WO2024254518A2 - Compositions of lipid delivery particles and method of use thereof - Google Patents
Compositions of lipid delivery particles and method of use thereof Download PDFInfo
- Publication number
- WO2024254518A2 WO2024254518A2 PCT/US2024/033099 US2024033099W WO2024254518A2 WO 2024254518 A2 WO2024254518 A2 WO 2024254518A2 US 2024033099 W US2024033099 W US 2024033099W WO 2024254518 A2 WO2024254518 A2 WO 2024254518A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- delivery particle
- lipid delivery
- protein
- protease
- cases
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/48—Preparations in capsules, e.g. of gelatin, of chocolate
- A61K9/50—Microcapsules having a gas, liquid or semi-solid filling; Solid microparticles or pellets surrounded by a distinct coating layer, e.g. coated microspheres, coated drug crystals
- A61K9/51—Nanocapsules; Nanoparticles
- A61K9/5107—Excipients; Inactive ingredients
- A61K9/5123—Organic compounds, e.g. fats, sugars
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/50—Fusion polypeptide containing protease site
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
Definitions
- a lipid delivery particle comprising: a lipid membrane on the external side; and a chimeric protein in the core of the lipid delivery particle comprising (i) a plasma membrane recruitment element; (ii) a heterologous payload; (iii) one or more cleavable linkers; and (iv) a protease, wherein the one or more cleavable linkers is cleavable by the protease, wherein the one or more cleavable linkers is positioned such that cleavage by the protease releases the heterologous payload from the chimeric protein.
- the protease is a viral protease. In some embodiments, the viral protease is selected from Table 7. In some embodiments, the lipid delivery particle further comprises an envelope protein. In some embodiments, the envelope protein has a viral origin. In some embodiments, the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein has a human origin. In some embodiments, the envelope protein is selected from Table 2.
- the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 49-82.
- the plasma membrane recruitment element comprises a Gag protein. In some embodiments, the Gag protein comprises a retroviral Gag protein. In some embodiments, the Gag protein comprises a Gag protein from human endogenous retrovirus. In some embodiments, the Gag protein comprises an endogenous Gag protein from a mammal. In some embodiments, the plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
- PH Pleckstrin Homology
- the Pleckstrin Homology domain is coupled to the heterologous payload. In some embodiments, the Pleckstrin Homology domain is reversibly coupled to the heterologous payload. In some embodiments, the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by one of the one or more cleavable linker. In some embodiments, the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain. In some embodiments, the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
- the plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof. In some embodiments, the nuclear export signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 353-453.
- the nuclear export signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 353-453. In some embodiments, the nuclear localization signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the nuclear localization signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the one or more cleavable linkers comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 126-171.
- the one or more cleavable linkers comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171.
- the cleavage by the protease is inhibitable by a reversible protease inhibitor.
- the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease.
- the protease inhibitor is selected from the group consisting of: Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
- a lipid delivery particle comprising: a lipid membrane on the external side; a first chimeric protein in the lipid delivery particle comprising (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) a cleavable linker; and a second chimeric protein in the lipid delivery particle comprising (i) a second plasma membrane recruitment element and (ii) a protease, wherein the cleavable linker is cleavable by the protease, wherein the cleavable linker is positioned such that cleavage by the protease releases the heterologous payload from the first chimeric protein, wherein the protease comprises an amino acid sequence of at least 80%, 85%, 90%, 95%, or 99% sequence identity to any one of SEQ ID NOs: 106-110.
- the cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to any one of SEQ ID NOs: 126-128 or SEQ ID NOs: 134-138. In some embodiments, the cleavable linker comprises an amino acid sequence of any one of SEQ ID NOs: 126-128 or SEQ ID NOs: 134-138.
- a lipid delivery particle comprising: a lipid membrane on the external side; a first chimeric protein in the lipid delivery particle comprising (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) a cleavable linker; and a second chimeric protein in the lipid delivery particle comprising (i) a second plasma membrane recruitment element and (ii) a protease, wherein the second chimeric protein lacks a viral polymerase, wherein the cleavable linker is cleavable by the protease, wherein the cleavable linkers is positioned such that cleavage by the protease releases the heterologous payload from the first chimeric protein.
- the protease comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95% or 99% sequence identity to an amino acid sequence set forth in any one of SEQ ID NOs: 105-125. In some embodiments, the protease comprises an amino acid sequence set forth in any one of SEQ ID NOs: 105-125.
- a lipid delivery particle comprising: a lipid membrane on the external side; a first chimeric protein in the lipid delivery particle comprising (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) a cleavable linker; and a second chimeric protein in the lipid delivery particle comprising (i) a second plasma membrane recruitment element and (ii) a first protease.
- the lipid delivery particle further comprises a second protease.
- the first chimeric protein comprises the second protease.
- the first chimeric protein comprises from N-terminus to C-terminus the first plasma membrane recruitment element, the second protease, and the heterologous payload.
- the first chimeric protein comprises from N-terminus to C-terminus the first plasma membrane recruitment element, the heterologous payload, and the second protease.
- the second chimeric protein comprises the second protease.
- the second chimeric protein comprises from N-terminus to C-terminus the second plasma recruitment element, the first protease, and the second protease. In some embodiments, the second chimeric protein comprises from N-terminus to C-terminus the second plasma recruitment element, the second protease, and the first protease. In some embodiments, the lipid delivery particle further comprises a third chimeric protein in the lipid delivery particle, wherein the third chimeric protein comprising (i) a third plasma membrane recruitment element, and (ii) the second protease. In some embodiments, the third chimeric protein forms a dimer with the first chimeric protein or the second chimeric protein.
- the third chimeric protein forms the dimer with the first chimeric protein or the second chimeric protein via a leucine zipper pair, an inducible heteromerization domain, an cohesin-dockerin interaction, a spycatcher-spytag covalent interaction, or an electrostatic interaction between positively and negatively charged amino acids.
- the cleavable linker is cleavable by the first protease and the second protease. In some embodiments, the cleavable linker is cleavable by the first protease. In some embodiments, the cleavable linker is cleavable by the second protease.
- the cleavable linker is positioned such that cleavage by the protease releases the heterologous payload from the first chimeric protein.
- the first protease and the second protease are the same. In some embodiments, the first protease and the second protease are different. In some embodiments, the first protease comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95% or 99% sequence identity to an amino acid sequence set forth in any one of SEQ ID NOs: 105-125. In some embodiments, the first protease comprises an amino acid sequence set forth in any one of SEQ ID NOs: 105-125.
- the first protease is a murine leukemia virus (MLV) protease. In some embodiments, the first protease is a human immunodeficiency virus (HIV) protease.
- the second protease comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95% or 99% sequence identity to an amino acid sequence set forth in any one of SEQ ID NOs: 105-125. In some embodiments, the second protease comprises an amino acid sequence set forth in any one of SEQ ID NOs: 105-125. In some embodiments, the second protease is a murine leukemia virus (MLV) protease.
- the second protease is a human immunodeficiency virus (HIV) protease.
- the cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to set forth in any one of SEQ ID NOs: 126-171.
- the cleavable linker comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171.
- the cleavage by the protease releasing the heterologous payload from the chimeric protein is inhibited by a reversible protease inhibitor.
- the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease.
- the protease inhibitor is selected from the group consisting of: Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
- the reversible protease inhibitor delays the release of payload from the chimeric protein until the reversible protease inhibitor is removed.
- the second chimeric protein further comprises a second cleavable linker.
- the second cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 126-171.
- the second cleavable linker comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171.
- the lipid delivery particle further comprises an envelope protein.
- the envelope protein has a viral origin.
- the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein has a human origin. In some embodiments, the envelope protein is selected from Table 2. In some embodiments, the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 49-82.
- the first plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
- the Pleckstrin Homology domain is coupled to the heterologous payload.
- the Pleckstrin Homology domain is reversibly coupled to the heterologous payload.
- the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker.
- the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain.
- the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
- the first plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the first plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the first plasma membrane recruitment element comprises a Gag protein. In some embodiments, the Gag protein comprises a retroviral Gag protein. In some embodiments, the Gag protein comprises a Gag protein from human endogenous retrovirus. In some embodiments, the Gag protein comprises an endogenous Gag protein from a mammal.
- the second plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
- the Pleckstrin Homology domain is coupled to the heterologous payload.
- the Pleckstrin Homology domain is reversibly coupled to the heterologous payload.
- the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker.
- the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain.
- the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
- the second plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the second plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the second plasma membrane recruitment element comprises a Gag protein. In some embodiments, the Gag protein comprises a retroviral Gag protein. In some embodiments, the Gag protein comprises a Gag protein from human endogenous retrovirus. In some embodiments, the Gag protein comprises an endogenous Gag protein from a mammal.
- the third plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
- the Pleckstrin Homology domain is coupled to the heterologous payload.
- the Pleckstrin Homology domain is reversibly coupled to the heterologous payload.
- the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker.
- the heterologous payload is coupled to a C- terminus of the Pleckstrin Homology domain.
- the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
- the third plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1- 48. In some embodiments, the third plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the third plasma membrane recruitment element comprises a Gag protein. In some embodiments, the Gag protein comprises a retroviral Gag protein. In some embodiments, the Gag protein comprises a Gag protein from human endogenous retrovirus. In some embodiments, the Gag protein comprises an endogenous Gag protein from a mammal. In some embodiments, the first plasma membrane recruitment element is the same as the second plasma membrane recruitment element.
- the first chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof.
- the second chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof.
- the nuclear export signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 352-453. In some embodiments, the nuclear export signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 352-453.
- the nuclear localization signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the nuclear localization signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 454-559.
- the heterologous payload is a therapeutic agent. In some embodiments, the therapeutic agent is covalently linked to the plasma membrane recruitment element via the cleavable linker. In some embodiments, the therapeutic agent is coupled to the cleavable linker or the plasma recruitment element by conjugation. In some embodiments, the therapeutic agent is a gene-editing agent.
- the geneediting agent comprises a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; a nucleic acid encoding a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; or a ribonucleoprotein complex (RNP) comprising a CRISPR- based genome editing or modulating protein.
- the therapeutic agent is a nucleic-acid based agent, a small molecule, or a recombinant protein.
- Described herein is a system comprising: (a) the lipid delivery particle disclosed herein; and (b) a reversible protease inhibitor, wherein the cleavage by the protease is inhibitable by the reversible protease inhibitor, wherein the release of payload is delayed until the reversible protease inhibitor is removed from the system.
- the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease.
- the protease inhibitor is selected from the group consisting of: Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
- a chimeric protein for delivering a heterologous payload to a target cell comprising: (i) a plasma membrane recruitment element; (ii) a heterologous payload; (iii) one or more protease cleavable linkers; and (iv) a first protease, wherein the one or more cleavable linkers are cleavable by the protease, wherein the one or more cleavable linkers are positioned such that cleavage by the protease releases the heterologous payload from the chimeric protein construct.
- the chimeric protein further comprises a second protease.
- the second protease is a viral protease.
- the first protease is a viral protease.
- the viral protease is selected from Table 7.
- the plasma membrane recruitment element comprises a Gag protein.
- the Gag protein comprises a retroviral Gag protein.
- the Gag protein comprises a Gag protein from human endogenous retrovirus.
- the Gag protein comprises an endogenous Gag protein from a mammal.
- the plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
- the Pleckstrin Homology domain is coupled to the heterologous payload. In some embodiments, the Pleckstrin Homology domain is reversibly coupled to the heterologous payload. In some embodiments, the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker. In some embodiments, the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain. In some embodiments, the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
- the plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof. In some embodiments, the nuclear export signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 352-453.
- the nuclear export signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 352-453. In some embodiments, the nuclear localization signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the nuclear localization signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 126- 138.
- the cleavable linker comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-138.
- the heterologous payload is a therapeutic agent.
- the therapeutic agent is a gene-editing reagent.
- the gene-editing reagent comprises a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; a nucleic acid encoding a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; or a ribonucleoprotein complex (RNP) comprising a CRISPR- based genome editing or modulating protein.
- the therapeutic agent is a nucleic-acid based agent, a small molecule, or a recombinant protein. [0015] Described herein is a nucleic acid encoding the chimeric protein disclosed herein.
- lipid delivery particle comprising: (i) a lipid membrane on the external side; and (ii) the chimeric protein disclosed herein in the lipid delivery particle.
- the lipid delivery particle further comprises an envelope protein.
- the envelope protein has a viral origin.
- the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
- the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 83-104.
- the envelope protein has a human origin.
- the envelope protein is selected from Table 2.
- the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 49-82.
- Described herein is a method of delivering a heterologous payload to a target cell, the method comprising contacting the target cell with the lipid delivery particle disclosed herein.
- Described herein is a method of producing the lipid delivery particle disclosed herein, the method comprising providing a producer cell comprising a nucleic acid molecule encoding the chimeric protein, and using the producer cell to produce the lipid delivery particle disclosed herein.
- lipid delivery particle Described herein is a method of producing the lipid delivery particle disclosed herein, the method comprising providing a producer cell comprising a first nucleic acid molecule encoding the first chimeric protein and, and using the producer cell to produce the lipid delivery particle disclosed herein.
- FIG.1A and IB illustrate the structure of a lipid delivery particle comprising chimeric proteins.
- FIG. 2A and 2B illustrate the structures of chimeric proteins.
- FIGs. 3 A-3E illustrate the exemplary structures of chimeric proteins in a lipid delivery particle.
- lipid delivery particles capable of delivering a heterologous payload (e.g. a protein, a gene-editing agent, a small molecule) to a target cells.
- a heterologous payload e.g. a protein, a gene-editing agent, a small molecule
- the lipid delivery particle comprises a lipid membrane on the external side and a chimeric protein in the core, as shown in FIG. 1.
- the chimeric protein comprises (i) a plasma membrane recruitment element; (ii) a heterologous payload; (iii) one or more cleavable linkers; and (iv) a protease.
- the one or more cleavable linkers is cleavable by the protease.
- the cleavable linker is positioned such that cleavage by the protease releases the payload from the chimeric protein.
- the lipid delivery particle comprises a lipid membrane on the external side, a first chimeric protein in the lipid delivery particle, and a second chimeric in the lipid delivery particle.
- the first chimeric protein comprises (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) one or more cleavable linkers.
- the second chimeric protein comprises (i) a second plasma membrane recruitment element; and (ii) a protease.
- the second chimeric protein further comprises a second cleavable linker.
- the one or more cleavable linkers is cleavable by the protease.
- the cleavable linker is positioned such that cleavage by the protease releases the payload from the chimeric protein.
- the cleavage by the protease is delayed by adding a reversible protease inhibitor and then removing the protease inhibitor.
- systems comprising the lipid delivery particles disclosed herein and a reversible protease inhibitor. In some cases, the release of payload is delayed until the reversible protease inhibitor is removed from the system.
- the chimeric protein for delivering a heterologous payload to a target cells.
- the chimeric protein comprises (i) a plasma membrane recruitment element; (ii) the heterologous payload; (iii) one or more cleavable linkers; and (iv) a protease.
- the chimeric protein further comprises a nuclear localization signal, a nuclear exporting signal, or a combination thereof.
- the one or more cleavable linkers is cleavable by the protease.
- the cleavable linker is positioned such that cleavage by the protease releases the payload from the chimeric protein.
- nucleic acid molecules encoding the chimeric proteins are also described herein are cells (e.g., producer cells) comprising nucleic acid molecules encoding the chimeric proteins and expressing the chimeric proteins.
- Also provided herein are methods for making the LPD comprising providing a producer cell comprising a nucleic acid molecule encoding a chimeric protein comprising (a) a plasma membrane recruitment element; (b) a heterologous payload, (iii) one or more cleavable linkers; and (iv) a protease.
- Also provided herein are methods for making the LPD comprising providing a producer cell comprising a first nucleic acid molecule encoding a first chimeric protein comprising (a) a plasma membrane recruitment element; (b) a heterologous payload, and (c) one or more cleavable linkers; and a second nucleic acid molecule encoding a second chimeric protein comprising (a) a second plasma membrane recruitment element and (b) a protease.
- the second chimeric protein further comprises a second cleavable linker.
- the cleavage by the protease is delayed by adding a reversible protease inhibitor to the producer cell and then removing the protease inhibitor before or during purifying the LPD.
- a chimeric protein disclosed herein can refer to a protein comprised of a first amino acid sequence derived from a first source, fused to a second amino acid sequence derived from a second source, wherein the first and second source are not the same.
- a first source and a second source that are not the same can include two different biological entities, or two different proteins from the same biological entity, or a biological entity and a non-biological entity.
- a chimeric protein can include for example, a protein derived from at least 2 different biological sources.
- a biological source can include any non-synthetically produced nucleic acid or amino acid sequence (e.g.
- a synthetic source can include a protein or nucleic acid sequence produced chemically and not by a biological system (e.g. solid phase synthesis of amino acid sequences).
- a chimeric protein can also include a protein derived from at least 2 different synthetic sources or a protein derived from at least one biological source and at least one synthetic source.
- the lipid delivery particle provided herein comprises a membrane.
- the membrane of the lipid delivery particle can comprise a lipid layer, such as a single layer or a lipid bilayer.
- the membrane of the lipid delivery particle is a lipid bilayer.
- the membrane of the lipid delivery particle is from plasma membrane, endoplasmic reticulum, or a combination thereof.
- the membrane of the lipid delivery particle is from Golgi complex, ER Golgi intermediate compartment, or nuclear envelope.
- the membrane of the lipid delivery particle is from plasma membrane.
- the membrane of the lipid delivery particle is a phospholipid bilayer.
- the lipid delivery particle provided herein comprises an envelope protein.
- the envelope protein can be associated with the outside boundary or the surface of the lipid delivery particle, for example, the membrane or envelope of the lipid delivery particle.
- the membrane of the lipid delivery particle can comprise a lipid layer, such as a single layer or a lipid bilayer.
- the membrane of the lipid delivery particle is from plasma membrane, endoplasmic reticulum, or a combination thereof.
- the membrane of the lipid delivery particle is from Golgi complex, ER Golgi intermediate compartment, or nuclear envelope.
- the membrane of the lipid delivery particle is from plasma membrane.
- the membrane of the lipid delivery particle is a phospholipid bilayer.
- the envelope protein can be associated with the membrane of the lipid delivery particle in various manners.
- the envelope protein can be anchored or attached to the external membrane of the particle or anchored or attached to the internal membrane of the particle.
- the envelope protein can be embedded or inserted in the membrane, spanning through the membrane, with certain portions located at the outside of the membrane, or certain portions extending to the inside of the particle, or both.
- the envelope protein within the lipid delivery particle described herein can be overexpressed from an exogenous source, such as plasmids or stably integrated transgenes, in the production cells.
- the envelope protein can play a role in the delivery of the lipid delivery particle to a target cell and release of the components of the lipid delivery particle within the target cell.
- the envelope protein can contact with the surface of a target cell and participate in the fusion of the lipid delivery particle and the membrane of the target cell.
- the envelope protein can participate in the fusion of the lipid delivery particle with the membrane of the target cell via any appropriate mechanism, such as those described in White et al. Crit Rev Biochem Mol Biol. 2008; 43(3): 189-219.
- One example of the fusion mechanisms is unifying Trimer-of-Hairpins Fusion Mechanism.
- Membrane fusion can occur after allosteric priming by binding to a target receptor. In some cases, membrane fusion occurs after proteolysis.
- membrane fusion occurs after isomerization of disulfide bridges. In some cases, membrane fusion occurs by internalization and then priming of fusion via (i) cathepsin-mediated proteolysis, or (ii) low pH/acidification.
- the cathepsin-mediated proteolysis can be pH dependent or pH independent. Other fusion triggering mechanisms can include low PH, binding to target cell receptors, and a receptor followed by low pH.
- the envelope protein can also play a role in the formation of the lipid delivery particle.
- the envelope protein can interact with another component within the lipid delivery particle and participate in the assembly of the lipid delivery particle, for example, in a producer cell.
- the envelope protein can make contact with another envelope protein and form an oligomer embedded within the membrane.
- the envelope protein can be a glycoprotein, for example, a transmembrane glycoprotein.
- envelope protein comprises multiple membrane-spanning regions. These multiple membrane-spanning regions can oligomerize and form channels in the membrane.
- the envelope protein is fused with a targeting moiety.
- the targeting moiety recognizes a specific molecule (e.g., antigen, receptor, or other membrane protein) on the surface of a target cell to allow targeted cell entry with more specificity.
- the targeting moiety is specific for a certain cell type or is specific for a certain target cell.
- the targeting moiety can be fused to the envelope protein at a position that is located at an outside of the lipid delivery particle.
- the targeting moiety includes scFvs, antibody variable regions, nanobodies, T-cell receptor variable regions, other antigen-binding fragments or their mimetics, such as DARPins.
- the targeting moiety is a protein ligand from the human ligandome.
- the targeting moiety can be a natural peptide or a synthetic peptide.
- the targeting moiety is not fused with the envelope protein and is attached to the membrane of the lipid delivery particle from the outside, for example, via a transmembrane domain.
- a targeting moiety can include, e.g., an antibody or an antigen-binding fragment thereof (e.g., Fab, Fab', F(ab')2, Fv fragments, scFv antibody fragments, disulfide-linked Fvs (sdFv), a Fd fragment consisting of the VH and CHI domains, linear antibodies, single domain antibodies such as sdAb (either VL or VH), nanobodies, or camelid VHH domains), an antigen-binding fibronectin type III (Fn3) scaffold such as a fibronectin polypeptide minibody, a ligand, a cytokine, a chemokine, or a T cell receptor (TCRs).
- an antibody or an antigen-binding fragment thereof e.g., Fab, Fab', F(ab')2, Fv fragments, scFv antibody fragments, disulfide-linked Fvs (sdFv), a Fd fragment consisting
- Membrane-fusion proteins can be re-targeted by non-covalently conjugating a targeting moiety to the membrane-fusion protein or targeting protein (e.g. the hemagglutinin protein).
- the membrane-fusion protein can be engineered to bind the Fc region of an antibody that targets an antigen on a target cell, redirecting the membrane fusion activity towards cells that display the antibody’s target.
- the targeting moiety linked to the membrane-fusion protein binds a cell surface marker on the target cell, e.g., a protein, glycoprotein, receptor, cell surface ligand, agonist, lipid, sugar, class I transmembrane protein, class II transmembrane protein, or class III transmembrane protein.
- a cell surface marker on the target cell e.g., a protein, glycoprotein, receptor, cell surface ligand, agonist, lipid, sugar, class I transmembrane protein, class II transmembrane protein, or class III transmembrane protein.
- the lipid delivery particles disclosed herein display targeting moieties that are not conjugated to the membrane-fusion protein or other proteins in order to redirect the fusion activity of the lipid delivery particle towards a cell that is bound by the targeting moiety, or to affect tropism of the lipid delivery particle toward the target cell.
- an envelope protein has a viral origin.
- a suitable envelope protein is from a DNA virus, an RNA virus, or a retrovirus.
- the envelope protein can be envelope protein from Herpesviruses, Avian sarcoma leukosis virus, Poxviruses, Hepadnaviruses, Asfarviridae, Flaviviruses, Alphaviruses, Togaviruses, Coronaviruses, Hepatitis D, Orthomyxoviruses, Rhabdovirus, Bunyaviruses, Filoviruses, Oncoretroviruses, lentiviruses, Spumaviruses.
- envelope protein can be envelope protein from lentiviruses, for example, human immunodeficiency virus (HIV), simian immunodeficiency virus (SIV), feline immunodeficiency virus (FIV) and equine infectious anemia virus (EIAV).
- HIV human immunodeficiency virus
- SIV simian immunodeficiency virus
- FV feline immunodeficiency virus
- EIAV equine infectious anemia virus
- an envelope protein is a fusion of two different envelope proteins, wherein each comes from a different virus. Additional suitable envelope proteins that are from viral origins and their functions are described in White JM et al.. Crit Rev Biochem Mol Biol. 2008 May- Jun;43(3): 189-219.
- the envelope protein is a vesicular stomatitis virus glycoprotein (VSVG) or a biologically active mutant thereof.
- VSVG vesicular stomatitis virus glycoprotein
- a “biologically active mutant” disclosed herein in connection with a reference protein can refer to a mutant of the reference protein that remains displaying one or more biological activities that are of same nature as the reference protein, which are relevant to the context in which the reference protein is used in the lipid delivery particle disclosed herein, while the level of the one or more biological activities of the biologically active mutant can be either similar as or different than the reference protein.
- the biologically active mutant of a VSVG in the context of an envelope protein remains displaying the biological activities of an envelope protein, e.g., mediating membrane fusion, tropism of the lipid delivery particle toward a target cell, or both.
- a mutant as described in the present disclosure is equivalent to a biologically active mutant.
- the envelope protein is a Human immunodeficiency virus GP160 or a biologically active mutant thereof.
- the envelope protein is a Baboon Endogenous Retrovirus (BaEVTR) glycoprotein or a biologically active mutant thereof.
- the envelope protein is a modified Baboon Endogenous Retrovirus (BaEVTRless) glycoprotein or a biologically active mutant thereof.
- the envelope protein is the fusion protein of Vesicular stomatitis Indiana virus and Rabies virus Glycoproteins (FuG-E) or a biologically active mutant thereof.
- the envelope protein pantropic murine leukemia virus envelope protein (MLV) or a biologically active mutant thereof.
- the envelope protein is a modified Fusion protein of Vesicular stomatitis Indiana virus and Rabies virus Glycoproteins (FuG-E P440E) or a biologically active mutant thereof.
- the envelope protein is an ecotropic Murine Leukemia Virus envelope protein (MLV ENV ecotropic) or a biologically active mutant thereof.
- the envelope protein is an amphotrophic Murine Leukemia Virus envelope protein (MLV ENV amphotropic) or a biologically active mutant thereof.
- the envelope protein is a Moloney murine leukemia virus envelope protein (MMLV) or a biologically active mutant thereof.
- the envelope protein is a Moloney murine sarcoma virus envelope protein (MoMSVg) or a biologically active mutant thereof.
- the envelope protein is a moloney murine leukemia virus 10A1 strain Glycoprotein (MLV 10A1) or a biologically active mutant thereof.
- the envelope protein is a xenotropic murine leukemia virus envelope protein (MLV ENV xenotropic) or a biologically active mutant thereof.
- the envelope protein is a xenotropic murine leukemia virus-related envelope protein (XMRV) or a biologically active mutant thereof.
- the envelope protein is a Baculovirus envelope glycoprotein (GP64) or a biologically active mutant thereof.
- the envelope protein is an endogenous feline virus envelope protein (RD114 ENV) or a biologically active mutant thereof.
- the envelope protein is a mammalian endogenous retrovirus protein, or a biologically active mutant thereof.
- the mammalian endogenous retrovirus protein can be a koala retrovirus protein (KoRV) or a Jaagsiekte sheep retrovirus protein (enJSRV), or a biologically active mutant thereof.
- the envelope protein is a simian endogenous type D retrovirus protein (RD-114) or a biologically active mutant thereof.
- the envelope protein is a gibbon ape leukemia virus envelope protein (GALV) or a biologically active mutant thereof.
- the envelope protein is a feline leukemia virus envelope protein (FLV) or a biologically active mutant thereof.
- the envelope protein is a mouse mammary tumor virus envelope protein (MMTV) or a biologically active mutant thereof.
- the envelope protein is an avian leukosis virus envelope protein or a biologically active mutant thereof.
- the envelope protein is a rous sarcoma virus envelope protein or a biologically active mutant thereof.
- the envelope protein can direct the lipid delivery particles to fuse with a certain type of target cells rather than other cells.
- the lipid delivery particle can preferentially target different cell types (z.e., tropisms of the lipid delivery particles), such as liver cells, ocular cells, nerve cells, lung cells, immune cells, muscle cells, and any other cell types of interest.
- the envelope protein can be a glycoprotein from human hepatitis viruses or a biologically active mutant thereof, e.g., Hepatitis B virus (HBV) or hepatitis C virus (HCV), VSV-G glycoprotein or a biologically active mutant thereof, a Marburg virus glycoprotein or a biologically active mutant thereof, an Ebola virus glycoprotein or a biologically active mutant thereof.
- HBV Hepatitis B virus
- HCV hepatitis C virus
- VSV-G glycoprotein or a biologically active mutant thereof e.g., hepatitis B virus (HBV) or hepatitis C virus (HCV)
- VSV-G glycoprotein or a biologically active mutant thereof e.g., a Marburg virus glycoprotein or a biologically active mutant thereof, an Ebola virus glycoprotein or a biologically active mutant thereof.
- a target muscle cell for example, a skeletal muscle cell
- the envelope protein can be a Ross River virus glycoprotein or a
- the envelope protein can be an Ebola virus glycoprotein or a biologically active mutant thereof, a Marburg virus glycoprotein or a biologically active mutant thereof, or a VSV-G or a biologically active mutant thereof.
- a target immune cell for example, CD8+ T cell, an HTLV-1 glycoprotein or a biologically active mutant thereof, or a VSV- G glycoprotein or a biologically active mutant thereof.
- the envelope protein can be a HIV-1 envelope or a biologically active mutant thereof, a HTLV-1 glycoprotein or a biologically active mutant thereof, or a VSV-G glycoprotein or a biologically active mutant thereof.
- the envelope protein can be a respiratory syncytial virus glycoprotein or a biologically active mutant thereof, or a SARS-CoV glycoprotein or a biologically active mutant thereof.
- the envelope protein can be a rabies glycoprotein or a biologically active mutant thereof, a Mokola virus glycoprotein or a biologically active mutant thereof, a Semliki Forest virus glycoprotein or a biologically active mutant thereof, a Venezuelan equine encephalitis virus glycoprotein or a biologically active mutant thereof, or a VSV-G or a biologically active mutant thereof.
- the envelope protein can be an Ebola virus glycoprotein or a biologically active mutant thereof, a Marburg virus glycoprotein or a biologically active mutant thereof, or a VSV-G or a biologically active mutant thereof.
- the envelope protein comprises the sequences set forth in Table 1.
- the envelope protein comprises the sequences set forth in Table 1 with at least one amino acid substitution, deletion, or insertion.
- N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein.
- the envelope protein comprises the sequences set forth in Table 1 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
- the envelope protein comprises one or more of the sequences set forth in Table 1 with at least one amino acid substitution, deletion, or insertion.
- N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein.
- the envelope protein comprises one or more of the sequences set forth in Table 1 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
- the envelope protein comprises any one of the sequences set forth in Table 1 with at least one amino acid substitution, deletion, or insertion.
- N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein.
- the envelope protein comprises any one of the sequences set forth in Table 1 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
- the envelope protein comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in Table 1.
- the envelope protein comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104
- the envelope protein comprises an amino acid sequence that has at least about 50% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
- the envelope protein comprises an amino acid sequence that has at least about 60% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 70% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 75% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
- the envelope protein comprises an amino acid sequence that has at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 80% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 85% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
- the envelope protein comprises an amino acid sequence that has at least about 90% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 95% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104 In some cases, the envelope protein comprises an amino acid sequence that has at least about 96% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 97% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
- the envelope protein comprises an amino acid sequence that has at least about 98% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
- the envelope protein in the lipid delivery particle described herein has a human origin, e.g., has significant sequence similarity to a human wild-type protein, such as at least 90%, at least 95%, at least 98%, or at least 99%.
- Using an envelope protein of a human origin can have benefits such as providing a minimized immunogenicity and better tolerance in a human subject receiving the lipid delivery particles.
- the lipid delivery particle comprising an envelope protein of a human origin can comprise another component that is from human origin or from non-human origin (e.g., a payload or a plasma membrane recruitment element).
- An envelope protein that is from human origin can include, example, envelope proteins or glycoproteins of human endogenous retroviruses (HERVs), other human endogenous envelope proteins, or other human endogenous proteins that serve a similar function of recognizing and/or fusing with membrane of a target cell (e.g., clathrin adaptor protein complex- 1, CHMP4C, Proteolipid protein 1, TSAP6, immunoglobulin variable domains, or a biologically active mutant thereof).
- HERVs human endogenous retroviruses
- a target cell e.g., clathrin adaptor protein complex- 1, CHMP4C, Proteolipid protein 1, TSAP6, immunoglobulin variable domains, or a biologically active mutant thereof.
- the envelope protein is a HERV envelope protein such as any one of those listed in Table 2.
- the envelope protein is a hENVHl or a biologically active mutant thereof.
- the envelope protein is a hENVH2 or a biologically active mutant thereof.
- the envelope protein is a hENVH3 or a biologically active mutant thereof.
- the envelope protein is a hENVKl or a biologically active mutant thereof.
- the envelope protein is a hENVK2 or a biologically active mutant thereof.
- the envelope protein is a hENVK3 or a biologically active mutant thereof.
- the envelope protein is a hENVK4 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVK5 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVK6 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVT or a biologically active mutant thereof. In some cases, the envelope protein is a hENVW or a biologically active mutant thereof. In some cases, the envelope protein is a hENVFRD or a biologically active mutant thereof. In some cases, the envelope protein is a hENVR or a biologically active mutant thereof.
- the envelope protein is a hENVR(b) or a biologically active mutant thereof. In some cases, the envelope protein is a hENVR(c)2 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVR(c)l or a biologically active mutant thereof. In some cases, the envelope protein is a hENVKcon or a biologically active mutant thereof. In some cases, the envelope protein is a truncated HERV protein.
- the envelope protein comprises the sequences set forth in Table 3.
- the envelope protein comprises the sequences set forth in Table 3 with at least one amino acid substitution, deletion, or insertion. For example, for those amino acid sequences start with a N-terminal methionine, the N-terminal methionine can be absent.
- the envelope protein comprises the sequences set forth in Table 3 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
- the envelope protein comprises one or more of the sequences set forth in Table 3 with at least one amino acid substitution, deletion, or insertion.
- N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein.
- the envelope protein comprises one or more of the sequences set forth in Table 3 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
- the envelope protein comprises any one of the sequences set forth in Table 3 with at least one amino acid substitution, deletion, or insertion.
- N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein.
- the envelope protein comprises any one of the sequences set forth in Table 3 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
- the envelope protein comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 50% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 60% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82.
- the envelope protein comprises an amino acid sequence that has at least about 70% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82 In some cases, the envelope protein comprises an amino acid sequence that has at least about 75% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49- 82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82.
- the envelope protein comprises an amino acid sequence that has at least about 80% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 85% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 90% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 95% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82.
- the envelope protein comprises an amino acid sequence that has at least about 96% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82 In some cases, the envelope protein comprises an amino acid sequence that has at least about 97% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49- 82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 98% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82.
- the lipid delivery particle provided herein comprises a plasma membrane recruitment element.
- the lipid delivery particle comprises at least about 1, at least about 2, at least about 3, at least about 4, at least about 5, at least about 6, at least about 7, at least about 8, at least about 9, at least about 10, or more plasma membrane recruitment elements.
- the lipid delivery particle comprises at most about 1, at most about 2, at most about 3, at most about 4, at most about 5, at most about 6, at most about 7, at most about 8, at most about 9, or at most about 10 plasma membrane recruitment elements.
- the lipid delivery particle disclosed herein can comprise a membrane.
- the membrane encapsulates a payload.
- the lipid delivery particle comprises a plasma membrane recruitment element, for example, inside the cavity of the lipid delivery particle.
- the plasma membrane recruitment element can localize itself to the membrane of the lipid delivery particles.
- the plasma membrane recruitment element can be utilized to recruit a component (e.g., a payload) to the membrane of the lipid delivery particles via forming a chimeric protein of the plasma membrane recruitment element and a component to be localized to the membrane or other mechanisms of attachment.
- the membrane encapsulates a protein core.
- at least a portion of the plasma membrane recruitment element forms the basic structure of the lipid delivery particle, such as a portion of the protein core inside the lipid delivery particle.
- at least a portion of the plasma membrane recruitment element binds to the membrane of the lipid delivery particle from the inside.
- the plasma membrane recruitment element can play a role in the assembly of the lipid delivery particle, such as packing various components e.g., a payload) into the lipid delivery particles.
- the plasma membrane recruitment element can direct budding of the lipid delivery particles from a producer cell.
- expressing plasma membrane recruitment element alone or together with an envelope protein disclosed herein in a producer cell can lead to formation of the lipid delivery particle.
- the plasma membrane recruitment element has a viral origin.
- the plasma membrane recruitment element comprises a retroviral gag protein, e.g., a retroviral polyprotein that comprises one or more of a matrix (MA) polypeptide, an RNA-binding phosphoprotein polypeptide, a capsid (CA) polypeptide, or a nucleocapsid (NC) polypeptide.
- the plasma membrane recruitment element can comprise HIV gag or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a gag from murine leukemia virus (MLV) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a gag from Moloney murine leukemia virus (MMLV) or a biologically active mutant thereof.
- the plasma membrane recruitment element forms structural protein that forms the protein core of the lipid delivery particles described herein.
- the plasma membrane recruitment element can comprise Respiratory syncytial virus (RSV) M or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Human Papillomavirus (HPV) LI protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise HPV L2 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Hepatitis B virus (HBV) core protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Hepatitis C virus (HCV) core protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise hepatitis E virus (HeV) M protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Chikungunya virus (CHIKV) C-E3-E2-6k-El or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise RSV NP or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Human metapneumovirus (HMPV) M or a biologically active mutant thereof.
- the plasma membrane can comprise a glycoprotein from a flavivirus.
- the flavivirus can comprise Chikungunya virus, Zika virus, Dengue virus, or West Niles virus.
- the plasma membrane recruitment element can comprise Zika virus (ZIKV) C or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise ZIKV prM/M or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Dengaue virus (DENV) C-prM or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise West Nile Virus (WNV) prME protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise WNV CprME protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Filovirus VP40 or Z protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Baculovirus Pl protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Rotavirus VP7 or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Rotavirus VP2 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Rotavirus VP6 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Porcine Circovirus Type 2 (PCV2) capsid or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise baculovirus VP2 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise baculovirus VP5 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise baculovirus VP3 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise or baculovirus VP7 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Ebola nucleocapsid or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Parovirus VP1 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Parovirus VP2 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Newcastle disease virus (NDV) M protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Human polyomavirus 2 (JCPyV) VP1 protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise Human parainfluenza virus type 3 (HPIV3) M protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise HPIV3N protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise or Mumps virus (MuV) M proteins or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise SARS M protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise SARS E protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise SARS N protein or a biologically active mutant thereof.
- the plasma membrane recruitment element is a mammalian protein or part thereof.
- the plasma membrane recruitment element can include a pleckstrin homology (PH) domain or a transmembrane domain of a mammalian protein, such as a mouse protein or a human protein.
- the plasma membrane recruitment element has a human origin. Utilizing the plasma membrane recruitment element of a human origin in the lipid delivery particle can give rise to reduced immunogenicity for administration to a human subject.
- the plasma membrane recruitment element can include a gag from human endogenous retrovirus, such as Human Endogenous Retrovirus K (e.g., HERV-K113, HERV-K101, HERV- K102, HERV-K104, HERV-K107, HERV-K108, HERV-K109, HERV-K115, HERV- Kl lp22, and HERV-K12ql3) and Human Endogenous Retrovirus-W (HERV-W) or a biologically active mutant thereof.
- the plasma membrane recruitment element can include a hGAGK con or a biologically active mutant thereof.
- the plasma membrane recruitment element can include an endogenous gag of a mammal (e.g., human) from retrotransposons (e.g., Arc from vertebrate lineage of Ty3/gypsy retrotransposon), which are also ancestral to retroviruses.
- the plasma membrane recruitment element comprises a portion from human Arc.
- the plasma membrane recruitment element can include a pleckstrin homology (PH) domain from a mammalian protein or a biologically active mutant thereof.
- the plasma membrane recruitment element can include a pleckstrin homology (PH) domain from a human protein or a biologically active mutant thereof.
- the PH domains can play a role in protein-membrane interactions via binding to phosphatidylinositol phosphate (PIP), for example PIP2 or PIP3, or other lipids or proteins within the membrane of the lipid delivery particles.
- PIP phosphatidylinositol phosphate
- PH domains with different sequences can have varied affinities and selectivity when binding different PIPs.
- the plasma membrane recruitment element can include a PH domain of phospholipase C51 (e.g., human phospholipase C51) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of Aktl (e.g., human Aktl) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a mutant PH domain of human Aktl with E17K substitution or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of 3 -phosphoinositidedependent protein kinase 1 (e.g., human 3 -phosphoinositide-dependent protein kinase 1) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of Dappl (e.g., human Dappl) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of Grpl (e.g., mouse Grpl) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of human Grpl or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of OSBP (e.g., human OSBP) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of Btkl (e.g., human Btkl) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of FAPP1 (e.g., human FAPP1) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of CERT (e.g., human CERT) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of PKD (e.g., human PKD) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of PHLPP1 (e.g., human PHLPP1) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of SWAP70 (e.g., human SWAP70) or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a PH domain of MAPKAP1 (e.g., human MAPKAP1) or a biologically active mutant thereof.
- the plasma membrane recruitment element can also include a membrane protein (e.g., a human membrane protein), a transmembrane domain thereof, or a biologically active mutant thereof.
- the transmembrane domain of a human protein can be a tetraspanin or a biologically active mutant thereof.
- the plasma membrane recruitment element comprises a transmembrane domain of human CD9 or a biologically active mutant thereof.
- the plasma membrane recruitment element comprises a transmembrane domain of human CD47 or a biologically active mutant thereof.
- the plasma membrane recruitment element comprises a transmembrane domain of human CD63 or a biologically active mutant thereof.
- the plasma membrane recruitment element comprises a transmembrane domain of human CD81, or a biologically active mutant thereof.
- the plasma membrane recruitment element can comprise a retroviral gag or a biologically active mutant thereof.
- the mutant of a retroviral gag can include only a portion of the retroviral gag.
- the plasma membrane recruitment element can include a gag of an alpha retrovirus or a biologically active mutant thereof.
- the plasma membrane recruitment element can a beta retrovirus or biologically active mutant thereof.
- the plasma membrane recruitment element can include a gamma retrovirus or biologically active mutant thereof.
- the plasma membrane recruitment element can include a delta retrovirus or biologically active mutant thereof.
- the plasma membrane recruitment element can include or biologically active mutant thereof.
- the plasma membrane recruitment element can include an epsilon retrovirus or biologically active mutant thereof.
- the plasma membrane recruitment element can include a spumavirus or biologically active mutant thereof.
- the retroviral gag can include a gag of HIV (e.g., HIV-1), a gag of murine leukemia virus (MLV), a gag of Moloney murine leukemia virus (MMLV), a gag of Simian immunodeficiency virus (SIV), a gag of Rous sarcoma virus (RSV), a gag of human T- cell leukemia virus type-1 (HTLV), or a gag of bovine leukemia virus (BLV), or a biologically active mutant thereof.
- the plasma membrane recruitment element can include a gag of HIV (e.g., HIV-1) or a biologically active mutant thereof.
- the plasma membrane recruitment element can include a gag of MLV or a biologically active mutant thereof.
- the plasma membrane recruitment element can include a gag of RSV or a biologically active mutant thereof.
- the plasma membrane recruitment element can include a gag of Friend murine leukemia virus (FMLV) or biologically active mutant thereof.
- the plasma membrane recruitment element comprises one or more of the sequences set forth in Table 4 with at least one amino acid substitution, deletion, or insertion.
- N-terminal methionine can be absent from the plasma membrane recruitment element of the lipid delivery particle provided herein relative to the wild-type plasma membrane recruitment element.
- the plasma membrane recruitment element comprises one or more of the sequences set forth in Table 4 and a heterologous peptide sequence fused to the N- terminal or C-terminal.
- the plasma membrane recruitment element comprises any one of the sequences set forth in Table 4 with at least one amino acid substitution, deletion, or insertion.
- N-terminal methionine can be absent from the plasma membrane recruitment element of the lipid delivery particle provided herein relative to the wild-type plasma membrane recruitment element.
- the plasma membrane recruitment element comprises any one of the sequences set forth in Table 4 and a heterologous peptide sequence fused to the N- terminal or C-terminal.
- the plasma membrane recruitment element comprises the sequences set forth in Table 4 with a further truncation on the N-terminus. For example, for those amino acid sequences start with a N-terminal methionine, the N-terminal methionine can be absent.
- the plasma membrane recruitment element comprises the sequences set forth in Table 4 with a further truncation on the C-terminus.
- the plasma membrane recruitment element comprises the sequences set forth in Table 4 with one amino acid substitution.
- the plasma membrane recruitment element comprises the sequences set forth in Table 4 with two or more amino acid substitutions.
- the plasma membrane recruitment element comprises the sequences set forth in Table 4 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
- the plasma membrane recruitment element comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in Table 4.
- the plasma membrane recruitment element comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
- the plasma membrane recruitment element comprises an amino acid sequence that has at least about 50% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 60% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 70% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 75% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1- 48.
- the plasma membrane recruitment element comprises an amino acid sequence that has at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48 In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 80% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48 In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 85% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
- the plasma membrane recruitment element comprises an amino acid sequence that has at least about 90% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 95% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 96% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 97% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
- the plasma membrane recruitment element comprises an amino acid sequence that has at least about 98% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
- *hGAGKcon is a consensus sequence derived from ten proviral GAG sequences encoded by human genomic sequences.
- the GAG sequences used to derive this consensus GAG sequence are from the following HERVs: HERV-K113, HERV-K101, HERV-K102, HERV- K104, HERV-K107, HERVK108, HERV-K109, HERV-K115, HERV- Kllp22, and HERV- K12ql3.
- the lipid delivery particle disclosed herein comprises a protein core that is composed of at least a structural protein of a viral origin, for instance, a retroviral gag protein.
- the lipid delivery particle comprises a retroviral gag-pro-pol polyprotein, e.g., a gag-pro-pol poly protein from HIV, MMLV, or FMLV, which can help assemble a protein core of the lipid delivery particle.
- some of the gag-pro-pol polyprotein is cleaved, e.g., by pro (protease) present freely or in the gag-pro-pol polyprotein.
- the cleavage by pro can be inefficient, and the resultant cleavage products can include gag polyprotein, gag-pro polyprotein, free pro, and free pol (polymerase).
- a retroviral gag polyprotein can be further cleaved into MA, CA, NC, and other small fragments, if any.
- the lipid delivery particle comprises a retroviral gag-pro polyprotein without the pol component, and the gag-pro polyprotein can help form a protein core of the lipid delivery particle.
- the gag-pro can also be cleaved by pro, in some cases, inefficiently, into separate gag and pro proteins. In some cases, there can be different plasma membrane recruitment elements in a lipid delivery particle.
- a gag-pro or gag-pro-pol polyprotein from one species of virus can help assemble form a protein core of the lipid delivery particle, while a chimeric protein in the lipid delivery particle, discussed infra, can comprise a payload fused with a gag protein from a different species of virus (e.g., an MMLV), or from a HERV, or a PH domain or transmembrane domain of a huma protein (e.g, a PH domain of human Aktl with E17K substitution).
- a retrovirus e.g., a HIV
- a chimeric protein in the lipid delivery particle discussed infra, can comprise a payload fused with a gag protein from a different species of virus (e.g., an MMLV), or from a HERV, or a PH domain or transmembrane domain of a huma protein (e.g, a PH domain of human Aktl with E17K substitution).
- the present disclosure provides a chimeric protein comprising a plasma membrane recruitment element and a payload that is a protein or a fragment thereof.
- the lipid delivery particle comprises a chimeric protein comprising a plasma membrane recruitment element and a payload that is a protein or a fragment thereof.
- the lipid delivery particle comprises at least about 1, at least about 2, at least about 3, at least about 4, at least about 5, at least about 6, at least about 7, at least about 8, at least about 9, at least about 10, or more chimeric proteins.
- the lipid delivery particle comprises at most about 1, at most about 2, at most about 3, at most about 4, at most about 5, at most about 6, at most about 7, at most about 8, at most about 9, or at most about 10 chimeric proteins.
- the plasma membrane recruitment element and the payload are fused directly in the chimeric protein.
- the plasma membrane recruitment element and the payload are fused indirectly via a linker.
- the linker between the plasma membrane recruitment element and the payload is a cleavable linker that is recognized by a protease.
- the chimeric protein (e.g., comprising a gag protein) can form at least part of a protein core of the lipid delivery particle.
- a lipid delivery particle can comprise two or more chimeric proteins.
- the chimeric protein can include a structural protein.
- the structural protein can comprise a plasma membrane recruitment element (e.g., retroviral gag protein).
- the plasma membrane recruitment element can be fused to a payload.
- the two or more chimeric proteins comprise the same structural protein.
- the two or more chimeric proteins comprise different structural proteins.
- the two or more chimeric proteins comprise different payloads.
- the chimeric protein comprises a payload that comprises a nucleic acid-binding moiety.
- the payload further comprises a guide nucleic acid molecule that forms a ribonucleoprotein complex with the nucleic acid-binding moiety.
- the chimeric protein is suitable for delivery by a lipid delivery particle disclosed herein.
- the lipid delivery particle of the present disclosure further comprises a protease that recognizes the cleavable linker in the chimeric protein and cuts the chimeric protein at the cleavable linker.
- the payload can be separated from the plasma membrane recruitment element.
- the lipid delivery particle comprises at least about 1, at least about 2, at least about 3, at least about 4, at least about 5, at least about 6, at least about 7, at least about 8, at least about 9, at least about 10, or more proteases.
- the lipid delivery particle comprises at most about 1, at most about 2, at most about 3, at most about 4, at most about 5, at most about 6, at most about 7, at most about 8, at most about 9, or at most about 10 proteases.
- the payload is present as a "free" entity separate from the plasma membrane recruitment element.
- the payload can be free and present within an inside of the protein core of the lipid delivery particle.
- the chimeric protein comprises a protease.
- the chimeric protein comprises a first protease and a second protease.
- the protease is part of a second chimeric protein comprising a second plasma membrane recruitment element and the protease, where the second plasma membrane recruitment element can be either different from or same as the plasma membrane recruitment element that is fused with the payload.
- the chimeric protein comprises a dimerization element that helps it to form a dimer with another chimeric protein.
- the dimerization element is a leucine zipper pair, an inducible heteromerization domain, an cohesin-dockerin interaction, a spy catcher- spy tag covalent interaction, or an electrostatic interaction between positively and negatively charged amino acids.
- the chimeric protein disclosed herein also comprises one or more non- cleavable linkers that operably link components together.
- the non-cleavable linker can be any suitable linker sequence that is used for chimeric protein construction, such as peptide linkers that consist of glycine (Gly) and serine (Ser) residues.
- the non-cleavable linker comprises an amino acid sequence selected from the group consisting of: (GS)x (SEQ ID NO: 564), (GGS)x (SEQ ID NO: 565), (GGGGS)x (SEQ ID NO: 566), (GGSG)x (SEQ ID NO: 567), and (SGGG)x (SEQ ID NO: 568), and wherein x is an integer from 1 to 50.
- the chimeric protein of the present disclosure comprises a nuclear export signal (NES) sequence that can direct transport of the chimeric protein out of the nucleus of a cell, e.g., a producer cell.
- NES nuclear export signal
- the chimeric protein disclosed herein has one of the following configurations of components positioned in an order from N-terminus to C-terminus: [plasma membrane recruitment element]-[cleavable linker]-[payload];
- n is an integer in the range of from 1 to 10, and denotes the number of repeats of the NES sequence.
- Non-cleavable linker sequence can be present or absent in any of the foregoing configurations between any two neighboring components.
- the payload sequence in the chimeric protein can have one or more NLS sequences, at its N-terminus, C- terminus, or both.
- n is an integer in the range of from 1 to 10, and denotes the number of repeats of the NES sequence.
- Non-cleavable linker sequence can be present or absent in any of the foregoing configurations between any two neighboring components.
- the payload sequence in the chimeric protein can have one or more NLS sequences, at its N- terminus, C-terminus, or both.
- nuclear export signal refers to a sequence of amino acids that targets a payload protein for export from the nucleus.
- NES nuclear export signal
- NES is a short target peptide sequence containing four hydrophobic residues. These residues target the protein for export from the nucleus to the cytoplasm through the nuclear pore complex.
- a chimeric protein provided herein can comprise 1 NES, 2 NESs, 3 NESs, 4 NESs, 5 NESs, 6 NESs, 7 NESs, 8 NESs, 9 NESs, or 10 NESs.
- the NES is located at the N-terminus, C-terminus, or in an internal region of the chimeric protein.
- a NES is coupled between the plasma membrane recruitment element and the payload in the chimeric protein.
- the NES sequence that is used in the chimeric protein comprises LQLPPLERLTL (SEQ ID NO: 403) derived from HIV-1 Rev protein, or any of the sequences having at least 80% identity thereto.
- the NES sequence comprises LALKLAGLDI (SEQ ID NO: 352) or NELALKL AGLDI (SEQ ID NO: 416), derived from PKIa, or any of the sequences having at least 80% identity thereto.
- the NES sequence that is used in the chimeric protein comprises an amino acid sequence as set forth in Table 5.
- the NES sequence comprises any one of the sequences set forth in Table 5.
- the NES sequence comprises one or more of the sequences set forth in Table 5.
- the NES sequence comprises more than one, more than two, more than three, more than four, more than five, more than six, more than seven, more than eight, more than nine, or more than ten of the sequences set forth in Table 5. In some cases, the NES sequences comprises multiple sequences set forth in Table 5.
- the NES sequence comprises an amino acid sequence having 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity to any sequence listed in Table 5.
- the NES sequence comprises an amino acid sequence having 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity to any sequence set forth in SEQ ID NOs: 352-453.
- the NES sequence described herein comprises a sequence with greater than 80% sequence identity to any sequence listed in Table 5. The transport of payload proteins within a cell is enabled through both NES and nuclear export receptors.
- the NES described herein is associated with a nuclear export receptor (e.g., CRM-1).
- the NES may be conditionally active or inactive.
- the NES sequence disclosed herein comprises a sequence such as those described in T la Cour, et al., Nucleic Acids Res. 2003;31(l):393-396; and Xu D, et al. Mol Biol Cell. 2012 Sep;23(18):3673-6, each of which is incorporated herein by reference in its entirety. Any of the NES sequences described in the NES sequence database (NESdb®; prodata.swmed.edu/LRNes) or (NESbase; services. healthtech.
- dtu.dk/datasets/NESbase- 1.0 can be used in a chimeric protein disclosed herein, e.g., for the purpose of packaging a payload into the molecular assembly, e.g., the lipid delivery particle.
- a chimeric protein disclosed herein include a nuclear export sequence (NES).
- the NES facilitates localization of the chimeric protein in the cytosol of a target cell relative to the nucleus.
- a chimeric protein disclosed herein includes at least one NES sequences, such as, 2 or more, 3 or more, 4 or more, or 5 or more NES sequences.
- one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the N-terminus and/or the C- terminus of the chimeric protein.
- the chimeric protein disclosed herein comprises only one NES sequence.
- the chimeric protein disclosed herein comprises two NES sequences.
- the chimeric protein disclosed herein comprises three NES sequences.
- one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the N-terminus of the chimeric protein. In some cases, one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the C-terminus of the chimeric protein. In some cases, one or more NES sequences (3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) both the N-terminus and the C-terminus of the chimeric protein. In some cases, an NES sequence is positioned at the N-terminus and an NES sequence is positioned at the C-terminus of the chimeric protein.
- a payload is a protein that is delivered as part of the chimeric protein disclosed herein, e.g., operably linked to a structural protein (e.g., human endogenous retroviral structural protein or a Plasma membrane recruitment element).
- the one or more NES sequences are positioned at or near the one or both ends of the payload protein sequence inside the chimeric protein.
- one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the N-terminus and/or the C- terminus of the payload protein sequence.
- one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the N-terminus of the payload protein sequence. In some cases, one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the C-terminus of the payload protein sequence. In some cases, one or more NES sequences (3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) both the N-terminus and the C-terminus of the payload protein sequence.
- an NES sequence is positioned at the N-terminus and an NES sequence is positioned at the C- terminus of the payload protein sequence.
- the chimeric protein disclosed herein comprises only one NES sequence.
- the chimeric protein comprises only one NES sequence, and the NES sequence is positioned at or near (e.g., within 50 amino acids of) the N- terminus of the payload protein.
- NESs nuclear export sequences
- NESs can direct export of proteins from the nucleus to the cytoplasm.
- NESs can bind directly to the export karyopherin CRM1 (also known as exportin 1), which can escort payload proteins through the nuclear pore complex.
- a payload described herein comprises one or more nuclear localization sequences (NLS).
- NLS nuclear localization sequences
- the term “nuclear localization signal” refers to a sequence of amino acids that targets a payload e.g., a protein or a short polypeptide), which the NLS is present within or coupled to, to localize to the nucleus.
- an NLS facilitates the import of a polypeptide comprising an NLS into the cell nucleus.
- a polypeptide can comprise 1 NLS, 2 NLSs, 3 NLSs, 4 NLSs, 5 NLSs, 6 NLSs, 7 NLSs, 8 NLSs, 9 NLSs, or 10 NLSs.
- the NLS is located at the N-terminus, C-terminus, or in an internal region of the polypeptide. In some cases, a NLS is coupled to a nucleic acid binding domain described elsewhere herein. In some cases, a NLS is coupled to a nucleic acid modifying domain described elsewhere herein. In some cases, a NLS is coupled to a guidable polypeptide domain, a deaminase domain, or a reverse transcriptase domain. In some cases, a NLS is covalently linked to a nucleic acid binding domain described elsewhere herein. In some cases, a NLS is covalently linked to a nucleic acid modifying domain described elsewhere herein.
- a NLS is covalently linked to a guidable polypeptide domain, a deaminase domain, or a reverse transcriptase domain.
- a nucleic acid binding domain does not comprise an NLS.
- a nucleic acid binding domain does not comprise an NLS.
- a guidable polypeptide domain, a deaminase domain, or a reverse transcriptase domain does not comprise an NLS. Examples of NLS are provided in Table 6 below.
- the NLS comprises an amino acid sequence as set forth in Table 6. In some cases, the NLS comprises any one of the sequences set forth in Table 6. In some cases, the NLS comprises one or more of the sequences set forth in Table 6. In some cases, the NLS comprises more than one of the sequences set forth in Table 6. In some cases, the NLS comprises multiple sequences set forth in Table 6. In some cases, NLS sequence can comprise an amino acid sequence having 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity to any sequence listed in Table 6. In some cases, the NLS sequence described herein can comprise a sequence with greater than 80% sequence identity to any sequence listed in Table 6.
- NLS sequence can comprise an amino acid sequence having 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity to any sequence set forth in SEQ ID NOs: 454-477.
- a chimeric protein disclosed herein includes a nuclear localization sequence (NLS).
- NLS nuclear localization sequence
- the NLS facilitates delivery of the chimeric protein, or a payload released from the chimeric protein (for instance, released from the chimeric protein following cleavage of a cleavable linker), into the nucleus of a target cell.
- a payload is a protein and is delivered as part of the chimeric protein disclosed herein, e.g., operably linked to a structural protein (e.g., plasma membrane recruitment element).
- the one or more NLS sequences are positioned at or near the one or both ends of the payload protein sequence of the chimeric protein.
- a chimeric protein includes (e.g., is fused to) between 2 and 5 NLS sequences (e.g., 2-4, or 2-3 NLSs).
- NLS sequences include an NLS sequence derived from: the NLS of the SV40 virus large T-antigen, having the amino acid sequence PKKKRKV (SEQ ID NO: 468); the NLS from nucleoplasmin (e.g., the nucleoplasmin bipartite NLS with the sequence KRPAATKKAGQAKKKK (SEQ ID NO: 460); the c-myc NLS having the amino acid sequence PAAKRVKLD (SEQ ID NO: 467) or RQRRNELKRSP (SEQ ID NO: 541); the hRNPAl M9 NLS having the sequence NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY (SEQ ID NO: 542); the sequence RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV (SEQ ID NO: 543) of the IBB domain from importin-alpha; the sequences VSRKRPRP (SEQ ID NO: 477) and PPKKA
- NLS sequence examples include KRTADGSEFESPKKKRKV (SEQ ID NO: 462), KKTELQTTNAENKTKKL (SEQ ID NO: 554), KRGINDRNFWRGENGRKTR (SEQ ID NO: 555), RKSGKIAAIVVKRPRK (SEQ ID NO: 556), and MDSLLMNRRKFLYQFKNVRWAKGRRETYLC (SEQ ID NO: 463), SPKKKRKVEAS (SEQ ID NO: 557), encoded by AGCCCCAAGAAgAAGAGaAAGGTGGAGGCCAGC (SEQ ID NO: 558), GPKKKRKVAAA (SEQ ID NO: 559), as well as any of those described in Cokol et al., EMBO Rep., 2000, 1(5): 411-415 and Freitas et al., Current Genomics, 2009, 10(8): 550-7; Lu, J., et la., Cell Commun Signal 19, 60 (20
- the chimeric protein comprises a cleavable linker in between two or more components.
- the chimeric protein can comprise a cleavable linker between a payload protein sequence and a plasma membrane recruitment element sequence (e.g., retroviral gag protein sequence).
- the cleavable linker separates the plasma membrane recruitment element sequence from a NLS sequence, and/or a NES sequence at its N-terminus or C-terminus.
- the cleavable linker can separate the payload protein sequence from the plasma membrane recruitment element sequence, NLS sequence, and/or NES sequence at its N-terminus or C-terminus.
- cleavable linker sequences that can be used in the chimeric protein include TSTLLMENSS (SEQ ID NO: 114), PRSSLYPALTP (SEQ ID NO: 115), VQALVLTQ (SEQ ID NO: 562), and PLQVLTLNIERR (SEQ ID NO: 563), and sequences having at least 80% identity to any one of the foregoing.
- the cleavable linker sequence provided herein can be a cleavable sequence that is recognized and cleaved by any applicable protease, such as a viral protease, a bacterial protease, or a eukaryotic protease (e.g., a protease derived from a plant, an animal, or a fungus).
- a viral protease such as a viral protease, a bacterial protease, or a eukaryotic protease (e.g., a protease derived from a plant, an animal, or a fungus).
- the cleavable sequence is recognized by a retroviral protease (pro), such as pro protein derived from Moloney murine leukemia virus (MMLV) or Friend murine leukemia virus (FMLV).
- pro retroviral protease
- the viral protease disclosed herein comprises a viral protease described in Reynolds et al., “The SARS-CoV-2 SSHHPS Recognized by the Papain-like Protease.” ACS infectious diseases 2021 : 7(6): 1483-1502; Farsani et al., “Identification of a Novel Human Rhinovirus C Type by Antibody Capture VIDISCA-454.” Viruses 2015: 7(1):239-251; and Kolykhalov et al., “Specificity of the hepatitis C virus NS3 serine protease: effects of substitutions at the 3/4A, 4A/4B, 4B/5A, and 5A/5B cleavage sites on polyprotein processing.” Journal of Virology 1994: 68(11): 7525-33, each of which is incorporated herein by reference in its entirety.
- the viral protease is the tobacco etch virus (TEV) protease, the hepatitis C (HCV) NS3 protease, adenovirus protease, alphavirus protease, flavivirus protease, herpesvirus protease, picomavirus protease, or the Moloney Murine Leukemia Virus (MMLV) protease.
- TSV tobacco etch virus
- HCV hepatitis C
- adenovirus protease adenovirus protease
- alphavirus protease flavivirus protease
- herpesvirus protease herpesvirus protease
- picomavirus protease picomavirus protease
- the viral protease comprises an amino acid sequence at least 70%, 75%, 80%, 85%, 90%, 95% or 99% sequence identify to an amino acid sequence set forth in Table 7.
- the viral protease comprises an amino acid sequence set
- the lipid delivery particle further comprises a protease that recognizes the cleavable linker sequence, such as pro protein derived from Moloney murine leukemia virus (MMLV) or Friend murine leukemia virus (FMLV), or protease that is of other viral origin, bacterial origin, or eukaryotic origin.
- MMLV Moloney murine leukemia virus
- FMLV Friend murine leukemia virus
- protease that is of other viral origin, bacterial origin, or eukaryotic origin.
- the cleavable linker disclosed herein comprises a sequence such as the target cleavage sequences described in Reynolds et al., “The SARS-CoV-2 SSHHPS Recognized by the Papain-like Protease.” ACS infectious diseases 2021 : 7(6): 1483-1502; Farsani et al., “Identification of a Novel Human Rhinovirus C Type by Antibody Capture VIDISCA-454.” Viruses 2015: 7(1):239-251; and Kolykhalov et al., “Specificity of the hepatitis C virus NS3 serine protease: effects of substitutions at the 3/4A, 4A/4B, 4B/5A, and 5A/5B cleavage sites on polyprotein processing.” Journal of Virology 1994: 68(11): 7525-33, each of which is incorporated herein by reference in its entirety.
- the cleavable linker is cleavable by at least about 1, at least about 2, at least about 3, at least about 4, at least about 5, at least about 6, at least about 7, at least about 8, at least about 9, at least about 10, or more proteases. In some cases, the cleavable linker is cleavable by at most about 1, at most about 2, at most about 3, at most about 4, at most about 5, at most about 6, at most about 7, at most about 8, at most about 9, or at most about 10 proteases. In some cases, the cleavable linker comprises an amino acid sequence at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to an amino acid sequence set forth in Table 8. In some cases, the cleavable linker comprises an amino acid sequence set forth in Table 8.
- the chimeric protein comprises one cleavable linker. In some cases, the chimeric protein comprises two or more cleavable linkers. In some cases, the cleavable site is positioned between the plasma recruitment element and the heterologous payload. In some cases, the cleavable linkers are positioned in either side of the protease. In some cases, the protease cleaves the chimeric protein at the cleavable linker and release the heterologous payload from the remainder of the chimeric protein.
- cleavage at the cleavable linker by the protease is inhibited by adding a reversible protease inhibitor.
- reversible protease inhibitor refers to an protease inhibitor whose inhibitory activity is removed when the inhibitor is no long present.
- the protease inhibitor can be an inhibitor of a retroviral protease, a HIV protease, a HCV protease, or an aspartic acid protease.
- the protease inhibitor is selected from Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir.
- adding protease inhibitor delays the cleavage by the protease until the protease inhibitor is removed.
- releasing the heterologous payload from the remainder of the chimeric protein is delayed until the reversible protease inhibitor is removed.
- chimeric protein sequences comprising a plasma recruitment element, a cleavable linker, and a protease:
- a payload in a lipid delivery particle of the present disclosure can comprise a protein, a polypeptide, a nucleic acid (e.g., DNA or RNA), or any combinations thereof.
- the payload is a heterologous payload.
- the heterologous payload is a therapeutic agent.
- the therapeutic agent is a gene-editing agent.
- the gene-editing agent comprises a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; a nucleic acid encoding a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; or a ribonucleoprotein complex (RNP) comprising a CRISPR- based genome editing or modulating protein.
- the therapeutic agent is a nucleic-acid based agent, a small molecule, or a recombinant protein.
- the payload can be a part of the chimeric protein disclosed herein or can comprise a part of the chimeric protein disclosed herein.
- the payload can include an entity in the lipid delivery particle separate from the chimeric protein disclosed herein.
- the payload is a protein or polypeptide coupled to a plasma membrane recruitment element.
- the payload comprises a first moiety (e.g., a nucleic acidbinding protein) that is fused to a plasma membrane recruitment element, and further comprises a second moiety that is coupled to the first moiety via covalent or non-covalent interaction.
- the first moiety can be a nucleic acid binding protein that is fused with the plasma membrane recruitment element
- the second moiety can be a nucleic acid molecule that binds to the nucleic acid binding protein.
- a payload is directly packaged within the lipid delivery particles and delivered into a target cell in its free form.
- a payload can be fused to a plasma membrane recruitment element (e.g., pleckstrin homology domain) and form a chimeric protein as part of the lipid delivery particles, and then delivered into the target cell.
- the plasma membrane recruitment element e.g., pleckstrin homology domain
- the payload in its free form or as part of a chimeric protein is within the inside cavity of the protein core of the lipid delivery particles disclosed herein.
- the payload in its free form derives from a cleavage of the chimeric protein comprising the payload.
- the plasma membrane recruitment element e.g., pleckstrin homology domain
- the payload e.g., heterologous payload.
- the plasma membrane recruitment element e.g., pleckstrin homology domain
- the payload e.g., heterologous payload
- the payload e.g., heterologous payload
- the payload e.g., heterologous payload
- the payload is reversibly coupled to the plasma membrane recruitment element (e.g., pleckstrin homology domain) by one of the one or more cleavable linker.
- the payload (e.g., heterologous payload) is coupled to a C-terminus of the plasma membrane recruitment element (e.g., pleckstrin homology domain). In some cases, the payload (e.g., heterologous payload) is coupled to an N-terminus of the plasma membrane recruitment element (e.g., pleckstrin homology domain).
- a lipid delivery particle can deliver more than one payload.
- Each of the payloads can independently comprise nucleic acid-binding moiety, a nucleic acid-modifying moiety, a fusion protein, or a nucleic acid, or any combinations thereof.
- the plasma membrane recruitment element and the payload are coupled via any suitable method.
- Covalent coupling between the plasma membrane recruitment element and a payload peptide can include inteins that can form peptide bonds, direct proteinprotein chimeras generated from a single reading frame.
- nucleic acids base pairing to other nucleic acids via hydrogen bonding interactions (e.g., DNA/RNA, DNA/DNA, or RNA/RNA hybrids), protein-protein binding, or protein-nucleic acid molecule binding can be involved for the coupling between the plasma membrane recruitment element and the payload.
- protein-nucleic acid molecule binding examples include an RNA binding protein (RBP) and an RBP binding sequence (e.g., an RNA) that binds to the RBP.
- RBP RNA binding protein
- RBP binding sequence e.g., an RNA
- each of the plasma membrane recruitment element and the payload is fused to a heterologous sequence, and the two heterologous sequences dimerize or multimerize with or without the need for a chemical compound to induce the protein-protein binding, such as a single-stranded nucleic acid sequence or protein dimerization domains).
- each of the plasma membrane recruitment element and the payload is fused to one member of a pair of binding partners (e.g., antibody and its target antigen).
- the plasma membrane recruitment element is fused to an RBP, and the payload is fused to a RBP binding sequence.
- suitable protein domains or nucleic acid molecules for forming the non-covalent connections include single chain variable fragments, nanobodies, affibodies, DmrA/DmrB/DmrC, FKBP/FRB, dDZFs, Leucine zippers, proteins that bind to DNA and/or RNA, optogenetic protein domains that can dimerize or multimerize in the presence of certain light wavelengths, proteins with quaternary structural interactions, and/or naturally reconstituting split proteins.
- RBPs and their RBP binding sequences examples include a sequence having at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in Table 9.
- RBPs and their RBP binding sequences that can be used include a sequence having at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 478-513
- the RBP comprises an amino acid sequence as set forth in Table 9.
- the RBP comprises any one of the sequences set forth in Table 9.
- the RBP comprises one or more of the sequences set forth in Table 9.
- the RBP comprises more than one of the sequences set forth in Table 9.
- the RBP comprises multiple sequences set forth in Table 9.
- the RBP binding sequence comprises an amino acid sequence as set forth in Table 9.
- the RBP binding sequence comprises any one of the sequences set forth in Table 9.
- the RBP binding sequence comprises one or more of the sequences set forth in Table 9.
- the RBP binding sequence comprises more than one of the sequences set forth in Table 9.
- the RBP binding sequence comprises multiple sequences set forth in Table 9. Table 9. Exemplary RNA binding proteins (RBP) and corresponding RBP binding sequences
- nucleic acid binding domains and nucleic acid modifying domains are nucleic acid binding domains and nucleic acid modifying domains
- the payload comprises a nucleic acid-binding moiety, a nucleic acidmodifying moiety, a fusion protein, or a nucleic acid.
- the payload comprises a nucleic acid-binding domain, e.g., a DNA-binding protein domain or polypeptide or an RNA- binding domain or polypeptide e.g., an RNA-binding protein (RBP).
- a nucleic acid-binding moiety can be capable of binding a nucleic acid.
- a nucleic acid-binding domain can bind to a nucleic acid in a nonspecific or a site-specific manner.
- the nucleic acid-binding moiety binds to a nucleic acid in a site-specific manner.
- a nucleic acid-binding moiety can comprise an aptamer binding domain that selectively binds to a specific target.
- a nucleic acid-binding moiety recognizes a specific recognition sequence in the target nucleic acid.
- a nucleic acid-binding moiety comprises an aptamer binding domain.
- a nucleic acid binding moiety selectively binds to a sequence or a structural element in a nucleic acid molecule.
- an RNA-binding domain selectively binds to a specific sequence motif in an RNA molecule.
- a nucleic acid-binding moiety selectively binds to a structural element in a nucleic acid molecule.
- a nucleic acid-binding domain can bind to a stem-loop in a nucleic acid molecule.
- a nucleic acid-binding moiety is or comprises a guidable polypeptide domain, a transcriptional regulatory domain, or a nucleic acid-modifying domain.
- a guidable polypeptide domain can be capable of binding to a polynucleotide (e.g. an RNA guide) that can direct the guidable polypeptide domain a target site.
- the guidable polypeptide domain forms a complex with the RNA guide and recognizes the target sequence through DNA- RNA base pairing.
- a nucleic-acid binding moiety is or comprises a transcriptional regulatory domain.
- a nucleic-binding moiety can help recruit a transcriptional repressor or activator to a target site.
- a nucleic acid-binding moiety is or comprises a nucleic acid-modifying moiety.
- the present disclosure uses nucleic acid-binding moieties to recruit a nucleic acid-modifying moiety to a target site.
- a nucleic-acid binding moiety comprises catalytic activity.
- a nucleic acid-binding moiety is catalytically inactive.
- a nucleic-acid binding moiety comprising catalytic activity is modified to have a reduced level of activity compared to its wild-type counterpart.
- the payload in the present disclosure comprises a nucleic acid modifying domain.
- a nucleic acid-modifying domain can comprise a polypeptide domain, a nucleic acid or a combination thereof (e.g., a ribonucleoprotein complex).
- a nucleic acid-modifying domain can be capable of modifying nucleic acid, such as cleaving double-stranded nucleic acid; nicking a single-stranded nucleic acid; introducing a mutation, deletion, or insertion in a nucleic acid; methylating or demethylating a nucleic acid, or altering the structure of DNA (e.g., changing chromatin structure through modifying histones).
- a nucleic acid modifying domain can comprise a nuclease domain, a nickase domain, a deaminase domain, a polymerase, reverse transcriptase domain, a recombinase domain, a transposase domain, or an epigenetic modifying domain.
- a nuclease domain can be capable of cleaving phosphodiester bonds between nucleotides in nucleic acids.
- a nuclease domain can comprise an exonuclease (e.g., a nuclease capable of cleaving nucleic acids from the ends) or an endonuclease (e.g., a nuclease capable of cleaving nucleic acids in the middle).
- a nucleic acid modifying effector or nucleic acid binding domain is a nickase, which can be capable of cleaving a single-strand in a double- stranded DNA.
- Nucleic acid modifying domains can be useful for gene editing, or for regulating, activating, or inhibiting gene expression.
- the payload in the present disclosure comprises a guidable polypeptide domain (e.g., a CRISPR-Cas protein domain).
- a guidable polypeptide domain is capable of binding to a polynucleotide (e.g., a RNA guide) that directs it to a target site.
- the guidable polypeptide domain forms a complex with the polynucleotide and recognizes the target sequence through DNA-RNA base pairing.
- a guidable polypeptide domain is a CRISPR/CRISPR-associated (Cas) domain.
- a CRISPR domain can be a natural or an engineered domain.
- a Cas protein or domain can be derived from a CRISPR system or share structural and/or functional similarities to a protein involved in a CRISPR system.
- the guidable polypeptide domain is any suitable nuclease, e.g., a CRISPR- associated (Cas) protein or a Cas nuclease which functions in a non-naturally occurring CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats)/Cas (CRISPR-associated) system.
- a CRISPR-associated (Cas) protein or a Cas nuclease which functions in a non-naturally occurring CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats)/Cas (CRISPR-associated) system.
- this system can provide adaptive immunity against foreign DNA (Barrangou, R., et al, “CRISPR provides acquired resistance against viruses in prokaryotes,” Science (2007) 315: 1709-1712; Makarova, K.S., et al, “Evolution and classification of the CRISPR-Cas systems,” Nat Rev Microbiol (2011) 9:467- 477; Garneau, J.
- Suitable nucleases include CRISPR-associated (Cas) proteins or Cas nucleases including type I CRISPR-associated (Cas) polypeptides, type II CRISPR-associated (Cas) polypeptides (e.g., Cas9 or Cas 14), type III CRISPR-associated (Cas) polypeptides, type IV CRISPR- associated (Cas) polypeptides, type V CRISPR-associated (Cas) polypeptides (e.g., Cpfl/Casl2a, C2cl, or c2c3), and type VI CRISPR-associated (Cas) polypeptides (e.g., C2c2/Casl3a, Casl3b, Casl3c, Casl3d).
- type I CRISPR-associated (Cas) polypeptides e.g., Cas9 or Cas 14
- type III CRISPR-associated (Cas) polypeptides e
- a CRISPR system is a system encoding DNA sequence arrays known as clustered regularly interspaced short palindromic repeats (CRISPRs), which can be found in microbial genomes or phage genomes.
- CRISPR systems comprise genes encoding CRISPR- associated (Cas) proteins and/or small RNA guide molecules (e.g., crRNA or tracrRNA) that assemble with the CRISPR domain.
- the CRISPR-Cas domain forms a complex with one or more RNA guide molecules to form an effector ribonucleoprotein complex.
- the effector ribonucleoprotein complex can recognize a target sequence through sequence specific DNA-RNA base pairing with a spacer sequence in the RNA guide.
- target recognition activates one or more nuclease domains (e.g., a RuvC domain or HNH domain) in the CRISPR domain to make a double-stranded cut at the target DNA.
- a CRISPR-Cas domain complexed with an RNA guide can be capable of inactivating target gene through a gene knockout.
- the CRISPR domain is used to enable gene insertion and/or deletion, which can inactivate, modify, or restore the gene’s function.
- One or more components of a CRISPR/Cas system (e.g., modified and/or unmodified) delivered by the lipid delivery particles disclosed herein can be utilized as a genome engineering tool in a wide variety of organisms including diverse mammals, animals, plants, and yeast.
- a CRISPR/Cas system can comprise a guide nucleic acid such as a guide RNA (gRNA) complexed with a Cas protein for targeted regulation of gene expression and/or activity or nucleic acid editing.
- gRNA guide RNA
- RNA-guided Cas protein e.g., a Cas nuclease such as a Cas9 nuclease
- a target polynucleotide e.g., DNA
- the Cas protein if possessing nuclease activity, can cleave the DNA (Gasiunas, G., et al, “Cas9-crRNA ribonucleoprotein complex mediates specific DNA cleavage for adaptive immunity in bacteria,” Proc Natl Acad Sci USA (2012) 109: E2579-E2 86; Jinek, M., et al, “A programmable dual- RNA-guided DNA endonuclease in adaptive bacterial immunity,” Science (2012) 337:816-821; Sternberg, S.
- the Cas protein is mutated and/or modified to yield a nuclease deficient protein or a protein with decreased nuclease activity relative to a wild-type Cas protein.
- a nuclease deficient protein can retain the ability to bind DNA but can lack or have reduced nucleic acid cleavage activity.
- a protein encoded by a donor sequence comprises a Cas nuclease (e.g., retaining wild-type nuclease activity, having reduced nuclease activity, and/or lacking nuclease activity) can function in a CRISPR/Cas system to regulate the level and/or activity of a target gene or protein (e.g., decrease, increase, or elimination).
- the Cas protein can bind to a target polynucleotide and prevent transcription by physical obstruction or edit a nucleic acid sequence to yield non-functional gene products.
- the Cas protein cleaves both strands of DNA.
- the Cas protein cleaves one strand of DNA.
- the nuclease is a Cas protein that forms a complex with a guide nucleic acid, such as a guide RNA (gRNA).
- gRNA guide RNA
- the donor sequence disclosed herein encodes a Cas protein that forms a complex with a single guide nucleic acid, such as a single guide RNA (sgRNA).
- the donor sequence disclosed herein encodes a Cas protein that forms a complex with two separate RNA molecules of a dual guide nucleic acid (dgRNA).
- the donor sequence in the lipid delivery particles disclosed herein comprises or encodes an RNA-binding protein (RBP) optionally complexed with a guide nucleic acid, such as a guide RNA (e.g., sgRNA, dgRNA), which is able to form a complex with a Cas protein.
- the gRNA comprises a scaffolding sequences that tethers the gRNA to the Cas protein.
- the gRNA comprises a scaffolding sequence and a spacer sequence that directs the Cas protein to a specific locus.
- the scaffolding sequence is configured to bind to the positively charged groves in the Cas9 protein.
- the scaffolding sequence is configured to bind to the Cas protein in the payload.
- Cas undergoes a conformational change when the gRNA binds to the target locus.
- the conformational change in Cas shifts the molecule from an inactive, non-DNA binding conformation into an active DNA-binding conformation.
- the Cas protein undergoes a confirmational change if the spacer sequence has sufficient homology to the sequence at the target locus.
- gRNAs can be modified. Exemplary modifications to the gRNA are provided in United States Patent Number 11,479,767 B2, United States Patent Application Publication Number US2020/0339980 Al, and United States Patent Application Publication Number US2021/0079389 Al, each of which is incorporated herein by reference in its entirety.
- One or more components of any suitable CRISPR/Cas system can be delivered by the lipid delivery particle described in the present disclosure.
- a CRISPR/Cas system can be referred to using a variety of naming systems. Exemplary naming systems are provided in Makarova, K.S. et al, “An updated evolutionary classification of CRISPR-Cas systems,” Nat Rev Microbiol (2015) 13:722-736 and Shmakov, S. et al, “Discovery and Functional Characterization of Diverse Class 2 CRISPR-Cas Systems,” Mol Cell (2015) 60: 1-13.
- a CRISPR/Cas system can be a type I, a type II, a type III, a type IV, a type V, a type VI system, or any other suitable CRISPR/Cas system.
- a CRISPR/Cas system as used herein can be a Class 1, Class 2, or any other suitably classified CRISPR/Cas system. Class 1 or Class 2 determination can be based upon the genes encoding the effector module. Class 1 systems generally have a multi-subunit crRNA- effector complex, whereas Class 2 systems generally have a single protein, such as Cas9, Cpfl, C2cl, C2c2, C2c3, or a crRNA-effector complex.
- a Class 1 CRISPR/Cas system can use a complex of multiple Cas proteins to effect regulation.
- a Class 1 CRISPR/Cas system can comprise, for example, type I (e.g., I, IA, IB, IC, ID, IE, IF, IU), type III (e.g., Ill, IIIA, IIIB, IIIC, IIID), and type IV (e.g, IV, IVA, IVB) CRISPR/Cas type.
- a Class 2 CRISPR/Cas system can use a single large Cas protein to effect regulation.
- a Class 2 CRISPR/Cas systems can comprise, for example, type II (e.g., II, IIA, IIB) and type V CRISPR/Cas type.
- CRISPR systems can be complementary to each other, and/or can lend functional units in trans to facilitate CRISPR locus targeting.
- Cas proteins that can be used as part of the CRISPR systems described herein include c2cl, Cas 13a (formerly C2c2), Cas 13b, Cas 13c, Cas 13d, c2c3, Casl, CaslB, Cas2, Cas3, Cas4, Cas5, Cas5e (CasD), Cas6, Cas6e, Cas6f, Cas7, Cas8a, Cas8al, Cas8a2, Cas8b, Cas8c, Cas9 (Csnl or Csxl2), CaslO, CaslOd, Casl4, CaslO, CaslOd, CasF, CasG, CasH, Casl2a (formerly Cpfl), Csyl, Csy2, Csy3, Csel (CasA), Cse2 (Cas
- mutant Cas9 proteins or Cas9 variants include SpG, SpCas9-NG. Cas9-NRNH, SpG, SpRY, Cas9-VQR, Cas9-EQR, SaCas9-KKH, Nme2Cas9, eNme2-C, eNme2-C.NR, eNme2-T.l, eNme2-T.2, SpRY, eSpCas9(l.
- a CRISPR system can comprise single subunit or multi-subunit effectors.
- a CRISPR system is a Class 1 CRISPR system.
- a Class 1 CRISPR system can be a type I, type III, or a type IV system.
- a Class 1 type I CRISPR system can comprise a multi-subunit effector.
- a Class 1 type I CRISPR system comprises a protein or domain in the Cascade- Cas3 protein complex.
- a Class 1 type I CRISPR system can comprise a Cas6, Cas7, Cas5, Casl 1, Cas8, or Cas3 domain.
- a Class 1 type III CRISPR system can comprise a multi-subunit effector.
- a Class 1 type III CRISPR system comprises a Csm complex or a Cmr complex.
- a Class 1 type III CRISPR system comprises a Cas6, a Cas7 (Csm3 or Cmr4), a Cas7-related (Csm5, Cmrl, or Cmr6), a Cas5 (e.g., Csm4 or Cmr5), a Casl l (e.g., Csm2 or Cmr3), or a CaslO (e.g., Csml or Cmr2) domain.
- a Class 1 type IV CRISPR system can comprise a Cas6, a Cas7, a Cas5, a Casl 1, a Cas8 (e.g., Csfl), or a DinG or CysH domain.
- a CRISPR system comprises Cmrl, Cmr3, Cmr4, Cmr5, or Cmr6.
- a CRISPR system comprises Csbl, Csb2, or Csb3.
- a CRISPR system can comprise Csfl, Csf2, Csf3, or Csf4.
- a CRISPR system can comprise Csn2, Csm2, Csm3, Csm4, Csm5, or Csm6.
- a CRISPR system can comprise Cscl or Csc2.
- a CRISPR system can comprise Cast, CaslB, Cas2, or Cas4.
- a CRISPR system can comprise Csyl, Csy2, or Csy3.
- a CRISPR system can comprise Csel or Cse2.
- a CRISPR system can comprise Csn2.
- a CRISPR system can comprise CsaX, Csxl, Csx3, CsxlO, Csxl4, Csxl5, Csxl6, or Csxl7.
- a CRISPR system comprises a modified version of any one of the foregoing Cas proteins.
- a modified version of the foregoing Cas protein comprises a nickase mutation.
- the nickase mutation corresponds to the D10A mutation of the wild type Cas9 protein. In some cases, the nickase mutation corresponds to the H840A mutation of the wild type Cas9 protein. In some cases, the nickase mutation occurs in the RuvC domain of the wild type Cas9 protein. In some cases, the nickase mutation occurs in the HNH domain of the wild type Cas9 protein. In some cases the RuvC domain can be mutated to prevent cleavage of the non-target DNA strand. In some cases the HNH domain can be mutated to prevent cleavage of the target DNA strand. In some cases, a modified version of the foregoing Cas protein comprises one or more mutations that disrupt cleavage activity.
- a Cas protein with disrupted cleavage activity is catalytically inactive or catalytically dead.
- the catalytically dead mutations occur in the RuvC domain and the HNH domain of the wild type Cas9 protein.
- the catalytically inactive mutations correspond to the D10A mutation and the H840A mutation of the wild type Cas9 protein.
- a CRISPR system is a Class 2 CRISPR system.
- a Class 2 CRISPR system can be a Class 2 type II CRISPR system, a Class 2 type V CRISPR system, or a Class 2 type VI CRISPR system.
- a Class 2 type II CRISPR system can comprise a Cas9 domain (also known as Csnl and Csxl2).
- a Cas9 domain can be a SpyCas9, a GeoCas9, a SauCas9, a KhuCas9, a AinCas9, an FmaCas9, a SgaCas9, a ScCas9, a SauriCas9 domain.
- a Cas9 domain can be a hyperactive Cas9 domain.
- a Class 2 type V CRISPR system can comprise a Casl2 domain.
- a Casl2 domain can be a Casl2a, a Casl2b, a Casl2bl, a Casl2c, a Casl2d, a Casl2e, a Casl2f, a Cas 12g, a Casl2h, a Casl2i, a Casl2j, a Cas 12k, a Cas 121, or a Cas 12m domain.
- a Class 2 type VI CRISPR system can comprise a Casl3 domain.
- a CRISPR system comprises a circularly permuted Cas9.
- a CRISPR system comprises CjCas9, Casl3a, Casl3b, Casl3c, or Casl3d. In some cases, a CRISPR system comprises Casl4, xCas9, or SpCas9-NG.
- a CRISPR-Cas domain comprises one or more subdomains.
- a Cas9 domain can comprise a Reel, a Rec2, a Rec3, a RuvC, an HNH, or a Wedge/PAM- interacting domain.
- a Casl2 domain can comprise a Reel, Rec2, a crRNA oligonucleotide binding domain (OBD), a Nuc domain, a PAM-interacting (PI) domain, or a RuvC domain.
- the RuvC domain comprises nuclease activity.
- the HNH domain comprises nuclease activity.
- the PAM-interacting domain can bind to a protospacer adjacent motif (PAM) sequence that is next to a target sequence in a target nucleic acid molecule.
- PAM recognition can help activate a nuclease domain to make a cut at the target sequence.
- a CRISPR protein or domain is an engineered or mutated variant of a protein involved in a CRISPR system.
- An engineered or mutated CRISPR domain can comprise a truncation, a deletion of a part of one or more domains or subdomains, or a mutation of an active site (e.g., a RuvC active site or HNH active site).
- a CRISPR domain with a mutation of one or more active sites is catalytically inactive (e.g., dCas9).
- a CRISPR domain with one or more mutated active sites comprises less than 90%, less than 80%, less than 70%, less than 60%, less than 50%, less than 40%, less than 30%, less than 20%, less than 10%, less than 5%, or less than 1% of the nuclease activity of its wildtype counterpart.
- a dCas9 can result from the point mutations D10A in the RuvC domain and the point mutation H840A in the HNH domain.
- a mutation can result in a CRISPR nickase.
- a nickase can generate nick or a single- stranded cut.
- a nickase can generate a nick in the strand complementary to the RNA guide (e.g., the targeting strand) or in the strand on the non-targeting strand.
- a RuvC mutation D10A in a Cas9 domain can produce a Cas9 nickase domain that nicks the targeting strand.
- An HNH mutation H840A in a Cas9 domain can produce a Cas9 nickase domain that nicks the non-targeting strand.
- a Cas protein can comprise one or more domains. Examples of domains include, guide nucleic acid recognition and/or binding domain, nuclease domains (e.g., DNase or RNase domains, RuvC, HNH), DNA binding domain, RNA binding domain, helicase domains, proteinprotein interaction domains, and dimerization domains.
- a guide nucleic acid recognition and/or binding domain can interact with a guide nucleic acid.
- a nuclease domain can comprise catalytic activity for nucleic acid cleavage.
- a nuclease domain can lack catalytic activity to prevent nucleic acid cleavage.
- a Cas protein can be a chimeric Cas protein that is fused to other proteins or polypeptides.
- a Cas protein can be a chimera of various Cas proteins, for example, comprising domains from different Cas proteins.
- a CRISPR system comprises an Argonaute (Ago) domain.
- Casl4 protein or polypeptide can bind and/or modify (e.g., cleave, nick, methylate, demethylate, etc.) a target nucleic acid and/or a polypeptide associated with target nucleic acid (e.g., methylation or acetylation of a histone tail) (e.g., in some cases the CasZ protein includes a chimeric partner with an activity, and in some cases the CasZ protein provides nuclease activity).
- the Casl4 protein or polypeptide is a naturally occurring protein (e.g., naturally occurs in prokaryotic cells) (e.g., a naturally occurring protein (e.g., naturally occurs in prokaryotic cells) (e.g., a
- a Casl4 protein includes 3 partial RuvC domains (RuvC-I, RuvC-II, and RuvC-III, also referred to herein as subdomains) that are not contiguous with respect to the primary amino acid sequence of the Cast 4 protein but form a RuvC domain once the protein is produced and folds.
- a naturally occurring Cast 4 protein functions as an endonuclease that catalyzes cleavage at a specific sequence in a targeted nucleic acid (e.g., a double stranded DNA (dsDNA)).
- the sequence specificity is provided by the associated guide RNA, which hybridizes to a target sequence within the target DNA.
- the naturally occurring Casl4 guide RNA is a crRNA, where the crRNA includes (i) a guide sequence that hybridizes to a target sequence in the target DNA and (ii) a protein binding segment that binds to the Cast 4 protein.
- Examples of Cast 4 proteins include those described U.S. Patent Publication Nos. US20200172886 and US20210214697, Harrington LB etal., Science.
- the donor sequence disclosed herein encodes Casl4 polypeptide or a nucleic acid molecule encoding Casl4 polypeptide. In some cases, the donor sequence disclosed herein encodes Casl4a polypeptide. In some cases, the donor sequence disclosed herein encodes Casl4b polypeptide. In some cases, the donor sequence disclosed herein encodes Cast 4c polypeptide.
- a Cas protein can be from any suitable organism. Examples include Streptococcus pyogenes, Streptococcus thermophilus, Streptococcus sp., Staphylococcus aureus, Nocardiopsis rougevillei, Streptomyces pristinae spiralis, Streptomyces viridochromo genes, Streptomyces viridochromogenes, Streptosporangium roseum, Streptosporangium roseum, AlicyclobacHlus acidocaldarius, Bacillus pseudomycoides, Bacillus selenitireducens, Exiguobacterium sibiricum, Lactobacillus delbrueckii, Lactobacillus salivarius, Microscilla marina, Burkholderiales bacterium, Polaromonas naphthalenivorans, Polaromonas sp., Crocosphaera watsonii, Cyanothece sp., Microcysti
- the organism is Streptococcus pyogenes (S. pyogenes). In some aspects, the organism is Staphylococcus aureus (S. aureus). In some aspects, the organism is Streptococcus thermophilus (S. therm ophilus).
- a Cas protein can be derived from a variety of bacterial species including Veillonella atypical, Fusobacterium nucleatum, Filifactor alocis, Solobacterium moorei, Coprococcus catus, Treponema denticola, Peptoniphilus duerdenii, Catenib acterium mitsuokai, Streptococcus mutans, Listeria innocua, Listeria seeligeri, Listeria weihenstephanensis FSL R90317, Listeria weihenstephanensis FSL M60635, Staphylococcus pseudintermedius, Acidaminococcus intestine, Olsenella uli, Oenococcus kitaharae, Bifidobacterium bifidum, Lactobacillus rhamnosus, Lactobacillus gasseri, Finegoldia magna, Mycoplasma mobile, Mycoplasma gallisepticum, Myco
- Torquens Ilyobacter polytropus, Ruminococcus albus, Akkermansia muciniphila, Acidothermus cellulolyticus, Bifidobacterium longum, Bifidobacterium dentium, Corynebacterium diphtheria, Elusimicrobium minutum, Nitratifractor salsuginis, Sphaerochaeta globus, Fibrobacter succinogenes subsp.
- Jejuni Helicobacter mustelae, Bacillus cereus, Acidovorax ebreus, Clostridium perfringens, Parvibaculum lavamentivorans, Roseburia intestinalis, Neisseria meningitidis, Pasteurella multocida subsp. Multocida, Sutterella wadsworthensis, proteobacterium, Legionella pneumophila, Parasutterella excrementihominis, Wolinella succinogenes, and Francisella novicida.
- a Cas protein as disclosed herein can be a wildtype or a modified form of a Cas protein.
- a Cas protein can be an active variant, inactive variant, or fragment of a wild type or modified Cas protein.
- a Cas protein can comprise an amino acid change such as a deletion, insertion, substitution, variant, mutation, fusion, chimera, or any combination thereof relative to a wildtype version of the Cas protein.
- a Cas protein can be a polypeptide with at least about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity or sequence similarity to a wild type exemplary Cas protein.
- a Cas protein can be a polypeptide with at most about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% sequence identity and/or sequence similarity to a wild type exemplary Cas protein. Variants or fragments can comprise at least about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity or sequence similarity to a wild type or modified Cas protein or a portion thereof. Variants or fragments can be targeted to a nucleic acid locus in complex with a guide nucleic acid while lacking nucleic acid cleavage activity.
- a Cas protein can comprise one or more nuclease domains, such as DNase domains.
- a Cas9 protein can comprise a RuvC-like nuclease domain and/or an HNH-like nuclease domain. The RuvC and HNH domains can each cut a different strand of doublestranded DNA to make a double-stranded break in the DNA.
- a Cas protein can comprise only one nuclease domain (e.g., Cpfl comprises RuvC domain but lacks HNH domain).
- a Cas protein can comprise an amino acid sequence having at least about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity or sequence similarity to a nuclease domain (e.g., RuvC domain, HNH domain) of a wild-type Cas protein.
- a nuclease domain e.g., RuvC domain, HNH domain
- a Cas protein can be modified to optimize regulation of gene expression.
- a Cas protein can be modified to increase or decrease nucleic acid binding affinity, nucleic acid binding specificity, and/or enzymatic activity.
- Cas proteins can also be modified to change any other activity or property of the protein, such as stability.
- one or more nuclease domains of the Cas protein can be modified, deleted, or inactivated, or a Cas protein can be truncated to remove domains that are not essential for the function of the protein or to optimize (e.g., enhance or reduce) the activity of the Cas protein for regulating gene expression.
- the prime editor delivered by the lipid delivery particles of the present disclosure contain a nuclease-null DNA binding protein derived from a DNA nuclease that can induce transcriptional activation or repression of a target DNA sequence.
- the donor sequence encodes a nuclease-null RNA binding protein derived from an RNA nuclease that can induce transcriptional activation or repression of a target RNA sequence.
- a doner sequence can encode a Cas protein which lacks cleavage activity.
- a Cas protein can be a chimeric protein.
- a Cas protein can be fused to a heterologous functional domain.
- a heterologous functional domain can comprise a cleavage domain, an epigenetic modification domain, a transcriptional activation domain, or a transcriptional repressor domain.
- a Cas protein can also be fused to a heterologous polypeptide providing increased or decreased stability. The fused domain or heterologous polypeptide can be located at the N-terminus, the C-terminus, or internally within the Cas protein.
- genes can be of any gene of interest. It is contemplated that genetic homologues of a gene described herein are covered. For example, a gene can exhibit a certain identity and/or homology to genes disclosed herein. Therefore, it is contemplated that a gene that exhibits or exhibits about 50%, 55%, 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% homology (at the nucleic acid or protein level) can be modified.
- a gene that exhibits or exhibits about 50%, 55%, 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% identity (at the nucleic acid or protein level) can be modified.
- a Cas protein can be provided in any form.
- a Cas protein can be provided in the form of a protein, such as a Cas protein alone or complexed with a guide nucleic acid.
- a Cas protein can be provided in the form of a nucleic acid encoding the Cas protein, such as an RNA (e.g., messenger RNA (mRNA)) or DNA.
- RNA e.g., messenger RNA (mRNA)
- DNA DNA
- nucleic acid encoding the Cas protein that is part of the prime editor can be codon optimized for efficient translation into protein in a particular cell or organism.
- a Cas protein is a dead Cas protein.
- a dead Cas protein can be a protein that lacks nucleic acid cleavage activity.
- a Cas protein can comprise a modified form of a wild type Cas protein.
- the modified form of the wild type Cas protein can comprise an amino acid change (e.g., deletion, insertion, or substitution) that reduces the nucleic acid-cleaving activity of the Cas protein.
- the modified form of the Cas protein can have less than 90%, less than 80%, less than 70%, less than 60%, less than 50%, less than 40%, less than 30%, less than 20%, less than 10%, less than 5%, or less than 1% of the nucleic acid-cleaving activity of the wild-type Cas protein (e.g., Cas9 from S. pyogenes).
- the modified form of Cas protein can have no substantial nucleic acid-cleaving activity.
- a Cas protein When a Cas protein is a modified form that has no substantial nucleic acid-cleaving activity, it can be referred to as enzymatically inactive and/or “dead” (abbreviated by “d”).
- a dead Cas protein e.g., dCas, dCas9 can bind to a target polynucleotide but may not cleave the target polynucleotide.
- a dead Cas protein is a dead Cas9 protein.
- a dCas9 polypeptide can associate with a guide nucleic acid molecule (e.g., PEgRNA) to activate or repress transcription of target DNA.
- Guide nucleic acid molecules can be introduced into cells expressing the engineered chimeric receptor polypeptide. In some cases, such cells contain one or more different guide nucleic acid molecules that target the same nucleic acid. In other cases, the guide nucleic acid molecules target different nucleic acids in the cell.
- the nucleic acids targeted by the guide nucleic acid molecule can be any that are expressed in a cell such as an immune cell.
- the nucleic acids targeted can be a gene involved in immune cell regulation. In some embodiments, the nucleic acid is associated with cancer.
- the nucleic acid associated with cancer can be a cell cycle gene, cell response gene, apoptosis gene, or phagocytosis gene.
- the recombinant guide nucleic acid molecule can be recognized by a CRISPR protein, a nuclease- null CRISPR protein, variants thereof, derivatives thereof, or fragments thereof.
- Enzymatically inactive can refer to a polypeptide that can bind to a nucleic acid sequence in a polynucleotide in a sequence-specific manner, but may not cleave a target polynucleotide.
- An enzymatically inactive site-directed polypeptide can comprise an enzymatically inactive domain (e.g., nuclease domain).
- Enzymatically inactive can refer to no activity.
- Enzymatically inactive can refer to substantially no activity.
- Enzymatically inactive can refer to essentially no activity.
- Enzymatically inactive can refer to an activity less than 1%, less than 2%, less than 3%, less than 4%, less than 5%, less than 6%, less than 7%, less than 8%, less than 9%, or less than 10% activity compared to a wild-type exemplary activity (e.g., nucleic acid cleaving activity, wild-type Cas9 activity).
- a wild-type exemplary activity e.g., nucleic acid cleaving activity, wild-type Cas9 activity.
- One or a plurality of the nuclease domains (e.g., RuvC, HNH) of a Cas protein can be deleted or mutated so that they are no longer functional or comprise reduced nuclease activity (e.g., deactivated or dead Cas, i.e., “dCas”).
- nuclease domains e.g., RuvC, HNH
- dCas deactivated or dead Cas
- a Cas protein comprising at least two nuclease domains (e.g., Cas9)
- the resulting Cas protein can generate a single-strand break at a CRISPR RNA (crRNA) recognition sequence within a double-stranded DNA but not a double-strand break.
- crRNA CRISPR RNA
- Such a nickase can cleave the complementary strand or the non-complementary strand, but may not cleave both.
- the resulting Cas protein can have a reduced or no ability to cleave both strands of a double-stranded DNA.
- An example of a mutation that can convert a Cas9 protein into a nickase is a D10A (aspartate to alanine at position 10 of Cas9) mutation in the RuvC domain of Cas9 from S. pyogenes.
- H939A (histidine to alanine at amino acid position 839) or H840A (histidine to alanine at amino acid position 840) in the HNH domain of Cas9 from S. pyogenes can convert the Cas9 into a nickase.
- An example of a mutation that can convert a Cas9 protein into a dead Cas9 is a D10A (aspartate to alanine at position 10 of Cas9) mutation in the RuvC domain and H939A (histidine to alanine at amino acid position 839) or H840A (histidine to alanine at amino acid position 840) in the HNH domain of Cas9 from S. pyogenes.
- a dead Cas protein can comprise one or more mutations relative to a wild-type version of the protein.
- the mutation can result in less than 90%, less than 80%, less than 70%, less than 60%, less than 50%, less than 40%, less than 30%, less than 20%, less than 10%, less than 5%, or less than 1% of the nucleic acid-cleaving activity in one or more of the plurality of nucleic acidcleaving domains of the wild-type Cas protein.
- the mutation can result in one or more of the plurality of nucleic acid-cleaving domains retaining the ability to cleave the complementary strand of the target nucleic acid but reducing its ability to cleave the non-complementary strand of the target nucleic acid.
- the mutation can result in one or more of the plurality of nucleic acidcleaving domains retaining the ability to cleave the non-complementary strand of the target nucleic acid but reducing its ability to cleave the complementary strand of the target nucleic acid.
- the mutation can result in one or more of the plurality of nucleic acid-cleaving domains lacking the ability to cleave the complementary strand and the non-complementary strand of the target nucleic acid.
- the residues to be mutated in a nuclease domain can correspond to one or more catalytic residues of the nuclease. For example, residues in the wild type exemplary S.
- pyogenes Cas9 polypeptide such as Asp 10, His840, Asn854 and Asn856 can be mutated to inactivate one or more of the plurality of nucleic acid-cleaving domains (e.g., nuclease domains).
- the residues to be mutated in a nuclease domain of a Cas protein can correspond to residues Asp 10, His840, Asn854 and Asn856 in the wild type S.
- pyogenes Cas9 polypeptide for example, as determined by sequence and/or structural alignment.
- residues D10, G12, G17, E762, H840, N854, N863, H982, H983, A984, D986, and/or A987 can be mutated.
- D10A, G12A, G17A, E762A, H840A, N854A, N863A, H982A, H983A, A984A, and/or D986A can be suitable.
- a D10A mutation can be combined with one or more of H840A, N854A, or N856A mutations to produce a Cas9 protein substantially lacking DNA cleavage activity (e.g., a dead Cas9 protein).
- a H840A mutation can be combined with one or more of D10A, N854A, or N856A mutations to produce a site-directed polypeptide substantially lacking DNA cleavage activity.
- a N854A mutation can be combined with one or more of H840A, D10A, or N856A mutations to produce a site-directed polypeptide substantially lacking DNA cleavage activity.
- a N856A mutation can be combined with one or more of H840A, N854A, or D10A mutations to produce a site-directed polypeptide substantially lacking DNA cleavage activity.
- a dCas9 can be fused to other proteins.
- dCas9 can be fused to SunTag, KRAB, VPS4, P3000, VPR, VP64, V64-p65-Rta, VP160, VP192, HDAC1, DNMT3A, TET1, SPH, KRAB-MeCP2, epigenetic regulators, or other proteins.
- a dCas9 fusion comprises a ZIM3 KRAB-Cas9 fusion.
- a Cas9 fusion can be a paired dCas9 system.
- the dCas9 can be part of a SAM system or REDMAP system.
- Examples of Cas9 variants and fusion proteins can be found in Li, T. et al., Sig Transduct Target Ther 8, 36 (2023), which is incorporated in its entirety.
- a Cas protein is a Class 2 Cas protein. In some embodiments, a Cas protein is a type II Cas protein. In some embodiments, the Cas protein is a Cas9 protein, a modified version of a Cas9 protein, or derived from a Cas9 protein. For example, a Cas9 protein lacking cleavage activity. In some embodiments, the Cas9 protein is a Cas9 protein from S. pyogenes (e.g., SwissProt accession number Q99ZW2). In some embodiments, the Cas9 protein is a Cas9 from S. aureus e.g., SwissProt accession number J7RUA5).
- S. pyogenes e.g., SwissProt accession number Q99ZW2
- the Cas9 protein is a Cas9 from S. aureus e.g., SwissProt accession number J7RUA5.
- the Cas9 protein is a modified version of a Cas9 protein from S. pyogenes or S. Aureus.
- the Cas9 protein is derived from a Cas9 protein from S. pyogenes or S. Aureus.
- a S. pyogenes or S. Aureus Cas9 protein lacking cleavage activity.
- Cas9 can generally refer to a polypeptide with at least about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% sequence identity and/or sequence similarity to a wild type exemplary Cas9 polypeptide (e.g., Cas9 from S. pyogenes .
- Cas9 can refer to a polypeptide with at most about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% sequence identity and/or sequence similarity to a wild type exemplary Cas9 polypeptide (e.g., from S. pyogenes ⁇ .
- Cas9 can refer to the wildtype or a modified form of the Cas9 protein that can comprise an amino acid change such as a deletion, insertion, substitution, variant, mutation, fusion, chimera, or any combination thereof.
- a guidable polypeptide domain is a Cas9 or variant thereof.
- the Cas9 or variant thereof is a nuclease active Cas9 domain, a nuclease inactive Cas9 domain, or a Cas9 nickase domain or a variant thereof.
- a guidable polypeptide domain is Cas9, Casl2e, Casl2d, Casl2a, Casl2bl, Casl3a, Casl2c, or Argonaute (Ago domain), any of which optionally has a nickase activity.
- a guidable polypeptide domain comprises an amino acid sequence at least 80%, 85%, 90%, 95%, or 99% identical to any one of sequences listed in Table 10 below. In some embodiments, a guidable polypeptide domain comprises an amino acid sequence at least 80%, 85%, 90%, 95%, or 99% identical to any one of sequences set forth in SEQ ID NOs: 1000-1020. In some cases, a guidable polypeptide domain is a Cas9 H840A nickase. In some cases, a guidable polypeptide domain is Cas9 D10A nickase. Cas9-H840A. In some cases, a guidable polypeptide domain is a Casl2a/b nickase.
- the payload in the present disclosure comprises a polymerase (e.g., reverse transcriptase).
- a polymerase can comprise a natural or an engineered domain.
- a polymerase can be capable of synthesizing nucleic acids.
- a polymerase can be a DNA polymerase or an RNA polymerase.
- a polymerase is a reverse transcriptase.
- a reverse transcriptase can synthesize DNA from deoxyribonucleotides.
- a reverse transcriptase adds deoxyribonucleotides to the 3’ end of a nucleic acid primer to synthesize DNA.
- a reverse transcriptase uses an RNA template and uses base-pairing interactions to synthesize a DNA strand that is complementary to the RNA template.
- the reverse transcriptase domain can be a reverse transcriptase from any organism, phage, virus, or an engineered or mutated variant.
- the reverse transcriptase domain can be a reverse transcriptase derived from or sharing structural or sequencing similarity to a reverse transcriptase in a CRISPR system.
- the reverse transcriptase can be an M-MLV or HIV reverse transcriptase.
- the reverse transcriptase can be a human LINE- 1 reverse transcriptase or a group II intron reverse transcriptase.
- the reverse transcriptase can be a human endogenous retrovirus reverse transcriptase.
- a nucleic-acid modifying effector or a nucleic acid-binding moiety comprises a transposase domain.
- a transposase domain can be a natural or an engineered domain.
- a transposase domain can be capable of aiding the translocation of a transposable element, a nucleic acid sequence that can change its position within a genome.
- a transposase domain comprises a TnsA, a TnsB, a TnsC, or a TnsD domain.
- a transposase domain comprises a TniQ domain.
- a transposase domain is derived from or shares sequence or structural similarity with a transposase in a CRISPR system (e.g., a CRISPR-associated transposase).
- a transposase domain is derived from or share sequence or structural similarity with a transposase domain from a type I CRISPR-associated transposon (CAST) system.
- CAST CRISPR-associated transposon
- transposase domain is derived from or share sequence or structural similarity with a transposase domain from a type V CRISPR-associated transposon (CAST) system.
- a transposase domain can be capable of binding to a guidable polypeptide domain.
- a transposase domain is coupled to a guidable polypeptide domain.
- a transposase domain is capable of binding to a type I CRISPR-Cas domain (e.g., a Cascade domain, a Cas8 domain, or a Cas5 domain).
- a transposase domain is capable of binding to a type V CRISPR-Cas domain (e.g., a Casl2 domain).
- a transposase domain is capable of mediating targeted insertion of a nucleic acid into a target nucleic acid.
- a transposase domain is capable of mediating targeted insertion of a nucleic acid that is at least 5 kb, at least 6 kb, at least 7 kb, at least 8kb, at least 9kb, at least lOkb, at least 1 Ikb, at least 12kb, at least 13kb, at least 14kb, or at least 15 kb into a target nucleic acid.
- the payload comprises a transcriptional regulatory domain.
- a transcriptional regulatory domain can be a natural or an engineered domain.
- a transcriptional regulatory domain can be capable of regulating, activating, or inhibiting gene expression.
- a transcriptional repressor can silence gene expression by binding to the promoter of a gene.
- a transcriptional activator can bind to enhancers or regulatory elements to activate expression of a gene.
- a transcriptional regulatory domain can comprise a transcription factor.
- a transcriptional regulatory domain can comprise a transcriptional activation domain or a transcriptional repression domain.
- a transcriptional activation domain can be or comprise a CAP domain, a VP64 domain, a p65 domain, an Rta domain, a synergistic activation mediator (SAM) domain, a SunTag domain, a VPR domain, a DNA demethylase domain, a histone methyltransferase domain, a histone acetyltransferase domain, or a histone demethylase domain.
- SAM synergistic activation mediator
- a transcriptional repression domain can be or comprise a dCas9 domain, a KRAB domain, a Sin3 interacting domain (SID), or a MePC2 domain, a DNA methyltransferase domain, a histone deacetylase domain, a histone methyltransferase domain, or a histone demethylase domain.
- a transcriptional regulatory domain comprises an epigenetic modifying effector domain.
- an epigenetic modifying effector can be a DNA methyltransferase, a DNA demethylase, a histone methyltransferase, a histone demethylase, a histone acetyltransferase, or a histone deacetylase domain.
- a DNA methyltransferase domain can be capable of methylating a nucleic acid.
- a DNA demethylase domain can be capable of demethylating a nucleic acid.
- a histone methyltransferase domain can be capable of methylating a histone.
- a histone demethylase domain can be capable of demethylating a histone.
- a histone acetyltransferase domain can be capable of adding an acetyl group to a histone.
- a histone deacetylase domain can be capable of removing an acetyl group from a histone.
- the payload comprises a zinc finger domain.
- a zinc finger domain can be a natural or an engineered domain.
- a zinc finger domain can bind to a specific DNA sequence in a target nucleic acid.
- a zinc finger domain can comprise from 1 to 10, from 2 to 10, from 3 to 10, from 4 to 10, from 5 to 10, from 6 to 10, from 7 to 10, from 8 to 10, from 9 to 10 zinc fingers, from 1 to 8, from 2 to 8, from 3 to 8, from 4 to 8, from 5 to 8, from 6 to 8, from 7 to 8, from 8 to 8, from 9 to 8 zinc fingers.
- a zinc finger domain comprises a two- handed zinc finger domain.
- a two handed zinc finger domain can comprise two clusters of zinc finger domains that are separated by intervening amino acids.
- a two handed zinc finger domain can bind to two noncontiguous target DNA sequences.
- the spacing between the two noncontiguous target sequences comprises from 1 to 15, from 1 to 12, from 1 to 10, from 1 to 8, or from 1 to 5 nucleotides.
- a two handed type of zinc finger binding protein can be SIP1.
- a cluster of zinc finger domains in a two handed zinc finger domain can be capable of binding to a unique target nucleic acid sequence.
- the payload comprises a TALE domain.
- a TALE domain can be a natural or an engineered domain.
- a TALE domain can bind to a specific DNA sequence.
- a TALE domain can comprise one or more effector domains.
- a TALE effector domain can comprise a central repeat domain comprising tandem repeats.
- a tandem repeat can comprise repeat variable residues (RVD).
- RVD repeat variable residues
- One or more RVDs can detect a specific DNA base.
- Different TALE effector domains may have a different number of repeats and a different order of their repeats.
- the C-terminal repeat is usually shorter in length (e.g., about 20 amino acids). Sequential repeats and their RVDs can recognize sequential DNA bases.
- a TALE domain described herein can be derived from a TALE effector from a bacterial species.
- the TALE domain can be engineered to target a given nucleic acid sequence based on their DNA base specificities.
- the TALE domain can be engineered to remove or add a TALE effector domain.
- the TALE domain corresponds to a perfect match to a nucleic acid target sequence.
- the TALE domain of an epigenetic effector corresponds to one or more mismatches to a target base in the target nucleic acid.
- the payload in the present disclosure comprises a fusion protein.
- a fusion protein can comprise two or more polypeptide domains of any of the polypeptide domains described elsewhere herein.
- a fusion protein can be a natural or an engineered fusion protein.
- the two or more polypeptide domains are coupled together.
- the two or more polypeptide domains can be coupled together directly or coupled together indirectly.
- a first polypeptide domain can be coupled directly to a second polypeptide domain.
- the first polypeptide domain can be coupled indirectly to the second polypeptide domain by coupling with a third polypeptide domain that is coupled directly to the second polypeptide domain.
- a first polypeptide domain is coupled to the N-terminus of a second polypeptide domain. In some cases, a first polypeptide domain is coupled to the C- terminus of a second polypeptide domain. In some cases, a first polypeptide domain is coupled to an internal component of a second polypeptide domain. In some cases, the two or more polypeptide domains are covalently linked. In some cases, the two or more polypeptide domains are noncovalently linked. In some cases, the two or more polypeptide domains are coupled together by a linker. For example, a linker may be a peptide linker. A linker can be a rigid linker, which helps maintain a fixed distance between the polypeptide domains that it links.
- a linker can be a flexible linker, which can allow some flexibility in movement of one polypeptide domain relative to the other polypeptide domain that it is linked to.
- a linker is a cleavable linker.
- a cleavable linker can comprise a disulfide bond.
- a cleavable linker can be an enzymatic cleavable linker, e.g., a linker comprising a protease cleavage site.
- the present disclosure provides fusion proteins comprising a guidable polypeptide domain (e.g., a CRISPR domain).
- a fusion protein comprising a guidable polypeptide domain can comprise one or more of a FokI domain, a deaminase domain, a reverse transcriptase domain, an RNA binding domain, a transcriptional regulatory domain, a plasma membrane recruitment domain, a transmembrane domain, a signaling domain, a receptor domain, a packaging domain, or a targeting domain.
- the present disclosure provides a fusion protein comprising a guidable polypeptide domain (e.g., a CRISPR domain) coupled to a deaminase domain.
- a guidable polypeptide domain e.g., a CRISPR domain
- a base editor can be capable of editing a nucleic acid sequence in a target nucleic acid molecule.
- a base editor can be capable of enabling the generation of base conversions or point mutations in a target nucleic acid.
- a cytosine base editor can comprise a guidable polypeptide domain (e.g., a CRISPR domain) and a cytidine deaminase domain.
- An adenine base editor can comprise CRISPR domain and an adenosine deaminase domain.
- a base editor enables the conversion of C to G, A to I, or C to U.
- a cytosine base editor can be capable of enabling the conversion of a C-G base pair to a T-A base pair.
- a glycosylase base editor can be capable of enabling the conversion of a G-C base pair to a C-G base pair or a G-T base pair.
- An adenine base editor can be capable of enabling the conversion of an A-T base pair to a G-C base pair.
- a base editor comprises a catalytically inactive guidable polypeptide domain (e.g., a CRISPR domain) (e.g., dCas9, dCasl2a, or dCasl3b).
- the base editor comprises a guidable polypeptide nickase domain (e.g., nCas9).
- the base editor enables a base pair conversion without introducing a double-stranded break.
- the base editor enables base pair conversions in a target window.
- the base editor comprises a targeting window of from 1 to 20 bases, from 1 to 19 bases, from 1 to 18 bases, from 1 to 17 bases, from 1 to 16 bases, from 1 to 15 bases, from 1 to 14 bases, from 1 to 13 bases, from 1 to 12 bases, from 1 to 11 bases, from 1 to 10 bases, from 1 to 9 bases, from 1 to 8 bases, from 1 to 7 bases, from 1 to 6 bases, from 1 to 5 bases, from 1 to 4 bases, from 1 to 3 bases, or from 1 to 2 bases.
- a base editor has a targeting window of from 3 to 10 bases, from 3 to 9 bases, from 3 to 8 bases, from 3 to 7 bases, from 3 to 6 bases, from 3 to 5 bases, or from 3 to 4 bases.
- the guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the N-terminus of a deaminase domain. In some cases, the guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the C-terminus of a deaminase domain. In some cases, the guidable polypeptide domain (e.g., a CRISPR domain) is coupled to an internal component of a deaminase domain.
- the fusion protein comprises a guidable polypeptide domain (e.g., a CRISPR domain) coupled to a reverse transcriptase domain.
- a guidable polypeptide domain (e.g., a CRISPR domain) coupled to a reverse transcriptase can be capable of enabling prime editing.
- a prime editor can be capable of editing a nucleic acid sequence in a target nucleic acid molecule.
- a prime editor can be capable of mediating insertion or deletion of a nucleic acid sequence in a target nucleic acid molecule.
- the prime editor enables a sequence insertion or sequence deletion without introducing a double-stranded break.
- the prime editor introduces a nick at the target site.
- the prime editor can enable insertion of a template sequence in a target nucleic acid molecule.
- the template sequence can comprise the desired edit.
- a prime editor reverse transcribes a template sequence to synthesize a complementary strand.
- the synthesized complementary strand is inserted in the target nucleic acid molecule.
- the prime editor uses a primer to carry out reverse transcription.
- the prime editor can install nucleotides to the 3’ end of a primer strand.
- a primer strand is generated by nicking the target nucleic acid molecule.
- nicking a strand of the target nucleic acid molecule produces a flap with a 3’ OH group.
- a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the N-terminus of a reverse transcriptase domain. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the C-terminus of a reverse transcriptase domain. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to an internal component of a reverse transcriptase domain.
- the fusion protein comprises a guidable polypeptide domain (e.g., a CRISPR domain) coupled to a transcriptional regulatory domain.
- a guidable polypeptide domain e.g., a CRISPR domain
- a transcriptional regulatory domain e.g., a CRISPR domain
- a guidable polypeptide domain e.g., a CRISPR domain
- a transcriptional activation domain e.g., a CRISPR domain
- a guidable polypeptide domain e.g., a CRISPR domain
- a transcriptional repression domain e.
- guidable polypeptide domain (e.g., a CRISPR domain) is coupled to a transcriptional regulatory domain.
- a guidable polypeptide domain (e.g., a CRISPR domain) coupled to a transcriptional regulatory domain can be capable of enabling CRISPR interference (CRISPRi) or CRISPR activation (CRISPRa).
- CRISPRi CRISPR interference
- CRISPRa CRISPR activation
- a guidable polypeptide domain (e.g., a CRISPR domain) can be coupled to a transcriptional regulatory domain such as P3000 or DNMT3.
- a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the C-terminus of a transcriptional regulatory domain.
- a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to an internal component of a transcriptional regulatory domain.
- Any of the payloads described herein can further comprise a plasma membrane recruitment domain, transmembrane domain, a signaling domain, a receptor domain, a packaging domain, or a targeting domain.
- Any of payloads described herein can comprise or be engineered to comprise a protein tag, a peptide tag, or small molecule tag.
- a payload can comprise a small nuclear localization signal (NLS), a nuclear export signal (NES), a cell penetrating peptide (CPP), a mitochondria penetrating peptide (MPP), a solubility tag, or a fluorescent tag.
- the payload to be delivered by the lipid containing particles of the present disclosure comprises a nucleobase editor (also termed as “base editor”) or one or more components of a nucleobase editing (also termed as “base editing”) complex.
- base editor can refer to an agent comprising a polypeptide that is capable of making a modification to a base (e.g., A, T, C, G, or U) within a nucleic acid sequence (e.g., DNA or RNA).
- the base editor is capable of deaminating a base within a nucleic acid.
- the base editor is capable of deaminating a base within a DNA molecule.
- the base editor is capable of deaminating an adenosine (A) in DNA.
- the base editor is capable of deaminating a cytosine (C) in DNA.
- the base editor is capable of converting a guanine (G) in DNA through a glycoylase.
- the payload in the present disclosure comprises a deaminase domain.
- the deaminase domain can be a natural or an engineered domain.
- a deaminase domain can be capable of carrying out deamination reactions in DNA.
- a deaminase domain can be capable of enabling the generation of base conversions or point mutations in a target nucleic acid.
- a deaminase domain can be a cytidine deaminase domain or an adenosine deaminase domain.
- a cytidine deaminase domain can be capable of converting cytosine to uracil.
- a cytidine deaminase domain can be capable of enabling the conversion of a C-G base pair to a T-A base pair.
- a cytidine deaminase can be or comprise a APOB EC 1 cytidine deaminase.
- An adenosine deaminase domain can be capable of converting an adenosine to hypoxanthine.
- An adenosine deaminase domain can be capable of converting an adenosine to an inosine.
- An adenosine deaminase can comprise TadA or a TadA mutant. In some embodiments, TadA comprises a monomer.
- TadA comprises a heterodimer comrpsiing a wildtype TadA and a mutated Tad A.
- TadA comprises a homodimer comprising two wildtype TadA domains or two mutated TadA domains.
- An adenosine deaminase domain can be capable of enabling the conversion of an A-T base pair to a G-C base pair.
- a deaminase domain can be a mutated variant. In some cases, a deaminase domain enables the conversion of C to G, A to I, or C to U.
- the payload in the present disclosure comprises a glycosylase domain.
- the glycosylase domain can be a natural or an engineered domain.
- a glycosylase-based guanine base editor can be designed to remove G, and the AP site generated is repaired by translesion synthesis and/or DNA replication, leading to G-to-C or G-to-T conversion.
- a glycosylase domain can be capable of enabling the generation of base conversions or point mutations in a target nucleic acid.
- a glycosylase domain can be a guanine glycosylase domain. Examples of glycosylase base edits can be found in Sun N, et al., Mol Ther. 2022 Jul 6;30(7):2452-2463 and Huawei Tong, et al., National Science Review, Volume 10, Issue 8, August 2023, each of which is incorporated in its entirety herein.
- the base editor disclosed herein comprises a deaminase or a functional domain thereof (“deaminase domain”) that catalyzes deamination reaction.
- deaminase or “deaminase domain,” as used herein, refers to a protein or enzyme that catalyzes a deamination reaction.
- the deaminase or deaminase domain is an adenosine deaminase, catalyzing the deamination of adenosine, converting it to the nucleoside hypoxanthine.
- the deaminase or deaminase domain is a cytidine deaminase, catalyzing the hydrolytic deamination of cytidine or deoxycytidine to uridine or deoxyuridine, respectively.
- the deaminase or deaminase domain is a cytidine deaminase domain, catalyzing the hydrolytic deamination of cytosine to uracil.
- the deaminase or deaminase domain is a naturally- occurring deaminase from an organism, such as a human, chimpanzee, gorilla, monkey, cow, dog, rat, or mouse.
- the deaminase or deaminase domain is a variant of a naturally-occurring deaminase from an organism, that does not occur in nature.
- the deaminase or deaminase domain is at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75% at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to a naturally-occurring deaminase from an organism.
- an “adenosine deaminase” is an enzyme that catalyzes the deamination of adenosine, converting it to the nucleoside hypoxanthine.
- an adenosine base hydrogen bonds to a thymine base (or a uracil in case of RNA).
- the hypoxanthine undergoes hydrogen bond pairing with cytosine.
- a conversion of “A” to hypoxanthine by adenosine deaminase will cause the insertion of “C” instead of a “T” during cellular repair and/or replication processes. Since the cytosine “C” pairs with guanine “G”, the adenosine deaminase in coordination with DNA replication causes the conversion of an A»T pairing to a C»G pairing in the double-stranded DNA molecule.
- the base editor is a chimeric protein comprising a nucleic acid programmable R/DNA binding protein (napR/DNAbp) fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase) domain.
- a deaminase e.g., cytidine deaminase or adenosine deaminase
- nucleic acid programmable D/RNA binding protein refers to any protein that can associate (e.g., form a complex) with one or more nucleic acid molecules (i.e., which can broadly be referred to as a “napR/DNAbp-programming nucleic acid molecule” and includes, for example, guide RNA in the case of Cas systems) which direct or otherwise program the protein to localize to a specific target nucleotide sequence (e.g., a gene locus of a genome, or an RNA molecule) that is complementary to the one or more nucleic acid molecules (or a portion or region thereof) associated with the protein, thereby causing the protein to bind to the nucleotide sequence at the specific target site.
- a specific target nucleotide sequence e.g., a gene locus of a genome, or an RNA molecule
- napR/DNAbp embraces CRISPR Cas9 proteins, as well as Cas9 equivalents, homologs, orthologs, or paralogs, whether naturally occurring or non-naturally occurring (e.g., engineered or recombinant), and can include a Cas9 equivalent from any type of CRISPR system (e.g., type II, V, VI), including Cpfl (a type-V CRISPR-Cas systems), C2cl (a type V CRISPR-Cas system), C2c2 (a type VI CRISPR-Cas system) and C2c3 (a type V CRISPR-Cas system).
- Cpfl a type-V CRISPR-Cas systems
- C2cl a type V CRISPR-Cas system
- C2c2 a type VI CRISPR-Cas system
- C2c3 a type V CRISPR-Cas system
- C2c2 is a single-component programmable RNA-guided RNA-targeting CRISPR effector,” Science 2016; 353(6299), the contents of which are incorporated herein by reference.
- the nucleic acid programmable R/DNA binding protein (napR/DNAbp) that can be used in connection with this disclosure are not limited to CRISPR-Cas systems.
- the present disclosure embraces any such programmable protein, such as the Argonaute protein from Natronobacterium gregoryi (NgAgo) which can also be used for DNA-guided genome editing.
- NgAgo-guide DNA system does not require a PAM sequence or guide RNA molecules, which means genome editing can be performed simply by the expression of generic NgAgo protein and introduction of synthetic oligonucleotides on any genomic sequence. See Gao F, Shen X Z, Jiang F, Wu Y, Han C. DNA- guided genome editing using the Natronobacterium gregoryi Argonaute. Nat Biotechnol 2016; 34(7):768-73, which is incorporated herein by reference.
- the napR/DNAbp is derived from a nuclease disclosed herein, such as, Cas9 (e.g, dCas9 and nCas9), CasX, CasY, Cast 4, Cpfl, C2cl, C2c2, C2c3, Argonaute protein, or a variant thereof.
- Cas9 e.g, dCas9 and nCas9
- CasX CasY
- Cast 4 Cast 4
- Cpfl C2cl
- C2c2, C2c3, Argonaute protein or a variant thereof.
- the base editor comprises a Cas9 (e.g., dCas9 and nCas9), CasX, CasY, Cpfl, C2cl, C2c2, C2c3, or Argonaute protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- a deaminase e.g., cytidine deaminase or adenosine deaminase
- the base editor comprises a Cas9 nickase (nCas9) fused to an deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the base editor comprises a CasX protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the base editor comprises a nuclease-inactive Cas9 (dCas9) fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the base editor comprises a CasY protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the base editor comprises a Casl4 protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the base editor comprises a Cpfl protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the base editor comprises a C2cl protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the base editor comprises a C2c2 protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the base editor comprises a C2c3 protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the base editor comprises an Argonaute protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
- the adenosine deaminases provided herein are capable of deaminating adenosine. In some embodiments, the adenosine deaminases provided herein are capable of deaminating adenosine in a deoxyadenosine residue of DNA.
- the adenosine deaminase can be derived from any suitable organism (e.g., E. coli). In some embodiments, the adenosine deaminase is a naturally-occurring adenosine deaminase that includes one or more mutations corresponding to any of the mutations provided herein (e.g., mutations in ecTadA).
- adenosine deaminase is from a prokaryote.
- the adenosine deaminase is from a bacterium. In some embodiments, the adenosine deaminase is from Escherichia coli, Staphylococcus aureus, Salmonella typhi, Shewanella putrefaciens, Haemophilus influenzae, Caulobacter crescentus, or Bacillus subtilis. In some embodiments, the adenosine deaminase is from E. coli.
- the deaminase domain of the base editor disclosed herein is derived from a cytidine deaminase.
- the cytidine deaminase domain is derived from the apolipoprotein B mRNA-editing complex (APOBEC) family deaminase, such as APOBEC1 deaminase, APOBEC2 deaminase, APOBEC3A deaminase, APOBEC3B deaminase, APOBEC3C deaminase, APOBEC3D deaminase, APOBEC3F deaminase, APOBEC3G deaminase, or APOBEC3H deaminase.
- APOBEC apolipoprotein B mRNA-editing complex
- the cytidine deaminase is a modification of an APOBEC family deaminase. In some cases, the cytidine deaminase is an evolved derivative of an APOBEC family deaminase.
- the base editor comprises BE1, BE2, BE3, BE4, BE4max, or another base editor variant.
- the base editor comprises BE4max (R33 A) AUGI-hUNG complex (CGBE1).
- the base editor is fused to, or further comprises as part of a chimeric protein, an inhibitor of base excision repair, for example, a uracil clycosylase inhibitor (UGI) domain.
- a UGI domain reduces off target effects, specifically the conversion of C to G or C to A.
- the base editor disclosed herein is a chimeric protein that comprises a structure such as, NH2-[deaminase domain]-[napR/DNAbp]-[UGI domain]-COOH; NH2- [deaminase domain]-[napR/DNAbp]-[UGI]-[UGI]-COOH; NH2- [deaminase domain]- [napR/DNAbp]-[UGI]-COOH; NH2-[UGI]-[ deaminase domain]-[napR/DNAbp]-COOH; NH2- [deaminase domain]-[UGI]-[napR/DNAbp]-COOH; NH2-[napR/DNAbp]-[UGI]-[deaminase domain]-COOH; or NH2-[napR/DNAbp]-[deaminase domain]-[UGI
- the base editor is fused to, or further comprises as part of a chimeric protein, a uracil binding protein (UBP).
- UBP uracil binding protein
- uracil binding protein or “UBP,” as used herein, refers to a protein that is capable of binding to uracil.
- the uracil binding protein is a uracil modifying enzyme.
- the uracil binding protein is a uracil base excision enzyme.
- the uracil binding protein is a uracil DNA glycosylase (UDG).
- a uracil binding protein binds uracil with an affinity that is at least 1%, 2%, 3%, 5%, 10%, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, or at least 95% of the affinity that a wild type UDG (e.g., a human UDG) binds to uracil.
- the term “base excision enzyme” or “BEE,” as used herein, refers to a protein that is capable of removing a base (e.g., A, T, C, G, or U) from a nucleic acid molecule (e.g., DNA or RNA).
- a BEE is capable of removing a cytosine from DNA.
- a BEE is capable of removing a thymine from DNA.
- Exemplary BEEs include, without limitation UDG Tyrl47Ala, and UDG Asn204Asp as described in Sang et al., “A Unique Uracil-DNA binding protein of the uracil DNA glycosylase superfamily,” Nucleic Acids Research, Vol. 43, No. 17 2015; the entire contents of which are hereby incorporated by reference.
- the UBP is a uracil modifying enzyme. In some embodiments, the UBP is a uracil base excision enzyme. In some embodiments, the UBP is a uracil DNA glycosylase. In some embodiments, the UBP is any of the uracil binding proteins provided herein.
- the UBP can be a UDG, a UdgX, a UdgX*, a UdgX On, or a SMUG1.
- the UBP comprises an amino acid sequence that is at least 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 99.5% identical to a uracil binding protein, a uracil base excision enzyme or a uracil DNA glycosylase (UDG) enzyme.
- the base editor is fused to, or comprises as a part of the chimeric protein, a nucleic acid polymerase domain (NAP).
- NAP nucleic acid polymerase domain
- the nucleic acid polymerase domain is a eukaryotic nucleic acid polymerase domain.
- the nucleic acid polymerase domain is a DNA polymerase domain.
- the nucleic acid polymerase domain has translesion polymerase activity.
- the nucleic acid polymerase domain is a translesion DNA polymerase.
- the nucleic acid polymerase domain is from Rev7, Revl complex, polymerase iota, polymerase kappa, and polymerase eta.
- the nucleic acid polymerase domain is selected from the group of eukaryotic polymerases consisting of alpha, beta, gamma, delta, epsilon, gamma, eta, iota, kappa, lambda, mu, and nu.
- the base editor disclosed herein is a chimeric protein that comprises a structure such as, NH2-[deaminase domain] -[napR/DNAbp domain]-[UBP]-[NAP]-COOH; NH2- [deaminase domain]-[napR/DNAbp]-[NAP]-[UBP]-COOH; NH2- [deaminase domain] -[NAP] - [napR/DNAbp]-[UBP]-COOH; or NH2-[NAP]-[ deaminase domain]-[napR/DNAbp]-[UBP]- COOH; wherein each instance of ‘-” comprises an optional linker.
- the base editor disclosed herein is complexed with a napR/DNAbp- programming nucleic acid molecule.
- the base editing system disclose herein comprises a base editor and a napR/DNAbp-programming nucleic acid molecule, e.g., the base editor complexed with the napR/DNAbp-programming nucleic acid molecule.
- the lipid containing particles of the present disclosure deliver a base editing system that comprises both a base editor and a napR/DNAbp-programming nucleic acid molecule, e.g., the base editor complexed with the napR/DNAbp-programming nucleic acid molecule.
- a base editor is delivered separately from the napR/DNAbp-programming nucleic acid molecule through lipid containing particles disclosed herein, or together with other delivery methods, into a cell.
- the term “napR/DNAbp-programming nucleic acid molecule” or equivalently “guide sequence” refers the one or more nucleic acid molecules which associate with and direct or otherwise program a napR/DNAbp protein to localize to a specific target nucleotide sequence (e.g., a gene locus of a genome) that is complementary to the one or more nucleic acid molecules (or a portion or region thereof) associated with the protein, thereby causing the napR/DNAbp protein to bind to the nucleotide sequence at the specific target site.
- a specific target nucleotide sequence e.g., a gene locus of a genome
- An example is a guide RNA of a Cas protein of a CRISPR-Cas genome editing system.
- Exemplary configurations, sequences, and mutations thereof for deaminase domains, napR/DNAbp domains, UGI domains, and whole base editor proteins, and exemplary configurations of a base editing system (e.g., comprising both a base editor and a napR/DNAbp- programming nucleic acid molecule) that can be delivered by a lipid containing particle disclosed herein include those described in U.S. Patent Publication Nos.
- Exemplary configurations, sequences, and mutations thereof for deaminase domains, napR/DNAbp domains, UGI domains, and whole base editor proteins, that can be delivered by a lipid containing particle disclosed herein also include those described in Komor AC et al. Nature. 2016 May 19;533(7603):420-4; Kim YB et al. Nat Biotechnol. 2017 Apr;35(4):371-376; Rees HA et al. Nat Commun. 2017 Jun 6;8: 15790; Newby GA et al. Mol Ther. 2021 Nov
- the lipid delivery particles disclosed herein is capable of delivering a payload, such as a prime editing system, or one or more components thereof, such as a ribonucleoprotein (RNP) complex, into a cell in vitro, ex vivo, or in vivo.
- a payload such as a prime editing system, or one or more components thereof, such as a ribonucleoprotein (RNP) complex
- RNP ribonucleoprotein
- the prime editing system, or one or more components thereof is within the inside cavity of the protein core of the lipid delivery particles disclosed herein.
- Prime editing system is a ‘search-and-replace’ genome editing technology by which the genome of living organisms can be modified.
- the term "prime editing system” or “prime editor (PE)” refers the compositions involved in genome editing using target-primed reverse transcription (TPRT) describe herein, can comprise a nucleic acid-guided polypeptide, e.g., nucleic acid-guided polypeptide, a nucleic acid polymerase, chimeric proteins (e.g., comprising guidable polypeptide domain and reverse transcriptase), guide nucleic acid molecule (e.g., guide RNAs), and complexes comprising fusion proteins and guide RNAs, as well as accessory elements, such as second strand nicking components and 5' endogenous DNA flap removal endonucleases (e.g., FEN1) for helping to drive the prime editing process towards the edited product formation.
- TPRT target-primed reverse transcription
- the prime editing system disclosed herein comprises a ribonucleoprotein (RNP) complex.
- the RNP complex comprises a prime editor and a guide nucleic acid molecule.
- the prime editor is formed between one or more proteins and one or more polynucleotides.
- the prime editor can comprise a nucleic acid- guided polypeptide.
- the guidable polypeptide domain can comprise a nucleic acid-guided polypeptide, for example a nuclease (e.g., a Cas protein).
- the prime editor can comprise a fusion protein, comprising a nucleic acid programmable R/DNA binding protein (e.g., a nuclease, such as a Cas protein) and a nucleic acid polymerase (e.g., a reverse transcriptase or any suitable DNA polymerase).
- the nucleic acid polymerase is coupled to the nucleic acid-guided polypeptide.
- the guide nucleic acid molecule can comprise a guide nucleic acid molecule, e.g., a guide RNA.
- the prime editor is operably linked to the guide nucleic acid molecule via a linker, forming the RNP complex.
- prime editing system comprises a fusion protein that comprises an engineered Cas9 nickase and a reverse transcriptase, and the fusion protein is paired with an engineered prime editing guide RNA (PEgRNA).
- PEgRNA can direct Cas9 to a target site within a host cell where the lipid delivery particles are delivered.
- the peg RNA can encode the information for installing the desired edit.
- the prime editing system can function through a multi-step process: 1) the Cas9 domain can bind and nick the target genomic DNA site, which is specified by a spacer sequence in the PEgRNA; 2) the reverse transcriptase can use the nicked genomic DNA as a primer to initiate synthesis of an edited DNA strand using an engineered extension on the PEgRNA as a template for reverse transcription, which can generate a single-stranded 3' flap containing the edited DNA sequence; 3) cellular DNA repair mechanism can resolve the 3' flap intermediate by the displacement of a 5' flap species that occurs via invasion by the edited 3' flap, excision of the 5' flap containing the original DNA sequence, and ligation of the new 3' flap to incorporate the edited DNA strand, forming a heteroduplex of one edited and one unedited strand; and 4) cellular DNA repair mechanism can replace the unedited strand within the heteroduplex using the edited strand as a template for repair, which completes this editing process.
- the prime editing machinery edits a target DNA molecule. In some embodiments, the prime editing machinery edits a target RNA molecule. Examples of targeting RNA molecules using prime editing are described in international patent application WO2021072328 and U.S. Patent Application number US20230357766, each of which is incorporated in its entirety.
- a prime editing system is a multi-flap prime editing system that can simultaneously edit both DNA strands.
- a dual-flap prime editing system comprises two PEgRNAs, which can be used to target opposite strands of a genomic site and direct the synthesis of two complementary 3’ flaps containing edited DNA sequence.
- the pair of edited DNA strands (3’ flaps) does not need to directly compete with 5’ flaps in endogenous genomic DNA, as the complementary edited strand is available for hybridization instead.
- both strands of the duplex are synthesized as edited DNA, the dual-flap prime editing system obviates the need for the replacement of the non-edited complementary DNA strand.
- cellular DNA repair machinery can only excise the paired 5’ flaps (original genomic DNA) and ligate the paired 3’ flaps into the locus.
- a prime editing system can be paired with a separate Cas9 nickase and a separate gRNA that nicks the DNA at a locus that is different than the locus targeted by the PEgRNA.
- one or more prime editing systems can be paired, each targeting a different locus.
- pairing of two prime editing systems, each of which targets a different locus on the same chromosome can install large insertions, deletions, or modifications.
- pairing of two prime editing systems, each of which targets a different locus can install large structural modifications.
- a prime editor can install up to 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 modifications.
- a prime editor can install 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, or more modifications.
- a prime editor can install up to about 25, about 30, about 35, about 40, about 45, about 50, about 55, about 60, about 65, about 70, about 75, about 80, about 85, about 90, about 95, or about 100 modifications.
- a prime editor can install more than about 25, about 30, about 35, about 40, about 45, about 50, about 55, about 60, about 65, about 70, about 75, about 80, about 85, about 90, about 95, or about 100 modifications.
- a prime editor can install more than 100 modifications.
- more than one prime editor can be used to install mutations more than 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, or more modifications. In some embodiments, more than one prime editor can be used to install mutations more than about 25, about 30, about 35, about 40, about 45, about 50, about 55, about 60, about 65, about 70, about 75, about 80, about 85, about 90, about 95, or about 100 modifications. In some embodiments, more than one prime editor can be used to install mutations more than about Ikb, 5kb, lOkb, 20kb, 30kb, 40kb, 50kb, 60kb, 70kb, 80kb, 90kb, or more.
- Prime editors PEI, PE2, PE3, PE4, or PE5, some of which are described in Liu, D. et al., Nature 2019, 576, 149-157 and Huang Z, Liu G. Front Bioeng Biotechnol. 2023;l 1 : 1039315, U.S. Patent Application numbers US20210292769, US20230090221, US2022078655, US20230220374, each of which is hereby incorporated by reference herein in its entirety.
- PE prime editors
- the prime editor comprises a reverse transcriptase (RT) fused with Cas9 H 840A nickase (Cas9n (H840A)) and a primeediting guide RNA (pegRNA).
- RT comprises an RNA-dependent DNA polymerase.
- the RT comprises a protein derived from a retrovirus.
- the RT comprises Moloney Murine Leukemia Virus (M-MMLV) RT.
- the RT comprises a RT from HFV, LtrA, HERV-Kcon, Tel4c, Marathon, Gst-IIC, MA-INT5, or another RT ortholog.
- the RT is modified, mutated, truncated, or evolved. In some cases, the RT comprises a full length RT protein. In some cases, the RT comprises a truncated RT. In some cases, the RT is fused to the Cas protein. In some cases, the RT is fused to the Cas protein at the N terminus to the Cas protein. In some cases, the RT is fused to the Cas protein at the C terminus of the Cas protein. In some cases, the RT is fused to the Cas protein as an inlaid fusion. In some cases, the RT is untethered to the Cas protein.
- Prime editing architecture examples are described in Grunewald, J., et al., Nat Biotechnol 41, 337 -343 (2023) and Gao Z, et al., Mol Ther. 2022; 30(9):2942-2951, each of which is incorporated herein in its entirety.
- the prime editor comprises (a) a fusion protein having the following N- terminus to C-terminus structure: [NLS]-[Cas9(H840A)]- [linker]-[MMLV_RT(wt)] and (b) a PEgRNA.
- the prime editor comprises (a) a fusion protein having the following N- terminus to C-terminus structure: [NLS]-[Cas9(H840A)]-[linker]- [MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)] and (b) a PEgRNA.
- the prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [NLS]-[Cas9(H840A)]-[linker]-[MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)]; (b) a PEgRNA; and (c) a nicking guide RNA that introduces a nick in the non-edited DNA strand.
- the addition of nicking guide RNA increases the chances of the unedited strand to be repaired rather than the edited strand.
- the prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [NLS]- [Cas9(H840A)]-[linker]-[MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)]; (b) a PEgRNA; and (c) a nicking guide RNA that is designed with a spacer that matches only the edited strand but not the original allele before editing, so that the nicking guide RNA is not introduced until after the desired edit is installed.
- the prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [NLS]-[Cas9(H840A)]- [linker]-[MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)]; (b) a PEgRNA; and (c) evading specific DNA mismatch repair (MMR) protein, such as co-expression of a dominant negative MMR protein, such as MLHldn e.g., MLH1 A754-756).
- MMR DNA mismatch repair
- the prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [NLS]-[Cas9(H840A)]-[linker]-[MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)]; (b) a PEgRNA; (c) a nicking guide RNA that introduces a nick in the non-edited DNA strand; and (d) evading specific DNA mismatch repair (MMR) protein, such as co-expression of a dominant negative MMR protein, such as MLHldn (e.g, MLH1 A754-756).
- MMR DNA mismatch repair
- Evading MMR protein such as by co-expression of MMR protein MLHldn can increase efficiency of prime editing, as described in International Publication No., WO2023102538 and Chen et al., Cell Volume 184, Issue 22, 28 October 2021, Pages 5635-5652. e29, each of which is hereby incorporated by reference herein in its entirety.
- An exemplary sequence for MLHldn is: MSFVAGVIRRLDETVVNRIAAGEVIQRPANAIKEMIENCLDAKSTSIQVIVKEGGLKLIQI QDNGTGIRKEDLDIVCERFTTSKLQSFEDLASISTYGFRGEALASISHVAHVTITTKTADG KCAYRASYSDGKLKAPPKPCAGNQGTQITVEDLFYNIATRRKALKNPSEEYGKILEVVG RYSVHNAGISFSVKKQGETVADVRTLPNASTVDNIRSIFGNAVSRELIEIGCEDKTLAFK MNGYISNANYSVKKCIFLLFINHRLVESTSLRKAIETVYAAYLPKNTHPFLYLSLEISPQN VDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKS TTSLTSSSTSGSSDKVYAHQMVRTDSREQKLDAFLQPLSKPLSSQPQA
- the foregoing prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [bipartite NLSI-[Cas9(R221K)(N394K)(H840A)]-[linker]-[MMLV_RT(D200N)(T330P)(L603W)]- [bipartite NLS]-[NLS] instead.
- the components in the foregoing prime editors are packaged in a single lipid delivery particle.
- the components in the foregoing prime editors are packaged in two or more lipid deliver particles that are delivered to the recipient cell simultaneously. In some cases, the components in the foregoing prime editors are packaged in two or more lipid deliver particles that are delivered to the recipient cell sequentially.
- the prime editing system can comprise a flap endonuclease (e.g, FEN1 or variant thereof) that is delivered as a part of the lipid delivery particle (e.g, fused to a plasma membrane recruitment element as a chimeric protein).
- the flap endonuclease can comprise naturally occurring enzymes that process the removal of 5' flaps formed during cellular processes, including DNA replication.
- the flap endonuclease includes those described in Patel et al., Nucleic Acids Research, 2012, 40(10): 4507-4519 and Tsutakawa et al., Cell, 2011, 145(2): 198-211, each of which is incorporated herein by reference in its entirety.
- Additional elements that can be delivered as a part of the prime editing system via the lipid delivery particles (e.g., fused to the nucleic acid-guided polypeptide, or fused to plasma membrane recruitment element) described herein include inhibitor of base repair (e.g., proteins that inhibit a nucleic acid repair enzyme, for example, a base excision repair enzyme), uracil glycosylase inhibitor domains (e.g., protein that inhibits a uracil-DNA glycosylase base-excision repair enzyme), epitope tags, and reporter gene sequences, including those described in International Publication No. WO2023205744, which is incorporated herein by reference in its entirety.
- inhibitor of base repair e.g., proteins that inhibit a nucleic acid repair enzyme, for example, a base excision repair enzyme
- uracil glycosylase inhibitor domains e.g., protein that inhibits a uracil-DNA glycosylase base-excision repair enzyme
- epitope tags e.g.,
- the payload to be delivered by the lipid containing particles of the present disclosure comprises an epigenetic editor or one or more components of an epigenetic editing complex (e.g., comprising an epigenetic editor and a nucleic acid molecule that guides the epigenetic editor to bind and/or modify one or more specific target sequences).
- an epigenetic editing complex e.g., comprising an epigenetic editor and a nucleic acid molecule that guides the epigenetic editor to bind and/or modify one or more specific target sequences.
- the epigenetic editor or epigenetic editing complex disclosed herein has epigenetic activities, such as, methyltransferase activity, demethylase activity, dismutase activity, alkylation activity, depurination activity, oxidation activity, pyrimidine dimer forming activity, integrase activity, transposase activity, recombinase activity, polymerase activity, ligase activity, helicase activity, photolyase activity or glycosylase activity, acetyltransferase activity, deacetylase activity, kinase activity, phosphatase activity, ubiquitin ligase activity, deubiquitinating activity, adenylation activity, deadenylation activity, SUMOylating activity, deSUMOylating activity, ribosylation activity, deribosylation activity, myristoylation activity, remodelling activity, protease activity, oxidoreductase activity, transfera
- epigenetic activities such
- the epigenetic editor or epigenetic editing complex disclosed herein has a chromosome modification enzyme, or a functional domain that has the functional activity equivalent to a chromosome modification enzyme, such as a methylase, demethylase, acetylase, deacetylase, deaminase, phosphorylase, dephosphorylase, histone modifying enzyme, or nucleotide modifying enzyme.
- a chromosome modification enzyme such as a methylase, demethylase, acetylase, deacetylase, deaminase, phosphorylase, dephosphorylase, histone modifying enzyme, or nucleotide modifying enzyme.
- the epigenetic editor or epigenetic editing complex disclosed herein has a histone modifying enzyme, or a functional domain that has the functional activity equivalent to a histone modifying enzyme.
- the epigenetic editor or epigenetic editing complex disclosed herein has a nucleotide modifying enzyme, or a functional
- the epigenetic editor or epigenetic editing system comprises a protein domain that represses expression of the target gene.
- the epigenetic editor or epigenetic editing system can comprise a functional domain derived from a zinc finger repressor protein. Sequences of exemplary functional domains of an epigenetic editor or epigenetic editing system that can reduce or silence target gene expression are provided can be found in PCT/US2021/030643 and Tycko et al.
- the epigenetic editor or epigenetic editing system makes an epigenetic modification at a target gene that activates expression of the target gene.
- the epigenetic editor or epigenetic editing system modifies the chemical modification of DNA or histone residues associated with the DNA at a target gene harboring the target sequence, thereby activating or increasing expression of the target gene.
- the epigenetic editor or epigenetic editing system comprises a DNA demethylase, a DNA dioxygenase, a DNA hydroxylase, or a histone demethylase domain.
- the lipid delivery particle of the present disclosure comprises a payload comprising a nucleic acid.
- the nucleic acid as a payload can comprise or be composed of one or more nucleotides. Nucleotides are referred to by their commonly accepted single-letter codes: A represents adenine, C represents cytosine, G represents guanine, T represents thymine, U represents uracil, I represents inosine. Unless otherwise indicated, nucleotide sequences are written from left to right in a 5' to 3' orientation.
- the nucleic acid as a payload comprises a polynucleotide.
- the nucleic acid as a payload can comprise DNA or RNA.
- the nucleic acid as a payload comprises or encodes a gene.
- the nucleic acid as a payload can comprise or encode any of the polynucleotides described elsewhere herein.
- the nucleic acid as a payload can be a vector encoding any of the polypeptide domains described elsewhere herein.
- the nucleic acid as a payload is an engineered polynucleotide.
- the payload does not comprise a repair template.
- the double stranded break is repaired through non-homologous end joining.
- the payload comprises a repair template.
- the repair template can be double-stranded or single-stranded.
- the repair template can comprise a template sequence comprising a desired edit to be introduced in a target nucleic acid molecule.
- the repair template is a homology-directed repair template.
- a homology-directed repair template can comprise a homology arm that is homologous to a sequence in the target nucleic acid.
- the payload comprises a DNA-synthesis template comprising a DNA-synthesis template sequence.
- the DNA-synthesis template can comprise a desired edit to be introduced in a target nucleic acid molecule.
- the DNA-synthesis template can be a template for a DNA polymerase or a reverse transcriptase to carry out DNA synthesis.
- a prime editor can use the DNA synthesis template sequence to synthesize a DNA strand that is complementary to the DNA synthesis template sequence.
- the DNA strand is inserted into the target nucleic acid.
- the nucleic acid comprising the DNA synthesis template sequence also comprises a primerbinding sequence.
- a primer-binding sequence can be complementary to a sequence in a primer strand to which a DNA polymerase or reverse transcriptase can add nucleotides.
- the primer strand is part of a target nucleic acid molecule.
- a primer-binding sequence can be complementary to a sequence in the target nucleic acid.
- the payload comprises a double-stranded DNA containing a desired gene sequence to be inserted in the target nucleic acid molecule.
- the double-stranded DNA is configured to couple to a transposase domain.
- the payload is delivered in the same particle as the transposase domain. In some cases, the payload is delivered in a separate particle as the transposase domain.
- the payload comprises a polynucleotide that is configured to bind to a guidable polypeptide domain.
- the polynucleotide directs a guidable polypeptide domain to a sequence in a target nucleic acid molecule.
- the polynucleotide comprises a scaffold segment configured to bind to a guidable polypeptide domain (e.g., Cas9 or Casl2).
- polynucleotide comprises a spacer sequence that is complementary to a target sequence in the target nucleic acid molecule and is capable of hybridizing to the target sequence.
- the polynucleotide can be a natural molecule or an engineered or synthetic molecule.
- the polynucleotide can be derived or share sequence or structural similarities to CRISPR RNA (crRNA), a tracrRNA, or a scoutRNA encoded in a CRISPR system.
- the polynucleotide is engineered to be a single RNA guide (sgRNA) comprising elements of the crRNA and the tracrRNA.
- the polynucleotide comprises a scaffold segment and a spacer sequence. The scaffold segment can be configured to bind to a guidable polypeptide domain.
- the scaffold segment can be specific to a specific type of guidable polypeptide (e.g., Cas9 or Casl2).
- the spacer sequence is programmed to be any sequence.
- the spacer sequence is programmed to a sequence complementary to a target nucleic acid sequence.
- the payload comprises a polynucleotide that is a guide nucleic acid molecule for a prime editing system, e.g., a prime editing guide RNA (PEgRNA).
- a guide nucleic acid molecule for a prime editing system comprises two or more guide RNAs.
- a guide nucleic acid molecule for a prime editing system comprises a nicking guide RNA.
- a guide RNA comprises (A) a primer binding site, (B) a clamp segment, (C) a sequence encoding new genetic information that replaces the targeted sequence, (D) an aptamer, (E) spacer, or (F) scaffold, or any combinations thereof.
- a guide RNA comprises a sequence encoding new genetic information that replaces the targeted sequence, a spacer, and scaffold.
- a guide RNA comprises a spacer and scaffold.
- the guide nucleic acid molecule is heterologous to the cell or host receiving the lipid delivery particle.
- the PEgRNA comprises an extended single guide RNA (sgRNA) containing a primer binding site (PBS) and a template sequence for nucleic acid polymerase (e.g., reverse transcriptase or DNA polymerase).
- a PEgRNA can comprise an architecture corresponding to 5'-[spacer]-[guide RNA core]-[extension arm]-3'.
- the spacer sequence can comprise about 20 nucleotides in length.
- the spacer sequence can bind to a protospacer in a target nucleic acid molecule.
- the spacer sequence can guide the nucleic acid-guided polypeptide (e.g., Cas9) to the target nucleic acid molecule.
- the guide RNA core can be responsible for binding of the nucleic acid-guided polypeptide e.g., Cas9).
- the extension arm can comprise a primer binding site, an edit template, and a homology arm, in a 3' to 5' direction.
- the PEgRNA can further comprise, optionally, a 3’ end modifier region, 5’ end modifier region, a transcriptional signal at the 3’ end.
- the PEgRNA can optionally comprise a secondary structure, such as, hairpins, stem/loops, toe loops, RNA-binding protein recruitment domains e.g., the MS2 aptamer which recruits and binds to the MS2cp protein).
- the PEgRNA comprises an aptamer and the prime editor further comprises an aptamer binding protein e.g., fused to Cas protein or reverse transcriptase).
- Guide RNAs including an aptamer include those described in International Publication No. W02023205708, which is hereby incorporated herein by reference in its entirety.
- Homology arm can encode a portion of a resulting reverse transcriptase-encoded single strand DNA flap to be integrated into the target DNA site by replacing the endogenous strand.
- the portion of the single strand DNA flap encoded by the homology arm is complementary to the non-edited strand of the target DNA sequence, which facilitates the displacement of the endogenous strand and annealing of the single strand DNA flap in its place, thereby installing the edit.
- the edit template can comprise a sequence corresponding to new genetic information that replaces the targeted sequence, i.e., a single strand RNA of the PEgRNA that codes for a complementary single strand DNA that is either the sense or the antisense strand of the new genetic information that replaces the targeted sequence and which is incorporated into the genomic DNA target locus through the prime editing process.
- the primer binding site allows the 3’ end of the nicked DNA strand to hybridize to the PEgRNA, while the reverse transcriptase template serves as a template for the synthesis of edited genetic information.
- a prime editing system can allow DNA synthesis based on the reverse transcriptase template at a nick site a single 3' flap, which becomes integrated into a target nucleic acid on the same strand.
- a prime editing system can be a multi-flap prime editing system that generate pairs or multiple pairs of 3' flaps on different strands, which form duplexes comprising desired edits and which become incorporated into target nucleic acid molecules, e.g., at specific loci or edit sites in a genome.
- the pairs or multiple pairs of 3' flaps form duplexes because they comprise reverse complementary sequences which anneal to one another once generated by the prime editors described herein.
- the duplexes can be incorporated into the target site by cell-driven mechanisms that naturally replace the endogenous duplex sequences located between adjacent nick sites.
- the new duplex sequences can be introduced at one or more locations (e.g., at adjacent genomic loci or on two different chromosomal locations), and can comprise one or more sequences of interest, e.g., protein-encoding sequence, peptide-encoding sequence, or RNA-encoding sequence.
- the payload comprises a polynucleotide comprising a scaffold segment, a spacer sequence, a DNA synthesis template, and a primer-binding sequence.
- the scaffold segment and a spacer sequence are on a first nucleic acid molecule and the DNA synthesis template and the primer-binding sequence are on a second nucleic acid molecule.
- the guide RNA further comprises a clamp segment. In some cases, the guide RNA comprising, from 3’ to 5’, a primer binding site, a sequence encoding at least a portion of the first recombinase recognition sequence, a clamp segment, scaffold, and spacer.
- the clamp segment comprises a sequence that, after being reverse transcribed is at least partially complementary to a genomic site close to the primer binding site and where the spacer binds.
- the clamp segment can enhance integration efficiency of the new genetic material that replaces the target sequence at the double-stranded target DNA sequence relative to a guide RNA without the clamp segment.
- the clamp segment can allow for a reduced number of nucleotides in the primer binding site need to bind its genomic site and facilitate reverse transcription, which in turn enables design of a guide RNA that is shorter than conventional guide RNAs used for other gene editing methods.
- the clamp segment is described in International Publication No. WO2023215831, which is hereby incorporated herein by reference in its entirety.
- a guide RNA can complete the insertion of new genetic material that replaces the target sequence without another guide RNA when delivered to a cell together with a prime editor described herein.
- the guide RNA can complete the insertion of the new genetic material that replaces the target sequence with a second guide RNA that is a nicking guide RNA when delivered together with a prime editor described herein.
- a guide RNA comprises two or more guide RNAs.
- the two or more guide RNAs comprise a first guide RNA encoding at least a first portion of new genetic material that replaces the target sequence.
- the two or more guide RNAs comprise a second guide RNA encoding at least a second portion of the new genetic material that replaces the target sequence.
- the first guide RNA and the second guide RNA work in a pair and collectively encode the new genetic material that replaces the target sequence, thereby inserting the new genetic material that replaces the target sequence into the genome of a cell receiving the lipid delivery particles in a site-specific manner.
- the first and the second portion of the new genetic material that replaces the target sequence have at least 6bp overlap. In some cases, the first portion of the new genetic material that replaces the target sequence is 46 bp. In some cases, the first portion of the new genetic material that replaces the target sequence is 42 bp. In some cases, the first portion or the second portion of the new genetic material that replaces the target sequence is 36 bp, 38 bp, 40 bp, 42 bp, 44 bp, or 46 bp.
- the first guide RNA comprises a first spacer.
- the second guide RNA comprises a second spacer. The first spacer and the second spacer bind to two genomic target sites that are within 5-100 bp from each other.
- the double strand DNA between the two genomic target sites are deleted and the full sequence of the new genetic material that replaces the target sequence is inserted instead.
- the deletion can be mediated by the following steps: (a) reverse transcription of the sequence encoding the first portion of the new genetic material that replaces the target sequence in the first guide RNA and the sequence encoding the second portion of the new genetic material that replaces the target sequence in the second guide RNA, wherein the first and the second portion of the new genetic material that replaces the target sequence having at least 6bp overlap, (b) annealing of the two overlapped portion of the new genetic material that replaces the target sequence, (c) synthesis of the second strand comprising the full sequence of the new genetic material that replaces the target sequence, (d) excision of the original DNA sequence, and (e) ligation of the pair nicks.
- the mechanism, process, and components of this process include those described in International Publication Nos. WO2023122764,
- the payload comprises a polypeptide domain described herein coupled to a polynucleotide domain described herein.
- the payload comprises a polypeptide domain described herein complexed to a polynucleotide domain described herein.
- the payload comprises a ribonucleoprotein.
- the payload may comprise a guidable polypeptide domain complexed to a polynucleotide configured to bind to the guidable polypeptide domain (e.g., Cas9 complexed with an RNA guide).
- Any of the payloads described herein can further comprise a plasma membrane recruitment element, a transmembrane domain, a signaling domain, a receptor domain, a packaging domain, or a targeting domain.
- Any of payloads described herein can comprise or be engineered to comprise a protein tag, a peptide tag, or small molecule tag.
- a payload can comprise a nuclear localization signal (NLS), a nuclear export signal (NES), a cell penetrating peptide (CPP), a mitochondria penetrating peptide (MPP), a solubility tag, a fluorescent tag, or any combinations thereof.
- the payload in the lipid delivery particle of the present disclosure comprises a recombinant protein.
- the payload can be a diagnostic imaging agent, such as a contrast agent.
- the payload comprises a therapeutic agent, including, but not limited to, a nuclease, a recombinase, a growth factor, an antibody, a chimeric antigen receptor, a T cell receptor, a cytokine, a cytokine inhibitor or agonist, a transcription factor, an organelle, a nucleic acid molecule, a therapeutic DNA, a therapeutic RNA, a retrotransposon, a reverse transcriptase, an oligonucleotide, an aptazyme, an aptamer, or a ribozyme, a generic or specific kinase inhibitor, a small molecule drug, an immunomodulator, a tumor suppressor, a developmental regulator, a cancer vaccine, an anesthetic, an enzyme, a
- the payload can be a prophylactic agent.
- the payload comprises a biomarker.
- the payload can also comprise an exogenous antigen or an enzyme.
- the payload comprises a metabolite molecule.
- the payload comprises a lipid molecule.
- the payload comprises a structural protein.
- the payload comprises a hormone or a hormonal protein.
- composition, methods of production, methods of purification related to the lipid delivery particles provided herein.
- the lipid delivery particles can be produced from producer cell lines that are either transiently transfected with at least one plasmid or stably expressing constructs that have been integrated into the producer cell line genomic DNA.
- Producer cell lines can be generated by stably integrating genetic material with a gene of interest into a host cell line.
- the genetic material is transiently expressed in a producer cell line.
- the genetic material is expressed via viral methods.
- the genetic material is expressed via non-viral methods.
- a producer cell line grows in a serum-free medium or in suspension.
- a producer cell line can be grown in serum-free medium and suspension simultaneously.
- producer cell lines can be generated with adherent cells (e.g., cells cultured in media and attached to a substrate).
- Producer cells can be used to produce the lipid delivery particles described herein.
- generating a producer cell line comprises transfecting cells (e.g., cells of a
- the method of producing the lipid delivery particle further comprises providing new media to promote transient production of the lipid delivery particles.
- the mammalian cell type includes a HT1080 cell, a COS cell, a HeLa cell, a Chinese Hamster Ovary (CHO) cell, or a HEK 293 cell.
- HEK293 cells are cells derived from human embryonic kidney cells grown in tissue culture.
- the HEK293 cell is a HEK293, 293E, 293T, 293F, 293FT, or 293T Gesicle cell.
- the producer cell line can be transformed with a viral vector or non-viral method in any number of means including calcium phosphate and the like.
- the cells can be cultured under conditions for production of lipid delivery particles.
- Exemplary culturing conditions can include refeeding cells in appropriate media, addition of CO2, and humidity.
- culturing conditions includes addition of antibiotics, anti-fungals, and/or growth factors.
- the medium can be harvested after 24, 48, 72, or 96 hours, or at any appropriate time point to allow sufficient production of the lipid delivery particles.
- the lipid delivery particles in the media can be isolated and collected using any number of techniques known in the art.
- the lipid delivery particles are purified, wherein the lipid delivery particles are washed or resuspended in an appropriate buffer or media or at particular concentration.
- Adherent cells can be first transfected to produce lipid delivery particles.
- transfection occurs by the addition or expression of exogenous nucleic acid sequences via non-viral methods (e.g., by electroporation, microinjection, or a chemical system such as DEAE-dextran or cationic polymers).
- transfection occurs by the addition or expression of exogenous nucleic acid sequences via viral methods (e.g., by infecting the cells with a viral vector, such as an adenoviral vector, adeno-associate viral vector, a lentiviral vector, a herpes viral vector, or a HSV vector).
- a viral vector such as an adenoviral vector, adeno-associate viral vector, a lentiviral vector, a herpes viral vector, or a HSV vector.
- the cells are from a HEK293 cell line (e.g., HEK293, 293E, or 293T).
- the cells are cultured in a medium. In some cases, cells can be cultured in the medium for 5, 10, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24 or 25 hours.
- cells can be cultured in the medium for between 10-20 hours. In some cases, cells can be cultured in the medium for 18 hours. [0205] Following incorporation into the transfection medium, cells are transferred to a new solution. In some cases, the new solution is new media. In some cases, the new media promotes the production of the lipid delivery particles. In some cases, the cells incorporate into the new media for between 10-50 hours. In some cases, the cells incorporate into the new media for 10, 20, 30, 35, 40, 45, or 50 hours. In some cases, the cells incorporate into the new media for 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39 or 40 hours. The media can then be harvested. The harvested media can be filtered, and the lipid delivery particles can be collected. Filtration can comprise microfiltration and/or depth filtration. In some cases, the lipid delivery particles can undergo further purification and/or concentration methods that maintain the structural integrity of the particles.
- RNA and protein from a producer cell can get packaged and/or incorporated into lipid delivery vehicles of the present disclosure.
- the components of the lipid delivery particles, such as a payload is loaded via the packaging and assembly process of the lipid delivery particle.
- the payload can be a polypeptide or protein that is packaged into the lipid delivery particle as a part of a chimeric protein as disclosed herein.
- the payload is assembled into the lipid delivery particle as an independent entity, e.g., not as a part of a chimeric protein.
- the lipid delivery particle provided herein is loaded with a payload by utilizing any suitable method for delivering a biological or chemical payload through a lipid membrane, such as nucleofection, electroporation, lipid-based, polymer-based, or CaCh transfection, sonication, freeze thaw, incubation at various temperatures, or heat shock of lipid delivery particles mixed with payload.
- the nucleic acid molecules such as a template RNA described herein, are loaded into the lipid delivery particle by direct loading, such as electroporation of the lipid delivery particle in vitro.
- the nucleic acid molecules are loaded into the lipid delivery particle by binding to a nucleic acid binding protein (e.g., Cas protein) that is part of the lipid delivery particle or is already loaded into the lipid delivery particle.
- a nucleic acid binding protein e.g., Cas protein
- a first payload is a polypeptide that is assembled into the lipid delivery particle as a part of a chimeric protein
- a second payload is a separate protein or nucleic acid (RNA or DNA) that interacts with (e.g., binds) the first payload, and thus is loaded into the lipid delivery particle via the interaction between the first payload and the second payload.
- the second payload can be loaded into the lipid delivery particle via a transfection-like technique or any other suitable method.
- lipid delivery particle or pharmaceutical composition comprising contacting a cell with the lipid delivery particle described herein.
- the cell is a mammalian cell, such as a human cell.
- the cell is within a subject in need of treatment for a disease or a condition.
- contact comprising administering the lipid delivery particle described herein to the subject, such as via injections.
- the method comprises administering the lipid delivery particle, system, or pharmaceutical composition described herein to a subject in need thereof, such as via injections.
- lipid delivery particle or pharmaceutical composition also provided herein are methods of producing a lipid delivery particle or pharmaceutical composition according to some embodiments of the present disclosure.
- the method comprises contacting a producer cell with compositions described herein.
- the lipid delivery particles are produced from producer cell lines that are either transiently transfected with at least one plasmid or stably expressing constructs that have been integrated into the producer cell line genomic DNA.
- the producer cell culture medium is harvested 24-, 48-, 72-, or 96-hours post-transfection.
- the producer cell culture medium is harvested between 40- and 48-hours post-transfection. The harvested medium can undergo centrifugation steps to remove producer cell debris while maintaining the structural integrity of the lipid delivery particle.
- the producer cell medium is centrifuged, e.g., at 500g for 5 minutes.
- the clarified lipid delivery particle containing supernatant can then be collected and filtered.
- the lipid delivery particles are further concentrated.
- the lipid delivery particles are further concentrated by ultracentrifugation.
- the lipid delivery particles are concentrated 50-fold, 100-fold, 200-fold, 500-fold, 1000-fold, 2000-fold, 3000-fold, or 5000-fold.
- the concentrated lipid delivery particles are resuspended, e.g., in cold PBS.
- the concentrated lipid delivery particles are frozen, e.g., frozen at a rate of -l°C/min and stored at -80°C.
- the purification methods can comprise chromatographic methods (e.g., anion exchange chromatography), ultrafiltration methods (e.g., tangential flow filtration), clarifying normal flow filtration, and/or sterilizing membrane filtration.
- chromatographic methods e.g., anion exchange chromatography
- ultrafiltration methods e.g., tangential flow filtration
- clarifying normal flow filtration e.g., tangential flow filtration
- sterilizing membrane filtration e.g., chromatographic methods
- Anion exchange chromatography can separate substances based on net-surface charge, using an ion-exchange resin.
- Tangential flow filtration can separate molecules using ultrafiltration membranes.
- the membrane pore size used for tangential flow filtration can retain a biological product of a size less than 1000 kDa, less than 750 kDa, less than 500 kDa, less than 250 kDa, less than 200 kDa, less than 150 kDa, less than 100 kDa, or less than 50 kDa.
- Normal flow filtration assists in the clarification of biofluid by convecting the substance directly toward a membrane under an applied pressure.
- normal flow filtration can comprise a membrane pore size of greater than 0.1 pm, greater than 0.2 pm, greater than 0.3 pm, greater than 0.4 pm, greater than 0.5 pm, greater than 0.6 pm, greater than 0.7 pm, greater than 0.8 pm, greater than 0.9 pm, greater than 1.0 pm, greater than 1.5 pm, or greater than 2.0 pm.
- normal flow filtration can comprise a membrane pore size of 0.2 pm, 0.45 pm, 0.8 pm, 1.2 pm, or 2.0 pm. Sterilizing membrane filtration can be used to sterilize heat-sensitive liquid without exposure to denaturing hear.
- sterilizing membrane filtration can comprise a membrane pore size of about 0.1 pm, about 0.2 pm, about 0.3 pm, about 0.4 pm, or about 0.5 pm. In some cases, sterilizing membrane filtration can comprise a membrane pore size of about 0.2 pm or 0.22 pm.
- nucleic acid molecules that encode one or more of the components of the lipid delivery particles of the present disclosure.
- a nucleic acid molecule encoding the chimeric protein is provided.
- a nucleic acid molecule encoding the envelope protein is also provided.
- compositions or systems that include nucleic acid molecules that encode one or more of the components of the lipid delivery particles of the present disclosure.
- a composition can comprise a first nucleic acid sequence encoding a first chimeric protein described herein and a second nucleic acid sequence encoding a second chimeric protein described herein.
- a composition can comprise a first nucleic acid sequence encoding a first chimeric protein described herein, a second nucleic acid sequence encoding a second chimeric protein described herein, and a third nucleic acid sequence encoding a third chimeric protein described herein.
- a system can comprise the lipid delivery particles of the present disclosure and a reversible protease inhibitor.
- the protease inhibitor inhibits the protease cleavage.
- the release of payload is delayed until the reversible protease inhibitor is removed from the system.
- the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease.
- the protease inhibitor is selected from the group consisting of Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
- compositions or systems can be used for producing a lipid delivery particle of the present disclosure, for instance, by transfecting or otherwise delivering the nucleic acid molecules in the compositions or systems into a producer cell.
- the nucleic acid molecules can be expressed in the producer cell, the result of which assemble, package, and subsequently cause the producer cell to release the lipid delivery particle.
- a lipid delivery particle of the present disclosure facilitates gene editing efficiency greater than 40%, greater than 50%, greater than 60%, or more. In some cases, a lipid delivery particle of the present disclosure facilitates gene editing efficiency greater than 70%. In some cases, a lipid delivery particle of the present disclosure facilitates gene editing efficiency comprising 8-fold increase of base editing efficiency when compared to a conventional VLP (e.g., the VLPs described in Mangeot, P. E. et al. Genome editing in primary cells and in vivo using viral-derived Nanoblades loaded with Cas9-sgRNA ribonucleoproteins. Nat. Commun. 10, 45 (2019).).
- VLP e.g., the VLPs described in Mangeot, P. E. et al. Genome editing in primary cells and in vivo using viral-derived Nanoblades loaded with Cas9-sgRNA ribonucleoproteins. Nat. Commun. 10, 45 (2019).
- a lipid delivery particle of the present disclosure facilitates gene editing efficiency comprising 8-fold increase of prime editing efficiency when compared to a conventional VLP.
- a lipid delivery particle of the present disclosure exhibits reduced immunogenicity in transduced target cells.
- a lipid delivery particle of the present disclosure produces reduced off-target genome editing in target cells when delivering genome editing system into the target cells when compared to a conventional VLP.
- a lipid delivery particle of the present disclosure leads to more than 100-fold reduction in Cas-independent off-target editing when compared to a conventional VLP.
- a lipid delivery particle of the present disclosure leads to at least 10-fold, such as 12- to 900-fold, lower Cas-dependent off-target editing when compared to a conventional VLP.
- a pharmaceutical formulation comprising the lipid delivery particle disclosed herein and optionally further comprising a pharmaceutically acceptable carrier, excipient, or additive.
- pharmaceutical formulation refers to a composition formulated for pharmaceutical use.
- pharmaceutical formulations comprise an immunologically effective amount of one or more cells, vectors, lipid delivery particles, or compositions disclosed herein, and optionally one or more other components which are pharmaceutically acceptable.
- the pharmaceutical formulation comprises additional agents, e.g., for specific delivery, increasing half-life, or other therapeutic benefit.
- the pharmaceutical formulation may comprise one or more of dimethylsulfoxide (DMSO), dextrose, water, succinate, poly I: poly C, poly-L-lysine, carboxymethylcellulose, and/or chloride.
- DMSO dimethylsulfoxide
- a “pharmaceutically acceptable carrier” is an agent that is compatible with the other ingredients of the formulation and not injurious to the tissue of the subject (e.g., physiologically compatible, sterile, physiologic pH, etc.)
- a pharmaceutically acceptable carrier comprises any vehicle, such as a liquid or solid filler, diluent, excipient, manufacturing aid (e.g., lubricant, talc magnesium, calcium or zinc stearate, or steric acid), or solvent encapsulating material, involved in carrying or transporting the compound from one site (e.g., the delivery site) of the body, to another site (e.g., organ, tissue or portion of the body).
- Some exemplary materials which can serve as pharmaceutically-acceptable carriers include: (1) sugars, such as lactose, glucose and sucrose; (2) starches, such as corn starch and potato starch; (3) cellulose, and its derivatives, such as sodium carboxymethyl cellulose, methylcellulose, ethyl cellulose, microcrystalline cellulose and cellulose acetate; (4) powdered tragacanthin; (5) malt; (6) gelatin; (7) lubricating agents, such as magnesium stearate, sodium lauryl sulfate and talc; (8) excipients, such as cocoa butter and suppository waxes; (9) oils, such as peanut oil, cottonseed oil, safflower oil, sesame oil, olive oil, corn oil and soybean oil; (10) glycols, such as propylene glycol; (11) polyols, such as glycerin, sorbitol, mannitol and polyethylene glycol (PEG); (12) esters, such as
- Pharmaceutical formulation disclosed herein can comprise one or more pH buffering compounds to maintain the pH of the formulation at a predetermined level that reflects physiological pH, such as in the range of about 5.0 to about 8.0.
- the pH of the pharmaceutical formulation can be about 4, about 5, about 6, about 7, about 8 or about 9.
- the pH buffering compound used in the aqueous liquid formulation can be an amino acid or mixture of amino acids, such as histidine or a mixture of amino acids such as histidine and glycine.
- the pH buffering compound can be an agent which does not chelate calcium ions.
- Exemplary pH buffering compounds include imidazole and acetate ions.
- the pH buffering compound can be present in any amount suitable to maintain the pH of the formulation at a predetermined level.
- compositions described herein can be prepared by any method known or hereafter developed in the art of pharmacology.
- preparatory methods include the step of bringing the active ingredient(s) into association with an excipient and/or one or more other accessory ingredients, and then, optionally, shaping and/or packaging the product into a desired single- or multi-dose unit.
- compositions can additionally comprise a pharmaceutically acceptable excipient, which, as used herein, includes any and all solvents, dispersion media, diluents, or other liquid vehicles, dispersion or suspension aids, surface active agents, isotonic agents, thickening or emulsifying agents, preservatives, solid binders, lubricants, and the like, as suited to the particular dosage form desired.
- a pharmaceutically acceptable excipient includes any and all solvents, dispersion media, diluents, or other liquid vehicles, dispersion or suspension aids, surface active agents, isotonic agents, thickening or emulsifying agents, preservatives, solid binders, lubricants, and the like, as suited to the particular dosage form desired.
- a lipid delivery particle provided herein can find use in a variety of fields and methods.
- the lipid delivery particle of the present disclosure can be used to deliver one or more payloads, such as a ribonucleoprotein complex to a cell.
- the target cells to which the lipid delivery particles are delivered are in vitro cells, ex vivo cells, or in vivo cells.
- the lipid delivery particles of the present disclosure can be applicable for delivery of freights into a variety of cell types, such as, animal cells, plant cells, bacteria cells, algal cells, or fungal cells.
- lipid delivery particle described herein a system described herein, a composition described herein, or pharmaceutical composition according to some embodiments of the present disclosure.
- the present disclosure provides methods of treating, preventing, or diagnosing a condition, disease, or disorder.
- a composition, kit, or method described herein can be used to treat, prevent, or diagnose a condition, disease, or disorder.
- the condition, disease, or disorder can comprise a cancer, an immune disorder, an autoimmune disorder, a metabolic disorder, a hormonal disorder, an inflammatory disorder, a developmental disorder, a reproductive disorder, an imprinting disorder, a genetic disorder, a neurological disorder, or a neurodegenerative disorder.
- the condition, disease, or disorder comprises a liver disorder, an eye disorder, a heart disorder, a kidney disorder, a skin disorder, a blood disorder, a fibrotic disorder, a skeletal disorder, or a muscle order.
- the condition, disease, or disorder is caused by a genetic mutation (e.g., an insertion, deletion, or point mutation).
- the condition, disease, or disorder is hereditary.
- the condition, disease, or disorder is caused by a virus or bacteria or fungus.
- the condition, disease, or disorder is caused by aberrant gene expression.
- the condition, disease, or disorder is a result of age. In some embodiments, the condition, disease, or disorder is chronic.
- the subject in the method of present disclosure can be an animal.
- the subject is an animal cell.
- the subject is a mammal.
- the subject is a human.
- the subject is an aquaculture animal (fish, crabs, shrimp, oysters etc.), a mammal.
- the animals cell is from, for example, a pet or zoo animal (cats, dogs, lizards, birds (e.g., parrots), lions, tigers and bears etc.), from a farm or working animal (horses, cows (e.g., dairy and beef cattle) pigs, chickens, turkeys, hens or roosters, goats, sheep, etc.), or a human.
- the target cell as disclosed herein is in a subject to whom the method of the present disclosure is applicable.
- the methods described herein can be therapeutic or veterinary methods for treating a subject.
- the methods described herein are used to treat a disease resulting from a non-functional, poorly functional, or poorly expressed protein or gene product, for instance, resulting from a genetic mutation in one or more cells of the subject.
- the methods described herein are used to treat a genetic disease (e.g., a mutation, a substitution, a deletion, an expansion, or a recombination), a monogenic disease, an inherited metabolic disease, a cancer, a neurodegenerative disease, a cardiovascular disease, a pulmonary disease, a renal disease, a liver disease, a genetic disease, a vascular disease, ophthalmic disease, musculoskeletal disease, lymphatic disease, auditory and inner ear disease, a metabolic disease, an inflammatory disease, an autoimmune disease, or an infectious disease.
- a retinal disease e.g., Leber congenital amaurosis
- kits comprising the unit doses containing the lipid delivery particles, systems, compositions or pharmaceutical compositions of the present disclosure.
- the kit comprises the lipid delivery particles, compositions, or pharmaceutical formulations of the present disclosure; and an informational medium containing instructions for administering the lipid delivery particle, composition, or pharmaceutical formulation to a subject.
- the kit can include a label indicating the intended use of lipid delivery particle, composition, or pharmaceutical formulation in the kit. Label can include any writing, or recorded material supplied on or with the kit, or which otherwise accompanies the kit.
- kits of the present disclosure can include, alternatively or additionally, diagnostic agents and/or other therapeutic agents.
- the kit includes cells or pharmaceutical formulations of the present disclosure and a diagnostic agent that can be used in a diagnostic method for diagnosing a condition, disease, or disorder in a subject.
- the composition or pharmaceutical formulation described herein is prepared for administration to a subject.
- the pharmaceutical formulation is prepared to induce a therapeutic or prophylactic effect in a subject.
- Suitable routes of administrating the pharmaceutical formulation described herein include transdermal, intravesical, intravenous, intravascular, intraosseus, topical, subcutaneous, intradermal, intralesional, intraarticular, intraperitoneal, transmucosal, gingival, intradental, intracochlear, transtympanic, intraorgan, epidural, intrathecal, intramuscular, periocular, intratumoral, intracerebral, intravitreal, and intracerebroventricular administration.
- the pharmaceutical formulation described herein is administered locally to a diseased site (e.g., site of infection or tumor site).
- the pharmaceutical composition described herein is delivered in a controlled release system.
- a pump is used.
- polymeric materials is used for controlled release.
- the pharmaceutical composition described herein is administered to a subject by injection, by means of a catheter, by means of a suppository, or by means of an implant, the implant being of a porous, non-porous, or gelatinous material, including a membrane, such as a sialastic membrane, or a fiber.
- the pharmaceutical formulation is formulated in accordance with routine procedures as a formulation adapted for intravenous or subcutaneous administration to a subject.
- pharmaceutical formulations for administration by injection are solutions in sterile isotonic use as solubilizing agent and a local anesthetic such as lignocaine to ease pain at the site of the injection.
- the ingredients can be supplied either separately or mixed together in unit dosage form, for example, as a dry lyophilized powder or water free concentrate in a hermetically sealed container such as an ampoule or sachets indicating the quantity of active agent.
- the pharmaceutical is to be administered by infusion, it is dispensed with an infusion bottle containing sterile pharmaceutical grade water or saline.
- an ampoule of sterile water for injection or saline is provided so that the ingredients can be mixed prior to administration.
- a pharmaceutical formulation as described herein can be administered or packaged as a unit dose, for example, in reference to a pharmaceutical formulation to physically discrete units suitable as unitary dosage for the subject, each unit containing a predetermined quantity of active material calculated to produce the desired therapeutic effect in association with the required diluent, carrier, or vehicle.
- Example 1 Payload delivery efficiency of the lipid delivery particles in hematopoietic stem cells (HSCs)
- chimeric protein with base editors are produced by transient transfection of producer cells (e.g. 293T Gesicle cells or 293FT cells). Producer cells are seeded in tissue culture flasks. After 20-24 h, cells are transfected using the jetPRIME transfection reagent (Polyplus) according to the manufacturer’s protocols.
- the chimeric protein construct is provided in FIGs.2A-B and FIGs 3 A-3E.
- LDP- BEs are further concentrated using PEG-it Virus Precipitation Solution or ultracentrifugation.
- LDP-BE pellets are resuspended in cold PBS and centrifuged to remove debris. LDP-BEs are frozen store at -80°C. LDP-BEs are thawed on ice immediately prior to use.
- Example 2 delivering the lipid delivery particles to the target cell in vitro
- Lipid delivery particles comprising a chimeric protein with base editors (LDP-BE) are produced by transient transfection of producer cells (e.g. 293T Gesicle cells or 293FT cells). Producer cells are seeded in tissue culture flasks. After 20-24 h, cells are transfected using the jetPRIME transfection reagent (Polyplus) according to the manufacturer’s protocols.
- the chimeric protein construct is provided in FIGs.2A-B and FIGs.3A-3E.
- a protease inhibitor e.g., atazanavir
- producer cell supernatant is harvested and centrifuged to remove cell debris.
- the protease inhibitor is removed by exchanging the buffer, using chromatography.
- the clarified VLP-containing supernatant is filtered through a filter.
- LDP-BEs are further concentrated using PEG-it Virus Precipitation Solution or ultracentrifugation.
- LDP-BE pellets are resuspended in cold PBS and centrifuged to remove debris.
- LDP-BEs are frozen store at -80°C. LDP-BEs are thawed on ice immediately prior to use.
- Example 3 delivering the lipid delivery particles to the target cell in vitro
- Target cells e.g. Hela cells or fibroblast cells
- the cells are allowed to adhere.
- LDP-BEs are added to the culture medium together with Vectofusin. Cells are incubated at 37°C.
- Example 4 assessing the efficiency of payload delivery in vitro
- Target cells transduced with LDP-BEs are lysed. Protein extracts are separated by electrophoresis and transferred to a PVDF membrane. The membrane is blocked for 1 h at room temperature and then is incubated with mouse-anti-Cas9 antibody. The membrane is washed and imaged. The relative amounts of cleaved BE and full-length RIP receptor-BE are quantified by densitometry using ImageJ, and the fraction of cleaved BE relative to total (cleaved + full-length) BE is calculated.
- Target cells treated with LDP-BEs are plated on the wells.
- CellTiter-Glo reagent is added to each well in the dark.
- Cells are incubated for 10 min at room temperature and solution is transferred into black 96-well flat bottom plates. The luminescence is measured.
- the percentage of viable cells in LDP -BE treated wells is calculated by normalizing the luminescence reading from each treatment well to the luminescence of PBS treated negative control cells.
- Target cells transduced with LDP-BEs are lysed and genomic DNA is harvested for next generation sequencing to quantify gene editing frequency 1 week after transduction.
- Example 5 delivering the lipid delivery particles to the target cell in vivo
- P0 ventricle injections are performed as described in Levy et al., 2020.
- the LDP -BE injection solution is loaded via front filling using the included Drummond plungers.
- P0 pups are anaesthetized until they are immobile and unresponsive to a toe pinch. Then, the LDP -BE injection mix is injected freehand into each ventricle.
- Mouse subre tinal injection Mice are anesthetized by intraperitoneal injection. Subretinal injections are performed under an ophthalmic surgical microscope. An incision is made through the cornea adjacent to the limbus at the nasal side. Each mouse is injected with LDP-BE mix in the eye. After injections, pupils are hydrated for recovery.
- Example 6 assessing the efficiency of payload delivery in vivo
- Tissue are fixed in 4% PFA overnight at 4°C. Paraffin block is prepared, and followed by hematoxylin and eosin staining for histopathological examination.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Biophysics (AREA)
- Virology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Zoology (AREA)
- Physics & Mathematics (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Animal Behavior & Ethology (AREA)
- Optics & Photonics (AREA)
- Pharmacology & Pharmacy (AREA)
- Nanotechnology (AREA)
- Epidemiology (AREA)
- Public Health (AREA)
- Plant Pathology (AREA)
- Microbiology (AREA)
- Gastroenterology & Hepatology (AREA)
- Veterinary Medicine (AREA)
- Medicinal Preparation (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
The present disclosure relates to lipid delivery particles for delivery of payloads across cell membrane into the target cell. The present disclosure relates to lipid delivery particles comprising a lipid membrane on the external side and a chimeric protein in the core comprising a transmembrane domain, a heterologous payload, and a cleavable linker cleavable by protease expressed in the target cells. The systems and methods described herein provide for: the ability to produce the lipid delivery particles and the ability to delivery payloads such as proteins and small molecules into the target cells.
Description
COMPOSITIONS OF LIPID DELIVERY PARTICLES AND METHOD OF USE
THEREOF
CROSS-REFERENCE
[0001] This application claims the benefit of U.S. Provisional Application No. 63/471,691, filed June 7, 2023, which application is incorporated herein by reference in its entirety.
BACKGROUND
[0002] Delivery of therapeutic payloads into the cells has been a significant challenge in drug development because payloads, such as proteins, cannot freely diffuse across the cell membrane. Although viral based constructs have been developed to deliver therapeutic payloads, these constructs often have low efficacy and/or create considerable side effects. There is a need for improved delivery of payloads into cells.
SUMMARY
[0003] Described herein is a lipid delivery particle, comprising: a lipid membrane on the external side; and a chimeric protein in the core of the lipid delivery particle comprising (i) a plasma membrane recruitment element; (ii) a heterologous payload; (iii) one or more cleavable linkers; and (iv) a protease, wherein the one or more cleavable linkers is cleavable by the protease, wherein the one or more cleavable linkers is positioned such that cleavage by the protease releases the heterologous payload from the chimeric protein.
[0004] In some embodiments, the protease is a viral protease. In some embodiments, the viral protease is selected from Table 7. In some embodiments, the lipid delivery particle further comprises an envelope protein. In some embodiments, the envelope protein has a viral origin. In some embodiments, the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein has a human origin. In some embodiments, the envelope protein is selected from Table 2. In some embodiments, the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 49-82. In some embodiments, the plasma membrane recruitment element comprises a Gag protein. In some embodiments, the Gag protein comprises a retroviral Gag protein. In some embodiments, the Gag protein comprises a Gag protein from human endogenous retrovirus. In some embodiments, the Gag protein comprises an endogenous Gag protein from a
mammal. In some embodiments, the plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain. In some embodiments, the Pleckstrin Homology domain is coupled to the heterologous payload. In some embodiments, the Pleckstrin Homology domain is reversibly coupled to the heterologous payload. In some embodiments, the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by one of the one or more cleavable linker. In some embodiments, the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain. In some embodiments, the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain. In some embodiments, the plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof. In some embodiments, the nuclear export signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 353-453. In some embodiments, the nuclear export signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 353-453. In some embodiments, the nuclear localization signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the nuclear localization signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the one or more cleavable linkers comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 126-171. In some embodiments, the one or more cleavable linkers comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171. In some embodiments, the cleavage by the protease is inhibitable by a reversible protease inhibitor. In some embodiments, the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease. In some embodiments, the protease inhibitor is selected from the group consisting of: Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
[0005] Described herein is a lipid delivery particle comprising: a lipid membrane on the external side; a first chimeric protein in the lipid delivery particle comprising (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) a cleavable linker; and a second chimeric protein in the lipid delivery particle comprising (i) a second plasma membrane
recruitment element and (ii) a protease, wherein the cleavable linker is cleavable by the protease, wherein the cleavable linker is positioned such that cleavage by the protease releases the heterologous payload from the first chimeric protein, wherein the protease comprises an amino acid sequence of at least 80%, 85%, 90%, 95%, or 99% sequence identity to any one of SEQ ID NOs: 106-110.
[0006] In some embodiments, the cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to any one of SEQ ID NOs: 126-128 or SEQ ID NOs: 134-138. In some embodiments, the cleavable linker comprises an amino acid sequence of any one of SEQ ID NOs: 126-128 or SEQ ID NOs: 134-138.
[0007] Described herein is a lipid delivery particle, comprising: a lipid membrane on the external side; a first chimeric protein in the lipid delivery particle comprising (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) a cleavable linker; and a second chimeric protein in the lipid delivery particle comprising (i) a second plasma membrane recruitment element and (ii) a protease, wherein the second chimeric protein lacks a viral polymerase, wherein the cleavable linker is cleavable by the protease, wherein the cleavable linkers is positioned such that cleavage by the protease releases the heterologous payload from the first chimeric protein.
[0008] In some embodiments, the protease comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95% or 99% sequence identity to an amino acid sequence set forth in any one of SEQ ID NOs: 105-125. In some embodiments, the protease comprises an amino acid sequence set forth in any one of SEQ ID NOs: 105-125.
[0009] Described herein is a lipid delivery particle, comprising: a lipid membrane on the external side; a first chimeric protein in the lipid delivery particle comprising (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) a cleavable linker; and a second chimeric protein in the lipid delivery particle comprising (i) a second plasma membrane recruitment element and (ii) a first protease.
[0010] In some embodiments, the lipid delivery particle further comprises a second protease. In some embodiments, the first chimeric protein comprises the second protease. In some embodiments, the first chimeric protein comprises from N-terminus to C-terminus the first plasma membrane recruitment element, the second protease, and the heterologous payload. In some embodiments, the first chimeric protein comprises from N-terminus to C-terminus the first plasma membrane recruitment element, the heterologous payload, and the second protease. In some embodiments, the second chimeric protein comprises the second protease. In some embodiments, the second chimeric protein comprises from N-terminus to C-terminus the second plasma recruitment element, the first protease, and the second protease. In some embodiments,
the second chimeric protein comprises from N-terminus to C-terminus the second plasma recruitment element, the second protease, and the first protease. In some embodiments, the lipid delivery particle further comprises a third chimeric protein in the lipid delivery particle, wherein the third chimeric protein comprising (i) a third plasma membrane recruitment element, and (ii) the second protease. In some embodiments, the third chimeric protein forms a dimer with the first chimeric protein or the second chimeric protein. In some embodiments, the third chimeric protein forms the dimer with the first chimeric protein or the second chimeric protein via a leucine zipper pair, an inducible heteromerization domain, an cohesin-dockerin interaction, a spycatcher-spytag covalent interaction, or an electrostatic interaction between positively and negatively charged amino acids. In some embodiments, the cleavable linker is cleavable by the first protease and the second protease. In some embodiments, the cleavable linker is cleavable by the first protease. In some embodiments, the cleavable linker is cleavable by the second protease. In some embodiments, the cleavable linker is positioned such that cleavage by the protease releases the heterologous payload from the first chimeric protein. In some embodiments, the first protease and the second protease are the same. In some embodiments, the first protease and the second protease are different. In some embodiments, the first protease comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95% or 99% sequence identity to an amino acid sequence set forth in any one of SEQ ID NOs: 105-125. In some embodiments, the first protease comprises an amino acid sequence set forth in any one of SEQ ID NOs: 105-125. In some embodiments, the first protease is a murine leukemia virus (MLV) protease. In some embodiments, the first protease is a human immunodeficiency virus (HIV) protease. In some embodiments, the second protease comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95% or 99% sequence identity to an amino acid sequence set forth in any one of SEQ ID NOs: 105-125. In some embodiments, the second protease comprises an amino acid sequence set forth in any one of SEQ ID NOs: 105-125. In some embodiments, the second protease is a murine leukemia virus (MLV) protease. In some embodiments, the second protease is a human immunodeficiency virus (HIV) protease. In some embodiments, the cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to set forth in any one of SEQ ID NOs: 126-171. In some embodiments, the cleavable linker comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171. In some embodiments, the cleavage by the protease releasing the heterologous payload from the chimeric protein is inhibited by a reversible protease inhibitor. In some embodiments, the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease. In some embodiments, the protease inhibitor is selected from the group consisting of: Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23,
Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof. In some embodiments, the reversible protease inhibitor delays the release of payload from the chimeric protein until the reversible protease inhibitor is removed. In some embodiments, the second chimeric protein further comprises a second cleavable linker. In some embodiments, the second cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 126-171. In some embodiments, the second cleavable linker comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171. In some embodiments, the lipid delivery particle further comprises an envelope protein. In some embodiments, the envelope protein has a viral origin. In some embodiments, the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein has a human origin. In some embodiments, the envelope protein is selected from Table 2. In some embodiments, the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 49-82. In some embodiments, the first plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain. In some embodiments, the Pleckstrin Homology domain is coupled to the heterologous payload. In some embodiments, the Pleckstrin Homology domain is reversibly coupled to the heterologous payload. In some embodiments, the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker. In some embodiments, the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain. In some embodiments, the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain. In some embodiments, the first plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the first plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the first plasma membrane recruitment element comprises a Gag protein. In some embodiments, the Gag protein comprises a retroviral Gag protein. In some embodiments, the Gag protein comprises a Gag protein from human endogenous retrovirus. In some embodiments, the Gag protein comprises an endogenous Gag protein from a mammal. In some embodiments, the second plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain. In some embodiments, the Pleckstrin
Homology domain is coupled to the heterologous payload. In some embodiments, the Pleckstrin Homology domain is reversibly coupled to the heterologous payload. In some embodiments, the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker. In some embodiments, the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain. In some embodiments, the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain. In some embodiments, the second plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the second plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the second plasma membrane recruitment element comprises a Gag protein. In some embodiments, the Gag protein comprises a retroviral Gag protein. In some embodiments, the Gag protein comprises a Gag protein from human endogenous retrovirus. In some embodiments, the Gag protein comprises an endogenous Gag protein from a mammal. In some embodiments, the third plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain. In some embodiments, the Pleckstrin Homology domain is coupled to the heterologous payload. In some embodiments, the Pleckstrin Homology domain is reversibly coupled to the heterologous payload. In some embodiments, the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker. In some embodiments, the heterologous payload is coupled to a C- terminus of the Pleckstrin Homology domain. In some embodiments, the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain. In some embodiments, the third plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1- 48. In some embodiments, the third plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the third plasma membrane recruitment element comprises a Gag protein. In some embodiments, the Gag protein comprises a retroviral Gag protein. In some embodiments, the Gag protein comprises a Gag protein from human endogenous retrovirus. In some embodiments, the Gag protein comprises an endogenous Gag protein from a mammal. In some embodiments, the first plasma membrane recruitment element is the same as the second plasma membrane recruitment element. In some embodiments, the first chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof. In some embodiments, the second chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof. In some embodiments, the nuclear export signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ
ID NOs: 352-453. In some embodiments, the nuclear export signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 352-453. In some embodiments, the nuclear localization signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the nuclear localization signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the heterologous payload is a therapeutic agent. In some embodiments, the therapeutic agent is covalently linked to the plasma membrane recruitment element via the cleavable linker. In some embodiments, the therapeutic agent is coupled to the cleavable linker or the plasma recruitment element by conjugation. In some embodiments, the therapeutic agent is a gene-editing agent. In some embodiments, the geneediting agent comprises a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; a nucleic acid encoding a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; or a ribonucleoprotein complex (RNP) comprising a CRISPR- based genome editing or modulating protein. In some embodiments, the therapeutic agent is a nucleic-acid based agent, a small molecule, or a recombinant protein.
[0011] Described herein is a system comprising: (a) the lipid delivery particle disclosed herein; and (b) a reversible protease inhibitor, wherein the cleavage by the protease is inhibitable by the reversible protease inhibitor, wherein the release of payload is delayed until the reversible protease inhibitor is removed from the system.
[0012] In some embodiments, the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease. In some embodiments, the protease inhibitor is selected from the group consisting of: Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
[0013] Described herein is a chimeric protein for delivering a heterologous payload to a target cell, comprising: (i) a plasma membrane recruitment element; (ii) a heterologous payload; (iii) one or more protease cleavable linkers; and (iv) a first protease, wherein the one or more cleavable linkers are cleavable by the protease, wherein the one or more cleavable linkers are positioned such that cleavage by the protease releases the heterologous payload from the chimeric protein construct.
[0014] In some embodiments, the chimeric protein further comprises a second protease. In some embodiments, the second protease is a viral protease. In some embodiments, the first protease is a viral protease. In some embodiments, the viral protease is selected from Table 7. In some
embodiments, the plasma membrane recruitment element comprises a Gag protein. In some embodiments, the Gag protein comprises a retroviral Gag protein. In some embodiments, the Gag protein comprises a Gag protein from human endogenous retrovirus. In some embodiments, the Gag protein comprises an endogenous Gag protein from a mammal. In some embodiments, the plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain. In some embodiments, the Pleckstrin Homology domain is coupled to the heterologous payload. In some embodiments, the Pleckstrin Homology domain is reversibly coupled to the heterologous payload. In some embodiments, the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker. In some embodiments, the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain. In some embodiments, the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain. In some embodiments, the plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48. In some embodiments, the chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof. In some embodiments, the nuclear export signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 352-453. In some embodiments, the nuclear export signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 352-453. In some embodiments, the nuclear localization signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the nuclear localization signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 454-559. In some embodiments, the cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 126- 138. In some embodiments, the cleavable linker comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-138. In some embodiments, the heterologous payload is a therapeutic agent. In some embodiments, the therapeutic agent is a gene-editing reagent. In some embodiments, the gene-editing reagent comprises a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; a nucleic acid encoding a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; or a ribonucleoprotein complex (RNP) comprising a CRISPR- based genome editing or modulating protein. In some embodiments, the therapeutic agent is a nucleic-acid based agent, a small molecule, or a recombinant protein.
[0015] Described herein is a nucleic acid encoding the chimeric protein disclosed herein.
[0016] Described herein is a lipid delivery particle, comprising: (i) a lipid membrane on the external side; and (ii) the chimeric protein disclosed herein in the lipid delivery particle.
[0017] In some embodiments, the lipid delivery particle further comprises an envelope protein. In some embodiments, the envelope protein has a viral origin. In some embodiments, the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 83-104. In some embodiments, the envelope protein has a human origin. In some embodiments, the envelope protein is selected from Table 2. In some embodiments, the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some embodiments, the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 49-82.
[0018] Described herein is a method of delivering a heterologous payload to a target cell, the method comprising contacting the target cell with the lipid delivery particle disclosed herein. [0019] Described herein is a method of producing the lipid delivery particle disclosed herein, the method comprising providing a producer cell comprising a nucleic acid molecule encoding the chimeric protein, and using the producer cell to produce the lipid delivery particle disclosed herein.
[0020] Described herein is a method of producing the lipid delivery particle disclosed herein, the method comprising providing a producer cell comprising a first nucleic acid molecule encoding the first chimeric protein and, and using the producer cell to produce the lipid delivery particle disclosed herein.
INCORPORATION BY REFERENCE
[0021] All publications, patents, and patent applications mentioned in this specification are herein incorporated by reference to the same extent as if each individual publication, patent, or patent application was specifically and individually indicated to be incorporated by reference.
BRIEF DESCRIPTION OF THE DRAWINGS
[0022] The novel features of the invention are set forth with particularity in the appended claims. A better understanding of the features and advantages of the present invention will be obtained by reference to the following detailed description that sets forth illustrative embodiments, in which the principles of the invention are utilized, and the accompanying drawings of which:
[0023] FIG.1A and IB illustrate the structure of a lipid delivery particle comprising chimeric proteins.
[0024] FIG. 2A and 2B illustrate the structures of chimeric proteins.
[0025] FIGs. 3 A-3E illustrate the exemplary structures of chimeric proteins in a lipid delivery particle.
DETAILED DESCRIPTION
[0026] Provided herein, in certain embodiments, are lipid delivery particles (LDPs) capable of delivering a heterologous payload (e.g. a protein, a gene-editing agent, a small molecule) to a target cells. In some cases, the lipid delivery particle comprises a lipid membrane on the external side and a chimeric protein in the core, as shown in FIG. 1. In some cases, the chimeric protein comprises (i) a plasma membrane recruitment element; (ii) a heterologous payload; (iii) one or more cleavable linkers; and (iv) a protease. In some cases, the one or more cleavable linkers is cleavable by the protease. In some cases, the cleavable linker is positioned such that cleavage by the protease releases the payload from the chimeric protein. In other cases, the lipid delivery particle comprises a lipid membrane on the external side, a first chimeric protein in the lipid delivery particle, and a second chimeric in the lipid delivery particle. In some cases, the first chimeric protein comprises (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) one or more cleavable linkers. In some cases, the second chimeric protein comprises (i) a second plasma membrane recruitment element; and (ii) a protease. In some cases, the second chimeric protein further comprises a second cleavable linker. In some cases, the one or more cleavable linkers is cleavable by the protease. In some cases, the cleavable linker is positioned such that cleavage by the protease releases the payload from the chimeric protein. In some cases, the cleavage by the protease is delayed by adding a reversible protease inhibitor and then removing the protease inhibitor. Also provided herein are systems comprising the lipid delivery particles disclosed herein and a reversible protease inhibitor. In some cases, the release of payload is delayed until the reversible protease inhibitor is removed from the system.
[0027] Also provided herein are chimeric proteins for delivering a heterologous payload to a target cells. In some cases, the chimeric protein comprises (i) a plasma membrane recruitment element; (ii) the heterologous payload; (iii) one or more cleavable linkers; and (iv) a protease. In some cases, the chimeric protein further comprises a nuclear localization signal, a nuclear exporting signal, or a combination thereof. In some cases, the one or more cleavable linkers is cleavable by the protease. In some cases, the cleavable linker is positioned such that cleavage by the protease releases the payload from the chimeric protein. Also described herein are nucleic acid molecules encoding the chimeric proteins. Also described herein are cells (e.g., producer
cells) comprising nucleic acid molecules encoding the chimeric proteins and expressing the chimeric proteins.
[0028] Also provided herein are methods for making the LPD comprising providing a producer cell comprising a nucleic acid molecule encoding a chimeric protein comprising (a) a plasma membrane recruitment element; (b) a heterologous payload, (iii) one or more cleavable linkers; and (iv) a protease. Also provided herein are methods for making the LPD comprising providing a producer cell comprising a first nucleic acid molecule encoding a first chimeric protein comprising (a) a plasma membrane recruitment element; (b) a heterologous payload, and (c) one or more cleavable linkers; and a second nucleic acid molecule encoding a second chimeric protein comprising (a) a second plasma membrane recruitment element and (b) a protease. In some cases, the second chimeric protein further comprises a second cleavable linker. Also provided herein are methods of purifying the LPD comprising the chimeric proteins and methods of administering LPD comprising the chimeric proteins to a target cell. In some cases, the cleavage by the protease is delayed by adding a reversible protease inhibitor to the producer cell and then removing the protease inhibitor before or during purifying the LPD.
[0029] A chimeric protein disclosed herein can refer to a protein comprised of a first amino acid sequence derived from a first source, fused to a second amino acid sequence derived from a second source, wherein the first and second source are not the same. A first source and a second source that are not the same can include two different biological entities, or two different proteins from the same biological entity, or a biological entity and a non-biological entity. A chimeric protein can include for example, a protein derived from at least 2 different biological sources. A biological source can include any non-synthetically produced nucleic acid or amino acid sequence (e.g. a genomic or cDNA sequence, a plasmid or viral vector, a native virion or a mutant or analog, as further described herein, of any of the above). A synthetic source can include a protein or nucleic acid sequence produced chemically and not by a biological system (e.g. solid phase synthesis of amino acid sequences). A chimeric protein can also include a protein derived from at least 2 different synthetic sources or a protein derived from at least one biological source and at least one synthetic source.
LIPID DELIVERY PARTICLE MEMBRANE
[0030] In some aspects, the lipid delivery particle provided herein comprises a membrane. The membrane of the lipid delivery particle can comprise a lipid layer, such as a single layer or a lipid bilayer. In some cases, the membrane of the lipid delivery particle is a lipid bilayer. In some cases, the membrane of the lipid delivery particle is from plasma membrane, endoplasmic reticulum, or a combination thereof. In some cases, the membrane of the lipid delivery particle is from Golgi complex, ER Golgi intermediate compartment, or nuclear envelope. In some cases,
the membrane of the lipid delivery particle is from plasma membrane. In some cases, the membrane of the lipid delivery particle is a phospholipid bilayer.
ENVELOPE PROTEIN
[0031] In some aspects, the lipid delivery particle provided herein comprises an envelope protein. The envelope protein can be associated with the outside boundary or the surface of the lipid delivery particle, for example, the membrane or envelope of the lipid delivery particle. [0032] The membrane of the lipid delivery particle can comprise a lipid layer, such as a single layer or a lipid bilayer. In some cases, the membrane of the lipid delivery particle is from plasma membrane, endoplasmic reticulum, or a combination thereof. In some cases, the membrane of the lipid delivery particle is from Golgi complex, ER Golgi intermediate compartment, or nuclear envelope. In some cases, the membrane of the lipid delivery particle is from plasma membrane. In some cases, the membrane of the lipid delivery particle is a phospholipid bilayer.
[0033] The envelope protein can be associated with the membrane of the lipid delivery particle in various manners. For example, the envelope protein can be anchored or attached to the external membrane of the particle or anchored or attached to the internal membrane of the particle. The envelope protein can be embedded or inserted in the membrane, spanning through the membrane, with certain portions located at the outside of the membrane, or certain portions extending to the inside of the particle, or both. The envelope protein within the lipid delivery particle described herein can be overexpressed from an exogenous source, such as plasmids or stably integrated transgenes, in the production cells.
[0034] The envelope protein can play a role in the delivery of the lipid delivery particle to a target cell and release of the components of the lipid delivery particle within the target cell. The envelope protein can contact with the surface of a target cell and participate in the fusion of the lipid delivery particle and the membrane of the target cell. The envelope protein can participate in the fusion of the lipid delivery particle with the membrane of the target cell via any appropriate mechanism, such as those described in White et al. Crit Rev Biochem Mol Biol. 2008; 43(3): 189-219. One example of the fusion mechanisms is unifying Trimer-of-Hairpins Fusion Mechanism. Membrane fusion can occur after allosteric priming by binding to a target receptor. In some cases, membrane fusion occurs after proteolysis. In some cases, membrane fusion occurs after isomerization of disulfide bridges. In some cases, membrane fusion occurs by internalization and then priming of fusion via (i) cathepsin-mediated proteolysis, or (ii) low pH/acidification. The cathepsin-mediated proteolysis can be pH dependent or pH independent. Other fusion triggering mechanisms can include low PH, binding to target cell receptors, and a receptor followed by low pH. The envelope protein can also play a role in the formation of the lipid delivery particle. The envelope protein can interact with another component within the lipid
delivery particle and participate in the assembly of the lipid delivery particle, for example, in a producer cell. The envelope protein can make contact with another envelope protein and form an oligomer embedded within the membrane. The envelope protein can be a glycoprotein, for example, a transmembrane glycoprotein. In some cases, envelope protein comprises multiple membrane-spanning regions. These multiple membrane-spanning regions can oligomerize and form channels in the membrane.
[0035] In some cases, the envelope protein is fused with a targeting moiety. In some cases, the targeting moiety recognizes a specific molecule (e.g., antigen, receptor, or other membrane protein) on the surface of a target cell to allow targeted cell entry with more specificity. In some cases, the targeting moiety is specific for a certain cell type or is specific for a certain target cell. The targeting moiety can be fused to the envelope protein at a position that is located at an outside of the lipid delivery particle. For example, the targeting moiety includes scFvs, antibody variable regions, nanobodies, T-cell receptor variable regions, other antigen-binding fragments or their mimetics, such as DARPins. In some cases, the targeting moiety is a protein ligand from the human ligandome. The targeting moiety can be a natural peptide or a synthetic peptide. In some cases, the targeting moiety is not fused with the envelope protein and is attached to the membrane of the lipid delivery particle from the outside, for example, via a transmembrane domain.
[0036] A targeting moiety can include, e.g., an antibody or an antigen-binding fragment thereof (e.g., Fab, Fab', F(ab')2, Fv fragments, scFv antibody fragments, disulfide-linked Fvs (sdFv), a Fd fragment consisting of the VH and CHI domains, linear antibodies, single domain antibodies such as sdAb (either VL or VH), nanobodies, or camelid VHH domains), an antigen-binding fibronectin type III (Fn3) scaffold such as a fibronectin polypeptide minibody, a ligand, a cytokine, a chemokine, or a T cell receptor (TCRs). Membrane-fusion proteins can be re-targeted by non-covalently conjugating a targeting moiety to the membrane-fusion protein or targeting protein (e.g. the hemagglutinin protein). For example, the membrane-fusion protein can be engineered to bind the Fc region of an antibody that targets an antigen on a target cell, redirecting the membrane fusion activity towards cells that display the antibody’s target.
[0037] In some cases, the targeting moiety linked to the membrane-fusion protein binds a cell surface marker on the target cell, e.g., a protein, glycoprotein, receptor, cell surface ligand, agonist, lipid, sugar, class I transmembrane protein, class II transmembrane protein, or class III transmembrane protein.
[0038] In some cases, the lipid delivery particles disclosed herein display targeting moieties that are not conjugated to the membrane-fusion protein or other proteins in order to redirect the fusion
activity of the lipid delivery particle towards a cell that is bound by the targeting moiety, or to affect tropism of the lipid delivery particle toward the target cell.
Envelope protein of viral origin
[0039] In some cases, an envelope protein has a viral origin. For example, a suitable envelope protein is from a DNA virus, an RNA virus, or a retrovirus. The envelope protein can be envelope protein from Herpesviruses, Avian sarcoma leukosis virus, Poxviruses, Hepadnaviruses, Asfarviridae, Flaviviruses, Alphaviruses, Togaviruses, Coronaviruses, Hepatitis D, Orthomyxoviruses, Rhabdovirus, Bunyaviruses, Filoviruses, Oncoretroviruses, lentiviruses, Spumaviruses. In some cases, envelope protein can be envelope protein from lentiviruses, for example, human immunodeficiency virus (HIV), simian immunodeficiency virus (SIV), feline immunodeficiency virus (FIV) and equine infectious anemia virus (EIAV). In some cases, an envelope protein is a fusion of two different envelope proteins, wherein each comes from a different virus. Additional suitable envelope proteins that are from viral origins and their functions are described in White JM et al.. Crit Rev Biochem Mol Biol. 2008 May- Jun;43(3): 189-219.
[0040] In some cases, the envelope protein is a vesicular stomatitis virus glycoprotein (VSVG) or a biologically active mutant thereof. A “biologically active mutant” disclosed herein in connection with a reference protein can refer to a mutant of the reference protein that remains displaying one or more biological activities that are of same nature as the reference protein, which are relevant to the context in which the reference protein is used in the lipid delivery particle disclosed herein, while the level of the one or more biological activities of the biologically active mutant can be either similar as or different than the reference protein. For instance, the biologically active mutant of a VSVG in the context of an envelope protein remains displaying the biological activities of an envelope protein, e.g., mediating membrane fusion, tropism of the lipid delivery particle toward a target cell, or both. Unless otherwise noted, a mutant as described in the present disclosure is equivalent to a biologically active mutant. In some cases, the envelope protein is a Human immunodeficiency virus GP160 or a biologically active mutant thereof. In some cases, the envelope protein is a Baboon Endogenous Retrovirus (BaEVTR) glycoprotein or a biologically active mutant thereof. In some cases, the envelope protein is a modified Baboon Endogenous Retrovirus (BaEVTRless) glycoprotein or a biologically active mutant thereof. In some cases, the envelope protein is the fusion protein of Vesicular stomatitis Indiana virus and Rabies virus Glycoproteins (FuG-E) or a biologically active mutant thereof. In some cases, the envelope protein pantropic murine leukemia virus envelope protein (MLV) or a biologically active mutant thereof. In some cases, the envelope protein is a modified Fusion protein of Vesicular stomatitis Indiana virus and Rabies virus
Glycoproteins (FuG-E P440E) or a biologically active mutant thereof. In some cases, the envelope protein is an ecotropic Murine Leukemia Virus envelope protein (MLV ENV ecotropic) or a biologically active mutant thereof. In some cases, the envelope protein is an amphotrophic Murine Leukemia Virus envelope protein (MLV ENV amphotropic) or a biologically active mutant thereof. In some cases, the envelope protein is a Moloney murine leukemia virus envelope protein (MMLV) or a biologically active mutant thereof. In some cases, the envelope protein is a Moloney murine sarcoma virus envelope protein (MoMSVg) or a biologically active mutant thereof. In some cases, the envelope protein is a moloney murine leukemia virus 10A1 strain Glycoprotein (MLV 10A1) or a biologically active mutant thereof. In some cases, the envelope protein is a xenotropic murine leukemia virus envelope protein (MLV ENV xenotropic) or a biologically active mutant thereof. In some cases, the envelope protein is a xenotropic murine leukemia virus-related envelope protein (XMRV) or a biologically active mutant thereof. In some cases, the envelope protein is a Baculovirus envelope glycoprotein (GP64) or a biologically active mutant thereof. In some cases, the envelope protein is an endogenous feline virus envelope protein (RD114 ENV) or a biologically active mutant thereof. In some cases, the envelope protein is a mammalian endogenous retrovirus protein, or a biologically active mutant thereof. The mammalian endogenous retrovirus protein can be a koala retrovirus protein (KoRV) or a Jaagsiekte sheep retrovirus protein (enJSRV), or a biologically active mutant thereof. [0041] In some cases, the envelope protein is a simian endogenous type D retrovirus protein (RD-114) or a biologically active mutant thereof. In some cases, the envelope protein is a gibbon ape leukemia virus envelope protein (GALV) or a biologically active mutant thereof. In some cases, the envelope protein is a feline leukemia virus envelope protein (FLV) or a biologically active mutant thereof. In some cases, the envelope protein is a mouse mammary tumor virus envelope protein (MMTV) or a biologically active mutant thereof. In some cases, the envelope protein is an avian leukosis virus envelope protein or a biologically active mutant thereof. In some cases, the envelope protein is a rous sarcoma virus envelope protein or a biologically active mutant thereof.
[0042] In some cases, the envelope protein can direct the lipid delivery particles to fuse with a certain type of target cells rather than other cells. For example, based on the specific type of envelope protein associated with the membrane of the lipid delivery particle, the lipid delivery particle can preferentially target different cell types (z.e., tropisms of the lipid delivery particles), such as liver cells, ocular cells, nerve cells, lung cells, immune cells, muscle cells, and any other cell types of interest. For example, to fuse with a target liver cells, the envelope protein can be a glycoprotein from human hepatitis viruses or a biologically active mutant thereof, e.g., Hepatitis B virus (HBV) or hepatitis C virus (HCV), VSV-G glycoprotein or a biologically active mutant
thereof, a Marburg virus glycoprotein or a biologically active mutant thereof, an Ebola virus glycoprotein or a biologically active mutant thereof. To fuse with a target muscle cell, for example, a skeletal muscle cell, the envelope protein can be a Ross River virus glycoprotein or a biologically active mutant thereof, or a VSV-G or a biologically active mutant thereof. To fuse with a target ocular cell, for example, a photoreceptor cell or a retinal cell, the envelope protein can be an Ebola virus glycoprotein or a biologically active mutant thereof, a Marburg virus glycoprotein or a biologically active mutant thereof, or a VSV-G or a biologically active mutant thereof. To fuse with a target immune cell, for example, CD8+ T cell, an HTLV-1 glycoprotein or a biologically active mutant thereof, or a VSV- G glycoprotein or a biologically active mutant thereof. To fuse with a target immune cell, for example, CD4+ T cell, the envelope protein can be a HIV-1 envelope or a biologically active mutant thereof, a HTLV-1 glycoprotein or a biologically active mutant thereof, or a VSV-G glycoprotein or a biologically active mutant thereof. To fuse with a target lung cells, the envelope protein can be a respiratory syncytial virus glycoprotein or a biologically active mutant thereof, or a SARS-CoV glycoprotein or a biologically active mutant thereof. To fuse with a target nerve cell, such as a cell from the central nervous system cell (e.g., neurons, glial cells including oligodendrocytes, astrocytes and microglia), the envelope protein can be a rabies glycoprotein or a biologically active mutant thereof, a Mokola virus glycoprotein or a biologically active mutant thereof, a Semliki Forest virus glycoprotein or a biologically active mutant thereof, a Venezuelan equine encephalitis virus glycoprotein or a biologically active mutant thereof, or a VSV-G or a biologically active mutant thereof. To fuse with a target sensory cell, such as an auditory cell, including hair cells, cochlear cells, etc., the envelope protein can be an Ebola virus glycoprotein or a biologically active mutant thereof, a Marburg virus glycoprotein or a biologically active mutant thereof, or a VSV-G or a biologically active mutant thereof.
[0043] In some cases, the envelope protein comprises the sequences set forth in Table 1. In some cases, the envelope protein comprises the sequences set forth in Table 1 with at least one amino acid substitution, deletion, or insertion. For instance, N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein. In some cases, the envelope protein comprises the sequences set forth in Table 1 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
[0044] In some cases, the envelope protein comprises one or more of the sequences set forth in Table 1 with at least one amino acid substitution, deletion, or insertion. For instance, N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein. In some cases, the envelope protein comprises
one or more of the sequences set forth in Table 1 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
[0045] In some cases, the envelope protein comprises any one of the sequences set forth in Table 1 with at least one amino acid substitution, deletion, or insertion. For instance, N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein. In some cases, the envelope protein comprises any one of the sequences set forth in Table 1 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
[0046] In some cases, the envelope protein comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in Table 1. In some cases, the envelope protein comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104 In some cases, the envelope protein comprises an amino acid sequence that has at least about 50% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 60% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 70% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 75% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 80% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 85% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 90% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 95% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104 In some cases, the envelope protein comprises an amino acid sequence that has at least about 96% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 97% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
In some cases, the envelope protein comprises an amino acid sequence that has at least about 98% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104. In some cases, the envelope protein comprises an amino acid sequence that has at least about 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
Table 1. Exemplary envelope proteins from virus origin






Envelope protein of human origin
[0047] In some aspects, the envelope protein in the lipid delivery particle described herein has a human origin, e.g., has significant sequence similarity to a human wild-type protein, such as at least 90%, at least 95%, at least 98%, or at least 99%. Using an envelope protein of a human origin can have benefits such as providing a minimized immunogenicity and better tolerance in a human subject receiving the lipid delivery particles. The lipid delivery particle comprising an envelope protein of a human origin can comprise another component that is from human origin or from non-human origin (e.g., a payload or a plasma membrane recruitment element). An envelope protein that is from human origin can include, example, envelope proteins or glycoproteins of human endogenous retroviruses (HERVs), other human endogenous envelope proteins, or other human endogenous proteins that serve a similar function of recognizing and/or fusing with membrane of a target cell (e.g., clathrin adaptor protein complex- 1, CHMP4C, Proteolipid protein 1, TSAP6, immunoglobulin variable domains, or a biologically active mutant thereof).
[0048] In some cases, the envelope protein is a HERV envelope protein such as any one of those listed in Table 2. In some cases, the envelope protein is a hENVHl or a biologically active mutant thereof. In some cases, the envelope protein is a hENVH2 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVH3 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVKl or a biologically active mutant thereof. In some cases, the envelope protein is a hENVK2 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVK3 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVK4 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVK5 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVK6 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVT or a biologically active mutant thereof. In some cases, the envelope protein is a hENVW or a biologically active mutant thereof. In some cases, the envelope protein is a hENVFRD or a biologically active mutant thereof. In some cases, the envelope protein is a hENVR or a biologically active mutant thereof. In some cases, the envelope protein is a hENVR(b) or a biologically active mutant thereof. In some cases, the envelope protein is a
hENVR(c)2 or a biologically active mutant thereof. In some cases, the envelope protein is a hENVR(c)l or a biologically active mutant thereof. In some cases, the envelope protein is a hENVKcon or a biologically active mutant thereof. In some cases, the envelope protein is a truncated HERV protein.
Table 2. Exemplary HERV envelope proteins
[0049] In some cases, the envelope protein comprises the sequences set forth in Table 3. In some cases, the envelope protein comprises the sequences set forth in Table 3 with at least one amino acid substitution, deletion, or insertion. For example, for those amino acid sequences start with a N-terminal methionine, the N-terminal methionine can be absent. In some cases, the envelope protein comprises the sequences set forth in Table 3 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
[0050] In some cases, the envelope protein comprises one or more of the sequences set forth in Table 3 with at least one amino acid substitution, deletion, or insertion. For instance, N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein. In some cases, the envelope protein comprises one or more of the sequences set forth in Table 3 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
[0051] In some cases, the envelope protein comprises any one of the sequences set forth in Table 3 with at least one amino acid substitution, deletion, or insertion. For instance, N-terminal methionine can be absent from the envelope protein of the lipid delivery particle provided herein relative to the wild-type viral envelope protein. In some cases, the envelope protein comprises any one of the sequences set forth in Table 3 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
[0052] In some cases, the envelope protein comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 50% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 60% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 70% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82 In some cases, the envelope protein comprises an amino acid sequence that has at least about 75% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49- 82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 80% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 85% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 90% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 95% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 96% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82 In some cases, the envelope protein comprises an amino acid sequence that has at least about 97% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49- 82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 98% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82. In some cases, the envelope protein comprises an amino acid sequence that has at least about 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82.
Table 3. Exemplary sequences for human HERV envelope proteins










PLASMA MEMBRANE RECRUITMENT ELEMENT
[0053] In some aspects, the lipid delivery particle provided herein comprises a plasma membrane recruitment element. In some cases, the lipid delivery particle comprises at least about 1, at least about 2, at least about 3, at least about 4, at least about 5, at least about 6, at least about 7, at least about 8, at least about 9, at least about 10, or more plasma membrane recruitment elements. In some cases, the lipid delivery particle comprises at most about 1, at most about 2, at most about 3, at most about 4, at most about 5, at most about 6, at most about 7, at most about 8, at most about 9, or at most about 10 plasma membrane recruitment elements. The lipid delivery particle disclosed herein can comprise a membrane. In some cases, the membrane encapsulates a payload. In some cases, the lipid delivery particle comprises a plasma membrane recruitment element, for example, inside the cavity of the lipid delivery particle. The plasma membrane recruitment element can localize itself to the membrane of the lipid delivery particles. The plasma membrane recruitment element can be utilized to recruit a component (e.g., a payload) to the membrane of the lipid delivery particles via forming a chimeric protein of the plasma membrane recruitment element and a component to be localized to the membrane or other mechanisms of attachment. In some cases, the membrane encapsulates a protein core. In some cases, at least a portion of the plasma membrane recruitment element forms the basic structure of the lipid delivery particle, such as a portion of the protein core inside the lipid delivery particle. In some cases, at least a portion of the plasma membrane recruitment element binds to the membrane of the lipid delivery particle from the inside.
[0054] The plasma membrane recruitment element can play a role in the assembly of the lipid delivery particle, such as packing various components e.g., a payload) into the lipid delivery particles. The plasma membrane recruitment element can direct budding of the lipid delivery particles from a producer cell. In some cases, expressing plasma membrane recruitment element alone or together with an envelope protein disclosed herein in a producer cell can lead to formation of the lipid delivery particle.
[0055] In some cases, the plasma membrane recruitment element has a viral origin. For instance, the plasma membrane recruitment element comprises a retroviral gag protein, e.g., a retroviral polyprotein that comprises one or more of a matrix (MA) polypeptide, an RNA-binding phosphoprotein polypeptide, a capsid (CA) polypeptide, or a nucleocapsid (NC) polypeptide. The plasma membrane recruitment element can comprise HIV gag or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a gag from murine leukemia virus (MLV) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a gag from Moloney murine leukemia virus (MMLV) or a biologically active mutant thereof. In some cases, the plasma membrane recruitment element forms structural protein that forms the protein core of the lipid delivery particles described herein. The plasma membrane recruitment element can comprise Respiratory syncytial virus (RSV) M or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Human Papillomavirus (HPV) LI protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise HPV L2 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Hepatitis B virus (HBV) core protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Hepatitis C virus (HCV) core protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise hepatitis E virus (HeV) M protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Chikungunya virus (CHIKV) C-E3-E2-6k-El or a biologically active mutant thereof. The plasma membrane recruitment element can comprise RSV NP or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Human metapneumovirus (HMPV) M or a biologically active mutant thereof. The plasma membrane can comprise a glycoprotein from a flavivirus. The flavivirus can comprise Chikungunya virus, Zika virus, Dengue virus, or West Niles virus. The plasma membrane recruitment element can comprise Zika virus (ZIKV) C or a biologically active mutant thereof. The plasma membrane recruitment element can comprise ZIKV prM/M or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Dengaue virus (DENV) C-prM or a biologically active mutant thereof. The plasma membrane recruitment element can comprise West Nile Virus (WNV) prME protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise WNV CprME protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Filovirus VP40 or Z protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Baculovirus Pl protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Rotavirus VP7 or a biologically active mutant thereof. The plasma membrane recruitment element can comprise
Rotavirus VP2 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Rotavirus VP6 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Porcine Circovirus Type 2 (PCV2) capsid or a biologically active mutant thereof. The plasma membrane recruitment element can comprise baculovirus VP2 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise baculovirus VP5 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise baculovirus VP3 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise or baculovirus VP7 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Ebola nucleocapsid or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Parovirus VP1 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Parovirus VP2 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Newcastle disease virus (NDV) M protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Human polyomavirus 2 (JCPyV) VP1 protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise Human parainfluenza virus type 3 (HPIV3) M protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise HPIV3N protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise or Mumps virus (MuV) M proteins or a biologically active mutant thereof. The plasma membrane recruitment element can comprise SARS M protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise SARS E protein or a biologically active mutant thereof. The plasma membrane recruitment element can comprise SARS N protein or a biologically active mutant thereof.
[0056] In some cases, the plasma membrane recruitment element is a mammalian protein or part thereof. For example, the plasma membrane recruitment element can include a pleckstrin homology (PH) domain or a transmembrane domain of a mammalian protein, such as a mouse protein or a human protein. In some cases, the plasma membrane recruitment element has a human origin. Utilizing the plasma membrane recruitment element of a human origin in the lipid delivery particle can give rise to reduced immunogenicity for administration to a human subject. The plasma membrane recruitment element can include a gag from human endogenous retrovirus, such as Human Endogenous Retrovirus K (e.g., HERV-K113, HERV-K101, HERV- K102, HERV-K104, HERV-K107, HERV-K108, HERV-K109, HERV-K115, HERV- Kl lp22, and HERV-K12ql3) and Human Endogenous Retrovirus-W (HERV-W) or a biologically active mutant thereof. The plasma membrane recruitment element can include a hGAGKcon or a
biologically active mutant thereof. The plasma membrane recruitment element can include an endogenous gag of a mammal (e.g., human) from retrotransposons (e.g., Arc from vertebrate lineage of Ty3/gypsy retrotransposon), which are also ancestral to retroviruses. In some cases, the plasma membrane recruitment element comprises a portion from human Arc.
[0057] The plasma membrane recruitment element can include a pleckstrin homology (PH) domain from a mammalian protein or a biologically active mutant thereof. The plasma membrane recruitment element can include a pleckstrin homology (PH) domain from a human protein or a biologically active mutant thereof. The PH domains can play a role in protein-membrane interactions via binding to phosphatidylinositol phosphate (PIP), for example PIP2 or PIP3, or other lipids or proteins within the membrane of the lipid delivery particles. PH domains with different sequences can have varied affinities and selectivity when binding different PIPs. The plasma membrane recruitment element can include a PH domain of phospholipase C51 (e.g., human phospholipase C51) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of Aktl (e.g., human Aktl) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a mutant PH domain of human Aktl with E17K substitution or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of 3 -phosphoinositidedependent protein kinase 1 (e.g., human 3 -phosphoinositide-dependent protein kinase 1) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of Dappl (e.g., human Dappl) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of Grpl (e.g., mouse Grpl) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of human Grpl or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of OSBP (e.g., human OSBP) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of Btkl (e.g., human Btkl) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of FAPP1 (e.g., human FAPP1) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of CERT (e.g., human CERT) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of PKD (e.g., human PKD) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of PHLPP1 (e.g., human PHLPP1) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of SWAP70 (e.g., human SWAP70) or a biologically active mutant thereof. The plasma membrane recruitment element can comprise a PH domain of MAPKAP1 (e.g., human MAPKAP1) or a biologically active mutant thereof.
[0058] The plasma membrane recruitment element can also include a membrane protein (e.g., a human membrane protein), a transmembrane domain thereof, or a biologically active mutant thereof. For example, the transmembrane domain of a human protein can be a tetraspanin or a biologically active mutant thereof. In some cases, the plasma membrane recruitment element comprises a transmembrane domain of human CD9 or a biologically active mutant thereof. In some cases, the plasma membrane recruitment element comprises a transmembrane domain of human CD47 or a biologically active mutant thereof. In some cases, the plasma membrane recruitment element comprises a transmembrane domain of human CD63 or a biologically active mutant thereof. In some cases, the plasma membrane recruitment element comprises a transmembrane domain of human CD81, or a biologically active mutant thereof.
[0059] The plasma membrane recruitment element can comprise a retroviral gag or a biologically active mutant thereof. The mutant of a retroviral gag can include only a portion of the retroviral gag. The plasma membrane recruitment element can include a gag of an alpha retrovirus or a biologically active mutant thereof. The plasma membrane recruitment element can a beta retrovirus or biologically active mutant thereof. The plasma membrane recruitment element can include a gamma retrovirus or biologically active mutant thereof. The plasma membrane recruitment element can include a delta retrovirus or biologically active mutant thereof. The plasma membrane recruitment element can include or biologically active mutant thereof. The plasma membrane recruitment element can include an epsilon retrovirus or biologically active mutant thereof. The plasma membrane recruitment element can include a spumavirus or biologically active mutant thereof. The retroviral gag can include a gag of HIV (e.g., HIV-1), a gag of murine leukemia virus (MLV), a gag of Moloney murine leukemia virus (MMLV), a gag of Simian immunodeficiency virus (SIV), a gag of Rous sarcoma virus (RSV), a gag of human T- cell leukemia virus type-1 (HTLV), or a gag of bovine leukemia virus (BLV), or a biologically active mutant thereof. The plasma membrane recruitment element can include a gag of HIV (e.g., HIV-1) or a biologically active mutant thereof. The plasma membrane recruitment element can include a gag of MLV or a biologically active mutant thereof. The plasma membrane recruitment element can include a gag of RSV or a biologically active mutant thereof. The plasma membrane recruitment element can include a gag of Friend murine leukemia virus (FMLV) or biologically active mutant thereof.
[0060] In some cases, the plasma membrane recruitment element comprises one or more of the sequences set forth in Table 4 with at least one amino acid substitution, deletion, or insertion. For instance, N-terminal methionine can be absent from the plasma membrane recruitment element of the lipid delivery particle provided herein relative to the wild-type plasma membrane recruitment element. In some cases, the plasma membrane recruitment element comprises one or
more of the sequences set forth in Table 4 and a heterologous peptide sequence fused to the N- terminal or C-terminal.
[0061] In some cases, the plasma membrane recruitment element comprises any one of the sequences set forth in Table 4 with at least one amino acid substitution, deletion, or insertion. For instance, N-terminal methionine can be absent from the plasma membrane recruitment element of the lipid delivery particle provided herein relative to the wild-type plasma membrane recruitment element. In some cases, the plasma membrane recruitment element comprises any one of the sequences set forth in Table 4 and a heterologous peptide sequence fused to the N- terminal or C-terminal.
[0062] In some cases, the plasma membrane recruitment element comprises the sequences set forth in Table 4 with a further truncation on the N-terminus. For example, for those amino acid sequences start with a N-terminal methionine, the N-terminal methionine can be absent. In some cases, the plasma membrane recruitment element comprises the sequences set forth in Table 4 with a further truncation on the C-terminus. In some cases, the plasma membrane recruitment element comprises the sequences set forth in Table 4 with one amino acid substitution. In some cases, the plasma membrane recruitment element comprises the sequences set forth in Table 4 with two or more amino acid substitutions. In some cases, the plasma membrane recruitment element comprises the sequences set forth in Table 4 and a heterologous peptide sequence fused to the N-terminal or C-terminal.
[0063] In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in Table 4. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 50% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 60% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 70% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 75% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1- 48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%,
93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48 In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 80% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48 In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 85% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 90% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 95% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 96% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 97% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 98% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48. In some cases, the plasma membrane recruitment element comprises an amino acid sequence that has at least about 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
Table 4. Exemplary plasma membrane recruitment elements and their sequences





*hGAGKcon is a consensus sequence derived from ten proviral GAG sequences encoded by human genomic sequences. The GAG sequences used to derive this consensus GAG sequence are from the following HERVs: HERV-K113, HERV-K101, HERV-K102, HERV- K104, HERV-K107, HERVK108, HERV-K109, HERV-K115, HERV- Kllp22, and HERV- K12ql3.
[0064] In some cases, the lipid delivery particle disclosed herein comprises a protein core that is composed of at least a structural protein of a viral origin, for instance, a retroviral gag protein. In some of these cases, the lipid delivery particle comprises a retroviral gag-pro-pol polyprotein, e.g., a gag-pro-pol poly protein from HIV, MMLV, or FMLV, which can help assemble a protein core of the lipid delivery particle. In some of these cases, some of the gag-pro-pol polyprotein is cleaved, e.g., by pro (protease) present freely or in the gag-pro-pol polyprotein. Without wishing to be bound by any particular theory, the cleavage by pro can be inefficient, and the resultant cleavage products can include gag polyprotein, gag-pro polyprotein, free pro, and free pol (polymerase). In some cases, a retroviral gag polyprotein can be further cleaved into MA, CA, NC, and other small fragments, if any. In some other cases, the lipid delivery particle comprises a retroviral gag-pro polyprotein without the pol component, and the gag-pro polyprotein can help form a protein core of the lipid delivery particle. The gag-pro can also be cleaved by pro, in some cases, inefficiently, into separate gag and pro proteins. In some cases, there can be different plasma membrane recruitment elements in a lipid delivery particle. For instance, a gag-pro or gag-pro-pol polyprotein from one species of virus (e.g., a retrovirus, e.g., a HIV) can help assemble form a protein core of the lipid delivery particle, while a chimeric protein in the lipid delivery particle, discussed infra, can comprise a payload fused with a gag protein from a different species of virus (e.g., an MMLV), or from a HERV, or a PH domain or transmembrane domain of a huma protein (e.g, a PH domain of human Aktl with E17K substitution).
CHIMERIC PROTEIN
[0065] In aspects, the present disclosure provides a chimeric protein comprising a plasma membrane recruitment element and a payload that is a protein or a fragment thereof. In some aspects, the lipid delivery particle comprises a chimeric protein comprising a plasma membrane recruitment element and a payload that is a protein or a fragment thereof. In some cases, the lipid delivery particle comprises at least about 1, at least about 2, at least about 3, at least about 4, at least about 5, at least about 6, at least about 7, at least about 8, at least about 9, at least about 10, or more chimeric proteins. In some cases, the lipid delivery particle comprises at most about 1, at most about 2, at most about 3, at most about 4, at most about 5, at most about 6, at most about 7, at most about 8, at most about 9, or at most about 10 chimeric proteins. In some cases, the plasma membrane recruitment element and the payload are fused directly in the chimeric protein. In other cases, the plasma membrane recruitment element and the payload are fused indirectly via a linker. In some cases, the linker between the plasma membrane recruitment element and the payload is a cleavable linker that is recognized by a protease.
[0066] The chimeric protein (e.g., comprising a gag protein) can form at least part of a protein core of the lipid delivery particle. A lipid delivery particle can comprise two or more chimeric proteins. The chimeric protein can include a structural protein. The structural protein can comprise a plasma membrane recruitment element (e.g., retroviral gag protein). The plasma membrane recruitment element can be fused to a payload. In some cases, the two or more chimeric proteins comprise the same structural protein. In some cases, the two or more chimeric proteins comprise different structural proteins. In some cases, the two or more chimeric proteins comprise different payloads. In some cases, the chimeric protein comprises a payload that comprises a nucleic acid-binding moiety. In some cases, the payload further comprises a guide nucleic acid molecule that forms a ribonucleoprotein complex with the nucleic acid-binding moiety. In some cases, the chimeric protein is suitable for delivery by a lipid delivery particle disclosed herein.
[0067] In some cases, the lipid delivery particle of the present disclosure further comprises a protease that recognizes the cleavable linker in the chimeric protein and cuts the chimeric protein at the cleavable linker. As a result of the cleavage at the cleavable linker by the protease, the payload can be separated from the plasma membrane recruitment element. In some cases, the lipid delivery particle comprises at least about 1, at least about 2, at least about 3, at least about 4, at least about 5, at least about 6, at least about 7, at least about 8, at least about 9, at least about 10, or more proteases. In some cases, the lipid delivery particle comprises at most about 1, at most about 2, at most about 3, at most about 4, at most about 5, at most about 6, at most about 7, at most about 8, at most about 9, or at most about 10 proteases. In some cases, the payload is present as a "free" entity separate from the plasma membrane recruitment element. For instance,
the payload can be free and present within an inside of the protein core of the lipid delivery particle. In some cases, the chimeric protein comprises a protease. In some cases, the chimeric protein comprises a first protease and a second protease. In some cases, the protease is part of a second chimeric protein comprising a second plasma membrane recruitment element and the protease, where the second plasma membrane recruitment element can be either different from or same as the plasma membrane recruitment element that is fused with the payload. In some cases, the chimeric protein comprises a dimerization element that helps it to form a dimer with another chimeric protein. In some cases, the dimerization element is a leucine zipper pair, an inducible heteromerization domain, an cohesin-dockerin interaction, a spy catcher- spy tag covalent interaction, or an electrostatic interaction between positively and negatively charged amino acids. [0068] In some cases, the chimeric protein disclosed herein also comprises one or more non- cleavable linkers that operably link components together. The non-cleavable linker can be any suitable linker sequence that is used for chimeric protein construction, such as peptide linkers that consist of glycine (Gly) and serine (Ser) residues. In some embodiments, the non-cleavable linker comprises an amino acid sequence selected from the group consisting of: (GS)x (SEQ ID NO: 564), (GGS)x (SEQ ID NO: 565), (GGGGS)x (SEQ ID NO: 566), (GGSG)x (SEQ ID NO: 567), and (SGGG)x (SEQ ID NO: 568), and wherein x is an integer from 1 to 50.
[0069] In some cases, the chimeric protein of the present disclosure comprises a nuclear export signal (NES) sequence that can direct transport of the chimeric protein out of the nucleus of a cell, e.g., a producer cell.
[0070] In some cases, the chimeric protein disclosed herein has one of the following configurations of components positioned in an order from N-terminus to C-terminus: [plasma membrane recruitment element]-[cleavable linker]-[payload];
[plasma membrane recruitment element]-[protease]- [cleavable linker]-[payload]; [plasma membrane recruitment element]-[cleavable linker]-[payload]-[protease];
[plasma membrane recruitment element]-[cleavable linker] -[protease]- [cleavable linker]- [payload];
[plasma membrane recruitment element] -[dimerization element] -[protease]; [dimerization element] -[protease] ;
[plasma membrane recruitment element] -[protease l]-[protease 2];
[plasma membrane recruitment element] -[protease];
[plasma membrane recruitment element]-[n * NES]-[cleavable linker]-[payload]; [plasma membrane recruitment element]-[cleavable linker]-[payload]-[n * NES]; [plasma membrane recruitment element]-[cleavable linker]-[n * NES]-[payload];
[plasma membrane recruitment element]-[cleavable linker l]-[payload]-[cleavable linker 2]-[n * NES];
[payload]-[cleavable linker]-[n * NES]-[plasma membrane recruitment element]; [payload]-[n * NES]-[cleavable linker]-[plasma membrane recruitment element]; [n * NES]-[payload]-[cleavable linker]-[plasma membrane recruitment element];
[n * NES]-[cleavable linker l]-[payload]-[cleavable linker 2]-[plasma membrane recruitment element]; and
[payload]-[cleavable linker]-[plasma membrane recruitment element]; wherein n is an integer in the range of from 1 to 10, and denotes the number of repeats of the NES sequence. Non-cleavable linker sequence can be present or absent in any of the foregoing configurations between any two neighboring components. As provided herein, the payload sequence in the chimeric protein can have one or more NLS sequences, at its N-terminus, C- terminus, or both.
[n * NES] -[cleavable linker l]-[payload]-[cleavable linker 2]-[plasma membrane recruitment element]; and
[payload] -[cleavable linker]-[plasma membrane recruitment element]; wherein n is an integer in the range of from 1 to 10, and denotes the number of repeats of the NES sequence. Non-cleavable linker sequence can be present or absent in any of the foregoing configurations between any two neighboring components. As provided herein, the payload sequence in the chimeric protein can have one or more NLS sequences, at its N- terminus, C-terminus, or both.
Nuclear Export Signal
[0071] Direction of nuclear transport within the cell can be governed by nuclear targeting signals within payload proteins or coupled to (e.g., fused with) the payload proteins. As used herein, the term “nuclear export signal” refers to a sequence of amino acids that targets a payload protein for export from the nucleus. In some cases, a nuclear export signal (NES) is a short target peptide sequence containing four hydrophobic residues. These residues target the protein for export from the nucleus to the cytoplasm through the nuclear pore complex. A chimeric protein provided herein can comprise 1 NES, 2 NESs, 3 NESs, 4 NESs, 5 NESs, 6 NESs, 7 NESs, 8 NESs, 9 NESs, or 10 NESs. In some cases, the NES is located at the N-terminus, C-terminus, or in an internal region of the chimeric protein. In some cases, a NES is coupled between the plasma membrane recruitment element and the payload in the chimeric protein. In some cases, there is a cleavable linker between the plasma membrane recruitment element and the payload in the chimeric protein, and one or more NESs present on the same of the cleavable linker as the plasma membrane recruitment element.
[0072] In some cases, the NES sequence that is used in the chimeric protein comprises LQLPPLERLTL (SEQ ID NO: 403) derived from HIV-1 Rev protein, or any of the sequences having at least 80% identity thereto. In some cases, the NES sequence comprises LALKLAGLDI (SEQ ID NO: 352) or NELALKL AGLDI (SEQ ID NO: 416), derived from PKIa, or any of the sequences having at least 80% identity thereto. In some cases, the NES sequence that is used in the chimeric protein comprises an amino acid sequence as set forth in Table 5. In some cases, the NES sequence comprises any one of the sequences set forth in Table 5. In some cases, the NES sequence comprises one or more of the sequences set forth in Table 5. In some cases, the NES sequence comprises more than one, more than two, more than three, more than four, more than five, more than six, more than seven, more than eight, more than nine, or more than ten of the sequences set forth in Table 5. In some cases, the NES sequences comprises multiple sequences set forth in Table 5.
[0073] In some cases, the NES sequence comprises an amino acid sequence having 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity to any sequence listed in Table 5. In some cases, the NES sequence comprises an amino acid sequence having 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity to any sequence set forth in SEQ ID NOs: 352-453. In some cases, the NES sequence described herein comprises a sequence with greater than 80% sequence identity to any sequence listed in Table 5. The transport of payload proteins within a cell is enabled through both NES and nuclear export receptors. In some cases, the NES described herein is associated with a nuclear export receptor (e.g., CRM-1). In some cases, the NES may be conditionally active or inactive. In some cases, the NES sequence disclosed herein comprises a sequence such as those described in T la Cour, et al., Nucleic Acids Res. 2003;31(l):393-396; and Xu D, et al. Mol Biol Cell. 2012 Sep;23(18):3673-6, each of which is incorporated herein by reference in its entirety. Any of the NES sequences described in the NES sequence database (NESdb®; prodata.swmed.edu/LRNes) or (NESbase; services. healthtech. dtu.dk/datasets/NESbase- 1.0) can be used in a chimeric protein disclosed herein, e.g., for the purpose of packaging a payload into the molecular assembly, e.g., the lipid delivery particle.
[0074] In some cases, a chimeric protein disclosed herein include a nuclear export sequence (NES). In some cases, the NES facilitates localization of the chimeric protein in the cytosol of a target cell relative to the nucleus.
[0075] In some cases, a chimeric protein disclosed herein includes at least one NES sequences, such as, 2 or more, 3 or more, 4 or more, or 5 or more NES sequences. In some cases, one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the N-terminus and/or the C- terminus of the
chimeric protein. In some cases, the chimeric protein disclosed herein comprises only one NES sequence. In some cases, the chimeric protein disclosed herein comprises two NES sequences. In some cases, the chimeric protein disclosed herein comprises three NES sequences. In some cases, one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the N-terminus of the chimeric protein. In some cases, one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the C-terminus of the chimeric protein. In some cases, one or more NES sequences (3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) both the N-terminus and the C-terminus of the chimeric protein. In some cases, an NES sequence is positioned at the N-terminus and an NES sequence is positioned at the C-terminus of the chimeric protein.
[0076] In some cases, a payload is a protein that is delivered as part of the chimeric protein disclosed herein, e.g., operably linked to a structural protein (e.g., human endogenous retroviral structural protein or a Plasma membrane recruitment element). In some embodiments, the one or more NES sequences are positioned at or near the one or both ends of the payload protein sequence inside the chimeric protein. For example, in some cases, one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the N-terminus and/or the C- terminus of the payload protein sequence. In some cases, one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the N-terminus of the payload protein sequence. In some cases, one or more NES sequences (2 or more, 3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) the C-terminus of the payload protein sequence. In some cases, one or more NES sequences (3 or more, 4 or more, or 5 or more NES sequences) are positioned at or near (e.g., within 50 amino acids of) both the N-terminus and the C-terminus of the payload protein sequence. In some cases, an NES sequence is positioned at the N-terminus and an NES sequence is positioned at the C- terminus of the payload protein sequence. In some cases, the chimeric protein disclosed herein comprises only one NES sequence. In some cases, the chimeric protein comprises only one NES sequence, and the NES sequence is positioned at or near (e.g., within 50 amino acids of) the N- terminus of the payload protein.
[0077] In eukaryotic cells, transport of proteins between the nucleus and the cytoplasm can be mediated by transport factors in the karyopherin-P family, which are also known as importins and exportins. The direction of nuclear-cytoplasmic transport can be dictated by nuclear targeting signals within the payload proteins. Nuclear export sequences (NESs) can direct export of proteins from the nucleus to the cytoplasm. NESs can bind directly to the export karyopherin
CRM1 (also known as exportin 1), which can escort payload proteins through the nuclear pore complex.
Table 5. Exemplary NES sequences

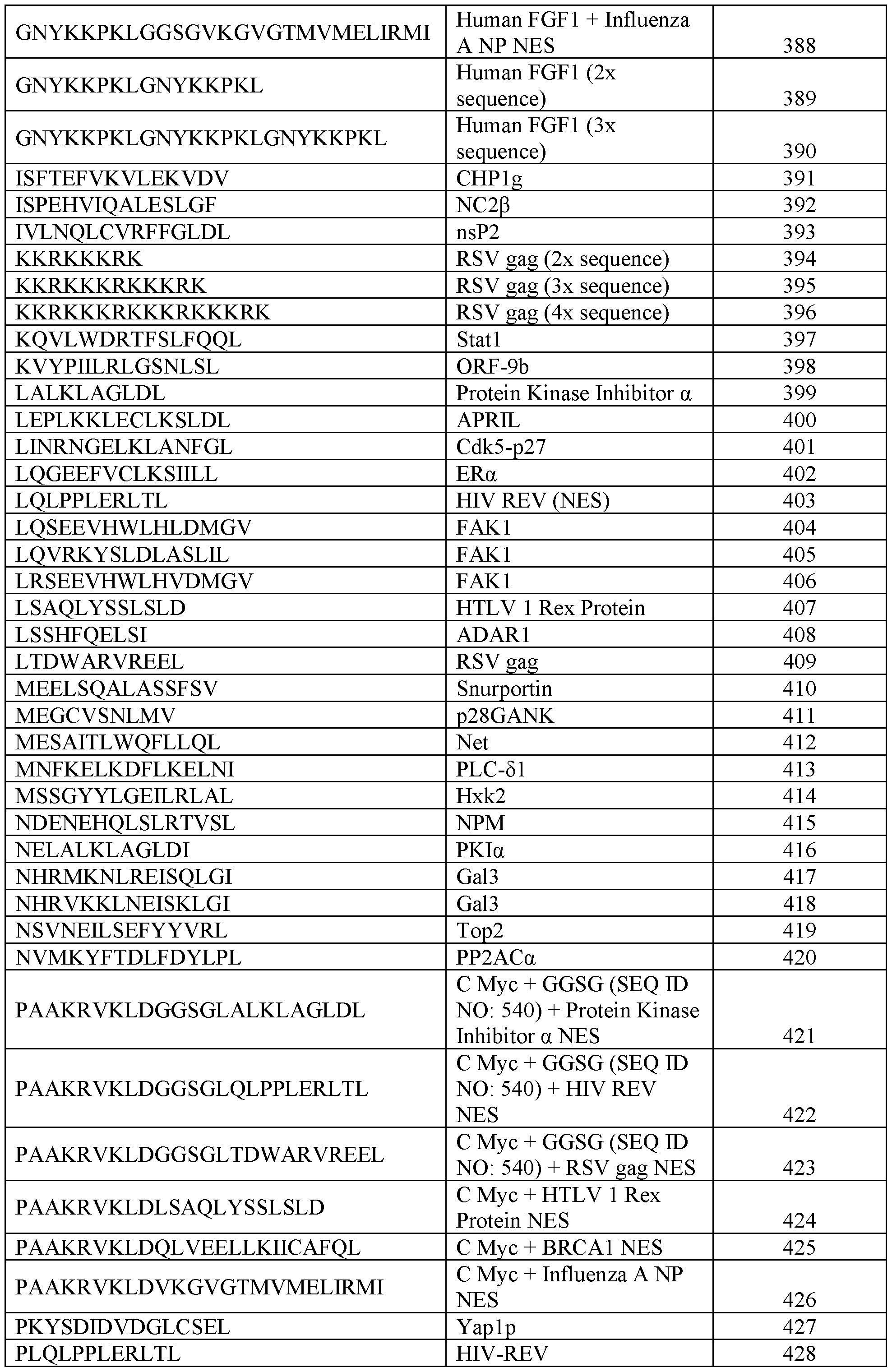
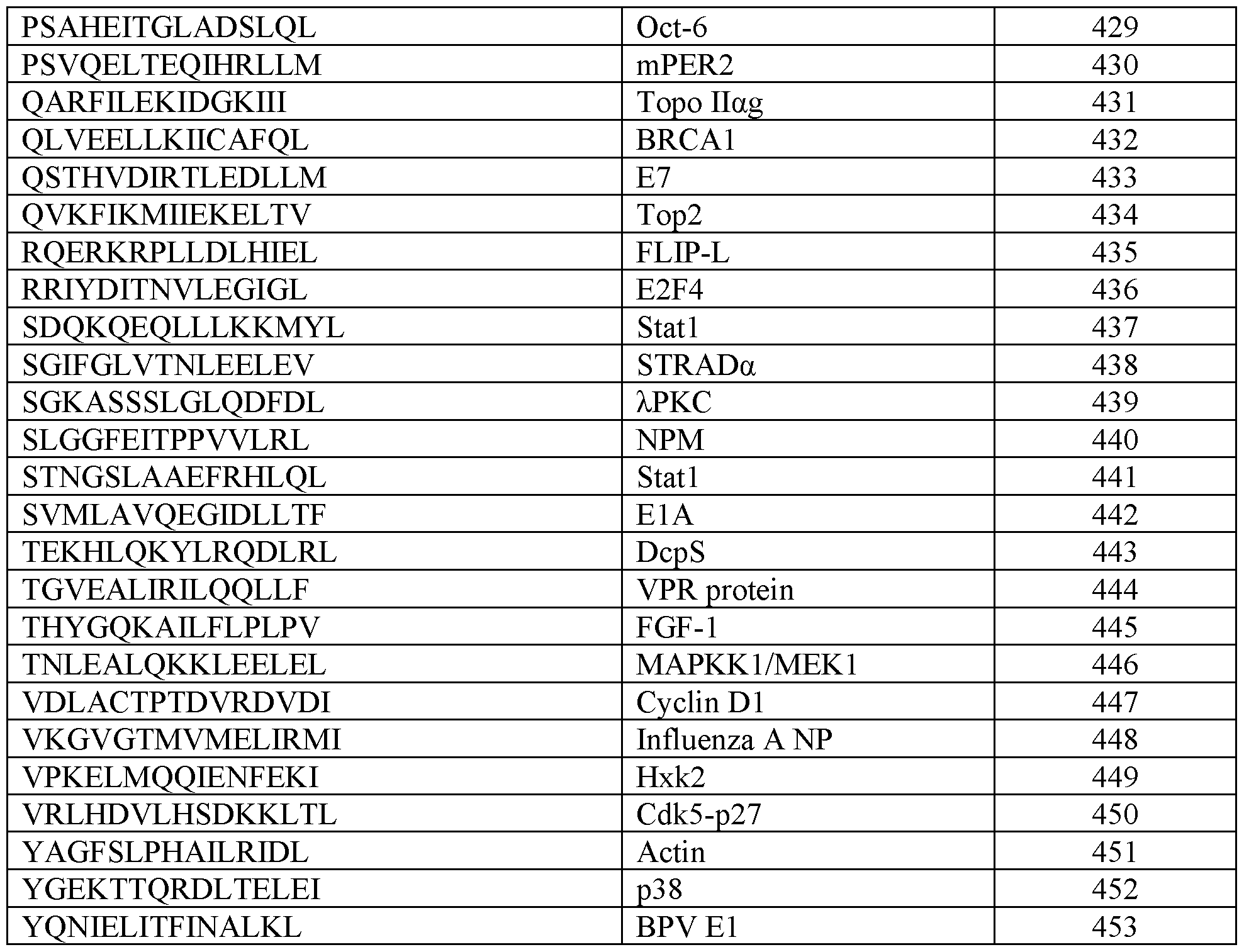
Nuclear Localization Signal
[0078] In some instances, a payload described herein comprises one or more nuclear localization sequences (NLS). As used herein, the term “nuclear localization signal” refers to a sequence of amino acids that targets a payload e.g., a protein or a short polypeptide), which the NLS is present within or coupled to, to localize to the nucleus. In some cases, an NLS facilitates the import of a polypeptide comprising an NLS into the cell nucleus. A polypeptide can comprise 1 NLS, 2 NLSs, 3 NLSs, 4 NLSs, 5 NLSs, 6 NLSs, 7 NLSs, 8 NLSs, 9 NLSs, or 10 NLSs. In some cases, the NLS is located at the N-terminus, C-terminus, or in an internal region of the polypeptide. In some cases, a NLS is coupled to a nucleic acid binding domain described elsewhere herein. In some cases, a NLS is coupled to a nucleic acid modifying domain described elsewhere herein. In some cases, a NLS is coupled to a guidable polypeptide domain, a deaminase domain, or a reverse transcriptase domain. In some cases, a NLS is covalently linked to a nucleic acid binding domain described elsewhere herein. In some cases, a NLS is covalently linked to a nucleic acid modifying domain described elsewhere herein. In some cases, a NLS is covalently linked to a guidable polypeptide domain, a deaminase domain, or a reverse transcriptase domain. In some cases, a nucleic acid binding domain does not comprise an NLS. In some cases, a nucleic acid binding domain does not comprise an NLS. In some cases, a guidable
polypeptide domain, a deaminase domain, or a reverse transcriptase domain does not comprise an NLS. Examples of NLS are provided in Table 6 below.
[0079] In some cases, the NLS comprises an amino acid sequence as set forth in Table 6. In some cases, the NLS comprises any one of the sequences set forth in Table 6. In some cases, the NLS comprises one or more of the sequences set forth in Table 6. In some cases, the NLS comprises more than one of the sequences set forth in Table 6. In some cases, the NLS comprises multiple sequences set forth in Table 6. In some cases, NLS sequence can comprise an amino acid sequence having 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity to any sequence listed in Table 6. In some cases, the NLS sequence described herein can comprise a sequence with greater than 80% sequence identity to any sequence listed in Table 6. In some cases, NLS sequence can comprise an amino acid sequence having 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity to any sequence set forth in SEQ ID NOs: 454-477.
[0080] In some cases, a chimeric protein disclosed herein includes a nuclear localization sequence (NLS). In some cases, the NLS facilitates delivery of the chimeric protein, or a payload released from the chimeric protein (for instance, released from the chimeric protein following cleavage of a cleavable linker), into the nucleus of a target cell.
[0081] In some cases, a payload is a protein and is delivered as part of the chimeric protein disclosed herein, e.g., operably linked to a structural protein (e.g., plasma membrane recruitment element). In some embodiments, the one or more NLS sequences are positioned at or near the one or both ends of the payload protein sequence of the chimeric protein. In some cases, a chimeric protein includes (e.g., is fused to) between 2 and 5 NLS sequences (e.g., 2-4, or 2-3 NLSs). Examples of NLS sequences include an NLS sequence derived from: the NLS of the SV40 virus large T-antigen, having the amino acid sequence PKKKRKV (SEQ ID NO: 468); the NLS from nucleoplasmin (e.g., the nucleoplasmin bipartite NLS with the sequence KRPAATKKAGQAKKKK (SEQ ID NO: 460); the c-myc NLS having the amino acid sequence PAAKRVKLD (SEQ ID NO: 467) or RQRRNELKRSP (SEQ ID NO: 541); the hRNPAl M9 NLS having the sequence NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY (SEQ ID NO: 542); the sequence RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV (SEQ ID NO: 543) of the IBB domain from importin-alpha; the sequences VSRKRPRP (SEQ ID NO: 477) and PPKKARED (SEQ ID NO: 544) of the myoma T protein; the sequence PQPKKKPL (SEQ ID NO: 545) of human p53; the sequence SALIKKKKKMAP (SEQ ID NO: 546) of mouse c-abl IV; the sequences DRLRR (SEQ ID NO: 547) and PKQKKRK (SEQ ID NO: 548) of the influenza virus NS1; the sequence RKLKKKIKKL (SEQ ID NO: 549) of the Hepatitis virus delta antigen; the sequence REKKKFLKRR (SEQ ID NO: 550) of the mouse Mxl
protein; the sequence KRKGDE VDGVDEV AKKKS KK (SEQ ID NO: 551) of the human poly(ADP-ribose) polymerase; and the sequence RKCLQAGMNLEARKTKK (SEQ ID NO: 552) of the steroid hormone receptors (human) glucocorticoid, and sequences having at least 80% identity to the foregoing. In some cases, an NLS comprises the amino acid sequence MDSLLMNRRKFLY QFKNVRWAKGRRETYLC (SEQ ID NO: 553).
[0082] Other examples of an NLS sequence include KRTADGSEFESPKKKRKV (SEQ ID NO: 462), KKTELQTTNAENKTKKL (SEQ ID NO: 554), KRGINDRNFWRGENGRKTR (SEQ ID NO: 555), RKSGKIAAIVVKRPRK (SEQ ID NO: 556), and MDSLLMNRRKFLYQFKNVRWAKGRRETYLC (SEQ ID NO: 463), SPKKKRKVEAS (SEQ ID NO: 557), encoded by AGCCCCAAGAAgAAGAGaAAGGTGGAGGCCAGC (SEQ ID NO: 558), GPKKKRKVAAA (SEQ ID NO: 559), as well as any of those described in Cokol et al., EMBO Rep., 2000, 1(5): 411-415 and Freitas et al., Current Genomics, 2009, 10(8): 550-7; Lu, J., et la., Cell Commun Signal 19, 60 (2021); international publication no. WO/2001/038547, each of which is incorporated herein by reference in its entirety, and sequences having at least 80% identity to the foregoing.
[0083] In some embodiments, the chimeric protein comprises one NES sequence and two NLS sequences. In some cases of these embodiments, the NES sequence, NLS sequences, and the payload protein sequence are positioned in an order from N-terminus to C-terminus as follows: NES-NLS-payload protein-NLS. In some embodiments, the chimeric protein comprises two or more NES sequences and two NLS sequences. In some cases of these embodiments, the NES sequences, NLS sequences, and the payload protein sequence are positioned in an order from N- terminus to C-terminus as follows: n X NES (n >=2)-NLS-payload protein-NLS.
Table 6. Exemplary NLS sequences

Cleavable linker
[0084] In some cases, the chimeric protein comprises a cleavable linker in between two or more components. For instance, the chimeric protein can comprise a cleavable linker between a payload protein sequence and a plasma membrane recruitment element sequence (e.g., retroviral gag protein sequence). In some cases, the cleavable linker separates the plasma membrane recruitment element sequence from a NLS sequence, and/or a NES sequence at its N-terminus or C-terminus. The cleavable linker can separate the payload protein sequence from the plasma membrane recruitment element sequence, NLS sequence, and/or NES sequence at its N-terminus or C-terminus. Examples of cleavable linker sequences that can be used in the chimeric protein include TSTLLMENSS (SEQ ID NO: 114), PRSSLYPALTP (SEQ ID NO: 115), VQALVLTQ
(SEQ ID NO: 562), and PLQVLTLNIERR (SEQ ID NO: 563), and sequences having at least 80% identity to any one of the foregoing.
[0085] The cleavable linker sequence provided herein can be a cleavable sequence that is recognized and cleaved by any applicable protease, such as a viral protease, a bacterial protease, or a eukaryotic protease (e.g., a protease derived from a plant, an animal, or a fungus). In some cases, the cleavable sequence is recognized by a retroviral protease (pro), such as pro protein derived from Moloney murine leukemia virus (MMLV) or Friend murine leukemia virus (FMLV). In some cases, the viral protease disclosed herein comprises a viral protease described in Reynolds et al., “The SARS-CoV-2 SSHHPS Recognized by the Papain-like Protease.” ACS infectious diseases 2021 : 7(6): 1483-1502; Farsani et al., “Identification of a Novel Human Rhinovirus C Type by Antibody Capture VIDISCA-454.” Viruses 2015: 7(1):239-251; and Kolykhalov et al., “Specificity of the hepatitis C virus NS3 serine protease: effects of substitutions at the 3/4A, 4A/4B, 4B/5A, and 5A/5B cleavage sites on polyprotein processing.” Journal of Virology 1994: 68(11): 7525-33, each of which is incorporated herein by reference in its entirety. In some cases, the viral protease is the tobacco etch virus (TEV) protease, the hepatitis C (HCV) NS3 protease, adenovirus protease, alphavirus protease, flavivirus protease, herpesvirus protease, picomavirus protease, or the Moloney Murine Leukemia Virus (MMLV) protease. In some cases, the viral protease comprises an amino acid sequence at least 70%, 75%, 80%, 85%, 90%, 95% or 99% sequence identify to an amino acid sequence set forth in Table 7. In some cases, the viral protease comprises an amino acid sequence set forth in Table 7.
Table 7: Exemplary amino acid sequence of the viral proteases


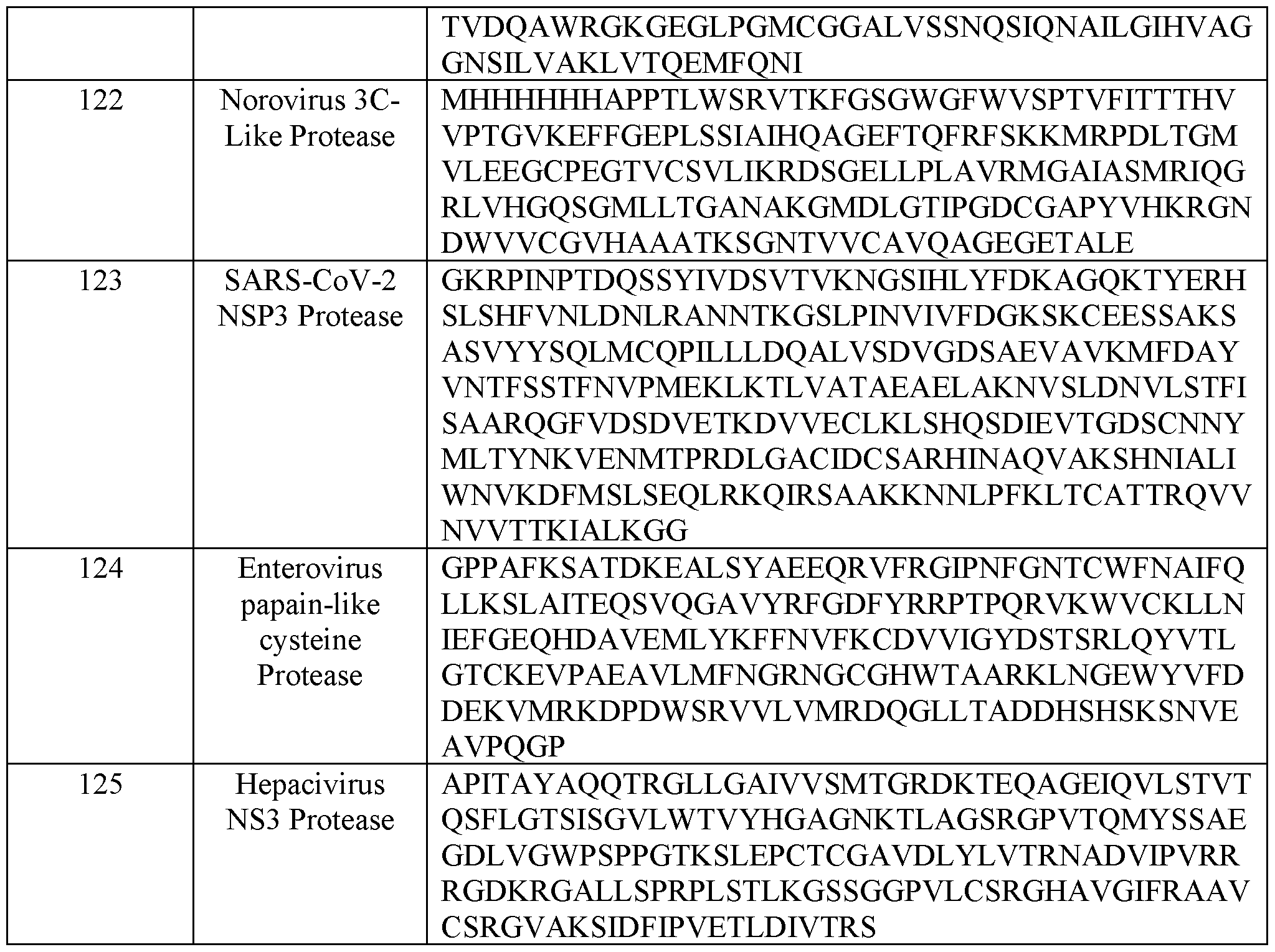
[0086] In some cases, the lipid delivery particle further comprises a protease that recognizes the cleavable linker sequence, such as pro protein derived from Moloney murine leukemia virus (MMLV) or Friend murine leukemia virus (FMLV), or protease that is of other viral origin, bacterial origin, or eukaryotic origin. In some cases, the cleavable linker disclosed herein comprises a sequence such as the target cleavage sequences described in Reynolds et al., “The SARS-CoV-2 SSHHPS Recognized by the Papain-like Protease.” ACS infectious diseases 2021 : 7(6): 1483-1502; Farsani et al., “Identification of a Novel Human Rhinovirus C Type by Antibody Capture VIDISCA-454.” Viruses 2015: 7(1):239-251; and Kolykhalov et al., “Specificity of the hepatitis C virus NS3 serine protease: effects of substitutions at the 3/4A, 4A/4B, 4B/5A, and 5A/5B cleavage sites on polyprotein processing.” Journal of Virology 1994: 68(11): 7525-33, each of which is incorporated herein by reference in its entirety. In some cases, the cleavable linker is cleavable by at least about 1, at least about 2, at least about 3, at least about 4, at least about 5, at least about 6, at least about 7, at least about 8, at least about 9, at least about 10, or more proteases. In some cases, the cleavable linker is cleavable by at most about 1, at most about 2, at most about 3, at most about 4, at most about 5, at most about 6, at most about 7, at most about 8, at most about 9, or at most about 10 proteases. In some cases, the cleavable linker comprises an amino acid sequence at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, or 99%
sequence identity to an amino acid sequence set forth in Table 8. In some cases, the cleavable linker comprises an amino acid sequence set forth in Table 8.
Table 8: Exemplary amino acid sequence of the protease cleavable linker



[0087] In some cases, the chimeric protein comprises one cleavable linker. In some cases, the chimeric protein comprises two or more cleavable linkers. In some cases, the cleavable site is positioned between the plasma recruitment element and the heterologous payload. In some cases, the cleavable linkers are positioned in either side of the protease. In some cases, the protease cleaves the chimeric protein at the cleavable linker and release the heterologous payload from the remainder of the chimeric protein.
[0088] In some cases, cleavage at the cleavable linker by the protease is inhibited by adding a reversible protease inhibitor. The term “reversible protease inhibitor” as used herein refers to an
protease inhibitor whose inhibitory activity is removed when the inhibitor is no long present. The protease inhibitor can be an inhibitor of a retroviral protease, a HIV protease, a HCV protease, or an aspartic acid protease. In some cases, the protease inhibitor is selected from Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir. In some cases, adding protease inhibitor delays the cleavage by the protease until the protease inhibitor is removed. In some cases, releasing the heterologous payload from the remainder of the chimeric protein is delayed until the reversible protease inhibitor is removed.
[0089] The following are two non-limiting examples of the chimeric protein sequences comprising a plasma recruitment element, a cleavable linker, and a protease:
Chimeric protein 1 (SEQ ID NO: 172):
MSDVAIVKEGWLHKRGEYIKTWRPRYFLLKNDGTFIGYKERPQDVDQREAPLNNFSVA QCQLMKTERPRPNTFIIRCLQWTTVIERTFHVETPEEREEWTTAIQTVADGLKKQEEEEM DFRSGSPSDNSGAEEMEVSLAKPKHRVTMNEFEYLKLLGKGTFGKVDPPVVGDGSGSG GVSGGGSGGGSGGGSLTLTSTLLMENSSGGGGSGGGSGGGSTLDDQGGQGQEPPPEPRI TLKVGGQPVTFLVDTGAQHSVLTQNPGPLSDKSAWVQGATGGKRYRWTTDRKVHLAT GKVTHSFLHVPDCPYPLLGRDLLTKLKAQIHFEGSGAQVMGPMGQPLQVL
Chimeric protein 2 (SEQ ID NO: 173):
MGQTVTTPLSLTLGHWKDVERIAHNQSVDVKKRRWVTFCSAEWPTFNVGWPRDGTFN RDLITQVKIKVFSPGPHGHPDQVPYIVTWEALAFDPPPWVKPFVHPKPPPPLPPSAPSLPL EPPRSTPPRSSLYPALTPSLGAKPKPQVLSDSGGPLIDLLTEDPPPYRDPRPPPSDRDGNGG EATPAGEAPDPSPMASRLRGRREPPVADSTTSQAFPLRAGGNGQLQYWPFSSSDLYNWK NNNPSFSEDPGKLTALIESVLITHQPTWDDCQQLLGTLLTGEEKQRVLLEARKAVRGDD GRPTQLPNEVDAAFPLERPDWDYTTQAGRNHLVHYRQLLLAGLQNAGRSPTNLAKVK GITQGPNESPSAFLERLKEAYRRYTPYDPEDPGQETNVSMSFIWQSAPDIGRKLERLEDL KNKTLGDLVREAEKIFNKRETPEEREERIRRETEEKEERRRTEDEQKEKERDRRRHREMS KLLATVVSGQKQDRQGGERRRSQLDRDQCAYCKEKGHWAKDCPKKPRGPRGPRPQTS LLTLDDSGGGSGGGSGGGSLTLTSTLLMENSSGGGGSGGGSGGGSTLDDQGGQGQEPPP EPRITLKVGGQPVTFLVDTGAQHSVLTQNPGPLSDKSAWVQGATGGKRYRWTTDRKVH LATGKVTHSFLHVPDCPYPLLGRDLLTKLKAQIHFEGSGAQVMGPMGQPLQVL
PAYLOAD
[0090] A payload in a lipid delivery particle of the present disclosure can comprise a protein, a polypeptide, a nucleic acid (e.g., DNA or RNA), or any combinations thereof. In some embodiments, the payload is a heterologous payload. In some embodiments, the heterologous payload is a therapeutic agent. In some embodiments, the therapeutic agent is a gene-editing agent. In some embodiments, the gene-editing agent comprises a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; a nucleic acid encoding a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; or a ribonucleoprotein complex (RNP)
comprising a CRISPR- based genome editing or modulating protein. In some embodiments, the therapeutic agent is a nucleic-acid based agent, a small molecule, or a recombinant protein. [0091] The payload can be a part of the chimeric protein disclosed herein or can comprise a part of the chimeric protein disclosed herein. Alternatively or additionally, the payload can include an entity in the lipid delivery particle separate from the chimeric protein disclosed herein. For instance, in some cases, the payload is a protein or polypeptide coupled to a plasma membrane recruitment element. In some cases, the payload comprises a first moiety (e.g., a nucleic acidbinding protein) that is fused to a plasma membrane recruitment element, and further comprises a second moiety that is coupled to the first moiety via covalent or non-covalent interaction. For instance, the first moiety can be a nucleic acid binding protein that is fused with the plasma membrane recruitment element, and the second moiety can be a nucleic acid molecule that binds to the nucleic acid binding protein.
[0092] In some cases, a payload is directly packaged within the lipid delivery particles and delivered into a target cell in its free form. In some cases, a payload can be fused to a plasma membrane recruitment element (e.g., pleckstrin homology domain) and form a chimeric protein as part of the lipid delivery particles, and then delivered into the target cell. In some cases, the plasma membrane recruitment element (e.g., pleckstrin homology domain) forms at least part of a protein core of the lipid delivery particle. In some embodiments, the payload in its free form or as part of a chimeric protein is within the inside cavity of the protein core of the lipid delivery particles disclosed herein. In some cases, the payload in its free form derives from a cleavage of the chimeric protein comprising the payload. In some cases, the plasma membrane recruitment element (e.g., pleckstrin homology domain) is coupled to the payload (e.g., heterologous payload). In some cases, the plasma membrane recruitment element (e.g., pleckstrin homology domain) is reversibly coupled to the payload (e.g., heterologous payload). In some cases, the payload (e.g., heterologous payload) is reversibly coupled to the plasma membrane recruitment element (e.g., pleckstrin homology domain) by one of the one or more cleavable linker. In some cases, the payload (e.g., heterologous payload) is coupled to a C-terminus of the plasma membrane recruitment element (e.g., pleckstrin homology domain). In some cases, the payload (e.g., heterologous payload) is coupled to an N-terminus of the plasma membrane recruitment element (e.g., pleckstrin homology domain).
[0093] In some cases, a lipid delivery particle can deliver more than one payload. Each of the payloads can independently comprise nucleic acid-binding moiety, a nucleic acid-modifying moiety, a fusion protein, or a nucleic acid, or any combinations thereof.
[0094] In some embodiments, the plasma membrane recruitment element and the payload are coupled via any suitable method. Covalent coupling between the plasma membrane recruitment
element and a payload peptide can include inteins that can form peptide bonds, direct proteinprotein chimeras generated from a single reading frame. In some cases, nucleic acids base pairing to other nucleic acids via hydrogen bonding interactions (e.g., DNA/RNA, DNA/DNA, or RNA/RNA hybrids), protein-protein binding, or protein-nucleic acid molecule binding can be involved for the coupling between the plasma membrane recruitment element and the payload. Examples of protein-nucleic acid molecule binding include an RNA binding protein (RBP) and an RBP binding sequence (e.g., an RNA) that binds to the RBP. In some embodiments, each of the plasma membrane recruitment element and the payload is fused to a heterologous sequence, and the two heterologous sequences dimerize or multimerize with or without the need for a chemical compound to induce the protein-protein binding, such as a single-stranded nucleic acid sequence or protein dimerization domains). In some embodiments, each of the plasma membrane recruitment element and the payload is fused to one member of a pair of binding partners (e.g., antibody and its target antigen). In some embodiments, the plasma membrane recruitment element is fused to an RBP, and the payload is fused to a RBP binding sequence. Examples of suitable protein domains or nucleic acid molecules for forming the non-covalent connections include single chain variable fragments, nanobodies, affibodies, DmrA/DmrB/DmrC, FKBP/FRB, dDZFs, Leucine zippers, proteins that bind to DNA and/or RNA, optogenetic protein domains that can dimerize or multimerize in the presence of certain light wavelengths, proteins with quaternary structural interactions, and/or naturally reconstituting split proteins. Examples of RBPs and their RBP binding sequences that can be used include a sequence having at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in Table 9. Examples of RBPs and their RBP binding sequences that can be used include a sequence having at least about 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a sequence set forth in any one of SEQ ID NOs: 478-513 In some cases, the RBP comprises an amino acid sequence as set forth in Table 9. In some cases, the RBP comprises any one of the sequences set forth in Table 9. In some cases, the RBP comprises one or more of the sequences set forth in Table 9. In some cases, the RBP comprises more than one of the sequences set forth in Table 9. In some cases, the RBP comprises multiple sequences set forth in Table 9. In some cases, the RBP binding sequence comprises an amino acid sequence as set forth in Table 9. In some cases, the RBP binding sequence comprises any one of the sequences set forth in Table 9. In some cases, the RBP binding sequence comprises one or more of the sequences set forth in Table 9. In some cases, the RBP binding sequence comprises more than one of the sequences set forth in Table 9. In some cases, the RBP binding sequence comprises multiple sequences set forth in Table 9.
Table 9. Exemplary RNA binding proteins (RBP) and corresponding RBP binding sequences
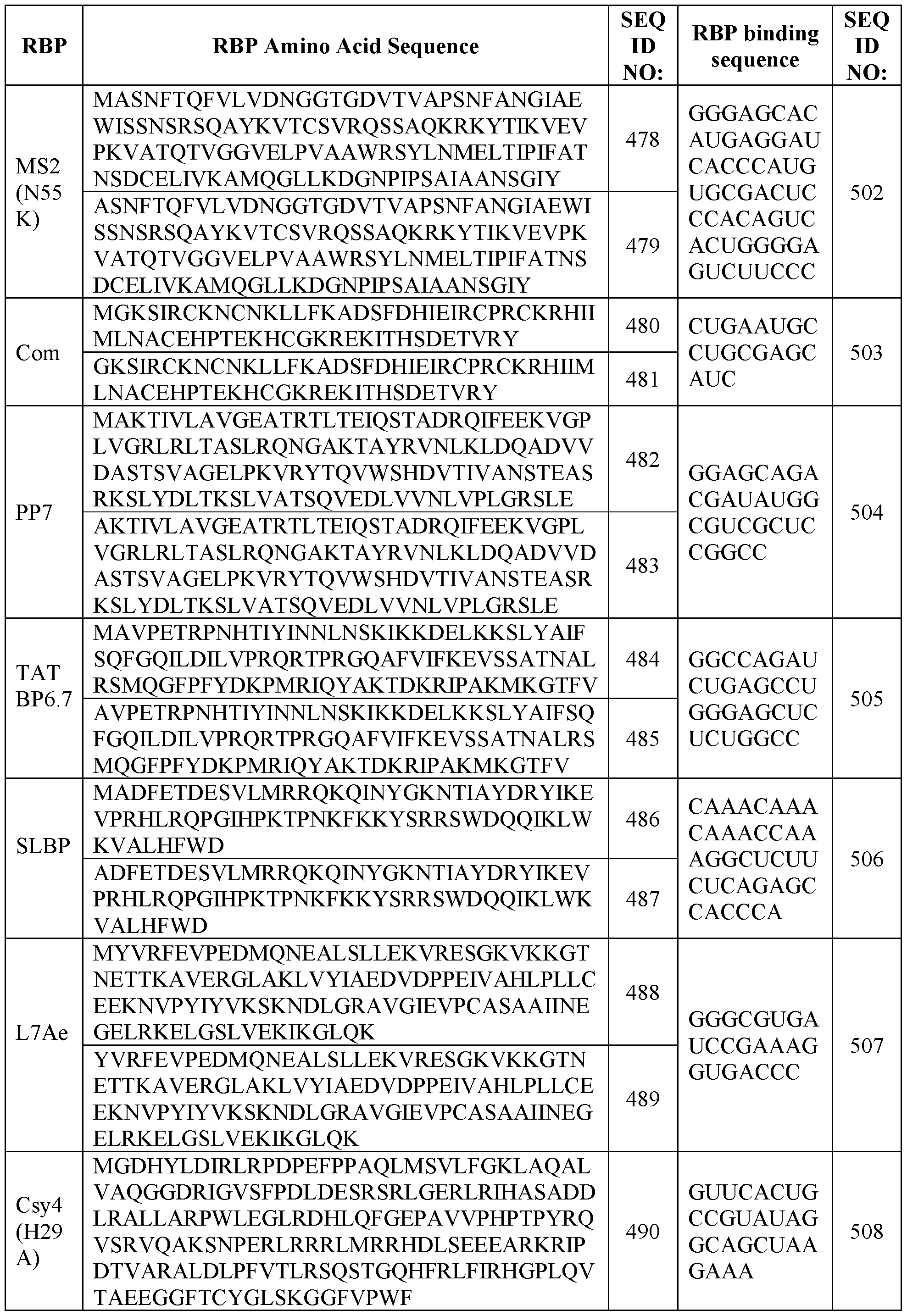

Nucleic acid binding domains and nucleic acid modifying domains
[0095] In some cases, the payload comprises a nucleic acid-binding moiety, a nucleic acidmodifying moiety, a fusion protein, or a nucleic acid. In some cases, the payload comprises a nucleic acid-binding domain, e.g., a DNA-binding protein domain or polypeptide or an RNA- binding domain or polypeptide e.g., an RNA-binding protein (RBP). A nucleic acid-binding moiety can be capable of binding a nucleic acid. A nucleic acid-binding domain can bind to a nucleic acid in a nonspecific or a site-specific manner.
[0096] In some cases, the nucleic acid-binding moiety binds to a nucleic acid in a site-specific manner. For example, a nucleic acid-binding moiety can comprise an aptamer binding domain
that selectively binds to a specific target. In some cases, a nucleic acid-binding moiety recognizes a specific recognition sequence in the target nucleic acid. In some cases, a nucleic acid-binding moiety comprises an aptamer binding domain. In some cases, a nucleic acid binding moiety selectively binds to a sequence or a structural element in a nucleic acid molecule. In some cases, an RNA-binding domain selectively binds to a specific sequence motif in an RNA molecule. In some cases, a nucleic acid-binding moiety selectively binds to a structural element in a nucleic acid molecule. For example, a nucleic acid-binding domain can bind to a stem-loop in a nucleic acid molecule.
[0097] In some cases, a nucleic acid-binding moiety is or comprises a guidable polypeptide domain, a transcriptional regulatory domain, or a nucleic acid-modifying domain. A guidable polypeptide domain can be capable of binding to a polynucleotide (e.g. an RNA guide) that can direct the guidable polypeptide domain a target site. In some cases, the guidable polypeptide domain forms a complex with the RNA guide and recognizes the target sequence through DNA- RNA base pairing. In some cases, a nucleic-acid binding moiety is or comprises a transcriptional regulatory domain. In other cases, a nucleic-binding moiety can help recruit a transcriptional repressor or activator to a target site. In some cases, a nucleic acid-binding moiety is or comprises a nucleic acid-modifying moiety. In some cases, the present disclosure uses nucleic acid-binding moieties to recruit a nucleic acid-modifying moiety to a target site. In some cases, a nucleic-acid binding moiety comprises catalytic activity. In other cases, a nucleic acid-binding moiety is catalytically inactive. In some cases, a nucleic-acid binding moiety comprising catalytic activity is modified to have a reduced level of activity compared to its wild-type counterpart. [0098] In some cases, the payload in the present disclosure comprises a nucleic acid modifying domain. A nucleic acid-modifying domain can comprise a polypeptide domain, a nucleic acid or a combination thereof (e.g., a ribonucleoprotein complex). A nucleic acid-modifying domain can be capable of modifying nucleic acid, such as cleaving double-stranded nucleic acid; nicking a single-stranded nucleic acid; introducing a mutation, deletion, or insertion in a nucleic acid; methylating or demethylating a nucleic acid, or altering the structure of DNA (e.g., changing chromatin structure through modifying histones). For example, a nucleic acid modifying domain can comprise a nuclease domain, a nickase domain, a deaminase domain, a polymerase, reverse transcriptase domain, a recombinase domain, a transposase domain, or an epigenetic modifying domain. A nuclease domain can be capable of cleaving phosphodiester bonds between nucleotides in nucleic acids. A nuclease domain can comprise an exonuclease (e.g., a nuclease capable of cleaving nucleic acids from the ends) or an endonuclease (e.g., a nuclease capable of cleaving nucleic acids in the middle). In some cases, a nucleic acid modifying effector or nucleic acid binding domain is a nickase, which can be capable of cleaving a single-strand in a double-
stranded DNA. Nucleic acid modifying domains can be useful for gene editing, or for regulating, activating, or inhibiting gene expression.
Guidable polypeptide domain
[0099] In some cases, the payload in the present disclosure comprises a guidable polypeptide domain (e.g., a CRISPR-Cas protein domain). In some cases, a guidable polypeptide domain is capable of binding to a polynucleotide (e.g., a RNA guide) that directs it to a target site. In some cases, the guidable polypeptide domain forms a complex with the polynucleotide and recognizes the target sequence through DNA-RNA base pairing.
[0100] In some cases, a guidable polypeptide domain is a CRISPR/CRISPR-associated (Cas) domain. A CRISPR domain can be a natural or an engineered domain. A Cas protein or domain can be derived from a CRISPR system or share structural and/or functional similarities to a protein involved in a CRISPR system.
[0101] In some cases, the guidable polypeptide domain is any suitable nuclease, e.g., a CRISPR- associated (Cas) protein or a Cas nuclease which functions in a non-naturally occurring CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats)/Cas (CRISPR-associated) system. In bacteria, this system can provide adaptive immunity against foreign DNA (Barrangou, R., et al, “CRISPR provides acquired resistance against viruses in prokaryotes,” Science (2007) 315: 1709-1712; Makarova, K.S., et al, “Evolution and classification of the CRISPR-Cas systems,” Nat Rev Microbiol (2011) 9:467- 477; Garneau, J. E., et al, “The CRISPR/Cas bacterial immune system cleaves bacteriophage and plasmid DNA,” Nature (2010) 468:67-71 ; Sapranauskas, R., et al, “The Streptococcus thermophilus CRISPR/Cas system provides immunity in Escherichia coli,” Nucleic Acids Res (2011) 39: 9275-9282).
[0102] Suitable nucleases include CRISPR-associated (Cas) proteins or Cas nucleases including type I CRISPR-associated (Cas) polypeptides, type II CRISPR-associated (Cas) polypeptides (e.g., Cas9 or Cas 14), type III CRISPR-associated (Cas) polypeptides, type IV CRISPR- associated (Cas) polypeptides, type V CRISPR-associated (Cas) polypeptides (e.g., Cpfl/Casl2a, C2cl, or c2c3), and type VI CRISPR-associated (Cas) polypeptides (e.g., C2c2/Casl3a, Casl3b, Casl3c, Casl3d).
[0103] A CRISPR system is a system encoding DNA sequence arrays known as clustered regularly interspaced short palindromic repeats (CRISPRs), which can be found in microbial genomes or phage genomes. In some cases, CRISPR systems comprise genes encoding CRISPR- associated (Cas) proteins and/or small RNA guide molecules (e.g., crRNA or tracrRNA) that assemble with the CRISPR domain. In some cases, the CRISPR-Cas domain forms a complex with one or more RNA guide molecules to form an effector ribonucleoprotein complex. The effector ribonucleoprotein complex can recognize a target sequence through sequence specific
DNA-RNA base pairing with a spacer sequence in the RNA guide. In some cases, target recognition activates one or more nuclease domains (e.g., a RuvC domain or HNH domain) in the CRISPR domain to make a double-stranded cut at the target DNA. A CRISPR-Cas domain complexed with an RNA guide can be capable of inactivating target gene through a gene knockout. In some cases, the CRISPR domain is used to enable gene insertion and/or deletion, which can inactivate, modify, or restore the gene’s function.
[0104] One or more components of a CRISPR/Cas system (e.g., modified and/or unmodified) delivered by the lipid delivery particles disclosed herein can be utilized as a genome engineering tool in a wide variety of organisms including diverse mammals, animals, plants, and yeast. A CRISPR/Cas system can comprise a guide nucleic acid such as a guide RNA (gRNA) complexed with a Cas protein for targeted regulation of gene expression and/or activity or nucleic acid editing. An RNA-guided Cas protein (e.g., a Cas nuclease such as a Cas9 nuclease) can specifically bind a target polynucleotide (e.g., DNA) in a sequence-dependent manner. The Cas protein, if possessing nuclease activity, can cleave the DNA (Gasiunas, G., et al, “Cas9-crRNA ribonucleoprotein complex mediates specific DNA cleavage for adaptive immunity in bacteria,” Proc Natl Acad Sci USA (2012) 109: E2579-E2 86; Jinek, M., et al, “A programmable dual- RNA-guided DNA endonuclease in adaptive bacterial immunity,” Science (2012) 337:816-821; Sternberg, S. H., et al, “DNA interrogation by the CRISPR RNA-guided endonuclease Cas9,” Nature (2014) 507:62; Deltcheva, E., et al, “CRISPR RNA maturation by trans-encoded small RNA and host factor RNase III,” Nature (201 1) 471 :602-607), and has been widely used for programmable genome editing in a variety of organisms and model systems (Cong, L., et al, “Multiplex genome engineering using CRISPR Cas systems,” Science (2013) 339:819-823; Jiang, W ., et al, “RNA-guided editing of bacterial genomes using CRISPR-Cas systems,” Nat. Biotechnol. (2013) 31 : 233-239; Sander, J. D. & Joung, J. K, “CRISPR-Cas systems for editing, regulating and targeting genomes,” Nature Biotechnol. (2014) 32:347-355).
[0105] In some cases, the Cas protein is mutated and/or modified to yield a nuclease deficient protein or a protein with decreased nuclease activity relative to a wild-type Cas protein. A nuclease deficient protein can retain the ability to bind DNA but can lack or have reduced nucleic acid cleavage activity. A protein encoded by a donor sequence comprises a Cas nuclease (e.g., retaining wild-type nuclease activity, having reduced nuclease activity, and/or lacking nuclease activity) can function in a CRISPR/Cas system to regulate the level and/or activity of a target gene or protein (e.g., decrease, increase, or elimination). The Cas protein can bind to a target polynucleotide and prevent transcription by physical obstruction or edit a nucleic acid sequence to yield non-functional gene products. In some cases, the Cas protein cleaves both strands of DNA. In some cases, the Cas protein cleaves one strand of DNA.
[0106] In some embodiments, the nuclease is a Cas protein that forms a complex with a guide nucleic acid, such as a guide RNA (gRNA). In some embodiments, the donor sequence disclosed herein encodes a Cas protein that forms a complex with a single guide nucleic acid, such as a single guide RNA (sgRNA). In some embodiments, the donor sequence disclosed herein encodes a Cas protein that forms a complex with two separate RNA molecules of a dual guide nucleic acid (dgRNA). In some embodiments, the donor sequence in the lipid delivery particles disclosed herein comprises or encodes an RNA-binding protein (RBP) optionally complexed with a guide nucleic acid, such as a guide RNA (e.g., sgRNA, dgRNA), which is able to form a complex with a Cas protein. In some embodiments, the gRNA comprises a scaffolding sequences that tethers the gRNA to the Cas protein. In some embodiments, the gRNA comprises a scaffolding sequence and a spacer sequence that directs the Cas protein to a specific locus. In some embodiments, the scaffolding sequence is configured to bind to the positively charged groves in the Cas9 protein. In some embodiments, the scaffolding sequence is configured to bind to the Cas protein in the payload. In some cases, Cas undergoes a conformational change when the gRNA binds to the target locus. In some cases, the conformational change in Cas shifts the molecule from an inactive, non-DNA binding conformation into an active DNA-binding conformation. In some cases, the Cas protein undergoes a confirmational change if the spacer sequence has sufficient homology to the sequence at the target locus. In some embodiments, gRNAs can be modified. Exemplary modifications to the gRNA are provided in United States Patent Number 11,479,767 B2, United States Patent Application Publication Number US2020/0339980 Al, and United States Patent Application Publication Number US2021/0079389 Al, each of which is incorporated herein by reference in its entirety.
[0107] One or more components of any suitable CRISPR/Cas system can be delivered by the lipid delivery particle described in the present disclosure. A CRISPR/Cas system can be referred to using a variety of naming systems. Exemplary naming systems are provided in Makarova, K.S. et al, “An updated evolutionary classification of CRISPR-Cas systems,” Nat Rev Microbiol (2015) 13:722-736 and Shmakov, S. et al, “Discovery and Functional Characterization of Diverse Class 2 CRISPR-Cas Systems,” Mol Cell (2015) 60: 1-13. A CRISPR/Cas system can be a type I, a type II, a type III, a type IV, a type V, a type VI system, or any other suitable CRISPR/Cas system. A CRISPR/Cas system as used herein can be a Class 1, Class 2, or any other suitably classified CRISPR/Cas system. Class 1 or Class 2 determination can be based upon the genes encoding the effector module. Class 1 systems generally have a multi-subunit crRNA- effector complex, whereas Class 2 systems generally have a single protein, such as Cas9, Cpfl, C2cl, C2c2, C2c3, or a crRNA-effector complex. A Class 1 CRISPR/Cas system can use a complex of multiple Cas proteins to effect regulation. A Class 1 CRISPR/Cas system can
comprise, for example, type I (e.g., I, IA, IB, IC, ID, IE, IF, IU), type III (e.g., Ill, IIIA, IIIB, IIIC, IIID), and type IV (e.g, IV, IVA, IVB) CRISPR/Cas type. A Class 2 CRISPR/Cas system can use a single large Cas protein to effect regulation. A Class 2 CRISPR/Cas systems can comprise, for example, type II (e.g., II, IIA, IIB) and type V CRISPR/Cas type. CRISPR systems can be complementary to each other, and/or can lend functional units in trans to facilitate CRISPR locus targeting. Examples of Cas proteins that can be used as part of the CRISPR systems described herein include c2cl, Cas 13a (formerly C2c2), Cas 13b, Cas 13c, Cas 13d, c2c3, Casl, CaslB, Cas2, Cas3, Cas4, Cas5, Cas5e (CasD), Cas6, Cas6e, Cas6f, Cas7, Cas8a, Cas8al, Cas8a2, Cas8b, Cas8c, Cas9 (Csnl or Csxl2), CaslO, CaslOd, Casl4, CaslO, CaslOd, CasF, CasG, CasH, Casl2a (formerly Cpfl), Csyl, Csy2, Csy3, Csel (CasA), Cse2 (CasB), Cse3 (CasE), Cse4 (CasC), Cscl, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmrl, Cmr3, Cmr4, Cmr5, Cmr6, Csbl, Csb2, Csb3, Csxl7, Csxl4, CsxlO, Csxl6, CasX, Csx3, Csxl, Csxl5, Csfl, Csf2, Csf3, Csf4, and Cul966, and homologs or modified versions thereof. Examples of mutant Cas9 proteins or Cas9 variants include SpG, SpCas9-NG. Cas9-NRNH, SpG, SpRY, Cas9-VQR, Cas9-EQR, SaCas9-KKH, Nme2Cas9, eNme2-C, eNme2-C.NR, eNme2-T.l, eNme2-T.2, SpRY, eSpCas9(l. l), SpCas9-HFl, nSpCas9, eSpCas9, Sniper-Cas9, HypaCas9, evoCas9, Cas9TX, HscCas9-vl.2, superFi-Cas9, efSaCas9, SaCas9-HF, Cas9-HF, Cas mini, SaCas9, SpCas9(H840A), dSpCas9, SpCas9(N863A), SpCas9(D839A), SpCas9(H983A), as well as others described in Chuang CK et al., IntJMol Sci. 2021 Sep 13;22(18):9872 and Li, T. et al., Sig Transduct Target Ther 8, 36 (2023), each of, which is incorporated herein by reference in its entirety.
[0108] A CRISPR system can comprise single subunit or multi-subunit effectors. In some cases, a CRISPR system is a Class 1 CRISPR system. A Class 1 CRISPR system can be a type I, type III, or a type IV system. A Class 1 type I CRISPR system can comprise a multi-subunit effector. In some cases, a Class 1 type I CRISPR system comprises a protein or domain in the Cascade- Cas3 protein complex. A Class 1 type I CRISPR system can comprise a Cas6, Cas7, Cas5, Casl 1, Cas8, or Cas3 domain. A Class 1 type III CRISPR system can comprise a multi-subunit effector. In some cases, a Class 1 type III CRISPR system comprises a Csm complex or a Cmr complex. In some cases, a Class 1 type III CRISPR system comprises a Cas6, a Cas7 (Csm3 or Cmr4), a Cas7-related (Csm5, Cmrl, or Cmr6), a Cas5 (e.g., Csm4 or Cmr5), a Casl l (e.g., Csm2 or Cmr3), or a CaslO (e.g., Csml or Cmr2) domain. A Class 1 type IV CRISPR system can comprise a Cas6, a Cas7, a Cas5, a Casl 1, a Cas8 (e.g., Csfl), or a DinG or CysH domain. In some cases, a CRISPR system comprises Cmrl, Cmr3, Cmr4, Cmr5, or Cmr6. In some cases, a CRISPR system comprises Csbl, Csb2, or Csb3. A CRISPR system can comprise Csfl, Csf2, Csf3, or Csf4. A CRISPR system can comprise Csn2, Csm2, Csm3, Csm4, Csm5, or
Csm6. A CRISPR system can comprise Cscl or Csc2. A CRISPR system can comprise Cast, CaslB, Cas2, or Cas4. A CRISPR system can comprise Csyl, Csy2, or Csy3. A CRISPR system can comprise Csel or Cse2. A CRISPR system can comprise Csn2. A CRISPR system can comprise CsaX, Csxl, Csx3, CsxlO, Csxl4, Csxl5, Csxl6, or Csxl7. In some cases, a CRISPR system comprises a modified version of any one of the foregoing Cas proteins. In some cases, a modified version of the foregoing Cas protein comprises a nickase mutation. In some cases, the nickase mutation corresponds to the D10A mutation of the wild type Cas9 protein. In some cases, the nickase mutation corresponds to the H840A mutation of the wild type Cas9 protein. In some cases, the nickase mutation occurs in the RuvC domain of the wild type Cas9 protein. In some cases, the nickase mutation occurs in the HNH domain of the wild type Cas9 protein. In some cases the RuvC domain can be mutated to prevent cleavage of the non-target DNA strand. In some cases the HNH domain can be mutated to prevent cleavage of the target DNA strand. In some cases, a modified version of the foregoing Cas protein comprises one or more mutations that disrupt cleavage activity. In some cases, a Cas protein with disrupted cleavage activity is catalytically inactive or catalytically dead. In some cases, the catalytically dead mutations occur in the RuvC domain and the HNH domain of the wild type Cas9 protein. In some cases, the catalytically inactive mutations correspond to the D10A mutation and the H840A mutation of the wild type Cas9 protein.
[0109] In some cases, a CRISPR system is a Class 2 CRISPR system. A Class 2 CRISPR system can be a Class 2 type II CRISPR system, a Class 2 type V CRISPR system, or a Class 2 type VI CRISPR system. A Class 2 type II CRISPR system can comprise a Cas9 domain (also known as Csnl and Csxl2). A Cas9 domain can be a SpyCas9, a GeoCas9, a SauCas9, a KhuCas9, a AinCas9, an FmaCas9, a SgaCas9, a ScCas9, a SauriCas9 domain. A Cas9 domain can be a hyperactive Cas9 domain. A Class 2 type V CRISPR system can comprise a Casl2 domain. A Casl2 domain can be a Casl2a, a Casl2b, a Casl2bl, a Casl2c, a Casl2d, a Casl2e, a Casl2f, a Cas 12g, a Casl2h, a Casl2i, a Casl2j, a Cas 12k, a Cas 121, or a Cas 12m domain. A Class 2 type VI CRISPR system can comprise a Casl3 domain.
[0110] In some cases, a CRISPR system comprises a circularly permuted Cas9.
[OHl] In some cases, a CRISPR system comprises CjCas9, Casl3a, Casl3b, Casl3c, or Casl3d. In some cases, a CRISPR system comprises Casl4, xCas9, or SpCas9-NG.
[0112] In some cases, a CRISPR-Cas domain comprises one or more subdomains. For example, a Cas9 domain can comprise a Reel, a Rec2, a Rec3, a RuvC, an HNH, or a Wedge/PAM- interacting domain. A Casl2 domain can comprise a Reel, Rec2, a crRNA oligonucleotide binding domain (OBD), a Nuc domain, a PAM-interacting (PI) domain, or a RuvC domain. In some cases, the RuvC domain comprises nuclease activity. In some cases, the HNH domain
comprises nuclease activity. The PAM-interacting domain can bind to a protospacer adjacent motif (PAM) sequence that is next to a target sequence in a target nucleic acid molecule. PAM recognition can help activate a nuclease domain to make a cut at the target sequence. In some cases, a CRISPR protein or domain is an engineered or mutated variant of a protein involved in a CRISPR system. An engineered or mutated CRISPR domain can comprise a truncation, a deletion of a part of one or more domains or subdomains, or a mutation of an active site (e.g., a RuvC active site or HNH active site). In some cases, a CRISPR domain with a mutation of one or more active sites is catalytically inactive (e.g., dCas9). In some cases, a CRISPR domain with one or more mutated active sites comprises less than 90%, less than 80%, less than 70%, less than 60%, less than 50%, less than 40%, less than 30%, less than 20%, less than 10%, less than 5%, or less than 1% of the nuclease activity of its wildtype counterpart. For example, a dCas9 can result from the point mutations D10A in the RuvC domain and the point mutation H840A in the HNH domain. In other cases, a mutation can result in a CRISPR nickase. A nickase can generate nick or a single- stranded cut. A nickase can generate a nick in the strand complementary to the RNA guide (e.g., the targeting strand) or in the strand on the non-targeting strand. For example, a RuvC mutation D10A in a Cas9 domain can produce a Cas9 nickase domain that nicks the targeting strand. An HNH mutation H840A in a Cas9 domain can produce a Cas9 nickase domain that nicks the non-targeting strand.
[0113] A Cas protein can comprise one or more domains. Examples of domains include, guide nucleic acid recognition and/or binding domain, nuclease domains (e.g., DNase or RNase domains, RuvC, HNH), DNA binding domain, RNA binding domain, helicase domains, proteinprotein interaction domains, and dimerization domains. A guide nucleic acid recognition and/or binding domain can interact with a guide nucleic acid. A nuclease domain can comprise catalytic activity for nucleic acid cleavage. A nuclease domain can lack catalytic activity to prevent nucleic acid cleavage. A Cas protein can be a chimeric Cas protein that is fused to other proteins or polypeptides. A Cas protein can be a chimera of various Cas proteins, for example, comprising domains from different Cas proteins.
[0114] In some cases, a CRISPR system comprises an Argonaute (Ago) domain.
[0115] Another example of a Cas protein that can be used as part of the prime editor includes Casl4. A Casl4 protein or polypeptide (also termed as “CasZ” protein or polypeptide) can bind and/or modify (e.g., cleave, nick, methylate, demethylate, etc.) a target nucleic acid and/or a polypeptide associated with target nucleic acid (e.g., methylation or acetylation of a histone tail) (e.g., in some cases the CasZ protein includes a chimeric partner with an activity, and in some cases the CasZ protein provides nuclease activity). In some cases, the Casl4 protein or polypeptide is a naturally occurring protein (e.g., naturally occurs in prokaryotic cells) (e.g., a
-n-
CasZ protein). In other cases, the Casl4 protein or polypeptide not a naturally occurring polypeptide (e.g., the Casl4 protein is a variant Casl4 protein, a chimeric protein, and the like). A Casl4 protein includes 3 partial RuvC domains (RuvC-I, RuvC-II, and RuvC-III, also referred to herein as subdomains) that are not contiguous with respect to the primary amino acid sequence of the Cast 4 protein but form a RuvC domain once the protein is produced and folds. A naturally occurring Cast 4 protein functions as an endonuclease that catalyzes cleavage at a specific sequence in a targeted nucleic acid (e.g., a double stranded DNA (dsDNA)). The sequence specificity is provided by the associated guide RNA, which hybridizes to a target sequence within the target DNA. The naturally occurring Casl4 guide RNA is a crRNA, where the crRNA includes (i) a guide sequence that hybridizes to a target sequence in the target DNA and (ii) a protein binding segment that binds to the Cast 4 protein. Examples of Cast 4 proteins include those described U.S. Patent Publication Nos. US20200172886 and US20210214697, Harrington LB etal., Science. 2018 Nov 16;362(6416):839-842; Aquino- Jarquin G. Nanomedicine. 2019 Jun; 18:428-431; each of which is incorporated herein by reference in its entirety. In some cases, the donor sequence disclosed herein encodes Casl4 polypeptide or a nucleic acid molecule encoding Casl4 polypeptide. In some cases, the donor sequence disclosed herein encodes Casl4a polypeptide. In some cases, the donor sequence disclosed herein encodes Casl4b polypeptide. In some cases, the donor sequence disclosed herein encodes Cast 4c polypeptide.
[0116] A Cas protein can be from any suitable organism. Examples include Streptococcus pyogenes, Streptococcus thermophilus, Streptococcus sp., Staphylococcus aureus, Nocardiopsis dassonvillei, Streptomyces pristinae spiralis, Streptomyces viridochromo genes, Streptomyces viridochromogenes, Streptosporangium roseum, Streptosporangium roseum, AlicyclobacHlus acidocaldarius, Bacillus pseudomycoides, Bacillus selenitireducens, Exiguobacterium sibiricum, Lactobacillus delbrueckii, Lactobacillus salivarius, Microscilla marina, Burkholderiales bacterium, Polaromonas naphthalenivorans, Polaromonas sp., Crocosphaera watsonii, Cyanothece sp., Microcystis aeruginosa, Pseudomonas aeruginosa, Synechococcus sp., Acetohalobium arabaticum, Ammonifex degensii, Caldicelulosiruptor becscii, Candidatus Desulforudis, Clostridium botulinum, Clostridium difficile, Finegoldia magna, Natranaerobius thermophilus, Pelotomaculum thermopropionicum, Acidithiobacillus caldus, Acidithiobacillus ferrooxidans, Allochromatium vinosum, Marinobacter sp., Nitrosococcus halophilus, Nitrosococcus watsoni, Pseudoalteromonas haloplanktis, Ktedonobacter racemifer, Methanohalobium evestigatum, Anabaena variabilis, Nodularia spumigena, Nostoc sp., Arthrospira maxima, Arthrospira platensis, Arthrospira sp., Lyngbya sp., Microcoleus chthonoplastes, Oscillatoria sp., Petrotoga mobilis, Thermosipho africanus, Acaryochloris marina, Leptotrichia shahii, Leptotrichia wadeii, Leptotrichia wadeii F0279, Rhodobacter
capsulatus SB 1003, Rhodobacter capsulatus R121, Rhodobacter capsulatus DE442, Lachnospiraceae bacterium NK4A179, Lachnospiraceae bacterium MA2020, Clostridium aminophilum DSM 10710, Paludibacter propionicigenes WB4, Carnob acterium gallinarum DMS4847, Carnobacterium gallinarum DSM4847, and Francisella novici da. In some aspects, the organism is Streptococcus pyogenes (S. pyogenes). In some aspects, the organism is Staphylococcus aureus (S. aureus). In some aspects, the organism is Streptococcus thermophilus (S. therm ophilus).
[0117] A Cas protein can be derived from a variety of bacterial species including Veillonella atypical, Fusobacterium nucleatum, Filifactor alocis, Solobacterium moorei, Coprococcus catus, Treponema denticola, Peptoniphilus duerdenii, Catenib acterium mitsuokai, Streptococcus mutans, Listeria innocua, Listeria seeligeri, Listeria weihenstephanensis FSL R90317, Listeria weihenstephanensis FSL M60635, Staphylococcus pseudintermedius, Acidaminococcus intestine, Olsenella uli, Oenococcus kitaharae, Bifidobacterium bifidum, Lactobacillus rhamnosus, Lactobacillus gasseri, Finegoldia magna, Mycoplasma mobile, Mycoplasma gallisepticum, Mycoplasma ovipneumoniae, Mycoplasma canis, Mycoplasma synoviae, Eubacterium rectale, Streptococcus thermophilus, Eubacterium dolichum, Lactobacillus coryniformis subsp. Torquens, Ilyobacter polytropus, Ruminococcus albus, Akkermansia muciniphila, Acidothermus cellulolyticus, Bifidobacterium longum, Bifidobacterium dentium, Corynebacterium diphtheria, Elusimicrobium minutum, Nitratifractor salsuginis, Sphaerochaeta globus, Fibrobacter succinogenes subsp. Succinogenes, Bacteroides fragilis, Capnocytophaga ochracea, Rhodopseudomonas palustris, Prevotella micans, Prevotella ruminicola, Fl avob acterium columnare, Aminomonas paucivorans, Rhodospirillum rubrum, Candidatus Puniceispirillum marinum, Verminephrobacter eiseniae, Ralstonia syzygii, Dinoroseobacter shibae, Azospirillum, Nitrobacter hamburgensis, Bradyrhizobium, Wolinella succinogenes, Campylobacter jejuni subsp. Jejuni, Helicobacter mustelae, Bacillus cereus, Acidovorax ebreus, Clostridium perfringens, Parvibaculum lavamentivorans, Roseburia intestinalis, Neisseria meningitidis, Pasteurella multocida subsp. Multocida, Sutterella wadsworthensis, proteobacterium, Legionella pneumophila, Parasutterella excrementihominis, Wolinella succinogenes, and Francisella novicida.
[0118] A Cas protein as disclosed herein can be a wildtype or a modified form of a Cas protein. A Cas protein can be an active variant, inactive variant, or fragment of a wild type or modified Cas protein. A Cas protein can comprise an amino acid change such as a deletion, insertion, substitution, variant, mutation, fusion, chimera, or any combination thereof relative to a wildtype version of the Cas protein. A Cas protein can be a polypeptide with at least about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%,
99%, or 100% sequence identity or sequence similarity to a wild type exemplary Cas protein. A Cas protein can be a polypeptide with at most about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% sequence identity and/or sequence similarity to a wild type exemplary Cas protein. Variants or fragments can comprise at least about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity or sequence similarity to a wild type or modified Cas protein or a portion thereof. Variants or fragments can be targeted to a nucleic acid locus in complex with a guide nucleic acid while lacking nucleic acid cleavage activity.
[0119] A Cas protein can comprise one or more nuclease domains, such as DNase domains. For example, a Cas9 protein can comprise a RuvC-like nuclease domain and/or an HNH-like nuclease domain. The RuvC and HNH domains can each cut a different strand of doublestranded DNA to make a double-stranded break in the DNA. A Cas protein can comprise only one nuclease domain (e.g., Cpfl comprises RuvC domain but lacks HNH domain).
[0120] A Cas protein can comprise an amino acid sequence having at least about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity or sequence similarity to a nuclease domain (e.g., RuvC domain, HNH domain) of a wild-type Cas protein.
[0121] A Cas protein can be modified to optimize regulation of gene expression. A Cas protein can be modified to increase or decrease nucleic acid binding affinity, nucleic acid binding specificity, and/or enzymatic activity. Cas proteins can also be modified to change any other activity or property of the protein, such as stability. For example, one or more nuclease domains of the Cas protein can be modified, deleted, or inactivated, or a Cas protein can be truncated to remove domains that are not essential for the function of the protein or to optimize (e.g., enhance or reduce) the activity of the Cas protein for regulating gene expression.
[0122] In some embodiments, the prime editor delivered by the lipid delivery particles of the present disclosure contain a nuclease-null DNA binding protein derived from a DNA nuclease that can induce transcriptional activation or repression of a target DNA sequence. In some embodiments, the donor sequence encodes a nuclease-null RNA binding protein derived from an RNA nuclease that can induce transcriptional activation or repression of a target RNA sequence. For example, a doner sequence can encode a Cas protein which lacks cleavage activity.
[0123] A Cas protein can be a chimeric protein. For example, a Cas protein can be fused to a heterologous functional domain. A heterologous functional domain can comprise a cleavage domain, an epigenetic modification domain, a transcriptional activation domain, or a transcriptional repressor domain. A Cas protein can also be fused to a heterologous polypeptide
providing increased or decreased stability. The fused domain or heterologous polypeptide can be located at the N-terminus, the C-terminus, or internally within the Cas protein.
[0124] The regulation of genes can be of any gene of interest. It is contemplated that genetic homologues of a gene described herein are covered. For example, a gene can exhibit a certain identity and/or homology to genes disclosed herein. Therefore, it is contemplated that a gene that exhibits or exhibits about 50%, 55%, 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% homology (at the nucleic acid or protein level) can be modified. It is also contemplated that a gene that exhibits or exhibits about 50%, 55%, 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 100% identity (at the nucleic acid or protein level) can be modified.
[0125] A Cas protein can be provided in any form. For example, a Cas protein can be provided in the form of a protein, such as a Cas protein alone or complexed with a guide nucleic acid. A Cas protein can be provided in the form of a nucleic acid encoding the Cas protein, such as an RNA (e.g., messenger RNA (mRNA)) or DNA.
[0126] The nucleic acid encoding the Cas protein that is part of the prime editor can be codon optimized for efficient translation into protein in a particular cell or organism.
[0127] In some embodiments, a Cas protein is a dead Cas protein. A dead Cas protein can be a protein that lacks nucleic acid cleavage activity.
[0128] A Cas protein can comprise a modified form of a wild type Cas protein. The modified form of the wild type Cas protein can comprise an amino acid change (e.g., deletion, insertion, or substitution) that reduces the nucleic acid-cleaving activity of the Cas protein. For example, the modified form of the Cas protein can have less than 90%, less than 80%, less than 70%, less than 60%, less than 50%, less than 40%, less than 30%, less than 20%, less than 10%, less than 5%, or less than 1% of the nucleic acid-cleaving activity of the wild-type Cas protein (e.g., Cas9 from S. pyogenes). The modified form of Cas protein can have no substantial nucleic acid-cleaving activity. When a Cas protein is a modified form that has no substantial nucleic acid-cleaving activity, it can be referred to as enzymatically inactive and/or “dead” (abbreviated by “d”). A dead Cas protein (e.g., dCas, dCas9) can bind to a target polynucleotide but may not cleave the target polynucleotide. In some aspects, a dead Cas protein is a dead Cas9 protein.
[0129] A dCas9 polypeptide can associate with a guide nucleic acid molecule (e.g., PEgRNA) to activate or repress transcription of target DNA. Guide nucleic acid molecules can be introduced into cells expressing the engineered chimeric receptor polypeptide. In some cases, such cells contain one or more different guide nucleic acid molecules that target the same nucleic acid. In other cases, the guide nucleic acid molecules target different nucleic acids in the cell. The nucleic
acids targeted by the guide nucleic acid molecule can be any that are expressed in a cell such as an immune cell. The nucleic acids targeted can be a gene involved in immune cell regulation. In some embodiments, the nucleic acid is associated with cancer. The nucleic acid associated with cancer can be a cell cycle gene, cell response gene, apoptosis gene, or phagocytosis gene. The recombinant guide nucleic acid molecule can be recognized by a CRISPR protein, a nuclease- null CRISPR protein, variants thereof, derivatives thereof, or fragments thereof.
[0130] Enzymatically inactive can refer to a polypeptide that can bind to a nucleic acid sequence in a polynucleotide in a sequence-specific manner, but may not cleave a target polynucleotide. An enzymatically inactive site-directed polypeptide can comprise an enzymatically inactive domain (e.g., nuclease domain). Enzymatically inactive can refer to no activity. Enzymatically inactive can refer to substantially no activity. Enzymatically inactive can refer to essentially no activity. Enzymatically inactive can refer to an activity less than 1%, less than 2%, less than 3%, less than 4%, less than 5%, less than 6%, less than 7%, less than 8%, less than 9%, or less than 10% activity compared to a wild-type exemplary activity (e.g., nucleic acid cleaving activity, wild-type Cas9 activity).
[0131] One or a plurality of the nuclease domains (e.g., RuvC, HNH) of a Cas protein can be deleted or mutated so that they are no longer functional or comprise reduced nuclease activity (e.g., deactivated or dead Cas, i.e., “dCas”). For example, in a Cas protein comprising at least two nuclease domains (e.g., Cas9), if one of the nuclease domains is deleted or mutated, the resulting Cas protein, known as a nickase, can generate a single-strand break at a CRISPR RNA (crRNA) recognition sequence within a double-stranded DNA but not a double-strand break. Such a nickase can cleave the complementary strand or the non-complementary strand, but may not cleave both. If all of the nuclease domains of a Cas protein (e.g., both RuvC and HNH nuclease domains in a Cas9 protein; RuvC nuclease domain in a Cpfl protein) are deleted or mutated, the resulting Cas protein can have a reduced or no ability to cleave both strands of a double-stranded DNA. An example of a mutation that can convert a Cas9 protein into a nickase is a D10A (aspartate to alanine at position 10 of Cas9) mutation in the RuvC domain of Cas9 from S. pyogenes. H939A (histidine to alanine at amino acid position 839) or H840A (histidine to alanine at amino acid position 840) in the HNH domain of Cas9 from S. pyogenes can convert the Cas9 into a nickase. An example of a mutation that can convert a Cas9 protein into a dead Cas9 is a D10A (aspartate to alanine at position 10 of Cas9) mutation in the RuvC domain and H939A (histidine to alanine at amino acid position 839) or H840A (histidine to alanine at amino acid position 840) in the HNH domain of Cas9 from S. pyogenes.
[0132] A dead Cas protein can comprise one or more mutations relative to a wild-type version of the protein. The mutation can result in less than 90%, less than 80%, less than 70%, less than
60%, less than 50%, less than 40%, less than 30%, less than 20%, less than 10%, less than 5%, or less than 1% of the nucleic acid-cleaving activity in one or more of the plurality of nucleic acidcleaving domains of the wild-type Cas protein. The mutation can result in one or more of the plurality of nucleic acid-cleaving domains retaining the ability to cleave the complementary strand of the target nucleic acid but reducing its ability to cleave the non-complementary strand of the target nucleic acid. The mutation can result in one or more of the plurality of nucleic acidcleaving domains retaining the ability to cleave the non-complementary strand of the target nucleic acid but reducing its ability to cleave the complementary strand of the target nucleic acid. The mutation can result in one or more of the plurality of nucleic acid-cleaving domains lacking the ability to cleave the complementary strand and the non-complementary strand of the target nucleic acid. The residues to be mutated in a nuclease domain can correspond to one or more catalytic residues of the nuclease. For example, residues in the wild type exemplary S. pyogenes Cas9 polypeptide such as Asp 10, His840, Asn854 and Asn856 can be mutated to inactivate one or more of the plurality of nucleic acid-cleaving domains (e.g., nuclease domains). The residues to be mutated in a nuclease domain of a Cas protein can correspond to residues Asp 10, His840, Asn854 and Asn856 in the wild type S. pyogenes Cas9 polypeptide, for example, as determined by sequence and/or structural alignment.
[0133] As examples, residues D10, G12, G17, E762, H840, N854, N863, H982, H983, A984, D986, and/or A987 (or the corresponding mutations of any of the Cas proteins) can be mutated. For example, e.g., D10A, G12A, G17A, E762A, H840A, N854A, N863A, H982A, H983A, A984A, and/or D986A. Mutations other than alanine substitutions can be suitable.
[0134] A D10A mutation can be combined with one or more of H840A, N854A, or N856A mutations to produce a Cas9 protein substantially lacking DNA cleavage activity (e.g., a dead Cas9 protein). A H840A mutation can be combined with one or more of D10A, N854A, or N856A mutations to produce a site-directed polypeptide substantially lacking DNA cleavage activity. A N854A mutation can be combined with one or more of H840A, D10A, or N856A mutations to produce a site-directed polypeptide substantially lacking DNA cleavage activity. A N856A mutation can be combined with one or more of H840A, N854A, or D10A mutations to produce a site-directed polypeptide substantially lacking DNA cleavage activity.
[0135] In some cases, a dCas9 can be fused to other proteins. In some cases, dCas9 can be fused to SunTag, KRAB, VPS4, P3000, VPR, VP64, V64-p65-Rta, VP160, VP192, HDAC1, DNMT3A, TET1, SPH, KRAB-MeCP2, epigenetic regulators, or other proteins. In some cases, a dCas9 fusion comprises a ZIM3 KRAB-Cas9 fusion. In some cases, a Cas9 fusion can be a paired dCas9 system. In some cases, the dCas9 can be part of a SAM system or REDMAP
system. Examples of Cas9 variants and fusion proteins can be found in Li, T. et al., Sig Transduct Target Ther 8, 36 (2023), which is incorporated in its entirety.
[0136] In some embodiments, a Cas protein is a Class 2 Cas protein. In some embodiments, a Cas protein is a type II Cas protein. In some embodiments, the Cas protein is a Cas9 protein, a modified version of a Cas9 protein, or derived from a Cas9 protein. For example, a Cas9 protein lacking cleavage activity. In some embodiments, the Cas9 protein is a Cas9 protein from S. pyogenes (e.g., SwissProt accession number Q99ZW2). In some embodiments, the Cas9 protein is a Cas9 from S. aureus e.g., SwissProt accession number J7RUA5). In some embodiments, the Cas9 protein is a modified version of a Cas9 protein from S. pyogenes or S. Aureus. In some embodiments, the Cas9 protein is derived from a Cas9 protein from S. pyogenes or S. Aureus. For example, a S. pyogenes or S. Aureus Cas9 protein lacking cleavage activity.
[0137] Cas9 can generally refer to a polypeptide with at least about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% sequence identity and/or sequence similarity to a wild type exemplary Cas9 polypeptide (e.g., Cas9 from S. pyogenes . Cas9 can refer to a polypeptide with at most about 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% sequence identity and/or sequence similarity to a wild type exemplary Cas9 polypeptide (e.g., from S. pyogenes}. Cas9 can refer to the wildtype or a modified form of the Cas9 protein that can comprise an amino acid change such as a deletion, insertion, substitution, variant, mutation, fusion, chimera, or any combination thereof.
[0138] In some embodiments, a guidable polypeptide domain is a Cas9 or variant thereof. In some embodiments, the Cas9 or variant thereof is a nuclease active Cas9 domain, a nuclease inactive Cas9 domain, or a Cas9 nickase domain or a variant thereof. In some embodiments, a guidable polypeptide domain is Cas9, Casl2e, Casl2d, Casl2a, Casl2bl, Casl3a, Casl2c, or Argonaute (Ago domain), any of which optionally has a nickase activity. In some embodiments, a guidable polypeptide domain comprises an amino acid sequence at least 80%, 85%, 90%, 95%, or 99% identical to any one of sequences listed in Table 10 below. In some embodiments, a guidable polypeptide domain comprises an amino acid sequence at least 80%, 85%, 90%, 95%, or 99% identical to any one of sequences set forth in SEQ ID NOs: 1000-1020. In some cases, a guidable polypeptide domain is a Cas9 H840A nickase. In some cases, a guidable polypeptide domain is Cas9 D10A nickase. Cas9-H840A. In some cases, a guidable polypeptide domain is a Casl2a/b nickase.
Table 10. Exemplary guidable polypeptide domain sequences









Polymerase
[0139] In some cases, the payload in the present disclosure comprises a polymerase (e.g., reverse transcriptase). A polymerase can comprise a natural or an engineered domain. A polymerase can be capable of synthesizing nucleic acids. A polymerase can be a DNA polymerase or an RNA polymerase. In some cases, a polymerase is a reverse transcriptase. A reverse transcriptase can synthesize DNA from deoxyribonucleotides. In some cases, a reverse transcriptase adds deoxyribonucleotides to the 3’ end of a nucleic acid primer to synthesize DNA. In some cases, a reverse transcriptase uses an RNA template and uses base-pairing interactions to synthesize a DNA strand that is complementary to the RNA template. The reverse transcriptase domain can be a reverse transcriptase from any organism, phage, virus, or an engineered or mutated variant. The reverse transcriptase domain can be a reverse transcriptase derived from or sharing structural or sequencing similarity to a reverse transcriptase in a CRISPR system. The reverse transcriptase can be an M-MLV or HIV reverse transcriptase. The reverse transcriptase can be a human LINE- 1 reverse transcriptase or a group II intron reverse transcriptase. The reverse transcriptase can be a human endogenous retrovirus reverse transcriptase.
Transposase domain
[0140] In some cases, a nucleic-acid modifying effector or a nucleic acid-binding moiety comprises a transposase domain. A transposase domain can be a natural or an engineered domain. A transposase domain can be capable of aiding the translocation of a transposable
element, a nucleic acid sequence that can change its position within a genome. In some cases, a transposase domain comprises a TnsA, a TnsB, a TnsC, or a TnsD domain. In some cases, a transposase domain comprises a TniQ domain. In some cases, a transposase domain is derived from or shares sequence or structural similarity with a transposase in a CRISPR system (e.g., a CRISPR-associated transposase). In some cases, a transposase domain is derived from or share sequence or structural similarity with a transposase domain from a type I CRISPR-associated transposon (CAST) system. In some cases, transposase domain is derived from or share sequence or structural similarity with a transposase domain from a type V CRISPR-associated transposon (CAST) system. A transposase domain can be capable of binding to a guidable polypeptide domain. In some cases, a transposase domain is coupled to a guidable polypeptide domain. In some cases, a transposase domain is capable of binding to a type I CRISPR-Cas domain (e.g., a Cascade domain, a Cas8 domain, or a Cas5 domain). In some cases, a transposase domain is capable of binding to a type V CRISPR-Cas domain (e.g., a Casl2 domain). In some cases, a transposase domain is capable of mediating targeted insertion of a nucleic acid into a target nucleic acid. In some cases, a transposase domain is capable of mediating targeted insertion of a nucleic acid that is at least 5 kb, at least 6 kb, at least 7 kb, at least 8kb, at least 9kb, at least lOkb, at least 1 Ikb, at least 12kb, at least 13kb, at least 14kb, or at least 15 kb into a target nucleic acid.
Transcriptional regulatory domain
[0141] In some cases, the payload comprises a transcriptional regulatory domain. A transcriptional regulatory domain can be a natural or an engineered domain. A transcriptional regulatory domain can be capable of regulating, activating, or inhibiting gene expression. For example, a transcriptional repressor can silence gene expression by binding to the promoter of a gene. A transcriptional activator can bind to enhancers or regulatory elements to activate expression of a gene. A transcriptional regulatory domain can comprise a transcription factor. A transcriptional regulatory domain can comprise a transcriptional activation domain or a transcriptional repression domain. For example, a transcriptional activation domain can be or comprise a CAP domain, a VP64 domain, a p65 domain, an Rta domain, a synergistic activation mediator (SAM) domain, a SunTag domain, a VPR domain, a DNA demethylase domain, a histone methyltransferase domain, a histone acetyltransferase domain, or a histone demethylase domain. A transcriptional repression domain can be or comprise a dCas9 domain, a KRAB domain, a Sin3 interacting domain (SID), or a MePC2 domain, a DNA methyltransferase domain, a histone deacetylase domain, a histone methyltransferase domain, or a histone demethylase domain. In some cases, a transcriptional regulatory domain comprises an epigenetic modifying effector domain. For example, an epigenetic modifying effector can be a DNA
methyltransferase, a DNA demethylase, a histone methyltransferase, a histone demethylase, a histone acetyltransferase, or a histone deacetylase domain. A DNA methyltransferase domain can be capable of methylating a nucleic acid. A DNA demethylase domain can be capable of demethylating a nucleic acid. A histone methyltransferase domain can be capable of methylating a histone. A histone demethylase domain can be capable of demethylating a histone. A histone acetyltransferase domain can be capable of adding an acetyl group to a histone. A histone deacetylase domain can be capable of removing an acetyl group from a histone.
Zinc finger domain
[0142] In some embodiments, the payload comprises a zinc finger domain. A zinc finger domain can be a natural or an engineered domain. A zinc finger domain can bind to a specific DNA sequence in a target nucleic acid. A zinc finger domain can comprise from 1 to 10, from 2 to 10, from 3 to 10, from 4 to 10, from 5 to 10, from 6 to 10, from 7 to 10, from 8 to 10, from 9 to 10 zinc fingers, from 1 to 8, from 2 to 8, from 3 to 8, from 4 to 8, from 5 to 8, from 6 to 8, from 7 to 8, from 8 to 8, from 9 to 8 zinc fingers. In some cases, a zinc finger domain comprises a two- handed zinc finger domain. A two handed zinc finger domain can comprise two clusters of zinc finger domains that are separated by intervening amino acids. A two handed zinc finger domain can bind to two noncontiguous target DNA sequences. In some cases, the spacing between the two noncontiguous target sequences comprises from 1 to 15, from 1 to 12, from 1 to 10, from 1 to 8, or from 1 to 5 nucleotides. For example, a two handed type of zinc finger binding protein can be SIP1. A cluster of zinc finger domains in a two handed zinc finger domain can be capable of binding to a unique target nucleic acid sequence.
[0143] TALE domain
[0144] In some embodiments, the payload comprises a TALE domain. A TALE domain can be a natural or an engineered domain. A TALE domain can bind to a specific DNA sequence. A TALE domain can comprise one or more effector domains. A TALE effector domain can comprise a central repeat domain comprising tandem repeats. A tandem repeat can comprise repeat variable residues (RVD). One or more RVDs can detect a specific DNA base. Different TALE effector domains may have a different number of repeats and a different order of their repeats. The C-terminal repeat is usually shorter in length (e.g., about 20 amino acids). Sequential repeats and their RVDs can recognize sequential DNA bases.
[0145] A TALE domain described herein can be derived from a TALE effector from a bacterial species. The TALE domain can be engineered to target a given nucleic acid sequence based on their DNA base specificities. The TALE domain can be engineered to remove or add a TALE effector domain. In some cases, the TALE domain corresponds to a perfect match to a nucleic
acid target sequence. In some cases, the TALE domain of an epigenetic effector corresponds to one or more mismatches to a target base in the target nucleic acid.
Fusion protein
[0146] In some cases, the payload in the present disclosure comprises a fusion protein. A fusion protein can comprise two or more polypeptide domains of any of the polypeptide domains described elsewhere herein. A fusion protein can be a natural or an engineered fusion protein. In some cases, the two or more polypeptide domains are coupled together. The two or more polypeptide domains can be coupled together directly or coupled together indirectly. For example, a first polypeptide domain can be coupled directly to a second polypeptide domain. Alternatively, the first polypeptide domain can be coupled indirectly to the second polypeptide domain by coupling with a third polypeptide domain that is coupled directly to the second polypeptide domain. In some cases, a first polypeptide domain is coupled to the N-terminus of a second polypeptide domain. In some cases, a first polypeptide domain is coupled to the C- terminus of a second polypeptide domain. In some cases, a first polypeptide domain is coupled to an internal component of a second polypeptide domain. In some cases, the two or more polypeptide domains are covalently linked. In some cases, the two or more polypeptide domains are noncovalently linked. In some cases, the two or more polypeptide domains are coupled together by a linker. For example, a linker may be a peptide linker. A linker can be a rigid linker, which helps maintain a fixed distance between the polypeptide domains that it links. A linker can be a flexible linker, which can allow some flexibility in movement of one polypeptide domain relative to the other polypeptide domain that it is linked to. In some cases, a linker is a cleavable linker. For example, a cleavable linker can comprise a disulfide bond. Alternatively, a cleavable linker can be an enzymatic cleavable linker, e.g., a linker comprising a protease cleavage site. [0147] The present disclosure provides fusion proteins comprising a guidable polypeptide domain (e.g., a CRISPR domain). A fusion protein comprising a guidable polypeptide domain (e.g., a CRISPR domain) can comprise one or more of a FokI domain, a deaminase domain, a reverse transcriptase domain, an RNA binding domain, a transcriptional regulatory domain, a plasma membrane recruitment domain, a transmembrane domain, a signaling domain, a receptor domain, a packaging domain, or a targeting domain.
[0148] In some cases, the present disclosure provides a fusion protein comprising a guidable polypeptide domain (e.g., a CRISPR domain) coupled to a deaminase domain. A guidable polypeptide domain (e.g., a CRISPR domain) coupled to a deaminase domain can be used for base editing. A base editor can be capable of editing a nucleic acid sequence in a target nucleic acid molecule. A base editor can be capable of enabling the generation of base conversions or point mutations in a target nucleic acid. For example, a cytosine base editor can comprise a
guidable polypeptide domain (e.g., a CRISPR domain) and a cytidine deaminase domain. An adenine base editor can comprise CRISPR domain and an adenosine deaminase domain. In some cases, a base editor enables the conversion of C to G, A to I, or C to U. A cytosine base editor can be capable of enabling the conversion of a C-G base pair to a T-A base pair. A glycosylase base editor can be capable of enabling the conversion of a G-C base pair to a C-G base pair or a G-T base pair. An adenine base editor can be capable of enabling the conversion of an A-T base pair to a G-C base pair. In some cases, a base editor comprises a catalytically inactive guidable polypeptide domain (e.g., a CRISPR domain) (e.g., dCas9, dCasl2a, or dCasl3b). In other cases, the base editor comprises a guidable polypeptide nickase domain (e.g., nCas9). In some cases, the base editor enables a base pair conversion without introducing a double-stranded break. In some cases, the base editor enables base pair conversions in a target window. In some cases, the base editor comprises a targeting window of from 1 to 20 bases, from 1 to 19 bases, from 1 to 18 bases, from 1 to 17 bases, from 1 to 16 bases, from 1 to 15 bases, from 1 to 14 bases, from 1 to 13 bases, from 1 to 12 bases, from 1 to 11 bases, from 1 to 10 bases, from 1 to 9 bases, from 1 to 8 bases, from 1 to 7 bases, from 1 to 6 bases, from 1 to 5 bases, from 1 to 4 bases, from 1 to 3 bases, or from 1 to 2 bases. In some cases, a base editor has a targeting window of from 3 to 10 bases, from 3 to 9 bases, from 3 to 8 bases, from 3 to 7 bases, from 3 to 6 bases, from 3 to 5 bases, or from 3 to 4 bases. In some cases, the guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the N-terminus of a deaminase domain. In some cases, the guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the C-terminus of a deaminase domain. In some cases, the guidable polypeptide domain (e.g., a CRISPR domain) is coupled to an internal component of a deaminase domain.
[0149] In some cases, the fusion protein comprises a guidable polypeptide domain (e.g., a CRISPR domain) coupled to a reverse transcriptase domain. A guidable polypeptide domain (e.g., a CRISPR domain) coupled to a reverse transcriptase can be capable of enabling prime editing. A prime editor can be capable of editing a nucleic acid sequence in a target nucleic acid molecule. A prime editor can be capable of mediating insertion or deletion of a nucleic acid sequence in a target nucleic acid molecule. In some cases, the prime editor enables a sequence insertion or sequence deletion without introducing a double-stranded break. In some cases, the prime editor introduces a nick at the target site. The prime editor can enable insertion of a template sequence in a target nucleic acid molecule. The template sequence can comprise the desired edit. In some cases, a prime editor reverse transcribes a template sequence to synthesize a complementary strand. In some cases, the synthesized complementary strand is inserted in the target nucleic acid molecule. In some cases, the prime editor uses a primer to carry out reverse transcription. The prime editor can install nucleotides to the 3’ end of a primer strand. In some
cases, a primer strand is generated by nicking the target nucleic acid molecule. In some cases, nicking a strand of the target nucleic acid molecule produces a flap with a 3’ OH group. In some cases, the prime editor uses the flap with the 3’ OH group as the primer to carry out reverse transcription. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the N-terminus of a reverse transcriptase domain. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the C-terminus of a reverse transcriptase domain. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to an internal component of a reverse transcriptase domain.
[0150] In some cases, the fusion protein comprises a guidable polypeptide domain (e.g., a CRISPR domain) coupled to a transcriptional regulatory domain. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to a transcriptional regulatory domain. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to a transcriptional activation domain. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to a transcriptional repression domain. In some cases, guidable polypeptide domain (e.g., a CRISPR domain) is coupled to a transcriptional regulatory domain. A guidable polypeptide domain (e.g., a CRISPR domain) coupled to a transcriptional regulatory domain can be capable of enabling CRISPR interference (CRISPRi) or CRISPR activation (CRISPRa). In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) can be coupled to a transcriptional regulatory domain such as P3000 or DNMT3. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to the C-terminus of a transcriptional regulatory domain. In some cases, a guidable polypeptide domain (e.g., a CRISPR domain) is coupled to an internal component of a transcriptional regulatory domain. Any of the payloads described herein can further comprise a plasma membrane recruitment domain, transmembrane domain, a signaling domain, a receptor domain, a packaging domain, or a targeting domain. Any of payloads described herein can comprise or be engineered to comprise a protein tag, a peptide tag, or small molecule tag. For example, a payload can comprise a small nuclear localization signal (NLS), a nuclear export signal (NES), a cell penetrating peptide (CPP), a mitochondria penetrating peptide (MPP), a solubility tag, or a fluorescent tag.
Base editor
[0151] In some cases, the payload to be delivered by the lipid containing particles of the present disclosure comprises a nucleobase editor (also termed as “base editor”) or one or more components of a nucleobase editing (also termed as “base editing”) complex.
[0152] The term “base editor (BE), ” or “nucleobase editor (NBE),” as used herein, can refer to an agent comprising a polypeptide that is capable of making a modification to a base (e.g., A, T, C, G, or U) within a nucleic acid sequence (e.g., DNA or RNA). In some embodiments,
the base editor is capable of deaminating a base within a nucleic acid. In some embodiments, the base editor is capable of deaminating a base within a DNA molecule. In some embodiments, the base editor is capable of deaminating an adenosine (A) in DNA. In some embodiments, the base editor is capable of deaminating a cytosine (C) in DNA. In some embodiments, the base editor is capable of converting a guanine (G) in DNA through a glycoylase.
[0153] In some cases, the payload in the present disclosure comprises a deaminase domain. The deaminase domain can be a natural or an engineered domain. A deaminase domain can be capable of carrying out deamination reactions in DNA. A deaminase domain can be capable of enabling the generation of base conversions or point mutations in a target nucleic acid. For example, a deaminase domain can be a cytidine deaminase domain or an adenosine deaminase domain. A cytidine deaminase domain can be capable of converting cytosine to uracil. A cytidine deaminase domain can be capable of enabling the conversion of a C-G base pair to a T-A base pair. For example, a cytidine deaminase can be or comprise a APOB EC 1 cytidine deaminase. An adenosine deaminase domain can be capable of converting an adenosine to hypoxanthine. An adenosine deaminase domain can be capable of converting an adenosine to an inosine. An adenosine deaminase can comprise TadA or a TadA mutant. In some embodiments, TadA comprises a monomer. In some embodiments, TadA comprises a heterodimer comrpsiing a wildtype TadA and a mutated Tad A. In some embodiments, TadA comprises a homodimer comprising two wildtype TadA domains or two mutated TadA domains. An adenosine deaminase domain can be capable of enabling the conversion of an A-T base pair to a G-C base pair. A deaminase domain can be a mutated variant. In some cases, a deaminase domain enables the conversion of C to G, A to I, or C to U.
[0154] In some cases, the payload in the present disclosure comprises a glycosylase domain. The glycosylase domain can be a natural or an engineered domain. A glycosylase-based guanine base editor can be designed to remove G, and the AP site generated is repaired by translesion synthesis and/or DNA replication, leading to G-to-C or G-to-T conversion. A glycosylase domain can be capable of enabling the generation of base conversions or point mutations in a target nucleic acid. For example, a glycosylase domain can be a guanine glycosylase domain. Examples of glycosylase base edits can be found in Sun N, et al., Mol Ther. 2022 Jul 6;30(7):2452-2463 and Huawei Tong, et al., National Science Review, Volume 10, Issue 8, August 2023, each of which is incorporated in its entirety herein.
[0155] In some cases, the base editor disclosed herein comprises a deaminase or a functional domain thereof (“deaminase domain”) that catalyzes deamination reaction.
[0156] The term "deaminase" or "deaminase domain," as used herein, refers to a protein or enzyme that catalyzes a deamination reaction. In some embodiments, the deaminase or
deaminase domain is an adenosine deaminase, catalyzing the deamination of adenosine, converting it to the nucleoside hypoxanthine. In some embodiments, the deaminase or deaminase domain is a cytidine deaminase, catalyzing the hydrolytic deamination of cytidine or deoxycytidine to uridine or deoxyuridine, respectively. In some embodiments, the deaminase or deaminase domain is a cytidine deaminase domain, catalyzing the hydrolytic deamination of cytosine to uracil. In some embodiments, the deaminase or deaminase domain is a naturally- occurring deaminase from an organism, such as a human, chimpanzee, gorilla, monkey, cow, dog, rat, or mouse. In some embodiments, the deaminase or deaminase domain is a variant of a naturally-occurring deaminase from an organism, that does not occur in nature. For example, in some embodiments, the deaminase or deaminase domain is at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75% at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to a naturally-occurring deaminase from an organism.
[0157] As used herein, an “adenosine deaminase” is an enzyme that catalyzes the deamination of adenosine, converting it to the nucleoside hypoxanthine. Under standard Watson-Crick hydrogen bond pairing, an adenosine base hydrogen bonds to a thymine base (or a uracil in case of RNA). When adenine is converted to hypoxanthine, the hypoxanthine undergoes hydrogen bond pairing with cytosine. Thus, a conversion of “A” to hypoxanthine by adenosine deaminase will cause the insertion of “C” instead of a “T” during cellular repair and/or replication processes. Since the cytosine “C” pairs with guanine “G”, the adenosine deaminase in coordination with DNA replication causes the conversion of an A»T pairing to a C»G pairing in the double-stranded DNA molecule.
[0158] In some embodiments, the base editor is a chimeric protein comprising a nucleic acid programmable R/DNA binding protein (napR/DNAbp) fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase) domain. The term “nucleic acid programmable D/RNA binding protein (napR/DNAbp)” refers to any protein that can associate (e.g., form a complex) with one or more nucleic acid molecules (i.e., which can broadly be referred to as a “napR/DNAbp-programming nucleic acid molecule” and includes, for example, guide RNA in the case of Cas systems) which direct or otherwise program the protein to localize to a specific target nucleotide sequence (e.g., a gene locus of a genome, or an RNA molecule) that is complementary to the one or more nucleic acid molecules (or a portion or region thereof) associated with the protein, thereby causing the protein to bind to the nucleotide sequence at the specific target site. This term napR/DNAbp embraces CRISPR Cas9 proteins, as well as Cas9 equivalents, homologs, orthologs, or paralogs, whether naturally occurring or non-naturally occurring (e.g., engineered or recombinant), and can include a Cas9 equivalent from any type of
CRISPR system (e.g., type II, V, VI), including Cpfl (a type-V CRISPR-Cas systems), C2cl (a type V CRISPR-Cas system), C2c2 (a type VI CRISPR-Cas system) and C2c3 (a type V CRISPR-Cas system). Further Cas-equivalents are described in Makarova et al., “C2c2 is a single-component programmable RNA-guided RNA-targeting CRISPR effector,” Science 2016; 353(6299), the contents of which are incorporated herein by reference. However, the nucleic acid programmable R/DNA binding protein (napR/DNAbp) that can be used in connection with this disclosure are not limited to CRISPR-Cas systems. The present disclosure embraces any such programmable protein, such as the Argonaute protein from Natronobacterium gregoryi (NgAgo) which can also be used for DNA-guided genome editing. NgAgo-guide DNA system does not require a PAM sequence or guide RNA molecules, which means genome editing can be performed simply by the expression of generic NgAgo protein and introduction of synthetic oligonucleotides on any genomic sequence. See Gao F, Shen X Z, Jiang F, Wu Y, Han C. DNA- guided genome editing using the Natronobacterium gregoryi Argonaute. Nat Biotechnol 2016; 34(7):768-73, which is incorporated herein by reference.
[0159] In some cases, the napR/DNAbp is derived from a nuclease disclosed herein, such as, Cas9 (e.g, dCas9 and nCas9), CasX, CasY, Cast 4, Cpfl, C2cl, C2c2, C2c3, Argonaute protein, or a variant thereof. In some embodiments, the base editor comprises a Cas9 (e.g., dCas9 and nCas9), CasX, CasY, Cpfl, C2cl, C2c2, C2c3, or Argonaute protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises a Cas9 nickase (nCas9) fused to an deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises a CasX protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises a nuclease-inactive Cas9 (dCas9) fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises a CasY protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises a Casl4 protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises a Cpfl protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises a C2cl protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises a C2c2 protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises a C2c3 protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase). In some embodiments, the base editor comprises an Argonaute protein fused to a deaminase (e.g., cytidine deaminase or adenosine deaminase).
[0160] In some embodiments, the adenosine deaminases provided herein are capable of deaminating adenosine. In some embodiments, the adenosine deaminases provided herein are capable of deaminating adenosine in a deoxyadenosine residue of DNA. The adenosine deaminase can be derived from any suitable organism (e.g., E. coli). In some embodiments, the adenosine deaminase is a naturally-occurring adenosine deaminase that includes one or more mutations corresponding to any of the mutations provided herein (e.g., mutations in ecTadA). One of skill in the art will be able to identify the corresponding residue in any homologous protein and in the respective encoding nucleic acid by methods well known in the art, e.g., by sequence alignment and determination of homologous residues. Accordingly, one of skill in the art would be able to generate mutations in any naturally-occurring adenosine deaminase (e.g., having homology to ecTadA) that corresponds to any of the mutations described herein, e.g., any of the mutations identified in ecTadA. In some embodiments, the adenosine deaminase is from a prokaryote. In some embodiments, the adenosine deaminase is from a bacterium. In some embodiments, the adenosine deaminase is from Escherichia coli, Staphylococcus aureus, Salmonella typhi, Shewanella putrefaciens, Haemophilus influenzae, Caulobacter crescentus, or Bacillus subtilis. In some embodiments, the adenosine deaminase is from E. coli.
[0161] In some cases, the deaminase domain of the base editor disclosed herein is derived from a cytidine deaminase. In some cases, the cytidine deaminase domain is derived from the apolipoprotein B mRNA-editing complex (APOBEC) family deaminase, such as APOBEC1 deaminase, APOBEC2 deaminase, APOBEC3A deaminase, APOBEC3B deaminase, APOBEC3C deaminase, APOBEC3D deaminase, APOBEC3F deaminase, APOBEC3G deaminase, or APOBEC3H deaminase. In some cases, the cytidine deaminase is a modification of an APOBEC family deaminase. In some cases, the cytidine deaminase is an evolved derivative of an APOBEC family deaminase.
[0162] In some embodiments, the base editor comprises BE1, BE2, BE3, BE4, BE4max, or another base editor variant. In some embodiments, the base editor comprises BE4max (R33 A) AUGI-hUNG complex (CGBE1).
[0163] In some embodiments, the base editor is fused to, or further comprises as part of a chimeric protein, an inhibitor of base excision repair, for example, a uracil clycosylase inhibitor (UGI) domain. In some embodiments, the base editor is fused to one, two, or three UGI domains. In some embodiments, the base editor is fused to one or more UGI domains. In some embodiments, a UGI domain reduces off target effects, specifically the conversion of C to G or C to A.
[0164] In some cases, the base editor disclosed herein is a chimeric protein that comprises a structure such as, NH2-[deaminase domain]-[napR/DNAbp]-[UGI domain]-COOH; NH2-
[deaminase domain]-[napR/DNAbp]-[UGI]-[UGI]-COOH; NH2- [deaminase domain]- [napR/DNAbp]-[UGI]-COOH; NH2-[UGI]-[ deaminase domain]-[napR/DNAbp]-COOH; NH2- [deaminase domain]-[UGI]-[napR/DNAbp]-COOH; NH2-[napR/DNAbp]-[UGI]-[deaminase domain]-COOH; or NH2-[napR/DNAbp]-[deaminase domain]-[UGI]-COOH; wherein each instance of comprises an optional linker.
[0165] In some cases, the base editor is fused to, or further comprises as part of a chimeric protein, a uracil binding protein (UBP). The term “uracil binding protein” or “UBP,” as used herein, refers to a protein that is capable of binding to uracil. In some embodiments, the uracil binding protein is a uracil modifying enzyme. In some embodiments, the uracil binding protein is a uracil base excision enzyme. In some embodiments, the uracil binding protein is a uracil DNA glycosylase (UDG). In some embodiments, a uracil binding protein binds uracil with an affinity that is at least 1%, 2%, 3%, 5%, 10%, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, or at least 95% of the affinity that a wild type UDG (e.g., a human UDG) binds to uracil. The term “base excision enzyme” or “BEE,” as used herein, refers to a protein that is capable of removing a base (e.g., A, T, C, G, or U) from a nucleic acid molecule (e.g., DNA or RNA). In some embodiments, a BEE is capable of removing a cytosine from DNA. In some embodiments, a BEE is capable of removing a thymine from DNA. Exemplary BEEs include, without limitation UDG Tyrl47Ala, and UDG Asn204Asp as described in Sang et al., “A Unique Uracil-DNA binding protein of the uracil DNA glycosylase superfamily,” Nucleic Acids Research, Vol. 43, No. 17 2015; the entire contents of which are hereby incorporated by reference.
[0166] In some embodiments, the UBP is a uracil modifying enzyme. In some embodiments, the UBP is a uracil base excision enzyme. In some embodiments, the UBP is a uracil DNA glycosylase. In some embodiments, the UBP is any of the uracil binding proteins provided herein. For example, the UBP can be a UDG, a UdgX, a UdgX*, a UdgX On, or a SMUG1. In some embodiments, the UBP comprises an amino acid sequence that is at least 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 99.5% identical to a uracil binding protein, a uracil base excision enzyme or a uracil DNA glycosylase (UDG) enzyme.
[0167] In some cases, the base editor is fused to, or comprises as a part of the chimeric protein, a nucleic acid polymerase domain (NAP). For instance, the nucleic acid polymerase domain is a eukaryotic nucleic acid polymerase domain. In some cases, the nucleic acid polymerase domain is a DNA polymerase domain. In some cases, the nucleic acid polymerase domain has translesion polymerase activity. In some cases, the nucleic acid polymerase domain is a translesion DNA polymerase. In some cases, the nucleic acid polymerase domain is from Rev7, Revl complex, polymerase iota, polymerase kappa, and polymerase eta. In some cases, the
nucleic acid polymerase domain is selected from the group of eukaryotic polymerases consisting of alpha, beta, gamma, delta, epsilon, gamma, eta, iota, kappa, lambda, mu, and nu.
[0168] In some cases, the base editor disclosed herein is a chimeric protein that comprises a structure such as, NH2-[deaminase domain] -[napR/DNAbp domain]-[UBP]-[NAP]-COOH; NH2- [deaminase domain]-[napR/DNAbp]-[NAP]-[UBP]-COOH; NH2- [deaminase domain] -[NAP] - [napR/DNAbp]-[UBP]-COOH; or NH2-[NAP]-[ deaminase domain]-[napR/DNAbp]-[UBP]- COOH; wherein each instance of ‘-” comprises an optional linker.
[0169] In some cases, the base editor disclosed herein is complexed with a napR/DNAbp- programming nucleic acid molecule. In some cases, the base editing system disclose herein comprises a base editor and a napR/DNAbp-programming nucleic acid molecule, e.g., the base editor complexed with the napR/DNAbp-programming nucleic acid molecule. In some cases, the lipid containing particles of the present disclosure deliver a base editing system that comprises both a base editor and a napR/DNAbp-programming nucleic acid molecule, e.g., the base editor complexed with the napR/DNAbp-programming nucleic acid molecule. In some cases, a base editor is delivered separately from the napR/DNAbp-programming nucleic acid molecule through lipid containing particles disclosed herein, or together with other delivery methods, into a cell. [0170] The term “napR/DNAbp-programming nucleic acid molecule” or equivalently “guide sequence” refers the one or more nucleic acid molecules which associate with and direct or otherwise program a napR/DNAbp protein to localize to a specific target nucleotide sequence (e.g., a gene locus of a genome) that is complementary to the one or more nucleic acid molecules (or a portion or region thereof) associated with the protein, thereby causing the napR/DNAbp protein to bind to the nucleotide sequence at the specific target site. An example is a guide RNA of a Cas protein of a CRISPR-Cas genome editing system.
[0171] Exemplary configurations, sequences, and mutations thereof for deaminase domains, napR/DNAbp domains, UGI domains, and whole base editor proteins, and exemplary configurations of a base editing system (e.g., comprising both a base editor and a napR/DNAbp- programming nucleic acid molecule) that can be delivered by a lipid containing particle disclosed herein include those described in U.S. Patent Publication Nos. US20170121693, US20180073012, US20180312828, US20180170984, US2020010835, US2020172931, US20210230577, US20210198330, US20210277379, US2020399626, US2021371858, US2021380955, US2021277379, US2021301274, US20220127622, US20220313799, US20230055682, US20230159913, US20230086199, US20220127622, US20220313799, US20230279373, US20230055682, each of which is incorporated herein by reference in its entirety. Exemplary configurations, sequences, and mutations thereof for deaminase domains, napR/DNAbp domains, UGI domains, and whole base editor proteins, that can be delivered by a
lipid containing particle disclosed herein also include those described in Komor AC et al. Nature. 2016 May 19;533(7603):420-4; Kim YB et al. Nat Biotechnol. 2017 Apr;35(4):371-376; Rees HA et al. Nat Commun. 2017 Jun 6;8: 15790; Newby GA et al. Mol Ther. 2021 Nov
3;29(11):3107-3124; Huang TP et al. Nat Protoc. 2021 Feb;16(2): 1089-1128; Lapinaite A et al. Science. 2020 Jul 31;369(6503):566-571; Anzalone AV et al. Nat Biotechnol. 2020
Jul;38(7): 824-844; Rees HA et al. Nat Rev Genet. 2018 Dec;19(12):770-788; Koblan LW et al. Nat Biotechnol. 2018 Oct;36(9):843-846; and Gaudelli NM et al. Nature. 2017 Nov 23;551(7681):464-471; each of which is incorporated herein by reference in its entirety.
Prime editor
[0172] In some cases, the lipid delivery particles disclosed herein is capable of delivering a payload, such as a prime editing system, or one or more components thereof, such as a ribonucleoprotein (RNP) complex, into a cell in vitro, ex vivo, or in vivo. In some embodiments, the prime editing system, or one or more components thereof, is within the inside cavity of the protein core of the lipid delivery particles disclosed herein.
[0173] Prime editing system is a ‘search-and-replace’ genome editing technology by which the genome of living organisms can be modified. The term "prime editing system" or "prime editor (PE)" refers the compositions involved in genome editing using target-primed reverse transcription (TPRT) describe herein, can comprise a nucleic acid-guided polypeptide, e.g., nucleic acid-guided polypeptide, a nucleic acid polymerase, chimeric proteins (e.g., comprising guidable polypeptide domain and reverse transcriptase), guide nucleic acid molecule (e.g., guide RNAs), and complexes comprising fusion proteins and guide RNAs, as well as accessory elements, such as second strand nicking components and 5' endogenous DNA flap removal endonucleases (e.g., FEN1) for helping to drive the prime editing process towards the edited product formation.
[0174] In some embodiments, the prime editing system disclosed herein comprises a ribonucleoprotein (RNP) complex. In some cases, the RNP complex comprises a prime editor and a guide nucleic acid molecule. In some cases, the prime editor is formed between one or more proteins and one or more polynucleotides. The prime editor can comprise a nucleic acid- guided polypeptide. The guidable polypeptide domain can comprise a nucleic acid-guided polypeptide, for example a nuclease (e.g., a Cas protein). For instance, the prime editor can comprise a fusion protein, comprising a nucleic acid programmable R/DNA binding protein (e.g., a nuclease, such as a Cas protein) and a nucleic acid polymerase (e.g., a reverse transcriptase or any suitable DNA polymerase). In some cases, the nucleic acid polymerase is coupled to the nucleic acid-guided polypeptide. In some cases, the guide nucleic acid molecule can comprise a guide nucleic acid molecule, e.g., a guide RNA. In some cases, the prime editor is operably
linked to the guide nucleic acid molecule via a linker, forming the RNP complex. In some cases, the prime editor is directly linked to the guide nucleic acid molecule, forming the RNP complex. [0175] In a specific instance, prime editing system comprises a fusion protein that comprises an engineered Cas9 nickase and a reverse transcriptase, and the fusion protein is paired with an engineered prime editing guide RNA (PEgRNA). In some cases, the PEgRNA can direct Cas9 to a target site within a host cell where the lipid delivery particles are delivered. In some cases, the peg RNA can encode the information for installing the desired edit. In some cases, the prime editing system can function through a multi-step process: 1) the Cas9 domain can bind and nick the target genomic DNA site, which is specified by a spacer sequence in the PEgRNA; 2) the reverse transcriptase can use the nicked genomic DNA as a primer to initiate synthesis of an edited DNA strand using an engineered extension on the PEgRNA as a template for reverse transcription, which can generate a single-stranded 3' flap containing the edited DNA sequence; 3) cellular DNA repair mechanism can resolve the 3' flap intermediate by the displacement of a 5' flap species that occurs via invasion by the edited 3' flap, excision of the 5' flap containing the original DNA sequence, and ligation of the new 3' flap to incorporate the edited DNA strand, forming a heteroduplex of one edited and one unedited strand; and 4) cellular DNA repair mechanism can replace the unedited strand within the heteroduplex using the edited strand as a template for repair, which completes this editing process. In some embodiments, the prime editing machinery edits a target DNA molecule. In some embodiments, the prime editing machinery edits a target RNA molecule. Examples of targeting RNA molecules using prime editing are described in international patent application WO2021072328 and U.S. Patent Application number US20230357766, each of which is incorporated in its entirety. In other instances, a prime editing system is a multi-flap prime editing system that can simultaneously edit both DNA strands. For example, a dual-flap prime editing system comprises two PEgRNAs, which can be used to target opposite strands of a genomic site and direct the synthesis of two complementary 3’ flaps containing edited DNA sequence. The pair of edited DNA strands (3’ flaps) does not need to directly compete with 5’ flaps in endogenous genomic DNA, as the complementary edited strand is available for hybridization instead. In this instance, both strands of the duplex are synthesized as edited DNA, the dual-flap prime editing system obviates the need for the replacement of the non-edited complementary DNA strand. Instead, cellular DNA repair machinery can only excise the paired 5’ flaps (original genomic DNA) and ligate the paired 3’ flaps into the locus.
[0176] In some embodiments, a prime editing system can be paired with a separate Cas9 nickase and a separate gRNA that nicks the DNA at a locus that is different than the locus targeted by the PEgRNA. In some embodiments, one or more prime editing systems can be paired, each
targeting a different locus. In some cases, pairing of two prime editing systems, each of which targets a different locus on the same chromosome, can install large insertions, deletions, or modifications. In some cases, pairing of two prime editing systems, each of which targets a different locus, can install large structural modifications. In some embodiments, a prime editor can install up to 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 modifications. In some embodiments, a prime editor can install 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, or more modifications. In some embodiments, a prime editor can install up to about 25, about 30, about 35, about 40, about 45, about 50, about 55, about 60, about 65, about 70, about 75, about 80, about 85, about 90, about 95, or about 100 modifications. In some embodiments, a prime editor can install more than about 25, about 30, about 35, about 40, about 45, about 50, about 55, about 60, about 65, about 70, about 75, about 80, about 85, about 90, about 95, or about 100 modifications. In some cases, a prime editor can install more than 100 modifications. In some embodiments, more than one prime editor can be used to install mutations more than 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, or more modifications. In some embodiments, more than one prime editor can be used to install mutations more than about 25, about 30, about 35, about 40, about 45, about 50, about 55, about 60, about 65, about 70, about 75, about 80, about 85, about 90, about 95, or about 100 modifications. In some embodiments, more than one prime editor can be used to install mutations more than about Ikb, 5kb, lOkb, 20kb, 30kb, 40kb, 50kb, 60kb, 70kb, 80kb, 90kb, or more.
[0177] Different variants of prime editors have been developed, such as prime editors (PE) PEI, PE2, PE3, PE4, or PE5, some of which are described in Liu, D. et al., Nature 2019, 576, 149-157 and Huang Z, Liu G. Front Bioeng Biotechnol. 2023;l 1 : 1039315, U.S. Patent Application numbers US20210292769, US20230090221, US2022078655, US20230220374, each of which is hereby incorporated by reference herein in its entirety. In some cases, the prime editor comprises a reverse transcriptase (RT) fused with Cas9 H 840A nickase (Cas9n (H840A)) and a primeediting guide RNA (pegRNA). In some cases, the RT comprises an RNA-dependent DNA polymerase. In some cases, the RT comprises a protein derived from a retrovirus. In some embodiments, the RT comprises Moloney Murine Leukemia Virus (M-MMLV) RT. In some embodiments, the RT comprises a RT from HFV, LtrA, HERV-Kcon, Tel4c, Marathon, Gst-IIC, MA-INT5, or another RT ortholog. In some cases, the RT is modified, mutated, truncated, or evolved. In some cases, the RT comprises a full length RT protein. In some cases, the RT comprises a truncated RT. In some cases, the RT is fused to the Cas protein. In some cases, the RT is fused to the Cas protein at the N terminus to the Cas protein. In some cases, the RT is fused to the Cas protein at the C terminus of the Cas protein. In some cases, the RT is fused to the Cas protein as an inlaid fusion. In some cases, the RT is untethered to the Cas protein. Examples of
prime editing architecture are described in Grunewald, J., et al., Nat Biotechnol 41, 337 -343 (2023) and Gao Z, et al., Mol Ther. 2022; 30(9):2942-2951, each of which is incorporated herein in its entirety.
[0178] In some cases, the prime editor comprises (a) a fusion protein having the following N- terminus to C-terminus structure: [NLS]-[Cas9(H840A)]- [linker]-[MMLV_RT(wt)] and (b) a PEgRNA. In some cases, the prime editor comprises (a) a fusion protein having the following N- terminus to C-terminus structure: [NLS]-[Cas9(H840A)]-[linker]- [MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)] and (b) a PEgRNA. In some cases, the prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [NLS]-[Cas9(H840A)]-[linker]-[MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)]; (b) a PEgRNA; and (c) a nicking guide RNA that introduces a nick in the non-edited DNA strand. In some cases, the addition of nicking guide RNA increases the chances of the unedited strand to be repaired rather than the edited strand. In some cases, the prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [NLS]- [Cas9(H840A)]-[linker]-[MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)]; (b) a PEgRNA; and (c) a nicking guide RNA that is designed with a spacer that matches only the edited strand but not the original allele before editing, so that the nicking guide RNA is not introduced until after the desired edit is installed. In some cases, the prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [NLS]-[Cas9(H840A)]- [linker]-[MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)]; (b) a PEgRNA; and (c) evading specific DNA mismatch repair (MMR) protein, such as co-expression of a dominant negative MMR protein, such as MLHldn e.g., MLH1 A754-756). In some cases, the prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [NLS]-[Cas9(H840A)]-[linker]-[MMLV_RT(D200N)(T330P)(L603W)(T306K) (W313F)]; (b) a PEgRNA; (c) a nicking guide RNA that introduces a nick in the non-edited DNA strand; and (d) evading specific DNA mismatch repair (MMR) protein, such as co-expression of a dominant negative MMR protein, such as MLHldn (e.g, MLH1 A754-756). Evading MMR protein, such as by co-expression of MMR protein MLHldn can increase efficiency of prime editing, as described in International Publication No., WO2023102538 and Chen et al., Cell Volume 184, Issue 22, 28 October 2021, Pages 5635-5652. e29, each of which is hereby incorporated by reference herein in its entirety. An exemplary sequence for MLHldn (MLH1 A754-756) is: MSFVAGVIRRLDETVVNRIAAGEVIQRPANAIKEMIENCLDAKSTSIQVIVKEGGLKLIQI QDNGTGIRKEDLDIVCERFTTSKLQSFEDLASISTYGFRGEALASISHVAHVTITTKTADG KCAYRASYSDGKLKAPPKPCAGNQGTQITVEDLFYNIATRRKALKNPSEEYGKILEVVG RYSVHNAGISFSVKKQGETVADVRTLPNASTVDNIRSIFGNAVSRELIEIGCEDKTLAFK
MNGYISNANYSVKKCIFLLFINHRLVESTSLRKAIETVYAAYLPKNTHPFLYLSLEISPQN VDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKS TTSLTSSSTSGSSDKVYAHQMVRTDSREQKLDAFLQPLSKPLSSQPQAIVTEDKTDISSGR ARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSEKRGPTSSNPRKRHREDSDVEM VEDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWAL AQHQTKLYLLNTTKLSEELFYQILIYDFANFGVLRLSEPAPLFDLAMLALDSPESGWTEE DGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLAT EVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYK ALRSHILPPKHFTEDGNILQLANLPDLYKVF. In some cases, other strategies for evading MMR protein can be adopted, such as installing silent mutations next to the desired edit or coexpressing an antibody targeting the MMR protein. In some cases, the foregoing prime editor comprises (a) a fusion protein having the following N-terminus to C-terminus structure: [bipartite NLSI-[Cas9(R221K)(N394K)(H840A)]-[linker]-[MMLV_RT(D200N)(T330P)(L603W)]- [bipartite NLS]-[NLS] instead. In some cases, the components in the foregoing prime editors are packaged in a single lipid delivery particle. In some cases, the components in the foregoing prime editors are packaged in two or more lipid deliver particles that are delivered to the recipient cell simultaneously. In some cases, the components in the foregoing prime editors are packaged in two or more lipid deliver particles that are delivered to the recipient cell sequentially.
[0179] In some cases, the prime editing system can comprise a flap endonuclease (e.g, FEN1 or variant thereof) that is delivered as a part of the lipid delivery particle (e.g, fused to a plasma membrane recruitment element as a chimeric protein). The flap endonuclease can comprise naturally occurring enzymes that process the removal of 5' flaps formed during cellular processes, including DNA replication. The flap endonuclease includes those described in Patel et al., Nucleic Acids Research, 2012, 40(10): 4507-4519 and Tsutakawa et al., Cell, 2011, 145(2): 198-211, each of which is incorporated herein by reference in its entirety.
[0180] Additional elements that can be delivered as a part of the prime editing system via the lipid delivery particles (e.g., fused to the nucleic acid-guided polypeptide, or fused to plasma membrane recruitment element) described herein include inhibitor of base repair (e.g., proteins that inhibit a nucleic acid repair enzyme, for example, a base excision repair enzyme), uracil glycosylase inhibitor domains (e.g., protein that inhibits a uracil-DNA glycosylase base-excision repair enzyme), epitope tags, and reporter gene sequences, including those described in International Publication No. WO2023205744, which is incorporated herein by reference in its entirety.
Epigenetic editor
[0181] In some cases, the payload to be delivered by the lipid containing particles of the present disclosure comprises an epigenetic editor or one or more components of an epigenetic editing complex (e.g., comprising an epigenetic editor and a nucleic acid molecule that guides the epigenetic editor to bind and/or modify one or more specific target sequences).
[0182] In some cases, the epigenetic editor or epigenetic editing complex disclosed herein has epigenetic activities, such as, methyltransferase activity, demethylase activity, dismutase activity, alkylation activity, depurination activity, oxidation activity, pyrimidine dimer forming activity, integrase activity, transposase activity, recombinase activity, polymerase activity, ligase activity, helicase activity, photolyase activity or glycosylase activity, acetyltransferase activity, deacetylase activity, kinase activity, phosphatase activity, ubiquitin ligase activity, deubiquitinating activity, adenylation activity, deadenylation activity, SUMOylating activity, deSUMOylating activity, ribosylation activity, deribosylation activity, myristoylation activity, remodelling activity, protease activity, oxidoreductase activity, transferase activity, hydrolase activity, lyase activity, isomerase activity, synthase activity, synthetase activity, or demyristoylation activity. In some cases, the epigenetic editor or epigenetic editing complex disclosed herein has a chromosome modification enzyme, or a functional domain that has the functional activity equivalent to a chromosome modification enzyme, such as a methylase, demethylase, acetylase, deacetylase, deaminase, phosphorylase, dephosphorylase, histone modifying enzyme, or nucleotide modifying enzyme. In some cases, the epigenetic editor or epigenetic editing complex disclosed herein has a histone modifying enzyme, or a functional domain that has the functional activity equivalent to a histone modifying enzyme. In some cases, the epigenetic editor or epigenetic editing complex disclosed herein has a nucleotide modifying enzyme, or a functional domain that has the functional activity equivalent to a nucleotide modifying enzyme.
[0183] In some embodiments, the epigenetic editor or epigenetic editing system comprises a protein domain that represses expression of the target gene. For example, the epigenetic editor or epigenetic editing system can comprise a functional domain derived from a zinc finger repressor protein. Sequences of exemplary functional domains of an epigenetic editor or epigenetic editing system that can reduce or silence target gene expression are provided can be found in PCT/US2021/030643 and Tycko et al. (Tycko J, DelRosso N, Hess GT, Aradhana, Banerjee A, Mukund A, Van MV, Ego BK, Yao D, Spees K, Suzuki P, Marinov GK, Kundaje A, Bassik MC, Bintu L. High-Throughput Discovery and Characterization of Human Transcriptional Effectors. Cell. 2020 Dec 23;183(7):2020-2035.el6. doi: 10.1016/j .cell.2020.11.024. Epub 2020 Dec 15. PMID: 33326746; PMCID: PMC8178797.), each of which is incorporated here by reference in its entirety.
[0184] In some embodiments, the epigenetic editor or epigenetic editing system makes an epigenetic modification at a target gene that activates expression of the target gene. In some embodiments, the epigenetic editor or epigenetic editing system modifies the chemical modification of DNA or histone residues associated with the DNA at a target gene harboring the target sequence, thereby activating or increasing expression of the target gene. In some embodiments, the epigenetic editor or epigenetic editing system comprises a DNA demethylase, a DNA dioxygenase, a DNA hydroxylase, or a histone demethylase domain.
Nucleic acids and polynucleotides
[0185] In some cases, the lipid delivery particle of the present disclosure comprises a payload comprising a nucleic acid. The nucleic acid as a payload can comprise or be composed of one or more nucleotides. Nucleotides are referred to by their commonly accepted single-letter codes: A represents adenine, C represents cytosine, G represents guanine, T represents thymine, U represents uracil, I represents inosine. Unless otherwise indicated, nucleotide sequences are written from left to right in a 5' to 3' orientation. In some cases, the nucleic acid as a payload comprises a polynucleotide. The nucleic acid as a payload can comprise DNA or RNA. In some cases, the nucleic acid as a payload comprises or encodes a gene. The nucleic acid as a payload can comprise or encode any of the polynucleotides described elsewhere herein. The nucleic acid as a payload can be a vector encoding any of the polypeptide domains described elsewhere herein. In some cases, the nucleic acid as a payload is an engineered polynucleotide.
[0186] In some cases, the payload does not comprise a repair template. In some cases, the double stranded break is repaired through non-homologous end joining. In some cases, the payload comprises a repair template. The repair template can be double-stranded or single-stranded. The repair template can comprise a template sequence comprising a desired edit to be introduced in a target nucleic acid molecule. In some cases, the repair template is a homology-directed repair template. A homology-directed repair template can comprise a homology arm that is homologous to a sequence in the target nucleic acid. In some cases, the payload comprises a DNA-synthesis template comprising a DNA-synthesis template sequence. The DNA-synthesis template can comprise a desired edit to be introduced in a target nucleic acid molecule. The DNA-synthesis template can be a template for a DNA polymerase or a reverse transcriptase to carry out DNA synthesis. For example, in prime editing, a prime editor can use the DNA synthesis template sequence to synthesize a DNA strand that is complementary to the DNA synthesis template sequence. In some cases, the DNA strand is inserted into the target nucleic acid. In some cases, the nucleic acid comprising the DNA synthesis template sequence also comprises a primerbinding sequence. A primer-binding sequence can be complementary to a sequence in a primer strand to which a DNA polymerase or reverse transcriptase can add nucleotides. In some cases,
the primer strand is part of a target nucleic acid molecule. A primer-binding sequence can be complementary to a sequence in the target nucleic acid.
[0187] In some cases, the payload comprises a double-stranded DNA containing a desired gene sequence to be inserted in the target nucleic acid molecule. In some cases, the double-stranded DNA is configured to couple to a transposase domain. In some cases, the payload is delivered in the same particle as the transposase domain. In some cases, the payload is delivered in a separate particle as the transposase domain.
[0188] In some cases, the payload comprises a polynucleotide that is configured to bind to a guidable polypeptide domain. In some cases, the polynucleotide directs a guidable polypeptide domain to a sequence in a target nucleic acid molecule. In some cases, the polynucleotide comprises a scaffold segment configured to bind to a guidable polypeptide domain (e.g., Cas9 or Casl2). In some cases, polynucleotide comprises a spacer sequence that is complementary to a target sequence in the target nucleic acid molecule and is capable of hybridizing to the target sequence. The polynucleotide can be a natural molecule or an engineered or synthetic molecule. The polynucleotide can be derived or share sequence or structural similarities to CRISPR RNA (crRNA), a tracrRNA, or a scoutRNA encoded in a CRISPR system. In some cases, the polynucleotide is engineered to be a single RNA guide (sgRNA) comprising elements of the crRNA and the tracrRNA. In some cases, the polynucleotide comprises a scaffold segment and a spacer sequence. The scaffold segment can be configured to bind to a guidable polypeptide domain. The scaffold segment can be specific to a specific type of guidable polypeptide (e.g., Cas9 or Casl2). In some cases, the spacer sequence is programmed to be any sequence. In some cases, the spacer sequence is programmed to a sequence complementary to a target nucleic acid sequence.
[0189] In some cases, the payload comprises a polynucleotide that is a guide nucleic acid molecule for a prime editing system, e.g., a prime editing guide RNA (PEgRNA). In some cases, the PEgRNA is capable of (i) identifying a target nucleotide sequence to be edited, and (ii) encoding new genetic information that replaces the targeted sequence. In some cases, a guide nucleic acid molecule for a prime editing system comprises two or more guide RNAs. In some cases, a guide nucleic acid molecule for a prime editing system comprises a nicking guide RNA. In some cases, a guide RNA comprises (A) a primer binding site, (B) a clamp segment, (C) a sequence encoding new genetic information that replaces the targeted sequence, (D) an aptamer, (E) spacer, or (F) scaffold, or any combinations thereof. In some cases, a guide RNA comprises a sequence encoding new genetic information that replaces the targeted sequence, a spacer, and scaffold. In some cases, a guide RNA comprises a spacer and scaffold. In some cases, the guide nucleic acid molecule is heterologous to the cell or host receiving the lipid delivery particle.
[0190] In some cases, the PEgRNA comprises an extended single guide RNA (sgRNA) containing a primer binding site (PBS) and a template sequence for nucleic acid polymerase (e.g., reverse transcriptase or DNA polymerase). For example, a PEgRNA can comprise an architecture corresponding to 5'-[spacer]-[guide RNA core]-[extension arm]-3'. The spacer sequence can comprise about 20 nucleotides in length. The spacer sequence can bind to a protospacer in a target nucleic acid molecule. The spacer sequence can guide the nucleic acid-guided polypeptide (e.g., Cas9) to the target nucleic acid molecule. The guide RNA core can be responsible for binding of the nucleic acid-guided polypeptide e.g., Cas9). The extension arm can comprise a primer binding site, an edit template, and a homology arm, in a 3' to 5' direction. The PEgRNA can further comprise, optionally, a 3’ end modifier region, 5’ end modifier region, a transcriptional signal at the 3’ end. The PEgRNA can optionally comprise a secondary structure, such as, hairpins, stem/loops, toe loops, RNA-binding protein recruitment domains e.g., the MS2 aptamer which recruits and binds to the MS2cp protein). In some cases, the PEgRNA comprises an aptamer and the prime editor further comprises an aptamer binding protein e.g., fused to Cas protein or reverse transcriptase). Guide RNAs including an aptamer include those described in International Publication No. W02023205708, which is hereby incorporated herein by reference in its entirety. Homology arm can encode a portion of a resulting reverse transcriptase-encoded single strand DNA flap to be integrated into the target DNA site by replacing the endogenous strand. The portion of the single strand DNA flap encoded by the homology arm is complementary to the non-edited strand of the target DNA sequence, which facilitates the displacement of the endogenous strand and annealing of the single strand DNA flap in its place, thereby installing the edit. The edit template can comprise a sequence corresponding to new genetic information that replaces the targeted sequence, i.e., a single strand RNA of the PEgRNA that codes for a complementary single strand DNA that is either the sense or the antisense strand of the new genetic information that replaces the targeted sequence and which is incorporated into the genomic DNA target locus through the prime editing process.
[0191] In some cases, during genome editing, the primer binding site allows the 3’ end of the nicked DNA strand to hybridize to the PEgRNA, while the reverse transcriptase template serves as a template for the synthesis of edited genetic information. A prime editing system can allow DNA synthesis based on the reverse transcriptase template at a nick site a single 3' flap, which becomes integrated into a target nucleic acid on the same strand. In other embodiments, a prime editing system can be a multi-flap prime editing system that generate pairs or multiple pairs of 3' flaps on different strands, which form duplexes comprising desired edits and which become incorporated into target nucleic acid molecules, e.g., at specific loci or edit sites in a genome. In some embodiments, the pairs or multiple pairs of 3' flaps form duplexes because they comprise
reverse complementary sequences which anneal to one another once generated by the prime editors described herein. The duplexes can be incorporated into the target site by cell-driven mechanisms that naturally replace the endogenous duplex sequences located between adjacent nick sites. In certain embodiments, the new duplex sequences can be introduced at one or more locations (e.g., at adjacent genomic loci or on two different chromosomal locations), and can comprise one or more sequences of interest, e.g., protein-encoding sequence, peptide-encoding sequence, or RNA-encoding sequence.
[0192] In some cases, the payload comprises a polynucleotide comprising a scaffold segment, a spacer sequence, a DNA synthesis template, and a primer-binding sequence. In some cases, the scaffold segment and a spacer sequence are on a first nucleic acid molecule and the DNA synthesis template and the primer-binding sequence are on a second nucleic acid molecule. [0193] In some cases, the guide RNA further comprises a clamp segment. In some cases, the guide RNA comprising, from 3’ to 5’, a primer binding site, a sequence encoding at least a portion of the first recombinase recognition sequence, a clamp segment, scaffold, and spacer. The clamp segment comprises a sequence that, after being reverse transcribed is at least partially complementary to a genomic site close to the primer binding site and where the spacer binds. Without wishing to be bound by a certain theory, the clamp segment can enhance integration efficiency of the new genetic material that replaces the target sequence at the double-stranded target DNA sequence relative to a guide RNA without the clamp segment. The clamp segment can allow for a reduced number of nucleotides in the primer binding site need to bind its genomic site and facilitate reverse transcription, which in turn enables design of a guide RNA that is shorter than conventional guide RNAs used for other gene editing methods. The clamp segment is described in International Publication No. WO2023215831, which is hereby incorporated herein by reference in its entirety.
[0194] In some cases, a guide RNA can complete the insertion of new genetic material that replaces the target sequence without another guide RNA when delivered to a cell together with a prime editor described herein. The guide RNA can complete the insertion of the new genetic material that replaces the target sequence with a second guide RNA that is a nicking guide RNA when delivered together with a prime editor described herein.
[0195] In some cases, a guide RNA comprises two or more guide RNAs. In some cases, the two or more guide RNAs comprise a first guide RNA encoding at least a first portion of new genetic material that replaces the target sequence. In some cases, the two or more guide RNAs comprise a second guide RNA encoding at least a second portion of the new genetic material that replaces the target sequence. In some cases, the first guide RNA and the second guide RNA work in a pair and collectively encode the new genetic material that replaces the target sequence, thereby
inserting the new genetic material that replaces the target sequence into the genome of a cell receiving the lipid delivery particles in a site-specific manner. In some cases, the first and the second portion of the new genetic material that replaces the target sequence have at least 6bp overlap. In some cases, the first portion of the new genetic material that replaces the target sequence is 46 bp. In some cases, the first portion of the new genetic material that replaces the target sequence is 42 bp. In some cases, the first portion or the second portion of the new genetic material that replaces the target sequence is 36 bp, 38 bp, 40 bp, 42 bp, 44 bp, or 46 bp. The first guide RNA comprises a first spacer. The second guide RNA comprises a second spacer. The first spacer and the second spacer bind to two genomic target sites that are within 5-100 bp from each other. When the two or more guide RNAs are delivered to a cell together with a prime editor, the double strand DNA between the two genomic target sites are deleted and the full sequence of the new genetic material that replaces the target sequence is inserted instead. The deletion can be mediated by the following steps: (a) reverse transcription of the sequence encoding the first portion of the new genetic material that replaces the target sequence in the first guide RNA and the sequence encoding the second portion of the new genetic material that replaces the target sequence in the second guide RNA, wherein the first and the second portion of the new genetic material that replaces the target sequence having at least 6bp overlap, (b) annealing of the two overlapped portion of the new genetic material that replaces the target sequence, (c) synthesis of the second strand comprising the full sequence of the new genetic material that replaces the target sequence, (d) excision of the original DNA sequence, and (e) ligation of the pair nicks. The mechanism, process, and components of this process include those described in International Publication Nos. WO2023122764, W02023205710, and WO2023225670, each of which is hereby incorporated herein by reference in its entirety.
[0196] In some cases, the payload comprises a polypeptide domain described herein coupled to a polynucleotide domain described herein. In some cases, the payload comprises a polypeptide domain described herein complexed to a polynucleotide domain described herein. In some cases, the payload comprises a ribonucleoprotein. For example, the payload may comprise a guidable polypeptide domain complexed to a polynucleotide configured to bind to the guidable polypeptide domain (e.g., Cas9 complexed with an RNA guide).
[0197] Any of the payloads described herein can further comprise a plasma membrane recruitment element, a transmembrane domain, a signaling domain, a receptor domain, a packaging domain, or a targeting domain. Any of payloads described herein can comprise or be engineered to comprise a protein tag, a peptide tag, or small molecule tag. For example, a payload can comprise a nuclear localization signal (NLS), a nuclear export signal (NES), a cell
penetrating peptide (CPP), a mitochondria penetrating peptide (MPP), a solubility tag, a fluorescent tag, or any combinations thereof.
Other Payloads
[0198] In some cases, the payload in the lipid delivery particle of the present disclosure comprises a recombinant protein. The payload can be a diagnostic imaging agent, such as a contrast agent. In some cases, the payload comprises a therapeutic agent, including, but not limited to, a nuclease, a recombinase, a growth factor, an antibody, a chimeric antigen receptor, a T cell receptor, a cytokine, a cytokine inhibitor or agonist, a transcription factor, an organelle, a nucleic acid molecule, a therapeutic DNA, a therapeutic RNA, a retrotransposon, a reverse transcriptase, an oligonucleotide, an aptazyme, an aptamer, or a ribozyme, a generic or specific kinase inhibitor, a small molecule drug, an immunomodulator, a tumor suppressor, a developmental regulator, a cancer vaccine, an anesthetic, an enzyme, a hormone, a ligand, a receptor, a T cell receptor, a transposon, a retrotransposon, a DNA polymerase, a RNA dependent DNA polymerase, a homing endonuclease, interferons, chemokines, insulin, growth factors, an antisense oligonucleotide, an RNAi, a shRNA, and any combination thereof. The payload can be a prophylactic agent. In some cases, the payload comprises a biomarker. The payload can also comprise an exogenous antigen or an enzyme. In some cases, the payload comprises a metabolite molecule. In some cases, the payload comprises a lipid molecule. In some cases, the payload comprises a structural protein. In some cases, the payload comprises a hormone or a hormonal protein.
PRODUCTION OF LIPID DELIVERY PARTICLES
[0199] In some aspects, provided herein are composition, methods of production, methods of purification related to the lipid delivery particles provided herein. In some cases, the lipid delivery particles can be produced from producer cell lines that are either transiently transfected with at least one plasmid or stably expressing constructs that have been integrated into the producer cell line genomic DNA.
[0200] Producer cell lines can be generated by stably integrating genetic material with a gene of interest into a host cell line. In some cases, the genetic material is transiently expressed in a producer cell line. In some cases, the genetic material is expressed via viral methods. In some cases, the genetic material is expressed via non-viral methods. In some cases, a producer cell line grows in a serum-free medium or in suspension. A producer cell line can be grown in serum-free medium and suspension simultaneously. In some cases, producer cell lines can be generated with adherent cells (e.g., cells cultured in media and attached to a substrate).
[0201] Producer cells can be used to produce the lipid delivery particles described herein. In some cases, generating a producer cell line comprises transfecting cells (e.g., cells of a
-Im
mammalian cell type) with genetic material of the present disclosure, culturing the cells to produce the lipid delivery particles, obtaining a media from the mammalian cell producing the lipid delivery particles, collecting and filtering the harvested media, and, optionally, purifying the lipid delivery particles to retain structural integrity. In some cases, the method of producing the lipid delivery particle further comprises providing new media to promote transient production of the lipid delivery particles. In some cases, the mammalian cell type includes a HT1080 cell, a COS cell, a HeLa cell, a Chinese Hamster Ovary (CHO) cell, or a HEK 293 cell. HEK293 cells are cells derived from human embryonic kidney cells grown in tissue culture. In some cases, the HEK293 cell is a HEK293, 293E, 293T, 293F, 293FT, or 293T Gesicle cell. The producer cell line can be transformed with a viral vector or non-viral method in any number of means including calcium phosphate and the like.
[0202] Following transfection, the cells can be cultured under conditions for production of lipid delivery particles. Exemplary culturing conditions can include refeeding cells in appropriate media, addition of CO2, and humidity. In some cases, culturing conditions includes addition of antibiotics, anti-fungals, and/or growth factors. The medium can be harvested after 24, 48, 72, or 96 hours, or at any appropriate time point to allow sufficient production of the lipid delivery particles.
[0203] Optionally, the lipid delivery particles in the media can be isolated and collected using any number of techniques known in the art. In some cases, the lipid delivery particles are purified, wherein the lipid delivery particles are washed or resuspended in an appropriate buffer or media or at particular concentration.
[0204] In an aspect, disclosed herein are methods of manufacturing producer cell lines that comprise the lipid delivery particles of the present disclosure. Adherent cells can be first transfected to produce lipid delivery particles. In some cases, transfection occurs by the addition or expression of exogenous nucleic acid sequences via non-viral methods (e.g., by electroporation, microinjection, or a chemical system such as DEAE-dextran or cationic polymers). In some cases, transfection occurs by the addition or expression of exogenous nucleic acid sequences via viral methods (e.g., by infecting the cells with a viral vector, such as an adenoviral vector, adeno-associate viral vector, a lentiviral vector, a herpes viral vector, or a HSV vector). In some cases, the cells are from a HEK293 cell line (e.g., HEK293, 293E, or 293T). In some cases, to transfect DNA into the host cells, the cells are cultured in a medium. In some cases, cells can be cultured in the medium for 5, 10, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24 or 25 hours. In some cases, cells can be cultured in the medium for between 10-20 hours. In some cases, cells can be cultured in the medium for 18 hours.
[0205] Following incorporation into the transfection medium, cells are transferred to a new solution. In some cases, the new solution is new media. In some cases, the new media promotes the production of the lipid delivery particles. In some cases, the cells incorporate into the new media for between 10-50 hours. In some cases, the cells incorporate into the new media for 10, 20, 30, 35, 40, 45, or 50 hours. In some cases, the cells incorporate into the new media for 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39 or 40 hours. The media can then be harvested. The harvested media can be filtered, and the lipid delivery particles can be collected. Filtration can comprise microfiltration and/or depth filtration. In some cases, the lipid delivery particles can undergo further purification and/or concentration methods that maintain the structural integrity of the particles.
[0206] In some aspects, provided herein is a method of loading a lipid delivery particle with components such as a payload. RNA and protein from a producer cell can get packaged and/or incorporated into lipid delivery vehicles of the present disclosure. In some cases, the components of the lipid delivery particles, such as a payload, is loaded via the packaging and assembly process of the lipid delivery particle. For instance, the payload can be a polypeptide or protein that is packaged into the lipid delivery particle as a part of a chimeric protein as disclosed herein. [0207] In some cases, the payload is assembled into the lipid delivery particle as an independent entity, e.g., not as a part of a chimeric protein. In other embodiments, the lipid delivery particle provided herein is loaded with a payload by utilizing any suitable method for delivering a biological or chemical payload through a lipid membrane, such as nucleofection, electroporation, lipid-based, polymer-based, or CaCh transfection, sonication, freeze thaw, incubation at various temperatures, or heat shock of lipid delivery particles mixed with payload. In some cases, the nucleic acid molecules, such as a template RNA described herein, are loaded into the lipid delivery particle by direct loading, such as electroporation of the lipid delivery particle in vitro. In some cases, the nucleic acid molecules are loaded into the lipid delivery particle by binding to a nucleic acid binding protein (e.g., Cas protein) that is part of the lipid delivery particle or is already loaded into the lipid delivery particle.
[0208] There can be more than one type of loading techniques utilized for loading payloads (e.g., for loading more than one type of payloads) into the lipid delivery particle. For instance, in some cases, a first payload is a polypeptide that is assembled into the lipid delivery particle as a part of a chimeric protein, and a second payload is a separate protein or nucleic acid (RNA or DNA) that interacts with (e.g., binds) the first payload, and thus is loaded into the lipid delivery particle via the interaction between the first payload and the second payload. Alternatively, the second payload can be loaded into the lipid delivery particle via a transfection-like technique or any other suitable method.
[0209] In aspects, also provided herein are methods of using a lipid delivery particle or pharmaceutical composition according to some embodiments of the present disclosure, comprising contacting a cell with the lipid delivery particle described herein. In some cases, the cell is a mammalian cell, such as a human cell. In some cases, the cell is within a subject in need of treatment for a disease or a condition. In some cases, contact comprising administering the lipid delivery particle described herein to the subject, such as via injections.
[0210] In aspects, also provided herein are methods of administering a lipid delivery particle, systems, or pharmaceutical compositions according to some embodiments of the present disclosure. In some cases, the method comprises administering the lipid delivery particle, system, or pharmaceutical composition described herein to a subject in need thereof, such as via injections.
[0211] In aspects, also provided herein are methods of producing a lipid delivery particle or pharmaceutical composition according to some embodiments of the present disclosure. In some cases, the method comprises contacting a producer cell with compositions described herein. Methods of purification
[0212] In an aspect, described herein are methods of purifying lipid delivery particles. In some cases, the lipid delivery particles are produced from producer cell lines that are either transiently transfected with at least one plasmid or stably expressing constructs that have been integrated into the producer cell line genomic DNA. In some cases, the producer cell culture medium is harvested 24-, 48-, 72-, or 96-hours post-transfection. In some cases, the producer cell culture medium is harvested between 40- and 48-hours post-transfection. The harvested medium can undergo centrifugation steps to remove producer cell debris while maintaining the structural integrity of the lipid delivery particle. In some cases, during harvesting, the producer cell medium is centrifuged, e.g., at 500g for 5 minutes. The clarified lipid delivery particle containing supernatant can then be collected and filtered. In some cases, the lipid delivery particles are further concentrated. In some cases, the lipid delivery particles are further concentrated by ultracentrifugation. In some cases, the lipid delivery particles are concentrated 50-fold, 100-fold, 200-fold, 500-fold, 1000-fold, 2000-fold, 3000-fold, or 5000-fold. In some cases, the concentrated lipid delivery particles are resuspended, e.g., in cold PBS. In some cases, the concentrated lipid delivery particles are frozen, e.g., frozen at a rate of -l°C/min and stored at -80°C.
[0213] In some cases, the purification methods can comprise chromatographic methods (e.g., anion exchange chromatography), ultrafiltration methods (e.g., tangential flow filtration), clarifying normal flow filtration, and/or sterilizing membrane filtration. Anion exchange chromatography can separate substances based on net-surface charge, using an ion-exchange
resin. Tangential flow filtration can separate molecules using ultrafiltration membranes. In some cases, the membrane pore size used for tangential flow filtration can retain a biological product of a size less than 1000 kDa, less than 750 kDa, less than 500 kDa, less than 250 kDa, less than 200 kDa, less than 150 kDa, less than 100 kDa, or less than 50 kDa. Normal flow filtration assists in the clarification of biofluid by convecting the substance directly toward a membrane under an applied pressure. In some cases, normal flow filtration can comprise a membrane pore size of greater than 0.1 pm, greater than 0.2 pm, greater than 0.3 pm, greater than 0.4 pm, greater than 0.5 pm, greater than 0.6 pm, greater than 0.7 pm, greater than 0.8 pm, greater than 0.9 pm, greater than 1.0 pm, greater than 1.5 pm, or greater than 2.0 pm. In some cases, normal flow filtration can comprise a membrane pore size of 0.2 pm, 0.45 pm, 0.8 pm, 1.2 pm, or 2.0 pm. Sterilizing membrane filtration can be used to sterilize heat-sensitive liquid without exposure to denaturing hear. In some cases, sterilizing membrane filtration can comprise a membrane pore size of about 0.1 pm, about 0.2 pm, about 0.3 pm, about 0.4 pm, or about 0.5 pm. In some cases, sterilizing membrane filtration can comprise a membrane pore size of about 0.2 pm or 0.22 pm. COMPOSITIONS AND SYSTEMS
[0214] In aspects, also provided herein are nucleic acid molecules that encode one or more of the components of the lipid delivery particles of the present disclosure. For instance, a nucleic acid molecule encoding the chimeric protein is provided. A nucleic acid molecule encoding the envelope protein is also provided.
[0215] In aspects, provided herein are compositions or systems that include nucleic acid molecules that encode one or more of the components of the lipid delivery particles of the present disclosure.
[0216] A composition can comprise a first nucleic acid sequence encoding a first chimeric protein described herein and a second nucleic acid sequence encoding a second chimeric protein described herein. A composition can comprise a first nucleic acid sequence encoding a first chimeric protein described herein, a second nucleic acid sequence encoding a second chimeric protein described herein, and a third nucleic acid sequence encoding a third chimeric protein described herein.
[0217] A system can comprise the lipid delivery particles of the present disclosure and a reversible protease inhibitor. In some cases, the protease inhibitor inhibits the protease cleavage. In some cases, the release of payload is delayed until the reversible protease inhibitor is removed from the system. In some cases, the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease. In some cases, the protease inhibitor is selected from the group consisting of Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23,
Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
[0218] The compositions or systems can be used for producing a lipid delivery particle of the present disclosure, for instance, by transfecting or otherwise delivering the nucleic acid molecules in the compositions or systems into a producer cell. The nucleic acid molecules can be expressed in the producer cell, the result of which assemble, package, and subsequently cause the producer cell to release the lipid delivery particle.
[0219] In some cases, a lipid delivery particle of the present disclosure facilitates gene editing efficiency greater than 40%, greater than 50%, greater than 60%, or more. In some cases, a lipid delivery particle of the present disclosure facilitates gene editing efficiency greater than 70%. In some cases, a lipid delivery particle of the present disclosure facilitates gene editing efficiency comprising 8-fold increase of base editing efficiency when compared to a conventional VLP (e.g., the VLPs described in Mangeot, P. E. et al. Genome editing in primary cells and in vivo using viral-derived Nanoblades loaded with Cas9-sgRNA ribonucleoproteins. Nat. Commun. 10, 45 (2019).). In some cases, a lipid delivery particle of the present disclosure facilitates gene editing efficiency comprising 8-fold increase of prime editing efficiency when compared to a conventional VLP. In some cases, a lipid delivery particle of the present disclosure exhibits reduced immunogenicity in transduced target cells. In some cases, a lipid delivery particle of the present disclosure produces reduced off-target genome editing in target cells when delivering genome editing system into the target cells when compared to a conventional VLP. In some cases, a lipid delivery particle of the present disclosure leads to more than 100-fold reduction in Cas-independent off-target editing when compared to a conventional VLP. In some cases, a lipid delivery particle of the present disclosure leads to at least 10-fold, such as 12- to 900-fold, lower Cas-dependent off-target editing when compared to a conventional VLP.
PHARMACEUTICAL COMPOSITION
[0220] In an aspect, disclosed herein is a pharmaceutical formulation comprising the lipid delivery particle disclosed herein and optionally further comprising a pharmaceutically acceptable carrier, excipient, or additive. The term “pharmaceutical formulation”, as used herein, refers to a composition formulated for pharmaceutical use. The terms such as “excipient,” “carrier,” “pharmaceutically acceptable carrier” or the like are used interchangeably herein. Pharmaceutical formulations comprise an immunologically effective amount of one or more cells, vectors, lipid delivery particles, or compositions disclosed herein, and optionally one or more other components which are pharmaceutically acceptable. In some cases, the pharmaceutical formulation comprises additional agents, e.g., for specific delivery, increasing half-life, or other therapeutic benefit. In some cases, the pharmaceutical formulation may
comprise one or more of dimethylsulfoxide (DMSO), dextrose, water, succinate, poly I: poly C, poly-L-lysine, carboxymethylcellulose, and/or chloride.
[0221] As used herein, a “pharmaceutically acceptable carrier” is an agent that is compatible with the other ingredients of the formulation and not injurious to the tissue of the subject (e.g., physiologically compatible, sterile, physiologic pH, etc.) In some cases, a pharmaceutically acceptable carrier comprises any vehicle, such as a liquid or solid filler, diluent, excipient, manufacturing aid (e.g., lubricant, talc magnesium, calcium or zinc stearate, or steric acid), or solvent encapsulating material, involved in carrying or transporting the compound from one site (e.g., the delivery site) of the body, to another site (e.g., organ, tissue or portion of the body). [0222] Some exemplary materials which can serve as pharmaceutically-acceptable carriers include: (1) sugars, such as lactose, glucose and sucrose; (2) starches, such as corn starch and potato starch; (3) cellulose, and its derivatives, such as sodium carboxymethyl cellulose, methylcellulose, ethyl cellulose, microcrystalline cellulose and cellulose acetate; (4) powdered tragacanthin; (5) malt; (6) gelatin; (7) lubricating agents, such as magnesium stearate, sodium lauryl sulfate and talc; (8) excipients, such as cocoa butter and suppository waxes; (9) oils, such as peanut oil, cottonseed oil, safflower oil, sesame oil, olive oil, corn oil and soybean oil; (10) glycols, such as propylene glycol; (11) polyols, such as glycerin, sorbitol, mannitol and polyethylene glycol (PEG); (12) esters, such as ethyl oleate and ethyl laurate; (13) agar; (14) buffering agents, such as magnesium hydroxide and aluminum hydroxide; (15) alginic acid; (16) pyrogen-free water; (17) isotonic saline; (18) Ringer's solution; (19) ethyl alcohol; (20) pH buffered solutions; (21) polyesters, polycarbonates and/or polyanhydrides; (22) bulking agents, such as polypeptides and amino acids; (23) serum alcohols, such as ethanol; and (24) other nontoxic compatible substances employed in pharmaceutical formulations. Wetting agents, coloring agents, release agents, coating agents, sweetening agents, flavoring agents, perfuming agents, preservative and antioxidants can also be present in the formulation.
[0223] Pharmaceutical formulation disclosed herein can comprise one or more pH buffering compounds to maintain the pH of the formulation at a predetermined level that reflects physiological pH, such as in the range of about 5.0 to about 8.0. The pH of the pharmaceutical formulation can be about 4, about 5, about 6, about 7, about 8 or about 9. The pH buffering compound used in the aqueous liquid formulation can be an amino acid or mixture of amino acids, such as histidine or a mixture of amino acids such as histidine and glycine. The pH buffering compound can be an agent which does not chelate calcium ions. Exemplary pH buffering compounds include imidazole and acetate ions. The pH buffering compound can be present in any amount suitable to maintain the pH of the formulation at a predetermined level.
[0224] The pharmaceutical formulations described herein can be prepared by any method known or hereafter developed in the art of pharmacology. In general, such preparatory methods include the step of bringing the active ingredient(s) into association with an excipient and/or one or more other accessory ingredients, and then, optionally, shaping and/or packaging the product into a desired single- or multi-dose unit. Pharmaceutical formulations can additionally comprise a pharmaceutically acceptable excipient, which, as used herein, includes any and all solvents, dispersion media, diluents, or other liquid vehicles, dispersion or suspension aids, surface active agents, isotonic agents, thickening or emulsifying agents, preservatives, solid binders, lubricants, and the like, as suited to the particular dosage form desired.
METHOD OF TREATMENT, PREVENTION, OR DIAGNOSIS
[0225] A lipid delivery particle provided herein can find use in a variety of fields and methods. In some cases, the lipid delivery particle of the present disclosure can be used to deliver one or more payloads, such as a ribonucleoprotein complex to a cell. In some cases, the target cells to which the lipid delivery particles are delivered are in vitro cells, ex vivo cells, or in vivo cells. The lipid delivery particles of the present disclosure can be applicable for delivery of freights into a variety of cell types, such as, animal cells, plant cells, bacteria cells, algal cells, or fungal cells.
[0226] In aspects, also provided herein are methods of treating a subject by administering a lipid delivery particle described herein, a system described herein, a composition described herein, or pharmaceutical composition according to some embodiments of the present disclosure.
[0227] In some cases, the present disclosure provides methods of treating, preventing, or diagnosing a condition, disease, or disorder. In some cases, a composition, kit, or method described herein can be used to treat, prevent, or diagnose a condition, disease, or disorder. The condition, disease, or disorder can comprise a cancer, an immune disorder, an autoimmune disorder, a metabolic disorder, a hormonal disorder, an inflammatory disorder, a developmental disorder, a reproductive disorder, an imprinting disorder, a genetic disorder, a neurological disorder, or a neurodegenerative disorder. In some cases, the condition, disease, or disorder comprises a liver disorder, an eye disorder, a heart disorder, a kidney disorder, a skin disorder, a blood disorder, a fibrotic disorder, a skeletal disorder, or a muscle order. In some cases, the condition, disease, or disorder is caused by a genetic mutation (e.g., an insertion, deletion, or point mutation). In some cases, the condition, disease, or disorder is hereditary. In some cases, the condition, disease, or disorder is caused by a virus or bacteria or fungus. In some cases, the condition, disease, or disorder is caused by aberrant gene expression. In some cases, the condition, disease, or disorder is a result of age. In some embodiments, the condition, disease, or disorder is chronic.
[0228] The subject in the method of present disclosure can be an animal. In some embodiments, the subject is an animal cell. In some embodiments, the subject is a mammal. In some embodiments, the subject is a human. In some embodiments, the subject is an aquaculture animal (fish, crabs, shrimp, oysters etc.), a mammal. In some embodiments, the animals cell is from, for example, a pet or zoo animal (cats, dogs, lizards, birds (e.g., parrots), lions, tigers and bears etc.), from a farm or working animal (horses, cows (e.g., dairy and beef cattle) pigs, chickens, turkeys, hens or roosters, goats, sheep, etc.), or a human. In some embodiments, the target cell as disclosed herein is in a subject to whom the method of the present disclosure is applicable. [0229] The methods described herein can be therapeutic or veterinary methods for treating a subject. In some embodiments, the methods described herein are used to treat a disease resulting from a non-functional, poorly functional, or poorly expressed protein or gene product, for instance, resulting from a genetic mutation in one or more cells of the subject. In some embodiments, the methods described herein are used to treat a genetic disease (e.g., a mutation, a substitution, a deletion, an expansion, or a recombination), a monogenic disease, an inherited metabolic disease, a cancer, a neurodegenerative disease, a cardiovascular disease, a pulmonary disease, a renal disease, a liver disease, a genetic disease, a vascular disease, ophthalmic disease, musculoskeletal disease, lymphatic disease, auditory and inner ear disease, a metabolic disease, an inflammatory disease, an autoimmune disease, or an infectious disease. In some cases, provided herein are pharmaceutical compositions and methods for treating a retinal disease, e.g., Leber congenital amaurosis, by administering a pharmaceutical composition formulated for subretinal injection.
KIT
[0230] In aspects, also provided herein are kits comprising the unit doses containing the lipid delivery particles, systems, compositions or pharmaceutical compositions of the present disclosure. In some embodiments, the kit comprises the lipid delivery particles, compositions, or pharmaceutical formulations of the present disclosure; and an informational medium containing instructions for administering the lipid delivery particle, composition, or pharmaceutical formulation to a subject. The kit can include a label indicating the intended use of lipid delivery particle, composition, or pharmaceutical formulation in the kit. Label can include any writing, or recorded material supplied on or with the kit, or which otherwise accompanies the kit.
[0231] A kit of the present disclosure can include, alternatively or additionally, diagnostic agents and/or other therapeutic agents. In some cases, the kit includes cells or pharmaceutical formulations of the present disclosure and a diagnostic agent that can be used in a diagnostic method for diagnosing a condition, disease, or disorder in a subject.
METHODS OF ADMINISTERING
[0232] In some cases, the composition or pharmaceutical formulation described herein is prepared for administration to a subject. In some cases, the pharmaceutical formulation is prepared to induce a therapeutic or prophylactic effect in a subject. Suitable routes of administrating the pharmaceutical formulation described herein include transdermal, intravesical, intravenous, intravascular, intraosseus, topical, subcutaneous, intradermal, intralesional, intraarticular, intraperitoneal, transmucosal, gingival, intradental, intracochlear, transtympanic, intraorgan, epidural, intrathecal, intramuscular, periocular, intratumoral, intracerebral, intravitreal, and intracerebroventricular administration. In some cases, the pharmaceutical formulation described herein is administered locally to a diseased site (e.g., site of infection or tumor site). In some cases, the pharmaceutical composition described herein is delivered in a controlled release system. In some cases, a pump is used. In some cases, polymeric materials is used for controlled release. In some cases, the pharmaceutical composition described herein is administered to a subject by injection, by means of a catheter, by means of a suppository, or by means of an implant, the implant being of a porous, non-porous, or gelatinous material, including a membrane, such as a sialastic membrane, or a fiber. In some cases, the pharmaceutical formulation is formulated in accordance with routine procedures as a formulation adapted for intravenous or subcutaneous administration to a subject. In some cases, pharmaceutical formulations for administration by injection are solutions in sterile isotonic use as solubilizing agent and a local anesthetic such as lignocaine to ease pain at the site of the injection. Generally, the ingredients can be supplied either separately or mixed together in unit dosage form, for example, as a dry lyophilized powder or water free concentrate in a hermetically sealed container such as an ampoule or sachets indicating the quantity of active agent. In some cases, if the pharmaceutical is to be administered by infusion, it is dispensed with an infusion bottle containing sterile pharmaceutical grade water or saline. In some cases, if the pharmaceutical formulation is administered by injection, an ampoule of sterile water for injection or saline is provided so that the ingredients can be mixed prior to administration.
[0233] A pharmaceutical formulation as described herein can be administered or packaged as a unit dose, for example, in reference to a pharmaceutical formulation to physically discrete units suitable as unitary dosage for the subject, each unit containing a predetermined quantity of active material calculated to produce the desired therapeutic effect in association with the required diluent, carrier, or vehicle.
EXAMPLES
[0234] The following examples are provided to further illustrate some embodiments of the present disclosure but are not intended to limit the scope of the disclosure; it will be understood
by their exemplary nature that other procedures, methodologies, or techniques known to those skilled in the art can alternatively be used.
Example 1: Payload delivery efficiency of the lipid delivery particles in hematopoietic stem cells (HSCs)
[0235] Lipid delivery particles
[0236] chimeric protein with base editors (LDP -BE) are produced by transient transfection of producer cells (e.g. 293T Gesicle cells or 293FT cells). Producer cells are seeded in tissue culture flasks. After 20-24 h, cells are transfected using the jetPRIME transfection reagent (Polyplus) according to the manufacturer’s protocols. The chimeric protein construct is provided in FIGs.2A-B and FIGs 3 A-3E.
[0237] About 48h post-transfection, producer cell supernatant is harvested and centrifuged to remove cell debris. The clarified VLP-containing supernatant is filtered through a filter. LDP- BEs are further concentrated using PEG-it Virus Precipitation Solution or ultracentrifugation. For LDP -BE used in vivo, LDP-BE pellets are resuspended in cold PBS and centrifuged to remove debris. LDP-BEs are frozen store at -80°C. LDP-BEs are thawed on ice immediately prior to use.
Example 2: delivering the lipid delivery particles to the target cell in vitro
[0238] Lipid delivery particles comprising a chimeric protein with base editors (LDP-BE) are produced by transient transfection of producer cells (e.g. 293T Gesicle cells or 293FT cells). Producer cells are seeded in tissue culture flasks. After 20-24 h, cells are transfected using the jetPRIME transfection reagent (Polyplus) according to the manufacturer’s protocols. The chimeric protein construct is provided in FIGs.2A-B and FIGs.3A-3E. A protease inhibitor (e.g., atazanavir) is added to the culture at the time of transfection and up to 24 hours after transfection. [0239] About 48 hours post transfection, producer cell supernatant is harvested and centrifuged to remove cell debris. The protease inhibitor is removed by exchanging the buffer, using chromatography. The clarified VLP-containing supernatant is filtered through a filter. LDP-BEs are further concentrated using PEG-it Virus Precipitation Solution or ultracentrifugation. For LDP-BE used in vivo, LDP-BE pellets are resuspended in cold PBS and centrifuged to remove debris. LDP-BEs are frozen store at -80°C. LDP-BEs are thawed on ice immediately prior to use.
Example 3: delivering the lipid delivery particles to the target cell in vitro
[0240] Target cells (e.g. Hela cells or fibroblast cells) are seeded in tissue culture plates. The cells are allowed to adhere. LDP-BEs are added to the culture medium together with Vectofusin. Cells are incubated at 37°C.
Example 4: assessing the efficiency of payload delivery in vitro
[0241] Western blot analysis
[0242] Target cells transduced with LDP-BEs are lysed. Protein extracts are separated by electrophoresis and transferred to a PVDF membrane. The membrane is blocked for 1 h at room temperature and then is incubated with mouse-anti-Cas9 antibody. The membrane is washed and imaged. The relative amounts of cleaved BE and full-length RIP receptor-BE are quantified by densitometry using ImageJ, and the fraction of cleaved BE relative to total (cleaved + full-length) BE is calculated.
[0243] Cell viability assays
[0244] Target cells treated with LDP-BEs are plated on the wells. CellTiter-Glo reagent is added to each well in the dark. Cells are incubated for 10 min at room temperature and solution is transferred into black 96-well flat bottom plates. The luminescence is measured. The percentage of viable cells in LDP -BE treated wells is calculated by normalizing the luminescence reading from each treatment well to the luminescence of PBS treated negative control cells.
[0245] Gene editing efficiency assays
[0246] Target cells transduced with LDP-BEs are lysed and genomic DNA is harvested for next generation sequencing to quantify gene editing frequency 1 week after transduction.
Example 5: delivering the lipid delivery particles to the target cell in vivo
[0247] P0 ventricle injections
[0248] P0 ventricle injections are performed as described in Levy et al., 2020. The LDP -BE injection solution is loaded via front filling using the included Drummond plungers. P0 pups are anaesthetized until they are immobile and unresponsive to a toe pinch. Then, the LDP -BE injection mix is injected freehand into each ventricle.
[0249] Retro-orbital injections
[0250] Following anesthesia induction, as measured by unresponsiveness to bilateral toe pinch, the right eye is protruded by gentle pressure on the skin, and an insulin syringe is advanced, with the bevel facing away from the eye, into the retrobulbar sinus where LDP-BE mix is slowly injected. One drop of Proparacaine Hydrochloride Ophthalmic Solution is then applied to the eye as an analgesic.
[0251] Mouse subre tinal injection
[0252] Mice are anesthetized by intraperitoneal injection. Subretinal injections are performed under an ophthalmic surgical microscope. An incision is made through the cornea adjacent to the limbus at the nasal side. Each mouse is injected with LDP-BE mix in the eye. After injections, pupils are hydrated for recovery.
Example 6: assessing the efficiency of payload delivery in vivo
[0253] Histology and staining
[0254] Tissue are fixed in 4% PFA overnight at 4°C. Paraffin block is prepared, and followed by hematoxylin and eosin staining for histopathological examination.
[0255] Western blot analysis of mouse tissues
[0256] Mouse tissues are collected and lysed. Protein extracts are separated by electrophoresis and transferred to a PVDF membrane. The membrane is blocked for 1 h at room temperature and then is incubated with appropriate antibodies. Images are taken, and quantity of proteins are analyzed.
[0257] While preferred embodiments of the present invention have been shown and described herein, it will be obvious to those skilled in the art that such embodiments are provided by way of example only. Numerous variations, changes, and substitutions will now occur to those skilled in the art without departing from the invention. It should be understood that various alternatives to the embodiments of the invention described herein may be employed in practicing the invention. It is intended that the following claims define the scope of the invention and that methods and structures within the scope of these claims and their equivalents be covered thereby.
Claims
1. A lipid delivery particle, comprising: a lipid membrane on the external side; and a chimeric protein in the lipid delivery particle comprising (i) a plasma membrane recruitment element; (ii) a heterologous payload; (iii) one or more cleavable linkers; and (iv) a protease, wherein the one or more cleavable linkers are cleavable by the protease, wherein the one or more cleavable linkers are positioned such that cleavage by the protease releases the heterologous payload from the chimeric protein.
2. The lipid delivery particle of claim 1, wherein the protease is a viral protease.
3. The lipid delivery particle of claim 2, wherein the viral protease is selected from Table 7.
4. The lipid delivery particle of any one of claims 1-3, wherein the lipid delivery particle further comprises an envelope protein.
5. The lipid delivery particle of claim 4, wherein the envelope protein has a viral origin.
6. The lipid delivery particle of claim 5, wherein the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
7. The lipid delivery particle of claim 6, wherein the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 83-104.
8. The lipid delivery particle of claim 4, wherein the envelope protein has a human origin.
9. The lipid delivery particle of claim 8, wherein the envelope protein is selected from Table 2
10. The lipid delivery particle of claim 8, wherein the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82.
11. The lipid delivery particle of claim 10, wherein the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 49-82.
12. The lipid delivery particle of any one of claims 1-11, wherein the plasma membrane recruitment element comprises a Gag protein.
13. The lipid delivery particle of claim 12, wherein the Gag protein comprises a retroviral Gag protein.
14. The lipid delivery particle of claim 12, wherein the Gag protein comprises a Gag protein from human endogenous retrovirus.
15. The lipid delivery particle of claim 12, wherein the Gag protein comprises an endogenous Gag protein from a mammal.
16. The lipid delivery particle of any one of claims 1-15, wherein the plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
17. The lipid delivery particle of claim 16, wherein the Pleckstrin Homology domain is coupled to the heterologous payload.
18. The lipid delivery particle of claim 17, wherein the Pleckstrin Homology domain is reversibly coupled to the heterologous payload.
19. The lipid delivery particle of claim 18, wherein the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by one of the one or more cleavable linker.
20. The lipid delivery particle of any one of claims 16-18, wherein the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain.
21. The lipid delivery particle of any one of claims 16-18, wherein the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
22. The lipid delivery particle of any one of claims 1-21, wherein the plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
23. The lipid delivery particle of claim 22, wherein the plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48.
24. The lipid delivery particle of any one of claims 1-23, wherein the chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof.
25. The lipid delivery particle of claim 24, wherein the nuclear export signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 353-453.
26. The lipid delivery particle of claim 25, wherein the nuclear export signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 353-453.
27. The lipid delivery particle of any one of claims 24-26, wherein the nuclear localization signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 454-559.
28. The lipid delivery particle of claim 27, wherein the nuclear localization signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 454-559.
29. The lipid delivery particle of any one of claims 1-28, wherein the one or more cleavable linkers comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 126-171.
30. The lipid delivery particle of any one of claims 1-29, wherein the one or more cleavable linkers comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171.
31. The lipid delivery particle of any one of claims 1-30, wherein the cleavage by the protease is inhibitable by a reversible protease inhibitor.
32. The lipid delivery particle of claim 31, wherein the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease.
33. The lipid delivery particle of claim 31 or 32, wherein the protease inhibitor is selected from the group consisting of: Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
34. A lipid delivery particle, comprising: a lipid membrane on the external side; a first chimeric protein in the lipid delivery particle comprising (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) a cleavable linker; and a second chimeric protein in the lipid delivery particle comprising (i) a second plasma membrane recruitment element and (ii) a protease, wherein the cleavable linker is cleavable by the protease, wherein the cleavable linkers is positioned such that cleavage by the protease releases the heterologous payload from the first chimeric protein, wherein the protease comprises an amino acid sequence of at least 80%, 85%, 90%, 95%, or 99% sequence identity to SEQ ID NOs: 106-110.
35. The lipid delivery particle of claim 34, wherein the cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to the sequence set forth in any one of SEQ ID NOs: 126-128 or SEQ ID NOs: 134-138.
36. The lipid delivery particle of claim 34, wherein the cleavable linker comprises the sequence set forth in any one of SEQ ID NOs: 126-128 or SEQ ID NOs: 134-138.
37. A lipid delivery particle, comprising: a lipid membrane on the external side; a first chimeric protein in the lipid delivery particle comprising (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) a cleavable linker; and a second chimeric protein in the lipid delivery particle comprising (i) a second plasma membrane recruitment element and (ii) a protease, wherein the second chimeric protein lacks a viral polymerase, wherein the cleavable linker is cleavable by the protease, wherein the cleavable linker is positioned such that cleavage by the protease releases the heterologous payload from the first chimeric protein.
38. The lipid delivery particle of claim 37, wherein the protease comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95% or 99% sequence identity to an amino acid sequence set forth in any one of SEQ ID NOs: 105-125.
39. The lipid delivery particle of claim 37, wherein the protease comprises an amino acid sequence set forth in any one of SEQ ID NOs: 105-125.
40. A lipid delivery particle, comprising: a lipid membrane on the external side; a first chimeric protein in the lipid delivery particle comprising (i) a first plasma membrane recruitment element; (ii) a heterologous payload; and (iii) a cleavable linker; and a second chimeric protein in the lipid delivery particle comprising (i) a second plasma membrane recruitment element and (ii) a first protease.
41. The lipid delivery particle of claim 40, wherein the lipid delivery particle further comprises a second protease.
42. The lipid delivery particle of claim 41, wherein the first chimeric protein comprises the second protease.
43. The lipid delivery particle of claim 42, wherein the first chimeric protein comprises from N-terminus to C-terminus the first plasma membrane recruitment element, the second protease, and the heterologous payload.
44. The lipid delivery particle of claim 42, wherein the first chimeric protein comprises from N-terminus to C-terminus the first plasma membrane recruitment element, the heterologous payload, and the second protease.
45. The lipid delivery particle of claim 41, wherein the second chimeric protein comprises the second protease.
46. The lipid delivery particle of claim 45, wherein the second chimeric protein comprises from N-terminus to C-terminus the second plasma recruitment element, the first protease, and the second protease.
47. The lipid delivery particle of claim 45, wherein the second chimeric protein comprises from N-terminus to C-terminus the second plasma recruitment element, the second protease, and the first protease.
48. The lipid delivery particle of claim 41, wherein the lipid delivery particle further comprises a third chimeric protein in the lipid delivery particle, wherein the third chimeric protein comprising (i) a third plasma membrane recruitment element, and (ii) the second protease.
49. The lipid delivery particle of claim 48, wherein the third chimeric protein forms a dimer with the first chimeric protein or the second chimeric protein.
50. The lipid delivery particle of claim 49, wherein the third chimeric protein forms the dimer with the first chimeric protein or the second chimeric protein via a leucine zipper pair, an inducible heteromerization domain, an cohesin-dockerin interaction, a spy catcher- spy tag covalent interaction, or an electrostatic interaction between positively and negatively charged amino acids.
51. The lipid delivery particle of any one of claims 41-50, wherein the cleavable linker is cleavable by the first protease and the second protease.
52. The lipid delivery particle of any one of claims 40-50, wherein the cleavable linker is cleavable by the first protease.
53. The lipid delivery particle of any one of claims 41-50, wherein the cleavable linker is cleavable by the second protease.
54. The lipid delivery particle of any one of claims 40-53, wherein the cleavable linker is positioned such that cleavage by the protease releases the heterologous payload from the first chimeric protein.
55. The lipid delivery particle of claims 41-54, wherein the first protease and the second protease are the same.
56. The lipid delivery particle of claims 41-54, wherein the first protease and the second protease are different.
57. The lipid delivery particle of any one of claims 40-56, wherein the first protease comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95% or 99% sequence identity to an amino acid sequence set forth in any one of SEQ ID NOs: 105-125.
58. The lipid delivery particle of any one of claims 40-56, wherein the first protease comprises an amino acid sequence set forth in any one of SEQ ID NOs: 105-125.
59. The lipid delivery particle of any one of claims 40-58, wherein the first protease is a murine leukemia virus (MLV) protease.
60. The lipid delivery particle of any one of claims 40-58, wherein the first protease is a human immunodeficiency virus (HIV) protease.
61. The lipid delivery particle of any one of claims 41-60, wherein the second protease comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95% or 99% sequence identity to an amino acid sequence set forth in any one of SEQ ID NOs: 105-125.
62. The lipid delivery particle of any one of claims 41-60, wherein the second protease comprises an amino acid sequence set forth in any one of SEQ ID NOs: 105-125.
63. The lipid delivery particle of any one of claims 41-62, wherein the second protease is a murine leukemia virus (MLV) protease.
64. The lipid delivery particle of any one of claims 41-62, wherein the second protease is a human immunodeficiency virus (HIV) protease.
65. The lipid delivery particle of any one of claims 37-64, wherein the cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to set forth in any one of SEQ ID NOs: 126-171.
66. The lipid delivery particle of any one of claims 37-64, wherein the cleavable linker comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171.
67. The lipid delivery particle of any one of claims 34-66, wherein the cleavage by the protease releasing the heterologous payload from the chimeric protein is inhibited by a reversible protease inhibitor.
68. The lipid delivery particle of claim 67, wherein the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease.
69. The lipid delivery particle of claim 67, wherein the protease inhibitor is selected from the group consisting of: Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
70. The lipid delivery particle of claims 67-69, wherein the reversible protease inhibitor delays the release of payload from the chimeric protein until the reversible protease inhibitor is removed.
71. The lipid delivery particle of any one of claims 34-70, wherein the second chimeric protein further comprises a second cleavable linker.
72. The lipid delivery particle of claim 71, wherein the second cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 126-171.
73. The lipid delivery particle of claim 71, wherein the second cleavable linker comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171.
74. The lipid delivery particle of any one of claims 40-73, wherein the lipid delivery particle further comprises an envelope protein.
75. The lipid delivery particle of claim 74, wherein the envelope protein has a viral origin.
76. The lipid delivery particle of claim 75, wherein the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
77. The lipid delivery particle of claim 76, wherein the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 83-104.
78. The lipid delivery particle of claim 74, wherein the envelope protein has a human origin.
79. The lipid delivery particle of claim 78, wherein the envelope protein is selected from Table
2
80. The lipid delivery particle of claim 78, wherein the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82.
81. The lipid delivery particle of claim 80, wherein the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 49-82.
82. The lipid delivery particle of any one of claims 40-81, wherein the first plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
83. The lipid delivery particle of claim 82, wherein the Pleckstrin Homology domain is coupled to the heterologous payload.
84. The lipid delivery particle of claim 83, wherein the Pleckstrin Homology domain is reversibly coupled to the heterologous payload.
85. The lipid delivery particle of claim 84, wherein the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker.
86. The lipid delivery particle of any one of claims 83-85, wherein the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain.
87. The lipid delivery particle of any one of claims 83-85, wherein the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
88. The lipid delivery particle of any one of claims 40-87, wherein the first plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
89. The lipid delivery particle of claim 88, wherein the first plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48.
90. The lipid delivery particle of any one of claims 40-89, wherein the first plasma membrane recruitment element comprises a Gag protein.
91. The lipid delivery particle of claim 90, wherein the Gag protein comprises a retroviral Gag protein.
92. The lipid delivery particle of claim 90, wherein the Gag protein comprises a Gag protein from human endogenous retrovirus.
93. The lipid delivery particle of claim 90, wherein the Gag protein comprises an endogenous Gag protein from a mammal.
94. The lipid delivery particle of any one of claims 40-93, wherein the second plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
95. The lipid delivery particle of claim 94, wherein the Pleckstrin Homology domain is coupled to the heterologous payload.
96. The lipid delivery particle of claim 95, wherein the Pleckstrin Homology domain is reversibly coupled to the heterologous payload.
97. The lipid delivery particle of claim 96, wherein the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker.
98. The lipid delivery particle of any one of claims 95-97, wherein the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain.
99. The lipid delivery particle of any one of claims 95-97, wherein the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
100. The lipid delivery particle of any one of claims 40-99, wherein the second plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
101. The lipid delivery particle of claim 100, wherein the second plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48.
102. The lipid delivery particle of any one of claims 40-101, wherein the second plasma membrane recruitment element comprises a Gag protein.
103. The lipid delivery particle of claim 102, wherein the Gag protein comprises a retroviral Gag protein.
104. The lipid delivery particle of claim 102, wherein the Gag protein comprises a Gag protein from human endogenous retrovirus.
105. The lipid delivery particle of claim 102, wherein the Gag protein comprises an endogenous Gag protein from a mammal.
106. The lipid delivery particle of any one of claims 40-105, wherein the third plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
107. The lipid delivery particle of claim 106, wherein the Pleckstrin Homology domain is coupled to the heterologous payload.
108. The lipid delivery particle of claim 107, wherein the Pleckstrin Homology domain is reversibly coupled to the heterologous payload.
109. The lipid delivery particle of claim 108, wherein the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker.
110. The lipid delivery particle of any one of claims 107-109, wherein the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain.
111. The lipid delivery particle of any one of claims 107-109, wherein the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
112. The lipid delivery particle of any one of claims 40-111, wherein the third plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
113. The lipid delivery particle of claim 112, wherein the third plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48.
114. The lipid delivery particle of any one of claims 40-113, wherein the third plasma membrane recruitment element comprises a Gag protein.
115. The lipid delivery particle of claim 114, wherein the Gag protein comprises a retroviral Gag protein.
116. The lipid delivery particle of claim 114, wherein the Gag protein comprises a Gag protein from human endogenous retrovirus.
117. The lipid delivery particle of claim 114, wherein the Gag protein comprises an endogenous Gag protein from a mammal.
118. The lipid delivery particle of any one of claims 34-117, wherein the first plasma membrane recruitment element is the same as the second plasma membrane recruitment element.
119. The lipid delivery particle of any one of claims 34-118, wherein the first chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof.
120. The lipid delivery particle of any one of claims 34-119, wherein the second chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof.
121. The lipid delivery particle of claim 119 or 120, wherein the nuclear export signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 353-453.
122. The lipid delivery particle of claim 121, wherein the nuclear export signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 353-453.
123. The lipid delivery particle of claim 119 or 120, wherein the nuclear localization signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 454-559.
124. The lipid delivery particle of claim 123, wherein the nuclear localization signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 454-559.
125. The lipid delivery particle of claim any proceeding claim, wherein the heterologous payload is a therapeutic agent.
126. The lipid delivery particle of claim 125, wherein the therapeutic agent is covalently linked to the plasma membrane recruitment element via the cleavable linker.
127. The lipid delivery particle of claim 125, wherein the therapeutic agent is coupled to the cleavable linker or the plasma recruitment element by conjugation.
128. The lipid delivery particle of any one of claims 125-127, wherein the therapeutic agent is a gene-editing agent.
129. The lipid delivery particle of claim 128, wherein the gene-editing agent comprises a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; a nucleic acid encoding a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; or a ribonucleoprotein complex (RNP) comprising a CRISPR- based genome editing or modulating protein.
130. The lipid delivery particle of any one of claims 125-127, wherein the therapeutic agent is a nucleic-acid based agent, a small molecule, or a recombinant protein.
131. A system, comprising (a) the lipid delivery particle of any one of claims 1-130 and (b) a reversible protease inhibitor, wherein the cleavage by the protease is inhibitable by the reversible protease inhibitor, wherein the release of payload is delayed until the reversible protease inhibitor is removed from the system.
132. The system of claim 131, wherein the reversible protease inhibitor inhibits a retroviral protease, a HIV protease, an HCV protease, or an aspartic acid protease.
133. The system of claim 131 or 132, wherein the protease inhibitor is selected from the group consisting of: Atazanavir, Darunavir, Fosamprenavir, Indinavir, Lopinavir, Ritonavir, Nelfinavir, Saquinavir, Tipranavir, TL-3, Pepstatin A, DMP-23, Asunaprevir, Boceprevir, Glecaprevir, Grazoprevir, Paritaprevir, Simeprevir, Telaprevir, Voxilaprevir, and combinations thereof.
134. A chimeric protein for delivering a heterologous payload to a target cell, comprising: (i) a plasma membrane recruitment element; (ii) a heterologous payload; (iii) one or more protease cleavable linkers; and (iv) a first protease, wherein the one or more cleavable linkers are cleavable by the protease, wherein the one or more cleavable linkers are positioned such that cleavage by the protease releases the heterologous payload from the chimeric protein construct.
135. The chimeric protein of claim 134, wherein the chimeric protein further comprises a second protease.
136. The chimeric protein of claim 135, wherein the second protease is a viral protease.
137. The chimeric protein of any one of claims 134-136, wherein the first protease is a viral protease.
138. The chimeric protein of any one of claims 136-137, wherein the viral protease is selected from Table 7.
139. The chimeric protein of any one of claims 134-138, wherein the plasma membrane recruitment element comprises a Gag protein.
MO. The chimeric protein particle of claim 139, wherein the Gag protein comprises a retroviral Gag protein.
Ml. The chimeric protein particle of claim 139, wherein the Gag protein comprises a Gag protein from human endogenous retrovirus.
M2. The chimeric protein particle of claim 139, wherein the Gag protein comprises an endogenous Gag protein from a mammal.
143. The chimeric protein of any one of claims 134-142, wherein the plasma membrane recruitment element comprises a Pleckstrin Homology (PH) domain.
144. The chimeric protein of claim 143, wherein the Pleckstrin Homology domain is coupled to the heterologous payload.
145. The chimeric protein of claim 144, wherein the Pleckstrin Homology domain is reversibly coupled to the heterologous payload.
146. The chimeric protein of claim 145, wherein the heterologous payload is reversibly coupled to the Pleckstrin Homology domain by the cleavable linker.
147. The chimeric protein of any one of claims 143-146, wherein the heterologous payload is coupled to a C-terminus of the Pleckstrin Homology domain.
148. The chimeric protein of any one of claims 143-146, wherein the heterologous payload is coupled to an N-terminus of the Pleckstrin Homology domain.
149. The chimeric protein of any one of claims 134-148, wherein the plasma membrane recruitment element comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 1-48.
150. The chimeric protein of claim 149, wherein the plasma membrane recruitment element comprises an amino acid sequence set forth in any one of SEQ ID NOs: 1-48.
151. The chimeric protein of any one of claims 134-150, wherein the chimeric protein further comprises a nuclear export signal, a nuclear localization signal, or a combination thereof.
152. The chimeric protein of claim 151, wherein the nuclear export signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 353-453.
153. The chimeric protein of claim 152, wherein the nuclear export signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 353-453.
154. The chimeric protein of claim 151, wherein the nuclear localization signal comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 454-559.
155. The chimeric protein of claim 154, wherein the nuclear localization signal comprises an amino acid sequence set forth in any one of SEQ ID NOs: 454-559.
-MO-
156. The chimeric protein of any one of claims 134-152, wherein the cleavable linker comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 126-171.
157. The chimeric protein of any one of claims 134-156, wherein the cleavable linker comprises an amino acid sequence set forth in any one of SEQ ID NOs: 126-171.
158. The chimeric protein of any one of claims 134-157, wherein the heterologous payload is a therapeutic agent.
159. The chimeric protein construct of claim 158, wherein the therapeutic agent is a geneediting reagent.
160. The chimeric protein construct of claim 159, wherein the gene-editing reagent comprises a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; a nucleic acid encoding a zinc finger (ZF), transcription activator-like effector (TALE), and/or CRISPR-based genome editing or modulating protein; or a ribonucleoprotein complex (RNP) comprising a CRISPR- based genome editing or modulating protein.
161. The chimeric protein construct of claim 158, wherein the therapeutic agent is a nucleic- acid based agent, a small molecule, or a recombinant protein.
162. A nucleic acid encoding the chimeric protein of any one of claims 134-161.
163. A lipid delivery particle, comprising: (i) a lipid membrane on the external side; and (ii) the chimeric protein of any one of claims 134-161 in the core.
164. The lipid delivery particle of claim 163, wherein the lipid delivery particle further comprises an envelope protein.
165. The lipid delivery particle of claim 164, wherein the envelope protein has a viral origin.
166. The lipid delivery particle of claim 165, wherein the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 83-104.
167. The lipid delivery particle of claim 166, wherein the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 83-104.
168. The lipid delivery particle of claim 164, wherein the envelope protein has a human origin.
169. The lipid delivery particle of claim 168, wherein the envelope protein is selected from
Table 2
170. The lipid delivery particle of claim 168, wherein the envelope protein comprises an amino acid sequence having at least 80%, 85%, 90%, 95%, or 99% sequence identity to a sequence set forth in any one of SEQ ID NOs: 49-82.
171. The lipid delivery particle of claim 170, wherein the envelope protein comprises an amino acid sequence set forth in any one of SEQ ID NOs: 49-82.
172. A method of delivering a heterologous payload to a target cell, the method comprising contacting the target cell with the lipid delivery particle of any one of claims 1-130.
173. A method of producing the lipid delivery particle of any one of claims 1-39, the method comprising providing a producer cell comprising a nucleic acid molecule encoding the chimeric protein, and using the producer cell to produce the lipid delivery particle of any one of claims 1-39.
174. A method of producing the lipid delivery particle of any one of claims 40-130, the method comprising providing a producer cell comprising a first nucleic acid molecule encoding the first chimeric protein and, and using the producer cell to produce the lipid delivery particle of any one of claims 40-130.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202363471691P | 2023-06-07 | 2023-06-07 | |
| US63/471,691 | 2023-06-07 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2024254518A2 true WO2024254518A2 (en) | 2024-12-12 |
| WO2024254518A3 WO2024254518A3 (en) | 2025-03-06 |
Family
ID=93796415
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2024/033099 Pending WO2024254518A2 (en) | 2023-06-07 | 2024-06-07 | Compositions of lipid delivery particles and method of use thereof |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2024254518A2 (en) |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7485446B2 (en) * | 2006-02-21 | 2009-02-03 | The Board Of Trustees Of The University Of Illinois | Stable retrovirus and methods of use |
| PL3981437T3 (en) * | 2014-04-23 | 2025-02-24 | Modernatx, Inc. | Nucleic acid vaccines |
| CA3135428A1 (en) * | 2019-03-29 | 2020-10-08 | Trustees Of Boston University | Chimeric antigen receptor (car) modulation |
| US20220259617A1 (en) * | 2019-06-13 | 2022-08-18 | The General Hospital Corporation | Engineered human-endogenous virus-like particles and methods of use thereof for delivery to cells |
| AU2020398658A1 (en) * | 2019-12-06 | 2022-07-07 | Scribe Therapeutics Inc. | Particle delivery systems |
-
2024
- 2024-06-07 WO PCT/US2024/033099 patent/WO2024254518A2/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| WO2024254518A3 (en) | 2025-03-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20250034549A1 (en) | Compositions and methods for efficient in vivo delivery | |
| US20240067940A1 (en) | Methods and compositions for editing nucleotide sequences | |
| US20250064979A1 (en) | Self-assembling virus-like particles for delivery of prime editors and methods of making and using same | |
| US20250382334A1 (en) | Self-assembling virus-like particles for delivery of nucleic acid programmable fusion proteins and methods of making and using same | |
| KR20210044213A (en) | Vesicles for trace-free delivery of guide RNA molecules and/or guide RNA molecule/RNA-guided nuclease complex(s) and methods of production thereof | |
| US20250367322A1 (en) | Nucleobase editing system and method of using same for modifying nucleic acid sequences | |
| UA118957C2 (en) | METHOD AND COMPOSITION FOR TREATMENT OF GENETIC DISEASE | |
| CA2932439A1 (en) | Crispr-cas systems and methods for altering expression of gene products, structural information and inducible modular cas enzymes | |
| JP2022540318A (en) | Targeted gene-editing constructs and methods of using same | |
| US20260009027A1 (en) | Prime editing-mediated readthrough of premature termination codons (pert) | |
| WO2024215652A2 (en) | Directed evolution of engineered virus-like particles (evlps) | |
| WO2024020346A2 (en) | Gene editing components, systems, and methods of use | |
| CA3211495A1 (en) | Novel crispr enzymes, methods, systems and uses thereof | |
| WO2020225287A1 (en) | Lentiviral nanoparticles | |
| JP2025519070A (en) | Compositions and methods for efficient in vivo delivery | |
| US20250340901A1 (en) | Gene editing components, systems, and methods of use | |
| WO2024138033A2 (en) | Compositions and methods for delivery of nucleic acid editors | |
| WO2024254346A1 (en) | Engineered viral like particles (evlps) for the selective transduction of target cells | |
| JP2024540390A (en) | Mobile elements and their chimeric constructs | |
| WO2024178144A1 (en) | Methods and compositions for editing nucleotide sequences | |
| WO2024254550A1 (en) | Compositions and methods for promoting payload delivery in cells | |
| EP3640334A1 (en) | Genome editing system for repeat expansion mutation | |
| WO2024254518A2 (en) | Compositions of lipid delivery particles and method of use thereof | |
| CA3187571A1 (en) | Tunneling nanotube cells and methods of use thereof for delivery of biomolecules | |
| WO2024254530A1 (en) | Pleckstrin holomogy domains for delivery of protein payloads to a target cell |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24820174 Country of ref document: EP Kind code of ref document: A2 |