Classical model selection via simulated annealing
 Ruth King
Ruth King2003, Journal of the Royal Statistical Society: Series B (Statistical Methodology)
visibility
…
description
17 pages
link
1 file
The classical approach to statistical analysis is usually based upon finding values for model parameters that maximise the likelihood function. Model choice in this context is often also based upon the likelihood function, but with the addition of a penalty term for the number of parameters. Though models may be compared pairwise using likelihood ratio tests for example, various criteria such as the AIC have been proposed as alternatives when multiple models need to be compared. In practical terms, the classical approach to model selection usually involves maximising the likelihood function associated with each competing model and then calculating the corresponding criteria value(s). However, when large numbers of models are possible, this quickly becomes infeasible unless a method that simultaneously maximises over both parameter and model space is available. In this paper we propose an extension to the traditional simulated annealing algorithm that allows for moves that not only change parameter values but that also move between competing models. This transdimensional simulated annealing algorithm can therefore be used to locate models and parameters that minimise criteria such as the AIC, but within a single algorithm, removing the need for large numbers of simulations to be run. We discuss the implementation of the trans-dimensional simulated annealing algorithm and use simulation studies to examine their performance in realistically complex modelling situations. We illustrate our ideas with a pedagogic example based upon the analysis of an autoregressive time series and two more detailed examples: one on variable selection for logistic regression and the other on model selection for the analysis of integrated recapture/recovery data.
Sign up for access to the world's latest research
checkGet notified about relevant papers
checkSave papers to use in your research
checkJoin the discussion with peers
checkTrack your impact
Figures (2)

Related papers
A unified approach to model selection using the likelihood ratio test
Methods in Ecology and Evolution, 2011
1. Ecological count data typically exhibit complexities such as overdispersion and zero-inflation, and are often weakly associated with a relatively large number of correlated covariates. The use of an appropriate statistical model for inference is therefore essential. A common selection criteria for choosing between nested models is the likelihood ratio test (LRT). Widely used alternatives to the LRT are based on information-theoretic metrics such as the Akaike Information Criterion. 2. It is widely believed that the LRT can only be used to compare the performance of nested models -i.e. in situations where one model is a special case of another. There are many situations in which it is important to compare non-nested models, so, if true, this would be a substantial drawback of using LRTs for model comparison. In reality, however, it is actually possible to use the LRT for comparing both nested and non-nested models. This fact is well-established in the statistical literature, but not widely used in ecological studies. 3. The main obstacle to the use of the LRT with non-nested models has, until relatively recently, been the fact that it is difficult to explicitly write down a formula for the distribution of the LRT statistic under the null hypothesis that one of the models is true. With modern computing power it is possible to overcome this difficulty by using a simulation-based approach. 4. To demonstrate the practical application of the LRT to both nested and non-nested model comparisons, a case study involving data on questing tick (Ixodes ricinus) abundance is presented. These data contain complexities typical in ecological analyses, such as zero-inflation and overdispersion, for which comparison between models of differing structure -e.g. non-nested models -is of particular importance. 5. Choosing between competing statistical models is an essential part of any applied ecological analysis. The LRT is a standard statistical test for comparing nested models. By use of simulation the LRT can also be used in an analogous fashion to compare non-nested models, thereby providing a unified approach for model comparison within the null hypothesis testing paradigm. A simple practical guide is provided in how to apply this approach to the key models required in the analyses of count data.
Optimal Model Assessment, Selection, and Combination
Journal of the American Statistical Association, 2006
Central to statistical theory and application is statistical modeling, which typically involves choosing a single model or combining a number of models of different sizes and from different sources. Whereas model selection seeks a single best modeling procedure, model combination combines the strength of different modeling procedures. In this article we look at several key issues and argue that model assessment is the key to model selection and combination. Most important, we introduce a general technique of optimal model assessment based on data perturbation, thus yielding optimal selection, in particular model selection and combination. From a frequentist perspective, we advocate model combination over a selected subset of modeling procedures, because it controls bias while reducing variability, hence yielding better performance in terms of the accuracy of estimation and prediction. To realize the potential of model combination, we develop methodologies for determining the optimal tuning parameter, such as weights and subsets for combining via optimal model assessment. We present simulated and real data examples to illustrate main aspects.
Model selection on solid ground: Rigorous comparison of nine ways to evaluate Bayesian model evidence
Water Resources Research, 2014
Bayesian model selection or averaging objectively ranks a number of plausible, competing conceptual models based on Bayes' theorem. It implicitly performs an optimal trade-off between performance in fitting available data and minimum model complexity. The procedure requires determining Bayesian model evidence (BME), which is the likelihood of the observed data integrated over each model's parameter space. The computation of this integral is highly challenging because it is as high-dimensional as the number of model parameters. Three classes of techniques to compute BME are available, each with its own challenges and limitations: (1) Exact and fast analytical solutions are limited by strong assumptions. Numerical evaluation quickly becomes unfeasible for expensive models.
Assessing the simulation performances of multiple model selection algorithm
2015
The Autometrics is an algorithm for single equation model selection. It is a hybrid method which combines expanding and contracting search techniques. In this study, the algorithm is extended for multiple equa- tions modelling known as SURE-Autometrics. The aim of this paper is to as- sess the performance of the extended algorithm using various simulation ex- periment conditions. The capability of the algorithm in finding the true spec- ification of multiple models is measured by the percentage of simulation outcomes. Overall results show that the algorithm has performed well for a model with two equations. The findings also indicated that the number of variables in the true models affect the algorithm performances. Hence, this study suggests improvement on the algorithm development for future re- search.
A comparison of a large number of model selection criteria
2008
Abstract This paper uses Monte Carlo analysis to compare the performance of a large number of model selection criteria (MSC), including information criteria, General-to-Specific modelling, Bayesian Model Averaging, and portfolio models. We use Mean Squared Error (MSE) as our measure of MSC performance. The decomposition of MSE into Bias and Variance provides a useful decomposition for understanding MSC performance.
Incorporating Parameter Estimability Into Model Selection
Frontiers in Ecology and Evolution, 2019
We investigate a class of information criteria based on the informational complexity criterion (ICC), which penalizes model fit based on the degree of dependency among parameters. In addition to existing forms of ICC, we develop a new complexity measure that uses the coefficient of variation matrix, a measure of parameter estimability, and a novel compound criterion that accounts for both the number of parameters and their informational complexity. We compared the performance of ICC and these variants to more traditionally used information criteria (i.e., AIC, AICc, BIC) in three different simulation experiments: simple linear models, nonlinear population abundance growth models, and nonlinear plant biomass growth models. Criterion performance was evaluated using the frequency of selecting the generating model, the frequency of selecting the model with the best predictive ability, and the frequency of selecting the model with the minimum Kullback-Leibler divergence. We found that the relative performance of each criterion depended on the model set, process variance, and sample size used. However, one of the compound criteria performed best on average across all conditions at identifying both the model used to generate the data and at identifying the best predictive model. This result is an important step forward in developing information criterion that select parsimonious models with interpretable and tranferrable parameters.
Objective Bayesian Methods for Model Selection: Introduction and Comparison
Institute of Mathematical Statistics Lecture Notes - Monograph Series, 2001
The basics of the Bayesian approach to model selection are first presented, as well as the motivations for the Bayesian approach. We then review four methods of developing default Bayesian procedures that have undergone considerable recent development, the Conventional Prior approach, the Bayes Information Criterion, the Intrinsic Bayes Factor, and the Fractional Bayes Factor. As part of the review, these methods are illustrated on examples involving the normal linear model. The later part of the chapter focuses on comparison of the four approaches, and includes an extensive discussion of criteria for judging model selection procedures.
Balancing Statistics and Ecology: Lumping Experimental Data for Model Selection
2003
Ecological experiments often accumulate data by carrying out many replicate trials, each containing a limited number of observations, which are then pooled and analysed in the search for a pattern. Replicating trials may be the only way to obtain sufficient data, yet lumping disregards the possibility of differences in experimental conditions influencing the overall pattern. This paper discusses how to deal with this dilemma in model selection. Three methods of model selection are introduced: likelihood-ratio testing, the Akaike Information Criterion (AIC) with or without small-sample correction and the Bayesian Information Criterion (BIC). Subsequently, we apply the AICc method to an example on size-dependent seed dispersal by scatterhoarding rodents. The example involves binary data on the selection and removal of Carapa procera (Meliaceae) seeds by scatterhoarding rodents in replicate trials during years of different ambient seed abundance. The question is whether there is an optimum size for seeds to be removed and dispersed by the rodents. We fit five models, varying from no effect of seed mass to an optimum seed mass. We show that lumping the data produces the expected pattern but gives a poor fit compared to analyses in which grouping levels are taken into account. Three methods of grouping were used: per group a fixed parameter value; per group a randomly drawn parameter value; and some parameters fixed per group and others constant for all groups. Model fitting with some parameters fixed for all groups, and others depending on the trial give the best fit. The general pattern is however rather weak. We explore how far models must differ in order to be able to discriminate between them, using the minimum Kullback-Leibler distance as a measure for the difference. We then show by simulation that the differences are too small to discriminate at all between the five models tested at the level of replicate trials. We recommend a combined approach in which the level of lumping trials is chosen by the amount of variation explained in comparison to an analysis at the trial level. It is shown that combining data from different trials only leads to an increase in the probability of identifying the correct model with the AIC criterion if the distance of all simpler (=less extended models) to the simulated model is sufficiently large in each trial. Otherwise, increasing the number of replicate trials might even lead to a decrease in the power of the AIC.
Model selection for environmental data
Environmetrics, 2007
A practical approach is proposed for model selection and discrimination among nested and non-nested probability distributions. Some existing problems with traditional model selection approaches are addressed, including standard testing of a null hypothesis against a more general alternative and the use of some well-known discrimination criteria for non-nested distributions. A generalized information criterion (GIC) is used to choose from two or more model structures or probability distributions. For each set of random samples, all model structures that do not perform significantly worse than other candidates are selected. The two-and three-parameter gamma, Weibull and lognormal distributions are used to compare the discrimination procedures with traditional approaches. Monte Carlo experiments are empIoyed to examine the performances of the criteria and tests over large sets of finite samples. For each distribution, the Monte Carlo procedure is undertaken for various representative sets of parameter values which are encountered in fitting environmental quality data.
A jackknife type approach to statistical model selection
Procedures such as Akaike information criterion (AIC), Bayesian information criterion (BIC), minimum description length (MDL), and bootstrap information criterion have been developed in the statistical literature for model selection. Most of these methods use estimation of bias. This bias, which is inevitable in model selection problems, arises from estimating the distance between an unknown true model and an estimated model. Instead of bias estimation, a bias reduction based on jackknife type procedure is developed in this paper. The jackknife method selects a model of minimum Kullback-Leibler divergence through bias reduction. It is shown that (a) the jackknife maximum likelihood estimator is consistent, (b) the jackknife estimate of the log likelihood is asymptotically unbiased, and (c) the stochastic order of the jackknife log likelihood estimate is Oðlog log nÞ. Because of these properties, the jackknife information criterion is applicable to problems of choosing a model from separated families especially when the true model is unknown. Compared to popular information criteria which are only applicable to nested models such as regression and time series settings, the jackknife information criterion is more robust in terms of filtering various types of candidate models in choosing the best approximating model. the model selection criterion (AIC) that leads to the model of the minimum KL divergence. For an unknown density g, however, AIC chooses a model that maximizes the estimate of E g ½log f y ðXÞ. Yet, the bias cannot be avoided from estimating the likelihood as well as model parameters with the same data set. The estimated bias appears as a penalty term in AIC. In fact, as y g is unknown, it is replaced by its maximum likelihood estimate. The resulting bias is then estimated using E½ P i log fŷ ðX i ÞÀnE g ðlog fŷ ðZÞ, where random variable Z is independent of the data and has density g. Here the model evaluation is done from the stand point of prediction . However, the jackknife based approach in this article gets around this bias estimation problem, without explicit estimation. Regardless of their theoretical and historical background, BIC, MDL, and other modified model selection criteria that are similar to AIC are popular among practitioners.
Introduction
Ì Ð ×× Ð ÔÔÖÓ ØÓ ×Ø Ø ×Ø Ð Ò ÐÝ× × × Ù×Ù ÐÐÝ × ÙÔÓÒ ¬Ò Ò Ú ÐÙ × ÓÖ ÑÓ Ð Ô Ö Ñ Ø Ö× Ø Ø Ñ Ü Ñ × Ø Ð Ð ÓÓ ÙÒØ ÓÒº Î Ö ÓÙ× Ø Ò ÕÙ × Ú Ò ÔÖÓÔÓ× Ø Ø Ñ Ý Ù× Û Ò Ø × Ñ Ü Ñ ÒÒÓØ Ó Ø Ò Ò ÐÝØ ÐÐݺ Ë AE Ð Ö Ò Å ´½ µ¸ÁÒ Ö´½ ¾µ¸ ÑÔ×Ø Ö
Trans-Dimensional Simulated Annealing
Data and Results
ÌÓ ÐÐÙ×ØÖ
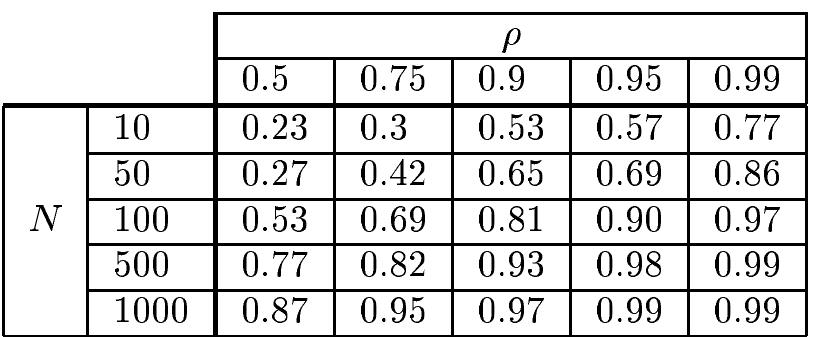
Ö× ÑÓÒ ÓÙ×¸Ý Ø ÔÐ Ù× Ð ¸ÑÓ Ð ØÓ ×Ö Ø Ö Ð Ø ÓÒ× Ô ØÛ Ò Ò ÖÝ ÓÙØÓÑ Ò × Ø Ó Ò Ô Ò ÒØ ÜÔÐ Ò ØÓÖÝ Ú Ö Ð ×º Ï ÒÓØ Ø Ò ÖÝ Ö ×ÔÓÒ× Ú Ö Ð Ý Ý ´Ý ½ Ý Ò µ¸ Ò ××ÙÑ Ø Ø Û Ú È ÔÓØ ÒØ Ð ÜÔÐ Ò ØÓÖÝ Ú Ö Ð × Ü ½ Ü ¾ Ü È º ÁÒ Ö Ø Ù× Ò ×׸ Ò × Ö ÒØ Ö ×Ø Ò Û Ø Ö ÔÖÓ×Ô Ø Ú ÓÒ×ÙÑ Ö× Û ÐÐ Ô Ý Ø Ö Ö Ø ÓÖ ÒÓغ Ì Ñ Ó Ö Ø¹×ÓÖ Ò × ØÓ ÑÓ Ð ÓÖ ÔÖ Ø Ø ÔÖÓ Ð ØÝ Ø Ø ÓÒ×ÙÑ Ö ÔÓ×× ×× Ò ÖØ Ò Ö Ø Ö ×Ø × × ØÓ ÓÒ× Ö × ÔÓØ ÒØ Ð Ö × º × Ò ÐÐÙ×ØÖ Ø ÓÒ Ó ÐÓ ×Ø Ö Ö ×× ÓÒ
Results
ÔÔÐÝ Ò Ø Ì Ë Ð ÓÖ Ø Ñ ØÓ Ø Ö Ø ×ÓÖ Ò Ø ×Ö ÓÚ ¸Û Ø Ò Ò Ø Ð Ø ÑÔ Ö¹ ØÙÖ Ì ¼ ½¼ Û Û Ö Ù Ý ØÓÖ ¼ Ú ÖÝ ½¼¼¼ Ø Ö Ø ÓÒ׺ Ï Ô Ö ÓÖÑ ½ ¼¼ Ø ÑÔ Ö ØÙÖ Ö ÙØ ÓÒ× ×Ó Ø Ø ÓÙÖ ¬Ò Ð Ø ÑÔ Ö ØÙÖ × ÔÔÖÓÜ Ñ Ø ÐÝ ¼ ¼¼¾ Ò ¸ × ÓÖ × ÓÙÖ ÔÖÓÔÓ× Ð Ô Ö Ñ Ø Ö× ÙÔÓÒ Ø ÅÄ ³× ÖÓÑ Ø × ØÙÖ Ø ÑÓ Ðº Ì Ì Ë Ð ÓÖ Ø Ñ Û × ÖÙÒ ¾¼ Ø Ñ × ÖÓÑ Ú Ö ÓÙ× Ò Ø Ð ÑÓ Ð ÓÒ¬ ÙÖ Ø ÓÒ× Ò ØÓÓ ÔÔÖÓÜ Ñ Ø ÐÝ ÓÙÖ× ØÓ ÓÑÔÐ Ø º Ì ÓÐÐÓÛ Ò ÑÓ Ð × ÙÔÓÒ ½½ ÓÚ Ö Ø × Û × Ó Ø Ò ÖÓÑ ½ Ó Ø × ÖÙÒ׺
Example II Recapture/Recovery Models
Related papers
Beet seed priming with growth regulators
Semina-ciencias Agrarias, 2017
Determinants of positive and negative consequences of alcohol consumption in college students: alcohol use, gender, and psychological characteristics
Addictive Behaviors, 2005
Scanning Electron Microscopy in Paleoanthropological Research
… Technology and Education of Microscopy: An …, 2003
ANALYSIS OF MANIPULATION OF THE RUSSIAN FEDERATION IN
THE 2016 PRESIDENTIAL ELECTIONS OF THE UNITED STATES OF
AMERICA WITHIN THE SCOPE OF INTELLIGENCE TECHNIQUES
Güvenlik Bilimleri Dergisi,, 2019
Canonical solution of classical magnetic models with long-range couplings
Journal of Physics A-mathematical and General, 2003
Experiment and prediction of a cavity type separated flow
Applied Scientific Research, 1996
An empirical analysis of cross-national economic growth, 1951-1980
Journal of Monetary Economics, 1989
Force and position control of grasp in multiple robotic mechanisms
Journal of Robotic Systems, 1996
Components, Systems and Technological Discontinuities
Long Range Planning, 2008
Age, Sex & Nutritional Status Modify CD4+T-Cell Recovery Rate in HIV/Tuberculosis Co-infected Patients on cART
International journal of infectious diseases : IJID : official publication of the International Society for Infectious Diseases, 2015
Edukasi Cara Identifikasi Boraks Pada Bakso Menggunakan Sari Bunga Telang (Clitoria ternatea L.) Di Desa Sungai Pinang
BATOBO Jurnal Pengabdian Kepada Masyarakat, 2023
MELTS Modelling of Prehistoric Mount Etna, Valle del Bove
Goldschmidt Abstracts, 2020
Effectors, Effectors et encore des Effectors: The XIV International Congress on Molecular-Plant Microbe Interactions, Quebec
Molecular Plant-Microbe Interactions®, 2009
Using a Random Perturbation-based Scheme for establishing Authentic Associations in Wireless Mesh Network
International Journal of Computer Applications, 2014
Related topics
Stochastic ProcessEconometricsStatisticsData AnalysisTime SeriesStatistical AnalysisSimulated AnnealingLaw of large numbersAlgorithmTime series analysisLogistic RegressionTeachingOptimizationSamplingModel SelectionVariable SelectionPrey Choice ModelAutocorrelationImplementationIRT-likelihood RatioRegression ModelSimulation StudyAutoregressionAkaike Information CriterionMarkov chainCapture recaptureStatistical TheoryCaptureMultiple modelLocation ModelLikelihood FunctionMonte Carlo MethodStatistical Regression