


Spatio-Temporal Sentiment Mining of COVID-19 Arabic Social Media


<p>The Workflow of our methodology to analyze the social data.</p> "> Figure 2
<p>Reprocess COVID-19 tweets dataset.</p> "> Figure 3
<p>Percentage of the Geo-tagged tweets in the new COVID-19 Tweets Dataset after applying the Location Extraction algorithm.</p> "> Figure 4
<p>Tweets and Hashtags in Arab and non-Arab Countries.</p> "> Figure 5
<p>Monthly distribution of Top 10 Topics in the Tweets Dataset.</p> "> Figure 6
<p>Top topics distributed globally.</p> "> Figure 7
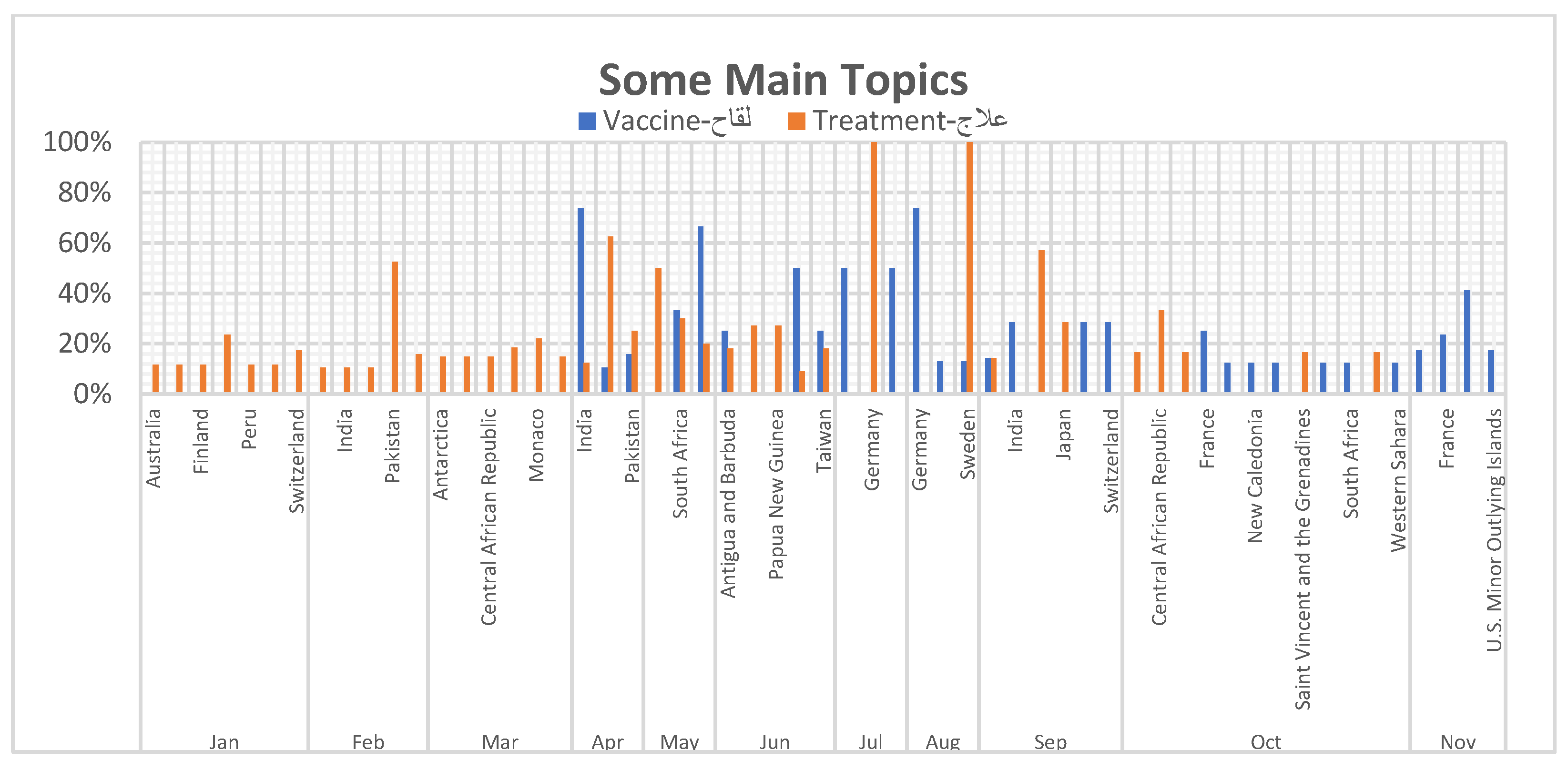
<p>Main topics in Arab and non-Arab countries.</p> "> Figure 8
<p>SA of COVID-19 Arabic Tweets.</p> "> Figure 9
<p>SA Classifiers’ performance applied on Arabic Datasets.</p> "> Figure 10
<p>Correlation between SA and the Official Health Records.</p> "> Figure 11
<p>Correlation between SA and the Official Health Records in Arab and Non-Arab Countries.</p> "> Figure 12
<p>Correlation between lockdown and Official COVID-19 New Cases in Arab Countries.</p> "> Figure 13
<p>Correlation between lockdown and Official COVID-19 New Cases in Non-Arab Countries.</p> "> Figure 14
<p>Correlation between Lockdown and SA in Arab Countries.</p> "> Figure 15
<p>Correlation between Lockdown and SA in Non-Arab Countries.</p> "> Figure 16
<p>Correlation between main topics and SA in Arab countries.</p> "> Figure 17
<p>Correlation between main topics and SA in non-Arab countries.</p> "> Figure A1
<p>Monthly distribution of tweets and Hashtags.</p> "> Figure A2
<p>Sample of Arabic tweets with English translation.</p> "> Figure A3
<p>Monthly distribution of Geo and Non-geo tweets in Tweets Dataset.</p> "> Figure A4
<p>Word cloud of the top topics in the COVID-19 Arabic Tweets Dataset.</p> "> Figure A5
<p>Top 5 Topics in Arab and Non-Arab Countries.</p> "> Figure A6
<p>Monthly Top Topics in Arab and Non-Arab Countries.</p> "> Figure A7
<p>Top 5 Topics in Top 10 Countries.</p> "> Figure A8
<p>Frequency-Occurrence of Some Main Topics in Arab Countries.</p> "> Figure A9
<p>Frequency-Occurrence of Some Main Topics in Non-Arab Countries.</p> "> Figure A10
<p>Top Sentiment (Positive/Negative/Neutral) in Arab Countries.</p> "> Figure A11
<p>Correlation between SA and Official Health Records in some countries.</p> "> Figure A12
<p>Distribution of Arabic Tweets.</p> "> Figure A13
<p>Distribution of Arabic Hashtags.</p> "> Figure A14
<p>Distribution of Users.</p> "> Figure A15
<p>Sentiment Analysis of Arabic Tweets.</p> "> Figure A16
<p>Word Cloud of Sentiment Analysis of Arabic Tweets over the world.</p> "> Figure A17
<p>Distribution of COVID-19 Cases.</p> "> Figure A18
<p>Covid-19 Lockdown Days.</p> ">
Abstract
:1. Introduction
- We used the dataset gathered in previous work [7] that contains Arabic tweets related to COVID-19 from two publicly shared datasets within the time frame from January 2020 to November 2020 (about 5.5M tweets). Then, we enhanced our previous approach for a location inference technique from non-geotagged tweets based on user profiles and textual content, which increased the total percentage of location-enabled tweets. We developed our Geo-Database containing bilingual (English and Arabic) names of world countries, their capitals, and the famous towns in the Arab world.
- We implemented several mechanisms for topic-based analysis using occurrence-based and statistical correlation approaches to examine the spatio-temporal distribution of trending topics related to COVID-19.
- We conducted a correlation-based analysis between Arabic tweets and official health data collected from online platforms.
- We extend our previous work [7] of sentiment analysis by developing a deep learning model with bidirectional representations from the unlabeled text by conditioning on both left and right contexts in all layers. We also enhanced our detection mechanism at many spatial granularity levels (regions, countries, and cities) and different topic scales. It leverages unique insights from users’ feedback on top controversial topics (lockdown, vaccination, etc.).
- We conducted a comprehensive set of experiments and visualized our results based on the generated geo-social dataset, sentiment analysis, official health records, and lockdown data worldwide.
2. Related Work
2.1. Data Collection and Classification
2.2. Geolocation Analysis
2.3. Topic Analysis and Semantic Analysis
2.4. Misleading Information Detection
2.5. Discussion
3. Research Methods
3.1. Dataset Collection
3.2. Features Extraction
- Convert HTML to normal text, which removes the HTML tags.
- Remove links (remove all hyperlinks of advertisements, retweets, etc.)
- Remove diacritics (remove Arabic diacritics)
- Remove punctuation (remove Arabic punctuation characters)
- Normalize and Tokenize Arabic text (We used our own Python code for tokenization)
- Remove Stop Words (remove Arabic stop words based on a list contains 750 words that published by Alrefaie [32])
- Remove empty lines (remove extra empty lines and extra white spaces).
| Algorithm 1: Location Extraction |
 |
3.3. Topic Clustering
3.4. Sentiment Analysis
| Algorithm 2: Sentiment Extraction |
 |
4. Results and Discussion
4.1. Correlation Analysis
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| SA | Sentiment Analysis |
| NLP | Natural Language Processing |
| ML | Machine Learning |
| CNN | Convolutional Neural Network |
| NMF | Matrix Factorization |
| FCM | Fuzzy C-Means |
| DT | Decision Tree |
| SVM | Support Vector Machine |
| SA | Sentiment Analysis |
| NLP | Natural Language Processing |
| ML | Machine Learning |
| CNN | Convolutional Neural Network |
| NMF | Matrix Factorization |
| FCM | Fuzzy C-Means |
| DT | Decision Tree |
| SVM | Support Vector Machine |
| MNB | Multinomial Naïve Bayes |
| BoW | Bag of Words |
| RF | Random Forest |
| WHO | World Health Organization |
| ECDC | European Centre for Disease Prevention and Control |
| JHU | Johns Hopkins University |
| ASTC | Arabic Sentiment Twitter Corpus |
| SS2030 | Arabic Sentiment Analysis Dataset |
| ArSAS | Arabic Speech-Act and Sentiment Corpus of Tweets |
| BERT | Bidirectional Encoder Representations from Transformers |
Appendix A. More Detailed Figures


















References
- Kemp, S. Digital 2021: Global Overview Report. 2021. Available online: https://datareportal.com/reports/digital-2021-global-overview-report (accessed on 5 October 2021).
- Mohsen, A.M.; Hassan, H.A.; Idrees, A.M. A proposed approach for emotion lexicon enrichment. Int. J. Comput. Electr. Autom. Control. Inf. Eng. 2016, 10, 242–251. [Google Scholar]
- Mostafa, A.M. Advanced Automatic Lexicon with Sentiment Analysis Algorithms for Arabic Reviews. Am. J. Appl. Sci. 2017, 14, 754–765. [Google Scholar] [CrossRef]
- Miniwatts Marketing Group. Internet World Users by Language: Top 10 Languages. Available online: https://datareportal.com/reports/digital-2021-global-overview-report (accessed on 14 October 2021).
- Miniwatts Marketing Group. Middle East Internet Statistics, Population, Facebook and Telecommunications Reports. 2021. Available online: https://eipss-eg.org/wp-content/uploads/2015/10/stats5.htm (accessed on 1 November 2021).
- Salameh, Y. How Many Countries Speak Arabic around the World? 2020. Available online: https://www.tarjama.com/how-many-countries-that-speak-arabic-around-the-world/ (accessed on 22 June 2021).
- Elsaka, T.; Afyouni, I.; Hashem, I.A.T.; AL-Aghbari, Z. Multi-scale Sentiment Analysis of Location-Enriched COVID-19 Arabic Social Data. In Proceedings of the International Conference on Discovery Science, Halifax, NS, Canada, 11–13 October 2021; Springer: Cham, Switzerland, 2021; pp. 194–203. [Google Scholar]
- Ptáček, T.; Habernal, I.; Hong, J. Sarcasm detection on czech and english twitter. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 25–29 August 2014; Dublin City University and Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 213–223. [Google Scholar]
- Badaro, G.; Baly, R.; Hajj, H.; Habash, N.; El-Hajj, W. A large scale Arabic sentiment lexicon for Arabic opinion mining. In Proceedings of the EMNLP 2014 Workshop on Arabic Natural Language Processing (ANLP), Doha, Qatar, 25 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 165–173. [Google Scholar]
- Asghar, M.Z.; Khan, A.; Ahmad, S.; Kundi, F.M. A review of feature extraction in sentiment analysis. J. Basic Appl. Sci. Res. 2014, 4, 181–186. [Google Scholar]
- Alanazi, E.; Alashaikh, A.; Alqurashi, S.; Alanazi, A. Identifying and Ranking Common COVID-19 Symptoms From Tweets in Arabic: Content Analysis. J. Med. Internet Res. 2020, 22, e21329. [Google Scholar] [CrossRef]
- Haouari, F.; Hasanain, M.; Suwaileh, R.; Elsayed, T. Arcov-19: The first arabic COVID-19 twitter dataset with propagation networks. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 9 April 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 82–91. [Google Scholar]
- Alharbi, A.; Lee, M. Kawarith: An Arabic Twitter Corpus for Crisis Events. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kiev, Ukraine, 19–20 April 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 42–52. [Google Scholar]
- Hamdy, A.; Youssef, A.; Ryan, C. Arabic Hands-on Analysis, Clustering and Classification of Large Arabic Twitter Data set on COVID-19. Int. J. Simul. Syst. Sci. Technol. 2021, 22, 6.1–6.6. [Google Scholar]
- Qazi, U.; Imran, M.; Ofli, F. Geocov19: A dataset of hundreds of millions of multilingual Covid-19 tweets with location information. Sigspatial Spec. 2020, 12, 6–15. [Google Scholar] [CrossRef]
- Lamsal, R. Design and analysis of a large-scale COVID-19 tweets dataset. Appl. Intell. 2021, 51, 2790–2804. [Google Scholar] [CrossRef]
- Alshalan, R.; Al-Khalifa, H.; Alsaeed, D.; Al-Baity, H.; Alshalan, S. Detection of Hate Speech in COVID-19–Related Tweets in the Arab Region: Deep Learning and Topic Modeling Approach. J. Med. Internet Res. 2020, 22, e22609. [Google Scholar] [CrossRef]
- Alsafari, S.; Sadaoui, S.; Mouhoub, M. Hate and offensive speech detection on arabic social media. Online Soc. Netw. Media 2020, 19, 100096. [Google Scholar] [CrossRef]
- Hamoui, B.; Alashaikh, A.; Alanazi, E. COVID-19: What Are Arabic Tweeters Talking about? In Proceedings of the International Conference on Computational Data and Social Networks, Dallas, TX, USA, 11–13 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 425–436. [Google Scholar]
- Al-Laith, A.; Alenezi, M. Monitoring People’s Emotions and Symptoms from Arabic Tweets during the COVID-19 Pandemic. Information 2021, 12, 86. [Google Scholar] [CrossRef]
- Bahja, M.; Hammad, R.; Kuhail, M.A. Capturing Public Concerns About Coronavirus Using Arabic Tweets: An NLP-Driven Approach. In Proceedings of the 2020 IEEE/ACM 13th International Conference on Utility and Cloud Computing (UCC), 7–10 December 2020; IEEE: Leicester, UK, 2020; pp. 310–315. [Google Scholar]
- Essam, B.A.; Abdo, M.S. How Do Arab Tweeters Perceive the COVID-19 Pandemic? J. Psycholinguist. Res. 2021, 50, 507–521. [Google Scholar] [CrossRef]
- Manguri, K.H.; Ramadhan, R.N.; Amin, P.R.M. Twitter sentiment analysis on worldwide COVID-19 outbreaks. Kurd. J. Appl. Res. 2020, 5, 54–65. [Google Scholar] [CrossRef]
- Chakraborty, K.; Bhatia, S.; Bhattacharyya, S.; Platos, J.; Bag, R.; Hassanien, A.E. Sentiment Analysis of COVID-19 tweets by Deep Learning Classifiers—A study to show how popularity is affecting accuracy in social media. Appl. Soft Comput. 2020, 97, 106754. [Google Scholar] [CrossRef]
- Kabir, M.Y.; Madria, S. EMOCOV: Machine learning for emotion detection, analysis and visualization using COVID-19 tweets. Online Soc. Netw. Media 2021, 23, 100135. [Google Scholar] [CrossRef]
- Hussain, A.; Tahir, A.; Hussain, Z.; Sheikh, Z.; Gogate, M.; Dashtipour, K.; Ali, A.; Sheikh, A. Artificial intelligence–enabled analysis of public attitudes on facebook and twitter toward COVID-19 vaccines in the united kingdom and the united states: Observational study. J. Med. Internet Res. 2021, 23, e26627. [Google Scholar] [CrossRef]
- Kastrati, Z.; Ahmedi, L.; Kurti, A.; Kadriu, F.; Murtezaj, D.; Gashi, F. A deep learning sentiment analyser for social media comments in low-resource languages. Electronics 2021, 10, 1133. [Google Scholar] [CrossRef]
- Imran, A.S.; Daudpota, S.M.; Kastrati, Z.; Batra, R. Cross-cultural polarity and emotion detection using sentiment analysis and deep learning on COVID-19 related tweets. IEEE Access 2020, 8, 181074–181090. [Google Scholar] [CrossRef]
- Alsudias, L.; Rayson, P. COVID-19 and Arabic Twitter: How can Arab World Governments and Public Health Organizations Learn from Social Media? In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020. [Google Scholar]
- Elhadad, M.K.; Li, K.F.; Gebali, F. COVID-19-FAKES: A Twitter (Arabic/English) dataset for detecting misleading information on COVID-19. In International Conference on Intelligent Networking and Collaborative Systems; Springer: Cham, Switzerland, 2020; pp. 256–268. [Google Scholar]
- Hussein, A.; Ghneim, N.; Joukhadar, A. DamascusTeam at NLP4IF2021: Fighting the Arabic COVID-19 Infodemic on Twitter Using AraBERT. In Proceedings of the Fourth Workshop on NLP for Internet Freedom: Censorship, Disinformation, and Propaganda, Online, 6 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 93–98. [Google Scholar]
- Alrefaie, M. Arabic-Stop-Words [Github Repository]. 2016. Available online: https://github.com/mohataher/arabic-stop-words/blob/master/README.md (accessed on 15 December 2021).
- Khomutnikova, E.; Gunbina, E.; Zhurkova, M.; Fetyukov, F. Semantics and etymology of english astionyms in the aspect of linguistic geography. In European Proceedings of Social and Behavioural Sciences EpSBS; European Publisher: London, UK, 2020; pp. 505–513. [Google Scholar]
- Soliman, A.B.; Eissa, K.; El-Beltagy, S.R. Aravec: A set of arabic word embedding models for use in arabic nlp. Procedia Comput. Sci. 2017, 117, 256–265. [Google Scholar] [CrossRef]
- Kapoor, A.; Singhal, A. A comparative study of K-Means, K-Means++ and Fuzzy C-Means clustering algorithms. In Proceedings of the 2017 3rd International Conference on Computational Intelligence and Communication Technology (CICT), Ghaziabad, India, 9–10 February 2017; IEEE: Ghaziabad, India, 2017; pp. 1–6. [Google Scholar]
- Vijayarani, S.; Ilamathi, M.J.; Nithya, M. Preprocessing techniques for text mining—An overview. Int. J. Comput. Sci. Commun. Netw. 2015, 5, 7–16. [Google Scholar]
- Duwairi, R.M.; Qarqaz, I. A framework for Arabic sentiment analysis using supervised classification. Int. J. Data Min. Model. Manag. 2016, 8, 369–381. [Google Scholar] [CrossRef]
- Salameh, M.; Mohammad, S.; Kiritchenko, S. Sentiment after translation: A case-study on arabic social media posts. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 767–777. [Google Scholar]
- Mohammad, S.M.; Salameh, M.; Kiritchenko, S. How translation alters sentiment. J. Artif. Intell. Res. 2016, 55, 95–130. [Google Scholar] [CrossRef]
- Mohammad, S.; Salameh, M.; Kiritchenko, S. Sentiment lexicons for Arabic social media. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; European Language Resources Association (ELRA): Portoroz, Slovenia, 2016; pp. 33–37. [Google Scholar]
- Kiritchenko, S.; Mohammad, S.; Salameh, M. SemEval-2016 Task 7: Determining Sentiment Intensity of English and Arabic Phrases. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 42–51. [Google Scholar] [CrossRef]
- El-Beltagy, S.R.; Ali, A. Open issues in the sentiment analysis of Arabic social media: A case study. In Proceedings of the 2013 9th International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 17–19 March 2013; IEEE: Al Ain, United Arab Emirates, 2013; pp. 215–220. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Safaya, A.; Abdullatif, M.; Yuret, D. KUISAIL at SemEval-2020 Task 12: BERT-CNN for Offensive Speech Identification in Social Media. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; International Committee for Computational Linguistics: Barcelona, Spain, 2020; pp. 2054–2059. [Google Scholar]
- Saad, M. Arabic Sentiment Twitter Corpus. 2020. Available online: https://www.kaggle.com/mksaad/arabic-sentiment-twitter-corpus (accessed on 6 May 2021).
- Alyami, S. Arabic Sentiment Analysis Dataset SS2030 Dataset. 2019. Available online: https://www.kaggle.com/datasets/snalyami3/arabic-sentiment-analysis-dataset-ss2030-dataset (accessed on 7 May 2021).
- Khooli, A. Arabic 100k Reviews. 2020. Available online: https://www.kaggle.com/datasets/abedkhooli/arabic-100k-reviews (accessed on 8 May 2021).
- Elmadany, A.; Mubarak, H.; Magdy, W. Arsas: An arabic speech-act and sentiment corpus of tweets. OSACT 2018, 3, 20. [Google Scholar]
- Li, R.Y.M.; Yue, X.G. COVID-19 in Wuhan: Pressing realities and city management. Front. Public Health 2020, 8, 1079. [Google Scholar] [CrossRef]
- Ullah, A.A.; Nawaz, F.; Chattoraj, D. Locked up under lockdown: The COVID-19 pandemic and the migrant population. Soc. Sci. Humanit. Open 2021, 3, 100126. [Google Scholar] [CrossRef]
- Hale, T.; Petherick, A.; Phillips, T.; Webster, S. Variation in government responses to COVID-19. Blavatnik Sch. Gov. Work. Pap. 2020, 31, 2011–2020. [Google Scholar]
- Megahed, M. Sequence Labeling Architectures in Diglossia—A Case Study of Arabic and Its Dialects. Master’s Thesis, Humboldt University of Berlin, Berlin, Germany, 28 October 2021. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Purpose | Tweets | Lang. | Time Frame | Technique | Features |
|---|---|---|---|---|---|---|
| [11] | Describe Arabic tweets dataset on COVID-19 | 3,934,610 | Arabic | 1 January 2020–30 April 2020 | Statistical Analysis | Tweets frequency |
| [12] | Present and analyze Arabic Twitter dataset | 748 K | Arabic | 27 January 2020–31 March 2020 | Statistical Analysis | tweets frequency |
| [13] | Finetune a BERT model to classify multilabel tweets about crisis events | 1.6 M | Arabic | 2018–2020 | LDA model and BERT model | Topic frequency |
| [14] | Study from different perspectives of analysis, and classification | 3,934,610 | Arabic | 1 January 2020–15 April 2020 | Classification and Clustering | Word2Vec |
| [15] | Present Twitter dataset, infer geo-information and analysis dataset | 524 M | Multi-lingual | 1 February 2020–1 May 2020 | Statistical Analysis | tweet, location, and language frequency |
| [16] | Present and analyze COV19 Tweets Datasets and sentiment scores | 310 M, 141 k Geo tweets | English | 20 March 2020–17 July 2020 | Statistical and Sentiment Analysis | unigrams and bigrams, and topic modeling |
| [17] | Identify hate speech related to the COVID-19 pandemic | 547,554 | Arabic | 27 January 2020–30 August 2020 | pre-trained convolutional neural network (CNN) model | TF-IDF vectors (unigrams and bigrams) |
| [18] | Build Arabic hate and offensive speech detection system | 800,000 | Arabic and English | April to September 2019 | tweet annotation with ML classifiers | unigram, word, and char-ngrams, word embeddings and contextual word embedding |
| [19] | Examine the most popular topics raised among Arabic users | 3,934,610 | Arabic | 1 January 2020–30 April 2020 | Non-negative Matrix Factorization (NMF) | TF-IDF and Topic Coherence-Word2Vec |
| [20] | Analyze the emotional reactions of citizens | 300,000 | Arabic | 1 January 2020–30 August 2020 | rule-based technique | Emotion frequency |
| [21] | Determine the relevancy of the tweets and people feelings/emotions | 782,391 | Arabic | 16 February 2020–10 July 2020 | ML and NLP | Frequency of themes labeling |
| [22] | Analysis of Arab tweets about COVID-19 | 1,920,593 | Arabic | 1 February 2020–30 April 2020 | topics frequency and lexicon-based analysis | Most frequent features |
| [23] | Measure sentiment analysis | 500,000 | Arabic | 9 April 2020–15 April 2020 | Sentiment analysis | Word and tweet frequency |
| [24] | Demonstrate how people have tweeted regarding COVID19 | 226,668 | Arabic | 1 December 2019–31 May 2020 | Sentiment analysis | Word Vector |
| [25] | Detect distinct emotions in COVID-19 tweets | 500 M | Arabic | 5 March 2020–31 December 2020 | neural network model | word vectors |
| [28] | detect sentiment polarity and emotion recognition | 460,286 | English | 12 February 2020–30 April 2020 | Deep long short-term memory (LSTM) | Linguistic Inquiry and Word Count |
| [29] | Identify topics, detect rumors, and predict tweets’ source | 1,048,575 | Arabic | 1 December 2019–30 April 2020 | Cluster Analysis and Rumor Detection | Word frequency, count vector and TF-IDF |
| [30] | Annotate misleading Information dataset about COVID-19 Twitter dataset | 3,047,255 English and 216,209 Arabic | English and Arabic | 4 February 2020–10 March 2020 | Statistical Analysis and ML | TF, TF-IDF- (N-gram, character level) |
| [31] | Analyse social-media public sentiment in the UK and the US towards COVID-19 vaccinations | 300M | English | 1 March 2020–22 November 2020 | DL BERT | VADER and TextBlob |
| Month | COVID-19 Arabic | ArCOV-19 | New Dataset | Total Words | Unique Words | Unique Hashtag | User IDs |
|---|---|---|---|---|---|---|---|
| January | 208,974 | 130,002 | 338,976 | 7,179,808 | 103,823 | 5046 | 103,823 |
| February | 383,474 | 178,095 | 561,569 | 11,311,723 | 188,158 | 9207 | 188,158 |
| March | 1,479,692 | 430,235 | 1,909,927 | 41,123,366 | 615,374 | 23,820 | 615,374 |
| April | 1,307,424 | 287,754 | 1,595,178 | 32,870,009 | 516,120 | 18,777 | 516,120 |
| May | 0 | 251,670 | 251,670 | 5,575,970 | 89,974 | 11,619 | 89,974 |
| June | 0 | 212,380 | 212,380 | 4,567,400 | 81,060 | 10,679 | 81,060 |
| July | 0 | 192,754 | 192,754 | 4,063,514 | 68,352 | 9340 | 68,352 |
| August | 0 | 166,825 | 166,825 | 3,487,262 | 64,475 | 8069 | 64,475 |
| September | 0 | 113,199 | 113,199 | 2,323,648 | 47,711 | 5553 | 47,711 |
| October | 0 | 105,634 | 105,634 | 2,144,079 | 43,297 | 5050 | 43,297 |
| November | 0 | 93,958 | 93,958 | 1,915,613 | 39,354 | 4477 | 39,354 |
| Total | 3,379,564 | 2,162,506 | 5,542,070 | 116,562,392 | 1,224,684 | 48,954 | 1,224,684 |
| Main Topic | Coverage | Description | Example of Top Topics |
|---|---|---|---|
| Corona | 55.74% | Topics related to Coronavirus | New injuries, checkup, Virus, Corona, COVID-19 |
| Prayer | 25.68% | Topics related to prayers to God usually raised by Arab people | Save us, heal me by your ability, Protect from your torment, Your generosity, and mercy |
| Lockdown | 13.90% | Topics related to actions done by governments against the COVID-19 pandemic | Curfew, School closure, Separate service, Closing |
| Hospital | 3.41% | Topics related to tweets discuss entering hospitals and their procedures | Quarantine Hospital, Isolation Hospital, Oxygen, Anesthesia |
| Disease’s Symptoms | 0.44% | Topics related to symptoms of Coronavirus | fever, cough, tiredness, headache, sore throat, diarrhea |
| Diseases | 0.23% | Topics related to other diseases rather than Coronavirus | Pneumonia, Kidney failure, Nervous breakdown, Heart failure |
| Feeling | 0.16% | Topics related to feelings about Coronavirus | kindness, laugh, discontent |
| Treatment | 0.12% | Topics related to treatment of Coronavirus | Enzymes, Tamiflu, Stem cells, Hydroxy chloroquine |
| Religious | 0.11% | Topics related to religious activities | Fasting, Fasting, Pilgrimage |
| Vaccine | 0.11% | Topics related to all talks about vaccine production or distribution | Vaccine, immunization, Serum |
| Sterilization | 0.02% | Topics related to sterilization actions | Antiseptic, Chlorine, Wash off |
| Organization | 0.01% | Topics related to organizations mentions | Health organization, Reuters |
| Miscellaneous | 0.07% | Miscellaneous topics | Rationalization, make a complaint, Electricity shut down |
| Dataset Name | Total Tweets | Pos. Tweets | Neg. Tweets |
|---|---|---|---|
| Arabic Sentiment Twitter Corpus (ASTC) [45] | 58,751 | 29,849 | 28,902 |
| Arabic Sentiment Analysis Dataset (SS2030) [46] | 4252 | 2436 | 1816 |
| 100 k Arabic Reviews [47] | 66,666 | 33,333 | 33,333 |
| Arabic Speech-Act and Sentiment Corpus of Tweets (ArSAS) [48] | 11,784 | 4400 | 7384 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elsaka, T.; Afyouni, I.; Hashem, I.; Al Aghbari, Z. Spatio-Temporal Sentiment Mining of COVID-19 Arabic Social Media. ISPRS Int. J. Geo-Inf. 2022, 11, 476. https://doi.org/10.3390/ijgi11090476
Elsaka T, Afyouni I, Hashem I, Al Aghbari Z. Spatio-Temporal Sentiment Mining of COVID-19 Arabic Social Media. ISPRS International Journal of Geo-Information. 2022; 11(9):476. https://doi.org/10.3390/ijgi11090476
Chicago/Turabian StyleElsaka, Tarek, Imad Afyouni, Ibrahim Hashem, and Zaher Al Aghbari. 2022. "Spatio-Temporal Sentiment Mining of COVID-19 Arabic Social Media" ISPRS International Journal of Geo-Information 11, no. 9: 476. https://doi.org/10.3390/ijgi11090476