WO2025133951A1 - Ionizable lipids suitable for lipid nanoparticles - Google Patents
Ionizable lipids suitable for lipid nanoparticles Download PDFInfo
- Publication number
- WO2025133951A1 WO2025133951A1 PCT/IB2024/062841 IB2024062841W WO2025133951A1 WO 2025133951 A1 WO2025133951 A1 WO 2025133951A1 IB 2024062841 W IB2024062841 W IB 2024062841W WO 2025133951 A1 WO2025133951 A1 WO 2025133951A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- lipid
- lipid nanoparticle
- mol
- nucleotides
- nanoparticle
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07F—ACYCLIC, CARBOCYCLIC OR HETEROCYCLIC COMPOUNDS CONTAINING ELEMENTS OTHER THAN CARBON, HYDROGEN, HALOGEN, OXYGEN, NITROGEN, SULFUR, SELENIUM OR TELLURIUM
- C07F7/00—Compounds containing elements of Groups 4 or 14 of the Periodic Table
- C07F7/02—Silicon compounds
- C07F7/08—Compounds having one or more C—Si linkages
- C07F7/18—Compounds having one or more C—Si linkages as well as one or more C—O—Si linkages
- C07F7/1804—Compounds having Si-O-C linkages
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/695—Silicon compounds
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/48—Preparations in capsules, e.g. of gelatin, of chocolate
- A61K9/50—Microcapsules having a gas, liquid or semi-solid filling; Solid microparticles or pellets surrounded by a distinct coating layer, e.g. coated microspheres, coated drug crystals
- A61K9/51—Nanocapsules; Nanoparticles
- A61K9/5107—Excipients; Inactive ingredients
- A61K9/5123—Organic compounds, e.g. fats, sugars
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/16—Drugs for disorders of the alimentary tract or the digestive system for liver or gallbladder disorders, e.g. hepatoprotective agents, cholagogues, litholytics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/88—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation using microencapsulation, e.g. using amphiphile liposome vesicle
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/0008—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition
- A61K48/0025—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition wherein the non-active part clearly interacts with the delivered nucleic acid
- A61K48/0041—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition wherein the non-active part clearly interacts with the delivered nucleic acid the non-active part being polymeric
Definitions
- LNPs Lipid nanoparticles
- LNPs can have limitations including suboptimal biodistribution and/or clearance rates, induction of immune responses, potential for off-target effects, and low expression efficiencies of delivered payloads such as mRNA Therefore, the development of next-generation LNPs with, for example, enhanced stability, targeted delivery, and minimized side effects is important for fully realizing the potential of LNPs in the field of nucleic acid therapeutics.
- the present disclosure addresses these needs and provides associated and other advantages.
- the disclosure provides a compound having the formula: or the formula of a pharmaceutically acceptable salt thereof.
- R 1 and R 2 of formula (la) are each independently hydrogen or C 1-4 alkyl. Alternatively, R 1 and R 2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl.
- R 3 , R 4 , and R 5 of formula (la) are each independently cis C 5-20 alkenyl or C 5-20 alkynyl having only one unsaturated bond.
- Subscript n of formula (la) is an integer from 4 to 8
- the disclosure provides a lipid nanoparticle having a pKa from 5.8 to 6.9, i.e., a pKa that is no less than 5.8 and no greater than 6.9.
- the lipid nanoparticle includes an ionizable lipid or a pharmaceutically acceptable salt thereof.
- the ionizable lipid has the formula:
- R 1 and R 2 of formula (I) are each independently hydrogen, C 1-4 alkyl, or 2- to 4-membered heteroalkyl, wherein the alkyl and heteroalkyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C 1-6 hydroxyalkyl, or fluorine.
- R 1 and R 2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C 1-6 hydroxyalkyl, or fluorine.
- R 3 , R 4 , and R 5 of formula (I) are each independently C 5-20 alkyl, C 5-20 alkenyl, C 5-20 alkynyl, or C 5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C 1-6 alkyl or C 2-6 alkenyl.
- R 6 and R 7 of formula (I) are each independently hydrogen, C 1-20 alkyl, C 1-20 alkenyl, or C 1-20 alkynyl, with the proviso that no more than one of R 6 and R 7 is hydrogen.
- R 6 and R 7 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl.
- R 8 and R 9 of formula (I) are each independently hydrogen, C 1-20 alkyl, C 1-20 alkenyl, or C 1-20 alkynyl, with the proviso that no more than one of R 8 and R 9 is hydrogen. Alternatively, R 8 and R 9 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl.
- R 10 and R 11 of formula (I) are each independently hydrogen, C 1-20 alkyl, C 1-20 alkenyl, or C 1-20 alkynyl, with the proviso that no more than one of R 10 and R 11 is hydrogen. Alternatively, R 10 and R 11 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl.
- Each R 12 and R 13 is independently hydrogen or C 1- 6 alkyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C 1-6 hydroxyalkyl, or fluorine. Alternatively, R 12 and R 13 can be combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl.
- X 1 , X 2 , and X 3 of formula (I) are each independently a covalent bond, C 1-6 alkylene, C 1-6 alkenylene, or C 1-6 alkynylene.
- Subscript n of formula (I) is an integer from 2 to 10.
- the disclosure provides a lipid nanoparticle that includes a phospholipid or a pharmaceutically acceptable salt thereof, and an ionizable lipid or a pharmaceutically acceptable salt thereof.
- the phospholipid includes one or more unsaturated tails and a head group having a positively charged nitrogen.
- the ionizable lipid has the formula:
- R 1 and R 2 of formula (I) are each independently hydrogen, C 1-4 alkyl, or 2- to 4-membered heteroalkyl, wherein the alkyl and heteroalkyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C 1-6 hydroxyalkyl, or fluorine.
- R 1 and R 2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C 1-6 hydroxyalkyl, or fluorine.
- R 3 , R 4 , and R 5 of formula (I) are each independently C 5-20 alkyl, C 5-20 alkenyl, C 5-20 alkynyl, or C 5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C 1-6 alkyl or C 2-6 alkenyl.
- R 6 and R 7 of formula (I) are each independently hydrogen, C 1-20 alkyl, C 1-20 alkenyl, or C 1-20 alkynyl. Alternatively, R 6 and R 7 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl.
- R 8 and R 9 of formula (I) are each independently hydrogen, C 1-20 alkyl, C 1-20 alkenyl, or C 1-20 alkynyl. Alternatively, R 8 and R 9 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl.
- R 10 and R 11 of formula (I) are each independently hydrogen, C 1-20 alkyl, C 1-20 alkenyl, or C 1-20 alkynyl. Alternatively, R 10 and R 11 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl.
- Each R 12 and R 13 is independently hydrogen or C 1-6 alkyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C 1-6 hydroxyalkyl, or fluorine. Alternatively, R 12 and R 13 can be combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl.
- X 1 , X 2 , and X 3 of formula (I) are each independently a covalent bond, C 1-6 alkylene, C 1-6 alkenylene, or C 1-6 alkynylene.
- Subscript n of formula (I) is an integer from 2 to 10.
- the disclosure provides a composition, e.g., a pharmaceutical composition.
- the pharmaceutical composition includes a pharmaceutically acceptable carrier or a pharmaceutically acceptable excipient.
- the pharmaceutical composition further includes a lipid nanoparticle as disclosed herein or a compound as disclosed herein.
- the disclosure provides a method of introducing a nucleic acid to a cell.
- the method includes contacting the cell with a lipid nanoparticle as disclosed herein, wherein the lipid nanoparticle includes the nucleic acid.
- the disclosure provides an in vivo method of delivering a nucleic acid to a subject.
- the method includes administering to the subject a lipid nanoparticle as disclosed herein, wherein the lipid nanoparticle includes the nucleic acid.
- the disclosure provides a method of preventing or treating a disease or disorder in a subject.
- the method includes administering to the subject an amount, e.g., a therapeutically effective amount, of a lipid nanoparticle as disclosed herein, a compound as disclosed herein, and/or a pharmaceutical composition as disclosed herein.
- the disclosure provides a method of editing genomic information in a cell.
- the method includes contacting the cell with a lipid nanoparticle as disclosed herein, wherein the lipid nanoparticle includes a nucleic acid.
- the nucleic acid and/or a protein encoded by the nucleic acid is a component of a gene editing system.
- FIG. 1 presents a graph plotting tdTomato activity in the livers of mice administered various lipid nanoparticle formulations in accordance with provided embodiments, where the lipid nanoparticles contained tdTomato mRNA.
- FIG. 2 presents a graph demonstrating determination of the pKa of a lipid nanoparticle formulated in accordance with a provided embodiment. The pKa was measured as the pH at which 50% of the ionizable lipids of the lipid nanoparticle became ionized.
- substituent groups are specified by their conventional chemical formulae, written from left to right, they equally encompass the chemically identical substituents that would result from writing the structure from right to left, e.g., -CH 2 O- is equivalent to -OCH 2 -.
- the compounds of the present disclosure may also contain unnatural proportions of atomic isotopes at one or more of the atoms that constitute such compounds.
- the compounds may be labeled with isotopes, such as for example deuterium ( 2 H), tritium ( 3 H), iodine- 125 ( 125 I), carbon- 13 ( 13 C), or carbon- 14 ( 14 C). All isotopic variations of the compounds of the present disclosure, whether radioactive or not, are encompassed within the scope of the present disclosure.
- substitution when used in relation to a chemical substance, refers to replacement of a hydrogen atom with a non-hydrogen atom or covalently bonded group of atoms.
- the atom or group of atoms replacing the hydrogen atom is referred to as a “substituent.”
- member when used in relation to a chemical substance, refers to a non-hydrogen atom of a covalently bonded group of atoms, e.g., a compound or substituent thereof.
- a phospholipid optionally includes a combination of two or more phospholipids, and the like.
- the terms “including,” “comprising,” “having,” “containing,” and variations thereof, are inclusive and open-ended and do not exclude additional, unrecited elements or method steps beyond those explicitly recited.
- the phrase “consisting of’ is closed and excludes any element, step, or ingredient not explicitly specified.
- the phrase “consisting essentially of’ limits the scope of the described feature to the specified materials or steps and those that do not materially affect the basic and novel characteristics of the disclosed feature.
- lipid particle refers to a particle comprising a phospholipid and an ionizable lipid.
- a lipid particle may comprise additional lipid components, such as a sterol and/or a conjugated lipid, and may further comprise a nucleic acid, wherein the nucleic acid may be encapsulated within the particle .
- Lipid particles and their method of preparation are disclosed in, e.g., U.S. Patent Application Publication Nos. 2004/0142025 and 2007/0042031, and International Patent Application Publication No. WO 2012/000104.
- phospholipid refers to a lipid species having a phosphate- containing hydrophilic “head group” and a hydrophobic moiety.
- the hydrophobic moiety can comprise one or more hydrophobic groups, most typically two hydrophobic groups.
- the hydrophobic groups are also referred to as hydrophobic “tails,” and can be derived from fatty acids and joined by an alcohol residue, e.g., glycerol.
- Exemplary structures of phospholipids include phosphatidylcholine, phosphatidylethanolamine, phosphatidylserine, phosphatidylinositol, phosphatidic acid, phosphatidylcholine, lysophosphatidylcholine, and lysophosphatidylethanolamine
- ionizable lipid refers to a lipid species that carries a net positive charge at a selected pH, such as an acidic pH or physiological pH.
- an ionizable lipid includes an ionizable primary, secondary, or tertiary amine (e.g., pH titratable) head group.
- ionizable lipids promote encapsulation of a negatively charged nucleic acid (e.g., mRNA or siRNA) payload during particle formation.
- ionizable lipids promote endosomal fusion and cytoplasmic release of a payload following cellular uptake of a lipid nanoparticle.
- conjugated lipid refers to a polymer-conjugated lipid, e.g., a polymer-conjugated lipid that inhibits aggregation of lipid particles.
- lipid conjugates include, but are not limited to, polyamide oligomers (e.g., ATTA-lipid conjugates), polysarcosine-lipid conjugates, polyoxazoline (POZ)-lipid conjugates, PEG-lipid conjugates, such as PEG coupled to dialkyloxypropyls, PEG coupled to diacylglycerols, PEG coupled to cholesterol, PEG coupled to phosphatidylethanolamines, PEG conjugated to ceramides (see, e.g., U.S.
- PEG can be conjugated directly to the lipid or may be linked to the lipid via a linker moiety.
- Any linker moiety suitable for coupling the polymer to a lipid can be used including, e.g., non-ester containing linker moieties and ester-containing linker moieties.
- salt refers to acid or base salts of the compounds of the present disclosure.
- a “pharmaceutically acceptable salt” is one that is compatible with other ingredients of a formulation composition containing the compound, and that is not deleterious to a recipient thereof, i.e., a subject. It is thus understood that the pharmaceutically acceptable salts do not cause a significant adverse toxicological effect on the subject.
- alkyl refers to a straight or branched, saturated, aliphatic radical having the number of carbon atoms indicated.
- a branched alkyl may include one or more branches having a geminal, vicinal, and/or isolated pattern.
- an alkyl may include gem-methyl groups.
- Alkyl may also refer to alkyl groups having up to 40 carbon atoms, such as, but not limited to heptyl, octyl, nonyl, decyl, etc. In some aspects, i.e., when indicated in the disclosure, alkyl groups may be substituted. Unless otherwise specified, “substituted alkyl” groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy. In some embodiments including one or more halogen substitutions, fluorine is preferred.
- alkylene refers to a straight or branched, saturated, aliphatic radical having the number of carbon atoms indicated, and linking at least two other groups, i.e., a divalent hydrocarbon radical.
- the two moieties linked to the alkylene may be linked to the same atom or different atoms of the alkylene group.
- a straight chain alkylene may be the bivalent radical of -(CH 2 ) n - where n is 1, 2, 3, 4, 5 or 6.
- a branched alkylene may include one or more branches having a geminal, vicinal, and/or isolated pattern.
- an alkylene may include gem-methyl groups.
- alkenyl refers to an alkyl group having at least one carbon-carbon double bond.
- Alkenyl may include any number of carbons, such as C 2 , C 2-3 , C 2-4 , C 2-5 , C 2-6 , C 2-7 , C 2-8 , C 2-9 , C 2-10 , C 3 , C 3-4 , C 3-5 , C 3-6, C 4 , C 4-5 , C 4-6 , C 5 , C 5-6 , and C 6 .
- Alkenyl groups may have any suitable number of double bonds, including, but not limited to, 1, 2, 3, 4, 5 or more.
- alkenyl groups include, but are not limited to, vinyl (ethenyl), propenyl, isopropenyl, 1-butenyl, 2-butenyl, isobutenyl, butadienyl, 1-pentenyl, 2-pentenyl, isopentenyl, 1,3 -pentadienyl, 1,4-pentadienyl, 1-hexenyl, 2-hexenyl, 3-hexenyl, 1,3-hexadienyl, 1,4-hexadienyl, 1,5-hexadienyl, 2,4-hexadienyl, and 1,3, 5 -hexatrienyl.
- alkenylene groups may be substituted.
- substituted alkenylene groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy.
- alkynyl refers to an alkyl group having at least one carbon-carbon triple bond.
- Alkynyl may include any number of carbons, such as C 2 , C 2-3 , C 2-4 , C 2-5 , C 2-6 , C 2-7 , C 2-8 , C 2-9 , C 2-10 , C 3 , C 3-4 , C 3-5 , C 3-6 , C 4 , C 4-5, C4-6 , C 5 , C 5-6 , and C 6 .
- alkynyl groups may be substituted.
- substituted alkynyl groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy. In some embodiments including one or more halogen substitutions, fluorine is preferred.
- substituted alkynylene groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy.
- alkoxy refers to a substituted alkyl group, as defined above, having an oxygen atom that connects the alkyl group to the point of attachment: alkyl- O-.
- alkoxy groups may have any suitable number of carbon atoms, such as C 1-6 .
- Alkoxy groups include, for example, methoxy, ethoxy, propoxy, isopropoxy, butoxy, 2-butoxy, isobutoxy, secbutoxy, tertbutoxy, pentoxy, hexoxy, etc.
- hydroxyalkyl or “alkylhydroxy” refer to an alkyl group, as defined above, where at least one of the hydrogen atoms is replaced with a hydroxy group.
- alkylhydroxy groups can have any suitable number of carbon atoms, such as C 1-6 .
- Exemplary alkylhydroxy groups include, but are not limited to, hydroxy-methyl, hydroxyethyl (where the hydroxy is in the 1- or 2-position), hydroxypropyl (where the hydroxy is in the 1-, 2- or 3-position), hydroxybutyl (where the hydroxy is in the 1-, 2-, 3- or 4-position), hydroxypentyl (where the hydroxy is in the 1-, 2-, 3-, 4- or 5 -position), hydroxyhexyl (where the hydroxy is in the 1-, 2-, 3-, 4-, 5- or 6-position), 1,2-dihydroxyethyl, and the like.
- heteroalkyl refers to an alkyl group of any suitable length and having any number of (e.g., from 1 to 3) heteroatoms such as N, O or S.
- the heteroatoms may also be oxidized, such as, but not limited to, -S(O)- and -S(O) 2 -.
- heteroalkyl may include ethers, thioethers and alkyl-amines.
- the heteroatom portion of the heteroalkyl may replace a hydrogen of the alkyl group to form a hydroxy, thio, or amino group.
- the heteroatom portion may be the connecting atom, or be inserted between two carbon atoms.
- heteroalkyl groups may be substituted.
- substituted heteroalkyl groups may be substituted with one or more groups selected from halo, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy.
- cycloalkyl by itself or as part of another substituent, refers to a saturated or partially unsaturated, monocyclic, fused polycyclic, spiro polycyclic, or bridged polycyclic ring assembly containing from 3 to 12 ring atoms, or the number of atoms indicated. Cycloalkyl may include any number of carbons, such as C 3-6 , C 4-6 , C 5-6 , C 3-8 , C 4-8, C 5-8 , C 6-8 , C 3-9 , C 3-10 , C 3-11 , and C 3-12 .
- Saturated monocyclic cycloalkyl rings include, for example, cyclopropyl, cyclobutyl, cyclopentyl, cyclohexyl, and cyclooctyl.
- Saturated bicyclic and polycyclic cycloalkyl rings include, for example, bicyclofl. l. l]pentane, norbomane, [2.2.2] bicyclooctane, decahydronaphthalene and adamantane. Cycloalkyl groups may also be partially unsaturated, having one or more double or triple bonds in the ring.
- Representative cycloalkyl groups that are partially unsaturated include, but are not limited to, cyclobutene, cyclopentene, cyclohexene, cyclohexadiene (1,3- and 1,4-isomers), cycloheptene, cycloheptadiene, cyclooctene, cyclooctadiene (1,3-, 1,4- and 1,5-isomers), norbomene, and norbomadiene.
- exemplary groups include, but are not limited to cyclopropyl, cyclobutyl, cyclopentyl, cyclohexyl, cycloheptyl and cyclooctyl.
- exemplary groups include, but are not limited to cyclopropyl, cyclobutyl, cyclopentyl, and cyclohexyl. In some aspects, i.e., when indicated in the disclosure, cycloalkyl groups may be substituted.
- substituted cycloalkyl groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy. In some embodiments including one or more halogen substitutions, fluorine is preferred.
- heterocyclyl refers to a saturated heterocyclyl ring system having from 3 to 15 ring members or the number of atoms indicated, a partially unsaturated non-aromatic ring, or a partially unsaturated, non- aromatic fused, spiro, or bridged multiple-ring system in which one or more of the carbon atoms are each independently replaced with the same or different heteroatom such as N, O or S.
- the heteroatoms may be oxidized to form moieties such as, but not limited to, -S(O)- and -S(O) 2 -.
- Heterocyclyl groups may include any number of ring atoms, such as, C 3-6 , C 4-6 , C 5-6 , C 3-8 , C 4-8 , C 5-8 , C 6-8 , C 3-9 , C 3-10 , C 3-1 1 , C 3-12 , or C 3-15 , wherein at least one of the carbon atoms is replaced by a heteroatom. Any suitable number of carbon ring atoms may be replaced with heteroatoms in the heterocyclyl groups, such as 1, 2, 3, or 4, or 1 to 2, 1 to 3, 1 to 4, 2 to 3, 2 to 4, or 3 to 4.
- the heterocyclyl group may include groups such as aziridine, azetidine, pyrrolidine, piperidine, azepane, azocane, quinuclidine, pyrazolidine, imidazolidine, piperazine (1,2-, 1,3- and 1,4-isomers), oxirane, oxetane, tetrahydrofuran, oxane (tetrahydropyran), oxepane, thiirane, thietane, thiolane (tetrahydrothiophene), thiane (tetrahydrothiopyran), oxazolidine, isoxazolidine, thiazolidine, isothiazolidine, dioxolane, dithiolane, morpholine, thiomorpholine, dioxane, or dithiane.
- groups such as aziridine, azetidine, pyrrolidine, piperidine, azepan
- heterocycloalkyl rings of heterocyclyl groups may also be fused to aromatic or non-aromatic rings to form members including, but not limited to, indoline.
- Heterocyclyl groups thus include partially unsaturated ring systems containing one or more double bonds, including fused ring systems with one aromatic ring and one non-aromatic ring, but not fully aromatic ring systems.
- Examples include dihydroquinolines, e.g., 3,4- dihydroquinoline, dihydroisoquinolines, e.g., 1,2-dihydroisoquinoline, tetrahydroquinolines, e.g., 1,2,3,4-tetrahydroquinoline, tetrahydroisoquinoline, dihydroimidazole, tetrahydroimidazole, etc., isoindoline, isoindolones (e.g., isoindolin-1-one), isatin, dihydrophthalazine, quinolinone, spiro [cyclopropane- 1,1'- isoindolin]-3'-one, and the like.
- dihydroquinolines e.g., 3,4- dihydroquinoline
- dihydroisoquinolines e.g., 1,2-dihydroisoquinoline
- tetrahydroquinolines e.g., 1,2,3,4-t
- Heterocyclyl groups may have 3-15 members, or 3-12 members, or 3-10 members, or 3-7 members, or 5-6 members.
- the heterocyclyl groups may be linked via any position on the ring.
- aziridine may be 1- or 2-aziridine
- azetidine may be 1- or 2- azetidine
- pyrrolidine may be 1-, 2- or 3 -pyrrolidine
- piperidine may be 1-, 2-, 3- or 4-piperidine
- pyrazolidine may be 1-, 2-, 3-, or 4-pyrazolidine
- imidazolidine may be 1-, 2-, 3- or 4-imidazolidine
- piperazine may be 1-, 2-, 3- or 4-piperazine
- tetrahydrofuran may be
- oxazolidine may be 2-, 3-, 4- or 5-oxazolidine, isoxazolidine may be
- heterocyclyl groups may be substituted.
- substituted heterocyclyl groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy. In some embodiments including one or more halogen substitutions, fluorine is preferred.
- halo and “halogen,” by themselves or as part of another substituent, refer to a fluorine, chlorine, bromine, or iodine atom.
- nitro by itself or as part of another substituent refers to the moiety -NO 2 .
- nucleic acid refers to deoxyribonucleic acids (DNA) or ribonucleic acids (RNA) and polymers thereof in either single- or double-stranded form. Unless specifically limited, the term encompasses nucleic acids containing nucleotide analogs or modified backbone residues or linkages, which are synthetic, naturally occurring, and non- naturally occurring, that have similar binding properties as the reference nucleotide and are metabolized in a manner similar to reference nucleotides. Non-limiting examples of nucleotide analogs are described in, e.g., International Patent Application No. WO 2007/024708.
- nucleic acids including such nucleotide analogs, modified backbone residues, or linkages include, without limitation, those containing phosphorothioates, phosphoramidates, methyl phosphonates, chiral-methyl phosphonates, 2'-O-methyl ribonucleotides, and peptide nucleic acids (PNAs).
- PNAs peptide nucleic acids
- a particular nucleic acid sequence also implicitly encompasses conservatively modified variants thereof (e.g., degenerate codon substitutions), alleles, orthologs, single nucleotide polymorphisms (SNPs), and complementary sequences, as well as the sequence explicitly indicated.
- a polynucleotide can comprise modified nucleotides, such as methylated nucleotides, nucleotide analogs, and/or nucleosides suitable for reducing the immunogenicity of RNA, such as those described in International Patent Application No. WO 2007/024708. If present, modifications to the nucleotide structure can be imparted before or after assembly of the polymer. The sequence of nucleotides can be interrupted by non-nucleotide components. A polynucleotide can be further modified after polymerization, such as by conjugation with a labeling component. Polynucleotide sequences, when provided, are listed in the 5' to 3' direction, unless stated otherwise.
- Nucleic acids or polynucleotides can be double- or triple -stranded nucleic acids, as well as single-stranded molecules. In double- or triple-stranded nucleic acids, the nucleic acid strands need not be coextensive, for example, a double-stranded nucleic acid need not be double-stranded along the entire length of both strands.
- Nucleic acid modifications can include addition of chemical groups that incorporate additional charge, polarizability, hydrogen bonding, electrostatic interaction, and functionality to the individual nucleic acid bases or to the nucleic acid as a whole.
- Nucleic acid(s) can be derived from a completely chemical synthesis process, such as a solid phase-mediated chemical synthesis, from a biological source, such as through isolation from any species that produces nucleic acid, or from processes that involve the manipulation of nucleic acids by molecular biology tools, such as DNA replication, PCR amplification, reverse transcription, in vitro transcription such as described in, e.g., International Patent Application Publication No. WO 2007/024708, or from a combination of those processes.
- a completely chemical synthesis process such as a solid phase-mediated chemical synthesis
- a biological source such as through isolation from any species that produces nucleic acid, or from processes that involve the manipulation of nucleic acids by molecular biology tools, such as DNA replication, PCR amplification, reverse transcription, in vitro transcription such as described in, e.g., International Patent Application Publication No. WO 2007/024708, or from a combination of those processes.
- the term “fully encapsulated” indicates that the nucleic acid in the particles is not significantly degraded after exposure to serum or a nuclease assay that would significantly degrade free nucleic acids.
- a fully encapsulated system preferably less than 25% of particle nucleic acid is degraded in a treatment that would normally degrade 100% of free nucleic acid, more preferably less than 10% and most preferably less than 5% of the particle nucleic acid is degraded.
- Fully encapsulated also suggests that the particles are serum stable, that is, that they do not rapidly decompose into their component parts upon in vivo administration.
- the term “contacting” refers to either the direct or indirect in vitro or in vivo delivering of lipid nanoparticles to the surfaces of cells, e.g., by providing lipid nanoparticles at or proximate to a location of the cells to be contacted.
- the in vitro contacting may involve, for example, cells in a cell culture or tissue culture.
- the cell culture or tissue culture may include cells in a suspension and/or adherent cells.
- the contacted cells may be of same cell type or of two or more different cell types. Merely for illustration, different contacted cell types may include, for example, hepatocytes and hepatic stellate cells.
- different cell types are cultured together before and/or during the contacting with lipid nanoparticles.
- different cell types are cultured separately.
- one cell type of two or more cell types to be contacted is specifically cultured in the absence of any other cell types of the two or more cell types.
- hepatic stellate cells are cultured, either alone or in combination with other cell types from the liver, such as, e.g., liver cells, prior to and/or during the contacting.
- the tissue culture is a liver tissue culture.
- the in vivo contacting of cells typically involves administering the lipid nanoparticles to a subject, where the cells are within the body of the subject.
- the administering is proximate to the location of the contacted cells within the subject’s body. In other examples, the administering is distal to the location of the contacted cells, and the lipid nanoparticles migrate to the cell location, e.g., via the targeting capabilities of the particles.
- the term “subject” refers to a vertebrate, and preferably to a mammal.
- Mammalian subjects for which the provided composition is suitable include, but are not limited to, mice, rats, simians, humans, farm animals, sport animals, and pets.
- the subject is human.
- the subject is male.
- the subject is female.
- the subject is an adult.
- the subject is an adolescent.
- the subject is a child.
- the subject is above 10 years of age, e.g., above 20 years of age, above 30 years of age, above 40 years of age, above 50 years of age, above 60 years of age, above 70 years of age, or above 80 years of age. In some embodiments, the subject is less than 80 years of age, e.g., less than 70 years of age, less than 60 years of age, less than 50 years of age, less than 40 years of age, less than 30 years of age, less than 20 years of age, or less than 10 years of age.
- the terms “pharmaceutically acceptable excipient” and “pharmaceutically acceptable carrier” refer to a substance that aids the administration of an active agent to and absorption by a subject and may be included in the compositions of the present disclosure without causing a significant adverse toxicological effect on the subject.
- pharmaceutically acceptable excipients and carriers include water, NaCl, normal saline solutions, normal sucrose, normal glucose, binders, fillers, disintegrants, lubricants, coatings, and the like.
- pharmaceutically acceptable excipients and carriers include water, NaCl, normal saline solutions, normal sucrose, normal glucose, binders, fillers, disintegrants, lubricants, coatings, and the like.
- administering refers to oral administration, administration as a suppository, topical contact, parenteral, intravenous, intraperitoneal, intramuscular, intralesional, intranasal, subcutaneous, intrathecal, intracerebroventricular, intraparenchymal, subretinal, or intravitreal administration, or the implantation of a slow-release device e.g., a mini-osmotic pump, to the subject.
- a slow-release device e.g., a mini-osmotic pump
- the present disclosure provides various lipid nanoparticles that include an ionizable lipid or a pharmaceutically acceptable salt thereof.
- the ionizable lipid of the lipid nanoparticles is a nitrogen-containing silyl ether, and can be any of those described in further detail in Section B.2.
- the particular selection, composition, and amounts (e.g., relative amounts) of the ionizable lipid in the lipid nanoparticles provide surprising improvements in various properties of the lipid nanoparticles, e.g., properties advantageous for the delivery of nucleic acids. These improved properties include, for example, enhanced targeting, optimized stability, and decreased toxicity and immune stimulation.
- the lipid nanoparticles can be configured to have a size that is beneficial for particular applications, such as the in vivo or in vivo delivery of nucleic acids to a cell or to a subject.
- the provided lipid nanoparticles can have a mean diameter that is, for example, from about 40 nm to about 150 nm, from about 50 nm to about 150 nm, from about 60 nm to about 130 nm, from about 70 nm to about 110 nm, from about 60 nm to about 100 nm, from about 50 to about 80 nm, from about 60 to about 80 nm, from about 60 to about 90 nm, or from about 70 to about 90 nm.
- the lipid nanoparticles can be configured, e.g., through the selection of their components, to be substantially non-toxic.
- the ionizable lipid of the provided lipid nanoparticle comprises from about 30 mol % to about 80 mol % of the total lipid present in the particle (e.g., from about 40 mol % to about 70 mol %, from about 45 mol % to about 65 mol %, from about 45 mol % to about 60 mol %, or from about 50 mol % to about 60 mol % of the total lipid present in the particle); the phospholipid of the lipid nanoparticle comprises from about 3 mol % to about 20 mol % of the total lipid present in the particle (e.g., from about 5 mol % to about 15 mol %, or from about 8 mol % to about 12 mol % of the total lipid present in the particle); a cholesterol or derivative thereof of the lipid nanoparticle comprises from about 10 mol % to about 60 mol % of the total lipid present in the particle (e.g., from about 20 mol %
- the lipid nanoparticle includes the ionizable lipid comprising from about 52 mol % to about 57 mol % of the total lipid present in the particle, the phospholipid comprising from about 10 mol % to about 12 mol % of the total lipid present in the particle, a cholesterol or derivative thereof comprising about 31 mol % to about 34 mol % of the total lipid present in the particle, and a conjugated lipid comprising about 1 mol % to about 3 mol % of the total lipid present in the particle.
- the lipid nanoparticle includes the ionizable lipid comprising about 54.6 mol % of the total lipid present in the particle; the phospholipid comprising about 10.9 mol % of the total lipid present in the particle; a cholesterol or derivative thereof comprising about 32.8 mol % of the total lipid present in the particle; and a conjugated lipid comprising about 1.6 mol % of the total lipid present in the particle.
- the lipid nanoparticle includes the ionizable lipid comprising about 54.2 mol % of the total lipid present in the particle; the phospholipid comprising about 10.8 mol % of the total lipid present in the particle; a cholesterol or derivative thereof comprising about 32.5 mol % of the total lipid present in the particle; and a conjugated lipid comprising about 2.5 mol % of the total lipid present in the particle.
- the lipid nanoparticle described herein provides the nanoparticle with a pKa giving the nanoparticle targeting, stability, degradability, and toxicity properties advantageous for, e.g., the delivery of nucleic acids.
- the lipid nanoparticle has apKa from about 5.8 to about 6.9, e.g., from about 5.8 to about 6.8, from about 5.8 to about 6.7, from about 5.8 to about 6.6, from about 5.8 to about
- 6.6 from about 6.0 to about 6.5, from about 6.0 to about 6.4, from about 6.0 to about 6.3, from about 6.0 to about 6.2, from about 6.0 to about 6.1, from about 6.1 to about 6.9, from about 6.1 to about 6.8, from about 6.1 to about 6.7, from about 6. 1 to about 6.6, from about 6. 1 to about 6.5, from about 6. 1 to about 6.4, from about 6.1 to about 6.3, from about 6.
- the lipid nanoparticle exhibits advantageous targeting, stability,
- the pKa of the lipid nanoparticle described herein is determined using an assay measuring ionization at a temperature between about 34 °C and about 40 °C.
- the lipid nanoparticle has a pKa, as determined using an assay performed at a temperature between about 34 °C and about 40 °C, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above.
- the pKa of the lipid nanoparticle described herein is determined using an assay measuring ionization at a temperature of about 37 °C.
- the lipid nanoparticle has a pKa, as determined using an assay performed at a temperature of about 37 °C, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above.
- the pKa of the lipid nanoparticle described herein is determined using an assay measuring ionization at more than 5 different pH levels.
- the lipid nanoparticle has a pKa, as determined using an assay performed at more than 5 different pH levels, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above.
- the pKa of the lipid nanoparticle described herein is determined using an assay measuring ionization at more than 15 different pH levels.
- the lipid nanoparticle has a pKa, as determined using an assay performed at more than 15 different pH levels, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above.
- the pKa of the provided lipid nanoparticle is determined using in situ fluorescence titration, and preferably TNS fluorescence titration. This assay typically yields a sigmoidal curve showing fluorescence, such as TNS fluorescence, wherein the pKa of the provided lipid nanoparticle is determined to be the value that corresponds to 0.5 normalized fluorescence, such as normalized TNS fluorescence, on a scale from 0 to 1.0.
- the pKa of the provided lipid nanoparticle is determined using the assay described in Example 7.
- the lipid nanoparticle has a pKa, as determined using the assay described in Example 7, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above.
- the lipid nanoparticle preferably includes a phospholipid or a pharmaceutically acceptable salt thereof (preferably comprising between about 1 mol % and about 20 mol % of the total lipid present in the lipid nanoparticle), an ionizable lipid or a pharmaceutically acceptable salt thereof (preferably comprising between about 30 mol % and about 70 mol % of the total lipid present in the lipid nanoparticle), cholesterol or a derivative thereof (preferable comprising between about 0.1 mol % and about 5 mol % of the total lipid present in the lipid nanoparticle), and a conjugated lipid (preferably comprising between about 0.
- a phospholipid or a pharmaceutically acceptable salt thereof preferably comprising between about 1 mol % and about 20 mol % of the total lipid present in the lipid nanoparticle
- an ionizable lipid or a pharmaceutically acceptable salt thereof preferably comprising between about 30 mol % and about 70 mol % of the total lipid present in the lipid nanoparticle
- the lipid nanoparticle further includes a nucleic acid.
- the provided lipid nanoparticle has been demonstrated as having in vivo clearance and degradation characteristics that are particularly beneficial when the nanoparticle is used to administer a nucleic acid to a subject, e.g., to provide a treatment to the subject and/or to edit genetic information of the subject. Clearance and degradation rates that are too high can prevent a lipid nanoparticle from protecting a cargo, such as a nucleic acid cargo, and from successfully delivering it to its targeted destination within the subject. Alternatively, clearance and degradation rates that are too low can be associated with increased toxicity or undesirable off- target effects.
- One useful measure of these beneficial clearance and degradation characteristics involves a comparison of the amount of ionizable lipid in the liver of a subject at different time points following administering the lipid nanoparticle to the subject.
- Ionizable lipids are a major component of lipid nanoparticles, typically used in the highest molar amounts of the various lipids present in the particles. For applications that necessitate more frequent dosing, lipid accumulation in tissues may be exacerbated, resulting in potential tolerability challenges. Because the role of lipid nanoparticles in delivering nucleic acid payloads is essentially complete within hours after administration, there is no need for the lipid components of the particle to persist in tissues for a prolonged period of time.
- ionizable lipids that enable rapid clearance in tissues are preferred.
- the provided lipid nanoparticles exhibit such preferred clearance properties.
- a concentration of the ionizable lipid in the liver of subject 7 days after the administering is less than about 50%, e.g., less than about 45%, less than about 40%, less than about 35%, less than about 30%, less than about 25%, less than about 20%, less than about 15%, less than about 10%, or less than about 5% of a concentration of the ionizable lipid in the liver 24 hours after the administering.
- Each R 12 and R 13 can independently be hydrogen or C 1-6 alkyl optionally having one or more substitutions, wherein the substitutions can each independently be hydroxy, C 1-6 hydroxyalkyl, or fluorine. Alternatively, R 12 and R 13 can be combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl.
- X 1 , X 2 , and X 3 of formula (I) can each independently be a covalent bond, C 1-6 alkylene, C 1-6 alkenylene, or C 1-6 alkynylene.
- Subscript n of formula (I) is an integer that can be from 2 to 10.
- the disclosure also provides compounds, i.e., ionizable lipid compounds, having the structure of formula (I) or the structure of a salt, e.g., a pharmaceutically acceptable salt, thereof.
- one or more of R 3 , R 4 , and R 5 of formula (I) is C 6-12 alkenyl. In some embodiments, at least one of R 3 , R 4 , and R 5 of formula (I) is cis- C 6-12 alkenyl. In some embodiments, at least two of R 3 , R 4 , and R 5 are cis-C 6-12 alkenyl. In some embodiments, each of R 3 , R 4 , and R 5 is cis-C 6-12 alkenyl. In some embodiments, at least one of R 3 , R 4 , and R 5 of formula (I) is cis-C 6-12 alkenyl having only one double bond.
- R 6 , R 8 , and R 10 are C 1-20 alkenyl. In some embodiments, each of R 6 , R 8 , and R 10 are C 1-20 alkenyl. In some embodiments, at least one of R 6 , R 8 , and R 10 is cis- dec-4-ene-1-yl. In some embodiments, at least two of R 6 , R 8 , and R 10 are cis-dec-4-ene-1-yl. In some embodiments, each of R 6 , R 8 , and R 10 are cis-dec-4-ene-1-yl.
- At least one of R 7 , R 9 , and R 11 of formula (I) is hydrogen. In some embodiments, at least two of R 7 , R 9 , and R 11 are hydrogen. In some embodiments, each of R 7 , R 9 , and R 11 are hydrogen. In some embodiments, at least one of R 7 , R 9 , and R 11 is C 1-20 alkenyl. In some embodiments, at least two of R 7 , R 9 , and R 11 are C 1-20 alkenyl. In some embodiments, each of R 7 , R 9 , and R 11 are C 1-20 alkenyl. In some embodiments, at least one of R 7 , R 9 , and R 11 is C 1-20 alkynyl. In some embodiments, at least two of R 7 , R 9 , and R 11 are C 1-20 alkynyl. In some embodiments, each of R 7 , R 9 , and R 11 are C 1-20 alkynyl. In some embodiments, each of R 7 , R 9
- the total number of carbons in R 3 , R 6 , and R 7 , the total number of carbons in R 4 , R 8 , and R 9 , and the total number of carbons in R 5 , R 10 , and R 11 are each independently or identically 7, 8, 9, 10, 11, or 12.
- each R 12 and R 13 of formula (I) is hydrogen. In some embodiments, at least one R 12 or at least one R 13 is C 1-6 alkyl. In some embodiments, only one R 12 or R 13 is C 1-6 alkyl.
- Each R 12 or R 13 that is alkyl can independently be, for example, methyl, ethyl, propyl, isopropyl, butyl, isobutyl, sec-butyl, tert-butyl, pentyl, isopentyl, 2-methylbutyl, pentan-2 -yl, 3-methylbutan-2-yl, pentan-3-yl, neopentyl, tert-pentyl, hexyl, 4-methylpentyl, 3- methylpentyl, 2-methylpentyl, hexan-2-yl, 2,3 -dimethylbutyl, 4-methylpentan-2-yl, 3- methylpentan-2-yl, 2-ethylbutyl, hexan-3-yl, 3,3-dimethylbutyl, 2,2-dimethylbutyl, or 2- methylpentan-2-yl .
- At least one of X 1 , X 2 , and X 3 of formula (I) is a covalent bond. In some embodiments, at least two of X 1 , X 2 , and X 3 are a covalent bond. In some embodiments, each of X 1 , X 2 , and X 3 is a covalent bond. In some embodiments, at least one of X 1 , X 2 , and X 3 is C 1-6 alkylene. In some embodiments, at least two of X 1 , X 2 , and X 3 are C 1-6 alkylene. In some embodiments, each of X 1 , X 2 , and X 3 is C 1-6 alkylene.
- each of X 1 , X 2 , and X 3 is methylene. In some embodiments, at least one of X 1 , X 2 , and X 3 is C 1-6 alkenylene. In some embodiments, at least two of X 1 , X 2 , and X 3 are C 1-6 alkenylene. In some embodiments, each of X 1 , X 2 , and X 3 of formula (I) is C 1-6 alkenylene. In some embodiments, at least one of X 1 , X 2 , and X 3 is C 1-6 alkynylene. In some embodiments, at least two of X 1 , X 2 , and X 3 are C 1-6 alkynylene. In some embodiments, each of X 1 , X 2 , and X 3 of formula (I) is C 1- 6 alkynylene.
- n of formula (I) is from 2 to 9, from 2 to 8, from 2 to 7, from 2 to 6, from 2 to 5, from 2 to 4, from 2 to 3, from 3 to 10, from 3 to 9, from 3 to 8, from 3 to 7, from 3 to 6, from 3 to 5, from 3 to 4, from 4 to 10, from 4 to 9, from 4 to 8, from 4 to 7, from 4 to 6, from 4 to 5, from 5 to 10, from 5 to 9, from 5 to 8, from 5 to 7, from 5 to 6, from 6 to 10, from 6 to 9, from 6 to 8, from 6 to 7, from 7 to 10, from 7 to 9, from 7 to 8, from 8 to 10, from 8 to 9, or from 9 to 10.
- n is 2. In some examples, n is 3. In some examples, n is 4. In some examples, n is 5. In some examples, n is 6. In some examples, n is 7. In some examples, n is 8. In some examples, n is 9. In some examples, n is 10. In some examples, n is 6 to 8.
- the ionizable lipid of the present disclosure comprises a racemic mixture. In other embodiments, an ionizable lipid of the present disclosure comprises a mixture of one or more diastereomers. In certain embodiments, an ionizable lipid of the present disclosure comprises at least about 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, or 95% enantiomeric excess. In certain other embodiments, an ionizable lipid of the present disclosure is enriched in one diastereomer, such that the lipid comprises at least about 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, or 95% diastereomeric excess.
- an ionizable lipid of the present disclosure is chirally pure (e.g., comprises a single optical isomer).
- an ionizable lipid of the present disclosure is enriched in one optical isomer (e.g., an optically active isomer), such that the lipid comprises at least about 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, or 95% isomeric excess.
- the present disclosure provides the synthesis of any of the ionizable lipids disclosed herein as a racemic mixture or in optically pure form.
- the ionizable lipid of the provided lipid nanoparticle has the formula:
- R 3 , R 4 , and R 5 of formula (la) are as defined above for formula (I).
- the disclosure also provides compounds, i.e., ionizable lipid compounds, having the structure of formula (la) or the structure of a salt, e.g., a pharmaceutically acceptable salt, thereof.
- the ionizable lipid of the provided lipid nanoparticle includes one or more of:
- the ionizable lipid present in the lipid nanoparticle comprises about 40 mol %, about 45 mol %, about 50 mol %, about 55 mol %, about 60 mol %, or about 65 mol % of the total lipid present in the particle.
- the provided lipid nanoparticle further includes cholesterol or one or more derivatives thereof.
- the cholesterol or cholesterol derivative can be selected or configured to provide the lipid nanoparticle with a desired particle size, stability, and capacity for encapsulation of nucleic acids.
- the lipid nanoparticle can include, for example, cholestanol, cholestanone, cholestenone, coprostanol, cholesteryl-2'-hydroxyethyl ether, cholesteryl-4'- hydroxybutyl ether, cholesterol hydroxyethyl ether, cholesterol hydroxyhexyl ether, cholesterol stearate, cholesterol oleate, 7-betahydroxycholesterol, 7-alphahydroxycholesterol, 4-betahydroxycholesterol, cholesterol PEG, beta sitosterol, or any combination thereof.
- the lipid nanoparticle includes cholesterol, but substantially no derivative of cholesterol.
- the cholesterol or cholesterol derivative present in the lipid particle comprises about 20 mol %, about 25 mol %, about 30 mol %, about 35 mol %, about 40 mol %, about 45 mol %, or about 50 mol % of the total lipid present in the particle. 4. Conjugated Lipid
- Conjugated lipids suitable for use with the provided lipid nanoparticle include, but are not limited to, PEG-lipid conjugates, ATTA-lipid conjugates, cationic-polymer-lipid conjugates (CPLs), polyoxazoline (POZ)-lipids, polysarcosine (pSAR)-lipids and mixtures thereof.
- the lipid nanoparticle comprises either a PEG-lipid conjugate or an ATTA-lipid conjugate optionally together with a CPL.
- the conjugated lipid is a PEG-lipid.
- PEG-lipids include, but are not limited to, PEG coupled to dialkyloxypropyls (PEG-DAA) as described in, e.g., International Patent Application Publication No. WO 05/026372, PEG coupled to diacylglycerol (PEG-DAG) as described in, e.g., U.S. Patent Application Publication Nos. 2003/0077829 and 2005/0008689, PEG coupled to phospholipids such as phosphatidylethanolamine (PEG-PE), PEG conjugated to ceramides as described in, e.g., U.S. Pat. No.
- the provided lipid nanoparticle can include a one or more methyl capped PEG-lipid, one or more uncapped PEG-lipids, or a combination thereof.
- MePEG-OH monomethoxypolyethylene glycol
- MePEG-S monomethoxypolyethylene glycol-succinate
- MePEG-3-NHS monomethoxypolyethylene glycolsuccinimidyl succinate
- MePEG-NH2 monomethoxypolyethylene glycol-amine
- MePEG-TRES monomethoxypolyethylene glycol-tresylate
- Me PEG-IM monomethoxypolyethylene glycol-imidazolyl-carbonyl
- Other PEGs such as those described in U.S. Pat. Nos.
- 6,774,180 and 7,053,150 are also useful for preparing the PEG-lipid conjugates of the present disclosure.
- the disclosures of these patents are herein incorporated by reference in their entirety for all purposes.
- monomethoxypolyethyleneglycolacetic acid (McPEG-CTECOOH) is particularly useful for preparing PEG-lipid conjugates including, e.g., PEG-DAA conjugates.
- the PEG moiety of the PEG-lipid conjugates described herein may comprise an average molecular weight ranging from about 550 daltons to about 10,000 daltons. In certain instances, the PEG moiety has an average molecular weight of from about 750 daltons to about 5,000 daltons (e.g., from about 1,000 daltons to about 5,000 daltons, from about 1,500 daltons to about 3,000 daltons, from about 750 daltons to about 3,000 daltons, from about 750 daltons to about 2,000 daltons, etc.). In preferred embodiments, the PEG moiety has an average molecular weight of about 2,000 daltons or about 750 daltons.
- the PEG can be optionally substituted by an alkyl, alkoxy, acyl, or aryl group.
- the PEG can be conjugated directly to the lipid or may be linked to the lipid via a linker moiety.
- Any linker moiety suitable for coupling the PEG to a lipid can be used including, e.g., non-ester containing linker moieties and ester-containing linker moieties.
- the linker moiety is a non-ester containing linker moiety.
- non-ester containing linker moiety refers to a linker moiety that does not contain a carboxylic ester bond (-OC(O)-).
- Suitable non-ester containing linker moieties include, but are not limited to, amido (-C(O)NH-), amino (-NR-), carbonyl (-C(O)-), carbamate (NHC(O)O-), urea (-NHC(O)NH-), disulphide (-S-S-), ether (-O-), succinyl ((O)CCH 2 CH 2 C(O)-), succinamidyl (-NHC(O)CH 2 CH 2 C(O)NH-), ether, disulphide, as well as combinations thereof (such as a linker containing both a carbamate linker moiety and an amido linker moiety).
- a carbamate linker is used to couple the PEG to the lipid.
- an ester containing linker moiety is used to couple the PEG to the lipid.
- Suitable ester containing linker moieties include, e.g., carbonate (-OC(O)O-), succinoyl, phosphate esters (-O-(O)POH-O-), sulfonate esters, and combinations thereof.
- hydrophilic polymers can be used in place of PEG.
- suitable polymers include, but are not limited to, ATTA, cationic-polymers, polyoxazoline (POZ), polysarcosine, polyvinylpyrrolidone, polymethyloxazoline, polyethyloxazoline, polyhydroxypropyl methacrylamide, polymethacrylamide and poly dimethylacrylamide, polylactic acid, polyglycolic acid, poly (ethyl ethylene phosphate) (PEEP), and derivatized celluloses such as hydroxymethylcellulose or hydroxyethylcellulose.
- POZ polyoxazoline
- PEEP poly (ethyl ethylene phosphate)
- derivatized celluloses such as hydroxymethylcellulose or hydroxyethylcellulose.
- the conjugated lipid of the provided lipid nanoparticles can include , e.g., one or more of the following: a polyethyleneglycol (PEG)-lipid conjugate, a polyamide (ATTA)-lipid conjugate, or mixtures thereof.
- the nucleic acid-lipid particles comprise either a PEG-lipid conjugate or an ATTA-lipid conjugate.
- the conjugated lipids may comprise a PEG-lipid including, e.g., a PEG-diacylglycerol (DAG), a PEG dialkyloxypropyl (DAA), a PEG-phospholipid, a PEG-ceramide (Cer), or mixtures thereof.
- the PEG-DAA conjugate may be PEG-dilauryloxypropyl (C12), a PEG-dimyristyloxypropyl (C14), a PEG- dipalmityloxypropyl (C16), a PEG-distearyloxypropyl (C18), or mixtures thereof.
- PEG-lipid conjugates suitable for use in the provided lipid nanoparticle include, but are not limited to, mPEG2000-1,2-di-O-alkyl-sn3-carbomoylglyceride (PEG-C- DOMG).
- PEG-C- DOMG mPEG2000-1,2-di-O-alkyl-sn3-carbomoylglyceride
- the synthesis of PEG-C-DOMG is described in PCT Application No. PCT/US08/88676, filed Dec. 31, 2008, the disclosure of which is herein incorporated by reference in its entirety for all purposes.
- PEG-lipid conjugates suitable for use in the disclosure include, without limitation, 1-[8'-(1,2-dimyristoyl-3-propanoxy)-carboxamido- 3',6'-dioxaoctanyl]carbamoyl-w-methylpoly(ethylene glycol) (2 KPEG-DMG).
- 2 KPEG-DMG 1-[8'-(1,2-dimyristoyl-3-propanoxy)-carboxamido- 3',6'-dioxaoctanyl]carbamoyl-w-methylpoly(ethylene glycol)
- the conjugated lipid present in the provided lipid nanoparticle can comprise, for example, from about 0.1 mol % to about 10 mol %, from about 0.5 mol % to about 10 mol %, from about 1 mol % to about 10 mol %, from about 1.5 mol % to about 10 mol %, from about 2 mol % to about 10 mol %, from about 2.5 mol % to about 10 mol %, from about 3 mol % to about 10 mol %, from about 4 mol % to about 10 mol %, from about 5 mol % to about 10 mol %, from about 0.1 mol % to about 5 mol %, from about 0.3 mol % to about 5 mol %, from about 0.5 mol % to about 5 mol %, from about 1 mol
- the conjugated lipid present in the lipid nanoparticle comprises about 0.1 mol %, about 0.5 mol %, about 1 mol %, about 1.2 mol %, about 1.4 mol %, about 1.5 mol %, about 1.6 mol %, about 1.8 mol %, about 2 mol %, about 2.2 mol %, about 2.5 mol %, or about 3 mol % of the total lipid present in the particle.
- the rate at which the conjugated lipid exchanges out of the lipid nanoparticle can be controlled, for example, by varying the concentration of the lipid conjugate, by varying the molecular weight of the PEG, or by varying the chain length and degree of saturation of the acyl chain groups on the phosphatidylethanolamine or the ceramide.
- the provided lipid nanoparticles are associated with a nucleic acid.
- the composition of the lipid nanoparticle can be selected or configured such that nucleic acids, when present in lipid nanoparticles, are resistant in aqueous solution to degradation with a nuclease.
- Nucleic acid may be administered alone in the lipid nanoparticles described herein, or in combination (e.g., co-administered) with lipid particles comprising peptides, polypeptides, or small molecules such as conventional drugs.
- the nucleic acid is at least 50% encapsulated within the lipid nanoparticle; in one embodiment, the nucleic acid is at least 75% encapsulated within the lipid nanoparticle; in one embodiment, the nucleic acid is at least 90% encapsulated within the lipid nanoparticle; and in one embodiment, the nucleic acid is fully encapsulated within the lipid nanoparticle.
- the present disclosure provides a lipid nanoparticle formulation comprising a plurality or population of lipid nanoparticles.
- the nucleic acid is fully encapsulated within the lipid portion of the lipid nanoparticles such that from about 30% to about 100%, from about 40% to about 100%, from about 50% to about 100%, from about 60% to about 100%, from about 70% to about 100%, from about 80% to about 100%, from about 90% to about 100%, from about 30% to about 95%, from about 40% to about 95%, from about 50% to about 95%, from about 60% to about 95%, %, from about 70% to about 95%, from about 80% to about 95%, from about 85% to about 95%, from about 90% to about 95%, from about 30% to about 90%, from about 40% to about 90%, from about 50% to about 90%, from about 60% to about 90%, from about 70% to about 90%, from about 80% to about 90%, or at least about 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%
- the nucleic acid that is present in the lipid nanoparticles described herein can include or consist of any form of nucleic acid that is known.
- the nucleic acids used herein can be single-stranded DNA or RNA (e.g., ssDNA or ssRNA), or double -stranded DNA or RNA (e.g., dsDNA or dsRNA), or DNA-RNA hybrids.
- Single -stranded nucleic acids include, e.g., mRNA, guide RNA (gRNA), antisense oligonucleotides, ribozymes, mature miRNA, self-amplifying RNA (SAM), and triplex-forming oligonucleotides.
- double-stranded DNA examples include, e.g., structural genes, genes including control and termination regions, and self- replicating systems such as viral or plasmid DNA.
- double-stranded RNA examples include, e.g., siRNA and other RNAi agents such as aiRNA and pre-miRNA.
- Nucleic acids may be of various lengths, generally dependent upon the particular form of nucleic acid.
- mRNA, plasmids, or genes may be from about 1,000 to about 100,000 nucleotides in length.
- oligonucleotides may range from about 10 to about 100 nucleotides in length.
- oligonucleotides both single-stranded, double -stranded, and triple -stranded, may range in length from about 10 to about 60 nucleotides, from about 15 to about 60 nucleotides, from about 20 to about 50 nucleotides, from about 15 to about 30 nucleotides, or from about 20 to about 30 nucleotides in length.
- the nucleic acid of a provided lipid nanoparticle comprises or consists of a modified or substituted polynucleotide or oligonucleotide.
- Modified or substituted polynucleotides and oligonucleotides can be preferred over native forms in some instances because of properties such as, for example, enhanced cellular uptake, reduced immunogenicity, and increased stability in the presence of nucleases.
- the nucleic acid is an RNA molecule comprising at least one modified nucleotide.
- the RNA molecule comprises one, two, three, four, five, six, seven, eight, nine, ten, or more modified nucleotides in the double- stranded region.
- the RNA molecule e.g., siRNA
- less than about 25% e.g., less than about 25%, 20%, 15%, 10%, or 5%
- from about 1 % to about 25% e.g., from about l%-25%, 5%-25%, 10%-25%, 15%-25%, 20%-25%, or 10%-20%) of the nucleotides in the double-stranded region comprise modified nucleotides.
- the RNA molecule comprises modified nucleotides including, but not limited to, 2'-O-methyl (2'Ome) nucleotides, 2'-deoxy-2'-fluoro (2'F) nucleotides, 2'deoxy nucleotides, 2'-O-(2-methoxyethyl) (MOE) nucleotides, locked nucleic acid (LNA) nucleotides, and mixtures thereof.
- 2'-O-methyl (2'Ome) nucleotides 2'-deoxy-2'-fluoro (2'F) nucleotides
- MOE 2-methoxyethyl
- LNA locked nucleic acid
- the RNA comprises 2'Ome nucleotides (e.g., 2'Ome purine and/or pyrimidine nucleotides) such as, for example, 2'Ome- guanosine nucleotides, 2'Ome-uridine nucleotides, 2'Ome-adenosine nucleotides, 2'Ome- cytosine nucleotides, and mixtures thereof.
- the RNA does not comprise 2'Ome-cytosine nucleotides.
- the RNA comprises a hairpin loop structure.
- the RNA may comprise modified nucleotides in one strand (i.e., sense or antisense) or both strands of a double-stranded region of the RNA molecule.
- uridine and/or guanosine nucleotides are modified at selective positions in the double-stranded region of the RNA duplex.
- at least one, two, three, four, five, six, or more of the uridine nucleotides in the sense and/or antisense strand can be a modified uridine nucleotide such as a 2'Ome-uridine nucleotide.
- At least one, two, three, four, five, six, seven, or more 5 '-GU-3' motifs in an RNA sequence may be modified, e.g., by introducing mismatches to eliminate the 5'-GU-3' motifs and/or by introducing modified nucleotides such as 2'Ome nucleotides.
- the 5'-GU-3' motif can be in the sense strand, the antisense strand, or both strands of the RNA sequence.
- the 5'-GU-3' motifs may be adjacent to each other or, alternatively, they may be separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, or more nucleotides.
- the nucleic acid of a provided lipid nanoparticle includes or consists of an oligonucleotide.
- Oligonucleotides are generally classified as deoxyribooligonucleotides or ribooligonucleotides.
- a deoxyribooligonucleotide consists of a 5 -carbon sugar called deoxyribose joined covalently to phosphate at the 5' and 3' carbons of this sugar to form an alternating, unbranched polymer.
- a ribooligonucleotide consists of a similar repeating structure where the 5 -carbon sugar is ribose.
- an oligonucleotide (or a strand thereof) specifically hybridizes to or is complementary to a target polynucleotide sequence.
- the terms “specifically hybridizable” and “complementary” as used herein indicate a sufficient degree of complementarity such that stable and specific binding occurs between the DNA or RNA target and the oligonucleotide. It is understood that an oligonucleotide need not be 100% complementary to its target nucleic acid sequence to be specifically hybridizable.
- an oligonucleotide is specifically hybridizable when binding of the oligonucleotide to the target sequence interferes with the normal function of the target sequence to cause a loss of utility or expression therefrom, and there is a sufficient degree of complementarity to avoid non-specific binding of the oligonucleotide to non-target sequences under conditions in which specific binding is desired, i.e., under physiological conditions in the case of in vivo assays or therapeutic treatment, or, in the case of in vitro assays, under conditions in which the assays are conducted.
- the oligonucleotide may include 1, 2, 3, or more base substitutions as compared to the region of a gene or mRNA sequence that it is targeting or to which it specifically hybridizes. a) mRNA
- compositions comprising the lipid nanoparticles described herein and methods of use thereof for expressing one or more mRNA molecules (e.g., a cocktail of mRNA molecules) in a cell, e.g., a cell within an organism (e.g., a mammal, such as a human).
- mRNA molecules encode one or more polypeptides that is/are expressed within the cell.
- Lipid particle formulations comprising mRNA molecules described herein are useful for a variety of applications including protein replacement therapy, vaccines, cancer immunotherapy, and gene editing.
- the lipid nanoparticles include mRNA delivered (e.g., specifically delivered) to the liver for expression therein, e.g., for the editing of genomic information within cells of the liver.
- the lipid particles described herein are used for treating a disease, wherein expression of the polypeptides encoded by the mRNA molecules within a diseased organism (e.g., a mammal, such as a human) ameliorates one or more symptoms of the disease.
- a diseased organism e.g., a mammal, such as a human
- the compositions and methods described herein are particularly useful for treating human diseases caused by the absence, or reduced levels, of a functional polypeptide within the human body.
- the lipid particles described herein are used as a vaccine for preventing a disease, wherein expression of the polypeptides encoded by the mRNA molecules within an organism (e.g., a mammal, such as a human) elicits immunity against the disease.
- an organism e.g., a mammal, such as a human
- compositions and methods described herein are useful, for example, in preventing an infectious disease caused by a pathogen such as a virus (e.g., a coronavirus such as SARS-CoV-2) by expressing antigenic polypeptides (e.g., from mRNA molecules encoding viral proteins such as S (spike), E (envelope), M (membrane), or N (nucleocapsid) proteins or antigenic fragments thereof) to produce an immune response within an organism (e.g., a mammal, such as a human) by stimulating the adaptive immune system to create antibodies that target the pathogen.
- a pathogen such as a virus (e.g., a coronavirus such as SARS-CoV-2)
- antigenic polypeptides e.g., from mRNA molecules encoding viral proteins such as S (spike), E (envelope), M (membrane), or N (nucleocapsid) proteins or antigenic fragments thereof
- the lipid particles described herein are used as a vaccine for treating a disease, wherein expression of the polypeptides encoded by the mRNA molecules within an organism (e.g., a mammal, such as a human) elicits an immune response against diseased cells.
- an organism e.g., a mammal, such as a human
- the compositions and methods described herein are particularly useful for treating cancer by expressing antigenic polypeptides (e.g., from mRNA molecules encoding tumor-specific antigens or antigenic fragments thereof) to stimulate an adaptive immune response to create antibodies that target and destroy cancer cells.
- the mRNA molecules are fully encapsulated in lipid particle.
- the RNA of a provided lipid nanoparticle or a provided population of nanoparticles includes a cocktail of one or more types of mRNA together with one or more other types of RNA, e.g., gRNA, siRNA, miRNA, etc.
- either a lipid nanoparticle or a population of different lipid nanoparticles comprises at least one type of mRNA and at least one type of gRNA.
- the mRNA and gRNA can be within the same lipid nanoparticle or within different lipid nanoparticles.
- the different types of mRNA species present in the cocktail may be co-encapsulated in the same particle, or each type of mRNA species present in the cocktail may be encapsulated in a separate particle.
- the mRNA cocktail may be formulated in the particles described herein using a mixture of two or more individual mRNAs (each having a unique sequence) at identical, similar, or different concentrations or molar ratios.
- a cocktail of mRNAs (corresponding to a plurality of mRNAs with different sequences) is formulated using identical, similar, or different concentrations or molar ratios of each mRNA species, and the different types of mRNAs are co-encapsulated in the same particle.
- each type of mRNA species present in the cocktail is encapsulated in different particles at identical, similar, or different mRNA concentrations or molar ratios, and the particles thus formed (each containing a different mRNA payload) are administered separately (e.g., at different times in accordance with a prophylactic or therapeutic regimen), or are combined and administered together as a single unit dose (e.g., with a pharmaceutically acceptable carrier).
- the lipid particles are serum- stable, are resistant to nuclease degradation, and are substantially non-toxic to mammals such as humans.
- the mRNA molecules present in the provided lipid nanoparticles can include one, two, or more than two nucleoside modifications.
- the modified mRNA exhibits reduced degradation in a cell into which the mRNA is introduced, relative to a corresponding unmodified mRNA.
- modified nucleosides include pyridin-4-one ribonucleoside, 5 -aza-uridine, 2-thio-5-aza-uridine, 2-thiouridine, 4-thio-pseudouridine, 2-thio-pseudouridine, 5-hydroxyuridine, 3-methyluridine, 5-carboxymethyl-uridine, 1-carboxymethyl- pseudouridine, 5 -propynyl -uridine, 1-propynyl -pseudouridine, 5-taurinomethyluridine, 1- taurinomethy1-pseudouridine, 5-taurinomethyl-2-thio-uridine, l-taurinomethyl-4-thio-uridine, 5-methyl-uridine, 1-methyl -pseudouridine, 4-thio-1-methy1-pseudouridine, 2-thio-1-methyl- pseudouridine, 1-methyl-1-deaza-pseu
- modified nucleosides include 5 -aza-cytidine, pseudoisocytidine, 3-methyl-cytidine, N4-acetylcytidine, 5 -formylcytidine, N4- methylcytidine, 5 -hydroxymethylcytidine, 1-methyl -pseudoisocytidine, pyrrolo-cytidine, pyrrolo-pseudoisocytidine, 2-thio-cytidine, 2-thio-5 -methyl -cytidine, 4-thio- pseudoisocytidine, 4-thio-1-methyl -pseudoisocytidine, 4-thio-1-methyl-1-deaza- pseudoisocytidine, 1-methyl-1-deaza-pseudoisocytidine, zebularine, 5-aza-zebularine, 5- methyl-zebularine, 5-aza-2-thio-zebularine
- modified nucleosides include 2-aminopurine, 2,6- diaminopurine, 7-deaza-adenine, 7-deaza-8-aza-adenine, 7-deaza-2 -aminopurine, 7-deaza-8- aza-2-aminopurine, 7-deaza-2,6-diaminopurine, 7-deaza-8-aza-2,6-diaminopurine, 1- methyladenosine, N6-methyladenosine, N6-isopentenyladenosine, N6-(cri- hydroxyisopentenyl)adenosine, 2-mcthylthio-N6-(cis-hydroxyisopcntcnyl) adenosine, N6- glycinylcarbamoyladenosine, N6-threonylcarbamoyladenosine, 2-methylthio-N6-threonyl
- the modified nucleoside is 5'-O-(1-thiophosphate)-adenosine, 5 '-O-(1-thiophosphate)-cytidine, 5 '-O-(1-thiophosphate)-guanosine, 5 '-O-(1-thiophosphate)- uridine, or 5'-O-(1-thiophosphate)-pseudouridine.
- the a-thio substituted phosphate moiety is provided to confer stability to RNA polymers through the unnatural phosphorothioate backbone linkages.
- Phosphorothioate RNA have increased nuclease resistance and subsequently a longer half-life in a cellular environment.
- Phosphorothioate-linked nucleic acids are expected to also reduce the innate immune response through weaker binding/activation of cellular innate immune molecules.
- the present disclosure provides a modified nucleic acid containing a degradation domain, which is capable of being acted on in a directed manner within a cell.
- modified nucleosides include inosine, 1-methyl -inosine, wyosine, wybutosine, 7-deaza-guanosine, 7-deaza-8-aza-guanosine, 6-thio-guanosine, 6-thio- 7-deaza-guanosine, 6-thio-7-deaza-8-aza-guanosine, 7-methyl -guanosine, 6-thio-7-methyl- guanosine, 7-methylinosine, 6-methoxy-guanosine, 1-methylguanosine, N2-methylguanosine, N2,N2-dimethylguanosine, 8-oxo-guanosine, 7-methyl-8-oxo-guanosine, 1-methyl-6-thio- guanosine, N2-methyl-6-thio-guanosine, and N2,N2-dimethyl-6-thio-guanosine.
- the mRNA molecules present in the provided lipid nanoparticles may include other optional components.
- These optional components include, but are not limited to, untranslated regions, Kozak sequences, intronic nucleotide sequences, internal ribosome entry site (IRES), caps, and poly-A tails.
- a 5' untranslated region (UTR) and/or a 3' UTR may be included, wherein either or both may independently contain one or more different nucleoside modifications.
- nucleoside modifications may also be present in the translatable region.
- mRNA molecules containing a Kozak sequence are also be provided herein are mRNA molecules containing one or more intronic nucleotide sequences capable of being excised from the mRNA sequence.
- UTRs Untranslated regions of a gene are transcribed but not translated.
- the 5' UTR starts at the transcription start site and continues to the start codon but does not include the start codon; whereas the 3' UTR starts immediately following the stop codon and continues until the transcriptional termination signal.
- the regulatory features of a UTR can be incorporated into the mRNA used in the lipid particles described herein to increase the stability of the molecule.
- the specific features can also be incorporated to ensure controlled downregulation of the transcript in case they are misdirected to undesired tissue or organ sites.
- the 5' cap structure of an mRNA is involved in nuclear export, increasing mRNA stability, and binds the mRNA Cap Binding Protein (CBP), which is responsible for mRNA stability in the cell and translation competency through the association of CBP with poly(A) binding protein to form the mature cyclic mRNA species.
- CBP mRNA Cap Binding Protein
- the cap further assists the removal of 5' proximal introns removal during mRNA splicing.
- Endogenous mRNA molecules may be 5'-end capped, generating a 5'-ppp-5'- triphosphate linkage between a terminal guanosine cap residue and the 5 '-terminal transcribed sense nucleotide of the mRNA molecule.
- This 5'-guanylate cap may then be methylated to generate an N7-methyl-guanylate residue.
- the ribose sugars of the terminal and/or antiterminal transcribed nucleotides of the 5' end of the mRNA may optionally also be 2'-O-methylated.
- 5'- decapping through hydrolysis and cleavage of the guanylate cap structure may target an mRNA molecule for degradation.
- mRNA containing an internal ribosome entry site are also useful in the lipid nanoparticles described herein.
- An IRES may act as the sole ribosome binding site, or may serve as one of multiple ribosome binding sites of an mRNA.
- An mRNA containing more than one functional ribosome binding site may encode several peptides or polypeptides that are translated independently by the ribosomes (“multicistronic mRNA”).
- multicistronic mRNA When mRNA are provided with an IRES, further optionally provided is a second translatable region.
- IRES sequences include, without limitation, those from picomaviruses (e.g., FMDV), pest viruses (e.g., CFFV), polio viruses (PV), encephalomyocarditis viruses (ECMV), foot-and- mouth disease viruses (FMDV), hepatitis C viruses (HCV), classical swine fever viruses (CSFV), murine leukemia viruses (MLV), simian immune deficiency viruses (S1V), and cricket paralysis viruses (CrPV).
- picomaviruses e.g., FMDV
- pest viruses e.g., CFFV
- PV polio viruses
- ECMV encephalomyocarditis viruses
- FMDV foot-and- mouth disease viruses
- HCV hepatitis C viruses
- CSFV classical swine fever viruses
- MMV murine leukemia viruses
- S1V simian immune deficiency viruses
- CrPV cricket paralysis viruses
- a long chain of adenine nucleotides may be added to a polynucleotide such as an mRNA molecule in order to increase stability.
- a polynucleotide such as an mRNA molecule
- poly-A polymerase adds a chain of adenine nucleotides to the RNA.
- the length of a poly-A tail is greater than 30 nucleotides in length. In some embodiments, the poly-A tail is greater than 35 nucleotides in length (e.g., at least or greater than about 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 450, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2,000, 2,500, and 3,000 nucleotides).
- the poly-A tail is greater than 35 nucleotides in length (e.g., at least or greater than about 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 450, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900,
- the poly-A tail may be 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, or 100% greater in length than the mRNA. In other embodiments, the poly-A tail may be 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, or more of the total length of the mRNA.
- RNA, synthesizing RNA, hybridizing nucleic acids, making, and screening cDNA libraries, and performing PCR are well known in the art (see, e.g., Gubler and Hoffman, Gene, 25:263-269 (1983); Sambrook et al., Molecular Cloning, A Laboratory Manual (2 nd ed. 1989)) as are PCR methods (see, e.g., U.S. Patent Nos. 4,683,195 and 4,683,202; PCR Protocols: A Guide to Methods and Applications (Innis et al., eds, 1990)).
- Expression libraries are also well known to those of skill in the art.
- mRNA molecules are generated by in vitro transcription, followed by purification. Standard techniques for purifying mRNA, e.g., mRNA produced via in vivo transcription, are well known in the art.
- the provided lipid nanoparticle contains mRNA that is synthesized from a DNA template.
- mRNA that is synthesized from a DNA template.
- enzymes e.g., T7 RNA polymerase and/or derivatives thereof, such as optimized alternative enzymes
- nucleotides optionally including modified nucleotides as described herein
- optional mRNA components e.g., 5' caps.
- the lipid nanoparticle contains mRNA that is generated via in vitro transcription using a commercially available kit.
- kits suitable for generating mRNA contained by the provided lipid nanoparticles include, for example, the MEGASCRIPTTM T7 Transcription Kit available from Thermo Fisher Scientific.
- mRNA for use with the provided lipid nanoparticles can be generated using chemical synthesis processes, such as, for example, those described by Abe et al., ACS Chem. Biol. 2022, 17, 6, 1308-1314.
- the lipid nanoparticles include mRNA generated with mRNA printers, for example, any of those reviewed by Sheridan, 2022 Nature Biotechnol. 2022, 40, 1160-1162.
- the mRNA generated by any one or more of the methods described herein is purified before being used to form one or more provided lipid nanoparticles.
- mRNA purification techniques suitable for use with the mRNA of the provided lipid nanoparticles include, but are not limited to, HPLC purification, cellulose purification, tangential flow filtration, bead based purification (e.g., with purification with Dynabeads), silica based purification, precipitation, and combinations thereof.
- HPLC purification HPLC purification
- cellulose purification tangential flow filtration
- bead based purification e.g., with purification with Dynabeads
- silica based purification e.g., silica based purification
- precipitation e.g., precipitation, precipitation, and combinations thereof.
- Non-limiting examples of mRNA purification are described in, for example, International Patent Application Publication No. WO 2018/006052 Al.
- the mRNA component of the lipid nanoparticles described herein can be used to express a polypeptide of interest.
- Certain diseases in humans are caused by the absence or impairment of a functional protein in a cell type where the protein is normally present and active.
- the functional protein can be completely or partially absent due, e.g., to transcriptional inactivity of the encoding gene or due to the presence of a mutation in the encoding gene that renders the protein completely or partially non-functional.
- human diseases that are caused by complete or partial inactivation of a protein include methylmalonic academia (caused by defective methyhnalonyl-CoA mutase), glycogen storage disease type 1A (caused by a defective catalytic subunit of glucose-6-phosphatase), glycogen storage disease type IB (caused by a lack of glucose-6-phosphate translocase), fragile X syndrome (caused by a deficiency of FMRI protein), urea cycle disorder (caused by mutations in the ornithine transcarbamoylase (OTC) gene), Crigler-Najjar syndrome type 1 (caused by a genetic mutation leading to the lack of bilirubin uridine diphosphate glucuronosyltransferase (bilirubin-UGT)), alpha- 1 antitrypsin deficiency (caused by mutations in the SERPINA1 gene), thrombotic thrombocytopenic purpura (caused by mutations in a
- the mRNA component of the lipid nanoparticles described herein expresses an infectious disease antigen such as a viral, bacterial, fungal, protozoal, and/or helminthic infectious disease antigen.
- infectious disease antigen such as a viral, bacterial, fungal, protozoal, and/or helminthic infectious disease antigen.
- vaccines comprising lipid particles with antigen-encoding mRNA are particularly useful for preventing or treating the infectious disease.
- the infectious disease antigen is a viral infectious disease antigen from a coronavirus (e.g., SARS-CoV-1, SARS-CoV-2, MERS-CoV), influenza virus (e.g., influenza A, B, and C viruses), filovirus (e.g., Ebola virus, Marburg virus), arenavirus (e.g., Lassa virus, Junin virus, Machupo virus, Guanarito virus, Sabia virus), Zika virus, rabies virus, rhinovirus, simian immunodeficiency virus (SIV), human immunodeficiency virus (HIV), hepatitis viruses (e.g., hepatitis C virus), herpes simplex virus, human papilloma virus (HPV), or Epstein-Barr virus.
- a coronavirus e.g., SARS-CoV-1, SARS-CoV-2, MERS-CoV
- influenza virus e.g., influenza A, B, and C viruses
- filovirus
- the infectious disease antigen is a SARS-CoV-2 protein selected from the group consisting of S (spike) protein, E (envelope) protein, M (membrane) protein, N (nucleocapsid) protein, and an antigenic fragment thereof.
- S spike
- E envelope
- M membrane
- N nucleocapsid
- the development of antigen-specific immunity from an mRNA vaccine requires the transfection of antigen-presenting cells, such as dendritic cells. Administration is typically accomplished by intradermal, intramuscular, or subcutaneous injection, as dendritic cells densely populate skin tissue and skeletal muscle.
- the mRNA component of the lipid nanoparticles described herein expresses a tumor-associated antigen.
- cytotoxic T cells can target and destroy tumors.
- the mRNA component of a lipid particle described herein expresses a chimeric antigen receptor (CAR) for CAR T cell therapy.
- CAR chimeric antigen receptor
- a subject s T cells are isolated and transfected ex vivo with mRNA encoding CARs, which are protein fragments that are displayed on the T cell surface and bind to specific tumor epitopes. Following the re- introduction of the modified T cells into a subject, the CARs target and kill tumor cells.
- the mRNA component of the lipid particles described herein expresses a gene editing nuclease.
- gene editing nucleases include CRISPR/Cas nucleases (e.g., Cas9, Cpfl), zinc finger nucleases (ZFNs), transcription-activator like effector nucleases (TALEN), and meganucleases.
- CRISPR-mediated gene editing requires a Cas nuclease responsible for DNA cleavage and a short guide RNA (gRNA) that directs the Cas nuclease to cleave the DNA at a precise location.
- the gRNA targets the Cas nuclease to a gene in a viral genome.
- the viral genome is a SARS-CoV-2 genome and the gene is selected from the group consisting of orflab, S gene, ORF3a, E gene, M gene, ORF6, ORF7a, ORF8, N gene, and ORFIO.
- an mRNA encoding a Cas nuclease such as Cas9 and a gRNA are encapsulated in the same lipid particle.
- the mRNA encoding the Cas nuclease and the gRNA are encapsulated in separate lipid particles.
- the nucleic acid of a provided lipid nanoparticle includes or consists of siRNA.
- siRNA is interfering RNA capable of silencing the expression of a target sequence in vitro and/or in vivo.
- the siRNA may be of about 15-60, 15-50, or 15-40 (duplex) nucleotides in length, more typically about 15-30, 15-25, or 19-25 (duplex) nucleotides in length, and is preferably about 20-24, 21-22, or 21-23 (duplex) nucleotides in length (e.g., each complementary sequence of the double-stranded siRNA is 15-60, 15-50, 15-40, 15-30, 15-25, or 19-25 nucleotides in length, preferably about 20-24, 21-22, or 21-23 nucleotides in length, and the double-stranded siRNA is about 15-60, 15-50, 15-40, 15-30, 15-25, or 19-25 base pairs in length, preferably about 18-22, 19-20, or 19-21 base pairs in
- siRNA duplexes may comprise 3' overhangs of about 1 to about 4 nucleotides or about 2 to about 3 nucleotides and 5' phosphate termini.
- siRNA include, without limitation, a double-stranded polynucleotide molecule assembled from two separate stranded molecules, wherein one strand is the sense strand and the other is the complementary antisense strand; a double-stranded polynucleotide molecule assembled from a single stranded molecule, where the sense and antisense regions are linked by a nucleic acid-based or non-nucleic acid-based linker; a double- stranded polynucleotide molecule with a hairpin secondary structure having self- complementary sense and antisense regions; and a circular single -stranded polynucleotide molecule with two or more loop structures and a stem having self-complementary sense and antisense regions, where the circular polynucleotide can be processed in viv
- a modified siRNA molecule is less immunostimulatory than a corresponding unmodified siRNA sequence.
- the modified siRNA molecule with reduced immunostimulatory properties advantageously retains RNAi activity against the target sequence.
- the immunostimulatory properties of the modified siRNA molecule and its ability to silence target gene expression can be balanced or optimized by the introduction of minimal and selective 2'Ome modifications within the siRNA sequence such as, e.g., within the double-stranded region of the siRNA duplex.
- the modified siRNA is at least about 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 35 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91 %, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% less immunostimulatory than the corresponding unmodified siRNA.
- the immuno stimulatory properties of the modified siRNA molecule and the corresponding unmodified siRNA molecule can be determined by, for example, measuring INF-a and/or IL-6 levels from about two to about twelve hours after systemic administration in a mammal or transfection of a mammalian responder cell using an appropriate lipid-based delivery system (such as the LNP delivery system disclosed herein).
- a modified siRNA molecule has an IC 50 (i.e., half-maximal inhibitory concentration) less than or equal to ten-fold that of the corresponding unmodified siRNA (i.e., the modified siRNA has an IC 50 that is less than or equal to ten-times the IC 50 of the corresponding unmodified siRNA).
- the modified siRNA has an IC 50 less than or equal to three-fold that of the corresponding unmodified siRNA sequence.
- the modified siRNA has an IC 50 less than or equal to two-fold that of the corresponding unmodified siRNA. It will be readily apparent to those of skill in the art that a dose-response curve can be generated and the IC 50 values for the modified siRNA and the corresponding unmodified siRNA can be readily determined using methods known to those of skill in the art.
- a modified siRNA molecule is capable of silencing at least about 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70% ; 75%, 20 80%, 85%, 90%, 95%, or 100% of the expression of the target sequence relative to the corresponding unmodified siRNA sequence.
- the siRNA molecule does not comprise phosphate backbone modifications, e.g., in the sense and/or antisense strand of the double-stranded region.
- the siRNA comprises one, two, three, four, or more phosphate backbone modifications, e.g., in the sense and/or antisense strand of the double-stranded region.
- the siRNA does not comprise phosphate backbone modifications.
- the siRNA does not comprise 2'-deoxy nucleotides, e.g., in the sense and/or antisense strand of the double-stranded region.
- the siRNA comprises one, two, three, four, ormore 2'-deoxy nucleotides, e.g., in the sense and/or antisense strand of the double -stranded region. In preferred embodiments, the siRNA does not comprise 2'-deoxy nucleotides.
- the nucleotide at the 3'-end of the double-stranded region in the sense and/or antisense strand is not a modified nucleotide.
- the nucleotides near the 3'-end (e.g., within one, two, three, or four nucleotides of the 3'-end) of the double -stranded region in the sense and/or antisense strand are not modified nucleotides.
- the siRNA molecules described herein may have 3' overhangs of one, two, three, four, or more nucleotides on one or both sides of the double-stranded region, or may lack overhangs (i.e., have blunt ends) on one or both sides of the double -stranded region.
- the siRNA has 3' overhangs of two nucleotides on each side of the double-stranded region.
- the 3' overhang on the antisense strand has complementarity to the target sequence and the 3' overhang on the sense strand has complementarity to a complementary strand of the target sequence.
- the 3' overhangs do not have complementarity to the target sequence or the complementary strand thereof.
- the 3' overhangs comprise one, two, three, four, or more nucleotides such as 2'-deoxy (2'H) nucleotides.
- the 3' overhangs comprise deoxythymidine (dT) and/or uridine nucleotides.
- one or more of the nucleotides in the 3' overhangs on one or both sides of the double-stranded region comprise modified nucleotides.
- modified nucleotides include 2'OMe nucleotides, 2'-deoxy-2'F nucleotides, 2'-deoxy nucleotides, 2'-O-2-MOE nucleotides, LNA nucleotides, and mixtures thereof.
- one, two, three, four, or more nucleotides in the 3' overhangs present on the sense and/or antisense strand of the siRNA comprise 2'Ome nucleotides (e.g., 2'Ome purine and/or pyrimidine nucleotides) such as, for example, 2'Ome-guanosine nucleotides, 2'Ome-uridine nucleotides, 2'Ome-adenosine nucleotides, 2'Ome-cytosine nucleotides, and mixtures thereof.
- 2'Ome nucleotides e.g., 2'Ome purine and/or pyrimidine nucleotides
- 2'Ome-guanosine nucleotides e.g., 2'Ome-uridine nucleotides
- 2'Ome-adenosine nucleotides e.g., 2'Ome-cytosine nucleotides, and mixtures thereof.
- the siRNA may comprise at least one or a cocktail (e.g., at least two, three, four, five, six, seven, eight, nine, ten, or more) of unmodified and/or modified siRNA sequences that silence target gene expression.
- the cocktail of siRNA may comprise sequences which are directed to the same region or domain (e.g., a “hot spot”) and/or to different regions or domains of one or more target genes.
- one or more (e.g., at least two, three, four, five, six, seven, eight, nine, ten, or more) modified siRNA that silence target gene expression are present in a cocktail.
- one or more (e.g., at least two, three, four, five, six, seven, eight, nine, ten, or more) unmodified siRNA sequences that silence target gene expression are present in a cocktail.
- the antisense strand of the siRNA molecule comprises or consists of a sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, or 99% complementary to the target sequence or a portion thereof. In other embodiments, the antisense strand of the siRNA molecule comprises or consists of a sequence that is 100% complementary to the target sequence or a portion thereof. In further embodiments, the antisense strand of the siRNA molecule comprises or consists of a sequence that specifically hybridizes to the target sequence or a portion thereof.
- the sense strand of the siRNA molecule comprises or consists of a sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, or 99% complementary to the target sequence or a portion thereof. In additional embodiments, the sense strand of the siRNA molecule comprises or consists of a sequence that is 100% identical to the target sequence or a portion thereof.
- Suitable siRNA sequences can be identified using any means known in the art. Typically, the methods described in Elbashir et al., Nature, 411:494-498 (2001) and Elbashir et al., EMBO J., 20:6877-6888 (2001) are combined with rational design rules set forth in Reynolds et al., Nature Biotech., 22(3):326-330 (2004).
- the nucleotides immediately 3' to the dinucleotide sequences are identified as potential siRNA sequences (i.e., a target sequence or a sense strand sequence).
- the 19, 21, 23, 25, 27, 29, 31, 33, 35, or more nucleotides immediately 3' to the dinucleotide sequences are identified as potential siRNA sequences.
- the dinucleotide sequence is an AA or NA sequence and the 19 nucleotides immediately 3' to the AA or NA dinucleotide are identified as potential siRNA sequences.
- siRNA sequences are usually spaced at different positions along the length of the target gene. To further enhance silencing efficiency of the siRNA sequences, potential siRNA sequences may be analyzed to identify sites that do not contain regions of homology to other coding sequences, e.g., in the target cell or organism.
- a suitable siRNA sequence of about 21 base pairs typically will not have more than 16-17 contiguous base pairs of homology to coding sequences in the target cell or organism. If the siRNA sequences are to be expressed from an RNA Pol III promoter, siRNA sequences lacking more than 4 contiguous A’s or T’s are selected.
- potential siRNA sequences may be further analyzed based on siRNA duplex asymmetry as described in, e.g., Khvorova et al., Cell, 115:209-216 (2003); and Schwarz et al., Cell, 115: 199-208 (2003).
- potential siRNA sequences may be further analyzed based on secondary structure at the target site as described in, e.g., Luo et al., Biophys. Res. Commun., 318:303-310 (2004).
- a non-limiting example of an in vivo model for detecting an immune response includes an in vivo mouse cytokine induction assay as described in, e.g., Judge et al., Mai. Ther., 13:494- 505 (2006).
- Monoclonal antibodies that specifically bind cytokines and growth factors are commercially available from multiple sources and can be generated using methods known in the art (see, e.g., Kohler et al., Nature, 256: 495-497 (1975) and Harlow and Lane, ANTIBODIES, A LABORATORY MANUAL, Cold Spring Harbor Publication, New York (1999)).
- Generation of monoclonal antibodies has been previously described and can be accomplished by any means known in the art (Buhring et al., in Hybridoma, Vol. 10, No. 1, pp. 77-78 (1991)).
- the monoclonal antibody is labeled (e.g., with any composition detectable by spectroscopic, photochemical, biochemical, electrical, optical, or chemical means) to facilitate detection.
- siRNA can be provided in several forms including, e.g., as one or more isolated small- interfering RNA (siRNA) duplexes, as longer double-stranded RNA (dsRNA), or as siRNA or dsRNA transcribed from a transcriptional cassette in a DNA plasmid.
- siRNA can be chemically synthesized.
- the oligonucleotides that comprise the siRNA molecules can be synthesized using any of a variety of techniques known in the art, such as those described in Usman et al., J. Am. Chem. Soc., 109:7845 (1987); Scaringe et al., Nucl. Acids Res., 18:5433 (1990); Wincott et al., Nucl. Acids Res., 23:2677-2684 (1995); and Wincott et al., Methods Mol. Bio., 74:59 (1997).
- RNA population can be used to provide long precursor RNAs, or long precursor RNAs that have substantial or complete identity to a selected target sequence can be used to make the siRNA.
- the RNAs can be isolated from cells or tissue, synthesized, and/or cloned according to methods well known to those of skill in the art.
- the RNA can be a mixed population (obtained from cells or tissue, transcribed from cDNA, subtracted, selected, etc.), or can represent a single target sequence.
- RNA can be naturally occurring (e.g., isolated from tissue or cell samples), synthesized in vitro (e.g., using T7 or SP6 polymerase and PCR products or a cloned cDNA), or chemically synthesized.
- the complement is also transcribed in vitro and hybridized to form a dsRNA.
- the RNA complements are also provided (e.g., to form dsRNA for digestion by E.coli RNAse III or Dicer), e.g., by transcribing cDNAs corresponding to the RNA population, or by using RNA polymerases.
- the precursor RN As are then hybridized to form double stranded RN As for digestion.
- the dsRNAs can be directly administered to a subject or can be digested in vitro prior to administration.
- RNA, synthesizing RNA, hybridizing nucleic acids, making and screening cDNA libraries, and performing PCR are well known in the art (see, e.g., Gubler and Hoffman, Gene, 25:263-269 (1983); Sambrook et al., supra; Ausubel et al., supra), as are PCR methods (see, U.S. Pat. Nos. 4,683,195 and 4,683,202; PCR Protocols: A Guide to Methods and Applications (Innis et al., eds, 1990)).
- Expression libraries are also well known to those of skill in the art.
- siRNA are chemically synthesized.
- siRNA can also be generated by cleavage of longer dsRNA (e.g., dsRNA greater than about 25 nucleotides in length) with the E.coli RNase III or Dicer. These enzymes process the dsRNA into biologically active siRNA (see, e.g., Yang et al., Proc. Natl. Acad. Sci. USA, 99:9942-9947 (2002); Calegari et al., Proc. Natl. Acad. Sci.
- dsRNA are at least 50 nucleotides to about 100, 200, 300, 400, or 500 nucleotides in length.
- a dsRNA may be as long as 1000, 1500, 2000, 5000 nucleotides in length, or longer.
- the dsRNA can encode for an entire gene transcript or a partial gene transcript.
- siRNA may be encoded by a plasmid (e.g., transcribed as sequences that automatically fold into duplexes with hairpin loops).
- siRNA molecules can also be synthesized via a tandem synthesis technique, wherein both strands are synthesized as a single continuous oligonucleotide fragment or strand separated 20 by a cleavable linker that is subsequently cleaved to provide separate fragments or strands that hybridize to form the siRNA duplex.
- the linker can be a polynucleotide linker or a non-nucleotide linker.
- the tandem synthesis of siRNA can be readily adapted to both multiwell/multiplate synthesis platforms as well as large scale synthesis platforms employing batch reactors, synthesis columns, and the like.
- siRNA molecules can be assembled from two distinct oligonucleotides, wherein one oligonucleotide comprises the sense strand and the other comprises the antisense strand of the siRNA.
- each strand can be synthesized separately and joined together by hybridization or ligation following synthesis and/or deprotection.
- siRNA molecules can be synthesized as a single continuous oligonucleotide fragment, where the self-complementary sense and antisense regions hybridize to form an siRNA duplex having hairpin secondary structure.
- siRNA molecules comprise a duplex having two strands and at least one modified nucleotide in the double-stranded region, wherein each strand is about 15 to about 60 nucleotides in length.
- the modified siRNA is less immunostimulatory than a corresponding unmodified siRNA sequence, but retains the capability of silencing the expression of a target sequence.
- the degree of chemical modifications introduced into the siRNA molecule strikes a balance between reduction or abrogation of the immunostimulatory properties of the siRNA and retention of RNAi activity.
- an siRNA molecule that targets a gene of interest can be minimally modified (e.g., less than about 30%, 25%, 20%, 15%, 10%, or 5% modified) at selective uridine and/or guanosine nucleotides within the siRNA duplex to eliminate the immune response generated by the siRNA while retaining its capability to silence target gene expression.
- modified nucleotides include, but are not limited to, ribonucleotides having a 2'-O-methyl (2'Ome), 2'-deoxy-2'-fluoro (2'F), 2'-deoxy, 5-C-methyl, 2'-O-(2- methoxyethyl) (MOE), 4'-thio, 2'-amino, or 2'-C-allyl group.
- Modified nucleotides having a Northern conformation such as those described in, e.g., Saenger, Principles of Nucleic Acid Structure, Springer- Verlag Ed. (1984), are also suitable for use in siRNA molecules.
- Such modified nucleotides include, without limitation, locked nucleic acid (LNA) nucleotides (e.g., 2'-O, 4'-C-methylene-(D-ribofuranosyl) nucleotides), 2'-O-(2-methoxyethyl) (MOE) nucleotides, 2'-methyl-thio-ethyl nucleotides, 2'-deoxy-2'-fluoro (2'F) nucleotides, 2'-deoxy- 2'-chloro (2'Cl) nucleotides, and 2'-azido nucleotides.
- LNA locked nucleic acid
- MOE 2-methoxyethyl
- MOE 2-methoxyethyl) nucleotides
- 2'-methyl-thio-ethyl nucleotides 2'-methyl-thio-ethyl nucleotides
- 2'F 2-methoxy-2'-fluoro
- a G-clamp nucleotide refers to a modified cytosine analog wherein the modifications confer the ability to hydrogen bond both Watson-Crick and Hoogsteen faces of a complementary guanine nucleotide within a duplex (see, e.g., Lin et al., J. Am. Chem. Soc., 120:8531-8532 (1998)).
- nucleotides having a nucleotide base analog such as, for example, C-phenyl, C-naphthyl, other aromatic derivatives, inosine, azole carboxamides, and nitroazole derivatives such as 3- nitropyrrole, 4-nitroindole, 5 -nitroindole, and 6-nitroindole (see, e.g., Loakes, Nucl. Acids Res., 29:2437-2447 (2001)) can be incorporated into siRNA molecules.
- a nucleotide base analog such as, for example, C-phenyl, C-naphthyl, other aromatic derivatives, inosine, azole carboxamides, and nitroazole derivatives such as 3- nitropyrrole, 4-nitroindole, 5 -nitroindole, and 6-nitroindole (see, e.g., Loakes, Nucl. Acids Res., 29:2437-2447 (
- siRNA molecules may further comprise one or more chemical modifications such as terminal cap moieties, phosphate backbone modifications, and the like.
- terminal cap moieties include, without limitation, inverted deoxy abasic residues, glyceryl modifications, 4', 5 '-methylene nucleotides, 1-( ⁇ -D-erythrofuranosyl) nucleotides, 4'-thio nucleotides, carbocyclic nucleotides, 1,5-anhydrohexitol nucleotides, L- nucleotides, a-nucleotides, modified base nucleotides, threo-pentofuranosyl nucleotides, acyclic 3',4'-seco nucleotides, acyclic 3,4-dihydroxybutyl nucleotides, acyclic 3,5- dihydroxypentyl nucleotides, 3'-3'-inverted nucleotide moieties
- Non-limiting examples of phosphate backbone modifications include phosphorothioate, phosphorodithioate, methylphosphonate, phosphotriester, morpholino, amidate, carbamate, carboxymethyl, acetamidate, polyamide, sulfonate, sulfonamide, sulfamate, formacetal, thioformacetal, and alkylsilyl substitutions (see, e.g., Hunziker et al., Nucleic Acid Analogues: Synthesis and Properties, in Modern Synthetic Methods , VCH, 331- 417 (1995); Mesmaeker et al., Novel Backbone Replacements for Oligonucleotides, in Carbohydrate Modifications in Antisense Research, ACS, 24-39 (1994)).
- Such chemical modifications i.e., resulting in modified intemucleotide linkages.
- the sense and/or antisense strand of the siRNA molecule can further comprise a 3'-terminal overhang having about 1 to about 4 (e.g., 1, 2, 3, or 4) 2'-deoxy ribonucleotides and/or any combination of modified and unmodified nucleotides. Additional examples of modified nucleotides and types of chemical modifications that can be introduced into siRNA molecules are described, e.g., in UK Patent No. GB 2,397,818 B and U.S. Patent Application Publication Nos. 2004/0192626, 2005/0282188, and 2007/0135372.
- the siRNA molecules described herein can optionally comprise one or more non- nucleotides in one or both strands of the siRNA.
- non-nucleotide refers to any group or compound that can be incorporated into a nucleic acid chain in the place of one or more nucleotide units, including sugar and/or phosphate substitutions, and allows the remaining bases to exhibit their activity.
- the group or compound is abasic in that it does not contain a commonly recognized nucleotide base such as adenosine, guanine, cytosine, uracil, or thymine and therefore lacks a base at the 1’-position.
- chemical modification of the siRNA comprises attaching a conjugate to the siRNA molecule.
- the conjugate can be attached at the 5'- and/or 3'-end of the sense and/or antisense strand of the siRNA via a covalent attachment such as, e.g., a biodegradable linker.
- the conjugate can also be attached to the siRNA, e.g., through a carbamate group or other linking group (see, e.g., U.S. Patent Application Publication Nos. 2005/0074771, 2005/0043219, and 20050158727).
- the conjugate is a molecule that facilitates the delivery of the siRNA into a cell.
- conjugate molecules suitable for attachment to siRNA include, without limitation, steroids such as cholesterol, glycols such as polyethylene glycol (PEG), human serum albumin (HSA), fatty acids, carotenoids, terpenes, bile acids, folates (e.g., folic acid, folate analogs and derivatives thereof), sugars (e.g., galactose, galactosamine, N-acetyl galactosamine, glucose, mannose, fructose, fucose, etc.), phospholipids, peptides, ligands for cellular receptors capable of mediating cellular uptake, and combinations thereof (see, e.g., U.S. Patent Application Publication Nos.
- steroids such as cholesterol
- glycols such as polyethylene glycol (PEG), human serum albumin (HSA), fatty acids, carotenoids, terpenes, bile acids, folates (e.g., folic acid, folate analogs and derivatives
- Yet other examples include the 2'-O-alkyl amine, 2'-O-alkoxyalkyl amine, polyamine, C5-cationic modified pyrimidine, cationic peptide, guanidinium group, amidinium group, cationic amino acid conjugate molecules described in U.S. Patent Application Publication No. 2005/0153337. Additional examples include the hydrophobic group, membrane active compound, cell penetrating compound, cell targeting signal, interaction modifier, and steric stabilizer conjugate molecules described in U.S. Patent Application Publication No. 2004/0167090. Further examples include the conjugate molecules described in U.S. Patent Application Publication No. 2005/0239739.
- the type of conjugate used and the extent of conjugation to the siRNA molecule can be evaluated for improved pharmacokinetic profiles, bioavailability, and/or stability of the siRNA while retaining RNAi activity.
- one skilled in the art can screen siRNA molecules having various conjugates attached thereto to identify ones having improved properties and full RNAi activity using any of a variety of well-known in vitro cell culture or in vivo animal models.
- the provided lipid nanoparticles include asymmetrical interfering RNA (aiRNA) molecules that silence the expression of a target gene.
- aiRNA asymmetrical interfering RNA
- the aiRNA molecule comprises a double-stranded (duplex) region of about 10 to about 25 (base paired) nucleotides in length, wherein the aiRNA molecule comprises an antisense strand comprising 5' and 3' overhangs, and wherein the aiRNA molecule is capable of silencing target gene expression.
- the aiRNA molecule comprises a double-stranded (duplex) region of about 12-20, 12-19, 12-18, 13-17, or 14-17 (base paired) nucleotides in length, more typically 12, 13, 14, 15, 16, 17, 18, 19, or 20 (base paired) nucleotides in length.
- the 5' and 3' overhangs on the antisense strand comprise sequences that are complementary to the target RNA sequence, and may optionally further comprise nontargeting sequences.
- each of the 5' and 3' overhangs on the antisense strand comprises or consists of one, two, three, four, five, six, seven, or more nucleotides.
- the aiRNA molecule comprises modified nucleotides selected from the group consisting of 2'oMe nucleotides, 2'F nucleotides, 2'-deoxy nucleotides, 2'- OMOE nucleotides, LNA nucleotides, and mixtures thereof.
- the aiRNA molecule comprises 2'oMe nucleotides.
- the 2'Ome nucleotides may be selected from the group consisting of 2'oMe-guanosine nucleotides, 2'oMe- uridine nucleotides, and mixtures thereof.
- asymmetrical interfering RNA can recruit the RNA-induced silencing complex (RISC) and lead to effective silencing of a variety of genes in mammalian cells by mediating sequence -specific cleavage of the target sequence between nucleotide 10 and 11 relative to the 5' end of the antisense strand (Sun et al., Nat. Biotech., 26: 1379-1382 (2008)).
- RISC RNA-induced silencing complex
- an aiRNA molecule comprises a short RNA duplex having a sense strand and an antisense strand, wherein the duplex contains overhangs at the 3' and 5' ends of the antisense strand.
- aiRNA is generally asymmetric because the sense strand is shorter on both ends when compared to the complementary antisense strand.
- aiRNA molecules may be designed, synthesized, and annealed under conditions similar to those used for siRNA molecules.
- aiRNA sequences may be selected and generated using the methods described above for selecting siRNA sequences.
- aiRNA duplexes of various lengths may be designed with overhangs at the 3' and 5' ends of the antisense strand to target an mRNA of interest.
- the sense strand of the aiRNA molecule is about 10-25, 12-20, 12-19, 12-18, 13-17, or 14-17 nucleotides in length, more typically 12, 13, 14, 15, 16, 17, 18, 19, or 20 nucleotides in length.
- the antisense strand of the aiRNA molecule is about 15-60, 15-50, or 15-40 nucleotides in length, more typically about 15-30, 15-25, or 19-25 nucleotides in length, and is preferably about 20-24, 21-22, or 21- 23 nucleotides in length.
- the 5' antisense overhang contains one, two, three, four, or more nontargeting nucleotides (e.g., “AA”, “UU”, “dTdT”, etc.).
- the 3' antisense overhang contains one, two, three, four, or more nontargeting nucleotides (e.g., “AA”, “UU”, “dTdT”, etc.).
- the aiRNA molecules described herein may comprise one or more modified nucleotides, e.g., in the double -stranded (duplex) region and/or in the antisense overhangs.
- aiRNA sequences may comprise one or more of the modified nucleotides described above for siRNA sequences.
- the aiRNA molecule comprises 2'oMe nucleotides such as, for example, 2'oMe- guanosine nucleotides, 2'oMe-uridine nucleotides, or mixtures thereof.
- aiRNA molecules may comprise an antisense strand which corresponds to the antisense strand of an siRNA molecule, e.g., one of the siRNA molecules described herein.
- aiRNA molecules may be used to silence the expression of any of the target genes set forth above in the context of siRNA molecules, such as, e.g., genes associated with viral infection and survival, genes associated with metabolic diseases and disorders, genes associated with tumorigenesis and cell transformation, angiogenic genes, immunomodulator genes such as those associated with inflammatory and autoimmune responses, ligand receptor genes, and genes associated with neurodegenerative disorders.
- the provided lipid nanoparticles include microRNA (miRNA) molecules that silence the expression of a target gene.
- the miRNA molecule comprises about 15 to about 60 nucleotides in length, wherein the miRNA molecule is capable of silencing target gene expression.
- the miRNA molecule comprises about 15-50, 15-40, or 15-30 nucleotides in length, more typically about 15-25 or 19-25 nucleotides in length, and are preferably about 20-24, 21-22, or 21-23 nucleotides in length.
- the miRNA molecule is a mature miRNA molecule targeting an RNA sequence of interest.
- the miRNA molecule comprises modified nucleotides selected from the group consisting of 2'oMe nucleotides, 2'F nucleotides, 2'-deoxy nucleotides, 2'- OMOE nucleotides, LNA nucleotides, and mixtures thereof.
- the miRNA molecule comprises 2'oMe nucleotides.
- the 2'Ome nucleotides may be selected from the group consisting of 2'oMe-guanosine nucleotides, 2'oMe- uridine nucleotides, and mixtures thereof.
- miRNAs are single-stranded RNA molecules of about 21-23 nucleotides in length which regulate gene expression. miRNAs are encoded by genes from whose DNA they are transcribed, but miRNAs are not translated into protein (non-coding RNA); instead, each primary transcript (a pri-miRNA) is processed into a short stem-loop structure called a pre-miRNA and finally into a functional mature miRNA. Mature miRNA molecules are either partially or completely complementary to one or more messenger RNA (mRNA) molecules, and their main function is to downregulate gene expression.
- mRNA messenger RNA
- miRNA molecules The identification of miRNA molecules is described, e.g., in Lagos-Quintana et al., Science, 294:853-858; Lau et al., Science, 294:858-862; and Lee et al., Science, 294:862-864.
- miRNA are much longer than the processed mature miRNA molecule. miRNA are first transcribed as primary transcripts or pri-miRNA with a cap and poly-A tail and processed to short, ⁇ 70-nucleotide stem-loop structures known as pre-miRNA in the cell nucleus. This processing is performed in animals by a protein complex known as the Microprocessor complex, consisting of the nuclease Drosha and the double-stranded RNA binding protein Pasha (Denli et al., Nature, 432:231-235 (2004)).
- Microprocessor complex consisting of the nuclease Drosha and the double-stranded RNA binding protein Pasha (Denli et al., Nature, 432:231-235 (2004)).
- RNA-induced silencing complex (RISC) (Bernstein et al., Nature, 409:363-366 (2001). Either the sense strand or antisense strand of DNA can function as templates to give rise to miRNA.
- RISC RNA-induced silencing complex
- miRNA molecules may be used to silence the expression of any of the target genes set forth above in the context of siRNA molecules, such as, e.g., genes associated with viral infection and survival, genes associated with metabolic diseases and disorders, genes associated with tumorigenesis and cell transformation, angiogenic genes, immunomodulator genes such as those associated with inflammatory and autoimmune responses, ligand receptor genes, and genes associated with neurodegenerative disorders.
- the miRNA can be used to silence the expression of a SARS-CoV-2 gene encoding S (spike) protein, E (envelope) protein, M (membrane) protein, or N (nucleocapsid) protein.
- the nucleic acid of a provided lipid nanoparticle includes or consists of one or more self-amplifying RNA molecules.
- Self-amplifying RNA may also be referred to as self-replicating RNA, replication-competent RNA, replicons or RepRNA.
- RepRNA referred to as self-amplifying mRNA when derived from positive-strand viruses, is generated from a viral genome lacking at least one structural gene; it can translate and replicate (hence “self-amplifying”) without generating infectious progeny virus.
- the RepRNA technology may be used to insert a gene cassette encoding a desired antigen of interest.
- the alphaviral genome is divided into two open reading frames (ORFs): the first ORF encodes proteins for the RNA dependent RNA polymerase (replicase), and the second ORF encodes structural proteins.
- ORFs open reading frames
- the ORF encoding viral structural proteins may be replaced with any antigen of choice, while the viral replicase remains an integral part of the vaccine and drives intracellular amplification of the RNA after immunization.
- the nucleic acid of a provided lipid nanoparticle includes or consists of an antisense oligonucleotide directed to a target gene or sequence of interest.
- antisense oligonucleotide or “antisense” as used herein include oligonucleotides that are complementary to a targeted polynucleotide sequence. Antisense oligonucleotides are single strands of DNA or RNA that are complementary to a chosen sequence. Antisense RNA oligonucleotides prevent the translation of complementary RNA strands by binding to the RNA.
- Antisense DNA oligonucleotides can be used to target a specific, complementary (coding or non-coding) RNA. If binding occurs, this DNA/RNA hybrid can be degraded by the enzyme RNase H.
- antisense oligonucleotides comprise from about 10 to about 60 nucleotides or from about 15 to about 30 nucleotides.
- the term also encompasses antisense oligonucleotides that may not be exactly complementary to the desired target gene.
- the lipid nanoparticles described herein can be utilized in instances where non-target specific-activities are found with antisense, or where an antisense sequence containing one or more mismatches with the target sequence is the most preferred for a particular use.
- An antisense oligonucleotide can contain natural nucleotides, as well as non-natural or modified nucleotides (e.g., a modified nucleobase, modified intemucleoside linkage, and/or modified sugar such as those described herein).
- Antisense oligonucleotides have been demonstrated to be effective and targeted inhibitors of protein synthesis, and, consequently, can be used to specifically inhibit protein synthesis by a targeted gene.
- the efficacy of antisense oligonucleotides for inhibiting protein synthesis is well established. For example, the synthesis of polygalacturonase and the muscarine type 2 acetylcholine receptor are inhibited by antisense oligonucleotides directed to their respective mRNA sequences (see, U.S. Pat. Nos. 5,739,119 and 5,759,829).
- antisense constructs have also been described that inhibit and can be used to treat a variety of abnormal cellular proliferations, e.g., cancer (see, U.S. Pat. Nos. 5,747,470; 5,591,317; and 5,783,683). The disclosures of these references are herein incorporated by reference in their entirety for all purposes.
- antisense oligonucleotides are known in the art and can be readily adapted to produce an antisense oligonucleotide that targets any polynucleotide sequence. Selection of antisense oligonucleotide sequences specific for a given target sequence is based upon analysis of the chosen target sequence and determination of secondary structure, Tm, binding energy, and relative stability. Antisense oligonucleotides may be selected based upon their relative inability to form dimers, hairpins, or other secondary structures that would reduce or prohibit specific binding to the target mRNA in a host cell.
- Highly preferred target regions of the mRNA include those regions at or near the AUG translation initiation codon and those sequences that are substantially complementary to 5' regions of the mRNA.
- These secondary structure analyses and target site selection considerations can be performed, for example, using v.4 of the OLIGO primer analysis software (Molecular Biology Insights) and/or the BLASTN 2.0.5 algorithm software (Altschul et al., Nucleic Acids Res., 25:3389-402 (1997)).
- the antisense oligonucleotide component of the lipid particles described herein can be used to inhibit the expression or replication of a gene of interest.
- Genes of interest are set forth above in the context of siRNA molecules and include, but are not limited to, genes associated with viral infection and survival, genes associated with metabolic diseases and disorders (e.g., liver diseases and disorders), genes associated with tumorigenesis and cell transformation (e.g., cancer), angiogenic genes, immunomodulator genes such as those associated with inflammatory and autoimmune responses, ligand receptor genes, and genes associated with neurodegenerative disorders.
- the antisense oligonucleotide can hybridize to a SARS-CoV-2 gene (e.g., orflab, S gene, ORF3a, E gene, M gene, ORF6, ORF7a, ORF8, N gene, or ORF 10) and inhibit the expression or replication of the gene.
- SARS-CoV-2 gene e.g., orflab, S gene, ORF3a, E gene, M gene, ORF6, ORF7a, ORF8, N gene, or ORF 10.
- the nucleic acid of a provided lipid nanoparticle includes or consists of a ribozyme.
- Ribozymes are RNA-protein complexes having specific catalytic domains that possess endonuclease activity (see, Kim et al., Proc. Natl. Acad. Sci. USA., 84:8788-92 (1987); and Forster et al., Cell, 49:211-20 (1987)).
- ribozymes accelerate phosphoester transfer reactions with a high degree of specificity, often cleaving only one of several phosphoesters in an oligonucleotide substrate (see, Cech et al., Cell, 27:487-96 (1981); Michel et al., J. Mol. Biol., 216:585-610 (1990); Reinhold-Hurek et al., Nature, 357: 173-6 (1992)).
- This specificity has been attributed to the requirement that the substrate bind via specific base-pairing interactions to the internal guide sequence (IGS) of the ribozyme prior to chemical reaction.
- IGS internal guide sequence
- enzymatic nucleic acids act by first binding to a target RNA. Such binding occurs through the target binding portion of an enzymatic nucleic acid which is held in close proximity to an enzymatic portion of the molecule that acts to cleave the target RNA. Thus, the enzymatic nucleic acid first recognizes and then binds a target RNA through complementary base-pairing, and once bound to the correct site, acts enzymatically to cut the target RNA.
- RNA Strategic cleavage of such a target RNA will destroy its ability to direct synthesis of an encoded protein. After an enzymatic nucleic acid has bound and cleaved its RNA target, it is released from that RNA to search for another target and can repeatedly bind and cleave new targets.
- the enzymatic nucleic acid molecule may be formed in a hammerhead, hairpin, hepatitis 5 virus, group I intron or RNaseP RNA (in association with an RNA guide sequence), or Neurospora VS RNA motif, for example.
- hammerhead motifs are described in, e.g., Rossi et al., Nucleic Acids Res., 20:4559-65 (1992).
- hairpin motifs are described in, e.g., EP 0360257, Hampel et al., Biochemistry, 28:4929-33 (1989); Hampel et al., Nucleic Acids Res., 18:299-304 (1990); and U.S. Patent No.
- hepatitis 5 virus motif is described in, e.g., Perrotta et al., Biochemistry, 31: 11843-52 (1992).
- RNaseP motif is described in, e.g., Guerrier-Takada et al., Cell, 35:849-57 (1983).
- Examples of the Neurospora VS RNA ribozyme motif is described in, e.g., Saville et al., Cell, 61:685-96 (1990); Saville et al., Proc. Natl. Acad. Sci. USA, 88:8826-30 (1991); Collins et al., Biochemistry, 32:2795-9 (1993).
- Group I intron is described in, e.g., U.S. Patent No. 4,987,071.
- Important characteristics of enzymatic nucleic acid molecules are that they have a specific substrate binding site which is complementary to one or more of the target gene DNA or RNA regions, and that they have nucleotide sequences within or surrounding that substrate binding site which impart an RNA cleaving activity to the molecule.
- the ribozyme constructs need not be limited to specific motifs mentioned herein.
- Ribozymes may be designed as described in, e.g., PCT Publication Nos. WO 93/23569 and WO 94/02595, and synthesized to be tested in vitro and/or in vivo as described therein.
- Ribozyme activity can be optimized by altering the length of the ribozyme binding arms or chemically synthesizing ribozymes with modifications that prevent their degradation by serum ribonucleases (see, e.g., PCT Publication Nos. WO 92/07065, WO 93/15187, WO 91/03162, and WO 94/13688; EP 92110298.4; and U.S. Patent No. 5,334,711, which describe various chemical modifications that can be made to the sugar moieties of enzymatic RNA molecules), modifications which enhance their efficacy in cells, and removal of stem II bases to shorten RNA synthesis times and reduce chemical requirements.
- Immunostimulatorv Oligonucleotides see, e.g., PCT Publication Nos. WO 92/07065, WO 93/15187, WO 91/03162, and WO 94/13688; EP 92110298.4; and U.S. Patent No. 5,334,71
- the nucleic acid of a provided lipid nanoparticle includes or consists of an immunostimulatory oligonucleotide (ISS; single-or double-stranded) capable of inducing an immune response when administered to a subject, which may be a mammal such as a human.
- ISS immunostimulatory oligonucleotide
- ISS include, e.g., certain palindromes leading to hairpin secondary structures (see, Yamamoto et al., J. Immunol. , 148:4072-6 (1992)), or CpG motifs, as well as other known ISS features (such as multi-G domains; see; PCT Publication No. WO 96/11266).
- the nucleic acid comprises at least two CpG dinucleotides, wherein at least one cytosine in the CpG dinucleotides is methylated. In a further embodiment, each cytosine in the CpG dinucleotides present in the sequence is methylated. In another embodiment, the nucleic acid comprises a plurality of CpG dinucleotides, wherein at least one of the CpG dinucleotides comprises a methylated cytosine.
- the oligonucleotides used in the compositions and methods described herein have a phosphodiester (“PO”) backbone or a phosphorothioate (“PS”) backbone, and/or at least one methylated cytosine residue in a CpG motif.
- shRNA phosphodiester
- PS phosphorothioate
- the nucleic acid of a provided lipid nanoparticle includes or consists of shRNA.
- An shRNA molecule includes a short RNA sequence that makes a tight hairpin turn that can be used to silence gene expression via RNA interference.
- the shRNA molecules of the present disclosure may be chemically synthesized or transcribed from a transcriptional cassette in a DNA plasmid. The shRNA hairpin structure is cleaved by the cellular machinery into siRNA, which is then bound to the RNA-induced silencing complex (RISC).
- RISC RNA-induced silencing complex
- the shRNA molecules of the disclosure are typically about 15-60, 15-50, or 15-40 (duplex) nucleotides in length, more typically about 15-30, 15-25, or 19-25 (duplex) nucleotides in length, and are preferably about 20-24, 21-22, or 21-23 (duplex) nucleotides in length (e.g., each complementary sequence of the double-stranded shRNA is 15-60, 15-50, 15- 40, 15-30, 15-25, or 19-25 nucleotides in length, preferably about 20-24, 21-22, or 21-23 nucleotides in length, and the double-stranded shRNA is about 15-60, 15-50, 15-40, 15-30, 15- 25, or 19-25 base pairs in length, preferably about 18-22, 19-20, or 19-21 base pairs in length).
- the DsiRNA has a length sufficient such that it is processed by Dicer to produce an siRNA and has at least one of the following properties: (i) the DsiRNA is asymmetric, e.g., has a 3'-overhang on the antisense strand; and/or (ii) the DsiRNA has a modified 3'-end on the sense strand to direct orientation of Dicer binding and processing of the DsiRNA to an active siRNA.
- the sense strand comprises from about 22 to about 28 nucleotides and the antisense strand comprises from about 24 to about 30 nucleotides.
- the DsiRNA has an overhang on the 3'-end of the antisense strand and the sense strand is modified for Dicer processing.
- the 5 '-end of the sense strand has a phosphate.
- the 5 '-end of the antisense strand has a phosphate.
- the antisense strand or the sense strand or both strands have one or more 2'-O -methyl (2'OMe) modified nucleotides.
- the antisense strand contains 2'OMe modified nucleotides.
- the antisense stand contains a 3'-overhang that is comprised of 2'OMe modified nucleotides.
- the antisense strand could also include additional 2'OMe modified nucleotides.
- the sense and antisense strands anneal under biological conditions, such as the conditions found in the cytoplasm of a cell.
- a region of one of the sequences, particularly of the antisense strand, of the DsiRNA has a sequence length of at least about 19 nucleotides, where these nucleotides are in the 21-nucleotide region adjacent to the 3'-end of the antisense strand and are sufficiently complementary to a nucleotide sequence of the RNA produced from the target gene.
- the DsiRNA may also have one or more of the following additional properties: (a) the antisense strand has a right shift from the typical 21- mer (i.e., the antisense strand includes nucleotides on the right side of the molecule when compared to the typical 21-mer); (b) the strands may not be completely complementary (i.e., the strands may contain simple mismatch pairings); and (c) base modifications such as locked nucleic acid(s) may be included in the 5 '-end of the sense strand.
- the sense strand comprises from about 25 to about 28 nucleotides (e.g., 25, 26, 27, or 28 nucleotides), wherein the 2 nucleotides on the 3'-end of the sense strand are deoxyribonucleotides.
- the sense strand contains a phosphate at the 5 '-end.
- the antisense strand comprises from about 26 to about 30 nucleotides (e.g., 26, 27, 28, 29, or 30 nucleotides) and contains a 3'-overhang of 1-4 nucleotides.
- the nucleotides comprising the 3'- overhang are modified with 2'OMe modified ribonucleotides.
- the antisense strand contains alternating 2'OMe modified nucleotides beginning at the first monomer of the antisense strand adjacent to the 3'-overhang, and extending 15-19 nucleotides from the first monomer adjacent to the 3'-overhang. For example, for a 27-nucleotide antisense strand and counting the first base at the 5 '-end of the antisense strand as position number 1 , 2'OMe modifications would be placed at bases 9, 11, 13, 15, 17, 19, 21, 23, 25, 26, and 27.
- the DsiRNA has a length sufficient such that it is processed by Dicer to produce an siRNA and at least one of the following properties: (i) the DsiRNA is asymmetric, e.g., has a 3'-overhang on the sense strand; and (ii) the DsiRNA has a modified 3'-end on the antisense strand to direct orientation of Dicer binding and processing of the DsiRNA to an active siRNA.
- Suitable modifiers include nucleotides such as deoxyribonucleotides, acyclonucleotides, and the like, and sterically hindered molecules such as fluorescent molecules and the like.
- nucleotide modifiers When nucleotide modifiers are used, they replace ribonucleotides in the DsiRNA such that the length of the DsiRNA does not change.
- the DsiRNA has an overhang on the 3'-end of the sense strand and the antisense strand is modified for Dicer processing.
- the antisense strand has a 5'-phosphate. The sense and antisense strands anneal under biological conditions, such as the conditions found in the cytoplasm of a cell.
- a region of one of the sequences, particularly of the antisense strand, of the DsiRNA has a sequence length of at least 19 nucleotides, wherein these nucleotides are adjacent to the 3'-end of antisense strand and are sufficiently complementary to a nucleotide sequence of the RNA produced from the target gene.
- the DsiRNA may also have one or more of the following additional properties: (a) the antisense strand has a left shift from the typical 21-mer (i.e., the antisense strand includes nucleotides on the left side of the molecule when compared to the typical 21-mer); and (b) the strands may not be completely complementary, i.e., the strands may contain simple mismatch pairings.
- the DsiRNA has an asymmetric structure, with the sense strand having a 25-base pair length, and the antisense strand having a 27-base pair length with a 2-base 3'-overhang.
- this DsiRNA having an asymmetric structure further contains 2 deoxynucleotides at the 3'-end of the sense strand in place of two of the ribonucleotides.
- this DsiRNA having an asymmetric structure further contains 2'OMe modifications at positions 9, 11, 13, 15, 17, 19, 21, 23, and 25 of the antisense strand (wherein the first base at the 5 '-end of the antisense strand is position 1).
- this DsiRNA having an asymmetric structure further contains a 3'- overhang on the antisense strand comprising 1, 2, 3, or 42'OMe nucleotides (e.g., a 3'-overhang of2'OMe nucleotides at positions 26 and 27 on the antisense strand).
- the antisense siRNA may be modified to include about 1 to about 9 ribonucleotides on the 5'-end to provide a length of about 22 to about 28 nucleotides.
- the antisense strand has a length of 21 nucleotides, 1-7, preferably 2-5, or more preferably 4 ribonucleotides may be added on the 3'-end.
- the added ribonucleotides may have any sequence. Although the added ribonucleotides may be complementary to the target gene sequence, full complementarity between the target sequence and the antisense siRNA is not required. That is, the resultant antisense siRNA is sufficiently complementary with the target sequence.
- a sense strand is then produced that has about 24 to about 30 nucleotides.
- the sense strand is substantially complementary with the antisense strand to anneal to the antisense strand under biological conditions.
- the antisense strand is synthesized to contain a modified 3'-end to direct Dicer processing.
- the sense strand of the dsRNA has a 3'-overhang.
- the antisense strand is synthesized to contain a modified 3'-end for Dicer binding and processing and the sense strand of the dsRNA has a 3'-overhang.
- the nucleic acid of a provided lipid nanoparticle includes or consists of piRNA.
- the piRNA molecule bind to proteins of A piRNA molecule can be about 10 to 50 nucleotides in length, about 25 to 39 nucleotides in length, or about 26 to 31 nucleotides in length. See, e.g., U.S. Patent Application Pub. No. 2009/0062228.
- piRNA molecules represent the largest class of small non-coding RNA molecules.
- piRNAs can be substantially complementary to a target gene, and can selectively form RNA- protein complexes through interactions with the Piwi or Aubergine subclasses of Argonaute proteins.
- These piRNA complexes have been linked to both epigenetic and post-transcriptional gene silencing of retrotransposons and other genetic elements in germ line cells, particularly those in spermatogenesis. They are distinct from microRNA (miRNA) in size (typically 24-31 nt rather than 21-24 nt), lack of sequence conservation, and increased complexity.
- miRNA microRNA
- piRNAs are thought to be involved in gene silencing, specifically the silencing of transposons.
- piRNA has a role in RNA silencing via the formation of an RNA-induced silencing complex (RISC).
- RISC RNA-induced silencing complex
- the nucleic acid component (e.g., siRNA) of the lipid nanoparticles described herein can be used to downregulate or silence the translation (i.e., expression) of a gene of interest.
- Genes of interest include, but are not limited to, genes associated with viral infection and survival, genes associated with metabolic diseases and disorders (e.g., liver diseases and disorders), genes associated with tumorigenesis and cell transformation (e.g., cancer), angiogenic genes, immunomodulator genes such as those associated with inflammatory and autoimmune responses, ligand receptor genes, and genes associated with neurodegenerative disorders.
- the gene of interest is expressed in hepatocytes.
- Genes associated with viral infection and survival include those expressed by a virus in order to bind, enter, and replicate in a cell.
- viral sequences associated with chronic viral diseases include sequences of Filoviruses such as Ebola virus and Marburg virus (see, e.g., Geisbert et al., J. Infect. Dis., 193: 1650-1657 (2006)); Arenaviruses such as Lassa virus, Junin virus, Machupo virus, Guanarito virus, and Sabia virus (Buchmeier et al., Arenaviridae: the viruses and their replication, In: FIELDS VIROLOGY, Knipe et al.
- Influenza viruses such as Influenza A, B, and C viruses, (see, e.g., Steinhauer et al., Annu Rev Genet., 36:305-332 (2002); and Neumann et al., J Gen Viral., 83:2635-2662 (2002)); Hepatitis viruses (see, e.g., Hamasaki et al., FEBSLett, 543:51 (2003); Yokota et al., EMBO Rep., 4:602 (2003); Schlomai et al., Hepatology, 37:764 (2003); Wilson et al., Proc.
- Herpes viruses Jia et al., J. Viral., 77:3301 (2003)
- HPV Human Papilloma Viruses
- tissue culture of cells may be required, it is well-known in the art.
- Freshney Culture of Animal Cells, a Manual of Basic Technique, 3rd Ed., Wiley- Liss, New York (1994), Kuchler et al., Biochemical Methods in Cell Culture and Virology, Dowden, Hutchinson and Ross, Inc. (1977), and the references cited therein provide a general guide to the culture of cells.
- Cultured cell systems often will be in the form of monolayers of cells, although cell suspensions are also used.
- the provided ionizable lipids and lipid nanoparticles can be used to deliver a nucleic acid encoding a protein to the liver of a subject, such that the activity or secretion of the protein in the liver is more than about 20-fold greater, more than about 30-fold, more than about 40-fold, more than about 60-fold, more than about 100-fold, more than about 200-fold, more than about 300-fold, more than about 500-fold, more than about 700-fold, or more than about 1000-fold greater than an activity or expression of the protein in the spleen of the subject
- administration can be in any manner known in the art, e.g., by injection, oral administration, inhalation (e.g., intranasal or intratracheal), transdermal application, or rectal administration. Administration can be accomplished via single or divided doses.
- the pharmaceutical compositions can be administered parenterally, i.e., intraarticularly, intravenously, intraperitoneally, subcutaneously, or intramuscularly. In some embodiments, the pharmaceutical compositions are administered intravenously or intraperitoneally by a bolus injection (see, e.g., U.S. Patent No. 5,286,634).
- Intracellular nucleic acid delivery has also been discussed in Straubringer et al., Methods Enzymol., 101:512 (1983); Mannino et al., Biotechniques, 6:682 (1988); Nicolau et al., Crit. Rev. Ther. Drug Carrier Sy st ., 6:239 (1989); and Behr, Acc. Chem. Res., 26:274 (1993). Still other methods of administering lipid-based therapeutics are described in, for example, U.S. Patent Nos. 3,993,754; 4,145,410; 4,235,871; 4,224,179; 4,522,803; and 4,588,578.
- the pharmaceutical compositions may be delivered by intranasal sprays, inhalation, and/or other aerosol delivery vehicles.
- Methods for delivering nucleic acid compositions directly to the lungs via nasal aerosol sprays have been described in, e.g., U.S. Patent Nos. 5,756,353 and 5,804,212.
- the delivery of drugs using intranasal microparticle resins and lysophosphatidyl-glycerol compounds (U.S. Patent 5,725,871) are also well-known in the pharmaceutical arts.
- transmucosal drug delivery in the form of a polytetrafluoroethylene support matrix is described in U.S. Patent No. 5,780,045.
- Formulations suitable for parenteral administration include aqueous and non-aqueous, isotonic sterile injection solutions, which can contain antioxidants, buffers, bacteriostats, and solutes that render the formulation isotonic with the blood of the intended recipient, and aqueous and non-aqueous sterile suspensions that can include suspending agents, solubilizers, thickening agents, stabilizers, and preservatives.
- compositions are administered intravenously (e.g., by intravenous infusion), intramuscularly, pulmonarily, orally, topically, intranasally, intracerebrally, intraperitoneally, intravesically, or intrathecally.
- the lipid particle formulations are formulated with a suitable pharmaceutical carrier.
- a suitable pharmaceutical carrier may be employed in the compositions and methods described herein. Suitable formulations for use are found, for example, in Adejare, A. (Ed.). (2020). Remington: The Science and Practice of Pharmacy (23rd ed.) Elsevier.
- a variety of aqueous carriers may be used, for example, water, buffered water, 0.4% saline, 0.3% glycine, and the like, and may include glycoproteins for enhanced stability, such as albumin, lipoprotein, globulin, etc.
- compositions can be sterilized by conventional liposomal sterilization techniques, such as filtration.
- the compositions may contain pharmaceutically acceptable auxiliary substances as required to approximate physiological conditions, such as pH adjusting and buffering agents, tonicity adjusting agents, wetting agents, and the like, for example, sodium acetate, sodium lactate, sodium chloride, potassium chloride, calcium chloride, sorbitan monolaurate, triethanolamine oleate, etc.
- These compositions can be sterilized using the techniques referred to above or, alternatively, they can be produced under sterile conditions.
- the resulting aqueous solutions may be packaged for use or filtered under aseptic conditions and lyophilized, the lyophilized preparation being combined with a sterile aqueous solution prior to administration.
- the lipid particles described herein may be delivered via oral administration to a subject.
- the particles may be incorporated with excipients and used in the form of ingestible tablets, buccal tablets, troches, capsules, pills, lozenges, elixirs, mouthwash, suspensions, oral sprays, syrups, wafers, and the like (see, e.g., U.S. Patent Nos. 5,641,515, 5,580,579, and 5,792,451).
- These oral dosage forms may also contain binders, gelatin; excipients, lubricants, and/or flavoring agents.
- the unit dosage form When the unit dosage form is a capsule, it may contain, in addition to the materials described above, a liquid carrier. Various other materials may be present as coatings or to otherwise modify the physical form of the dosage unit.
- any material used in preparing any unit dosage form should be pharmaceutically pure and substantially non-toxic in the amounts employed.
- these oral formulations may contain at least about 0.1% of the lipid particles or more, although the percentage of the particles may, of course, be varied and may conveniently be between about 1% or about 2% and about 60% or about 70% or more of the weight or volume of the total formulation.
- the amount of particles in each therapeutically useful composition may be prepared is such a way that a suitable dosage will be obtained in any given unit dose of the compound. Factors such as solubility, bioavailability, biological half-life, route of administration, product shelflife, as well as other pharmacological considerations will be contemplated by one skilled in the art of preparing such pharmaceutical formulations, and as such, a variety of dosages and treatment regimens may be desirable.
- lipid particles can be incorporated into a broad range of topical dosage forms.
- a suspension containing lipid particles can be formulated and administered as gels, oils, emulsions, topical creams, pastes, ointments, lotions, foams, mousses, and the like.
- hosts include mammalian species, such as primates (e.g., humans and chimpanzees as well as other nonhuman primates), canines, felines, equines, bovines, ovines, caprines, rodents (e.g., rats and mice), lagomorphs, and swine.
- Some methods provided by the disclosure are useful for preventing or treating a disease or a disorder of a subject. These methods generally include administering one or more lipid nanoparticles, one or more ionizable lipids, or one or more pharmaceutical compositions to the subject, wherein the lipid nanoparticles include those described in Section B, the ionizable lipids include those described in Section B.2, and the pharmaceutical compositions include those described in Section C.
- the treating of the disease in the subject includes decreasing or eliminating one or more signs or symptoms of the disease.
- the methods described herein are used for the prevention or treatment of a liver disease or disorder. Because of, for example, the enhanced liver-targeting properties described in Section E.2 for the provided ionizable lipids and lipid nanoparticles, these materials are particularly useful for preventing or treating a disease of the liver, and/or preventing or treating a disease for which the modulation of the expression and/or activity of one or more proteins in the liver provides a desired therapeutic effect.
- liver diseases or disorders suitable for treatment with the provided methods include a fatty liver disease (such as, for example, alcoholic fatty liver disease (AFLD), non-alcoholic fatty liver disease (NAFLD), non-alcoholic steatohepatitis (NASH)), liver cirrhosis, liver fibrosis, a disease or disorder characterized by an increased liver enzyme (such as, for example, alanine transaminase (ALT) or aspartate transaminase (AST)), simple steatosis, steatohepatitis, parenchymal liver disease, viral hepatitis, hepatocellular carcinoma, and any of the complications of such conditions (including, but not limited to, heart or metabolic disease related to NASH or NAFLD, portal vein hypertension or thrombosis, esophageal or gastric varices or bleeding from those varices, and other liver-disease related co-morbidities).
- AFLD alcoholic fatty liver disease
- NAFLD non-alcoholic fatty liver
- Cancer generally includes any of various malignant neoplasms characterized by the proliferation of anaplastic cells that tend to invade surrounding tissue and metastasize to new body sites.
- Non-limiting examples of different types of cancer suitable for treatment using the provided methods include ovarian cancer, breast cancer, lung cancer, bladder cancer, thyroid cancer, liver cancer, pleural cancer, pancreatic cancer, cervical cancer, prostate cancer, testicular cancer, colorectal cancer, colon cancer, anal cancer, bile duct cancer, gastrointestinal carcinoid tumors, esophageal cancer, gall bladder cancer, rectal cancer, appendix cancer, small intestine cancer, stomach (gastric) cancer, renal cancer (i.e., renal cell carcinoma), cancer of the central nervous system, skin cancer, oral squamous cell carcinoma, choriocarcinomas, head and neck cancers, bone cancer, osteogenic sarcomas, fibrosarcoma, neuroblastoma,
- the cancer is an ⁇ v ⁇ 6 integrin-mediated disease or disorder.
- the cancer is lung cancer, breast cancer, colorectal cancer, pancreatic cancer, ovarian cancer, cervical cancer, oral squamous cell carcinoma, skin squamous cell carcinoma, stomach cancer, or endometrial cancer.
- the subject has a primary lesion (e.g., a primary tumor).
- the subject has a metastasis (e.g., a metastatic form of any of the cancer types described herein).
- the subject has a primary lesion and a metastasis.
- the subject has a pancreatic cancer such as locally advanced or metastatic pancreatic cancer, locally advanced, unresectable, or metastatic pancreatic adenocarcinoma or pancreatic ductal adenocarcinoma (PDAC).
- a pancreatic cancer such as locally advanced or metastatic pancreatic cancer, locally advanced, unresectable, or metastatic pancreatic adenocarcinoma or pancreatic ductal adenocarcinoma (PDAC).
- the provided methods are useful for treating an infection or infectious disease caused by, e.g., a virus, bacterium, fungus, parasite, or any other infectious agent.
- infectious diseases suitable for treatment using the provided methods include acquired immunodeficiency syndrome (AIDS/HIV) or HIV-related disorders, Alpers syndrome, anthrax, bovine spongiform encephalopathy (mad cow disease), chicken pox, cholera, conjunctivitis, Creutzfeldt-Jakob disease (CJD), dengue fever, Ebola, elephantiasis, encephalitis, fatal familial insomnia, Fifth’s disease, Gerstmann-Straussler- Scheinker syndrome, hantavirus, helicobacter pylori, hepatitis (hepatitis A, hepatitis B, hepatitis C), herpes, influenza (e.g., avian influenza A (bird flu)), Kuru, leprosy, Lyme
- AIDS/HIV acquired immunode
- the measured biomarker can be an indicator of an expression level of the protein or fragment by a target cell or target organism, e.g., the cell or organism to which the lipid nanoparticle or pharmaceutical composition is administered.
- the biomarker can be the protein or fragment itself, such that a measured level of the protein or fragment indicates the level of its expression.
- the measured biomarker can include or consist of one or more components of the immune system of the target cell or target organism.
- the biomarker can include or consist of one or more species of T cells, e.g., CD8 + T cells.
- the provided method further includes comparing the determined level of the one of more biomarkers in the obtained test sample to the level of the one or more biomarkers in a reference sample.
- the reference sample can be obtained, for example, from the subject, with the reference sample being obtained prior to the obtaining of the test sample, e.g., prior to the administering to the subject of the therapeutically effective amount of the provided materials.
- the reference sample can provide information about baseline levels of the biomarkers in the sample before the treatment
- the test sample can provide information about levels of the biomarkers after the treatment.
- the reference sample can be obtained, for example, from a different subject, e.g., a subject in which the treatment is not provided according to the provided methods.
- the reference sample can provide information about baseline levels of the biomarkers without treatment
- the test sample can provide information about levels of the biomarkers with treatment.
- the reference sample can also be obtained, for example, from a population of subjects, e.g., subjects in which the treatment is not provided according to the provided method. In this way, the reference sample can provide population-averaged information about baseline levels of the biomarkers without treatment, and the test sample can provide information about levels of the biomarkers with treatment.
- the reference sample can also be obtained from an individual or a population of individuals after treatment is provided according to the provided methods, and can serve as, for example, a positive control sample.
- the reference sample is obtained from normal tissue.
- the reference sample is obtained from abnormal tissue.
- an increase or a decrease relative to a normal control or reference sample can be indicative of the presence of a disease, or response to treatment for a disease.
- an increased level of a biomarker in a test sample, and hence the presence of a disease, e.g., an infectious disease or cancer, increased risk of the disease, or response to treatment is determined when the biomarker levels are at least, 1.1-fold, e.g., at least 1.2-fold, at least 1.3-fold, at least 1.4-fold, at least 1.5-fold, at least 1.6-fold, at least 1.7- fold, at least 1.8-fold, at least 1.9-fold, at least 2-fold, at least 3-fold, at least 4-fold, at least 5- fold, at least 6-fold, at least 7-fold, at least 8-fold, at least 9-fold, at least 10-fold, at least 11- fold, at least 12-fold, at least 13 -fold, at least 14-fold, at least 15-fold, at
- a decreased level of a biomarker in the test sample, and hence the presence of the disease, increased risk of the disease, or response to treatment is determined when the biomarker levels are at least 1.1-fold, e.g., at least 1.2-fold, at least 1.3-fold, at least 1.4-fold, at least 1.5-fold, at least 1.6-fold, at least 1.7-fold, at least 1.8-fold, at least 1.9-fold, at least 2-fold, at least 3 -fold, at least 4-fold, at least 5 -fold, at least 6-fold, at least 7-fold, at least 8-fold, at least 9-fold, at least 10-fold, at least 11-fold, at least 12-fold, at least 13-fold, at least 14-fold, at least 15-fold, at least 16-fold, at least 17-fold, at least 18-fold, at least 19-fold, or at least 20-fold lower in comparison to a control.
- the biomarker levels can be detected using any method known in the art, including the use of antibodies specific for the biomarkers.
- Exemplary methods include, without limitation, polymerase chain reaction (PCR), Western Blot, dot blot, ELISA, radioimmunoassay (RIA), immunoprecipitation, immunofluorescence, FACS analysis, electrochemiluminescence, and multiplex bead assays, e.g., using Luminex or fluorescent microbeads.
- PCR polymerase chain reaction
- Western Blot Western Blot
- dot blot ELISA
- radioimmunoassay RIA
- immunoprecipitation immunofluorescence
- FACS analysis e.g., electrochemiluminescence
- electrochemiluminescence e.g., electrochemiluminescence
- multiplex bead assays e.g., using Luminex or fluorescent microbeads.
- nucleic acid sequencing is employed.
- the presence of decreased or increased levels of one or more biomarkers is indicated by a detectable signal, e.g., a blot, fluorescence, chemiluminescence, color, or radioactivity, in an immunoassay or PCR reaction, e.g., quantitative PCR.
- a detectable signal e.g., a blot, fluorescence, chemiluminescence, color, or radioactivity
- This detectable signal can be compared to the signal from a reference sample or to a threshold value.
- the results of the biomarker level determinations are recorded in a tangible medium.
- the results of diagnostic assays e.g., the observation of the presence or decreased or increased presence of one or more biomarkers, and the diagnosis of whether or not there is an increased risk or the presence of a disease, e.g., an infectious disease or cancer, or whether or not a subject is responding to treatment can be recorded, for example, on paper or on electronic media, e.g., audio tape, a computer disk, a CD-ROM, or a flash drive.
- the provided method further includes the step of providing to the subject a diagnosis and/or the results of treatment.
- Some methods provided by the disclosure are useful for editing genetic information, e.g., a genome, in a cell. These methods generally include contacting the cell with one or more lipid nanoparticles, wherein the lipid nanoparticles include those described in Section B, and wherein the lipid nanoparticles include one or more nucleic acids of the type described in Section B.5.
- the nucleic acids, or proteins encoded by the nucleic acids can be components of a gene editing system.
- Gene editing systems with one or more components that may be either a nucleic acid delivered by a provided lipid nanoparticle, or a protein encoded by such a nucleic acid can be any of those known in the art.
- Exemplary gene editing systems include those using sequence specific nucleases, such as zine-finger nucleases, engineered or native meganucleases, TALE- endonucleases, an Argonaute (non-limiting examples of Argonaute proteins include Thermus thermophilus Argonaute (TtAgo), Pyrococcus furiosus Argonaute (PfAgo), and Natronobacterium gregoryi Argonaute (NgAgo)), or an RNA-guided endonucleases (for example, a Clustered Regularly Interspersed Short Palindromic Repeat (CRISPR)/Cas9 system, a CRISPR/Cpfl system, a CRISPR/CasX system, a CRISPR/Ca
- the nucleic acid of the lipid nanoparticle of the provided gene editing method encodes site-specific nuclease(s), any associated protein(s), template sequence(s), and/or desired modified sequence(s) for carrying out gene modification.
- the method includes contacting the cell with an expression cassette including additional nucleic acids associated with additional components of the gene editing system.
- a “dCas9- recombinase fusion protein” is a dCas9 with a protein fused to the dCas9 in such a manner that the recombinase is catalytically active on the DNA.
- the site-specific gene editing system includes a dCas9-cytosine deaminase fusion protein.
- the site-specific gene editing system includes a dCas9-adenine deaminase fusion protein.
- the site-specific gene editing system includes a dCas12a-cytosine deaminase fusion protein.
- the site-specific gene editing system includes a dCas 12a- adenine deaminase fusion protein.
- Embodiment 55 An embodiment of embodiment 54, wherein R 1 and R 2 are combined with the nitrogen to which they are attached to form pyrrolidyl or azetidyl.
- Embodiment 56 An embodiment of any one of embodiments 49-55, wherein R 3 , R 4 , and R 5 are each independently cis C 6-12 alkenyl having only one double bond.
- Embodiment 57 An embodiment of embodiment 56, wherein the double bond is in the 2-, 3-, 4-, or 5 -position of the alkenyl.
- Embodiment 59 An embodiment of any one of embodiments 49-58, wherein n is 5, 6, 7, or 8.
- Embodiment 60 An embodiment of embodiment 59, wherein n is 6 or 8.
- Embodiment 61 An embodiment of embodiments 60, wherein n is 6.
- Embodiment 62 An embodiment of embodiment 49, wherein the compound is:
- Embodiment 63 A lipid nanoparticle comprising the compound of any one of claims 49-62.
- Embodiment 65 A lipid nanoparticle comprising an ionizable lipid or a pharmaceutically acceptable salt thereof, the ionizable lipid having the formula: wherein the lipid nanoparticle has a pKa between 5.8 and 6.9, and wherein: R 1 and R 2 are each independently hydrogen , C 1-4 alkyl, or 2- to 4-membered heteroalkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl, wherein the alkyl, heteroalkyl, and heterocyclyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C 1-6 hydroxyalkyl, or fluorine; R 3 , R 4 , and R 5 are each independently C 5-20 alkyl, C 5-20 alkenyl, C 5-20 alkynyl, or C 5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C 1-6 alkyl or C
- Embodiment 66 An embodiment of embodiment 65, wherein the lipid nanoparticle further comprises a nucleic acid.
- Embodiment 68 An embodiment of embodiment 67, wherein the RNA comprises mRNA.
- Embodiment 69 An embodiment of any one of embodiments 66-68, wherein the nucleic acid encodes a protein.
- Embodiment 74 An embodiment of embodiment 73, wherein R 1 and R 2 are each independently methyl, ethyl, or isopropyl.
- Embodiment 76 An embodiment of any one of embodiments 65-72, wherein R 1 and R 2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered saturated heterocyclyl in which the nitrogen is the only heteroatom.
- Embodiment 77 An embodiment of embodiment 76, wherein R 1 and R 2 are combined with the nitrogen to which they are attached to form pyrrolidyl or azetidyl.
- Embodiment 78 An embodiment of any one of embodiments 65-77, wherein R 3 , R 4 , and R 5 are each independently cis C 6-12 alkenyl having only one double bond.
- Embodiment 79 An embodiment of embodiment 78, wherein the double bond is in the 2-, 3-, 4-, or 5 -position of the alkenyl.
- Embodiment 80 An embodiment of embodiment 79, wherein R 3 , R 4 , and R 5 are each identically cis-non-3-ene-1-yl or cis-oct-3-ene-1-yl.
- Embodiment 83 An embodiment of any one of embodiments 65-80, wherein R 6 , R 8 , and R 10 are each independently C 1-20 alkenyl.
- Embodiment 84 An embodiment of embodiment 83, wherein R 6 , R 8 , and R 10 are each cis-dec-4-ene-1-yl .
- Embodiment 85 An embodiment of any one of embodiments 65-84, wherein R 7 , R 9 , and R 11 are each identically hydrogen.
- Embodiment 86 An embodiment of any one of embodiments 65-85, wherein the total number of carbons in R 3 , R 6 , and R 7 ; the total number of carbons in R 4 , R 8 , and R 9 ; and the total number of carbons in R 5 , R 10 , and R 11 are each independently from 7 to 12.
- Embodiment 87 An embodiment of any one of embodiments 65-86, wherein each R 12 and R 13 is hydrogen.
- Embodiment 88 An embodiment of any one of embodiments 65-87, wherein X 1 , X 2 , and X 3 are each identically a covalent bond or methylene.
- Embodiment 89 An embodiment of any one of embodiments 65-88, wherein n is 5, 6, 7, or 8.
- Embodiment 90 An embodiment of embodiment 89, wherein n is 6 or 8.
- Embodiment 91 An embodiment of embodiment 90, wherein n is 6.
- Embodiment 92 An embodiment of any one of embodiments 65-91, wherein the lipid nanoparticle further comprises a phospholipid or a pharmaceutically acceptable salt thereof.
- Embodiment 93 An embodiment of embodiment 92, wherein the tails of the phospholipid are each saturated.
- Embodiment 94 An embodiment of embodiment 93, wherein the phospholipid comprises 1,2-distearoyl-sn-glycero-3-phosphocholine (DSPC).
- DSPC 1,2-distearoyl-sn-glycero-3-phosphocholine
- Embodiment 95 An embodiment of any one of embodiments 92-94, wherein the phospholipid or the pharmaceutically acceptable salt thereof comprises between 1 mol % and 20 mol % of the total lipid of the lipid nanoparticle.
- Embodiment 96 An embodiment of any one of embodiments 65-95, wherein the ionizable lipid or the pharmaceutically acceptable salt thereof comprises between 30 mol % and 70 mol % of the total lipid of the lipid nanoparticle.
- Embodiment 97 An embodiment of any one of embodiments 65-96, wherein the lipid nanoparticle further comprises cholesterol or a derivative thereof.
- Embodiment 99 An embodiment of any one of embodiments 65-98, wherein the lipid nanoparticle further comprises a conjugated lipid.
- Embodiment 100 An embodiment of embodiment 99, wherein the conjugated lipid comprises a polyethylene glycol (PEG)-lipid conjugate.
- PEG polyethylene glycol
- Embodiment 101 An embodiment of embodiment 99 or 100, wherein the conjugated lipid comprises between 0.1 mol % and 5 mol % of the total lipid of the lipid nanoparticle.
- Embodiment 103 An embodiment of any one of embodiments 65-91, wherein the lipid nanoparticle comprises: the ionizable lipid or the pharmaceutically acceptable salt thereof comprising between 52 mol % and 57 mol % of the total lipid present in the lipid nanoparticle; a phospholipid or a pharmaceutically acceptable salt thereof comprising between 10 mol % and 12 mol % of the total lipid present in the lipid nanoparticle; a cholesterol or a derivative thereof comprising between 31 mol % and 34 mol % of the total lipid present in the lipid nanoparticle; and a conjugated lipid comprising between 1 mol % and 3 mol % of the total lipid present in the lipid nanoparticle.
- Embodiment 104 An embodiment of any one of embodiments 65-103, wherein, following administering the lipid nanoparticle to a subject, a concentration of the ionizable lipid in the liver of subject 7 days after the administering is less than 50% of a concentration of the ionizable lipid in the liver 24 hours after the administering.
- Embodiment 108 An embodiment of embodiment 107, wherein the cell comprises a hepatocyte.
- Embodiment 115 An embodiment of embodiment 114, wherein the disease or disorder comprises an infection, a liver disease or disorder, or a cancer.
- Embodiment 119 The lipid nanoparticle of embodiment 46 or 72, for use in editing genomic information in a cell.
- the provided compounds can be synthesized by a variety of methods known to one of skill in the art (see Comprehensive Organic Transformations Richard C. Larock, 1989) or by an appropriate combination of generally well known synthetic methods. Techniques useful in synthesizing the disclosed compounds are both readily apparent and accessible to those of skill in the relevant art.
- the examples below are offered to illustrate certain of the diverse methods available for use in assembling the provided compounds. However, the examples are not intended to define the scope of reactions or reaction sequences that are useful in preparing the compounds. Exemplary structures below are named according to standard IUPAC nomenclature using the Cambridge Soft ChemDraw naming package.
- Lipids 5 to 24 and 26 to 29 were synthesized using a procedure analogous to that employed for lipid 4, using an appropriate haloalkylsilyl trichloride, lipid alcohol, and amine headgroup.
- Lipid 25 was synthesized according to literature procedures outlined in International Patent Application Publication No. WO 2013/126803A1.
- Lipids 26, 27, 28 and 29 were synthesized according to literature procedures outlined in International Patent Application Publication No. WO 2020/097520A1.
- tdTomato mRNA was diluted in 350 mM acetate buffer, pH 5 and nuclease-free water to achieve a final mRNA concentration of 0.366 mg/mL in 100 mM acetate buffer, pH 5.
- Lipid and nucleic acid solutions were mixed at equal volumes through a T-connector at a flow rate of 400 mL/min and subsequently diluted with about 4 volumes of PBS, pH 7.4.
- Diluted formulations were dialyzed in Slide-A-Lyzer dialysis units (MWCO 10,000) overnight at 4 °C against 10 mM Tris, 500 mM NaCl, pH 8 buffer.
- Dialyzed formulations were concentrated to approximately 0.6 mg/mL mRNA with VivaSpin concentrator units (MWCO 100,000) and subsequently dialyzed against 5 mM Tris, 10% sucrose, pH 8 buffer (T10S) overnight at 4 °C.
- Formulations in T10S buffer were fdtered through a 0.2-pm syringe fdter (polyethersulfone (PES) membrane). Concentration and encapsulation efficiency of the nucleic acid was determined using the RiboGreen assay.
- Particle size (Z -average) and polydispersity (PDI) were measured by dynamic light scattering (DLS) using a Malvern Nano Series Zetasizer.
- Frozen liver pieces were thawed and homogenized using a FASTPREP® homogenizer in 0.5 mL of lx Halt Inhibitor Cocktail (100X Halt Protease Inhibitor diluted in PBS pH 7.4). The lysate was centrifuged at 16,000 RPM for 10 minutes at 4 °C. 10 ⁇ L of supernatant was loaded into a clear non-binding 96-well plate and 90 ⁇ L of PBS was added to each well containing sample. Fluorescence was measured using a plate reader (Excitation 554 nm/ Emission 581 nm). tdTomato activity was quantified by comparing sample fluorescence to tdTomato protein standards.
- LNP formulations (2.5:54.2:32.5: 10.8 (PEG2000-C-DMA): (Lipid 4): (Cholesterol): (Phospholipid) encapsulating tdTomato mRNA payload and ionizable Lipid 4 were compared to benchmark control for activity in a tdTomato mouse model following intravenous administration (at 3 or 6 mg/kg dose).
- formulations containing Lipid 4 exhibited high levels of tdTomato activity in the liver, comparable to benchmark.
- Lipid 4-containing LNPs showed preferential delivery to the liver as evident in more than 100-fold higher in tdTomato activity in the liver compared to the spleen (Tables 6 and 7).
- Lipid 4 LNP formulations containing a tdTomato mRNA payload with different phospholipids were compared to benchmark control for activity in a tdTomato mouse model.
- LNPs were administered intravenously (as described previously) at a dose of 1.0 mg/kg.
- liver sections were collected and tdTomato activity assessed.
- All Lipid 4-containing formulations again showed preferential delivery to the liver as compared to levels in the spleen and higher levels of tdTomato activity in the liver were evident for all Lipid 4 formulations compared to benchmark.
- Particularly, Lipid 4 formulation containing POPC showed highest level of tdTomato expression (Table 8).
- LNP formulations containing a tdTomato mRNA payload with different silicon ether ionizable lipids were compared to benchmark control for activity in tdTomato mouse model.
- LNPs were formulated as described previously for molar ratios of 1.6:54.6:32.8: 10.9 (PEG2000-C-DMA): (Ionizable lipid):(Cholesterol):(DSPC).
- LNPs were administered intravenously (as described previously) at a dose of 1.0 mg/kg. 24 hours post-administration, liver sections were collected and assessed for tdTomato activity.
- the pKa of the various lipid nanoparticles comprising different ionizable lipids was determined using a microplate -based 6-(p-toluidino)-2-naphthalenesulfonyl chloride (TNS) assay.
- TMS 6-(p-toluidino)-2-naphthalenesulfonyl chloride
- buffers in the pH range of 4.5-8.0 were prepared and the final pH range consisted of 4.5, 5.0, 5.5, 5.8, 5.9, 6.0, 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.8, 7.0, 7.5, and 8.0.
- Each pH-adjusted buffer was then passed through 0.2-pm syringe filters (Acrodisc 32-mm Syringe Filters with 0.2-pm Supor Membrane Cat#4652) and the final pH was determined following filtration. Post-filtration pH values were used for determining the pKa.
- the samples were then mixed well with a pipette and fluorescence intensity was monitored at 37 °C for 90 mins (with measurements at 0 min, 30 mins, 60 mins, and 90 mins) in a Tecan Safire 2 fluorescence plate reader using excitation and emission wavelengths of 322 nm and 431 nm, respectively, with 20-nm slit widths.
- the fluorescence values at each pH were normalized to that of pH 4.5, where fluorescence value at pH 4.5 was treated as 100%.
- a sigmoidal best fit analysis was applied to the normalized data and the pKa was measured as the pH giving rise to half-maximal fluorescence intensity (FIG. 2).
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Genetics & Genomics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Biomedical Technology (AREA)
- General Chemical & Material Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Epidemiology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Physics & Mathematics (AREA)
- Nanotechnology (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Plant Pathology (AREA)
- Microbiology (AREA)
- Gastroenterology & Hepatology (AREA)
- Optics & Photonics (AREA)
- Biochemistry (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
The present disclosure provides nitrogen-containing silicon ether ionizable lipid compounds and lipid nanoparticles including the ionizable lipid. The disclosure further relates to lipid nanoparticles including a provided ionizable lipid compound together with a phospholipid, e.g., a phospholipid that includes at least one unsaturated tail and a head group having a positively charged nitrogen. The provided materials are particularly beneficial in applications involving delivery of a nucleic acid. The disclosure also provides pharmaceutical compositions and methods including the provided ionizable lipids and/or lipid nanoparticles.
Description
IONIZABLE LIPIDS SUITABLE FOR LIPID NANOPARTICLES
CROSS-REFERENCE TO RELATED APPLICATION
[0001] The present application claims priority from U.S. Provisional Application No. 63/613,515, filed December 21, 2023, and U.S. Provisional Application No. 63/566,701, filed March 18, 2024, the entire contents of which are incorporated herein by reference for all purposes.
BACKGROUND
[0002] Lipid nanoparticles (LNPs) have emerged as a critical technology in the field of drug delivery, particularly for the encapsulation and systemic delivery of nucleic acids such as mRNA and siRNA. Their importance lies in their ability to protect these therapeutic agents from degradation, enhance cellular uptake, and control the release of the encapsulated agent. Despite their success, however, there is a pressing need for improved LNPs. Current LNPs can have limitations including suboptimal biodistribution and/or clearance rates, induction of immune responses, potential for off-target effects, and low expression efficiencies of delivered payloads such as mRNA Therefore, the development of next-generation LNPs with, for example, enhanced stability, targeted delivery, and minimized side effects is important for fully realizing the potential of LNPs in the field of nucleic acid therapeutics. The present disclosure addresses these needs and provides associated and other advantages.
BRIEF SUMMARY
[0003] This summary provides a high-level overview of various aspects of the disclosure and introduces some of the concepts that are described and illustrated in the present document and the accompanying figures. The summary is not intended to identify key or essential features of the claimed subject matter, nor is it intended to be used in isolation to determine the scope of the claimed subject matter. Covered embodiments of the disclosure are defined by the claims, not this summary. The subject matter should be understood by reference to appropriate portions of the entire specification, any or all figures, and each claim. Some of the exemplary embodiments of the present disclosure are discussed below.
[0004] In one aspect, the disclosure provides a compound having the formula:
 or the formula of a pharmaceutically acceptable salt thereof. R1 and R2 of formula (la) are each independently hydrogen or C1-4 alkyl. Alternatively, R1 and R2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl. R3, R4, and R5 of formula (la) are each independently cis C5-20 alkenyl or C5-20 alkynyl having only one unsaturated bond. Subscript n of formula (la) is an integer from 4 to 8
or the formula of a pharmaceutically acceptable salt thereof. R1 and R2 of formula (la) are each independently hydrogen or C1-4 alkyl. Alternatively, R1 and R2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl. R3, R4, and R5 of formula (la) are each independently cis C5-20 alkenyl or C5-20 alkynyl having only one unsaturated bond. Subscript n of formula (la) is an integer from 4 to 8
[0005] In another aspect, the disclosure provides a lipid nanoparticle having a pKa from 5.8 to 6.9, i.e., a pKa that is no less than 5.8 and no greater than 6.9. The lipid nanoparticle includes an ionizable lipid or a pharmaceutically acceptable salt thereof. The ionizable lipid has the formula:

R1 and R2 of formula (I) are each independently hydrogen, C1-4 alkyl, or 2- to 4-membered heteroalkyl, wherein the alkyl and heteroalkyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine. Alternatively, R1 and R2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine. R3, R4, and R5 of formula (I) are each independently C5-20 alkyl, C5-20 alkenyl, C5-20 alkynyl, or C5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C1-6 alkyl or C2-6 alkenyl. R6 and R7 of formula (I) are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, with the proviso that no more than one of R6 and R7 is hydrogen. Alternatively, R6 and R7 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. R8 and R9 of formula (I) are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, with the proviso that no more than one of R8 and R9 is hydrogen. Alternatively, R8 and R9 are combined with the carbon to which they are attached to
form cyclopropyl or cyclobutyl. R10 and R11 of formula (I) are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, with the proviso that no more than one of R10 and R11 is hydrogen. Alternatively, R10 and R11 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. Each R12 and R13 is independently hydrogen or C1- 6 alkyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine. Alternatively, R12 and R13 can be combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. X1, X2, and X3 of formula (I) are each independently a covalent bond, C1-6 alkylene, C1-6 alkenylene, or C1-6 alkynylene. Subscript n of formula (I) is an integer from 2 to 10.
[0006] In another aspect, the disclosure provides a lipid nanoparticle that includes a phospholipid or a pharmaceutically acceptable salt thereof, and an ionizable lipid or a pharmaceutically acceptable salt thereof. The phospholipid includes one or more unsaturated tails and a head group having a positively charged nitrogen. The ionizable lipid has the formula:

R1 and R2 of formula (I) are each independently hydrogen, C1-4 alkyl, or 2- to 4-membered heteroalkyl, wherein the alkyl and heteroalkyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine. Alternatively, R1 and R2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine. R3, R4, and R5 of formula (I) are each independently C5-20 alkyl, C5-20 alkenyl, C5-20 alkynyl, or C5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C1-6 alkyl or C2-6 alkenyl. R6 and R7 of formula (I) are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl. Alternatively, R6 and R7 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. R8 and R9 of formula (I) are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl. Alternatively, R8 and R9 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. R10 and R11 of formula (I) are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20
alkynyl. Alternatively, R10 and R11 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. Each R12 and R13 is independently hydrogen or C1-6 alkyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine. Alternatively, R12 and R13 can be combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. X1, X2, and X3 of formula (I) are each independently a covalent bond, C1-6 alkylene, C1-6 alkenylene, or C1-6 alkynylene. Subscript n of formula (I) is an integer from 2 to 10.
[0007] In another aspect, the disclosure provides a composition, e.g., a pharmaceutical composition. The pharmaceutical composition includes a pharmaceutically acceptable carrier or a pharmaceutically acceptable excipient. The pharmaceutical composition further includes a lipid nanoparticle as disclosed herein or a compound as disclosed herein.
[0008] In another aspect, the disclosure provides a method of introducing a nucleic acid to a cell. The method includes contacting the cell with a lipid nanoparticle as disclosed herein, wherein the lipid nanoparticle includes the nucleic acid.
[0009] In another aspect, the disclosure provides an in vivo method of delivering a nucleic acid to a subject. The method includes administering to the subject a lipid nanoparticle as disclosed herein, wherein the lipid nanoparticle includes the nucleic acid.
[0010] In another aspect, the disclosure provides a method of preventing or treating a disease or disorder in a subject. The method includes administering to the subject an amount, e.g., a therapeutically effective amount, of a lipid nanoparticle as disclosed herein, a compound as disclosed herein, and/or a pharmaceutical composition as disclosed herein.
[0011] In another embodiment, the disclosure provides a method of editing genomic information in a cell. The method includes contacting the cell with a lipid nanoparticle as disclosed herein, wherein the lipid nanoparticle includes a nucleic acid. The nucleic acid and/or a protein encoded by the nucleic acid is a component of a gene editing system.
BRIEF DESCRIPTION OF DRAWINGS
[0012] FIG. 1 presents a graph plotting tdTomato activity in the livers of mice administered various lipid nanoparticle formulations in accordance with provided embodiments, where the lipid nanoparticles contained tdTomato mRNA.
[0013] FIG. 2 presents a graph demonstrating determination of the pKa of a lipid nanoparticle formulated in accordance with a provided embodiment. The pKa was measured as the pH at which 50% of the ionizable lipids of the lipid nanoparticle became ionized.
DETAILED DESCRIPTION
A. DEFINITIONS
[0014] Unless specifically indicated otherwise, all technical and scientific terms used herein have the same meaning as commonly understood by those of ordinary skill in the art to which this disclosure belongs. In addition, any method or material similar or equivalent to a method or material described herein can be used in the practice of the present disclosure. For purposes of the present disclosure, the following terms are defined.
[0015] The abbreviations used herein have their conventional meaning within the chemical and biological arts. Description of compounds of the present disclosure are limited by principles of chemical bonding known to those skilled in the art. Accordingly, where a group may be substituted by one or more of a number of substituents, such substitutions are selected so as to comply with principles of chemical bonding and to give compounds that are not inherently unstable and/or would be known to one of ordinary skill in the art as likely to be unstable under ambient conditions, such as aqueous, neutral, or physiological conditions. Where substituent groups are specified by their conventional chemical formulae, written from left to right, they equally encompass the chemically identical substituents that would result from writing the structure from right to left, e.g., -CH2O- is equivalent to -OCH2-.
[0016] Unless otherwise stated, the compounds of the present disclosure may also contain unnatural proportions of atomic isotopes at one or more of the atoms that constitute such compounds. For example, the compounds may be labeled with isotopes, such as for example deuterium (2H), tritium (3H), iodine- 125 (125I), carbon- 13 (13C), or carbon- 14 (14C). All isotopic variations of the compounds of the present disclosure, whether radioactive or not, are encompassed within the scope of the present disclosure.
[0017] As used herein, the term “substitution,” when used in relation to a chemical substance, refers to replacement of a hydrogen atom with a non-hydrogen atom or covalently bonded group of atoms. The atom or group of atoms replacing the hydrogen atom is referred to as a “substituent.”
[0018] As used herein, the term “member,” when used in relation to a chemical substance, refers to a non-hydrogen atom of a covalently bonded group of atoms, e.g., a compound or substituent thereof.
[0019] As used herein, the singular forms “a,” “an,” and “the” include plural referents unless the content clearly dictates otherwise. Thus, for example, reference to “a phospholipid” optionally includes a combination of two or more phospholipids, and the like.
[0020] As used herein, the terms “about” and “approximately,” when used to modify an amount specified in a numeric value or range, indicate that the numeric value as well as reasonable deviations from the value known to the skilled person in the art, for example ± 20%, ± 10%, or ± 5%, are within the intended meaning of the recited value.
[0021] As used herein, the term “and/or” refers to and encompasses any and all possible combinations of one or more of the associated listed items, as well as the lack of combinations when interpreted in the alternative (“or”).
[0022] As used herein, the terms “including,” “comprising,” “having,” “containing,” and variations thereof, are inclusive and open-ended and do not exclude additional, unrecited elements or method steps beyond those explicitly recited. As used herein, the phrase “consisting of’ is closed and excludes any element, step, or ingredient not explicitly specified. As used herein, the phrase “consisting essentially of’ limits the scope of the described feature to the specified materials or steps and those that do not materially affect the basic and novel characteristics of the disclosed feature.
[0023] As used herein, the terms “lipid particle,” “lipid nanoparticle,” and “LNP” refer to a particle comprising a phospholipid and an ionizable lipid. A lipid particle may comprise additional lipid components, such as a sterol and/or a conjugated lipid, and may further comprise a nucleic acid, wherein the nucleic acid may be encapsulated within the particle . Lipid particles and their method of preparation are disclosed in, e.g., U.S. Patent Application Publication Nos. 2004/0142025 and 2007/0042031, and International Patent Application Publication No. WO 2012/000104.
[0024] As used herein, the term “phospholipid” refers to a lipid species having a phosphate- containing hydrophilic “head group” and a hydrophobic moiety. The hydrophobic moiety can comprise one or more hydrophobic groups, most typically two hydrophobic groups. The hydrophobic groups are also referred to as hydrophobic “tails,” and can be derived from fatty
acids and joined by an alcohol residue, e.g., glycerol. Exemplary structures of phospholipids include phosphatidylcholine, phosphatidylethanolamine, phosphatidylserine, phosphatidylinositol, phosphatidic acid, phosphatidylcholine, lysophosphatidylcholine, and lysophosphatidylethanolamine
[0025] As used herein, the term “ionizable lipid” refers to a lipid species that carries a net positive charge at a selected pH, such as an acidic pH or physiological pH. In some cases, an ionizable lipid includes an ionizable primary, secondary, or tertiary amine (e.g., pH titratable) head group. In some instances, ionizable lipids promote encapsulation of a negatively charged nucleic acid (e.g., mRNA or siRNA) payload during particle formation. In some instances, ionizable lipids promote endosomal fusion and cytoplasmic release of a payload following cellular uptake of a lipid nanoparticle.
[0026] As used herein, the term “conjugated lipid” refers to a polymer-conjugated lipid, e.g., a polymer-conjugated lipid that inhibits aggregation of lipid particles. Such lipid conjugates include, but are not limited to, polyamide oligomers (e.g., ATTA-lipid conjugates), polysarcosine-lipid conjugates, polyoxazoline (POZ)-lipid conjugates, PEG-lipid conjugates, such as PEG coupled to dialkyloxypropyls, PEG coupled to diacylglycerols, PEG coupled to cholesterol, PEG coupled to phosphatidylethanolamines, PEG conjugated to ceramides (see, e.g., U.S. Pat. No. 5,885,613, the disclosure of which is herein incorporated by reference in its entirety for all purposes), cationic PEG lipids, and mixtures thereof. PEG can be conjugated directly to the lipid or may be linked to the lipid via a linker moiety. Any linker moiety suitable for coupling the polymer to a lipid can be used including, e.g., non-ester containing linker moieties and ester-containing linker moieties.
[0027] As used herein, the term “salt” refers to acid or base salts of the compounds of the present disclosure. A “pharmaceutically acceptable salt” is one that is compatible with other ingredients of a formulation composition containing the compound, and that is not deleterious to a recipient thereof, i.e., a subject. It is thus understood that the pharmaceutically acceptable salts do not cause a significant adverse toxicological effect on the subject.
[0028] As used herein, the term “alkyl,” by itself or as part of another substituent, refers to a straight or branched, saturated, aliphatic radical having the number of carbon atoms indicated. A branched alkyl may include one or more branches having a geminal, vicinal, and/or isolated pattern. For example, an alkyl may include gem-methyl groups. Alkyl may include any number of carbons, such as C1-2, C1-3, C1-4, C1-5, C1-6, C1-7, C1-8, C1-9, C1-10, C2-3, C2-4, C2-5, C2-6, C3-4,
C3-5, C3-6, C4-5, C4-6, and C5-6. For example, C1-6 alkyl includes, but is not limited to, methyl, ethyl, propyl, isopropyl, butyl, isobutyl, sec-butyl, tert-butyl, pentyl, isopentyl, hexyl, etc. Alkyl may also refer to alkyl groups having up to 40 carbon atoms, such as, but not limited to heptyl, octyl, nonyl, decyl, etc. In some aspects, i.e., when indicated in the disclosure, alkyl groups may be substituted. Unless otherwise specified, “substituted alkyl” groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy. In some embodiments including one or more halogen substitutions, fluorine is preferred.
[0029] As used herein, the term “alkylene,” by itself or as part of another substituent, refers to a straight or branched, saturated, aliphatic radical having the number of carbon atoms indicated, and linking at least two other groups, i.e., a divalent hydrocarbon radical. The two moieties linked to the alkylene may be linked to the same atom or different atoms of the alkylene group. For instance, a straight chain alkylene may be the bivalent radical of -(CH2)n- where n is 1, 2, 3, 4, 5 or 6. A branched alkylene may include one or more branches having a geminal, vicinal, and/or isolated pattern. For example, an alkylene may include gem-methyl groups. Representative alkylene groups include, but are not limited to, methylene, ethylene, propylene, isopropylene, butylene, isobutylene, sec-butylene, pentylene and hexylene. In some aspects, i.e., when indicated in the disclosure, alkylene groups may be substituted. Unless otherwise specified, “substituted alkylene” groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy.
[0030] As used herein, the term “alkenyl,” by itself or as part of another substituent, refers to an alkyl group having at least one carbon-carbon double bond. Alkenyl may include any number of carbons, such as C2, C2-3, C2-4, C2-5, C2-6, C2-7, C2-8, C2-9, C2-10, C3, C3-4, C3-5, C3-6, C4, C4-5, C4-6, C5, C5-6, and C6. Alkenyl groups may have any suitable number of double bonds, including, but not limited to, 1, 2, 3, 4, 5 or more. Examples of alkenyl groups include, but are not limited to, vinyl (ethenyl), propenyl, isopropenyl, 1-butenyl, 2-butenyl, isobutenyl, butadienyl, 1-pentenyl, 2-pentenyl, isopentenyl, 1,3 -pentadienyl, 1,4-pentadienyl, 1-hexenyl, 2-hexenyl, 3-hexenyl, 1,3-hexadienyl, 1,4-hexadienyl, 1,5-hexadienyl, 2,4-hexadienyl, and 1,3, 5 -hexatrienyl. In some aspects, i.e., when indicated in the disclosure, alkenyl groups may be substituted. Unless otherwise specified, “substituted alkenyl” groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy. In some embodiments including one or more halogen substitutions, fluorine is preferred.
[0031] As used herein, the term “alkenylene,” by itself or as part of another substituent, refers to an alkylene group having at least one carbon-carbon double bond and linking at least two other groups, i.e., a divalent hydrocarbon radical. The two moieties linked to the alkenylene may be linked to the same atom or different atoms of the alkenylene group. In some aspects, i.e., when indicated in the disclosure, alkenylene groups may be substituted. Unless otherwise specified, “substituted alkenylene” groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy.
[0032] As used herein, the term “alkynyl,” by itself or as part of another substituent, refers to an alkyl group having at least one carbon-carbon triple bond. Alkynyl may include any number of carbons, such as C2, C2-3, C2-4, C2-5, C2-6, C2-7, C2-8, C2-9, C2-10, C3, C3-4, C3-5, C3-6, C4, C4-5, C4-6, C5, C5-6, and C6. Examples of alkynyl groups include, but are not limited to, acetylenyl, propynyl, 1-butynyl, 2-butynyl, isobutynyl, sec-butynyl, butadiynyl, 1-pentynyl, 2-pentynyl, isopentynyl, 1,3-pentadiynyl, 1,4-pentadiynyl, 1-hexynyl, 2-hexynyl, 3-hexynyl, 1,3 -hexadiynyl, 1,4-hexadiynyl, 1,5 -hexadiynyl, 2,4-hexadiynyl, or 1,3,5-hexatriynyl. In some aspects, i.e., when indicated in the disclosure, alkynyl groups may be substituted. Unless otherwise specified, “substituted alkynyl” groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy. In some embodiments including one or more halogen substitutions, fluorine is preferred.
[0033] As used herein, the term “alkynylene,” by itself or as part of another substituent, refers to an alkynlene group having at least one carbon-carbon triple bond and linking at least two other groups, i.e., a divalent hydrocarbon radical. The two moieties linked to the alkynylene may be linked to the same atom or different atoms of the alkynylene group. In some aspects, i.e., when indicated in the disclosure, alkynylene groups may be substituted. Unless otherwise specified, “substituted alkynylene” groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy.
[0034] As used herein, the term “alkoxy” refers to a substituted alkyl group, as defined above, having an oxygen atom that connects the alkyl group to the point of attachment: alkyl- O-. As for the unsubstituted portion of the alkyl group, alkoxy groups may have any suitable number of carbon atoms, such as C1-6. Alkoxy groups include, for example, methoxy, ethoxy, propoxy, isopropoxy, butoxy, 2-butoxy, isobutoxy, secbutoxy, tertbutoxy, pentoxy, hexoxy, etc.
[0035] As used herein, the terms “hydroxyalkyl” or “alkylhydroxy” refer to an alkyl group, as defined above, where at least one of the hydrogen atoms is replaced with a hydroxy group. As for the unsubstituted portion of the alkyl group, alkylhydroxy groups can have any suitable number of carbon atoms, such as C1-6. Exemplary alkylhydroxy groups include, but are not limited to, hydroxy-methyl, hydroxyethyl (where the hydroxy is in the 1- or 2-position), hydroxypropyl (where the hydroxy is in the 1-, 2- or 3-position), hydroxybutyl (where the hydroxy is in the 1-, 2-, 3- or 4-position), hydroxypentyl (where the hydroxy is in the 1-, 2-, 3-, 4- or 5 -position), hydroxyhexyl (where the hydroxy is in the 1-, 2-, 3-, 4-, 5- or 6-position), 1,2-dihydroxyethyl, and the like.
[0036] As used herein, the term “heteroalkyl,” by itself or as part of another substituent, refers to an alkyl group of any suitable length and having any number of (e.g., from 1 to 3) heteroatoms such as N, O or S. The heteroatoms may also be oxidized, such as, but not limited to, -S(O)- and -S(O)2-. For example, heteroalkyl may include ethers, thioethers and alkyl-amines. The heteroatom portion of the heteroalkyl may replace a hydrogen of the alkyl group to form a hydroxy, thio, or amino group. Alternatively, the heteroatom portion may be the connecting atom, or be inserted between two carbon atoms. In some aspects, i.e., when indicated in the disclosure, heteroalkyl groups may be substituted. Unless otherwise specified, “substituted heteroalkyl” groups may be substituted with one or more groups selected from halo, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy.
[0037] As used herein, the term “cycloalkyl,” by itself or as part of another substituent, refers to a saturated or partially unsaturated, monocyclic, fused polycyclic, spiro polycyclic, or bridged polycyclic ring assembly containing from 3 to 12 ring atoms, or the number of atoms indicated. Cycloalkyl may include any number of carbons, such as C3-6, C4-6, C5-6, C3-8, C4-8, C5-8, C 6-8, C 3-9, C 3-10, C 3-11, and C3-12. Saturated monocyclic cycloalkyl rings include, for example, cyclopropyl, cyclobutyl, cyclopentyl, cyclohexyl, and cyclooctyl. Saturated bicyclic and polycyclic cycloalkyl rings include, for example, bicyclofl. l. l]pentane, norbomane, [2.2.2] bicyclooctane, decahydronaphthalene and adamantane. Cycloalkyl groups may also be partially unsaturated, having one or more double or triple bonds in the ring. Representative cycloalkyl groups that are partially unsaturated include, but are not limited to, cyclobutene, cyclopentene, cyclohexene, cyclohexadiene (1,3- and 1,4-isomers), cycloheptene, cycloheptadiene, cyclooctene, cyclooctadiene (1,3-, 1,4- and 1,5-isomers), norbomene, and norbomadiene. When cycloalkyl is a saturated monocyclic C3-8 cycloalkyl, exemplary groups include, but are not limited to cyclopropyl, cyclobutyl, cyclopentyl, cyclohexyl, cycloheptyl
and cyclooctyl. When cycloalkyl is a saturated monocyclic C3-6 cycloalkyl, exemplary groups include, but are not limited to cyclopropyl, cyclobutyl, cyclopentyl, and cyclohexyl. In some aspects, i.e., when indicated in the disclosure, cycloalkyl groups may be substituted. Unless otherwise specified, “substituted cycloalkyl” groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy. In some embodiments including one or more halogen substitutions, fluorine is preferred.
[0038] As used herein the term “heterocyclyl,” by itself or as part of another substituent, refers to a saturated heterocyclyl ring system having from 3 to 15 ring members or the number of atoms indicated, a partially unsaturated non-aromatic ring, or a partially unsaturated, non- aromatic fused, spiro, or bridged multiple-ring system in which one or more of the carbon atoms are each independently replaced with the same or different heteroatom such as N, O or S. The heteroatoms may be oxidized to form moieties such as, but not limited to, -S(O)- and -S(O)2-. Heterocyclyl groups may include any number of ring atoms, such as, C3-6, C4-6, C5-6, C3-8, C4-8, C5-8, C 6-8, C3-9, C3-10, C3-1 1, C3-12, or C3-15, wherein at least one of the carbon atoms is replaced by a heteroatom. Any suitable number of carbon ring atoms may be replaced with heteroatoms in the heterocyclyl groups, such as 1, 2, 3, or 4, or 1 to 2, 1 to 3, 1 to 4, 2 to 3, 2 to 4, or 3 to 4. The heterocyclyl group may include groups such as aziridine, azetidine, pyrrolidine, piperidine, azepane, azocane, quinuclidine, pyrazolidine, imidazolidine, piperazine (1,2-, 1,3- and 1,4-isomers), oxirane, oxetane, tetrahydrofuran, oxane (tetrahydropyran), oxepane, thiirane, thietane, thiolane (tetrahydrothiophene), thiane (tetrahydrothiopyran), oxazolidine, isoxazolidine, thiazolidine, isothiazolidine, dioxolane, dithiolane, morpholine, thiomorpholine, dioxane, or dithiane. One or more heterocycloalkyl rings of heterocyclyl groups may also be fused to aromatic or non-aromatic rings to form members including, but not limited to, indoline. Heterocyclyl groups thus include partially unsaturated ring systems containing one or more double bonds, including fused ring systems with one aromatic ring and one non-aromatic ring, but not fully aromatic ring systems. Examples include dihydroquinolines, e.g., 3,4- dihydroquinoline, dihydroisoquinolines, e.g., 1,2-dihydroisoquinoline, tetrahydroquinolines, e.g., 1,2,3,4-tetrahydroquinoline, tetrahydroisoquinoline, dihydroimidazole, tetrahydroimidazole, etc., isoindoline, isoindolones (e.g., isoindolin-1-one), isatin, dihydrophthalazine, quinolinone, spiro [cyclopropane- 1,1'- isoindolin]-3'-one, and the like. Heterocyclyl groups may have 3-15 members, or 3-12 members, or 3-10 members, or 3-7 members, or 5-6 members. The heterocyclyl groups may
be linked via any position on the ring. For example, aziridine may be 1- or 2-aziridine, azetidine may be 1- or 2- azetidine, pyrrolidine may be 1-, 2- or 3 -pyrrolidine, piperidine may be 1-, 2-, 3- or 4-piperidine, pyrazolidine may be 1-, 2-, 3-, or 4-pyrazolidine, imidazolidine may be 1-, 2-, 3- or 4-imidazolidine, piperazine may be 1-, 2-, 3- or 4-piperazine, tetrahydrofuran may be
1- or 2-tetrahydrofuran, oxazolidine may be 2-, 3-, 4- or 5-oxazolidine, isoxazolidine may be
2-, 3-, 4- or 5 -isoxazolidine, thiazolidine may be 2-, 3-, 4- or 5-thiazolidine, isothiazolidine may be 2-, 3-, 4- or 5- isothiazolidine, and morpholine may be 2-, 3- or 4-morpholine. In some aspects, i.e., when indicated in the disclosure, heterocyclyl groups may be substituted. Unless otherwise specified, “substituted heterocyclyl” groups may be substituted with one or more groups selected from halogen, hydroxy, amino, alkylamino, amido, acyl, oxo, nitro, cyano, and alkoxy. In some embodiments including one or more halogen substitutions, fluorine is preferred.
[0039] As used herein, the term “hydroxy,” by itself or as part of another substituent, refers to the moiety -OH.
[0040] As used herein, the terms “halo” and “halogen,” by themselves or as part of another substituent, refer to a fluorine, chlorine, bromine, or iodine atom.
[0041] As used herein, the term “oxo” by itself or as part of another substituent refers to an oxygen atom that is double-bonded to a compound (i.e., O=).
[0042] As used herein, the term “nitro” by itself or as part of another substituent refers to the moiety -NO2.
[0043] As used herein, the term “cyano” by itself or as part of another substituent refers to a group consisting of nitrogen triple-bonded to carbon: -C=N.
[0044] As used herein, the term “nucleic acid” refers to deoxyribonucleic acids (DNA) or ribonucleic acids (RNA) and polymers thereof in either single- or double-stranded form. Unless specifically limited, the term encompasses nucleic acids containing nucleotide analogs or modified backbone residues or linkages, which are synthetic, naturally occurring, and non- naturally occurring, that have similar binding properties as the reference nucleotide and are metabolized in a manner similar to reference nucleotides. Non-limiting examples of nucleotide analogs are described in, e.g., International Patent Application No. WO 2007/024708. Examples of nucleic acids including such nucleotide analogs, modified backbone residues, or linkages include, without limitation, those containing phosphorothioates, phosphoramidates,
methyl phosphonates, chiral-methyl phosphonates, 2'-O-methyl ribonucleotides, and peptide nucleic acids (PNAs). Unless otherwise indicated, a particular nucleic acid sequence also implicitly encompasses conservatively modified variants thereof (e.g., degenerate codon substitutions), alleles, orthologs, single nucleotide polymorphisms (SNPs), and complementary sequences, as well as the sequence explicitly indicated. Specifically, degenerate codon substitutions may be achieved by generating sequences in which the third position of one or more selected (or all) codons is substituted with mixed-base and/or deoxyinosine (Batzer et al., (191) Nucleic Acid Res. 19:5081; Ohtsuka et al., (1985) J. Biol. Chem. 260:2605; and Rossolini et al., (1994) Mol. Cell. Probes 8:91).
[0045] Non-limiting examples of polynucleotides or nucleic acids include DNA, RNA, coding or noncoding regions of a gene or gene fragment, intergenic DNA, loci (locus) defined from linkage analysis, exons, introns, messenger RNA (mRNA), transfer RNA (tRNA), ribosomal RNA (rRNA), short interfering RNA (siRNA), short-hairpin RNA (shRNA), micro- RNA (miRNA), small nucleolar RNA(snoRNA), ribozymes, deoxynucleotides (dNTPs), or dideoxynucleotides (ddNTPs). Polynucleotides can also include complementary DNA (cDNA), which is a DNA representation of mRNA, usually obtained by reverse transcription of messenger RNA (mRNA) or by amplification. Polynucleotides can also include DNA molecules produced synthetically or by amplification, genomic DNA (gDNA), recombinant polynucleotides, branched polynucleotides, plasmids, vectors, isolated DNA of any sequence, isolated RNA of any sequence, nucleic acid probes, or primers. A polynucleotide can comprise modified nucleotides, such as methylated nucleotides, nucleotide analogs, and/or nucleosides suitable for reducing the immunogenicity of RNA, such as those described in International Patent Application No. WO 2007/024708. If present, modifications to the nucleotide structure can be imparted before or after assembly of the polymer. The sequence of nucleotides can be interrupted by non-nucleotide components. A polynucleotide can be further modified after polymerization, such as by conjugation with a labeling component. Polynucleotide sequences, when provided, are listed in the 5' to 3' direction, unless stated otherwise.
[0046] Nucleic acids or polynucleotides can be double- or triple -stranded nucleic acids, as well as single-stranded molecules. In double- or triple-stranded nucleic acids, the nucleic acid strands need not be coextensive, for example, a double-stranded nucleic acid need not be double-stranded along the entire length of both strands.
[0047] Nucleic acid modifications can include addition of chemical groups that incorporate additional charge, polarizability, hydrogen bonding, electrostatic interaction, and functionality to the individual nucleic acid bases or to the nucleic acid as a whole. Such modifications include base modifications such as 2'-position sugar modifications, 5-position pyrimidine modifications, 8-position purine modifications, modifications at cytosine exocyclic amines, substitutions of S-bromo-uracil, backbone modifications, unusual base pairing combinations such as the isobases isocytidine and isoguanidine, and the like.
[0048] Nucleic acid(s) can be derived from a completely chemical synthesis process, such as a solid phase-mediated chemical synthesis, from a biological source, such as through isolation from any species that produces nucleic acid, or from processes that involve the manipulation of nucleic acids by molecular biology tools, such as DNA replication, PCR amplification, reverse transcription, in vitro transcription such as described in, e.g., International Patent Application Publication No. WO 2007/024708, or from a combination of those processes.
[0049] As used herein in the context of lipid nanoparticles and nucleic acids, the term “fully encapsulated” indicates that the nucleic acid in the particles is not significantly degraded after exposure to serum or a nuclease assay that would significantly degrade free nucleic acids. In a fully encapsulated system, preferably less than 25% of particle nucleic acid is degraded in a treatment that would normally degrade 100% of free nucleic acid, more preferably less than 10% and most preferably less than 5% of the particle nucleic acid is degraded. Fully encapsulated also suggests that the particles are serum stable, that is, that they do not rapidly decompose into their component parts upon in vivo administration.
[0050] As used herein in the context of lipid nanoparticles and cells, the term “contacting” refers to either the direct or indirect in vitro or in vivo delivering of lipid nanoparticles to the surfaces of cells, e.g., by providing lipid nanoparticles at or proximate to a location of the cells to be contacted. The in vitro contacting may involve, for example, cells in a cell culture or tissue culture. The cell culture or tissue culture may include cells in a suspension and/or adherent cells. The contacted cells may be of same cell type or of two or more different cell types. Merely for illustration, different contacted cell types may include, for example, hepatocytes and hepatic stellate cells. In some example, different cell types are cultured together before and/or during the contacting with lipid nanoparticles. In other examples, different cell types are cultured separately. In further examples, one cell type of two or more cell types to be contacted is specifically cultured in the absence of any other cell types of the
two or more cell types. In certain examples, hepatic stellate cells are cultured, either alone or in combination with other cell types from the liver, such as, e.g., liver cells, prior to and/or during the contacting. In some examples, the tissue culture is a liver tissue culture. The in vivo contacting of cells typically involves administering the lipid nanoparticles to a subject, where the cells are within the body of the subject. In some examples, the administering is proximate to the location of the contacted cells within the subject’s body. In other examples, the administering is distal to the location of the contacted cells, and the lipid nanoparticles migrate to the cell location, e.g., via the targeting capabilities of the particles.
[0051] As used herein, the term “subject” refers to a vertebrate, and preferably to a mammal. Mammalian subjects for which the provided composition is suitable include, but are not limited to, mice, rats, simians, humans, farm animals, sport animals, and pets. In some embodiments, the subject is human. In some embodiments, the subject is male. In some embodiments, the subject is female. In some embodiments, the subject is an adult. In some embodiments, the subject is an adolescent. In some embodiments, the subject is a child. In some embodiments, the subject is above 10 years of age, e.g., above 20 years of age, above 30 years of age, above 40 years of age, above 50 years of age, above 60 years of age, above 70 years of age, or above 80 years of age. In some embodiments, the subject is less than 80 years of age, e.g., less than 70 years of age, less than 60 years of age, less than 50 years of age, less than 40 years of age, less than 30 years of age, less than 20 years of age, or less than 10 years of age.
[0052] As used herein, the terms “pharmaceutically acceptable excipient” and “pharmaceutically acceptable carrier” refer to a substance that aids the administration of an active agent to and absorption by a subject and may be included in the compositions of the present disclosure without causing a significant adverse toxicological effect on the subject. Non-limiting examples of pharmaceutically acceptable excipients and carriers include water, NaCl, normal saline solutions, normal sucrose, normal glucose, binders, fillers, disintegrants, lubricants, coatings, and the like. One of skill in the art will recognize that other pharmaceutically acceptable excipients and carriers are useful in the present disclosure.
[0053] As used herein, the term “administering” refers to oral administration, administration as a suppository, topical contact, parenteral, intravenous, intraperitoneal, intramuscular, intralesional, intranasal, subcutaneous, intrathecal, intracerebroventricular, intraparenchymal, subretinal, or intravitreal administration, or the implantation of a slow-release device e.g., a mini-osmotic pump, to the subject.
[0054] As used herein, the term “therapeutically effective amount” refers to an amount or dose of a compound, composition, or formulation that produces therapeutic effects for which it is administered. The exact amount or dose will depend on the purpose of the treatment, and will be ascertainable by one skilled in the art using known techniques (see, e.g., Lieberman, Pharmaceutical Dosage Forms (vols. 1-3, 1992); Lloyd, The Art, Science and Technology of Pharmaceutical Compounding (1999); Pickar, Dosage Calculations (1999); and Remington: The Science and Practice of Pharmacy, 20th Edition, 2003, Gennaro, Ed., Lippincott, Williams & Wilkins).
[0055] As used here, the terms “treat”, “treating” and “treatment” refers to a procedure resulting in any indicia of success in the elimination or amelioration of an injury, pathology, condition, or symptom (e.g., pain), including any objective or subjective parameter such as abatement; remission; diminishing of symptoms or making the symptom, injury, pathology or condition more tolerable to the patient; decreasing the frequency or duration of the symptom or condition; or, in some situations, preventing the onset of one or more symptoms. The treatment or amelioration of symptoms can be based on any objective or subjective parameter; including, e.g., the result of a physical examination or laboratory test.
B. LIPID NANOPARTICLES
[0056] In one aspect, the present disclosure provides various lipid nanoparticles that include an ionizable lipid or a pharmaceutically acceptable salt thereof. The ionizable lipid of the lipid nanoparticles is a nitrogen-containing silyl ether, and can be any of those described in further detail in Section B.2. The particular selection, composition, and amounts (e.g., relative amounts) of the ionizable lipid in the lipid nanoparticles provide surprising improvements in various properties of the lipid nanoparticles, e.g., properties advantageous for the delivery of nucleic acids. These improved properties include, for example, enhanced targeting, optimized stability, and decreased toxicity and immune stimulation.
[0057] In some embodiments, the provided lipid nanoparticle further includes a phospholipid or a pharmaceutically acceptable salt thereof. In certain examples, the phospholipid of the lipid nanoparticles includes one or more unsaturated tails and a head group having a positively charged nitrogen, and is any of those described in further detail in Section B.l. The particular selection, composition, and amounts (e.g., relative amounts) of the phospholipid in the lipid nanoparticles can further contribute to the advantages of the lipid nanoparticles as delivery vehicles.
[0058] In some embodiments, the provided lipid nanoparticle further includes sterol, e.g., cholesterol or a derivative thereof. The cholesterol or derivative thereof can be any of those described in further detail in Section B.3. In some embodiments, the lipid nanoparticle further includes a conjugated lipid, e.g., a PEG-conjugated lipid. The conjugated lipid can be any of those described in further detail in Section B.4. The particular selection, composition, and amounts (e.g., relative amounts) of the cholesterol and/or conjugated lipid in the lipid nanoparticles can further contribute to the advantages of the lipid nanoparticles as delivery vehicles.
[0059] The lipid nanoparticles can be configured to have a size that is beneficial for particular applications, such as the in vivo or in vivo delivery of nucleic acids to a cell or to a subject. The provided lipid nanoparticles can have a mean diameter that is, for example, from about 40 nm to about 150 nm, from about 50 nm to about 150 nm, from about 60 nm to about 130 nm, from about 70 nm to about 110 nm, from about 60 nm to about 100 nm, from about 50 to about 80 nm, from about 60 to about 80 nm, from about 60 to about 90 nm, or from about 70 to about 90 nm. The lipid nanoparticles can be configured, e.g., through the selection of their components, to be substantially non-toxic.
[0060] In some examples, the ionizable lipid of the provided lipid nanoparticle comprises from about 30 mol % to about 80 mol % of the total lipid present in the particle (e.g., from about 40 mol % to about 70 mol %, from about 45 mol % to about 65 mol %, from about 45 mol % to about 60 mol %, or from about 50 mol % to about 60 mol % of the total lipid present in the particle); the phospholipid of the lipid nanoparticle comprises from about 3 mol % to about 20 mol % of the total lipid present in the particle (e.g., from about 5 mol % to about 15 mol %, or from about 8 mol % to about 12 mol % of the total lipid present in the particle); a cholesterol or derivative thereof of the lipid nanoparticle comprises from about 10 mol % to about 60 mol % of the total lipid present in the particle (e.g., from about 20 mol % to about 50 mol %, or from about 30 mol % to about 40 mol % of the total lipid present in the particle); and a conjugated lipid of the lipid nanoparticle comprises from about 0.1 mol % to about 10 mol % of the total lipid present in the particle (e.g., from about 0.1 mol % to about 5 mol % or from about 0.5 mol % to about 3 mol % of the total lipid present in the particle).
[0061] In particular examples, the lipid nanoparticle includes the ionizable lipid comprising from about 45 mol % to about 60 mol % of the total lipid present in the particle; the phospholipid comprising from about 8 mol % to about 12 mol % of the total lipid present in
the particle; a cholesterol or derivative thereof comprising from about 30 mol % to about 40 mol % of the total lipid present in the particle; and a conjugated lipid comprising from about 0.5 mol % to about 3 mol % of the total lipid present in the particle.
[0062] In some examples, the lipid nanoparticle includes the ionizable lipid comprising from about 52 mol % to about 57 mol % of the total lipid present in the particle, the phospholipid comprising from about 10 mol % to about 12 mol % of the total lipid present in the particle, a cholesterol or derivative thereof comprising about 31 mol % to about 34 mol % of the total lipid present in the particle, and a conjugated lipid comprising about 1 mol % to about 3 mol % of the total lipid present in the particle.
[0063] In one example, the lipid nanoparticle includes the ionizable lipid comprising about 54.6 mol % of the total lipid present in the particle; the phospholipid comprising about 10.9 mol % of the total lipid present in the particle; a cholesterol or derivative thereof comprising about 32.8 mol % of the total lipid present in the particle; and a conjugated lipid comprising about 1.6 mol % of the total lipid present in the particle.
[0064] In one example, the lipid nanoparticle includes the ionizable lipid comprising about 54.2 mol % of the total lipid present in the particle; the phospholipid comprising about 10.8 mol % of the total lipid present in the particle; a cholesterol or derivative thereof comprising about 32.5 mol % of the total lipid present in the particle; and a conjugated lipid comprising about 2.5 mol % of the total lipid present in the particle.
[0065] The specific configuration of the lipid nanoparticle described herein, and in particular the design and combination of the phospholipid and ionizable lipid it contains, provide the nanoparticle with a pKa giving the nanoparticle targeting, stability, degradability, and toxicity properties advantageous for, e.g., the delivery of nucleic acids. For example, in some embodiments, the lipid nanoparticle has apKa from about 5.8 to about 6.9, e.g., from about 5.8 to about 6.8, from about 5.8 to about 6.7, from about 5.8 to about 6.6, from about 5.8 to about
6.5, from about 5.8 to about 6.4, from about 5.8 to about 6.3, from about 5.8 to about 6.2, from about 5.8 to about 6.1, from about 5.8 to about 6.0, from about 5.8 to about 5.9, from about 5.9 to about 6.9, from about 5.9 to about 6.8, from about 5.9 to about 6.7, from about 5.9 to about
6.6, from about 5.9 to about 6.5, from about 5.9 to about 6.4, from about 5.9 to about 6.3 from about 5.9 to about 6.2, from about 5.9 to about 6.1, from about 5.9 to about 6.0, from about 6.0 to about 6.9, from about 6.0 to about 6.8, from about 6.0 to about 6.7, from about 6.0 to about
6.6, from about 6.0 to about 6.5, from about 6.0 to about 6.4, from about 6.0 to about 6.3, from
about 6.0 to about 6.2, from about 6.0 to about 6.1, from about 6.1 to about 6.9, from about 6.1 to about 6.8, from about 6.1 to about 6.7, from about 6. 1 to about 6.6, from about 6. 1 to about 6.5, from about 6. 1 to about 6.4, from about 6.1 to about 6.3, from about 6. 1 to about 6.2, from about 6.2 to about 6.9, from about 6.2 to about 6.8, from about 6.2 to about 6.7, from about 6.2 to about 6.6, from about 6.2 to about 6.5, from about 6.2 to about 6.4, from about 6.2 to about 6.3, from about 6.3 to about 6.9, from about 6.3 to about 6.8, from about 6.3 to about 6.7, from about 6.3 to about 6.6, from about 6.3 to about 6.5, from about 6.3 to about 6.4, from about 6.4 to about 6.9, from about 6.4 to about 6.4 to about 6.8, from about 6.4 to about 6.7, from about 6.4 to about 6.6, from about 6.4 to about 6.5, from about 6.5 to about 6.9, from about 6.5 to about 6.8, from about 6.5 to about 6.6, from about 6.6 to about 6.9, from about 6.6 to about 6.8, from about 6.6 to about 6.7, from about 6.7 to about 6.8, or from about 6.8 to about 6.9. In certain examples, the lipid nanoparticle exhibits advantageous targeting, stability, degradability, and toxicity properties in part because the lipid nanoparticle has a pKa from about 6.2 to about 6.5.
[0066] In a preferred embodiment, the pKa of the lipid nanoparticle described herein is determined using an assay measuring ionization at a temperature between about 34 °C and about 40 °C. In some embodiments, the lipid nanoparticle has a pKa, as determined using an assay performed at a temperature between about 34 °C and about 40 °C, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above. In particularly preferred embodiments, the pKa of the lipid nanoparticle described herein is determined using an assay measuring ionization at a temperature of about 37 °C. In some embodiments, the lipid nanoparticle has a pKa, as determined using an assay performed at a temperature of about 37 °C, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above.
[0067] In a preferred embodiment, the pKa of the lipid nanoparticle described herein is determined using an assay measuring ionization at more than 5 different pH levels. In some embodiments, the lipid nanoparticle has a pKa, as determined using an assay performed at more than 5 different pH levels, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above. In particularly preferred embodiments, the pKa of the lipid nanoparticle described herein is determined using an assay measuring ionization at more than 15 different pH levels. In some embodiments, the lipid nanoparticle has a pKa, as determined using an assay performed at more than 15 different pH levels, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above.
[0068] In a preferred embodiment, the pKa of the provided lipid nanoparticle is determined using in situ fluorescence titration, and preferably TNS fluorescence titration. This assay typically yields a sigmoidal curve showing fluorescence, such as TNS fluorescence, wherein the pKa of the provided lipid nanoparticle is determined to be the value that corresponds to 0.5 normalized fluorescence, such as normalized TNS fluorescence, on a scale from 0 to 1.0. For an illustrative non-limiting embodiment, see Fig. 2. In a preferred embodiment, the pKa of the provided lipid nanoparticle is determined using the assay described in Example 7. In some embodiments, the lipid nanoparticle has a pKa, as determined using the assay described in Example 7, that is from about 5.8 to about 6.9, or within any of the pKa ranges listed above.
[0069] For the purposes of determining the pKa of the lipid nanoparticle described herein, the lipid nanoparticle preferably includes a phospholipid or a pharmaceutically acceptable salt thereof (preferably comprising between about 1 mol % and about 20 mol % of the total lipid present in the lipid nanoparticle), an ionizable lipid or a pharmaceutically acceptable salt thereof (preferably comprising between about 30 mol % and about 70 mol % of the total lipid present in the lipid nanoparticle), cholesterol or a derivative thereof (preferable comprising between about 0.1 mol % and about 5 mol % of the total lipid present in the lipid nanoparticle), and a conjugated lipid (preferably comprising between about 0. 1 mol % and about 5 mol % of the total lipid present in the lipid nanoparticle). In particularly preferred embodiments, for determining the pKa of the lipid nanoparticle described herein, the lipid nanoparticle further includes a nucleic acid.
[0070] The provided lipid nanoparticle has been demonstrated as having in vivo clearance and degradation characteristics that are particularly beneficial when the nanoparticle is used to administer a nucleic acid to a subject, e.g., to provide a treatment to the subject and/or to edit genetic information of the subject. Clearance and degradation rates that are too high can prevent a lipid nanoparticle from protecting a cargo, such as a nucleic acid cargo, and from successfully delivering it to its targeted destination within the subject. Alternatively, clearance and degradation rates that are too low can be associated with increased toxicity or undesirable off- target effects.
[0071] One useful measure of these beneficial clearance and degradation characteristics involves a comparison of the amount of ionizable lipid in the liver of a subject at different time points following administering the lipid nanoparticle to the subject. Ionizable lipids are a major component of lipid nanoparticles, typically used in the highest molar amounts of the various
lipids present in the particles. For applications that necessitate more frequent dosing, lipid accumulation in tissues may be exacerbated, resulting in potential tolerability challenges. Because the role of lipid nanoparticles in delivering nucleic acid payloads is essentially complete within hours after administration, there is no need for the lipid components of the particle to persist in tissues for a prolonged period of time. As such, ionizable lipids that enable rapid clearance in tissues are preferred. The provided lipid nanoparticles exhibit such preferred clearance properties. For example, in some embodiments, following administering the lipid nanoparticle to a subject, a concentration of the ionizable lipid in the liver of subject 7 days after the administering is less than about 50%, e.g., less than about 45%, less than about 40%, less than about 35%, less than about 30%, less than about 25%, less than about 20%, less than about 15%, less than about 10%, or less than about 5% of a concentration of the ionizable lipid in the liver 24 hours after the administering. In some embodiments, following administering the lipid nanoparticle to a subject, a concentration of the ionizable lipid in the liver of subject 7 days after the administering is less than about 50%, e.g., less than about 45%, less than about 40%, less than about 35%, less than about 30%, less than about 25%, less than about 20%, less than about 15%, less than about 10%, or less than about 5% of a concentration of the ionizable lipid present in the total amount of lipid nanoparticles administered to the subject.
[0072] Conversely, for some applications a clearance rate for the lipid nanoparticles that is too low can be disfavored. For example, an excessively rapid clearance rate can be indicative of a lipid nanoparticle that degrades too quickly to effectively and/or efficiently deliver its payload to a target. Beneficially, in some embodiments, following administering the provided lipid nanoparticle to a subject, a concentration of the ionizable lipid in the liver of subject 7 days after the administering is greater than about 5%, e.g., greater than about 10%, greater than about 15%, greater than about 20%, greater than about 25%, greater than about 30%, greater than about 40%, or greater than about 45% of a concentration of the ionizable lipid in the liver 24 hours after the administering. In some embodiments, following administering the lipid nanoparticle to a subject, a concentration of the ionizable lipid in the liver of subject 7 days after the administering is greater than about 5%, e.g., greater than about 10%, greater than about 15%, greater than about 20%, greater than about 25%, greater than about 30%, greater than about 35%, greater than about 40%, or greater than about 45% of a concentration of the ionizable lipid present in the total amount of lipid nanoparticles administered to the subject.
[0073] In some embodiments, following administering the lipid nanoparticle to a subject, a concentration of the ionizable lipid in the liver of subject 7 days after the administering is
between about 5% and about 50%, e.g., between about 5% and about 45%, between about 5% and about 40%, between about 5% and about 35%, between about 5% and about 30%, between about 5% and about 25%, between about 5% and about 20%, between about 5% and about 15%, between about 5% and about 10%, between about 10% and about 50%, between about 10% and about 45%, between about 10% and about 40%, between about 10% and about 35%, between about 10% and about 30%, between about 10% and about 25%, between about 10% and about 20%, between about 10% and about 15%, between about 15% and about 50%, between about 15% and about 45%, between about 15% and about 40%, between about 15% and about 35%, between about 15% and about 30%, between about 15% and about 25%, between about 15% and about 20%, between about 20% and about 50%, between about 20% and about 45%, between about 20% and about 40%, between about 20% and about 35%, between about 20% and about 30%, between about 20% and about 25%, between about 25% and about 50%, between about 25% and about 45%, between about 25% and about 40%, between about 25% and about 35%, between about 25% and about 30%, between about 30% and about 50%, between about 30% and about 45%, between about 30% and about 40%, between about 30% and about 35%, between about 35% and about 50%, between about 35% and about 45%, between about 35% and about 40%, between about 40% and about 50%, between about 40% and about 45%, or between about 45% and about 50% of a concentration of the ionizable lipid in the liver 24 hours after the administering, or of a concentration of the ionizable lipid present in the total amount of lipid nanoparticles administered to the subject
[0074] The provided lipid nanoparticle also can exhibit advantageous specificity in delivering, e.g., nucleic acids, to a targeted site in a subject when the lipid nanoparticle is administered to the subject. One useful measure of these beneficial targeting specificity characteristics involves a comparison of measurements of the activity of a protein in a target organ (e.g., the liver) and the activity of the protein in a comparator organ (e.g., the spleen), e.g., when the protein is encoded by an mRNA payload of the lipid nanoparticle. For example, when the lipid nanoparticle is used in a method for delivering a nucleic acid encoding a protein desired to be active in, or secreted by cells of the subject’s liver, the activity or secretion of the protein in the liver can be significantly greater, e.g., more than about 20-fold greater, than in another organ, e.g., the spleen. In some embodiments, following administration of the lipid nanoparticle to a subject, an activity and/or expression of the protein in the liver of the subject is at least about 20-fold greater, e.g., at least about 30-fold, at least about 40-fold, at least about 60-fold, at least about 100-fold, at least about 200-fold, at least about 300-fold, at least about
500-fold, at least about 700-fold, or at least about 1000-fold greater than an activity or expression of the protein in the spleen of the subject.
1. Phospholipid
[0075] In some aspects, the provided lipid nanoparticle includes at least one phospholipid or pharmaceutically acceptable salt thereof, where the phospholipid has one or more unsaturated tails, and a head group with a positively charged nitrogen. The phospholipid can be selected or designed to provide the lipid nanoparticle with a desired particle size, stability, and capacity for encapsulation of nucleic acids. Further, lipid nanoparticles including the particular phospholipids described herein exhibit, for example, enhanced targeting, optimized clearance rates, and decreased toxicity and immune stimulation. In some embodiments, the lipid nanoparticle includes one species of phospholipid. In other embodiments, the lipid nanoparticle includes two or more species of phospholipids, e.g., three or more, four or more, five or more, six or more, seven or more, eight or more, nine or more, or ten or more species of phospholipids.
[0076] In some embodiments, the phospholipid of the provided lipid nanoparticle includes at least one unsaturated tail. In some examples, the phospholipid includes two unsaturated tails. In other examples, the phospholipid includes only one unsaturated tail. In some embodiments, at least one of the one or more unsaturated tails of the phospholipid has only one double bond. In some examples, each tail of the phospholipid has only one double bond. In other examples, only one tail of the phospholipid has only one double bond. In some embodiments, at least one of the one or more unsaturated tails of the phospholipid is a cis unsaturated tail. In some examples, each tail of the phospholipid is a cis unsaturated tail. In other examples, only one tail of the phospholipid is a cis unsaturated tail. In some embodiments, at least one of the one or more unsaturated tails of the phospholipid is C10-20 alkenyl. In some examples, each tail of the phospholipid is C10-20 alkenyl. In other examples, only one tail of the phospholipid is C10- 20 alkenyl.
[0077] In some embodiments, the phospholipid of the provided lipid nanoparticle is a phosphatidylcholine. For example, the phospholipid can be 1-palmitoyl-2-oleoyl-glycero-3- phosphocholine (POPC), 1,2-dioleoyl-sn-glycero-3-phosphocholine (DOPC), 1,2-divaccenoyl -sn-glycero-3-phosphocholine, 1,2-di[(8Z)octadecenoyl]-sn-glycero-3-phosphocholine, 1,2- dimyristoleoyl-sn-glycero-3-phosphocholine, 1,2-dimyristelaidoyl-sn-glycero-3- phosphocholine, 1,2-dipalmitoleoyl-sn-glycero-3-phosphocholine, 1,2-dipalmitelaidoyl-sn- glycero-3-phosphocholine, 1,2-dipetroselenoyl-sn-glycero-3-phosphocholine, 1,2-dielaidoyl-
sn-glycero-3-phosphocholine, 1,2-dilinoleoyl-sn-glycero-3-phosphocholine (DLPC), 1,2- dilinolenoyl-sn-glycero-3-phosphocholine, 1,2-dieicosenoyl-sn-glycero-3-phosphocholine, 1,2-dierucoyl-sn-glycero-3-phosphocholine (DEPC), 1,2-dinervonoyl-sn-glycero-3- phosphocholine, 1,2-didocosahexaenoyl-sn-glycero-3-phosphocholine, 1-pentadecanoyl-2- oleoyl-sn-glycero-3-phosphocholine, 1-palmitoyl-2-linoleoyl-sn-glycero-3-phosphocholine,
1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine, 1-palmitoyl -2 -docosahexaenoyl- sn-glycero-3-phosphocholine, l-stearoyl-2-oleoyl-sn-glycero-3-phosphocholine (SOPC), 1- stearoyl-2-linoleoyl-sn-glycero-3-phosphocholine, l-stearoyl-2-arachidonoyl-sn-glycero-3- phosphocholine, 1-stearoyl -2 -docosahexaenoyl-sn-glycero-3-phosphocholine, 1-oleoyl -2- myristoyl-sn-glycero-3-phosphocholine, 1-oleoyl -2 -palmitoyl-sn-glycero-3-phosphocholine, 1-oleoyl -2-stearoyl-sn-glycero-3-phosphocholine, 1-(8Z-octadecenoyl)-2-palmitoyl-sn- glycero-3-phosphocholine, 1-O-hexadecyl-2-oleoyl-sn-glycero-3-phosphocholine, 1-O- hexadecyl-2-arachidonoyl-sn-glycero-3-phosphocholine, 1-O-hexadecyl-2-(8Z, 11Z, 14Z- eicosatrienoyl)-sn-glycero-3-phosphocholine, 1-O-hexadecyl-2-(5Z,8Z, 11Z,14Z,17Z- eicosapentaenoyl)-sn-glycero-3-phosphocholine, 1-O-hexadecyl-2-docosahexaenoyl-sn- glycero-3-phosphocholine, 1-O-hexadecanyl-2-O-(9Z-octadecenyl)-sn-glycero-3- phosphocholine, 1,2-di-O-(9Z-octadecenyl)-sn-glycero-3-phosphocholine, or any combination of two or more of these. In some examples, at least one phospholipid of the lipid nanoparticle is a phosphatidylcholine. In some examples, every phospholipid of the lipid nanoparticle is a phosphatidylcholine .
[0078] In some embodiments, the phospholipid of the provided lipid nanoparticle is a phosphatidylethanolamine. For example, the phospholipid can be 1,2-dioleoyl-sn-glycero-3- phosphoethanolamine (DOPE), 1,2-dipahnitoleoyl-sn-glycero-3-phosphoethanolamine, 1,2- dielaidoyl-sn-glycero-3-phosphoethanolamine, 1,2-dilinoleoyl-sn-glycero-3- phosphoethanolamine, 1,2-dilinolenoyl-sn-glycero-3-phosphoethanolamine, 1,2- didocosahexaenoyl-sn-glycero-3-phosphoethanolamine, 1,2-diarachidonoyl-sn-glycero-3- phosphoethanolamine, 1-pentadecanoyl-2-oleoyl-sn-glycero-3-phosphoethanolamine, 1- palmitoyl-2-linoleoyl-sn-glycero-3-phosphoethanolamine, 1-palmitoyl-2-oleoyl-sn-glycero-3- phosphoethanolamine, 1-stearoyl -2 -oleoyl-sn-glycero-3-phosphoethanolamine, 1-palmitoyl -
2-arachidonoyl-sn-glycero-3-phosphoethanolamine, 1-palmitoyl-2-docosahexaenoyl-sn- glycero-3-phosphoethanolamine, 1-stearoyl -2 -arachidonoyl-sn-glycero-3- phosphoethanolamine, l-stearoyl-2-docosahexaenoyl-sn-glycero-3-phosphoethanolamine, 1- hexadecyl-2-(9Z-octadecenoyl)-sn-glycero-3-phosphoethanolamine, 1-O-hexadecanyl-2-O-
(9Z-octadecenyl)-sn-glycero-3-phosphoethanolamine, or any combination of two or more of these. In some examples, at least one phospholipid of the lipid nanoparticle is a phosphatidylethanolamine. In some examples, every phospholipid of the lipid nanoparticle is a phosphatidylethanolamine.
[0079] In some embodiments, the phospholipid of the provided lipid nanoparticle includes at least one phosphatidylcholine and at least one phosphatidylethanolamine.
[0080] In addition to the species of phospholipid, the amount of phospholipid included in the provided lipid nanoparticle has also been shown to provide the particle with its advantageous characteristics. The phospholipid present in the provided lipid nanoparticle can comprise, for example, from about 3 mol % to about 20 mol % of the total lipid present in the particle, e.g., from about 5 mol % to about 20 mol %, from about 8 mol % to about 20 mol %, from about 10 mol % to about 20 mol %, from about 3 mol % to about 15 mol %, from about 5 mol % to about 15 mol %, from about 8 mol %to about 15 mol %, from about 10 mol %to about 15 mol %, or from about 8 mol % to about 12 mol % of the total lipid present in the particle. In some embodiments, the phospholipid present in the lipid nanoparticle comprises about 5 mol %, about 6 mol %, about 7 mol %, about 8 mol %, about 9 mol %, about 10 mol %, about 11 mol %, about 12 mol %, about 13 mol %, about 14 mol %, or about 15 mol % of the total lipid present in the particle.
2. Ionizable Lipid
[0081] The provided lipid nanoparticle includes at least one ionizable lipid or pharmaceutically acceptable salt thereof, where the ionizable lipid is a nitrogen-containing silyl ether. The ionizable lipid can be selected or designed to provide the lipid nanoparticle with a desired particle size, stability, and capacity for encapsulation of nucleic acids. Further, lipid nanoparticles including the particular ionizable lipids described herein exhibit, for example enhanced targeting, optimized clearance rates, and decreased toxicity and immune stimulation. In some embodiments, the lipid nanoparticle includes one species of ionizable lipid. In other embodiments, the lipid nanoparticle includes two or more species of ionizable lipids, e.g., three or more, four or more, five or more, six or more, seven or more, eight or more, nine or more, or ten or more species of ionizable lipids.
[0082] The ionizable lipid of the provided lipid nanoparticle generally has the formula:

R1 and R2 of formula (I) can each independently be hydrogen , C1-4 alkyl, or 2- to 4-membered heteroalkyl, wherein the alkyl and heteroalkyl optionally have one or more substitutions, and wherein the substitutions can each independently be hydroxy, C1-6 hydroxyalkyl, or fluorine. Alternatively, R1 and R2 can be combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl optionally having one or more substitutions, wherein the substitutions can each independently be hydroxy, C1-6 hydroxyalkyl, or fluorine. R3, R4, and R5 of formula (I) can each independently be C5-20 alkyl, C5-20 alkenyl, C5-20 alkynyl, or C5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions can each independently be C1-6 alkyl or C2-6 alkenyl. R6 and R7 of formula (I) can each independently be hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl. Alternatively, R6 and R7 can be combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. R8 and R9 of formula (I) can each independently be hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl. Alternatively, R8 and R9 can be combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. R10 and R11 of formula (I) can each independently be hydrogen, C1- 20 alkyl, C1-20 alkenyl, or C1-20 alkynyl. Alternatively, R10 and R11 can be combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. Each R12 and R13 can independently be hydrogen or C1-6 alkyl optionally having one or more substitutions, wherein the substitutions can each independently be hydroxy, C1-6 hydroxyalkyl, or fluorine. Alternatively, R12 and R13 can be combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl. X1, X2, and X3 of formula (I) can each independently be a covalent bond, C1-6 alkylene, C1-6 alkenylene, or C1-6 alkynylene. Subscript n of formula (I) is an integer that can be from 2 to 10. In one aspect, the disclosure also provides compounds, i.e., ionizable lipid compounds, having the structure of formula (I) or the structure of a salt, e.g., a pharmaceutically acceptable salt, thereof.
[0083] In some embodiments, R1 of formula (I) is hydrogen. In some embodiments, R2 of formula (I) is hydrogen. In some examples, R1 and R2 are each hydrogen. In some embodiments, R1 is C1-4 alkyl. In some embodiments, R2 is C1-4 alkyl. In some embodiments, one of R1 and R2 is hydrogen, and the other of R1 and R2 is C1-4 alkyl. In some examples, R1
and R2 are each Ci4 alkyl. R1 and/or R2 can each independently be, for example, methyl, ethyl, propyl, butyl, isopropyl, isobutyl, sec-butyl, or tert-butyl. In some embodiments, R1 and R2 are each C1-3 alkyl. In some examples, R1 and R2 are each independently methyl, ethyl, or isopropyl. In some examples, R1 and R2 are each methyl.
[0084] In some embodiments, R1 and R2 of formula (I) are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl. In some embodiments, the nitrogen to which R1 and R2 are attached is the only heteroatom of the 3- to 8-membered heterocyclyl. In some examples, R1 and R2 combine with the nitrogen to which they are attached to form pyrrolidyl. In some examples, R1 and R2 combine with the nitrogen to which they are attached to form azetidyl.
[0085] In some embodiments, at least one of R3, R4, and R5 of formula (I) is C5-20 alkyl. In some embodiments, at least two of R3, R4, and R5 of formula (I) are each independently C5-20 alkyl. In some embodiments, each of R3, R4, and R5 of formula (I) is independently C5-20 alkyl. In some embodiments, at least one of R3, R4, and R5 of formula (I) is C5-20 alkenyl. In some embodiments, at least two of R3, R4, and R5 of formula (I) are each independently C5-20 alkenyl. In some embodiments, each of R3, R4, and R5 of formula (I) is independently C5-20 alkenyl. In some embodiments, at least one of R3, R4, and R5 of formula (I) is C5-20 alkynyl. In some embodiments, at least two of R3, R4, and R5 of formula (I) are each independently C5-20 alkynyl. In some embodiments, each of R3, R4, and R5 of formula (I) is independently C5-20 alkynyl. In some embodiments, at least one of R3, R4, and R5 of formula (I) is optionally substituted C5-12 cycloalkyl. In some embodiments, at least two of R3, R4, and R5 of formula (I) are each independently optionally substituted C5-12 cycloalkyl. In some embodiments, each of R3, R4, and R5 of formula (I) is independently optionally substituted C5-12 cycloalkyl.
[0086] In some embodiments, one or more of R3, R4, and R5 of formula (I) is C6-12 alkenyl. In some embodiments, at least one of R3, R4, and R5 of formula (I) is cis- C6-12 alkenyl. In some embodiments, at least two of R3, R4, and R5 are cis-C6-12 alkenyl. In some embodiments, each of R3, R4, and R5 is cis-C6-12 alkenyl. In some embodiments, at least one of R3, R4, and R5 of formula (I) is cis-C6-12 alkenyl having only one double bond. In some embodiments, at least two of R3, R4, and R5 are cis-C6-12 alkenyl having only one double bond. In some embodiments, each of R3, R4, and R5 is cis-C6-12 alkenyl having only one double bond. For each of R3, R4, and/or R5, the only one double bond can independently be, for example, in the 2-position, the 3-position, the 4-position, or the 5-position of, e.g., the cis-C6-12 alkenyl. In some examples, at
least one of R3, R4, and R5 is cis-non-3-ene-1-yl. In some examples, at least two of R3, R4, and R5 are cis-non-3-ene-1-yl. In some examples, each of R3, R4, and R5 is cis-non-3-ene-1-yl. In some examples, at least one of R3, R4, and R5 is cis-oct-3-ene-1-yl. In some examples, at least two of R3, R4, and R5 are cis-oct-3-ene-1-yl. In some examples, each of R3, R4, and R5 is cis- oct-3-ene-1-yl.
[0087] In some embodiments, at least one of R6, R8, and R10 of formula (I) is hydrogen. In some embodiments, at least two of R6, R8, and R10 are hydrogen. In some embodiments, each of R6, R8, and R10 are hydrogen. In some embodiments, at least one of R6, R8, and R10 is C1-20 alkyl. In some embodiments, at least two of R6, R8, and R10 are C1-20 alkyl. In some embodiments, each of R6, R8, and R10 are C1-20 alkyl. In some embodiments, at least one of R6, R8, and R10 is C1-4 alkyl. In some embodiments, at least two of R6, R8, and R10 are C1-4 alkyl. In some embodiments, each of R6, R8, and R10 are C1-4 alkyl. R6, R8, and/or R10 can each independently be, for example, methyl, ethyl, propyl, butyl, isopropyl, isobutyl, sec-butyl, or tert-butyl. In some embodiments, R6, R8, and R10 are each independently hydrogen, methyl, ethyl, or butyl. In some embodiments, at least one of R6, R8, and R10 is C1-20 alkenyl. In some embodiments, at least two of R6, R8, and R10 are C1-20 alkenyl. In some embodiments, each of R6, R8, and R10 are C1-20 alkenyl. In some embodiments, at least one of R6, R8, and R10 is cis- dec-4-ene-1-yl. In some embodiments, at least two of R6, R8, and R10 are cis-dec-4-ene-1-yl. In some embodiments, each of R6, R8, and R10 are cis-dec-4-ene-1-yl.
[0088] In some embodiments, at least one of R7, R9, and R11 of formula (I) is hydrogen. In some embodiments, at least two of R7, R9, and R11 are hydrogen. In some embodiments, each of R7, R9, and R11 are hydrogen. In some embodiments, at least one of R7, R9, and R11 is C1-20 alkenyl. In some embodiments, at least two of R7, R9, and R11 are C1-20 alkenyl. In some embodiments, each of R7, R9, and R11 are C1-20 alkenyl. In some embodiments, at least one of R7, R9, and R11 is C1-20 alkynyl. In some embodiments, at least two of R7, R9, and R11 are C1-20 alkynyl. In some embodiments, each of R7, R9, and R11 are C1-20 alkynyl.
[0089] The particular sizes of the hydrophobic regions of the ionizable lipid of the provided lipid nanoparticle have been shown to provide the particle with its advantageous properties. In some embodiments, the total number of carbons in R3, R6, and R7 of formula (I) is from 7 to 12. In some embodiments, the total number of carbons in R4, R8, and R9 of formula (I) is from 7 to 12. In some embodiments, the total number of carbons in R5, R10, and R11 of formula (I) is from 7 to 12. In some embodiments, the total number of carbons in R3, R6, and R7, the total
number of carbons in R4, R8, and R9, and the total number of carbons in R5, R10, and R11 are each independently or identically from 7 to 12, e.g., from 7 to 11, from 7 to 10, from 7 to 9, from 7 to 8, from 8 to 12, from 8 to 11, from 8 to 10, from 8 to 9, from 9 to 12, from 9 to 11, from 9 to 10, from 10 to 12, from 10 to 11, or from 11 to 12. In some embodiments, the total number of carbons in R3, R6, and R7, the total number of carbons in R4, R8, and R9, and the total number of carbons in R5, R10, and R11 are each independently or identically 7, 8, 9, 10, 11, or 12.
[0090] In some embodiments, each R12 and R13 of formula (I) is hydrogen. In some embodiments, at least one R12 or at least one R13 is C1-6 alkyl. In some embodiments, only one R12 or R13 is C1-6 alkyl. Each R12 or R13 that is alkyl can independently be, for example, methyl, ethyl, propyl, isopropyl, butyl, isobutyl, sec-butyl, tert-butyl, pentyl, isopentyl, 2-methylbutyl, pentan-2 -yl, 3-methylbutan-2-yl, pentan-3-yl, neopentyl, tert-pentyl, hexyl, 4-methylpentyl, 3- methylpentyl, 2-methylpentyl, hexan-2-yl, 2,3 -dimethylbutyl, 4-methylpentan-2-yl, 3- methylpentan-2-yl, 2-ethylbutyl, hexan-3-yl, 3,3-dimethylbutyl, 2,2-dimethylbutyl, or 2- methylpentan-2-yl .
[0091] In some embodiments, at least one of X1, X2, and X3 of formula (I) is a covalent bond. In some embodiments, at least two of X1, X2, and X3 are a covalent bond. In some embodiments, each of X1, X2, and X3 is a covalent bond. In some embodiments, at least one of X1, X2, and X3 is C1-6 alkylene. In some embodiments, at least two of X1, X2, and X3 are C1-6 alkylene. In some embodiments, each of X1, X2, and X3 is C1-6 alkylene. In one example, each of X1, X2, and X3 is methylene. In some embodiments, at least one of X1, X2, and X3 is C1-6 alkenylene. In some embodiments, at least two of X1, X2, and X3 are C1-6 alkenylene. In some embodiments, each of X1, X2, and X3 of formula (I) is C1-6 alkenylene. In some embodiments, at least one of X1, X2, and X3 is C1-6 alkynylene. In some embodiments, at least two of X1, X2, and X3 are C1-6 alkynylene. In some embodiments, each of X1, X2, and X3 of formula (I) is C1- 6 alkynylene.
[0092] The particular length of the hydrophilic head group of the ionizable lipid of the provided lipid nanoparticle has been shown to provide the particle with its advantageous properties. In some embodiments, subscript n of formula (I) is from 2 to 9, from 2 to 8, from 2 to 7, from 2 to 6, from 2 to 5, from 2 to 4, from 2 to 3, from 3 to 10, from 3 to 9, from 3 to 8, from 3 to 7, from 3 to 6, from 3 to 5, from 3 to 4, from 4 to 10, from 4 to 9, from 4 to 8, from 4 to 7, from 4 to 6, from 4 to 5, from 5 to 10, from 5 to 9, from 5 to 8, from 5 to 7, from 5 to 6,
from 6 to 10, from 6 to 9, from 6 to 8, from 6 to 7, from 7 to 10, from 7 to 9, from 7 to 8, from 8 to 10, from 8 to 9, or from 9 to 10. In some examples, n is 2. In some examples, n is 3. In some examples, n is 4. In some examples, n is 5. In some examples, n is 6. In some examples, n is 7. In some examples, n is 8. In some examples, n is 9. In some examples, n is 10. In some examples, n is 6 to 8.
[0093] In some embodiments, the ionizable lipid of the present disclosure comprises a racemic mixture. In other embodiments, an ionizable lipid of the present disclosure comprises a mixture of one or more diastereomers. In certain embodiments, an ionizable lipid of the present disclosure comprises at least about 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, or 95% enantiomeric excess. In certain other embodiments, an ionizable lipid of the present disclosure is enriched in one diastereomer, such that the lipid comprises at least about 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, or 95% diastereomeric excess. In certain additional embodiments, an ionizable lipid of the present disclosure is chirally pure (e.g., comprises a single optical isomer). In further embodiments, an ionizable lipid of the present disclosure is enriched in one optical isomer (e.g., an optically active isomer), such that the lipid comprises at least about 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, or 95% isomeric excess. The present disclosure provides the synthesis of any of the ionizable lipids disclosed herein as a racemic mixture or in optically pure form.
[0094] In some embodiments, the ionizable lipid of the provided lipid nanoparticle has the formula:

R3, R4, and R5 of formula (la) are as defined above for formula (I). In one aspect, the disclosure also provides compounds, i.e., ionizable lipid compounds, having the structure of formula (la) or the structure of a salt, e.g., a pharmaceutically acceptable salt, thereof.
[0095] In some embodiments, the ionizable lipid of the provided lipid nanoparticle includes one or more of:





In one aspect, the disclosure provides compounds having any of these structures, or salts, e.g., pharmaceutically acceptable salts, thereof.
[0096] In addition to the species of ionizable lipid, the amount of ionizable lipid included in the provided lipid nanoparticle has also been shown to provide the particle with its advantageous characteristics. The ionizable lipid present in the provided lipid nanoparticle can comprise, for example, from about 30 mol % to about 80 mol %, from about 40 mol % to about 80 mol %, from about 50 mol % to about 80 mol %, from about 30 mol % to about 70 mol %, from about 40 mol % to about 70 mol %, from about 50 mol % to about 70 mol %, from about
45 mol % to about 80 mol %, from about 45 mol % to about 70 mol %, from about 45 mol % to about 65 mol %, from about 45 mol % to about 60 mol %, from about 45 mol % to about 55 mol %, from about 50 mol % to about 65 mol %, from about 50 mol % to about 60 mol %, or from about 55 mol % to about 65 mol % of the total lipid present in the particle. In some embodiments, the ionizable lipid present in the lipid nanoparticle comprises about 40 mol %, about 45 mol %, about 50 mol %, about 55 mol %, about 60 mol %, or about 65 mol % of the total lipid present in the particle.
3. Cholesterol
[0097] In some embodiments, the provided lipid nanoparticle further includes cholesterol or one or more derivatives thereof. The cholesterol or cholesterol derivative can be selected or configured to provide the lipid nanoparticle with a desired particle size, stability, and capacity for encapsulation of nucleic acids. The lipid nanoparticle can include, for example, cholestanol, cholestanone, cholestenone, coprostanol, cholesteryl-2'-hydroxyethyl ether, cholesteryl-4'- hydroxybutyl ether, cholesterol hydroxyethyl ether, cholesterol hydroxyhexyl ether, cholesterol stearate, cholesterol oleate, 7-betahydroxycholesterol, 7-alphahydroxycholesterol, 4-betahydroxycholesterol, cholesterol PEG, beta sitosterol, or any combination thereof. In certain examples, the lipid nanoparticle includes cholesterol, but substantially no derivative of cholesterol.
[0098] In addition to the species of cholesterol or cholesterol derivative, the amount included in the provided lipid nanoparticle has also been shown to provide the particle with its advantageous characteristics. The cholesterol or cholesterol derivative present in the provided lipid nanoparticle can comprise, for example, from about 10 mol % to about 60 mol %, from about 20 mol % to about 60 mol %, from about 30 mol % to about 60 mol %, from about 40 mol % to about 60 mol %, from about 20 mol % to about 50 mol %, from about 30 mol % to about 50 mol %, from about 35 mol % to about 50 mol %, from about 40 mol % to about 50 mol %, from about 20 mol % to about 45 mol %, from about 25 mol % to about 45 mol %, from about 30 mol % to about 45 mol %, from about 35 mol % to about 45 mol %, from about 20 mol % to about 40 mol %, from about 25 mol % to about 40 mol %, or from about 30 mol % to about 40 mol % of the total lipid present in the particle. In some examples, the cholesterol or cholesterol derivative present in the lipid particle comprises about 20 mol %, about 25 mol %, about 30 mol %, about 35 mol %, about 40 mol %, about 45 mol %, or about 50 mol % of the total lipid present in the particle.
4. Conjugated Lipid
[0099] In some embodiments, the provided lipid nanoparticle further includes one or more conjugated lipids. The conjugated lipid can be selected or configured to control the size of the particle during formation, and/or to prevent particle aggregation by sterically stabilizing the LNP. The conjugated lipid of the lipid nanoparticle can be situated at the surface of the particle, with the hydrophilic polymer oriented outwardly, interfacing with the aqueous environment, and the lipid component buried in the particle to anchor it in place.
[0100] Conjugated lipids suitable for use with the provided lipid nanoparticle include, but are not limited to, PEG-lipid conjugates, ATTA-lipid conjugates, cationic-polymer-lipid conjugates (CPLs), polyoxazoline (POZ)-lipids, polysarcosine (pSAR)-lipids and mixtures thereof. In certain embodiments, the lipid nanoparticle comprises either a PEG-lipid conjugate or an ATTA-lipid conjugate optionally together with a CPL.
[0101] In a preferred embodiment, the conjugated lipid is a PEG-lipid. Examples of PEG- lipids include, but are not limited to, PEG coupled to dialkyloxypropyls (PEG-DAA) as described in, e.g., International Patent Application Publication No. WO 05/026372, PEG coupled to diacylglycerol (PEG-DAG) as described in, e.g., U.S. Patent Application Publication Nos. 2003/0077829 and 2005/0008689, PEG coupled to phospholipids such as phosphatidylethanolamine (PEG-PE), PEG conjugated to ceramides as described in, e.g., U.S. Pat. No. 5,885,613, PEG conjugated to cholesterol or a derivative thereof, mPEG(2000)-N,N- ditetradecylacetamide (ALC-0159), mPEG(2000)-stearate, 1,2-dimyristoyl-rac-glycero-3- methoxypolyethylene glycol-2000 (DMG-PEG 2000), R-3-[(co-methoxy- poly(ethyleneglycol)2000)carbamoyl)]-1,2-dimyristyloxypropyl-3-amine (PEG-C-DOMG), any of the PEG lipids described in International Patent Application Publication No. WO 2022/133344, and mixtures thereof. The disclosures of these patent documents are herein incorporated by reference in their entirety for all purposes. The provided lipid nanoparticle can include a one or more methyl capped PEG-lipid, one or more uncapped PEG-lipids, or a combination thereof.
[0102] PEG is a linear, water-soluble polymer of ethylene glycol repeating units. PEGs are classified by their molecular weights; for example, PEG 2000 has an average molecular weight of about 2,000 daltons, and PEG 5000 has an average molecular weight of about 5,000 daltons. Such molecular weights are average molecular weights due to polydispersity. PEGs are commercially available from Sigma Chemical Co. and other companies and include, for
example, the following: monomethoxypolyethylene glycol (MePEG-OH), monomethoxypolyethylene glycol-succinate (MePEG-S), monomethoxypolyethylene glycolsuccinimidyl succinate (MePEG-3-NHS), monomethoxypolyethylene glycol-amine (MePEG-NH2), monomethoxypolyethylene glycol-tresylate (MePEG-TRES), and monomethoxypolyethylene glycol-imidazolyl-carbonyl (Me PEG-IM). Other PEGs such as those described in U.S. Pat. Nos. 6,774,180 and 7,053,150 (e.g., mPEG (20 KDa) amine) are also useful for preparing the PEG-lipid conjugates of the present disclosure. The disclosures of these patents are herein incorporated by reference in their entirety for all purposes. In addition, monomethoxypolyethyleneglycolacetic acid (McPEG-CTECOOH) is particularly useful for preparing PEG-lipid conjugates including, e.g., PEG-DAA conjugates.
[0103] The PEG moiety of the PEG-lipid conjugates described herein may comprise an average molecular weight ranging from about 550 daltons to about 10,000 daltons. In certain instances, the PEG moiety has an average molecular weight of from about 750 daltons to about 5,000 daltons (e.g., from about 1,000 daltons to about 5,000 daltons, from about 1,500 daltons to about 3,000 daltons, from about 750 daltons to about 3,000 daltons, from about 750 daltons to about 2,000 daltons, etc.). In preferred embodiments, the PEG moiety has an average molecular weight of about 2,000 daltons or about 750 daltons.
[0104] In certain instances, the PEG can be optionally substituted by an alkyl, alkoxy, acyl, or aryl group. The PEG can be conjugated directly to the lipid or may be linked to the lipid via a linker moiety. Any linker moiety suitable for coupling the PEG to a lipid can be used including, e.g., non-ester containing linker moieties and ester-containing linker moieties. In a preferred embodiment, the linker moiety is a non-ester containing linker moiety. As used herein, the term “non-ester containing linker moiety” refers to a linker moiety that does not contain a carboxylic ester bond (-OC(O)-). Suitable non-ester containing linker moieties include, but are not limited to, amido (-C(O)NH-), amino (-NR-), carbonyl (-C(O)-), carbamate (NHC(O)O-), urea (-NHC(O)NH-), disulphide (-S-S-), ether (-O-), succinyl ((O)CCH2CH2C(O)-), succinamidyl (-NHC(O)CH2CH2C(O)NH-), ether, disulphide, as well as combinations thereof (such as a linker containing both a carbamate linker moiety and an amido linker moiety). In a preferred embodiment, a carbamate linker is used to couple the PEG to the lipid.
[0105] In other embodiments, an ester containing linker moiety is used to couple the PEG to the lipid. Suitable ester containing linker moieties include, e.g., carbonate (-OC(O)O-), succinoyl, phosphate esters (-O-(O)POH-O-), sulfonate esters, and combinations thereof.
[0106] In addition to the foregoing, it will be readily apparent to those of skill in the art that other hydrophilic polymers can be used in place of PEG. Examples of suitable polymers that can be used in place of PEG include, but are not limited to, ATTA, cationic-polymers, polyoxazoline (POZ), polysarcosine, polyvinylpyrrolidone, polymethyloxazoline, polyethyloxazoline, polyhydroxypropyl methacrylamide, polymethacrylamide and poly dimethylacrylamide, polylactic acid, polyglycolic acid, poly (ethyl ethylene phosphate) (PEEP), and derivatized celluloses such as hydroxymethylcellulose or hydroxyethylcellulose.
[0107] The conjugated lipid of the provided lipid nanoparticles can include , e.g., one or more of the following: a polyethyleneglycol (PEG)-lipid conjugate, a polyamide (ATTA)-lipid conjugate, or mixtures thereof. In one preferred embodiment, the nucleic acid-lipid particles comprise either a PEG-lipid conjugate or an ATTA-lipid conjugate. The conjugated lipids may comprise a PEG-lipid including, e.g., a PEG-diacylglycerol (DAG), a PEG dialkyloxypropyl (DAA), a PEG-phospholipid, a PEG-ceramide (Cer), or mixtures thereof. The PEG-DAA conjugate may be PEG-dilauryloxypropyl (C12), a PEG-dimyristyloxypropyl (C14), a PEG- dipalmityloxypropyl (C16), a PEG-distearyloxypropyl (C18), or mixtures thereof.
[0108] Additional PEG-lipid conjugates suitable for use in the provided lipid nanoparticle include, but are not limited to, mPEG2000-1,2-di-O-alkyl-sn3-carbomoylglyceride (PEG-C- DOMG). The synthesis of PEG-C-DOMG is described in PCT Application No. PCT/US08/88676, filed Dec. 31, 2008, the disclosure of which is herein incorporated by reference in its entirety for all purposes. Yet additional PEG-lipid conjugates suitable for use in the disclosure include, without limitation, 1-[8'-(1,2-dimyristoyl-3-propanoxy)-carboxamido- 3',6'-dioxaoctanyl]carbamoyl-w-methylpoly(ethylene glycol) (2 KPEG-DMG). The synthesis of 2 KPEG-DMG is described in U.S. Pat. No. 7,404,969, the disclosure of which is herein incorporated by reference in its entirety for all purposes.
[0109] In addition to the species of conjugated lipid, the amount of conjugated lipid included in the provided lipid nanoparticle has also been shown to provide the particle with its advantageous characteristics. The conjugated lipid present in the provided lipid nanoparticle can comprise, for example, from about 0.1 mol % to about 10 mol %, from about 0.5 mol % to about 10 mol %, from about 1 mol % to about 10 mol %, from about 1.5 mol % to about 10
mol %, from about 2 mol % to about 10 mol %, from about 2.5 mol % to about 10 mol %, from about 3 mol % to about 10 mol %, from about 4 mol % to about 10 mol %, from about 5 mol % to about 10 mol %, from about 0.1 mol % to about 5 mol %, from about 0.3 mol % to about 5 mol %, from about 0.5 mol % to about 5 mol %, from about 1 mol % to about 5 mol %, from about 1.5 mol % to about 5 mol %, from about 2 mol % to about 5 mol %, from about 2.5 mol % to about 5 mol %, from about 3 mol % to about 5 mol %, from about 0.1 mol % to about 3 mol %, from about 0.5 mol % to about 3 mol %, from about 1 mol % to about 3 mol %, from about 1.5 mol % to about 3 mol %, from about 2 mol % to about 3 mol %, from about 2.2 mol % to about 3 mol %, or from about 2.5 mol % to about 3 mol % of the total lipid present in the particle. In some examples, the conjugated lipid present in the lipid nanoparticle comprises about 0.1 mol %, about 0.5 mol %, about 1 mol %, about 1.2 mol %, about 1.4 mol %, about 1.5 mol %, about 1.6 mol %, about 1.8 mol %, about 2 mol %, about 2.2 mol %, about 2.5 mol %, or about 3 mol % of the total lipid present in the particle.
[0110] By controlling the composition and concentration of the conjugated lipid in the provided lipid nanoparticle, one can control the rate at which the conjugated lipid exchanges out of the lipid nanoparticle and, in turn, the rate at which the lipid nanoparticle becomes fusogenic. For instance, when a PEG-phosphatidylethanolamine conjugate or a PEG-ceramide conjugate is used as the conjugated lipid, the rate at which the lipid nanoparticle becomes fusogenic can be varied, for example, by varying the concentration of the lipid conjugate, by varying the molecular weight of the PEG, or by varying the chain length and degree of saturation of the acyl chain groups on the phosphatidylethanolamine or the ceramide. In addition, other variables including, for example, pH, temperature, ionic strength, etc. can be used to vary and/or control the rate at which the lipid nanoparticle becomes fusogenic. Other methods which can be used to control the rate at which the lipid nanoparticle becomes fusogenic will become apparent to those of skill in the art upon reading this disclosure.
5. Nucleic Acid
[0111] In some embodiments, the provided lipid nanoparticles are associated with a nucleic acid. The composition of the lipid nanoparticle can be selected or configured such that nucleic acids, when present in lipid nanoparticles, are resistant in aqueous solution to degradation with a nuclease. Nucleic acid may be administered alone in the lipid nanoparticles described herein, or in combination (e.g., co-administered) with lipid particles comprising peptides, polypeptides, or small molecules such as conventional drugs. In some embodiments, the
nucleic acid is at least 50% encapsulated within the lipid nanoparticle; in one embodiment, the nucleic acid is at least 75% encapsulated within the lipid nanoparticle; in one embodiment, the nucleic acid is at least 90% encapsulated within the lipid nanoparticle; and in one embodiment, the nucleic acid is fully encapsulated within the lipid nanoparticle.
[0112] In certain embodiments, the present disclosure provides a lipid nanoparticle formulation comprising a plurality or population of lipid nanoparticles. In some embodiments, the nucleic acid is fully encapsulated within the lipid portion of the lipid nanoparticles such that from about 30% to about 100%, from about 40% to about 100%, from about 50% to about 100%, from about 60% to about 100%, from about 70% to about 100%, from about 80% to about 100%, from about 90% to about 100%, from about 30% to about 95%, from about 40% to about 95%, from about 50% to about 95%, from about 60% to about 95%, %, from about 70% to about 95%, from about 80% to about 95%, from about 85% to about 95%, from about 90% to about 95%, from about 30% to about 90%, from about 40% to about 90%, from about 50% to about 90%, from about 60% to about 90%, from about 70% to about 90%, from about 80% to about 90%, or at least about 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% (or any fraction thereof or range therein) of the lipid nanoparticles in the plurality or population of lipid nanoparticles have the nucleic acid encapsulated therein.
[0113] The nucleic acid that is present in the lipid nanoparticles described herein can include or consist of any form of nucleic acid that is known. The nucleic acids used herein can be single-stranded DNA or RNA (e.g., ssDNA or ssRNA), or double -stranded DNA or RNA (e.g., dsDNA or dsRNA), or DNA-RNA hybrids. Single -stranded nucleic acids include, e.g., mRNA, guide RNA (gRNA), antisense oligonucleotides, ribozymes, mature miRNA, self-amplifying RNA (SAM), and triplex-forming oligonucleotides. Examples of double-stranded DNA include, e.g., structural genes, genes including control and termination regions, and self- replicating systems such as viral or plasmid DNA. Examples of double-stranded RNA include, e.g., siRNA and other RNAi agents such as aiRNA and pre-miRNA.
[0114] Nucleic acids may be of various lengths, generally dependent upon the particular form of nucleic acid. For example, in particular embodiments, mRNA, plasmids, or genes may be from about 1,000 to about 100,000 nucleotides in length. In particular embodiments, oligonucleotides may range from about 10 to about 100 nucleotides in length. In various related embodiments, oligonucleotides, both single-stranded, double -stranded, and triple -stranded,
may range in length from about 10 to about 60 nucleotides, from about 15 to about 60 nucleotides, from about 20 to about 50 nucleotides, from about 15 to about 30 nucleotides, or from about 20 to about 30 nucleotides in length.
[0115] In some embodiments, the nucleic acid of a provided lipid nanoparticle comprises or consists of a modified or substituted polynucleotide or oligonucleotide. Modified or substituted polynucleotides and oligonucleotides can be preferred over native forms in some instances because of properties such as, for example, enhanced cellular uptake, reduced immunogenicity, and increased stability in the presence of nucleases.
[0116] In some embodiments, the nucleic acid is an RNA molecule comprising at least one modified nucleotide. In certain preferred embodiments, the RNA molecule comprises one, two, three, four, five, six, seven, eight, nine, ten, or more modified nucleotides in the double- stranded region. In certain instances, the RNA molecule (e.g., siRNA) has a double-stranded region that comprises from about 1 % to about 100% (e.g., about 1%, 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, or 100%) modified nucleotides in the double-stranded region. In preferred embodiments, less than about 25% (e.g., less than about 25%, 20%, 15%, 10%, or 5%) or from about 1 % to about 25% (e.g., from about l%-25%, 5%-25%, 10%-25%, 15%-25%, 20%-25%, or 10%-20%) of the nucleotides in the double-stranded region comprise modified nucleotides.
[0117] In other embodiments, the RNA molecule comprises modified nucleotides including, but not limited to, 2'-O-methyl (2'Ome) nucleotides, 2'-deoxy-2'-fluoro (2'F) nucleotides, 2'deoxy nucleotides, 2'-O-(2-methoxyethyl) (MOE) nucleotides, locked nucleic acid (LNA) nucleotides, and mixtures thereof. In preferred embodiments, the RNA comprises 2'Ome nucleotides (e.g., 2'Ome purine and/or pyrimidine nucleotides) such as, for example, 2'Ome- guanosine nucleotides, 2'Ome-uridine nucleotides, 2'Ome-adenosine nucleotides, 2'Ome- cytosine nucleotides, and mixtures thereof. In certain instances, the RNA does not comprise 2'Ome-cytosine nucleotides. In other embodiments, the RNA comprises a hairpin loop structure.
[0118] The RNA may comprise modified nucleotides in one strand (i.e., sense or antisense) or both strands of a double-stranded region of the RNA molecule. Preferably, uridine and/or guanosine nucleotides are modified at selective positions in the double-stranded region of the RNA duplex. With regard to uridine nucleotide modifications, at least one, two, three, four, five, six, or more of the uridine nucleotides in the sense and/or antisense strand can be a
modified uridine nucleotide such as a 2'Ome-uridine nucleotide. In some embodiments, every uridine nucleotide in the sense and/or antisense strand is a 2'Ome-uridine nucleotide. With regard to guanosine nucleotide modifications, at least one, two, three, four, five, six, or more of the guanosine nucleotides in the sense and/or antisense strand can be a modified guanosine nucleotide such as a 2'Ome-guanosine nucleotide. In some embodiments, every guanosine nucleotide in the sense and/or antisense strand is a 2'Ome-guanosine nucleotide.
[0119] In certain embodiments, at least one, two, three, four, five, six, seven, or more 5 '-GU-3' motifs in an RNA sequence may be modified, e.g., by introducing mismatches to eliminate the 5'-GU-3' motifs and/or by introducing modified nucleotides such as 2'Ome nucleotides. The 5'-GU-3' motif can be in the sense strand, the antisense strand, or both strands of the RNA sequence. The 5'-GU-3' motifs may be adjacent to each other or, alternatively, they may be separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, or more nucleotides.
[0120] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of an oligonucleotide. Oligonucleotides are generally classified as deoxyribooligonucleotides or ribooligonucleotides. A deoxyribooligonucleotide consists of a 5 -carbon sugar called deoxyribose joined covalently to phosphate at the 5' and 3' carbons of this sugar to form an alternating, unbranched polymer. A ribooligonucleotide consists of a similar repeating structure where the 5 -carbon sugar is ribose.
[0121] In particular embodiments, an oligonucleotide (or a strand thereof) specifically hybridizes to or is complementary to a target polynucleotide sequence. The terms “specifically hybridizable” and “complementary” as used herein indicate a sufficient degree of complementarity such that stable and specific binding occurs between the DNA or RNA target and the oligonucleotide. It is understood that an oligonucleotide need not be 100% complementary to its target nucleic acid sequence to be specifically hybridizable. In some embodiments, an oligonucleotide is specifically hybridizable when binding of the oligonucleotide to the target sequence interferes with the normal function of the target sequence to cause a loss of utility or expression therefrom, and there is a sufficient degree of complementarity to avoid non-specific binding of the oligonucleotide to non-target sequences under conditions in which specific binding is desired, i.e., under physiological conditions in the case of in vivo assays or therapeutic treatment, or, in the case of in vitro assays, under conditions in which the assays are conducted. Thus, the oligonucleotide may include 1, 2, 3, or
more base substitutions as compared to the region of a gene or mRNA sequence that it is targeting or to which it specifically hybridizes. a) mRNA
[0122] Certain embodiments provide compositions comprising the lipid nanoparticles described herein and methods of use thereof for expressing one or more mRNA molecules (e.g., a cocktail of mRNA molecules) in a cell, e.g., a cell within an organism (e.g., a mammal, such as a human). The mRNA molecules encode one or more polypeptides that is/are expressed within the cell. Lipid particle formulations comprising mRNA molecules described herein are useful for a variety of applications including protein replacement therapy, vaccines, cancer immunotherapy, and gene editing. In particular embodiments, the lipid nanoparticles include mRNA delivered (e.g., specifically delivered) to the liver for expression therein, e.g., for the editing of genomic information within cells of the liver. In some embodiments, the lipid particles described herein are used for treating a disease, wherein expression of the polypeptides encoded by the mRNA molecules within a diseased organism (e.g., a mammal, such as a human) ameliorates one or more symptoms of the disease. The compositions and methods described herein are particularly useful for treating human diseases caused by the absence, or reduced levels, of a functional polypeptide within the human body. In other embodiments, the lipid particles described herein are used as a vaccine for preventing a disease, wherein expression of the polypeptides encoded by the mRNA molecules within an organism (e.g., a mammal, such as a human) elicits immunity against the disease. The compositions and methods described herein are useful, for example, in preventing an infectious disease caused by a pathogen such as a virus (e.g., a coronavirus such as SARS-CoV-2) by expressing antigenic polypeptides (e.g., from mRNA molecules encoding viral proteins such as S (spike), E (envelope), M (membrane), or N (nucleocapsid) proteins or antigenic fragments thereof) to produce an immune response within an organism (e.g., a mammal, such as a human) by stimulating the adaptive immune system to create antibodies that target the pathogen. In yet other embodiments, the lipid particles described herein are used as a vaccine for treating a disease, wherein expression of the polypeptides encoded by the mRNA molecules within an organism (e.g., a mammal, such as a human) elicits an immune response against diseased cells. The compositions and methods described herein are particularly useful for treating cancer by expressing antigenic polypeptides (e.g., from mRNA molecules encoding tumor-specific
antigens or antigenic fragments thereof) to stimulate an adaptive immune response to create antibodies that target and destroy cancer cells.
[0123] In some embodiments, the mRNA molecules are fully encapsulated in lipid particle. In some examples, the RNA of a provided lipid nanoparticle or a provided population of nanoparticles includes a cocktail of one or more types of mRNA together with one or more other types of RNA, e.g., gRNA, siRNA, miRNA, etc. In some particular examples useful for the editing of genomic information, either a lipid nanoparticle or a population of different lipid nanoparticles comprises at least one type of mRNA and at least one type of gRNA. In such examples, the mRNA and gRNA can be within the same lipid nanoparticle or within different lipid nanoparticles. Similarly, with respect to formulations comprising an mRNA cocktail, the different types of mRNA species present in the cocktail (e.g., mRNA having different sequences) may be co-encapsulated in the same particle, or each type of mRNA species present in the cocktail may be encapsulated in a separate particle. The mRNA cocktail may be formulated in the particles described herein using a mixture of two or more individual mRNAs (each having a unique sequence) at identical, similar, or different concentrations or molar ratios. In one embodiment, a cocktail of mRNAs (corresponding to a plurality of mRNAs with different sequences) is formulated using identical, similar, or different concentrations or molar ratios of each mRNA species, and the different types of mRNAs are co-encapsulated in the same particle. In another embodiment, each type of mRNA species present in the cocktail is encapsulated in different particles at identical, similar, or different mRNA concentrations or molar ratios, and the particles thus formed (each containing a different mRNA payload) are administered separately (e.g., at different times in accordance with a prophylactic or therapeutic regimen), or are combined and administered together as a single unit dose (e.g., with a pharmaceutically acceptable carrier). In particular embodiments, the lipid particles are serum- stable, are resistant to nuclease degradation, and are substantially non-toxic to mammals such as humans.
(1) Modifications to mRNA
[0124] The mRNA molecules present in the provided lipid nanoparticles can include one, two, or more than two nucleoside modifications. In some embodiments, the modified mRNA exhibits reduced degradation in a cell into which the mRNA is introduced, relative to a corresponding unmodified mRNA.
[0125] In some embodiments, modified nucleosides include pyridin-4-one ribonucleoside, 5 -aza-uridine, 2-thio-5-aza-uridine, 2-thiouridine, 4-thio-pseudouridine, 2-thio-pseudouridine, 5-hydroxyuridine, 3-methyluridine, 5-carboxymethyl-uridine, 1-carboxymethyl- pseudouridine, 5 -propynyl -uridine, 1-propynyl -pseudouridine, 5-taurinomethyluridine, 1- taurinomethy1-pseudouridine, 5-taurinomethyl-2-thio-uridine, l-taurinomethyl-4-thio-uridine, 5-methyl-uridine, 1-methyl -pseudouridine, 4-thio-1-methy1-pseudouridine, 2-thio-1-methyl- pseudouridine, 1-methyl-1-deaza-pseudouridine, 2-thio-1-methyl-1-deaza-pseudouridine, dihydrouridine, dihydropseudouridine, 2-thio-dihydrouridine, 2-thio-dihydropseudouridine, 2- methoxyuridine, 2- methoxy-4-thio-uridine, 4-methoxy-pseudouridine, and 4-methoxy-2 -thio- pseudouridine.
[0126] In some embodiments, modified nucleosides include 5 -aza-cytidine, pseudoisocytidine, 3-methyl-cytidine, N4-acetylcytidine, 5 -formylcytidine, N4- methylcytidine, 5 -hydroxymethylcytidine, 1-methyl -pseudoisocytidine, pyrrolo-cytidine, pyrrolo-pseudoisocytidine, 2-thio-cytidine, 2-thio-5 -methyl -cytidine, 4-thio- pseudoisocytidine, 4-thio-1-methyl -pseudoisocytidine, 4-thio-1-methyl-1-deaza- pseudoisocytidine, 1-methyl-1-deaza-pseudoisocytidine, zebularine, 5-aza-zebularine, 5- methyl-zebularine, 5-aza-2-thio-zebularine, 2-thio-zebularine, 2-methoxy-cytidine, 2- methoxy-5-methyl-cytidine, 4-methoxy-pseudoisocytidine, and 4-methoxy-l -methyl - pseudoisocytidine .
[0127] In other embodiments, modified nucleosides include 2-aminopurine, 2,6- diaminopurine, 7-deaza-adenine, 7-deaza-8-aza-adenine, 7-deaza-2 -aminopurine, 7-deaza-8- aza-2-aminopurine, 7-deaza-2,6-diaminopurine, 7-deaza-8-aza-2,6-diaminopurine, 1- methyladenosine, N6-methyladenosine, N6-isopentenyladenosine, N6-(cri- hydroxyisopentenyl)adenosine, 2-mcthylthio-N6-(cis-hydroxyisopcntcnyl) adenosine, N6- glycinylcarbamoyladenosine, N6-threonylcarbamoyladenosine, 2-methylthio-N6-threonyl carbamoyladenosine, N6,N6-dimethyladenosine, 7-methyladenine, 2-methylthio-adenine, and 2-methoxy-adenine .
[0128] In certain embodiments, the modified nucleoside is 5'-O-(1-thiophosphate)-adenosine, 5 '-O-(1-thiophosphate)-cytidine, 5 '-O-(1-thiophosphate)-guanosine, 5 '-O-(1-thiophosphate)- uridine, or 5'-O-(1-thiophosphate)-pseudouridine. The a-thio substituted phosphate moiety is provided to confer stability to RNA polymers through the unnatural phosphorothioate backbone linkages. Phosphorothioate RNA have increased nuclease resistance and
subsequently a longer half-life in a cellular environment. Phosphorothioate-linked nucleic acids are expected to also reduce the innate immune response through weaker binding/activation of cellular innate immune molecules.
[0129] In certain embodiments, it is desirable to intracellularly degrade a modified nucleic acid introduced into the cell, for example, if precise timing of protein production is desired. Thus, the present disclosure provides a modified nucleic acid containing a degradation domain, which is capable of being acted on in a directed manner within a cell.
[0130] In other embodiments, modified nucleosides include inosine, 1-methyl -inosine, wyosine, wybutosine, 7-deaza-guanosine, 7-deaza-8-aza-guanosine, 6-thio-guanosine, 6-thio- 7-deaza-guanosine, 6-thio-7-deaza-8-aza-guanosine, 7-methyl -guanosine, 6-thio-7-methyl- guanosine, 7-methylinosine, 6-methoxy-guanosine, 1-methylguanosine, N2-methylguanosine, N2,N2-dimethylguanosine, 8-oxo-guanosine, 7-methyl-8-oxo-guanosine, 1-methyl-6-thio- guanosine, N2-methyl-6-thio-guanosine, and N2,N2-dimethyl-6-thio-guanosine.
(2) Optional mRNA Components
[0131] In further embodiments, the mRNA molecules present in the provided lipid nanoparticles may include other optional components. These optional components include, but are not limited to, untranslated regions, Kozak sequences, intronic nucleotide sequences, internal ribosome entry site (IRES), caps, and poly-A tails. For example, a 5' untranslated region (UTR) and/or a 3' UTR may be included, wherein either or both may independently contain one or more different nucleoside modifications. In such embodiments, nucleoside modifications may also be present in the translatable region. Also provided are mRNA molecules containing a Kozak sequence. Additionally, provided herein are mRNA molecules containing one or more intronic nucleotide sequences capable of being excised from the mRNA sequence.
(a) Untranslated Regions (UTRs)
[0132] Untranslated regions (UTRs) of a gene are transcribed but not translated. The 5' UTR starts at the transcription start site and continues to the start codon but does not include the start codon; whereas the 3' UTR starts immediately following the stop codon and continues until the transcriptional termination signal. There is a growing body of evidence about the regulatory roles played by the UTRs in terms of stability of the mRNA molecule and translation. The regulatory features of a UTR can be incorporated into the mRNA used in the lipid particles
described herein to increase the stability of the molecule. The specific features can also be incorporated to ensure controlled downregulation of the transcript in case they are misdirected to undesired tissue or organ sites.
(b) 5' Capping
[0133] The 5' cap structure of an mRNA is involved in nuclear export, increasing mRNA stability, and binds the mRNA Cap Binding Protein (CBP), which is responsible for mRNA stability in the cell and translation competency through the association of CBP with poly(A) binding protein to form the mature cyclic mRNA species. The cap further assists the removal of 5' proximal introns removal during mRNA splicing.
[0134] Endogenous mRNA molecules may be 5'-end capped, generating a 5'-ppp-5'- triphosphate linkage between a terminal guanosine cap residue and the 5 '-terminal transcribed sense nucleotide of the mRNA molecule. This 5'-guanylate cap may then be methylated to generate an N7-methyl-guanylate residue. The ribose sugars of the terminal and/or antiterminal transcribed nucleotides of the 5' end of the mRNA may optionally also be 2'-O-methylated. 5'- decapping through hydrolysis and cleavage of the guanylate cap structure may target an mRNA molecule for degradation.
(c) IRES Sequences
[0135] mRNA containing an internal ribosome entry site (IRES) are also useful in the lipid nanoparticles described herein. An IRES may act as the sole ribosome binding site, or may serve as one of multiple ribosome binding sites of an mRNA. An mRNA containing more than one functional ribosome binding site may encode several peptides or polypeptides that are translated independently by the ribosomes (“multicistronic mRNA”). When mRNA are provided with an IRES, further optionally provided is a second translatable region. Examples of IRES sequences include, without limitation, those from picomaviruses (e.g., FMDV), pest viruses (e.g., CFFV), polio viruses (PV), encephalomyocarditis viruses (ECMV), foot-and- mouth disease viruses (FMDV), hepatitis C viruses (HCV), classical swine fever viruses (CSFV), murine leukemia viruses (MLV), simian immune deficiency viruses (S1V), and cricket paralysis viruses (CrPV).
(d) Polv-A Tails
[0136] During RNA processing, a long chain of adenine nucleotides (poly-A tail) may be added to a polynucleotide such as an mRNA molecule in order to increase stability. Immediately after transcription, the 3 ' end of the transcript may be cleaved to free a 3 ' hydroxyl . Then poly-A polymerase adds a chain of adenine nucleotides to the RNA. The process, called polyadenylation, adds a poly-A tail that can be between 100 and 250 residues long.
[0137] Generally, the length of a poly-A tail is greater than 30 nucleotides in length. In some embodiments, the poly-A tail is greater than 35 nucleotides in length (e.g., at least or greater than about 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 450, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2,000, 2,500, and 3,000 nucleotides). In some embodiments, the poly-A tail may be 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, or 100% greater in length than the mRNA. In other embodiments, the poly-A tail may be 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, or more of the total length of the mRNA.
(3) Generation of mRNA Molecules
[0138] Methods for isolating RNA, synthesizing RNA, hybridizing nucleic acids, making, and screening cDNA libraries, and performing PCR are well known in the art (see, e.g., Gubler and Hoffman, Gene, 25:263-269 (1983); Sambrook et al., Molecular Cloning, A Laboratory Manual (2nd ed. 1989)) as are PCR methods (see, e.g., U.S. Patent Nos. 4,683,195 and 4,683,202; PCR Protocols: A Guide to Methods and Applications (Innis et al., eds, 1990)). Expression libraries are also well known to those of skill in the art. Additional basic texts disclosing the general methods of use in the present disclosure include Kriegler, Gene Transfer and Expression: A Laboratory Manual (1990); and Current Protocols in Molecular Biology (Ausubel et al., eds., 1994). In some embodiments, mRNA molecules are generated by in vitro transcription, followed by purification. Standard techniques for purifying mRNA, e.g., mRNA produced via in vivo transcription, are well known in the art.
[0139] In some embodiments, the provided lipid nanoparticle contains mRNA that is synthesized from a DNA template. Processes for synthesizing mRNA from a DNA template are well-known, and generally involve the use of enzymes (e.g., T7 RNA polymerase and/or derivatives thereof, such as optimized alternative enzymes), nucleotides (optionally including modified nucleotides as described herein), and optional mRNA components (e.g., 5' caps.) In
some embodiments, the lipid nanoparticle contains mRNA that is generated via in vitro transcription using a commercially available kit. Commercially available kits suitable for generating mRNA contained by the provided lipid nanoparticles include, for example, the MEGASCRIPT™ T7 Transcription Kit available from Thermo Fisher Scientific. Alternatively or additionally, mRNA for use with the provided lipid nanoparticles can be generated using chemical synthesis processes, such as, for example, those described by Abe et al., ACS Chem. Biol. 2022, 17, 6, 1308-1314. In further embodiments, the lipid nanoparticles include mRNA generated with mRNA printers, for example, any of those reviewed by Sheridan, 2022 Nature Biotechnol. 2022, 40, 1160-1162.
[0140] In some embodiments, the mRNA generated by any one or more of the methods described herein is purified before being used to form one or more provided lipid nanoparticles. mRNA purification techniques suitable for use with the mRNA of the provided lipid nanoparticles include, but are not limited to, HPLC purification, cellulose purification, tangential flow filtration, bead based purification (e.g., with purification with Dynabeads), silica based purification, precipitation, and combinations thereof. Non-limiting examples of mRNA purification are described in, for example, International Patent Application Publication No. WO 2018/006052 Al.
(4) Polypeptides Encoded by mRNA
[0141] The mRNA component of the lipid nanoparticles described herein can be used to express a polypeptide of interest. Certain diseases in humans are caused by the absence or impairment of a functional protein in a cell type where the protein is normally present and active. The functional protein can be completely or partially absent due, e.g., to transcriptional inactivity of the encoding gene or due to the presence of a mutation in the encoding gene that renders the protein completely or partially non-functional. Examples of human diseases that are caused by complete or partial inactivation of a protein include methylmalonic academia (caused by defective methyhnalonyl-CoA mutase), glycogen storage disease type 1A (caused by a defective catalytic subunit of glucose-6-phosphatase), glycogen storage disease type IB (caused by a lack of glucose-6-phosphate translocase), fragile X syndrome (caused by a deficiency of FMRI protein), urea cycle disorder (caused by mutations in the ornithine transcarbamoylase (OTC) gene), Crigler-Najjar syndrome type 1 (caused by a genetic mutation leading to the lack of bilirubin uridine diphosphate glucuronosyltransferase (bilirubin-UGT)), alpha- 1 antitrypsin deficiency (caused by mutations in the SERPINA1 gene), thrombotic
thrombocytopenic purpura (caused by mutations in a disintegrin and metalloproteinase with a thrombospondin type 1 motif, member 13 (ADAMTS13) gene), acute intermittent porphyria (caused by a genetic mutation of the PBGD locus), Factor IX deficiency hemophilia B (caused by a deficiency of factor IX (FIX) protein), X-linked severe combined immunodeficiency (X- SCID) (caused by one or more mutations in the gene encoding the common gamma chain protein that is a component of the receptors for several interleukins that are involved in the development and maturation of B and T cells within the immune system), and X-linked adrenoleukodystrophy (X-ALD) (caused by one or more mutations in a peroxisomal membrane transporter protein gene called ABCD1).
[0142] In some embodiments, the mRNA component of the lipid nanoparticles described herein expresses an infectious disease antigen such as a viral, bacterial, fungal, protozoal, and/or helminthic infectious disease antigen. Such vaccines comprising lipid particles with antigen-encoding mRNA are particularly useful for preventing or treating the infectious disease. In certain embodiments, the infectious disease antigen is a viral infectious disease antigen from a coronavirus (e.g., SARS-CoV-1, SARS-CoV-2, MERS-CoV), influenza virus (e.g., influenza A, B, and C viruses), filovirus (e.g., Ebola virus, Marburg virus), arenavirus (e.g., Lassa virus, Junin virus, Machupo virus, Guanarito virus, Sabia virus), Zika virus, rabies virus, rhinovirus, simian immunodeficiency virus (SIV), human immunodeficiency virus (HIV), hepatitis viruses (e.g., hepatitis C virus), herpes simplex virus, human papilloma virus (HPV), or Epstein-Barr virus. In particular embodiments, the infectious disease antigen is a SARS-CoV-2 protein selected from the group consisting of S (spike) protein, E (envelope) protein, M (membrane) protein, N (nucleocapsid) protein, and an antigenic fragment thereof. In certain instances, the development of antigen-specific immunity from an mRNA vaccine requires the transfection of antigen-presenting cells, such as dendritic cells. Administration is typically accomplished by intradermal, intramuscular, or subcutaneous injection, as dendritic cells densely populate skin tissue and skeletal muscle.
[0143] In some embodiments, the mRNA component of the lipid nanoparticles described herein expresses a tumor-associated antigen. In certain instances, following the administration of an mRNA cancer vaccine to dendritic cells, cytotoxic T cells can target and destroy tumors. In other embodiments, the mRNA component of a lipid particle described herein expresses a chimeric antigen receptor (CAR) for CAR T cell therapy. Typically, a subject’s T cells are isolated and transfected ex vivo with mRNA encoding CARs, which are protein fragments that
are displayed on the T cell surface and bind to specific tumor epitopes. Following the re- introduction of the modified T cells into a subject, the CARs target and kill tumor cells.
[0144] In some embodiments, the mRNA component of the lipid particles described herein expresses a gene editing nuclease. Examples of gene editing nucleases include CRISPR/Cas nucleases (e.g., Cas9, Cpfl), zinc finger nucleases (ZFNs), transcription-activator like effector nucleases (TALEN), and meganucleases. CRISPR-mediated gene editing requires a Cas nuclease responsible for DNA cleavage and a short guide RNA (gRNA) that directs the Cas nuclease to cleave the DNA at a precise location. In some embodiments, the gRNA targets the Cas nuclease to a gene in a viral genome. As a non-limiting example, the viral genome is a SARS-CoV-2 genome and the gene is selected from the group consisting of orflab, S gene, ORF3a, E gene, M gene, ORF6, ORF7a, ORF8, N gene, and ORFIO. In certain instances, an mRNA encoding a Cas nuclease such as Cas9 and a gRNA are encapsulated in the same lipid particle. In other instances, the mRNA encoding the Cas nuclease and the gRNA are encapsulated in separate lipid particles. b) siRNA
[0145] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of siRNA. siRNA is interfering RNA capable of silencing the expression of a target sequence in vitro and/or in vivo. The siRNA may be of about 15-60, 15-50, or 15-40 (duplex) nucleotides in length, more typically about 15-30, 15-25, or 19-25 (duplex) nucleotides in length, and is preferably about 20-24, 21-22, or 21-23 (duplex) nucleotides in length (e.g., each complementary sequence of the double-stranded siRNA is 15-60, 15-50, 15-40, 15-30, 15-25, or 19-25 nucleotides in length, preferably about 20-24, 21-22, or 21-23 nucleotides in length, and the double-stranded siRNA is about 15-60, 15-50, 15-40, 15-30, 15-25, or 19-25 base pairs in length, preferably about 18-22, 19-20, or 19-21 base pairs in length). siRNA duplexes may comprise 3' overhangs of about 1 to about 4 nucleotides or about 2 to about 3 nucleotides and 5' phosphate termini. Examples of siRNA include, without limitation, a double-stranded polynucleotide molecule assembled from two separate stranded molecules, wherein one strand is the sense strand and the other is the complementary antisense strand; a double-stranded polynucleotide molecule assembled from a single stranded molecule, where the sense and antisense regions are linked by a nucleic acid-based or non-nucleic acid-based linker; a double- stranded polynucleotide molecule with a hairpin secondary structure having self- complementary sense and antisense regions; and a circular single -stranded polynucleotide
molecule with two or more loop structures and a stem having self-complementary sense and antisense regions, where the circular polynucleotide can be processed in vivo or in vitro to generate an active double-stranded siRNA molecule.
[0146] In some preferred embodiments, a modified siRNA molecule is less immunostimulatory than a corresponding unmodified siRNA sequence. In such embodiments, the modified siRNA molecule with reduced immunostimulatory properties advantageously retains RNAi activity against the target sequence. In another embodiment, the immunostimulatory properties of the modified siRNA molecule and its ability to silence target gene expression can be balanced or optimized by the introduction of minimal and selective 2'Ome modifications within the siRNA sequence such as, e.g., within the double-stranded region of the siRNA duplex. In certain instances, the modified siRNA is at least about 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 35 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91 %, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% less immunostimulatory than the corresponding unmodified siRNA. It will be readily apparent to those of skill in the art that the immuno stimulatory properties of the modified siRNA molecule and the corresponding unmodified siRNA molecule can be determined by, for example, measuring INF-a and/or IL-6 levels from about two to about twelve hours after systemic administration in a mammal or transfection of a mammalian responder cell using an appropriate lipid-based delivery system (such as the LNP delivery system disclosed herein).
[0147] In certain embodiments, a modified siRNA molecule has an IC50 (i.e., half-maximal inhibitory concentration) less than or equal to ten-fold that of the corresponding unmodified siRNA (i.e., the modified siRNA has an IC50 that is less than or equal to ten-times the IC50 of the corresponding unmodified siRNA). In other embodiments, the modified siRNA has an IC50 less than or equal to three-fold that of the corresponding unmodified siRNA sequence. In yet other embodiments, the modified siRNA has an IC50 less than or equal to two-fold that of the corresponding unmodified siRNA. It will be readily apparent to those of skill in the art that a dose-response curve can be generated and the IC50 values for the modified siRNA and the corresponding unmodified siRNA can be readily determined using methods known to those of skill in the art.
[0148] In yet another embodiment, a modified siRNA molecule is capable of silencing at least about 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%;
75%, 20 80%, 85%, 90%, 95%, or 100% of the expression of the target sequence relative to the corresponding unmodified siRNA sequence.
[0149] In some embodiments, the siRNA molecule does not comprise phosphate backbone modifications, e.g., in the sense and/or antisense strand of the double-stranded region. In other embodiments, the siRNA comprises one, two, three, four, or more phosphate backbone modifications, e.g., in the sense and/or antisense strand of the double-stranded region. In preferred embodiments, the siRNA does not comprise phosphate backbone modifications. In further embodiments, the siRNA does not comprise 2'-deoxy nucleotides, e.g., in the sense and/or antisense strand of the double-stranded region. In yet further embodiments, the siRNA comprises one, two, three, four, ormore 2'-deoxy nucleotides, e.g., in the sense and/or antisense strand of the double -stranded region. In preferred embodiments, the siRNA does not comprise 2'-deoxy nucleotides.
[0150] In certain instances, the nucleotide at the 3'-end of the double-stranded region in the sense and/or antisense strand is not a modified nucleotide. In certain other instances, the nucleotides near the 3'-end (e.g., within one, two, three, or four nucleotides of the 3'-end) of the double -stranded region in the sense and/or antisense strand are not modified nucleotides.
[0151] The siRNA molecules described herein may have 3' overhangs of one, two, three, four, or more nucleotides on one or both sides of the double-stranded region, or may lack overhangs (i.e., have blunt ends) on one or both sides of the double -stranded region. Preferably, the siRNA has 3' overhangs of two nucleotides on each side of the double-stranded region. In certain instances, the 3' overhang on the antisense strand has complementarity to the target sequence and the 3' overhang on the sense strand has complementarity to a complementary strand of the target sequence. Alternatively, the 3' overhangs do not have complementarity to the target sequence or the complementary strand thereof. In some embodiments, the 3' overhangs comprise one, two, three, four, or more nucleotides such as 2'-deoxy (2'H) nucleotides. In certain preferred embodiments, the 3' overhangs comprise deoxythymidine (dT) and/or uridine nucleotides. In other embodiments, one or more of the nucleotides in the 3' overhangs on one or both sides of the double-stranded region comprise modified nucleotides. Non-limiting examples of modified nucleotides are described above and include 2'OMe nucleotides, 2'-deoxy-2'F nucleotides, 2'-deoxy nucleotides, 2'-O-2-MOE nucleotides, LNA nucleotides, and mixtures thereof. In preferred embodiments, one, two, three, four, or more nucleotides in the 3' overhangs present on the sense and/or antisense strand of the siRNA
comprise 2'Ome nucleotides (e.g., 2'Ome purine and/or pyrimidine nucleotides) such as, for example, 2'Ome-guanosine nucleotides, 2'Ome-uridine nucleotides, 2'Ome-adenosine nucleotides, 2'Ome-cytosine nucleotides, and mixtures thereof.
[0152] The siRNA may comprise at least one or a cocktail (e.g., at least two, three, four, five, six, seven, eight, nine, ten, or more) of unmodified and/or modified siRNA sequences that silence target gene expression. The cocktail of siRNA may comprise sequences which are directed to the same region or domain (e.g., a “hot spot”) and/or to different regions or domains of one or more target genes. In certain instances, one or more (e.g., at least two, three, four, five, six, seven, eight, nine, ten, or more) modified siRNA that silence target gene expression are present in a cocktail. In certain other instances, one or more (e.g., at least two, three, four, five, six, seven, eight, nine, ten, or more) unmodified siRNA sequences that silence target gene expression are present in a cocktail.
[0153] In some embodiments, the antisense strand of the siRNA molecule comprises or consists of a sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, or 99% complementary to the target sequence or a portion thereof. In other embodiments, the antisense strand of the siRNA molecule comprises or consists of a sequence that is 100% complementary to the target sequence or a portion thereof. In further embodiments, the antisense strand of the siRNA molecule comprises or consists of a sequence that specifically hybridizes to the target sequence or a portion thereof.
[0154] In further embodiments, the sense strand of the siRNA molecule comprises or consists of a sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, or 99% complementary to the target sequence or a portion thereof. In additional embodiments, the sense strand of the siRNA molecule comprises or consists of a sequence that is 100% identical to the target sequence or a portion thereof.
(1) Selection of siRNA Sequences
[0155] Suitable siRNA sequences can be identified using any means known in the art. Typically, the methods described in Elbashir et al., Nature, 411:494-498 (2001) and Elbashir et al., EMBO J., 20:6877-6888 (2001) are combined with rational design rules set forth in Reynolds et al., Nature Biotech., 22(3):326-330 (2004). Generally, the nucleotide sequence 3' of the AUG start codon of a transcript from the target gene of interest is scanned for dinucleotide sequences (e.g., AA, NA, CC, GG, or UU, wherein N=C, G, or U) (see, e.g.,
Elbashir et al., EMBO J., 20:6877-6888 (2001)). The nucleotides immediately 3' to the dinucleotide sequences are identified as potential siRNA sequences (i.e., a target sequence or a sense strand sequence). Typically, the 19, 21, 23, 25, 27, 29, 31, 33, 35, or more nucleotides immediately 3' to the dinucleotide sequences are identified as potential siRNA sequences. In some embodiments, the dinucleotide sequence is an AA or NA sequence and the 19 nucleotides immediately 3' to the AA or NA dinucleotide are identified as potential siRNA sequences. siRNA sequences are usually spaced at different positions along the length of the target gene. To further enhance silencing efficiency of the siRNA sequences, potential siRNA sequences may be analyzed to identify sites that do not contain regions of homology to other coding sequences, e.g., in the target cell or organism. For example, a suitable siRNA sequence of about 21 base pairs typically will not have more than 16-17 contiguous base pairs of homology to coding sequences in the target cell or organism. If the siRNA sequences are to be expressed from an RNA Pol III promoter, siRNA sequences lacking more than 4 contiguous A’s or T’s are selected.
[0156] Once a potential siRNA sequence has been identified, a complementary sequence (i.e., an antisense strand sequence) can be designed. A potential siRNA sequence can also be analyzed using a variety of criteria known in the art. For example, to enhance their silencing efficiency, the siRNA sequences may be analyzed by a rational design algorithm to identify sequences that have one or more of the following features: (1) G/C content of about 25% to about 60% G/C; (2) at least 3 A/Us at positions 15-19 of the sense strand; (3) no internal repeats; (4) an A at position 19 of the sense strand; (5) an A at position 3 of the sense strand; (6) a U at position 10 of the sense strand; (7) no G/C at position 19 of the sense strand; and (8) no G at position 13 of the sense strand. One of skill in the art will appreciate that sequences with one or more of the foregoing characteristics may be selected for further analysis and testing as potential siRNA sequences.
[0157] Additionally, potential siRNA sequences with one or more of the following criteria can often be eliminated as siRNA: (1) sequences comprising a stretch of 4 or more of the same base in a row; (2) sequences comprising homopolymers of Gs (i.e., to reduce possible non- specific effects due to structural characteristics of these polymers; (3) sequences comprising triple base motifs (e.g., GGG, CCC, AAA, or TTT); (4) sequences comprising stretches of 7 or more G/Cs in a row; and (5) sequences comprising direct repeats of 4 or more bases within the candidates resulting in internal fold-back structures. However, one of skill in the art will
appreciate that sequences with one or more of the foregoing characteristics may still be selected for further analysis and testing as potential siRNA sequences.
[0158] In some embodiments, potential siRNA sequences may be further analyzed based on siRNA duplex asymmetry as described in, e.g., Khvorova et al., Cell, 115:209-216 (2003); and Schwarz et al., Cell, 115: 199-208 (2003). In other embodiments, potential siRNA sequences may be further analyzed based on secondary structure at the target site as described in, e.g., Luo et al., Biophys. Res. Commun., 318:303-310 (2004). For example, secondary structure at the target site can be modeled using the Mfold algorithm (available at www.bioinfo.rpi.edu/applications/mfold/ma/forml.cgi) to select siRNA sequences which favor accessibility at the target site where less secondary structure in the form of base-pairing and stem-loops is present.
[0159] Once a potential siRNA sequence has been identified, the sequence can be analyzed for the presence of any immunostimulatory properties, e.g., using an in vitro cytokine assay or an in vivo animal model. Motifs in the sense and/or antisense strand of the siRNA sequence such as GU-rich motifs (e.g., 5'-GU-3', 5'-UGU-3', 5'-GUGU-3', 5'-UGUGU-3', etc.) can also provide an indication of whether the sequence may be immunostimulatory. Once an siRNA molecule is found to be immunostimulatory, it can then be modified to decrease its immunostimulatory properties as described herein. As a non-limiting example, an siRNA sequence can be contacted with a mammalian responder cell under conditions such that the cell produces a detectable immune response to determine whether the siRNA is an immunostimulatory or a non-immunostimulatory siRNA. The mammalian responder cell may be from a naive mammal (i.e., a mammal that has not previously been in contact with the gene product of the siRNA sequence). The mammalian responder cell may be, e.g., a peripheral blood mononuclear cell (PBMC), a macrophage, and the like. The detectable immune response may comprise production of a cytokine or growth factor such as, e.g., TNF-a, IFN-a, IFN — , IFN-y, IL-6, IL-12, or a combination thereof. An siRNA molecule identified as being immunostimulatory can then be modified to decrease its immunostimulatory properties by replacing at least one of the nucleotides on the sense and/or antisense strand with modified nucleotides. For example, less than about 30% (e.g., less than about 30%, 25%, 20%, 15%, 10%, or 5%) of the nucleotides in the double-stranded region of the siRNA duplex can be replaced with modified nucleotides such as 2'Ome nucleotides. The modified siRNA can then be contacted with a mammalian responder cell as described above to confirm that its immunostimulatory properties have been reduced or abrogated.
[0160] Suitable in vitro assays for detecting an immune response include, but are not limited to, the double monoclonal antibody sandwich immunoassay technique of David et al. (U.S. Pat. No. 4,376, 110); monoclona1-polyclonal antibody sandwich assays (Wide et al., in Kirkham and Hunter, eds., Radioimmunoassay Methods, E. and S. Livingstone, Edinburgh (1970)); the “Western blot” method of Gordon et al. (U.S. Pat. No. 4,452,901); immunoprecipitation of labeled ligand (Brown et al., J. Biol. Chem., 255:4980-4983 (1980)); enzyme-linked immunosorbent assays (ELISA) as described, for example, by Raines et al., J. Biol. Chem., 257:5154-5160 (1982); immunocytochemical techniques, including the use of fluorochromes (Brooks et al., Clin. Exp. Immunol., 39:477 (1980)); and neutralization of activity (Bowen- Pope et al., Proc. Natl. Acad. Sci. USA, 81:2396-2400 (1984)). In addition to the immunoassays described above, a number of other immunoassays are available, including those described in U.S. Pat. Nos. 3,817,827; 3,850,752; 3,901,654; 3,935,074; 3,984,533; 3,996,345; 4,034,074; and 4,098,876. The disclosures of these references are herein incorporated by reference in their entirety for all purposes.
[0161] A non-limiting example of an in vivo model for detecting an immune response includes an in vivo mouse cytokine induction assay as described in, e.g., Judge et al., Mai. Ther., 13:494- 505 (2006). In certain embodiments, the assay that can be performed as follows: (1) siRNA can be administered by standard intravenous injection in the lateral tail vein; (2) blood can be collected by cardiac puncture about 6 hours after administration and processed as plasma for cytokine analysis; and (3) cytokines can be quantified using sandwich ELISA kits according to the manufacturer’s instructions (e.g., mouse and human IFN-a (PBL Biomedical; Piscataway, N.J.); human IL-6 and TNF-a (eBioscience; San Diego, Calif); and mouse IL-6, TNF-a, and IFN-y (BD Biosciences; San Diego, Calif)).
[0162] Monoclonal antibodies that specifically bind cytokines and growth factors are commercially available from multiple sources and can be generated using methods known in the art (see, e.g., Kohler et al., Nature, 256: 495-497 (1975) and Harlow and Lane, ANTIBODIES, A LABORATORY MANUAL, Cold Spring Harbor Publication, New York (1999)). Generation of monoclonal antibodies has been previously described and can be accomplished by any means known in the art (Buhring et al., in Hybridoma, Vol. 10, No. 1, pp. 77-78 (1991)). In some methods, the monoclonal antibody is labeled (e.g., with any composition detectable by spectroscopic, photochemical, biochemical, electrical, optical, or chemical means) to facilitate detection.
(2) Generation of siRNA Sequences
[0163] siRNA can be provided in several forms including, e.g., as one or more isolated small- interfering RNA (siRNA) duplexes, as longer double-stranded RNA (dsRNA), or as siRNA or dsRNA transcribed from a transcriptional cassette in a DNA plasmid. siRNA can be chemically synthesized. The oligonucleotides that comprise the siRNA molecules can be synthesized using any of a variety of techniques known in the art, such as those described in Usman et al., J. Am. Chem. Soc., 109:7845 (1987); Scaringe et al., Nucl. Acids Res., 18:5433 (1990); Wincott et al., Nucl. Acids Res., 23:2677-2684 (1995); and Wincott et al., Methods Mol. Bio., 74:59 (1997).
[0164] An RNA population can be used to provide long precursor RNAs, or long precursor RNAs that have substantial or complete identity to a selected target sequence can be used to make the siRNA. The RNAs can be isolated from cells or tissue, synthesized, and/or cloned according to methods well known to those of skill in the art. The RNA can be a mixed population (obtained from cells or tissue, transcribed from cDNA, subtracted, selected, etc.), or can represent a single target sequence. RNA can be naturally occurring (e.g., isolated from tissue or cell samples), synthesized in vitro (e.g., using T7 or SP6 polymerase and PCR products or a cloned cDNA), or chemically synthesized.
[0165] To form a long dsRNA, for synthetic RNAs, the complement is also transcribed in vitro and hybridized to form a dsRNA. If a naturally occurring RNA population is used, the RNA complements are also provided (e.g., to form dsRNA for digestion by E.coli RNAse III or Dicer), e.g., by transcribing cDNAs corresponding to the RNA population, or by using RNA polymerases. The precursor RN As are then hybridized to form double stranded RN As for digestion. The dsRNAs can be directly administered to a subject or can be digested in vitro prior to administration.
[0166] Methods for isolating RNA, synthesizing RNA, hybridizing nucleic acids, making and screening cDNA libraries, and performing PCR are well known in the art (see, e.g., Gubler and Hoffman, Gene, 25:263-269 (1983); Sambrook et al., supra; Ausubel et al., supra), as are PCR methods (see, U.S. Pat. Nos. 4,683,195 and 4,683,202; PCR Protocols: A Guide to Methods and Applications (Innis et al., eds, 1990)). Expression libraries are also well known to those of skill in the art. Additional basic texts disclosing the general methods of use in the provided embodiments include Sambrook et al., Molecular Cloning, A Laboratory Manual (2nd ed. 1989); Kriegler, Gene Transfer and Expression: A Laboratory Manual (1990); and Current
Protocols in Molecular Biology (Ausubel et al., eds., 1994). The disclosures ofthese references are herein incorporated by reference in their entirety for all purposes.
[0167] Preferably, siRNA are chemically synthesized. siRNA can also be generated by cleavage of longer dsRNA (e.g., dsRNA greater than about 25 nucleotides in length) with the E.coli RNase III or Dicer. These enzymes process the dsRNA into biologically active siRNA (see, e.g., Yang et al., Proc. Natl. Acad. Sci. USA, 99:9942-9947 (2002); Calegari et al., Proc. Natl. Acad. Sci. USA, 99: 14236 (2002); Byrom et al., Ambion TechNotes, 10(l):4-6 (2003); Kawasaki et al., Nucleic Acids Res., 31:981-987 (2003); Knight et al., Science, 293:2269-2271 (2001); and Robertson et al., J. Biol. Chem., 243:82 (1968)). Preferably, dsRNA are at least 50 nucleotides to about 100, 200, 300, 400, or 500 nucleotides in length. A dsRNA may be as long as 1000, 1500, 2000, 5000 nucleotides in length, or longer. The dsRNA can encode for an entire gene transcript or a partial gene transcript. In certain instances, siRNA may be encoded by a plasmid (e.g., transcribed as sequences that automatically fold into duplexes with hairpin loops).
[0168] siRNA molecules can also be synthesized via a tandem synthesis technique, wherein both strands are synthesized as a single continuous oligonucleotide fragment or strand separated 20 by a cleavable linker that is subsequently cleaved to provide separate fragments or strands that hybridize to form the siRNA duplex. The linker can be a polynucleotide linker or a non-nucleotide linker. The tandem synthesis of siRNA can be readily adapted to both multiwell/multiplate synthesis platforms as well as large scale synthesis platforms employing batch reactors, synthesis columns, and the like. Alternatively, siRNA molecules can be assembled from two distinct oligonucleotides, wherein one oligonucleotide comprises the sense strand and the other comprises the antisense strand of the siRNA. For example, each strand can be synthesized separately and joined together by hybridization or ligation following synthesis and/or deprotection. In certain other instances, siRNA molecules can be synthesized as a single continuous oligonucleotide fragment, where the self-complementary sense and antisense regions hybridize to form an siRNA duplex having hairpin secondary structure.
(3) Modification of siRNA Sequences
[0169] In certain aspects, siRNA molecules comprise a duplex having two strands and at least one modified nucleotide in the double-stranded region, wherein each strand is about 15 to about 60 nucleotides in length. Advantageously, the modified siRNA is less immunostimulatory than a corresponding unmodified siRNA sequence, but retains the
capability of silencing the expression of a target sequence. In preferred embodiments, the degree of chemical modifications introduced into the siRNA molecule strikes a balance between reduction or abrogation of the immunostimulatory properties of the siRNA and retention of RNAi activity. As a non-limiting example, an siRNA molecule that targets a gene of interest can be minimally modified (e.g., less than about 30%, 25%, 20%, 15%, 10%, or 5% modified) at selective uridine and/or guanosine nucleotides within the siRNA duplex to eliminate the immune response generated by the siRNA while retaining its capability to silence target gene expression.
[0170] Examples of modified nucleotides include, but are not limited to, ribonucleotides having a 2'-O-methyl (2'Ome), 2'-deoxy-2'-fluoro (2'F), 2'-deoxy, 5-C-methyl, 2'-O-(2- methoxyethyl) (MOE), 4'-thio, 2'-amino, or 2'-C-allyl group. Modified nucleotides having a Northern conformation such as those described in, e.g., Saenger, Principles of Nucleic Acid Structure, Springer- Verlag Ed. (1984), are also suitable for use in siRNA molecules. Such modified nucleotides include, without limitation, locked nucleic acid (LNA) nucleotides (e.g., 2'-O, 4'-C-methylene-(D-ribofuranosyl) nucleotides), 2'-O-(2-methoxyethyl) (MOE) nucleotides, 2'-methyl-thio-ethyl nucleotides, 2'-deoxy-2'-fluoro (2'F) nucleotides, 2'-deoxy- 2'-chloro (2'Cl) nucleotides, and 2'-azido nucleotides. In certain instances, the siRNA molecules described herein include one or more G-clamp nucleotides. A G-clamp nucleotide refers to a modified cytosine analog wherein the modifications confer the ability to hydrogen bond both Watson-Crick and Hoogsteen faces of a complementary guanine nucleotide within a duplex (see, e.g., Lin et al., J. Am. Chem. Soc., 120:8531-8532 (1998)). In addition, nucleotides having a nucleotide base analog such as, for example, C-phenyl, C-naphthyl, other aromatic derivatives, inosine, azole carboxamides, and nitroazole derivatives such as 3- nitropyrrole, 4-nitroindole, 5 -nitroindole, and 6-nitroindole (see, e.g., Loakes, Nucl. Acids Res., 29:2437-2447 (2001)) can be incorporated into siRNA molecules.
[0171] In certain embodiments, siRNA molecules may further comprise one or more chemical modifications such as terminal cap moieties, phosphate backbone modifications, and the like. Examples of terminal cap moieties include, without limitation, inverted deoxy abasic residues, glyceryl modifications, 4', 5 '-methylene nucleotides, 1-(β-D-erythrofuranosyl) nucleotides, 4'-thio nucleotides, carbocyclic nucleotides, 1,5-anhydrohexitol nucleotides, L- nucleotides, a-nucleotides, modified base nucleotides, threo-pentofuranosyl nucleotides, acyclic 3',4'-seco nucleotides, acyclic 3,4-dihydroxybutyl nucleotides, acyclic 3,5- dihydroxypentyl nucleotides, 3'-3'-inverted nucleotide moieties, 3'-3'-inverted abasic moieties,
3'-2'-inverted nucleotide moieties, 3'-2'-inverted abasic moieties, 5'-5'-inverted nucleotide moieties, 5 '-5 '-inverted abasic moieties, 3'-5 '-inverted deoxy abasic moieties, 5 '-amino-alkyl phosphate, 1,3-diamino-2-propyl phosphate, 3-aminopropyl phosphate, 6-aminohexyl phosphate, 1,2-aminododecyl phosphate, hydroxypropyl phosphate, 1,4-butanediol phosphate, 3'-phosphoramidate, 5'-phosphoramidate, hexylphosphate, aminohexyl phosphate, 3'- phosphate, 5 '-amino, 3'-phosphorothioate, 5'-phosphorothioate, phosphorodithioate, and bridging or non-bridging methylphosphonate or 5'-mercapto moieties (see, e.g., U.S. Patent No. 5,998,203; Beaucage et al., Tetrahedron 49: 1925 (1993)). Non-limiting examples of phosphate backbone modifications (i.e., resulting in modified intemucleotide linkages) include phosphorothioate, phosphorodithioate, methylphosphonate, phosphotriester, morpholino, amidate, carbamate, carboxymethyl, acetamidate, polyamide, sulfonate, sulfonamide, sulfamate, formacetal, thioformacetal, and alkylsilyl substitutions (see, e.g., Hunziker et al., Nucleic Acid Analogues: Synthesis and Properties, in Modern Synthetic Methods , VCH, 331- 417 (1995); Mesmaeker et al., Novel Backbone Replacements for Oligonucleotides, in Carbohydrate Modifications in Antisense Research, ACS, 24-39 (1994)). Such chemical modifications can occur at the 5 '-end and/or 3'-end of the sense strand, antisense strand, or both strands of the siRNA.
[0172] In some embodiments, the sense and/or antisense strand of the siRNA molecule can further comprise a 3'-terminal overhang having about 1 to about 4 (e.g., 1, 2, 3, or 4) 2'-deoxy ribonucleotides and/or any combination of modified and unmodified nucleotides. Additional examples of modified nucleotides and types of chemical modifications that can be introduced into siRNA molecules are described, e.g., in UK Patent No. GB 2,397,818 B and U.S. Patent Application Publication Nos. 2004/0192626, 2005/0282188, and 2007/0135372.
[0173] The siRNA molecules described herein can optionally comprise one or more non- nucleotides in one or both strands of the siRNA. As used herein, the term “non-nucleotide” refers to any group or compound that can be incorporated into a nucleic acid chain in the place of one or more nucleotide units, including sugar and/or phosphate substitutions, and allows the remaining bases to exhibit their activity. The group or compound is abasic in that it does not contain a commonly recognized nucleotide base such as adenosine, guanine, cytosine, uracil, or thymine and therefore lacks a base at the 1’-position.
[0174] In other embodiments, chemical modification of the siRNA comprises attaching a conjugate to the siRNA molecule. The conjugate can be attached at the 5'- and/or 3'-end of the
sense and/or antisense strand of the siRNA via a covalent attachment such as, e.g., a biodegradable linker. The conjugate can also be attached to the siRNA, e.g., through a carbamate group or other linking group (see, e.g., U.S. Patent Application Publication Nos. 2005/0074771, 2005/0043219, and 20050158727). In certain instances, the conjugate is a molecule that facilitates the delivery of the siRNA into a cell. Examples of conjugate molecules suitable for attachment to siRNA include, without limitation, steroids such as cholesterol, glycols such as polyethylene glycol (PEG), human serum albumin (HSA), fatty acids, carotenoids, terpenes, bile acids, folates (e.g., folic acid, folate analogs and derivatives thereof), sugars (e.g., galactose, galactosamine, N-acetyl galactosamine, glucose, mannose, fructose, fucose, etc.), phospholipids, peptides, ligands for cellular receptors capable of mediating cellular uptake, and combinations thereof (see, e.g., U.S. Patent Application Publication Nos. 2003/0130186, 2004/0110296, and 2004/0249178; U.S. Patent No. 6,753,423). Other examples include the lipophilic moiety, vitamin, polymer, peptide, protein, nucleic acid, small molecule, oligosaccharide, carbohydrate cluster, intercalator, minor groove binder, cleaving agent, and cross-linking agent conjugate molecules described in U.S. Patent Application Publication Nos. 2005/0119470 and 2005/0107325. Yet other examples include the 2'-O-alkyl amine, 2'-O-alkoxyalkyl amine, polyamine, C5-cationic modified pyrimidine, cationic peptide, guanidinium group, amidinium group, cationic amino acid conjugate molecules described in U.S. Patent Application Publication No. 2005/0153337. Additional examples include the hydrophobic group, membrane active compound, cell penetrating compound, cell targeting signal, interaction modifier, and steric stabilizer conjugate molecules described in U.S. Patent Application Publication No. 2004/0167090. Further examples include the conjugate molecules described in U.S. Patent Application Publication No. 2005/0239739. The type of conjugate used and the extent of conjugation to the siRNA molecule can be evaluated for improved pharmacokinetic profiles, bioavailability, and/or stability of the siRNA while retaining RNAi activity. As such, one skilled in the art can screen siRNA molecules having various conjugates attached thereto to identify ones having improved properties and full RNAi activity using any of a variety of well-known in vitro cell culture or in vivo animal models. c) aiRNA
[0175] In some embodiments, the provided lipid nanoparticles include asymmetrical interfering RNA (aiRNA) molecules that silence the expression of a target gene. In some examples, the aiRNA molecule comprises a double-stranded (duplex) region of about 10 to
about 25 (base paired) nucleotides in length, wherein the aiRNA molecule comprises an antisense strand comprising 5' and 3' overhangs, and wherein the aiRNA molecule is capable of silencing target gene expression.
[0176] In certain instances, the aiRNA molecule comprises a double-stranded (duplex) region of about 12-20, 12-19, 12-18, 13-17, or 14-17 (base paired) nucleotides in length, more typically 12, 13, 14, 15, 16, 17, 18, 19, or 20 (base paired) nucleotides in length. In certain other instances, the 5' and 3' overhangs on the antisense strand comprise sequences that are complementary to the target RNA sequence, and may optionally further comprise nontargeting sequences. In some embodiments, each of the 5' and 3' overhangs on the antisense strand comprises or consists of one, two, three, four, five, six, seven, or more nucleotides.
[0177] In other embodiments, the aiRNA molecule comprises modified nucleotides selected from the group consisting of 2'oMe nucleotides, 2'F nucleotides, 2'-deoxy nucleotides, 2'- OMOE nucleotides, LNA nucleotides, and mixtures thereof. In a preferred embodiment, the aiRNA molecule comprises 2'oMe nucleotides. As a non-limiting example, the 2'Ome nucleotides may be selected from the group consisting of 2'oMe-guanosine nucleotides, 2'oMe- uridine nucleotides, and mixtures thereof.
[0178] Like siRNA, asymmetrical interfering RNA (aiRNA) can recruit the RNA-induced silencing complex (RISC) and lead to effective silencing of a variety of genes in mammalian cells by mediating sequence -specific cleavage of the target sequence between nucleotide 10 and 11 relative to the 5' end of the antisense strand (Sun et al., Nat. Biotech., 26: 1379-1382 (2008)). Typically, an aiRNA molecule comprises a short RNA duplex having a sense strand and an antisense strand, wherein the duplex contains overhangs at the 3' and 5' ends of the antisense strand. The aiRNA is generally asymmetric because the sense strand is shorter on both ends when compared to the complementary antisense strand. In some embodiments, aiRNA molecules may be designed, synthesized, and annealed under conditions similar to those used for siRNA molecules. As a non-limiting example, aiRNA sequences may be selected and generated using the methods described above for selecting siRNA sequences.
[0179] In another embodiment, aiRNA duplexes of various lengths (e.g., about 10-25, 12- 20, 12-19, 12-18, 13-17, or 14-17 base pairs, more typically 12, 13, 14, 15, 16, 17, 18, 19, or 20 base pairs) may be designed with overhangs at the 3' and 5' ends of the antisense strand to target an mRNA of interest. In certain instances, the sense strand of the aiRNA molecule is about 10-25, 12-20, 12-19, 12-18, 13-17, or 14-17 nucleotides in length, more typically 12, 13,
14, 15, 16, 17, 18, 19, or 20 nucleotides in length. In certain other instances, the antisense strand of the aiRNA molecule is about 15-60, 15-50, or 15-40 nucleotides in length, more typically about 15-30, 15-25, or 19-25 nucleotides in length, and is preferably about 20-24, 21-22, or 21- 23 nucleotides in length.
[0180] In some embodiments, the 5' antisense overhang contains one, two, three, four, or more nontargeting nucleotides (e.g., “AA”, “UU”, “dTdT”, etc.). In other embodiments, the 3' antisense overhang contains one, two, three, four, or more nontargeting nucleotides (e.g., “AA”, “UU”, “dTdT”, etc.). In certain aspects, the aiRNA molecules described herein may comprise one or more modified nucleotides, e.g., in the double -stranded (duplex) region and/or in the antisense overhangs. As a non-limiting example, aiRNA sequences may comprise one or more of the modified nucleotides described above for siRNA sequences. In a preferred embodiment, the aiRNA molecule comprises 2'oMe nucleotides such as, for example, 2'oMe- guanosine nucleotides, 2'oMe-uridine nucleotides, or mixtures thereof.
[0181] In certain embodiments, aiRNA molecules may comprise an antisense strand which corresponds to the antisense strand of an siRNA molecule, e.g., one of the siRNA molecules described herein. In other embodiments, aiRNA molecules may be used to silence the expression of any of the target genes set forth above in the context of siRNA molecules, such as, e.g., genes associated with viral infection and survival, genes associated with metabolic diseases and disorders, genes associated with tumorigenesis and cell transformation, angiogenic genes, immunomodulator genes such as those associated with inflammatory and autoimmune responses, ligand receptor genes, and genes associated with neurodegenerative disorders. As a non-limiting example, the antisense oligonucleotide can be used to silence the expression of a SARS-CoV-2 gene encoding S (spike) protein, E (envelope) protein, M (membrane) protein, orN (nucleocapsid) protein. d) miRNA
[0182] In some embodiments, the provided lipid nanoparticles include microRNA (miRNA) molecules that silence the expression of a target gene. In some examples, the miRNA molecule comprises about 15 to about 60 nucleotides in length, wherein the miRNA molecule is capable of silencing target gene expression. In certain instances, the miRNA molecule comprises about 15-50, 15-40, or 15-30 nucleotides in length, more typically about 15-25 or 19-25 nucleotides in length, and are preferably about 20-24, 21-22, or 21-23 nucleotides in length. In a preferred
embodiment, the miRNA molecule is a mature miRNA molecule targeting an RNA sequence of interest.
[0183] In some embodiments, the miRNA molecule comprises modified nucleotides selected from the group consisting of 2'oMe nucleotides, 2'F nucleotides, 2'-deoxy nucleotides, 2'- OMOE nucleotides, LNA nucleotides, and mixtures thereof. In a preferred embodiment, the miRNA molecule comprises 2'oMe nucleotides. As a non-limiting example, the 2'Ome nucleotides may be selected from the group consisting of 2'oMe-guanosine nucleotides, 2'oMe- uridine nucleotides, and mixtures thereof.
[0184] Generally, microRNAs (miRNA) are single-stranded RNA molecules of about 21-23 nucleotides in length which regulate gene expression. miRNAs are encoded by genes from whose DNA they are transcribed, but miRNAs are not translated into protein (non-coding RNA); instead, each primary transcript (a pri-miRNA) is processed into a short stem-loop structure called a pre-miRNA and finally into a functional mature miRNA. Mature miRNA molecules are either partially or completely complementary to one or more messenger RNA (mRNA) molecules, and their main function is to downregulate gene expression. The identification of miRNA molecules is described, e.g., in Lagos-Quintana et al., Science, 294:853-858; Lau et al., Science, 294:858-862; and Lee et al., Science, 294:862-864.
[0185] The genes encoding miRNA are much longer than the processed mature miRNA molecule. miRNA are first transcribed as primary transcripts or pri-miRNA with a cap and poly-A tail and processed to short, ~70-nucleotide stem-loop structures known as pre-miRNA in the cell nucleus. This processing is performed in animals by a protein complex known as the Microprocessor complex, consisting of the nuclease Drosha and the double-stranded RNA binding protein Pasha (Denli et al., Nature, 432:231-235 (2004)). These pre-miRNA are then processed to mature miRNA in the cytoplasm by interaction with the endonuclease Dicer, which also initiates the formation of the RNA-induced silencing complex (RISC) (Bernstein et al., Nature, 409:363-366 (2001). Either the sense strand or antisense strand of DNA can function as templates to give rise to miRNA.
[0186] When Dicer cleaves the pre-miRNA stem-loop, two complementary short RNA molecules are formed, but only one is integrated into the RISC complex. This strand is known as the guide strand and is selected by the Argonaute protein, the catalytically active RNase in the RISC complex, on the basis of the stability of the 5' end (Preall et al., Curr. Biol., 16:530- 535 (2006)). The remaining strand, known as the anti-guide or passenger strand, is degraded
as a RISC complex substrate (Gregory et al., Cell, 123:631-640 (2005)). After integration into the active RISC complex, miRNAs base pair with their complementary mRNA molecules and induce target mRNA degradation and/or translational silencing.
[0187] Mammalian miRNA molecules are usually complementary to a site in the 3' UTR of the target mRNA sequence. In certain instances, the annealing of the miRNA to the target mRNA inhibits protein translation by blocking the protein translation machinery. In certain other instances, the annealing of the miRNA to the target mRNA facilitates the cleavage and degradation of the target mRNA through a process similar to RNA interference (RNAi). miRNA may also target methylation of genomic sites which correspond to targeted mRNA. Generally, miRNA function in association with a complement of proteins collectively termed the miRNP.
[0188] In some embodiments, the miRNA molecules described herein are about 15-100, 15- 90, 15-80, 15-75, 15-70, 15-60, 15-50, or 15-40 nucleotides in length, more typically about 15- 30, 15-25, or 19-25 nucleotides in length, and are preferably about 20-24, 21-22, or 21-23 nucleotides in length. In some embodiments, miRNA molecules comprises one or more modified nucleotides. As a non-limiting example, miRNA sequences may comprise one or more of the modified nucleotides described above for siRNA sequences. In a preferred embodiment, the miRNA molecule comprises 2'oMe nucleotides such as, for example, 2'oMe- guanosine nucleotides, 2'oMe-uridine nucleotides, or mixtures thereof.
[0189] In some embodiments, miRNA molecules may be used to silence the expression of any of the target genes set forth above in the context of siRNA molecules, such as, e.g., genes associated with viral infection and survival, genes associated with metabolic diseases and disorders, genes associated with tumorigenesis and cell transformation, angiogenic genes, immunomodulator genes such as those associated with inflammatory and autoimmune responses, ligand receptor genes, and genes associated with neurodegenerative disorders. As a non-limiting example, the miRNA can be used to silence the expression of a SARS-CoV-2 gene encoding S (spike) protein, E (envelope) protein, M (membrane) protein, or N (nucleocapsid) protein.
[0190] In other embodiments, one or more agents that block the activity of a miRNA targeting an mRNA of interest are administered using the lipid particles described herein. Examples of blocking agents include, but are not limited to, steric blocking oligonucleotides,
locked nucleic acid oligonucleotides, and Morpholino oligonucleotides. Such blocking agents may bind directly to the miRNA or to the miRNA binding site on the target mRNA. e) Self-Amplifying RNA
[0191] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of one or more self-amplifying RNA molecules. Self-amplifying RNA (sa-RNA) may also be referred to as self-replicating RNA, replication-competent RNA, replicons or RepRNA. RepRNA, referred to as self-amplifying mRNA when derived from positive-strand viruses, is generated from a viral genome lacking at least one structural gene; it can translate and replicate (hence “self-amplifying”) without generating infectious progeny virus. In certain embodiments, the RepRNA technology may be used to insert a gene cassette encoding a desired antigen of interest. For example, the alphaviral genome is divided into two open reading frames (ORFs): the first ORF encodes proteins for the RNA dependent RNA polymerase (replicase), and the second ORF encodes structural proteins. In saRNA vaccine constructs, the ORF encoding viral structural proteins may be replaced with any antigen of choice, while the viral replicase remains an integral part of the vaccine and drives intracellular amplification of the RNA after immunization. f) Antisense Oligonucleotides
[0192] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of an antisense oligonucleotide directed to a target gene or sequence of interest. The terms “antisense oligonucleotide” or “antisense” as used herein include oligonucleotides that are complementary to a targeted polynucleotide sequence. Antisense oligonucleotides are single strands of DNA or RNA that are complementary to a chosen sequence. Antisense RNA oligonucleotides prevent the translation of complementary RNA strands by binding to the RNA. Antisense DNA oligonucleotides can be used to target a specific, complementary (coding or non-coding) RNA. If binding occurs, this DNA/RNA hybrid can be degraded by the enzyme RNase H. In certain embodiments, antisense oligonucleotides comprise from about 10 to about 60 nucleotides or from about 15 to about 30 nucleotides. The term also encompasses antisense oligonucleotides that may not be exactly complementary to the desired target gene. Thus, the lipid nanoparticles described herein can be utilized in instances where non-target specific-activities are found with antisense, or where an antisense sequence containing one or more mismatches with the target sequence is the most preferred for a particular use. An
antisense oligonucleotide can contain natural nucleotides, as well as non-natural or modified nucleotides (e.g., a modified nucleobase, modified intemucleoside linkage, and/or modified sugar such as those described herein).
[0193] Antisense oligonucleotides have been demonstrated to be effective and targeted inhibitors of protein synthesis, and, consequently, can be used to specifically inhibit protein synthesis by a targeted gene. The efficacy of antisense oligonucleotides for inhibiting protein synthesis is well established. For example, the synthesis of polygalacturonase and the muscarine type 2 acetylcholine receptor are inhibited by antisense oligonucleotides directed to their respective mRNA sequences (see, U.S. Pat. Nos. 5,739,119 and 5,759,829). Furthermore, examples of antisense inhibition have been demonstrated with the nuclear protein cyclin, the multiple drug resistance gene (MDR1), ICAM-1, E-selectin, STK-1, striatal GABAA receptor, and human EGF (see, Jaskulski et al., Science, 240: 1544-6 (1988); Vasanthakumar et al., Cancer Commun., 1:225-32 (1989); Penis et al., Brain Res Mai Brain Res., 15; 57:310-20 (1998); and U.S. Pat. Nos. 5,801,154; 5,789,573; 5,718,709 and 5,610,288). Moreover, antisense constructs have also been described that inhibit and can be used to treat a variety of abnormal cellular proliferations, e.g., cancer (see, U.S. Pat. Nos. 5,747,470; 5,591,317; and 5,783,683). The disclosures of these references are herein incorporated by reference in their entirety for all purposes.
[0194] Methods of producing antisense oligonucleotides are known in the art and can be readily adapted to produce an antisense oligonucleotide that targets any polynucleotide sequence. Selection of antisense oligonucleotide sequences specific for a given target sequence is based upon analysis of the chosen target sequence and determination of secondary structure, Tm, binding energy, and relative stability. Antisense oligonucleotides may be selected based upon their relative inability to form dimers, hairpins, or other secondary structures that would reduce or prohibit specific binding to the target mRNA in a host cell. Highly preferred target regions of the mRNA include those regions at or near the AUG translation initiation codon and those sequences that are substantially complementary to 5' regions of the mRNA. These secondary structure analyses and target site selection considerations can be performed, for example, using v.4 of the OLIGO primer analysis software (Molecular Biology Insights) and/or the BLASTN 2.0.5 algorithm software (Altschul et al., Nucleic Acids Res., 25:3389-402 (1997)).
[0195] In some embodiments, the antisense oligonucleotide component of the lipid particles described herein can be used to inhibit the expression or replication of a gene of interest. Genes of interest are set forth above in the context of siRNA molecules and include, but are not limited to, genes associated with viral infection and survival, genes associated with metabolic diseases and disorders (e.g., liver diseases and disorders), genes associated with tumorigenesis and cell transformation (e.g., cancer), angiogenic genes, immunomodulator genes such as those associated with inflammatory and autoimmune responses, ligand receptor genes, and genes associated with neurodegenerative disorders. As a non-limiting example, the antisense oligonucleotide can hybridize to a SARS-CoV-2 gene (e.g., orflab, S gene, ORF3a, E gene, M gene, ORF6, ORF7a, ORF8, N gene, or ORF 10) and inhibit the expression or replication of the gene. g) Ribozymes
[0196] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of a ribozyme. Ribozymes are RNA-protein complexes having specific catalytic domains that possess endonuclease activity (see, Kim et al., Proc. Natl. Acad. Sci. USA., 84:8788-92 (1987); and Forster et al., Cell, 49:211-20 (1987)). For example, a large number of ribozymes accelerate phosphoester transfer reactions with a high degree of specificity, often cleaving only one of several phosphoesters in an oligonucleotide substrate (see, Cech et al., Cell, 27:487-96 (1981); Michel et al., J. Mol. Biol., 216:585-610 (1990); Reinhold-Hurek et al., Nature, 357: 173-6 (1992)). This specificity has been attributed to the requirement that the substrate bind via specific base-pairing interactions to the internal guide sequence (IGS) of the ribozyme prior to chemical reaction.
[0197] At least six basic varieties of naturally-occurring enzymatic RNA molecules are known presently. Each can catalyze the hydrolysis of RNA phosphodiester bonds in trans (and thus can cleave other RNA molecules) under physiological conditions. In general, enzymatic nucleic acids act by first binding to a target RNA. Such binding occurs through the target binding portion of an enzymatic nucleic acid which is held in close proximity to an enzymatic portion of the molecule that acts to cleave the target RNA. Thus, the enzymatic nucleic acid first recognizes and then binds a target RNA through complementary base-pairing, and once bound to the correct site, acts enzymatically to cut the target RNA. Strategic cleavage of such a target RNA will destroy its ability to direct synthesis of an encoded protein. After an
enzymatic nucleic acid has bound and cleaved its RNA target, it is released from that RNA to search for another target and can repeatedly bind and cleave new targets.
[0198] The enzymatic nucleic acid molecule may be formed in a hammerhead, hairpin, hepatitis 5 virus, group I intron or RNaseP RNA (in association with an RNA guide sequence), or Neurospora VS RNA motif, for example. Specific examples of hammerhead motifs are described in, e.g., Rossi et al., Nucleic Acids Res., 20:4559-65 (1992). Examples of hairpin motifs are described in, e.g., EP 0360257, Hampel et al., Biochemistry, 28:4929-33 (1989); Hampel et al., Nucleic Acids Res., 18:299-304 (1990); and U.S. Patent No. 5,631,359. An example of the hepatitis 5 virus motif is described in, e.g., Perrotta et al., Biochemistry, 31: 11843-52 (1992). An example of the RNaseP motif is described in, e.g., Guerrier-Takada et al., Cell, 35:849-57 (1983). Examples of the Neurospora VS RNA ribozyme motif is described in, e.g., Saville et al., Cell, 61:685-96 (1990); Saville et al., Proc. Natl. Acad. Sci. USA, 88:8826-30 (1991); Collins et al., Biochemistry, 32:2795-9 (1993). An example of the Group I intron is described in, e.g., U.S. Patent No. 4,987,071. Important characteristics of enzymatic nucleic acid molecules are that they have a specific substrate binding site which is complementary to one or more of the target gene DNA or RNA regions, and that they have nucleotide sequences within or surrounding that substrate binding site which impart an RNA cleaving activity to the molecule. Thus, the ribozyme constructs need not be limited to specific motifs mentioned herein.
[0199] Methods of producing a ribozyme targeted to any polynucleotide sequence are known in the art. Ribozymes may be designed as described in, e.g., PCT Publication Nos. WO 93/23569 and WO 94/02595, and synthesized to be tested in vitro and/or in vivo as described therein.
[0200] Ribozyme activity can be optimized by altering the length of the ribozyme binding arms or chemically synthesizing ribozymes with modifications that prevent their degradation by serum ribonucleases (see, e.g., PCT Publication Nos. WO 92/07065, WO 93/15187, WO 91/03162, and WO 94/13688; EP 92110298.4; and U.S. Patent No. 5,334,711, which describe various chemical modifications that can be made to the sugar moieties of enzymatic RNA molecules), modifications which enhance their efficacy in cells, and removal of stem II bases to shorten RNA synthesis times and reduce chemical requirements.
h) Immunostimulatorv Oligonucleotides
[0201] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of an immunostimulatory oligonucleotide (ISS; single-or double-stranded) capable of inducing an immune response when administered to a subject, which may be a mammal such as a human. ISS include, e.g., certain palindromes leading to hairpin secondary structures (see, Yamamoto et al., J. Immunol. , 148:4072-6 (1992)), or CpG motifs, as well as other known ISS features (such as multi-G domains; see; PCT Publication No. WO 96/11266).
[0202] Immunostimulatory nucleic acids are considered to be non-sequence specific when it is not required that they specifically bind to and reduce the expression of a target sequence in order to provoke an immune response. Thus, certain immunostimulatory nucleic acids may comprise a sequence corresponding to a region of a naturally-occurring gene or mRNA, but they may still be considered non-sequence specific immunostimulatory nucleic acids.
[0203] In one embodiment, the immunostimulatory nucleic acid or oligonucleotide comprises at least one CpG dinucleotide. The oligonucleotide or CpG dinucleotide may be unmethylated or methylated. In another embodiment, the immunostimulatory nucleic acid comprises at least one CpG dinucleotide having a methylated cytosine. In one embodiment, the nucleic acid comprises a single CpG dinucleotide, wherein the cytosine in the CpG dinucleotide is methylated. In an alternative embodiment, the nucleic acid comprises at least two CpG dinucleotides, wherein at least one cytosine in the CpG dinucleotides is methylated. In a further embodiment, each cytosine in the CpG dinucleotides present in the sequence is methylated. In another embodiment, the nucleic acid comprises a plurality of CpG dinucleotides, wherein at least one of the CpG dinucleotides comprises a methylated cytosine. In certain embodiments, the oligonucleotides used in the compositions and methods described herein have a phosphodiester (“PO”) backbone or a phosphorothioate (“PS”) backbone, and/or at least one methylated cytosine residue in a CpG motif. i) shRNA
[0204] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of shRNA. An shRNA molecule includes a short RNA sequence that makes a tight hairpin turn that can be used to silence gene expression via RNA interference. The shRNA molecules of the present disclosure may be chemically synthesized or transcribed from a transcriptional cassette in a DNA plasmid. The shRNA hairpin structure is cleaved by the
cellular machinery into siRNA, which is then bound to the RNA-induced silencing complex (RISC).
[0205] The shRNA molecules of the disclosure are typically about 15-60, 15-50, or 15-40 (duplex) nucleotides in length, more typically about 15-30, 15-25, or 19-25 (duplex) nucleotides in length, and are preferably about 20-24, 21-22, or 21-23 (duplex) nucleotides in length (e.g., each complementary sequence of the double-stranded shRNA is 15-60, 15-50, 15- 40, 15-30, 15-25, or 19-25 nucleotides in length, preferably about 20-24, 21-22, or 21-23 nucleotides in length, and the double-stranded shRNA is about 15-60, 15-50, 15-40, 15-30, 15- 25, or 19-25 base pairs in length, preferably about 18-22, 19-20, or 19-21 base pairs in length). shRNA duplexes may comprise 3' overhangs of about 1 to about 4 nucleotides or about 2 to about 3 nucleotides on the antisense strand and/or 5 '-phosphate termini on the sense strand. In some embodiments, the shRNA comprises a sense strand and/or antisense strand sequence of from about 15 to about 60 nucleotides in length (e.g., about 15-60, 15-55, 15-50, 15-45, 15-40, 15-35, 15-30, or 15-25 nucleotides in length), preferably from about 19 to about 40 nucleotides in length (e.g., about 19-40, 19-35, 19-30, or 19-25 nucleotides in length), more preferably from about 19 to about 23 nucleotides in length (e.g., 19, 20, 21, 22, or 23 nucleotides in length).
[0206] Non-limiting examples of shRNA include a double-stranded polynucleotide molecule assembled from a single-stranded molecule, where the sense and antisense regions are linked by a nucleic acid-based or non-nucleic acid-based linker; and a double -stranded polynucleotide molecule with a hairpin secondary structure having self-complementary sense and antisense regions. In preferred embodiments, the sense and antisense strands of the shRNA are linked by a loop structure comprising from about 1 to about 25 nucleotides, from about 2 to about 20 nucleotides, from about 4 to about 15 nucleotides, from about 5 to about 12 nucleotides, or 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, or more nucleotides.
[0207] Suitable shRNA sequences can be identified, synthesized, and modified using any means known in the art for designing, synthesizing, and modifying siRNA sequences. Additional embodiments related to the shRNA molecules of the present disclosure, as well as methods of designing and synthesizing such shRNA molecules, are described in U.S. Patent Application Publication No. 2011/0071208, the disclosure of which is herein incorporated by reference in its entirety for all purposes.
j) asRNA
[0208] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of asRNA. asRNA molecules, also referred to in the art as antisense transcripts, are naturally-occurring or synthetically produced single -stranded RNA molecules that are complementary to a protein-coding messenger RNA (mRNA) with which it hybridizes and thereby blocks the translation of the mRNA into a protein. Antisense transcript are classified into short (less than 200 nucleotides) and long (greater than 200 nucleotides) non-coding RNAs (ncRNAs).
[0209] The asRNA molecules may include a sequence complementary to a genomic sequence between 100, 80, 60, 40, 20, or 10 kb upstream of the transcription initiation site of a target gene to downstream of the transcription termination site. In some embodiments, the asRNA includes a sequence complementary to a genomic sequence between 1 kb upstream of the transcription initiation site of the target gene and 1 kb downstream of the transcription termination site of the target gene. In other embodiments, the asRNA includes a sequence complementary to a genomic sequence between 500, 250, or 100 nucleotides upstream of the transcription initiation site of the target gene to the downstream 500, 250 or 100 nucleotides of the transcription termination site of the target gene.
[0210] The asRNA molecule may include a sequence complementary to a genomic sequence comprising the coding region of the target gene. The asRNA may include a sequence complementary to a genomic sequence aligned with a promoter region of the target gene on the template strand. The gene can have a plurality of promoter regions. In this case, the asRNA can be aligned with one, two or more promoter regions. An online database of annotated gene loci can be used to identify a promoter region of a gene.
[0211] The alignment region between the asRNA molecule and the target gene promoter region may be as short as a single nucleotide in length, or can be at least 15 or at least 20 nucleotide length, or at least 25 nucleotide length, or at least 30, 35, 40, 45, or 50 nucleotide length, or at least 55, 60, 65, 70 or 75 nucleotide length, or at least 100 nucleotide length.
[0212] The primary natural function of asRNA molecules involves regulating gene expression, and synthetic versions have been used widely as research tools for gene knockdown and for therapeutic applications. asRNA molecules and their functions have been described in
the art (see e.g., Weiss et al. (1999) Cell. Mol. Life Sci. 55:334-358; Wahlstedt (2013) Nat. Rev. Drug Disc. 12:433-446; Pelechano and Steinmetz (2013) Nat. Rev. Genet. 14:880-893). k) DsiRNA
[0213] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of DsiRNA. DsiRNA molecules are processed in vivo by Dicer to produce an active siRNA which is incorporated into the RISC complex for RNA interference of a target gene. In some embodiments, the DsiRNA has a length sufficient such that it is processed by Dicer to produce an siRNA. According to these embodiments, the DsiRNA comprises (i) a first oligonucleotide sequence (also termed the sense strand) that is between about 25 and about 60 nucleotides in length (e.g., about 25-60, 25-55, 25-50, 25-45, 25-40, 25-35, or 25-30 nucleotides in length), preferably between about 25 and about 30 nucleotides in length (e.g., 25, 26, 27, 28, 29, or 30 nucleotides in length), and (ii) a second oligonucleotide sequence (also termed the antisense strand) that anneals to the first sequence under biological conditions, such as the conditions found in the cytoplasm of a cell. The second oligonucleotide sequence may be between about 25 and about 60 nucleotides in length (e.g., about 25-60, 25-55, 25-50, 25- 45, 25-40, 25-35, or 25-30 nucleotides in length), and is preferably between about 25 and about 30 nucleotides in length (e.g., 25, 26, 27, 28, 29, or 30 nucleotides in length). In addition, a region of one of the sequences, particularly of the antisense strand, of the DsiRNA has a sequence length of at least about 19 nucleotides, for example, from about 19 to about 60 nucleotides (e.g., about 19-60, 19-55, 19-50, 19-45, 19-40, 19-35, 19-30, or 19-25 nucleotides), preferably from about 19 to about 23 nucleotides (e.g., 19, 20, 21, 22, or 23 nucleotides) that are sufficiently complementary to a nucleotide sequence of the RNA produced from the target gene to trigger an RNAi response.
[0214] In some embodiments, the DsiRNA has a length sufficient such that it is processed by Dicer to produce an siRNA and has at least one of the following properties: (i) the DsiRNA is asymmetric, e.g., has a 3'-overhang on the antisense strand; and/or (ii) the DsiRNA has a modified 3'-end on the sense strand to direct orientation of Dicer binding and processing of the DsiRNA to an active siRNA. According to this latter embodiment, the sense strand comprises from about 22 to about 28 nucleotides and the antisense strand comprises from about 24 to about 30 nucleotides.
[0215] In some embodiments, the DsiRNA has an overhang on the 3'-end of the antisense strand. In some embodiments, the sense strand is modified for Dicer binding and processing by
suitable modifiers located at the 3'-end of the sense strand. Suitable modifiers include nucleotides such as deoxyribonucleotides, acyclonucleotides, and the like, and sterically hindered molecules such as fluorescent molecules and the like. When nucleotide modifiers are used, they replace ribonucleotides in the DsiRNA such that the length of the DsiRNA does not change. In some embodiments, the DsiRNA has an overhang on the 3'-end of the antisense strand and the sense strand is modified for Dicer processing. In some embodiments, the 5 '-end of the sense strand has a phosphate. In some embodiments, the 5 '-end of the antisense strand has a phosphate. In some embodiments, the antisense strand or the sense strand or both strands have one or more 2'-O -methyl (2'OMe) modified nucleotides. In some embodiments, the antisense strand contains 2'OMe modified nucleotides. In some embodiments, the antisense stand contains a 3'-overhang that is comprised of 2'OMe modified nucleotides. The antisense strand could also include additional 2'OMe modified nucleotides. The sense and antisense strands anneal under biological conditions, such as the conditions found in the cytoplasm of a cell. In addition, a region of one of the sequences, particularly of the antisense strand, of the DsiRNA has a sequence length of at least about 19 nucleotides, where these nucleotides are in the 21-nucleotide region adjacent to the 3'-end of the antisense strand and are sufficiently complementary to a nucleotide sequence of the RNA produced from the target gene. Further, in accordance with these embodiments, the DsiRNA may also have one or more of the following additional properties: (a) the antisense strand has a right shift from the typical 21- mer (i.e., the antisense strand includes nucleotides on the right side of the molecule when compared to the typical 21-mer); (b) the strands may not be completely complementary (i.e., the strands may contain simple mismatch pairings); and (c) base modifications such as locked nucleic acid(s) may be included in the 5 '-end of the sense strand.
[0216] In some embodiments, the sense strand comprises from about 25 to about 28 nucleotides (e.g., 25, 26, 27, or 28 nucleotides), wherein the 2 nucleotides on the 3'-end of the sense strand are deoxyribonucleotides. The sense strand contains a phosphate at the 5 '-end. The antisense strand comprises from about 26 to about 30 nucleotides (e.g., 26, 27, 28, 29, or 30 nucleotides) and contains a 3'-overhang of 1-4 nucleotides. The nucleotides comprising the 3'- overhang are modified with 2'OMe modified ribonucleotides. The antisense strand contains alternating 2'OMe modified nucleotides beginning at the first monomer of the antisense strand adjacent to the 3'-overhang, and extending 15-19 nucleotides from the first monomer adjacent to the 3'-overhang. For example, for a 27-nucleotide antisense strand and counting the first base
at the 5 '-end of the antisense strand as position number 1 , 2'OMe modifications would be placed at bases 9, 11, 13, 15, 17, 19, 21, 23, 25, 26, and 27.
[0217] In some embodiments, the DsiRNA has a length sufficient such that it is processed by Dicer to produce an siRNA and at least one of the following properties: (i) the DsiRNA is asymmetric, e.g., has a 3'-overhang on the sense strand; and (ii) the DsiRNA has a modified 3'-end on the antisense strand to direct orientation of Dicer binding and processing of the DsiRNA to an active siRNA. According to these embodiments, the sense strand comprises from about 24 to about 30 nucleotides (e.g., 24, 25, 26, 27, 28, 29, or 30 nucleotides) and the antisense strand comprises from about 22 to about 28 nucleotides (e.g., 22, 23, 24, 25, 26, 27, or 28 nucleotides). In some embodiments, the DsiRNA has an overhang on the 3'-end of the sense strand. In some embodiments, the antisense strand is modified for Dicer binding and processing by suitable modifiers located at the 3'-end of the antisense strand. Suitable modifiers include nucleotides such as deoxyribonucleotides, acyclonucleotides, and the like, and sterically hindered molecules such as fluorescent molecules and the like. When nucleotide modifiers are used, they replace ribonucleotides in the DsiRNA such that the length of the DsiRNA does not change. In some embodiments, the DsiRNA has an overhang on the 3'-end of the sense strand and the antisense strand is modified for Dicer processing. In some embodiments, the antisense strand has a 5'-phosphate. The sense and antisense strands anneal under biological conditions, such as the conditions found in the cytoplasm of a cell. In addition, a region of one of the sequences, particularly of the antisense strand, of the DsiRNA has a sequence length of at least 19 nucleotides, wherein these nucleotides are adjacent to the 3'-end of antisense strand and are sufficiently complementary to a nucleotide sequence of the RNA produced from the target gene. Further, in accordance with this embodiment, the DsiRNA may also have one or more of the following additional properties: (a) the antisense strand has a left shift from the typical 21-mer (i.e., the antisense strand includes nucleotides on the left side of the molecule when compared to the typical 21-mer); and (b) the strands may not be completely complementary, i.e., the strands may contain simple mismatch pairings.
[0218] In a preferred embodiment, the DsiRNA has an asymmetric structure, with the sense strand having a 25-base pair length, and the antisense strand having a 27-base pair length with a 2-base 3'-overhang. In certain instances, this DsiRNA having an asymmetric structure further contains 2 deoxynucleotides at the 3'-end of the sense strand in place of two of the ribonucleotides. In certain other instances, this DsiRNA having an asymmetric structure further contains 2'OMe modifications at positions 9, 11, 13, 15, 17, 19, 21, 23, and 25 of the antisense
strand (wherein the first base at the 5 '-end of the antisense strand is position 1). In certain additional instances, this DsiRNA having an asymmetric structure further contains a 3'- overhang on the antisense strand comprising 1, 2, 3, or 42'OMe nucleotides (e.g., a 3'-overhang of2'OMe nucleotides at positions 26 and 27 on the antisense strand).
[0219] In another embodiment, DsiRNA may be designed by first selecting an antisense strand siRNA sequence having a length of at least 19 nucleotides. In some instances, the antisense siRNA is modified to include about 5 to about 11 ribonucleotides on the 5 '-end to provide a length of about 24 to about 30 nucleotides. When the antisense strand has a length of 21 nucleotides, 3-9, preferably 4-7, or more preferably 6 nucleotides may be added on the 5'- end. Although the added ribonucleotides may be complementary to the target gene sequence, full complementarity between the target sequence and the antisense siRNA is not required. That is, the resultant antisense siRNA is sufficiently complementary with the target sequence. A sense strand is then produced that has about 22 to about 28 nucleotides. The sense strand is substantially complementary with the antisense strand to anneal to the antisense strand under biological conditions. In one embodiment, the sense strand is synthesized to contain a modified 3'-end to direct Dicer processing of the antisense strand. In another embodiment, the antisense strand of the dsRNA has a 3'-overhang. In a further embodiment, the sense strand is synthesized to contain a modified 3'-end for Dicer binding and processing and the antisense strand of the dsRNA has a 3'-overhang.
[0220] In a related embodiment, the antisense siRNA may be modified to include about 1 to about 9 ribonucleotides on the 5'-end to provide a length of about 22 to about 28 nucleotides. When the antisense strand has a length of 21 nucleotides, 1-7, preferably 2-5, or more preferably 4 ribonucleotides may be added on the 3'-end. The added ribonucleotides may have any sequence. Although the added ribonucleotides may be complementary to the target gene sequence, full complementarity between the target sequence and the antisense siRNA is not required. That is, the resultant antisense siRNA is sufficiently complementary with the target sequence. A sense strand is then produced that has about 24 to about 30 nucleotides. The sense strand is substantially complementary with the antisense strand to anneal to the antisense strand under biological conditions. In one embodiment, the antisense strand is synthesized to contain a modified 3'-end to direct Dicer processing. In another embodiment, the sense strand of the dsRNA has a 3'-overhang. In a further embodiment, the antisense strand is synthesized to contain a modified 3'-end for Dicer binding and processing and the sense strand of the dsRNA has a 3'-overhang.
[0221] Additional embodiments related to the DsiRNA molecules of the present disclosure, as well as methods of designing and synthesizing such DsiRNA molecules, are described in U.S. Patent Application Publication Nos. 2005/0244858, 2005/0277610, 2007/0265220, and 2011/0071208, the disclosures of which are herein incorporated by reference in their entirety for all purposes. l) piRNA
[0222] In some embodiments, the nucleic acid of a provided lipid nanoparticle includes or consists of piRNA. The piRNA molecule bind to proteins of A piRNA molecule can be about 10 to 50 nucleotides in length, about 25 to 39 nucleotides in length, or about 26 to 31 nucleotides in length. See, e.g., U.S. Patent Application Pub. No. 2009/0062228.
[0223] piRNA molecules represent the largest class of small non-coding RNA molecules. piRNAs can be substantially complementary to a target gene, and can selectively form RNA- protein complexes through interactions with the Piwi or Aubergine subclasses of Argonaute proteins. These piRNA complexes have been linked to both epigenetic and post-transcriptional gene silencing of retrotransposons and other genetic elements in germ line cells, particularly those in spermatogenesis. They are distinct from microRNA (miRNA) in size (typically 24-31 nt rather than 21-24 nt), lack of sequence conservation, and increased complexity. However, like other small RNAs, piRNAs are thought to be involved in gene silencing, specifically the silencing of transposons. The majority of piRNAs are antisense to transposon sequences, suggesting that transposons are the piRNA target. In mammals it appears that the activity of piRNAs in transposon silencing is most important during the development of the embryo, and in both C. elegans and humans, piRNAs are necessary for spermatogenesis. piRNA has a role in RNA silencing via the formation of an RNA-induced silencing complex (RISC). m) Target Genes of Downregulating Nucleic Acids
[0224] In certain embodiments, the nucleic acid component (e.g., siRNA) of the lipid nanoparticles described herein can be used to downregulate or silence the translation (i.e., expression) of a gene of interest. Genes of interest include, but are not limited to, genes associated with viral infection and survival, genes associated with metabolic diseases and disorders (e.g., liver diseases and disorders), genes associated with tumorigenesis and cell transformation (e.g., cancer), angiogenic genes, immunomodulator genes such as those associated with inflammatory and autoimmune responses, ligand receptor genes, and genes
associated with neurodegenerative disorders. In certain embodiments, the gene of interest is expressed in hepatocytes.
[0225] Genes associated with viral infection and survival include those expressed by a virus in order to bind, enter, and replicate in a cell. Of particular interest are viral sequences associated with chronic viral diseases. Viral sequences of particular interest include sequences of Filoviruses such as Ebola virus and Marburg virus (see, e.g., Geisbert et al., J. Infect. Dis., 193: 1650-1657 (2006)); Arenaviruses such as Lassa virus, Junin virus, Machupo virus, Guanarito virus, and Sabia virus (Buchmeier et al., Arenaviridae: the viruses and their replication, In: FIELDS VIROLOGY, Knipe et al. (eds.), 4th ed., Lippincott-Raven, Philadelphia, (2001)); Influenza viruses such as Influenza A, B, and C viruses, (see, e.g., Steinhauer et al., Annu Rev Genet., 36:305-332 (2002); and Neumann et al., J Gen Viral., 83:2635-2662 (2002)); Hepatitis viruses (see, e.g., Hamasaki et al., FEBSLett, 543:51 (2003); Yokota et al., EMBO Rep., 4:602 (2003); Schlomai et al., Hepatology, 37:764 (2003); Wilson et al., Proc. Natl. Acad. Sci. USA, 100:2783 (2003); Kapadia et al., Proc. Natl. Acad. Sci. USA, 100:2014 (2003); and FIELDS VIROLOGY, Knipe et al. (eds.), 4th ed., Lippincott-Raven, Philadelphia (2001)); Human Immunodeficiency Virus (HIV) (Banerjea et al., Mal Ther, 8:62 (2003); Song et al., J. Viral., 77:7174 (2003); Stephenson, JAMA, 289: 1494 (2003); Qin et al., Proc. Natl. Acad. Sci. USA, 100: 183 (2003)); Herpes viruses (Jia et al., J. Viral., 77:3301 (2003)); and Human Papilloma Viruses (HPV) (Hall et al., J. Viral., 77:6066 (2003); Jiang et al., Oncogene, 21:6041 (2002)).
[0226] Exemplary Filovirus nucleic acid sequences that can be silenced include, but are not limited to, nucleic acid sequences encoding structural proteins (e.g., VP30, VP35, nucleoprotein (NP), polymerase protein (L-pol)) and membrane-associated proteins (e.g., VP40, glycoprotein (GP), VP24). Complete genome sequences for Ebola virus are set forth in, e.g., Genbank Accession Nos. NC-002549; AY769362; NC-006432; NC-004161; AY729654; AY354458; AY142960; AB050936; AF522874; AF499101; AF272001; and AF086833. Ebola virus VP24 sequences are set forth in, e.g., Genbank Accession Nos. U77385 and AY058897. Ebola virus Lpol sequences are set forth in, e.g., Genbank Accession No. X67110. Ebola virus VP40 sequences are set forth in, e.g., Genbank Accession No. AY058896. Ebola virus NP sequences are set forth in, e.g., Genbank Accession No. AY058895. Ebola virus GP sequences are set forth in, e.g., Genbank Accession No. A Y058898; Sanchez et al., Virus Res., 29:215- 240 (1993); Will et al., J. Viral., 67: 1203-1210 (1993); Volchkov et al., FEBS Lett., 305: 181- 184 (1992); and U.S. Pat. No. 6,713,069. Additional Ebola virus sequences are set forth in,
e.g., Genbank Accession Nos. LI 1365 and X61274. Complete genome sequences for Marburg virus are set forth in, e.g., Genbank Accession Nos. NC-001608; AY430365; AY430366; and AY358025. Marburg virus GP sequences are set forth in, e.g., Genbank Accession Nos. AF005734; AF005733; and AF005732. Marburg virus VP35 sequences are set forth in, e.g., Genbank Accession Nos. AF005731 and AF005730. Additional Marburg virus sequences are set forth in, e.g., Genbank Accession Nos. X64406; Z29337; AF005735; and Z12132. Non- limiting examples of siRNA molecules targeting Ebola virus and Marburg virus nucleic acid sequences include those described in U.S. Patent Application Publication No. 2007/0135370, the disclosure of which is herein incorporated by reference in its entirety for all purposes.
[0227] Exemplary Influenza virus nucleic acid sequences that can be silenced include, but are not limited to, nucleic acid sequences encoding nucleoprotein (NP), matrix proteins (M 1 and M2), nonstructural proteins (NSl and NS2), RNA polymerase (PA, PB1, PB2), neuraminidase (NA), and haemagglutinin (HA). Influenza A NP sequences are set forth in, e.g., Genbank Accession Nos. NC-004522; AY818138; AB166863; AB188817; AB189046; AB189054; AB189062; AY646169; AY646177; AY651486; AY651493; AY651494;
AY651495; AY651496; AY651497; AY651498; AY651499; AY651500; AY651501;
AY651502; AY651503; AY651504; AY651505; AY651506; AY651507; AY651509;
AY651528; AY770996; AY790308; and AY818140. Influenza A PA sequences are set forth in, e.g., Genbank Accession Nos. AY818132; A Y790280; AY646171; AY818132;
AY818133; AY646179; AY818134; AY551934; AY651613; AY651610; AY651620;
AY651617; AY651600; AY651611; AY651606; AY651618; AY651608; AY651607;
AY651605; AY651609; AY651615; AY651616; AY651640; AY651614; AY651612;
AY651621; AY651619; AY770995; and AY724786. Non-limiting examples of siRNA molecules targeting Influenza virus nucleic acid sequences include those described in U.S. Patent Application Publication No. 2007/0218122, the disclosure of which is herein incorporated by reference in its entirety for all purposes.
[0228] Exemplary hepatitis virus nucleic acid sequences that can be silenced include, but are not limited to, nucleic acid sequences involved in transcription and translation (e.g., Enl, En2, X, P) and nucleic acid sequences encoding structural proteins (e.g., core proteins including Cp and Cp-related proteins, capsid and envelope proteins including S, M, and/or L proteins, or fragments thereof) (see, e.g., FIELDS VIROLOGY, supra). Exemplary Hepatitis C virus (HCV) nucleic acid sequences that can be silenced include, but are not limited to, the 5'- untranslated region (5' UTR), the 3'-untranslated region (3'-UTR), the polyprotein translation
initiation codon region, the internal ribosome entry site (IRES) sequence, and/or nucleic acid sequences encoding the core protein, the El protein, the E2 protein, the p7 protein, the NS2 protein, the NS3 protease/helicase, the NS4A protein, the NS4B protein, the NS5A protein, and/or the NS5B RNA-dependent RNA polymerase. HCV genome sequences are set forth in, e.g., Genbank Accession Nos. NC-004102 (HCV genotype la), AJ238799 (HCV genotype lb), NC-009823 (HCV genotype 2), NC-009824 (HCV genotype 3), NC-009825 (HCV genotype 4), NC-009826 (HCV genotype 5), and NC-009827 (HCV genotype 6). Hepatitis A virus nucleic acid sequences are set forth in, e.g., Genbank Accession No. NC-001489; Hepatitis B virus nucleic acid sequences are set forth in, e.g., Genbank Accession No. NC-003977; Hepatitis D virus nucleic acid sequence are set forth in, e.g., Genbank Accession No. NC- 001653; Hepatitis E virus nucleic acid sequences are set forth in, e.g., Genbank Accession No. NC-001434; and Hepatitis G virus nucleic acid sequences are set forth in, e.g., Genbank Accession No. NC-001710. Silencing of sequences that encode genes associated with viral infection and survival can conveniently be used in combination with the administration of conventional agents used to treat the viral condition. Non-limiting examples of siRNA molecules targeting hepatitis virus nucleic acid sequences include those described in U.S. Patent Application Publication Nos. 2006/0281175, 2005/0058982, and 2007/0149470; U.S. Pat. No. 7,348,314; and U.S. Provisional Application No. 61/162,127, fded Mar. 20, 2009, the disclosures of which are herein incorporated by reference in their entirety for all purposes.
[0229] Genes associated with metabolic diseases and disorders (e.g., disorders in which the liver is the target and liver diseases and disorders) include, for example, genes expressed in dyslipidemia (e.g., liver X receptors such as LXRa and LXR~ (Genbank Accession No. NM- 007121), famesoid X receptors (FXR) (Genbank Accession No. NM-005123), sterol- regulatory element binding protein (SREBP), site-1 protease (SIP), 3-hydroxy-3- methylglutaryl coenzyme A reductase (HMG coenzyme-A reductase), apolipoprotein B (ApoB) (Genbank Accession No. 20 NM-000384), apolipoprotein CIII (ApoC3) (Genbank Accession Nos. NM-000040 and NG- 008949 REGION: 5001.8164), and apolipoprotein E (ApoE) (Genbank Accession Nos. NM- 000041 and NG-007084 REGION: 5001.8612)); and diabetes (e.g., glucose 6-phosphatase) (see, e.g., Forman et al., Cell, 81:687 (1995); Seal et al., Mol. Endocrinol., 9:72 (1995), Zavacki et al., Proc. Natl. Acad. Sci. USA, 94:7909 (1997); Sakai et al., Cell, 85: 1037-1046 (1996); 25 Duncan et al., J. Biol. Chem., MT. 12778-12785 (1997); Willy et al., Genes Dev., 9: 1033-1045 (1995); Lehmann et al., J. Biol. Chem., 272:3137-3140 (1997); Janowski et al., Nature, 383:728-731 (1996); and Peet et al., Cell,
93:693-704 (1998)). One of skill in the art will appreciate that genes associated with metabolic diseases and disorders (e.g., diseases and disorders in which the liver is a target and liver diseases and disorders) include genes that are expressed in the liver itself as well as and genes expressed in other organs and tissues. Silencing of sequences that encode genes associated with metabolic diseases and disorders can conveniently be used in combination with the administration of conventional agents used to treat the disease or disorder. Non-limiting examples of siRNA molecules targeting the ApoB gene include those described in U.S. Patent Application Publication No. 2006/0134189, the disclosure of which is herein incorporated by reference in its entirety for all purposes. Non-limiting examples of siRNA molecules targeting the ApoC3 gene include those described in U.S. Provisional Application No. 61/147,235, filed Jan. 26, 2009, the disclosure of which is herein incorporated by reference in its entirety for all purposes.
[0230] Examples of gene sequences associated with tumorigenesis and cell transformation (e.g., cancer or other neoplasia) include mitotic kinesins such as Eg5 (KSP, KIF1 1; Genbank Accession No. NM-004523); serine/threonine kinases such as polo-like kinase 1 (PLK-1) (Genbank Accession No. NM-005030; Barr et al., Nat. Rev. Mai. Cell. Biol., 5:429-440 (2004)); tyrosine kinases such as WEE1 (Genbank Accession Nos. NM-003390 and NM- 001143976); inhibitors of apoptosis such as XIAP (Genbank Accession No. NM-001167); COP9 signalosome subunits such as CSN1, CSN2, CSN3, CSN4, CSN5 (JAB1; Genbank Accession No. NM-006837); CSN6, CSN7 A, CSN7B, and CSN8; ubiquitin ligases such as COP1 (RFWD2; Genbank Accession Nos. NM-022457 and NM-001001740); and histone deacetylases such as HDACl, HDAC2 (Genbank Accession No. NM-001527), HDAC3, HDAC4, HDAC5, HDAC6, HDAC7, HDAC8, HDAC9, etc. Non-limiting examples of siRNA molecules targeting the Eg5 and XIAP genes include those described in U.S. patent application Ser. No. 11/807,872, filed May 29, 2007, the disclosure of which is herein incorporated by reference in its entirety for all purposes. Non-limiting examples of siRNA molecules targeting the PLK-1 gene include those described in U.S. Patent Application Publication Nos. 2005/0107316 and 2007/0265438; and U.S. Patent Application Ser. No. 12/343,342, filed Dec. 23, 2008, the disclosures of which are herein incorporated by reference in their entirety for all purposes. Nonlimiting examples of siRNA molecules targeting the CSN5 gene include those described in U.S. Provisional Application No. 61/045,251, filed Apr. 15, 2008, the disclosure of which is herein incorporated by reference in its entirety for all purposes.
[0231] Additional examples of gene sequences associated with tumorigenesis and cell transformation include translocation sequences such as MLL fusion genes, BCR-ABL (Wilda et al., Oncogene, 21:5716 (2002); Scherr et al., Blood, 101: 1566 (2003)), TEL-AML1, EWS- fLil, TLS-FUS, PAX3-FKHR, BCL-2, AML1-ETO, and AML1-MTG8 (Heidenreich et al., Blood, 101:3157 (2003)); overexpressed sequences such as multidrug resistance genes (Nieth et al., FEBS Lett., 545: 144 (2003); Wu et al, Cancer Res. 63: 1515 (2003)), cyclins (Li et al., Cancer Res., 63:3593 (2003); Zou et al., Genes Dev., 16:2923 (2002)), beta-catenin (Verma et al., Clin Cancer Res., 9: 1291 (2003)), telomerase genes (Kosciolek et al., Mai Cancer Then, 2:209 (2003)), c-MYC, N-MYC, BCL-2, growth factor receptors (e.g., EGFR/ErbB 1 (Genbank Accession Nos. NM-005228, NM-201282, NM-201283, and NM-201284; see also, Nagy et al. Exp. Cell Res., 285:39-49 (2003), ErbB2/HER-2 (Genbank Accession Nos. NM- 004448 and NM-001005862), ErbB3 (Genbank Accession Nos. NM-001982 and NM- 001005915), and ErbB4 (Genbank Accession Nos. NM-005235 and NM-001042599); and mutated sequences such as RAS (reviewed in Tuschl and Borkhardt, Mai. Interventions, 2: 158 (2002)). Nonlimiting examples of siRNA molecules targeting the EGFR gene include those described in U.S. patent application Ser. No. 11/807,872, fded May 29, 2007, the disclosure of which is herein incorporated by reference in its entirety for all purposes.
[0232] Silencing of sequences that encode DNA repair enzymes find use in combination with the administration of chemotherapeutic agents (Collis et al., Cancer Res., 63: 1550 (2003)). Genes encoding proteins associated with tumor migration are also target sequences of interest, for example, integrins, selectins, and metalloproteinases. The foregoing examples are not exclusive. Those of skill in the art will understand that any whole or partial gene sequence that facilitates or promotes tumorigenesis or cell transformation, tumor growth, or tumor migration can be included as a template sequence.
[0233] Angiogenic genes are able to promote the formation of new vessels. Of particular interest is vascular endothelial growth factor (VEGF) (Reich et al., Mai. Vis., 9:210 (2003)) or VEGFR. siRNA sequences that target VEGFR are set forth in, e.g., GB 2396864; U.S. Patent Application Publication No. 2004/0142895; and CA 2456444, the disclosures of which are herein incorporated by reference in their entirety for all purposes.
[0234] Anti-angiogenic genes are able to inhibit neovascularization. These genes are particularly useful for treating those cancers in which angiogenesis plays a role in the pathological development of the disease. Examples of anti -angiogenic genes include, but are
not limited to, endostatin (see, e.g., U.S. Pat. No. 6,174,861), angiostatin (see, e.g., U U.S. Pat. No. 5,639,725), and VEGFR2 (see, e.g., Decaussin et al., J. Pathol., 188: 369-377 (1999)), the disclosures of which are herein incorporated by reference in their entirety for all purposes.
[0235] Immunomodulator genes are genes that modulate one or more immune responses. Examples of immunomodulator genes include, without limitation, cytokines such as growth factors (e.g., TGF-α, TGF-β, EGF, FGF, IGF, NGF, PDGF, CGF, GM-CSF, SCF, etc ), interleukins (e.g., IL-2, IL-4, IL-12 (Hill et al., J. Immunol., 171:691 (2003)), IL-15, IL-18, IL- 20, etc.), interferons (e.g., IFN-α, IFN-β, IFN-γ, etc.) and TNF. Fas and Fas ligand genes are also immunomodulator target sequences of interest (Song et al., Nat. Med., 9:347 (2003)). Genes encoding secondary signaling molecules in hematopoietic and lymphoid cells are also included in the present disclosure, for example, Tee family kinases such as Bruton’s tyrosine kinase (Btk) (Heinonen et al., FEBSLett, 527:274 (2002)).
[0236] Cell receptor ligands include ligands that are able to bind to cell surface receptors (e.g., insulin receptor, EPO receptor, G-protein coupled receptors, receptors with tyrosine kinase activity, cytokine receptors, growth factor receptors, etc.), to modulate (e.g., inhibit, activate, etc.) the physiological pathway that the receptor is involved in (e.g., glucose level modulation, blood cell development, mitogenesis, etc.). Examples of cell receptor ligands include, but are not limited to, cytokines, growth factors, interleukins, interferons, erythropoietin (EPO), insulin, glucagon, G-protein coupled receptor ligands, etc. Templates coding for an expansion of trinucleotide repeats (e.g., CAG repeats) find use in silencing pathogenic sequences in neurodegenerative disorders caused by the expansion of trinucleotide repeats, such as spinobulbular muscular atrophy and Huntington’s Disease (Caplen et al., Hum. Mai. Genet., 11: 175 (2002)).
[0237] Certain other target genes, which may be targeted by a nucleic acid (e.g., by siRNA) to downregulate or silence the expression of the gene, include but are not limited to, Actin, Alpha 2, Smooth Muscle, Aorta (ACTA2), Alcohol dehydrogenase IA (ADRIA), Alcohol dehydrogenase 4 (ADH4 ), Alcohol dehydrogenase 6 (ADH6), Afamin (AFM), Angiotensinogen (AGT), Serine-pyruvate aminotransferase (AGXT), Alpha-2-HS- glycoprotein (AHSG), Aldoketo reductase family I member C4 (AKRIC4), Serum albumin (ALB), alpha-1- microglobulin/bikunin precursor (AMBP), Angiopoietin-related protein 3 (ANGPTL3), Serum amyloid P-component (APCS), Apolipoprotein A-II (APOA2), Apolipoprotein B-100 (APOB), Apolipoprotein C3 (APOC3), Apolipoprotein C-IV (APOC4),
Apolipoprotein F (APOF), Beta-2-glycoprotein 1 (APOH), Aquaporin-9 (AQP9), Bile acid- CoA:amino acid N-acyltransferase (BAAT), C4b-binding protein beta chain (C4BPB), Putative uncharacterized protein encoded by LINC01554 (C5orf27), Complement factor 3 (C3), Complement Factor 5 (C5), Complement component C6 (C6), Complement component C8 alpha chain (CSA), Complement component C8 beta chain (C8B), Complement component C8 gamma chain (C8G), Complement component C9 (C9), Calmodulin Binding Transcription Activator 1 (CAMTAI), CD38 (CD38), Complement Factor B (CFB), Complement factor H- related protein 1 (CFHR1), Complement factor H-related protein 2 (CFHR2), Complement factor H-related protein 3 (CFHR3), Cannabinoid receptor 1 (CNR1), ceruloplasmin (CP), carboxypeptidase B2 (CPB2), Connective tissue growth factor (CTGF), C-X-C motif chemokine 2 (CXCL2), Cytochrome P450 1A2 (CYP1A2), Cytochrome P4502A6 (CYP2A6), Cytochrome P450 2C8 (CYP2C8), Cytochrome P450 2C9 (CYP2C9), Cytochrome P450 Family 2 Subfamily D Member 6 (CYP2D6), Cytochrome P450 2E1 (CYP2E1), Phylloquinone omega-hydroxylase CYP4F2 (CYP4F2), 7-alpha-hydroxycholest-4-en-3-one 12-alpha- hydroxylase (CYP8B 1), Dipeptidyl peptidase 4 (DPP4), coagulation factor 12 (F12), coagulation factor II (thrombin) (F2), coagulation factor IX (F9), fibrinogen alpha chain (FGA), fibrinogen beta chain (FGB), fibrinogen gamma chain (FGG), fibrinogen-like 1 (FGL1), flavin containing monooxygenase 3 (FM03), flavin containing monooxygenase 5 (FM05), group-specific component (vitamin D binding protein) (GC), Growth hormone receptor (GHR), glycine N-methyltransferase (GNMT), hyaluronan binding protein 2 (HABP2), hepcidin antimicrobial peptide (HAMP), hydroxyacid oxidase (glycolate oxidase) 1 (HA01), HGF activator (HGFAC), haptoglobin-related protein; haptoglobin (HPR), hemopexin (HPX), histidine-rich glycoprotein (HRG), hydroxysteroid (11-5 beta) dehydrogenase 1 (HSD11B1), hydroxysteroid (17-beta) dehydrogenase 13 (HSD17B13), Inter-alpha-trypsin inhibitor heavy chain Hl (ITIH1), Inter-alpha-trypsin inhibitor heavy chain H2 (ITIH2), Inter-alpha-trypsin inhibitor heavy chain H3 (ITIH3), Inter-alpha-trypsin inhibitor heavy chain H4 (ITIH4), Prekallikrein (KLKB1), Lactate dehydrogenase A (LDHA), liver expressed antimicrobial peptide 2 (LEAP2), leukocyte cell-derived chemotaxin 2 (LECT2), Lipoprotein (a) (LPA), mannan-binding lectin serine peptidase 2 (MASP2), S-adenosyl methionine synthase isoform type-1 (MAT1A), NADPH Oxidase 4 (N0X4), Poly [ADP-ribose] polymerase 1 (PARP1), paraoxonase 1 (P0N1), paraoxonase 3 (P0N3), Vitamin K-dependent protein C (PROC), Retinal dehydrogenase 16 (RDH16), serum amyloid A4, constitutive (SAA4), serine dehydratase (SDS), Serpin Family A Member 1 (SERPINA1), Serpin All (SERPINA11), Kallistatin (SERPINA4), Corticosteroid-binding globulin (SERPINA6), Antithrombin-III
(SERPINC1), Heparin cofactor 2 (SERPIND1), Serpin Family H Member 1 (SERPINH1), Solute Carrier Family 5 Member 2 (SLC5A2), Sodium/bile acid cotransporter (SLC1OA1), Solute carrier family 13 member 5 (SLC13A5), Solute carrier family 22 member 1 (SLC22A1), Solute carrier family 25 member 47 (SLC25A47), Solute carrier family 2, facilitated glucose transporter member 2 (SLC2A2), Sodium -coupled neutral amino acid transporter 4 (SLC38A4 ), Solute carrier organic anion transporter family member IB 1 (SLCO IB 1 ), Sphingomyelin Phosphodiesterase 1 (SMPD 1 ), Bile salt sulfotransferase (SULT2A1), tyrosine aminotransferase (TAT), tryptophan 2,3 -dioxygenase (TD02), UDP glucuronosyltransferase 2 family, polypeptide BIO (UGT2B10), UDP glucuronosyltransferase 2 family, polypeptide B 15 (UGT2B15), UDP glucuronosyltransferase 2 family, polypeptide B4 (UGT2B4) and vitronectin (VTN).
[0238] In addition to its utility in silencing the expression of any of the above-described genes for therapeutic purposes, certain nucleic acids (e.g., siRNA) described herein are also useful in research and development applications as well as diagnostic, prophylactic, prognostic, clinical, and other healthcare applications. As a non-limiting example, certain nucleic acids (e.g., siRNA) can be used in target validation studies directed at testing whether a gene of interest has the potential to be a therapeutic target. Certain nucleic acids (e.g., siRNA) can also be used in target identification studies aimed at discovering genes as potential therapeutic targets.
C. PHARMACEUTICAL COMPOSITIONS AND FORMULATIONS
[0239] In another aspect, the disclosure provides a pharmaceutical composition that include one or more of any of the lipid nanoparticles described herein in Section B, or one or more of the ionizable lipids described herein in Section B.2. In some embodiments, the pharmaceutical composition further includes a therapeutically effective amount of a pharmaceutically acceptable excipient. Additionally or alternatively, the pharmaceutical composition can include a pharmaceutically acceptable carrier.
[0240] The pharmaceutically acceptable carrier (e.g., physiological saline or phosphate buffer) can be selected in accordance with the route of administration and standard pharmaceutical practice. Generally, normal buffered saline (e.g., 135-150 mM NaCl) is used as the pharmaceutically acceptable carrier. Other suitable carriers include, e.g., water, buffered water, 0.4% saline, 0.3% glycine, and the like, including glycoproteins for enhanced stability, such as albumin, lipoprotein, globulin, etc. Additional suitable carriers are described in, e.g.,
Remington: The Science and Practice of Pharmacy, 23rd Edition (2020). The pharmaceutically acceptable carrier is generally added following particle formation. Thus, after the particle is formed, the particle can be diluted into pharmaceutically acceptable carriers such as normal buffered saline.
[0241] Examples of suitable excipients for use with the provided pharmaceutical compositions include, but are not limited to, lactose, dextrose, sucrose, sorbitol, mannitol, starches, gum acacia, calcium phosphate, alginates, tragacanth, gelatin, calcium silicate, microcrystalline cellulose, polyvinylpyrrolidone, cellulose, water, saline, syrup, methylcellulose, ethylcellulose, hydroxypropylmethylcellulose, and polyacrylic acids such as Carbopols, e.g., Carbopol 941, Carbopol 980, Carbopol 981, etc.
[0242] The provided pharmaceutical compositions can additionally include lubricating agents such as talc, magnesium stearate, and mineral oil; wetting agents; emulsifying agents; suspending agents; preserving agents such as methyl-, ethyl-, and propyl-hydroxy-benzoates (i.e., the parabens); pH adjusting agents such as inorganic and organic acids and bases; sweetening agents; coloring agents; and flavoring agents. The compositions can also comprise biodegradable polymer beads, dextran, and cyclodextrin inclusion complexes.
[0243] Pharmaceutical compositions that are liquid compositions, whether they are solutions, suspensions or other like form, can also include one or more of the following: sterile diluents such as water for injection, saline solution (preferably physiological saline), Ringer’s solution, isotonic sodium chloride, fixed oils such as synthetic mono or digylcerides which can serve as the solvent or suspending medium, polyethylene glycols, glycerin, cyclodextrin, propylene glycol or other solvents; antibacterial agents such as benzyl alcohol or methyl paraben; antioxidants such as ascorbic acid or sodium bisulfite; chelating agents such as ethylenediaminetetraacetic acid; buffers such as amino acids, acetates, citrates or phosphates; detergents, such as nonionic surfactants, polyols; and agents for the adjustment of tonicity such as sodium chloride or dextrose. The liquid compositions can include aqueous or oil suspensions, or emulsions, with sesame oil, com oil, cottonseed oil, or peanut oil, as well as elixirs, mannitol, dextrose, or a sterile aqueous solution, and similar pharmaceutical vehicles. Aqueous solutions in saline are also conventionally used for injection. Ethanol, glycerol, propylene glycol and liquid polyethylene glycol (and suitable mixtures thereof), cyclodextrin derivatives, and vegetable oils can also be employed. The proper fluidity can be maintained,
for example, by the use of a coating, such as lecithin, for the maintenance of the required particle size in the case of dispersion and by the use of surfactants.
[0244] The provided pharmaceutical compositions for administration are preferably sterile. The prevention of the action of microorganisms can be brought about by various antibacterial and antifungal agents, for example, parabens, chlorobutanol, phenol, sorbic acid and thimerosal. Compositions for administration can be enclosed in ampoule, a disposable syringe or a multiple-dose vial made of glass, plastic, or other material.
[0245] For oral administration, the provided pharmaceutical compositions can be in the form of tablets, lozenges, capsules, emulsions, suspensions, solutions, syrups, sprays, powders, and sustained-release formulations. Suitable excipients for oral administration include pharmaceutical grades of mannitol, lactose, starch, magnesium stearate, sodium saccharine, talcum, cellulose, glucose, gelatin, sucrose, magnesium carbonate, and the like.
[0246] For topical administration, the provided pharmaceutical compositions can be in the form of emulsions, lotions, gels, creams, jellies, solutions, suspensions, ointments, and transdermal patches. For delivery by inhalation, the composition can be delivered as a dry powder or in liquid form via a nebulizer. For parenteral administration, the compositions can be in the form of sterile injectable solutions and sterile packaged powders. Preferably, injectable solutions are formulated at a pH of about 4.5 to about 7.5.
[0247] The concentration of lipid nanoparticles in the provided pharmaceutical formulations can vary widely, e.g., from less than about 0.05%, usually at or at least about 2 to about 5%, to as much as about 10 to about 90% by weight, and can be selected primarily by fluid volumes, viscosities, etc., in accordance with the particular mode of administration selected. For example, the concentration may be increased to lower the fluid load associated with treatment. This may be particularly desirable in patients having atherosclerosis-associated congestive heart failure or severe hypertension. Alternatively, lipid nanoparticles composed of irritating lipids may be diluted to low concentrations to lessen inflammation at the site of administration.
[0248] The provided pharmaceutical compositions can be sterilized by conventional, well- known sterilization techniques. Aqueous solutions can be packaged for use or fdtered under aseptic conditions and lyophilized, the lyophilized preparation being combined with a sterile aqueous solution prior to administration. The compositions can contain pharmaceutically acceptable auxiliary substances as required to approximate physiological conditions, such as pH adjusting and buffering agents, tonicity adjusting agents and the like, for example, sodium
acetate, sodium lactate, sodium chloride, potassium chloride, and calcium chloride. Additionally, the lipid nanoparticle suspension can include lipid-protective agents which protect lipids against free-radical and lipid-peroxidative damages on storage. Lipophilic free- radical quenchers, such as alphatocopherol and water-soluble iron-specific chelators, such as ferrioxamine, are suitable.
D. KITS
[0249] In another aspect, the disclosure provides kits to facilitate and/or standardize the use of the materials described herein (i.e., the lipid nanoparticles described in Section B, the ionizable lipids described in Section B.2, and/or the pharmaceutical compositions described in Section C), as well as to facilitate the methods described herein (i.e., the methods described in Section E). Materials and reagents to carry out these various methods can be provided in kits to facilitate execution of the methods.
[0250] The provided kits can contain chemical reagents as well as other components. In addition, the kits containing the provided lipid nanoparticles, ionizable lipids, and/or pharmaceutical compositions can include, without limitation, instructions to the kit user. Kits can also be packaged for convenient storage and safe shipping, for example, as ampules or other vials packaged in a box having a lid.
[0251] The provided kits may comprise one or more containers, each of which is compartmentalized for holding the various elements of the lipid nanoparticles (e.g., the nucleic acids and the individual lipid components of the nanoparticles). In some embodiments, the kit may further comprise an endosomal membrane destabilizer (e.g., calcium ions). The kit typically contains the lipid nanoparticle compositions of the present disclosure, preferably in dehydrated form, with instructions for their rehydration and administration.
E. METHODS
[0252] In other aspects, the disclosure provides several methods for making and/or using the lipid nanoparticles described in Section B, the ionizable lipids described in Section B.2, and/or the pharmaceutical compositions described in Section C. The methods disclosed herein benefit from the improved properties of these provided materials, e.g., properties advantageous for the delivery of nucleic acids. These improved properties include, for example, enhanced targeting, optimized stability, and decreased toxicity and immune stimulation.
1. Introducing a nucleic acid to a cell
[0253] Some methods provided by the disclosure are useful for introducing a nucleic acid to a cell. These methods generally include contacting the cell with one or more lipid nanoparticles described in Section B. The nucleic acid introduced to the cell using the lipid nanoparticle can be, for example, any of those described in Section B.5. Once formed, the lipid nanoparticles described herein are particularly useful for the introduction of nucleic acids such as mRNA and/or siRNA into cells. The methods are carried out in vitro or in vivo by first forming the particles and then contacting the particles with the cells for a period of time sufficient for delivery of the nucleic acid to the cells to occur.
[0254] The lipid nanoparticles described herein can be adsorbed to almost any cell type with which they are mixed or contacted. Once adsorbed, the particles can either be endocytosed by a portion of the cells, exchange lipids with cell membranes, or fuse with the cells. Transfer or incorporation of the nucleic acid portion of the particle can take place via any one of these pathways. In particular, when fusion takes place, the particle membrane is integrated into the cell membrane and the contents of the particle combine with the intracellular fluid.
[0255] For in vitro applications, the delivery of nucleic acids (e.g., mRNA and/or siRNA) can be to any cell grown in culture, whether of plant or animal origin, vertebrate or invertebrate, and of any tissue or type. In certain embodiments, the cells are animal cells, e.g., mammalian cells such as human cells.
[0256] Contact between the cells and the lipid nanoparticles, when carried out in vitro, generally takes place in a biologically compatible medium. The concentration of particles can vary widely depending on the particular application, but is generally between about 1 pmol and about 10 mmol. Treatment of the cells with the lipid particles is generally carried out at physiological temperatures (about 37 °C) for periods of time ranging from about 1 hour to about 48 hours. In some examples, the contacting of the cells with the lipid nanoparticles is for a duration lasting from about 2 to about 4 hours.
[0257] In some embodiments, a lipid nanoparticle suspension is added to 60-80% confluent plated cells having a cell density of from about 103 to about 105 cells/ml, e.g., about 2 x 104 cells/ml. The concentration of the suspension added to the cells can be from about 0.01 to 0.2 μg/ml, e.g., about 0.1 μg/ml.
[0258] Using an Endosomal Release Parameter (ERP) assay, the delivery efficiency of the lipid particle can be optimized. An ERP assay is described in U.S. Patent Application Publication No. 20030077829. More particularly, the purpose of an ERP assay is to distinguish the effect of various cationic lipids and helper lipid components based on their relative effect on binding/uptake or fusion with/destabilization of the endosomal membrane. This assay allows one to determine quantitatively how each component of the lipid particle affects delivery efficiency, thereby optimizing the lipid particle. Usually, an ERP assay measures expression of a reporter protein (e.g., luciferase, [3-galactosidase, green fluorescent protein (GFP), etc.), and in some instances, a lipid particle formulation optimized for an expression plasmid will also be appropriate for encapsulating other types of nucleic acid such as mRNA. In some instances, an ERP assay can be adapted to measure downregulation of transcription or translation of a target sequence in the presence or absence of an interfering RNA (e.g., siRNA). In other instances, an ERP assay can be adapted to measure the expression of a target protein in the presence or absence of an mRNA. By comparing the ERPs for each of the various lipid particles, one can readily determine the optimized system, e.g., the lipid particle that has the greatest uptake in the cell.
[0259] The compositions and methods described herein are used to treat a wide variety of cell types, in vivo and in vitro. Suitable cells include, e.g., hematopoietic precursor (stem) cells, fibroblasts, keratinocytes, hepatocytes, immune cells, endothelial cells, skeletal and smooth muscle cells, osteoblasts, neurons, quiescent lymphocytes, terminally differentiated cells, slow or noncycling primary cells, parenchymal cells, lymphoid cells, epithelial cells, bone cells, and the like. In some embodiments, lipid particles comprising nucleic acid (e.g., mRNA) are delivered to immune cells such as e.g., antigen-presenting cells (e.g., dendritic cells, macrophages, B cells) and T cells (e.g., helper T cells, cytotoxic T cells, memory T cells, regulatory T cells, natural killer T cells). In some embodiments, lipid particles comprising nucleic acid (e.g., siRNA) are delivered to cancer cells such as, e.g., lung cancer cells, colon cancer cells, rectal cancer cells, anal cancer cells, bile duct cancer cells, small intestine cancer cells, stomach (gastric) cancer cells, esophageal cancer cells, gallbladder cancer cells, liver cancer cells, pancreatic cancer cells, appendix cancer cells, breast cancer cells, ovarian cancer cells, cervical cancer cells, prostate cancer cells, renal cancer cells, cancer cells of the central nervous system, glioblastoma tumor cells, skin cancer cells, lymphoma cells, choriocarcinoma tumor cells, head and neck cancer cells, osteogenic sarcoma tumor cells, and blood cancer cells.
[0260] In vivo delivery of lipid particles such as LNP encapsulating one or more nucleic acid molecules (e.g., interfering RNA (e.g., siRNA) or mRNA) is suited for targeting cells of any cell type. The methods and compositions can be employed with cells of a wide variety of vertebrates, including mammals, such as, e.g., canines, felines, equines, bovines, ovines, caprines, rodents (e.g., mice, rats, and guinea pigs), lagomorphs, swine, and primates (e.g. monkeys, chimpanzees, and humans).
[0261] To the extent that tissue culture of cells may be required, it is well-known in the art. For example, Freshney, Culture of Animal Cells, a Manual of Basic Technique, 3rd Ed., Wiley- Liss, New York (1994), Kuchler et al., Biochemical Methods in Cell Culture and Virology, Dowden, Hutchinson and Ross, Inc. (1977), and the references cited therein provide a general guide to the culture of cells. Cultured cell systems often will be in the form of monolayers of cells, although cell suspensions are also used.
2. Delivering a nucleic acid to a subject
[0262] Some methods provided by the disclosure are useful for delivering a nucleic acid to a subject. These methods generally include administering one or more lipid nanoparticles or one or more pharmaceutical compositions to the subject, wherein the lipid nanoparticles include those described in Section B, and the pharmaceutical compositions include those described in Section C. The nucleic acid delivered to the subject can be, for example, any of those described in Section B.5. In some embodiments, the lipid nanoparticles described herein are administered to a subject by systemic delivery, e.g., to a distal target cell via body systems such as the circulation. In certain embodiments, the present disclosure provides fully encapsulated lipid particles that protect the nucleic acid from nuclease degradation in serum, are nonimmunogenic, are small in size, and are suitable for repeat dosing.
[0263] In some embodiments, the ionizable lipids and lipid nanoparticles provided by the current disclosure are particularly useful for preferentially delivering nucleic acids, such as RNA, to the liver of a subject. The specific ionizable lipids and lipid nanoparticle configurations described in Section B advantageously result in materials exhibiting improved targeting of the liver relative to other organs of a subject to whom the materials are administered. For example, in certain embodiments, the provided ionizable lipids and lipid nanoparticles can be used to deliver a nucleic acid encoding a protein to the liver of a subject, such that the activity or secretion of the protein in the liver is more than about 20-fold greater, more than about 30-fold, more than about 40-fold, more than about 60-fold, more than about
100-fold, more than about 200-fold, more than about 300-fold, more than about 500-fold, more than about 700-fold, or more than about 1000-fold greater than an activity or expression of the protein in the spleen of the subject
[0264] For in vivo administration, administration can be in any manner known in the art, e.g., by injection, oral administration, inhalation (e.g., intranasal or intratracheal), transdermal application, or rectal administration. Administration can be accomplished via single or divided doses. The pharmaceutical compositions can be administered parenterally, i.e., intraarticularly, intravenously, intraperitoneally, subcutaneously, or intramuscularly. In some embodiments, the pharmaceutical compositions are administered intravenously or intraperitoneally by a bolus injection (see, e.g., U.S. Patent No. 5,286,634). Intracellular nucleic acid delivery has also been discussed in Straubringer et al., Methods Enzymol., 101:512 (1983); Mannino et al., Biotechniques, 6:682 (1988); Nicolau et al., Crit. Rev. Ther. Drug Carrier Sy st ., 6:239 (1989); and Behr, Acc. Chem. Res., 26:274 (1993). Still other methods of administering lipid-based therapeutics are described in, for example, U.S. Patent Nos. 3,993,754; 4,145,410; 4,235,871; 4,224,179; 4,522,803; and 4,588,578. The lipid nanoparticles can be administered by direct injection at the site of disease or by injection at a site distal from the site of disease (see, e.g., Culver, HUMAN GENE THERAPY, Mary Ann Liebert, Inc., Publishers, New York. pp. 70- 71(1994)).
[0265] The compositions described herein, either alone or in combination with other suitable components, can be made into aerosol formulations (i.e., they can be “nebulized”) to be administered via inhalation (e.g., intranasally or intratracheally) (see, Brigham et al., Am. J. Sci., 298:278 (1989)). Aerosol formulations can be placed into pressurized acceptable propellants, such as dichlorodifluoromethane, propane, nitrogen, and the like.
[0266] In certain embodiments, the pharmaceutical compositions may be delivered by intranasal sprays, inhalation, and/or other aerosol delivery vehicles. Methods for delivering nucleic acid compositions directly to the lungs via nasal aerosol sprays have been described in, e.g., U.S. Patent Nos. 5,756,353 and 5,804,212. Likewise, the delivery of drugs using intranasal microparticle resins and lysophosphatidyl-glycerol compounds (U.S. Patent 5,725,871) are also well-known in the pharmaceutical arts. Similarly, transmucosal drug delivery in the form of a polytetrafluoroethylene support matrix is described in U.S. Patent No. 5,780,045.
[0267] Formulations suitable for parenteral administration, such as, for example, by intraarticular (in the joints), intravenous, intramuscular, intradermal, intraperitoneal, and
subcutaneous routes, include aqueous and non-aqueous, isotonic sterile injection solutions, which can contain antioxidants, buffers, bacteriostats, and solutes that render the formulation isotonic with the blood of the intended recipient, and aqueous and non-aqueous sterile suspensions that can include suspending agents, solubilizers, thickening agents, stabilizers, and preservatives. In particular embodiments, the compositions are administered intravenously (e.g., by intravenous infusion), intramuscularly, pulmonarily, orally, topically, intranasally, intracerebrally, intraperitoneally, intravesically, or intrathecally.
[0268] Generally, when administered intravenously, the lipid particle formulations are formulated with a suitable pharmaceutical carrier. Many pharmaceutically acceptable carriers may be employed in the compositions and methods described herein. Suitable formulations for use are found, for example, in Adejare, A. (Ed.). (2020). Remington: The Science and Practice of Pharmacy (23rd ed.) Elsevier. A variety of aqueous carriers may be used, for example, water, buffered water, 0.4% saline, 0.3% glycine, and the like, and may include glycoproteins for enhanced stability, such as albumin, lipoprotein, globulin, etc. Generally, normal buffered saline (135-150 mMNaCl) is used as the pharmaceutically acceptable carrier, but other suitable carriers will suffice. These compositions can be sterilized by conventional liposomal sterilization techniques, such as filtration. The compositions may contain pharmaceutically acceptable auxiliary substances as required to approximate physiological conditions, such as pH adjusting and buffering agents, tonicity adjusting agents, wetting agents, and the like, for example, sodium acetate, sodium lactate, sodium chloride, potassium chloride, calcium chloride, sorbitan monolaurate, triethanolamine oleate, etc. These compositions can be sterilized using the techniques referred to above or, alternatively, they can be produced under sterile conditions. The resulting aqueous solutions may be packaged for use or filtered under aseptic conditions and lyophilized, the lyophilized preparation being combined with a sterile aqueous solution prior to administration.
[0269] In certain applications, the lipid particles described herein may be delivered via oral administration to a subject. The particles may be incorporated with excipients and used in the form of ingestible tablets, buccal tablets, troches, capsules, pills, lozenges, elixirs, mouthwash, suspensions, oral sprays, syrups, wafers, and the like (see, e.g., U.S. Patent Nos. 5,641,515, 5,580,579, and 5,792,451). These oral dosage forms may also contain binders, gelatin; excipients, lubricants, and/or flavoring agents. When the unit dosage form is a capsule, it may contain, in addition to the materials described above, a liquid carrier. Various other materials may be present as coatings or to otherwise modify the physical form of the dosage unit. Of
course, any material used in preparing any unit dosage form should be pharmaceutically pure and substantially non-toxic in the amounts employed.
[0270] Typically, these oral formulations may contain at least about 0.1% of the lipid particles or more, although the percentage of the particles may, of course, be varied and may conveniently be between about 1% or about 2% and about 60% or about 70% or more of the weight or volume of the total formulation. Naturally, the amount of particles in each therapeutically useful composition may be prepared is such a way that a suitable dosage will be obtained in any given unit dose of the compound. Factors such as solubility, bioavailability, biological half-life, route of administration, product shelflife, as well as other pharmacological considerations will be contemplated by one skilled in the art of preparing such pharmaceutical formulations, and as such, a variety of dosages and treatment regimens may be desirable.
[0271] Formulations suitable for oral administration can consist of: (a) liquid solutions, such as an effective amount of lipid particles comprising nucleic acid (e.g., mRNA) suspended in diluents such as water, saline, or PEG 400; (b) capsules, sachets, or tablets, each containing a predetermined amount of lipid particles comprising nucleic acid (e.g., mRNA), as liquids, solids, granules, or gelatin; (c) suspensions in an appropriate liquid; and (d) suitable emulsions. Tablet forms can include one or more of lactose, sucrose, mannitol, sorbitol, calcium phosphates, com starch, potato starch, microcrystalline cellulose, gelatin, colloidal silicon dioxide, talc, magnesium stearate, stearic acid, and other excipients, colorants, fdlers, binders, diluents, buffering agents, moistening agents, preservatives, flavoring agents, dyes, disintegrating agents, and pharmaceutically compatible carriers. Lozenge forms can comprise lipid particles comprising nucleic acid (e.g., mRNA) in a flavor, e.g., sucrose, as well as pastilles comprising the lipid particles in an inert base, such as gelatin and glycerin or sucrose and acacia emulsions, gels, and the like containing, in addition to the lipid particles, carriers known in the art.
[0272] In another example of their use, lipid particles can be incorporated into a broad range of topical dosage forms. For instance, a suspension containing lipid particles can be formulated and administered as gels, oils, emulsions, topical creams, pastes, ointments, lotions, foams, mousses, and the like.
[0273] When preparing pharmaceutical preparations of the lipid particles described herein, it is preferable to use quantities of the particles which have been purified to reduce or eliminate empty particles or particles with nucleic acid associated with the external surface.
[0274] The methods described herein may be practiced in a variety of hosts. Preferred hosts include mammalian species, such as primates (e.g., humans and chimpanzees as well as other nonhuman primates), canines, felines, equines, bovines, ovines, caprines, rodents (e.g., rats and mice), lagomorphs, and swine.
[0275] The amount of particles administered will depend upon the ratio of nucleic acid (e.g., mRNA) to lipid, the particular nucleic acid used, the disease or disorder being treated, the age, weight, and condition of the subject, and the judgment of the clinician, but will generally be between about 0.01 mg/kg and about 50 mg/kg of body weight, between about 0.1 mg/kg and about 5 mg/kg of body weight, or about 108- 1010 particles per administration (e.g., injection).
3. Treating a disease or disorder
[0276] Some methods provided by the disclosure are useful for preventing or treating a disease or a disorder of a subject. These methods generally include administering one or more lipid nanoparticles, one or more ionizable lipids, or one or more pharmaceutical compositions to the subject, wherein the lipid nanoparticles include those described in Section B, the ionizable lipids include those described in Section B.2, and the pharmaceutical compositions include those described in Section C. In some embodiments, the treating of the disease in the subject includes decreasing or eliminating one or more signs or symptoms of the disease.
[0277] In some embodiments, the methods described herein are used for the prevention or treatment of a liver disease or disorder. Because of, for example, the enhanced liver-targeting properties described in Section E.2 for the provided ionizable lipids and lipid nanoparticles, these materials are particularly useful for preventing or treating a disease of the liver, and/or preventing or treating a disease for which the modulation of the expression and/or activity of one or more proteins in the liver provides a desired therapeutic effect. Non-limiting examples of liver diseases or disorders suitable for treatment with the provided methods include a fatty liver disease (such as, for example, alcoholic fatty liver disease (AFLD), non-alcoholic fatty liver disease (NAFLD), non-alcoholic steatohepatitis (NASH)), liver cirrhosis, liver fibrosis, a disease or disorder characterized by an increased liver enzyme (such as, for example, alanine transaminase (ALT) or aspartate transaminase (AST)), simple steatosis, steatohepatitis, parenchymal liver disease, viral hepatitis, hepatocellular carcinoma, and any of the complications of such conditions (including, but not limited to, heart or metabolic disease related to NASH or NAFLD, portal vein hypertension or thrombosis, esophageal or gastric varices or bleeding from those varices, and other liver-disease related co-morbidities).
[0278] In particular embodiments, the methods described herein are used for the prevention or treatment of cancer. Cancer generally includes any of various malignant neoplasms characterized by the proliferation of anaplastic cells that tend to invade surrounding tissue and metastasize to new body sites. Non-limiting examples of different types of cancer suitable for treatment using the provided methods include ovarian cancer, breast cancer, lung cancer, bladder cancer, thyroid cancer, liver cancer, pleural cancer, pancreatic cancer, cervical cancer, prostate cancer, testicular cancer, colorectal cancer, colon cancer, anal cancer, bile duct cancer, gastrointestinal carcinoid tumors, esophageal cancer, gall bladder cancer, rectal cancer, appendix cancer, small intestine cancer, stomach (gastric) cancer, renal cancer (i.e., renal cell carcinoma), cancer of the central nervous system, skin cancer, oral squamous cell carcinoma, choriocarcinomas, head and neck cancers, bone cancer, osteogenic sarcomas, fibrosarcoma, neuroblastoma, glioma, melanoma, leukemia (e.g., acute lymphocytic leukemia, chronic lymphocytic leukemia, acute myelogenous leukemia, chronic myelogenous leukemia, or hairy cell leukemia), lymphoma (e.g., non-Hodgkin’s lymphoma, Hodgkin’s lymphoma, B-cell lymphoma, or Burkitt’s lymphoma), and multiple myeloma. In some embodiments, the cancer is an αvβ6 integrin-mediated disease or disorder. In certain embodiments, the cancer is lung cancer, breast cancer, colorectal cancer, pancreatic cancer, ovarian cancer, cervical cancer, oral squamous cell carcinoma, skin squamous cell carcinoma, stomach cancer, or endometrial cancer. In some cases, the subject has a primary lesion (e.g., a primary tumor). In some cases, the subject has a metastasis (e.g., a metastatic form of any of the cancer types described herein). In some cases, the subject has a primary lesion and a metastasis. In some embodiments, the subject has a pancreatic cancer such as locally advanced or metastatic pancreatic cancer, locally advanced, unresectable, or metastatic pancreatic adenocarcinoma or pancreatic ductal adenocarcinoma (PDAC).
[0279] In another embodiment, the provided methods are useful for treating an infection or infectious disease caused by, e.g., a virus, bacterium, fungus, parasite, or any other infectious agent. Non-limiting examples of infectious diseases suitable for treatment using the provided methods include acquired immunodeficiency syndrome (AIDS/HIV) or HIV-related disorders, Alpers syndrome, anthrax, bovine spongiform encephalopathy (mad cow disease), chicken pox, cholera, conjunctivitis, Creutzfeldt-Jakob disease (CJD), dengue fever, Ebola, elephantiasis, encephalitis, fatal familial insomnia, Fifth’s disease, Gerstmann-Straussler- Scheinker syndrome, hantavirus, helicobacter pylori, hepatitis (hepatitis A, hepatitis B, hepatitis C), herpes, influenza (e.g., avian influenza A (bird flu)), Kuru, leprosy, Lyme disease,
malaria, hemorrhagic fever (e.g., Rift Valley fever, Crimean-Congo hemorrhagic fever, Lassa fever, Marburg virus disease, and Ebola hemorrhagic fever), measles, meningitis (viral, bacterial), mononucleosis, nosocomial infections, otitis media, pelvic inflammatory disease (PID), plague, pneumonia, polio, prion disease, rabies, rheumatic fever, roseola, Ross River virus infection, rubella, salmonellosis, septic arthritis, sexually transmitted diseases (STDs), shingles, smallpox, strep throat, tetanus, toxic shock syndrome, toxoplasmosis, trachoma, tuberculosis, tularemia, typhoid fever, valley fever, whooping cough, and yellow fever.
[0280] In some embodiments, the provided method further includes obtaining a test sample from the subject. The test sample can include, for example, a blood sample, a tissue sample, a urine sample, a saliva sample, a cerebrospinal fluid sample, or a combination thereof. In some embodiments, the provided method further includes determining the level of one or more biomarkers in the obtained test sample. Determining the presence or level of biomarkers(s) can be used to, as non-limiting examples, determine response to treatment or to select an appropriate composition for the prevention or treatment of the disease.
[0281] In examples where the provided lipid nanoparticle or pharmaceutical composition includes a nucleic acid encoding a protein of interest or a fragment thereof, the measured biomarker can be an indicator of an expression level of the protein or fragment by a target cell or target organism, e.g., the cell or organism to which the lipid nanoparticle or pharmaceutical composition is administered. For example, the biomarker can be the protein or fragment itself, such that a measured level of the protein or fragment indicates the level of its expression. When the protein of interest is an antigen, the measured biomarker can include or consist of one or more components of the immune system of the target cell or target organism. For example, the biomarker can include or consist of one or more species of T cells, e.g., CD8+ T cells. In these ways, the determination of a level of a biomarker in a test sample can provide information related to the efficiency and/or effectiveness of the administration of the lipid nanoparticle in preventing or treating a disease or disorder.
[0282] In some embodiments, the provided method further includes comparing the determined level of the one of more biomarkers in the obtained test sample to the level of the one or more biomarkers in a reference sample. The reference sample can be obtained, for example, from the subject, with the reference sample being obtained prior to the obtaining of the test sample, e.g., prior to the administering to the subject of the therapeutically effective amount of the provided materials. In this way, the reference sample can provide information
about baseline levels of the biomarkers in the sample before the treatment, and the test sample can provide information about levels of the biomarkers after the treatment.
[0283] Alternatively, the reference sample can be obtained, for example, from a different subject, e.g., a subject in which the treatment is not provided according to the provided methods. In this way, the reference sample can provide information about baseline levels of the biomarkers without treatment, and the test sample can provide information about levels of the biomarkers with treatment. The reference sample can also be obtained, for example, from a population of subjects, e.g., subjects in which the treatment is not provided according to the provided method. In this way, the reference sample can provide population-averaged information about baseline levels of the biomarkers without treatment, and the test sample can provide information about levels of the biomarkers with treatment.
[0284] The reference sample can also be obtained from an individual or a population of individuals after treatment is provided according to the provided methods, and can serve as, for example, a positive control sample. In some embodiments, the reference sample is obtained from normal tissue. In some embodiments, the reference sample is obtained from abnormal tissue.
[0285] Depending on the biomarker, an increase or a decrease relative to a normal control or reference sample can be indicative of the presence of a disease, or response to treatment for a disease. In some embodiments, an increased level of a biomarker in a test sample, and hence the presence of a disease, e.g., an infectious disease or cancer, increased risk of the disease, or response to treatment is determined when the biomarker levels are at least, 1.1-fold, e.g., at least 1.2-fold, at least 1.3-fold, at least 1.4-fold, at least 1.5-fold, at least 1.6-fold, at least 1.7- fold, at least 1.8-fold, at least 1.9-fold, at least 2-fold, at least 3-fold, at least 4-fold, at least 5- fold, at least 6-fold, at least 7-fold, at least 8-fold, at least 9-fold, at least 10-fold, at least 11- fold, at least 12-fold, at least 13 -fold, at least 14-fold, at least 15-fold, at least 16-fold, at least 17-fold, at least 18-fold, at least 19-fold, or at least 20-fold higher in comparison to a control. In other embodiments, a decreased level of a biomarker in the test sample, and hence the presence of the disease, increased risk of the disease, or response to treatment is determined when the biomarker levels are at least 1.1-fold, e.g., at least 1.2-fold, at least 1.3-fold, at least 1.4-fold, at least 1.5-fold, at least 1.6-fold, at least 1.7-fold, at least 1.8-fold, at least 1.9-fold, at least 2-fold, at least 3 -fold, at least 4-fold, at least 5 -fold, at least 6-fold, at least 7-fold, at least 8-fold, at least 9-fold, at least 10-fold, at least 11-fold, at least 12-fold, at least 13-fold, at
least 14-fold, at least 15-fold, at least 16-fold, at least 17-fold, at least 18-fold, at least 19-fold, or at least 20-fold lower in comparison to a control.
[0286] The biomarker levels can be detected using any method known in the art, including the use of antibodies specific for the biomarkers. Exemplary methods include, without limitation, polymerase chain reaction (PCR), Western Blot, dot blot, ELISA, radioimmunoassay (RIA), immunoprecipitation, immunofluorescence, FACS analysis, electrochemiluminescence, and multiplex bead assays, e.g., using Luminex or fluorescent microbeads. In some instances, nucleic acid sequencing is employed.
[0287] In certain embodiments, the presence of decreased or increased levels of one or more biomarkers is indicated by a detectable signal, e.g., a blot, fluorescence, chemiluminescence, color, or radioactivity, in an immunoassay or PCR reaction, e.g., quantitative PCR. This detectable signal can be compared to the signal from a reference sample or to a threshold value.
[0288] In some embodiments, the results of the biomarker level determinations are recorded in a tangible medium. For example, the results of diagnostic assays, e.g., the observation of the presence or decreased or increased presence of one or more biomarkers, and the diagnosis of whether or not there is an increased risk or the presence of a disease, e.g., an infectious disease or cancer, or whether or not a subject is responding to treatment can be recorded, for example, on paper or on electronic media, e.g., audio tape, a computer disk, a CD-ROM, or a flash drive.
[0289] In some embodiments, the provided method further includes the step of providing to the subject a diagnosis and/or the results of treatment.
4. Editing genomic information
[0290] Some methods provided by the disclosure are useful for editing genetic information, e.g., a genome, in a cell. These methods generally include contacting the cell with one or more lipid nanoparticles, wherein the lipid nanoparticles include those described in Section B, and wherein the lipid nanoparticles include one or more nucleic acids of the type described in Section B.5. In particular, the nucleic acids, or proteins encoded by the nucleic acids, can be components of a gene editing system.
[0291] Gene editing systems with one or more components that may be either a nucleic acid delivered by a provided lipid nanoparticle, or a protein encoded by such a nucleic acid, can be any of those known in the art. Exemplary gene editing systems include those using sequence specific nucleases, such as zine-finger nucleases, engineered or native meganucleases, TALE-
endonucleases, an Argonaute (non-limiting examples of Argonaute proteins include Thermus thermophilus Argonaute (TtAgo), Pyrococcus furiosus Argonaute (PfAgo), and Natronobacterium gregoryi Argonaute (NgAgo)), or an RNA-guided endonucleases (for example, a Clustered Regularly Interspersed Short Palindromic Repeat (CRISPR)/Cas9 system, a CRISPR/Cpfl system, a CRISPR/CasX system, a CRISPR/CasY system, or a CRISPR/Cascade system). In some examples, gene editing systems use single -stranded oligonucleotides to introduce precise base pair modifications in a genome.
[0292] In some embodiments, the nucleic acid of the lipid nanoparticle of the provided gene editing method encodes site-specific nuclease(s), any associated protein(s), template sequence(s), and/or desired modified sequence(s) for carrying out gene modification. In some embodiments, the method includes contacting the cell with an expression cassette including additional nucleic acids associated with additional components of the gene editing system.
[0293] In some embodiments, the gene editing system of the provided method is a system for site-directed integration. Several methods for site-directed integration are known in the art involving different sequence-specific nucleases (or complexes of proteins or guide RNA or both) that cut the genomic DNA to produce a double strand break (DSB) or nick at a desired genomic site or locus. As understood in the art, during the process of repairing the DSB or nick introduced by the nuclease enzyme, the donor template DNA, transgene, or expression cassette may become integrated into the genome at the site of the DSB or nick. In some embodiments, breaks or nicks in the target DNA sequence are repaired by the natural processes of homologous recombination (HR) or non-homologous end-joining (NHEJ). In some embodiments, sequence modifications occur at or near the cleaved or nicked sites, which may include deletions or insertions that result in modification of the polynucleotide, or integration of exogenous nucleic acids by homologous recombination or NHEJ. The presence of the homology arm(s) in the DNA to be integrated may promote the adoption and targeting of the insertion sequence into the plant genome during the repair process through homologous recombination (homology directed recombination (HDR)), although an insertion event may occur through non- homologous end joining (NHEJ).
[0294] In some embodiments, a site-specific genome modification enzyme modifies the genome by inducing a single-strand break. In some embodiments, a site-specific genome modification enzyme modifies the genome by inducing a double-strand break. In some embodiments, recombination is promoted by providing a single-strand break inducing agent.
In some embodiments, recombination is promoted by providing a double-strand break inducing agent. In some embodiments, recombination is promoted by providing a strand separation inducing reagent. In one aspect, the site-specific genome modification enzyme is selected from an endonuclease, a recombinase, a transposase, a deaminase, a helicase, or any combination thereof. In some embodiments, recombination occurs between B chromosomes. In some embodiments, recombination occurs between a B chromosome and an A chromosome. In some embodiments, a site-specific genome modification enzyme comprises a cytidine deaminase. In some embodiments, a site-specific genome modification enzyme comprises an adenine deaminase. In some embodiments, the site-specific genome modification enzyme is a sequence-specific nuclease. a) RNA-Guided Nucleases
[0295] In some embodiments, the provided method for editing genomic information in a cell involves contacting the cell with a lipid nanoparticle having a nucleic acid associated with a gene editing system using RNA -guided nucleases. In some embodiments, the gene editing system uses at least one, at least two, at least three, at least four, at least five, at least six, at least seven, at least eight, at least nine, or at least ten RNA-guided nucleases. In some embodiments, the site-specific gene editing system is a CRISPR/Cas system. The CRISPR systems are based on RNA-guided engineered nucleases that use complementary base pairing to recognize DNA sequences at target sites. The CRISPR (clustered regularly interspaced short palindromic repeats)/Cas (CRISPR-associated) system is an alternative to synthetic proteins whose DNA-binding domains enable them to modify genomic DNA at specific sequences (e.g., ZFN and TALEN) In some examples, a site-specific gene editing system herein may comprise any RNA-guided Cas nuclease (non-limiting examples of RNA-guided nucleases include Cas1, Cas1B, Cas2, Cas3, Cas4, Cas5, Cas5e (CasD), Cas6, Cas7, Cas8, Cas8a, Cas8al , Cas8a2, Cas8b, Cas8c, Cas9 (also known as Csn1 and Csx12), Cas10, Cas10d, CasF, CasG, CasH, Cas 12, Cas 12a (Cpf1), Cas 12b (C2c1), Cas 12c (C2c3), Cas12d (CasY), Cas12e (CasX), Cas12f (Cas 14, C2c10), Cas12g, Cas12h, Cas12i, Cas12k (CsC5), Cas13, Cas13a (C2c2), Cas13b, Cas13c, Cas13d, Casl3x.1, C2c4, C2c8, C2c9, Csy1, Csy2, Csy3, Csel (CasA), Cse2 (CasB), Cse3 (CasE), Cse4 (CasC), Csc1, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmrl, Cmr3, Cmr4, Cmr5, Cmr6, Csb1, Csb2, Csb3, Csx17, Csx14, Csx10, Csx11, Csx16, Csx3, Csx1, Csx15, Csf1, Csf2, Csf3, Csf4, Cu1966, Mad7, GSU0054, homologs thereof, or modified versions thereof; and optionally, the guide RNA (gRNA) necessary for targeting the
respective nucleases. In some embodiments, a CRISPR/Cas9 system, a CRISPR/Cas12a system, a CRISPR/Cas12e system, or a CRISPR/Cas12d system may be used to generate modifications to a nucleic acid. The use of lipid nanoparticles to deliver Cas9 and guide RNA is described in, for example, International Patent Application Publication WO 2016/197133.
[0296] CRISPR/Cas systems are part of the adaptive immune system of bacteria and archaea, protecting them against invading nucleic acids such as viruses by cleaving the foreign DNA in a sequence-dependent manner. The immunity is acquired by the integration of short fragments of the invading DNA known as spacers between two adjacent repeats at the proximal end of a CRISPR locus. The CRISPR arrays, including the spacers, are transcribed during subsequent encounters with invasive DNA and are processed into small interfering CRISPR RNAs (crRNAs) approximately 40 nt in length, which combine with the trans-activating CRISPR RNA (tracrRNA) to activate and guide the Cas9 nuclease. This cleaves homologous double- stranded DNA sequences known as protospacers in the invading DNA. A prerequisite for cleavage is the presence of a conserved protospacer-adjacent motif (PAM) downstream of the target DNA, which usually has the sequence 5'-NGG-3' but less frequently NAG. Specificity is provided by the so-called “seed sequence” approximately 12 bases upstream of the PAM, which must match between the RNA and target DNA. Cas12a acts in a similar manner to Cas9, but Cas12a does not require a tracrRNA.
[0297] In some embodiments, the site-specific gene editing system includes a dCas9-Fokl fusion protein. In other embodiments, the site-specific gene editing system includes a dCas9- recombinase fusion protein. As used herein, a “dCas9” refers to a Cas9 endonuclease protein with one or more amino acid mutations that result in a Cas9 protein without endonuclease activity, but retaining RNA-guided site-specific DNA binding. As used herein, a “dCas9- recombinase fusion protein” is a dCas9 with a protein fused to the dCas9 in such a manner that the recombinase is catalytically active on the DNA. In some embodiments, the site-specific gene editing system includes a dCas9-cytosine deaminase fusion protein. In another aspect, the site-specific gene editing system includes a dCas9-adenine deaminase fusion protein. In some embodiments, the site-specific gene editing system includes a dCas12a-cytosine deaminase fusion protein. In other embodiments, the site-specific gene editing system includes a dCas 12a- adenine deaminase fusion protein.
[0298] In certain embodiments, the provided method is useful for introducing one or more gRNA molecules described herein into a cell by contacting the cell with a lipid nanoparticle
described herein. The provided lipid nanoparticles are useful, for example, for the therapeutic delivery of gRNAs that silence the expression of one or more target genes. In some embodiments, a cocktail of gRNAs that target different regions (e.g., overlapping and/or nonoverlapping sequences) of a target gene or transcript is formulated into the same or different nucleic acid-lipid particles, and the particles are administered to a mammal (e.g., a human) requiring such treatment. In certain embodiments, the mammal has been diagnosed with a specific disease or disorder. In certain instances, a therapeutically effective amount of the nucleic acid-lipid particles can be administered to the mammal.
[0299] In some embodiments, gRNA may be produced enzymatically or by partial/total organic synthesis, and modified ribonucleotides can be introduced by in vitro enzymatic or organic synthesis. In certain instances, the gRNA is prepared chemically. Methods of synthesizing nucleic acid molecules are known in the art, e.g., the chemical synthesis methods as described in Verma and Eckstein (1998) or as described herein.
[0300] Methods for isolating RNA, synthesizing RNA, hybridizing nucleic acids, making and screening cDNA libraries, and performing PCR are well known in the art (see, e.g., Gubler and Hoffman, Gene, 25:263-269 (1983); Sambrook et al., supra-, Ausubel et al., supra), as are PCR methods (see, U.S. Patent Nos. 4,683,195 and 4,683,202; PCR Protocols: A Guide to Methods and Applications (Innis et al., eds, 1990)). Expression libraries are also well known to those of skill in the art. Additional basic texts disclosing the general methods of use in the provided embodiments include Sambrook et al., Molecular Cloning, A Laboratory Manual (2nd ed. 1989); Kriegler, Gene Transfer and Expression: A Laboratory Manual (1990); and Current Protocols in Molecular Biology (Ausubel et al., eds., 1994). The disclosures of these references are herein incorporated by reference in their entirety for all purposes.
[0301] Preferably, gRNA are chemically synthesized. The oligonucleotides that comprise the gRNA molecules of the disclosure can be synthesized using any of a variety of techniques known in the art, such as those described in Usman et al., J. Am. Chem. Soc., 109:7845 (1987); Scaringe et al., Nucl. Acids Res., 18:5433 (1990); Wincott et al., Nucl. Acids Res., 23:2677- 2684 (1995); and Wincott et al., Methods Mol. Bio., 74:59 (1997). The synthesis of oligonucleotides makes use of common nucleic acid protecting and coupling groups, such as dimethoxytrityl at the 5' end and phosphoramidites at the 3' end. As a non-limiting example, small scale syntheses can be conducted on an Applied Biosystems synthesizer using a 0.2-pmol scale protocol. Alternatively, syntheses at the 0.2-pmol scale can be performed on a 96-well
plate synthesizer from Protogene (Palo Alto, CA). However, a larger or smaller scale of synthesis is also within the scope of this disclosure. Suitable reagents for oligonucleotide synthesis, methods for RNA deprotection, and methods for RNA purification are known to those of skill in the art. b) Recombinases
[0302] In some embodiments, the provided method for editing genomic information in a cell involves contacting the cell with a lipid nanoparticle having a nucleic acid associated with a gene editing system using a recombinase. Non-limiting examples of recombinases include a tyrosine recombinase attached to a DNA recognition motif provided herein is a Cre recombinase, a Gin recombinase, a Flp recombinase, or a Tnpl recombinase. In some embodiments, a Cre recombinase or a Gin recombinase is tethered to a zinc -finger DNA binding domain. The Flp-FRT site-directed recombination system comes from the 2 p plasmid from the baker’s yeast Saccharomyces cerevisiae. In this system, Flp recombinase (flippase) recombines sequences between flippase recognition target (FRT) sites. FRT sites comprise 34 nucleotides. Flp binds to the “arms” of the FRT sites (one arm is in reverse orientation) and cleaves the FRT site at either end of an intervening nucleic acid sequence. After cleavage, Flp recombines nucleic acid sequences between two FRT sites. Cre-lox is a site-directed recombination system derived from the bacteriophage Pl that is similar to the Flp-FRT recombination system. Cre-lox may be used to invert a nucleic acid sequence, delete a nucleic acid sequence, or translocate a nucleic acid sequence. In this system, Cre recombinase recombines a pair of lox nucleic acid sequences. Lox sites comprise 34 nucleotides, with the first and last 13 nucleotides (arms) being palindromic. During recombination, Cre recombinase protein binds to two lox sites on different nucleic acids and cleaves at the lox sites. The cleaved nucleic acids are spliced together (reciprocally translocated) and recombination is complete. In other embodiments, a lox site provided herein is a loxP, lox 2272, loxN, lox 511, lox 5171, lox71, lox66, M2, M3, M7, or M11 site.
[0303] In some embodiments, a serine recombinase attached to a DNA recognition motif is a PhiC31 integrase, an R4 integrase, or a TP-901 integrase. In other embodiments, a DNA transposase attached to a DNA binding domain is a TALE-piggyBac or a TALE-Mutator.
c) Zinc Finger Nucleases
[0304] In some embodiments, the provided method for editing genomic information in a cell involves contacting the cell with a lipid nanoparticle having a nucleic acid associated with a gene editing system using a zinc-finger nuclease (ZFN). ZFNs are synthetic proteins consisting of an engineered zinc finger DNA-binding domain fused to the cleavage domain of the Fold restriction nuclease. ZFNs may be designed to cleave almost any long stretch of double- stranded DNA for modification of the zinc finger DNA-binding domain. ZFNs form dimers from monomers composed of a non-specific DNA cleavage domain of Fold nuclease fused to a zinc finger array engineered to bind a target DNA sequence. The DNA-binding domain of a ZFN is typically composed of 3-4 zinc-finger arrays. The amino acids at positions -1, +2, +3, and +6 relative to the start of the zinc finger helix, which contribute to site -specific binding to the target DNA, may be changed and customized to fit specific target sequences. The other amino acids form the consensus backbone to generate ZFNs with different sequence specificities. Rules for selecting target sequences for ZFNs are known in the art. The Fold nuclease domain requires dimerization to cleave DNA and therefore two ZFNs with their C- terminal regions are needed to bind opposite DNA strands of the cleavage site (separated by 5- 7 nt). The ZFN monomer may cut the target site if the two-ZF -binding sites are palindromic. The term ZFN, as used herein, is broad and includes a monomeric ZFN that may cleave double stranded DNA without assistance from another ZFN. The term ZFN is also used to refer to one or both members of a pair of ZFNs that are engineered to work together to cleave DNA at the same site. The use of lipid nanoparticles to deliver nucleic acids associated with ZFNs is described in, for example, Conway et al. Mol Ther. 2019 Apr 10; 27(4):866-877.
[0305] Without being limited by any scientific theory, because the DNA-binding specificities of zinc finger domains may in principle be re-engineered using one of various methods, customized ZFNs may theoretically be constructed to target nearly any gene sequence. Publicly available methods for engineering zinc finger domains include Context-dependent Assembly (CoDA), Oligomerized Pool Engineering (OPEN), and Modular Assembly. d) Meganucleases
[0306] In some embodiments, the provided method for editing genomic information in a cell involves contacting the cell with a lipid nanoparticle having a nucleic acid associated with a gene editing system using a meganuclease. Meganucleases, which are commonly identified in
microbes, are unique enzymes with high activity and long recognition sequences (> 14 nt) resulting in site-specific digestion of target DNA. Engineered versions of naturally occurring meganucleases typically have extended DNA recognition sequences (for example, 14 to 40 nt). The engineering of meganucleases may be more challenging than that of ZFNs and TALENs because the DNA recognition and cleavage functions of meganucleases are intertwined in a single domain. Specialized methods of mutagenesis and high-throughput screening have been used to create novel meganuclease variants that recognize unique sequences and possess improved nuclease activity. e) Transcription Activator-Like Effector Nucleases
[0307] In some embodiments, the provided method for editing genomic information in a cell involves contacting the cell with a lipid nanoparticle having a nucleic acid associated with a gene editing system using a transcription activator-like effector nuclease (TALEN). TALENs are artificial restriction enzymes generated by fusing the transcription activator-like effector (TALE) DNA binding domain to a nuclease domain. In one aspect, the nuclease is selected from a group consisting of PvuII, MutH, TevI, FokI, Alwl, Mlyl, Sbfl, Sdal, StsI, CleDORF, Clo051, and Pept071. The term TALEN, as used herein, is broad and includes a monomeric TALEN that may cleave double stranded DNA without assistance from another TALEN. The term TALEN is also used to refer to one or both members of a pair of TALENs that work together to cleave DNA at the same site, transcription activator-like effectors (TALEs) may be engineered to bind practically any DNA sequence, such as a target sequence in a nucleic acid encoding an AUX/IAA protein. TALE proteins are DNA-binding domains derived from various plant bacterial pathogens of the genus Xanthomonas. The X pathogens secrete TALEs into the host plant cell during infection. The TALE moves to the nucleus, where it recognizes and binds to a specific DNA sequence in the promoter region of a specific DNA sequence in the promoter region of a specific gene in the host genome. TALE has a central DNA-binding domain composed of 13-28 repeat monomers of 33-34 amino acids. The amino acids of each monomer are highly conserved, except for hypervariable amino acid residues at positions 12 and 13. The two variable amino acids are called repeat-variable diresidues (RVDs). The amino acid pairs NI, NG, HD, and NN of RVDs preferentially recognize adenine, thymine, cytosine, and guanine/adenine, respectively, and modulation of RVDs may recognize consecutive DNA bases. This simple relationship between amino acid sequence and DNA recognition has
allowed for the engineering of specific DNA binding domains by selecting a combination of repeat segments containing the appropriate RVDs. f) Other Gene Editing Systems
[0308] In some embodiments, the provided method for editing genomic information in a cell involves contacting the cell with a lipid nanoparticle having a nucleic acid associated with a gene editing system using base editing. Base editing is a genome editing method that directly generates precise point mutations in genomic DNA or in cellular RNA without directly generating DSBs, requiring a DNA donor template, or relying on cellular HDR The use of lipid nanoparticles in the mediation of base editing is described in, for example, Rothgangl et al. Nat Biotechnol. 2021 Aug; 39(8):949-957.
[0309] In some embodiments, the provided method for editing genomic information in a cell involves contacting the cell with a lipid nanoparticle having a nucleic acid associated with a gene editing system using prime editing. Prime editing is a “search-and-replace: genome- editing technology that introduces all base-to-base conversions, as well as small insertions and deletions, without the need for double-strand breaks (DSBs) or donor DNA templates. It involves reverse transcription to introduce the correction to DNA genome. The use of lipid nanoparticles in the mediation of prime editing is described in, for example, Herrera-Barrera et al. AAPS J. 2023 Jun 28;25(4):65.
[0310] In some embodiments, the provided method for editing genomic information in a cell involves contacting the cell with a lipid nanoparticle having a nucleic acid associated with a gene editing system using Programmable Genomic Integration (PGI) and/or Programmable Addition via Site-specific Targeting Elements (PASTE). These techniques utilize programmable genome integration of large, diverse DNA cargo without DNA repair of exposed DNA double -strand breaks.
[0311] In some embodiments, the provided method for editing genomic information in a cell involves contacting the cell with a lipid nanoparticle having a nucleic acid associated with a gene editing system using transgene addition by cDNA synthesis insertion.
5. Preparing lipid nanoparticles
[0312] Some methods provided by the disclosure are useful for preparing one or more lipid nanoparticles, wherein the lipid nanoparticles include those described in Section B. The lipid
nanoparticles can be prepared via, for example, a continuous mixing method and/or a direct dilution process. In some embodiments, the methods include selecting, designing, and/or preparing one or more components of the lipid nanoparticle being prepared. For example, the methods can include selecting, designing, and/or preparing a phospholipid, an ionizable lipid, a cholesterol or derivative thereof, a conjugated lipid, and/or a nucleic acid.
[0313] In some embodiments, the lipid nanoparticles described herein are produced via a continuous mixing method, e.g., a process that includes providing an aqueous solution comprising a nucleic acid (e.g., any of the nucleic acids described in Section B.5) in a first reservoir, providing an organic lipid solution in a second reservoir, and mixing the aqueous solution with the organic lipid solution such that the organic lipid solution mixes with the aqueous solution so as to substantially instantaneously produce a lipid particle encapsulating the nucleic acid. This process and the apparatus for carrying this process are described in U.S. Patent Application Publication No. 2004/0142025.
[0314] In some examples, the organic lipid solution is an alcoholic solution that includes an alcoholic organic solvent and the lipids that will form the lipid nanoparticles. These lipids can include one or more conjugated lipids, one or more ionizable lipids or pharmaceutically acceptable salts thereof, one or more sterols or derivatives thereof, and one or more phospholipids or pharmaceutically acceptable salts thereof. For example, the conjugated lipid can be any of those described in Section B.4, the ionizable lipid can be any of those described in Section B.2, the sterol can be cholesterol or any of its derivatives described in Section B.3, and the phospholipid can be any of those described in Section B. 1. In some embodiments, the alcoholic organic solvent of the alcoholic solution includes or consists of ethanol. In some examples, the alcoholic solution is the product of combining the alcoholic organic solvent and a phospholipid solution, where the phospholipid solution includes or consists of a nonalcoholic organic solvent and the one or more phospholipids or pharmaceutically acceptable salts thereof. In some embodiments, the nonalcoholic organic solvent includes or consists of tetrahydrofuran.
[0315] The action of continuously introducing lipid and buffer solutions into a mixing environment, such as in a mixing chamber, causes a continuous dilution of the lipid solution with the buffer solution, thereby producing a lipid particle substantially instantaneously upon mixing. As used herein, the phrase “continuously diluting a lipid solution with a buffer solution” (and variations) generally means that the lipid solution is diluted sufficiently rapidly in a hydration process with sufficient force to effectuate vesicle generation. By mixing the
aqueous solution comprising a nucleic acid with the organic lipid solution, the organic lipid solution undergoes a continuous stepwise dilution in the presence of the buffer solution (i.e., aqueous solution) to produce a lipid particle.
[0316] The lipid nanoparticles formed using the continuous mixing method typically have a size of from about 40 nm to about 150 nm, from about 50 nm to about 150 nm, from about 60 nm to about 130 nm, from about 70 nm to about 110 nm, from about 60 nm to about 100 nm, from about 50 to about 80 nm, from about 60 to about 80 nm, from about 60 to about 90 nm, or from about 70 nm to about 90 nm. The particles thus formed do not aggregate and are optionally sized to achieve a uniform particle size.
[0317] In some embodiments, the lipid nanoparticles described herein are produced via a direct dilution process that includes forming a lipid particle solution and immediately and directly introducing the lipid particle solution into a collection vessel containing a controlled amount of dilution buffer. In certain embodiments, the collection vessel includes one or more elements configured to stir the contents of the collection vessel to facilitate dilution. In one embodiment, the amount of dilution buffer present in the collection vessel is substantially equal to the volume of lipid particle solution introduced thereto. As a non-limiting example, a lipid particle solution in 45% ethanol when introduced into the collection vessel containing an equal volume of dilution buffer will advantageously yield smaller particles.
[0318] In some embodiments, the lipid nanoparticles described herein are produced via a direct dilution process in which a third reservoir containing dilution buffer is fluidly coupled to a second mixing region. In this embodiment, the lipid particle solution formed in a first mixing region is immediately and directly mixed with dilution buffer in the second mixing region. In certain embodiments, the second mixing region includes a T-connector arranged so that the lipid particle solution and the dilution buffer flows meet as opposing 180 ° flows; however, connectors providing shallower angles can be used, e.g., from about 27 ° to about 180 °. A pump mechanism delivers a controllable flow of buffer to the second mixing region. In one embodiment, the flow rate of dilution buffer provided to the second mixing region is controlled to be substantially equal to the flow rate of lipid particle solution introduced thereto from the first mixing region. This embodiment advantageously allows for more control of the flow of dilution buffer mixing with the lipid particle solution in the second mixing region, and therefore also the concentration of lipid particle solution in buffer throughout the second mixing process. Such control of the dilution buffer flow rate advantageously allows for small
particle size formation at reduced concentrations. Examples of these processes and the apparatuses for carrying out these direct dilution processes are described in U.S. Patent No. 9,005,654.
[0319] The lipid particles formed using the direct dilution process typically have a size of from about 40 nm to about 150 nm, from about 50 nm to about 150 nm, from about 60 nm to about 130 nm, from about 70 nm to about 110 nm, from about 60 nm to about 100 nm, from about 50 to about 80 nm, from about 60 to about 80 nm, from about 60 to about 90 nm, or from about 70 nm to about 90 nm. The particles thus formed do not aggregate and are optionally sized to achieve a uniform particle size.
[0320] If needed, the lipid particles described herein can be sized by any of the methods available to one of skill in the art. The sizing may be conducted in order to achieve a desired size range and relatively narrow distribution of particle sizes. Several techniques are available for sizing the particles to a desired size, e.g. such as described in Lam et al. 2023, Adv. Mat., 35:26, 2211420. One sizing method, used for liposomes and equally applicable to the present particles, is described in U.S. Patent No. 4,737,323. Sonicating a particle suspension either by bath or probe sonication produces a progressive size reduction down to particles of less than about 50 nm in size. Homogenization is another method which relies on shearing energy to fragment larger particles into smaller ones. In a typical homogenization procedure, particles are recirculated through a standard emulsion homogenizer until selected particle sizes, typically between about 60 nm and about 80 nm, are observed. In both methods, the particle size distribution can be monitored by conventional laser-beam particle size discrimination, or QELS.
[0321] Extrusion of the particles through a smal1-pore polycarbonate membrane or an asymmetric ceramic membrane is also an effective method for reducing particle sizes to a relatively well-defined size distribution. Typically, the suspension is cycled through the membrane one or more times until the desired particle size distribution is achieved. The particles may be extruded through successively smaller-pore membranes, to achieve a gradual reduction in size.
[0322] In some examples, the solution of lipid particles formed using the direct dilution process is optionally concentrated. The concentrating can be performed, for example, using ultrafiltration (e.g., tangential flow dialysis). Additionally or alternatively, the concentrating can be performed using centrifugation. The concentration of the lipid particles can be increased,
for example, by about 1-100 fold, by 3-70 fold, by about 5-50 fold, or by about 10-20 fold. Additionally or alternatively, some or all of the organic solvent, e.g., the alcoholic organic solvent, can be removed from the solution formed using the direct dilution process. The solvent removal can include, for example, exchanging the solvent with an aqueous solution (e.g., an aqueous buffer). In some embodiments, this buffer exchange is performed using dialysis. The optional solvent removal can be performed before or after the optional concentrating of the lipid particles. Additionally or alternatively, the solution formed using the direct dilution process can be filtered, where the optional filtering can be performed before or after either of the optional concentrating of the lipid particles, or the optional removing of the organic solvent. Examples ofthese processes and apparatuses for carrying them out are described in U.S. Patent No. 9,005,654.
[0323] In some embodiments, the nucleic acid to lipid ratios (mass/mass ratios) in a formed lipid particle ranges from about 0.01 to about 0.2, from about 0.02 to about 0.1, from about 0.03 to about 0. 1, or from about 0.01 to about 0.08. The ratio of the starting materials can also fall within this range. In other embodiments, the lipid particle preparation uses about 400 μg nucleic acid per 10 mg total lipid or a nucleic acid to lipid mass ratio of about 0.01 to about 0.08, e.g., about 0.04, which corresponds to 1.25 mg of total lipid per 50 μg of nucleic acid. In certain embodiments, the particle has a nucleic acid:lipid mass ratio of about 0.08.
[0324] In other embodiments, the lipid to nucleic acid ratios (mass/mass ratios) in a formed lipid particle ranges from about 1 (1: 1) to about 100 (100: 1), from about 5 (5: 1) to about 100 (100: 1), from about 1 (1: 1) to about 50 (50: 1), from about 2 (2: 1) to about 50 (50: 1), from about 3 (3: 1) to about 50 (50: 1), from about 4 (4: 1) to about 50 (50: 1), from about 5 (5: 1) to about 50 (50: 1), from about 1 (1: 1) to about 25 (25: 1), from about 2 (2: 1) to about 25 (25: 1), from about 3 (3: 1) to about 25 (25: 1), from about 4 (4: 1) to about 25 (25: 1), from about 5 (5: 1) to about 25 (25: 1), from about 5 (5: 1) to about 20 (20: 1), from about 5 (5: 1) to about 15 (15: 1), from about 5 (5: 1) to about 10 (10: 1), about 5 (5: 1), 6 (6: 1), 7 (7: 1), 8 (8: 1), 9 (9: 1), 10 (10: 1), 11 (11: 1), 12 (12: 1), 13 (13: 1), 14 (14: 1), or 15 (15: 1). The ratio of the starting materials can also fall within this range.
F. EXEMPLARY EMBODIMENTS
[0325] The following embodiments are contemplated. All combinations of features and embodiments are contemplated.
[0326] Embodiment 1: A lipid nanoparticle comprising: a phospholipid or a pharmaceutically acceptable salt thereof, the phospholipid including one or more unsaturated tails and a head group having a positively charged nitrogen; and an ionizable lipid or a pharmaceutically acceptable salt thereof, the ionizable lipid having the formula:
 wherein: R1 and R2 are each independently hydrogen , C1-4 alkyl, or 2- to 4-membered heteroalkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8- membered heterocyclyl, wherein the alkyl, heteroalkyl, and heterocyclyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine; R3, R4, and R5 are each independently C5-20 alkyl, C5-20 alkenyl, C5- 20 alkynyl, or C5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C1-6 alkyl or C2-6 alkenyl; R6 and R7 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl; R8 and R9 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl; R10 and R11 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl; R12 and R13 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, or are each independently hydrogen or C1-6 alkyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine; X1, X2, and X3 are each independently a covalent bond, C1-6 alkylene, C1-6 alkenylene, or C1-6 alkynylene; and n is an integer from 2 to 10.
wherein: R1 and R2 are each independently hydrogen , C1-4 alkyl, or 2- to 4-membered heteroalkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8- membered heterocyclyl, wherein the alkyl, heteroalkyl, and heterocyclyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine; R3, R4, and R5 are each independently C5-20 alkyl, C5-20 alkenyl, C5- 20 alkynyl, or C5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C1-6 alkyl or C2-6 alkenyl; R6 and R7 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl; R8 and R9 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl; R10 and R11 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl; R12 and R13 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, or are each independently hydrogen or C1-6 alkyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine; X1, X2, and X3 are each independently a covalent bond, C1-6 alkylene, C1-6 alkenylene, or C1-6 alkynylene; and n is an integer from 2 to 10.
[0327] Embodiment 2: An embodiment of embodiment 1, wherein each of the one or more unsaturated tails of the phospholipid has only one double bond.
[0328] Embodiment 3 : An embodiment of embodiment 1 or 2, wherein each of the one more unsaturated tails of the phospholipid is a cis unsaturated tail.
[0329] Embodiment 4: An embodiment of any one of embodiments 1-3, wherein each of the one or more unsaturated tails of the phospholipid is C10-20 alkenyl.
[0330] Embodiment 5: An embodiment of any one of embodiments 1-4, wherein the phospholipid comprises a phosphatidylcholine.
[0331] Embodiment 6: An embodiment of embodiment 5, wherein the phospholipid comprises 1-palmitoyl -2 -oleoyl-glycero-3-phosphocholine (POPC), 1,2-dioleoyl-sn-glycero- 3-phosphocholine (DOPC), 1,2-divaccenoyl -sn-glycero-3-phosphocholine, 1,2- di[(8Z)octadecenoyl]-sn-glycero-3-phosphocholine, 1,2-dimyristoleoyl-sn-glycero-3- phosphocholine, 1,2-dimyristelaidoyl-sn-glycero-3-phosphocholine, 1,2-dipalmitoleoyl-sn- glycero-3-phosphocholine, 1,2-dipalmitelaidoyl-sn-glycero-3-phosphocholine, 1,2- dipetroselenoyl-sn-glycero-3-phosphocholine, 1,2-dielaidoyl-sn-glycero-3-phosphocholine, 1,2-dilinoleoyl-sn-glycero-3-phosphocholine (DLPC), 1,2-dilinolenoyl-sn-glycero-3 - phosphocholine, 1,2-dieicosenoyl-sn-glycero-3-phosphocholine, 1,2-dierucoyl-sn-glycero-3 - phosphocholine (DEPC), 1,2-dinervonoyl-sn-glycero-3-phosphocholine, 1,2- didocosahexaenoyl-sn-glycero-3-phosphocholine, 1-pentadecanoyl-2-oleoyl-sn-glycero-3- phosphocholine, 1-palmitoyl-2-linoleoyl-sn-glycero-3-phosphocholine, 1-palmitoyl -2- arachidonoyl-sn-glycero-3-phosphocholine, 1-palmitoyl-2-docosahexaenoyl-sn-glycero-3- phosphocholine, l-stearoyl-2-oleoyl-sn-glycero-3-phosphocholine (SOPC), 1-stearoyl -2- linoleoyl-sn-glycero-3-phosphocholine, 1-stearoyl -2 -arachidonoyl-sn-glycero-3- phosphocholine, 1-stearoyl -2 -docosahexaenoyl-sn-glycero-3-phosphocholine, 1 -oleoyl -2- myristoyl-sn-glycero-3-phosphocholine, 1-oleoyl -2 -palmitoyl-sn-glycero-3-phosphocholine, 1-oleoyl-2-stearoyl-sn-glycero-3-phosphocholine, 1-(8Z-octadecenoyl)-2-palmitoyl-sn- glycero-3-phosphocholine, 1-O-hexadecyl-2-oleoyl-sn-glycero-3-phosphocholine, 1-O- hexadecyl-2-arachidonoyl-sn-glycero-3-phosphocholine, 1-O-hexadecyl-2-(8Z, 11Z, 14Z- eicosatrienoyl)-sn-glycero-3-phosphocholine, 1-O-hexadecyl-2-(5Z,8Z,11Z,14Z,17Z- eicosapentaenoyl)-sn-glycero-3-phosphocholine, 1-O-hexadecyl-2-docosahexaenoyl-sn- glycero-3-phosphocholine, 1-O-hexadecanyl-2-O-(9Z-octadecenyl)-sn-glycero-3- phosphocholine, 1,2-di-O-(9Z-octadecenyl)-sn-glycero-3-phosphocholine, or a combination thereof.
[0332] Embodiment 7: An embodiment of any one of embodiments 1-6, wherein the phospholipid comprises a phosphatidylethanolamine.
[0333] Embodiment 8: An embodiment of embodiment 7, wherein the phospholipid comprises 1,2-dioleoyl-sn-glycero-3-phosphoethanolamine (DOPE), 1,2-dipalmitoleoyl-sn- glycero-3-phosphoethanolamine, 1,2-dielaidoyl-sn-glycero-3-phosphoethanolamine, 1,2- dilinoleoyl-sn-glycero-3-phosphoethanolamine, 1,2-dilinolenoyl-sn-glycero-3- phosphoethanolamine, 1,2-didocosahexaenoyl-sn-glycero-3-phosphoethanolamine, 1,2- diarachidonoyl-sn-glycero-3-phosphoethanolamine, 1-pentadecanoyl-2-oleoyl-sn-glycero-3- phosphoethanolamine, 1-palmitoyl -2 -linoleoyl-sn-glycero-3-phosphoethanolamine, 1- palmitoyl-2-oleoyl-sn-glycero-3-phosphoethanolamine, 1-stearoyl -2 -oleoyl-sn-glycero-3- phosphoethanolamine, 1-pahnitoyl-2-arachidonoyl-sn-glycero-3-phosphoethanolamine, 1- palmitoyl-2-docosahexaenoyl-sn-glycero-3-phosphoethanolamine, 1-stearoyl -2 -arachidonoyl- sn-glycero-3-phosphoethanolamine, 1-stearoyl -2 -docosahexaenoyl-sn-glycero-3- phosphoethanolamine, 1-hexadecyl -2-(9Z-octadecenoyl)-sn-glycero-3-phosphoethanolamine, 1-O-hexadecanyl-2-O-(9Z-octadecenyl)-sn-glycero-3-phosphoethanolamine, or a combination thereof.
[0334] Embodiment 9: An embodiment of any one of embodiments 1-8, wherein R1 and R2 are each independently hydrogen or C1-4 alkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl.
[0335] Embodiment 10: An embodiment of embodiment 9, wherein R1 and R2 are each independently C1-3 alkyl.
[0336] Embodiment 11: An embodiment of embodiment 10, wherein R1 and R2 are each independently methyl, ethyl, or isopropyl.
[0337] Embodiment 12: An embodiment of embodiment 11, wherein R1 and R2 are each methyl.
[0338] Embodiment 13: An embodiment of embodiment 9, wherein R1 and R2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered saturated heterocyclyl in which the nitrogen is the only heteroatom.
[0339] Embodiment 14: An embodiment of any one of embodiments 13, wherein R1 and R2 are combined with the nitrogen to which they are attached to form pyrrolidyl or azetidyl.
[0340] Embodiment 15: An embodiment of any one of embodiments 1-14, wherein R3, R4, and R5 are each independently cis C5-20 alkenyl having only one double bond.
[0341] Embodiment 16: An embodiment of embodiment 15, wherein R3, R4, and R5 are each independently cis C6-12 alkenyl having only one double bond.
[0342] Embodiment 17: An embodiment of embodiment 15 or 16, wherein the double bond is in the 2-, 3-, 4-, or 5-position of the alkenyl.
[0343] Embodiment 18: An embodiment of embodiment 17, wherein R3, R4, and R5 are each identically cis-non-3-ene-1-yl or cis-oct-3-ene-1-yl.
[0344] Embodiment 19: An embodiment of any one of embodiments 1-18, wherein R6, R8, and R10 are each independently hydrogen or C1-20 alkyl.
[0345] Embodiment 20: An embodiment of embodiment 19, wherein R6, R8, and R10 are each identically hydrogen, methyl, ethyl, or butyl.
[0346] Embodiment 21: An embodiment of any one of embodiments 1-18, wherein R6, R8, and R10 are each independently C1-20 alkenyl.
[0347] Embodiment 22 : An embodiment of embodiment 21 , wherein R6, R8, and R10 are each cis-dec-4-ene-1-yl .
[0348] Embodiment 23: An embodiment of any one of embodiments 1-22, wherein R7, R9, and R11 are each identically hydrogen.
[0349] Embodiment 24: An embodiment of any one of embodiments 1-23, wherein the total number of carbons in R3, R6, and R7; the total number of carbons in R4, R8, and R9; and the total number of carbons in R5, R10, and R11 are each independently from 7 to 12.
[0350] Embodiment 25: An embodiment of any one of embodiments 1-24, wherein each R12 and R13 is hydrogen.
[0351] Embodiment 26: An embodiment of any one of embodiments 1-25, wherein X1, X2, and X3 are each identically a covalent bond or methylene.
[0352] Embodiment 27: An embodiment of any one of embodiments 1-26, wherein n is 5, 6, 7, or 8.
[0353] Embodiment 28: An embodiment of embodiment 27, wherein n is 6 or 8.
[0354] Embodiment 29: An embodiment of embodiment 28, wherein n is 6.
[0355] Embodiment 30: An embodiment of embodiment 1, wherein the ionizable lipid has the formula:
 wherein: R1 and R2 are each independently hydrogen or C1-4 alkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl; R3, R4, and R5 are each independently cis C5-20 alkenyl or C5-20 alkynyl, each having only one unsaturated bond; and n is an integer from 4 to 8.
wherein: R1 and R2 are each independently hydrogen or C1-4 alkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl; R3, R4, and R5 are each independently cis C5-20 alkenyl or C5-20 alkynyl, each having only one unsaturated bond; and n is an integer from 4 to 8.
[0356] Embodiment 31 : An embodiment of embodiment 30, wherein R3, R4, and R5 are each independently cis C5-20 alkenyl having only one double bond.
[0357] Embodiment 32: An embodiment of embodiment 30, wherein the ionizable lipid comprises:





[0358] Embodiment 33: An embodiment of any one of embodiments 1-32, wherein the phospholipid or the pharmaceutically acceptable salt thereof comprises between 1 mol % and 20 mol % of the total lipid present in the lipid nanoparticle .
[0359] Embodiment 34: An embodiment of any one of embodiments 1-33, wherein the ionizable lipid or the pharmaceutically acceptable salt thereof comprises between 30 mol % and 70 mol % of the total lipid of the lipid nanoparticle .
[0360] Embodiment 35: An embodiment of any one of embodiments 1-34, wherein the lipid nanoparticle further comprises cholesterol or a derivative thereof.
[0361] Embodiment 36: An embodiment of embodiment 35, wherein the cholesterol or the derivative thereof comprises between 20 mol % and 60 mol % of the total lipid of the lipid nanoparticle .
[0362] Embodiment 37: An embodiment of any one of embodiments 1-36, wherein the lipid nanoparticle further comprises a conjugated lipid.
[0363] Embodiment 38: An embodiment of embodiment 37, wherein the conjugated lipid comprises a polyethylene glycol (PEG)-lipid conjugate.
[0364] Embodiment 39: An embodiment of embodiment 37 or 38, wherein the conjugated lipid comprises between 0.1 mol % and 5 mol % of the total lipid of the lipid nanoparticle .
[0365] Embodiment 40: An embodiment of any one of embodiments 1-39, wherein the lipid nanoparticle further comprises a nucleic acid.
[0366] Embodiment 41: An embodiment of embodiment 40, wherein the nucleic acid comprises RNA.
[0367] Embodiment 42: An embodiment of embodiment 41, wherein the RNA comprises mRNA.
[0368] Embodiment 43: An embodiment of any one of embodiments 40-42, wherein the nucleic acid encodes a protein.
[0369] Embodiment 44: An embodiment of embodiment 43, wherein the protein is functional in or secreted by hepatocytes.
[0370] Embodiment 45: An embodiment of embodiment 43 or 44, wherein, following administration of the lipid nanoparticle to a subject, an activity or expression of the protein in the liver of the subject is at least 20-fold greater than an activity or expression of the protein in the spleen of the subject.
[0371] Embodiment 46: An embodiment of any one of embodiments 40-45, wherein the nucleic acid, or a protein encoded by the nucleic acid, is a component of a gene editing system.
[0372] Embodiment 47: An embodiment of any one of embodiments 1-46, wherein the lipid nanoparticle has a pKa between 5.8 and 6.9, preferably wherein the pKa is determined using the assay described in Example 7.
[0373] Embodiment 48: An embodiment of any one of embodiments 1-47, wherein, following administering the lipid nanoparticle to a subject, a concentration of the ionizable lipid in the liver of subject 7 days after the administering is less than 50% of a concentration of the ionizable lipid in the liver 24 hours after the administering.
[0374] Embodiment 49: A compound having the formula:
 or the formula of a pharmaceutically acceptable salt thereof, wherein: R1 and R2 are each independently hydrogen or C1-4 alkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl; R3, R4, and R5 are each independently cis C5-20 alkenyl or C5-20 alkynyl, each having only one unsaturated bond; and n is an integer from 4 to 8.
or the formula of a pharmaceutically acceptable salt thereof, wherein: R1 and R2 are each independently hydrogen or C1-4 alkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl; R3, R4, and R5 are each independently cis C5-20 alkenyl or C5-20 alkynyl, each having only one unsaturated bond; and n is an integer from 4 to 8.
[0375] Embodiment 50: An embodiment of embodiment 49, wherein R3, R4, and R5 are each independently cis C5-20 alkenyl having only one double bond.
[0376] Embodiment 51: An embodiment of embodiment 49 or 50, wherein R1 and R2 are each independently C1-3 alkyl.
[0377] Embodiment 52: An embodiment of any one of embodiments 51, wherein R1 and R2 are each independently methyl, ethyl, or isopropyl.
[0378] Embodiment 53: An embodiment of embodiment 52, wherein R1 and R2 are each methyl.
[0379] Embodiment 54: An embodiment of embodiment 49 or 50, wherein R1 and R2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered saturated heterocyclyl in which the nitrogen is the only heteroatom.
[0380] Embodiment 55 : An embodiment of embodiment 54, wherein R1 and R2 are combined with the nitrogen to which they are attached to form pyrrolidyl or azetidyl.
[0381] Embodiment 56: An embodiment of any one of embodiments 49-55, wherein R3, R4, and R5 are each independently cis C6-12 alkenyl having only one double bond.
[0382] Embodiment 57: An embodiment of embodiment 56, wherein the double bond is in the 2-, 3-, 4-, or 5 -position of the alkenyl.
[0383] Embodiment 58: An embodiment of embodiment 57, wherein R3, R4, and R5 are each identically cis-non-3-ene-1-yl or cis-oct-3-ene-1-yl.
[0384] Embodiment 59: An embodiment of any one of embodiments 49-58, wherein n is 5, 6, 7, or 8.
[0385] Embodiment 60: An embodiment of embodiment 59, wherein n is 6 or 8.
[0386] Embodiment 61: An embodiment of embodiments 60, wherein n is 6.
[0387] Embodiment 62: An embodiment of embodiment 49, wherein the compound is:





[0388] Embodiment 63 : A lipid nanoparticle comprising the compound of any one of claims 49-62.
[0389] Embodiment 64: An embodiment of embodiment 63, wherein the lipid nanoparticle has a pKa between 5.8 and 6.9.
[0390] Embodiment 65: A lipid nanoparticle comprising an ionizable lipid or a pharmaceutically acceptable salt thereof, the ionizable lipid having the formula:
 wherein the lipid nanoparticle has a pKa between 5.8 and 6.9, and wherein: R1 and R2 are each independently hydrogen , C1-4 alkyl, or 2- to 4-membered heteroalkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl, wherein the alkyl, heteroalkyl, and heterocyclyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine; R3, R4, and R5 are each independently C5-20 alkyl, C5-20 alkenyl, C5-20 alkynyl, or C5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C1-6 alkyl or C2-6 alkenyl; R6 and R7 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, with the proviso that no more than one of R6 and R7 is hydrogen; R8 and R9 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, with the proviso that no more than one of R8 and R9 is hydrogen; R10 and R11 are each independently hydrogen, C1- 20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, with the proviso that no more than one of R10 and R11 is hydrogen; R12 and R13 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, or are each independently hydrogen or C1-6 alkyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine; X1, X2, and X3 are each independently a covalent bond, C1-6 alkylene, C1-6 alkenylene, or C1-6 alkynylene; and n is an integer from 2 to 10.
wherein the lipid nanoparticle has a pKa between 5.8 and 6.9, and wherein: R1 and R2 are each independently hydrogen , C1-4 alkyl, or 2- to 4-membered heteroalkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl, wherein the alkyl, heteroalkyl, and heterocyclyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine; R3, R4, and R5 are each independently C5-20 alkyl, C5-20 alkenyl, C5-20 alkynyl, or C5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C1-6 alkyl or C2-6 alkenyl; R6 and R7 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, with the proviso that no more than one of R6 and R7 is hydrogen; R8 and R9 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, with the proviso that no more than one of R8 and R9 is hydrogen; R10 and R11 are each independently hydrogen, C1- 20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, with the proviso that no more than one of R10 and R11 is hydrogen; R12 and R13 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, or are each independently hydrogen or C1-6 alkyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine; X1, X2, and X3 are each independently a covalent bond, C1-6 alkylene, C1-6 alkenylene, or C1-6 alkynylene; and n is an integer from 2 to 10.
[0391] Embodiment 66: An embodiment of embodiment 65, wherein the lipid nanoparticle further comprises a nucleic acid.
[0392] Embodiment 67: An embodiment of embodiment 66, wherein the nucleic acid comprises RNA.
[0393] Embodiment 68: An embodiment of embodiment 67, wherein the RNA comprises mRNA.
[0394] Embodiment 69: An embodiment of any one of embodiments 66-68, wherein the nucleic acid encodes a protein.
[0395] Embodiment 70: An embodiment of embodiment 69, wherein the protein is functional in or secreted by hepatocytes.
[0396] Embodiment 71: An embodiment of embodiment 69 or 70, wherein, following administration of the lipid nanoparticle to a subject, an activity or expression of the protein in the liver of the subject is at least 20-fold greater than an activity or expression of the protein in the spleen of the subject.
[0397] Embodiment 72: An embodiment of any one of embodiments 66-71, wherein the nucleic acid, or a protein encoded by the nucleic acid, is a component of a gene editing system.
[0398] Embodiment 73: An embodiment of any one of embodiments 65-72, wherein R1 and R2 are each independently C1-3 alkyl.
[0399] Embodiment 74: An embodiment of embodiment 73, wherein R1 and R2 are each independently methyl, ethyl, or isopropyl.
[0400] Embodiment 75: An embodiment of embodiment 74, wherein R1 and R2 are each methyl.
[0401] Embodiment 76: An embodiment of any one of embodiments 65-72, wherein R1 and R2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered saturated heterocyclyl in which the nitrogen is the only heteroatom.
[0402] Embodiment 77: An embodiment of embodiment 76, wherein R1 and R2 are combined with the nitrogen to which they are attached to form pyrrolidyl or azetidyl.
[0403] Embodiment 78: An embodiment of any one of embodiments 65-77, wherein R3, R4, and R5 are each independently cis C6-12 alkenyl having only one double bond.
[0404] Embodiment 79: An embodiment of embodiment 78, wherein the double bond is in the 2-, 3-, 4-, or 5 -position of the alkenyl.
[0405] Embodiment 80: An embodiment of embodiment 79, wherein R3, R4, and R5 are each identically cis-non-3-ene-1-yl or cis-oct-3-ene-1-yl.
[0406] Embodiment 81 : An embodiment of any one of embodiments 65-80, wherein R6, R8, and R10 are each independently hydrogen or C1-20 alkyl.
[0407] Embodiment 82: An embodiment of embodiment 81, wherein R6, R8, and R10 are each identically hydrogen, methyl, ethyl, or butyl.
[0408] Embodiment 83: An embodiment of any one of embodiments 65-80, wherein R6, R8, and R10 are each independently C1-20 alkenyl.
[0409] Embodiment 84: An embodiment of embodiment 83, wherein R6, R8, and R10 are each cis-dec-4-ene-1-yl .
[0410] Embodiment 85: An embodiment of any one of embodiments 65-84, wherein R7, R9, and R11 are each identically hydrogen.
[0411] Embodiment 86: An embodiment of any one of embodiments 65-85, wherein the total number of carbons in R3, R6, and R7; the total number of carbons in R4, R8, and R9; and the total number of carbons in R5, R10, and R11 are each independently from 7 to 12.
[0412] Embodiment 87: An embodiment of any one of embodiments 65-86, wherein each R12 and R13 is hydrogen.
[0413] Embodiment 88: An embodiment of any one of embodiments 65-87, wherein X1, X2, and X3 are each identically a covalent bond or methylene.
[0414] Embodiment 89: An embodiment of any one of embodiments 65-88, wherein n is 5, 6, 7, or 8.
[0415] Embodiment 90: An embodiment of embodiment 89, wherein n is 6 or 8.
[0416] Embodiment 91: An embodiment of embodiment 90, wherein n is 6.
[0417] Embodiment 92 : An embodiment of any one of embodiments 65-91, wherein the lipid nanoparticle further comprises a phospholipid or a pharmaceutically acceptable salt thereof.
[0418] Embodiment 93: An embodiment of embodiment 92, wherein the tails of the phospholipid are each saturated.
[0419] Embodiment 94: An embodiment of embodiment 93, wherein the phospholipid comprises 1,2-distearoyl-sn-glycero-3-phosphocholine (DSPC).
[0420] Embodiment 95: An embodiment of any one of embodiments 92-94, wherein the phospholipid or the pharmaceutically acceptable salt thereof comprises between 1 mol % and 20 mol % of the total lipid of the lipid nanoparticle.
[0421] Embodiment 96: An embodiment of any one of embodiments 65-95, wherein the ionizable lipid or the pharmaceutically acceptable salt thereof comprises between 30 mol % and 70 mol % of the total lipid of the lipid nanoparticle.
[0422] Embodiment 97 : An embodiment of any one of embodiments 65-96, wherein the lipid nanoparticle further comprises cholesterol or a derivative thereof.
[0423] Embodiment 98: An embodiment of embodiment 97, wherein the cholesterol or the derivative thereof comprises between 20 mol % and 60 mol % of the total lipid of the lipid nanoparticle.
[0424] Embodiment 99: An embodiment of any one of embodiments 65-98, wherein the lipid nanoparticle further comprises a conjugated lipid.
[0425] Embodiment 100: An embodiment of embodiment 99, wherein the conjugated lipid comprises a polyethylene glycol (PEG)-lipid conjugate.
[0426] Embodiment 101: An embodiment of embodiment 99 or 100, wherein the conjugated lipid comprises between 0.1 mol % and 5 mol % of the total lipid of the lipid nanoparticle.
[0427] Embodiment 102: An embodiment of any one of embodiments 65-91, wherein the lipid nanoparticle comprises: the ionizable lipid or the pharmaceutically acceptable salt thereof comprising between 45 mol % and 60 mol % of the total lipid present in the lipid nanoparticle; a phospholipid or a pharmaceutically acceptable salt thereof comprising between 8 mol % and 12 mol % of the total lipid present in the lipid nanoparticle; a cholesterol or a derivative thereof comprising between 30 mol % and 40 mol % of the total lipid present in the lipid nanoparticle; and a conjugated lipid comprising between 0.5 mol % and 3 mol % of the total lipid present in the lipid nanoparticle.
[0428] Embodiment 103: An embodiment of any one of embodiments 65-91, wherein the lipid nanoparticle comprises: the ionizable lipid or the pharmaceutically acceptable salt thereof comprising between 52 mol % and 57 mol % of the total lipid present in the lipid nanoparticle; a phospholipid or a pharmaceutically acceptable salt thereof comprising between 10 mol % and 12 mol % of the total lipid present in the lipid nanoparticle; a cholesterol or a derivative thereof comprising between 31 mol % and 34 mol % of the total lipid present in the lipid nanoparticle; and a conjugated lipid comprising between 1 mol % and 3 mol % of the total lipid present in the lipid nanoparticle.
[0429] Embodiment 104: An embodiment of any one of embodiments 65-103, wherein, following administering the lipid nanoparticle to a subject, a concentration of the ionizable lipid in the liver of subject 7 days after the administering is less than 50% of a concentration of the ionizable lipid in the liver 24 hours after the administering.
[0430] Embodiment 105: A pharmaceutical composition comprising: the lipid nanoparticle of any one of embodiments 1-48 and 63-104, or the compound of any one of embodiments 49- 62; and a pharmaceutically acceptable carrier or pharmaceutically acceptable excipient.
[0431] Embodiment 106: A method for introducing a nucleic acid into a cell, the method comprising contacting the cell with the lipid nanoparticle of any one of embodiments 1-48 and 63-104.
[0432] Embodiment 107: An embodiment of embodiment 106, wherein the cell is in a mammal.
[0433] Embodiment 108: An embodiment of embodiment 107, wherein the cell comprises a hepatocyte.
[0434] Embodiment 109: A method for the in vivo delivery of a nucleic acid, the method comprising administering to a subject the lipid nanoparticle of any one of embodiments 1-48 and 63-104.
[0435] Embodiment 110: A lipid nanoparticle of any one of embodiments 1-49 and 63-104, compound of any one of embodiments 49-62, or pharmaceutical composition of embodiment 103, for use in the in vivo delivery of a nucleic acid to a subject.
[0436] Embodiment 111: The use of the lipid nanoparticle of any one of embodiments 1-48 and 63-104, the compound of any one of embodiments 49-62, or the pharmaceutical composition of embodiment 105, to prepare a medicament for the in vivo delivery of a nucleic acid to a subject.
[0437] Embodiment 112: A method for preventing or treating a disease or disorder in a subject in need thereof, the method comprising administering to the subject the lipid nanoparticle of any one of embodiments 1-48 and 63-104, the compound of any one of embodiments 49-62, or the pharmaceutical composition of embodiment 105.
[0438] Embodiment 113: An embodiment of embodiment 112, wherein the disease or disorder comprises an infection, a liver disease or disorder, or a cancer.
[0439] Embodiment 114: A lipid nanoparticle of any one of embodiments 1-48 and 63-104, compound of any one of embodiments 49-62, or pharmaceutical composition of embodiment 105, for use in preventing or treating a disease or disorder in a subject.
[0440] Embodiment 115: An embodiment of embodiment 114, wherein the disease or disorder comprises an infection, a liver disease or disorder, or a cancer.
[0441] Embodiment 116: The use of a lipid nanoparticle of any one of embodiments 1-48 and 63-104, compound of any one of embodiments 49-62, or pharmaceutical composition of embodiment 105, to prepare a medicament for preventing or treating a disease or disorder in a subject.
[0442] Embodiment 117: An embodiment of embodiment 116, wherein the disease or disorder comprises an infection, a liver disease or disorder, or a cancer.
[0443] Embodiment 118: A method for editing genetic information in a cell, the method comprising contacting the cell with the lipid nanoparticle of embodiment 46 or 72.
[0444] Embodiment 119: The lipid nanoparticle of embodiment 46 or 72, for use in editing genomic information in a cell.
[0445] Embodiment 120: The use of the lipid nanoparticle of embodiment 46 or 72 to prepare a medicament for editing genomic information in a cell
EXAMPLES
[0446] The present disclosure will be described in greater detail by way of specific examples. The following examples are offered for illustrative purposes only, and are not intended to limit the disclosure in any manner.
Example 1. Ionizable lipid synthesis
[0447] The provided compounds can be synthesized by a variety of methods known to one of skill in the art (see Comprehensive Organic Transformations Richard C. Larock, 1989) or by an appropriate combination of generally well known synthetic methods. Techniques useful in synthesizing the disclosed compounds are both readily apparent and accessible to those of skill in the relevant art. The examples below are offered to illustrate certain of the diverse methods available for use in assembling the provided compounds. However, the examples are not intended to define the scope of reactions or reaction sequences that are useful in preparing
the compounds. Exemplary structures below are named according to standard IUPAC nomenclature using the Cambridge Soft ChemDraw naming package.
1. Synthesis of N,N-dimethyl-6-(tris(((Z)-undec-5-en-2-yl)oxy)silyl)hexan-1- amine (4)

[0448] A solution of (Z)-dec-4-enal (87.5 g, 567 mmol) in anhydrous ether (250 mL) was added dropwise over 30 minutes to a cooled solution (0 °C) of 3 M methylmagnesium bromide (87.9 g, 246 mL 737 mmol) in anhydrous ether (500 mL). The reaction was stirred overnight at RT then diluted with ether (500 mL), quenched with water (400 mL) and then 6 M HCl (approx. 200 mL). The aqueous layer was separated, and the remaining organic layer washed with brine (2 x 500 mL), dried on magnesium sulfate, filtered, and concentrated in vacuo to dryness. The residue was purified by automated flash chromatography (0-15% ethyl acetate in hexanes) to give (Z)-undec-5-en-2-ol 1 as a colorless oil (95 g, 98.3 %). 1H NMR (400 MHz,
δ 5.40 (p, J = 5.3 Hz, 2H), 3.84 (h, J= 6.2 Hz, 1H), 2.25 - 1.99 (m, 4H), 1.59 - 1.45 (m, 2H), 1.45 - 1.25 (m, 7H), 1.22 (d, J= 6.2 Hz, 3H), 0.91 (t, J= 6.7 Hz, 3H). b) Synthesis of (6-bromohexyl)tris(((Z)-undec-5-en-2-yl)oxy)silane (3):

[0449] To a cooled solution of (Z)-undec-5-en-2-ol 1 (95 g, 558 mmol) and triethylamine (75.3 g, 744 mmol) in diethyl ether (2 L) was slowly added (6-bromohexyl)trichlorosilane (55.5 g, 37 mL, 186 mmol) and stirred overnight at RT. The triethylammonium chloride byproduct was removed by filtration and the filtrate concentrated in vacuo to dryness. The crude (6- bromohexyl)tris(((Z)-undec-5-en-2-yl)oxy)silane 3 was used in the next step without further purification.
c) Synthesis of N,N-dimethyl-6-(tris(((Z)-undec-5-en-2- yl)oxy)silyl)hexan-1-amine (4):

[0450] A solution of (6-bromohexyl)tris(((Z)-undec-5-en-2-yl)oxy)silane 3 (110 g, 157 mmol) and 2 M solution of dimethylamine in THF (400 mL) was heated at 60 °C for 3 h in a 1-L Teflon sealed reaction vessel. After cooling to RT, the suspension was diluted with diethyl ether (500 mL) and washed with saturated sodium bicarbonate (2 x 500 mL) and brine (1 x 500 mL). The organic layer was dried on magnesium sulfate, fdtered, and concentrated in vacuo to dryness. Purification by automated chromatography (0-20% MeOH/DCM) gave N,N- dimethyl-6-(tris(((Z)-undec-5-en-2-yl)oxy)silyl)hexan-l -amine 4 as a clear colorless oil (87 g, 83%). 1H NMR (400 MHz, CDCl3) δ 5.35 (t, J = 4.9 Hz, 6H), 4.04 (dqd, J = 8.3, 5.3, 1.9 Hz, 3H), 2.21 (s, 8H), 2.17 - 1.96 (m, 12H), 1.55 (ddt, J = 12.7, 9.9, 6.2 Hz, 3H), 1.45 (ddd, J = 13.4, 9.2, 5.8 Hz, 7H), 1.39 - 1.24 (m, 22H), 1.19 (dd, J = 6.1, 1.6 Hz, 9H), 0.88 (t, J = 6.7 Hz, 9H), 0.62 - 0.54 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C41H81NO3Si 663.6; Found 664.2. UPLC purity (CAD): 97.7%
Table 1: Ionizable lipids 5 to 29, 33, 34, 41 and 47










2. Synthesis of Lipids 5 to 29
[0451] Lipids 5 to 24 and 26 to 29 (Table 1) were synthesized using a procedure analogous to that employed for lipid 4, using an appropriate haloalkylsilyl trichloride, lipid alcohol, and amine headgroup.
[0452] Lipid 25 was synthesized according to literature procedures outlined in International Patent Application Publication No. WO 2013/126803A1.
[0453] Lipids 26, 27, 28 and 29 were synthesized according to literature procedures outlined in International Patent Application Publication No. WO 2020/097520A1.
[0454] Lipid 5: 1H NMR (400 MHz, CDCl3) δ 5.35 (t, J = 4.8 Hz, 6H), 3.86 (ddt, J = 7.6, 5.8, 4.0 Hz, 3H), 2.31 (s, 8H), 2.17 - 1.94 (m, 12H), 1.61 - 1.41 (m, 16H), 1.39 - 1.22 (m, 18H), 0.94 - 0.81 (m, 18H), 0.67 - 0.55 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C42H83NO3Si 677.6; Found 678.2. UPLC purity (CAD): 97%
[0455] Lipid 6: 1H NMR (400 MHz, CDCl3) δ 5.42 - 5.29 (m, 6H), 4.04 (qdd, J= 6.3, 4.5, 2.1 Hz, 3H), 2.30 (s, 6H), 2.18 - 1.92 (m, 12H), 1.56 (ddt, J = 12.7, 9.8, 6.2 Hz, 5H), 1.44 (dddd, J= 13.2, 11.3, 6.5, 3.5 Hz, 5H), 1.38 - 1.22 (m, 18H), 1.19 (dt, J= 6.2, 1.1 Hz, 9H), 0.93 - 0.83 (m, 9H), 0.64 - 0.56 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C39H77NO3Si 635.6; Found 636.2. UPLC purity (CAD): 96%
[0456] Lipid 7: 1H NMR (400 MHz, CDCl3) δ 5.35 (t, J = 4.9 Hz, 6H), 4.03 (qtd, J = 8.3, 5.3, 2.1 Hz, 3H), 2.37 (t, J= 7.5 Hz, 8H), 2.18 - 1.96 (m, 12H), 1.61 - 1.48 (m, 5H), 1.48 - 1.38 (m, 5H), 1.38 - 1.21 (m, 20H), 1.19 (dt, J= 6.1, 1.2 Hz, 9H), 0.88 (t, J= 6.8 Hz, 9H), 0.63
- 0.53 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C40H79NO3Si 649.6; Found 650.2. UPLC purity (CAD): 96%
[0457] Lipid 8: 1H NMR (400 MHz, CDCl3) δ 5.35 (t, J = 4.9 Hz, 6H), 4.04 (qdd, J = 6.2, 4.5, 2.1 Hz, 3H), 2.66 - 2.37 (m, 6H), 2.18 - 1.92 (m, 12H), 1.79 (p, J = 3.2 Hz, 4H), 1.55 (ddq, J= 11.8, 7.8, 5.9 Hz, 5H), 1.45 (dddd, J= 13.2, 7.4, 5.5, 2.4 Hz, 5H), 1.38 - 1.20 (m, 20H), 1.19 (dt, J= 6.1, 1.2 Hz, 9H), 0.88 (t, J= 6.8 Hz, 9H), 0.64 - 0.53 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C42H81NO3Si 675.6; Found 676.2. UPLC purity (CAD): 98%
[0458] Lipid 9: 1H NMR (400 MHz, CDCl3) δ 5.35 (t, J= 4.9 Hz, 6H), 4.03 (p, J= 5.7 Hz, 4H), 3.71 (s, 3H), 3.05 - 2.56 (m, 4H), 2.24 - 1.97 (m, 17H), 1.84 (s, 2H), 1.55 (ddt, J= 12.6, 9.7, 6.2 Hz, 8H), 1.49 - 1.23 (m, 27H), 1.19 (d, J= 6.1 Hz, 9H), 0.88 (t, J= 6.8 Hz, 9H), 0.62
- 0.52 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C43H83NO3Si 689.6; Found 690.2. UPLC purity (CAD): 99%
[0459] Lipid 10: 1H NMR (400 MHz, CDCl3) δ 5.41 - 5.29 (m, 6H), 4.04 (qdd, J= 6.3, 4.5, 2.0 Hz, 3H), 2.27 - 2.17 (m, 8H), 2.17 - 1.93 (m, 13H), 1.60 - 1.37 (m, 10H), 1.36 - 1.23 (m, 12H), 1.19 (dt, J= 6.2, 1.2 Hz, 9H), 0.93 - 0.81 (m, 9H), 0.64 - 0.55 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C36H71NO3Si 593.5; Found 593.8. UPLC purity (CAD): 91%
[0460] Lipid 11: 1H NMR (400 MHz, CDCl3) δ 5.37 (t, J= 5.0 Hz, 6H), 4.06 (qdd, J= 6.3, 4.5, 2.0 Hz, 3H), 2.31 (t, J= 7.5 Hz, 8H), 2.21 - 1.95 (m, 13H), 1.64 - 1.41 (m, 10H), 1.35 (td, J= 6.5, 2.7 Hz, 14H), 1.21 (dt, J= 6.2, 1.2 Hz, 9H), 0.97 - 0.86 (m, 9H), 0.65 - 0.57 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C37H73NO3Si 607.5; Found 608.2. UPLC purity (CAD): 97%
[0461] Lipid 12: 1H NMR (400 MHz, CDCl3) δ 5.42 - 5.27 (m, 6H), 4.03 (qdd, J= 6.2, 4.4, 1.9 Hz, 3H), 2.28 - 2.17 (m, 8H), 2.17 - 1.91 (m, 12H), 1.55 (ddt, J= 12.6, 9.8, 6.2 Hz, 3H), 1.49 - 1.38 (m, 7H), 1.37 - 1.22 (m, 17H), 1.18 (dt, J= 6.2, 1.2 Hz, 9H), 0.93 - 0.82 (m, 9H), 0.63 - 0.52 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C38H75NO3Si 621.6; Found 622.0. UPLC purity (CAD): 92%
[0462] Lipid 13: 1H NMR (400 MHz, CDCl3) δ 5.41 - 5.27 (m, 6H), 4.03 (qdd, J= 6.3, 4.5,
2.1 Hz, 3H), 2.49 (dt, J= 4.5, 2.1 Hz, 4H), 2.45 - 2.37 (m, 2H), 2.17 - 1.92 (m, 12H), 1.83 - 1.71 (m, 4H), 1.62 - 1.49 (m, 5H), 1.50 - 1.37 (m, 5H), 1.31 (ddp, J = 9.2, 5.7, 2.6 Hz, 13H), 1.18 (dt, J= 6.2, 1.2 Hz, 9H), 0.93 - 0.81 (m, 9H), 0.66 - 0.55 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C38H73NO3Si 619.5; Found 619.8. UPLC purity (CAD): 91%
[0463] Lipid 14: 1H NMR (400 MHz, CDCl3) δ 5.42 - 5.27 (m, 6H), 4.03 (qdd, J= 6.2, 4.4, 2.0 Hz, 3H), 2.51 (d, J= 6.1 Hz, 4H), 2.47 - 2.36 (m, 2H), 2.19 - 1.91 (m, 12H), 1.85 - 1.71 (m, 4H), 1.61 - 1.51 (m, 4H), 1.49 - 1.37 (m, 6H), 1.31 (dq, J = 6.5, 3.5 Hz, 14H), 1.18 (dt, J = 6.2, 1.2 Hz, 9H), 0.95 - 0.80 (m, 9H), 0.63 - 0.52 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C39H75NO3Si 633.6; Found 633.8. UPLC purity (CAD): 90%
[0464] Lipid 15: 1H NMR (400 MHz, CDCl3) δ 5.41 - 5.28 (m, 6H), 4.03 (qdd, J= 6.2, 4.4, 2.0 Hz, 3H), 2.51 (d, J= 6.1 Hz, 4H), 2.48 - 2.39 (m, 2H), 2.18 - 1.90 (m, 12H), 1.84 - 1.73 (m, 4H), 1.60 - 1.47 (m, 5H), 1.42 (dddd, J= 11.9, 10.5, 5.8, 3.0 Hz, 5H), 1.32 (dp, J= 7.1, 2.8 Hz, 17H), 1.18 (dt, J= 6.2, 1.2 Hz, 9H), 0.94 - 0.81 (m, 9H), 0.63 - 0.52 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C40H77NO3Si 647.6; Found 647.8. UPLC purity (CAD): 91%
[0465] Lipid 16: 1H NMR (400 MHz, CDCl3) δ 5.35 (t, J= 4.9 Hz, 6H), 4.04 (qdd, J= 6.2, 4.4, 2.0 Hz, 3H), 3.57 (t, J= 5.4 Hz, 2H), 2.56 - 2.47 (m, 2H), 2.44 - 2.36 (m, 2H), 2.24 (s, 3H), 2.19 - 1.93 (m, 12H), 1.61 - 1.38 (m, 10H), 1.32 (h, J= 3.5 Hz, 12H), 1.19 (dt, J= 6.2,
1.2 Hz, 9H), 0.89 (td, J= 6.1, 3.8 Hz, 9H), 0.65 - 0.54 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C37H73NO4Si 623.5; Found 623.8. UPLC purity (CAD): 89%
[0466] Lipid 17: 1H NMR (400 MHz, CDCl3) δ 5.41 - 5.29 (m, 6H), 4.04 (qdd, J= 6.3, 4.6, 1.9 Hz, 3H), 3.57 (t, J= 5.4 Hz, 2H), 2.51 (t, J= 5.4 Hz, 2H), 2.38 (dd, J= 8.3, 6.5 Hz, 2H), 2.18 - 1.92 (m, 13H), 1.56 (ddt, J= 12.6, 9.8, 6.2 Hz, 3H), 1.44 (dddd, J= 13.6, 12.0, 8.0, 5.9 Hz, 7H), 1.32 (dq, J = 6.7, 3.4 Hz, 15H), 1.19 (dt, J= 6.1, 1.2 Hz, 9H), 0.89 (td, J= 6.1, 3.7 Hz, 9H), 0.64 - 0.53 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C38H75NO4Si 637.6; Found 637.8. UPLC purity (CAD): 89%
[0467] Lipid 18: 1H NMR (400 MHz, CDCl3) δ 5.46 - 5.27 (m, 6H), 4.03 (pdd, J= 6.2, 4.4, 1.9 Hz, 3H), 3.61 - 3.54 (m, 2H), 2.53 (t, J= 5.4 Hz, 2H), 2.43 - 2.35 (m, 2H), 2.25 (s, 3H), 2.17 - 1.94 (m, 12H), 1.56 (ddt, J= 12.7, 9.9, 6.2 Hz, 3H), 1.51 - 1.37 (m, 7H), 1.37 - 1.23 (m, J= 3.5, 2.9 Hz, 16H), 1.19 (dt, J= 6.2, 1.2 Hz, 9H), 0.96 - 0.81 (m, 9H), 0.62 - 0.50 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C39H77NO4Si 651.6; Found 651.8. UPLC purity (CAD): 92%
[0468] Lipid 19: 1H NMR (400 MHz, CDCl3) δ 5.35 (t, J= 5.0 Hz, 6H), 4.04 (qdd, J= 6.3, 4.5, 1.9 Hz, 3H), 2.20 (s, 8H), 2.17 - 1.97 (m, 12H), 1.55 (ddt, J= 12.6, 9.9, 6.2 Hz, 3H), 1.50
- 1.37 (m, 7H), 1.37 - 1.22 (m, 24H), 1.19 (dt, J= 6.1, 1.2 Hz, 9H), 0.93 - 0.83 (m, 9H), 0.62
- 0.54 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C42H83NO3Si 677.6; Found 678.2. UPLC purity (CAD): 99%
[0469] Lipid 20: 1H NMR (400 MHz, CDCl3) δ 5.35 (t, J= 5.0 Hz, 6H), 4.04 (tt, J= 8.3, 6.1 Hz, 3H), 2.21 (s, 8H), 2.19 - 1.97 (m, 13H), 1.58 - 1.50 (m, 3H), 1.50 - 1.37 (m, 7H), 1.37 - 1.22 (m, 26H), 1.19 (dt, J= 6.1, 1.2 Hz, 9H), 0.88 (t, J= 6.8 Hz, 9H), 0.61 - 0.54 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C43H85NO3Si 691.6; Found 692.2. UPLC purity (CAD): 97%
[0470] Lipid 21: 1H NMR (400 MHz, CDCl3) δ 5.38 (t, J= 4.9 Hz, 6H), 4.07 (dqd, J= 8.5, 5.4, 2.1 Hz, 3H), 2.71 (s, 6H), 2.21 - 1.98 (m, 12H), 1.58 (ddt, J= 12.6, 9.8, 6.2 Hz, 5H), 1.52
- 1.40 (m, 6H), 1.40 - 1.26 (m, 21H), 1.21 (dd, J= 6.1, 1.5 Hz, 15H), 0.91 (t, J= 6.8 Hz, 9H), 0.67 - 0.54 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C43H85NO3Si 691.6; Found 692.2. UPLC purity (CAD): 99%
[0471] Lipid 22: 1H NMR (400 MHz, CDCl3) δ 5.41 - 5.28 (m, 6H), 4.04 (s, 2H), 3.62 (dq, J= 13.1, 6.6 Hz, 3H), 2.89 (dt, J= 12.5, 4.2 Hz, 2H), 2.17 - 2.07 (m, 3H), 2.03 (td, J= 11.9, 5.8 Hz, 9H), 1.53 (s, 14H), 1.51 - 1.40 (m, 10H), 1.40 - 1.22 (m, 23H), 1.19 (dd, J = 6.1, 1.3 Hz, 8H), 0.89 (t, J = 6.8 Hz, 8H), 0.57 (s, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C45H89NO3Si 719.7; Found 720.3. UPLC purity (CAD): 92%
[0472] Lipid 23: 1H NMR (400 MHz, CDCl3) δ 9.54 (s, 1H), 5.38 (t, J= 4.9 Hz, 6H), 4.06 (s, 4H), 2.94 (s, 1H), 2.69 (t, J= 5.6 Hz, 2H), 2.04 (q, J= 6.5 Hz, 11H), 1.87 (s, 1H), 1.65 - 1.53 (m, 13H), 1.53 - 1.26 (m, 26H), 1.25 - 1.17 (m, 9H), 0.91 (t, J= 6.8 Hz, 9H), 0.62 - 0.54 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C40H79NO3Si 649.6; Found 650.2. UPLC purity (CAD): 99%
[0473] Lipid 24: 1H NMR (400 MHz, CDCl3) δ 5.38 (t, J= 4.9 Hz, 6H), 4.06 (dqd, J= 8.3, 5.2, 2.1 Hz, 3H), 3.69 - 3.55 (m, 1H), 3.31 (s, 5H), 2.48 (s, 2H), 2.23 - 2.11 (m, 4H), 2.11 - 1.96 (m, 9H), 1.58 (ddt, J= 12.6, 9.6, 6.2 Hz, 5H), 1.52 - 1.25 (m, 29H), 1.24 - 1.18 (m, 9H), 0.91 (t, J = 6.7 Hz, 9H), 0.70 - 0.51 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C42H81NO3Si 675.6; Found 676.2. UPLC purity (CAD): 95%
3. Synthesis of Lipids 33 and 34.
 a) Synthesis of (Z)-2-((undec-5-en-2-yloxy)carbonyl)benzoic acid (30):
a) Synthesis of (Z)-2-((undec-5-en-2-yloxy)carbonyl)benzoic acid (30):

[0474] A solution of (5Z)-undec-5-en-2-ol 1 (15 g, 88.0 mmol) and phthalic anhydride (13.7 g, 92.5 mmol) in toluene (100 mL) was refluxed 2 days (130 °C). The solution was cooled and concentrated to dryness. The viscous oil was suspended in water (500 mL) and solid sodium carbonate (18.7 g, 176.1 mmol) was slowly added. The suspension was extracted with ethyl acetate (300 mL) then the aqueous was acidified with 6 M HCl and extracted with ethyl acetate (300 mL), dried on magnesium sulfate, filtered, and concentrated to give 2-{[(5Z)-undec-5-en- 2-yloxy]carbonyl}benzoic acid as a colorless oil that solidified upon standing (24.6 g, 88%). b) Synthesis of (S.Z)-undec-5-en-2-ol (31):

[0475] A solution of brucine (6.2 g, 15.7 mmol) and 2-{[(5Z)-undec-5-en-2- yloxy] carbonyl [benzoic acid 30 (5 g, 15.703 mmol, 1 equiv.) was refluxed in the minimum amount of acetone (-40-50 mL). The oil bath was then switched off and slowly cooled to room temperature. Upon cooling (-1-2 hours), a crystalline solid was isolated by decanting the supernatant and rinsing the solid with acetone (10 mL). The solid was treated with 1 M HCl (100 mL), extracted with ethyl acetate, dried on magnesium sulfate, filtered, and concentrated to afford a sticky solid. The solid was dissolved in 1: 1 MeOH/THF (50 mL) and 5 M NaOH (1.25 eq., 25 mL) and stirred overnight at RT. The MeOH and THF was evaporated and the aqueous solution was extracted with hexanes (2 x 100 mL), dried on magnesium sulfate, filtered, and concentrated to dryness to give (2S,5Z)-undec-5-en-2-ol 31 (1 g, 37%, ee = 95%). Absolute stereochemistry and enantiomeric excess was determined by Mosher ester NMR analysis.
c) Synthesis of (6-bromohexyl)tris(((S.Z)-undec-5-en-2-yl)oxy)silane
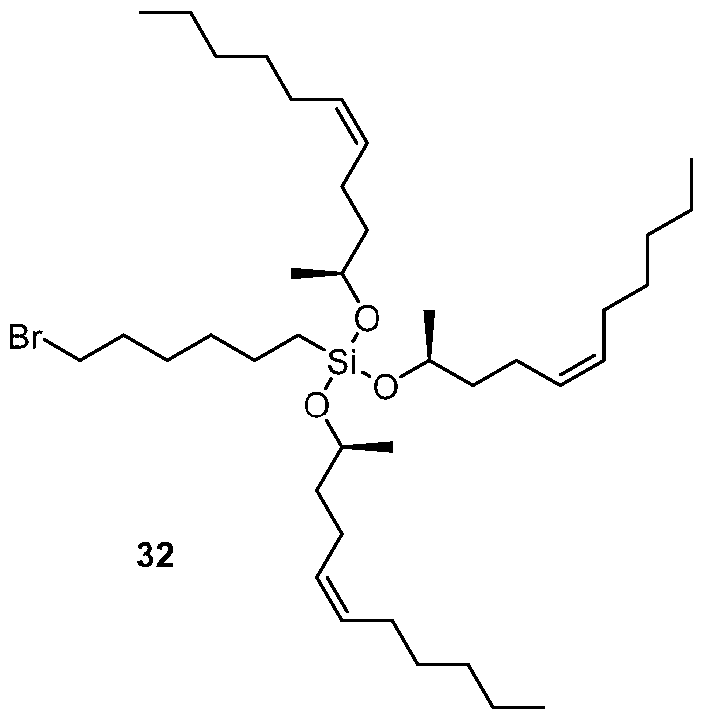
[0476] Compound 32 was prepared from (2S,5Z)-undec-5-en-2-ol (1 g, 5.9 mmol), Triethylamine (0.76 g, 1.1 mL, 7.6 mmol) and (6-bromohexyl)trichlorosilane (0.56 g, 0.37 mL, 1.9 mmol) using the same procedure described for compound 4. (6-Bromohexyl)tris[(2S,5Z)- undec-5-en-2-yloxy] silane 32 (1.3 g, quant.) was used in the next step without purification. d) Synthesis of l-(6-(tris(((S.Z)-undec-5-en-2-yl)oxy)silyl)hexyl)azetidine (33h

[0477] Compound 33 was prepared from (6-bromohexyl)tris[(2S,5Z)-undec-5-en-2- yloxy]silane (600 mg, 0.86 mmol) and azetidine (244 mg, 4.29 mmol) using the same procedure described for compound 5. l-(6-(Tris(((S,Z)-undec-5-en-2-yl)oxy)silyl)hexyl)azetidine 33 was isolated as a pale-yellow oil (281 mg, 48%). 1H NMR (400 MHz, CDCl3) δ 5.35 (t, J= 4.9 Hz, 6H), 4.03 (h, J= 6.0 Hz, 3H), 2.21 (s, 8H), 2.18 - 1.95 (m, 13H), 1.55 (ddt, J= 12.7, 9.9, 6.2 Hz, 3H), 1.49 - 1.38 (m, 7H), 1.38 - 1.22 (m, 23H), 1.19 (d, J= 6.1 Hz, 9H), 0.88 (t, J= 6.7
Hz, 9H), 0.58 (dd, J = 10.2, 6.1 Hz, 2H). LRMS (ESI+) m/z: [M + H]+Calcd for C42H8iNO3Si 675.6; Found 677.0. UPLC purity (CAD): 99% e) Synthesis of N,N-dimethyl-6-(tris(((S.Z)-undec-5 -en-2- yl)oxy)silyl)hexan-1-amine (34):

[0478] Compound 34 was prepared from (6-bromohexyl)tris[(2S,5Z)-undec-5-en-2- yloxy]silane (600 mg, 0.86 mmol) and 2 M Dimethylamine (4.3 mL, 8.6 mmol) using the same procedure described for compound 5. Dimethyl(6-{tris[(2S,5Z)-undec-5-en-2- yloxy] silyl }hexyl)amine 34 was isolated as a pale-yellow oil (367 mg, 64%). 1H NMR (400 MHz, CDCl3) δ 3.83 (t, J= 6.2 Hz, 6H), 3.17 (t, J= 7.0 Hz, 4H), 2.37 (t, J= 6.7 Hz, 2H), 2.26 (tt, J= 7.0, 2.5 Hz, 6H), 2.14 (td, J= 12, 3.6 Hz, 6H), 2.10 - 2.03 (m, 2H), 1.75 (p, J= 6.7 Hz, 7H), 1.70 - 1.46 (m, 11H), 1.44 - 1.22 (m, 15H), 0.90 (d, J= 6.7 Hz, 18H), 0.68 - 0.61 (m, 2H). LRMS (ESI+) m/z: [M + H]+ Calcd for C41H81NO3Si 663.6; Found 664.8. UPLC purity (CAD): 99%.


[0479] 3,4-dihydro-2H-pyran (26 g, 309.09 mmol) was added slowly to a stirred solution of pent-4-yn-1-ol (20 g, 237.9 mmol) and p-toluenesulfonic acid (4.5 g, 23.8 mmol) in DCM (200 mL). After stirring at room temperature overnight, the reaction mixture was diluted with water, washed with brine, dried over anhydrous magnesium sulfate, filtered, and concentrated to dryness. The residue was purified by column chromatography to give 2-(pent-4-yn-1- yloxy)tetrahydro-2H-pyran 35 as a pale-yellow oil (22 g, 55%). b) Synthesis of 2-((8-methylnon-4-vn-1-yl)oxy)tetrahvdro-2H-pyran (36):
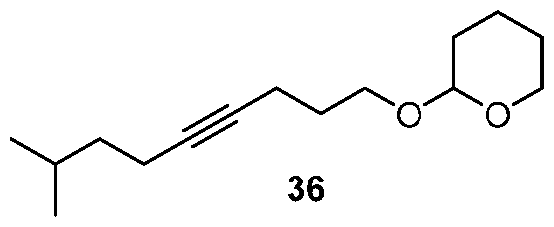 [0480] To a cooled solution (-78 °C) of 2-(pent-4-yn-1-yloxy)tetrahydro-2H-pyran 35 (10 g, 59.44 mmol, 1 equiv.) in THF (80 mL) was slowly added 2.5 M n-BuLi in hexanes (28.5 mL, 71.3 mmol) dropwise. After 30 min at -78 °C, HMPA (31.9 g, 31 mL, 178 mmol) was added followed by l-bromo-3-methylbutane (9.0 g, 7.1 mL, 59.4 mmol) and then the mixture was warmed to room temp and stirred for 30 minutes. The reaction was carefully quenched with water (50 mL) and concentrated to remove the THF/hexanes. The remaining aqueous solution was diluted with ethyl acetate (200 mL) and washed with water (200 mL) and brine (3 x 100 mL), dried on magnesium sulfate, filtered, and concentrated to dryness. The crude product was purified by column chromatography to give 2-((8-methylnon-4-yn-1-yl)oxy)tetrahydro-2H- pyran 36 as a colorless oil (11.4 g, 80%). c) Synthesis of 8-methylnon-4-yn-1-ol (37):
[0480] To a cooled solution (-78 °C) of 2-(pent-4-yn-1-yloxy)tetrahydro-2H-pyran 35 (10 g, 59.44 mmol, 1 equiv.) in THF (80 mL) was slowly added 2.5 M n-BuLi in hexanes (28.5 mL, 71.3 mmol) dropwise. After 30 min at -78 °C, HMPA (31.9 g, 31 mL, 178 mmol) was added followed by l-bromo-3-methylbutane (9.0 g, 7.1 mL, 59.4 mmol) and then the mixture was warmed to room temp and stirred for 30 minutes. The reaction was carefully quenched with water (50 mL) and concentrated to remove the THF/hexanes. The remaining aqueous solution was diluted with ethyl acetate (200 mL) and washed with water (200 mL) and brine (3 x 100 mL), dried on magnesium sulfate, filtered, and concentrated to dryness. The crude product was purified by column chromatography to give 2-((8-methylnon-4-yn-1-yl)oxy)tetrahydro-2H- pyran 36 as a colorless oil (11.4 g, 80%). c) Synthesis of 8-methylnon-4-yn-1-ol (37):

[0481] To a solution of 2-((8-methylnon-4-yn-1-yl)oxy)tetrahydro-2H-pyran 36 (11.4 g, 47.8 mmol) in MeOH (100 mL) was added p-toluenesulfonic acid (82 mg, 0.48 mmol). The solution was stirred overnight at RT then concentrated to dryness. The crude product was dissolved in ethyl acetate (150 mL), washed with saturated sodium bicarbonate (2 x 100 mL) and brine (1 x 100 mL), dried on magnesium sulfate, filtered, and concentrated in vacuo to dryness. The residue was purified by column chromatography to give 8-methylnon-4-yn-1-ol 37 as a colorless oil (6.5 g, 88%). d) Synthesis of 8-methylnon-4-vnal (38):

[0482] To a solution of 8-methylnon-4-yn-1-ol 37 (4 g, 25.9 mmol) in dichloromethane (100 mL) was added Dess-Martin periodinane (13.2 g, 31. 1 mmol.) and the solution was then stirred for 2 h at RT. The solution was concentrated to a slurry then diluted with hexanes (-100 mL). The solid was removed by filtration and the filtrate was stirred overnight with saturated bicarbonate solution to neutralize residual acetic acid. The hexane layer was dried on magnesium sulfate, filtered, and concentrated to dryness. The product, 8-methylnon-4-ynal 38, was used in the next step without further purification.
e) Synthesis of 9-methyldec-5-vn-2-ol (39):

[0483] A solution of 8-methylnon-4-ynal 38 (4 g, 26.3 mmol) in THF (10 mL) was added dropwise to a cooled solution of methyl magnesium bromide (17.5 mL, 3M in ether, 52.6 mmol) in THF (25 mL). The solution was stirred at RT for 1 hour then quenched with 1 M HCl (5 mL), diluted with ether (100 mL), and separated. The organic layer was dried on magnesium sulfate and filtered, and the product 39 was used in the next step without further purification. f) Synthesis of (6-bromohexyl)tris((9-methyldec-5-vn-2-yl)oxy)silane

[0484] Compound 40 was prepared from 9-methyldec-5-yn-2-ol (1 g, 5.9 mmol), (6- bromohexyl)trichlorosilane (0.57 g, 1.9 mmol), triethylamine (0.78 g, 1.08 mL, 7.7 mmol) using the same procedure described for compound 4. (6-Bromohexyl)tris[(9-methyldec-5-yn- 2-yl)oxy] silane 40 (1 g, 75%) was used in the next step without purification.
g) Synthesis of N.N-dimethyl-6-(tris((9-methyldec-5-vn-2-yl)oxy)silyl) hexan-1-amine (41):

[0485] Lipid 41 was prepared from (6-bromohexyl)tris[(9-methyldec-5-yn-2-yl)oxy] silane (1 g, 1.4 mmol) and 2.5M dimethylamine in THF (7.2 mL, 14.4 mmol) using the same procedure described for compound 5. Dimethyl(6-{tris[(9-methyldec-5-yn-2- yl)oxy]silyl}hexyl)amine 41 was isolated as acolorless oil (422 mg, 45%). 1HNMR(400 MHz, CDCl3) δ 4.10 (hept, J= 5.9 Hz, 3H), 2.26 - 2.10 (m, 20H), 1.73 - 1.51 (m, 11H), 1.51 - 1.23 (m, 14H), 1.19 (d, J = 6.1 Hz, 9H), 0.88 (d, J = 6.6 Hz, 18H), 0.64 - 0.57 (m, 2H). LRMS (ESI+) m/z: [M + H]+Calcd for C41H75NO3Si 657.6; Found 658.8. UPLC purity (CAD): 98%
5. Synthesis of Lipid 47
 a) Synthesis of 2-(dec-4-yn-1-yloxy)tetrahydro-2H-pyran (42)
a) Synthesis of 2-(dec-4-yn-1-yloxy)tetrahydro-2H-pyran (42)

[0486] Compound 42 was prepared from 2-(pent-4-yn-1-yloxy)tetrahydro-2H-pyran 35 (10 g, 59.4 mmol), 1-bromopentane (9.0 g, 59.4 mmol), 2.5 M n-BuLi in hexanes (28.5 mL), HMPA (31.0 g, 178.3 mmol) and THF (80 mL) using the same procedure as described for compound 36. 2-(Dec-4-yn-1-yloxy)tetrahydro-2H-pyran 42 was isolated as a colorless oil (11.6 g, 82%) b) Synthesis of dec-4-vn-1-ol (43):

[0487] Compound 43 was prepared from 2-(dec-4-yn-1-yloxy)tetrahydro-2H-pyran 42 ( 11.6 g, 48.7 mmol)), pTsOH (84 mg, 0.49 mmol), and methanol (100 mL) using the same procedure as described for compound 37. Dec-4-yn-1-ol 43 was isolated as a colorless oil (7.0 g, 93%).
c) Synthesis of dec-4-vnal (44):

[0488] Compound 44 was prepared from dec-4-yn-1-ol (750 mg, 4.9 mmol), Dess-Martin periodinane (2.3 g, 5.4 mmol) and dichloromethane (20 mL) using the same procedure as described for compound 38. Dec-4-ynal 44 was isolated as a colorless oil (0.72 g, 97%) d) Synthesis of undec-5-yn-2-ol (45):

[0489] Compound 45 was prepared from 3 M methylmagnesium bromide in diethyl ether (4.7 mL, 14.2 mmol), dec-4-ynal 44 (0.72 g, 4.7 mmol) and tetrahydrofuran (26 mL)using the same procedure as described for compound 39 . Undec-5-yn-2-ol 45 was isolated as a colorless oil (710 mg, 89%) e) Synthesis of (6-bromohexyl)tris(undec-5-yn-2-yloxy)silane (46):

[0490] Compound 46 was prepared from 9 undec-5-yn-2-ol 45 using the same procedure as described for compound 4. (6-Bromohexyl)tris(undec-5-yn-2-yloxy)silane 46 was used in the next step without purification.
f) Synthesis of N.N-dimethyl-6-(tris(undec-5-vn-2-yloxy)silyl)hexan-1- amine (47):

[0491] Lipid 47 was prepared from (6-bromohexyl)tris(undec-5-yn-2-yloxy)silane 46 (450 mg, 0.65 mmol) and 2M dimethylamine in THF (2.3mL, 4.5 mmol) using the same procedure as described for compound 5. N,N-Dimethyl-6-(tris(undec-5-yn-2-yloxy)silyl)hexan-1-amine 47 was isolated as a pale-yellow oil (98 mg, 23% over 2 steps). 1H NMR (400 MHz, CDCl3) δ 4.13 (h, J = 5.5 Hz, 3H), 2.25 (d, J = 11.8 Hz, 14H), 2.15 (t, J = 7.3 Hz, 6H), 1.65 (ddt, J = 292, 13.3, 6.4 Hz, 8H), 1.55 - 1.26 (m, 26H), 1.21 (d, J = 62 Hz, 9H), 0.92 (s, 9H), 0.67 - 0.59 (m, 2H). LRMS (ESI+) m/z: [M + H]+Calcd for C41H75NO3Si 657.6; Found 658.8. UPLC purity (CAD): 94%
Example 2. Lipid nanoparticle formulations
1. 1.6:54.6:32.8:10.9 (PEG2000-C-DMA):(Ionizable lipid 4):(Cholesterol):(Phospholipid) Composition
[0492] Lipids were dissolved in ethanol in a 4-component solution: PEG2000-C-DMA, ionizable lipid 4, cholesterol, and phospholipid (DSPC, DOPC, POPC, or DOPE). Lipid stocks were made at molar ratios of 1.6:54.6:32.8: 10.9 (PEG2000-C-DMA): (Ionizable lipid 4): (Cholesterol): (Phospholipid), achieving a total concentration of about 7 mg/mL in 100% ethanol. tdTomato mRNA was diluted in 350 mM acetate buffer, pH 5 and nuclease-free water to achieve a final mRNA concentration of 0.366 mg/mL in 100 mM acetate buffer, pH 5. Lipid and nucleic acid solutions were mixed at equal volumes through a T-connector at a flow rate of 400 mL/min and subsequently diluted with about 4 volumes of PBS, pH 7.4.
Diluted formulations were dialyzed in Slide-A-Lyzer dialysis units (MWCO 10,000) overnight at 4 °C against 10 mM Tris, 500 mM NaCl, pH 8 buffer. Dialyzed formulations were concentrated to approximately 0.6 mg/mL mRNA with VivaSpin concentrator units (MWCO 100,000) and subsequently dialyzed against 5 mM Tris, 10% sucrose, pH 8 buffer (T10S) overnight at 4 °C. Formulations in T10S buffer were fdtered through a 0.2-pm syringe fdter (polyethersulfone (PES) membrane). Concentration and encapsulation efficiency of the nucleic acid was determined using the RiboGreen assay. Particle size (Z -average) and polydispersity (PDI) were measured by dynamic light scattering (DLS) using a Malvern Nano Series Zetasizer.
2. 2.5:54.2:32.5:10.8 (PEG2000-C-DMA):(Ionizable lipid 4):(Cholesterol):(Phospholipid) Composition
[0493] The lipid solution was prepared as described above but at molar ratio of 2.5:54.2:32.5: 10.8 (PEG2000-C-DMA): (Lipid 4):(Cholesterol):(Phospholipid). tdTomato mRNA was diluted in 100 mM 2-(N-morpholino)ethanesulfonic acid (MES), pH 6 buffer and nuclease-free water to achieve a final mRNA of 0.092 mg/mL in 50 mM MES buffer, pH 6. Lipid and nucleic acid solutions were mixed at a 1 :4 lipidmucleic acid volume-to-volume (v/v) ratio through a T-connector at an offset flow rate of 100:400 mL/min lipidmucleic acid then diluted with 'A volume of 80 mM phosphate, 700 mM NaCl, pH 8.0 buffer. Ethanol was subsequently removed by tangential flow ultrafiltration, followed by buffer exchange into PBS, pH 7.4, then T10S buffer, pH 8.0. Formulations were sterile filtered through a 0.2-pm syringe filter (PES membrane). Nucleic acid concentration, encapsulation efficiency, particle size (Z- average), and polydispersity were measured as described above.
3. Particle characteristics of LNP formulations
[0494] LNP formulations containing Lipid 4 were all stable particles with high encapsulation efficiency (Tables 2 and 3). Additionally, formulations showed reproducibility in particle characteristics between different lots of Lipid 4 (Table 2).
Table 2. Particle characteristics of LNPs containing tdTomato mRNA with molar ratios of 1.6:54.6:32.8: 10.9 (PEG2000-C-DMA): (Ionizable lipid):(Cholesterol):(Phospholipid) for in vivo administration


Table 3. Particle characteristics of LNPs containing tdTomato with molar ratios of 2.5:54.2:32.5: 10.8 (PEG2000-C-DMA): (Ionizable lipid):(Cholesterol):(Phospholipid) for in vivo administration

Example 3. In vivo hepatic clearance of LNP containing Lipid 4 or related silicon lipids
1. LNP preparations
[0495] LNP formulations were prepared as described above at a molar ratio of 1.6:54.6:32.8: 10.9 (PEG2000-C-DMA): (Ionizable lipid):(Cholesterol):(DSPC). Note that the payload used was EGFP mRNA (Trilink). In addition to Lipid 4 and the benchmark Lipid 25, additional ionizable lipids tested include Lipid 6, Lipid 7, and Lipid 26.
2. In vivo administration of LNPs
[0496] LNP formulations containing EGFP mRNA were injected intravenously at 0.5 mg/kg to female BALB/c mice (7-8 weeks old). On the day of injection, LNP formulations were fdtered and diluted to the required dosing concentration with PBS, pH 7.4. At 24 hours post- injection, animals were sacrificed by injecting with a lethal dose of ketamine/xylazine. Liver samples (from left lateral lobe) were weighed and collected in FASTPREP' tubes and the tissues subsequently kept frozen on dry ice before being transferred to -80 °C for long-term storage.
3. Lipid LC-MS analysis
[0497] Frozen liver tissues were thawed and homogenized with a F ASTPREP' homogenizer in 20X volume of PBS, pH 7.4. Homogenates were centrifuged at 16,000 RPM for 10 minutes at 4 °C. 40 μL of lysate supernatant was plated into a deep well plate and subsequently diluted with 160 μL of an internal suitability standard. Plates were centrifuged at 1000 rpm for 15 min at 4 °C.
[0498] Analysis was performed using a Q-Exactive Orbitrap mass spectrometer (MS) coupled to an Thermo Vanquish lipid chromatography (LC), using reverse-phase LC separation with an ammonium acetate/isopropyl alcohol (IP A) gradient. Quantitation of the ionizable lipid was by parallel reaction monitoring against a calibration curve. Calibration used a similar class of synthetic lipid as internal standard.
[0499] Rate of clearance of ionizable lipid was determined by examining the amount of lipid remaining in liver at 24 hours post-intravenous administration of the LNPs. LNP formulations containing Lipid 6, Lipid 7, and Lipid 4 all demonstrated lower levels of ionizable lipid remaining when compared to benchmark. (Table 4).
Table 4. Ionizable lipid remaining in liver at 24 hours post intravenous administration of 0.5 mg/kg EGFP mRNA LNP in female BALB/c mice (n=4)

[0500] Rate of clearance was further examined for Lipid 4 over a 7-day time course. As a non-degradable Lipid, 25 remained at a relative constant lipid level in the liver over seven days. Lipid 4 showed a gradual clearance from the liver, in contrast to Lipid 26, which was undetectable in the liver by 24 hours (Table 5).
Table 5. Ionizable lipid remaining in liver over 7 days (time points at 24 h, 48 h, and Day 7) following intravenous administration of 0.5 mg/kg EGFP mRNA LNP in female BALB/c mice (n=4)

Example 4. Preferential intravenous delivery of LNP containing Lipid 4 to mouse liver
1. In vivo administration of tdTomato LNPs
[0501] LNP formulations containing tdTomato mRNA were injected intravenously at 3.0 or 6.0 mg/kg to female BALB/c mice (7-8 weeks old). On the day of injection, LNP formulations were fdtered and diluted to the required dosing concentration with PBS, pH 7.4. At 24 hours post-injection, animals were sacrificed by injecting with a lethal dose of ketamine/xylazine. Liver samples (from left lateral lobe) were weighed and collected in FASTPREP' tubes, where the tissues were subsequently kept frozen on dry ice before being transferred to -80 °C for long- term storage.
2. tdTomato activity analysis
[0502] Frozen liver pieces were thawed and homogenized using a FASTPREP® homogenizer in 0.5 mL of lx Halt Inhibitor Cocktail (100X Halt Protease Inhibitor diluted in PBS pH 7.4). The lysate was centrifuged at 16,000 RPM for 10 minutes at 4 °C. 10 μL of supernatant was loaded into a clear non-binding 96-well plate and 90 μL of PBS was added to each well containing sample. Fluorescence was measured using a plate reader (Excitation 554 nm/ Emission 581 nm). tdTomato activity was quantified by comparing sample fluorescence to tdTomato protein standards.
3. Performance of Lipid 4-containing LNPs in intravenous mouse models
[0503] LNP formulations (2.5:54.2:32.5: 10.8 (PEG2000-C-DMA): (Lipid 4): (Cholesterol): (Phospholipid) encapsulating tdTomato mRNA payload and ionizable Lipid 4 were compared
to benchmark control for activity in a tdTomato mouse model following intravenous administration (at 3 or 6 mg/kg dose). At 24 hours post-injection, formulations containing Lipid 4 exhibited high levels of tdTomato activity in the liver, comparable to benchmark. Additionally, Lipid 4-containing LNPs showed preferential delivery to the liver as evident in more than 100-fold higher in tdTomato activity in the liver compared to the spleen (Tables 6 and 7).
Table 6. tdTomato activity of 3.0 mg/kg LNP containing tdTomato mRNA at 24 hours following intravenous administration in female BALB/c mice (n=4).

Table 7. tdTomato activity of 6.0 mg/kg LNP containing tdTomato mRNA at 24 hours following intravenous administration in female BALB/c mice (n=4).
 Example 5. Performance of Lipid 4-containing LNPs with different phospholipids in an intravenous mouse model
Example 5. Performance of Lipid 4-containing LNPs with different phospholipids in an intravenous mouse model
[0504] Lipid 4 LNP formulations containing a tdTomato mRNA payload with different phospholipids (DSPC, DOPC, POPC, or DOPE) were compared to benchmark control for activity in a tdTomato mouse model. LNPs were administered intravenously (as described previously) at a dose of 1.0 mg/kg. 24 hours post-injection, liver sections were collected and tdTomato activity assessed. All Lipid 4-containing formulations again showed preferential delivery to the liver as compared to levels in the spleen and higher levels of tdTomato activity in the liver were evident for all Lipid 4 formulations compared to benchmark. Particularly, Lipid 4 formulation containing POPC showed highest level of tdTomato expression (Table 8).
Table 8. tdTomato activity of 1.0 mg/kg LNP containing tdTomato mRNA at 24 hours following intravenous administration in female BALB/c mice (n=4).

Example 6. Activity of various silicon ether lipids
[0505] LNP formulations containing a tdTomato mRNA payload with different silicon ether ionizable lipids (Lipid 4, Lipid 24, Lipid 27, Lipid 28, or Lipid 29) were compared to benchmark control for activity in tdTomato mouse model. LNPs were formulated as described previously for molar ratios of 1.6:54.6:32.8: 10.9 (PEG2000-C-DMA): (Ionizable lipid):(Cholesterol):(DSPC). LNPs were administered intravenously (as described previously) at a dose of 1.0 mg/kg. 24 hours post-administration, liver sections were collected and assessed for tdTomato activity. FIG. 1 presents results from this Example, indicating the respective pKa values of the tested formulations. Formulations containing Lipid 4 or Lipid 24 both showed higher levels of tdTomato activity in the liver compared to benchmark (Lipid 25). In contrast,
formulations containing Lipid 27, Lipid 28, or Lipid 29 were 5-15 fold lower in tdTomato activity in the liver compared to benchmark (FIG. 1).
Example 7. Determination of LNP pKa
[0506] The pKa of the various lipid nanoparticles comprising different ionizable lipids was determined using a microplate -based 6-(p-toluidino)-2-naphthalenesulfonyl chloride (TNS) assay. To start, a buffer system consisting of 20 mM sodium phosphate, 25 mM sodium citrate, 20 mM ammonium acetate, and 150 mM sodium chloride was prepared. In short, 5.36 g of sodium phosphate dibasic heptahydrate (Sigma-Aldrich Cat#S9390-lKG), 5.25 g of citric acid monohydrate (Sigma- Aldrich Cat#Cl 909-500G), 1.54 g ammonium acetate (Fluka Cat#17836-50G), and 8.77 g of sodium chloride (Sigma-Aldrich Cat#S9888-10KG) were weighed out and 1 L of MilliQ water was added (by weight to a tared container) to dissolve the powders. 40 mL of the buffer was subsequently sub-aliquoted into separate 50-mL Falcon tubes and the pH was adjusted to the target levels using 10 N sodium hydroxide at ambient temperature. Sixteen (16) buffers in the pH range of 4.5-8.0 were prepared and the final pH range consisted of 4.5, 5.0, 5.5, 5.8, 5.9, 6.0, 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.8, 7.0, 7.5, and 8.0. Each pH-adjusted buffer was then passed through 0.2-pm syringe filters (Acrodisc 32-mm Syringe Filters with 0.2-pm Supor Membrane Cat#4652) and the final pH was determined following filtration. Post-filtration pH values were used for determining the pKa.
[0507] Stock LNPs were prepared in phosphate-buffered saline at a concentration of 800 pM total lipid and TNS was prepared as a 240-pM stock solution in distilled water. In 96-well black fluorescence plates, the LNPs were diluted to 20 pM lipid in 200 μL buffered solution containing 6 pM TNS. Just prior to analysis, the buffers were pre-incubated to 37 °C in deep well plates. In the fluorescence plate, 190 μL of the warmed buffer was added followed by 5 μL of the TNS (240 pM), then 5 μL of the diluted LNP (20 pM). The samples were then mixed well with a pipette and fluorescence intensity was monitored at 37 °C for 90 mins (with measurements at 0 min, 30 mins, 60 mins, and 90 mins) in a Tecan Safire 2 fluorescence plate reader using excitation and emission wavelengths of 322 nm and 431 nm, respectively, with 20-nm slit widths. The fluorescence values at each pH were normalized to that of pH 4.5, where fluorescence value at pH 4.5 was treated as 100%. A sigmoidal best fit analysis was applied to the normalized data and the pKa was measured as the pH giving rise to half-maximal fluorescence intensity (FIG. 2).
[0508] Although the foregoing disclosure has been described in some detail by way of illustration and example for purpose of clarity of understanding, one of skill in the art will appreciate that certain changes and modifications within the spirit and scope of the disclosure may be practiced, e.g., within the scope of the appended claims. It should also be understood that aspects of the disclosure and portions of various recited embodiments and features can be combined or interchanged either in whole or in part. In the foregoing descriptions of the various embodiments, those embodiments which refer to another embodiment may be appropriately combined with other embodiments as will be appreciated by one of skill in the art. Furthermore, those of ordinary skill in the art will appreciate that the foregoing description is by way of example only and is not intended to limit the disclosure. In addition, each reference provided herein is incorporated by reference in its entirety for all purposes to the same extent as if each reference was individually incorporated by reference.
Claims
1. A compound having the formula:
 or the formula of a pharmaceutically acceptable salt thereof, wherein:
or the formula of a pharmaceutically acceptable salt thereof, wherein:
R1 and R2 are each independently hydrogen or C1-4 alkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl;
R3, R4, and R5 are each independently cis C5-20 alkenyl or C5-20 alkynyl, each having only one unsaturated bond; and n is an integer from 4 to 8.
2. The lipid nanoparticle of claim 1, wherein R3, R4, and R5 are each independently cis C5-20 alkenyl having only one double bond.
3. The compound of claim 1 or 2, wherein R1 and R2 are each independently C1-3 alkyl.
4. The compound of claim 3, wherein R1 and R2 are each independently methyl, ethyl, or isopropyl.
5. The compound of claim 4, wherein R1 and R2 are each methyl.
6. The compound of claim 1 or 2, wherein R1 and R2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered saturated heterocyclyl in which the nitrogen is the only heteroatom.
7. The compound of claim 6, wherein R1 and R2 are combined with the nitrogen to which they are attached to form pyrrolidyl or azetidyl.
8. The compound of any one of claims 1-7, wherein R3, R4, and R5 are each independently cis C6-12 alkenyl having only one double bond.
9. The compound of claim 8, wherein the double bond is in the 2-, 3-, 4-, or 5 -position of the alkenyl.
10. The compound of claim 9, wherein R3, R4, and R5 are each identically cis-non-3-ene-1-yl or cis-oct-3-ene-1-yl.
11. The compound of any one of claims 1-10, wherein n is 5, 6, 7, or 8.
12. The compound of claim 11, wherein n is 6 or 8.
13. The compound of claim 12, wherein n is 6.
14. The compound of claim 1, wherein the compound is:





15. A lipid nanoparticle comprising the compound of any one of claims 1- 14.
16. The lipid nanoparticle of claim 15, wherein the lipid nanoparticle has a pKa between 5.8 and 6.9.
17. A lipid nanoparticle comprising an ionizable lipid or a pharmaceutically acceptable salt thereof, the ionizable lipid having the formula:
 wherein the lipid nanoparticle has a pKa between 5.8 and 6.9, and wherein:
wherein the lipid nanoparticle has a pKa between 5.8 and 6.9, and wherein:
R1 and R2 are each independently hydrogen , C1-4 alkyl, or 2- to 4-membered heteroalkyl, or are combined with the nitrogen to which they are attached to form a 3- to 8-membered heterocyclyl, wherein the alkyl, heteroalkyl, and heterocyclyl optionally have one or more substitutions, and wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine;
R3, R4, and R5 are each independently C5-20 alkyl, C5-20 alkenyl, C5-20 alkynyl, or C5-12 cycloalkyl optionally having one or more substitutions, wherein the substitutions are each independently C1-6 alkyl or C2-6 alkenyl;
R6 and R7 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, with the proviso that no more than one of R6 and R7 is hydrogen;
R8 and R9 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, with the proviso that no more than one of R8 and R9 is hydrogen;
R10 and R11 are each independently hydrogen, C1-20 alkyl, C1-20 alkenyl, or C1-20 alkynyl, or are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, with the proviso that no more than one of R10 and R11 is hydrogen;
R12 and R13 are combined with the carbon to which they are attached to form cyclopropyl or cyclobutyl, or are each independently hydrogen or C1-6 alkyl optionally having one or more substitutions, wherein the substitutions are each independently hydroxy, C1-6 hydroxyalkyl, or fluorine;
X1, X2, and X3 are each independently a covalent bond, C1-6 alkylene, C1-6 alkenylene, or C1-6 alkynylene; and n is an integer from 2 to 10.
18. The lipid nanoparticle of claim 17, wherein the lipid nanoparticle further comprises a nucleic acid.
19. The lipid nanoparticle of claim 18, wherein the nucleic acid comprises RNA.
20. The lipid nanoparticle of claim 19, wherein the RNA comprises mRNA.
21. The lipid nanoparticle of any one of claims 18-20, wherein the nucleic acid encodes a protein.
22. The lipid nanoparticle of claim 21, wherein the protein is functional in or secreted by hepatocytes.
23. The lipid nanoparticle of claim 21 or 22, wherein, following administration of the lipid nanoparticle to a subject, an activity or expression of the protein in the liver of the subject is at least 20-fold greater than an activity or expression of the protein in the spleen of the subject.
24. The lipid nanoparticle of any one of claims 18-23, wherein the nucleic acid, or a protein encoded by the nucleic acid, is a component of a gene editing system.
25. The lipid nanoparticle of any one of claims 17-24, wherein R1 and R2 are each independently C1-3 alkyl.
26. The lipid nanoparticle of claim 25, wherein R1 and R2 are each independently methyl, ethyl, or isopropyl.
27. The lipid nanoparticle of claim 26, wherein R1 and R2 are each methyl.
28. The lipid nanoparticle of any one of claims 17-24, wherein R1 and R2 are combined with the nitrogen to which they are attached to form a 3- to 8-membered saturated heterocyclyl in which the nitrogen is the only heteroatom.
29. The lipid nanoparticle of claim 28, wherein R1 and R2 are combined with the nitrogen to which they are attached to form pyrrolidyl or azetidyl.
30. The lipid nanoparticle of any one of claims 17-29, wherein R3, R4, and R5 are each independently cis C6-12 alkenyl having only one double bond.
31. The lipid nanoparticle of claim 30, wherein the double bond is in the 2- , 3-, 4-, or 5-position of the alkenyl.
32. The lipid nanoparticle of claim 31, wherein R3, R4, and R5 are each identically cis-non-3-ene-1-yl or cis-oct-3-ene-1-yl.
33. The lipid nanoparticle of any one of claims 17-32, wherein R6, R8, and R10 are each independently hydrogen or C1-20 alkyl.
34. The lipid nanoparticle of claim 33, wherein R6, R8, and R10 are each identically hydrogen, methyl, ethyl, or butyl.
35. The lipid nanoparticle of any one of claims 17-32, wherein R6, R8, and R10 are each independently C1-20 alkenyl.
36. The lipid nanoparticle of claim 35, wherein R6, R8, and R10 are each cis- dec-4-ene-1-yl.
37. The lipid nanoparticle of any one of claims 17-36, wherein R7, R9, and R11 are each identically hydrogen.
38. The lipid nanoparticle of any one of claims 17-37, wherein the total number of carbons in R3, R6, and R7; the total number of carbons in R4, R8, and R9; and the total number of carbons in R5, R10, and R11 are each independently from 7 to 12.
39. The lipid nanoparticle of any one of claims 17-38, wherein each R12 and R13 is hydrogen.
40. The lipid nanoparticle of any one of claims 17-39, wherein X1, X2, and X3 are each identically a covalent bond or methylene.
41. The lipid nanoparticle of any one of claims 17-40, wherein n is 5, 6, 7, or 8.
42. The lipid nanoparticle of claim 41, wherein n is 6 or 8.
43. The lipid nanoparticle of claim 42, wherein n is 6.
44. The lipid nanoparticle of any one of claims 17-43, wherein the lipid nanoparticle further comprises a phospholipid or a pharmaceutically acceptable salt thereof.
45. The lipid nanoparticle of claim 44, wherein the tails of the phospholipid are each saturated.
46. The lipid nanoparticle of claim 45, wherein the phospholipid comprises 1,2-distearoyl-sn-glycero-3-phosphocholine (DSPC).
47. The lipid nanoparticle of any one of claims 44-46, wherein the phospholipid or the pharmaceutically acceptable salt thereof comprises between 1 mol % and 20 mol % of the total lipid of the lipid nanoparticle.
48. The lipid nanoparticle of any one of claims 17-47, wherein the ionizable lipid or the pharmaceutically acceptable salt thereof comprises between 30 mol % and 70 mol % of the total lipid of the lipid nanoparticle.
49. The lipid nanoparticle of any one of claims 17-48, wherein the lipid nanoparticle further comprises cholesterol or a derivative thereof.
50. The lipid nanoparticle of claim 49, wherein the cholesterol or the derivative thereof comprises between 20 mol % and 60 mol % of the total lipid of the lipid nanoparticle.
51. The lipid nanoparticle of any one of claims 17-50, wherein the lipid nanoparticle further comprises a conjugated lipid.
52. The lipid nanoparticle of claim 51, wherein the conjugated lipid comprises a polyethylene glycol (PEG)-lipid conjugate.
53. The lipid nanoparticle of claim 51 or 52, wherein the conjugated lipid comprises between 0.1 mol % and 5 mol % of the total lipid of the lipid nanoparticle.
54. The lipid nanoparticle of any one of claims 17-43, wherein the lipid nanoparticle comprises: the ionizable lipid or the pharmaceutically acceptable salt thereof comprising between 45 mol % and 60 mol % of the total lipid present in the lipid nanoparticle; a phospholipid or a pharmaceutically acceptable salt thereof comprising between 8 mol % and 12 mol % of the total lipid present in the lipid nanoparticle;
a cholesterol or a derivative thereof comprising between 30 mol % and 40 mol % of the total lipid present in the lipid nanoparticle; and a conjugated lipid comprising between 0.5 mol % and 3 mol % of the total lipid present in the lipid nanoparticle.
55. The lipid nanoparticle of any one of claims 17-43, wherein the lipid nanoparticle comprises: the ionizable lipid or the pharmaceutically acceptable salt thereof comprising between 52 mol % and 57 mol % of the total lipid present in the lipid nanoparticle; a phospholipid or a pharmaceutically acceptable salt thereof comprising between 10 mol % and 12 mol % of the total lipid present in the lipid nanoparticle; a cholesterol or a derivative thereof comprising between 31 mol % and 34 mol % of the total lipid present in the lipid nanoparticle; and a conjugated lipid comprising between 1 mol % and 3 mol % of the total lipid present in the lipid nanoparticle.
56. The lipid nanoparticle of any one of claims 17-55, wherein, following administering the lipid nanoparticle to a subject, a concentration of the ionizable lipid in the liver of subject 7 days after the administering is less than 50% of a concentration of the ionizable lipid in the liver 24 hours after the administering.
57. A pharmaceutical composition comprising: the lipid nanoparticle of any one of claims 15-56, or the compound of any one of claims 1-14; and a pharmaceutically acceptable carrier or pharmaceutically acceptable excipient.
58. A method for introducing a nucleic acid into a cell, the method comprising contacting the cell with the lipid nanoparticle of any one of claims 15-56.
59. The method of claim 58, wherein the cell is in a mammal.
60. The method of claim 59, wherein the cell comprises a hepatocyte.
61. A method for the in vivo delivery of a nucleic acid, the method comprising administering to a subject the lipid nanoparticle of any one of claims 15-56.
62. A lipid nanoparticle of any one of claims 15-56, compound of any one of claims 1-14, or pharmaceutical composition of claim 57, for use in the in vivo delivery of a nucleic acid to a subject.
63. The use of the lipid nanoparticle of any one of claims 15-56, the compound of any one of claims 1-14, or the pharmaceutical composition of claim 57, to prepare a medicament for the in vivo delivery of a nucleic acid to a subject.
64. A method for preventing or treating a disease or disorder in a subject in need thereof, the method comprising administering to the subject the lipid nanoparticle of any one of claims 15-56, the compound of any one of claims 1-14, or the pharmaceutical composition of claim 57.
65. The method of claim 64, wherein the disease or disorder comprises an infection, a liver disease or disorder, or a cancer.
66. A lipid nanoparticle of any one of claims 15-56, compound of any one of claims 1-14, or pharmaceutical composition of claim 57, for use in preventing or treating a disease or disorder in a subject.
67. The lipid nanoparticle, compound, or pharmaceutical composition of claim 66, wherein the disease or disorder comprises an infection, a liver disease or disorder, or a cancer.
68. The use of a lipid nanoparticle of any one of claims 15-56, compound of any one of claims 1-14, or pharmaceutical composition of claim 57, to prepare a medicament for preventing or treating a disease or disorder in a subject.
69. The use of claim 68, wherein the disease or disorder comprises an infection, a liver disease or disorder, or a cancer.
70. A method for editing genetic information in a cell, the method comprising contacting the cell with the lipid nanoparticle of claim 24.
71. The lipid nanoparticle of claim 24, for use in editing genomic information in a cell.
72. The use of the lipid nanoparticle of claim 24 to prepare a medicament for editing genomic information in a cell.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202363613515P | 2023-12-21 | 2023-12-21 | |
| US63/613,515 | 2023-12-21 | ||
| US202463566701P | 2024-03-18 | 2024-03-18 | |
| US63/566,701 | 2024-03-18 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2025133951A1 true WO2025133951A1 (en) | 2025-06-26 |
Family
ID=94284011
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/IB2024/062841 Pending WO2025133951A1 (en) | 2023-12-21 | 2024-12-18 | Ionizable lipids suitable for lipid nanoparticles |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2025133951A1 (en) |
Citations (96)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3817827A (en) | 1972-03-30 | 1974-06-18 | Scott Paper Co | Soft absorbent fibrous webs containing elastomeric bonding material and formed by creping and embossing |
| US3850752A (en) | 1970-11-10 | 1974-11-26 | Akzona Inc | Process for the demonstration and determination of low molecular compounds and of proteins capable of binding these compounds specifically |
| US3901654A (en) | 1971-06-21 | 1975-08-26 | Biological Developments | Receptor assays of biologically active compounds employing biologically specific receptors |
| US3935074A (en) | 1973-12-17 | 1976-01-27 | Syva Company | Antibody steric hindrance immunoassay with two antibodies |
| US3984533A (en) | 1975-11-13 | 1976-10-05 | General Electric Company | Electrophoretic method of detecting antigen-antibody reaction |
| US3993754A (en) | 1974-10-09 | 1976-11-23 | The United States Of America As Represented By The United States Energy Research And Development Administration | Liposome-encapsulated actinomycin for cancer chemotherapy |
| US3996345A (en) | 1974-08-12 | 1976-12-07 | Syva Company | Fluorescence quenching with immunological pairs in immunoassays |
| US4034074A (en) | 1974-09-19 | 1977-07-05 | The Board Of Trustees Of Leland Stanford Junior University | Universal reagent 2-site immunoradiometric assay using labelled anti (IgG) |
| US4098876A (en) | 1976-10-26 | 1978-07-04 | Corning Glass Works | Reverse sandwich immunoassay |
| US4145410A (en) | 1976-10-12 | 1979-03-20 | Sears Barry D | Method of preparing a controlled-release pharmaceutical preparation, and resulting composition |
| US4224179A (en) | 1977-08-05 | 1980-09-23 | Battelle Memorial Institute | Process for the preparation of liposomes in aqueous solution |
| US4235871A (en) | 1978-02-24 | 1980-11-25 | Papahadjopoulos Demetrios P | Method of encapsulating biologically active materials in lipid vesicles |
| US4376110A (en) | 1980-08-04 | 1983-03-08 | Hybritech, Incorporated | Immunometric assays using monoclonal antibodies |
| US4452901A (en) | 1980-03-20 | 1984-06-05 | Ciba-Geigy Corporation | Electrophoretically transferring electropherograms to nitrocellulose sheets for immuno-assays |
| US4522803A (en) | 1983-02-04 | 1985-06-11 | The Liposome Company, Inc. | Stable plurilamellar vesicles, their preparation and use |
| US4588578A (en) | 1983-08-08 | 1986-05-13 | The Liposome Company, Inc. | Lipid vesicles prepared in a monophase |
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US4737323A (en) | 1986-02-13 | 1988-04-12 | Liposome Technology, Inc. | Liposome extrusion method |
| EP0360257A2 (en) | 1988-09-20 | 1990-03-28 | The Board Of Regents For Northern Illinois University | RNA catalyst for cleaving specific RNA sequences |
| US4987071A (en) | 1986-12-03 | 1991-01-22 | University Patents, Inc. | RNA ribozyme polymerases, dephosphorylases, restriction endoribonucleases and methods |
| WO1991003162A1 (en) | 1989-08-31 | 1991-03-21 | City Of Hope | Chimeric dna-rna catalytic sequences |
| WO1992007065A1 (en) | 1990-10-12 | 1992-04-30 | MAX-PLANCK-Gesellschaft zur Förderung der Wissenschaften e.V. | Modified ribozymes |
| WO1993015187A1 (en) | 1992-01-31 | 1993-08-05 | Massachusetts Institute Of Technology | Nucleozymes |
| WO1993023569A1 (en) | 1992-05-11 | 1993-11-25 | Ribozyme Pharmaceuticals, Inc. | Method and reagent for inhibiting viral replication |
| WO1994002595A1 (en) | 1992-07-17 | 1994-02-03 | Ribozyme Pharmaceuticals, Inc. | Method and reagent for treatment of animal diseases |
| US5286634A (en) | 1989-09-28 | 1994-02-15 | Stadler Joan K | Synergistic method for host cell transformation |
| WO1994013688A1 (en) | 1992-12-08 | 1994-06-23 | Gene Shears Pty. Limited | Dna-armed ribozymes and minizymes |
| US5334711A (en) | 1991-06-20 | 1994-08-02 | Europaisches Laboratorium Fur Molekularbiologie (Embl) | Synthetic catalytic oligonucleotide structures |
| WO1996011266A2 (en) | 1994-10-05 | 1996-04-18 | Amgen Inc. | Method for inhibiting smooth muscle cell proliferation and oligonucleotides for use therein |
| US5580579A (en) | 1995-02-15 | 1996-12-03 | Nano Systems L.L.C. | Site-specific adhesion within the GI tract using nanoparticles stabilized by high molecular weight, linear poly (ethylene oxide) polymers |
| US5591317A (en) | 1994-02-16 | 1997-01-07 | Pitts, Jr.; M. Michael | Electrostatic device for water treatment |
| US5610288A (en) | 1993-01-27 | 1997-03-11 | Hekton Institute For Medical Research | Antisense polynucleotide inhibition of epidermal human growth factor receptor expression |
| US5631359A (en) | 1994-10-11 | 1997-05-20 | Ribozyme Pharmaceuticals, Inc. | Hairpin ribozymes |
| US5639725A (en) | 1994-04-26 | 1997-06-17 | Children's Hospital Medical Center Corp. | Angiostatin protein |
| US5641515A (en) | 1995-04-04 | 1997-06-24 | Elan Corporation, Plc | Controlled release biodegradable nanoparticles containing insulin |
| US5718709A (en) | 1988-09-24 | 1998-02-17 | Considine; John | Apparatus for removing tumours from hollow organs of the body |
| US5725871A (en) | 1989-08-18 | 1998-03-10 | Danbiosyst Uk Limited | Drug delivery compositions comprising lysophosphoglycerolipid |
| US5739119A (en) | 1996-11-15 | 1998-04-14 | Galli; Rachel L. | Antisense oligonucleotides specific for the muscarinic type 2 acetylcholine receptor MRNA |
| US5747470A (en) | 1995-06-07 | 1998-05-05 | Gen-Probe Incorporated | Method for inhibiting cellular proliferation using antisense oligonucleotides to gp130 mRNA |
| US5756353A (en) | 1991-12-17 | 1998-05-26 | The Regents Of The University Of California | Expression of cloned genes in the lung by aerosol-and liposome-based delivery |
| US5759829A (en) | 1986-03-28 | 1998-06-02 | Calgene, Inc. | Antisense regulation of gene expression in plant cells |
| US5780045A (en) | 1992-05-18 | 1998-07-14 | Minnesota Mining And Manufacturing Company | Transmucosal drug delivery device |
| US5783683A (en) | 1995-01-10 | 1998-07-21 | Genta Inc. | Antisense oligonucleotides which reduce expression of the FGFRI gene |
| US5789573A (en) | 1990-08-14 | 1998-08-04 | Isis Pharmaceuticals, Inc. | Antisense inhibition of ICAM-1, E-selectin, and CMV IE1/IE2 |
| US5792451A (en) | 1994-03-02 | 1998-08-11 | Emisphere Technologies, Inc. | Oral drug delivery compositions and methods |
| US5801154A (en) | 1993-10-18 | 1998-09-01 | Isis Pharmaceuticals, Inc. | Antisense oligonucleotide modulation of multidrug resistance-associated protein |
| US5804212A (en) | 1989-11-04 | 1998-09-08 | Danbiosyst Uk Limited | Small particle compositions for intranasal drug delivery |
| US5885613A (en) | 1994-09-30 | 1999-03-23 | The University Of British Columbia | Bilayer stabilizing components and their use in forming programmable fusogenic liposomes |
| US5998203A (en) | 1996-04-16 | 1999-12-07 | Ribozyme Pharmaceuticals, Inc. | Enzymatic nucleic acids containing 5'-and/or 3'-cap structures |
| US6174861B1 (en) | 1996-10-22 | 2001-01-16 | The Children's Medical Center Corporation | Methods of inhibiting angiogenesis via increasing in vivo concentrations of endostatin protein |
| US20030077829A1 (en) | 2001-04-30 | 2003-04-24 | Protiva Biotherapeutics Inc.. | Lipid-based formulations |
| US20030130186A1 (en) | 2001-07-20 | 2003-07-10 | Chandra Vargeese | Conjugates and compositions for cellular delivery |
| CA2456444A1 (en) | 2002-02-20 | 2003-08-28 | Sirna Therapeutics, Inc. | Rna interference mediated inhibition of vascular endothelial growth factor and vascular endothelial growth factor receptor gene expression using short interfering nucleic acid (sina) |
| US6713069B1 (en) | 1996-04-16 | 2004-03-30 | Board Of Supervisors Of Louisiana State University And Agricultural And Mechanical College | Compositions and methods for detecting, preventing, and treating African Hemorrhagic Fever |
| US20040110296A1 (en) | 2001-05-18 | 2004-06-10 | Ribozyme Pharmaceuticals, Inc. | Conjugates and compositions for cellular delivery |
| US6753423B1 (en) | 1990-01-11 | 2004-06-22 | Isis Pharmaceuticals, Inc. | Compositions and methods for enhanced biostability and altered biodistribution of oligonucleotides in mammals |
| US20040142025A1 (en) | 2002-06-28 | 2004-07-22 | Protiva Biotherapeutics Ltd. | Liposomal apparatus and manufacturing methods |
| US20040142895A1 (en) | 1995-10-26 | 2004-07-22 | Sirna Therapeutics, Inc. | Nucleic acid-based modulation of gene expression in the vascular endothelial growth factor pathway |
| US6774180B2 (en) | 2000-12-18 | 2004-08-10 | Nektar Therapeutics Al, Corporation | Synthesis of high molecular weight non-peptidic polymer derivatives |
| US20040167090A1 (en) | 2003-02-21 | 2004-08-26 | Monahan Sean D. | Covalent modification of RNA for in vitro and in vivo delivery |
| US20040192626A1 (en) | 2002-02-20 | 2004-09-30 | Mcswiggen James | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (siNA) |
| US20040249178A1 (en) | 2001-05-18 | 2004-12-09 | Sirna Therapeutics, Inc. | Conjugates and compositions for cellular delivery |
| US20050008689A1 (en) | 1997-05-14 | 2005-01-13 | Inex Pharmaceuticals Corporation | High efficiency encapsulation of charged therapeutic agents in lipid vesicles |
| US20050043219A1 (en) | 1991-10-24 | 2005-02-24 | Isis Pharmaceuticals, Inc. | Derivatized oligonucleotides having improved uptake and other properties |
| GB2397818B (en) | 2002-02-20 | 2005-03-09 | Sirna Therapeutics Inc | Rna interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (siNA) |
| US20050058982A1 (en) | 2002-07-26 | 2005-03-17 | Chiron Corporation | Modified small interfering RNA molecules and methods of use |
| WO2005026372A1 (en) | 2003-09-15 | 2005-03-24 | Protiva Biotherapeutics, Inc. | Polyethyleneglycol-modified lipid compounds and uses thereof |
| US20050074771A1 (en) | 1996-09-13 | 2005-04-07 | Isis Pharmaceuticals, Inc. | Carbamate-derivatized nucleosides and oligonucleosides |
| US20050107325A1 (en) | 2003-04-17 | 2005-05-19 | Muthiah Manoharan | Modified iRNA agents |
| US20050107316A1 (en) | 2002-02-22 | 2005-05-19 | Klaus Strebhardt | Agent for inhibiting development or progress of proliferative diseases and especially cancer diseases and pharmaceutical composition containing said agent |
| US20050119470A1 (en) | 1996-06-06 | 2005-06-02 | Muthiah Manoharan | Conjugated oligomeric compounds and their use in gene modulation |
| US20050153337A1 (en) | 2003-04-03 | 2005-07-14 | Muthiah Manoharan | iRNA conjugates |
| US20050239739A1 (en) | 2001-05-18 | 2005-10-27 | Sirna Therapeutics, Inc. | Conjugates and compositions for cellular delivery |
| US20050244858A1 (en) | 2004-03-15 | 2005-11-03 | City Of Hope | Methods and compositions for the specific inhibition of gene expression by double-stranded RNA |
| US20050282188A1 (en) | 2001-05-18 | 2005-12-22 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of gene expression using short interfering nucleic acid (siNA) |
| US7053150B2 (en) | 2000-12-18 | 2006-05-30 | Nektar Therapeutics Al, Corporation | Segmented polymers and their conjugates |
| US20060134189A1 (en) | 2004-11-17 | 2006-06-22 | Protiva Biotherapeutics, Inc | siRNA silencing of apolipoprotein B |
| US20070042031A1 (en) | 2005-07-27 | 2007-02-22 | Protiva Biotherapeutics, Inc. | Systems and methods for manufacturing liposomes |
| WO2007024708A2 (en) | 2005-08-23 | 2007-03-01 | The Trustees Of The University Of Pennsylvania | Rna containing modified nucleosides and methods of use thereof |
| US20070135372A1 (en) | 2005-11-02 | 2007-06-14 | Protiva Biotherapeutics, Inc. | Modified siRNA molecules and uses thereof |
| US20070135370A1 (en) | 2005-10-20 | 2007-06-14 | Protiva Biotherapeutics, Inc. | siRNA silencing of filovirus gene expression |
| US20070149470A1 (en) | 2004-09-10 | 2007-06-28 | Kaspar Roger L | Inhibition of viral gene expression using small interfering RNA |
| US20070218122A1 (en) | 2005-11-18 | 2007-09-20 | Protiva Biotherapeutics, Inc. | siRNA silencing of influenza virus gene expression |
| US20070265220A1 (en) | 2004-03-15 | 2007-11-15 | City Of Hope | Methods and compositions for the specific inhibition of gene expression by double-stranded RNA |
| US20070265438A1 (en) | 2002-11-14 | 2007-11-15 | Dharmacon, Inc. | siRNA targeting polo-like kinase-1 (PLK-1) |
| US7348314B2 (en) | 2001-10-12 | 2008-03-25 | Alnylam Europe Ag | Compositions and methods for inhibiting viral replication |
| US7404969B2 (en) | 2005-02-14 | 2008-07-29 | Sirna Therapeutics, Inc. | Lipid nanoparticle based compositions and methods for the delivery of biologically active molecules |
| US20090062228A1 (en) | 2007-03-07 | 2009-03-05 | Hannon Gregory J | piRNA and uses related thereto |
| US20110071208A1 (en) | 2009-06-05 | 2011-03-24 | Protiva Biotherapeutics, Inc. | Lipid encapsulated dicer-substrate interfering rna |
| WO2012000104A1 (en) | 2010-06-30 | 2012-01-05 | Protiva Biotherapeutics, Inc. | Non-liposomal systems for nucleic acid delivery |
| WO2013126803A1 (en) | 2012-02-24 | 2013-08-29 | Protiva Biotherapeutics Inc. | Trialkyl cationic lipids and methods of use thereof |
| WO2018006052A1 (en) | 2016-06-30 | 2018-01-04 | Protiva Biotherapeutics, Inc. | Compositions and methods for delivering messenger rna |
| WO2020097520A1 (en) | 2018-11-09 | 2020-05-14 | Arbutus Biopharma Corporation | Cationic lipids containing silicon |
| WO2022011156A1 (en) * | 2020-07-10 | 2022-01-13 | Genevant Sciences Gmbh | Lipid nanoparticles for delivering therapeutics to lungs |
| WO2022133344A1 (en) | 2020-12-18 | 2022-06-23 | Genevant Sciences Gmbh | Peg lipids and lipid nanoparticles |
-
2024
- 2024-12-18 WO PCT/IB2024/062841 patent/WO2025133951A1/en active Pending
Patent Citations (103)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3850752A (en) | 1970-11-10 | 1974-11-26 | Akzona Inc | Process for the demonstration and determination of low molecular compounds and of proteins capable of binding these compounds specifically |
| US3901654A (en) | 1971-06-21 | 1975-08-26 | Biological Developments | Receptor assays of biologically active compounds employing biologically specific receptors |
| US3817827A (en) | 1972-03-30 | 1974-06-18 | Scott Paper Co | Soft absorbent fibrous webs containing elastomeric bonding material and formed by creping and embossing |
| US3935074A (en) | 1973-12-17 | 1976-01-27 | Syva Company | Antibody steric hindrance immunoassay with two antibodies |
| US3996345A (en) | 1974-08-12 | 1976-12-07 | Syva Company | Fluorescence quenching with immunological pairs in immunoassays |
| US4034074A (en) | 1974-09-19 | 1977-07-05 | The Board Of Trustees Of Leland Stanford Junior University | Universal reagent 2-site immunoradiometric assay using labelled anti (IgG) |
| US3993754A (en) | 1974-10-09 | 1976-11-23 | The United States Of America As Represented By The United States Energy Research And Development Administration | Liposome-encapsulated actinomycin for cancer chemotherapy |
| US3984533A (en) | 1975-11-13 | 1976-10-05 | General Electric Company | Electrophoretic method of detecting antigen-antibody reaction |
| US4145410A (en) | 1976-10-12 | 1979-03-20 | Sears Barry D | Method of preparing a controlled-release pharmaceutical preparation, and resulting composition |
| US4098876A (en) | 1976-10-26 | 1978-07-04 | Corning Glass Works | Reverse sandwich immunoassay |
| US4224179A (en) | 1977-08-05 | 1980-09-23 | Battelle Memorial Institute | Process for the preparation of liposomes in aqueous solution |
| US4235871A (en) | 1978-02-24 | 1980-11-25 | Papahadjopoulos Demetrios P | Method of encapsulating biologically active materials in lipid vesicles |
| US4452901A (en) | 1980-03-20 | 1984-06-05 | Ciba-Geigy Corporation | Electrophoretically transferring electropherograms to nitrocellulose sheets for immuno-assays |
| US4376110A (en) | 1980-08-04 | 1983-03-08 | Hybritech, Incorporated | Immunometric assays using monoclonal antibodies |
| US4522803A (en) | 1983-02-04 | 1985-06-11 | The Liposome Company, Inc. | Stable plurilamellar vesicles, their preparation and use |
| US4588578A (en) | 1983-08-08 | 1986-05-13 | The Liposome Company, Inc. | Lipid vesicles prepared in a monophase |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US4683202B1 (en) | 1985-03-28 | 1990-11-27 | Cetus Corp | |
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| US4683195B1 (en) | 1986-01-30 | 1990-11-27 | Cetus Corp | |
| US4737323A (en) | 1986-02-13 | 1988-04-12 | Liposome Technology, Inc. | Liposome extrusion method |
| US5759829A (en) | 1986-03-28 | 1998-06-02 | Calgene, Inc. | Antisense regulation of gene expression in plant cells |
| US4987071A (en) | 1986-12-03 | 1991-01-22 | University Patents, Inc. | RNA ribozyme polymerases, dephosphorylases, restriction endoribonucleases and methods |
| EP0360257A2 (en) | 1988-09-20 | 1990-03-28 | The Board Of Regents For Northern Illinois University | RNA catalyst for cleaving specific RNA sequences |
| US5718709A (en) | 1988-09-24 | 1998-02-17 | Considine; John | Apparatus for removing tumours from hollow organs of the body |
| US5725871A (en) | 1989-08-18 | 1998-03-10 | Danbiosyst Uk Limited | Drug delivery compositions comprising lysophosphoglycerolipid |
| WO1991003162A1 (en) | 1989-08-31 | 1991-03-21 | City Of Hope | Chimeric dna-rna catalytic sequences |
| US5286634A (en) | 1989-09-28 | 1994-02-15 | Stadler Joan K | Synergistic method for host cell transformation |
| US5804212A (en) | 1989-11-04 | 1998-09-08 | Danbiosyst Uk Limited | Small particle compositions for intranasal drug delivery |
| US6753423B1 (en) | 1990-01-11 | 2004-06-22 | Isis Pharmaceuticals, Inc. | Compositions and methods for enhanced biostability and altered biodistribution of oligonucleotides in mammals |
| US5789573A (en) | 1990-08-14 | 1998-08-04 | Isis Pharmaceuticals, Inc. | Antisense inhibition of ICAM-1, E-selectin, and CMV IE1/IE2 |
| WO1992007065A1 (en) | 1990-10-12 | 1992-04-30 | MAX-PLANCK-Gesellschaft zur Förderung der Wissenschaften e.V. | Modified ribozymes |
| US5334711A (en) | 1991-06-20 | 1994-08-02 | Europaisches Laboratorium Fur Molekularbiologie (Embl) | Synthetic catalytic oligonucleotide structures |
| US20050043219A1 (en) | 1991-10-24 | 2005-02-24 | Isis Pharmaceuticals, Inc. | Derivatized oligonucleotides having improved uptake and other properties |
| US5756353A (en) | 1991-12-17 | 1998-05-26 | The Regents Of The University Of California | Expression of cloned genes in the lung by aerosol-and liposome-based delivery |
| WO1993015187A1 (en) | 1992-01-31 | 1993-08-05 | Massachusetts Institute Of Technology | Nucleozymes |
| WO1993023569A1 (en) | 1992-05-11 | 1993-11-25 | Ribozyme Pharmaceuticals, Inc. | Method and reagent for inhibiting viral replication |
| US5780045A (en) | 1992-05-18 | 1998-07-14 | Minnesota Mining And Manufacturing Company | Transmucosal drug delivery device |
| WO1994002595A1 (en) | 1992-07-17 | 1994-02-03 | Ribozyme Pharmaceuticals, Inc. | Method and reagent for treatment of animal diseases |
| US20050158727A1 (en) | 1992-10-23 | 2005-07-21 | Isis Pharmaceuticals, Inc. | Derivatized oligonucleotides having improved uptake and other properties |
| WO1994013688A1 (en) | 1992-12-08 | 1994-06-23 | Gene Shears Pty. Limited | Dna-armed ribozymes and minizymes |
| US5610288A (en) | 1993-01-27 | 1997-03-11 | Hekton Institute For Medical Research | Antisense polynucleotide inhibition of epidermal human growth factor receptor expression |
| US5801154A (en) | 1993-10-18 | 1998-09-01 | Isis Pharmaceuticals, Inc. | Antisense oligonucleotide modulation of multidrug resistance-associated protein |
| US5591317A (en) | 1994-02-16 | 1997-01-07 | Pitts, Jr.; M. Michael | Electrostatic device for water treatment |
| US5792451A (en) | 1994-03-02 | 1998-08-11 | Emisphere Technologies, Inc. | Oral drug delivery compositions and methods |
| US5639725A (en) | 1994-04-26 | 1997-06-17 | Children's Hospital Medical Center Corp. | Angiostatin protein |
| US5885613A (en) | 1994-09-30 | 1999-03-23 | The University Of British Columbia | Bilayer stabilizing components and their use in forming programmable fusogenic liposomes |
| WO1996011266A2 (en) | 1994-10-05 | 1996-04-18 | Amgen Inc. | Method for inhibiting smooth muscle cell proliferation and oligonucleotides for use therein |
| US5631359A (en) | 1994-10-11 | 1997-05-20 | Ribozyme Pharmaceuticals, Inc. | Hairpin ribozymes |
| US5783683A (en) | 1995-01-10 | 1998-07-21 | Genta Inc. | Antisense oligonucleotides which reduce expression of the FGFRI gene |
| US5580579A (en) | 1995-02-15 | 1996-12-03 | Nano Systems L.L.C. | Site-specific adhesion within the GI tract using nanoparticles stabilized by high molecular weight, linear poly (ethylene oxide) polymers |
| US5641515A (en) | 1995-04-04 | 1997-06-24 | Elan Corporation, Plc | Controlled release biodegradable nanoparticles containing insulin |
| US5747470A (en) | 1995-06-07 | 1998-05-05 | Gen-Probe Incorporated | Method for inhibiting cellular proliferation using antisense oligonucleotides to gp130 mRNA |
| US20040142895A1 (en) | 1995-10-26 | 2004-07-22 | Sirna Therapeutics, Inc. | Nucleic acid-based modulation of gene expression in the vascular endothelial growth factor pathway |
| US5998203A (en) | 1996-04-16 | 1999-12-07 | Ribozyme Pharmaceuticals, Inc. | Enzymatic nucleic acids containing 5'-and/or 3'-cap structures |
| US6713069B1 (en) | 1996-04-16 | 2004-03-30 | Board Of Supervisors Of Louisiana State University And Agricultural And Mechanical College | Compositions and methods for detecting, preventing, and treating African Hemorrhagic Fever |
| US20050119470A1 (en) | 1996-06-06 | 2005-06-02 | Muthiah Manoharan | Conjugated oligomeric compounds and their use in gene modulation |
| US20050074771A1 (en) | 1996-09-13 | 2005-04-07 | Isis Pharmaceuticals, Inc. | Carbamate-derivatized nucleosides and oligonucleosides |
| US6174861B1 (en) | 1996-10-22 | 2001-01-16 | The Children's Medical Center Corporation | Methods of inhibiting angiogenesis via increasing in vivo concentrations of endostatin protein |
| US5739119A (en) | 1996-11-15 | 1998-04-14 | Galli; Rachel L. | Antisense oligonucleotides specific for the muscarinic type 2 acetylcholine receptor MRNA |
| US20050008689A1 (en) | 1997-05-14 | 2005-01-13 | Inex Pharmaceuticals Corporation | High efficiency encapsulation of charged therapeutic agents in lipid vesicles |
| US6774180B2 (en) | 2000-12-18 | 2004-08-10 | Nektar Therapeutics Al, Corporation | Synthesis of high molecular weight non-peptidic polymer derivatives |
| US7053150B2 (en) | 2000-12-18 | 2006-05-30 | Nektar Therapeutics Al, Corporation | Segmented polymers and their conjugates |
| US20030077829A1 (en) | 2001-04-30 | 2003-04-24 | Protiva Biotherapeutics Inc.. | Lipid-based formulations |
| US20050282188A1 (en) | 2001-05-18 | 2005-12-22 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of gene expression using short interfering nucleic acid (siNA) |
| US20050239739A1 (en) | 2001-05-18 | 2005-10-27 | Sirna Therapeutics, Inc. | Conjugates and compositions for cellular delivery |
| US20040249178A1 (en) | 2001-05-18 | 2004-12-09 | Sirna Therapeutics, Inc. | Conjugates and compositions for cellular delivery |
| US20040110296A1 (en) | 2001-05-18 | 2004-06-10 | Ribozyme Pharmaceuticals, Inc. | Conjugates and compositions for cellular delivery |
| US20030130186A1 (en) | 2001-07-20 | 2003-07-10 | Chandra Vargeese | Conjugates and compositions for cellular delivery |
| US7348314B2 (en) | 2001-10-12 | 2008-03-25 | Alnylam Europe Ag | Compositions and methods for inhibiting viral replication |
| CA2456444A1 (en) | 2002-02-20 | 2003-08-28 | Sirna Therapeutics, Inc. | Rna interference mediated inhibition of vascular endothelial growth factor and vascular endothelial growth factor receptor gene expression using short interfering nucleic acid (sina) |
| GB2397818B (en) | 2002-02-20 | 2005-03-09 | Sirna Therapeutics Inc | Rna interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (siNA) |
| GB2396864A (en) | 2002-02-20 | 2004-07-07 | Sirna Therapeutics Inc | RNA interference mediated inhibition of vascular endothelial growth factor and vascular endothelial growth factor receptor gene expression |
| US20040192626A1 (en) | 2002-02-20 | 2004-09-30 | Mcswiggen James | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (siNA) |
| US20060281175A1 (en) | 2002-02-20 | 2006-12-14 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (siNA) |
| US20050107316A1 (en) | 2002-02-22 | 2005-05-19 | Klaus Strebhardt | Agent for inhibiting development or progress of proliferative diseases and especially cancer diseases and pharmaceutical composition containing said agent |
| US20040142025A1 (en) | 2002-06-28 | 2004-07-22 | Protiva Biotherapeutics Ltd. | Liposomal apparatus and manufacturing methods |
| US20050058982A1 (en) | 2002-07-26 | 2005-03-17 | Chiron Corporation | Modified small interfering RNA molecules and methods of use |
| US20070265438A1 (en) | 2002-11-14 | 2007-11-15 | Dharmacon, Inc. | siRNA targeting polo-like kinase-1 (PLK-1) |
| US20040167090A1 (en) | 2003-02-21 | 2004-08-26 | Monahan Sean D. | Covalent modification of RNA for in vitro and in vivo delivery |
| US20050153337A1 (en) | 2003-04-03 | 2005-07-14 | Muthiah Manoharan | iRNA conjugates |
| US20050107325A1 (en) | 2003-04-17 | 2005-05-19 | Muthiah Manoharan | Modified iRNA agents |
| WO2005026372A1 (en) | 2003-09-15 | 2005-03-24 | Protiva Biotherapeutics, Inc. | Polyethyleneglycol-modified lipid compounds and uses thereof |
| US20050277610A1 (en) | 2004-03-15 | 2005-12-15 | City Of Hope | Methods and compositions for the specific inhibition of gene expression by double-stranded RNA |
| US20070265220A1 (en) | 2004-03-15 | 2007-11-15 | City Of Hope | Methods and compositions for the specific inhibition of gene expression by double-stranded RNA |
| US20050244858A1 (en) | 2004-03-15 | 2005-11-03 | City Of Hope | Methods and compositions for the specific inhibition of gene expression by double-stranded RNA |
| US20070149470A1 (en) | 2004-09-10 | 2007-06-28 | Kaspar Roger L | Inhibition of viral gene expression using small interfering RNA |
| US20060134189A1 (en) | 2004-11-17 | 2006-06-22 | Protiva Biotherapeutics, Inc | siRNA silencing of apolipoprotein B |
| US7404969B2 (en) | 2005-02-14 | 2008-07-29 | Sirna Therapeutics, Inc. | Lipid nanoparticle based compositions and methods for the delivery of biologically active molecules |
| US20070042031A1 (en) | 2005-07-27 | 2007-02-22 | Protiva Biotherapeutics, Inc. | Systems and methods for manufacturing liposomes |
| US9005654B2 (en) | 2005-07-27 | 2015-04-14 | Protiva Biotherapeutics, Inc. | Systems and methods for manufacturing liposomes |
| WO2007024708A2 (en) | 2005-08-23 | 2007-03-01 | The Trustees Of The University Of Pennsylvania | Rna containing modified nucleosides and methods of use thereof |
| US20070135370A1 (en) | 2005-10-20 | 2007-06-14 | Protiva Biotherapeutics, Inc. | siRNA silencing of filovirus gene expression |
| US20070135372A1 (en) | 2005-11-02 | 2007-06-14 | Protiva Biotherapeutics, Inc. | Modified siRNA molecules and uses thereof |
| US20070218122A1 (en) | 2005-11-18 | 2007-09-20 | Protiva Biotherapeutics, Inc. | siRNA silencing of influenza virus gene expression |
| US20090062228A1 (en) | 2007-03-07 | 2009-03-05 | Hannon Gregory J | piRNA and uses related thereto |
| US20110071208A1 (en) | 2009-06-05 | 2011-03-24 | Protiva Biotherapeutics, Inc. | Lipid encapsulated dicer-substrate interfering rna |
| WO2012000104A1 (en) | 2010-06-30 | 2012-01-05 | Protiva Biotherapeutics, Inc. | Non-liposomal systems for nucleic acid delivery |
| WO2013126803A1 (en) | 2012-02-24 | 2013-08-29 | Protiva Biotherapeutics Inc. | Trialkyl cationic lipids and methods of use thereof |
| WO2018006052A1 (en) | 2016-06-30 | 2018-01-04 | Protiva Biotherapeutics, Inc. | Compositions and methods for delivering messenger rna |
| WO2020097520A1 (en) | 2018-11-09 | 2020-05-14 | Arbutus Biopharma Corporation | Cationic lipids containing silicon |
| WO2022011156A1 (en) * | 2020-07-10 | 2022-01-13 | Genevant Sciences Gmbh | Lipid nanoparticles for delivering therapeutics to lungs |
| WO2022133344A1 (en) | 2020-12-18 | 2022-06-23 | Genevant Sciences Gmbh | Peg lipids and lipid nanoparticles |
Non-Patent Citations (107)
| Title |
|---|
| "Radioimmunoassay Methods", 1970 |
| "Remington: The Science and Practice of Pharmacy", 2020, ELSEVIER |
| ABE ET AL., ACS CHEM. BIOL., vol. 17, no. 6, 2022, pages 1308 - 1314 |
| ALTSCHUL ET AL., NUCLEIC ACIDS RES., vol. 25, 1997, pages 3389 - 402 |
| BANERJEA ET AL., MAL. THER, vol. 8, 2003, pages 62 |
| BARR ET AL., NAT. REV. MAL. CELL. BIOL., vol. 5, 2004, pages 429 - 440 |
| BATZER ET AL., NUCLEIC ACID RES., vol. 19, no. 191, pages 5081 |
| BEAUCAGE ET AL., TETRAHEDRON, vol. 49, 1993, pages 1925 |
| BEHR, ACC. CHEM. RES.,, vol. 26, 1993, pages 274 |
| BERNSTEIN ET AL., NATURE, vol. 409, 2001, pages 363 - 366 |
| BOWEN-POPE ET AL., PROC. NATL. ACAD. SCI. USA, vol. 81, 1984, pages 2396 - 2400 |
| BRIGHAM ET AL., AM. J. SCI., vol. 298, 1989, pages 278 |
| BROOKS ET AL., CLIN. EXP. IMMUNOL., vol. 39, 1980, pages 477 |
| BROWN ET AL., J. BIOL. CHEM., vol. 255, 1980, pages 4980 - 4983 |
| BUCHMEIER ET AL.: "Arenaviridae: the viruses and their replication, In: FIELDS VIROLOGY", 2001, LIPPINCOTT-RAVEN |
| BUHRING ET AL., IN HYBRIDOMA, vol. 10, no. 1, 1991, pages 77 - 78 |
| BYROM ET AL., AMBION TECHNOTES, vol. 10, no. 1, 2003, pages 4 - 6 |
| CALEGARI ET AL., PROC. NATL. ACAD. SCI. USA, vol. 99, 2002, pages 14236 - 9947 |
| CAPLEN ET AL., HUM. MAL. GENET., vol. 11, 2002, pages 175 |
| CECH ET AL., CELL, vol. 27, 1981, pages 487 - 96 |
| COLLINS ET AL., BIOCHEMISTRY, vol. 32, 1993, pages 2795 - 9 |
| COLLIS ET AL., CANCER RES., vol. 63, 2003, pages 1550 |
| CONWAY ET AL., MOL THER., vol. 27, no. 4, 10 April 2019 (2019-04-10), pages 866 - 877 |
| DECAUSSIN ET AL., J. PATHOL., vol. 188, 1999, pages 369 - 377 |
| DENLI ET AL., NATURE, vol. 432, 2004, pages 231 - 235 |
| ELBASHIR ET AL., EMBO J, vol. 20, 2001, pages 6877 - 6888 |
| ELBASHIR ET AL., EMBO J., vol. 20, 2001, pages 6877 - 6888 |
| FORMAN ET AL., CELL, vol. 81, 1995, pages 687 - 417 |
| FORSTER ET AL., CELL, vol. 49, 1987, pages 211 - 20 |
| FRESHNEY: "Culture of Animal Cells, a Manual of Basic Technique", 1994, MARYANN LIEBERT, INC., pages: 70 - 71 |
| GEISBERT ET AL., J. INFECT. DIS., vol. 193, 2006, pages 1650 - 1657 |
| GREGORY ET AL., CELL, vol. 123, 2005, pages 631 - 640 |
| GUBLERHOFFMAN, GENE, vol. 25, 1983, pages 263 - 269 |
| GUERRIER-TAKADA ET AL., CELL, vol. 35, 1983, pages 849 - 57 |
| HALL ET AL., J. VIRAL., vol. 77, 2003, pages 6066 |
| HAMASAKI ET AL., FEBS LETT., vol. 545, 2003, pages 144 |
| HAMPEL ET AL., BIOCHEMISTRY, vol. 28, 1989, pages 4929 - 33 |
| HAMPEL ET AL., NUCLEIC ACIDS RES., vol. 18, 1990, pages 299 - 304 |
| HEIDENREICH ET AL., BLOOD, vol. 101, 2003, pages 3157 |
| HEINONEN ET AL., FEBS LETT., vol. 527, 2002, pages 274 |
| HERRERA-BARRERA ET AL., AAPS J., vol. 25, no. 4, 28 June 2023 (2023-06-28), pages 65 |
| HILL ET AL., J. IMMUNOL., vol. 171, 2003, pages 691 |
| JANOWSKI ET AL., NATURE, vol. 383, 1996, pages 728 - 731 |
| JUDGE ET AL., MAL. THER., vol. 13, 2006, pages 494 - 505 |
| KAPADIA ET AL., PROC. NATL. ACAD. SCI. USA, vol. 100, 2003, pages 2014 |
| KAWASAKI ET AL., NUCLEIC ACIDS RES., vol. 31, 2003, pages 981 - 987 |
| KHVOROVA ET AL., CELL, vol. 115, 2003, pages 199 - 208 |
| KIM ET AL., PROC. NATL. ACAD. SCI. USA., vol. 84, 1987, pages 8788 - 92 |
| KNIGHT ET AL., SCIENCE, vol. 293, 2001, pages 2269 - 2271 |
| KOHLER ET AL., NATURE, vol. 256, 1975, pages 495 - 497 |
| KOSCIOLEK ET AL., MAL CANCER THER., vol. 2, 2003, pages 209 |
| KUCHLER ET AL.: "Biochemical Methods in Cell Culture and Virology", 1977, DOWDEN, HUTCHINSON AND ROSS, INC |
| LAGOS-QUINTANA ET AL., SCIENCE, vol. 240, 1988, pages 1544 - 864 |
| LAM ET AL., ADV. MAT., vol. 35, no. 26, 2023, pages 2211420 |
| LEHMANN ET AL., J. BIOL. CHEM., vol. 272, 1997, pages 12778 - 12785 |
| LIN ET AL., J. AM. CHEM. SOC., vol. 120, 1998, pages 8531 - 8532 |
| LOAKES, NUCL. ACIDS RES., vol. 29, 2001, pages 2437 - 2447 |
| LUO ET AL., BIOPHYS. RES. COMMUN., vol. 318, 2004, pages 303 - 310 |
| MANNINO ET AL., BIOTECHNIQUES, vol. 6, 1988, pages 682 |
| MESMAEKER ET AL.: "Novel Backbone Replacements for Oligonucleotides, in Carbohydrate Modifications in Antisense Research", ACS, 1994, pages 24 - 39 |
| MICHEL ET AL., J. MOL. BIOL., vol. 216, 1990, pages 585 - 610 |
| NAGY ET AL., EXP. CELL RES., vol. 285, 2003, pages 39 - 49 |
| NEUMANN ET AL., J GEN VIRAL., vol. 83, 2002, pages 2635 - 2662 |
| NICOLAU ET AL., CRIT. REV. THER. DRUG CARRIER SYST., vol. 6, 1989, pages 239 |
| OHTSUKA ET AL., J. BIOL. CHEM., vol. 260, 1985, pages 2605 |
| PEET ET AL., CELL, vol. 93, 1998, pages 693 - 704 |
| PELECHANOSTEINMETZ, NAT. REV. GENET., vol. 14, 2013, pages 880 - 893 |
| PENIS ET AL., BRAIN RES MAL BRAIN RES., 15;, vol. 57, 1998, pages 310 - 20 |
| PERROTTA ET AL., BIOCHEMISTRY, vol. 31, 1992, pages 11843 - 52 |
| PREALL ET AL., CURR. BIOL., vol. 16, 2006, pages 530 - 535 |
| RAINES ET AL., J. BIOL. CHEM., vol. 257, 1982, pages 5154 - 5160 |
| REICH ET AL., MAL. VIS., vol. 9, 2003, pages 210 |
| REINHOLD-HUREK ET AL., NATURE, vol. 357, 1992, pages 173 - 6 |
| REYNOLDS ET AL., NATURE BIOTECH., vol. 22, no. 3, 2004, pages 326 - 330 |
| ROBERTSON ET AL., J. BIOL. CHEM., vol. 243, 1968, pages 82 |
| ROSSI ET AL., NUCLEIC ACIDS RES., vol. 20, 1992, pages 4559 - 65 |
| ROSSOLINI ET AL., MOL. CELL. PROBES, vol. 8, 1994, pages 91 |
| ROTHGANGL ET AL., NAT BIOTECHNOL., vol. 39, no. 8, August 2021 (2021-08-01), pages 949 - 957 |
| SAENGER: "Principles of Nucleic Acid Structure", 1984, SPRINGER-VERLAG ED. |
| SAKAI ET AL., CELL, vol. 85, 1996, pages 1037 - 1046 |
| SANCHEZ ET AL., VIRUS RES., vol. 29, 1993, pages 215 - 240 |
| SAVILLE ET AL., CELL, vol. 61, 1990, pages 685 - 96 |
| SAVILLE ET AL., PROC. NATL. ACAD. SCI. USA, vol. 88, 1991, pages 8826 - 30 |
| SCARINGE ET AL., NUCL. ACIDS RES., vol. 18, 1990, pages 5433 |
| SCHLOMAI ET AL., HEPATOLOGY, vol. 37, 2003, pages 764 |
| SEAL ET AL., MOL. ENDOCRINOL, vol. 9, 1995, pages 72 |
| SHERIDAN, NATURE BIOTECHNOL., vol. 40, 2022, pages 1160 - 1162 |
| SONG ET AL., NAT. MED., vol. 9, 2003, pages 347 |
| STEINHAUER ET AL., ANNU REV GENET., vol. 36, 2002, pages 305 - 332 |
| STEPHENSON, JAMA, vol. 289, 2003, pages 1494 |
| STRAUBRINGER ET AL., METHODS ENZYMOL., vol. 101, 1983, pages 512 |
| SUN ET AL., NAT. BIOTECH., vol. 26, 2008, pages 1379 - 1382 |
| USMAN ET AL., J. AM. CHEM. SOC., vol. 109, 1987, pages 7845 |
| VASANTHAKUMAR ET AL., CANCER COMMUN., vol. 1, 1989, pages 225 - 32 |
| VERMA ET AL., CLIN CANCER RES., vol. 9, 2003, pages 1291 |
| VOLCHKOV ET AL., FEBSLETT., vol. 305, 1992, pages 181 - 184 |
| WAHLSTEDT, NAT. REV. DRUG DISC., vol. 12, 2013, pages 433 - 446 |
| WEISS ET AL., CELL. MOL. LIFE SCI., vol. 55, 1999, pages 334 - 358 |
| WILDA ET AL., ONCOGENE, vol. 21, 2002, pages 5716 |
| WILL ET AL., J. VIRAL., vol. 67, 1993, pages 1203 - 1210 |
| WILLY ET AL., GENES DEV., vol. 9, 1995, pages 1033 - 1045 |
| WINCOTT ET AL., METHODS MOL. BIO., vol. 74, 1997, pages 59 |
| WINCOTT ET AL., NUCL. ACIDS RES., vol. 23, 1995, pages 2677 - 2684 |
| YAMAMOTO ET AL., J. IMMUNOL., vol. 148, 1992, pages 4072 - 6 |
| YOKOTA ET AL., EMBO REP., vol. 4, 2003, pages 602 |
| ZAVACKI ET AL., PROC. NATL. ACAD. SCI. USA, vol. 94, 1997, pages 7909 |
| ZOU ET AL., GENES DEV., vol. 16, 2002, pages 2923 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12357705B2 (en) | Negatively charged peg-lipid conjugates | |
| AU2019376161B2 (en) | Lipid nanoparticle formulations | |
| EP4262883B1 (en) | Peg lipids and lipid nanoparticles | |
| WO2020219941A1 (en) | Lipid nanoparticles | |
| JP2025019119A (en) | Silicon-containing cationic lipids | |
| US20250332112A1 (en) | Ionizable cationic lipids for lipid nanoparticles | |
| JP7709981B2 (en) | Cationic lipids for lipid nanoparticle delivery of therapeutic agents to hepatic stellate cells | |
| KR20230038217A (en) | Lipid nanoparticles for delivering therapeutics to the lungs | |
| JP2023513698A (en) | Cationic lipids for lipid nanoparticle delivery of therapeutic agents to hepatic stellate cells | |
| JP2025504682A (en) | Poly(alkyloxazoline)-lipid conjugates and lipid particles containing same | |
| WO2025133951A1 (en) | Ionizable lipids suitable for lipid nanoparticles | |
| HK40094731B (en) | Peg lipids and lipid nanoparticles | |
| HK40094731A (en) | Peg lipids and lipid nanoparticles | |
| EA050406B1 (en) | CATIONIC LIPIDS CONTAINING SILICON |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24838013 Country of ref document: EP Kind code of ref document: A1 |