive radio networks,”IEEE Wireless Commun.,vol.21,no.1,pp.52–60,Feb.2014.[15] S. Hu, Y. Yao, and Z. Yang, “Mac protocol identification using supportvector machines for cognitive radio networks,” IEEE Wireless Commun., vol. 21, no. 1, pp. 52–60, Feb. 2014.
[16]S.Wang,H.Liu,P.H.Gomes,and B.Krishnamachari,“Deep reinforcementlearning for dynamic multichannel access in wireless networks,”IEEETrans.Cogn.Commun.Netw.,vol.4,no.2,pp.257-265,Jun.2018.[16] S. Wang, H. Liu, P. H. Gomes, and B. Krishnamachari, "Deep reinforcement learning for dynamic multichannel access in wireless networks," IEEE Trans. Cogn. Commun. Netw., vol. 4, no. 2, pp. 257-265, Jun. 2018.
[17]M.W.Aslam,Z.Zhu,and A.K.Nandi,“Automatic modulationclassification using combination of genetic programming and KNN,”IEEETrans.Wireless Commun.,vol.11,no.8,pp.2742–2750,Jun.2012.[17] M.W.Aslam, Z.Zhu, and A.K.Nandi, “Automatic modulationclassification using combination of genetic programming and KNN,” IEEETrans.Wireless Commun.,vol.11,no.8,pp.2742–2750,Jun.2012.
[18]A.S.Liu and Z.Qi,“Automatic modulation classification based onthe combination of clustering and neural network,”The Journal of ChinaUniversities of Posts and Telecommunications,vol.18,no.4,pp.13,38–19,38,Apr.2011.[18] A.S.Liu and Z.Qi, “Automatic modulation classification based on the combination of clustering and neural network,” The Journal of ChinaUniversities of Posts and Telecommunications, vol.18, no.4, pp.13,38–19,38 , Apr. 2011.
[19]H.Sun,X.Chen,M.Hong,Q.Shi,X.Fu,and N.D.Sidiropoulos,“Learning tooptimize:Training deep neural networks for interference management,”IEEETrans.Signal Process.,vol.66,no.20,pp.5438-5453,Oct.2018.[19]H.Sun,X.Chen,M.Hong,Q.Shi,X.Fu,and N.D.Sidiropoulos,“Learning tooptimize:Training deep neural networks for interference management,”IEEETrans.Signal Process.,vol.66, no.20,pp.5438-5453,Oct.2018.
[20]K.Kim,J.Lee,and J.Choi,“Deep learning based pilot allocationscheme(DL-PAS)for 5G massive mimo system,”IEEE Commun.Lett.,vol.22,no.4,pp.828–831,Feb.2018.[20] K. Kim, J. Lee, and J. Choi, "Deep learning based pilot allocation scheme (DL-PAS) for 5G massive mimo system," IEEE Commun. Lett., vol. 22, no. 4, pp. 828–831, Feb. 2018.
[21]J.Joung,“Machine learning-based antenna selection in wirelesscommunications,”IEEE Commun.Lett.,vol.20,no.11,pp.2241–2244,Jul.2016.[21] J. Joung, "Machine learning-based antenna selection in wireless communications," IEEE Commun. Lett., vol. 20, no. 11, pp. 2241–2244, Jul. 2016.
[22]F.Liang,C.Shen,and F.Wu,“An iterative BP-CNN architecture forchannel decoding,”IEEE J.Sel.Topics Signal Process.,vol.12,no.1,pp.144–159,Jan.2018.[22] F.Liang, C.Shen, and F.Wu, “An iterative BP-CNN architecture for channel decoding,” IEEE J.Sel.Topics Signal Process., vol.12, no.1, pp.144–159 , Jan. 2018.
[23]T.O.Shea and J.Hoydis,“An introduction to deep learning for thephysical layer,”IEEE Trans.Cogn.Commun.Netw.,vol.3,no.4,pp.563–575,Oct.2017.[23] T.O.Shea and J.Hoydis, "An introduction to deep learning for the physical layer," IEEE Trans.Cogn.Commun.Netw., vol.3, no.4, pp.563–575, Oct.2017.
[24]S.Dorner,S.Cammerer,J.Hoydis,and S.T.Brink,“Deep learning basedcommunication over the air,”IEEE J.Select.Topics Signal Process.,vol.12,no.1,pp.132–143,Feb.2018.[24] S. Dorner, S. Cammerer, J. Hoydis, and S.T. Brink, "Deep learning based communication over the air," IEEE J.Select.Topics Signal Process., vol.12, no.1, pp.132– 143, Feb. 2018.
[25]V.Raj and S.Kalyani,“Backpropagating through the air:Deeplearning at physical layer without channel models,”IEEE Commun.Lett.,vol.22,no.11,pp.2278-2281,Nov.2018.[25] V.Raj and S.Kalyani, "Backpropagating through the air: Deeplearning at physical layer without channel models," IEEE Commun.Lett., vol.22, no.11, pp.2278-2281, Nov.2018.
[26]A.N.Milad,M.A.M,and Rahmadwati,“Neural network demodulator forquadrature amplitude modulation(QAM),”International Journal of AdvancedStudies in Computer Science and Engineering,vol.5,no.7,pp.10–14,2016.[26] A.N.Milad, M.A.M, and Rahmadwati, “Neural network demodulator for quadrature amplitude modulation (QAM),” International Journal of Advanced Studies in Computer Science and Engineering, vol.5, no.7, pp.10–14, 2016.
[27]M.Li,H.Zhong,and M.Li,“Neural network demodulator for frequencyshift keying,”in 2008 International Conference on Computer Science andSoftware Engineering,vol.4,pp.843–846,Dec.2008.[27] M.Li, H.Zhong, and M.Li, “Neural network demodulator for frequencyshift keying,” in 2008 International Conference on Computer Science and Software Engineering, vol.4, pp.843–846, Dec.2008.
[28]M.Zhang,Z.Liu,L.Li,and H.Wang,“Enhanced efficiency BPSKdemodulator based on one-dimensional convolutional neural network,”IEEEAccess,vol.6,pp.26939-26948,2018.[28] M. Zhang, Z. Liu, L. Li, and H. Wang, “Enhanced efficiency BPSK demodulator based on one-dimensional convolutional neural network,” IEEE Access, vol. 6, pp. 26939-26948, 2018.
[29]X.Lin,R.Liu,W.Hu,Y.Li,X.Zhou,and X.He,“A deep convolutionalnetwork demodulator for mixed signals with different modulation types,”inProc.IEEE 15th Intl Conf on Dependable,Autonomic and Secure Computing,pp.893–896,Nov.2017.[29] X.Lin, R.Liu, W.Hu, Y.Li, X.Zhou, and X.He, “A deep convolutionalnetwork demodulator for mixed signals with different modulation types,” inProc.IEEE 15th Intl Conf on Dependable , Autonomic and Secure Computing, pp.893–896, Nov.2017.
[30]A.S.Mohammad,N.Reddy,F.James,and C.Beard,“Demodulation of fadedwireless signals using deep convolutional neural networks,”in 2018 IEEE 8thAnnual Computing and Communication Workshop and Conference(CCWC),pp.969–975,Jan.2018.[30] A.S.Mohammad, N.Reddy, F.James, and C.Beard, “Demodulation of fadedwireless signals using deep convolutional neural networks,” in 2018 IEEE 8thAnnual Computing and Communication Workshop and Conference (CCWC), pp.969–975 , Jan. 2018.
[31]M.Fan and L.Wu,“Demodulator based on deep belief networks incommunication system,”in International Conference on Communication,Control,Computing and Electronics Engineering,pp.1–5,Jan.2017.[31] M.Fan and L.Wu, “Demodulator based on deep belief networks incommunication system,” in International Conference on Communication, Control, Computing and Electronics Engineering, pp.1–5, Jan.2017.
[32]L.Fang and L.Wu,“Deep learning detection method for signaldemodulation in short range multipath channel,”in IEEE InternationalConference on Opto-Electronic Information Processing,pp.16–20,Jul.2017.[32] L.Fang and L.Wu, “Deep learning detection method for signal demodulation in short range multipath channel,” in IEEE International Conference on Opto-Electronic Information Processing, pp.16–20, Jul.2017.
[33]M.

[34]H.Lee,I.Lee,and S.H.Lee,“Deep learning based transceiver designfor multi-colored VLC systems,”Optics Express,vol.26,no.5,pp.6222-6238,2018.[34] H. Lee, I. Lee, and S. H. Lee, “Deep learning based transceiver design for multi-colored VLC systems,” Optics Express, vol.26, no.5, pp.6222-6238, 2018.
[35]H.Lee,I.Lee,T.Q.S.Quek,and H.L.Sang,“Binary signaling design forvisible light communication:a deep learning framework,”Optics Express,vol.26,no.14,pp.18131-18142,2018.[35] H.Lee, I.Lee, T.Q.S.Quek, and H.L.Sang, “Binary signaling design forvisible light communication: a deep learning framework,” Optics Express, vol.26, no.14, pp.18131-18142, 2018 .
[36]J.Sola and J.Sevilla,“Importance of input data normalization forthe application of neural networks to complex industrial problems,”Nucl.Sci.,vol.44,no.3,pp.1464–1468,Jun.1997.[36] J.Sola and J.Sevilla, "Importance of input data normalization for the application of neural networks to complex industrial problems," Nucl.Sci., vol.44, no.3, pp.1464–1468, Jun.1997 .
[37]R.C.Gonzalez and R.E.Woods,Digital Image Processing(3rd Edition),Prentice-Hall,Inc.,2007.[37] RC Gonzalez and REWoods, Digital Image Processing ( 3rd Edition), Prentice-Hall, Inc., 2007.
[38]G.E.Hinton and R.R.Salakhutdinov,“Reducing the dimensionality ofdata with neural networks,”Science,vol.313,no.5786,pp.504–507,2006[38] G.E.Hinton and R.R.Salakhutdinov, "Reducing the dimensionality of data with neural networks," Science, vol.313, no.5786, pp.504–507, 2006
[39]D.E.Rumelhart and J.L.McClelland,Information Processing inDynamical Systems:Foundations of Harmony Theory,MIT Press,1987.[39] D.E. Rumelhart and J.L. McClelland, Information Processing in Dynamical Systems: Foundations of Harmony Theory, MIT Press, 1987.
[40]S.Haykin,Neural Networks:A Comprehensive Foundation(3rd Edi-tion),Macmillan,1998[40] S. Haykin, Neural Networks: A Comprehensive Foundation (3rd Edi-tion), Macmillan, 1998
[41]G.E.Hinton,“Training products of experts by minimizingcontrastive divergence,”Neural Computation,vol.14,no.8,pp.1771–1800,Aug.2002.[41] G.E.Hinton, “Training products of experts by minimizing contrastive divergence,” Neural Computation, vol.14, no.8, pp.1771–1800, Aug.2002.
[42]L.J.Buturovic and L.T.Citkusev,“Back propagation and forwardpropagation,”in Int.Joint Conf.Neural Networks,vol.4,pp.486–491,Jun.1992.[42] L.J.Buturovic and L.T.Citkusev, "Back propagation and forwardpropagation," in Int.Joint Conf.Neural Networks, vol.4, pp.486–491, Jun.1992.
[43]Y.Freund and R.E.Schapire,“A decision-theoretic generalization ofon-line learning and an application to boosting,”Comput.Syst.Sci.,vol.55,no.1,pp.119–139,1997.[43] Y.Freund and R.E.Schapire, "A decision-theoretic generalization of on-line learning and an application to boosting," Comput.Syst.Sci.,vol.55,no.1,pp.119–139,1997.
[44]I.Mukherjee,C.Rudin,and R.E.Schapire,“The rate of convergence ofAdaboost,”J.Mach.Learn.Res.,vol.14,no.3,pp.2315–2347,2011.[44] I.Mukherjee, C.Rudin, and R.E.Schapire, "The rate of convergence of Adaboost," J.Mach.Learn.Res., vol.14, no.3, pp.2315–2347, 2011.
[45]G.
[46]M.Riesenhuber and T.Poggio,“Hierarchical models of objectrecognition in cortex,”Nature neuroscience,vol.2,no.11,pp.1019-1025,1999.[46] M. Riesenhuber and T. Poggio, "Hierarchical models of objectrecognition in cortex," Nature neuroscience, vol.2, no.11, pp.1019-1025, 1999.
发明内容SUMMARY OF THE INVENTION
本发明针对现有技术的不足,提供了一种基于机器学习的物理层可见光通信方法,包括如下步骤:Aiming at the deficiencies of the prior art, the present invention provides a physical layer visible light communication method based on machine learning, comprising the following steps:
步骤1,建立VLC系统模型;
步骤2,采用基于卷积神经网络(convolutional neural network,CNN)、深度置信网络(deep belief network,DBN)、自适应增强(adaptive boosting,AdaBoost)的解调器中的任一种对建立的VLC系统模型进行解调。
步骤1包括:
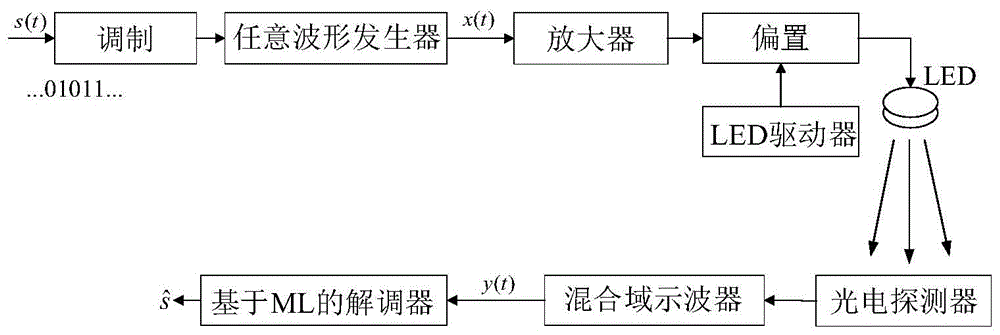
步骤1-1,建立一个端到端的VLC系统,其中包含单个发光二极管(light emittingdiodes,LEDs)发射器和单个光电探测器,发射信号x(t)如下:Step 1-1, build an end-to-end VLC system, which includes a single light emitting diode (LEDs) emitter and a single photodetector, the emission signal x(t) is as follows:
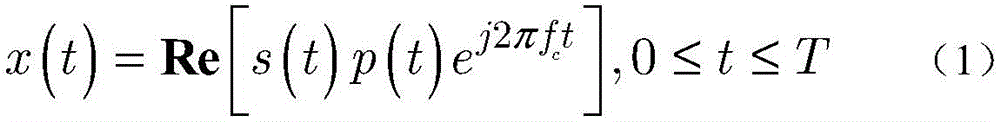
其中,t是时间,s(t)是基带信号,j是虚数单位,s(t)是基带信号,fc是载波频率,p(t)是信号脉冲,T是信号周期;Where, t is the time, s(t) is the baseband signal, j is the imaginary unit, s(t) is the baseband signal, fc is the carrier frequency, p( t ) is the signal pulse, and T is the signal period;
令g表示LED和光电探测器之间的信道,包括直射路径和多反射路径,在接收机处,接收信号y(t)如下:Let g denote the channel between the LED and the photodetector, including the direct path and the multi-reflection path, at the receiver, the received signal y(t) is as follows:
y(t)=gx(t)+n(t) (2)y(t)=gx(t)+n(t) (2)
其中,n(t)是所接收的噪声,通过数字模拟转换器,将接收到的模拟信号y(t)采样到数字信号;设
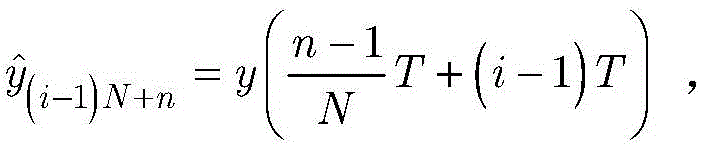
步骤1-2,设定训练数据集包含K个接收到的采样数据周期,i取值为1~K。将接收到的采样序列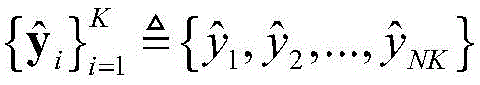
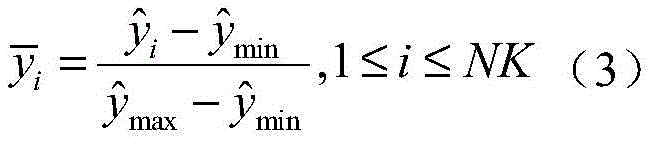
其中,
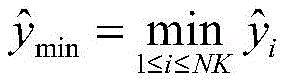

步骤1-3,对归一化的第i个向量
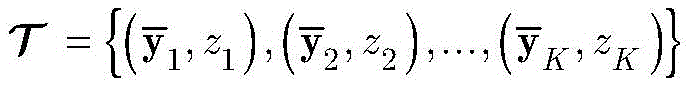


步骤2中,所述基于CNN的解调器包括一个可视化模块和一个CNN,当采用基于CNN的解调器对建立的VLC系统模型进行解调时,包括如下步骤:In
步骤a1,将接收到的数据向量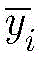

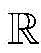
步骤a2,对X进行处理的CNN包括两个卷积层,两个池化层和一个全连接层,用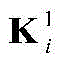
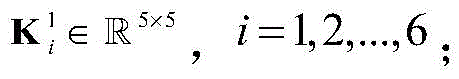

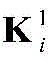
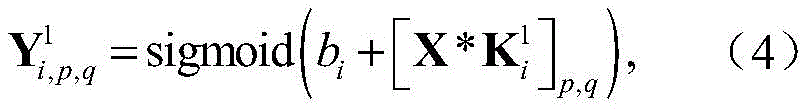
其中bi表示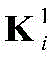

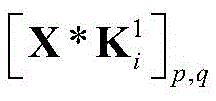
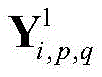
步骤a3,卷积层之后是一个池化层,对上一层输出的特征图执行下采样操作,使用最大池化的方法进行池化,感受野大小为2×2,用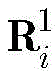
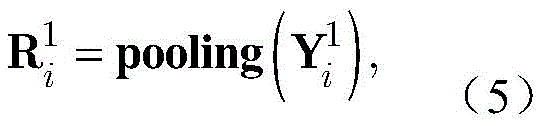
其中,pooling(·)表示下采样函数,
步骤a4,用
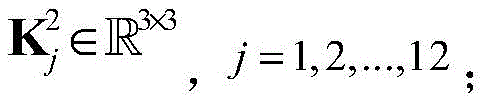


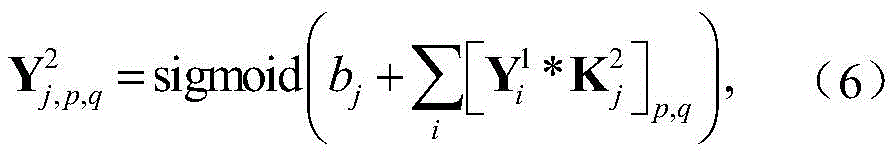
其中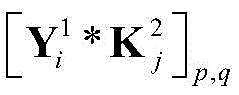

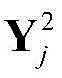
步骤a5,经过感受野为2×2的第二个池化层之后,其输出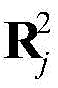
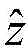

其中[y3]i表示y3中第i维元素的值,y3的维度由采用的调制方式决定。y3中最大元素对应的下标即是标签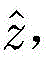
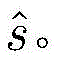
步骤a1包括:可视化模块进行如下处理:
步骤2中,当采用基于DBN的解调器对建立的VLC系统模型进行解调时,包括如下步骤:In
步骤b1,建立有三个受限玻尔兹曼机(Restricted boltzmann machines,RBM)的深度置信网络(Deep belief network,DBN),RBM是无向图形模型的一种实现,由显层v=[v1,v2,...,vm]T和隐层h=[h1,h2,...,hn]T构成,其中vi和hj分别表示显层的第i个单元的值和隐层的第j个单元的值,i取值为1~m,j取值为1~n;设W=[w1,w2,...,wn]T表示v和h之间的连接权矩阵,其中wj=[wj1,wj2,...,wjm]T,其中wji表示vi和hj之间的连接权重;a=[a1,a2,...,am]T和b=[b1,b2,...,bn]T分别表示v的偏置和h的偏置,其中ai表示vi的偏置,bj表示hj的偏置;Step b1, establish a deep belief network (DBN) with three restricted Boltzmann machines (Restricted boltzmann machines, RBM). RBM is an implementation of an undirected graphical model. 1 ,v 2 ,...,v m ] T and the hidden layer h=[h 1 ,h 2 ,...,h n ] T , where v i and h j represent the i-th unit of the display layer respectively and the value of the jth unit of the hidden layer, i is 1~m, j is 1~n; set W=[w 1 ,w 2 ,...,w n ] T represents v and The connection weight matrix between h, where w j =[w j1 ,w j2 ,...,w jm ] T , where w ji represents the connection weight between vi and h j ; a=[a 1 ,a 2 ,..., am ] T and b=[b 1 ,b 2 ,...,b n ] T represent the bias of v and the bias of h, respectively, where a i represents the bias of v i , b j represents the offset of h j ;
步骤b2,引入能量函数来表示RBM的状态,采用训练数据集
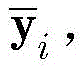
E(v,h)=-aTv-bTh-hTWv, (8)E(v,h)=-a T vb T hh T Wv, (8)
其中,
显层v的边缘分布p(v)表示如下:The marginal distribution p(v) of the display layer v is expressed as follows:

其中,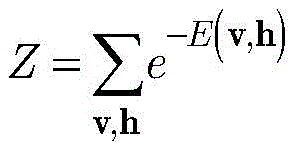
步骤b3,通过最大化如下无约束的对数最大似然函数来获得最优参数W,a,b:In step b3, the optimal parameters W, a, b are obtained by maximizing the following unconstrained log-maximum-likelihood function:
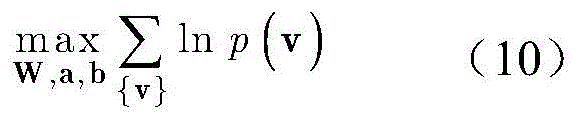
步骤b4,采用梯度下降法来解决步骤b3中的优化问题,变量W,a,b分别做如下更新:In step b4, the gradient descent method is used to solve the optimization problem in step b3, and the variables W, a, and b are updated as follows:

其中,ε代表学习率,取0.1,ΔW,Δa和Δb分别代表目标函数对W的偏导、对a的偏导和对b的偏导;Among them, ε represents the learning rate, which is taken as 0.1, and ΔW, Δa and Δb represent the partial derivative of the objective function to W, the partial derivative of a and the partial derivative of b, respectively;
步骤b5,变量W,a,b的偏导数分别近似为:In step b5, the partial derivatives of the variables W, a, and b are respectively approximated as:


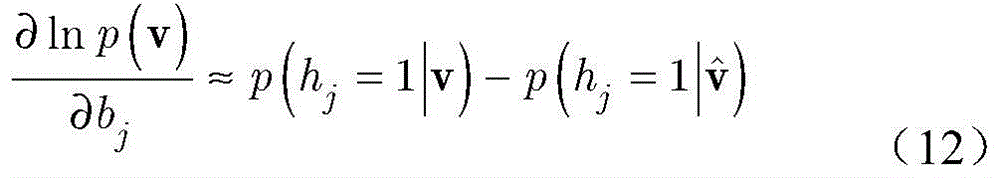
其中,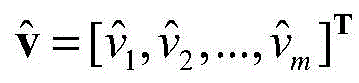
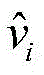

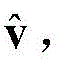

给定显层v,隐层h的各单元的分布如下:Given the explicit layer v, the distribution of the units in the hidden layer h is as follows:

依据公式(13)分布,按照下式产生隐层数据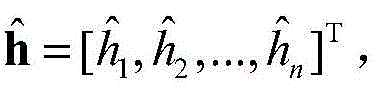

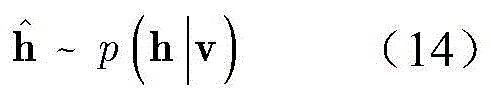
其中,p(h|v)表示给定显层v,得到隐层状态h的概率。Among them, p(h|v) represents the probability of obtaining the hidden layer state h given the visible layer v.
对于给定的隐层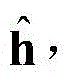
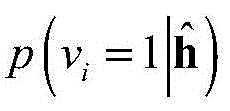

步骤b6,重构的显层数据
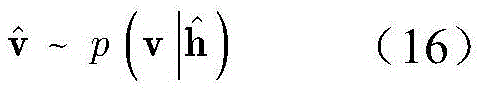
步骤b7,利用梯度下降法,得到第一个RBM的最优参数W,a,b后,将第一个RBM的隐层h视为第二个RBM的显层,令h(1)为第二个RBM的隐层;训练完第二个RBM的权重矩阵和偏置后,将h(1)看作第三个RBM的显层,令h(2)为第三个RBM的隐层;在训练第三个RBM之后,RBM的所有参数都通过一个有监督的反向传播算法来进行微调;在测试阶段,DBN被应用于信号解调,输出信号解调结果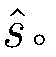
步骤2中,当采用基于自适应增强AdaBoost的解调器对建立的VLC系统模型进行解调时,包括如下步骤:In
步骤c1,设定强分类器是由Q个k最邻近(k-nearest neighbor,KNN)分类器组成,令k=1。对于第q个KNN分类器,训练数据集
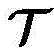
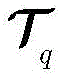
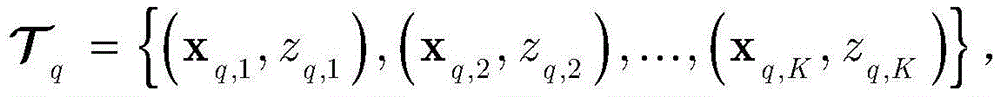
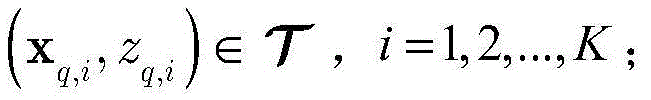

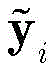


其中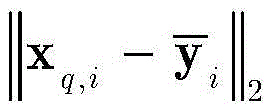
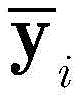
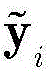
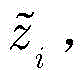

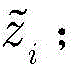
步骤c3,用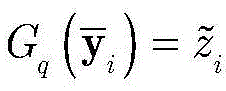
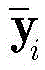
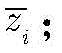
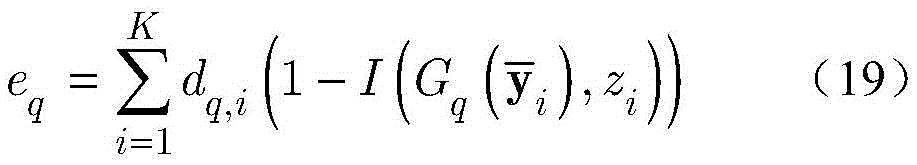
其中,I(a,b)是指示函数,定义如下:where I(a,b) is the indicator function, defined as follows:

令dq+1=[dq+1,1,dq+1,2,...,dq+1,K]T表示第q+1个KNN分类器对应的训练数据集
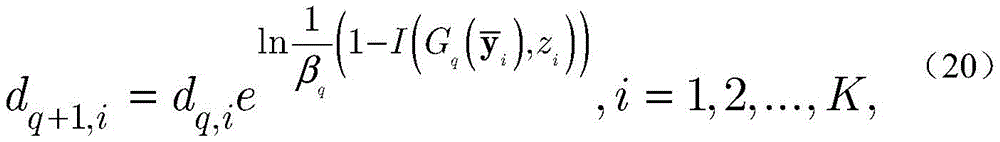
其中βq由函数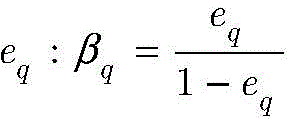
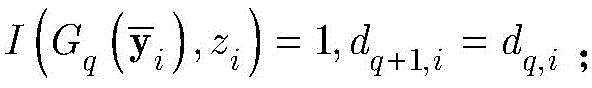
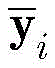

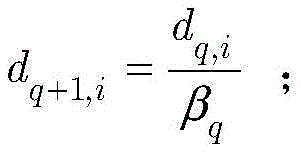
为重新评估样本的权重,通过如下归一化公式重新定义dq+1,i:To re-evaluate the weights of the samples, redefine d q+1,i by the following normalization formula:
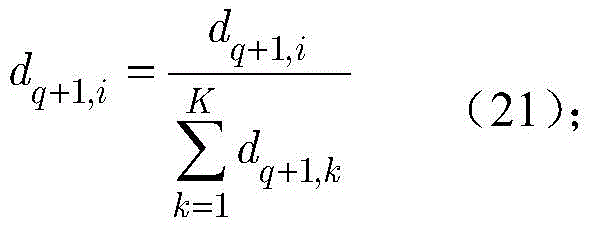
步骤c4,在生成Q个KNN分类器后,强分类器由下式定义:Step c4, after generating Q KNN classifiers, the strong classifier is defined by the following formula:
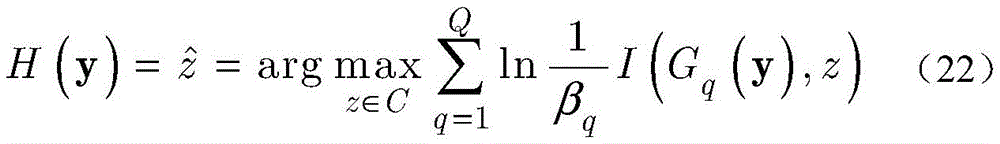
其中,H(y)表示强分类器对测试样本y的分类结果,用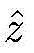



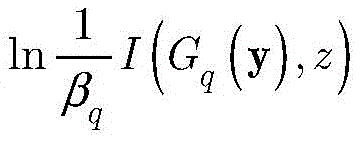
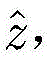
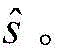
本发明提出了一种灵活的数据驱动的端到端VLC系统原型。利用提出的VLC系统原型,在真实的物理环境中采集了8种调制信号,即OOK、QPSK、4-PPM、16-QAM、32-QAM、64-QAM、128-QAM和256-QAM。此外,建立了一个开放的在线调制数据集,其中,八种调制信号的测量距离为0cm至140cm。The present invention proposes a flexible data-driven end-to-end VLC system prototype. Using the proposed VLC system prototype, eight modulated signals, namely OOK, QPSK, 4-PPM, 16-QAM, 32-QAM, 64-QAM, 128-QAM, and 256-QAM, were collected in a real physical environment. Furthermore, an open online modulation dataset was established, in which eight modulated signals were measured at distances ranging from 0 cm to 140 cm.
本发明提出了基于三个数据驱动的解调器。具体而言,提出了一个基于CNN的解调器,它具有两个卷积层和两个池化层。该分类器首先将调制信号转换为图像,然后通过图像分类对信号进行解调。此外,设计了一个基于DBN的由三个受限玻尔兹曼机(RBM)组成的解调器,用于提取调制特征。最后,提出了一种利用弱分类器KNN构造强分类器的AdaBoost信号解调器。The present invention proposes a demodulator based on three data drives. Specifically, a CNN-based demodulator is proposed with two convolutional layers and two pooling layers. The classifier first converts the modulated signal into an image, and then demodulates the signal through image classification. Furthermore, a DBN-based demodulator consisting of three restricted Boltzmann machines (RBMs) is designed to extract modulation features. Finally, an AdaBoost signal demodulator is proposed, which uses the weak classifier KNN to construct a strong classifier.
基于调制数据集,本发明研究了提出的三种数据驱动的解调器的性能。具体地说,随着传输距离的增加,三种解调器的性能降低。给定传输距离,使用的调制方式的阶数越高,解调的正确率越低。实验结果显示,基于AdaBoost的解调器在所有调制方案中表现最好。除此之外,在距离较近或者信噪比较高的情况下,应该使用高阶调制来实现最大有效速率。Based on the modulation dataset, the present invention investigates the performance of three proposed data-driven demodulators. Specifically, as the transmission distance increases, the performance of the three demodulators decreases. Given the transmission distance, the higher the order of the modulation method used, the lower the accuracy of demodulation. The experimental results show that the demodulator based on AdaBoost performs the best among all modulation schemes. In addition to this, higher order modulation should be used to achieve the maximum effective rate at short distances or with high signal-to-noise ratios.
附图说明Description of drawings
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。The present invention will be further described in detail below with reference to the accompanying drawings and specific embodiments, and the advantages of the above or other aspects of the present invention will become clearer.
图1是VLC系统示意图。Figure 1 is a schematic diagram of the VLC system.
图2是可视化模块示意图。Figure 2 is a schematic diagram of the visualization module.
图3是CNN示意图。Figure 3 is a schematic diagram of CNN.
图4是最大池化示意图。Figure 4 is a schematic diagram of max pooling.
图5是DBN结构示意图。FIG. 5 is a schematic diagram of a DBN structure.
图6是一个具有m个显层神经元和n个隐层神经元的RBM。Figure 6 is an RBM with m visible layer neurons and n hidden layer neurons.
图7是强分类器的产生过程。Figure 7 is the generation process of the strong classifier.
图8a显示了OOK调制信号相对于距离d的解调准确率。Figure 8a shows the demodulation accuracy of the OOK modulated signal with respect to the distance d.
图8b显示了32-QAM调制信号相对于距离d的解调准确率。Figure 8b shows the demodulation accuracy of the 32-QAM modulated signal with respect to distance d.
图8c显示了256-QAM调制信号相对于距离d的解调准确率。Figure 8c shows the demodulation accuracy of the 256-QAM modulated signal with respect to distance d.
图9显示了基于AdaBoost的解调器相对于距离d的准确率。Figure 9 shows the accuracy of the AdaBoost-based demodulator with respect to distance d.
图10显示了16-QAM和32-QAM调制信号的解调准确率与训练周期K的关系。Figure 10 shows the demodulation accuracy of 16-QAM and 32-QAM modulated signals as a function of training period K.
图11a显示了在N=40时,OOK、QPSK、4-PPM、32-QAM、64-QAM、128-QAM和256-QAM八种调制信号的解调准确率的距离d的关系。Figure 11a shows the relationship between the distance d of the demodulation accuracy of the eight modulated signals of OOK, QPSK, 4-PPM, 32-QAM, 64-QAM, 128-QAM and 256-QAM when N=40.
图11b显示了八种调制方案的有效速率Reff。Figure 11b shows the effective rate R eff for the eight modulation schemes.
具体实施方式Detailed ways
下面结合附图及实施例对本发明做进一步说明。The present invention will be further described below with reference to the accompanying drawings and embodiments.
(1)实验装置:(1) Experimental device:
本实施例在真实物理环境中建立了一个灵活的端到端可见光通信原型平台,能够对各种调制信号进行解调。基于所建立的原型平台,本实施例建立了来自实际通信系统的测量调制数据集,包括训练数据集和测试数据集,所有研究人员都可获得。实验装置如图1所示。This embodiment establishes a flexible end-to-end visible light communication prototype platform in a real physical environment, which can demodulate various modulated signals. Based on the established prototype platform, this embodiment establishes measurement modulation data sets from actual communication systems, including training data sets and test data sets, which are available to all researchers. The experimental setup is shown in Figure 1.
(2)系统模型:(2) System model:
考虑一个端到端的VLC系统,其中包含单个LED发射器和单个光电探测器,如图1所示。Consider an end-to-end VLC system containing a single LED emitter and a single photodetector, as shown in Figure 1.
利用数字调制方案,例如M元正交幅度调制(M-QAM),以及M元脉冲位置调制(M-PPM),发射信号x(t)如下:Using digital modulation schemes, such as M-ary quadrature amplitude modulation (M-QAM), and M-ary pulse position modulation (M-PPM), the transmit signal x(t) is as follows:
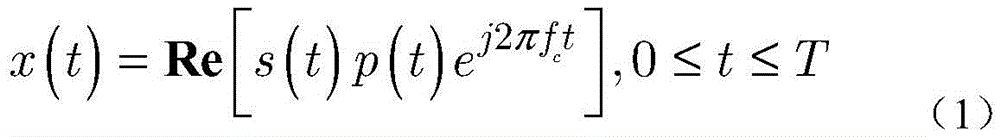
其中,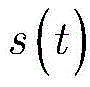
令g表示LED和光电探测器之间的信道,包括直射路径和多反射路径。在接收机处,接收信号y(t)给出如下:Let g denote the channel between the LED and the photodetector, including the direct path and the multi-reflection path. At the receiver, the received signal y(t) is given as:
y(t)=gx(t)+n(t) (2)y(t)=gx(t)+n(t) (2)
其中,n(t)是所接收的噪声。通过数字模拟转换器,将接收到的模拟信号y(t)采样到数字信号。设

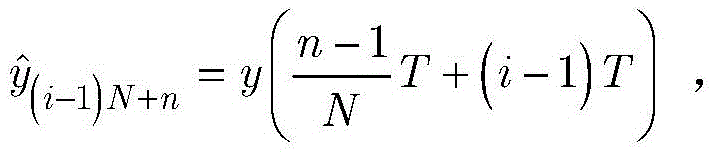
设定训练数据集包含K个接收到的采样数据周期,i取值为1~K。在基于ML的解调器处理之前,适当的归一化可以显著减少计算时间(参考文献[36])。因此,首先将接收到的采样序列
其中,in,

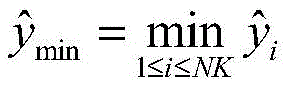

此外,对归一化的第i个向量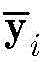

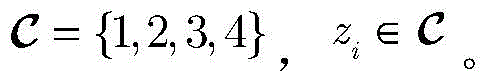
(3)基于CNN的解调器(3) CNN-based demodulator
与一般的神经网络相比,卷积神经网络(convolutional neural network,CNN)需的预处理更少。此外,它具有稀疏连接、权值共享等特点,结构更加简单,鲁棒性更强。本发明提出的基于CNN的解调器包括一个可视化模块和一个CNN。首先将接收到的数据向量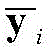


对X进行处理的CNN包括两个卷积层,两个池化层和一个全连接层,结构如图3所示,参数如表1所示。用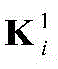
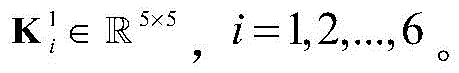

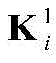
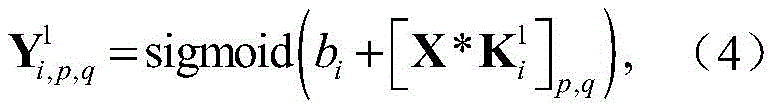
其中bi表示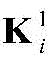
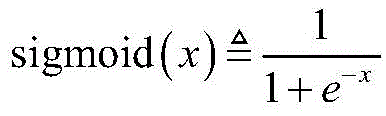

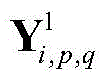

卷积层之后是一个池化层,对上一层输出的特征图执行下采样操作。池化可以减少参数的数目,减轻计算负担,提高网络的鲁棒性。本发明使用的池化方法为最大池化,感受野大小为2×2,如图4所示。The convolutional layer is followed by a pooling layer that performs a downsampling operation on the feature maps output by the previous layer. Pooling can reduce the number of parameters, reduce the computational burden, and improve the robustness of the network. The pooling method used in the present invention is maximum pooling, and the size of the receptive field is 2×2, as shown in FIG. 4 .
用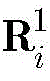
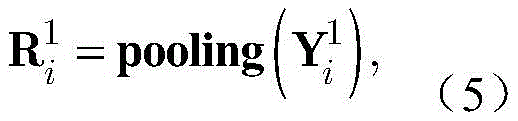
其中,pooling(·)表示下采样函数,
用
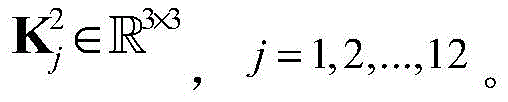


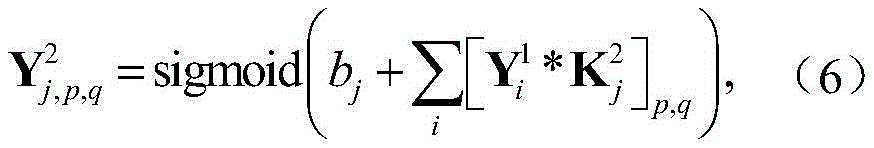
其中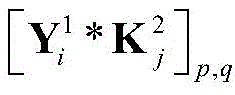
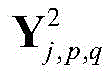
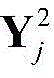
经过感受野为2×2的第二个池化层之后,其输出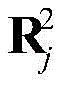
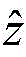
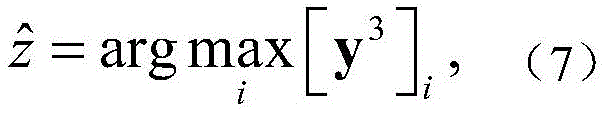
[y3]i表示y3中第i维元素的值,y3的维度由采用的调制方式决定。y3中最大元素对应的下标即是标签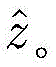
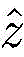

表1 CNN参数设置Table 1 CNN parameter settings
(4)基于DBN的解调器(4) DBN-based demodulator
由于DBN能有效地利用多重非线性变换从数据中提取高层次特征,因此被广泛地用于解决实际问题(参考文献[38])。本发明考虑有三个受限玻尔兹曼机(restrictedBoltzmann machines,RBMs)的DBN,每个RBM由显层v=[v1,v2,...,vm]T和隐层h=[h1,h2,...,hn]T构成,如图6所示,其中vi和hj分别表示显层的第i个单元和隐层的第j个单元。设W=[w1,w2,...,wn]T表示v和h之间的连接权矩阵,其wj=[wj1,wj2,...,wjm]T,j=1,2,...,n,wji表示vi和hj之间的连接权重。此外,a=[a1,a2,...,am]T和b=[b1,b2,...,bn]T分别表示v和h的偏置,其中ai表示vi的偏置,bj表示hj的偏置。Since DBN can effectively utilize multiple nonlinear transformations to extract high-level features from data, it is widely used to solve practical problems (Ref. [38]). The present invention considers a DBN with three restricted Boltzmann machines (RBMs), each RBM consisting of an explicit layer v=[v 1 ,v 2 ,..., vm ] T and a hidden layer h=[ h 1 , h 2 ,...,h n ] T , as shown in Figure 6, where vi and h j represent the i -th unit of the display layer and the j-th unit of the hidden layer, respectively. Let W=[w 1 ,w 2 ,...,w n ] T represent the connection weight matrix between v and h, and its w j =[w j1 ,w j2 ,...,w jm ] T ,j =1,2,...,n, w ji represents the connection weight between vi and h j . In addition, a=[a 1 ,a 2 ,..., am ] T and b=[b 1 ,b 2 ,...,b n ] T represent the biases of v and h, respectively, where a i represents The bias of v i , and b j represents the bias of h j .
受统计力学的启发,引入能量函数来表示RBM的状态(参考文献[39])。用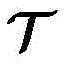

E(v,h)=-aTv-bTh-hTWv, (8)E(v,h)=-a T vb T hh T Wv, (8)
其中,
显层v的边缘分布如下:The edge distribution of the display layer v is as follows:

其中,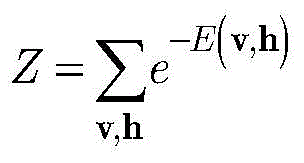
然后,可以通过如下最小化RBM(参考文献[40])的能量来获得最优参数W,a,b:Then, the optimal parameters W, a, b can be obtained by minimizing the energy of the RBM (Ref. [40]) as follows:

本发明采用了梯度下降法来解决优化问题(10)。具体而言,变量W,a,b分别做如下更新:The present invention adopts the gradient descent method to solve the optimization problem (10). Specifically, the variables W, a, and b are updated as follows:

其中,ε代表学习率,取0.1,ΔW,Δa和Δb分别代表W,a,b的梯度。Among them, ε represents the learning rate, which is taken as 0.1, and ΔW, Δa and Δb represent the gradients of W, a, and b, respectively.
进而,变量W,a,b的偏导数可以分别近似为Furthermore, the partial derivatives of the variables W, a, and b can be approximated as

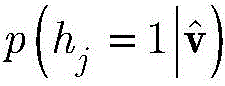

其中,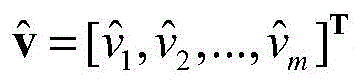
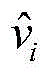
给定显层v,隐层h的第j个神经元被激活的概率p(hj=1|v)计算如下:Given the explicit layer v, the probability p(h j = 1|v) of the jth neuron being activated in the hidden layer h is calculated as follows:
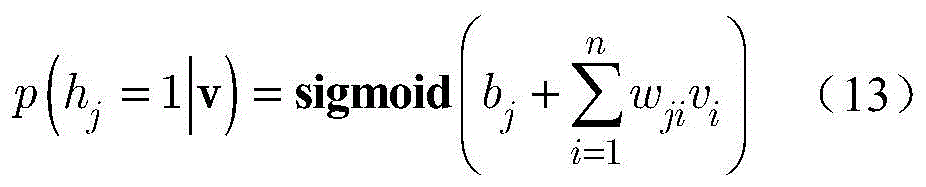
然后,依据公式(13)分布,产生
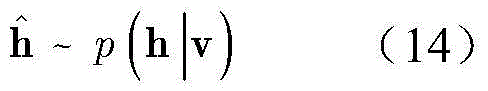
同样地,显层v的第i个神经元被激活的概率由下式给出:Likewise, the probability that the ith neuron of the display layer v is activated is given by:
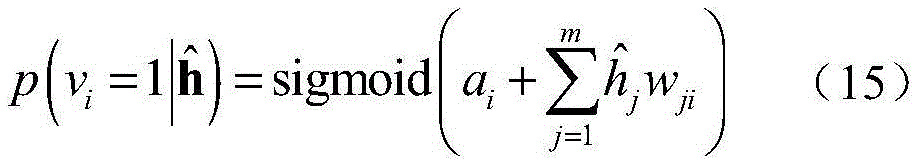
然后,重建的数据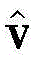
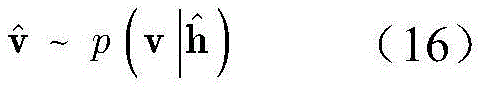
利用梯度下降法,可以得到第一种RBM的最优参数W,a,b。然后,将第一RBM的隐层h视为第二RBM的显层,令其隐层为h(1),如图6所示。训练完第二个RBM的权重矩阵和偏置后,将h(1)看作第三个RBM的显层,令h(2)为第三个RBM的隐层。在训练第三个RBM之后,RBM的所有参数(权重和偏差)都通过一个有监督的反向传播算法来进行微调(参考文献[42])。DBN模型的参数被更新以逼近最优分类器。训练后,将测试阶段的DBN网络应用于信号解调,输出信号解调结果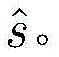
(5)基于ADABOOST的解调器(5) ADABOOST-based demodulator
Adaboost算法能够将多个独立的弱分类器集成为一个高性能的强分类器(参考文献[43])。本发明利用AdaBoost算法对信号进行解调,采用k-最邻近(KNN)算法作为弱分类器,令k=1。最终的强分类器H是所有KNN的组合,如图7所示。The Adaboost algorithm is able to integrate multiple independent weak classifiers into a high-performance strong classifier (Reference [43]). The present invention uses the AdaBoost algorithm to demodulate the signal, uses the k-nearest neighbor (KNN) algorithm as a weak classifier, and sets k=1. The final strong classifier H is the combination of all KNNs, as shown in Figure 7.
假设强分类器是由Q个KNN构成(参考文献[44])。对于第q个KNN分类器,样本集
根据dq对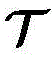
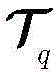
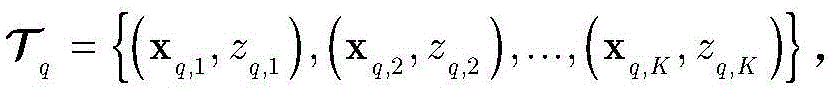
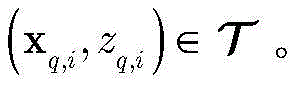


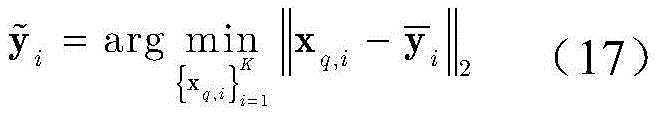
其中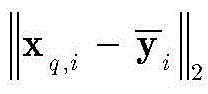


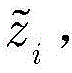
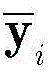

用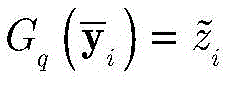
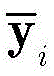

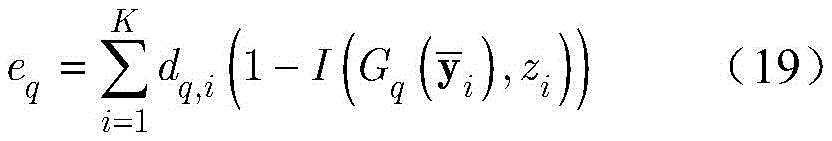
其中,I(a,b)是指示函数,定义如下:where I(a,b) is the indicator function, defined as follows:
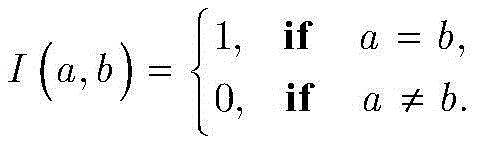
相似地,令dq+1=[dq+1,1,dq+1,2,...,dq+1,K]T表示第q+1个KNN对应的
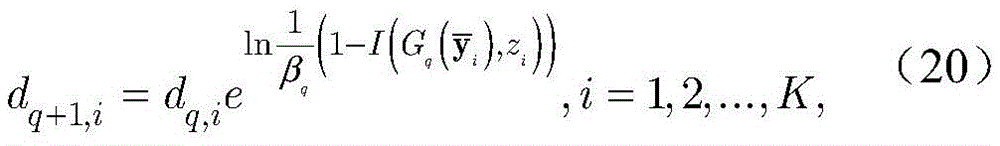
其中βq由函数

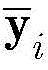
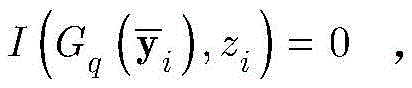
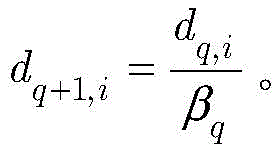
为了重新评估样本的权重,通过如下归一化公式重新定义dq+1,i:In order to re-evaluate the weights of the samples, d q+1,i is redefined by the following normalization formula:
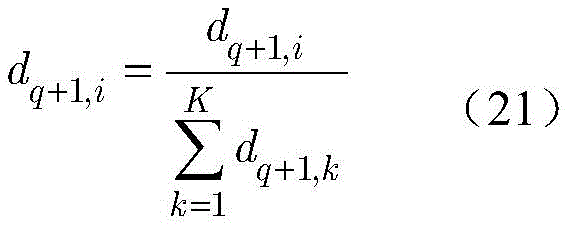
在生成Q个KNN分类器后,强分类器由下式定义:After generating Q KNN classifiers, a strong classifier is defined by:

其中,H(y)是强分类器,y是测试样本,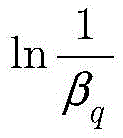
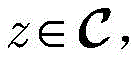
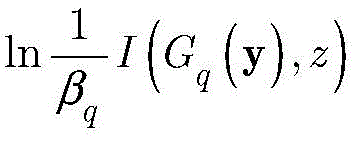
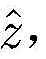

(6)实验结果及讨论(6) Experimental results and discussion
端到端VLC系统原型:End-to-end VLC system prototype:
提出一个端到端的VLC系统原型来产生实际的VLC调制数据集,并验证所提出的基于DL的解调方法,包括源计算机、任意函数发生器、放大器、直流偏置、LED、滑动导轨、光电探测器以及一个混合域示波器,如图8所示。表2列出了端到端VLC系统原型的器件参数。An end-to-end VLC system prototype is proposed to generate an actual VLC modulation dataset and validate the proposed DL-based demodulation method including source computer, arbitrary function generator, amplifier, DC bias, LED, sliding rail, optoelectronic detector and a mixed-domain oscilloscope, as shown in Figure 8. Table 2 lists the device parameters of the end-to-end VLC system prototype.
利用所提出的端到端VLC系统原型,收集了调制数据,并建立了一个用于ML处理的开放共享数据库。具有八种调制类型(即OOK,QPSK,4-PPM,16QAM,32QAM,64QAM,128QAM和256QAM,如表3所列出。对于每种调制方式,每个周期有四种采样点,即N=10、20、40、80。特别地,当采用4-PPM调制时,N=8、16、32、64。令d表示LED和光电探测器之间的距离。从d=0cm到d=140cm之间,每隔5cm收集一次数据。数据集的环境光的照度约为85Lux。在d=100cm处,LED的照度为492Lux。为了减小泛化误差,采用数据集的2/3作为训练集,1/3作为测试集。该数据库可以在https://pan.baidu.com/s/1ThsN3tQaTtFgHryZjqpTuw找到。Using the proposed end-to-end VLC system prototype, modulation data are collected and an open shared database for ML processing is established. There are eight modulation types (i.e. OOK, QPSK, 4-PPM, 16QAM, 32QAM, 64QAM, 128QAM and 256QAM, as listed in Table 3. For each modulation method, there are four sampling points per cycle, i.e. N = 10, 20, 40, 80. In particular, when using 4-PPM modulation, N=8, 16, 32, 64. Let d represent the distance between the LED and the photodetector. From d=0cm to d=140cm Data is collected every 5cm. The illumination of the ambient light in the dataset is about 85Lux. At d=100cm, the illumination of the LED is 492Lux. In order to reduce the generalization error, 2/3 of the dataset is used as the training set , 1/3 as the test set. The database can be found at https://pan.baidu.com/s/1ThsN3tQaTtFgHryZjqpTuw.
表2 器件参数Table 2 Device Parameters
表3 数据集Table 3 Dataset

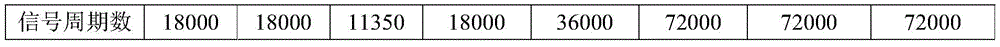
实验结果:Experimental results:
首先研究了所提出的基于CNN,DBN和AdaBoost的解调器相对于距离d的性能(N=40)。此外,基于支持向量机(SVM)和基于最大似然(Maximum Likelihood,MLD)的解调方法用来作为比较方法。The performance of the proposed demodulator based on CNN, DBN and AdaBoost with respect to distance d (N=40) is first investigated. In addition, support vector machine (SVM) based and maximum likelihood (Maximum Likelihood, MLD) based demodulation methods are used as comparison methods.
图8a、图8b、图8c分别显示了OOK、32-QAM和256-QAM调制信号相对于距离d的解调准确率。可以看出,所有方法的解调准确率都随着距离d的增大而降低。具体而言,图8a表明,当d≤70cm,所有解调器对OOK调制信号的解调准确率都接近100%;当70cm<d≤140cm,所提出的基于AdaBoost解调方法明显优于其他解调方法。图8b表明,对于d≤40cm,所有解调器对32-QAM调制信号的解调准确率都接近100%。对于40cm<d<140cm,基于AdaBoost的解调器在五种解调方法中准确率最高,并且基于DBN和SVM的解调器准确率相近,均高于基于CNN和基于最大似然的解调方法。这可能是因为CNN的池化操作后的组合输出通常是最活跃的元素值(参考文献[46]),忽略了波形各部分的相对位置信息。另外,实际信道的噪声并不服从高斯分布,这可能是基于最大似然的解调方法性能不佳的原因。图8c显示了所有解调器对256-QAM调制信号的解调准确率,其性能类似于图8b。Figures 8a, 8b, and 8c show the demodulation accuracy of OOK, 32-QAM and 256-QAM modulated signals with respect to distance d, respectively. It can be seen that the demodulation accuracy of all methods decreases as the distance d increases. Specifically, Figure 8a shows that when d≤70cm, the demodulation accuracy of all demodulators for OOK modulated signals is close to 100%; when 70cm<d≤140cm, the proposed AdaBoost-based demodulation method is significantly better than other demodulation methods demodulation method. Figure 8b shows that for d≤40cm, the demodulation accuracy of all demodulators for the 32-QAM modulated signal is close to 100%. For 40cm<d<140cm, the demodulator based on AdaBoost has the highest accuracy among the five demodulation methods, and the accuracy of the demodulator based on DBN and SVM is similar, which is higher than that based on CNN and maximum likelihood. method. This may be because the combined output after the pooling operation of CNN is usually the most active element value (Reference [46]), ignoring the relative position information of each part of the waveform. In addition, the noise of the actual channel does not obey the Gaussian distribution, which may be the reason for the poor performance of the maximum likelihood based demodulation method. Figure 8c shows the demodulation accuracy of all demodulators for a 256-QAM modulated signal, and its performance is similar to that of Figure 8b.
图9显示了基于AdaBoost的解调器相对于距离d的准确率,一个周期内具有不同采样点N=10,20,40,80。信号采用32-QAM调制方式。随着采样点数N的增加,解调准确率增加。此外,N=40时的解调准确率比N=80的情况要好,而N=40时所需存储量仅为N=80时的一半。Figure 9 shows the accuracy of the AdaBoost-based demodulator with respect to the distance d, with different sampling points N=10, 20, 40, 80 in one cycle. The signal adopts 32-QAM modulation. As the number of sampling points N increases, the demodulation accuracy increases. In addition, the demodulation accuracy rate when N=40 is better than that when N=80, and the required storage amount when N=40 is only half of that when N=80.
图10显示了基于AdaBoost的解调器的解调准确率与训练周期K的数目之间的关系,其中16-QAM调制信号在d=70cm处,32-QAM调制信号在d=60cm处。可以看出,对于16-QAM调制信号,解调准确率随着训练周期K的增加而增加,而当K≥4000时,解调准确率增长非常缓慢。同样,对于32-QAM调制信号,解调准确率随训练周期K的增加而增加,当K≥8000时,解调准确率几乎保持不变。比较16-QAM和32-QAM调制信号的解调准确率,对于较高的调制结束需要更多的训练周期K。Figure 10 shows the relationship between the demodulation accuracy of the AdaBoost-based demodulator and the number of training cycles K, where the 16-QAM modulated signal is at d=70cm and the 32-QAM modulated signal is at d=60cm. It can be seen that for the 16-QAM modulated signal, the demodulation accuracy increases with the increase of the training period K, and when K≥4000, the demodulation accuracy increases very slowly. Similarly, for the 32-QAM modulated signal, the demodulation accuracy increases with the increase of the training period K, and when K≥8000, the demodulation accuracy remains almost unchanged. Comparing the demodulation accuracy of 16-QAM and 32-QAM modulated signals, more training periods K are required for higher modulation ends.
图11a分别显示了在N=40时,OOK、QPSK、4-PPM、32-QAM、64-QAM、128-QAM和256-QAM八种调制信号的解调准确率的距离d的关系。可以看出,八种调制方案的解调准确率随着距离d的增大而降低。此外,对于给定的距离d,八种调制方案的解调准确率随着调制阶数的增加而降低,并且调制阶数越高,下降速率越快。Figure 11a shows the relationship between the distance d of the demodulation accuracy of the eight modulation signals of OOK, QPSK, 4-PPM, 32-QAM, 64-QAM, 128-QAM and 256-QAM when N=40. It can be seen that the demodulation accuracy of the eight modulation schemes decreases with the increase of the distance d. In addition, for a given distance d, the demodulation accuracy of the eight modulation schemes decreases with the increase of the modulation order, and the higher the modulation order, the faster the decline rate.
图11b显示了八种调制方案的有效速率Reff。随着距离d的增加,八种调制方案的有效率降低。当d≤30cm时,256-QAM的有效速率最高。当40cm<d≤50cm时,128-QAM调制方案具有最高的有效速率。当距离d从50cm增加到140cm时,64-QAM、32-QAM,和16-QAM依次获得最高的有效速率。因此,对于短距离或高信噪比的情况,最好使用高阶调制。Figure 11b shows the effective rate R eff for the eight modulation schemes. As the distance d increases, the effectiveness of the eight modulation schemes decreases. When d≤30cm, the effective rate of 256-QAM is the highest. When 40cm<d≤50cm, the 128-QAM modulation scheme has the highest effective rate. When the distance d increased from 50 cm to 140 cm, 64-QAM, 32-QAM, and 16-QAM sequentially obtained the highest effective rates. Therefore, for short range or high signal-to-noise ratio situations, higher order modulations are preferred.
为了克服现有技术的不足,本发明提出了基于机器学习(machine learning,ML)(参考文献[11])的VLC系统设计方法。由于其广泛的近似性、学习能力和自适应能力,机器学习能够基于数据驱动方法,去逼近未知的高度非线性和复杂函数(参考文献[12])。因此,ML(机器学习,Machine Learning)在很多领域有着广泛的应用,例如计算机视觉、自然语言处理、生物医学工程和机器人等。这种数据驱动的方法被认为是在复杂通信场景中从新的角度思考通信系统设计的一种富有前景的方法。In order to overcome the deficiencies of the prior art, the present invention proposes a VLC system design method based on machine learning (ML) (reference [11]). Due to its extensive approximation, learning ability, and adaptive ability, machine learning is able to approximate unknown highly nonlinear and complex functions based on data-driven methods (Reference [12]). Therefore, ML (Machine Learning) has a wide range of applications in many fields, such as computer vision, natural language processing, biomedical engineering, and robotics. This data-driven approach is considered a promising way to think about communication system design from a new perspective in complex communication scenarios.
本发明研究了ML在VLC系统物理层中信号解调中的应用。由于信号的幅度和相位代表了信号的信息,特征提取对于信号解调至关重要。因此,各种技术已被用于提取调制信号的特征。The invention studies the application of ML in signal demodulation in the physical layer of VLC system. Since the amplitude and phase of the signal represent the information of the signal, feature extraction is crucial for signal demodulation. Therefore, various techniques have been used to extract features of modulated signals.
本发明提供了一种基于机器学习的物理层可见光通信方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。The present invention provides a physical layer visible light communication method based on machine learning. There are many methods and approaches for implementing the technical solution. The above are only the preferred embodiments of the present invention. In other words, without departing from the principles of the present invention, several improvements and modifications can also be made, and these improvements and modifications should also be regarded as the protection scope of the present invention. All components not specified in this embodiment can be implemented by existing technologies.
Claims (1)

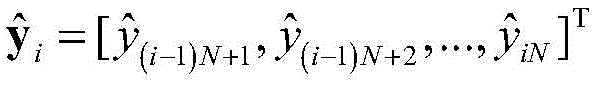
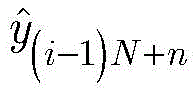

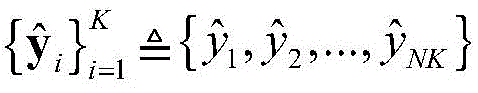

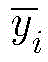

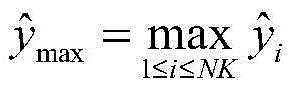

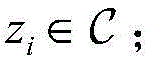

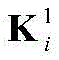

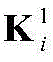
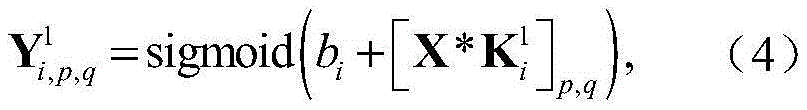

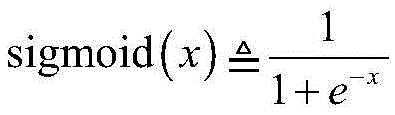
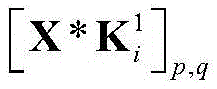
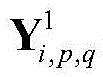
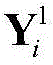
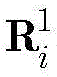
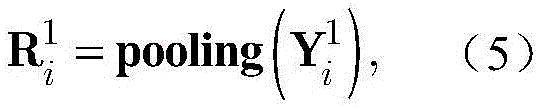
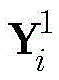
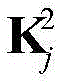





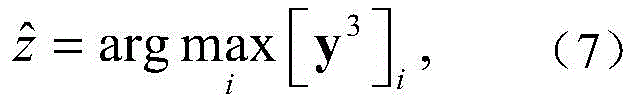






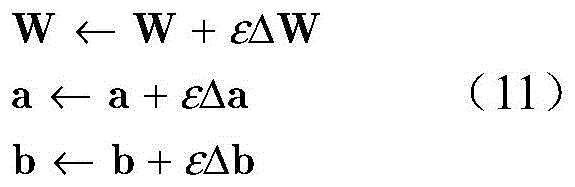
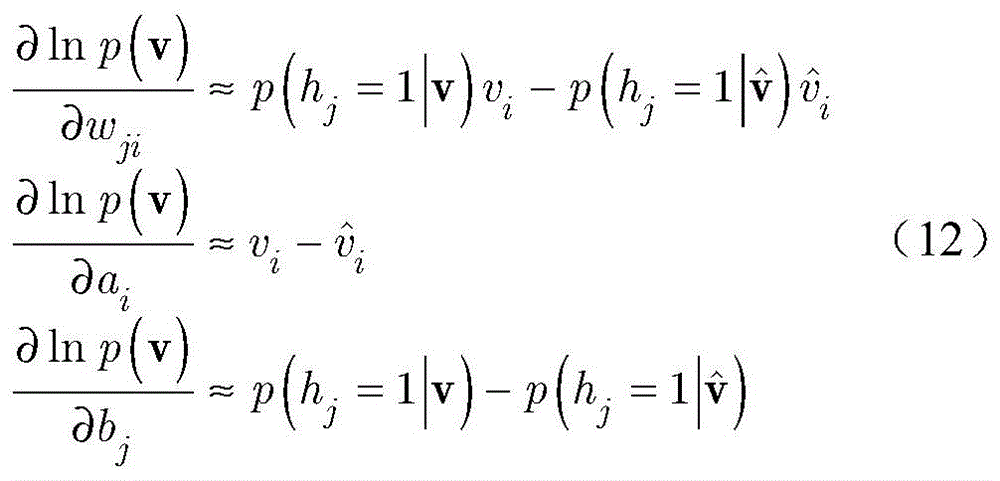
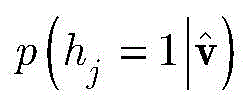



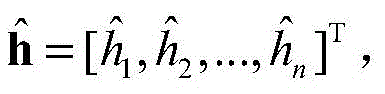
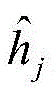

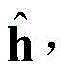

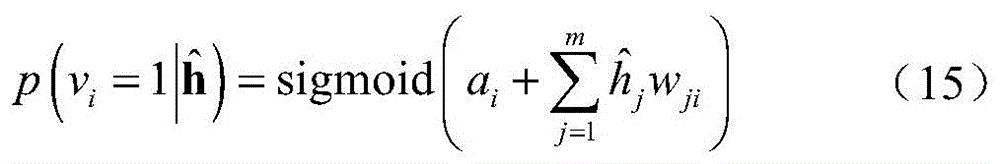

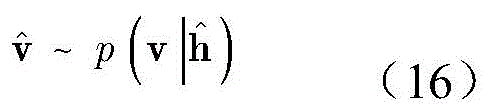

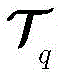


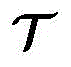
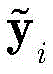
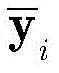
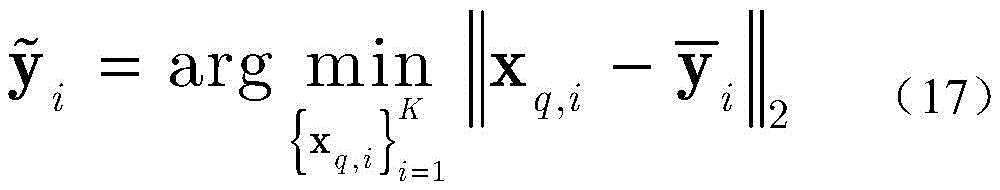
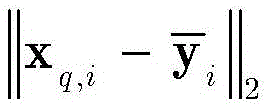
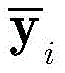
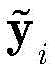
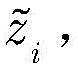


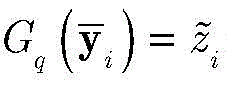
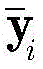

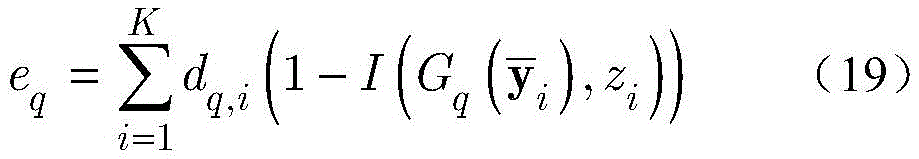


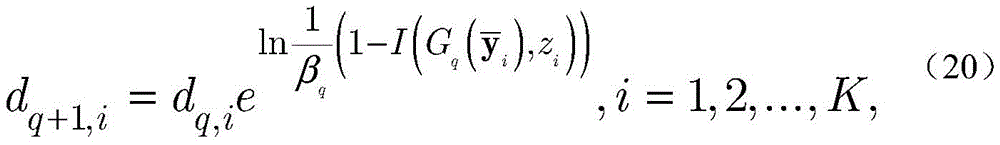
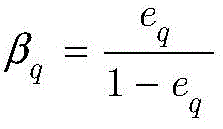


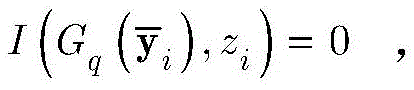
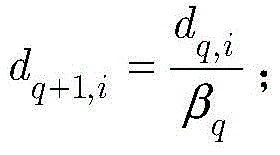


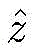

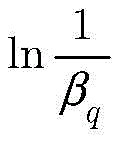
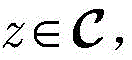
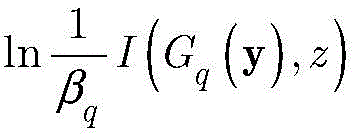
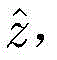
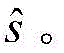
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811554831.8A CN109660297B (en) | 2018-12-19 | 2018-12-19 | A Machine Learning-Based Physical Layer Visible Light Communication Method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811554831.8A CN109660297B (en) | 2018-12-19 | 2018-12-19 | A Machine Learning-Based Physical Layer Visible Light Communication Method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109660297A CN109660297A (en) | 2019-04-19 |
| CN109660297B true CN109660297B (en) | 2020-04-28 |
Family
ID=66115141
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201811554831.8A Expired - Fee Related CN109660297B (en) | 2018-12-19 | 2018-12-19 | A Machine Learning-Based Physical Layer Visible Light Communication Method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109660297B (en) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110113288B (en) * | 2019-05-23 | 2021-06-22 | 徐州中矿康普盛通信科技有限公司 | Design and demodulation method of OFDM demodulator based on machine learning |
| WO2021008705A1 (en) * | 2019-07-18 | 2021-01-21 | Huawei Technologies Co., Ltd. | Photonic signal processing |
| WO2021025217A1 (en) * | 2019-08-08 | 2021-02-11 | 엘지전자 주식회사 | Artificial intelligence server |
| CN112398543B (en) * | 2019-08-19 | 2023-08-25 | 上海诺基亚贝尔股份有限公司 | Method, device, system, apparatus and computer readable medium for optical communication |
| CN110557177A (en) * | 2019-09-05 | 2019-12-10 | 重庆邮电大学 | DenseNet-based hybrid precoding method in millimeter wave large-scale MIMO system |
| CN115135358B (en) * | 2020-02-27 | 2024-07-02 | 美国西门子医学诊断股份有限公司 | Automatic sensor tracking verification using machine learning |
| CN111342896B (en) * | 2020-03-02 | 2021-04-02 | 深圳市南科信息科技有限公司 | Self-coding algorithm based on convolutional neural network |
| CN111865849B (en) * | 2020-06-30 | 2021-08-06 | 中国兵器科学研究院 | Signal modulation method and device and server |
| CN112511234B (en) * | 2020-11-10 | 2022-05-20 | 南昌大学 | Underwater single photon communication synchronous clock extraction method based on classification network |
| US12526054B2 (en) | 2021-02-08 | 2026-01-13 | Nec Corporation | Symbol constellation generation apparatus, control method, and computer-readable storage medium |
| CN113328807B (en) * | 2021-05-27 | 2023-04-18 | 长春理工大学 | DMPPM modulation method and system in deep space optical communication |
| CN114615499B (en) * | 2022-05-07 | 2022-09-16 | 北京邮电大学 | Semantic optical communication system and method for image transmission |
| CN115453778B (en) * | 2022-08-04 | 2024-02-27 | 中国电子科技集团公司第十四研究所 | A low-spurious electro-optical modulator bias point control device and method |
| CN119276372B (en) * | 2023-07-06 | 2025-11-18 | 复旦大学 | A visible light communication method for display and MIMO systems |
| CN117574280B (en) * | 2024-01-15 | 2024-04-16 | 长春理工大学 | Seeding quality detection method based on multivariate feature parameters and MDBO-RF |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103890781A (en) * | 2011-08-25 | 2014-06-25 | 康奈尔大学 | Retinal encoder for machine vision |
| CN108040496A (en) * | 2015-06-01 | 2018-05-15 | 尤尼伐控股有限公司 | The computer implemented method of distance of the detection object away from imaging sensor |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20130066452A1 (en) * | 2011-09-08 | 2013-03-14 | Yoshiyuki Kobayashi | Information processing device, estimator generating method and program |
-
2018
- 2018-12-19 CN CN201811554831.8A patent/CN109660297B/en not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103890781A (en) * | 2011-08-25 | 2014-06-25 | 康奈尔大学 | Retinal encoder for machine vision |
| CN108040496A (en) * | 2015-06-01 | 2018-05-15 | 尤尼伐控股有限公司 | The computer implemented method of distance of the detection object away from imaging sensor |
Also Published As
| Publication number | Publication date |
|---|---|
| CN109660297A (en) | 2019-04-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109660297B (en) | A Machine Learning-Based Physical Layer Visible Light Communication Method | |
| Ma et al. | Signal demodulation with machine learning methods for physical layer visible light communications: Prototype platform, open dataset, and algorithms | |
| Jdid et al. | Machine learning based automatic modulation recognition for wireless communications: A comprehensive survey | |
| Lu et al. | Deep learning aided robust joint channel classification, channel estimation, and signal detection for underwater optical communication | |
| Lin et al. | Contour stella image and deep learning for signal recognition in the physical layer | |
| Wang et al. | Data-driven deep learning for automatic modulation recognition in cognitive radios | |
| Huang et al. | Automatic modulation classification using contrastive fully convolutional network | |
| CN108234370B (en) | Recognition method of communication signal modulation mode based on convolutional neural network | |
| Zheng et al. | Toward next-generation signal intelligence: A hybrid knowledge and data-driven deep learning framework for radio signal classification | |
| Wang et al. | Deep learning for signal demodulation in physical layer wireless communications: Prototype platform, open dataset, and analytics | |
| Wu et al. | A deep learning approach for modulation recognition via exploiting temporal correlations | |
| CN109617845B (en) | Design and demodulation method of wireless communication demodulator based on deep learning | |
| Shi et al. | Particle swarm optimization-based deep neural network for digital modulation recognition | |
| Qu et al. | Enhancing automatic modulation recognition through robust global feature extraction | |
| CN111565160B (en) | A joint channel classification, estimation and detection method for marine communication system | |
| Bouchenak et al. | A semi-supervised modulation identification in MIMO systems: A deep learning strategy | |
| CN115913850A (en) | Open set modulation identification method based on residual error network | |
| CN114298113B (en) | A dual-path machine learning modulation pattern recognition method for the Internet of Things | |
| CN109120563A (en) | A kind of Modulation Identification method based on Artificial neural network ensemble | |
| Al‐Makhlasawy et al. | Modulation classification in the presence of adjacent channel interference using convolutional neural networks | |
| Wang et al. | A spatiotemporal multi-stream learning framework based on attention mechanism for automatic modulation recognition | |
| Chen et al. | Automatic modulation classification using multi-scale convolutional neural network | |
| Ke et al. | Application of adversarial examples in communication modulation classification | |
| Ağır et al. | The modulation classification methods in PPM–VLC systems | |
| Kharbouche et al. | Signal demodulation with Deep Learning Methods for visible light communication |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20200428 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |