

SocialMedia2Traffic: Derivation of Traffic Information from Social Media Data
 , , ,
, , ,  ,
, <p>Conceptual layers contributing to the whole SM2T infrastructure. They are stacked in increasing order of priority. The <span class="html-italic">Live Traffic layer</span> is generated using two identified Twitter proxies, along with the land-use land-cover POI and betweenness centrality (cf. main text). Note that on the left map only Twitter proxies are shown.</p> "> Figure 2
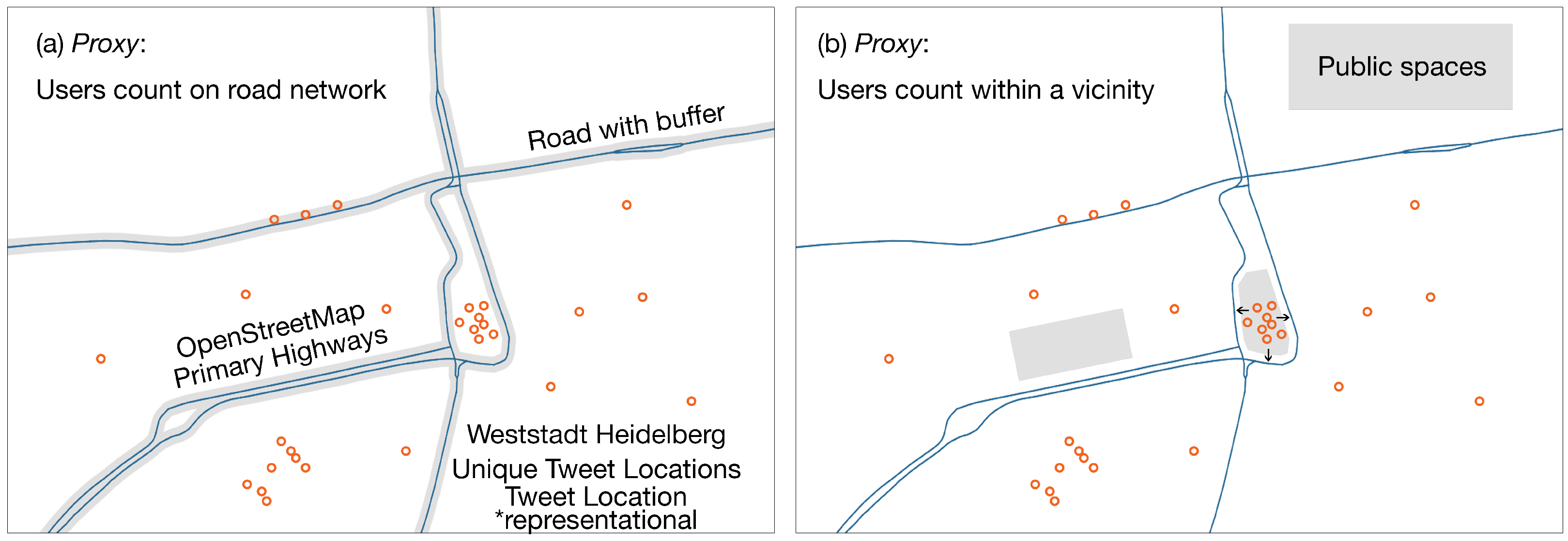
<p>A sample street network in the city of Heidelberg, Germany, showing (<b>a</b>) how geo-tagged tweets were selected based on the buffer around the highways for the “User count on a road segment” proxy, and (<b>b</b>) how a geo-tagged tweet cluster in a public space was used for the “User count within a vicinity” proxy.</p> "> Figure 3
<p>The figure shows four ways to aggregate land-use and land-cover POI data for a given tile. For (<b>a</b>), a simple counting of all POIs in an area of interest is performed. In (<b>b</b>) a pre-defined road buffer, per different highway type, is used to select only nearby POIs before counting. In (<b>c</b>) pre-defined weights, according to the importance of the infrastructure, are used while counting, and in (<b>d</b>) a pre-defined road buffer, per different highway type, in addition to weighting is used to select and prioritise only nearby POIs before counting.</p> "> Figure 4
<p>Accuracy of prediction of three traffic classes identified by the betweenness centrality measure, with the Uber Movement classes used as ground truth (<b>left</b>). Colours indicate the percentage of tiles correctly classified by the model using the adapted betweenness centrality as predictor. Extent of over/underestimation in wrongly classified classes using this proxy (<b>right</b>). Colours indicate the share of tiles incorrectly classified by the model using adapted betweenness centrality as a predictor.</p> "> Figure 5
<p>The plot compares the performance of two Twitter aggregation methods per tile: (i) <span class="html-italic">User count on a road segment</span> and (ii) <span class="html-italic">User count on a road segment</span> + <span class="html-italic">User count within a vicinity</span>. The colour indicates the difference in the percentage of correctly classified tiles between the predictions based on the two approaches. A positive value (blue) implies that the aggregation method using the combination of the two proxies is a better predictor.</p> "> Figure 6
<p>Degree of class imbalance in HTC vs. no-HTC labels per each dataset based on the Uber data (static class definitions). All instances with at least one empty feature space have been discarded. The x-axis shows the relationship between the number of HTC to no-HTC tiles per city for the different tile sizes. A value of 50% indicates perfectly balanced data. “Merged” represents the combination of all eleven cities.</p> "> Figure 7
<p>Visualising traffic congestion classes derived from all feature spaces using a quantile approach and validation (Uber) dataset for three cities (showing both edge case scenarios). The number of cells with predictions differs, as the predictors were not available for all tiles. The precision of the model predictions is presented in <a href="#ijgi-11-00482-f010" class="html-fig">Figure 10</a>.</p> "> Figure 8
<p>Comparison of the precision of five classification algorithms for different tile sizes. The three plots represent different datasets based on how empty cells were handled using the dummy value. The variability in the boxplots is due to the different precisions for the individual cities.</p> "> Figure 9
<p>Selecting the best-performing number of neighbours of the k-nearest neighbours classifier for different tile sizes. The red curve represents the combined cities. The different black colours represent the individual cities. The vertical blue line characterises the selected value of 30 nearest neighbours.</p> "> Figure 10
<p>The performance of the k-nearest neighbours classifier (k = 30) for different tile sizes, different cities and a combined dataset. For each city, the model was trained using a 5-fold cross-validation approach using all cities but the selected city and validated against the latter. For the combined dataset, the model was trained using a 5-fold cross-validation approach and with precision calculated for the whole dataset.</p> "> Figure A1
<p>SM2T architecture and interface.</p> ">
Abstract
:1. Introduction
- To test the existence of a direct as well as combined relationship between geo-tagged Twitter data/land-use land-cover POI/betweenness centrality and high traffic congestion on roads.
- To propose a framework to train the model and argue its fitness for purpose.
- We tested two Twitter-based proxies as a predictor: the number of users on a road segment and the number of users within a vicinity.
- We used land-use and land-cover-related POIs as an additional predictor and investigated four different ways of aggregating POI information for a given tile.
- We used an adapted centrality betweenness measure as an additional predictor. Betweenness centrality was measured with respect to a different set of POIs.
- We tested four different spatial resolutions for a regular grid-based tessellation model.
- We investigated different thematic resolutions: (i) using continuous traffic speed information and (ii) using traffic speed information classified into up to three congestion levels.
- We tested the performance of five machine learning models.
2. Methods and Data
2.1. Conceptual Framework
2.2. Cities Used for the Case Study
2.3. Uber Movement Data
2.4. Twitter Proxy
2.5. Land-Use and Land-Cover Point of Interest Proxy
2.6. Centrality Proxy
2.7. Spatial, Temporal and Thematic Resolution
2.8. Missing Data Handling
2.9. Machine Learning Methods Comparison
3. Results




4. Discussion and Limitation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AADT | Annual Average Daily Traffic |
| API | Application Programming Interface |
| GNSS | Global Navigation Satellite System |
| GPS | Global Positioning System |
| HTC | High Traffic Congestion |
| HTTP | Hyper Text Transfer Protocol |
| LTC | Low Traffic Congestion |
| ML | Machine Learning |
| MTC | Medium Traffic Congestion |
| NLP | Natural Language Processing |
| OD | Origin–Destination |
| OSM | OpenStreetMap |
| POI | Point of Interest |
| SDK | Software Development Kit |
| SM2T | SocialMedia2Traffic |
| VGI | Volunteered Geographic Information |
Appendix A. SM2T Architecture and Interface

References
- Ahas, R.; Aasa, A.; Silm, S.; Tiru, M. Daily rhythms of suburban commuters’ movements in the Tallinn metropolitan area: Case study with mobile positioning data. Transp. Res. Part Emerg. Technol. 2010, 18, 45–54. [Google Scholar] [CrossRef]
- Kang, C.; Ma, X.; Tong, D.; Liu, Y. Intra-urban human mobility patterns: An urban morphology perspective. Phys. A Stat. Mech. Appl. 2012, 391, 1702–1717. [Google Scholar] [CrossRef]
- Bar-Gera, H. Evaluation of a cellular phone-based system for measurements of traffic speeds and travel times: A case study from Israel. Transp. Res. Part C Emerg. Technol. 2007, 15, 380–391. [Google Scholar] [CrossRef]
- De Fabritiis, C.; Ragona, R.; Valenti, G. Traffic estimation and prediction based on real time floating car data. In Proceedings of the 2008 11th International IEEE Conference on Intelligent Transportation Systems, Beijing, China, 12–15 October 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 197–203. [Google Scholar]
- Herrera, J.C.; Work, D.B.; Herring, R.; Ban, X.J.; Jacobson, Q.; Bayen, A.M. Evaluation of traffic data obtained via GPS-enabled mobile phones: The Mobile Century field experiment. Transp. Res. Part C Emerg. Technol. 2010, 18, 568–583. [Google Scholar] [CrossRef]
- Steiger, E.; De Albuquerque, J.P.; Zipf, A. An advanced systematic literature review on spatiotemporal analyses of t witter data. Trans. GIS 2015, 19, 809–834. [Google Scholar] [CrossRef]
- Huang, W.; Xu, S.; Yan, Y.; Zipf, A. An exploration of the interaction between urban human activities and daily traffic conditions: A case study of Toronto, Canada. Cities 2019, 84, 8–22. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, R.Q. Understanding the removal of precise geotagging in tweets. Nat. Hum. Behav. 2020, 4, 1219–1221. [Google Scholar] [CrossRef]
- Yao, W.; Qian, S. From Twitter to traffic predictor: Next-day morning traffic prediction using social media data. Transp. Res. Part C Emerg. Technol. 2021, 124, 102938. [Google Scholar] [CrossRef]
- Yu, H.F.; Lo, H.Y.; Hsieh, H.P.; Lou, J.K.; McKenzie, T.G.; Chou, J.W.; Chung, P.H.; Ho, C.H.; Chang, C.F.; Wei, Y.H.; et al. Feature Engineering and Classifier Ensemble for KDD Cup 2010. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.367.249&rep=rep1&type=pdf (accessed on 26 June 2022).
- Weiss, D.; Nelson, A.; Vargas-Ruiz, C.; Gligorić, K.; Bavadekar, S.; Gabrilovich, E.; Bertozzi-Villa, A.; Rozier, J.; Gibson, H.; Shekel, T.; et al. Global maps of travel time to healthcare facilities. Nat. Med. 2020, 26, 1835–1838. [Google Scholar] [CrossRef]
- Keller, S.; Gabriel, R.; Guth, J. Machine learning framework for the estimation of average speed in rural road networks with openstreetmap data. ISPRS Int. J. Geo-Inf. 2020, 9, 638. [Google Scholar] [CrossRef]
- Pavlyuk, D.; Karatsoli, M.; Nathanail, E. Exploring the Potential of Social Media Content for Detecting Transport-Related Activities. In Proceedings of the International Conference on Reliability and Statistics in Transportation and Communication, Riga, Latvia, 17–20 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 138–149. [Google Scholar]
- Coffey, C.; Pozdnoukhov, A. Temporal decomposition and semantic enrichment of mobility flows. In Proceedings of the 6th ACM SIGSPATIAL International Workshop on Location-Based Social Networks, Orlando, FL, USA, 5 November 2013; pp. 34–43. [Google Scholar]
- Lee, J.H.; Gao, S.; Goulias, K.G. Comparing the origin-destination matrices from travel demand model and social media data. In Proceedings of the Transportation Research Board 95th Annual Meeting, Washington, DC, USA, 10–14 January 2016. [Google Scholar]
- Yang, F.; Jin, P.J.; Wan, X.; Li, R.; Ran, B. Dynamic origin-destination travel demand estimation using location based social networking data. In Proceedings of the Transportation Research Board 93rd Annual Meeting, Washington, DC, USA, 12–16 January 2014. [Google Scholar]
- Fonte, C.C.; Minghini, M.; Patriarca, J.; Antoniou, V.; See, L.; Skopeliti, A. Generating up-to-date and detailed land use and land cover maps using OpenStreetMap and GlobeLand30. ISPRS Int. J. Geo-Inf. 2017, 6, 125. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, P.; Cui, Y. A network centrality measure framework for analyzing urban traffic flow: A case study of Wuhan, China. Phys. A Stat. Mech. Appl. 2017, 478, 143–157. [Google Scholar] [CrossRef]
- Steiger, E.; Resch, B.; de Albuquerque, J.P.; Zipf, A. Mining and correlating traffic events from human sensor observations with official transport data using self-organizing-maps. Transp. Res. Part C Emerg. Technol. 2016, 73, 91–104. [Google Scholar] [CrossRef]
- Gao, S.; Yang, J.A.; Yan, B.; Hu, Y.; Janowicz, K.; McKenzie, G. Detecting origin-destination mobility flows from geotagged tweets in greater Los Angeles area. In Proceedings of the Eighth International Conference on Geographic Information Science, Vienna, Austria, 24–26 September 2014; pp. 1–4. [Google Scholar]
- Pun, L.; Zhao, P.; Liu, X. A multiple regression approach for traffic flow estimation. IEEE Access 2019, 7, 35998–36009. [Google Scholar] [CrossRef]
- Giles, J.R.; zu Erbach-Schoenberg, E.; Tatem, A.J.; Gardner, L.; Bjørnstad, O.N.; Metcalf, C.; Wesolowski, A. The duration of travel impacts the spatial dynamics of infectious diseases. Proc. Natl. Acad. Sci. USA 2020, 117, 22572–22579. [Google Scholar] [CrossRef]
- Cai, L.; Janowicz, K.; Mai, G.; Yan, B.; Zhu, R. Traffic transformer: Capturing the continuity and periodicity of time series for traffic forecasting. Trans. GIS 2020, 24, 736–755. [Google Scholar] [CrossRef]
- Guth, J.; Wursthorn, S.; Keller, S. Multi-parameter estimation of average speed in road networks using fuzzy control. ISPRS Int. J. Geo-Inf. 2020, 9, 55. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, T.; Ren, Y.; Xie, K. A novel residual graph convolution deep learning model for short-term network-based traffic forecasting. Int. J. Geogr. Inf. Sci. 2020, 34, 969–995. [Google Scholar] [CrossRef]
- Liu, X.; Huang, Q.; Gao, S.; Xia, J. Activity knowledge discovery: Detecting collective and individual activities with digital footprints and open source geographic data. Comput. Environ. Urban Syst. 2021, 85, 101551. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, J.; Li, W.; Gu, T.; Shi, W. Exploring traffic congestion correlation from multiple data sources. Pervasive Mob. Comput. 2017, 41, 470–483. [Google Scholar] [CrossRef]
- Jayasinghe, A.; Sano, K.; Nishiuchi, H. Explaining traffic flow patterns using centrality measures. Int. J. Traffic Transp. Eng. 2015, 5, 134–149. [Google Scholar] [CrossRef]
- Zhang, T.; Sun, L.; Yao, L.; Rong, J. Impact analysis of land use on traffic congestion using real-time traffic and POI. J. Adv. Transp. 2017, 2017, 7164790. [Google Scholar] [CrossRef]
- Neis, P.; Zipf, A. Openrouteservice. org Is Three Times “Open”: Combining OpenSource, OpenLS and OpenStreetMaps; GIS Research UK (GISRUK 08): Manchester, UK, 2008. [Google Scholar]
- Ren, Y.; Chen, H.; Han, Y.; Cheng, T.; Zhang, Y.; Chen, G. A hybrid integrated deep learning model for the prediction of citywide spatio-temporal flow volumes. Int. J. Geogr. Inf. Sci. 2020, 34, 802–823. [Google Scholar] [CrossRef]
- Lee, J.H.; Gao, S.; Goulias, K.G. Can Twitter data be used to validate travel demand models. In Proceedings of the 14th International Conference on Travel Behaviour Research, Windsor, UK, 19–23 July 2015. [Google Scholar]
- Cheng, Z.; Jian, S.; Rashidi, T.H.; Maghrebi, M.; Waller, S.T. Integrating household travel survey and social media data to improve the quality of od matrix: A comparative case study. IEEE Trans. Intell. Transp. Syst. 2020, 21, 2628–2636. [Google Scholar] [CrossRef]
- Yang, F.; Jin, P.J.; Cheng, Y.; Zhang, J.; Ran, B. Origin-destination estimation for non-commuting trips using location-based social networking data. Int. J. Sustain. Transp. 2015, 9, 551–564. [Google Scholar] [CrossRef]
- Uber Movement. 2021. Available online: https://movement.uber.com (accessed on 22 November 2021).
- GADM Database of Global Administrative Areas. 2012. Available online: https://gadm.org/index.html (accessed on 22 November 2021).
- Kruspe, A.; Häberle, M.; Hoffmann, E.J.; Rode-Hasinger, S.; Abdulahhad, K.; Zhu, X.X. Changes in Twitter geolocations: Insights and suggestions for future usage. In Proceedings of the 2021 EMNLP Workshop W-NUT: The Seventh Workshop on Noisy User-Generated Text, Online, 11 November 2021; pp. 212–221. [Google Scholar]
- POIs Table. 2022. Available online: https://gist.github.com/Zia-/d6f3bb5454d0026ea84de7f1086a62f1 (accessed on 26 June 2022).
- Freeman, L.C.; Borgatti, S.P.; White, D.R. Centrality in valued graphs: A measure of betweenness based on network flow. Soc. Netw. 1991, 13, 141–154. [Google Scholar] [CrossRef]
- Gao, S.; Wang, Y.; Gao, Y.; Liu, Y. Understanding urban traffic-flow characteristics: A rethinking of betweenness centrality. Environ. Plan. B Plan. Des. 2013, 40, 135–153. [Google Scholar] [CrossRef]
- Raifer, M.; Troilo, R.; Kowatsch, F.; Auer, M.; Loos, L.; Marx, S.; Przybill, K.; Fendrich, S.; Mocnik, F.B.; Zipf, A. OSHDB: A framework for spatio-temporal analysis of OpenStreetMap history data. Open Geospat. Data Softw. Stand. 2019, 4, 3. [Google Scholar] [CrossRef]
- Schiavina, M.; Freire, S.; MacManus, K. GHS Population Grid Multitemporal (1975, 1990, 2000, 2015) R2019A; European Commission, Joint Research Centre (JRC): Brussels, Belgium, 2019; Volume 10. [Google Scholar]
- Florczyk, A.; Corbane, C.; Ehrlich, D.; Freire, S.; Kemper, T.; Maffenini, L.; Melchiorri, M.; Pesaresi, M.; Politis, P.; Schiavina, M.; et al. GHSL Data Package 2019: Public Release GHS P2019; Publications Office of the European Union: Luxembourg, 2019. [Google Scholar]
- Yang, C.; Gidofalvi, G. Fast map matching, an algorithm integrating hidden Markov model with precomputation. Int. J. Geogr. Inf. Sci. 2018, 32, 547–570. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Int. Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Engineering Uber Predictions in Real Time with ELK. 2021. Available online: https://www.uber.com/en-DE/blog/elk/ (accessed on 22 November 2021).
- Hennessy, D.A.; Wiesenthal, D.L. The relationship between traffic congestion, driver stress and direct versus indirect coping behaviours. Ergonomics 1997, 40, 348–361. [Google Scholar] [CrossRef]
- Barrington-Leigh, C.; Millard-Ball, A. The world’s user-generated road map is more than 80% complete. PLoS ONE 2017, 12, e0180698. [Google Scholar] [CrossRef] [PubMed]
- Huang, B.; Carley, K.M. A large-scale empirical study of geotagging behavior on Twitter. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; ACM: New York, NY, USA, 2019; pp. 365–373. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Social Media | Publicly Available | User Location | Time Stamp | Datatype |
|---|---|---|---|---|
| Yes | Yes * | Yes | Multimedia message | |
| Foursquare | Yes | Yes | Yes | Search, discover and rank POI |
| Snapchat | Yes | Yes | Yes | Multimedia message |
| Flickr | Yes | Yes | Yes | Image and video message |
| No | No | Yes | Multimedia message | |
| No | No | Yes | Image and video message |
| Country | City |
|---|---|
| Brazil | Sao Paulo |
| Germany | Berlin |
| Kenya | Nairobi |
| Spain | Barcelona, Madrid |
| United Kingdom | London |
| Ukraine | Kyiv |
| USA | Cincinnati, New York City, San Francisco, Seattle |
| Twitter Users | Tweets | Uber Average Speed (kph) | |
|---|---|---|---|
| Barcelona | 44,758 | 542,076 | 33.43 |
| Berlin | 26,070 | 418,932 | 38.97 |
| Cincinnati | 11,445 | 157,754 | 51.55 |
| Kyiv | 5398 | 73,046 | 40.36 |
| London | 151,509 | 1,543,018 | 34.10 |
| Madrid | 58,505 | 552,925 | 40.53 |
| Nairobi | 12,750 | 130,681 | 30.55 |
| New York City | 198,144 | 3,981,137 | 31.17 |
| San Francisco | 77,356 | 1,380,504 | 44.44 |
| Sao Paulo | 89,599 | 1,263,890 | 27.04 |
| Seattle | 34,694 | 518,950 | 46.72 |
| Highway Type | HTC | MTC | LTC | Buffer in Vicinity | Buffer on Road |
|---|---|---|---|---|---|
| Speed bin (km/h) | (m) | (m) | |||
| Motorway | 0.0–37.3 | 37.3–62.1 | >62.1 | 300 | 11.25 |
| Trunk | 0.0–37.3 | 37.3–62.1 | >62.1 | 150 | 11.25 |
| Primary | 0.0–24.8 | 24.8–43.5 | >43.5 | 150 | 7.00 |
| Secondary | 0.0–24.8 | 24.8–43.5 | >43.5 | 50 | 7.00 |
| Tertiary | 0.0–24.8 | 24.8–43.5 | >43.5 | 50 | 6.50 |
| Residential | 0.0–18.6 | 18.6–37.3 | >37.3 | 50 | 6.00 |
| Key | Value |
|---|---|
| amenity | parking, parking_space, marketplace |
| highway | rest_area, services, pedestrian |
| leisure | park, garden |
| landuse | recreation_ground, grass, village_green, cemetery, meadow |
| Vehicle Speed Proxy | Availability | Complexity | Priority |
|---|---|---|---|
| Direct speed estimation | Low | Low | Very high |
| User count on a road segment | Medium | Medium | High |
| User count within a vicinity | High | High | Medium |
| Context-based | Low | Very high | Low |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zia, M.; Fürle, J.; Ludwig, C.; Lautenbach, S.; Gumbrich, S.; Zipf, A. SocialMedia2Traffic: Derivation of Traffic Information from Social Media Data. ISPRS Int. J. Geo-Inf. 2022, 11, 482. https://doi.org/10.3390/ijgi11090482
Zia M, Fürle J, Ludwig C, Lautenbach S, Gumbrich S, Zipf A. SocialMedia2Traffic: Derivation of Traffic Information from Social Media Data. ISPRS International Journal of Geo-Information. 2022; 11(9):482. https://doi.org/10.3390/ijgi11090482
Chicago/Turabian StyleZia, Mohammed, Johannes Fürle, Christina Ludwig, Sven Lautenbach, Stefan Gumbrich, and Alexander Zipf. 2022. "SocialMedia2Traffic: Derivation of Traffic Information from Social Media Data" ISPRS International Journal of Geo-Information 11, no. 9: 482. https://doi.org/10.3390/ijgi11090482
APA StyleZia, M., Fürle, J., Ludwig, C., Lautenbach, S., Gumbrich, S., & Zipf, A. (2022). SocialMedia2Traffic: Derivation of Traffic Information from Social Media Data. ISPRS International Journal of Geo-Information, 11(9), 482. https://doi.org/10.3390/ijgi11090482