CN1030652A - 形元汉字信息处理方法及其键盘 - Google Patents
形元汉字信息处理方法及其键盘 Download PDFInfo
- Publication number
- CN1030652A CN1030652A CN 87104866 CN87104866A CN1030652A CN 1030652 A CN1030652 A CN 1030652A CN 87104866 CN87104866 CN 87104866 CN 87104866 A CN87104866 A CN 87104866A CN 1030652 A CN1030652 A CN 1030652A
- Authority
- CN
- China
- Prior art keywords
- chinese
- code
- chinese character
- shape
- word
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000003672 processing method Methods 0.000 title claims abstract description 4
- 238000000034 method Methods 0.000 claims description 40
- 238000004458 analytical method Methods 0.000 claims description 9
- 230000010365 information processing Effects 0.000 claims description 5
- 238000003909 pattern recognition Methods 0.000 claims description 2
- 230000008901 benefit Effects 0.000 abstract description 6
- 230000008676 import Effects 0.000 description 13
- 238000000926 separation method Methods 0.000 description 6
- 238000010586 diagram Methods 0.000 description 5
- 241000092161 Pithys Species 0.000 description 3
- 235000013339 cereals Nutrition 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 239000012467 final product Substances 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- 239000002023 wood Substances 0.000 description 3
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 2
- 240000002853 Nelumbo nucifera Species 0.000 description 2
- 235000006508 Nelumbo nucifera Nutrition 0.000 description 2
- 235000006510 Nelumbo pentapetala Nutrition 0.000 description 2
- 238000004422 calculation algorithm Methods 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000001037 epileptic effect Effects 0.000 description 2
- 238000005194 fractionation Methods 0.000 description 2
- 239000000203 mixture Substances 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 238000005096 rolling process Methods 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 241000251468 Actinopterygii Species 0.000 description 1
- 244000000383 Allium odorum Species 0.000 description 1
- 235000018645 Allium odorum Nutrition 0.000 description 1
- 244000028550 Auricularia auricula Species 0.000 description 1
- 235000000023 Auricularia auricula Nutrition 0.000 description 1
- 241000283153 Cetacea Species 0.000 description 1
- 241000040710 Chela Species 0.000 description 1
- 229910000976 Electrical steel Inorganic materials 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 241000270666 Testudines Species 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 238000005452 bending Methods 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 230000002498 deadly effect Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 238000000151 deposition Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 230000005611 electricity Effects 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 230000003203 everyday effect Effects 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 238000009499 grossing Methods 0.000 description 1
- 239000011464 hollow brick Substances 0.000 description 1
- 229910052742 iron Inorganic materials 0.000 description 1
- 230000009191 jumping Effects 0.000 description 1
- 239000010985 leather Substances 0.000 description 1
- 238000010197 meta-analysis Methods 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 238000003825 pressing Methods 0.000 description 1
- NHDHVHZZCFYRSB-UHFFFAOYSA-N pyriproxyfen Chemical compound C=1C=CC=NC=1OC(C)COC(C=C1)=CC=C1OC1=CC=CC=C1 NHDHVHZZCFYRSB-UHFFFAOYSA-N 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 235000015170 shellfish Nutrition 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 239000002689 soil Substances 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images


Landscapes
- Document Processing Apparatus (AREA)
Abstract
形元汉字信息处理方法是一项以图论原理为基
础,用于编字典、计算机汉字编码输入和计算机手写
汉字识别的综合性发明。发明将汉字字形中的连通
线图(即形元)分为各种类型。以形元拆拼汉字,同时
保持部件拼字快速的优点用形元号码字典查字,只记
十个号码,三级简码不用记忆。使用全部简码,99%
的字只用一至三键即可输入。
Description
本发明属于汉字信息处理技术。
现国内已有数百种汉字编码方案,大致分三种类型:一、容易学习但输入较慢,如拼音码;二、输入较快但难学难记,如部件码;三、难度与速度介于二者之间。目前还没有一种既容易学习,又可快速输入,能取代所有方法成为全国统一编码的方法。
部件编码法重码少,码长短,只要背熟部件,拼字迅速,输入快,优点多,但数以百计的人工部件难学、难记、难分类是其致命弱点。某天然部件是否属某码人工部件范围,属何类,与何字母对应,本质上全要靠强制记忆。只适于专业操作人员部件码一般只考虑计算机输入一种用途,故多以字母为代码,中国人对字母顺序远不如对数字顺序熟悉,故不适于编制群众使用的字典,不能使一般人及学生在未接触计算机之前就已掌握汉字编码,因而难以向全社会普及。在中国,如果计算机汉字编码不和字典结合起来,就不可能彻底解决普及问题。
美国王安公司的三角编码三百多部件主要靠强制记忆,非专职人员难以掌握。
钱码输入速度快,但全部字根基本依靠强制记忆。
王永民码在分类和普及上有独到之处,但五笔字形码的部件分类仍难记忆。只知某部件属某区,但部件第二笔多不符合键位规律,故属何键位仍要强制记忆,而且任一天然部件是否属于该码部件仍须逐一记忆。对少于四个字根的汉字,须补一个“末笔和字型交叉识别码”,汉字字型归类有时很困难,该码虽有简单易学的五笔划法,但向真正实用的五笔字型码过渡跳跃性太大。该码输入速度高,主要靠简码和词语码,其它编码法亦能做到,为帮助使用者记部件,四川《大众》汉字输入法造出26个复杂的“模拟汉字”如“  ”等;《汉字十类字元歌决定位电脑输入法》编出八十句之多的歌诀,如“为兼耳旁卫服寻”“革识竖插尹头横”之类。部件编码记忆之难可见一斑。
”等;《汉字十类字元歌决定位电脑输入法》编出八十句之多的歌诀,如“为兼耳旁卫服寻”“革识竖插尹头横”之类。部件编码记忆之难可见一斑。
总之,所有部件编码法缺陷产生的原因正如郭平欣,张淞芝著《汉字信息处理技术》一书中所指出的:“部件本身太多;有些部件可分可合,造成歧意;部件使用频度相差很大,但频度再低的部件也无法舍去;占全体汉字25%的多拼字更增加拼字的困难。所以用组字部件拼汉字是相当复杂的,至今还不能找到一条非常理想的组字规则”“文字和语言一样是逐步形成的,它具有社会性和历史性,我们很难用形式上的几条法则和规律来强行统一,只能承认它的复杂性。”
由此可见,只要采用部件做为汉字“拼形字母”进行编码,其缺陷是无法克服的,这个事实已为数百部件编码法所证实只有跳出部件系统,才能找到理想的组字规则和汉字字形的简明规律。本发明的目的就是要找一种既不需要记忆人工部件系统,实际上又以部件拼字的方法。
在手写汉字计算机识别方面,目前联机输入识别虽有进展,但对字形规范和笔顺正确的要求较高,难以普遍适用,对已经写在纸上的汉字进行脱机识别则更为困难。
实际上现有技术在记录,分析,存贮等手段上已相当先进,但因对汉字字形结构的根本规律未掌握,故未能突破。
目前识别汉字的途径之一是结构分析法,它以五百个汉字部件为基础,以结构运算符表示部件间的位置关系,用这种形式文法来分析汉字,如
赢=亡  口
口  (月
(月  贝 凡)
贝 凡)
蘅=艹  (行 (_ 田
(行 (_ 田  大))
大))
(见陈明远著《语言文字的信息处理》)
这种方法之所以未能在识别手写汉字方面有较大突破其原因与部件编码法一样,在于部件本身形式复杂,变化多,数量多,分析部件的难度并不低于分析汉字本身。部件是文字学概念,不是数学概念,不便于计算机处理。
邮政编码的识别也未完全成功,所以对人手写编码数字要求工整,否则难以识别。
综上,汉字编码与手写汉字识别困难的焦点全在于未能找到适合于数学处理的简明的汉字字形规律。
为此本发明对汉字字形进行了研究,在字根与笔划这两级之间发现了“连通线图”这一级结构,汉字中的连通线图就是笔划相连通形成的线条图形,如“一乙人口手开”等,也可以看做连通电路,每个字根和汉字都是由一个或几个连通线图组成的。如:
设=丶 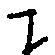 几又 连=车丶
几又 连=车丶
木=木 耳=耳
由此可见,连通线图正是汉字的纯形元件。本发明谓之“形元”,它与西文字母都是连通线图,都是字根与单字的拼形字母,所以真正与西文字母对应的同级结构应该是形元。
而汉字的字根是历史上形成的兼有形、音、义属性的元件,并非纯形元件。所以形状复杂,数量巨大,界限模糊,它应该对应于西文字根,不宜做为“拼形字母”。
连通线图在数学处理上比连,散错杂的字根要容易得多。分析连通线图最有力的数学工具是现代数学分枝-图论。
本发明运用图论及图论在物理学中的应用-电路图,对连通线图分析如下:
连通线图可分为“回路”和“树”两部分,回路即如“口”之类的闭合路径,从连通线图中取出回路:剩下的部分叫“树”树电路与汉字笔形的对应大致如下:
图论概念 电路概念 汉字笔形
两个端点的边 直电路 直笔(一丨丿  )
)
二叉树 弯折电路 折拐( _厂弓)
三叉树 三支路的节点电路 丁字形连接笔形
四叉树 四支路的节点电路 四叉笔形(十力)
五叉树 五支路的节点电路 五叉笔形(大)
六叉树 六支路的节点电路 六叉笔形(木)
从图论观点看,电路图和文字都是线图,线图分类形式能概括连通图的所有变化,支路、节点、回路能描述任何复杂电路,所以直、曲、丁、叉、框也能拼出所有字根和汉字,这就是形元原理的科学依据。
从纯形概念出发,一个汉字可分为离散结构和连通线图两个基本层次,连通线图服从图论规律,由连通线图组成的离散结构服从更高一级规律(见16页“数理字形学”),这就是汉字字形(不搀杂任何字义字音属性)的简明规律。
用形元分析汉字最为直观,凡连接在一起的笔画就组成一个连通线图。人们一眼就能看出汉字中的连通线图及直、曲、丁、叉、框等结构形态特征。
运用连通线图原理建立的形元编码系统有以下优点:
分类严密 科学性强,直、曲、丁、叉、框组成一个从简单到复杂的递进系统。每类定义简单明确,某形元属何类,一眼可知,决无歧义,彻底解决了部件编码的分类困难。
任何部件都可由形元拼出,所以没有必要硬性规定人工部件范围,从而彻底解决了部件编码逐一记忆的最大困难。
形元分类灵活,类别可多可少,可分可合,可用字母做代码,也可用数字做代码,所以可编字典。
记忆量极少,规则简单,直观性强,学习容易,适于所有初学者。
因各部件都有固定号码,实际上仍是以部件拼字,保持了部件编码拼字迅速的优点。
从字典码向计算机输入码过渡自然简单,只要会查字典,在字典码前加一个音码即能输入汉字,不加音码亦可输入,若在学校中普及该字典,学生从小熟知形元号码,将来就能做到人人都可以不经培训直接输入汉字,使汉字输入和西文输入一样方便,“不学就会”。
形元码第一、二方案主要采用音形结合码,用汉语拼音第一个字母做为音码,即使遇到生字,也能通过模糊键顺利输入,如果不愿用音码,也可用纯形码,只用十个数字键即可输入,第三方案主要采用纯形码输入。
形元码采用三级简码,一级简码字直接标示在键面上。一键输入,二,三级简码字自动显示,不用硬记,初学者亦可使用,重码很少,且能以命令方式消除全部重码,实现无重码输入。
形元码兼有词汇码,词语码,专用简码,能高速输入,适合各种专业人员使用。
所以形元码是一种既容易学习,又能高速输入。适于各种用户的编码方法,它是本发明向全国统一编码努力的一种尝试。
在手写汉字识别方面,本发明以形元为基础,以本发明的数理字形学为形式文法,便于计算机处理,由于该法以形元为基础,且与笔顺无关,所以即使字形不规范,笔顺不正确,但只要图形基本特征不变就能识别。
由于该法由计算机根据程序对手写汉字图象自行分析出形元码,再由使用者通过键盘与汉字对应,从而建立形元码库,所以对同一个字的各种习惯写法分析出的各种形元码都能与该字对应,因此能识别各种习惯写法,最终将实现凡是人们普遍能识别的字计算机也能识别的理想。
用同样的方法也能识别不工整的手写邮政编码数字图象。
本发明的形元编码法共有三个实施方案,以第一方案为最佳方案,该方案用途有二、编字典和计算机汉字输入,先说明字典码。
字典码中形元与号码关系见图一,该码以“最大连通子图”为形元,以其中主要特征(即最复杂特征)为形元分类标志,即“有丁不管拐,有叉不管丁”,尽量取大号,图中形元只列出常见例型,凡符合定义者一律属该表形元,不必记忆,字形以字典字头为准,该字典附有《汉字部件形元号码表》以备查考、易混淆部件极少,列有专表。
图一中“丁接点”即指“三支路节点”,“交叉点”即指“三支路以上的节点”。
凡框形无论与它笔连通与否,一律连同形成框形的笔画整体拆出另算,这与图论中把连通线图拆为“回路”和“树”相近,如“古”应拆写为“十、口”;“里”应拆为“甲,二”。
凡框形内有回路或由笔划将几个框形连在一起时一律加一附号,其号码等于框内回路的数目,如日=02,皿=93,弗=94,串=04,目=92。离散型部件“点组”(其中点与它笔的组合只限于图一中所列例型)与框形一样整体拆分,如“羊=丷  ”;“米=丷木”;“忄=八丨”;“火=丷人”。
”;“米=丷木”;“忄=八丨”;“火=丷人”。
编码方法如下:
在编码时依从“首笔优先”原则,即按书写顺序,首笔在先的形元号码亦在先,如“水=  ”,号码为64。
”,号码为64。
为减少重码,字典码规定“鱼、虫、疒”三个部件取首尾两码做为简码,即
部件 原码 简码
鱼 5041 51
虫 025 05
疒 343 33
凡四码以上汉字一律取一、二、三、末四个号码,如“音”原始号码为313102,只取3132,凡不足四码者,一律补取末笔号码,如“号=054”“乙=44”;“估=5701”;补取后仍不足四码者,字典码一律补零凑足四位,输入码不必补零。
上述所有分类号码,规则,简码只用两组口诀即可概括:
形元口诀 编码口诀
横一垂二三点捺 形元尽量取大号
拐四丁五多丁六 点组框形整体拆
单叉七,多叉八 首笔在先先编码
岔框为九方框0 前三后一补末笔
框中有框加附号 不够四位补零头
附号等于小框数 鱼虫病头取首尾
由于形元直观,规则简单,据初步试验,一般人只要几小时就能完全学会,两三天后编码可相当熟练。以形元号码编字典查字迅速,该字典附有音序检字表和部首检字表,本发明备有浅显易懂适于中,初等文化程度的人学习的字典说明书,一般人看过一遍就能掌握。
用计算机输入汉字时,在字典码前加一音码,即汉语拼音第一个字母,即构成音形输入码,它与后面要讲的纯形输入码统称为输入码。
为减少重码,输入码的键盘标示在字典码和英文键盘的基础上略作调整,见图二,其中数字键键面上典型形元(该类形元代表)与字母键上的字母均为红色,其余为黑色,ZH.CH.SH三个字母以AI.U代。
输入码中遇到数字键右下方所标形元时,依标示输入,如:
汉字 字典码 输入码
招 8501 1501
权 7930 293
鲸 5133 0133
辩 3137 9737
音形码规则简单,但变化丰富,所以重码很少,如以下这组字音,形都很相似,却无一重码。
敖=A893 鏊=A8953
遨=A8934 骜=A8951
嶅=A8952 隞=A4893
熬=A8933 廒=A3489
獒=A8973 嗷=A0893
聱=A8993 璈=A7893
螯=A8905 慠=A3289
鳌=A8901 傲=A5893
(这些字中有三个已超出国标一二级汉字范围)
音形码有三级简码,全都不必由人工死记硬背,一级简码字直接标在字母键上,一键即可输入,不必按分隔键,字母就是分隔码,一级简码与全码不兼容,这25个最高频字的全码不编入程序,直接依简码输入。
二、三级简码采用内存自动显示方式,为此在程序设计上与一般方式有所不同。
当按下字母键时,屏幕编辑位置上显示该字母键上的汉字,光标在该字下方,不前移。以下两个数码每键入一个时,都在原编辑位置上依次换成以已键入的字符串开头的所有输入码中的高频汉字,光标仍不前移,这两次换上的高频汉字即二、三级简码。
当键入第三、四个数字码时,原位依次换成与已键入的字符串相应的汉字,直到键入下一个字母时,光标才前移,同时在新的编辑位置上显示该字母键上的汉字,即字母键同时起分隔键作用,什么时候按字母键,什么时候移光标。
上述过程举例如下:
键入字符 显示 显示字全码 键入字符说明
L 了 一级简码
L3 六 L3133 二级简码
L32 类 L3273 三级简码
L323 类 L3273 空码
L3231 粒 L3231 全码
L3231D 粒的 一级简码
LD 了的 一级简码
二、三级简码与全码兼容,其中除一般高频字外,还包括全部单元字(即由一个形元构成的字,如“尸”,“韭”等)和重码字组中的高频字,这两类字数量很少,且都是常用字,不会影响简码输入效率。
采用上述程序,在全码尚未完全键入时,简码字已自动显示,本来想以L3133输入“六”字,但只键入L3时,“六”字已显示出来,就可以接着输入下文了,所以连初学者也可不背简码表,直接使用简码,待熟练之后,即可不看屏幕盲打,由于数以千计的简码字只用一,二,三键即可输入,所以动态平均码长极短,单字输入极快。
当使用者熟记重码高频字的简码之后,就可以以命令方式使所有重码高频字唯一对应简码,如“甸”和“佃”的全码都是D5041,“甸”的简码为D50,当下达消除重码命令后,“甸”唯一对应D50,从而使“甸”与“佃”消除重码关系,对个别几个简码难以消除的重码字可以安排在空码内(即换一个音码),从而实现完全无重码输入。
另外的初学者也可用命令方式取消上述命令返回原状态。
对要求单字码长更短的专业操作员,如发报员可加用如下简码:把所有码长为二和三的空码全部编入高频字,谓之专用简码,以命令方式启用,没有命令时,仍为空码,以防一般人员因疏忽误键入空码时,出现不需要的字。
专用简码编制原则为:音码采用该字声母或韵母,形码采用该字形元首码或尾码,或首尾码。这样,占汉字频度99%以上的2775个高频字只用一、二、三键即可输入,从数学上可以证明,这种方法是用数字键和(或)字母键的所有可能编码中单字码长最短的,无论其它方法规则有多难,甚至全部汉字都采用死记的简码,其动态平均码长也无法短于上述方法。
其余频度不到1%的四千个非常用字,仍用全码输入,无须记忆,对电报码来说,最难记忆的恰恰是非常用字部分,所以这种编码用于发电报,将是单字码长最短,学习最容易的编码。
对于完全不熟悉音码或不愿意用音码的人,可以用纯形码输入,只用十个数字亦能得到很好的输入效率,比音形码更简单。
纯形码每字五码,取汉字形元的第一、二、三、四、末五码如“编=51393;骥=51653”。
如果该字形元只有四码、则补取末笔号码,如“码=50511;设=34493”,
如果该字形元只有三码,则补取首末笔号码,如“那=92442;挐=90842”。
如果该字形元只有二码,则补取该字首,末笔号码并补零,如“节=84120;杰=23130”。
如果该字形元只有一码,则补取该字首末笔号码并补零如“斤=62200;牛=32200”“刀=54200;乙=44400”。
由于音形码中的数码最长不超过四码。不会与纯形码相混。所以不必切换,可兼容混用,纯形码满五键后光标前移,在屏幕的编辑位置上显示汉字,重码字全部显示在提示行中供选用。
形元码中空格键可起分隔键作用,按空格键表示一个字结束,但光标不前移。
词汇及词语输入有两种方式
萏D“,如超过一个则按字母顺序显示在提示行中以供选择,软件中同时备有汉语拼音码,可用一个标识键切换使用,以输入只知音而形不清楚的字。
如果字形分析不清,亦可用V代替一或两个形元输入,如输入去=QV3”则提示行中显示所有符合QV3的汉字及其形元号码,其中必有“去653”,可知“去”字并非“Q73”。
输入时,可出现两种报警信号,输入空码后,当键入下一字的音码时,响笛声一下,光标在原位不动,等待纠正。
出现重码,响笛声两下,如果使用的是音形码,则重码字组中的高频字显示在编辑位置上,若用此字,可继续键入下文,若不用则按空格键一下,原位即换上低频字,如果重码为一码三字(该情况极少)响笛声三下,若需要其中最低频字,则按空格键两下。
软件中备有国标一,二级全部汉字,如不够用可自行扩充。如果扩充的汉字输入码与原字库中汉字输入码相同,则做为重码处理。
第二实施方案与第一实施方案大致相同,都是以数码为主,亦可编字典,其区别主要在于形元定义与键盘排列不同,见图三、图四。
第二实施方案须将连通线图拆成纯丁,纯叉,纯框,如“土=71大73”对内有笔形的框形。须将外框与框内笔形拆开,如日=01,电=07,巴=92,尹=91。
该法的特点在于音形码中不必加末笔号码,纯形码中不
词汇码(两字及三字词汇),定义一个词汇标识键,按下词汇标识键,表示紧跟其后的三个字符代表词汇。
三字词汇用该词汇的三个音码表示,如“无线电=WXD;共产党=GID”。两字词汇在两个音码后补第一字的形元首码,如“学习=XX3,信息=XX5”。如有重码则取第二字的首码,如“消息=XX2”。这样可得到六千个以上的双字词汇。
用户也可以自己定义词汇,方法可以是:三字词汇第二码换为该字形元首码,如“空心砖=K3A;软骨鱼=R9Y”,双字词汇先取第一字的形元首码,再取两字音码,如“硅钢=5GG;分馏=2FL”也可以由用户自由选用其它方法。
词语码(四字以上,128字以下的词语):以该词语第一、二、三、末字的音码直接输入即可,如“社会科学=UHKX,中华人民共和国=AHRG”因词语码与单字码兼容,不用标识键,而一级简码又可以直接组词,为避免混淆,一级简码组词满三字时要按分隔键,如“这就是=AIU  ”
”
词汇标识键兼做偏旁部首标识键,三个字符取该部首形元号码加末笔或加首末笔号码,如“艹=812;扌=111;氵=344”,字母键V是模糊键,可代替任意码元输入,凡有模糊键的输入码,一律以空格键结束。
如果遇到不会读或发音没把握的字可以用V代替音码输入,如“萏=V8561”,如果形元号码为8561的字只有一个,则显示在编辑位置上,并在提示行显示该字的音码,如必加首笔号码,只加末笔号码即可,所以熟练后输入速度很快,另外该法输入码与字典码一致性较高。
第三实施方案以字母和数字共同做为形元代码,其形元定义与键盘见图五,图六。
键位以形元系统分区排列,井然有序,易学易记,输入方便。分区示意图见图七,示意图中黑粗线为代表性形元(代表一类的形元)与非代表性元(固定的偏旁部首)分区线,即左为代表性形元,右为非代表性形元。
键面上凡代表性形元一律为黑色,非代表性形元一律为红色,字母一律为绿色,如在 中“日”为红色,其余为黑色:在  中,“K”为绿色,“扌”为红色,“丁”为黑色。
中,“K”为绿色,“扌”为红色,“丁”为黑色。
输入码一律为四码一字,分音形码与纯形码两种。
音形码首码为音码,其余三码取每字首,二、末三个形元,只有两个形元者加补末笔号码,只有一个形元者加补首末笔号码。
一级简码即键盘上所示汉字,一键加一空格键输入,二,三级简码的输入方法原则上与第一实施方案相同,亦为自动显示,无须记忆。
字母U为模糊键,声母“SH”以“V”代。
词汇。语句一律为四码,两字词汇取每字输入码的前两码,如“北京=BRJ6”三字词汇取三字音码加补最后一字的形元首码,如“熔解热=RJRK”;四字以上,一百二十八字以下的词语取一、二、三,末字的音码,如“资产阶级自由化=ZIJH”。
纯形码与音形码以命令方式切换。
纯形码取该字一、二、三、末四个形元,只有三个形元加补末笔号码,两个形元加补首末笔号码,一个形元加补首末笔号码及空格键。
词汇语句一律为四码,两字词汇取每字输入码的前两码,如“北京=RE6Z”;三字词汇取两字首码和第三字前两码,如“溶解热=8EKG”;四字以上,一百二十八字以下的词语取一,二,三,末字的首码,如“资产阶级自由化=86QE
第三实施方案中的词语码与单字码兼容混用。
该方案适于键盘输入,击键次数少,重码少,输入效率高,但不适于编字典,不便于向社会普及。
本发明向一般用户提供上述方案中全部单字全码及简码
本发明的手写汉字图象识别具体方案如下:
本发明以字母代表形元,以数学运算符号代表各形元之间的平面位置关系,并以一整套运算法则将其组织为一个有机的整体,用以分析手写汉字图象,这种方法谓之数理字形学方法,用该法分析汉字得出形元码与汉字内码对应,由计算机识别,字符表见图八。
为区别拐的方向与次数,拐笔字母前须附有两位数字,第一位为按顺时针拐弯的次数,第二位为按逆时针拐弯的次数。很显然,两个数字之和应等于拐点数,如:

乚=02L  =01A
=01A
乛=10Z =01V
乙=12Z 弓=42Z
在手写汉字中,最复杂,最模糊的情况是三支路节点的丁字形连接笔形,在手写汉字中有将近一半的偏旁部首都与其它部分相连接。所以本发明在形元中取消该类形元,笔划之间只要未形成回路,无论连接与否一律以断开论。
由拐笔组成的叉要按运算法则算出并括在一起,表示属于一个连通线图,如
七=(J02Z) 九=(K+12Z)
又=(10ZX)  =(J10L)
=(J10L)
为分析汉字,本发明定义以下概念。
“区”:整个单字所占区域或被形元之间的分隔沟分开的区域“分区”:区内的区
等位形元:在  中,B与C中等位;在
中,B与C中等位;在  中E与F等位,依此可推出以下等位关系式:
中E与F等位,依此可推出以下等位关系式:
M(E+F) 晶= ( + )
(E+F)M 架=((K+20Z)+Q)6K
M+EF 枯=6K+JQ
EF+M 计=D11Z+J
贯通形元;在一个区中,一形元左右两边都没有形元时,该形元称为该区的横贯通形元,在一个区中,一形元上下都没有形元时,该形元称为该区的竖贯通形元。
为分析汉字结构时便于运算,本发明推出以下定律与法则:
结合律:E+F+G=(E+F)+G=E+(F+G)
EFG=(EF)G=E(FG)
交换律:两形元交换位置时要变号
E+F=F-E
QR=R÷Q
结合交换律:
在三个以上形元的同号表达式中,任意两个形元交换时,要先结合再交换。
E+F+G=(E+F)+G=(F-E)+G
=G-(F-E)
EFG=(EF)G=(F÷E)G=G÷(F÷E)
同号去括号法则:只有当括号内外为同种运算符号时,才能去括号,如上例:
G-(F-E)=G-F-E
G÷(F÷E)=G÷F÷E
等位分配律:在  的等位结构式中有
的等位结构式中有
(E+F)(B+C)=EB+FC
结合等位分配律:在  的等位结构式中有
的等位结构式中有
(E+F+G)(B+C)=((E+F)+G)(B+C)
=(E+F)B+GC
合并同类项法则:

如“林=26K”;“卅=3J”
乘方法则:

如“丰=J3;氵=D2P”。
在分析形元之间的关系时,应遵循如下法则:
方向顺序法则:从左到右,从上到下进行分析。
先乘除后加减法则:当两个方向顺序矛盾时,应优先从上向下分析,如  应分析为MB+NC。
应分析为MB+NC。
贯通分区法则:贯通形元把全区分为分区,按分区方向顺序分析。
分割沟分区法则:当全区中无贯通形元时,以分割沟为分区界限。
形元优先顺序法则:在拆分形元时,优先拆分复杂形元顺序如下:回_叉_拐_直,具体顺序如下:

依上述法则,回路内外的笔形应分算,如
井=2H+2SQ2S+2H
冉=H+S (S+10L)+H
聿=S(3H+  +H)J
+H)J
计算机对手写汉字字形分析编码的过程如下:按形元优先顺序拆分;按贯通形元分区;没有贯通形元时,按分隔沟分区;重复以上步骤,直到分为单个形元为止;按法则组码,遇上减号,除号,通过运算定律尽量化成加号,乘号,遇上括号在法则允许范围内去括号,运算到底即得出该图形的形元码。
目前在计算机识别汉字时,都要进行预处理。如粗化,平滑化,细化等,可使手写汉字图象尽量规格化,如粗化能使未连结上的回路连上,使不该出头而出头的误差淹没,即使由于粗化使本不该连接的地方连上也不要紧,因为没有丁字笔型的形元,所以丁接点都要拆开。
预处理中的参变量(如粗化程度,点或钩的阈值等)由外部控制,以便不断调整,找出最佳值。
汉字识别的流程见图九,虚线框内即汉字识别程序,
通常汉字识别都是由人预先建立汉字图形特征信息库,然后输入汉字图形来对照识别,这样的信息库即使每字预备几种不同模式,也无法保证可以识别。
因形元码包含汉字的全息特征,每种不同图形对应不同的形元码,所以采用另一种方法,首先让计算机识别标准手写体汉字,自行分析出形元码,将手写字迹显示在屏幕上,人们由键盘输入该汉字,由计算机将该字形元码与内码建立对应关系,这种建立形元码库方法比人工建库方便得多。
不仅如此,因为人们用不着接触形元码,所以不必关心码式是否“正确”,是否符合预期码式,只要不同图形能得到不同形元码,同种图形在同样程序下能得到同一形元码,就能达到识别汉字的目的,即使是“错误”码式,但因为人已通过键盘使其与该汉字内码对应,所以输出的仍是正确汉字,这样就降低了对编制程序的要求。
该机投入实用,第一步可识别较工整的字,凡不能识别者,即反馈到接受端,从信息暂存中提出该字字迹由人识别键入该字,即一字对应多码,形元码库逐步扩大,识别能力逐步提高。
以后即可逐步识别一般手写汉字,由计算机控制,凡同一图形得到的同一码式三次不能识别者再补充到码库中,这样可防止偶然出现的怪字存入,只将有一定普遍性的习惯字存入,直至凡是人们普遍能认识的字计算机都能识别。
按以上方法一字对应多码,但计算机库容不会紧张,原因
一、码式简练、笔画很多的“赢”字,其码式为:
赢=DH01LQ( (P+10L)+20ZPD+22ZD)
不超过30个字符,一般字在20个字符以下,平均10个字符左右。原因二,同一码式对应的图形允许误差较大。无论笔形歪斜,大小,连接与否只要基本图形不变,就属同一码式,习惯写法有限,所以一字不会对应太多的形元码式。
因为该法共有30个码元,仅以码长从1到20计,其组合可能性就达3.5×1029种之多,所以重码可能性极小,实际上只要图形不同,码式就不会相同,对于个别可能重码的字如“未”和“末”可事先编入辨别重码的程序、分辨两横长短即可。
预处理参变量可根据各人书写习惯而调整。
由于形元码不牵涉笔顺,故适应性强,对联机手写汉字识别和脱机手写汉字识别都能应用。
由于运算符号有正逆两种(即+,-,×,÷)又能依运算定律逆推,所以即使遇到复杂情况也能妥善处理。
该方法用于邮政编码识别,其中拐笔可以只用Z代替不区分起笔类型,对竖的方向规定也要符合数字写法倾斜一些。数字只有十个,对每个数字贮存大量形元码,就可以减少对人写编码时工整程度的限制,举例如下。
1=S
2=11Z 2=10ZQ+N
3=21Z
4=01Z+J 4=QS+H
5=13Z 5=T11Z
6=PQ 6=P+PQ
7=10Z =10Z+J
8=Q 8=(01Z+P)Q
9=QS 9=Q(P+10Z)
附图说明
图一 第一实施方案形元表
图二 第一实施方案键盘表
图三 第二实施方案形元表
图四 第二实施方案键盘表
图五 第三实施方案形元表
图六 第三实施方案键盘表
图七 第三实施方案键盘分区示意图
图八 手写汉字计算机识别用的字符表
图九 手写汉字计算机识别流程示意图
Claims (11)
1、一种形元汉字信息处理方法,其特征是运用图论原理将汉字字形中的连通线图进行分类而形成的汉字编码体系。
2、如同权利要求书1所形成的三种形元编码方案使用的形元表即图一,图三,图五,说明各类形元的定义及例型,是进行字形编码的基础。
3、如同权利要求1和2所形成的三种形元码计算机输入用的键盘排列图,即图二,图四,图六,图七,依据形元在中文信息处理时的使用概率和形元系统分区原理,标明字形码字音码及一级简码与键的关系。
4、如同权利要求1和2,对GB-2312(80)中全部6763个汉字依形编码,形成两套形元号码字典用的汉字编码本。
5、如同权利要求3和4,对GB-2312(80)中全部6763个汉字进行编码,形成了三套计算机汉字输入用的汉字编码本,其中含有汉字全码及一,二,三级简码。
6、按照权利要求2和3,使内存简码自动显示,可帮助使用者记忆二、三级简码。
7、按照权利要求2和3,以命令方式使重码字组中高频字唯一对应简码,从而消除全部重码。当使用者熟悉简码后,即可进行无重码输入。
8、按照权利要求1形成的一种手写汉字图象计算机识别用的数理字形学方法,说明形元之间的平面位置关系,以便计算机分析汉字字形结构。
9、如同权利要求1和8所述的方法,将汉字形元用字母表示将形元之间的平面位置关系用数学运算符号表示,形成了形元及运算符号表,即图八,它是手写汉字图象计算机识别的基础。
10、按照权利要求8和9由计算机对手写汉字图象自行分析出形元码,并由使用者通过键盘与该汉字对应,逐一建立形元码库,从而使计算机可以识别各种习惯写法的手写汉字。
11、按照前述权利要求1-10中的任何一条,对汉字和中文词组进行编码的方法,可以用在字典,一切大、中、小、微型中文信息处理电脑系统。汉字电传机、汉字电脑打字机、汉字终端机、电报、通讯系统、计算机汉字图象识别系统和邮政编码识别系统中。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 87104866 CN1020052C (zh) | 1987-07-12 | 1987-07-12 | 形元汉字信息处理方法及其键盘 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 87104866 CN1020052C (zh) | 1987-07-12 | 1987-07-12 | 形元汉字信息处理方法及其键盘 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1030652A true CN1030652A (zh) | 1989-01-25 |
| CN1020052C CN1020052C (zh) | 1993-03-10 |
Family
ID=4815041
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN 87104866 Expired - Fee Related CN1020052C (zh) | 1987-07-12 | 1987-07-12 | 形元汉字信息处理方法及其键盘 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN1020052C (zh) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1036161C (zh) * | 1992-09-17 | 1997-10-15 | 戴顺天 | 两笔字型汉字输入法 |
| CN102156548A (zh) * | 2011-03-01 | 2011-08-17 | 华兴初 | 汉字表征码、编码方法与键盘 |
| CN104731365A (zh) * | 2015-03-31 | 2015-06-24 | 苏州乐聚一堂电子科技有限公司 | 快速拆分输入法 |
-
1987
- 1987-07-12 CN CN 87104866 patent/CN1020052C/zh not_active Expired - Fee Related
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1036161C (zh) * | 1992-09-17 | 1997-10-15 | 戴顺天 | 两笔字型汉字输入法 |
| CN102156548A (zh) * | 2011-03-01 | 2011-08-17 | 华兴初 | 汉字表征码、编码方法与键盘 |
| CN102156548B (zh) * | 2011-03-01 | 2013-06-26 | 华兴初 | 汉字表征码、编码方法与键盘 |
| CN104731365A (zh) * | 2015-03-31 | 2015-06-24 | 苏州乐聚一堂电子科技有限公司 | 快速拆分输入法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN1020052C (zh) | 1993-03-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1171162C (zh) | 基于字符分类检索字符串的装置和方法 | |
| CN1040276A (zh) | 简繁字根汉字输入技术及其键盘 | |
| CN1135060A (zh) | 语言处理装置和方法 | |
| CN1379882A (zh) | 将二维数据转换为标准形式的方法 | |
| CN1119760C (zh) | 自然语言处理装置及方法 | |
| CN1030652A (zh) | 形元汉字信息处理方法及其键盘 | |
| CN1641633A (zh) | 基于成熟工艺文档的工艺术语提取、规律分析和重用方法 | |
| CN1143231C (zh) | 汉语信息处理装置 | |
| CN1573662A (zh) | 汉字输入输出方法及装置 | |
| CN1121645C (zh) | 音形字理码汉字输入方法 | |
| CN1399191A (zh) | 汉语语音识别词库的处理方法 | |
| CN1045021C (zh) | 中文数码电脑汉字输入法及其键盘 | |
| CN1275732A (zh) | 汉语键盘输入系统及其应用技术 | |
| CN1591293A (zh) | 汉字拼形输入法 | |
| CN1218217A (zh) | 一种计算机汉字编码和输入法 | |
| CN1453692A (zh) | 一种汉字拼形输入法的智能输入处理方法 | |
| CN1123819C (zh) | 计算机汉字键位码输入方法 | |
| CN1259615C (zh) | 字母键盘和数字键盘通用汉字输入法及其左半字形识别法 | |
| CN1092186A (zh) | 汉字数控方位码及输入方法 | |
| CN1019527B (zh) | 字符的图元输入方法及其键盘 | |
| CN1317906A (zh) | 移动通信与计算机信息处理中英文数字化输入集成系统 | |
| CN1421766A (zh) | 汉字双笔码输入法 | |
| CN1818837A (zh) | 规范应用汉语拼音方案的汉字输入法 | |
| CN1192014A (zh) | 以第二种文字检索以第一种文字建立之产业科技资料库的方法 | |
| CN1208187A (zh) | 一种全息万能汉字键盘及输入方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C19 | Lapse of patent right due to non-payment of the annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee |