WO2025049524A1 - Cxcr4 antibody-resistant modified receptors - Google Patents
Cxcr4 antibody-resistant modified receptors Download PDFInfo
- Publication number
- WO2025049524A1 WO2025049524A1 PCT/US2024/044111 US2024044111W WO2025049524A1 WO 2025049524 A1 WO2025049524 A1 WO 2025049524A1 US 2024044111 W US2024044111 W US 2024044111W WO 2025049524 A1 WO2025049524 A1 WO 2025049524A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- cxcr4
- cells
- isoform
- seq
- set forth
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2866—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for cytokines, lymphokines, interferons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/28—Bone marrow; Haematopoietic stem cells; Mesenchymal stem cells of any origin, e.g. adipose-derived stem cells
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/715—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
- C07K14/7158—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons for chemokines
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1138—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against receptors or cell surface proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPR]
Definitions
- Hematopoietic stem cell transplant can fully replace the hematopoietic system of the transplant recipient with donor-derived cells.
- This approach can be curative for hematologic malignancies, genetic deficiencies of blood lineages, and severe autoimmune diseases refractory to standard treatment.
- patients must first undergo treatments — termed host conditioning — that partially or fully ablate their immune system to facilitate HSCT graft uptake.
- host conditioning treatments that partially or fully ablate their immune system to facilitate HSCT graft uptake.
- Traditional approaches to transplant host conditioning employ genotoxins, such as chemotherapeutic agents and radiation, with little specificity for the desired target cells. The associated risks of off-target tissue damage, secondary malignancies, and opportunistic infection thus limit the application of HSCT to a treatment of last resort.
- HSCs Host hematopoietic stem cells
- BM bone marrow
- CXCR4 C-X-C motif chemokine receptor 4
- GPCR G-protein-coupled receptor
- Methods for improving engraftment of donor cells in a subject in need thereof are provided. Also provided are combinations or combination medicaments for administration to a subject in need thereof. Also provided are isolated cells or populations of cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4. Also provided are methods of making the isolated cells or populations of cells. Also provided are genetically engineered C-X-C chemokine receptor type 4 (CXCR4) proteins and nucleic acids encoding the proteins.
- CXCR4 C-X-C chemokine receptor type 4
- methods for improving engraftment of donor cells in a subject in need thereof comprise: (a) providing donor cells that have been modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4, wherein the second isoform is expressed in host cells of the subject; (b) administering the donor cells to the subject, and (c) selectively inhibiting host cells in the subject based on their expression of the second isoform of CXCR4, thereby improving engraftment of donor cells in the subject.
- CXCR4 C-X-C chemokine receptor type 4
- the selective inhibition of host cells in step (c) does not comprise ablation of host cells by an active killing mechanism.
- the selective inhibition in step (c) comprises selectively depleting host cells from the bone marrow.
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
- the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such methods, the donor cells express only the first isoform of CXCR4.
- the first isoform of CXCR4 is expressed from an expression vector in the donor cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the donor cells.
- the genomic locus is an endogenous CXCR4 genomic locus.
- the genomic locus is not an endogenous CXCR4 genomic locus.
- the selective inhibition in step (c) comprises administering a CXCR4 antagonist to the subject, wherein the CXCR4 antagonist specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4, optionally wherein step (c) comprises multiple administrations of the CXCR4 antagonist.
- the CXCR4 antagonist is an antigen-binding protein.
- the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13
- the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the CXCR4 antagonist blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position S I 78 to position R183 and/or within a region from position R188 to position LI 94 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the donor cells and/or the host cells are hematopoietic cells, optionally wherein the donor cells and/or host cells are immune cells.
- the donor cells and/or the host cells are lymphocytes or lymphoid progenitor cells.
- the donor cells and/or the host cells are T cells.
- the donor cells and/or the host cells are alpha beta T cells.
- the donor cells and/or the host cells are gamma delta T cells.
- the donor cells and/or the host cells are tumor infiltrating lymphocytes (TILs).
- the donor cells and/or the host cells are B cells, optionally wherein the donor cells and/or the host cells are immature B cells, and the method depletes host mature B cells from the bone marrow.
- the donor cells and/or the host cells are NK cells.
- the donor cells and/or the host cells are hematopoietic stem and progenitor cells.
- the donor cells and/or the host cells are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells.
- the donor cells are derived from induced pluripotent stem cells.
- the subject is a mammal or a non-human mammal, and the donor cells are mammalian cells or non-human mammalian cells.
- the subject is a human, and the donor cells are human cells.
- the donor cells comprise or express a therapeutic molecule.
- the therapeutic molecule does not target CXCR4.
- the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
- the donor cells are autologous.
- the donor cells are allogeneic or syngeneic.
- the subject has a disease or disorder, and the method is for treating the disease or disorder in the subject.
- the subject has cancer.
- the cancer is a solid tumor cancer.
- the cancer is a hematologic cancer.
- the subject has a hematopoietic malignancy, and the method is for treating the hematopoietic malignancy in the subject.
- the subject has defective immune cells or a genetic deficiency in hematopoiesis.
- the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
- steps (b) and (c) occur simultaneously.
- step (b) occurs prior to step (c), optionally wherein step (c) comprises multiple administrations of a CXCR4 antagonist subsequent to step (b).
- step (b) occurs subsequent to step (c), optionally wherein step (c) comprises multiple administrations of a CXCR4 antagonist prior to step (b).
- step (c) occurs both prior to and subsequent to step (b), optionally wherein step (c) comprises multiple administrations of a CXCR4 antagonist prior to step (b) and/or multiple administrations of the CXCR4 antagonist subsequent to step (b).
- the method further comprises generating the donor cells by modifying a population of cells to express the first isoform of CXCR4 prior to step (a).
- the population of cells is a population of induced pluripotent stem cells
- the method further comprises differentiating the induced pluripotent stem cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the induced pluripotent stem cells are differentiated into hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, NK cells, hematopoietic stem cells, or hematopoietic stem and progenitor cells.
- the population of cells is a population of hematopoietic stem cells or hematopoietic stem and progenitor cells
- the method further comprises differentiating the hematopoietic stem cells or hematopoietic stem and progenitor cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the hematopoietic stem cells or hematopoietic stem and progenitor cells are differentiated into differentiated hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, or NK cells.
- generating the donor cells comprises introducing an expression vector encoding the first isoform of CXCR4 to express the first isoform of CXCR4 prior to step (a), or wherein generating the donor cells comprises editing a genomic locus in the population of cells to express the first isoform of CXCR4 prior to step (a).
- the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus.
- the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
- ZFN zinc finger nuclease
- TALEN transcription activator-like effector nuclease
- Some such methods comprise: (a) providing donor cells that have been modified to express a first isoform of CXCR4, wherein the first isoform of CXCR4 is different from a second isoform of CXCR4, wherein the second isoform is expressed in host cells of the subject; (b) administering the donor cells to the subject, and (c) providing the subject with means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
- the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 selectively inhibits host cells in the subject based on their expression of the second isoform of CXCR4.
- the selective inhibition of host cells does not comprise ablation of host cells by an active killing mechanism.
- the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
- the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
- the donor cells express only the first isoform of CXCR4.
- the first isoform of CXCR4 is expressed from an expression vector in the donor cells, or a genomic locus has been edited to express the first isoform of CXCR4 in the donor cells.
- the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus.
- the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
- the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
- the altered epitope is in a binding region of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 such that the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4.
- both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
- steps (b) and (c) occur simultaneously.
- step (b) occurs prior to step (c), optionally wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 subsequent to step (b).
- step (b) occurs subsequent to step (c), optionally wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 prior to step (b).
- step (c) occurs both prior to and subsequent to step (b), optionally wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 prior to step (b) and/or multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 subsequent to step (b).
- the donor cells and/or the host cells are hematopoietic cells, optionally wherein the donor cells and/or host cells are immune cells.
- the donor cells and/or the host cells are lymphocytes or lymphoid progenitor cells.
- the donor cells and/or the host cells are T cells. In some such methods, the donor cells and/or the host cells are alpha beta T cells. In some such methods, the donor cells and/or the host cells are gamma delta T cells. In some such methods, the donor cells and/or the host cells are tumor infdtrating lymphocytes (TILs). In some such methods, the donor cells and/or the host cells are B cells, optionally wherein the donor cells and/or the host cells are immature B cells, and the method depletes host mature B cells from the bone marrow. In some such methods, the donor cells and/or the host cells are NK cells.
- TILs tumor infdtrating lymphocytes
- the donor cells and/or the host cells are hematopoietic stem and progenitor cells. In some such methods, the donor cells and/or the host cells are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such methods, the donor cells are derived from induced pluripotent stem cells. In some such methods, the subject is a mammal or a non-human mammal, and the donor cells are mammalian cells or non-human mammalian cells. In some such methods, the subject is a human, and the donor cells are human cells.
- the donor cells comprise or express a therapeutic molecule.
- the therapeutic molecule does not target CXCR4.
- the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
- the donor cells are autologous. In some such methods, the donor cells are allogeneic or syngeneic. In some such methods, the subject has a disease or disorder, and the method is for treating the disease or disorder in the subject. In some such methods, the subject has cancer, optionally wherein the cancer is a solid tumor cancer or a hematologic cancer. In some such methods, the subject has a hematopoietic malignancy, and the method is for treating the hematopoietic malignancy in the subject. In some such methods, the subject has defective immune cells or a genetic deficiency in hematopoiesis, optionally wherein the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
- SCID severe combined immunodeficiency
- the method further comprises generating the donor cells by modifying a population of cells to express the first isoform of CXCR4 prior to step (a).
- the population of cells is a population of induced pluripotent stem cells
- the method further comprises differentiating the induced pluripotent stem cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the induced pluripotent stem cells are differentiated into hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, NK cells, hematopoietic stem cells, or hematopoietic stem and progenitor cells.
- the population of cells is a population of hematopoietic stem cells or hematopoietic stem and progenitor cells
- the method further comprises differentiating the hematopoietic stem cells or hematopoietic stem and progenitor cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the hematopoietic stem cells or hematopoietic stem and progenitor cells are differentiated into differentiated hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, or NK cells.
- generating the donor cells comprises introducing an expression vector encoding the first isoform of CXCR4 to express the first isoform of CXCR4 prior to step (a), or generating the donor cells comprises editing a genomic locus in the population of cells to express the first isoform of CXCR4 prior to step (a).
- the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus.
- the editing comprises introducing into the population of cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the donor cells that express the first isoform of CXCR4.
- the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
- ZFN zinc finger nuclease
- TALEN transcription activator-like effector nuclease
- the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117- 131 .
- the Cas protein is a Cas9 protein.
- the exogenous donor nucleic acid comprises homology arms.
- the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN).
- the method further comprises isolating the population of cells from the subject or from a different subject prior to modifying the population of cells.
- the combination medicament comprises: (a) a population of donor cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4; and (b) a CXCR4 antagonist that specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4.
- CXCR4 C-X-C chemokine receptor type 4
- the CXCR4 antagonist selectively inhibits host cells in the subject based on their expression of the second isoform of CXCR4.
- the selective inhibition of host cells does not comprise ablation of host cells by an active killing mechanism.
- the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
- the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such combination medicaments, the donor cells express only the first isoform of CXCR4.
- the first isoform of CXCR4 is expressed from an expression vector in the population of donor cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the population of donor cells.
- the genomic locus is an endogenous CXCR4 genomic locus. In some such combination medicaments, the genomic locus is not an endogenous CXCR4 genomic locus.
- the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
- the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
- the altered epitope is in a binding region of the CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4.
- both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the CXCR4 antagonist blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position SI 78 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the CXCR4 antagonist is an antigen-binding protein.
- the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13
- the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29
- the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
- the donor cells are hematopoietic cells, optionally wherein the donor cells are immune cells.
- the donor cells are lymphocytes or lymphoid progenitor cells.
- the donor cells are T cells.
- the donor cells are alpha beta T cells.
- the donor cells are gamma delta T cells.
- the donor cells are tumor infiltrating lymphocytes (TILs).
- TILs tumor infiltrating lymphocytes
- the donor cells are B cells.
- the donor cells are NK cells.
- the donor cells are hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such combination medicaments, the donor cells are derived from induced pluripotent stem cells or are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such combination medicaments, the subject is a mammal or a nonhuman mammal, and the donor cells are mammalian cells or non-human mammalian cells. In some such combination medicaments, the subject is a human, and the donor cells are human cells. In some such combination medicaments, the donor cells comprise or express a therapeutic molecule. In some such combination medicaments, the therapeutic molecule does not target CXCR4.
- the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
- the donor cells are autologous.
- the donor cells are allogeneic or syngeneic.
- the subject has a disease or disorder, and the combination medicament is for treating the disease or disorder in the subject.
- the subject has cancer.
- the cancer is a solid tumor cancer.
- the cancer is a hematologic cancer.
- the subject has a hematopoietic malignancy, and the combination medicament is for treating the hematopoietic malignancy in the subject.
- the subject has defective immune cells or a genetic deficiency in hematopoiesis.
- the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
- SCID severe combined immunodeficiency
- Some such combination medicaments comprise: (a) a population of donor cells modified to express a first isoform of CXCR4, wherein the first isoform of CXCR4 is different from a second isoform of CXCR4; and (b) means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
- the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 selectively inhibits host cells in the subject based on their expression of the second isoform of CXCR4.
- the selective inhibition of host cells does not comprise ablation of host cells by an active killing mechanism.
- the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
- the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
- the donor cells express only the first isoform of CXCR4.
- the first isoform of CXCR4 is expressed from an expression vector in the population of donor cells, or a genomic locus has been edited to express the first isoform of CXCR4 in the population of donor cells.
- the genomic locus is an endogenous CXCR4 genomic locus.
- the genomic locus is not an endogenous CXCR4 genomic locus.
- the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
- the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
- the altered epitope is in a binding region of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 such that the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4.
- both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position SI 78 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, DI 93 A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the donor cells are hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such combination medicaments, the donor cells are derived from induced pluripotent stem cells or are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such combination medicaments, the subject is a mammal or a nonhuman mammal, and the donor cells are mammalian cells or non-human mammalian cells. In some such combination medicaments, the subject is a human, and the donor cells are human cells.
- the donor cells comprise or express a therapeutic molecule.
- the therapeutic molecule does not target CXCR4.
- the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
- the donor cells are autologous. In some such combination medicaments, the donor cells are allogeneic or syngeneic. In some such combination medicaments, the subject has a disease or disorder, and the combination medicament is for treating the disease or disorder in the subject. In some such combination medicaments, the subject has cancer, optionally wherein the cancer is a solid tumor cancer or a hematologic cancer. In some such combination medicaments, the subject has a hematopoietic malignancy, and the combination medicament is for treating the hematopoietic malignancy in the subject.
- isolated cells or populations of cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4.
- the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, wherein the altered epitope is in a binding region of a CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4, and wherein the first isoform of CXCR4 retains binding to its endogenous ligands.
- the mutation is an artificial mutation.
- both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the CXCR4 antagonist blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
- the cell or cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
- the cell or cells express only the first isoform of CXCR4.
- the first isoform of CXCR4 is expressed from an expression vector in the cell or cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the cell or cells.
- the genomic locus is an endogenous CXCR4 genomic locus. In some such isolated cells or populations of cells, the genomic locus is not an endogenous CXCR4 genomic locus.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position S 178 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the first isoform and the second isoform are immunologically distinguishable by the CXCR4 antagonist, wherein the CXCR4 antagonist specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4.
- the CXCR4 antagonist is an antigen-binding protein.
- the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13
- the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively
- the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
- the cell or cells are hematopoietic cell(s), optionally wherein the cell or cells are immune cell(s).
- the cell or cells are lymphocytes or lymphoid progenitor cell(s).
- the cell or cells are T cell(s).
- the cell or cells are alpha beta T cell(s).
- the cell or cells are gamma delta T cell(s).
- the cell or cells are tumor infdtrating lymphocyte(s) (TILs).
- the cell or cells are B cell(s). In some such isolated cells or populations of cells, the cell or cells are NK cell(s). In some such isolated cells or populations of cells, the cell or cells are hematopoietic stem cell(s) or hematopoietic stem and progenitor cell(s). In some such isolated cells or populations of cells, the cell or cells are induced pluripotent stem cell(s). In some such isolated cells or populations of cells, the cell or cells are mammalian cell(s) or non-human mammalian cell(s). In some such isolated cells or populations of cells, the cell or cells are human cell(s). In some such isolated cells or populations of cells, the cell or cells comprise or express a therapeutic molecule.
- the therapeutic molecule does not target CXCR4.
- the cell or cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
- the cell or cells are isolated from a subject.
- the cell or cells are for use in treatment of a subject having cells expressing the second isoform of CXCR4.
- the cell or cells are isolated from the subject.
- methods of making any of the above isolated cells or populations of cells comprise modifying a cell or population of cells to express the first isoform of CXCR4.
- the modifying comprises introducing an expression vector encoding the first isoform of CXCR4, or wherein the modifying comprises editing a genomic locus to express the first isoform of CXCR4.
- the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus.
- the editing comprises introducing into the cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the cells that express the first isoform of CXCR4.
- the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
- ZFN zinc finger nuclease
- TALEN transcription activator-like effector nuclease
- the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131.
- the Cas protein is a Cas9 protein.
- the exogenous donor nucleic acid comprises homology arms.
- the exogenous donor nucleic acid is a singlestranded oligodeoxynucleotide (ssODN).
- ssODN singlestranded oligodeoxynucleotide
- Some such genetically engineered proteins comprise an artificial mutation to provide an altered epitope, wherein the altered epitope is in a binding region of a CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered human CXCR4 protein compared to its ability to bind and/or inhibit a wild type human CXCR4 protein, and wherein the genetically engineered human CXCR4 protein retains binding to its endogenous ligand(s).
- the genetically engineered CXCR4 protein is functionally indistinguishable but immunologically distinguishable from a native CXCR4 protein.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the genetically engineered CXCR4 protein and the native CXCR4 protein are functionally indistinguishable but immunologically distinguishable by the CXCR4 antagonist.
- the CXCR4 antagonist is an antigenbinding protein.
- the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13
- the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigenbinding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29
- the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
- CXCR4 C-X-C chemokine receptor type 4
- methods of making a genetically engineered human C-X-C chemokine receptor type 4 (CXCR4) protein comprising an artificial mutation to provide an altered epitope, wherein the altered epitope is in a binding region of a CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered human CXCR4 protein compared to its ability to bind and/or inhibit a wild type human CXCR4 protein, and wherein the genetically engineered human CXCR4 protein retains binding to its endogenous ligand(s).
- CXCR4 C-X-C chemokine receptor type 4
- Some such methods comprise: (a) determining an epitope in the binding region of the CXCR4 antagonist; (b) selecting a site at which to generate the artificial mutation to provide the altered epitope in the binding region of the CXCR4 antagonist; (c) generating the genetically engineered human CXCR4 protein comprising the artificial mutation to provide the altered epitope in the binding region of the CXCR4 antagonist; and (d) testing the genetically engineered human CXCR4 protein to determine whether the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered human CXCR4 protein compared to its ability to bind and/or inhibit a wild type human CXCR4 protein and to determine whether the genetically engineered human CXCR4 protein retains binding to its endogenous ligand(s).
- the epitope of the CXCR4 antagonist is determined by alanine scanning mutational analysis, peptide blot analysis, peptide cleavage analysis, crystallographic studies, NMR analysis, epitope excision, epitope extraction, chemical modification of antigens, and/or hydrogen/deuterium exchange detected by mass spectrometry.
- the epitope of the CXCR4 antagonist is determined by high-resolution cryogenic electron microscopy analysis of the CXCR4 antagonist complexed with a human CXCR4 protein.
- the site of the artificial mutation is selected so that it: (I) is non-conserved between different mammalian species; (II) does not result in a secondary structure change; (III) is at a site that is accessible to ligand binding; (IV) is not located at a site involved in a predicted or experimentally established or confirmed protein-protein interaction; (V) does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking; (VI) does not result in deleting or introducing a posttranslational protein modification site; and/or (VII) is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction.
- generating the genetically engineered human CXCR4 protein comprises modifying a cell or population of cells to express the genetically engineered human CXCR4 protein.
- the modifying comprises introducing an expression vector encoding the genetically engineered human CXCR4 protein, or the modifying comprises editing a genomic locus to express the genetically engineered human CXCR4 protein.
- the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus.
- the editing comprises introducing into the cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate cells that express the genetically engineered human CXCR4 protein.
- the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
- ZFN zinc finger nuclease
- TALEN transcription activator-like effector nuclease
- the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131.
- the Cas protein is a Cas9 protein.
- the exogenous donor nucleic acid comprises homology arms. In some such methods, the exogenous donor nucleic acid is a single- stranded oligodeoxynucleotide (ssODN).
- the genetically engineered human CXCR4 protein is functionally indistinguishable but immunologically distinguishable from a native CXCR4 protein.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position SI 78 to position R183 and/or within a region from position R188 to position LI 94 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178 E179insK, S178 E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the genetically engineered human CXCR4 protein and the native CXCR4 protein are functionally indistinguishable but immunologically distinguishable by the CXCR4 antagonist.
- the CXCR4 antagonist is an antigen-binding protein.
- the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29
- the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
- CXCR4 C-X-C chemokine receptor type 4
- methods of making the isolated cells or populations of cells comprising modifying a cell or population of cells to express the first isoform of CXCR4, genetically engineered C-X-C chemokine receptor type 4 (CXCR4) proteins comprising an artificial mutation to provide an altered epitope, and nucleic acids encoding the genetically engineered CXCR4 proteins.
- methods for in vivo selective depletion of non-edited cells from the bone marrow and repopulation with edited cells in a subject in need thereof comprise: (a) providing edited cells that have been modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4, wherein the second isoform is expressed in non-edited cells of the subject; (b) administering the edited cells to the subject, and (c) selectively depleting non-edited cells from the bone marrow in the subject based on their expression of the second isoform of CXCR4.
- CXCR4 C-X-C chemokine receptor type 4
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
- the edited cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
- the edited cells express only the first isoform of CXCR4.
- a genomic locus has been edited to express the first isoform of CXCR4 in the edited cells.
- the genomic locus is a CXCR4 genomic locus.
- the genomic locus is not a CXCR4 genomic locus.
- the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
- the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
- the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the selective depletion in step (c) comprises administering a CXCR4 antagonist to the subject, wherein the CXCR4 antagonist specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4.
- the CXCR4 antagonist is an antigen-binding protein.
- the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
- the edited cells are hematopoietic cells.
- the edited cells are lymphocytes or lymphoid progenitor cells.
- the edited cells are T cells.
- the edited cells are alpha beta T cells.
- the edited cells are gamma delta T cells.
- the edited cells are tumor infdtrating lymphocytes (TILs).
- TILs tumor infdtrating lymphocytes
- the edited cells are B cells, optionally wherein the edited cells are immature B cells, and the method depletes non-edited mature B cells from the bone marrow.
- the edited cells are NK cells.
- the edited cells are hematopoietic stem and progenitor cells.
- the edited cells are derived from induced pluripotent stem cells.
- the edited cells are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells.
- the subject is a mammal or a non-human mammal, and the edited cells are mammalian cells or non-human mammalian cells.
- the subject is a human, and the edited cells are human cells.
- the edited cells comprise or express a therapeutic molecule.
- the edited cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- the edited cells are autologous.
- the edited cells are allogeneic or syngeneic.
- the subject has a hematopoietic malignancy
- the method is for treating the hematopoietic malignancy in the subject.
- the subject has cancer.
- the cancer is a hematologic cancer.
- the subject has defective immune cells or a genetic deficiency in hematopoiesis.
- the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
- steps (b) and (c) occur simultaneously. In some such methods, step (b) occurs prior to step (c). In some such methods, step (b) occurs subsequent to step (c). [0065] Some such methods further comprise generating the edited cells by modifying a population of cells to express the first isoform of CXCR4 prior to step (a).
- the population of cells is a population of induced pluripotent stem cells
- the method further comprises differentiating the edited induced pluripotent stem cells prior to step (a) into the edited cells that are administered in step (a), optionally wherein the induced pluripotent stem cells are differentiated into hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, NK cells, hematopoietic stem cells, or hematopoietic stem and progenitor cells.
- the population of cells is a population of hematopoietic stem cells or hematopoietic stem and progenitor cells
- the method further comprises differentiating the edited hematopoietic stem cells or hematopoietic stem and progenitor cells prior to step (a) into the edited cells that are administered in step (a), optionally wherein the hematopoietic stem cells or hematopoietic stem and progenitor cells are differentiated into differentiated hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, or NK cells.
- generating the edited cells comprises editing a genomic locus in the population of cells to express the first isoform of CXCR4 prior to step (a).
- the genomic locus is a CXCR4 genomic locus.
- the genomic locus is not a CXCR4 genomic locus.
- the editing comprises introducing into the population of cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the edited cells that express the first isoform of CXCR4.
- the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
- ZFN zinc finger nuclease
- TALEN transcription activator-like effector nuclease
- the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA- targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131.
- the Cas protein is a Cas9 protein.
- the exogenous donor nucleic acid comprises homology arms.
- the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN).
- combination medicaments for administration to a subject in need thereof.
- Some such combination medicaments comprise: (a) a population of cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4; and (b) a CXCR4 antagonist that specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4.
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
- the cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such combination medicaments, the cells express only the first isoform of CXCR4. In some such combination medicaments, a genomic locus has been edited to express the first isoform of CXCR4 in the population of cells. In some such combination medicaments, the genomic locus is a CXCR4 genomic locus. In some such combination medicaments, the genomic locus is not a CXCR4 genomic locus.
- the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
- the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
- the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position SI 78 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the CXCR4 antagonist is an antigen-binding protein.
- the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
- the cells are hematopoietic cells.
- the cells are lymphocytes or lymphoid progenitor cells.
- the cells are T cells.
- the cells are alpha beta T cells.
- the cells are gamma delta T cells.
- the cells are tumor infiltrating lymphocytes (TILs).
- TILs tumor infiltrating lymphocytes
- the cells are B cells.
- the cells are NK cells.
- the cells are hematopoietic stem cells or hematopoietic stem and progenitor cells.
- the cells are derived from induced pluripotent stem cells or are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells.
- the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells.
- the subject is a human, and the cells are human cells.
- the cells comprise or express a therapeutic molecule.
- the cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- the cells are autologous.
- the cells are allogeneic or syngeneic.
- the subject has a hematopoietic malignancy, and the combination medicament is for treating the hematopoietic malignancy in the subject.
- the subject has cancer.
- the cancer is a hematologic cancer.
- the subject has defective immune cells or a genetic deficiency in hematopoiesis.
- the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
- isolated cells or populations of cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4.
- CXCR4 C-X-C chemokine receptor type 4
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
- the cell or cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
- the cell or cells express only the first isoform of CXCR4.
- the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
- the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
- a genomic locus has been edited to express the first isoform of CXCR4 in the cell or cells.
- the genomic locus is a CXCR4 genomic locus.
- the genomic locus is not a CXCR4 genomic locus.
- the cell or cells further comprise an exogenous donor nucleic acid comprising the artificial mutation and a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus.
- the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
- ZFN zinc finger nuclease
- TALEN transcription activator-like effector nuclease
- the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA- targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131.
- the Cas protein is a Cas9 protein.
- the exogenous donor nucleic acid comprises homology arms. In some such isolated cells or populations of cells, the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN).
- the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable by a CXCR4 antagonist.
- the CXCR4 antagonist is an antigen-binding protein.
- the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
- the cell or cells are hematopoietic cell(s).
- the cell or cells are lymphocytes or lymphoid progenitor cell(s).
- the cell or cells are T cell(s).
- the cell or cells are alpha beta T cell(s).
- the cell or cells are gamma delta T cell(s).
- the cell or cells are tumor infiltrating lymphocyte(s) (TILs).
- TILs tumor infiltrating lymphocyte(s)
- the cell or cells are B cell(s).
- the cell or cells are NK cell(s). In some such isolated cells or populations of cells, the cell or cells are hematopoietic stem cell(s) or hematopoietic stem and progenitor cell(s). In some such isolated cells or populations of cells, the cell or cells are induced pluripotent stem cell(s). In some such isolated cells or populations of cells, the cell or cells are mammalian cell(s) or non-human mammalian cell(s). In some such isolated cells or populations of cells, the cell or cells are human cell(s). In some such isolated cells or populations of cells, the cell or cells comprise or express a therapeutic molecule.
- the cell or cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- CAR chimeric antigen receptor
- TCR exogenous T cell receptor
- the cell or cells are isolated from a subject.
- Some such isolated cells or populations of cells are for use in treatment of a subject having cells expressing the second isoform of CXCR4.
- the cell or cells are isolated from the subject.
- modifying comprises editing a genomic locus to express the first isoform of CXCR4.
- the genomic locus is a CXCR4 genomic locus. In some such methods, the genomic locus is not a CXCR4 genomic locus.
- the editing comprises introducing into the cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the edited cells that express the first isoform of CXCR4.
- the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
- ZFN zinc finger nuclease
- TALEN transcription activator-like effector nuclease
- the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131.
- the Cas protein is a Cas9 protein.
- the exogenous donor nucleic acid comprises homology arms. In some such methods, the exogenous donor nucleic acid is a singlestranded oligodeoxynucleotide (ssODN).
- CXCR4 C-X-C chemokine receptor type 4
- the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
- the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
- the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
- the genetically engineered CXCR4 protein and the native CXCR4 protein are functionally indistinguishable but immunologically distinguishable by a CXCR4 antagonist.
- the CXCR4 antagonist is an antigen-binding protein.
- the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
- the CXCR4 protein is a human CXCR4 protein.
- nucleic acids encoding any of the above genetically engineered CXCR4 proteins.
- FIGS 1A-1B Schematic of C-X-C motif chemokine receptor 4 (CXCR4) antibodyresistant modified receptor (ARMoR) strategy.
- CXCR4 C-X-C motif chemokine receptor 4
- ARMoR antibodyresistant modified receptor
- FIGs 2A-2B Anti-human CXCR4 (REGN7663, REGN7664) administration leads to leukocyte mobilization in CXCR4-humanized mice.
- Figure 2A shows a schematic of the experiment, and Figure 2B shows the experimental data.
- Figures 3A-3B Mobilization of hematopoietic progenitors in CXCR4-humanized mice following 5 consecutive doses of anti-CXCR4 REGN7664.
- Figure 3A shows a schematic of the experiment, and Figure 3B shows the experimental data.
- FIGS 4A-4B CXCR4 blockade in vivo with anti-CXCR4 strongly reduces recirculating mature B cells in the bone marrow (BM).
- Figure 4A shows a schematic of the experiment, and Figure 4B shows the experimental data.
- Figure 5 Effects of in vivo CXCR4 blockade on BM-resident mature and progenitor B cells.
- Figure 6 Human/mouse CXCR4 domain-swap chimeric constructs designed to test binding sites of anti-human-CXCR4 antibodies.
- FIGs 7A-7D Anti-human-CXCR4 monoclonal antibodies (mAbs) REGN7663 and REGN7664 bind the extracellular loop 2 (ECL2) domain of CXCR4.
- Figures 8A-8D Stable cell lines expressing domain-swap chimeric constructs confirm REGN7663 and REGN7664 binding in ECL2 region of human CXCR4.
- Figure 9 Modifications within the human CXCR4 ECL2 region designed to map binding determinants of anti-CXCR4 REGN7663 and REGN7664.
- Figures 10A-10D Determinants of anti-human-CXCR4 REGN7663 and REGN7664 binding in ECL2 domain.
- FIG. 11 Schematic of bioassay for CXCR4 signaling function in response to ligand
- CXCL12 C-X-C motif chemokine 12
- FIGS 12A-12C CXCR4 variants resistant to anti-CXCR4 binding retain signaling function in response to ligand CXCL12.
- Figure 13 Schematic of bioassay for blockade of CXCR4 signaling function by anti-
- FIGS 14A-14B CXCR4 variants with a loss of REGN7664 binding are resistant to REGN7664-mediated signaling block.
- Figure 15 Additional CXCR4 variants with alterations in established binding regions.
- Figures 16A-16B Anti-CXCR4 binding to additional human CXCR4 variants.
- FIGs 17A-17B Re-confirmation of anti-CXCR4 REGN7663 and REGN7664 binding patterns on select CXCR4 ARMoR variants in 293.CRE.Luc.CXCR4.KO bioassay cells.
- Figure 18 Antibody-resistant CXCR4 variants with minimal modifications retain signaling function in response to CXCL12.
- protein polypeptide
- polypeptide polymeric forms of amino acids of any length, including coded and non-coded amino acids and chemically or biochemically modified or derivatized amino acids.
- the terms also include polymers that have been modified, such as polypeptides having modified peptide backbones.
- domain refers to any part of a protein or polypeptide having a particular function or structure.
- Proteins are said to have an “N-terminus” (amino-terminus) and a “C-terminus” (carboxy -terminus or carboxyl-terminus).
- N-terminus relates to the start of a protein or polypeptide, terminated by an amino acid with a free amine group (-NH2).
- C- terminus relates to the end of an amino acid chain (protein or polypeptide), terminated by a free carboxyl group (-COOH).
- nucleic acid and “polynucleotide,” used interchangeably herein, include polymeric forms of nucleotides of any length, including ribonucleotides, deoxyribonucleotides, or analogs or modified versions thereof. They include single-, double-, and multi-stranded DNA or RNA, genomic DNA, cDNA, DNA-RNA hybrids, and polymers comprising purine bases, pyrimidine bases, or other natural, chemically modified, biochemically modified, non-natural, or derivatized nucleotide bases.
- Nucleic acids are said to have “5’ ends” and “3’ ends” because mononucleotides are reacted to make oligonucleotides in a manner such that the 5’ phosphate of one mononucleotide pentose ring is attached to the 3’ oxygen of its neighbor in one direction via a phosphodiester linkage.
- An end of an oligonucleotide is referred to as the “5’ end” if its 5’ phosphate is not linked to the 3’ oxygen of a mononucleotide pentose ring.
- An end of an oligonucleotide is referred to as the “3’ end” if its 3’ oxygen is not linked to a 5’ phosphate of another mononucleotide pentose ring.
- a nucleic acid sequence even if internal to a larger oligonucleotide, also may be said to have 5’ and 3’ ends.
- discrete elements are referred to as being “upstream” or 5’ of the “downstream” or 3’ elements.
- expression vector or “expression construct” or “expression cassette” refers to a recombinant nucleic acid containing a desired coding sequence operably linked to appropriate nucleic acid sequences necessary for the expression of the operably linked coding sequence in a particular host cell or organism.
- Nucleic acid sequences necessary for expression in prokaryotes usually include a promoter, an operator (optional), and a ribosome binding site, as well as other sequences.
- Eukaryotic cells are generally known to utilize promoters, enhancers, and termination and polyadenylation signals, although some elements may be deleted and other elements added without sacrificing the necessary expression.
- a “promoter” is a regulatory region of DNA usually comprising a TATA box capable of directing RNA polymerase II to initiate RNA synthesis at the appropriate transcription initiation site for a particular polynucleotide sequence.
- a “promoter” or “promoter sequence” is a DNA regulatory region capable of binding an RNA polymerase in a cell (e.g., directly or through other promoter-bound proteins or substances) and initiating transcription of a coding sequence.
- a promoter may be operably linked to other expression control sequences, including enhancer and repressor sequences and/or with a polynucleotide of the invention.
- Promoters which may be used to control gene expression include, but are not limited to, cytomegalovirus (CMV) promoter (U.S. Pat. Nos. 5,385,839 and 5,168,062, each of which is herein incorporated by reference in its entirety for all purposes), the SV40 early promoter region (Benoist et al. (1981) Nature 290:304-310, herein incorporated by reference in its entirety for all purposes), the promoter contained in the 3' long terminal repeat of Rous sarcoma virus (Yamamoto et al. (1980) Cell 22:787-797, herein incorporated by reference in its entirety for all purposes), the herpes thymidine kinase promoter (Wagner et al.
- CMV cytomegalovirus
- a promoter may additionally comprise other regions which influence the transcription initiation rate.
- the promoter sequences modulate transcription of an operably linked polynucleotide.
- a promoter can be active in one or more of the cell types (e.g., but not limited to, a eukaryotic cell, a non-human mammalian cell, a human cell, a rodent cell, a pluripotent cell, a one-cell stage embryo, a differentiated cell, or a combination thereof).
- a promoter can be, for example, a constitutively active promoter, a conditional promoter, an inducible promoter, a temporally restricted promoter (e.g., but not limited to, a developmentally regulated promoter), or a spatially restricted promoter (e.g., but not limited to, a cell-specific or tissue-specific promoter).
- “Operable linkage” or being “operably linked” includes juxtaposition of two or more components (e.g., but not limited to, a promoter and another sequence element) such that both components function normally and allow the possibility that at least one of the components can mediate a function that is exerted upon at least one of the other components.
- a promoter can be operably linked to a coding sequence if the promoter controls the level of transcription of the coding sequence in response to the presence or absence of one or more transcriptional regulatory factors.
- Operable linkage can include such sequences being contiguous with each other or acting in trans (e.g., but not limited to, a regulatory sequence can act at a distance to control transcription of the coding sequence).
- a polynucleotide encoding a polypeptide is “operably linked” to a promoter or other expression control sequence when, in a cell or other expression system, the sequence directs RNA polymerase mediated transcription of the coding sequence into RNA, preferably mRNA, which then may be RNA spliced (if it contains introns) and, optionally, translated into a protein encoded by the coding sequence.
- RNA preferably mRNA
- isolated with respect to proteins, nucleic acids, and cells includes proteins, nucleic acids, and cells that are relatively purified with respect to other cellular or organism components that may normally be present in situ, up to and including a substantially pure preparation of the protein, nucleic acid, or cell.
- isolated antigen-binding proteins e.g., antibodies or antigen-binding fragments thereof
- polypeptides polynucleotides and vectors
- biological molecules include nucleic acids, proteins, other antibodies or antigen-binding fragments, lipids, carbohydrates, or other material such as cellular debris and growth medium.
- An isolated antigen-binding protein may further be at least partially free of expression system components such as biological molecules from a host cell or of the growth medium thereof.
- isolated is not intended to refer to a complete absence of such biological molecules (e.g., minor or insignificant amounts of impurity may remain) or to an absence of water, buffers, or salts or to components of a pharmaceutical formulation that includes the antigen-binding proteins (e.g., antibodies or antigen-binding fragments).
- antigen-binding proteins e.g., antibodies or antigen-binding fragments
- the term “isolated” may include proteins and nucleic acids that have no naturally occurring counterpart or proteins or nucleic acids that have been chemically synthesized and are thus substantially uncontaminated by other proteins or nucleic acids.
- isolated may include proteins, nucleic acids, or cells that have been separated or purified from most other cellular components or organism components with which they are naturally accompanied (e g., but not limited to, other cellular proteins, nucleic acids, or cellular or extracellular components).
- Codon optimization takes advantage of the degeneracy of codons, as exhibited by the multiplicity of three-base pair codon combinations that specify an amino acid, and generally includes a process of modifying a nucleic acid sequence for enhanced expression in particular host cells by replacing at least one codon of the native sequence with a codon that is more frequently or most frequently used in the genes of the host cell while maintaining the native amino acid sequence.
- a nucleic acid encoding a protein can be modified to substitute codons having a higher frequency of usage in a given prokaryotic or eukaryotic cell, including a bacterial cell, a yeast cell, a human cell, a non-human cell, a mammalian cell, a rodent cell, a mouse cell, a rat cell, a hamster cell, or any other host cell, as compared to the naturally occurring nucleic acid sequence.
- Codon usage tables are readily available, for example, at the “Codon Usage Database.” These tables can be adapted in a number of ways. See Nakamura et al. (2000) Nucleic Acids Res.
- locus refers to a specific location of a gene (or significant sequence), DNA sequence, polypeptide-encoding sequence, or position on a chromosome of the genome of an organism.
- locus may refer to the specific location of a CXCR4 gene, CXCR4 DNA sequence, CXCR4-protein-encoding sequence, or CXCR4 position on a chromosome of the genome of an organism that has been identified as to where such a sequence resides.
- a “CXCR4 locus” may comprise a regulatory element of a CXCR4 gene, including, as a non-limiting example, an enhancer, a promoter, 5’ and/or 3’ untranslated region (UTR), or a combination thereof.
- the term “gene” refers to DNA sequences in a chromosome that may contain, if naturally present, at least one coding and at least one non-coding region.
- the DNA sequence in a chromosome that codes for a product e.g., but not limited to, an RNA product and/or a polypeptide product
- non-coding sequences including regulatory sequences (e g., but not limited to, promoters, enhancers, and transcription factor binding sites), polyadenylation signals, internal ribosome entry sites, silencers, insulating sequence, and matrix attachment regions may be present in a gene. These sequences may be close to the coding region of the gene (e.g., but not limited to, within 10 kb) or at distant sites, and they influence the level or rate of transcription and translation of the gene.
- allele refers to a variant form of a gene. Some genes have a variety of different forms, which are located at the same position, or genetic locus, on a chromosome. A diploid organism has two alleles at each genetic locus. Each pair of alleles represents the genotype of a specific genetic locus. Genotypes are described as homozygous if there are two identical alleles at a particular locus and as heterozygous if the two alleles differ.
- wild type includes entities having a structure (e.g., but not limited to, nucleotide sequence or amino acid sequence sequence) as found in a normal (as contrasted with mutant, diseased, altered, or so forth) state or context. Wild type genes and polypeptides often exist in multiple different forms (e.g., alleles).
- variant refers to a nucleotide sequence differing from the sequence most prevalent in a population (e.g., but not limited to, by one nucleotide) or a protein sequence different from the sequence most prevalent in a population (e.g., but not limited to, by one amino acid).
- fragment when referring to a protein, means a protein that is shorter or has fewer amino acids than the full-length protein.
- fragment when referring to a nucleic acid, means a nucleic acid that is shorter or has fewer nucleotides than the full-length nucleic acid.
- Non-limiting examples of a protein fragment can include an N-terminal fragment (i.e., removal of a portion of the C-terminal end of the protein), a C-terminal fragment (i.e., removal of a portion of the N-terminal end of the protein), or an internal fragment (i.e., removal of a portion of an internal portion of the protein).
- sequence identity in the context of two polynucleotides or polypeptide sequences refers to the residues in the two sequences that are the same when aligned for maximum correspondence over a specified comparison window.
- residue positions which are not identical often differ by conservative amino acid substitutions, where amino acid residues are substituted for other amino acid residues with similar chemical properties (e.g., but not limited to, charge or hydrophobicity) and therefore do not change the functional properties of the molecule.
- sequences differ in conservative substitutions the percent sequence identity may be adjusted upwards to correct for the conservative nature of the substitution.
- Sequences that differ by such conservative substitutions are said to have “sequence similarity” or “similarity.” Means for making this adjustment are well known. Typically, this involves scoring a conservative substitution as a partial rather than a full mismatch, thereby increasing the percentage sequence identity. Thus, as a non-limiting example, where an identical amino acid is given a score of 1 and a nonconservative substitution is given a score of zero, a conservative substitution is given a score between zero and 1. The scoring of conservative substitutions is calculated, e.g., as implemented in the program PC/GENE (Intelligenetics, Mountain View, California).
- Percentage of sequence identity includes the value determined by comparing two optimally aligned sequences (greatest number of perfectly matched residues) over a comparison window, wherein the portion of the polynucleotide sequence in the comparison window may comprise additions or deletions (i.e., gaps) as compared to the reference sequence (which does not comprise additions or deletions) for optimal alignment of the two sequences. The percentage is calculated by determining the number of positions at which the identical nucleic acid base or amino acid residue occurs in both sequences to yield the number of matched positions, dividing the number of matched positions by the total number of positions in the window of comparison, and multiplying the result by 100 to yield the percentage of sequence identity. Unless otherwise specified (e.g., the shorter sequence includes a linked heterologous sequence), the comparison window is the full length of the shorter of the two sequences being compared.
- sequence identity/similarity values include the value obtained using GAP Version 10 using the following parameters: % identity and % similarity for a nucleotide sequence using GAP Weight of 50 and Length Weight of 3, and the nwsgapdna.cmp scoring matrix; % identity and % similarity for an amino acid sequence using GAP Weight of 8 and Length Weight of 2, and the BLOSUM62 scoring matrix; or any equivalent program thereof.
- “Equivalent program” includes any sequence comparison program that, for any two sequences in question, generates an alignment having identical nucleotide or amino acid residue matches and an identical percent sequence identity when compared to the corresponding alignment generated by GAP Version 10.
- zrt vitro includes artificial environments and processes or reactions that occur within an artificial environment (e.g., but not limited to, a test tube or an isolated cell or cell line).
- in vivo includes natural environments (e.g., but not limited to, an organism or body or a cell or tissue within an organism or body) and to processes or reactions that occur within a natural environment.
- ex vivo includes cells that have been removed from the body of an individual and processes or reactions that occur within such cells.
- Designation of a range of values includes all integers within or defining the range, and all subranges defined by integers within the range.
- Immune cell therapies hold enormous promise for many human diseases.
- One of the oldest examples is bone marrow transplantation, in which a recipient’s entire immune system can be replaced with an autologous or allogeneic bone marrow graft. This procedure allows the correction of congenital hematopoietic deficiencies, and also the re-population of the immune system following treatments to eradicate hematologic malignancies.
- Newer examples include immune cells engineered with antigen receptors to target tumors (e.g., CAR-T, eTCR, CAR-NK, and CAR-macrophage). In all these cases, patients must undergo “conditioning” regimens prior to cell transplant, which can serve to “make room” in the host immune niche to support donor cell uptake, and in some cases to suppress host versus graft immune responses that can lead to graft rejection.
- Conditioning regimens range in intensity from partially to fully myeloablative, the latter necessary when pathogenic host immune cells must be fully eradicated (e.g., for hematologic malignances). Regardless, the current standards of care for host conditioning have major drawbacks.
- conditioning agents are toxins (e.g., DNA damagers) that are not specific for the desired target cells, and thus carry harmful and even life-threatening risks for patients.
- conditioning agents are as toxic to donor cells as to host, and so must be discontinued prior to transplant to avoid inhibition of life-saving cellular therapies.
- Lymphosuppressive agents have numerous potential applications to host conditioning for transplant and adoptive cell therapies: (1) preventing rejection of allogeneic grafts through T and NK cell suppression (e.g., bone marrow transplant; gene corrective cell therapies); (2) non- genotoxic clearance of immune niche space for engineered cell therapies (e.g., CAR-T, TCR-T, Treg, NK, B cell, progenitor cells); (3) elimination of endogenous cytokine “sinks,” making essential factors more available to grafter cells; and (4) immune suppression post-transplant that is gentler and less toxic than standard of care agents.
- T and NK cell suppression e.g., bone marrow transplant; gene corrective cell therapies
- engineered cell therapies e.g., CAR-T, TCR-T, Treg, NK, B cell, progenitor cells
- elimination of endogenous cytokine “sinksinks,” making essential factors more available to grafter cells e.g., CAR-
- An obstacle to use of lymphosuppressive agents as conditioning therapies is the susceptibility of grafted cells, in addition to the target host cells, to their effects.
- Provided herein is a strategy to address these challenges through (1) the development of targeted conditioning regimens leveraging, e.g., antibodies that specifically target the desired host cells — as monotherapies, combinations, bispecific antibodies, antibody drug conjugates (ADCs), or scFv- engineered CAR-T, and (2) modification of donor cells to render them resistant to, e.g., these antibody-based conditioning agents.
- ADCs antibody drug conjugates
- scFv- engineered CAR-T modification of donor cells to render them resistant to, e.g., these antibody-based conditioning agents.
- Collectively this comprises the antibody-resistant modified receptor (ARMoR) concept.
- the underlying idea is to engineer minimal changes to immune cell receptors in grafted donor cells that will abolish binding by suppressive antibody agents.
- FIG. 1A and IB A schematic of this strategy is shown in Figures 1A and IB, using the example of an engineered C- X-C motif chemokine receptor 4 (CXCR4) variant that is resistant to anti-CXCR4 mediated blockade of interaction of CXCR4 with its ligand C-X-C motif chemokine 12 (CXCL12).
- CXCR4 C- X-C motif chemokine receptor 4
- CXCL12 CXCL12
- the goal is to introduce into a cell therapy product a fully functional form of the receptor that is not recognized by the conditioning agent. This can be achieved with alterations to the antibody recognition site that abolish binding but preserve receptor function.
- host cells remain susceptible to the conditioning agent, but engineered grafted cells are resistant and thus gain a competitive advantage in re-populating the host.
- the fundamental aim is to afford grafted cellular therapies a competitive advantage in the host patient, by applying selective pressure that specifically targets host cells while sparing donor-derived cell therapies.
- Methods for improving engraftment of donor cells in a subject thereof are provided. Such methods can comprise providing donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4), administering the donor cells to the subject, and then selectively depleting host cells in the subject based on their expression of a second isoform of the target protein, thereby improving engraftment of donor cells in the subject.
- a target protein e.g., CXCR4
- such methods can comprise providing donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4), administering the donor cells to the subject, and then selectively inhibiting host cells in the subject based on their expression of a second isoform of the target protein, thereby improving engraftment of donor cells in the subject.
- a target protein e.g., CXCR4
- the selective inhibition can comprise selectively depleting host cells from the bone marrow.
- such methods can comprise providing donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4), administering the donor cells to the subject, and then selectively ablating host cells in the subject based on their expression of a second isoform of the target protein, thereby improving engraftment of donor cells in the subject.
- the donor cells can express only the first isoform, or they can express both the first and second isoforms of the target protein.
- the first isoform can be functionally indistinguishable but immunologically distinguishable from the second isoform of the target protein.
- the selective inhibition of host cells can be based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein.
- the selective inhibition of host cells can be based on their expression of the second isoform regardless of their expression of the first isoform of the target protein.
- Selective inhibition of host cells does not comprise ablation (i.e., killing) of host cells by a mechanism extrinsic to a cell, such as via an active killing mechanism.
- Selective inhibition of host cells does not comprise ablation (i.e., killing) of host cells by an active killing mechanism.
- An active killing mechanism means the agent directly kills the host cells by cytotoxic mechanisms (e.g., antibody-drug conjugate (ADC), antibody radioconjugate (ARC), CAR-T, or other engineered cytotoxicity) or recruits host cytotoxic effector mechanisms (e.g., complement-dependent cytotoxicity (CDC), antibody-dependent cellular cytotoxicity (ADCC), antibody-dependent cellular phagocytosis (ADCP)), as opposed blocking a cellular function (e.g. growth or cytokine signaling, chemotactic tissue homing, cell-cell adhesion; e.g., as with selective inhibition) without engaging extrinsic cytotoxic effectors.
- cytotoxic mechanisms e.g., antibody-drug conjugate (ADC), antibody radioconjugate (ARC), CAR-T, or other engineered cytotoxicity
- host cytotoxic effector mechanisms e.g., complement-dependent cytotoxicity (CDC), antibody-dependent cellular cytotoxicity (ADCC), antibody-dependent
- Non-ablative conditioning may avoid undesired and harmful effects of ablative agents, including direct killing of non-target (e.g., non-hematopoietic) cells expressing drug target antigens, indirect toxicities to target-adjacent tissues, and prolonged immune suppression in the post-transplant period.
- non-target e.g., non-hematopoietic
- the selective inhibition of host cells can comprise: (1) blocking growth of the host cells to provide a competitive growth advantage to the donor cells; (2) blocking localization or trafficking of the host cells to provide a competitive homing advantage to the donor cells; (3) blocking a cell-cell interaction or adhesion of the host cells to provide a competitive tissue infiltration advantage to the donor cells; or (4) blocking immune cell activation in the host cells to provide a competitive advantage to the donor cells.
- the selective inhibition of host cells can comprise selectively depleting host cells from the bone marrow.
- the combination comprises (1) a population of donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4) and (2) an agent (e.g., antagonist, such as an antigen-binding protein) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
- a target protein e.g., CXCR4
- an agent e.g., antagonist, such as an antigen-binding protein
- selective depletion means selective mobilization of non-edited cells from the bone marrow to the periphery.
- Such methods can comprise providing cells edited to express a first isoform of a target protein (e.g., C-X-C motif chemokine receptor 4 (CXCR4)), administering the edited cells to the subject, and then selectively depleting non-edited cells in the subject based on their expression of the second isoform of the target protein (e.g., based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein, or based on their expression of the second isoform regardless of their of expression of the first isoform of the target protein).
- the first isoform can be functionally indistinguishable but immunologically distinguishable from a second isoform of the target protein.
- the edited cells can express only the first isoform, or they can express both the first and second isoforms of the target protein.
- combinations for administration to a subject in need thereof wherein the combination comprises (1) a population of cells edited to express a first isoform of a target protein (e.g., CXCR4) and (2) an agent (e.g., antagonist, such as an anti-CXCR4 antigen-binding protein) that specifically binds to a second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
- a target protein e.g., CXCR4
- an agent e.g., antagonist, such as an anti-CXCR4 antigen-binding protein
- Isolated cells or populations of cells are also provided modified to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein.
- the cells can express only the first isoform, or they can express both the first and second isoforms.
- the first isoform can be functionally indistinguishable but immunologically distinguishable from the second isoform.
- the cells can express only the first isoform, or they can express both the first and second isoforms.
- Isolated cells or populations of cells are also provided in which a genomic locus has been edited to express the first isoform of the target protein that is different from the second isoform. Methods of making such cells are also provided.
- Isolated cells or populations of cells are also provided that are edited (i.e., modified) to express a first isoform of CXCR4 that is different from a second isoform of CXCR4.
- the first isoform can be functionally indistinguishable but immunologically distinguishable from a second isoform of the target protein.
- the edited cells can express only the first isoform, or they can express both the first and second isoforms of the target protein. Methods of making such cells are also provided, and engineered CXCR4 proteins and nucleic acids encoding engineered CXCR4 proteins are also provided.
- the cells in the compositions and methods comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR) (e.g., CAR-T cells, CAR-NK cells), or an exogenous T cell receptor (TCR).
- a therapeutic molecule such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR) (e.g., CAR-T cells, CAR-NK cells), or an exogenous T cell receptor (TCR).
- the therapeutic molecule, immunoglobulin, CAR, or exogenous TCR does not target the target protein (e.g., CXCR4).
- the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule).
- the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer).
- the therapeutic molecule may target diseased cells and/or an antigen expressed on the diseased cells (e g., a tumor-associated antigen).
- methods for improving engraftment of donor cells in a subject can comprise providing donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells of the subject.
- the target protein can be, for example CXCR4.
- the first isoform can be functionally indistinguishable but immunologically distinguishable from a second isoform of the target protein.
- the donor cells express only the first isoform of the target protein.
- the donor cells express both the first and second isoforms of the target protein.
- Such methods can comprise providing donor cells in which a target genomic locus has been edited to express the first isoform of a target protein.
- the donor cells can then be administered to the subject, and host cells in the subject can be selectively depleted based on their expression of the second isoform of the target protein, thereby improving engraftment of donor cells in the subject.
- the donor cells can then be administered to the subject, and the subject can be provided with means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
- the selective depletion of host cells can be based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein.
- the selective depletion of host cells can be based on their expression of the second isoform regardless of their expression of the first isoform of the target protein.
- host cells in the subject can be selectively inhibited based on their expression of the second isoform of the target protein, thereby improving engraftment of donor cells in the subject.
- the selective inhibition of host cells can be based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein.
- the selective inhibition of host cells can be based on their expression of the second isoform regardless of their expression of the first isoform of the target protein.
- host cells in the subject can be selectively ablated based on their expression of the second isoform of the target protein, thereby improving engraftment of donor cells in the subject.
- the selective ablation of host cells can be based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein.
- the selective depletion of host cells can be based on their expression of the second isoform regardless of their expression of the first isoform of the target protein.
- the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
- selective depletion means selective mobilization of non-edited cells from the bone marrow to the periphery.
- Such methods can comprise providing edited cells that have been modified to express a first isoform of a target protein that is different from a second isoform of the target protein, wherein the second isoform is expressed in non-edited cells of the subject.
- the first isoform can be functionally indistinguishable but immunologically distinguishable from a second isoform of the target protein.
- the edited cells express only the first isoform of the target protein (e.g., CXCR4). In other embodiments, the edited cells express both the first and second isoforms of the target protein (e.g., CXCR4).
- the edited cells can then be administered to the subject, and non-edited cells in the subject can be selectively depleted based on their expression of the second isoform of the target protein (e.g., based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein, or based on their expression of the second isoform regardless of their of expression of the first isoform of the target protein).
- Such selective depletion can include, in a non-limiting example, bone marrow egress of non-edited cells in the subject to “make room” in the host immune niche for engraftment of the edited cells administered to the subject.
- the donor cells or edited cells can be any suitable cells.
- the host cells or non-edited cells can be any suitable cells.
- the cells are immune cells.
- the cells are hematopoietic cells.
- the term hematopoietic cell refers to a cell originated from a hematopoietic stem cell or a hematopoietic progenitor cell and/or originated from an erythroid, lymphoid, or myeloid lineage.
- the cells are immune cells.
- immune cell refers to any cell derived from a hematopoietic stem cell that plays a role in the immune response.
- Immune cells include, without limitation, lymphocytes, such as T cells and B cells, antigen-presenting cells (APC), dendritic cells, monocytes, macrophages, natural killer (NK) cells, mast cells, basophils, eosinophils, or neutrophils, as well as any progenitors of such cells.
- the cells are lymphocytes or lymphoid progenitor cells.
- the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infiltrating lymphocytes (TILs), or any combination thereof).
- the cells are alpha beta T cells. In some embodiments, the cells are gamma delta T cells. In some embodiments, the cells are TILs. In some embodiments, the cells are B cells. In some embodiments, the cells are natural killer (NK) cells. In some embodiments, the cells are innate lymphoid cells. In some embodiments, the cells are dendritic cells. In some embodiments, the cells are hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) or descendants thereof.
- HSCs hematopoietic stem cells
- HSPCs hematopoietic stem and progenitor cells
- HSCs are capable of giving rise to both myeloid and lymphoid progenitor cells that further give rise to myeloid cells (e.g., monocytes, macrophages, neutrophils, basophils, dendritic cells, erythrocytes, platelets, etc.) and lymphoid cells (e.g., T cells, B cells, NK cells), respectively.
- myeloid cells e.g., monocytes, macrophages, neutrophils, basophils, dendritic cells, erythrocytes, platelets, etc.
- lymphoid cells e.g., T cells, B cells, NK cells
- the cells are derived from induced pluripotent stem cells (e.g., NK cells derived from induced pluripotent stem cells).
- the cells are derived from HSCs or HSPCs.
- the cells comprise a genetic modification (insertion of a transgene, correction of a mutation, deletion or inactivation of a gene (e g., insertion of premature stop codon or insertion of regulatory repressor sequence), or a change in an epigenetic modification important for expression of a gene) correcting or counteracting a disease-related gene defect present in a subject.
- the cells e.g., donor cells or edited cells
- the cells comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR) (e.g., CAR-T cells, CAR-NK cells), or an exogenous T cell receptor (TCR).
- a therapeutic molecule such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR) (e.g., CAR-T cells, CAR-NK cells), or an exogenous T cell receptor (TCR).
- CAR chimeric antigen receptor
- TCR exogenous T cell receptor
- the cells e.g., donor cells or edited cells
- the cells comprise a bicistronic nucleic acid construct encoding the therapeutic molecule and the first isoform of the target protein. See, e.g., Yeku et al. (2017) Sci. Rep. 7
- the bicistronic construct can encode both a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and the first isoform (e.g., a modified isoform) of the target protein (e.g., CXCR4).
- a therapeutic protein e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin
- the first isoform e.g., a modified isoform of the target protein (e.g., CXCR4).
- the bicistronic construct encodes a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and a modified isoform of CXCR4.
- a therapeutic protein e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin
- the therapeutic molecule, immunoglobulin, CAR, or exogenous TCR does not target the target protein (e.g., CXCR4).
- the cells e.g., donor cells or edited cells
- the cells e.g., donor cells or edited cells
- the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule).
- the therapeutic molecule targets diseased cells and/or an antigen expressed on the diseased cells (e.g., a tumor-associated antigen).
- the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer).
- the target protein e.g., the target protein does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer.
- Exemplary types of cancers and tumors that can be treated are described elsewhere herein.
- the donor cells are autologous (i.e., from the subject).
- the donor cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation).
- the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the donor cells are mammalian cells or non-human mammalian cells).
- the donor cells are human cells (e.g., the subject is a human, and the cells are human cells).
- the target protein is C-X-C chemokine receptor type 4 (also known as C-X-C motif chemokine receptor 4, CXCR4, FB22, Fusin, HM89, LCR1, Leukocyte-derived seven transmembrane domain receptor (LESTR), Lipopolysaccharide-associated protein 3 (LAP-3; LPS-associated protein 3), NPY3R, NPYRL, Stromal cell-derived factor 1 receptor (SDF-1 receptor), and CD184).
- C-X-C chemokine receptor type 4 also known as C-X-C motif chemokine receptor 4, CXCR4, FB22, Fusin, HM89, LCR1, Leukocyte-derived seven transmembrane domain receptor (LESTR), Lipopolysaccharide-associated protein 3 (LAP-3; LPS-associated protein 3), NPY3R, NPYRL, Stromal cell-derived factor 1 receptor (SDF-1 receptor), and CD184).
- CXCR4 is a 7- transmembrane receptor for the C-X-C chemokine CXCL12/SDF-1 that plays a role in cell migration and transduces a signal by increasing intracellular calcium ion levels and enhancing MAPK1/MAPK3 activation.
- CXCR4 can also act as a receptor for extracellular ubiquitin, the binding of which leads to enhanced intracellular calcium levels and reduced cellular cAMP.
- CXCR4 is involved in hematopoiesis, cardiac ventricular septum formation, and plays an essential role in vascularization of the gastrointestinal tract.
- CXCR4 also has several roles in pathogen response, including binding bacterial lipopolysaccharide (LPS) to mediate an LPS- induced inflammatory response that comprises TNF secretion by monocytes and serving as a coreceptor (with CD4) human immunodeficiency virus (HIV) to promote Env-mediated fusion of the virus with T cells.
- LPS bacterial lipopolysaccharide
- HAV human immunodeficiency virus
- the target protein is human CXCR4.
- Human CXCR4 is assigned UniProt Accession No. P61073.
- the canonical isoform of human CXCR4 is assigned UniProt Accession No. P61073-1 and NCBI Accession No. NP_003458.1 and is set forth in SEQ ID NO: 1.
- An exemplary messenger RNA encoding the canonical isoform of human CXCR4 is assigned NCBI Accession No. NM_003467.3 and is set forth in SEQ ID NO: 2.
- the coding sequence for the canonical isoform of human CXCR4 is assigned CCDS ID CCDS46420.1 and is set forth in SEQ ID NO: 3.
- CXCR4 human C-X-C motif chemokine receptor 4
- NCBI GenelD 7852 NCBI GenelD 7852. It is at location 2q22.1 (assembly: GRCh38.pl4 (GCF 000001405.40); location: NC 000002.12 (136114349..136118149, complement)).
- the expression “functionally indistinguishable” refers to a first and a second isoform that are equally capable of performing the same function (e.g., binding to an endogenous ligand (e.g., CXCL12 for CXCR4) and/or activating downstream signaling pathways (e.g., CXCR4 signaling pathways)) within a cell (e.g., without significant impairment).
- the first and the second isoform are functionally largely indistinguishable.
- a slight functional impairment can be acceptable.
- the function that is largely indistinguishable can be, for example, binding to an endogenous ligand (e.g., CXCL12 for CXCR4) and/or activating downstream signaling pathways.
- the function can be binding to the endogenous ligand (e.g., CXCL12 for CXCR4) and activating downstream signaling pathways.
- the expression “immunologically distinguishable” refers to a first and a second isoform of a protein that can be distinguished by an antigen-binding protein (e.g., specifically binding to either the first or the second isoform but not the other), such as the antigen-binding protein specifically binding only to the second (unmodified) isoform of the target protein.
- the antigen-binding proteins are able to discriminate between the two isoforms by specifically binding only one isoform, but not the other one.
- the endogenous ligand e g., CXCL12 for CXCR4
- binds both the first and second isoforms e.g., equally, or with only slight impairment
- an engineered antigen-binding protein such as an antibody is able to discriminate between the two isoforms by specifically binding only one isoform, but not the other one (e.g., specifically binding only to the second but not the first isoform).
- the second isoform of the target protein refers to the form that is present in the subject.
- the second isoform of the target protein refers to the wild type form or native form of the target protein (i.e., the form that usually occurs in nature)
- the first isoform refers to an isoform obtained by introducing a mutation in the nucleic acid sequence encoding the second isoform.
- the native form of a protein refers to a protein that is encoded by a nucleic acid sequence within the genome of the cell and that has not been inserted or mutated by genetic manipulation (i.e., a native protein is a protein that is not a transgenic protein or a genetically engineered protein).
- the mutation in the first isoform can be any type of mutation and any size mutation.
- the mutation comprises an insertion, a deletion and/or a substitution of 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids (e.g., 1-20 amino acids, 1-5 amino acids, 1-3 amino acids, or 1 amino acid).
- the mutation comprises one or more (e.g., three) substitutions (e.g., comprises one or more (e.g., three) substitutions of 1 amino acid each).
- the mutation consists essentially of one or more (e.g., three) substitutions (e.g., consists essentially of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation consists of one or more (e.g., three) substitutions (e.g., consists of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation comprises an insertion (e.g., comprises an insertion of 1 amino acid). In some embodiments, the mutation consists essentially of an insertion (e.g., consists essentially of an insertion of 1 amino acid).
- the mutation consists of an insertion (e.g., consists of an insertion of 1 amino acid).
- the mutation can be at any site in the target protein.
- the target protein is a cell surface protein
- the mutation can in some embodiments be in the extracellular domain of the target protein.
- the site of the mutation can be a site that is non-conserved between different mammalian species.
- the mutation does not result in a secondary structure change in the surface protein.
- the mutation is within the epitope targeted by an antigen-binding protein or is at a site that is accessible to ligand binding.
- the mutation is not located at a site involved in a predicted or experimentally established or confirmed proteinprotein interaction of the surface protein. In some embodiments, the mutation does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking. In some embodiments, the mutation does not result in deleting or introducing a posttranslational protein modification site, such as a glycosylation site. In some embodiments, the mutation is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction. In instances where an antibody or antigen-binding protein reactive against a target protein already exists, the information regarding the epitope of the target protein that is recognized by the antibody or antigen-binding protein can be used to select the site of the mutation.
- the first isoform of the target protein is a genetically engineered isoform of the target protein.
- the first isoform of the target protein can be genetically engineered to comprise a mutation (e.g., an artificial mutation that is not naturally occurring) to provide an altered epitope.
- the altered epitope can be, for example, in the binding region of an antigen-binding protein such as an antibody.
- the target protein is CXCR4 (e.g., human CXCR4), and the altered epitope is in a binding region of the REGN7663 or REGN7664 anti-CXCR4 antibodies described elsewhere herein.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) encoded by nucleotides within coding exon 2 of the CXCR4 gene (e.g., human CXCR4 gene).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the ECL2 region of CXCR4 (e.g., human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position A175 to position V198 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position SI 78 to position R183 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position R188 to position LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the REGN7663 and REGN7664 binding region (SEQ ID NO: 57).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198.
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198.
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., an insertion) between Al 75 and N 176, between N176 and VI 77, between VI 77 and S178, between S178 and E179, between E179 and A180, between A180 and D181, between D181 and D182, between D182 and R183, between R183 and Y184, between Y184 and 1185, between 1185 and C186, between C186 and D187, between D187 and R188, between R188 and Fl 89, between Fl 89 and Y190, between Y190 and Pl 91, between P191 and N192, between N192 and DI 93, and/or between DI 93 and LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e g., an insertion) between S178 and E179.
- the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198, and a mutation (e.g., an insertion) between S178 and E179.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) or combination of mutations as set forth in Table 1.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion), or combination of mutations, as set forth in pMM626, pMM630, pMM632, pMM633, and pMM640 (corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively).
- a mutation e.g., a substitution and/or insertion
- pMM626, pMM630, pMM632, pMM633, and pMM640 corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively.
- the mutation can comprise a mutation (e.g., a substitution) at position F189, N192, D193, E179, D181, and/or D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); a mutation (e.g., an insertion) between SI 78 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); or any combination thereof of CXCR4 (e.g., human CXCR4).
- a mutation e.g., a substitution
- SI 78 and E179 of CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- any combination thereof of CXCR4 e.g., human CXCR4
- a mutation at a position within CXCR4 encompasses mutations (e.g., substitutions and/or insertions) including only the residue at that position or mutations (e.g., substitutions and/or insertions) including the residue at that position as well as other residues at other positions.
- the nomenclature of the amino acid position for the mutations or residue disclosed herein refer to the position of the mutation or residue in the canonical isoform of human CXCR4 set forth in SEQ ID NO: 1.
- the mutation comprises a mutation (e.g., a substitution) at position Fl 89 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises a mutation (e.g., a substitution) at position N192 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable N192 substitution is an N192A substitution.
- the mutation comprises a mutation (e.g., a substitution) at position DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable DI 93 substitution is an DI 93 A substitution.
- the mutation comprises a mutation (e.g., a substitution) at positions Fl 89, N192, and DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- suitable Fl 89, N192, and DI 92 substitutions are F189A, N192A, and D192A substitutions.
- the mutation comprises an insertion between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- Suitable insertions include an S178_E179insK (e g., insertion of K between S178 and E179), S178_E179insY (e.g., insertion of Y between S178 and E179), and S178_E179insR (e.g., insertion of R between S178 and E179).
- the mutation comprises a mutation (e.g., a substitution) at position E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable E179 substitution is an E179R substitution.
- the mutation comprises a mutation (e.g., a substitution) at position D181 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- a suitable DI 81 substitution is an D181R substitution.
- the mutation comprises a mutation (e.g., a substitution) at position DI 82 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable DI 82 substitution is an D182R substitution.
- the mutation comprises a mutation (e.g., a substitution) at positions E179, D181, and D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- suitable E179, D181, and D182 substitutions are E179R, D181R, and D182R substitutions.
- the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 91 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of F189A, N192A, and N193 A relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 95 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insK relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 97 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insY relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 98 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insR relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 105 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of E179R, D181R, and D182R relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the donor cells or edited cells can be administered to the subject by any suitable means.
- the term administering refers to administration of a composition (e.g., the donor cells or edited cells) to a subject or system (e.g., but not limited to, to a cell, organ, tissue, organism, or relevant component or set of components thereof).
- the route of administration may vary depending, for example, on the subject or system to which the composition is being administered, the nature of the composition, the purpose of the administration, and so forth.
- administration or “administering” is intended to include routes of introducing the donor cells or edited cells to a subject to perform their intended function.
- nonlimiting examples of routes of administration which can be used include, e.g., injection (subcutaneous, intravenous, parenterally, intraperitoneally, intrathecal), such as intravenous injection.
- the donor cells or edited cells are administered by intravenous injection. Administration may involve intermittent dosing or continuous dosing (e.g., but not limited to, perfusion) for at least a selected period of time.
- the donor cells or edited cells can be administered alone, or in conjunction with either another agent (e g., but not limited to, an agent for selective inhibition or selective depletion of host cells or non-edited cells in the subject) or with a pharmaceutically acceptable carrier, or both.
- the donor cells or edited cells can be administered prior to the administration of the other agent, simultaneously with the agent, or after the administration of the agent.
- the host cells or non-edited cells in the subject can be selectively inhibited or selectively depleted (e.g., mobilized from their immune cell niche) based on their expression of the second isoform of the target protein (e.g., based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein, or based on their expression of the second isoform regardless of their of expression of the first isoform of the target protein) by any suitable means.
- they can be depleted or inhibited based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein.
- selective inhibition or selective depletion means selective mobilization of host cells or non-edited cells from the bone marrow to the periphery.
- the selective inhibition or selective depletion of the host cells or non-edited cells can occur before administration of the donor cells or edited cells, simultaneously with the administration of the donor cells or edited cells, or after administration of the donor cells or edited cells.
- Selective depletion refers to selectively reducing the total number or concentration of cells (e.g., in the bone marrow) expressing a certain isoform of the target protein.
- Selective depletion of cells expressing a second isoform can correspond to enrichment of cells expressing the first isoform.
- selective depletion refers to selective ablation of host cells.
- Selective ablation of host cells refers to ablation (i.e., killing) of host cells by an active killing mechanism.
- An active killing mechanism means the agent directly kills the host cells by cytotoxic mechanisms (e.g., antibody-drug conjugate (ADC), antibody radioconjugate (ARC), CAR-T, or other engineered cytotoxicity) or recruits host cytotoxic effector mechanisms (e.g., complement-dependent cytotoxicity (CDC), antibody-dependent cellular cytotoxicity (ADCC), antibody-dependent cellular phagocytosis (ADCP)), as opposed blocking a cellular function (e.g.
- the selective depletion of host cells or non-edited cells comprises ablating the host cells or nonedited cells via an active killing mechanism such as complement-dependent cytotoxicity (CDC), antibody-dependent cellular cytotoxicity (ADCC), antibody-dependent cellular phagocytosis (ADCP), antibody-drug conjugate (ADC), CAR-T, or other engineered cytotoxicity.
- an active killing mechanism such as complement-dependent cytotoxicity (CDC), antibody-dependent cellular cytotoxicity (ADCC), antibody-dependent cellular phagocytosis (ADCP), antibody-drug conjugate (ADC), CAR-T, or other engineered cytotoxicity.
- selective depletion refers to selective inhibition of host cells.
- selective inhibition of host cells does not comprise ablation (i.e., killing) of host cells by an active killing mechanism. That is, selective inhibition of host cells does not comprise cytotoxic ablation of host cells.
- the selective inhibition of host cells or non-edited cells does not comprise ablation or killing of host cells or non-edited cells, even indirectly.
- the selective inhibition or selective depletion of host cells or non-edited cells comprises: (1) blocking growth of the host cells or non-edited cells (e.g., blocking proliferation or immune cell activation) to provide a competitive growth advantage to the donor cells or edited cells; (2) blocking localization or trafficking of the host cells or nonedited cells to provide a competitive homing advantage to the donor cells or edited cells; (3) blocking a cell-cell interaction or adhesion of the host cells or non-edited cells to provide a competitive tissue infiltration advantage to the donor cells or edited cells; or (4) blocking immune cell activation in the host cells or non-edited cells to provide a competitive advantage to the donor cells or edited cells.
- blocking growth of the host cells or non-edited cells e.g., blocking proliferation or immune cell activation
- the selective inhibition or selective depletion of host cells or non-edited cells comprises selectively depleting host cells from the bone marrow.
- selective inhibition of host cells without cytotoxic ablation has potential to improve the safety and efficacy of cell therapy and transplant treatments.
- Non-ablative conditioning may avoid undesired and harmful effects of ablative agents, including direct killing of non-target (e.g., non-hematopoietic) cells expressing drug target antigens, indirect toxicides to target-adjacent tissues, and prolonged immune suppression in the post-transplant period.
- Selective blockade or suppression of essential host cell factors can enhance the expansion, persistence, and trafficking of resistant donor cells by affording favorable competition for limiting host factors (e.g., cytokine, chemokines) and immune niche space, without harsh and potentially toxic ablative agents.
- host factors e.g., cytokine, chemokines
- the method can comprise providing the subject with means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
- the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise providing the subject with means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
- the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise administering an agent (e.g., an antagonist, an antigen-binding protein, or a population of cells (i.e., immune effector cells such as chimeric antigen receptor T cells (CAR-T)) expressing an antigen-binding protein)) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
- an agent e.g., an antagonist, an antigen-binding protein, or a population of cells (i.e., immune effector cells such as chimeric antigen receptor T cells (CAR-T)) expressing an antigen-binding protein
- the agent can be an antagonist that blocks interaction between an endogenous ligand and the second isoform of the target protein but does not block interaction between the endogenous ligand and the first isoform of the target protein.
- the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise administering an antagonist (e.g., an antigen-binding protein or a population of cells (i.e., immune effector cells such as chimeric antigen receptor T cells (CAR-T)) expressing an antigen-binding protein) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein (e.g., an antagonist that blocks interaction between the endogenous ligand (e.g., CXCL12) and the second isoform of the target protein (e.g., CXCR4), but does not block interaction between the endogenous ligand and the first isoform of the target protein).
- an antagonist e.g., an antigen-binding protein or a population of cells (i.e., immune effector cells such as chimeric antigen receptor T cells (CAR-T)
- CAR-T chimeric antigen receptor T cells
- the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise administering an antigen-binding protein (e.g., an isolated antigen-binding protein) or one or more nucleic acids encoding the antigen-binding protein, such as an antibody (e.g., human antibody, monoclonal antibody, and/or recombinant antibody) or an antigen-binding fragment thereof that specifically binds to the second isoform of the target protein (or an antigenic fragment thereof (e.g., the extracellular domain)) but does not specifically bind to the first isoform of the target protein.
- an antigen-binding protein e.g., an isolated antigen-binding protein
- nucleic acids encoding the antigen-binding protein such as an antibody (e.g., human antibody, monoclonal antibody, and/or recombinant antibody) or an antigen-binding fragment thereof that specifically binds to the second isoform of the target protein (or an antigenic fragment
- the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise administering a population of cells (i.e., immune effector cells) expressing an antigen-binding protein (e.g., T cells expressing a chimeric antigen receptor or an exogenous T cell receptor) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
- an antigen-binding protein e.g., T cells expressing a chimeric antigen receptor or an exogenous T cell receptor
- Immune effector cells are cells that are capable of effecting or enhancing an immune response.
- selective depletion e.g., selective ablation
- cytotoxic mechanisms e.g., antibody-drug conjugate (ADC), antibody radioconjugate (ARC), CAR-T, or other engineered cytotoxicity.
- ADC antibody-drug conjugate
- ARC antibody radioconjugate
- CAR-T CAR-T
- selective depletion e.g., selective ablation
- selective ablation can be achieved by recruiting host cytotoxic effector mechanisms (e.g., complement-dependent cytotoxicity (CDC), antibodydependent cellular cytotoxicity (ADCC), antibody-dependent cellular phagocytosis (ADCP)), as opposed blocking a cellular function (e.g.
- CDC complement-dependent cytotoxicity
- ADCC antibodydependent cellular cytotoxicity
- ADCP antibody-dependent cellular phagocytosis
- the antigen-binding protein is coupled to a toxin, thereby forming an immunotoxin. In some embodiments, the antigen-binding protein is not coupled to a toxin. In some embodiments, the antigen-binding protein is a bispecific antigen-binding protein that can simultaneously bind to two different antigens.
- selective depletion can be achieved by complement-dependent cytotoxicity (CDC), by antibody-dependent cellular cytotoxicity (ADCC), by antibody-dependent cellular phagocytosis (ADCP), or by an antibody-drug conjugate (ADC).
- CDC complement-dependent cytotoxicity
- ADCC antibody-dependent cellular cytotoxicity
- ADCP antibody-dependent cellular phagocytosis
- ADC antibody-drug conjugate
- selective inhibition or selective depletion is not achieved by cytotoxic mechanisms or by recruiting host cytotoxic effector mechanisms.
- selective inhibition or selective depletion is achieved by blocking a cellular function (e.g., growth or cytokine signaling, chemotactic tissue homing, cell-cell adhesion) without engaging extrinsic cytotoxic effectors.
- a cellular function e.g., growth or cytokine signaling, chemotactic tissue homing, cell-cell adhesion
- selective inhibition or selective depletion can be achieved by selectively depleting host cells from the bone marrow.
- selective inhibition or selective depletion is not achieved by complementdependent cytotoxicity (CDC), by antibody-dependent cellular cytotoxicity (ADCC), by antibody-dependent cellular phagocytosis (ADCP), or by an antibody-drug conjugate (ADC).
- CDC complementdependent cytotoxicity
- ADCC antibody-dependent cellular cytotoxicity
- ADCP antibody-dependent cellular phagocytosis
- ADC antibody-drug conjugate
- Toxins or drugs compatible for use in antibody-drug conjugate are well known in the art. See, e.g., Peters et al. (2015) Biosci. Rep. 35(4):e00225, Beck et al. (2017) Nature Reviews Drug Discovery 16:315-337; Marin- Acevedo et al. (2016) J. Hematol. Oncol.
- the antibody-drug conjugate may further comprise a linker (e.g., a peptide linker, such as a cleavable linker) attaching the antigenbinding protein (e.g., antibody) and drug molecule.
- a linker e.g., a peptide linker, such as a cleavable linker
- Selective inhibition or selective depletion can also be effected by administration of an antigen-binding protein that is not coupled to an effector compound such as a drug or a toxin.
- selective inhibition or selective depletion is achieved by blocking binding by an endogenous ligand (e.g., CXCL12 for CXCR4).
- an agent for selective inhibition or selective depletion of host cells or non-edited cells is administered, the agent can in some embodiments be administered simultaneously with the donor cells or edited cells. In some embodiments, the donor cells or edited cells are administered after the agent.
- the donor cells or edited cells are administered within 1 day after the agent, or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more after the agent.
- the donor cells or edited cells are administered before the agent.
- the donor cells or edited cells are administered within 1 day before the agent, or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more before the agent.
- the donor cells or edited cells are administered in multiple administrations (e.g., doses). In some embodiments, the donor cells or edited cells are administered to the subject once. In some embodiments, the donor cells or edited cells are administered to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the donor cells or edited cells are administered to the subject at a regular interval (e.g., every 6 months). In methods in which an agent for selective inhibition or selective depletion of host cells or non-edited cells is administered, it can, in some embodiments, be administered in multiple administrations (e.g., doses). In some embodiments, the agent is administered to the subject once.
- the agent is administered to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the agent is administered to the subject at a regular interval (e.g., every 6 months). [00167] In some embodiments, the agent is administered to the subject prior to administration of the donor cells or edited cells and after administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject prior to administration of the donor cells or edited cells and after administration of the donor cells or edited cells, and the donor cells or edited cells are administered to the subject once.
- the agent is administered to the subject about 1 to about 2 weeks prior to administration of the donor cells or edited cells and is administered to the subject about 1 to about 2 weeks after administration of the donor cells or edited cells (e.g., to give the donor cells or edited cells a competitive advantage).
- the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells and in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells.
- multiple administrations e.g., at least 2, at least 3, at least 4, at least 5 or more times
- about 10 6 to 10 11 donor cells or edited cells are administered. In some embodiments it may be desirable to administer fewer than 10 6 cells to the subject. In some embodiments, it may be desirable to administer more than 10 11 cells to the subject. In some embodiments, one or more doses of cells includes about 10 6 cells to about 10 11 cells, about 10 7 cells to about IO 10 cells, about 10 8 cells to about 10 9 cells, about 10 6 cells to about 10 8 cells, about 10 7 cells to about 10 9 cells, about 10 7 cells to about IO 10 cells, about 10 7 cells to about 10 11 cells, about 10 8 cells to about IO 10 cells, about 10 8 cells to about 10 11 cells, about 10 9 cells to about IO 10 cells, about 10 9 cells to about 10 11 cells, or about IO 10 cells to about 10 11 cells. In some embodiments, one or more doses of cells includes about 10 6 to 10 7 cells per kg.
- an “antagonist” includes molecules that inhibit an activity of the target protein to any detectable degree.
- an antagonist of CXCR4 includes molecules that inhibit an activity of CXCR4 (e.g., binding of CXCR4 to CXCL12/SDF-1) to any detectable degree.
- the agent for selective inhibition or selective depletion of host cells or non-edited cells is an antigen-binding protein.
- the term “specifically binds” or “binds specifically” refers to those antigen-binding proteins (e.g., antibodies or antigen-binding fragments thereof) having a binding affinity to an antigen, such as CXCR4 protein, expressed as KD, of at least about 10' 7 M (e g., 10' 8 M, 10’ 9 M, 1C)' 1O M, 10' 11 M or IO’ 12 M), as measured by real-time, label free bio-layer interferometry assay, for example, at 25°C or 37°C, e.g., an Octet® HTX biosensor, or by surface plasmon resonance, e.g., BIACORETM, or by solution-affinity ELISA.
- an antigen such as CXCR4 protein
- the antigen-binding proteins used herein specifically bind to CXCR4 protein or human CXCR4 protein (e.g., wild type or native CXCR4 protein, such as wild type or native human CXCR4 protein).
- “Anti- CXCR4” refers to an antigen-binding protein (or another molecule), for example an antibody or antigen-binding fragment thereof, that binds specifically to CXCR4.
- An antigen is a molecule, such as a peptide (e.g., CXCR4 or a fragment thereof (an antigenic fragment)), to which, for example, an antibody binds.
- a peptide e.g., CXCR4 or a fragment thereof (an antigenic fragment)
- the specific region on an antigen that an antibody recognizes and binds to is called the epitope.
- epitope refers to an antigenic determinant (e.g., on CXCR4) that interacts with a specific antigen-binding site of an antigen-binding protein, e.g., a variable region of an antibody molecule, known as a paratope.
- a single antigen may have more than one epitope.
- different antigen-binding proteins e.g., antibodies
- epitopes may be defined as structural or functional.
- Epitopes are generally a subset of the structural epitopes and have those residues that directly contribute to the affinity of the interaction.
- Epitopes may be linear or conformational, that is, composed of non-linear amino acids.
- epitopes may include determinants that are chemically active surface groupings of molecules such as amino acids, sugar side chains, phosphoryl groups, or sulfonyl groups, and, in certain embodiments, may have specific three-dimensional structural characteristics, and/or specific charge characteristics.
- Epitopes to which the antigen-binding proteins used in the present invention bind may be included in fragments of CXCR4, e.g., human CXCR4, for example the extracellular loop 2 (ECL2) of human CXCR4 or a portion or fragment thereof.
- CXCR4 e.g., human CXCR4
- ECL2 extracellular loop 2
- Methods for determining the epitope of an antigen-binding protein include alanine scanning mutational analysis, peptide blot analysis (Reineke (2004) Methods Mol. Biol. 248: 443-63, herein incorporated by reference in its entirety for all purposes), peptide cleavage analysis, crystallographic studies and NMR analysis.
- methods such as epitope excision, epitope extraction and chemical modification of antigens can be employed (Tomer (2000) Prot. Sci. 9: 487-496, herein incorporated by reference in its entirety for all purposes).
- Another method that can be used to identify the amino acids within a polypeptide with which an antigen-binding protein (e.g., antibody or fragment or polypeptide) interacts is hydrogen/deuterium exchange detected by mass spectrometry. See, e.g., Ehring (1999) Analytical Biochemistry 267: 252-259; Engen and Smith (2001) Anal. Chem. 73: 256A-265A, each of which is herein incorporated by reference in its entirety for all purposes.
- antibody refers to immunoglobulin molecules comprising four polypeptide chains, two heavy chains (HCs) and two light chains (LCs) inter-connected by disulfide bonds (i.e., “full antibody molecules”) (e.g., IgG) — for example REGN7663 and REGN7664.
- the antibody heavy chain comprises SEQ ID NO: 110 or a variant thereof
- the antibody light chain comprises SEQ ID NO: 112 or a variant thereof (REGN7663)
- the antibody heavy chain comprises SEQ ID NO: 114 or a variant thereof
- the antibody light chain comprises SEQ ID NO: 116 or a variant thereof (REGN7664).
- each antibody heavy chain comprises a heavy chain variable region (“HCVR” or “VH”) (e.g., SEQ ID NO: 5 or a variant thereof for REGN7663, and SEQ ID NO: 21 or a variant thereof for REGN7664) and a heavy chain constant region (including domains CHI, CH2 and CH3); and each antibody light chain (LC) comprises a light chain variable region (“LCVR” or “VL”) (e.g., SEQ ID NO: 13 or a variant thereof for REGN7663, and SEQ ID NO: 29 or a variant thereof for REGN7664) and a light chain constant region (CL).
- HCVR heavy chain variable region
- VH heavy chain variable region
- VL light chain variable region
- VH and VL regions can be further subdivided into regions of hypervariability, termed complementarity determining regions (CDR), interspersed with regions that are more conserved, termed framework regions (FR).
- CDR complementarity determining regions
- FR framework regions
- Each VH and VL comprises three CDRs and four FRs, arranged from amino-terminus to carboxy-terminus in the following order: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4.
- the FRs of the antibody (or antigen binding fragment thereof) are identical to the human germline sequences or are naturally or artificially modified.
- variable domains of both the heavy and light immunoglobulin chains comprise three hypervariable regions, also called complementarity determining regions (CDRs), located within relatively conserved framework regions (FR).
- CDRs complementarity determining regions
- FR framework regions
- both light and heavy chains variable domains comprise FR1, CDR1, FR2, CDR2, FR3, CDR3 and FR4.
- the assignment of amino acids to each domain is in accordance with the definitions of Sequences of Proteins of Immunological Interest, Kabat et al.; National Institutes of Health, Bethesda, Md.; 5 th ed.; NIH Publ. No. 91-3242 (1991); Kabat (1978) Adv. Prot. Chem.
- antigen-binding proteins in some embodiments include antibodies and antigen-binding fragments including the CDRs of a VH and the CDRs of a VL, which VH and VL comprise amino acid sequences as set forth herein (or a variant thereof), wherein the CDRs are as defined according to Kabat and/or Chothia.
- antigen-binding portion or “antigen-binding fragment” of an antibody or antigen-binding protein, and the like, as used herein, include any naturally occurring, enzymatically obtainable, synthetic, or genetically engineered polypeptide or glycoprotein that specifically binds an antigen to form a complex.
- Non-limiting examples of antigen-binding fragments include: (i) Fab fragments; (ii) F(ab')2 fragments; (iii) Fd fragments (heavy chain portion of a Fab fragment cleaved with papain); (iv) Fv fragments (a VH or VL); and (v) singlechain Fv (scFv) molecules; consisting of the amino acid residues that mimic the hypervariable region of an antibody (e.g., an isolated complementarity determining region (CDR) such as a CDR3 peptide), or a constrained FR3-CDR3-FR4 peptide.
- CDR complementarity determining region
- the antigen-binding fragment comprises three or more CDRs of REGN7663 or REGN7664 (e g., CDR-H1, CDR-H2 and CDR-H3; or CDR-L1, CDR-L2 and CDR-L3).
- the antigen-binding protein is a “neutralizing” or “antagonist” anti-target protein antigen-binding protein (e.g., antibody or antigen-binding fragment), including molecules that inhibit an activity of the target protein (e.g., inhibiting binding of a receptor to one of its ligands) to any detectable degree.
- a neutralizing or “antagonist” anti-target protein antigen-binding protein e.g., antibody or antigen-binding fragment
- molecules that inhibit an activity of the target protein e.g., inhibiting binding of a receptor to one of its ligands
- the antigen-binding proteins can comprise monoclonal antigen-binding proteins, e.g., antibodies and antigen-binding fragments thereof, as well as monoclonal compositions comprising a plurality of isolated monoclonal antigen-binding proteins.
- monoclonal antibody or “mAb,” as used herein, refers to a member of a population of substantially homogeneous antibodies, i.e., the antibody molecules comprising the population are identical in amino acid sequence except for possible naturally occurring mutations that may be present in minor amounts.
- a “plurality” of such monoclonal antibodies and fragments in a composition refers to a concentration of identical (in amino acid sequence except for possible naturally occurring mutations that may be present in minor amounts) antibodies and fragments which is above that which would normally occur in nature, e.g., in the blood of a host organism such as a mouse or a human.
- the antigen-binding protein e.g., antibody or antigen-binding fragment comprises a heavy chain constant domain, e.g., of the type IgA (e.g., IgAl or IgA2), IgD, IgE, IgG (e.g., IgGl, IgG2, IgG3 and IgG4 (e.g., comprising a S228P and/or S108P mutation)) or IgM.
- the antigen-binding protein e.g., antibody or antigen- binding fragment, comprises a light chain constant domain, e g., of the type kappa or lambda.
- the antigen-binding protein includes antigen-binding proteins comprising the variable domains set forth herein (e.g., REGN7663 or REGN7664) which are linked to a heavy and/or light chain constant domain, e.g., as set forth above.
- the antigen-binding protein is a human antigen-binding protein (e.g., antibodies or antigen-binding fragments thereof such as REGN7663 or REGN7664).
- human antigen-binding protein such as an antibody or antigen-binding fragment, as used herein, includes antibodies and fragments having variable and constant regions derived from human germline immunoglobulin sequences whether in a human cell or grafted into a nonhuman cell, e.g., a mouse cell. See, e.g., US8502018, US6596541, or US5789215, each of which is herein incorporated by reference in its entirety for all purposes.
- human antibodies and antigen-binding fragments may, in some embodiments, include amino acid residues not encoded by human germline immunoglobulin sequences (e.g., having mutations introduced by random or site-specific mutagenesis in vitro or by somatic mutation in vivo), for example in the CDRs and, in particular, CDR3.
- human antibody as used herein, is not intended to include mAbs in which CDR sequences derived from the germline of another mammalian species (e.g., mouse) have been grafted onto human FR sequences.
- the term includes antibodies recombinantly produced in a non-human mammal or in cells of a non-human mammal.
- the term is not intended to include antibodies isolated from or generated in a human subject.
- the antigen-binding protein is a chimeric antigen-binding protein (e.g., chimeric antibodies comprising the variable domains which are set forth herein (e.g., from REGN7663 or REGN7664)).
- a “chimeric antibody” is an antibody having the variable domain from a first antibody and the constant domain from a second antibody, where the first and second antibodies are from different species. See, e.g., US4816567; and Morrison et al., (1984) Proc. Natl. Acad. Sci. U.S.A. 81: 6851-6855, each of which is herein incorporated by reference in its entirety for all purposes.
- the antigen-binding protein is a recombinant antigen-binding protein (e.g., recombinant antigen-binding proteins as set forth herein (e.g., REGN7663 or REGN7664)).
- recombinant antigen-binding proteins such as antibodies or antigenbinding fragments thereof, refers to such molecules created, expressed, isolated or obtained by technologies or methods known in the art as recombinant DNA technology which include, e.g., DNA splicing and transgenic expression.
- the term includes antibodies expressed in a non-human mammal (including transgenic non-human mammals, e.g., transgenic mice), or a host cell (e.g., Chinese hamster ovary (CHO) cell) or cellular expression system or isolated from a recombinant combinatorial human antibody library.
- a non-human mammal including transgenic non-human mammals, e.g., transgenic mice
- a host cell e.g., Chinese hamster ovary (CHO) cell
- cellular expression system e.g., isolated from a recombinant combinatorial human antibody library.
- the antigen-binding protein is an antigen-binding fragment of an antibody (e.g., an antigen-binding fragment of an antigen-binding protein set forth herein, for example, REGN7663 or REGN7664).
- An antigen-binding fragment of an antibody will, in some embodiments, comprise at least one variable domain.
- the variable domain may be of any size or amino acid composition and will generally comprise at least one (e.g., 3) CDR(s), which is adjacent to or in frame with one or more framework sequences.
- the VH and VL domains may be situated relative to one another in any suitable arrangement.
- variable region may be dimeric and contain VH-VH, VH-VL or VL-VL dimers.
- the antigen-binding fragment of an antibody may contain a monomeric VH and/or VL domain which are bound non-covalently.
- the antigen-binding fragment of an antibody may contain at least one variable domain covalently linked to at least one constant domain.
- Non-limiting, exemplary configurations of variable and constant domains that may be found within an antigenbinding fragment of an antibody include: (i) Vn-Ciil; (ii) VII-CII2; OD VII-CII3; (iv) Vii-Cul- CH2; (V) VH-CH1-CH2-CH3 ; (vi) VH-CH2-CH3 ; (vii) VH-CL; (viii) VL-CH1 ; (ix) VL-CH2; (X) VL- CH3; (xi) VL-CH1 -CH2; (xii) VL-CH1 -CH2-CH3; (xiii) VL-CH2-CH3 ; and (xiv) VL-CL.
- variable and constant domains may be either directly linked to one another or may be linked by a full or partial hinge or linker region.
- a hinge region may consist of at least 2 (e g., 5, 10, 15, 20, 40, 60, or more) amino acids, which result in a flexible or semi-flexible linkage between adjacent variable and/or constant domains in a single polypeptide molecule.
- an antigen-binding fragment of an antibody may comprise a homo-dimer or heterodimer (or other multimer) of any of the variable and constant domain configurations listed above in noncovalent association with one another and/or with one or more monomeric VH or VL domain (e.g., by disulfide bond(s)).
- the antigen-binding proteins may be monospecific or multi-specific (e.g., bispecific), such as monospecific as well as multispecific (e g., bispecific) antigen-binding fragments comprising one or more variable domains from an antigen-binding protein that is specifically set forth herein (e.g., REGN7663 or REGN7664).
- the antigen-binding protein is an antigen-binding protein, such as an antibody (e.g., human antibody, monoclonal antibody, or recombinant antibody) or an antigen-binding fragment thereof, that specifically binds to CXCR4 protein or an antigenic fragment thereof (e.g., the extracellular domain of CXCR4 or human CXCR4).
- the antigen-binding protein can comprise any polypeptide that includes an amino acid sequence set forth in SEQ ID NO: 110, 112, 114, and/or 116 or a variant thereof.
- the antigenbinding protein can comprise any polypeptide that includes an amino acid sequence set forth in SEQ ID NO: 5, 13, 21, and/or 29 or a variant thereof.
- the antigen-binding protein can comprise PF-06747143, ulocuplumab, or LY2624587. See, e.g., Kashyap et al. (2017) J. Hematol. Oncol. 10(1): 112 and Peng et al. (2016) PLoS One l l(3):e010585, each of which is herein incorporated by reference in its entirety for all purposes.
- the antigenbinding protein comprises one or more other polypeptides, e.g., a human Fc (e.g., a human IgG such as an IgGl or IgG4 (e.g., comprising a S108P mutation)).
- Antigen-binding proteins that bind to the same epitope on CXCR4 as or compete for binding to CXCR4 with any of the antigen-binding proteins set forth herein (e.g., REGN7663 or REGN7664), can also be used.
- the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) includes an immunoglobulin heavy chain that comprises a VH (e.g., an HC) including the combination of heavy chain CDRs (CDR-H1, CDR-H2 and CDR-H3) set forth in SEQ ID NOS: 7, 9, and 11, respectively, and/or an immunoglobulin light chain that comprises a VL (e.g., a LC) including the combination of light chain CDRs (CDR-L1, CDR-L2 and CDR-L3) set forth in SEQ ID NOS: 15, 17, and 19, respectively.
- a VH e.g., an HC
- CDR-H1, CDR-H2 and CDR-H3 heavy chain CDRs
- an immunoglobulin light chain that comprises a VL (e.g., a LC) including the combination of light chain CDRs (CDR-L1, CDR-L2 and CDR-L3) set forth in SEQ ID NOS
- the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) includes an immunoglobulin heavy and light chain that comprises a VH (e.g., an HC) and a VL (e.g., a LC), respectively, including the combination of heavy and light chain CDRs (CDR-H1, CDR-H2 and CDR-H3; and CDR-L1, CDR-L2 and CDR-L3) set forth in SEQ ID NOS: 7, 9, 11, 15, 17, and 19, respectively.
- VH e.g., an HC
- VL e.g., a LC
- the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) includes an immunoglobulin heavy chain that comprises a VH (e.g., an HC) including the combination of heavy chain CDRs (CDR-H1, CDR-H2 and CDR-H3) set forth in SEQ ID NOS: 23, 25, and 27, respectively, and/or an immunoglobulin light chain that comprises a VL (e.g., a LC) including the combination of light chain CDRs (CDR-L1, CDR-L2 and CDR-L3) set forth in SEQ ID NOS: 31, 33, and 35, respectively.
- VH e.g., an HC
- CDR-H1 CDR-H2 and CDR-H3 set forth in SEQ ID NOS: 23, 25, and 27, respectively
- an immunoglobulin light chain that comprises a VL (e.g., a LC) including the combination of light chain CDRs (CDR-L1, CDR-L2 and CDR-L
- the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) includes an immunoglobulin heavy and light chain that comprises a VH (e.g., an HC) and a VL (e.g., a LC), respectively, including the combination of heavy and light chain CDRs (CDR-H1, CDR-H2 and CDR-H3; and CDR-L1, CDR-L2 and CDR-L3) set forth in SEQ ID NOS: 23, 25, 27, 31, 33, and 35, respectively.
- VH e.g., an HC
- VL e.g., a LC
- the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) comprises polypeptide pairs that comprise the following VH and VL amino acid sequences: SEQ ID NOS: 5 and 13, respectively.
- the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) comprises polypeptide pairs that comprise the following VH and VL amino acid sequences: SEQ ID NOS: 21 and 29, respectively.
- the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) comprises immunoglobulin VHS and VLS, or HCs and LCs, which comprise a variant amino acid sequence having 70% or more (e.g., 80%, 85%, 90%, 95%, 97% or 99%) overall amino acid sequence identity or similarity to the amino acid sequences of the corresponding VHS, VLS, HCS or LCs specifically set forth herein, but wherein the CDR-L1, CDR-L2, CDR-L3, CDR-H1, CDR-H2 and CDR-H3 of such immunoglobulins are not variants and comprise the amino acid sequences set forth herein.
- the CDRs within variant antigen-binding proteins are not, themselves, variants.
- the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) binds to the same epitope as REGN7663. In some embodiments, the antigen-binding protein (e.g., an antibody or antigen-binding fragment thereof) competes for binding to CXCR4 with REGN7663. In some embodiments, the antigen-binding protein (e.g., an antibody or antigen-binding fragment thereof) binds to the same epitope as REGN7664. In some embodiments, the antigen-binding protein (e.g., an antibody or antigen-binding fragment thereof) competes for binding to CXCR4 with REGN7664.
- Compets refers to an antigen-binding protein (e.g., antibody or antigen-binding fragment thereof) that binds to an antigen (e.g., CXCR4) and inhibits or blocks the binding of another antigen-binding protein (e.g., antibody or antigen-binding fragment thereof) to the antigen.
- an antigen e.g., CXCR4
- another antigen-binding protein e.g., antibody or antigen-binding fragment thereof
- competition occurs in one such orientation.
- the first antigen-binding protein (e.g., antibody) and second antigen-binding protein (e.g., antibody) may bind to the same epitope.
- the first and second antigenbinding proteins (e.g., antibodies) may bind to different, but, for example, overlapping or nonoverlapping epitopes, wherein binding of one inhibits or blocks the binding of the second antibody, e.g., via steric hindrance.
- Competition between antigen-binding proteins (e.g., antibodies) may be measured by methods known in the art, for example, by a real-time, label- free bio-layer interferometry assay.
- binding competition between anti-CXCR4 antigenbinding proteins can be determined using a real time, label-free bio-layer interferometry assay on an Octet RED384 biosensor (Pall ForteBio Corp.).
- the antigen-binding protein is a variant of REGN7663. In some embodiments, the antigen-binding protein is a variant of REGN7664.
- an antibody or antigen-binding fragment which is modified in some way retains the ability to specifically bind to CXCR4, e.g., retains at least 10% of its CXCR4 binding activity (when compared to the parental antibody) when that activity is expressed on a molar basis.
- an antibody or antigen-binding fragment retains at least 20%, 50%, 70%, 80%, 90%, 95% or 100% or more of the CXCR4 binding affinity as the parental antibody.
- an antibody or antigen-binding fragment may include conservative or non-conservative amino acid substitutions (referred to as “conservative variants” or “function conserved variants” of the antibody) that do not substantially alter its biologic activity.
- a “variant” of such a polypeptide refers to a polypeptide comprising an amino acid sequence that is at least about 70-99.9% (e.g., at least 70, 72, 74, 75, 76, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 99.5, or 99.9%) identical or similar to a referenced amino acid sequence that is set forth herein (e.g., any of SEQ ID NOS: 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, or 35); when the comparison is performed by a BLAST algorithm wherein the parameters of the algorithm are selected
- a variant of a polypeptide may include a polypeptide such as an immunoglobulin chain (e.g., an REGN7663 HC, LC, VH, VL, or CDR thereof or an REGN7664 HC, LC, VH, VL, or CDR thereof) which may include the amino acid sequence of the reference polypeptide whose amino acid sequence is specifically set forth herein but for one or more (e.g., 1, 2, 3, 4, 5, 6, 7, 8, 9 or 10) mutations, e.g., one or more missense mutations (e.g., conservative substitutions), non-sense mutations, deletions, or insertions.
- an immunoglobulin chain e.g., an REGN7663 HC, LC, VH, VL, or CDR thereof or an REGN7664 HC, LC, VH, VL, or CDR thereof
- anti-CXCR4 antigenbinding proteins which include an immunoglobulin light chain (or VL) variant comprising the amino acid sequence set forth in SEQ ID NO: 13 or 29 but having one or more of such mutations and/or an immunoglobulin heavy chain (or VH) variant comprising the amino acid sequence set forth in SEQ ID NO: 5 or 21 but having one or more of such mutations may be used in some embodiments.
- an immunoglobulin light chain (or VL) variant comprising the amino acid sequence set forth in SEQ ID NO: 13 or 29 but having one or more of such mutations
- an immunoglobulin heavy chain (or VH) variant comprising the amino acid sequence set forth in SEQ ID NO: 5 or 21 but having one or more of such mutations
- anti-CXCR4 antigen-binding proteins which include an immunoglobulin light chain variant comprising the amino acid sequence set forth in SEQ ID NO: 112 or 116 but having one or more of such mutations and/or an immunoglobulin heavy chain variant comprising the amino acid sequence set forth in SEQ ID NO: 110 or 114 but having one or more of such mutations may be used in some embodiments.
- an anti- CXCR4 antigen-binding protein includes an immunoglobulin light chain variant comprising CDR-L1, CDR-L2 and CDR-L3 wherein one or more (e.g., 1 or 2 or 3) of such CDRs has one or more of such mutations (e.g., conservative substitutions) and/or an immunoglobulin heavy chain variant comprising CDR-H1, CDR-H2 and CDR-H3 wherein one or more (e.g., 1 or 2 or 3) of such CDRs has one or more of such mutations (e.g., conservative substitutions).
- an immunoglobulin light chain variant comprising CDR-L1, CDR-L2 and CDR-L3 wherein one or more (e.g., 1 or 2 or 3) of such CDRs has one or more of such mutations (e.g., conservative substitutions).
- BLAST ALGORITHMS Altschul et al. (2005) FEBS J 272(20): 5101-5109; Altschul et al. (1990) J. Mol. Biol. 215:403-410; Gish et al. (1993) Nature Genet. 3:266-272; Madden et al. ( 1996) Meth. Enzymol. 266: 131-141; Altschul et al. (1997) Nucleic Acids Res. 25:3389-3402; Zhang et al. (1997) Genome Res. 7:649-656; Wootton et al. (1993) Comput. Chem.
- Those of skill in this art recognize that, in general, single amino acid substitutions in non-essential regions of a polypeptide do not substantially alter biological activity (see, e.g., Watson et al.
- Anti-CXCR4 antigenbinding proteins comprising such conservatively modified variant immunoglobulin chains may be used in some embodiments.
- Examples of groups of amino acids that have side chains with similar chemical properties include: (1) aliphatic side chains: glycine, alanine, valine, leucine and isoleucine; (2) aliphatic-hydroxyl side chains: serine and threonine; (3) amide-containing side chains: asparagine and glutamine; (4) aromatic side chains: phenylalanine, tyrosine, and tryptophan; (5) basic side chains: lysine, arginine, and histidine; (6) acidic side chains: aspartate and glutamate, and (7) sulfur-containing side chains: cysteine and methionine.
- a conservative replacement is any change having a positive value in the PAM250 log-likelihood matrix disclosed in Gonnet et al. (1992) Science 256: 1443-45, herein incorporated by reference in its entirety for all purposes.
- REGN7663 refers to an anti-CXCR4 antigen-binding protein
- VH immunoglobulin heavy chain or variable region thereof
- REGN7663 e.g., SEQ ID NO: 5 (or a variant thereof) or SEQ ID NO: 110 (or a variant thereof)
- VL immunoglobulin light chain or variable region thereof
- REGN7663 e.g., SEQ ID NO: 13 (or a variant thereof) or SEQ ID NO: 112 (or a variant thereof)
- CDR-H1 or a variant thereof
- CDR-H2 or a variant thereof
- CDR-H3 or a variant thereof
- the VH is linked to an IgG constant heavy chain domain, for example, human IgG constant heavy chain domain (e.g., IgGl or IgG4 (e.g., comprising the S228P and/or S108P mutation)) and/or the VL is linked to a light chain constant domain, for example a human light chain constant domain (e.g., lambda or kappa constant light chain domain).
- a human light chain constant domain e.g., lambda or kappa constant light chain domain.
- polynucleotides encoding one or more of any such immunoglobulin chains are provided.
- REGN7664 refers to an anti-CXCR4 antigen-binding protein
- VH immunoglobulin heavy chain or variable region thereof
- REGN7664 e.g., SEQ ID NO: 21 (or a variant thereof) or SEQ ID NO: 114 (or a variant thereof)
- VL immunoglobulin light chain or variable region thereof
- REGN7664 e.g., SEQ ID NO: 29 (or a variant thereof) or SEQ ID NO: 116 (or a variant thereof)
- SEQ ID NO: 29 or a variant thereof
- SEQ ID NO: 116 or a variant thereof
- the VH is linked to an IgG constant heavy chain domain, for example, human IgG constant heavy chain domain (e.g., IgGl or IgG4 (e.g., comprising the S228P and/or SI 08P mutation)) and/or the VL is linked to a light chain constant domain, for example a human light chain constant domain (e.g., lambda or kappa constant light chain domain).
- a human light chain constant domain e.g., lambda or kappa constant light chain domain.
- polynucleotides encoding one or more of any such immunoglobulin chains are provided.
- the antigen-binding protein (e.g., antibodies and antigenbinding fragments thereof (e.g., REGN7663 or REGN7664)) comprises immunoglobulin chains including the amino acid sequences specifically set forth herein (and variants thereof) as well as cellular and in vitro post-translational modifications to the antibody or fragment.
- the antigen-binding proteins include antibodies and antigen-binding fragments thereof that specifically bind to CXCR4 comprising heavy and/or light chain amino acid sequences set forth herein as well as antibodies and fragments wherein one or more asparagine, serine and/or threonine residues is glycosylated, one or more asparagine residues is deamidated, one or more residues (e.g., Met, Trp and/or His) is oxidized, the N-terminal glutamine is pyroglutamate (pyroE) and/or the C-terminal lysine or other amino acid is missing.
- one or more asparagine, serine and/or threonine residues is glycosylated
- one or more asparagine residues is deamidated
- one or more residues e.g., Met, Trp and/or His
- the N-terminal glutamine is pyroglutamate (pyroE) and/or the C-terminal lysine or
- nucleic acid(s) encoding antigen-binding proteins are provided.
- a nucleic acid encoding an antigen-binding protein comprises deoxyribonucleic acid (DNA) or ribonucleic acid (RNA).
- Such nucleic acids can be DNA, RNA, or hybrids or derivatives of either DNA or RNA.
- the nucleic acid can be codon-optimized for efficient translation into protein in a particular cell or organism.
- the nucleic acid can be modified to substitute codons having a higher frequency of usage in a human cell, a mammalian cell, a rodent cell, a mouse cell, a rat cell, or any other host cell of interest, as compared to the naturally occurring polynucleotide sequence.
- Any portion or fragment of a nucleic acid molecule can be produced by: (1) isolating the molecule from its natural milieu; (2) using recombinant DNA technology (e.g., but not limited to, PCR amplification or cloning); or (3) using chemical synthesis methods.
- Nucleic acids can comprise modifications for improved stability or reduced immunogenicity.
- Non-limiting examples of modifications include: (1) alteration or replacement of one or both of the nonlinking phosphate oxygens and/or of one or more of the linking phosphate oxygens in the phosphodiester backbone linkage; (2) alteration or replacement of a constituent of a ribose sugar such as alteration or replacement of the 2’ hydroxyl on the ribose sugar; (3) replacement of the phosphate moiety with dephospho linkers; (4) modification or replacement of a naturally occurring nucleobase; (5) replacement or modification of a ribose-phosphate backbone; (6) modification of the 3’ end or 5’ end of the oligonucleotide (e.g., but not limited to, removal, modification or replacement of a terminal phosphate group or conjugation of a moiety); and (7) modification of the sugar.
- modifications include: (1) alteration or replacement of one or both of the nonlinking phosphate oxygens and/or of one or more of the linking phosphate oxygens in the phosphodiester backbone linkage
- nucleic acids can include any polynucleotide, for example, encoding an immunoglobulin HC, LC, VH, VL, CDR-H, or CDR-L of REGN7663 or encoding an immunoglobulin HC, LC, VH, VL, CDR-H, or CDR-L of REGN7664; optionally, which is operably linked to a promoter or other expression control sequence.
- nucleic acids can include any polynucleotide (e.g., DNA) that includes a nucleotide sequence set forth in SEQ ID NO: 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 109, 111, 113, or 115.
- a polynucleotide of interest is fused to a secretion signal sequence.
- the nucleic acids can be in the form of an expression construct as defined elsewhere herein.
- the nucleic acids can include regulatory regions that control expression of the nucleic acid molecule (e.g., but not limited to, transcription or translation control regions), full-length or partial coding regions, and combinations thereof.
- the nucleic acids can be operably linked to a promoter active in a cell or organism of interest.
- Promoters that can be used in such expression constructs include promoters active, for example, in one or more of a eukaryotic cell, such as a mammalian cell (e.g., a nonhuman mammalian cell or a human cell), such as a rodent cell (e.g., but not limited to, a mouse cell, or a rat cell).
- a eukaryotic cell such as a mammalian cell (e.g., a nonhuman mammalian cell or a human cell), such as a rodent cell (e.g., but not limited to, a mouse cell, or a rat cell).
- Such promoters can be, for example, conditional promoters, inducible promoters, constitutive promoters, or tissue-specific promoters.
- the nucleic acid(s) comprise the following polynucleotide pair encoding a HC and LC: SEQ ID NO: 109 and SEQ ID NO: 111. In some embodiments, the nucleic acid(s) comprise the following polynucleotide pair encoding a HC and LC: SEQ ID NO: 113 and SEQ ID NO: 115. In some embodiments, the nucleic acid(s) comprise the following polynucleotide pair encoding a VH and VL: SEQ ID NO: 4 and SEQ ID NO: 12.
- the nucleic acid(s) comprise the following polynucleotide pair encoding a VH and VL: SEQ ID NO: 20 and SEQ ID NO: 28. In some embodiments, the nucleic acid(s) comprise the following polynucleotide set which encode a CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 and CDR-L3: SEQ ID NOS: 6, 8, 10, 14, 16, and 18.
- the nucleic acid(s) comprise the following polynucleotide set which encode a CDR-H1, CDR-H2, CDR-H3, CDR- LI, CDR-L2 and CDR-L3: SEQ ID NOS: 22, 24, 26, 30, 32, and 34.
- the nucleic acid(s) include polynucleotides encoding immunoglobulin polypeptide chains which are variants of those whose nucleotide sequence is specifically set forth herein.
- a “variant” of such a polynucleotide or nucleic acids refers to a polynucleotide or nucleic acid comprising a nucleotide sequence that is at least about 70-99.9% (e.g., 70, 72, 74, 75, 76, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 99.5, 99.9%) identical to a referenced nucleotide sequence that is set forth herein; when the comparison is performed by a BLAST algorithm wherein the parameters of the algorithm are selected to give the largest match between the respective sequences over the entire length of the respective reference sequences (e.g., expect threshold: 10; word size: 28; max matches in a query range: 0; match/mismatch scores: 1, -2; gap costs: linear).
- a variant of a nucleotide sequence specifically set forth herein comprises one or more (e g., 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 or 12) point mutations, insertions (e.g., in frame insertions) or deletions (e.g., in frame deletions) of one or more nucleotides.
- Such mutations may, in some embodiments, be missense or nonsense mutations.
- such a variant polynucleotide encodes an immunoglobulin polypeptide chain which can be incorporated into an anti-CXCR4 antigen-binding protein, i.e., such that the protein retains specific binding to CXCR4.
- the antigen-binding protein is an anti-CXCR4 antibody or antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs consist essentially of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs consist essentially of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs comprise the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs consist essentially of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs consist essentially of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the three light chain CDRs consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
- the antigen-binding protein is an anti-CXCR4 antibody or antigen-binding fragment thereof.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs consist essentially of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs consist essentially of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs comprise the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs consist essentially of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs consist essentially of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the three light chain CDRs consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
- the immunoglobulin light chain or variable region thereof comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain or variable region thereof consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain or variable region thereof consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13
- the immunoglobulin heavy chain or variable region thereof consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain or variable region thereof comprises the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain or variable region thereof consists essentially of the sequence set forth in SEQ ID NO: 13 and the immunoglobulin heavy chain or variable region thereof consists essentially of the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain or variable region thereof consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof consists of the sequence set forth in SEQ ID NO: 5.
- the immunoglobulin light chain comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 112 and the immunoglobulin heavy chain comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 110.
- the immunoglobulin light chain consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 112
- the immunoglobulin heavy chain consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 110.
- the immunoglobulin light chain consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 112, and the immunoglobulin heavy chain consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 110.
- the immunoglobulin light chain comprises the sequence set forth in SEQ ID NO: 112 and the immunoglobulin heavy chain comprises the sequence set forth in SEQ ID NO: 110.
- the immunoglobulin light chain consists essentially of the sequence set forth in SEQ ID NO: 112
- the immunoglobulin heavy chain consists essentially of the sequence set forth in SEQ ID NO: 110.
- the immunoglobulin light chain consists of the sequence set forth in SEQ ID NO: 112 and the immunoglobulin heavy chain consists of the sequence set forth in SEQ ID NO: 110.
- the immunoglobulin light chain or variable region thereof comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain or variable region thereof consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain or variable region thereof consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain or variable region thereof comprises the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain or variable region thereof consists essentially of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof consists essentially of the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain or variable region thereof consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof consists of the sequence set forth in SEQ ID NO: 21.
- the immunoglobulin light chain comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 116
- the immunoglobulin heavy chain comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 114.
- the immunoglobulin light chain consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 116
- the immunoglobulin heavy chain consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 114.
- the immunoglobulin light chain consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 114.
- the immunoglobulin light chain comprises the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain comprises the sequence set forth in SEQ ID NO: 114.
- the immunoglobulin light chain consists essentially of the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain consists essentially of the sequence set forth in SEQ ID NO: 114.
- the immunoglobulin light chain consists of the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain consists of the sequence set forth in SEQ ID NO: 114.
- the agent for selective inhibition or selective depletion of host cells or non-edited cells can be administered to the subject by any suitable means.
- the term administering refers to administration of a composition to a subject or system (e.g., but not limited to, to a cell, organ, tissue, organism, or relevant component or set of components thereof).
- the route of administration may vary depending, for example, on the subject or system to which the composition is being administered, the nature of the composition, the purpose of the administration, and so forth.
- administration or “administering” is intended to include routes of introducing the agent to a subject to perform its intended function.
- non-limiting examples of routes of administration which can be used include injection (subcutaneous, intravenous, parenterally, intraperitoneally, intrathecal), oral, inhalation, rectal and transdermal.
- administration to a subject may be bronchial (including by bronchial instillation), buccal, enteral, interdermal, intra-arterial, intradermal, intragastric, intramedullary, intramuscular, intranasal, intraperitoneal, intrathecal, intravenous, intraventricular, mucosal, nasal, oral, rectal, subcutaneous, sublingual, topical, tracheal (including by intratracheal instillation), transdermal, vaginal and/or vitreal.
- Agents can be administered in tablets or capsule form (e.g., but not limited to, by injection, inhalation, eye lotion, ointment, suppository, and so forth), topically by lotion or ointment, or rectally by suppositories.
- Administration can be in a bolus or can be by continuous infusion.
- Administration may involve intermittent dosing or continuous dosing (e.g., but not limited to, perfusion) for at least a selected period of time.
- the agent can be coated with or disposed in a selected material to protect it from natural conditions which may detrimentally affect its ability to perform its intended function.
- the agent can be administered alone, or in conjunction with either another agent (e.g., but not limited to, the donor cells or edited cells described herein) or with a pharmaceutically acceptable carrier, or both.
- the agent can be administered prior to the administration of the other agent, simultaneously with the agent, or after the administration of the agent.
- the agent can also be administered in a proform which is converted into its active metabolite, or more active metabolite in vivo.
- a subject can include, for example, any type of animal or mammal.
- Mammals include, for example, humans, non-human mammals, non-human primates, monkeys, apes, cats, dogs, horses, bulls, deer, bison, sheep, rabbits, rodents (e.g., but not limited to, mice, rats, hamsters, and guinea pigs), and livestock (e.g., but not limited to, bovine species such as cows and steer; ovine species such as sheep and goats; and porcine species such as pigs and boars).
- Birds include, for example, chickens, turkeys, ostrich, geese, and ducks. Domesticated animals and agricultural animals are also included.
- the term “non-human mammal” excludes humans. Particular non-limiting examples of non-human mammals include rodents, such as mice and rats.
- the subject is a human.
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non- edited cells in a subject described herein can further comprise generating the donor cells or edited cells by modifying a population of cells to express the first isoform of the target protein (e.g., CXCR4 protein). Suitable methods and reagents for generating donor cells or edited cells are described in more detail elsewhere herein.
- the target protein e.g., CXCR4 protein
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject described herein can further comprise isolating a population of cells from the subject (or from a different subject) prior to modifying the population of cells to express the first isoform of the target protein (e.g., CXCR4 protein).
- the isolated cells can be, for example, any suitable cells.
- the cells are immune cells.
- the cells are hematopoietic cells.
- the cells are lymphocytes or lymphoid progenitor cells.
- the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infiltrating lymphocytes (TILs), or any combination thereof).
- the cells are alpha beta T cells.
- the cells are gamma delta T cells.
- the cells are TILs.
- the cells are B cells.
- the cells are natural killer (NK) cells.
- the cells are innate lymphoid cells.
- the cells are dendritic cells.
- the cells are hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) or descendants thereof.
- HSCs are capable of giving rise to both myeloid and lymphoid progenitor cells that further give rise to myeloid cells (e.g., monocytes, macrophages, neutrophils, basophils, dendritic cells, erythrocytes, platelets, etc.) and lymphoid cells (e.g., T cells, B cells, NK cells), respectively.
- the donor cells or edited cells are autologous (i.e., from the subject).
- the donor cells or edited cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation).
- the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells).
- the cells are human cells (e.g., the subject is a human, and the cells are human cells).
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein can further comprise generating the donor cells or edited cells by modifying a population of induced pluripotent stem cells (e.g., human induced pluripotent stem cells (iPSCs)) to express the first isoform of the target protein (e.g., CXCR4 protein) and then differentiating the induced pluripotent cells into a different cell type prior to administration to the subject.
- the induced pluripotent stem cells can be differentiated into any suitable cells.
- the cells are immune cells.
- the cells are hematopoietic cells.
- the cells are lymphocytes or lymphoid progenitor cells.
- the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infdtrating lymphocytes (TILs), or any combination thereof).
- the cells are alpha beta T cells.
- the cells are gamma delta T cells.
- the cells are TILs.
- the cells are B cells.
- the cells are natural killer (NK) cells.
- the cells are innate lymphoid cells. In some embodiments, the cells are dendritic cells. In some embodiments, the cells are hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) or descendants thereof.
- HSC refers to the true stem cells that give rise to all blood and immune lineages. HPSCs include HSCs but also more differentiated progenitors that give rise to more restricted lineages. For instance, some HSPCs might only be able to develop to myeloid lineages, or lymphoid, or erythroid, and so forth.
- HSCs are capable of giving rise to both myeloid and lymphoid progenitor cells that further give rise to myeloid cells (e.g., monocytes, macrophages, neutrophils, basophils, dendritic cells, erythrocytes, platelets, etc.) and lymphoid cells (e.g., T cells, B cells, NK cells), respectively.
- the donor cells or edited cells are autologous (i.e., from the subject).
- the donor cells or edited cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation).
- the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells).
- the cells are human cells (e.g., the subject is a human, and the cells are human cells).
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein can further comprise generating the donor cells or edited cells by modifying a population of hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) (e.g., human HSCs or HSPCs) to express the first isoform of the target protein (e.g., CXCR4 protein) and then differentiating the HSCs or HSPCs into a different cell type prior to administration to the subject.
- the HSCs or HSPCs can be differentiated into any suitable cells.
- the cells are immune cells. In some embodiments, the cells are hematopoietic cells. In some embodiments, the cells are lymphocytes or lymphoid progenitor cells. In some embodiments, the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infdtrating lymphocytes (TILs), or any combination thereof). In some embodiments, the cells are alpha beta T cells. In some embodiments, the cells are gamma delta T cells. In some embodiments, the cells are TILs. In some embodiments, the cells are B cells.
- the cells are immature B cells. In some embodiments, the cells are mature B cells. In some embodiments, the cells are natural killer (NK) cells. In some embodiments, the cells are innate lymphoid cells. In some embodiments, the cells are dendritic cells. In some embodiments, the donor cells or edited cells are autologous (i.e., from the subject). In some embodiments, the donor cells or edited cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation).
- the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells).
- the cells are human cells (e.g., the subject is a human, and the cells are human cells).
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein can further comprise generating the donor cells or edited cells.
- the donor cells or edited cells can be generated by modifying a population of cells to express the first isoform of the target protein (e.g., CXCR4 protein).
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject described herein can further comprise generating the donor cells or edited cells by editing a target genomic locus (e.g., CXCR4 locus) in a population of cells to express the first isoform of the target protein (e.g., CXCR4 protein).
- the donor cells or edited cells can express only the first isoform, or they can express both the first and second isoforms of the target protein (e.g., being modified to express the first isoform of the target protein but retaining expression of the second isoform of the target protein).
- generating donor cells or edited cells can comprise introducing an expression vector into a population of cells, wherein the expression vector expresses the first isoform of the target protein (e.g., CXCR4 protein).
- the expression vectors can comprise the entire coding sequence for the first isoform of the target protein (e.g., CXCR4), operably linked to a promoter suitable for driving expression in the donor cells or edited cells.
- Any suitable promoter can be used.
- a promoter specific for or active in hematopoietic cells or a subset of hematopoietic cells can be used.
- a constitutive promoter can be used.
- the expression vector can be a bicistronic expression vector encoding the therapeutic molecule and the first isoform of the target protein (e.g., CXCR4) and a therapeutic molecule (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) as described elsewhere herein. See, e.g., Yeku et al. (2017) Set. Rep.
- the vector can be a viral vector, such as a lentiviral vector or an adeno-associated virus (AAV) vector.
- AAV adeno-associated virus
- a lentiviral vector is used.
- an AAV vector is used, such as an AAV vector with a serotype for expression in hematopoietic cells (e.g., AAV6).
- the endogenous locus encoding the second isoform of the target protein can also be modified (e.g., disrupted) so that the first isoform is expressed but the second isoform is not.
- the endogenous locus can be modified to comprise an insertion, a deletion, or one or more point mutations in the endogenous locus (e.g., CXCR4 locus) resulting in loss of expression of functional target protein (e.g., CXCR4).
- Such loci can comprise a deletion or disruption of all of the endogenous coding sequence or can comprise a deletion or disruption of a fragment of (i.e., a part of or portion of) the endogenous locus.
- a 5’ fragment of the coding sequence can be deleted or disrupted (e.g., including the start codon).
- the endogenous locus can be modified such that the start codon of the endogenous locus has been deleted or has been disrupted or mutated such that the start codon is no longer functional.
- the start codon can be disrupted by a deletion or insertion within the start codon.
- the start codon can be mutated by, for example, by a substitution of one or more nucleotides.
- a 3’ fragment of the endogenous locus can be deleted or disrupted (e.g., including the stop codon).
- an internal fragment of the endogenous locus can be deleted or disrupted.
- all of the coding sequence in the endogenous locus can be deleted or disrupted.
- the endogenous locus can remain unmodified, and both the first and second isoforms are expressed.
- generating donor cells or edited cells can comprise editing a genomic locus in a population of cells to express the first isoform of the target protein (e.g., CXCR4 protein)).
- the genomic locus can be the endogenous locus encoding the target protein, it can be a safe harbor locus, or it can be a random genomic locus targeted by random integration.
- Safe harbor loci include chromosomal loci where transgenes or other exogenous nucleic acid inserts can be stably and reliably expressed in all tissues of interest without overtly altering cell behavior or phenotype (i.e., without any deleterious effects on the host cell). See, e.g., Sadelain et al. (2012) Nat.
- the safe harbor locus can be one in which expression of the inserted gene sequence is not perturbed by any read-through expression from neighboring genes.
- safe harbor loci can include chromosomal loci where exogenous DNA can integrate and function in a predictable manner without adversely affecting endogenous gene structure or expression.
- Safe harbor loci can include extragenic regions or intragenic regions such as, for example, loci within genes that are non-essential, dispensable, or able to be disrupted without overt phenotypic consequences.
- Such safe harbor loci can offer an open chromatin configuration in all tissues and can be ubiquitously expressed during embryonic development and in adults.
- safe harbor loci can be targeted with high efficiency, and safe harbor loci can be disrupted with no overt phenotype.
- examples of safe harbor loci include albumin, CCR5, HPRT, AAVS1, and Rosa26. See, e.g., US Patent Nos. 7,888,121; 7,972,854; 7,914,796; 7,951,925; 8,110,379; 8,409,861; 8,586,526; and US Patent Publication Nos.
- the genomic locus is an endogenous genomic locus encoding the target protein (e.g., the target protein is CXCR4, and the genomic locus is a CXCR4 genomic locus).
- the genomic locus is not an endogenous genomic locus encoding the target protein (e.g., the target protein is CXCR4, and the genomic locus is not a CXCR4 genomic locus).
- the coding sequence for the first isoform of the target protein e.g., CXCR4
- the endogenous locus encoding the second isoform of the target protein can also be modified (e.g., disrupted) so that the first isoform is expressed but the second isoform is not.
- the endogenous locus can be modified to comprise an insertion, a deletion, or one or more point mutations in the endogenous locus (e g., CXCR4 locus) resulting in loss of expression of functional target protein (e.g., CXCR4).
- Such loci can comprise a deletion or disruption of all of the endogenous coding sequence or can comprise a deletion or disruption of a fragment of (i.e., a part of or portion of) the endogenous locus.
- a 5’ fragment of the coding sequence can be deleted or disrupted (e.g., including the start codon).
- the endogenous locus can be modified such that the start codon of the endogenous locus has been deleted or has been disrupted or mutated such that the start codon is no longer functional.
- the start codon can be disrupted by a deletion or insertion within the start codon.
- the start codon can be mutated by, for example, by a substitution of one or more nucleotides.
- a 3’ fragment of the endogenous locus can be deleted or disrupted (e.g., including the stop codon).
- an internal fragment of the endogenous locus can be deleted or disrupted.
- all of the coding sequence in the endogenous locus can be deleted or disrupted.
- generated donor cells or edited cells can comprise editing a target genomic locus (e.g., CXCR4 locus) in a population of cells to express the first isoform of the target protein (e.g., CXCR4 protein).
- a target genomic locus e.g., CXCR4 locus
- the first isoform of the target protein e.g., CXCR4 protein
- the editing can comprise introducing into the population of cells (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the target genomic locus and (2) an exogenous donor nucleic acid.
- the nuclease can cleave the target genomic locus, and the exogenous donor nucleic acid can be inserted into the target genomic locus or can recombine with the target genomic locus to generate the donor cells or edited cells that express the first isoform of the target protein.
- the isoform switch can be effected using base editors. See, e.g., Komor et al. (2016) Nature 533(7603):420-424, herein incorporated by reference in its entirety for all purposes. This approach allows editing of the desired amino acid without the need for a double-stranded DNA break.
- nuclease agent can be used.
- the methods can utilize nuclease agents such as Clustered Regularly Interspersed Short Palindromic Repeats (CRISPR)/CRISPR-associated (Cas) systems, zinc finger nuclease (ZFN) systems, or Transcription Activator-Like Effector Nuclease (TALEN) systems or components of such systems to modify a target genomic locus (e.g., a CXCR4 gene such as a human CXCR4 gene).
- CRISPR Clustered Regularly Interspersed Short Palindromic Repeats
- Cas CRISPR-associated
- ZFN zinc finger nuclease
- TALEN Transcription Activator-Like Effector Nuclease
- the nuclease agents involve the use of engineered cleavage systems to induce a double strand break or a nick (i.e., a single strand break) in a nuclease target site.
- Cleavage or nicking can occur through the use of specific nucleases such as engineered ZFNs, TALENs, or CRISPR/Cas systems with an engineered guide RNA to guide specific cleavage or nicking of the nuclease target site.
- Any nuclease agent that induces a nick or double-strand break at a desired target sequence can be used in the methods and compositions disclosed herein.
- the nuclease agent can be used to create a targeted genetic modification in the CXCR4 gene (e.g., human CXCR4 gene).
- the targeted genetic modification in some embodiments can comprise a targeted genetic modification in coding exon 2 of CXCR4 (e.g., coding exon 2 of human CXCR4).
- the targeted genetic modification is in coding exon 2 of human CXCR4.
- the nuclease agent is a CRISPR/Cas system. In some embodiments, the nuclease agent comprises one or more ZFNs. In some embodiments, the nuclease agent comprises one or more TALENs.
- CRISPR/Cas systems include transcripts and other elements involved in the expression of, or directing the activity of, Cas genes.
- a CRISPR/Cas system can be, for example, a type I, a type II, a type III system, or a type V system (e.g., subtype V-A or subtype V-B).
- CRISPR/Cas systems can employ CRISPR/Cas systems by utilizing CRISPR complexes (comprising a guide RNA (gRNA) complexed with a Cas protein) for site- directed binding or cleavage of nucleic acids.
- CRISPR/Cas system targeting a target genomic locus comprises a Cas protein (or a nucleic acid encoding the Cas protein) and one or more guide RNAs (or DNAs encoding the one or more guide RNAs), with each of the one or more guide RNAs targeting a different guide RNA target sequence in the target genomic locus.
- CRISPR/Cas systems used in the compositions and methods disclosed herein can be non-naturally occurring.
- a non-naturally occurring system includes anything indicating the involvement of the hand of man, such as one or more components of the system being altered or mutated from their naturally occurring state, being at least substantially free from at least one other component with which they are naturally associated in nature, or being associated with at least one other component with which they are not naturally associated.
- some CRISPR/Cas systems employ non-naturally occurring CRISPR complexes comprising a gRNA and a Cas protein that do not naturally occur together, employ a Cas protein that does not occur naturally, or employ a gRNA that does not occur naturally.
- nuclease agents and CRISPR/Cas systems described in the compositions and methods disclosed herein target a nuclease target sequence (e g., a guide RNA target sequence) in a target genomic locus encoding a target protein.
- the nuclease target sequence is in a CXCR4 gene.
- the nuclease target sequence is in a human CXCR4 gene.
- the nuclease target sequence is in coding exon 2 of a CXCR4 gene.
- nuclease target sequence is in coding exon 2 of a human CXCR4 gene.
- Cas proteins generally comprise at least one RNA recognition or binding domain that can interact with guide RNAs.
- Cas proteins can also comprise nuclease domains (e.g., DNase domains or RNase domains), DNA-binding domains, helicase domains, protein-protein interaction domains, dimerization domains, and other domains. Some such domains (e g., DNase domains) can be from a native Cas protein. Other such domains can be added to make a modified Cas protein.
- a nuclease domain possesses catalytic activity for nucleic acid cleavage, which includes the breakage of the covalent bonds of a nucleic acid molecule.
- Cleavage can produce blunt ends or staggered ends, and it can be single-stranded or doublestranded.
- a wild type Cas9 protein will typically create a blunt cleavage product.
- a wild type Cpfl protein e.g., FnCpfl
- FnCpfl can result in a cleavage product with a 5- nucleotide 5’ overhang, with the cleavage occurring after the 18th base pair from the PAM sequence on the non-targeted strand and after the 23rd base on the targeted strand.
- a Cas protein can have full cleavage activity to create a double-strand break at a target genomic locus (e.g., a double-strand break with blunt ends), or it can be a nickase that creates a single-strand break at a target genomic locus.
- Cas proteins include Casl, CaslB, Cas2, Cas3, Cas4, Cas5, Cas5e (CasD), Cas6, Cas6e, Cas6f, Cas7, Cas8al, Cas8a2, Cas8b, Cas8c, Cas9 (Csnl or Csxl2), CaslO, CaslOd, CasF, CasG, CasH, Csyl, Csy2, Csy3, Csel (CasA), Cse2 (CasB), Cse3 (CasE), Cse4 (CasC), Cscl, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmrl, Cmr3, Cmr4, Cmr5, Cmr6, Csbl, Csb2, Csb3, Csxl7, Csxl4, Csx
- An exemplary Cas protein is a Cas9 protein or a protein derived from a Cas9 protein.
- Cas9 proteins are from a type II CRISPR/Cas system and typically share four key motifs with a conserved architecture. Motifs 1, 2, and 4 are RuvC-like motifs, and motif 3 is an HNH motif.
- Exemplary Cas9 proteins are from Streptococcus pyogenes, Streptococcus thermophilus, Streptococcus sp., Staphylococcus aureus, Nocardiopsis rougevillei, Streptomyces pristinaespiralis, Streptomyces viridochromogenes, Streptomyces viridochromogenes, Streptosporangium roseum, Streptosporangium roseum, Alicyclobacillus acidocaldarius, Bacillus pseudomycoides, Bacillus selenitireducens, Exiguobacterium sibiricum, Lactobacillus delbrueckii, Lactobacillus salivarius, Microscilla marina, Burkholderiales bacterium, Polaromonas naphthalenivorans, Polaromonas sp., Crocosphaera watsonii, Cyanothece sp., Microcystis aeruginos
- Cas9 from S. pyogenes (SpCas9) (e.g., assigned UniProt accession number Q99ZW2) is an exemplary Cas9 protein.
- SpCas9 protein sequence is set forth in SEQ ID NO: 36 (encoded by the DNA sequence set forth in SEQ ID NO: 37).
- Smaller Cas9 proteins e.g., Cas9 proteins whose coding sequences are compatible with the maximum AAV packaging capacity when combined with a guide RNA coding sequence and regulatory elements for the Cas9 and guide RNA, such as SaCas9 and CjCas9 and Nme2Cas9 are other exemplary Cas9 proteins.
- Cas9 from S. aureus (SaCas9) (e.g., assigned UniProt accession number I7RUA5) is another exemplary Cas9 protein.
- Cas9 from Campylobacter jejuni CjCas9
- Cas9 from Campylobacter jejuni CjCas9
- CjCas9 e.g., assigned UniProt accession number Q0P897
- SaCas9 is smaller than SpCas9
- CjCas9 is smaller than both SaCas9 and SpCas9.
- Cas9 from Neisseria meningitidis (Nme2Cas9) is another exemplary Cas9 protein. See, e.g., Edraki et al. (2019) Mol. Cell 73(4):714-726, herein incorporated by reference in its entirety for all purposes.
- Cas9 proteins from Streptococcus thermophilus are other exemplary Cas9 proteins.
- Cas9 from Francisella novicida (FnCas9) or the RHA Franc isella novicida Cas9 variant that recognizes an alternative PAM (E1369R/E1449H/R1556A substitutions) are other exemplary Cas9 proteins.
- Cas9 proteins are reviewed, e.g., in Cebrian-Serrano and Davies (2017) Mamm. Genome 28(7):247-261, herein incorporated by reference in its entirety for all purposes.
- Examples of Cas9 coding sequences, Cas9 mRNAs, and Cas9 protein sequences are provided in WO 2013/176772, WO 2014/065596, WO 2016/106121, WO 2019/067910, WO 2020/082042, US 2020/0270617, WO 2020/082041, US 2020/0268906, WO 2020/082046, and US 2020/0289628, each of which is herein incorporated by reference in its entirety for all purposes.
- ORFs and Cas9 amino acid sequences are provided in Table 30 at paragraph [0449] WO 2019/067910, and specific examples of Cas9 mRNAs and ORFs are provided in paragraphs [0214]-[0234] of WO 2019/067910. See also WO 2020/082046 A2 (pp. 84-85) and Table 24 in WO 2020/069296, each of which is herein incorporated by reference in its entirety for all purposes.
- Cpfl CRISPR from Prevotella and Francisella 1; Casl2a
- Cpfl is a large protein (about 1300 amino acids) that contains a RuvC-like nuclease domain homologous to the corresponding domain of Cas9 along with a counterpart to the characteristic arginine-rich cluster of Cas9.
- Cpfl lacks the HNH nuclease domain that is present in Cas9 proteins, and the RuvC-like domain is contiguous in the Cpfl sequence, in contrast to Cas9 where it contains long inserts including the HNH domain. See, e.g., Zetsche et al.
- Exemplary Cpfl proteins are from Francisella tularensis 7, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC20177, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011 GWA2 33 10, Parcubacteria bacterium GW2011 GWC2 44 17, Smithella sp. SCADC, Acidaminococcus sp.
- PA 31.6 Lachnospiraceae bacterium MA2020 , Candidates Methanoplasma lermilum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens, and Porphyromonas macacae.
- Cpfl from Francisella novicida AV ⁇ (FnCpfl; assigned UniProt accession number A0Q7Q2) is an exemplary Cpfl protein.
- CasX is an RNA-guided DNA endonuclease that generates a staggered double-strand break in DNA. CasX is less than 1000 amino acids in size.
- Exemplary CasX proteins are from Deltaproteobacteria (DpbCasX or DpbCasl2e) and Planctomycetes (PlmCasX or PlmCasl2e). Like Cpfl, CasX uses a single RuvC active site for DNA cleavage. See, e.g., Liu et al. (2019) Nature 566(7743):218-223, herein incorporated by reference in its entirety for all purposes.
- CasO CasPhi or Cas l2j
- CasO is less than 1000 amino acids in size (e.g., 700-800 amino acids).
- Cas cleavage generates staggered 5’ overhangs.
- a single RuvC active site in Cas is capable of crRNA processing and DNA cutting. See, e.g., Pausch et al. (2020) Science 369(6501):333-337, herein incorporated by reference in its entirety for all purposes.
- Cas proteins can be wild type proteins (i.e., those that occur in nature), modified Cas proteins (i.e., Cas protein variants), or fragments of wild type or modified Cas proteins.
- Cas proteins can also be active variants or fragments with respect to catalytic activity of wild type or modified Cas proteins. Active variants or fragments with respect to catalytic activity can comprise at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% or more sequence identity to the wild type or modified Cas protein or a portion thereof, wherein the active variants retain the ability to cut at a desired cleavage site and hence retain nick-inducing or double-strand-break-inducing activity. Assays for nick-inducing or double-strand-break-inducing activity are known and generally measure the overall activity and specificity of the Cas protein on DNA substrates containing the cleavage site.
- modified Cas protein is the modified SpCas9-HFl protein, which is a high-fidelity variant of Streptococcus pyogenes Cas9 harboring alterations (N497A/R661A/Q695A/Q926A) designed to reduce non-specific DNA contacts. See, e.g., Kleinstiver et al. (2016) Nature 529(7587):490-495, herein incorporated by reference in its entirety for all purposes.
- modified Cas protein is the modified eSpCas9 variant (K848A/K1003A/R1060A) designed to reduce off-target effects. See, e.g., Slaymaker et al.
- SpCas9 variants include K855A and K810A/K1003A/R1060A. These and other modified Cas proteins are reviewed, e.g., in Cebrian-Serrano and Davies (2017) Mamm. Genome 28(7):247-261, herein incorporated by reference in its entirety for all purposes.
- Another example of a modified Cas9 protein is xCas9, which is a SpCas9 variant that can recognize an expanded range of PAM sequences. See, e.g., Hu et al. (2016) Nature 556:57-63, herein incorporated by reference in its entirety for all purposes.
- Cas proteins can be modified to increase or decrease one or more of nucleic acid binding affinity, nucleic acid binding specificity, and enzymatic activity. Cas proteins can also be modified to change any other activity or property of the protein, such as stability. For example, one or more nuclease domains of the Cas protein can be modified, deleted, or inactivated, or a Cas protein can be truncated to remove domains that are not essential for the function of the protein or to optimize (e.g., enhance or reduce) the activity of or a property of the Cas protein. [00246] Cas proteins can comprise at least one nuclease domain, such as a DNase domain.
- a wild type Cpfl protein generally comprises a RuvC-like domain that cleaves both strands of target DNA, perhaps in a dimeric configuration.
- CasX and Cas ⁇ l generally comprise a single RuvC-like domain that cleaves both strands of a target DNA.
- Cas proteins can also comprise at least two nuclease domains, such as DNase domains.
- a wild type Cas9 protein generally comprises a RuvC-like nuclease domain and an HNH-like nuclease domain. The RuvC and HNH domains can each cut a different strand of double-stranded DNAto make a double-stranded break in the DNA. See, e.g., Jinek et al. (2012) Science 337(6096):816- 821, herein incorporated by reference in its entirety for all purposes.
- One or more of the nuclease domains can be deleted or mutated so that they are no longer functional or have reduced nuclease activity.
- the resulting Cas9 protein can be referred to as a nickase and can generate a single-strand break within a double-stranded target DNA but not a doublestrand break (i.e., it can cleave the complementary strand or the non-complementary strand, but not both). If none of the nuclease domains is deleted or mutated in a Cas9 protein, the Cas9 protein will retain double-strand-break-inducing activity.
- An example of a mutation that converts Cas9 into a nickase is a D10A (aspartate to alanine at position 10 of Cas9) mutation in the RuvC domain of Cas9 from S. pyogenes.
- H939A histidine to alanine at amino acid position 839
- H840A histidine to alanine at amino acid position 840
- N863 A asparagine to alanine at amino acid position N863 in the HNH domain of Cas9 from 5.
- pyogenes can convert the Cas9 into a nickase.
- Other examples of mutations that convert Cas9 into a nickase include the corresponding mutations to Cas9 from S.
- thermophilus See, e.g., Sapranauskas et al. (2011) Nucleic Acids Res. 39(21):9275-9282 and WO 2013/141680, each of which is herein incorporated by reference in its entirety for all purposes.
- Such mutations can be generated using methods such as site-directed mutagenesis, PCR-mediated mutagenesis, or total gene synthesis. Examples of other mutations creating nickases can be found, for example, in WO 2013/176772 and WO 2013/142578, each of which is herein incorporated by reference in its entirety for all purposes.
- Examples of inactivating mutations in the catalytic domains of xCas9 are the same as those described above for SpCas9.
- Examples of inactivating mutations in the catalytic domains of Staphylococcus aureus Cas9 proteins are also known.
- the Staphylococcus aureus Cas9 enzyme may comprise a substitution at position N580 (e.g., N580A substitution) or a substitution at position D10 (e.g., D10A substitution) to generate a Cas nickase. See, e.g., WO 2016/106236, herein incorporated by reference in its entirety for all purposes.
- Examples of inactivating mutations in the catalytic domains of Nme2Cas9 are also known (e.g., D16A or H588A).
- Examples of inactivating mutations in the catalytic domains of StlCas9 are also known (e.g., D9A, D598A, H599A, or N622A).
- Examples of inactivating mutations in the catalytic domains of St3Cas9 are also known (e.g., D10A or N870A).
- Examples of inactivating mutations in the catalytic domains of CjCas9 are also known (e.g., combination of D8A or H559A).
- Examples of inactivating mutations in the catalytic domains of FnCas9 and RHAFnCas9 are also known (e.g., N995A).
- inactivating mutations in the catalytic domains of Cpfl proteins are also known.
- Cpfl proteins from Francisella novicida U112 (FnCpfl), Acidaminococcus sp. BV3L6 (AsCpfl), Lachnospiraceae bacterium ND2006 (LbCpfl), and Moraxella bovoculi 237 (MbCpfl Cpfl)
- such mutations can include mutations at positions 908, 993, or 1263 of AsCpfl or corresponding positions in Cpfl orthologs, or positions 832, 925, 947, or 1180 of LbCpfl or corresponding positions in Cpfl orthologs.
- Such mutations can include, for example one or more of mutations D908A, E993 A, and D1263A of AsCpfl or corresponding mutations in Cpfl orthologs, or D832A, E925A, D947A, and DI 180 A of LbCpfl or corresponding mutations in Cpfl orthologs. See, e.g., US 2016/0208243, herein incorporated by reference in its entirety for all purposes.
- Examples of inactivating mutations in the catalytic domains of CasX proteins are also known. With reference to CasX proteins from Deltaproteobacteria, D672A, E769A, and D935A (individually or in combination) or corresponding positions in other CasX orthologs are inactivating.
- Cas proteins can also be operably linked to heterologous polypeptides as fusion proteins.
- a Cas protein can be fused to a cleavage domain. See WO 2014/089290, herein incorporated by reference in its entirety for all purposesCas proteins can also be fused to a heterologous polypeptide providing increased or decreased stability.
- the fused domain or heterologous polypeptide can be located at the N-terminus, the C-terminus, or internally within the Cas protein.
- a Cas protein can be fused to one or more heterologous polypeptides that provide for subcellular localization.
- heterologous polypeptides can include, for example, one or more nuclear localization signals (NLS) such as the monopartite SV40 NLS and/or a bipartite alpha-importin NLS for targeting to the nucleus, a mitochondrial localization signal for targeting to the mitochondria, an ER retention signal, and the like.
- NLS nuclear localization signals
- Such subcellular localization signals can be located at the N-terminus, the C- terminus, or anywhere within the Cas protein.
- An NLS can comprise a stretch of basic amino acids and can be a monopartite sequence or a bipartite sequence.
- a Cas protein can comprise two or more NLSs, including an NLS (e.g., an alpha-importin NLS or a monopartite NLS) at the N-terminus and an NLS (e.g., an SV40 NLS or a bipartite NLS) at the C-terminus.
- a Cas protein can also comprise two or more NLSs at the N-terminus and/or two or more NLSs at the C-terminus.
- a Cas protein may, for example, be fused with 1-10 NLSs (e.g., fused with 1-5 NLSs or fused with one NLS. Where one NLS is used, the NLS may be linked at the N-terminus or the C-terminus of the Cas protein sequence. It may also be inserted within the Cas protein sequence. Alternatively, the Cas protein may be fused with more than one NLS. For example, the Cas protein may be fused with 2, 3, 4, or 5 NLSs. In a specific example, the Cas protein may be fused with two NLSs. In certain circumstances, the two NLSs may be the same (e.g., two SV40 NLSs) or different.
- the Cas protein can be fused to two SV40 NLS sequences linked at the carboxy terminus.
- the Cas protein may be fused with two NLSs, one linked at the N-terminus and one at the C-terminus.
- the Cas protein may be fused with 3 NLSs or with no NLS.
- the NLS may be a monopartite sequence, such as, e.g., the SV40 NLS, PKKKRKV (SEQ ID NO: 38) or PKKKRRV (SEQ ID NO: 39).
- the NLS may be a bipartite sequence, such as the NLS of nucleoplasmin, KRPAATKKAGQAKKKK (SEQ ID NO: 40).
- a single PKKKRKV (SEQ ID NO: 38) NLS may be linked at the C-terminus of the Cas protein.
- One or more linkers are optionally included at the fusion site.
- Cas proteins can also be operably linked to a cell-penetrating domain or protein transduction domain.
- the cell-penetrating domain can be derived from the HIV-1 TAT protein, the TLM cell-penetrating motif from human hepatitis B virus, MPG, Pep-1, VP22, a cell penetrating peptide from Herpes simplex virus, or a polyarginine peptide sequence. See, e.g., WO 2014/089290 and WO 2013/176772, each of which is herein incorporated by reference in its entirety for all purposes.
- the cell-penetrating domain can be located at the N-terminus, the C- terminus, or anywhere within the Cas protein.
- Cas proteins can be provided in any form.
- a Cas protein can be provided in the form of a protein, such as a Cas protein complexed with a gRNA.
- a Cas protein can be provided in the form of a nucleic acid encoding the Cas protein, such as an RNA (e.g., messenger RNA (mRNA)) or DNA.
- the nucleic acid encoding the Cas protein can be codon optimized for efficient translation into protein in a particular cell or organism.
- the nucleic acid encoding the Cas protein can be modified to substitute codons having a higher frequency of usage in a bacterial cell, a yeast cell, a human cell, a non-human cell, a mammalian cell, a rodent cell, a mouse cell, a rat cell, or any other host cell of interest, as compared to the naturally occurring polynucleotide sequence.
- the Cas protein can be transiently, conditionally, or constitutively expressed in the cell.
- Nucleic acids encoding Cas proteins can be stably integrated in the genome of a cell and operably linked to a promoter active in the cell.
- nucleic acids encoding Cas proteins can be operably linked to a promoter in an expression construct.
- Expression constructs include any nucleic acid constructs capable of directing expression of a gene or other nucleic acid sequence of interest (e.g., a Cas gene) and which can transfer such a nucleic acid sequence of interest to a target cell.
- the nucleic acid encoding the Cas protein can be in a vector comprising a DNA encoding a gRNA.
- Promoters that can be used in an expression construct include promoters active, for example, in a human cell or a human hematopoietic cell. Such promoters can be, for example, conditional promoters, inducible promoters, constitutive promoters, or tissue-specific promoters.
- the promoter can be a bidirectional promoter driving expression of both a Cas protein in one direction and a guide RNA in the other direction.
- Such bidirectional promoters can consist of (1) a complete, conventional, unidirectional Pol III promoter that contains 3 external control elements: a distal sequence element (DSE), a proximal sequence element (PSE), and a TATA box; and (2) a second basic Pol III promoter that includes a PSE and a TATA box fused to the 5’ terminus of the DSE in reverse orientation.
- DSE distal sequence element
- PSE proximal sequence element
- TATA box a second basic Pol III promoter that includes a PSE and a TATA box fused to the 5’ terminus of the DSE in reverse orientation.
- the DSE is adjacent to the PSE and the TATA box
- the promoter can be rendered bidirectional by creating a hybrid promoter in which transcription in the reverse direction is controlled by appending a PSE and TATA box derived from the U6 promoter.
- promotors are accepted by regulatory authorities for use in humans. In certain embodiments, promotors drive expression in hematopoietic cells.
- Different promoters can be used to drive Cas expression or Cas9 expression.
- small promoters are used so that the Cas or Cas9 coding sequence can fit into an AAV construct.
- Cas or Cas9 and one or more gRNAs e.g., 1 gRNA or 2 gRNAs or 3 gRNAs or 4 gRNAs
- LNP -mediated delivery e.g., in the form of RNA
- AAV adeno-associated virus
- the nuclease agent can be CRISPR/Cas9, and a Cas9 mRNA and a gRNA (e.g., targeting a CXCR4 gene (e.g., a human CXCR4 gene)) can be delivered via LNP -mediated delivery or AAV- mediated delivery.
- the Cas or Cas9 and the gRNA(s) can be delivered in a single AAV or via two separate AAV s.
- a first AAV can carry a Cas or Cas9 expression cassette
- a second AAV can carry a gRNA expression cassette.
- a first AAV can carry a Cas or Cas9 expression cassette
- a second AAV can carry two or more gRNA expression cassettes.
- a single AAV can carry a Cas or Cas9 expression cassette (e.g., Cas or Cas9 coding sequence operably linked to a promoter) and a gRNA expression cassette (e.g., gRNA coding sequence operably linked to a promoter).
- a single AAV can carry a Cas or Cas9 expression cassette (e.g., Cas or Cas9 coding sequence operably linked to a promoter) and two or more gRNA expression cassettes (e.g., gRNA coding sequences operably linked to promoters).
- Different promoters can be used to drive expression of the gRNA, such as a U6 promoter or the small tRNA Gin.
- different promoters can be used to drive Cas9 expression.
- small promoters are used so that the Cas9 coding sequence can fit into an AAV construct.
- small Cas9 proteins e.g., SaCas9 or CjCas9 are used to maximize the AAV packaging capacity).
- Cas proteins provided as mRNAs can be modified for improved stability and/or immunogenicity properties. The modifications may be made to one or more nucleosides within the mRNA. mRNA encoding Cas proteins can also be capped. Cas mRNAs can further comprise a poly-adenylated (poly-A or poly(A) or poly-adenine) tail.
- a Cas mRNA can include a modification to one or more nucleosides within the mRNA, the Cas mRNA can be capped, and the Cas mRNA can comprise a poly(A) tail.
- Guide RNAs are an RNA molecule that binds to a Cas protein (e.g., Cas9 protein) and targets the Cas protein to a specific location within a target DNA.
- Guide RNAs can comprise two segments: a “DNA-targeting segment” (also called “guide sequence”) and a “protein-binding segment.” “Segment” includes a section or region of a molecule, such as a contiguous stretch of nucleotides in an RNA.
- gRNAs such as those for Cas9
- an “activator-RNA” e.g., tracrRNA
- a “targeter-RNA” e.g., CRISPR RNA or crRNA
- gRNAs are a single RNA molecule (single RNA polynucleotide), which can also be called a “single-molecule gRNA,” a “singleguide RNA,” or an “sgRNA.” See, e.g., WO 2013/176772, WO 2014/065596, WO 2014/089290, WO 2014/093622, WO 2014/099750, WO 2013/142578, and WO 2014/131833, each of which is herein incorporated by reference in its entirety for all purposes.
- a guide RNA can refer to either a CRISPR RNA (crRNA) or the combination of a crRNA and a trans-activating CRISPR RNA (tracrRNA).
- the crRNA and tracrRNA can be associated as a single RNA molecule (single guide RNA or sgRNA) or in two separate RNA molecules (dual guide RNA or dgRNA).
- a single-guide RNA can comprise a crRNA fused to a tracrRNA (e.g., via a linker).
- a crRNA is needed to achieve binding to a target sequence.
- guide RNA and gRNA include both double-molecule (i.e., modular) gRNAs and single-molecule gRNAs.
- a gRNA is a A. pyogenes Cas9 gRNA or an equivalent thereof.
- a gRNA is a S. aureus Cas9 gRNA or an equivalent thereof.
- An exemplary two-molecule gRNA comprises a crRNA-like (“CRISPR RNA” or “targeter-RNA” or “crRNA” or “crRNA repeat”) molecule and a corresponding tracrRNA-like (“trans-activating CRISPR RNA” or “activator-RNA” or “tracrRNA”) molecule.
- a crRNA comprises both the DNA-targeting segment (single-stranded) of the gRNA and a stretch of nucleotides that forms one half of the dsRNA duplex of the protein-binding segment of the gRNA.
- An example of a crRNA tail (e.g., for use with S.
- pyogenes Cas9 located downstream (3’) of the DNA-targeting segment, comprises, consists essentially of, or consists of GUUUUAGAGCUAUGCU (SEQ ID NO: 41) or GUUUUAGAGCUAUGCUGUUUUG (SEQ ID NO: 42). Any of the DNA-targeting segments disclosed herein can be joined to the 5’ end of SEQ ID NO: 41 or 42 to form a crRNA.
- a corresponding tracrRNA comprises a stretch of nucleotides that forms the other half of the dsRNA duplex of the protein-binding segment of the gRNA.
- a stretch of nucleotides of a crRNA are complementary to and hybridize with a stretch of nucleotides of a tracrRNA to form the dsRNA duplex of the protein-binding domain of the gRNA.
- each crRNA can be said to have a corresponding tracrRNA. Examples of tracrRNA sequences (e g., for use with S.
- pyogenes Cas9 comprise, consist essentially of, or consist of any one of AGCAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACC GAGUCGGUGCUUU (SEQ ID NO: 43), AAACAGCAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGG CACCGAGUCGGUGCUUUU (SEQ ID NO: 44), or GUUGGAACCAUUCAAAACAGCAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCA ACUUGAAAAAGUGGCACCGAGUCGGUGC (SEQ ID NO: 45).
- the crRNA and the corresponding tracrRNA hybridize to form a gRNA.
- the crRNA can be the gRNA.
- the crRNA additionally provides the single-stranded DNA-targeting segment that hybridizes to the complementary strand of a target DNA. If used for modification within a cell, the exact sequence of a given crRNA or tracrRNA molecule can be designed to be specific to the species in which the RNA molecules will be used. See, e.g., Mali et al. (2013) Science 339(6121):823-826; Jinek et al.
- the DNA-targeting segment (crRNA) of a given gRNA comprises a nucleotide sequence that is complementary to a sequence on the complementary strand of the target DNA, as described in more detail below.
- the DNA-targeting segment of a gRNA interacts with the target DNA in a sequence-specific manner via hybridization (i.e., base pairing).
- the nucleotide sequence of the DNA-targeting segment may vary and determines the location within the target DNA with which the gRNA and the target DNA will interact.
- the DNA-targeting segment of a subject gRNA can be modified to hybridize to any desired sequence within a target DNA.
- Naturally occurring crRNAs differ depending on the CRISPR/Cas system and organism but often contain a targeting segment of between 21 to 72 nucleotides length, flanked by two direct repeats (DR) of a length of between 21 to 46 nucleotides (see, e.g., WO 2014/131833, herein incorporated by reference in its entirety for all purposes).
- DR direct repeats
- the DRs are 36 nucleotides long and the targeting segment is 30 nucleotides long.
- the 3’ located DR is complementary to and hybridizes with the corresponding tracrRNA, which in turn binds to the Cas protein.
- the DNA-targeting segment can have, for example, a length of at least about 12, at least about 15, at least about 17, at least about 18, at least about 19, at least about 20, at least about 25, at least about 30, at least about 35, or at least about 40 nucleotides.
- Such DNA- targeting segments can have, for example, a length from about 12 to about 100, from about 12 to about 80, from about 12 to about 50, from about 12 to about 40, from about 12 to about 30, from about 12 to about 25, or from about 12 to about 20 nucleotides.
- the DNA targeting segment can be from about 15 to about 25 nucleotides (e.g., from about 17 to about 20 nucleotides, or about 17, 18, 19, or 20 nucleotides).
- a typical DNA-targeting segment is between 16 and 20 nucleotides in length or between 17 and 20 nucleotides in length.
- a typical DNA-targeting segment is between 21 and 23 nucleotides in length.
- Cpfl a typical DNA-targeting segment is at least 16 nucleotides in length or at least 18 nucleotides in length.
- the DNA-targeting segment can be about 20 nucleotides in length. However, shorter and longer sequences can also be used for the targeting segment (e.g., 15-25 nucleotides in length, such as 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 nucleotides in length).
- the degree of identity between the DNA-targeting segment and the corresponding guide RNA target sequence (or degree of complementarity between the DNA-targeting segment and the other strand of the guide RNA target sequence) can be, for example, about 75%, about 80%, about 85%, about 90%, about 95%, or 100%.
- the DNA-targeting segment and the corresponding guide RNA target sequence can contain one or more mismatches.
- the DNA- targeting segment of the guide RNA and the corresponding guide RNA target sequence can contain 1-4, 1-3, 1-2, 1, 2, 3, or 4 mismatches (e.g., where the total length of the guide RNA
- I l l target sequence is at least 17, at least 18, at least 19, or at least 20 or more nucleotides).
- the DNA-targeting segment of the guide RNA and the corresponding guide RNA target sequence can contain 1-4, 1-3, 1-2, 1, 2, 3, or 4 mismatches where the total length of the guide RNA target sequence 20 nucleotides.
- a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment (i.e., guide sequence) comprising, consisting essentially of, or consisting of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146.
- a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment comprising, consisting essentially of, or consisting of at least 17, at least 18, at least 19, or at least 20 contiguous nucleotides of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132- 146.
- a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment that is at least 75%, at least 80%, at least 85%, at least 90%, or at least 95% identical to the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146.
- a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment that is at least 90% or at least 95% identical to the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146.
- a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment that is at least 75%, at least 80%, at least 85%, at least 90%, or at least 95% identical to at least 17, at least 18, at least 19, or at least 20 contiguous nucleotides of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132- 146.
- a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment that is at least 90% or at least 95% identical to at least 17, at least 18, at least 19, or at least 20 contiguous nucleotides of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146.
- a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment comprising, consisting essentially of, or consisting of a sequence that differs by no more than 3, no more than 2, or no more than 1 nucleotide from the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146.
- a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment comprising, consisting essentially of, or consisting of a sequence that differs by no more than 3, no more than 2, or no more than 1 nucleotide from at least 17, at least 18, at least 19, or at least 20 contiguous nucleotides of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132- 146.
- two or more guide RNAs targeting the target genomic locus (e.g., CXCR4 or human CXCR4) are used.
- TracrRNAs can be in any form (e.g., full-length tracrRNAs or active partial tracrRNAs) and of varying lengths. They can include primary transcripts or processed forms.
- tracrRNAs (as part of a single-guide RNA or as a separate molecule as part of a two- molecule gRNA) may comprise, consist essentially of, or consist of all or a portion of a wild type tracrRNA sequence (e.g., about or more than about 20, 26, 32, 45, 48, 54, 63, 67, 85, or more nucleotides of a wild type tracrRNA sequence). Examples of wild type tracrRNA sequences from S.
- pyogenes include 171-nucleotide, 89-nucleotide, 75 -nucleotide, and 65-nucleotide versions. See, e.g., Deltcheva et al. (2011) Nature 471(7340):602-607; WO 2014/093661, each of which is herein incorporated by reference in its entirety for all purposes.
- Examples of tracrRNAs within single-guide RNAs (sgRNAs) include the tracrRNA segments found within +48, +54, +67, and +85 versions of sgRNAs, where “+n” indicates that up to the +n nucleotide of wild type tracrRNA is included in the sgRNA. See US 8,697,359, herein incorporated by reference in its entirety for all purposes.
- the percent complementarity between the DNA-targeting segment of the guide RNA and the complementary strand of the target DNA can be at least 60% (e.g., at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100%).
- the percent complementarity between the DNA-targeting segment and the complementary strand of the target DNA can be at least 60% over about 20 contiguous nucleotides.
- the percent complementarity between the DNA-targeting segment and the complementary strand of the target DNA can be 100% over the 14 contiguous nucleotides at the 5’ end of the complementary strand of the target DNA and as low as 0% over the remainder.
- the DNA-targeting segment can be considered to be 14 nucleotides in length.
- the percent complementarity between the DNA-targeting segment and the complementary strand of the target DNA can be 100% over the seven contiguous nucleotides at the 5’ end of the complementary strand of the target DNA and as low as 0% over the remainder.
- the DNA-targeting segment can be considered to be 7 nucleotides in length.
- at least 17 nucleotides within the DNA-targeting segment are complementary to the complementary strand of the target DNA.
- the DNA-targeting segment can be 20 nucleotides in length and can comprise 1, 2, or 3 mismatches with the complementary strand of the target DNA.
- the mismatches are not adjacent to the region of the complementary strand corresponding to the protospacer adjacent motif (PAM) sequence (i.e., the reverse complement of the PAM sequence) (e.g., the mismatches are in the 5’ end of the DNA- targeting segment of the guide RNA, or the mismatches are at least 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, or 19 base pairs away from the region of the complementary strand corresponding to the PAM sequence).
- PAM protospacer adjacent motif
- the protein-binding segment of a gRNA can comprise two stretches of nucleotides that are complementary to one another.
- the complementary nucleotides of the protein-binding segment hybridize to form a double-stranded RNA duplex (dsRNA).
- the protein-binding segment of a subject gRNA interacts with a Cas protein, and the gRNA directs the bound Cas protein to a specific nucleotide sequence within target DNA via the DNA-targeting segment.
- Single-guide RNAs can comprise a DNA-targeting segment and a scaffold sequence (i.e., the protein-binding or Cas-binding sequence of the guide RNA).
- a scaffold sequence i.e., the protein-binding or Cas-binding sequence of the guide RNA
- Exemplary scaffold sequences e.g., for use with 5.
- pyogenes Cas9 comprise, consist essentially of, or consist of
- Guide RNAs targeting any of the guide RNA target sequences disclosed herein can include, for example, a DNA-targeting segment on the 5’ end of the guide RNA fused to any of the exemplary guide RNA scaffold sequences on the 3’ end of the guide RNA.
- Guide RNAs can include modifications or sequences that provide for additional desirable features (e.g., modified or regulated stability; subcellular targeting; tracking with a fluorescent label; a binding site for a protein or protein complex; and the like). That is, guide RNAs can include one or more modified nucleosides or nucleotides, or one or more non- naturally and/or naturally occurring components or configurations that are used instead of or in addition to the canonical A, G, C, and U residues.
- modifications include, for example, a 5’ cap (e.g., a 7-methylguanylate cap (m7G)); a 3’ poly adenylated tail (i.e., a 3’ poly(A) tail); a riboswitch sequence (e.g., to allow for regulated stability and/or regulated accessibility by proteins and/or protein complexes); a stability control sequence; a sequence that forms a dsRNA duplex (i.e., a hairpin); a modification or sequence that targets the RNA to a subcellular location (e.g., nucleus); a modification or sequence that provides for tracking (e.g., direct conjugation to a fluorescent molecule, conjugation to a moiety that facilitates fluorescent detection, a sequence that allows for fluorescent detection, and so forth); a modification or sequence that provides a binding site for proteins (e.g., proteins that act on DNA, including transcriptional activators, transcriptional repressors, DNA methyltransferases, DNA
- a bulge can be an unpaired region of nucleotides within the duplex made up of the crRNA-like region and the minimum tracrRNA-like region.
- a bulge can comprise, on one side of the duplex, an unpaired 5'-XXXY-3' where X is any purine and Y can be a nucleotide that can form a wobble pair with a nucleotide on the opposite strand, and an unpaired nucleotide region on the other side of the duplex.
- Guide RNAs can comprise modified nucleosides and modified nucleotides including, for example, one or more of the following: (1) alteration or replacement of one or both of the non-linking phosphate oxygens and/or of one or more of the linking phosphate oxygens in the phosphodiester backbone linkage (an exemplary backbone modification); (2) alteration or replacement of a constituent of the ribose sugar such as alteration or replacement of the 2’ hydroxyl on the ribose sugar (an exemplary sugar modification); (3) replacement (e.g., wholesale replacement) of the phosphate moiety with dephospho linkers (an exemplary backbone modification); (4) modification or replacement of a naturally occurring nucleobase, including with a non-canonical nucleobase (an exemplary base modification); (5) replacement or modification of the ribose-phosphate backbone (an exemplary backbone modification); (6) modification of the 3’ end or 5’ end of the oligonucleotide (e.g., removal,
- RNA modifications include modifications of or replacement of uracils or poly-uracil tracts. See, e.g., WO 2015/048577 and US 2016/0237455, each of which is herein incorporated by reference in its entirety for all purposes. Similar modifications can be made to Cas-encoding nucleic acids, such as Cas mRNAs. For example, Cas mRNAs can be modified by depletion of uridine using synonymous codons.
- modified gRNAs and/or mRNAs comprising residues (nucleosides and nucleotides) that can have two, three, four, or more modifications.
- a modified residue can have a modified sugar and a modified nucleobase.
- every base of a gRNA is modified (e.g., all bases have a modified phosphate group, such as a phosphorothioate group).
- all or substantially all of the phosphate groups of a gRNA can be replaced with phosphorothioate groups.
- a modified gRNA can comprise at least one modified residue at or near the 5’ end.
- a modified gRNA can comprise at least one modified residue at or near the 3’ end.
- Some gRNAs comprise one, two, three or more modified residues. For example, at least 5%, at least 10%, at least 15%, at least 20%, at least 25%, at least 30%, at least 35%, at least 40%, at least 45%, at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100% of the positions in a modified gRNA can be modified nucleosides or nucleotides.
- Unmodified nucleic acids can be prone to degradation. Exogenous nucleic acids can also induce an innate immune response. Modifications can help introduce stability and reduce immunogenicity.
- Some gRNAs described herein can contain one or more modified nucleosides or nucleotides to introduce stability toward intracellular or serum-based nucleases. Some modified gRNAs described herein can exhibit a reduced innate immune response when introduced into a population of cells.
- each of the crRNA and the tracrRNA can contain modifications. Such modifications may be at one or both ends of the crRNA and/or tracrRNA.
- one or more residues at one or both ends of the sgRNA may be chemically modified, and/or internal nucleosides may be modified, and/or the entire sgRNA may be chemically modified.
- Some gRNAs comprise a 5’ end modification.
- Some gRNAs comprise a 3’ end modification.
- Some gRNAs comprise a 5’ end modification and a 3’ end modification.
- the guide RNAs disclosed herein can comprise one of the modification patterns disclosed in WO 2018/107028 Al, herein incorporated by reference in its entirety for all purposes.
- the guide RNAs disclosed herein can also comprise one of the structures/modification patterns disclosed in US 2017/0114334, herein incorporated by reference in its entirety for all purposes.
- the guide RNAs disclosed herein can also comprise one of the structures/modification patterns disclosed in WO 2017/136794, WO 2017/004279, US 2018/0187186, or US 2019/0048338, each of which is herein incorporated by reference in its entirety for all purposes.
- any of the guide RNAs described herein can comprise at least one modification.
- the at least one modification comprises a 2’-O-methyl (2’-0-Me) modified nucleotide, a phosphorothioate (PS) bond between nucleotides, a 2’-fluoro (2’-F) modified nucleotide, or a combination thereof.
- the at least one modification can comprise a 2’-O-methyl (2’-0-Me) modified nucleotide.
- the at least one modification can comprise a phosphorothioate (PS) bond between nucleotides.
- the at least one modification can comprise a 2’-fluoro (2’-F) modified nucleotide.
- a guide RNA described herein comprises one or more 2’- O-methyl (2’-0-Me) modified nucleotides and one or more phosphorothioate (PS) bonds between nucleotides.
- Guide RNAs can be provided in any form.
- the gRNA can be provided in the form of RNA, either as two molecules (separate crRNA and tracrRNA) or as one molecule (sgRNA), and optionally in the form of a complex with a Cas protein.
- the gRNA can also be provided in the form of DNA encoding the gRNA.
- the DNA encoding the gRNA can encode a single RNA molecule (sgRNA) or separate RNA molecules (e.g., separate crRNA and tracrRNA). In the latter case, the DNA encoding the gRNA can be provided as one DNA molecule or as separate DNA molecules encoding the crRNA and tracrRNA, respectively.
- the gRNA can be transiently, conditionally, or constitutively expressed in the cell.
- DNAs encoding gRNAs can be stably integrated into the genome of the cell and operably linked to a promoter active in the cell.
- DNAs encoding gRNAs can be operably linked to a promoter in an expression construct.
- the DNA encoding the gRNA can be in a vector comprising a heterologous nucleic acid, such as a nucleic acid encoding a Cas protein.
- it can be in a vector or a plasmid that is separate from the vector comprising the nucleic acid encoding the Cas protein.
- Promoters that can be used in such expression constructs include promoters active, for example, in a human cell or a human hematopoietic cell. Such promoters can be, for example, conditional promoters, inducible promoters, constitutive promoters, or tissue-specific promoters. Such promoters can also be, for example, bidirectional promoters. Specific examples of suitable promoters include an RNA polymerase III promoter, such as a human U6 promoter, a rat U6 polymerase III promoter, or a mouse U6 polymerase III promoter.
- gRNAs can be prepared by various other methods.
- gRNAs can be prepared by in vitro transcription using, for example, T7 RNA polymerase (see, e.g., WO 2014/089290 and WO 2014/065596, each of which is herein incorporated by reference in its entirety for all purposes).
- Guide RNAs can also be a synthetically produced molecule prepared by chemical synthesis.
- Guide RNAs can be in compositions comprising one or more guide RNAs (e.g., 1, 2, 3, 4, or more guide RNAs) and a carrier increasing the stability of the guide RNA (e.g., prolonging the period under given conditions of storage (e.g., -20°C, 4°C, or ambient temperature) for which degradation products remain below a threshold, such below 0.5% by weight of the starting nucleic acid or protein; or increasing the stability in vivo).
- a carrier increasing the stability of the guide RNA (e.g., prolonging the period under given conditions of storage (e.g., -20°C, 4°C, or ambient temperature) for which degradation products remain below a threshold, such below 0.5% by weight of the starting nucleic acid or protein; or increasing the stability in vivo).
- Non-limiting examples of such carriers include poly(lactic acid) (PLA) microspheres, poly(D,L-lactic-coglycolic-acid) (PLGA) microspheres, liposomes, micelles, inverse micelles, lipid cochleates, and lipid microtubules.
- Such compositions can further comprise a Cas protein, such as a Cas9 protein, or a nucleic acid encoding a Cas protein.
- Target DNAs for guide RNAs include nucleic acid sequences present in a DNA to which a DNA-targeting segment of a gRNA will bind, provided sufficient conditions for binding exist.
- Suitable DNA/RNA binding conditions include physiological conditions normally present in a cell.
- Other suitable DNA/RNA binding conditions e.g., conditions in a cell-free system are known in the art see, e.g., Molecular Cloning: A Laboratory Manual, 3rd Ed. (Sambrook et al., Harbor Laboratory Press 2001), herein incorporated by reference in its entirety for all purposes).
- the strand of the target DNA that is complementary to and hybridizes with the gRNA can be called the “complementary strand,” and the strand of the target DNA that is complementary to the “complementary strand” (and is therefore not complementary to the Cas protein or gRNA) can be called “noncomplementary strand” or “template strand.”
- the target DNA includes both the sequence on the complementary strand to which the guide RNA hybridizes and the corresponding sequence on the non-complementary strand (e.g., adjacent to the protospacer adjacent motif (PAM)).
- the term “guide RNA target sequence” as used herein refers specifically to the sequence on the non-complementary strand corresponding to (i.e., the reverse complement of) the sequence to which the guide RNA hybridizes on the complementary strand. That is, the guide RNA target sequence refers to the sequence on the non- complementary strand adjacent to the PAM (e.g., upstream or 5’ of the PAM in the case of Cas9).
- a guide RNA target sequence is equivalent to the DNA-targeting segment of a guide RNA, but with thymines instead of uracils.
- a guide RNA target sequence for an SpCas9 enzyme can refer to the sequence upstream of the 5’-NGG-3’ PAM on the non-complementary strand.
- a guide RNA is designed to have complementarity to the complementary strand of a target DNA, where hybridization between the DNA-targeting segment of the guide RNA and the complementary strand of the target DNA promotes the formation of a CRISPR complex. Full complementarity is not necessarily required, provided that there is sufficient complementarity to cause hybridization and promote formation of a CRISPR complex.
- a guide RNA is referred to herein as targeting a guide RNA target sequence, what is meant is that the guide RNA hybridizes to the complementary strand sequence of the target DNA that is the reverse complement of the guide RNA target sequence on the non-compl ementary strand.
- a target DNA or guide RNA target sequence can comprise any polynucleotide, and can be located, for example, in the nucleus or cytoplasm of a cell or within an organelle of a cell.
- a target DNA or guide RNA target sequence can be any nucleic acid sequence endogenous or exogenous to a cell.
- the guide RNA target sequence can be a sequence coding a gene product (e.g., a protein) or a non-coding sequence (e.g., a regulatory sequence) or can include both.
- Site-specific binding and cleavage of a target DNA by a Cas protein can occur at locations determined by both (i) base-pairing complementarity between the guide RNA and the complementary strand of the target DNA and (ii) a short motif, called the protospacer adjacent motif (PAM), in the non-complementary strand of the target DNA.
- the PAM can flank the guide RNA target sequence.
- the guide RNA target sequence can be flanked on the 3’ end by the PAM (e.g., for Cas9).
- the guide RNA target sequence can be flanked on the 5’ end by the PAM (e.g., for Cpfl).
- the cleavage site of Cas proteins can be about 1 to about 10 or about 2 to about 5 base pairs (e.g., 3 base pairs) upstream or downstream of the PAM sequence (e.g., within the guide RNA target sequence).
- the PAM sequence i.e., on the non-complementary strand
- the PAM sequence can be 5’-NiGG-3’, where Ni is any DNA nucleotide, and where the PAM is immediately 3’ of the guide RNA target sequence on the non- complementary strand of the target DNA.
- the sequence corresponding to the PAM on the complementary strand would be 5’-CCN2-3’, where N2 is any DNA nucleotide and is immediately 5’ of the sequence to which the DNA-targeting segment of the guide RNA hybridizes on the complementary strand of the target DNA.
- Cas9 from S In the case of Cas9 from S.
- the PAM can be NNGRRT or NNGRR, where N can A, G, C, or T, and R can be G or A.
- the PAM can be, for example, NNNNACAC or NNNNRYAC, where N can be A, G, C, or T, and R can be G or A.
- the PAM sequence can be upstream of the 5’ end and have the sequence 5’-TTN-3’.
- the PAM can have the sequence 5’-TTCN-3’.
- the PAM can have the sequence 5’-TBN-3’, where B is G, T, or C.
- RNA target sequence is a 20-nucleotide DNA sequence immediately preceding an NGG motif recognized by an SpCas9 protein.
- two examples of guide RNA target sequences plus PAMs are GN19NGG (SEQ ID NO: 54) or N20NGG (SEQ ID NO: 55). See, e.g., WO 2014/165825, herein incorporated by reference in its entirety for all purposes.
- the guanine at the 5’ end can facilitate transcription by RNA polymerase in cells.
- guide RNA target sequences plus PAMs can include two guanine nucleotides at the 5’ end (e.g., GGN20NGG; SEQ ID NO: 56) to facilitate efficient transcription by T7 polymerase in vitro. See, e.g., WO 2014/065596, herein incorporated by reference in its entirety for all purposes.
- Other guide RNA target sequences plus PAMs can have between 4-22 nucleotides in length of SEQ ID NOS: 54-56, including the 5’ G or GG and the 3’ GG or NGG.
- Yet other guide RNA target sequences plus PAMs can have between 14 and 20 nucleotides in length of SEQ ID NOS: 54-56.
- Formation of a CRISPR complex hybridized to a target DNA can result in cleavage of one or both strands of the target DNA within or near the region corresponding to the guide RNA target sequence (i.e., the guide RNA target sequence on the non-complementary strand of the target DNA and the reverse complement on the complementary strand to which the guide RNA hybridizes).
- the cleavage site can be within the guide RNA target sequence (e.g., at a defined location relative to the PAM sequence).
- the “cleavage site” includes the position of a target DNA at which a Cas protein produces a single-strand break or a double-strand break.
- the cleavage site can be on only one strand (e.g., when a nickase is used) or on both strands of a double-stranded DNA.
- Cleavage sites can be at the same position on both strands (producing blunt ends; e.g., Cas9)) or can be at different sites on each strand (producing staggered ends (i.e., overhangs); e.g., Cpfl).
- Staggered ends can be produced, for example, by using two Cas proteins, each of which produces a single-strand break at a different cleavage site on a different strand, thereby producing a double-strand break.
- a first nickase can create a singlestrand break on the first strand of double-stranded DNA (dsDNA), and a second nickase can create a single-strand break on the second strand of dsDNA such that overhanging sequences are created.
- the guide RNA target sequence or cleavage site of the nickase on the first strand is separated from the guide RNA target sequence or cleavage site of the nickase on the second strand by at least 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 75, 100, 250, 500, or 1,000 base pairs.
- the guide RNA target sequence can also be selected to minimize off-target modification or avoid off-target effects (e.g., by avoiding two or fewer mismatches to off-target genomic sequences).
- a guide RNA targeting human CXCR4 e.g., coding exon 2 of human
- RNA targeting human CXCR4 e.g., coding exon 2 of human CXCR4
- exogenous Donor Nucleic Acids Any suitable exogenous donor nucleic acid can be used in the methods disclosed herein.
- the exogenous donor nucleic acid comprises the entire coding sequence for the first isoform of the target protein (e.g., CXCR4).
- the coding sequence for the first isoform of the target protein e.g., CXCR4 is operably linked to a promoter suitable for driving expression in the donor cells or edited cells.
- the coding sequence for the first isoform of the target protein (e.g., CXCR4) is not operably linked to a promoter in the exogenous donor nucleic acid but will be operably linked to an endogenous promoter at the target genomic locus once the exogenous donor nucleic acid recombines with or is integrated into the target genomic locus.
- the exogenous donor nucleic acid does not comprise the entire coding sequence for the first isoform of the target protein (e.g., CXCR4).
- the exogenous donor nucleic acid may comprise a portion of the coding sequence for the first isoform of the target protein (e.g., CXCR4), wherein the portion comprises the mutation that distinguishes the first isoform from the second isoform.
- the exogenous donor nucleic acids can comprise a mutation to modify the target genomic locus encoding the target protein so that it encodes the first isoform of the target protein.
- the exogenous donor nucleic acid recombines with the target genomic locus via non-homologous end joining (NHEJ)-mediated ligation or through a homology-directed repair event.
- NHEJ non-homologous end joining
- repair with the exogenous donor nucleic acid removes or disrupts the nuclease target sequence so that alleles that have been targeted cannot be re-targeted by the nuclease agent.
- the exogenous donor nucleic acid can target any sequence in the target genomic locus (e.g., CXCR4 gene, human CXCR4 gene).
- the exogenous donor nucleic acid targets coding exon 2 of a CXCR4 gene (e.g., coding exon 2 of a human CXCR4 gene).
- the exogenous donor nucleic acid targets coding exon 2 of a CXCR4 gene (e.g., coding exon 2 of a human CXCR4 gene). In some embodiments, the exogenous donor nucleic acid targets exons 2 and 3 of a CXCR4 gene (e.g., exons 2 and 3 of a human CXCR4 gene). Some exogenous donor nucleic acids comprise homology arms. Other exogenous donor nucleic acids do not comprise homology arms.
- the exogenous donor nucleic acids can be capable of insertion into a target genomic locus (e.g., CXCR4) by homology- directed repair, and/or they can be capable of insertion into a target genomic locus (e.g., CXCR4) by non-homologous end joining.
- a target genomic locus e.g., CXCR4
- CXCR4 target genomic locus
- Exogenous donor nucleic acids can comprise deoxyribonucleic acid (DNA) or ribonucleic acid (RNA), they can be single-stranded or double-stranded, and they can be in linear or circular form.
- an exogenous donor nucleic acid can be a single-stranded oligodeoxynucleotide (ssODN). See, e.g., Yoshimi et al. (2016) Nat. Commun. 7:10431, herein incorporated by reference in its entirety for all purposes.
- Exogenous donor nucleic acids can be naked nucleic acids or can be delivered by viruses, such as AAV.
- the exogenous donor nucleic acid can be delivered via AAV and can be capable of insertion into a target genomic locus by non-homologous end joining (e.g., the exogenous donor nucleic acid can be one that does not comprise homology arms).
- An exemplary exogenous donor nucleic acid is between about 50 nucleotides to about 5 kb in length, is between about 50 nucleotides to about 3 kb in length, or is between about 50 to about 1,000 nucleotides in length.
- Other exemplary exogenous donor nucleic acids are between about 40 to about 200 nucleotides in length.
- an exogenous donor nucleic acid can be between about 50-60, 60-70, 70-80, 80-90, 90-100, 100-110, 110-120, 120-130, 130-140, 140-150, 150-160, 160-170, 170-180, 180-190, or 190-200 nucleotides in length.
- an exogenous donor nucleic acid can be between about 50-100, 100-200, 200-300, 300-400, 400- 500, 500-600, 600-700, 700-800, 800-900, or 900-1000 nucleotides in length.
- an exogenous donor nucleic acid can be between about 1-1.5, 1.5-2, 2-2.5, 2.5-3, 3-3.5, 3.5-4, 4-4.5, or 4.5-5 kb in length.
- an exogenous donor nucleic acid can be, for example, no more than 5 kb, 4.5 kb, 4 kb, 3.5 kb, 3 kb, 2.5 kb, 2 kb, 1.5 kb, 1 kb, 900 nucleotides, 800 nucleotides, 700 nucleotides, 600 nucleotides, 500 nucleotides, 400 nucleotides, 300 nucleotides, 200 nucleotides, 100 nucleotides, or 50 nucleotides in length.
- Exogenous donor nucleic acids e.g., targeting vectors
- an exogenous donor nucleic acid is an ssODN that is between about 80 nucleotides and about 200 nucleotides in length.
- an exogenous donor nucleic acid is an ssODN that is between about 80 nucleotides and about 3 kb in length.
- Such an ssODN can have homology arms, for example, that are each between about 40 nucleotides and about 60 nucleotides in length.
- Such an ssODN can also have homology arms, for example, that are each between about 30 nucleotides and 100 nucleotides in length.
- the homology arms can be symmetrical (e.g., each 40 nucleotides or each 60 nucleotides in length), or they can be asymmetrical (e.g., one homology arm that is 36 nucleotides in length, and one homology arm that is 91 nucleotides in length).
- an exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 200 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 90 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 60 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 90 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 130 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 150 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 160 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 170 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 180 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 190 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 200 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 130 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 150 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 160 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 170 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 180 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 190 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 200 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 130 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 150 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 160 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 170 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 180 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 190 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 200 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 50 and about 100 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 40 nucleotides and about 110 nucleotides in length. [00296] In one example, the exogenous donor nucleic acid is an ssODN that is about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is about 90 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is about 60 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is about 30 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 110 nucleotides and about 130 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 100 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 150 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 80 nucleotides and about 160 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 70 nucleotides and about 170 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 180 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 80 nucleotides and about 100 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 70 nucleotides and about 110 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 50 nucleotides and about 130 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 40 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 150 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 50 nucleotides and about 70 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 40 nucleotides and about 80 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 90 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 20 nucleotides and about 100 nucleotides in length.
- the exogenous donor nucleic acid is an ssODN that is between about 20 nucleotides and about 40 nucleotides in length.
- Exogenous donor nucleic acids can include modifications or sequences that provide for additional desirable features (e.g., modified or regulated stability; tracking or detecting with a fluorescent label; a binding site for a protein or protein complex; and so forth).
- Exogenous donor nucleic acids can comprise one or more fluorescent labels, purification tags, epitope tags, or a combination thereof.
- an exogenous donor nucleic acid can comprise one or more fluorescent labels (e.g., fluorescent proteins or other fluorophores or dyes), such as at least 1, at least 2, at least 3, at least 4, or at least 5 fluorescent labels.
- fluorescent labels include fluorophores such as fluorescein (e.g., 6-carboxyfluorescein (6-FAM)), Texas Red, HEX, Cy3, Cy5, Cy5.5, Pacific Blue, 5-(and-6)-carboxytetramethylrhodamine (TAMRA), and Cy7.
- fluorescent dyes are available commercially for labeling oligonucleotides (e.g., from Integrated DNA Technologies).
- Such fluorescent labels can be used, for example, to detect an exogenous donor nucleic acid that has been directly integrated into a cleaved target nucleic acid having protruding ends compatible with the ends of the exogenous donor nucleic acid.
- the label or tag can be at the 5’ end, the 3’ end, or internally within the exogenous donor nucleic acid.
- an exogenous donor nucleic acid can be conjugated at 5’ end with the IR700 fluorophore from Integrated DNA Technologies (5TRDYE®700).
- Exogenous donor nucleic acids can also comprise nucleic acid inserts including segments of DNA to be integrated in the target genomic locus (i.e., to modify the target genomic locus such that it encodes the first isoform of the target protein). Integration of a nucleic acid insert in the target genomic locus can result in addition of a nucleic acid sequence of interest to the target genomic locus, deletion of a nucleic acid sequence of interest in the target genomic locus, or replacement of a nucleic acid sequence of interest in the target genomic locus (i.e., deletion and insertion; or substitution). Some exogenous donor nucleic acids are designed for insertion of a nucleic acid insert in the target genomic locus without any corresponding deletion in the target genomic locus.
- exogenous donor nucleic acids are designed to delete a nucleic acid sequence of interest in the target genomic locus without any corresponding insertion of a nucleic acid insert.
- exogenous donor nucleic acids are designed to delete a nucleic acid sequence of interest in the target genomic locus and replace it with a nucleic acid insert (e.g., a substitution).
- the nucleic acid insert or the corresponding nucleic acid in the target genomic locus being deleted and/or replaced can be various lengths.
- An exemplary nucleic acid insert or corresponding nucleic acid in the target genomic locus being deleted and/or replaced is between about 1 nucleotide to about 5 kb in length or is between about 1 nucleotide to about 1,000 nucleotides in length.
- a nucleic acid insert or a corresponding nucleic acid in the target genomic locus being deleted and/or replaced can be between about 1-10, 10-20, 20-30, 30- 40, 40-50, 50-60, 60-70, 70-80, 80-90, 90-100, 100-110, 110-120, 120-130, 130-140, 140-150, 150-160, 160-170, 170-180, 180-190, or 190-120 nucleotides in length.
- a nucleic acid insert or a corresponding nucleic acid in the target genomic locus being deleted and/or replaced can be between 1-100, 100-200, 200-300, 300-400, 400-500, 500-600, 600-700, 700-800, 800- 900, or 900-1000 nucleotides in length.
- a nucleic acid insert or a corresponding nucleic acid in the target genomic locus being deleted and/or replaced can be between about 1- 1.5, 1.5-2, 2-2.5, 2.5-3, 3-3.5, 3.5-4, 4-4.5, or 4.5-5 kb in length or longer.
- the nucleic acid insert can comprise a sequence that is homologous or orthologous to all or part of sequence targeted for replacement.
- the nucleic acid insert can comprise a sequence that comprises one or more point mutations (e.g., 1, 2, 3, 4, 5, or more) compared with a sequence targeted for replacement in the target genomic locus.
- point mutations can result in a conservative amino acid substitution (e.g., substitution of aspartic acid [Asp, D] with glutamic acid [Glu, E]) in the encoded polypeptide.
- exogenous donor nucleic acids are capable of insertion into a target genomic locus by non- homologous end joining. In some cases, such exogenous donor nucleic acids do not comprise homology arms. For example, such exogenous donor nucleic acids can be inserted into a blunt end double-strand break following cleavage with a nuclease agent.
- the exogenous donor nucleic acid can be delivered via AAV and can be capable of insertion into a target genomic locus by non-homologous end joining (e.g., the exogenous donor nucleic acid can be one that does not comprise homology arms).
- the exogenous donor nucleic acid can be inserted via homology-independent targeted integration.
- the insert sequence in the exogenous donor nucleic acid to be inserted into a target genomic locus can be flanked on each side by a target site for a nuclease agent (e.g., the same target site as in the target genomic locus, and the same nuclease agent being used to cleave the target site in the target genomic locus).
- the nuclease agent can then cleave the target sites flanking the insert sequence.
- the exogenous donor nucleic acid is delivered AAV-mediated delivery, and cleavage of the target sites flanking the insert sequence can remove the inverted terminal repeats (ITRs) of the AAV.
- the target site in the target genomic locus e g., a gRNA target sequence including the flanking protospacer adjacent motif
- the target site in the target genomic locus is no longer present if the insert sequence is inserted into the target genomic locus in the correct orientation but it is reformed if the insert sequence is inserted into the target genomic locus in the opposite orientation. This can help ensure that the insert sequence is inserted in the correct orientation for expression.
- exogenous donor nucleic acids have short single-stranded regions at the 5’ end and/or the 3’ end that are complementary to one or more overhangs created by nuclease- mediated cleavage in the target genomic locus.
- some exogenous donor nucleic acids have short single-stranded regions at the 5’ end and/or the 3’ end that are complementary to one or more overhangs created by nuclease-mediated cleavage at 5’ and/or 3’ target sequences in the target genomic locus.
- Some such exogenous donor nucleic acids have a complementary region only at the 5’ end or only at the 3’ end.
- exogenous donor nucleic acids have a complementary region only at the 5’ end complementary to an overhang created at a 5’ target sequence in the target genomic locus or only at the 3’ end complementary to an overhang created at a 3’ target sequence in the target genomic locus.
- Other such exogenous donor nucleic acids have complementary regions at both the 5’ and 3’ ends.
- other such exogenous donor nucleic acids have complementary regions at both the 5’ and 3’ ends e g., complementary to first and second overhangs, respectively, generated by nuclease-mediated cleavage in the target genomic locus.
- the single-stranded complementary regions can extend from the 5’ end of the top strand of the donor nucleic acid and the 5’ end of the bottom strand of the donor nucleic acid, creating 5’ overhangs on each end.
- the single-stranded complementary region can extend from the 3’ end of the top strand of the donor nucleic acid and from the 3’ end of the bottom strand of the template, creating 3’ overhangs.
- the complementary regions can be of any length sufficient to promote ligation between the exogenous donor nucleic acid and the target nucleic acid.
- Exemplary complementary regions are between about 1 to about 5 nucleotides in length, between about 1 to about 25 nucleotides in length, or between about 5 to about 150 nucleotides in length.
- a complementary region can be at least about 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 nucleotides in length.
- the complementary region can be about 5-10, 10-20, 20-30, 30-40, 40-50, 50-60, 60-70, 70-80, 80- 90, 90-100, 100-110, 110-120, 120-130, 130-140, or 140-150 nucleotides in length, or longer.
- Such complementary regions can be complementary to overhangs created by two pairs of nickases. Two double-strand breaks with staggered ends can be created by using first and second nickases that cleave opposite strands of DNAto create a first double-strand break, and third and fourth nickases that cleave opposite strands of DNA to create a second double-strand break.
- a Cas protein can be used to nick first, second, third, and fourth guide RNA target sequences corresponding with first, second, third, and fourth guide RNAs.
- the first and second guide RNA target sequences can be positioned to create a first cleavage site such that the nicks created by the first and second nickases on the first and second strands of DNA create a double-strand break (i.e., the first cleavage site comprises the nicks within the first and second guide RNA target sequences).
- the third and fourth guide RNA target sequences can be positioned to create a second cleavage site such that the nicks created by the third and fourth nickases on the first and second strands of DNA create a double-strand break (i.e., the second cleavage site comprises the nicks within the third and fourth guide RNA target sequences).
- the nicks within the first and second guide RNA target sequences and/or the third and fourth guide RNA target sequences can be off-set nicks that create overhangs.
- the offset window can be, for example, at least about 5 bp, 10 bp, 20 bp, 30 bp, 40 bp, 50 bp, 60 bp, 70 bp, 80 bp, 90 bp, 100 bp or more. See Ran et al. (2013) Cell 154:1380-1389; Mali et al. (2013) Nat.
- a double-stranded exogenous donor nucleic acid can be designed with single-stranded complementary regions that are complementary to the overhangs created by the nicks within the first and second guide RNA target sequences and by the nicks within the third and fourth guide RNA target sequences.
- Such an exogenous donor nucleic acid can then be inserted by non-homologous-end-joining-mediated ligation.
- exogenous donor nucleic acids comprise homology arms. If the exogenous donor nucleic acid also comprises a nucleic acid insert, the homology arms can flank the nucleic acid insert. For ease of reference, the homology arms are referred to herein as 5’ and 3’ (i.e., upstream and downstream) homology arms. This terminology relates to the relative position of the homology arms to the nucleic acid insert within the exogenous donor nucleic acid.
- the 5’ and 3’ homology arms correspond to regions within the target genomic locus, which are referred to herein as “5’ target sequence” and “3’ target sequence,” respectively.
- a homology arm and a 5’ target sequence or 3’ target sequence “correspond” or are “corresponding” to one another when the two regions share a sufficient level of sequence identity to one another to act as substrates for a homologous recombination reaction.
- the term “homology” includes DNA sequences that are either identical or share sequence identity to a corresponding sequence.
- the sequence identity between a given target sequence and the corresponding homology arm found in the exogenous donor nucleic acid can be any degree of sequence identity that allows for homologous recombination to occur.
- the amount of sequence identity shared by the homology arm of the exogenous donor nucleic acid (or a fragment thereof) and the target sequence (or a fragment thereof) can be at least 50%, 55%, 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% or 100% sequence identity, such that the sequences undergo homologous recombination.
- a corresponding region of homology between the homology arm and the corresponding target sequence can be of any length that is sufficient to promote homologous recombination.
- Exemplary homology arms are between about 25 nucleotides to about 2.5 kb in length, are between about 25 nucleotides to about 1.5 kb in length, or are between about 25 to about 500 nucleotides in length.
- a given homology arm (or each of the homology arms) and/or corresponding target sequence can comprise corresponding regions of homology that are between about 25-30, 30-40, 40-50, 50-60, 60-70, 70-80, 80-90, 90-100, 100-150, 150-200, 200-250, 250-300, 300-350, 350-400, 400-450, or 450- 500 nucleotides in length, such that the homology arms have sufficient homology to undergo homologous recombination with the corresponding target sequences within the target nucleic acid.
- a given homology arm (or each homology arm) and/or corresponding target sequence can comprise corresponding regions of homology that are between about 0.5 kb to about 1 kb, about 1 kb to about 1.5 kb, about 1.5 kb to about 2 kb, or about 2 kb to about 2.5 kb in length.
- the homology arms can each be about 750 nucleotides in length.
- the homology arms can be symmetrical (each about the same size in length), or they can be asymmetrical (one longer than the other).
- the 5’ and 3’ target sequences are optionally located in sufficient proximity to the nuclease cleavage site (e.g., within sufficient proximity to the nuclease target sequence) so as to promote the occurrence of a homologous recombination event between the target sequences and the homology arms upon a single-strand break (nick) or double-strand break at the nuclease cleavage site.
- nuclease cleavage site includes a DNA sequence at which a nick or doublestrand break is created by a nuclease agent (e.g., a Cas9 protein complexed with a guide RNA).
- a nuclease agent e.g., a Cas9 protein complexed with a guide RNA.
- the target sequences within the targeted locus that correspond to the 5’ and 3’ homology arms of the exogenous donor nucleic acid are “located in sufficient proximity” to a nuclease cleavage site if the distance is such as to promote the occurrence of a homologous recombination event between the 5’ and 3’ target sequences and the homology arms upon a single-strand break or double-strand break at the nuclease cleavage site.
- the target sequences corresponding to the 5’ and/or 3’ homology arms of the exogenous donor nucleic acid can be, for example, within at least 1 nucleotide of a given nuclease cleavage site or within at least 10 nucleotides to about 1,000 nucleotides of a given nuclease cleavage site.
- the nuclease cleavage site can be immediately adjacent to at least one or both of the target sequences.
- target sequences that correspond to the homology arms of the exogenous donor nucleic acid and the nuclease cleavage site can vary.
- target sequences can be located 5’ to the nuclease cleavage site, target sequences can be located 3’ to the nuclease cleavage site, or the target sequences can flank the nuclease cleavage site.
- the mutation in the first isoform can be any type of mutation and any size mutation.
- the mutation comprises an insertion, a deletion and/or a substitution of 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids (e.g., 1-20 amino acids, 1-5 amino acids, 1-3 amino acids, or 1 amino acid).
- the mutation comprises one or more (e.g., three) substitutions (e.g., comprises one or more (e.g., three) substitutions of 1 amino acid each).
- the mutation consists essentially of one or more (e.g., three) substitutions (e.g., consists essentially of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation consists of one or more (e.g., three) substitutions (e.g., consists of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation comprises an insertion (e.g., comprises an insertion of 1 amino acid). In some embodiments, the mutation consists essentially of an insertion (e.g., consists essentially of an insertion of 1 amino acid).
- the mutation consists of an insertion (e.g., consists of an insertion of 1 amino acid).
- the mutation can be at any site in the target protein.
- the target protein is a cell surface protein
- the mutation can in some embodiments be in the extracellular domain of the target protein.
- the site of the mutation can be a site that is non-conserved between different mammalian species.
- the mutation does not result in a secondary structure change in the surface protein.
- the mutation is within the epitope targeted by an antigen-binding protein or is at a site that is accessible to ligand binding.
- the mutation is not located at a site involved in a predicted or experimentally established or confirmed protein-protein interaction of the surface protein. In some embodiments, the mutation does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking. In some embodiments, the mutation does not result in deleting or introducing a posttranslational protein modification site, such as a glycosylation site. In some embodiments, the mutation is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction. In instances where an antibody or antigen-binding protein reactive against a target protein already exists, the information regarding the epitope of the target protein that is recognized by the antibody or antigen-binding protein can be used to select the site of the mutation.
- the first isoform of the target protein is a genetically engineered isoform of the target protein.
- the first isoform of the target protein can be genetically engineered to comprise a mutation (e.g., an artificial mutation that is not naturally occurring) to provide an altered epitope.
- the altered epitope can be, for example, in the binding region of an antigen-binding protein such as an antibody.
- the target protein is CXCR4 (e.g., human CXCR4), and the altered epitope is in a binding region of the REGN7663 or REGN7664 anti-CXCR4 antibodies described elsewhere herein.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) encoded by nucleotides within coding exon 2 of the CXCR4 gene (e.g., human CXCR4 gene).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the ECL2 region of CXCR4 (e.g., human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position A175 to position V198 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position SI 78 to position R183 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position R188 to position LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the REGN7663 and REGN7664 binding region (SEQ ID NO: 57).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198.
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198.
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., an insertion) between A175 and N176, between N176 and V177, between V177 and S178, between S178 and E179, between E179 and A180, between A180 and D181, between D181 and D182, between D182 and R183, between R183 and Y184, between Y184 and 1185, between 1185 and C186, between C186 and D187, between D187 and R188, between R188 and Fl 89, between Fl 89 and Y190, between Y190 and Pl 91, between Pl 91 and N192, between N192 and D193, and/or between D193 and L194 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., an insertion) between S178 and E179.
- the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198, and a mutation (e.g., an insertion) between S178 and E179.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) or combination of mutations as set forth in Table 1.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion), or combination of mutations, as set forth in pMM626, pMM630, pMM632, pMM633, and pMM640 (corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively).
- a mutation e.g., a substitution and/or insertion
- pMM626, pMM630, pMM632, pMM633, and pMM640 corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively.
- the mutation can comprise a mutation (e.g., a substitution) at position F189, N192, D193, E179, D181, and/or D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); a mutation (e.g., an insertion) between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); or any combination thereof of CXCR4 (e.g., human CXCR4).
- a mutation e.g., a substitution
- S178 and E179 of CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- any combination thereof of CXCR4 e.g., human CXCR4
- a mutation at a position within CXCR4 encompasses mutations (e.g., substitutions and/or insertions) including only the residue at that position or mutations (e.g., substitutions and/or insertions) including the residue at that position as well as other residues at other positions.
- the nomenclature of the amino acid position for the mutations or residue disclosed herein refer to the position of the mutation or residue in the canonical isoform of human CXCR4 set forth in SEQ ID NO: 1.
- the mutation comprises a mutation (e.g., a substitution) at position Fl 89 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- a suitable Fl 89 substitution is an F189A substitution.
- the mutation comprises a mutation (e.g., a substitution) at position N192 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable N192 substitution is an N192A substitution.
- the mutation comprises a mutation (e.g., a substitution) at position DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable DI 93 substitution is an DI 93 A substitution.
- the mutation comprises a mutation (e.g., a substitution) at positions Fl 89, N192, and DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- suitable Fl 89, N192, and DI 92 substitutions are F189A, N192A, and D192A substitutions.
- the mutation comprises an insertion between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- suitable insertions include an S178_E179insK (e.g., insertion of K between SI 78 and El 79), S178_E179insY (e.g., insertion of Y between S178 and E179), and S178_E179insR (e.g., insertion of R between SI 78 and El 79).
- the mutation comprises a mutation (e.g., a substitution) at position E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable E179 substitution is an E179R substitution.
- the mutation comprises a mutation (e.g., a substitution) at position D181 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable D181 substitution is an D181R substitution.
- the mutation comprises a mutation (e.g., a substitution) at position DI 82 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- a suitable DI 82 substitution is an D182R substitution.
- the mutation comprises a mutation (e.g., a substitution) at positions E179, D181, and D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- suitable E179, D181, and D182 substitutions are E179R, D181R, and D182R substitutions.
- the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 91 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of F189A, N192A, and N193 A relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 95 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insK relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 97 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of SI 78_E179insY relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 98 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insR relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 105 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of E179R, D181R, and D182R relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for the treatment of a disease or disorder (e.g., any malignancy, such as any cancer) in a subject, and the methods can comprise administering a therapeutically effective amount of the donor cells or edited cells to the subject.
- a disease or disorder e.g., any malignancy, such as any cancer
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject described herein are methods for the treatment of a hematopoietic malignancy or a hematologic malignancy, and the methods can comprise administering a therapeutically effective amount of the donor cells or edited cells to the subject. In some embodiments, the methods can further comprise administering a therapeutically effective amount of the agent for selective inhibition or selective depletion of host cells or non-edited cells (e.g., antagonist or the antigenbinding protein or the population of immune effector cells).
- the agent for selective inhibition or selective depletion of host cells or non-edited cells e.g., antagonist or the antigenbinding protein or the population of immune effector cells.
- the administered cells comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigenbinding fragment thereof), a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- a therapeutic molecule such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigenbinding fragment thereof), a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- the therapeutic molecule, immunoglobulin, CAR, or exogenous TCR does not target the target protein (e.g., CXCR4).
- the administered cells comprise or express an immunoglobulin, a CAR, or an exogenous TCR.
- the administered cells comprise or express a CAR or an exogenous TCR.
- the terms “treat,” “treating,” and “treatment” mean to relieve or alleviate at least one symptom associated with the disease or disorder, or to slow or reverse the progression of the disease or disorder.
- the term “treat” also denotes to arrest, delay the onset (i.e., the period prior to clinical manifestation of a disease) and/or reduce the risk of developing or worsening a disease.
- the term “treat” may mean eliminate or reduce the number or replication of cancer cells, and/or prevent, delay or inhibit metastasis, etc.
- the term “effective amount” may be used interchangeably with the term “therapeutically effective amount” and refers to that quantity of an agent (e g., antagonist or antigen-binding protein or population of immune effector cells), cell population (e g., donor cells or edited cells), or pharmaceutical composition (e.g., a composition comprising an agent and/or donor cells or edited cells such as hematopoietic cells) that is sufficient to result in a desired activity upon administration to a subject in need thereof.
- an agent e e g., antagonist or antigen-binding protein or population of immune effector cells
- cell population e g., donor cells or edited cells
- pharmaceutical composition e.g., a composition comprising an agent and/or donor cells or edited cells such as hematopoietic cells
- the term “effective amount” refers to that quantity of a compound, cell population, or pharmaceutical composition that is sufficient to delay the manifestation, arrest the progression, relieve or alleviate at least one symptom of a disease or disorder (e.g., any malignancy, such as cancer) treated by the methods of the present disclosure. Effective amounts vary, as recognized by those skilled in the art, depending on the particular condition being treated, the severity of the condition, the individual patient parameters including age, physical condition, size, gender and weight, the duration of the treatment, the nature of concurrent therapy (if any), the specific route of administration and like factors within the knowledge and expertise of the health practitioner.
- the effective amount alleviates, relieves, ameliorates, improves, reduces the symptoms, or delays the progression of any disease or disorder in the subject.
- the subject is a human.
- the subject is a human patient having a hematopoietic malignancy or a hematologic malignancy.
- the subject is a human patient having cancer (e.g., any type of cancer).
- a typical number of cells (e.g., immune cells or hematopoietic cells) administered to a mammal can be, for example, in the range of about 10 6 to IO 11 cells. In some embodiments it may be desirable to administer fewer than 10 6 cells to the subject. In some embodiments, it may be desirable to administer more than 10 11 cells to the subject.
- one or more doses of cells includes about 10 6 cells to about 10 11 cells, about 10 7 cells to about IO 10 cells, about 10 8 cells to about 10 9 cells, about 10 6 cells to about 10 8 cells, about 10 7 cells to about 10 9 cells, about 10 7 cells to about IO 10 cells, about 10 7 cells to about 10 11 cells, about 10 8 cells to about IO 10 cells, about 10 8 cells to about 10 11 cells, about 10 9 cells to about IO 10 cells, about 10 9 cells to about 10 11 cells, or about IO 10 cells to about 10 11 cells.
- one or more doses of cells includes about 10 6 to 10 7 cells per kg-
- the donor cells or edited cells may be administered in a pharmaceutically acceptable carrier or excipient as a pharmaceutical composition. See, e.g., Zhang et al. (2020) World J. Clin. Oncol. 11(5):275-282 and Atouf (2016) AAPS J. 18(4):844-848, each of which is herein incorporated by reference in its entirety for all purposes.
- compositions and/or cells described herein refers to molecular entities and other ingredients of such compositions that are physiologically tolerable and do not typically produce untoward reactions when administered to a mammal (e.g., a human).
- pharmaceutically acceptable means approved by a regulatory agency of the Federal or a state government or listed in the U.S. Pharmacopeia or other generally recognized pharmacopeia for use in mammals, and more particularly in humans.
- “Acceptable” means that the carrier is compatible with the active ingredient of the composition (e.g., the nucleic acids, vectors, cells, or therapeutic antibodies) and does not negatively affect the subject to which the composition(s) are administered.
- compositions and/or cells to be used in the present methods can comprise pharmaceutically acceptable carriers, excipients, or stabilizers in the form of lyophilized formations or aqueous solutions.
- Pharmaceutically acceptable carriers including buffers, are well known in the art, and may comprise phosphate, citrate, and other organic acids; antioxidants including ascorbic acid and methionine; preservatives; low molecular weight polypeptides; proteins, such as serum albumin, gelatin, or immunoglobulins; amino acids; hydrophobic polymers; monosaccharides; disaccharides; and other carbohydrates; metal complexes; and/or non-ionic surfactants. See, e.g., Remington: The Science and Practice of Pharmacy 20th Ed.
- the agent for selective inhibition or selective depletion of host cells or non-edited cells can in some embodiments be administered simultaneously with the donor cells or edited cells. In some embodiments, the donor cells or edited cells are administered after agent.
- the donor cells or edited cells are administered within a day after the agent or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more after the agent.
- the donor cells or edited cells are administered before the agent.
- the donor cells or edited cells are administered within a day before the agent or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more before the agent.
- the donor cells or edited cells are administered in multiple administrations (e.g., doses). In some embodiments, the donor cells or edited cells are administered to the subject once. In some embodiments, the donor cells or edited cells are administered to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the donor cells or edited cells are administered to the subject at a regular interval (e.g., every 6 months). In some embodiments, the agent for selective inhibition or selective depletion of host cells or non-edited cells is administered in multiple administrations (e g., doses). In some embodiments, the agent is administered to the subject once.
- the agent is administered to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the agent is administered to the subject at a regular interval (e.g., every 6 months).
- the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells and in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells.
- multiple administrations e.g., at least 2, at least 3, at least 4, at least 5 or more times
- the subject has a disease, such as a cancer, and the methods are for treating the disease (e.g., the cancer).
- the donor cells or edited cells can be engineered to express a therapeutic agent for treating that disease (e.g., if the disease is a cancer, the donor cells or edited cells can be engineered to express a CAR or exogenous TCR with antitumor reactivity).
- the subject e.g., human subject
- a hematopoietic malignancy refers to a malignant abnormality involving hematopoietic cells (e.g., blood cells, including progenitor and stem cells).
- hematopoietic malignancies include, without limitation, Hodgkin’s lymphoma, non-Hodgkin’s lymphoma, leukemia, and multiple myeloma.
- Exemplary leukemias include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myelogenous leukemia, acute lymphoblastic leukemia or chronic lymphoblastic leukemia, and chronic lymphoid leukemia.
- the subject has a cancer, such as a solid tumor cancer or a liquid tumor cancer. In some embodiments, the subject has a solid tumor cancer.
- a solid tumor is a solid mass of cancer cells that grow in organ systems and can occur anywhere in the body, such as breast cancer.
- liquid tumors are cancers that develop in the blood, bone marrow, or lymph nodes and includes leukemia, lymphoma, and myeloma.
- the subject has a cancer, such as a hematologic cancer.
- Hematologic cancers are cancers that begin in blood-forming tissue, such as the bone marrow, or in the cells of the immune system. Examples of hematologic cancers include leukemia, lymphoma, and multiple myeloma. Hematologic cancers are also referred to blood cancer.
- the subject has a hematopoietic disorder.
- the subject has defective immune cells or a genetic deficiency in hematopoiesis, such as sickle cell disease or severe combined immunodeficiency (SCID).
- the subject has a genetic hematopoietic disease (e.g., thalassemia).
- the subject has a T-cell -mediated diseases, such as an IPEX-like syndrome, a CTLA-4-associated immune dysregulation, a hemophagocytic syndrome, ALPS syndrome, or a syndrome caused by heterozygous PTEN germline mutations.
- the subject has an autoimmune disease.
- the subject has graft-versus-host-disease.
- the methods are for correction of congenital hematopoietic deficiencies.
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for conditioning a subject’s tissues (e.g., bone marrow) for engraftment or transplant. Such methods can be useful for treating such diseases without causing the toxicities that are observed in response to traditional conditioning therapies.
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for treating a subject defective or deficient in one or more cell types of the hematopoietic lineage.
- the methods can, in some embodiments, reconstitute the defective or deficient population of cells in vivo, thereby treating the pathology associated with the defect or depletion in the endogenous blood cell population.
- compositions and methods described herein can thus be used to treat a non- malignant hemoglobinopathy (e.g., a hemoglobinopathy selected from the group consisting of sickle cell anemia, thalassemia, Fanconi anemia, aplastic anemia, and Wiskott-Aldrich syndrome).
- a malignancy or proliferative disorder such as a cancer, such as a hematologic cancer or a myeloproliferative disease.
- compositions and methods described herein may be administered to a patient so as to deplete a population of endogenous hematopoietic stem cells prior to hematopoietic stem cell transplantation therapy, in which case the transplanted cells can home to a niche created by the endogenous cell depletion step and establish productive hematopoiesis. This, in turn, can reconstitute a population of cells depleted during cancer cell eradication, such as during systemic chemotherapy.
- Exemplary hematological cancers that can be treated using the compositions and methods described herein include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myeloid leukemia, chronic lymphoid leukemia, multiple myeloma, diffuse large B-cell lymphoma, and non-Hodgkin's lymphoma, as well as other cancerous conditions, including neuroblastoma.
- the donor cells or edited cells can be engineered to express a therapeutic agent for treating disease or the cancer (e.g., the donor cells or edited cells can be engineered to express a CAR or exogenous TCR with anti-tumor reactivity).
- the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule).
- the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer).
- the therapeutic molecule may target the diseased cells and/or an antigen expressed on the diseased cells (e.g., a tumor- associated antigen).
- Exemplary cancers that can be treated using the compositions and methods described herein include, without limitation, adenoid cystic carcinoma, adrenal gland cancer, anal cancer, basal cell carcinoma, bile duct cancer, bladder cancer, bone cancer, brain cancer, breast cancer, carcinoid tumor, cervical cancer, colorectal cancer, ductal carcinoma, endometrial cancer, esophageal cancer, gastric cancer, gastrointestinal stromal tumor - GIST, HER2-positive breast cancer, islet cell tumor, kidney cancer, laryngeal cancer, leukemia - acute lymphoblastic leukemia, leukemia - acute lymphocytic (ALL), leukemia - acute myeloid (AML), leukemia - adult, leukemia - childhood, leukemia - chronic lymphocytic (CLL), leukemia - chronic myeloid (CML), liver cancer, lobular carcinoma, lung cancer, lung cancer - small cell, lymphoma - Hodgkin’s, lympho
- Exemplary hematological cancers that can be treated using the compositions and methods described herein include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myeloid leukemia, chronic lymphoid leukemia, multiple myeloma, diffuse large B-cell lymphoma, and non-Hodgkin’s lymphoma, as well as other cancerous conditions, including neuroblastoma.
- Exemplary solid tumors that can be treated using the compositions and methods described herein include, without limitation, sarcomas and carcinomas.
- Sarcomas are tumors in a blood vessel, bone, fat tissue, ligament, lymph vessel, muscle or tendon.
- Carcinomas are tumors that form in epithelial cells. Epithelial cells are found in the skin, glands and the linings of organs.
- combinations are provided for administration to a subject in need thereof.
- such combinations comprise: (1) a population of donor cells or edited cells that express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) means for specifically binding the second isoform of the target protein but not the first isoform of the target protein.
- a target protein e.g., CXCR4
- such combinations comprise: (1) a population of donor cells or edited cells that express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) an agent (e.g., an antagonist or an antigen-binding protein or a population of immune effector cells) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
- a target protein e.g., CXCR4
- an agent e.g., an antagonist or an antigen-binding protein or a population of immune effector cells
- such combinations comprise: (1) a population of donor cells or edited cells that have been modified to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) means for specifically binding the second isoform of the target protein but not the first isoform of the target protein.
- a target protein e.g., CXCR4
- combinations e.g., combination medicaments
- combinations are provided for administration to a subject in need thereof.
- such combinations comprise: (1) a population of donor cells or edited cells that have been modified to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) an agent (e.g., an antagonist or an antigen-binding protein or a population of immune effector cells) that specifically binds to the second isoform of the target protein (e.g., CXCR4) but does not specifically bind to the first isoform of the target protein (e.g., CXCR4).
- a target protein e.g., CXCR4
- an agent e.g., an antagonist or an antigen-binding protein or a population of immune effector cells
- the first isoform and the second isoform can be functionally indistinguishable but immunologically distinguishable.
- such combinations comprise: (1) a population of donor cells or edited cells in which a target genomic locus has been edited to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) means for specifically binding the second isoform of the target protein but not the first isoform of the target protein.
- a target protein e.g., CXCR4
- such combinations comprise: (1) a population of donor cells or edited cells in which a target genomic locus has been edited to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) an agent (e.g., an antagonist or an antigen-binding protein or a population of immune effector cells) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
- the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
- the donor cells or edited cells express only the first isoform of the target protein (e.g., CXCR4). In other embodiments, the donor cells or edited cells express both the first and second isoforms of the target protein (e.g., CXCR4).
- the donor cells or edited cells can be any suitable cells as described above in the context of methods for selective inhibition or selective depletion of host cells or non-edited cells in a subject.
- the target protein can be any suitable target protein as described above in the context of methods for selective inhibition or selective depletion of host cells or non-edited cells in a subject.
- the target protein is C-X-C motif chemokine receptor 4 (CXCR4).
- the target protein is human CXCR4.
- the donor cells or edited cells can be any suitable cells as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject.
- the donor cells or edited cells comprise a genetic modification (insertion of a transgene, correction of a mutation, deletion or inactivation of a gene (e.g., insertion of premature stop codon or insertion of regulatory repressor sequence), or a change in an epigenetic modification important for expression of a gene) correcting or counteracting a disease-related gene defect present in a subject.
- the donor cells or edited cells comprise a transgene.
- the donor cells or edited cells comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR) (e.g., CAR-T cells, CAR-NK cells), or an exogenous T cell receptor (TCR).
- a therapeutic molecule such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR) (e.g., CAR-T cells, CAR-NK cells), or an exogenous T cell receptor (TCR).
- CAR chimeric antigen receptor
- TCR exogenous T cell receptor
- the donor cells or edited cells comprise a bicistronic nucleic acid construct encoding the therapeutic molecule and the first isoform of the target protein. See, e.g., Yeku et al. (2017) Sci. Rep. 7(1): 10541 and Ra
- the bicistronic construct can encode both a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and the first isoform (e.g., a modified isoform) of the target protein (e.g., CXCR4).
- a therapeutic protein e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin
- the first isoform e.g., a modified isoform of the target protein (e.g., CXCR4).
- the bicistronic construct encodes a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and a modified isoform of CXCR4.
- a therapeutic protein e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin
- the therapeutic molecule, immunoglobulin, CAR, or exogenous TCR does not target the target protein (e.g., CXCR4).
- the donor cells or edited cells comprise or express an immunoglobulin, a CAR, or an exogenous TCR.
- the donor cells or edited cells comprise or express a CAR or an exogenous TCR.
- the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above (e.g., CXCR4) is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule).
- any type of cancer e.g., not dependent on whether the target protein is related to the disease or cancer
- the target protein discussed above e.g., CXCR4
- the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein (e.g., CXCR4) does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer).
- the target protein e.g., CXCR4
- Exemplary types of cancers and tumors that can be treated are described elsewhere herein.
- the therapeutic molecule may target the diseased cells and/or an antigen expressed on the diseased cells (e.g., a tumor-associated antigen).
- the donor cells or edited cells are autologous (i.e., from the subject).
- the donor cells or edited cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation).
- the donor cells or edited cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the donor cells or edited cells are mammalian cells or non-human mammalian cells).
- the donor cells or edited cells are human cells (e.g., the subject is a human, and the cells are human cells).
- the second isoform of the target protein refers to the form that is present in the subject.
- the second isoform of the target protein refers to the wild type form or native form of the target protein (i.e., the form that usually occurs in nature)
- the first isoform refers to an isoform obtained by introducing a mutation in the nucleic acid sequence encoding the second isoform.
- the native form of a protein refers to a protein that is encoded by a nucleic acid sequence within the genome of the cell and that has not been inserted or mutated by genetic manipulation (i.e., a native protein is a protein that is not a transgenic protein or a genetically engineered protein).
- the mutation in the first isoform can be any type of mutation and any size mutation.
- the mutation comprises an insertion, a deletion and/or a substitution of 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids (e.g., 1-20 amino acids, 1-5 amino acids, 1-3 amino acids, or 1 amino acid).
- the mutation comprises one or more (e.g., three) substitutions (e.g., comprises one or more (e.g., three) substitutions of 1 amino acid each).
- the mutation consists essentially of one or more (e.g., three) substitutions (e.g., consists essentially of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation consists of one or more (e.g., three) substitutions (e.g., consists of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation comprises an insertion (e.g., comprises an insertion of 1 amino acid). In some embodiments, the mutation consists essentially of an insertion (e.g., consists essentially of an insertion of 1 amino acid).
- the mutation consists of an insertion (e.g., consists of an insertion of 1 amino acid).
- the mutation can be at any site in the target protein.
- the target protein is a cell surface protein
- the mutation can in some embodiments be in the extracellular domain of the target protein.
- the site of the mutation can be a site that is non-conserved between different mammalian species.
- the mutation does not result in a secondary structure change in the surface protein.
- the mutation is within the epitope targeted by an antigen-binding protein or is at a site that is accessible to ligand binding.
- the mutation is not located at a site involved in a predicted or experimentally established or confirmed proteinprotein interaction of the surface protein. In some embodiments, the mutation does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking. In some embodiments, the mutation does not result in deleting or introducing a posttranslational protein modification site, such as a glycosylation site. In some embodiments, the mutation is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction. In instances where an antibody or antigen-binding protein reactive against a target protein already exists, the information regarding the epitope of the target protein that is recognized by the antibody or antigen-binding protein can be used to select the site of the mutation.
- the mutation in the first isoform can be any type of mutation and any size mutation as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject.
- the first isoform of the target protein is a genetically engineered isoform of the target protein.
- the first isoform of the target protein can be genetically engineered to comprise a mutation (e.g., an artificial mutation that is not naturally occurring) to provide an altered epitope.
- the altered epitope can be, for example, in the binding region of an antigen-binding protein such as an antibody.
- the target protein is CXCR4 (e.g., human CXCR4)
- the altered epitope is in a binding region of the REGN7663 or REGN7664 anti-CXCR4 antibodies described elsewhere herein.
- the ECL2 region of human CXCR4 which is from position A175 to position V198 of human CXCR4 (SEQ ID NO: 1), is necessary and sufficient for REGN7663 and REGN7664 binding.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) encoded by nucleotides within coding exon 2 of the CXCR4 gene (e.g., human CXCR4 gene).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the ECL2 region of CXCR4 (e.g., human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position A175 to position V198 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- a mutation e.g., a substitution and/or insertion
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position SI 78 to position R183 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position R188 to position LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the REGN7663 and REGN7664 binding region (SEQ ID NO: 57).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198.
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198.
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., an insertion) between A175 and N176, between N176 and V177, between V177 and S178, between S178 and E179, between E179 and A180, between A180 and D181, between D181 and D182, between D182 and R183, between R183 and Y184, between Y184 and 1185, between 1185 and Cl 86, between Cl 86 and DI 87, between DI 87 and R188, between R188 and Fl 89, between Fl 89 and Y190, between Y190 and Pl 91, between P191 and N192, between N192 and DI 93, and/or between DI 93 and LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., an insertion) between SI 78 and El 79.
- the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198, and a mutation (e.g., an insertion) between S178 and E179.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) or combination of mutations as set forth in Table 1.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion), or combination of mutations, as set forth in pMM626, pMM630, pMM632, pMM633, and pMM640 (corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively).
- a mutation e.g., a substitution and/or insertion
- pMM626, pMM630, pMM632, pMM633, and pMM640 corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively.
- the mutation can comprise a mutation (e.g., a substitution) at position Fl 89, N192, D193, E179, D181, and/or D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); a mutation (e.g., an insertion) between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); or any combination thereof of CXCR4 (e.g., human CXCR4).
- a mutation e.g., a substitution
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- S178 and E179 of CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- a mutation at a position within CXCR4 encompasses mutations (e.g., substitutions and/or insertions) including only the residue at that position or mutations (e.g., substitutions and/or insertions) including the residue at that position as well as other residues at other positions.
- the nomenclature of the amino acid position for the mutations or residue disclosed herein refer to the position of the mutation or residue in the canonical isoform of human CXCR4 set forth in SEQ ID NO: 1.
- the mutation comprises a mutation (e.g., a substitution) at position F189 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- a suitable Fl 89 substitution is an F189A substitution.
- the mutation comprises a mutation (e.g., a substitution) at position N192 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable N192 substitution is an N192A substitution.
- the mutation comprises a mutation (e.g., a substitution) at position DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable DI 93 substitution is an DI 93 A substitution.
- the mutation comprises a mutation (e.g., a substitution) at positions F189, N192, and D193 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- suitable Fl 89, N192, and DI 92 substitutions are F189A, N192A, and D192A substitutions.
- the mutation comprises an insertion between SI 78 and El 79 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4.
- suitable insertions include an S178_E179insK (e.g., insertion of K between S178 and E179), S178_E179insY (e.g., insertion of Y between S178 and E179), and S178_E179insR (e.g., insertion of R between S178 and E179).
- the mutation comprises a mutation (e.g., a substitution) at position El 79 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable E179 substitution is an E179R substitution.
- the mutation comprises a mutation (e.g., a substitution) at position DI 81 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable DI 81 substitution is an DI 81R substitution.
- the mutation comprises a mutation (e.g., a substitution) at position DI 82 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- a suitable DI 82 substitution is an D182R substitution.
- the mutation comprises a mutation (e.g., a substitution) at positions E179, D181, and D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- suitable E179, D181, and D182 substitutions are E179R, D181R, and D182R substitutions.
- the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 91 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of F189A, N192A, and N193 A relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 95 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insK relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 97 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178 E179insY relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 98 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insR relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 105 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of E179R, D181R, and D182R relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the agent for selective inhibition or selective depletion of cells expressing a first isoform can be any suitable agent as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject.
- the agent comprises an antagonist that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
- the agent comprises an antigen-binding protein that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
- the agent comprises a population of cells (i.e., immune effector cells such as chimeric antigen receptor T cells (CAR- T)) expressing an antigen-binding protein that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
- a population of cells i.e., immune effector cells such as chimeric antigen receptor T cells (CAR- T)
- CAR- T chimeric antigen receptor T cells
- the agent can in some embodiments be for administration simultaneously with the donor cells or edited cells.
- the donor cells or edited cells are for administration after the agent.
- the donor cells or edited cells are for administration within a day after the agent or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more after the agent.
- the donor cells or edited cells are for administration before the agent.
- the donor cells or edited cells are for administration within a day before the agent or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more before the agent.
- the donor cells or edited cells are for administration in multiple administrations (e.g., doses). In some embodiments, the donor cells or edited cells are for administration to the subject once. In some embodiments, the donor cells or edited cells are for administration to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the donor cells or edited cells are for administration to the subject at a regular interval (e.g., every 6 months). In some embodiments, the agent is for administration in multiple administrations (e.g., doses). In some embodiments, the agent is for administration to the subject once.
- the agent is for administration to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the agent is for administration to the subject at a regular interval (e.g., every 6 months).
- the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells and in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells.
- multiple administrations e.g., at least 2, at least 3, at least 4, at least 5 or more times
- the agent comprises an antigen-binding protein as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject.
- selective depletion means selective mobilization of host cells or non-edited cells from the bone marrow to the periphery.
- the agent comprises an anti- CXCR4 antigen-binding protein as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject, e.g., a method in which the agent blocks interaction of endogenous ligand with the target on the host cells or non-edited cells.
- the agent comprises REGN7663, or a variant thereof as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject or an antigen-binding protein that binds to the same epitope as REGN7663.
- the agent comprises REGN7664, or a variant thereof as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject or an antigen-binding protein that binds to the same epitope as REGN7664.
- the agent comprises one or more nucleic acids encoding an antigen-binding protein as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject.
- the donor cells or edited cells can be engineered to express a therapeutic molecule for cell therapy as described elsewhere herein with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above (e.g., CXCR4) is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule).
- any type of cancer e.g., not dependent on whether the target protein is related to the disease or cancer
- the target protein discussed above e.g., CXCR4
- the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein (e.g., CXCR4) does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer).
- the therapeutic molecule may target the diseased cells and/or an antigen expressed on the diseased cells (e.g., a tumor- associated antigen).
- a subject can include, for example, any type of animal or mammal.
- Mammals include, for example, humans, non-human mammals, non-human primates, monkeys, apes, cats, dogs, horses, bulls, deer, bison, sheep, rabbits, rodents (e.g., but not limited to, mice, rats, hamsters, and guinea pigs), and livestock (e.g., but not limited to, bovine species such as cows and steer; ovine species such as sheep and goats; and porcine species such as pigs and boars).
- Birds include, for example, chickens, turkeys, ostrich, geese, and ducks. Domesticated animals and agricultural animals are also included.
- the term “non-human mammal” excludes humans. Particular non-limiting examples of non-human mammals include rodents, such as mice and rats. In some embodiments of the present invention, the subject is a human.
- the combination (e.g., combination medicament) is used for any of the methods for the treatment as described in more detail above.
- the combination e.g., combination medicament
- the combination is used for any of the methods for the treatment of a hematopoietic malignancy or a hematologic malignancy as described in more detail above.
- the combination is used for any of the methods for the treatment of a cancer (e.g., any type of cancer) as described in more detail above.
- the subject has a disease, such as a cancer, and the methods are for treating the disease (e.g., the cancer).
- the donor cells or edited cells can be engineered to express a therapeutic agent for treating that disease (e.g., if the disease is a cancer, the donor cells or edited cells can be engineered to express a CAR or exogenous TCR with antitumor reactivity).
- the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above (e.g., CXCR4) is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule).
- any type of cancer e.g., not dependent on whether the target protein is related to the disease or cancer
- the target protein discussed above e.g., CXCR4
- the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein (e.g., CXCR4) does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer).
- the therapeutic molecule may target the diseased cells and/or an antigen expressed on the diseased cells (e.g., a tumor-associated antigen).
- the subject e.g., human subject
- a hematopoietic malignancy refers to a malignant abnormality involving hematopoietic cells (e.g., blood cells, including progenitor and stem cells).
- hematopoietic malignancies include, without limitation, Hodgkin’s lymphoma, non-Hodgkin’s lymphoma, leukemia, and multiple myeloma.
- Exemplary leukemias include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myelogenous leukemia, acute lymphoblastic leukemia or chronic lymphoblastic leukemia, and chronic lymphoid leukemia.
- the subject has a cancer, such as a solid tumor cancer or a liquid tumor cancer.
- the subject has a solid tumor cancer.
- a solid tumor is a solid mass of cancer cells that grow in organ systems and can occur anywhere in the body, such as breast cancer.
- liquid tumors are cancers that develop in the blood, bone marrow, or lymph nodes and includes leukemia, lymphoma, and myeloma.
- the subject has a cancer, such as a hematologic cancer.
- Hematologic cancers are cancers that begin in blood-forming tissue, such as the bone marrow, or in the cells of the immune system. Examples of hematologic cancers include leukemia, lymphoma, and multiple myeloma. Hematologic cancers are also referred to blood cancer.
- the subject has a hematopoietic disorder.
- the subject has defective immune cells or a genetic deficiency in hematopoiesis, such as sickle cell disease or severe combined immunodeficiency (SCID).
- SCID severe combined immunodeficiency
- the subject has a genetic hematopoietic disease (e.g., thalassemia).
- the subject has a T-cell-mediated diseases, such as an IPEX-like syndrome, a CTLA-4-associated immune dysregulation, a hemophagocytic syndrome, ALPS syndrome, or a syndrome caused by heterozygous PTEN germline mutations.
- a T-cell-mediated diseases such as an IPEX-like syndrome, a CTLA-4-associated immune dysregulation, a hemophagocytic syndrome, ALPS syndrome, or a syndrome caused by heterozygous PTEN germline mutations.
- the subject has an autoimmune disease.
- the subject has graft-versus-host-disease.
- the methods are for correction of congenital hematopoietic deficiencies.
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for conditioning a subject’s tissues (e.g., bone marrow) for engraftment or transplant. Such methods can be useful for treating such diseases without causing the toxicities that are observed in response to traditional conditioning therapies.
- any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for treating a subject defective or deficient in one or more cell types of the hematopoietic lineage.
- the methods can, in some embodiments, reconstitute the defective or deficient population of cells in vivo, thereby treating the pathology associated with the defect or depletion in the endogenous blood cell population.
- the compositions and methods described herein can thus be used to treat a non- malignant hemoglobinopathy (e.g., a hemoglobinopathy selected from the group consisting of sickle cell anemia, thalassemia, Fanconi anemia, aplastic anemia, and Wiskott-Aldrich syndrome).
- a malignancy or proliferative disorder such as a cancer, such as hematologic cancer or a myeloproliferative disease.
- compositions and methods described herein may be administered to a patient so as to deplete a population of endogenous hematopoietic stem cells prior to hematopoietic stem cell transplantation therapy, in which case the transplanted cells can home to a niche created by the endogenous cell depletion step and establish productive hematopoiesis. This, in turn, can reconstitute a population of cells depleted during cancer cell eradication, such as during systemic chemotherapy.
- the donor cells or edited cells can be engineered to express a therapeutic agent for treating the cancer (e.g., the donor cells or edited cells can be engineered to express a CAR or exogenous TCR with anti-tumor reactivity).
- exemplary cancers that can be treated using the compositions and methods described herein include, without limitation, adenoid cystic carcinoma, adrenal gland cancer, anal cancer, basal cell carcinoma, bile duct cancer, bladder cancer, bone cancer, brain cancer, breast cancer, carcinoid tumor, cervical cancer, colorectal cancer, ductal carcinoma, endometrial cancer, esophageal cancer, gastric cancer, gastrointestinal stromal tumor - GIST, HER2-positive breast cancer, islet cell tumor, kidney cancer, laryngeal cancer, leukemia - acute lymphoblastic leukemia, leukemia - acute lymphocytic (ALL), leukemia - acute myeloid (AML), leukemia - adult, leukemia - childhood, leukemia
- Exemplary hematological cancers that can be treated using the compositions and methods described herein include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myeloid leukemia, chronic lymphoid leukemia, multiple myeloma, diffuse large B-cell lymphoma, and non-Hodgkin’s lymphoma, as well as other cancerous conditions, including neuroblastoma.
- Exemplary solid tumors that can be treated using the compositions and methods described herein include, without limitation, sarcomas and carcinomas.
- Sarcomas are tumors in a blood vessel, bone, fat tissue, ligament, lymph vessel, muscle or tendon.
- Carcinomas are tumors that form in epithelial cells. Epithelial cells are found in the skin, glands and the linings of organs.
- CXCR4 C-X-C motif chemokine receptor 4
- the genetically engineered CXCR4 protein can comprise any mutation as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject.
- the mutation in the genetically engineered CXCR4 protein can be any type of mutation and any size mutation as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject.
- the altered epitope can be, for example, in the binding region of an antigen-binding protein such as an antibody.
- the target protein is CXCR4 (e g., human CXCR4)
- the altered epitope is in a binding region of the REGN7663 or REGN7664 anti-CXCR4 antibodies described elsewhere herein.
- the ECL2 region of human CXCR4 which is from position A175 to position V198 of human CXCR4 (SEQ ID NO: 1), is necessary and sufficient for REGN7663 and REGN7664 binding.
- the mutation can comprise a mutation (e g., a substitution and/or insertion) encoded by nucleotides within coding exon 2 of the CXCR4 gene (e.g., human CXCR4 gene).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the ECL2 region of CXCR4 (e.g., human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position A175 to position V198 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- a mutation e.g., a substitution and/or insertion
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position SI 78 to position R183 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position R188 to position L194 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the REGN7663 and REGN7664 binding region (SEQ ID NO: 57).
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198.
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198.
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., an insertion) between A175 and N176, between N176 and V177, between V177 and S178, between S178 and E179, between E179 and A180, between A180 and D181, between D181 and D182, between D182 and R183, between R183 and Y184, between Y184 and 1185, between 1185 and C186, between 0186 and D187, between D187 and R188, between R188 and F189, between F189 and Y190, between Y190 and P191, between P191 and N192, between N192 and D193, and/or between DI 93 and L194 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- the mutation can comprise a mutation (e.g., an insertion) between S178 and E179.
- the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198, and a mutation (e.g., an insertion) between S178 and E179.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion) or combination of mutations as set forth in Table 1.
- the mutation can comprise a mutation (e.g., a substitution and/or insertion), or combination of mutations, as set forth in pMM626, pMM630, pMM632, pMM633, and pMM640 (corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively).
- a mutation e.g., a substitution and/or insertion
- pMM626, pMM630, pMM632, pMM633, and pMM640 corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively.
- the mutation can comprise a mutation (e.g., a substitution) at position Fl 89, N192, D193, E179, D181, and/or D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); a mutation (e.g., an insertion) between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); or any combination thereof of CXCR4 (e.g., human CXCR4).
- a mutation e.g., a substitution
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- S178 and E179 of CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4
- a mutation at a position within CXCR4 encompasses mutations (e.g., substitutions and/or insertions) including only the residue at that position or mutations (e.g., substitutions and/or insertions) including the residue at that position as well as other residues at other positions.
- the nomenclature of the amino acid position for the mutations or residue disclosed herein refer to the position of the mutation or residue in the canonical isoform of human CXCR4 set forth in SEQ ID NO: 1.
- the mutation comprises a mutation (e.g., a substitution) at position F189 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- a suitable Fl 89 substitution is an F189A substitution.
- the mutation comprises a mutation (e.g., a substitution) at position N192 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable N192 substitution is an N192A substitution.
- the mutation comprises a mutation (e.g., a substitution) at position D193 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable DI 93 substitution is an DI 93 A substitution.
- the mutation comprises a mutation (e.g., a substitution) at positions Fl 89, N192, and DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- suitable Fl 89, N192, and DI 92 substitutions are F189A, N192A, and D192A substitutions.
- the mutation comprises an insertion between SI 78 and El 79 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- CXCR4 e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4.
- suitable insertions include an S178 E179insK (e.g., insertion of K between S178 and E179), S178_E179insY (e.g., insertion of Y between S178 and E179), and S178_E179insR (e.g., insertion of R between S178 and E179).
- the mutation comprises a mutation (e.g., a substitution) at position E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable E179 substitution is an E179R substitution.
- the mutation comprises a mutation (e.g., a substitution) at position DI 81 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- An example of a suitable DI 81 substitution is an DI 81R substitution.
- the mutation comprises a mutation (e.g., a substitution) at position DI 82 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- a suitable DI 82 substitution is an D182R substitution.
- the mutation comprises a mutation (e.g., a substitution) at positions E179, D181, and D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4).
- suitable E179, D181, and D182 substitutions are E179R, D181R, and D182R substitutions.
- the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 91 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of F189A, N192A, and N193 A relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 95 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insK relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 97 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insY relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 98 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of S178_E179insR relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 105 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1.
- the mutation comprises, consists essentially of, or consist of E179R, D181R, and D182R relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
- nucleic acids encoding the genetically engineered CXCR4 protein are also provided.
- the nucleic acid comprises deoxyribonucleic acid (DNA) or ribonucleic acid (RNA).
- DNA deoxyribonucleic acid
- RNA ribonucleic acid
- Such nucleic acids can be DNA, RNA, or hybrids or derivatives of either DNA or RNA.
- the nucleic acid can be codon-optimized for efficient translation into protein in a particular cell or organism.
- the nucleic acid can be modified to substitute codons having a higher frequency of usage in a human cell, a mammalian cell, a rodent cell, a mouse cell, a rat cell, or any other host cell of interest, as compared to the naturally occurring polynucleotide sequence.
- Any portion or fragment of a nucleic acid molecule can be produced by: (1) isolating the molecule from its natural milieu; (2) using recombinant DNA technology (e.g., but not limited to, PCR amplification or cloning); or (3) using chemical synthesis methods.
- Nucleic acids can comprise modifications for improved stability or reduced immunogenicity.
- Non-limiting examples of modifications include: (1) alteration or replacement of one or both of the nonlinking phosphate oxygens and/or of one or more of the linking phosphate oxygens in the phosphodiester backbone linkage; (2) alteration or replacement of a constituent of a ribose sugar such as alteration or replacement of the 2’ hydroxyl on the ribose sugar; (3) replacement of the phosphate moiety with dephospho linkers; (4) modification or replacement of a naturally occurring nucleobase; (5) replacement or modification of a ribose-phosphate backbone; (6) modification of the 3’ end or 5’ end of the oligonucleotide (e.g., but not limited to, removal, modification or replacement of a terminal phosphate group or conjugation of a moiety); and (7) modification of the sugar.
- modifications include: (1) alteration or replacement of one or both of the nonlinking phosphate oxygens and/or of one or more of the linking phosphate oxygens in the phosphodiester backbone linkage
- the nucleic acids can be in the form of an expression construct as defined elsewhere herein.
- the nucleic acids can include regulatory regions that control expression of the nucleic acid molecule (e.g., but not limited to, transcription or translation control regions), full-length or partial coding regions, and combinations thereof.
- the nucleic acids can be operably linked to a promoter active in a cell or organism of interest.
- Promoters that can be used in such expression constructs include promoters active, for example, in one or more of a eukaryotic cell, such as a mammalian cell (e.g., a nonhuman mammalian cell or a human cell), such as a rodent cell (e.g., but not limited to, a mouse cell, or a rat cell).
- a eukaryotic cell such as a mammalian cell (e.g., a nonhuman mammalian cell or a human cell), such as a rodent cell (e.g., but not limited to, a mouse cell, or a rat cell).
- Such promoters can be, for example, conditional promoters, inducible promoters, constitutive promoters, or tissue-specific promoters.
- methods of making the genetically engineered CXCR4 proteins are also provided.
- such methods can comprise determining an epitope in the binding region of a CXCR4 antagonist.
- the epitope of the CXCR4 antagonist can be determined by alanine scanning mutational analysis.
- the epitope of the CXCR4 antagonist can be determined by peptide blot analysis.
- the epitope of the CXCR4 antagonist can be determined by peptide cleavage analysis.
- the epitope of the CXCR4 antagonist can be determined by crystallographic studies.
- the epitope of the CXCR4 antagonist can be determined by NMR analysis. In some embodiments, the epitope of the CXCR4 antagonist can be determined by epitope excision. In some embodiments, the epitope of the CXCR4 antagonist can be determined by epitope extraction. In some embodiments, the epitope of the CXCR4 antagonist can be determined by chemical modification of antigens. In some embodiments, the epitope of the CXCR4 antagonist can be determined by hydrogen/deuterium exchange detected by mass spectrometry. In some embodiments, the epitope of the CXCR4 antagonist is determined by high-resolution cryogenic electron microscopy analysis of the CXCR4 antagonist complexed with a CXCR4 protein (e.g., human CXCR4 protein).
- a CXCR4 protein e.g., human CXCR4 protein
- such methods can further comprise selecting a site at which to generate the artificial mutation to provide the altered epitope in the binding region of the CXCR4 antagonist.
- the site of the artificial mutation is selected so that it is non- conserved between different mammalian species.
- the site of the artificial mutation is selected so that it does not result in a secondary structure change.
- the site of the artificial mutation is selected so that it is at a site that is accessible to ligand binding.
- the site of the artificial mutation is selected so that it is not located at a site involved in a predicted or experimentally established or confirmed proteinprotein interaction.
- the site of the artificial mutation is selected so that it does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking. In some embodiments, the site of the artificial mutation is selected so that it does not result in deleting or introducing a posttranslational protein modification site. In some embodiments, the site of the artificial mutation is selected so that it is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction.
- such methods can further comprise generating the genetically engineered CXCR4 protein (e.g., human CXCR4 protein).
- generating the genetically engineered CXCR4 protein can comprise modifying a cell or population of cells to express the genetically engineered CXCR4 protein (e.g., human CXCR4 protein) as described in more detail elsewhere herein.
- such methods can further comprise testing the genetically engineered CXCR4 protein (e.g., human CXCR4 protein) to determine whether the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered CXCR4 protein (e.g., human CXCR4 protein) compared to its ability to bind and/or inhibit a wild type CXCR4 protein (e.g., human CXCR4 protein) and to determine whether the genetically engineered CXCR4 protein (e.g., human CXCR4 protein) retains binding to its endogenous ligand(s).
- the genetically engineered CXCR4 protein e.g., human CXCR4 protein
- cells or populations of cells comprising the genetically engineered CXCR4 protein are also provided.
- the genetically engineered CXCR4 protein is the only form of CXCR4 expressed by the cells.
- the cells express both the genetically engineered CXCR4 protein and the endogenous CXCR4 protein.
- the cells can be any suitable cells as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject.
- the cells are immune cells.
- the cells are hematopoietic cells.
- the cells are lymphocytes or lymphoid progenitor cells.
- the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infiltrating lymphocytes (TILs), or any combination thereof).
- the cells are alpha beta T cells.
- the cells are gamma delta T cells.
- the cells are TILs.
- the cells are B cells.
- the cells are natural killer (NK) cells.
- the cells are innate lymphoid cells.
- the cells are dendritic cells.
- the cells are hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) or descendants thereof.
- HSCs are capable of giving rise to both myeloid and lymphoid progenitor cells that further give rise to myeloid cells (e g., monocytes, macrophages, neutrophils, basophils, dendritic cells, erythrocytes, platelets, etc.) and lymphoid cells (e.g., T cells, B cells, NK cells), respectively.
- the cells are induced pluripotent stem cells (e.g., human induced pluripotent stem cells).
- the cells are derived from induced pluripotent stem cells (e.g., NK cells derived from induced pluripotent stem cells).
- the cells are HSCs or HSPCs. In some embodiments, the cells are derived from HSCs or HSPCs.
- the cells comprise a genetic modification (insertion of a transgene, correction of a mutation, deletion or inactivation of a gene (e.g., insertion of premature stop codon or insertion of regulatory repressor sequence), or a change in an epigenetic modification important for expression of a gene) correcting or counteracting a disease-related gene defect present in a subject.
- the cells comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
- the cells comprise a bicistronic nucleic acid construct encoding the therapeutic molecule and the first isoform of the target protein.
- a bicistronic nucleic acid construct encoding the therapeutic molecule and the first isoform of the target protein.
- the bicistronic construct can encode both a therapeutic protein (e.g., a CAR, a TCR or antigenbinding fragment of a TCR, or an immunoglobulin) and the first isoform (e.g., a modified isoform) of the target protein (e.g., CXCR4).
- the bicistronic construct encodes a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and a modified isoform of CXCR4.
- the therapeutic molecule, immunoglobulin, CAR, or exogenous TCR does not target the target protein (e.g., CXCR4).
- the cells comprise or express an immunoglobulin, a CAR, or an exogenous TCR. In some embodiments, the cells comprise or express a CAR or an exogenous TCR.
- the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule).
- the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein (e.g., CXCR4) does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer).
- the target protein e.g., CXCR4
- Exemplary types of cancers and tumors that can be treated are described elsewhere herein.
- the therapeutic molecule targets the diseased cells and/or an antigen expressed by the diseased cells (e.g., a tumor-associated antigen).
- the cells are autologous (i.e., from the subject).
- the cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation).
- the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells).
- the cells are human cells (e.g., the subject is a human, and the cells are human cells).
- the cells can further comprise an exogenous donor nucleic acid (e.g., comprising the mutation) and/or a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in a target genomic locus (e.g., a CXCR4 genomic locus).
- exogenous donor nucleic acids and nuclease agents are described above in the context of methods for generating donor cells or edited cells.
- nucleotide and amino acid sequences listed in the accompanying sequence listing are shown using standard letter abbreviations for nucleotide bases, and three-letter code for amino acids.
- the nucleotide sequences follow the standard convention of beginning at the 5’ end of the sequence and proceeding forward (i.e., from left to right in each line) to the 3’ end. Only one strand of each nucleotide sequence is shown, but the complementary strand is understood to be included by any reference to the displayed strand.
- codon degenerate variants thereof that encode the same amino acid sequence are also provided.
- RNA sequences that encode the same amino acid sequence are also provided (by replacing the thymines with uracils).
- the amino acid sequences follow the standard convention of beginning at the amino terminus of the sequence and proceeding forward (i.e., from left to right in each line) to the carboxy terminus.
- Example 1 CXCR4 blocking antibodies mobilize bone marrow resident leukocytes in vivo, with greatest effects on mature B cells.
- CXCR4 C-X-C motif chemokine receptor 4
- CXCL12 C-X-C motif chemokine 12
- antibody, small molecule, or peptide antagonists causes mobilization of mature and progenitor immune cells from the bone marrow to peripheral sites, as illustrated in Figure 1A.
- CXCR4 C-X-C motif chemokine receptor 4
- CXCL12 C-X-C motif chemokine 12
- FIG. 1A Blocking the interaction of C-X-C motif chemokine receptor 4 (CXCR4) with its ligand C-X-C motif chemokine 12 (CXCL12) with antibody, small molecule, or peptide antagonists causes mobilization of mature and progenitor immune cells from the bone marrow to peripheral sites, as illustrated in Figure 1A.
- ARMoR antibody-resistant variant CXCR4
- WT wild-type
- FIG. 3B The graphs display frequencies of lineage-negative cKIT + (LK) and lineage-negative cKIT + Scal + (LSK) cells within total lineagenegative cells.
- LK lineage-negative cKIT +
- LSK lineage-negative cKIT + Scal +
- FIG. 4A illustrates the study design for these experiments.
- Fourteen to 15- week-old CXCR4-humanized male mice were administered a daily intravenous dose of 10 mg/kg of anti-CXCR4 REGN7664 (squares, 5 mice), anti-CXCR4 REGN7663 (hexagons, 4 mice) or REGN1945, isotype (triangles, 6 mice) for 5 consecutive days (arrows) or a single dose two hours prior to terminal tissue collection (arrowhead).
- FIG. 4B Representative flow cytometry plots of BM-resident B cells (B220 + CD43 negatlve ) cells in CXCR4-humanized mice treated with 5 doses (top row) or single dose (bottom row) of anti-CXCR4 REGN7664 or isotype REGN1945 are shown in Figure 4B. Definitions of B cell subsets in bone marrow were based on Harris et al. (2020) JoVE e61565. We observed significantly decreased frequencies of BM mature B cells (B220 + CD43 neg IgM + IgD + ) following REGN7664 blocking antibody administration, as indicated by the bolded rectangular gates on the flow plots.
- Stable cell lines expressing domain-swap chimeric constructs confirmed REGN7663 and REGN7664 bind the ECL2 region of human CXCR4.
- CXCR4 signaling by further addition of its ligand CXCL12 counteracts cAMP induction, leading to suppressed CRE.Luc (right panel).
- endogenous CXCR4 was knocked out in the bioassay line (293.CRE.Luc.CXCR4.KO).
- CXCR4 variants shown to be resistant to anti-CXCR4 REGN7663 and/or REGN7664 binding in Figure 10 were evaluated for signaling function in response to ligand CXCL12 in the bioassay described above. Analysis of CXCR4 variants was split across two different experiments, each including the same control constructs (pMM330, pMM331, pMM341). 293.CRE.Luc.CXCR4.KO cells transduced with indicated CXCR4 variants were incubated with 5 mM forskolin and a dose titration of human CXCL12 ranging from 0-5 nM for 5-6 hours, followed by measurement of luciferase activity. Results for these experiments are shown in Figures 12A and 12B.
- Y-axis values were calculated by dividing the luminescence readout at each concentration of ligand by the luminescence readout for that line in media containing forskolin alone (no CXCL12). Suppression of CRE.Luc activity indicates CXCL12-mediated signaling. Values are the mean of three technical replicate assay wells, +/- S.D. Expression of CXCR4 variants in the bioassay lines was confirmed by flow cytometry using anti-CXCR4 clone 2B11 ( Figure 12C). As shown in Figures 12A and 12B, CXCR4 variants resistant to anti- CXCR4 binding retained signaling function in response to ligand CXCL12.
- CRE.Luc bioassay shown in Figure 11 was then adapted, as shown in Figure 13, to test blockade of CXCL12-dependent signaling function by anti-CXCR4 mAbs.
- CXCR4 variant constructs demonstrated reduced binding of REGN7664 and/or REGN7663.
- Re-confirmation of anti-CXCR4 REGN7664 ( Figure 17A) and REGN7663 ( Figure 17B) binding patterns on select CXCR4 ARMoR variants was then performed in 293.CRE.Luc.CXCR4.KO bioassay cells, as described above.
- CXCR4 variants with diminished antibody binding achieved with minimal changes from WT CXCR4 (indicated by dashed arrows) were selected for further characterization.
- CXCR4/CXCL12 signaling bioassays performed as described above and shown in Figure 18, demonstrated that antibody-resistant CXCR4 variants retained signaling function in response to CXCL12 ligand. Values are the mean of three technical replicate assay wells, +/- S.D.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- Cell Biology (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Molecular Biology (AREA)
- Developmental Biology & Embryology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Epidemiology (AREA)
- Pharmacology & Pharmacy (AREA)
- Virology (AREA)
- Biotechnology (AREA)
- Engineering & Computer Science (AREA)
- Hematology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
Methods for improving engraftment of donor cells in a subject thereof are provided. Such methods can comprise providing cells that have been modified to express a first isoform of a target protein (e.g., C-X-C motif chemokine receptor 4 (CXCR4)), administering the donor cells to the subject, and then selectively inhibiting host cells in the subject based on their expression of the second isoform of the target protein, thereby improving engraftment of donor cells in the subject. Also provided are combinations for administration to a subject in need thereof, wherein the combination comprises (1) a population of donor cells modified to express a first isoform of a target protein (e.g., CXCR4) and (2) an antagonist (e.g., anti-CXCR4 antigen-binding protein) that specifically binds to a second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
Description
CXCR4 ANTIBODY-RESISTANT MODIFIED RECEPTORS
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application claims the benefit of US Application No. 63/579,165, filed August 28, 2023, and US Application No. 63/611,395, filed December 18, 2023, each of which is herein incorporated by reference in its entirety for all purposes.
REFERENCE TO A SEQUENCE LISTING SUBMITTED AS AN XML FILE
[0002] The Sequence Listing written in file 617845SEQLIST.xml is 140,705 bytes, was created on August 26, 2024, and is hereby incorporated by reference.
BACKGROUND
[0003] Hematopoietic stem cell transplant (HSCT) can fully replace the hematopoietic system of the transplant recipient with donor-derived cells. This approach can be curative for hematologic malignancies, genetic deficiencies of blood lineages, and severe autoimmune diseases refractory to standard treatment. However, patients must first undergo treatments — termed host conditioning — that partially or fully ablate their immune system to facilitate HSCT graft uptake. Traditional approaches to transplant host conditioning employ genotoxins, such as chemotherapeutic agents and radiation, with little specificity for the desired target cells. The associated risks of off-target tissue damage, secondary malignancies, and opportunistic infection thus limit the application of HSCT to a treatment of last resort.
[0004] Monoclonal antibody (mAb) and related therapies allow targeting of specific cell populations, and thus a path to safer, more effective conditioning regimens. Host hematopoietic stem cells (HSCs) can be depleted by antibodies that block the function of essential surface molecules, or that engage Fc-mediated effector mechanisms. Alternatively, agents that displace HSCs from their resident niches in the bone marrow (BM) could facilitate the engraftment of donor HSCs. Blockade of C-X-C motif chemokine receptor 4 (CXCR4), a G-protein-coupled receptor (GPCR) that is essential for localization of hematopoietic cells to and within BM, is known to trigger mobilization of mature and progenitor immune cells from BM to peripheral sites. Small molecule, peptide, and mAb agents that occlude the interaction of CXCR4 with its
ligand C-X-C motif chemokine 12 (CXCL12; also known as SDF1) have this effect in preclinical models and in patients. However, a major challenge with such conditioning methods is that donor HSCs, along with host, would be susceptible to CXCR4 blocking agents during the engraftment window.
SUMMARY
[0005] Methods for improving engraftment of donor cells in a subject in need thereof are provided. Also provided are combinations or combination medicaments for administration to a subject in need thereof. Also provided are isolated cells or populations of cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4. Also provided are methods of making the isolated cells or populations of cells. Also provided are genetically engineered C-X-C chemokine receptor type 4 (CXCR4) proteins and nucleic acids encoding the proteins.
[0006] In one aspect, provided are methods for improving engraftment of donor cells in a subject in need thereof. Some such methods comprise: (a) providing donor cells that have been modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4, wherein the second isoform is expressed in host cells of the subject; (b) administering the donor cells to the subject, and (c) selectively inhibiting host cells in the subject based on their expression of the second isoform of CXCR4, thereby improving engraftment of donor cells in the subject.
[0007] In some such methods, the selective inhibition of host cells in step (c) does not comprise ablation of host cells by an active killing mechanism. In some such methods, the selective inhibition in step (c) comprises selectively depleting host cells from the bone marrow. In some such methods, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable. In some such methods, the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such methods, the donor cells express only the first isoform of CXCR4. In some such methods, the first isoform of CXCR4 is expressed from an expression vector in the donor cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the donor cells. In some such methods, the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus.
[0008] In some such methods, the selective inhibition in step (c) comprises administering a CXCR4 antagonist to the subject, wherein the CXCR4 antagonist specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4, optionally wherein step (c) comprises multiple administrations of the CXCR4 antagonist. In some such methods, the CXCR4 antagonist is an antigen-binding protein. In some such methods, the antigen-binding protein is an antibody or an antigen-binding fragment thereof. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such methods, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some such methods, the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such methods,
the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some such methods, the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
[0009] In some such methods, the first isoform of CXCR4 is a genetically engineered isoform of CXCR4. In some such methods, the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation. In some such methods, the altered epitope is in a binding region of the CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4. In some such methods, both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the CXCR4 antagonist blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
[0010] In some such methods, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such methods, the mutation comprises an insertion, deletion, or substitution within a region from position S I 78 to position R183 and/or within a region from position R188 to position LI 94 of CXCR4. In some such methods, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
[0011] In some such methods, the donor cells and/or the host cells are hematopoietic cells,
optionally wherein the donor cells and/or host cells are immune cells. In some such methods, the donor cells and/or the host cells are lymphocytes or lymphoid progenitor cells. In some such methods, the donor cells and/or the host cells are T cells. In some such methods, the donor cells and/or the host cells are alpha beta T cells. In some such methods, the donor cells and/or the host cells are gamma delta T cells. In some such methods, the donor cells and/or the host cells are tumor infiltrating lymphocytes (TILs). In some such methods, the donor cells and/or the host cells are B cells, optionally wherein the donor cells and/or the host cells are immature B cells, and the method depletes host mature B cells from the bone marrow. In some such methods, the donor cells and/or the host cells are NK cells. In some such methods, the donor cells and/or the host cells are hematopoietic stem and progenitor cells. In some such methods, the donor cells and/or the host cells are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such methods, the donor cells are derived from induced pluripotent stem cells. In some such methods, the subject is a mammal or a non-human mammal, and the donor cells are mammalian cells or non-human mammalian cells. In some such methods, the subject is a human, and the donor cells are human cells. In some such methods, the donor cells comprise or express a therapeutic molecule. In some such methods, the therapeutic molecule does not target CXCR4. In some such methods, the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR). In some such methods, the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4. In some such methods, the donor cells are autologous. In some such methods, the donor cells are allogeneic or syngeneic.
[0012] In some such methods, the subject has a disease or disorder, and the method is for treating the disease or disorder in the subject. In some such methods, the subject has cancer. In some such methods, the cancer is a solid tumor cancer. In some such methods, the cancer is a hematologic cancer. In some such methods, the subject has a hematopoietic malignancy, and the method is for treating the hematopoietic malignancy in the subject. In some such methods, the subject has defective immune cells or a genetic deficiency in hematopoiesis. In some such methods, the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
[0013] In some such methods, steps (b) and (c) occur simultaneously. In some such methods, step (b) occurs prior to step (c), optionally wherein step (c) comprises multiple administrations of
a CXCR4 antagonist subsequent to step (b). In some such methods, step (b) occurs subsequent to step (c), optionally wherein step (c) comprises multiple administrations of a CXCR4 antagonist prior to step (b). In some such methods, step (c) occurs both prior to and subsequent to step (b), optionally wherein step (c) comprises multiple administrations of a CXCR4 antagonist prior to step (b) and/or multiple administrations of the CXCR4 antagonist subsequent to step (b).
[0014] In some such methods, the method further comprises generating the donor cells by modifying a population of cells to express the first isoform of CXCR4 prior to step (a). In some such methods, the population of cells is a population of induced pluripotent stem cells, and the method further comprises differentiating the induced pluripotent stem cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the induced pluripotent stem cells are differentiated into hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, NK cells, hematopoietic stem cells, or hematopoietic stem and progenitor cells. In some such methods, the population of cells is a population of hematopoietic stem cells or hematopoietic stem and progenitor cells, and the method further comprises differentiating the hematopoietic stem cells or hematopoietic stem and progenitor cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the hematopoietic stem cells or hematopoietic stem and progenitor cells are differentiated into differentiated hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, or NK cells. In some such methods, generating the donor cells comprises introducing an expression vector encoding the first isoform of CXCR4 to express the first isoform of CXCR4 prior to step (a), or wherein generating the donor cells comprises editing a genomic locus in the population of cells to express the first isoform of CXCR4 prior to step (a). In some such methods, the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus. In some such methods, the editing comprises introducing into the population of cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the donor cells that express the first isoform of CXCR4. In some such methods, the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide
RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence. In some such methods, the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117- 131. In some such methods, the Cas protein is a Cas9 protein. In some such methods, the exogenous donor nucleic acid comprises homology arms. In some such methods, the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN). In some such methods, the method further comprises isolating the population of cells from the subject or from a different subject prior to modifying the population of cells.
[0015] Some such methods comprise: (a) providing donor cells that have been modified to express a first isoform of CXCR4, wherein the first isoform of CXCR4 is different from a second isoform of CXCR4, wherein the second isoform is expressed in host cells of the subject; (b) administering the donor cells to the subject, and (c) providing the subject with means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
[0016] In some such methods, the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 selectively inhibits host cells in the subject based on their expression of the second isoform of CXCR4. In some such methods, the selective inhibition of host cells does not comprise ablation of host cells by an active killing mechanism. In some such methods, the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
[0017] In some such methods, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable. In some such methods, the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such methods, the donor cells express only the first isoform of CXCR4. In some such methods, the first isoform of CXCR4 is expressed from an expression vector in the donor cells, or a genomic locus has been edited to express the first isoform of CXCR4 in the donor cells. In some such methods, the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus.
[0018] In some such methods, the first isoform of CXCR4 is a genetically engineered
isoform of CXCR4. In some such methods, the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation. In some such methods, the altered epitope is in a binding region of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 such that the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4. In some such methods, both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4. In some such methods, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such methods, the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4. In some such methods, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R. [0019] In some such methods, step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4. In some such methods, steps (b) and (c) occur simultaneously. In some such methods, step (b) occurs prior to step (c), optionally wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 subsequent to step (b). In some such methods, step (b) occurs subsequent to step (c), optionally wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 prior to step (b). In some such methods, step (c) occurs both prior to and subsequent to step (b), optionally wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 prior to step (b) and/or multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 subsequent to step (b).
[0020] In some such methods, the donor cells and/or the host cells are hematopoietic cells, optionally wherein the donor cells and/or host cells are immune cells. In some such methods, the donor cells and/or the host cells are lymphocytes or lymphoid progenitor cells. In some such methods, the donor cells and/or the host cells are T cells. In some such methods, the donor cells and/or the host cells are alpha beta T cells. In some such methods, the donor cells and/or the host cells are gamma delta T cells. In some such methods, the donor cells and/or the host cells are tumor infdtrating lymphocytes (TILs). In some such methods, the donor cells and/or the host cells are B cells, optionally wherein the donor cells and/or the host cells are immature B cells, and the method depletes host mature B cells from the bone marrow. In some such methods, the donor cells and/or the host cells are NK cells. In some such methods, the donor cells and/or the host cells are hematopoietic stem and progenitor cells. In some such methods, the donor cells and/or the host cells are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such methods, the donor cells are derived from induced pluripotent stem cells. In some such methods, the subject is a mammal or a non-human mammal, and the donor cells are mammalian cells or non-human mammalian cells. In some such methods, the subject is a human, and the donor cells are human cells.
[0021] In some such methods, the donor cells comprise or express a therapeutic molecule. In some such methods, the therapeutic molecule does not target CXCR4. In some such methods, the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR). In some such methods, the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
[0022] In some such methods, the donor cells are autologous. In some such methods, the donor cells are allogeneic or syngeneic. In some such methods, the subject has a disease or disorder, and the method is for treating the disease or disorder in the subject. In some such methods, the subject has cancer, optionally wherein the cancer is a solid tumor cancer or a hematologic cancer. In some such methods, the subject has a hematopoietic malignancy, and the method is for treating the hematopoietic malignancy in the subject. In some such methods, the subject has defective immune cells or a genetic deficiency in hematopoiesis, optionally wherein the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
[0023] In some such methods, the method further comprises generating the donor cells by
modifying a population of cells to express the first isoform of CXCR4 prior to step (a). In some such methods, the population of cells is a population of induced pluripotent stem cells, and the method further comprises differentiating the induced pluripotent stem cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the induced pluripotent stem cells are differentiated into hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, NK cells, hematopoietic stem cells, or hematopoietic stem and progenitor cells. In some such methods, the population of cells is a population of hematopoietic stem cells or hematopoietic stem and progenitor cells, and the method further comprises differentiating the hematopoietic stem cells or hematopoietic stem and progenitor cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the hematopoietic stem cells or hematopoietic stem and progenitor cells are differentiated into differentiated hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, or NK cells. In some such methods, generating the donor cells comprises introducing an expression vector encoding the first isoform of CXCR4 to express the first isoform of CXCR4 prior to step (a), or generating the donor cells comprises editing a genomic locus in the population of cells to express the first isoform of CXCR4 prior to step (a). In some such methods, the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus. In some such methods, the editing comprises introducing into the population of cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the donor cells that express the first isoform of CXCR4. In some such methods, the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence. In some such methods, the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-
131 . In some such methods, the Cas protein is a Cas9 protein. In some such methods, the exogenous donor nucleic acid comprises homology arms. In some such methods, the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN).
[0024] In some such methods, the method further comprises isolating the population of cells from the subject or from a different subject prior to modifying the population of cells.
[0025] In another aspect, provided are combination medicaments for administration to a subject in need thereof. In some such combination medicaments, the combination medicament comprises: (a) a population of donor cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4; and (b) a CXCR4 antagonist that specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4.
[0026] In some such combination medicaments, the CXCR4 antagonist selectively inhibits host cells in the subject based on their expression of the second isoform of CXCR4. In some such combination medicaments, the selective inhibition of host cells does not comprise ablation of host cells by an active killing mechanism. In some such combination medicaments, the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow. In some such combination medicaments, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable. In some such combination medicaments, the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such combination medicaments, the donor cells express only the first isoform of CXCR4. In some such combination medicaments, the first isoform of CXCR4 is expressed from an expression vector in the population of donor cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the population of donor cells. In some such combination medicaments, the genomic locus is an endogenous CXCR4 genomic locus. In some such combination medicaments, the genomic locus is not an endogenous CXCR4 genomic locus.
[0027] In some such combination medicaments, the first isoform of CXCR4 is a genetically engineered isoform of CXCR4. In some such combination medicaments, the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation. In some such combination medicaments, the altered epitope is in a binding region of the CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the first isoform of
CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4. In some such combination medicaments, both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the CXCR4 antagonist blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4. In some such combination medicaments, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such combination medicaments, the mutation comprises an insertion, deletion, or substitution within a region from position SI 78 to position R183 and/or within a region from position R188 to position L194 of CXCR4. In some such combination medicaments, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R. [0028] In some such combination medicaments, the CXCR4 antagonist is an antigen-binding protein. In some such combination medicaments, the antigen-binding protein is an antibody or an antigen-binding fragment thereof. In some such combination medicaments, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such combination medicaments, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such combination medicaments, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some such combination medicaments, the immunoglobulin light chain variable region comprises, consists
essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5. In some such combination medicaments, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such combination medicaments, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such combination medicaments, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some such combination medicaments, the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
[0029] In some such combination medicaments, the donor cells are hematopoietic cells, optionally wherein the donor cells are immune cells. In some such combination medicaments, the donor cells are lymphocytes or lymphoid progenitor cells. In some such combination medicaments, the donor cells are T cells. In some such combination medicaments, the donor cells are alpha beta T cells. In some such combination medicaments, the donor cells are gamma delta T cells. In some such combination medicaments, the donor cells are tumor infiltrating lymphocytes (TILs). In some such combination medicaments, the donor cells are B cells. In some such combination medicaments, the donor cells are NK cells. In some such combination medicaments, the donor cells are hematopoietic stem cells or hematopoietic stem and progenitor
cells. In some such combination medicaments, the donor cells are derived from induced pluripotent stem cells or are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such combination medicaments, the subject is a mammal or a nonhuman mammal, and the donor cells are mammalian cells or non-human mammalian cells. In some such combination medicaments, the subject is a human, and the donor cells are human cells. In some such combination medicaments, the donor cells comprise or express a therapeutic molecule. In some such combination medicaments, the therapeutic molecule does not target CXCR4. In some such combination medicaments, the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR). In some such combination medicaments, the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4. In some such combination medicaments, the donor cells are autologous. In some such combination medicaments, the donor cells are allogeneic or syngeneic.
[0030] In some such combination medicaments, the subject has a disease or disorder, and the combination medicament is for treating the disease or disorder in the subject. In some such combination medicaments, the subject has cancer. In some such combination medicaments, the cancer is a solid tumor cancer. In some such combination medicaments, the cancer is a hematologic cancer. In some such combination medicaments, the subject has a hematopoietic malignancy, and the combination medicament is for treating the hematopoietic malignancy in the subject. In some such combination medicaments, the subject has defective immune cells or a genetic deficiency in hematopoiesis. In some such combination medicaments, the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID). [0031] Some such combination medicaments comprise: (a) a population of donor cells modified to express a first isoform of CXCR4, wherein the first isoform of CXCR4 is different from a second isoform of CXCR4; and (b) means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
[0032] In some such combination medicaments, the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 selectively inhibits host cells in the subject based on their expression of the second isoform of CXCR4. In some such combination medicaments, the selective inhibition of host cells does not comprise ablation of host cells by an active killing mechanism. In some such combination medicaments, the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
[0033] In some such combination medicaments, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable. In some such combination medicaments, the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such combination medicaments, the donor cells express only the first isoform of CXCR4. In some such combination medicaments, the first isoform of CXCR4 is expressed from an expression vector in the population of donor cells, or a genomic locus has been edited to express the first isoform of CXCR4 in the population of donor cells. In some such combination medicaments, the genomic locus is an endogenous CXCR4 genomic locus. In some such combination medicaments, the genomic locus is not an endogenous CXCR4 genomic locus. [0034] In some such combination medicaments, the first isoform of CXCR4 is a genetically engineered isoform of CXCR4. In some such combination medicaments, the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation. In some such combination medicaments, the altered epitope is in a binding region of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 such that the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4. In some such combination medicaments, both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4. In some such combination medicaments, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such combination medicaments, the mutation comprises an insertion, deletion, or substitution within a region from position SI 78 to position R183 and/or within a region from position R188 to position L194 of CXCR4. In some such combination medicaments, the mutation comprises one or more mutations selected from: F189A, N192A, DI 93 A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
[0035] In some such combination medicaments, the donor cells are hematopoietic cells,
optionally wherein the donor cells are immune cells. In some such combination medicaments, the donor cells are lymphocytes or lymphoid progenitor cells. In some such combination medicaments, the donor cells are T cells. In some such combination medicaments, the donor cells are alpha beta T cells. In some such combination medicaments, the donor cells are gamma delta T cells. In some such combination medicaments, the donor cells are tumor infiltrating lymphocytes (TILs). In some such combination medicaments, the donor cells are B cells. In some such combination medicaments, the donor cells are NK cells. In some such combination medicaments, the donor cells are hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such combination medicaments, the donor cells are derived from induced pluripotent stem cells or are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such combination medicaments, the subject is a mammal or a nonhuman mammal, and the donor cells are mammalian cells or non-human mammalian cells. In some such combination medicaments, the subject is a human, and the donor cells are human cells.
[0036] In some such combination medicaments, the donor cells comprise or express a therapeutic molecule. In some such combination medicaments, the therapeutic molecule does not target CXCR4. In some such combination medicaments, the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR). In some such combination medicaments, the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
[0037] In some such combination medicaments, the donor cells are autologous. In some such combination medicaments, the donor cells are allogeneic or syngeneic. In some such combination medicaments, the subject has a disease or disorder, and the combination medicament is for treating the disease or disorder in the subject. In some such combination medicaments, the subject has cancer, optionally wherein the cancer is a solid tumor cancer or a hematologic cancer. In some such combination medicaments, the subject has a hematopoietic malignancy, and the combination medicament is for treating the hematopoietic malignancy in the subject. In some such combination medicaments, the subject has defective immune cells or a genetic deficiency in hematopoiesis, optionally wherein the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
[0038] In another aspect, provided are isolated cells or populations of cells modified to
express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4. In some such isolated cells or populations of cells, the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, wherein the altered epitope is in a binding region of a CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4, and wherein the first isoform of CXCR4 retains binding to its endogenous ligands.
[0039] In some such isolated cells or populations of cells, the mutation is an artificial mutation. In some such isolated cells or populations of cells, both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the CXCR4 antagonist blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4. In some such isolated cells or populations of cells, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable. In some such isolated cells or populations of cells, the cell or cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such isolated cells or populations of cells, the cell or cells express only the first isoform of CXCR4. In some such isolated cells or populations of cells, the first isoform of CXCR4 is expressed from an expression vector in the cell or cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the cell or cells. In some such isolated cells or populations of cells, the genomic locus is an endogenous CXCR4 genomic locus. In some such isolated cells or populations of cells, the genomic locus is not an endogenous CXCR4 genomic locus.
[0040] In some such isolated cells or populations of cells, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such isolated cells or populations of cells, the mutation comprises an insertion, deletion, or substitution within a region from position S 178 to position R183 and/or within a region from position R188 to position L194 of CXCR4. In some such isolated cells or populations of cells, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R. In some such isolated cells or populations of cells, the first isoform and the second
isoform are immunologically distinguishable by the CXCR4 antagonist, wherein the CXCR4 antagonist specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4.
[0041] In some such isolated cells or populations of cells, the CXCR4 antagonist is an antigen-binding protein. In some such isolated cells or populations of cells, the antigen-binding protein is an antibody or an antigen-binding fragment thereof. In some such isolated cells or populations of cells, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such isolated cells or populations of cells, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such isolated cells or populations of cells, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some such isolated cells or populations of cells, the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5. In some such isolated cells or populations of cells, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at
least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such isolated cells or populations of cells, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such isolated cells or populations of cells, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some such isolated cells or populations of cells, the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
[0042] In some such isolated cells or populations of cells, the cell or cells are hematopoietic cell(s), optionally wherein the cell or cells are immune cell(s). In some such isolated cells or populations of cells, the cell or cells are lymphocytes or lymphoid progenitor cell(s). In some such isolated cells or populations of cells, the cell or cells are T cell(s). In some such isolated cells or populations of cells, the cell or cells are alpha beta T cell(s). In some such isolated cells or populations of cells, the cell or cells are gamma delta T cell(s). In some such isolated cells or populations of cells, the cell or cells are tumor infdtrating lymphocyte(s) (TILs). In some such isolated cells or populations of cells, the cell or cells are B cell(s). In some such isolated cells or populations of cells, the cell or cells are NK cell(s). In some such isolated cells or populations of cells, the cell or cells are hematopoietic stem cell(s) or hematopoietic stem and progenitor cell(s). In some such isolated cells or populations of cells, the cell or cells are induced pluripotent stem cell(s). In some such isolated cells or populations of cells, the cell or cells are mammalian cell(s) or non-human mammalian cell(s). In some such isolated cells or populations of cells, the cell or cells are human cell(s). In some such isolated cells or populations of cells, the cell or cells comprise or express a therapeutic molecule. In some such isolated cells or populations of cells, the therapeutic molecule does not target CXCR4. In some such isolated cells or populations of cells, the cell or cells comprise or express an immunoglobulin, a chimeric antigen receptor
(CAR), or an exogenous T cell receptor (TCR). In some such isolated cells or populations of cells, the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4. In some such isolated cells or populations of cells, the cell or cells are isolated from a subject. In some such isolated cells or populations of cells, the cell or cells are for use in treatment of a subject having cells expressing the second isoform of CXCR4. In some such isolated cells or populations of cells, the cell or cells are isolated from the subject.
[0043] In another aspect, provided are methods of making any of the above isolated cells or populations of cells. Some such methods comprise modifying a cell or population of cells to express the first isoform of CXCR4.
[0044] In some such methods, the modifying comprises introducing an expression vector encoding the first isoform of CXCR4, or wherein the modifying comprises editing a genomic locus to express the first isoform of CXCR4. In some such methods, the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus.
[0045] In some such methods, the editing comprises introducing into the cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the cells that express the first isoform of CXCR4. In some such methods, the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence. In some such methods, the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131. In some such methods, the Cas protein is a Cas9 protein. In some such methods, the exogenous donor nucleic acid comprises homology arms. In some such methods, the exogenous donor nucleic acid is a singlestranded oligodeoxynucleotide (ssODN).
[0046] In another aspect, provided are genetically engineered human C-X-C chemokine receptor type 4 (CXCR4) proteins. Some such genetically engineered proteins comprise an artificial mutation to provide an altered epitope, wherein the altered epitope is in a binding region of a CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered human CXCR4 protein compared to its ability to bind and/or inhibit a wild type human CXCR4 protein, and wherein the genetically engineered human CXCR4 protein retains binding to its endogenous ligand(s).
[0047] In some such genetically engineered proteins, the genetically engineered CXCR4 protein is functionally indistinguishable but immunologically distinguishable from a native CXCR4 protein.
[0048] In some such genetically engineered proteins, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such genetically engineered proteins, the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4. In some such genetically engineered proteins, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R. In some such genetically engineered proteins, the genetically engineered CXCR4 protein and the native CXCR4 protein are functionally indistinguishable but immunologically distinguishable by the CXCR4 antagonist.
[0049] In some such genetically engineered proteins, the CXCR4 antagonist is an antigenbinding protein. In some such genetically engineered proteins, the antigen-binding protein is an antibody or an antigen-binding fragment thereof. In some such genetically engineered proteins, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such genetically engineered proteins, the three
light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such genetically engineered proteins, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some such genetically engineered proteins, the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5. In some such genetically engineered proteins, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such genetically engineered proteins, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such genetically engineered proteins, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigenbinding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some such genetically engineered proteins, the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
[0050] In another aspect, provided are nucleic acids encoding any of the above genetically engineered human CXCR4 proteins, optionally wherein the nucleic acid is an expression vector encoding the genetically engineered human CXCR4 protein.
[0051] In another aspect, provided are methods of making a genetically engineered human C-X-C chemokine receptor type 4 (CXCR4) protein comprising an artificial mutation to provide an altered epitope, wherein the altered epitope is in a binding region of a CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered human CXCR4 protein compared to its ability to bind and/or inhibit a wild type human CXCR4 protein, and wherein the genetically engineered human CXCR4 protein retains binding to its endogenous ligand(s). Some such methods comprise: (a) determining an epitope in the binding region of the CXCR4 antagonist; (b) selecting a site at which to generate the artificial mutation to provide the altered epitope in the binding region of the CXCR4 antagonist; (c) generating the genetically engineered human CXCR4 protein comprising the artificial mutation to provide the altered epitope in the binding region of the CXCR4 antagonist; and (d) testing the genetically engineered human CXCR4 protein to determine whether the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered human CXCR4 protein compared to its ability to bind and/or inhibit a wild type human CXCR4 protein and to determine whether the genetically engineered human CXCR4 protein retains binding to its endogenous ligand(s).
[0052] In some such methods, the epitope of the CXCR4 antagonist is determined by alanine scanning mutational analysis, peptide blot analysis, peptide cleavage analysis, crystallographic studies, NMR analysis, epitope excision, epitope extraction, chemical modification of antigens, and/or hydrogen/deuterium exchange detected by mass spectrometry. In some such methods, the epitope of the CXCR4 antagonist is determined by high-resolution cryogenic electron microscopy analysis of the CXCR4 antagonist complexed with a human CXCR4 protein. In some such methods, the site of the artificial mutation is selected so that it: (I) is non-conserved between different mammalian species; (II) does not result in a secondary structure change; (III) is at a site that is accessible to ligand binding; (IV) is not located at a site involved in a predicted or experimentally established or confirmed protein-protein interaction; (V) does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking; (VI) does not result in deleting or introducing a posttranslational protein modification
site; and/or (VII) is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction.
[0053] In some such methods, generating the genetically engineered human CXCR4 protein comprises modifying a cell or population of cells to express the genetically engineered human CXCR4 protein. In some such methods, the modifying comprises introducing an expression vector encoding the genetically engineered human CXCR4 protein, or the modifying comprises editing a genomic locus to express the genetically engineered human CXCR4 protein. In some such methods, the genomic locus is an endogenous CXCR4 genomic locus. In some such methods, the genomic locus is not an endogenous CXCR4 genomic locus. In some such methods, the editing comprises introducing into the cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate cells that express the genetically engineered human CXCR4 protein. In some such methods, the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence. In some such methods, the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131. In some such methods, the Cas protein is a Cas9 protein. In some such methods, the exogenous donor nucleic acid comprises homology arms. In some such methods, the exogenous donor nucleic acid is a single- stranded oligodeoxynucleotide (ssODN).
[0054] In some such methods, the genetically engineered human CXCR4 protein is functionally indistinguishable but immunologically distinguishable from a native CXCR4 protein.
[0055] In some such methods, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such methods, the mutation comprises an insertion, deletion, or substitution
within a region from position SI 78 to position R183 and/or within a region from position R188 to position LI 94 of CXCR4. In some such methods, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178 E179insK, S178 E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
[0056] In some such methods, the genetically engineered human CXCR4 protein and the native CXCR4 protein are functionally indistinguishable but immunologically distinguishable by the CXCR4 antagonist. In some such methods, the CXCR4 antagonist is an antigen-binding protein. In some such methods, the antigen-binding protein is an antibody or an antigen-binding fragment thereof. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such methods, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some such methods, the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising
three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such methods, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the antigen-binding protein comprises an immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some such methods, the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
[0057] Provided herein are methods for in vivo selective depletion of non-edited cells from the bone marrow and repopulation with edited cells in a subject in need thereof, combination medicaments for administration to a subject in need thereof, isolated cells or populations of cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4, methods of making the isolated cells or populations of cells comprising modifying a cell or population of cells to express the first isoform of CXCR4, genetically engineered C-X-C chemokine receptor type 4 (CXCR4) proteins comprising an artificial mutation to provide an altered epitope, and nucleic acids encoding the genetically engineered CXCR4 proteins.
[0058] In one aspect, provided are methods for in vivo selective depletion of non-edited cells from the bone marrow and repopulation with edited cells in a subject in need thereof. Some such methods comprise: (a) providing edited cells that have been modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4, wherein the second isoform is expressed in non-edited cells of the subject; (b) administering the edited cells to the subject, and (c) selectively depleting non-edited cells from
the bone marrow in the subject based on their expression of the second isoform of CXCR4. [0059] In some such methods, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable. In some such methods, the edited cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such methods, the edited cells express only the first isoform of CXCR4. In some such methods, a genomic locus has been edited to express the first isoform of CXCR4 in the edited cells. In some such methods, the genomic locus is a CXCR4 genomic locus. In some such methods, the genomic locus is not a CXCR4 genomic locus.
[0060] In some such methods, the first isoform of CXCR4 is a genetically engineered isoform of CXCR4. In some such methods, the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation. In some such methods, the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such methods, the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such methods, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such methods, the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4. In some such methods, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
[0061] In some such methods, the selective depletion in step (c) comprises administering a CXCR4 antagonist to the subject, wherein the CXCR4 antagonist specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4. In some such methods, the CXCR4 antagonist is an antigen-binding protein. In some such methods, the antigen-binding protein is an antibody or an antigen-binding fragment thereof. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such methods, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such methods, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some such methods, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5. In some such methods, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such methods, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively,
and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such methods, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some such methods, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
[0062] In some such methods, the edited cells are hematopoietic cells. In some such methods, the edited cells are lymphocytes or lymphoid progenitor cells. In some such methods, the edited cells are T cells. In some such methods, the edited cells are alpha beta T cells. In some such methods, the edited cells are gamma delta T cells. In some such methods, the edited cells are tumor infdtrating lymphocytes (TILs). In some such methods, the edited cells are B cells, optionally wherein the edited cells are immature B cells, and the method depletes non-edited mature B cells from the bone marrow. In some such methods, the edited cells are NK cells. In some such methods, the edited cells are hematopoietic stem and progenitor cells. In some such methods, the edited cells are derived from induced pluripotent stem cells. In some such methods, the edited cells are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such methods, the subject is a mammal or a non-human mammal, and the edited cells are mammalian cells or non-human mammalian cells. In some such methods, the subject is a human, and the edited cells are human cells. In some such methods, the edited cells comprise or express a therapeutic molecule. In some such methods, the edited cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR). In some such methods, the edited cells are autologous. In some such methods, the edited cells are allogeneic or syngeneic.
[0063] In some such methods, the subject has a hematopoietic malignancy, and the method is for treating the hematopoietic malignancy in the subject. In some such methods, the subject has cancer. In some such methods, the cancer is a hematologic cancer. In some such methods, the subject has defective immune cells or a genetic deficiency in hematopoiesis. In some such
methods, the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
[0064] In some such methods, steps (b) and (c) occur simultaneously. In some such methods, step (b) occurs prior to step (c). In some such methods, step (b) occurs subsequent to step (c). [0065] Some such methods further comprise generating the edited cells by modifying a population of cells to express the first isoform of CXCR4 prior to step (a). In some such methods, the population of cells is a population of induced pluripotent stem cells, and the method further comprises differentiating the edited induced pluripotent stem cells prior to step (a) into the edited cells that are administered in step (a), optionally wherein the induced pluripotent stem cells are differentiated into hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, NK cells, hematopoietic stem cells, or hematopoietic stem and progenitor cells. In some such methods, the population of cells is a population of hematopoietic stem cells or hematopoietic stem and progenitor cells, and the method further comprises differentiating the edited hematopoietic stem cells or hematopoietic stem and progenitor cells prior to step (a) into the edited cells that are administered in step (a), optionally wherein the hematopoietic stem cells or hematopoietic stem and progenitor cells are differentiated into differentiated hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, or NK cells.
[0066] In some such methods, generating the edited cells comprises editing a genomic locus in the population of cells to express the first isoform of CXCR4 prior to step (a). In some such methods, the genomic locus is a CXCR4 genomic locus. In some such methods, the genomic locus is not a CXCR4 genomic locus. In some such methods, the editing comprises introducing into the population of cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the edited cells that express the first isoform of CXCR4. In some such methods, the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence. In some such methods, the
nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA- targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131. In some such methods, the Cas protein is a Cas9 protein. In some such methods, the exogenous donor nucleic acid comprises homology arms. In some such methods, the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN). Some such methods further comprise isolating the population of cells from the subject or from a different subject prior to modifying the population of cells.
[0067] In another aspect, provided are combination medicaments for administration to a subject in need thereof. Some such combination medicaments comprise: (a) a population of cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4; and (b) a CXCR4 antagonist that specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4. [0068] In some such combination medicaments, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable. In some such combination medicaments, the cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such combination medicaments, the cells express only the first isoform of CXCR4. In some such combination medicaments, a genomic locus has been edited to express the first isoform of CXCR4 in the population of cells. In some such combination medicaments, the genomic locus is a CXCR4 genomic locus. In some such combination medicaments, the genomic locus is not a CXCR4 genomic locus.
[0069] In some such combination medicaments, the first isoform of CXCR4 is a genetically engineered isoform of CXCR4. In some such combination medicaments, the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation. In some such combination medicaments, the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and
11, respectively. In some such combination medicaments, the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such combination medicaments, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such combination medicaments, the mutation comprises an insertion, deletion, or substitution within a region from position SI 78 to position R183 and/or within a region from position R188 to position L194 of CXCR4. In some such combination medicaments, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
[0070] In some such combination medicaments, the CXCR4 antagonist is an antigen-binding protein. In some such combination medicaments, the antigen-binding protein is an antibody or an antigen-binding fragment thereof. In some such combination medicaments, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such combination medicaments, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such combination medicaments, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises, consists
essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some such combination medicaments, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5. In some such combination medicaments, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such combination medicaments, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such combination medicaments, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some such combination medicaments, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
[0071] In some such combination medicaments, the cells are hematopoietic cells. In some such combination medicaments, the cells are lymphocytes or lymphoid progenitor cells. In some such combination medicaments, the cells are T cells. In some such combination medicaments, the cells are alpha beta T cells. In some such combination medicaments, the cells are gamma delta T cells. In some such combination medicaments, the cells are tumor infiltrating lymphocytes (TILs). In some such combination medicaments, the cells are B cells. In some such combination medicaments, the cells are NK cells. In some such combination medicaments, the
cells are hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such combination medicaments, the cells are derived from induced pluripotent stem cells or are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells. In some such combination medicaments, the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells. In some such combination medicaments, the subject is a human, and the cells are human cells. In some such combination medicaments, the cells comprise or express a therapeutic molecule. In some such combination medicaments, the cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR). In some such combination medicaments, the cells are autologous. In some such combination medicaments, the cells are allogeneic or syngeneic.
[0072] In some such combination medicaments, the subject has a hematopoietic malignancy, and the combination medicament is for treating the hematopoietic malignancy in the subject. In some such combination medicaments, the subject has cancer. In some such combination medicaments, the cancer is a hematologic cancer. In some such combination medicaments, the subject has defective immune cells or a genetic deficiency in hematopoiesis. In some such combination medicaments, the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
[0073] In another aspect, provided are isolated cells or populations of cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4.
[0074] In some such isolated cells or populations of cells, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable. In some such isolated cells or populations of cells, the cell or cells express both the first isoform of CXCR4 and the second isoform of CXCR4. In some such isolated cells or populations of cells, the cell or cells express only the first isoform of CXCR4. In some such isolated cells or populations of cells, the first isoform of CXCR4 is a genetically engineered isoform of CXCR4. In some such isolated cells or populations of cells, the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation. In some such isolated cells or populations of cells, a genomic locus has been edited to express the first isoform of CXCR4 in the cell or cells. In some such isolated cells or populations of cells, the genomic locus is a CXCR4 genomic locus. In some such isolated cells or populations of cells,
the genomic locus is not a CXCR4 genomic locus.
[0075] In some such isolated cells or populations of cells, the cell or cells further comprise an exogenous donor nucleic acid comprising the artificial mutation and a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus. In some such isolated cells or populations of cells, the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence. In some such isolated cells or populations of cells, the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA- targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131. In some such isolated cells or populations of cells, the Cas protein is a Cas9 protein. In some such isolated cells or populations of cells, the exogenous donor nucleic acid comprises homology arms. In some such isolated cells or populations of cells, the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN).
[0076] In some such isolated cells or populations of cells, the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such isolated cells or populations of cells, the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such isolated cells or populations of cells, the mutation is in the
extracellular loop 2 (ECL2) region of CXCR4. In some such isolated cells or populations of cells, the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4. In some such isolated cells or populations of cells, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
[0077] In some such isolated cells or populations of cells, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable by a CXCR4 antagonist. In some such isolated cells or populations of cells, the CXCR4 antagonist is an antigen-binding protein. In some such isolated cells or populations of cells, the antigen-binding protein is an antibody or an antigen-binding fragment thereof. In some such isolated cells or populations of cells, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such isolated cells or populations of cells, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such isolated cells or populations of cells, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some such isolated cells or populations of cells, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or
consists of the sequence set forth in SEQ ID NO: 5. In some such isolated cells or populations of cells, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such isolated cells or populations of cells, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such isolated cells or populations of cells, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some such isolated cells or populations of cells, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
[0078] In some such isolated cells or populations of cells, the cell or cells are hematopoietic cell(s). In some such isolated cells or populations of cells, the cell or cells are lymphocytes or lymphoid progenitor cell(s). In some such isolated cells or populations of cells, the cell or cells are T cell(s). In some such isolated cells or populations of cells, the cell or cells are alpha beta T cell(s). In some such isolated cells or populations of cells, the cell or cells are gamma delta T cell(s).In some such isolated cells or populations of cells, the cell or cells are tumor infiltrating lymphocyte(s) (TILs). In some such isolated cells or populations of cells, the cell or cells are B cell(s). In some such isolated cells or populations of cells, the cell or cells are NK cell(s). In some such isolated cells or populations of cells, the cell or cells are hematopoietic stem cell(s) or hematopoietic stem and progenitor cell(s). In some such isolated cells or populations of cells, the cell or cells are induced pluripotent stem cell(s). In some such isolated cells or populations of
cells, the cell or cells are mammalian cell(s) or non-human mammalian cell(s). In some such isolated cells or populations of cells, the cell or cells are human cell(s). In some such isolated cells or populations of cells, the cell or cells comprise or express a therapeutic molecule. In some such isolated cells or populations of cells, the cell or cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR). In some such isolated cells or populations of cells, the cell or cells are isolated from a subject. [0079] Some such isolated cells or populations of cells are for use in treatment of a subject having cells expressing the second isoform of CXCR4. In some such isolated cells or populations of cells, the cell or cells are isolated from the subject.
[0080] In another aspect, provided are methods of making any of the above isolated cells or populations of cells, comprising modifying a cell or population of cells to express the first isoform of CXCR4. In some such methods, the modifying comprises editing a genomic locus to express the first isoform of CXCR4. In some such methods, the genomic locus is a CXCR4 genomic locus. In some such methods, the genomic locus is not a CXCR4 genomic locus.
[0081] In some such methods, the editing comprises introducing into the cells: (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and (2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the edited cells that express the first isoform of CXCR4. In some such methods, the nuclease agent comprises: (a) a zinc finger nuclease (ZFN); (b) a transcription activator-like effector nuclease (TALEN); or (c) (i) a Cas protein; and (ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence. In some such methods, the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131. In some such methods, the Cas protein is a Cas9 protein. In some such methods, the exogenous donor nucleic acid comprises homology arms. In some such methods, the exogenous donor nucleic acid is a singlestranded oligodeoxynucleotide (ssODN).
[0082] In another aspect, provided are genetically engineered C-X-C chemokine receptor type 4 (CXCR4) proteins comprising an artificial mutation to provide an altered epitope. In some such genetically engineered CXCR4 proteins, the genetically engineered CXCR4 protein is functionally indistinguishable but immunologically distinguishable from a native CXCR4 protein. In some such genetically engineered CXCR4 proteins, the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such genetically engineered CXCR4 proteins, the altered epitope is in a binding region of an antibody comprising an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such genetically engineered CXCR4 proteins, the mutation is in the extracellular loop 2 (ECL2) region of CXCR4. In some such genetically engineered CXCR4 proteins, the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4. In some such genetically engineered CXCR4 proteins, the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
[0083] In some such genetically engineered CXCR4 proteins, the genetically engineered CXCR4 protein and the native CXCR4 protein are functionally indistinguishable but immunologically distinguishable by a CXCR4 antagonist. In some such genetically engineered CXCR4 proteins, the CXCR4 antagonist is an antigen-binding protein. In some such genetically engineered CXCR4 proteins, the antigen-binding protein is an antibody or an antigen-binding
fragment thereof. In some such genetically engineered CXCR4 proteins, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such genetically engineered CXCR4 proteins, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some such genetically engineered CXCR4 proteins, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some such genetically engineered CXCR4 proteins, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5. In some such genetically engineered CXCR4 proteins, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such genetically engineered CXCR4 proteins, the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some such genetically engineered CXCR4 proteins, the immunoglobulin light chain or variable region
thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some such genetically engineered CXCR4 proteins, the immunoglobulin light chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
[0084] In some such genetically engineered CXCR4 proteins, the CXCR4 protein is a human CXCR4 protein.
[0085] In another aspect, provided are nucleic acids encoding any of the above genetically engineered CXCR4 proteins.
BRIEF DESCRIPTION OF THE FIGURES
[0086] Figures 1A-1B. Schematic of C-X-C motif chemokine receptor 4 (CXCR4) antibodyresistant modified receptor (ARMoR) strategy.
[0087] Figures 2A-2B. Anti-human CXCR4 (REGN7663, REGN7664) administration leads to leukocyte mobilization in CXCR4-humanized mice. Figure 2A shows a schematic of the experiment, and Figure 2B shows the experimental data.
[0088] Figures 3A-3B. Mobilization of hematopoietic progenitors in CXCR4-humanized mice following 5 consecutive doses of anti-CXCR4 REGN7664. Figure 3A shows a schematic of the experiment, and Figure 3B shows the experimental data.
[0089] Figures 4A-4B. CXCR4 blockade in vivo with anti-CXCR4 strongly reduces recirculating mature B cells in the bone marrow (BM). Figure 4A shows a schematic of the experiment, and Figure 4B shows the experimental data.
[0090] Figure 5. Effects of in vivo CXCR4 blockade on BM-resident mature and progenitor B cells.
[0091] Figure 6. Human/mouse CXCR4 domain-swap chimeric constructs designed to test binding sites of anti-human-CXCR4 antibodies.
[0092] Figures 7A-7D. Anti-human-CXCR4 monoclonal antibodies (mAbs) REGN7663 and REGN7664 bind the extracellular loop 2 (ECL2) domain of CXCR4.
[0093] Figures 8A-8D. Stable cell lines expressing domain-swap chimeric constructs confirm REGN7663 and REGN7664 binding in ECL2 region of human CXCR4.
[0094] Figure 9. Modifications within the human CXCR4 ECL2 region designed to map binding determinants of anti-CXCR4 REGN7663 and REGN7664.
[0095] Figures 10A-10D. Determinants of anti-human-CXCR4 REGN7663 and REGN7664 binding in ECL2 domain.
[0096] Figure 11. Schematic of bioassay for CXCR4 signaling function in response to ligand
C-X-C motif chemokine 12 (CXCL12).
[0097] Figures 12A-12C. CXCR4 variants resistant to anti-CXCR4 binding retain signaling function in response to ligand CXCL12.
[0098] Figure 13. Schematic of bioassay for blockade of CXCR4 signaling function by anti-
CXCR4 mAbs.
[0099] Figures 14A-14B. CXCR4 variants with a loss of REGN7664 binding are resistant to REGN7664-mediated signaling block.
[00100] Figure 15. Additional CXCR4 variants with alterations in established binding regions.
[00101] Figures 16A-16B. Anti-CXCR4 binding to additional human CXCR4 variants.
[00102] Figures 17A-17B. Re-confirmation of anti-CXCR4 REGN7663 and REGN7664 binding patterns on select CXCR4 ARMoR variants in 293.CRE.Luc.CXCR4.KO bioassay cells. [00103] Figure 18. Antibody-resistant CXCR4 variants with minimal modifications retain signaling function in response to CXCL12.
DEFINITIONS
[00104] The terms “protein,” “polypeptide,” and “peptide,” used interchangeably herein, include polymeric forms of amino acids of any length, including coded and non-coded amino acids and chemically or biochemically modified or derivatized amino acids. The terms also include polymers that have been modified, such as polypeptides having modified peptide backbones. The term “domain” refers to any part of a protein or polypeptide having a particular function or structure.
[00105] Proteins are said to have an “N-terminus” (amino-terminus) and a “C-terminus” (carboxy -terminus or carboxyl-terminus). The term “N-terminus” relates to the start of a protein
or polypeptide, terminated by an amino acid with a free amine group (-NH2). The term “C- terminus” relates to the end of an amino acid chain (protein or polypeptide), terminated by a free carboxyl group (-COOH).
[00106] The terms “nucleic acid” and “polynucleotide,” used interchangeably herein, include polymeric forms of nucleotides of any length, including ribonucleotides, deoxyribonucleotides, or analogs or modified versions thereof. They include single-, double-, and multi-stranded DNA or RNA, genomic DNA, cDNA, DNA-RNA hybrids, and polymers comprising purine bases, pyrimidine bases, or other natural, chemically modified, biochemically modified, non-natural, or derivatized nucleotide bases.
[00107] Nucleic acids are said to have “5’ ends” and “3’ ends” because mononucleotides are reacted to make oligonucleotides in a manner such that the 5’ phosphate of one mononucleotide pentose ring is attached to the 3’ oxygen of its neighbor in one direction via a phosphodiester linkage. An end of an oligonucleotide is referred to as the “5’ end” if its 5’ phosphate is not linked to the 3’ oxygen of a mononucleotide pentose ring. An end of an oligonucleotide is referred to as the “3’ end” if its 3’ oxygen is not linked to a 5’ phosphate of another mononucleotide pentose ring. A nucleic acid sequence, even if internal to a larger oligonucleotide, also may be said to have 5’ and 3’ ends. In either a linear or circular DNA molecule, discrete elements are referred to as being “upstream” or 5’ of the “downstream” or 3’ elements.
[00108] The term “expression vector” or “expression construct” or “expression cassette” refers to a recombinant nucleic acid containing a desired coding sequence operably linked to appropriate nucleic acid sequences necessary for the expression of the operably linked coding sequence in a particular host cell or organism. Nucleic acid sequences necessary for expression in prokaryotes usually include a promoter, an operator (optional), and a ribosome binding site, as well as other sequences. Eukaryotic cells are generally known to utilize promoters, enhancers, and termination and polyadenylation signals, although some elements may be deleted and other elements added without sacrificing the necessary expression.
[00109] A “promoter” is a regulatory region of DNA usually comprising a TATA box capable of directing RNA polymerase II to initiate RNA synthesis at the appropriate transcription initiation site for a particular polynucleotide sequence. In general, a “promoter” or “promoter sequence” is a DNA regulatory region capable of binding an RNA polymerase in a cell (e.g.,
directly or through other promoter-bound proteins or substances) and initiating transcription of a coding sequence. A promoter may be operably linked to other expression control sequences, including enhancer and repressor sequences and/or with a polynucleotide of the invention. Promoters which may be used to control gene expression include, but are not limited to, cytomegalovirus (CMV) promoter (U.S. Pat. Nos. 5,385,839 and 5,168,062, each of which is herein incorporated by reference in its entirety for all purposes), the SV40 early promoter region (Benoist et al. (1981) Nature 290:304-310, herein incorporated by reference in its entirety for all purposes), the promoter contained in the 3' long terminal repeat of Rous sarcoma virus (Yamamoto et al. (1980) Cell 22:787-797, herein incorporated by reference in its entirety for all purposes), the herpes thymidine kinase promoter (Wagner et al. (1981) Proc. Natl. Acad. Sci. U.S.A. 78: 1441-1445, herein incorporated by reference in its entirety for all purposes), the regulatory sequences of the metallothionein gene (Brinster et al. (1982) Nature 296:39-42, herein incorporated by reference in its entirety for all purposes); prokaryotic expression vectors such as the beta-lactamase promoter (VIlla-Komaroff et al. (1978) Proc. Natl. Acad. Sci. U.S.A. 75:3727- 3731, herein incorporated by reference in its entirety for all purposes), or the tac promoter (DeBoer et al. (1983) Proc. Natl. Acad. Sci. U.S.A. 80:21-25; see also “Useful proteins from recombinant bacteria” in Scientific American (1980) 242:74-94, each of which is herein incorporated by reference in its entirety for all purposes); and promoter elements from yeast or other fungi such as the Gal4 promoter, the ADC (alcohol dehydrogenase) promoter, PGK (phosphoglycerol kinase) promoter or the alkaline phosphatase promoter.
[00110] In some embodiments, a promoter may additionally comprise other regions which influence the transcription initiation rate. The promoter sequences modulate transcription of an operably linked polynucleotide. A promoter can be active in one or more of the cell types (e.g., but not limited to, a eukaryotic cell, a non-human mammalian cell, a human cell, a rodent cell, a pluripotent cell, a one-cell stage embryo, a differentiated cell, or a combination thereof). A promoter can be, for example, a constitutively active promoter, a conditional promoter, an inducible promoter, a temporally restricted promoter (e.g., but not limited to, a developmentally regulated promoter), or a spatially restricted promoter (e.g., but not limited to, a cell-specific or tissue-specific promoter).
[00111] “Operable linkage” or being “operably linked” includes juxtaposition of two or more components (e.g., but not limited to, a promoter and another sequence element) such that both
components function normally and allow the possibility that at least one of the components can mediate a function that is exerted upon at least one of the other components. As a non-limiting example, a promoter can be operably linked to a coding sequence if the promoter controls the level of transcription of the coding sequence in response to the presence or absence of one or more transcriptional regulatory factors. Operable linkage can include such sequences being contiguous with each other or acting in trans (e.g., but not limited to, a regulatory sequence can act at a distance to control transcription of the coding sequence). A polynucleotide encoding a polypeptide is “operably linked” to a promoter or other expression control sequence when, in a cell or other expression system, the sequence directs RNA polymerase mediated transcription of the coding sequence into RNA, preferably mRNA, which then may be RNA spliced (if it contains introns) and, optionally, translated into a protein encoded by the coding sequence. [00112] The term “isolated” with respect to proteins, nucleic acids, and cells includes proteins, nucleic acids, and cells that are relatively purified with respect to other cellular or organism components that may normally be present in situ, up to and including a substantially pure preparation of the protein, nucleic acid, or cell. “Isolated” antigen-binding proteins (e.g., antibodies or antigen-binding fragments thereof), polypeptides, polynucleotides and vectors, are at least partially free of other biological molecules from the cells or cell culture from which they are produced. Such biological molecules include nucleic acids, proteins, other antibodies or antigen-binding fragments, lipids, carbohydrates, or other material such as cellular debris and growth medium. An isolated antigen-binding protein may further be at least partially free of expression system components such as biological molecules from a host cell or of the growth medium thereof. Generally, the term “isolated” is not intended to refer to a complete absence of such biological molecules (e.g., minor or insignificant amounts of impurity may remain) or to an absence of water, buffers, or salts or to components of a pharmaceutical formulation that includes the antigen-binding proteins (e.g., antibodies or antigen-binding fragments).
[00113] In some embodiments, the term “isolated” may include proteins and nucleic acids that have no naturally occurring counterpart or proteins or nucleic acids that have been chemically synthesized and are thus substantially uncontaminated by other proteins or nucleic acids. The term “isolated” may include proteins, nucleic acids, or cells that have been separated or purified from most other cellular components or organism components with which they are naturally
accompanied (e g., but not limited to, other cellular proteins, nucleic acids, or cellular or extracellular components).
[00114] “Codon optimization” takes advantage of the degeneracy of codons, as exhibited by the multiplicity of three-base pair codon combinations that specify an amino acid, and generally includes a process of modifying a nucleic acid sequence for enhanced expression in particular host cells by replacing at least one codon of the native sequence with a codon that is more frequently or most frequently used in the genes of the host cell while maintaining the native amino acid sequence. As a non-limiting example, a nucleic acid encoding a protein can be modified to substitute codons having a higher frequency of usage in a given prokaryotic or eukaryotic cell, including a bacterial cell, a yeast cell, a human cell, a non-human cell, a mammalian cell, a rodent cell, a mouse cell, a rat cell, a hamster cell, or any other host cell, as compared to the naturally occurring nucleic acid sequence. Codon usage tables are readily available, for example, at the “Codon Usage Database.” These tables can be adapted in a number of ways. See Nakamura et al. (2000) Nucleic Acids Res. 28( I ):292, herein incorporated by reference in its entirety for all purposes. Computer algorithms for codon optimization of a particular sequence for expression in a particular host are also available (see, e.g., Gene Forge). [00115] The term “locus” refers to a specific location of a gene (or significant sequence), DNA sequence, polypeptide-encoding sequence, or position on a chromosome of the genome of an organism. As a non-limiting example, a “CXCR4 locus” may refer to the specific location of a CXCR4 gene, CXCR4 DNA sequence, CXCR4-protein-encoding sequence, or CXCR4 position on a chromosome of the genome of an organism that has been identified as to where such a sequence resides. A “CXCR4 locus” may comprise a regulatory element of a CXCR4 gene, including, as a non-limiting example, an enhancer, a promoter, 5’ and/or 3’ untranslated region (UTR), or a combination thereof.
[00116] The term “gene” refers to DNA sequences in a chromosome that may contain, if naturally present, at least one coding and at least one non-coding region. The DNA sequence in a chromosome that codes for a product (e.g., but not limited to, an RNA product and/or a polypeptide product) can include the coding region interrupted with non-coding introns and sequence located adjacent to the coding region on both the 5’ and 3’ ends such that the gene corresponds to the full-length mRNA (including the 5’ and 3’ untranslated sequences). Additionally, other non-coding sequences including regulatory sequences (e g., but not limited
to, promoters, enhancers, and transcription factor binding sites), polyadenylation signals, internal ribosome entry sites, silencers, insulating sequence, and matrix attachment regions may be present in a gene. These sequences may be close to the coding region of the gene (e.g., but not limited to, within 10 kb) or at distant sites, and they influence the level or rate of transcription and translation of the gene.
[00117] The term “allele” refers to a variant form of a gene. Some genes have a variety of different forms, which are located at the same position, or genetic locus, on a chromosome. A diploid organism has two alleles at each genetic locus. Each pair of alleles represents the genotype of a specific genetic locus. Genotypes are described as homozygous if there are two identical alleles at a particular locus and as heterozygous if the two alleles differ.
[00118] The term “wild type” includes entities having a structure (e.g., but not limited to, nucleotide sequence or amino acid sequence sequence) as found in a normal (as contrasted with mutant, diseased, altered, or so forth) state or context. Wild type genes and polypeptides often exist in multiple different forms (e.g., alleles).
[00119] The term “variant” refers to a nucleotide sequence differing from the sequence most prevalent in a population (e.g., but not limited to, by one nucleotide) or a protein sequence different from the sequence most prevalent in a population (e.g., but not limited to, by one amino acid).
[00120] The term “fragment,” when referring to a protein, means a protein that is shorter or has fewer amino acids than the full-length protein. The term “fragment,” when referring to a nucleic acid, means a nucleic acid that is shorter or has fewer nucleotides than the full-length nucleic acid. Non-limiting examples of a protein fragment can include an N-terminal fragment (i.e., removal of a portion of the C-terminal end of the protein), a C-terminal fragment (i.e., removal of a portion of the N-terminal end of the protein), or an internal fragment (i.e., removal of a portion of an internal portion of the protein).
[00121] “Sequence identity” or “identity” in the context of two polynucleotides or polypeptide sequences refers to the residues in the two sequences that are the same when aligned for maximum correspondence over a specified comparison window. When percentage of sequence identity is used in reference to proteins, residue positions which are not identical often differ by conservative amino acid substitutions, where amino acid residues are substituted for other amino acid residues with similar chemical properties (e.g., but not limited to, charge or hydrophobicity)
and therefore do not change the functional properties of the molecule. When sequences differ in conservative substitutions, the percent sequence identity may be adjusted upwards to correct for the conservative nature of the substitution. Sequences that differ by such conservative substitutions are said to have “sequence similarity” or “similarity.” Means for making this adjustment are well known. Typically, this involves scoring a conservative substitution as a partial rather than a full mismatch, thereby increasing the percentage sequence identity. Thus, as a non-limiting example, where an identical amino acid is given a score of 1 and a nonconservative substitution is given a score of zero, a conservative substitution is given a score between zero and 1. The scoring of conservative substitutions is calculated, e.g., as implemented in the program PC/GENE (Intelligenetics, Mountain View, California).
[00122] “Percentage of sequence identity” includes the value determined by comparing two optimally aligned sequences (greatest number of perfectly matched residues) over a comparison window, wherein the portion of the polynucleotide sequence in the comparison window may comprise additions or deletions (i.e., gaps) as compared to the reference sequence (which does not comprise additions or deletions) for optimal alignment of the two sequences. The percentage is calculated by determining the number of positions at which the identical nucleic acid base or amino acid residue occurs in both sequences to yield the number of matched positions, dividing the number of matched positions by the total number of positions in the window of comparison, and multiplying the result by 100 to yield the percentage of sequence identity. Unless otherwise specified (e.g., the shorter sequence includes a linked heterologous sequence), the comparison window is the full length of the shorter of the two sequences being compared.
[00123] Unless otherwise stated, sequence identity/similarity values include the value obtained using GAP Version 10 using the following parameters: % identity and % similarity for a nucleotide sequence using GAP Weight of 50 and Length Weight of 3, and the nwsgapdna.cmp scoring matrix; % identity and % similarity for an amino acid sequence using GAP Weight of 8 and Length Weight of 2, and the BLOSUM62 scoring matrix; or any equivalent program thereof. “Equivalent program” includes any sequence comparison program that, for any two sequences in question, generates an alignment having identical nucleotide or amino acid residue matches and an identical percent sequence identity when compared to the corresponding alignment generated by GAP Version 10.
[00124] The term “zrt vitro" includes artificial environments and processes or reactions that occur within an artificial environment (e.g., but not limited to, a test tube or an isolated cell or cell line). The term “in vivo" includes natural environments (e.g., but not limited to, an organism or body or a cell or tissue within an organism or body) and to processes or reactions that occur within a natural environment. The term “ex vivo" includes cells that have been removed from the body of an individual and processes or reactions that occur within such cells.
[00125] “Optional” or “optionally” means that the subsequently described event or circumstance may or may not occur and that the description includes instances in which the event or circumstance occurs and instances in which the event or circumstance does not.
[00126] Designation of a range of values includes all integers within or defining the range, and all subranges defined by integers within the range.
[00127] Unless otherwise apparent from the context, the term “about” encompasses values ± 5 of a stated value.
[00128] The term “and/or” refers to and encompasses any and all possible combinations of one or more of the associated listed items, as well as the lack of combinations when interpreted in the alternative (“or”).
[00129] The term “or” refers to any one member of a particular list.
[00130] The singular forms of the articles “a,” “an,” and “the” include plural references unless the context clearly dictates otherwise. For example, the term “a protein” or “at least one protein” can include a plurality of proteins, including mixtures thereof.
[00131] Statistically significant means p <0.05.
DETAILED DESCRIPTION
I. Overview
[00132] Immune cell therapies hold enormous promise for many human diseases. One of the oldest examples is bone marrow transplantation, in which a recipient’s entire immune system can be replaced with an autologous or allogeneic bone marrow graft. This procedure allows the correction of congenital hematopoietic deficiencies, and also the re-population of the immune system following treatments to eradicate hematologic malignancies. Newer examples include immune cells engineered with antigen receptors to target tumors (e.g., CAR-T, eTCR, CAR-NK, and CAR-macrophage). In all these cases, patients must undergo “conditioning” regimens prior
to cell transplant, which can serve to “make room” in the host immune niche to support donor cell uptake, and in some cases to suppress host versus graft immune responses that can lead to graft rejection.
[00133] Conditioning regimens range in intensity from partially to fully myeloablative, the latter necessary when pathogenic host immune cells must be fully eradicated (e.g., for hematologic malignances). Regardless, the current standards of care for host conditioning have major drawbacks. First, conditioning agents are toxins (e.g., DNA damagers) that are not specific for the desired target cells, and thus carry harmful and even life-threatening risks for patients. Moreover, conditioning agents are as toxic to donor cells as to host, and so must be discontinued prior to transplant to avoid inhibition of life-saving cellular therapies. These challenges usually limit the application of cell therapies to dire instances when no treatment alternatives remain. [00134] Lymphosuppressive agents have numerous potential applications to host conditioning for transplant and adoptive cell therapies: (1) preventing rejection of allogeneic grafts through T and NK cell suppression (e.g., bone marrow transplant; gene corrective cell therapies); (2) non- genotoxic clearance of immune niche space for engineered cell therapies (e.g., CAR-T, TCR-T, Treg, NK, B cell, progenitor cells); (3) elimination of endogenous cytokine “sinks,” making essential factors more available to grafter cells; and (4) immune suppression post-transplant that is gentler and less toxic than standard of care agents.
[00135] An obstacle to use of lymphosuppressive agents as conditioning therapies is the susceptibility of grafted cells, in addition to the target host cells, to their effects. Provided herein is a strategy to address these challenges through (1) the development of targeted conditioning regimens leveraging, e.g., antibodies that specifically target the desired host cells — as monotherapies, combinations, bispecific antibodies, antibody drug conjugates (ADCs), or scFv- engineered CAR-T, and (2) modification of donor cells to render them resistant to, e.g., these antibody-based conditioning agents. Collectively this comprises the antibody-resistant modified receptor (ARMoR) concept. The underlying idea is to engineer minimal changes to immune cell receptors in grafted donor cells that will abolish binding by suppressive antibody agents. A schematic of this strategy is shown in Figures 1A and IB, using the example of an engineered C- X-C motif chemokine receptor 4 (CXCR4) variant that is resistant to anti-CXCR4 mediated blockade of interaction of CXCR4 with its ligand C-X-C motif chemokine 12 (CXCL12). The goal is to introduce into a cell therapy product a fully functional form of the receptor that is not
recognized by the conditioning agent. This can be achieved with alterations to the antibody recognition site that abolish binding but preserve receptor function. As a result, host cells remain susceptible to the conditioning agent, but engineered grafted cells are resistant and thus gain a competitive advantage in re-populating the host. The fundamental aim is to afford grafted cellular therapies a competitive advantage in the host patient, by applying selective pressure that specifically targets host cells while sparing donor-derived cell therapies.
[00136] Methods for improving engraftment of donor cells in a subject thereof are provided. Such methods can comprise providing donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4), administering the donor cells to the subject, and then selectively depleting host cells in the subject based on their expression of a second isoform of the target protein, thereby improving engraftment of donor cells in the subject. For example, such methods can comprise providing donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4), administering the donor cells to the subject, and then selectively inhibiting host cells in the subject based on their expression of a second isoform of the target protein, thereby improving engraftment of donor cells in the subject. For example, the selective inhibition can comprise selectively depleting host cells from the bone marrow. Alternatively, such methods can comprise providing donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4), administering the donor cells to the subject, and then selectively ablating host cells in the subject based on their expression of a second isoform of the target protein, thereby improving engraftment of donor cells in the subject. The donor cells can express only the first isoform, or they can express both the first and second isoforms of the target protein. The first isoform can be functionally indistinguishable but immunologically distinguishable from the second isoform of the target protein. In some embodiments, the selective inhibition of host cells can be based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein. Alternatively, the selective inhibition of host cells can be based on their expression of the second isoform regardless of their expression of the first isoform of the target protein. Selective inhibition of host cells does not comprise ablation (i.e., killing) of host cells by a mechanism extrinsic to a cell, such as via an active killing mechanism. Selective inhibition of host cells does not comprise ablation (i.e., killing) of host cells by an active killing mechanism. An active killing mechanism means the agent directly kills the host cells by
cytotoxic mechanisms (e.g., antibody-drug conjugate (ADC), antibody radioconjugate (ARC), CAR-T, or other engineered cytotoxicity) or recruits host cytotoxic effector mechanisms (e.g., complement-dependent cytotoxicity (CDC), antibody-dependent cellular cytotoxicity (ADCC), antibody-dependent cellular phagocytosis (ADCP)), as opposed blocking a cellular function (e.g. growth or cytokine signaling, chemotactic tissue homing, cell-cell adhesion; e.g., as with selective inhibition) without engaging extrinsic cytotoxic effectors. Such host cytotoxic effector mechanisms are well known. See, e.g., Yu et al. (2020) J. Hematol. Oncol. 13(1):45 and Gogesch et al. (2021) Int. J. Mol. Set. 22(16):8947, each of which is herein incorporated by reference in its entirety for all purposes. As a novel conditioning strategy, selective inhibition of host cells without cytotoxic ablation has potential to improve the safety and efficacy of cell therapy and transplant treatments. Non-ablative conditioning may avoid undesired and harmful effects of ablative agents, including direct killing of non-target (e.g., non-hematopoietic) cells expressing drug target antigens, indirect toxicities to target-adjacent tissues, and prolonged immune suppression in the post-transplant period. Selective blockade or suppression of essential host cell factors can enhance the expansion, persistence, and trafficking of resistant donor cells by affording favorable competition for limiting host factors (e.g., cytokine, chemokines) and immune niche space, without harsh and potentially toxic ablative agents. In some embodiments, the selective inhibition of host cells can comprise: (1) blocking growth of the host cells to provide a competitive growth advantage to the donor cells; (2) blocking localization or trafficking of the host cells to provide a competitive homing advantage to the donor cells; (3) blocking a cell-cell interaction or adhesion of the host cells to provide a competitive tissue infiltration advantage to the donor cells; or (4) blocking immune cell activation in the host cells to provide a competitive advantage to the donor cells. In some embodiments, the selective inhibition of host cells can comprise selectively depleting host cells from the bone marrow. Also provided are combinations for administration to a subject in need thereof, wherein the combination comprises (1) a population of donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4) and (2) an agent (e.g., antagonist, such as an antigen-binding protein) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
[00137] Methods for in vivo selective depletion of non-edited cells (and repopulation with edited cells) in a subject thereof are provided. In some embodiments, selective depletion means
selective mobilization of non-edited cells from the bone marrow to the periphery. Such methods can comprise providing cells edited to express a first isoform of a target protein (e.g., C-X-C motif chemokine receptor 4 (CXCR4)), administering the edited cells to the subject, and then selectively depleting non-edited cells in the subject based on their expression of the second isoform of the target protein (e.g., based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein, or based on their expression of the second isoform regardless of their of expression of the first isoform of the target protein). The first isoform can be functionally indistinguishable but immunologically distinguishable from a second isoform of the target protein. The edited cells can express only the first isoform, or they can express both the first and second isoforms of the target protein. Also provided are combinations for administration to a subject in need thereof, wherein the combination comprises (1) a population of cells edited to express a first isoform of a target protein (e.g., CXCR4) and (2) an agent (e.g., antagonist, such as an anti-CXCR4 antigen-binding protein) that specifically binds to a second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
[00138] Isolated cells or populations of cells are also provided modified to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein. The cells can express only the first isoform, or they can express both the first and second isoforms. The first isoform can be functionally indistinguishable but immunologically distinguishable from the second isoform. The cells can express only the first isoform, or they can express both the first and second isoforms. Isolated cells or populations of cells are also provided in which a genomic locus has been edited to express the first isoform of the target protein that is different from the second isoform. Methods of making such cells are also provided.
[00139] Isolated cells or populations of cells are also provided that are edited (i.e., modified) to express a first isoform of CXCR4 that is different from a second isoform of CXCR4. The first isoform can be functionally indistinguishable but immunologically distinguishable from a second isoform of the target protein. The edited cells can express only the first isoform, or they can express both the first and second isoforms of the target protein. Methods of making such cells are also provided, and engineered CXCR4 proteins and nucleic acids encoding engineered CXCR4 proteins are also provided.
[00140] In some embodiments, the cells (e.g., donor cells or edited cells) in the compositions and methods comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR) (e.g., CAR-T cells, CAR-NK cells), or an exogenous T cell receptor (TCR). In some embodiments, the therapeutic molecule, immunoglobulin, CAR, or exogenous TCR does not target the target protein (e.g., CXCR4). For example, the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule). For example, the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer). In some such embodiments, the therapeutic molecule may target diseased cells and/or an antigen expressed on the diseased cells (e g., a tumor-associated antigen).
II. Methods for Improving Engraftment of Donor Cells in a Subject
[00141] In some embodiments of the present invention, methods for improving engraftment of donor cells in a subject are provided. Such methods can comprise providing donor cells that express (e.g., that have been modified to express) a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells of the subject. The target protein can be, for example CXCR4. The first isoform can be functionally indistinguishable but immunologically distinguishable from a second isoform of the target protein. In some embodiments, the donor cells express only the first isoform of the target protein. In other embodiments, the donor cells express both the first and second isoforms of the target protein. Such methods can comprise providing donor cells in which a target genomic locus has been edited to express the first isoform of a target protein. The donor cells can then be administered to the subject, and host cells in the subject can be selectively depleted based on their expression of the second isoform of the target protein, thereby improving engraftment of donor cells in the subject. Similarly, the donor cells can then be administered to
the subject, and the subject can be provided with means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4. For example, the selective depletion of host cells can be based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein. Alternatively, the selective depletion of host cells can be based on their expression of the second isoform regardless of their expression of the first isoform of the target protein. For example, host cells in the subject can be selectively inhibited based on their expression of the second isoform of the target protein, thereby improving engraftment of donor cells in the subject. For example, the selective inhibition of host cells can be based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein. Alternatively, the selective inhibition of host cells can be based on their expression of the second isoform regardless of their expression of the first isoform of the target protein. Alternatively, host cells in the subject can be selectively ablated based on their expression of the second isoform of the target protein, thereby improving engraftment of donor cells in the subject. For example, the selective ablation of host cells can be based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein. Alternatively, the selective depletion of host cells can be based on their expression of the second isoform regardless of their expression of the first isoform of the target protein. In some embodiments, the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
[00142] In some embodiments of the present invention, methods for selective depletion of non-edited cells (and repopulation with edited cells) in a subject are provided. In some embodiments, selective depletion means selective mobilization of non-edited cells from the bone marrow to the periphery. Such methods can comprise providing edited cells that have been modified to express a first isoform of a target protein that is different from a second isoform of the target protein, wherein the second isoform is expressed in non-edited cells of the subject. The first isoform can be functionally indistinguishable but immunologically distinguishable from a second isoform of the target protein. In some embodiments, the edited cells express only the first isoform of the target protein (e.g., CXCR4). In other embodiments, the edited cells express both the first and second isoforms of the target protein (e.g., CXCR4). The edited cells can then be administered to the subject, and non-edited cells in the subject can be selectively depleted based on their expression of the second isoform of the target protein (e.g., based on their expression of
only the second isoform of the target protein and their lack of expression of the first isoform of the target protein, or based on their expression of the second isoform regardless of their of expression of the first isoform of the target protein). Such selective depletion can include, in a non-limiting example, bone marrow egress of non-edited cells in the subject to “make room” in the host immune niche for engraftment of the edited cells administered to the subject.
[00143] The donor cells or edited cells can be any suitable cells. Likewise, the host cells or non-edited cells can be any suitable cells. In some embodiments, the cells are immune cells. In some embodiments, the cells are hematopoietic cells. The term hematopoietic cell refers to a cell originated from a hematopoietic stem cell or a hematopoietic progenitor cell and/or originated from an erythroid, lymphoid, or myeloid lineage. In some embodiments, the cells are immune cells. The term immune cell refers to any cell derived from a hematopoietic stem cell that plays a role in the immune response. Immune cells include, without limitation, lymphocytes, such as T cells and B cells, antigen-presenting cells (APC), dendritic cells, monocytes, macrophages, natural killer (NK) cells, mast cells, basophils, eosinophils, or neutrophils, as well as any progenitors of such cells. In some embodiments, the cells are lymphocytes or lymphoid progenitor cells. In some embodiments, the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infiltrating lymphocytes (TILs), or any combination thereof). In some embodiments, the cells are alpha beta T cells. In some embodiments, the cells are gamma delta T cells. In some embodiments, the cells are TILs. In some embodiments, the cells are B cells. In some embodiments, the cells are natural killer (NK) cells. In some embodiments, the cells are innate lymphoid cells. In some embodiments, the cells are dendritic cells. In some embodiments, the cells are hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) or descendants thereof. HSCs are capable of giving rise to both myeloid and lymphoid progenitor cells that further give rise to myeloid cells (e.g., monocytes, macrophages, neutrophils, basophils, dendritic cells, erythrocytes, platelets, etc.) and lymphoid cells (e.g., T cells, B cells, NK cells), respectively. In some embodiments, the cells are derived from induced pluripotent stem cells (e.g., NK cells derived from induced pluripotent stem cells). In some embodiments, the cells are derived from HSCs or HSPCs.
[00144] In some embodiments, the cells (e.g., donor cells or edited cells) comprise a genetic modification (insertion of a transgene, correction of a mutation, deletion or inactivation of a gene
(e g., insertion of premature stop codon or insertion of regulatory repressor sequence), or a change in an epigenetic modification important for expression of a gene) correcting or counteracting a disease-related gene defect present in a subject. In some embodiments, the cells (e.g., donor cells or edited cells) comprise a transgene. In some embodiments, the cells (e.g., donor cells or edited cells) comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR) (e.g., CAR-T cells, CAR-NK cells), or an exogenous T cell receptor (TCR). In some embodiments, the cells (e.g., donor cells or edited cells) comprise a bicistronic nucleic acid construct encoding the therapeutic molecule and the first isoform of the target protein. See, e.g., Yeku et al. (2017) Sci. Rep. 7(1): 10541 and Rafiq et al. (2018) Nat. BiotechnoL 36(9):847-856, each of which is herein incorporated by reference in its entirety for all purposes, for examples of bicistronic constructs for expressing CARs and another molecule. For example, the bicistronic construct can encode both a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and the first isoform (e.g., a modified isoform) of the target protein (e.g., CXCR4). In one embodiment, the bicistronic construct encodes a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and a modified isoform of CXCR4. In some embodiments, the therapeutic molecule, immunoglobulin, CAR, or exogenous TCR does not target the target protein (e.g., CXCR4). In some embodiments, the cells (e.g., donor cells or edited cells) comprise or express an immunoglobulin, a CAR, or an exogenous TCR. In some embodiments, the cells (e.g., donor cells or edited cells) comprise or express a CAR or an exogenous TCR. For example, the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule). In some embodiments, the therapeutic molecule targets diseased cells and/or an antigen expressed on the diseased cells (e.g., a tumor-associated antigen). For example, the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein does not cause the disease or cancer, and/or expression of the target protein is not
correlated with the disease or cancer). Exemplary types of cancers and tumors that can be treated are described elsewhere herein.
[00145] In some embodiments, the donor cells are autologous (i.e., from the subject). In some embodiments, the donor cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation). In some embodiments, the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the donor cells are mammalian cells or non-human mammalian cells). In some embodiments, the donor cells are human cells (e.g., the subject is a human, and the cells are human cells).
[00146] In some embodiments of the present invention, the target protein is C-X-C chemokine receptor type 4 (also known as C-X-C motif chemokine receptor 4, CXCR4, FB22, Fusin, HM89, LCR1, Leukocyte-derived seven transmembrane domain receptor (LESTR), Lipopolysaccharide-associated protein 3 (LAP-3; LPS-associated protein 3), NPY3R, NPYRL, Stromal cell-derived factor 1 receptor (SDF-1 receptor), and CD184). CXCR4 is a 7- transmembrane receptor for the C-X-C chemokine CXCL12/SDF-1 that plays a role in cell migration and transduces a signal by increasing intracellular calcium ion levels and enhancing MAPK1/MAPK3 activation. CXCR4 can also act as a receptor for extracellular ubiquitin, the binding of which leads to enhanced intracellular calcium levels and reduced cellular cAMP. CXCR4 is involved in hematopoiesis, cardiac ventricular septum formation, and plays an essential role in vascularization of the gastrointestinal tract. CXCR4 also has several roles in pathogen response, including binding bacterial lipopolysaccharide (LPS) to mediate an LPS- induced inflammatory response that comprises TNF secretion by monocytes and serving as a coreceptor (with CD4) human immunodeficiency virus (HIV) to promote Env-mediated fusion of the virus with T cells.
[00147] In some embodiments, the target protein is human CXCR4. Human CXCR4 is assigned UniProt Accession No. P61073. The canonical isoform of human CXCR4 is assigned UniProt Accession No. P61073-1 and NCBI Accession No. NP_003458.1 and is set forth in SEQ ID NO: 1. An exemplary messenger RNA encoding the canonical isoform of human CXCR4 is assigned NCBI Accession No. NM_003467.3 and is set forth in SEQ ID NO: 2. The coding sequence for the canonical isoform of human CXCR4 is assigned CCDS ID CCDS46420.1 and
is set forth in SEQ ID NO: 3. The gene encoding human C-X-C motif chemokine receptor 4 is called CXCR4, is on chromosome 2, and is assigned NCBI GenelD 7852. It is at location 2q22.1 (assembly: GRCh38.pl4 (GCF 000001405.40); location: NC 000002.12 (136114349..136118149, complement)).
[00148] The expression “functionally indistinguishable” refers to a first and a second isoform that are equally capable of performing the same function (e.g., binding to an endogenous ligand (e.g., CXCL12 for CXCR4) and/or activating downstream signaling pathways (e.g., CXCR4 signaling pathways)) within a cell (e.g., without significant impairment). In other words, the first and the second isoform are functionally largely indistinguishable. In certain embodiments, a slight functional impairment can be acceptable. The function that is largely indistinguishable can be, for example, binding to an endogenous ligand (e.g., CXCL12 for CXCR4) and/or activating downstream signaling pathways. In some embodiments, the function can be binding to the endogenous ligand (e.g., CXCL12 for CXCR4) and activating downstream signaling pathways. The expression “immunologically distinguishable” refers to a first and a second isoform of a protein that can be distinguished by an antigen-binding protein (e.g., specifically binding to either the first or the second isoform but not the other), such as the antigen-binding protein specifically binding only to the second (unmodified) isoform of the target protein. In other words, the antigen-binding proteins are able to discriminate between the two isoforms by specifically binding only one isoform, but not the other one. In a specific embodiment, the endogenous ligand (e g., CXCL12 for CXCR4) binds both the first and second isoforms (e.g., equally, or with only slight impairment), but an engineered antigen-binding protein such as an antibody is able to discriminate between the two isoforms by specifically binding only one isoform, but not the other one (e.g., specifically binding only to the second but not the first isoform).
[00149] In some embodiments, the second isoform of the target protein refers to the form that is present in the subject. In some embodiments, the second isoform of the target protein refers to the wild type form or native form of the target protein (i.e., the form that usually occurs in nature), and the first isoform refers to an isoform obtained by introducing a mutation in the nucleic acid sequence encoding the second isoform. The native form of a protein refers to a protein that is encoded by a nucleic acid sequence within the genome of the cell and that has not been inserted or mutated by genetic manipulation (i.e., a native protein is a protein that is not a
transgenic protein or a genetically engineered protein).
[00150] The mutation in the first isoform can be any type of mutation and any size mutation. In some embodiments, the mutation comprises an insertion, a deletion and/or a substitution of 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids (e.g., 1-20 amino acids, 1-5 amino acids, 1-3 amino acids, or 1 amino acid). In some embodiments, the mutation comprises one or more (e.g., three) substitutions (e.g., comprises one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation consists essentially of one or more (e.g., three) substitutions (e.g., consists essentially of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation consists of one or more (e.g., three) substitutions (e.g., consists of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation comprises an insertion (e.g., comprises an insertion of 1 amino acid). In some embodiments, the mutation consists essentially of an insertion (e.g., consists essentially of an insertion of 1 amino acid). In some embodiments, the mutation consists of an insertion (e.g., consists of an insertion of 1 amino acid). The mutation can be at any site in the target protein. For example, if the target protein is a cell surface protein, the mutation can in some embodiments be in the extracellular domain of the target protein. In some embodiments, the site of the mutation can be a site that is non-conserved between different mammalian species. In some embodiments, the mutation does not result in a secondary structure change in the surface protein. In some embodiments, the mutation is within the epitope targeted by an antigen-binding protein or is at a site that is accessible to ligand binding. In some embodiments, the mutation is not located at a site involved in a predicted or experimentally established or confirmed proteinprotein interaction of the surface protein. In some embodiments, the mutation does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking. In some embodiments, the mutation does not result in deleting or introducing a posttranslational protein modification site, such as a glycosylation site. In some embodiments, the mutation is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction. In instances where an antibody or antigen-binding protein reactive against a target protein already exists, the information regarding the epitope of the target protein that is recognized by the antibody or antigen-binding protein can be used to select the site of the mutation.
[00151] In some embodiments, the first isoform of the target protein is a genetically
engineered isoform of the target protein. For example, the first isoform of the target protein can be genetically engineered to comprise a mutation (e.g., an artificial mutation that is not naturally occurring) to provide an altered epitope. The altered epitope can be, for example, in the binding region of an antigen-binding protein such as an antibody. In some embodiments, the target protein is CXCR4 (e.g., human CXCR4), and the altered epitope is in a binding region of the REGN7663 or REGN7664 anti-CXCR4 antibodies described elsewhere herein. The ECL2 region of human CXCR4, which is from position A175 to position V198 of human CXCR4 (SEQ ID NO: 1), is necessary and sufficient for REGN7663 and REGN7664 binding. In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) encoded by nucleotides within coding exon 2 of the CXCR4 gene (e.g., human CXCR4 gene). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the ECL2 region of CXCR4 (e.g., human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position A175 to position V198 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position SI 78 to position R183 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position R188 to position LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the REGN7663 and REGN7664 binding region (SEQ ID NO: 57). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198. In some embodiments, the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198. In some embodiments, the mutation can comprise a
mutation (e.g., an insertion) between Al 75 and N 176, between N176 and VI 77, between VI 77 and S178, between S178 and E179, between E179 and A180, between A180 and D181, between D181 and D182, between D182 and R183, between R183 and Y184, between Y184 and 1185, between 1185 and C186, between C186 and D187, between D187 and R188, between R188 and Fl 89, between Fl 89 and Y190, between Y190 and Pl 91, between P191 and N192, between N192 and DI 93, and/or between DI 93 and LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e g., an insertion) between S178 and E179. In some embodiments, the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198, and a mutation (e.g., an insertion) between S178 and E179. In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) or combination of mutations as set forth in Table 1.
[00152] Table 1. Human CXCR4 ECL2 Fragment Variants.


[00153] In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion), or combination of mutations, as set forth in pMM626, pMM630, pMM632, pMM633, and pMM640 (corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively). For example, the mutation can comprise a mutation (e.g., a substitution) at position F189, N192, D193, E179, D181, and/or D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of
CXCR4 when aligned with human CXCR4); a mutation (e.g., an insertion) between SI 78 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); or any combination thereof of CXCR4 (e.g., human CXCR4). A mutation at a position within CXCR4 encompasses mutations (e.g., substitutions and/or insertions) including only the residue at that position or mutations (e.g., substitutions and/or insertions) including the residue at that position as well as other residues at other positions. The nomenclature of the amino acid position for the mutations or residue disclosed herein refer to the position of the mutation or residue in the canonical isoform of human CXCR4 set forth in SEQ ID NO: 1. [00154] In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position Fl 89 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable Fl 89 substitution is an F189A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position N192 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable N192 substitution is an N192A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 93 substitution is an DI 93 A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at positions Fl 89, N192, and DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable Fl 89, N192, and DI 92 substitutions are F189A, N192A, and D192A substitutions. In some embodiments, the mutation comprises an insertion between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable insertions include an S178_E179insK (e g., insertion of K between S178 and E179), S178_E179insY (e.g., insertion of Y between S178 and E179), and S178_E179insR (e.g., insertion of R between S178 and E179). In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable E179 substitution is an E179R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position D181 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable
DI 81 substitution is an D181R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position DI 82 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 82 substitution is an D182R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at positions E179, D181, and D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable E179, D181, and D182 substitutions are E179R, D181R, and D182R substitutions. [00155] In some embodiments, the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 91 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of F189A, N192A, and N193 A relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00156] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 95 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insK relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00157] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 97 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insY relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00158] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 98 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insR relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00159] In some embodiments, the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 105 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of E179R, D181R, and D182R relative to SEQ ID NO: 1 (or a corresponding region of
CXCR4 when aligned with human CXCR4).
[00160] The donor cells or edited cells can be administered to the subject by any suitable means. The term administering refers to administration of a composition (e.g., the donor cells or edited cells) to a subject or system (e.g., but not limited to, to a cell, organ, tissue, organism, or relevant component or set of components thereof). The route of administration may vary depending, for example, on the subject or system to which the composition is being administered, the nature of the composition, the purpose of the administration, and so forth. The term “administration” or “administering” is intended to include routes of introducing the donor cells or edited cells to a subject to perform their intended function. In some embodiments, nonlimiting examples of routes of administration which can be used include, e.g., injection (subcutaneous, intravenous, parenterally, intraperitoneally, intrathecal), such as intravenous injection. In some embodiments of the present invention, the donor cells or edited cells are administered by intravenous injection. Administration may involve intermittent dosing or continuous dosing (e.g., but not limited to, perfusion) for at least a selected period of time. The donor cells or edited cells can be administered alone, or in conjunction with either another agent (e g., but not limited to, an agent for selective inhibition or selective depletion of host cells or non-edited cells in the subject) or with a pharmaceutically acceptable carrier, or both. The donor cells or edited cells can be administered prior to the administration of the other agent, simultaneously with the agent, or after the administration of the agent.
[00161] The host cells or non-edited cells in the subject can be selectively inhibited or selectively depleted (e.g., mobilized from their immune cell niche) based on their expression of the second isoform of the target protein (e.g., based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein, or based on their expression of the second isoform regardless of their of expression of the first isoform of the target protein) by any suitable means. For example, they can be depleted or inhibited based on their expression of only the second isoform of the target protein and their lack of expression of the first isoform of the target protein. Alternatively, they can be depleted or inhibited based on their expression of the second isoform regardless of their expression of the first isoform of the target protein. In some embodiments, selective inhibition or selective depletion means selective mobilization of host cells or non-edited cells from the bone marrow to the periphery. The selective inhibition or selective depletion of the host cells or non-edited cells
can occur before administration of the donor cells or edited cells, simultaneously with the administration of the donor cells or edited cells, or after administration of the donor cells or edited cells. Selective depletion refers to selectively reducing the total number or concentration of cells (e.g., in the bone marrow) expressing a certain isoform of the target protein. Selective depletion of cells expressing a second isoform can correspond to enrichment of cells expressing the first isoform.
[00162] In some embodiments, selective depletion refers to selective ablation of host cells. Selective ablation of host cells refers to ablation (i.e., killing) of host cells by an active killing mechanism. An active killing mechanism means the agent directly kills the host cells by cytotoxic mechanisms (e.g., antibody-drug conjugate (ADC), antibody radioconjugate (ARC), CAR-T, or other engineered cytotoxicity) or recruits host cytotoxic effector mechanisms (e.g., complement-dependent cytotoxicity (CDC), antibody-dependent cellular cytotoxicity (ADCC), antibody-dependent cellular phagocytosis (ADCP)), as opposed blocking a cellular function (e.g. growth or cytokine signaling, chemotactic tissue homing, cell-cell adhesion; e.g., as with selective inhibition) without engaging extrinsic cytotoxic effectors. In some embodiments, the selective depletion of host cells or non-edited cells comprises ablating the host cells or nonedited cells via an active killing mechanism such as complement-dependent cytotoxicity (CDC), antibody-dependent cellular cytotoxicity (ADCC), antibody-dependent cellular phagocytosis (ADCP), antibody-drug conjugate (ADC), CAR-T, or other engineered cytotoxicity.
[00163] In other embodiments, selective depletion refers to selective inhibition of host cells. In contrast to selective ablation, selective inhibition of host cells does not comprise ablation (i.e., killing) of host cells by an active killing mechanism. That is, selective inhibition of host cells does not comprise cytotoxic ablation of host cells. In some embodiments, the selective inhibition of host cells or non-edited cells does not comprise ablation or killing of host cells or non-edited cells, even indirectly. In some embodiments, the selective inhibition or selective depletion of host cells or non-edited cells comprises: (1) blocking growth of the host cells or non-edited cells (e.g., blocking proliferation or immune cell activation) to provide a competitive growth advantage to the donor cells or edited cells; (2) blocking localization or trafficking of the host cells or nonedited cells to provide a competitive homing advantage to the donor cells or edited cells; (3) blocking a cell-cell interaction or adhesion of the host cells or non-edited cells to provide a competitive tissue infiltration advantage to the donor cells or edited cells; or (4) blocking
immune cell activation in the host cells or non-edited cells to provide a competitive advantage to the donor cells or edited cells. For example, in some embodiments, the selective inhibition or selective depletion of host cells or non-edited cells comprises selectively depleting host cells from the bone marrow. As a novel conditioning strategy, selective inhibition of host cells without cytotoxic ablation has potential to improve the safety and efficacy of cell therapy and transplant treatments. Non-ablative conditioning may avoid undesired and harmful effects of ablative agents, including direct killing of non-target (e.g., non-hematopoietic) cells expressing drug target antigens, indirect toxicides to target-adjacent tissues, and prolonged immune suppression in the post-transplant period. Selective blockade or suppression of essential host cell factors can enhance the expansion, persistence, and trafficking of resistant donor cells by affording favorable competition for limiting host factors (e.g., cytokine, chemokines) and immune niche space, without harsh and potentially toxic ablative agents.
[00164] In some embodiments of the present invention, the method can comprise providing the subject with means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4. In some embodiments of the present invention, the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise providing the subject with means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4. In some embodiments of the present invention, the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise administering an agent (e.g., an antagonist, an antigen-binding protein, or a population of cells (i.e., immune effector cells such as chimeric antigen receptor T cells (CAR-T)) expressing an antigen-binding protein)) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein. For example, the agent can be an antagonist that blocks interaction between an endogenous ligand and the second isoform of the target protein but does not block interaction between the endogenous ligand and the first isoform of the target protein. In some embodiments of the present invention, the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise administering an antagonist (e.g., an antigen-binding protein or a population of cells (i.e., immune effector cells such as chimeric antigen receptor T cells (CAR-T)) expressing an antigen-binding protein) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein (e.g., an antagonist that blocks interaction between the
endogenous ligand (e.g., CXCL12) and the second isoform of the target protein (e.g., CXCR4), but does not block interaction between the endogenous ligand and the first isoform of the target protein). In some embodiments of the present invention, the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise administering an antigen-binding protein (e.g., an isolated antigen-binding protein) or one or more nucleic acids encoding the antigen-binding protein, such as an antibody (e.g., human antibody, monoclonal antibody, and/or recombinant antibody) or an antigen-binding fragment thereof that specifically binds to the second isoform of the target protein (or an antigenic fragment thereof (e.g., the extracellular domain)) but does not specifically bind to the first isoform of the target protein. In some embodiments of the present invention, the selective inhibition or selective depletion of the host cells or non-edited cells in the subject can comprise administering a population of cells (i.e., immune effector cells) expressing an antigen-binding protein (e.g., T cells expressing a chimeric antigen receptor or an exogenous T cell receptor) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein. Immune effector cells are cells that are capable of effecting or enhancing an immune response. In some embodiments (i.e., for selective ablation), selective depletion (e.g., selective ablation) can be achieved by cytotoxic mechanisms (e.g., antibody-drug conjugate (ADC), antibody radioconjugate (ARC), CAR-T, or other engineered cytotoxicity). In some embodiments (i.e., for selective ablation), selective depletion (e.g., selective ablation) can be achieved by recruiting host cytotoxic effector mechanisms (e.g., complement-dependent cytotoxicity (CDC), antibodydependent cellular cytotoxicity (ADCC), antibody-dependent cellular phagocytosis (ADCP)), as opposed blocking a cellular function (e.g. growth or cytokine signaling, chemotactic tissue homing, cell-cell adhesion; e.g., as with selective inhibition) without engaging extrinsic cytotoxic effectors. In some embodiments (e.g., for selective ablation), the antigen-binding protein is coupled to a toxin, thereby forming an immunotoxin. In some embodiments, the antigen-binding protein is not coupled to a toxin. In some embodiments, the antigen-binding protein is a bispecific antigen-binding protein that can simultaneously bind to two different antigens. In some embodiments, selective depletion (e.g., selective ablation) can be achieved by complement-dependent cytotoxicity (CDC), by antibody-dependent cellular cytotoxicity (ADCC), by antibody-dependent cellular phagocytosis (ADCP), or by an antibody-drug conjugate (ADC). In some embodiments, selective inhibition or selective depletion is not
achieved by cytotoxic mechanisms or by recruiting host cytotoxic effector mechanisms. In some embodiments, selective inhibition or selective depletion is achieved by blocking a cellular function (e.g., growth or cytokine signaling, chemotactic tissue homing, cell-cell adhesion) without engaging extrinsic cytotoxic effectors. For example, selective inhibition or selective depletion can be achieved by selectively depleting host cells from the bone marrow. In some embodiments, selective inhibition or selective depletion is not achieved by complementdependent cytotoxicity (CDC), by antibody-dependent cellular cytotoxicity (ADCC), by antibody-dependent cellular phagocytosis (ADCP), or by an antibody-drug conjugate (ADC). Toxins or drugs compatible for use in antibody-drug conjugate are well known in the art. See, e.g., Peters et al. (2015) Biosci. Rep. 35(4):e00225, Beck et al. (2017) Nature Reviews Drug Discovery 16:315-337; Marin- Acevedo et al. (2018) J. Hematol. Oncol. 11 :8; Elgundi et al. (2017) Advanced Drug Delivery Reviews 122: 2-19, each of which is herein incorporated by reference in its entirety for all purposes. In some embodiments, the antibody-drug conjugate may further comprise a linker (e.g., a peptide linker, such as a cleavable linker) attaching the antigenbinding protein (e.g., antibody) and drug molecule. Selective inhibition or selective depletion can also be effected by administration of an antigen-binding protein that is not coupled to an effector compound such as a drug or a toxin. In some embodiments, selective inhibition or selective depletion is achieved by blocking binding by an endogenous ligand (e.g., CXCL12 for CXCR4). [00165] In methods in which an agent for selective inhibition or selective depletion of host cells or non-edited cells is administered, the agent can in some embodiments be administered simultaneously with the donor cells or edited cells. In some embodiments, the donor cells or edited cells are administered after the agent. For example, in some embodiments, the donor cells or edited cells are administered within 1 day after the agent, or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more after the agent. In some embodiments, the donor cells or edited cells are administered before the agent. For example, in some embodiments, the donor cells or edited cells are administered within 1 day before the agent, or at least about 1 day, at least about 2 days, at least about 3 days, at least
about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more before the agent.
[00166] In some embodiments, the donor cells or edited cells are administered in multiple administrations (e.g., doses). In some embodiments, the donor cells or edited cells are administered to the subject once. In some embodiments, the donor cells or edited cells are administered to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the donor cells or edited cells are administered to the subject at a regular interval (e.g., every 6 months). In methods in which an agent for selective inhibition or selective depletion of host cells or non-edited cells is administered, it can, in some embodiments, be administered in multiple administrations (e.g., doses). In some embodiments, the agent is administered to the subject once. In some embodiments, the agent is administered to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the agent is administered to the subject at a regular interval (e.g., every 6 months). [00167] In some embodiments, the agent is administered to the subject prior to administration of the donor cells or edited cells and after administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject prior to administration of the donor cells or edited cells and after administration of the donor cells or edited cells, and the donor cells or edited cells are administered to the subject once. In some embodiments, for example, the agent is administered to the subject about 1 to about 2 weeks prior to administration of the donor cells or edited cells and is administered to the subject about 1 to about 2 weeks after administration of the donor cells or edited cells (e.g., to give the donor cells or edited cells a competitive advantage).
[00168] In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at
least 5 or more times) prior to administration of the donor cells or edited cells and in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells.
[00169] In some embodiments, about 106to 1011 donor cells or edited cells are administered. In some embodiments it may be desirable to administer fewer than 106 cells to the subject. In some embodiments, it may be desirable to administer more than 1011 cells to the subject. In some embodiments, one or more doses of cells includes about 106 cells to about 1011 cells, about 107 cells to about IO10 cells, about 108 cells to about 109 cells, about 106 cells to about 108 cells, about 107 cells to about 109 cells, about 107 cells to about IO10 cells, about 107 cells to about 1011 cells, about 108 cells to about IO10 cells, about 108 cells to about 1011 cells, about 109 cells to about IO10 cells, about 109 cells to about 1011 cells, or about IO10 cells to about 1011 cells. In some embodiments, one or more doses of cells includes about 106 to 107 cells per kg.
[00170] An “antagonist” includes molecules that inhibit an activity of the target protein to any detectable degree. For example, an antagonist of CXCR4 includes molecules that inhibit an activity of CXCR4 (e.g., binding of CXCR4 to CXCL12/SDF-1) to any detectable degree.
[00171] In some embodiments, the agent for selective inhibition or selective depletion of host cells or non-edited cells is an antigen-binding protein.
[00172] The term “specifically binds” or “binds specifically” refers to those antigen-binding proteins (e.g., antibodies or antigen-binding fragments thereof) having a binding affinity to an antigen, such as CXCR4 protein, expressed as KD, of at least about 10'7 M (e g., 10'8 M, 10’9 M, 1C)'1OM, 10'11 M or IO’12 M), as measured by real-time, label free bio-layer interferometry assay, for example, at 25°C or 37°C, e.g., an Octet® HTX biosensor, or by surface plasmon resonance, e.g., BIACORETM, or by solution-affinity ELISA. In some embodiments, the antigen-binding proteins used herein specifically bind to CXCR4 protein or human CXCR4 protein (e.g., wild type or native CXCR4 protein, such as wild type or native human CXCR4 protein). “Anti- CXCR4” refers to an antigen-binding protein (or another molecule), for example an antibody or antigen-binding fragment thereof, that binds specifically to CXCR4.
[00173] An antigen is a molecule, such as a peptide (e.g., CXCR4 or a fragment thereof (an antigenic fragment)), to which, for example, an antibody binds. The specific region on an antigen that an antibody recognizes and binds to is called the epitope.
[00174] The term “epitope” refers to an antigenic determinant (e.g., on CXCR4) that interacts
with a specific antigen-binding site of an antigen-binding protein, e.g., a variable region of an antibody molecule, known as a paratope. A single antigen may have more than one epitope. Thus, different antigen-binding proteins (e.g., antibodies) may bind to different areas on an antigen and may have different biological effects. The term “epitope” may also refer to a site on an antigen to which B and/or T cells respond and/or to a region of an antigen that is bound by an antibody. Epitopes may be defined as structural or functional. Functional epitopes are generally a subset of the structural epitopes and have those residues that directly contribute to the affinity of the interaction. Epitopes may be linear or conformational, that is, composed of non-linear amino acids. In certain embodiments, epitopes may include determinants that are chemically active surface groupings of molecules such as amino acids, sugar side chains, phosphoryl groups, or sulfonyl groups, and, in certain embodiments, may have specific three-dimensional structural characteristics, and/or specific charge characteristics. Epitopes to which the antigen-binding proteins used in the present invention bind may be included in fragments of CXCR4, e.g., human CXCR4, for example the extracellular loop 2 (ECL2) of human CXCR4 or a portion or fragment thereof.
[00175] Methods for determining the epitope of an antigen-binding protein, e.g., antibody or fragment or polypeptide, include alanine scanning mutational analysis, peptide blot analysis (Reineke (2004) Methods Mol. Biol. 248: 443-63, herein incorporated by reference in its entirety for all purposes), peptide cleavage analysis, crystallographic studies and NMR analysis. In addition, methods such as epitope excision, epitope extraction and chemical modification of antigens can be employed (Tomer (2000) Prot. Sci. 9: 487-496, herein incorporated by reference in its entirety for all purposes). Another method that can be used to identify the amino acids within a polypeptide with which an antigen-binding protein (e.g., antibody or fragment or polypeptide) interacts is hydrogen/deuterium exchange detected by mass spectrometry. See, e.g., Ehring (1999) Analytical Biochemistry 267: 252-259; Engen and Smith (2001) Anal. Chem. 73: 256A-265A, each of which is herein incorporated by reference in its entirety for all purposes. [00176] The term “antibody,” as used herein, refers to immunoglobulin molecules comprising four polypeptide chains, two heavy chains (HCs) and two light chains (LCs) inter-connected by disulfide bonds (i.e., “full antibody molecules”) (e.g., IgG) — for example REGN7663 and REGN7664. In some embodiments, the antibody heavy chain comprises SEQ ID NO: 110 or a variant thereof, and the antibody light chain comprises SEQ ID NO: 112 or a variant thereof
(REGN7663), or the antibody heavy chain comprises SEQ ID NO: 114 or a variant thereof, and the antibody light chain comprises SEQ ID NO: 116 or a variant thereof (REGN7664). In some embodiments, each antibody heavy chain (HC) comprises a heavy chain variable region (“HCVR” or “VH”) (e.g., SEQ ID NO: 5 or a variant thereof for REGN7663, and SEQ ID NO: 21 or a variant thereof for REGN7664) and a heavy chain constant region (including domains CHI, CH2 and CH3); and each antibody light chain (LC) comprises a light chain variable region (“LCVR” or “VL”) (e.g., SEQ ID NO: 13 or a variant thereof for REGN7663, and SEQ ID NO: 29 or a variant thereof for REGN7664) and a light chain constant region (CL). The VH and VL regions can be further subdivided into regions of hypervariability, termed complementarity determining regions (CDR), interspersed with regions that are more conserved, termed framework regions (FR). Each VH and VL comprises three CDRs and four FRs, arranged from amino-terminus to carboxy-terminus in the following order: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4. In certain embodiments, the FRs of the antibody (or antigen binding fragment thereof) are identical to the human germline sequences or are naturally or artificially modified. [00177] Typically, the variable domains of both the heavy and light immunoglobulin chains comprise three hypervariable regions, also called complementarity determining regions (CDRs), located within relatively conserved framework regions (FR). In general, from N-terminal to C- terminal, both light and heavy chains variable domains comprise FR1, CDR1, FR2, CDR2, FR3, CDR3 and FR4. In some embodiments, the assignment of amino acids to each domain is in accordance with the definitions of Sequences of Proteins of Immunological Interest, Kabat et al.; National Institutes of Health, Bethesda, Md.; 5th ed.; NIH Publ. No. 91-3242 (1991); Kabat (1978) Adv. Prot. Chem. 32: 1-75; Kabat et al., (1977) J. Biol. Chem. 252:6609-6616; Chothia et al., (1987) J. Mol. Biol. 196:901-917 or Chothia et al., (1989) Nature 342:878-883, each of which is herein incorporated by reference in its entirety for all purposes. Thus, antigen-binding proteins in some embodiments include antibodies and antigen-binding fragments including the CDRs of a VH and the CDRs of a VL, which VH and VL comprise amino acid sequences as set forth herein (or a variant thereof), wherein the CDRs are as defined according to Kabat and/or Chothia.
[00178] The terms “antigen-binding portion” or “antigen-binding fragment” of an antibody or antigen-binding protein, and the like, as used herein, include any naturally occurring, enzymatically obtainable, synthetic, or genetically engineered polypeptide or glycoprotein that
specifically binds an antigen to form a complex. Non-limiting examples of antigen-binding fragments include: (i) Fab fragments; (ii) F(ab')2 fragments; (iii) Fd fragments (heavy chain portion of a Fab fragment cleaved with papain); (iv) Fv fragments (a VH or VL); and (v) singlechain Fv (scFv) molecules; consisting of the amino acid residues that mimic the hypervariable region of an antibody (e.g., an isolated complementarity determining region (CDR) such as a CDR3 peptide), or a constrained FR3-CDR3-FR4 peptide. Other engineered molecules, such as domain-specific antibodies, single domain antibodies, domain-deleted antibodies, chimeric antibodies, CDR-grafted antibodies, diabodies, triabodies, tetrabodies, minibodies and small modular immunopharmaceuticals (SMIPs), are also encompassed within the expression “antigenbinding fragment,” as used herein. In some embodiments, the antigen-binding fragment comprises three or more CDRs of REGN7663 or REGN7664 (e g., CDR-H1, CDR-H2 and CDR-H3; or CDR-L1, CDR-L2 and CDR-L3).
[00179] In some embodiments, the antigen-binding protein is a “neutralizing” or “antagonist” anti-target protein antigen-binding protein (e.g., antibody or antigen-binding fragment), including molecules that inhibit an activity of the target protein (e.g., inhibiting binding of a receptor to one of its ligands) to any detectable degree.
[00180] In some embodiments, the antigen-binding proteins can comprise monoclonal antigen-binding proteins, e.g., antibodies and antigen-binding fragments thereof, as well as monoclonal compositions comprising a plurality of isolated monoclonal antigen-binding proteins. The term “monoclonal antibody” or “mAb,” as used herein, refers to a member of a population of substantially homogeneous antibodies, i.e., the antibody molecules comprising the population are identical in amino acid sequence except for possible naturally occurring mutations that may be present in minor amounts. A “plurality” of such monoclonal antibodies and fragments in a composition refers to a concentration of identical (in amino acid sequence except for possible naturally occurring mutations that may be present in minor amounts) antibodies and fragments which is above that which would normally occur in nature, e.g., in the blood of a host organism such as a mouse or a human.
[00181] In some embodiments, the antigen-binding protein, e.g., antibody or antigen-binding fragment comprises a heavy chain constant domain, e.g., of the type IgA (e.g., IgAl or IgA2), IgD, IgE, IgG (e.g., IgGl, IgG2, IgG3 and IgG4 (e.g., comprising a S228P and/or S108P mutation)) or IgM. In some embodiments, the antigen-binding protein, e.g., antibody or antigen-
binding fragment, comprises a light chain constant domain, e g., of the type kappa or lambda. In some embodiments, the antigen-binding protein includes antigen-binding proteins comprising the variable domains set forth herein (e.g., REGN7663 or REGN7664) which are linked to a heavy and/or light chain constant domain, e.g., as set forth above.
[00182] In some embodiments, the antigen-binding protein is a human antigen-binding protein (e.g., antibodies or antigen-binding fragments thereof such as REGN7663 or REGN7664). The term “human” antigen-binding protein, such as an antibody or antigen-binding fragment, as used herein, includes antibodies and fragments having variable and constant regions derived from human germline immunoglobulin sequences whether in a human cell or grafted into a nonhuman cell, e.g., a mouse cell. See, e.g., US8502018, US6596541, or US5789215, each of which is herein incorporated by reference in its entirety for all purposes. The human antibodies and antigen-binding fragments may, in some embodiments, include amino acid residues not encoded by human germline immunoglobulin sequences (e.g., having mutations introduced by random or site-specific mutagenesis in vitro or by somatic mutation in vivo), for example in the CDRs and, in particular, CDR3. However, the term “human antibody,” as used herein, is not intended to include mAbs in which CDR sequences derived from the germline of another mammalian species (e.g., mouse) have been grafted onto human FR sequences. The term includes antibodies recombinantly produced in a non-human mammal or in cells of a non-human mammal. The term is not intended to include antibodies isolated from or generated in a human subject.
[00183] In some embodiments, the antigen-binding protein is a chimeric antigen-binding protein (e.g., chimeric antibodies comprising the variable domains which are set forth herein (e.g., from REGN7663 or REGN7664)). As used herein, a “chimeric antibody” is an antibody having the variable domain from a first antibody and the constant domain from a second antibody, where the first and second antibodies are from different species. See, e.g., US4816567; and Morrison et al., (1984) Proc. Natl. Acad. Sci. U.S.A. 81: 6851-6855, each of which is herein incorporated by reference in its entirety for all purposes.
[00184] In some embodiments, the antigen-binding protein is a recombinant antigen-binding protein (e.g., recombinant antigen-binding proteins as set forth herein (e.g., REGN7663 or REGN7664)). The term “recombinant” antigen-binding proteins, such as antibodies or antigenbinding fragments thereof, refers to such molecules created, expressed, isolated or obtained by technologies or methods known in the art as recombinant DNA technology which include, e.g.,
DNA splicing and transgenic expression. The term includes antibodies expressed in a non-human mammal (including transgenic non-human mammals, e.g., transgenic mice), or a host cell (e.g., Chinese hamster ovary (CHO) cell) or cellular expression system or isolated from a recombinant combinatorial human antibody library.
[00185] In some embodiments, the antigen-binding protein is an antigen-binding fragment of an antibody (e.g., an antigen-binding fragment of an antigen-binding protein set forth herein, for example, REGN7663 or REGN7664). An antigen-binding fragment of an antibody will, in some embodiments, comprise at least one variable domain. The variable domain may be of any size or amino acid composition and will generally comprise at least one (e.g., 3) CDR(s), which is adjacent to or in frame with one or more framework sequences. In antigen-binding fragments having a VH domain associated with a VL domain, the VH and VL domains may be situated relative to one another in any suitable arrangement. For example, the variable region may be dimeric and contain VH-VH, VH-VL or VL-VL dimers. Alternatively, the antigen-binding fragment of an antibody may contain a monomeric VH and/or VL domain which are bound non-covalently. [00186] In certain embodiments, the antigen-binding fragment of an antibody may contain at least one variable domain covalently linked to at least one constant domain. Non-limiting, exemplary configurations of variable and constant domains that may be found within an antigenbinding fragment of an antibody include: (i) Vn-Ciil; (ii) VII-CII2; OD VII-CII3; (iv) Vii-Cul- CH2; (V) VH-CH1-CH2-CH3 ; (vi) VH-CH2-CH3 ; (vii) VH-CL; (viii) VL-CH1 ; (ix) VL-CH2; (X) VL- CH3; (xi) VL-CH1 -CH2; (xii) VL-CH1 -CH2-CH3; (xiii) VL-CH2-CH3 ; and (xiv) VL-CL. In any configuration of variable and constant domains, including any of the exemplary configurations listed above, the variable and constant domains may be either directly linked to one another or may be linked by a full or partial hinge or linker region. A hinge region may consist of at least 2 (e g., 5, 10, 15, 20, 40, 60, or more) amino acids, which result in a flexible or semi-flexible linkage between adjacent variable and/or constant domains in a single polypeptide molecule. Moreover, an antigen-binding fragment of an antibody may comprise a homo-dimer or heterodimer (or other multimer) of any of the variable and constant domain configurations listed above in noncovalent association with one another and/or with one or more monomeric VH or VL domain (e.g., by disulfide bond(s)).
[00187] The antigen-binding proteins (e.g., antibodies and antigen-binding fragments) may be monospecific or multi-specific (e.g., bispecific), such as monospecific as well as multispecific
(e g., bispecific) antigen-binding fragments comprising one or more variable domains from an antigen-binding protein that is specifically set forth herein (e.g., REGN7663 or REGN7664).
[00188] In some embodiments, the antigen-binding protein is an antigen-binding protein, such as an antibody (e.g., human antibody, monoclonal antibody, or recombinant antibody) or an antigen-binding fragment thereof, that specifically binds to CXCR4 protein or an antigenic fragment thereof (e.g., the extracellular domain of CXCR4 or human CXCR4). For example, the antigen-binding protein can comprise any polypeptide that includes an amino acid sequence set forth in SEQ ID NO: 110, 112, 114, and/or 116 or a variant thereof. For example, the antigenbinding protein can comprise any polypeptide that includes an amino acid sequence set forth in SEQ ID NO: 5, 13, 21, and/or 29 or a variant thereof. In another example, the antigen-binding protein can comprise PF-06747143, ulocuplumab, or LY2624587. See, e.g., Kashyap et al. (2017) J. Hematol. Oncol. 10(1): 112 and Peng et al. (2016) PLoS One l l(3):e010585, each of which is herein incorporated by reference in its entirety for all purposes. Optionally, the antigenbinding protein comprises one or more other polypeptides, e.g., a human Fc (e.g., a human IgG such as an IgGl or IgG4 (e.g., comprising a S108P mutation)). Antigen-binding proteins that bind to the same epitope on CXCR4 as or compete for binding to CXCR4 with any of the antigen-binding proteins set forth herein (e.g., REGN7663 or REGN7664), can also be used. [00189] In some embodiments, the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) includes an immunoglobulin heavy chain that comprises a VH (e.g., an HC) including the combination of heavy chain CDRs (CDR-H1, CDR-H2 and CDR-H3) set forth in SEQ ID NOS: 7, 9, and 11, respectively, and/or an immunoglobulin light chain that comprises a VL (e.g., a LC) including the combination of light chain CDRs (CDR-L1, CDR-L2 and CDR-L3) set forth in SEQ ID NOS: 15, 17, and 19, respectively.
[00190] In some embodiments, the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) includes an immunoglobulin heavy and light chain that comprises a VH (e.g., an HC) and a VL (e.g., a LC), respectively, including the combination of heavy and light chain CDRs (CDR-H1, CDR-H2 and CDR-H3; and CDR-L1, CDR-L2 and CDR-L3) set forth in SEQ ID NOS: 7, 9, 11, 15, 17, and 19, respectively.
[00191] In some embodiments, the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) includes an immunoglobulin heavy chain that comprises a VH (e.g., an HC) including the combination of heavy chain CDRs (CDR-H1, CDR-H2 and CDR-H3) set
forth in SEQ ID NOS: 23, 25, and 27, respectively, and/or an immunoglobulin light chain that comprises a VL (e.g., a LC) including the combination of light chain CDRs (CDR-L1, CDR-L2 and CDR-L3) set forth in SEQ ID NOS: 31, 33, and 35, respectively.
[00192] In some embodiments, the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) includes an immunoglobulin heavy and light chain that comprises a VH (e.g., an HC) and a VL (e.g., a LC), respectively, including the combination of heavy and light chain CDRs (CDR-H1, CDR-H2 and CDR-H3; and CDR-L1, CDR-L2 and CDR-L3) set forth in SEQ ID NOS: 23, 25, 27, 31, 33, and 35, respectively.
[00193] In some embodiments, the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) comprises polypeptide pairs that comprise the following VH and VL amino acid sequences: SEQ ID NOS: 5 and 13, respectively.
[00194] In some embodiments, the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) comprises polypeptide pairs that comprise the following VH and VL amino acid sequences: SEQ ID NOS: 21 and 29, respectively.
[00195] In some embodiments, the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) comprises immunoglobulin VHS and VLS, or HCs and LCs, which comprise a variant amino acid sequence having 70% or more (e.g., 80%, 85%, 90%, 95%, 97% or 99%) overall amino acid sequence identity or similarity to the amino acid sequences of the corresponding VHS, VLS, HCS or LCs specifically set forth herein, but wherein the CDR-L1, CDR-L2, CDR-L3, CDR-H1, CDR-H2 and CDR-H3 of such immunoglobulins are not variants and comprise the amino acid sequences set forth herein. Thus, in such embodiments, the CDRs within variant antigen-binding proteins are not, themselves, variants.
[00196] In some embodiments, the antigen-binding protein (e.g., an antibody or antigenbinding fragment thereof) binds to the same epitope as REGN7663. In some embodiments, the antigen-binding protein (e.g., an antibody or antigen-binding fragment thereof) competes for binding to CXCR4 with REGN7663. In some embodiments, the antigen-binding protein (e.g., an antibody or antigen-binding fragment thereof) binds to the same epitope as REGN7664. In some embodiments, the antigen-binding protein (e.g., an antibody or antigen-binding fragment thereof) competes for binding to CXCR4 with REGN7664. The term “competes,” as used herein, refers to an antigen-binding protein (e.g., antibody or antigen-binding fragment thereof) that binds to an antigen (e.g., CXCR4) and inhibits or blocks the binding of another antigen-binding protein (e.g.,
antibody or antigen-binding fragment thereof) to the antigen. Unless otherwise stated, the term also includes competition between two antigen-binding proteins e.g., antibodies, in both orientations, i.e., a first antibody that binds antigen and blocks binding by a second antibody and vice versa. Thus, in some embodiments, competition occurs in one such orientation. In certain embodiments, the first antigen-binding protein (e.g., antibody) and second antigen-binding protein (e.g., antibody) may bind to the same epitope. Alternatively, the first and second antigenbinding proteins (e.g., antibodies) may bind to different, but, for example, overlapping or nonoverlapping epitopes, wherein binding of one inhibits or blocks the binding of the second antibody, e.g., via steric hindrance. Competition between antigen-binding proteins (e.g., antibodies) may be measured by methods known in the art, for example, by a real-time, label- free bio-layer interferometry assay. Also, binding competition between anti-CXCR4 antigenbinding proteins (e.g., monoclonal antibodies (mAbs)) can be determined using a real time, label-free bio-layer interferometry assay on an Octet RED384 biosensor (Pall ForteBio Corp.). [00197] In some embodiments, the antigen-binding protein is a variant of REGN7663. In some embodiments, the antigen-binding protein is a variant of REGN7664. Typically, an antibody or antigen-binding fragment which is modified in some way retains the ability to specifically bind to CXCR4, e.g., retains at least 10% of its CXCR4 binding activity (when compared to the parental antibody) when that activity is expressed on a molar basis. Preferably, an antibody or antigen-binding fragment retains at least 20%, 50%, 70%, 80%, 90%, 95% or 100% or more of the CXCR4 binding affinity as the parental antibody. It is also intended that an antibody or antigen-binding fragment may include conservative or non-conservative amino acid substitutions (referred to as “conservative variants” or “function conserved variants” of the antibody) that do not substantially alter its biologic activity.
[00198] A “variant” of such a polypeptide, such as an immunoglobulin chain (e.g., an REGN7663 VH, VL, or CDR thereof or an REGN7664 VH, VL, or CDR thereof comprising the amino acid sequence specifically set forth herein), refers to a polypeptide comprising an amino acid sequence that is at least about 70-99.9% (e.g., at least 70, 72, 74, 75, 76, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 99.5, or 99.9%) identical or similar to a referenced amino acid sequence that is set forth herein (e.g., any of SEQ ID NOS: 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, or 35); when the comparison is performed by a BLAST algorithm wherein the parameters of the algorithm are selected to give the largest match between
the respective sequences over the entire length of the respective reference sequences (e.g., expect threshold: 10; word size: 3; max matches in a query range: 0; BLOSUM 62 matrix; gap costs: existence 11, extension 1; conditional compositional score matrix adjustment).
[00199] Moreover, a variant of a polypeptide may include a polypeptide such as an immunoglobulin chain (e.g., an REGN7663 HC, LC, VH, VL, or CDR thereof or an REGN7664 HC, LC, VH, VL, or CDR thereof) which may include the amino acid sequence of the reference polypeptide whose amino acid sequence is specifically set forth herein but for one or more (e.g., 1, 2, 3, 4, 5, 6, 7, 8, 9 or 10) mutations, e.g., one or more missense mutations (e.g., conservative substitutions), non-sense mutations, deletions, or insertions. For example, anti-CXCR4 antigenbinding proteins which include an immunoglobulin light chain (or VL) variant comprising the amino acid sequence set forth in SEQ ID NO: 13 or 29 but having one or more of such mutations and/or an immunoglobulin heavy chain (or VH) variant comprising the amino acid sequence set forth in SEQ ID NO: 5 or 21 but having one or more of such mutations may be used in some embodiments. For example, anti-CXCR4 antigen-binding proteins which include an immunoglobulin light chain variant comprising the amino acid sequence set forth in SEQ ID NO: 112 or 116 but having one or more of such mutations and/or an immunoglobulin heavy chain variant comprising the amino acid sequence set forth in SEQ ID NO: 110 or 114 but having one or more of such mutations may be used in some embodiments. In some embodiments, an anti- CXCR4 antigen-binding protein includes an immunoglobulin light chain variant comprising CDR-L1, CDR-L2 and CDR-L3 wherein one or more (e.g., 1 or 2 or 3) of such CDRs has one or more of such mutations (e.g., conservative substitutions) and/or an immunoglobulin heavy chain variant comprising CDR-H1, CDR-H2 and CDR-H3 wherein one or more (e.g., 1 or 2 or 3) of such CDRs has one or more of such mutations (e.g., conservative substitutions).
[00200] The following references relate to BLAST algorithms often used for sequence analysis: BLAST ALGORITHMS: Altschul et al. (2005) FEBS J 272(20): 5101-5109; Altschul et al. (1990) J. Mol. Biol. 215:403-410; Gish et al. (1993) Nature Genet. 3:266-272; Madden et al. ( 1996) Meth. Enzymol. 266: 131-141; Altschul et al. (1997) Nucleic Acids Res. 25:3389-3402; Zhang et al. (1997) Genome Res. 7:649-656; Wootton et al. (1993) Comput. Chem. 17: 149-163; Hancock et al. (1994) Comput. Appl. Biosci. 10:67-70; ALIGNMENT SCORING SYSTEMS: Dayhoff et al. “A model of evolutionary change in proteins.” in Atlas of Protein Sequence and Structure, (1978) vol. 5, suppl. 3. M. O. Dayhoff (ed.), pp. 345-352, Natl. Biomed. Res. Found.,
Washington, D.C.; Schwartz, R. M., et al., “Matrices for detecting distant relationships.” In Atlas of Protein Sequence and Structure, (1978) vol. 5, suppl. 3." M. O. Dayhoff (ed ), pp. 353-358, Natl. Biomed. Res. Found., Washington, D.C.; Altschul (1991) ./. Mol. Biol. 219:555-565; States et al. (1991) Methods 3:66-70; Henikoff et al. (1992) Proc. Natl. Acad. Sci. U.S.A. 89:10915- 10919; Altschul et al. (1993) J. Mol. Evol. 36:290-300; ALIGNMENT STATISTICS: Karlin et al. (1990) Proc. Natl. Acad. Sci. U.S.A. 87:2264-2268; Karlin et al. (1993) Proc. Natl. Acad. Sci. U.S.A. 90:5873-5877; Dembo et al. (1994) Ann. Prob. 22:2022-2039; and Altschul, “Evaluating the statistical significance of multiple distinct local alignments.” in Theoretical and Computational Methods in Genome Research (S. Suhai, ed.), (1997) pp. 1-14, Plenum, N.Y., each of which is herein incorporated by reference in its entirety for all purposes.
[00201] A “conservatively modified variant” or a “conservative substitution,” e.g., of an immunoglobulin chain set forth herein, refers to a variant wherein there is one or more substitutions of amino acids in a polypeptide with other amino acids having similar characteristics (e.g., charge, side-chain size, hydrophobicity /hydrophilicity, backbone conformation and rigidity, etc.). Such changes can frequently be made without significantly disrupting the biological activity of the antibody or fragment. Those of skill in this art recognize that, in general, single amino acid substitutions in non-essential regions of a polypeptide do not substantially alter biological activity (see, e.g., Watson et al. (1987) Molecular Biology of the Gene, The Benjamin/Cummings Pub. Co., p. 224 (4th Ed.), herein incorporated by reference in its entirety for all purposes). In addition, substitutions of structurally or functionally similar amino acids are less likely to significantly disrupt biological activity. Anti-CXCR4 antigenbinding proteins comprising such conservatively modified variant immunoglobulin chains may be used in some embodiments.
[00202] Examples of groups of amino acids that have side chains with similar chemical properties include: (1) aliphatic side chains: glycine, alanine, valine, leucine and isoleucine; (2) aliphatic-hydroxyl side chains: serine and threonine; (3) amide-containing side chains: asparagine and glutamine; (4) aromatic side chains: phenylalanine, tyrosine, and tryptophan; (5) basic side chains: lysine, arginine, and histidine; (6) acidic side chains: aspartate and glutamate, and (7) sulfur-containing side chains: cysteine and methionine. Alternatively, a conservative replacement is any change having a positive value in the PAM250 log-likelihood matrix disclosed in Gonnet et al. (1992) Science 256: 1443-45, herein incorporated by reference in its
entirety for all purposes.
[00203] REGN7663, unless otherwise stated, refers to an anti-CXCR4 antigen-binding protein
(e.g., antibodies and antigen-binding fragments thereof (including multispecific antigen-binding proteins)) comprising an immunoglobulin heavy chain or variable region thereof (VH) comprising the amino acid sequence specifically set forth herein for REGN7663 (e.g., SEQ ID NO: 5 (or a variant thereof) or SEQ ID NO: 110 (or a variant thereof)) and/or an immunoglobulin light chain or variable region thereof (VL) comprising the amino acid sequence specifically set forth herein for REGN7663 (e g., SEQ ID NO: 13 (or a variant thereof) or SEQ ID NO: 112 (or a variant thereof)), respectively; and/or that comprise a heavy chain or Vu that comprises the CDRs thereof (CDR-H1 (or a variant thereof), CDR-H2 (or a variant thereof) and CDR-H3 (or a variant thereof)) and/or a light chain or VL that comprises the CDRs thereof (CDR-L1 (or a variant thereof), CDR-L2 (or a variant thereof) and CDR-L3 (or a variant thereof)). In some embodiments, the VH is linked to an IgG constant heavy chain domain, for example, human IgG constant heavy chain domain (e.g., IgGl or IgG4 (e.g., comprising the S228P and/or S108P mutation)) and/or the VL is linked to a light chain constant domain, for example a human light chain constant domain (e.g., lambda or kappa constant light chain domain). In some embodiments, polynucleotides encoding one or more of any such immunoglobulin chains (e.g., Vu, VL, and/or CDRs) are provided.
[00204] REGN7664, unless otherwise stated, refers to an anti-CXCR4 antigen-binding protein
(e.g., antibodies and antigen-binding fragments thereof (including multispecific antigen-binding proteins)) comprising an immunoglobulin heavy chain or variable region thereof (VH) comprising the amino acid sequence specifically set forth herein for REGN7664 (e.g., SEQ ID NO: 21 (or a variant thereof) or SEQ ID NO: 114 (or a variant thereof)) and/or an immunoglobulin light chain or variable region thereof (VL) comprising the amino acid sequence specifically set forth herein for REGN7664 (e.g., SEQ ID NO: 29 (or a variant thereof) or SEQ ID NO: 116 (or a variant thereof)), respectively; and/or that comprise a heavy chain or VH that comprises the CDRs thereof (CDR-H1 (or a variant thereof), CDR-H2 (or a variant thereof) and CDR-H3 (or a variant thereof)) and/or a light chain or VL that comprises the CDRs thereof (CDR-L1 (or a variant thereof), CDR-L2 (or a variant thereof) and CDR-L3 (or a variant thereof)). In some embodiments, the VH is linked to an IgG constant heavy chain domain, for example, human IgG constant heavy chain domain (e.g., IgGl or IgG4 (e.g., comprising the
S228P and/or SI 08P mutation)) and/or the VL is linked to a light chain constant domain, for example a human light chain constant domain (e.g., lambda or kappa constant light chain domain). In some embodiments, polynucleotides encoding one or more of any such immunoglobulin chains (e.g., VH, VL, and/or CDRs) are provided.
[00205] In some embodiments, the antigen-binding protein (e.g., antibodies and antigenbinding fragments thereof (e.g., REGN7663 or REGN7664)) comprises immunoglobulin chains including the amino acid sequences specifically set forth herein (and variants thereof) as well as cellular and in vitro post-translational modifications to the antibody or fragment. For example, the antigen-binding proteins include antibodies and antigen-binding fragments thereof that specifically bind to CXCR4 comprising heavy and/or light chain amino acid sequences set forth herein as well as antibodies and fragments wherein one or more asparagine, serine and/or threonine residues is glycosylated, one or more asparagine residues is deamidated, one or more residues (e.g., Met, Trp and/or His) is oxidized, the N-terminal glutamine is pyroglutamate (pyroE) and/or the C-terminal lysine or other amino acid is missing.
[00206] In some embodiments, nucleic acid(s) encoding antigen-binding proteins are provided. A nucleic acid encoding an antigen-binding protein comprises deoxyribonucleic acid (DNA) or ribonucleic acid (RNA). Such nucleic acids can be DNA, RNA, or hybrids or derivatives of either DNA or RNA. Optionally, in some embodiments, the nucleic acid can be codon-optimized for efficient translation into protein in a particular cell or organism. As a nonlimiting example, the nucleic acid can be modified to substitute codons having a higher frequency of usage in a human cell, a mammalian cell, a rodent cell, a mouse cell, a rat cell, or any other host cell of interest, as compared to the naturally occurring polynucleotide sequence. Any portion or fragment of a nucleic acid molecule can be produced by: (1) isolating the molecule from its natural milieu; (2) using recombinant DNA technology (e.g., but not limited to, PCR amplification or cloning); or (3) using chemical synthesis methods. Nucleic acids can comprise modifications for improved stability or reduced immunogenicity. Non-limiting examples of modifications include: (1) alteration or replacement of one or both of the nonlinking phosphate oxygens and/or of one or more of the linking phosphate oxygens in the phosphodiester backbone linkage; (2) alteration or replacement of a constituent of a ribose sugar such as alteration or replacement of the 2’ hydroxyl on the ribose sugar; (3) replacement of the phosphate moiety with dephospho linkers; (4) modification or replacement of a naturally
occurring nucleobase; (5) replacement or modification of a ribose-phosphate backbone; (6) modification of the 3’ end or 5’ end of the oligonucleotide (e.g., but not limited to, removal, modification or replacement of a terminal phosphate group or conjugation of a moiety); and (7) modification of the sugar.
[00207] Such nucleic acids can include any polynucleotide, for example, encoding an immunoglobulin HC, LC, VH, VL, CDR-H, or CDR-L of REGN7663 or encoding an immunoglobulin HC, LC, VH, VL, CDR-H, or CDR-L of REGN7664; optionally, which is operably linked to a promoter or other expression control sequence. For example, such nucleic acids can include any polynucleotide (e.g., DNA) that includes a nucleotide sequence set forth in SEQ ID NO: 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 109, 111, 113, or 115. In some embodiments, a polynucleotide of interest is fused to a secretion signal sequence.
[00208] In some embodiments, the nucleic acids can be in the form of an expression construct as defined elsewhere herein. As a non-limiting example, the nucleic acids can include regulatory regions that control expression of the nucleic acid molecule (e.g., but not limited to, transcription or translation control regions), full-length or partial coding regions, and combinations thereof. As a non-limiting example, the nucleic acids can be operably linked to a promoter active in a cell or organism of interest. Promoters that can be used in such expression constructs include promoters active, for example, in one or more of a eukaryotic cell, such as a mammalian cell (e.g., a nonhuman mammalian cell or a human cell), such as a rodent cell (e.g., but not limited to, a mouse cell, or a rat cell). Such promoters can be, for example, conditional promoters, inducible promoters, constitutive promoters, or tissue-specific promoters.
[00209] In some embodiments, the nucleic acid(s) comprise the following polynucleotide pair encoding a HC and LC: SEQ ID NO: 109 and SEQ ID NO: 111. In some embodiments, the nucleic acid(s) comprise the following polynucleotide pair encoding a HC and LC: SEQ ID NO: 113 and SEQ ID NO: 115. In some embodiments, the nucleic acid(s) comprise the following polynucleotide pair encoding a VH and VL: SEQ ID NO: 4 and SEQ ID NO: 12. In some embodiments, the nucleic acid(s) comprise the following polynucleotide pair encoding a VH and VL: SEQ ID NO: 20 and SEQ ID NO: 28. In some embodiments, the nucleic acid(s) comprise the following polynucleotide set which encode a CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 and CDR-L3: SEQ ID NOS: 6, 8, 10, 14, 16, and 18. In some embodiments, the nucleic acid(s) comprise the following polynucleotide set which encode a CDR-H1, CDR-H2, CDR-H3, CDR-
LI, CDR-L2 and CDR-L3: SEQ ID NOS: 22, 24, 26, 30, 32, and 34. In some embodiments, the nucleic acid(s) include polynucleotides encoding immunoglobulin polypeptide chains which are variants of those whose nucleotide sequence is specifically set forth herein. A “variant” of such a polynucleotide or nucleic acids refers to a polynucleotide or nucleic acid comprising a nucleotide sequence that is at least about 70-99.9% (e.g., 70, 72, 74, 75, 76, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 99.5, 99.9%) identical to a referenced nucleotide sequence that is set forth herein; when the comparison is performed by a BLAST algorithm wherein the parameters of the algorithm are selected to give the largest match between the respective sequences over the entire length of the respective reference sequences (e.g., expect threshold: 10; word size: 28; max matches in a query range: 0; match/mismatch scores: 1, -2; gap costs: linear). In some embodiments, a variant of a nucleotide sequence specifically set forth herein comprises one or more (e g., 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 or 12) point mutations, insertions (e.g., in frame insertions) or deletions (e.g., in frame deletions) of one or more nucleotides. Such mutations may, in some embodiments, be missense or nonsense mutations. In some embodiments, such a variant polynucleotide encodes an immunoglobulin polypeptide chain which can be incorporated into an anti-CXCR4 antigen-binding protein, i.e., such that the protein retains specific binding to CXCR4.
[00210] In some embodiments, the antigen-binding protein is an anti-CXCR4 antibody or antigen-binding fragment thereof. In some embodiments, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some embodiments, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs consist essentially of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs consist essentially of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some embodiments, the antigen-binding protein
comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
[00211] In some embodiments, the three light chain CDRs comprise the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs comprise the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some embodiments, the three light chain CDRs consist essentially of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs consist essentially of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. In some embodiments, the three light chain CDRs consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and the three heavy chain CDRs consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively. [00212] In some embodiments, the antigen-binding protein is an anti-CXCR4 antibody or antigen-binding fragment thereof. In some embodiments, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some embodiments, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs consist essentially of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs consist essentially of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some embodiments, the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs consist of sequences at least 90% identical to
the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
[00213] In some embodiments, the three light chain CDRs comprise the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs comprise the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some embodiments, the three light chain CDRs consist essentially of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs consist essentially of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively. In some embodiments, the three light chain CDRs consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and the three heavy chain CDRs consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
[00214] In some embodiments, the immunoglobulin light chain or variable region thereof comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some embodiments, the immunoglobulin light chain or variable region thereof consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5. In some embodiments, the immunoglobulin light chain or variable region thereof consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
[00215] In some embodiments, the immunoglobulin light chain or variable region thereof comprises the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof comprises the sequence set forth in SEQ ID NO: 5. In some embodiments, the immunoglobulin light chain or variable region thereof consists essentially of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof consists essentially of the sequence set forth in SEQ ID NO: 5. In some embodiments, the immunoglobulin light chain or variable region thereof consists of the sequence set forth in SEQ ID NO: 13, and the immunoglobulin heavy chain or variable region thereof
consists of the sequence set forth in SEQ ID NO: 5.
[00216] In some embodiments, the immunoglobulin light chain comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 112, and the immunoglobulin heavy chain comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 110. In some embodiments, the immunoglobulin light chain consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 112, and the immunoglobulin heavy chain consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 110. In some embodiments, the immunoglobulin light chain consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 112, and the immunoglobulin heavy chain consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 110. [00217] In some embodiments, the immunoglobulin light chain comprises the sequence set forth in SEQ ID NO: 112, and the immunoglobulin heavy chain comprises the sequence set forth in SEQ ID NO: 110. In some embodiments, the immunoglobulin light chain consists essentially of the sequence set forth in SEQ ID NO: 112, and the immunoglobulin heavy chain consists essentially of the sequence set forth in SEQ ID NO: 110. In some embodiments, the immunoglobulin light chain consists of the sequence set forth in SEQ ID NO: 112, and the immunoglobulin heavy chain consists of the sequence set forth in SEQ ID NO: 110.
[00218] In some embodiments, the immunoglobulin light chain or variable region thereof comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some embodiments, the immunoglobulin light chain or variable region thereof consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21. In some embodiments, the immunoglobulin light chain or variable region thereof consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
[00219] In some embodiments, the immunoglobulin light chain or variable region thereof comprises the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof comprises the sequence set forth in SEQ ID NO: 21. In some
embodiments, the immunoglobulin light chain or variable region thereof consists essentially of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof consists essentially of the sequence set forth in SEQ ID NO: 21. In some embodiments, the immunoglobulin light chain or variable region thereof consists of the sequence set forth in SEQ ID NO: 29, and the immunoglobulin heavy chain or variable region thereof consists of the sequence set forth in SEQ ID NO: 21.
[00220] In some embodiments, the immunoglobulin light chain comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain comprises a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 114. In some embodiments, the immunoglobulin light chain consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain consists essentially of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 114. In some embodiments, the immunoglobulin light chain consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 114. [00221] In some embodiments, the immunoglobulin light chain comprises the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain comprises the sequence set forth in SEQ ID NO: 114. In some embodiments, the immunoglobulin light chain consists essentially of the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain consists essentially of the sequence set forth in SEQ ID NO: 114. In some embodiments, the immunoglobulin light chain consists of the sequence set forth in SEQ ID NO: 116, and the immunoglobulin heavy chain consists of the sequence set forth in SEQ ID NO: 114.
[00222] The agent for selective inhibition or selective depletion of host cells or non-edited cells can be administered to the subject by any suitable means. The term administering refers to administration of a composition to a subject or system (e.g., but not limited to, to a cell, organ, tissue, organism, or relevant component or set of components thereof). The route of administration may vary depending, for example, on the subject or system to which the composition is being administered, the nature of the composition, the purpose of the administration, and so forth. The term “administration” or “administering” is intended to include routes of introducing the agent to a subject to perform its intended function. In some embodiments, non-limiting examples of routes of administration which can be used include
injection (subcutaneous, intravenous, parenterally, intraperitoneally, intrathecal), oral, inhalation, rectal and transdermal. As non-limiting examples, administration to a subject (e.g., but not limited to, to a human or a rodent) may be bronchial (including by bronchial instillation), buccal, enteral, interdermal, intra-arterial, intradermal, intragastric, intramedullary, intramuscular, intranasal, intraperitoneal, intrathecal, intravenous, intraventricular, mucosal, nasal, oral, rectal, subcutaneous, sublingual, topical, tracheal (including by intratracheal instillation), transdermal, vaginal and/or vitreal. Agents can be administered in tablets or capsule form (e.g., but not limited to, by injection, inhalation, eye lotion, ointment, suppository, and so forth), topically by lotion or ointment, or rectally by suppositories. Administration can be in a bolus or can be by continuous infusion. Administration may involve intermittent dosing or continuous dosing (e.g., but not limited to, perfusion) for at least a selected period of time. Depending on the route of administration, the agent can be coated with or disposed in a selected material to protect it from natural conditions which may detrimentally affect its ability to perform its intended function. The agent can be administered alone, or in conjunction with either another agent (e.g., but not limited to, the donor cells or edited cells described herein) or with a pharmaceutically acceptable carrier, or both. The agent can be administered prior to the administration of the other agent, simultaneously with the agent, or after the administration of the agent. Furthermore, the agent can also be administered in a proform which is converted into its active metabolite, or more active metabolite in vivo.
[00223] In some embodiments of the present invention, a subject can include, for example, any type of animal or mammal. Mammals include, for example, humans, non-human mammals, non-human primates, monkeys, apes, cats, dogs, horses, bulls, deer, bison, sheep, rabbits, rodents (e.g., but not limited to, mice, rats, hamsters, and guinea pigs), and livestock (e.g., but not limited to, bovine species such as cows and steer; ovine species such as sheep and goats; and porcine species such as pigs and boars). Birds include, for example, chickens, turkeys, ostrich, geese, and ducks. Domesticated animals and agricultural animals are also included. The term “non-human mammal” excludes humans. Particular non-limiting examples of non-human mammals include rodents, such as mice and rats. In some embodiments of the present invention, the subject is a human.
[00224] In some embodiments of the present invention, any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-
edited cells in a subject described herein can further comprise generating the donor cells or edited cells by modifying a population of cells to express the first isoform of the target protein (e.g., CXCR4 protein). Suitable methods and reagents for generating donor cells or edited cells are described in more detail elsewhere herein. In some embodiments of the present invention, any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject described herein can further comprise isolating a population of cells from the subject (or from a different subject) prior to modifying the population of cells to express the first isoform of the target protein (e.g., CXCR4 protein). The isolated cells can be, for example, any suitable cells. In some embodiments, the cells are immune cells. In some embodiments, the cells are hematopoietic cells. In some embodiments, the cells are lymphocytes or lymphoid progenitor cells. In some embodiments, the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infiltrating lymphocytes (TILs), or any combination thereof). In some embodiments, the cells are alpha beta T cells. In some embodiments, the cells are gamma delta T cells. In some embodiments, the cells are TILs. In some embodiments, the cells are B cells. In some embodiments, the cells are natural killer (NK) cells. In some embodiments, the cells are innate lymphoid cells. In some embodiments, the cells are dendritic cells. In some embodiments, the cells are hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) or descendants thereof. HSCs are capable of giving rise to both myeloid and lymphoid progenitor cells that further give rise to myeloid cells (e.g., monocytes, macrophages, neutrophils, basophils, dendritic cells, erythrocytes, platelets, etc.) and lymphoid cells (e.g., T cells, B cells, NK cells), respectively. In some embodiments, the donor cells or edited cells are autologous (i.e., from the subject). In some embodiments, the donor cells or edited cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation). In some embodiments, the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells). In some embodiments, the cells are human cells (e.g., the subject is a human, and the cells are human cells).
[00225] In some embodiments of the present invention, any of the methods for improving
engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein can further comprise generating the donor cells or edited cells by modifying a population of induced pluripotent stem cells (e.g., human induced pluripotent stem cells (iPSCs)) to express the first isoform of the target protein (e.g., CXCR4 protein) and then differentiating the induced pluripotent cells into a different cell type prior to administration to the subject. For example, the induced pluripotent stem cells can be differentiated into any suitable cells. In some embodiments, the cells are immune cells. In some embodiments, the cells are hematopoietic cells. In some embodiments, the cells are lymphocytes or lymphoid progenitor cells. In some embodiments, the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infdtrating lymphocytes (TILs), or any combination thereof). In some embodiments, the cells are alpha beta T cells. In some embodiments, the cells are gamma delta T cells. In some embodiments, the cells are TILs. In some embodiments, the cells are B cells. In some embodiments, the cells are natural killer (NK) cells. In some embodiments, the cells are innate lymphoid cells. In some embodiments, the cells are dendritic cells. In some embodiments, the cells are hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) or descendants thereof. HSC refers to the true stem cells that give rise to all blood and immune lineages. HPSCs include HSCs but also more differentiated progenitors that give rise to more restricted lineages. For instance, some HSPCs might only be able to develop to myeloid lineages, or lymphoid, or erythroid, and so forth. HSCs are capable of giving rise to both myeloid and lymphoid progenitor cells that further give rise to myeloid cells (e.g., monocytes, macrophages, neutrophils, basophils, dendritic cells, erythrocytes, platelets, etc.) and lymphoid cells (e.g., T cells, B cells, NK cells), respectively. In some embodiments, the donor cells or edited cells are autologous (i.e., from the subject). In some embodiments, the donor cells or edited cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation). In some embodiments, the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells). In some embodiments, the cells are human cells (e.g., the subject is a human, and the cells are human cells).
[00226] In some embodiments of the present invention, any of the methods for improving
engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein can further comprise generating the donor cells or edited cells by modifying a population of hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) (e.g., human HSCs or HSPCs) to express the first isoform of the target protein (e.g., CXCR4 protein) and then differentiating the HSCs or HSPCs into a different cell type prior to administration to the subject. For example, the HSCs or HSPCs can be differentiated into any suitable cells. In some embodiments, the cells are immune cells. In some embodiments, the cells are hematopoietic cells. In some embodiments, the cells are lymphocytes or lymphoid progenitor cells. In some embodiments, the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infdtrating lymphocytes (TILs), or any combination thereof). In some embodiments, the cells are alpha beta T cells. In some embodiments, the cells are gamma delta T cells. In some embodiments, the cells are TILs. In some embodiments, the cells are B cells. In some embodiments, the cells are immature B cells. In some embodiments, the cells are mature B cells. In some embodiments, the cells are natural killer (NK) cells. In some embodiments, the cells are innate lymphoid cells. In some embodiments, the cells are dendritic cells. In some embodiments, the donor cells or edited cells are autologous (i.e., from the subject). In some embodiments, the donor cells or edited cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation). In some embodiments, the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells). In some embodiments, the cells are human cells (e.g., the subject is a human, and the cells are human cells).
III. Methods for Generating Donor Cells or Edited Cells
[00227] In some embodiments of the present invention, any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein can further comprise generating the donor cells or edited cells. The donor cells or edited cells can be generated by modifying a population of cells to express the first isoform of the target protein (e.g., CXCR4 protein). In some embodiments of
the present invention, any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject described herein can further comprise generating the donor cells or edited cells by editing a target genomic locus (e.g., CXCR4 locus) in a population of cells to express the first isoform of the target protein (e.g., CXCR4 protein). The donor cells or edited cells can express only the first isoform, or they can express both the first and second isoforms of the target protein (e.g., being modified to express the first isoform of the target protein but retaining expression of the second isoform of the target protein).
[00228] In some embodiments, generating donor cells or edited cells can comprise introducing an expression vector into a population of cells, wherein the expression vector expresses the first isoform of the target protein (e.g., CXCR4 protein). Such expression vectors can comprise the entire coding sequence for the first isoform of the target protein (e.g., CXCR4), operably linked to a promoter suitable for driving expression in the donor cells or edited cells. Any suitable promoter can be used. In one example, a promoter specific for or active in hematopoietic cells or a subset of hematopoietic cells can be used. In another example, a constitutive promoter can be used. Examples of such promoters include human cytomegalovirus (hCMV), chicken beta- actin/CMV enhancer (CAG), and elongation factor- 1 alpha (EFl alpha). As another example, an inducible promoter can be used. In some embodiments, the expression vector can be a bicistronic expression vector encoding the therapeutic molecule and the first isoform of the target protein (e.g., CXCR4) and a therapeutic molecule (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) as described elsewhere herein. See, e.g., Yeku et al. (2017) Set. Rep. 7(1): 10541 and Rafiq et al. (2018) Nat. BiotechnoL 36(9):847-856, each of which is herein incorporated by reference in its entirety for all purposes, for examples of bicistronic constructs expressing CARs and another molecule. Any suitable vector can be used. For example, the vector can be a viral vector, such as a lentiviral vector or an adeno-associated virus (AAV) vector. In some embodiments, a lentiviral vector is used. In some embodiments, an AAV vector is used, such as an AAV vector with a serotype for expression in hematopoietic cells (e.g., AAV6). Optionally, the endogenous locus encoding the second isoform of the target protein can also be modified (e.g., disrupted) so that the first isoform is expressed but the second isoform is not. As one example, the endogenous locus can be modified to comprise an insertion, a deletion, or one or more point mutations in the endogenous locus (e.g., CXCR4 locus) resulting in loss of
expression of functional target protein (e.g., CXCR4). Such loci can comprise a deletion or disruption of all of the endogenous coding sequence or can comprise a deletion or disruption of a fragment of (i.e., a part of or portion of) the endogenous locus. In one example, a 5’ fragment of the coding sequence can be deleted or disrupted (e.g., including the start codon). As one example, the endogenous locus can be modified such that the start codon of the endogenous locus has been deleted or has been disrupted or mutated such that the start codon is no longer functional. For example, the start codon can be disrupted by a deletion or insertion within the start codon. Alternatively, the start codon can be mutated by, for example, by a substitution of one or more nucleotides. In another example, a 3’ fragment of the endogenous locus can be deleted or disrupted (e.g., including the stop codon). In another example, an internal fragment of the endogenous locus can be deleted or disrupted. In another example, all of the coding sequence in the endogenous locus can be deleted or disrupted. Alternatively, the endogenous locus can remain unmodified, and both the first and second isoforms are expressed.
[00229] In some embodiments, generating donor cells or edited cells can comprise editing a genomic locus in a population of cells to express the first isoform of the target protein (e.g., CXCR4 protein)). The genomic locus can be the endogenous locus encoding the target protein, it can be a safe harbor locus, or it can be a random genomic locus targeted by random integration. Safe harbor loci include chromosomal loci where transgenes or other exogenous nucleic acid inserts can be stably and reliably expressed in all tissues of interest without overtly altering cell behavior or phenotype (i.e., without any deleterious effects on the host cell). See, e.g., Sadelain et al. (2012) Nat. Rev. Cancer 12:51-58, herein incorporated by reference in its entirety for all purposes. For example, the safe harbor locus can be one in which expression of the inserted gene sequence is not perturbed by any read-through expression from neighboring genes. For example, safe harbor loci can include chromosomal loci where exogenous DNA can integrate and function in a predictable manner without adversely affecting endogenous gene structure or expression. Safe harbor loci can include extragenic regions or intragenic regions such as, for example, loci within genes that are non-essential, dispensable, or able to be disrupted without overt phenotypic consequences. Such safe harbor loci can offer an open chromatin configuration in all tissues and can be ubiquitously expressed during embryonic development and in adults. See, e.g., Zambrowicz et al. (1997) Proc. Natl. Acad. Set. U.S.A. 94:3789-3794, herein incorporated by reference in its entirety for all purposes. In addition, the safe harbor loci can be targeted with
high efficiency, and safe harbor loci can be disrupted with no overt phenotype. Examples of safe harbor loci include albumin, CCR5, HPRT, AAVS1, and Rosa26. See, e.g., US Patent Nos. 7,888,121; 7,972,854; 7,914,796; 7,951,925; 8,110,379; 8,409,861; 8,586,526; and US Patent Publication Nos. 2003/0232410; 2005/0208489; 2005/0026157; 2006/0063231; 2008/0159996; 2010/00218264; 2012/0017290; 2011/0265198; 2013/0137104; 2013/0122591; 2013/0177983; 2013/0177960; and 2013/0122591, each of which is herein incorporated by reference in its entirety for all purposes. In some embodiments, the genomic locus is an endogenous genomic locus encoding the target protein (e.g., the target protein is CXCR4, and the genomic locus is a CXCR4 genomic locus). In some embodiments, the genomic locus is not an endogenous genomic locus encoding the target protein (e.g., the target protein is CXCR4, and the genomic locus is not a CXCR4 genomic locus). The coding sequence for the first isoform of the target protein (e.g., CXCR4) can be operably linked to a promoter suitable for driving expression in the donor cells or edited cells. Optionally, the endogenous locus encoding the second isoform of the target protein can also be modified (e.g., disrupted) so that the first isoform is expressed but the second isoform is not. As one example, the endogenous locus can be modified to comprise an insertion, a deletion, or one or more point mutations in the endogenous locus (e g., CXCR4 locus) resulting in loss of expression of functional target protein (e.g., CXCR4). Such loci can comprise a deletion or disruption of all of the endogenous coding sequence or can comprise a deletion or disruption of a fragment of (i.e., a part of or portion of) the endogenous locus. In one example, a 5’ fragment of the coding sequence can be deleted or disrupted (e.g., including the start codon). As one example, the endogenous locus can be modified such that the start codon of the endogenous locus has been deleted or has been disrupted or mutated such that the start codon is no longer functional. For example, the start codon can be disrupted by a deletion or insertion within the start codon. Alternatively, the start codon can be mutated by, for example, by a substitution of one or more nucleotides. In another example, a 3’ fragment of the endogenous locus can be deleted or disrupted (e.g., including the stop codon). In another example, an internal fragment of the endogenous locus can be deleted or disrupted. In another example, all of the coding sequence in the endogenous locus can be deleted or disrupted. Alternatively, the endogenous locus can remain unmodified, and both the first and second isoforms are expressed. [00230] In some embodiments, generated donor cells or edited cells can comprise editing a target genomic locus (e.g., CXCR4 locus) in a population of cells to express the first isoform of
the target protein (e.g., CXCR4 protein).
[00231] In some embodiments, the editing can comprise introducing into the population of cells (1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the target genomic locus and (2) an exogenous donor nucleic acid. The nuclease can cleave the target genomic locus, and the exogenous donor nucleic acid can be inserted into the target genomic locus or can recombine with the target genomic locus to generate the donor cells or edited cells that express the first isoform of the target protein. However, the skilled person is aware that alternative methods can also be used. For example, in some embodiments, the isoform switch can be effected using base editors. See, e.g., Komor et al. (2016) Nature 533(7603):420-424, herein incorporated by reference in its entirety for all purposes. This approach allows editing of the desired amino acid without the need for a double-stranded DNA break.
[00232] Any suitable nuclease agent can be used. In some embodiments, for example, the methods can utilize nuclease agents such as Clustered Regularly Interspersed Short Palindromic Repeats (CRISPR)/CRISPR-associated (Cas) systems, zinc finger nuclease (ZFN) systems, or Transcription Activator-Like Effector Nuclease (TALEN) systems or components of such systems to modify a target genomic locus (e.g., a CXCR4 gene such as a human CXCR4 gene). Generally, the nuclease agents involve the use of engineered cleavage systems to induce a double strand break or a nick (i.e., a single strand break) in a nuclease target site. Cleavage or nicking can occur through the use of specific nucleases such as engineered ZFNs, TALENs, or CRISPR/Cas systems with an engineered guide RNA to guide specific cleavage or nicking of the nuclease target site. Any nuclease agent that induces a nick or double-strand break at a desired target sequence can be used in the methods and compositions disclosed herein. The nuclease agent can be used to create a targeted genetic modification in the CXCR4 gene (e.g., human CXCR4 gene). For example, the targeted genetic modification in some embodiments can comprise a targeted genetic modification in coding exon 2 of CXCR4 (e.g., coding exon 2 of human CXCR4). In some embodiments, the targeted genetic modification is in coding exon 2 of human CXCR4.
[00233] In some embodiments, the nuclease agent is a CRISPR/Cas system. In some embodiments, the nuclease agent comprises one or more ZFNs. In some embodiments, the nuclease agent comprises one or more TALENs.
[00234] CRISPR/Cas systems include transcripts and other elements involved in the expression of, or directing the activity of, Cas genes. A CRISPR/Cas system can be, for example, a type I, a type II, a type III system, or a type V system (e.g., subtype V-A or subtype V-B). The methods and compositions disclosed herein can employ CRISPR/Cas systems by utilizing CRISPR complexes (comprising a guide RNA (gRNA) complexed with a Cas protein) for site- directed binding or cleavage of nucleic acids. A CRISPR/Cas system targeting a target genomic locus comprises a Cas protein (or a nucleic acid encoding the Cas protein) and one or more guide RNAs (or DNAs encoding the one or more guide RNAs), with each of the one or more guide RNAs targeting a different guide RNA target sequence in the target genomic locus.
[00235] CRISPR/Cas systems used in the compositions and methods disclosed herein can be non-naturally occurring. A non-naturally occurring system includes anything indicating the involvement of the hand of man, such as one or more components of the system being altered or mutated from their naturally occurring state, being at least substantially free from at least one other component with which they are naturally associated in nature, or being associated with at least one other component with which they are not naturally associated. For example, some CRISPR/Cas systems employ non-naturally occurring CRISPR complexes comprising a gRNA and a Cas protein that do not naturally occur together, employ a Cas protein that does not occur naturally, or employ a gRNA that does not occur naturally.
[00236] The nuclease agents and CRISPR/Cas systems described in the compositions and methods disclosed herein target a nuclease target sequence (e g., a guide RNA target sequence) in a target genomic locus encoding a target protein. In some embodiments, the nuclease target sequence is in a CXCR4 gene. In some embodiments, the nuclease target sequence is in a human CXCR4 gene. In some embodiments, the nuclease target sequence is in coding exon 2 of a CXCR4 gene. In some embodiments, the nuclease target sequence is in coding exon 2 of a human CXCR4 gene.
[00237] Cas Proteins. Cas proteins generally comprise at least one RNA recognition or binding domain that can interact with guide RNAs. Cas proteins can also comprise nuclease domains (e.g., DNase domains or RNase domains), DNA-binding domains, helicase domains, protein-protein interaction domains, dimerization domains, and other domains. Some such domains (e g., DNase domains) can be from a native Cas protein. Other such domains can be added to make a modified Cas protein. A nuclease domain possesses catalytic activity for nucleic
acid cleavage, which includes the breakage of the covalent bonds of a nucleic acid molecule. Cleavage can produce blunt ends or staggered ends, and it can be single-stranded or doublestranded. For example, a wild type Cas9 protein will typically create a blunt cleavage product. Alternatively, a wild type Cpfl protein (e.g., FnCpfl) can result in a cleavage product with a 5- nucleotide 5’ overhang, with the cleavage occurring after the 18th base pair from the PAM sequence on the non-targeted strand and after the 23rd base on the targeted strand. A Cas protein can have full cleavage activity to create a double-strand break at a target genomic locus (e.g., a double-strand break with blunt ends), or it can be a nickase that creates a single-strand break at a target genomic locus.
[00238] Examples of Cas proteins include Casl, CaslB, Cas2, Cas3, Cas4, Cas5, Cas5e (CasD), Cas6, Cas6e, Cas6f, Cas7, Cas8al, Cas8a2, Cas8b, Cas8c, Cas9 (Csnl or Csxl2), CaslO, CaslOd, CasF, CasG, CasH, Csyl, Csy2, Csy3, Csel (CasA), Cse2 (CasB), Cse3 (CasE), Cse4 (CasC), Cscl, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmrl, Cmr3, Cmr4, Cmr5, Cmr6, Csbl, Csb2, Csb3, Csxl7, Csxl4, CsxlO, Csxl6, CsaX, Csx3, Csxl, Csxl5, Csfl, Csf2, Csfl, Csf4, and Cul966, and homologs or modified versions thereof.
[00239] An exemplary Cas protein is a Cas9 protein or a protein derived from a Cas9 protein. Cas9 proteins are from a type II CRISPR/Cas system and typically share four key motifs with a conserved architecture. Motifs 1, 2, and 4 are RuvC-like motifs, and motif 3 is an HNH motif. Exemplary Cas9 proteins are from Streptococcus pyogenes, Streptococcus thermophilus, Streptococcus sp., Staphylococcus aureus, Nocardiopsis dassonvillei, Streptomyces pristinaespiralis, Streptomyces viridochromogenes, Streptomyces viridochromogenes, Streptosporangium roseum, Streptosporangium roseum, Alicyclobacillus acidocaldarius, Bacillus pseudomycoides, Bacillus selenitireducens, Exiguobacterium sibiricum, Lactobacillus delbrueckii, Lactobacillus salivarius, Microscilla marina, Burkholderiales bacterium, Polaromonas naphthalenivorans, Polaromonas sp., Crocosphaera watsonii, Cyanothece sp., Microcystis aeruginosa, Synechococcus sp., Acetohalobium arabaticum, Ammonifex degensii, Caldicelulosiruptor becscii, Candidatus Desulforudis, Clostridium botulinum, Clostridium difficile, Finegoldia magna, Natranaerobius thermophilus, Pelotomaculum thermopropionicum, Acidithiobacillus caldus, Acidithiobacillus ferrooxidans, Allochromatium vinosum, Marinobacter sp., Nitrosococcus halophilus, Nitrosococcus watsoni, Pseudoalteromonas haloplanktis, Ktedonobacter racemifer, Methanohalobium evestigatum, Anabaena variabilis, Nodularia
spumigena, Nostoc sp., Arthrospira maxima, Arthrospira platensis, Arthrospira sp., Lyngbya sp., Microcoleus chthonoplastes, Oscillatoria sp., Petrotoga mobilis, Thermosipho africanus, Acaryochloris marina, Neisseria meningitidis, or Campylobacter jejuni. Additional examples of the Cas9 family members are described in WO 2014/131833, herein incorporated by reference in its entirety for all purposes. Cas9 from S. pyogenes (SpCas9) (e.g., assigned UniProt accession number Q99ZW2) is an exemplary Cas9 protein. An exemplary SpCas9 protein sequence is set forth in SEQ ID NO: 36 (encoded by the DNA sequence set forth in SEQ ID NO: 37). Smaller Cas9 proteins (e.g., Cas9 proteins whose coding sequences are compatible with the maximum AAV packaging capacity when combined with a guide RNA coding sequence and regulatory elements for the Cas9 and guide RNA, such as SaCas9 and CjCas9 and Nme2Cas9) are other exemplary Cas9 proteins. For example, Cas9 from S. aureus (SaCas9) (e.g., assigned UniProt accession number I7RUA5) is another exemplary Cas9 protein. Likewise, Cas9 from Campylobacter jejuni (CjCas9) (e.g., assigned UniProt accession number Q0P897) is another exemplary Cas9 protein. See, e.g., Kim et al. (2017) Nat. Commun. 8: 14500, herein incorporated by reference in its entirety for all purposes. SaCas9 is smaller than SpCas9, and CjCas9 is smaller than both SaCas9 and SpCas9. Cas9 from Neisseria meningitidis (Nme2Cas9) is another exemplary Cas9 protein. See, e.g., Edraki et al. (2019) Mol. Cell 73(4):714-726, herein incorporated by reference in its entirety for all purposes. Cas9 proteins from Streptococcus thermophilus (e.g., Streptococcus thermophilus LMD-9 Cas9 encoded by the CRISPR1 locus (StlCas9) or Streptococcus thermophilus Cas9 from the CRISPR3 locus (St3Cas9)) are other exemplary Cas9 proteins. Cas9 from Francisella novicida (FnCas9) or the RHA Franc isella novicida Cas9 variant that recognizes an alternative PAM (E1369R/E1449H/R1556A substitutions) are other exemplary Cas9 proteins. These and other exemplary Cas9 proteins are reviewed, e.g., in Cebrian-Serrano and Davies (2017) Mamm. Genome 28(7):247-261, herein incorporated by reference in its entirety for all purposes. Examples of Cas9 coding sequences, Cas9 mRNAs, and Cas9 protein sequences are provided in WO 2013/176772, WO 2014/065596, WO 2016/106121, WO 2019/067910, WO 2020/082042, US 2020/0270617, WO 2020/082041, US 2020/0268906, WO 2020/082046, and US 2020/0289628, each of which is herein incorporated by reference in its entirety for all purposes. Specific examples of ORFs and Cas9 amino acid sequences are provided in Table 30 at paragraph [0449] WO 2019/067910, and specific examples of Cas9 mRNAs and ORFs are provided in paragraphs [0214]-[0234] of WO
2019/067910. See also WO 2020/082046 A2 (pp. 84-85) and Table 24 in WO 2020/069296, each of which is herein incorporated by reference in its entirety for all purposes.
[00240] Another example of a Cas protein is a Cpfl (CRISPR from Prevotella and Francisella 1; Casl2a) protein. Cpfl is a large protein (about 1300 amino acids) that contains a RuvC-like nuclease domain homologous to the corresponding domain of Cas9 along with a counterpart to the characteristic arginine-rich cluster of Cas9. However, Cpfl lacks the HNH nuclease domain that is present in Cas9 proteins, and the RuvC-like domain is contiguous in the Cpfl sequence, in contrast to Cas9 where it contains long inserts including the HNH domain. See, e.g., Zetsche et al. (2015) Cell 163(3):759-771 , herein incorporated by reference in its entirety for all purposes. Exemplary Cpfl proteins are from Francisella tularensis 7, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC20177, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011 GWA2 33 10, Parcubacteria bacterium GW2011 GWC2 44 17, Smithella sp. SCADC, Acidaminococcus sp. PA 31.6, Lachnospiraceae bacterium MA2020 , Candidates Methanoplasma lermilum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens, and Porphyromonas macacae.
Cpfl from Francisella novicida AV\ (FnCpfl; assigned UniProt accession number A0Q7Q2) is an exemplary Cpfl protein.
[00241] Another example of a Cas protein is CasX (Casl2e). CasX is an RNA-guided DNA endonuclease that generates a staggered double-strand break in DNA. CasX is less than 1000 amino acids in size. Exemplary CasX proteins are from Deltaproteobacteria (DpbCasX or DpbCasl2e) and Planctomycetes (PlmCasX or PlmCasl2e). Like Cpfl, CasX uses a single RuvC active site for DNA cleavage. See, e.g., Liu et al. (2019) Nature 566(7743):218-223, herein incorporated by reference in its entirety for all purposes.
[00242] Another example of a Cas protein is CasO (CasPhi or Cas l2j), which is uniquely found in bacteriophages. CasO is less than 1000 amino acids in size (e.g., 700-800 amino acids). Cas cleavage generates staggered 5’ overhangs. A single RuvC active site in Cas is capable of crRNA processing and DNA cutting. See, e.g., Pausch et al. (2020) Science 369(6501):333-337, herein incorporated by reference in its entirety for all purposes.
[00243] Cas proteins can be wild type proteins (i.e., those that occur in nature), modified Cas proteins (i.e., Cas protein variants), or fragments of wild type or modified Cas proteins. Cas
proteins can also be active variants or fragments with respect to catalytic activity of wild type or modified Cas proteins. Active variants or fragments with respect to catalytic activity can comprise at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% or more sequence identity to the wild type or modified Cas protein or a portion thereof, wherein the active variants retain the ability to cut at a desired cleavage site and hence retain nick-inducing or double-strand-break-inducing activity. Assays for nick-inducing or double-strand-break-inducing activity are known and generally measure the overall activity and specificity of the Cas protein on DNA substrates containing the cleavage site.
[00244] One example of a modified Cas protein is the modified SpCas9-HFl protein, which is a high-fidelity variant of Streptococcus pyogenes Cas9 harboring alterations (N497A/R661A/Q695A/Q926A) designed to reduce non-specific DNA contacts. See, e.g., Kleinstiver et al. (2016) Nature 529(7587):490-495, herein incorporated by reference in its entirety for all purposes. Another example of a modified Cas protein is the modified eSpCas9 variant (K848A/K1003A/R1060A) designed to reduce off-target effects. See, e.g., Slaymaker et al. (2016) Science 351(6268):84-88, herein incorporated by reference in its entirety for all purposes. Other SpCas9 variants include K855A and K810A/K1003A/R1060A. These and other modified Cas proteins are reviewed, e.g., in Cebrian-Serrano and Davies (2017) Mamm. Genome 28(7):247-261, herein incorporated by reference in its entirety for all purposes. Another example of a modified Cas9 protein is xCas9, which is a SpCas9 variant that can recognize an expanded range of PAM sequences. See, e.g., Hu et al. (2018) Nature 556:57-63, herein incorporated by reference in its entirety for all purposes.
[00245] Cas proteins can be modified to increase or decrease one or more of nucleic acid binding affinity, nucleic acid binding specificity, and enzymatic activity. Cas proteins can also be modified to change any other activity or property of the protein, such as stability. For example, one or more nuclease domains of the Cas protein can be modified, deleted, or inactivated, or a Cas protein can be truncated to remove domains that are not essential for the function of the protein or to optimize (e.g., enhance or reduce) the activity of or a property of the Cas protein. [00246] Cas proteins can comprise at least one nuclease domain, such as a DNase domain. For example, a wild type Cpfl protein generally comprises a RuvC-like domain that cleaves both strands of target DNA, perhaps in a dimeric configuration. Likewise, CasX and Cas<l» generally comprise a single RuvC-like domain that cleaves both strands of a target DNA. Cas proteins can
also comprise at least two nuclease domains, such as DNase domains. For example, a wild type Cas9 protein generally comprises a RuvC-like nuclease domain and an HNH-like nuclease domain. The RuvC and HNH domains can each cut a different strand of double-stranded DNAto make a double-stranded break in the DNA. See, e.g., Jinek et al. (2012) Science 337(6096):816- 821, herein incorporated by reference in its entirety for all purposes.
[00247] One or more of the nuclease domains can be deleted or mutated so that they are no longer functional or have reduced nuclease activity. For example, if one of the nuclease domains is deleted or mutated in a Cas9 protein, the resulting Cas9 protein can be referred to as a nickase and can generate a single-strand break within a double-stranded target DNA but not a doublestrand break (i.e., it can cleave the complementary strand or the non-complementary strand, but not both). If none of the nuclease domains is deleted or mutated in a Cas9 protein, the Cas9 protein will retain double-strand-break-inducing activity. An example of a mutation that converts Cas9 into a nickase is a D10A (aspartate to alanine at position 10 of Cas9) mutation in the RuvC domain of Cas9 from S. pyogenes. Likewise, H939A (histidine to alanine at amino acid position 839), H840A (histidine to alanine at amino acid position 840), or N863 A (asparagine to alanine at amino acid position N863) in the HNH domain of Cas9 from 5. pyogenes can convert the Cas9 into a nickase. Other examples of mutations that convert Cas9 into a nickase include the corresponding mutations to Cas9 from S. thermophilus . See, e.g., Sapranauskas et al. (2011) Nucleic Acids Res. 39(21):9275-9282 and WO 2013/141680, each of which is herein incorporated by reference in its entirety for all purposes. Such mutations can be generated using methods such as site-directed mutagenesis, PCR-mediated mutagenesis, or total gene synthesis. Examples of other mutations creating nickases can be found, for example, in WO 2013/176772 and WO 2013/142578, each of which is herein incorporated by reference in its entirety for all purposes.
[00248] Examples of inactivating mutations in the catalytic domains of xCas9 are the same as those described above for SpCas9. Examples of inactivating mutations in the catalytic domains of Staphylococcus aureus Cas9 proteins are also known. For example, the Staphylococcus aureus Cas9 enzyme (SaCas9) may comprise a substitution at position N580 (e.g., N580A substitution) or a substitution at position D10 (e.g., D10A substitution) to generate a Cas nickase. See, e.g., WO 2016/106236, herein incorporated by reference in its entirety for all purposes. Examples of inactivating mutations in the catalytic domains of Nme2Cas9 are also known (e.g., D16A or
H588A). Examples of inactivating mutations in the catalytic domains of StlCas9 are also known (e.g., D9A, D598A, H599A, or N622A). Examples of inactivating mutations in the catalytic domains of St3Cas9 are also known (e.g., D10A or N870A). Examples of inactivating mutations in the catalytic domains of CjCas9 are also known (e.g., combination of D8A or H559A). Examples of inactivating mutations in the catalytic domains of FnCas9 and RHAFnCas9 are also known (e.g., N995A).
[00249] Examples of inactivating mutations in the catalytic domains of Cpfl proteins are also known. With reference to Cpfl proteins from Francisella novicida U112 (FnCpfl), Acidaminococcus sp. BV3L6 (AsCpfl), Lachnospiraceae bacterium ND2006 (LbCpfl), and Moraxella bovoculi 237 (MbCpfl Cpfl), such mutations can include mutations at positions 908, 993, or 1263 of AsCpfl or corresponding positions in Cpfl orthologs, or positions 832, 925, 947, or 1180 of LbCpfl or corresponding positions in Cpfl orthologs. Such mutations can include, for example one or more of mutations D908A, E993 A, and D1263A of AsCpfl or corresponding mutations in Cpfl orthologs, or D832A, E925A, D947A, and DI 180 A of LbCpfl or corresponding mutations in Cpfl orthologs. See, e.g., US 2016/0208243, herein incorporated by reference in its entirety for all purposes. Examples of inactivating mutations in the catalytic domains of CasX proteins are also known. With reference to CasX proteins from Deltaproteobacteria, D672A, E769A, and D935A (individually or in combination) or corresponding positions in other CasX orthologs are inactivating. See, e.g., Liu et al. (2019) Nature 566(7743):218-223, herein incorporated by reference in its entirety for all purposes. Examples of inactivating mutations in the catalytic domains of CasO proteins are also known. For example, D371A and D394A, alone or in combination, are inactivating mutations. See, e.g., Pausch et al. (2020) Science 369(6501):333-337, herein incorporated by reference in its entirety for all purposes.
[00250] Cas proteins can also be operably linked to heterologous polypeptides as fusion proteins. For example, a Cas protein can be fused to a cleavage domain. See WO 2014/089290, herein incorporated by reference in its entirety for all purposesCas proteins can also be fused to a heterologous polypeptide providing increased or decreased stability. The fused domain or heterologous polypeptide can be located at the N-terminus, the C-terminus, or internally within the Cas protein.
[00251] As one example, a Cas protein can be fused to one or more heterologous polypeptides that provide for subcellular localization. Such heterologous polypeptides can include, for example, one or more nuclear localization signals (NLS) such as the monopartite SV40 NLS and/or a bipartite alpha-importin NLS for targeting to the nucleus, a mitochondrial localization signal for targeting to the mitochondria, an ER retention signal, and the like. See, e.g., Lange et al. (2007) J. Biol. Chem. 282(8):5101-5105, herein incorporated by reference in its entirety for all purposes. Such subcellular localization signals can be located at the N-terminus, the C- terminus, or anywhere within the Cas protein. An NLS can comprise a stretch of basic amino acids and can be a monopartite sequence or a bipartite sequence. Optionally, a Cas protein can comprise two or more NLSs, including an NLS (e.g., an alpha-importin NLS or a monopartite NLS) at the N-terminus and an NLS (e.g., an SV40 NLS or a bipartite NLS) at the C-terminus. A Cas protein can also comprise two or more NLSs at the N-terminus and/or two or more NLSs at the C-terminus.
[00252] A Cas protein may, for example, be fused with 1-10 NLSs (e.g., fused with 1-5 NLSs or fused with one NLS. Where one NLS is used, the NLS may be linked at the N-terminus or the C-terminus of the Cas protein sequence. It may also be inserted within the Cas protein sequence. Alternatively, the Cas protein may be fused with more than one NLS. For example, the Cas protein may be fused with 2, 3, 4, or 5 NLSs. In a specific example, the Cas protein may be fused with two NLSs. In certain circumstances, the two NLSs may be the same (e.g., two SV40 NLSs) or different. For example, the Cas protein can be fused to two SV40 NLS sequences linked at the carboxy terminus. Alternatively, the Cas protein may be fused with two NLSs, one linked at the N-terminus and one at the C-terminus. In other examples, the Cas protein may be fused with 3 NLSs or with no NLS. The NLS may be a monopartite sequence, such as, e.g., the SV40 NLS, PKKKRKV (SEQ ID NO: 38) or PKKKRRV (SEQ ID NO: 39). The NLS may be a bipartite sequence, such as the NLS of nucleoplasmin, KRPAATKKAGQAKKKK (SEQ ID NO: 40). In a specific example, a single PKKKRKV (SEQ ID NO: 38) NLS may be linked at the C-terminus of the Cas protein. One or more linkers are optionally included at the fusion site.
[00253] Cas proteins can also be operably linked to a cell-penetrating domain or protein transduction domain. For example, the cell-penetrating domain can be derived from the HIV-1 TAT protein, the TLM cell-penetrating motif from human hepatitis B virus, MPG, Pep-1, VP22, a cell penetrating peptide from Herpes simplex virus, or a polyarginine peptide sequence. See, e.g.,
WO 2014/089290 and WO 2013/176772, each of which is herein incorporated by reference in its entirety for all purposes. The cell-penetrating domain can be located at the N-terminus, the C- terminus, or anywhere within the Cas protein.
[00254] Cas proteins can be provided in any form. For example, a Cas protein can be provided in the form of a protein, such as a Cas protein complexed with a gRNA. Alternatively, a Cas protein can be provided in the form of a nucleic acid encoding the Cas protein, such as an RNA (e.g., messenger RNA (mRNA)) or DNA. Optionally, the nucleic acid encoding the Cas protein can be codon optimized for efficient translation into protein in a particular cell or organism. For example, the nucleic acid encoding the Cas protein can be modified to substitute codons having a higher frequency of usage in a bacterial cell, a yeast cell, a human cell, a non-human cell, a mammalian cell, a rodent cell, a mouse cell, a rat cell, or any other host cell of interest, as compared to the naturally occurring polynucleotide sequence. When a nucleic acid encoding the Cas protein is introduced into the cell, the Cas protein can be transiently, conditionally, or constitutively expressed in the cell.
[00255] Nucleic acids encoding Cas proteins can be stably integrated in the genome of a cell and operably linked to a promoter active in the cell. Alternatively, nucleic acids encoding Cas proteins can be operably linked to a promoter in an expression construct. Expression constructs include any nucleic acid constructs capable of directing expression of a gene or other nucleic acid sequence of interest (e.g., a Cas gene) and which can transfer such a nucleic acid sequence of interest to a target cell. For example, the nucleic acid encoding the Cas protein can be in a vector comprising a DNA encoding a gRNA. Alternatively, it can be in a vector or plasmid that is separate from the vector comprising the DNA encoding the gRNA. Promoters that can be used in an expression construct include promoters active, for example, in a human cell or a human hematopoietic cell. Such promoters can be, for example, conditional promoters, inducible promoters, constitutive promoters, or tissue-specific promoters. Optionally, the promoter can be a bidirectional promoter driving expression of both a Cas protein in one direction and a guide RNA in the other direction. Such bidirectional promoters can consist of (1) a complete, conventional, unidirectional Pol III promoter that contains 3 external control elements: a distal sequence element (DSE), a proximal sequence element (PSE), and a TATA box; and (2) a second basic Pol III promoter that includes a PSE and a TATA box fused to the 5’ terminus of the DSE in reverse orientation. For example, in the Hl promoter, the DSE is adjacent to the PSE and the
TATA box, and the promoter can be rendered bidirectional by creating a hybrid promoter in which transcription in the reverse direction is controlled by appending a PSE and TATA box derived from the U6 promoter. See, e.g., US 2016/0074535, herein incorporated by references in its entirety for all purposes. Use of a bidirectional promoter to express genes encoding a Cas protein and a guide RNA simultaneously allow for the generation of compact expression cassettes to facilitate delivery. In certain embodiments, promotors are accepted by regulatory authorities for use in humans. In certain embodiments, promotors drive expression in hematopoietic cells.
[00256] Different promoters can be used to drive Cas expression or Cas9 expression. In some methods, small promoters are used so that the Cas or Cas9 coding sequence can fit into an AAV construct. For example, Cas or Cas9 and one or more gRNAs (e.g., 1 gRNA or 2 gRNAs or 3 gRNAs or 4 gRNAs) can be delivered via LNP -mediated delivery (e.g., in the form of RNA) or adeno-associated virus (AAV)-mediated delivery (e.g., AAV8-mediated delivery). For example, the nuclease agent can be CRISPR/Cas9, and a Cas9 mRNA and a gRNA (e.g., targeting a CXCR4 gene (e.g., a human CXCR4 gene)) can be delivered via LNP -mediated delivery or AAV- mediated delivery. The Cas or Cas9 and the gRNA(s) can be delivered in a single AAV or via two separate AAV s. For example, a first AAV can carry a Cas or Cas9 expression cassette, and a second AAV can carry a gRNA expression cassette. Similarly, a first AAV can carry a Cas or Cas9 expression cassette, and a second AAV can carry two or more gRNA expression cassettes. Alternatively, a single AAV can carry a Cas or Cas9 expression cassette (e.g., Cas or Cas9 coding sequence operably linked to a promoter) and a gRNA expression cassette (e.g., gRNA coding sequence operably linked to a promoter). Similarly, a single AAV can carry a Cas or Cas9 expression cassette (e.g., Cas or Cas9 coding sequence operably linked to a promoter) and two or more gRNA expression cassettes (e.g., gRNA coding sequences operably linked to promoters). Different promoters can be used to drive expression of the gRNA, such as a U6 promoter or the small tRNA Gin. Likewise, different promoters can be used to drive Cas9 expression. For example, small promoters are used so that the Cas9 coding sequence can fit into an AAV construct. Similarly, small Cas9 proteins (e.g., SaCas9 or CjCas9 are used to maximize the AAV packaging capacity).
[00257] Cas proteins provided as mRNAs can be modified for improved stability and/or immunogenicity properties. The modifications may be made to one or more nucleosides within
the mRNA. mRNA encoding Cas proteins can also be capped. Cas mRNAs can further comprise a poly-adenylated (poly-A or poly(A) or poly-adenine) tail. For example, a Cas mRNA can include a modification to one or more nucleosides within the mRNA, the Cas mRNA can be capped, and the Cas mRNA can comprise a poly(A) tail.
[00258] Guide RNAs. A “guide RNA” or “gRNA” is an RNA molecule that binds to a Cas protein (e.g., Cas9 protein) and targets the Cas protein to a specific location within a target DNA. Guide RNAs can comprise two segments: a “DNA-targeting segment” (also called “guide sequence”) and a “protein-binding segment.” “Segment” includes a section or region of a molecule, such as a contiguous stretch of nucleotides in an RNA. Some gRNAs, such as those for Cas9, can comprise two separate RNA molecules: an “activator-RNA” (e.g., tracrRNA) and a “targeter-RNA” (e.g., CRISPR RNA or crRNA). Other gRNAs are a single RNA molecule (single RNA polynucleotide), which can also be called a “single-molecule gRNA,” a “singleguide RNA,” or an “sgRNA.” See, e.g., WO 2013/176772, WO 2014/065596, WO 2014/089290, WO 2014/093622, WO 2014/099750, WO 2013/142578, and WO 2014/131833, each of which is herein incorporated by reference in its entirety for all purposes. A guide RNA can refer to either a CRISPR RNA (crRNA) or the combination of a crRNA and a trans-activating CRISPR RNA (tracrRNA). The crRNA and tracrRNA can be associated as a single RNA molecule (single guide RNA or sgRNA) or in two separate RNA molecules (dual guide RNA or dgRNA). For Cas9, for example, a single-guide RNA can comprise a crRNA fused to a tracrRNA (e.g., via a linker). For Cpfl and Cas®, for example, only a crRNA is needed to achieve binding to a target sequence. The terms “guide RNA” and “gRNA” include both double-molecule (i.e., modular) gRNAs and single-molecule gRNAs. In some of the methods and compositions disclosed herein, a gRNA is a A. pyogenes Cas9 gRNA or an equivalent thereof. In some of the methods and compositions disclosed herein, a gRNA is a S. aureus Cas9 gRNA or an equivalent thereof.
[00259] An exemplary two-molecule gRNA comprises a crRNA-like (“CRISPR RNA” or “targeter-RNA” or “crRNA” or “crRNA repeat”) molecule and a corresponding tracrRNA-like (“trans-activating CRISPR RNA” or “activator-RNA” or “tracrRNA”) molecule. A crRNA comprises both the DNA-targeting segment (single-stranded) of the gRNA and a stretch of nucleotides that forms one half of the dsRNA duplex of the protein-binding segment of the gRNA. An example of a crRNA tail (e.g., for use with S. pyogenes Cas9), located downstream (3’) of the DNA-targeting segment, comprises, consists essentially of, or consists of
GUUUUAGAGCUAUGCU (SEQ ID NO: 41) or GUUUUAGAGCUAUGCUGUUUUG (SEQ ID NO: 42). Any of the DNA-targeting segments disclosed herein can be joined to the 5’ end of SEQ ID NO: 41 or 42 to form a crRNA.
[00260] A corresponding tracrRNA (activator-RNA) comprises a stretch of nucleotides that forms the other half of the dsRNA duplex of the protein-binding segment of the gRNA. A stretch of nucleotides of a crRNA are complementary to and hybridize with a stretch of nucleotides of a tracrRNA to form the dsRNA duplex of the protein-binding domain of the gRNA. As such, each crRNA can be said to have a corresponding tracrRNA. Examples of tracrRNA sequences (e g., for use with S. pyogenes Cas9) comprise, consist essentially of, or consist of any one of AGCAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACC GAGUCGGUGCUUU (SEQ ID NO: 43), AAACAGCAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGG CACCGAGUCGGUGCUUUU (SEQ ID NO: 44), or GUUGGAACCAUUCAAAACAGCAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCA ACUUGAAAAAGUGGCACCGAGUCGGUGC (SEQ ID NO: 45).
[00261] In systems in which both a crRNA and a tracrRNA are needed, the crRNA and the corresponding tracrRNA hybridize to form a gRNA. In systems in which only a crRNA is needed, the crRNA can be the gRNA. The crRNA additionally provides the single-stranded DNA-targeting segment that hybridizes to the complementary strand of a target DNA. If used for modification within a cell, the exact sequence of a given crRNA or tracrRNA molecule can be designed to be specific to the species in which the RNA molecules will be used. See, e.g., Mali et al. (2013) Science 339(6121):823-826; Jinek et al. (2012) Science 337(6096): 816-821; Hwang et al. (2013) Nat. Biotechnol. 31(3):227-229; Jiang et al. (2013) Nat. Biotechnol. 3 l(3):233-239; and Cong et al. (2013) Science 339(6121):819-823, each of which is herein incorporated by reference in its entirety for all purposes.
[00262] The DNA-targeting segment (crRNA) of a given gRNA comprises a nucleotide sequence that is complementary to a sequence on the complementary strand of the target DNA, as described in more detail below. The DNA-targeting segment of a gRNA interacts with the target DNA in a sequence-specific manner via hybridization (i.e., base pairing). As such, the nucleotide sequence of the DNA-targeting segment may vary and determines the location within the target DNA with which the gRNA and the target DNA will interact. The DNA-targeting
segment of a subject gRNA can be modified to hybridize to any desired sequence within a target DNA. Naturally occurring crRNAs differ depending on the CRISPR/Cas system and organism but often contain a targeting segment of between 21 to 72 nucleotides length, flanked by two direct repeats (DR) of a length of between 21 to 46 nucleotides (see, e.g., WO 2014/131833, herein incorporated by reference in its entirety for all purposes). In the case of S. pyogenes, the DRs are 36 nucleotides long and the targeting segment is 30 nucleotides long. The 3’ located DR is complementary to and hybridizes with the corresponding tracrRNA, which in turn binds to the Cas protein.
[00263] The DNA-targeting segment can have, for example, a length of at least about 12, at least about 15, at least about 17, at least about 18, at least about 19, at least about 20, at least about 25, at least about 30, at least about 35, or at least about 40 nucleotides. Such DNA- targeting segments can have, for example, a length from about 12 to about 100, from about 12 to about 80, from about 12 to about 50, from about 12 to about 40, from about 12 to about 30, from about 12 to about 25, or from about 12 to about 20 nucleotides. For example, the DNA targeting segment can be from about 15 to about 25 nucleotides (e.g., from about 17 to about 20 nucleotides, or about 17, 18, 19, or 20 nucleotides). See, e.g., US 2016/0024523, herein incorporated by reference in its entirety for all purposes. For Cas9 from S. pyogenes, a typical DNA-targeting segment is between 16 and 20 nucleotides in length or between 17 and 20 nucleotides in length. For Cas9 from 5. aureus, a typical DNA-targeting segment is between 21 and 23 nucleotides in length. For Cpfl, a typical DNA-targeting segment is at least 16 nucleotides in length or at least 18 nucleotides in length.
[00264] In one example, the DNA-targeting segment can be about 20 nucleotides in length. However, shorter and longer sequences can also be used for the targeting segment (e.g., 15-25 nucleotides in length, such as 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 nucleotides in length). The degree of identity between the DNA-targeting segment and the corresponding guide RNA target sequence (or degree of complementarity between the DNA-targeting segment and the other strand of the guide RNA target sequence) can be, for example, about 75%, about 80%, about 85%, about 90%, about 95%, or 100%. The DNA-targeting segment and the corresponding guide RNA target sequence can contain one or more mismatches. For example, the DNA- targeting segment of the guide RNA and the corresponding guide RNA target sequence can contain 1-4, 1-3, 1-2, 1, 2, 3, or 4 mismatches (e.g., where the total length of the guide RNA
I l l
target sequence is at least 17, at least 18, at least 19, or at least 20 or more nucleotides). For example, the DNA-targeting segment of the guide RNA and the corresponding guide RNA target sequence can contain 1-4, 1-3, 1-2, 1, 2, 3, or 4 mismatches where the total length of the guide RNA target sequence 20 nucleotides.
[00265] As one example, a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment (i.e., guide sequence) comprising, consisting essentially of, or consisting of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146. Alternatively, a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment comprising, consisting essentially of, or consisting of at least 17, at least 18, at least 19, or at least 20 contiguous nucleotides of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132- 146. Alternatively, a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment that is at least 75%, at least 80%, at least 85%, at least 90%, or at least 95% identical to the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146. Alternatively, a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment that is at least 90% or at least 95% identical to the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146. Alternatively, a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment that is at least 75%, at least 80%, at least 85%, at least 90%, or at least 95% identical to at least 17, at least 18, at least 19, or at least 20 contiguous nucleotides of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132- 146. Alternatively, a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment that is at least 90% or at least 95% identical to at least 17, at least 18, at least 19, or at least 20 contiguous nucleotides of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146. Alternatively, a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment comprising, consisting essentially of, or consisting of a sequence that differs by no more than 3, no more than 2, or no more than 1 nucleotide from the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132-146. Alternatively, a guide RNA targeting human CXCR4 (e.g., human CXCR4 coding exon 2) can comprise a DNA-targeting segment comprising, consisting essentially of, or consisting of a sequence that differs by no more than 3, no more than
2, or no more than 1 nucleotide from at least 17, at least 18, at least 19, or at least 20 contiguous nucleotides of the sequence (DNA-targeting segment) set forth in any one of SEQ ID NOS: 132- 146. In some cases, two or more guide RNAs targeting the target genomic locus (e.g., CXCR4 or human CXCR4) are used.
[00266] TracrRNAs can be in any form (e.g., full-length tracrRNAs or active partial tracrRNAs) and of varying lengths. They can include primary transcripts or processed forms. For example, tracrRNAs (as part of a single-guide RNA or as a separate molecule as part of a two- molecule gRNA) may comprise, consist essentially of, or consist of all or a portion of a wild type tracrRNA sequence (e.g., about or more than about 20, 26, 32, 45, 48, 54, 63, 67, 85, or more nucleotides of a wild type tracrRNA sequence). Examples of wild type tracrRNA sequences from S. pyogenes include 171-nucleotide, 89-nucleotide, 75 -nucleotide, and 65-nucleotide versions. See, e.g., Deltcheva et al. (2011) Nature 471(7340):602-607; WO 2014/093661, each of which is herein incorporated by reference in its entirety for all purposes. Examples of tracrRNAs within single-guide RNAs (sgRNAs) include the tracrRNA segments found within +48, +54, +67, and +85 versions of sgRNAs, where “+n” indicates that up to the +n nucleotide of wild type tracrRNA is included in the sgRNA. See US 8,697,359, herein incorporated by reference in its entirety for all purposes.
[00267] The percent complementarity between the DNA-targeting segment of the guide RNA and the complementary strand of the target DNA can be at least 60% (e.g., at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100%). The percent complementarity between the DNA-targeting segment and the complementary strand of the target DNA can be at least 60% over about 20 contiguous nucleotides. As an example, the percent complementarity between the DNA-targeting segment and the complementary strand of the target DNA can be 100% over the 14 contiguous nucleotides at the 5’ end of the complementary strand of the target DNA and as low as 0% over the remainder. In such a case, the DNA-targeting segment can be considered to be 14 nucleotides in length. As another example, the percent complementarity between the DNA-targeting segment and the complementary strand of the target DNA can be 100% over the seven contiguous nucleotides at the 5’ end of the complementary strand of the target DNA and as low as 0% over the remainder. In such a case, the DNA-targeting segment can be considered to be 7 nucleotides in length. In some guide RNAs, at least 17 nucleotides within the DNA-targeting segment are complementary
to the complementary strand of the target DNA. For example, the DNA-targeting segment can be 20 nucleotides in length and can comprise 1, 2, or 3 mismatches with the complementary strand of the target DNA. In one example, the mismatches are not adjacent to the region of the complementary strand corresponding to the protospacer adjacent motif (PAM) sequence (i.e., the reverse complement of the PAM sequence) (e.g., the mismatches are in the 5’ end of the DNA- targeting segment of the guide RNA, or the mismatches are at least 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, or 19 base pairs away from the region of the complementary strand corresponding to the PAM sequence).
[00268] The protein-binding segment of a gRNA can comprise two stretches of nucleotides that are complementary to one another. The complementary nucleotides of the protein-binding segment hybridize to form a double-stranded RNA duplex (dsRNA). The protein-binding segment of a subject gRNA interacts with a Cas protein, and the gRNA directs the bound Cas protein to a specific nucleotide sequence within target DNA via the DNA-targeting segment. [00269] Single-guide RNAs can comprise a DNA-targeting segment and a scaffold sequence (i.e., the protein-binding or Cas-binding sequence of the guide RNA). For example, such guide RNAs can have a 5’ DNA-targeting segment joined to a 3’ scaffold sequence. Exemplary scaffold sequences (e.g., for use with 5. pyogenes Cas9) comprise, consist essentially of, or consist of
GUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGA AAAAGUGGCACCGAGUCGGUGCU (version 1; SEQ ID NO: 46);
GUUGGAACCAUUCAAAACAGCAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCA ACUUGAAAAAGUGGCACCGAGUCGGUGC (version 2; SEQ ID NO: 47);
GUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGA AAAAGUGGCACCGAGUCGGUGC (version 3; SEQ ID NO: 48); and GUUUAAGAGCUAUGCUGGAAACAGCAUAGCAAGUUUAAAUAAGGCUAGUCCGUU AUCAACUUGAAAAAGUGGCACCGAGUCGGUGC (version 4; SEQ ID NO: 49);
GUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGA AAAAGUGGCACCGAGUCGGUGCUUUUUUU (version 5; SEQ ID NO: 50);
GUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGA AAAAGUGGCACCGAGUCGGUGCUUUU (version 6; SEQ ID NO: 51);
GUUUAAGAGCUAUGCUGGAAACAGCAUAGCAAGUUUAAAUAAGGCUAGUCCGUU
AUCAACUUGAAAAAGUGGCACCGAGUCGGUGCUUUUUU (version 7; SEQ ID NO: 52); or
GUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGG CACCGAGUCGGUGC (version 8; SEQ ID NO: 53). In some guide sgRNAs, the four terminal U residues of version 6 are not present. In some sgRNAs, only 1, 2, or 3 of the four terminal U residues of version 6 are present. Guide RNAs targeting any of the guide RNA target sequences disclosed herein can include, for example, a DNA-targeting segment on the 5’ end of the guide RNA fused to any of the exemplary guide RNA scaffold sequences on the 3’ end of the guide RNA. That is, any of the DNA-targeting segments disclosed herein can be joined to the 5’ end of any one of the above scaffold sequences to form a single guide RNA (chimeric guide RNA). [00270] Guide RNAs can include modifications or sequences that provide for additional desirable features (e.g., modified or regulated stability; subcellular targeting; tracking with a fluorescent label; a binding site for a protein or protein complex; and the like). That is, guide RNAs can include one or more modified nucleosides or nucleotides, or one or more non- naturally and/or naturally occurring components or configurations that are used instead of or in addition to the canonical A, G, C, and U residues. Examples of such modifications include, for example, a 5’ cap (e.g., a 7-methylguanylate cap (m7G)); a 3’ poly adenylated tail (i.e., a 3’ poly(A) tail); a riboswitch sequence (e.g., to allow for regulated stability and/or regulated accessibility by proteins and/or protein complexes); a stability control sequence; a sequence that forms a dsRNA duplex (i.e., a hairpin); a modification or sequence that targets the RNA to a subcellular location (e.g., nucleus); a modification or sequence that provides for tracking (e.g., direct conjugation to a fluorescent molecule, conjugation to a moiety that facilitates fluorescent detection, a sequence that allows for fluorescent detection, and so forth); a modification or sequence that provides a binding site for proteins (e.g., proteins that act on DNA, including transcriptional activators, transcriptional repressors, DNA methyltransferases, DNA demethylases, histone acetyltransferases, histone deacetylases, and the like); and combinations thereof. Other examples of modifications include engineered stem loop duplex structures, engineered bulge regions, engineered hairpins 3’ of the stem loop duplex structure, or any combination thereof. See, e.g., US 2015/0376586, herein incorporated by reference in its entirety for all purposes. A bulge can be an unpaired region of nucleotides within the duplex made up of the crRNA-like region and the minimum tracrRNA-like region. A bulge can comprise, on one
side of the duplex, an unpaired 5'-XXXY-3' where X is any purine and Y can be a nucleotide that can form a wobble pair with a nucleotide on the opposite strand, and an unpaired nucleotide region on the other side of the duplex.
[00271] Guide RNAs can comprise modified nucleosides and modified nucleotides including, for example, one or more of the following: (1) alteration or replacement of one or both of the non-linking phosphate oxygens and/or of one or more of the linking phosphate oxygens in the phosphodiester backbone linkage (an exemplary backbone modification); (2) alteration or replacement of a constituent of the ribose sugar such as alteration or replacement of the 2’ hydroxyl on the ribose sugar (an exemplary sugar modification); (3) replacement (e.g., wholesale replacement) of the phosphate moiety with dephospho linkers (an exemplary backbone modification); (4) modification or replacement of a naturally occurring nucleobase, including with a non-canonical nucleobase (an exemplary base modification); (5) replacement or modification of the ribose-phosphate backbone (an exemplary backbone modification); (6) modification of the 3’ end or 5’ end of the oligonucleotide (e.g., removal, modification or replacement of a terminal phosphate group or conjugation of a moiety, cap, or linker (such 3’ or 5’ cap modifications may comprise a sugar and/or backbone modification); and (7) modification or replacement of the sugar (an exemplary sugar modification). Other possible guide RNA modifications include modifications of or replacement of uracils or poly-uracil tracts. See, e.g., WO 2015/048577 and US 2016/0237455, each of which is herein incorporated by reference in its entirety for all purposes. Similar modifications can be made to Cas-encoding nucleic acids, such as Cas mRNAs. For example, Cas mRNAs can be modified by depletion of uridine using synonymous codons.
[00272] Chemical modifications such as those listed above can be combined to provide modified gRNAs and/or mRNAs comprising residues (nucleosides and nucleotides) that can have two, three, four, or more modifications. For example, a modified residue can have a modified sugar and a modified nucleobase. In one example, every base of a gRNAis modified (e.g., all bases have a modified phosphate group, such as a phosphorothioate group). For example, all or substantially all of the phosphate groups of a gRNA can be replaced with phosphorothioate groups. Alternatively, or additionally, a modified gRNA can comprise at least one modified residue at or near the 5’ end. Alternatively, or additionally, a modified gRNA can comprise at least one modified residue at or near the 3’ end.
[00273] Some gRNAs comprise one, two, three or more modified residues. For example, at least 5%, at least 10%, at least 15%, at least 20%, at least 25%, at least 30%, at least 35%, at least 40%, at least 45%, at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or 100% of the positions in a modified gRNA can be modified nucleosides or nucleotides.
[00274] Unmodified nucleic acids can be prone to degradation. Exogenous nucleic acids can also induce an innate immune response. Modifications can help introduce stability and reduce immunogenicity. Some gRNAs described herein can contain one or more modified nucleosides or nucleotides to introduce stability toward intracellular or serum-based nucleases. Some modified gRNAs described herein can exhibit a reduced innate immune response when introduced into a population of cells.
[00275] In a dual guide RNA, each of the crRNA and the tracrRNA can contain modifications. Such modifications may be at one or both ends of the crRNA and/or tracrRNA. In a sgRNA, one or more residues at one or both ends of the sgRNA may be chemically modified, and/or internal nucleosides may be modified, and/or the entire sgRNA may be chemically modified. Some gRNAs comprise a 5’ end modification. Some gRNAs comprise a 3’ end modification. Some gRNAs comprise a 5’ end modification and a 3’ end modification.
[00276] The guide RNAs disclosed herein can comprise one of the modification patterns disclosed in WO 2018/107028 Al, herein incorporated by reference in its entirety for all purposes. The guide RNAs disclosed herein can also comprise one of the structures/modification patterns disclosed in US 2017/0114334, herein incorporated by reference in its entirety for all purposes. The guide RNAs disclosed herein can also comprise one of the structures/modification patterns disclosed in WO 2017/136794, WO 2017/004279, US 2018/0187186, or US 2019/0048338, each of which is herein incorporated by reference in its entirety for all purposes. [00277] As one example, any of the guide RNAs described herein can comprise at least one modification. In one example, the at least one modification comprises a 2’-O-methyl (2’-0-Me) modified nucleotide, a phosphorothioate (PS) bond between nucleotides, a 2’-fluoro (2’-F) modified nucleotide, or a combination thereof. For example, the at least one modification can comprise a 2’-O-methyl (2’-0-Me) modified nucleotide. Alternatively, or additionally, the at least one modification can comprise a phosphorothioate (PS) bond between nucleotides. Alternatively, or additionally, the at least one modification can comprise a 2’-fluoro (2’-F)
modified nucleotide. In one example, a guide RNA described herein comprises one or more 2’- O-methyl (2’-0-Me) modified nucleotides and one or more phosphorothioate (PS) bonds between nucleotides.
[00278] Guide RNAs can be provided in any form. For example, the gRNA can be provided in the form of RNA, either as two molecules (separate crRNA and tracrRNA) or as one molecule (sgRNA), and optionally in the form of a complex with a Cas protein. The gRNA can also be provided in the form of DNA encoding the gRNA. The DNA encoding the gRNA can encode a single RNA molecule (sgRNA) or separate RNA molecules (e.g., separate crRNA and tracrRNA). In the latter case, the DNA encoding the gRNA can be provided as one DNA molecule or as separate DNA molecules encoding the crRNA and tracrRNA, respectively.
[00279] When a gRNA is provided in the form of DNA, the gRNA can be transiently, conditionally, or constitutively expressed in the cell. DNAs encoding gRNAs can be stably integrated into the genome of the cell and operably linked to a promoter active in the cell. Alternatively, DNAs encoding gRNAs can be operably linked to a promoter in an expression construct. For example, the DNA encoding the gRNA can be in a vector comprising a heterologous nucleic acid, such as a nucleic acid encoding a Cas protein. Alternatively, it can be in a vector or a plasmid that is separate from the vector comprising the nucleic acid encoding the Cas protein. Promoters that can be used in such expression constructs include promoters active, for example, in a human cell or a human hematopoietic cell. Such promoters can be, for example, conditional promoters, inducible promoters, constitutive promoters, or tissue-specific promoters. Such promoters can also be, for example, bidirectional promoters. Specific examples of suitable promoters include an RNA polymerase III promoter, such as a human U6 promoter, a rat U6 polymerase III promoter, or a mouse U6 polymerase III promoter.
[00280] Alternatively, gRNAs can be prepared by various other methods. For example, gRNAs can be prepared by in vitro transcription using, for example, T7 RNA polymerase (see, e.g., WO 2014/089290 and WO 2014/065596, each of which is herein incorporated by reference in its entirety for all purposes). Guide RNAs can also be a synthetically produced molecule prepared by chemical synthesis.
[00281] Guide RNAs (or nucleic acids encoding guide RNAs) can be in compositions comprising one or more guide RNAs (e.g., 1, 2, 3, 4, or more guide RNAs) and a carrier increasing the stability of the guide RNA (e.g., prolonging the period under given conditions of
storage (e.g., -20°C, 4°C, or ambient temperature) for which degradation products remain below a threshold, such below 0.5% by weight of the starting nucleic acid or protein; or increasing the stability in vivo). Non-limiting examples of such carriers include poly(lactic acid) (PLA) microspheres, poly(D,L-lactic-coglycolic-acid) (PLGA) microspheres, liposomes, micelles, inverse micelles, lipid cochleates, and lipid microtubules. Such compositions can further comprise a Cas protein, such as a Cas9 protein, or a nucleic acid encoding a Cas protein.
[00282] Guide RNA Target Sequences. Target DNAs for guide RNAs include nucleic acid sequences present in a DNA to which a DNA-targeting segment of a gRNA will bind, provided sufficient conditions for binding exist. Suitable DNA/RNA binding conditions include physiological conditions normally present in a cell. Other suitable DNA/RNA binding conditions (e.g., conditions in a cell-free system) are known in the art see, e.g., Molecular Cloning: A Laboratory Manual, 3rd Ed. (Sambrook et al., Harbor Laboratory Press 2001), herein incorporated by reference in its entirety for all purposes). The strand of the target DNA that is complementary to and hybridizes with the gRNA can be called the “complementary strand,” and the strand of the target DNA that is complementary to the “complementary strand” (and is therefore not complementary to the Cas protein or gRNA) can be called “noncomplementary strand” or “template strand.”
[00283] The target DNA includes both the sequence on the complementary strand to which the guide RNA hybridizes and the corresponding sequence on the non-complementary strand (e.g., adjacent to the protospacer adjacent motif (PAM)). The term “guide RNA target sequence” as used herein refers specifically to the sequence on the non-complementary strand corresponding to (i.e., the reverse complement of) the sequence to which the guide RNA hybridizes on the complementary strand. That is, the guide RNA target sequence refers to the sequence on the non- complementary strand adjacent to the PAM (e.g., upstream or 5’ of the PAM in the case of Cas9). A guide RNA target sequence is equivalent to the DNA-targeting segment of a guide RNA, but with thymines instead of uracils. As one example, a guide RNA target sequence for an SpCas9 enzyme can refer to the sequence upstream of the 5’-NGG-3’ PAM on the non-complementary strand. A guide RNA is designed to have complementarity to the complementary strand of a target DNA, where hybridization between the DNA-targeting segment of the guide RNA and the complementary strand of the target DNA promotes the formation of a CRISPR complex. Full complementarity is not necessarily required, provided that there is sufficient complementarity to
cause hybridization and promote formation of a CRISPR complex. If a guide RNA is referred to herein as targeting a guide RNA target sequence, what is meant is that the guide RNA hybridizes to the complementary strand sequence of the target DNA that is the reverse complement of the guide RNA target sequence on the non-compl ementary strand.
[00284] A target DNA or guide RNA target sequence can comprise any polynucleotide, and can be located, for example, in the nucleus or cytoplasm of a cell or within an organelle of a cell. A target DNA or guide RNA target sequence can be any nucleic acid sequence endogenous or exogenous to a cell. The guide RNA target sequence can be a sequence coding a gene product (e.g., a protein) or a non-coding sequence (e.g., a regulatory sequence) or can include both.
[00285] Site-specific binding and cleavage of a target DNA by a Cas protein can occur at locations determined by both (i) base-pairing complementarity between the guide RNA and the complementary strand of the target DNA and (ii) a short motif, called the protospacer adjacent motif (PAM), in the non-complementary strand of the target DNA. The PAM can flank the guide RNA target sequence. Optionally, the guide RNA target sequence can be flanked on the 3’ end by the PAM (e.g., for Cas9). Alternatively, the guide RNA target sequence can be flanked on the 5’ end by the PAM (e.g., for Cpfl). For example, the cleavage site of Cas proteins can be about 1 to about 10 or about 2 to about 5 base pairs (e.g., 3 base pairs) upstream or downstream of the PAM sequence (e.g., within the guide RNA target sequence). In the case of SpCas9, the PAM sequence (i.e., on the non-complementary strand) can be 5’-NiGG-3’, where Ni is any DNA nucleotide, and where the PAM is immediately 3’ of the guide RNA target sequence on the non- complementary strand of the target DNA. As such, the sequence corresponding to the PAM on the complementary strand (i.e., the reverse complement) would be 5’-CCN2-3’, where N2 is any DNA nucleotide and is immediately 5’ of the sequence to which the DNA-targeting segment of the guide RNA hybridizes on the complementary strand of the target DNA. In some such cases, Ni and N2 can be complementary and the Ni- N2 base pair can be any base pair (e.g., Ni=C and N2=G; NI=G and N2=C; Ni=A and N2=T; or Ni=T, and N2=A). In the case of Cas9 from S. aureus, the PAM can be NNGRRT or NNGRR, where N can A, G, C, or T, and R can be G or A. In the case of Cas9 from C. jejuni, the PAM can be, for example, NNNNACAC or NNNNRYAC, where N can be A, G, C, or T, and R can be G or A. In some cases (e.g., for FnCpfl), the PAM sequence can be upstream of the 5’ end and have the sequence 5’-TTN-3’. In the case of
DpbCasX, the PAM can have the sequence 5’-TTCN-3’. In the case of Cas , the PAM can have the sequence 5’-TBN-3’, where B is G, T, or C.
[00286] An example of a guide RNA target sequence is a 20-nucleotide DNA sequence immediately preceding an NGG motif recognized by an SpCas9 protein. For example, two examples of guide RNA target sequences plus PAMs are GN19NGG (SEQ ID NO: 54) or N20NGG (SEQ ID NO: 55). See, e.g., WO 2014/165825, herein incorporated by reference in its entirety for all purposes. The guanine at the 5’ end can facilitate transcription by RNA polymerase in cells. Other examples of guide RNA target sequences plus PAMs can include two guanine nucleotides at the 5’ end (e.g., GGN20NGG; SEQ ID NO: 56) to facilitate efficient transcription by T7 polymerase in vitro. See, e.g., WO 2014/065596, herein incorporated by reference in its entirety for all purposes. Other guide RNA target sequences plus PAMs can have between 4-22 nucleotides in length of SEQ ID NOS: 54-56, including the 5’ G or GG and the 3’ GG or NGG. Yet other guide RNA target sequences plus PAMs can have between 14 and 20 nucleotides in length of SEQ ID NOS: 54-56.
[00287] Formation of a CRISPR complex hybridized to a target DNA can result in cleavage of one or both strands of the target DNA within or near the region corresponding to the guide RNA target sequence (i.e., the guide RNA target sequence on the non-complementary strand of the target DNA and the reverse complement on the complementary strand to which the guide RNA hybridizes). For example, the cleavage site can be within the guide RNA target sequence (e.g., at a defined location relative to the PAM sequence). The “cleavage site” includes the position of a target DNA at which a Cas protein produces a single-strand break or a double-strand break. The cleavage site can be on only one strand (e.g., when a nickase is used) or on both strands of a double-stranded DNA. Cleavage sites can be at the same position on both strands (producing blunt ends; e.g., Cas9)) or can be at different sites on each strand (producing staggered ends (i.e., overhangs); e.g., Cpfl). Staggered ends can be produced, for example, by using two Cas proteins, each of which produces a single-strand break at a different cleavage site on a different strand, thereby producing a double-strand break. For example, a first nickase can create a singlestrand break on the first strand of double-stranded DNA (dsDNA), and a second nickase can create a single-strand break on the second strand of dsDNA such that overhanging sequences are created. In some cases, the guide RNA target sequence or cleavage site of the nickase on the first strand is separated from the guide RNA target sequence or cleavage site of the nickase on the
second strand by at least 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 75, 100, 250, 500, or 1,000 base pairs.
[00288] The guide RNA target sequence can also be selected to minimize off-target modification or avoid off-target effects (e.g., by avoiding two or fewer mismatches to off-target genomic sequences).
[00289] As one example, a guide RNA targeting human CXCR4 (e.g., coding exon 2 of human
CXCR4) can target the guide RNA target sequence set forth in any one of SEQ ID NOS: 117- 131. As another example, a guide RNA targeting human CXCR4 (e.g., coding exon 2 of human CXCR4) can target at least 17, at least 18, at least 19, or at least 20 contiguous nucleotides of the guide RNA target sequence set forth in any one of SEQ ID NOS: 117-131.
[00290] Exogenous Donor Nucleic Acids. Any suitable exogenous donor nucleic acid can be used in the methods disclosed herein. In some embodiments, the exogenous donor nucleic acid comprises the entire coding sequence for the first isoform of the target protein (e.g., CXCR4). In some embodiments, the coding sequence for the first isoform of the target protein (e.g., CXCR4) is operably linked to a promoter suitable for driving expression in the donor cells or edited cells. Alternatively, the coding sequence for the first isoform of the target protein (e.g., CXCR4) is not operably linked to a promoter in the exogenous donor nucleic acid but will be operably linked to an endogenous promoter at the target genomic locus once the exogenous donor nucleic acid recombines with or is integrated into the target genomic locus. In other embodiments, the exogenous donor nucleic acid does not comprise the entire coding sequence for the first isoform of the target protein (e.g., CXCR4). For example, the exogenous donor nucleic acid may comprise a portion of the coding sequence for the first isoform of the target protein (e.g., CXCR4), wherein the portion comprises the mutation that distinguishes the first isoform from the second isoform. For example, the exogenous donor nucleic acids can comprise a mutation to modify the target genomic locus encoding the target protein so that it encodes the first isoform of the target protein. In some embodiments, the exogenous donor nucleic acid recombines with the target genomic locus via non-homologous end joining (NHEJ)-mediated ligation or through a homology-directed repair event. Optionally, repair with the exogenous donor nucleic acid removes or disrupts the nuclease target sequence so that alleles that have been targeted cannot be re-targeted by the nuclease agent.
[00291] The exogenous donor nucleic acid can target any sequence in the target genomic locus (e.g., CXCR4 gene, human CXCR4 gene). In some embodiments, the exogenous donor nucleic acid targets coding exon 2 of a CXCR4 gene (e.g., coding exon 2 of a human CXCR4 gene). In some embodiments, the exogenous donor nucleic acid targets coding exon 2 of a CXCR4 gene (e.g., coding exon 2 of a human CXCR4 gene). In some embodiments, the exogenous donor nucleic acid targets exons 2 and 3 of a CXCR4 gene (e.g., exons 2 and 3 of a human CXCR4 gene). Some exogenous donor nucleic acids comprise homology arms. Other exogenous donor nucleic acids do not comprise homology arms. The exogenous donor nucleic acids can be capable of insertion into a target genomic locus (e.g., CXCR4) by homology- directed repair, and/or they can be capable of insertion into a target genomic locus (e.g., CXCR4) by non-homologous end joining.
[00292] Exogenous donor nucleic acids can comprise deoxyribonucleic acid (DNA) or ribonucleic acid (RNA), they can be single-stranded or double-stranded, and they can be in linear or circular form. For example, an exogenous donor nucleic acid can be a single-stranded oligodeoxynucleotide (ssODN). See, e.g., Yoshimi et al. (2016) Nat. Commun. 7:10431, herein incorporated by reference in its entirety for all purposes. Exogenous donor nucleic acids can be naked nucleic acids or can be delivered by viruses, such as AAV. In a specific example, the exogenous donor nucleic acid can be delivered via AAV and can be capable of insertion into a target genomic locus by non-homologous end joining (e.g., the exogenous donor nucleic acid can be one that does not comprise homology arms).
[00293] An exemplary exogenous donor nucleic acid is between about 50 nucleotides to about 5 kb in length, is between about 50 nucleotides to about 3 kb in length, or is between about 50 to about 1,000 nucleotides in length. Other exemplary exogenous donor nucleic acids are between about 40 to about 200 nucleotides in length. For example, an exogenous donor nucleic acid can be between about 50-60, 60-70, 70-80, 80-90, 90-100, 100-110, 110-120, 120-130, 130-140, 140-150, 150-160, 160-170, 170-180, 180-190, or 190-200 nucleotides in length. Alternatively, an exogenous donor nucleic acid can be between about 50-100, 100-200, 200-300, 300-400, 400- 500, 500-600, 600-700, 700-800, 800-900, or 900-1000 nucleotides in length. Alternatively, an exogenous donor nucleic acid can be between about 1-1.5, 1.5-2, 2-2.5, 2.5-3, 3-3.5, 3.5-4, 4-4.5, or 4.5-5 kb in length. Alternatively, an exogenous donor nucleic acid can be, for example, no more than 5 kb, 4.5 kb, 4 kb, 3.5 kb, 3 kb, 2.5 kb, 2 kb, 1.5 kb, 1 kb, 900 nucleotides, 800
nucleotides, 700 nucleotides, 600 nucleotides, 500 nucleotides, 400 nucleotides, 300 nucleotides, 200 nucleotides, 100 nucleotides, or 50 nucleotides in length. Exogenous donor nucleic acids (e.g., targeting vectors) can also be longer.
[00294] In one example, an exogenous donor nucleic acid is an ssODN that is between about 80 nucleotides and about 200 nucleotides in length. In another example, an exogenous donor nucleic acid is an ssODN that is between about 80 nucleotides and about 3 kb in length. Such an ssODN can have homology arms, for example, that are each between about 40 nucleotides and about 60 nucleotides in length. Such an ssODN can also have homology arms, for example, that are each between about 30 nucleotides and 100 nucleotides in length. The homology arms can be symmetrical (e.g., each 40 nucleotides or each 60 nucleotides in length), or they can be asymmetrical (e.g., one homology arm that is 36 nucleotides in length, and one homology arm that is 91 nucleotides in length).
[00295] In one example, an exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 200 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 90 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 60 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 90 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 130 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 150 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 160 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 170 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about
30 nucleotides and about 180 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 190 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 200 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 130 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 150 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 160 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 170 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 180 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 190 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 200 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 130 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 150 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 160 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 170 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 180 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 190 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 200 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 50 and about 100 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 40 nucleotides and about 110 nucleotides in length.
[00296] In one example, the exogenous donor nucleic acid is an ssODN that is about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is about 90 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is about 60 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is about 30 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 110 nucleotides and about 130 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 100 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 90 nucleotides and about 150 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 80 nucleotides and about 160 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 70 nucleotides and about 170 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 180 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 80 nucleotides and about 100 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 70 nucleotides and about 110 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 60 nucleotides and about 120 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 50 nucleotides and about 130 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 40 nucleotides and about 140 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 150 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 50 nucleotides and about 70 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 40 nucleotides and about 80 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 30 nucleotides and about 90 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 20 nucleotides and about 100 nucleotides in length. In another example, the exogenous donor nucleic acid is an ssODN that is between about 20 nucleotides and about 40 nucleotides in length.
[00297] Exogenous donor nucleic acids can include modifications or sequences that provide for additional desirable features (e.g., modified or regulated stability; tracking or detecting with a fluorescent label; a binding site for a protein or protein complex; and so forth). Exogenous donor nucleic acids can comprise one or more fluorescent labels, purification tags, epitope tags, or a combination thereof. For example, an exogenous donor nucleic acid can comprise one or more fluorescent labels (e.g., fluorescent proteins or other fluorophores or dyes), such as at least 1, at least 2, at least 3, at least 4, or at least 5 fluorescent labels. Exemplary fluorescent labels include fluorophores such as fluorescein (e.g., 6-carboxyfluorescein (6-FAM)), Texas Red, HEX, Cy3, Cy5, Cy5.5, Pacific Blue, 5-(and-6)-carboxytetramethylrhodamine (TAMRA), and Cy7. A wide range of fluorescent dyes are available commercially for labeling oligonucleotides (e.g., from Integrated DNA Technologies). Such fluorescent labels (e.g., internal fluorescent labels) can be used, for example, to detect an exogenous donor nucleic acid that has been directly integrated into a cleaved target nucleic acid having protruding ends compatible with the ends of the exogenous donor nucleic acid. The label or tag can be at the 5’ end, the 3’ end, or internally within the exogenous donor nucleic acid. For example, an exogenous donor nucleic acid can be conjugated at 5’ end with the IR700 fluorophore from Integrated DNA Technologies (5TRDYE®700).
[00298] Exogenous donor nucleic acids can also comprise nucleic acid inserts including segments of DNA to be integrated in the target genomic locus (i.e., to modify the target genomic locus such that it encodes the first isoform of the target protein). Integration of a nucleic acid insert in the target genomic locus can result in addition of a nucleic acid sequence of interest to the target genomic locus, deletion of a nucleic acid sequence of interest in the target genomic locus, or replacement of a nucleic acid sequence of interest in the target genomic locus (i.e., deletion and insertion; or substitution). Some exogenous donor nucleic acids are designed for insertion of a nucleic acid insert in the target genomic locus without any corresponding deletion in the target genomic locus. Other exogenous donor nucleic acids are designed to delete a nucleic acid sequence of interest in the target genomic locus without any corresponding insertion of a nucleic acid insert. Yet other exogenous donor nucleic acids are designed to delete a nucleic acid sequence of interest in the target genomic locus and replace it with a nucleic acid insert (e.g., a substitution).
[00299] The nucleic acid insert or the corresponding nucleic acid in the target genomic locus being deleted and/or replaced can be various lengths. An exemplary nucleic acid insert or corresponding nucleic acid in the target genomic locus being deleted and/or replaced is between about 1 nucleotide to about 5 kb in length or is between about 1 nucleotide to about 1,000 nucleotides in length. For example, a nucleic acid insert or a corresponding nucleic acid in the target genomic locus being deleted and/or replaced can be between about 1-10, 10-20, 20-30, 30- 40, 40-50, 50-60, 60-70, 70-80, 80-90, 90-100, 100-110, 110-120, 120-130, 130-140, 140-150, 150-160, 160-170, 170-180, 180-190, or 190-120 nucleotides in length. Likewise, a nucleic acid insert or a corresponding nucleic acid in the target genomic locus being deleted and/or replaced can be between 1-100, 100-200, 200-300, 300-400, 400-500, 500-600, 600-700, 700-800, 800- 900, or 900-1000 nucleotides in length. Likewise, a nucleic acid insert or a corresponding nucleic acid in the target genomic locus being deleted and/or replaced can be between about 1- 1.5, 1.5-2, 2-2.5, 2.5-3, 3-3.5, 3.5-4, 4-4.5, or 4.5-5 kb in length or longer.
[00300] The nucleic acid insert can comprise a sequence that is homologous or orthologous to all or part of sequence targeted for replacement. For example, the nucleic acid insert can comprise a sequence that comprises one or more point mutations (e.g., 1, 2, 3, 4, 5, or more) compared with a sequence targeted for replacement in the target genomic locus. Optionally, such point mutations can result in a conservative amino acid substitution (e.g., substitution of aspartic acid [Asp, D] with glutamic acid [Glu, E]) in the encoded polypeptide.
[00301] Donor Nucleic Acids for Non-Homologous-End-Joining-Mediated Insertion. Some exogenous donor nucleic acids are capable of insertion into a target genomic locus by non- homologous end joining. In some cases, such exogenous donor nucleic acids do not comprise homology arms. For example, such exogenous donor nucleic acids can be inserted into a blunt end double-strand break following cleavage with a nuclease agent. In a specific example, the exogenous donor nucleic acid can be delivered via AAV and can be capable of insertion into a target genomic locus by non-homologous end joining (e.g., the exogenous donor nucleic acid can be one that does not comprise homology arms). In a specific example, the exogenous donor nucleic acid can be inserted via homology-independent targeted integration. For example, the insert sequence in the exogenous donor nucleic acid to be inserted into a target genomic locus can be flanked on each side by a target site for a nuclease agent (e.g., the same target site as in the target genomic locus, and the same nuclease agent being used to cleave the target site in the
target genomic locus). The nuclease agent can then cleave the target sites flanking the insert sequence. In a specific example, the exogenous donor nucleic acid is delivered AAV-mediated delivery, and cleavage of the target sites flanking the insert sequence can remove the inverted terminal repeats (ITRs) of the AAV. In some methods, the target site in the target genomic locus (e g., a gRNA target sequence including the flanking protospacer adjacent motif) is no longer present if the insert sequence is inserted into the target genomic locus in the correct orientation but it is reformed if the insert sequence is inserted into the target genomic locus in the opposite orientation. This can help ensure that the insert sequence is inserted in the correct orientation for expression.
[00302] Other exogenous donor nucleic acids have short single-stranded regions at the 5’ end and/or the 3’ end that are complementary to one or more overhangs created by nuclease- mediated cleavage in the target genomic locus. For example, some exogenous donor nucleic acids have short single-stranded regions at the 5’ end and/or the 3’ end that are complementary to one or more overhangs created by nuclease-mediated cleavage at 5’ and/or 3’ target sequences in the target genomic locus. Some such exogenous donor nucleic acids have a complementary region only at the 5’ end or only at the 3’ end. For example, some such exogenous donor nucleic acids have a complementary region only at the 5’ end complementary to an overhang created at a 5’ target sequence in the target genomic locus or only at the 3’ end complementary to an overhang created at a 3’ target sequence in the target genomic locus. Other such exogenous donor nucleic acids have complementary regions at both the 5’ and 3’ ends. For example, other such exogenous donor nucleic acids have complementary regions at both the 5’ and 3’ ends e g., complementary to first and second overhangs, respectively, generated by nuclease-mediated cleavage in the target genomic locus. For example, if the exogenous donor nucleic acid is double-stranded, the single-stranded complementary regions can extend from the 5’ end of the top strand of the donor nucleic acid and the 5’ end of the bottom strand of the donor nucleic acid, creating 5’ overhangs on each end. Alternatively, the single-stranded complementary region can extend from the 3’ end of the top strand of the donor nucleic acid and from the 3’ end of the bottom strand of the template, creating 3’ overhangs.
[00303] The complementary regions can be of any length sufficient to promote ligation between the exogenous donor nucleic acid and the target nucleic acid. Exemplary complementary regions are between about 1 to about 5 nucleotides in length, between about 1 to
about 25 nucleotides in length, or between about 5 to about 150 nucleotides in length. For example, a complementary region can be at least about 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 nucleotides in length. Alternatively, the complementary region can be about 5-10, 10-20, 20-30, 30-40, 40-50, 50-60, 60-70, 70-80, 80- 90, 90-100, 100-110, 110-120, 120-130, 130-140, or 140-150 nucleotides in length, or longer. [00304] Such complementary regions can be complementary to overhangs created by two pairs of nickases. Two double-strand breaks with staggered ends can be created by using first and second nickases that cleave opposite strands of DNAto create a first double-strand break, and third and fourth nickases that cleave opposite strands of DNA to create a second double-strand break. For example, a Cas protein can be used to nick first, second, third, and fourth guide RNA target sequences corresponding with first, second, third, and fourth guide RNAs. The first and second guide RNA target sequences can be positioned to create a first cleavage site such that the nicks created by the first and second nickases on the first and second strands of DNA create a double-strand break (i.e., the first cleavage site comprises the nicks within the first and second guide RNA target sequences). Likewise, the third and fourth guide RNA target sequences can be positioned to create a second cleavage site such that the nicks created by the third and fourth nickases on the first and second strands of DNA create a double-strand break (i.e., the second cleavage site comprises the nicks within the third and fourth guide RNA target sequences).
Optionally, the nicks within the first and second guide RNA target sequences and/or the third and fourth guide RNA target sequences can be off-set nicks that create overhangs. The offset window can be, for example, at least about 5 bp, 10 bp, 20 bp, 30 bp, 40 bp, 50 bp, 60 bp, 70 bp, 80 bp, 90 bp, 100 bp or more. See Ran et al. (2013) Cell 154:1380-1389; Mali et al. (2013) Nat.
Biotech. 31 :833-838; and Shen et al. (2014) Nat. Methods 11:399-404, each of which is herein incorporated by reference in its entirety for all purposes. In such cases, a double-stranded exogenous donor nucleic acid can be designed with single-stranded complementary regions that are complementary to the overhangs created by the nicks within the first and second guide RNA target sequences and by the nicks within the third and fourth guide RNA target sequences. Such an exogenous donor nucleic acid can then be inserted by non-homologous-end-joining-mediated ligation.
[00305] Donor Nucleic Acids for Insertion by Homology-Directed Repair. Some exogenous donor nucleic acids comprise homology arms. If the exogenous donor nucleic acid also
comprises a nucleic acid insert, the homology arms can flank the nucleic acid insert. For ease of reference, the homology arms are referred to herein as 5’ and 3’ (i.e., upstream and downstream) homology arms. This terminology relates to the relative position of the homology arms to the nucleic acid insert within the exogenous donor nucleic acid. The 5’ and 3’ homology arms correspond to regions within the target genomic locus, which are referred to herein as “5’ target sequence” and “3’ target sequence,” respectively.
[00306] A homology arm and a 5’ target sequence or 3’ target sequence “correspond” or are “corresponding” to one another when the two regions share a sufficient level of sequence identity to one another to act as substrates for a homologous recombination reaction. The term “homology” includes DNA sequences that are either identical or share sequence identity to a corresponding sequence. The sequence identity between a given target sequence and the corresponding homology arm found in the exogenous donor nucleic acid can be any degree of sequence identity that allows for homologous recombination to occur. For example, the amount of sequence identity shared by the homology arm of the exogenous donor nucleic acid (or a fragment thereof) and the target sequence (or a fragment thereof) can be at least 50%, 55%, 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% or 100% sequence identity, such that the sequences undergo homologous recombination. Moreover, a corresponding region of homology between the homology arm and the corresponding target sequence can be of any length that is sufficient to promote homologous recombination. Exemplary homology arms are between about 25 nucleotides to about 2.5 kb in length, are between about 25 nucleotides to about 1.5 kb in length, or are between about 25 to about 500 nucleotides in length. For example, a given homology arm (or each of the homology arms) and/or corresponding target sequence can comprise corresponding regions of homology that are between about 25-30, 30-40, 40-50, 50-60, 60-70, 70-80, 80-90, 90-100, 100-150, 150-200, 200-250, 250-300, 300-350, 350-400, 400-450, or 450- 500 nucleotides in length, such that the homology arms have sufficient homology to undergo homologous recombination with the corresponding target sequences within the target nucleic acid. Alternatively, a given homology arm (or each homology arm) and/or corresponding target sequence can comprise corresponding regions of homology that are between about 0.5 kb to about 1 kb, about 1 kb to about 1.5 kb, about 1.5 kb to about 2 kb, or about 2 kb to about 2.5 kb in length. For example, the homology arms can each be about 750 nucleotides in length. The
homology arms can be symmetrical (each about the same size in length), or they can be asymmetrical (one longer than the other).
[00307] When a nuclease agent is used in combination with an exogenous donor nucleic acid, the 5’ and 3’ target sequences are optionally located in sufficient proximity to the nuclease cleavage site (e.g., within sufficient proximity to the nuclease target sequence) so as to promote the occurrence of a homologous recombination event between the target sequences and the homology arms upon a single-strand break (nick) or double-strand break at the nuclease cleavage site. The term “nuclease cleavage site” includes a DNA sequence at which a nick or doublestrand break is created by a nuclease agent (e.g., a Cas9 protein complexed with a guide RNA). The target sequences within the targeted locus that correspond to the 5’ and 3’ homology arms of the exogenous donor nucleic acid are “located in sufficient proximity” to a nuclease cleavage site if the distance is such as to promote the occurrence of a homologous recombination event between the 5’ and 3’ target sequences and the homology arms upon a single-strand break or double-strand break at the nuclease cleavage site. Thus, the target sequences corresponding to the 5’ and/or 3’ homology arms of the exogenous donor nucleic acid can be, for example, within at least 1 nucleotide of a given nuclease cleavage site or within at least 10 nucleotides to about 1,000 nucleotides of a given nuclease cleavage site. As an example, the nuclease cleavage site can be immediately adjacent to at least one or both of the target sequences.
[00308] The spatial relationship of the target sequences that correspond to the homology arms of the exogenous donor nucleic acid and the nuclease cleavage site can vary. For example, target sequences can be located 5’ to the nuclease cleavage site, target sequences can be located 3’ to the nuclease cleavage site, or the target sequences can flank the nuclease cleavage site.
[00309] Targeted Genetic Modifications. The mutation in the first isoform can be any type of mutation and any size mutation. In some embodiments, the mutation comprises an insertion, a deletion and/or a substitution of 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids (e.g., 1-20 amino acids, 1-5 amino acids, 1-3 amino acids, or 1 amino acid). In some embodiments, the mutation comprises one or more (e.g., three) substitutions (e.g., comprises one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation consists essentially of one or more (e.g., three) substitutions (e.g., consists essentially of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation consists of one or more (e.g., three) substitutions (e.g., consists of
one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation comprises an insertion (e.g., comprises an insertion of 1 amino acid). In some embodiments, the mutation consists essentially of an insertion (e.g., consists essentially of an insertion of 1 amino acid). In some embodiments, the mutation consists of an insertion (e.g., consists of an insertion of 1 amino acid). The mutation can be at any site in the target protein. For example, if the target protein is a cell surface protein, the mutation can in some embodiments be in the extracellular domain of the target protein. In some embodiments, the site of the mutation can be a site that is non-conserved between different mammalian species. In some embodiments, the mutation does not result in a secondary structure change in the surface protein. In some embodiments, the mutation is within the epitope targeted by an antigen-binding protein or is at a site that is accessible to ligand binding. In some embodiments, the mutation is not located at a site involved in a predicted or experimentally established or confirmed protein-protein interaction of the surface protein. In some embodiments, the mutation does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking. In some embodiments, the mutation does not result in deleting or introducing a posttranslational protein modification site, such as a glycosylation site. In some embodiments, the mutation is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction. In instances where an antibody or antigen-binding protein reactive against a target protein already exists, the information regarding the epitope of the target protein that is recognized by the antibody or antigen-binding protein can be used to select the site of the mutation.
[00310] In some embodiments, the first isoform of the target protein is a genetically engineered isoform of the target protein. For example, the first isoform of the target protein can be genetically engineered to comprise a mutation (e.g., an artificial mutation that is not naturally occurring) to provide an altered epitope. The altered epitope can be, for example, in the binding region of an antigen-binding protein such as an antibody. In some embodiments, the target protein is CXCR4 (e.g., human CXCR4), and the altered epitope is in a binding region of the REGN7663 or REGN7664 anti-CXCR4 antibodies described elsewhere herein. The ECL2 region of human CXCR4, which is from position A175 to position V198 of human CXCR4 (SEQ ID NO: 1), is necessary and sufficient for REGN7663 and REGN7664 binding. In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion)
encoded by nucleotides within coding exon 2 of the CXCR4 gene (e.g., human CXCR4 gene). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the ECL2 region of CXCR4 (e.g., human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position A175 to position V198 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position SI 78 to position R183 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position R188 to position LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the REGN7663 and REGN7664 binding region (SEQ ID NO: 57). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198. In some embodiments, the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198. In some embodiments, the mutation can comprise a mutation (e.g., an insertion) between A175 and N176, between N176 and V177, between V177 and S178, between S178 and E179, between E179 and A180, between A180 and D181, between D181 and D182, between D182 and R183, between R183 and Y184, between Y184 and 1185, between 1185 and C186, between C186 and D187, between D187 and R188, between R188 and Fl 89, between Fl 89 and Y190, between Y190 and Pl 91, between Pl 91 and N192, between N192 and D193, and/or between D193 and L194 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., an insertion) between S178 and E179. In some embodiments, the mutation can comprise a mutation (e.g., a substitution) at one or more of the
following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198, and a mutation (e.g., an insertion) between S178 and E179. In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) or combination of mutations as set forth in Table 1.
[00311] In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion), or combination of mutations, as set forth in pMM626, pMM630, pMM632, pMM633, and pMM640 (corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively). For example, the mutation can comprise a mutation (e.g., a substitution) at position F189, N192, D193, E179, D181, and/or D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); a mutation (e.g., an insertion) between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); or any combination thereof of CXCR4 (e.g., human CXCR4). A mutation at a position within CXCR4 encompasses mutations (e.g., substitutions and/or insertions) including only the residue at that position or mutations (e.g., substitutions and/or insertions) including the residue at that position as well as other residues at other positions. The nomenclature of the amino acid position for the mutations or residue disclosed herein refer to the position of the mutation or residue in the canonical isoform of human CXCR4 set forth in SEQ ID NO: 1.
[00312] In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position Fl 89 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable Fl 89 substitution is an F189A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position N192 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable N192 substitution is an N192A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 93 substitution is an DI 93 A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at positions Fl 89, N192, and DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable Fl 89, N192, and DI 92
substitutions are F189A, N192A, and D192A substitutions. In some embodiments, the mutation comprises an insertion between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable insertions include an S178_E179insK (e.g., insertion of K between SI 78 and El 79), S178_E179insY (e.g., insertion of Y between S178 and E179), and S178_E179insR (e.g., insertion of R between SI 78 and El 79). In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable E179 substitution is an E179R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position D181 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable D181 substitution is an D181R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position DI 82 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 82 substitution is an D182R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at positions E179, D181, and D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable E179, D181, and D182 substitutions are E179R, D181R, and D182R substitutions. [00313] In some embodiments, the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 91 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of F189A, N192A, and N193 A relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00314] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 95 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insK relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00315] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 97 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or
consist of SI 78_E179insY relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00316] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 98 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insR relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00317] In some embodiments, the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 105 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of E179R, D181R, and D182R relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
IV. Methods for Treatment in a Subject
[00318] In some embodiments of the present invention, any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for the treatment of a disease or disorder (e.g., any malignancy, such as any cancer) in a subject, and the methods can comprise administering a therapeutically effective amount of the donor cells or edited cells to the subject. In some embodiments of the present invention, any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject described herein are methods for the treatment of a hematopoietic malignancy or a hematologic malignancy, and the methods can comprise administering a therapeutically effective amount of the donor cells or edited cells to the subject. In some embodiments, the methods can further comprise administering a therapeutically effective amount of the agent for selective inhibition or selective depletion of host cells or non-edited cells (e.g., antagonist or the antigenbinding protein or the population of immune effector cells).
[00319] In some embodiments, the administered cells comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigenbinding fragment thereof), a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR). In some embodiments, the therapeutic molecule, immunoglobulin, CAR, or exogenous
TCR does not target the target protein (e.g., CXCR4). In some embodiments, the administered cells comprise or express an immunoglobulin, a CAR, or an exogenous TCR. In some embodiments, the administered cells comprise or express a CAR or an exogenous TCR.
[00320] As used herein, the terms “treat,” “treating,” and “treatment” mean to relieve or alleviate at least one symptom associated with the disease or disorder, or to slow or reverse the progression of the disease or disorder. Within the meaning of the present disclosure, the term “treat” also denotes to arrest, delay the onset (i.e., the period prior to clinical manifestation of a disease) and/or reduce the risk of developing or worsening a disease. For example, in connection with cancer, the term “treat” may mean eliminate or reduce the number or replication of cancer cells, and/or prevent, delay or inhibit metastasis, etc.
[00321] As used herein the term “effective amount” may be used interchangeably with the term “therapeutically effective amount” and refers to that quantity of an agent (e g., antagonist or antigen-binding protein or population of immune effector cells), cell population (e g., donor cells or edited cells), or pharmaceutical composition (e.g., a composition comprising an agent and/or donor cells or edited cells such as hematopoietic cells) that is sufficient to result in a desired activity upon administration to a subject in need thereof. Within the context of the present disclosure, the term “effective amount” refers to that quantity of a compound, cell population, or pharmaceutical composition that is sufficient to delay the manifestation, arrest the progression, relieve or alleviate at least one symptom of a disease or disorder (e.g., any malignancy, such as cancer) treated by the methods of the present disclosure. Effective amounts vary, as recognized by those skilled in the art, depending on the particular condition being treated, the severity of the condition, the individual patient parameters including age, physical condition, size, gender and weight, the duration of the treatment, the nature of concurrent therapy (if any), the specific route of administration and like factors within the knowledge and expertise of the health practitioner. In some embodiments, the effective amount alleviates, relieves, ameliorates, improves, reduces the symptoms, or delays the progression of any disease or disorder in the subject. In some embodiments, the subject is a human. In some embodiments, the subject is a human patient having a hematopoietic malignancy or a hematologic malignancy. In some embodiments, the subject is a human patient having cancer (e.g., any type of cancer).
[00322] In some embodiments, a typical number of cells (e.g., immune cells or hematopoietic cells) administered to a mammal (e.g., a human) can be, for example, in the range of about 106to
IO11 cells. In some embodiments it may be desirable to administer fewer than 106 cells to the subject. In some embodiments, it may be desirable to administer more than 1011 cells to the subject. In some embodiments, one or more doses of cells includes about 106 cells to about 1011 cells, about 107 cells to about IO10 cells, about 108 cells to about 109 cells, about 106 cells to about 108 cells, about 107 cells to about 109 cells, about 107 cells to about IO10 cells, about 107 cells to about 1011 cells, about 108 cells to about IO10 cells, about 108 cells to about 1011 cells, about 109 cells to about IO10 cells, about 109 cells to about 1011 cells, or about IO10 cells to about 1011 cells. In some embodiments, one or more doses of cells includes about 106 to 107 cells per kg-
[00323] The donor cells or edited cells (and/or the agent for selective inhibition or selective depletion of host cells or non-edited cells) may be administered in a pharmaceutically acceptable carrier or excipient as a pharmaceutical composition. See, e.g., Zhang et al. (2020) World J. Clin. Oncol. 11(5):275-282 and Atouf (2016) AAPS J. 18(4):844-848, each of which is herein incorporated by reference in its entirety for all purposes. The phrase “pharmaceutically acceptable,” as used in connection with compositions and/or cells described herein, refers to molecular entities and other ingredients of such compositions that are physiologically tolerable and do not typically produce untoward reactions when administered to a mammal (e.g., a human). In some embodiments, the term “pharmaceutically acceptable” means approved by a regulatory agency of the Federal or a state government or listed in the U.S. Pharmacopeia or other generally recognized pharmacopeia for use in mammals, and more particularly in humans. “Acceptable” means that the carrier is compatible with the active ingredient of the composition (e.g., the nucleic acids, vectors, cells, or therapeutic antibodies) and does not negatively affect the subject to which the composition(s) are administered. Any of the pharmaceutical compositions and/or cells to be used in the present methods can comprise pharmaceutically acceptable carriers, excipients, or stabilizers in the form of lyophilized formations or aqueous solutions. Pharmaceutically acceptable carriers, including buffers, are well known in the art, and may comprise phosphate, citrate, and other organic acids; antioxidants including ascorbic acid and methionine; preservatives; low molecular weight polypeptides; proteins, such as serum albumin, gelatin, or immunoglobulins; amino acids; hydrophobic polymers; monosaccharides; disaccharides; and other carbohydrates; metal complexes; and/or non-ionic surfactants. See, e.g., Remington: The Science and Practice of Pharmacy 20th Ed. (2000) Lippincott Williams and
Wilkins, Ed. K. E. Hoover, herein incorporated by reference in its entirety for all purposes. [00324] The agent for selective inhibition or selective depletion of host cells or non-edited cells can in some embodiments be administered simultaneously with the donor cells or edited cells. In some embodiments, the donor cells or edited cells are administered after agent. For example, in some embodiments, the donor cells or edited cells are administered within a day after the agent or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more after the agent. In some embodiments, the donor cells or edited cells are administered before the agent. For example, in some embodiments, the donor cells or edited cells are administered within a day before the agent or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more before the agent.
[00325] In some embodiments, the donor cells or edited cells are administered in multiple administrations (e.g., doses). In some embodiments, the donor cells or edited cells are administered to the subject once. In some embodiments, the donor cells or edited cells are administered to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the donor cells or edited cells are administered to the subject at a regular interval (e.g., every 6 months). In some embodiments, the agent for selective inhibition or selective depletion of host cells or non-edited cells is administered in multiple administrations (e g., doses). In some embodiments, the agent is administered to the subject once. In some embodiments, the agent is administered to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the agent is administered to the subject at a regular interval (e.g., every 6 months).
[00326] In some embodiments, the agent is administered to the subject in multiple
administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells and in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells.
[00327] In some embodiments, the subject has a disease, such as a cancer, and the methods are for treating the disease (e.g., the cancer). For example, the donor cells or edited cells can be engineered to express a therapeutic agent for treating that disease (e.g., if the disease is a cancer, the donor cells or edited cells can be engineered to express a CAR or exogenous TCR with antitumor reactivity). In some embodiments, the subject (e.g., human subject) has a hematopoietic malignancy. As used herein a hematopoietic malignancy refers to a malignant abnormality involving hematopoietic cells (e.g., blood cells, including progenitor and stem cells). Examples of hematopoietic malignancies include, without limitation, Hodgkin’s lymphoma, non-Hodgkin’s lymphoma, leukemia, and multiple myeloma. Exemplary leukemias include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myelogenous leukemia, acute lymphoblastic leukemia or chronic lymphoblastic leukemia, and chronic lymphoid leukemia. [00328] In some embodiments, the subject has a cancer, such as a solid tumor cancer or a liquid tumor cancer. In some embodiments, the subject has a solid tumor cancer. A solid tumor is a solid mass of cancer cells that grow in organ systems and can occur anywhere in the body, such as breast cancer. In contrast, liquid tumors are cancers that develop in the blood, bone marrow, or lymph nodes and includes leukemia, lymphoma, and myeloma. In some embodiments, the subject has a cancer, such as a hematologic cancer. Hematologic cancers are cancers that begin in blood-forming tissue, such as the bone marrow, or in the cells of the immune system. Examples of hematologic cancers include leukemia, lymphoma, and multiple myeloma. Hematologic cancers are also referred to blood cancer. In some embodiments, the subject has a hematopoietic disorder. In some embodiments, the subject has defective immune cells or a genetic deficiency in hematopoiesis, such as sickle cell disease or severe combined immunodeficiency (SCID). In some embodiments, the subject has a genetic hematopoietic disease (e.g., thalassemia). In some
embodiments, the subject has a T-cell -mediated diseases, such as an IPEX-like syndrome, a CTLA-4-associated immune dysregulation, a hemophagocytic syndrome, ALPS syndrome, or a syndrome caused by heterozygous PTEN germline mutations. In some embodiments, the subject has an autoimmune disease. In some embodiments, the subject has graft-versus-host-disease. In some embodiments, the methods are for correction of congenital hematopoietic deficiencies. [00329] In some embodiments of the present invention, any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for conditioning a subject’s tissues (e.g., bone marrow) for engraftment or transplant. Such methods can be useful for treating such diseases without causing the toxicities that are observed in response to traditional conditioning therapies. In some embodiments of the present invention, any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for treating a subject defective or deficient in one or more cell types of the hematopoietic lineage. The methods can, in some embodiments, reconstitute the defective or deficient population of cells in vivo, thereby treating the pathology associated with the defect or depletion in the endogenous blood cell population. In some embodiments, the compositions and methods described herein can thus be used to treat a non- malignant hemoglobinopathy (e.g., a hemoglobinopathy selected from the group consisting of sickle cell anemia, thalassemia, Fanconi anemia, aplastic anemia, and Wiskott-Aldrich syndrome). In some embodiments, the compositions and methods described herein can be used to treat a malignancy or proliferative disorder, such as a cancer, such as a hematologic cancer or a myeloproliferative disease. In the case of cancer treatment, in some embodiments the compositions and methods described herein may be administered to a patient so as to deplete a population of endogenous hematopoietic stem cells prior to hematopoietic stem cell transplantation therapy, in which case the transplanted cells can home to a niche created by the endogenous cell depletion step and establish productive hematopoiesis. This, in turn, can reconstitute a population of cells depleted during cancer cell eradication, such as during systemic chemotherapy. Exemplary hematological cancers that can be treated using the compositions and methods described herein include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myeloid leukemia, chronic lymphoid leukemia, multiple myeloma, diffuse large B-cell lymphoma, and non-Hodgkin's lymphoma, as well as other cancerous conditions,
including neuroblastoma.
[00330] In some embodiments, the donor cells or edited cells can be engineered to express a therapeutic agent for treating disease or the cancer (e.g., the donor cells or edited cells can be engineered to express a CAR or exogenous TCR with anti-tumor reactivity). For example, the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule). For example, the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer). In some embodiments, the therapeutic molecule may target the diseased cells and/or an antigen expressed on the diseased cells (e.g., a tumor- associated antigen).
[00331] Exemplary cancers that can be treated using the compositions and methods described herein include, without limitation, adenoid cystic carcinoma, adrenal gland cancer, anal cancer, basal cell carcinoma, bile duct cancer, bladder cancer, bone cancer, brain cancer, breast cancer, carcinoid tumor, cervical cancer, colorectal cancer, ductal carcinoma, endometrial cancer, esophageal cancer, gastric cancer, gastrointestinal stromal tumor - GIST, HER2-positive breast cancer, islet cell tumor, kidney cancer, laryngeal cancer, leukemia - acute lymphoblastic leukemia, leukemia - acute lymphocytic (ALL), leukemia - acute myeloid (AML), leukemia - adult, leukemia - childhood, leukemia - chronic lymphocytic (CLL), leukemia - chronic myeloid (CML), liver cancer, lobular carcinoma, lung cancer, lung cancer - small cell, lymphoma - Hodgkin’s, lymphoma - non-Hodgkin’s, malignant glioma, melanoma, meningioma, multiple myeloma, nasopharyngeal cancer, neuroendocrine cancer, oral cancer, osteosarcoma, ovarian cancer, pancreatic cancer, pancreatic neuroendocrine cancer, parathyroid cancer, penile cancer, peritoneal cancer, pituitary gland cancer, prostate cancer, renal cell carcinoma, retinoblastoma, salivary gland cancer, sarcoma, sarcoma - Kaposi, skin cancer, small intestine cancer, stomach cancer, testicular cancer, thymoma, thyroid cancer, uterine (endometrial) cancer, vaginal cancer, Wilms’ tumor. Exemplary hematological cancers that can be treated using the compositions and
methods described herein include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myeloid leukemia, chronic lymphoid leukemia, multiple myeloma, diffuse large B-cell lymphoma, and non-Hodgkin’s lymphoma, as well as other cancerous conditions, including neuroblastoma. Exemplary solid tumors that can be treated using the compositions and methods described herein include, without limitation, sarcomas and carcinomas. Sarcomas are tumors in a blood vessel, bone, fat tissue, ligament, lymph vessel, muscle or tendon. Carcinomas are tumors that form in epithelial cells. Epithelial cells are found in the skin, glands and the linings of organs.
V. Combination Medicaments
[00332] In some embodiments of the present invention, combinations (e.g., combination medicaments) are provided for administration to a subject in need thereof. In some embodiments, such combinations comprise: (1) a population of donor cells or edited cells that express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) means for specifically binding the second isoform of the target protein but not the first isoform of the target protein. In some embodiments, such combinations comprise: (1) a population of donor cells or edited cells that express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) an agent (e.g., an antagonist or an antigen-binding protein or a population of immune effector cells) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein. In some embodiments of the present invention, combinations (e.g., combination medicaments) are provided for administration to a subject in need thereof. In some embodiments, such combinations comprise: (1) a population of donor cells or edited cells that have been modified to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) means for specifically binding the second isoform of the target protein but not the first isoform of the target protein. In some embodiments of the present invention, combinations (e.g., combination medicaments) are provided for administration to a subject in need thereof. In some embodiments, such combinations comprise: (1) a population of
donor cells or edited cells that have been modified to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) an agent (e.g., an antagonist or an antigen-binding protein or a population of immune effector cells) that specifically binds to the second isoform of the target protein (e.g., CXCR4) but does not specifically bind to the first isoform of the target protein (e.g., CXCR4). The first isoform and the second isoform can be functionally indistinguishable but immunologically distinguishable. In some embodiments, such combinations comprise: (1) a population of donor cells or edited cells in which a target genomic locus has been edited to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) means for specifically binding the second isoform of the target protein but not the first isoform of the target protein. In some embodiments, such combinations comprise: (1) a population of donor cells or edited cells in which a target genomic locus has been edited to express a first isoform of a target protein (e.g., CXCR4) that is different from a second isoform of the target protein, wherein the second isoform is expressed in host cells or non-edited cells of the subject, and (2) an agent (e.g., an antagonist or an antigen-binding protein or a population of immune effector cells) that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein. In some embodiments, the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable. In some embodiments, the donor cells or edited cells express only the first isoform of the target protein (e.g., CXCR4). In other embodiments, the donor cells or edited cells express both the first and second isoforms of the target protein (e.g., CXCR4).
[00333] The donor cells or edited cells can be any suitable cells as described above in the context of methods for selective inhibition or selective depletion of host cells or non-edited cells in a subject. The target protein can be any suitable target protein as described above in the context of methods for selective inhibition or selective depletion of host cells or non-edited cells in a subject. In some embodiments of the present invention, the target protein is C-X-C motif chemokine receptor 4 (CXCR4). In some embodiments of the present invention, the target protein is human CXCR4.
[00334] The donor cells or edited cells can be any suitable cells as described above in the
context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject. In some embodiments, the donor cells or edited cells comprise a genetic modification (insertion of a transgene, correction of a mutation, deletion or inactivation of a gene (e.g., insertion of premature stop codon or insertion of regulatory repressor sequence), or a change in an epigenetic modification important for expression of a gene) correcting or counteracting a disease-related gene defect present in a subject. In some embodiments, the donor cells or edited cells comprise a transgene. In some embodiments, the donor cells or edited cells comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR) (e.g., CAR-T cells, CAR-NK cells), or an exogenous T cell receptor (TCR). In some embodiments, the donor cells or edited cells comprise a bicistronic nucleic acid construct encoding the therapeutic molecule and the first isoform of the target protein. See, e.g., Yeku et al. (2017) Sci. Rep. 7(1): 10541 and Rafiq et al. (2018) Nat. Biotechnol. 36(9):847-856, each of which is herein incorporated by reference in its entirety for all purposes, for examples of bicistronic constructs expressing CARs and another molecule. For example, the bicistronic construct can encode both a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and the first isoform (e.g., a modified isoform) of the target protein (e.g., CXCR4). In one embodiment, the bicistronic construct encodes a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and a modified isoform of CXCR4. In some embodiments, the therapeutic molecule, immunoglobulin, CAR, or exogenous TCR does not target the target protein (e.g., CXCR4). In some embodiments, the donor cells or edited cells comprise or express an immunoglobulin, a CAR, or an exogenous TCR. In some embodiments, the donor cells or edited cells comprise or express a CAR or an exogenous TCR. For example, the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above (e.g., CXCR4) is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule). For example, the disease or cancer can be a disease or cancer that is not associated with the target
protein (e.g., the target protein (e.g., CXCR4) does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer). Exemplary types of cancers and tumors that can be treated are described elsewhere herein. In some embodiments, the therapeutic molecule may target the diseased cells and/or an antigen expressed on the diseased cells (e.g., a tumor-associated antigen).
[00335] In some embodiments, the donor cells or edited cells are autologous (i.e., from the subject). In some embodiments, the donor cells or edited cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation). In some embodiments, the donor cells or edited cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the donor cells or edited cells are mammalian cells or non-human mammalian cells). In some embodiments, the donor cells or edited cells are human cells (e.g., the subject is a human, and the cells are human cells).
[00336] In some embodiments, the second isoform of the target protein refers to the form that is present in the subject. In some embodiments, the second isoform of the target protein refers to the wild type form or native form of the target protein (i.e., the form that usually occurs in nature), and the first isoform refers to an isoform obtained by introducing a mutation in the nucleic acid sequence encoding the second isoform. The native form of a protein refers to a protein that is encoded by a nucleic acid sequence within the genome of the cell and that has not been inserted or mutated by genetic manipulation (i.e., a native protein is a protein that is not a transgenic protein or a genetically engineered protein).
[00337] The mutation in the first isoform can be any type of mutation and any size mutation. In some embodiments, the mutation comprises an insertion, a deletion and/or a substitution of 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids (e.g., 1-20 amino acids, 1-5 amino acids, 1-3 amino acids, or 1 amino acid). In some embodiments, the mutation comprises one or more (e.g., three) substitutions (e.g., comprises one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation consists essentially of one or more (e.g., three) substitutions (e.g., consists essentially of one or more (e.g., three) substitutions of 1 amino acid each). In some embodiments, the mutation consists of one or more (e.g., three) substitutions (e.g., consists of one or more (e.g., three) substitutions of 1 amino acid
each). In some embodiments, the mutation comprises an insertion (e.g., comprises an insertion of 1 amino acid). In some embodiments, the mutation consists essentially of an insertion (e.g., consists essentially of an insertion of 1 amino acid). In some embodiments, the mutation consists of an insertion (e.g., consists of an insertion of 1 amino acid). The mutation can be at any site in the target protein. For example, if the target protein is a cell surface protein, the mutation can in some embodiments be in the extracellular domain of the target protein. In some embodiments, the site of the mutation can be a site that is non-conserved between different mammalian species. In some embodiments, the mutation does not result in a secondary structure change in the surface protein. In some embodiments, the mutation is within the epitope targeted by an antigen-binding protein or is at a site that is accessible to ligand binding. In some embodiments, the mutation is not located at a site involved in a predicted or experimentally established or confirmed proteinprotein interaction of the surface protein. In some embodiments, the mutation does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking. In some embodiments, the mutation does not result in deleting or introducing a posttranslational protein modification site, such as a glycosylation site. In some embodiments, the mutation is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction. In instances where an antibody or antigen-binding protein reactive against a target protein already exists, the information regarding the epitope of the target protein that is recognized by the antibody or antigen-binding protein can be used to select the site of the mutation.
[00338] In some embodiments, the mutation in the first isoform can be any type of mutation and any size mutation as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject. In some embodiments, the first isoform of the target protein is a genetically engineered isoform of the target protein. For example, the first isoform of the target protein can be genetically engineered to comprise a mutation (e.g., an artificial mutation that is not naturally occurring) to provide an altered epitope. The altered epitope can be, for example, in the binding region of an antigen-binding protein such as an antibody. In some embodiments, the target protein is CXCR4 (e.g., human CXCR4), and the altered epitope is in a binding region of the REGN7663 or REGN7664 anti-CXCR4 antibodies described elsewhere herein. The ECL2 region of human CXCR4, which is from position A175 to position V198 of human CXCR4 (SEQ
ID NO: 1), is necessary and sufficient for REGN7663 and REGN7664 binding. In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) encoded by nucleotides within coding exon 2 of the CXCR4 gene (e.g., human CXCR4 gene). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the ECL2 region of CXCR4 (e.g., human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position A175 to position V198 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position SI 78 to position R183 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position R188 to position LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the REGN7663 and REGN7664 binding region (SEQ ID NO: 57). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198. In some embodiments, the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198. In some embodiments, the mutation can comprise a mutation (e.g., an insertion) between A175 and N176, between N176 and V177, between V177 and S178, between S178 and E179, between E179 and A180, between A180 and D181, between D181 and D182, between D182 and R183, between R183 and Y184, between Y184 and 1185, between 1185 and Cl 86, between Cl 86 and DI 87, between DI 87 and R188, between R188 and Fl 89, between Fl 89 and Y190, between Y190 and Pl 91, between P191 and N192, between N192 and DI 93, and/or between DI 93 and LI 94 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the
mutation can comprise a mutation (e.g., an insertion) between SI 78 and El 79. In some embodiments, the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198, and a mutation (e.g., an insertion) between S178 and E179. In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) or combination of mutations as set forth in Table 1.
[00339] In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion), or combination of mutations, as set forth in pMM626, pMM630, pMM632, pMM633, and pMM640 (corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively). For example, the mutation can comprise a mutation (e.g., a substitution) at position Fl 89, N192, D193, E179, D181, and/or D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); a mutation (e.g., an insertion) between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); or any combination thereof of CXCR4 (e.g., human CXCR4). A mutation at a position within CXCR4 encompasses mutations (e.g., substitutions and/or insertions) including only the residue at that position or mutations (e.g., substitutions and/or insertions) including the residue at that position as well as other residues at other positions. The nomenclature of the amino acid position for the mutations or residue disclosed herein refer to the position of the mutation or residue in the canonical isoform of human CXCR4 set forth in SEQ ID NO: 1.
[00340] In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position F189 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable Fl 89 substitution is an F189A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position N192 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable N192 substitution is an N192A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 93 substitution is an DI 93 A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at
positions F189, N192, and D193 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable Fl 89, N192, and DI 92 substitutions are F189A, N192A, and D192A substitutions. In some embodiments, the mutation comprises an insertion between SI 78 and El 79 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable insertions include an S178_E179insK (e.g., insertion of K between S178 and E179), S178_E179insY (e.g., insertion of Y between S178 and E179), and S178_E179insR (e.g., insertion of R between S178 and E179). In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position El 79 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable E179 substitution is an E179R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position DI 81 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 81 substitution is an DI 81R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position DI 82 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 82 substitution is an D182R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at positions E179, D181, and D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable E179, D181, and D182 substitutions are E179R, D181R, and D182R substitutions. [00341] In some embodiments, the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 91 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of F189A, N192A, and N193 A relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00342] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 95 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insK relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00343] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth
in SEQ ID NO: 97 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178 E179insY relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00344] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 98 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insR relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00345] In some embodiments, the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 105 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of E179R, D181R, and D182R relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00346] The agent for selective inhibition or selective depletion of cells expressing a first isoform can be any suitable agent as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject. In some embodiments, the agent comprises an antagonist that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein. In some embodiments, the agent comprises an antigen-binding protein that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein. In some embodiments, the agent comprises a population of cells (i.e., immune effector cells such as chimeric antigen receptor T cells (CAR- T)) expressing an antigen-binding protein that specifically binds to the second isoform of the target protein but does not specifically bind to the first isoform of the target protein.
[00347] The agent can in some embodiments be for administration simultaneously with the donor cells or edited cells. In some embodiments, the donor cells or edited cells are for administration after the agent. For example, in some embodiments, the donor cells or edited cells are for administration within a day after the agent or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5
weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more after the agent. In some embodiments, the donor cells or edited cells are for administration before the agent. For example, in some embodiments, the donor cells or edited cells are for administration within a day before the agent or at least about 1 day, at least about 2 days, at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 1 week, at least about 2 weeks, at least about 3 weeks, at least about 4 weeks, at least about 5 weeks, at least about 6 weeks, at least about 7 weeks, at least about 8 weeks, at least about 9 weeks, at least about 10 weeks, at least about 11 weeks, at least about 12 weeks, at least about 3 months, at least about 4 months, at least about 5 months, at least about 6 months or more before the agent. [00348] In some embodiments, the donor cells or edited cells are for administration in multiple administrations (e.g., doses). In some embodiments, the donor cells or edited cells are for administration to the subject once. In some embodiments, the donor cells or edited cells are for administration to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the donor cells or edited cells are for administration to the subject at a regular interval (e.g., every 6 months). In some embodiments, the agent is for administration in multiple administrations (e.g., doses). In some embodiments, the agent is for administration to the subject once. In some embodiments, the agent is for administration to the subject more than once (e.g., at least 2, at least 3, at least 4, at least 5 or more times). In some embodiments, the agent is for administration to the subject at a regular interval (e.g., every 6 months).
[00349] In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells. In some embodiments, the agent is administered to the subject in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) prior to administration of the donor cells or edited cells and in multiple administrations (e.g., at least 2, at least 3, at least 4, at least 5 or more times) after administration of the donor cells or edited cells.
[00350] In some embodiments, the agent comprises an antigen-binding protein as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject. In some embodiments, selective depletion means selective mobilization of host cells or non-edited cells from the bone marrow to the periphery. In some embodiments, the agent comprises an anti- CXCR4 antigen-binding protein as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject, e.g., a method in which the agent blocks interaction of endogenous ligand with the target on the host cells or non-edited cells. In some embodiments, the agent comprises REGN7663, or a variant thereof as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject or an antigen-binding protein that binds to the same epitope as REGN7663. In some embodiments, the agent comprises REGN7664, or a variant thereof as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject or an antigen-binding protein that binds to the same epitope as REGN7664. In some embodiments, the agent comprises one or more nucleic acids encoding an antigen-binding protein as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject. In some embodiments, the donor cells or edited cells can be engineered to express a therapeutic molecule for cell therapy as described elsewhere herein with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above (e.g., CXCR4) is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule). For example, the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein (e.g., CXCR4) does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer). In some embodiments, the therapeutic molecule may target the diseased cells and/or an antigen expressed on the diseased cells (e.g., a tumor- associated antigen).
[00351] In some embodiments of the present invention, a subject can include, for example, any type of animal or mammal. Mammals include, for example, humans, non-human mammals, non-human primates, monkeys, apes, cats, dogs, horses, bulls, deer, bison, sheep, rabbits, rodents (e.g., but not limited to, mice, rats, hamsters, and guinea pigs), and livestock (e.g., but not limited to, bovine species such as cows and steer; ovine species such as sheep and goats; and porcine species such as pigs and boars). Birds include, for example, chickens, turkeys, ostrich, geese, and ducks. Domesticated animals and agricultural animals are also included. The term “non-human mammal” excludes humans. Particular non-limiting examples of non-human mammals include rodents, such as mice and rats. In some embodiments of the present invention, the subject is a human.
[00352] In some embodiments of the present invention, the combination (e.g., combination medicament) is used for any of the methods for the treatment as described in more detail above. In some embodiments of the present invention, the combination (e.g., combination medicament) is used for any of the methods for the treatment of a hematopoietic malignancy or a hematologic malignancy as described in more detail above. In some embodiments of the present invention, the combination (e.g., combination medicament) is used for any of the methods for the treatment of a cancer (e.g., any type of cancer) as described in more detail above.
[00353] In some embodiments, the subject has a disease, such as a cancer, and the methods are for treating the disease (e.g., the cancer). For example, the donor cells or edited cells can be engineered to express a therapeutic agent for treating that disease (e.g., if the disease is a cancer, the donor cells or edited cells can be engineered to express a CAR or exogenous TCR with antitumor reactivity). For example, the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above (e.g., CXCR4) is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule). For example, the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein (e.g., CXCR4) does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer). In some embodiments, the therapeutic molecule may target the diseased cells
and/or an antigen expressed on the diseased cells (e.g., a tumor-associated antigen).
[00354] In some embodiments, the subject (e.g., human subject) has a hematopoietic malignancy. As used herein a hematopoietic malignancy refers to a malignant abnormality involving hematopoietic cells (e.g., blood cells, including progenitor and stem cells). Examples of hematopoietic malignancies include, without limitation, Hodgkin’s lymphoma, non-Hodgkin’s lymphoma, leukemia, and multiple myeloma. Exemplary leukemias include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myelogenous leukemia, acute lymphoblastic leukemia or chronic lymphoblastic leukemia, and chronic lymphoid leukemia. [00355] In some embodiments, the subject has a cancer, such as a solid tumor cancer or a liquid tumor cancer. In some embodiments, the subject has a solid tumor cancer. A solid tumor is a solid mass of cancer cells that grow in organ systems and can occur anywhere in the body, such as breast cancer. In contrast, liquid tumors are cancers that develop in the blood, bone marrow, or lymph nodes and includes leukemia, lymphoma, and myeloma. In some embodiments, the subject has a cancer, such as a hematologic cancer. Hematologic cancers are cancers that begin in blood-forming tissue, such as the bone marrow, or in the cells of the immune system. Examples of hematologic cancers include leukemia, lymphoma, and multiple myeloma. Hematologic cancers are also referred to blood cancer. In some embodiments, the subject has a hematopoietic disorder. In some embodiments, the subject has defective immune cells or a genetic deficiency in hematopoiesis, such as sickle cell disease or severe combined immunodeficiency (SCID). In some embodiments, the subject has a genetic hematopoietic disease (e.g., thalassemia). In some embodiments, the subject has a T-cell-mediated diseases, such as an IPEX-like syndrome, a CTLA-4-associated immune dysregulation, a hemophagocytic syndrome, ALPS syndrome, or a syndrome caused by heterozygous PTEN germline mutations. In some embodiments, the subject has an autoimmune disease. In some embodiments, the subject has graft-versus-host-disease. In some embodiments, the methods are for correction of congenital hematopoietic deficiencies.
[00356] In some embodiments of the present invention, any of the methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for conditioning a subject’s tissues (e.g., bone marrow) for engraftment or transplant. Such methods can be useful for treating such diseases without causing the toxicities that are observed in response to traditional conditioning therapies. In some embodiments of the present invention, any of the methods for improving
engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject described herein are methods for treating a subject defective or deficient in one or more cell types of the hematopoietic lineage. The methods can, in some embodiments, reconstitute the defective or deficient population of cells in vivo, thereby treating the pathology associated with the defect or depletion in the endogenous blood cell population. In some embodiments, the compositions and methods described herein can thus be used to treat a non- malignant hemoglobinopathy (e.g., a hemoglobinopathy selected from the group consisting of sickle cell anemia, thalassemia, Fanconi anemia, aplastic anemia, and Wiskott-Aldrich syndrome). In some embodiments, the compositions and methods described herein can be used to treat a malignancy or proliferative disorder, such as a cancer, such as hematologic cancer or a myeloproliferative disease. In the case of cancer treatment, in some embodiments the compositions and methods described herein may be administered to a patient so as to deplete a population of endogenous hematopoietic stem cells prior to hematopoietic stem cell transplantation therapy, in which case the transplanted cells can home to a niche created by the endogenous cell depletion step and establish productive hematopoiesis. This, in turn, can reconstitute a population of cells depleted during cancer cell eradication, such as during systemic chemotherapy. In some embodiments, the donor cells or edited cells can be engineered to express a therapeutic agent for treating the cancer (e.g., the donor cells or edited cells can be engineered to express a CAR or exogenous TCR with anti-tumor reactivity). Exemplary cancers that can be treated using the compositions and methods described herein include, without limitation, adenoid cystic carcinoma, adrenal gland cancer, anal cancer, basal cell carcinoma, bile duct cancer, bladder cancer, bone cancer, brain cancer, breast cancer, carcinoid tumor, cervical cancer, colorectal cancer, ductal carcinoma, endometrial cancer, esophageal cancer, gastric cancer, gastrointestinal stromal tumor - GIST, HER2-positive breast cancer, islet cell tumor, kidney cancer, laryngeal cancer, leukemia - acute lymphoblastic leukemia, leukemia - acute lymphocytic (ALL), leukemia - acute myeloid (AML), leukemia - adult, leukemia - childhood, leukemia - chronic lymphocytic (CLL), leukemia - chronic myeloid (CML), liver cancer, lobular carcinoma, lung cancer, lung cancer - small cell, lymphoma - Hodgkin’s, lymphoma - non-Hodgkin’s, malignant glioma, melanoma, meningioma, multiple myeloma, nasopharyngeal cancer, neuroendocrine cancer, oral cancer, osteosarcoma, ovarian cancer, pancreatic cancer, pancreatic neuroendocrine cancer, parathyroid cancer, penile cancer, peritoneal cancer, pituitary gland
cancer, prostate cancer, renal cell carcinoma, retinoblastoma, salivary gland cancer, sarcoma, sarcoma - Kaposi, skin cancer, small intestine cancer, stomach cancer, testicular cancer, thymoma, thyroid cancer, uterine (endometrial) cancer, vaginal cancer, Wilms’ tumor. Exemplary hematological cancers that can be treated using the compositions and methods described herein include, without limitation, acute myeloid leukemia, acute lymphoid leukemia, chronic myeloid leukemia, chronic lymphoid leukemia, multiple myeloma, diffuse large B-cell lymphoma, and non-Hodgkin’s lymphoma, as well as other cancerous conditions, including neuroblastoma. Exemplary solid tumors that can be treated using the compositions and methods described herein include, without limitation, sarcomas and carcinomas. Sarcomas are tumors in a blood vessel, bone, fat tissue, ligament, lymph vessel, muscle or tendon. Carcinomas are tumors that form in epithelial cells. Epithelial cells are found in the skin, glands and the linings of organs.
VI. Engineered CXCR4 Proteins and Cell(s) Comprising Modified CXCR4 Proteins
[00357] In some embodiments of the present invention, genetically engineered C-X-C motif chemokine receptor 4 (CXCR4) proteins are provided comprising an artificial mutation to provide an altered epitope. In some embodiments, the genetically engineered CXCR4 protein is functionally indistinguishable but immunologically distinguishable from a native or wild type CXCR4 protein.
[00358] The genetically engineered CXCR4 protein can comprise any mutation as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject. In some embodiments, the mutation in the genetically engineered CXCR4 protein can be any type of mutation and any size mutation as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or nonedited cells in a subject. The altered epitope can be, for example, in the binding region of an antigen-binding protein such as an antibody. In some embodiments, the target protein is CXCR4 (e g., human CXCR4), and the altered epitope is in a binding region of the REGN7663 or REGN7664 anti-CXCR4 antibodies described elsewhere herein. The ECL2 region of human CXCR4, which is from position A175 to position V198 of human CXCR4 (SEQ ID NO: 1), is necessary and sufficient for REGN7663 and REGN7664 binding. In some embodiments, the mutation can comprise a mutation (e g., a substitution and/or insertion) encoded by nucleotides
within coding exon 2 of the CXCR4 gene (e.g., human CXCR4 gene). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the ECL2 region of CXCR4 (e.g., human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position A175 to position V198 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position SI 78 to position R183 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the region from position R188 to position L194 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) within the REGN7663 and REGN7664 binding region (SEQ ID NO: 57). In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198. In some embodiments, the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198. In some embodiments, the mutation can comprise a mutation (e.g., an insertion) between A175 and N176, between N176 and V177, between V177 and S178, between S178 and E179, between E179 and A180, between A180 and D181, between D181 and D182, between D182 and R183, between R183 and Y184, between Y184 and 1185, between 1185 and C186, between 0186 and D187, between D187 and R188, between R188 and F189, between F189 and Y190, between Y190 and P191, between P191 and N192, between N192 and D193, and/or between DI 93 and L194 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). In some embodiments, the mutation can comprise a mutation (e.g., an insertion) between S178 and E179. In some embodiments, the mutation can comprise a mutation (e.g., a substitution) at one or more of the following positions of CXCR4 (e.g., human CXCR4 or a
corresponding region of CXCR4 when aligned with human CXCR4): A175, N176, V177, S178, E179, A180, D181, D182, R183, Y184, 1185, C186, D187, R188, F189, Y190, P191, N192, D193, L194, W195, V196, V197, and V198, and a mutation (e.g., an insertion) between S178 and E179. In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion) or combination of mutations as set forth in Table 1.
[00359] In some embodiments, the mutation can comprise a mutation (e.g., a substitution and/or insertion), or combination of mutations, as set forth in pMM626, pMM630, pMM632, pMM633, and pMM640 (corresponding to SEQ ID NOS: 91, 95, 97, 98, and 105, respectively). For example, the mutation can comprise a mutation (e.g., a substitution) at position Fl 89, N192, D193, E179, D181, and/or D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); a mutation (e.g., an insertion) between S178 and E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4); or any combination thereof of CXCR4 (e.g., human CXCR4). A mutation at a position within CXCR4 encompasses mutations (e.g., substitutions and/or insertions) including only the residue at that position or mutations (e.g., substitutions and/or insertions) including the residue at that position as well as other residues at other positions. The nomenclature of the amino acid position for the mutations or residue disclosed herein refer to the position of the mutation or residue in the canonical isoform of human CXCR4 set forth in SEQ ID NO: 1.
[00360] In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position F189 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable Fl 89 substitution is an F189A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position N192 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable N192 substitution is an N192A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position D193 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 93 substitution is an DI 93 A substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at positions Fl 89, N192, and DI 93 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable Fl 89, N192, and DI 92 substitutions are F189A, N192A, and D192A substitutions. In some embodiments, the mutation
comprises an insertion between SI 78 and El 79 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable insertions include an S178 E179insK (e.g., insertion of K between S178 and E179), S178_E179insY (e.g., insertion of Y between S178 and E179), and S178_E179insR (e.g., insertion of R between S178 and E179). In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position E179 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable E179 substitution is an E179R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position DI 81 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 81 substitution is an DI 81R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at position DI 82 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). An example of a suitable DI 82 substitution is an D182R substitution. In some embodiments, the mutation comprises a mutation (e.g., a substitution) at positions E179, D181, and D182 of CXCR4 (e.g., human CXCR4 or a corresponding region of CXCR4 when aligned with human CXCR4). Examples of suitable E179, D181, and D182 substitutions are E179R, D181R, and D182R substitutions. [00361] In some embodiments, the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 91 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of F189A, N192A, and N193 A relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00362] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 95 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insK relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00363] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 97 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insY relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when
aligned with human CXCR4).
[00364] In some embodiments, the mutation comprises the mutation (e.g., insertion) set forth in SEQ ID NO: 98 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of S178_E179insR relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00365] In some embodiments, the mutation comprises the mutations (e.g., substitutions) set forth in SEQ ID NO: 105 relative to SEQ ID NO: 57 or relative to positions 175 to 198 of SEQ ID NO: 1. In other words, in some embodiments, the mutation comprises, consists essentially of, or consist of E179R, D181R, and D182R relative to SEQ ID NO: 1 (or a corresponding region of CXCR4 when aligned with human CXCR4).
[00366] In some embodiments of the present invention, nucleic acids encoding the genetically engineered CXCR4 protein are also provided. In some embodiments, the nucleic acid comprises deoxyribonucleic acid (DNA) or ribonucleic acid (RNA). Such nucleic acids can be DNA, RNA, or hybrids or derivatives of either DNA or RNA. Optionally, in some embodiments, the nucleic acid can be codon-optimized for efficient translation into protein in a particular cell or organism. As a non-limiting example, the nucleic acid can be modified to substitute codons having a higher frequency of usage in a human cell, a mammalian cell, a rodent cell, a mouse cell, a rat cell, or any other host cell of interest, as compared to the naturally occurring polynucleotide sequence. Any portion or fragment of a nucleic acid molecule can be produced by: (1) isolating the molecule from its natural milieu; (2) using recombinant DNA technology (e.g., but not limited to, PCR amplification or cloning); or (3) using chemical synthesis methods. Nucleic acids can comprise modifications for improved stability or reduced immunogenicity. Non-limiting examples of modifications include: (1) alteration or replacement of one or both of the nonlinking phosphate oxygens and/or of one or more of the linking phosphate oxygens in the phosphodiester backbone linkage; (2) alteration or replacement of a constituent of a ribose sugar such as alteration or replacement of the 2’ hydroxyl on the ribose sugar; (3) replacement of the phosphate moiety with dephospho linkers; (4) modification or replacement of a naturally occurring nucleobase; (5) replacement or modification of a ribose-phosphate backbone; (6) modification of the 3’ end or 5’ end of the oligonucleotide (e.g., but not limited to, removal, modification or replacement of a terminal phosphate group or conjugation of a moiety); and (7)
modification of the sugar.
[00367] In some embodiments, the nucleic acids can be in the form of an expression construct as defined elsewhere herein. As a non-limiting example, the nucleic acids can include regulatory regions that control expression of the nucleic acid molecule (e.g., but not limited to, transcription or translation control regions), full-length or partial coding regions, and combinations thereof. As a non-limiting example, the nucleic acids can be operably linked to a promoter active in a cell or organism of interest. Promoters that can be used in such expression constructs include promoters active, for example, in one or more of a eukaryotic cell, such as a mammalian cell (e.g., a nonhuman mammalian cell or a human cell), such as a rodent cell (e.g., but not limited to, a mouse cell, or a rat cell). Such promoters can be, for example, conditional promoters, inducible promoters, constitutive promoters, or tissue-specific promoters.
[00368] In some embodiments of the present invention, methods of making the genetically engineered CXCR4 proteins (e.g., human CXCR4 proteins) are also provided. In some embodiments, such methods can comprise determining an epitope in the binding region of a CXCR4 antagonist. In some embodiments, the epitope of the CXCR4 antagonist can be determined by alanine scanning mutational analysis. In some embodiments, the epitope of the CXCR4 antagonist can be determined by peptide blot analysis. In some embodiments, the epitope of the CXCR4 antagonist can be determined by peptide cleavage analysis. In some embodiments, the epitope of the CXCR4 antagonist can be determined by crystallographic studies. In some embodiments, the epitope of the CXCR4 antagonist can be determined by NMR analysis. In some embodiments, the epitope of the CXCR4 antagonist can be determined by epitope excision. In some embodiments, the epitope of the CXCR4 antagonist can be determined by epitope extraction. In some embodiments, the epitope of the CXCR4 antagonist can be determined by chemical modification of antigens. In some embodiments, the epitope of the CXCR4 antagonist can be determined by hydrogen/deuterium exchange detected by mass spectrometry. In some embodiments, the epitope of the CXCR4 antagonist is determined by high-resolution cryogenic electron microscopy analysis of the CXCR4 antagonist complexed with a CXCR4 protein (e.g., human CXCR4 protein).
[00369] In some embodiments, such methods can further comprise selecting a site at which to generate the artificial mutation to provide the altered epitope in the binding region of the CXCR4 antagonist. In some embodiments, the site of the artificial mutation is selected so that it is non-
conserved between different mammalian species. In some embodiments, the site of the artificial mutation is selected so that it does not result in a secondary structure change. In some embodiments, the site of the artificial mutation is selected so that it is at a site that is accessible to ligand binding. In some embodiments, the site of the artificial mutation is selected so that it is not located at a site involved in a predicted or experimentally established or confirmed proteinprotein interaction. In some embodiments, the site of the artificial mutation is selected so that it does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking. In some embodiments, the site of the artificial mutation is selected so that it does not result in deleting or introducing a posttranslational protein modification site. In some embodiments, the site of the artificial mutation is selected so that it is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction.
[00370] In some embodiments, such methods can further comprise generating the genetically engineered CXCR4 protein (e.g., human CXCR4 protein). For example, generating the genetically engineered CXCR4 protein (e.g., human CXCR4 protein) can comprise modifying a cell or population of cells to express the genetically engineered CXCR4 protein (e.g., human CXCR4 protein) as described in more detail elsewhere herein.
[00371] In some embodiments, such methods can further comprise testing the genetically engineered CXCR4 protein (e.g., human CXCR4 protein) to determine whether the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered CXCR4 protein (e.g., human CXCR4 protein) compared to its ability to bind and/or inhibit a wild type CXCR4 protein (e.g., human CXCR4 protein) and to determine whether the genetically engineered CXCR4 protein (e.g., human CXCR4 protein) retains binding to its endogenous ligand(s).
[00372] In some embodiments of the present invention, cells or populations of cells comprising the genetically engineered CXCR4 protein are also provided. In some embodiments, the genetically engineered CXCR4 protein is the only form of CXCR4 expressed by the cells. In other embodiments, the cells express both the genetically engineered CXCR4 protein and the endogenous CXCR4 protein. The cells can be any suitable cells as described above in the context of methods for improving engraftment of donor cells or for selective inhibition or selective depletion of host cells or non-edited cells in a subject. In some embodiments, the cells are
immune cells. In some embodiments, the cells are hematopoietic cells. In some embodiments, the cells are lymphocytes or lymphoid progenitor cells. In some embodiments, the cells are T cells (e.g., CD4+ T cells, CD8+ T cells, memory T cells, regulatory T cells, gamma delta T cells, mucosal-associated invariant T cells (MAIT), tumor infiltrating lymphocytes (TILs), or any combination thereof). In some embodiments, the cells are alpha beta T cells. In some embodiments, the cells are gamma delta T cells. In some embodiments, the cells are TILs. In some embodiments, the cells are B cells. In some embodiments, the cells are natural killer (NK) cells. In some embodiments, the cells are innate lymphoid cells. In some embodiments, the cells are dendritic cells. In some embodiments, the cells are hematopoietic stem cells (HSCs) or hematopoietic stem and progenitor cells (HSPCs) or descendants thereof. HSCs are capable of giving rise to both myeloid and lymphoid progenitor cells that further give rise to myeloid cells (e g., monocytes, macrophages, neutrophils, basophils, dendritic cells, erythrocytes, platelets, etc.) and lymphoid cells (e.g., T cells, B cells, NK cells), respectively. In some embodiments, the cells are induced pluripotent stem cells (e.g., human induced pluripotent stem cells). In some embodiments, the cells are derived from induced pluripotent stem cells (e.g., NK cells derived from induced pluripotent stem cells). In some embodiments, the cells are HSCs or HSPCs. In some embodiments, the cells are derived from HSCs or HSPCs.
[00373] In some embodiments, the cells comprise a genetic modification (insertion of a transgene, correction of a mutation, deletion or inactivation of a gene (e.g., insertion of premature stop codon or insertion of regulatory repressor sequence), or a change in an epigenetic modification important for expression of a gene) correcting or counteracting a disease-related gene defect present in a subject. In some embodiments, the cells comprise or express a therapeutic molecule, such as a therapeutic protein or enzyme, an immunoglobulin (e.g., antibody or antigen-binding fragment thereof), a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR). In some embodiments, the cells comprise a bicistronic nucleic acid construct encoding the therapeutic molecule and the first isoform of the target protein. See, e.g., Yeku et al. (2017) Sci. Rep. 7(1): 10541 and Rafiq et al. (2018) Nat. BiotechnoL 36(9):847- 856, each of which is herein incorporated by reference in its entirety for all purposes, for examples of bicistronic constructs expressing CARs and another molecule. For example, the bicistronic construct can encode both a therapeutic protein (e.g., a CAR, a TCR or antigenbinding fragment of a TCR, or an immunoglobulin) and the first isoform (e.g., a modified
isoform) of the target protein (e.g., CXCR4). In one embodiment, the bicistronic construct encodes a therapeutic protein (e.g., a CAR, a TCR or antigen-binding fragment of a TCR, or an immunoglobulin) and a modified isoform of CXCR4. In some embodiments, the therapeutic molecule, immunoglobulin, CAR, or exogenous TCR does not target the target protein (e.g., CXCR4). In some embodiments, the cells comprise or express an immunoglobulin, a CAR, or an exogenous TCR. In some embodiments, the cells comprise or express a CAR or an exogenous TCR. For example, the donor cells or edited cells can be engineered to express a therapeutic molecule with therapeutic activity against any disease, such as any type of cancer (e.g., not dependent on whether the target protein is related to the disease or cancer), including disease or cancers that are unrelated to the target protein (e.g., the target protein discussed above is not what is being targeted to treat the disease or cancer, but the compositions and methods disclosed herein can provide a competitive advantage to the cells comprising or expressing the therapeutic molecule). For example, the disease or cancer can be a disease or cancer that is not associated with the target protein (e.g., the target protein (e.g., CXCR4) does not cause the disease or cancer, and/or expression of the target protein is not correlated with the disease or cancer). Exemplary types of cancers and tumors that can be treated are described elsewhere herein. In some embodiments, the therapeutic molecule targets the diseased cells and/or an antigen expressed by the diseased cells (e.g., a tumor-associated antigen).
[00374] In some embodiments, the cells are autologous (i.e., from the subject). In some embodiments, the cells are allogeneic (i.e., not from the subject) or syngeneic (i.e., genetically identical, or sufficiently identical and immunologically compatible as to allow for transplantation). In some embodiments, the cells are mammalian cells or non-human mammalian cells (e.g., mouse or rat cells or non-human primate cells) (e.g., the subject is a mammal or a non-human mammal, and the cells are mammalian cells or non-human mammalian cells). In some embodiments, the cells are human cells (e.g., the subject is a human, and the cells are human cells).
[00375] In some embodiments, the cells can further comprise an exogenous donor nucleic acid (e.g., comprising the mutation) and/or a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in a target genomic locus (e.g., a CXCR4 genomic locus). Such exogenous donor nucleic acids and nuclease agents are described above in the context of methods for generating donor cells or
edited cells.
[00376] All patent fdings, websites, other publications, accession numbers and the like cited above or below are incorporated by reference in their entirety for all purposes to the same extent as if each individual item were specifically and individually indicated to be so incorporated by reference. Any feature, step, element, embodiment, or aspect of the invention can be used in combination with any other unless specifically indicated otherwise. Although the present invention has been described in some detail by way of illustration and example for purposes of clarity and understanding, it will be apparent that certain changes and modifications may be practiced within the scope of the appended claims.
BRIEF DESCRIPTION OF THE SEQUENCES
[00377] The nucleotide and amino acid sequences listed in the accompanying sequence listing are shown using standard letter abbreviations for nucleotide bases, and three-letter code for amino acids. The nucleotide sequences follow the standard convention of beginning at the 5’ end of the sequence and proceeding forward (i.e., from left to right in each line) to the 3’ end. Only one strand of each nucleotide sequence is shown, but the complementary strand is understood to be included by any reference to the displayed strand. When a nucleotide sequence encoding an amino acid sequence is provided, it is understood that codon degenerate variants thereof that encode the same amino acid sequence are also provided. When a DNA sequence encoding an amino acid sequence is provided, it is understood that RNA sequences that encode the same amino acid sequence are also provided (by replacing the thymines with uracils). The amino acid sequences follow the standard convention of beginning at the amino terminus of the sequence and proceeding forward (i.e., from left to right in each line) to the carboxy terminus.
Table 2. Description of Sequences.


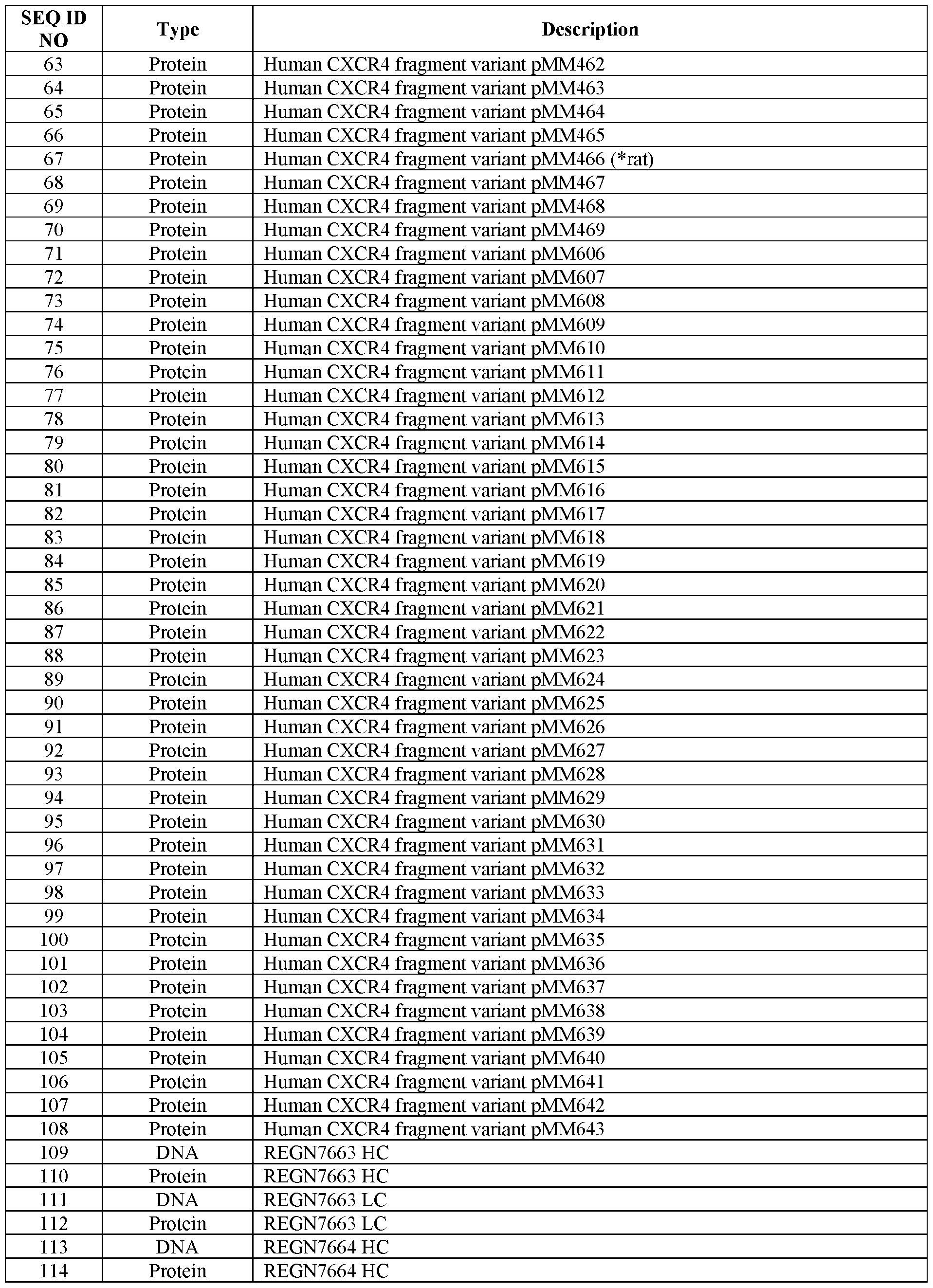

EXAMPLES
Example 1. CXCR4 blocking antibodies mobilize bone marrow resident leukocytes in vivo, with greatest effects on mature B cells.
[00378] Blocking the interaction of C-X-C motif chemokine receptor 4 (CXCR4) with its ligand C-X-C motif chemokine 12 (CXCL12) with antibody, small molecule, or peptide antagonists causes mobilization of mature and progenitor immune cells from the bone marrow to peripheral sites, as illustrated in Figure 1A. In a transplant setting, engineering of donor immune cells with an antibody-resistant variant CXCR4 (ARMoR), as depicted in the schematic of Figure IB, would render them resistant to the effects of anti-CXCR4 mobilization, while host cells expressing wild-type (WT) CXCR4 would remain susceptible. Thus, inclusion of CXCR4 blocking agents in a pre-transplant host conditioning regimen, followed by transplantation of donor cells expression a CXCR4 ARMoR, could afford a competitive advantage to donor cells and enhance levels of donor engraftment.
[00379] Thus, we first sought to examine the effects of anti-human CXCR4 monoclonal antibodies (mAbs) in vivo, with the experimental strategy shown in Figure 2A. Fourteen to 15- week-old CXCR4-humanized male mice were administered a single intravenous dose of 10 mg/kg of anti-CXCR4 REGN7664 (squares, 5 mice), anti-CXCR4 REGN7663 (hexagons, 4 mice) or isotype (human IgG4) REGN1945 (triangles, 6 mice). Sequences for REGN7663 and REGN7664 are shown in Table 3.
[00380] Table 3. REGN7663 and REGN7664 Sequences.



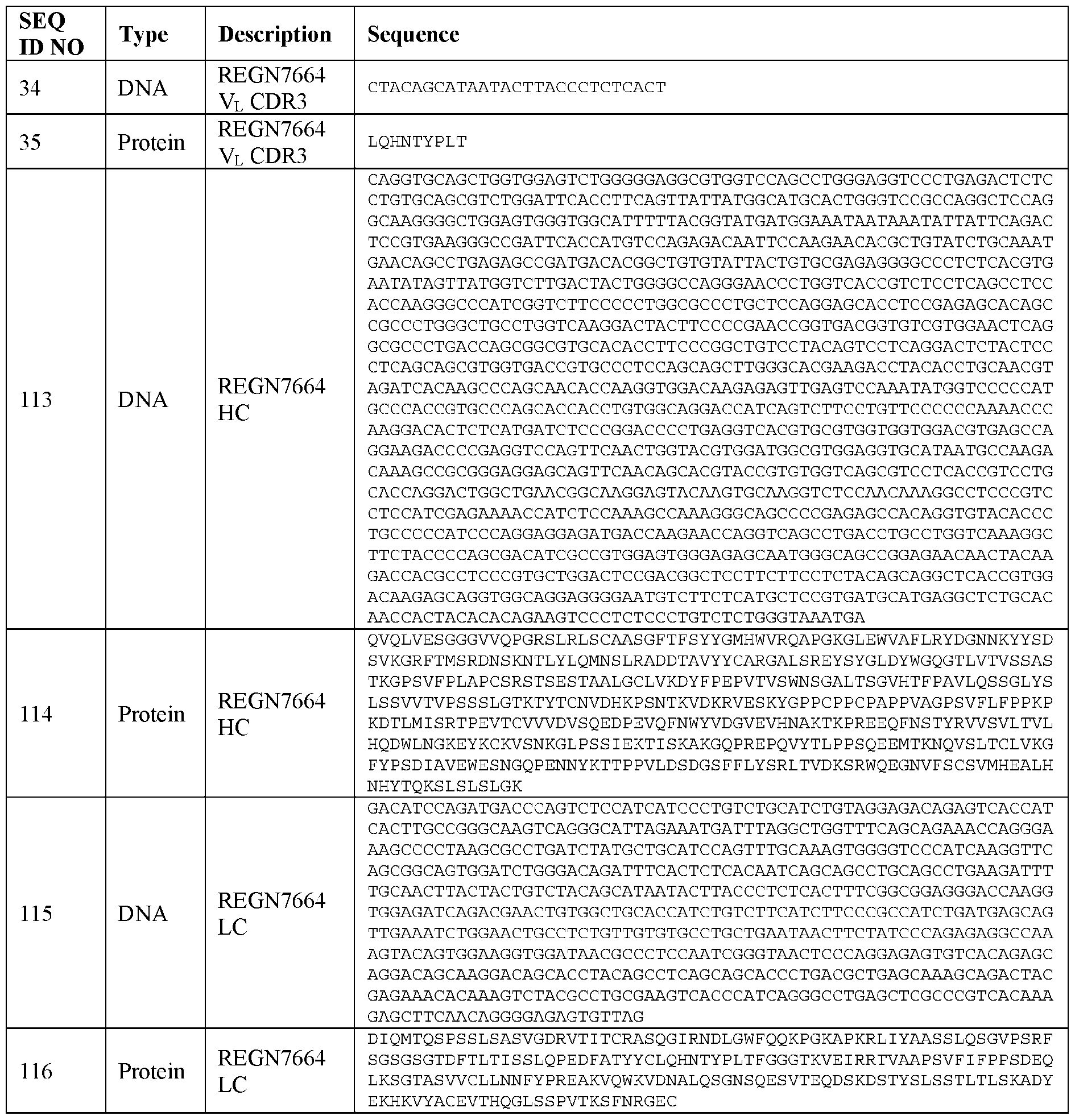
[00381] Complete blood counts were determined prior to treatment and 2 and 6 hours postinjection, and the results are shown in Figure 2B. Graphs display counts of total white blood cells (WBCs), four WBC subsets, and red blood cells (RBCs) in antibody-treated CXCR4 humanized mice throughout the course of the study. We observed significant increases in counts of immune cells with REGN7663 and REGN7664 administration versus isotype (but not RBCs), which indicates mobilization of CXCR4-expressing leukocytes from the bone marrow (BM) to
the peripheral blood (REGN7664 vs REGN1945, *<0.05, **<0.005; REGN7663 vs REGN1945, &<0.05, &&<0.005, Dunnett’s multiple comparison test).
[00382] We next determined whether consecutive doses of anti-CXCR4 REGN7664 could achieve immune progenitor cell mobilization from bone marrow. The study design to examine the effects of repeated anti-human CXCR4 dosing in vivo is shown in Figure 3A. Fourteen to 15-week-old CXCR4-humanized male mice were administered a daily intravenous dose of 10 mg/kg of anti-CXCR4 REGN7664 (squares, 5 mice), anti-CXCR4 REGN7663 (hexagons, 4 mice) or REGN1945, isotype (triangles, 6 mice) for 5 consecutive days. Two hours after the final antibody dose, peripheral blood was collected via cardiac puncture and analyzed by flow cytometry, the results of which are shown in Figure 3B. The graphs display frequencies of lineage-negative cKIT+ (LK) and lineage-negative cKIT+Scal+ (LSK) cells within total lineagenegative cells. There were significantly increased frequencies of HSPC subsets in the peripheral blood, including LSK and LK cells, which indicates mobilization of these subsets from the BM to the peripheral blood following multiple REGN7664 doses (REGN7664 vs REGN1945, **<0.005, multiple unpaired t tests with Benjamini, Krieger, Yekutieli method [Q=l%]).
[00383] We then further determined the effect of CXCR4 blockade in vivo on mature B cells and their progenitors in the bone marrow, with either consecutive doses or a single dose of anti- CXCR4 mAh. Figure 4A illustrates the study design for these experiments. Fourteen to 15- week-old CXCR4-humanized male mice were administered a daily intravenous dose of 10 mg/kg of anti-CXCR4 REGN7664 (squares, 5 mice), anti-CXCR4 REGN7663 (hexagons, 4 mice) or REGN1945, isotype (triangles, 6 mice) for 5 consecutive days (arrows) or a single dose two hours prior to terminal tissue collection (arrowhead). Representative flow cytometry plots of BM-resident B cells (B220+CD43negatlve) cells in CXCR4-humanized mice treated with 5 doses (top row) or single dose (bottom row) of anti-CXCR4 REGN7664 or isotype REGN1945 are shown in Figure 4B. Definitions of B cell subsets in bone marrow were based on Harris et al. (2020) JoVE e61565. We observed significantly decreased frequencies of BM mature B cells (B220+CD43neg IgM+IgD+) following REGN7664 blocking antibody administration, as indicated by the bolded rectangular gates on the flow plots. The effects of in vivo CXCR4 blockade with anti-CXCR4 REGN7663 or REGN7664 in CXCR4-humanized mice on mature and progenitor B cells in BM are summarized in Figure 5. Anti-CXCR4 treatment(s) led to significantly reduced mature, re-circulating B cells and corresponding increased proportions of early pre-B cells
(REGN7664 vs REGN1945, *<0.05, **<0.005, ***<0.001, ****<0.0001 ; REGN7663 vs
REGN1945, &<0.05, &&<0.005, &&&<0.001, &&&&<0.0001; two-way ANOVA with
Tukey’s multiple comparison).
Example 2. Development and analysis of REGN7663-resistant and REGN7664-resistant CXCR4 variants.
Development of anti-CXCR4 mAb-resistant CXCR4 ARMoR variants
[00384] Having demonstrated successful mobilization of mature and progenitor immune cells from the bone marrow to peripheral sites following in vivo administration of the anti-CXCR4 mAbs REGN7663 and REGN7664, we next sought to develop a CXCR4 antibody-resistant modified receptor (ARMoR). To do so, we created human/mouse CXCR4 domain-swap chimeric constructs that were designed to test the binding sites of anti-human-CXCR4 antibodies. Figure 6 shows a schematic of the seven-pass transmembrane protein CXCR4 for both human (black bars) and mouse (white bars) (N term. = N-terminal domain; ICL = intracellular loop; ECL = extracellular loop; C term. = C-terminal domain), along with various domain-swap chimeric constructs used to determine the binding region of human-specific anti- CXCR4 antibodies.
[00385] 293 cells lacking endogenous CXCR4 (via CRISPR editing) were transiently transfected with the chimeric constructs shown in Figure 6, and surface expression was measured by flow cytometry with anti-human CXCR4 REGN7664 (Figure 7A), anti-human CXCR4 REGN7663 (Figure 7B), isotype (h!gG4) control mAb REGN1945 (Figure 7C), and human/mouse cross-reactive anti-CXCR4 clone 2B11 (Figure 7D) (gMFI = geometric mean fluorescence intensity). The dashed lines in Figures 7A and 7B indicate background fluorescence levels established by non-transfected control. As demonstrated by the black bars in Figures 7A and 7B, anti-human-CXCR4 mAbs REGN7663 and REGN7664 bind the extracellular loop 2 (ECL2) domain of CXCR4.
[00386] Next, stable cell lines expressing the domain-swapped constructs were created to confirm the results of the transient expression experiments. To do so, 293 cells lacking endogenous CXCR4 were transduced with lentivirus encoding select chimeric constructs shown in Figure 6 and selected with puromycin to establish stable expression lines. Surface expression of CXCR4 variants was measured by flow cytometry with anti-human CXCR4 REGN7664
(Figure 8A), anti-human CXCR4 REGN7663 (Figure 8B), isotype (h!gG4) control mAb REGN1945 (Figure 8C), and human/mouse cross-reactive anti-CXCR4 clone 2B11 (Figure 8D) (gMFI = geometric mean fluorescence intensity). Stable cell lines expressing domain-swap chimeric constructs confirmed REGN7663 and REGN7664 bind the ECL2 region of human CXCR4.
[00387] To further map the binding determinants of anti-human-CXCR4 REGN7663 and REGN7664, a series of twelve constructs with residue murinizations within the ECL2 region were designed, as shown in Figure 9. The human sequence is represented by CAPITAL letters, the mouse sequence by lowercase letters, and the amino acid residues that differ between mouse and human are underlined. Construct pMM466 encodes the rat sequence of the CXCR4 ECL2. [00388] 293 cells lacking endogenous CXCR4 were transduced with lentivirus encoding the
CXCR4 variant constructs shown in Figure 9 and selected with puromycin to establish stable expression lines. Surface expression of CXCR4 variants was measured by flow cytometry with anti-human CXCR4 REGN7664 (Figure 10A), anti-human CXCR4 REGN7663 (Figure 10B), secondary antibody alone (anti-human-IgG conjugated to PE) (Figure 10C), and human/mouse cross-reactive anti-CXCR4 clone 2B 11 (Figure 10D) (gMFI = geometric mean fluorescence intensity). Reduced binding was achieved in several of the murinized constructs, as well as the rat CXCR4 sequence.
Evaluation of anti-CXCR4-resistant CXCR4 ARMoR variant signaling
[00389] We next sought to examine whether the CXCR4 variants resistant to anti-CXCR4 binding retained the ability to signal in response to CXCL12 ligand stimulation. To do so, a bioassay for CXCR4 signaling was developed using 293 cells engineered with a cyclic AMP (cAMP) response element (CRE)-driven luciferase (Luc) reporter (293.CRE.Luc), as shown in Figure 11. Addition of adenylyl cyclase agonist forskolin leads to elevated cellular cAMP and corresponding CRE.Luc activity (left panel). Activation of CXCR4 signaling by further addition of its ligand CXCL12 counteracts cAMP induction, leading to suppressed CRE.Luc (right panel). To facilitate testing of engineered CXCR4 variants, endogenous CXCR4 was knocked out in the bioassay line (293.CRE.Luc.CXCR4.KO).
[00390] CXCR4 variants shown to be resistant to anti-CXCR4 REGN7663 and/or REGN7664 binding in Figure 10 were evaluated for signaling function in response to ligand CXCL12 in the
bioassay described above. Analysis of CXCR4 variants was split across two different experiments, each including the same control constructs (pMM330, pMM331, pMM341). 293.CRE.Luc.CXCR4.KO cells transduced with indicated CXCR4 variants were incubated with 5 mM forskolin and a dose titration of human CXCL12 ranging from 0-5 nM for 5-6 hours, followed by measurement of luciferase activity. Results for these experiments are shown in Figures 12A and 12B. Y-axis values were calculated by dividing the luminescence readout at each concentration of ligand by the luminescence readout for that line in media containing forskolin alone (no CXCL12). Suppression of CRE.Luc activity indicates CXCL12-mediated signaling. Values are the mean of three technical replicate assay wells, +/- S.D. Expression of CXCR4 variants in the bioassay lines was confirmed by flow cytometry using anti-CXCR4 clone 2B11 (Figure 12C). As shown in Figures 12A and 12B, CXCR4 variants resistant to anti- CXCR4 binding retained signaling function in response to ligand CXCL12.
[00391] The 293. CRE.Luc bioassay shown in Figure 11 was then adapted, as shown in Figure 13, to test blockade of CXCL12-dependent signaling function by anti-CXCR4 mAbs. Bioassay cell lines expressing CXCR4 variants with ablated REGN7664 binding, along with controls (pMM330 and pMM458) retaining binding, were evaluated for blockade of CXCL12/CXCR4 signaling by REGN7664. 293.CRE.Luc.CXCR4.KO cells transduced with indicated CXCR4 variants were incubated with 10 pM forskolin, 10 nM human CXCL12, and the indicated titrations of anti-CXCR4 REGN7664 (Figure 14A) or isotype REGN1945 (human IgG4) (Figure 14B). A restoration of CRE.Luc activity, as observed for pMM330 and pMM458 in the presence of REGN7664, indicates effective signaling block. Failure to restore CRE.Luc activity in the presence of REGN7664 was observed for variants with ablated REGN7664 binding. Values shown are the mean of three technical replicate assay wells, +/- S.D. As expected, CXCR4 variants with a loss of REGN7664 binding were resistant to REGN7664- mediated signaling block.
Development of additional anti-CXCR4 mAb-resistant CXCR4 ARMoR variants
[00392] Additional CXCR4 variants, shown in Figure 15, were designed to further interrogate the binding determinants established in Figure 9, above. The human sequence is represented by CAPITAL letters, the mouse sequence by lowercase letters and other substitutions (neither human nor mouse) are shown in BOLDED CAPITAL letters.
[00393] Binding of anti-CXCR4 REGN7664 (Figure 16A) and REGN7663 (Figure 16B) to CXCR4 variants was measured by flow cytometry on stably transduced 293T cells, as described above. Values for non-transduced and fully human CXCR4-transduced (pMM330) cells were averaged from three independent measurements, while other values were measured once. Several of the CXCR4 variant constructs demonstrated reduced binding of REGN7664 and/or REGN7663. Re-confirmation of anti-CXCR4 REGN7664 (Figure 17A) and REGN7663 (Figure 17B) binding patterns on select CXCR4 ARMoR variants was then performed in 293.CRE.Luc.CXCR4.KO bioassay cells, as described above. CXCR4 variants with diminished antibody binding achieved with minimal changes from WT CXCR4 (indicated by dashed arrows) were selected for further characterization. CXCR4/CXCL12 signaling bioassays, performed as described above and shown in Figure 18, demonstrated that antibody-resistant CXCR4 variants retained signaling function in response to CXCL12 ligand. Values are the mean of three technical replicate assay wells, +/- S.D.
Claims
1. A method for improving engraftment of donor cells in a subject in need thereof, comprising:
(a) providing donor cells that have been modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4, wherein the second isoform is expressed in host cells of the subject;
(b) administering the donor cells to the subject, and
(c) selectively inhibiting host cells in the subject based on their expression of the second isoform of CXCR4, thereby improving engraftment of donor cells in the subject.
2. The method of claim 1, wherein the selective inhibition of host cells in step (c) does not comprise ablation of host cells by an active killing mechanism.
3. The method of claim 1 or 2, wherein the selective inhibition in step (c) comprises selectively depleting host cells from the bone marrow.
4. The method any preceding claim, wherein the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
5. The method of any preceding claim, wherein the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
6. The method of any one of claims 1-4, wherein the donor cells express only the first isoform of CXCR4.
7. The method of any preceding claim, wherein the first isoform of CXCR4 is expressed from an expression vector in the donor cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the donor cells.
8. The method of claim 7, wherein the genomic locus is an endogenous CXCR4 genomic locus.
9. The method of claim 7, wherein the genomic locus is not an endogenous CXCR4 genomic locus.
10. The method of any preceding claim, wherein the selective inhibition in step (c) comprises administering a CXCR4 antagonist to the subject, wherein the CXCR4 antagonist specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4, optionally wherein step (c) comprises multiple administrations of the CXCR4 antagonist.
11. The method of claim 10, wherein the CXCR4 antagonist is an antigenbinding protein.
12. The method of claim 11, wherein the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
13. The method of claim 11 or 12, wherein the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
14. The method of claim 13, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
15. The method of claim 11 or 12, wherein the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and
wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
16. The method of claim 15, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
17. The method of claim 11 or 12, wherein the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
18. The method of claim 17, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
19. The method of claim 11 or 12, wherein the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
20. The method of claim 19, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
21. The method of any preceding claim, wherein the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
22. The method of any preceding claim, wherein the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
23. The method of any one of claims 10-20, wherein the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation, wherein the altered epitope is in a binding region of the CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4.
24. The method of claim 23, wherein both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the CXCR4 antagonist blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
25. The method of any one of claims 22-24, wherein the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
26. The method of any one of claims 22-25, wherein the mutation comprises an insertion, deletion, or substitution within a region from position SI 78 to position R183 and/or within a region from position R188 to position LI 94 of CXCR4.
27. The method of any one of claims 22-26, wherein the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK,
S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178 E179insR; or (5) E179R, D181R, and D182R.
28. The method of any preceding claim, wherein steps (b) and (c) occur simultaneously.
29. The method of any one of claims 1-27, wherein:
(I) step (b) occurs prior to step (c), optionally wherein step (c) comprises multiple administrations of a CXCR4 antagonist subsequent to step (b);
(II) step (b) occurs subsequent to step (c), optionally wherein step (c) comprises multiple administrations of a CXCR4 antagonist prior to step (b); or
(III) step (c) occurs both prior to and subsequent to step (b), optionally wherein step (c) comprises multiple administrations of a CXCR4 antagonist prior to step (b) and/or multiple administrations of the CXCR4 antagonist subsequent to step (b).
30. A method for improving engraftment of donor cells in a subject in need thereof, comprising:
(a) providing donor cells that have been modified to express a first isoform of CXCR4, wherein the first isoform of CXCR4 is different from a second isoform of CXCR4, wherein the second isoform is expressed in host cells of the subject;
(b) administering the donor cells to the subject, and
(c) providing the subject with means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
31. The method of claim 30, wherein the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 selectively inhibits host cells in the subject based on their expression of the second isoform of CXCR4.
32. The method of claim 31, wherein the selective inhibition of host cells does not comprise ablation of host cells by an active killing mechanism.
33. The method of claim 31 or 32, wherein the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
34. The method any one of claims 30-33, wherein the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
35. The method of any one of claims 30-34, wherein the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
36. The method of any one of claims 30-34, wherein the donor cells express only the first isoform of CXCR4.
37. The method of any one of claims 30-36, wherein the first isoform of CXCR4 is expressed from an expression vector in the donor cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the donor cells.
38. The method of claim 37, wherein the genomic locus is an endogenous CXCR4 genomic locus.
39. The method of claim 37, wherein the genomic locus is not an endogenous CXCR4 genomic locus.
40. The method of any one of claims 30-39, wherein the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
41. The method of any one of claims 30-40, wherein the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
42. The method of claim 41, wherein the altered epitope is in a binding region of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 such that the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4.
43. The method of claim 42, wherein both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
44. The method of any one of claims 41-43, wherein the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
45. The method of any one of claims 41-44, wherein the mutation an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position LI 94 of CXCR4.
46. The method of any one of claims 41-45, wherein the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
47. The method of any one of claims 30-46, wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
48. The method of any one of claims 30-47, wherein steps (b) and (c) occur simultaneously.
49. The method of any one of claims 30-47, wherein:
(I) step (b) occurs prior to step (c), optionally wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 subsequent to step (b);
(II) step (b) occurs subsequent to step (c), optionally wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 prior to step (b); or
(III) step (c) occurs both prior to and subsequent to step (b), optionally wherein step (c) comprises multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 prior to step (b) and/or multiple administrations of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 subsequent to step (b).
50. The method of any preceding claim, wherein:
(I) the donor cells and/or the host cells are hematopoietic cells, optionally wherein the donor cells and/or host cells are immune cells;
(II) the donor cells and/or the host cells are lymphocytes or lymphoid progenitor cells;
(III) the donor cells and/or the host cells are T cells;
(IV) the donor cells and/or the host cells are tumor infiltrating lymphocytes
(TILs);
(V) the donor cells and/or the host cells are B cells, optionally wherein the donor cells and/or the host cells are immature B cells, and the method depletes host mature B cells from the bone marrow;
(VI) the donor cells and/or the host cells are NK cells;
(VII) the donor cells and/or the host cells are hematopoietic stem and progenitor cells;
(VIII) the donor cells and/or the host cells are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells; or
(IX) the donor cells are derived from induced pluripotent stem cells.
51. The method of any preceding claim, wherein the subject is a mammal or a non-human mammal, and the donor cells are mammalian cells or non-human mammalian cells.
52. The method of any preceding claim, wherein the subject is a human, and the donor cells are human cells.
53. The method of any preceding claim, wherein the donor cells comprise or express a therapeutic molecule.
54. The method of claim 53, wherein the therapeutic molecule does not target
CXCR4.
55. The method of any preceding claim, wherein the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
56. The method of claim 55, wherein the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
57. The method of any preceding claim, wherein the donor cells are autologous.
58. The method of any one of claims 1-56, wherein the donor cells are allogeneic or syngeneic.
59. The method of any preceding claim, wherein the subject has a disease or disorder, and the method is for treating the disease or disorder in the subject.
60. The method of any preceding claim, wherein the subject has cancer, optionally wherein the cancer is a solid tumor cancer or a hematologic cancer.
61. The method of any preceding claim, wherein the subject has a hematopoietic malignancy, and the method is for treating the hematopoietic malignancy in the subject.
62. The method of any preceding claim, wherein the subject has defective immune cells or a genetic deficiency in hematopoiesis, optionally wherein the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
63. The method of any preceding claim, further comprising generating the donor cells by modifying a population of cells to express the first isoform of CXCR4 prior to step (a).
64. The method of claim 63, wherein:
(I) the population of cells is a population of induced pluripotent stem cells, and the method further comprises differentiating the induced pluripotent stem cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the induced pluripotent stem cells are differentiated into hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, NK cells, hematopoietic stem cells, or hematopoietic stem and progenitor cells; or
(II) the population of cells is a population of hematopoietic stem cells or hematopoietic stem and progenitor cells, and the method further comprises differentiating the hematopoietic stem cells or hematopoietic stem and progenitor cells prior to step (a) into the donor cells that are administered in step (a), optionally wherein the hematopoietic stem cells or hematopoietic stem and progenitor cells are differentiated into differentiated hematopoietic cells, lymphocytes or lymphoid progenitor cells, T cells, B cells, or NK cells.
65. The method of claim 63 or 64, wherein generating the donor cells comprises introducing an expression vector encoding the first isoform of CXCR4 to express the first isoform of CXCR4 prior to step (a), or wherein generating the donor cells comprises editing a genomic locus in the population of cells to express the first isoform of CXCR4 prior to step (a).
66. The method of claim 65, wherein the genomic locus is an endogenous CXCR4 genomic locus.
67. The method of claim 65, wherein the genomic locus is not an endogenous CXCR4 genomic locus.
68. The method of any one of claims 65-67, wherein the editing comprises introducing into the population of cells:
(1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and
(2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the donor cells that express the first isoform of CXCR4.
69. The method of claim 68, wherein the nuclease agent comprises:
(a) a zinc finger nuclease (ZFN);
(b) a transcription activator-like effector nuclease (TALEN); or
(c) (i) a Cas protein; and
(ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
70. The method of claim 69, wherein the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131.
71. The method of claim 69 or 70, wherein the Cas protein is a Cas9 protein.
72. The method of any one of claims 68-71, wherein the exogenous donor nucleic acid comprises homology arms.
73. The method of any one of claims 68-72, wherein the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN).
74. The method of any one of claims 63-73, further comprising isolating the population of cells from the subject or from a different subject prior to modifying the population of cells.
75. A combination medicament for administration to a subject in need thereof, comprising:
(a) a population of donor cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4; and
(b) a CXCR4 antagonist that specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4.
76. The combination medicament of claim 75, wherein the CXCR4 antagonist
selectively inhibits host cells in the subject based on their expression of the second isoform of CXCR4.
77. The combination medicament of claim 76, wherein the selective inhibition of host cells does not comprise ablation of host cells by an active killing mechanism.
78. The combination medicament of claim 76 or 77, wherein the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
79. The combination medicament of any one of claims 75-78, wherein the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
80. The combination medicament of any one of claims 75-79, wherein the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
81. The combination medicament of any one of claims 75-79, wherein the donor cells express only the first isoform of CXCR4.
82. The combination medicament of any one of claims 75-81, wherein the first isoform of CXCR4 is expressed from an expression vector in the population of donor cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the population of donor cells.
83. The combination medicament of claim 82, wherein the genomic locus is an endogenous CXCR4 genomic locus.
84. The combination medicament of claim 82, wherein the genomic locus is not an endogenous CXCR4 genomic locus.
85. The combination medicament of any one of claims 75-84, wherein the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
86. The combination medicament of any one of claims 75-85, wherein the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
87. The combination medicament of claim 86, wherein the altered epitope is in a binding region of the CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4.
88. The combination medicament of claim 87, wherein both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the CXCR4 antagonist blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
89. The combination medicament of any one of claims 86-88, wherein the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
90. The combination medicament of any one of claims 86-89, wherein the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position LI 94 of CXCR4.
91. The combination medicament of any one of claims 86-90, wherein the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
92. The combination medicament of any one of claims 75-91, wherein the CXCR4 antagonist is an antigen-binding protein.
93. The combination medicament of claim 92, wherein the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
94. The combination medicament of claim 92 or 93, wherein the antigenbinding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
95. The combination medicament of claim 94, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
96. The combination medicament of claim 92 or 93, wherein the antigenbinding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
97. The combination medicament of claim 96, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
98. The combination medicament of claim 92 or 93, wherein the antigenbinding protein comprises an immunoglobulin light chain or variable region thereof comprising
three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
99. The combination medicament of claim 98, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
100. The combination medicament of claim 92 or 93, wherein the antigenbinding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
101. The combination medicament of claim 100, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
102. A combination medicament for administration to a subject in need thereof, comprising:
(a) a population of donor cells modified to express a first isoform of CXCR4, wherein the first isoform of CXCR4 is different from a second isoform of CXCR4; and
(b) means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4.
103. The combination medicament of claim 102, wherein the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 selectively inhibits host cells in the subject based on their expression of the second isoform of CXCR4.
104. The combination medicament of claim 103, wherein the selective inhibition of host cells does not comprise ablation of host cells by an active killing mechanism.
105. The combination medicament of claim 103 or 104, wherein the selective inhibition of host cells comprises selectively depleting host cells from the bone marrow.
106. The combination medicament of any one of claims 102-105, wherein the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
107. The combination medicament of any one of claims 102-106, wherein the donor cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
108. The combination medicament of any one of claims 102-106, wherein the donor cells express only the first isoform of CXCR4.
109. The combination medicament of any one of claims 102-108, wherein the first isoform of CXCR4 is expressed from an expression vector in the population of donor cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the population of donor cells.
110. The combination medicament of claim 109, wherein the genomic locus is an endogenous CXCR4 genomic locus.
111. The combination medicament of claim 109, wherein the genomic locus is not an endogenous CXCR4 genomic locus.
112. The combination medicament of any one of claims 102-111 , wherein the first isoform of CXCR4 is a genetically engineered isoform of CXCR4.
113. The combination medicament of any one of claims 102-112, wherein the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, optionally wherein the mutation is an artificial mutation.
114. The combination medicament of claim 113, wherein the altered epitope is in a binding region of the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 such that the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4.
115. The combination medicament of claim 114, wherein both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an endogenous ligand, optionally wherein the means for specifically binding the second isoform of CXCR4 but not the first isoform of CXCR4 blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
116. The combination medicament of any one of claims 113-115, wherein the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
117. The combination medicament of any one of claims 113-116, wherein the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position LI 94 of CXCR4.
118. The combination medicament of any one of claims 113-117, wherein the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
119. The combination medicament of any one of claims 75-118, wherein:
(I) the donor cells are hematopoietic cells, optionally wherein the donor cells are immune cells;
(II) the donor cells are lymphocytes or lymphoid progenitor cells;
(III) the donor cells are T cells;
(IV) the donor cells are tumor infiltrating lymphocytes (TTLs);
(V) the donor cells are B cells;
(VI) the donor cells are NK cells;
(VII) the donor cells are hematopoietic stem cells or hematopoietic stem and progenitor cells; or
(VIII) the donor cells are derived from induced pluripotent stem cells or are derived from hematopoietic stem cells or hematopoietic stem and progenitor cells.
120. The combination medicament of any one of claims 75-119, wherein the subject is a mammal or a non-human mammal, and the donor cells are mammalian cells or nonhuman mammalian cells.
121. The combination medicament of any one of claims 75-120, wherein the subject is a human, and the donor cells are human cells.
122. The combination medicament of any one of claims 75-121, wherein the donor cells comprise or express a therapeutic molecule.
123. The combination medicament of claim 122, wherein the therapeutic molecule does not target CXCR4.
124. The combination medicament of any one of claims 75-123, wherein the donor cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
125. The combination medicament of claim 124, wherein the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
126. The combination medicament of any one of claims 75-125, wherein the donor cells are autologous.
127. The combination medicament of any one of claims 75-125, wherein the donor cells are allogeneic or syngeneic.
128. The combination medicament of any one of claims 75-127, wherein the subject has a disease or disorder, and the combination medicament is for treating the disease or disorder in the subject.
129. The combination medicament of any one of claims 75-128, wherein the subject has cancer, optionally wherein the cancer is a solid tumor cancer or a hematologic cancer.
130. The combination medicament of any one of claims 75-129, wherein the subject has a hematopoietic malignancy, and the combination medicament is for treating the hematopoietic malignancy in the subject.
131. The combination medicament of any one of claims 75-130, wherein the subject has defective immune cells or a genetic deficiency in hematopoiesis, optionally wherein the genetic deficiency in hematopoiesis is sickle cell disease or severe combined immunodeficiency (SCID).
132. An isolated cell or population of cells modified to express a first isoform of C-X-C chemokine receptor type 4 (CXCR4) that is different from a second isoform of CXCR4, wherein the first isoform of CXCR4 is genetically engineered to comprise a mutation to provide an altered epitope, wherein the altered epitope is in a binding region of a CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the first isoform of CXCR4 compared to its ability to bind and/or inhibit the second isoform of CXCR4, and wherein the first isoform of CXCR4 retains binding to its endogenous ligands.
133. The isolated cell or population of cells of claim 132, wherein the mutation is an artificial mutation.
134. The isolated cell or population of cells of claim 132 or 133, wherein both the first isoform of CXCR4 and the second isoform of CXCR4 retain the ability to bind to an
endogenous ligand, optionally wherein the CXCR4 antagonist blocks the binding of the endogenous ligand to the second isoform of CXCR4 but not the first isoform of CXCR4.
135. The isolated cell or population of cells of any one of claims 132-134, wherein the first isoform and the second isoform are functionally indistinguishable but immunologically distinguishable.
136. The isolated cell or population of cells of any one of claims 132-135, wherein the cell or cells express both the first isoform of CXCR4 and the second isoform of CXCR4.
137. The isolated cell or population of cells of any one of claims 132-135, wherein the cell or cells express only the first isoform of CXCR4.
138. The isolated cell or population of cells of any one of claims 132-137, wherein the first isoform of CXCR4 is expressed from an expression vector in the cell or cells, or wherein a genomic locus has been edited to express the first isoform of CXCR4 in the cell or cells.
139. The isolated cell or population of cells of claim 138, wherein the genomic locus is an endogenous CXCR4 genomic locus.
140. The isolated cell or population of cells of claim 138, wherein the genomic locus is not an endogenous CXCR4 genomic locus.
141. The isolated cell or population of cells of any one of claims 132-140, wherein the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
142. The isolated cell or population of cells of any one of claims 132-141, wherein the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
143. The isolated cell or population of cells of any one of claims 132-142, wherein the mutation comprises one or more mutations selected from: F189A, N192A, D193A,
S178_E179insK, S178_E179insY, S178_E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178 E179insY; (4) S178 E179insR; or (5) E179R, D181R, and D182R.
144. The isolated cell or population of cells of any one of claims 132-143, wherein the first isoform and the second isoform are immunologically distinguishable by the CXCR4 antagonist, wherein the CXCR4 antagonist specifically binds to the second isoform of CXCR4 but does not specifically bind to the first isoform of CXCR4.
145. The isolated cell or population of cells of claim 144, wherein the CXCR4 antagonist is an antigen-binding protein.
146. The isolated cell or population of cells of claim 145, wherein the antigenbinding protein is an antibody or an antigen-binding fragment thereof.
147. The isolated cell or population of cells of claim 145 or 146, wherein the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
148. The isolated cell or population of cells of claim 147, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
149. The isolated cell or population of cells of claim 145 or 146, wherein the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises,
consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
150. The isolated cell or population of cells of claim 149, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
151. The isolated cell or population of cells of claim 145 or 146, wherein the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
152. The isolated cell or population of cells of claim 151, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
153. The isolated cell or population of cells of claim 145 or 146, wherein the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and
wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
154. The isolated cell or population of cells of claim 153, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
155. The isolated cell or population of cells of any one of claims 132-154, wherein:
(I) the cell or cells are hematopoietic cell(s), optionally wherein the cell or cells are immune cell(s);
(II) the cell or cells are lymphocytes or lymphoid progenitor cell(s);
(III) the cell or cells are T cell(s);
(IV) the cell or cells are tumor infdtrating lymphocyte(s) (TILs);
(V) the cell or cells are B cell(s);
(VI) the cell or cells are NK cell(s);
(VII) the cell or cells are hematopoietic stem cell(s) or hematopoietic stem and progenitor cell(s); or
(VIII) the cell or cells are induced pluripotent stem cell(s).
156. The isolated cell or population of cells of any one of claims 132-155, wherein the cell or cells are mammalian cell(s) or non-human mammalian cell(s).
157. The isolated cell or population of cells of any one of claims 132-156, wherein the cell or cells are human cell(s).
158. The isolated cell or population of cells of any one of claims 132-157, wherein the cell or cells comprise or express a therapeutic molecule.
159. The isolated cell or population of cells of claim 158, wherein the therapeutic molecule does not target CXCR4.
160. The isolated cell or population of cells of any one of claims 132-159, wherein the cell or cells comprise or express an immunoglobulin, a chimeric antigen receptor (CAR), or an exogenous T cell receptor (TCR).
161. The isolated cell or population of cells of claim 160, wherein the immunoglobulin, the CAR, or the exogenous TCR does not target CXCR4.
162. The isolated cell or population of cells of any one of claims 132-161, wherein the cell or cells are isolated from a subject.
163. The isolated cell or population of cells of any one of claims 132-162 for use in treatment of a subject having cells expressing the second isoform of CXCR4.
164. The isolated cell or population of cells for use of claim 163, wherein the cell or cells are isolated from the subject.
165. A method of making the isolated cell or population of cells of any one of claims 132-164, comprising modifying a cell or population of cells to express the first isoform of CXCR4.
166. The method of claim 165, wherein the modifying comprises introducing an expression vector encoding the first isoform of CXCR4, or wherein the modifying comprises editing a genomic locus to express the first isoform of CXCR4.
167. The method of claim 166, wherein the genomic locus is an endogenous CXCR4 genomic locus.
168. The method of claim 166, wherein the genomic locus is not an endogenous CXCR4 genomic locus.
169. The method of any one of 166-168, wherein the editing comprises introducing into the cells:
(1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and
(2) an exogenous donor nucleic acid,
wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate the cells that express the first isoform of CXCR4.
170. The method of claim 169, wherein the nuclease agent comprises:
(a) a zinc finger nuclease (ZFN);
(b) a transcription activator-like effector nuclease (TALEN); or
(c) (i) a Cas protein; and
(ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
171. The method of claim 170, wherein the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131.
172. The method of claim 170 or 171, wherein the Cas protein is a Cas9 protein.
173. The method of any one of claims 169-172, wherein the exogenous donor nucleic acid comprises homology arms.
174. The method of any one of claims 169-173, wherein the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN).
175. A genetically engineered human C-X-C chemokine receptor type 4 (CXCR4) protein comprising an artificial mutation to provide an altered epitope, wherein the altered epitope is in a binding region of a CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered human CXCR4 protein compared to its ability to bind and/or inhibit a wild type human CXCR4 protein, and wherein the genetically engineered human CXCR4 protein retains binding to its endogenous ligand(s).
176. The genetically engineered human CXCR4 protein of claim 175, wherein the genetically engineered CXCR4 protein is functionally indistinguishable but immunologically distinguishable from a native CXCR4 protein.
177. The genetically engineered human CXCR4 protein of claim 175 or 176, wherein the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
178. The genetically engineered human CXCR4 protein of any one of claims 175-177, wherein the mutation comprises an insertion, deletion, or substitution within a region from position S178 to position R183 and/or within a region from position R188 to position L194 of CXCR4.
179. The genetically engineered human CXCR4 protein of any one of claims 175-178, wherein the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178_E179insY, S 178_E 179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
180. The genetically engineered human CXCR4 protein of any one of claims 175-179, wherein the genetically engineered CXCR4 protein and the native CXCR4 protein are functionally indistinguishable but immunologically distinguishable by the CXCR4 antagonist.
181. The genetically engineered human CXCR4 protein of claim 180, wherein the CXCR4 antagonist is an antigen-binding protein.
182. The genetically engineered human CXCR4 protein of claim 181, wherein the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
183. The genetically engineered human CXCR4 protein of claim 181 or 182, wherein the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs,
wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
184. The genetically engineered human CXCR4 protein of claim 183, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
185. The genetically engineered human CXCR4 protein of claim 181 or 182, wherein the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
186. The genetically engineered human CXCR4 protein of claim 185, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
187. The genetically engineered human CXCR4 protein of claim 181 or 182 wherein the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs,
wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
188. The genetically engineered human CXCR4 protein of claim 187, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
189. The genetically engineered human CXCR4 protein of claim 181 or 182, wherein the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21 .
190. The genetically engineered human CXCR4 protein of claim 189, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
191. A nucleic acid encoding the genetically engineered human CXCR4 protein of any one of claims 175-190, optionally wherein the nucleic acid is an expression vector encoding the genetically engineered human CXCR4 protein.
192. A method of making a genetically engineered human C-X-C chemokine receptor type 4 (CXCR4) protein comprising an artificial mutation to provide an altered epitope,
wherein the altered epitope is in a binding region of a CXCR4 antagonist such that the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered human CXCR4 protein compared to its ability to bind and/or inhibit a wild type human CXCR4 protein, and wherein the genetically engineered human CXCR4 protein retains binding to its endogenous ligand(s), comprising:
(a) determining an epitope in the binding region of the CXCR4 antagonist;
(b) selecting a site at which to generate the artificial mutation to provide the altered epitope in the binding region of the CXCR4 antagonist;
(c) generating the genetically engineered human CXCR4 protein comprising the artificial mutation to provide the altered epitope in the binding region of the CXCR4 antagonist; and
(d) testing the genetically engineered human CXCR4 protein to determine whether the CXCR4 antagonist exhibits reduced or abolished ability to bind and/or inhibit the genetically engineered human CXCR4 protein compared to its ability to bind and/or inhibit a wild type human CXCR4 protein and to determine whether the genetically engineered human CXCR4 protein retains binding to its endogenous ligand(s).
193. The method of claim 192, wherein the epitope of the CXCR4 antagonist is determined by alanine scanning mutational analysis, peptide blot analysis, peptide cleavage analysis, crystallographic studies, NMR analysis, epitope excision, epitope extraction, chemical modification of antigens, and/or hydrogen/deuterium exchange detected by mass spectrometry.
194. The method of claim 192 or 193, wherein the epitope of the CXCR4 antagonist is determined by high-resolution cryogenic electron microscopy analysis of the CXCR4 antagonist complexed with a human CXCR4 protein.
195. The method of any one of claims 192-194, wherein the site of the artificial mutation is selected so that it:
(I) is non-conserved between different mammalian species;
(II) does not result in a secondary structure change;
(III) is at a site that is accessible to ligand binding;
(IV) is not located at a site involved in a predicted or experimentally established or confirmed protein-protein interaction;
(V) does not result in deleting or introducing a disulfide bond inter- or intramolecular interaction or a hydrophobic stacking;
(VI) does not result in deleting or introducing a posttranslational protein modification site; and/or
(VII) is located at a site that has a unique topology compared to other mammalian proteins according to crystal structure analysis or computer-aided structure prediction.
196. The method of any one of claims 192-195, wherein generating the genetically engineered human CXCR4 protein comprises modifying a cell or population of cells to express the genetically engineered human CXCR4 protein.
197. The method of claim 196, wherein the modifying comprises introducing an expression vector encoding the genetically engineered human CXCR4 protein, or wherein the modifying comprises editing a genomic locus to express the genetically engineered human CXCR4 protein.
198. The method of claim 197, wherein the genomic locus is an endogenous CXCR4 genomic locus.
199. The method of claim 197, wherein the genomic locus is not an endogenous CXCR4 genomic locus.
200. The method of any one of claims 197-199, wherein the editing comprises introducing into the cells:
(1) a nuclease agent or one or more nucleic acids encoding the nuclease agent, wherein the nuclease agent targets a nuclease target sequence in the genomic locus; and
(2) an exogenous donor nucleic acid, wherein the nuclease agent cleaves the genomic locus and the exogenous donor nucleic acid is inserted into the genomic locus or recombines with the genomic locus to generate cells that express the genetically engineered human CXCR4 protein.
201 . The method of claim 200, wherein the nuclease agent comprises:
(a) a zinc finger nuclease (ZFN);
(b) a transcription activator-like effector nuclease (TALEN); or
(c) (i) a Cas protein; and
(ii) a guide RNA, wherein the guide RNA comprises a DNA-targeting segment that targets a guide RNA target sequence that is the nuclease target sequence, and wherein the guide RNA binds to the Cas protein and targets the Cas protein to the guide RNA target sequence.
202. The method of claim 201, wherein the nuclease agent comprises the Cas protein and the guide RNA, optionally wherein the DNA-targeting segment comprises the sequence set forth in any one of SEQ ID NOS: 132-146 or optionally wherein the guide RNA target sequence comprises the sequence set forth in any one of SEQ ID NOS: 117-131.
203. The method of claim 201 or 202, wherein the Cas protein is a Cas9 protein.
204. The method of any one of claims 200-203, wherein the exogenous donor nucleic acid comprises homology arms.
205. The method of any one of claims 200-204, wherein the exogenous donor nucleic acid is a single-stranded oligodeoxynucleotide (ssODN).
206. The method of any one of claims 192-205, wherein the genetically engineered human CXCR4 protein is functionally indistinguishable but immunologically distinguishable from a native CXCR4 protein.
207. The method of any one of claims 192-206, wherein the mutation is in the extracellular loop 2 (ECL2) region of CXCR4.
208. The method of any one of claims 192-207, wherein the mutation comprises an insertion, deletion, or substitution within a region from position SI 78 to position R183 and/or within a region from position R188 to position LI 94 of CXCR4.
209. The method of any one of claims 192-208, wherein the mutation comprises one or more mutations selected from: F189A, N192A, D193A, S178_E179insK, S178 E179insY, S178 E179insR, E179R, D181R, and D182R, optionally wherein the mutation comprises: (1) F189A, N192A, and D193A; (2) S178_E179insK; (3) S178_E179insY; (4) S178_E179insR; or (5) E179R, D181R, and D182R.
210. The method of any one of claims 192-209, wherein the genetically engineered human CXCR4 protein and the native CXCR4 protein are functionally indistinguishable but immunologically distinguishable by the CXCR4 antagonist.
211. The method of any one of claims 192-210, wherein the CXCR4 antagonist is an antigen-binding protein.
212. The method of claim 211, wherein the antigen-binding protein is an antibody or an antigen-binding fragment thereof.
213. The method of claim 211 or 212, wherein the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
214. The method of claim 213, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 15, 17, and 19, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 7, 9, and 11, respectively.
215. The method of claim 211 or 212, wherein the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 13, and wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 5.
216. The method of claim 215, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 13, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 5.
217. The method of claim 211 or 212, wherein the antigen-binding protein comprises an immunoglobulin light chain or variable region thereof comprising three light chain CDRs and an immunoglobulin heavy chain or variable region thereof comprising three heavy chain CDRs, wherein the three light chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of sequences at least 90% identical to the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
218. The method of claim 217, wherein the three light chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 31, 33, and 35, respectively, and wherein the three heavy chain CDRs comprise, consist essentially of, or consist of the sequences set forth in SEQ ID NOS: 23, 25, and 27, respectively.
219. The method of claim 211 or 212, wherein the antigen-binding protein comprises an immunoglobulin light chain variable region that comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 29, and
wherein the antigen-binding protein comprises an immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of a sequence at least 90% identical to the sequence set forth in SEQ ID NO: 21.
220. The method of claim 219, wherein the immunoglobulin light chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 29, and wherein the immunoglobulin heavy chain variable region comprises, consists essentially of, or consists of the sequence set forth in SEQ ID NO: 21.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202363579165P | 2023-08-28 | 2023-08-28 | |
| US63/579,165 | 2023-08-28 | ||
| US202363611395P | 2023-12-18 | 2023-12-18 | |
| US63/611,395 | 2023-12-18 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2025049524A1 true WO2025049524A1 (en) | 2025-03-06 |
Family
ID=92801377
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2024/044111 Pending WO2025049524A1 (en) | 2023-08-28 | 2024-08-28 | Cxcr4 antibody-resistant modified receptors |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2025049524A1 (en) |
Citations (48)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US5168062A (en) | 1985-01-30 | 1992-12-01 | University Of Iowa Research Foundation | Transfer vectors and microorganisms containing human cytomegalovirus immediate-early promoter-regulatory DNA sequence |
| US5789215A (en) | 1991-08-20 | 1998-08-04 | Genpharm International | Gene targeting in animal cells using isogenic DNA constructs |
| US6596541B2 (en) | 2000-10-31 | 2003-07-22 | Regeneron Pharmaceuticals, Inc. | Methods of modifying eukaryotic cells |
| US20030232410A1 (en) | 2002-03-21 | 2003-12-18 | Monika Liljedahl | Methods and compositions for using zinc finger endonucleases to enhance homologous recombination |
| US20050026157A1 (en) | 2002-09-05 | 2005-02-03 | David Baltimore | Use of chimeric nucleases to stimulate gene targeting |
| US20050208489A1 (en) | 2002-01-23 | 2005-09-22 | Dana Carroll | Targeted chromosomal mutagenasis using zinc finger nucleases |
| US20060063231A1 (en) | 2004-09-16 | 2006-03-23 | Sangamo Biosciences, Inc. | Compositions and methods for protein production |
| US20080159996A1 (en) | 2006-05-25 | 2008-07-03 | Dale Ando | Methods and compositions for gene inactivation |
| US20100218264A1 (en) | 2008-12-04 | 2010-08-26 | Sangamo Biosciences, Inc. | Genome editing in rats using zinc-finger nucleases |
| US7888121B2 (en) | 2003-08-08 | 2011-02-15 | Sangamo Biosciences, Inc. | Methods and compositions for targeted cleavage and recombination |
| US7914796B2 (en) | 2006-05-25 | 2011-03-29 | Sangamo Biosciences, Inc. | Engineered cleavage half-domains |
| US7972854B2 (en) | 2004-02-05 | 2011-07-05 | Sangamo Biosciences, Inc. | Methods and compositions for targeted cleavage and recombination |
| US20110265198A1 (en) | 2010-04-26 | 2011-10-27 | Sangamo Biosciences, Inc. | Genome editing of a Rosa locus using nucleases |
| US8110379B2 (en) | 2007-04-26 | 2012-02-07 | Sangamo Biosciences, Inc. | Targeted integration into the PPP1R12C locus |
| US8409861B2 (en) | 2003-08-08 | 2013-04-02 | Sangamo Biosciences, Inc. | Targeted deletion of cellular DNA sequences |
| US20130122591A1 (en) | 2011-10-27 | 2013-05-16 | The Regents Of The University Of California | Methods and compositions for modification of the hprt locus |
| US20130177983A1 (en) | 2011-09-21 | 2013-07-11 | Sangamo Bioscience, Inc. | Methods and compositions for regulation of transgene expression |
| WO2013142578A1 (en) | 2012-03-20 | 2013-09-26 | Vilnius University | RNA-DIRECTED DNA CLEAVAGE BY THE Cas9-crRNA COMPLEX |
| WO2013141680A1 (en) | 2012-03-20 | 2013-09-26 | Vilnius University | RNA-DIRECTED DNA CLEAVAGE BY THE Cas9-crRNA COMPLEX |
| US8586526B2 (en) | 2010-05-17 | 2013-11-19 | Sangamo Biosciences, Inc. | DNA-binding proteins and uses thereof |
| WO2013176772A1 (en) | 2012-05-25 | 2013-11-28 | The Regents Of The University Of California | Methods and compositions for rna-directed target dna modification and for rna-directed modulation of transcription |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| WO2014065596A1 (en) | 2012-10-23 | 2014-05-01 | Toolgen Incorporated | Composition for cleaving a target dna comprising a guide rna specific for the target dna and cas protein-encoding nucleic acid or cas protein, and use thereof |
| WO2014089290A1 (en) | 2012-12-06 | 2014-06-12 | Sigma-Aldrich Co. Llc | Crispr-based genome modification and regulation |
| WO2014093622A2 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| WO2014099750A2 (en) | 2012-12-17 | 2014-06-26 | President And Fellows Of Harvard College | Rna-guided human genome engineering |
| WO2014131833A1 (en) | 2013-02-27 | 2014-09-04 | Helmholtz Zentrum München Deutsches Forschungszentrum Für Gesundheit Und Umwelt (Gmbh) | Gene editing in the oocyte by cas9 nucleases |
| US20140286936A1 (en) * | 2013-03-15 | 2014-09-25 | Sdix, Llc | Anti-human cxcr4 antibodies |
| WO2014165825A2 (en) | 2013-04-04 | 2014-10-09 | President And Fellows Of Harvard College | Therapeutic uses of genome editing with crispr/cas systems |
| WO2015048577A2 (en) | 2013-09-27 | 2015-04-02 | Editas Medicine, Inc. | Crispr-related methods and compositions |
| US20150376586A1 (en) | 2014-06-25 | 2015-12-31 | Caribou Biosciences, Inc. | RNA Modification to Engineer Cas9 Activity |
| US20160024523A1 (en) | 2013-03-15 | 2016-01-28 | The General Hospital Corporation | Using Truncated Guide RNAs (tru-gRNAs) to Increase Specificity for RNA-Guided Genome Editing |
| US20160074535A1 (en) | 2014-06-16 | 2016-03-17 | The Johns Hopkins University | Compositions and methods for the expression of crispr guide rnas using the h1 promoter |
| WO2016106121A1 (en) | 2014-12-23 | 2016-06-30 | Syngenta Participations Ag | Methods and compositions for identifying and enriching for cells comprising site specific genomic modifications |
| WO2016106236A1 (en) | 2014-12-23 | 2016-06-30 | The Broad Institute Inc. | Rna-targeting system |
| US20160208243A1 (en) | 2015-06-18 | 2016-07-21 | The Broad Institute, Inc. | Novel crispr enzymes and systems |
| WO2017004279A2 (en) | 2015-06-29 | 2017-01-05 | Massachusetts Institute Of Technology | Compositions comprising nucleic acids and methods of using the same |
| WO2017136794A1 (en) | 2016-02-03 | 2017-08-10 | Massachusetts Institute Of Technology | Structure-guided chemical modification of guide rna and its applications |
| WO2018107028A1 (en) | 2016-12-08 | 2018-06-14 | Intellia Therapeutics, Inc. | Modified guide rnas |
| WO2019067910A1 (en) | 2017-09-29 | 2019-04-04 | Intellia Therapeutics, Inc. | Polynucleotides, compositions, and methods for genome editing |
| WO2019219838A1 (en) * | 2018-05-16 | 2019-11-21 | Ospedale San Raffaele S.R.L. | Compositions and methods for haematopoietic stem cell transplantation |
| WO2020069296A1 (en) | 2018-09-28 | 2020-04-02 | Intellia Therapeutics, Inc. | Compositions and methods for lactate dehydrogenase (ldha) gene editing |
| WO2020082041A1 (en) | 2018-10-18 | 2020-04-23 | Intellia Therapeutics, Inc. | Nucleic acid constructs and methods of use |
| WO2020082046A2 (en) | 2018-10-18 | 2020-04-23 | Intellia Therapeutics, Inc. | Compositions and methods for expressing factor ix |
| WO2020082042A2 (en) | 2018-10-18 | 2020-04-23 | Intellia Therapeutics, Inc. | Compositions and methods for transgene expression from an albumin locus |
| WO2023209223A1 (en) * | 2022-04-28 | 2023-11-02 | Ospedale San Raffaele S.R.L. | Methods for haematopoietic stem cell transplantation |
| WO2024073606A1 (en) * | 2022-09-28 | 2024-04-04 | Regeneron Pharmaceuticals, Inc. | Antibody resistant modified receptors to enhance cell-based therapies |
-
2024
- 2024-08-28 WO PCT/US2024/044111 patent/WO2025049524A1/en active Pending
Patent Citations (62)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US5168062A (en) | 1985-01-30 | 1992-12-01 | University Of Iowa Research Foundation | Transfer vectors and microorganisms containing human cytomegalovirus immediate-early promoter-regulatory DNA sequence |
| US5385839A (en) | 1985-01-30 | 1995-01-31 | University Of Iowa Research Foundation | Transfer vectors and microorganisms containing human cytomegalovirus immediate-early promoter regulatory DNA sequence |
| US5789215A (en) | 1991-08-20 | 1998-08-04 | Genpharm International | Gene targeting in animal cells using isogenic DNA constructs |
| US6596541B2 (en) | 2000-10-31 | 2003-07-22 | Regeneron Pharmaceuticals, Inc. | Methods of modifying eukaryotic cells |
| US8502018B2 (en) | 2000-10-31 | 2013-08-06 | Regeneron Pharmaceuticals, Inc. | Methods of modifying eukaryotic cells |
| US20050208489A1 (en) | 2002-01-23 | 2005-09-22 | Dana Carroll | Targeted chromosomal mutagenasis using zinc finger nucleases |
| US20030232410A1 (en) | 2002-03-21 | 2003-12-18 | Monika Liljedahl | Methods and compositions for using zinc finger endonucleases to enhance homologous recombination |
| US20050026157A1 (en) | 2002-09-05 | 2005-02-03 | David Baltimore | Use of chimeric nucleases to stimulate gene targeting |
| US7888121B2 (en) | 2003-08-08 | 2011-02-15 | Sangamo Biosciences, Inc. | Methods and compositions for targeted cleavage and recombination |
| US8409861B2 (en) | 2003-08-08 | 2013-04-02 | Sangamo Biosciences, Inc. | Targeted deletion of cellular DNA sequences |
| US7972854B2 (en) | 2004-02-05 | 2011-07-05 | Sangamo Biosciences, Inc. | Methods and compositions for targeted cleavage and recombination |
| US20060063231A1 (en) | 2004-09-16 | 2006-03-23 | Sangamo Biosciences, Inc. | Compositions and methods for protein production |
| US20080159996A1 (en) | 2006-05-25 | 2008-07-03 | Dale Ando | Methods and compositions for gene inactivation |
| US7951925B2 (en) | 2006-05-25 | 2011-05-31 | Sangamo Biosciences, Inc. | Methods and compositions for gene inactivation |
| US7914796B2 (en) | 2006-05-25 | 2011-03-29 | Sangamo Biosciences, Inc. | Engineered cleavage half-domains |
| US8110379B2 (en) | 2007-04-26 | 2012-02-07 | Sangamo Biosciences, Inc. | Targeted integration into the PPP1R12C locus |
| US20100218264A1 (en) | 2008-12-04 | 2010-08-26 | Sangamo Biosciences, Inc. | Genome editing in rats using zinc-finger nucleases |
| US20110265198A1 (en) | 2010-04-26 | 2011-10-27 | Sangamo Biosciences, Inc. | Genome editing of a Rosa locus using nucleases |
| US20120017290A1 (en) | 2010-04-26 | 2012-01-19 | Sigma Aldrich Company | Genome editing of a Rosa locus using zinc-finger nucleases |
| US8586526B2 (en) | 2010-05-17 | 2013-11-19 | Sangamo Biosciences, Inc. | DNA-binding proteins and uses thereof |
| US20130177983A1 (en) | 2011-09-21 | 2013-07-11 | Sangamo Bioscience, Inc. | Methods and compositions for regulation of transgene expression |
| US20130177960A1 (en) | 2011-09-21 | 2013-07-11 | Sangamo Biosciences, Inc. | Methods and compositions for regulation of transgene expression |
| US20130137104A1 (en) | 2011-10-27 | 2013-05-30 | The Regents Of The University Of California | Methods and compositions for modification of the hprt locus |
| US20130122591A1 (en) | 2011-10-27 | 2013-05-16 | The Regents Of The University Of California | Methods and compositions for modification of the hprt locus |
| WO2013142578A1 (en) | 2012-03-20 | 2013-09-26 | Vilnius University | RNA-DIRECTED DNA CLEAVAGE BY THE Cas9-crRNA COMPLEX |
| WO2013141680A1 (en) | 2012-03-20 | 2013-09-26 | Vilnius University | RNA-DIRECTED DNA CLEAVAGE BY THE Cas9-crRNA COMPLEX |
| WO2013176772A1 (en) | 2012-05-25 | 2013-11-28 | The Regents Of The University Of California | Methods and compositions for rna-directed target dna modification and for rna-directed modulation of transcription |
| WO2014065596A1 (en) | 2012-10-23 | 2014-05-01 | Toolgen Incorporated | Composition for cleaving a target dna comprising a guide rna specific for the target dna and cas protein-encoding nucleic acid or cas protein, and use thereof |
| WO2014089290A1 (en) | 2012-12-06 | 2014-06-12 | Sigma-Aldrich Co. Llc | Crispr-based genome modification and regulation |
| WO2014093661A2 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Crispr-cas systems and methods for altering expression of gene products |
| WO2014093622A2 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| WO2014099750A2 (en) | 2012-12-17 | 2014-06-26 | President And Fellows Of Harvard College | Rna-guided human genome engineering |
| WO2014131833A1 (en) | 2013-02-27 | 2014-09-04 | Helmholtz Zentrum München Deutsches Forschungszentrum Für Gesundheit Und Umwelt (Gmbh) | Gene editing in the oocyte by cas9 nucleases |
| US20140286936A1 (en) * | 2013-03-15 | 2014-09-25 | Sdix, Llc | Anti-human cxcr4 antibodies |
| US20160024523A1 (en) | 2013-03-15 | 2016-01-28 | The General Hospital Corporation | Using Truncated Guide RNAs (tru-gRNAs) to Increase Specificity for RNA-Guided Genome Editing |
| WO2014165825A2 (en) | 2013-04-04 | 2014-10-09 | President And Fellows Of Harvard College | Therapeutic uses of genome editing with crispr/cas systems |
| US20160237455A1 (en) | 2013-09-27 | 2016-08-18 | Editas Medicine, Inc. | Crispr-related methods and compositions |
| WO2015048577A2 (en) | 2013-09-27 | 2015-04-02 | Editas Medicine, Inc. | Crispr-related methods and compositions |
| US20160074535A1 (en) | 2014-06-16 | 2016-03-17 | The Johns Hopkins University | Compositions and methods for the expression of crispr guide rnas using the h1 promoter |
| US20170114334A1 (en) | 2014-06-25 | 2017-04-27 | Caribou Biosciences, Inc. | RNA Modification to Engineer Cas9 Activity |
| US20150376586A1 (en) | 2014-06-25 | 2015-12-31 | Caribou Biosciences, Inc. | RNA Modification to Engineer Cas9 Activity |
| WO2016106236A1 (en) | 2014-12-23 | 2016-06-30 | The Broad Institute Inc. | Rna-targeting system |
| WO2016106121A1 (en) | 2014-12-23 | 2016-06-30 | Syngenta Participations Ag | Methods and compositions for identifying and enriching for cells comprising site specific genomic modifications |
| US20160208243A1 (en) | 2015-06-18 | 2016-07-21 | The Broad Institute, Inc. | Novel crispr enzymes and systems |
| WO2017004279A2 (en) | 2015-06-29 | 2017-01-05 | Massachusetts Institute Of Technology | Compositions comprising nucleic acids and methods of using the same |
| US20180187186A1 (en) | 2015-06-29 | 2018-07-05 | Massachusetts Institute Of Technology | Compositions comprising nucleic acids and methods of using the same |
| WO2017136794A1 (en) | 2016-02-03 | 2017-08-10 | Massachusetts Institute Of Technology | Structure-guided chemical modification of guide rna and its applications |
| US20190048338A1 (en) | 2016-02-03 | 2019-02-14 | Massachusetts Institute Of Technology | Structure-guided chemical modification of guide rna and its applications |
| WO2018107028A1 (en) | 2016-12-08 | 2018-06-14 | Intellia Therapeutics, Inc. | Modified guide rnas |
| WO2019067910A1 (en) | 2017-09-29 | 2019-04-04 | Intellia Therapeutics, Inc. | Polynucleotides, compositions, and methods for genome editing |
| WO2019219838A1 (en) * | 2018-05-16 | 2019-11-21 | Ospedale San Raffaele S.R.L. | Compositions and methods for haematopoietic stem cell transplantation |
| WO2020069296A1 (en) | 2018-09-28 | 2020-04-02 | Intellia Therapeutics, Inc. | Compositions and methods for lactate dehydrogenase (ldha) gene editing |
| WO2020082041A1 (en) | 2018-10-18 | 2020-04-23 | Intellia Therapeutics, Inc. | Nucleic acid constructs and methods of use |
| WO2020082046A2 (en) | 2018-10-18 | 2020-04-23 | Intellia Therapeutics, Inc. | Compositions and methods for expressing factor ix |
| WO2020082042A2 (en) | 2018-10-18 | 2020-04-23 | Intellia Therapeutics, Inc. | Compositions and methods for transgene expression from an albumin locus |
| US20200270617A1 (en) | 2018-10-18 | 2020-08-27 | Intellia Therapeutics, Inc. | Compositions and methods for transgene expression from an albumin locus |
| US20200268906A1 (en) | 2018-10-18 | 2020-08-27 | Intellia Therapeutics, Inc. | Nucleic acid constructs and methods of use |
| US20200289628A1 (en) | 2018-10-18 | 2020-09-17 | Intellia Therapeutics, Inc. | Compositions and methods for expressing factor ix |
| WO2023209223A1 (en) * | 2022-04-28 | 2023-11-02 | Ospedale San Raffaele S.R.L. | Methods for haematopoietic stem cell transplantation |
| WO2024073606A1 (en) * | 2022-09-28 | 2024-04-04 | Regeneron Pharmaceuticals, Inc. | Antibody resistant modified receptors to enhance cell-based therapies |
Non-Patent Citations (76)
| Title |
|---|
| "Molecular Cloning: A Laboratory Manual", 2001, HARBOR LABORATORY PRESS |
| "NCBI", Database accession no. NM_003467.3 |
| "Remington: The Science and Practice of Pharmacy", 2000, LIPPINCOTT WILLIAMS AND WILKINS |
| "UniProt", Database accession no. P61073-1 |
| "Useful proteins from recombinant bacteria", SCIENTIFIC AMERICAN, vol. 242, 1980, pages 74 - 94 |
| ALTSCHUL ET AL., FEBS J, vol. 272, no. 20, 2005, pages 5101 - 5109 |
| ALTSCHUL ET AL., J. MOL. BIOL., vol. 215, 1990, pages 403 - 410 |
| ALTSCHUL ET AL., J. MOL. EVOL, vol. 36, 1993, pages 290 - 300 |
| ALTSCHUL ET AL., NUCLEIC ACIDS RES., vol. 25, 1997, pages 3389 - 3402 |
| ALTSCHUL, J. MOL. BIOL., vol. 219, 1991, pages 555 - 565 |
| ALTSCHUL: "Theoretical and Computational Methods in Genome Research", 1997, PLENUM, article "Evaluating the statistical significance of multiple distinct local alignments", pages: 1 - 14 |
| ATOUF, AAPS J, vol. 18, no. 4, 2016, pages 844 - 848 |
| BECK ET AL., NATURE REVIEWS DRUG DISCOVERY, vol. 16, 2017, pages 315 - 337 |
| BENOIST ET AL., NATURE, vol. 290, 1981, pages 304 - 310 |
| BRINSTER ET AL., NATURE, vol. 296, 1982, pages 39 - 42 |
| BUSILLO ET AL: "Regulation of CXCR4 signaling", BIOCHIMICA ET BIOPHYSICA ACTA, ELSEVIER, AMSTERDAM, NL, vol. 1768, no. 4, 28 March 2007 (2007-03-28), pages 952 - 963, XP022000793, ISSN: 0005-2736, DOI: 10.1016/J.BBAMEM.2006.11.002 * |
| CEBRIAN-SERRANODAVIES, MAMM. GENOME, vol. 28, no. 7, 2017, pages 247 - 261 |
| CHOTHIA ET AL., J. MOL. BIOL., vol. 196, 1987, pages 901 - 917 |
| CHOTHIA ET AL., NATURE, vol. 342, 1989, pages 878 - 883 |
| CONG ET AL., SCIENCE, vol. 339, no. 6121, 2013, pages 819 - 823 |
| DEBOER ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 80, 1983, pages 21 - 25 |
| DELTCHEVA ET AL., NATURE, vol. 471, no. 7340, 2011, pages 602 - 607 |
| DEMBO ET AL., ANN. PROB, vol. 22, 1994, pages 2022 - 2039 |
| EDRAKI ET AL., MOL. CELL, vol. 73, no. 4, 2019, pages 714 - 726 |
| EHRING, ANALYTICAL BIOCHEMISTRY, vol. 267, 1999, pages 252 - 259 |
| ELGUNDI, ADVANCED DRUG DELIVERY REVIEWS, vol. 122, 2017, pages 2 - 19 |
| ENGENSMITH, ANAL. CHEM., 2001, pages 256A - 265A |
| G. N. JONES ET AL: "Upregulating CXCR4 in Human Fetal Mesenchymal Stem Cells Enhances Engraftment and Bone Mechanics in a Mouse Model of Osteogenesis Imperfecta", STEM CELLS TRANSLATIONAL MEDICINE, vol. 1, no. 1, 7 December 2011 (2011-12-07), pages 70 - 78, XP055098907, ISSN: 2157-6564, DOI: 10.5966/sctm.2011-0007 * |
| GISH ET AL., NATURE GENET., vol. 3, 1993, pages 266 - 272 |
| GOGESCH ET AL., INT. J. MOL. SCI, vol. 22, no. 16, 2021, pages 8947 |
| GONNET ET AL., SCIENCE, vol. 256, 1992, pages 1443 - 45 |
| HANCOCK ET AL., COMPUT. APPL. BIOSCI, vol. 10, 1994, pages 67 - 70 |
| HENIKOFF ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 90, 1993, pages 10915 - 10919 |
| HU ET AL., NATURE, vol. 556, 2018, pages 57 - 63 |
| JIANG ET AL., NAT. BIOTECHNOL., vol. 31, no. 3, 2013, pages 233 - 239 |
| JINEK ET AL., SCIENCE, vol. 337, no. 6096, 2012, pages 816 - 821 |
| JINEK ET AL., SCIENCE, vol. 337, no. 6096, pages 816 - 821 |
| KABAT ET AL., J. BIOL. CHEM., vol. 252, 1977, pages 6609 - 6616 |
| KABAT, ADV. PROT. CHEM, vol. 32, 1978, pages 1 - 75 |
| KASHYAP, J. HEMCZTOL. ONCOL, vol. 10, no. 1, 2017, pages 112 |
| KIM ET AL., NAT. COMMUN., vol. 8, 2017, pages 14500 |
| KLEINSTIVER ET AL., NATURE, vol. 529, no. 7587, 2016, pages 490 - 495 |
| KWON SEONG GYU ET AL: "Role of stem cell mobilization in the treatment of ischemic diseases", ARCHIVES OF PHARMACAL RESEARCH, NATL. FISHERIES UNIVERSITY , PUSAN, KR, vol. 42, no. 3, 24 January 2019 (2019-01-24), pages 224 - 231, XP036737383, ISSN: 0253-6269, [retrieved on 20190124], DOI: 10.1007/S12272-019-01123-2 * |
| LANGE ET AL., J. BIOL. CHEM, vol. 282, no. 8, 2007, pages 5101 - 5105 |
| LIU ET AL., NATURE, vol. 566, no. 7743, 2019, pages 218 - 223 |
| MADDEN ET AL., METH. ENZYMOL, vol. 266, 1996, pages 131 - 141 |
| MALI ET AL., NAT. BIOTECH., vol. 31, 2013, pages 833 - 838 |
| MARIN-ACEVEDO ET AL., J. HEMATOL. ONCOL, vol. 11, 2018, pages 8 |
| MORRISON ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 81, 1984, pages 6851 - 6855 |
| NAKAMURA ET AL., NUCLEIC ACIDS RES., vol. 28, no. 1, 2000, pages 292 |
| NATL. BIOMED. RES. FOUND. |
| PAUSCH ET AL., SCIENCE, vol. 369, no. 6501, 2020, pages 333 - 337 |
| PENG ET AL., PLOS ONE, vol. 11, no. 3, 2016, pages 010585 |
| PETERS ET AL., BIOSCI. REP, vol. 35, no. 4, 2015, pages 00225 |
| RAFIQ ET AL., NAT. BIOTECHNOL., vol. 36, no. 9, 2018, pages 847 - 856 |
| RAN ET AL., CELL, vol. 154, 2013, pages 1380 - 1389 |
| REINEKE, METHODS MOL. BIOL, vol. 248, 2004, pages 443 - 63 |
| SADELAIN ET AL., NAT. REV. CANCER, vol. 12, 2012, pages 51 - 58 |
| SAPRANAUSKAS ET AL., NUCLEIC ACIDS RES., vol. 39, no. 21, 2011, pages 9275 - 9282 |
| SCHWARTZ, R. M ET AL.: "Atlas of Protein Sequence and Structure", vol. 5, 1978, article "Matrices for detecting distant relationships", pages: 353 - 358 |
| SHEN ET AL., NAT. METHODS, vol. 11, 2014, pages 399 - 404 |
| SLAYMAKER ET AL., SCIENCE, vol. 351, no. 6268, 2016, pages 84 - 88 |
| STATES ET AL., METHODS, vol. 3, 1991, pages 66 - 70 |
| TOMER, PROT. SCI, vol. 9, 2000, pages 487 - 496 |
| VILLA-KOMAROFF ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 75, 1978, pages 3727 - 3731 |
| WAGNER ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 78, 1981, pages 1441 - 1445 |
| WATSON ET AL.: "Molecular Biology of the Gene", 1987, THE BENJAMIN/CUMMINGS PUB. CO, pages: 224 |
| WOOTTON ET AL., COMPUT. CHEM, vol. 17, 1993, pages 149 - 163 |
| YAMAMOTO ET AL., CELL, vol. 22, 1980, pages 787 - 797 |
| YEKU ET AL., SCI. REP, vol. 7, no. 1, 2017, pages 10541 |
| YOSHIMI ET AL., NAT. COMMUN., vol. 7, 2016, pages 10431 |
| YU ET AL., J. HEMATOL. ONCOL, vol. 13, no. 1, 2020, pages 45 |
| ZAMBROWICZ ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 94, 1997, pages 3789 - 3794 |
| ZETSCHE ET AL., CELL, vol. 163, no. 3, 2015, pages 759 - 771 |
| ZHANG ET AL., GENOME RES, vol. 7, 1997, pages 649 - 656 |
| ZHANG ET AL., WORLD J. CLIN. ONCOL, vol. 11, no. 5, 2020, pages 275 - 282 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11649438B2 (en) | Methods and compositions for treating cancer | |
| JP6965466B2 (en) | Manipulated cascade components and cascade complexes | |
| JP7471289B2 (en) | Anti-LIV1 immune cell cancer therapy | |
| US20250074965A1 (en) | Anti-ptk7 immune cell cancer therapy | |
| KR20180031671A (en) | CRISPR / CAS-related methods and compositions for improving transplantation | |
| CN113227141A (en) | anti-CD 33 immune cell cancer therapy | |
| US20240390460A1 (en) | Antibody resistant modified receptors to enhance cell-based therapies | |
| US20240409603A1 (en) | Modified stem cell compositions and methods for use | |
| US20220380776A1 (en) | Base editor-mediated cd33 reduction to selectively protect therapeutic cells | |
| WO2024006774A2 (en) | Compositions and methods for non-genotoxic cell conditioning | |
| JP2023512469A (en) | Genetically modified T cells expressing BCMA-specific chimeric antigen receptors and their use in cancer therapy | |
| WO2025049524A1 (en) | Cxcr4 antibody-resistant modified receptors | |
| US20250345431A1 (en) | Genetically engineered t cells expressing a cd19 chimeric antigen receptor (car) and uses thereof for allogeneic cell therapy | |
| WO2024062388A2 (en) | Genetically engineered immune cells expressing chimeric antigen receptor targeting cd20 | |
| WO2024173594A1 (en) | Modified stem cell compositions and methods for use | |
| WO2024238562A2 (en) | Methods and compositions for anti-cd45 based non-genotoxic conditioning | |
| WO2024173592A1 (en) | Modified stem cell compositions and methods for use | |
| KR20250131813A (en) | Epitope manipulation of the KIT cell-surface receptor | |
| EP4547718A1 (en) | Chimeric antigen receptor targeting gpc-3 and immune cells expressing such for therapeutic uses | |
| HK40055048A (en) | Anti-ptk7 immune cell cancer therapy | |
| HK40055630A (en) | Anti-liv1 immune cell cancer therapy |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24772814 Country of ref document: EP Kind code of ref document: A1 |