WO2025072482A1 - Immunoglobulin a protease polypeptides, polynucleotides, and uses thereof - Google Patents
Immunoglobulin a protease polypeptides, polynucleotides, and uses thereof Download PDFInfo
- Publication number
- WO2025072482A1 WO2025072482A1 PCT/US2024/048607 US2024048607W WO2025072482A1 WO 2025072482 A1 WO2025072482 A1 WO 2025072482A1 US 2024048607 W US2024048607 W US 2024048607W WO 2025072482 A1 WO2025072482 A1 WO 2025072482A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- polypeptide
- mrna
- utr
- sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/52—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from bacteria or Archaea
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/0008—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition
- A61K48/0025—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition wherein the non-active part clearly interacts with the delivered nucleic acid
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/005—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'active' part of the composition delivered, i.e. the nucleic acid delivered
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/88—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation using microencapsulation, e.g. using amphiphile liposome vesicle
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/21—Serine endopeptidases (3.4.21)
- C12Y304/21072—IgA-specific serine endopeptidase (3.4.21.72)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/24—Metalloendopeptidases (3.4.24)
- C12Y304/24013—IgA-specific metalloendopeptidase (3.4.24.13)
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2207/00—Modified animals
- A01K2207/15—Humanized animals
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/05—Animals comprising random inserted nucleic acids (transgenic)
- A01K2217/052—Animals comprising random inserted nucleic acids (transgenic) inducing gain of function
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/20—Animal model comprising regulated expression system
- A01K2217/206—Animal model comprising tissue-specific expression system, e.g. tissue specific expression of transgene, of Cre recombinase
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/0008—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition
- A61K48/0025—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition wherein the non-active part clearly interacts with the delivered nucleic acid
- A61K48/0041—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition wherein the non-active part clearly interacts with the delivered nucleic acid the non-active part being polymeric
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/005—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'active' part of the composition delivered, i.e. the nucleic acid delivered
- A61K48/0066—Manipulation of the nucleic acid to modify its expression pattern, e.g. enhance its duration of expression, achieved by the presence of particular introns in the delivered nucleic acid
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2830/00—Vector systems having a special element relevant for transcription
Definitions
- Immunoglobulin Al nephropathy also known as Berger disease, is a kidney disease in which IgA builds up in the kidneys, causing inflammation and damage to kidney filtration in the glomerulus. Signs and symptoms of IgAN can include foamy or cola-or tea-colored urine, blood in the urine, pain on one or both sides of the rubs, edema, high blood pressure, weakness, fatigue, and kidney failure. There is no cure for IgAN. Standard of care includes blood pressure drugs, immunosuppressants, omega-3 fatty acids, cholesterol medication, and diuretics. Treatment may also include dialysis or a kidney transplant. There remains an unmet need for improved treatment for IgAN.
- Immunoglobulin Al proteases are a group of secreted bacterial endopeptidases that cleave human immunoglobulin Al (IgAl) in the hinge region sequence. As demonstrated in animal models, the administration of IgAP can degrade IgAl -containing immune complex deposited in glomeruli and can ameliorate impaired renal function, e.g., proteinuria and hematuria.
- IgAPs immunoglobulin Al proteases
- the present disclosure provides immunoglobulin A protease (IgAP) polypeptides and polynucleotides (e.g., mRNA) for the treatment of IgA nephropathy (IgAN).
- IgAN IgA nephropathy
- the present disclosure also provides deimmunized IgAP polypeptides and polynucleotides (e.g., mRNA) for the treatment of IgAN.
- the mRNA therapeutics of the invention are well-suited for the treatment of IgAN as the technology provides for the intracellular delivery of mRNA encoding an immunoglobulin A protease (IgAP) protein followed by de novo synthesis of functional IgAP protein within target cells.
- the disclosure provides a polypeptide comprising an immunoglobulin A protease (IgAP) protease domain and an amino acid sequence that is at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100% identical to positions 815-995 of SEQ ID NO:2, wherein the polypeptide does not comprise an IgAP autotransporter domain, and wherein the polypeptide cleaves a human IgAl.
- the polypeptide does not comprise an IgAP autocleavage site.
- the polypeptide does not comprise amino acids corresponding to positions 996-1,688 of SEQ ID NO:2.
- the polypeptide does not comprise amino acids corresponding to positions 996-1688 of SEQ ID NO:2.
- the polypeptide optionally includes a signal peptide, and wherein the polypeptide is 950 to 1,050 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
- the polypeptide optionally includes a signal peptide, and wherein the polypeptide is 995 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
- the polypeptide comprises an amino acid sequence that is at least 95%, at least 97%, at least 98%, or at least 99% identical to the amino acid sequence of any one of SEQ ID NOs:4-6.
- the polypeptide comprises a substitution at one or more amino acids corresponding to any one of W430, Y523, F690, R77, Y86, Y127, Y128, A178, Y242, Y328, A333, T350, L463, V482, 1483, L484, F497, V509, V510, T566, 1577, Y612, N699, V742, N879, L913, F934, K935, L936, Y912, and Y979 of SEQ ID NO:6.
- the polypeptide comprises one or more substitutions corresponding to any one of W430A, Y523A, F690A, R77A, Y86A, Y127A, Y128A, A178K, Y242A, Y328A, A333G, T350G, L463A, V482A, I483A, L484A, F497A, V509A, V510A, T566G, I577A, Y612A, N699A, V742L, N879A, L913A, F934A, K935A, L936A, Y912A, and Y979A of SEQ ID NO:6.
- the polypeptide comprises: (a) substitutions at the amino acids corresponding to W430, Y523, and F690 of SEQ ID NO:6; (b) substitutions at the amino acids corresponding to Y86, L463, and 1577 of SEQ ID NO:6; (c) substitutions at the amino acids corresponding to Y328, Y523, and F690 of SEQ ID NO:6; (d) substitutions at the amino acids corresponding to Y127 and Y128 of SEQ ID NO:6; (e) substitutions at the amino acids corresponding to V509 and V510 of SEQ ID NO:6; (f) substitutions at the amino acids corresponding to Y912 and L913 of SEQ ID NO:6; (g) substitution at the amino acid corresponding to R77 of SEQ ID NO:6; (h) substitution at the amino acid corresponding to Y86 of SEQ ID NO:6; (i) substitution at the amino acid corresponding to Y242 of SEQ ID NO:6;
- the polypeptide comprises: (a) substitutions corresponding to W430A, Y523A, and F690A of SEQ ID NO:6; (b) substitutions corresponding to Y86A, L463A, and I577A of SEQ ID NO:6; (c) substitutions corresponding to Y328A, Y523A, and F690A of SEQ ID NO:6; (d) substitutions corresponding to Y127A and Y128A of SEQ ID NO:6; (e) substitutions corresponding to V509A and V510A of SEQ ID NO:6; (f) substitutions corresponding to Y912A and L913A of SEQ ID NO:6; (g) a substitution corresponding to R77A of SEQ ID NO:6; (h) a substitution corresponding to Y86A of SEQ ID NO:6; (i) a substitution corresponding to Y242A of SEQ ID NO:6; (j) a substitution corresponding
- the polypeptide comprises an amino acid sequence that is at least 95%, at least 97%, at least 98%, or at least 99% identical to the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49. In some instances, the polypeptide comprises the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49. In some instances, the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49 and optionally a signal peptide. In some instances, the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs:351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350.
- the polypeptide consists of the amino acid sequence of SEQ ID NO:80. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO: 80 and optionally a signal peptide. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:351.
- the polypeptide comprises the amino acid sequence of any one of SEQ ID NOs: 4-6. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:4 and optionally a signal peptide. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:5 or SEQ ID NO:6.
- the disclosure provides a polypeptide comprising an amino acid sequence that is at least 90%, at least 95%, or 100% identical to the amino acid sequence of SEQ ID NO:4, wherein the polypeptide optionally includes a signal peptide, wherein the polypeptide is 950 to 1,050 amino acids in length not inclusive of the signal peptide, if present in the polypeptide, and wherein the polypeptide cleaves a human IgAl .
- the C-terminus of the polypeptide corresponds to position 995 of SEQ ID NO:4.
- the polypeptide is 995 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
- the disclosure provides a polypeptide comprising an amino acid sequence that is at least 90%, at least 95%, or 100% identical to the amino acid sequence of SEQ ID NO: 80, wherein the polypeptide optionally includes a signal peptide, wherein the polypeptide is 950 to 1,050 amino acids in length not inclusive of the signal peptide, if present in the polypeptide, and wherein the polypeptide cleaves a human IgAl .
- the C-terminus of the polypeptide corresponds to position 995 of SEQ ID NO:80.
- the polypeptide is 995 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
- the disclosure provides an mRNA comprising an open reading frame (ORF) encoding any one of the foregoing polypeptides.
- ORF open reading frame
- the ORF is at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical to the nucleic acid sequence set forth in SEQ ID NO:27 or SEQ ID NO:28.
- the ORF comprises the nucleic acid sequence set forth in SEQ ID NO:27 or SEQ ID NO:28.
- the mRNA further comprises a 5' untranslated region (UTR) comprising the nucleic acid sequence of SEQ ID NO:56 or SEQ ID NO:58.
- the mRNA further comprises a 3' UTR comprising the nucleic acid sequence of SEQ ID NO: 114 or SEQ ID NO: 139. In some instances, the mRNA comprises the nucleic acid sequence of any one of SEQ ID NOs: 29-32.
- the ORF is at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical to the nucleic acid sequence set forth in any one of SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151.
- the ORF comprises the nucleic acid sequence set forth in SEQ ID NO: 153 or SEQ ID NO: 154.
- the mRNA further comprises a 5' untranslated region (UTR) comprising the nucleic acid sequence of SEQ ID NO:50, SEQ ID NO:56 or SEQ ID NO:58.
- the mRNA further comprises a 3' UTR comprising the nucleic acid sequence of SEQ ID NO: 114, SEQ ID NO: 132, SEQ ID NO: 138, or SEQ ID NO: 139.
- the mRNA comprises the nucleic acid sequence of any one of SEQ ID NOs: 301-319.
- the mRNA comprises the nucleic acid sequence of SEQ ID NO:318 or SEQ ID NO:319.
- the mRNA comprises a 5' terminal cap.
- the 5' terminal cap comprises a m 7 GpppG2 OMe, m7G-ppp-Gm-A, m7G-ppp-Gm-AG, CapO, Capl, ARC A, inosine, Nl-methyl-guanosine, 2 '-fluoro-guanosine, 7-deaza- guanosine, 8-oxo-guanosine, 2-amino-guanosine, LNA-guanosine, 2-azidoguanosine, Cap2, Cap4, 5' methylG cap, or an analog thereof.
- the mRNA comprises a poly-A region.
- the poly-A region is at least about 10, at least about 20, at least about 30, at least about 40, at least about 50, at least about 60, at least about 70, at least about 80, at least about 90 nucleotides in length, or at least about 100 nucleotides in length. In some instances, the poly-A region is at least about 100 nucleotides in length.
- all of the uracils of the mRNA are Nl- methylpseudouracils. In some instances, all of the uracils in the mRNA are 5- methoxyuracils.
- the disclosure provides a pharmaceutical composition comprising any one of the foregoing polypeptides, and a pharmaceutically acceptable excipient.
- the disclosure provides a pharmaceutical composition comprising any one of the foregoing mRNAs, and a pharmaceutically acceptable excipient.
- the disclosure provides a lipid nanoparticle comprising any one of the foregoing mRNAs.
- the lipid nanoparticle comprises an ionizable lipid, a structural lipid, a phospholipid, and a polyethylene glycol (PEG)- modified lipid.
- the ionizable lipid is Compound II or a salt thereof.
- the structural lipid is cholesterol.
- the phospholipid is l,2-distearoyl-sn-glycero-3-phosphocholine (DSPC) or l,2-dioleoyl-sn-glycero-3- phosphoethanolamine (DOPE).
- the PEG-modified lipid is PEG-DMG or Compound I.
- the disclosure provides a method of expressing a polypeptide in a human subject in need thereof, the method comprising administering to the human subject an effective amount of any one of the foregoing polypeptides, any one of the foregoing mRNAs, a any one of the foregoing pharmaceutical compositions, or any one of the foregoing lipid nanoparticles.
- a method for treating IgA nephropathy in a human subject in need thereof comprising administering to the human subject an effective amount of any one of the foregoing polypeptides, any one of the foregoing mRNAs, a any one of the foregoing pharmaceutical compositions, or any one of the foregoing lipid nanoparticles.
- FIG. 1 is a western blot depicting IgAlP, full length IgAl, cleaved IgAl, and beta-Actin protein levels for IgAl incubated with lysates or supernatants from cells transfected with mRNA encoding GFP or a truncated IgAP (SEQ ID NO:3).
- FIG. 2A is a western blot depicting IgAlP protein levels in lysates or supernatants (“Supe”) from cells transfected with mRNA encoding GFP or truncated IgAP (SEQ ID NOs:7-13).
- FIG. 2B is a western blot depicting full length IgAl, cleaved IgAl, and beta- Actin protein levels for IgAl incubated with lysates or supernatants (“Supe”) from cells transfected with mRNA encoding GFP or truncated IgAP as described in FIG. 2A.
- FIG. 3 is a western blot depicting IgAP, uncleaved IgAl, and cleaved IgAl protein levels in plasma (top) or kidney (bottom) samples from mice treated with IgAPl (SEQ ID NO:7), IgAP2 (SEQ ID NO:8), or PBS.
- FIG. 4A is a western blot depicting Fc ⁇ and Fab ⁇ fragments in sera harvested (at the indicated timepoints) from mice treated with the indicated constructs (0.25 mg/kg for mRNA). Left: 5 seconds exposure; right: 40 seconds exposures.
- FIG. 4B is a western blot depicting Fc ⁇ and Fab ⁇ fragments in sera harvested (at the indicated timepoints) from mice treated with the indicated constructs (0.5 mg/kg for mRNA). Left: 5 seconds exposure; right: 40 seconds exposures.
- FIG. 4C is a western blot depicting Fc ⁇ and Fab ⁇ fragments in sera harvested (at the indicated timepoints) from mice treated with the indicated constructs (1.0 mg/kg for mRNA). Left: 5 seconds exposure; right: 40 seconds exposures.
- FIG. 5 is a western blot depicting Fab ⁇ fragment in urine harvested (at the indicated timepoints) from mice treated with the indicated constructs.
- FIG. 6 is a graph depicting IgAl serum levels at the indicated timepoints after treatment with GFP mRNA or IgAP mRNA.
- FIG. 7 is a graph depicting serum Gd-IgAl levels at the indicated timepoints after treatment with GFP mRNA or IgAP mRNA.
- FIG. 9 is a graph depicting Gd-IgAl levels in sera from mice treated with GFP mRNA (triangles), IgAP mRNA with miRNA binding sites in the UTR (squares), or IgAP mRNA without miRNA binding sites in the UTR (circles).
- FIG. 10 is a graph depicting anti-IgAP Ig antibody levels in sera from mice treated with GFP mRNA (triangles), IgAP mRNA with miRNA binding sites in the UTR (squares), or IgAP mRNA without miRNA binding sites in the UTR (circles).
- FIG. 11 is a graph depicting hematuria inhibition rate (%) in urine from mice treated with GFP mRNA (triangles), IgAP mRNA with miRNA binding sites in the UTR (squares), or IgAP mRNA without miRNA binding sites in the UTR (circles).
- FIG. 12 is a graph depicting the score (percent) of IgAl deposits in kidney mesangium at the indicated timepoints after treatment with GFP mRNA (GFP), IgAP mRNA (mRNA), or recombinant IgAlP protein (IgAlP).
- GFP GFP mRNA
- mRNA IgAP mRNA
- IgAlP recombinant IgAlP protein
- FIG. 13 is a series of western blots depicting IgAP in sera harvested (at the indicated timepoints) from mice from Groups 1-5 (see Table 8).
- FIG. 14 is a graph depicting anti-IgA protease (IgG) concentration in sera harvested (at the indicated timepoints) from mice from Groups 1-5 (see Table 8). For each timepoint, the bars are, from left to right: Group 1, Group 2, Group 3, Group 4, and Group 5, respectively.
- IgG anti-IgA protease
- FIG. 15 is a graph depicting the percent mean T-cell stimulation by donor for cells exposed to IgAP (SEQ ID NO:4 with a C-terminal tag of SEQ ID NO:324) or deimmunized IgAP (SEQ ID NO:80 with a C-terminal tag of SEQ ID NO:324).
- FIG. 16A is a graph depicting DRB1 allele frequency distribution of the donor panel (right bars for each allele) compared to the global population (left bars for each allele).
- FIG. 16B is a graph depicting DRB1 allele frequency distribution of the donor panel (right bars for each allele) compared to the global population (left bars for each allele).
- FIG. 16C is a graph depicting DQB1 allele frequency distribution of the donor panel (right bars for each allele) compared to the global population (left bars for each allele).
- FIG. 16D is a graph depicting DPB1 allele frequency distribution of the donor panel (right bars for each allele) compared to the global population (left bars for each allele).
- FIG. 17 is a graph depicting serum human galactose deficient (GD) IgAl decreased levels at the indicated timepoints.
- FIG. 18 is a western blot depicting Fc ⁇ and Fab ⁇ fragments in sera harvested (at the indicated timepoints) from mice treated with deimmunized IgAP mRNA.
- MWM molecular weight marker
- IgAlP 0 sera from mouse before treatment
- IgAlp 30 sera from mouse 30-hours after recombinant IgAlP treatment
- GFP sera from mouse treated with GFP-mRNA-LNP
- 1 Wk-6Wk sera from mouse 1, 2, 3, 4, 5, or 6 weeks, respectively, after treatment with deimmunized IgAP mRNA-LNP.
- FIG. 19 is a western blot depicting Fab ⁇ fragments in urine harvested (at the indicated timepoints) from mice treated with deimmunized IgAP mRNA.
- MWM molecular weight marker
- IgAlP 0 urine from mouse before treatment
- IgAlP 30 urine from mouse 30-hours after recombinant IgAlP treatment
- GFP urine from mouse treated with GFP-mRNA-LNP
- -24 urine from mouse 24 hours prior to treatment with deimmunized IgAP mRNA-LNP
- 3WK, 6WK urine from mouse 3 or 6 weeks, respectively, after treatment with deimmunized IgAP mRNA-LNP.
- FIG. 20 is a graph depicting IgAl deposits positivity rate (percent) for mice after 6 weeks of treatment with GFP mRNA (left) or deimmunized IgAP mRNA (right).
- FIG. 21 is a graph depicting serum IgAlP in representative mice from each treatment group. Arrow points to detected IgAlP.
- - sample buffer
- GFP sera from mouse grated with GFP-mRNA LNP
- -24 sera from mouse before injection
- 1 WK- 6WK sera from mouse 1, 2, 3, 4, 5, or 6 weeks, respectively, after treatment with deimmunized IgAP mRNA-LNP
- IgAlP + more concentrated IgAlP
- IgAlp- less concentrated IgAlP.
- FIG. 22 is a series of graphs depicting IgG anti-IgAlP levels (top) or IgG anti-Ovalbumin levels (bottom) after 6 weeks of treatment with the indicated constructs. From left to right for each graph: mRNA-LNP-GFP; mRNA-LNP GFP + ovalbumin; mRNA-LNP-IgAlP; and mRNA-LNP-IgAlP + ovalbumin.
- Immunoglobulin A proteases are a group of secreted bacterial endopeptidases that cleave human immunoglobulin Al (IgAl) in the hinge region sequence.
- IgAPs contain a signal sequence (e.g., amino acids 1-26 of SEQ ID NO: 1), a protease domain (e g., amino acids 26-878 of SEQ ID NO:1), an autocleavage site (e g., amino acids 1,022-1,034 of SEQ ID NO: 1), and an autotransporter beta domain (e.g., amino acids 1,469-1,649 of SEQ ID NO: 1).
- the IgAP autotransporter beta domain directs secretion of the IgAP out of the bacterial cell.
- the IgAP protease domain contains an IgA protease enzymatic active motif (e g., amino acids 297-304 of SEQ ID NO: 1).
- IgAP also contains a sequence (e.g., amino acids 879-1021 of SEQ ID NOT) that is required for cleavage activity after secretion from a mammalian cell.
- IgAP degrades IgAl- containing immune complex deposited in glomeruli and ameliorates impaired renal function, e.g., proteinuria and hematuria.
- Haemophilus influenzae IgAP protein sequence is described at the RefSeq database under accession number OBX53260.1 ("peptidase [Haemophilus influenzae]”), SEQ ID NOT below.
- This exemplary IgAP proprotein is 1,714 amino acids long and has a signal peptide at positions 1-26 of SEQ ID NO: 1. It is noted that the specific nucleic acid sequences encoding the reference protein sequence in the RefSeq sequences are coding sequence (CDS) as indicated in the respective RefSeq database entry.
- CDS coding sequence
- the polynucleotides disclosed herein comprise one or more sequences encoding an IgAP protein or variant thereof that is suitable for use in mRNA therapy (e.g., for treating IgAN).
- An IgAP for use in mammals may be truncated to remove the autotransporter beta domain (or a portion thereof), which is used for secretion of native IgAP from a bacterial cell.
- the IgAP proteins described herein are truncated IgAP proteins lacking an IgAP beta autotransporter domain (e.g., amino acids 1,469-1,649 of SEQ ID NO: 1), optionally lacking the amino acid sequence from the IgAP autocleavage site to the end of the IgAP protein (e.g., amino acids 1022-1714 of SEQ ID NO: 1), while retaining the ability to cleave a human IgAl (e.g., after secretion of the IgAP from a mammalian cell, e.g., a HepG2 cell).
- IgAP beta autotransporter domain e.g., amino acids 1,469-1,649 of SEQ ID NO: 1
- amino acids 1022-1714 of SEQ ID NO: 1 amino acids 1022-1714 of SEQ ID NO: 1
- the IgAP proteins described herein comprise an amino acid sequence that is at least 70%, at least 75%, at least 80%, at least 85%>, at least 90%, at least 95%, or 100%> identical to the amino acid sequence between the IgAP protease domain and the IgAP autocleavage site (e g., at least 70%, at least 75%o, at least 80%>, at least 85%>, at least 90%>, at least 95%o, or 100%o identical to amino acids 815-995 of SEQ ID NO:2 (i.e., amino acids 879-1021 of SEQ ID NO: 1)).
- the IgAP protein comprises an amino acid sequence that is at least at least 90%o, at least 95%, or 100%) identical to the amino acid sequence of SEQ ID NO:4, and optionally a signal peptide, wherein the IgAP protein does not comprise an IgAP autotransporter beta domain (e.g., amino acids 1,469-1,649 of SEQ ID NO: 1), optionally wherein the IgAP protein does not comprise the amino acid sequence from the autocleavage site to the end of the IgAP protein (e.g., amino acids 1022-1714 of SEQ ID NO: 1).
- the signal peptide is present in the IgAP proprotein and is cleaved off during processing of the proprotein into the mature form.
- the IgAP protein comprises a signal peptide (i.e., in its proprotein form), and in some instances the IgAP protein does not comprise a signal peptide (i.e., in its mature form).
- SEQ ID NOs: 5 and 6 are exemplary IgAP proteins each consisting of a signal peptide and the amino acids corresponding to positions 1-995 of SEQ ID NO:2.
- the IgAP protein comprises an amino acid sequence that is at least at least 90%o , at least 95%>, or 100% identical to the amino acid sequence of SEQ ID NO: 5 or 6.
- the IgAP protein does not comprise an IgAP autocleavage site (e.g., amino acids 1,022-1,034 of SEQ ID NO: 1). In some instances, the IgAP protein does not comprise an amino acid sequence that is at least 70%, at least 75%>, at least 80%, at least 85%o, at least 90%>, at least 95%o, or 100%) identical to amino acids 996-1,688 of SEQ ID N0:2.
- the IgAP protein comprises an IgAP protease domain (e.g., amino acids 26-878 of SEQ ID NO: 1) and an amino acid sequence that is at least is at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100% identical to the amino acid sequence between the IgAP protease domain and the IgAP autocleavage site (e.g., at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100% identical to amino acids 815-995 of SEQ ID NO:2), and optionally a signal peptide, wherein the IgAP protein does not comprise an IgAP autotransporter beta domain (e.g., amino acids 1469-1649 of SEQ ID NO: 1).
- IgAP protease domain e.g., amino acids 26-878 of SEQ ID NO: 1
- an amino acid sequence that is at least is at least is at least 70%, at least 75%, at least
- the IgAP protein is 950 to 1,050, 960 to 1,050, 970 to 1040, 980 to 1030, 990 to 1020, 995 to 1010, 995 to 1020, 995 to 1030, 995 to 1040, or 995 to 1050 amino acids in length (not inclusive of a signal peptide).
- the IgAP protein comprises or consists of the amino acid sequence set forth in SEQ ID NO:4 (and optionally includes a signal peptide).
- the IgAP protein comprises or consists of the amino acid sequence set forth in SEQ ID NO:5.
- the IgAP protein comprises or consists of the amino acid sequence set forth in SEQ ID NO:6.
- the IgAP protein is 995 amino acids in length (not inclusive of a signal peptide).
- the C-terminus of the IgAP protein corresponds to position 995 of SEQ ID NO:4.
- the IgAP protein cleaves human IgAl (e.g., after secretion from a mammalian cell, e.g., a HepG2 cell, e.g., as determined by an assay described in the working examples herein).
- a polynucleotide disclosed herein comprises a sequence encoding the IgAP protein of SEQ ID NO:4 (and optionally a signal peptide).
- a polynucleotide disclosed herein comprises a sequence encoding the IgAP protein of SEQ ID NO:5. In some embodiments, a polynucleotide disclosed herein comprises a sequence encoding the IgAP protein of SEQ ID NO:6.
- the present application addresses the problem of IgAl accumulation in subjects suffering from IgAN by providing a polynucleotide, e.g., mRNA, that encodes IgAP or functional fragment thereof (e.g., SEQ ID NO:4), wherein the polynucleotide is sequence-optimized.
- the working examples also identify sites in the IgAP proteins described herein that may be deimmunized.
- an IgAP polypeptide described herein comprises a substitution at one or more amino acids corresponding to any one of W430, Y523, F690, R77, Y86, Y127, Y128, A178, Y242, Y328, A333, T350, L463, V482, 1483, L484, F497, V509, V510, T566, 1577, Y612, N699, V742, N879, L913, F934, K935, L936, Y912, and Y979 of SEQ ID NO:6.
- the polypeptide comprises one or more substitutions corresponding to any one of W430A, Y523A, F690A, R77A, Y86A, Y127A, Y128A, A178K, Y242A, Y328A, A333G, T350G, L463A, V482A, I483A, L484A, F497A, V509A, V510A, T566G, I577A, Y612A, N699A, V742L, N879A, L913A, F934A, K935A, L936A, Y912A, and Y979A of SEQ ID NO:6.
- the polypeptide comprises: (a) substitutions at the amino acids corresponding to W430, Y523, and F690 of SEQ ID NO:6; (b) substitutions at the amino acids corresponding to Y86, L463, and 1577 of SEQ ID NO:6; (c) substitutions at the amino acids corresponding to Y328, Y523, and F690 of SEQ ID NO:6; (d) substitutions at the amino acids corresponding to Y127 and Y128 of SEQ ID NO:6; (e) substitutions at the amino acids corresponding to V509 and V510 of SEQ ID NO:6; (f) substitutions at the amino acids corresponding to Y912 and L913 of SEQ ID NO:6; (g) substitution at the amino acid corresponding to R77 of SEQ ID NO:6; (h) substitution at the amino acid corresponding to Y86 of SEQ ID NO:6; (i) substitution at the amino acid corresponding to Y242 of SEQ ID NO:6; (j) substitution
- the polypeptide comprises: (a) substitutions corresponding to W430A, Y523A, and F690A of SEQ ID NO:6; (b) substitutions corresponding to Y86A, L463A, and I577A of SEQ ID NO:6; (c) substitutions corresponding to Y328A, Y523A, and F690A of SEQ ID NO:6; (d) substitutions corresponding to Y127A and Y128A of SEQ ID NO:6; (e) substitutions corresponding to V509A and V510A of SEQ ID NO:6; (f) substitutions corresponding to Y912A and L913A of SEQ ID NO:6; (g) a substitution corresponding to R77A of SEQ ID NO:6; (h) a substitution corresponding to Y86A of SEQ ID NO:6; (i) a substitution corresponding to Y242A of SEQ ID NO:6; (j) a substitution corresponding to W430A
- the polypeptide comprises an amino acid sequence that is at least 95%, at least 97%, at least 98%, or at least 99% identical to the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49. In some instances, the polypeptide comprises the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49. In some instances, the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49 and optionally a signal peptide.
- the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs: 351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:80. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:80 and optionally a signal peptide. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:351. Polynucleotides and Open Reading Frames (ORFs)
- the instant invention features mRNAs for use in treating IgA nephropathy.
- the mRNAs featured for use in the invention are administered to subjects and encode an IgAP protein described herein in vivo.
- the invention relates to polynucleotides, e.g., mRNA, comprising an open reading frame of linked nucleosides encoding an IgAP protein described herein (e.g., isoforms, functional fragment, fusions, or variants thereof).
- the invention provides sequence-optimized polynucleotides comprising nucleotides encoding the polypeptide sequence of an IgAP protein, or sequence having high sequence identity with those sequence optimized polynucleotides.
- the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises a nucleotide sequence (e.g., an ORF) encoding an IgAP protein described herein, wherein the nucleotide sequence has at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to SEQ ID NO:27 or SEQ ID NO:28.
- a nucleotide sequence e.g., an ORF
- the polynucleotide of the invention (e.g., an RNA, e.g., an mRNA) comprises a nucleotide sequence (e.g., an ORF, e.g., SEQ ID NO:27 or SEQ ID NO:28) encoding an IgAP protein described herein further comprises a 5'-UTR (e.g., SEQ ID NO: 58) and a 3'-UTR (e.g., SEQ ID NO: 114 or SEQ ID NO: 139).
- a nucleotide sequence e.g., an ORF, e.g., SEQ ID NO:27 or SEQ ID NO:28
- an IgAP protein described herein further comprises a 5'-UTR (e.g., SEQ ID NO: 58) and a 3'-UTR (e.g., SEQ ID NO: 114 or SEQ ID NO: 139).
- the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:29. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:30. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:31.
- the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:32.
- the polynucleotide (e.g., a RNA, e.g., an mRNA) comprises a 5' terminal cap (e.g., m 7 Gp-ppGm-A, m 7 Gp-ppGm-G, CapO, Capl, ARCA, inosine, Nl- methyl-guanosine, 2 '-fluoro-guanosine, 7-deaza-guanosine, 8-oxo-guanosine, 2-amino- guanosine, LNA-guanosine, 2-azidoguanosine, Cap2, Cap4, 5' methylG cap, or an analog thereof) and a poly-A-tail region (e.g., about 100 nucleotides in length).
- the mRNA comprises a polyA tail.
- the poly A tail is 50-150 (SEQ ID NO: 197), 75-150 (SEQ ID NO: 198), 85-150 (SEQ ID NO: 199), 90-120 (SEQ ID NO: 193), 90-130 (SEQ ID NO: 194), or 90-150 (SEQ ID NO: 192) nucleotides in length.
- the poly A tail is 100 nucleotides in length (SEQ ID NO: 195).
- the poly A tail is protected (e.g., with an inverted deoxythymidine).
- the poly A tail comprises A100-UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO: 211). In some instances, the poly A tail is A100- UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO: 211).
- the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises a nucleotide sequence (e.g., an ORF) encoding an IgAP protein described herein, wherein the nucleotide sequence has at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to any one of SEQ ID NOs:153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151.
- a nucleotide sequence e.g., an ORF
- the polynucleotide does not include a sequence encoding a C-terminal tag (e.g., a sequence encoding SEQ ID NO:324). In some instances, the polynucleotide includes a sequence encoding a C- terminal tag (e g., a sequence encoding SEQ ID NO:324).
- the polynucleotide of the invention (e.g., an RNA, e.g., an mRNA) comprises a nucleotide sequence (e.g., an ORF, e.g., SEQ ID NO: 153 or SEQ ID NO: 154) encoding an IgAP protein described herein further comprises a 5'-UTR (e.g., SEQ ID NO:50) and a 3'-UTR (e.g., SEQ ID NO:132).
- the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of any one of SEQ ID NOs:301-319.
- the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:318. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:319.
- the polynucleotide (e.g., a RNA, e.g., an mRNA) comprises a 5' terminal cap (e.g., m 7 Gp-ppGm-A, m 7 Gp- ppGm-G, CapO, Capl, ARC A, inosine, Nl-methyl-guanosine, 2'-fluoro-guanosine, 7- deaza-guanosine, 8-oxo-guanosine, 2-amino-guanosine, LNA-guanosine, 2- azidoguanosine, Cap2, Cap4, 5' methylG cap, or an analog thereof) and a poly-A-tail region (e.g., about 100 nucleotides in length).
- a 5' terminal cap e.g., m 7 Gp-ppGm-A, m 7 Gp- ppGm-G, CapO, Capl, ARC A, inosine, Nl-methyl-gua
- the mRNA comprises a polyA tail.
- the poly A tail is 50-150 (SEQ ID NO:197), 75-150 (SEQ ID NO: 198), 85-150 (SEQ ID NO: 199), 90-120 (SEQ ID NO: 193), 90-130 (SEQ ID NO: 194), or 90-150 (SEQ ID NO: 192) nucleotides in length.
- the poly A tail is 100 nucleotides in length (SEQ ID NO: 195).
- the poly A tail is protected (e.g., with an inverted deoxy-thymidine).
- the poly A tail comprises A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO: 211). In some instances, the poly A tail is A100-UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO: 211).
- the polynucleotide of the invention e.g., a RNA, e.g., an mRNA
- a nucleotide sequence e.g., an ORF
- IgAP protein is single stranded or double stranded.
- the polynucleotide of the invention comprising a nucleotide sequence (e.g., an ORF) encoding an IgAP protein is DNA or RNA.
- the polynucleotide of the invention is RNA.
- the polynucleotide of the invention is, or functions as, an mRNA.
- the mRNA comprises a nucleotide sequence (e.g., an ORF) that encodes at least one IgAP protein, and is capable of being translated to produce the encoded IgAP protein described herein in vitro, in vivo, in situ or ex vivo.
- the polynucleotide of the invention (e.g., a RNA, e.g., an mRNA) comprises a sequence-optimized nucleotide sequence (e.g., an ORF) encoding an IgAP protein described herein, wherein the polynucleotide comprises at least one chemically modified nucleobase, e.g., N1 -methylpseudouracil or 5-methoxyuracil.
- all uracils in the polynucleotide are N1 -methylpseudouracils.
- all uracils in the polynucleotide are 5-methoxyuracils.
- the polynucleotide further comprises a miRNA binding site, e.g., a miRNA binding site that binds to miR-142 and/or a miRNA binding site that binds to miR-126.
- the polynucleotide e.g., a RNA, e.g., an mRNA
- a delivery agent comprising, e.g., a compound having the Formula (I), e g., Compound II or Compound B; a compound having the Formula (III), (IV), (V), or (VI), e.g., Compound VI or Compound I, or any combination thereof.
- the delivery agent comprises an ionizable amino lipid (e.g., Compound II, VI, or B), a helper lipid (e.g., DSPC), a sterol (e.g., Cholesterol), and a PEG lipid (e.g., Compound I or PEG-DMG), e.g., with a mole ratio in the range of about (i) 40-50 mol% ionizable amino lipid (e.g., Compound II, VI, or B), optionally 45-50 mol% ionizable amino lipid, for example, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48-49 mol%, or 49-50 mol% for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol%; (ii) 30-45
- the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G), a 5'UTR (e.g., any one of SEQ ID NOs:50-79), an ORF sequence of SEQ ID NO:27, a 3'UTR (e.g., any one of SEQ ID NOs: 100-136 and 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils.
- a 5'-terminal cap e., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G
- a 5'UTR e.g.
- the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid, some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
- the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G), a 5'UTR (e.g., any one of SEQ ID NOs:50-79), an ORF sequence of SEQ ID NO:28, a 3'UTR (e.g., any one of SEQ ID NOs: 100-136 and 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils.
- a 5'-terminal cap e., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G
- a 5'UTR e.g.
- the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid, some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
- the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G), a 5'UTR (e.g., any one of SEQ ID NOs:50-79), an ORF sequence of SEQ ID NO:153, a 3'UTR (e.g., any one of SEQ ID NOs: 100-136, 138, and 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils.
- a 5'-terminal cap e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G
- the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid, some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
- the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G), a 5'UTR (e.g., any one of SEQ ID NOs: 50-79), an ORF sequence of SEQ ID NO: 154, a 3'UTR (e.g., any one of SEQ ID NOs: 100-136, 138, and 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils.
- a 5'-terminal cap e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G
- the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid. Some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
- the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G), a 5'UTR (e.g., SEQ ID NO:58), an ORF sequence of SEQ ID NO:27, a 3'UTR (e g., SEQ ID NO:114 or SEQ ID NO: 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO:195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils.
- a 5'-terminal cap e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G
- a 5'UTR e.g., SEQ ID NO:
- the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid. Some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
- the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G), a 5'UTR (e.g., SEQ ID NO:58), an ORF sequence of SEQ ID NO:28, a 3'UTR (e g., SEQ ID NO:114 or SEQ ID NO: 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils.
- a 5'-terminal cap e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G
- a 5'UTR e.g., SEQ ID NO
- the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid. Some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
- the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G), a 5'UTR (e.g, SEQ ID NO:58), an ORF sequence of SEQ ID NO: 153, a 3'UTR (e.g, SEQ ID NO: 138), and a poly A tail (e.g, about 100 nt in length, e.g, SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils.
- a 5'-terminal cap e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G
- a 5'UTR e.g, SEQ ID NO:58
- the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid. Some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
- the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G), a 5'UTR (e.g., SEQ ID NO:50), an ORF sequence of SEQ ID NO: 154, a 3'UTR (e g., SEQ ID NO: 132), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils.
- a 5'-terminal cap e.g., Capl, e.g., m 7 Gp-ppGm-A or m 7 Gp-ppGm-G
- a 5'UTR e.g., SEQ ID NO:50
- the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid, some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
- the polynucleotides e.g., a RNA, e.g., an mRNA
- RNA e.g., an mRNA
- the peptides encoded by these signal sequences are known by a variety of names, including targeting peptides, transit peptides, and signal peptides.
- the polynucleotide (e.g., a RNA, e.g., an mRNA) comprises a nucleotide sequence (e.g., an ORF) that encodes a signal peptide operably linked to a nucleotide sequence that encodes an IgAP protein described herein.
- a nucleotide sequence e.g., an ORF
- the "signal sequence” or “signal peptide” is a polynucleotide or polypeptide, respectively, which is from about 30-210, e g., about 45- 80 or 15-60 nucleotides (e.g., about 20, 30, 40, 50, 60, or 70 amino acids) in length that, optionally, is incorporated at the 5' (or N-terminus) of the coding region or the polypeptide, respectively. Addition of these sequences results in trafficking the encoded polypeptide to a desired site, such as the endoplasmic reticulum or the mitochondria through one or more targeting pathways. Some signal peptides are cleaved from the protein, for example by a signal peptidase after the proteins are transported to the desired site.
- the polynucleotide of the invention comprises a nucleotide sequence encoding an IgAP protein, wherein the nucleotide sequence further comprises a 5' nucleic acid sequence encoding a heterologous signal peptide.
- the polynucleotide of the invention comprises a nucleotide sequence encoding an IgAP protein, wherein the nucleotide sequence further comprises a 5' nucleic acid sequence encoding a heterologous signal peptide.
- the heterologous signal peptide comprises the amino acid sequence of the signal peptide is MLKNKKFKLNFIALTVAYALAPYTEA (SEQ ID NO:320), MGVKVLF ALICIA VAEA (SEQ ID NO:321), or METPAQLLFLLLLWLPDTTG (SEQ ID NO:322).
- the polynucleotide of the invention e.g., a RNA, e.g., an mRNA
- polynucleotides of the invention comprise a single ORF encoding an IgAP protein described herein.
- two or more polypeptides of interest can be genetically fused, i.e., two or more polypeptides can be encoded by the same ORF.
- the polynucleotide can comprise a nucleic acid sequence encoding a linker (e.g., a G4S (SEQ ID NO: 200) peptide linker or another linker known in the art) between two or more polypeptides of interest.
- a linker e.g., a G4S (SEQ ID NO: 200) peptide linker or another linker known in the art
- a polynucleotide of the invention e.g., a RNA, e.g., an mRNA
- a polynucleotide of the invention can comprise two, three, four, or more ORFs, each expressing a polypeptide of interest.
- the mRNAs of the disclosure encode more than one IgAP domain or a heterologous domain, referred to herein as multimer constructs.
- the mRNA further encodes a linker located between each domain.
- the linker can be, for example, a cleavable linker or protease-sensitive linker.
- the linker is selected from the group consisting of F2A linker, P2A linker, T2A linker, E2A linker, and combinations thereof.
- This family of self-cleaving peptide linkers, referred to as 2A peptides has been described in the art (see for example, Kim, J.H. et al.
- the linker is an F2A linker.
- the linker is a GGGS (SEQ ID NO: 201) linker.
- the multimer construct contains three domains with intervening linkers, having the structure: domain- linker-domain-linker-domain e.g., IgAP domain-linker-IgAP domain.
- the cleavable linker is an F2A linker (e.g., having the amino acid sequence GSGVKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 189)).
- the cleavable linker is a T2A linker (e.g., having the amino acid sequence GSGEGRGSLLTCGDVEENPGP (SEQ ID NO: 190)), a P2A linker (e.g, having the amino acid sequence GSGATNFSLLKQAGDVEENPGP (SEQ ID NO: 191)) or an E2A linker (e.g, having the amino acid sequence GSGQCTNYALLKLAGDVESNPGP (SEQ ID NO: 186)).
- linkers may be suitable for use in the constructs of the invention (e.g, encoded by the polynucleotides of the invention).
- the skilled artisan will likewise appreciate that other multi ci str onic constructs may be suitable for use in the invention.
- the construct design yields approximately equimolar amounts of intrabody and/or domain thereof encoded by the constructs of the invention.
- the self-cleaving peptide may be, but is not limited to, a 2A peptide.
- 2A peptides are known and available in the art and may be used, including e.g, the foot and mouth disease virus (FMDV) 2A peptide, the equine rhinitis A virus 2A peptide, the Thosea asigna virus 2A peptide, and the porcine teschovirus-1 2A peptide.
- FMDV foot and mouth disease virus
- 2A peptides are used by several viruses to generate two proteins from one transcript by ribosome-skipping, such that a normal peptide bond is impaired at the 2A peptide sequence, resulting in two discontinuous proteins being produced from one translation event.
- the 2A peptide may have the protein sequence of SEQ ID NO: 191, fragments or variants thereof. In one embodiment, the 2A peptide cleaves between the last glycine and last proline.
- the polynucleotides of the present invention may include a polynucleotide sequence encoding the 2A peptide having the protein sequence of fragments or variants of SEQ ID NO: 191.
- a polynucleotide sequence encoding the 2A peptide is GGAAGCGGAGCUACUAACUUCAGCCUGCUGAAGCAGGCUGGAGACGUGG AGGAGAACCCUGGACCU (SEQ ID NO: 187).
- a 2A peptide is encoded by the following sequence: 5'- UCCGGACUCAGAUCCGGGGAUCUCAAAAUUGUCGCUCCUGUCAAACAAAC UCUUAACUUUGAUUUACUCAAACUGGCTGGGGAUGUAGAAAGCAAUCCAG GTCCACUC-3'(SEQ ID NO: 188).
- the polynucleotide sequence of the 2A peptide may be modified or codon optimized by the methods described herein and/or are known in the art.
- this sequence may be used to separate the coding regions of two or more polypeptides of interest.
- the sequence encoding the F2A peptide may be between a first coding region A and a second coding region B (A-F2Apep-B).
- F2A peptide results in the cleavage of the one long protein between the glycine and the proline at the end of the F2A peptide sequence (NPGP (SEQ ID NO:205) is cleaved to result in NPG and P) thus creating separate protein A (with 21 amino acids of the F2A peptide attached, ending with NPG) and separate protein B (with 1 amino acid, P, of the F2A peptide attached).
- NPGP SEQ ID NO:205
- Protein A and protein B may be the same or different peptides or polypeptides of interest (e.g., an IgAP protein described herein). Sequence-Optimized Nucleotide Sequences Encoding IgAP Proteins
- the polynucleotide of the invention comprises a sequence-optimized nucleotide sequence encoding an IgAP protein disclosed herein.
- the polynucleotide of the invention comprises an open reading frame (ORF) encoding an IgAP protein, wherein the ORF has been sequence optimized.
- ORF open reading frame
- An exemplary sequence-optimized nucleotide sequence encoding an IgAP protein is set forth as SEQ ID NO:27.
- Another exemplary sequence-optimized nucleotide sequence encoding an IgAP protein is set forth as SEQ ID NO:28.
- Additionally exemplary sequence-optimized nucleotide sequences encoding an IgAP protein are set forth in SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151.
- the sequence optimized IgAP sequence is used to practice the methods disclosed herein.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' cap such as provided herein, for example, m 7 Gp-ppGm-A or m 7 Gp-ppGm- G;
- an open reading frame encoding an IgAP protein (e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO:6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
- an IgAP protein e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO:6
- a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
- a 3' UTR comprising a nucleotide sequence set forth in Table 2 or Table 3, e.g., SEQ ID NO: 114 or SEQ ID NO: 139;
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' cap such as provided herein, for example, m 7 Gp-ppGm-A or m 7 Gp-ppGm- G;
- an open reading frame encoding an IgAP protein (e.g., any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49, optionally including a signal peptide, e g., the IgAP protein of any one of SEQ ID NOs: 351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as any one of SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151;
- a 3' UTR comprising a nucleotide sequence set forth in Table 2 or Table 3, e.g., SEQ ID NO: 132 or SEQ ID NO: 138;
- a poly-A tail provided above e.g., SEQ ID NO: 195.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' cap such as provided herein, for example, m 7 Gp-ppGm-A or m 7 Gp-ppGm- G;
- an open reading frame encoding an IgAP protein e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
- a 3' UTR comprising a nucleotide sequence set forth in Table 2 or Table 3, e.g., SEQ ID NO: 114 or SEQ ID NO: 139; and (vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' cap such as provided herein, for example, m 7 Gp-ppGm-A or m 7 Gp-ppGm- G;
- an open reading frame encoding an IgAP protein (e g., any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49, optionally including a signal peptide, e.g., the IgAP protein of any one of SEQ ID NOs: 351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as any one of SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151;
- a 3' UTR comprising a nucleotide sequence set forth in Table 2 or Table 3, e.g., SEQ ID NO: 132;
- a poly-A tail provided above e.g., SEQ ID NO: 195.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' cap such as provided herein, for example, m 7 Gp-ppGm-A or m 7 Gp-ppGm- G;
- an open reading frame encoding an IgAP protein e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
- a poly-A tail provided above e.g., SEQ ID NO: 195.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' cap such as provided herein, for example, m 7 Gp-ppGm-A or m 7 Gp-ppGm- G;
- an open reading frame encoding an IgAP protein e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
- a poly-A tail provided above e.g., SEQ ID NO: 195.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' cap such as provided herein, for example, m 7 Gp-ppGm-A or m 7 Gp-ppGm- G;
- an open reading frame encoding an IgAP protein e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
- a poly-A tail provided above e.g., SEQ ID NO: 195.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' cap such as provided herein, for example, m 7 Gp-ppGm-A or m 7 Gp-ppGm- G;
- an open reading frame encoding an IgAP protein e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
- a poly-A tail provided above e.g., SEQ ID NO: 195.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' cap such as provided herein, for example, m 7 Gp-ppGm-A or m 7 Gp-ppGm- G;
- an open reading frame encoding an IgAP protein e.g., SEQ ID NO: 80, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO:351), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO: 153 or SEQ ID NO: 154;
- a poly-A tail provided above e.g., SEQ ID NO: 195.
- all uracils in the polynucleotide are N1 -methylpseudouracil (G5).
- all uracils in the polynucleotide are 5-methoxyuracil (G6).
- sequence-optimized nucleotide sequences disclosed herein are distinct from the corresponding wild type nucleotide acid sequences and from other known sequence-optimized nucleotide sequences, e.g., these sequence-optimized nucleic acids have unique compositional characteristics.
- the percentage of uracil or thymine nucleobases in a sequence-optimized nucleotide sequence is modified (e.g., reduced) with respect to the percentage of uracil or thymine nucleobases in the reference wild-type nucleotide sequence.
- a sequence is referred to as a uracil -modified or thymine-modified sequence.
- the percentage of uracil or thymine content in a nucleotide sequence can be determined by dividing the number of uracils or thymines in a sequence by the total number of nucleotides and multiplying by 100.
- the sequence-optimized nucleotide sequence has a lower uracil or thymine content than the uracil or thymine content in the reference wild-type sequence.
- the uracil or thymine content in a sequence-optimized nucleotide sequence of the invention is greater than the uracil or thymine content in the reference wild-type sequence and still maintain beneficial effects, e.g., increased expression and/or reduced Toll-Like Receptor (TLR) response when compared to the reference wild-type sequence.
- TLR Toll-Like Receptor
- an ORF of any one or more of the sequences provided herein may be codon optimized.
- Codon optimization in some embodiments, may be used to match codon frequencies in target and host organisms to ensure proper folding; bias GC content to increase mRNA stability or reduce secondary structures; minimize tandem repeat codons or base runs that may impair gene construction or expression; customize transcriptional and translational control regions; insert or remove protein trafficking sequences; remove/add post translation modification sites in encoded protein (e.g., glycosylation sites); add, remove or shuffle protein domains; insert or delete restriction sites; modify ribosome binding sites and mRNA degradation sites; adjust translational rates to allow the various domains of the protein to fold properly; or reduce or eliminate problem secondary structures within the polynucleotide.
- Codon optimization tools, algorithms and services are known in the art - non-limiting examples include services from GeneArt (Life Technologies), DNA2.0 (Menlo Park CA) and/or proprietary methods.
- the open reading frame (ORF) sequence is optimized using optimization algorithms.
- An Identification and Ratio Determination (IDR) sequence is a sequence of a biological molecule (e.g., nucleic acid or protein) that, when combined with the sequence of a target biological molecule, serves to identify the target biological molecule.
- a biological molecule e.g., nucleic acid or protein
- an IDR sequence is a heterologous sequence that is incorporated within or appended to a sequence of a target biological molecule and can be used as a reference to identify the target molecule.
- a nucleic acid e.g., mRNA
- a target sequence of interest e.g., a coding sequence encoding a therapeutic and/or antigenic peptide or protein
- a unique IDR sequence e.g., a unique IDR sequence.
- RNA species may comprise an IDR sequence that differs from the IDR sequence of other RNA species (e.g., RNA(s) having different coding sequence(s)).
- IDR sequence thus identifies a particular RNA species, and so the abundance of IDR sequences may be measured to determine the abundance of each RNA species in a composition.
- Use of distinct IDR sequences to identify RNA species allows for analysis of multivalent RNA compositions (e.g., containing multiple RNA species) containing RNA species with similar coding sequences and/or lengths, which could otherwise be difficult to distinguish using PCR- or chromatography-based analysis of full-length RNAs.
- Each RNA species in a multivalent RNA composition may comprise an IDR sequence that is not a sequence isomer of an IDR sequence of another RNA species in a multivalent RNA composition (e.g., the IDR sequence does not have the same number of adenosine nucleotides, the same number of cytosine nucleotides, the same number of guanine nucleotides, and the same number of uracil nucleotides, as another IDR sequence in the composition, even if those sequences have different sequences).
- Having identical nucleotide compositions causes sequence isomers to have the same mass, presenting a challenge to distinguishing sequence isomers using mass-based identification methods (e.g., mass spectrometry).
- Each RNA species in a multivalent RNA composition may comprise an IDR sequence having a mass that differs from the mass of IDR sequences of each other RNA species in a multivalent RNA composition.
- the mass of each IDR sequence may differ from the mass of other IDR sequences by at least 9 Da, at least 25 Da, at least 25 Da, or at least 50 Da.
- Use of IDR sequences with distinct masses allows RNA fragments comprising different IDR sequences to be distinguished using mass-based analysis methods (e.g, mass spectrometry), which do not require reverse transcription, amplification, or sequencing of RNAs.
- Each RNA species in an RNA composition may comprises an IDR sequence with a different length.
- each IDR sequence may have a length independently selected from 0 to 25 nucleotides.
- the length of a nucleic acid influences the rate at which the nucleic acid traverses a chromatography column, and so the use of IDR sequences of different lengths on different RNA species allows RNA fragments having different IDR sequences to be distinguished using chromatography-based methods (e.g, LC-UV).
- IDR sequences may be chosen such that no IDR sequence comprises a start codon, ‘AUG’. Lack of a start codon in an IDR sequence prevents undesired translation of nucleotide sequences within and/or downstream from the IDR sequence.
- IDR sequences may be chosen such that no IDR sequence comprises a recognition site for a restriction enzyme. In one example, no IDR sequence comprises a recognition site for Xbal, ‘UCUAG’ . Lack of a recognition site for a restriction enzyme (e.g., Xbal recognition site ‘UCUAG’) allows the restriction enzyme to be used in generating and modifying a DNA template for in vitro transcription, without affecting the IDR sequence or sequence of the transcribed RNA.
- the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises a chemically modified nucleobase, for example, a chemically modified uracil, e.g., pseudouracil, N1 -methylpseudouracil, 5-methoxyuracil, or the like.
- a chemically modified uracil e.g., pseudouracil, N1 -methylpseudouracil, 5-methoxyuracil, or the like.
- the mRNA is a uracil-modified sequence comprising an ORF encoding an IgAP protein described herein, wherein the mRNA comprises a chemically modified nucleobase, for example, a chemically modified uracil, e.g., pseudouracil, N1 -methylpseudouracil, or 5-methoxyuracil.
- a chemically modified uracil e.g., pseudouracil, N1 -methylpseudouracil, or 5-methoxyuracil.
- modified uracil in the polynucleotide is at least about 25%, at least about 30%, at least about 40%, at least about 50%, at least about 60%, at least about 70%, at least about 80%, at least 90%, at least 95%, at least 99%, or about 100% modified uracil.
- uracil in the polynucleotide is at least 95% modified uracil.
- uracil in the polynucleotide is 100% modified uracil.
- modified uracil in the polynucleotide is at least 95% modified uracil overall uracil content can be adjusted such that an mRNA provides suitable protein expression levels while inducing little to no immune response.
- the uracil content of the ORF is between about 100% and about 150%, between about 100% and about 110%, between about 105% and about 115%, between about 110% and about 120%, between about 115% and about 125%, between about 120% and about 130%, between about 125% and about 135%, between about 130% and about 140%, between about 135% and about 145%, between about 140% and about 150% of the theoretical minimum uracil content in the corresponding wild-type ORF (%UTM).
- the uracil content of the ORF is between about 121% and about 136% or between 123% and 134% of the %UTM. In some embodiments, the uracil content of the ORF encoding an IgAP protein described herein is about 115%, about 120%, about 125%, about 130%, about 135%, about 140%, about 145%, or about 150% of the %UTM.
- uracil can refer to modified uracil and/or naturally occurring uracil.
- the uracil content in the ORF of the mRNA encoding an IgAP protein of the invention is less than about 30%, about 25%, about 20%, about 15%, or about 10% of the total nucleobase content in the ORF. In some embodiments, the uracil content in the ORF is between about 10% and about 20% of the total nucleobase content in the ORF. In other embodiments, the uracil content in the ORF is between about 10% and about 25% of the total nucleobase content in the ORF. In one embodiment, the uracil content in the ORF of the mRNA encoding an IgAP protein is less than about 20% of the total nucleobase content in the open reading frame.
- uracil can refer to modified uracil and/or naturally occurring uracil.
- the ORF of the mRNA encoding an IgAP protein having modified uracil and adjusted uracil content has increased Cytosine (C), Guanine (G), or Guanine/Cytosine (G/C) content (absolute or relative).
- the overall increase in C, G, or G/C content (absolute or relative) of the ORF is at least about 2%, at least about 3%, at least about 4%, at least about 5%, at least about 6%, at least about 7%, at least about 10%, at least about 15%, at least about 20%, at least about 40%, at least about 50%, at least about 60%, at least about 70%, at least about 80%, at least about 90%, at least about 95%, or at least about 100% relative to the G/C content (absolute or relative) of the wild-type ORF.
- the G, the C, or the G/C content in the ORF is less than about 100%, less than about 90%, less than about 85%, or less than about 80% of the theoretical maximum G, C, or G/C content of the corresponding wild type nucleotide sequence encoding the IgAP protein (%GTMX; %CTMX, or %G/CTMX).
- the increases in G and/or C content (absolute or relative) described herein can be conducted by replacing synonymous codons with low G, C, or G/C content with synonymous codons having higher G, C, or G/C content.
- the increase in G and/or C content (absolute or relative) is conducted by replacing a codon ending with U with a synonymous codon ending with G or C.
- the ORF of the mRNA encoding an IgAP protein of the invention comprises modified uracil and has an adjusted uracil content containing less uracil pairs (UU) and/or uracil triplets (UUU) and/or uracil quadruplets (UUUU) than the corresponding wild-type nucleotide sequence encoding the IgAP protein.
- the ORF of the mRNA encoding an IgAP protein of the invention contains no uracil pairs and/or uracil triplets and/or uracil quadruplets.
- uracil pairs and/or uracil triplets and/or uracil quadruplets are reduced below a certain threshold, e.g., no more than 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 occurrences in the ORF of the mRNA encoding the IgAP protein.
- the ORF of the mRNA encoding the IgAP protein of the invention contains less than 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, or 1 nonphenylalanine uracil pairs and/or triplets.
- the ORF of the mRNA encoding the IgAP protein contains no non-phenylalanine uracil pairs and/or triplets.
- the ORF of the mRNA encoding an IgAP protein of the invention comprises modified uracil and has an adjusted uracil content containing less uracil-rich clusters than the corresponding wild-type nucleotide sequence encoding the IgAP protein.
- the ORF of the mRNA encoding the IgAP protein of the invention contains uracil-rich clusters that are shorter in length than corresponding uracil-rich clusters in the corresponding wild-type nucleotide sequence encoding the IgAP protein.
- alternative lower frequency codons are employed. At least about 5%, at least about 10%, at least about 15%, at least about 20%, at least about 25%, at least about 30%, at least about 35%, at least about 40%, at least about 45%, at least about 50%, at least about 55%, at least about 60%, at least about 65%, at least about 70%, at least about 75%, at least about 80%, at least about 85%, at least about 90%, at least about 95%, at least about 99%, or 100% of the codons in the IgAP protein-encoding ORF of the modified uracil -comprising mRNA are substituted with alternative codons, each alternative codon having a codon frequency lower than the codon frequency of the substituted codon in the synonymous codon set.
- the ORF also has adjusted uracil content, as described above.
- at least one codon in the ORF of the mRNA encoding the IgAP protein is substituted with an alternative codon having a codon frequency lower than the codon frequency of the substituted codon in the synonymous codon set.
- the adjusted uracil content, IgAP protein-encoding ORF of the modified uracil -comprising mRNA exhibits expression levels of IgAP protein when administered to a mammalian cell that are higher than expression levels of IgAP from the corresponding wild-type mRNA.
- the mammalian cell is a mouse cell, a rat cell, or a rabbit cell.
- the mammalian cell is a monkey cell or a human cell.
- the human cell is a HeLa cell, a BJ fibroblast cell, or a peripheral blood mononuclear cell (PBMC).
- PBMC peripheral blood mononuclear cell
- IgAP is expressed at a level higher than expression levels of IgAP from the corresponding wild-type mRNA when the mRNA is administered to a mammalian cell in vivo.
- the mRNA is administered to mice, rabbits, rats, monkeys, or humans.
- mice are null mice.
- the mRNA is administered intravenously or intramuscularly.
- the IgAP protein is expressed when the mRNA is administered to a mammalian cell in vitro.
- the expression is increased by at least about 2-fold, at least about 5-fold, at least about 10-fold, at least about 50-fold, at least about 500-fold, at least about 1500- fold, or at least about 3000-fold. In other embodiments, the expression is increased by at least about 10%, about 20%, about 30%, about 40%, about 50%, 60%, about 70%, about 80%, about 90%, or about 100%.
- adjusted uracil content, IgAP protein-encoding ORF of the modified uracil-comprising mRNA exhibits increased stability. In some embodiments, the mRNA exhibits increased stability in a cell relative to the stability of a corresponding wild-type mRNA under the same conditions.
- the mRNA exhibits increased stability including resistance to nucleases, thermal stability, and/or increased stabilization of secondary structure.
- increased stability exhibited by the mRNA is measured by determining the half-life of the mRNA (e.g., in a plasma, serum, cell, or tissue sample) and/or determining the area under the curve (AUC) of the protein expression by the mRNA over time (e.g., in vitro or in vivo).
- AUC area under the curve
- the mRNA of the present invention induces a detectably lower immune response (e.g., innate or acquired) relative to the immune response induced by a corresponding wild-type mRNA under the same conditions.
- the mRNA of the present disclosure induces a detectably lower immune response (e.g., innate or acquired) relative to the immune response induced by an mRNA that encodes for an IgAP protein but does not comprise modified uracil under the same conditions, or relative to the immune response induced by an mRNA that encodes for an IgAP protein and that comprises modified uracil but that does not have adjusted uracil content under the same conditions.
- the innate immune response can be manifested by increased expression of pro-inflammatory cytokines, activation of intracellular PRRs (RIG-I, MDA5, etc.), cell death, and/or termination or reduction in protein translation.
- a reduction in the innate immune response can be measured by expression or activity level of Type 1 interferons (e.g., IFN-a, IFN-P, IFN-K, IFN-5, IFN- s, IFN-T, IFN-CO, and IFN-Q or the expression of interferon-regulated genes such as the toll-like receptors (e.g., TLR7 and TLR8), and/or by decreased cell death following one or more administrations of the mRNA of the invention into a cell.
- Type 1 interferons e.g., IFN-a, IFN-P, IFN-K, IFN-5, IFN- s, IFN-T, IFN-CO, and IFN-Q
- interferon-regulated genes such as the toll-
- the expression of Type- 1 interferons by a mammalian cell in response to the mRNA of the present disclosure is reduced by at least 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 99%, 99.9%, or greater than 99.9% relative to a corresponding wild-type mRNA, to an mRNA that encodes an IgAP but does not comprise modified uracil, or to an mRNA that encodes an IgAP protein and that comprises modified uracil but that does not have adjusted uracil content.
- the interferon is IFN- ⁇ .
- cell death frequency caused by administration of mRNA of the present disclosure to a mammalian cell is 10%, 25%, 50%, 75%, 85%, 90%, 95%, or over 95% less than the cell death frequency observed with a corresponding wild-type mRNA, an mRNA that encodes for an IgAP protein but does not comprise modified uracil, or mRNA that encodes for an IgAP protein and that comprises modified uracil but that does not have adjusted uracil content.
- the mammalian cell is a BI fibroblast cell.
- the mammalian cell is a splenocyte.
- the mammalian cell is that of a mouse or a rat.
- the mammalian cell is that of a human.
- the mRNA of the present disclosure does not substantially induce an innate immune response of a mammalian cell into which the mRNA is introduced.
- the disclosure includes modified polynucleotides comprising a polynucleotide described herein (e g., a polynucleotide, e.g. mRNA, comprising a nucleotide sequence encoding an IgAP protein described herein.
- the modified polynucleotides can be chemically modified and/or structurally modified.
- modified polynucleotides can be referred to as "modified polynucleotides.”
- nucleosides and nucleotides of a polynucleotide e.g., RNA polynucleotides, such as mRNA polynucleotides
- a polynucleotide e.g., RNA polynucleotides, such as mRNA polynucleotides
- a “nucleoside” refers to a compound containing a sugar molecule (e.g., a pentose or ribose) or a derivative thereof in combination with an organic base (e.g., a purine or pyrimidine) or a derivative thereof (also referred to herein as "nucleobase”).
- a “nucleotide” refers to a nucleoside including a phosphate group.
- Modified nucleotides can be synthesized by any useful method, such as, for example, chemically, enzymatically, or recombinantly, to include one or more modified or non-natural nucleosides.
- Polynucleotides can comprise a region or regions of linked nucleosides. Such regions can have variable backbone linkages. The linkages can be standard phosphodiester linkages, in which case the polynucleotides would comprise regions of nucleotides.
- modified polynucleotides disclosed herein can comprise various distinct modifications.
- the modified polynucleotides contain one, two, or more (optionally different) nucleoside or nucleotide modifications.
- a modified polynucleotide, introduced to a cell can exhibit one or more desirable properties, e.g., improved protein expression, reduced immunogenicity, or reduced degradation in the cell, as compared to an unmodified polynucleotide.
- a polynucleotide of the present invention e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein is structurally modified.
- a "structural" modification is one in which two or more linked nucleosides are inserted, deleted, duplicated, inverted or randomized in a polynucleotide without significant chemical modification to the nucleotides themselves. Because chemical bonds will necessarily be broken and reformed to effect a structural modification, structural modifications are of a chemical nature and hence are chemical modifications. However, structural modifications will result in a different sequence of nucleotides.
- the polynucleotide "ATCG” can be chemically modified to "AT-5meC-G".
- the same polynucleotide can be structurally modified from “ATCG” to "ATCCCG”.
- the dinucleotide "CC” has been inserted, resulting in a structural modification to the polynucleotide.
- compositions of the present disclosure comprise, in some embodiments, at least one nucleic acid (e.g., RNA) having an open reading frame encoding an IgAP protein, wherein the nucleic acid comprises nucleotides and/or nucleosides that can be standard (unmodified) or modified as is known in the art.
- nucleotides and nucleosides of the present disclosure comprise modified nucleotides or nucleosides.
- modified nucleotides and nucleosides can be naturally-occurring modified nucleotides and nucleosides or non-naturally occurring modified nucleotides and nucleosides.
- modifications can include those at the sugar, backbone, or nucleobase portion of the nucleotide and/or nucleoside as are recognized in the art.
- a naturally-occurring modified nucleotide or nucleotide of the disclosure is one as is generally known or recognized in the art.
- Nonlimiting examples of such naturally occurring modified nucleotides and nucleotides can be found, inter alia, in the widely recognized MODOMICS database.
- a non-naturally occurring modified nucleotide or nucleoside of the disclosure is one as is generally known or recognized in the art.
- Nonlimiting examples of such non-naturally occurring modified nucleotides and nucleosides can be found, inter alia, in published US application Nos. PCT7US2012/058519;
- PCT/US2014/070413 PC T7US2015/36773; PCT7US2015/36759; PCT7US2015/36771; or PCT/IB2017/051367 all of which are incorporated by reference herein.
- RNA e.g., mRNA
- nucleotides and nucleosides of the present disclosure comprise standard nucleoside residues such as those present in transcribed RNA (e.g. A, G, C, or U).
- nucleotides and nucleosides of the present disclosure comprise standard deoxyribonucleosides such as those present in DNA (e.g. dA, dG, dC, or dT).
- nucleic acids of the disclosure can comprise standard nucleotides and nucleosides, naturally-occurring nucleotides and nucleosides, non-naturally-occurring nucleotides and nucleosides, or any combination thereof.
- Nucleic acids of the disclosure e.g., DNA nucleic acids and RNA nucleic acids, such as mRNA nucleic acids
- Nucleic acids of the disclosure in some embodiments, comprise various (more than one) different types of standard and/or modified nucleotides and nucleosides.
- a particular region of a nucleic acid contains one, two or more (optionally different) types of standard and/or modified nucleotides and nucleosides.
- a modified RNA nucleic acid e.g., a modified mRNA nucleic acid
- a modified RNA nucleic acid introduced to a cell or organism, exhibits reduced degradation in the cell or organism, respectively, relative to an unmodified nucleic acid comprising standard nucleotides and nucleosides.
- a modified RNA nucleic acid (e.g., a modified mRNA nucleic acid), introduced into a cell or organism, may exhibit reduced immunogenicity in the cell or organism, respectively (e.g., a reduced innate response) relative to an unmodified nucleic acid comprising standard nucleotides and nucleosides.
- Nucleic acids e.g., RNA nucleic acids, such as mRNA nucleic acids
- Nucleic acids in some embodiments, comprise non-natural modified nucleotides that are introduced during synthesis or post-synthesis of the nucleic acids to achieve desired functions or properties.
- the modifications may be present on internucleotide linkages, purine or pyrimidine bases, or sugars.
- the modification may be introduced with chemical synthesis or with a polymerase enzyme at the terminal of a chain or anywhere else in the chain. Any of the regions of a nucleic acid may be chemically modified.
- nucleic acid e.g., RNA nucleic acids, such as mRNA nucleic acids.
- a “nucleoside” refers to a compound containing a sugar molecule (e.g., a pentose or ribose) or a derivative thereof in combination with an organic base (e.g., a purine or pyrimidine) or a derivative thereof (also referred to herein as “nucleobase”).
- nucleotide refers to a nucleoside, including a phosphate group.
- Modified nucleotides may by synthesized by any useful method, such as, for example, chemically, enzymatically, or recombinantly, to include one or more modified or non-natural nucleosides.
- Nucleic acids can comprise a region or regions of linked nucleosides. Such regions may have variable backbone linkages. The linkages can be standard phosphodiester linkages, in which case the nucleic acids would comprise regions of nucleotides.
- Modified nucleotide base pairing encompasses not only the standard adenosine-thymine, adenosine-uracil, or guanosine-cytosine base pairs, but also base pairs formed between nucleotides and/or modified nucleotides comprising non-standard or modified bases, wherein the arrangement of hydrogen bond donors and hydrogen bond acceptors permits hydrogen bonding between a non-standard base and a standard base or between two complementary non-standard base structures, such as, for example, in those nucleic acids having at least one chemical modification.
- One example of such nonstandard base pairing is the base pairing between the modified nucleotide inosine and adenine, cytosine or uracil. Any combination of base/ sugar or linker may be incorporated into nucleic acids of the present disclosure.
- modified nucleobases in nucleic acids comprise Nl-methyl-pseudouri dine (ml ⁇ ), 1-ethyl-pseudouridine (el ⁇ ), 5-methoxy-uridine (mo5U), 5-methyl-cytidine (m5C), and/or pseudouridine ( ⁇ ).
- modified nucleobases in nucleic acids comprise 5 -methoxy methyl uridine, 5-methylthio uridine, 1 -methoxymethyl pseudouridine, 5-methyl cytidine, and/or 5-methoxy cytidine.
- the polyribonucleotide includes a combination of at least two (e.g., 2, 3, 4 or more) of any of the aforementioned modified nucleobases, including but not limited to chemical modifications.
- a RNA nucleic acid of the disclosure comprises Nl- methyl-pseudouri dine (ml ⁇ ) substitutions at one or more or all uridine positions of the nucleic acid.
- a RNA nucleic acid of the disclosure comprises Nl- methyl-pseudouri dine (ml ⁇ ) substitutions at one or more or all uridine positions of the nucleic acid and 5-methyl cytidine substitutions at one or more or all cytidine positions of the nucleic acid.
- a RNA nucleic acid of the disclosure comprises pseudouridine ( ⁇ ) substitutions at one or more or all uridine positions of the nucleic acid.
- a RNA nucleic acid of the disclosure comprises pseudouridine ( ⁇ ) substitutions at one or more or all uridine positions of the nucleic acid and 5-methyl cytidine substitutions at one or more or all cytidine positions of the nucleic acid.
- a RNA nucleic acid of the disclosure comprises uridine at one or more or all uridine positions of the nucleic acid.
- nucleic acids e.g., RNA nucleic acids, such as mRNA nucleic acids
- RNA nucleic acids are uniformly modified (e.g., fully modified, modified throughout the entire sequence) for a particular modification.
- a nucleic acid can be uniformly modified with Nl-methyl-pseudouri dine, meaning that all uridine residues in the mRNA sequence are replaced with Nl-methyl-pseudouridine.
- a nucleic acid can be uniformly modified for any type of nucleoside residue present in the sequence by replacement with a modified residue such as those set forth above.
- nucleic acids of the present disclosure may be partially or fully modified along the entire length of the molecule.
- one or more or all or a given type of nucleotide e.g., purine or pyrimidine, or any one or more or all of A, G, U, C
- nucleotides X in a nucleic acid of the present disclosure are modified nucleotides, wherein X may be any one of nucleotides A, G, U, C, or any one of the combinations A+G, A+U, A+C, G+U, G+C, U+C, A+G+U, A+G+C, G+U+C or A+G+C.
- the nucleic acid may contain from about 1% to about 100% modified nucleotides (either in relation to overall nucleotide content, or in relation to one or more types of nucleotide, i.e., any one or more of A, G, U or C) or any intervening percentage (e.g., from 1% to 20%, from 1% to 25%, from 1% to 50%, from 1% to 60%, from 1% to 70%, from 1% to 80%, from 1% to 90%, from 1% to 95%, from 10% to 20%, from 10% to 25%, from 10% to 50%, from 10% to 60%, from 10% to 70%, from 10% to 80%, from 10% to 90%, from 10% to 95%, from 10% to 100%, from 20% to 25%, from 20% to 50%, from 20% to 60%, from 20% to 70%, from 20% to 80%, from 20% to 90%, from 20% to 95%, from 20% to 100%, from 50% to 60%, from 50% to 70%, from 50% to 80%, from 50% to 90%, from 50% to 95%, from 50% to 100%, from 50% to 100%
- the nucleic acids may contain at a minimum 1% and at maximum 100% modified nucleotides, or any intervening percentage, such as at least 5% modified nucleotides, at least 10% modified nucleotides, at least 25% modified nucleotides, at least 50% modified nucleotides, at least 80% modified nucleotides, or at least 90% modified nucleotides.
- the nucleic acids may contain a modified pyrimidine such as a modified uracil or cytosine.
- At least 5%, at least 10%, at least 25%, at least 50%, at least 80%, at least 90% or 100% of the uracil in the nucleic acid is replaced with a modified uracil (e.g., a 5-substituted uracil).
- the modified uracil can be replaced by a compound having a single unique structure, or can be replaced by a plurality of compounds having different structures (e.g., 2, 3, 4 or more unique structures).
- cytosine in the nucleic acid is replaced with a modified cytosine (e.g., a 5-substituted cytosine).
- the modified cytosine can be replaced by a compound having a single unique structure, or can be replaced by a plurality of compounds having different structures (e.g., 2, 3, 4 or more unique structures).
- Untranslated regions are nucleic acid sections of a polynucleotide before a start codon (5' UTR) and after a stop codon (3' UTR) that are not translated.
- a polynucleotide e.g., a ribonucleic acid (RNA), e.g., a messenger RNA (mRNA)
- RNA e.g., a messenger RNA (mRNA)
- RNA messenger RNA
- ORF open reading frame
- IgAP protein described herein further comprises UTR (e.g., a 5' UTR or functional fragment thereof, a 3' UTR or functional fragment thereof, or a combination thereof).
- a UTR (e.g., 5' UTR or 3' UTR) can be homologous or heterologous to the coding region in a polynucleotide.
- the UTR is homologous to the ORF encoding the IgAP protein.
- the UTR is heterologous to the ORF encoding the IgAP protein.
- the polynucleotide comprises two or more 5' UTRs or functional fragments thereof, each of which has the same or different nucleotide sequences. In some embodiments, the polynucleotide comprises two or more 3' UTRs or functional fragments thereof, each of which has the same or different nucleotide sequences.
- the 5' UTR or functional fragment thereof, 3' UTR or functional fragment thereof, or any combination thereof is sequence optimized.
- the 5 'UTR or functional fragment thereof, 3’ UTR or functional fragment thereof, or any combination thereof comprises at least one chemically modified nucleobase, e.g., N1 -methylpseudouracil or 5 -methoxyuracil.
- UTRs can have features that provide a regulatory role, e.g., increased or decreased stability, localization and/or translation efficiency.
- a polynucleotide comprising a UTR can be administered to a cell, tissue, or organism, and one or more regulatory features can be measured using routine methods.
- a functional fragment of a 5' UTR or 3' UTR comprises one or more regulatory features of a full length 5' or 3' UTR, respectively.
- Natural 5 'UTRs bear features that play roles in translation initiation. They harbor signatures like Kozak sequences that are commonly known to be involved in the process by which the ribosome initiates translation of many genes. Kozak sequences have the consensus CCR(A/G)CCAUGG, where R is a purine (adenine or guanine) three bases upstream of the start codon (AUG), which is followed by another ‘G’. 5' UTRs also have been known to form secondary structures that are involved in elongation factor binding. [0153] By engineering the features typically found in abundantly expressed genes of specific target organs, one can enhance the stability and protein production of a polynucleotide.
- liver-expressed mRNA such as albumin, serum amyloid A, Apolipoprotein A/B/E, transferrin, alpha fetoprotein, erythropoietin, or Factor VIII, can enhance expression of polynucleotides in hepatic cell lines or liver.
- 5 'UTR from other tissue-specific mRNA to improve expression in that tissue is possible for muscle (e.g., MyoD, Myosin, Myoglobin, Myogenin, Herculin), for endothelial cells (e.g., Tie-1, CD36), for myeloid cells (e.g., C/EBP, AML1, G-CSF, GM-CSF, CDl lb, MSR, Fr-1, i-NOS), for leukocytes e.g., CD45, CD18), for adipose tissue (e.g., CD36, GLUT4, ACRP30, adiponectin) and for lung epithelial cells (e.g., SP-A/B/C/D).
- muscle e.g., MyoD, Myosin, Myoglobin, Myogenin, Herculin
- endothelial cells e.g., Tie-1, CD36
- myeloid cells e.g.,
- UTRs are selected from a family of transcripts whose proteins share a common function, structure, feature or property.
- an encoded polypeptide can belong to a family of proteins (i.e., that share at least one function, structure, feature, localization, origin, or expression pattern), which are expressed in a particular cell, tissue or at some time during development.
- the UTRs from any of the genes or mRNA can be swapped for any other UTR of the same or different family of proteins to create a new polynucleotide.
- the 5' UTR and the 3' UTR can be heterologous.
- the 5’ UTR can be derived from a different species than the 3' UTR.
- the 3' UTR can be derived from a different species than the 5' UTR.
- Additional exemplary UTRs of the application include, but are not limited to, one or more 5 'UTR and/or 3 'UTR derived from the nucleic acid sequence of: a globin, such as an a- or P-globin (e.g., aXenopus, mouse, rabbit, or human globin); a strong Kozak translational initiation signal; a CYBA (e.g., human cytochrome b-245 a polypeptide); an albumin (e.g., human albumin?); a HSD17B4 (hydroxysteroid (17-0) dehydrogenase); a virus e.g., a tobacco etch virus (TEV), a Venezuelan equine encephalitis virus (VEEV), a Dengue virus, a cytomegalovirus (CMV) (e.g., CMV immediate early 1 (IE1)), a hepatitis virus (e.g., hepatitis B virus), a
- the 5' UTR is selected from the group consisting of a 0-globin 5' UTR; a 5'UTR containing a strong Kozak translational initiation signal; a cytochrome b-245 a polypeptide (CYBA) 5' UTR; a hydroxysteroid (17-0) dehydrogenase (HSD17B4) 5' UTR; a Tobacco etch virus (TEV) 5' UTR; a Vietnamese equine encephalitis virus (TEEV) 5' UTR; a 5' proximal open reading frame of rubella virus (RV) RNA encoding nonstructural proteins; a Dengue virus (DEN) 5' UTR; a heat shock protein 70 (Hsp70) 5' UTR; a eIF4G 5' UTR; a GLUT1 5’ UTR; functional fragments thereof and any combination thereof.
- CYBA cytochrome b-245 a polypeptide
- HSD17B4 hydroxysteroid (17
- the 3' UTR is selected from the group consisting of a P-globin 3' UTR; a CYBA 3' UTR; an albumin 3' UTR; a growth hormone (GH) 3' UTR; a VEEV 3' UTR; a hepatitis B virus (HBV) 3' UTR; a-globin 3 'UTR; a DEN 3' UTR; a PAV barley yellow dwarf virus (BYDV-PAV) 3' UTR; an elongation factor 1 al (EEF1A1) 3' UTR; a manganese superoxide dismutase (MnSOD) 3' UTR; a p subunit of mitochondrial H(+)-ATP synthase (P-mRNA) 3' UTR; a GLUT1 3' UTR; a MEF2A 3' UTR; a P-F 1-ATPase 3 ' UTR; functional fragments thereof and combinations thereof.
- GH growth hormone
- HBV
- Wild-type UTRs derived from any gene or mRNA can be incorporated into the polynucleotides of the invention.
- a UTR can be altered relative to a wild type or native UTR to produce a variant UTR, e.g., by changing the orientation or location of the UTR relative to the ORF; or by inclusion of additional nucleotides, deletion of nucleotides, swapping or transposition of nucleotides.
- variants of 5' or 3' UTRs can be utilized, for example, mutants of wild type UTRs, or variants wherein one or more nucleotides are added to or removed from a terminus of the UTR.
- one or more synthetic UTRs can be used in combination with one or more non-synthetic UTRs. See, e.g., Mandal and Rossi, Nat. Protoc. 2013 8(3): 568-82, the contents of which are incorporated herein by reference in their entirety.
- UTRs or portions thereof can be placed in the same orientation as in the transcript from which they were selected or can be altered in orientation or location. Hence, a 5' and/or 3' UTR can be inverted, shortened, lengthened, or combined with one or more other 5' UTRs or 3' UTRs.
- the polynucleotide comprises multiple UTRs, e.g., a double, a triple or a quadruple 5' UTR or 3' UTR.
- a double UTR comprises two copies of the same UTR either in series or substantially in series.
- a double beta-globin 3'UTR can be used (see US2010/0129877, the contents of which are incorporated herein by reference in its entirety).
- polynucleotides of the invention can comprise combinations of features.
- the ORF can be flanked by a 5 'UTR that comprises a strong Kozak translational initiation signal and/or a 3'UTR comprising an oligo(dT) sequence for templated addition of a poly-A tail.
- a 5'UTR can comprise a first polynucleotide fragment and a second polynucleotide fragment from the same and/or different UTRs (see, e.g., US2010/0293625, herein incorporated by reference in its entirety).
- non-UTR sequences can be used as regions or subregions within the polynucleotides of the invention.
- introns or portions of intron sequences can be incorporated into the polynucleotides of the invention. Incorporation of intronic sequences can increase protein production as well as polynucleotide expression levels.
- the polynucleotide of the invention comprises an internal ribosome entry site (IRES) instead of or in addition to a UTR (see, e.g., Yakubov et al., Biochem. Biophys. Res. Commun. 2010 394(1): 189-193, the contents of which are incorporated herein by reference in their entirety).
- ITR internal ribosome entry site
- the polynucleotide comprises an IRES instead of a 5' UTR sequence. In some embodiments, the polynucleotide comprises an ORF and a viral capsid sequence. In some embodiments, the polynucleotide comprises a synthetic 5' UTR in combination with a non-synthetic 3 ' UTR.
- the UTR can also include at least one translation enhancer polynucleotide, translation enhancer element, or translational enhancer elements (collectively, "TEE," which refers to nucleic acid sequences that increase the amount of polypeptide or protein produced from a polynucleotide.
- TEE translation enhancer polynucleotide, translation enhancer element, or translational enhancer elements
- the TEE can be located between the transcription promoter and the start codon.
- the 5' UTR comprises a TEE.
- a TEE is a conserved element in a UTR that can promote translational activity of a nucleic acid such as, but not limited to, cap-dependent or capindependent translation.
- 5' UTR sequences are important for ribosome recruitment to the mRNA and have been reported to play a role in translation (Hinnebusch A, et al., (2016) Science, 352:6292: 1413-6).
- a polynucleotide e.g., mRNA, comprising an open reading frame encoding an IgAP protein described herein, which polynucleotide has a 5' UTR that confers an increased half-life, increased expression and/or increased activity of the polypeptide encoded by said polynucleotide, or of the polynucleotide itself.
- a polynucleotide disclosed herein comprises: (a) a 5'-UTR (e.g., as provided in Table 1 or a variant or fragment thereof); (b) a coding region comprising a stop element (e.g., as described herein); and (c) a 3'-UTR (e.g., as described herein), and LNP compositions comprising the same.
- the polynucleotide comprises a 5'-UTR comprising a sequence provided in Table 1 or a variant or fragment thereof (e.g., a functional variant or fragment thereof).
- the polynucleotide comprises a 5'-UTR comprising the sequence of SEQ ID NO:58.
- the polynucleotide having a 5' UTR sequence provided in Table 1 or a variant or fragment thereof has an increase in the half-life of the polynucleotide, e.g., about 1.5-20-fold increase in half-life of the polynucleotide.
- the increase in half-life is about 1.5, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 or 20-fold, or more.
- the increase in half life is about 1.5-fold or more.
- the increase in half life is about 2-fold or more.
- the increase in half life is about 3-fold or more.
- the increase in half life is about 4-fold or more.
- the increase in half life is about 5-fold or more.
- the polynucleotide having a 5' UTR sequence provided in Table 1 or a variant or fragment thereof results in an increased level and/or activity, e.g., output, of the polypeptide encoded by the polynucleotide.
- the 5 'UTR results in about 1.5-20-fold increase in level and/or activity, e.g., output, of the polypeptide encoded by the polynucleotide.
- the increase in level and/or activity is about 1.5, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 or 20-fold, or more. In an embodiment, the increase in level and/or activity is about 1.5-fold or more.
- the increase in level and/or activity is about 2-fold or more. In an embodiment, the increase in level and/or activity is about 3-fold or more. In an embodiment, the increase in level and/or activity is about 4-fold or more. In an embodiment, the increase in level and/or activity is about 5-fold or more.
- the increase is compared to an otherwise similar polynucleotide which does not have a 5' UTR, has a different 5' UTR, or does not have a 5' UTR described in Table 1 or a variant or fragment thereof.
- the increase in half-life of the polynucleotide is measured according to an assay that measures the half-life of a polynucleotide.
- the increase in level and/or activity, e.g., output, of the polypeptide encoded by the polynucleotide is measured according to an assay that measures the level and/or activity of a polypeptide.
- the 5' UTR comprises a sequence provided in Table 1 or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to a 5' UTR sequence provided in Table 1, or a variant or a fragment thereof.
- the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, SEQ ID NO: 55, SEQ ID NO: 56, SEQ ID NO: 57, or SEQ ID NO: 58.
- the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 50. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 51. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 52.
- the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 53. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 54. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 55.
- the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 56. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 57. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 58.
- the 5' UTR comprises the sequence of SEQ ID NO:58. In an embodiment, the 5' UTR consists of the sequence of SEQ ID NO:58.
- a 5' UTR sequence provided in Table 1 has a first nucleotide which is an A. In an embodiment, a 5' UTR sequence provided in Table 1 has a first nucleotide which is a G.
- the 5' UTR comprises a variant of SEQ ID NO: 50.
- the variant of SEQ ID NO: 50 comprises a nucleic acid sequence of Formula A:
- a ACU AGC AAGCUUUUGUUCU C GC C (Ns C C)x (SEQ ID NO: 59), wherein:
- (Ns)x is a guanine and x is an integer from 0 to 1;
- (N4)X is a cytosine and x is an integer from 0 to 1;
- NG is a uracil or cytosine
- N7 is a uracil or guanine
- Ns is adenine or guanine and x is an integer from 0 to 1.
- (N 2 )X is a uracil and x is 0. In an embodiment (N 2 )X is a uracil and x is 1. In an embodiment (N 2 ) x is a uracil and x is 2. In an embodiment (N 2 )x is a uracil and x is 3. In an embodiment, (N 2 )x is a uracil and x is 4. In an embodiment (N 2 ) x is a uracil and x is 5.
- (Ns)x is a guanine and x is 0. In an embodiment, (Na)x is a guanine and x is 1.
- (N4)x is a cytosine and x is 0. In an embodiment, (N4)x is a cytosine and x is 1. [0183] In an embodiment (Ns)x is a uracil and x is 0. In an embodiment (Ns)x is a uracil and x is 1. In an embodiment (Ns)x is a uracil and x is 2. In an embodiment (Ns)x is a uracil and x is 3. In an embodiment, (Ns)x is a uracil and x is 4. In an embodiment (Ns)x is a uracil and x is 5.
- Nr> is a uracil.
- Ne is a cytosine.
- N? is a uracil.
- N? is a guanine.
- Ns is an adenine and x is 0.
- Ns is an adenine and x is 1.
- Ns is a guanine and x is 0. In an embodiment, Ns is a guanine and x is 1.
- the 5' UTR comprises a variant of SEQ ID NO: 58.
- the variant of SEQ ID NO: 58 comprises a sequence with at least 58%, 60%, 70%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, or 99% identity to SEQ ID NO: 58.
- the variant of SEQ ID NO: 58 comprises a sequence with at least 58% identity to SEQ ID NO: 58.
- the variant of SEQ ID NO: 58 comprises a sequence with at least 60% identity to SEQ ID NO: 58.
- the variant of SEQ ID NO: 58 comprises a sequence with at least 70% identity to SEQ ID NO: 58.
- the variant of SEQ ID NO: 58 comprises a sequence with at least 80% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 90% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 95% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 96% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 97% identity to SEQ ID NO: 58.
- the variant of SEQ ID NO: 58 comprises a sequence with at least 98% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 99% identity to SEQ ID NO: 58.
- the variant of SEQ ID NO: 58 comprises a uridine content of at least 5%, 10%, 20%, 30%, 40%, 58%, 60%, 70%, or 80%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 5%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 10%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 20%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 30%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 40%.
- the variant of SEQ ID NO: 58 comprises a uridine content of at least 58%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 60%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 70%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 80%.
- the variant of SEQ ID NO: 58 comprises at least 2, 3, 4, 5, 6 or 7 consecutive uridines (e.g., a polyuridine tract).
- the polyuridine tract in the variant of SEQ ID NO: 58 comprises at least 1-7, 2-7, 3-7, 4-7, 5-7, 6-7, 1-6, 1-5, 1-4, 1-3, 1-2, 2-6, or 3-5 consecutive uridines.
- the polyuridine tract in the variant of SEQ ID NO: 58 comprises 4 consecutive uridines.
- the polyuridine tract in the variant of SEQ ID NO: 58 comprises 5 consecutive uridines.
- the variant of SEQ ID NO: 58 comprises 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, or 15 polyuridine tracts. In an embodiment, the variant of SEQ ID NO: 58 comprises 3 polyuridine tracts. In an embodiment, the variant of SEQ ID NO: 58 comprises 4 polyuridine tracts. In an embodiment, the variant of SEQ ID NO: 58 comprises 5 polyuridine tracts.
- one or more of the polyuridine tracts are adjacent to a different polyuridine tract.
- each of, e.g, all, the polyuridine tracts are adjacent to each other, e.g., all of the polyuridine tracts are contiguous.
- one or more of the polyuridine tracts are separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18. 19, 20, 30, 40, 50 or 60 nucleotides.
- each of, e.g., all of, the polyuridine tracts are separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18. 19, 20, 30, 40, 50 or 60 nucleotides.
- a first polyuridine tract and a second polyuridine tract are adjacent to each other.
- a subsequent, e.g., third, fourth, fifth, sixth or seventh, eighth, ninth, or tenth, polyuridine tract is separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18. 19, 20, 30, 40, 50 or 60 nucleotides from the first polyuridine tract, the second polyuridine tract, or any one of the subsequent polyuridine tracts.
- a first polyuridine tract is separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18. 19, 20, 30, 40, 50 or 60 nucleotides from a subsequent polyuridine tract, e.g., a second, third, fourth, fifth, sixth or seventh, eighth, ninth, or tenth polyuridine tract.
- a subsequent polyuridine tract e.g., a second, third, fourth, fifth, sixth or seventh, eighth, ninth, or tenth polyuridine tract.
- one or more of the subsequent polyuridine tracts are adjacent to a different polyuridine tract.
- the 5' UTR comprises a Kozak sequence, e.g., a GCCRCC nucleotide sequence wherein R is an adenine or guanine.
- the Kozak sequence is disposed at the 3' end of the 5 'UTR sequence.
- the polynucleotide (e.g., mRNA) comprising an open reading frame encoding an IgAP protein and comprising a 5' UTR sequence disclosed herein is formulated as an LNP.
- the LNP composition comprises: (i) an ionizable lipid, e.g., an amino lipid; (ii) a sterol or other structural lipid; (iii) a noncationic helper lipid or phospholipid; and (iv) a PEG-lipid.
- the LNP compositions of the disclosure are used in a method of treating IgAN in a subject.
- an LNP composition comprising a polynucleotide disclosed herein encoding an IgAP protein, e.g., as described herein, can be administered with an additional agent, e.g., as described herein.
- a polynucleotide disclosed herein comprises: (a) a 5'-UTR (e.g., as described herein); (b) a coding region comprising a stop element (e.g., as described herein); and (c) a 3'-UTR (e.g., as provided in Table 2 or a variant or fragment thereof), and LNP compositions comprising the same.
- the polynucleotide comprises a 3'-UTR comprising a sequence provided in Table 2 or a variant or fragment thereof.
- the polynucleotide having a 3' UTR sequence provided in Table 2 or a variant or fragment thereof results in an increased half-life of the polynucleotide, e.g., about 1.5-10-fold increase in half-life of the polynucleotide.
- the increase in half-life is about 1.5, 2, 3, 4, 5, 6, 7, 8, 9, or 10-fold, or more.
- the increase in half-life is about 1.5-fold or more.
- the increase in half-life is about 2-fold or more.
- the increase in half-life is about 3-fold or more.
- the increase in half-life is about 4-fold or more.
- the increase in half-life is about 5-fold or more. In an embodiment, the increase in half-life is about 6-fold or more. In an embodiment, the increase in half-life is about 7-fold or more. In an embodiment, the increase in half-life is about 8-fold. In an embodiment, the increase in half-life is about 9-fold or more. In an embodiment, the increase in half-life is about 10-fold or more.
- the polynucleotide having a 3' UTR sequence provided in Table 2 or a variant or fragment thereof results in a polynucleotide with a mean half-life score of greater than 10.
- the polynucleotide having a 3' UTR sequence provided in Table 2 or a variant or fragment thereof results in an increased level and/or activity, e.g., output, of the polypeptide encoded by the polynucleotide.
- the increase is compared to an otherwise similar polynucleotide which does not have a 3' UTR, has a different 3' UTR, or does not have a 3 ' UTR of Table 2 or a variant or fragment thereof.
- the polynucleotide comprises a 3' UTR sequence provided in Table 2 or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to a 3' UTR sequence provided in Table 2, or a fragment thereof.
- the 3' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 100, SEQ ID NO: 101, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO:115, or SEQ ID NO: 137.
- the 3' UTR comprises the sequence of SEQ ID NO: 100, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 100.
- the 3' UTR comprises the sequence of SEQ ID NO: 101, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 101.
- the 3' UTR comprises the sequence of SEQ ID NO: 102, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 102.
- the 3' UTR comprises the sequence of SEQ ID NO: 103, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 103.
- the 3' UTR comprises the sequence of SEQ ID NO: 104, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 104.
- the 3' UTR comprises the sequence of SEQ ID NO: 105, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 105.
- the 3' UTR comprises the sequence of SEQ ID NO: 106, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 106.
- the 3' UTR comprises the sequence of SEQ ID NO: 107, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 107.
- the 3' UTR comprises the sequence of SEQ ID NO: 108, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 108.
- the 3' UTR comprises the sequence of SEQ ID NO: 109, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 109.
- the 3' UTR comprises the sequence of SEQ ID NO: 110, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 110.
- the 3' UTR comprises the sequence of SEQ ID NO: 111, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 111.
- the 3' UTR comprises the sequence of SEQ ID NO: 112, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 112.
- the 3' UTR comprises the sequence of SEQ ID NO: 113, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 113.
- the 3' UTR comprises the sequence of SEQ ID NO: 114, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 114.
- the 3' UTR comprises the sequence of SEQ ID NO: 115, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 115. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 115, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 137.
- the 3' UTR comprises a micro RNA (miRNA) binding site, e.g., as described herein, which binds to a miR present in a human cell.
- the 3' UTR comprises a miRNA binding site of SEQ ID NO: 212, SEQ ID NO: 174, SEQ ID NO: 152 or a combination thereof.
- the 3' UTR comprises a plurality of miRNA binding sites, e.g., 2, 3, 4, 5, 6, 7 or 8 miRNA binding sites.
- the plurality of miRNA binding sites comprises the same or different miRNA binding sites.
- miR122 bs CAAACACCAUUGUCACACUCCA (SEQ ID NO: 212)
- miR-142-3p bs UCCAUAAAGUAGGAAACACUACA (SEQ ID NO: 174)
- miR-126 bs CGCAUUAUUACUCACGGUACGA (SEQ ID NO: 152)
- a polynucleotide encoding a polypeptide wherein the polynucleotide comprises: (a) a 5'-UTR, e.g., as described herein; (b) a coding region comprising a stop element (e.g., as described herein); and (c) a 3'-UTR (e.g., as described herein).
- an LNP composition comprising a polynucleotide comprising an open reading frame encoding an IgAP protein and comprising a 3' UTR disclosed herein comprises: (i) an ionizable lipid, e.g., an amino lipid; (ii) a sterol or other structural lipid; (iii) a non-cationic helper lipid or phospholipid; and (iv) a PEG-lipid.
- the LNP compositions of the disclosure are used in a method of treating IgAN in a subject.
- an LNP composition comprising a polynucleotide disclosed herein encoding an IgAP protein, e.g., as described herein, can be administered with an additional agent, e.g., as described herein.
- the disclosure also includes a polynucleotide that comprises both a 5' Cap and a polynucleotide of the present invention (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein to be expressed).
- the 5' cap structure of a natural mRNA is involved in nuclear export, increasing mRNA stability and binds the mRNA Cap Binding Protein (CBP), which is responsible for mRNA stability in the cell and translation competency through the association of CBP with poly(A) binding protein to form the mature cyclic mRNA species.
- CBP mRNA Cap Binding Protein
- the cap further assists the removal of 5' proximal introns during mRNA splicing.
- Endogenous mRNA molecules can be 5'-end capped generating a 5'-ppp-5'- triphosphate linkage between a terminal guanosine cap residue and the 5 '-terminal transcribed sense nucleotide of the mRNA molecule.
- This 5 '-guanylate cap can then be methylated to generate an N7-methyl-guanylate residue.
- the ribose sugars of the terminal and/or anteterminal transcribed nucleotides of the 5' end of the mRNA can optionally also be 2'-O-methylated.
- 5 '-decapping through hydrolysis and cleavage of the guanylate cap structure can target a nucleic acid molecule, such as an mRNA molecule, for degradation.
- the polynucleotides of the present invention e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein
- incorporate a cap moiety e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein
- polynucleotides of the present invention comprise a non-hydrolyzable cap structure preventing decapping and thus increasing mRNA halflife. Because cap structure hydrolysis requires cleavage of 5 '-ppp-5' phosphorodiester linkages, modified nucleotides can be used during the capping reaction. For example, a Vaccinia Capping Enzyme from New England Biolabs (Ipswich, MA) can be used with a-thio-guanosine nucleotides according to the manufacturer's instructions to create a phosphorothioate linkage in the 5 '-ppp-5' cap. Additional modified guanosine nucleotides can be used such as a-methyl -phosphonate and seleno-phosphate nucleotides.
- Additional modifications include, but are not limited to, 2'-O-methylation of the ribose sugars of 5 '-terminal and/or 5'-anteterminal nucleotides of the polynucleotide (as mentioned above) on the 2'-hydroxyl group of the sugar ring.
- Multiple distinct 5 '-cap structures can be used to generate the 5 '-cap of a nucleic acid molecule, such as a polynucleotide that functions as an mRNA molecule.
- Cap analogs which herein are also referred to as synthetic cap analogs, chemical caps, chemical cap analogs, or structural or functional cap analogs, differ from natural (i.e., endogenous, wild-type or physiological) 5 '-caps in their chemical structure, while retaining cap function.
- Cap analogs can be chemically (i.e., non-enzymatically) or enzymatically synthesized and/or linked to the polynucleotides of the invention.
- the Anti-Reverse Cap Analog (ARCA) cap contains two guanines linked by a 5 '-5 '-triphosphate group, wherein one guanine contains an N7 methyl group as well as a 3'-O-methyl group (z.e., N7,3'-O-dimethyl-guanosine-5'- triphosphate-5 '-guanosine (m 7 G-3 'mppp-G; which can equivalently be designated 3' O- Me-m 7 G(5')ppp(5')G).
- the 3'-0 atom of the other, unmodified, guanine becomes linked to the 5'-terminal nucleotide of the capped polynucleotide.
- N7- and 3 '-O-methlyated guanine provides the terminal moiety of the capped polynucleotide.
- Another exemplary cap is mCAP, which is similar to ARCA but has a 2'-O- methyl group on guanosine (i.e., N7,2'-O-dimethyl-guanosine-5'-triphosphate-5'- guanosine, m 7 Gm-ppp-G).
- Another exemplary cap is m 7 G-ppp-Gm-A i.e., N7, guanosine-5 '- triphosphate-2 '-O-dimethyl -guanosine-ad enosine) .
- the cap is a dinucleotide cap analog.
- the dinucleotide cap analog can be modified at different phosphate positions with a boranophosphate group or a phosphoroselenoate group such as the dinucleotide cap analogs described in U.S. Patent No. US 8,519,110, the contents of which are herein incorporated by reference in its entirety.
- the cap is a cap analog is a N7-(4- chlorophenoxyethyl) substituted dinucleotide form of a cap analog known in the art and/or described herein.
- Non-limiting examples of a N7-(4-chlorophenoxyethyl) substituted dinucleotide form of a cap analog include a N7-(4-chlorophenoxyethyl)- G(5')ppp(5')G and a N7-(4-chlorophenoxyethyl)-m 3 ' °G(5')ppp(5')G cap analog (See, e.g., the various cap analogs and the methods of synthesizing cap analogs described in Kore et al.
- a cap analog of the present invention is a 4-chloro/bromophenoxyethyl analog.
- Polynucleotides of the invention can also be capped post-manufacture (whether IVT or chemical synthesis), using enzymes, in order to generate more authentic 5 '-cap structures.
- the phrase "more authentic” refers to a feature that closely mirrors or mimics, either structurally or functionally, an endogenous or wild type feature. That is, a "more authentic" feature is better representative of an endogenous, wild-type, natural or physiological cellular function and/or structure as compared to synthetic features or analogs, etc., of the prior art, or which outperforms the corresponding endogenous, wild-type, natural or physiological feature in one or more respects.
- Non-limiting examples of more authentic 5 'cap structures of the present invention are those that, among other things, have enhanced binding of cap binding proteins, increased half-life, reduced susceptibility to 5' endonucleases and/or reduced 5 'decapping, as compared to synthetic 5 'cap structures known in the art (or to a wild-type, natural or physiological 5'cap structure).
- recombinant Vaccinia Virus Capping Enzyme and recombinant 2’-O-methyltransferase enzyme can create a canonical 5 '-5 '-triphosphate linkage between the 5'-terminal nucleotide of a polynucleotide and a guanine cap nucleotide wherein the cap guanine contains an N7 methylation and the 5'- terminal nucleotide of the mRNA contains a 2'-O-methyl.
- Capl structure Such a structure is termed the Capl structure.
- Cap structures include, but are not limited to, 7mG(5')ppp(5')NlpN2p (cap 0), 7mG(5')ppp(5')NlmpNp (cap 1), and 7mG(5')- ppp(5')NlmpN2mp (cap 2).
- capping chimeric polynucleotides postmanufacture can be more efficient as nearly 100% of the chimeric polynucleotides can be capped. This is in contrast to -80% when a cap analog is linked to a chimeric polynucleotide in the course of an in vitro transcription reaction.
- 5' terminal caps can include endogenous caps or cap analogs.
- a 5' terminal cap can comprise a guanine analog.
- Useful guanine analogs include, but are not limited to, inosine, Nl- methyl-guanosine, 2 'fluoro-guanosine, 7-deaza-guanosine, 8-oxo-guanosine, 2-amino- guanosine, LNA-guanosine, and 2-azido-guanosine.
- caps including those that can be used in co-transcriptional capping methods for ribonucleic acid (RNA) synthesis, using RNA polymerase, e.g., wild type RNA polymerase or variants thereof, e g., such as those variants described herein.
- RNA polymerase e.g., wild type RNA polymerase or variants thereof, e g., such as those variants described herein.
- caps can be added when RNA is produced in a “one-pot” reaction, without the need for a separate capping reaction.
- the methods in some embodiments, comprise reacting a polynucleotide template with an RNA polymerase variant, nucleoside triphosphates, and a cap analog under in vitro transcription reaction conditions to produce RNA transcript.
- cap includes the inverted G nucleotide and can comprise one or more additional nucleotides 3' of the inverted G nucleotide, e.g., 1, 2, 3, or more nucleotides 3' of the inverted G nucleotide and 5' to the 5' UTR, e.g., a 5' UTR described herein.
- Exemplary caps comprise a sequence of GG, GA, or GGA, wherein the underlined, italicized G is an in inverted G nucleotide followed by a 5 '-5 '-triphosphate group.
- a cap comprises a compound of formula (I) stereoisomer, tautomer or salt thereof, wherein ring Bi is a modified or unmodified Guanine; ring B2 and ring B3 each independently is a nucleobase or a modified nucleobase;
- X2 is O, S(O) P , NR24 or CR 25 R 26 in which p is 0, 1, or 2;
- Yo O or CR 6 R 7 ;
- Y1 is O, S(O) n , CR 6 R 7 , or NR 8 , in which n is 0, 1 , or 2; each — is a single bond or absent, wherein when each — is a single bond, Yi is O, S(O)n, CR.6R7, or NR 8 ; and when each — is absent, Yi is void;
- Y2 is (0P(0)R 4 ) m in which m is 0, 1, or 2, or -0-(CR4oR4i)u-Qo-(CR42R43)v-, in which Qo is a bond, O, S(O)r, NR 44 , or CR45R46, r is 0, 1 , or 2, and each of u and v independently is 1, 2, 3 or 4; each R2 and R2' independently is halo, LNA, or OR3; each R3 independently is H, C 1 -C 6 alkyl, C 2 -C 6 alkenyl, or C 2 -C 6 alkynyl and R3, when being C 1 -C 6 alkyl, C 2 -C 6 alkenyl, or C 2 -C 6 alkynyl, is optionally substituted with one or more of halo, OH and C 1 -C 6 alkoxyl that is optionally substituted with one or more OH or OC(O)-C 1 -C6 al
- R44 is H, C 1 -C 6 alkyl, or an amine protecting group; each of R45 and R46 independently is H, OP(O)R4?R48, or C 1 -C 6 alkyl optionally substituted with one or more OP(O)R4?R48, and each of R47 and R48, independently is H, halo, C 1 -C 6 alkyl, OH, SH, SeH, or BH3 .
- a cap analog may include any of the cap analogs described in international publication WO 2017/066797, published on 20 April 2017, incorporated by reference herein in its entirety.
- the B2 middle position can be a non-ribose molecule, such as arabinose.
- R2 is ethyl-based.
- a cap comprises the following structure:
- a cap comprises the following structure:
- a cap comprises the following structure:
- a cap comprises the following structure:
- R is an alkyl (e.g., C 1 -C 6 alkyl). In some embodiments, R is a methyl group e.g., C 1 alkyl). In some embodiments, R is an ethyl group (e.g., C2 alkyl).
- a cap comprises a sequence selected from the following sequences: GAA, GAC, GAG, GAU, GCA, GCC, GCG, GCU, GGA , GGC, GGG, GGU, GUA, GUC, GUG, and GUU.
- a cap comprises GAA.
- a cap comprises GAC.
- a cap comprises GAG.
- a cap comprises GAU.
- a cap comprises GCA.
- a cap comprises GCC.
- a cap comprises GCG.
- a cap comprises GCU.
- a cap comprises GGA.
- a cap comprises GGC. In some embodiments, a cap comprises GGG. In some embodiments, a cap comprises GGU. In some embodiments, a cap comprises GUA. In some embodiments, a cap comprises GUC. In some embodiments, a cap comprises GUG. In some embodiments, a cap comprises GUU.
- a cap comprises a sequence selected from the following sequences: m 7 GpppApA, m 7 GpppApC, m 7 GpppApG, m 7 GpppApU, m 7 GpppCpA, m 7 GpppCpC, m 7 GpppCpG, m 7 GpppCpU, m 7 GpppGpA, m 7 GpppGpC, m 7 GpppGpG, m 7 GpppGpU, m 7 GpppUpA, m 7 GpppUpC, m 7 GpppUpG, and m 7 GpppUpU.
- a cap comprises m 7 GpppApA. In some embodiments, a cap comprises m 7 GpppApC. In some embodiments, a cap comprises m 7 GpppApG. In some embodiments, a cap comprises m 7 GpppApU. In some embodiments, a cap comprises m 7 GpppCpA. In some embodiments, a cap comprises m 7 GpppCpC. In some embodiments, a cap comprises m 7 GpppCpG. In some embodiments, a cap comprises m 7 GpppCpU. In some embodiments, a cap comprises m 7 GpppGpA.
- a cap comprises m 7 GpppGpC. In some embodiments, a cap comprises m 7 GpppGpG. In some embodiments, a cap comprises m 7 GpppGpU. In some embodiments, a cap comprises m 7 GpppUpA. In some embodiments, a cap comprises m 7 GpppUpC. In some embodiments, a cap comprises m 7 GpppUpG. In some embodiments, a cap comprises m 7 GpppUpU.
- a cap in some embodiments, comprises a sequence selected from the following sequences: m 7 G 3'OMe pppApA, m 7 G 3'OMe pppApC, m 7 G 3'OMe pppApG, m 7 G 3'OMe pppApU, m 7 G 3'OMe pppCpA, m 7 G 3'OMe pppCpC, m 7 G 3'OMe pppCpG, m 7 G 3'OMe PPpCpU, m 7 G 3'OMe PPpGpA, m 7 G 3'OMe pppGpC, m 7 G 3'OMe pppGpG, m 7 G 3'OMe pppGpU, m 7 G 3'OMe pppUpA, m 7 G 3'OMe pppUpC, m 7 G 3'OMe pppUpC, m 7 G 3'OMe pppUpG,
- a cap comprises m 7 G 3 OMe pppApA. In some embodiments, a cap comprises m 7 G 3'OMe pppApC. In some embodiments, a cap comprises m 7 G 3'OMe pppApG. In some embodiments, a cap comprises m 7 G 3 OMe pppApU. In some embodiments, a cap comprises m 7 G 3'OMe pppCpA. In some embodiments, a cap comprises m 7 G 3'OMe pppCpC. In some embodiments, a cap comprises m 7 G 3'OMe pppCpG.
- a cap comprises m 7 G 3'OMe pppCpU. In some embodiments, a cap comprises m 7 G 3'OMe pppGpA. In some embodiments, a cap comprises m 7 G 3'OMe pppGpC. In some embodiments, a cap comprises m 7 G 3'OMe pppGpG. In some embodiments, a cap comprises m 7 G 3'OMe pppGpU. In some embodiments, a cap comprises m 7 G 3'OMe pppUpA. In some embodiments, a cap comprises m 7 G 3'OMe pppUpC. In some embodiments, a cap comprises m 7 G 3'OMe pppUpG. In some embodiments, a cap comprises m 7 G 3'OMe pppUpU.
- a cap in other embodiments, comprises a sequence selected from the following sequences: m 7 G 3'OMe pppA 2'OMe pA, m 7 G 3'OMe pppA 2'OMe pC, m 7 G 3'OMe pppA 2'OMe pG, m 7 G 3'OMe pppA 2'OMe pU, m 7 G 3'OMe pppC 2'OMe pA, m 7 G 3'OMe pppC 2'OMe pC, m 7 G 3'OMe pppC 2'OMe pG, m 7 G 3'OMe pppC 2'OMe pU, m 7 G 3'OMe pppG 2'OMe pA, m 7 G 3'OMe pppG 2'OMe pC, m 7 G 3'OMe pppG 2'OMe pA, m 7 G 3'OMe pppG 2'OMe
- a cap comprises m 7 G 3'OMe pppA 2'OMe pA. In some embodiments, a cap comprises m 7 G 3'OMe pppA 2'OMe pC. In some embodiments, a cap comprises m 7 G 3'OMe pppA 2'OMe pG. In some embodiments, a cap comprises m 7 G 3'OMe pppA 2'OMe pU. In some embodiments, a cap comprises m 7 G 3'OMe pppC 2'OMe pA. In some embodiments, a cap comprises m 7 G 3'OMe pppC 2'OMe pC.
- a cap comprises m 7 G 3'OMe pppC 2'OMe pG. In some embodiments, a cap comprises m 7 G 3'OMe pppC 2'OMe pU. In some embodiments, a cap comprises m 7 G 3'OMe pppG 2'OMe pA. In some embodiments, a cap comprises m 7 G 3'OMe pppG 2'OMe pC. In some embodiments, a cap comprises m 7 G 3'OMe pppG 2'OMe pG. In some embodiments, a cap comprises m 7 G 3'OMe pppG 2'OMe pU.
- a cap comprises m 7 G 3'OMe pppU 2'OMe pA. In some embodiments, a cap comprises m 7 G 3'OMe pppU 2'OMe pC. In some embodiments, a cap comprises m 7 G 3'OMe pppU 2'OMe pG. In some embodiments, a cap comprises m 7 G 3'OMe pppU 2'OMe pU.
- a cap in still other embodiments, comprises a sequence selected from the following sequences: m 7 GpppA 2'OMe pA, m 7 GpppA 2'OMe pC, m 7 GpppA 2'OMe pG, m 7 GpppA 2'OMe pU, m 7 GpppC 2'OMe pA, m 7 GpppC 2'OMe pC, m 7 GpppC 2'OMe pG, m 7 GpppC 2'OMe pU, m 7 GpppG 2'OMe pA, m 7 GpppG 2'OMe pC, m 7 GpppG 2'OMe pG, m 7 GpppG2 OM e pU, m 7 GpppU 2'OMe pA, m 7 GpppU 2'OMe pC, m 7 GpppU 2'OMe pG, and m 7 GpppU 2
- a cap comprises m 7 GpppA2 OM e pA. In some embodiments, a cap comprises m 7 GpppA2 OMepC. In some embodiments, a cap comprises m 7 GpppA2 OMepG. In some embodiments, a cap comprises m 7 GpppA 2'OMe pU. In some embodiments, a cap comprises m 7 GpppC2 OMepA. In some embodiments, a cap comprises m 7 GpppC2 OMepC. In some embodiments, a cap comprises m 7 GpppC 2'OMe pG.
- a trinucleotide cap comprises m 7 GpppC2 OM e pU. In some embodiments, a cap comprises m 7 GpppG 2'OMe pA. In some embodiments, a cap comprises m 7 GpppG 2'OMe pC. In some embodiments, a cap comprises m 7 GpppG 2'OMe pG. In some embodiments, a cap comprises m 7 GpppG 2'OMe pU. In some embodiments, a cap comprises m 7 GpppU 2'OMe pA. In some embodiments, a cap comprises m 7 GpppU2 OMepC. In some embodiments, a cap comprises m 7 GpppU 2'OMe pG. In some embodiments, a cap comprises m 7 GpppU 2'OMe pU.
- a cap comprises m 7 Gpppm 6 A2'o me pG. In some embodiments, a cap comprises m 7 Gpppe 6 A2'OmepG.
- a cap comprises GAG. In some embodiments, a cap comprises GCG. In some embodiments, a cap comprises GUG. In some embodiments, a cap comprises GGG.
- a cap comprises any one of the following structures:
- the cap comprises m7 GpppNiN2N3, where Ni, N2, and N3 are optional (i.e., can be absent or one or more can be present) and are independently a natural, a modified, or an unnatural nucleoside base.
- m7 G is further methylated, e.g., at the 3' position.
- the m7 G comprises an O-methyl at the 3' position.
- Ni, N2, and N3 if present, optionally, are independently an adenine, a uracil, a guanidine, a thymine, or a cytosine.
- one or more (or all) of Ni, N2, and N3, if present, are methylated, e.g., at the 2' position. In some embodiments, one or more (or all) of Ni, N2, and N3. if present have an O-methyl at the 2' position.
- the cap comprises the following structure:
- Bi, B2, and B3 are independently a natural, a modified, or an unnatural nucleoside based; and Ri, R2, R3, and R4 are independently OH or O-m ethyl.
- R3 is O-methyl and R4 is OH.
- R3 and R4 are O- methyl.
- R4 is O-methyl.
- Ri is OH, R2 is OH, R3 is O-methyl, and R4 is OH.
- Ri is OH, R2 is OH, R3 is O- methyl, and R4 is O-methyl.
- At least one of Ri and R2 is O- methyl, R3 is O-methyl, and R4 is OH. In some embodiments, at least one of Ri and R2 is O-methyl, R3 is O-methyl, and R4 is O-methyl.
- Bi, B3, and B3 are natural nucleoside bases. In some embodiments, at least one of Bi, B2, and B3 is a modified or unnatural base. In some embodiments, at least one of Bi, B2, and B3 is N6-methyladenine. In some embodiments, Bi is adenine, cytosine, thymine, or uracil. In some embodiments, Bi is adenine, B2 is uracil, and B3 is adenine. In some embodiments, Ri and R2 are OH, R3 and R4 are O- methyl, Bi is adenine, B2 is uracil, and B3 is adenine.
- the cap comprises a sequence selected from the following sequences: GAAA, GACA, GAGA, GAUA, GCAA, GCCA, GCGA, GCUA, GGAA, GGCA, GGGA, GGUA, GUCA, and GUUA.
- the cap comprises a sequence selected from the following sequences: GAAG, GACG, GAGG, GAUG, GCAG, GCCG, GCGG, GCUG, GGAG, GGCG, GGGG, GGUG, GUCG, GUGG, and GUUG.
- the cap comprises a sequence selected from the following sequences: GAAU, GACU, GAGU, GAUU, GCAU, GCCU, GCGU, GCUU, GGAU, GGCU, GGGU, GGUU, GUAU, GUCU, GUGU, and GUUU.
- the cap comprises a sequence selected from the following sequences: GAAC, GACC, GAGC, GAUC, GCAC, GCCC, GCGC, GCUC, GGAC, GGCC, GGGC, GGUC, GUAC, GUCC, GUGC, and GUUC.
- a cap in some embodiments, comprises a sequence selected from the following sequences: m 7 G 3'OMe pppApApN, m 7 G 3'OMe pppApCpN, m 7 G 3'OMe pppApGpN, m 7 G 3'OMe pppApUpN, m 7 G 3'OMe pppCpApN, m 7 G 3'OMe pppCpCpN, m 7 G 3'OMe pppCpGpN, m 7 G 3'OMe pppCpUpN, m 7 G 3'OMe pppGpApN, m 7 G 3'OMe pppGpCpN, m 7 G 3'OMe pppGpCpN, m 7 G 3'OMe pppGpApN, m 7 G 3'OMe pppGpCpN, m 7 G 3'OMe pppGpGpN,
- a cap in other embodiments, comprises a sequence selected from the following sequences: m 7 G 3'OMe pppA 2'OMe pApN, m 7 G 3'OMe pppA2 OMepCpN, m 7 G 3'OMe pppA 2'OMe pGpN, m 7 G 3'OMe pppA 2'OMe pUpN, m 7 G 3'OMe pppC 2'OMe pApN, m 7 G 3'OMe pppC 2'OMe pCpN, m 7 G 3'OMe pppC 2'OMe pGpN, m 7 G 3'OMe pppC 2'OMe pUpN, m 7 G 3'OMe pppG 2'OMe pApN, m 7 G 3'OMe pppG 2'OMe pCpN, m 7 G 3'OMe pppC 2'OMe pUp
- a cap in still other embodiments, comprises a sequence selected from the following sequences: m 7 GpppA 2'OMe pApN, m 7 GpppA 2'OMe pCpN, m 7 GpppA 2'OMe pGpN, m 7 GpppA2 OMepUpN, m 7 GpppC 2'OMe pApN, m 7 GpppC 2'OMe pCpN, m 7 GpppC 2'OMe pGpN, m 7 GpppC 2'OMe pUpN, m 7 GpppG 2'OMe pApN, m 7 GpppG 2'OMe pCpN, m 7 GpppG 2'OMe pG 2'OMe pCpN, m 7 GpppG 2'OMe pGpN, m 7 GpppG 2'OMe pUpN, m 7 GpppU 2'OMe
- a cap in other embodiments, comprises a sequence selected from the following sequences: m 7 G 3'OMe pppA 2'OMe pA 2'OMe pN, m 7 G 3'OMe pppA 2'OMe pC 2 OMe pN, m 7 G 3'OMe pppA 2'OMe pG 2'OMe pN, m 7 G 3'OMe pppA 2'OMe pU 2'OMe pN, m 7 G 3'OMe pppC 2'OMe pA 2'OMe pN, m 7 G 3'OMe pppC 2'OMe pC 2'OMe pN, m 7 G 3'OMe pppC 2'OMe pG 2'OMe pN, m 7 G 3'OMe pppC 2'OMe pU 2'OMe pN, m 7 G 3'OMe pppG 2'OMe pN,
- a cap in still other embodiments, comprises a sequence selected from the following sequences: m 7 GpppA 2'OMe pA 2'OMe pN, m 7 GpppA 2'OMe pC 2'OMe pN, m 7 GpppA 2'OMe pG 2'OMe pN, m 7 GpppA 2'OMe pU 2'OMe pN, m 7 GpppC 2'OMe pA 2'OMe pN, m 7 GpppC 2'OMe pC 2'OMe pN, m 7 GpppC 2'OMe pG 2'OMe pN, m 7 GpppC 2'OMe pU 2'OMe pN, m 7 GpppG 2'OMe pA 2'OMe pN, m 7 GpppG 2'OMe pC 2'OMe pN, m 7 GpppG 2'OMe pA 2
- a cap comprises GGAG. In some embodiments, a cap comprises the following structure:
- the polynucleotides of the present disclosure e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein further comprise a poly-A tail.
- terminal groups on the poly-A tail can be incorporated for stabilization.
- a poly-A tail comprises des-3' hydroxyl tails.
- RNA processing a long chain of adenine nucleotides (poly-A tail) can be added to a polynucleotide such as an mRNA molecule in order to increase stability. Immediately after transcription, the 3' end of the transcript can be cleaved to free a 3' hydroxyl. Then poly-A polymerase adds a chain of adenine nucleotides to the RNA.
- polyadenylation adds a poly-A tail that can be between, for example, approximately 80 to approximately 250 residues long, including approximately 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 210, 220, 230, 240 or 250 residues long.
- the poly-A tail is 100 nucleotides in length (SEQ ID NO: 195).
- PolyA tails can also be added after the construct is exported from the nucleus.
- terminal groups on the poly A tail can be incorporated for stabilization.
- Polynucleotides of the present invention can include des-3' hydroxyl tails. They can also include structural moieties or 2'-Omethyl modifications as taught by Junjie Li, et al. (Current Biology, Vol. 15, 1501-1507, August 23, 2005, the contents of which are incorporated herein by reference in its entirety).
- the polynucleotides of the present invention can be designed to encode transcripts with alternative polyA tail structures including histone mRNA. According to Norbury, "Terminal uridylation has also been detected on human replication-dependent histone mRNAs. The turnover of these mRNAs is thought to be important for the prevention of potentially toxic histone accumulation following the completion or inhibition of chromosomal DNA replication.
- mRNAs are distinguished by their lack of a 3 ' poly(A) tail, the function of which is instead assumed by a stable stem-loop structure and its cognate stem-loop binding protein (SLBP); the latter carries out the same functions as those of PABP on polyadenylated mRNAs" (Norbury, "Cytoplasmic RNA: a case of the tail wagging the dog," Nature Reviews Molecular Cell Biology; AOP, published online 29 August 2013; doi: 10.1038/nrm3645) the contents of which are incorporated herein by reference in its entirety.
- SLBP stem-loop binding protein
- the length of a poly-A tail when present, is greater than 30 nucleotides in length. In another embodiment, the poly-A tail is greater than 35 nucleotides in length (e.g., at least or greater than about 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 450, 500, 600, 700, 800, 900, 1,000, 1,100, 1,200, 1,300, 1,400, 1,500, 1,600, 1,700, 1,800, 1,900, 2,000, 2,500, and 3,000 nucleotides).
- the poly-A tail is greater than 35 nucleotides in length (e.g., at least or greater than about 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 450, 500, 600, 700, 800, 900, 1,000, 1,100, 1,200, 1,300, 1,400, 1,500, 1,600,
- the polynucleotide or region thereof includes from about 30 to about 3,000 nucleotides (e.g., from 30 to 50, from 30 to 100, from 30 to 250, from 30 to 500, from 30 to 750, from 30 to 1,000, from 30 to 1,500, from 30 to 2,000, from 30 to 2,500, from 50 to 100, from 50 to 250, from 50 to 500, from 50 to 750, from 50 to 1,000, from 50 to 1,500, from 50 to 2,000, from 50 to 2,500, from 50 to 3,000, from 100 to 500, from 100 to 750, from 100 to 1,000, from 100 to 1,500, from 100 to 2,000, from 100 to 2,500, from 100 to 3,000, from 500 to 750, from 500 to 1,000, from 500 to 1,500, from 500 to 2,000, from 500 to 2,500, from 500 to 3,000, from 1,000 to 1,500, from 1,000 to 2,000, from 1,000 to 2,500, from 1,000 to 3,000, from 1,500 to 2,000, from
- the poly-A tail is designed relative to the length of the overall polynucleotide or the length of a particular region of the polynucleotide. This design can be based on the length of a coding region, the length of a particular feature or region or based on the length of the ultimate product expressed from the polynucleotides.
- the poly-A tail can be 10, 20, 30, 40, 50, 60, 70, 80, 90, or 100% greater in length than the polynucleotide or feature thereof.
- the poly-A tail can also be designed as a fraction of the polynucleotides to which it belongs.
- the poly-A tail can be 10, 20, 30, 40, 50, 60, 70, 80, or 90% or more of the total length of the construct, a construct region or the total length of the construct minus the poly-A tail.
- engineered binding sites and conjugation of polynucleotides for Poly-A binding protein can enhance expression.
- multiple distinct polynucleotides can be linked together via the PABP (Poly-A binding protein) through the 3 '-end using modified nucleotides at the 3'- terminus of the poly-A tail.
- Transfection experiments can be conducted in relevant cell lines at and protein production can be assayed by ELISA at 12hr, 24hr, 48hr, 72hr and day 7 post-transfection.
- the polynucleotides of the present invention are designed to include a polyA-G quartet region.
- the G-quartet is a cyclic hydrogen bonded array of four guanine nucleotides that can be formed by G-rich sequences in both DNA and RNA.
- the G-quartet is incorporated at the end of the poly-A tail.
- the resultant polynucleotide is assayed for stability, protein production and other parameters including half-life at various time points. It has been discovered that the polyA-G quartet results in protein production from an mRNA equivalent to at least 75% of that seen using a poly-A tail of 120 nucleotides alone (SEQ ID NO: 196).
- the polyA tail comprises an alternative nucleoside, e.g., inverted thymidine.
- PolyA tails comprising an alternative nucleoside, e.g., inverted thymidine may be generated as described herein. For instance, mRNA constructs may be modified by ligation to stabilize the poly (A) tail.
- Ligation may be performed using 0.5-1.5 mg/mL mRNA (5' Capl, 3' A100), 50 mM Tris-HCl pH 7.5, 10 mM MgCb, 1 mM TCEP, 1000 units/mL T4 RNA Ligase 1, 1 mM ATP, 20% w/v polyethylene glycol 8000, and 5: 1 molar ratio of modifying oligo to mRNA.
- Modifying oligo has a sequence of 5'-phosphate-AAAAAAAAAAAAAAAAAAAAAAAAAAAA-(inverted deoxy thy mi dine (idT) (SEQ ID NO:209)) (see below).
- Stable tail mRNA are purified by, e g., dT purification, reverse phase purification, hydroxyapatite purification, ultrafiltration into water, and sterile filtration.
- the resulting stable tail-containing mRNAs contain the following structure at the 3 'end, starting with the polyA region: Aioo- UCUAGAAAAAAAAAAAAAAAAAA-inverted deoxythymidine (SEQ ID NO:211).
- the polyA tail comprises A100-UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO:211). In some instances, the polyA tail consists of A100- UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO:211).
- the invention also includes a polynucleotide that comprises both a start codon region and the polynucleotide described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein.
- the polynucleotides of the present invention can have regions that are analogous to or function like a start codon region.
- the translation of a polynucleotide can initiate on a codon that is not the start codon AUG.
- Translation of the polynucleotide can initiate on an alternative start codon such as, but not limited to, ACG, AGG, AAG, CTG/CUG, GTG/GUG, ATA/AUA, ATT/AUU, TTG/UUG (see Touriol et al. Biology of the C 6 ll 95 (2003) 169-178 and Matsuda and Mauro PLoS ONE, 2010 5: 11; the contents of each of which are herein incorporated by reference in its entirety).
- the translation of a polynucleotide begins on the alternative start codon ACG.
- polynucleotide translation begins on the alternative start codon CTG or CUG.
- the translation of a polynucleotide begins on the alternative start codon GTG or GUG.
- Nucleotides flanking a codon that initiates translation such as, but not limited to, a start codon or an alternative start codon, are known to affect the translation efficiency, the length and/or the structure of the polynucleotide. (See, e.g., Matsuda and Mauro PLoS ONE, 2010 5: 11; the contents of which are herein incorporated by reference in its entirety). Masking any of the nucleotides flanking a codon that initiates translation can be used to alter the position of translation initiation, translation efficiency, length and/or structure of a polynucleotide.
- a masking agent can be used near the start codon or alternative start codon in order to mask or hide the codon to reduce the probability of translation initiation at the masked start codon or alternative start codon.
- masking agents include antisense locked nucleic acids (LNA) polynucleotides and exon-junction complexes (EJCs) (See, e.g., Matsuda and Mauro describing masking agents LNA polynucleotides and EJCs (PLoS ONE, 2010 5: 11); the contents of which are herein incorporated by reference in its entirety).
- a masking agent can be used to mask a start codon of a polynucleotide in order to increase the likelihood that translation will initiate on an alternative start codon.
- a masking agent can be used to mask a first start codon or alternative start codon in order to increase the chance that translation will initiate on a start codon or alternative start codon downstream to the masked start codon or alternative start codon.
- a start codon or alternative start codon can be located within a perfect complement for a miRNA binding site.
- the perfect complement of a miRNA binding site can help control the translation, length and/or structure of the polynucleotide similar to a masking agent.
- the start codon or alternative start codon can be located in the middle of a perfect complement for a miRNA binding site.
- the start codon or alternative start codon can be located after the first nucleotide, second nucleotide, third nucleotide, fourth nucleotide, fifth nucleotide, sixth nucleotide, seventh nucleotide, eighth nucleotide, ninth nucleotide, tenth nucleotide, eleventh nucleotide, twelfth nucleotide, thirteenth nucleotide, fourteenth nucleotide, fifteenth nucleotide, sixteenth nucleotide, seventeenth nucleotide, eighteenth nucleotide, nineteenth nucleotide, twentieth nucleotide or twenty-first nucleotide.
- the start codon of a polynucleotide can be removed from the polynucleotide sequence in order to have the translation of the polynucleotide begin on a codon that is not the start codon. Translation of the polynucleotide can begin on the codon following the removed start codon or on a downstream start codon or an alternative start codon.
- the start codon ATG or AUG is removed as the first 3 nucleotides of the polynucleotide sequence in order to have translation initiate on a downstream start codon or alternative start codon.
- the polynucleotide sequence where the start codon was removed can further comprise at least one masking agent for the downstream start codon and/or alternative start codons in order to control or attempt to control the initiation of translation, the length of the polynucleotide and/or the structure of the polynucleotide.
- the invention also includes a polynucleotide that comprises both a stop codon region and the polynucleotide described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein.
- the polynucleotides of the present invention can include at least two stop codons before the 3' untranslated region (UTR).
- the stop codon can be selected from TGA, TAA and TAG in the case of DNA, or from UGA, UAA and UAG in the case of RNA.
- the polynucleotides of the present invention include the stop codon TGA in the case or DNA, or the stop codon UGA in the case of RNA, and one additional stop codon.
- the addition stop codon can be TAA or UAA.
- the polynucleotides of the present invention include three consecutive stop codons, four stop codons, or more.
- any of the polynucleotides disclosed herein can comprise one, two, three, or all of the following elements: (a) a 5 '-UTR, e.g., as described herein; (b) a coding region comprising a stop element (e.g., as described herein); (c) a 3'-UTR (e.g., as described herein) and; optionally (d) a 3' stabilizing region, e.g., as described herein. Also disclosed herein are LNP compositions comprising the same.
- a polynucleotide of the disclosure comprises (a) a 5' UTR described in Table 1 or a variant or fragment thereof and (b) a coding region comprising a stop element provided herein.
- the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein.
- the polynucleotide further comprises a 3' stabilizing region, e.g., as described herein.
- a polynucleotide of the disclosure comprises (a) a 5' UTR described in Table 1 or a variant or fragment thereof and (c) a 3' UTR described in Table 2 or a variant or fragment thereof.
- the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein.
- the polynucleotide further comprises a 3' stabilizing region, e.g., as described herein.
- a polynucleotide of the disclosure comprises (c) a 3' UTR described in Table 2 or a variant or fragment thereof and (b) a coding region comprising a stop element provided herein.
- the polynucleotide comprises a sequence provided in Table 3.
- the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein.
- the polynucleotide further comprises a 3' stabilizing region, e.g., as described herein.
- a polynucleotide of the disclosure comprises (a) a 5' UTR described in Table 1 or a variant or fragment thereof; (b) a coding region comprising a stop element provided herein; and (c) a 3 ' UTR described in Table 2 or a variant or fragment thereof.
- the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein.
- the polynucleotide further comprises a 3' stabilizing region, e.g., as described herein.
- a polynucleotide of the disclosure comprises (a) a 5' UTR described in Table 1 or a variant or fragment thereof, (b) a coding region comprising a stop element provided herein; and (c) a 3' UTR comprising the sequence of SEQ ID NO: 139.
- the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein.
- Table 3 Exemplary 3' UTR and stop element sequences
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- a 5' UTR such as the sequences provided above;
- an ORF encoding an IgAP protein (e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO:5 or SEQ ID NO:6), wherein the ORF has at least 90%, at least 95%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to the sequence of SEQ ID NO:27 or SEQ ID NO:28;
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- an ORF encoding an IgAP protein (e.g., any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49, optionally including a signal peptide, e.g., the IgAP protein of any one of SEQ ID NOs: 351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350), wherein the ORF has at least 90%, at least 95%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to the sequence of any one of SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151;
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
- an ORF encoding an IgAP protein (e.g., SEQ ID NO:80, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO:351), wherein the ORF has at least 90%, at least 95%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to the sequence of SEQ ID NO: 153 or SEQ ID NO: 154;
- an IgAP protein e.g., SEQ ID NO:80, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO:351
- the ORF has at least 90%, at least 95%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to the sequence of SEQ ID NO: 153 or SEQ ID NO: 154;
- the polynucleotide further comprises a miRNA binding site, e.g., a miRNA binding site that binds to miRNA-142.
- the 5' UTR comprises the miRNA binding site.
- the 3' UTR comprises the miRNA binding site.
- a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100% identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:4 (not inclusive of a signal peptide).
- a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100% identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:5.
- a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100% identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:6.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding a polypeptide, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a 5' UTR, (3) a nucleotide sequence ORF of SEQ ID NO:27, (3) a stop codon, (4) a 3 'UTR, and (5) a poly-A tail provided above, for example, a poly-A tail of SEQ ID NO: 195 or A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding a polypeptide, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a 5' UTR, (3) a nucleotide sequence ORF of SEQ ID NO:28, (3) a stop codon, (4) a 3 'UTR, and (5) a poly-A tail provided above, for example, a poly-A tail of SEQ ID NO: 195 or A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID N0:211).
- a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100% identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:80 (not inclusive of a signal peptide).
- a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100% identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:351.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding a polypeptide, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a 5' UTR, (3) a nucleotide sequence ORF of SEQ ID NO: 153, (3) a stop codon, (4) a 3 'UTR, and (5) a poly-A tail provided above, for example, a poly-A tail of SEQ ID NO: 195 or A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID N0:211).
- a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G
- a 5' UTR for example, a nucleotide sequence ORF of SEQ ID NO:
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding a polypeptide, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a 5' UTR, (3) a nucleotide sequence ORF of SEQ ID NO: 154, (3) a stop codon, (4) a 3 'UTR, and (5) a poly-A tail provided above, for example, a poly-A tail of SEQ ID NO: 195 or A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
- a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G
- a 5' UTR for example, a nucleotide sequence ORF of SEQ ID NO:
- SEQ ID NO:29 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:28, and 3' UTR of SEQ ID NO: 114.
- SEQ ID NO:30 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:28, and 3' UTR of SEQ ID NO: 139.
- SEQ ID NO:31 consists from 5' to 3' end: 5' UTR of SEQ ID NO: 56, ORF Sequence of SEQ ID NO:28, and 3' UTR of SEQ ID NO: 114.
- SEQ ID NO : 32 consi sts from 5 ' to 3 ' end : 5 ' UTR of SEQ ID NO : 56, ORF Sequence of SEQ ID NO:27, and 3' UTR of SEQ ID NO: 114.
- SEQ ID NO:300 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:28, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:301 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:85, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:302 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 87, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:303 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:88, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:304 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:90, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:305 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 91, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:306 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:93, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:307 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:94, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:308 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:95, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:309 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:96, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:310 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:97, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:311 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:99, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:312 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO : 141 , and 3 ' UTR of SEQ ID NO : 138.
- SEQ ID NO :313 consists from 5' to 3' end: 5' UTR of SEQ ID NO: 58, ORF Sequence of SEQ ID NO : 144, and 3 ' UTR of SEQ ID NO : 138.
- SEQ ID NO:314 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 145, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:315 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 146, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO:316 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 150, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO :317 consists from 5' to 3' end: 5' UTR of SEQ ID NO: 58, ORF Sequence of SEQ ID NO : 151 , and 3 ' UTR of SEQ ID NO : 138.
- SEQ ID NO:318 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 153, and 3' UTR of SEQ ID NO: 138.
- SEQ ID NO : 319 consi sts from 5 ' to 3 ' end : 5 ' UTR of SEQ ID NO : 50, ORF
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:29, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
- SEQ ID NO:29 all uracils therein are replaced by Nl- methylpseudouracil.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:30, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
- SEQ ID NO:30 all uracils therein are replaced by Nl- methylpseudouracil.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:31, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
- SEQ ID NO:31 all uracils therein are replaced by Nl- methylpseudouracil.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:32, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
- SEQ ID NO:32 in constructs with SEQ ID NO:32, all uracils therein are replaced by Nl- methylpseudouracil.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:300, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
- SEQ ID NO:32 all uracils therein are replaced by Nl- methylpseudouracil.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:318, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
- SEQ ID NO:32 all uracils therein are replaced by Nl- methylpseudouracil.
- a polynucleotide of the present disclosure for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m 7 Gp-ppGm-A or m 7 Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:319, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
- SEQ ID NO:32 all uracils therein are replaced by Nl- methylpseudouracil.
- the present disclosure also provides methods for making a polynucleotide of the invention (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein) or a complement thereof.
- a polynucleotide e.g., a RNA, e.g., an mRNA
- IVT in vitro transcription
- a polynucleotide e.g., a RNA, e.g., an mRNA
- encoding an IgAP protein can be constructed by chemical synthesis using an oligonucleotide synthesizer.
- a polynucleotide e.g., a RNA, e.g., an mRNA
- encoding an IgAP protein is made by using a host cell.
- a polynucleotide e.g., a RNA, e.g., an mRNA
- encoding an IgAP protein is made by one or more combination of the IVT, chemical synthesis, host cell expression, or any other methods known in the art.
- Naturally occurring nucleosides, non-naturally occurring nucleosides, or combinations thereof, can totally or partially naturally replace occurring nucleosides present in the candidate nucleotide sequence and can be incorporated into a sequence- optimized nucleotide sequence (e.g., a RNA, e.g., an mRNA) encoding an IgAP protein.
- a sequence- optimized nucleotide sequence e.g., a RNA, e.g., an mRNA
- the resultant polynucleotides, e.g., mRNAs can then be examined for their ability to produce protein and/or produce a therapeutic outcome.
- compositions and formulations that comprise any of the polynucleotides described above.
- the composition or formulation further comprises a delivery agent.
- the composition or formulation can contain a polynucleotide comprising a sequence optimized nucleic acid sequence disclosed herein which encodes an IgAP protein described herein.
- the composition or formulation can contain a polynucleotide (e.g., a RNA, e.g., an mRNA) comprising a polynucleotide (e.g., an ORF) having significant sequence identity to a sequence optimized nucleic acid sequence disclosed herein which encodes an IgAP protein.
- the polynucleotide further comprises a miRNA binding site, e.g., a miRNA binding site that binds miR-126, miR-142, miR-144, miR-146, miR-150, miR- 155, miR-16, miR-21, miR-223, miR-24, miR-27 and miR-26a.
- a miRNA binding site e.g., a miRNA binding site that binds miR-126, miR-142, miR-144, miR-146, miR-150, miR- 155, miR-16, miR-21, miR-223, miR-24, miR-27 and miR-26a.
- compositions or formulation can optionally comprise one or more additional active substances, e.g., therapeutically and/or prophylactically active substances.
- Pharmaceutical compositions or formulation of the present invention can be sterile and/or pyrogen-free. General considerations in the formulation and/or manufacture of pharmaceutical agents can be found, for example, in Remington: The Science and Practice of Pharmacy 21 st ed., Lippincott Williams & Wilkins, 2005 (incorporated herein by reference in its entirety).
- compositions are administered to humans, human patients or subjects.
- the phrase "active ingredient” generally refers to polynucleotides to be delivered as described herein.
- Formulations and pharmaceutical compositions described herein can be prepared by any method known or hereafter developed in the art of pharmacology. In general, such preparatory methods include the step of associating the active ingredient with an excipient and/or one or more other accessory ingredients, and then, if necessary and/or desirable, dividing, shaping and/or packaging the product into a desired single- or multi-dose unit.
- a pharmaceutical composition or formulation in accordance with the present disclosure can be prepared, packaged, and/or sold in bulk, as a single unit dose, and/or as a plurality of single unit doses.
- a "unit dose" refers to a discrete amount of the pharmaceutical composition comprising a predetermined amount of the active ingredient.
- the amount of the active ingredient is generally equal to the dosage of the active ingredient that would be administered to a subject and/or a convenient fraction of such a dosage such as, for example, one-half or one-third of such a dosage.
- Relative amounts of the active ingredient, the pharmaceutically acceptable excipient, and/or any additional ingredients in a pharmaceutical composition in accordance with the present disclosure can vary, depending upon the identity, size, and/or condition of the subject being treated and further depending upon the route by which the composition is to be administered.
- the compositions and formulations described herein can contain at least one polynucleotide of the invention.
- the composition or formulation can contain 1, 2, 3, 4 or 5 polynucleotides of the invention.
- the compositions or formulations described herein can comprise more than one type of polynucleotide.
- the composition or formulation can comprise a polynucleotide in linear and circular form.
- the composition or formulation can comprise a circular polynucleotide and an in vitro transcribed (IVT) polynucleotide.
- the composition or formulation can comprise an IVT polynucleotide, a chimeric polynucleotide and a circular polynucleotide.
- compositions and formulations are principally directed to pharmaceutical compositions and formulations that are suitable for administration to humans, it will be understood by the skilled artisan that such compositions are generally suitable for administration to any other animal, e.g., to non-human animals, e.g. non-human mammals.
- the present invention provides pharmaceutical formulations that comprise a polynucleotide described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein).
- a polynucleotide described herein e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein.
- the polynucleotides described herein can be formulated using one or more excipients to: (1) increase stability; (2) increase cell transfection; (3) permit the sustained or delayed release (e.g., from a depot formulation of the polynucleotide);
- the pharmaceutical formulation further comprises a delivery agent comprising, e.g., a compound having the Formula (I), e.g., Compound II or Compound B; or a compound having the Formula (III), (IV), (V), or (VI), e.g., Compound I or VI, or any combination thereof.
- a delivery agent comprising, e.g., a compound having the Formula (I), e.g., Compound II or Compound B; or a compound having the Formula (III), (IV), (V), or (VI), e.g., Compound I or VI, or any combination thereof.
- the delivery agent comprises an ionizable amino lipid (e.g., Compound II, VI, or B), a helper lipid (e.g., DSPC), a sterol (e.g., Cholesterol), and a PEG lipid (e.g., Compound I or PEG-DMG), e.g., with a mole ratio in the range of about (i) 40-50 mol% ionizable amino lipid (e.g., Compound II, VI, or B), optionally 45-50 mol% ionizable amino lipid, for example, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48-49 mol%, or 49-50 mol% for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol%; (ii) 30-45
- a pharmaceutically acceptable excipient includes, but are not limited to, any and all solvents, dispersion media, or other liquid vehicles, dispersion or suspension aids, diluents, granulating and/or dispersing agents, surface active agents, isotonic agents, thickening or emulsifying agents, preservatives, binders, lubricants or oil, coloring, sweetening or flavoring agents, stabilizers, antioxidants, antimicrobial or antifungal agents, osmolality adjusting agents, pH adjusting agents, buffers, chelants, cyoprotectants, and/or bulking agents, as suited to the particular dosage form desired.
- Exemplary diluents include, but are not limited to, calcium or sodium carbonate, calcium phosphate, calcium hydrogen phosphate, sodium phosphate, lactose, sucrose, cellulose, microcrystalline cellulose, kaolin, mannitol, sorbitol, etc., and/or combinations thereof.
- Exemplary surface active agents and/or emulsifiers include, but are not limited to, natural emulsifiers (e.g., acacia, agar, alginic acid, sodium alginate, tragacanth, chondrux, cholesterol, xanthan, pectin, gelatin, egg yolk, casein, wool fat, cholesterol, wax, and lecithin), sorbitan fatty acid esters (e.g., polyoxyethylene sorbitan monooleate [TWEEN®80], sorbitan monopalmitate [SPAN®40], glyceryl monooleate, polyoxyethylene esters, polyethylene glycol fatty acid esters (e.g., CREMOPHOR®),
- natural emulsifiers e.g., acacia, agar, alginic acid, sodium alginate, tragacanth, chondrux, cholesterol, xanthan, pectin, gelatin, egg yolk, casein, wool fat
- I l l polyoxyethylene ethers e.g., polyoxyethylene lauryl ether [BRIJ®30]
- PLUORINC®F 68 polyoxyethylene lauryl ether [BRIJ®30]
- PLUORINC®F 68 polyoxyethylene lauryl ether [BRIJ®30]
- PLUORINC®F 68 polyoxyethylene lauryl ether [BRIJ®30]
- PLUORINC®F 68 polyoxyethylene lauryl ether
- POLOXAMER®188 etc. and/or combinations thereof.
- Exemplary binding agents include, but are not limited to, starch, gelatin, sugars (e.g., sucrose, glucose, dextrose, dextrin, molasses, lactose, lactitol, mannitol), amino acids (e.g., glycine), natural and synthetic gums (e g., acacia, sodium alginate), ethylcellulose, hydroxyethylcellulose, hydroxypropyl methylcellulose, etc., and combinations thereof.
- sugars e.g., sucrose, glucose, dextrose, dextrin, molasses, lactose, lactitol, mannitol
- amino acids e.g., glycine
- natural and synthetic gums e g., acacia, sodium alginate
- ethylcellulose hydroxyethylcellulose, hydroxypropyl methylcellulose, etc., and combinations thereof.
- Oxidation is a potential degradation pathway for mRNA, especially for liquid mRNA formulations.
- antioxidants can be added to the formulations.
- Exemplary antioxidants include, but are not limited to, alpha tocopherol, ascorbic acid, ascorbyl palmitate, benzyl alcohol, butylated hydroxyanisole, m-cresol, methionine, butylated hydroxytoluene, monothioglycerol, sodium or potassium metabisulfite, propionic acid, propyl gallate, sodium ascorbate, etc., and combinations thereof.
- Exemplary chelating agents include, but are not limited to, ethylenediaminetetraacetic acid (EDTA), citric acid monohydrate, disodium edetate, fumaric acid, malic acid, phosphoric acid, sodium edetate, tartaric acid, trisodium edetate, etc., and combinations thereof.
- EDTA ethylenediaminetetraacetic acid
- citric acid monohydrate disodium edetate
- fumaric acid malic acid
- phosphoric acid sodium edetate
- tartaric acid trisodium edetate, etc.
- antimicrobial or antifungal agents include, but are not limited to, benzalkonium chloride, benzethonium chloride, methyl paraben, ethyl paraben, propyl paraben, butyl paraben, benzoic acid, hydroxybenzoic acid, potassium or sodium benzoate, potassium or sodium sorbate, sodium propionate, sorbic acid, etc., and combinations thereof.
- Exemplary preservatives include, but are not limited to, vitamin A, vitamin C, vitamin E, beta-carotene, citric acid, ascorbic acid, butylated hydroxyanisol, ethylenediamine, sodium lauryl sulfate (SLS), sodium lauryl ether sulfate (SLES), etc., and combinations thereof.
- the pH of polynucleotide solutions is maintained between pH 5 and pH 8 to improve stability.
- exemplary buffers to control pH can include, but are not limited to sodium phosphate, sodium citrate, sodium succinate, histidine (or histidine-HCl), sodium malate, sodium carbonate, etc., and/or combinations thereof.
- Exemplary lubricating agents include, but are not limited to, magnesium stearate, calcium stearate, stearic acid, silica, talc, malt, hydrogenated vegetable oils, polyethylene glycol, sodium benzoate, sodium or magnesium lauryl sulfate, etc., and combinations thereof.
- the pharmaceutical composition or formulation described here can contain a cryoprotectant to stabilize a polynucleotide described herein during freezing.
- cryoprotectants include, but are not limited to mannitol, sucrose, trehalose, lactose, glycerol, dextrose, etc., and combinations thereof.
- the pharmaceutical composition or formulation described here can contain a bulking agent in lyophilized polynucleotide formulations to yield a "pharmaceutically elegant" cake, stabilize the lyophilized polynucleotides during long term (e.g., 36 month) storage.
- exemplary bulking agents of the present invention can include, but are not limited to sucrose, trehalose, mannitol, glycine, lactose, raffinose, and combinations thereof.
- the pharmaceutical composition or formulation further comprises a delivery agent.
- the delivery agent of the present disclosure can include, without limitation, liposomes, lipid nanoparticles, lipidoids, polymers, lipoplexes, microvesicles, exosomes, peptides, proteins, cells transfected with polynucleotides, hyaluronidase, nanoparticle mimics, nanotubes, conjugates, and combinations thereof.
- the present disclosure provides pharmaceutical compositions with advantageous properties.
- the lipid compositions described herein may be advantageously used in lipid nanoparticle compositions for the delivery of therapeutic and/or prophylactic agents, e.g., mRNAs, to mammalian cells or organs.
- the lipids described herein have litle or no immunogenicity.
- the lipid compounds disclosed herein have a lower immunogenicity as compared to a reference lipid (e.g., MC 3 , KC2, or DLinDMA).
- a formulation comprising a lipid disclosed herein and a therapeutic or prophylactic agent, e.g., mRNA, has an increased therapeutic index as compared to a corresponding formulation which comprises a reference lipid (e.g., MC 3 , KC2, or DLinDMA) and the same therapeutic or prophylactic agent.
- a reference lipid e.g., MC 3 , KC2, or DLinDMA
- compositions comprising:
- nucleic acids of the invention are formulated in a lipid nanoparticle (LNP).
- LNP lipid nanoparticle
- Lipid nanoparticles typically comprise ionizable cationic lipid, non-cationic lipid, sterol and PEG lipid components along with the nucleic acid cargo of interest.
- the lipid nanoparticles of the invention can be generated using components, compositions, and methods as are generally known in the art, see for example PCT/US2016/052352; PCT/US2016/068300; PCT/US2017/037551; PCT/US2015/027400; PCT/US2016/047406; PCT/US2016000129;
- Nucleic acids of the present disclosure are typically formulated in lipid nanoparticle.
- the lipid nanoparticle comprises at least one ionizable cationic lipid, at least one non-cationic lipid, at least one sterol, and/or at least one polyethylene glycol (PEG)-modified lipid.
- the lipid nanoparticle comprises a molar ratio of 20- 60% ionizable cationic lipid.
- the lipid nanoparticle may comprise a molar ratio of 40-50 mol%, optionally 45-50 mol%, for example, 45-46 mol%, 46-47 mol%, 47- 48 mol%, 48-49 mol%, or 49-50 mol%, for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol% ionizable cationic lipid.
- the lipid nanoparticle comprises a molar ratio of 5-25% non-cationic lipid.
- the lipid nanoparticle may comprise a molar ratio of 5- 15 mol%, optionally 10-12 mol%, for example, 5-6 mol%, 6-7 mol%, 7-8 mol%, 8-9 mol%, 9-10 mol%, 10-11 mol%, 11-12 mol%, 12-13 mol%, 13-14 mol%, or 14-15 mol% non-cationic lipid.
- the lipid nanoparticle comprises a molar ratio of 25- 55% sterol.
- the lipid nanoparticle may comprise a molar ratio of 30-45 mol%, optionally 35-40 mol%, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33- 34 mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 38-38 mol%, 38-39 mol%, or 39-40 mol% sterol.
- the lipid nanoparticle comprises a molar ratio of 0.5- 15% PEG-modified lipid.
- the lipid nanoparticle may comprise a molar ratio of 1-5%, optionally 1-3 mol%, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol% PEG-modified lipid.
- the lipid nanoparticle comprises a molar ratio of 20- 60% ionizable cationic lipid, 5-25% non-cationic lipid, 25-55% sterol, and 0.5-15% PEG- modified lipid.
- the lipid nanoparticle comprises a molar ratio of 40- 50% ionizable cationic lipid, 5-15% non-cationic lipid, 30-45% sterol, and 1-5% PEG- modified lipid.
- the lipid nanoparticle comprises a molar ratio of 45- 50% ionizable cationic lipid, 10-12% non-cationic lipid, 35-40% sterol, and 1-3% PEG- modified lipid. [0398] In some embodiments, the lipid nanoparticle comprises a molar ratio of 45- 50% ionizable cationic lipid, 10-12% non-cationic lipid, 35-40% sterol, and 1.5-2.5% PEG-modified lipid.
- the disclosure relates to a compound of Formula (I): r its N-oxide, or a salt or isomer thereof, wherein R’ a is R’ brailcllcd ; wherein denotes a point of attachment; wherein R a “, R ap , R a and R a ⁇ are each independently selected from the group consisting of H, C 2-12 alkyl, and C 2-12 alkenyl;
- R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and
- R 4 is selected from the group consisting of -(CH 2 ) n OH, wherein n is selected from the group consisting wherein denotes a point of attachment;
- R 10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R 5 is independently selected from the group consisting of C 1-3 alkyl, C2-3 alkenyl, and H; each R 6 is independently selected from the group consisting of C 1-3 alkyl, C2-3 alkenyl, and H;
- M and M’ are each independently selected from the group consisting of -C(O)O- and
- R’ is a C 1 -12 alkyl or C 2-12 alkenyl
- 1 is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13.
- R’ a is R' brancbed ;
- R' branched is denotes a point of attachment;
- R a ⁇ , R a ⁇ , R a ⁇ , and R a8 are each H;
- R 2 and R 3 are each C 1-14 alkyl;
- R 4 is -(CH 2 ) n OH; n is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each -C(O)O-;
- R’ is a C1-12 alkyl; 1 is 5; and m is 7.
- R’ a is R ,branched ;
- R' branched is denotes a point of attachment;
- R a “, R a ⁇ , R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C 1-14 alkyl;
- R 4 is -(CH 2 ) n OH; n is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each -C(O)O-;
- R’ is a C1-12 alkyl; 1 is 3; and m is 7.
- R’ a is R' brancbed .
- R' brancbed j s denotes a point of attachment;
- R a ⁇ is C 2-12 alkyl;
- R a ⁇ , R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C 1-14 alkyl;
- R 4 is alkyl);
- n2 is 2;
- R 5 is H;
- each R 6 is H;
- M and M’ are each -C(0)0-;
- R’ is a C1-12 alkyl; 1 is 5; and m is 7.
- R’ a is R' brancbed ; denotes a point of attachment; R a ⁇ , R a ⁇ and R a ⁇ are each H; R a ⁇ is C 2-12 alkyl; R 2 and R 3 are each C 1-14 alkyl; R 4 is -(CH 2 ) n OH; n is 2; each R 5 is H; each R 6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 5; and m is 7.
- the compound of Formula (I) is selected from:
- the compound of Formula (I) is: (Compound II).
- the compound of Formula (I) is:
- the compound of Formula (I) is:
- the compound of Formula (I) is: (Compound B).
- the disclosure relates to a compound of Formula (la): r its N-oxide, or a salt or isomer thereof, wherein R’ a is R' brancbed ; wherein wherein R a ⁇ , R a ⁇ , and R a ⁇ are each independently selected from the group consisting of H, C 2-12 alkyl, and C 2-12 alkenyl;
- R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and
- R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting wherein denotes a point of attachment;
- R 10 is N(R)2; each R is independently selected from the group consisting of C 1 -6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R 5 is independently selected from the group consisting of C 1-3 alkyl, C2-3 alkenyl, and H; each R 6 is independently selected from the group consisting of C 1-3 alkyl, C2-3 alkenyl, and H;
- M and M’ are each independently selected from the group consisting of -C(O)O- and
- R’ is a C1-12 alkyl or C 2-12 alkenyl
- 1 is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13.
- the disclosure relates to a compound of Formula (lb): r its N-oxide, or a salt or isomer thereof, wherein R’ a is R' brancbed ; wherein R' brancbed j s; . wherein denotes a point of attachment; wherein R a ⁇ , R a ⁇ , R a ⁇ , and R a ⁇ are each independently selected from the group consisting of H, C 2-12 alkyl, and C 2-12 alkenyl;
- R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and
- R 4 is -(CH 2 )nOH, wherein n is selected from the group consisting of 1, 2, 3, 4, and each R 5 is independently selected from the group consisting of C 1-3 alkyl, C2-3 alkenyl, and H; each R 6 is independently selected from the group consisting of C 1-3 alkyl, C2-3 alkenyl, and H;
- M and M’ are each independently selected from the group consisting of -C(O)O- and
- R’ is a C 1-12 alkyl or C 2-12 alkenyl
- 1 is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13.
- R’ a is R' brancbed ;
- R' brancbed denotes a point of attachment;
- R a ⁇ ⁇ R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C 1-14 alkyl;
- R 4 is -(CH 2 ) n OH; n is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each -C(O)O-;
- R’ is a C 1-12 alkyl; 1 is 5; and m is 7.
- R' a is R' brancbed ;
- R' brancbed is denotes a point of attachment;
- R a ⁇ , R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C 1-14 alkyl;
- R 4 is -(CH 2 ) n OH; n is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each -C(0)0-;
- R’ is a C 1-12 alkyl; 1 is 3; and m is 7.
- R’ a is R ,branched ; R' brancbed is denotes a point of attachment; R ap and R a ⁇ are each H; R a ⁇ is C 2-12 alkyl; R 2 and R 3 are each C 1-14 alkyl; R 4 is -(CH 2 ) n OH; n is 2; each R 3 is H; each R 6 is H;
- M and M’ are each -C(O)O-; R’ is a C 1-12 alkyl; 1 is 5; and m is 7.
- the disclosure relates to a compound of Formula (Ic): (Ic) or its N-oxide, or a salt or isomer thereof, wherein R’ a is R' brancbed ; wherein
- R’ branched is: ; wherein denotes a point of attachment; wherein R a ⁇ , R a ⁇ , R a ⁇ , and R a ⁇ are each independently selected from the group consisting of H, C 2-12 alkyl, and C 2-12 alkenyl;
- R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and
- R 10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R 5 is independently selected from the group consisting of C 1-3 alkyl, C2-3 alkenyl, and H; each R 6 is independently selected from the group consisting of C 1-3 alkyl, C2-3 alkenyl, and H;
- M and M’ are each independently selected from the group consisting of -C(O)O- and
- R’ is a C 1 -12 alkyl or C 2-12 alkenyl
- 1 is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13.
- R ap , R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C 1-14 alkyl; denotes a point of attachment;
- R 10 is NH(CI-6 alkyl);
- n2 is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each -C(O)O-;
- R’ is a
- the compound of Formula (Ic) is: (Compound A).
- the disclosure relates to a compound of Formula (II):
- R’ a is R' brancbed or R’ cycllc ; wherein wherein ? denotes a point of attachment; R a ⁇ and R a ⁇ are each independently selected from the group consisting of H, C1-12 alkyl, and C 2-12 alkenyl, wherein at least one of R a ⁇ and R a ⁇ is selected from the group consisting of C1-12 alkyl and C 2-12 alkenyl;
- R b ⁇ and R bS are each independently selected from the group consisting of H, C1-12 alkyl, and C 2-12 alkenyl, wherein at least one of R b / and R bS is selected from the group consisting of C1-12 alkyl and C 2-12 alkenyl;
- R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and
- R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting wherein ? denotes a point of attachment; wherein R 10 is N(R)2; each R is independently selected from the group consisting of C 1 -6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C 2-12 alkenyl;
- Y a is a C 3 -6 carbocycle
- R*” a i s selected from the group consisting of C1-15 alkyl and C2-15 alkenyl; and s is 2 or 3; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
- 1 is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9.
- the disclosure relates to a compound of Formula (Il-a): wherein R’ a is R' brancbed or R’ cycllc ; wherein wherein ? denotes a point of attachment; R a ⁇ and R a6 are each independently selected from the group consisting of H, C1-12 alkyl, and C 2-12 alkenyl, wherein at least one of R a ⁇ and R a ⁇ is selected from the group consisting of C1-12 alkyl and C 2-12 alkenyl;
- R b ⁇ and R bS are each independently selected from the group consisting of H, C1-12 alkyl, and C 2-12 alkenyl, wherein at least one of R by and R bS is selected from the group consisting of C1-12 alkyl and C 2-12 alkenyl;
- R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and
- R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting wherein denotes a point of attachment;
- R 10 is N(R)2; each R is independently selected from the group consisting of C 1 -6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C 2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
- 1 is selected from 1 , 2, 3, 4, 5, 6, 7, 8, and 9.
- the disclosure relates to a compound of Formula (Il-b): r its N-oxide, or a salt or isomer thereof, wherein R’ a is R’ branehed O r R’ cycllc ; wherein wherein denotes a point of attachment; R a ⁇ and R by are each independently selected from the group consisting of C1-12 alkyl and C 2-12 alkenyl;
- R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and
- R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting wherein denotes a point of attachment;
- R 10 is N(R)2; each R is independently selected from the group consisting of C 1 -6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C 2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
- 1 is selected from 1 , 2, 3, 4, 5, 6, 7, 8, and 9.
- the disclosure relates to a compound of Formula (II-c): wherein R’ a is R’ branehed O r R’ cycllc ; wherein wherein ? denotes a point of attachment; wherein R a ⁇ is selected from the group consisting of C1-12 alkyl and C 2-12 alkenyl;
- R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and
- R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting wherein denotes a point of attachment;
- R 10 is N(R)2; each R is independently selected from the group consisting of C 1 -6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10;
- R’ is a C1-12 alkyl or C 2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
- 1 is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9.
- the disclosure relates to a compound of Formula (Il-d): wherein R’ a is R’ branehed O r R’ cycllc ; wherein wherein ? denotes a point of attachment; wherein R a ⁇ and R by are each independently selected from the group consisting of
- R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting wherein denotes a point of attachment; wherein R 10 is N(R) 2 ; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C 2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
- 1 is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9.
- the disclosure relates to a compound of Formula (Il-e): wherein denotes a point of attachment; wherein R a ⁇ is selected from the group consisting of C1-12 alkyl and C 2-12 alkenyl;
- R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and
- R 4 is -(CH 2 )nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5;
- R’ is a C1-12 alkyl or C 2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
- 1 is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9.
- m and 1 are each independently selected from 4, 5, and 6. In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (Il-d), or (Il-e), m and 1 are each 5. [0422] In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (II-d), or (Il-e), each R’ independently is a C1-12 alkyl. In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (Il-d), or (Il-e), each R’ independently is a C2-5 alkyl.
- R’ b is: and R 2 and R 3 are each independently a C 1-14 alkyl.
- R 2 and R 3 are each independently a C 1-14 alkyl.
- R’ b is: R 2 and R 3 are each independently a C 6 -io alkyl.
- R’ b is: are each a Cs alkyl.
- R a ⁇ is a C1-12 alkyl and R 2 and R 3 are each independently a C 6 -io alkyl.
- R' brancbed i s are each independently a C 6 -io alkyl.
- (II- is a C 2-6 alkyl, and R 2 and R 3 are each a Cx alkyl.
- R by are each a C1-12 alkyl.
- R' brancbed is: and R a ⁇ and R by are each a C 2-6 alkyl.
- m and 1 are each independently selected from 4, 5, and 6 and each R’ independently is a C1-12 alkyl.
- m and 1 are each 5 and each R’ independently is a C2-5 alkyl.
- R' branched is; is: are each independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, and R a ⁇ and R by are each a C 1-12 alkyl.
- R by , m and 1 are each 5, each R’ independently is a C2-5 alkyl, and R a ⁇ and R by are each a C 2-6 alkyl.
- R' branched is: are each independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, R a ⁇ is a C1-12 alkyl and R 2 and R 3 are each independently a C 6 -io alkyl.
- Formula ( is: , m and 1 are each 5, R’ is a C2-5 alkyl, R a ⁇ is a C 2-6 alkyl, and R 2 and R 3 are each a Cx alkyl.
- R' brancbed is: is: are each independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, R a ⁇ and R b / are each a C1-12 alkyl, and R 4 is , wherein R 10 is NH(CI-6 alkyl), and n2 is 2.
- R 10 is NH(CH3) and n2 is 2.
- R' branched is: are each independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, R 2 and R 3 are each independently a C 6 -io alkyl, R a ⁇ is a C1-12 alkyl, and R 4 is , wherein
- R 10 is NH(CI-6 alkyl) and n2 is 2. In some embodiments of the compound of Formula
- R' branched is: and R >b is: , m and 1 are each 5, R’ is a C2-5 alkyl, R a ⁇ is a C 2-6 alkyl, R 2 and R 3 are each a C 8
- alkyl and R 4 is , wherein R 10 is NH(CH 3 ) and n2 is 2.
- R 4 is -(CH 2 ) n OH and n is 2, 3, or 4. In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (Il-d), or (Il-e), R 4 is -(CH 2 ) n OH and n is 2.
- R' branched is: , R’ b is: , m and 1 are each independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, R a ⁇ and R by are each a C1-12 alkyl, R 4 is -(CH 2 ) n OH, and n is 2, 3, or 4.
- R' branched is : R a Y R b Y , , m and 1 are each 5, each R’ independently is a C2-5 alkyl, R a ⁇ and R by are each a C 2-6 alkyl, R 4 is -(CH 2 ) n OH, and n is 2.
- the disclosure relates to a compound of Formula (Il-f):
- R’ a is R' brancbed or R’ cycllc ; wherein wherein ? denotes a point of attachment; R a ⁇ is a C 1 -12 alkyl;
- R 2 and R 3 are each independently a C 1 -i4 alkyl
- R 4 is -(CH 2 )nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and
- R’ is a C1-12 alkyl; m is selected from 4, 5, and 6; and
- 1 is selected from 4, 5, and 6.
- n and 1 are each 5, and n is 2, 3, or 4.
- R’ is a C2-5 alkyl
- R a ⁇ is a C 2-6 alkyl
- R 2 and R 3 are each a C 6 -io alkyl.
- m and 1 are each 5, n is 2, 3, or 4, R’ is a C2-5 alkyl, R a ⁇ is a C 2-6 alkyl, and R 2 and R 3 are each a C 6 -io alkyl.
- the disclosure relates to a compound of Formula (Il-g): R’ is a C2-5 alkyl; and
- R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting wherein denotes a point of attachment, R 10 is NH(CI-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3.
- the disclosure relates to a compound of Formula (Il-h):
- R a ⁇ and R b '-' are each independently a C 2-6 alkyl; each R’ independently is a C2-5 alkyl; and
- R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting wherein denotes a point of attachment, R 10 is NH(CI-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3.
- R 4 is , wherein
- R 10 is NH(CH 3 ) and n2 is 2.
- R 4 is - (CH 2 ) 2 OH.
- the disclosure relates to a compound having the Formula
- Ri, R2, R3, R4, and Rs are independently selected from the group consisting of Cs-
- each M is independently selected from the group consisting of -C(O)O-, -OC(O)-, -OC(O)O-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -S C(S)-,
- X 1 , X 2 , and X 3 are independently selected from the group consisting of a bond, -CH2-,
- each Y is independently a C 3 -6 carbocycle;
- each R’ is independently selected from the group consisting of C1-12 alkyl, C 2-12 alkenyl, and H; and each R” is independently selected from
- Ri, R2, R3, R4, and Rs are each C5-20 alkyl; X 1 is -CH2-; and X 2 and X 3 are each -C(O)-.
- the compound of Formula (III) is: (Compound VI), or a salt or isomer thereof.
- the lipid composition of the lipid nanoparticle composition disclosed herein can comprise one or more phospholipids, for example, one or more saturated or (poly)unsaturated phospholipids or a combination thereof.
- phospholipids comprise a phospholipid moiety and one or more fatty acid moieties.
- a phospholipid moiety can be selected, for example, from the non-limiting group consisting of phosphatidyl choline, phosphatidyl ethanolamine, phosphatidyl glycerol, phosphatidyl serine, phosphatidic acid, 2-lysophosphatidyl choline, and a sphingomyelin.
- a fatty acid moiety can be selected, for example, from the non-limiting group consisting of lauric acid, myristic acid, myristoleic acid, palmitic acid, palmitoleic acid, stearic acid, oleic acid, linoleic acid, alpha-linolenic acid, erucic acid, phytanoic acid, arachidic acid, arachidonic acid, eicosapentaenoic acid, behenic acid, docosapentaenoic acid, and docosahexaenoic acid.
- Particular phospholipids can facilitate fusion to a membrane.
- a cationic phospholipid can interact with one or more negatively charged phospholipids of a membrane (e.g., a cellular or intracellular membrane). Fusion of a phospholipid to a membrane can allow one or more elements (e.g., a therapeutic agent) of a lipid- containing composition (e.g., LNPs) to pass through the membrane permitting, e.g., delivery of the one or more elements to a target tissue.
- elements e.g., a therapeutic agent
- a lipid- containing composition e.g., LNPs
- Non-natural phospholipid species including natural species with modifications and substitutions including branching, oxidation, cyclization, and alkynes are also contemplated.
- a phospholipid can be functionalized with or cross-linked to one or more alkynes (e.g., an alkenyl group in which one or more double bonds is replaced with a triple bond).
- alkynes e.g., an alkenyl group in which one or more double bonds is replaced with a triple bond.
- an alkyne group can undergo a copper-catalyzed cycloaddition upon exposure to an azide.
- Such reactions can be useful in functionalizing a lipid bilayer of a nanoparticle composition to facilitate membrane permeation or cellular recognition or in conjugating a nanoparticle composition to a useful component such as a targeting or imaging moiety (e.g., a dye).
- Phospholipids include, but are not limited to, glycerophospholipids such as phosphatidylcholines, phosphatidylethanolamines, phosphatidylserines, phosphatidylinositols, phosphatidy glycerols, and phosphatidic acids. Phospholipids also include phosphosphingolipid, such as sphingomyelin.
- a phospholipid of the invention comprises 1,2- distearoyl-sn-glycero-3-phosphocholine (DSPC), l,2-dioleoyl-sn-glycero-3- phosphoethanolamine (DOPE), l,2-dilinoleoyl-sn-glycero-3 -phosphocholine (DLPC), 1,2-dimyristoyl-sn-gly cero-phosphocholine (DMPC), l,2-dioleoyl-sn-glycero-3- phosphocholine (DOPC), l,2-dipalmitoyl-sn-glycero-3 -phosphocholine (DPPC), 1,2- diundecanoyl-sn-glycero-phosphocholine (DUPC), 1 -palmitoyl-2-oleoyl-sn-glycero-3- phosphocholine (POPC), l,2-di-O-octade
- DOPE 1,2- diste
- a phospholipid useful or potentially useful in the present invention is an analog or variant of DSPC.
- a phospholipid useful or potentially useful in the present invention is a compound of Formula (IV): or a salt thereof, wherein: each R 1 is independently optionally substituted alkyl; or optionally two R 1 are joined together with the intervening atoms to form optionally substituted monocyclic carbocyclyl or optionally substituted monocyclic heterocyclyl; or optionally three R 1 are joined together with the intervening atoms to form optionally substituted bicyclic carbocyclyl or optionally substitute bicyclic heterocyclyl; n is i, 2, 3, 4, 5, 6, 7, 8, 9, or 10; m is O, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10;
- each instance of L 2 is independently a bond or optionally substituted C 1 -6 alkylene, wherein one methylene unit of the optionally substituted C 1 -6 alkylene is optionally replaced with O, N(R N ), S, C(O), C(O)N(R N ), NR N C(O), C(O)O, OC(O), - OC(O)O, OC(O)N(R N ), NR N C(O)O, or NR N C(O)N(R N ); each instance of R 2 is independently optionally substituted C 1-3 0 alkyl, optionally substituted C 1-3 0 alkenyl, or optionally substituted C 1-3 0 alkynyl; optionally wherein one or more methylene units of R 2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclyl ene, optionally substituted arylene, NR N C(S), NR N C(S)N(R N );
- Ring B is optionally substituted carbocyclyl, optionally substituted heterocyclyl, optionally substituted aryl, or optionally substituted heteroaryl; and p is 1 or 2; provided that the compound is not of the Formula: wherein each instance of R 2 is independently unsubstituted alkyl, unsubstituted alkenyl, or unsubstituted alkynyl.
- the phospholipids may be one or more of the phospholipids described in U.S. Application No. 62/520,530.
- a phospholipid useful or potentially useful in the present invention comprises a modified phospholipid head (e.g., a modified choline group).
- a phospholipid with a modified head is DSPC, or analog thereof, with a modified quaternary amine.
- at least one of R 1 is not methyl.
- at least one of R 1 is not hydrogen or methyl.
- the compound of Formula (IV) is of one of the following Formulae:
- each t is independently 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10
- each u is independently 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10
- each v is independently 1, 2, or 3.
- a compound of Formula (IV) is of Formula (IV-a):
- a phospholipid useful or potentially useful in the present invention comprises a cyclic moiety in place of the glyceride moiety.
- a phospholipid useful in the present invention is DSPC, or analog thereof, with a cyclic moiety in place of the glyceride moiety.
- the compound of Formula (IV) is of Formula (IV-b): or a salt thereof.
- a phospholipid useful or potentially useful in the present invention comprises a modified tail.
- a phospholipid useful or potentially useful in the present invention is DSPC, or analog thereof, with a modified tail.
- a “modified tail” may be a tail with shorter or longer aliphatic chains, aliphatic chains with branching introduced, aliphatic chains with substituents introduced, aliphatic chains wherein one or more methylenes are replaced by cyclic or heteroatom groups, or any combination thereof.
- the compound of Formula (IV) is of Formula (IV-c): (IV-c), or a salt thereof, wherein: each x is independently an integer between 0-30, inclusive; and each instance is G is independently selected from the group consisting of optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(R N ), O, S, C(O), C(O)N(R N ), NR N C(O), NR N C(O)N(R N ), C(O)O, OC(O), OC(O)O, OC(O)N(R N ), NR N C(O)O, C(O)S, possibility represents a separate embodiment of the present invention.
- a phospholipid useful or potentially useful in the present invention comprises a modified phosphocholine moiety, wherein the alkyl chain linking the quaternary amine to the phosphoryl group is not ethylene (e.g., n is not 2). Therefore, in certain embodiments, a phospholipid useful or potentially useful in the present invention is a compound of Formula (IV), wherein n is 1, 3, 4, 5, 6, 7, 8, 9, or 10. For example, in certain embodiments, a compound of Formula (IV) is of one of the following Formulae: or a salt thereof.
- a phospholipid useful or potentially useful in the present invention comprises a modified phosphocholine moiety, wherein the alkyl chain linking the quaternary amine to the phosphoryl group is not ethylene (e. ., n is not 2). Therefore, in certain embodiments, a phospholipid useful.
- an alternative lipid is used in place of a phospholipid of the present disclosure.
- an alternative lipid of the invention is oleic acid.
- the alternative lipid is one of the following:
- the lipid composition of a pharmaceutical composition disclosed herein can comprise one or more structural lipids.
- structural lipid refers to sterols and also to lipids containing sterol moieties.
- Structural lipids can be selected from the group including but not limited to, cholesterol, fecosterol, sitosterol, ergosterol, campesterol, stigmasterol, brassicasterol, tomatidine, tomatine, ursolic acid, alpha-tocopherol, hopanoids, phytosterols, steroids, and mixtures thereof.
- the structural lipid is a sterol.
- sterols are a subgroup of steroids consisting of steroid alcohols.
- the structural lipid is a steroid.
- the structural lipid is cholesterol.
- the structural lipid is an analog of cholesterol.
- the structural lipid is alpha- tocopherol.
- the structural lipids may be one or more of the structural lipids described in U.S. Application No. 62/520,530.
- the lipid composition of a pharmaceutical composition disclosed herein can comprise one or more a polyethylene glycol (PEG) lipid.
- PEG polyethylene glycol
- PEG-lipid refers to polyethylene glycol (PEG)- modified lipids.
- PEG-lipids include PEG-modified phosphatidylethanolamine and phosphatidic acid, PEG-ceramide conjugates (e.g., PEG- C 6 rC14 or PEG-C 6 rC20), PEG-modified dialkylamines and PEG-modified 1,2- diacyloxypropan-3 -amines.
- PEGylated lipids are also referred to as PEGylated lipids.
- a PEG lipid can be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid.
- the PEG-lipid includes, but not limited to 1,2- dimyristoyl-sn-glycerol methoxypolyethylene glycol (PEG-DMG), 1,2-distearoyl-sn- glycero-3-phosphoethanolamine-N-[amino(polyethylene glycol)] (PEG-DSPE), PEG- disteryl glycerol (PEG-DSG), PEG-dipalmetoleyl, PEG-dioleyl, PEG-distearyl, PEG- diacylglycamide (PEG-DAG), PEG-dipalmitoyl phosphatidylethanolamine (PEG-DPPE), or PEG-1, 2-dimyristyloxlpropyl-3 -amine (PEG-c-DMA).
- PEG-DMG 1,2- dimyristoyl-sn-glycerol methoxypolyethylene glycol
- PEG-DSPE 1,2-distearoyl-sn- gly
- the PEG-lipid is selected from the group consisting of a PEG-modified phosphatidylethanolamine, a PEG-modified phosphatidic acid, a PEG- modified ceramide, a PEG-modified dialkylamine, a PEG-modified diacylglycerol, a PEG-modified dialkylglycerol, and mixtures thereof.
- the lipid moiety of the PEG-lipids includes those having lengths of from about C 1 4to about C22, preferably from about C 1 4to about C 1 6.
- a PEG moiety for example an mPEG-NFb, has a size of about 1000, 2000, 5000, 10,000, 15,000 or 20,000 daltons.
- the PEG-lipid is PEG 2 k-DMG.
- the lipid nanoparticles described herein can comprise a PEG lipid which is a non-diffusible PEG.
- PEG lipid which is a non-diffusible PEG.
- non-diffusible PEGs include PEG-DSG and PEG-DSPE.
- PEG-lipids are known in the art, such as those described in U.S. Patent No. 8158601 and International Publ. No. WO 2015/130584 A2, which are incorporated herein by reference in their entirety.
- lipid component of a lipid nanoparticle composition may include one or more molecules comprising polyethylene glycol, such as PEG or PEG-modified lipids. Such species may be alternately referred to as PEGylated lipids.
- a PEG lipid is a lipid modified with polyethylene glycol.
- a PEG lipid may be selected from the non-limiting group including PEG-modified phosphatidylethanolamines, PEG-modified phosphatidic acids, PEG-modified ceramides, PEG-modified dialkylamines, PEG-modified di acylglycerols, PEG-modified dialkylglycerols, and mixtures thereof.
- a PEG lipid may be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid.
- PEG-modified lipids are a modified form of PEG DMG.
- PEG-DMG has the following structure:
- PEG lipids useful in the present invention can be PEGylated lipids described in International Publication No. WO2012099755, the contents of which is herein incorporated by reference in its entirety. Any of these exemplary PEG lipids described herein may be modified to comprise a hydroxyl group on the PEG chain.
- the PEG lipid is a PEG-OH lipid.
- a “PEG-OH lipid” (also referred to herein as “hydroxy- PEGylated lipid”) is a PEGylated lipid having one or more hydroxyl (-OH) groups on the lipid.
- the PEG-OH lipid includes one or more hydroxyl groups on the PEG chain.
- a PEG-OH or hydroxy -PEGylated lipid comprises an -OH group at the terminus of the PEG chain.
- a PEG lipid useful in the present invention is a compound of Formula (V).
- V is a compound of Formula (V).
- R 3 is -OR°
- R° is hydrogen, optionally substituted alkyl, or an oxygen protecting group; r is an integer between 1 and 100, inclusive;
- L 1 is optionally substituted C 1 -io alkylene, wherein at least one methylene of the optionally substituted C 1 -io alkylene is independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, O, N(R N ), S, C(O), C(O)N(R N ), NR C(O), C(O)O, OC(O), OC(O)O, OC(O)N(R N ), NR N C(O)O, or NR N C(O)N(R N );
- D is a moiety obtained by click chemistry or a moiety cleavable under physiological conditions; m is O, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10;
- each instance of L 2 is independently a bond or optionally substituted C 1 -6 alkylene, wherein one methylene unit of the optionally substituted C 1 -6 alkylene is optionally replaced with O, N(R N ), S, C(O), C(O)N(R N ), NR N C(O), C(O)O, OC(O), - OC(O)O, OC(O)N(R N ), NR N C(O)O, or NR N C(O)N(R N ); each instance of R 2 is independently optionally substituted C 1-3 0 alkyl, optionally substituted C 1-3 0 alkenyl, or optionally substituted C 1-3 0 alkynyl; optionally wherein one or more methylene units of R 2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, NR N C(S), NR N C(S)N(R N ), S
- Ring B is optionally substituted carbocyclyl, optionally substituted heterocyclyl, optionally substituted aryl, or optionally substituted heteroaryl; and p is 1 or 2.
- the compound of Formula (V) is a PEG-OH lipid (z.e., R 3 is -OR°, and R° is hydrogen).
- the compound of Formula (V) is of Formula (V-OH): (V-OH), or a salt thereof.
- a PEG lipid useful in the present invention is a PEGylated fatty acid.
- a PEG lipid useful in the present invention is a compound of Formula (VI).
- R 3 is-OR°
- R° is hydrogen, optionally substituted alkyl or an oxygen protecting group; r is an integer between 1 and 100, inclusive;
- R is optionally substituted C10-40 alkyl, optionally substituted C10-40 alkenyl, or optionally substituted C10-40 alkynyl; and optionally one or more methylene groups of R 5 are replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, - 0S(0)0, 0S(0)2, S(0) 2 0, 0S(0) 2 0, N(R N )S(O), S(O)N(R N ), N(R N )S(O)N(R N ), - OS(O)N(R N ), N(R N )S(O)O, S(0) 2 , N(R N )S(O) 2 , S(O) 2 N(R N ), N(R N )S(O) 2 N(R N ), - OS(O) 2 N(R N ), or N(R N )S(O) 2 O; and each instance of R N is independently
- the compound of Formula (VI) is of Formula (VI-
- r is 45.
- the compound of Formula (VI) is N-(2-aminoethyl)-2-aminoethyl
- the lipid composition of the pharmaceutical compositions disclosed herein does not comprise a PEG-lipid.
- the PEG-lipids may be one or more of the PEG lipids described in U.S. Application No. 62/520,530.
- a PEG lipid of the invention comprises a PEG- modified phosphatidylethanolamine, a PEG-modified phosphatidic acid, a PEG-modified ceramide, a PEG-modified dialkylamine, a PEG-modified diacylglycerol, a PEG- modified dialkylglycerol, and mixtures thereof.
- the PEG- modified lipid is PEG-DMG, PEG-c-DOMG (also referred to as PEG-DOMG), PEG- DSG and/or PEG-DPG.
- a LNP of the invention comprises an ionizable cationic lipid of any of Formula I, II or III, a phospholipid comprising DSPC, a structural lipid, and a PEG lipid comprising PEG-DMG.
- a LNP of the invention comprises an ionizable cationic lipid of any of Formula I, II or III, a phospholipid comprising DSPC, a structural lipid, and a PEG lipid comprising a compound having Formula VI.
- a LNP of the invention comprises an ionizable cationic lipid of Formula I, II or III, a phospholipid comprising a compound having Formula IV, a structural lipid, and the PEG lipid comprising a compound having Formula V or VI.
- a LNP of the invention comprises an ionizable cationic lipid of Formula I, II or III, a phospholipid comprising a compound having Formula IV, a structural lipid, and the PEG lipid comprising a compound having Formula V or VI.
- a LNP of the invention comprises an ionizable cationic lipid of Formula I, II or III, a phospholipid having Formula IV, a structural lipid, and a PEG lipid comprising a compound having Formula VI.
- a LNP of the invention comprises an ionizable cationic lipid of and a PEG lipid comprising Formula VI.
- a LNP of the invention comprises an ionizable cationic lipid of and an alternative lipid comprising oleic acid.
- a LNP of the invention comprises an ionizable cationic lipid of an alternative lipid comprising oleic acid, a structural lipid comprising cholesterol, and a PEG lipid comprising a compound having Formula VI.
- a LNP of the invention comprises an ionizable cationic lipid of a phospholipid comprising DOPE, a structural lipid comprising cholesterol, and a PEG lipid comprising a compound having Formula VI.
- a LNP of the invention comprises an ionizable cationic lipid of a phospholipid comprising DOPE, a structural lipid comprising cholesterol, and a PEG lipid comprising a compound having Formula VI.
- a LNP of the invention comprises an N:P ratio of from about 2: 1 to about 30:1.
- a LNP of the invention comprises an N:P ratio of about 6: 1.
- a LNP of the invention comprises an N:P ratio of about 3: 1.
- a LNP of the invention comprises a wt/wt ratio of the ionizable cationic lipid component to the RNA of from about 10: 1 to about 100: 1.
- a LNP of the invention comprises a wt/wt ratio of the ionizable cationic lipid component to the RNA of about 20: 1.
- a LNP of the invention comprises a wt/wt ratio of the ionizable cationic lipid component to the RNA of about 10: 1.
- a LNP of the invention has a mean diameter from about 50nm to about 150nm.
- a LNP of the invention has a mean diameter from about 70nm to about 120nm.
- alkyl As used herein, the term “alkyl”, “alkyl group”, or “alkylene” means a linear or branched, saturated hydrocarbon including one or more carbon atoms (e.g., one, two, three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, fourteen, fifteen, sixteen, seventeen, eighteen, nineteen, twenty, or more carbon atoms), which is optionally substituted.
- C 1-14 alkyl means an optionally substituted linear or branched, saturated hydrocarbon including 1-14 carbon atoms. Unless otherwise specified, an alkyl group described herein refers to both unsubstituted and substituted alkyl groups.
- alkenyl means a linear or branched hydrocarbon including two or more carbon atoms (e g., two, three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, fourteen, fifteen, sixteen, seventeen, eighteen, nineteen, twenty, or more carbon atoms) and at least one double bond, which is optionally substituted.
- C2-14 alkenyl means an optionally substituted linear or branched hydrocarbon including 2-14 carbon atoms and at least one carbon-carbon double bond.
- An alkenyl group may include one, two, three, four, or more carbon-carbon double bonds.
- C 1 s alkenyl may include one or more double bonds.
- a C 1 s alkenyl group including two double bonds may be a linoleyl group.
- an alkenyl group described herein refers to both unsubstituted and substituted alkenyl groups.
- alkynyl means a linear or branched hydrocarbon including two or more carbon atoms (e g., two, three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, fourteen, fifteen, sixteen, seventeen, eighteen, nineteen, twenty, or more carbon atoms) and at least one carboncarbon triple bond, which is optionally substituted.
- the notation "C2-14 alkynyl” means an optionally substituted linear or branched hydrocarbon including 2-14 carbon atoms and at least one carbon-carbon triple bond.
- An alkynyl group may include one, two, three, four, or more carbon-carbon triple bonds.
- C 1 s alkynyl may include one or more carbon-carbon triple bonds.
- an alkynyl group described herein refers to both unsubstituted and substituted alkynyl groups.
- the term "carbocycle” or “carbocyclic group” means an optionally substituted mono- or multi-cyclic system including one or more rings of carbon atoms. Rings may be three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, fourteen, fifteen, sixteen, seventeen, eighteen, nineteen, or twenty membered rings.
- the notation "C 3 -6 carbocycle” means a carbocycle including a single ring having 3-6 carbon atoms. Carbocycles may include one or more carbon-carbon double or triple bonds and may be non-aromatic or aromatic (e.g., cycloalkyl or aryl groups).
- carbocycles include cyclopropyl, cyclopentyl, cyclohexyl, phenyl, naphthyl, and 1,2 dihydronaphthyl groups.
- cycloalkyl as used herein means a non-aromatic carbocycle and may or may not include any double or triple bond.
- carbocycles described herein refers to both unsubstituted and substituted carbocycle groups, i.e., optionally substituted carbocycles.
- heterocycle or “heterocyclic group” means an optionally substituted mono- or multi-cyclic system including one or more rings, where at least one ring includes at least one heteroatom.
- Heteroatoms may be, for example, nitrogen, oxygen, or sulfur atoms. Rings may be three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, or fourteen membered rings.
- Heterocycles may include one or more double or triple bonds and may be non-aromatic or aromatic (e.g., heterocycloalkyl or heteroaryl groups).
- heterocycles include imidazolyl, imidazolidinyl, oxazolyl, oxazolidinyl, thiazolyl, thiazolidinyl, pyrazolidinyl, pyrazolyl, isoxazolidinyl, isoxazolyl, isothiazolidinyl, isothiazolyl, morpholinyl, pyrrolyl, pyrrolidinyl, furyl, tetrahydrofuryl, thiophenyl, pyridinyl, piperidinyl, quinolyl, and isoquinolyl groups.
- heterocycloalkyl as used herein means a non-aromatic heterocycle and may or may not include any double or triple bond. Unless otherwise specified, heterocycles described herein refers to both unsubstituted and substituted heterocycle groups, i.e., optionally substituted heterocycles.
- heteroalkyl refers respectively to an alkyl, alkenyl, alkynyl group, as defined herein, which further comprises one or more (e.g., 1, 2, 3, or 4) heteroatoms (e.g., oxygen, sulfur, nitrogen, boron, silicon, phosphorus) wherein the one or more heteroatoms is inserted between adjacent carbon atoms within the parent carbon chain and/or one or more heteroatoms is inserted between a carbon atom and the parent molecule, i.e., between the point of attachment.
- heteroatoms e.g., oxygen, sulfur, nitrogen, boron, silicon, phosphorus
- heteroalkyls, heteroalkenyls, or heteroalkynyls described herein refers to both unsubstituted and substituted heteroalkyls, heteroalkenyls, or heteroalkynyls, i.e., optionally substituted heteroalkyls, heteroalkenyls, or heteroalkynyls.
- a “biodegradable group” is a group that may facilitate faster metabolism of a lipid in a mammalian entity.
- a biodegradable group may be selected from the group consisting of, but is not limited to, -C(O)O-, -OC(O)-, -C(O)N(R')-, - N(R')C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR')O-, -S(O)2-, an aryl group, and a heteroaryl group.
- an "aryl group” is an optionally substituted carbocyclic group including one or more aromatic rings.
- aryl groups include phenyl and naphthyl groups.
- a "heteroaryl group” is an optionally substituted heterocyclic group including one or more aromatic rings.
- heteroaryl groups include pyrrolyl, furyl, thiophenyl, imidazolyl, oxazolyl, and thiazolyl. Both aryl and heteroaryl groups may be optionally substituted.
- M and M' can be selected from the non-limiting group consisting of optionally substituted phenyl, oxazole, and thiazole.
- M and M' can be independently selected from the list of biodegradable groups above.
- aryl or heteroaryl groups described herein refers to both unsubstituted and substituted groups, i.e., optionally substituted aryl or heteroaryl groups.
- Alkyl, alkenyl, and cyclyl (e.g., carbocyclyl and heterocyclyl) groups may be optionally substituted unless otherwise specified.
- R is an alkyl or alkenyl group, as defined herein.
- the substituent groups themselves may be further substituted with, for example, one, two, three, four, five, or six substituents as defined herein.
- a C1-6 alkyl group may be further substituted with one, two, three, four, five, or six substituents as described herein.
- N-hydroxy compounds can be prepared by oxidation of the parent amine by an oxidizing agent such as m CPBA.
- nitrogen-containing compounds are also considered, when allowed by valency and structure, to cover both the compound as shown and its N-hydroxy (i.e., N-OH) and N-alkoxy (i.e., N-OR, wherein R is substituted or unsubstituted C 1 -C 6 alkyl, C 1 -C 6 alkenyl, C 1 -C 6 alkynyl, 3-14-membered carbocycle or 3-14-membered heterocycle) derivatives.
- N-OH N-hydroxy
- N-alkoxy i.e., N-OR, wherein R is substituted or unsubstituted C 1 -C 6 alkyl, C 1 -C 6 alkenyl, C 1 -C 6 alkynyl, 3-14-membered carbocycle or 3-14-membered heterocycle
- the lipid composition of a pharmaceutical composition disclosed herein can include one or more components in addition to those described above.
- the lipid composition can include one or more permeability enhancer molecules, carbohydrates, polymers, surface altering agents (e.g., surfactants), or other components.
- a permeability enhancer molecule can be a molecule described by U.S. Patent Application Publication No. 2005/0222064.
- Carbohydrates can include simple sugars (e.g., glucose) and polysaccharides (e.g., glycogen and derivatives and analogs thereof).
- a polymer can be included in and/or used to encapsulate or partially encapsulate a pharmaceutical composition disclosed herein (e.g., a pharmaceutical composition in lipid nanoparticle form).
- a polymer can be biodegradable and/or biocompatible.
- a polymer can be selected from, but is not limited to, polyamines, polyethers, polyamides, polyesters, polycarbamates, polyureas, polycarbonates, polystyrenes, polyimides, polysulfones, polyurethanes, polyacetylenes, polyethylenes, polyethyleneimines, polyisocyanates, polyacrylates, polymethacrylates, polyacrylonitriles, and polyarylates.
- the ratio between the lipid composition and the polynucleotide range can be from about 10:1 to about 60:1 (wt/wt).
- the ratio between the lipid composition and the polynucleotide can be about 10:1, 11:1, 12:1, 13:1, 14:1, 15:1, 16:1, 17:1, 18:1, 19:1, 20:1, 21:1, 22:1, 23:1, 24:1, 25:1, 26:1, 27:1, 28:1, 29:1, 30:1, 31:1, 32:1, 33:1, 34:1, 35:1, 36:1, 37:1, 38:1, 39:1, 40:1, 41:1, 42:1, 43:1, 44:1, 45:1, 46:1, 47:1, 48:1, 49:1, 50:1, 51:1, 52:1, 53:1, 54:1, 55:1, 56:1, 57:1, 58:1, 59:1 or 60:1 (wt/wt). In some embodiments, the wt/wt ratio of the lipid composition to the polynucleotide encoding a therapeutic agent is about 20:1 or about 15:1.
- the pharmaceutical composition disclosed herein can contain more than one polypeptides.
- a pharmaceutical composition disclosed herein can contain two or more polynucleotides (e.g., RNA, e.g., mRNA).
- the lipid nanoparticles described herein can comprise polynucleotides (e.g., mRNA) in a lipid:polynucleotide weight ratio of 5:1, 10:1, 15:1, 20:1, 25:1, 30:1, 35:1, 40:1, 45:1, 50:1, 55:1, 60:1 or 70:1, or a range or any of these ratios such as, but not limited to, 5: 1 to about 10:1, from about 5: 1 to about 15:1, from about 5:1 to about 20:1, from about 5:1 to about 25:1, from about 5:1 to about 30:1, from about 5:1 to about 35:1, from about 5:1 to about 40:1, from about 5:1 to about 45:1, from about 5:1 to about 50:1, from about 5:1 to about 55:1, from about 5:1 to about 60:1, from about 5:1 to about 70:1, from about 10:1 to about 15:1, from about 10:1 to about 20:1, from about 10:1
- the lipid nanoparticles described herein can comprise the polynucleotide in a concentration from approximately 0.1 mg/ml to 2 mg/ml such as, but not limited to, 0.1 mg/ml, 0.2 mg/ml, 0.3 mg/ml, 0.4 mg/ml, 0.5 mg/ml, 0.6 mg/ml, 0.7 mg/ml, 0.8 mg/ml, 0.9 mg/ml, 1.0 mg/ml, 1.1 mg/ml, 1.2 mg/ml, 1.3 mg/ml, 1.4 mg/ml, 1.5 mg/ml, 1.6 mg/ml, 1.7 mg/ml, 1.8 mg/ml, 1.9 mg/ml, 2.0 mg/ml or greater than 2.0 mg/ml.
- the pharmaceutical compositions disclosed herein are formulated as lipid nanoparticles (LNP). Accordingly, the present disclosure also provides nanoparticle compositions comprising (i) a lipid composition comprising a delivery agent such as compound as described herein, and (ii) a polynucleotide encoding an IgAP protein. In such nanoparticle composition, the lipid composition disclosed herein can encapsulate the polynucleotide encoding an IgAP protein.
- Nanoparticle compositions are typically sized on the order of micrometers or smaller and can include a lipid bilayer.
- Nanoparticle compositions encompass lipid nanoparticles (LNPs), liposomes (e.g., lipid vesicles), and lipoplexes.
- LNPs lipid nanoparticles
- liposomes e.g., lipid vesicles
- lipoplexes e.g., lipoplexes.
- a nanoparticle composition can be a liposome having a lipid bilayer with a diameter of 500 nm or less.
- Nanoparticle compositions include, for example, lipid nanoparticles (LNPs), liposomes, and lipoplexes.
- LNPs lipid nanoparticles
- nanoparticle compositions are vesicles including one or more lipid bilayers.
- a nanoparticle composition includes two or more concentric bilayers separated by aqueous compartments.
- Lipid bilayers can be functionalized and/or crosslinked to one another.
- Lipid bilayers can include one or more ligands, proteins, or channels.
- a lipid nanoparticle comprises an ionizable amino lipid, a structural lipid, a phospholipid, and mRNA.
- the LNP comprises an ionizable amino lipid, a PEG-modified lipid, a sterol and a structural lipid.
- the LNP has a molar ratio of about 40-50% ionizable amino lipid; about 5- 15% structural lipid; about 30-45% sterol; and about 1-5% PEG-modified lipid.
- the LNP has a poly dispersity value of less than 0.4. In some embodiments, the LNP has a net neutral charge at a neutral pH. In some embodiments, the LNP has a mean diameter of 50-150 nm. In some embodiments, the LNP has a mean diameter of 80-100 nm.
- lipid refers to a small molecule that has hydrophobic or amphiphilic properties. Lipids may be naturally occurring or synthetic. Examples of classes of lipids include, but are not limited to, fats, waxes, sterol - containing metabolites, vitamins, fatty acids, glycerolipids, glycerophospholipids, sphingolipids, saccharolipids, and polyketides, and prenol lipids. In some instances, the amphiphilic properties of some lipids leads them to form liposomes, vesicles, or membranes in aqueous media.
- a lipid nanoparticle may comprise an ionizable amino lipid.
- the term “ionizable amino lipid” has its ordinary meaning in the art and may refer to a lipid comprising one or more charged moieties.
- an ionizable amino lipid may be positively charged or negatively charged.
- An ionizable amino lipid may be positively charged, in which case it can be referred to as “cationic lipid”.
- an ionizable amino lipid molecule may comprise an amine group, and can be referred to as an ionizable amino lipid.
- a “charged moiety” is a chemical moiety that carries a formal electronic charge, e.g., monovalent (+1, or -1), divalent (+2, or -2), trivalent (+3, or -3), etc.
- the charged moiety may be anionic (i.e., negatively charged) or cationic (i.e., positively charged).
- Examples of positively-charged moieties include amine groups (e g., primary, secondary, and/or tertiary amines), ammonium groups, pyridinium group, guanidine groups, and imidizolium groups.
- the charged moieties comprise amine groups.
- Examples of negatively- charged groups or precursors thereof include carboxylate groups, sulfonate groups, sulfate groups, phosphonate groups, phosphate groups, hydroxyl groups, and the like.
- the charge of the charged moiety may vary, in some cases, with the environmental conditions, for example, changes in pH may alter the charge of the moiety, and/or cause the moiety to become charged or uncharged. In general, the charge density of the molecule may be selected as desired.
- charge does not refer to a “partial negative charge” or “partial positive charge” on a molecule.
- the terms “partial negative charge” and “partial positive charge” are given its ordinary meaning in the art.
- a “partial negative charge” may result when a functional group comprises a bond that becomes polarized such that electron density is pulled toward one atom of the bond, creating a partial negative charge on the atom.
- the ionizable amino lipid is sometimes referred to in the art as an “ionizable cationic lipid”.
- the ionizable amino lipid may have a positively charged hydrophilic head and a hydrophobic tail that are connected via a linker structure.
- an ionizable amino lipid may also be a lipid including a cyclic amine group.
- the ionizable amino lipid may be selected from, but not limited to, an ionizable amino lipid described in International Publication Nos. WO2013086354 and WO2013116126; the contents of each of which are herein incorporated by reference in their entirety.
- the ionizable amino lipid may be selected from, but not limited to, Formula CLI-CLXXXII of US Patent No. 7,404,969; each of which is herein incorporated by reference in their entirety.
- the lipid may be a cleavable lipid such as those described in International Publication No. WO2012170889, herein incorporated by reference in its entirety.
- the lipid may be synthesized by methods known in the art and/or as described in International Publication Nos. WO2013086354; the contents of each of which are herein incorporated by reference in their entirety.
- Nanoparticle compositions can be characterized by a variety of methods. For example, microscopy (e.g., transmission electron microscopy or scanning electron microscopy) can be used to examine the morphology and size distribution of a nanoparticle composition. Dynamic light scattering or potentiometry (e.g., potentiometric titrations) can be used to measure zeta potentials. Dynamic light scattering can also be utilized to determine particle sizes. Instruments such as the Zetasizer Nano ZS (Malvern Instruments Ltd, Malvern, Worcestershire, UK) can also be used to measure multiple characteristics of a nanoparticle composition, such as particle size, poly dispersity index, and zeta potential.
- microscopy e.g., transmission electron microscopy or scanning electron microscopy
- Dynamic light scattering or potentiometry e.g., potentiometric titrations
- Dynamic light scattering can also be utilized to determine particle sizes.
- Instruments such as the Ze
- the size of the nanoparticles can help counter biological reactions such as, but not limited to, inflammation, or can increase the biological effect of the polynucleotide.
- size or mean size in the context of nanoparticle compositions refers to the mean diameter of a nanoparticle composition.
- the polynucleotide encoding an IgAP protein are formulated in lipid nanoparticles having a diameter from about 10 to about 100 nm such as, but not limited to, about 10 to about 20 nm, about 10 to about 30 nm, about 10 to about 40 nm, about 10 to about 50 nm, about 10 to about 60 nm, about 10 to about 70 nm, about 10 to about 80 nm, about 10 to about 90 nm, about 20 to about 30 nm, about 20 to about 40 nm, about 20 to about 50 nm, about 20 to about 60 nm, about 20 to about 70 nm, about 20 to about 80 nm, about 20 to about 90 nm, about 20 to about 100 nm, about 30 to about 40 nm, about 30 to about 50 nm, about 30 to about 60 nm, about 30 to about 70 nm, about 30 to about 80 nm, about 30 to about 90 nm, about 30 to about 100 nm,
- the nanoparticles have a diameter from about 10 to 500 nm. In one embodiment, the nanoparticle has a diameter greater than 100 nm, greater than 150 nm, greater than 200 nm, greater than 250 nm, greater than 300 nm, greater than 350 nm, greater than 400 nm, greater than 450 nm, greater than 500 nm, greater than 550 nm, greater than 600 nm, greater than 650 nm, greater than 700 nm, greater than 750 nm, greater than 800 nm, greater than 850 nm, greater than 900 nm, greater than 950 nm or greater than 1000 nm.
- the largest dimension of a nanoparticle composition is 1 pm or shorter (e.g., 1 pm, 900 nm, 800 nm, 700 nm, 600 nm, 500 nm, 400 nm, 300 nm, 200 nm, 175 nm, 150 nm, 125 nm, 100 nm, 75 nm, 50 nm, or shorter).
- a nanoparticle composition can be relatively homogenous.
- a poly dispersity index can be used to indicate the homogeneity of a nanoparticle composition, e.g., the particle size distribution of the nanoparticle composition.
- a small (e.g., less than 0.3) poly dispersity index generally indicates a narrow particle size distribution.
- a nanoparticle composition can have a poly dispersity index from about 0 to about 0.25, such as 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.10, 0.11, 0.12, 0.13, 0.14, 0.15, 0.16, 0.17, 0.18, 0.19, 0.20, 0.21, 0.22, 0.23, 0.24, or 0.25.
- the poly dispersity index of a nanoparticle composition disclosed herein can be from about 0.10 to about 0.20.
- the zeta potential of a nanoparticle composition can be used to indicate the electrokinetic potential of the composition.
- the zeta potential can describe the surface charge of a nanoparticle composition.
- Nanoparticle compositions with relatively low charges, positive or negative, are generally desirable, as more highly charged species can interact undesirably with cells, tissues, and other elements in the body.
- the zeta potential of a nanoparticle composition disclosed herein can be from about -10 mV to about +20 mV, from about -10 mV to about +15 mV, from about 10 mV to about +10 mV, from about -10 mV to about +5 mV, from about - 10 mV to about 0 mV, from about -10 mV to about -5 mV, from about -5 mV to about +20 mV, from about -5 mV to about +15 mV, from about -5 mV to about +10 mV, from about -5 mV to about +5 mV, from about -5 mV to about 0 mV, from about 0 mV to about +20 mV, from about 0 mV to about +15 mV, from about 0 mV to about +10 mV, from about 0 mV to about +5 mV, from about 0 mV to about +20
- the zeta potential of the lipid nanoparticles can be from about 0 mV to about 100 mV, from about 0 mV to about 90 mV, from about 0 mV to about 80 mV, from about 0 mV to about 70 mV, from about 0 mV to about 60 mV, from about 0 mV to about 50 mV, from about 0 mV to about 40 mV, from about 0 mV to about 30 mV, from about 0 mV to about 20 mV, from about 0 mV to about 10 mV, from about 10 mV to about 100 mV, from about 10 mV to about 90 mV, from about 10 mV to about 80 mV, from about 10 mV to about 70 mV, from about 10 mV to about 60 mV, from about 10 mV to about 50 mV, from about 10 mV to about 40 mV
- the zeta potential of the lipid nanoparticles can be from about 10 mV to about 50 mV, from about 15 mV to about 45 mV, from about 20 mV to about 40 mV, and from about 25 mV to about 35 mV. In some embodiments, the zeta potential of the lipid nanoparticles can be about 10 mV, about 20 mV, about 30 mV, about 40 mV, about 50 mV, about 60 mV, about 70 mV, about 80 mV, about 90 mV, and about 100 mV.
- encapsulation efficiency of a polynucleotide describes the amount of the polynucleotide that is encapsulated by or otherwise associated with a nanoparticle composition after preparation, relative to the initial amount provided.
- encapsulation can refer to complete, substantial, or partial enclosure, confinement, surrounding, or encasement.
- Encapsulation efficiency is desirably high (e.g., close to 100%).
- the encapsulation efficiency can be measured, for example, by comparing the amount of the polynucleotide in a solution containing the nanoparticle composition before and after breaking up the nanoparticle composition with one or more organic solvents or detergents.
- the encapsulation efficiency of a polynucleotide can be at least 50%, for example 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100%. In some embodiments, the encapsulation efficiency can be at least 80%. In certain embodiments, the encapsulation efficiency can be at least 90%.
- the amount of a polynucleotide present in a pharmaceutical composition disclosed herein can depend on multiple factors such as the size of the polynucleotide, desired target and/or application, or other properties of the nanoparticle composition as well as on the properties of the polynucleotide.
- the amount of an mRNA useful in a nanoparticle composition can depend on the size (expressed as length, or molecular mass), sequence, and other characteristics of the mRNA.
- the relative amounts of a polynucleotide in a nanoparticle composition can also vary.
- the relative amounts of the lipid composition and the polynucleotide present in a lipid nanoparticle composition of the present disclosure can be optimized according to considerations of efficacy and tolerability.
- the N:P ratio can serve as a useful metric.
- N:P ratio of a nanoparticle composition controls both expression and tolerability
- nanoparticle compositions with low N:P ratios and strong expression are desirable.
- N:P ratios vary according to the ratio of lipids to RNA in a nanoparticle composition.
- a lower N:P ratio is preferred.
- the one or more RNA, lipids, and amounts thereof can be selected to provide an N:P ratio from about 2: 1 to about 30: 1, such as 2: 1, 3: 1, 4: 1, 5: 1, 6:1, 7: 1, 8:1, 9: 1, 10: 1, 12:1, 14: 1, 16: 1, 18:1, 20:1, 22: 1, 24: 1, 26: 1, 28: 1, or 30: 1.
- the N:P ratio can be from about 2: 1 to about 8: 1. In other embodiments, the N:P ratio is from about 5: 1 to about 8: 1. In certain embodiments, the N:P ratio is between 5:1 and 6:1. In one specific aspect, the N:P ratio is about is about 5.67: 1.
- the present disclosure also provides methods of producing lipid nanoparticles comprising encapsulating a polynucleotide.
- Such method comprises using any of the pharmaceutical compositions disclosed herein and producing lipid nanoparticles in accordance with methods of production of lipid nanoparticles known in the art. See, e.g., Wang et al. (2015) “Delivery of oligonucleotides with lipid nanoparticles” Adv. Drug Deliv. Rev. 87:68-80; Silva et al. (2015) “Delivery Systems for Biopharmaceuticals. Part I: Nanoparticles and Microparticles” Curr. Pharm. Technol. 16: 940-954; Naseri et al.
- ionizable lipids are susceptible to the formation of lipid-polynucleotide adducts.
- ionizable lipids that comprise a tertiary amine group may decompose into one or both of a secondary amine and a reactive aldehyde species capable of interacting with polynucleotides (such as mRNA) to form an ionizable lipid-polynucleotide adduct impurity that can be detected by reverse phase ion pair chromatography (RP-IP HPLC).
- RP-IP HPLC reverse phase ion pair chromatography
- the ionizable lipid-polynucleotide adduct impurity is an aldehyde-mRNA adduct impurity.
- LNP compositions with a reduced content of ionizable lipid-polynucleotide adduct impurity, such as wherein less than about 20%, less than about 10%, less than about 5%, or less than about 1%, of the mRNA is in the form of ionizable lipid-polynucleotide adduct impurity, as may be measured by RP-IP HPLC.
- an LNP composition wherein less than about 10%, less than about 5%, or less than about 1%, of the mRNA is in the form of ionizable lipid-polynucleotide adduct impurity, including less than 10%, less than 5%, or less than 1%, as may be measured by RP-IP HPLC.
- an amount of lipid aldehydes in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of N-oxide compounds in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of transition metals, such as Fe, in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of alkyl halide compounds in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of anhydride compounds in the composition is less than about 50 ppm, including less than 50 ppm.
- an amount of ketone compounds in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of conjugated diene compounds in the composition is less than about 50 ppm, including less than 50 ppm.
- the composition is stable against the formation of ionizable lipid-polynucleotide adduct impurity.
- an amount of ionizable lipid- polynucleotide adduct impurity in the composition increases at an average rate of less than about 2% per day when stored at a temperature of about 25 °C or below, including at an average rate of less than 2% per day.
- an amount of ionizable lipidpolynucleotide adduct impurity in the composition increases at an average rate of less than about 0.5% per day when stored at a temperature of about 5 °C or below, including at an average rate of less than 0.5% per day.
- an amount of ionizable lipid-polynucleotide adduct impurity in the composition increases at an average rate of less than about 0.5% per day when stored at a refrigerated temperature, optionally wherein the refrigerated temperature is about 5 °C.
- Lipid vehicle (e.g., LNP) compositions with a reduced content of ionizable lipid-polynucleotide adduct impurity can be prepared by methods that inhibit formation of one or both of N-oxides and aldehydes. Such methods may comprise treating a composition comprising an ionizable lipid comprising a tertiary amine group to inhibit formation of one or both of N-oxides and aldehydes, such as by treating the composition with a reducing agent; treating the composition with a chelating agent; adjusting the pH of the composition; adjusting the temperature of the composition; and adjusting the buffer in the composition.
- LNP ionizable lipid-polynucleotide adduct impurity
- Such methods may comprise, prior to combining the ionizable lipid with a polynucleotide, one or more of treating the ionizable lipid with a scavenging agent; treating the ionizable lipid with a reductive treatment agent; treating the ionizable lipid with a reducing agent; treating the ionizable lipid with a chelating agent; treating the polynucleotide with a reducing agent; and treating the polynucleotide with a chelating agent.
- the scavenging agent, reductive treatment agent, and/or reducing agent may be an agent that reacts with aldehyde, ketone, anhydride and/or diene compounds.
- a scavenging agent may comprise one or more selected from (O-(2,3,4,5,6-Pentafluorobenzyl)hydroxylamine hydrochloride) (PFBHA), methoxyamine (e.g., methoxyamine hydrochloride), benzyloxyamine (e.g., benzyloxyamine hydrochloride), ethoxyamine (e.g., ethoxyamine hydrochloride), 4-[2- (aminooxy)ethyl]morpholine dihydrochloride, butoxyamine (e.g., tert-butoxyamine hydrochloride), 4-Dimethylaminopyridine (DMAP), l,4-diazabicyclo[2.2.2]octane (DABCO), Triethylamine (TEA), Piperidine 4-carboxylate (BPPC), and combinations thereof.
- PFBHA fluorobenzyl)hydroxylamine hydrochloride
- methoxyamine e.g., methoxyamine
- a reductive treatment agent may comprise a boron compound (e.g., sodium borohydride and/or bis(pinacolato)diboron).
- a reductive treatment agent may comprise a boron compound, such as one or both of sodium borohydride and bis(pinacolato)diboron).
- a chelating agent may comprise immobilized iminodiacetic acid.
- a reducing agent may comprise an immobilized reducing agent, such as immobilized diphenylphosphine on silica (Si-DPP), immobilized thiol on agarose (Ag- Thiol), immobilized cysteine on silica (Si-Cysteine), immobilized thiol on silica (Si- Thiol), or a combination thereof.
- an immobilized reducing agent such as immobilized diphenylphosphine on silica (Si-DPP), immobilized thiol on agarose (Ag- Thiol), immobilized cysteine on silica (Si-Cysteine), immobilized thiol on silica (Si- Thiol), or a combination thereof.
- a reducing agent may comprise a free reducing agent, such as potassium metabisulfite, sodium thioglycolate, tris(2-carboxyethyl)phosphine (TCEP), sodium thiosulfate, N-acetyl cysteine, glutathione, dithiothreitol (DTT), cystamine, dithioerythritol (DTE), dichlorodiphenyltrichloroethane (DDT), homocysteine, lipoic acid, or a combination thereof.
- TCEP tris(2-carboxyethyl)phosphine
- DTT dithiothreitol
- cystamine cystamine
- DTE dithioerythritol
- DDT dichlorodiphenyltrichloroethane
- homocysteine lipoic acid, or a combination thereof.
- the pH may be, or adjusted to be, a pH of from about 7 to about 9.
- a buffer may be selected from sodium phosphate, sodium citrate, sodium succinate, histidine, histidine-HCl, sodium malate, sodium carbonate, and TRIS (tris(hydroxymethyl)aminomethane).
- a buffer may be TRIS and may be, or adjusted to be, from about 20 mM to about 150 mM TRIS.
- the temperature of the composition may be, or adjusted to be, 25 °C or less.
- composition may also comprise a free reducing agent or antioxidant.
- compositions or formulations of the present disclosure comprise a delivery agent, e.g., a liposome, a lioplexes, a lipid nanoparticle, or any combination thereof.
- a delivery agent e.g., a liposome, a lioplexes, a lipid nanoparticle, or any combination thereof.
- the polynucleotides described herein e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein can be formulated using one or more liposomes, lipoplexes, or lipid nanoparticles.
- Liposomes, lipoplexes, or lipid nanoparticles can be used to improve the efficacy of the polynucleotides directed protein production as these formulations can increase cell transfection by the polynucleotide; and/or increase the translation of encoded protein.
- the liposomes, lipoplexes, or lipid nanoparticles can also be used to increase the stability of the polynucleotides.
- Liposomes are artificially-prepared vesicles that can primarily be composed of a lipid bilayer and can be used as a delivery vehicle for the administration of pharmaceutical formulations. Liposomes can be of different sizes.
- a multilamellar vesicle (MLV) can be hundreds of nanometers in diameter, and can contain a series of concentric bilayers separated by narrow aqueous compartments.
- a small unicellular vesicle (SUV) can be smaller than 50 nm in diameter, and a large unilamellar vesicle (LUV) can be between 50 and 500 nm in diameter.
- Liposome design can include, but is not limited to, opsonins or ligands to improve the attachment of liposomes to unhealthy tissue or to activate events such as, but not limited to, endocytosis.
- Liposomes can contain a low or a high pH value in order to improve the delivery of the pharmaceutical formulations.
- liposomes can depend on the pharmaceutical formulation entrapped and the liposomal ingredients, the nature of the medium in which the lipid vesicles are dispersed, the effective concentration of the entrapped substance and its potential toxicity, any additional processes involved during the application and/or delivery of the vesicles, the optimal size, poly dispersity and the shelf-life of the vesicles for the intended application, and the batch-to-batch reproducibility and scale up production of safe and efficient liposomal products, etc.
- liposomes such as synthetic membrane vesicles can be prepared by the methods, apparatus and devices described in U.S. Pub. Nos. US20130177638, US20130177637, US20130177636, US20130177635, US20130177634, US20130177633, US20130183375, US20130183373, and US20130183372.
- the polynucleotides described herein can be encapsulated by the liposome and/or it can be contained in an aqueous core that can then be encapsulated by the liposome as described in, e.g., Inti. Pub. Nos.
- the polynucleotides described herein can be formulated in a cationic oil-in-water emulsion where the emulsion particle comprises an oil core and a cationic lipid that can interact with the polynucleotide anchoring the molecule to the emulsion particle.
- the polynucleotides described herein can be formulated in a water-in-oil emulsion comprising a continuous hydrophobic phase in which the hydrophilic phase is dispersed.
- Exemplary emulsions can be made by the methods described in Inti. Pub. Nos. W02012006380 and W0201087791, each of which is herein incorporated by reference in its entirety.
- the polynucleotides described herein can be formulated in a lipid-polycation complex.
- the formation of the lipid-polycation complex can be accomplished by methods as described in, e.g., U.S. Pub. No. US20120178702.
- the polycation can include a cationic peptide or a polypeptide such as, but not limited to, polylysine, polyornithine and/or polyarginine and the cationic peptides described in Inti. Pub. No. WO2012013326 or U.S. Pub. No. US20130142818.
- Each of the references is herein incorporated by reference in its entirety.
- the polynucleotides described herein can be formulated in a lipid nanoparticle (LNP) such as those described in Inti. Pub. Nos. WO2013123523, WO20 12170930, WO2011127255 and W02008103276; and U.S. Pub. No.
- LNP lipid nanoparticle
- Lipid nanoparticle formulations typically comprise one or more lipids.
- the lipid is an ionizable amino lipid, sometimes referred to in the art as an “ionizable cationic lipid”.
- lipid nanoparticle formulations further comprise other components, including a phospholipid, a structural lipid, and a molecule capable of reducing particle aggregation, for example a PEG or PEG-modified lipid.
- Exemplary ionizable amino lipids include, but not limited to, any Compounds II, VI, A, and B disclosed herein, DLin-mC 3 -DMA (MC 3 ), DLin-DMA, DLenDMa, DLin-D-DMa, DLin-K-DMA, dLin-M-C2-DMa, DLin-K-DMA, DLin-KC2-DMA, DLin-KC 3 -DMA, DLin-KC4-DMA, DLin-C2K-DMA, DLin-MP-DMA, DODMA, 98N12-5, Cl 2-200, DLin-C-DAP, DLin-DAC, DLinDAP, DLinAP, DLin-EG-DMA, DLin-2-DMAP, KL10, KL22, KL25, Octyl-CLinDMA, Octyl-CLinDMA (2R), Octyl- CLinDMA (2S), Octy
- exemplary ionizable amino lipids include, (13Z,16Z)-N,N-dimethyl-3 -nonyldocosa- 13, 16-dien-l -amine (L608), (20Z,23Z)- N,N-dimethylnonacosa-20,23 -dien- 10-amine, (17Z,20Z)-N,N-dimemylhexacosa- 17,20- dien-9-amine, (16Z, 19Z)-N5N-dimethylpentacosa- 16,19-dien-8-amine, ( 13Z, 16Z)-N,N- dimethyldocosa-13 , 16-dien-5-amine, ( 12Z, 15Z)-N,N-dimethylhenicosa- 12, 15-dien-4- amine, ( 14Z, 17Z)-N,N-dimethyltricosa- 14, 17-dien-6-amine, ( 15Z, 18Z)-N,N- dimethyltetracos
- Phospholipids include, but are not limited to, glycerophospholipids such as phosphatidylcholines, phosphatidylethanolamines, phosphatidylserines, phosphatidylinositols, phosphatidy glycerols, and phosphatidic acids. Phospholipids also include phosphosphingolipid, such as sphingomyelin.
- the phospholipids are DLPC, DMPC, DOPC, DPPC, DSPC, DUPC, 18:0 Diether PC, DLnPC, DAPC, DHAPC, DOPE, 4ME 16:0 pE, DSPE, DLPE,DLnPE, DAPE, DHAPE, DOPG, and any combination thereof.
- the phospholipids are MPPC, MSPC, PMPC, PSPC, SMPC, SPPC, DHAPE, DOPG, and any combination thereof.
- the amount of phospholipids (e.g., DSPC) in the lipid composition ranges from about 1 mol% to about 20 mol%.
- the amount of phospholipids (e.g., DSPC) in the lipid composition ranges from about 5-15 mol%, optionally 10-12 mol%, for example, 5-6 mol%, 6-7 mol%, 7-8 mol%, 8-9 mol%, 9-10 mol%, 10-11 mol%, l l-12 mol%, 12-13 mol%, 13-14 mol%, or 14-15 mol%.
- the structural lipids include sterols and lipids containing sterol moieties.
- the structural lipids include cholesterol, fecosterol, sitosterol, ergosterol, campesterol, stigmasterol, brassicasterol, tomatidine, tomatine, ursolic acid, alpha-tocopherol, and mixtures thereof.
- the structural lipid is cholesterol.
- the amount of the structural lipids (e.g., cholesterol) in the lipid composition ranges from about 20 mol% to about 60 mol%.
- the amount of the structural lipids (e.g., cholesterol) in the lipid composition ranges from about 30-45 mol%, optionally 35-40 mol%, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 38-38 mol%, 38-39 mol%, or 39-40 mol%.
- the PEG-modified lipids include PEG-modified phosphatidylethanolamine and phosphatidic acid, PEG-ceramide conjugates (e.g., PEG-CerC14 or PEG-CerC20), PEG-modified dialkylamines and PEG-modified l,2-diacyloxypropan-3 -amines.
- PEGylated lipids are also referred to as PEGylated lipids.
- a PEG lipid can be PEG-c- DOMG, PEG-DMG, PEG-DLPE, PEG DMPE, PEG-DPPC, or a PEG-DSPE lipid.
- the PEG-lipid are 1,2-dimyristoyl-sn-glycerol methoxypolyethylene glycol (PEG-DMG), l,2-distearoyl-sn-glycero-3-phosphoethanolamine-N- [amino(polyethylene glycol)] (PEG-DSPE), PEG-disteryl glycerol (PEG-DSG), PEG- dipalmetoleyl, PEG-dioleyl, PEG-distearyl, PEG-diacylglycamide (PEG-DAG), PEG- dipalmitoyl phosphatidylethanolamine (PEG-DPPE), or PEG-1, 2-dimyristyloxlpropyl-3- amine (PEG-c-DMA).
- PEG-DMG 1,2-dimyristoyl-sn-glycerol methoxypolyethylene glycol
- PEG-DSPE l,2-distearoyl-sn-g
- the PEG moiety has a size of about 1000, 2000, 5000, 10,000, 15,000 or 20,000 daltons. In some embodiments, the amount of PEG-lipid in the lipid composition ranges from about 0 mol% to about 5 mol%. In some embodiments, the amount of PEG-lipid in the lipid composition ranges from about 1-5%, optionally 1-3 mol%, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol%.
- the LNP formulations described herein can additionally comprise a permeability enhancer molecule.
- permeability enhancer molecules are described in U.S. Pub. No. US20050222064, herein incorporated by reference in its entirety.
- the LNP formulations can further contain a phosphate conjugate.
- the phosphate conjugate can increase in vivo circulation times and/or increase the targeted delivery of the nanoparticle.
- Phosphate conjugates can be made by the methods described in, e.g., Inti. Pub. No. WO2013033438 or U.S. Pub. No. US20130196948.
- the LNP formulation can also contain a polymer conjugate (e.g., a water soluble conjugate) as described in, e.g, U.S. Pub. Nos. US20130059360, US20130196948, and US20130072709. Each of the references is herein incorporated by reference in its entirety.
- the LNP formulations can comprise a conjugate to enhance the delivery of nanoparticles of the present invention in a subject. Further, the conjugate can inhibit phagocytic clearance of the nanoparticles in a subject.
- the conjugate can be a "self peptide designed from the human membrane protein CD47 (e.g., the "self particles described by Rodriguez et al, Science 2013 339, 971-975, herein incorporated by reference in its entirety). As shown by Rodriguez et al. the self peptides delayed macrophage-mediated clearance of nanoparticles which enhanced delivery of the nanoparticles.
- the LNP formulations can comprise a carbohydrate carrier.
- the carbohydrate carrier can include, but is not limited to, an anhydride- modified phytoglycogen or glycogen-type material, phytoglycogen octenyl succinate, phytoglycogen beta-dextrin, anhydride-modified phytoglycogen beta-dextrin (e.g., Inti. Pub. No. W02012109121, herein incorporated by reference in its entirety).
- the LNP formulations can be coated with a surfactant or polymer to improve the delivery of the particle.
- the LNP can be coated with a hydrophilic coating such as, but not limited to, PEG coatings and/or coatings that have a neutral surface charge as described in U.S. Pub. No. US20130183244, herein incorporated by reference in its entirety.
- the LNP formulations can be engineered to alter the surface properties of particles so that the lipid nanoparticles can penetrate the mucosal barrier as described in U.S. Pat. No. 8,241,670 or Inti. Pub. No. WO2013110028, each of which is herein incorporated by reference in its entirety.
- the LNP engineered to penetrate mucus can comprise a polymeric material (i.e., a polymeric core) and/or a polymer-vitamin conjugate and/or a tri-block copolymer.
- the polymeric material can include, but is not limited to, polyamines, polyethers, polyamides, polyesters, polycarbamates, polyureas, polycarbonates, poly(styrenes), polyimides, polysulfones, polyurethanes, polyacetylenes, polyethylenes, polyethyeneimines, polyisocyanates, polyacrylates, polymethacrylates, polyacrylonitriles, and polyarylates.
- LNP engineered to penetrate mucus can also include surface altering agents such as, but not limited to, polynucleotides, anionic proteins (e.g., bovine serum albumin), surfactants (e.g., cationic surfactants such as for example dimethyldioctadecyl- ammonium bromide), sugars or sugar derivatives (e.g., cyclodextrin), nucleic acids, polymers (e.g., heparin, polyethylene glycol and poloxamer), mucolytic agents (e.g., N- acetylcysteine, mugwort, bromelain, papain, clerodendrum, acetylcysteine, bromhexine, carbocisteine, eprazinone, mesna, ambroxol, sobrerol, domiodol, letosteine, stepronin, tiopronin, gelsolin, thymosin
- the mucus penetrating LNP can be a hypotonic formulation comprising a mucosal penetration enhancing coating.
- the formulation can be hypotonic for the epithelium to which it is being delivered.
- hypotonic formulations can be found in, e.g., Inti. Pub. No. WO2013110028, herein incorporated by reference in its entirety.
- the polynucleotide described herein is formulated as a lipoplex, such as, without limitation, the ATUPLEXTM system, the DACC system, the DBTC system and other siRNA-lipoplex technology from Silence Therapeutics (London, United Kingdom), STEMFECTTM from STEMGENT® (Cambridge, MA), and polyethylenimine (PEI) or protamine-based targeted and non-targeted delivery of nucleic acids (Aleku et al. Cancer Res. 2008 68:9788-9798; Strumberg et al.
- a lipoplex such as, without limitation, the ATUPLEXTM system, the DACC system, the DBTC system and other siRNA-lipoplex technology from Silence Therapeutics (London, United Kingdom), STEMFECTTM from STEMGENT® (Cambridge, MA), and polyethylenimine (PEI) or protamine-based targeted and non-targeted delivery of nucleic acids (Aleku et al. Cancer Res. 2008 68:
- the polynucleotides described herein are formulated as a solid lipid nanoparticle (SLN), which can be spherical with an average diameter between 10 to 1000 nm.
- SLN possess a solid lipid core matrix that can solubilize lipophilic molecules and can be stabilized with surfactants and/or emulsifiers.
- Exemplary SLN can be those as described in Inti. Pub. No. W02013105101, herein incorporated by reference in its entirety.
- the polynucleotides described herein can be formulated for controlled release and/or targeted delivery.
- controlled release refers to a pharmaceutical composition or compound release profde that conforms to a particular pattern of release to effect a therapeutic outcome.
- the polynucleotides can be encapsulated into a delivery agent described herein and/or known in the art for controlled release and/or targeted delivery.
- encapsulate means to enclose, surround or encase. As it relates to the formulation of the compounds of the invention, encapsulation can be substantial, complete or partial.
- substantially encapsulated means that at least greater than 50, 60, 70, 80, 85, 90, 95, 96, 97, 98, 99, or greater than 99% of the pharmaceutical composition or compound of the invention can be enclosed, surrounded or encased within the delivery agent.
- Partially encapsulation means that less than 10, 10, 20, 30, 40 50 or less of the pharmaceutical composition or compound of the invention can be enclosed, surrounded or encased within the delivery agent.
- encapsulation can be determined by measuring the escape or the activity of the pharmaceutical composition or compound of the invention using fluorescence and/or electron micrograph. For example, at least 1, 5, 10, 20, 30, 40, 50, 60, 70, 80, 85, 90, 95, 96, 97, 98, 99, 99.9, or greater than 99% of the pharmaceutical composition or compound of the invention are encapsulated in the delivery agent.
- the polynucleotides described herein can be encapsulated in a therapeutic nanoparticle, referred to herein as "therapeutic nanoparticle polynucleotides.”
- Therapeutic nanoparticles can be formulated by methods described in, e.g., Inti. Pub. Nos. W02010005740, W02010030763, W02010005721, W02010005723, and WO2012054923; and U.S. Pub. Nos.
- the therapeutic nanoparticle polynucleotide can be formulated for sustained release.
- sustained release refers to a pharmaceutical composition or compound that conforms to a release rate over a specific period of time. The period of time can include, but is not limited to, hours, days, weeks, months and years.
- the sustained release nanoparticle of the polynucleotides described herein can be formulated as disclosed in Inti. Pub. No. W02010075072 and U.S. Pub. Nos. US20100216804, US20110217377, US20120201859 and US20130150295, each of which is herein incorporated by reference in their entirety.
- the therapeutic nanoparticle polynucleotide can be formulated to be target specific, such as those described in Inti. Pub. Nos. WO2008121949, W02010005726, W02010005725, WO2011084521 and WO2011084518; and U.S. Pub. Nos. US20100069426, US20120004293 and US20100104655, each of which is herein incorporated by reference in its entirety.
- the LNPs can be prepared using microfluidic mixers or micromixers.
- Exemplary microfluidic mixers can include, but are not limited to, a slit interdigital micromixer including, but not limited to those manufactured by Microinnova (Allerheiligen bei Wildon, Austria) and/or a staggered herringbone micromixer (SHM) (see Zhigaltsevet al., "Bottom-up design and synthesis of limit size lipid nanoparticle systems with aqueous and triglyceride cores using millisecond microfluidic mixing," Langmuir 28:3633-40 (2012); Belliveau et al., “Microfluidic synthesis of highly potent limit-size lipid nanoparticles for in vivo delivery of siRNA," Molecular Therapy-Nucleic Acids. I :e37 (2012); Chen et al., “Rapid discovery of potent siRNA-containing lipid nanoparticles enabled by controlled microfluidic formulation," J. Am. Chem. Soc.
- micromixers include Slit Interdigital Microstructured Mixer (SIMM-V2) or a Standard Slit Interdigital Micro Mixer (SSIMM) or Caterpillar (CPMM) or Impinging-j et (IJMM,) from the Institut fur Mikrotechnik Mainz GmbH, Mainz Germany.
- methods of making LNP using SHM further comprise mixing at least two input streams wherein mixing occurs by microstructure-induced chaotic advection (MICA).
- MICA microstructure-induced chaotic advection
- This method can also comprise a surface for fluid mixing wherein the surface changes orientations during fluid cycling.
- Methods of generating LNPs using SHM include those disclosed in U.S. Pub. Nos. US20040262223 and US20120276209, each of which is incorporated herein by reference in their entirety.
- the polynucleotides described herein can be formulated in lipid nanoparticles using microfluidic technology (see Whitesides, George M., “The Origins and the Future of Microfluidics,” Nature 442: 368-373 (2006); and Abraham et al., "Chaotic Mixer for Microchannels,” Science 295: 647-651 (2002); each of which is herein incorporated by reference in its entirety).
- the polynucleotides can be formulated in lipid nanoparticles using a micromixer chip such as, but not limited to, those from Harvard Apparatus (Holliston, MA) or Dolomite Microfluidics (Royston, UK).
- a micromixer chip can be used for rapid mixing of two or more fluid streams with a split and recombine mechanism.
- the polynucleotides described herein can be formulated in lipid nanoparticles having a diameter from about 1 nm to about 100 nm such as, but not limited to, about 1 nm to about 20 nm, from about 1 nm to about 30 nm, from about 1 nm to about 40 nm, from about 1 nm to about 50 nm, from about 1 nm to about 60 nm, from about 1 nm to about 70 nm, from about 1 nm to about 80 nm, from about 1 nm to about 90 nm, from about 5 nm to about from 100 nm, from about 5 nm to about 10 nm, about 5 nm to about 20 nm, from about 5 nm to about 30 nm, from about 5 nm to about 40 nm, from about 5 nm to about 50 nm, from about 5 nm to about 60 nm, from about 5 nm
- the lipid nanoparticles can have a diameter from about 10 to 500 nm. In one embodiment, the lipid nanoparticle can have a diameter greater than 100 nm, greater than 150 nm, greater than 200 nm, greater than 250 nm, greater than 300 nm, greater than 350 nm, greater than 400 nm, greater than 450 nm, greater than 500 nm, greater than 550 nm, greater than 600 nm, greater than 650 nm, greater than 700 nm, greater than 750 nm, greater than 800 nm, greater than 850 nm, greater than 900 nm, greater than 950 nm or greater than 1000 nm.
- the polynucleotides can be delivered using smaller LNPs.
- Such particles can comprise a diameter from below 0.1 pm up to 100 nm such as, but not limited to, less than 0.1 pm, less than 1.0 pm, less than 5pm, less than 10 pm, less than 15 um, less than 20 um, less than 25 um, less than 30 um, less than 35 um, less than 40 um, less than 50 um, less than 55 um, less than 60 um, less than 65 um, less than 70 um, less than 75 um, less than 80 um, less than 85 um, less than 90 um, less than 95 um, less than 100 um, less than 125 um, less than 150 um, less than 175 um, less than 200 um, less than 225 um, less than 250 um, less than 275 um, less than 300 um, less than 325 um, less than 350 um, less than 375 um, less than 400 um, less than 425 um, less than 450 um, less than 475 um, less than 500 um, less than 525 um, less
- the nanoparticles and microparticles described herein can be geometrically engineered to modulate macrophage and/or the immune response.
- the geometrically engineered particles can have varied shapes, sizes and/or surface charges to incorporate the polynucleotides described herein for targeted delivery such as, but not limited to, pulmonary delivery (see, e.g., Inti. Pub. No. W02013082111, herein incorporated by reference in its entirety).
- Other physical features the geometrically engineering particles can include, but are not limited to, fenestrations, angled arms, asymmetry and surface roughness, charge that can alter the interactions with cells and tissues.
- the nanoparticles described herein are stealth nanoparticles or target-specific stealth nanoparticles such as, but not limited to, those described in U.S. Pub. No. US20130172406, herein incorporated by reference in its entirety.
- the stealth or target-specific stealth nanoparticles can comprise a polymeric matrix, which can comprise two or more polymers such as, but not limited to, polyethylenes, polycarbonates, polyanhydrides, polyhydroxyacids, polypropylfumerates, polycaprolactones, polyamides, polyacetals, polyethers, polyesters, poly(orthoesters), polycyanoacrylates, polyvinyl alcohols, polyurethanes, polyphosphazenes, polyacrylates, polymethacrylates, polycyanoacrylates, polyureas, polystyrenes, polyamines, polyesters, polyanhydrides, polyethers, polyurethanes, polymethacrylates, polyacrylates, polycyanoacrylates, or combinations thereof.
- polymers such as, but not limited to, polyethylenes, polycarbonates, polyanhydrides, polyhydroxyacids, polypropylfumerates, polycaprolactones, polyamides, polyacetals, polyethers, polyester
- compositions or formulations of the present disclosure comprise a delivery agent, e.g., a lipidoid.
- a delivery agent e.g., a lipidoid.
- the polynucleotides described herein e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein can be formulated with lipidoids. Complexes, micelles, liposomes or particles can be prepared containing these lipidoids and therefore to achieve an effective delivery of the polynucleotide, as judged by the production of an encoded protein, following the injection of a lipidoid formulation via localized and/or systemic routes of administration. Lipidoid complexes of polynucleotides can be administered by various means including, but not limited to, intravenous, intramuscular, or subcutaneous routes.
- Formulations with the different lipidoids including, but not limited to penta[3-(l-laurylaminopropionyl)]-tri ethylenetetramine hydrochloride (TETA-5LAP; also known as 98N12-5, see Murugaiah et al., Analytical Biochemistry, 401 :61 (2010)), Cl 2-200 (including derivatives and variants), and MD1, can be tested for in vivo activity.
- the lipidoid "98N12-5" is disclosed by Akinc et al., Mol Ther. 2009 17:872-879.
- the lipidoid "C12-200” is disclosed by Love et al., Proc Natl Acad Sci U S A. 2010 107: 1864-1869 and Liu and Huang, Molecular Therapy. 2010 669-670.
- Each of the references is herein incorporated by reference in its entirety.
- the polynucleotides described herein can be formulated in an aminoalcohol lipidoid.
- Aminoalcohol lipidoids can be prepared by the methods described in U.S. Patent No. 8,450,298 (herein incorporated by reference in its entirety).
- the lipidoid formulations can include particles comprising either 3 or 4 or more components in addition to polynucleotides.
- Lipidoids and polynucleotide formulations comprising lipidoids are described in Inti. Pub. No. WO 2015051214 (herein incorporated by reference in its entirety.
- the polynucleotides described herein e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein and hyaluronidase for injection (e.g., intramuscular or subcutaneous injection).
- Hyaluronidase catalyzes the hydrolysis of hyaluronan, which is a constituent of the interstitial barrier.
- Hyaluronidase lowers the viscosity of hyaluronan, thereby increases tissue permeability (Frost, Expert Opin. Drug Deliv. (2007) 4:427-440).
- the hyaluronidase can be used to increase the number of cells exposed to the polynucleotides administered intramuscularly, or subcutaneously.
- the polynucleotides described herein e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein is encapsulated within and/or absorbed to a nanoparticle mimic.
- a nanoparticle mimic can mimic the delivery function organisms or particles such as, but not limited to, pathogens, viruses, bacteria, fungus, parasites, prions and cells.
- the polynucleotides described herein can be encapsulated in a non-viron particle that can mimic the delivery function of a virus (see e.g., Inti. Pub. No. W02012006376 and U.S. Pub. Nos. US20130171241 and US20130195968, each of which is herein incorporated by reference in its entirety).
- compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein in self-assembled nanoparticles, or amphiphilic macromolecules (AMs) for delivery.
- AMs comprise biocompatible amphiphilic polymers that have an alkylated sugar backbone covalently linked to polyethylene glycol).
- the AMs self-assemble to form micelles.
- Nucleic acid self-assembled nanoparticles are described in Inti. Appl. No. PCT/US2014/027077, and AMs and methods of forming AMs are described in U.S. Pub. No. US20130217753, each of which is herein incorporated by reference in its entirety.
- compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein and a cation or anion, such as Z n2+ , Ca 2+ , Cu 2+ , Mg 2+ and combinations thereof.
- exemplary formulations can include polymers and a polynucleotide complexed with a metal cation as described in, e.g., U.S. Pat. Nos. 6,265,389 and 6,555,525, each of which is herein incorporated by reference in its entirety.
- cationic nanoparticles can contain a combination of divalent and monovalent cations.
- the delivery of polynucleotides in cationic nanoparticles or in one or more depot comprising cationic nanoparticles can improve polynucleotide bioavailability by acting as a long-acting depot and/or reducing the rate of degradation by nucleases.
- compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein that is formulation with an amino acid lipid.
- Amino acid lipids are lipophilic compounds comprising an amino acid residue and one or more lipophilic tails.
- Non-limiting examples of amino acid lipids and methods of making amino acid lipids are described in U.S. Pat. No. 8,501,824.
- the amino acid lipid formulations can deliver a polynucleotide in releasable form that comprises an amino acid lipid that binds and releases the polynucleotides.
- the release of the polynucleotides described herein can be provided by an acid-labile linker as described in, e.g., U.S. Pat. Nos. 7,098,032, 6,897,196, 6,426,086, 7,138,382, 5,563,250, and 5,505,931, each of which is herein incorporated by reference in its entirety.
- compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein in an interpolyelectrolyte complex.
- Interpolyelectrolyte complexes are formed when charge-dynamic polymers are complexed with one or more anionic molecules.
- Non-limiting examples of chargedynamic polymers and interpolyelectrolyte complexes and methods of making interpolyelectrolyte complexes are described in U.S. Pat. No. 8,524,368, herein incorporated by reference in its entirety. Crystalline Polymeric Systems
- compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein in crystalline polymeric systems.
- Crystalline polymeric systems are polymers with crystalline moieties and/or terminal units comprising crystalline moieties. Exemplary polymers are described in U.S. Pat. No. 8,524,259 (herein incorporated by reference in its entirety).
- compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein and a natural and/or synthetic polymer.
- the polymers include, but not limited to, polyethenes, polyethylene glycol (PEG), poly(l-lysine)(PLL), PEG grafted to PLL, cationic lipopolymer, biodegradable cationic lipopolymer, polyethyleneimine (PEI), cross-linked branched poly(alkylene imines), a polyamine derivative, a modified poloxamer, elastic biodegradable polymer, biodegradable copolymer, biodegradable polyester copolymer, biodegradable polyester copolymer, multiblock copolymers, poly[a-(4-aminobutyl)-L- glycolic acid) (PAGA), biodegradable cross-linked cationic multi-block copolymers, polycarbonates, polyanhydrides, polyhydroxyacids, polypropylfumerates, polycaprolactones, polyamides, polyacetals, polyethers, polyesters, poly(orthoesters), polycyanoacrylates, polyvinyl
- Exemplary polymers include, DYNAMIC POLYCONIUGATE® (Arrowhead Research Corp., Pasadena, CA) formulations from MIRUS® Bio (Madison, WI) and Roche Madison (Madison, WI), PHASERXTM polymer formulations such as, without limitation, SMARTT POLYMER TECHNOLOGYTM (PHASERX®, Seattle, WA), DMRI/DOPE, poloxamer, VAXFECTIN® adjuvant from Vical (San Diego, CA), chitosan, cyclodextrin from Calando Pharmaceuticals (Pasadena, CA), dendrimers and poly(lactic-co-glycolic acid) (PLGA) polymers.
- RONDELTM RNAi/Oligonucleotide Nanoparticle Delivery
- PHASERX® Seattle, WA
- the polymer formulations allow a sustained or delayed release of the polynucleotide (e.g., following intramuscular or subcutaneous injection).
- the altered release profile for the polynucleotide can result in, for example, translation of an encoded protein over an extended period of time.
- the polymer formulation can also be used to increase the stability of the polynucleotide.
- Sustained release formulations can include, but are not limited to, PLGA microspheres, ethylene vinyl acetate (EV Ac), poloxamer, GELSITE® (Nanotherapeutics, Inc. Alachua, FL), HYLENEX® (Halozyme Therapeutics, San Diego CA), surgical sealants such as fibrinogen polymers (Ethicon Inc. Cornelia, GA), TISSELL® (Baxter International, Inc. Deerfield, IL), PEG-based sealants, and COSEAL® (Baxter International, Inc. Deerfield, IL).
- modified mRNA can be formulated in PLGA microspheres by preparing the PLGA microspheres with tunable release rates (e.g., days and weeks) and encapsulating the modified mRNA in the PLGA microspheres while maintaining the integrity of the modified mRNA during the encapsulation process.
- EVAc are non-biodegradable, biocompatible polymers that are used extensively in pre-clinical sustained release implant applications (e.g., extended release products Ocusert a pilocarpine ophthalmic insert for glaucoma or progestasert a sustained release progesterone intrauterine device; transdermal delivery systems Testoderm, Duragesic and Selegiline; catheters).
- Poloxamer F-407 NF is a hydrophilic, non-ionic surfactant triblock copolymer of polyoxyethylene-polyoxypropylene-polyoxyethylene having a low viscosity at temperatures less than 5°C and forms a solid gel at temperatures greater than 15°C.
- the polynucleotides described herein can be formulated with the polymeric compound of PEG grafted with PLL as described in U.S. Pat. No. 6,177,274.
- the polynucleotides described herein can be formulated with a block copolymer such as a PLGA-PEG block copolymer (see e.g., U.S. Pub. No. US20120004293 and U.S. Pat. Nos. 8,236,330 and 8,246,968), or a PLGA-PEG-PLGA block copolymer (see e.g., U.S. Pat. No. 6,004,573).
- a block copolymer such as a PLGA-PEG block copolymer (see e.g., U.S. Pub. No. US20120004293 and U.S. Pat. Nos. 8,236,330 and 8,246,968), or a PLGA-PEG-PLGA block copolymer (see e.g
- the polynucleotides described herein can be formulated with at least one amine-containing polymer such as, but not limited to polylysine, polyethylene imine, poly(amidoamine) dendrimers, poly(amine-co-esters) or combinations thereof.
- amine-containing polymer such as, but not limited to polylysine, polyethylene imine, poly(amidoamine) dendrimers, poly(amine-co-esters) or combinations thereof.
- Exemplary polyamine polymers and their use as delivery agents are described in, e g., U.S. Pat. Nos. 8,460,696, 8,236,280, each of which is herein incorporated by reference in its entirety.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- Medicinal Chemistry (AREA)
- Veterinary Medicine (AREA)
- Microbiology (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Urology & Nephrology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
This disclosure relates to immunoglobulin A protease (IgAP) polypeptides and polynucleotides (e.g., mRNA) encoding the same for use in treating IgA nephropathy. The disclosure also relates to delivery agents (e.g., lipid nanoparticles) and compositions comprising the IgAP polypeptides and IgAP polynucleotides (e.g., mRNAs) of the disclosure.
Description
IMMUNOGLOBULIN A PROTEASE POLYPEPTIDES, POLYNUCLEOTIDES, AND USES THEREOF
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application claims the priority benefit of U.S. Provisional Application No. 63/540,710, filed September 27, 2023, the content of which is incorporated by reference in its entirety herein.
SEQUENCE LISTING
[0002] The instant application contains a Sequence Listing which has been submitted electronically in XML file format and is hereby incorporated by reference in its entirety. Said XML copy, created on September 26, 2024, is named 45817- 0143WOl_SL.xml and is 504,677 bytes in size.
BACKGROUND
[0003] Immunoglobulin Al nephropathy (IgAN), also known as Berger disease, is a kidney disease in which IgA builds up in the kidneys, causing inflammation and damage to kidney filtration in the glomerulus. Signs and symptoms of IgAN can include foamy or cola-or tea-colored urine, blood in the urine, pain on one or both sides of the rubs, edema, high blood pressure, weakness, fatigue, and kidney failure. There is no cure for IgAN. Standard of care includes blood pressure drugs, immunosuppressants, omega-3 fatty acids, cholesterol medication, and diuretics. Treatment may also include dialysis or a kidney transplant. There remains an unmet need for improved treatment for IgAN.
[0004] Immunoglobulin Al proteases (IgAPs) are a group of secreted bacterial endopeptidases that cleave human immunoglobulin Al (IgAl) in the hinge region sequence. As demonstrated in animal models, the administration of IgAP can degrade IgAl -containing immune complex deposited in glomeruli and can ameliorate impaired renal function, e.g., proteinuria and hematuria.
SUMMARY
[0005] The present disclosure provides immunoglobulin A protease (IgAP) polypeptides and polynucleotides (e.g., mRNA) for the treatment of IgA nephropathy (IgAN). The present disclosure also provides deimmunized IgAP polypeptides and polynucleotides (e.g., mRNA) for the treatment of IgAN. The mRNA therapeutics of the invention are well-suited for the treatment of IgAN as the technology provides for the intracellular delivery of mRNA encoding an immunoglobulin A protease (IgAP) protein followed by de novo synthesis of functional IgAP protein within target cells.
[0006] In certain aspects, the disclosure provides a polypeptide comprising an immunoglobulin A protease (IgAP) protease domain and an amino acid sequence that is at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100% identical to positions 815-995 of SEQ ID NO:2, wherein the polypeptide does not comprise an IgAP autotransporter domain, and wherein the polypeptide cleaves a human IgAl. In some instances, the polypeptide does not comprise an IgAP autocleavage site. In some instances, the polypeptide does not comprise amino acids corresponding to positions 996-1,688 of SEQ ID NO:2. In some instances, the polypeptide does not comprise amino acids corresponding to positions 996-1688 of SEQ ID NO:2. In some instances, the polypeptide optionally includes a signal peptide, and wherein the polypeptide is 950 to 1,050 amino acids in length not inclusive of the signal peptide, if present in the polypeptide. In some instances, the polypeptide optionally includes a signal peptide, and wherein the polypeptide is 995 amino acids in length not inclusive of the signal peptide, if present in the polypeptide. In some instances, the polypeptide comprises an amino acid sequence that is at least 95%, at least 97%, at least 98%, or at least 99% identical to the amino acid sequence of any one of SEQ ID NOs:4-6.
[0007] In some instances, the polypeptide comprises a substitution at one or more amino acids corresponding to any one of W430, Y523, F690, R77, Y86, Y127, Y128, A178, Y242, Y328, A333, T350, L463, V482, 1483, L484, F497, V509, V510, T566, 1577, Y612, N699, V742, N879, L913, F934, K935, L936, Y912, and Y979 of SEQ ID NO:6. In some instances, the polypeptide comprises one or more substitutions
corresponding to any one of W430A, Y523A, F690A, R77A, Y86A, Y127A, Y128A, A178K, Y242A, Y328A, A333G, T350G, L463A, V482A, I483A, L484A, F497A, V509A, V510A, T566G, I577A, Y612A, N699A, V742L, N879A, L913A, F934A, K935A, L936A, Y912A, and Y979A of SEQ ID NO:6.
[0008] In some instances, the polypeptide comprises: (a) substitutions at the amino acids corresponding to W430, Y523, and F690 of SEQ ID NO:6; (b) substitutions at the amino acids corresponding to Y86, L463, and 1577 of SEQ ID NO:6; (c) substitutions at the amino acids corresponding to Y328, Y523, and F690 of SEQ ID NO:6; (d) substitutions at the amino acids corresponding to Y127 and Y128 of SEQ ID NO:6; (e) substitutions at the amino acids corresponding to V509 and V510 of SEQ ID NO:6; (f) substitutions at the amino acids corresponding to Y912 and L913 of SEQ ID NO:6; (g) substitution at the amino acid corresponding to R77 of SEQ ID NO:6; (h) substitution at the amino acid corresponding to Y86 of SEQ ID NO:6; (i) substitution at the amino acid corresponding to Y242 of SEQ ID NO:6; (j) substitution at the amino acid corresponding to W430 of SEQ ID NO:6; (k) substitution at the amino acid corresponding to T566 of SEQ ID NO:6; (1) substitution at the amino acid corresponding to F497 of SEQ ID NO:6; (m) substitution at the amino acid corresponding to Y612 of SEQ ID NO: 6; (n) substitutions at the amino acids corresponding to A178, A333, and V742 of SEQ ID NO:6; (o) substitutions at the amino acids corresponding to T350, N699, and N879 of SEQ ID NO:6; (p) substitution at the amino acid corresponding to V482 of SEQ ID NO:6; (q) substitutions at the amino acids corresponding to Y127, Y128, W430, Y523, and F690 of SEQ ID NO:6; or (r) substitutions at the amino acids corresponding to Y127, Y128, W430, Y523, F690, V509, and V510 of SEQ ID NO:6.
[0009] In some instances, the polypeptide comprises: (a) substitutions corresponding to W430A, Y523A, and F690A of SEQ ID NO:6; (b) substitutions corresponding to Y86A, L463A, and I577A of SEQ ID NO:6; (c) substitutions corresponding to Y328A, Y523A, and F690A of SEQ ID NO:6; (d) substitutions corresponding to Y127A and Y128A of SEQ ID NO:6; (e) substitutions corresponding to V509A and V510A of SEQ ID NO:6; (f) substitutions corresponding to Y912A and L913A of SEQ ID NO:6; (g) a
substitution corresponding to R77A of SEQ ID NO:6; (h) a substitution corresponding to Y86A of SEQ ID NO:6; (i) a substitution corresponding to Y242A of SEQ ID NO:6; (j) a substitution corresponding to W430A of SEQ ID NO:6; (k) a substitution corresponding to T566G of SEQ ID NO:6; (1) a substitution corresponding to F497A of SEQ ID NO:6; (m) a substitution corresponding to Y612A of SEQ ID NO:6; (n) substitutions corresponding to A178K, A333G, and V742L of SEQ ID NO:6; (o) substitutions corresponding to T350G, N699A, and N879A of SEQ ID NO:6; (p) a substitution corresponding to V482A of SEQ ID NO:6; (q) substitutions corresponding to Y127A, Y128A, W430A, Y523A, and F690A of SEQ ID NO:6; or (r) substitutions corresponding to Y127A, Y128A, W430A, Y523A, F690A, V509A, and V510A of SEQ ID NO:6. [0010] In some instances, the polypeptide comprises an amino acid sequence that is at least 95%, at least 97%, at least 98%, or at least 99% identical to the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49. In some instances, the polypeptide comprises the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49. In some instances, the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49 and optionally a signal peptide. In some instances, the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs:351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350.
[0011] In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:80. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO: 80 and optionally a signal peptide. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:351.
[0012] In some instances, the polypeptide comprises the amino acid sequence of any one of SEQ ID NOs: 4-6. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:4 and optionally a signal peptide. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:5 or SEQ ID NO:6.
[0013] In certain aspects, the disclosure provides a polypeptide comprising an amino acid sequence that is at least 90%, at least 95%, or 100% identical to the amino acid sequence of SEQ ID NO:4, wherein the polypeptide optionally includes a signal peptide, wherein the polypeptide is 950 to 1,050 amino acids in length not inclusive of the signal peptide, if present in the polypeptide, and wherein the polypeptide cleaves a human IgAl . In some instances, the C-terminus of the polypeptide corresponds to position 995 of SEQ ID NO:4. In some isntances, the polypeptide is 995 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
[0014] In certain aspects, the disclosure provides a polypeptide comprising an amino acid sequence that is at least 90%, at least 95%, or 100% identical to the amino acid sequence of SEQ ID NO: 80, wherein the polypeptide optionally includes a signal peptide, wherein the polypeptide is 950 to 1,050 amino acids in length not inclusive of the signal peptide, if present in the polypeptide, and wherein the polypeptide cleaves a human IgAl . In some instances, the C-terminus of the polypeptide corresponds to position 995 of SEQ ID NO:80. In some isntances, the polypeptide is 995 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
[0015] In certain aspects, the disclosure provides an mRNA comprising an open reading frame (ORF) encoding any one of the foregoing polypeptides.
[0016] In some instances, the ORF is at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical to the nucleic acid sequence set forth in SEQ ID NO:27 or SEQ ID NO:28. In some instances, the ORF comprises the nucleic acid sequence set forth in SEQ ID NO:27 or SEQ ID NO:28. In some instnaces, the mRNA further comprises a 5' untranslated region (UTR) comprising the nucleic acid sequence of SEQ ID NO:56 or SEQ ID NO:58. In some instances, the mRNA further comprises a 3' UTR comprising the nucleic acid sequence of SEQ ID NO: 114 or SEQ ID NO: 139. In some instances, the mRNA comprises the nucleic acid sequence of any one of SEQ ID NOs: 29-32.
[0017] In some instances, the ORF is at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical to the nucleic acid sequence set forth in any one of SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151. In some instances, the ORF comprises the nucleic acid sequence set forth in SEQ ID NO: 153 or SEQ ID NO: 154. In some instnaces, the mRNA further comprises a 5' untranslated region (UTR) comprising the nucleic acid sequence of SEQ ID NO:50, SEQ ID NO:56 or SEQ ID NO:58. In some instances, the mRNA further comprises a 3' UTR comprising the nucleic acid sequence of SEQ ID NO: 114, SEQ ID NO: 132, SEQ ID NO: 138, or SEQ ID NO: 139. In some instances, the mRNA comprises the nucleic acid sequence of any one of SEQ ID NOs: 301-319. In some instances, the mRNA comprises the nucleic acid sequence of SEQ ID NO:318 or SEQ ID NO:319.
[0018] In some instances, the mRNA comprises a 5' terminal cap. In some instances, the 5' terminal cap comprises a m7GpppG2 OMe, m7G-ppp-Gm-A, m7G-ppp-Gm-AG, CapO, Capl, ARC A, inosine, Nl-methyl-guanosine, 2 '-fluoro-guanosine, 7-deaza- guanosine, 8-oxo-guanosine, 2-amino-guanosine, LNA-guanosine, 2-azidoguanosine, Cap2, Cap4, 5' methylG cap, or an analog thereof.
[0019] In some instances, the mRNA comprises a poly-A region. In some instances, the poly-A region is at least about 10, at least about 20, at least about 30, at least about 40, at least about 50, at least about 60, at least about 70, at least about 80, at least about 90 nucleotides in length, or at least about 100 nucleotides in length. In some instances, the poly-A region is at least about 100 nucleotides in length.
[0020] In some instances, all of the uracils of the mRNA are Nl- methylpseudouracils. In some instances, all of the uracils in the mRNA are 5- methoxyuracils.
[0021] In certain aspects, the disclosure provides a pharmaceutical composition comprising any one of the foregoing polypeptides, and a pharmaceutically acceptable excipient.
[0022] In certain aspects, the disclosure provides a pharmaceutical composition comprising any one of the foregoing mRNAs, and a pharmaceutically acceptable excipient.
[0023] In certain aspects, the disclosure provides a lipid nanoparticle comprising any one of the foregoing mRNAs. In some instances, the lipid nanoparticle comprises an ionizable lipid, a structural lipid, a phospholipid, and a polyethylene glycol (PEG)- modified lipid. In some instances, the ionizable lipid is Compound II or a salt thereof. In some instances, the structural lipid is cholesterol. In some instances, the phospholipid is l,2-distearoyl-sn-glycero-3-phosphocholine (DSPC) or l,2-dioleoyl-sn-glycero-3- phosphoethanolamine (DOPE). In some instances, the PEG-modified lipid is PEG-DMG or Compound I.
[0024] In certain aspects, the disclosure provides a method of expressing a polypeptide in a human subject in need thereof, the method comprising administering to the human subject an effective amount of any one of the foregoing polypeptides, any one of the foregoing mRNAs, a any one of the foregoing pharmaceutical compositions, or any one of the foregoing lipid nanoparticles.
[0025] A method for treating IgA nephropathy in a human subject in need thereof, the method comprising administering to the human subject an effective amount of any one of the foregoing polypeptides, any one of the foregoing mRNAs, a any one of the foregoing pharmaceutical compositions, or any one of the foregoing lipid nanoparticles.
BRIEF DESCRIPTION OF THE DRAWINGS
[0026] FIG. 1 is a western blot depicting IgAlP, full length IgAl, cleaved IgAl, and beta-Actin protein levels for IgAl incubated with lysates or supernatants from cells transfected with mRNA encoding GFP or a truncated IgAP (SEQ ID NO:3).
[0027] FIG. 2A is a western blot depicting IgAlP protein levels in lysates or supernatants (“Supe”) from cells transfected with mRNA encoding GFP or truncated IgAP (SEQ ID NOs:7-13).
[0028] FIG. 2B is a western blot depicting full length IgAl, cleaved IgAl, and beta- Actin protein levels for IgAl incubated with lysates or supernatants (“Supe”) from cells transfected with mRNA encoding GFP or truncated IgAP as described in FIG. 2A.
[0029] FIG. 3 is a western blot depicting IgAP, uncleaved IgAl, and cleaved IgAl protein levels in plasma (top) or kidney (bottom) samples from mice treated with IgAPl (SEQ ID NO:7), IgAP2 (SEQ ID NO:8), or PBS.
[0030] FIG. 4A is a western blot depicting Fcα and Fabα fragments in sera harvested (at the indicated timepoints) from mice treated with the indicated constructs (0.25 mg/kg for mRNA). Left: 5 seconds exposure; right: 40 seconds exposures.
[0031] FIG. 4B is a western blot depicting Fcα and Fabα fragments in sera harvested (at the indicated timepoints) from mice treated with the indicated constructs (0.5 mg/kg for mRNA). Left: 5 seconds exposure; right: 40 seconds exposures.
[0032] FIG. 4C is a western blot depicting Fcα and Fabα fragments in sera harvested (at the indicated timepoints) from mice treated with the indicated constructs (1.0 mg/kg for mRNA). Left: 5 seconds exposure; right: 40 seconds exposures.
[0033] FIG. 5 is a western blot depicting Fabα fragment in urine harvested (at the indicated timepoints) from mice treated with the indicated constructs.
[0034] FIG. 6 is a graph depicting IgAl serum levels at the indicated timepoints after treatment with GFP mRNA or IgAP mRNA.
[0035] FIG. 7 is a graph depicting serum Gd-IgAl levels at the indicated timepoints after treatment with GFP mRNA or IgAP mRNA.
[0036] FIG. 8 is a graph depicting score (%) of IgAl immunohistochemistry positivity at the indicated timepoints for kidneys from mice treated with the indicated constructs, mpk = mg/kg.
[0037] FIG. 9 is a graph depicting Gd-IgAl levels in sera from mice treated with GFP mRNA (triangles), IgAP mRNA with miRNA binding sites in the UTR (squares), or IgAP mRNA without miRNA binding sites in the UTR (circles).
[0038] FIG. 10 is a graph depicting anti-IgAP Ig antibody levels in sera from mice treated with GFP mRNA (triangles), IgAP mRNA with miRNA binding sites in the UTR (squares), or IgAP mRNA without miRNA binding sites in the UTR (circles).
[0039] FIG. 11 is a graph depicting hematuria inhibition rate (%) in urine from mice treated with GFP mRNA (triangles), IgAP mRNA with miRNA binding sites in the UTR (squares), or IgAP mRNA without miRNA binding sites in the UTR (circles).
[0040] FIG. 12 is a graph depicting the score (percent) of IgAl deposits in kidney mesangium at the indicated timepoints after treatment with GFP mRNA (GFP), IgAP mRNA (mRNA), or recombinant IgAlP protein (IgAlP). For each timepoint, the bars are, from left to right: GFP, mRNA 1 mg/kg, mRNA 0.5 mg/kg, mRNA 0.25 mg/kg, and IgAlP 3 mg/kg, respectively.
[0041] FIG. 13 is a series of western blots depicting IgAP in sera harvested (at the indicated timepoints) from mice from Groups 1-5 (see Table 8).
[0042] FIG. 14 is a graph depicting anti-IgA protease (IgG) concentration in sera harvested (at the indicated timepoints) from mice from Groups 1-5 (see Table 8). For each timepoint, the bars are, from left to right: Group 1, Group 2, Group 3, Group 4, and Group 5, respectively.
[0043] FIG. 15 is a graph depicting the percent mean T-cell stimulation by donor for cells exposed to IgAP (SEQ ID NO:4 with a C-terminal tag of SEQ ID NO:324) or deimmunized IgAP (SEQ ID NO:80 with a C-terminal tag of SEQ ID NO:324).
[0044] FIG. 16A is a graph depicting DRB1 allele frequency distribution of the donor panel (right bars for each allele) compared to the global population (left bars for each allele).
[0045] FIG. 16B is a graph depicting DRB1 allele frequency distribution of the donor panel (right bars for each allele) compared to the global population (left bars for each allele).
[0046] FIG. 16C is a graph depicting DQB1 allele frequency distribution of the donor panel (right bars for each allele) compared to the global population (left bars for each allele).
[0047] FIG. 16D is a graph depicting DPB1 allele frequency distribution of the donor panel (right bars for each allele) compared to the global population (left bars for each allele).
[0048] FIG. 17 is a graph depicting serum human galactose deficient (GD) IgAl decreased levels at the indicated timepoints.
[0049] FIG. 18 is a western blot depicting Fcα and Fabα fragments in sera harvested (at the indicated timepoints) from mice treated with deimmunized IgAP mRNA. MWM=molecular weight marker; IgAlP 0 = sera from mouse before treatment; IgAlp 30: sera from mouse 30-hours after recombinant IgAlP treatment; GFP=sera from mouse treated with GFP-mRNA-LNP; 1 Wk-6Wk=sera from mouse 1, 2, 3, 4, 5, or 6 weeks, respectively, after treatment with deimmunized IgAP mRNA-LNP.
[0050] FIG. 19 is a western blot depicting Fabα fragments in urine harvested (at the indicated timepoints) from mice treated with deimmunized IgAP mRNA.
MWM=molecular weight marker; IgAlP 0 = urine from mouse before treatment; IgAlP 30: urine from mouse 30-hours after recombinant IgAlP treatment; GFP= urine from mouse treated with GFP-mRNA-LNP; -24=urine from mouse 24 hours prior to treatment with deimmunized IgAP mRNA-LNP; 3WK, 6WK=urine from mouse 3 or 6 weeks, respectively, after treatment with deimmunized IgAP mRNA-LNP.
[0051] FIG. 20 is a graph depicting IgAl deposits positivity rate (percent) for mice after 6 weeks of treatment with GFP mRNA (left) or deimmunized IgAP mRNA (right). [0052] FIG. 21 is a graph depicting serum IgAlP in representative mice from each treatment group. Arrow points to detected IgAlP. -=sample buffer; GFP=sera from mouse grated with GFP-mRNA LNP; -24=sera from mouse before injection; 1 WK- 6WK=sera from mouse 1, 2, 3, 4, 5, or 6 weeks, respectively, after treatment with deimmunized IgAP mRNA-LNP; IgAlP +=more concentrated IgAlP; IgAlp-=less concentrated IgAlP.
[0053] FIG. 22 is a series of graphs depicting IgG anti-IgAlP levels (top) or IgG anti-Ovalbumin levels (bottom) after 6 weeks of treatment with the indicated constructs.
From left to right for each graph: mRNA-LNP-GFP; mRNA-LNP GFP + ovalbumin; mRNA-LNP-IgAlP; and mRNA-LNP-IgAlP + ovalbumin.
DETAILED DESCRIPTION
Immunoglobulin A Protease
[0054] Immunoglobulin A proteases (IgAPs) are a group of secreted bacterial endopeptidases that cleave human immunoglobulin Al (IgAl) in the hinge region sequence. IgAPs contain a signal sequence (e.g., amino acids 1-26 of SEQ ID NO: 1), a protease domain (e g., amino acids 26-878 of SEQ ID NO:1), an autocleavage site (e g., amino acids 1,022-1,034 of SEQ ID NO: 1), and an autotransporter beta domain (e.g., amino acids 1,469-1,649 of SEQ ID NO: 1). The IgAP autotransporter beta domain directs secretion of the IgAP out of the bacterial cell. The IgAP protease domain contains an IgA protease enzymatic active motif (e g., amino acids 297-304 of SEQ ID NO: 1).
The working examples demonstrate that IgAP also contains a sequence (e.g., amino acids 879-1021 of SEQ ID NOT) that is required for cleavage activity after secretion from a mammalian cell.
[0055] As demonstrated in animal models, administration of IgAP degrades IgAl- containing immune complex deposited in glomeruli and ameliorates impaired renal function, e.g., proteinuria and hematuria.
[0056] An exemplary Haemophilus influenzae IgAP protein sequence is described at the RefSeq database under accession number OBX53260.1 ("peptidase [Haemophilus influenzae]"), SEQ ID NOT below.
1 mlknkkfkln fialtvayal apyteaalvr ddvdyqifrd faenkgkfsv gatnvevrdk
61 knnnlgsvlp kdipmidfsv vdvdkriatl inpqywgvk hvsngvnelh f gnlngnmnn
121 gnakahrdvs seenryytve kndfpkenak sfttkeeqda qkrredyymp rldkfvteva
181 pieastassd agtyndqnky pafvrlgsgt qfiyekgayy klilsqkdnk gnllknwdig
241 gnnlklvgna ytygiagtpy kvnhenngli gfgns keehs dpkgilsqdp Itnyavlgds
301 gsplfvydre kgkwlflgsy dfwagynkks wqewniykpe faktvldkdt agsltgsktq
361 ytwkatgnts visngsesln vdlfdssqdt dskknnhgks vtlrgsgtlt Insninqgag
421 glffegdyev kgtsdsttwk gagvsvadgk tvtwkvhnpq sdrlakigkg tlivegkgen
481 kgllkvgdgt vilkqqadan nkvkafsqvg ivsgrstwl nddkqvdpns iyf gf rggrl
541 dlngnslkfd hirnidegar Ivnhntskss tvtitgdnli tdpnqinqiy tieaqdedyp
601 Irirsipygk qlyfnqdnyt yytlrkgast rselpknsge snenwlymgk tsdeakrnvm
661 nhinnermng fngyfgeeeg kdngnlnvtf kgkseqnrfl Itggtnlngd Itvekgtlf 1
721 sgrptphard iagisstnkd phfaennew veddwinrnf katninvtnn atlysgrnve
781 sitsnitasn kaqvhigykt gdtvcvrsdy tgyvtcttdk Isdkalnsfn atnvf gnvnl
841 sdnanftlgk anlfgtiqsk gnsqvrlten shwhltgnsd vhrldltngh ihlnaqndan
901 kvttyntlni snlsgngsfy yltdlsnkqg dkvwknsas gdfklnvksk tgepnhnelt
961 Ifdasnatrn nlnvslvgnt vdlgawkytl ketngrydly npevekrnqt vdttnittpn
1021 niqadvpsvq snneetarve apvpppapat psettktvae nskqesktia kneqdatetr
1081 sqndevakea kpsveanpqt nevaqsgskt eetqttetke takvetektq eapqvasqas
1141 pkqaepapek vstdtkveet qvqaqlqtqp ttvtaaeats pnskpaeetq psektnaepv
1201 tpvvsanqae nttdqpteke ktqeapkvts qvspkqeqse tvqpqavles envptvnnae
1261 evqaqlqtqp satvsteqpa ketssnveqp vtesttvntr nsavgnpekt tqpavnsess
1321 esksrrkrsi sqpqetstne ttvadnsess nkpksrrkrs vsqpqetsae ettvtstekt
1381 tvadnsksnk tntrrrsrrs vrsvphdvgq atsgndrsam plsnltstnt navisdamak
1441 aqfvalnvgk avsqhisqle mnnegqynvw vsntsmnkny sseqyrrfss kstqtqlgwd
1501 qtisnnvqlg gvftyvrnsn nfdkass knt laqvnfys ky yadnhwylgi dlgygkf qsn
1561 Iqtshnakfa rhtaqfglta gkafnlgnfg itpivgvrys ylsnadfald qarikvnpis
1621 vktafaqvdl sytyhlgefs vtpilsaryd anqgsgkinv nqydfaynve nqqqynaglk
1681 Ikyhnvklsl iggltkakqa ekqktaelkl sfsf (SEQ ID NO: 1)
This exemplary IgAP proprotein is 1,714 amino acids long and has a signal peptide at positions 1-26 of SEQ ID NO: 1. It is noted that the specific nucleic acid sequences encoding the reference protein sequence in the RefSeq sequences are coding sequence (CDS) as indicated in the respective RefSeq database entry.
[0057] In some embodiments, the polynucleotides disclosed herein comprise one or more sequences encoding an IgAP protein or variant thereof that is suitable for use in mRNA therapy (e.g., for treating IgAN). An IgAP for use in mammals may be truncated to remove the autotransporter beta domain (or a portion thereof), which is used for secretion of native IgAP from a bacterial cell. The IgAP proteins described herein (and the polynucleotide sequences encoding the same) are truncated IgAP proteins lacking an IgAP beta autotransporter domain (e.g., amino acids 1,469-1,649 of SEQ ID NO: 1), optionally lacking the amino acid sequence from the IgAP autocleavage site to the end of
the IgAP protein (e.g., amino acids 1022-1714 of SEQ ID NO: 1), while retaining the ability to cleave a human IgAl (e.g., after secretion of the IgAP from a mammalian cell, e.g., a HepG2 cell). The working examples surprisingly demonstrate that the region between the protease domain and the autocleavage site N-terminal to the IgAP autotransporter beta domain is required for protease activity after secretion from a mammalian cell (see Example 3). Thus, in some instances, the IgAP proteins described herein comprise an amino acid sequence that is at least 70%, at least 75%, at least 80%, at least 85%>, at least 90%, at least 95%, or 100%> identical to the amino acid sequence between the IgAP protease domain and the IgAP autocleavage site (e g., at least 70%, at least 75%o, at least 80%>, at least 85%>, at least 90%>, at least 95%o, or 100%o identical to amino acids 815-995 of SEQ ID NO:2 (i.e., amino acids 879-1021 of SEQ ID NO: 1)). In some instances, the IgAP protein comprises an amino acid sequence that is at least at least 90%o, at least 95%, or 100%) identical to the amino acid sequence of SEQ ID NO:4, and optionally a signal peptide, wherein the IgAP protein does not comprise an IgAP autotransporter beta domain (e.g., amino acids 1,469-1,649 of SEQ ID NO: 1), optionally wherein the IgAP protein does not comprise the amino acid sequence from the autocleavage site to the end of the IgAP protein (e.g., amino acids 1022-1714 of SEQ ID NO: 1). The signal peptide is present in the IgAP proprotein and is cleaved off during processing of the proprotein into the mature form. Thus, in some instances, the IgAP protein comprises a signal peptide (i.e., in its proprotein form), and in some instances the IgAP protein does not comprise a signal peptide (i.e., in its mature form). For instance, SEQ ID NOs: 5 and 6 are exemplary IgAP proteins each consisting of a signal peptide and the amino acids corresponding to positions 1-995 of SEQ ID NO:2. In some instances, the IgAP protein comprises an amino acid sequence that is at least at least 90%o , at least 95%>, or 100% identical to the amino acid sequence of SEQ ID NO: 5 or 6. In some instances, the IgAP protein does not comprise an IgAP autocleavage site (e.g., amino acids 1,022-1,034 of SEQ ID NO: 1). In some instances, the IgAP protein does not comprise an amino acid sequence that is at least 70%, at least 75%>, at least 80%, at least 85%o, at least 90%>, at least 95%o, or 100%) identical to amino acids 996-1,688 of SEQ ID
N0:2. In some instances, the IgAP protein comprises an IgAP protease domain (e.g., amino acids 26-878 of SEQ ID NO: 1) and an amino acid sequence that is at least is at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100% identical to the amino acid sequence between the IgAP protease domain and the IgAP autocleavage site (e.g., at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100% identical to amino acids 815-995 of SEQ ID NO:2), and optionally a signal peptide, wherein the IgAP protein does not comprise an IgAP autotransporter beta domain (e.g., amino acids 1469-1649 of SEQ ID NO: 1). In some instances, the IgAP protein is 950 to 1,050, 960 to 1,050, 970 to 1040, 980 to 1030, 990 to 1020, 995 to 1010, 995 to 1020, 995 to 1030, 995 to 1040, or 995 to 1050 amino acids in length (not inclusive of a signal peptide). In some instances, the IgAP protein comprises or consists of the amino acid sequence set forth in SEQ ID NO:4 (and optionally includes a signal peptide). In some instances, the IgAP protein comprises or consists of the amino acid sequence set forth in SEQ ID NO:5. In some instances, the IgAP protein comprises or consists of the amino acid sequence set forth in SEQ ID NO:6. In some instances, the IgAP protein is 995 amino acids in length (not inclusive of a signal peptide). In some instances, the C-terminus of the IgAP protein corresponds to position 995 of SEQ ID NO:4. In some instances, the IgAP protein cleaves human IgAl (e.g., after secretion from a mammalian cell, e.g., a HepG2 cell, e.g., as determined by an assay described in the working examples herein). In some embodiments, a polynucleotide disclosed herein comprises a sequence encoding the IgAP protein of SEQ ID NO:4 (and optionally a signal peptide). In some embodiments, a polynucleotide disclosed herein comprises a sequence encoding the IgAP protein of SEQ ID NO:5. In some embodiments, a polynucleotide disclosed herein comprises a sequence encoding the IgAP protein of SEQ ID NO:6. In certain aspects, the present application addresses the problem of IgAl accumulation in subjects suffering from IgAN by providing a polynucleotide, e.g., mRNA, that encodes IgAP or functional fragment thereof (e.g., SEQ ID NO:4), wherein the polynucleotide is sequence-optimized.
[0058] The working examples also identify sites in the IgAP proteins described herein that may be deimmunized. Thus, in some instances an IgAP polypeptide described herein comprises a substitution at one or more amino acids corresponding to any one of W430, Y523, F690, R77, Y86, Y127, Y128, A178, Y242, Y328, A333, T350, L463, V482, 1483, L484, F497, V509, V510, T566, 1577, Y612, N699, V742, N879, L913, F934, K935, L936, Y912, and Y979 of SEQ ID NO:6. In some instances, the polypeptide comprises one or more substitutions corresponding to any one of W430A, Y523A, F690A, R77A, Y86A, Y127A, Y128A, A178K, Y242A, Y328A, A333G, T350G, L463A, V482A, I483A, L484A, F497A, V509A, V510A, T566G, I577A, Y612A, N699A, V742L, N879A, L913A, F934A, K935A, L936A, Y912A, and Y979A of SEQ ID NO:6. In some instances, the polypeptide comprises: (a) substitutions at the amino acids corresponding to W430, Y523, and F690 of SEQ ID NO:6; (b) substitutions at the amino acids corresponding to Y86, L463, and 1577 of SEQ ID NO:6; (c) substitutions at the amino acids corresponding to Y328, Y523, and F690 of SEQ ID NO:6; (d) substitutions at the amino acids corresponding to Y127 and Y128 of SEQ ID NO:6; (e) substitutions at the amino acids corresponding to V509 and V510 of SEQ ID NO:6; (f) substitutions at the amino acids corresponding to Y912 and L913 of SEQ ID NO:6; (g) substitution at the amino acid corresponding to R77 of SEQ ID NO:6; (h) substitution at the amino acid corresponding to Y86 of SEQ ID NO:6; (i) substitution at the amino acid corresponding to Y242 of SEQ ID NO:6; (j) substitution at the amino acid corresponding to W430 of SEQ ID NO:6; (k) substitution at the amino acid corresponding to T566 of SEQ ID NO:6; (1) substitution at the amino acid corresponding to F497 of SEQ ID NO:6; (m) substitution at the amino acid corresponding to Y612 of SEQ ID NO:6; (n) substitutions at the amino acids corresponding to A178, A333, and V742 of SEQ ID NO:6; (o) substitutions at the amino acids corresponding to T350, N699, and N879 of SEQ ID NO:6; (p) substitution at the amino acid corresponding to V482 of SEQ ID NO:6; (q) substitutions at the amino acids corresponding to Y127, Y128, W430, Y523, and F690 of SEQ ID NO:6; or (r) substitutions at the amino acids corresponding to Y127, Y128, W430, Y523, F690, V509, and V510 of SEQ ID NO:6. In
some instances, the polypeptide comprises: (a) substitutions corresponding to W430A, Y523A, and F690A of SEQ ID NO:6; (b) substitutions corresponding to Y86A, L463A, and I577A of SEQ ID NO:6; (c) substitutions corresponding to Y328A, Y523A, and F690A of SEQ ID NO:6; (d) substitutions corresponding to Y127A and Y128A of SEQ ID NO:6; (e) substitutions corresponding to V509A and V510A of SEQ ID NO:6; (f) substitutions corresponding to Y912A and L913A of SEQ ID NO:6; (g) a substitution corresponding to R77A of SEQ ID NO:6; (h) a substitution corresponding to Y86A of SEQ ID NO:6; (i) a substitution corresponding to Y242A of SEQ ID NO:6; (j) a substitution corresponding to W430A of SEQ ID NO:6; (k) a substitution corresponding to T566G of SEQ ID NO:6; (1) a substitution corresponding to F497A of SEQ ID NO:6; (m) a substitution corresponding to Y612A of SEQ ID NO:6; (n) substitutions corresponding to A178K, A333G, and V742L of SEQ ID NO:6; (o) substitutions corresponding to T350G, N699A, and N879A of SEQ ID NO:6; (p) a substitution corresponding to V482A of SEQ ID NO:6; (q) substitutions corresponding to Y127A, Y128A, W430A, Y523A, and F690A of SEQ ID NO:6; or (r) substitutions corresponding to Y127A, Y128A, W430A, Y523A, F690A, V509A, and V510A of SEQ ID N0:6. In some instances, the polypeptide comprises an amino acid sequence that is at least 95%, at least 97%, at least 98%, or at least 99% identical to the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49. In some instances, the polypeptide comprises the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49. In some instances, the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49 and optionally a signal peptide. In some instances, the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs: 351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:80. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:80 and optionally a signal peptide. In some instances, the polypeptide consists of the amino acid sequence of SEQ ID NO:351.
Polynucleotides and Open Reading Frames (ORFs)
[0059] The instant invention features mRNAs for use in treating IgA nephropathy. The mRNAs featured for use in the invention are administered to subjects and encode an IgAP protein described herein in vivo. Accordingly, the invention relates to polynucleotides, e.g., mRNA, comprising an open reading frame of linked nucleosides encoding an IgAP protein described herein (e.g., isoforms, functional fragment, fusions, or variants thereof). In particular, the invention provides sequence-optimized polynucleotides comprising nucleotides encoding the polypeptide sequence of an IgAP protein, or sequence having high sequence identity with those sequence optimized polynucleotides.
[0060] In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises a nucleotide sequence (e.g., an ORF) encoding an IgAP protein described herein, wherein the nucleotide sequence has at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to SEQ ID NO:27 or SEQ ID NO:28.
[0061] In some embodiments, the polynucleotide of the invention (e.g., an RNA, e.g., an mRNA) comprises a nucleotide sequence (e.g., an ORF, e.g., SEQ ID NO:27 or SEQ ID NO:28) encoding an IgAP protein described herein further comprises a 5'-UTR (e.g., SEQ ID NO: 58) and a 3'-UTR (e.g., SEQ ID NO: 114 or SEQ ID NO: 139). In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:29. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:30. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:31. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:32. In a further embodiment, the polynucleotide (e.g., a RNA, e.g., an mRNA) comprises a 5' terminal cap (e.g., m7Gp-ppGm-A, m7Gp-ppGm-G, CapO, Capl, ARCA, inosine, Nl-
methyl-guanosine, 2 '-fluoro-guanosine, 7-deaza-guanosine, 8-oxo-guanosine, 2-amino- guanosine, LNA-guanosine, 2-azidoguanosine, Cap2, Cap4, 5' methylG cap, or an analog thereof) and a poly-A-tail region (e.g., about 100 nucleotides in length). In some embodiments, the mRNA comprises a polyA tail. In some instances, the poly A tail is 50-150 (SEQ ID NO: 197), 75-150 (SEQ ID NO: 198), 85-150 (SEQ ID NO: 199), 90-120 (SEQ ID NO: 193), 90-130 (SEQ ID NO: 194), or 90-150 (SEQ ID NO: 192) nucleotides in length. In some instances, the poly A tail is 100 nucleotides in length (SEQ ID NO: 195). In some instances, the poly A tail is protected (e.g., with an inverted deoxythymidine). In some instances, the poly A tail comprises A100-UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO: 211). In some instances, the poly A tail is A100- UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO: 211).
[0062] In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises a nucleotide sequence (e.g., an ORF) encoding an IgAP protein described herein, wherein the nucleotide sequence has at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to any one of SEQ ID NOs:153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151. In some instances, the polynucleotide does not include a sequence encoding a C-terminal tag (e.g., a sequence encoding SEQ ID NO:324). In some instances, the polynucleotide includes a sequence encoding a C- terminal tag (e g., a sequence encoding SEQ ID NO:324).
[0063] In some embodiments, the polynucleotide of the invention (e.g., an RNA, e.g., an mRNA) comprises a nucleotide sequence (e.g., an ORF, e.g., SEQ ID NO: 153 or SEQ ID NO: 154) encoding an IgAP protein described herein further comprises a 5'-UTR (e.g., SEQ ID NO:50) and a 3'-UTR (e.g., SEQ ID NO:132). In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of any one of SEQ ID NOs:301-319. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:318. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises the sequence of SEQ ID NO:319. In a further embodiment, the polynucleotide
(e.g., a RNA, e.g., an mRNA) comprises a 5' terminal cap (e.g., m7Gp-ppGm-A, m7Gp- ppGm-G, CapO, Capl, ARC A, inosine, Nl-methyl-guanosine, 2'-fluoro-guanosine, 7- deaza-guanosine, 8-oxo-guanosine, 2-amino-guanosine, LNA-guanosine, 2- azidoguanosine, Cap2, Cap4, 5' methylG cap, or an analog thereof) and a poly-A-tail region (e.g., about 100 nucleotides in length). In some embodiments, the mRNA comprises a polyA tail. In some instances, the poly A tail is 50-150 (SEQ ID NO:197), 75-150 (SEQ ID NO: 198), 85-150 (SEQ ID NO: 199), 90-120 (SEQ ID NO: 193), 90-130 (SEQ ID NO: 194), or 90-150 (SEQ ID NO: 192) nucleotides in length. In some instances, the poly A tail is 100 nucleotides in length (SEQ ID NO: 195). In some instances, the poly A tail is protected (e.g., with an inverted deoxy-thymidine). In some instances, the poly A tail comprises A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO: 211). In some instances, the poly A tail is A100-UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO: 211).
[0064] In some embodiments, the polynucleotide of the invention (e.g., a RNA, e.g., an mRNA) comprises a nucleotide sequence (e.g., an ORF) encoding an IgAP protein is single stranded or double stranded.
[0065] In some embodiments, the polynucleotide of the invention comprising a nucleotide sequence (e.g., an ORF) encoding an IgAP protein is DNA or RNA. In some embodiments, the polynucleotide of the invention is RNA. In some embodiments, the polynucleotide of the invention is, or functions as, an mRNA. In some embodiments, the mRNA comprises a nucleotide sequence (e.g., an ORF) that encodes at least one IgAP protein, and is capable of being translated to produce the encoded IgAP protein described herein in vitro, in vivo, in situ or ex vivo.
[0066] In some embodiments, the polynucleotide of the invention (e.g., a RNA, e.g., an mRNA) comprises a sequence-optimized nucleotide sequence (e.g., an ORF) encoding an IgAP protein described herein, wherein the polynucleotide comprises at least one chemically modified nucleobase, e.g., N1 -methylpseudouracil or 5-methoxyuracil. In certain embodiments, all uracils in the polynucleotide are N1 -methylpseudouracils. In other embodiments, all uracils in the polynucleotide are 5-methoxyuracils. In some
embodiments, the polynucleotide further comprises a miRNA binding site, e.g., a miRNA binding site that binds to miR-142 and/or a miRNA binding site that binds to miR-126. [0067] In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) disclosed herein is formulated with a delivery agent comprising, e.g., a compound having the Formula (I), e g., Compound II or Compound B; a compound having the Formula (III), (IV), (V), or (VI), e.g., Compound VI or Compound I, or any combination thereof. In some embodiments, the delivery agent comprises an ionizable amino lipid (e.g., Compound II, VI, or B), a helper lipid (e.g., DSPC), a sterol (e.g., Cholesterol), and a PEG lipid (e.g., Compound I or PEG-DMG), e.g., with a mole ratio in the range of about (i) 40-50 mol% ionizable amino lipid (e.g., Compound II, VI, or B), optionally 45-50 mol% ionizable amino lipid, for example, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48-49 mol%, or 49-50 mol% for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol%; (ii) 30-45 mol% sterol (e.g., cholesterol), optionally 35-42 mol% sterol, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 37-38 mol%, 38-39 mol%, or 39-40 mol%, or 40-42 mol% sterol; (iii) 5-15 mol% helper lipid (e.g., DSPC), optionally 10-15 mol% helper lipid, for example, 5-6 mol%, 6-7 mol%, 7-8 mol%, 8-9 mol%, 9-10 mol%, 10-11 mol%, 11-12 mol%, 12-13 mol%, 13-14 mol%, or 14-15 mol% helper lipid; and (iv) 1-5% PEG lipid (e.g., Compound I or PEG-DMG), optionally 1-5 mol% PEG lipid, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol% PEG lipid. In some embodiments, the delivery agent comprises Compound II, Cholesterol, DSPC, and Compound I.
[0068] In some embodiments, the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e g., Capl, e.g., m7Gp-ppGm-A or m7Gp-ppGm-G), a 5'UTR (e.g., any one of SEQ ID NOs:50-79), an ORF sequence of SEQ ID NO:27, a 3'UTR (e.g., any one of SEQ ID NOs: 100-136 and 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils. In some embodiments, the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or
Compound I as the PEG lipid, some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
[0069] In some embodiments, the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e g., Capl, e.g., m7Gp-ppGm-A or m7Gp-ppGm-G), a 5'UTR (e.g., any one of SEQ ID NOs:50-79), an ORF sequence of SEQ ID NO:28, a 3'UTR (e.g., any one of SEQ ID NOs: 100-136 and 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils. In some embodiments, the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid, some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
[0070] In some embodiments, the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m7Gp-ppGm-A or m7Gp-ppGm-G), a 5'UTR (e.g., any one of SEQ ID NOs:50-79), an ORF sequence of SEQ ID NO:153, a 3'UTR (e.g., any one of SEQ ID NOs: 100-136, 138, and 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils. In some embodiments, the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid, some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
[0071] In some embodiments, the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m7Gp-ppGm-A or m7Gp-ppGm-G), a 5'UTR (e.g., any one of SEQ ID NOs: 50-79), an ORF sequence of SEQ ID NO: 154, a 3'UTR (e.g., any one of SEQ ID NOs: 100-136, 138, and 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils. In some embodiments, the delivery agent comprises
Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid. Some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
[0072] In some embodiments, the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m7Gp-ppGm-A or m7Gp-ppGm-G), a 5'UTR (e.g., SEQ ID NO:58), an ORF sequence of SEQ ID NO:27, a 3'UTR (e g., SEQ ID NO:114 or SEQ ID NO: 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO:195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils. In some embodiments, the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid. Some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
[0073] In some embodiments, the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m7Gp-ppGm-A or m7Gp-ppGm-G), a 5'UTR (e.g., SEQ ID NO:58), an ORF sequence of SEQ ID NO:28, a 3'UTR (e g., SEQ ID NO:114 or SEQ ID NO: 139), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils. In some embodiments, the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid. Some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
[0074] In some embodiments, the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m7Gp-ppGm-A or m7Gp-ppGm-G), a 5'UTR (e.g, SEQ ID NO:58), an ORF sequence of SEQ ID NO: 153, a 3'UTR (e.g, SEQ ID NO: 138), and a poly A tail (e.g, about 100 nt in length, e.g, SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils. In some embodiments, the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid. Some
embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
[0075] In some embodiments, the polynucleotide of the disclosure is an mRNA that comprises a 5'-terminal cap (e.g., Capl, e.g., m7Gp-ppGm-A or m7Gp-ppGm-G), a 5'UTR (e.g., SEQ ID NO:50), an ORF sequence of SEQ ID NO: 154, a 3'UTR (e g., SEQ ID NO: 132), and a poly A tail (e.g., about 100 nt in length, e.g., SEQ ID NO: 195), wherein all uracils in the polynucleotide are N1 -methylpseudouracils. In some embodiments, the delivery agent comprises Compound II or Compound VI as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid, some embodiments, the delivery agent comprises Compound B as the ionizable amino lipid and PEG-DMG or Compound I as the PEG lipid.
Signal Sequences
[0076] The polynucleotides (e.g., a RNA, e.g., an mRNA) of the invention can also comprise nucleotide sequences that encode additional features that facilitate trafficking of the encoded polypeptides to therapeutically relevant sites. One such feature that aids in protein trafficking is the signal sequence, or targeting sequence. The peptides encoded by these signal sequences are known by a variety of names, including targeting peptides, transit peptides, and signal peptides. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) comprises a nucleotide sequence (e.g., an ORF) that encodes a signal peptide operably linked to a nucleotide sequence that encodes an IgAP protein described herein.
[0077] In some embodiments, the "signal sequence" or "signal peptide" is a polynucleotide or polypeptide, respectively, which is from about 30-210, e g., about 45- 80 or 15-60 nucleotides (e.g., about 20, 30, 40, 50, 60, or 70 amino acids) in length that, optionally, is incorporated at the 5' (or N-terminus) of the coding region or the polypeptide, respectively. Addition of these sequences results in trafficking the encoded polypeptide to a desired site, such as the endoplasmic reticulum or the mitochondria through one or more targeting pathways. Some signal peptides are cleaved from the
protein, for example by a signal peptidase after the proteins are transported to the desired site.
[0078] In some embodiments, the polynucleotide of the invention comprises a nucleotide sequence encoding an IgAP protein, wherein the nucleotide sequence further comprises a 5' nucleic acid sequence encoding a heterologous signal peptide.
[0079] In some embodiments, the polynucleotide of the invention comprises a nucleotide sequence encoding an IgAP protein, wherein the nucleotide sequence further comprises a 5' nucleic acid sequence encoding a heterologous signal peptide. In some embodiments, the heterologous signal peptide comprises the amino acid sequence of the signal peptide is MLKNKKFKLNFIALTVAYALAPYTEA (SEQ ID NO:320), MGVKVLF ALICIA VAEA (SEQ ID NO:321), or METPAQLLFLLLLWLPDTTG (SEQ ID NO:322).
Fusion Proteins
[0080] In some embodiments, the polynucleotide of the invention (e.g., a RNA, e.g., an mRNA) can comprise more than one nucleic acid sequence (e.g., an ORF) encoding a polypeptide of interest. In some embodiments, polynucleotides of the invention comprise a single ORF encoding an IgAP protein described herein. In some embodiments, two or more polypeptides of interest can be genetically fused, i.e., two or more polypeptides can be encoded by the same ORF. In some embodiments, the polynucleotide can comprise a nucleic acid sequence encoding a linker (e.g., a G4S (SEQ ID NO: 200) peptide linker or another linker known in the art) between two or more polypeptides of interest.
[0081] In some embodiments, a polynucleotide of the invention (e.g., a RNA, e.g., an mRNA) can comprise two, three, four, or more ORFs, each expressing a polypeptide of interest.
Linkers and Cleavable Peptides
[0082] In certain embodiments, the mRNAs of the disclosure encode more than one IgAP domain or a heterologous domain, referred to herein as multimer constructs. In certain embodiments of the multimer constructs, the mRNA further encodes a linker
located between each domain. The linker can be, for example, a cleavable linker or protease-sensitive linker. In certain embodiments, the linker is selected from the group consisting of F2A linker, P2A linker, T2A linker, E2A linker, and combinations thereof. This family of self-cleaving peptide linkers, referred to as 2A peptides, has been described in the art (see for example, Kim, J.H. et al. (2011) PLoS ONE 6:el8556). In certain embodiments, the linker is an F2A linker. In certain embodiments, the linker is a GGGS (SEQ ID NO: 201) linker. In certain embodiments, the linker is a (GGGS)n (SEQ ID NO: 202) linker, wherein n =2, 3,4, or 5. In certain embodiments, the multimer construct contains three domains with intervening linkers, having the structure: domain- linker-domain-linker-domain e.g., IgAP domain-linker-IgAP domain.
[0083] In one embodiment, the cleavable linker is an F2A linker (e.g., having the amino acid sequence GSGVKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 189)). In other embodiments, the cleavable linker is a T2A linker (e.g., having the amino acid sequence GSGEGRGSLLTCGDVEENPGP (SEQ ID NO: 190)), a P2A linker (e.g, having the amino acid sequence GSGATNFSLLKQAGDVEENPGP (SEQ ID NO: 191)) or an E2A linker (e.g, having the amino acid sequence GSGQCTNYALLKLAGDVESNPGP (SEQ ID NO: 186)). The skilled artisan will appreciate that other art-recognized linkers may be suitable for use in the constructs of the invention (e.g, encoded by the polynucleotides of the invention). The skilled artisan will likewise appreciate that other multi ci str onic constructs may be suitable for use in the invention. In exemplary embodiments, the construct design yields approximately equimolar amounts of intrabody and/or domain thereof encoded by the constructs of the invention.
[0084] In one embodiment, the self-cleaving peptide may be, but is not limited to, a 2A peptide. A variety of 2A peptides are known and available in the art and may be used, including e.g, the foot and mouth disease virus (FMDV) 2A peptide, the equine rhinitis A virus 2A peptide, the Thosea asigna virus 2A peptide, and the porcine teschovirus-1 2A peptide. 2A peptides are used by several viruses to generate two proteins from one transcript by ribosome-skipping, such that a normal peptide bond is
impaired at the 2A peptide sequence, resulting in two discontinuous proteins being produced from one translation event. As a non-limiting example, the 2A peptide may have the protein sequence of SEQ ID NO: 191, fragments or variants thereof. In one embodiment, the 2A peptide cleaves between the last glycine and last proline. As another non-limiting example, the polynucleotides of the present invention may include a polynucleotide sequence encoding the 2A peptide having the protein sequence of fragments or variants of SEQ ID NO: 191. One example of a polynucleotide sequence encoding the 2A peptide is GGAAGCGGAGCUACUAACUUCAGCCUGCUGAAGCAGGCUGGAGACGUGG AGGAGAACCCUGGACCU (SEQ ID NO: 187). In one illustrative embodiment, a 2A peptide is encoded by the following sequence: 5'- UCCGGACUCAGAUCCGGGGAUCUCAAAAUUGUCGCUCCUGUCAAACAAAC UCUUAACUUUGAUUUACUCAAACUGGCTGGGGAUGUAGAAAGCAAUCCAG GTCCACUC-3'(SEQ ID NO: 188). The polynucleotide sequence of the 2A peptide may be modified or codon optimized by the methods described herein and/or are known in the art.
[0085] In one embodiment, this sequence may be used to separate the coding regions of two or more polypeptides of interest. As a non-limiting example, the sequence encoding the F2A peptide may be between a first coding region A and a second coding region B (A-F2Apep-B). The presence of the F2A peptide results in the cleavage of the one long protein between the glycine and the proline at the end of the F2A peptide sequence (NPGP (SEQ ID NO:205) is cleaved to result in NPG and P) thus creating separate protein A (with 21 amino acids of the F2A peptide attached, ending with NPG) and separate protein B (with 1 amino acid, P, of the F2A peptide attached). Likewise, for other 2A peptides (P2A, T2A and E2A), the presence of the peptide in a long protein results in cleavage between the glycine and proline at the end of the 2A peptide sequence (NPGP (SEQ ID NO:205) is cleaved to result in NPG and P). Protein A and protein B may be the same or different peptides or polypeptides of interest (e.g., an IgAP protein described herein).
Sequence-Optimized Nucleotide Sequences Encoding IgAP Proteins
[0086] In some embodiments, the polynucleotide of the invention comprises a sequence-optimized nucleotide sequence encoding an IgAP protein disclosed herein. In some embodiments, the polynucleotide of the invention comprises an open reading frame (ORF) encoding an IgAP protein, wherein the ORF has been sequence optimized.
[0087] An exemplary sequence-optimized nucleotide sequence encoding an IgAP protein is set forth as SEQ ID NO:27. Another exemplary sequence-optimized nucleotide sequence encoding an IgAP protein is set forth as SEQ ID NO:28. Additionally exemplary sequence-optimized nucleotide sequences encoding an IgAP protein are set forth in SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151. In some embodiments, the sequence optimized IgAP sequence is used to practice the methods disclosed herein.
[0088] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided herein, for example, m7Gp-ppGm-A or m7Gp-ppGm- G;
(ii) a 5' UTR comprising a nucleotide sequence set forth in Table 1;
(iii) an open reading frame encoding an IgAP protein (e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO:6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
(iv) at least one stop codon (if not present at 5' terminus of 3 'UTR);
(v) a 3' UTR comprising a nucleotide sequence set forth in Table 2 or Table 3, e.g., SEQ ID NO: 114 or SEQ ID NO: 139; and
(vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
[0089] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided herein, for example, m7Gp-ppGm-A or m7Gp-ppGm- G;
(ii) a 5' UTR comprising a nucleotide sequence set forth in Table 1;
(iii) an open reading frame encoding an IgAP protein (e.g., any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49, optionally including a signal peptide, e g., the IgAP protein of any one of SEQ ID NOs: 351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as any one of SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151;
(iv) at least one stop codon (if not present at 5' terminus of 3 'UTR);
(v) a 3' UTR comprising a nucleotide sequence set forth in Table 2 or Table 3, e.g., SEQ ID NO: 132 or SEQ ID NO: 138; and
(vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
[0090] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided herein, for example, m7Gp-ppGm-A or m7Gp-ppGm- G;
(ii) a 5' UTR comprising the nucleotide sequence set forth in SEQ ID NO:58;
(iii) an open reading frame encoding an IgAP protein (e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
(iv) at least one stop codon (if not present at 5' terminus of 3 'UTR);
(v) a 3' UTR comprising a nucleotide sequence set forth in Table 2 or Table 3, e.g., SEQ ID NO: 114 or SEQ ID NO: 139; and
(vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
[0091] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided herein, for example, m7Gp-ppGm-A or m7Gp-ppGm- G;
(ii) a 5' UTR comprising the nucleotide sequence set forth in SEQ ID NO:50;
(iii) an open reading frame encoding an IgAP protein (e g., any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49, optionally including a signal peptide, e.g., the IgAP protein of any one of SEQ ID NOs: 351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as any one of SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151;
(iv) at least one stop codon (if not present at 5' terminus of 3 'UTR);
(v) a 3' UTR comprising a nucleotide sequence set forth in Table 2 or Table 3, e.g., SEQ ID NO: 132; and
(vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
[0092] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided herein, for example, m7Gp-ppGm-A or m7Gp-ppGm- G;
(ii) a 5' UTR comprising a nucleotide sequence set forth in Table 1;
(iii) an open reading frame encoding an IgAP protein (e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
(iv) at least one stop codon (if not present at 5' terminus of 3 'UTR);
(v) a 3' UTR comprising the nucleotide sequence set forth in SEQ ID NO:114; and
(vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
[0093] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided herein, for example, m7Gp-ppGm-A or m7Gp-ppGm- G;
(ii) a 5' UTR comprising a nucleotide sequence set forth in Table 1;
(iii) an open reading frame encoding an IgAP protein (e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
(iv) at least one stop codon (if not present at 5' terminus of 3 'UTR);
(v) a 3' UTR comprising the nucleotide sequence set forth in SEQ ID NO: 139; and
(vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
[0094] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided herein, for example, m7Gp-ppGm-A or m7Gp-ppGm- G;
(ii) a 5' UTR comprising the nucleotide sequence set forth in SEQ ID NO:58;
(iii) an open reading frame encoding an IgAP protein (e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
(iv) at least one stop codon (if not present at 5' terminus of 3 'UTR);
(v) a 3' UTR comprising the nucleotide sequence set forth in SEQ ID NO:114; and
(vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
[0095] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided herein, for example, m7Gp-ppGm-A or m7Gp-ppGm- G;
(ii) a 5' UTR comprising the nucleotide sequence set forth in SEQ ID NO:58;
(iii) an open reading frame encoding an IgAP protein (e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO: 5 or SEQ ID NO: 6), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO:27 or SEQ ID NO:28;
(iv) at least one stop codon (if not present at 5' terminus of 3 'UTR);
(v) a 3' UTR comprising the nucleotide sequence set forth in SEQ ID NO: 139; and
(vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
[0096] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided herein, for example, m7Gp-ppGm-A or m7Gp-ppGm- G;
(ii) a 5' UTR comprising the nucleotide sequence set forth in SEQ ID NO:58;
(iii) an open reading frame encoding an IgAP protein (e.g., SEQ ID NO: 80, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO:351), e.g., a sequence optimized nucleic acid sequence encoding an IgAP protein set forth as SEQ ID NO: 153 or SEQ ID NO: 154;
(iv) at least one stop codon (if not present at 5' terminus of 3 'UTR);
(v) a 3' UTR comprising the nucleotide sequence set forth in SEQ ID NO: 132; and
(vi) a poly-A tail provided above (e.g., SEQ ID NO: 195).
[0097] In certain embodiments, all uracils in the polynucleotide are N1 -methylpseudouracil (G5).
[0098] In certain embodiments, all uracils in the polynucleotide are 5-methoxyuracil (G6).
[0099] The sequence-optimized nucleotide sequences disclosed herein are distinct from the corresponding wild type nucleotide acid sequences and from other known sequence-optimized nucleotide sequences, e.g., these sequence-optimized nucleic acids have unique compositional characteristics.
[00100] In some embodiments, the percentage of uracil or thymine nucleobases in a sequence-optimized nucleotide sequence (e.g., encoding an IgAP protein described herein) is modified (e.g., reduced) with respect to the percentage of uracil or thymine nucleobases in the reference wild-type nucleotide sequence. Such a sequence is referred to as a uracil -modified or thymine-modified sequence. The percentage of uracil or thymine content in a nucleotide sequence can be determined by dividing the number of uracils or thymines in a sequence by the total number of nucleotides and multiplying by 100. In some embodiments, the sequence-optimized nucleotide sequence has a lower uracil or thymine content than the uracil or thymine content in the reference wild-type sequence. In some embodiments, the uracil or thymine content in a sequence-optimized nucleotide sequence of the invention is greater than the uracil or thymine content in the reference wild-type sequence and still maintain beneficial effects, e.g., increased expression and/or reduced Toll-Like Receptor (TLR) response when compared to the reference wild-type sequence.
[00101] Methods for optimizing codon usage are known in the art. For example, an ORF of any one or more of the sequences provided herein may be codon optimized. Codon optimization, in some embodiments, may be used to match codon frequencies in target and host organisms to ensure proper folding; bias GC content to increase mRNA
stability or reduce secondary structures; minimize tandem repeat codons or base runs that may impair gene construction or expression; customize transcriptional and translational control regions; insert or remove protein trafficking sequences; remove/add post translation modification sites in encoded protein (e.g., glycosylation sites); add, remove or shuffle protein domains; insert or delete restriction sites; modify ribosome binding sites and mRNA degradation sites; adjust translational rates to allow the various domains of the protein to fold properly; or reduce or eliminate problem secondary structures within the polynucleotide. Codon optimization tools, algorithms and services are known in the art - non-limiting examples include services from GeneArt (Life Technologies), DNA2.0 (Menlo Park CA) and/or proprietary methods. In some embodiments, the open reading frame (ORF) sequence is optimized using optimization algorithms.
Identification and Ratio Determination (IDR) Sequences
[00102] An Identification and Ratio Determination (IDR) sequence is a sequence of a biological molecule (e.g., nucleic acid or protein) that, when combined with the sequence of a target biological molecule, serves to identify the target biological molecule.
Typically, an IDR sequence is a heterologous sequence that is incorporated within or appended to a sequence of a target biological molecule and can be used as a reference to identify the target molecule. Thus, in some embodiments, a nucleic acid (e.g., mRNA) comprises (i) a target sequence of interest (e.g., a coding sequence encoding a therapeutic and/or antigenic peptide or protein); and (ii) a unique IDR sequence.
[00103] An RNA species (e.g., RNA having a given coding sequence) may comprise an IDR sequence that differs from the IDR sequence of other RNA species (e.g., RNA(s) having different coding sequence(s)). Each IDR sequence thus identifies a particular RNA species, and so the abundance of IDR sequences may be measured to determine the abundance of each RNA species in a composition. Use of distinct IDR sequences to identify RNA species allows for analysis of multivalent RNA compositions (e.g., containing multiple RNA species) containing RNA species with similar coding sequences
and/or lengths, which could otherwise be difficult to distinguish using PCR- or chromatography-based analysis of full-length RNAs.
[00104] Each RNA species in a multivalent RNA composition may comprise an IDR sequence that is not a sequence isomer of an IDR sequence of another RNA species in a multivalent RNA composition (e.g., the IDR sequence does not have the same number of adenosine nucleotides, the same number of cytosine nucleotides, the same number of guanine nucleotides, and the same number of uracil nucleotides, as another IDR sequence in the composition, even if those sequences have different sequences). Having identical nucleotide compositions causes sequence isomers to have the same mass, presenting a challenge to distinguishing sequence isomers using mass-based identification methods (e.g., mass spectrometry).
[00105] Each RNA species in a multivalent RNA composition may comprise an IDR sequence having a mass that differs from the mass of IDR sequences of each other RNA species in a multivalent RNA composition. For example, the mass of each IDR sequence may differ from the mass of other IDR sequences by at least 9 Da, at least 25 Da, at least 25 Da, or at least 50 Da. Use of IDR sequences with distinct masses allows RNA fragments comprising different IDR sequences to be distinguished using mass-based analysis methods (e.g, mass spectrometry), which do not require reverse transcription, amplification, or sequencing of RNAs.
[00106] Each RNA species in an RNA composition may comprises an IDR sequence with a different length. For example, each IDR sequence may have a length independently selected from 0 to 25 nucleotides. The length of a nucleic acid influences the rate at which the nucleic acid traverses a chromatography column, and so the use of IDR sequences of different lengths on different RNA species allows RNA fragments having different IDR sequences to be distinguished using chromatography-based methods (e.g, LC-UV).
[00107] IDR sequences may be chosen such that no IDR sequence comprises a start codon, ‘AUG’. Lack of a start codon in an IDR sequence prevents undesired translation of nucleotide sequences within and/or downstream from the IDR sequence.
[00108] IDR sequences may be chosen such that no IDR sequence comprises a recognition site for a restriction enzyme. In one example, no IDR sequence comprises a recognition site for Xbal, ‘UCUAG’ . Lack of a recognition site for a restriction enzyme (e.g., Xbal recognition site ‘UCUAG’) allows the restriction enzyme to be used in generating and modifying a DNA template for in vitro transcription, without affecting the IDR sequence or sequence of the transcribed RNA.
Modified Nucleotide Sequences Encoding IgAP Proteins
[00109] In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) of the invention comprises a chemically modified nucleobase, for example, a chemically modified uracil, e.g., pseudouracil, N1 -methylpseudouracil, 5-methoxyuracil, or the like. In some embodiments, the mRNA is a uracil-modified sequence comprising an ORF encoding an IgAP protein described herein, wherein the mRNA comprises a chemically modified nucleobase, for example, a chemically modified uracil, e.g., pseudouracil, N1 -methylpseudouracil, or 5-methoxyuracil.
[0110] In certain aspects of the invention, when the modified uracil base is connected to a ribose sugar, as it is in polynucleotides, the resulting modified nucleoside or nucleotide is referred to as modified uridine. In some embodiments, uracil in the polynucleotide is at least about 25%, at least about 30%, at least about 40%, at least about 50%, at least about 60%, at least about 70%, at least about 80%, at least 90%, at least 95%, at least 99%, or about 100% modified uracil. In one embodiment, uracil in the polynucleotide is at least 95% modified uracil. In another embodiment, uracil in the polynucleotide is 100% modified uracil.
[OHl] In embodiments where uracil in the polynucleotide is at least 95% modified uracil overall uracil content can be adjusted such that an mRNA provides suitable protein expression levels while inducing little to no immune response. In some embodiments, the uracil content of the ORF is between about 100% and about 150%, between about 100% and about 110%, between about 105% and about 115%, between about 110% and about 120%, between about 115% and about 125%, between about 120% and about
130%, between about 125% and about 135%, between about 130% and about 140%, between about 135% and about 145%, between about 140% and about 150% of the theoretical minimum uracil content in the corresponding wild-type ORF (%UTM). In other embodiments, the uracil content of the ORF is between about 121% and about 136% or between 123% and 134% of the %UTM. In some embodiments, the uracil content of the ORF encoding an IgAP protein described herein is about 115%, about 120%, about 125%, about 130%, about 135%, about 140%, about 145%, or about 150% of the %UTM. In this context, the term "uracil" can refer to modified uracil and/or naturally occurring uracil.
[0112] In some embodiments, the uracil content in the ORF of the mRNA encoding an IgAP protein of the invention is less than about 30%, about 25%, about 20%, about 15%, or about 10% of the total nucleobase content in the ORF. In some embodiments, the uracil content in the ORF is between about 10% and about 20% of the total nucleobase content in the ORF. In other embodiments, the uracil content in the ORF is between about 10% and about 25% of the total nucleobase content in the ORF. In one embodiment, the uracil content in the ORF of the mRNA encoding an IgAP protein is less than about 20% of the total nucleobase content in the open reading frame. In this context, the term "uracil" can refer to modified uracil and/or naturally occurring uracil. [0113] In further embodiments, the ORF of the mRNA encoding an IgAP protein having modified uracil and adjusted uracil content has increased Cytosine (C), Guanine (G), or Guanine/Cytosine (G/C) content (absolute or relative). In some embodiments, the overall increase in C, G, or G/C content (absolute or relative) of the ORF is at least about 2%, at least about 3%, at least about 4%, at least about 5%, at least about 6%, at least about 7%, at least about 10%, at least about 15%, at least about 20%, at least about 40%, at least about 50%, at least about 60%, at least about 70%, at least about 80%, at least about 90%, at least about 95%, or at least about 100% relative to the G/C content (absolute or relative) of the wild-type ORF. In some embodiments, the G, the C, or the G/C content in the ORF is less than about 100%, less than about 90%, less than about 85%, or less than about 80% of the theoretical maximum G, C, or G/C content of the
corresponding wild type nucleotide sequence encoding the IgAP protein (%GTMX; %CTMX, or %G/CTMX). In some embodiments, the increases in G and/or C content (absolute or relative) described herein can be conducted by replacing synonymous codons with low G, C, or G/C content with synonymous codons having higher G, C, or G/C content. In other embodiments, the increase in G and/or C content (absolute or relative) is conducted by replacing a codon ending with U with a synonymous codon ending with G or C.
[0114] In further embodiments, the ORF of the mRNA encoding an IgAP protein of the invention comprises modified uracil and has an adjusted uracil content containing less uracil pairs (UU) and/or uracil triplets (UUU) and/or uracil quadruplets (UUUU) than the corresponding wild-type nucleotide sequence encoding the IgAP protein. In some embodiments, the ORF of the mRNA encoding an IgAP protein of the invention contains no uracil pairs and/or uracil triplets and/or uracil quadruplets. In some embodiments, uracil pairs and/or uracil triplets and/or uracil quadruplets are reduced below a certain threshold, e.g., no more than 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 occurrences in the ORF of the mRNA encoding the IgAP protein. In a particular embodiment, the ORF of the mRNA encoding the IgAP protein of the invention contains less than 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, or 1 nonphenylalanine uracil pairs and/or triplets. In another embodiment, the ORF of the mRNA encoding the IgAP protein contains no non-phenylalanine uracil pairs and/or triplets.
[0115] In further embodiments, the ORF of the mRNA encoding an IgAP protein of the invention comprises modified uracil and has an adjusted uracil content containing less uracil-rich clusters than the corresponding wild-type nucleotide sequence encoding the IgAP protein. In some embodiments, the ORF of the mRNA encoding the IgAP protein of the invention contains uracil-rich clusters that are shorter in length than corresponding uracil-rich clusters in the corresponding wild-type nucleotide sequence encoding the IgAP protein.
[0116] In further embodiments, alternative lower frequency codons are employed. At least about 5%, at least about 10%, at least about 15%, at least about 20%, at least about
25%, at least about 30%, at least about 35%, at least about 40%, at least about 45%, at least about 50%, at least about 55%, at least about 60%, at least about 65%, at least about 70%, at least about 75%, at least about 80%, at least about 85%, at least about 90%, at least about 95%, at least about 99%, or 100% of the codons in the IgAP protein-encoding ORF of the modified uracil -comprising mRNA are substituted with alternative codons, each alternative codon having a codon frequency lower than the codon frequency of the substituted codon in the synonymous codon set. The ORF also has adjusted uracil content, as described above. In some embodiments, at least one codon in the ORF of the mRNA encoding the IgAP protein is substituted with an alternative codon having a codon frequency lower than the codon frequency of the substituted codon in the synonymous codon set.
[0117] In some embodiments, the adjusted uracil content, IgAP protein-encoding ORF of the modified uracil -comprising mRNA exhibits expression levels of IgAP protein when administered to a mammalian cell that are higher than expression levels of IgAP from the corresponding wild-type mRNA. In some embodiments, the mammalian cell is a mouse cell, a rat cell, or a rabbit cell. In other embodiments, the mammalian cell is a monkey cell or a human cell. In some embodiments, the human cell is a HeLa cell, a BJ fibroblast cell, or a peripheral blood mononuclear cell (PBMC). In some embodiments, IgAP is expressed at a level higher than expression levels of IgAP from the corresponding wild-type mRNA when the mRNA is administered to a mammalian cell in vivo. In some embodiments, the mRNA is administered to mice, rabbits, rats, monkeys, or humans. In one embodiment, mice are null mice. In some embodiments, the mRNA is administered intravenously or intramuscularly. In other embodiments, the IgAP protein is expressed when the mRNA is administered to a mammalian cell in vitro. In some embodiments, the expression is increased by at least about 2-fold, at least about 5-fold, at least about 10-fold, at least about 50-fold, at least about 500-fold, at least about 1500- fold, or at least about 3000-fold. In other embodiments, the expression is increased by at least about 10%, about 20%, about 30%, about 40%, about 50%, 60%, about 70%, about 80%, about 90%, or about 100%.
[0118] In some embodiments, adjusted uracil content, IgAP protein-encoding ORF of the modified uracil-comprising mRNA exhibits increased stability. In some embodiments, the mRNA exhibits increased stability in a cell relative to the stability of a corresponding wild-type mRNA under the same conditions. In some embodiments, the mRNA exhibits increased stability including resistance to nucleases, thermal stability, and/or increased stabilization of secondary structure. In some embodiments, increased stability exhibited by the mRNA is measured by determining the half-life of the mRNA (e.g., in a plasma, serum, cell, or tissue sample) and/or determining the area under the curve (AUC) of the protein expression by the mRNA over time (e.g., in vitro or in vivo). An mRNA is identified as having increased stability if the half-life and/or the AUC is greater than the half-life and/or the AUC of a corresponding wild-type mRNA under the same conditions.
[0119] In some embodiments, the mRNA of the present invention induces a detectably lower immune response (e.g., innate or acquired) relative to the immune response induced by a corresponding wild-type mRNA under the same conditions. In other embodiments, the mRNA of the present disclosure induces a detectably lower immune response (e.g., innate or acquired) relative to the immune response induced by an mRNA that encodes for an IgAP protein but does not comprise modified uracil under the same conditions, or relative to the immune response induced by an mRNA that encodes for an IgAP protein and that comprises modified uracil but that does not have adjusted uracil content under the same conditions. The innate immune response can be manifested by increased expression of pro-inflammatory cytokines, activation of intracellular PRRs (RIG-I, MDA5, etc.), cell death, and/or termination or reduction in protein translation. In some embodiments, a reduction in the innate immune response can be measured by expression or activity level of Type 1 interferons (e.g., IFN-a, IFN-P, IFN-K, IFN-5, IFN- s, IFN-T, IFN-CO, and IFN-Q or the expression of interferon-regulated genes such as the toll-like receptors (e.g., TLR7 and TLR8), and/or by decreased cell death following one or more administrations of the mRNA of the invention into a cell.
[0120] In some embodiments, the expression of Type- 1 interferons by a mammalian cell in response to the mRNA of the present disclosure is reduced by at least 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 99%, 99.9%, or greater than 99.9% relative to a corresponding wild-type mRNA, to an mRNA that encodes an IgAP but does not comprise modified uracil, or to an mRNA that encodes an IgAP protein and that comprises modified uracil but that does not have adjusted uracil content. In some embodiments, the interferon is IFN-β. In some embodiments, cell death frequency caused by administration of mRNA of the present disclosure to a mammalian cell is 10%, 25%, 50%, 75%, 85%, 90%, 95%, or over 95% less than the cell death frequency observed with a corresponding wild-type mRNA, an mRNA that encodes for an IgAP protein but does not comprise modified uracil, or mRNA that encodes for an IgAP protein and that comprises modified uracil but that does not have adjusted uracil content. In some embodiments, the mammalian cell is a BI fibroblast cell. In other embodiments, the mammalian cell is a splenocyte. In some embodiments, the mammalian cell is that of a mouse or a rat. In other embodiments, the mammalian cell is that of a human. In one embodiment, the mRNA of the present disclosure does not substantially induce an innate immune response of a mammalian cell into which the mRNA is introduced.
Methods for Modifying Polynucleotides
[0121] The disclosure includes modified polynucleotides comprising a polynucleotide described herein (e g., a polynucleotide, e.g. mRNA, comprising a nucleotide sequence encoding an IgAP protein described herein. The modified polynucleotides can be chemically modified and/or structurally modified. When the polynucleotides of the present invention are chemically and/or structurally modified the polynucleotides can be referred to as "modified polynucleotides."
[0122] The present disclosure provides for modified nucleosides and nucleotides of a polynucleotide (e.g., RNA polynucleotides, such as mRNA polynucleotides) encoding an IgAP protein. A "nucleoside" refers to a compound containing a sugar molecule (e.g., a pentose or ribose) or a derivative thereof in combination with an organic base (e.g., a
purine or pyrimidine) or a derivative thereof (also referred to herein as "nucleobase"). A “nucleotide" refers to a nucleoside including a phosphate group. Modified nucleotides can be synthesized by any useful method, such as, for example, chemically, enzymatically, or recombinantly, to include one or more modified or non-natural nucleosides. Polynucleotides can comprise a region or regions of linked nucleosides. Such regions can have variable backbone linkages. The linkages can be standard phosphodiester linkages, in which case the polynucleotides would comprise regions of nucleotides.
[0123] The modified polynucleotides disclosed herein can comprise various distinct modifications. In some embodiments, the modified polynucleotides contain one, two, or more (optionally different) nucleoside or nucleotide modifications. In some embodiments, a modified polynucleotide, introduced to a cell can exhibit one or more desirable properties, e.g., improved protein expression, reduced immunogenicity, or reduced degradation in the cell, as compared to an unmodified polynucleotide.
[0124] In some embodiments, a polynucleotide of the present invention (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein is structurally modified. As used herein, a "structural" modification is one in which two or more linked nucleosides are inserted, deleted, duplicated, inverted or randomized in a polynucleotide without significant chemical modification to the nucleotides themselves. Because chemical bonds will necessarily be broken and reformed to effect a structural modification, structural modifications are of a chemical nature and hence are chemical modifications. However, structural modifications will result in a different sequence of nucleotides. For example, the polynucleotide "ATCG" can be chemically modified to "AT-5meC-G". The same polynucleotide can be structurally modified from "ATCG" to "ATCCCG". Here, the dinucleotide "CC" has been inserted, resulting in a structural modification to the polynucleotide.
[0125] Therapeutic compositions of the present disclosure comprise, in some embodiments, at least one nucleic acid (e.g., RNA) having an open reading frame encoding an IgAP protein, wherein the nucleic acid comprises nucleotides and/or
nucleosides that can be standard (unmodified) or modified as is known in the art. In some embodiments, nucleotides and nucleosides of the present disclosure comprise modified nucleotides or nucleosides. Such modified nucleotides and nucleosides can be naturally-occurring modified nucleotides and nucleosides or non-naturally occurring modified nucleotides and nucleosides. Such modifications can include those at the sugar, backbone, or nucleobase portion of the nucleotide and/or nucleoside as are recognized in the art.
[0126] In some embodiments, a naturally-occurring modified nucleotide or nucleotide of the disclosure is one as is generally known or recognized in the art. Nonlimiting examples of such naturally occurring modified nucleotides and nucleotides can be found, inter alia, in the widely recognized MODOMICS database.
[0127] In some embodiments, a non-naturally occurring modified nucleotide or nucleoside of the disclosure is one as is generally known or recognized in the art. Nonlimiting examples of such non-naturally occurring modified nucleotides and nucleosides can be found, inter alia, in published US application Nos. PCT7US2012/058519;
PCT/US2013/075177; PCT/US2014/058897; PCT/US2014/058891;
PCT/US2014/070413; PC T7US2015/36773; PCT7US2015/36759; PCT7US2015/36771; or PCT/IB2017/051367 all of which are incorporated by reference herein.
[0128] In some embodiments, at least one RNA (e.g., mRNA) of the present disclosure is not chemically modified and comprises the standard ribonucleotides consisting of adenosine, guanosine, cytosine and uridine. In some embodiments, nucleotides and nucleosides of the present disclosure comprise standard nucleoside residues such as those present in transcribed RNA (e.g. A, G, C, or U). In some embodiments, nucleotides and nucleosides of the present disclosure comprise standard deoxyribonucleosides such as those present in DNA (e.g. dA, dG, dC, or dT).
[0129] Hence, nucleic acids of the disclosure (e.g., DNA nucleic acids and RNA nucleic acids, such as mRNA nucleic acids) can comprise standard nucleotides and nucleosides, naturally-occurring nucleotides and nucleosides, non-naturally-occurring nucleotides and nucleosides, or any combination thereof.
[0130] Nucleic acids of the disclosure (e.g., DNA nucleic acids and RNA nucleic acids, such as mRNA nucleic acids), in some embodiments, comprise various (more than one) different types of standard and/or modified nucleotides and nucleosides. In some embodiments, a particular region of a nucleic acid contains one, two or more (optionally different) types of standard and/or modified nucleotides and nucleosides.
[0131] In some embodiments, a modified RNA nucleic acid (e.g., a modified mRNA nucleic acid), introduced to a cell or organism, exhibits reduced degradation in the cell or organism, respectively, relative to an unmodified nucleic acid comprising standard nucleotides and nucleosides.
[0132] In some embodiments, a modified RNA nucleic acid (e.g., a modified mRNA nucleic acid), introduced into a cell or organism, may exhibit reduced immunogenicity in the cell or organism, respectively (e.g., a reduced innate response) relative to an unmodified nucleic acid comprising standard nucleotides and nucleosides.
[0133] Nucleic acids (e.g., RNA nucleic acids, such as mRNA nucleic acids), in some embodiments, comprise non-natural modified nucleotides that are introduced during synthesis or post-synthesis of the nucleic acids to achieve desired functions or properties. The modifications may be present on internucleotide linkages, purine or pyrimidine bases, or sugars. The modification may be introduced with chemical synthesis or with a polymerase enzyme at the terminal of a chain or anywhere else in the chain. Any of the regions of a nucleic acid may be chemically modified.
[0134] The present disclosure provides for modified nucleosides and nucleotides of a nucleic acid (e.g., RNA nucleic acids, such as mRNA nucleic acids). A “nucleoside” refers to a compound containing a sugar molecule (e.g., a pentose or ribose) or a derivative thereof in combination with an organic base (e.g., a purine or pyrimidine) or a derivative thereof (also referred to herein as “nucleobase”). A “nucleotide” refers to a nucleoside, including a phosphate group. Modified nucleotides may by synthesized by any useful method, such as, for example, chemically, enzymatically, or recombinantly, to include one or more modified or non-natural nucleosides. Nucleic acids can comprise a region or regions of linked nucleosides. Such regions may have variable backbone
linkages. The linkages can be standard phosphodiester linkages, in which case the nucleic acids would comprise regions of nucleotides.
[0135] Modified nucleotide base pairing encompasses not only the standard adenosine-thymine, adenosine-uracil, or guanosine-cytosine base pairs, but also base pairs formed between nucleotides and/or modified nucleotides comprising non-standard or modified bases, wherein the arrangement of hydrogen bond donors and hydrogen bond acceptors permits hydrogen bonding between a non-standard base and a standard base or between two complementary non-standard base structures, such as, for example, in those nucleic acids having at least one chemical modification. One example of such nonstandard base pairing is the base pairing between the modified nucleotide inosine and adenine, cytosine or uracil. Any combination of base/ sugar or linker may be incorporated into nucleic acids of the present disclosure.
[0136] In some embodiments, modified nucleobases in nucleic acids (e.g., RNA nucleic acids, such as mRNA nucleic acids) comprise Nl-methyl-pseudouri dine (mlΨ), 1-ethyl-pseudouridine (elΨ), 5-methoxy-uridine (mo5U), 5-methyl-cytidine (m5C), and/or pseudouridine (Ψ). In some embodiments, modified nucleobases in nucleic acids e.g., RNA nucleic acids, such as mRNA nucleic acids) comprise 5 -methoxy methyl uridine, 5-methylthio uridine, 1 -methoxymethyl pseudouridine, 5-methyl cytidine, and/or 5-methoxy cytidine. In some embodiments, the polyribonucleotide includes a combination of at least two (e.g., 2, 3, 4 or more) of any of the aforementioned modified nucleobases, including but not limited to chemical modifications.
[0137] In some embodiments, a RNA nucleic acid of the disclosure comprises Nl- methyl-pseudouri dine (mlΨ) substitutions at one or more or all uridine positions of the nucleic acid.
[0138] In some embodiments, a RNA nucleic acid of the disclosure comprises Nl- methyl-pseudouri dine (mlΨ) substitutions at one or more or all uridine positions of the nucleic acid and 5-methyl cytidine substitutions at one or more or all cytidine positions of the nucleic acid.
[0139] In some embodiments, a RNA nucleic acid of the disclosure comprises pseudouridine (Ψ) substitutions at one or more or all uridine positions of the nucleic acid. [0140] In some embodiments, a RNA nucleic acid of the disclosure comprises pseudouridine (Ψ) substitutions at one or more or all uridine positions of the nucleic acid and 5-methyl cytidine substitutions at one or more or all cytidine positions of the nucleic acid.
[0141] In some embodiments, a RNA nucleic acid of the disclosure comprises uridine at one or more or all uridine positions of the nucleic acid.
[0142] In some embodiments, nucleic acids (e.g., RNA nucleic acids, such as mRNA nucleic acids) are uniformly modified (e.g., fully modified, modified throughout the entire sequence) for a particular modification. For example, a nucleic acid can be uniformly modified with Nl-methyl-pseudouri dine, meaning that all uridine residues in the mRNA sequence are replaced with Nl-methyl-pseudouridine. Similarly, a nucleic acid can be uniformly modified for any type of nucleoside residue present in the sequence by replacement with a modified residue such as those set forth above.
[0143] The nucleic acids of the present disclosure may be partially or fully modified along the entire length of the molecule. For example, one or more or all or a given type of nucleotide (e.g., purine or pyrimidine, or any one or more or all of A, G, U, C) may be uniformly modified in a nucleic acid of the disclosure, or in a predetermined sequence region thereof (e.g., in the mRNA including or excluding the polyA tail). In some embodiments, all nucleotides X in a nucleic acid of the present disclosure (or in a sequence region thereof) are modified nucleotides, wherein X may be any one of nucleotides A, G, U, C, or any one of the combinations A+G, A+U, A+C, G+U, G+C, U+C, A+G+U, A+G+C, G+U+C or A+G+C.
[0144] The nucleic acid may contain from about 1% to about 100% modified nucleotides (either in relation to overall nucleotide content, or in relation to one or more types of nucleotide, i.e., any one or more of A, G, U or C) or any intervening percentage (e.g., from 1% to 20%, from 1% to 25%, from 1% to 50%, from 1% to 60%, from 1% to 70%, from 1% to 80%, from 1% to 90%, from 1% to 95%, from 10% to 20%, from 10%
to 25%, from 10% to 50%, from 10% to 60%, from 10% to 70%, from 10% to 80%, from 10% to 90%, from 10% to 95%, from 10% to 100%, from 20% to 25%, from 20% to 50%, from 20% to 60%, from 20% to 70%, from 20% to 80%, from 20% to 90%, from 20% to 95%, from 20% to 100%, from 50% to 60%, from 50% to 70%, from 50% to 80%, from 50% to 90%, from 50% to 95%, from 50% to 100%, from 70% to 80%, from 70% to 90%, from 70% to 95%, from 70% to 100%, from 80% to 90%, from 80% to 95%, from 80% to 100%, from 90% to 95%, from 90% to 100%, and from 95% to 100%). It will be understood that any remaining percentage is accounted for by the presence of unmodified A, G, U, or C.
[0145] The nucleic acids may contain at a minimum 1% and at maximum 100% modified nucleotides, or any intervening percentage, such as at least 5% modified nucleotides, at least 10% modified nucleotides, at least 25% modified nucleotides, at least 50% modified nucleotides, at least 80% modified nucleotides, or at least 90% modified nucleotides. For example, the nucleic acids may contain a modified pyrimidine such as a modified uracil or cytosine. In some embodiments, at least 5%, at least 10%, at least 25%, at least 50%, at least 80%, at least 90% or 100% of the uracil in the nucleic acid is replaced with a modified uracil (e.g., a 5-substituted uracil). The modified uracil can be replaced by a compound having a single unique structure, or can be replaced by a plurality of compounds having different structures (e.g., 2, 3, 4 or more unique structures). In some embodiments, at least 5%, at least 10%, at least 25%, at least 50%, at least 80%, at least 90% or 100% of the cytosine in the nucleic acid is replaced with a modified cytosine (e.g., a 5-substituted cytosine). The modified cytosine can be replaced by a compound having a single unique structure, or can be replaced by a plurality of compounds having different structures (e.g., 2, 3, 4 or more unique structures).
Untranslated Regions (UTRs)
[0146] Untranslated regions (UTRs) are nucleic acid sections of a polynucleotide before a start codon (5' UTR) and after a stop codon (3' UTR) that are not translated. In some embodiments, a polynucleotide (e.g., a ribonucleic acid (RNA), e.g., a messenger
RNA (mRNA)) of the invention comprising an open reading frame (ORF) encoding an IgAP protein described herein further comprises UTR (e.g., a 5' UTR or functional fragment thereof, a 3' UTR or functional fragment thereof, or a combination thereof). [0147] A UTR (e.g., 5' UTR or 3' UTR) can be homologous or heterologous to the coding region in a polynucleotide. In some embodiments, the UTR is homologous to the ORF encoding the IgAP protein. In some embodiments, the UTR is heterologous to the ORF encoding the IgAP protein.
[0148] In some embodiments, the polynucleotide comprises two or more 5' UTRs or functional fragments thereof, each of which has the same or different nucleotide sequences. In some embodiments, the polynucleotide comprises two or more 3' UTRs or functional fragments thereof, each of which has the same or different nucleotide sequences.
[0149] In some embodiments, the 5' UTR or functional fragment thereof, 3' UTR or functional fragment thereof, or any combination thereof is sequence optimized.
[0150] In some embodiments, the 5 'UTR or functional fragment thereof, 3’ UTR or functional fragment thereof, or any combination thereof comprises at least one chemically modified nucleobase, e.g., N1 -methylpseudouracil or 5 -methoxyuracil.
[0151] UTRs can have features that provide a regulatory role, e.g., increased or decreased stability, localization and/or translation efficiency. A polynucleotide comprising a UTR can be administered to a cell, tissue, or organism, and one or more regulatory features can be measured using routine methods. In some embodiments, a functional fragment of a 5' UTR or 3' UTR comprises one or more regulatory features of a full length 5' or 3' UTR, respectively.
[0152] Natural 5 'UTRs bear features that play roles in translation initiation. They harbor signatures like Kozak sequences that are commonly known to be involved in the process by which the ribosome initiates translation of many genes. Kozak sequences have the consensus CCR(A/G)CCAUGG, where R is a purine (adenine or guanine) three bases upstream of the start codon (AUG), which is followed by another ‘G’. 5' UTRs also have been known to form secondary structures that are involved in elongation factor binding.
[0153] By engineering the features typically found in abundantly expressed genes of specific target organs, one can enhance the stability and protein production of a polynucleotide. For example, introduction of 5' UTR of liver-expressed mRNA, such as albumin, serum amyloid A, Apolipoprotein A/B/E, transferrin, alpha fetoprotein, erythropoietin, or Factor VIII, can enhance expression of polynucleotides in hepatic cell lines or liver. Likewise, use of 5 'UTR from other tissue-specific mRNA to improve expression in that tissue is possible for muscle (e.g., MyoD, Myosin, Myoglobin, Myogenin, Herculin), for endothelial cells (e.g., Tie-1, CD36), for myeloid cells (e.g., C/EBP, AML1, G-CSF, GM-CSF, CDl lb, MSR, Fr-1, i-NOS), for leukocytes e.g., CD45, CD18), for adipose tissue (e.g., CD36, GLUT4, ACRP30, adiponectin) and for lung epithelial cells (e.g., SP-A/B/C/D).
[0154] In some embodiments, UTRs are selected from a family of transcripts whose proteins share a common function, structure, feature or property. For example, an encoded polypeptide can belong to a family of proteins (i.e., that share at least one function, structure, feature, localization, origin, or expression pattern), which are expressed in a particular cell, tissue or at some time during development. The UTRs from any of the genes or mRNA can be swapped for any other UTR of the same or different family of proteins to create a new polynucleotide.
[0155] In some embodiments, the 5' UTR and the 3' UTR can be heterologous. In some embodiments, the 5’ UTR can be derived from a different species than the 3' UTR. In some embodiments, the 3' UTR can be derived from a different species than the 5' UTR.
[0156] Co-owned International Patent Application No. PCT/US2014/021522 (Publ. No. WO 2014/164253, incorporated herein by reference in its entirety) provides a listing of exemplary UTRs that can be utilized in the polynucleotide of the present invention as flanking regions to an ORF.
[0157] Additional exemplary UTRs of the application include, but are not limited to, one or more 5 'UTR and/or 3 'UTR derived from the nucleic acid sequence of: a globin, such as an a- or P-globin (e.g., aXenopus, mouse, rabbit, or human globin); a strong
Kozak translational initiation signal; a CYBA (e.g., human cytochrome b-245 a polypeptide); an albumin (e.g., human albumin?); a HSD17B4 (hydroxysteroid (17-0) dehydrogenase); a virus e.g., a tobacco etch virus (TEV), a Venezuelan equine encephalitis virus (VEEV), a Dengue virus, a cytomegalovirus (CMV) (e.g., CMV immediate early 1 (IE1)), a hepatitis virus (e.g., hepatitis B virus), a sindbis virus, or a PAV barley yellow dwarf virus); a heat shock protein (e.g., hsp70); a translation initiation factor (e.g., elF4G); a glucose transporter (e.g., hGLUTl (human glucose transporter 1)); an actin (e.g., human a or 0 actin); a GAPDH; a tubulin; a histone; a citric acid cycle enzyme; a topoisomerase (e.g., a 5'UTR of a TOP gene lacking the 5' TOP motif (the oligopyrimidine tract)); a ribosomal protein Large 32 (L32); a ribosomal protein (e.g., human or mouse ribosomal protein, such as, for example, rps9); an ATP synthase (e.g., ATP5A1 or the 0 subunit of mitochondrial H+-ATP synthase); a growth hormone e (e.g., bovine (bGH) or human (hGH)); an elongation factor (e.g., elongation factor 1 al (EEF1A1)); a manganese superoxide dismutase (MnSOD); a myocyte enhancer factor 2A (MEF2A); a 0-Fl-ATPase, a creatine kinase, a myoglobin, a granulocyte-colony stimulating factor (G-CSF); a collagen (e.g., collagen type I, alpha 2 (CollA2), collagen type I, alpha 1 (Coll Al), collagen type VI, alpha 2 (Col6A2), collagen type VI, alpha 1 (C0I6AI)); a ribophorin (e.g., ribophorin I (RPNI)); a low density lipoprotein receptor- related protein (e.g., LRP1); a cardiotrophin-like cytokine factor (e.g., Nntl); calreticulin (Calr); a procollagen-lysine, 2-oxoglutarate 5-dioxygenase 1 (Plodl); and a nucleobindin (e.g., Nucbl).
[0158] In some embodiments, the 5' UTR is selected from the group consisting of a 0-globin 5' UTR; a 5'UTR containing a strong Kozak translational initiation signal; a cytochrome b-245 a polypeptide (CYBA) 5' UTR; a hydroxysteroid (17-0) dehydrogenase (HSD17B4) 5' UTR; a Tobacco etch virus (TEV) 5' UTR; a Venezuelen equine encephalitis virus (TEEV) 5' UTR; a 5' proximal open reading frame of rubella virus (RV) RNA encoding nonstructural proteins; a Dengue virus (DEN) 5' UTR; a heat shock protein 70 (Hsp70) 5' UTR; a eIF4G 5' UTR; a GLUT1 5’ UTR; functional fragments thereof and any combination thereof.
[0159] In some embodiments, the 3' UTR is selected from the group consisting of a P-globin 3' UTR; a CYBA 3' UTR; an albumin 3' UTR; a growth hormone (GH) 3' UTR; a VEEV 3' UTR; a hepatitis B virus (HBV) 3' UTR; a-globin 3 'UTR; a DEN 3' UTR; a PAV barley yellow dwarf virus (BYDV-PAV) 3' UTR; an elongation factor 1 al (EEF1A1) 3' UTR; a manganese superoxide dismutase (MnSOD) 3' UTR; a p subunit of mitochondrial H(+)-ATP synthase (P-mRNA) 3' UTR; a GLUT1 3' UTR; a MEF2A 3' UTR; a P-F 1-ATPase 3 ' UTR; functional fragments thereof and combinations thereof. [0160] Wild-type UTRs derived from any gene or mRNA can be incorporated into the polynucleotides of the invention. In some embodiments, a UTR can be altered relative to a wild type or native UTR to produce a variant UTR, e.g., by changing the orientation or location of the UTR relative to the ORF; or by inclusion of additional nucleotides, deletion of nucleotides, swapping or transposition of nucleotides. In some embodiments, variants of 5' or 3' UTRs can be utilized, for example, mutants of wild type UTRs, or variants wherein one or more nucleotides are added to or removed from a terminus of the UTR.
[0161] Additionally, one or more synthetic UTRs can be used in combination with one or more non-synthetic UTRs. See, e.g., Mandal and Rossi, Nat. Protoc. 2013 8(3): 568-82, the contents of which are incorporated herein by reference in their entirety. [0162] UTRs or portions thereof can be placed in the same orientation as in the transcript from which they were selected or can be altered in orientation or location. Hence, a 5' and/or 3' UTR can be inverted, shortened, lengthened, or combined with one or more other 5' UTRs or 3' UTRs.
[0163] In some embodiments, the polynucleotide comprises multiple UTRs, e.g., a double, a triple or a quadruple 5' UTR or 3' UTR. For example, a double UTR comprises two copies of the same UTR either in series or substantially in series. For example, a double beta-globin 3'UTR can be used (see US2010/0129877, the contents of which are incorporated herein by reference in its entirety).
[0164] The polynucleotides of the invention can comprise combinations of features.
For example, the ORF can be flanked by a 5 'UTR that comprises a strong Kozak
translational initiation signal and/or a 3'UTR comprising an oligo(dT) sequence for templated addition of a poly-A tail. A 5'UTR can comprise a first polynucleotide fragment and a second polynucleotide fragment from the same and/or different UTRs (see, e.g., US2010/0293625, herein incorporated by reference in its entirety).
[0165] Other non-UTR sequences can be used as regions or subregions within the polynucleotides of the invention. For example, introns or portions of intron sequences can be incorporated into the polynucleotides of the invention. Incorporation of intronic sequences can increase protein production as well as polynucleotide expression levels. In some embodiments, the polynucleotide of the invention comprises an internal ribosome entry site (IRES) instead of or in addition to a UTR (see, e.g., Yakubov et al., Biochem. Biophys. Res. Commun. 2010 394(1): 189-193, the contents of which are incorporated herein by reference in their entirety). In some embodiments, the polynucleotide comprises an IRES instead of a 5' UTR sequence. In some embodiments, the polynucleotide comprises an ORF and a viral capsid sequence. In some embodiments, the polynucleotide comprises a synthetic 5' UTR in combination with a non-synthetic 3 ' UTR.
[0166] In some embodiments, the UTR can also include at least one translation enhancer polynucleotide, translation enhancer element, or translational enhancer elements (collectively, "TEE," which refers to nucleic acid sequences that increase the amount of polypeptide or protein produced from a polynucleotide. As a non-limiting example, the TEE can be located between the transcription promoter and the start codon. In some embodiments, the 5' UTR comprises a TEE.
[0167] In one aspect, a TEE is a conserved element in a UTR that can promote translational activity of a nucleic acid such as, but not limited to, cap-dependent or capindependent translation.
5' UTR sequences
[0168] 5' UTR sequences are important for ribosome recruitment to the mRNA and have been reported to play a role in translation (Hinnebusch A, et al., (2016) Science, 352:6292: 1413-6).
[0169] Disclosed herein, inter alia, is a polynucleotide, e.g., mRNA, comprising an open reading frame encoding an IgAP protein described herein, which polynucleotide has a 5' UTR that confers an increased half-life, increased expression and/or increased activity of the polypeptide encoded by said polynucleotide, or of the polynucleotide itself. In an embodiment, a polynucleotide disclosed herein comprises: (a) a 5'-UTR (e.g., as provided in Table 1 or a variant or fragment thereof); (b) a coding region comprising a stop element (e.g., as described herein); and (c) a 3'-UTR (e.g., as described herein), and LNP compositions comprising the same. In an embodiment, the polynucleotide comprises a 5'-UTR comprising a sequence provided in Table 1 or a variant or fragment thereof (e.g., a functional variant or fragment thereof). In an embodiment, the polynucleotide comprises a 5'-UTR comprising the sequence of SEQ ID NO:58.
[0170] In an embodiment, the polynucleotide having a 5' UTR sequence provided in Table 1 or a variant or fragment thereof, has an increase in the half-life of the polynucleotide, e.g., about 1.5-20-fold increase in half-life of the polynucleotide. In an embodiment, the increase in half-life is about 1.5, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 or 20-fold, or more. In an embodiment, the increase in half life is about 1.5-fold or more. In an embodiment, the increase in half life is about 2-fold or more. In an embodiment, the increase in half life is about 3-fold or more. In an embodiment, the increase in half life is about 4-fold or more. In an embodiment, the increase in half life is about 5-fold or more.
[0171] In an embodiment, the polynucleotide having a 5' UTR sequence provided in Table 1 or a variant or fragment thereof, results in an increased level and/or activity, e.g., output, of the polypeptide encoded by the polynucleotide. In an embodiment, the 5 'UTR results in about 1.5-20-fold increase in level and/or activity, e.g., output, of the polypeptide encoded by the polynucleotide. In an embodiment, the increase in level and/or activity is about 1.5, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 or
20-fold, or more. In an embodiment, the increase in level and/or activity is about 1.5-fold or more. In an embodiment, the increase in level and/or activity is about 2-fold or more. In an embodiment, the increase in level and/or activity is about 3-fold or more. In an embodiment, the increase in level and/or activity is about 4-fold or more. In an embodiment, the increase in level and/or activity is about 5-fold or more.
[0172] In an embodiment, the increase is compared to an otherwise similar polynucleotide which does not have a 5' UTR, has a different 5' UTR, or does not have a 5' UTR described in Table 1 or a variant or fragment thereof.
[0173] In an embodiment, the increase in half-life of the polynucleotide is measured according to an assay that measures the half-life of a polynucleotide.
[0174] In an embodiment, the increase in level and/or activity, e.g., output, of the polypeptide encoded by the polynucleotide is measured according to an assay that measures the level and/or activity of a polypeptide.
[0175] In an embodiment, the 5' UTR comprises a sequence provided in Table 1 or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to a 5' UTR sequence provided in Table 1, or a variant or a fragment thereof. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, SEQ ID NO: 55, SEQ ID NO: 56, SEQ ID NO: 57, or SEQ ID NO: 58.
[0176] In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 50. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 51. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 52. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 53. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 54. In an embodiment, the 5'
UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 55. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 56. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 57. In an embodiment, the 5' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 58.
[0177] In an embodiment, the 5' UTR comprises the sequence of SEQ ID NO:58. In an embodiment, the 5' UTR consists of the sequence of SEQ ID NO:58.
[0178] In an embodiment, a 5' UTR sequence provided in Table 1 has a first nucleotide which is an A. In an embodiment, a 5' UTR sequence provided in Table 1 has a first nucleotide which is a G.
Table 1: 5' UTR sequences




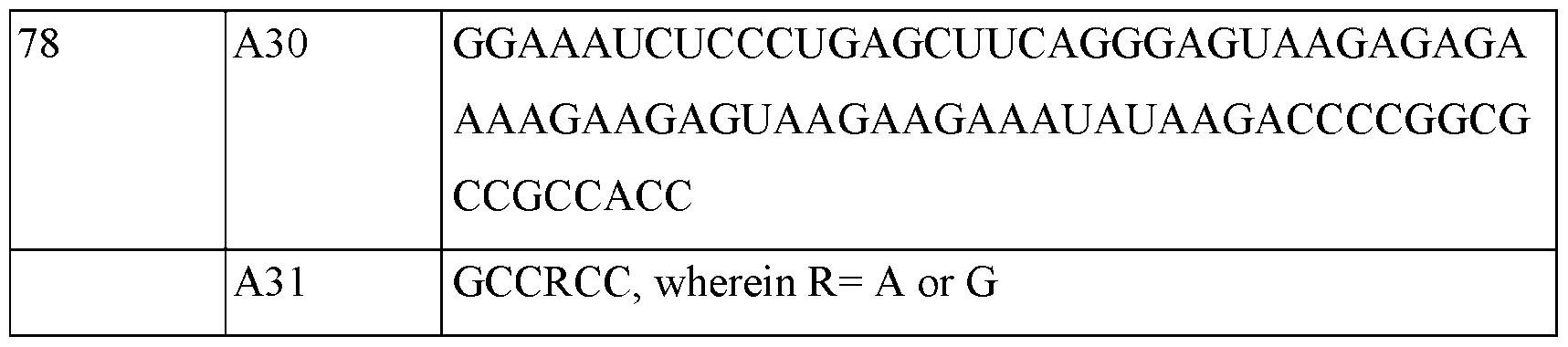
[0179] In an embodiment, the 5' UTR comprises a variant of SEQ ID NO: 50. In an embodiment, the variant of SEQ ID NO: 50 comprises a nucleic acid sequence of Formula A:
GGAAAUCGC AAAA(N2)x(N3)xCU(N4)x(N5)xCGC GUUAGAUUU CUUUUAGUUUUCUNeN C A ACU AGC AAGCUUUUUGUUCU C GC C (Ns C C)x (SEQ ID NO: 59), wherein:
(N2)X is a uracil and x is an integer from 0 to 5, e.g., wherein x =3 or 4;
(Ns)x is a guanine and x is an integer from 0 to 1;
(N4)X is a cytosine and x is an integer from 0 to 1;
(Ns)x is a uracil and x is an integer from 0 to 5, e.g., wherein x =2 or 3;
NG is a uracil or cytosine;
N7 is a uracil or guanine;
Ns is adenine or guanine and x is an integer from 0 to 1.
[0180] In an embodiment (N2)X is a uracil and x is 0. In an embodiment (N2)X is a uracil and x is 1. In an embodiment (N2)x is a uracil and x is 2. In an embodiment (N2)x is a uracil and x is 3. In an embodiment, (N2)x is a uracil and x is 4. In an embodiment (N2)x is a uracil and x is 5.
[0181] In an embodiment, (Ns)x is a guanine and x is 0. In an embodiment, (Na)x is a guanine and x is 1.
[0182] In an embodiment, (N4)x is a cytosine and x is 0. In an embodiment, (N4)x is a cytosine and x is 1.
[0183] In an embodiment (Ns)x is a uracil and x is 0. In an embodiment (Ns)x is a uracil and x is 1. In an embodiment (Ns)x is a uracil and x is 2. In an embodiment (Ns)x is a uracil and x is 3. In an embodiment, (Ns)x is a uracil and x is 4. In an embodiment (Ns)x is a uracil and x is 5.
[0184] In an embodiment, Nr> is a uracil. In an embodiment, Ne is a cytosine. [0185] In an embodiment, N? is a uracil. In an embodiment, N? is a guanine. [0186] In an embodiment, Ns is an adenine and x is 0. In an embodiment, Ns is an adenine and x is 1.
[0187] In an embodiment, Ns is a guanine and x is 0. In an embodiment, Ns is a guanine and x is 1.
[0188] In an embodiment, the 5' UTR comprises a variant of SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 58%, 60%, 70%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, or 99% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 58% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 60% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 70% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 80% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 90% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 95% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 96% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 97% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 98% identity to SEQ ID NO: 58. In an embodiment, the variant of SEQ ID NO: 58 comprises a sequence with at least 99% identity to SEQ ID NO: 58.
[0189] In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 5%, 10%, 20%, 30%, 40%, 58%, 60%, 70%, or 80%. In an embodiment, the
variant of SEQ ID NO: 58 comprises a uridine content of at least 5%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 10%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 20%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 30%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 40%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 58%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 60%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 70%. In an embodiment, the variant of SEQ ID NO: 58 comprises a uridine content of at least 80%.
[0190] In an embodiment, the variant of SEQ ID NO: 58 comprises at least 2, 3, 4, 5, 6 or 7 consecutive uridines (e.g., a polyuridine tract). In an embodiment, the polyuridine tract in the variant of SEQ ID NO: 58 comprises at least 1-7, 2-7, 3-7, 4-7, 5-7, 6-7, 1-6, 1-5, 1-4, 1-3, 1-2, 2-6, or 3-5 consecutive uridines. In an embodiment, the polyuridine tract in the variant of SEQ ID NO: 58 comprises 4 consecutive uridines. In an embodiment, the polyuridine tract in the variant of SEQ ID NO: 58 comprises 5 consecutive uridines.
[0191] In an embodiment, the variant of SEQ ID NO: 58 comprises 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, or 15 polyuridine tracts. In an embodiment, the variant of SEQ ID NO: 58 comprises 3 polyuridine tracts. In an embodiment, the variant of SEQ ID NO: 58 comprises 4 polyuridine tracts. In an embodiment, the variant of SEQ ID NO: 58 comprises 5 polyuridine tracts.
[0192] In an embodiment, one or more of the polyuridine tracts are adjacent to a different polyuridine tract. In an embodiment, each of, e.g, all, the polyuridine tracts are adjacent to each other, e.g., all of the polyuridine tracts are contiguous.
[0193] In an embodiment, one or more of the polyuridine tracts are separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18. 19, 20, 30, 40, 50 or 60 nucleotides. In an embodiment, each of, e.g., all of, the polyuridine tracts are separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18. 19, 20, 30, 40, 50 or 60 nucleotides.
[0194] In an embodiment, a first polyuridine tract and a second polyuridine tract are adjacent to each other.
[0195] In an embodiment, a subsequent, e.g., third, fourth, fifth, sixth or seventh, eighth, ninth, or tenth, polyuridine tract is separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18. 19, 20, 30, 40, 50 or 60 nucleotides from the first polyuridine tract, the second polyuridine tract, or any one of the subsequent polyuridine tracts.
[0196] In an embodiment, a first polyuridine tract is separated by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18. 19, 20, 30, 40, 50 or 60 nucleotides from a subsequent polyuridine tract, e.g., a second, third, fourth, fifth, sixth or seventh, eighth, ninth, or tenth polyuridine tract. In an embodiment, one or more of the subsequent polyuridine tracts are adjacent to a different polyuridine tract.
[0197] In an embodiment, the 5' UTR comprises a Kozak sequence, e.g., a GCCRCC nucleotide sequence wherein R is an adenine or guanine. In an embodiment, the Kozak sequence is disposed at the 3' end of the 5 'UTR sequence.
[0198] In an aspect, the polynucleotide (e.g., mRNA) comprising an open reading frame encoding an IgAP protein and comprising a 5' UTR sequence disclosed herein is formulated as an LNP. In an embodiment, the LNP composition comprises: (i) an ionizable lipid, e.g., an amino lipid; (ii) a sterol or other structural lipid; (iii) a noncationic helper lipid or phospholipid; and (iv) a PEG-lipid.
[0199] In another aspect, the LNP compositions of the disclosure are used in a method of treating IgAN in a subject.
[0200] In an aspect, an LNP composition comprising a polynucleotide disclosed herein encoding an IgAP protein, e.g., as described herein, can be administered with an additional agent, e.g., as described herein.
3' UTR sequences
[0201] 3 UTR sequences have been shown to influence translation, half-life, and subcellular localization of mRNAs (Mayr C., Cold Spring Harb Persp Biol 2019 Oct 1;1 l(10):a034728).
[0202] Disclosed herein, inter alia, is a polynucleotide, e.g., mRNA, comprising an open reading frame encoding an IgAP protein described herein, which polynucleotide has a 3' UTR that confers an increased half-life, increased expression and/or increased activity of the polypeptide encoded by said polynucleotide, or of the polynucleotide itself. In an embodiment, a polynucleotide disclosed herein comprises: (a) a 5'-UTR (e.g., as described herein); (b) a coding region comprising a stop element (e.g., as described herein); and (c) a 3'-UTR (e.g., as provided in Table 2 or a variant or fragment thereof), and LNP compositions comprising the same. In an embodiment, the polynucleotide comprises a 3'-UTR comprising a sequence provided in Table 2 or a variant or fragment thereof.
[0203] In an embodiment, the polynucleotide having a 3' UTR sequence provided in Table 2 or a variant or fragment thereof, results in an increased half-life of the polynucleotide, e.g., about 1.5-10-fold increase in half-life of the polynucleotide. In an embodiment, the increase in half-life is about 1.5, 2, 3, 4, 5, 6, 7, 8, 9, or 10-fold, or more. In an embodiment, the increase in half-life is about 1.5-fold or more. In an embodiment, the increase in half-life is about 2-fold or more. In an embodiment, the increase in half-life is about 3-fold or more. In an embodiment, the increase in half-life is about 4-fold or more. In an embodiment, the increase in half-life is about 5-fold or more. In an embodiment, the increase in half-life is about 6-fold or more. In an embodiment, the increase in half-life is about 7-fold or more. In an embodiment, the increase in half-life is about 8-fold. In an embodiment, the increase in half-life is about 9-fold or more. In an embodiment, the increase in half-life is about 10-fold or more.
[0204] In an embodiment, the polynucleotide having a 3' UTR sequence provided in Table 2 or a variant or fragment thereof, results in a polynucleotide with a mean half-life score of greater than 10.
[0205] In an embodiment, the polynucleotide having a 3' UTR sequence provided in Table 2 or a variant or fragment thereof, results in an increased level and/or activity, e.g., output, of the polypeptide encoded by the polynucleotide.
[0206] In an embodiment, the increase is compared to an otherwise similar polynucleotide which does not have a 3' UTR, has a different 3' UTR, or does not have a 3 ' UTR of Table 2 or a variant or fragment thereof.
[0207] In an embodiment, the polynucleotide comprises a 3' UTR sequence provided in Table 2 or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to a 3' UTR sequence provided in Table 2, or a fragment thereof. In an embodiment, the 3' UTR comprises a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 100, SEQ ID NO: 101, SEQ ID NO: 102, SEQ ID NO: 103, SEQ ID NO: 104, SEQ ID NO: 105, SEQ ID NO: 106, SEQ ID NO: 107, SEQ ID NO: 108, SEQ ID NO: 109, SEQ ID NO: 110, SEQ ID NO: 111, SEQ ID NO: 112, SEQ ID NO: 113, SEQ ID NO: 114, SEQ ID NO:115, or SEQ ID NO: 137. [0208] In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 100, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 100. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 101, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 101. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 102, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 102. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 103, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 103. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 104, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 104. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 105, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 105. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 106, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 106. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 107, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 107. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO:
108, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 108. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 109, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 109. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 110, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 110. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 111, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 111. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 112, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 112. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 113, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 113. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 114, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 114. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 115, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 115. In an embodiment, the 3' UTR comprises the sequence of SEQ ID NO: 115, or a sequence with at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to SEQ ID NO: 137.





[0209] In an embodiment, the 3' UTR comprises a micro RNA (miRNA) binding site, e.g., as described herein, which binds to a miR present in a human cell. In an embodiment, the 3' UTR comprises a miRNA binding site of SEQ ID NO: 212, SEQ ID NO: 174, SEQ ID NO: 152 or a combination thereof. In an embodiment, the 3' UTR comprises a plurality of miRNA binding sites, e.g., 2, 3, 4, 5, 6, 7 or 8 miRNA binding sites. In an embodiment, the plurality of miRNA binding sites comprises the same or different miRNA binding sites. miR122 bs = CAAACACCAUUGUCACACUCCA (SEQ ID NO: 212) miR-142-3p bs = UCCAUAAAGUAGGAAACACUACA (SEQ ID NO: 174) miR-126 bs = CGCAUUAUUACUCACGGUACGA (SEQ ID NO: 152)
[0210] In an aspect, disclosed herein is a polynucleotide encoding a polypeptide, wherein the polynucleotide comprises: (a) a 5'-UTR, e.g., as described herein; (b) a
coding region comprising a stop element (e.g., as described herein); and (c) a 3'-UTR (e.g., as described herein).
[0211] In an aspect, an LNP composition comprising a polynucleotide comprising an open reading frame encoding an IgAP protein and comprising a 3' UTR disclosed herein comprises: (i) an ionizable lipid, e.g., an amino lipid; (ii) a sterol or other structural lipid; (iii) a non-cationic helper lipid or phospholipid; and (iv) a PEG-lipid.
[0212] In another aspect, the LNP compositions of the disclosure are used in a method of treating IgAN in a subject.
[0213] In an aspect, an LNP composition comprising a polynucleotide disclosed herein encoding an IgAP protein, e.g., as described herein, can be administered with an additional agent, e.g., as described herein.
Regions having a 5' Cap
[0214] The disclosure also includes a polynucleotide that comprises both a 5' Cap and a polynucleotide of the present invention (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein to be expressed).
[0215] The 5' cap structure of a natural mRNA is involved in nuclear export, increasing mRNA stability and binds the mRNA Cap Binding Protein (CBP), which is responsible for mRNA stability in the cell and translation competency through the association of CBP with poly(A) binding protein to form the mature cyclic mRNA species. The cap further assists the removal of 5' proximal introns during mRNA splicing. [0216] Endogenous mRNA molecules can be 5'-end capped generating a 5'-ppp-5'- triphosphate linkage between a terminal guanosine cap residue and the 5 '-terminal transcribed sense nucleotide of the mRNA molecule. This 5 '-guanylate cap can then be methylated to generate an N7-methyl-guanylate residue. The ribose sugars of the terminal and/or anteterminal transcribed nucleotides of the 5' end of the mRNA can optionally also be 2'-O-methylated. 5 '-decapping through hydrolysis and cleavage of the guanylate cap structure can target a nucleic acid molecule, such as an mRNA molecule, for degradation.
[0217] In some embodiments, the polynucleotides of the present invention (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein) incorporate a cap moiety.
[0218] In some embodiments, polynucleotides of the present invention comprise a non-hydrolyzable cap structure preventing decapping and thus increasing mRNA halflife. Because cap structure hydrolysis requires cleavage of 5 '-ppp-5' phosphorodiester linkages, modified nucleotides can be used during the capping reaction. For example, a Vaccinia Capping Enzyme from New England Biolabs (Ipswich, MA) can be used with a-thio-guanosine nucleotides according to the manufacturer's instructions to create a phosphorothioate linkage in the 5 '-ppp-5' cap. Additional modified guanosine nucleotides can be used such as a-methyl -phosphonate and seleno-phosphate nucleotides.
[0219] Additional modifications include, but are not limited to, 2'-O-methylation of the ribose sugars of 5 '-terminal and/or 5'-anteterminal nucleotides of the polynucleotide (as mentioned above) on the 2'-hydroxyl group of the sugar ring. Multiple distinct 5 '-cap structures can be used to generate the 5 '-cap of a nucleic acid molecule, such as a polynucleotide that functions as an mRNA molecule. Cap analogs, which herein are also referred to as synthetic cap analogs, chemical caps, chemical cap analogs, or structural or functional cap analogs, differ from natural (i.e., endogenous, wild-type or physiological) 5 '-caps in their chemical structure, while retaining cap function. Cap analogs can be chemically (i.e., non-enzymatically) or enzymatically synthesized and/or linked to the polynucleotides of the invention.
[0220] For example, the Anti-Reverse Cap Analog (ARCA) cap contains two guanines linked by a 5 '-5 '-triphosphate group, wherein one guanine contains an N7 methyl group as well as a 3'-O-methyl group (z.e., N7,3'-O-dimethyl-guanosine-5'- triphosphate-5 '-guanosine (m7G-3 'mppp-G; which can equivalently be designated 3' O- Me-m7G(5')ppp(5')G). The 3'-0 atom of the other, unmodified, guanine becomes linked to the 5'-terminal nucleotide of the capped polynucleotide. The N7- and 3 '-O-methlyated guanine provides the terminal moiety of the capped polynucleotide.
[0221] Another exemplary cap is mCAP, which is similar to ARCA but has a 2'-O- methyl group on guanosine (i.e., N7,2'-O-dimethyl-guanosine-5'-triphosphate-5'- guanosine, m7Gm-ppp-G).
[0222] Another exemplary cap is m7G-ppp-Gm-A i.e., N7, guanosine-5 '- triphosphate-2 '-O-dimethyl -guanosine-ad enosine) .
[0223] In some embodiments, the cap is a dinucleotide cap analog. As a non-limiting example, the dinucleotide cap analog can be modified at different phosphate positions with a boranophosphate group or a phosphoroselenoate group such as the dinucleotide cap analogs described in U.S. Patent No. US 8,519,110, the contents of which are herein incorporated by reference in its entirety.
[0224] In another embodiment, the cap is a cap analog is a N7-(4- chlorophenoxyethyl) substituted dinucleotide form of a cap analog known in the art and/or described herein. Non-limiting examples of a N7-(4-chlorophenoxyethyl) substituted dinucleotide form of a cap analog include a N7-(4-chlorophenoxyethyl)- G(5')ppp(5')G and a N7-(4-chlorophenoxyethyl)-m3' °G(5')ppp(5')G cap analog (See, e.g., the various cap analogs and the methods of synthesizing cap analogs described in Kore et al. Bioorganic & Medicinal Chemistry 2013 21 :4570-4574; the contents of which are herein incorporated by reference in its entirety). In another embodiment, a cap analog of the present invention is a 4-chloro/bromophenoxyethyl analog.
[0225] Polynucleotides of the invention can also be capped post-manufacture (whether IVT or chemical synthesis), using enzymes, in order to generate more authentic 5 '-cap structures. As used herein, the phrase "more authentic" refers to a feature that closely mirrors or mimics, either structurally or functionally, an endogenous or wild type feature. That is, a "more authentic" feature is better representative of an endogenous, wild-type, natural or physiological cellular function and/or structure as compared to synthetic features or analogs, etc., of the prior art, or which outperforms the corresponding endogenous, wild-type, natural or physiological feature in one or more respects. Non-limiting examples of more authentic 5 'cap structures of the present invention are those that, among other things, have enhanced binding of cap binding
proteins, increased half-life, reduced susceptibility to 5' endonucleases and/or reduced 5 'decapping, as compared to synthetic 5 'cap structures known in the art (or to a wild-type, natural or physiological 5'cap structure). For example, recombinant Vaccinia Virus Capping Enzyme and recombinant 2’-O-methyltransferase enzyme can create a canonical 5 '-5 '-triphosphate linkage between the 5'-terminal nucleotide of a polynucleotide and a guanine cap nucleotide wherein the cap guanine contains an N7 methylation and the 5'- terminal nucleotide of the mRNA contains a 2'-O-methyl. Such a structure is termed the Capl structure. This cap results in a higher translational -competency and cellular stability and a reduced activation of cellular pro-inflammatory cytokines, as compared, e.g., to other 5'cap analog structures known in the art. Cap structures include, but are not limited to, 7mG(5')ppp(5')NlpN2p (cap 0), 7mG(5')ppp(5')NlmpNp (cap 1), and 7mG(5')- ppp(5')NlmpN2mp (cap 2).
[0226] As a non-limiting example, capping chimeric polynucleotides postmanufacture can be more efficient as nearly 100% of the chimeric polynucleotides can be capped. This is in contrast to -80% when a cap analog is linked to a chimeric polynucleotide in the course of an in vitro transcription reaction.
[0227] According to the present invention, 5' terminal caps can include endogenous caps or cap analogs. According to the present invention, a 5' terminal cap can comprise a guanine analog. Useful guanine analogs include, but are not limited to, inosine, Nl- methyl-guanosine, 2 'fluoro-guanosine, 7-deaza-guanosine, 8-oxo-guanosine, 2-amino- guanosine, LNA-guanosine, and 2-azido-guanosine.
[0228] Also provided herein are exemplary caps including those that can be used in co-transcriptional capping methods for ribonucleic acid (RNA) synthesis, using RNA polymerase, e.g., wild type RNA polymerase or variants thereof, e g., such as those variants described herein. In one embodiment, caps can be added when RNA is produced in a “one-pot” reaction, without the need for a separate capping reaction. Thus, the methods, in some embodiments, comprise reacting a polynucleotide template with an RNA polymerase variant, nucleoside triphosphates, and a cap analog under in vitro transcription reaction conditions to produce RNA transcript.
[0229] As used here the term “cap” includes the inverted G nucleotide and can comprise one or more additional nucleotides 3' of the inverted G nucleotide, e.g., 1, 2, 3, or more nucleotides 3' of the inverted G nucleotide and 5' to the 5' UTR, e.g., a 5' UTR described herein.
[0230] Exemplary caps comprise a sequence of GG, GA, or GGA, wherein the underlined, italicized G is an in inverted G nucleotide followed by a 5 '-5 '-triphosphate group.
[0231] In one embodiment, a cap comprises a compound of formula (I)
 stereoisomer, tautomer or salt thereof, wherein
stereoisomer, tautomer or salt thereof, wherein
 ring Bi is a modified or unmodified Guanine; ring B2 and ring B3 each independently is a nucleobase or a modified nucleobase;
ring Bi is a modified or unmodified Guanine; ring B2 and ring B3 each independently is a nucleobase or a modified nucleobase;
X2 is O, S(O)P, NR24 or CR25R26 in which p is 0, 1, or 2;
Yo is O or CR6R7;
Y1 is O, S(O)n, CR6R7, or NR8, in which n is 0, 1 , or 2;
each — is a single bond or absent, wherein when each — is a single bond, Yi is O, S(O)n, CR.6R7, or NR8; and when each — is absent, Yi is void;
Y2 is (0P(0)R4)m in which m is 0, 1, or 2, or -0-(CR4oR4i)u-Qo-(CR42R43)v-, in which Qo is a bond, O, S(O)r, NR44, or CR45R46, r is 0, 1 , or 2, and each of u and v independently is 1, 2, 3 or 4; each R2 and R2' independently is halo, LNA, or OR3; each R3 independently is H, C1-C6 alkyl, C2-C6 alkenyl, or C2-C6 alkynyl and R3, when being C1-C6 alkyl, C2-C6 alkenyl, or C2-C6 alkynyl, is optionally substituted with one or more of halo, OH and C1-C6 alkoxyl that is optionally substituted with one or more OH or OC(O)-C1-C6 alkyl; each R4 and R4' independently is H, halo, C1-C6 alkyl, OH, SH, SeH, or BH3- each of R6, R7, and R8, independently, is -Q1-T1, in which Qi is a bond or C1-C3 alkyl linker optionally substituted with one or more of halo, cyano, OH and C1-C6 alkoxy, and Ti is H, halo, OH, COOH, cyano, or Rs1, in which Rsi is C1-C3 alkyl, C2-C6 alkenyl, C2-C6 alkynyl, C1- C6 alkoxyl, C(O)O- C1-C6 alkyl, C3-C8 cycloalkyl, C6-C1o aryl, NR31R32, (NR3iR32R33)+, 4 to 12- membered heterocycloalkyl, or 5- or 6-membered heteroaryl, and Rsi is optionally substituted with one or more substituents selected from the group consisting of halo, OH, oxo, C1-C6 alkyl, COOH, C(O)O-C1-C6 alkyl, cyano, C1-C6 alkoxyl, NR31R32, (NR3iR32R33)+, C3-C8 cycloalkyl, C6-C10 aryl, 4 to 12-membered heterocycloalkyl, and 5- or 6-membered heteroaryl; each of R10, R11, R12, R13 R14, and R15, independently, is -Q2-T2, in which Q2 is a bond or C1-C3 alkyl linker optionally substituted with one or more of halo, cyano, OH and C1-C6 alkoxy, and T2 is H, halo, OH, NH2, cyano, NO2, N3, Rs2, or ORs2, in which Rs2 is C1-C6 alkyl, C2-C6 alkenyl, C2-C6 alkynyl, C3-C8 cycloalkyl, C6-C1o aryl, NHC(O)-C1- C6 alkyl, NR31R32, (NR31R32R33)-, 4 to 12-membered heterocycloalkyl, or 5- or 6- membered heteroaryl, and Rs2 is optionally substituted with one or more substituents selected from the group consisting of halo, OH, oxo, C1-C6 alkyl, COOH, C(O)O-C1-C6 alkyl, cyano, C1 - C6 alkoxyl, NR31R32, (NR3iR32R33)+, C3-C8 cycloalkyl, C6-C1o aryl, 4 to
12-membered heterocycloalkyl, and 5- or 6- membered heteroaryl; or alternatively R12 together with R14 is oxo, or R13 together with R15 is oxo, each of R20, R21, R22, and R23 independently is -Q3-T3, in which Q3 is a bond or C1-C3 alkyl linker optionally substituted with one or more of halo, cyano, OH and C1-C6 alkoxy, and T3 is H, halo, OH, NH2, cyano, NO2, N3, Rs3, or ORs3, in which Rs3 is C1- C6 alkyl, C2-C6 alkenyl, C2-C6 alkynyl, C3-C8 cycloalkyl, C6-C1o aryl, NHC(O)-C1- C6 alkyl, mono-C1-C6 alkylamino, di-C1-C6 alkylamino, 4 to 12-membered heterocycloalkyl, or 5- or 6-membered heteroaryl, and Rss is optionally substituted with one or more substituents selected from the group consisting of halo, OH, oxo, C1-C6 alkyl, COOH, C(O)O-C1-C6 alkyl, cyano, C1-C6 alkoxyl, amino, mono-C1-C6 alkylamino, di-C1-C6 alkylamino, C3-C8 cycloalkyl, C6-C1o aryl, 4 to 12-membered heterocycloalkyl, and 5- or 6-membered heteroaryl; each of R24, R25, and R26 independently is H or C1-C6 alkyl; each of R27 and R28 independently is H or OR29; or R27 and R28 together form O- R30-O; each R29 independently is H, C1-C6 alkyl, C2-C6 alkenyl, or C2-C6 alkynyl and R29, when being C1-C6 alkyl, C2-C6 alkenyl, or C2-C6 alkynyl, is optionally substituted with one or more of halo, OH and C1-C6 alkoxyl that is optionally substituted with one or more OH or OC(O)-C1-C6 alkyl; 0 is C1-C6 alkylene optionally substituted with one or more of halo, OH and C1- C6 alkoxyl; each of R31, R2, and R33, independently is H, C1-C6 alkyl, C3-C8 cycloalkyl, C6- C10 aryl, 4 to 12-membered heterocycloalkyl, or 5- or 6-membered heteroaryl; each of R40, R41, R42, and R43 independently is H, halo, OH, cyano, N3, OP(O)R4?R48, or C1-C6 alkyl optionally substituted with one or more OP(O)R4?R48, or one R41 and one R43, together with the carbon atoms to which they are attached and Qo, form C4-C10 cycloalkyl, 4- to 14-membered heterocycloalkyl, C6-C1o aryl, or 5- to 14- membered heteroaryl, and each of the cycloalkyl, heterocycloalkyl, phenyl, or 5- to 6- membered heteroaryl is optionally substituted with one or more of OH, halo, cyano, N3,
oxo, OP(O)R47R48, C1-C6 alkyl, C1-C6 haloalkyl, COOH, C(O)O-C1-C6 alkyl, C1-C6 alkoxyl, C1-C6 haloalkoxyl, amino, mono-C1-C6 alkylamino, and di-C1-C6 alkylamino;
R44 is H, C1-C6 alkyl, or an amine protecting group; each of R45 and R46 independently is H, OP(O)R4?R48, or C1-C6 alkyl optionally substituted with one or more OP(O)R4?R48, and each of R47 and R48, independently is H, halo, C1-C6 alkyl, OH, SH, SeH, or BH3 . [00232] It should be understood that a cap analog, as provided herein, may include any of the cap analogs described in international publication WO 2017/066797, published on 20 April 2017, incorporated by reference herein in its entirety.
[00233] In some embodiments, the B2 middle position can be a non-ribose molecule, such as arabinose.
[00234] In some embodiments R2 is ethyl-based.
[00235] Thus, in some embodiments, a cap comprises the following structure:

[0236] In other embodiments, a cap comprises the following structure:

[00237] In yet other embodiments, a cap comprises the following structure:

[00238] In still other embodiments, a cap comprises the following structure:

[0239] In some embodiments, R is an alkyl (e.g., C1-C6 alkyl). In some embodiments, R is a methyl group e.g., C1 alkyl). In some embodiments, R is an ethyl group (e.g., C2 alkyl).
[0240] In some embodiments, a cap comprises a sequence selected from the following sequences: GAA, GAC, GAG, GAU, GCA, GCC, GCG, GCU, GGA , GGC, GGG, GGU, GUA, GUC, GUG, and GUU. In some embodiments, a cap comprises GAA. In some embodiments, a cap comprises GAC. In some embodiments, a cap comprises GAG. In some embodiments, a cap comprises GAU. In some embodiments, a cap comprises GCA. In some embodiments, a cap comprises GCC. In some embodiments, a cap comprises GCG. In some embodiments, a cap comprises GCU. In some embodiments, a cap comprises GGA. In some embodiments, a cap comprises GGC. In some embodiments, a cap comprises GGG. In some embodiments, a cap comprises GGU. In some embodiments, a cap comprises GUA. In some embodiments, a cap comprises GUC. In some embodiments, a cap comprises GUG. In some embodiments, a cap comprises GUU.
[0241] In some embodiments, a cap comprises a sequence selected from the following sequences: m7GpppApA, m7GpppApC, m7GpppApG, m7GpppApU, m7GpppCpA, m7GpppCpC, m7GpppCpG, m7GpppCpU, m7GpppGpA, m7GpppGpC,
m7GpppGpG, m7GpppGpU, m7GpppUpA, m7GpppUpC, m7GpppUpG, and m7GpppUpU.
[0242] In some embodiments, a cap comprises m7GpppApA. In some embodiments, a cap comprises m7GpppApC. In some embodiments, a cap comprises m7GpppApG. In some embodiments, a cap comprises m7GpppApU. In some embodiments, a cap comprises m7GpppCpA. In some embodiments, a cap comprises m7GpppCpC. In some embodiments, a cap comprises m7GpppCpG. In some embodiments, a cap comprises m7GpppCpU. In some embodiments, a cap comprises m7GpppGpA. In some embodiments, a cap comprises m7GpppGpC. In some embodiments, a cap comprises m7GpppGpG. In some embodiments, a cap comprises m7GpppGpU. In some embodiments, a cap comprises m7GpppUpA. In some embodiments, a cap comprises m7GpppUpC. In some embodiments, a cap comprises m7GpppUpG. In some embodiments, a cap comprises m7GpppUpU.
[0243] A cap, in some embodiments, comprises a sequence selected from the following sequences: m7G3'OMepppApA, m7G3'OMepppApC, m7G3'OMepppApG, m7G3'OMepppApU, m7G3'OMepppCpA, m7G3'OMepppCpC, m7G3'OMepppCpG, m7G3'OMePPpCpU, m7G3'OMePPpGpA, m7G3'OMepppGpC, m7G3'OMepppGpG, m7G3'OMepppGpU, m7G3'OMepppUpA, m7G3'OMepppUpC, m7G3'OMepppUpG, and m7G3'OMePPpUpU.
[0244] In some embodiments, a cap comprises m7G3 OMepppApA. In some embodiments, a cap comprises m7G3'OMepppApC. In some embodiments, a cap comprises m7G3'OMepppApG. In some embodiments, a cap comprises m7G3 OMepppApU. In some embodiments, a cap comprises m7G3'OMepppCpA. In some embodiments, a cap comprises m7G3'OMepppCpC. In some embodiments, a cap comprises m7G3'OMepppCpG. In some embodiments, a cap comprises m7G3'OMepppCpU. In some embodiments, a cap comprises m7G3'OMepppGpA. In some embodiments, a cap comprises m7G3'OMepppGpC. In some embodiments, a cap comprises m7G3'OMepppGpG. In some embodiments, a cap comprises m7G3'OMepppGpU. In some embodiments, a cap comprises m7G3'OMepppUpA. In some
embodiments, a cap comprises m7G3'OMepppUpC. In some embodiments, a cap comprises m7G3'OMepppUpG. In some embodiments, a cap comprises m7G3'OMepppUpU.
[0245] A cap, in other embodiments, comprises a sequence selected from the following sequences: m7G3'OMepppA2'OMepA, m7G3'OMepppA2'OMepC, m7G3'OMepppA2'OMepG, m7G3'OMepppA2'OMepU, m7G3'OMepppC2'OMepA, m7G3'OMepppC2'OMepC, m7G3'OMepppC2'OMepG, m7G3'OMepppC2'OMepU, m7G3'OMepppG2'OMepA, m7G3'OMepppG2'OMepC, m7G3'OMepppG2'OMepG, m7G3'OMepppG2'OMepU, m7G3'OMepppU2'OMepA, m7G3'OMepppU2'OMepC, m7G3'OMepppU2'OMepG, and m7G3'OMepppU2'OMepU.
[0246] In some embodiments, a cap comprises m7G3'OMepppA2'OMepA. In some embodiments, a cap comprises m7G3'OMepppA2'OMepC. In some embodiments, a cap comprises m7G3'OMepppA2'OMepG. In some embodiments, a cap comprises m7G3'OMepppA2'OMepU. In some embodiments, a cap comprises m7G3'OMepppC2'OMepA. In some embodiments, a cap comprises m7G3'OMepppC2'OMepC. In some embodiments, a cap comprises m7G3'OMepppC2'OMepG. In some embodiments, a cap comprises m7G3'OMepppC2'OMepU. In some embodiments, a cap comprises m7G3'OMepppG2'OMepA. In some embodiments, a cap comprises m7G3'OMepppG2'OMepC. In some embodiments, a cap comprises m7G3'OMepppG2'OMepG. In some embodiments, a cap comprises m7G3'OMepppG2'OMepU. In some embodiments, a cap comprises m7G3'OMepppU2'OMepA. In some embodiments, a cap comprises m7G3'OMepppU2'OMepC. In some embodiments, a cap comprises m7G3'OMepppU2'OMepG. In some embodiments, a cap comprises m7G3'OMepppU2'OMepU.
[0247] A cap, in still other embodiments, comprises a sequence selected from the following sequences: m7GpppA2'OMepA, m7GpppA2'OMepC, m7GpppA2'OMepG, m7GpppA2'OMepU, m7GpppC2'OMepA, m7GpppC2'OMepC, m7GpppC2'OMepG, m7GpppC2'OMepU, m7GpppG2'OMepA, m7GpppG2'OMepC, m7GpppG2'OMepG,
m7GpppG2 OMepU, m7GpppU2'OMepA, m7GpppU2'OMepC, m7GpppU2'OMepG, and m7GpppU2OMepU.
[0248] In some embodiments, a cap comprises m7GpppA2 OMepA. In some embodiments, a cap comprises m7GpppA2 OMepC. In some embodiments, a cap comprises m7GpppA2 OMepG. In some embodiments, a cap comprises m7GpppA2'OMepU. In some embodiments, a cap comprises m7GpppC2 OMepA. In some embodiments, a cap comprises m7GpppC2 OMepC. In some embodiments, a cap comprises m7GpppC2'OMepG. In some embodiments, a trinucleotide cap comprises m7GpppC2 OMepU. In some embodiments, a cap comprises m7GpppG2'OMepA. In some embodiments, a cap comprises m7GpppG2'OMepC. In some embodiments, a cap comprises m7GpppG2'OMepG. In some embodiments, a cap comprises m7GpppG2'OMepU. In some embodiments, a cap comprises m7GpppU2'OMepA. In some embodiments, a cap comprises m7GpppU2 OMepC. In some embodiments, a cap comprises m7GpppU2'OMepG. In some embodiments, a cap comprises m7GpppU2'OMepU.
[0249] In some embodiments, a cap comprises m7Gpppm6A2'omepG. In some embodiments, a cap comprises m7Gpppe6A2'OmepG.
[0250] In some embodiments, a cap comprises GAG. In some embodiments, a cap comprises GCG. In some embodiments, a cap comprises GUG. In some embodiments, a cap comprises GGG.
[0251] In some embodiments, a cap comprises any one of the following structures:


[0252] In some embodiments, the cap comprises m7GpppNiN2N3, where Ni, N2, and N3 are optional (i.e., can be absent or one or more can be present) and are independently a natural, a modified, or an unnatural nucleoside base. In some embodiments, m7G is further methylated, e.g., at the 3' position. In some embodiments, the m7G comprises an O-methyl at the 3' position. In some embodiments Ni, N2, and N3 if present, optionally, are independently an adenine, a uracil, a guanidine, a thymine, or a cytosine. In some embodiments, one or more (or all) of Ni, N2, and N3, if present, are methylated, e.g., at the 2' position. In some embodiments, one or more (or all) of Ni, N2, and N3. if present have an O-methyl at the 2' position.
[0253] In some embodiments, the cap comprises the following structure:

[0254] In some embodiments, Bi, B3, and B3 are natural nucleoside bases. In some embodiments, at least one of Bi, B2, and B3 is a modified or unnatural base. In some embodiments, at least one of Bi, B2, and B3 is N6-methyladenine. In some embodiments, Bi is adenine, cytosine, thymine, or uracil. In some embodiments, Bi is adenine, B2 is uracil, and B3 is adenine. In some embodiments, Ri and R2 are OH, R3 and R4 are O- methyl, Bi is adenine, B2 is uracil, and B3 is adenine.
[0255] In some embodiments the cap comprises a sequence selected from the following sequences: GAAA, GACA, GAGA, GAUA, GCAA, GCCA, GCGA, GCUA, GGAA, GGCA, GGGA, GGUA, GUCA, and GUUA. In some embodiments the cap comprises a sequence selected from the following sequences: GAAG, GACG, GAGG, GAUG, GCAG, GCCG, GCGG, GCUG, GGAG, GGCG, GGGG, GGUG, GUCG,
GUGG, and GUUG. In some embodiments the cap comprises a sequence selected from the following sequences: GAAU, GACU, GAGU, GAUU, GCAU, GCCU, GCGU, GCUU, GGAU, GGCU, GGGU, GGUU, GUAU, GUCU, GUGU, and GUUU. In some embodiments the cap comprises a sequence selected from the following sequences: GAAC, GACC, GAGC, GAUC, GCAC, GCCC, GCGC, GCUC, GGAC, GGCC, GGGC, GGUC, GUAC, GUCC, GUGC, and GUUC.
[0256] A cap, in some embodiments, comprises a sequence selected from the following sequences: m7G3'OMepppApApN, m7G3'OMepppApCpN, m7G3'OMepppApGpN, m7G3'OMepppApUpN, m7G3'OMepppCpApN, m7G3'OMepppCpCpN, m7G3'OMepppCpGpN, m7G3'OMepppCpUpN, m7G3'OMepppGpApN, m7G3'OMepppGpCpN, m7G3'OMepppGpGpN, m7G3'OMepppGpUpN, m7G3'OMepppUpApN, m7G3'OMepppUpCpN, m7G3'OMepppUpGpN, and m7G3'OMepppUpUpN, where N is a natural, a modified, or an unnatural nucleoside base.
[0257] A cap, in other embodiments, comprises a sequence selected from the following sequences: m7G3'OMepppA2'OMepApN, m7G3'OMepppA2 OMepCpN, m7G3'OMepppA2'OMepGpN, m7G3'OMepppA2'OMepUpN, m7G3'OMepppC2'OMepApN, m7G3'OMepppC2'OMepCpN, m7G3'OMepppC2'OMepGpN, m7G3'OMepppC2'OMepUpN, m7G3'OMepppG2'OMepApN, m7G3'OMepppG2'OMepCpN, m7G3'OMepppG2'OMepGpN, m7G3'OMepppG2'OMepUpN, m7G3'OMepppU2'OMepApN, m7G3'OMepppU2'OMepCpN, m7G3'OMepppU2'OMepGpN, and m7G3'OMepppU2'OMepUpN, where N is a natural, a modified, or an unnatural nucleoside base.
[0258] A cap, in still other embodiments, comprises a sequence selected from the following sequences: m7GpppA2'OMepApN, m7GpppA2'OMepCpN, m7GpppA2'OMepGpN, m7GpppA2 OMepUpN, m7GpppC2'OMepApN, m7GpppC2'OMepCpN, m7GpppC2'OMepGpN, m7GpppC2'OMepUpN, m7GpppG2'OMepApN, m7GpppG2'OMepCpN, m7GpppG2'OMepGpN, m7GpppG2'OMepUpN, m7GpppU2'OMepApN, m7GpppU2'OMepCpN, m7GpppU2'OMepGpN, and m7GpppU2'OMepUpN, where N is a natural, a modified, or an unnatural nucleoside base.
[0259] A cap, in other embodiments, comprises a sequence selected from the following sequences: m7G3'OMepppA2'OMepA2'OMepN, m7G3'OMepppA2'OMepC2 OMepN, m7G3'OMepppA2'OMepG2'OMepN, m7G3'OMepppA2'OMepU2'OMepN, m7G3'OMepppC2'OMepA2'OMepN, m7G3'OMepppC2'OMepC2'OMepN, m7G3'OMepppC2'OMepG2'OMepN, m7G3'OMepppC2'OMepU2'OMepN, m7G3'OMepppG2'OMepA2'OMepN, m7G3'OMepppG2'OMepC2'OMepN, m7G3'OMepppG2'OMepG2'OMepN, m7G3'OMepppG2'OMepU2'OMepN, m7G3'OMepppU2'OMepA2'OMepN, m7G3'OMepppU2'OMepC2'OMepN, m7G3'OMepppU2'OMepG2'OMepN, and m7G3'OMepppU2'OMepU2'OMepN, where N is a natural, a modified, or an unnatural nucleoside base.
[0260] A cap, in still other embodiments, comprises a sequence selected from the following sequences: m7GpppA2'OMepA2'OMepN, m7GpppA2'OMepC2'OMepN, m7GpppA2'OMepG2'OMepN, m7GpppA2'OMepU2'OMepN, m7GpppC2'OMepA2'OMepN, m7GpppC2'OMepC2'OMepN, m7GpppC2'OMepG2'OMepN, m7GpppC2'OMepU2'OMepN, m7GpppG2'OMepA2'OMepN, m7GpppG2'OMepC2'OMepN, m7GpppG2'OMepG2'OMepN, m7GpppG2'OMepU2'OMepN, m7GpppU2'OMepA2'OMepN, m7GpppU2'OMepC2'OMepN, m7GpppU2'OMepG2'OMepN, and m7GpppU2'OMepU2'OMepN, where N is a natural, a modified, or an unnatural nucleoside base.
[0261] In some embodiments, a cap comprises GGAG. In some embodiments, a cap comprises the following structure:

(X).
Poly-A Tails
[0262] In some embodiments, the polynucleotides of the present disclosure (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein further comprise a poly-A tail. In further embodiments, terminal groups on the poly-A tail can be incorporated for stabilization. In other embodiments, a poly-A tail comprises des-3' hydroxyl tails.
[0263] During RNA processing, a long chain of adenine nucleotides (poly-A tail) can be added to a polynucleotide such as an mRNA molecule in order to increase stability. Immediately after transcription, the 3' end of the transcript can be cleaved to free a 3' hydroxyl. Then poly-A polymerase adds a chain of adenine nucleotides to the RNA. The process, called polyadenylation, adds a poly-A tail that can be between, for example, approximately 80 to approximately 250 residues long, including approximately 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 210, 220, 230, 240 or 250 residues long. In one embodiment, the poly-A tail is 100 nucleotides in length (SEQ ID NO: 195). [0264] PolyA tails can also be added after the construct is exported from the nucleus.
[0265] According to the present invention, terminal groups on the poly A tail can be incorporated for stabilization. Polynucleotides of the present invention can include des-3' hydroxyl tails. They can also include structural moieties or 2'-Omethyl modifications as taught by Junjie Li, et al. (Current Biology, Vol. 15, 1501-1507, August 23, 2005, the contents of which are incorporated herein by reference in its entirety).
[0266] The polynucleotides of the present invention can be designed to encode transcripts with alternative polyA tail structures including histone mRNA. According to Norbury, "Terminal uridylation has also been detected on human replication-dependent histone mRNAs. The turnover of these mRNAs is thought to be important for the prevention of potentially toxic histone accumulation following the completion or inhibition of chromosomal DNA replication. These mRNAs are distinguished by their lack of a 3 ' poly(A) tail, the function of which is instead assumed by a stable stem-loop structure and its cognate stem-loop binding protein (SLBP); the latter carries out the same functions as those of PABP on polyadenylated mRNAs" (Norbury, "Cytoplasmic RNA: a case of the tail wagging the dog," Nature Reviews Molecular Cell Biology; AOP, published online 29 August 2013; doi: 10.1038/nrm3645) the contents of which are incorporated herein by reference in its entirety.
[0267] Unique poly-A tail lengths provide certain advantages to the polynucleotides of the present invention. Generally, the length of a poly-A tail, when present, is greater than 30 nucleotides in length. In another embodiment, the poly-A tail is greater than 35 nucleotides in length (e.g., at least or greater than about 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 450, 500, 600, 700, 800, 900, 1,000, 1,100, 1,200, 1,300, 1,400, 1,500, 1,600, 1,700, 1,800, 1,900, 2,000, 2,500, and 3,000 nucleotides).
[0268] In some embodiments, the polynucleotide or region thereof includes from about 30 to about 3,000 nucleotides (e.g., from 30 to 50, from 30 to 100, from 30 to 250, from 30 to 500, from 30 to 750, from 30 to 1,000, from 30 to 1,500, from 30 to 2,000, from 30 to 2,500, from 50 to 100, from 50 to 250, from 50 to 500, from 50 to 750, from 50 to 1,000, from 50 to 1,500, from 50 to 2,000, from 50 to 2,500, from 50 to 3,000, from
100 to 500, from 100 to 750, from 100 to 1,000, from 100 to 1,500, from 100 to 2,000, from 100 to 2,500, from 100 to 3,000, from 500 to 750, from 500 to 1,000, from 500 to 1,500, from 500 to 2,000, from 500 to 2,500, from 500 to 3,000, from 1,000 to 1,500, from 1,000 to 2,000, from 1,000 to 2,500, from 1,000 to 3,000, from 1,500 to 2,000, from
1.500 to 2,500, from 1,500 to 3,000, from 2,000 to 3,000, from 2,000 to 2,500, and from
2.500 to 3,000).
[0269] In some embodiments, the poly-A tail is designed relative to the length of the overall polynucleotide or the length of a particular region of the polynucleotide. This design can be based on the length of a coding region, the length of a particular feature or region or based on the length of the ultimate product expressed from the polynucleotides.
[0270] In this context, the poly-A tail can be 10, 20, 30, 40, 50, 60, 70, 80, 90, or 100% greater in length than the polynucleotide or feature thereof. The poly-A tail can also be designed as a fraction of the polynucleotides to which it belongs. In this context, the poly-A tail can be 10, 20, 30, 40, 50, 60, 70, 80, or 90% or more of the total length of the construct, a construct region or the total length of the construct minus the poly-A tail. Further, engineered binding sites and conjugation of polynucleotides for Poly-A binding protein can enhance expression.
[0271] Additionally, multiple distinct polynucleotides can be linked together via the PABP (Poly-A binding protein) through the 3 '-end using modified nucleotides at the 3'- terminus of the poly-A tail. Transfection experiments can be conducted in relevant cell lines at and protein production can be assayed by ELISA at 12hr, 24hr, 48hr, 72hr and day 7 post-transfection.
[0272] In some embodiments, the polynucleotides of the present invention are designed to include a polyA-G Quartet region. The G-quartet is a cyclic hydrogen bonded array of four guanine nucleotides that can be formed by G-rich sequences in both DNA and RNA. In this embodiment, the G-quartet is incorporated at the end of the poly-A tail. The resultant polynucleotide is assayed for stability, protein production and other parameters including half-life at various time points. It has been discovered that the
polyA-G quartet results in protein production from an mRNA equivalent to at least 75% of that seen using a poly-A tail of 120 nucleotides alone (SEQ ID NO: 196).
[0273] In some embodiments, the polyA tail comprises an alternative nucleoside, e.g., inverted thymidine. PolyA tails comprising an alternative nucleoside, e.g., inverted thymidine, may be generated as described herein. For instance, mRNA constructs may be modified by ligation to stabilize the poly (A) tail. Ligation may be performed using 0.5-1.5 mg/mL mRNA (5' Capl, 3' A100), 50 mM Tris-HCl pH 7.5, 10 mM MgCb, 1 mM TCEP, 1000 units/mL T4 RNA Ligase 1, 1 mM ATP, 20% w/v polyethylene glycol 8000, and 5: 1 molar ratio of modifying oligo to mRNA. Modifying oligo has a sequence of 5'-phosphate-AAAAAAAAAAAAAAAAAAAA-(inverted deoxy thy mi dine (idT) (SEQ ID NO:209)) (see below). Ligation reactions are mixed and incubated at room temperature (~22°C) for, e.g., 4 hours. Stable tail mRNA are purified by, e g., dT purification, reverse phase purification, hydroxyapatite purification, ultrafiltration into water, and sterile filtration. The resulting stable tail-containing mRNAs contain the following structure at the 3 'end, starting with the polyA region: Aioo- UCUAGAAAAAAAAAAAAAAAAAAAA-inverted deoxythymidine (SEQ ID NO:211).
[0274] Modifying oligo to stabilize tail (5'-phosphate- AAAAAAAAAAAAAAAAAAAA-(inverted deoxythymidine)(SEQ ID NO:209)):
 [0275] In some instances, the polyA tail comprises A100-UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO:211). In some instances, the polyA tail consists of A100- UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO:211).
[0275] In some instances, the polyA tail comprises A100-UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO:211). In some instances, the polyA tail consists of A100- UCUAG-A20-inverted deoxy -thymidine (SEQ ID NO:211).
Start codon region
[0276] The invention also includes a polynucleotide that comprises both a start codon region and the polynucleotide described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein. In some embodiments, the polynucleotides of the present invention can have regions that are analogous to or function like a start codon region.
[0277] In some embodiments, the translation of a polynucleotide can initiate on a codon that is not the start codon AUG. Translation of the polynucleotide can initiate on an alternative start codon such as, but not limited to, ACG, AGG, AAG, CTG/CUG, GTG/GUG, ATA/AUA, ATT/AUU, TTG/UUG (see Touriol et al. Biology of the C6ll 95 (2003) 169-178 and Matsuda and Mauro PLoS ONE, 2010 5: 11; the contents of each of which are herein incorporated by reference in its entirety).
[0278] As a non-limiting example, the translation of a polynucleotide begins on the alternative start codon ACG. As another non-limiting example, polynucleotide translation begins on the alternative start codon CTG or CUG. As yet another non-limiting example, the translation of a polynucleotide begins on the alternative start codon GTG or GUG.
[0279] Nucleotides flanking a codon that initiates translation such as, but not limited to, a start codon or an alternative start codon, are known to affect the translation efficiency, the length and/or the structure of the polynucleotide. (See, e.g., Matsuda and Mauro PLoS ONE, 2010 5: 11; the contents of which are herein incorporated by reference in its entirety). Masking any of the nucleotides flanking a codon that initiates translation can be used to alter the position of translation initiation, translation efficiency, length and/or structure of a polynucleotide.
[0280] In some embodiments, a masking agent can be used near the start codon or alternative start codon in order to mask or hide the codon to reduce the probability of
translation initiation at the masked start codon or alternative start codon. Non-limiting examples of masking agents include antisense locked nucleic acids (LNA) polynucleotides and exon-junction complexes (EJCs) (See, e.g., Matsuda and Mauro describing masking agents LNA polynucleotides and EJCs (PLoS ONE, 2010 5: 11); the contents of which are herein incorporated by reference in its entirety).
[0281] In another embodiment, a masking agent can be used to mask a start codon of a polynucleotide in order to increase the likelihood that translation will initiate on an alternative start codon. In some embodiments, a masking agent can be used to mask a first start codon or alternative start codon in order to increase the chance that translation will initiate on a start codon or alternative start codon downstream to the masked start codon or alternative start codon.
[0282] In some embodiments, a start codon or alternative start codon can be located within a perfect complement for a miRNA binding site. The perfect complement of a miRNA binding site can help control the translation, length and/or structure of the polynucleotide similar to a masking agent. As a non-limiting example, the start codon or alternative start codon can be located in the middle of a perfect complement for a miRNA binding site. The start codon or alternative start codon can be located after the first nucleotide, second nucleotide, third nucleotide, fourth nucleotide, fifth nucleotide, sixth nucleotide, seventh nucleotide, eighth nucleotide, ninth nucleotide, tenth nucleotide, eleventh nucleotide, twelfth nucleotide, thirteenth nucleotide, fourteenth nucleotide, fifteenth nucleotide, sixteenth nucleotide, seventeenth nucleotide, eighteenth nucleotide, nineteenth nucleotide, twentieth nucleotide or twenty-first nucleotide.
[0283] In another embodiment, the start codon of a polynucleotide can be removed from the polynucleotide sequence in order to have the translation of the polynucleotide begin on a codon that is not the start codon. Translation of the polynucleotide can begin on the codon following the removed start codon or on a downstream start codon or an alternative start codon. In a non-limiting example, the start codon ATG or AUG is removed as the first 3 nucleotides of the polynucleotide sequence in order to have translation initiate on a downstream start codon or alternative start codon. The
polynucleotide sequence where the start codon was removed can further comprise at least one masking agent for the downstream start codon and/or alternative start codons in order to control or attempt to control the initiation of translation, the length of the polynucleotide and/or the structure of the polynucleotide.
Stop Codon Region
[0284] The invention also includes a polynucleotide that comprises both a stop codon region and the polynucleotide described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein. In some embodiments, the polynucleotides of the present invention can include at least two stop codons before the 3' untranslated region (UTR). The stop codon can be selected from TGA, TAA and TAG in the case of DNA, or from UGA, UAA and UAG in the case of RNA. In some embodiments, the polynucleotides of the present invention include the stop codon TGA in the case or DNA, or the stop codon UGA in the case of RNA, and one additional stop codon. In a further embodiment the addition stop codon can be TAA or UAA. In another embodiment, the polynucleotides of the present invention include three consecutive stop codons, four stop codons, or more.
Combination of mRNA elements
[0285] Any of the polynucleotides disclosed herein can comprise one, two, three, or all of the following elements: (a) a 5 '-UTR, e.g., as described herein; (b) a coding region comprising a stop element (e.g., as described herein); (c) a 3'-UTR (e.g., as described herein) and; optionally (d) a 3' stabilizing region, e.g., as described herein. Also disclosed herein are LNP compositions comprising the same.
[0286] In an embodiment, a polynucleotide of the disclosure comprises (a) a 5' UTR described in Table 1 or a variant or fragment thereof and (b) a coding region comprising a stop element provided herein. In an embodiment, the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein. In an
embodiment, the polynucleotide further comprises a 3' stabilizing region, e.g., as described herein.
[0287] In an embodiment, a polynucleotide of the disclosure comprises (a) a 5' UTR described in Table 1 or a variant or fragment thereof and (c) a 3' UTR described in Table 2 or a variant or fragment thereof. In an embodiment, the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein. In an embodiment, the polynucleotide further comprises a 3' stabilizing region, e.g., as described herein.
[0288] In an embodiment, a polynucleotide of the disclosure comprises (c) a 3' UTR described in Table 2 or a variant or fragment thereof and (b) a coding region comprising a stop element provided herein. In an embodiment, the polynucleotide comprises a sequence provided in Table 3. In an embodiment, the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein. In an embodiment, the polynucleotide further comprises a 3' stabilizing region, e.g., as described herein.
[0289] In an embodiment, a polynucleotide of the disclosure comprises (a) a 5' UTR described in Table 1 or a variant or fragment thereof; (b) a coding region comprising a stop element provided herein; and (c) a 3 ' UTR described in Table 2 or a variant or fragment thereof. In an embodiment, the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein. In an embodiment, the polynucleotide further comprises a 3' stabilizing region, e.g., as described herein.
[0290] In an embodiment, a polynucleotide of the disclosure comprises (a) a 5' UTR described in Table 1 or a variant or fragment thereof, (b) a coding region comprising a stop element provided herein; and (c) a 3' UTR comprising the sequence of SEQ ID NO: 139. In an embodiment, the polynucleotide further comprises a cap structure, e.g., as described herein, or a poly A tail, e.g., as described herein.
Table 3: Exemplary 3' UTR and stop element sequences


Polynucleotide Comprising an mRNA Encoding an IgAP Protein
[0291] In certain embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided above;
(ii) a 5' UTR, such as the sequences provided above;
(iii) an ORF encoding an IgAP protein (e.g., SEQ ID NO:4, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO:5 or SEQ ID NO:6), wherein the ORF has at least 90%, at least 95%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to the sequence of SEQ ID NO:27 or SEQ ID NO:28;
(iv) at least one stop codon;
(v) a 3' UTR, such as the sequences provided above; and
(vi) a poly- A tail provided above.
[0292] In certain embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided above;
(ii) a 5' UTR, such as the sequences provided above;
(iii) an ORF encoding an IgAP protein (e.g., any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49, optionally including a signal peptide, e.g., the IgAP protein of any one of SEQ ID NOs: 351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350), wherein the ORF has at least 90%, at least 95%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to the sequence of any one of SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151;
(iv) at least one stop codon;
(v) a 3' UTR, such as the sequences provided above; and
(vi) a poly-A tail provided above.
[0293] In certain embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises from 5' to 3' end:
(i) a 5' cap such as provided above;
(ii) a 5' UTR, such as the sequences provided above;
(iii) an ORF encoding an IgAP protein (e.g., SEQ ID NO:80, optionally including a signal peptide, e.g., the IgAP protein of SEQ ID NO:351), wherein the ORF has at least
90%, at least 95%, at least 97%, at least 98%, at least 99%, or 100% sequence identity to the sequence of SEQ ID NO: 153 or SEQ ID NO: 154;
(iv) at least one stop codon;
(v) a 3' UTR, such as the sequences provided above; and
(vi) a poly-A tail provided above.
[0294] In some embodiments, the polynucleotide further comprises a miRNA binding site, e.g., a miRNA binding site that binds to miRNA-142. In some embodiments, the 5' UTR comprises the miRNA binding site. In some embodiments, the 3' UTR comprises the miRNA binding site.
[0295] In some embodiments, a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100% identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:4 (not inclusive of a signal peptide).
[0296] In some embodiments, a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100% identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:5.
[0297] In some embodiments, a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100%
identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:6.
[0298] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding a polypeptide, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a 5' UTR, (3) a nucleotide sequence ORF of SEQ ID NO:27, (3) a stop codon, (4) a 3 'UTR, and (5) a poly-A tail provided above, for example, a poly-A tail of SEQ ID NO: 195 or A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
[0299] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding a polypeptide, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a 5' UTR, (3) a nucleotide sequence ORF of SEQ ID NO:28, (3) a stop codon, (4) a 3 'UTR, and (5) a poly-A tail provided above, for example, a poly-A tail of SEQ ID NO: 195 or A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID N0:211).
[0300] In some embodiments, a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100% identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:80 (not inclusive of a signal peptide).
[0301] In some embodiments, a polynucleotide of the present disclosure comprises a nucleotide sequence encoding a polypeptide sequence at least 70%, at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96% , at least 97%, at least 98%, at least 99%, or 100% identical to the protein sequence of an IgAP protein having the amino acid sequence of SEQ ID NO:351.
[0302] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding a polypeptide, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a 5' UTR, (3) a nucleotide sequence ORF of SEQ ID NO: 153, (3) a stop codon, (4) a 3 'UTR, and (5) a poly-A tail provided above, for example, a poly-A tail of SEQ ID NO: 195 or A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID N0:211).
[0303] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding a polypeptide, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a 5' UTR, (3) a nucleotide sequence ORF of SEQ ID NO: 154, (3) a stop codon, (4) a 3 'UTR, and (5) a poly-A tail provided above, for example, a poly-A tail of SEQ ID NO: 195 or A100-UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211).
[0304] Exemplary IgAP nucleotide constructs are described below.
[0305] SEQ ID NO:29 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:28, and 3' UTR of SEQ ID NO: 114.
[0306] SEQ ID NO:30 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:28, and 3' UTR of SEQ ID NO: 139.
[0307] SEQ ID NO:31 consists from 5' to 3' end: 5' UTR of SEQ ID NO: 56, ORF Sequence of SEQ ID NO:28, and 3' UTR of SEQ ID NO: 114.
[0308] SEQ ID NO : 32 consi sts from 5 ' to 3 ' end : 5 ' UTR of SEQ ID NO : 56, ORF Sequence of SEQ ID NO:27, and 3' UTR of SEQ ID NO: 114.
[0309] SEQ ID NO:300 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:28, and 3' UTR of SEQ ID NO: 138.
[0310] SEQ ID NO:301 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:85, and 3' UTR of SEQ ID NO: 138.
[0311] SEQ ID NO:302 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 87, and 3' UTR of SEQ ID NO: 138.
[0312] SEQ ID NO:303 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:88, and 3' UTR of SEQ ID NO: 138.
[0313] SEQ ID NO:304 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:90, and 3' UTR of SEQ ID NO: 138.
[0314] SEQ ID NO:305 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 91, and 3' UTR of SEQ ID NO: 138.
[0315] SEQ ID NO:306 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:93, and 3' UTR of SEQ ID NO: 138.
[0316] SEQ ID NO:307 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:94, and 3' UTR of SEQ ID NO: 138.
[0317] SEQ ID NO:308 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:95, and 3' UTR of SEQ ID NO: 138.
[0318] SEQ ID NO:309 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:96, and 3' UTR of SEQ ID NO: 138.
[0319] SEQ ID NO:310 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:97, and 3' UTR of SEQ ID NO: 138.
[0320] SEQ ID NO:311 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO:99, and 3' UTR of SEQ ID NO: 138.
[0321] SEQ ID NO:312 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO : 141 , and 3 ' UTR of SEQ ID NO : 138.
[0322] SEQ ID NO :313 consists from 5' to 3' end: 5' UTR of SEQ ID NO: 58, ORF Sequence of SEQ ID NO : 144, and 3 ' UTR of SEQ ID NO : 138.
[0323] SEQ ID NO:314 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 145, and 3' UTR of SEQ ID NO: 138.
[0324] SEQ ID NO:315 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 146, and 3' UTR of SEQ ID NO: 138.
[0325] SEQ ID NO:316 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 150, and 3' UTR of SEQ ID NO: 138.
[0326] SEQ ID NO :317 consists from 5' to 3' end: 5' UTR of SEQ ID NO: 58, ORF Sequence of SEQ ID NO : 151 , and 3 ' UTR of SEQ ID NO : 138.
[0327] SEQ ID NO:318 consists from 5' to 3' end: 5' UTR of SEQ ID NO:58, ORF Sequence of SEQ ID NO: 153, and 3' UTR of SEQ ID NO: 138.
[0328] SEQ ID NO : 319 consi sts from 5 ' to 3 ' end : 5 ' UTR of SEQ ID NO : 50, ORF
Sequence of SEQ ID NO: 154, and 3' UTR of SEQ ID NO: 132.
[0329] In certain embodiments, in a construct with SEQ ID NO:29, all uracils therein are replaced by N1 -methylpseudouracil.
[0330] In certain embodiments, in a construct with SEQ ID NO:30, all uracils therein are replaced by N1 -methylpseudouracil.
[0331] In certain embodiments, in a construct with SEQ ID NO:31, all uracils therein are replaced by N1 -methylpseudouracil.
[0332] In certain embodiments, in a construct with SEQ ID NO:32, all uracils therein are replaced by N1 -methylpseudouracil.
[0333] In certain embodiments, in a construct with SEQ ID NO:300, all uracils therein are replaced by N1 -methylpseudouracil.
[0334] In certain embodiments, in a construct with SEQ ID NO:301, all uracils therein are replaced by N1 -methylpseudouracil.
[0335] In certain embodiments, in a construct with SEQ ID NO:302, all uracils therein are replaced by N1 -methylpseudouracil.
[0336] In certain embodiments, in a construct with SEQ ID NO:303, all uracils therein are replaced by N1 -methylpseudouracil.
[0337] In certain embodiments, in a construct with SEQ ID NO:304, all uracils therein are replaced by N1 -methylpseudouracil.
[0338] In certain embodiments, in a construct with SEQ ID NO:305, all uracils therein are replaced by N1 -methylpseudouracil.
[0339] In certain embodiments, in a construct with SEQ ID NO:306, all uracils therein are replaced by N1 -methylpseudouracil.
[0340] In certain embodiments, in a construct with SEQ ID NO:307, all uracils therein are replaced by N1 -methylpseudouracil.
[0341] In certain embodiments, in a construct with SEQ ID NO:308, all uracils therein are replaced by N1 -methylpseudouracil.
[0342] In certain embodiments, in a construct with SEQ ID NO:309, all uracils therein are replaced by N1 -methylpseudouracil.
[0343] In certain embodiments, in a construct with SEQ ID NO:310, all uracils therein are replaced by N1 -methylpseudouracil.
[0344] In certain embodiments, in a construct with SEQ ID NO:311, all uracils therein are replaced by N1 -methylpseudouracil.
[0345] In certain embodiments, in a construct with SEQ ID NO:312, all uracils therein are replaced by N1 -methylpseudouracil.
[0346] In certain embodiments, in a construct with SEQ ID NO:313, all uracils therein are replaced by N1 -methylpseudouracil.
[0347] In certain embodiments, in a construct with SEQ ID NO:314, all uracils therein are replaced by N1 -methylpseudouracil.
[0348] In certain embodiments, in a construct with SEQ ID NO:315, all uracils therein are replaced by N1 -methylpseudouracil.
[0349] In certain embodiments, in a construct with SEQ ID NO:316, all uracils therein are replaced by N1 -methylpseudouracil.
[0350] In certain embodiments, in a construct with SEQ ID NO:317, all uracils therein are replaced by N1 -methylpseudouracil.
[0351] In certain embodiments, in a construct with SEQ ID NO:318, all uracils therein are replaced by N1 -methylpseudouracil.
[0352] In certain embodiments, in a construct with SEQ ID NO:319, all uracils therein are replaced by N1 -methylpseudouracil.
[0353] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:29, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100-
UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211). In certain embodiments, in constructs with SEQ ID NO:29, all uracils therein are replaced by Nl- methylpseudouracil.
[0354] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:30, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211). In certain embodiments, in constructs with SEQ ID NO:30, all uracils therein are replaced by Nl- methylpseudouracil.
[0355] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:31, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211). In certain embodiments, in constructs with SEQ ID NO:31, all uracils therein are replaced by Nl- methylpseudouracil.
[0356] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:32, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211). In certain embodiments, in constructs with SEQ ID NO:32, all uracils therein are replaced by Nl- methylpseudouracil.
[0357] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein,
comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:300, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211). In certain embodiments, in constructs with SEQ ID NO:32, all uracils therein are replaced by Nl- methylpseudouracil.
[0358] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:318, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211). In certain embodiments, in constructs with SEQ ID NO:32, all uracils therein are replaced by Nl- methylpseudouracil.
[0359] In some embodiments, a polynucleotide of the present disclosure, for example a polynucleotide comprising an mRNA nucleotide sequence encoding an IgAP protein, comprises (1) a 5' cap such as provided above, for example, m7Gp-ppGm-A or m7Gp- ppGm-G, (2) a nucleotide sequence of SEQ ID NO:319, and (3) a poly-A tail provided above, for example, a poly A tail of -100 residues, e.g., SEQ ID NO: 195 or A100- UCUAG-A20-inverted deoxy-thymidine (SEQ ID NO:211). In certain embodiments, in constructs with SEQ ID NO:32, all uracils therein are replaced by Nl- methylpseudouracil.
[0360] TABLE 4 - Modified mRNA constructs including ORFs encoding IgAP (constructs comprise an m7Gp-ppGm-A or or m7Gp-ppGm-G 5 ' terminal cap and a 3' terminal PolyA region)


Methods of Making Polynucleotides
[0361] The present disclosure also provides methods for making a polynucleotide of the invention (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein) or a complement thereof.
[0362] In some aspects, a polynucleotide (e.g., a RNA, e.g., an mRNA) disclosed herein, and encoding an IgAP protein, can be constructed using in vitro transcription (IVT). In other aspects, a polynucleotide (e.g., a RNA, e.g., an mRNA) disclosed herein, and encoding an IgAP protein, can be constructed by chemical synthesis using an oligonucleotide synthesizer.
[0363] In other aspects, a polynucleotide (e.g., a RNA, e.g., an mRNA) disclosed herein, and encoding an IgAP protein is made by using a host cell. In certain aspects, a polynucleotide (e.g., a RNA, e.g., an mRNA) disclosed herein, and encoding an IgAP protein is made by one or more combination of the IVT, chemical synthesis, host cell expression, or any other methods known in the art.
[0364] Naturally occurring nucleosides, non-naturally occurring nucleosides, or combinations thereof, can totally or partially naturally replace occurring nucleosides present in the candidate nucleotide sequence and can be incorporated into a sequence- optimized nucleotide sequence (e.g., a RNA, e.g., an mRNA) encoding an IgAP protein. The resultant polynucleotides, e.g., mRNAs, can then be examined for their ability to produce protein and/or produce a therapeutic outcome.
Pharmaceutical Compositions and Formulations
[0365] The present invention provides pharmaceutical compositions and formulations that comprise any of the polynucleotides described above. In some embodiments, the composition or formulation further comprises a delivery agent.
[0366] In some embodiments, the composition or formulation can contain a polynucleotide comprising a sequence optimized nucleic acid sequence disclosed herein which encodes an IgAP protein described herein. In some embodiments, the composition or formulation can contain a polynucleotide (e.g., a RNA, e.g., an mRNA) comprising a polynucleotide (e.g., an ORF) having significant sequence identity to a sequence optimized nucleic acid sequence disclosed herein which encodes an IgAP protein. In some embodiments, the polynucleotide further comprises a miRNA binding site, e.g., a miRNA binding site that binds miR-126, miR-142, miR-144, miR-146, miR-150, miR- 155, miR-16, miR-21, miR-223, miR-24, miR-27 and miR-26a.
[0367] Pharmaceutical compositions or formulation can optionally comprise one or more additional active substances, e.g., therapeutically and/or prophylactically active substances. Pharmaceutical compositions or formulation of the present invention can be sterile and/or pyrogen-free. General considerations in the formulation and/or manufacture
of pharmaceutical agents can be found, for example, in Remington: The Science and Practice of Pharmacy 21st ed., Lippincott Williams & Wilkins, 2005 (incorporated herein by reference in its entirety). In some embodiments, compositions are administered to humans, human patients or subjects. For the purposes of the present disclosure, the phrase "active ingredient" generally refers to polynucleotides to be delivered as described herein. [0368] Formulations and pharmaceutical compositions described herein can be prepared by any method known or hereafter developed in the art of pharmacology. In general, such preparatory methods include the step of associating the active ingredient with an excipient and/or one or more other accessory ingredients, and then, if necessary and/or desirable, dividing, shaping and/or packaging the product into a desired single- or multi-dose unit.
[0369] A pharmaceutical composition or formulation in accordance with the present disclosure can be prepared, packaged, and/or sold in bulk, as a single unit dose, and/or as a plurality of single unit doses. As used herein, a "unit dose" refers to a discrete amount of the pharmaceutical composition comprising a predetermined amount of the active ingredient. The amount of the active ingredient is generally equal to the dosage of the active ingredient that would be administered to a subject and/or a convenient fraction of such a dosage such as, for example, one-half or one-third of such a dosage.
[0370] Relative amounts of the active ingredient, the pharmaceutically acceptable excipient, and/or any additional ingredients in a pharmaceutical composition in accordance with the present disclosure can vary, depending upon the identity, size, and/or condition of the subject being treated and further depending upon the route by which the composition is to be administered.
[0371] In some embodiments, the compositions and formulations described herein can contain at least one polynucleotide of the invention. As a non-limiting example, the composition or formulation can contain 1, 2, 3, 4 or 5 polynucleotides of the invention. In some embodiments, the compositions or formulations described herein can comprise more than one type of polynucleotide. In some embodiments, the composition or formulation can comprise a polynucleotide in linear and circular form. In another
embodiment, the composition or formulation can comprise a circular polynucleotide and an in vitro transcribed (IVT) polynucleotide. In yet another embodiment, the composition or formulation can comprise an IVT polynucleotide, a chimeric polynucleotide and a circular polynucleotide.
[0372] Although the descriptions of pharmaceutical compositions and formulations provided herein are principally directed to pharmaceutical compositions and formulations that are suitable for administration to humans, it will be understood by the skilled artisan that such compositions are generally suitable for administration to any other animal, e.g., to non-human animals, e.g. non-human mammals.
[0373] The present invention provides pharmaceutical formulations that comprise a polynucleotide described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein). The polynucleotides described herein can be formulated using one or more excipients to: (1) increase stability; (2) increase cell transfection; (3) permit the sustained or delayed release (e.g., from a depot formulation of the polynucleotide);
(4) alter the biodistribution (e.g., target the polynucleotide to specific tissues or cell types); (5) increase the translation of encoded protein in vivo; and/or (6) alter the release profile of encoded protein in vivo. In some embodiments, the pharmaceutical formulation further comprises a delivery agent comprising, e.g., a compound having the Formula (I), e.g., Compound II or Compound B; or a compound having the Formula (III), (IV), (V), or (VI), e.g., Compound I or VI, or any combination thereof. In some embodiments, the delivery agent comprises an ionizable amino lipid (e.g., Compound II, VI, or B), a helper lipid (e.g., DSPC), a sterol (e.g., Cholesterol), and a PEG lipid (e.g., Compound I or PEG-DMG), e.g., with a mole ratio in the range of about (i) 40-50 mol% ionizable amino lipid (e.g., Compound II, VI, or B), optionally 45-50 mol% ionizable amino lipid, for example, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48-49 mol%, or 49-50 mol% for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol%; (ii) 30-45 mol% sterol (e.g., cholesterol), optionally 35-42 mol% sterol, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33- 34 mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 37-38 mol%, 38-39 mol%, or 39-40
mol%, or 40-42 mol% sterol; (iii) 5-15 mol% helper lipid (e.g., DSPC), optionally 10-15 mol% helper lipid, for example, 5-6 mol%, 6-7 mol%, 7-8 mol%, 8-9 mol%, 9-10 mol%, 10-11 mol%, 11-12 mol%, 12-13 mol%, 13-14 mol%, or 14-15 mol% helper lipid; and (iv) 1-5% PEG lipid (e.g., Compound I or PEG-DMG), optionally 1-5 mol% PEG lipid, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol% PEG lipid. In some embodiments, the delivery agent comprises Compound B, Cholesterol, DSPC, and Compound I.
[0374] A pharmaceutically acceptable excipient, as used herein, includes, but are not limited to, any and all solvents, dispersion media, or other liquid vehicles, dispersion or suspension aids, diluents, granulating and/or dispersing agents, surface active agents, isotonic agents, thickening or emulsifying agents, preservatives, binders, lubricants or oil, coloring, sweetening or flavoring agents, stabilizers, antioxidants, antimicrobial or antifungal agents, osmolality adjusting agents, pH adjusting agents, buffers, chelants, cyoprotectants, and/or bulking agents, as suited to the particular dosage form desired. Various excipients for Formulating pharmaceutical compositions and techniques for preparing the composition are known in the art (see Remington: The Science and Practice of Pharmacy, 21st Edition, A. R. Gennaro (Lippincott, Williams & Wilkins, Baltimore, MD, 2006; incorporated herein by reference in its entirety).
[0375] Exemplary diluents include, but are not limited to, calcium or sodium carbonate, calcium phosphate, calcium hydrogen phosphate, sodium phosphate, lactose, sucrose, cellulose, microcrystalline cellulose, kaolin, mannitol, sorbitol, etc., and/or combinations thereof.
[0376] Exemplary surface active agents and/or emulsifiers include, but are not limited to, natural emulsifiers (e.g., acacia, agar, alginic acid, sodium alginate, tragacanth, chondrux, cholesterol, xanthan, pectin, gelatin, egg yolk, casein, wool fat, cholesterol, wax, and lecithin), sorbitan fatty acid esters (e.g., polyoxyethylene sorbitan monooleate [TWEEN®80], sorbitan monopalmitate [SPAN®40], glyceryl monooleate, polyoxyethylene esters, polyethylene glycol fatty acid esters (e.g., CREMOPHOR®),
I l l
polyoxyethylene ethers (e.g., polyoxyethylene lauryl ether [BRIJ®30]), PLUORINC®F 68, POLOXAMER®188, etc. and/or combinations thereof.
[0377] Exemplary binding agents include, but are not limited to, starch, gelatin, sugars (e.g., sucrose, glucose, dextrose, dextrin, molasses, lactose, lactitol, mannitol), amino acids (e.g., glycine), natural and synthetic gums (e g., acacia, sodium alginate), ethylcellulose, hydroxyethylcellulose, hydroxypropyl methylcellulose, etc., and combinations thereof.
[0378] Oxidation is a potential degradation pathway for mRNA, especially for liquid mRNA formulations. In order to prevent oxidation, antioxidants can be added to the formulations. Exemplary antioxidants include, but are not limited to, alpha tocopherol, ascorbic acid, ascorbyl palmitate, benzyl alcohol, butylated hydroxyanisole, m-cresol, methionine, butylated hydroxytoluene, monothioglycerol, sodium or potassium metabisulfite, propionic acid, propyl gallate, sodium ascorbate, etc., and combinations thereof.
[0379] Exemplary chelating agents include, but are not limited to, ethylenediaminetetraacetic acid (EDTA), citric acid monohydrate, disodium edetate, fumaric acid, malic acid, phosphoric acid, sodium edetate, tartaric acid, trisodium edetate, etc., and combinations thereof.
[0380] Exemplary antimicrobial or antifungal agents include, but are not limited to, benzalkonium chloride, benzethonium chloride, methyl paraben, ethyl paraben, propyl paraben, butyl paraben, benzoic acid, hydroxybenzoic acid, potassium or sodium benzoate, potassium or sodium sorbate, sodium propionate, sorbic acid, etc., and combinations thereof.
[0381] Exemplary preservatives include, but are not limited to, vitamin A, vitamin C, vitamin E, beta-carotene, citric acid, ascorbic acid, butylated hydroxyanisol, ethylenediamine, sodium lauryl sulfate (SLS), sodium lauryl ether sulfate (SLES), etc., and combinations thereof.
[0382] In some embodiments, the pH of polynucleotide solutions is maintained between pH 5 and pH 8 to improve stability. Exemplary buffers to control pH can
include, but are not limited to sodium phosphate, sodium citrate, sodium succinate, histidine (or histidine-HCl), sodium malate, sodium carbonate, etc., and/or combinations thereof.
[0383] Exemplary lubricating agents include, but are not limited to, magnesium stearate, calcium stearate, stearic acid, silica, talc, malt, hydrogenated vegetable oils, polyethylene glycol, sodium benzoate, sodium or magnesium lauryl sulfate, etc., and combinations thereof.
[0384] The pharmaceutical composition or formulation described here can contain a cryoprotectant to stabilize a polynucleotide described herein during freezing. Exemplary cryoprotectants include, but are not limited to mannitol, sucrose, trehalose, lactose, glycerol, dextrose, etc., and combinations thereof.
[0385] The pharmaceutical composition or formulation described here can contain a bulking agent in lyophilized polynucleotide formulations to yield a "pharmaceutically elegant" cake, stabilize the lyophilized polynucleotides during long term (e.g., 36 month) storage. Exemplary bulking agents of the present invention can include, but are not limited to sucrose, trehalose, mannitol, glycine, lactose, raffinose, and combinations thereof.
[0386] In some embodiments, the pharmaceutical composition or formulation further comprises a delivery agent. The delivery agent of the present disclosure can include, without limitation, liposomes, lipid nanoparticles, lipidoids, polymers, lipoplexes, microvesicles, exosomes, peptides, proteins, cells transfected with polynucleotides, hyaluronidase, nanoparticle mimics, nanotubes, conjugates, and combinations thereof.
Delivery Agents
Lipid Compound
[0387] The present disclosure provides pharmaceutical compositions with advantageous properties. The lipid compositions described herein may be advantageously used in lipid nanoparticle compositions for the delivery of therapeutic and/or prophylactic agents, e.g., mRNAs, to mammalian cells or organs. For example, the lipids described
herein have litle or no immunogenicity. For example, the lipid compounds disclosed herein have a lower immunogenicity as compared to a reference lipid (e.g., MC3 , KC2, or DLinDMA). For example, a formulation comprising a lipid disclosed herein and a therapeutic or prophylactic agent, e.g., mRNA, has an increased therapeutic index as compared to a corresponding formulation which comprises a reference lipid (e.g., MC3 , KC2, or DLinDMA) and the same therapeutic or prophylactic agent.
[0388] In certain embodiments, the present application provides pharmaceutical compositions comprising:
(a) a polynucleotide comprising a nucleotide sequence encoding an IgAP protein described herein; and
(b) a delivery agent.
Lipid Nanoparticle Formulations
[0389] In some embodiments, nucleic acids of the invention (e.g., IgAP mRNA) are formulated in a lipid nanoparticle (LNP). Lipid nanoparticles typically comprise ionizable cationic lipid, non-cationic lipid, sterol and PEG lipid components along with the nucleic acid cargo of interest. The lipid nanoparticles of the invention can be generated using components, compositions, and methods as are generally known in the art, see for example PCT/US2016/052352; PCT/US2016/068300; PCT/US2017/037551; PCT/US2015/027400; PCT/US2016/047406; PCT/US2016000129;
PCT/US2016/014280; PCT/US2016/014280; PCT/US2017/038426;
PCT/US2014/027077; PCT/US2014/055394; PCT/US2016/52117;
PCT/US2012/069610; PCT/US2017/027492; PCT/US2016/059575 and PCT/US2016/069491 all of which are incorporated by reference herein in their entirety. [0390] Nucleic acids of the present disclosure (e.g., IgAP mRNA) are typically formulated in lipid nanoparticle. In some embodiments, the lipid nanoparticle comprises at least one ionizable cationic lipid, at least one non-cationic lipid, at least one sterol, and/or at least one polyethylene glycol (PEG)-modified lipid.
[0391] In some embodiments, the lipid nanoparticle comprises a molar ratio of 20- 60% ionizable cationic lipid. For example, the lipid nanoparticle may comprise a molar ratio of 40-50 mol%, optionally 45-50 mol%, for example, 45-46 mol%, 46-47 mol%, 47- 48 mol%, 48-49 mol%, or 49-50 mol%, for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol% ionizable cationic lipid.
[0392] In some embodiments, the lipid nanoparticle comprises a molar ratio of 5-25% non-cationic lipid. For example, the lipid nanoparticle may comprise a molar ratio of 5- 15 mol%, optionally 10-12 mol%, for example, 5-6 mol%, 6-7 mol%, 7-8 mol%, 8-9 mol%, 9-10 mol%, 10-11 mol%, 11-12 mol%, 12-13 mol%, 13-14 mol%, or 14-15 mol% non-cationic lipid.
[0393] In some embodiments, the lipid nanoparticle comprises a molar ratio of 25- 55% sterol. For example, the lipid nanoparticle may comprise a molar ratio of 30-45 mol%, optionally 35-40 mol%, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33- 34 mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 38-38 mol%, 38-39 mol%, or 39-40 mol% sterol.
[0394] In some embodiments, the lipid nanoparticle comprises a molar ratio of 0.5- 15% PEG-modified lipid. For example, the lipid nanoparticle may comprise a molar ratio of 1-5%, optionally 1-3 mol%, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol% PEG-modified lipid.
[0395] In some embodiments, the lipid nanoparticle comprises a molar ratio of 20- 60% ionizable cationic lipid, 5-25% non-cationic lipid, 25-55% sterol, and 0.5-15% PEG- modified lipid.
[0396] In some embodiments, the lipid nanoparticle comprises a molar ratio of 40- 50% ionizable cationic lipid, 5-15% non-cationic lipid, 30-45% sterol, and 1-5% PEG- modified lipid.
[0397] In some embodiments, the lipid nanoparticle comprises a molar ratio of 45- 50% ionizable cationic lipid, 10-12% non-cationic lipid, 35-40% sterol, and 1-3% PEG- modified lipid.
[0398] In some embodiments, the lipid nanoparticle comprises a molar ratio of 45- 50% ionizable cationic lipid, 10-12% non-cationic lipid, 35-40% sterol, and 1.5-2.5% PEG-modified lipid.
Ionizable amino lipids
[0399] In some aspects, the disclosure relates to a compound of Formula (I):
 r its N-oxide, or a salt or isomer thereof, wherein R’a is R’brailcllcd; wherein
r its N-oxide, or a salt or isomer thereof, wherein R’a is R’brailcllcd; wherein
 denotes a point of attachment; wherein Ra“, Rap, Ra and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl;
denotes a point of attachment; wherein Ra“, Rap, Ra and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl;
R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and
C2-14 alkenyl;
R4 is selected from the group consisting of -(CH2)nOH, wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein
denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10;
each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H;
M and M’ are each independently selected from the group consisting of -C(O)O- and
-0C(0)-;
R’ is a C1-12 alkyl or C2-12 alkenyl;
1 is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13.
In some embodiments of the compounds of Formula (I), R’a is R'brancbed;
R'branched is
 denotes a point of attachment; Raα, Ra^, Raγ, and Ra8 are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 5; and m is 7. [0400] In some embodiments of the compounds of Formula (I), R’a is R,branched;
denotes a point of attachment; Raα, Ra^, Raγ, and Ra8 are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 5; and m is 7. [0400] In some embodiments of the compounds of Formula (I), R’a is R,branched;
R'branched is
 denotes a point of attachment; Ra“, Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 3; and m is 7. [0401] In some embodiments of the compounds of Formula (I), R’a is R'brancbed. R'brancbed js
denotes a point of attachment; Ra“, Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 3; and m is 7. [0401] In some embodiments of the compounds of Formula (I), R’a is R'brancbed. R'brancbed js
 denotes a point of attachment; Raα is C2-12 alkyl; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is
denotes a point of attachment; Raα is C2-12 alkyl; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is
 alkyl); n2 is 2; R5 is H; each R6 is H; M and M’ are each -C(0)0-; R’ is a C1-12 alkyl; 1 is 5; and m is 7.
alkyl); n2 is 2; R5 is H; each R6 is H; M and M’ are each -C(0)0-; R’ is a C1-12 alkyl; 1 is 5; and m is 7.
[0402] In some embodiments of the compounds of Formula (I), R’a is R'brancbed;
 denotes a point of attachment; Raα, Raβ and Raδ are each H; Raγ is C2-12 alkyl; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 5; and m is 7.
denotes a point of attachment; Raα, Raβ and Raδ are each H; Raγ is C2-12 alkyl; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 5; and m is 7.
[0403] In some embodiments, the compound of Formula (I) is selected from:

[0404] In some embodiments, the compound of Formula (I) is:
 (Compound II).
(Compound II).
[0405] In some embodiments, the compound of Formula (I) is:

[0406] In some embodiments, the compound of Formula (I) is:

[0407] In some embodiments, the compound of Formula (I) is:
 (Compound B).
(Compound B).
[0408] In some aspects, the disclosure relates to a compound of Formula (la):
 r its N-oxide, or a salt or isomer thereof, wherein R’a is R'brancbed; wherein
r its N-oxide, or a salt or isomer thereof, wherein R’a is R'brancbed; wherein
 wherein Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl;
wherein Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl;
R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and
C2-14 alkenyl;
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein
denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H;
M and M’ are each independently selected from the group consisting of -C(O)O- and
-OC(O)-;
R’ is a C1-12 alkyl or C2-12 alkenyl;
1 is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13.
In some aspects, the disclosure relates to a compound of Formula (lb):
 r its N-oxide, or a salt or isomer thereof, wherein R’a is R'brancbed; wherein
R'brancbed js;
r its N-oxide, or a salt or isomer thereof, wherein R’a is R'brancbed; wherein
R'brancbed js;
 . wherein denotes a point of attachment;
. wherein denotes a point of attachment;
 wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl;
wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl;
R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and
C2-14 alkenyl;
R4 is -(CH2)nOH, wherein n is selected from the group consisting of 1, 2, 3, 4, and each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H;
M and M’ are each independently selected from the group consisting of -C(O)O- and
-OC(O)-;
R’ is a C 1-12 alkyl or C2-12 alkenyl;
1 is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13.
[0409] In some embodiments of Formula (I) or (lb), R’a is R'brancbed; R'brancbed

 denotes a point of attachment; Raβ\ Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 5; and m is 7.
[0410] In some embodiments of Formula (I) or (lb), R'a is R'brancbed; R'brancbed is
denotes a point of attachment; Raβ\ Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 5; and m is 7.
[0410] In some embodiments of Formula (I) or (lb), R'a is R'brancbed; R'brancbed is
 denotes a point of attachment; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(0)0-; R’ is a C1-12 alkyl; 1 is 3; and m is 7.
denotes a point of attachment; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(0)0-; R’ is a C1-12 alkyl; 1 is 3; and m is 7.
[0411] In some embodiments of Formula (I) or (lb), R’a is R,branched; R'brancbed is
 denotes a point of attachment; Rap and Raδ are each H; Raγ is C2-12 alkyl; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R3 is H; each R6 is H;
denotes a point of attachment; Rap and Raδ are each H; Raγ is C2-12 alkyl; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R3 is H; each R6 is H;
M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; 1 is 5; and m is 7.
[0412] In some aspects, the disclosure relates to a compound of Formula (Ic):
 (Ic) or its N-oxide, or a salt or isomer thereof, wherein R’a is R'brancbed; wherein
(Ic) or its N-oxide, or a salt or isomer thereof, wherein R’a is R'brancbed; wherein
R’ branched : is:
 ; wherein
; wherein
 denotes a point of attachment; wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl;
denotes a point of attachment; wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl;
R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and
C2-14 alkenyl;
 wherein ? denotes a point of attachment; wherein
wherein ? denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H;
M and M’ are each independently selected from the group consisting of -C(O)O- and
-0C(0)-;
R’ is a C1-12 alkyl or C2-12 alkenyl;
1 is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13.
[0413] In some embodiments,
 denotes a point of attachment; Rap, Raγ, and Raδ are each H; Ra“ is C2-12 alkyl; R2 and R3 are each C1-14 alkyl;
denotes a point of attachment; Rap, Raγ, and Raδ are each H; Ra“ is C2-12 alkyl; R2 and R3 are each C1-14 alkyl;
 denotes a point of attachment; R10 is NH(CI-6 alkyl); n2 is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a
denotes a point of attachment; R10 is NH(CI-6 alkyl); n2 is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a
C1-12 alkyl; 1 is 5; and m is 7.
[0414] In some embodiments, the compound of Formula (Ic) is:
 (Compound A).
(Compound A).
[0415] In some aspects, the disclosure relates to a compound of Formula (II):


Rb ■ and RbS are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Rb / and RbS is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and
C2-14 alkenyl;
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein ? denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl;
wherein ? denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl;
Ya is a C3-6 carbocycle;
R*”a is selected from the group consisting of C1-15 alkyl and C2-15 alkenyl; and s is 2 or 3; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
1 is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9.
[0416] In some aspects, the disclosure relates to a compound of Formula (Il-a):
 wherein R’a is R'brancbed or R’cycllc; wherein
wherein R’a is R'brancbed or R’cycllc; wherein
 wherein ? denotes a point of attachment; Raγ and Ra6 are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Raγ and Raδ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
wherein ? denotes a point of attachment; Raγ and Ra6 are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Raγ and Raδ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
Rb ■ and RbS are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Rby and RbS is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and
C2-14 alkenyl;
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein
denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
1 is selected from 1 , 2, 3, 4, 5, 6, 7, 8, and 9.
[0417] In some aspects, the disclosure relates to a compound of Formula (Il-b):
 r its N-oxide, or a salt or isomer thereof, wherein R’a is R’branehed Or R’cycllc; wherein
r its N-oxide, or a salt or isomer thereof, wherein R’a is R’branehed Or R’cycllc; wherein
 wherein
wherein
 denotes a point of attachment; Raγ and Rby are each independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
denotes a point of attachment; Raγ and Rby are each independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and
C2-14 alkenyl;
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein
denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
1 is selected from 1 , 2, 3, 4, 5, 6, 7, 8, and 9.
[0418] In some aspects, the disclosure relates to a compound of Formula (II-c):
 wherein R’a is R’branehed Or R’cycllc; wherein
wherein R’a is R’branehed Or R’cycllc; wherein
 wherein ? denotes a point of attachment; wherein Raγ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
wherein ? denotes a point of attachment; wherein Raγ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and
C2-14 alkenyl;
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein
denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10;
R’ is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
1 is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9.
[0419] In some aspects, the disclosure relates to a compound of Formula (Il-d):
 wherein R’a is R’branehed Or R’cycllc; wherein
wherein R’a is R’branehed Or R’cycllc; wherein
 wherein ? denotes a point of attachment; wherein Raγ and Rby are each independently selected from the group consisting of
wherein ? denotes a point of attachment; wherein Raγ and Rby are each independently selected from the group consisting of
C1-12 alkyl and C2-12 alkenyl;
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
1 is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9.
[0420] In some aspects, the disclosure relates to a compound of Formula (Il-e):
 wherein
wherein
 denotes a point of attachment; wherein Raγ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
denotes a point of attachment; wherein Raγ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl;
R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and
C2-14 alkenyl;
R4 is -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5;
R’ is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
1 is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9.
[0421] In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (Il-d), or (Il-e), m and 1 are each independently selected from 4, 5, and 6. In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (Il-d), or (Il-e), m and 1 are each 5.
[0422] In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (II-d), or (Il-e), each R’ independently is a C1-12 alkyl. In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (Il-d), or (Il-e), each R’ independently is a C2-5 alkyl.
[0423] In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c),
(II-d), or (Il-e), R’b is:
 and R2 and R3 are each independently a C1-14 alkyl. In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (Il-d), or (Il-e),
and R2 and R3 are each independently a C1-14 alkyl. In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (Il-d), or (Il-e),
R’b is:
 R2 and R3 are each independently a C6-io alkyl. In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (II-d), or (Il-e), R’b is:
R2 and R3 are each independently a C6-io alkyl. In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (II-d), or (Il-e), R’b is:
 are each a Cs alkyl.
are each a Cs alkyl.
[0424] In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c),
 , Raγ is a C1-12 alkyl and R2 and R3 are each independently a C6-io alkyl. In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (II-d), or (Il-e), R'brancbed is:
, Raγ is a C1-12 alkyl and R2 and R3 are each independently a C6-io alkyl. In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c), (II-d), or (Il-e), R'brancbed is:
 are each independently a C6-io alkyl. In some embodiments of the compound of Formula (II), (II-
are each independently a C6-io alkyl. In some embodiments of the compound of Formula (II), (II-
 is a C2-6 alkyl, and R2 and R3 are each a Cx alkyl.
is a C2-6 alkyl, and R2 and R3 are each a Cx alkyl.
[0425] In some embodiments of the compound of Formula (II), (Il-a), (II-b), (II-c),
(II-d), or (Il-e), R'branched is;
 is:
is:

Rby are each a C1-12 alkyl. In some embodiments of the compound of Formula (II), (Il-a),
(Il-b), (II-c), (II-d), or (Il-e), R'brancbed is:
 and Raγ and Rby are each a C2-6 alkyl.
and Raγ and Rby are each a C2-6 alkyl.
[0426] In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (II-d), or (Il-e), m and 1 are each independently selected from 4, 5, and 6 and each R’ independently is a C1-12 alkyl. In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (II-d), or (Il-e), m and 1 are each 5 and each R’ independently is a C2-5 alkyl.
[0427] In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c),
(II-d), or (Il-e), R'branched is;
 is:
is:
 are each independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, and Raγ and Rby are each a C1-12 alkyl. In some embodiments of the compound of Formula
are each independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, and Raγ and Rby are each a C1-12 alkyl. In some embodiments of the compound of Formula
(II), (Il-a), (Il-b), (II-c), (II-d), or (Il-e), R'brancbed is:

Rby
 , m and 1 are each 5, each R’ independently is a C2-5 alkyl, and Raγ and Rby are each a C2-6 alkyl.
, m and 1 are each 5, each R’ independently is a C2-5 alkyl, and Raγ and Rby are each a C2-6 alkyl.
[0428] In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c),
(II-d), or (Il-e), R'branched is:
 is:
is:
 are each independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, Raγ is a C1-12 alkyl and R2 and R3 are each independently a C6-io alkyl. In some embodiments of the compound of
are each independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, Raγ is a C1-12 alkyl and R2 and R3 are each independently a C6-io alkyl. In some embodiments of the compound of
Formula (
 is:
is:
 , m and 1 are each 5, R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a Cx alkyl.
, m and 1 are each 5, R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a Cx alkyl.
[0429] In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c),
 wherein R10 is NH(CI-6 alkyl) and n2 is 2. In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (II-d), or (II-e),
wherein R10 is NH(CI-6 alkyl) and n2 is 2. In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (II-d), or (II-e),
 wherein R10 is NH(CH3) and n2 is 2.
wherein R10 is NH(CH3) and n2 is 2.
[0430] In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c),
(II-d), or (II-e), R'brancbed is:
 is:
is:
 are each independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, Raγ and Rb / are each a C1-12 alkyl, and R4 is
are each independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, Raγ and Rb / are each a C1-12 alkyl, and R4 is
 , wherein R10 is NH(CI-6 alkyl), and n2 is 2. In some embodiments of the compound of Formula (II), (Il-a), (Il-b),
, wherein R10 is NH(CI-6 alkyl), and n2 is 2. In some embodiments of the compound of Formula (II), (Il-a), (Il-b),
 are each 5, each R’ independently is a C2-5 alkyl, Raγ and Rby are each a C2-6 alkyl, and R4
are each 5, each R’ independently is a C2-5 alkyl, Raγ and Rby are each a C2-6 alkyl, and R4
 wherein R10 is NH(CH3) and n2 is 2.
wherein R10 is NH(CH3) and n2 is 2.
[0431] In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c),
(II-d), or (II-e), R'branched is:
 is:
is:
 are each
independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, R2 and R3 are each independently a C6-io alkyl, Raγ is a C1-12 alkyl, and R4 is
are each
independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, R2 and R3 are each independently a C6-io alkyl, Raγ is a C1-12 alkyl, and R4 is
 , wherein
, wherein
R10 is NH(CI-6 alkyl) and n2 is 2. In some embodiments of the compound of Formula
(II), (IIa), (Il-b), (II-c), (II-d), or (Il-e), R'branched is: and R>b is:
 , m and 1 are each 5, R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, R2 and R3 are each a C8
, m and 1 are each 5, R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, R2 and R3 are each a C8
. alkyl, and R4 is , wherein R10 is NH(CH3) and n2 is 2.

[0432] In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (Il-d), or (Il-e), R4 is -(CH2)nOH and n is 2, 3, or 4. In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (Il-d), or (Il-e), R4 is -(CH2)nOH and n is 2.
[0433] In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c),
(II-d), or (Il-e), R'branched is:
 , R’b is:
, R’b is:
 , m and 1 are each independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, Raγ and Rby are each a C1-12 alkyl, R4 is -(CH2)nOH, and n is 2, 3, or 4. In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (II-d), or (Il-e), R'branched is: RaY RbY
, m and 1 are each independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, Raγ and Rby are each a C1-12 alkyl, R4 is -(CH2)nOH, and n is 2, 3, or 4. In some embodiments of the compound of Formula (II), (Il-a), (Il-b), (II-c), (II-d), or (Il-e), R'branched is: RaY RbY
 , , m and 1 are each 5, each R’ independently is a C2-5 alkyl, Raγ and Rby are each a C2-6 alkyl, R4 is -(CH2)nOH, and n is 2.
, , m and 1 are each 5, each R’ independently is a C2-5 alkyl, Raγ and Rby are each a C2-6 alkyl, R4 is -(CH2)nOH, and n is 2.
[0434] In some aspects, the disclosure relates to a compound of Formula (Il-f):


R2 and R3 are each independently a C1-i4 alkyl;
R4 is -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and
R’ is a C1-12 alkyl; m is selected from 4, 5, and 6; and
1 is selected from 4, 5, and 6.
[0435] In some embodiments of the compound of Formula (Il-f), m and 1 are each 5, and n is 2, 3, or 4.
[0436] In some embodiments of the compound of Formula (Il-f) R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a C6-io alkyl.
[0437] In some embodiments of the compound of Formula (Il-f), m and 1 are each 5, n is 2, 3, or 4, R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a C6-io alkyl.
[0438] In some aspects, the disclosure relates to a compound of Formula (Il-g):
 R’ is a C2-5 alkyl; and
R’ is a C2-5 alkyl; and
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment, R10 is NH(CI-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3.
denotes a point of attachment, R10 is NH(CI-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3.
[0439] In some aspects, the disclosure relates to a compound of Formula (Il-h):
 Raγ and Rb'-' are each independently a C2-6 alkyl; each R’ independently is a C2-5 alkyl; and
Raγ and Rb'-' are each independently a C2-6 alkyl; each R’ independently is a C2-5 alkyl; and
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment, R10 is NH(CI-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3.
denotes a point of attachment, R10 is NH(CI-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3.
[0440] In some embodiments of the compound of Formula (Il-g) or (11-h), R4 is
 , wherein
, wherein
R10 is NH(CH3) and n2 is 2.
[0441] In some embodiments of the compound of Formula (Il-g) or (Il-h), R4 is - (CH2)2OH.
[0442] In some aspects, the disclosure relates to a compound having the Formula
(III):
 or a salt or isomer thereof, wherein
or a salt or isomer thereof, wherein
Ri, R2, R3, R4, and Rs are independently selected from the group consisting of Cs-
20 alkyl, C5-20 alkenyl, -R”MR’, -R*YR”, -YR”, and -R*OR”; each M is independently selected from the group consisting of -C(O)O-, -OC(O)-, -OC(O)O-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -S C(S)-,
-CH(OH)-, -P(O)(OR’)O-, -S(O)2-, an aryl group, and a heteroaryl group;
X1, X2, and X3 are independently selected from the group consisting of a bond, -CH2-,
-(CH2)2-, -CHR-, -CHY-, -C(O)-, -C(O)O-, -OC(O)-, -C(O)-CH2-, -CH2-C(O)-, -C(O)O-CH2-, -OC(O)-CH2-, -CH2-C(O)O-, -CH2-OC(O)-, -CH(OH)-, -C(S)-, and -CH(SH)-; each Y is independently a C3-6 carbocycle; each R* is independently selected from the group consisting of C1-12 alkyl and C2- 12 alkenyl; each R is independently selected from the group consisting of C1-3 alkyl and a C3-6 carbocycle; each R’ is independently selected from the group consisting of C1-12 alkyl, C2-12 alkenyl, and H; and each R” is independently selected from the group consisting of C3-12 alkyl and C3-
12 alkenyl, and wherein: i) at least one of X1, X2, and X3 is not -CH2-; and/or
ii) at least one of Ri, R2, R3, R4, and Rs is -R”MR’.
[0443] In some embodiments, Ri, R2, R3, R4, and Rs are each C5-20 alkyl; X1 is -CH2-; and X2 and X3 are each -C(O)-.
[0444] In some embodiments, the compound of Formula (III) is:
 (Compound VI), or a salt or isomer thereof.
(Compound VI), or a salt or isomer thereof.
Phospholipids
[0445] The lipid composition of the lipid nanoparticle composition disclosed herein can comprise one or more phospholipids, for example, one or more saturated or (poly)unsaturated phospholipids or a combination thereof. In general, phospholipids comprise a phospholipid moiety and one or more fatty acid moieties.
[0446] A phospholipid moiety can be selected, for example, from the non-limiting group consisting of phosphatidyl choline, phosphatidyl ethanolamine, phosphatidyl glycerol, phosphatidyl serine, phosphatidic acid, 2-lysophosphatidyl choline, and a sphingomyelin.
[0447] A fatty acid moiety can be selected, for example, from the non-limiting group consisting of lauric acid, myristic acid, myristoleic acid, palmitic acid, palmitoleic acid, stearic acid, oleic acid, linoleic acid, alpha-linolenic acid, erucic acid, phytanoic acid, arachidic acid, arachidonic acid, eicosapentaenoic acid, behenic acid, docosapentaenoic acid, and docosahexaenoic acid.
[0448] Particular phospholipids can facilitate fusion to a membrane. For example, a cationic phospholipid can interact with one or more negatively charged phospholipids of a membrane (e.g., a cellular or intracellular membrane). Fusion of a phospholipid to a membrane can allow one or more elements (e.g., a therapeutic agent) of a lipid- containing composition (e.g., LNPs) to pass through the membrane permitting, e.g., delivery of the one or more elements to a target tissue.
[0449] Non-natural phospholipid species including natural species with modifications and substitutions including branching, oxidation, cyclization, and alkynes are also contemplated. For example, a phospholipid can be functionalized with or cross-linked to one or more alkynes (e.g., an alkenyl group in which one or more double bonds is replaced with a triple bond). Under appropriate reaction conditions, an alkyne group can undergo a copper-catalyzed cycloaddition upon exposure to an azide. Such reactions can be useful in functionalizing a lipid bilayer of a nanoparticle composition to facilitate membrane permeation or cellular recognition or in conjugating a nanoparticle composition to a useful component such as a targeting or imaging moiety (e.g., a dye). [0450] Phospholipids include, but are not limited to, glycerophospholipids such as phosphatidylcholines, phosphatidylethanolamines, phosphatidylserines, phosphatidylinositols, phosphatidy glycerols, and phosphatidic acids. Phospholipids also include phosphosphingolipid, such as sphingomyelin.
[0451] In some embodiments, a phospholipid of the invention comprises 1,2- distearoyl-sn-glycero-3-phosphocholine (DSPC), l,2-dioleoyl-sn-glycero-3- phosphoethanolamine (DOPE), l,2-dilinoleoyl-sn-glycero-3 -phosphocholine (DLPC), 1,2-dimyristoyl-sn-gly cero-phosphocholine (DMPC), l,2-dioleoyl-sn-glycero-3- phosphocholine (DOPC), l,2-dipalmitoyl-sn-glycero-3 -phosphocholine (DPPC), 1,2- diundecanoyl-sn-glycero-phosphocholine (DUPC), 1 -palmitoyl-2-oleoyl-sn-glycero-3- phosphocholine (POPC), l,2-di-O-octadecenyl-sn-glycero-3-phosphocholine (18:0 Diether PC), l-oleoyl-2 cholesterylhemisuccinoyl-sn-glycero-3-phosphocholine (OChemsPC), l-hexadecyl-sn-glycero-3-phosphocholine (C16 Lyso PC), 1,2- dilinolenoyl-sn-glycero-3-phosphocholine,l,2-diarachidonoyl-sn-glycero-3- phosphocholine, l,2-didocosahexaenoyl-sn-glycero-3-phosphocholine, 1,2-diphytanoyl- sn-glycero-3-phosphoethanolamine (ME 16.0 PE), l,2-distearoyl-sn-glycero-3- phosphoethanolamine, l,2-dilinoleoyl-sn-glycero-3-phosphoethanolamine, 1,2- dilinolenoyl-sn-glycero-3 -phosphoethanolamine, l,2-diarachidonoyl-sn-glycero-3- phosphoethanolamine, l,2-didocosahexaenoyl-sn-glycero-3 -phosphoethanolamine, 1,2-
di oleoyl-sn-glycero-3-phospho-rac-(l -glycerol) sodium salt (DOPG), sphingomyelin, and mixtures thereof.
[0452] In certain embodiments, a phospholipid useful or potentially useful in the present invention is an analog or variant of DSPC. In certain embodiments, a phospholipid useful or potentially useful in the present invention is a compound of Formula (IV):
 or a salt thereof, wherein: each R1 is independently optionally substituted alkyl; or optionally two R1 are joined together with the intervening atoms to form optionally substituted monocyclic carbocyclyl or optionally substituted monocyclic heterocyclyl; or optionally three R1 are joined together with the intervening atoms to form optionally substituted bicyclic carbocyclyl or optionally substitute bicyclic heterocyclyl; n is i, 2, 3, 4, 5, 6, 7, 8, 9, or 10; m is O, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10;
or a salt thereof, wherein: each R1 is independently optionally substituted alkyl; or optionally two R1 are joined together with the intervening atoms to form optionally substituted monocyclic carbocyclyl or optionally substituted monocyclic heterocyclyl; or optionally three R1 are joined together with the intervening atoms to form optionally substituted bicyclic carbocyclyl or optionally substitute bicyclic heterocyclyl; n is i, 2, 3, 4, 5, 6, 7, 8, 9, or 10; m is O, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10;
A is of the Formula:
 each instance of L2 is independently a bond or optionally substituted C1-6 alkylene, wherein one methylene unit of the optionally substituted C1-6 alkylene is optionally replaced with O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), - OC(O)O, OC(O)N(RN), NRNC(O)O, or NRNC(O)N(RN); each instance of R2 is independently optionally substituted C1-30 alkyl, optionally substituted C1-30 alkenyl, or optionally substituted C1-30 alkynyl; optionally wherein one or more methylene units of R2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclyl ene, optionally substituted arylene,
each instance of L2 is independently a bond or optionally substituted C1-6 alkylene, wherein one methylene unit of the optionally substituted C1-6 alkylene is optionally replaced with O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), - OC(O)O, OC(O)N(RN), NRNC(O)O, or NRNC(O)N(RN); each instance of R2 is independently optionally substituted C1-30 alkyl, optionally substituted C1-30 alkenyl, or optionally substituted C1-30 alkynyl; optionally wherein one or more methylene units of R2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclyl ene, optionally substituted arylene,
 NRNC(S), NRNC(S)N(RN), S(O), OS(O), S(O)O, OS(O)O, OS(O)2, S(O)2O, OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, S(O)2, - N(RN)S(0)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or N(RN)S(O)2O; each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group;
NRNC(S), NRNC(S)N(RN), S(O), OS(O), S(O)O, OS(O)O, OS(O)2, S(O)2O, OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, S(O)2, - N(RN)S(0)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or N(RN)S(O)2O; each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group;
Ring B is optionally substituted carbocyclyl, optionally substituted heterocyclyl, optionally substituted aryl, or optionally substituted heteroaryl; and p is 1 or 2; provided that the compound is not of the Formula:
 wherein each instance of R2 is independently unsubstituted alkyl, unsubstituted alkenyl, or unsubstituted alkynyl.
wherein each instance of R2 is independently unsubstituted alkyl, unsubstituted alkenyl, or unsubstituted alkynyl.
[0453] In some embodiments, the phospholipids may be one or more of the phospholipids described in U.S. Application No. 62/520,530.
Phospholipid Head Modifications
[0454] In certain embodiments, a phospholipid useful or potentially useful in the present invention comprises a modified phospholipid head (e.g., a modified choline group). In certain embodiments, a phospholipid with a modified head is DSPC, or analog thereof, with a modified quaternary amine. For example, in embodiments of Formula (IV), at least one of R1 is not methyl. In certain embodiments, at least one of R1 is not hydrogen or methyl. In certain embodiments, the compound of Formula (IV) is of one of the following Formulae:

[0455] In certain embodiments, a compound of Formula (IV) is of Formula (IV-a):

(IV-a), or a salt thereof.
[0456] In certain embodiments, a phospholipid useful or potentially useful in the present invention comprises a cyclic moiety in place of the glyceride moiety. In certain embodiments, a phospholipid useful in the present invention is DSPC, or analog thereof, with a cyclic moiety in place of the glyceride moiety. In certain embodiments, the compound of Formula (IV) is of Formula (IV-b):
 or a salt thereof.
or a salt thereof.
Phospholipid Tail Modifications
[0457] In certain embodiments, a phospholipid useful or potentially useful in the present invention comprises a modified tail. In certain embodiments, a phospholipid useful or potentially useful in the present invention is DSPC, or analog thereof, with a modified tail. As described herein, a “modified tail” may be a tail with shorter or longer aliphatic chains, aliphatic chains with branching introduced, aliphatic chains with substituents introduced, aliphatic chains wherein one or more methylenes are replaced by cyclic or heteroatom groups, or any combination thereof. For example, in certain embodiments, the compound of (IV) is of Formula (IV-a), or a salt thereof, wherein at least one instance of R2 is each instance of R2 is optionally substituted C1-30 alkyl, wherein one or more methylene units of R2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(RN), O, S, C(O), C(O)N(RN), NRNC(O), NRNC(O)N(RN), C(O)O, OC(O), OC(O)O, OC(O)N(RN), NRNC(O)O, C(O)S, SC(O), - C(=NRN), C(=NRN)N(RN), NRNC(=NRN), NRNC(=NRN)N(RN), C(S), C(S)N(RN), - NRNC(S), NRNC(S)N(RN), S(O), OS(O), S(O)O, OS(O)O, OS(O)2, S(O)2O, OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, S(O)2, - N(RN)S(0)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or N(RN)S(O)2O.
[0458] In certain embodiments, the compound of Formula (IV) is of Formula (IV-c):
 (IV-c), or a salt thereof, wherein: each x is independently an integer between 0-30, inclusive; and each instance is G is independently selected from the group consisting of optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(RN), O, S, C(O), C(O)N(RN), NRNC(O), NRNC(O)N(RN), C(O)O, OC(O), OC(O)O, OC(O)N(RN), NRNC(O)O, C(O)S,
(IV-c), or a salt thereof, wherein: each x is independently an integer between 0-30, inclusive; and each instance is G is independently selected from the group consisting of optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(RN), O, S, C(O), C(O)N(RN), NRNC(O), NRNC(O)N(RN), C(O)O, OC(O), OC(O)O, OC(O)N(RN), NRNC(O)O, C(O)S,
 possibility represents a separate embodiment of the present invention.
possibility represents a separate embodiment of the present invention.
[0459] In certain embodiments, a phospholipid useful or potentially useful in the present invention comprises a modified phosphocholine moiety, wherein the alkyl chain linking the quaternary amine to the phosphoryl group is not ethylene (e.g., n is not 2). Therefore, in certain embodiments, a phospholipid useful or potentially useful in the present invention is a compound of Formula (IV), wherein n is 1, 3, 4, 5, 6, 7, 8, 9, or 10. For example, in certain embodiments, a compound of Formula (IV) is of one of the following Formulae:
 or a salt thereof.
or a salt thereof.
Alternative Lipids
[0460] In certain embodiments, a phospholipid useful or potentially useful in the present invention comprises a modified phosphocholine moiety, wherein the alkyl chain linking the quaternary amine to the phosphoryl group is not ethylene (e. ., n is not 2). Therefore, in certain embodiments, a phospholipid useful.
[0461] In certain embodiments, an alternative lipid is used in place of a phospholipid of the present disclosure.
[0462] In certain embodiments, an alternative lipid of the invention is oleic acid.
[0463] In certain embodiments, the alternative lipid is one of the following:


Structural Lipids
[0464] The lipid composition of a pharmaceutical composition disclosed herein can comprise one or more structural lipids. As used herein, the term "structural lipid" refers to sterols and also to lipids containing sterol moieties.
[0465] Incorporation of structural lipids in the lipid nanoparticle may help mitigate aggregation of other lipids in the particle. Structural lipids can be selected from the group including but not limited to, cholesterol, fecosterol, sitosterol, ergosterol, campesterol, stigmasterol, brassicasterol, tomatidine, tomatine, ursolic acid, alpha-tocopherol, hopanoids, phytosterols, steroids, and mixtures thereof. In some embodiments, the structural lipid is a sterol. As defined herein, "sterols" are a subgroup of steroids consisting of steroid alcohols. In certain embodiments, the structural lipid is a steroid. In certain embodiments, the structural lipid is cholesterol. In certain embodiments, the structural lipid is an analog of cholesterol. In certain embodiments, the structural lipid is alpha- tocopherol.
[0466] In some embodiments, the structural lipids may be one or more of the structural lipids described in U.S. Application No. 62/520,530.
Polyethylene Glycol (PEG)-Lipids
[0467] The lipid composition of a pharmaceutical composition disclosed herein can comprise one or more a polyethylene glycol (PEG) lipid.
[0468] As used herein, the term “PEG-lipid” refers to polyethylene glycol (PEG)- modified lipids. Non-limiting examples of PEG-lipids include PEG-modified phosphatidylethanolamine and phosphatidic acid, PEG-ceramide conjugates (e.g., PEG- C6rC14 or PEG-C6rC20), PEG-modified dialkylamines and PEG-modified 1,2-
diacyloxypropan-3 -amines. Such lipids are also referred to as PEGylated lipids. For example, a PEG lipid can be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid.
[0469] In some embodiments, the PEG-lipid includes, but not limited to 1,2- dimyristoyl-sn-glycerol methoxypolyethylene glycol (PEG-DMG), 1,2-distearoyl-sn- glycero-3-phosphoethanolamine-N-[amino(polyethylene glycol)] (PEG-DSPE), PEG- disteryl glycerol (PEG-DSG), PEG-dipalmetoleyl, PEG-dioleyl, PEG-distearyl, PEG- diacylglycamide (PEG-DAG), PEG-dipalmitoyl phosphatidylethanolamine (PEG-DPPE), or PEG-1, 2-dimyristyloxlpropyl-3 -amine (PEG-c-DMA).
[0470] In one embodiment, the PEG-lipid is selected from the group consisting of a PEG-modified phosphatidylethanolamine, a PEG-modified phosphatidic acid, a PEG- modified ceramide, a PEG-modified dialkylamine, a PEG-modified diacylglycerol, a PEG-modified dialkylglycerol, and mixtures thereof.
[0471] In some embodiments, the lipid moiety of the PEG-lipids includes those having lengths of from about C14to about C22, preferably from about C14to about C16. In some embodiments, a PEG moiety, for example an mPEG-NFb, has a size of about 1000, 2000, 5000, 10,000, 15,000 or 20,000 daltons. In one embodiment, the PEG-lipid is PEG2k-DMG.
[0472] In one embodiment, the lipid nanoparticles described herein can comprise a PEG lipid which is a non-diffusible PEG. Non-limiting examples of non-diffusible PEGs include PEG-DSG and PEG-DSPE.
[0473] PEG-lipids are known in the art, such as those described in U.S. Patent No. 8158601 and International Publ. No. WO 2015/130584 A2, which are incorporated herein by reference in their entirety.
[0474] In general, some of the other lipid components (e.g., PEG lipids) of various Formulae, described herein may be synthesized as described International Patent Application No. PCT/US2016/000129, filed December 10, 2016, entitled “Compositions and Methods for Delivery of Therapeutic Agents,” which is incorporated by reference in its entirety.
[0475] The lipid component of a lipid nanoparticle composition may include one or more molecules comprising polyethylene glycol, such as PEG or PEG-modified lipids. Such species may be alternately referred to as PEGylated lipids. A PEG lipid is a lipid modified with polyethylene glycol. A PEG lipid may be selected from the non-limiting group including PEG-modified phosphatidylethanolamines, PEG-modified phosphatidic acids, PEG-modified ceramides, PEG-modified dialkylamines, PEG-modified di acylglycerols, PEG-modified dialkylglycerols, and mixtures thereof. For example, a PEG lipid may be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid.
[0476] In some embodiments the PEG-modified lipids are a modified form of PEG DMG. PEG-DMG has the following structure:

[0477] In one embodiment, PEG lipids useful in the present invention can be PEGylated lipids described in International Publication No. WO2012099755, the contents of which is herein incorporated by reference in its entirety. Any of these exemplary PEG lipids described herein may be modified to comprise a hydroxyl group on the PEG chain. In certain embodiments, the PEG lipid is a PEG-OH lipid. As generally defined herein, a “PEG-OH lipid” (also referred to herein as “hydroxy- PEGylated lipid”) is a PEGylated lipid having one or more hydroxyl (-OH) groups on the lipid. In certain embodiments, the PEG-OH lipid includes one or more hydroxyl groups on the PEG chain. In certain embodiments, a PEG-OH or hydroxy -PEGylated lipid comprises an -OH group at the terminus of the PEG chain. Each possibility represents a separate embodiment of the present invention.
[0478] In certain embodiments, a PEG lipid useful in the present invention is a compound of Formula (V). Provided herein are compounds of Formula (V):
(V),
 or salts thereof, wherein:
or salts thereof, wherein:
R3 is -OR°;
R° is hydrogen, optionally substituted alkyl, or an oxygen protecting group; r is an integer between 1 and 100, inclusive;
L1 is optionally substituted C1-io alkylene, wherein at least one methylene of the optionally substituted C1-io alkylene is independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, O, N(RN), S, C(O), C(O)N(RN), NR C(O), C(O)O, OC(O), OC(O)O, OC(O)N(RN), NRNC(O)O, or NRNC(O)N(RN);
D is a moiety obtained by click chemistry or a moiety cleavable under physiological conditions; m is O, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10;
A is of the Formula:
 each instance of L2 is independently a bond or optionally substituted C1-6 alkylene, wherein one methylene unit of the optionally substituted C1-6 alkylene is optionally replaced with O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), - OC(O)O, OC(O)N(RN), NRNC(O)O, or NRNC(O)N(RN); each instance of R2 is independently optionally substituted C1-30 alkyl, optionally substituted C1-30 alkenyl, or optionally substituted C1-30 alkynyl; optionally wherein one or more methylene units of R2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene,
each instance of L2 is independently a bond or optionally substituted C1-6 alkylene, wherein one methylene unit of the optionally substituted C1-6 alkylene is optionally replaced with O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), - OC(O)O, OC(O)N(RN), NRNC(O)O, or NRNC(O)N(RN); each instance of R2 is independently optionally substituted C1-30 alkyl, optionally substituted C1-30 alkenyl, or optionally substituted C1-30 alkynyl; optionally wherein one or more methylene units of R2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene,
 NRNC(S), NRNC(S)N(RN), S(O) , OS(O), S(O)O, OS(O)O, OS(O)2, S(O)2O, OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, S(O)2, - N(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or N(RN)S(O)2O;
each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group;
NRNC(S), NRNC(S)N(RN), S(O) , OS(O), S(O)O, OS(O)O, OS(O)2, S(O)2O, OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, S(O)2, - N(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or N(RN)S(O)2O;
each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group;
Ring B is optionally substituted carbocyclyl, optionally substituted heterocyclyl, optionally substituted aryl, or optionally substituted heteroaryl; and p is 1 or 2.
[0479] In certain embodiments, the compound of Formula (V) is a PEG-OH lipid (z.e., R3 is -OR°, and R° is hydrogen). In certain embodiments, the compound of Formula (V) is of Formula (V-OH):
 (V-OH), or a salt thereof.
(V-OH), or a salt thereof.
[0480] In certain embodiments, a PEG lipid useful in the present invention is a PEGylated fatty acid. In certain embodiments, a PEG lipid useful in the present invention is a compound of Formula (VI). Provided herein are compounds of Formula (VI):

(VI), or a salts thereof, wherein:
R3 is-OR°;
R° is hydrogen, optionally substituted alkyl or an oxygen protecting group; r is an integer between 1 and 100, inclusive;
R is optionally substituted C10-40 alkyl, optionally substituted C10-40 alkenyl, or optionally substituted C10-40 alkynyl; and optionally one or more methylene groups of R5 are replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, -
 0S(0)0, 0S(0)2, S(0)20, 0S(0)20, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), - OS(O)N(RN), N(RN)S(O)O, S(0)2, N(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), - OS(O)2N(RN), or N(RN)S(O)2O; and each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group.
0S(0)0, 0S(0)2, S(0)20, 0S(0)20, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), - OS(O)N(RN), N(RN)S(O)O, S(0)2, N(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), - OS(O)2N(RN), or N(RN)S(O)2O; and each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group.
[0481] In certain embodiments, the compound of Formula (VI) is of Formula (VI-
OH):
 or a salt thereof In some embodiments, r is 45.
or a salt thereof In some embodiments, r is 45.
[0482] In yet other embodiments the compound of Formula (VI) Is:
 or a salt thereof.
or a salt thereof.
[0483] In one embodiment, the compound of Formula (VI) is

(Compound I).
[0484] In some aspects, the lipid composition of the pharmaceutical compositions disclosed herein does not comprise a PEG-lipid.
[0485] In some embodiments, the PEG-lipids may be one or more of the PEG lipids described in U.S. Application No. 62/520,530.
[0486] In some embodiments, a PEG lipid of the invention comprises a PEG- modified phosphatidylethanolamine, a PEG-modified phosphatidic acid, a PEG-modified ceramide, a PEG-modified dialkylamine, a PEG-modified diacylglycerol, a PEG- modified dialkylglycerol, and mixtures thereof. In some embodiments, the PEG- modified lipid is PEG-DMG, PEG-c-DOMG (also referred to as PEG-DOMG), PEG- DSG and/or PEG-DPG.
[0487] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of any of Formula I, II or III, a phospholipid comprising DSPC, a structural lipid, and a PEG lipid comprising PEG-DMG.
[0488] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of any of Formula I, II or III, a phospholipid comprising DSPC, a structural lipid, and a PEG lipid comprising a compound having Formula VI.
[0489] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of Formula I, II or III, a phospholipid comprising a compound having Formula IV, a structural lipid, and the PEG lipid comprising a compound having Formula V or VI.
[0490] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of Formula I, II or III, a phospholipid comprising a compound having Formula IV, a structural lipid, and the PEG lipid comprising a compound having Formula V or VI.
[0491] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of Formula I, II or III, a phospholipid having Formula IV, a structural lipid, and a PEG lipid comprising a compound having Formula VI.
[0492] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of
 and a PEG lipid comprising Formula VI.
and a PEG lipid comprising Formula VI.
[0493] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of
 and an alternative lipid comprising oleic acid.
and an alternative lipid comprising oleic acid.
[0494] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of
 an alternative lipid comprising oleic acid, a structural lipid comprising cholesterol, and a PEG lipid comprising a compound having Formula VI.
an alternative lipid comprising oleic acid, a structural lipid comprising cholesterol, and a PEG lipid comprising a compound having Formula VI.
[0495] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of
 a phospholipid comprising DOPE, a structural lipid comprising cholesterol, and a PEG lipid comprising a compound having Formula VI.
a phospholipid comprising DOPE, a structural lipid comprising cholesterol, and a PEG lipid comprising a compound having Formula VI.
[0496] In some embodiments, a LNP of the invention comprises an ionizable cationic lipid of
 a phospholipid comprising DOPE, a structural lipid comprising cholesterol, and a PEG lipid comprising a compound having Formula VI.
a phospholipid comprising DOPE, a structural lipid comprising cholesterol, and a PEG lipid comprising a compound having Formula VI.
[0497] In some embodiments, a LNP of the invention comprises an N:P ratio of from about 2: 1 to about 30:1.
[0498] In some embodiments, a LNP of the invention comprises an N:P ratio of about 6: 1.
[0499] In some embodiments, a LNP of the invention comprises an N:P ratio of about 3: 1.
[0500] In some embodiments, a LNP of the invention comprises a wt/wt ratio of the ionizable cationic lipid component to the RNA of from about 10: 1 to about 100: 1.
[0501] In some embodiments, a LNP of the invention comprises a wt/wt ratio of the ionizable cationic lipid component to the RNA of about 20: 1.
[0502] In some embodiments, a LNP of the invention comprises a wt/wt ratio of the ionizable cationic lipid component to the RNA of about 10: 1.
[0503] In some embodiments, a LNP of the invention has a mean diameter from about 50nm to about 150nm.
[0504] In some embodiments, a LNP of the invention has a mean diameter from about 70nm to about 120nm.
[0505] As used herein, the term "alkyl", "alkyl group", or "alkylene" means a linear or branched, saturated hydrocarbon including one or more carbon atoms (e.g., one, two, three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, fourteen, fifteen, sixteen, seventeen, eighteen, nineteen, twenty, or more carbon atoms), which is optionally substituted. The notation "C1-14 alkyl" means an optionally substituted linear or branched, saturated hydrocarbon including 1-14 carbon atoms. Unless otherwise specified, an alkyl group described herein refers to both unsubstituted and substituted alkyl groups.
[0506] As used herein, the term "alkenyl", "alkenyl group", or "alkenylene" means a linear or branched hydrocarbon including two or more carbon atoms (e g., two, three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, fourteen, fifteen, sixteen, seventeen, eighteen, nineteen, twenty, or more carbon atoms) and at least one double bond, which is optionally substituted. The notation "C2-14 alkenyl" means an optionally substituted linear or branched hydrocarbon including 2-14 carbon atoms and at least one carbon-carbon double bond. An alkenyl group may include one, two, three, four, or more
carbon-carbon double bonds. For example, C1s alkenyl may include one or more double bonds. A C1s alkenyl group including two double bonds may be a linoleyl group. Unless otherwise specified, an alkenyl group described herein refers to both unsubstituted and substituted alkenyl groups.
[0507] As used herein, the term "alkynyl", "alkynyl group", or "alkynylene" means a linear or branched hydrocarbon including two or more carbon atoms (e g., two, three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, fourteen, fifteen, sixteen, seventeen, eighteen, nineteen, twenty, or more carbon atoms) and at least one carboncarbon triple bond, which is optionally substituted. The notation "C2-14 alkynyl" means an optionally substituted linear or branched hydrocarbon including 2-14 carbon atoms and at least one carbon-carbon triple bond. An alkynyl group may include one, two, three, four, or more carbon-carbon triple bonds. For example, C1s alkynyl may include one or more carbon-carbon triple bonds. Unless otherwise specified, an alkynyl group described herein refers to both unsubstituted and substituted alkynyl groups.
[0508] As used herein, the term "carbocycle" or "carbocyclic group" means an optionally substituted mono- or multi-cyclic system including one or more rings of carbon atoms. Rings may be three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, fourteen, fifteen, sixteen, seventeen, eighteen, nineteen, or twenty membered rings. The notation "C3-6 carbocycle" means a carbocycle including a single ring having 3-6 carbon atoms. Carbocycles may include one or more carbon-carbon double or triple bonds and may be non-aromatic or aromatic (e.g., cycloalkyl or aryl groups). Examples of carbocycles include cyclopropyl, cyclopentyl, cyclohexyl, phenyl, naphthyl, and 1,2 dihydronaphthyl groups. The term "cycloalkyl" as used herein means a non-aromatic carbocycle and may or may not include any double or triple bond. Unless otherwise specified, carbocycles described herein refers to both unsubstituted and substituted carbocycle groups, i.e., optionally substituted carbocycles.
[0509] As used herein, the term "heterocycle" or "heterocyclic group" means an optionally substituted mono- or multi-cyclic system including one or more rings, where at least one ring includes at least one heteroatom. Heteroatoms may be, for example,
nitrogen, oxygen, or sulfur atoms. Rings may be three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirteen, or fourteen membered rings. Heterocycles may include one or more double or triple bonds and may be non-aromatic or aromatic (e.g., heterocycloalkyl or heteroaryl groups). Examples of heterocycles include imidazolyl, imidazolidinyl, oxazolyl, oxazolidinyl, thiazolyl, thiazolidinyl, pyrazolidinyl, pyrazolyl, isoxazolidinyl, isoxazolyl, isothiazolidinyl, isothiazolyl, morpholinyl, pyrrolyl, pyrrolidinyl, furyl, tetrahydrofuryl, thiophenyl, pyridinyl, piperidinyl, quinolyl, and isoquinolyl groups. The term "heterocycloalkyl" as used herein means a non-aromatic heterocycle and may or may not include any double or triple bond. Unless otherwise specified, heterocycles described herein refers to both unsubstituted and substituted heterocycle groups, i.e., optionally substituted heterocycles.
[0510] As used herein, the term "heteroalkyl", "heteroalkenyl", or "heteroalky nyl", refers respectively to an alkyl, alkenyl, alkynyl group, as defined herein, which further comprises one or more (e.g., 1, 2, 3, or 4) heteroatoms (e.g., oxygen, sulfur, nitrogen, boron, silicon, phosphorus) wherein the one or more heteroatoms is inserted between adjacent carbon atoms within the parent carbon chain and/or one or more heteroatoms is inserted between a carbon atom and the parent molecule, i.e., between the point of attachment. Unless otherwise specified, heteroalkyls, heteroalkenyls, or heteroalkynyls described herein refers to both unsubstituted and substituted heteroalkyls, heteroalkenyls, or heteroalkynyls, i.e., optionally substituted heteroalkyls, heteroalkenyls, or heteroalkynyls.
[0511] As used herein, a "biodegradable group" is a group that may facilitate faster metabolism of a lipid in a mammalian entity. A biodegradable group may be selected from the group consisting of, but is not limited to, -C(O)O-, -OC(O)-, -C(O)N(R')-, - N(R')C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR')O-, -S(O)2-, an aryl group, and a heteroaryl group. As used herein, an "aryl group" is an optionally substituted carbocyclic group including one or more aromatic rings. Examples of aryl groups include phenyl and naphthyl groups. As used herein, a "heteroaryl group" is an optionally substituted heterocyclic group including one or more aromatic rings.
Examples of heteroaryl groups include pyrrolyl, furyl, thiophenyl, imidazolyl, oxazolyl, and thiazolyl. Both aryl and heteroaryl groups may be optionally substituted. For example, M and M' can be selected from the non-limiting group consisting of optionally substituted phenyl, oxazole, and thiazole. In the Formulas herein, M and M' can be independently selected from the list of biodegradable groups above. Unless otherwise specified, aryl or heteroaryl groups described herein refers to both unsubstituted and substituted groups, i.e., optionally substituted aryl or heteroaryl groups.
[0512] Alkyl, alkenyl, and cyclyl (e.g., carbocyclyl and heterocyclyl) groups may be optionally substituted unless otherwise specified. Optional substituents may be selected from the group consisting of, but are not limited to, a halogen atom (e.g., a chloride, bromide, fluoride, or iodide group), a carboxylic acid (e.g., C(O)OH), an alcohol (e.g., a hydroxyl, OH), an ester (e.g., C(O)OR OC(O)R), an aldehyde (e.g., C(O)H), a carbonyl (e.g., C(O)R, alternatively represented by C=O), an acyl halide (e.g., C(O)X, in which X is a halide selected from bromide, fluoride, chloride, and iodide), a carbonate (e.g., OC(O)OR), an alkoxy (e.g., OR), an acetal (e.g., C(OR)2R"", in which each OR are alkoxy groups that can be the same or different and R"" is an alkyl or alkenyl group), a phosphate (e.g., P(O)43'), a thiol (e g., SH), a sulfoxide (e.g., S(O)R), a sulfmic acid (e.g., S(O)OH), a sulfonic acid (e.g., S(O)2OH), a thial (e.g., C(S)H), a sulfate (e.g., S(O)42’), a sulfonyl (e.g., S(O)2 ), an amide (e.g., C(O)NR2, or N(R)C(O)R), an azido (e.g., N3), a nitro (e.g., NO2), a cyano (e.g., CN), an isocyano (e.g., NC), an acyloxy (e.g., OC(O)R), an amino (e.g., NR2, NRH, or NH2), a carbamoyl (e.g., OC(O)NR2, OC(O)NRH, or OC(O)NH2), a sulfonamide (e.g., S(O)2NR2, S(O)2NRH, S(O)2NH2, N(R)S(O)2R, N(H)S(O)2R, N(R)S(O)2H, or N(H)S(O)2H), an alkyl group, an alkenyl group, and a cyclyl (e.g., carbocyclyl or heterocyclyl) group. In any of the preceding, R is an alkyl or alkenyl group, as defined herein. In some embodiments, the substituent groups themselves may be further substituted with, for example, one, two, three, four, five, or six substituents as defined herein. For example, a C1-6 alkyl group may be further substituted with one, two, three, four, five, or six substituents as described herein.
[0513] Compounds of the disclosure that contain nitrogens can be converted to N- oxides by treatment with an oxidizing agent (e.g., 3-chloroperoxybenzoic acid (mCPBA) and/or hydrogen peroxides) to afford other compounds of the disclosure. Thus, all shown and claimed nitrogen-containing compounds are considered, when allowed by valency and structure, to include both the compound as shown and its N-oxide derivative (which can be designated as N->0 or N+-O-). Furthermore, in other instances, the nitrogens in the compounds of the disclosure can be converted to N-hydroxy or N-alkoxy compounds. For example, N-hydroxy compounds can be prepared by oxidation of the parent amine by an oxidizing agent such as m CPBA. All shown and claimed nitrogen-containing compounds are also considered, when allowed by valency and structure, to cover both the compound as shown and its N-hydroxy (i.e., N-OH) and N-alkoxy (i.e., N-OR, wherein R is substituted or unsubstituted C1-C6 alkyl, C1-C6 alkenyl, C1-C6 alkynyl, 3-14-membered carbocycle or 3-14-membered heterocycle) derivatives.
(vi) Other Lipid Composition Components
[0514] The lipid composition of a pharmaceutical composition disclosed herein can include one or more components in addition to those described above. For example, the lipid composition can include one or more permeability enhancer molecules, carbohydrates, polymers, surface altering agents (e.g., surfactants), or other components. For example, a permeability enhancer molecule can be a molecule described by U.S. Patent Application Publication No. 2005/0222064. Carbohydrates can include simple sugars (e.g., glucose) and polysaccharides (e.g., glycogen and derivatives and analogs thereof).
[0515] A polymer can be included in and/or used to encapsulate or partially encapsulate a pharmaceutical composition disclosed herein (e.g., a pharmaceutical composition in lipid nanoparticle form). A polymer can be biodegradable and/or biocompatible. A polymer can be selected from, but is not limited to, polyamines, polyethers, polyamides, polyesters, polycarbamates, polyureas, polycarbonates, polystyrenes, polyimides, polysulfones, polyurethanes, polyacetylenes, polyethylenes,
polyethyleneimines, polyisocyanates, polyacrylates, polymethacrylates, polyacrylonitriles, and polyarylates.
[0516] The ratio between the lipid composition and the polynucleotide range can be from about 10:1 to about 60:1 (wt/wt).
[0517] In some embodiments, the ratio between the lipid composition and the polynucleotide can be about 10:1, 11:1, 12:1, 13:1, 14:1, 15:1, 16:1, 17:1, 18:1, 19:1, 20:1, 21:1, 22:1, 23:1, 24:1, 25:1, 26:1, 27:1, 28:1, 29:1, 30:1, 31:1, 32:1, 33:1, 34:1, 35:1, 36:1, 37:1, 38:1, 39:1, 40:1, 41:1, 42:1, 43:1, 44:1, 45:1, 46:1, 47:1, 48:1, 49:1, 50:1, 51:1, 52:1, 53:1, 54:1, 55:1, 56:1, 57:1, 58:1, 59:1 or 60:1 (wt/wt). In some embodiments, the wt/wt ratio of the lipid composition to the polynucleotide encoding a therapeutic agent is about 20:1 or about 15:1.
[0518] In some embodiments, the pharmaceutical composition disclosed herein can contain more than one polypeptides. For example, a pharmaceutical composition disclosed herein can contain two or more polynucleotides (e.g., RNA, e.g., mRNA). [0519] In one embodiment, the lipid nanoparticles described herein can comprise polynucleotides (e.g., mRNA) in a lipid:polynucleotide weight ratio of 5:1, 10:1, 15:1, 20:1, 25:1, 30:1, 35:1, 40:1, 45:1, 50:1, 55:1, 60:1 or 70:1, or a range or any of these ratios such as, but not limited to, 5: 1 to about 10:1, from about 5: 1 to about 15:1, from about 5:1 to about 20:1, from about 5:1 to about 25:1, from about 5:1 to about 30:1, from about 5:1 to about 35:1, from about 5:1 to about 40:1, from about 5:1 to about 45:1, from about 5:1 to about 50:1, from about 5:1 to about 55:1, from about 5:1 to about 60:1, from about 5:1 to about 70:1, from about 10:1 to about 15:1, from about 10:1 to about 20:1, from about 10:1 to about 25:1, from about 10:1 to about 30:1, from about 10:1 to about 35:1, from about 10:1 to about 40:1, from about 10:1 to about 45:1, from about 10:1 to about 50:1, from about 10:1 to about 55:1, from about 10:1 to about 60:1, from about 10:1 to about 70:1, from about 15:1 to about 20:1, from about 15:1 to about 25:1, from about 15:1 to about 30:1, from about 15:1 to about 35:1, from about 15:1 to about 40:1, from about 15:1 to about 45:1, from about 15:1 to about 50:1, from about 15:1 to about 55:1, from about 15:1 to about 60:1 or from about 15:1 to about 70:1.
[0520] In one embodiment, the lipid nanoparticles described herein can comprise the polynucleotide in a concentration from approximately 0.1 mg/ml to 2 mg/ml such as, but not limited to, 0.1 mg/ml, 0.2 mg/ml, 0.3 mg/ml, 0.4 mg/ml, 0.5 mg/ml, 0.6 mg/ml, 0.7 mg/ml, 0.8 mg/ml, 0.9 mg/ml, 1.0 mg/ml, 1.1 mg/ml, 1.2 mg/ml, 1.3 mg/ml, 1.4 mg/ml, 1.5 mg/ml, 1.6 mg/ml, 1.7 mg/ml, 1.8 mg/ml, 1.9 mg/ml, 2.0 mg/ml or greater than 2.0 mg/ml.
(vii) Nanoparticle Compositions
[0521] In some embodiments, the pharmaceutical compositions disclosed herein are formulated as lipid nanoparticles (LNP). Accordingly, the present disclosure also provides nanoparticle compositions comprising (i) a lipid composition comprising a delivery agent such as compound as described herein, and (ii) a polynucleotide encoding an IgAP protein. In such nanoparticle composition, the lipid composition disclosed herein can encapsulate the polynucleotide encoding an IgAP protein.
[0522] Nanoparticle compositions are typically sized on the order of micrometers or smaller and can include a lipid bilayer. Nanoparticle compositions encompass lipid nanoparticles (LNPs), liposomes (e.g., lipid vesicles), and lipoplexes. For example, a nanoparticle composition can be a liposome having a lipid bilayer with a diameter of 500 nm or less.
[0523] Nanoparticle compositions include, for example, lipid nanoparticles (LNPs), liposomes, and lipoplexes. In some embodiments, nanoparticle compositions are vesicles including one or more lipid bilayers. In certain embodiments, a nanoparticle composition includes two or more concentric bilayers separated by aqueous compartments. Lipid bilayers can be functionalized and/or crosslinked to one another. Lipid bilayers can include one or more ligands, proteins, or channels.
[0524] In one embodiment, a lipid nanoparticle comprises an ionizable amino lipid, a structural lipid, a phospholipid, and mRNA. In some embodiments, the LNP comprises an ionizable amino lipid, a PEG-modified lipid, a sterol and a structural lipid. In some
embodiments, the LNP has a molar ratio of about 40-50% ionizable amino lipid; about 5- 15% structural lipid; about 30-45% sterol; and about 1-5% PEG-modified lipid.
[0525] In some embodiments, the LNP has a poly dispersity value of less than 0.4. In some embodiments, the LNP has a net neutral charge at a neutral pH. In some embodiments, the LNP has a mean diameter of 50-150 nm. In some embodiments, the LNP has a mean diameter of 80-100 nm.
[0526] As generally defined herein, the term “lipid” refers to a small molecule that has hydrophobic or amphiphilic properties. Lipids may be naturally occurring or synthetic. Examples of classes of lipids include, but are not limited to, fats, waxes, sterol - containing metabolites, vitamins, fatty acids, glycerolipids, glycerophospholipids, sphingolipids, saccharolipids, and polyketides, and prenol lipids. In some instances, the amphiphilic properties of some lipids leads them to form liposomes, vesicles, or membranes in aqueous media.
[0527] In some embodiments, a lipid nanoparticle (LNP) may comprise an ionizable amino lipid. As used herein, the term “ionizable amino lipid” has its ordinary meaning in the art and may refer to a lipid comprising one or more charged moieties. In some embodiments, an ionizable amino lipid may be positively charged or negatively charged. An ionizable amino lipid may be positively charged, in which case it can be referred to as “cationic lipid”. In certain embodiments, an ionizable amino lipid molecule may comprise an amine group, and can be referred to as an ionizable amino lipid. As used herein, a “charged moiety” is a chemical moiety that carries a formal electronic charge, e.g., monovalent (+1, or -1), divalent (+2, or -2), trivalent (+3, or -3), etc. The charged moiety may be anionic (i.e., negatively charged) or cationic (i.e., positively charged).
Examples of positively-charged moieties include amine groups (e g., primary, secondary, and/or tertiary amines), ammonium groups, pyridinium group, guanidine groups, and imidizolium groups. In a particular embodiment, the charged moieties comprise amine groups. Examples of negatively- charged groups or precursors thereof, include carboxylate groups, sulfonate groups, sulfate groups, phosphonate groups, phosphate groups, hydroxyl groups, and the like. The charge of the charged moiety may vary, in
some cases, with the environmental conditions, for example, changes in pH may alter the charge of the moiety, and/or cause the moiety to become charged or uncharged. In general, the charge density of the molecule may be selected as desired.
[0528] It should be understood that the terms “charged” or “charged moiety” does not refer to a “partial negative charge" or “partial positive charge" on a molecule. The terms “partial negative charge" and “partial positive charge" are given its ordinary meaning in the art. A “partial negative charge" may result when a functional group comprises a bond that becomes polarized such that electron density is pulled toward one atom of the bond, creating a partial negative charge on the atom. Those of ordinary skill in the art will, in general, recognize bonds that can become polarized in this way.
[0529] The ionizable amino lipid is sometimes referred to in the art as an “ionizable cationic lipid”. In one embodiment, the ionizable amino lipid may have a positively charged hydrophilic head and a hydrophobic tail that are connected via a linker structure. [0530] In addition to these, an ionizable amino lipid may also be a lipid including a cyclic amine group.
[0531] In one embodiment, the ionizable amino lipid may be selected from, but not limited to, an ionizable amino lipid described in International Publication Nos. WO2013086354 and WO2013116126; the contents of each of which are herein incorporated by reference in their entirety.
[0532] In yet another embodiment, the ionizable amino lipid may be selected from, but not limited to, Formula CLI-CLXXXXII of US Patent No. 7,404,969; each of which is herein incorporated by reference in their entirety.
[0533] In one embodiment, the lipid may be a cleavable lipid such as those described in International Publication No. WO2012170889, herein incorporated by reference in its entirety. In one embodiment, the lipid may be synthesized by methods known in the art and/or as described in International Publication Nos. WO2013086354; the contents of each of which are herein incorporated by reference in their entirety.
[0534] Nanoparticle compositions can be characterized by a variety of methods. For example, microscopy (e.g., transmission electron microscopy or scanning electron
microscopy) can be used to examine the morphology and size distribution of a nanoparticle composition. Dynamic light scattering or potentiometry (e.g., potentiometric titrations) can be used to measure zeta potentials. Dynamic light scattering can also be utilized to determine particle sizes. Instruments such as the Zetasizer Nano ZS (Malvern Instruments Ltd, Malvern, Worcestershire, UK) can also be used to measure multiple characteristics of a nanoparticle composition, such as particle size, poly dispersity index, and zeta potential.
[00535] The size of the nanoparticles can help counter biological reactions such as, but not limited to, inflammation, or can increase the biological effect of the polynucleotide. [0536] As used herein, “size” or “mean size” in the context of nanoparticle compositions refers to the mean diameter of a nanoparticle composition.
[0537] In one embodiment, the polynucleotide encoding an IgAP protein are formulated in lipid nanoparticles having a diameter from about 10 to about 100 nm such as, but not limited to, about 10 to about 20 nm, about 10 to about 30 nm, about 10 to about 40 nm, about 10 to about 50 nm, about 10 to about 60 nm, about 10 to about 70 nm, about 10 to about 80 nm, about 10 to about 90 nm, about 20 to about 30 nm, about 20 to about 40 nm, about 20 to about 50 nm, about 20 to about 60 nm, about 20 to about 70 nm, about 20 to about 80 nm, about 20 to about 90 nm, about 20 to about 100 nm, about 30 to about 40 nm, about 30 to about 50 nm, about 30 to about 60 nm, about 30 to about 70 nm, about 30 to about 80 nm, about 30 to about 90 nm, about 30 to about 100 nm, about 40 to about 50 nm, about 40 to about 60 nm, about 40 to about 70 nm, about 40 to about 80 nm, about 40 to about 90 nm, about 40 to about 100 nm, about 50 to about 60 nm, about 50 to about 70 nm, about 50 to about 80 nm, about 50 to about 90 nm, about 50 to about 100 nm, about 60 to about 70 nm, about 60 to about 80 nm, about 60 to about 90 nm, about 60 to about 100 nm, about 70 to about 80 nm, about 70 to about 90 nm, about 70 to about 100 nm, about 80 to about 90 nm, about 80 to about 100 nm and/or about 90 to about 100 nm.
[0538] In one embodiment, the nanoparticles have a diameter from about 10 to 500 nm. In one embodiment, the nanoparticle has a diameter greater than 100 nm, greater
than 150 nm, greater than 200 nm, greater than 250 nm, greater than 300 nm, greater than 350 nm, greater than 400 nm, greater than 450 nm, greater than 500 nm, greater than 550 nm, greater than 600 nm, greater than 650 nm, greater than 700 nm, greater than 750 nm, greater than 800 nm, greater than 850 nm, greater than 900 nm, greater than 950 nm or greater than 1000 nm.
[0539] In some embodiments, the largest dimension of a nanoparticle composition is 1 pm or shorter (e.g., 1 pm, 900 nm, 800 nm, 700 nm, 600 nm, 500 nm, 400 nm, 300 nm, 200 nm, 175 nm, 150 nm, 125 nm, 100 nm, 75 nm, 50 nm, or shorter).
[0540] A nanoparticle composition can be relatively homogenous. A poly dispersity index can be used to indicate the homogeneity of a nanoparticle composition, e.g., the particle size distribution of the nanoparticle composition. A small (e.g., less than 0.3) poly dispersity index generally indicates a narrow particle size distribution. A nanoparticle composition can have a poly dispersity index from about 0 to about 0.25, such as 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.10, 0.11, 0.12, 0.13, 0.14, 0.15, 0.16, 0.17, 0.18, 0.19, 0.20, 0.21, 0.22, 0.23, 0.24, or 0.25. In some embodiments, the poly dispersity index of a nanoparticle composition disclosed herein can be from about 0.10 to about 0.20.
[0541] The zeta potential of a nanoparticle composition can be used to indicate the electrokinetic potential of the composition. For example, the zeta potential can describe the surface charge of a nanoparticle composition. Nanoparticle compositions with relatively low charges, positive or negative, are generally desirable, as more highly charged species can interact undesirably with cells, tissues, and other elements in the body. In some embodiments, the zeta potential of a nanoparticle composition disclosed herein can be from about -10 mV to about +20 mV, from about -10 mV to about +15 mV, from about 10 mV to about +10 mV, from about -10 mV to about +5 mV, from about - 10 mV to about 0 mV, from about -10 mV to about -5 mV, from about -5 mV to about +20 mV, from about -5 mV to about +15 mV, from about -5 mV to about +10 mV, from about -5 mV to about +5 mV, from about -5 mV to about 0 mV, from about 0 mV to about +20 mV, from about 0 mV to about +15 mV, from about 0 mV to about +10 mV,
from about 0 mV to about +5 mV, from about +5 mV to about +20 mV, from about +5 mV to about +15 mV, or from about +5 mV to about +10 mV.
[0542] In some embodiments, the zeta potential of the lipid nanoparticles can be from about 0 mV to about 100 mV, from about 0 mV to about 90 mV, from about 0 mV to about 80 mV, from about 0 mV to about 70 mV, from about 0 mV to about 60 mV, from about 0 mV to about 50 mV, from about 0 mV to about 40 mV, from about 0 mV to about 30 mV, from about 0 mV to about 20 mV, from about 0 mV to about 10 mV, from about 10 mV to about 100 mV, from about 10 mV to about 90 mV, from about 10 mV to about 80 mV, from about 10 mV to about 70 mV, from about 10 mV to about 60 mV, from about 10 mV to about 50 mV, from about 10 mV to about 40 mV, from about 10 mV to about 30 mV, from about 10 mV to about 20 mV, from about 20 mV to about 100 mV, from about 20 mV to about 90 mV, from about 20 mV to about 80 mV, from about 20 mV to about 70 mV, from about 20 mV to about 60 mV, from about 20 mV to about 50 mV, from about 20 mV to about 40 mV, from about 20 mV to about 30 mV, from about 30 mV to about 100 mV, from about 30 mV to about 90 mV, from about 30 mV to about 80 mV, from about 30 mV to about 70 mV, from about 30 mV to about 60 mV, from about 30 mV to about 50 mV, from about 30 mV to about 40 mV, from about 40 mV to about 100 mV, from about 40 mV to about 90 mV, from about 40 mV to about 80 mV, from about 40 mV to about 70 mV, from about 40 mV to about 60 mV, and from about 40 mV to about 50 mV. In some embodiments, the zeta potential of the lipid nanoparticles can be from about 10 mV to about 50 mV, from about 15 mV to about 45 mV, from about 20 mV to about 40 mV, and from about 25 mV to about 35 mV. In some embodiments, the zeta potential of the lipid nanoparticles can be about 10 mV, about 20 mV, about 30 mV, about 40 mV, about 50 mV, about 60 mV, about 70 mV, about 80 mV, about 90 mV, and about 100 mV.
[0543] The term “encapsulation efficiency” of a polynucleotide describes the amount of the polynucleotide that is encapsulated by or otherwise associated with a nanoparticle composition after preparation, relative to the initial amount provided. As used herein,
“encapsulation” can refer to complete, substantial, or partial enclosure, confinement, surrounding, or encasement.
[0544] Encapsulation efficiency is desirably high (e.g., close to 100%). The encapsulation efficiency can be measured, for example, by comparing the amount of the polynucleotide in a solution containing the nanoparticle composition before and after breaking up the nanoparticle composition with one or more organic solvents or detergents.
[0545] Fluorescence can be used to measure the amount of free polynucleotide in a solution. For the nanoparticle compositions described herein, the encapsulation efficiency of a polynucleotide can be at least 50%, for example 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100%. In some embodiments, the encapsulation efficiency can be at least 80%. In certain embodiments, the encapsulation efficiency can be at least 90%.
[0546] The amount of a polynucleotide present in a pharmaceutical composition disclosed herein can depend on multiple factors such as the size of the polynucleotide, desired target and/or application, or other properties of the nanoparticle composition as well as on the properties of the polynucleotide.
[0547] For example, the amount of an mRNA useful in a nanoparticle composition can depend on the size (expressed as length, or molecular mass), sequence, and other characteristics of the mRNA. The relative amounts of a polynucleotide in a nanoparticle composition can also vary.
[0548] The relative amounts of the lipid composition and the polynucleotide present in a lipid nanoparticle composition of the present disclosure can be optimized according to considerations of efficacy and tolerability. For compositions including an mRNA as a polynucleotide, the N:P ratio can serve as a useful metric.
[0549] As the N:P ratio of a nanoparticle composition controls both expression and tolerability, nanoparticle compositions with low N:P ratios and strong expression are desirable. N:P ratios vary according to the ratio of lipids to RNA in a nanoparticle composition.
[0550] In general, a lower N:P ratio is preferred. The one or more RNA, lipids, and amounts thereof can be selected to provide an N:P ratio from about 2: 1 to about 30: 1, such as 2: 1, 3: 1, 4: 1, 5: 1, 6:1, 7: 1, 8:1, 9: 1, 10: 1, 12:1, 14: 1, 16: 1, 18:1, 20:1, 22: 1, 24: 1, 26: 1, 28: 1, or 30: 1. In certain embodiments, the N:P ratio can be from about 2: 1 to about 8: 1. In other embodiments, the N:P ratio is from about 5: 1 to about 8: 1. In certain embodiments, the N:P ratio is between 5:1 and 6:1. In one specific aspect, the N:P ratio is about is about 5.67: 1.
[0551] In addition to providing nanoparticle compositions, the present disclosure also provides methods of producing lipid nanoparticles comprising encapsulating a polynucleotide. Such method comprises using any of the pharmaceutical compositions disclosed herein and producing lipid nanoparticles in accordance with methods of production of lipid nanoparticles known in the art. See, e.g., Wang et al. (2015) “Delivery of oligonucleotides with lipid nanoparticles” Adv. Drug Deliv. Rev. 87:68-80; Silva et al. (2015) “Delivery Systems for Biopharmaceuticals. Part I: Nanoparticles and Microparticles” Curr. Pharm. Technol. 16: 940-954; Naseri et al. (2015) “Solid Lipid Nanoparticles and Nanostructured Lipid Carriers: Structure, Preparation and Application” Adv. Pharm. Bull. 5:305-13; Silva et al. (2015) “Lipid nanoparticles for the delivery of biopharmaceuticals” Curr. Pharm. Biotechnol. 16:291-302, and references cited therein. mRNA-Lipid Adducts
[0552] It has been determined that certain ionizable lipids are susceptible to the formation of lipid-polynucleotide adducts. In particular, ionizable lipids that comprise a tertiary amine group may decompose into one or both of a secondary amine and a reactive aldehyde species capable of interacting with polynucleotides (such as mRNA) to form an ionizable lipid-polynucleotide adduct impurity that can be detected by reverse phase ion pair chromatography (RP-IP HPLC). For example, oxidation of the tertiary amine may lead to N-oxide formation that can undergo acid/base-catalyzed hydrolysis at the amine to generate aldehydes and secondary amines which may form adducts with
mRNA. Thus, in some aspects, the ionizable lipid-polynucleotide adduct impurity is an aldehyde-mRNA adduct impurity.
[0553] It also has been determined that such adducts may disrupt mRNA translation and impact the activity of lipid nanoparticle (LNP) formulated mRNA products. Thus, it can be advantageous to prepare and use LNP compositions with a reduced content of ionizable lipid-polynucleotide adduct impurity, such as wherein less than about 20%, less than about 10%, less than about 5%, or less than about 1%, of the mRNA is in the form of ionizable lipid-polynucleotide adduct impurity, as may be measured by RP-IP HPLC. Thus, in accordance with some aspects, an LNP composition is provided wherein less than about 10%, less than about 5%, or less than about 1%, of the mRNA is in the form of ionizable lipid-polynucleotide adduct impurity, including less than 10%, less than 5%, or less than 1%, as may be measured by RP-IP HPLC.
[0554] In some aspects, an amount of lipid aldehydes in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of N-oxide compounds in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of transition metals, such as Fe, in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of alkyl halide compounds in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of anhydride compounds in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of ketone compounds in the composition is less than about 50 ppm, including less than 50 ppm. Additionally or alternatively, in some aspects an amount of conjugated diene compounds in the composition is less than about 50 ppm, including less than 50 ppm.
[0555] In some aspects, the composition is stable against the formation of ionizable lipid-polynucleotide adduct impurity. In some aspects, an amount of ionizable lipid- polynucleotide adduct impurity in the composition increases at an average rate of less than about 2% per day when stored at a temperature of about 25 °C or below, including at
an average rate of less than 2% per day. In some aspects, an amount of ionizable lipidpolynucleotide adduct impurity in the composition increases at an average rate of less than about 0.5% per day when stored at a temperature of about 5 °C or below, including at an average rate of less than 0.5% per day. In some aspects, an amount of ionizable lipid-polynucleotide adduct impurity in the composition increases at an average rate of less than about 0.5% per day when stored at a refrigerated temperature, optionally wherein the refrigerated temperature is about 5 °C.
[0556] Lipid vehicle (e.g., LNP) compositions with a reduced content of ionizable lipid-polynucleotide adduct impurity can be prepared by methods that inhibit formation of one or both of N-oxides and aldehydes. Such methods may comprise treating a composition comprising an ionizable lipid comprising a tertiary amine group to inhibit formation of one or both of N-oxides and aldehydes, such as by treating the composition with a reducing agent; treating the composition with a chelating agent; adjusting the pH of the composition; adjusting the temperature of the composition; and adjusting the buffer in the composition. Such methods may comprise, prior to combining the ionizable lipid with a polynucleotide, one or more of treating the ionizable lipid with a scavenging agent; treating the ionizable lipid with a reductive treatment agent; treating the ionizable lipid with a reducing agent; treating the ionizable lipid with a chelating agent; treating the polynucleotide with a reducing agent; and treating the polynucleotide with a chelating agent.
[0557] In accordance with any of the foregoing, the scavenging agent, reductive treatment agent, and/or reducing agent may be an agent that reacts with aldehyde, ketone, anhydride and/or diene compounds. A scavenging agent may comprise one or more selected from (O-(2,3,4,5,6-Pentafluorobenzyl)hydroxylamine hydrochloride) (PFBHA), methoxyamine (e.g., methoxyamine hydrochloride), benzyloxyamine (e.g., benzyloxyamine hydrochloride), ethoxyamine (e.g., ethoxyamine hydrochloride), 4-[2- (aminooxy)ethyl]morpholine dihydrochloride, butoxyamine (e.g., tert-butoxyamine hydrochloride), 4-Dimethylaminopyridine (DMAP), l,4-diazabicyclo[2.2.2]octane (DABCO), Triethylamine (TEA), Piperidine 4-carboxylate (BPPC), and combinations
thereof. A reductive treatment agent may comprise a boron compound (e.g., sodium borohydride and/or bis(pinacolato)diboron). A reductive treatment agent may comprise a boron compound, such as one or both of sodium borohydride and bis(pinacolato)diboron). A chelating agent may comprise immobilized iminodiacetic acid. A reducing agent may comprise an immobilized reducing agent, such as immobilized diphenylphosphine on silica (Si-DPP), immobilized thiol on agarose (Ag- Thiol), immobilized cysteine on silica (Si-Cysteine), immobilized thiol on silica (Si- Thiol), or a combination thereof. A reducing agent may comprise a free reducing agent, such as potassium metabisulfite, sodium thioglycolate, tris(2-carboxyethyl)phosphine (TCEP), sodium thiosulfate, N-acetyl cysteine, glutathione, dithiothreitol (DTT), cystamine, dithioerythritol (DTE), dichlorodiphenyltrichloroethane (DDT), homocysteine, lipoic acid, or a combination thereof.
[0558] In accordance with any of the foregoing, the pH may be, or adjusted to be, a pH of from about 7 to about 9.
[0559] In accordance with any of the foregoing, a buffer may be selected from sodium phosphate, sodium citrate, sodium succinate, histidine, histidine-HCl, sodium malate, sodium carbonate, and TRIS (tris(hydroxymethyl)aminomethane). In accordance with any of the foregoing, a buffer may be TRIS and may be, or adjusted to be, from about 20 mM to about 150 mM TRIS.
[0560] In accordance with any of the foregoing, the temperature of the composition may be, or adjusted to be, 25 °C or less.
[0561] The composition may also comprise a free reducing agent or antioxidant.
Other Delivery Agents
Liposomes, Lipoplexes, and Lipid Nanopartides
[0562] In some embodiments, the compositions or formulations of the present disclosure comprise a delivery agent, e.g., a liposome, a lioplexes, a lipid nanoparticle, or any combination thereof. The polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein can be formulated using one
or more liposomes, lipoplexes, or lipid nanoparticles. Liposomes, lipoplexes, or lipid nanoparticles can be used to improve the efficacy of the polynucleotides directed protein production as these formulations can increase cell transfection by the polynucleotide; and/or increase the translation of encoded protein. The liposomes, lipoplexes, or lipid nanoparticles can also be used to increase the stability of the polynucleotides.
[0563] Liposomes are artificially-prepared vesicles that can primarily be composed of a lipid bilayer and can be used as a delivery vehicle for the administration of pharmaceutical formulations. Liposomes can be of different sizes. A multilamellar vesicle (MLV) can be hundreds of nanometers in diameter, and can contain a series of concentric bilayers separated by narrow aqueous compartments. A small unicellular vesicle (SUV) can be smaller than 50 nm in diameter, and a large unilamellar vesicle (LUV) can be between 50 and 500 nm in diameter. Liposome design can include, but is not limited to, opsonins or ligands to improve the attachment of liposomes to unhealthy tissue or to activate events such as, but not limited to, endocytosis. Liposomes can contain a low or a high pH value in order to improve the delivery of the pharmaceutical formulations.
[0564] The formation of liposomes can depend on the pharmaceutical formulation entrapped and the liposomal ingredients, the nature of the medium in which the lipid vesicles are dispersed, the effective concentration of the entrapped substance and its potential toxicity, any additional processes involved during the application and/or delivery of the vesicles, the optimal size, poly dispersity and the shelf-life of the vesicles for the intended application, and the batch-to-batch reproducibility and scale up production of safe and efficient liposomal products, etc.
[0565] As a non-limiting example, liposomes such as synthetic membrane vesicles can be prepared by the methods, apparatus and devices described in U.S. Pub. Nos. US20130177638, US20130177637, US20130177636, US20130177635, US20130177634, US20130177633, US20130183375, US20130183373, and US20130183372. In some embodiments, the polynucleotides described herein can be encapsulated by the liposome and/or it can be contained in an aqueous core that can then
be encapsulated by the liposome as described in, e.g., Inti. Pub. Nos. W02012031046, W02012031043, W02012030901, W02012006378, and WO2013086526; and U.S. Pub.Nos. US20130189351, US20130195969 and US20130202684. Each of the references in herein incorporated by reference in its entirety.
[0566] In some embodiments, the polynucleotides described herein can be formulated in a cationic oil-in-water emulsion where the emulsion particle comprises an oil core and a cationic lipid that can interact with the polynucleotide anchoring the molecule to the emulsion particle. In some embodiments, the polynucleotides described herein can be formulated in a water-in-oil emulsion comprising a continuous hydrophobic phase in which the hydrophilic phase is dispersed. Exemplary emulsions can be made by the methods described in Inti. Pub. Nos. W02012006380 and W0201087791, each of which is herein incorporated by reference in its entirety.
[0567] In some embodiments, the polynucleotides described herein can be formulated in a lipid-polycation complex. The formation of the lipid-polycation complex can be accomplished by methods as described in, e.g., U.S. Pub. No. US20120178702. As a non-limiting example, the polycation can include a cationic peptide or a polypeptide such as, but not limited to, polylysine, polyornithine and/or polyarginine and the cationic peptides described in Inti. Pub. No. WO2012013326 or U.S. Pub. No. US20130142818. Each of the references is herein incorporated by reference in its entirety.
[0568] In some embodiments, the polynucleotides described herein can be formulated in a lipid nanoparticle (LNP) such as those described in Inti. Pub. Nos. WO2013123523, WO20 12170930, WO2011127255 and W02008103276; and U.S. Pub. No.
US20130171646, each of which is herein incorporated by reference in its entirety.
[0569] Lipid nanoparticle formulations typically comprise one or more lipids. In some embodiments, the lipid is an ionizable amino lipid, sometimes referred to in the art as an “ionizable cationic lipid”. In some embodiments, lipid nanoparticle formulations further comprise other components, including a phospholipid, a structural lipid, and a molecule capable of reducing particle aggregation, for example a PEG or PEG-modified lipid.
[0570] Exemplary ionizable amino lipids include, but not limited to, any Compounds II, VI, A, and B disclosed herein, DLin-mC3 -DMA (MC3 ), DLin-DMA, DLenDMa, DLin-D-DMa, DLin-K-DMA, dLin-M-C2-DMa, DLin-K-DMA, DLin-KC2-DMA, DLin-KC3 -DMA, DLin-KC4-DMA, DLin-C2K-DMA, DLin-MP-DMA, DODMA, 98N12-5, Cl 2-200, DLin-C-DAP, DLin-DAC, DLinDAP, DLinAP, DLin-EG-DMA, DLin-2-DMAP, KL10, KL22, KL25, Octyl-CLinDMA, Octyl-CLinDMA (2R), Octyl- CLinDMA (2S), and any combination thereof. Other exemplary ionizable amino lipids include, (13Z,16Z)-N,N-dimethyl-3 -nonyldocosa- 13, 16-dien-l -amine (L608), (20Z,23Z)- N,N-dimethylnonacosa-20,23 -dien- 10-amine, (17Z,20Z)-N,N-dimemylhexacosa- 17,20- dien-9-amine, (16Z, 19Z)-N5N-dimethylpentacosa- 16,19-dien-8-amine, ( 13Z, 16Z)-N,N- dimethyldocosa-13 , 16-dien-5-amine, ( 12Z, 15Z)-N,N-dimethylhenicosa- 12, 15-dien-4- amine, ( 14Z, 17Z)-N,N-dimethyltricosa- 14, 17-dien-6-amine, ( 15Z, 18Z)-N,N- dimethyltetracosa- 15,18-dien-7-amine, ( 18Z,21 Z)-N,N-dimethylheptacosa- 18,21 -dien- 10-amine, (15Z, 18Z)-N,N-dimethyltetracosa- 15,18-dien-5-amine, (14Z, 17Z)-N,N- dimethyltricosa- 14, 17-dien-4-amine, ( 19Z,22Z)-N,N-dimeihyloctacosa- 19,22-dien-9- amine, ( 18Z,2 lZ)-N,N-dimethylheptacosa- 18,21 -dien-8-amine, ( 17Z,20Z)-N,N- dimethylhexacosa- 17,20-dien-7-amine, (16Z, 19Z)-N,N-dimethylpentacosa- 16,19-dien-6- amine, (22Z,25Z)-N,N-dimethylhentriaconta-22,25-dien-l 0-amine, (21Z,24Z)-N,N- dimethyltriaconta-21,24-dien-9-amine, (18Z)-N,N-dimetylheptacos-18-en-l 0-amine, ( 17Z)-N,N-dimethylhexacos- 17-en-9-amine, ( 19Z,22Z)-N,N-dimethyloctacosa- 19,22- dien-7-amine, N,N-dimethylheptacosan-l 0-amine, (20Z,23Z)-N-ethyl-N- methylnonacosa-20,23 -dien- 10-amine, 1-[(1 lZ,14Z)-l-nonylicosa-l 1,14-dien-l- yl]pyrrolidine, (20Z)-N,N-dimethylheptacos-20-en-l 0-amine, (15Z)-N,N-dimethyl eptacos- 15-en- 10-amine, ( 14Z)-N,N-dimethylnonacos- 14-en- 10-amine, ( 17Z)-N,N- dimethylnonacos- 17-en- 10-amine, (24Z)-N,N-dimethyltritriacont-24-en- 10-amine, (20Z)-N,N-dimethylnonacos-20-en-l 0-amine, (22Z)-N,N-dimethylhentriacont-22-en-10- amine, (16Z)-N,N-dimethylpentacos-16-en-8-amine, (12Z,15Z)-N,N-dimethyl-2- nonylhenicosa- 12, 15-dien-l -amine, N,N-dimethyl-l-[(lS,2R)-2-octylcyclopropyl] eptadecan-8-amine, l-[(lS,2R)-2-hexylcyclopropyl]-N,N-dimethylnonadecan-l 0-amine,
N,N-dimethyl- 1 -[( 1 S,2R)-2-octylcyclopropyl]nonadecan- 10-amine, N,N-dimethyl-21 - [(lS,2R)-2-octylcyclopropyl]henicosan-10-amine, N,N-dimethyl-l-[(lS,2S)-2-{[(lR,2R)- 2-pentylcycIopropyl]methyl}cyclopropyl]nonadecan-l O-amine, N,N-dimethyl-l- [(lS,2R)-2-octylcyclopropyl]hexadecan-8-amine, N,N-dimethyl-[(lR,2S)-2- undecyIcyclopropyl]tetradecan-5-amine, N,N-dimethyl-3-{7-[(lS,2R)-2- octylcyclopropyl]heptyl}dodecan-l -amine, l-[(lR,2S)-2-heptylcyclopropyl]-N,N- dimethyloctadecan-9-amine, 1 -[( 1 S,2R)-2-decylcyclopropyl]-N,N-dimethylpentadecan-6- amine, N,N-dimethyl-l-[(lS,2R)-2-octylcyclopropyl]pentadecan-8-amine, R-N,N- dimethyl- 1 -[(9Z, 12Z)-octadeca-9, 12-dien- 1 -yloxy]-3-(octyloxy)propan-2-amine, S-N,N- dimethyl-l-[(9Z, 12Z)-octadeca-9,12-dien-l-yloxy]-3-(octyloxy)propan-2-amine, l-{2- [(9Z,12Z)-octadeca-9,12-dien-l-yloxy]-l -[(octyloxy )methyl]ethyl}pyrrolidine, (2S)-N,N- dimethyl- 1 -[(9Z, 12Z)-octadeca-9, 12-dien- 1 -yloxy]-3-[(5Z)-oct-5-en- 1 -yloxy]propan-2- amine, l-{2-[(9Z,12Z)-octadeca-9,12-dien-l-yloxy]-l-[(octyloxy)methyl]ethyl}azetidine, (2S)-l-(hexyloxy)-N,N-dimethyl-3-[(9Z,12Z)-octadeca-9,12-dien-l-yloxy]propan-2- amine, (2S)- l-(heptyloxy)-N, N-dimethyl-3-[(9Z, 12Z)-octadeca-9,l 2-dien- 1- yloxy]propan-2-amine, N,N-dimethyl-l -(nonyl oxy)-3-[(9Z, 12Z)-octadeca-9, 12-dien-l- yloxy]propan-2-amine, N,N-dimethyl-l-[(9Z)-octadec-9-en-l-yloxy]-3-(octyloxy)propan-
2-amine; (2S)-N,N-dimethyl-l-[(6Z,9Z,12Z)-octadeca-6,9,12-trien-l-yloxy]-3- (octyloxy)propan-2-amine, (2S)-1-[(1 lZ,14Z)-icosa-l l,14-dien-l-yloxy]-N,N-dimethyl-
3 -(pentyl oxy )propan-2-amine, (2S)- 1 -(hexyloxy)-3-[( 11Z, 14Z)-icosa- 11,14-dien-l- yloxy]-N,N-dimethylpropan-2-amine, 1-[(1 lZ,14Z)-icosa-l l,14-dien-l-yloxy]-N,N- dimethyl-3-(octyloxy)propan-2-amine, l-[(13Z,16Z)-docosa-13,16-dien-l-yloxy]-N,N- dimethyl-3-(octyloxy)propan-2-amine, (2S)-1-[(13Z, 16Z)-docosa-13,16-dien-l-yloxy]- 3 -(hexyloxy)-N,N-dimethylpropan-2-amine, (2S)- 1 -[(13Z)-docos- 13 -en- 1 -yloxy]-3 - (hexyloxy)-N,N-dimethylpropan-2-amine, l-[(13Z)-docos-13-en-l-yloxy]-N,N-dimethyl- 3-(octyloxy)propan-2-amine, l-[(9Z)-hexadec-9-en-l-yloxy]-N,N-dimethyl-3- (octyloxy)propan-2-amine, (2R)-N,N-dimethyl-H(l-metoyloctyl)oxy]-3-[(9Z,12Z)- octadeca-9,12-dien- l-yloxy]propan-2-amine, (2R)-l-[(3,7-dimethyloctyl)oxy]-N,N- dimethyl-3-[(9Z, 12Z)-octadeca-9,12-dien-l-yloxy]propan-2-amine, N,N-dimethyl-l-
(octyloxy)-3-({ 8-[(l S,2S)-2-{ [(lR,2R)-2- pentylcyclopropyl]methyl}cyclopropyl]octyl}oxy)propan-2-amine, N,N-dimethyl-l-{ [8- (2-oclylcyclopropyl)octyl]oxy}-3-(octyloxy)propan-2-amine, and (11E,2OZ,23Z)-N,N- dimethylnonacosa-1 l,20,2-trien-10-amine, and any combination thereof.
[0571] Phospholipids include, but are not limited to, glycerophospholipids such as phosphatidylcholines, phosphatidylethanolamines, phosphatidylserines, phosphatidylinositols, phosphatidy glycerols, and phosphatidic acids. Phospholipids also include phosphosphingolipid, such as sphingomyelin. In some embodiments, the phospholipids are DLPC, DMPC, DOPC, DPPC, DSPC, DUPC, 18:0 Diether PC, DLnPC, DAPC, DHAPC, DOPE, 4ME 16:0 pE, DSPE, DLPE,DLnPE, DAPE, DHAPE, DOPG, and any combination thereof. In some embodiments, the phospholipids are MPPC, MSPC, PMPC, PSPC, SMPC, SPPC, DHAPE, DOPG, and any combination thereof. In some embodiments, the amount of phospholipids (e.g., DSPC) in the lipid composition ranges from about 1 mol% to about 20 mol%. In some embodiments, the amount of phospholipids (e.g., DSPC) in the lipid composition ranges from about 5-15 mol%, optionally 10-12 mol%, for example, 5-6 mol%, 6-7 mol%, 7-8 mol%, 8-9 mol%, 9-10 mol%, 10-11 mol%, l l-12 mol%, 12-13 mol%, 13-14 mol%, or 14-15 mol%.
[0572] The structural lipids include sterols and lipids containing sterol moieties. In some embodiments, the structural lipids include cholesterol, fecosterol, sitosterol, ergosterol, campesterol, stigmasterol, brassicasterol, tomatidine, tomatine, ursolic acid, alpha-tocopherol, and mixtures thereof. In some embodiments, the structural lipid is cholesterol. In some embodiments, the amount of the structural lipids (e.g., cholesterol) in the lipid composition ranges from about 20 mol% to about 60 mol%. In some embodiments, the amount of the structural lipids (e.g., cholesterol) in the lipid composition ranges from about 30-45 mol%, optionally 35-40 mol%, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 38-38 mol%, 38-39 mol%, or 39-40 mol%.
[0573] The PEG-modified lipids include PEG-modified phosphatidylethanolamine and phosphatidic acid, PEG-ceramide conjugates (e.g., PEG-CerC14 or PEG-CerC20),
PEG-modified dialkylamines and PEG-modified l,2-diacyloxypropan-3 -amines. Such lipids are also referred to as PEGylated lipids. For example, a PEG lipid can be PEG-c- DOMG, PEG-DMG, PEG-DLPE, PEG DMPE, PEG-DPPC, or a PEG-DSPE lipid. In some embodiments, the PEG-lipid are 1,2-dimyristoyl-sn-glycerol methoxypolyethylene glycol (PEG-DMG), l,2-distearoyl-sn-glycero-3-phosphoethanolamine-N- [amino(polyethylene glycol)] (PEG-DSPE), PEG-disteryl glycerol (PEG-DSG), PEG- dipalmetoleyl, PEG-dioleyl, PEG-distearyl, PEG-diacylglycamide (PEG-DAG), PEG- dipalmitoyl phosphatidylethanolamine (PEG-DPPE), or PEG-1, 2-dimyristyloxlpropyl-3- amine (PEG-c-DMA). In some embodiments, the PEG moiety has a size of about 1000, 2000, 5000, 10,000, 15,000 or 20,000 daltons. In some embodiments, the amount of PEG-lipid in the lipid composition ranges from about 0 mol% to about 5 mol%. In some embodiments, the amount of PEG-lipid in the lipid composition ranges from about 1-5%, optionally 1-3 mol%, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol%.
[0574] In some embodiments, the LNP formulations described herein can additionally comprise a permeability enhancer molecule. Non-limiting permeability enhancer molecules are described in U.S. Pub. No. US20050222064, herein incorporated by reference in its entirety.
[0575] The LNP formulations can further contain a phosphate conjugate. The phosphate conjugate can increase in vivo circulation times and/or increase the targeted delivery of the nanoparticle. Phosphate conjugates can be made by the methods described in, e.g., Inti. Pub. No. WO2013033438 or U.S. Pub. No. US20130196948. The LNP formulation can also contain a polymer conjugate (e.g., a water soluble conjugate) as described in, e.g, U.S. Pub. Nos. US20130059360, US20130196948, and US20130072709. Each of the references is herein incorporated by reference in its entirety.
[0576] The LNP formulations can comprise a conjugate to enhance the delivery of nanoparticles of the present invention in a subject. Further, the conjugate can inhibit phagocytic clearance of the nanoparticles in a subject. In some embodiments, the
conjugate can be a "self peptide designed from the human membrane protein CD47 (e.g., the "self particles described by Rodriguez et al, Science 2013 339, 971-975, herein incorporated by reference in its entirety). As shown by Rodriguez et al. the self peptides delayed macrophage-mediated clearance of nanoparticles which enhanced delivery of the nanoparticles.
[0577] The LNP formulations can comprise a carbohydrate carrier. As a non-limiting example, the carbohydrate carrier can include, but is not limited to, an anhydride- modified phytoglycogen or glycogen-type material, phytoglycogen octenyl succinate, phytoglycogen beta-dextrin, anhydride-modified phytoglycogen beta-dextrin (e.g., Inti. Pub. No. W02012109121, herein incorporated by reference in its entirety).
[0578] The LNP formulations can be coated with a surfactant or polymer to improve the delivery of the particle. In some embodiments, the LNP can be coated with a hydrophilic coating such as, but not limited to, PEG coatings and/or coatings that have a neutral surface charge as described in U.S. Pub. No. US20130183244, herein incorporated by reference in its entirety.
[0579] The LNP formulations can be engineered to alter the surface properties of particles so that the lipid nanoparticles can penetrate the mucosal barrier as described in U.S. Pat. No. 8,241,670 or Inti. Pub. No. WO2013110028, each of which is herein incorporated by reference in its entirety.
[0580] The LNP engineered to penetrate mucus can comprise a polymeric material (i.e., a polymeric core) and/or a polymer-vitamin conjugate and/or a tri-block copolymer. The polymeric material can include, but is not limited to, polyamines, polyethers, polyamides, polyesters, polycarbamates, polyureas, polycarbonates, poly(styrenes), polyimides, polysulfones, polyurethanes, polyacetylenes, polyethylenes, polyethyeneimines, polyisocyanates, polyacrylates, polymethacrylates, polyacrylonitriles, and polyarylates.
[0581] LNP engineered to penetrate mucus can also include surface altering agents such as, but not limited to, polynucleotides, anionic proteins (e.g., bovine serum albumin), surfactants (e.g., cationic surfactants such as for example dimethyldioctadecyl-
ammonium bromide), sugars or sugar derivatives (e.g., cyclodextrin), nucleic acids, polymers (e.g., heparin, polyethylene glycol and poloxamer), mucolytic agents (e.g., N- acetylcysteine, mugwort, bromelain, papain, clerodendrum, acetylcysteine, bromhexine, carbocisteine, eprazinone, mesna, ambroxol, sobrerol, domiodol, letosteine, stepronin, tiopronin, gelsolin, thymosin P4 domase alfa, neltenexine, erdosteine) and various DNases including rhDNase.
[0582] In some embodiments, the mucus penetrating LNP can be a hypotonic formulation comprising a mucosal penetration enhancing coating. The formulation can be hypotonic for the epithelium to which it is being delivered. Non-limiting examples of hypotonic formulations can be found in, e.g., Inti. Pub. No. WO2013110028, herein incorporated by reference in its entirety.
[0583] In some embodiments, the polynucleotide described herein is formulated as a lipoplex, such as, without limitation, the ATUPLEXTM system, the DACC system, the DBTC system and other siRNA-lipoplex technology from Silence Therapeutics (London, United Kingdom), STEMFECTTM from STEMGENT® (Cambridge, MA), and polyethylenimine (PEI) or protamine-based targeted and non-targeted delivery of nucleic acids (Aleku et al. Cancer Res. 2008 68:9788-9798; Strumberg et al. Int J Clin Pharmacol Ther 2012 50:76-78; Santel et al., Gene Ther 2006 13: 1222-1234; Santel et al., Gene Ther 2006 13: 1360-1370; Gutbier et al., Pulm Pharmacol. Ther. 2010 23:334-344;
Kaufmann et al. Microvasc Res 2010 80:286-293Weide et al. J Immunother. 2009 32:498-507; Weide et al. J Immunother. 2008 31 : 180-188; Pascolo Expert Opin. Biol. Ther. 4: 1285-1294; Fotin-Mleczek et al., 2011 J. Immunother. 34: 1-15; Song et al., Nature Biotechnol. 2005, 23:709-717; Peer et al., Proc Natl Acad Sci U S A. 2007 6;104:4095-4100; deFougerolles Hum Gene Ther. 2008 19: 125-132; all of which are incorporated herein by reference in its entirety).
[0584] In some embodiments, the polynucleotides described herein are formulated as a solid lipid nanoparticle (SLN), which can be spherical with an average diameter between 10 to 1000 nm. SLN possess a solid lipid core matrix that can solubilize lipophilic molecules and can be stabilized with surfactants and/or emulsifiers. Exemplary
SLN can be those as described in Inti. Pub. No. W02013105101, herein incorporated by reference in its entirety.
[0585] In some embodiments, the polynucleotides described herein can be formulated for controlled release and/or targeted delivery. As used herein, "controlled release" refers to a pharmaceutical composition or compound release profde that conforms to a particular pattern of release to effect a therapeutic outcome. In one embodiment, the polynucleotides can be encapsulated into a delivery agent described herein and/or known in the art for controlled release and/or targeted delivery. As used herein, the term "encapsulate" means to enclose, surround or encase. As it relates to the formulation of the compounds of the invention, encapsulation can be substantial, complete or partial. The term "substantially encapsulated" means that at least greater than 50, 60, 70, 80, 85, 90, 95, 96, 97, 98, 99, or greater than 99% of the pharmaceutical composition or compound of the invention can be enclosed, surrounded or encased within the delivery agent. "Partially encapsulation" means that less than 10, 10, 20, 30, 40 50 or less of the pharmaceutical composition or compound of the invention can be enclosed, surrounded or encased within the delivery agent.
[0586] Advantageously, encapsulation can be determined by measuring the escape or the activity of the pharmaceutical composition or compound of the invention using fluorescence and/or electron micrograph. For example, at least 1, 5, 10, 20, 30, 40, 50, 60, 70, 80, 85, 90, 95, 96, 97, 98, 99, 99.9, or greater than 99% of the pharmaceutical composition or compound of the invention are encapsulated in the delivery agent.
[0587] In some embodiments, the polynucleotides described herein can be encapsulated in a therapeutic nanoparticle, referred to herein as "therapeutic nanoparticle polynucleotides." Therapeutic nanoparticles can be formulated by methods described in, e.g., Inti. Pub. Nos. W02010005740, W02010030763, W02010005721, W02010005723, and WO2012054923; and U.S. Pub. Nos. US20110262491, US20100104645, US20100087337, US20100068285, US20110274759, US20100068286, US20120288541, US20120140790, US20130123351 and
US20130230567; and U.S. Pat. Nos. 8,206,747, 8,293,276, 8,318,208 and 8,318,211, each of which is herein incorporated by reference in its entirety.
[0588] In some embodiments, the therapeutic nanoparticle polynucleotide can be formulated for sustained release. As used herein, "sustained release" refers to a pharmaceutical composition or compound that conforms to a release rate over a specific period of time. The period of time can include, but is not limited to, hours, days, weeks, months and years. As a non-limiting example, the sustained release nanoparticle of the polynucleotides described herein can be formulated as disclosed in Inti. Pub. No. W02010075072 and U.S. Pub. Nos. US20100216804, US20110217377, US20120201859 and US20130150295, each of which is herein incorporated by reference in their entirety.
[0589] In some embodiments, the therapeutic nanoparticle polynucleotide can be formulated to be target specific, such as those described in Inti. Pub. Nos. WO2008121949, W02010005726, W02010005725, WO2011084521 and WO2011084518; and U.S. Pub. Nos. US20100069426, US20120004293 and US20100104655, each of which is herein incorporated by reference in its entirety. [0590] The LNPs can be prepared using microfluidic mixers or micromixers. Exemplary microfluidic mixers can include, but are not limited to, a slit interdigital micromixer including, but not limited to those manufactured by Microinnova (Allerheiligen bei Wildon, Austria) and/or a staggered herringbone micromixer (SHM) (see Zhigaltsevet al., "Bottom-up design and synthesis of limit size lipid nanoparticle systems with aqueous and triglyceride cores using millisecond microfluidic mixing," Langmuir 28:3633-40 (2012); Belliveau et al., "Microfluidic synthesis of highly potent limit-size lipid nanoparticles for in vivo delivery of siRNA," Molecular Therapy-Nucleic Acids. I :e37 (2012); Chen et al., "Rapid discovery of potent siRNA-containing lipid nanoparticles enabled by controlled microfluidic formulation," J. Am. Chem. Soc.
134(16):6948-51 (2012); each of which is herein incorporated by reference in its entirety). Exemplary micromixers include Slit Interdigital Microstructured Mixer (SIMM-V2) or a Standard Slit Interdigital Micro Mixer (SSIMM) or Caterpillar (CPMM)
or Impinging-j et (IJMM,) from the Institut fur Mikrotechnik Mainz GmbH, Mainz Germany. In some embodiments, methods of making LNP using SHM further comprise mixing at least two input streams wherein mixing occurs by microstructure-induced chaotic advection (MICA). According to this method, fluid streams flow through channels present in a herringbone pattern causing rotational flow and folding the fluids around each other. This method can also comprise a surface for fluid mixing wherein the surface changes orientations during fluid cycling. Methods of generating LNPs using SHM include those disclosed in U.S. Pub. Nos. US20040262223 and US20120276209, each of which is incorporated herein by reference in their entirety.
[0591] In some embodiments, the polynucleotides described herein can be formulated in lipid nanoparticles using microfluidic technology (see Whitesides, George M., "The Origins and the Future of Microfluidics," Nature 442: 368-373 (2006); and Abraham et al., "Chaotic Mixer for Microchannels," Science 295: 647-651 (2002); each of which is herein incorporated by reference in its entirety). In some embodiments, the polynucleotides can be formulated in lipid nanoparticles using a micromixer chip such as, but not limited to, those from Harvard Apparatus (Holliston, MA) or Dolomite Microfluidics (Royston, UK). A micromixer chip can be used for rapid mixing of two or more fluid streams with a split and recombine mechanism.
[0592] In some embodiments, the polynucleotides described herein can be formulated in lipid nanoparticles having a diameter from about 1 nm to about 100 nm such as, but not limited to, about 1 nm to about 20 nm, from about 1 nm to about 30 nm, from about 1 nm to about 40 nm, from about 1 nm to about 50 nm, from about 1 nm to about 60 nm, from about 1 nm to about 70 nm, from about 1 nm to about 80 nm, from about 1 nm to about 90 nm, from about 5 nm to about from 100 nm, from about 5 nm to about 10 nm, about 5 nm to about 20 nm, from about 5 nm to about 30 nm, from about 5 nm to about 40 nm, from about 5 nm to about 50 nm, from about 5 nm to about 60 nm, from about 5 nm to about 70 nm, from about 5 nm to about 80 nm, from about 5 nm to about 90 nm, about 10 to about 20 nm, about 10 to about 30 nm, about 10 to about 40 nm, about 10 to about 50 nm, about 10 to about 60 nm, about 10 to about 70 nm, about 10 to about 80 nm,
about 10 to about 90 nm, about 20 to about 30 nm, about 20 to about 40 nm, about 20 to about 50 nm, about 20 to about 60 nm, about 20 to about 70 nm, about 20 to about 80 nm, about 20 to about 90 nm, about 20 to about 100 nm, about 30 to about 40 nm, about 30 to about 50 nm, about 30 to about 60 nm, about 30 to about 70 nm, about 30 to about 80 nm, about 30 to about 90 nm, about 30 to about 100 nm, about 40 to about 50 nm, about 40 to about 60 nm, about 40 to about 70 nm, about 40 to about 80 nm, about 40 to about 90 nm, about 40 to about 100 nm, about 50 to about 60 nm, about 50 to about 70 nm about 50 to about 80 nm, about 50 to about 90 nm, about 50 to about 100 nm, about 60 to about 70 nm, about 60 to about 80 nm, about 60 to about 90 nm, about 60 to about 100 nm, about 70 to about 80 nm, about 70 to about 90 nm, about 70 to about 100 nm, about 80 to about 90 nm, about 80 to about 100 nm and/or about 90 to about 100 nm.
[0593] In some embodiments, the lipid nanoparticles can have a diameter from about 10 to 500 nm. In one embodiment, the lipid nanoparticle can have a diameter greater than 100 nm, greater than 150 nm, greater than 200 nm, greater than 250 nm, greater than 300 nm, greater than 350 nm, greater than 400 nm, greater than 450 nm, greater than 500 nm, greater than 550 nm, greater than 600 nm, greater than 650 nm, greater than 700 nm, greater than 750 nm, greater than 800 nm, greater than 850 nm, greater than 900 nm, greater than 950 nm or greater than 1000 nm.
[0594] In some embodiments, the polynucleotides can be delivered using smaller LNPs. Such particles can comprise a diameter from below 0.1 pm up to 100 nm such as, but not limited to, less than 0.1 pm, less than 1.0 pm, less than 5pm, less than 10 pm, less than 15 um, less than 20 um, less than 25 um, less than 30 um, less than 35 um, less than 40 um, less than 50 um, less than 55 um, less than 60 um, less than 65 um, less than 70 um, less than 75 um, less than 80 um, less than 85 um, less than 90 um, less than 95 um, less than 100 um, less than 125 um, less than 150 um, less than 175 um, less than 200 um, less than 225 um, less than 250 um, less than 275 um, less than 300 um, less than 325 um, less than 350 um, less than 375 um, less than 400 um, less than 425 um, less than 450 um, less than 475 um, less than 500 um, less than 525 um, less than 550 um, less than 575 um, less than 600 um, less than 625 um, less than 650 um, less than 675 um, less than 700 um,
less than 725 um, less than 750 um, less than 775 um, less than 800 um, less than 825 um, less than 850 um, less than 875 um, less than 900 um, less than 925 um, less than 950 um, or less than 975 um.
[0595] The nanoparticles and microparticles described herein can be geometrically engineered to modulate macrophage and/or the immune response. The geometrically engineered particles can have varied shapes, sizes and/or surface charges to incorporate the polynucleotides described herein for targeted delivery such as, but not limited to, pulmonary delivery (see, e.g., Inti. Pub. No. W02013082111, herein incorporated by reference in its entirety). Other physical features the geometrically engineering particles can include, but are not limited to, fenestrations, angled arms, asymmetry and surface roughness, charge that can alter the interactions with cells and tissues.
[0596] In some embodiment, the nanoparticles described herein are stealth nanoparticles or target-specific stealth nanoparticles such as, but not limited to, those described in U.S. Pub. No. US20130172406, herein incorporated by reference in its entirety. The stealth or target-specific stealth nanoparticles can comprise a polymeric matrix, which can comprise two or more polymers such as, but not limited to, polyethylenes, polycarbonates, polyanhydrides, polyhydroxyacids, polypropylfumerates, polycaprolactones, polyamides, polyacetals, polyethers, polyesters, poly(orthoesters), polycyanoacrylates, polyvinyl alcohols, polyurethanes, polyphosphazenes, polyacrylates, polymethacrylates, polycyanoacrylates, polyureas, polystyrenes, polyamines, polyesters, polyanhydrides, polyethers, polyurethanes, polymethacrylates, polyacrylates, polycyanoacrylates, or combinations thereof.
Lipidoids
[0597] In some embodiments, the compositions or formulations of the present disclosure comprise a delivery agent, e.g., a lipidoid. The polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein can be formulated with lipidoids. Complexes, micelles, liposomes or particles can be prepared containing these lipidoids and therefore to achieve an effective delivery of the polynucleotide, as judged by the production of an encoded protein, following the
injection of a lipidoid formulation via localized and/or systemic routes of administration. Lipidoid complexes of polynucleotides can be administered by various means including, but not limited to, intravenous, intramuscular, or subcutaneous routes.
[0598] The synthesis of lipidoids is described in literature (see Mahon et al., Bioconjug. Chem. 2010 21 :1448-1454; Schroeder et al., J Intern Med. 2010 267:9-21; Akinc et al., Nat Biotechnol. 2008 26:561-569; Love et al., Proc Natl Acad Sci U S A. 2010 107:1864-1869; Si egwart et al., Proc Natl Acad Sci U S A. 2011 108: 12996-3001; all of which are incorporated herein in their entireties).
[0599] Formulations with the different lipidoids, including, but not limited to penta[3-(l-laurylaminopropionyl)]-tri ethylenetetramine hydrochloride (TETA-5LAP; also known as 98N12-5, see Murugaiah et al., Analytical Biochemistry, 401 :61 (2010)), Cl 2-200 (including derivatives and variants), and MD1, can be tested for in vivo activity. The lipidoid "98N12-5" is disclosed by Akinc et al., Mol Ther. 2009 17:872-879. The lipidoid "C12-200" is disclosed by Love et al., Proc Natl Acad Sci U S A. 2010 107: 1864-1869 and Liu and Huang, Molecular Therapy. 2010 669-670. Each of the references is herein incorporated by reference in its entirety.
[0600] In one embodiment, the polynucleotides described herein can be formulated in an aminoalcohol lipidoid. Aminoalcohol lipidoids can be prepared by the methods described in U.S. Patent No. 8,450,298 (herein incorporated by reference in its entirety).
[0601] The lipidoid formulations can include particles comprising either 3 or 4 or more components in addition to polynucleotides. Lipidoids and polynucleotide formulations comprising lipidoids are described in Inti. Pub. No. WO 2015051214 (herein incorporated by reference in its entirety.
Hyaluronidase
[0602] In some embodiments, the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein and hyaluronidase for injection (e.g., intramuscular or subcutaneous injection). Hyaluronidase catalyzes the hydrolysis of hyaluronan, which is a constituent of the interstitial barrier. Hyaluronidase lowers the viscosity of hyaluronan, thereby increases tissue permeability
(Frost, Expert Opin. Drug Deliv. (2007) 4:427-440). Alternatively, the hyaluronidase can be used to increase the number of cells exposed to the polynucleotides administered intramuscularly, or subcutaneously.
Nanoparticle Mimics
[0603] In some embodiments, the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein is encapsulated within and/or absorbed to a nanoparticle mimic. A nanoparticle mimic can mimic the delivery function organisms or particles such as, but not limited to, pathogens, viruses, bacteria, fungus, parasites, prions and cells. As a non-limiting example, the polynucleotides described herein can be encapsulated in a non-viron particle that can mimic the delivery function of a virus (see e.g., Inti. Pub. No. W02012006376 and U.S. Pub. Nos. US20130171241 and US20130195968, each of which is herein incorporated by reference in its entirety).
Self-Assembled Nanoparticles, or Self-Assembled Macromolecules
[0604] In some embodiments, the compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein in self-assembled nanoparticles, or amphiphilic macromolecules (AMs) for delivery. AMs comprise biocompatible amphiphilic polymers that have an alkylated sugar backbone covalently linked to polyethylene glycol). In aqueous solution, the AMs self-assemble to form micelles. Nucleic acid self-assembled nanoparticles are described in Inti. Appl. No. PCT/US2014/027077, and AMs and methods of forming AMs are described in U.S. Pub. No. US20130217753, each of which is herein incorporated by reference in its entirety.
Cations and Anions
[0605] In some embodiments, the compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein and a cation or anion, such as Zn2+, Ca2+, Cu2+, Mg2+ and combinations thereof. Exemplary formulations can include
polymers and a polynucleotide complexed with a metal cation as described in, e.g., U.S. Pat. Nos. 6,265,389 and 6,555,525, each of which is herein incorporated by reference in its entirety. In some embodiments, cationic nanoparticles can contain a combination of divalent and monovalent cations. The delivery of polynucleotides in cationic nanoparticles or in one or more depot comprising cationic nanoparticles can improve polynucleotide bioavailability by acting as a long-acting depot and/or reducing the rate of degradation by nucleases.
Amino Acid Lipids
[0606] In some embodiments, the compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein that is formulation with an amino acid lipid. Amino acid lipids are lipophilic compounds comprising an amino acid residue and one or more lipophilic tails. Non-limiting examples of amino acid lipids and methods of making amino acid lipids are described in U.S. Pat. No. 8,501,824. The amino acid lipid formulations can deliver a polynucleotide in releasable form that comprises an amino acid lipid that binds and releases the polynucleotides. As a nonlimiting example, the release of the polynucleotides described herein can be provided by an acid-labile linker as described in, e.g., U.S. Pat. Nos. 7,098,032, 6,897,196, 6,426,086, 7,138,382, 5,563,250, and 5,505,931, each of which is herein incorporated by reference in its entirety.
Interpolyelectrolyte Complexes
[0607] In some embodiments, the compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein in an interpolyelectrolyte complex. Interpolyelectrolyte complexes are formed when charge-dynamic polymers are complexed with one or more anionic molecules. Non-limiting examples of chargedynamic polymers and interpolyelectrolyte complexes and methods of making interpolyelectrolyte complexes are described in U.S. Pat. No. 8,524,368, herein incorporated by reference in its entirety.
Crystalline Polymeric Systems
[0608] In some embodiments, the compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein in crystalline polymeric systems. Crystalline polymeric systems are polymers with crystalline moieties and/or terminal units comprising crystalline moieties. Exemplary polymers are described in U.S. Pat. No. 8,524,259 (herein incorporated by reference in its entirety).
Polymers, Biodegradable Nanoparticles, and Core-Shell Nanoparticles
[0609] In some embodiments, the compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein and a natural and/or synthetic polymer. The polymers include, but not limited to, polyethenes, polyethylene glycol (PEG), poly(l-lysine)(PLL), PEG grafted to PLL, cationic lipopolymer, biodegradable cationic lipopolymer, polyethyleneimine (PEI), cross-linked branched poly(alkylene imines), a polyamine derivative, a modified poloxamer, elastic biodegradable polymer, biodegradable copolymer, biodegradable polyester copolymer, biodegradable polyester copolymer, multiblock copolymers, poly[a-(4-aminobutyl)-L- glycolic acid) (PAGA), biodegradable cross-linked cationic multi-block copolymers, polycarbonates, polyanhydrides, polyhydroxyacids, polypropylfumerates, polycaprolactones, polyamides, polyacetals, polyethers, polyesters, poly(orthoesters), polycyanoacrylates, polyvinyl alcohols, polyurethanes, polyphosphazenes, polyureas, polystyrenes, polyamines, polylysine, poly(ethylene imine), poly(serine ester), poly(L- lactide-co-L-lysine), poly(4-hydroxy-L-proline ester), amine-containing polymers, dextran polymers, dextran polymer derivatives or combinations thereof.
[0610] Exemplary polymers include, DYNAMIC POLYCONIUGATE® (Arrowhead Research Corp., Pasadena, CA) formulations from MIRUS® Bio (Madison, WI) and Roche Madison (Madison, WI), PHASERXTM polymer formulations such as, without limitation, SMARTT POLYMER TECHNOLOGY™ (PHASERX®, Seattle, WA), DMRI/DOPE, poloxamer, VAXFECTIN® adjuvant from Vical (San Diego, CA),
chitosan, cyclodextrin from Calando Pharmaceuticals (Pasadena, CA), dendrimers and poly(lactic-co-glycolic acid) (PLGA) polymers. RONDELTM (RNAi/Oligonucleotide Nanoparticle Delivery) polymers (Arrowhead Research Corporation, Pasadena, CA) and pH responsive co-block polymers such as PHASERX® (Seattle, WA).
[0611] The polymer formulations allow a sustained or delayed release of the polynucleotide (e.g., following intramuscular or subcutaneous injection). The altered release profile for the polynucleotide can result in, for example, translation of an encoded protein over an extended period of time. The polymer formulation can also be used to increase the stability of the polynucleotide. Sustained release formulations can include, but are not limited to, PLGA microspheres, ethylene vinyl acetate (EV Ac), poloxamer, GELSITE® (Nanotherapeutics, Inc. Alachua, FL), HYLENEX® (Halozyme Therapeutics, San Diego CA), surgical sealants such as fibrinogen polymers (Ethicon Inc. Cornelia, GA), TISSELL® (Baxter International, Inc. Deerfield, IL), PEG-based sealants, and COSEAL® (Baxter International, Inc. Deerfield, IL).
[0612] As a non-limiting example modified mRNA can be formulated in PLGA microspheres by preparing the PLGA microspheres with tunable release rates (e.g., days and weeks) and encapsulating the modified mRNA in the PLGA microspheres while maintaining the integrity of the modified mRNA during the encapsulation process. EVAc are non-biodegradable, biocompatible polymers that are used extensively in pre-clinical sustained release implant applications (e.g., extended release products Ocusert a pilocarpine ophthalmic insert for glaucoma or progestasert a sustained release progesterone intrauterine device; transdermal delivery systems Testoderm, Duragesic and Selegiline; catheters). Poloxamer F-407 NF is a hydrophilic, non-ionic surfactant triblock copolymer of polyoxyethylene-polyoxypropylene-polyoxyethylene having a low viscosity at temperatures less than 5°C and forms a solid gel at temperatures greater than 15°C.
[0613] As a non-limiting example, the polynucleotides described herein can be formulated with the polymeric compound of PEG grafted with PLL as described in U.S. Pat. No. 6,177,274. As another non-limiting example, the polynucleotides described
herein can be formulated with a block copolymer such as a PLGA-PEG block copolymer (see e.g., U.S. Pub. No. US20120004293 and U.S. Pat. Nos. 8,236,330 and 8,246,968), or a PLGA-PEG-PLGA block copolymer (see e.g., U.S. Pat. No. 6,004,573). Each of the references is herein incorporated by reference in its entirety.
[0614] In some embodiments, the polynucleotides described herein can be formulated with at least one amine-containing polymer such as, but not limited to polylysine, polyethylene imine, poly(amidoamine) dendrimers, poly(amine-co-esters) or combinations thereof. Exemplary polyamine polymers and their use as delivery agents are described in, e g., U.S. Pat. Nos. 8,460,696, 8,236,280, each of which is herein incorporated by reference in its entirety.
[0615] In some embodiments, the polynucleotides described herein can be formulated in a biodegradable cationic lipopolymer, a biodegradable polymer, or a biodegradable copolymer, a biodegradable polyester copolymer, a biodegradable polyester polymer, a linear biodegradable copolymer, PAGA, a biodegradable cross-linked cationic multiblock copolymer or combinations thereof as described in, e.g., U.S. Pat. Nos. 6,696,038, 6,517,869, 6,267,987, 6,217,912, 6,652,886, 8,057,821, and 8,444,992; U.S. Pub. Nos. US20030073619, US20040142474, US20100004315, US2012009145 and US20130195920; and Inti Pub. Nos. W02006063249 and WO2013086322, each of which is herein incorporated by reference in its entirety.
[0616] In some embodiments, the polynucleotides described herein can be formulated in or with at least one cyclodextrin polymer as described in U.S. Pub. No.
US20130184453. In some embodiments, the polynucleotides described herein can be formulated in or with at least one crosslinked cation-binding polymers as described in Inti. Pub. Nos. WO2013106072, WO2013106073 and WO2013106086. In some embodiments, the polynucleotides described herein can be formulated in or with at least PEGylated albumin polymer as described in U.S. Pub. No. US20130231287. Each of the references is herein incorporated by reference in its entirety.
[0617] In some embodiments, the polynucleotides disclosed herein can be formulated as a nanoparticle using a combination of polymers, lipids, and/or other biodegradable
agents, such as, but not limited to, calcium phosphate. Components can be combined in a core-shell, hybrid, and/or layer-by-layer architecture, to allow for fine-tuning of the nanoparticle for delivery (Wang et al., Nat Mater. 2006 5:791-796; Fuller et al., Biomaterials. 2008 29: 1526-1532; DeKoker et al., Adv Drug Deliv Rev. 2011 63:748- 761; Endres et al., Biomaterials. 2011 32:7721-7731; Su et al., Mol Pharm. 2011 Jun 6;8(3):774-87; herein incorporated by reference in their entireties). As a non-limiting example, the nanoparticle can comprise a plurality of polymers such as, but not limited to hydrophilic-hydrophobic polymers (e.g., PEG-PLGA), hydrophobic polymers (e.g., PEG) and/or hydrophilic polymers (Inti. Pub. No. WO20120225129, herein incorporated by reference in its entirety).
[0618] The use of core-shell nanoparticles has additionally focused on a high- throughput approach to synthesize cationic cross-linked nanogel cores and various shells (Siegwart et al., Proc Natl Acad Sci U S A. 2011 108: 12996-13001; herein incorporated by reference in its entirety). The complexation, delivery, and internalization of the polymeric nanoparticles can be precisely controlled by altering the chemical composition in both the core and shell components of the nanoparticle. For example, the core-shell nanoparticles can efficiently deliver siRNA to mouse hepatocytes after they covalently attach cholesterol to the nanoparticle.
[0619] In some embodiments, a hollow lipid core comprising a middle PLGA layer and an outer neutral lipid layer containing PEG can be used to delivery of the polynucleotides as described herein. In some embodiments, the lipid nanoparticles can comprise a core of the polynucleotides disclosed herein and a polymer shell, which is used to protect the polynucleotides in the core. The polymer shell can be any of the polymers described herein and are known in the art. The polymer shell can be used to protect the polynucleotides in the core.
[0620] Core-shell nanoparticles for use with the polynucleotides described herein are described in U.S. Pat. No. 8,313,777 or Inti. Pub. No. WO2013124867, each of which is herein incorporated by reference in their entirety.
Peptides and Proteins
[0621] In some embodiments, the compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein) that is formulated with peptides and/or proteins to increase transfection of cells by the polynucleotide, and/or to alter the biodistribution of the polynucleotide (e.g., by targeting specific tissues or cell types), and/or increase the translation of encoded protein (e.g., Inti. Pub. Nos.
WO2012110636 and WO2013123298. In some embodiments, the peptides can be those described in U.S. Pub. Nos. US20130129726, US20130137644 and US20130164219. Each of the references is herein incorporated by reference in its entirety.
Conjugates
[0622] In some embodiments, the compositions or formulations of the present disclosure comprise the polynucleotides described herein (e.g., a polynucleotide comprising a nucleotide sequence encoding an IgAP protein) that is covalently linked to a carrier or targeting group, or including two encoding regions that together produce a fusion protein (e.g., bearing a targeting group and therapeutic protein or peptide) as a conjugate. The conjugate can be a peptide that selectively directs the nanoparticle to neurons in a tissue or organism, or assists in crossing the blood-brain barrier.
[0623] The conjugates include a naturally occurring substance, such as a protein (e.g., human serum albumin (HSA), low-density lipoprotein (LDL), high-density lipoprotein (HDL), or globulin); an carbohydrate (e.g., a dextran, pullulan, chitin, chitosan, inulin, cyclodextrin or hyaluronic acid); or a lipid. The ligand can also be a recombinant or synthetic molecule, such as a synthetic polymer, e.g., a synthetic polyamino acid, an oligonucleotide (e.g., an aptamer). Examples of polyamino acids include polyamino acid is a polylysine (PLL), poly L-aspartic acid, poly L-glutamic acid, styrene-maleic acid anhydride copolymer, poly(L-lactide-co-glycolied) copolymer, divinyl ether-maleic anhydride copolymer, N-(2-hydroxypropyl)methacrylamide copolymer (HMPA), polyethylene glycol (PEG), polyvinyl alcohol (PVA), polyurethane, poly(2-ethylacryllic acid), N-isopropyl acrylamide polymers, or polyphosphazine. Example of polyamines include: polyethylenimine, polylysine (PLL), spermine, spermidine, polyamine,
pseudopeptide-polyamine, peptidomimetic polyamine, dendrimer polyamine, arginine, amidine, protamine, cationic lipid, cationic porphyrin, quaternary salt of a polyamine, or an alpha helical peptide.
[0624] In some embodiments, the conjugate can function as a carrier for the polynucleotide disclosed herein. The conjugate can comprise a cationic polymer such as, but not limited to, polyamine, polylysine, polyalkylenimine, and polyethylenimine that can be grafted to with poly(ethylene glycol). Exemplary conjugates and their preparations are described in U.S. Pat. No. 6,586,524 and U.S. Pub. No. US20130211249, each of which herein is incorporated by reference in its entirety.
[0625] The conjugates can also include targeting groups, e.g., a cell or tissue targeting agent, e.g., a lectin, glycoprotein, lipid or protein, e.g., an antibody, that binds to a specified cell type such as a kidney cell. A targeting group can be a thyrotropin, melanotropin, lectin, glycoprotein, surfactant protein A, Mucin carbohydrate, multivalent lactose, multivalent galactose, N-acetyl-galactosamine, N-acetyl-glucosamine multivalent mannose, multivalent fucose, glycosylated polyaminoacids, multivalent galactose, transferrin, bisphosphonate, polyglutamate, polyaspartate, a lipid, cholesterol, a steroid, bile acid, folate, vitamin B12, biotin, an RGD peptide, an RGD peptide mimetic or an aptamer.
[0626] Targeting groups can be proteins, e.g., glycoproteins, or peptides, e.g., molecules having a specific affinity for a co-ligand, or antibodies e.g., an antibody, that binds to a specified cell type such as an endothelial cell or bone cell. Targeting groups can also include hormones and hormone receptors. They can also include non-peptidic species, such as lipids, lectins, carbohydrates, vitamins, cofactors, multivalent lactose, multivalent galactose, N-acetyl-galactosamine, N-acetyl-glucosamine multivalent mannose, multivalent frucose, or aptamers. The ligand can be, for example, a lipopolysaccharide, or an activator of p38 MAP kinase.
[0627] The targeting group can be any ligand that is capable of targeting a specific receptor. Examples include, without limitation, folate, GalNAc, galactose, mannose, mannose-6P, aptamers, integrin receptor ligands, chemokine receptor ligands, transferrin,
biotin, serotonin receptor ligands, PSMA, endothelin, GCPII, somatostatin, LDL, and HDL ligands. In particular embodiments, the targeting group is an aptamer. The aptamer can be unmodified or have any combination of modifications disclosed herein. As a nonlimiting example, the targeting group can be a glutathione receptor (GR)-binding conjugate for targeted delivery across the blood-central nervous system barrier as described in, e.g., U.S. Pub. No. US2013021661012 (herein incorporated by reference in its entirety).
[0628] In some embodiments, the conjugate can be a synergistic biomolecule- polymer conjugate, which comprises a long-acting continuous-release system to provide a greater therapeutic efficacy. The synergistic biomolecule-polymer conjugate can be those described in U.S. Pub. No. US20130195799. In some embodiments, the conjugate can be an aptamer conjugate as described in Inti. Pat. Pub. No. W02012040524. In some embodiments, the conjugate can be an amine containing polymer conjugate as described in U.S. Pat. No. 8,507,653. Each of the references is herein incorporated by reference in its entirety. In some embodiments, the polynucleotides can be conjugated to SMARTT POLYMER TECHNOLOGY® (PHASERX®, Inc. Seattle, WA).
[0629] In some embodiments, the polynucleotides described herein are covalently conjugated to a cell penetrating polypeptide, which can also include a signal sequence or a targeting sequence. The conjugates can be designed to have increased stability, and/or increased cell transfection; and/or altered the biodistribution (e.g., targeted to specific tissues or cell types).
[0630] In some embodiments, the polynucleotides described herein can be conjugated to an agent to enhance delivery. In some embodiments, the agent can be a monomer or polymer such as a targeting monomer or a polymer having targeting blocks as described in Inti. Pub. No. WO2011062965. In some embodiments, the agent can be a transport agent covalently coupled to a polynucleotide as described in, e.g., U.S. Pat. Nos. 6,835.393 and 7,374,778. In some embodiments, the agent can be a membrane barrier transport enhancing agent such as those described in U.S. Pat. Nos. 7,737,108 and 8,003,129. Each of the references is herein incorporated by reference in its entirety.
Methods of Use
[0631] The polynucleotides, pharmaceutical compositions and formulations described above are used in the preparation, manufacture and therapeutic use of compositions to treat IgAN.
[0632] IgAN is a kidney disease in which IgA builds up in the kidneys, causing inflammation and damage to kidney filtration in the glomerulus. Signs and symptoms of IgAN can include foamy or cola-or tea-colored urine, blood in the urine, pain on one or both sides of the rubs, edema, high blood pressure, weakness, fatigue, and kidney failure. Standard of care includes blood pressure drugs, immunosuppressants, omega-3 fatty acids, cholesterol medication, diuretics. Treatment may include dialysis or a kidney transplant.
[0633] In some embodiments, the polynucleotides, pharmaceutical compositions and formulations of the invention are used to treat IgAN for both inpatient and follow-up dosing. In further embodiments, a polynucleotide, pharmaceutical composition or formulation of the present disclosure is used to relieve IgAN symptoms, prevent disease progression and mortality, decrease IgAN hospitalization, prevent or delay kidney transplant, and/or prevent or delay dialysis.
[0634] In some embodiments, the polynucleotides, pharmaceutical compositions and formulations of the invention are used in methods for increasing the levels of IgAP proteins in a subject with IgAN. For instance, one aspect of the invention provides a method of alleviating the symptoms of IgAN, comprising the administration of a composition or formulation comprising a polynucleotide encoding IgAP to that subject (e.g., an mRNA encoding an IgAP protein).
[0635] In some embodiments, the administration of the polynucleotide, pharmaceutical composition or formulation of the present disclosure results in expression of IgAP protein in cells of the subject. In some embodiments, administering the polynucleotide, pharmaceutical composition or formulation of the present disclosure results in an increase of IgAP protein activity in the subject. For example, in some
embodiments, the polynucleotides of the present disclosure are used in methods of administering a composition or formulation comprising an mRNA encoding an IgAP protein to a subject, wherein the method results in an increase of IgAP protein activity in at least some cells of a subject.
[0636] In some embodiments, the administration of the polynucleotide, pharmaceutical composition or formulation of the present disclosure results in expression of an IgAP protein in at least some of the cells of a subject that persists for a period of time sufficient to allow significant metabolism to occur.
[0637] In another embodiment, the polynucleotides, pharmaceutical compositions, or formulations of the present disclosure can be repeatedly administered such that IgAP protein is expressed at a therapeutic level for a period of time sufficient to have a beneficial biological effect as described herein.
[0638] In some embodiments, the method or use comprises administering a polynucleotide, e.g., mRNA, comprising a nucleotide sequence having sequence similarity to a polynucleotide of SEQ ID NO:27, wherein the polynucleotide encodes an IgAP protein.
[0639] In some embodiments, the method or use comprises administering a polynucleotide, e.g., mRNA, comprising a nucleotide sequence having sequence similarity to a polynucleotide of SEQ ID NO:28, wherein the polynucleotide encodes an IgAP protein.
[0640] In some embodiments, the method or use comprises administering a polynucleotide, e.g., mRNA, comprising a nucleotide sequence having sequence similarity to a polynucleotide of SEQ ID NO: 153, wherein the polynucleotide encodes an IgAP protein.
[0641] In some embodiments, the method or use comprises administering a polynucleotide, e.g., mRNA, comprising a nucleotide sequence having sequence similarity to a polynucleotide of SEQ ID NO: 154, wherein the polynucleotide encodes an IgAP protein.
[0642] Other aspects of the present disclosure relate to transplantation of cells containing polynucleotides to a mammalian subject. Administration of cells to mammalian subjects is known to those of ordinary skill in the art, and includes, but is not limited to, local implantation (e.g., topical or subcutaneous administration), organ delivery or systemic injection (e.g., intravenous injection or inhalation), and the formulation of cells in pharmaceutically acceptable carriers.
[0643] The present disclosure also provides methods to provide IgAP activity in a subject with IgAN, comprising administering to the subject a therapeutically effective amount of a composition or formulation comprising mRNA encoding an IgAP protein disclosed herein.
[0644] In some aspects, the IgAP activity in a subject with IgAN, after administering to the subject a therapeutically effective amount of a composition or formulation comprising mRNA encoding an IgAP protein disclosed herein (e g., after a single dose administration) is maintained for at least 1 day, at least 2 days, at least 3 days, at least 4 days, at least 5 days, at least 6 days, at least 7 days, at least 8 days, at least 9 days, at least 10 days, at least 12 days, at least 14 days, at least 21 days, or at least 28 days.
[0645] The present disclosure also provides a method to treat, prevent, or ameliorate the symptoms of IgAN, comprising administering to the subject a therapeutically effective amount of a composition or formulation comprising mRNA encoding an IgAP protein disclosed herein. In some aspects, the administration of a therapeutically effective amount of a composition or formulation comprising mRNA encoding an IgAP protein disclosed herein to a subject in need of treatment for IgAN results in reducing the symptoms of IgAN.
[0646] In some embodiments, the polynucleotides (e.g., mRNA), pharmaceutical compositions and formulations used in the methods of the invention comprise a uracil- modified sequence encoding an IgAP protein disclosed herein and a miRNA binding site disclosed herein, e.g., a miRNA binding site that binds to miR-142 and/or a miRNA binding site that binds to miR-126. In some embodiments, the uracil-modified sequence encoding an IgAP protein comprises at least one chemically modified nucleobase, e.g.,
N1 -methylpseudouracil or 5 -methoxyuracil. In some embodiments, at least 95% of a type of nucleobase (e.g., uracil) in a uracil-modified sequence encoding an IgAP protein of the invention are modified nucleobases. In some embodiments, at least 95% of uracil in a uracil-modified sequence encoding an IgAP protein is 1-N-m ethylpseudouridine or 5- methoxyuridine. In some embodiments, the polynucleotide (e.g., a RNA, e.g., an mRNA) disclosed herein is formulated with a delivery agent comprising, e.g., a compound having the Formula (I), e.g., Compound II or Compound B; or a compound having the Formula (III), (IV), (V), or (VI), e.g., Compound I or Compound VI, or any combination thereof. In some embodiments, the delivery agent comprises an ionizable amino lipid (e.g., Compound II, VI, or B), a helper lipid (e.g., DSPC), a sterol (e.g., Cholesterol), and a PEG lipid (e.g., Compound I or PEG-DMG), e.g., with a mole ratio in the range of about (i) 40-50 mol% ionizable amino lipid (e.g., Compound II, VI, or B), optionally 45-50 mol% ionizable amino lipid, for example, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48-49 mol%, or 49-50 mol% for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol%; (ii) 30-45 mol% sterol (e.g., cholesterol), optionally 35-42 mol% sterol, for example, 30- 31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 37-38 mol%, 38-39 mol%, or 39-40 mol%, or 40-42 mol% sterol; (iii) 5-15 mol% helper lipid (e.g., DSPC), optionally 10-15 mol% helper lipid, for example, 5-6 mol%, 6- 7 mol%, 7-8 mol%, 8-9 mol%, 9-10 mol%, 10-11 mol%, 11-12 mol%, 12-13 mol%, 13- 14 mol%, or 14-15 mol% helper lipid; and (iv) 1-5% PEG lipid (e.g., Compound I or PEG-DMG), optionally 1-5 mol% PEG lipid, for example 1.5 to 2.5 mol%, 1-2 mol%, 2- 3 mol%, 3-4 mol%, or 4-5 mol% PEG lipid. In some embodiments, the delivery agent comprises Compound II, Cholesterol, DSPC, and Compound I.
[0647] The skilled artisan will appreciate that the therapeutic effectiveness of a drug or a treatment of the instant invention can be characterized or determined by measuring the level of expression of an encoded protein in a sample or in samples taken from a subject (e.g., from a preclinical test subject (rodent, primate, etc.) or from a clinical subject (human)). Likewise, the therapeutic effectiveness of a drug or a treatment of the
instant invention can be characterized or determined by measuring the level of activity of an encoded protein (e.g., enzyme) in a sample or in samples taken from a subject (e.g., from a preclinical test subject (rodent, primate, etc.) or from a clinical subject (human). Furthermore, the therapeutic effectiveness of a drug or a treatment of the instant invention can be characterized or determined by measuring the level of an appropriate biomarker in sample(s) taken from a subject. Levels of protein and/or biomarkers can be determined post-administration with a single dose of an mRNA therapeutic of the invention or can be determined and/or monitored at several time points following administration with a single dose or can be determined and/or monitored throughout a course of treatment, e.g., a multi-dose treatment.
IgAP Protein Expression Levels
[0648] C6rtain aspects of the invention feature measurement, determination and/or monitoring of the expression level or levels of IgAP protein in a subject, for example, in an animal (e.g., rodents, primates, and the like) or in a human subject. Animals include normal, healthy or wildtype animals, as well as animal models for use in understanding IgAN and treatments thereof. Exemplary animal models include rodent models, for example, alKICD89Tg mouse model expressing IgAl and CD89 (Berthelot et al., 2012, J Exp Med,209(4):793-806). IgAP protein expression levels can be measured or determined by any art-recognized method for determining protein levels in biological samples, e.g., serum or plasma sample. The term "level" or "level of a protein" as used herein, preferably means the weight, mass or concentration of the protein within a sample or a subject. It will be understood by the skilled artisan that in certain embodiments the sample may be subjected, e g., to any of the following: purification, precipitation, separation, e.g. centrifugation and/or HPLC, and subsequently subjected to determining the level of the protein, e.g., using mass and/or spectrometric analysis. In exemplary embodiments, enzyme-linked immunosorbent assay (ELISA) can be used to determine protein expression levels. In other exemplary embodiments, protein purification, separation and LC-MS can be used as a means for determining the level of a protein
according to the invention. In some embodiments, an mRNA therapy of the invention (e.g., a single intravenous dose) results in IgAP protein expression levels in the plasma or serum of the subject for at least 6 hours, at least 12 hours, at least 24 hours, at least 36 hours, at least 48 hours, at least 60 hours, at least 72 hours, at least 84 hours, at least 96 hours, at least 108 hours, at least 122 hours after administration of a single dose of the mRNA therapy.
IgAP Protein Activity
[0649] Further aspects of the invention feature measurement, determination and/or monitoring of the activity level(s) of IgAP protein in a subject, for example, in an animal (e.g., rodent, primate, and the like) or in a human subject. Activity levels can be measured or determined by any art-recognized method for determining activity levels in biological samples. The term "activity level" as used herein, preferably means the activity of the protein per volume, mass or weight of sample or total protein within a sample.
[0650] In exemplary embodiments, an mRNA therapy of the invention features a pharmaceutical composition comprising a dose of mRNA effective to result in at least 5 U/mg, at least 10 U/mg, at least 20 U/mg, at least 30 U/mg, at least 40 U/mg, at least 50 U/mg, at least 60 U/mg, at least 70 U/mg, at least 80 U/mg, at least 90 U/mg, at least 100 U/mg, or at least 150 U/mg of IgAP activity in tissue (e.g., plasma) between 6 and 12 hours, or between 12 and 24, between 24 and 48, or between 48 and 72 hours post administration (e.g., at 48 or at 72 hours post administration). In exemplary embodiments, an mRNA therapy of the invention features a pharmaceutical composition comprising a dose of mRNA effective to result in at least 50 U/mg, at least 100 U/mg, at least 200 U/mg, at least 300 U/mg, at least 400 U/mg, at least 500 U/mg, at least 600 U/mg, at least 700 U/mg, at least 800 U/mg, at least 900 U/mg, at least 1,000 U/mg, or at least 1,500 U/mg of IgAP activity in plasma between 6 and 12 hours, or between 12 and 24, between 24 and 48, or between 48 and 72 hours post administration (e.g., at 48 or at 72 hours post administration).
[0651] In exemplary embodiments, an mRNA therapy of the invention features a pharmaceutical composition comprising a single intravenous dose of mRNA that results in the above-described levels of activity. In another embodiment, an mRNA therapy of the invention features a pharmaceutical composition which can be administered in multiple single unit intravenous doses of mRNA that maintain the above-described levels of activity.
IgAP Biomarkers
[0652] Further aspects of the invention feature determining the level (or levels) of a biomarker, e.g., IgA, eGFR, cystatin C, proteinuria, hematuria, blood pressure, determined in a sample or subject as compared to a level (e.g., a reference level) of the same or another biomarker in another sample, e.g., from the same patient, from another patient, from a control and/or from the same or different time points, and/or a physiologic level, and/or an elevated level, and/or a supraphysiologic level, and/or a level of a control. The skilled artisan will be familiar with physiologic levels of biomarkers, for example, levels in normal or wildtype animals, normal or healthy subjects, and the like, in particular, the level or levels characteristic of subjects who are healthy and/or normal functioning. As used herein, the phrase “elevated level” means amounts greater than normally found in a normal or wildtype preclinical animal or in a normal or healthy subject, e.g. a human subject. As used herein, the term “supraphysiologic” means amounts greater than normally found in a normal or wildtype preclinical animal or in a normal or healthy subject, e.g. a human subject, optionally producing a significantly enhanced physiologic response. As used herein, the term "comparing" or "compared to" preferably means the mathematical comparison of the two or more values, e.g., of the levels of the biomarker(s). It will thus be readily apparent to the skilled artisan whether one of the values is higher, lower or identical to another value or group of values if at least two of such values are compared with each other. Comparing or comparison to can be in the context, for example, of comparing to a control value, e.g., as compared to a reference IgA, cystatin C, eGFR, proteinuria, hematuria, blood pressure level in said
subject prior to administration (e.g., in a person suffering from IgAN) or in a normal or healthy subject. Comparing or comparison to can also be in the context, for example, of comparing to a control value, e.g., as compared to a reference IgA, eGFR, proteinuria, hematuria, blood pressure level in said subject prior to administration (e.g., in a person suffering from IgAN) or in a normal or healthy subject.
[0653] As used herein, a “control” is preferably a sample from a subject wherein the IgAN status of said subject is known. In one embodiment, a control is a sample of a healthy patient. In another embodiment, the control is a sample from at least one subject having a known IgAN status, for example, a severe, mild, or healthy IgAN status, e.g. a control patient. In another embodiment, the control is a sample from a subject not being treated for IgAN. In a still further embodiment, the control is a sample from a single subject or a pool of samples from different subjects and/or samples taken from the subject(s) at different time points.
[0654] The term "level" or "level of a biomarker" as used herein, preferably means the mass, weight or concentration of a biomarker of the invention within a sample or a subject in the context of a nucleic acid or protein biomarker. Biomarkers of the invention include, for example, IgA, proteinuria, hematuria. It will be understood by the skilled artisan that in certain embodiments the sample may be subjected to, e.g., one or more of the following: substance purification, precipitation, separation, e.g. centrifugation and/or HPLC and subsequently subjected to determining the level of the biomarker, e.g. using mass spectrometric analysis. In exemplary embodiments, LC-MS can be used as a means for determining the level of a biomarker according to the invention. Biomarkers also include, for example, proteinuria, hematuria, blood pressure, and estimated glomerular filtration rate (eGFR).
[0655] The term "determining the level" of a biomarker as used herein can mean methods which include quantifying an amount of at least one substance in a sample from a subject, for example, in a bodily fluid from the subject (e.g., serum, plasma, urine, blood, lymph, fecal, etc.) or in a tissue of the subject (e.g., liver, heart, spleen kidney, etc.). The term "determining the level" of a biomarker as used herein can mean methods
which include quantifying rate of the biomarker, e.g., the eGFR or blood pressure, in the subject.
[0656] The term "reference level" as used herein can refer to levels (e.g., of a biomarker) in a subject prior to administration of an mRNA therapy of the invention (e.g., in a person suffering from IgAN) or in a normal or healthy subject.
[0657] In some embodiments, comparing the level of the biomarker in a sample from a subject in need of treatment for IgAN or in a subject being treated for IgAN to a control level of the biomarker comprises comparing the level of the biomarker in the sample from the subject (in need of treatment or being treated for IgAN) to a baseline or reference level, wherein if a level of the biomarker in the sample from the subject (in need of treatment or being treated for IgAN) is elevated, increased or higher compared to the baseline or reference level, this is indicative that the subject is suffering from IgAN and/or is in need of treatment; and/or wherein if a level of the biomarker in the sample from the subject (in need of treatment or being treated for IgAN) is decreased or lower compared to the baseline level this is indicative that the subject is not suffering from, is successfully being treated for IgAN, or is not in need of treatment for IgAN. The stronger the reduction (e.g., at least 2-fold, at least 3 -fold, at least 4-fold, at least 5-fold, at least 6- fold, at least 7-fold, at least 8-fold, at least 10-fold reduction and/or at least 10%, at least 20%, at least 30% at least 40%, at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% reduction) of the level of a biomarker, e.g., IgA, cystatin C, eGFR, proteinuria, hematuria, blood pressure, within a certain time period, e.g., within 6 hours, within 12 hours, 24 hours, 36 hours, 48 hours, 60 hours, or 72 hours, and/or for a certain duration of time, e.g., 48 hours, 72 hours, 96 hours, 120 hours, 144 hours, 1 week, 2 weeks, 3 weeks, 4 weeks, 1 month, 2 months, 3 months, 4 months, 5 months, 6 months, 7 months, 8 months, 9 months, 10 months, 11 months, 12 months, 18 months, 24 months, etc. the more successful is a therapy, such as for example an mRNA therapy of the invention (e.g., a single dose or a multiple regimen).
[0658] A reduction of at least about 20%, at least about 30%, at least about 40%, at least about 50%, at least about 60%, at least about 70%, at least about 80%, at least about
90%, at least 100% or more of the level of biomarker in a subject, for example a IgA, cystatin C, proteinuria, hematuria, blood pressure, within 1, 2, 3, 4, 5, 6 or more days following administration is indicative of a dose suitable for successful treatment IgAN, wherein reduction as used herein, preferably means that the level of biomarker determined at the end of a specified time period (e.g., post-administration, for example, of a single intravenous dose) is compared to the level of the same biomarker determined at the beginning of said time period (e.g., pre-administration of said dose). Exemplary time periods include 12, 24, 48, 72, 96, 120 or 144 hours post administration, in particular 24, 48, 72 or 96 hours post administration.
[0659] A sustained reduction in biomarker levels (e.g., IgA, cystatin C, proteinuria, hematuria, blood pressure) is particularly indicative of mRNA therapeutic dosing and/or administration regimens successful for treatment of IgAN. Such sustained reduction can be referred to herein as “duration” of effect. In exemplary embodiments, a reduction of at least about 40%, at least about 50%, at least about 60%, at least about 65%, at least about 70%, at least about 75%, at least about 80%, at least about 85%, at least about 90%, or at least about 95% or more of the level of biomarker in a subject, for example IgA, cystatin C, proteinuria, hematuria, blood pressure, within 4, 5, 6, 7, 8 or more days following administration is indicative of a successful therapeutic approach. In exemplary embodiments, sustained reduction in substrate (e.g., biomarker) levels in one or more samples (e.g., fluids and/or tissues) is preferred. For example, mRNA therapies resulting in sustained reduction in IgA, cystatin C, proteinuria, hematuria, optionally in combination with sustained reduction of said biomarker is indicative of successful treatment.
[0660] In some embodiments, comparing the level of the biomarker in a sample from a subject in need of treatment for IgAN or in a subject being treated for IgAN to a control level of the biomarker comprises comparing the level of the biomarker in the sample from the subject (in need of treatment or being treated for IgAN) to a baseline or reference level, wherein if a level of the biomarker in the sample from the subject (in need of treatment or being treated for IgAN) is decreased or lower compared to the
baseline or reference level, this is indicative that the subject is suffering from IgAN and/or is in need of treatment; and/or wherein if a level of the biomarker in the sample from the subject (in need of treatment or being treated for IgAN) is increased, elevated, or higher compared to the baseline level this is indicative that the subject is not suffering from, is successfully being treated for IgAN, or is not in need of treatment for IgAN. The stronger the increase (e.g., at least 2-fold, at least 3-fold, at least 4-fold, at least 5-fold, at least 6-fold, at least 7-fold, at least 8-fold, at least 10-fold reduction and/or at least 10%, at least 20%, at least 30% at least 40%, at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% increase) of the level of a biomarker, e g., eGFR, within a certain time period, e.g., within 6 hours, within 12 hours, 24 hours, 36 hours, 48 hours, 60 hours, or 72 hours, and/or for a certain duration of time, e.g., 48 hours, 72 hours, 96 hours, 120 hours, 144 hours, 1 week, 2 weeks, 3 weeks, 4 weeks, 1 month, 2 months, 3 months, 4 months, 5 months, 6 months, 7 months, 8 months, 9 months, 10 months, 11 months, 12 months, 18 months, 24 months, etc. the more successful is a therapy, such as for example an mRNA therapy of the invention (e.g., a single dose or a multiple regimen).
[0661] An increase of at least about 20%, at least about 30%, at least about 40%, at least about 50%, at least about 60%, at least about 70%, at least about 80%, at least about 90%, at least 100% or more of the level of biomarker in a subject, for example, eGFR level, within 1, 2, 3, 4, 5, 6 or more days following administration is indicative of a dose suitable for successful treatment of IgAN, wherein increase as used herein, preferably means that the level of biomarker determined at the end of a specified time period (e.g., post-administration, for example, of a single intravenous dose) is compared to the level of the same biomarker determined at the beginning of said time period (e.g., preadministration of said dose). Exemplary time periods include 12, 24, 48, 72, 96, 120 or 144 hours post administration, in particular 24, 48, 72 or 96 hours post administration. [0662] A sustained increase in biomarker levels (e.g., eGFR) is particularly indicative of mRNA therapeutic dosing and/or administration regimens successful for treatment of IgAN. Such sustained reduction can be referred to herein as “duration” of effect. In
exemplary embodiments, an increase of at least about 40%, at least about 50%, at least about 60%, at least about 65%, at least about 70%, at least about 75%, at least about 80%, at least about 85%, at least about 90%, or at least about 95% or more of the level of biomarker in a subject, for example, eGFR, within 4, 5, 6, 7, 8 or more days following administration is indicative of a successful therapeutic approach. In exemplary embodiments, sustained increase in biomarker level is preferred. For example, mRNA therapies resulting in sustained increase in eGFR, optionally in combination with sustained increase of said biomarker, is indicative of successful treatment.
Compositions and Formulations for Use
[0663] C6rtain aspects of the invention are directed to compositions or formulations comprising any of the polynucleotides disclosed above.
[0664] In some embodiments, the composition or formulation comprises:
(i) a polynucleotide (e.g., a RNA, e.g., an mRNA) comprising a sequence-optimized nucleotide sequence (e.g., an ORF) encoding an IgAP protein described herein, wherein the polynucleotide comprises at least one chemically modified nucleobase, e.g.,
N1 -methyl pseudouracil or 5-methoxyuracil (e.g., wherein at least about 25%, at least about 30%, at least about 40%, at least about 50%, at least about 60%, at least about 70%, at least about 80%, at least about 90%, at least about 95%, at least about 99%, or 100% of the uracils are N1 -methylpseudouracils or 5-methoxyuracils), and wherein the polynucleotide further comprises a miRNA binding site, e.g., a miRNA binding site that binds to miR-142 (e.g., a miR-142-3p or miR-142-5p binding site) and/or a miRNA binding site that binds to miR-126 (e.g., a miR-126-3p or miR-126-5p binding site); and
(ii) a delivery agent comprising a compound having the Formula (I), e.g., Compound II or Compound B; a compound having the Formula (III), (IV), (V), or (VI), e.g., Compound I or Compound VI, or any combination thereof. In some embodiments, the delivery agent is a lipid nanoparticle comprising Compound II, Compound VI, a salt or a stereoisomer thereof, or any combination thereof. In some embodiments, the delivery agent comprises an ionizable amino lipid (e.g., Compound II, VI, or B), a helper lipid (e.g., DSPC), a
sterol (e.g., Cholesterol), and a PEG lipid (e.g., Compound I or PEG-DMG), e.g., with a mole ratio in the range of about (i) 40-50 mol% ionizable amino lipid (e.g., Compound II, VI, or B), optionally 45-50 mol % ionizable amino lipid, for example, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48-49 mol%, or 49-50 mol% for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol%; (ii) 30-45 mol% sterol (e.g., cholesterol), optionally 35-42 mol% sterol, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol%, 35-35 mol%, 35-36 mol%, 36-37 mol%, 37-38 mol%, 38-39 mol%, or 39-40 mol%, or 40-42 mol% sterol; (iii) 5-15 mol% helper lipid (e.g., DSPC), optionally 10-15 mol% helper lipid, for example, 5-6 mol%, 6-7 mol%, 7-8 mol%, 8-9 mol%, 9-10 mol%, 10-11 mol%, 11-12 mol%, 12-13 mol%, 13-14 mol%, or 14-15 mol% helper lipid; and (iv) 1-5% PEG lipid (e.g., Compound I or PEG-DMG), optionally 1-5 mol% PEG lipid, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol% PEG lipid. In some embodiments, the delivery agent comprises Compound II, Cholesterol, DSPC, and Compound I.
[0665] In some embodiments, the uracil or thymine content of the ORF relative to the theoretical minimum uracil or thymine content of a nucleotide sequence encoding the IgAP protein (%UTM or %TTM), is between about 100% and about 150%.
[0666] In some embodiments, the polynucleotides, compositions or formulations above are used to treat IgAN.
Definitions
[0667] In order that the present disclosure can be more readily understood, certain terms are first defined. As used in this application, except as otherwise expressly provided herein, each of the following terms shall have the meaning set forth below. Additional definitions are set forth throughout the application.
[0668] The invention includes embodiments in which exactly one member of the group is present in, employed in, or otherwise relevant to a given product or process. The invention includes embodiments in which more than one, or all of the group members are present in, employed in, or otherwise relevant to a given product or process.
[0669] In this specification and the appended claims, the singular forms "a", "an" and "the" include plural referents unless the context clearly dictates otherwise. The terms "a" (or "an"), as well as the terms "one or more," and "at least one" can be used interchangeably herein. In certain aspects, the term "a" or "an" means "single." In other aspects, the term "a" or "an" includes "two or more" or "multiple."
[0670] Furthermore, "and/or" where used herein is to be taken as specific disclosure of each of the two specified features or components with or without the other. Thus, the term "and/or" as used in a phrase such as "A and/or B" herein is intended to include "A and B," "A or B," "A" (alone), and "B" (alone). Likewise, the term "and/or" as used in a phrase such as "A, B, and/or C" is intended to encompass each of the following aspects: A, B, and C; A, B, or C; A or C; A or B; B or C; A and C; A and B; B and C; A (alone); B (alone); and C (alone).
[0671] Unless defined otherwise, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this disclosure is related. For example, the Concise Dictionary of Biomedicine and Molecular Biology, luo, Pei-Show, 2nd ed., 2002, CRC Press; The Dictionary of C6ll and Molecular Biology, 3rd ed., 1999, Academic Press; and the Oxford Dictionary Of Biochemistry And Molecular Biology, Revised, 2000, Oxford University Press, provide one of skill with a general dictionary of many of the terms used in this disclosure.
[0672] Wherever aspects are described herein with the language "comprising," otherwise analogous aspects described in terms of "consisting of' and/or "consisting essentially of' are also provided.
[0673] Units, prefixes, and symbols are denoted in their Systeme International de Unites (SI) accepted form. Numeric ranges are inclusive of the numbers defining the range. Where a range of values is recited, it is to be understood that each intervening integer value, and each fraction thereof, between the recited upper and lower limits of that range is also specifically disclosed, along with each subrange between such values. The upper and lower limits of any range can independently be included in or excluded from the range, and each range where either, neither or both limits are included is also
encompassed within the invention. Where a value is explicitly recited, it is to be understood that values which are about the same quantity or amount as the recited value are also within the scope of the invention. Where a combination is disclosed, each subcombination of the elements of that combination is also specifically disclosed and is within the scope of the invention. Conversely, where different elements or groups of elements are individually disclosed, combinations thereof are also disclosed. Where any element of an invention is disclosed as having a plurality of alternatives, examples of that invention in which each alternative is excluded singly or in any combination with the other alternatives are also hereby disclosed; more than one element of an invention can have such exclusions, and all combinations of elements having such exclusions are hereby disclosed.
[0674] Nucleotides are referred to by their commonly accepted single-letter codes. Unless otherwise indicated, nucleic acids are written left to right in 5' to 3' orientation. Nucleobases are referred to herein by their commonly known one-letter symbols recommended by the IUPAC-IUB Biochemical Nomenclature Commission. Accordingly, A represents adenine, C represents cytosine, G represents guanine, T represents thymine, U represents uracil.
[0675] Amino acids are referred to herein by either their commonly known three letter symbols or by the one-letter symbols recommended by the IUPAC-IUB Biochemical Nomenclature Commission. Unless otherwise indicated, amino acid sequences are written left to right in amino to carboxy orientation.
[0676] About: The term "about" as used in connection with a numerical value throughout the specification and the claims denotes an interval of accuracy, familiar and acceptable to a person skilled in the art, such interval of accuracy is ± 10 %.
[0677] Where ranges are given, endpoints are included. Furthermore, unless otherwise indicated or otherwise evident from the context and understanding of one of ordinary skill in the art, values that are expressed as ranges can assume any specific value or subrange within the stated ranges in different embodiments of the invention, to the
tenth of the unit of the lower limit of the range, unless the context clearly dictates otherwise.
[0678] Approximately: As used herein, the term "approximately," as applied to one or more values of interest, refers to a value that is similar to a stated reference value. In certain embodiments, the term "approximately" refers to a range of values that fall within 25%, 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 1%, or less in either direction (greater than or less than) of the stated reference value unless otherwise stated or otherwise evident from the context (except where such number would exceed 100% of a possible value).
[0679] Dosing regimen. As used herein, a "dosing regimen" or a "dosing regimen" is a schedule of administration or physician determined regimen of treatment, prophylaxis, or palliative care.
[0680] Effective Amount: As used herein, the term "effective amount" of an agent is that amount sufficient to effect beneficial or desired results, for example, clinical results, and, as such, an "effective amount" depends upon the context in which it is being applied. For example, in the context of administering an agent that treats a protein buildup (e.g., IgA buildup in IgAN), an effective amount of an agent is, for example, an amount of mRNA expressing sufficient IgAP to ameliorate, reduce, eliminate, or prevent the symptoms and/or biomarkers associated with the protein buildup (e.g., IgAl deposition in the kidney mycanigium and/or hematuria), as compared to the severity of the symptom and/or amount or levels of biomarkers observed without administration of the agent. The term "effective amount" can be used interchangeably with "effective dose," "therapeutically effective amount," or "therapeutically effective dose."
[0681] Ionizable amino lipid. The term “ionizable amino lipid” includes those lipids having one, two, three, or more fatty acid or fatty alkyl chains and a pH-titratable amino head group (e.g., an alkylamino or dialkylamino head group). An ionizable amino lipid is typically protonated (i.e., positively charged) at a pH below the pKa of the amino head group and is substantially not charged at a pH above the pKa. Such ionizable amino lipids include, but are not limited to DLin-MC3 -DMA (MC3 ), (13Z,165Z)-N,N-dimethyl-3-
nonydocosa-13-16-dien-l-amine (L608), and a compound of any one of Formula I, II, and II described herein (e g., any one of Compound II, Compound VI, and Compound B). [0682] Methods of Administration'. As used herein, “methods of administration” can include intravenous, intramuscular, intradermal, subcutaneous, or other methods of delivering a composition to a subject. A method of administration can be selected to target delivery (e.g., to specifically deliver) to a specific region or system of a body. [0683] Nanoparticle Composition. As used herein, a “nanoparticle composition” is a composition comprising one or more lipids. Nanoparticle compositions are typically sized on the order of micrometers or smaller and can include a lipid bilayer. Nanoparticle compositions encompass lipid nanoparticles (LNPs), liposomes (e.g., lipid vesicles), and lipoplexes. For example, a nanoparticle composition can be a liposome having a lipid bilayer with a diameter of 500 nm or less.
[0684] The phrase "nucleotide sequence encoding" refers to the nucleic acid (e.g., an mRNA or DNA molecule) coding sequence which encodes a polypeptide. The coding sequence can further include initiation and termination signals operably linked to regulatory elements including a promoter and polyadenylation signal capable of directing expression in the cells of an individual or mammal to which the nucleic acid is administered. The coding sequence can further include sequences that encode signal peptides.
[0685] Patient: As used herein, "patient" refers to a subject who can seek or be in need of treatment, requires treatment, is receiving treatment, will receive treatment, or a subject who is under care by a trained professional for a particular disease or condition. In some embodiments, the treatment is needed, required, or received to prevent or decrease the risk of developing acute disease, i.e., it is a prophylactic treatment.
[0686] Pseudouridine: As used herein, pseudouridine (\|>) refers to the C-glycoside isomer of the nucleoside uridine. A "pseudouridine analog" is any modification, variant, isoform or derivative of pseudouridine. For example, pseudouridine analogs include but are not limited to 1-carboxymethyl-pseudouridine, 1-propynyl-pseudouridine, 1- taurinomethyl-pseudouridine, 1 -taurinomethyl-4-thio-pseudouridine, 1 -
methylpseudouridine
 (also known as Nl-methyl-pseudouridine), l-methyl-4-thio- pseudouridine (nris ), 4-thio-l-methyl-pseudouridine, 3-methyl-pseudouridine (m3qr), 2- thio-l-methyl-pseudouridine, 1 -methyl- 1-deaza-pseudouridine, 2-thio-l -methyl- 1 -deazapseudouridine, dihydropseudouridine, 2-thio-dihydropseudouridine, 2-methoxyuridine, 2- methoxy-4-thio-uridine, 4-methoxy-pseudouridine, 4-methoxy-2-thio-pseudouridine, 1- methyl-3-(3-amino-3-carboxypropyl)pseudouridine (acp3 y), and 2'-O-methyl- pseudouridine (\pm).
(also known as Nl-methyl-pseudouridine), l-methyl-4-thio- pseudouridine (nris ), 4-thio-l-methyl-pseudouridine, 3-methyl-pseudouridine (m3qr), 2- thio-l-methyl-pseudouridine, 1 -methyl- 1-deaza-pseudouridine, 2-thio-l -methyl- 1 -deazapseudouridine, dihydropseudouridine, 2-thio-dihydropseudouridine, 2-methoxyuridine, 2- methoxy-4-thio-uridine, 4-methoxy-pseudouridine, 4-methoxy-2-thio-pseudouridine, 1- methyl-3-(3-amino-3-carboxypropyl)pseudouridine (acp3 y), and 2'-O-methyl- pseudouridine (\pm).
[0687] Subject: By "subject" or "individual" or "animal" or "patient" or "mammal," is meant any subject, particularly a mammalian subject, for whom diagnosis, prognosis, or therapy is desired. Mammalian subjects include, but are not limited to, humans, domestic animals, farm animals, zoo animals, sport animals, pet animals such as dogs, cats, guinea pigs, rabbits, rats, mice, horses, cattle, cows; primates such as apes, monkeys, orangutans, and chimpanzees; canids such as dogs and wolves; felids such as cats, lions, and tigers; equids such as horses, donkeys, and zebras; bears, food animals such as cows, pigs, and sheep; ungulates such as deer and giraffes; rodents such as mice, rats, hamsters and guinea pigs; and so on. In certain embodiments, the mammal is a human subject. In other embodiments, a subject is a human patient. In a particular embodiment, a subject is a human patient in need of treatment.
[0688] Therapeutically effective amount: As used herein, the term "therapeutically effective amount" means an amount of an agent to be delivered (e.g., nucleic acid, drug, therapeutic agent, diagnostic agent, prophylactic agent, etc.) that is sufficient, when administered to a subject suffering from or susceptible to an infection, disease, disorder, and/or condition, to treat, improve symptoms of, diagnose, prevent, and/or delay the onset of the infection, disease, disorder, and/or condition.
[0689] Uracil'. Uracil is one of the four nucleobases in the nucleic acid of RNA, and it is represented by the letter U. Uracil can be attached to a ribose ring, or more specifically, a ribofuranose via a -Ni-glycosidic bond to yield the nucleoside uridine. The nucleoside uridine is also commonly abbreviated according to the one letter code of its nucleobase, i.e., U. Thus, in the context of the present disclosure, when a monomer in
a polynucleotide sequence is U, such U is designated interchangeably as a "uracil" or a "uridine."
[0690] Uridine Content. The terms "uridine content" or "uracil content" are interchangeable and refer to the amount of uracil or uridine present in a certain nucleic acid sequence. Uridine content or uracil content can be expressed as an absolute value (total number of uridine or uracil in the sequence) or relative (uridine or uracil percentage respect to the total number of nucleobases in the nucleic acid sequence).
[0691] Uridine -Modified Sequence The terms "uridine-modified sequence" refers to a sequence optimized nucleic acid (e.g., a synthetic mRNA sequence) with a different overall or local uridine content (higher or lower uridine content) or with different uridine patterns (e.g., gradient distribution or clustering) with respect to the uridine content and/or uridine patterns of a candidate nucleic acid sequence. In the content of the present disclosure, the terms "uridine-modified sequence" and "uracil-modified sequence" are considered equivalent and interchangeable.
[0692] Nucleobase'. As used herein, the term “nucleobase” (alternatively “nucleotide base” or “nitrogenous base”) refers to a purine or pyrimidine heterocyclic compound found in nucleic acids, including any derivatives or analogs of the naturally occurring purines and pyrimidines that confer improved properties (e.g., binding affinity, nuclease resistance, chemical stability) to a nucleic acid or a portion or segment thereof. Adenine, cytosine, guanine, thymine, and uracil are the nucleobases predominately found in natural nucleic acids. Other natural, non-natural, and/or synthetic nucleobases, as known in the art and/or described herein, can be incorporated into nucleic acids. Unless otherwise specified, the nucleobase sequence of a SEQ ID NO described herein encompasses both natural nucleobases and chemically modified nucleobases (e.g., a “U” designation in a SEQ ID NO encompasses both uracil and chemically modified uracil).
[0693] Nucleoside/Nucleotide'. As used herein, the term “nucleoside” refers to a compound containing a sugar molecule (e.g., a ribose in RNA or a deoxyribose in DNA), or derivative or analog thereof, covalently linked to a nucleobase (e.g., a purine or pyrimidine), or a derivative or analog thereof (also referred to herein as “nucleobase”),
but lacking an intemucleoside linking group (e.g., a phosphate group). As used herein, the term “nucleotide” refers to a nucleoside covalently bonded to an intemucleoside linking group (e.g., a phosphate group), or any derivative, analog, or modification thereof that confers improved chemical and/or functional properties (e.g., binding affinity, nuclease resistance, chemical stability) to a nucleic acid or a portion or segment thereof. [0694] Nucleic acid: As used herein, the term “nucleic acid” is used in its broadest sense and encompasses any compound and/or substance that includes a polymer of nucleotides, or derivatives or analogs thereof. These polymers are often referred to as “polynucleotides”. Accordingly, as used herein the terms “nucleic acid” and “polynucleotide” are equivalent and are used interchangeably. Exemplary nucleic acids or polynucleotides of the disclosure include, but are not limited to, ribonucleic acids (RNAs), deoxyribonucleic acids (DNAs), DNA-RNA hybrids, RNAi-inducing agents, RNAi agents, siRNAs, shRNAs, mRNAs, modified mRNAs, miRNAs, antisense RNAs, ribozymes, catalytic DNA, RNAs that induce triple helix formation, threose nucleic acids (TNAs), glycol nucleic acids (GNAs), peptide nucleic acids (PNAs), locked nucleic acids (LNAs, including LNA having a P-D-ribo configuration, a-LNA having an a-L-ribo configuration (a diastereomer of LNA), 2'-amino-LNA having a 2'-amino functionalization, and 2'-amino-a-LNA having a 2'-amino functionalization) or hybrids thereof.
[0695] Open Reading Frame . As used herein, the term “open reading frame”, abbreviated as “ORF”, refers to a segment or region of an mRNA molecule that encodes a polypeptide. The ORF comprises a continuous stretch of non-overlapping, in-frame codons, beginning with the initiation codon and ending with a stop codon, and is translated by the ribosome.
Equivalents and Scope
[0696] Those skilled in the art will recognize, or be able to ascertain using no more than routine experimentation, many equivalents to the specific embodiments in accordance with the invention described herein. The scope of the present invention is not
intended to be limited to the above Description, but rather is as set forth in the appended claims.
[0697] In the claims, articles such as "a," "an," and "the" can mean one or more than one unless indicated to the contrary or otherwise evident from the context. Claims or descriptions that include "or" between one or more members of a group are considered satisfied if one, more than one, or all of the group members are present in, employed in, or otherwise relevant to a given product or process unless indicated to the contrary or otherwise evident from the context. The invention includes embodiments in which exactly one member of the group is present in, employed in, or otherwise relevant to a given product or process. The invention includes embodiments in which more than one, or all of the group members are present in, employed in, or otherwise relevant to a given product or process.
[0698] It is also noted that the term "comprising" is intended to be open and permits but does not require the inclusion of additional elements or steps. When the term "comprising" is used herein, the term "consisting of is thus also encompassed and disclosed.
[0699] Where ranges are given, endpoints are included. Furthermore, it is to be understood that unless otherwise indicated or otherwise evident from the context and understanding of one of ordinary skill in the art, values that are expressed as ranges can assume any specific value or subrange within the stated ranges in different embodiments of the invention, to the tenth of the unit of the lower limit of the range, unless the context clearly dictates otherwise.
[0700] In addition, it is to be understood that any particular embodiment of the present invention that falls within the prior art can be explicitly excluded from any one or more of the claims. Since such embodiments are deemed to be known to one of ordinary skill in the art, they can be excluded even if the exclusion is not set forth explicitly herein. Any particular embodiment of the compositions of the invention (e.g., any nucleic acid or protein encoded thereby; any method of production; any method of use; etc.) can
be excluded from any one or more claims, for any reason, whether or not related to the existence of prior art.
[0701] All cited sources, for example, references, publications, databases, database entries, and art cited herein, are incorporated into this application by reference, even if not expressly stated in the citation. In case of conflicting statements of a cited source and the instant application, the statement in the instant application shall control.
[0702] Section and table headings are not intended to be limiting.
EXAMPLES
EXAMPLE 1: Synthesis of mRNAs Encoding IgAP Polypeptides
[0703] mRNAs encoding IgAP polypeptides can be constructed, e.g., by using the ORF sequence (amino acid) provided in SEQ ID NO:4. The IgAP polypeptide can have a leader sequence (e.g., MLKNKKFKLNFIALTVAYALAPYTEA (SEQ ID NO:320), MGVKVLF ALICIA VAEA (SEQ ID NO:321), or METPAQLLFLLLLWLPDTTG (SEQ ID NO:322)).
[0704] Exemplary sequence optimized nucleotide sequence encoding IgAP polypeptides are provided in SEQ ID NOs:25-28.
[0705] The mRNA sequence includes both 5' and 3' UTR regions flanking the ORF sequence (nucleotide). In an exemplary construct, the 5' UTR and 3' UTR sequences are SEQ ID NOs:58 and 114), respectively.
5 UTR:
GGAAAUCGCAAAAUUUUCUUUUCGCGUUAGAUUUCUUUUAGUUUUCUUUC AACUAGCAAGCUUUUUGUUCUCGCCGCCGCC (SEQ ID NO: 58)
3 UTR:
UGAUAAUAGUCCAUAAAGUAGGAAACACUACAGCUGGAGCCUCGGUGGCC
UAGCUUCUUGCCCCUUGGGCCUCCAUAAAGUAGGAAACACUACAUCCCCCC
AGCCCCUCCUCCCCUUCCUGCACCCGUACCCCCUCCAUAAAGUAGGAAACA CUACAGUGGUCUUUGAAUAAAGUCUGAGUGGGCGGC (SEQ ID NO: 114)
In another exemplary construct, the 5' UTR and 3' UTR sequences are SEQ ID NOs:58 and 139), respectively.
5 'UTR:
GGAAAUCGCAAAAUUUUCUUUUCGCGUUAGAUUUCUUUUAGUUUUCUUUC AACUAGCAAGCUUUUUGUUCUCGCCGCCGCC (SEQ ID NO:58)
3 'UTR:
UAAAGCUCCCCGGGGGCCUCGGUGGCCUAGCUUCUUGCCCCUUGGGCCUCC CCCCAGCCCCUCCUCCCCUUCCUGCACCCGUACCCCCGUGGUCUUUGAAUA AAGUCUGAGUGGGCGGC (SEQ ID NO: 139)
[0706] The IgAP mRNA sequence is prepared as modified mRNA. Specifically, during in vitro transcription, modified mRNA can be generated using N1 - methylpseudouridine-5'-Triphosphate to ensure that the mRNAs contain 100% Nl- methylpseudouridine instead of uridine. Alternatively, during in vitro transcription, modified mRNA can be generated using Nl-methoxyuridine-5 '-Triphosphate to ensure that the mRNAs contain 100% 5-methoxyuridine instead of uridine. Further, IgAP mRNA can be synthesized with a primer that introduces a polyA-tail, and a cap structure is generated on both mRNAs using co-transcriptional capping to incorporate a m7G-ppp- Gm-AG 5' capl. Alternatively, IgAP mRNA can be synthesized and the polyA-tail introduced during Gibson assembly of the DNA template.
EXAMPLE 2: Production of Nanoparticle Compositions
A. Production of nanoparticle compositions
[0707] Nanoparticles can be made with mixing processes such as microfluidics and T-junction mixing of two fluid streams, one of which contains the polynucleotide and the other has the lipid components.
[0708] Lipid compositions are prepared by combining an ionizable amino lipid disclosed herein, e.g., a lipid according to Formula (I) such as Compound II or a lipid according to Formula (III) such as Compound VI, a phospholipid (such as DOPE or DSPC, obtainable from Avanti Polar Lipids, Alabaster, AL), a PEG lipid (such as 1,2 dimyristoyl sn glycerol meth oxypoly ethylene glycol, also known as PEG-DMG, obtainable from Avanti Polar Lipids, Alabaster, AL), and a structural lipid (such as cholesterol, obtainable from Sigma Aldrich, Taufkirchen, Germany, or a corticosteroid (such as prednisolone, dexamethasone, prednisone, and hydrocortisone), or a combination thereof) at concentrations of about 50 mM in ethanol. Solutions should be refrigerated for storage at, for example, -20° C. Lipids are combined to yield desired molar ratios and diluted with water and ethanol to a final lipid concentration of between about 5.5 mM and about 25 mM.
[0709] Nanoparticle compositions including a polynucleotide and a lipid composition are prepared by combining the lipid solution with a solution including the a polynucleotide at lipid composition to polynucleotide wt:wt ratios between about 5: 1 and about 50:1. The lipid solution is rapidly injected using a NanoAssemblr microfluidic based system at flow rates between about 10 ml/min and about 18 ml/min into the polynucleotide solution to produce a suspension with a water to ethanol ratio between about 1 : 1 and about 4:1.
[0710] For nanoparticle compositions including an RNA, solutions of the RNA at concentrations of 0.1 mg/ml in deionized water are diluted in 50 mM sodium citrate buffer at a pH between 3 and 4 to form a stock solution.
[0711] Nanoparticle compositions can be processed by dialysis to remove ethanol and achieve buffer exchange. Formulations are dialyzed twice against phosphate buffered saline (PBS), pH 7.4, at volumes 200 times that of the primary product using Slide-A- Lyzer cassettes (Thermo Fisher Scientific Inc., Rockford, IL) with a molecular weight cutoff of 10 kD. The first dialysis is carried out at room temperature for 3 hours. The formulations are then dialyzed overnight at 4° C. The resulting nanoparticle suspension is filtered through 0.2 pm sterile filters (Sarstedt, Numbrecht, Germany) into glass vials
and sealed with crimp closures. Nanoparticle composition solutions of 0.01 mg/ml to 0.10 mg/ml are generally obtained.
[0712] The method described above induces nano-precipitation and particle formation. Alternative processes including, but not limited to, T-junction and direct injection, can be used to achieve the same nano-precipitation.
B. Characterization of nanoparticle compositions
[0713] A Zetasizer Nano ZS (Malvern Instruments Ltd, Malvern, Worcestershire, UK) can be used to determine the particle size, the poly dispersity index (PDI) and the zeta potential of the nanoparticle compositions in IxPBS in determining particle size and 15 mM PBS in determining zeta potential.
[0714] Ultraviolet-visible spectroscopy can be used to determine the concentration of a polynucleotide (e.g., RNA) in nanoparticle compositions. 100 pL of the diluted formulation in 1 *PBS is added to 900 pL of a 4: 1 (v/v) mixture of methanol and chloroform. After mixing, the absorbance spectrum of the solution is recorded, for example, between 230 nm and 330 nm on a DU 800 spectrophotometer (Beckman Coulter, Beckman Coulter, Inc., Brea, CA). The concentration of polynucleotide in the nanoparticle composition can be calculated based on the extinction coefficient of the polynucleotide used in the composition and on the difference between the absorbance at a wavelength of, for example, 260 nm and the baseline value at a wavelength of, for example, 330 nm.
[0715] For nanoparticle compositions including an RNA, a QUANT-IT™ RIBOGREEN® RNA assay (Invitrogen Corporation Carlsbad, CA) can be used to evaluate the encapsulation of an RNA by the nanoparticle composition. The samples are diluted to a concentration of approximately 5 pg/mL in a TE buffer solution (10 mM Tris-HCl, 1 mM EDTA, pH 7.5). 50 pL of the diluted samples are transferred to a polystyrene 96 well plate and either 50 pL of TE buffer or 50 pL of a 2% Triton X-100 solution is added to the wells. The plate is incubated at a temperature of 37° C for 15 minutes. The RIBOGREEN® reagent is diluted 1 : 100 in TE buffer, and 100 pL of this solution is added to each well. The fluorescence intensity can be measured using a
fluorescence plate reader (Wallac Victor 1420 Multilablel Counter; Perkin Elmer, Waltham, MA) at an excitation wavelength of, for example, about 480 nm and an emission wavelength of, for example, about 520 nm. The fluorescence values of the reagent blank are subtracted from that of each of the samples and the percentage of free RNA is determined by dividing the fluorescence intensity of the intact sample (without addition of Triton X-100) by the fluorescence value of the disrupted sample (caused by the addition of Triton X-100).
[0716] Exemplary formulations of the nanoparticle compositions are presented in the Table 5 below. The term "Compound" refers to an ionizable amino lipid such as MC3 , Compound II, Compound VI, or Compound B. "Phospholipid" can be DSPC or DOPE. "PEG-lipid" can be PEG-DMG or Compound I.
Table 5. Exemplary Formulations of Nanoparticles


EXAMPLE 3: Design and Synthesis of IgAP Polypeptides and In Vitro and In Vivo Expression and Activity
[0717] HepG2 cells were transfected with mRNA encoding a truncated IgAP polypeptide containing amino acids 1-814 of SEQ ID NO:2 and tagged with C-terminal tag (SEQ ID NO:3). Twenty-four hours post-transfection, lysates or supernatants were harvested. Recombinant IgAl or GFP was incubated with the lysates or supernatants overnight at 37 °C. After incubation, samples were run on a western blot and probed with anti-V5 (C6ll Signaling Technology; Cat. No. 13202), anti-IgAl (Abeam; Cat. No. ab214003), and anti -Beta- Actin (Cell Signaling Technology; Cat. No. 3700) antibodies (FIG. 1)
[0718] FIG. 1 is a western blot depicting IgAlP, full length IgAl, cleaved IgAl, and beta-Actin protein levels for IgAl incubated with lysates or supernatants from cells transfected with mRNA encoding GFP or a truncated IgAP containing amino acids 1-814 of SEQ ID NO:2 (SEQ ID NO:3). The truncated IgAPi-su polypeptide from lysate
samples, but not supernatant samples, mediated cleavage of IgAl. These data indicate that the truncated IgAP containing amino acids 1-814 of SEQ ID NO:2 is present in the lysates and supernatants; however, its activity is only detected in the lysates and not in its secreted form.
[0719] Additional truncated IgAP polypeptides were generated as described in Table 6 below to determine if the region between L814 (numbered according to SEQ ID NO:2) and the autocleavage site at 1996 (numbered according to SEQ ID NO:2) — N-terminal to the autotransporter domain — is critical for refolding after secretion in mammalian cells. These truncated IgAP polypeptides were tested for intracellular and extracellular expression and activity, as described for FIG. 1, and compared against truncated counterparts excluding the 815-995 amino acids.
[0720] Table 6. Exemplary Truncated IgAP proteins.


[0721] FIG. 2A is a western blot depicting IgAlP protein levels in lysates or supernatants from HepG2 cells transfected with mRNA encoding GFP or truncated IgAP (SEQ ID NOs: 7-13). Each of the constructs was expressed intracellularly and extracellularly.
[0722] FIG. 2B is a western blot depicting full length IgAl, cleaved IgAl, and beta- Actin protein levels for IgAl incubated with lysates or supernatants from HepG2 cells transfected with mRNA encoding GFP or truncated IgAP (SEQ ID NOs: 7-13). IgAPi-995 supernatants and lysates mediated cleavage of IgAl (see IgAPl and IgAP2). In contrast, only the lysates — and not the supernatants — for IgAPi-sw mediated cleavage of IgAl (see IgAP5, lgAP6, IgAP7, and M3). These data indicate that the truncated IgAP containing amino acids 1-995 of SEQ ID NO:2 is both present and active in both the intracellular (lysate) and extracellular (supernatant) samples. These data indicate that the region between the protease domain and the autocleavage site is required for post-secretion activity in mammalian cells.
[0723] To determine if truncated IgAPi-995 polypeptide is secreted and active in vivo, CD-I mice (n=6/group) were administered 1 mg/kg of mRNA encoding IgAPl (amino acid sequence: SEQ ID NO:7; 5'UTR: SEQ ID NO:56; ORF nucleic acid sequence: SEQ ID NO:25; 3'UTR: SEQ ID NO: 114) or IgAP2 (amino acid sequence: SEQ ID NO:8; 5'UTR: SEQ ID NO: 56; ORF nucleic acid sequence: SEQ ID NO:26; 3'UTR: SEQ ID NO: 114) via Compound II/DMG-containing lipid nanoparticles or were administered phosphate buffered saline (PBS). Plasma, liver, and kidney were harvested 6 hours postdosing and evaluated for IgAP expression and activity via western blot.
[0724] FIG. 3 is a western blot depicting IgAP, uncleaved IgAl, and cleaved IgAl protein levels in plasma (top) or liver (bottom) samples from mice treated with IgAPl
(amino acid sequence: SEQ ID NO:7; ORF nucleic acid sequence: SEQ ID NO:25) or IgAP2 (amino acid sequence: SEQ ID NO:8; ORF nucleic acid sequence: SEQ ID NO:26), or PBS. IgAPl and IgAP2 expression was detected in plasma. IgAPl and IgAP2 activity was detected in both plasma and liver samples. IgAPl and IgAP2 expression and activity were not detected in kidney samples (data not shown).
EXAMPLE 4: In Vivo Activity of IgAP Polypeptide in a IgAN Mouse Model
[0725] To assess the expression and activity of the truncated IgAPi-995 polypeptide in an in vivo model of IgA nephropathy (IgAN), 12-week-old transgenic mice expressing human IgAl and CD89 (ulKI-CD89Tg) (N=24 animals, 4 groups of 6 animals) received a 0.25, 0.5 or 1 mg/kg dose of lipid nanoparticles (Compound II/DMG) encapsulating truncated IgAP mRNA (IgAPi-995; amino acid sequence: SEQ ID NO:7; 5'UTR: SEQ ID NO:58; ORF nucleic acid sequence: SEQ ID NO:26; 3'UTR: SEQ ID NO: 139), lipid nanoparticles encapsulating GFP mRNA, or PBS. Two mice were used received bacterial IgAl-P (Lechner et al., J. Am. Soc. Nephrol. 2016, 27(9):2622-9). All treatments were intravenously injected at tail vein. Serial bleeds either 24 hours before intravenous injection or post-intravenous injection at 8, 24, 48, 96, and 168 hours were performed for IgAl serum collections. The urine was also collected at the same time points. Mice were sacrificed either at 24 hours (n=3) or at 168 hours (n=3) post- intravenous injection. Serum levels of IgAl were measured by polyclonal and monoclonal antibodies using anti-human IgA sandwich ELISA (Bethyl and BD laboratories, respectively). Gd-IgAl levels were measured by KM55 kit (IBL, lapan). IgAl fragments were analyzed by SDS-10% PAGE and Western blots in serum and urine. Immunohistochemistry for hlgAl was performed in kidneys. Anti-IgAlP IgG antibody assay was established for immunogenicity evaluation.
[0726] Western blot data revealed IgAl Fab and Fc fragments in sera of mice treated with IgAP mRNA-lipid nanoparticle (LNP) in a dose-dependent manner with maximal action at 1 mg/kg starting at 8 hours throughout 96 hours, indicating the ability of such
mRNA-LNP products to cleave serum IgAl in vivo (FIG. 4A-FIG. 4C). No effect was seen with GFP mRNA-LNP (FIG. 4A-FIG. 4C). Moreover, Fabαl fragments were also detected in urine as early as 8 hours after injection for all doses (FIG. 5). Fabαl fragments were detected in urine at 168 hours only for the 1 mg/kg dose of IgAP mRNA- LNP (FIG. 5). IgAl serum levels decreased after IgAP mRNA-LNP treatment, reaching lowest levels (50-60%) after 48-96 hours post-injection (FIG. 6). Serum Gd-IgAl was also decreased (FIG. 7). Kidney glomeruli were scored for % IgAl positivity using imaging analysis software; 15 glomeruli were scored per mouse and data points are averaged score for each mouse. Percent IgAl positivity was significantly decreased for 1 mg/kg dose of IgAP at 24 hours (FIG. 8).
[0727] This example demonstrates that IgAP mRNA-LNPs are active in an in vivo model of IgAN.
EXAMPLE 5: IgAP polynucleotides with altered UTRs
[0728] alKI-CD89Tg mice were serially dosed (6 weekly 1 mg/kg doses) with lipid nanoparticles (Compound II/DMG) encapsulating IgAP mRNA (amino acid sequence: SEQ ID NO: 8) with or without UTR miRNA binding sites or lipid nanoparticles (Compound II/DMG) encapsulating GFP mRNA. IgAP mRNA construct sequences are provided in Table 7 below. All treatments were intravenously injected at tail vein.
Serial bleeds and urine were taken 24 hours post-intravenous injection at 1, 2, 3, 4, 5, and 6 weeks. Serum Gd-IgAl levels were measured by KM55 kit (IBL, Japan). IgAl fragments were analyzed by SDS-10% PAGE and Western blots in serum and urine. Anti-IgAlP IgG antibody assay was established for immunogenicity evaluation.
[0729] Table 7. Construct Sequences


[0730] Serum Gd-IgAl was decreased in mice receiving IgAP mRNA (FIG. 9). Anti-IgAP antibodies were not observed in mice administered IgAP mRNA with miRNA binding sites (FIG. 10). Mice administered IgAP mRNA with miRNA binding sites had significantly decreased hematuria in urine samples FIG. 11), indicating improved kidney heath in animals receiving IgAP mRNA with miRNA binding sites.
[0731] IgAP2 was not detected in sera of the mice after administration of the IgAP mRNA. Six-weeks after dosing, IgG deposits were decreased in glomerulus of mice administered the IgAP mRNA with miRNA binding sites (5'UTR: SEQ ID NO:58, ORF: SEQ ID NO:26; 3'UTR: SEQ ID NO: 138) compared to mice administered GFP mRNA or IgAP mRNA without miRNA binding sites (5'UTR: SEQ ID NO:58, ORF: SEQ ID NO:26; 3'UTR: SEQ ID NO: 139).
EXAMPLE 6: In Vivo Activity of IgAP Polypeptide in a IgAN Mouse Model
[0732] This example provides additional data from the study of Example 4. IgAl deposits in kidney mesangium were scored at 24, 30, and 168 hours after intravenous injection. IgAl deposits in kidney mesangium were decreased at 24 hours-post administration in mice administered 1 mg/kg of lipid nanoparticles (Compound II/DMG) encapsulating truncated IgAP mRNA (lgAPi-995; amino acid sequence: SEQ ID NO:7; 5'UTR: SEQ ID NO: 58; ORF nucleic acid sequence: SEQ ID NO:26; 3'UTR: SEQ ID NO: 139) (FIG. 12).
EXAMPLE 7: IgAP polynucleotides with altered UTRs
[0733] CD-I mice were serially dosed (6 weekly 0.5 mg/kg doses) with lipid nanoparticles (Compound II/DMG) encapsulating IgAP mRNA with or without miRNA targets in the UTRs as described in Table 8, or with PBS. All treatments were intravenously injected at tail vein. Serial bleeds were taken 24 hours post-intravenous injection at 1, 2, 3, 4, 5, and 6 weeks. Serum IgAl fragments were analyzed by SDS- 10% PAGE and Western blots (FIG. 13). Anti-IgAlP IgG antibody assay was established for immunogenicity evaluation (FIG. 14).
[0734] Table 8. Construct Sequences.

EXAMPLE 8: Deimmunized IgAP
[0735] mRNAs encoding deimmunized IgAP polypeptides were generated. Briefly, donor T-cells were treated with truncated IgAP mRNA (IgAPi-995; amino acid sequence: SEQ ID NO:7), cells were subsequently lysed, HLA-peptide molecules were recovered in an immune affinity step, and peptides were recovered from the HLA-peptide molecules. LC-MS/MS analysis of the recovered peptides was performed. For MCHII-binding peptides, peptides having an expectation value of less than or equal to 0.3 were identified for each donor. The peptides were ranked according to the number of occurrences and the top 30 peptides across three loci were selected for ProMap naive T cell proliferation assay. For the ProMap naive T cell proliferation assay, peripheral blood mononuclear
cells were labeled with CFSE dye, cultured with the top 30 peptides, and flow cytometry and CD4 staining was performed to quantitate T cell proliferation. Peptides identified as immunogenic were subjected to in silica alanine-scanning to identify which positions could be deimmunized. Constructs bearing identified deimmunized positions were generated. See Table 9. The constructs described in Table 9 were tested in vitro for expression and activity as described in Example 3. The tested constructs further included a C-terminal tag (GKPIPNPLLGLDST, SEQ ID NO:324). All constructs except for IgAP2.3, IgAP2.6, IgAP2.9, IgAP2.18, IgAP2.19, and IgAP2.23 expressed. Constructs IgAP2.1, IgAP2.15, IgAP2.29, IgAP2.30, and IgAP2.31 expressed but had no activity. Construct IgAP2.27 was not tested for expression or activity.
[0736] Table 9. Mutations are numbered relative to SEQ ID NO:6. The protein sequence is the protein sequence without the leader sequence
(MGVKVLF ALICIA VAEA, SEQ ID NO:321) and without the C-termainl tag (GKPIPNPLLGLDST, SEQ ID NO:324). SEQ ID NOs: 320-348 correspond to SEQ ID
NOs: 15-24, 33-45, 48, 49, and 80-83, respectively, with the additional N-terminal leader sequence MGVKVLF ALICIA VAEA (SEQ ID NO:321).


[0737] The ability of deimmunized IgAP to induce helper CD4+ T cell proliferation was performed. Briefly, dendritic cells loaded with tuberculin purified protein derivative (PPD), keyhole limpet hemocyanin (KLH), IgAP (SEQ ID NO:4, with C-terminal tag of SEQ ID NO:324), or deimmunized IgAP (SEQ ID NO:80, with C-terminal tag of SEQ ID NO:324) were mixed with CFSE-labeled PBMCs and CD4+ T cell proliferation was measured by flow cytometry using CFSE dye dilution and allele frequency was determined. Results are depicted in Table 10. All of the donors responded to PPD and KLH antigens (100% antigenicity). Twenty-two of the 44 total donors responded to IgAP (50% antigenicity), while eight of the 44 total donors responded to deimmunized IgAP (18.18% antigenicity). FIG. 15 depicts the % mean stimulation for each donor for IgAP vs. deimmunized IgAP. FIGs. 16A-16D is a series of graphs depicting the percentage of alleles for the study donors.
[0738] Table 10. Response index (RI) values for each test proteina s generated by percent antigenicity and percent stimulation (percentage stimulation above background >0.5%, SEM=2)

EXAMPLE 10: In vivo Study of of Deimmunized IgAP
[0739] Nineteen-week old alKI-CD89Tg mice were serially dosed (6 weekly 1 mg/kg doses) with lipid nanoparticles (Compound Il/DMG) encapsulating deimmunized
IgAP mRNA (5’UTR: SEQ ID NO:50, ORF: SEQ ID NO:154, further including sequence encoding C-terminal tag of SEQ ID NO: 324, 3’UTR: SEQ ID NO: 132) or lipid nanoparticles (Compound II/DMG) encapsulating GFP mRNA. All treatments were intravenously injected at tail vein. Serial bleeds and urine were taken 24 hours post- intravenous injection at 1, 2, 3, 4, 5, and 6 weeks and IHC and IF of kidney glomeruli were performed at 24 hours after the 6th week injection.
[0740] IgAl levels decreased throught weeks 1-6 in mice administered deimmunized IgAP mRNA (FIG. 17). Western blot data revealed IgAl Fab and Fc fragments in sera of mice treated with IgAP mRNA-LNP, indicating the ability of such mRNA-LNP products to cleave serum IgAl in vivo (FIG. 18). Western blot data revealed IgAl Fab fragments in urine of mice treated with IgAP mRNA-LNP, indicating the ability of such mRNA-LNP products to cleave serum IgAl in vivo (FIG. 19). IgAl deposition in kidney mesangium was significantly reduced after 6 weeks of treatment (FIG. 20). Finally, IgAlP was detectd in serum of mice after treatment (FIG. 21).
[0741] In a separate study, 17-week old alKI-CD89Tg mice were serially dosed (6 weekly 1 mg/kg doses) with lipid nanoparticles (Compound A/Compound I) encapsulating deimmunized IgAP mRNA (ORF: SEQ ID NO: 154, further including sequence encoding C-terminal tag of SEQ ID NO:324) comprising UTR with miR-142 target sites or lipid nanoparticles (Compound II/DMG) encapsulating GFP mRNA. All treattments were intravenously injected at tail vein. Mice in each group were additionally administered 10 ug ovalubumin via intramuscular injection after the first and third week injections. Serial bleeds were taken 24 hours post-intravenous injection at 1, 2, 3, 4, 5, and 6 weeks. IgG anti-IgAlP and IgG anti-ovalbumin levels were detected.
Deimmunized IgAP mRNA abolished immunogenicity against IgAlP and partially against ovalbumin after six weeks of treatment (FIG. 22).
SEQUENCES




























































Claims
1. A polypeptide comprising an immunoglobulin A protease (IgAP) protease domain and an amino acid sequence that is at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100% identical to positions 815-995 of SEQ ID NO: 2, wherein the polypeptide does not comprise an IgAP autotransporter domain, and wherein the polypeptide cleaves a human IgAl .
2. The polypeptide of claim 1, wherein the polypeptide does not comprise an IgAP autocleavage site.
3. The polypeptide of claim 1 or 2, wherein the polypeptide does not comprise amino acids corresponding to positions 996-1,688 of SEQ ID NO:2.
4. The polypeptide of any one of claims 1 to 3, wherein the polypeptide optionally includes a signal peptide, and wherein the polypeptide is 950 to 1,050 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
5. The polypeptide of any one of claims 1 to 3, wherein the polypeptide optionally includes a signal peptide, and wherein the polypeptide is 995 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
6. The polypeptide of any one of claims 1 to 4, wherein the polypeptide comprises an amino acid sequence that is at least 95%, at least 97%, at least 98%, or at least 99% identical to the amino acid sequence of any one of SEQ ID NOs:4-6.
7. The polypeptide of any one of claims 1 to 6, wherein the polypeptide comprises a substitution at one or more amino acids corresponding to any one of W430, Y523, F690, R77, Y86, Y127, Y128, A178, Y242, Y328, A333, T35O, L463, V482,
1483, L484, F497, V509, V510, T566, 1577, Y612, N699, V742, N879, L913, F934, K935, L936, Y912, and Y979 of SEQ ID NO:6.
8. The polypeptide of any one of claims 1 to 6, wherein the polypeptide comprises one or more substitutions corresponding to any one of W430A, Y523A, F690A, R77A, Y86A, Y127A, Y128A, A178K, Y242A, Y328A, A333G, T350G, L463A, V482A, 1483 A, L484A, F497A, V509A, V510A, T566G, I577A, Y612A, N699A, V742L, N879A, L913A, F934A, K935A, L936A, Y912A, and Y979A of SEQ ID N0:6.
9. The polypeptide of any one of claims 1 to 6, wherein the polypeptide comprises:
(i) substitutions at the amino acids corresponding to W430, Y523, and F690 of SEQ ID NO: 6;
(ii) substitutions at the amino acids corresponding to Y86, L463, and 1577 of SEQ ID NO: 6;
(iii) substitutions at the amino acids corresponding to Y328, Y523, and F690 of SEQ ID NO: 6;
(iv) substitutions at the amino acids corresponding to Y127 and Y128 of SEQ ID NO: 6;
(v) substitutions at the amino acids corresponding to V509 and V510 of SEQ ID NO: 6;
(vi) substitutions at the amino acids corresponding to Y912 and L913 of SEQ ID NO: 6;
(vii) substitution at the amino acid corresponding to R77 of SEQ ID NO:6;
(viii) substitution at the amino acid corresponding to Y86 of SEQ ID NO:6;
(ix) substitution at the amino acid corresponding to Y242 of SEQ ID NO:6;
(x) substitution at the amino acid corresponding to W430 of SEQ ID NO:6;
(xi) substitution at the amino acid corresponding to T566 of SEQ ID NO:6;
(xii) substitution at the amino acid corresponding to F497 of SEQ ID NO:6;
(xiii) substitution at the amino acid corresponding to Y612 of SEQ ID NO:6;
(xiv) substitutions at the amino acids corresponding to A178, A333, and V742 of SEQ ID NO: 6;
(xv) substitutions at the amino acids corresponding to T350, N699, and N879 of SEQ ID NO: 6;
(xvi) substitution at the amino acid corresponding to V482 of SEQ ID NO:6;
(xvii) substitutions at the amino acids corresponding to Y127, Y128, W430, Y523, and F690 of SEQ ID NO:6; or
(xviii) substitutions at the amino acids corresponding to Y127, Y128, W430, Y523, F690, V509, and V510 of SEQ ID NO:6.
10. The polypeptide of any one of claims 1 to 6, wherein the polypeptide comprises:
(i) substitutions corresponding to W430A, Y523A, and F690A of SEQ ID NO: 6;
(ii) substitutions corresponding to Y86A, L463A, and I577A of SEQ ID NO: 6;
(iii) substitutions corresponding to Y328A, Y523A, and F690A of SEQ ID NO: 6;
(iv) substitutions corresponding to Y127A and Y128A of SEQ ID NO:6;
(v) substitutions corresponding to V509A and V510A of SEQ ID NO:6;
(vi) substitutions corresponding to Y912A and L913A of SEQ ID NO:6;
(vii) a substitution corresponding to R77A of SEQ ID NO: 6;
(viii) a substitution corresponding to Y86A of SEQ ID NO:6;
(ix) a substitution corresponding to Y242A of SEQ ID NO:6;
(x) a substitution corresponding to W430A of SEQ ID NO:6;
(xi) a substitution corresponding to T566G of SEQ ID NO:6;
(xii) a substitution corresponding to F497A of SEQ ID NO:6;
(xiii) a substitution corresponding to Y612A of SEQ ID NO:6;
(xiv) substitutions corresponding to A178K, A333G, and V742L of SEQ ID NO: 6;
(xv) substitutions corresponding to T35OG, N699A, and N879A of SEQ ID NO: 6;
(xvi) a substitution corresponding to V482A of SEQ ID NO:6;
(xvii) substitutions corresponding to Y127A, Y128A, W430A, Y523A, and F690A of SEQ ID NO: 6; or
(xviii) substitutions corresponding to Y127A, Y 128A, W430A, Y523A, F690A, V509A, and V510A of SEQ ID N0:6.
11. The polypeptide of any one of claims 1 to 4, wherein the polypeptide comprises an amino acid sequence that is at least 95%, at least 97%, at least 98%, or at least 99% identical to the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49.
12. The polypeptide of any one of claims 1 to 4, wherein the polypeptide comprises the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42-44, 48, and 49.
13. The polypeptide of claim 1, wherein the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs: 80, 16, 18, 19, 21, 22, 24, 33-36, 38, 39, 42- 44, 48, and 49 and optionally a signal peptide.
14. The polypeptide of claim 1, wherein the polypeptide consists of the amino acid sequence of SEQ ID NO: 80 and optionally a signal peptide.
15. The polypeptide of claim 1, wherein the polypeptide consists of the amino acid sequence of any one of SEQ ID NOs: 351, 327, 329, 330, 332, 333, 335-339, 341, 342, 345-347, 349, and 350.
16. The polypeptide of claim 1, wherein the polypeptide consists of the amino acid sequence of SEQ ID NO : 351.
17. The polypeptide of any one of claims 1 to 4, wherein the polypeptide comprises the amino acid sequence of any one of SEQ ID NOs: 4-6.
18. The polypeptide of claim 1, wherein the polypeptide consists of the amino acid sequence of SEQ ID NO:4 and optionally a signal peptide.
19. The polypeptide of claim 1, wherein the polypeptide consists of the amino acid sequence of SEQ ID NO:5 or SEQ ID NO:6.
20. A polypeptide comprising an amino acid sequence that is at least 90%, at least 95%, or 100% identical to the amino acid sequence of SEQ ID NO:4, wherein the polypeptide optionally includes a signal peptide, wherein the polypeptide is 950 to 1,050 amino acids in length not inclusive of the signal peptide, if present in the polypeptide, and wherein the polypeptide cleaves a human IgAl.
21. The polypeptide of claim 20, wherein the C-terminus of the polypeptide corresponds to position 995 of SEQ ID NO:4.
22. The polypeptide of claim 20 or 21, wherein the polypeptide is 995 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
23. A polypeptide comprising an amino acid sequence that is at least 90%, at least 95%, or 100% identical to the amino acid sequence of SEQ ID NO: 80, wherein the polypeptide optionally includes a signal peptide, wherein the polypeptide is 950 to 1,050 amino acids in length not inclusive of the signal peptide, if present in the polypeptide, and wherein the polypeptide cleaves a human IgAl.
24. The polypeptide of claim 21, wherein the C-terminus of the polypeptide corresponds to position 995 of SEQ ID NO: 80.
25. The polypeptide of claim 21 or 22, wherein the polypeptide is 995 amino acids in length not inclusive of the signal peptide, if present in the polypeptide.
26. A messenger RNA (mRNA) comprising an open reading frame (ORF) encoding the polypeptide of any one of claims 1 to 25.
27. The mRNA of claim 26, wherein the ORF is at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical to the nucleic acid sequence set forth in SEQ ID NO:27 or SEQ ID NO:28.
28. The mRNA of claim 27, wherein the ORF comprises the nucleic acid sequence set forth in SEQ ID NO:27 or SEQ ID NO:28.
29. The mRNA of claim 26, wherein the ORF is at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% identical to the nucleic acid sequence set forth in any one of SEQ ID NOs: 153, 154, 85, 87, 88, 90, 91, 93-97, 99, 141, 144-146, 150, and 151.
30. The mRNA of claim 26, wherein the ORF comprises the nucleic acid sequence set forth in SEQ ID NO: 153 or 154.
31. The mRNA of any one of claims 26 to 28, further comprising a 5 ' untranslated region (UTR) comprising the nucleic acid sequence of SEQ ID NO:50, SEQ ID NO:56, or SEQ ID NO:58.
32. The mRNA of any one of claims 26 to 31, further comprising a 3 ' UTR comprising the nucleic acid sequence of SEQ ID NO: 114, SEQ ID NO: 132, SEQ ID NO: 138, or SEQ ID NO: 139.
33. The mRNA of claim 26, wherein the mRNA comprises the nucleic acid sequence of any one of SEQ ID NOs: 29-32.
34. The mRNA of claim 26, wherein the mRNA comprises the nucleic acid sequence of any one of SEQ ID NOs: 301-319.
35. The mRNA of claim 26, wherein the mRNA comprises the nucleic acid sequence of SEQ ID NO: 318 or 319.
36. The mRNA of any one of claims 26 to 33, wherein the mRNA comprises a 5' terminal cap.
37. The mRNA of claim 36, wherein the 5' terminal cap comprises a m7GpppG2OMe, m7G-ppp-Gm-A, m7G-ppp-Gm-AG, CapO, Capl, ARC A, inosine, N1 -methylguanosine, 2'-fluoro-guanosine, 7-deaza-guanosine, 8-oxo-guanosine, 2-amino- guanosine, LNA-guanosine, 2-azidoguanosine, Cap2, Cap4, 5' methylG cap, or an analog thereof.
38. The mRNA of any one of claims 26 to 37, wherein the mRNA comprises a poly- A region.
39. The mRNA of claim 38, wherein the poly-A region is at least about 10, at least about 20, at least about 30, at least about 40, at least about 50, at least about 60, at least about 70, at least about 80, at least about 90 nucleotides in length, or at least about 100 nucleotides in length.
40. The mRNA of claim 39, wherein the poly-A region is at least about 100 nucleotides in length.
41. The mRNA of any one of claims 26 to 40, wherein all of the uracils of the mRNA are N1 -methylpseudouracils.
42. The mRNA of any one of claims 26 to 40, wherein all of the uracils in the mRNA are 5-methoxyuracils.
43. A pharmaceutical composition comprising the polypeptide of any one of claims 1 to 25, and a pharmaceutically acceptable excipient.
44. A pharmaceutical composition comprising the mRNA of any one of claims 26 to 42, and a pharmaceutically acceptable excipient.
45. A lipid nanoparticle comprising the mRNA of any one of claims 26 to 42.
46. The lipid nanoparticle of claim 45, wherein the lipid nanoparticle comprises an ionizable lipid, a structural lipid, a phospholipid, and a polyethylene glycol (PEG)-modified lipid.
47. The lipid nanoparticle of claim 46, wherein the ionizable lipid is Compound II or a salt thereof.
48. The lipid nanoparticle of claim 46 or 47, wherein the structural lipid is cholesterol.
49. The lipid nanoparticle of any one of claims 46 to 48, wherein the phospholipid is l,2-distearoyl-sn-glycero-3-phosphocholine (DSPC) or l,2-dioleoyl-sn-glycero-3- phosphoethanolamine (DOPE).
50. The lipid nanoparticle of any one of claims 46 to 49, wherein the PEG-modified lipid is PEG-DMG or Compound I.
51. A method of expressing a polypeptide in a human subject in need thereof, the method comprising administering to the human subject an effective amount of the polypeptide of any one of claims 1 to 25, the mRNA of any one of claims 26 to 42, the pharmaceutical composition of claim 43 or 44, or the lipid nanoparticle of any one of claims 45 to 50.
52. A method for treating IgA nephropathy in a human subject in need thereof, the method comprising administering to the human subject an effective amount of the polypeptide of any one of claims 1 to 25, the mRNA of any one of claims 26 to 42, the pharmaceutical composition of claim 43 or 44, or the lipid nanoparticle of any one of claims 45 to 50.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202363540710P | 2023-09-27 | 2023-09-27 | |
| US63/540,710 | 2023-09-27 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2025072482A1 true WO2025072482A1 (en) | 2025-04-03 |
Family
ID=93037390
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2024/048607 Pending WO2025072482A1 (en) | 2023-09-27 | 2024-09-26 | Immunoglobulin a protease polypeptides, polynucleotides, and uses thereof |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2025072482A1 (en) |
Citations (107)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5505931A (en) | 1993-03-04 | 1996-04-09 | The Dow Chemical Company | Acid cleavable compounds, their preparation and use as bifunctional acid-labile crosslinking agents |
| US5563250A (en) | 1987-12-02 | 1996-10-08 | Neorx Corporation | Cleavable conjugates for the delivery and release of agents in native form |
| US5965424A (en) * | 1991-01-11 | 1999-10-12 | Boehringer Mannheim Gmbh | Methods for making neisseria or hemophilus IgA protease and DNA encoding the proteases |
| US6004573A (en) | 1997-10-03 | 1999-12-21 | Macromed, Inc. | Biodegradable low molecular weight triblock poly(lactide-co-glycolide) polyethylene glycol copolymers having reverse thermal gelation properties |
| US6177274B1 (en) | 1998-05-20 | 2001-01-23 | Expression Genetics, Inc. | Hepatocyte targeting polyethylene glyco-grafted poly-L-lysine polymeric gene carrier |
| US6217912B1 (en) | 1998-07-13 | 2001-04-17 | Expression Genetics, Inc. | Polyester analogue of poly-L-lysine as a soluble, biodegradable gene delivery carrier |
| US6265389B1 (en) | 1995-08-31 | 2001-07-24 | Alkermes Controlled Therapeutics, Inc. | Microencapsulation and sustained release of oligonucleotides |
| US6267987B1 (en) | 1997-12-12 | 2001-07-31 | Samyang Corporation | Positively charged poly[alpha-(omega-aminoalkyl) glycolic acid] for the delivery of a bioactive agent via tissue and cellular uptake |
| US6426086B1 (en) | 1998-02-03 | 2002-07-30 | The Regents Of The University Of California | pH-sensitive, serum-stable liposomes |
| US6517869B1 (en) | 1997-12-12 | 2003-02-11 | Expression Genetics, Inc. | Positively charged poly(alpha-(omega-aminoalkyl)lycolic acid) for the delivery of a bioactive agent via tissue and cellular uptake |
| US20030073619A1 (en) | 2000-09-14 | 2003-04-17 | Mahato Ram I. | Novel cationic lipopolymer as biocompatible gene delivery agent |
| US6586524B2 (en) | 2001-07-19 | 2003-07-01 | Expression Genetics, Inc. | Cellular targeting poly(ethylene glycol)-grafted polymeric gene carrier |
| US6652886B2 (en) | 2001-02-16 | 2003-11-25 | Expression Genetics | Biodegradable cationic copolymers of poly (alkylenimine) and poly (ethylene glycol) for the delivery of bioactive agents |
| US20040142474A1 (en) | 2000-09-14 | 2004-07-22 | Expression Genetics, Inc. | Novel cationic lipopolymer as a biocompatible gene delivery agent |
| US6835393B2 (en) | 1998-01-05 | 2004-12-28 | University Of Washington | Enhanced transport using membrane disruptive agents |
| US20040262223A1 (en) | 2001-07-27 | 2004-12-30 | President And Fellows Of Harvard College | Laminar mixing apparatus and methods |
| US6897196B1 (en) | 2001-02-07 | 2005-05-24 | The Regents Of The University Of California | pH sensitive lipids based on ortho ester linkers, composition and method |
| US20050222064A1 (en) | 2002-02-20 | 2005-10-06 | Sirna Therapeutics, Inc. | Polycationic compositions for cellular delivery of polynucleotides |
| WO2006063249A2 (en) | 2004-12-10 | 2006-06-15 | Justin Hanes | Functionalized poly (ether-anhydride) block copolymers |
| US7098032B2 (en) | 2001-01-02 | 2006-08-29 | Mirus Bio Corporation | Compositions and methods for drug delivery using pH sensitive molecules |
| US7138382B2 (en) | 1999-06-07 | 2006-11-21 | Mirus Bio Corporation | Compositions and methods for drug delivery using pH sensitive molecules |
| US7404969B2 (en) | 2005-02-14 | 2008-07-29 | Sirna Therapeutics, Inc. | Lipid nanoparticle based compositions and methods for the delivery of biologically active molecules |
| WO2008103276A2 (en) | 2007-02-16 | 2008-08-28 | Merck & Co., Inc. | Compositions and methods for potentiated activity of biologicaly active molecules |
| WO2008121949A1 (en) | 2007-03-30 | 2008-10-09 | Bind Biosciences, Inc. | Cancer cell targeting using nanoparticles |
| US20100004315A1 (en) | 2008-03-14 | 2010-01-07 | Gregory Slobodkin | Biodegradable Cross-Linked Branched Poly(Alkylene Imines) |
| WO2010005740A2 (en) | 2008-06-16 | 2010-01-14 | Bind Biosciences, Inc. | Methods for the preparation of targeting agent functionalized diblock copolymers for use in fabrication of therapeutic targeted nanoparticles |
| WO2010005725A2 (en) | 2008-06-16 | 2010-01-14 | Bind Biosciences, Inc. | Therapeutic polymeric nanoparticles comprising vinca alkaloids and methods of making and using same |
| WO2010005726A2 (en) | 2008-06-16 | 2010-01-14 | Bind Biosciences Inc. | Therapeutic polymeric nanoparticles with mtor inhibitors and methods of making and using same |
| WO2010005723A2 (en) | 2008-06-16 | 2010-01-14 | Bind Biosciences, Inc. | Drug loaded polymeric nanoparticles and methods of making and using same |
| WO2010030763A2 (en) | 2008-09-10 | 2010-03-18 | Bind Biosciences, Inc. | High throughput fabrication of nanoparticles |
| US20100129877A1 (en) | 2005-09-28 | 2010-05-27 | Ugur Sahin | Modification of RNA, Producing an Increased Transcript Stability and Translation Efficiency |
| US7737108B1 (en) | 2000-01-07 | 2010-06-15 | University Of Washington | Enhanced transport using membrane disruptive agents |
| WO2010075072A2 (en) | 2008-12-15 | 2010-07-01 | Bind Biosciences | Long circulating nanoparticles for sustained release of therapeutic agents |
| WO2010087791A1 (en) | 2009-01-27 | 2010-08-05 | Utc Power Corporation | Distributively cooled, integrated water-gas shift reactor and vaporizer |
| WO2010118337A2 (en) * | 2009-04-10 | 2010-10-14 | Biomarin Pharmaceutical Inc. | Methods of enhancing yield of active iga protease |
| WO2010123885A2 (en) * | 2009-04-20 | 2010-10-28 | Tufts Medical Center, Inc. | Iga1 protease polypeptide agents and uses thereof |
| US20100293625A1 (en) | 2007-09-26 | 2010-11-18 | Interexon Corporation | Synthetic 5'UTRs, Expression Vectors, and Methods for Increasing Transgene Expression |
| WO2011062965A2 (en) | 2009-11-18 | 2011-05-26 | University Of Washington Through Its Center For Commercialization | Targeting monomers and polymers having targeting blocks |
| WO2011084521A2 (en) | 2009-12-15 | 2011-07-14 | Bind Biosciences, Inc. | Therapeutic polymeric nanoparticles comprising epothilone and methods of making and using same |
| WO2011084518A2 (en) | 2009-12-15 | 2011-07-14 | Bind Biosciences, Inc. | Therapeutic polymeric nanoparticles comprising corticosteroids and methods of making and using same |
| WO2011127255A1 (en) | 2010-04-08 | 2011-10-13 | Merck Sharp & Dohme Corp. | Preparation of lipid nanoparticles |
| US20110262491A1 (en) | 2010-04-12 | 2011-10-27 | Selecta Biosciences, Inc. | Emulsions and methods of making nanocarriers |
| US8057821B2 (en) | 2004-11-03 | 2011-11-15 | Egen, Inc. | Biodegradable cross-linked cationic multi-block copolymers for gene delivery and methods of making thereof |
| WO2012006380A2 (en) | 2010-07-06 | 2012-01-12 | Novartis Ag | Cationic oil-in-water emulsions |
| WO2012006378A1 (en) | 2010-07-06 | 2012-01-12 | Novartis Ag | Liposomes with lipids having an advantageous pka- value for rna delivery |
| WO2012006376A2 (en) | 2010-07-06 | 2012-01-12 | Novartis Ag | Virion-like delivery particles for self-replicating rna molecules |
| WO2012013326A1 (en) | 2010-07-30 | 2012-02-02 | Curevac Gmbh | Complexation of nucleic acids with disulfide-crosslinked cationic components for transfection and immunostimulation |
| WO2012031043A1 (en) | 2010-08-31 | 2012-03-08 | Novartis Ag | Pegylated liposomes for delivery of immunogen-encoding rna |
| WO2012030901A1 (en) | 2010-08-31 | 2012-03-08 | Novartis Ag | Small liposomes for delivery of immunogen-encoding rna |
| WO2012031046A2 (en) | 2010-08-31 | 2012-03-08 | Novartis Ag | Lipids suitable for liposomal delivery of protein-coding rna |
| WO2012040524A1 (en) | 2010-09-24 | 2012-03-29 | Mallinckrodt Llc | Aptamer conjugates for targeting of therapeutic and/or diagnostic nanocarriers |
| US8158601B2 (en) | 2009-06-10 | 2012-04-17 | Alnylam Pharmaceuticals, Inc. | Lipid formulation |
| WO2012054923A2 (en) | 2010-10-22 | 2012-04-26 | Bind Biosciences, Inc. | Therapeutic nanoparticles with high molecular weight copolymers |
| US20120140790A1 (en) | 2009-12-15 | 2012-06-07 | Ali Mir M | Therapeutic Polymeric Nanoparticle Compositions with High Glass Transition Termperature or High Molecular Weight Copolymers |
| US20120178702A1 (en) | 1995-01-23 | 2012-07-12 | University Of Pittsburgh | Stable lipid-comprising drug delivery complexes and methods for their production |
| WO2012099755A1 (en) | 2011-01-11 | 2012-07-26 | Alnylam Pharmaceuticals, Inc. | Pegylated lipids and their use for drug delivery |
| US8236280B2 (en) | 2003-12-19 | 2012-08-07 | University Of Cincinnati | Polyamides for nucleic acid delivery |
| US20120201859A1 (en) | 2002-05-02 | 2012-08-09 | Carrasquillo Karen G | Drug Delivery Systems and Use Thereof |
| US8241670B2 (en) | 2004-04-15 | 2012-08-14 | Chiasma Inc. | Compositions capable of facilitating penetration across a biological barrier |
| WO2012109121A1 (en) | 2011-02-07 | 2012-08-16 | Purdue Research Foundation | Carbohydrate nanoparticles for prolonged efficacy of antimicrobial peptide |
| WO2012110636A2 (en) | 2011-02-18 | 2012-08-23 | Instituto Nacional De Investigación Y Tecnología Agraria Y Alimentaria (Inia) | Carrier peptides for cell delivery |
| US20120276209A1 (en) | 2009-11-04 | 2012-11-01 | The University Of British Columbia | Nucleic acid-containing lipid particles and related methods |
| US8313777B2 (en) | 2006-10-05 | 2012-11-20 | The Johns Hopkins University | Water-dispersible oral, parenteral, and topical formulations for poorly water soluble drugs using smart polymeric nanoparticles |
| WO2012170930A1 (en) | 2011-06-08 | 2012-12-13 | Shire Human Genetic Therapies, Inc | Lipid nanoparticle compositions and methods for mrna delivery |
| WO2012170889A1 (en) | 2011-06-08 | 2012-12-13 | Shire Human Genetic Therapies, Inc. | Cleavable lipids |
| US20130059360A1 (en) | 2005-04-12 | 2013-03-07 | Nektar Therapeutics | Polymer-based compositions and conjugates of antimicrobial agents |
| WO2013033438A2 (en) | 2011-08-31 | 2013-03-07 | Mallinckrodt Llc | Nanoparticle peg modification with h-phosphonates |
| US20130072709A1 (en) | 2006-02-21 | 2013-03-21 | Nektar Therapeutics | Segmented Degradable Polymers and Conjugates Made Therefrom |
| US8444992B2 (en) | 2005-09-01 | 2013-05-21 | Novartis Vaccines And Diagnostics Gmbh | Multiple vaccination including serogroup C meningococcus |
| US20130129726A1 (en) | 2006-02-20 | 2013-05-23 | Kyunglim Lee | Peptide having cell membrane penetrating activity |
| US8450298B2 (en) | 2008-11-07 | 2013-05-28 | Massachusetts Institute Of Technology | Aminoalcohol lipidoids and uses thereof |
| US20130137644A1 (en) | 2005-12-16 | 2013-05-30 | Cellectis | Cell penetrating peptide conjugates for delivering of nucleic acids into a cell |
| WO2013082111A2 (en) | 2011-11-29 | 2013-06-06 | The University Of North Carolina At Chapel Hill | Geometrically engineered particles and methods for modulating macrophage or immune responses |
| US8460696B2 (en) | 2009-03-20 | 2013-06-11 | Egen, Inc. | Polyamine derivatives |
| WO2013086322A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Branched alkyl and cycloalkyl terminated biodegradable lipids for the delivery of active agents |
| US20130150295A1 (en) | 2006-12-21 | 2013-06-13 | Stryker Corporation | Sustained-Release Formulations Comprising Crystals, Macromolecular Gels, and Particulate Suspensions of Biologic Agents |
| WO2013086354A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Biodegradable lipids for the delivery of active agents |
| WO2013086526A1 (en) | 2011-12-09 | 2013-06-13 | The Regents Of The University Of California | Liposomal drug encapsulation |
| US20130164219A1 (en) | 2010-06-14 | 2013-06-27 | Hoffmann-La Roche Inc. | Cell-penetrating peptides and uses thereof |
| US20130171646A1 (en) | 2010-08-09 | 2013-07-04 | So Jung PARK | Nanop article-oligonucleotide hybrid structures and methods of use thereof |
| US20130177634A1 (en) | 2010-04-09 | 2013-07-11 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| WO2013105101A1 (en) | 2012-01-13 | 2013-07-18 | Department Of Biotechnology | Solid lipid nanoparticles entrapping hydrophilic/ amphiphilic drug and a process for preparing the same |
| WO2013106086A1 (en) | 2012-01-10 | 2013-07-18 | Sorbent Therapeutics, Inc. | Compositions comprising crosslinked cation-binding polymers and uses thereof |
| US20130184453A1 (en) | 1998-07-01 | 2013-07-18 | California Institute Of Technology | Linear cyclodextrin copolymers |
| WO2013106073A1 (en) | 2012-01-10 | 2013-07-18 | Sorbent Therapeutics, Inc. | Compositions comprising crosslinked cation-binding polymers and uses thereof |
| WO2013106072A1 (en) | 2012-01-10 | 2013-07-18 | Sorbent Therapeutics, Inc. | Compositions comprising crosslinked cation-binding polymers and uses thereof |
| US20130183244A1 (en) | 2010-09-10 | 2013-07-18 | The Johns Hopkins University | Rapid Diffusion of Large Polymeric Nanoparticles in the Mammalian Brain |
| WO2013110028A1 (en) | 2012-01-19 | 2013-07-25 | The Johns Hopkins University | Nanoparticle formulations with enhanced mucosal penetration |
| US20130196948A1 (en) | 2010-06-25 | 2013-08-01 | Massachusetts Insitute Of Technology | Polymers for biomaterials and therapeutics |
| US20130195799A1 (en) | 2010-08-19 | 2013-08-01 | Peg Biosciences, Inc. | Synergistic biomolecule-polymer conjugates |
| US8501824B2 (en) | 2007-05-04 | 2013-08-06 | Marina Biotech, Inc. | Amino acid lipids and uses thereof |
| WO2013116126A1 (en) | 2012-02-01 | 2013-08-08 | Merck Sharp & Dohme Corp. | Novel low molecular weight, biodegradable cationic lipids for oligonucleotide delivery |
| US8507653B2 (en) | 2006-12-27 | 2013-08-13 | Nektar Therapeutics | Factor IX moiety-polymer conjugates having a releasable linkage |
| US20130211249A1 (en) | 2010-07-22 | 2013-08-15 | The Johns Hopkins University | Drug eluting hydrogels for catheter delivery |
| WO2013123523A1 (en) | 2012-02-19 | 2013-08-22 | Nvigen, Inc. | Uses of porous nanostructure in delivery |
| WO2013123298A1 (en) | 2012-02-17 | 2013-08-22 | University Of Georgia Research Foundation, Inc. | Nanoparticles for mitochondrial trafficking of agents |
| US20130217753A1 (en) | 2011-02-22 | 2013-08-22 | Rutgers, The State University Of New Jersey | Amphiphilic macromolecules for nucleic acid delivery |
| US8519110B2 (en) | 2008-06-06 | 2013-08-27 | Board Of Supervisors Of Louisiana State University And Agricultural And Mechanical College | mRNA cap analogs |
| WO2013124867A1 (en) | 2012-02-21 | 2013-08-29 | Amrita Vishwa Vidyapeetham University | Polymer - polymer or polymer - protein core - shell nano medicine loaded with multiple drug molecules |
| US8524368B2 (en) | 2003-07-09 | 2013-09-03 | Wisconsin Alumni Research Foundation | Charge-dynamic polymers and delivery of anionic compounds |
| US8524259B2 (en) | 2006-12-05 | 2013-09-03 | Landec Corporation | Systems and methods for delivery of materials |
| US20130231287A1 (en) | 2010-02-25 | 2013-09-05 | Parimala Nacharaju | Pegylated albumin polymers and uses thereof |
| WO2014164253A1 (en) | 2013-03-09 | 2014-10-09 | Moderna Therapeutics, Inc. | Heterologous untranslated regions for mrna |
| WO2015051214A1 (en) | 2013-10-03 | 2015-04-09 | Moderna Therapeutics, Inc. | Polynucleotides encoding low density lipoprotein receptor |
| WO2015130584A2 (en) | 2014-02-25 | 2015-09-03 | Merck Sharp & Dohme Corp. | Lipid nanoparticle vaccine adjuvants and antigen delivery systems |
| WO2017066797A1 (en) | 2015-10-16 | 2017-04-20 | Modernatx, Inc. | Trinucleotide mrna cap analogs |
| WO2023143563A1 (en) * | 2022-01-29 | 2023-08-03 | 北京大学第一医院 | Iga protease truncation, fusion protein comprising iga protease truncation, and use thereof |
-
2024
- 2024-09-26 WO PCT/US2024/048607 patent/WO2025072482A1/en active Pending
Patent Citations (148)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5563250A (en) | 1987-12-02 | 1996-10-08 | Neorx Corporation | Cleavable conjugates for the delivery and release of agents in native form |
| US5965424A (en) * | 1991-01-11 | 1999-10-12 | Boehringer Mannheim Gmbh | Methods for making neisseria or hemophilus IgA protease and DNA encoding the proteases |
| US5505931A (en) | 1993-03-04 | 1996-04-09 | The Dow Chemical Company | Acid cleavable compounds, their preparation and use as bifunctional acid-labile crosslinking agents |
| US20120178702A1 (en) | 1995-01-23 | 2012-07-12 | University Of Pittsburgh | Stable lipid-comprising drug delivery complexes and methods for their production |
| US6265389B1 (en) | 1995-08-31 | 2001-07-24 | Alkermes Controlled Therapeutics, Inc. | Microencapsulation and sustained release of oligonucleotides |
| US6555525B2 (en) | 1995-08-31 | 2003-04-29 | Alkermes Controlled Therapeutics, Inc. | Microencapsulation and sustained release of oligonucleotides |
| US6004573A (en) | 1997-10-03 | 1999-12-21 | Macromed, Inc. | Biodegradable low molecular weight triblock poly(lactide-co-glycolide) polyethylene glycol copolymers having reverse thermal gelation properties |
| US6517869B1 (en) | 1997-12-12 | 2003-02-11 | Expression Genetics, Inc. | Positively charged poly(alpha-(omega-aminoalkyl)lycolic acid) for the delivery of a bioactive agent via tissue and cellular uptake |
| US6267987B1 (en) | 1997-12-12 | 2001-07-31 | Samyang Corporation | Positively charged poly[alpha-(omega-aminoalkyl) glycolic acid] for the delivery of a bioactive agent via tissue and cellular uptake |
| US8003129B2 (en) | 1998-01-05 | 2011-08-23 | University Of Washington | Enhanced transport using membrane disruptive agents |
| US6835393B2 (en) | 1998-01-05 | 2004-12-28 | University Of Washington | Enhanced transport using membrane disruptive agents |
| US7374778B2 (en) | 1998-01-05 | 2008-05-20 | University Of Washington | Enhanced transport using membrane disruptive agents |
| US6426086B1 (en) | 1998-02-03 | 2002-07-30 | The Regents Of The University Of California | pH-sensitive, serum-stable liposomes |
| US6177274B1 (en) | 1998-05-20 | 2001-01-23 | Expression Genetics, Inc. | Hepatocyte targeting polyethylene glyco-grafted poly-L-lysine polymeric gene carrier |
| US20130184453A1 (en) | 1998-07-01 | 2013-07-18 | California Institute Of Technology | Linear cyclodextrin copolymers |
| US6217912B1 (en) | 1998-07-13 | 2001-04-17 | Expression Genetics, Inc. | Polyester analogue of poly-L-lysine as a soluble, biodegradable gene delivery carrier |
| US7138382B2 (en) | 1999-06-07 | 2006-11-21 | Mirus Bio Corporation | Compositions and methods for drug delivery using pH sensitive molecules |
| US7737108B1 (en) | 2000-01-07 | 2010-06-15 | University Of Washington | Enhanced transport using membrane disruptive agents |
| US20030073619A1 (en) | 2000-09-14 | 2003-04-17 | Mahato Ram I. | Novel cationic lipopolymer as biocompatible gene delivery agent |
| US20040142474A1 (en) | 2000-09-14 | 2004-07-22 | Expression Genetics, Inc. | Novel cationic lipopolymer as a biocompatible gene delivery agent |
| US6696038B1 (en) | 2000-09-14 | 2004-02-24 | Expression Genetics, Inc. | Cationic lipopolymer as biocompatible gene delivery agent |
| US7098032B2 (en) | 2001-01-02 | 2006-08-29 | Mirus Bio Corporation | Compositions and methods for drug delivery using pH sensitive molecules |
| US6897196B1 (en) | 2001-02-07 | 2005-05-24 | The Regents Of The University Of California | pH sensitive lipids based on ortho ester linkers, composition and method |
| US6652886B2 (en) | 2001-02-16 | 2003-11-25 | Expression Genetics | Biodegradable cationic copolymers of poly (alkylenimine) and poly (ethylene glycol) for the delivery of bioactive agents |
| US6586524B2 (en) | 2001-07-19 | 2003-07-01 | Expression Genetics, Inc. | Cellular targeting poly(ethylene glycol)-grafted polymeric gene carrier |
| US20040262223A1 (en) | 2001-07-27 | 2004-12-30 | President And Fellows Of Harvard College | Laminar mixing apparatus and methods |
| US20050222064A1 (en) | 2002-02-20 | 2005-10-06 | Sirna Therapeutics, Inc. | Polycationic compositions for cellular delivery of polynucleotides |
| US20120201859A1 (en) | 2002-05-02 | 2012-08-09 | Carrasquillo Karen G | Drug Delivery Systems and Use Thereof |
| US8524368B2 (en) | 2003-07-09 | 2013-09-03 | Wisconsin Alumni Research Foundation | Charge-dynamic polymers and delivery of anionic compounds |
| US8236280B2 (en) | 2003-12-19 | 2012-08-07 | University Of Cincinnati | Polyamides for nucleic acid delivery |
| US8241670B2 (en) | 2004-04-15 | 2012-08-14 | Chiasma Inc. | Compositions capable of facilitating penetration across a biological barrier |
| US20120009145A1 (en) | 2004-11-03 | 2012-01-12 | Gregory Slobodkin | Biodegradable Cross-Linked Cationic Multi-block Copolymers for Gene Delivery and Methods of Making Thereof |
| US8057821B2 (en) | 2004-11-03 | 2011-11-15 | Egen, Inc. | Biodegradable cross-linked cationic multi-block copolymers for gene delivery and methods of making thereof |
| WO2006063249A2 (en) | 2004-12-10 | 2006-06-15 | Justin Hanes | Functionalized poly (ether-anhydride) block copolymers |
| US7404969B2 (en) | 2005-02-14 | 2008-07-29 | Sirna Therapeutics, Inc. | Lipid nanoparticle based compositions and methods for the delivery of biologically active molecules |
| US20130059360A1 (en) | 2005-04-12 | 2013-03-07 | Nektar Therapeutics | Polymer-based compositions and conjugates of antimicrobial agents |
| US8444992B2 (en) | 2005-09-01 | 2013-05-21 | Novartis Vaccines And Diagnostics Gmbh | Multiple vaccination including serogroup C meningococcus |
| US20100129877A1 (en) | 2005-09-28 | 2010-05-27 | Ugur Sahin | Modification of RNA, Producing an Increased Transcript Stability and Translation Efficiency |
| US20130137644A1 (en) | 2005-12-16 | 2013-05-30 | Cellectis | Cell penetrating peptide conjugates for delivering of nucleic acids into a cell |
| US20130129726A1 (en) | 2006-02-20 | 2013-05-23 | Kyunglim Lee | Peptide having cell membrane penetrating activity |
| US20130072709A1 (en) | 2006-02-21 | 2013-03-21 | Nektar Therapeutics | Segmented Degradable Polymers and Conjugates Made Therefrom |
| US8313777B2 (en) | 2006-10-05 | 2012-11-20 | The Johns Hopkins University | Water-dispersible oral, parenteral, and topical formulations for poorly water soluble drugs using smart polymeric nanoparticles |
| US8524259B2 (en) | 2006-12-05 | 2013-09-03 | Landec Corporation | Systems and methods for delivery of materials |
| US20130150295A1 (en) | 2006-12-21 | 2013-06-13 | Stryker Corporation | Sustained-Release Formulations Comprising Crystals, Macromolecular Gels, and Particulate Suspensions of Biologic Agents |
| US8507653B2 (en) | 2006-12-27 | 2013-08-13 | Nektar Therapeutics | Factor IX moiety-polymer conjugates having a releasable linkage |
| WO2008103276A2 (en) | 2007-02-16 | 2008-08-28 | Merck & Co., Inc. | Compositions and methods for potentiated activity of biologicaly active molecules |
| US8246968B2 (en) | 2007-03-30 | 2012-08-21 | Bind Biosciences, Inc. | Cancer cell targeting using nanoparticles |
| WO2008121949A1 (en) | 2007-03-30 | 2008-10-09 | Bind Biosciences, Inc. | Cancer cell targeting using nanoparticles |
| US8501824B2 (en) | 2007-05-04 | 2013-08-06 | Marina Biotech, Inc. | Amino acid lipids and uses thereof |
| US20100293625A1 (en) | 2007-09-26 | 2010-11-18 | Interexon Corporation | Synthetic 5'UTRs, Expression Vectors, and Methods for Increasing Transgene Expression |
| US8236330B2 (en) | 2007-09-28 | 2012-08-07 | Bind Biosciences, Inc. | Cancer cell targeting using nanoparticles |
| US20130172406A1 (en) | 2007-09-28 | 2013-07-04 | Bind Biosciences, Inc. | Cancer Cell Targeting Using Nanoparticles |
| US20120004293A1 (en) | 2007-09-28 | 2012-01-05 | Zale Stephen E | Cancer Cell Targeting Using Nanoparticles |
| US20100004315A1 (en) | 2008-03-14 | 2010-01-07 | Gregory Slobodkin | Biodegradable Cross-Linked Branched Poly(Alkylene Imines) |
| US8519110B2 (en) | 2008-06-06 | 2013-08-27 | Board Of Supervisors Of Louisiana State University And Agricultural And Mechanical College | mRNA cap analogs |
| US20100104655A1 (en) | 2008-06-16 | 2010-04-29 | Zale Stephen E | Therapeutic Polymeric Nanoparticles Comprising Vinca Alkaloids and Methods of Making and Using Same |
| WO2010005723A2 (en) | 2008-06-16 | 2010-01-14 | Bind Biosciences, Inc. | Drug loaded polymeric nanoparticles and methods of making and using same |
| US8318208B1 (en) | 2008-06-16 | 2012-11-27 | Bind Biosciences, Inc. | Drug loaded polymeric nanoparticles and methods of making and using same |
| US20130230567A1 (en) | 2008-06-16 | 2013-09-05 | Bind Therapeutics, Inc. | Drug Loaded Polymeric Nanoparticles and Methods of Making and Using Same |
| US20100068285A1 (en) | 2008-06-16 | 2010-03-18 | Zale Stephen E | Drug Loaded Polymeric Nanoparticles and Methods of Making and Using Same |
| US20120288541A1 (en) | 2008-06-16 | 2012-11-15 | Zale Stephen E | Drug Loaded Polymeric Nanoparticles and Methods of Making and Using Same |
| WO2010005740A2 (en) | 2008-06-16 | 2010-01-14 | Bind Biosciences, Inc. | Methods for the preparation of targeting agent functionalized diblock copolymers for use in fabrication of therapeutic targeted nanoparticles |
| WO2010005725A2 (en) | 2008-06-16 | 2010-01-14 | Bind Biosciences, Inc. | Therapeutic polymeric nanoparticles comprising vinca alkaloids and methods of making and using same |
| WO2010005726A2 (en) | 2008-06-16 | 2010-01-14 | Bind Biosciences Inc. | Therapeutic polymeric nanoparticles with mtor inhibitors and methods of making and using same |
| US20100069426A1 (en) | 2008-06-16 | 2010-03-18 | Zale Stephen E | Therapeutic polymeric nanoparticles with mTor inhibitors and methods of making and using same |
| WO2010005721A2 (en) | 2008-06-16 | 2010-01-14 | Bind Biosciences, Inc. | Drug loaded polymeric nanoparticles and methods of making and using same |
| US20110274759A1 (en) | 2008-06-16 | 2011-11-10 | Greg Troiano | Drug Loaded Polymeric Nanoparticles and Methods of Making and Using Same |
| US20100068286A1 (en) | 2008-06-16 | 2010-03-18 | Greg Troiano | Drug Loaded Polymeric Nanoparticles and Methods of Making and Using Same |
| US8318211B2 (en) | 2008-06-16 | 2012-11-27 | Bind Biosciences, Inc. | Therapeutic polymeric nanoparticles comprising vinca alkaloids and methods of making and using same |
| US20100104645A1 (en) | 2008-06-16 | 2010-04-29 | Bind Biosciences, Inc. | Methods for the preparation of targeting agent functionalized diblock copolymers for use in fabrication of therapeutic targeted nanoparticles |
| US8206747B2 (en) | 2008-06-16 | 2012-06-26 | Bind Biosciences, Inc. | Drug loaded polymeric nanoparticles and methods of making and using same |
| US8293276B2 (en) | 2008-06-16 | 2012-10-23 | Bind Biosciences, Inc. | Drug loaded polymeric nanoparticles and methods of making and using same |
| US20100087337A1 (en) | 2008-09-10 | 2010-04-08 | Bind Biosciences, Inc. | High Throughput Fabrication of Nanoparticles |
| US20130123351A1 (en) | 2008-09-10 | 2013-05-16 | Bind Biosciences, Inc. | High throughput fabrication of nanoparticles |
| WO2010030763A2 (en) | 2008-09-10 | 2010-03-18 | Bind Biosciences, Inc. | High throughput fabrication of nanoparticles |
| US8450298B2 (en) | 2008-11-07 | 2013-05-28 | Massachusetts Institute Of Technology | Aminoalcohol lipidoids and uses thereof |
| WO2010075072A2 (en) | 2008-12-15 | 2010-07-01 | Bind Biosciences | Long circulating nanoparticles for sustained release of therapeutic agents |
| US20110217377A1 (en) | 2008-12-15 | 2011-09-08 | Zale Stephen E | Long Circulating Nanoparticles for Sustained Release of Therapeutic Agents |
| US20100216804A1 (en) | 2008-12-15 | 2010-08-26 | Zale Stephen E | Long Circulating Nanoparticles for Sustained Release of Therapeutic Agents |
| WO2010087791A1 (en) | 2009-01-27 | 2010-08-05 | Utc Power Corporation | Distributively cooled, integrated water-gas shift reactor and vaporizer |
| US8460696B2 (en) | 2009-03-20 | 2013-06-11 | Egen, Inc. | Polyamine derivatives |
| WO2010118337A2 (en) * | 2009-04-10 | 2010-10-14 | Biomarin Pharmaceutical Inc. | Methods of enhancing yield of active iga protease |
| WO2010123885A2 (en) * | 2009-04-20 | 2010-10-28 | Tufts Medical Center, Inc. | Iga1 protease polypeptide agents and uses thereof |
| US8158601B2 (en) | 2009-06-10 | 2012-04-17 | Alnylam Pharmaceuticals, Inc. | Lipid formulation |
| US20120276209A1 (en) | 2009-11-04 | 2012-11-01 | The University Of British Columbia | Nucleic acid-containing lipid particles and related methods |
| WO2011062965A2 (en) | 2009-11-18 | 2011-05-26 | University Of Washington Through Its Center For Commercialization | Targeting monomers and polymers having targeting blocks |
| WO2011084518A2 (en) | 2009-12-15 | 2011-07-14 | Bind Biosciences, Inc. | Therapeutic polymeric nanoparticles comprising corticosteroids and methods of making and using same |
| US20120140790A1 (en) | 2009-12-15 | 2012-06-07 | Ali Mir M | Therapeutic Polymeric Nanoparticle Compositions with High Glass Transition Termperature or High Molecular Weight Copolymers |
| WO2011084521A2 (en) | 2009-12-15 | 2011-07-14 | Bind Biosciences, Inc. | Therapeutic polymeric nanoparticles comprising epothilone and methods of making and using same |
| US20130231287A1 (en) | 2010-02-25 | 2013-09-05 | Parimala Nacharaju | Pegylated albumin polymers and uses thereof |
| WO2011127255A1 (en) | 2010-04-08 | 2011-10-13 | Merck Sharp & Dohme Corp. | Preparation of lipid nanoparticles |
| US20130183372A1 (en) | 2010-04-09 | 2013-07-18 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| US20130177637A1 (en) | 2010-04-09 | 2013-07-11 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| US20130177636A1 (en) | 2010-04-09 | 2013-07-11 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| US20130177635A1 (en) | 2010-04-09 | 2013-07-11 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| US20130177633A1 (en) | 2010-04-09 | 2013-07-11 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| US20130183375A1 (en) | 2010-04-09 | 2013-07-18 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| US20130177638A1 (en) | 2010-04-09 | 2013-07-11 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| US20130183373A1 (en) | 2010-04-09 | 2013-07-18 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| US20130177634A1 (en) | 2010-04-09 | 2013-07-11 | Pacira Pharmaceuticals, Inc. | Method for formulating large diameter synthetic membrane vesicles |
| US20110262491A1 (en) | 2010-04-12 | 2011-10-27 | Selecta Biosciences, Inc. | Emulsions and methods of making nanocarriers |
| US20130164219A1 (en) | 2010-06-14 | 2013-06-27 | Hoffmann-La Roche Inc. | Cell-penetrating peptides and uses thereof |
| US20130196948A1 (en) | 2010-06-25 | 2013-08-01 | Massachusetts Insitute Of Technology | Polymers for biomaterials and therapeutics |
| US20130195968A1 (en) | 2010-07-06 | 2013-08-01 | Novartis Ag | Virion-like delivery particles for self-replicating rna molecules |
| WO2012006376A2 (en) | 2010-07-06 | 2012-01-12 | Novartis Ag | Virion-like delivery particles for self-replicating rna molecules |
| WO2012006380A2 (en) | 2010-07-06 | 2012-01-12 | Novartis Ag | Cationic oil-in-water emulsions |
| US20130171241A1 (en) | 2010-07-06 | 2013-07-04 | Novartis Ag | Liposomes with lipids having an advantageous pka-value for rna delivery |
| WO2012006378A1 (en) | 2010-07-06 | 2012-01-12 | Novartis Ag | Liposomes with lipids having an advantageous pka- value for rna delivery |
| US20130211249A1 (en) | 2010-07-22 | 2013-08-15 | The Johns Hopkins University | Drug eluting hydrogels for catheter delivery |
| US20130142818A1 (en) | 2010-07-30 | 2013-06-06 | Curevac Gmbh | Complexation of nucleic acids with disulfide-crosslinked cationic components for transfection and immunostimulation |
| WO2012013326A1 (en) | 2010-07-30 | 2012-02-02 | Curevac Gmbh | Complexation of nucleic acids with disulfide-crosslinked cationic components for transfection and immunostimulation |
| US20130171646A1 (en) | 2010-08-09 | 2013-07-04 | So Jung PARK | Nanop article-oligonucleotide hybrid structures and methods of use thereof |
| US20130195799A1 (en) | 2010-08-19 | 2013-08-01 | Peg Biosciences, Inc. | Synergistic biomolecule-polymer conjugates |
| WO2012031043A1 (en) | 2010-08-31 | 2012-03-08 | Novartis Ag | Pegylated liposomes for delivery of immunogen-encoding rna |
| WO2012030901A1 (en) | 2010-08-31 | 2012-03-08 | Novartis Ag | Small liposomes for delivery of immunogen-encoding rna |
| US20130202684A1 (en) | 2010-08-31 | 2013-08-08 | Lichtstrasse | Pegylated liposomes for delivery of immunogen encoding rna |
| WO2012031046A2 (en) | 2010-08-31 | 2012-03-08 | Novartis Ag | Lipids suitable for liposomal delivery of protein-coding rna |
| US20130195969A1 (en) | 2010-08-31 | 2013-08-01 | Novartis Ag | Small liposomes for delivery of immunogen encoding rna |
| US20130189351A1 (en) | 2010-08-31 | 2013-07-25 | Novartis Ag | Lipids suitable for liposomal delivery of protein coding rna |
| US20130183244A1 (en) | 2010-09-10 | 2013-07-18 | The Johns Hopkins University | Rapid Diffusion of Large Polymeric Nanoparticles in the Mammalian Brain |
| WO2012040524A1 (en) | 2010-09-24 | 2012-03-29 | Mallinckrodt Llc | Aptamer conjugates for targeting of therapeutic and/or diagnostic nanocarriers |
| WO2012054923A2 (en) | 2010-10-22 | 2012-04-26 | Bind Biosciences, Inc. | Therapeutic nanoparticles with high molecular weight copolymers |
| WO2012099755A1 (en) | 2011-01-11 | 2012-07-26 | Alnylam Pharmaceuticals, Inc. | Pegylated lipids and their use for drug delivery |
| WO2012109121A1 (en) | 2011-02-07 | 2012-08-16 | Purdue Research Foundation | Carbohydrate nanoparticles for prolonged efficacy of antimicrobial peptide |
| WO2012110636A2 (en) | 2011-02-18 | 2012-08-23 | Instituto Nacional De Investigación Y Tecnología Agraria Y Alimentaria (Inia) | Carrier peptides for cell delivery |
| US20130217753A1 (en) | 2011-02-22 | 2013-08-22 | Rutgers, The State University Of New Jersey | Amphiphilic macromolecules for nucleic acid delivery |
| WO2012170930A1 (en) | 2011-06-08 | 2012-12-13 | Shire Human Genetic Therapies, Inc | Lipid nanoparticle compositions and methods for mrna delivery |
| WO2012170889A1 (en) | 2011-06-08 | 2012-12-13 | Shire Human Genetic Therapies, Inc. | Cleavable lipids |
| WO2013033438A2 (en) | 2011-08-31 | 2013-03-07 | Mallinckrodt Llc | Nanoparticle peg modification with h-phosphonates |
| WO2013082111A2 (en) | 2011-11-29 | 2013-06-06 | The University Of North Carolina At Chapel Hill | Geometrically engineered particles and methods for modulating macrophage or immune responses |
| WO2013086354A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Biodegradable lipids for the delivery of active agents |
| US20130195920A1 (en) | 2011-12-07 | 2013-08-01 | Alnylam Pharmaceuticals, Inc. | Biodegradable lipids for the delivery of active agents |
| WO2013086322A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Branched alkyl and cycloalkyl terminated biodegradable lipids for the delivery of active agents |
| WO2013086526A1 (en) | 2011-12-09 | 2013-06-13 | The Regents Of The University Of California | Liposomal drug encapsulation |
| WO2013106086A1 (en) | 2012-01-10 | 2013-07-18 | Sorbent Therapeutics, Inc. | Compositions comprising crosslinked cation-binding polymers and uses thereof |
| WO2013106073A1 (en) | 2012-01-10 | 2013-07-18 | Sorbent Therapeutics, Inc. | Compositions comprising crosslinked cation-binding polymers and uses thereof |
| WO2013106072A1 (en) | 2012-01-10 | 2013-07-18 | Sorbent Therapeutics, Inc. | Compositions comprising crosslinked cation-binding polymers and uses thereof |
| WO2013105101A1 (en) | 2012-01-13 | 2013-07-18 | Department Of Biotechnology | Solid lipid nanoparticles entrapping hydrophilic/ amphiphilic drug and a process for preparing the same |
| WO2013110028A1 (en) | 2012-01-19 | 2013-07-25 | The Johns Hopkins University | Nanoparticle formulations with enhanced mucosal penetration |
| WO2013116126A1 (en) | 2012-02-01 | 2013-08-08 | Merck Sharp & Dohme Corp. | Novel low molecular weight, biodegradable cationic lipids for oligonucleotide delivery |
| WO2013123298A1 (en) | 2012-02-17 | 2013-08-22 | University Of Georgia Research Foundation, Inc. | Nanoparticles for mitochondrial trafficking of agents |
| WO2013123523A1 (en) | 2012-02-19 | 2013-08-22 | Nvigen, Inc. | Uses of porous nanostructure in delivery |
| WO2013124867A1 (en) | 2012-02-21 | 2013-08-29 | Amrita Vishwa Vidyapeetham University | Polymer - polymer or polymer - protein core - shell nano medicine loaded with multiple drug molecules |
| WO2014164253A1 (en) | 2013-03-09 | 2014-10-09 | Moderna Therapeutics, Inc. | Heterologous untranslated regions for mrna |
| WO2015051214A1 (en) | 2013-10-03 | 2015-04-09 | Moderna Therapeutics, Inc. | Polynucleotides encoding low density lipoprotein receptor |
| WO2015130584A2 (en) | 2014-02-25 | 2015-09-03 | Merck Sharp & Dohme Corp. | Lipid nanoparticle vaccine adjuvants and antigen delivery systems |
| WO2017066797A1 (en) | 2015-10-16 | 2017-04-20 | Modernatx, Inc. | Trinucleotide mrna cap analogs |
| WO2023143563A1 (en) * | 2022-01-29 | 2023-08-03 | 北京大学第一医院 | Iga protease truncation, fusion protein comprising iga protease truncation, and use thereof |
Non-Patent Citations (56)
| Title |
|---|
| "Concise Dictionary of Biomedicine and Molecular Biology", 2002, CRC PRESS |
| "Oxford Dictionary Of Biochemistry And Molecular Biology", 2000, OXFORD UNIVERSITY PRESS |
| "The Dictionary of Cell and Molecular Biology", 1999, ACADEMIC PRESS |
| ABRAHAM ET AL.: "Chaotic Mixer for Microchannels", SCIENCE, vol. 295, 2002, pages 647 - 651 |
| AKINC ET AL., MOL THER., vol. 17, 2009, pages 872 - 879 |
| AKINC ET AL., NAT BIOTECHNOL., vol. 26, 2008, pages 561 - 569 |
| ALEKU ET AL., CANCER RES., vol. 68, 2008, pages 9788 - 9798 |
| BELLIVEAU ET AL.: "Microfluidic synthesis of highly potent limit-size lipid nanoparticles for in vivo delivery of siRNA", MOLECULAR THERAPY-NUCLEIC ACIDS., vol. 1, 2012, pages 37 |
| BERTHELOT ET AL., J EXP MED, vol. 209, no. 4, 2012, pages 793 - 806 |
| CHEN ET AL.: "Rapid discovery of potent siRNA-containing lipid nanoparticles enabled by controlled microfluidic formulation", J. AM. CHEM. SOC., vol. 134, no. 16, 2012, pages 6948 - 51, XP002715254, DOI: 10.1021/ja301621z |
| DATABASE Geneseq [online] 23 December 2010 (2010-12-23), "Haemophilus influenzae IgA1 protease sequence, SEQ ID: 24.", retrieved from EBI accession no. GSP:AYL24864 Database accession no. AYL24864 * |
| DATABASE Geneseq [online] 9 December 2010 (2010-12-09), "Haemophilus influenzae C-terminal His-tagged IgA1 protease, SEQ ID 22 #2.", retrieved from EBI accession no. GSP:AYK39446 Database accession no. AYK39446 * |
| DATABASE NCBI Reference Sequence [online] 7 September 2023 (2023-09-07), ANONYMOUS: "S6 family peptidase [Haemophilus influenzae] - Protein - NCBI", XP093233077, retrieved from https://www.ncbi.nlm.nih.gov/protein/1042184274?sat=58&satkey=41258262 Database accession no. WP_065245164.1 * |
| DEFOUGEROLLES HUM GENE THER., vol. 19, 2008, pages 125 - 132 |
| DEKOKER ET AL., ADV DRUG DELIV REV., vol. 63, 2011, pages 748 - 761 |
| ENDRES ET AL., BIOMATERIALS, vol. 32, 2011, pages 7721 - 7731 |
| FOTIN-MLECZEK ET AL., J. IMMUNOTHER., vol. 34, 2011, pages 1 - 15 |
| FROST, EXPERT OPIN. DRUG DELIV., vol. 4, 2007, pages 427 - 440 |
| FULLER ET AL., BIOMATERIALS, vol. 29, 2008, pages 1526 - 1532 |
| GUTBIER ET AL., PULM PHARMACOL. THER., vol. 23, 2010, pages 334 - 344 |
| HINNEBUSCH A ET AL., SCIENCE, vol. 352, no. 6292, 2016, pages 1413 - 6 |
| JUNJIE LI ET AL., CURRENT BIOLOGY, vol. 15, 23 August 2005 (2005-08-23), pages 1501 - 1507 |
| KAUFMANN ET AL., MICROVASC RES, vol. 80, 2010, pages 286 - 293 |
| KORE ET AL., BIOORGANIC & MEDICINAL CHEMISTRY, vol. 21, 2013, pages 4570 - 4574 |
| LAMM MICHAEL E ET AL: "Microbial IgA protease removes IgA immune complexes from mouse glomeruli In Vivo: Potential therapy for IgA nephropathy", THE AMERICAN JOURNAL OF PATHOLOGY; [10640], ELSEVIER INC, US, vol. 172, no. 1, 1 January 2008 (2008-01-01), pages 31 - 36, XP002608944, ISSN: 0002-9440, [retrieved on 20071228], DOI: 10.2353/AJPATH.2008.070131 * |
| LECHNER ET AL., J. AM. SOC. NEPHROL., vol. 27, no. 9, 2016, pages 2622 - 9 |
| LIUHUANG, MOLECULAR THERAPY, 2010, pages 669 - 670 |
| LONG SHINONG ET AL: "The Expression of Soluble and Active Recombinant Haemophilus influenzae IgA1 Protease in E. coli", JOURNAL OF BIOMEDICINE AND BIOTECHNOLOGY, vol. 2010, 1 January 2010 (2010-01-01), pages 1 - 9, XP093233727, ISSN: 1110-7243, Retrieved from the Internet <URL:http://downloads.hindawi.com/journals/bmri/2010/253983.pdf> DOI: 10.1155/2010/253983 * |
| LOVE ET AL., PROC NATL ACAD SCI U S A., vol. 107, 2010, pages 1864 - 1869 |
| MAHON ET AL., BIOCONJUG. CHEM., vol. 21, 2010, pages 1448 - 1454 |
| MANDALROSSI, NAT. PROTOC., vol. 8, no. 3, 2013, pages 568 - 82 |
| MATSUDAMAURO, PLOS ONE, vol. 5, 2010, pages 11 |
| MAYR C., COLD SPRING HARB PERSP BIOL, vol. 11, no. 10, 1 October 2019 (2019-10-01), pages 034728 |
| MURUGAIAH ET AL., ANALYTICAL BIOCHEMISTRY, vol. 401, no. 61, 2010 |
| NASERI ET AL.: "Solid Lipid Nanoparticles and Nanostructured Lipid Carriers: Structure, Preparation and Application", ADV. PHARM. BULL., vol. 5, 2015, pages 305 - 13 |
| NATURE REVIEWS MOLECULAR CELL BIOLOGY, 29 August 2013 (2013-08-29) |
| PARSONS H K ET AL: "Immunoglobulin A1 proteases: a structure-function update", BIOCHEMICAL SOCIETY TRANSACTIONS, PORTLAND PRESS LTD, GB, vol. 32, no. 6, 1 December 2004 (2004-12-01), pages 1130 - 1132, XP002587566, ISSN: 0300-5127 * |
| PASCOLO EXPERT OPIN. BIOL. THER., vol. 4, pages 1285 - 1294 |
| PEER ET AL., PROC NATL ACAD SCI U S A., vol. 6, no. 104, 2007, pages 4095 - 4100 |
| RODRIGUEZ ET AL., SCIENCE, vol. 339, 2013, pages 971 - 975 |
| SANTEL ET AL., GENE THER, vol. 13, 2006, pages 1360 - 1370 |
| SCHROEDER ET AL., J INTERN MED., vol. 267, 2010, pages 9 - 21 |
| SIEGWART ET AL., PROC NATL ACAD SCI U S A., vol. 108, 2011, pages 12996 - 13001 |
| SILVA ET AL.: "Lipid nanoparticles for the delivery of biopharmaceuticals", CURR. PHARM. BIOTECHNOL., vol. 16, 2015, pages 291 - 302, XP055602369 |
| SILVA: "Delivery Systems for Biopharmaceuticals. Part I: Nanoparticles and Microparticles", CURR. PHARM. TECHNOL., vol. 16, 2015, pages 940 - 954 |
| SONG ET AL., NATURE BIOTECHNOL., vol. 23, 2005, pages 709 - 717 |
| STRUMBERG ET AL., INT J CLIN PHARMACOL THER, vol. 50, 2012, pages 76 - 78 |
| SU ET AL., MOL PHARM., vol. 8, no. 3, 6 June 2011 (2011-06-06), pages 774 - 87 |
| TOURIOL ET AL., BIOLOGY OF THE CELL, vol. 95, 2003, pages 169 - 178 |
| WANG ET AL., NAT MATER., vol. 5, 2006, pages 791 - 796 |
| WANG ET AL.: "Delivery of oligonucleotides with lipid nanoparticles", ADV. DRUG DELIV. REV., vol. 87, 2015, pages 68 - 80 |
| WEIDE ET AL., J IMMUNOTHER., vol. 31, 2008, pages 180 - 188 |
| WEIDE ET AL., J IMMUNOTHER., vol. 32, 2009, pages 498 - 507 |
| WHITESIDESGEORGE M.: "The Origins and the Future of Microfluidics", NATURE, vol. 442, 2006, pages 368 - 373, XP055123139, DOI: 10.1038/nature05058 |
| YAKUBOV ET AL., BIOCHEM. BIOPHYS. RES. COMMUN., vol. 394, no. 1, 2010, pages 189 - 193 |
| ZHIGALTSEVET: "Bottom-up design and synthesis of limit size lipid nanoparticle systems with aqueous and triglyceride cores using millisecond microfluidic mixing", LANGMUIR, vol. 28, 2012, pages 3633 - 40, XP055150435, DOI: 10.1021/la204833h |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220226438A1 (en) | Compositions for skin and wounds and methods of use thereof | |
| JP7423522B2 (en) | Polynucleotide encoding ornithine transcarbamylase for the treatment of urea cycle disorders | |
| US20250017867A1 (en) | Polynucleotides encoding relaxin for the treatment of fibrosis and/or cardiovascular disease | |
| JP7424976B2 (en) | Polynucleotide encoding propionyl-CoA carboxylase alpha and beta subunits for the treatment of propionic acidemia | |
| US20240207444A1 (en) | Lipid nanoparticles containing polynucleotides encoding phenylalanine hydroxylase and uses thereof | |
| US20230406895A1 (en) | Polynucleotides encoding cystic fibrosis transmembrane conductance regulator for the treatment of cystic fibrosis | |
| US20230235298A1 (en) | Phenylalanine hydroxylase variants and uses thereof | |
| US11802146B2 (en) | Polynucleotides encoding anti-chikungunya virus antibodies | |
| US20240207374A1 (en) | Lipid nanoparticles containing polynucleotides encoding glucose-6-phosphatase and uses thereof | |
| US20240226025A1 (en) | Polynucleotides encoding methylmalonyl-coa mutase for the treatment of methylmalonic acidemia | |
| WO2024197033A1 (en) | Polynucleotides encoding relaxin for the treatment of heart failure | |
| WO2025072482A1 (en) | Immunoglobulin a protease polypeptides, polynucleotides, and uses thereof | |
| EP4499850A2 (en) | Messenger ribonucleic acids with extended half-life | |
| WO2023287751A1 (en) | Polynucleotides encoding propionyl-coa carboxylase alpha and beta subunits for the treatment of propionic acidemia | |
| US20250221931A1 (en) | Polynucleotides encoding fanconi anemia, complementation group proteins for the treatment of fanconi anemia | |
| US20240189449A1 (en) | Lipid nanoparticles and polynucleotides encoding ornithine transcarbamylase for the treatment of ornithine transcarbamylase deficiency | |
| US20240216288A1 (en) | Lipid nanoparticles containing polynucleotides encoding propionyl-coa carboxylase alpha and beta subunits and uses thereof | |
| WO2023009499A1 (en) | Polynucleotides encoding glucose-6-phosphatase for the treatment of glycogen storage disease type 1a (gsd1a) | |
| US20260035714A1 (en) | Engineered polynucleotides for cell selective expression | |
| US20260035707A1 (en) | Engineered polynucleotides for temporal control of expression | |
| US20240376445A1 (en) | Polynucleotides encoding uridine diphosphate glycosyltransferase 1 family, polypeptide a1 for the treatment of crigler-najjar syndrome | |
| EP4637786A2 (en) | Small nuclear ribonucleoprotein 13 polypeptides, polynucleotides, and uses thereof | |
| WO2025255199A1 (en) | Argininosuccinate synthase 1 and argininosuccinate lyase polypeptides and polynucleotides and uses thereof | |
| WO2025059290A1 (en) | Polynucleotides encoding phenylalanine hydroxylase for the treatment of phenylketonuria | |
| US20240269248A1 (en) | Polynucleotides encoding methylmalonyl-coa mutase for the treatment of methylmalonic acidemia |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24787373 Country of ref document: EP Kind code of ref document: A1 |