


Techniques for reducing costs in LLM architectures
Introduction
Large Language Models (LLMs) represent the cutting-edge of artificial intelligence, driving advancements in everything from natural language processing to autonomous agentic systems. These models, including well-known architectures like GPT, LLaMA, and Gemini, are defined by their vast parameter counts and complex network structures. Advanced mathematical approaches and architectures have significantly enhanced LLMs' capabilities. Due to their vast scale and parameter size, these models exhibit emergent abilities, enabling human-level reasoning across diverse tasks. This makes LLMs powerful tools in frontline research and applications, from medicine to engineering.
However, these systems demand significant data and computational resources for training and inference. The financial implications of developing and deploying LLMs are considerable, with costs encompassing data acquisition, computational power, and ongoing maintenance.
What’s covered in this article:
- An examination of LLMs' complex architecture and associated cost factors
- The importance of cost optimization for sustainable AI development
- Democratization and accessibility of LLM technologies
- Practical coding examples and optimization strategies
- Effective cost management techniques for LLM projects
LLMs: Types and Application Architectures
LLMs are trained on large datasets. These models have millions to even trillions of parameters, making them memory and power-hungry machines. The architecture of these models is sophisticated and complex, leading to extended development and training times. This complexity arises from the elaborate information flow within the network, including attention mechanisms, skip connections and various gating mechanisms. Despite their complexity, most modern LLMs share a common architectural backbone, primarily consisting of:
- Tokenizer: This is the first component that breaks down words into smaller words or subwords called tokens. Some commonly used tokenizers are the tiktoken by OpenAI and SentencePiece by Huggingface.
- Embedding model: This is the initial layer of the LLM that converts tokens into numerical vectors, which are then fed into the Transformer. The embedding model acts as a lookup table, where each token is associated with a specific vector representation. These embeddings capture semantic information about the tokens, facilitating the generation process.
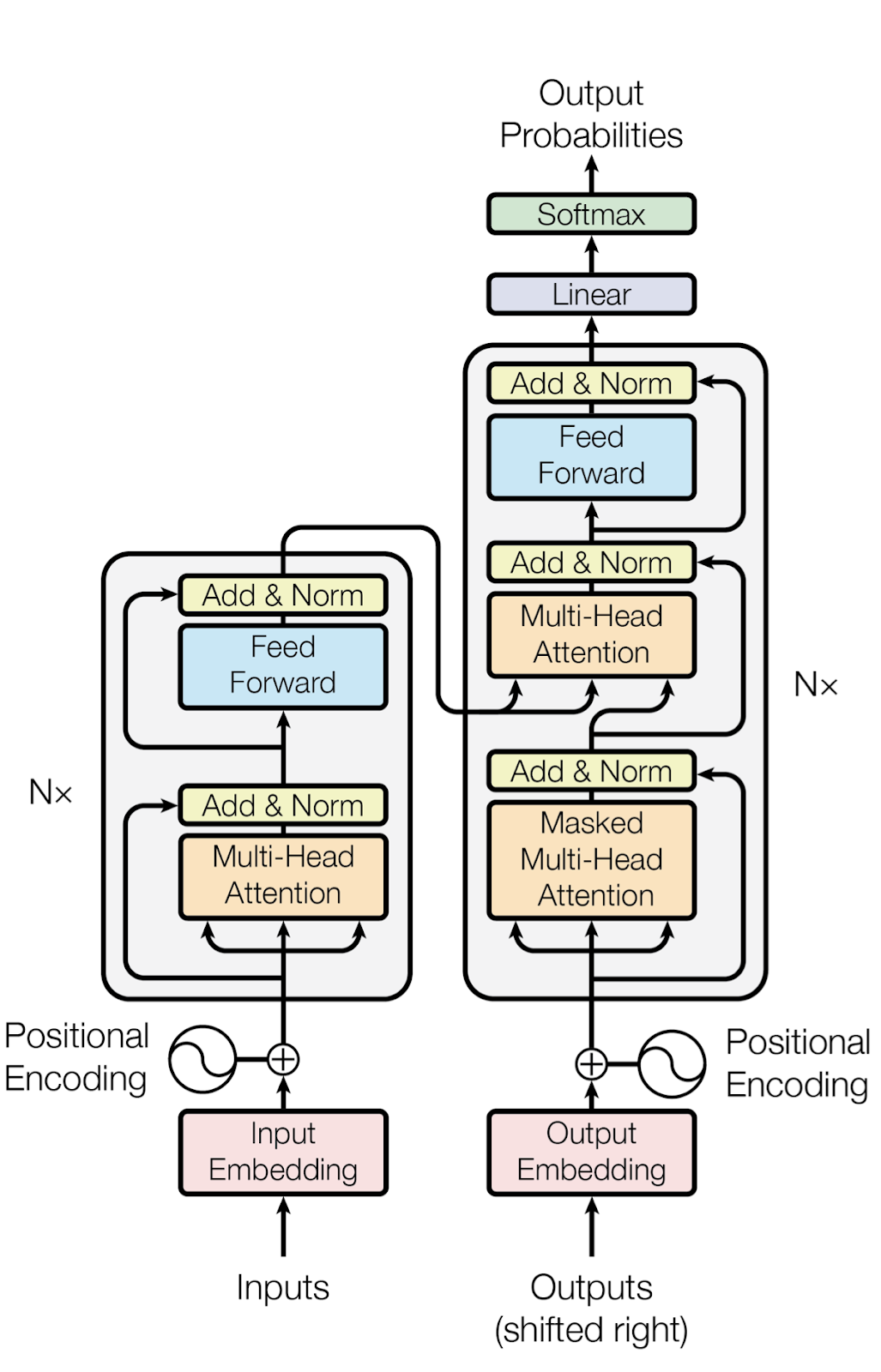
- Transformer: Transformer models are sophisticated architectures designed to handle data sequences and perform sequence-to-sequence prediction tasks, such as translating English to French. They do it by utilizing layers equipped with self-attention mechanisms and feedforward neural networks. Initially, input sentences are converted into numerical embeddings that capture the semantic essence of each token, complemented by positional encodings that inject sequence order information into the model. The model employs multi-head attention to explore various relational aspects between tokens, leveraging softmax functions to assign appropriate attention weights. To enhance training stability and efficiency, transformers use layer normalization and residual connections, with feedforward neural networks further processing each layer's output to capture complex patterns and relationships. The architecture typically features multiple stacked layers, enhancing the model's ability to derive abstract features, and in tasks like translation, a decoder is added atop the encoder to generate the final output sequence.
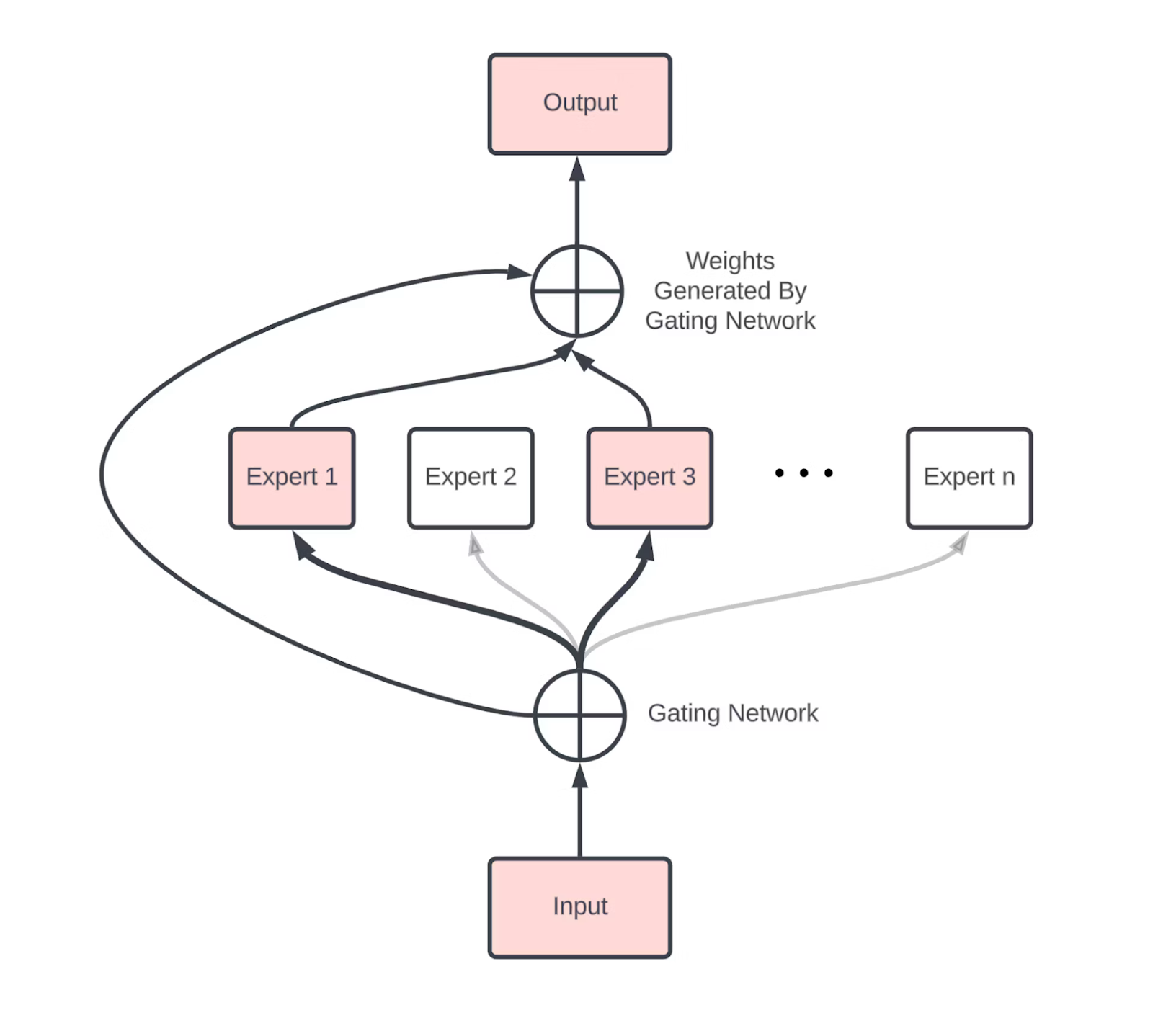
Mixture of Experts (MoE): The MoE (Mixture of Experts) model is a machine learning approach that uses multiple specialized sub-models, known as experts, to process data and make predictions. It includes a gating mechanism that selects the most relevant experts for each input, ensuring the input is directed to those with the best-suited knowledge. This design allows the model to scale and increase capacity efficiently without significantly increasing computational cost, making MoE ideal for tasks requiring diverse expertise and large-scale learning.
Retrieval-Augmented Generation: This retrieval system integrates external and, more importantly, current information into the LLM. We will examine it in detail in the next section.
Now, let’s explore some of the well-known architectures and different approaches that make them effective.
LLMs architectures
Here are some of the most widely known models — open-sourced and closed-sourced.
Gemini series: Gemini was developed by Google DeepMind and was introduced in 2023. It represents Google's most advanced and flexible model, optimized for multimodal tasks across text, audio, image, and video inputs. Its architecture leverages the Mixture of Experts (MoE) technique, enhancing efficiency by activating only the most relevant sub-models for given inputs, thus allowing high scalability without a proportional increase in computational costs.
GPT series: OpenAI developed the GPT series of models – GPT-1, 2, 3, ChatGPT, GPT4 and 4o, it is one of the leading companies in the development and innovation of LLMs. They primarily use the transformer architecture to build such models and have been scaling them to produce more powerful models. These models use a Decoder-Only approach and are autoregressive, meaning they generate text by predicting the next word or token in a sequence at a time.
T5: T5 stands for Text-to-Text Transfer Transformer, developed by Google in 2020. As the name suggests, the model is built on the transformer architecture, which leverages the encoder-decoder approach. The architecture supported a wide range of tasks with a unified text-to-text approach, meaning it treated every NLP task as a text generation task.
LLaMa series: The LLaMa series was developed by Meta AI research. They are open-sourced models designed for personal and commercial use. Both models utilize the transformer model and are auto-regressive, just like the GPTs. These unsupervised pre-trained models can be fine-tuned as instruction-based tasks with Supervised Fine-Tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF). Both of these approaches allow the model to be aligned with human preferences.
Phi series: Microsoft developed the Phi series. These models range from 1.3B to 3.8B parameters. Interestingly, although there are LLMs, they are considered small language models compared to LLaMA 3, which has 70B parameters, and GPT-3, which has 175B parameters. Developing these models aims to achieve promising results and performance with much larger models. All three models use a transformer as their main architecture.
- Phi 1: It is a straightforward transformer-based model with 1.3B parameters.
- Phi 2 is a scaled-up version of Phi 1 with 2.7B parameters.
- Phi 3: It uses a dense decoder-only transformer architecture like the GPTs. Interestingly, it was SFT and Direct Preference Optimization (DPO) to achieve state-of-the-art and for human alignment purposes. It is a 3.8B parameter model.
Mistral series: The Mistral series is an open-source or, more rightly, open-weights model. This series of models is developed by Mistral AI, and they putting efforts to bring LLM for individual plus commercial use. They are known for efficiency, transparency, and high performance. Again, these models leverage transformers as their base architecture and approach sliding window attention (SAW), GQA, local attention, and MoE. Their models are:
- Mistral 7B, a 7B parameter model
- Mistral 8x7B, a 45B parameter potential model that uses only 12B with MoE.
- Mistral 8x22B, a 141B parameter potential model that uses only 39B with MoE.There are many other models, such as the Claude series by Anthropic, a transformer-based model that is fine-tuned using Constitutional AI to ensure it is helpful, honest, and harmless. These models are multimodal and use language prompts to yield results, and they are closed-sourced.
There are many other models, such as the Claude series by Anthropic, a transformer-based model that is fine-tuned using Constitutional AI to ensure it is helpful, honest, and harmless. These models are multimodal and use language prompts to yield results, and they are closed-sourced.
As you saw, most of these LLMs leverage transformer architecture and adopt various approaches to make it work and yield the right results.
RAG architectures
LLMs excel at learning representations and generating results based on the prompts they receive. Their effectiveness depends on the amount, quality, and type of training data. Essentially, LLMs act like libraries, storing all training data and retrieving relevant information when prompted. However, they can only produce results based on this data and not handle information outside it.
To address this limitation, (RAG) was introduced, which allows LLMs to access and use current data.
RAG combines LLM functionalities such as text summarization, question-answering, text generation, etc, with an external retrieval system. In this way, LLMs can be enhanced to produce up-to-date information. In essence, RAG architecture for LLM applications supplements the LLM’s parametric knowledge with non-parametric knowledge obtained from data sources when responding to prompts.
RAG has three important steps:
- Indexing: This stage involves preparing and organizing external data sources. Data is chunked into smaller pieces and stored in a vector database, enabling efficient retrieval based on semantic similarity. The indexing process ensures the data is structured and readily accessible for subsequent retrieval.
- Retrieval: In this stage, relevant information is retrieved from the indexed data based on the input query. Techniques such as semantic search and keyword matching convert the query into vector embeddings, which are then used to find the most relevant data chunks. This step ensures that the retrieved information closely matches the input query, providing accurate and relevant context.
- Generation: The final stage involves feeding the retrieved and integrated data into the LLM and the original query to generate a comprehensive response. The LLM leverages both its pre-trained knowledge and the newly retrieved information to produce a well-informed and contextually relevant output. Iterative refinement may be employed to improve the quality of the response based on the additional data.

Types of RAGs
Now, let us understand the three types of RAGs currently used.
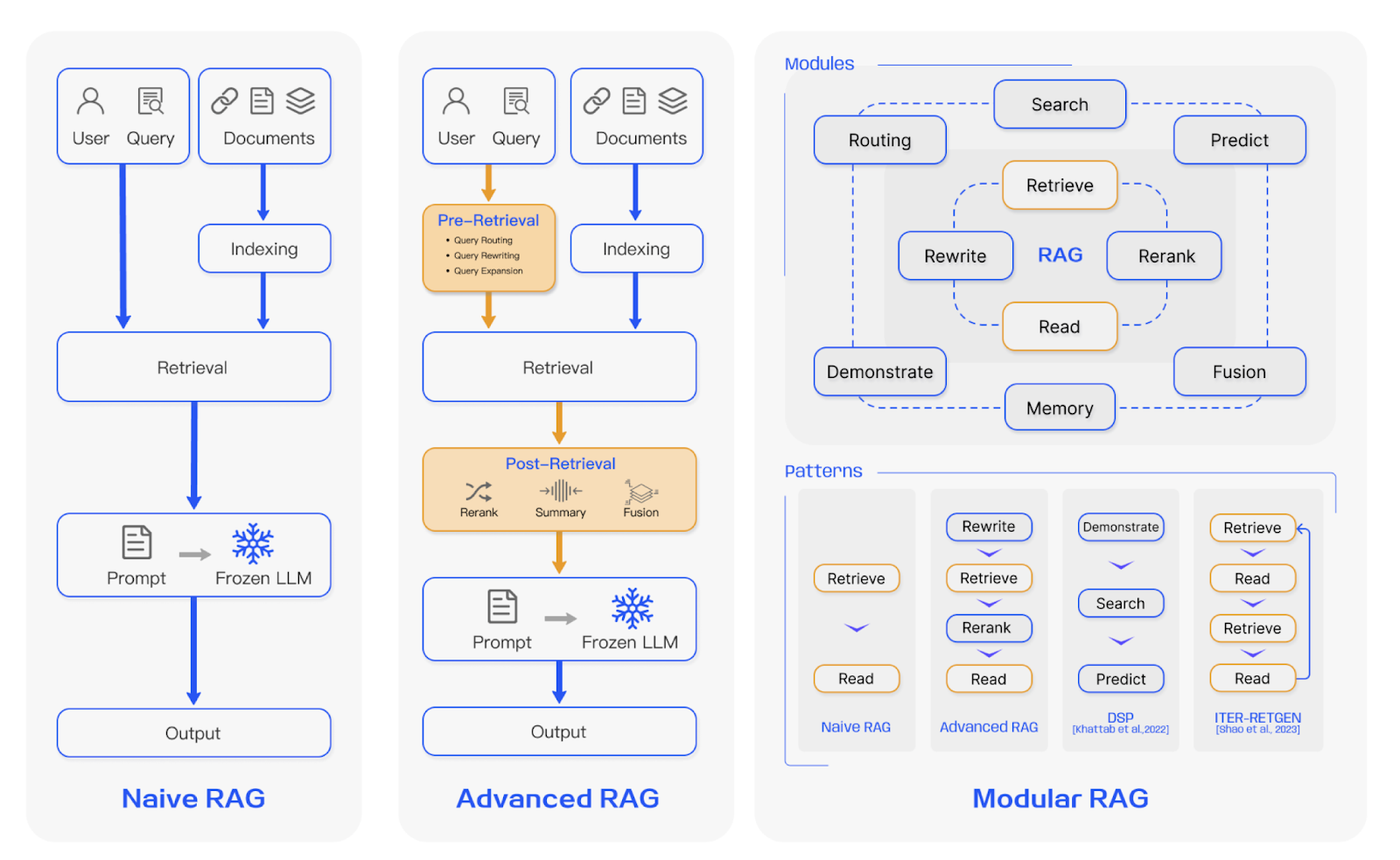
Naive RAG: This is the simplest and most basic type of RAG. It follows the three steps that we discussed above. However, it lacks sophisticated methods, resulting in issues like low precision and recall during retrieval, potential hallucinations or the generation of incorrect responses, and ineffective integration of the retrieved context.
Advanced RAG: It is built on the Naive RAG and improves its drawbacks by leveraging approaches like:
- Pre-retrieval processes: It enhances prompts to make them more contextually rich, using methods like query rewriting and transformation to ensure better retrieval results. Techniques such as embedding models like BERT are used to calculate similarity and rank documents based on relevance.
- Post-retrieval processes: These involve refining the retrieved information received before feeding it into the LLMs. Here, the documents are re-ranked based on their relevance, and the top documents are selected, which are then fed into the LLM for response generation. This makes the context coherent with the prompt.
Modular RAG: It uses enhanced functionalities compared to the previous RAGs for better adaptability. It incorporates methods like:
Hybrid Search: Hybrid search combines different search methods, including keyword-based and semantic search. These methods retrieve more contextually relevant information, making it useful for handling diverse query types and information needs.
Recursive Retrieval and Querying: This technique involves a recursive process where initial retrieval results are used as a chain-of-thought technique to refine subsequent searches. This technique progressively retrieves larger, more context-rich information.
Step-back Approach: The step-back approach involves generating hypothetical answers to prompts and using these answers to retrieve relevant documents. This method helps in generating more grounded and contextually accurate responses.
Sub-queries: This involves breaking down complex prompts into smaller, more manageable questions. Each sub-prompt retrieves relevant data, which is then combined to form a comprehensive response. This approach is particularly useful for complex, multi-faceted queries.
Hypothetical Document Embeddings (HyDE): HyDE generates hypothetical answers to queries, embeds these answers, and uses them to retrieve documents similar to hypothetical answers. This technique helps retrieve more relevant information by focusing on the expected answer rather than the query itself.
Semantic Cache and RAG memory
Semantic Cache is a storage system used to enhance the efficiency of RAG systems. It stores all the prompts and their responses. Unlike traditional caching methods that rely on exact match criteria, semantic caching identifies and stores responses based on the semantic meaning of the queries, allowing for more flexible and efficient retrieval.
Here is an example workflow:
- Prompt Handling: The system handles the initial prompt and systematically parses it to identify key terms and intent.
- Cache Lookup: The system then searches the cache to find related terms. If the term is available in the cache, the related response is retrieved; if not, a new entry is made. A new entry is made based on the semantic search to find a query with the highest similarity score, or preretrieval and postretrieval processes are executed to generate a new response.
- Cache Update: The cache is updated with new entries or information.
RAG memory involves storing and retrieving relevant parts of previous interactions between the user and the system. This is critical for maintaining context in ongoing conversations and providing personalized responses based on stored user information. By integrating semantic cache and the contextual retrieval capabilities of RAG, systems like ChatGPT can deliver contextually appropriate and efficient responses, enhancing user interaction and satisfaction.
Common use cases for LLM architectures
So far, we have seen the different types of LLM architectures, systems, and approaches that enhance them. But where do we use LLM, and how are they catering to the needs of individual humans and organizations to make lives more productive and meaningful?
Here are some of the use cases:
- Chatbots and Virtual Assistants: LLMs are the core of conversational systems such as ChatGPT, Gemini, Claude, etc. They can engage users in natural dialogue, provide customer support, answer FAQs, and assist with booking or shopping decisions. These models understand context and maintain the flow of conversation, making interactions more fluid.
- Code and Content Generation: LLMs can facilitate the generation of written content such as articles, reports, and narratives. They can assist writers, blogs, researchers, and journalists by drafting initial versions of stories. They can also help content marketers generate diverse types of content at scale. They are very adept at helping novice and expert coders in coding.
- Summarization: LLMs are very capable of condensing large volumes of text into concise summaries and key points. This capability is valuable for digesting news, research papers, or extensive reports. It also supports decision-making processes and quick information retrieval.
- Sentiment Analysis: LLMs can analyze sentiments expressed in text using their analyzing capabilities. This is useful for monitoring social media, customer feedback, and market research. It also helps companies gauge public opinion and customer satisfaction.
- Legal and Compliance Documentation: LLMs help automate the drafting and review of legal documents, ensure compliance with regulations, and streamline the administrative burdens in legal practices.
- Drug Discovery and Healthcare: In the healthcare sector, LLMs can help medical teams process medical documentation, generate patient reports with medical notes, and even understand the scans. Scientists also use Medical-based LLMs in drug discovery processes by analyzing scientific literature and clinical data.
What are the different types of costs associated with LLM architectures?
Let us now discuss the costs associated with developing an LLM.
Data Management Costs
- Data Collection: Involves sourcing diverse datasets, including multilingual and domain-specific corpora, from various digital sources, essential for developing a robust LLM.
- Data Annotation: This requires human intervention for categorization and quality assurance, ensuring the dataset's relevance and accuracy for model training.
- Data Preparation and Curation: Entails preprocessing tasks such as data cleansing, privacy filtering, and removing redundancies, utilizing tools like NeMo Curator for efficiency.
Training Costs
The main costs associated with training an LLM from scratch can be explained in three primary categories:
- Computational Resources: The cost of computational resources is a major factor in training LLMs. For instance, if GPT-3 was trained on one single GPU, it take 355 years to complete the training. The extensive use of GPUs accelerates the computational speed and significantly increases the financial burden. For more complex and larger models like Google's Gemini Ultra and GPT-4, the estimated costs are exponentially higher due to the need for advanced and more extensive hardware setups.
- Data Acquisition and Processing: In the previous section, we saw the cost of three areas of data management. As such, the vast datasets required for training LLMs involve considerable data collection, storage, annotating, and processing expenses. Training GPT-3 on a dataset comprising 570 billion words exemplifies the scale and the associated cost of managing such large data volumes. The quality and diversity of the data also affect the cost, with high-quality, well-curated datasets demanding more financial resources for acquisition and preparation.
- Model Size and Architectural Complexity: The architecture of LLMs, characterized by their size and complexity, directly impacts the training cost. Larger models with more parameters require more memory and processing power, escalating costs dramatically. The progression from smaller models like the original Transformer to massive undertakings like GPT-4 illustrates how scaling up model size contributes to a steep rise in financial requirements.
Fine-Tuning Costs
Let’s be honest: developing an LLM from scratch is not budget-friendly, so an alternative is to fine-tune it. However, the cost of fine-tuning an LLM varies significantly across different platforms and models.
- OpenAI Fine-Tuning API: OpenAI provides a fine-tuning service for its models, including versions like GPT-3.5. The costs are specified per thousand tokens processed, with distinct rates for training and inference phases. For example:
- Finetuning: Approximately $3 per million tokens
These costs underline the operational expenses for using OpenAI's fine-tuning service, which can accumulate significantly depending on the volume of data processed and the frequency of model interactions.
- Other Platforms: Other AI platforms also offer LLM fine-tuning services, each with their specific pricing structures:
- Google Cloud AI offers fine-tuning services, with costs generally tied to the amount of computing used, which varies depending on the specifics of the model and the data volume.
- Microsoft Azure: Azure offers AI model fine-tuning capabilities, with costs associated primarily with computing and storage resources tailored to the scale and complexity of the tasks.
- Hugging Face: They offer a wide variety of open-sourced and pre-trained models like BERT, GPTs, and LLaMA. While the use of pre-trained models is free, fine-tuning them for specific tasks can lead to costs related to computing and data handling. Whether you are opting to fine-tune on a local machine or the cloud, predominant factors related to cost will be fine-tuning time, GPU clusters, and storage.
- Fundamental AI Research or Meta Research: Fundamental AI Research (FAIR) by Meta also provides several influential models, such as RoBERTa, BART, and the LLaMA series, which are available on platforms like Hugging Face. Like Hugging Face's model offerings, the direct use of these pre-trained models is free. However, fine-tuning them on specific datasets involves computational costs, particularly if large-scale compute resources or specialized hardware like GPUs or TPUs are employed.
Infrastructure and Operational Costs
- Vector Databases: Managing data vectors created during fine-tuning or inference requires robust databases that handle multiple requests, especially with heavy traffic. VDB service providers can charge based on the requirements, with costs varying by data volume and database choice.
- Monitoring, Observability and Evaluation: Monitoring tools like Arize ensure model efficacy and performance, integral to maintaining operational integrity.
- Cloud Platform Expenses: Utilizing cloud services for model hosting requires substantial investment in compute and storage resources, which impacts the overall financial footprint.
The financial aspects of deploying LLM architectures span from initial data management to ongoing operational expenses, encompassing data handling, model training, inference execution, and infrastructural support. Each cost area is important in deploying effective LLM solutions, requiring careful planning and optimization to balance performance with cost efficiency.
Techniques to reduce costs for LLM architecture
Reducing the financial burden of deploying LLMs requires various strategic approaches, each aiming to optimize different areas of the LLM lifecycle. These strategies include refining model architecture, optimizing data handling, and enhancing operational procedures.
Model Architecture Optimization
Knowledge Distillation: In knowledge distillation, we implement a smaller model (student) that learns to replicate the performance of a larger model (teacher), thus requiring fewer computational resources. To understand knowledge distillation, let’s look at the following code.
In the KnowledgeDistillationTrainer class, we streamline the training of a smaller student model using a larger teacher model. In a nutshell, the distillation happens in the compute_loss method. Here is a breakdown:
- Initialization: The constructor sets up the trainer and links it to the teacher_model.
- Loss Calculation:
- Outputs: The student and teacher models generate predictions from the same inputs.
- Cross-Entropy Loss: This measures how well the student's predictions match the actual labels.
- Distillation Loss: We soften the outputs using a temperature parameter, then compute the Kullback-Leibler divergence to quantify how closely the student's softened predictions match the teacher’s. In other words, we are lenient with the student and strict with the teacher’s performance.
3. Combined Loss: The final loss blends the cross-entropy and distillation losses, balancing direct learning from data with learning from the teacher.
This setup helps the student model efficiently learn complex patterns from the teacher model while conserving computational resources.
Pruning: It is a technique used to reduce the complexity and size of neural networks. It is a general approach that systematically removes less important neurons or connections (weights) from the model. This is a very efficient technique in LLM as most of the LLMs are undertrained, as we established earlier.
This method enhances the computational efficiency and reduces the memory footprint of LLMs, which are known for their extensive parameter counts.
Mathematically, pruning involves determining the "importance" of weights. The Importance can be quantified in several ways, but a common method is based on the magnitude of weights. The hypothesis is that smaller weights impact the model's decision process less.
Pruning is done in the following steps:
- Training: First, the model is fully trained to convergence, ensuring it learns the necessary patterns and relationships in the data.
- Weight Ranking: Weights are then ranked based on their magnitudes.
- Pruning: A threshold is set, and weights below this threshold are pruned (set to zero), simplifying the model. The pruning can be done either globally across all layers or locally within each layer.
- Fine-tuning: Often, the pruned model is fine-tuned to restore the remaining weights and recover any performance loss caused by the pruning step.
Quantization effectively reduces the numerical precision of models, leading to enhanced memory efficiency and faster computational performance. This approach can be quite helpful for deploying LLMs in resource-constrained environments.
Let’s understand how quantization works and its implications for LLMs:
- Memory and Computational Efficiency
- Storage Optimization: By reducing the precision from 32-bit floating points to 4-bit integers, quantization decreases a model's size to about one-eighth of its original, significantly conserving storage space. This is vital for applications in devices with limited storage capacity.
- Speed Enhancement: Lower precision arithmetic is generally faster on many modern processors, particularly those in mobile and embedded systems, facilitating quicker model inference.
2. Accuracy Considerations:
- Accuracy Trade-offs: Quantization can compromise model accuracy due to its reduced granularity of data representation. However, this loss can be mitigated through proper calibration, where the model is adjusted post-quantization to closely match the original model's output.
- Calibration Process: Calibration involves fine-tuning the quantization parameters using a subset of training data, ensuring that the quantized model still performs robustly despite its reduced precision.
3. Deployment and Software Support:
- Hardware Compatibility: The extent of quantization support can vary across different hardware platforms. While most support standard 8-bit quantization, support for lower bit depths like 4-bit may vary, influencing the choice of quantization strategy.
- Tooling and Library Support: Tools like Huggingface offer functionalities that simplify the implementation of quantization, but the level of support and ease of use can differ significantly. This affects how smoothly quantized models can be integrated and deployed across various platforms.
By understanding and strategically applying quantization, developers can significantly optimize the deployment of LLMs, balancing performance with computational and storage efficiency. This makes quantization an invaluable technique in the toolkit for anyone working with advanced AI models in constrained environments.
Let’s look at the small and simple code below. It uses the Huggingface library to perform model quantization.
The quantized model is a 125M parameter model from Facebook. Using the Huggingface GPTQConfig, you can significantly reduce the size of the model. In the example above the model is quantized to 4 bits and weight will be grouped to apply the same scale or offset in quantization, and in this case, each group will contain 128 elements.
Prompt/Token Compression
Efficient Prompt Construction: Condensing prompts to their essential elements reduces token count, enhances response speed, and reduces computational costs. This approach must balance efficiency with the risk of losing important contextual information, necessitating advanced techniques to maintain prompt integrity.
As such, here are some platforms that can help you with efficient, prompt construction:
- Usage: Experiment with various prompts and see immediate outputs from models like GPT-3.5.
- Cost Optimization: Helps fine-tune prompts without extensive trial and error, reducing the compute costs associated with multiple model runs.
2. AI21 Labs Prompt Engineering Tools
- Usage: Design and refine prompts with interactive interfaces and guidelines.
- Cost Optimization: By creating more efficient prompts, you can reduce the number of API calls and processing time, leading to lower costs
3. Promptable
- Usage: Tools for prompt optimization, interactive design, and performance analytics.
- Cost Optimization: Optimized prompts lead to more accurate initial results, reducing the need for repeated model queries and thus saving on costs.
- Usage: Efficiently break down text into tokens.
- Cost Optimization: Accurate tokenization can help in managing token limits effectively, reducing the number of tokens processed per query
Model Training Optimization
Mixed-Precision Training: It employs lower precision formats (e.g., FP16) during training phases to cut memory usage and accelerate the process, maintaining accuracy through careful management of weight conversions and gradient calculations.
It is interesting to know that the model gradients are computed at 16-bit precision and converted back to 32-bit precision during the optimization step. It is called mixed precision because computations are performed in half-precision, and others are performed at full precision.
In the code below, we again use the Huggingface library to perform mixed precision training.
All we need to do is enable the f16 flag as true in the TrainingArgument class and pass it into the Trainer class along with the model we want to train.
Leveraging Open-Source Models
Utilizing open-source models like GPT or LLaMA can be more cost-effective than proprietary options, offering extensive flexibility for customization and fine-tuning. As such, Huggingface offers a wide spectrum of open-sourced AI models for various tasks and datasets.
Fine-Tuning Methods — PEFT techniques
Parameter-efficient fine-tuning (PEFT) techniques such as Low-Rank Adaptation (LoRA) and Quantized Low-Rank Adaptation (Q-LoRA) have emerged as vital tools to fine-tune LLMs. They have been playing a crucial part in efficient LLM development. Early startups and individuals are making the most out of the PEFT techniques.
Let’s discuss the two famous PEFT techniques.
LoRA: The LoRA paper was released on 17 June 2021 to address the need to fine-tune GPT-3. The idea was to freeze the pre-trained model weights and employ trainable rank decomposition matrices in each layer of the Transformer architecture. This approach promises to greatly reduce the number of trainable parameters for downstream tasks.
This approach allows for fine-tuning the model with a small increase in the number of parameters, which is negligible compared to directly modifying the entire matrix W.
In the code below, we again use the Huggingface library to perform PEFT using LoRA. All you have to do is install the peft module and configure LoraConfig accordingly.
LoRA is so efficient that according to the authors, “LoRA can reduce the trainable parameters by 10,000 times and the GPU memory requirement by 3 times”.
Q-LoRA: Q-LoRA extends the LoRA concept by incorporating quantization into the low-rank matrices.
A and B. Hence, the name quantized Low-Rank Adaptation. This reduces the memory footprint and enhances computational efficiency during the fine-tuning process.
When working with QLoRA you must install bitsandbytes. This library allows us to perform QLoRA efficiently. The library is a part of Huggingface and only supports CUDA GPUs.
Optimizing LLM Operations (LLMOps)
Incorporates strategies like hardware acceleration, serverless computing, and efficient data handling (batching, caching) to optimize runtime and reduce operational costs. You can look at these platforms for optimizing LLM operation:
- Dataiku LLM Cost Guard: This platform focuses on comprehensive cost monitoring and optimization for LLM operations. It tracks expenses by application, user, or project and includes features like response caching to reduce computation costs, making it ideal for managing and lowering LLM development expenses.
- Weights & Biases: Offers experiment tracking, hyperparameter optimization, and workflow automation. It also provides tools for exploring and debugging LLM applications, helping teams identify cost-saving opportunities through efficient model management and resource allocation.
- Amazon SageMaker: Integrates with AWS services to provide automated model tuning and scalable deployment, which helps optimize resource usage and reduce unnecessary costs during model training and deployment.
- Google Cloud Vertex AI: Provides tools for automated model development with AutoML and custom model training. Its integration with Google Cloud services ensures efficient resource management, leading to potential cost reductions through optimized workflows.
- Microsoft Azure Machine Learning: Supports pre-built models and automated machine learning tasks, which can reduce development time and associated costs. Its seamless integration with Azure services further optimizes resource usage
Usage Monitoring
It is always better to monitor your costs while working with LLMs. We have already discussed some major tools and techniques. Now, let us briefly discuss two platforms enabling you to do so.
CAST AI
If you are working on Kubernetes, consider CAST AI. It is a web-based platform that allows you to optimize your Kubernetes cost by 50% or more. You can automatically manage and monitor your clusters using AWS, GCD, or Azure. It uses advanced ML algorithms and a comprehensive UI to display all the important areas of cloud spending.

Dataiku LLM Cost Guard
Dataiku is an end-to-end AI platform that allows you to build, deploy, and manage your AI projects in a single platform. It has extended its solution to manage and monitor the cost related to LLM development. Dataiku has introduced the LLM Cost Guard, a component of their LLM Mesh platform. This innovative tool is designed to provide comprehensive cost monitoring and management for LLMs, ensuring that organizations can control expenses while maximizing the benefits of their AI investments.

Adopting these strategies can markedly diminish the costs associated with LLM architectures while sustaining or enhancing performance. Each technique addresses distinct components of the LLM deployment process, from initial model setup and training to ongoing operational management, which is pivotal for cost-efficient LLM utilization.
Conclusion
This article covers the essential architecture of Large Language Models and the considerable costs associated with developing these advanced AI systems. We discussed how costs are associated at various stages, from data acquisition and computational demands to fine-tuning and maintenance.
Importantly, we've highlighted the necessity of cost optimization to save resources and make these technologies accessible to a wider range of developers and researchers. The coding examples aim to connect theoretical concepts with practical applications, offering tangible strategies to apply these cost-saving measures effectively.
With this understanding, you are better equipped to develop, deploy, and cost-effectively optimize Large Language Models, ensuring your projects are both innovative and financially manageable.


