WO2024206835A1 - Circular mrna and production thereof - Google Patents
Circular mrna and production thereof Download PDFInfo
- Publication number
- WO2024206835A1 WO2024206835A1 PCT/US2024/022251 US2024022251W WO2024206835A1 WO 2024206835 A1 WO2024206835 A1 WO 2024206835A1 US 2024022251 W US2024022251 W US 2024022251W WO 2024206835 A1 WO2024206835 A1 WO 2024206835A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- mir
- hsa
- rna
- circular rna
- circular
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/7115—Nucleic acids or oligonucleotides having modified bases, i.e. other than adenine, guanine, cytosine, uracil or thymine
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P19/00—Preparation of compounds containing saccharide radicals
- C12P19/26—Preparation of nitrogen-containing carbohydrates
- C12P19/28—N-glycosides
- C12P19/30—Nucleotides
- C12P19/34—Polynucleotides, e.g. nucleic acids, oligoribonucleotides
Definitions
- mRNA encoding a desired therapeutic protein can be administered to a subject for in vivo expression of the protein to therapeutic effect.
- the long-term efficacy of administered mRNA is hindered by the instability of mRNA in cells, where it is degraded by terminal exonucleases.
- SUMMARY Provided herein are circular RNAs, which have no 5′ or 3′ terminal nucleotides and are thus not susceptible to hydrolysis by exonucleases.
- IVTT In vitro transcription
- RNAs containing modified nucleotides comprising N6-methyladenosine (m6A) allows for transcription of RNAs containing modified nucleotides comprising N6-methyladenosine (m6A).
- m6A-modified nucleotides reduce the immunostimulatory activity of circular RNA molecules, such as by decreasing the ability of the m6A-modified circular RNA to be recognized by innate immune factors (e.g., RIG-I) that mediate degradation of foreign RNA, and this decreased immunostimulatory activity allows modified circular RNAs to persist for extended periods of time in vivo, relative to unmodified RNAs.
- innate immune factors e.g., RIG-I
- miRNA target sequences could be incorporated into circular RNAs to cause selective degradation in immune cells, thereby enhancing stability of the circular RNAs in target tissue.
- incorporation of miRNA target sequences into circular RNAs allowed selective degradation of administered circular RNAs in liver macrophages, but not neighboring hepatocytes. This resulting absence of the administered circular RNA from liver macrophage further increased the half-life of circular RNA in hepatocytes and total abundance of circular RNA in the liver.
- RNA circular ribonucleic acid
- ORF open reading frame
- the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF.
- the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell.
- the one or more miRNAs are specific to macrophages.
- the one or more miRNAs are specific to Kupffer cells.
- the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223.
- the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs. In some embodiments, the circular RNA comprises an open reading frame encoding a vaccine antigen or therapeutic protein. In some embodiments, the circular RNA comprises, in 5′- to-3′-order: a 5′ untranslated region (UTR), an internal ribosome entry site (IRES), the ORF, and a 3′ UTR. In some embodiments, the circular RNA further comprises a polyA or polyAC region.
- the polyA or polyAC region is between the 5′ UTR and the IRES. In some embodiments, the polyA or polyAC region is between the open reading frame and the 3′ UTR. In some embodiments, the ORF is codon-optimized for expression in a mammalian cell. In some embodiments, the ORF is codon-optimized for expression in a human cell. In some embodiments, substantially all nucleotides at uridine positions comprise N1- methylpseudouridine. In some embodiments, substantially all nucleotides at cytidine positions comprise 5-methylcytidine, and substantially all nucleotides at uridine positions comprise 5- methyluridine.
- the circular RNA further comprises comprising a lipid delivery vehicle in contact with the circular RNA.
- the lipid delivery vehicle is a lipid nanoparticle comprising 20–60 mol% ionizable lipid, 5–25 mol% non-cationic lipid, 2–4 mol% PEG-modified lipid, and 25–55 mol% sterol.
- the ionizable lipid 18 In some embodiments, 0.25 mol% to 1.0 mol% of the PEG-modified lipid is present in a core of the lipid nanoparticle. In some embodiments, 2.0 mol% to 2.75 mol% of the PEG- modified lipid is not in the core of the lipid nanoparticle.
- the PEG- modified lipid is PEG-DMG or 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate.
- Some aspects relate to a method for producing a circular ribonucleic acid, the method comprising: (i) incubating an in vitro transcription (IVT) reaction mixture under conditions such that a linear RNA comprising an open reading frame (ORF) encoding a protein is transcribed, wherein the IVT reaction mixture comprises a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP), wherein 15–90%, 15–80%, 15–60%, 15–40%, 15–20%, 20–30%, 30–40%, 40–50%, 50– 75%, or 75–90% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A); and (ii) circularizing the linear RNA, wherein the circularizing comprises
- the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF.
- the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell.
- the one or more miRNAs are specific to macrophages.
- the one or more miRNAs are specific to Kupffer cells.
- the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223.
- the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs.
- substantially all UTPs in the IVT reaction mixture are N1- methylpseudouridine triphosphate. In some embodiments, substantially all UTPs in the IVT reaction mixture comprise 5-methyluridine, and wherein substantially all CTPs in the IVT reaction mixture comprise 5-methylcytidine.
- the RNA polymerase is selected from the group consisting of T7 RNA polymerase, a T3 RNA polymerase, a K11 RNA polymerase, and SP6 RNA polymerase. In some embodiments, the RNA polymerase is a T7 RNA polymerase. In some embodiments, the RNA polymerase is a T7 RNA polymerase variant having an amino acid sequence selected from any one of SEQ ID NOs: 1–4.
- Some aspects relate to a method for improving stability of a circular ribonucleic acid (circular RNA) comprising a nucleotide sequence, the nucleotide sequence comprising an open reading frame (ORF) encoding a protein, the method comprising: (i) substituting one or more nucleotides at adenosine positions with modified nucleotides comprising N6-methyladenosine (m6A) to produce a modified nucleotide sequence, wherein 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 5–7%, 7–10%, 10–15%, 15–20%, 20– 25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, or 90–95% of nucleotides at adenosine positions in the modified nucleotide sequence comprise m6A; and (ii) synthesizing
- the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF.
- the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell.
- the one or more miRNAs are specific to macrophages.
- the one or more miRNAs are specific to Kupffer cells.
- the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223.
- the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs.
- a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position.
- a coefficient of degradation of the circular RNA in a mammalian cell is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to control circular RNA comprising the same nucleotide sequence as the circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position.
- a level of expression, in a mammalian cell, of the protein encoded by the ORF of the circular RNA is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position.
- a level of expression in a mammalian cell of the protein encoded by the ORF of the circular RNA is at least 50% of a level of expression of a control linear messenger ribonucleic acid (mRNA) comprising the ORF.
- mRNA control linear messenger ribonucleic acid
- a coefficient of degradation of the circular RNA in a mammal is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to a control linear messenger ribonucleic acid (mRNA) comprising the ORF.
- the mammalian cell is a human cell.
- FIG.1 shows a flowchart describing the process of producing circular RNA, comprising the steps of 1) in vitro transcription of mRNA from a DNA template; 2) splinted ligation of linear mRNA to produce circular RNA; and 3) HPLC purification to separate circular RNA from other reaction components (e.g., linear mRNA).
- FIGs.2A–2B show a time course of circular RNA abundance and expression in vivo following administration to BALB/c mice of lipid nanoparticles containing circular RNAs produced by IVT in which ATPs were (i) 100% unmodified ATP; (ii) 10% m6ATP and 90% unmodified ATP (producing mRNAs with ⁇ 3% m6A nucleotides); or (iii) 30% m6ATP and 70% unmodified ATP (producing mRNAs with ⁇ 10% m6A nucleotides).
- FIG.2A shows kinetics of circular RNA abundance in liver, or PBS control at 24 hours post-administration.
- FIG.2B shows expression of the encoded protein, Antigen 1 (Ag1).
- FIGs.3A–3D show a second time course of circular RNA abundance and expression in vivo following administration to BALB/c mice of lipid nanoparticles containing circular RNAs produced by IVT in which ATPs were (i) 100% unmodified ATP, or (ii) 30% m6ATP and 70% unmodified ATP.
- FIG.3A shows abundance of circular RNA in liver tissue sections, as visualized by RNAscope.
- FIG.3B shows circular RNA abundance in livers as measured by qPCR.
- FIG.3C shows liver sections as in FIG.3A, including sections from mice administered circular RNAs containing three target sequences for miR-142.
- FIG.3D shows circular RNA abundance as in FIG.3B, including in livers of mice administered circular RNAs containing three target sequences for miR-142.
- dark stain corresponds to RNA
- round areas of light staining correspond to nuclei.
- Irregularly shaped cells are Kupffer cells and hexagonal cells with prominent nuclei are hepatocytes.
- RNA staining is darker in Kupffer cells then hepatocytes but both cell types are positive for RNA.
- FIG.4 shows a third time course of circular RNA abundance in vivo following administration to BALB/c mice of lipid nanoparticles containing circular RNAs lacking an IRES and produced by IVT in which ATPs were (i) 100% unmodified ATP, or (ii) 30% m6ATP and 70% unmodified ATP.
- FIGs.5A–5C show a fourth time course of linear and circular RNA abundance in vivo following administration to BALB/c mice of lipid nanoparticles containing (i) circular RNAs produced by IVT with 30% m6ATP and 70% unmodified ATP, (ii) circular RNAs produced by IVT with 100% unmodified ATP, or (iii) linear mRNAs produced by IVT with 100% unmodified ATP.
- FIG.5A shows results where circular RNAs contained a CVB3 IRES.
- FIG. 5B shows results where circular RNAs contained an EMCV IRES.
- FIG.5C shows results where circular RNAs contained a SaliFHB IRES.
- FIGs.6A–6B show a fifth time course of linear and circular RNA abundance in vivo following administration to BALB/c mice of lipid nanoparticles containing (i) circular RNAs produced by IVT with 30% m6ATP and 70% unmodified ATP, (ii) circular RNAs produced by IVT with 100% unmodified ATP, or (iii) linear mRNAs produced by IVT with 100% unmodified ATP.
- FIG.6A shows results where circular RNAs contained a SaliFHB IRES.
- FIG.6B shows results where circular RNAs contained a CVB3 IRES.
- FIGs.7A–7C show results of a mouse study evaluating m6A modification on circular RNA stability and protein expression.
- FIGs.7A and 7B shows circular RNA and linear mRNA abundance over time in mouse livers.
- FIG.7C shows kinetics of protein expression from circular RNAs and linear mRNAs over time.
- DETAILED DESCRIPTION Provided are methods of producing circular RNAs and compositions comprising circular RNAs.
- circular RNAs Unlike linear mRNAs, circular RNAs have no 5′ or 3′ terminal nucleotides and are thus not susceptible to degradation by exonucleases.
- IVTT In vitro transcription
- m6A N6-methyladenosine
- RIG-I innate immune factors
- incorporation of one or more target sequences for an miRNA allows selective degradation of the circular RNA in a desired cell type (e.g., macrophages), which may otherwise indirectly reduce circular RNA abundance in neighboring cells (e.g., by secretion of interferons).
- a desired cell type e.g., macrophages
- Such targeted degradation of circular RNA in undesired cell types increases the half-life of circular RNAs in desired cell types, thereby prolonging in vivo persistence and therapeutic efficacy.
- Circular RNA Some aspects relate to circular RNAs comprising N6-methyladenosine-modified nucleotides.
- Some aspects relate to methods of producing circular RNAs comprising N6- methyladenosine-modified nucleotides by in vitro transcription of an RNA followed by circularizing the transcribed RNA. Some aspects relate to methods of improving stability of a circular RNA comprising a nucleotide sequence comprising an ORF, where the methods comprise: (i) substituting one or more nucleotides at adenosine positions in the nucleotide sequence to produce a modified nucleotide sequence; and (ii) synthesizing a circular RNA having the modified nucleotide sequence.
- a circular RNA is an RNA with no 5′ terminal nucleotide or 3′ terminal nucleotide.
- Circular RNAs may comprise one or more modified adenosine nucleotides comprising N6-methyladenosine (m6A). Incorporation of such N6-methyladenosine nucleotides increases the stability of circular RNAs in mammalian cells.
- m6A N6-methyladenosine
- Circular RNAs in which 5–100% of the nucleotides at adenosine positions RNA are modified nucleotides comprising N6- methyladenosine.
- Circular RNAs may also comprise a combination of unmodified adenosine nucleotides comprising natural adenosine and modified nucleotides at adenosine positions comprising N6-methyladenosine.
- some aspects relate to circular RNAs in which 5–95% of the nucleotides at adenosine positions comprise N6-methyladenosine.
- the percentage of nucleotides at adenosine positions that comprise N6-methyladenosine may be any percentage that is at least 5% and at most 100%. For example, in some embodiments, 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 10–80%,10–60%, 10– 50%,10–40%, 10–30%,10–25%, 10–20%, 5–7%, 7–10%, 10–15%, 15–20%, 20–25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, 90–95%, or 95–100% of the nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 40% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 5% to about 20% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 40% of nucleotides at adenosine positions comprise N6- methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 7% to about 9% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 12% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 12% to about 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 15% to about 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 20% to about 25% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 30% to about 40% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 40% to about 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 50% to about 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 60% to about 70% of nucleotides at adenosine positions comprise N6- methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 80% to about 90% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 90% to about 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 95% to about 100% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 10% to about 15% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 30% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 5% and less than 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 7% and less than 9% of nucleotides at adenosine positions comprise N6-methyladenosine.
- greater than 7% and less than 10% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 10% and less than 12% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 12% and less than 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 15% and less than 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 20% and less than 25% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 30% and less than 40% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 40% and less than 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 50% and less than 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 60% and less than 70% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 80% and less than 90% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 90% and less than 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 95% and less than 100% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 10% and less than 15% of nucleotides at adenosine positions comprise N6-methyladenosine.
- greater than 10% and less than 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 10% and less than 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 10% and less than 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 5% and up to 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 7% and up to 9% of nucleotides at adenosine positions comprise N6-methyladenosine.
- At least 7% and up embodiments, at least 10% and up to 12% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, at least 12% and up to 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 15% and up to 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 20% and up to 25% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 30% and up to 40% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 40% and up to 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 50% and up to 60% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, at least 60% and up to 70% of nucleotides at adenosine positions comprise N6-methyladenosine.
- At least 70% and up to 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 80% and up to 90% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 90% and up to 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 95% and up to 100% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 10% and up to 15% of nucleotides at adenosine positions comprise N6-methyladenosine.
- At least 10% and up to 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, at least 10% and up to 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, or 20% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine.
- about 5% of nucleotides at adenosine positions comprise N6-methyladenosine.
- about 6% of nucleotides at adenosine positions comprise N6- methyladenosine.
- about 7% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 9% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 11% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 12% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 14% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 16% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 17% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 19% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 21% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 22% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 24% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 5% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 6% of nucleotides at adenosine positions comprise N6- methyladenosine.
- nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 8% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 9% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 11% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 13% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 14% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 16% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 17% of nucleotides at adenosine positions comprise N6-methyladenosine.
- 18% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 19% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 21% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 22% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 23% of nucleotides at adenosine positions comprise N6-methyladenosine.
- nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 25% of nucleotides at adenosine positions comprise N6-methyladenosine.
- the proportion of nucleotides at adenosine positions that comprise N6-methyladenosine may be determined by any method suitable for detecting and/or measuring modified nucleotides on a nucleic acid. Methods of detecting N6-methyladenosine modification are known in the art, and reviewed, e.g., in Zhu et al., Int J Mol Med.2019.43(6):2267–2278.
- a circular RNA further comprises one or more target sequences for a microRNA (miRNA).
- miRNA microRNA
- the inclusion of a target sequence for a miRNA allows for degradation of the circular miRNA in the presence of any one of the miRNAs that hybridize with the target sequence on the circular RNA.
- a target sequence of a miRNA refers to a nucleic acid sequence that is complementary to a miRNA.
- a first nucleic acid sequence is complementary to a second nucleic acid sequence if a nucleic acid comprising the first sequence binds (hybridizes) to a nucleic acid comprising the second sequence, forming a nucleic acid that is at least partially double-stranded through hydrogen bonds between base pairs on the miRNA and target sequence.
- a first sequence is most complementary to a second sequence when the first sequence comprises a sequence of bases that form canonical Watson- Crick base pairs (i.e., A–U, A–T, C–G) with the target sequence, in reverse order relative to the order of bases in the target sequence.
- a nucleic acid with this sequence of complementary bases in reverse order is said to have the reverse complement of the target sequence.
- the reverse complement of the target sequence AAGUCCA is TGGACTT (DNA) or UGGACUU (RNA).
- a miRNA may still bind (hybridize) to a target sequence even if the sequence of the miRNA differs from the exact reverse complement of the target sequence by one or more nucleotides, provided the sequence of the miRNA is sufficiently similar to the reverse complement of the target sequence.
- the exact level of sequence identity between the sequence of a miRNA and the reverse complement of the target sequence that is sufficient for a miRNA to bind to a given target sequence will depend on the sequences of the miRNA and target sequence, for example, the nucleotide composition and/or length, as well as the binding conditions (e.g., in vivo human physiological conditions).
- RNA-induced silencing complex e.g., Pratt and MacRae. J Biol Chem.2009.284(27):17897–17901.
- a circular RNA comprises more than one miRNA target sequence.
- a circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one or more miRNAs.
- Circular RNAs comprising multiple target sequences for one or more miRNAs may include multiple target sequences for the same miRNA.
- a circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for the same miRNA.
- a circular RNA comprises 1–50, 1–40, 1–30, 1–25, 1– 20, 1–15, 1–10, or 1–5 target sequences for a single miRNA.
- a circular RNA comprises 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 target sequences for a single miRNA.
- a circular RNA comprises 3 target sequences for a single miRNA.
- Circular RNAs comprising multiple target sequences for one or more miRNAs may include distinct target sequences for different miRNAs.
- a circular RNA comprises one or more target sequences for a first miRNA, and one or more target sequences for a second miRNA that is different from the first miRNA.
- a circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 miRNA target sequences, each target sequence being hybridized by a different miRNA.
- a circular RNA comprises one or more target sequences for each of 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 different miRNAs.
- the presence of a miRNA is a miRNA biomarker signature for a specific cell type in a specific stage of development.
- Methods of identifying a miRNA biomarker signature in a specific tissue or cell are known in the art. Information about the sequences, origins, and functions of known miRNAs maybe found in publicly available databases (e.g., mirbase.org, all versions, as described in Kozomara et al., Nucleic Acids Res 201442:D68-D73; Kozomara et al., Nucleic Acids Res 201139:D152-D157; Griffiths-Jones et al., Nucleic Acids Res 200836:D154-D158; Griffiths-Jones et al., Nucleic Acids Res 2006 34:D140-D144; and Griffiths-Jones et al., Nucleic Acids Res 200432:D109-D111, including the most recently released version miRBase 21, which contains “high confidence” miRNAs).
- Non-limiting examples of miRNAs that are expressed in cells, and for which target sequences may be present on a circular RNA include: FF4, FF5, hsa-let-7a-2-3p, hsa-let-7a-3p, hsa-let-7a-5p, hsa-let-7b-3p, hsa-let-7b-5p, hsa-let-7c-5p, hsa-let-7d-3p, hsa-let-7d-5p, hsa-let- 7e-3p, hsa-let-7e-5p, hsa-let-7f-1-3p, hsa-let-7f-2-3p, hsa-let-7f-5p, hsa-let-7g-3p, hsa-let-7g-5p, hsa-let-7i-5p, hsa-miR-1, hsa-miR-1-3p, hsa-miR-1-5p, hs
- the presence of a miRNA is a miRNA biomarker signature for an immune cell.
- the miRNA is specific to an immune cell.
- a miRNA is considered specific to a particular cell type if the presence of that miRNA in a cell indicates to the skilled artisan that that cell belongs to that particular cell type.
- miR-142 is expressed in various immune cells, and so the presence of one or more miR-142 target sequences on the circular RNA allows its selective degradation in immune cells, but maintenance in non-immune cells.
- RNAs in immune cells such as macrophages stimulates innate immune receptors (e.g., STING, RIG-I, OAS), which signal to nearby cells (e.g., by secretion of type I interferons IFN- ⁇ and/or IFN- ⁇ ) and cause degradation of RNA or limit translation in those cells.
- innate immune receptors e.g., STING, RIG-I, OAS
- selective degradation of circular RNA in immune cells therefore limits activation of such immune responses, allowing prolonged maintenance and translation of the circular RNA in other cells.
- RNA e.g., circular RNA
- exemplary miRs identified as being abundantly and differentially expressed in dendritic cells include miR-223- 3p, 21-5p, 23a-3p, let-7d- 3p, miR-191-5p, and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of a circular RNA in DCs.
- exemplary miRs identified as being abundantly and differentially expressed in monocytes include miR-4454, miR-7975, miR-181a-5p, miR-548aa, and miR-548t-3p, and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of circular RNA in monocytes.
- miR-23a, miR-142, and miR-223 are expressed in multiple immune cell types (e.g., miR-142 is expressed in T cells, DCs, neutrophils, natural killer (NK) cells, monocytes, and macrophages), and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of circular RNA in multiple immune cells.
- miR-142 is expressed in T cells, DCs, neutrophils, natural killer (NK) cells, monocytes, and macrophages
- NK natural killer
- the circular RNA comprises one or more target sequences for miR- 23a.
- the circular RNA comprises one or more target sequences for miR- 142. In some embodiments, the circular RNA comprises one or more target sequences for miR- 223. In some embodiments, the circular RNA comprises one or more target sequences for miR- 33b-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-346. In some embodiments, the circular RNA comprises one or more target sequences for miR-1205. In some embodiments, the circular RNA comprises one or more target sequences for miR-548a1. In some embodiments, the circular RNA comprises one or more target sequences for miR-1228-3p. In some embodiments, the circular RNA comprises one or more target sequences for miR-223-3p.
- the circular RNA comprises one or more target sequences for miR-21-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-23a-3p. In some embodiments, the circular RNA comprises one or more target sequences for let-7d-3p. In some embodiments, the circular RNA comprises one or more target sequences for miR-191-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-4454. In some embodiments, the circular RNA comprises one or more target sequences for miR-7975. In some embodiments, the circular RNA comprises one or more target sequences for miR-181a-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-548aa.
- the circular RNA comprises one or more target sequences for miR-548t-3p.
- the miRNA that hybridizes to the target sequence on the circular RNA is expressed in a specific type of immune cell.
- the miRNA is specific to an immune cell.
- a miRNA is considered specific to a particular cell type if the presence of that miRNA in a cell indicates to the skilled artisan that that cell belongs to that particular cell type.
- the immune cell a T cell precursor.
- the immune cell a hematopoietic stem cell.
- the immune cell a macrophage or macrophage precursor.
- the immune cell is a macrophage.
- the immune cell a monocyte. In some embodiments, the immune cell a tissue-resident macrophage. In some embodiments, the immune cell an adipose tissue macrophage, monocyte, Kupffer cell, sinus histiocyte, alveolar macrophage, microglia, Hofbauer cell, intraglomerular mesangial cell, osteoclast, Langerhans cell, epithelioid cell, red pulp macrophage, peritoneal macrophage, or Peyer’s patch macrophage. Circular RNAs may be produced by forming a covalent bond between two non-adjacent nucleotides of a linear RNA.
- a circular RNA containing the entire sequence of a linear RNA by ligating the 5′ terminal nucleotide to the 3′ terminal nucleotide may form a covalent bond with a subsequent nucleotide of the linear RNA, which may be the 3′ terminal nucleotide or an internal nucleotide of the linear RNA.
- a circular RNA formed does not comprise nucleotides upstream of that first nucleotide.
- a subsequent nucleotide that forms a covalent bond with a first nucleotide is an internal nucleotide
- the circular RNA formed does not comprise nucleotides downstream from that subsequent nucleotide.
- a circular RNA is produced by ligating a 5′ terminal nucleotide and a 3′ terminal nucleotide of the linear RNA using an RNA ligase.
- the 5′ terminal nucleotide comprises a 5′ terminal phosphate
- the 3′ terminal nucleotide comprises a 3′ terminal hydroxyl
- the RNA ligase is a T4 RNA ligase.
- the RNA ligase is a T4 RNA ligase I.
- the RNA ligase is a T4 RNA ligase II.
- the 5′ terminal nucleotide comprises a 5′ terminal hydroxyl
- the 3′ terminal nucleotide comprises a 3′ terminal phosphate
- the RNA ligase is an RtcB RNA ligase.
- the RNA ligase is a SplintR ligase.
- the 5′ and 3′ terminal nucleotides of the RNA must be close enough for the RNA ligase to form a bond between both nucleotides.
- Methods of placing both nucleotides of a linear nucleic acid close enough for ligation to occur, and of circularizing an RNA are generally known in the art. See, e.g., Petkovic et al., Nucleic Acids Res., 2015.43(4):2454–2465.
- Non- limiting examples of circularization methods include splinted ligation and ribozyme-mediated circularization.
- the ligating is conducted by splinted ligation.
- a nucleic acid to be ligated e.g., linear RNA
- a splint nucleic acid such as a DNA oligonucleotide
- the 5′ terminal nucleotide of the linear RNA is adjacent to the 3′ terminal nucleotide of the RNA in an RNA:splint nucleic acid hybrid.
- the RNA:splint nucleic acid is contacted with an RNA ligase that forms a covalent bond between the 5′ terminal nucleotide and the 3′ terminal nucleotide of the RNA.
- an RNA ligase that forms a covalent bond between the 5′ terminal nucleotide and the 3′ terminal nucleotide of the RNA.
- one or more of the last nucleotides of the RNA are bound to a first hybridization sequence in the splint nucleic acid, and one or more of the first nucleotides of the RNA are bound to a second hybridization sequence in the splint nucleic acid that is 3′ to (downstream of) the first hybridization sequence.
- the first hybridization sequence comprises 5 or more nucleotides, and the first hybridization sequence is complementary to at least the first five (5) nucleotides of the RNA.
- the first hybridization sequence comprises 10 or more, 15 or more, 20 or more, 25 or more, 30 or more, 35 or more, 40 or more, 45 or more, or 50 or more nucleotides, and at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or up to 100% of the nucleotides of the first hybridization sequence are complementary are complementary to the last N nucleotides of the RNA, where N is the length of the first hybridization sequence.
- the second hybridization sequence comprises 5 or more nucleotides, and the second hybridization sequence is complementary to at least the last five (5) nucleotides of the RNA.
- the second hybridization sequence comprises 10 or more, 15 or more, 20 or more, 25 or more, 30 or more, 35 or more, 40 or more, 45 or more, or 50 or more nucleotides, and at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or up to 100% of the nucleotides of the second hybridization sequence are complementary are complementary to the last N nucleotides of the RNA, where N is the length of the second hybridization sequence.
- At least the first five (5) nucleotides of the RNA hybridize with the first hybridization sequence. In some embodiments, at least the last five (5) nucleotides of the RNA hybridize with the second hybridization sequence. In some embodiments, at least the first five (5) nucleotides of the RNA hybridize with the first hybridization sequence, and at least the last five (5) nucleotides of the RNA hybridize with the second hybridization sequence. In some embodiments, the last nucleotide of the first hybridization sequence and the first nucleotide of the second hybridization sequence are adjacent in the splint nucleic acid, and are not separated by any other nucleotides.
- the splint nucleic acid is a DNA. In some embodiments, the splint nucleic acid is an RNA. In some embodiments, the RNA is circularized by a ribozyme. A ribozyme is a nucleic acid that catalyzes a reaction, such as the formation of a covalent bond between two nucleotides. In some embodiments, prior to circularization, the RNA comprises a 3′ intron that is 5′ to (upstream of) the 5′ UTR of the RNA, and a 5′ intron that is 3′ to (downstream of) the poly-A region and/or one or more structural sequences of the RNA.
- Ribozymes and other enzymes that catalyze splicing of pre-mRNA to remove introns can catalyze the formation of a covalent bond between the nucleotide that is 5′ to the 5′ intron and the nucleotide that is 3′ to 3′ intron, resulting in the formation of a circular RNA. See, e.g., Wesselhoeft et al., Nat Commun.2018. 9:2629.
- the method further comprises, after the in vitro transcribing of (i) and before the circularizing of (ii), contacting the linear RNA with a polyphosphatase.
- Polyphosphatases are enzymes that remove excess phosphates from the 5’ terminal nucleotide of a nucleic acid, producing a nucleic acid with a 5’ monophosphate group.
- Treatment of linear RNAs with polyphosphates serves multiple purposes that are useful in the production of circular RNAs. First, removal of excess phosphates prevents them from interfering in the circularization reaction, as the ligation of a 3’ terminal nucleotide to a 5’ terminal nucleotide is more efficient when the 5’ terminal nucleotide comprises only a single 5’ phosphate.
- RNAs comprising terminal 5’ triphosphate groups are agonists for the innate immune receptor RIG-I.
- Some embodiments of methods comprise introducing a 5′ phosphatase into a mixture comprising a linear RNA.
- a 5′ phosphatase removes one or more 5′ phosphates from a nucleic acid (e.g., RNA).
- the 5′ terminal nucleotide of a linear RNA produced by IVT may comprise multiple phosphates, such as a series of three phosphates (5′ triphosphate), with one phosphate in the series being bonded to the 5′ carbon of the 5′ terminal nucleotide.
- 5′ triphosphates can have multiple undesired effects, such as inhibiting circularization and reducing the stability of the RNA, and thus removal of 5′ triphosphates may thus improve the efficiency of circularization.
- a 5′ phosphate may be removed after a 3′ phosphate is introduced to the 3′ terminal nucleotide of an RNA, to produce an linear RNA with a 5′ hydroxyl and 3′ phosphate, which can be circularized using an RtcB RNA ligase.
- the 5′ phosphatase is a calf intestinal phosphatase or Antarctic phosphatase.
- the 5′ phosphatase is a calf intestinal phosphatase.
- the 5′ phosphatase is an Antarctic phosphatase.
- Some embodiments of the methods comprise introducing a DNase into the IVT mixture or a composition comprising circular RNA, to hydrolyze DNA template that remains in the IVT mixture or was co-purified with the circular RNA.
- the presence of DNA in a composition can facilitate cleavage and/or degradation of circular RNA, such as by forming a DNA:RNA hybrid that is recognized by restriction enzymes or other endonucleases. Additionally, the formation of a DNA:RNA hybrid can prevent ribosome attachment, translation initiation, and/or elongation. Minimizing the presence of DNA in a circular RNA composition can thus enhance the stability and efficiency of translation of circular RNAs.
- the concentration of DNA in a composition is 10% (%w/w) or less, 9% or less, 8% or less, 7% or less, 6% or less, 5% or less, 4% or less, 3% or less, 2% or less, or 1% or less. In some embodiments, the concentration of DNA is 1% (%w/w) or less, 0.9% or less, 0.8% or less, 0.7% or less, 0.6% or less, 0.5% or less, 0.4% or less, 0.3% or less, 0.2% or less, or 0.1% or less. In some embodiments, the concentration of DNA is 1% (%w/w) or less. In some embodiments, the concentration of DNA is 0.75% (%w/w) or less.
- the concentration of DNA is 0.5% (%w/w) or less. In some embodiments, the concentration of DNA is 0.25% (%w/w) or less. In some embodiments, the concentration of DNA is 0.1% (%w/w) or less.
- Methods of measuring the concentration of DNA in a composition include spectroscopy (NanoDrop) analysis, PCR, gel electrophoresis, and Southern blotting. The concentration of DNA may be measured before or after digestion of DNA template molecules with DNAses, digestion of RNA molecules with RNAses, and/or separation of DNA molecules from RNA molecules, such as through chromatography. In some embodiments, the concentration of DNA refers to the concentration of DNA polynucleotides in the composition.
- the concentration of DNA refers to the concentration of DNA polynucleotides and free nucleotides, including nucleotide triphosphates.
- the DNase is introduced before the linear RNA is circularized.
- the DNase may be introduced at least 1, at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, or at least 8 hours before the linear RNA is circularized.
- the DNase is introduced after the linear RNA is circularized.
- the DNase is introduced at least 1, at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, or at least 8 hours after the linear RNA is circularized.
- the DNase is introduced at about the same as the linear RNA is circularized.
- the DNase is introduced no more than 2 hours before and no more than 2 hours after the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 90 minutes before and no more than 90 minutes after the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 1 hour before and no more than 1 hour after the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 30 minutes before and no more than 30 minutes after the linear RNA is circularized. The DNase may remain in the mixture after digestion of residual DNA occurs, or RNA may be purified to remove the DNase, along with DNA fragments and deoxyribonucleotides, before other steps of the method, such as circularization.
- the DNase is incubated in the mixture for at least 30 minutes, at least 1 hour, at least 90 minutes, at least 2 hours, at least 3 hours, at least 4 hours, at least 5 hours, at least 6 hours, at least 7 hours, at least 8 hours, at least 9 hours, at least 10 hours, at least 11 hours, or at least 12 hours, up to a maximum of 24 hours.
- the DNse is removed prior to circularization to prevent degradation of the DNA splint.
- DNase is added after circularization to promote degradation of the DNA splint and release of the circular RNA.
- Exonucleases hydrolyze internucleoside linkages (e.g., phosphate backbone) between a terminal nucleotide and adjacent nucleotide of a nucleic acid, which releases the terminal nucleotide from the nucleic acid.
- internucleoside linkages e.g., phosphate backbone
- Continued hydrolysis of internucleoside linkages and consequent removal of nucleotides from a nucleic acid results in degradation of linear nucleic acids, such as linear mRNAs.
- Exposing a composition containing circular RNAs and linear RNAs to exonucleases selectively degrades the linear RNAs, without affecting the circular RNAs, which lack terminal nucleotides.
- RNAs can be enriched for circular RNAs through exonuclease activity.
- at least one exonuclease is a 5′ exonuclease.5′ exonucleases remove 5′ terminal nucleotides from nucleic acids.
- the 5′ exonuclease is an XRN-1 exonuclease.
- at least one exonuclease is a 3′ exonuclease.3′ exonucleases remove 3′ terminal nucleotides from nucleic acids.
- the 3′ exonuclease is RNase R.
- a 5′ exonuclease and a 3′ exonuclease are introduced into a mixture comprising a circular RNA.
- the combination of a 5′ exonuclease and 3′ exonuclease increases the rate of linear RNA degradation, as nucleotides may independently be removed from both ends of a linear nucleic acid.
- the circular RNA comprises an internal ribosome entry site (IRES).
- IRES internal ribosome entry site
- IRES internal ribosome entry site
- IRES sequences include sequences derived from a wide variety of viruses, such as from leader sequences of picornaviruses such as the encephalomyocarditis virus (EMCV) UTR (Jang et al., J Virol.1989. 63: 1651-1660), the polio leader sequence, the hepatitis A virus leader, the hepatitis C virus IRES, human rhinovirus type 2 IRES (Dobrikova et al., Proc Natl Acad Sci U S A.2003.
- EMCV encephalomyocarditis virus
- RNA may comprise any of a variety of nonviral IRES sequences, such as IRES sequences from yeast, as well as the human angiotensin II type 1 receptor IRES (Martin et al., Mol Cell Endocrinol.
- fibroblast growth factor IRESs FGF-1 IRES and FGF-2 IRES, Martineau et al., Mol Cell Biol. 2004.24(17):7622-7635
- VEGF vascular endothelial growth factor
- RNA.2006.12(6):1074-1083 insulin-like growth factor II (IGF-II) IRES (Pedersen et al., Biochem J.2002.363(Pt l):37-44).
- IGF-II insulin-like growth factor II
- plasmids sold e.g., by Clontech (Mountain View, CA), Invivogen (San Diego, CA), Addgene (Cambridge, MA) and GeneCopoeia (Rockville, MD). See also IRESite: The database of experimentally verified IRES structures (iresite.org).
- a circular RNA comprises a coxsackievirus B3 (CVB3) IRES.
- a circular RNA comprises an EMCV IRES.
- a circular RNA comprises a salivirus IRES. See Sweeney et al., J Virol.2012.86(3):1468–1486.
- the salivirus IRES is present in or derived from Salivirus FHB (SaliFHB). See GenBank Accession No. KM023140.1.
- the circular RNA comprises, in 5′-to-3′ order: a 5′ untranslated region (UTR), an IRES, an open reading frame encoding a protein, and a 3′ untranslated region.
- the circular RNA further comprises a polyA or polyAC region.
- the polyA or polyAC region is between the 5′ UTR and the IRES.
- the polyA or polyAC region is between the open reading frame and the 3′ UTR.
- the polyA or polyAC region is between the 3′ UTR and the 5′ UTR.
- the circular RNA does not comprise a polyA or polyAC region.
- a circular RNA comprises, in 5′-to-3′ order: a 5′ untranslated region (5′ UTR), a first polyA or polyAC region, an internal ribosome entry site (IRES), an open reading frame encoding a protein, a second polyA or polyAC region, and a 3′ untranslated region.
- 5′ UTR 5′ untranslated region
- IRS internal ribosome entry site
- open reading frame encoding a protein
- second polyA or polyAC region a 3′ untranslated region.
- at least 70%, at least 75%, at least 80%, at least 85%, at least 95%, or up to 100% of the RNAs in the composition are circular RNAs.
- RNAs that are circular RNAs are generally known in the art and include, without limitation, high-performance liquid chromatography (HPLC), column chromatography, endonuclease digestion, exonuclease digestion, and gel electrophoresis.
- HPLC high-performance liquid chromatography
- column chromatography endonuclease digestion
- exonuclease digestion endonuclease digestion
- gel electrophoresis gel electrophoresis.
- the structure of circular RNAs allows them to be distinguished from linear RNAs of the same sequence by chromatography methods, so that the relative fraction of circular and linear RNAs can be quantified by chromatographic analysis.
- circular RNAs produce distinct peaks on an HPLC chromatogram, and the relative areas under the curves (AUCs) of peaks that indicate linear RNAs or circular RNAs can be compared to calculate the fraction of RNAs that are circular.
- AUCs relative areas under the curves
- RNA peak with 4 times the AUC of a linear RNA peak indicates that the composition contains 80% circular RNA and 20% linear RNA.
- single-molecule molecular biology techniques such as long-read sequencing, limiting dilution, and/or digital droplet analysis, allow circular and linear RNAs to be distinguished based on sequence differences.
- primers that amplify the ligation junction of a circular RNA, but not a sequence present in the linear RNA allow for the selective amplification of circular RNAs or cDNA made by reverse transcription of circular RNAs. See, e.g., Zhang et al. Nat Commun.2020.11(1):90 and Panda et al.
- amplification from a linear RNA template ends once a polymerase reaches the end of the RNA, while amplification of a circular RNA template may continue indefinitely, such that the size of amplicons from a given template indicate whether amplification began with a linear or circular template.
- Circular RNAs may differ from linear RNAs comprising the same nucleic acid sequence. In some embodiments, the circular RNA is more resistant to degradation by exonucleases, relative to a linear RNA.
- the circular RNA is more resistant to phosphorylation by a kinase, relative to a linear RNA. In some embodiments, the circular RNA is more resistant to dephosphorylation by a phosphatase, relative to a linear RNA. In some embodiments, the circular RNA is supercoiled. In some embodiments, the circular RNA does not comprise a secondary structure. As a circular RNA has no 5′ terminal nucleotide, the circular RNA does not comprise a 5′ cap. In some embodiments, the circular RNA cannot be bound by a 5′ cap-binding protein.
- Some aspects relate to methods of improving stability of a circular RNA comprising a nucleotide sequence comprising an ORF, where the methods comprise: (i) substituting one or more nucleotides at adenosine positions in the nucleotide sequence to produce a modified nucleotide sequence in which 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 5–7%, 7–10%, 10–15%, 15–20%, 20–25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, or 90–95%; and (ii) synthesizing a circular RNA having the modified nucleotide sequence.
- Circular RNAs having a given modified nucleotide sequence may be synthesized by any suitable method, such IVT to produce a linear RNA followed by circularizing the linear RNA, or ligating two or more linear RNAs and circularizing the ligated RNA.
- Some embodiments of methods of improving circular RNA stability result in production of circular RNAs that express an encoded protein in a mammalian cell at a level that is at least 50% of the level of expression of a reference (control) circular RNA having the same nucleotide sequence, but in which all nucleotides at adenosine positions are unmodified (e.g., not N6- methyladenosine nucleotides).
- circular RNAs express one or more encoded proteins in a mammalian cell at a level that is at least 50% of the level of expression of a reference (control) circular RNA having the same nucleotide sequence, but in which all nucleotides at adenosine positions are unmodified (e.g., not N6-methyladenosine nucleotides).
- a reduction in the level of an mRNA results in a reduction in the level of a polypeptide expressed therefrom.
- the level of expression from a circular RNA may be determined using standard techniques for detecting proteins and measuring protein abundance, including western blotting, ELISA, and Bradford assays.
- a circular RNA a level of expression in a mammalian cell that is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, at least 100%, at least 120%, at least 150%, at least 175%, at least 200%, at least 250%, at least 300%, at least 350%, at least 400%, at least 450%, or at least 500% of the level of expression of a control circular RNA having the same nucleotide sequence as the circular RNA, but in which each nucleotide at an adenosine position is an unmodified adenosine nucleotide.
- the level of expression from the circular RNA is at least 50–80%, 80–100%, 100– 120%, 120–150%, 150–200%, 200–300%, 300–400%, or 400–500% of the level of expression from the control circular RNA.
- mammalian cells for use in evaluating expression of an RNA include, without limitation, humans, mice, rats, hamsters, guinea pigs, cats, dogs, chimpanzees, macaques, baboons, and gorillas.
- the mammalian cell is a human cell.
- Some embodiments of methods of improving circular RNA stability result in production of circular RNAs that are stable for longer periods of time in cells than control circular RNAs having the same sequence but lacking N6-methyladenosine nucleotides (i.e., control circular RNAs in which all nucleotides at adenosine positions are unmodified adenosine nucleotides).
- Some embodiments of circular RNAs are stable for longer periods of time in cells than control circular RNAs having the same sequence but lacking N6-methyladenosine nucleotides (i.e., control circular RNAs in which all nucleotides at adenosine positions are unmodified adenosine nucleotides).
- the circular RNA has a coefficient of degradation in a mammalian cell that is no more than 90% of a coefficient of degradation in the mammalian cell of a control circular RNA having the same nucleotide sequence as the circular RNA, and in which all nucleotides at adenosine positions are unmodified adenosine nucleotides.
- a “coefficient of degradation” refers to a parameter of an equation describing the loss of nucleic acid over time.
- Circular RNAs typically have a defined sequence, which may include an open reading frame encoding a protein to be expressed in cells.
- Circular RNA abundance may be measured by any method known in the art for detecting or measuring nucleic acids, such as RT-PCR or northern blotting.
- a positive value of ⁇ indicates exponential decay, while a negative ⁇ indicates exponential growth, with larger absolute values of ⁇ indicating faster decay or growth, respectively.
- the coefficient of degradation is expressed in units of hour -1 .
- a circular RNA has a coefficient of degradation in a mammalian cell that is no more than 90%, no more than 80%, no more than 70%, no more than 60%, no more than 50%, no more than 40%, no more than 30%, no more than 20%, no more than 10%, or no more than 5% of a coefficient of degradation of a control circular RNA having the same nucleotide sequence, but in which all nucleotides at adenosine positions are unmodified adenosine nucleotides.
- the circular RNA has a coefficient of degradation that is 40– 60%, 60–80%, or 80–95% of the coefficient of degradation of the control circular RNA. In some embodiments, the coefficient of degradation is measured over 1–168, 1–144, 1–120, 1–96, 1–72, 1–48, 1–24, 24–48, 48–72, 72–96, 96–120, 120–144, or 144–168 hours. In some embodiments, the coefficient of degradation is measured over 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 18, 24, 30, 36, 42, 48, 72, 96, 120, 144, or 168 hours.
- the circular RNA has a half-life in a mammalian cell that is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of the control circular RNA having the same nucleotide sequence as the circular RNA, but in which all nucleotides at adenosine positions are unmodified adenosine nucleotides.
- the circular RNA has a half-life that is 100–120%, 120– 150%, 150–200%, 200–300%, 300–400%, 400–500%, 500–600%, 600–700%, 700–800%, 800– 900%, or 900–1000% of the half-life of the control circular RNA.
- half-life refers to the amount of time required for 50% of circular RNA molecules to be cleaved to produce one or more non-circular RNAs.
- RNA molecules having the same nucleotide sequence and a half-life of 12 hours were introduced into a mammalian cell, only 500 of the circular RNA molecules would be intact after 12 hours, with the remaining circular RNAs having been cleaved to produce linear RNAs or multiple linear RNAs.
- Examples of ⁇ mammalian cells for use in evaluating degradation (e.g., measuring a coefficient of degradation and/or half-life) of an RNA include, without limitation, humans, mice, rats, hamsters, guinea pigs, cats, dogs, chimpanzees, macaques, baboons, and gorillas.
- the mammalian cell is a human cell.
- IVTT in vitro transcription
- RNA transcript e.g., linear RNA
- in vitro transcription produces (e.g., synthesizes) an RNA transcript (e.g., linear RNA) by forming a reaction mixture comprising a DNA template, an RNA polymerase (e.g., T7 RNA polymerase or T7 RNA polymerase variant), NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP) (and optionally modified forms of one or more NTPs), and a transcription buffer; and incubating the reaction mixture to allow the RNA polymerase to transcribe an RNA transcript from the DNA template.
- an RNA polymerase e.g., T7 RNA polymerase or T7 RNA polymerase variant
- NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate
- This linear RNA produced by IVT may then be circularized by any suitable method.
- two non- adjacent nucleotides of the linear RNA produced by IVT can then be ligated to produce a circular RNA.
- IVT methods may involve a modification in the amount (e.g., molar amount and/or quantity) and type of nucleotide triphosphates in the reaction mixture.
- Inclusion of N6- methyladenosine (m6A) triphosphate (m6ATP) in the reaction mixture allows for incorporation of N6-methyladenosine nucleotides into an RNA transcript.
- some aspects relate to IVT methods in which 15–100% of ATPs in the reaction mixture are modified ATPs comprising N6- methyladenosine (m6ATP). Further, use of a combination of unmodified ATP and m6ATP allows for transcription of an RNA that contains a mixture of unmodified adenosine nucleotides and N6-methyladenosine nucleotides. Thus, some aspects relate to IVT methods in which 15– 95% of the ATPs in the reaction mixture are modified ATPs comprising N6-methyladenosine (m6ATP). The percentage of ATPs in the reaction mixture that are m6ATP may be any percentage that is at least 15% and at most 100% or 95%.
- 15–20%, 20– 25%, 25–30%, 30–35%, 35–40%, 40–45%, 45–50%, 50–55%, 55–60%, 60–65%, 65–70%, 70– 75%, 75–80%, 80–85%, 85–90%, 90–95%, or 95–100% of ATPs in the reaction mixture are m6ATP.
- 15–20%, 20–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70– 80%, 80–90%, 90–95%, or 95–100% of ATPs in the reaction mixture are m6ATP.
- 15–30%, 30–45%, 45–60%, 60–75%, or 75–90% of ATPs in the reaction mixture are m6ATP.
- 15–90%, 15–80%, 15–60%, 15–40%, 15–20%, 20–30%, 30–40%, 40–50%, 50–75%, or 75–90% of ATPs in the reaction mixture are m6ATP.
- about 15% to about 90% of ATPs in the reaction mixture are m6ATP.
- about 15% to about 80% of ATPs in the reaction mixture are m6ATP.
- about 15% to about 60% of ATPs in the reaction mixture are m6ATP.
- ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 20% of ATPs in the reaction mixture are m6ATP. In some embodiments about 20% to about 30% of ATPs in the reaction mixture are m6ATP. In some embodiments about 30% to about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments about 40% to about 50% of ATPs in the reaction mixture are m6ATP. In some embodiments about 50% to about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments about 75% to about 90% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 30% of ATPs in the reaction mixture are m6ATP.
- about 30% to about 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 45% to about 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 60% to about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 75% to about 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 95% to about 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 30% to about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 15% and less than 30% of ATPs in the reaction mixture are m6ATP.
- greater than 30% and less than 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 45% and less than 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 60% and less than 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 75% and less than 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 95% and less than 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 30% and less than 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 15% and up to 30% of ATPs in the reaction mixture are m6ATP.
- At least 30% and up to 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 45% and up to 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 60% and up to 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 75% and up to 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 95% and up to 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 30% and up to 75% of ATPs in the reaction mixture are m6ATP.
- about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, about 90%, about 95%, or about 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 25% of ATPs in the reaction mixture are of ATPs in the reaction mixture are m6ATP. In some embodiments, about 30% of ATPs in the reaction mixture are m6ATP.
- about 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 55% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 65% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 70% of ATPs in the reaction mixture are m6ATP.
- about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 80% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 85% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 90% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 100% of ATPs in the reaction mixture are m6ATP.
- 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, or 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% of ATPs in the reaction mixture are m6ATP. In some embodiments, 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, 25% of ATPs in the reaction mixture are of ATPs in the reaction mixture are m6ATP. In some embodiments, 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, 35% of ATPs in the reaction mixture are m6ATP.
- 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, 55% of ATPs in the reaction mixture are m6ATP. In some embodiments, 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, 65% of ATPs in the reaction mixture are m6ATP. In some embodiments, 70% of ATPs in the reaction mixture are m6ATP. In some embodiments, 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, 80% of ATPs in the reaction mixture are m6ATP.
- 85% of ATPs in the reaction mixture are m6ATP. In some embodiments, 90% of ATPs in the reaction mixture are m6ATP. In some embodiments, 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, the percentage of ATPs in the reaction mixture that comprise N6- methyladenosine (i.e., are m6ATP) is no higher than a certain amount.
- no more than 80%, no more than 75%, no more than 70%, no more than 60%, no more than 50%, no more than 40%, no more than 30%, or no more than 20% of ATPs in the reaction mixture comprise N6-methyladenosine.
- the percentage of ATPs in the reaction mixture that are m6ATP is no more than 80%, 75%, 70%, 60%, 50%, 45%, 40%, 35%, 30%, 25%, or 20%.
- no more than 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 50% of ATPs in the reaction mixture are m6ATP.
- no more than 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 30% of ATPs in the reaction mixture are m6ATP.
- 15% to 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 25% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 25% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 25% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 20% of ATPs in the reaction mixture are m6ATP.
- the UTP in a reaction mixture is natural (unmodified uridine triphosphate), and the reaction mixture does not comprise modified UTP.
- at least one UTP in the reaction mixture is a modified UTP.
- the modified UTP may comprise any modified nucleobase, sugar, and/or phosphate.
- the modified UTP comprises N1-methylpseudouridine.
- the modified UTP comprises pseudouridine ( ⁇ ), N1-methylpseudouridine (m1 ⁇ ), 2-thiouridine, 4-thiouridine, 2-thio-1- methyl-1-deaza-pseudouridine, 2-thio-1-methyl-pseudouridine, 2-thio-5-aza-uridine , 2-thio- dihydropseudouridine, 2-thio-dihydrouridine, 2-thio-pseudouridine, 4-methoxy-2-thio- pseudouridine, 4-methoxy-pseudouridine, 4-thio-1-methyl-pseudouridine, 4-thio-pseudouridine, 5-aza-uridine, dihydropseudouridine, 5-methoxyuridine, or 2′-O-methyluridine.
- At least 10%, at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of UTPs in the reaction mixture comprise N1- methylpseudouridine. In some embodiments, 100% of UTPs in the reaction mixture comprise N1-methylpseudouridine.
- cDNA encoding the polynucleotides may be transcribed using an in vitro transcription (IVT) system.
- RNA e.g., mRNA
- the RNA is prepared in accordance with any one or more of the methods described in WO 2018/053209 or WO 2019/036682, each of which is incorporated by reference herein to the extent it discloses RNA preparation.
- the RNA (e.g., pre-mRNA) transcript is generated using a non- amplified, linearized DNA template in an in vitro transcription reaction to generate the RNA transcript.
- the template DNA is isolated DNA.
- the template DNA is cDNA.
- the cDNA is formed by reverse transcription of an RNA, for example, an mRNA.
- cells e.g., bacterial cells, e.g., E. coli, e.g., DH-1 cells are transfected with the plasmid DNA template.
- the transfected cells are cultured to replicate the plasmid DNA which is then isolated and purified.
- the DNA template includes an RNA polymerase promoter, e.g., a T7 promoter located 5 ' to and operably linked to the gene of interest.
- an in vitro transcription template encodes a 5′ untranslated (UTR) region, contains an open reading frame, and encodes a 3′ UTR and a polyA or polyAC region.
- the particular nucleic acid sequence composition and length of an in vitro transcription template will depend on the RNA (e.g., circular RNA) encoded by the template.
- a nucleic acid e.g., template DNA and/or RNA
- a nucleic acid may include 200 to 500, 200 to 1000, 200 to 1500, 200 to 3000, 500 to 1000, 500 to 1500, 500 to 2000, 500 to 3000, 1000 to 1500, 1000 to 2000, 1000 to 3000, 1500 to 3000, or 2000 to 3000 nucleotides.
- An in vitro transcription system typically comprises a transcription buffer (e.g., with magnesium), nucleotide triphosphates (NTPs), an RNase inhibitor and a polymerase (e.g., T7 RNA polymerase).
- NTPs nucleotide triphosphates
- RNase inhibitor e.g., T7 RNA polymerase
- a polymerase e.g., T7 RNA polymerase
- one or more of the NTPs is a chemically modified NTP (e.g., with N1-methylpseudouridine or other chemical modification(s)).
- a chemically modified NTP may comprise a modified nucleobase, modified sugar, and/or modified phosphate.
- Modified NTPs may include modified nucleobases.
- an NTP used in IVT may include a modified uracil nucleobase selected from pseudouracil ( ⁇ ), N1- methylpseudouracil (m1 ⁇ ), 1-ethylpseudouracil, 2-thiouracil, 4′-thiouracil, 2-thio-1-methyl-1- deaza-pseudouracil, 2-thio-1-methyl-pseudouracil, 2-thio-5-aza-uracil, 2-thio- dihydropseudouracil, 2-thio-dihydrouracil, 2-thio-pseudouracil, 4-methoxy-2-thio-pseudouracil, 4-methoxy-pseudouracil, 4-thio-1-methyl-pseudouracil, 4-
- an NTP includes a modified guanine nucleobase selected from digoxigeninated guanine, 6-thioguanine, 7-deazaguanine, 7-deaza-7-propargylaminoguanine, 8-oxoguanine, araguanine, biotin-16-7-deaza-7-propargylaminoguanine, isoguanine, N2-methylguanine, O6- methylguanine, thienoguanine, and 2,6-daminoguanine.
- a modified guanine nucleobase selected from digoxigeninated guanine, 6-thioguanine, 7-deazaguanine, 7-deaza-7-propargylaminoguanine, 8-oxoguanine, araguanine, biotin-16-7-deaza-7-propargylaminoguanine, isoguanine, N2-methylguanine, O6- methylguanine, thienoguanine
- an NTP used in IVT may include a modified cytosine nucleobase selected from digoxigeninated cytosine, 2- thiocytosine, 5-aminoallylcytosine, 5-bromocytosine, 5-carboxycytosine, 5-formylcytosine, 5- hydroxycytosine, 5-hydroxymethylcytosine, 5-methoxycytosine, 5-methylcytosine, 5- propargylaminocytosine, 5-propynylcytosine, 6-azacytosine, aracytosine, cyanine 3-5- propargylaminocytosine, cyanine 3-aminoallylcytosine, cyanine 5-6-propargylaminocytosine, cyanine 5-aminoallylcytosine, desthiobiotin-6-aminoallylcytosine, N4-biotin-OBEA-cytosine, N4-methylcytosine, pseudoisocytosine, and thienocytosine.
- an NTP includes a modified adenine nucleobase selected from digoxigeninated adenine, N6- methyladenine, 7-deazaadenine, 7-deaza-7-propargylaminoadenine, 8-azaadenine, 8- azidoadenine, 8-chloroadenine, 8-oxoadenine, araadenine, N1-methyladenine, N6- methyladenine, 3-deazaadenine, 2,6-diaminoadenine, 2-methyl-thio-N6-isopentenyladenine (ms2i6A), 2-methylthio-N6-methyladenine (ms2m6A), N6-(cis-hydroxyisopentenyl)adenine (io6A), 2-methylthio-N6-(cis-hydroxyisopentenyl)adenine (ms2io6A), N6- glycinylcarbamoyladenine
- an IVT reaction mixture includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified nucleobases.
- Modified NTPs may include modified sugars.
- an NTP used in IVT may include a modified sugar selected from 2′-thioribose, 2′,3′-dideoxyribose, 2′-amino-2′- deoxyribose, 2′ deoxyribose, 2′-azido-2′-deoxyribose, 2′-fluoro-2′-deoxyribose, 2′-O- methylribose, 2′-O-methyldeoxyribose, 3′-amino-2′,3′-dideoxyribose, 3′-azido-2′,3′- dideoxyribose, 3′-deoxyribose, 3′-O-(2-nitrobenzyl)-2′-deoxyribose, 3′-O
- an IVT reaction mixture includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified sugars.
- Modified NTPs may include modified phosphates.
- a modified phosphate group is a phosphate group that differs from the canonical structure of phosphate.
- an NTP used in IVT may include a modified phosphate selected from phosphorothioate (PS), thiophosphate, 5′-O-methylphosphonate, 3′-O-methylphosphonate, 5′-hydroxyphosphonate, hydroxyphosphanate, phosphoroselenoate, selenophosphate, phosphoramidate, carbophosphonate, methylphosphonate, phenylphosphonate, ethylphosphonate, H-phosphonate, guanidinium ring, triazole ring, boranophosphate (BP), methylphosphonate, and guanidinopropyl phosphoramidate.
- PS phosphorothioate
- thiophosphate 5′-O-methylphosphonate
- 3′-O-methylphosphonate 5′-hydroxyphosphonate, hydroxyphosphanate
- phosphoroselenoate selenophosphate
- phosphoramidate carbophosphonate
- methylphosphonate phen
- an IVT reaction mixture includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified phosphates.
- the NTPs comprise adenosine triphosphate (ATP), cytidine triphosphate (CTP), uridine triphosphate (UTP), and guanosine triphosphate (GTP).
- one or more of the NTPs comprises a chemical modification (e.g., a modified nucleobase, modified sugar, and/or modified phosphate).
- the ratios of NTPs may vary. In some embodiments, the ratio of GTP:ATP:CTP:UTP is 1:1:1:1.
- the amount of the GTP or an analogue thereof is greater than an amount of the UTP or an analogue thereof. In some embodiments, the amount of the GTP is greater than the amount of the UTP. In some embodiments, the amount of ATP is greater than the amount of UTP, and the amount of CTP is greater than the amount of UTP. In some embodiments, the amount of the GTP or an analogue thereof is greater than an amount of the UTP or an analogue thereof. In some embodiments, an IVT system comprises an at least 2:1 ratio of GTP concentration to ATP concentration, an at least 2:1 ratio of GTP concentration to CTP concentration, and an at least 4:1 ratio of GTP concentration to UTP concentration.
- an IVT system comprises a 2:1 ratio of GTP concentration to ATP concentration, a 2:1 ratio of GTP concentration to CTP concentration, and a 4:1 ratio of GTP concentration to UTP concentration.
- an IVT system comprises guanosine diphosphate (GDP).
- GDP guanosine diphosphate
- an IVT system comprises an at least 3:1 ratio of GTP plus GDP concentration to ATP concentration, an at least 6:1 ratio of GTP plus GDP concentration to CTP concentration, and an at least 6:1 ratio of GTP plus GDP concentration to UTP concentration.
- an IVT system comprises guanosine monophosphate (GMP).
- an IVT system comprises an at least 3:1 ratio of GTP plus GMP concentration to ATP concentration, an at least 6:1 ratio of GTP plus GMP concentration to CTP concentration, and an at least 6:1 ratio of GTP plus GMP concentration to UTP concentration.
- concentration of a given NTP e.g., ATP
- concentration of the natural NTP e.g., unmodified ATP
- all analogues of that NTP e.g., m6ATP
- the NTPs may be manufactured in house, may be selected from a supplier, or may be synthesized.
- the NTPs may be natural and/or unnatural (modified) NTPs.
- Any number of RNA polymerases or variants may be used in IVT methods.
- the polymerase may be selected from, but is not limited to, a phage RNA polymerase, e.g., a T7 RNA polymerase, a T3 RNA polymerase, a SP6 RNA polymerase, and/or mutant polymerases such as, but not limited to, polymerases able to incorporate modified nucleic acids and/or modified nucleotides, including chemically modified nucleic acids and/or nucleotides.
- an IVT reaction uses an RNA polymerase selected from the group consisting of T7 RNA polymerase, T3 RNA polymerase, K11 RNA polymerase, and SP6 RNA polymerase.
- an IVT reaction uses a T3 RNA polymerase.
- an IVT reaction uses an SP6 RNA polymerase.
- an IVT reaction uses a K11 RNA polymerase.
- an IVT reaction uses a T7 RNA polymerase.
- a wild-type T7 polymerase is used in an IVT reaction.
- a mutant T7 polymerase is used in an IVT reaction.
- a T7 RNA polymerase variant comprises an amino acid sequence that shares at least 50%, 60%, 70%, 80%, 90%, 95%, or 99% identity with a wild-type T7 (WT T7) polymerase.
- the T7 polymerase variant is a T7 polymerase variant described by International Application Publication Number WO2019/036682 or WO2020/172239, each of which is incorporated herein by reference to the extent it discloses RNA polymerases.
- a T7 RNA polymerase variant comprises an amino acid sequence with at least 50%, 60%, 70%, 80%, 90%, 95%, or 99% sequence identity to the amino acid sequence of any one of SEQ ID NOs: 1–4.
- the RNA polymerase (e.g., T7 RNA polymerase or T7 RNA polymerase variant) is present in a reaction (e.g., an IVT reaction) at a concentration of 0.01 mg/ml to 1 mg/ml.
- a reaction e.g., an IVT reaction
- the RNA polymerase may be present in a reaction at a concentration of 0.01 mg/mL, 0.05 mg/ml, 0.1 mg/ml, 0.5 mg/ml or 1.0 mg/ml.
- the T7 RNA polymerase variant comprises the amino acid sequence of any one of SEQ ID NOs: 1–4.
- T7 RNA polymerase variants with one or more mutations relative to WT T7 RNA polymerase have several advantages in IVT reactions, including improved speed, fidelity, and reduced production of double-stranded RNA (dsRNA) transcripts.
- Double-stranded RNA transcripts in which at least a portion of an RNA transcript is hybridized to another RNA molecule, elicit an innate immune response when introduced into a cell, causing degradation of both strands of a dsRNA.
- Minimizing the formation of dsRNA transcripts during IVT enables the production of less immunogenic, and thus more stable, circular RNA compositions.
- the concentration of double-stranded RNA in a composition comprising RNA is 5% (%w/w) or less, 4% or less, 3% or less, 2.5% or less, 2% or less, 1.75% or less, 1.5% or less, 1.25% or less, 1% or less, 0.9% or less, 0.8% or less, 0.7% or less, 0.6% or less, 0.5% or less, 0.4% or less, 0.3% or less, 0.25% or less, 0.2% or less, 0.175% or less, 0.15% or less, 0.125% or less, or 0.1% or less.
- the concentration of double-stranded RNA in a composition comprising RNA is 0.05% (%w/w) or less, 0.04% or less, 0.03% or less, 0.02% or less, or 0.01% or less.
- Methods of measuring the presence and/or amount of dsRNA in a composition are known in the art. Non-limiting examples of methods for measuring dsRNA content of a sample include ELISAs and immunoblotting using antibodies specific to dsRNA.
- the total mass of RNA in a sample can be measured using techniques such as spectroscopy (NanoDrop), qRT-PCR, and/or ddPCR, and the mass of dsRNA can be measured using an intercalating agent that fluoresces when bound to dsRNA, such as acridine orange, with the dsRNA concentration being calculated by division.
- concentration of dsRNA in a composition refers to the mass of RNA nucleotides that are part of a double- stranded RNA:RNA hybrid, with other unhybridized nucleotides from either RNA in the hybrid not contributing to the amount of dsRNA in a composition.
- the concentration of dsRNA in a sample refers to the concentration of RNA molecules containing nucleotides that are part of an RNA:RNA hybrid.
- the RNA composition produced using a T7 variant RNA polymerase is less immunogenic than an RNA composition produced using a WT T7 RNA polymerase.
- Methods of determining the immunogenicity of an RNA composition include analysis of innate immune receptor (e.g., RIG-I, TLR3, MDA5) stimulation and/or phosphorylation, quantification of cytokine (e.g., IP- 10) production by qRT-PCR, RNAseq, and/or ELISA, measurement of RNAi pathway activity, upregulation and/or activation of antiviral proteins (e.g., MAVS), and analysis of cell death.
- innate immune receptor e.g., RIG-I, TLR3, MDA5
- cytokine e.g., IP- 10
- Percent identity refers to a quantitative measurement of the similarity between two sequences (e.g., nucleic acid or amino acid). Percent identity can be determined using the algorithms of Karlin and Altschul, Proc. Natl. Acad. Sci. USA 87:2264-68, 1990, modified as in Karlin and Altschul, Proc. Natl. Acad. Sci. USA 90:5873-77, 1993. Such algorithms are incorporated into the NBLAST and XBLAST programs (version 2.0) of Altschul et al., J. Mol.
- An IVT system in some embodiments, comprises magnesium buffer, dithiothreitol (DTT) spermidine, pyrophosphatase, and/or RNase inhibitor. In some embodiments, an IVT system omits an RNase inhibitor. An IVT system may be incubated at 25 degrees Celsius or at 37 degrees Celsius. Other temperatures may be used, depending in part on the polymerase (e.g., use of a variant polymerase).
- RNA transcript is not capped via enzymatic capping prior to circularization.
- Nucleic acids Some aspects relate to compositions comprising nucleic acids (e.g., RNA (e.g., circular RNA)) and methods of producing nucleic acids.
- nucleic acid includes multiple nucleotides (i.e., molecules comprising a sugar (e.g., ribose or deoxyribose) linked to a phosphate group and to an exchangeable organic base, which is either a substituted pyrimidine (e.g., cytosine (C), thymine (T) or uracil (U)) or a substituted purine (e.g., adenine (A) or guanine (G))).
- a substituted pyrimidine e.g., cytosine (C), thymine (T) or uracil (U)
- a substituted purine e.g., adenine (A) or guanine (G)
- nucleic acid includes polyribonucleotides as well as polydeoxyribonucleotides.
- nucleic acid also includes polynucleosides (i.e., a polynucleotide minus the phosphate) and any other organic base containing polymer.
- Non- limiting examples of nucleic acids include chromosomes, genomic loci, genes, or gene segments that encode polynucleotides or polypeptides, coding sequences, non-coding sequences (e.g., intron, 5′-UTR, or 3′-UTR) of a gene, pri-mRNA, pre-mRNA, cDNA, mRNA, etc.
- a nucleic acid e.g., circular RNA
- a nucleic acid e.g., RNA
- RNA includes nucleotides having an organic group, such as a methyl group, attached to a nucleic acid base at the N6 position.
- an RNA comprises one or more N6-methyladenosine nucleotides.
- a phosphate, sugar, or nucleic acid base of a nucleotide may also be substituted for another phosphate, sugar, or nucleic acid base.
- a uridine nucleoside may be substituted for a pseudouridine nucleoside, in which the uracil base is attached to the sugar by a carbon-carbon bond rather than a nitrogen-carbon bond.
- a nucleic acid e.g., circular RNA
- a nucleic acid is heterogeneous in backbone composition thereby containing any possible combination of polymer units linked together such as peptide-nucleic acids (which have an amino acid backbone with nucleic acid bases).
- the modified nucleotides may be present at positions corresponding to a given nucleobase (e.g., adenine positions) or nucleoside comprising a given nucleobase (e.g., adenosine positions).
- a given nucleobase e.g., adenine positions
- nucleoside e.g., adenosine positions
- Positions specified using a given nucleobase or nucleoside refer to the sequence information encoded by the nucleobase (e.g., adenosine or adenine positions refer to the locations of “A”s in a nucleotide sequence), and so the presence of modified nucleotides comprising a modified form of the given nucleobase at those positions does not change the sequence information (e.g., encoded amino acid sequence) of the nucleic acid.
- the nucleic acids may include nucleic acid sequences that have been removed from their naturally occurring environment, recombinant or cloned DNA isolates, and chemically synthesized analogues or analogues biologically synthesized by heterologous systems.
- an “engineered nucleic acid” is a nucleic acid that does not occur in nature. It should be understood, however, that while an engineered nucleic acid as a whole is not naturally- occurring, it may include nucleotide sequences that occur in nature.
- an engineered nucleic acid comprises nucleotide sequences from different organisms (e.g., from different species).
- an engineered nucleic acid includes a bacterial nucleotide sequence, a human nucleotide sequence, and/or a viral nucleotide sequence.
- Engineered nucleic acids include recombinant nucleic acids and synthetic nucleic acids.
- a “recombinant nucleic acid” is a molecule that is constructed by joining nucleic acids (e.g., isolated nucleic acids, synthetic nucleic acids, or a combination thereof) and, in some embodiments, can replicate in a living cell.
- a “synthetic nucleic acid” is a molecule that is amplified or chemically, or by other means, synthesized.
- a synthetic nucleic acid includes those that are chemically modified, or otherwise modified, but can base pair with naturally-occurring nucleic acid molecules.
- Recombinant and synthetic nucleic acids also include those molecules that result from the replication of either of the foregoing.
- a nucleic may comprise naturally occurring nucleotides and/or non-naturally occurring nucleotides such as modified nucleotides.
- a nucleic acid is present in (or on) a vector.
- vectors include but are not limited to bacterial plasmids, phage, cosmids, phasmids, fosmids, bacterial artificial chromosomes, yeast artificial chromosomes, viruses, and retroviruses (for example vaccinia, adenovirus, adeno-associated virus, lentivirus, herpes-simplex virus, Epstein-Barr virus, fowlpox virus, pseudorabies, baculovirus) and vectors derived therefrom.
- a nucleic acid used as an input molecule for in vitro transcription (IVT) is present in a plasmid vector.
- IVT in vitro transcription
- isolated denotes that the polynucleotide sequence has been removed from its natural genetic milieu and is thus free of other extraneous or unwanted coding sequences (but may include naturally occurring 5′ and 3′ untranslated regions such as promoters and terminators), and is in a form suitable for use within genetically engineered protein production systems.
- isolated molecules are those that are separated from their natural environment.
- 5′ and 3′ are used herein to describe features of a nucleic acid sequence related to either the position of genetic elements and/or the direction of events (5′ to 3′), such as e.g. transcription by RNA polymerase or translation by the ribosome which proceeds in 5′ to 3′ direction. Synonyms are upstream (5′) and downstream (3′). Conventionally, DNA sequences, gene maps, vector cards and RNA sequences are drawn with 5′ to 3′ from left to right or the 5′ to 3′ direction is indicated with arrows, wherein the arrowhead points in the 3′ direction. Accordingly, 5′ (upstream) indicates genetic elements positioned towards the left-hand side, and 3′ (downstream) indicates genetic elements positioned towards the right-hand side, when following this convention.
- a nucleic acid typically comprises a plurality of nucleotides.
- a nucleotide includes a nitrogenous base, a five-carbon sugar (ribose or deoxyribose), and at least one phosphate group.
- Nucleotides include nucleoside monophosphates, nucleoside diphosphates, and nucleoside triphosphates.
- a nucleoside monophosphate includes a nucleobase linked to a ribose and a single phosphate; a nucleoside diphosphate (NDP) includes a nucleobase linked to a ribose and two phosphates; and a nucleoside triphosphate (NTP) includes a nucleobase linked to a ribose and three phosphates.
- Nucleotide analogs are compounds that have the general structure of a nucleotide or are structurally similar to a nucleotide.
- Nucleotide analogs include an analog of the nucleobase, an analog of the sugar and/or an analog of the phosphate group(s) of a nucleotide.
- a nucleoside includes a nitrogenous base and a 5-carbon sugar. Thus, a nucleoside plus a phosphate group yields a nucleotide.
- Nucleoside analogs are compounds that have the general structure of a nucleoside or are structurally similar to a nucleoside.
- Nucleoside analogs for example, include an analog of the nucleobase and/or an analog of the sugar of a nucleoside.
- nucleotide includes naturally occurring nucleotides, synthetic nucleotides and modified nucleotides, unless indicated otherwise.
- naturally occurring nucleotides used for the production of RNA include adenosine triphosphate (ATP), guanosine triphosphate (GTP), cytidine triphosphate (CTP), uridine triphosphate (UTP), and uridine triphosphate (UTP).
- adenosine diphosphate (ADP), guanosine diphosphate (GDP), cytidine diphosphate (CDP), and/or uridine diphosphate (UDP) are used.
- adenosine monophosphate AMP
- GMP guanosine monophosphate
- CMP cytidine monophosphate
- UMP uridine monophosphate
- GMP is used.
- Use of GMP which may initiate in vitro transcription of RNAs with 5′-terminal guanosine nucleotides, allows production of a linear RNA with a 5′-terminal monophosphate, such that the 5′ and 3′ termini of the resulting RNA may be ligated to produce a circular RNA without the need for a separate step to produce the 5′-terminal phosphate.
- nucleotide analogs include, but are not limited to, antiviral nucleotide analogs, phosphate analogs (soluble or immobilized, hydrolyzable or non-hydrolyzable), dinucleotide, trinucleotide, tetranucleotide, e.g., a cap analog, or a precursor/substrate for enzymatic capping (vaccinia or ligase), a nucleotide labeled with a functional group to facilitate ligation/conjugation of cap or 5 ⁇ moiety (IRES), a nucleotide labeled with a 5 ⁇ PO4 to facilitate ligation of cap or 5 ⁇ moiety, or a nucleotide labeled with a functional group/protecting group that can be chemically or enzymatically cleaved.
- antiviral nucleotide analogs phosphate analogs (soluble or immobilized, hydrolyzable or non-hydrolyz
- antiviral nucleotide/nucleoside analogs include, but are not limited, to Ganciclovir, Entecavir, Telbivudine, Vidarabine and Cidofovir.
- Modified nucleotides may include modified nucleobases.
- an RNA may include a modified uracil nucleobase selected from pseudouracil ( ⁇ ), N1-methylpseudouracil (m1 ⁇ ), 1-ethylpseudouracil, 2-thiouracil, 4′-thiouracil, 2-thio-1-methyl-1-deaza-pseudouracil, 2-thio-1-methyl-pseudouracil, 2-thio-5-aza-uracil, 2-thio- dihydropseudouracil, 2-thio-dihydrouracil, 2-thio-pseudouracil, 4-methoxy-2-thio-pseudouracil, 4-methoxy-pseudouracil, 4-thio-1-methyl-pseudouracil, 4-thio-pseudouracil, 5-aza-uracil, dihydropseudouracil, 5-methyluracil, 5-methyluracil
- an RNA e.g., RNA transcript or circular RNA
- a modified guanine nucleobase selected from digoxigeninated guanine, 6-thioguanine, 7-deazaguanine, 7-deaza-7- propargylaminoguanine, 8-oxoguanine, araguanine, biotin-16-7-deaza-7- propargylaminoguanine, isoguanine, N2-methylguanine, O6-methylguanine, thienoguanine, and 2,6-daminoguanine.
- a modified guanine nucleobase selected from digoxigeninated guanine, 6-thioguanine, 7-deazaguanine, 7-deaza-7- propargylaminoguanine, 8-oxoguanine, araguanine, biotin-16-7-deaza-7- propargylaminoguanine, isoguanine, N2-methylguanine, O6-
- an RNA transcript may include a modified cytosine nucleobase selected from digoxigeninated cytosine, 2-thiocytosine, 5-aminoallylcytosine, 5- bromocytosine, 5-carboxycytosine, 5-formylcytosine, 5-hydroxycytosine, 5- hydroxymethylcytosine, 5-methoxycytosine, 5-methylcytosine, 5-propargylaminocytosine, 5- propynylcytosine, 6-azacytosine, aracytosine, cyanine 3-5-propargylaminocytosine, cyanine 3- aminoallylcytosine, cyanine 5-6-propargylaminocytosine, cyanine 5-aminoallylcytosine, desthiobiotin-6-aminoallylcytosine, N4-biotin-OBEA-cytosine, N4-methylcytosine, pseudoisocytosine, and thienocytosine.
- an RNA (e.g., RNA transcript or circular RNA) includes a modified adenine nucleobase selected from digoxigeninated adenine, N6-methyladenine, 7-deazaadenine, 7-deaza-7-propargylaminoadenine, 8-azaadenine, 8- azidoadenine, 8-chloroadenine, 8-oxoadenine, araadenine, N1-methyladenine, N6- methyladenine, 3-deazaadenine, 2,6-diaminoadenine, 2-methyl-thio-N6-isopentenyladenine (ms2i6A), 2-methylthio-N6-methyladenine (ms2m6A), N6-(cis-hydroxyisopentenyl)adenine (io6A), 2-methylthio-N6-(cis-hydroxyisopentenyl)adenine (ms2io6A), N6--(cis-
- an RNA e.g., RNA transcript or circular RNA
- RNA includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified nucleobases.
- Modified nucleotides may include modified sugars.
- an RNA may include a modified sugar selected from 2′-thioribose, 2′,3′- dideoxyribose, 2′-amino-2′-deoxyribose, 2′ deoxyribose, 2′-azido-2′-deoxyribose, 2′-fluoro-2′- deoxyribose, 2′-O-methylribose, 2′-O-methyldeoxyribose, 3′-amino-2′,3′-dideoxyribose, 3′- azido-2′,3′-dideoxyribose, 3′-deoxyribose, 3′-O-(2-nitrobenzyl)-2′-deoxyribose, 3′-O- methylribose, 5′-aminoribose, 5′-thioribose, 5-nitro-1-indolyl-2′-deoxyribo
- an RNA (e.g., RNA transcript or circular RNA) includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified sugars.
- Modified nucleotides may include modified phosphates.
- a modified phosphate group is a phosphate group that differs from the canonical structure of phosphate.
- An example of a canonical structure of a phosphate is shown below: , where R5 and R3 are atoms or molecules to which the canonical phosphate is bonded.
- R 5 may refer to the upstream nucleotide of the nucleic acid
- R 3 may refer to the downstream nucleotide of the nucleic acid.
- the canonical structure of phosphate also refers to structures in which one or more hydroxyl groups of the phosphate are deprotonated, or in which an oxygen atom of the phosphate is bonded to an adjacent nucleotide in a nucleic acid sequence.
- an RNA may include a modified phosphate selected from phosphorothioate (PS), thiophosphate, 5′-O-methylphosphonate, 3′-O-methylphosphonate, 5′- hydroxyphosphonate, hydroxyphosphanate, phosphoroselenoate, selenophosphate, phosphoramidate, carbophosphonate, methylphosphonate, phenylphosphonate, ethylphosphonate, H-phosphonate, guanidinium ring, triazole ring, boranophosphate (BP), methylphosphonate, and guanidinopropyl phosphoramidate.
- PS phosphorothioate
- thiophosphate 5′-O-methylphosphonate
- 3′-O-methylphosphonate 5′- hydroxyphosphonate
- hydroxyphosphanate phosphoroselenoate
- selenophosphate selenophosphate
- phosphoramidate carbophosphonate, methylphospho
- an RNA (e.g., RNA transcript or circular RNA) includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified phosphates.
- an RNA comprises modified nucleotide(s) at one or more uridine positions.
- an RNA comprises N1-methylpseudouridine nucleotide(s) at one or more uridine positions.
- at least 20%, at least 40%, at least 60%, or at least 80% of nucleotides at uridine positions comprise N1-methylpseudouridine.
- substantially all nucleotides at uridine positions comprise N1- methylpseudouridine.
- an RNA comprises 5-methyluridine nucleotide(s) at one or uridine positions. In some embodiments, at least 20%, at least 40%, at least 60%, or at least 80% of nucleotides at uridine positions comprise 5-methyluridine. In some embodiments, substantially all nucleotides at uridine positions comprise 5-methyluridine. In some embodiments, an RNA comprises one or more modified nucleotides at cytidine positions. In some embodiments, an RNA comprises 5-methylcytidine nucleotide(s) at one or cytidine positions.
- RNAs may be used to produce polypeptides of interest, such as therapeutic proteins and/or vaccine antigens.
- an RNA encodes a vaccine antigen.
- an RNA encodes a therapeutic protein.
- the encoded polypeptide comprises 9–10,000, 9–9,000, 9–8,000, 9–7,000, 9–6,000, 9–5,000, 9–4,000, 9– 3,000, 9–2,000, 9–1,000, 9–500, 9–400, 9–300, 9–200, 9–100, 9–10,000, 100–9,000, 100–8,000, 100–7,000, 100–6,000, 100–5,000, 100–4,000, 100–3,000, 100–2,000, 100–1,000, 100–500, 100–400, 100–300, 100–200, 100–9,000, 200–10,000, 200–9,000200–8,000, 200–7,000, 200– 6,000, 200–5,000, 200–4,000, 200–3,000, 200–2,000, 200–1,000, 200–500, 200–400, 500– 10,000, 500–9,000, 500–8,000, 500–7,000, 500–6,000, 500–5,000, 500–4,000, 500–3,000, 500– 2,000, 500–1,000, 1,000–10,000, 1,000–9,000, 1,000–8,000, 1,000–7,000, 1,000–6,000, 1,000– 5,000, 1,000–4,000, 1,000–3,000,
- the encoded polypeptide consists of 9–10,000, 9–9,000, 9–8,000, 9–7,000, 9–6,000, 9–5,000, 9– 4,000, 9–3,000, 9–2,000, 9–1,000, 9–500, 9–400, 9–300, 9–200, 9–100, 9–10,000, 100–9,000, 100–8,000, 100–7,000, 100–6,000, 100–5,000, 100–4,000, 100–3,000, 100–2,000, 100–1,000, 100–500, 100–400, 100–300, 100–200, 100–9,000, 200–10,000, 200–9,000200–8,000, 200– 7,000, 200–6,000, 200–5,000, 200–4,000, 200–3,000, 200–2,000, 200–1,000, 200–500, 200– 400, 500–10,000, 500–9,000, 500–8,000, 500–7,000, 500–6,000, 500–5,000, 500–4,000, 500– 3,000, 500–2,000, 500–1,000, 1,000–10,000, 1,000–9,000, 1,000–8,000, 1,000–7,000, 1,000– 6,000, 1,000–5,000, 1,000–5,000, 1,000–4,000, 1,000–
- the encoded polypeptide comprises 9–5,000 amino acids. In some embodiments, the encoded polypeptide consists of 9–5,000 amino acids. In some embodiments, the encoded polypeptide comprises 20–4,000 amino acids. In some embodiments, the encoded polypeptide consists of 20–4,000 amino acids. In some embodiments, the encoded polypeptide comprises 30–3,000 amino acids. In some embodiments, the encoded polypeptide consists of 30–3,000 amino acids. In some embodiments, the encoded polypeptide comprises 40–2,000 amino acids. In some embodiments, the encoded polypeptide consists of 40–2,000 amino acids. In some embodiments, the encoded polypeptide comprises 50–1,500 amino acids. In some embodiments, the encoded polypeptide consists of 50–1,500 amino acids.
- the encoded polypeptide comprises 100–5,000 amino acids. In some embodiments, the encoded polypeptide consists of 100–5,000 amino acids. In some embodiments, the encoded polypeptide comprises 200–4,000 amino acids. In some embodiments, the encoded polypeptide consists of 200–4,000 amino acids. In some embodiments, the encoded polypeptide comprises 300–3,000 amino acids. In some embodiments, the encoded polypeptide consists of 300–3,000 amino acids. In some embodiments, the encoded polypeptide comprises 400–2,000 amino acids. In some embodiments, the encoded polypeptide consists of 400–2,000 amino acids. In some embodiments, the encoded polypeptide comprises 500–1,500 amino acids. In some embodiments, the encoded polypeptide consists of 500–1,500 amino acids.
- RNA compositions comprise one or more RNAs that encode peptides or proteins that interact or complex in a cell or subject to form a multi- subunit protein (e.g., an antibody comprising a heavy chain and a light chain, a multi-subunit receptor protein, a multi-subunit signaling protein, a multi-subunit antigen, etc.) or a multivalent vaccine.
- Therapeutic proteins mediate a variety of effects in a host cell or in a subject to treat a disease or ameliorate the signs and symptoms of a disease.
- a therapeutic protein can replace a protein that is deficient or abnormal, augment the function of an endogenous protein, provide a novel function to a cell (e.g., inhibit or activate an endogenous cellular activity, or act as a delivery agent for another therapeutic compound (e.g., an antibody-drug conjugate).
- Therapeutic RNA may be useful for the treatment of the following diseases and conditions: bacterial infections, viral infections, parasitic infections, cell proliferation disorders, genetic disorders, and autoimmune disorders. Other diseases and conditions are encompassed herein.
- a protein or proteins of interest encoded by an RNA composition can be essentially any protein or peptide (e.g., peptide antigen).
- a therapeutic peptide or therapeutic protein is a biologic.
- a biologic is a polypeptide-based molecule that may be used to treat, cure, mitigate, prevent, or diagnose a serious or life-threatening disease or medical condition.
- Biologics include, but are not limited to, allergenic extracts (e.g. for allergy shots and tests), blood components, gene therapy products, human tissue or cellular products used in transplantation, vaccines, monoclonal antibodies, cytokines, growth factors, enzymes, thrombolytics, and immunomodulators, among others.
- the therapeutic protein is a cytokine, a growth factor, an antibody (e.g., monoclonal antibody), a fusion protein, or a vaccine (e.g., an RNA encoding one or more peptide antigens designed to elicit an immune response in a subject).
- therapeutic proteins include blood factors (such as Factor VIII and Factor VII), complement factors, Low Density Lipoprotein Receptor (LDLR) and MUT1.
- cytokines include interleukins, interferons, chemokines, lymphokines and the like.
- Non-limiting examples of growth factors include erythropoietin, EGFs, PDGFs, FGFs, TGFs, IGFs, TNFs, CSFs, MCSFs, GMCSFs and the like.
- Non-limiting examples of antibodies include adalimumab, infliximab, rituximab, ipilimumab, tocilizumab, canakinumab, itolizumab, tralokinumab, anti- influenza virus monoclonal antibody, anti-Chikungunya virus monoclonal antibody, anti-Zika virus monoclonal antibody, anti-SARS-CoV-2 monoclonal antibody.
- Non-limiting examples of fusion proteins include, for example, etanercept, abatacept and belatacept.
- Non-limiting examples of multivalent vaccines include, for example, multivalent cytomegalovirus (CMV) vaccine, and personalized cancer vaccines.
- CMV multivalent cytomegalovirus
- One or more biologics currently being marketed or in development may be encoded by the RNA. While not wishing to be bound by theory, it is believed that incorporation of the encoding polynucleotides of a known biologic into the RNA will result in improved therapeutic efficacy due at least in part to the specificity, purity and/or selectivity of the construct designs.
- RNA composition may encode one or more antibodies (e.g., may comprise a first RNA encoding an antibody heavy chain and a second RNA encoding an antibody light chain).
- antibody includes monoclonal antibodies (including full length antibodies which have an immunoglobulin Fc region), antibody compositions with polyepitopic specificity, multispecific antibodies (e.g., bispecific antibodies, diabodies, and single-chain molecules), as well as antibody fragments.
- immunoglobulin Ig is used interchangeably with “antibody” herein.
- a monoclonal antibody is an antibody obtained from a population of substantially homogeneous antibodies, i.e., the individual antibodies comprising the population are identical except for possible naturally occurring mutations and/or post-translation modifications (e.g., isomerizations, amidations) that may be present in minor amounts. Monoclonal antibodies are highly specific, being directed against a single antigenic site.
- Monoclonal antibodies specifically include chimeric antibodies (immunoglobulins) in which a portion of the heavy and/or light chain is identical with or homologous to corresponding sequences in antibodies derived from a particular species or belonging to a particular antibody class or subclass, while the remainder of the chain(s) is(are) identical with or homologous to corresponding sequences in antibodies derived from another species or belonging to another antibody class or subclass, as well as fragments of such antibodies, so long as they exhibit the desired biological activity.
- Chimeric antibodies include, but are not limited to, “primatized” antibodies comprising variable domain antigen-binding sequences derived from a non-human primate (e.g., Old World Monkey, Ape etc.) and human constant region sequences.
- Antibodies encoded in the RNA compositions may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, blood, cardiovascular, CNS, poisoning (including antivenoms), dermatology, endocrinology, gastrointestinal, medical imaging, musculoskeletal, oncology, immunology, respiratory, sensory and anti-infective.
- An RNA may encode one or more vaccine antigens.
- a vaccine antigen is a biological preparation that improves immunity to a particular disease or infectious agent.
- One or more vaccine antigens currently being marketed or in development may be encoded by the RNA.
- Vaccine antigens encoded in the RNA may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, cancer, allergy, and infectious disease.
- a vaccine may be a personalized vaccine in the form of a concatemer or individual RNAs encoding peptide epitopes or a combination thereof.
- An RNA may encode on or more antimicrobial peptides (AMP) or antiviral peptides (AVP).
- AMPs and AVPs have been isolated and described from a wide range of animals such as, but not limited to, microorganisms, invertebrates, plants, amphibians, birds, fish, and mammals.
- the anti-microbial polypeptides may block cell fusion and/or viral entry by one or more enveloped viruses (e.g., HIV, HCV).
- the anti-microbial polypeptide can comprise or consist of a synthetic peptide corresponding to a region, e.g., a consecutive sequence of at least about 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, or 60 amino acids of the transmembrane subunit of a viral envelope protein, e.g., HIV-1 gp120 or gp41.
- a viral envelope protein e.g., HIV-1 gp120 or gp41.
- the amino acid and nucleotide sequences of HIV-1 gp120 or gp41 are described in, e.g., Kuiken et al., (2008). “HIV Sequence Compendium,” Los Alamos National Laboratory.
- RNAs e.g., circular RNAs are used for in vitro translation and microinjection.
- RNA transcripts are used for RNA structure, processing and catalysis studies. In some embodiments, RNA transcripts are used for RNA amplification. In some embodiments, RNA transcripts are used as anti-sense RNA for gene expression modulation. In some embodiments, an RNA is codon optimized. Codon optimization methods are known in the art.
- Codon optimization may be used to match codon frequencies in target and host organisms to ensure proper folding; bias %G/C content to increase RNA thermodynamic stability or reduce secondary structures; minimize tandem repeat codons or base runs that may impair gene construction or expression; customize transcriptional and translational control regions; insert or remove protein trafficking sequences; remove/add post translation modification sites in encoded protein (e.g., glycosylation sites); add, remove or shuffle protein domains; insert or delete restriction sites; modify ribosome binding sites and RNA degradation sites; adjust translational rates to allow the various domains of the protein to fold properly; or reduce or eliminate problem secondary structures within the polynucleotide.
- Codon optimization tools, algorithms and services are known in the art – non-limiting examples include services from GeneArt (Life Technologies), DNA2.0 (Menlo Park CA) and/or proprietary methods.
- the open reading frame (ORF) sequence is optimized using optimization algorithms.
- a codon optimized sequence shares less than 95% sequence identity to a naturally occurring or wild-type sequence ORF (e.g., a naturally occurring or wild- type RNA sequence encoding the polypeptide).
- a codon optimized sequence shares less than 90% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide).
- a codon optimized sequence shares less than 85% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares less than 80% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares less than 75% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide).
- a codon optimized sequence shares between 65% and 85% (e.g., between about 67% and about 85% or between about 67% and about 80%) sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares between 65% and 75% or about 80% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide).
- modified RNAs When transfected into mammalian host cells, some embodiments of modified RNAs have a stability of between 12-18 hours, or greater than 18 hours, e.g., 24, 36, 48, 60, 72, or greater than 72 hours and are capable of being expressed by the mammalian host cells.
- a codon optimized RNA may be one in which the %G/C content is increased.
- the %G/C-content of nucleic acid molecules e.g., circular RNA may influence the stability of the RNA.
- RNA having an increased number of guanine (G) and/or cytosine (C) nucleotides may be more thermodynamically stable than RNA containing a large number of adenine (A) and uracil (U) nucleotides.
- WO 2002/098443 discloses a pharmaceutical composition containing an mRNA stabilized by sequence modifications in the translated region. Due to the degeneracy of the genetic code, the modifications work by substituting existing codons for those that promote greater RNA stability without changing the resulting amino acid. The approach is limited to coding regions of the RNA.
- Untranslated regions are sections of a nucleic acid before a start codon (5′ UTR) and after a stop codon (3′ UTR) that are not translated.
- a nucleic acid e.g., a ribonucleic acid (RNA), e.g., a circular RNA
- ORF open reading frame
- UTR e.g., a 5′ UTR or functional fragment thereof, a 3′ UTR or functional fragment thereof, or a combination thereof.
- a UTR can be homologous or heterologous to the coding region in a nucleic acid.
- the UTR is homologous to the ORF encoding the one or more proteins. In some embodiments, the UTR is heterologous to the ORF encoding the one or more proteins.
- the nucleic acid comprises two or more 5′ UTRs or functional fragments thereof, each of which have the same or different nucleotide sequences. In some embodiments, the nucleic acid comprises two or more 3′ UTRs or functional fragments thereof, each of which have the same or different nucleotide sequences. In some embodiments, the 5′ UTR or functional fragment thereof, 3′ UTR or functional fragment thereof, or any combination thereof is sequence optimized.
- the 5′ UTR or functional fragment thereof, 3′ UTR or functional fragment thereof, or any combination thereof comprises at least one chemically modified nucleobase, e.g., 5-methoxyuracil.
- UTRs can have features that provide a regulatory role, e.g., increased or decreased stability, localization, and/or translation efficiency.
- a nucleic acid comprising a UTR can be administered to a cell, tissue, or organism, and one or more regulatory features can be measured using routine methods.
- a functional fragment of a 5′ UTR or 3′ UTR comprises one or more regulatory features of a full length 5′ or 3′ UTR, respectively. Natural 5′ UTRs bear features that play roles in translation initiation.
- 5′ UTRs also have been known to form secondary structures that are involved in elongation factor binding.
- introduction of 5′ UTR of liver-expressed mRNA, such as albumin, serum amyloid A, Apolipoprotein A/B/E, transferrin, alpha fetoprotein, erythropoietin, or Factor VIII can enhance expression of nucleic acids in hepatic cell lines or liver.
- tissue-specific mRNA to improve expression in that tissue is possible for muscle (e.g., MyoD, Myosin, Myoglobin, Myogenin, Herculin), for endothelial cells (e.g., Tie-1, CD36), for myeloid cells (e.g., C/EBP, AML1, G-CSF, GM-CSF, CD11b, MSR, Fr-1, i-NOS), for leukocytes (e.g., CD45, CD18), for adipose tissue (e.g., CD36, GLUT4, ACRP30, adiponectin), and for lung epithelial cells (e.g., SP-A/B/C/D).
- muscle e.g., MyoD, Myosin, Myoglobin, Myogenin, Herculin
- endothelial cells e.g., Tie-1, CD36
- myeloid cells e.g., C/EBP, AML1, G
- UTRs are selected from a family of transcripts whose proteins share a common function, structure, feature, or property.
- an encoded polypeptide can belong to a family of proteins (i.e., that share at least one function, structure, feature, localization, origin, or expression pattern), which are expressed in a particular cell, tissue or at some time during development.
- the UTRs from any of the genes or circular RNA can be swapped for any other UTR of the same or different family of proteins to create a new nucleic acid.
- the 5′ UTR and the 3′ UTR can be heterologous.
- the 5′ UTR can be derived from a different species than the 3′ UTR.
- the 3′ UTR can be derived from a different species than the 5′ UTR.
- International Patent Application No. PCT/US2014/021522 (Publ. No. WO/2014/164253) provides a listing of exemplary UTRs that may be utilized in the nucleic acids as flanking regions to an ORF. This publication is incorporated by reference herein for this purpose.
- Additional exemplary UTRs that may be utilized in the nucleic acids include, but are not limited to, one or more 5′ UTRs and/or 3′ UTRs derived from the nucleic acid sequence of: a globin, such as an ⁇ - or ⁇ -globin (e.g., a Xenopus, mouse, rabbit, or human globin); a strong Kozak translational initiation signal; a CYBA (e.g., human cytochrome b-245 ⁇ polypeptide); an albumin (e.g., human albumin7); a HSD17B4 (hydroxysteroid (17- ⁇ ) dehydrogenase); a virus (e.g., a tobacco etch virus (TEV), a Venezuelan equine encephalitis virus (VEEV), a Dengue virus, a cytomegalovirus (CMV; e.g., CMV immediate early 1 (IE1)), a hepatitis virus (e.g., hepatit
- the 5′ UTR is selected from the group consisting of a ⁇ -globin 5′ UTR; a 5′ UTR containing a strong Kozak translational initiation signal; a cytochrome b-245 ⁇ polypeptide (CYBA) 5′ UTR; a hydroxysteroid (17- ⁇ ) dehydrogenase (HSD17B4) 5′ UTR; a Tobacco etch virus (TEV) 5′ UTR; a Vietnamese equine encephalitis virus (TEEV) 5′ UTR; a 5′ proximal open reading frame of rubella virus (RV) RNA encoding nonstructural proteins; a Dengue virus (DEN) 5′ UTR; a heat shock protein 70 (Hsp70) 5′ UTR; a eIF4G 5′ UTR; a GLUT1 5′ UTR; functional fragments thereof and any combination thereof.
- CYBA cytochrome b-245 ⁇ polypeptide
- HSD17B4 hydroxysteroid
- the 3′ UTR is selected from the group consisting of a ⁇ -globin 3′ UTR; a CYBA 3′ UTR; an albumin 3′ UTR; a growth hormone (GH) 3′ UTR; a VEEV 3′ UTR; a hepatitis B virus (HBV) 3′ UTR; ⁇ -globin 3′ UTR; a DEN 3′ UTR; a PAV barley yellow dwarf virus (BYDV-PAV) 3′ UTR; an elongation factor 1 ⁇ 1 (EEF1A1) 3′ UTR; a manganese superoxide dismutase (MnSOD) 3′ UTR; a ⁇ subunit of mitochondrial H(+)-ATP synthase ( ⁇ - mRNA) 3′ UTR; a GLUT13′ UTR; a MEF2A 3′ UTR; a ⁇ -F1-ATPase 3′ UTR; functional fragments thereof and combinations thereof.
- Wild-type UTRs derived from any gene or mRNA can be incorporated into the nucleic acids (e.g., circular RNAs).
- a UTR can be altered relative to a wild type or native UTR to produce a variant UTR, e.g., by changing the orientation or location of the UTR relative to the ORF; or by inclusion of additional nucleotides, deletion of nucleotides, swapping or transposition of nucleotides.
- variants of 5′ or 3′ UTRs can be utilized, for example, mutants of wild type UTRs, or variants wherein one or more nucleotides are added to or removed from a terminus of the UTR.
- one or more synthetic UTRs can be used in combination with one or more non-synthetic UTRs. See, e.g., Mandal and Rossi, Nat. Protoc.20138(3):568-82, and sequences available at www.addgene.org, the contents of each are incorporated herein by reference in their entirety. UTRs or portions thereof can be placed in the same orientation as in the transcript from which they were selected or can be altered in orientation or location. Hence, a 5′ and/or 3′ UTR can be inverted, shortened, lengthened, or combined with one or more other 5′ UTRs or 3′ UTRs.
- the nucleic acid may comprise multiple UTRs, e.g., a double, a triple or a quadruple 5′ UTR or 3′ UTR.
- a double UTR comprises two copies of the same UTR either in series or substantially in series.
- a double beta-globin 3′ UTR can be used (see, e.g., US 2010/0129877, the contents of which are incorporated herein by reference for this purpose).
- Nucleic acids can comprise combinations of features.
- the ORF can be flanked by a 5′ UTR that comprises a strong Kozak translational initiation signal and/or a 3′ UTR comprising an oligo(dT) sequence for templated addition of a polyA tail.
- a 5′ UTR can comprise a first nucleic acid fragment and a second nucleic acid fragment from the same and/or different UTRs (see, e.g., US 2010/0293625, herein incorporated by reference for this purpose).
- Other non-UTR sequences can be used as regions or subregions within nucleic acids.
- introns or portions of intron sequences can be incorporated into nucleic acids. Incorporation of intronic sequences can increase protein production as well as nucleic acid expression levels.
- the nucleic acid comprises an internal ribosome entry site (IRES) instead of or in addition to a UTR (see, e.g., Yakubov et al., Biochem.
- IRS internal ribosome entry site
- the nucleic acid comprises an IRES instead of a 5′ UTR sequence. In some embodiments, the nucleic acid comprises an IRES that is located between a 5′ UTR and an open reading frame. In some embodiments, the nucleic acid comprises an ORF encoding a viral capsid sequence. In some embodiments, the nucleic acid comprises a synthetic 5′ UTR in combination with a non-synthetic 3′ UTR.
- the UTR can also include at least one translation enhancer nucleic acid, translation enhancer element, or translational enhancer elements (collectively, “TEE,” which refers to nucleic acid sequences that increase the amount of polypeptide or protein produced from a polynucleotide.
- TEE translation enhancer nucleic acid, translation enhancer element, or translational enhancer elements
- the TEE can include those described in US2009/0226470, incorporated herein by reference for this purpose, and others known in the art.
- the TEE can be located between the transcription promoter and the start codon.
- the 5′ UTR comprises a TEE.
- a TEE is a conserved element in a UTR that can promote translational activity of a nucleic acid such as, but not limited to, cap-dependent or cap-independent translation.
- the TEE comprises the TEE sequence in the 5′-leader of the Gtx homeodomain protein. See, e.g., Chappell et al., PNAS.2004.101:9590-9594, incorporated herein by reference for this purpose.
- PolyA and polyAC regions Some aspects relate to circular RNAs containing one or more polyA or polyAC regions, and/or methods of producing circular RNAs containing one or more polyA or polyAC regions.
- a “polyA region” is a region of an RNA that is downstream, e.g., directly downstream (i.e., 3′), from the open reading frame and/or the 3′ UTR that contains multiple, consecutive adenosine monophosphates.
- a “polyAC region” is a region of an RNA that is downstream, e.g., directly downstream from (i.e., 3′), from the open reading frame and/or the 3′ UTR that contains multiple adenosine monophosphates and multiple cytidine monophosphates.
- a polyA or polyAC region may contain 10 to 300 adenosine monophosphates and/or cytidine monophosphates.
- a polyA or polyAC region may contain 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 210, 220, 230, 240, 250, 260, 270, 280, 290 or 300 adenosine monophosphates and/or cytidine monophosphates.
- a polyA or polyAC region contains 50 to 250 nucleotides selected from adenosine monophosphates and and/or cytidine monophosphates.
- polyadenylation efficiency refers to the amount (e.g., expressed as a percentage) of RNAs having polyA or polyAC region that are produced by an IVT reaction using an input DNA relative to the total number of RNAs produced in the IVT reaction using the input DNA.
- the polyadenylation efficiency of an IVT reaction may vary, for example depending upon the RNA polymerase used, amount or purity of input DNA used, etc.
- the polyadenylation efficiency of an IVT reaction is greater than 85%, 90%, 95%, or 99.9%.
- Methods of calculating polyadenylation efficiency are known, for example by determining the amount of polyA or polyAC region-containing RNA relative to total RNA produced in an IVT reaction by column chromatography (e.g., oligo-dT chromatography).
- RNAs in a circular RNA composition comprise a polyA or polyAC region.
- at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 99.9% of each RNA in a circular RNA composition comprise a polyA or polyAC region.
- the polyadenylation efficiency (e.g., percentage of polyA or polyAC region- containing RNAs in a circular RNA composition) may be measured i) after the IVT reaction and before purification, or ii) after the circular RNA composition has been purified (e.g., by chromatography, such as oligo-dT chromatography).
- Unique polyA or polyAC region lengths provide certain advantages to nucleic acids. Generally, the length of a polyA or polyAC region, when present, is greater than 10 nucleotides in length.
- the polyA or polyAC region is greater In another embodiment, the polyA or polyAC region is at least 15 nucleotides in length (e.g., at least or greater than about 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 450, 500, 600, 700, 800, 900, 1,000, 1,100, 1,200, 1,300, 1,400, 1,500, 1,600, 1,700, 1,800, 1,900, 2,000, 2,500, or 3,000 nucleotides). In some embodiments, the polyA or polyAC region is designed relative to the length of the overall nucleic acid or the length of a particular region of the nucleic acid.
- the polyA or polyAC region can be 10, 20, 30, 40, 50, 60, 70, 80, 90, or 100% greater in length than the nucleic acid or feature thereof.
- the polyA or polyAC region can also be designed as a fraction of the nucleic acid to which it belongs.
- the polyA or polyAC region can be 10, 20, 30, 40, 50, 60, 70, 80, or 90% or more of the total length of the construct, a construct region or the total length of the construct minus the polyA or polyAC region.
- a circular RNA comprises multiple polyA or polyAC regions that are separated by one or more intervening sequences of the circular RNA.
- a circular RNA comprises a first polyA or polyAC region that is upstream of the open reading frame, and a second polyA or polyAC region that is downstream of the open reading frame.
- the first polyA or polyAC region is located upstream of the 5′ UTR.
- the first polyA or polyAC region is located downstream of the 5′ UTR and upstream of the open reading frame and/or an internal ribosome entry site (IRES).
- IRS internal ribosome entry site
- the second polyA or polyAC region is downstream of the 3′ UTR. In some embodiments, the second polyA or polyAC region is downstream of the open reading frame, and upstream of the 3′ UTR.
- a circular RNA comprises, in 5′-to-3′ order: a 5′ UTR, a first polyA or polyAC region, an IRES, an open reading frame, a second polyA or polyAC region, and a 3′ UTR. In some embodiments, each polyA or polyAC region is the same length. In other embodiments, the first and second polyA or polyAC regions are different lengths.
- An Identification and Ratio Determination (IDR) sequence is a sequence of a biological molecule (e.g., nucleic acid or protein) that, when combined with the sequence of a target biological molecule, serves to identify the target biological molecule.
- an IDR sequence is a heterologous sequence that is incorporated within or appended to a sequence of a target biological molecule and can be used as a reference to identify the target molecule.
- a nucleic acid e.g., circular RNA
- a target sequence of interest e.g., a coding sequence encoding a therapeutic and/or antigenic peptide or protein
- a unique IDR sequence e.g., an RNA species (e.g., RNA having a given coding sequence) may comprise an IDR sequence that differs from the IDR sequence of other RNA species (e.g., RNA(s) having different coding sequence(s)).
- Each IDR sequence thus identifies a particular RNA species, and so the abundance of IDR sequences may be measured to determine the abundance of each RNA species in a composition.
- RNA species Use of distinct IDR sequences to identify RNA species allows for analysis of multivalent RNA compositions (e.g., containing multiple RNA species) containing RNA species with similar coding sequences and/or lengths, which could otherwise be difficult to distinguish using PCR- or chromatography-based analysis of full-length RNAs.
- Each RNA species in a multivalent RNA composition may comprise an IDR sequence that is not a sequence isomer of an IDR sequence of another RNA species in a multivalent RNA composition (e.g., the IDR sequence does not have the same number of adenine nucleotides, the same number of cytosine nucleotides, the same number of guanine nucleotides, and the same number of uracil nucleotides, as another IDR sequence in the composition, even if those sequences have different sequences).
- Having identical nucleotide compositions causes sequence isomers to have the same mass, presenting a challenge to distinguishing sequence isomers using mass-based identification methods (e.g., mass spectrometry).
- Each RNA species in a multivalent RNA composition may comprise an IDR sequence having a mass that differs from the mass of IDR sequences of each other RNA species in a multivalent RNA composition.
- the mass of each IDR sequence may differ from the mass of other IDR sequences by at least 9 Da, at least 25 Da, at least 25 Da, or at least 50 Da.
- Use of IDR sequences with distinct masses allows RNA fragments comprising different IDR sequences to be distinguished using mass-based analysis methods (e.g., mass spectrometry), which do not require reverse transcription, amplification, or sequencing of RNAs.
- Each RNA species in an RNA composition may comprises an IDR sequence with a different length.
- each IDR sequence may have a length independently selected from 0 to 25 nucleotides.
- the length of a nucleic acid influences the rate at which the nucleic acid traverses a chromatography column, and so the use of IDR sequences of different lengths on different RNA species allows RNA fragments having different IDR sequences to be distinguished using chromatography-based methods (e.g., LC-UV).
- IDR sequences may be chosen such that no IDR sequence comprises a start codon, ‘AUG’. Lack of a start codon in an IDR sequence prevents undesired translation of nucleotide sequences within and/or downstream from the IDR sequence.
- IDR sequences may be chosen such that no IDR sequence comprises a recognition site for a restriction enzyme.
- no IDR sequence comprises a recognition site for XbaI, ‘UCUAG’.
- Lack of a recognition site for a restriction enzyme e.g., XbaI recognition site ‘UCUAG’) allows the restriction enzyme to be used in generating and modifying a DNA template for in vitro transcription, without affecting the IDR sequence or sequence of the transcribed RNA.
- Nucleic acid production Chemical synthesis Solid-phase chemical synthesis. Nucleic acids may be manufactured in whole or in part using solid phase techniques. Solid-phase chemical synthesis of nucleic acids is an automated method wherein molecules are immobilized on a solid support and synthesized step by step in a reactant solution.
- Solid-phase synthesis is useful in site-specific introduction of chemical modifications in the nucleic acid sequences.
- the synthesis of nucleic acids by the sequential addition of monomer building blocks may be carried out in a liquid phase.
- the synthetic methods discussed above each has its own advantages and limitations. Attempts have been conducted to combine these methods to overcome the limitations. Such combinations of methods are within the scope of methods.
- the use of solid-phase or liquid- phase chemical synthesis in combination with enzymatic ligation provides an efficient way to generate long chain nucleic acids that cannot be obtained by chemical synthesis alone. Ligation Assembling nucleic acids by a ligase may also be used.
- DNA or RNA ligases promote intermolecular ligation of the 5′ and 3′ ends of polynucleotide chains through the formation of a phosphodiester bond.
- Nucleic acids such as chimeric polynucleotides and/or circular nucleic acids may be prepared by ligation of one or more regions or subregions. DNA fragments can be joined by a ligase catalyzed reaction to create recombinant DNA with different functions. Two oligodeoxynucleotides, one with a 5′ phosphoryl group and another with a free 3′ hydroxyl group, serve as substrates for a DNA ligase.
- nucleic acid clean-up may be performed by methods known in the arts such as, but not limited to, AGENCOURT® beads (Beckman Coulter Genomics, Danvers, MA), poly-T beads, LNATM oligo-T capture probes (EXIQON® Inc, Vedbaek, Denmark) or HPLC based purification methods such as, but not limited to, strong anion exchange HPLC, weak anion exchange HPLC, reverse phase HPLC (RP-HPLC), and hydrophobic interaction HPLC (HIC- HPLC).
- AGENCOURT® beads Beckman Coulter Genomics, Danvers, MA
- poly-T beads poly-T beads
- LNATM oligo-T capture probes EXIQON® Inc, Vedbaek, Denmark
- HPLC based purification methods such as, but not limited to, strong anion exchange HPLC, weak anion exchange HPLC, reverse phase HPLC (RP-HPLC), and hydrophobic interaction HPLC (HIC- HPLC).
- purified when used in relation to a nucleic acid such as a “purified nucleic acid” refers to one that is separated from at least one contaminant.
- a “contaminant” is any substance that makes another unfit, impure or inferior.
- a purified nucleic acid e.g., DNA and RNA
- a quality assurance and/or quality control check may be conducted using methods such as, but not limited to, gel electrophoresis, UV absorbance, or analytical HPLC.
- the nucleic acids may be sequenced by methods including, but not limited to reverse-transcriptase-PCR. Quantification In some embodiments, the nucleic acids may be quantified in exosomes or when derived from one or more bodily fluid.
- Bodily fluids include peripheral blood, serum, plasma, ascites, urine, cerebrospinal fluid (CSF), sputum, saliva, bone marrow, synovial fluid, aqueous humor, amniotic fluid, cerumen, breast milk, broncheoalveolar lavage fluid, semen, prostatic fluid, cowper's fluid or pre-ejaculatory fluid, sweat, fecal matter, hair, tears, cyst fluid, pleural and peritoneal fluid, pericardial fluid, lymph, chyme, chyle, bile, interstitial fluid, menses, pus, sebum, vomit, vaginal secretions, mucosal secretion, stool water, pancreatic juice, lavage fluids from sinus cavities, bronchopulmonary aspirates, blastocyl cavity fluid, and umbilical cord blood.
- CSF cerebrospinal fluid
- saliva aqueous humor
- amniotic fluid cerumen
- breast milk broncheoalveolar lavage fluid
- exosomes may be retrieved from an organ selected from the group consisting of lung, heart, pancreas, stomach, intestine, bladder, kidney, ovary, testis, skin, colon, breast, prostate, brain, esophagus, liver, and placenta.
- Assays may be performed using construct specific probes, cytometry, qRT-PCR, real- time PCR, PCR, flow cytometry, electrophoresis, mass spectrometry, or combinations thereof while the exosomes may be isolated using immunohistochemical methods such as enzyme linked immunosorbent assay (ELISA) methods.
- ELISA enzyme linked immunosorbent assay
- Exosomes may also be isolated by size exclusion chromatography, density gradient centrifugation, differential centrifugation, nanomembrane ultrafiltration, immunoabsorbent capture, affinity purification, microfluidic separation, or combinations thereof. These methods afford the investigator the ability to monitor, in real time, the level of nucleic acids remaining or delivered. This is possible because the nucleic acids, in some embodiments, differ from the endogenous forms due to the structural or chemical modifications.
- the nucleic acid may be quantified using methods such as, but not limited to, ultraviolet visible spectroscopy (UV/Vis).
- UV/Vis ultraviolet visible spectroscopy
- a non-limiting example of a UV/Vis spectrometer is a NANODROP® spectrometer (ThermoFisher, Waltham, MA).
- the quantified nucleic acid may be analyzed in order to determine if the nucleic acid may be of proper size, check that no degradation of the nucleic acid has occurred. Degradation of the nucleic acid may be checked by methods such as, but not limited to, agarose gel electrophoresis, HPLC based purification methods such as, but not limited to, strong anion exchange HPLC, weak anion exchange HPLC, reverse phase HPLC (RP-HPLC), and hydrophobic interaction HPLC (HIC- HPLC), liquid chromatography-mass spectrometry (LCMS), capillary electrophoresis (CE) and capillary gel electrophoresis (CGE). Multivalent in vitro transcription (IVT) Some aspects relate to multivalent in vitro transcription.
- Multivalent in vitro transcription refers to contacting two or more DNA templates (e.g., a first input DNA and a second input DNA) with an RNA polymerase (e.g., a T7 RNA polymerase) under conditions that result in the production of RNA transcripts.
- RNA polymerase e.g., a T7 RNA polymerase
- Each input DNA (e.g., in a population of input DNA templates) in a co-IVT reaction may be obtained from a different source than other input DNAs.
- each input DNA may be obtained from a different bacterial cell or population or bacterial cells.
- a first input DNA can be produced in bacterial cell population A
- a second input DNA can be produced in bacterial cell population B
- a third input DNA can be produced in bacterial cell population C, where each of A, B, and C are not the same bacterial culture (e.g., co-cultured in the same container or plate).
- different input DNAs are obtained by separate synthesis reactions or produced by separate amplification reactions.
- the amounts of input DNAs used in multivalent co-IVT reactions may be normalized. Normalization may be based, for example, on the molar masses, lengths, nucleotide contents, degradation rates, and/or purity of input DNAs.
- normalization is based on the degradation rate of resulting RNAs. Normalization may be based on the lowest level of a certain characteristic present among the input DNAs (e.g., lowest molar mass, degradation rate (e.g., of the input DNA and/or output RNA), nucleotide content, purity, and/or polyadenylation efficiency). Alternatively, normalization may be based on the highest level of a certain characteristic present among the input DNAs (e.g., highest molar mass, degradation rate (e.g., of the input DNA and/or output RNA), nucleotide context, purity, and/or polyadenylation efficiency).
- normalization is based on the rate of RNA production from the input DNAs (e.g., the highest rate of RNA production of an input DNA or the lowest rate of RNA production of an input DNA in a reaction mixture).
- the amount of one or more input DNAs may be adjusted and/or normalized to improve production of RNA compositions having a pre-defined or desired ratio of RNA components. Adjusting and/or normalizing amounts of input DNAs may compensate for differences between input DNAs (e.g., large differences in lengths of two input DNAs, or different polyadenylation efficiencies) that can affect the ratio of RNAs in a multivalent RNA composition, thereby allowing for the production of RNA compositions having desired ratios of different RNAs.
- the amount of two input DNAs present in a co-IVT reaction may be determined by selecting a desired molar ratio of a first RNA to a second RNA, calculating the mass of each DNA template necessary to achieve the same molar ratio between input DNAs, and combining input DNAs encoding each of the first and second RNAs in the same molar ratio.
- the number of input DNAs (e.g., populations of input DNA molecules) used in an IVT reaction may vary, depending upon the number of different RNA molecules desired to be included in the multivalent RNA composition.
- An IVT reaction mixture may comprise 2 or more different input DNAs (e.g., 2, 3, 4, 5, 6, 7, 8, 9, 10, or more different input DNAs).
- the concentration of each of the populations of DNA molecules may also vary.
- the input DNAs may be added to an IVT reaction are a predefined DNA ratio, which may comprise a ratio between 2, 3, 4, 5, 6, 7, 8, 9, 10, or more different input DNAs (e.g., depending on the number of different RNAs in a composition).
- the size of two or more input DNAs (e.g., DNAs in two or more different populations of input DNAs) may also vary.
- the mass of each population of input DNA molecules in an IVT reaction may also vary.
- the molar ratio between populations of input DNA molecules in an IVT reaction may also vary. Different input DNA molecules used in an IVT reaction may have a different length (e.g., comprises a different number of nucleotides).
- a co-IVT reaction may include co-transcription of at least 2 different input DNAs (e.g., at least 2 of DNA A, B, C, D, E, F, F, H, I, J, etc.) at a ratio of A:B:C:D:E:F:G:H:I:J, wherein if DNA A is normalized to 1, one or more of DNA B, C, D, E, F, G, H, I, J, etc. can each independently be present at an amount (e.g., a concentration) that is from 0.01 to 100 times the amount (e.g., a concentration) of A.
- One or more of DNA B, C, D, E, F, G, H, I, or J may also be absent.
- a multivalent RNA composition may be produced by combining RNA transcripts (e.g., circular RNA) from separate sources. For example, each of two or more DNA templates may be transcribed in separate IVT reactions, and combined to produce a multivalent RNA composition. Separate RNAs may be circularized separately before being combined, or linear RNAs may be combined and circularized in a single circularization reaction. RNAs may be combined in any desired amount to produce a multivalent RNA composition comprising two or more RNAs in a specific ratio. RNA purification methods Some aspects relate to methods of producing circular RNAs and purifying circular RNAs by reverse phase chromatography.
- Chromatography refers to a process of separating components of a mixture based on differentiating characteristics of the components, such as interaction with a mobile and/or stationary phase of a chromatography column.
- reverse phase chromatography a mixture is introduced to a hydrophobic mobile phase, with the mobile phase and mixture passing over a hydrophilic stationary phase.
- Components of the mixture migrate through the stationary phase at different rates, depending on their relative affinity for the mobile and stationary phases.
- the amount of time required for a component (e.g., circular RNA) of the mixture to migrate through the stationary phase is also referred to as the “retention time” of the component.
- Mobile phases typically comprise one or more solvent solutions, each of which comprises a solvent and one or more ion pairing agents.
- one or more solvent solutions (e.g., 1, 2, 3, 4, 5, or more) of the mobile phase comprise a combination of at least one ion pairing agent (e.g., 1, 2, 3, 4, 5, or more).
- an “ion pairing agent” or an “ion pair” refers to an agent (e.g., a small molecule) that functions as a counter ion to a charged (e.g., ionized or ionizable) functional group on an HPLC analyte (e.g., a nucleic acid) and thereby changes the retention time of the analyte as it moves through the stationary phase of an HPLC column.
- ion paring agents are classified as cationic ion pairing agents (which interact with negatively charged functional groups) or anionic ion pairing agents (which interact with positively charged functional groups).
- ion pairing agent and “ion pair” further encompass an associated counter-ion (e.g., acetate, phosphate, bicarbonate, bromide, chloride, citrate, nitrate, nitrite, oxide, sulfate and the like, for cationic ion pairing agents, and sodium, calcium, and the like, for anionic ion pairing agents).
- one or more ion pairing agents utilized is a cationic ion pairing agent.
- cationic ion pairing agents include but are not limited to certain protonated or quaternary amines (including e.g., primary, secondary and tertiary amines) and salts thereof, such as a trietheylammonium salt (e.g., triethylammonium acetate (TEAA)), a tributylammonium salt (e.g., tetrabutylammonium phosphate (TBAP) or tetrabutylammonium chloride (TBAC)), a hexylammonium salt (e.g., hexylammonium acetate (HAA)), a dibutylammonium salt (e.g., dibutylammonium acetate (DBAA)), a tetrapropylammonium salt (e.g., tetrapropylammonium bromide (TPAB)), a dodecyltrimethylammonium salt (
- one or more solvent solutions of the mobile phase comprise a combination of two or more ion pairing agents selected from the group consisting of a trietheylammonium salt, tributylammonium salt, hexylammonium salt, dibutylammonium salt, tetrapropylammonium salt, dodecyltrimethylammonium salt, tetra(decyl)ammonium salt, dihexylammonium salt, dipropylammonium salt, myristyltrimethylammonium salt, tetraethylammonium salt, tetraheptylammonium salt, tetrahexylammonium salt, tetrakis(decyl)ammonium salt, tetramethylammonium salt, tetraoctylammonium salt, and tetrapentylammonium salt.
- a trietheylammonium salt tributylammonium salt,
- a salt of a cation refers to a composition comprising the cation and an anionic counter ion.
- a “tetrabutylammonium salt” may refer to tetrabutylammonium phosphate, tetrabutylammonium chloride, tetrabutylammonium bromide, tetrabutylammonium phosphate, or another composition comprising the cation tetrabutylammonium and an anionic counter ion.
- the ion pairing agent comprises a cation and an anionic counter ion, wherein the cation is selected from the group consisting of trietheylammonium, tributylammonium, hexylammonium, dibutylammonium, tetrapropylammonium, dodecyltrimethylammonium, tetra(decyl)ammonium, dihexylammonium, dipropylammonium, myristyltrimethylammonium, tetraethylammonium, tetraheptylammonium, tetrahexylammonium, tetrakis(decyl)ammonium, tetramethylammonium, tetraoctylammonium, and tetrapentylammonium, and the anionic counter ion is selected from the group consisting of a bromide, chloride, phosphate, and
- one or more solvent solutions of the mobile phase comprise an ion pairing agent selected from the group consisting of HAA, TBAP, TPAB, TBAC, DBAA, TEAA, DTMAC, TDAB, DHAA, DPAA MTEAB, TEAB, THepAB, THexAB, TrDAB, TMAB, TOAB, and TPeAB.
- one or more solvent solutions of the mobile phase comprise a combination of (i) TPAB and TBAC, (ii) DBAA and TEAA, or (iii) TBAP and TEAA.
- one or more solvent solutions of the mobile phase comprise a combination of TPAB and TBAC.
- one or more solvent solutions of the mobile phase comprise a combination of DBAA and TEAA.
- Protonated and quaternary amine ion pairing agents can be represented by the following formula: wherein each R independently is hydrogen, optionally substituted aliphatic, optionally substituted heteroaliphatic, optionally substituted aryl or optionally substituted heteroaryl; provided that at least one instance of R is not hydrogen; and A is an anionic counter ion.
- aliphatic refers to alkyl, alkenyl, alkynyl, and carbocyclic groups.
- heteroaliphatic refers to heteroalkyl, heteroalkenyl, heteroalkynyl, and heterocyclic groups.
- aryl refers to a radical of a monocyclic or polycyclic (e.g., bicyclic or tricyclic) 4n+2 aromatic ring system (e.g., having 6, 10, or 14 ⁇ electrons shared in a cyclic array) having 6–14 ring carbon atoms and zero heteroatoms provided in the aromatic ring system (“C6–14 aryl”).
- heteroaryl refers to a radical of a 5–14 membered monocyclic or polycyclic (e.g., bicyclic, tricyclic) 4n+2 aromatic ring system (e.g., having 6, 10, or 14 ⁇ electrons shared in a cyclic array) having ring carbon atoms and 1–4 ring heteroatoms provided in the aromatic ring system, wherein each heteroatom is independently selected from nitrogen, oxygen, and sulfur (“5–14 membered heteroaryl”).
- Suitable anionic counter ions include, but are not limited to, acetate, trifluoroacetate, phosphate, chloride, bromide hexafluorophosphate, sulfate, methylsulfonate, trifluoromethylsulfonate, 1,1,1,3,3,3-hexafluoro- 2-propanol (HFIP), 1,1,1,3,3,3-hexafluoro-2-methyl-2-propanol (HFMIP) and the like.
- HFIP 1,1,1,3,3,3-hexafluoro-2-methyl-2-propanol
- substituted means that at least one hydrogen present on a group is replaced with a permissible substituent, e.g., a substituent which upon substitution results in a stable compound, e.g., a compound which does not spontaneously undergo transformation such as by rearrangement, cyclization, elimination, or other reaction.
- a solvent solution of the mobile phase e.g., a first solvent solution or a second solvent solution
- at least two ion pairing agents are in a molar ratio of between about 1:1,000 to about 1,000:1, such that the nucleic acids and if present, lipids, traverse the column at different rates.
- the at least two ion pairing agents are in a molar ratio between about 1:1,000 to about 1,000:1, 1:900 to about 900:1, 1:800 to about 800:1, 1:700 to about 700:1, 1:600 to about 600:1, 1:500 to about 500:1, 1:400 to about 400:1, about 1:300 to about 300:1, about 1:200 to about 200:1, about 1:100 to about 100:1, about 50:1 to about 1:50, about 40:1 to about 1:40, about 30:1 to about 1:30, about 20:1 to about 1:20, or about 10:1 to about 1:10.
- each solvent solution comprises at least two ion pairing agents in a molar ratio of between about 1:100 to about 100:1.
- the at least two ion pairing agents are in a molar ratio between about 1:100 to about 100:1, 1:90 to about 90:1, 1:80 to about 80:1, 1:70 to about 70:1, 1:60 to about 60:1, 1:50 to about 50:1, 1:40 to about 40:1, about 1:30 to about 30:1, about 1:20 to about 20:1, about 1:10 to about 10:1, about 5:1 to about 1:5, about 4:1 to about 1:4, about 3:1 to about 1:3, or about 2:1 to about 1:2.
- the at least two ion pairing agents are in a 1:1 molar ratio.
- a solvent solution of the mobile phase (e.g., a first solvent solution or a second solvent solution) comprises at least two ion pairing agents that are in a molar ratio of between about 1:6 to about 6:1, such that the nucleic acids and if present, lipids, traverse the column at different rates.
- each solvent solution comprises at least two ion pairing agents in a molar ratio of between about 1:4 to about 4:1.
- the at least two ion pairing agents are in a molar ratio between about 1:3 to about 3:1, about 1:2 to about 2:1, or about 1:1.5 to about 1.5:1.
- the at least two ion pairing agents are in a 1:1 molar ratio.
- the concentration of each ion pairing agent in a solvent solution may range from about 1 mM to about 25 M (e.g., about 1 mM, about 2 mM, about 5 mM, about 10 mM, about 50 mM, about 100 mM, about 200 mM, about 500 mM, about 1 M, about 1.2 M, about 1.5 M, about 1.75 M, about 2M, about 2.25 M, about 2.5 M, about 2.75 M, about 3 M, about 3.25 M, about 3.5 M, about 3.75 M, about 4 M, about 4.25 M, about 4.5 M, about 4.75 M, about 5 M, about 5.5 M, about 6 M, about 6.5 M, about 7 M, about 7.5 M, about 8 M, about 8.5 M, about 9 M, about 9.5 M, about 10 M, about 11 M, about 12 M, about 13 M, about 14 M, about 15 M, about 16 M, about 17 M, about 18 M, about 19
- the concentration of an ion pairing agent in a mobile phase ranges from about, 10 mM–20 M, 20 mM–15 M, 30 mM–2 M, 40 mM–10 M, 50 mM–8 M, 75 mM–5 M, 100 mM–2.5 M, 125 mM–2 M, 150 mM–1.5 M, 175 mM–1 M, or 200 mM–500 mM.
- the concentration of each of the ion pairing agents independently ranges from about, 10 mM–20 M, 20 mM–15 M, 30 mM–12 M, 40 mM–10 M, 50 mM–8 M, 75 mM–5 M, 100 mM–2.5 M, 125 mM–2 M, 150 mM–1.5 M, 175 mM–1 M, or 200 mM–500 mM.
- a first or second solvent solution comprises a single ion pairing agent, which is present in an amount from about, 10 mM–20 M, 20 mM–15 M, 30 mM–12 M, 40 mM– 10 M, 50 mM–8 M, 75 mM–5 M, 100 mM–2.5 M, 125 mM–2 M, 150 mM–1.5 M, 175 mM–1 M, or 200 mM–500 mM.
- the concentration of each ion pairing agent in a solvent solution may range from about 1 mM to about 2 M (e.g., about 1 mM, about 2 mM, about 5 mM, about 10 mM, about 50 mM, about 100 mM, about 200 mM, about 500 mM, about 1 M, about 1.2 M, about 1.5 M, or about 2M), inclusive.
- the concentration of an ion pairing agent in a mobile phase ranges from about, 10 mM–1M, 40 mM–300 mM, 50 mM-500 mM, 75 mM-400 mM, 100 mM-300 mM, 200-300 mM, 200-250 mM, or 250-300 mM.
- the concentration of each of the ion pairing agents independently ranges from about, 10 mM–1M, 40 mM–300 mM, 50 mM-500 mM, 75 mM-400 mM, 100 mM- 300 mM, 200-300 mM, 200-250 mM, or 250-300 mM.
- two ion pairing agents are present at concentrations of about 20 mM: 40 mM, 50 mM: 50 mM, 50 mM: 60 mM, 50 mM: 75 mM, 50 mM: 100 mM, 50 mM:150 mM, 100 mM: 100 mM, 100 mM: 125 mM, 100 mM: 150 mM, 100 mM: 175 mM, 100 mM: 200 mM, 100 mM: 200 mM, 100 mM: 250 mM, 100 mM: 300 mM, 125 mM: 125 mM, 125 mM: 150 mM, 125 mM: 175 mM, 125 mM: 200 mM, 125 mM: 250 mM, 125 mM: 300 mM, 150 mM: 175 mM, 150 mM: 200 mM, 125 mM: 250 mM
- ion pairing agent concentrations include but are not limited to 40 mM TEAA: 20 mM DBAA, 100 mM TEAA: 50 mM DBAA, 50 mM TBAP: 50 mM TEAA, 250 mM TBAP: 250 mM TEAA, 300 mM TBAP: 300 mM TEAA, 50 mM TBAP: 150 mM TEAA, 125 mM TBAP: 250 mM TEAA, 250 mM TBAP: 250 mM TEAA, 300 mM TBAP: 300 mM TEAA, 50 mM DBAA: 50 mM TEAA, 60 mM DBAA: 50 mM TEAA, 75 mM DBAA: 50 mM TEAA, 175 mM DBAA: 125 mM TEAA, 100 mM DBAA: 100 mM TEAA, 50 mM TBAP: 100 mM TB
- one or more solvent solutions of the mobile phase comprise a combination of TPAB and TBAC.
- the concentrations of TPAB and TBAC independently range from 50 mM- 300 mM.
- one or more solvent solutions of the mobile phase comprise 200 mM TPAB: 200 mM TBAC, 250 mM TPAB: 250 mM TBAC, or 300 mM TPAB: 300 mM TBAC.
- one or more solvent solutions of the mobile phase comprise 250 mM TPAB: 250 mM TBAC.
- Ion pairing agents are generally dispersed within a mobile phase.
- a “mobile phase” is an aqueous solution comprising water and/or one or more organic solvents used to carry an HPLC analyte (or analytes), such as a nucleic acid or mixture of nucleic acids or a pharmaceutical composition comprising a nucleic acid or mixture of nucleic acids, through an HPLC column.
- a mobile phase for use in HPLC methods comprises multiple (e.g., 2, 3, 4, 5, or more) solvent solutions.
- the mobile phase comprises two solvent solutions, a first solvent solution and a second solvent solution (e.g., Mobile Phase A, and Mobile Phase B).
- a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:1,000 to 1,000:1.
- each solvent solution e.g., the first solvent solution and the second solvent solution
- each solvent solution comprises at least two ion pairing agents in a molar ratio of 1:1,000 to 1,000:1.
- a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:100 to 100:1.
- each solvent solution e.g., the first solvent solution and the second solvent solution
- a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:75 to 75:1.
- each solvent solution e.g., the first solvent solution and the second solvent solution
- each solvent solution comprises at least two ion pairing agents in a molar ratio of 1:75 to 75:1.
- a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:50 to 50:1.
- each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:50 to 50:1.
- a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:25 to 25:1.
- each solvent solution e.g., the first solvent solution and the second solvent solution
- each solvent solution comprises at least two ion pairing agents in a molar ratio of 1:25 to 25:1.
- a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:10 to 10:1.
- each solvent solution e.g., the first solvent solution and the second solvent solution
- a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:6 to 6:1.
- each solvent solution e.g., the first solvent solution and the second solvent solution
- each solvent solution comprises at least two ion pairing agents in a molar ratio of 1:6 to 6:1.
- a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:4 to 4:1.
- each solvent solution e.g., the first solvent solution and the second solvent solution
- at least one solvent solution of the mobile phase comprises an organic solvent.
- an IP-RP HPLC mobile phase comprises a polar organic solvent.
- polar organic solvents suitable for inclusion in a mobile phase include but are not limited to alcohols, ketones, nitrates, esters, amides and alkylsulfoxides.
- the mobile phase e.g., at least one solvent solution of the mobile phase
- the mobile phase (e.g., at least one solvent solution of the mobile phase) comprises one or more organic solvents selected form the group consisting of acetone, acetonitrile, dimethylformamide, dimethylsulfoxide (DMSO), ethanol, hexylene glycol, isopropanol, methanol, methyl acetate, propanol, and tetrahydrofuran.
- the mobile phase (e.g., at least one solvent solution of the mobile phase) comprises acetonitrile.
- a mobile phase (e.g., at least one solvent solution of the mobile phase) comprises additional components, for example as described in U.S.
- the concentration of organic solvent in a mobile phase can vary.
- the volume percentage (v/v) of an organic solvent in a mobile phase varies from 0% (absent) to about 100% of a mobile phase.
- the volume percentage of organic solvent in a mobile phase e.g., at least one solvent solution of the mobile phase
- the volume percentage of organic solvent in a mobile phase is between about 25% and about 60% v/v.
- the volume percentage of organic solvent in a mobile phase is at least about 50% v/v. In some embodiments, the volume percentage of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is about 50% to about 95%, about 55% to about 90%, about 60% to about 85%, about 65% to about 80%, or about 70% v/v to about 75% v/v.
- the concentration of organic solvent in a mobile phase is about 5%, about 10%, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, about 90% v/v, or about 95% v/v.
- the first solvent solution does not comprise an organic solvent.
- the volume percentage of organic solvent in the second solvent solution is at least about 50% v/v.
- the volume percentage of organic solvent in the second solvent solution is about 50% to about 95%, about 55% to about 90%, about 60% to about 85%, about 65% to about 80%, or about 70% v/v to about 75% v/v. In some embodiments, the volume percentage of organic solvent in the second solvent solution is about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, about 90% v/v, or about 95% v/v.
- the pH of the mobile phase e.g., the pH of each solvent solution of the mobile phase
- the pH of the mobile phase is between about pH 5.0 and pH 9.5 (e.g., about 5.0, about 5.5, about 6.0, about 6.5, about 7.0, about 7.5, about 8.0, about 8.5, about 9.0, or about 9.5). In some embodiments, the pH of the mobile phase is between about pH 6.8 and pH 9.0 (e.g., about 6.8, about 7.0, about 7.2, about 7.4, about 7.6, about 7.8, about 8.0, about 8.3, about 8.5, or about 9.0). In some embodiments, the pH of the mobile phase is about 8.0.
- the pH of the first solvent solution is between about pH 5.0 and pH 9.5 (e.g., about 5.0, about 5.5, about 6.0, about 6.5, about 7.0, about 7.5, about 8.0, about 8.5, about 9.0, or about 9.5). In some embodiments, the pH of the first solvent solution is between about pH 6.8 and pH 9.0 (e.g., about 6.8, about 7.0, about 7.2, about 7.4, about 7.6, about 7.8, about 8.0, about 8.3, about 8.5, or about 9.0). In some embodiments, the pH of the first solvent solution is about 8.0.
- the pH of the second solvent solution is between about pH 5.0 and pH 9.5 (e.g., about 5.0, about 5.5, about 6.0, about 6.5, about 7.0, about 7.5, about 8.0, about 8.5, about 9.0, or about 9.5). In some embodiments, the pH of the second solvent solution is between about pH 6.8 and pH 9.0 (e.g., about 6.8, about 7.0, about 7.2, about 7.4, about 7.6, about 7.8, about 8.0, about 8.3, or about 8.5). In some embodiments, the pH of the second solvent solution is about 8.0.
- the concentration of two or more solvent solutions in a mobile phase can vary.
- the volume percentage of the first solvent solution may range from about 0% (absent) to about 100%.
- the volume percentage of the first solvent solution may range from about 5%, about 10%, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, or about 90% v/v.
- the volume percentage of the second solvent solution of a mobile phase may range from about 5%, about 10%, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, or about 90% v/v.
- the ratio of the first solvent solution to the second solvent solution is held constant (e.g., isocratic) during elution of the nucleic acid.
- the ratio of the first solvent solution to the second solvent solution can vary throughout the elution step.
- the ratio of the first solvent solution is increased relative to the second solvent solution during the elution step. In some embodiments, the ratio of the first solvent solution is decreased relative to the second solvent solution during the elution step.
- concentration of one or more ion pairing agents in a mobile phase e.g., a solvent solution
- the relative ratios of the at least two ion pairing agents in a mobile phase (or solvent solution) may vary or be held constant (e.g., isocratic) during the eluting step.
- the ratio of a first ion pairing agent is increased relative to a second ion pairing agent during the elution step.
- the ratio of a first ion pairing agent is increased relative to a second ion pairing agent during the elution step.
- the ratio of TPAB to TBAC ranges from about 4:1 to about 1:4, about 3:1 to about 1:3, about 2:1 to about 1:2, or about 1:1 to 1:3.
- the mobile phase e.g., a solvent solution
- Any suitable HPLC column e.g., stationary phase
- a “HPLC column” is a solid structure or support that contains a medium (e.g.
- the stationary phase through which the mobile phase and HPLC sample (e.g., a sample containing HPLC analytes, such as nucleic acids) is eluted.
- HPLC sample e.g., a sample containing HPLC analytes, such as nucleic acids
- the composition and chemical properties of the stationary phase determine the retention time of HPLC analytes.
- the stationary phase is non- polar.
- non-polar stationary phases include but are not limited to resin, silica (e.g., alkylated and non-alkylated silica), polystyrenes (e.g., alkylated and non-alkylated polystyrenes), polystyrene divinylbenzenes, etc.
- a stationary phase comprises particles, for example porous particles.
- a stationary phase e.g., particles of a stationary phase
- hydrophobic e.g., made of an intrinsically hydrophobic material, such as polystyrene divinylbenzene
- a stationary phase is a membrane or monolithic stationary phase.
- the particle size (e.g., as measured by the diameter of the particle) of an HPLC stationary phase can vary. In some embodiments, the particle size of a HPLC stationary phase ranges from about 1 ⁇ m to about 100 ⁇ m (e.g., any value between 1 and 100, inclusive) in diameter.
- the particle size of a HPLC stationary phase ranges from about 2 ⁇ m to about 10 ⁇ m, about 2 ⁇ m to about 6 ⁇ m, or about 4 ⁇ m in diameter.
- the pore size of particles (e.g., as measured by the diameter of the pore) can also vary.
- the particles comprise pores having a diameter of about 100 ⁇ to about 10,000 ⁇ .
- the particles comprise pores having a diameter of about 100 ⁇ to about 5000 ⁇ , about 100 ⁇ to about 1000 ⁇ , or about 1000 ⁇ to about 2000 ⁇ .
- the stationary phase comprises polystyrene divinylbenzene, for example as used in PLRP-S 4000 columns or DNAPac-RP columns.
- a sample being added to the stationary phase may be diluted in a surfactant.
- Surfactants may include, but are not limited to, one or more of Triton, polysorbate 20, 40, 60, and 80, sodium lauryl sulfate, etc.
- the percentage of the surfactant ranges from about 1% to 5%, or about 5% to 10%.
- the percentage of the surfactant is about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, or 10%.
- the sample being added to the stationary phase is diluted in the first solvent solution (e.g., Mobile phase A).
- a circular RNA is separated from other nucleic acids of a mixture (e.g., linear RNAs, DNA templates or fragments) by size exclusion chromatography.
- Size exclusion chromatography also known as molecular sieving, separates components of a mixture based on size.
- size exclusion chromatography is conducted by adding a mixture containing a desired nucleic acid to a stationary phase containing solid particles in a column. Larger nucleic acids migrate through the stationary phase more quickly, while smaller nucleic acids interact more readily with particles of the stationary phase, and thus take longer to reach the bottom of the column. These differences in retention times allow mixtures to be separated into component parts by eluting distinct components from the column at different times.
- the secondary structure of a nucleic acid also influences the retention time of a nucleic acid in size exclusion chromatography column stationary phase.
- size exclusion chromatography may be used to separate circular RNAs from linear RNAs having the same sequence, as well as RNA fragments produced by exonuclease digestion, DNA splints, DNA templates, and DNA fragments produced by DNase digestion.
- the step of size exclusion chromatography is conducted before the step of reverse phase column chromatography. In some embodiments, the step of size exclusion chromatography is conducted after the step of reverse phase column chromatography.
- the nucleic acids are formulated as a lipid composition, such as a composition comprising a lipid nanoparticle, a liposome, and/or a lipoplex.
- the lipid composition e.g., lipid nanoparticle, liposome, and/or lipoplex
- the lipid composition does not comprise protamine.
- the lipid composition does comprise protamine.
- nucleic acids are formulated as lipid nanoparticle (LNP) compositions.
- Lipid nanoparticles typically comprise ionizable lipid (e.g., ionizable amino lipid), non-cationic lipid (e.g., phospholipid), structural lipid (e.g., sterol), and PEG-modified lipid components along with the nucleic acid cargo of interest.
- ionizable lipid e.g., ionizable amino lipid
- non-cationic lipid e.g., phospholipid
- structural lipid e.g., sterol
- PEG-modified lipid components along with the nucleic acid cargo of interest.
- the lipid nanoparticles can be generated using components, compositions, and methods as are generally known in the art, see for example PCT/US2016/052352; PCT/US2016/068300; PCT/US2017/037551; PCT/US2015/027400; PCT/US2016/047406; PCT/US2016/000129; PCT/US2016/014280; PCT/US2017/038426; PCT/US2014/027077; PCT/US2014/055394; PCT/US2016/052117; PCT/US2012/069610; PCT/US2017/027492; PCT/US2016/059575; PCT/US2016/069491; PCT/US2016/069493; and PCT/US2014/066242, all of which are incorporated by reference herein to the extent they disclose lipid nanoparticles and preparation thereof.
- the lipid nanoparticle comprises a molar ratio of 20-60% ionizable lipid, 5-25% non-cationic lipid, 25-55% structural lipid, and 0.5-15% PEG-modified lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 20-60% ionizable lipid, 5-30% non-cationic lipid, 10-55% structural lipid, and 0.5-15% PEG-modified lipid.
- the lipid nanoparticle comprises 40-50 mol% ionizable lipid, optionally 45-50 mol%, for example, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48-49 mol%, or 49-50 mol% for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol%. In some embodiments, the lipid nanoparticle comprises 20-60 mol% ionizable lipid.
- the lipid nanoparticle may comprise 20-50 mol%, 20-40 mol%, 20-30 mol%, 30-60 mol%, 30-50 mol%, 30-40 mol%, 40-60 mol%, 40-50 mol%, or 50-60 mol% ionizable lipid.
- the lipid nanoparticle comprises 20 mol%, 30 mol%, 40 mol%, 50 mol%, or 60 mol% ionizable lipid.
- the lipid nanoparticle comprises 35 mol%, 36 mol%, 37 mol%, 38 mol%, 39 mol%, 40 mol%, 41 mol%, 42 mol%, 43 mol%, 44 mol%, 45 mol%, 46 mol%, 47 mol%, 48 mol%, 49 mol%, 50 mol%, 51 mol%, 52 mol%, 53 mol%, 54 mol%, or 55 mol% ionizable lipid. In some embodiments, the lipid nanoparticle comprises 45–55 mole percent (mol%) ionizable lipid.
- lipid nanoparticle may comprise 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, or 55 mol% ionizable lipid.
- R 1 is NR N -C4-10 cycloalkenyl optionally substituted with one or more oxo or -N(R N
- the ionizable lipid is of Formula (IL*-I): (IL*-Ia) or a salt thereof, wherein: R 1 , o, m, n, M, M’, R 2c , and R 3c are as defined for variable IL*; and R 3a is C1-8 alkyl.
- ionizable lipid is of Formula (IL*-Ia): or a salt thereof, wherein: R 1 , o, m, n, M, M’, R 2c , and R 3c are as defined for Formula IL*; and R 3a is C 1-8 alkyl.
- the ionizable lipid is of Formula (IL*-Ia’): (IL*-Ia’) or a salt thereof, wherein: o, M, M’, R 2c and R 3c are as defined for variable IL*; and R 3a is C1-8 alkyl.
- the ionizable lipid is of Formula (IL*-Iia): (IL*-Iia) or a salt thereof, wherein: R 1 , o, m, n, M, M’, R 2c , and R 3c are as defined for Formula IL*; and R 3a is C 1-8 alkyl.
- the ionizable lipid is of Formula (IL*-II’): (IL*-II’) or a salt thereof, wherein: o, M, M’, R 2c and R 3c are as defined for variable IL*; and R 3a is C 1-8 alkyl.
- the ionizable lipid is of Formula (IL*-III): (IL*-III) or a salt thereof, wherein: R 1 , o, m, n, M, M’, R 2c , and R 3c are as defined for variable IL*; R 2a is a C1-8 alkyl; and R 3a is C1-8 alkyl.
- the ionizable lipid is of Formula (IL*-IIIa): or a salt thereof, wherein: R 1 , o, m, n, M, M’, R 2c , and R 3c are as defined for variable IL*; R 2b is a C 1-8 alkyl; and R 3a is C1-8 alkyl.
- the ionizable lipid is of Formula (IL*-IIIa): or a salt thereof, wherein: R 1 , o, M, M’, R 2c , and R 3c are as defined for variable IL*; R 2a is a C1-8 alkyl; and R 3a is C1-8 alkyl.
- the ionizable lipid is of Formula (IL*-IIIa’): (IL*-IIIa’) or a salt thereof, wherein: R 1 , o, M, M’, R 2c , and R 3c are as defined for variable IL*; R 2a is a C 1-8 alkyl; and R 3a is C1-8 alkyl.
- the ionizable lipid is of Formula (IL*-IIIb): (IL*-IIIb) or a salt thereof, wherein: R 1 , o, M, M’, R 2c , and R 3c are as defined for variable IL*; R 2a is a C 1-8 alkyl; and R 3a is C 1-8 alkyl.
- the ionizable lipid is of Formula (IL*-IIIb’): (IL*-IIIb’) or a salt thereof, wherein: R 1 , o, M, M’, R 2c , and R 3c are as defined for variable IL*; R 2a is a C 1-8 alkyl; and R 3a is C1-8 alkyl.
- the ionizable lipid is of Formula (IL*-IV): (IL*-IV) or a salt thereof, wherein: R 1 , o, m, n, M, M’, R 2c , and R 3c are as defined for variable IL*; R 2b is a C1-8 alkyl; and R 3a is C 1-8 alkyl.
- the ionizable lipid is of Formula (IL*-Iva): (IL*-Iva) or a salt thereof, wherein: R 1 , o, m, n, M, M’, R 2c , and R 3c are as defined for variable IL*; R 2b is a C 1-8 alkyl; and R 3a is C1-8 alkyl.
- the ionizable lipid is of Formula (IL*-Iva’): (IL*-Iva) or a salt thereof, wherein: o, M, M’, R 2c , and R 3c are as defined for variable IL*; R 2a is a C1-8 alkyl; and R 3a is C 1-8 alkyl.
- Variables o, R 1 , R N , R N’ , R N’’ of Ionizable Lipid In some embodiments of the ionizable lipid, o is 1. In some embodiments of the ionizable lipid, o is 2. In some embodiments of the ionizable lipid, o is 3.
- o is 4. In some embodiments of the ionizable lipid, R 1 is -OH. In some embodiments of the ionizable lipid, R N is H. In some embodiments of the ionizable lipid, R N is methyl. In some embodiments of the ionizable lipid, R N is ethyl. In some embodiments of the ionizable lipid, R 1 is -NR N -cyclobutenyl, wherein the cyclobutenyl is optionally substituted with one or more oxo or -N(R N’ R N’’ ). In some embodiments of the ionizable lipid, R N’ is H.
- R N’ is methyl. In some embodiments of the ionizable lipid, R N’ is ethyl. In some embodiments of the ionizable lipid, R N’’ is H. In some embodiments of the ionizable lipid, R N’’ is methyl. In some embodiments of the ionizable lipid, R N’’ is ethyl. In some embodiments of the ionizable lipid, R N’ is H and R N’’ is methyl.
- m is 4. In some embodiments of the ionizable lipid, m is 5. In some embodiments of the ionizable lipid, m is 6. In some embodiments of the ionizable lipid, m is 7. In some embodiments of the ionizable lipid, m is 8. In some embodiments of the ionizable lipid, m is 4. In some embodiments of the ionizable lipid, n is 5. In some embodiments of the ionizable lipid, n is 6.
- R 2 , R 2a , R 2b , R 2c of Ionizable Lipid In some embodiments of the ionizable lipid, R 2 is . In some embodiments of the ionizable lipid, R 2a is hydrogen. In some embodiments of the ionizable lipid, R 2a is methyl. In some embodiments of the ionizable lipid, R 2a is ethyl.
- R 2a is propyl. In some embodiments of the ionizable lipid, R 2a is butyl. In some embodiments of the ionizable lipid, R 2a is pentyl. In some embodiments of the ionizable lipid, R 2a is hexyl. In some embodiments of the ionizable lipid, R 2a is heptyl. In some embodiments of the ionizable lipid, R 2a is octyl. In some embodiments of the ionizable lipid, R 2b is hydrogen. In some embodiments of the ionizable lipid, R 2b is methyl.
- R 2b is ethyl. In some embodiments of the ionizable lipid, R 2b is propyl. In some embodiments of the ionizable lipid, R 2b is butyl. In some embodiments of the ionizable lipid, R 2b is pentyl. In some embodiments of the ionizable lipid, R 2b is hexyl. In some embodiments of the ionizable lipid, R 2b is heptyl. In some embodiments of the ionizable lipid, R 2b is octyl. In some embodiments of the ionizable lipid, R 2a is hydrogen and R 2b is hydrogen.
- R 2a is hexyl and R 2b is hydrogen. In some embodiments of the ionizable lipid, R 2a is octyl and R 2b is hydrogen. In some embodiments of the ionizable lipid, R 2a is hydrogen and R 2b is butyl. In some embodiments of the ionizable lipid, R 2c is methyl. In some embodiments of the ionizable lipid, R 2c is ethyl. In some embodiments of the ionizable lipid, R 2c is propyl. In some embodiments of the ionizable lipid, R 2c is butyl.
- R 2c is pentyl. In some embodiments of the ionizable lipid, R 2c is hexyl. In some embodiments of the ionizable lipid, R 2c is heptyl. In some embodiments of the ionizable lipid, R 2c is octyl. In some embodiments of the ionizable lipid, R 2 is –(C1-6 alkylene)-(C3-8 cycloalkyl)-C1-6 alkyl. In some embodiments of the ionizable lipid, R 2 is –(C 1-6 alkylene)-(cyclohexyl)-C 1-6 alkyl.
- R 2 is –(C1-6 alkylene)-(cyclopentyl)-C1-6 alkyl.
- Variables R 3 , R 3a , R 3b , and R 3c of Ionizable Lipid In some embodiments of the ionizable lipid, .
- R 3a is hydrogen. In some embodiments of the ionizable lipid, R 3a is methyl. In some embodiments of the ionizable lipid, R 3a is ethyl. In some embodiments of the ionizable lipid, R 3a is propyl.
- R 3a is butyl. In some embodiments of the ionizable lipid, R 3a is pentyl. In some embodiments of the ionizable lipid, R 3a is hexyl. In some embodiments of the ionizable lipid, R 3a is heptyl. In some embodiments of the ionizable lipid, R 3a is octyl. In some embodiments of the ionizable lipid, R 3b is hydrogen. In some embodiments of the ionizable lipid, R 3b is methyl. In some embodiments of the ionizable lipid, R 3b is ethyl.
- R 3b is propyl. In some embodiments of the ionizable lipid, R 3b is butyl. In some embodiments of the ionizable lipid, R 3b is pentyl. In some embodiments of the ionizable lipid, R 3b is hexyl. In some embodiments of the ionizable lipid, R 3b is heptyl. In some embodiments of the ionizable lipid, R 3b is octyl. In some embodiments of the ionizable lipid, R 3a is octyl and R 3b is hydrogen.
- R 3a is ethyl and R 3b is hydrogen. In some embodiments of the ionizable lipid, R 3a is hexyl and R 3b is hydrogen. In some embodiments of the ionizable lipid, R 3c is methyl. In some embodiments of the ionizable lipid, R 3c is ethyl. In some embodiments of the ionizable lipid, R 3c is propyl. In some embodiments of the ionizable lipid, R 3c is butyl. In some embodiments of the ionizable lipid, R 3c is pentyl.
- R 3c is hexyl. In some embodiments of the ionizable lipid, R 3c is heptyl. In some embodiments of the ionizable lipid, R 3c is octyl.
- variables o, R 1 , R N , R N’ , R N’ , m, n, M, M’, R 2 , R 2a , R 2b , R 2c , R 3 , R 3a , R 3b , and R 3c can each be, where applicable, selected from the groups described herein, and any group described herein for any of variables o,.R 1 , R N , R N’ , R N’ , m, n, M, M’, R 2 , R 2a , R 2b , R 2c , R 3 , R 3a , R 3b , and R 3c can be combined, where applicable, with any group described herein for one or more of the remainder of variables o, R 1 , R N , R N’ , R N’ , m, n, M, M’, R 2 , R 2a , R 2b , R 2c , R 3
- the ionizable lipid is a compound selected from: In some embodiments, the ionizable lipid is In some embodiments, the ionizable lipid is In some embodiments, the ionizable lipid is In some embodiments, the ionizable lipid is Without wishing to be bound by theory, it is understood that an ionizable lipid may have a positive or partial positive charge at physiological pH. Such lipids may be referred to as cationic or ionizable (amino)lipids. Lipids may also be zwitterionic, i.e., neutral molecules having both a positive and a negative charge.
- the ionizable amino lipid of a lipid nanoparticle is a compound of Formula (AI): its N-oxide, or a salt or isomer thereof, wherein R’ a is R’ branched ; wherein denotes a point of attachment; wherein R a ⁇ , R a ⁇ , R a ⁇ , and R a ⁇ are each independently selected from the group consisting of H, C 2-12 alkyl, and C 2-12 alkenyl; R 2 and R 3 are each independently selected from the group consisting of C1-14 alkyl and C 2-14 alkenyl; R 4 is selected from the group consisting of -(CH 2 ) n OH, wherein n is selected from the group consisting wherein denotes a point of attachment; wherein R 10 is N(R) 2 ; each R is independently selected from the group consisting of C 1-6 alkyl, C 2-3 alkenyl, and H; and n2 is selected from the group consisting
- R’ a is R’ branched ;
- R’ branched is denotes a point of attachment;
- R a ⁇ , R a ⁇ , R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C 1-14 alkyl;
- R 4 is -(CH 2 ) n OH; n is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each -C(O)O-;
- R’ is a C 1-12 alkyl; l is 5; and
- m is 7.
- R’ a is R’ branched ;
- R’ branched is denotes a point of attachment;
- R a ⁇ , R a ⁇ , R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C1-14 alkyl;
- R 4 is -(CH2)nOH; n is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each -C(O)O-;
- R’ is a C1-12 alkyl; l is 3; and
- m is 7.
- R’ a is R’ branched ;
- R’ branched is denotes a point of attachment;
- R a ⁇ is C 2-12 alkyl;
- R a ⁇ , R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C1-14 alkyl;
- n2 is 2;
- R 5 is H;
- each R 6 is H;
- M and M’ are each -C(O)O-;
- R’ is a C1-12 alkyl; l is 5; and m is 7.
- R’ a is R’ branched ;
- R’ branched is denotes a point of attachment;
- R a ⁇ , R a ⁇ , and R a ⁇ are each H;
- R a ⁇ is C2- 12 alkyl;
- R2 and R 3 are each C 1-14 alkyl;
- R 4 is -(CH 2 ) n OH; n is 2;
- each R 5 is H; each R 6 is H;
- M and M’ are each -C(O)O-;
- R’ is a C 1-12 alkyl; l is 5; and
- m is 7.
- the compound of Formula (AI) is selected from: , .
- the ionizable amino lipid of Formula (AI) is a compound of Formula (AIa): its N-oxide, or a salt or isomer thereof, wherein R’ a is R’ branched ; wherein denotes a point of attachment; wherein R a ⁇ , R a ⁇ , and R a ⁇ are each independently selected from the group consisting of H, C 2-12 alkyl, and C 2-12 alkenyl; R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and C2-14 alkenyl; R 4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting wherein denotes a point of attachment; wherein R 10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C 2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R 5 is independently selected
- the ionizable amino lipid of Formula (AI) is a compound of Formula (AIb): its N-oxide, or a salt or isomer thereof, wherein R’ a is R’ branched ; wherein R’ branched denotes a point of attachment; wherein R a ⁇ , R a ⁇ , R a ⁇ , and R a ⁇ are each independently selected from the group consisting of H, C 2-12 alkyl, and C 2-12 alkenyl; R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and C2-14 alkenyl; R 4 is -(CH2)nOH, wherein n is selected from the group consisting of 1, 2, 3, 4, and 5; each R 5 is independently selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl, and H; each R 6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are each independently selected
- R’ a is R’ branched ;
- R’ branched is denotes a point of attachment;
- R a ⁇ , R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C1-14 alkyl;
- R 4 is -(CH2)nOH;
- n is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each - C(O)O-;
- R’ is a C 1-12 alkyl; l is 5; and m is 7.
- R’ a is R’ branched ;
- R’ branched is denotes a point of attachment;
- R a ⁇ , R a ⁇ , and R a ⁇ are each H;
- R 2 and R 3 are each C1-14 alkyl;
- R 4 is -(CH2)nOH;
- n is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each - C(O)O-;
- R’ is a C 1-12 alkyl; l is 3; and m is 7.
- R’ a is R’ branched ;
- R’ branched is denotes a point of attachment;
- R a ⁇ and R a ⁇ are each H;
- R a ⁇ is C2-12 alkyl;
- R 2 and R 3 are each C 1-14 alkyl;
- R 4 is -(CH 2 ) n OH;
- n is 2;
- each R 5 is H;
- each R 6 is H;
- M and M’ are each -C(O)O-;
- R’ is a C1-12 alkyl; l is 5; and m is 7.
- the ionizable amino lipid of Formula (AI) is a compound of Formula (AIc): its N-oxide, or a salt or isomer thereof, wherein R’ a is R’ branched ; wherein denotes a point of attachment; wherein R a ⁇ , R a ⁇ , R a ⁇ , and R a ⁇ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl; R 2 and R 3 are each independently selected from the group consisting of C1-14 alkyl and C 2-14 alkenyl; , wherein denotes a point of attachment; whereinR 10 is N(R)2; each R is independently selected from the group consisting of C 1-6 alkyl, C 2-3 alkenyl, and H; n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R 5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl,
- R a ⁇ , R a ⁇ , and R a ⁇ are each H; R a ⁇ is C 2-12 alkyl; R 2 and R 3 are each C 1-14 alkyl; denotes a point of attachment; R 10 is NH(C1-6 alkyl); n2 is 2; each R 5 is H; each R 6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7.
- the compound of Formula (AIc) is: Formula (AII)
- the ionizable amino lipid is a compound of Formula (AII): wherein R’ a is R’ branched or R’ cyclic ; wherein a R a ⁇ and R a ⁇ are each independently selected from the group consisting of H, C 1-12 alkyl, and C2-12 alkenyl, wherein at least one of R a ⁇ and R a ⁇ is selected from the group consisting of C1- 12 alkyl and C2-12 alkenyl; R b ⁇ and R b ⁇ are each independently selected from the group consisting of H, C 1-12 alkyl, and C 2-12 alkenyl, wherein at least one of R b ⁇ and R b ⁇ is selected from the group consisting of C 1- 12 alkyl and C2-12 alkenyl; R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and C 2-14 alkenyl; R 4 is selected from
- the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-a): wherein R’ a is R’ branched or R’ cyclic ; wherein wherein denotes a point of attachment; R a ⁇ and R a ⁇ are each independently selected from the group consisting of H, C 1-12 alkyl, and C2-12 alkenyl, wherein at least one of R a ⁇ and R a ⁇ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R b ⁇ and R b ⁇ are each independently selected from the group consisting of H, C 1-12 alkyl, and C 2-12 alkenyl, wherein at least one of R b ⁇ and R b ⁇ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R 2 and R 3 are each independently selected from the group consisting of C1-14 alkyl and C 2-14 alkenyl; R 4 is selected from the group consisting
- the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-b): its N-oxide, or a salt or isomer thereof, wherein R’ a is R’ branched or R’ cyclic ; wherein wherein denotes a point of attachment; R a ⁇ and R b ⁇ are each independently selected from the group consisting of C1-12 alkyl and C 2-12 alkenyl; R 2 and R 3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting wherein denotes a point of attachment; wherein R 10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’
- the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-c): wherein R’ a is R’ branched or R’ cyclic ; wherein wherein denotes a point of attachment; wherein R a ⁇ is selected from the group consisting of C 1-12 alkyl and C 2-12 alkenyl; R 2 and R 3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R 4 is selected from the group consisting of -(CH 2 ) n OH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5, and , wherein denotes a point of attachment; wherein R 10 is N(R) 2 ; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; R’ is a C 1-12 alkyl or C
- the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-d): its N-oxide, or a salt or isomer thereof, wherein R’ a is R’ branched or R’ cyclic ; wherein wherein denotes a point of attachment; wherein R a ⁇ and R b ⁇ are each independently selected from the group consisting of C 1-12 alkyl and C 2-12 alkenyl; R 4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting wherein denotes a point of attachment; wherein R 10 is N(R) 2 ; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C 1-12 alkyl or C 2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7,
- the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-e): wherein denotes a point of attachment; wherein R a ⁇ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R 2 and R 3 are each independently selected from the group consisting of C 1-14 alkyl and C2-14 alkenyl; R 4 is -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5; R’ is a C 1-12 alkyl or C 2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9.
- m and l are each independently selected from 4, 5, and 6. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), m and l are each 5. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), each R’ independently is a C 1-12 alkyl.
- each R’ independently is a C2-5 alkyl.
- R’ b is: and R 2 and R 3 are each independently a C1-14 alkyl.
- R’ b is: and R 2 and R 3 are each independently a C 6-10 alkyl.
- R 2 and R 3 are each a C 8 alkyl.
- R 3 are each independently a C6-10 alkyl.
- alkyl In some embodiments of the compound of Formula embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), alkyl, and R 2 and R 3 are each a C8 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- are each a C 1-12 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), and R b ⁇ are each a C2-6 alkyl.
- m and l are each independently selected from 4, 5, and 6 and each R’ independently is a C1-12 alkyl.
- m and l are each 5 and each R’ independently is a C2-5 alkyl.
- each R’ independently is a C1-12 alkyl, and R a ⁇ and R b ⁇ are each a C1-12 alkyl.
- each R’ independently is a C 2-5 alkyl, and R a ⁇ and R b ⁇ are each a C 2-6 alkyl.
- R’ is a C1-12 alkyl
- R a ⁇ is a C1-12 alkyl
- R 2 and R 3 are each independently a C6-10 alkyl.
- R’ is a C 2- 5 alkyl
- R a ⁇ is a C2-6 alkyl
- R 2 and R 3 are each a C8 alkyl.
- each R’ independently is a C1-12 alkyl
- R a ⁇ and R b ⁇ are each a C 1-12 alkyl
- R 10 is NH(C 1-6 alkyl)
- n2 is 2.
- R’ branched is: is: independently is a C2-5 alkyl, R a ⁇ and R b ⁇ are each a C2-6 alkyl, , wherein R 10 is NH(CH 3 ) and n2 is 2.
- (AII), (AII-a), (AII-b), (AII-c), (AII- are each independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, R 2 and R 3 are each independently a C 6-10 alkyl, R a ⁇ is a C 1-12 alkyl, wherein R 10 is NH(C 1-6 alkyl) and n2 is 2.
- R’ is a C2- 5 alkyl
- R a ⁇ is a C 2-6 alkyl
- R 2 and R 3 are each a C 8 alkyl
- R 10 is NH(CH 3 ) and n2 is 2.
- R 4 is -(CH 2 ) n OH and n is 2, 3, or 4.
- R 4 is -(CH 2 ) n OH and n is 2.
- each R’ independently is a C1-12 alkyl
- R a ⁇ and R b ⁇ are each a C 1-12 alkyl
- R 4 is -(CH 2 ) n OH
- n is 2, 3, or 4.
- R’ b is: , m and l are each 5, each R’ independently is a C 2-5 alkyl, R a ⁇ and R b ⁇ are each a C2-6 alkyl, R 4 is -(CH2)nOH, and n is 2.
- the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-f): wherein denotes a point of attachment; R a ⁇ is a C 1-12 alkyl; R 2 and R 3 are each independently a C 1-14 alkyl; R 4 is -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5; R’ is a C1-12 alkyl; m is selected from 4, 5, and 6; and l is selected from 4, 5, and 6.
- m and l are each 5, and n is 2, 3, or 4.
- R’ is a C2-5 alkyl, R a ⁇ is a C2-6 alkyl, and R 2 and R 3 are each a C6-10 alkyl.
- m and l are each 5, n is 2, 3, or 4
- R’ is a C 2-5 alkyl, R a ⁇ is a C 2-6 alkyl, and R 2 and R 3 are each a C 6-10 alkyl.
- the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-g): its N-oxide, or a salt or isomer thereof; wherein R a ⁇ is a C2-6 alkyl; R’ is a C2-5 alkyl; and R 4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting wherein denotes a point of attachment, R 10 is NH(C1-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3.
- the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-h): its N-oxide, or a salt or isomer thereof; wherein R a ⁇ and R b ⁇ are each independently a C 2-6 alkyl; each R’ independently is a C2-5 alkyl; and R 4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting wherein denotes a point of attachment, R 10 is NH(C 1-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3.
- R 4 is , wherein R 10 is NH(CH 3 ) and n2 is 2. In some embodiments of the compound of Formula (AII-g) or (AII-h), R 4 is -(CH2)2OH.
- the ionizable amino lipids of a lipid nanoparticle may be one or more of compounds of Formula (AIII): or their N-oxides, or salts or isomers thereof, wherein: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R 2 and R 3 are independently selected from the group consisting of H, C 1-14 alkyl, C 2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R 2 and R 3 , together with the atom to which they are attached, form a heterocycle or carbocycle; R 4 is selected from the group consisting of hydrogen, a C 3-6 carbocycle, -(CH 2 ) n Q, -(CH 2 ) n CHQR, -CHQR, -CQ(R) 2 , and unsubstitute
- another subset of compounds of Formula (AIII) includes those in which: R 1 is selected from the group consisting of C 5-30 alkyl, C 5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a C3-6 carbocycle, a 5- to 14-membered heteroaryl having one or more heteroatoms selected from N, O, and S, -OR, -
- another subset of compounds of Formula (AIII) includes those in which: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R 4 is selected from the group consisting of a C 3-6 carbocycle, -(CH 2 ) n Q, -(CH 2 ) n CHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a C3-6 carbocycle, a 5- to 14-membered heterocycle having one or more heteroatoms selected from N, O, and S,
- another subset of compounds of Formula (AIII) includes those in which: R 1 is selected from the group consisting of C 5-30 alkyl, C 5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R 2 and R 3 , together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R) 2 , and unsubstituted C 1-6 alkyl, where Q is selected from a C 3-6 carbocycle, a 5- to 14-membered heteroaryl having one or more heteroatoms selected from N, O, and S,
- another subset of compounds of Formula (AIII) includes those in which R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R 2 and R 3 are independently selected from the group consisting of H, C 2-14 alkyl, C 2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R 2 and R 3 , together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is -(CH2)nQ or -(CH2)nCHQR, where Q is -N(R)2, and n is selected from 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R 6 is independently selected from the group consisting of C 1-3 alkyl, C 2-3 alkenyl, and H; M and M’ are independently selected from each
- another subset of compounds of Formula (AIII) includes those in which R 1 is selected from the group consisting of C 5-30 alkyl, C 5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R 2 and R 3 , together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of -(CH2)nQ, -(CH2)nCHQR, -CHQR, and -CQ(R) 2 , where Q is -N(R) 2 , and n is selected from 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R 6 is independently selected from the group consisting of
- m is 5, 7, or 9.
- Q is OH, -NHC(S)N(R) 2 , or -NHC(O)N(R) 2 .
- Q is -N(R)C(O)R, or -N(R)S(O)2R.
- a subset of compounds of Formula (AIII) includes those of Formula (AIII-B): or its N-oxide, or a salt or isomer thereof in which all variables are as defined herein.
- m is selected from 5, 6, 7, 8, and 9;
- M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group
- m is 5, 7, or 9.
- Q is OH, -NHC(S)N(R)2, or -NHC(O)N(R)2.
- Q is -N(R)C(O)R, or -N(R)S(O) 2 R.
- the compounds of Formula (AIII) are of Formula (AIII-D), or their N-oxides, or salts or isomers thereof, wherein R4 is as described in this Lipid Compositions section.
- the compounds of Formula (AIII) are of Formula (AIII-E), or their N-oxides, or salts or isomers thereof, wherein R 4 is as described in this in this Lipid Compositions section.
- the compounds of Formula (AIII) are of Formula (AIII-F) or (AIII-G): or their N-oxides, or salts or isomers thereof, wherein R 4 is as described in this in this Lipid Compositions section.
- the compounds of Formula (AIII) are of Formula (AIII-H): their N-oxides, or salts or isomers thereof, wherein M is -C(O)O- or –OC(O)-, M” is C1-6 alkyl or C2-6 alkenyl, R2 and R3 are independently selected from the group consisting of C5-14 alkyl and C5-14 alkenyl, and n is selected from 2, 3, and 4.
- the compounds of Formula (AIII) are of Formula (AIII-I): or their N-oxides, or salts or isomers thereof, wherein n is 2, 3, or 4; and m, R’, R”, and R 2 through R 6 are as described in this in this Lipid Compositions section.
- each of R 2 and R 3 may be independently selected from the group consisting of C 5-14 alkyl and C 5-14 alkenyl.
- an ionizable amino lipid of comprises a compound having structure: In some embodiments, an ionizable amino lipid comprises a compound having structure: In a further embodiment, the compounds of Formula (AIII) are of Formula (AIII-J), (AIII-J), or their N-oxides, or salts or isomers thereof, wherein l is selected from 1, 2, 3, 4, and 5; m is selected from 5, 6, 7, 8, and 9; M1 is a bond or M’; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group, and a heteroaryl group; and R 2 and R 3 are independently selected from the group consisting of H, C1-14 alkyl, and C2-14 alkenyl.
- M is C1-6 alkyl (e.g., C1-4 alkyl) or C2-6 alkenyl (e.g. C2-4 alkenyl).
- R2 and R 3 are independently selected from the group consisting of C 5-14 alkyl and C 5-14 alkenyl.
- the ionizable amino lipids are one or more of the compounds described in U.S. Application Nos.
- the central amine moiety of a lipid according to Formula (AIII), (AIII-A), (AIII-B), (AIII-C), (AIII-D), (AIII-E), (AIII-F), (AIII-G), (AIII-H), (AIII-I), or (AIII-J) may be protonated at a physiological pH.
- a lipid may have a positive or partial positive charge at physiological pH.
- Such amino lipids may be referred to as cationic lipids, ionizable lipids, cationic amino lipids, or ionizable amino lipids.
- Amino lipids may also be zwitterionic, i.e., neutral molecules having both a positive and a negative charge.
- the ionizable amino lipids of a lipid nanoparticle may be one or more of compounds of formula (AIV), t is 1 or 2; A 1 and A 2 are each independently selected from CH or N; Z is CH 2 or absent wherein when Z is CH 2 , the dashed lines (1) and (2) each represent a single bond; and when Z is absent, the dashed lines (1) and (2) are both absent; R 1 , R 2 , R 3 , R 4 , and R 5 are independently selected from the group consisting of C 5-20 alkyl, C 5-20 alkenyl, -R”MR’, -R*YR”, -YR”, and -R*OR”; RX1 and RX2 are each independently H or C1-3 alkyl; each M is independently selected from the group consisting of -C(O)O-, -OC(O)-, -OC(O)O-, -C(O)N(R’)-, -N(R’)
- the compound is of any of formulae (AIVa)-(AIVh):
- the ionizable amino lipid is salt thereof.
- the central amine moiety of a lipid according to Formula (AIV), (AIVa), (AIVb), (AIVc), (AIVd), (AIVe), (AIVf), (AIVg), or (AIVh) may be protonated at a physiological pH.
- a lipid may have a positive or partial positive charge at physiological pH.
- the lipid nanoparticle comprises a lipid having the structure: or a pharmaceutically acceptable salt thereof, wherein: each R 1a is independently hydrogen, R 1c , or R 1d ; each R 1b is independently R 1c or R 1d ; each R 1c is independently –[CH 2 ] 2 C(O)X 1 R 3 ; each R 1d Is independently -C(O)R 4 ; each R 2 is independently -[C(R 2a )2]cR 2b ; each R 2a is independently hydrogen or C 1 -C 6 alkyl; R 2b is -N(L1-B)2; -(OCH2CH2)6OH; or -(OCH2CH2)bOCH3; each R 3 and R 4 is independently C6-C30 aliphatic; each I.
- each B is independently hydrogen or an ionizable nitrogen-containing group
- each X 1 is independently a covalent bond or O
- each a is independently an integer of 1-10
- each b is independently an integer of 1-10
- each c is independently an integer of 1-10.
- the lipid nanoparticle comprises a lipid having the structure: or a pharmaceutically acceptable salt thereof, wherein R1 and R2 are the same or different, each a linear or branched alkyl with 1-9 carbons, or as alkenyl or alkynyl with 2 to 11 carbon atoms, L1 and L2 are the same or different, each a linear alkyl having 5 to 18 carbon atoms, or form a heterocycle with N, X 1 is a bond, or is -CO-O- whereby L 2 -CO-O-R 2 is formed, X2 is S or O, L3 is a bond or a lower alkyl, or form a heterocycle with N, R 3 is a lower alkyl, and R 4 and R 5 are the same or different, each a lower alkyl.
- the lipid nanoparticle comprises an ionizable lipid having the structure: or a pharmaceutically acceptable salt thereof.
- the lipid nanoparticle comprises a lipid having the structure: (A2), or a pharmaceutically acceptable salt thereof.
- the lipid nanoparticle comprises a lipid having the structure: (A3), or a pharmaceutically acceptable salt thereof.
- the lipid nanoparticle comprises a lipid having the structure: (A4), or a pharmaceutically acceptable salt thereof.
- the lipid nanoparticle comprises a lipid having the structure: (A5), or a pharmaceutically acceptable salt thereof.
- the lipid nanoparticle comprises a lipid having the structure: (A6), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure: (A7), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure: pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure: pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure: pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure: (A11), or a pharmaceutically acceptable salt thereof.
- Non-cationic lipids comprise one or more non-cationic lipids.
- Non-cationic lipids may be phospholipids.
- the lipid nanoparticle comprises 5-25 mol% non-cationic lipid.
- the lipid nanoparticle may comprise 5-20 mol%, 5-15 mol%, 5-10 mol%, 10-25 mol%, 10-20 mol%, 10-25 mol%, 15-25 mol%, 15-20 mol%, or 20-25 mol% non-cationic lipid.
- the lipid nanoparticle comprises 5 mol%, 10 mol%, 15 mol%, 20 mol%, or 25 mol% non-cationic lipid.
- a non-cationic lipid comprises 1,2-distearoyl-sn-glycero-3- phosphocholine (DSPC), 1,2-dioleoyl-sn-glycero-3-phosphoethanolamine (DOPE), 1,2- dilinoleoyl-sn-glycero-3-phosphocholine (DLPc), 1,2-dimyristoyl-sn-gly cero-phosphocholine (DMPC), 1,2-dioleoyl-sn-glycero-3-phosphocholine (DOPC), l,2-dipalmitoyl-sn-glycero-3- phosphocholine (DPPC), 1,2-diundecanoyl-sn-glycero-phosphocholine (DUPC), 1-palmitoyl-2- oleoyl-sn-glycero-3-phosphocholine (POPC), 1,2-di-O-octadecenyl-sn-glycero
- the lipid nanoparticle comprises 5–15 mol%, 5–10 mol%, or 10– 15 mol% DSPC.
- the lipid nanoparticle may comprise 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, or 15 mol% DSPC.
- the lipid composition of the lipid nanoparticle compositions can comprise one or more phospholipids, for example, one or more saturated or (poly)unsaturated phospholipids or a combination thereof.
- phospholipids comprise a phospholipid moiety and one or more fatty acid moieties.
- a phospholipid moiety can be selected, for example, from the non-limiting group consisting of phosphatidyl choline, phosphatidyl ethanolamine, phosphatidyl glycerol, phosphatidyl serine, phosphatidic acid, 2-lysophosphatidyl choline, and a sphingomyelin.
- a fatty acid moiety can be selected, for example, from the non-limiting group consisting of lauric acid, myristic acid, myristoleic acid, palmitic acid, palmitoleic acid, stearic acid, oleic acid, linoleic acid, alpha-linolenic acid, erucic acid, phytanoic acid, arachidic acid, arachidonic acid, eicosapentaenoic acid, behenic acid, docosapentaenoic acid, and docosahexaenoic acid.
- Particular phospholipids can facilitate fusion to a membrane.
- a cationic phospholipid can interact with one or more negatively charged phospholipids of a membrane (e.g., a cellular or intracellular membrane). Fusion of a phospholipid to a membrane can allow one or more elements (e.g., a therapeutic agent) of a lipid-containing composition (e.g., LNPs) to pass through the membrane permitting, e.g., delivery of the one or more elements to a target tissue.
- elements e.g., a therapeutic agent
- a lipid-containing composition e.g., LNPs
- Non-natural phospholipid species including natural species with modifications and substitutions including branching, oxidation, cyclization, and alkynes are also contemplated.
- a phospholipid can be functionalized with or cross-linked to one or more alkynes (e.g., an alkenyl group in which one or more double bonds is replaced with a triple bond).
- alkynes e.g., an alkenyl group in which one or more double bonds is replaced with a triple bond.
- an alkyne group can undergo a copper-catalyzed cycloaddition upon exposure to an azide.
- Such reactions can be useful in functionalizing a lipid bilayer of a nanoparticle composition to facilitate membrane permeation or cellular recognition or in conjugating a nanoparticle composition to a useful component such as a targeting or imaging moiety (e.g., a dye).
- Phospholipids include, but are not limited to, glycerophospholipids such as phosphatidylcholines, phosphatidylethanolamines, phosphatidylserines, phosphatidylinositols, phosphatidy glycerols, and phosphatidic acids. Phospholipids also include phosphosphingolipid, such as sphingomyelin.
- a phospholipid comprises 1,2-distearoyl-sn-glycero-3- phosphocholine (DSPC), 1,2-Distearoyl-sn-glycero-3-phosphoethanolamine (DSPE), 1,2- dioleoyl-sn-glycero-3-phosphoethanolamine (DOPE), 1,2-dilinoleoyl-sn-glycero-3- phosphocholine (DLPc), 1,2-dimyristoyl-sn-gly cero-phosphocholine (DMPC), 1,2-dioleoyl-sn- glycero-3-phosphocholine (DOPC), l,2-dipalmitoyl-sn-glycero-3-phosphocholine (DPPC), 1,2- diundecanoyl-sn-glycero-phosphocholine (DUPC), 1-palmitoyl-2-oleoyl-sn-glycero-3- phosphocholine (POPC), 1,2-di
- a phospholipid is an analog or variant of DSPC.
- a phospholipid is a compound of Formula (HI): or a salt thereof, wherein: each R 1 is independently optionally substituted alkyl; or optionally two R 1 are joined together with the intervening atoms to form optionally substituted monocyclic carbocyclyl or optionally substituted monocyclic heterocyclyl; or optionally three R 1 are joined together with the intervening atoms to form optionally substituted bicyclic carbocyclyl or optionally substitute bicyclic heterocyclyl; n is 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10; m is 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10; A is of the formula: each instance of L 2 is independently a bond or optionally substituted C 1-6 alkylene, wherein one methylene unit of the optionally substituted C1-6 alkylene is optionally replaced with O, N(R N ), S, C(O), C(O)N(R N)
- the compound is not of the formula: , wherein each instance of R 2 is independently unsubstituted alkyl, unsubstituted alkenyl, or unsubstituted alkynyl.
- the phospholipids may be one or more of the phospholipids described in PCT Application No. PCT/US2018/037922.
- the lipid nanoparticle comprises a molar ratio of 5-25% non- cationic lipid relative to the other lipid components.
- the lipid nanoparticle may comprise a molar ratio of 5-30%, 5-15%, 5-10%, 10-25%, 10-20%, 10-25%, 15-25%, 15-20%, 20-25%, or 25-30% non-cationic lipid.
- the lipid nanoparticle comprises a molar ratio of 5%, 10%, 15%, 20%, 25%, or 30% non-cationic lipid.
- the lipid nanoparticle comprises a molar ratio of 5-25% phospholipid relative to the other lipid components.
- the lipid nanoparticle may comprise a molar ratio of 5-30%, 5-15%, 5-10%, 10-25%, 10-20%, 10-25%, 15-25%, 15-20%, 20-25%, or 25-30% phospholipid.
- the lipid nanoparticle comprises a molar ratio of 5%, 10%, 15%, 20%, 25%, or 30% phospholipid lipid.
- Structural lipids The lipid composition of a pharmaceutical composition can comprise one or more structural lipids.
- structural lipid includes sterols and also to lipids containing sterol moieties. Incorporation of structural lipids in the lipid nanoparticle may help mitigate aggregation of other lipids in the particle.
- Structural lipids can be selected from the group including but not limited to, cholesterol, fecosterol, sitosterol, ergosterol, campesterol, stigmasterol, brassicasterol, tomatidine, tomatine, ursolic acid, alpha-tocopherol, hopanoids, phytosterols, steroids, and mixtures thereof.
- the structural lipid is a sterol.
- “sterols” are a subgroup of steroids consisting of steroid alcohols.
- the structural lipid is a steroid.
- the structural lipid is cholesterol.
- the structural lipid is an analog of cholesterol.
- the structural lipid is alpha-tocopherol.
- the structural lipids may be one or more of the structural lipids described in U.S. Application No.16/493,814.
- the lipid nanoparticle comprises a molar ratio of 25-55% structural lipid relative to the other lipid components.
- the lipid nanoparticle may comprise a molar ratio of 10-55%, 25-50%, 25-45%, 25-40%, 25-35%, 25-30%, 30-55%, 30- 50%, 30-45%, 30-40%, 30-35%, 35-55%, 35-50%, 35-45%, 35-40%, 40-55%, 40-50%, 40-45%, 45-55%, 45-50%, or 50-55% structural lipid.
- the lipid nanoparticle comprises a molar ratio of 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, or 55% structural lipid.
- the lipid nanoparticle comprises 30-45 mol% sterol, optionally 35-40 mol%, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol%, 34-35 mol%, 35-36 mol%, 36-37 mol%, 37-38 mol%, 38-39 mol%, or 39-40 mol%.
- the lipid nanoparticle comprises 25-55 mol% sterol.
- the lipid nanoparticle may comprise 25-50 mol%, 25-45 mol%, 25-40 mol%, 25-35 mol%, 25-30 mol%, 30-55 mol%, 30- 50 mol%, 30-45 mol%, 30-40 mol%, 30-35 mol%, 35-55 mol%, 35-50 mol%, 35-45 mol%, 35- 40 mol%, 40-55 mol%, 40-50 mol%, 40-45 mol%, 45-55 mol%, 45-50 mol%, or 50-55 mol% sterol.
- the lipid nanoparticle comprises 25 mol%, 30 mol%, 35 mol%, 40 mol%, 45 mol%, 50 mol%, or 55 mol% sterol. In some embodiments, the lipid nanoparticle comprises 35 – 40 mol% cholesterol. For example, the lipid nanoparticle may comprise 35, 35.5, 36, 36.5, 37, 37.5, 38, 38.5, 39, 39.5, or 40 mol% cholesterol.
- Polyethylene glycol (PEG)-Lipids The lipid composition of a pharmaceutical composition can comprise one or more polyethylene glycol (PEG)-modified lipids.
- PEG-lipid or “PEG-modified lipid” refers to polyethylene glycol (PEG)-modified lipids.
- PEG-modified lipids include PEG- modified phosphatidylethanolamine and phosphatidic acid, PEG-ceramide conjugates (e.g., PEG-CerC14 or PEG-CerC20), PEG-modified dialkylamines, and PEG-modified 1,2- diacyloxypropan-3-amines.
- PEG-lipid PEG-modified lipids
- PEG-modified lipids include PEG- modified phosphatidylethanolamine and phosphatidic acid, PEG-ceramide conjugates (e.g., PEG-CerC14 or PEG-CerC20), PEG-modified dialkylamines, and PEG-modified 1,2- diacyloxypropan-3-amines.
- PEGylated lipids PEGylated lipids.
- a PEG-modified lipid can be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid.
- the PEG-modified lipid includes, but not limited to 1,2- dimyristoyl-sn-glycerol methoxypolyethylene glycol (PEG-DMG), 1,2-distearoyl-sn-glycero-3- phosphoethanolamine-N-[amino(polyethylene glycol)] (PEG-DSPE), PEG-disteryl glycerol (PEG-DSG), PEG-dipalmetoleyl, PEG-dioleyl, PEG-distearyl, PEG-diacylglycamide (PEG- DAG), PEG-dipalmitoyl phosphatidylethanolamine (PEG-DPPE), or PEG-l,2- dimyristyloxlpropy
- the PEG-modified lipid is selected from the group consisting of a PEG-modified phosphatidylethanolamine, a PEG-modified phosphatidic acid, a PEG-modified ceramide, a PEG-modified dialkylamine, a PEG-modified diacylglycerol, a PEG-modified dialkylglycerol, and mixtures thereof.
- the PEG-modified lipid is PEG- DMG, PEG-c-DOMG (also referred to as PEG-DOMG), PEG-DSG, and/or PEG-DPG.
- the lipid moiety of the PEG-modified lipids includes those having lengths of from about C 14 to about C 22 , preferably from about C 14 to about C 16 .
- a PEG moiety for example an mPEG-NH2
- the PEG-modified lipid is PEG2k- DMG.
- lipid nanoparticles can comprise a PEG-modified lipid which is a non-diffusible PEG.
- Non-limiting examples of non-diffusible PEGs include PEG-DSG and PEG-DSPE.
- PEG-modified lipids are known in the art, such as those described in U.S. Patent No. 8158601 and International Publ. No. WO 2015/130584 A2, which are incorporated herein by reference to the extent they describe PEG-modified lipids.
- some of the other lipid components (e.g., PEG-modified lipids) of various formulae may be synthesized as described International Patent Application No. PCT/US2016/000129, filed December 10, 2016, entitled “Compositions and Methods for Delivery of Therapeutic Agents,” which is incorporated by reference to the extent they disclose lipid components and production.
- the lipid component of a lipid nanoparticle composition may include one or more molecules comprising polyethylene glycol, such as PEG or PEG-modified lipids. Such species may be alternately referred to as PEGylated lipids.
- a PEG-modified lipid is a lipid modified with polyethylene glycol.
- a PEG-modified lipid may be selected from the non-limiting group including PEG-modified phosphatidylethanolamines, PEG-modified phosphatidic acids, PEG- modified ceramides, PEG-modified dialkylamines, PEG-modified diacylglycerols, PEG- modified dialkylglycerols, and mixtures thereof.
- a PEG-modified lipid may be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid.
- the PEG-modified lipids are a modified form of PEG DMG.
- PEG- DMG has the following structure:
- PEG-modified lipids can be PEGylated lipids described in International Publication No. WO 2012/099755, which is herein incorporated by reference to the extent it discloses PEG-modified lipids. Any of these exemplary PEG-modified lipids may be modified to comprise a hydroxyl group on the PEG chain.
- the PEG- modified lipid is a PEG-OH lipid.
- a “PEG-OH lipid” (also referred to herein as “hydroxy-PEGylated lipid”) is a PEGylated lipid having one or more hydroxyl (– OH) groups on the lipid.
- the PEG-OH lipid includes one or more hydroxyl groups on the PEG chain.
- a PEG-OH or hydroxy-PEGylated lipid comprises an –OH group at the terminus of the PEG chain.
- a PEG-modified lipid is a compound of Formula (PI): or salts thereof, wherein: R 3 is –OR O ; R O is hydrogen, optionally substituted alkyl, or an oxygen protecting group; r is an integer between 1 and 100, inclusive; L 1 is optionally substituted C1-10 alkylene, wherein at least one methylene of the optionally substituted C 1-10 alkylene is independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, O, N(R N ), S, C(O), C(O)N(R N ), NR N C(O), C(O)O, OC(O), OC(O)O, OC(O)N(R N ), NR N C(O)O, or NR N C(O)N(R N ); D is a moiety obtained by click chemistry or a moiety cleavable under physiological
- the compound of Fomula (PI) is a PEG-OH lipid (i.e., R 3 is – OR O , and R O is hydrogen).
- the compound of Formula (PI) is of Formula (PI-OH): (PI-OH), or a salt thereof.
- Formula (PII) In certain embodiments, a PEG-modified lipid is a PEGylated fatty acid. In certain embodiments, a PEG-modified lipid is a compound of Formula (PII).
- the compound of Formula (PII) is of Formula (PII-OH): or a salt thereof.
- r is 40-50.
- the compound of Formula (PII) is: . or a salt thereof.
- the compound of Formula (PII) is .
- the lipid composition of the pharmaceutical composition does not comprise a PEG-modified lipid.
- the PEG-modified lipids may be one or more of the PEG- modified lipids described in U.S. Application No.15/674,872.
- the lipid nanoparticle comprises a molar ratio of 0.5-15% PEG- modified lipid relative to the other lipid components.
- the lipid nanoparticle may comprise a molar ratio of 0.5-10%, 0.5-5%, 1-15%, 1-10%, 1-5%, 2-15%, 2-10%, 2-5%, 5-15%, 5-10%, or 10-15% PEG-modified lipid.
- the lipid nanoparticle comprises a molar ratio of 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, or 15% PEG-modified lipid.
- the lipid nanoparticle comprises 1-5% PEG-modified lipid, optionally 1-3 mol%, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol%.
- the lipid nanoparticle comprises 0.5-15 mol% PEG-modified lipid.
- the lipid nanoparticle may comprise 0.5-10 mol%, 0.5-5 mol%, 1-15 mol%, 1-10 mol%, 1-5 mol%, 2-15 mol%, 2-10 mol%, 2-5 mol%, 5-15 mol%, 5-10 mol%, or 10-15 mol%.
- the lipid nanoparticle comprises 0.5 mol%, 1 mol%, 2 mol%, 3 mol%, 4 mol%, 5 mol%, 6 mol%, 7 mol%, 8 mol%, 9 mol%, 10 mol%, 11 mol%, 12 mol%, 13 mol%, 14 mol%, or 15 mol% PEG-modified lipid.
- Some embodiments comprise adding PEG to a composition comprising an LNP encapsulating a nucleic acid (e.g., which already includes PEG in the amounts listed above).
- a lipid nanoparticle comprises a first PEG-modified lipid in a core of the LNP, and a second PEG-modified lipid outside of the core of the LNP.
- the first and second PEG-modified lipids of the core and outside the core may the same PEG-modified lipids (i.e., have the same structure), or be different PEG-modified lipids (i.e., have different structures).
- both PEG-modified lipids are 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate.
- both PEG-modified lipids are PEG-DMG.
- the first PEG-modified lipid is PEG-DMG and the second PEG-modified lipid is 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate.
- the first PEG-modified lipid is 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate and the second PEG-modified lipid is PEG-DMG.
- 0.25 mol% to 1.0 mol% (as a percentage of lipids in the LNP) of the first PEG-modified lipid is in the core of the lipid nanoparticle. In some embodiments, 0.25 mol% to 0.50 mol% of the first PEG-modified lipid is in the core of the lipid nanoparticle. In some embodiments, 0.25 mol%, 0.50 mol%, 0.75 mol%, or 1.0 mol% of the first PEG-modified lipid is in the core of the LNP. In some embodiments, 2.0 mol% to 2.75 mol% of the second PEG-modified lipid is outside the core of the LNP.
- the LNP comprises 3.0 mol% PEG-modified lipids.
- LNPs having certain amounts of a PEG-modified lipid in the core and certain amounts of a PEG-modified lipid outside of the core, and methods of producing the same, are disclosed in PCT Publication No. WO 2023/018773, which is incorporated by reference herein to the extent it discloses lipid nanoparticles and methods of producing lipid nanoparticles.
- the lipid nanoparticle comprises 20-60 mol% ionizable lipid, 5-25 mol% non-cationic lipid, 25-55 mol% sterol, and 0.5-15 mol% PEG-modified lipid.
- a LNP comprises an ionizable lipid of Compound (I-18), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG.
- a LNP comprises 20-60 mol% ionizable lipid of Compound (I-18), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG.
- a LNP comprises an ionizable lipid of Compound (I-25), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG.
- a LNP comprises 20-60 mol% ionizable lipid of Compound (I-25), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG.
- a LNP comprises an ionizable lipid of Compound (I-301), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG- modified lipid is DMG-PEG.
- a LNP comprises 20-60 mol% ionizable lipid of Compound (I-301), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG- PEG.
- a LNP comprises an ionizable lipid of Compound (II-6), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG.
- a LNP comprises 20-60 mol% ionizable lipid of Compound (II-6), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG.
- a LNP comprises an ionizable lipid of Compound (IL**), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG.
- a LNP comprises 20-60 mol% ionizable lipid of Compound (IL**), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG.
- a LNP comprises an ionizable lipid of any of Formula (IL*), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising PEG- DMG.
- a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5- 25 mol% phospholipid comprising DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG- modified lipid comprising DMG-PEG.
- a LNP comprises an ionizable lipid of any of Formula (IL*), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII).
- a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid comprising DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII).
- a LNP comprises an ionizable lipid of Formula (IL*), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG- modified lipid comprising a compound having Formula (PI) or (PII).
- a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG- modified lipid comprising a compound having Formula (PI) or (PII).
- a LNP comprises an ionizable lipid of Formula (IL*), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG- modified lipid comprising a compound having Formula (PI) or (PII).
- a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG- modified lipid modified lipid comprising a compound having Formula (PI) or (PII).
- a LNP comprises an ionizable lipid of Formula (IL*), a phospholipid having Formula (HI), a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII).
- a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII).
- a LNP comprises an ionizable amino lipid of Compound 1, wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG- modified lipid is DMG-PEG.
- a LNP comprises 20-60 mol% ionizable lipid of Compound 1, 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% PEG-modified lipid DMG-PEG.
- a LNP comprises an ionizable amino lipid of Compound 2, wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG- modified lipid is DMG-PEG.
- a LNP comprises 20-60 mol% ionizable lipid of Compound 2, 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% PEG-modified lipid DMG-PEG.
- a LNP comprises an ionizable amino lipid of any of Formula (AIII), (AIV), or (AV), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising PEG-DMG.
- a LNP comprises 20-60 mol% ionizable lipid of any of Formula (AIII), (AIV), or (AV), 5-25 mol% DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising DMG-PEG.
- a LNP comprises an ionizable amino lipid of any of Formula (AIII), (AIV), or (AV), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII).
- a LNP comprises 20- 60 mol% ionizable lipid of any of Formula (AIII), (AIV), or (AV), 5-25 mol% DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII).
- a LNP comprises an ionizable amino lipid of Formula (AIII), (AIV), or (AV), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG-modified lipid comprising a compound having Formula (PI) or (PII).
- a LNP comprises 20-60 mol% ionizable lipid of Formula (AIII), (AIV), or (AV), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PI) or (PII).
- a LNP comprises an ionizable amino lipid of Formula (AIII), (AIV), or (AV), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG-modified lipid comprising a compound having Formula (PI) or (PII).
- a LNP comprises 20-60 mol% ionizable lipid of Formula (AIII), (AIV), or (AV), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PI) or (PII).
- a LNP comprises an ionizable amino lipid of Formula (AIII), (AIV), or (AV), a phospholipid having Formula (HI), a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII).
- a LNP comprises 20- 60 mol% ionizable lipid of Formula (AIII), (AIV), or (AV), 5-25 mol% phospholipid having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII).
- the lipid nanoparticle comprises 49 mol% ionizable lipid, 10 mol% DSPC, 38.5 mol% cholesterol, and 2.5 mol% DMG-PEG. In some embodiments, the lipid nanoparticle comprises 49 mol% ionizable lipid, 11 mol% DSPC, 38.5 mol% cholesterol, and 1.5 mol% DMG-PEG. In some embodiments, the lipid nanoparticle comprises 48 mol% ionizable lipid, 11 mol% DSPC, 38.5 mol% cholesterol, and 2.5 mol% DMG-PEG. In some embodiments, a LNP comprises an N:P ratio of from about 2:1 to about 30:1.
- a LNP comprises an N:P ratio of about 6:1. In some embodiments, a LNP comprises an N:P ratio of about 3:1, 4:1, or 5:1. In some embodiments, a LNP comprises a wt/wt ratio of the ionizable lipid component to the RNA of from about 10:1 to about 100:1. In some embodiments, a LNP comprises a wt/wt ratio of the ionizable lipid component to the RNA of about 20:1. In some embodiments, a LNP comprises a wt/wt ratio of the ionizable lipid component to the RNA of about 10:1.
- Some embodiments comprise a composition having one or more LNPs having a diameter of about 150 nm or less, such as about 140 nm, 130 nm, 120 nm, 110 nm, 100 nm, 90 nm, 80 nm, 70 nm, 60 nm, 50 nm, 40 nm, 30 nm, or 20 nm or less.
- Some embodiments comprise a composition having a mean LNP diameter of about 150 nm or less, such as about 140 nm, 130 nm, 120 nm, 110 nm, 100 nm, 90 nm, 80 nm, 70 nm, 60 nm, 50 nm, 40 nm, 30 nm, or 20 nm or less.
- the composition has a mean LNP diameter from about 30nm to about 150nm, or a mean diameter from about 60nm to about 120nm.
- an LNP further comprises one or more cargo molecules, including but not limited to nucleic acids (e.g., circular RNA, mRNA, plasmid DNA, DNA or RNA oligonucleotides, siRNA, shRNA, snRNA, snoRNA, lncRNA, etc.), small molecules, proteins and peptides. Effective in vivo delivery of nucleic acids represents a continuing medical challenge.
- Exogenous nucleic acids i.e., originating from outside of a cell or organism
- a particulate carrier e.g., lipid nanoparticles
- the particulate carrier should be formulated to have minimal particle aggregation, be relatively stable prior to intracellular delivery, effectively deliver nucleic acids intracellularly, and illicit no or minimal immune response.
- many conventional particulate carriers have relied on the presence and/or concentration of certain components (e.g., PEG-modified lipid).
- a LNP comprises one or more ionizable molecules (e.g., amino lipids or ionizable lipids).
- the ionizable molecule may comprise a charged group and may have a certain pKa.
- the pKa of the ionizable molecule may be greater than or equal to about 6, greater than or equal to about 6.2, greater than or equal to about 6.5, greater than or equal to about 6.8, greater than or equal to about 7, greater than or equal to about 7.2, greater than or equal to about 7.5, greater than or equal to about 7.8, greater than or equal to about 8.
- the pKa of the ionizable molecule may be less than or equal to about 10, less than or equal to about 9.8, less than or equal to about 9.5, less than or equal to about 9.2, less than or equal to about 9.0, less than or equal to about 8.8, or less than or equal to about 8.5.
- each type of ionizable molecule may independently have a pKa in one or more of the ranges described above.
- an ionizable molecule comprises one or more charged groups.
- an ionizable molecule may be positively charged or negatively charged.
- an ionizable molecule may be positively charged.
- an ionizable molecule may comprise an amine group.
- the term “ionizable molecule” has its ordinary meaning in the art and may refer to a molecule or matrix comprising one or more charged moiety.
- a “charged moiety” is a chemical moiety that carries a formal electronic charge, e.g., monovalent (+1, or -1), divalent (+2, or -2), trivalent (+3, or -3), etc.
- the charged moiety may be anionic (i.e., negatively charged) or cationic (i.e., positively charged).
- Examples of positively-charged moieties include amine groups (e.g., primary, secondary, and/or tertiary amines), ammonium groups, pyridinium group, guanidine groups, and imidizolium groups.
- the charged moieties comprise amine groups.
- Examples of negatively- charged groups or precursors thereof include carboxylate groups, sulfonate groups, sulfate groups, phosphonate groups, phosphate groups, hydroxyl groups, and the like.
- the charge of the charged moiety may vary, in some cases, with the environmental conditions, for example, changes in pH may alter the charge of the moiety, and/or cause the moiety to become charged or uncharged.
- an ionizable molecule e.g., an amino lipid or ionizable lipid
- an ionizable molecule may include one or more precursor moieties that can be converted to charged moieties.
- the ionizable molecule may include a neutral moiety that can be hydrolyzed to form a charged moiety, such as those described above.
- the molecule or matrix may include an amide, which can be hydrolyzed to form an amine, respectively.
- a given chemical moiety carries a formal electronic charge (for example, by inspection, pH titration, ionic conductivity measurements, etc.), and/or whether a given chemical moiety can be reacted (e.g., hydrolyzed) to form a chemical moiety that carries a formal electronic charge.
- the ionizable molecule e.g., amino lipid or ionizable lipid
- the molecular weight of an ionizable molecule is less than or equal to about 2,500 g/mol, less than or equal to about 2,000 g/mol, less than or equal to about 1,500 g/mol, less than or equal to about 1,250 g/mol, less than or equal to about 1,000 g/mol, less than or equal to about 900 g/mol, less than or equal to about 800 g/mol, less than or equal to about 700 g/mol, less than or equal to about 600 g/mol, less than or equal to about 500 g/mol, less than or equal to about 400 g/mol, less than or equal to about 300 g/mol, less than or equal to about 200 g/mol, or less than or equal to about 100 g/mol.
- the molecular weight of an ionizable molecule is greater than or equal to about 100 g/mol, greater than or equal to about 200 g/mol, greater than or equal to about 300 g/mol, greater than or equal to about 400 g/mol, greater than or equal to about 500 g/mol, greater than or equal to about 600 g/mol, greater than or equal to about 700 g/mol, greater than or equal to about 1000 g/mol, greater than or equal to about 1,250 g/mol, greater than or equal to about 1,500 g/mol, greater than or equal to about 1,750 g/mol, greater than or equal to about 2,000 g/mol, or greater than or equal to about 2,250 g/mol.
- each type of ionizable molecule may independently have a molecular weight in one or more of the ranges described above.
- the percentage (e.g., by weight, or by mole) of a single type of ionizable molecule (e.g., amino lipid or ionizable lipid) and/or of all the ionizable molecules within a particle may be greater than or equal to about 15%, greater than or equal to about 16%, greater than or equal to about 17%, greater than or equal to about 18%, greater than or equal to about 19%, greater than or equal to about 20%, greater than or equal to about 21%, greater than or equal to about 22%, greater than or equal to about 23%, greater than or equal to about 24%, greater than or equal to about 25%, greater than or equal to about 30%, greater than or equal to about 35%, greater than or equal to about 40%, greater than or equal to about 42%, greater than or equal to about 45%, greater than or equal to about 48%, greater than or equal to about 50%, greater than or equal to about 52%, greater than or equal to about 55%, greater than or equal to about 58%, greater than
- the percentage (e.g., by weight, or by mole) may be less than or equal to about 70%, less than or equal to about 68%, less than or equal to about 65%, less than or equal to about 62%, less than or equal to about 60%, less than or equal to about 58%, less than or equal to about 55%, less than or equal to about 52%, less than or equal to about 50%, or less than or equal to about 48%. Combinations of the above referenced ranges are also possible (e.g., greater than or equal to 20% and less than or equal to about 60%, greater than or equal to 40% and less than or equal to about 55%, etc.).
- each type of ionizable molecule may independently have a percentage (e.g., by weight, or by mole) in one or more of the ranges described above.
- the percentage e.g., by weight, or by mole
- the percentage may be determined by extracting the ionizable molecule(s) from the dried particles using, e.g., organic solvents, and measuring the quantity of the agent using high pressure liquid chromatography (i.e., HPLC), liquid chromatography-mass spectrometry (LC-MS), nuclear magnetic resonance (NMR), or mass spectrometry (MS).
- HPLC may be used to quantify the amount of a component, by, e.g., comparing the area under the curve of a HPLC chromatogram to a standard curve.
- charge or “charged moiety” does not refer to a “partial negative charge” or “partial positive charge” on a molecule.
- partial negative charge and “partial positive charge” are given their ordinary meaning in the art.
- the composition comprises a liposome.
- a liposome is a lipid particle comprising lipids arranged into one or more concentric lipid bilayers around a central region. The central region of a liposome may comprise an aqueous solution, suspension, or other aqueous composition.
- the composition comprises a lipoplex.
- a lipoplex is a lipid particle comprising a cationic liposome and a nucleic acid (e.g., circular RNA). Lipoplexes may be formed by contacting a liposome comprising a cationic lipid with a nucleic acid.
- a lipoplex may comprise multiple concentric lipid bilayers, each concentric bilayer separated by one or more nucleic acids.
- the central region of the lipoplex may comprise an aqueous solution, suspension, or other aqueous composition.
- the composition comprises a lipopolyplex.
- a lipopolyplex is a lipid particle comprising a lipid bilayer surrounding a complex of a cationic polymer and a nucleic acid (e.g., circular RNA).
- a lipopolyplex may be formed by contacting a cationic liposome (e.g., liposome comprising a cationic lipid) with the complex of nucleic acid and cationic polymer.
- the central region of the lipopolyplex may comprise an aqueous solution, suspension, or other aqueous composition.
- the composition comprises a cationic nanoemulsion.
- a cationic nanoemulsion comprises a cationic lipid, hydrophilic surfactant, and hydrophobic surfactant.
- a liposome, lipoplex, lipopolyplex, or cationic nanoemulsion may comprise a sterol.
- a liposome, lipoplex, lipopolyplex, or cationic nanoemulsion may comprise a neutral lipid.
- a liposome, lipoplex, lipopolyplex, or cationic nanoemulsion may comprise a PEG-modified lipid.
- Stabilizing Compounds Some embodiments of compositions are stabilized pharmaceutical compositions.
- Various non-viral delivery systems, including nanoparticle formulations present attractive opportunities to overcome many challenges associated with RNA delivery.
- Lipid nanoparticles LNPs
- LNPs Lipid nanoparticles
- lipids have been shown to degrade nucleic acids, including RNA, and lipid nanoparticle formulations undergo rapid loss of purity when stored as refrigerated liquids.
- RNA encapsulated within LNPs is lower than that of unencapsulated RNA.
- a class of compounds has been found to stabilize nucleic acids within a lipid carrier such as an LNP, an unexpected and unprecedented discovery which enables applications including extended refrigerated liquid shelf-life, extended in-use periods at room temperature, and extended in-use stability at physiological temperatures up to higher temperatures such as 40°C.
- Such stabilizing compounds solve a critical problem, as current manufacturing processes and formulations experience a 5-10% purity loss during LNP formation and processing that is typical with current large-scale LNP production.
- the stabilized pharmaceutical composition comprises a nucleic acid formulation comprising a nucleic acid and a stabilizing compound (e.g., a compound of Formula (I), of Formula (II), or a tautomer or solvate thereof).
- a stabilizing compound e.g., a compound of Formula (I), of Formula (II), or a tautomer or solvate thereof.
- the stabilized pharmaceutical composition comprises a nucleic acid formulation comprising a nucleic acid and a lipid, and a compound of Formula (I): or a tautomer or solvate thereof, wherein: is a single bond or a double bond; R 1 is H; R 2 is OCH3, or together with R 3 is OCH2O; R 3 is OCH3, or together with R 2 is OCH 2 O; R 4 is H; R 5 is H or OCH 3 ; R 6 is OCH 3 ; R 7 is H or OCH 3 ; R 8 is H; R 9 is H or CH 3 ; and X is a pharmaceutically acceptable anion, e.g., a halide such as chloride.
- the compound of Formula (I) has the structure of: Formula (Ia) Formula (Ib) Formula (Ic) or a tautomer or solvate thereof.
- the stabilized pharmaceutical composition comprises a nucleic acid formulation comprising a nucleic acid and a lipid, and a compound of Formula (II): or a tautomer or solvate thereof, wherein: R 10 is H; R 11 is H; R 12 together with R 13 is OCH 2 O; R 14 is H; R 15 together with R 16 is OCH2O; R 17 is H; and X is a pharmaceutically acceptable anion, e.g., a halide such as chloride.
- the compound of Formula (II) has the structure of: Formula (IIa), or a tautomer or solvate thereof. Stabilizing compounds of Formulas (I), (Ia), (Ib), (Ic), (II), and (Iia) are described in International Application No. PCT/US2022/025967, which is incorporated by reference herein for this purpose.
- the nucleic acid formulation comprises lipid nanoparticles. In some embodiments, the nucleic acid is circular RNA.
- the stabilizing compound (“the compound”) has a purity of at least 70%, 80%, 90%, 95%, or 99%. In some embodiments, the compound contains fewer than 100ppm of elemental metals.
- the stabilized pharmaceutical composition (“the composition”) comprises a pharmaceutically acceptable metal chelator, e.g., EDTA (ethylenediaminetetraacetic acid) or DTPA (diethylenetriaminepentaacetic acid).
- the composition is an aqueous solution.
- the compound is present at a concentration between about 0.1mM and about 10mM in the aqueous solution.
- the aqueous solution has a pH of or about 5 to 8, including pH of about 5, 5.5, 6, 6.5, 7, 7.5, or 8.
- the aqueous solution does not comprise NaCl.
- the aqueous solution comprises NaCl in a concentration of or about 150mM. In some embodiments, the aqueous solution comprises a phosphate buffer, a tris buffer, an acetate buffer, a histidine buffer, or a citrate buffer. In some embodiments, microbial growth in the composition is inhibited by the compound. In some embodiments, the composition is characterized as having a circular RNA purity level of greater than 60%, greater than 70%, greater than 80%, or greater than 90% main peak circular RNA purity after at least thirty days of storage. In some embodiments, the composition comprises a circular RNA purity level of greater than 50% main peak circular RNA purity after at least six months of storage. In some embodiments, the storage is at room temperature.
- the composition comprises a lipid nanoparticle encapsulating a circular RNA, and the composition comprises less than 50%, less than 60%, less than 70%, less than 80%, less than 90%, or less than 95% RNA fragments after at least thirty days of storage.
- the storage temperature is greater than room temperature. In some embodiments, the storage temperature is about 4°C.
- the compound interacts with the nucleic acid comprised within a lipid nanostructure (e.g., a lipid nanoparticle, liposome, or lipoplex), e.g., via pi-pi stacking and/or by changing backbone helicity of the nucleic acid.
- the compound intercalates with a nucleic acid.
- the compound binds with a nucleic acid, e.g., reversible binding, and/or binding to the stranded regions of the nucleic acid.
- the compound self-associates, binds to nucleic acid ribose contacts, and/or binds to nucleic acid base contacts.
- the compound does not substantially bind to nucleic acid phosphate contacts.
- the positive charge of the compound contributes to nucleic acid binding.
- the compound interacts with a nucleic acid and provides shielding from solvent, e.g., water.
- the compound shields ribose from solvent more than the compound shields the phosphate groups of the nucleic acid.
- the solvent exposure is measured by the solvent accessible surface area (SASA).
- a stabilizing compound decreases the solvent accessible area of ribose to about 5- 10 nm 2 . In some embodiments, a stabilizing compound decreases the solvent accessible area of ribose to about 6-8 nm 2 . In some embodiments, a stabilizing compound decreases the solvent accessible area of phosphate to about 9-12 nm 2 . In some embodiments, a stabilizing compound decreases the solvent accessible area of phosphate to about 10-11 nm 2 . In some embodiments, a nucleic acid that is conformationally stabilized by the compound exhibits thermal unfolding temperatures (measured by circular dichroism or DSC, for example) that are higher than in the absence of the compound.
- the compound confers increased stability, e.g., thermal stability, to the nucleic acid in a folded structure, e.g., relative to its unfolded or less folded or more linear form.
- the compound causes compaction of the nucleic acid upon interaction with the nucleic acid.
- the compound causes a decrease in the hydrodynamic radius of the nucleic acid molecule upon interaction with the nucleic acid.
- a stabilizing compound causes compaction or a decrease in the hydrodynamic radius of a nucleic acid molecule by 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, or more.
- a stabilizing compound causes compaction or a decrease in the hydrodynamic radius of a nucleic acid molecule when the compound is in a concentration of 1 ⁇ M, 2 ⁇ M, 3 ⁇ M, 4 ⁇ M, 5 ⁇ M, 6 ⁇ M, 7 ⁇ M, 8 ⁇ M, 9 ⁇ M, 10 ⁇ M, 15 ⁇ M, 20 ⁇ M, 25 ⁇ M, 30 ⁇ M, 35 ⁇ M, 40 ⁇ M, 45 ⁇ M, 50 ⁇ M, 60 ⁇ M, 70 ⁇ M, 80 ⁇ M, 90 ⁇ M, or 100 ⁇ M.
- Pharmaceutical compositions Some aspects relate to pharmaceutical compositions comprising circular RNAs.
- Circular RNA compositions may be formulated or administered in combination with one or more pharmaceutically acceptable excipients.
- circular RNA compositions can be formulated using one or more excipients to: (1) increase stability; (2) increase cell transfection; (3) permit the sustained or delayed release (e.g., from a depot formulation); (4) alter the biodistribution (e.g., target to specific tissues or cell types); (5) increase the translation of encoded protein in vivo; and/or (6) alter the release profile of encoded protein (antigen) in vivo.
- excipients can include, without limitation, lipidoids, liposomes, lipid nanoparticles, polymers, lipoplexes, core-shell nanoparticles, peptides, proteins, cells transfected with circular RNA compositions (e.g., for transplantation into a subject), hyaluronidase, nanoparticle mimics and combinations thereof.
- circular RNA compositions comprise at least one additional active substance, such as, for example, a therapeutically active substance, a prophylactically active substance, or a combination of both.
- Circular RNA compositions may be sterile, pyrogen- free, or both sterile and pyrogen-free.
- General considerations in the formulation and/or manufacture of pharmaceutical agents, such as vaccine compositions, may be found, for example, in Remington: The Science and Practice of Pharmacy 21st ed., Lippincott Williams & Wilkins, 2005 (incorporated herein by reference in its entirety for this purpose).
- Formulations of the circular RNA compositions may be prepared by any method known or hereafter developed in the art of pharmacology.
- such preparatory methods include the step of bringing the active ingredient(s) (e.g., circular RNA of the circular RNA composition) into association with an excipient and/or one or more other accessory ingredients, and then, if necessary and/or desirable, dividing, shaping and/or packaging the product into a desired single- or multi-dose unit.
- the formulation of any of the compositions can include one or more components in addition to those described above.
- the lipid composition can include one or more permeability enhancer molecules, carbohydrates, polymers, surface altering agents (e.g., surfactants), or other components.
- a permeability enhancer molecule can be a molecule described by U.S. Patent Application Publication No.2005/0222064.
- Carbohydrates can include simple sugars (e.g., glucose) and polysaccharides (e.g., glycogen and derivatives and analogs thereof).
- a polymer can be included in and/or used to encapsulate or partially encapsulate a pharmaceutical composition (e.g., a pharmaceutical composition in lipid nanoparticle form).
- a polymer can be biodegradable and/or biocompatible.
- a polymer can be selected from, but is not limited to, polyamines, polyethers, polyamides, polyesters, polycarbamates, polyureas, polycarbonates, polystyrenes, polyimides, polysulfones, polyurethanes, polyacetylenes, polyethylenes, polyethyleneimines, polyisocyanates, polyacrylates, polymethacrylates, polyacrylonitriles, and polyarylates.
- the compositions may be formulated as lipid nanoparticles (LNPs). Accordingly, some aspects relate to compositions comprising (i) a lipid composition comprising a delivery agent, and (ii) a circular RNA.
- the lipid composition can encapsulate the circular RNA.
- Nanoparticle compositions are typically sized on the order of micrometers or smaller and can include a lipid bilayer. Nanoparticle compositions encompass lipid nanoparticles (LNPs), liposomes (e.g., lipid vesicles), and lipoplexes.
- LNPs lipid nanoparticles
- a nanoparticle composition can be a liposome having a lipid bilayer with a diameter of 500 nm or less.
- Nanoparticle compositions include, for example, lipid nanoparticles (LNPs), liposomes, and lipoplexes.
- nanoparticle compositions are vesicles including one or more lipid bilayers.
- a nanoparticle composition includes two or more concentric bilayers separated by aqueous compartments.
- Lipid bilayers can be functionalized and/or crosslinked to one another.
- Lipid bilayers can include one or more ligands, proteins, or channels.
- a lipid nanoparticle comprises an ionizable lipid, a structural lipid, a phospholipid, and circular RNA.
- the LNP comprises an ionizable lipid, a PEG-modified lipid, a phospholipid, and a structural lipid.
- the term “lipid” refers to a small molecule that has hydrophobic or amphiphilic properties. Lipids may be naturally occurring or synthetic.
- lipids examples include, but are not limited to, fats, waxes, sterol-containing metabolites, vitamins, fatty acids, glycerolipids, glycerophospholipids, sphingolipids, saccharolipids, and polyketides, and prenol lipids.
- the amphiphilic properties of some lipids lead them to form liposomes, vesicles, or membranes in aqueous media.
- a lipid nanoparticle may comprise an ionizable lipid.
- the term “ionizable lipid” has its ordinary meaning in the art and may refer to a lipid comprising one or more charged moieties.
- an ionizable lipid may be positively charged or negatively charged.
- An ionizable lipid may be positively charged, in which case it can be referred to as “cationic lipid”.
- an ionizable lipid molecule may comprise an amine group, and can be referred to as an ionizable amino lipids.
- a “charged moiety” is a chemical moiety that carries a formal electronic charge, e.g., monovalent (+1, or -1), divalent (+2, or -2), trivalent (+3, or -3), etc. The charged moiety may be anionic (i.e., negatively charged) or cationic (i.e., positively charged).
- Examples of positively- charged moieties include amine groups (e.g., primary, secondary, and/or tertiary amines), ammonium groups, pyridinium group, guanidine groups, and imidizolium groups.
- the charged moieties comprise amine groups.
- Examples of negatively- charged groups or precursors thereof include carboxylate groups, sulfonate groups, sulfate groups, phosphonate groups, phosphate groups, hydroxyl groups, and the like.
- the charge of the charged moiety may vary, in some cases, with the environmental conditions, for example, changes in pH may alter the charge of the moiety, and/or cause the moiety to become charged or uncharged.
- Ionizable lipids can also be the compounds disclosed in International Publication Nos.: WO2017075531, WO2015199952, WO2013086354, or WO2013116126, or selected from formulae CLI- CLXXXXII of US Patent No.7,404,969; each of which is hereby incorporated by reference to the extent it discloses ionizable lipids. It should be understood that the terms “charged” or “charged moiety” does not refer to a “partial negative charge” or “partial positive charge” on a molecule. The terms “partial negative charge” and “partial positive charge” are given their ordinary meaning in the art.
- a “partial negative charge” may result when a functional group comprises a bond that becomes polarized such that electron density is pulled toward one atom of the bond, creating a partial negative charge on the atom.
- the ionizable lipid is an ionizable amino lipid, sometimes referred to in the art as an “ionizable cationic lipid”.
- the ionizable amino lipid may have a positively charged hydrophilic head and a hydrophobic tail that are connected via a linker structure.
- an ionizable lipid may also be a lipid including a cyclic amine group.
- Circular RNAs may be present in contact with lipid delivery vehicles (e.g., lipid nanoparticles).
- the lipid nanoparticle comprises at least one ionizable amino lipid, at least one non-cationic lipid, at least one sterol, and/or at least one polyethylene glycol (PEG)-modified lipid.
- Nanoparticle compositions can be characterized by a variety of methods. For example, microscopy (e.g., transmission electron microscopy or scanning electron microscopy) can be used to examine the morphology and size distribution of a nanoparticle composition. Dynamic light scattering or potentiometry (e.g., potentiometric titrations) can be used to measure zeta potentials.
- Dynamic light scattering can also be utilized to determine particle sizes. Instruments such as the Zetasizer Nano ZS (Malvern Instruments Ltd, Malvern, Worcestershire, UK) can also be used to measure multiple characteristics of a nanoparticle composition, such as particle size, polydispersity index, and zeta potential. Nanoparticle compositions can be characterized by a variety of methods. For example, microscopy (e.g., transmission electron microscopy or scanning electron microscopy) can be used to examine the morphology and size distribution of a nanoparticle composition. Dynamic light scattering or potentiometry (e.g., potentiometric titrations) can be used to measure zeta potentials.
- microscopy e.g., transmission electron microscopy or scanning electron microscopy
- Dynamic light scattering or potentiometry e.g., potentiometric titrations
- potentiometric titrations can be used to measure zeta potentials.
- Dynamic light scattering can also be utilized to determine particle sizes.
- Instruments such as the Zetasizer Nano ZS (Malvern Instruments Ltd, Malvern, Worcestershire, UK) can also be used to measure multiple characteristics of a nanoparticle composition, such as particle size, polydispersity index, and zeta potential.
- the size of the nanoparticles can help counter biological reactions such as, but not limited to, inflammation, or can increase the biological effect of the polynucleotide.
- size or “mean size” in the context of nanoparticle compositions refers to the mean diameter of a nanoparticle composition.
- Circular RNA compositions comprise circular RNA molecules that may include but are not limited to circular mRNA (including modified circular mRNA), long non-coding circular RNA (lncRNA), and self-replicating circular RNA.
- the circular RNA encodes a peptide or polypeptide (e.g., a therapeutic peptide or therapeutic polypeptide).
- the circular RNAs may be used in a myriad of applications.
- the circular RNA transcripts in a composition may be used to produce one or more polypeptides of interest, e.g., therapeutic proteins, vaccine antigens, and the like.
- the circular RNAs are therapeutic RNAs.
- a therapeutic RNA is an RNA that encodes a therapeutic protein (the term “protein” encompasses peptides).
- circular RNA compositions comprise one or more circular RNAs that encode peptides or proteins that interact or complex in a cell or subject to form a multi-subunit protein (e.g., an antibody comprising a heavy chain and a light chain, a multi-subunit receptor protein, etc.) or a multivalent vaccine.
- Therapeutic proteins mediate a variety of effects in a host cell or in a subject to treat a disease or ameliorate the signs and symptoms of a disease.
- a therapeutic protein can replace a protein that is deficient or abnormal, augment the function of an endogenous protein, provide a novel function to a cell (e.g., inhibit or activate an endogenous cellular activity, or act as a delivery agent for another therapeutic compound (e.g., an antibody-drug conjugate).
- Therapeutic RNA may be useful for the treatment of the following diseases and conditions: bacterial infections, viral infections, parasitic infections, cell proliferation disorders, genetic disorders, and autoimmune disorders. Other diseases and conditions are encompassed herein.
- a protein or proteins of interest encoded by a circular RNA composition can be essentially any protein or pool of peptides (e.g., peptide antigens).
- a therapeutic peptide or therapeutic protein is a biologic.
- a biologic is a polypeptide-based molecule that may be used to treat, cure, mitigate, prevent, or diagnose a serious or life-threatening disease or medical condition.
- Biologics include, but are not limited to, allergenic extracts (e.g. for allergy shots and tests), blood components, gene therapy products, human tissue or cellular products used in transplantation, vaccines, monoclonal antibodies, cytokines, growth factors, enzymes, thrombolytics, and immunomodulators, among others.
- the therapeutic protein is a cytokine, a growth factor, an antibody (e.g., monoclonal antibody), a fusion protein, or a multivalent vaccine (e.g., a circular RNA encoding peptide antigens designed to elicit an immune response in a subject).
- therapeutic proteins include blood factors (such as Factor VIII and Factor VII), complement factors, Low Density Lipoprotein Receptor (LDLR) and MUT1.
- cytokines include interleukins, interferons, chemokines, lymphokines and the like.
- Non-limiting examples of growth factors include erythropoietin, EGFs, PDGFs, FGFs, TGFs, IGFs, TNFs, CSFs, MCSFs, GMCSFs and the like.
- Non-limiting examples of antibodies include adalimumab, infliximab, rituximab, ipilimumab, tocilizumab, canakinumab, itolizumab, tralokinumab, anti-influenza virus monoclonal antibody, anti-Chikungunya virus monoclonal antibody, anti-Zika virus monoclonal antibody, anti-SARS-CoV-2 monoclonal antibody.
- Non- limiting examples of fusion proteins include, for example, etanercept, abatacept and belatacept.
- Non-limiting examples of multivalent vaccines include, for example, multivalent Cytomegalovirus (CMV) vaccine, and personalized cancer vaccines.
- CMV Cytomegalovirus
- One or more biologics currently being marketed or in development may be encoded by the circular RNA of the present invention. While not wishing to be bound by theory, it is believed that encoding a known biologic using a circular RNA will result in improved therapeutic efficacy due at least in part to the specificity, purity and/or selectivity of the construct designs.
- a circular RNA composition may encode one or more antibodies (e.g., may comprise a first open reading frame encoding an antibody heavy chain and a second open reading frame encoding an antibody light chain).
- antibody includes monoclonal antibodies (including full length antibodies which have an immunoglobulin Fc region), antibody compositions with polyepitopic specificity, multispecific antibodies (e.g., bispecific antibodies, diabodies, and single-chain molecules), as well as antibody fragments.
- immunoglobulin Ig is used interchangeably with “antibody” herein.
- a monoclonal antibody is an antibody obtained from a population of substantially homogeneous antibodies, i.e., the individual antibodies comprising the population are identical except for possible naturally occurring mutations and/or post-translation modifications (e.g., isomerizations, amidations) that may be present in minor amounts. Monoclonal antibodies are highly specific, being directed against a single antigenic site.
- Monoclonal antibodies specifically include chimeric antibodies (immunoglobulins) in which a portion of the heavy and/or light chain is identical with or homologous to corresponding sequences in antibodies derived from a particular species or belonging to a particular antibody class or subclass, while the remainder of the chain(s) is(are) identical with or homologous to corresponding sequences in antibodies derived from another species or belonging to another antibody class or subclass, as well as fragments of such antibodies, so long as they exhibit the desired biological activity.
- Chimeric antibodies include, but are not limited to, “primatized” antibodies comprising variable domain antigen-binding sequences derived from a non-human primate (e.g., Old World Monkey, Ape etc.) and human constant region sequences.
- Antibodies encoded by circular RNAs may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, blood, cardiovascular, CNS, poisoning (including antivenoms), dermatology, endocrinology, gastrointestinal, medical imaging, musculoskeletal, oncology, immunology, respiratory, sensory and anti-infective.
- a circular RNA composition may encode one or more vaccine antigens.
- a vaccine antigen is a biological preparation that improves immunity to a particular disease or infectious agent.
- One or more vaccine antigens currently being marketed or in development may be encoded by the circular RNA.
- Vaccine antigens encoded by the RNA may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, cancer, allergy and infectious disease.
- a vaccine may be a personalized vaccine in the form of a concatemer of individual linear RNAs, which are then circularized, or individual circular RNAs, collectively encoding peptide epitopes or a combination thereof.
- a circular RNA composition may be designed to encode on or more antimicrobial peptides (AMP) or antiviral peptides (AVP).
- AMPs and AVPs have been isolated and described from a wide range of animals such as, but not limited to, microorganisms, invertebrates, plants, amphibians, birds, fish, and mammals.
- the anti-microbial polypeptides may block cell fusion and/or viral entry by one or more enveloped viruses (e.g., HIV, HCV).
- the anti- microbial polypeptide can comprise or consist of a synthetic peptide corresponding to a region, e.g., a consecutive sequence of at least about 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, or 60 amino acids of the transmembrane subunit of a viral envelope protein, e.g., HIV-1 gp120 or gp41.
- a viral envelope protein e.g., HIV-1 gp120 or gp41.
- the amino acid and nucleotide sequences of HIV-1 gp120 or gp41 are described in, e.g., Kuiken et al., (2008). “HIV Sequence Compendium,” Los Alamos National Laboratory.
- circular RNAs are used as radiolabeled RNA probes.
- circular RNAs are used for non-isotopic RNA labeling.
- circular RNAs are used as guide RNA (gRNA) for gene targeting.
- gRNA guide RNA
- circular RNAs e.g., mRNA
- mRNA guide RNA
- circular RNAs are used for in vitro translation and micro injection.
- circular RNAs are used for RNA structure, processing and catalysis studies.
- circular RNAs are used for RNA amplification.
- circular RNAs are used as anti-sense RNA for gene expression experiment.
- RNA Circular RNA compositions were produced by 1) in vitro transcription (IVT) to produce linear RNAs, 2) splinted ligation of linear RNAs to produce circular RNAs, and 3) high- performance liquid chromatography (HPLC) purification to separate circular RNAs from linear RNAs and other reaction components (FIG.1).
- IVTT in vitro transcription
- HPLC high- performance liquid chromatography
- In vitro transcription used a plasmid as DNA template, with a T7 RNA polymerase transcribing an uncapped linear RNA containing, in 5′-to- 3′ order: a 5′ UTR, an open reading frame, and a 3′ UTR.
- Each of the 5′ and 3′ UTRs were polyAC spacer sequences.
- NTPs present in the IVT mixture included unmodified CTP, unmodified GTP, and unmodified UTP, as well as ATP in varying proportions of unmodified ATP and N6-methyladenosine triphosphate (m6ATP), as indicated, to produce RNAs containing unmodified nucleotides or some amount of N6-methyladenosine nucleotides. It was determined that m6ATP was incorporated less efficiently than unmodified ATP, with an IVT mixture containing 30% m6ATP and 70% unmodified ATP yielding RNAs containing about 10% N6- methyladenosine nucleotides and about 90% unmodified N6-methyladenosine nucleotides.
- m6ATP N6-methyladenosine triphosphate
- RNAs containing about 3% N6-methyladenosine nucleotides and about 97% unmodified adenosine nucleotides were incubated with a DNA splint oligonucleotide that was complementary to sequences at the 5′ and 3′ ends of the RNA, so that both ends of the linear RNA hybridized with the DNA splint in a manner that placed the 5′ and 3′ terminal nucleotides of the linear RNA adjacent to each other in the linear RNA:DNA splint hybrid.
- RNA ligase was added, which formed a covalent bond between the terminal nucleotides of the linear RNA to produce a circular RNA. Circular RNAs were then purified using HPLC Stability and translation of circular RNAs were tested in vivo.
- Mice were intravenously administered one of a panel of lipid nanoparticle (LNP)-RNA compositions listed in Table 1. At various timepoints, mice were euthanized to collect liver and serum samples to measure RNA abundance (FIG.2A) and protein concentrations (FIG.2B). Table 1: Panel of LNP compositions containing circular RNAs. The results of this study are shown in FIGs.2A–2B.
- LNP lipid nanoparticle
- RNAs containing N6- methyladenosine (m6A) nucleotides were more stable in vivo, compared to circular RNAs without m6A, with RNAs containing ⁇ 10% m6A nucleotides (made using IVT with 30% m6ATP) being more stable than those containing only ⁇ 3% m6A nucleotides (made using IVT with 10% m6ATP) (FIG.2A). While lower amounts of the encoded protein were observed in mice administered RNAs containing 10% m6A nucleotides, similar amounts of protein were detected in mice administered RNAs containing 3% m6A nucleotides and those administered unmodified RNAs for 48 hours (FIG.2B).
- mice were intravenously administered one of a panel of LNP- RNA compositions listed in Table 2. At various timepoints, mice were euthanized to collect liver samples to visualize RNA in liver cells (FIG.3A, 3C) and measure RNA abundance by qPCR (FIG.3B, 3D). Table 2: Panel of LNP compositions containing circular RNAs.
- FIGs.3A–3D The results of this experiment are shown in FIGs.3A–3D. While both unmodified and m6A-modified RNAs were detected in liver cells 6 hours post-administration, only liver sections from mice administered m6A-modified RNAs were detectable at 24 and 48 hours post- administration (FIG.3A). RNA abundance, as measured by qPCR, corroborated this finding, as the abundance of unmodified RNA decreased by about 10-fold between 6 and 24 hours post- administration (FIG.3B). While inclusion of m6A nucleotides was observed to extend the persistence of circular RNAs in both hepatocytes and Kupffer cells, a third arm of this experiment evaluated the interaction between Kupffer cells, hepatocytes, and RNA stability.
- RNA abundance was maintained at higher levels in mice administered RNAs containing miR-142 target sequences, relative to mice administered RNAs without miR target sequences (FIG.3D), and RNA was observed in hepatocytes for the duration of the study (FIG. 3C).
- mice were intravenously administered one of a panel of LNP-RNA compositions listed in Table 3. At various timepoints, mice were euthanized to collect liver samples, to measure RNA abundance in liver by qPCR (FIG.4).
- Table 3 Panel of LNP compositions containing circular RNAs. The results of this experiment are shown in FIG.4. Consistent with previous results, circular RNAs lacking IRES cassettes containing m6A nucleotides were observed at higher abundance than unmodified circular RNAs (FIG.4). This result suggested that the increase in circular RNA stability by incorporation of N6-methyladenosine nucleotides is not unique to RNAs containing a CVB3 IRES.
- mice were intravenously administered one of a panel of LNP-RNA compositions listed in Table 4.
- mice were euthanized to collect liver samples, to measure RNA abundance in liver by qPCR (FIGs.5A–5C).
- Table 4 Panel of LNP compositions containing circular RNAs. The results of this experiment are shown in FIGs.5A–5C.
- mice were intravenously administered one of a panel of LNP-RNA compositions listed in Table 5. These RNAs encoded Ag2, a different protein from the Ag1 encoded by RNAs tested in the experiments described above. At various timepoints, mice were euthanized to collect liver samples, to measure RNA abundance in liver by qPCR (FIGs.6A– 6B).
- Table 5 Panel of LNP compositions containing circular RNAs. The results of this experiment are shown in FIGs.6A–6B. Consistent with previous results, incorporation of m6A nucleotides extended circular RNA half-life for RNAs containing either SaliFHB or CVB IRES. This result indicate that the extension of RNA half-life is not unique to a protein encoded by the RNA.
- Example 2 Stability of circular RNAs containing N6-methyladenosine Circular RNAs were produced by IVT in which varying percentages of adenosine nucleotide triphosphates contained N6-methyladenosine (m6A).
- IVT reaction mixtures contained 30%, 50%, 75%, or 100% N6-methyladenosine triphosphate (m6ATP), and a complementary percentage (70%, 50%, 25%, or 0%) of unmodified ATP, followed by circularization.
- Control linear RNAs were produced by IVT in which all uridine nucleotide triphosphates were N1-methylpseudouridine triphosphate. All circular RNAs contained SaliFHB IRESes.
- BALB/c mice (4 mice per timepoint per RNA group) were intravenously administered an LNP-RNA composition containing one of these RNAs. RNA abundance (by qRT-PCR) and protein expression (by luminescence from encoded luciferase) was monitored over time in mouse livers.
- composition comprising a circular messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a protein, wherein 5–100% of the adenine nucleotides of the mRNA are modified adenine nucleotides comprising N6-methyladenosine (m6A).
- composition of Embodiment 1, wherein a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 3.
- composition of Embodiment 1 wherein a level of expression, in a mammalian cell, of the protein encoded by the open reading frame of the circular RNA is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 5.
- a composition comprising a circular messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a protein, wherein 5–95% of the adenine nucleotides of the mRNA are modified adenine nucleotides comprising N6-methyladenosine (m6A).
- mRNA circular messenger ribonucleic acid
- m6A N6-methyladenosine
- each uridine nucleotide of the circular RNA comprises N1-methylpseudouridine.
- the circular RNA comprises one or more target sequences for a miRNA. 15.
- the composition of Embodiment 14, wherein the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for the miRNA.
- 16 The composition of Embodiment 14 or 15, wherein the miRNA is miR-23a, miR-142, or miR-223.
- 17. The composition of any one of Embodiments 1–16, wherein the circular RNA comprises an internal ribosome entry site (IRES).
- IRES internal ribosome entry site
- the composition of any one of Embodiments 1–17, wherein the circular RNA comprises, in 5′ to 3′ order, a 5′ untranslated region (UTR), an IRES, an open reading frame encoding a protein, and a 3′ UTR. 19.
- composition of Embodiment 18, wherein the circular RNA further comprises a polyA or polyAC region.
- the composition of Embodiment 19, wherein the polyA or polyAC region is between the 5′ UTR and the IRES.
- the composition of Embodiment 19, wherein the polyA or polyAC region is between the open reading frame and the 3′ UTR.
- the composition of any one of Embodiments 18–21, wherein a level of expression in a mammalian cell of the polypeptide encoded by the ORF of the circular RNA is at least 50% of a level of expression of a reference linear mRNA comprising the ORF.
- 25. The composition of Embodiment 23, wherein the ORF is codon-optimized for expression in a human cell.
- 26. The composition of any one of Embodiments 1–25, wherein the RNA is in a lipid nanoparticle.
- composition of Embodiment 26, wherein the lipid nanoparticle comprises: an ionizable amino lipid.
- the lipid nanoparticle further comprises: a non-cationic lipid; a sterol; and a polyethylene glycol (PEG)-modified lipid.
- PEG polyethylene glycol
- a method for producing circular messenger ribonucleic acid comprising: (i)(a) forming a reaction mixture comprising a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP); (i)(b) incubating the reaction mixture under conditions such that the mRNA is transcribed, thereby producing an in vitro transcribed (IVT) linear mRNA; and (ii) circularizing the linear mRNA, wherein the circularizing comprises forming a covalent bond between a first nucleotide of the linear mRNA and a subsequent nucleotide of the linear mRNA to produce a circular RNA, wherein 15–100% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A).
- ATP a
- composition of Embodiment 30, wherein a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide.
- composition of Embodiment 30, wherein a level of expression, in a mammalian cell, of a protein encoded by an open reading frame of the circular RNA is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide.
- a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide.
- a method for producing circular messenger ribonucleic acid comprising: (i)(a) forming a reaction mixture comprising a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP); (i)(b) incubating the reaction mixture under conditions such that the mRNA is transcribed, thereby producing an in vitro transcribed (IVT) linear mRNA; and (ii) circularizing the linear mRNA, wherein the circularizing comprises forming a covalent bond between a first nucleotide of the linear mRNA and a subsequent nucleotide of the linear mRNA to produce a circular RNA, wherein 15–95% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A).
- ATP a
- the UTP is a modified UTP comprising pseudouridine ( ⁇ ), N1-methylpseudouridine (m1 ⁇ ), 2-thiouridine, 4-thiouridine, 2- thio-1-methyl-1-deaza-pseudouridine, 2-thio-1-methyl-pseudouridine, 2-thio-5-aza-uridine , 2- thio-dihydropseudouridine, 2-thio-dihydrouridine, 2-thio-pseudouridine, 4-methoxy-2-thio- pseudouridine, 4-methoxy-pseudouridine, 4-thio-1-methyl-pseudouridine, 4-thio-pseudouridine, 5-aza-uridine,
- RNA polymerase is selected from the group consisting of T7 RNA polymerase, a T3 RNA polymerase, a K11 RNA polymerase, and SP6 RNA polymerase. 43. The method of any one of Embodiments 30–42, wherein the RNA polymerase is a T7 RNA polymerase. 44.
- circularizing the linear mRNA comprises contacting the linear mRNA with a splint nucleic acid and an RNA ligase, wherein the splint nucleic acid is a nucleic acid that hybridizes with the linear mRNA, wherein the linear RNA forms a circular secondary structure when hybridized to the splint nucleic acid.
- the splint nucleic acid comprises: (a) a first hybridization sequence comprising 5 or more nucleotides, wherein the first hybridization sequence is complementary to at least the first 5 nucleotides of the linear mRNA; and (b) a second hybridization sequence comprising 5 or more nucleotides, wherein the second hybridization sequence is complementary to at least the last 5 nucleotides of the linear mRNA, wherein at least the first 5 nucleotides of the linear mRNA hybridize with the first hybridization sequence, and at least the last five nucleotides of the linear mRNA hybridize with the second hybridization sequence. 46.
- RNA ligase is T4 RNA ligase II.
- a 5′ terminal nucleotide of the linear mRNA comprises a 5′ terminal hydroxyl
- a 3′ terminal nucleotide of the linear mRNA comprises a 3′ terminal phosphate
- the RNA ligase is an RtcB RNA ligase.
- the method further comprises, after the in vitro transcribing of (i)(b) and before the circularizing of (ii), contacting the linear mRNA with a polyphosphatase.
- any one of Embodiments 30–51 wherein the method further comprises contacting a mixture comprising a circular RNA with one or more exonucleases, whereby the exonuclease hydrolyzes one or more internucleoside linkages of the linear mRNA, thereby releasing a terminal nucleotide from the linear mRNA.
- 53. The method of Embodiment 52, wherein at least one exonuclease is a 5′ exonuclease.
- 54. The method of Embodiment 53, wherein the 5′ exonuclease is XRN-1. 55.
- Embodiment 52 wherein at least one exonuclease is a 3′ exonuclease.
- the method further comprises adding a 5′ phosphatase into a mixture comprising the linear mRNA, whereby the 5′ phosphatase removes one or more 5′ phosphates from the linear mRNA. 59.
- the Dnase is introduced at about the same time as the linear mRNA is circularized. 63.
- Embodiment 62 wherein the Dnase is introduced after the linear mRNA is circularized.
- 64 A composition comprising a circular RNA produced by the method of any one of Embodiments 30–63.
- inventive embodiments have been described and illustrated herein, those of ordinary skill in the art will readily envision a variety of other means and/or structures for performing the function and/or obtaining the results and/or one or more of the advantages described herein, and each of such variations and/or modifications is deemed to be within the scope of the inventive embodiments described herein.
- any combination of two or more such features, systems, articles, materials, kits, and/or methods, if such features, systems, articles, materials, kits, and/or methods are not mutually inconsistent, is included within the inventive scope of the present disclosure.
- All definitions, as defined and used herein, should be understood to control over dictionary definitions, definitions in documents incorporated by reference, and/or ordinary meanings of the defined terms. All references, patents and patent applications disclosed herein are incorporated by reference with respect to the subject matter for which each is cited, which in some cases may encompass the entirety of the document.
- a reference to “A and/or B”, when used in conjunction with open-ended language such as “comprising” can refer, in some embodiments, to A only (optionally including elements other than B); in another embodiment, to B only (optionally including elements other than A); in yet another embodiment, to both A and B (optionally including other elements); etc.
- “or” should be understood to have the same meaning as “and/or” as defined above.
- At least one of A and B can refer, in some embodiments, to at least one, optionally including more than one, A, with no B present (and optionally including elements other than B); in another embodiment, to at least one, optionally including more than one, B, with no A present (and optionally including elements other than A); in yet another embodiment, to at least one, optionally including more than one, A, and at least one, optionally including more than one, B (and optionally including other elements); etc.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Microbiology (AREA)
- Epidemiology (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Physics & Mathematics (AREA)
- Medicinal Chemistry (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
Provided herein are methods of producing circular RNAs with a combination of unmodified adenosine nucleotides and modified nucleotides comprising N6-methyladenosine (m6A) by in vitro transcription using a reaction mixture in which some ATPs are unmodified ATP and some percentage are N6-methyladenosine triphosphate (m6ATP). Also provided are circular RNAs in which some adenosine nucleotides comprise unmodified adenosine and some percentage comprise N6-methyladenosine.
Description
CIRCULAR MRNA AND PRODUCTION THEREOF RELATED APPLICATION This application claims the benefit under 35 U.S.C. § 119(e) of U.S. Provisional Application No.63/493,182, filed March 30, 2023, the contents of which are incorporated by reference herein in their entirety. REFERENCE TO AN ELECTRONIC SEQUENCE LISTING The contents of the electronic sequence listing (M137870265WO00-SEQ-NTJ.xml; Size: 7,973 bytes; and Date of Creation: March 29, 2024) are incorporated by reference herein in their entirety. BACKGROUND Messenger RNA (mRNA) is an emerging alternative to conventional small molecule and protein therapeutics due to the potency and programmability of mRNA. mRNA encoding a desired therapeutic protein can be administered to a subject for in vivo expression of the protein to therapeutic effect. Despite recent successes, the long-term efficacy of administered mRNA is hindered by the instability of mRNA in cells, where it is degraded by terminal exonucleases. SUMMARY Provided herein are circular RNAs, which have no 5′ or 3′ terminal nucleotides and are thus not susceptible to hydrolysis by exonucleases. In vitro transcription (IVT) of linear RNA, followed by ligation of the 5′ and 3′ terminal nucleotides, produces circular RNAs with improved stability relative to the linear mRNAs, and are thus able to be translated for longer periods of time. Additionally, use of an IVT reaction mixture in which some adenosine triphosphates (ATPs) are modified N6-methyladenosine triphosphate (m6ATP) allows for transcription of RNAs containing modified nucleotides comprising N6-methyladenosine (m6A). m6A-modified nucleotides reduce the immunostimulatory activity of circular RNA molecules, such as by decreasing the ability of the m6A-modified circular RNA to be recognized by innate immune factors (e.g., RIG-I) that mediate degradation of foreign RNA, and this decreased immunostimulatory activity allows modified circular RNAs to persist for extended periods of time in vivo, relative to unmodified RNAs. Moreover, it was discovered that miRNA target sequences could be incorporated into circular RNAs to cause selective degradation in immune cells, thereby enhancing stability of the circular RNAs in target tissue. For example, incorporation of miRNA target sequences into circular RNAs allowed selective degradation of administered circular RNAs in liver macrophages, but not neighboring hepatocytes. This resulting absence of the administered circular RNA from liver macrophage further increased the
half-life of circular RNA in hepatocytes and total abundance of circular RNA in the liver. Incorporation of m6A-modified nucleotides and/or miRNA target sequences into circular RNAs effectively produces circular RNAs with resistance to exonuclease activity, reduced immunostimulatory activity, improved intracellular stability, and improved in vivo persistence, relative to comparable linear mRNAs or unmodified circular RNAs. Therefore, these circular RNAs are useful for prolonged expression of therapeutic proteins following introduction to cells or subjects. Accordingly, some aspects relate to a circular ribonucleic acid (circular RNA) comprising an open reading frame (ORF) encoding a protein, wherein 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 5–7%, 7–10%, 10–15%, 15–20%, 20–25%, 25–30%, 30–40%, 40– 50%, 50–60%, 60–70%, 70–80%, 80–90%, or 90–95% of nucleotides at adenosine positions comprise N6-methyladenosine (m6A). In some embodiments, 10–25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF. In some embodiments, the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell. In some embodiments, the one or more miRNAs are specific to macrophages. In some embodiments, the one or more miRNAs are specific to Kupffer cells. In some embodiments, the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs. In some embodiments, the circular RNA comprises an open reading frame encoding a vaccine antigen or therapeutic protein. In some embodiments, the circular RNA comprises, in 5′- to-3′-order: a 5′ untranslated region (UTR), an internal ribosome entry site (IRES), the ORF, and a 3′ UTR. In some embodiments, the circular RNA further comprises a polyA or polyAC region. In some embodiments, the polyA or polyAC region is between the 5′ UTR and the IRES. In some embodiments, the polyA or polyAC region is between the open reading frame and the 3′ UTR. In some embodiments, the ORF is codon-optimized for expression in a mammalian cell. In some embodiments, the ORF is codon-optimized for expression in a human cell. In some embodiments, substantially all nucleotides at uridine positions comprise N1- methylpseudouridine. In some embodiments, substantially all nucleotides at cytidine positions comprise 5-methylcytidine, and substantially all nucleotides at uridine positions comprise 5- methyluridine.
In some embodiments, the circular RNA further comprises comprising a lipid delivery vehicle in contact with the circular RNA. In some embodiments, the lipid delivery vehicle is a lipid nanoparticle comprising 20–60 mol% ionizable lipid, 5–25 mol% non-cationic lipid, 2–4 mol% PEG-modified lipid, and 25–55 mol% sterol. In some embodiments, the ionizable lipid is a compound of Formula (IL*):
 , or a salt thereof, wherein: R1 is -OH, -NRN-C4-10 cycloalkenyl optionally substituted with one or more oxo or - N(RN’RN’’); RN is H or C1-6 alkyl; RN’ is H or C1-6 alkyl; RN’’ is H or C1-6 alkyl; o is 1, 2, 3, or 4; n is 4, 5, 6, 7, or 8; m is 4, 5, 6, 7, or 8; M is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R2; M’ is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R3; R2 is
, or a salt thereof, wherein: R1 is -OH, -NRN-C4-10 cycloalkenyl optionally substituted with one or more oxo or - N(RN’RN’’); RN is H or C1-6 alkyl; RN’ is H or C1-6 alkyl; RN’’ is H or C1-6 alkyl; o is 1, 2, 3, or 4; n is 4, 5, 6, 7, or 8; m is 4, 5, 6, 7, or 8; M is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R2; M’ is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R3; R2 is
 or –(C1-6 alkylene)-(C3-8 cycloalkyl)-C1-6 alkyl; R2a is -H or C1-10 alkyl; R2b is -H or C1-10 alkyl; alkenyl;
or –(C1-6 alkylene)-(C3-8 cycloalkyl)-C1-6 alkyl; R2a is -H or C1-10 alkyl; R2b is -H or C1-10 alkyl; alkenyl;
 R3a is H or C1-10 alkyl; R3b is H or C1-8 alkyl; and R3c is C1-10 alkyl or C2-8 alkenyl. In some embodiments, the ionizable lipid
R3a is H or C1-10 alkyl; R3b is H or C1-8 alkyl; and R3c is C1-10 alkyl or C2-8 alkenyl. In some embodiments, the ionizable lipid
 18).
In some embodiments, 0.25 mol% to 1.0 mol% of the PEG-modified lipid is present in a core of the lipid nanoparticle. In some embodiments, 2.0 mol% to 2.75 mol% of the PEG- modified lipid is not in the core of the lipid nanoparticle. In some embodiments, the PEG- modified lipid is PEG-DMG or 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate. Some aspects relate to a method for producing a circular ribonucleic acid, the method comprising: (i) incubating an in vitro transcription (IVT) reaction mixture under conditions such that a linear RNA comprising an open reading frame (ORF) encoding a protein is transcribed, wherein the IVT reaction mixture comprises a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP), wherein 15–90%, 15–80%, 15–60%, 15–40%, 15–20%, 20–30%, 30–40%, 40–50%, 50– 75%, or 75–90% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A); and (ii) circularizing the linear RNA, wherein the circularizing comprises forming a covalent bond between a first nucleotide of the linear RNA and a subsequent nucleotide of the linear RNA to produce a circular RNA. In some embodiments, 30–75% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A). In some embodiments, the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF. In some embodiments, the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell. In some embodiments, the one or more miRNAs are specific to macrophages. In some embodiments, the one or more miRNAs are specific to Kupffer cells. In some embodiments, the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs. In some embodiments, substantially all UTPs in the IVT reaction mixture are N1- methylpseudouridine triphosphate. In some embodiments, substantially all UTPs in the IVT reaction mixture comprise 5-methyluridine, and wherein substantially all CTPs in the IVT reaction mixture comprise 5-methylcytidine. In some embodiments, the RNA polymerase is selected from the group consisting of T7 RNA polymerase, a T3 RNA polymerase, a K11 RNA polymerase, and SP6 RNA polymerase.
In some embodiments, the RNA polymerase is a T7 RNA polymerase. In some embodiments, the RNA polymerase is a T7 RNA polymerase variant having an amino acid sequence selected from any one of SEQ ID NOs: 1–4. Some aspects relate to a method for improving stability of a circular ribonucleic acid (circular RNA) comprising a nucleotide sequence, the nucleotide sequence comprising an open reading frame (ORF) encoding a protein, the method comprising: (i) substituting one or more nucleotides at adenosine positions with modified nucleotides comprising N6-methyladenosine (m6A) to produce a modified nucleotide sequence, wherein 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 5–7%, 7–10%, 10–15%, 15–20%, 20– 25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, or 90–95% of nucleotides at adenosine positions in the modified nucleotide sequence comprise m6A; and (ii) synthesizing a circular RNA comprising the modified nucleotide sequence. In some embodiments, 10–25% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF. In some embodiments, the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell. In some embodiments, the one or more miRNAs are specific to macrophages. In some embodiments, the one or more miRNAs are specific to Kupffer cells. In some embodiments, the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs. In some embodiments, a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position. In some embodiments, a coefficient of degradation of the circular RNA in a mammalian cell is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to control circular RNA comprising the same nucleotide sequence as the circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position. In some embodiments, a level of expression, in a mammalian cell, of the protein encoded by the ORF of the circular RNA is at
least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position. In some embodiments, a level of expression in a mammalian cell of the protein encoded by the ORF of the circular RNA is at least 50% of a level of expression of a control linear messenger ribonucleic acid (mRNA) comprising the ORF. In some embodiments, a coefficient of degradation of the circular RNA in a mammal is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to a control linear messenger ribonucleic acid (mRNA) comprising the ORF. In some embodiments, the mammalian cell is a human cell. BRIEF DESCRIPTION OF THE DRAWINGS FIG.1 shows a flowchart describing the process of producing circular RNA, comprising the steps of 1) in vitro transcription of mRNA from a DNA template; 2) splinted ligation of linear mRNA to produce circular RNA; and 3) HPLC purification to separate circular RNA from other reaction components (e.g., linear mRNA). FIGs.2A–2B show a time course of circular RNA abundance and expression in vivo following administration to BALB/c mice of lipid nanoparticles containing circular RNAs produced by IVT in which ATPs were (i) 100% unmodified ATP; (ii) 10% m6ATP and 90% unmodified ATP (producing mRNAs with ~3% m6A nucleotides); or (iii) 30% m6ATP and 70% unmodified ATP (producing mRNAs with ~10% m6A nucleotides). FIG.2A shows kinetics of circular RNA abundance in liver, or PBS control at 24 hours post-administration. FIG.2B shows expression of the encoded protein, Antigen 1 (Ag1). FIGs.3A–3D show a second time course of circular RNA abundance and expression in vivo following administration to BALB/c mice of lipid nanoparticles containing circular RNAs produced by IVT in which ATPs were (i) 100% unmodified ATP, or (ii) 30% m6ATP and 70% unmodified ATP. FIG.3A shows abundance of circular RNA in liver tissue sections, as visualized by RNAscope. FIG.3B shows circular RNA abundance in livers as measured by qPCR. FIG.3C shows liver sections as in FIG.3A, including sections from mice administered circular RNAs containing three target sequences for miR-142. FIG.3D shows circular RNA abundance as in FIG.3B, including in livers of mice administered circular RNAs containing three target sequences for miR-142. In tissue sections, dark stain corresponds to RNA, while round areas of light staining correspond to nuclei. Irregularly shaped cells are Kupffer cells and hexagonal cells with prominent nuclei are hepatocytes. RNA staining is darker in Kupffer cells then hepatocytes but both cell types are positive for RNA.
FIG.4 shows a third time course of circular RNA abundance in vivo following administration to BALB/c mice of lipid nanoparticles containing circular RNAs lacking an IRES and produced by IVT in which ATPs were (i) 100% unmodified ATP, or (ii) 30% m6ATP and 70% unmodified ATP. FIGs.5A–5C show a fourth time course of linear and circular RNA abundance in vivo following administration to BALB/c mice of lipid nanoparticles containing (i) circular RNAs produced by IVT with 30% m6ATP and 70% unmodified ATP, (ii) circular RNAs produced by IVT with 100% unmodified ATP, or (iii) linear mRNAs produced by IVT with 100% unmodified ATP. FIG.5A shows results where circular RNAs contained a CVB3 IRES. FIG. 5B shows results where circular RNAs contained an EMCV IRES. FIG.5C shows results where circular RNAs contained a SaliFHB IRES. FIGs.6A–6B show a fifth time course of linear and circular RNA abundance in vivo following administration to BALB/c mice of lipid nanoparticles containing (i) circular RNAs produced by IVT with 30% m6ATP and 70% unmodified ATP, (ii) circular RNAs produced by IVT with 100% unmodified ATP, or (iii) linear mRNAs produced by IVT with 100% unmodified ATP. Each mRNA encoded Ag2, a different protein from Ag1 encoded by mRNAs tested in FIGs.2A–5C. FIG.6A shows results where circular RNAs contained a SaliFHB IRES. FIG.6B shows results where circular RNAs contained a CVB3 IRES. FIGs.7A–7C show results of a mouse study evaluating m6A modification on circular RNA stability and protein expression. FIGs.7A and 7B shows circular RNA and linear mRNA abundance over time in mouse livers. FIG.7C shows kinetics of protein expression from circular RNAs and linear mRNAs over time. DETAILED DESCRIPTION Provided are methods of producing circular RNAs and compositions comprising circular RNAs. Unlike linear mRNAs, circular RNAs have no 5′ or 3′ terminal nucleotides and are thus not susceptible to degradation by exonucleases. In vitro transcription (IVT) to produce linear RNA, followed by ligation of the 5′ and 3′ terminal nucleotides, produces circular RNAs with improve stability relative to the linear RNAs. These circular RNAs can be translated for extended durations in cells. The stability of circular RNAs in cells may be further improved through incorporation of N6-methyladenosine (m6A)-modified nucleotides, which reduce binding by innate immune factors (e.g., RIG-I) and consequent triggering of an antiviral response that can hinder translation and induce cleavage of the circular RNA. In addition, incorporation of one or more target sequences for an miRNA allows selective degradation of the circular RNA in a desired cell type (e.g., macrophages), which may otherwise indirectly reduce circular RNA abundance in neighboring cells (e.g., by secretion of interferons). Such targeted
degradation of circular RNA in undesired cell types increases the half-life of circular RNAs in desired cell types, thereby prolonging in vivo persistence and therapeutic efficacy. Circular RNA Some aspects relate to circular RNAs comprising N6-methyladenosine-modified nucleotides. Some aspects relate to methods of producing circular RNAs comprising N6- methyladenosine-modified nucleotides by in vitro transcription of an RNA followed by circularizing the transcribed RNA. Some aspects relate to methods of improving stability of a circular RNA comprising a nucleotide sequence comprising an ORF, where the methods comprise: (i) substituting one or more nucleotides at adenosine positions in the nucleotide sequence to produce a modified nucleotide sequence; and (ii) synthesizing a circular RNA having the modified nucleotide sequence. A circular RNA is an RNA with no 5′ terminal nucleotide or 3′ terminal nucleotide. Every nucleotide in a circular RNA is covalently bonded to both 1) a 5′ adjacent nucleotide; and 2) a 3′ adjacent nucleotide. In a circular RNA with a nucleic acid sequence comprising every nucleotide of the circular RNA in 5′-to-3′ order, the last nucleotide of the nucleic acid sequence is covalently bonded to the first nucleotide of the nucleic acid sequence. Circular RNAs may comprise one or more modified adenosine nucleotides comprising N6-methyladenosine (m6A). Incorporation of such N6-methyladenosine nucleotides increases the stability of circular RNAs in mammalian cells. Thus, some aspects relate to circular RNAs in which 5–100% of the nucleotides at adenosine positions RNA are modified nucleotides comprising N6- methyladenosine. Circular RNAs may also comprise a combination of unmodified adenosine nucleotides comprising natural adenosine and modified nucleotides at adenosine positions comprising N6-methyladenosine. For example, some aspects relate to circular RNAs in which 5–95% of the nucleotides at adenosine positions comprise N6-methyladenosine. In a circular RNA, the percentage of nucleotides at adenosine positions that comprise N6-methyladenosine may be any percentage that is at least 5% and at most 100%. For example, in some embodiments, 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 10–80%,10–60%, 10– 50%,10–40%, 10–30%,10–25%, 10–20%, 5–7%, 7–10%, 10–15%, 15–20%, 20–25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, 90–95%, or 95–100% of the nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some
embodiments, about 5% to about 40% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 5% to about 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 40% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 10% to about 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 7% to about 9% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 7% to about 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 12% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 12% to about 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 15% to about 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 20% to about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 25% to about 30% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 30% to about 40% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 40% to about 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 50% to about 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 60% to about 70% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 70% to about 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 80% to about 90% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 90% to about 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 95% to about 100% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 10% to about 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 20% of
nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 30% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 5% and less than 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 7% and less than 9% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 7% and less than 10% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 10% and less than 12% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 12% and less than 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 15% and less than 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 20% and less than 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 25% and less than 30% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 30% and less than 40% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 40% and less than 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 50% and less than 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 60% and less than 70% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 70% and less than 80% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 80% and less than 90% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 90% and less than 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 95% and less than 100% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 10% and less than 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 10% and less than 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 10% and less than 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 10% and less than 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 5% and up to 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 7% and up to 9% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 7% and up
embodiments, at least 10% and up to 12% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, at least 12% and up to 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 15% and up to 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 20% and up to 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 25% and up to 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 30% and up to 40% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 40% and up to 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 50% and up to 60% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, at least 60% and up to 70% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 70% and up to 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 80% and up to 90% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 90% and up to 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 95% and up to 100% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 10% and up to 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 10% and up to 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, at least 10% and up to 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, or 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, 20%, 21%, 22%, 23%, 24%, or 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 6% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 8% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 9% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 11% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 12% of nucleotides at adenosine positions comprise N6-methyladenosine.
In some embodiments, about 13% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 14% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 16% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 17% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 18% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 19% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 21% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 22% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 23% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 24% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 5% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 6% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 7% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 8% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 9% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 11% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 12% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 13% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 14% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 16% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 17% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 18% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 19% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 21% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 22% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 23% of nucleotides at adenosine
positions comprise N6-methyladenosine. In some embodiments, 24% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 25% of nucleotides at adenosine positions comprise N6-methyladenosine. The proportion of nucleotides at adenosine positions that comprise N6-methyladenosine may be determined by any method suitable for detecting and/or measuring modified nucleotides on a nucleic acid. Methods of detecting N6-methyladenosine modification are known in the art, and reviewed, e.g., in Zhu et al., Int J Mol Med.2019.43(6):2267–2278. In some embodiments, a circular RNA further comprises one or more target sequences for a microRNA (miRNA). The inclusion of a target sequence for a miRNA allows for degradation of the circular miRNA in the presence of any one of the miRNAs that hybridize with the target sequence on the circular RNA. A target sequence of a miRNA, as used herein, refers to a nucleic acid sequence that is complementary to a miRNA. A first nucleic acid sequence is complementary to a second nucleic acid sequence if a nucleic acid comprising the first sequence binds (hybridizes) to a nucleic acid comprising the second sequence, forming a nucleic acid that is at least partially double-stranded through hydrogen bonds between base pairs on the miRNA and target sequence. A first sequence is most complementary to a second sequence when the first sequence comprises a sequence of bases that form canonical Watson- Crick base pairs (i.e., A–U, A–T, C–G) with the target sequence, in reverse order relative to the order of bases in the target sequence. A nucleic acid with this sequence of complementary bases in reverse order is said to have the reverse complement of the target sequence. For example, the reverse complement of the target sequence AAGUCCA is TGGACTT (DNA) or UGGACUU (RNA). A miRNA may still bind (hybridize) to a target sequence even if the sequence of the miRNA differs from the exact reverse complement of the target sequence by one or more nucleotides, provided the sequence of the miRNA is sufficiently similar to the reverse complement of the target sequence. The exact level of sequence identity between the sequence of a miRNA and the reverse complement of the target sequence that is sufficient for a miRNA to bind to a given target sequence will depend on the sequences of the miRNA and target sequence, for example, the nucleotide composition and/or length, as well as the binding conditions (e.g., in vivo human physiological conditions). Methods of determining whether a miRNA comprising a given sequence binds (hybridizes) to a nucleic acid comprising a target sequence are well known in the art. Following binding of a miRNA to a target sequence, the nucleic acid comprising the target sequence is degraded by an RNA-induced silencing complex. See, e.g., Pratt and MacRae. J Biol Chem.2009.284(27):17897–17901.
In some embodiments, a circular RNA comprises more than one miRNA target sequence. In some embodiments, a circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one or more miRNAs. Circular RNAs comprising multiple target sequences for one or more miRNAs may include multiple target sequences for the same miRNA. In some embodiments, a circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for the same miRNA. In some embodiments, a circular RNA comprises 1–50, 1–40, 1–30, 1–25, 1– 20, 1–15, 1–10, or 1–5 target sequences for a single miRNA. In some embodiments, a circular RNA comprises 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 target sequences for a single miRNA. In some embodiments, a circular RNA comprises 3 target sequences for a single miRNA. Circular RNAs comprising multiple target sequences for one or more miRNAs may include distinct target sequences for different miRNAs. In some embodiments, a circular RNA comprises one or more target sequences for a first miRNA, and one or more target sequences for a second miRNA that is different from the first miRNA. In some embodiments, a circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 miRNA target sequences, each target sequence being hybridized by a different miRNA. In some embodiments, a circular RNA comprises one or more target sequences for each of 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 different miRNAs. In some embodiments, the presence of a miRNA is a miRNA biomarker signature for a specific cell type in a specific stage of development. Methods of identifying a miRNA biomarker signature in a specific tissue or cell are known in the art. Information about the sequences, origins, and functions of known miRNAs maybe found in publicly available databases (e.g., mirbase.org, all versions, as described in Kozomara et al., Nucleic Acids Res 201442:D68-D73; Kozomara et al., Nucleic Acids Res 201139:D152-D157; Griffiths-Jones et al., Nucleic Acids Res 200836:D154-D158; Griffiths-Jones et al., Nucleic Acids Res 2006 34:D140-D144; and Griffiths-Jones et al., Nucleic Acids Res 200432:D109-D111, including the most recently released version miRBase 21, which contains “high confidence” miRNAs). Non-limiting examples of miRNAs that are expressed in cells, and for which target sequences may be present on a circular RNA, include: FF4, FF5, hsa-let-7a-2-3p, hsa-let-7a-3p, hsa-let-7a-5p, hsa-let-7b-3p, hsa-let-7b-5p, hsa-let-7c-5p, hsa-let-7d-3p, hsa-let-7d-5p, hsa-let- 7e-3p, hsa-let-7e-5p, hsa-let-7f-1-3p, hsa-let-7f-2-3p, hsa-let-7f-5p, hsa-let-7g-3p, hsa-let-7g-5p, hsa-let-7i-5p, hsa-miR-1, hsa-miR-1-3p, hsa-miR-1-5p, hsa-miR-100-3p, hsa-miR-100-5p, hsa- miR-101-3p, hsa-miR-101-5p, hsa-miR-103a-2-5p, hsa-miR-103a-3p, hsa-miR-105-3p, hsa- miR-105-5p, hsa-miR-106a-3p, hsa-miR-106a-5p, hsa-miR-106b-3p, hsa-miR-106b-5p, hsa- miR-107, hsa-miR-10a-3p, hsa-miR-10a-5p, hsa-miR-10b-3p, hsa-miR-10b-5p, hsa-miR-1185-
1-3p, hsa-miR-1185-2-3p, hsa-miR-1185-5p, hsa-miR-122-3p, hsa-miR-122a-5p, hsa-miR- 1249-3p, hsa-miR-1249-5p, hsa-miR-124a-3p, hsa-miR-125a-3p, hsa-miR-125a-5p, hsa-miR- 125b-1-3p, hsa-miR-125b-2-3p, hsa-miR-125b-5p, hsa-miR-126-3p, hsa-miR-126-5p, hsa-miR- 127-3p, hsa-miR-1271-3p, hsa-miR-1271-5p, hsa-miR-1278, hsa-miR-128-1-5p, hsa-miR-128- 2-5p, hsa-miR-128-3p, hsa-miR-1285-3p, hsa-miR-1285-5p, hsa-miR-1287-3p, hsa-miR-1287- 5p, hsa-miR-129-1-3p, hsa-miR-129-2-3p, hsa-miR-129-5p, hsa-miR-1296-3p, hsa-miR-1296- 5p, hsa-miR-1304-3p, hsa-miR-1304-5p, hsa-miR-1306-3p, hsa-miR-1306-5p, hsa-miR-1307- 3p, hsa-miR-1307-5p, hsa-miR-130a-3p, hsa-miR-130b-3p, hsa-miR-130b-5p, hsa-miR-132-3p, hsa-miR-132-5p, hsa-miR-133a-3p, hsa-miR-133a-5p, hsa-miR-133b, hsa-miR-134-3p, hsa- miR-134-5p, hsa-miR-135a-3p, hsa-miR-135a-5p, hsa-miR-135b-3p, hsa-miR-135b-5p, hsa- miR-136-3p, hsa-miR-136-5p, hsa-miR-138-1-3p, hsa-miR-138-5p, hsa-miR-139-3p, hsa-miR- 139-5p, hsa-miR-140-3p, hsa-miR-140-5p, hsa-miR-141-3p, hsa-miR-141-5p, hsa-miR-142-3p, hsa-miR-142-5p, hsa-miR-143-3p, hsa-miR-143-5p, hsa-miR-144-3p, hsa-miR-144-5p, hsa- miR-145-5p, hsa-miR-146a-3p, hsa-miR-146a-5p, hsa-miR-147a, hsa-miR-148a-3p, hsa-miR- 148a-5p, hsa-miR-148b-3p, hsa-miR-148b-5p, hsa-miR-149-3p, hsa-miR-144-3p, hsa-miR-150- 3p, hsa-miR-150-5p, hsa-miR-151a-3p, hsa-miR-151a-5p, hsa-miR-152-3p, hsa-miR-152-5p, hsa-miR-154-3p, hsa-miR-154-5p, hsa-miR-155-3p, hsa-miR-155-5p, hsa-miR-15a-3p, hsa- miR-15a-5p, hsa-miR-15b-3p, hsa-miR-15b-5p, hsa-miR-16-1-3p, hsa-miR-16-2-3p, hsa-miR- 16-5p, hsa-miR-17-3p, hsa-miR-17-5p, hsa-miR-181a-3p, hsa-miR-181a-5p, hsa-miR-181b-2- 3p, hsa-miR-181b-5p, hsa-miR-181c-5p, hsa-miR-181d-3p, hsa-miR-181d-5p, hsa-miR-182-3p, hsa-miR-182-5p, hsa-miR-183-3p, hsa-miR-183-5p, hsa-miR-185-3p, hsa-miR-185-5p, hsa- miR-186-3p, hsa-miR-186-5p, hsa-miR-188-3p, hsa-miR-188-5p, hsa-miR-18a-3p, hsa-miR- 18a-5p, hsa-miR-18b-5p, hsa-miR-1908-3p, hsa-miR-1908-5p, hsa-miR-190a-3p, hsa-miR- 190a-5p, hsa-miR-191-3p, hsa-miR-191-5p, hsa-miR-1910-3p, hsa-miR-1910-5p, hsa-miR-192- 3p, hsa-miR-192-5p, hsa-miR-193a-3p, hsa-miR-193a-5p, hsa-miR-193b-3p, hsa-miR-193b-5p, hsa-miR-194-3p, hsa-miR-194-5p, hsa-miR-195-3p, hsa-miR-195-5p, hsa-miR-196a-3p, hsa- miR-196a-5p, hsa-miR-196b-3p, hsa-miR-196b-5p, hsa-miR-197-3p, hsa-miR-197-5p, hsa-miR- 199a-3p, hsa-miR-199a-5p, hsa-miR-199b-3p, hsa-miR-199b-5p, hsa-miR-19a-3p, hsa-miR- 19a-5p, hsa-miR-19b-1-5p, hsa-miR-19b-2-5p, hsa-miR-19b-3p, hsa-miR-200a-3p, hsa-miR- 200a-5p, hsa-miR-200b-3p, hsa-miR-200b-5p, hsa-miR-200c-3p, hsa-miR-200c-5p, hsa-miR- 202-3p, hsa-miR-202-5p, hsa-miR-203a-3p, hsa-miR-203a-5p, hsa-miR-204-5p, hsa-miR-208b- 3p, hsa-miR-208b-5p, hsa-miR-20a-3p, hsa-miR-20a-5p, hsa-miR-20b-3p, hsa-miR-20b-5p, hsa-miR-21-5p, hsa-miR-210-3p, hsa-miR-210-5p, hsa-miR-211-3p, hsa-miR-211-5p, hsa-miR- 2116-3p, hsa-miR-2116-5p, hsa-miR-212-3p, hsa-miR-214-3p, hsa-miR-215-5p, hsa-miR-217, JG_miR-218-1-3p, hsa-miR-218-5p, hsa-miR-219a-1-3p, hsa-miR-219a-2-3p, hsa-miR-219a-5p,
hsa-miR-219b-3p, hsa-miR-219b-5p, hsa-miR-22-3p, hsa-miR-22-5p, hsa-miR-221-3p, hsa- miR-221-5p, hsa-miR-222-3p, hsa-miR-222-5p, hsa-miR-223-3p, hsa-miR-223-5p, hsa-miR- 23a-3p, hsa-miR-23a-5p, hsa-miR-23b-3p, hsa-miR-24-1-5p, hsa-miR-25-3p, hsa-miR-25-5p, hsa-miR-26a-1-3p, hsa-miR-26a-2-3p, hsa-miR-26a-5p, hsa-miR-26b-5p, hsa-miR-27a-3p, hsa- miR-27a-5p, hsa-miR-27b-3p, hsa-miR-27b-5p, hsa-miR-28-3p, hsa-miR-28-5p, hsa-miR-296- 3p, hsa-miR-296-5p, hsa-miR-299-3p, hsa-miR-299-5p, hsa-miR-29a-3p, hsa-miR-29a-5p, hsa- miR-29b-1-5p, hsa-miR-29b-3p, hsa-miR-29c-3p, hsa-miR-301a-3p, hsa-miR-301a-5p, hsa- miR-301b-3p, hsa-miR-301b-5p, hsa-miR-302a-3p, hsa-miR-302a-5p, hsa-miR-302b-5p, hsa- miR-302c-3p, hsa-miR-302c-5p, hsa-miR-3065-3p, hsa-miR-3065-5p, hsa-miR-3074-3p, hsa- miR-3074-5p, hsa-miR-30a-3p, hsa-miR-30a-5p, hsa-miR-30b-3p, hsa-miR-30b-5p, hsa-miR- 30c-1-3p, hsa-miR-30c-2-3p, hsa-miR-30c-5p, hsa-miR-30d-3p, hsa-miR-30d-5p, hsa-miR-30e- 3p, hsa-miR-30e-5p, hsa-miR-31-3p, hsa-miR-31-5p, hsa-miR-3130-3p, hsa-miR-3130-5p, hsa- miR-3140-3p, hsa-miR-3140-5p, hsa-miR-3144-3p, hsa-miR-3144-5p, hsa-miR-3158-3p, hsa- miR-3158-5p, hsa-miR-32-3p, hsa-miR-32-5p, hsa-miR-320a, hsa-miR-323a-3p, hsa-miR-323a- 5p, hsa-miR-324-3p, hsa-miR-324-5p, hsa-miR-326, hsa-miR-328-3p, hsa-miR-328-5p, hsa- miR-329-3p, hsa-miR-329-5p, hsa-miR-330-3p, hsa-miR-330-5p, hsa-miR-331-3p, hsa-miR- 331-5p, hsa-miR-335-3p, hsa-miR-335-5p, hsa-miR-337-3p, hsa-miR-337-5p, hsa-miR-338-3p, hsa-miR-338-5p, hsa-miR-339-3p, hsa-miR-339-5p, hsa-miR-33a-3p, hsa-miR-33a-5p, hsa- miR-33b-3p, hsa-miR-33b-5p, hsa-miR-340-3p, hsa-miR-340-5p, hsa-miR-342-3p, hsa-miR- 342-5p, hsa-miR-345-3p, hsa-miR-345-5p, hsa-miR-34a-3p, hsa-miR-34a-5p, hsa-miR-34b-3p, hsa-miR-34b-5p, hsa-miR-34c-3p, hsa-miR-34c-5p, hsa-miR-3605-3p, hsa-miR-3605-5p, hsa- miR-361-3p, hsa-miR-361-5p, hsa-miR-3613-3p, hsa-miR-3613-5p, hsa-miR-3614-3p, hsa- miR-3614-5p, hsa-miR-362-3p, hsa-miR-362-5p, hsa-miR-363-3p, hsa-miR-363-5p, hsa-miR- 365a-3p, hsa-miR-365a-5p, hsa-miR-365b-3p, hsa-miR-365b-5p, hsa-miR-369-3p, hsa-miR- 369-5p, hsa-miR-370-3p, hsa-miR-370-5p, hsa-miR-374a-3p, hsa-miR-374a-5p, hsa-miR-374b- 3p, hsa-miR-374b-5p, hsa-miR-375, hsa-miR-376a-2-5p, hsa-miR-376a-3p, hsa-miR-376a-5p, hsa-miR-376c-3p, hsa-miR-376c-5p, hsa-miR-377-3p, hsa-miR-377-5p, hsa-miR-378a-3p, hsa- miR-378a-5p, hsa-miR-379-3p, hsa-miR-379-5p, hsa-miR-381-3p, hsa-miR-381-5p, hsa-miR- 382-3p, hsa-miR-382-5p, hsa-miR-409-3p, hsa-miR-409-5p, hsa-miR-411-3p, hsa-miR-411-5p, hsa-miR-412-3p, hsa-miR-421, hsa-miR-423-3p, hsa-miR-423-5p, hsa-miR-424-3p, hsa-miR- 424-5p, hsa-miR-425-3p, hsa-miR-425-5p, hsa-miR-431-3p, hsa-miR-431-5p, hsa-miR-432-5p, hsa-miR-433-3p, hsa-miR-433-5p, hsa-miR-449a, hsa-miR-449b-5p, hsa-miR-450a-1-3p, hsa- miR-450a-2-3p, hsa-miR-450a-5p, hsa-miR-450b-3p, hsa-miR-450b-5p, hsa-miR-451a, hsa- miR-452-3p, hsa-miR-4524a-3p, hsa-miR-4524a-5p, hsa-miR-4536-3p, hsa-miR-4536-5p, hsa- miR-454-3p, hsa-miR-454-5p, hsa-miR-4707-3p, hsa-miR-4707-5p, hsa-miR-4755-3p, hsa-
miR-4755-5p, hsa-miR-4787-3p, hsa-miR-4787-5p, hsa-miR-483-3p, hsa-miR-483-5p, hsa- miR-484, hsa-miR-485-3p, hsa-miR-485-5p, hsa-miR-487b-3p, hsa-miR-487b-5p, hsa-miR- 488-3p, hsa-miR-488-5p, hsa-miR-489-3p, hsa-miR-490-3p, hsa-miR-490-5p, hsa-miR-491-3p, hsa-miR-491-5p, hsa-miR-493-3p, hsa-miR-493-5p, hsa-miR-494-3p, hsa-miR-494-5p, hsa- miR-495-3p, hsa-miR-495-5p, hsa-miR-497-3p, hsa-miR-497-5p, hsa-miR-498, hsa-miR-5001- 3p, hsa-miR-5001-5p, hsa-miR-500a-3p, hsa-miR-500a-5p, hsa-miR-5010-3p, hsa-miR-5010- 5p, hsa-miR-503-3p, hsa-miR-503-5p, hsa-miR-504-3p, hsa-miR-504-5p, hsa-miR-505-3p, hsa- miR-505-5p, hsa-miR-506-3p, hsa-miR-506-5p, hsa-miR-508-3p, hsa-miR-508-5p, hsa-miR- 509-3-5p, hsa-miR-509-3p, hsa-miR-509-5p, hsa-miR-510-3p, hsa-miR-510-5p, hsa-miR-512- 5p, hsa-miR-513c-3p, hsa-miR-513c-5p, hsa-miR-514a-3p, hsa-miR-514a-5p, hsa-miR-514b-3p, hsa-miR-514b-5p, hsa-miR-516b-5p, hsa-miR-518c-3p, hsa-miR-518f-3p, hsa-miR-5196-3p, hsa-miR-5196-5p, hsa-miR-519a-3p, hsa-miR-519a-5p, hsa-miR-519c-3p, hsa-miR-519e-3p, hsa-miR-520c-3p, hsa-miR-520f-3p, hsa-miR-520g-3p, hsa-miR-520h, hsa-miR-522-3p, hsa- miR-525-5p, hsa-miR-526b-5p, hsa-miR-532-3p, hsa-miR-532-5p, hsa-miR-539-3p, hsa-miR- 539-5p, hsa-miR-542-3p, hsa-miR-542-5p, hsa-miR-543, hsa-miR-545-3p, hsa-miR-545-5p, hsa-miR-548a-3p, hsa-miR-548a-5p, hsa-miR-548ar-3p, hsa-miR-548ar-5p, hsa-miR-548b-3p, hsa-miR-548d-3p, hsa-miR-548d-5p, hsa-miR-548e-3p, hsa-miR-548e-5p, hsa-miR-548h-3p, hsa-miR-548h-5p, hsa-miR-548j-3p, hsa-miR-548j-5p, hsa-miR-548o-3p, hsa-miR-548o-5p, hsa-miR-548v, hsa-miR-551b-3p, hsa-miR-551b-5p, hsa-miR-552-3p, hsa-miR-556-3p, hsa- miR-556-5p, hsa-miR-561-3p, hsa-miR-561-5p, hsa-miR-562, hsa-miR-567, hsa-miR-569, hsa- miR-570-3p, hsa-miR-570-5p, hsa-miR-571, hsa-miR-574-3p, hsa-miR-574-5p, hsa-miR-576- 3p, hsa-miR-576-5p, hsa-miR-577, hsa-miR-579-3p, hsa-miR-579-5p, hsa-miR-582-3p, hsa- miR-582-5p, hsa-miR-584-3p, hsa-miR-584-5p, hsa-miR-589-3p, hsa-miR-589-5p, hsa-miR- 590-3p, hsa-miR-590-5p, hsa-miR-595, hsa-miR-606, hsa-miR-607, hsa-miR-610, hsa-miR- 615-3p, hsa-miR-615-5p, hsa-miR-616-3p, hsa-miR-616-5p, hsa-miR-617, hsa-miR-619-5p, hsa-miR-624-3p, hsa-miR-624-5p, hsa-miR-625-3p, hsa-miR-625-5p, hsa-miR-627-3p, hsa- miR-627-5p, hsa-miR-628-3p, hsa-miR-628-5p, hsa-miR-629-3p, hsa-miR-629-5p, hsa-miR- 630, hsa-miR-633, hsa-miR-634, hsa-miR-635, hsa-miR-636, hsa-miR-640, hsa-miR-642a-3p, hsa-miR-642a-5p, hsa-miR-643, hsa-miR-645, hsa-miR-648, hsa-miR-6503-3p, hsa-miR-6503- 5p, hsa-miR-651-3p, hsa-miR-651-5p, hsa-miR-6511a-3p, hsa-miR-6511a-5p, hsa-miR-652-3p, hsa-miR-652-5p, hsa-miR-653-5p, hsa-miR-654-3p, hsa-miR-654-5p, hsa-miR-657, hsa-miR- 659-3p, hsa-miR-660-3p, hsa-miR-660-5p, hsa-miR-664b-3p, hsa-miR-664b-5p, hsa-miR-671- 3p, hsa-miR-671-5p, hsa-miR-675-3p, hsa-miR-675-5p, hsa-miR-7-1-3p, hsa-miR-7-5p, hsa- miR-708-3p, hsa-miR-708-5p, hsa-miR-744-3p, hsa-miR-744-5p, hsa-miR-758-3p, hsa-miR- 758-5p, hsa-miR-765, hsa-miR-766-3p, hsa-miR-766-5p, hsa-miR-767-3p, hsa-miR-767-5p,
hsa-miR-769-3p, hsa-miR-769-5p, hsa-miR-802, hsa-miR-873-3p, hsa-miR-873-5p, hsa-miR- 874-3p, hsa-miR-874-5p, hsa-miR-876-3p, hsa-miR-876-5p, hsa-miR-885-3p, hsa-miR-885-5p, hsa-miR-887-3p, hsa-miR-887-5p, hsa-miR-9-3p, hsa-miR-9-5p, hsa-miR-92a-1-5p, hsa-miR- 92a-2-5p, hsa-miR-92a-3p, hsa-miR-92b-3p, hsa-miR-92b-5p, hsa-miR-93-3p, hsa-miR-93-5p, hsa-miR-941, hsa-miR-942-3p, hsa-miR-942-5p, hsa-miR-96-3p, hsa-miR-96-5p, hsa-miR-98- 3p, hsa-miR-98-5p, hsa-miR-99a-3p, hsa-miR-99a-5p, hsa-miR-99b-3p, and hsa-miR-99b-5p. In some embodiments, the presence of a miRNA is a miRNA biomarker signature for an immune cell. In some embodiments, the miRNA is specific to an immune cell. A miRNA is considered specific to a particular cell type if the presence of that miRNA in a cell indicates to the skilled artisan that that cell belongs to that particular cell type. For example, miR-142 is expressed in various immune cells, and so the presence of one or more miR-142 target sequences on the circular RNA allows its selective degradation in immune cells, but maintenance in non-immune cells. Without wishing to be bound by theory, it is expected that the presence of foreign RNAs in immune cells such as macrophages stimulates innate immune receptors (e.g., STING, RIG-I, OAS), which signal to nearby cells (e.g., by secretion of type I interferons IFN-α and/or IFN-β) and cause degradation of RNA or limit translation in those cells. Selective degradation of circular RNA in immune cells therefore limits activation of such immune responses, allowing prolonged maintenance and translation of the circular RNA in other cells. Inclusion of one or more target sequences for miR-23a, miR-142, and/or miR-223, or other miRNAs specifically expressed in immune cells, thus allows prolonged maintenance and translation of the circular RNA in other cells not expressing the miRNA. Exemplary miRs identified as being abundantly and differentially expressed in macrophages include miR-33b-5p, miR-346, miR-1205, miR-548al, and miR-1228-3p, and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of an RNA (e.g., circular RNA) in macrophages. Similarly, exemplary miRs identified as being abundantly and differentially expressed in dendritic cells include miR-223- 3p, 21-5p, 23a-3p, let-7d- 3p, miR-191-5p, and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of a circular RNA in DCs. Exemplary miRs identified as being abundantly and differentially expressed in monocytes include miR-4454, miR-7975, miR-181a-5p, miR-548aa, and miR-548t-3p, and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of circular RNA in monocytes. More generally, miR-23a, miR-142, and miR-223 are expressed in multiple immune cell types (e.g., miR-142 is expressed in T cells, DCs, neutrophils, natural killer (NK) cells, monocytes, and macrophages), and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of circular RNA in
multiple immune cells. These and other relationships between immune cell type and miRNA abundance are described in PCT Publication No. WO 2020/227537, the contents of which are incorporated by reference to the extent they disclose miRNAs and their abundance in immune cells. In some embodiments, the circular RNA comprises one or more target sequences for miR- 23a. In some embodiments, the circular RNA comprises one or more target sequences for miR- 142. In some embodiments, the circular RNA comprises one or more target sequences for miR- 223. In some embodiments, the circular RNA comprises one or more target sequences for miR- 33b-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-346. In some embodiments, the circular RNA comprises one or more target sequences for miR-1205. In some embodiments, the circular RNA comprises one or more target sequences for miR-548a1. In some embodiments, the circular RNA comprises one or more target sequences for miR-1228-3p. In some embodiments, the circular RNA comprises one or more target sequences for miR-223-3p. In some embodiments, the circular RNA comprises one or more target sequences for miR-21-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-23a-3p. In some embodiments, the circular RNA comprises one or more target sequences for let-7d-3p. In some embodiments, the circular RNA comprises one or more target sequences for miR-191-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-4454. In some embodiments, the circular RNA comprises one or more target sequences for miR-7975. In some embodiments, the circular RNA comprises one or more target sequences for miR-181a-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-548aa. In some embodiments, the circular RNA comprises one or more target sequences for miR-548t-3p. In some embodiments, the miRNA that hybridizes to the target sequence on the circular RNA is expressed in a specific type of immune cell. In some embodiments, the miRNA is specific to an immune cell. A miRNA is considered specific to a particular cell type if the presence of that miRNA in a cell indicates to the skilled artisan that that cell belongs to that particular cell type. In some embodiments, the immune cell a T cell precursor. In some embodiments, the immune cell a hematopoietic stem cell. In some embodiments, the immune cell a macrophage or macrophage precursor. In some embodiments, the immune cell is a macrophage. In some embodiments, the immune cell a monocyte. In some embodiments, the immune cell a tissue-resident macrophage. In some embodiments, the immune cell an adipose tissue macrophage, monocyte, Kupffer cell, sinus histiocyte, alveolar macrophage, microglia, Hofbauer cell, intraglomerular mesangial cell, osteoclast, Langerhans cell, epithelioid cell, red pulp macrophage, peritoneal macrophage, or Peyer’s patch macrophage.
Circular RNAs may be produced by forming a covalent bond between two non-adjacent nucleotides of a linear RNA. For example, a circular RNA containing the entire sequence of a linear RNA by ligating the 5′ terminal nucleotide to the 3′ terminal nucleotide. Alternatively, a first nucleotide, which may be the 5′ terminal nucleotide or an internal nucleotide of the linear RNA, may form a covalent bond with a subsequent nucleotide of the linear RNA, which may be the 3′ terminal nucleotide or an internal nucleotide of the linear RNA. In embodiments where a first nucleotide that forms a covalent bond with a subsequence nucleotide is an internal nucleotide, the circular RNA formed does not comprise nucleotides upstream of that first nucleotide. Similarly, in embodiments where a subsequent nucleotide that forms a covalent bond with a first nucleotide is an internal nucleotide, the circular RNA formed does not comprise nucleotides downstream from that subsequent nucleotide. In some embodiments, a circular RNA is produced by ligating a 5′ terminal nucleotide and a 3′ terminal nucleotide of the linear RNA using an RNA ligase. In some embodiments, the 5′ terminal nucleotide comprises a 5′ terminal phosphate, and the 3′ terminal nucleotide comprises a 3′ terminal hydroxyl. In some embodiments, the RNA ligase is a T4 RNA ligase. In some embodiments, the RNA ligase is a T4 RNA ligase I. In some embodiments, the RNA ligase is a T4 RNA ligase II. In some embodiments, the 5′ terminal nucleotide comprises a 5′ terminal hydroxyl, the 3′ terminal nucleotide comprises a 3′ terminal phosphate, and the RNA ligase is an RtcB RNA ligase. In some embodiments, the RNA ligase is a SplintR ligase. For ligation to occur, the 5′ and 3′ terminal nucleotides of the RNA must be close enough for the RNA ligase to form a bond between both nucleotides. Methods of placing both nucleotides of a linear nucleic acid close enough for ligation to occur, and of circularizing an RNA, are generally known in the art. See, e.g., Petkovic et al., Nucleic Acids Res., 2015.43(4):2454–2465. Non- limiting examples of circularization methods include splinted ligation and ribozyme-mediated circularization. In some embodiments, the ligating is conducted by splinted ligation. In splinted ligation, a nucleic acid to be ligated (e.g., linear RNA), is contacted with a splint nucleic acid, such as a DNA oligonucleotide, which hybridizes to 5′ and 3′ terminal sequences, such that hybridization places the 5′ and 3′ terminal nucleotide in close proximity. In some embodiments, the 5′ terminal nucleotide of the linear RNA is adjacent to the 3′ terminal nucleotide of the RNA in an RNA:splint nucleic acid hybrid. After forming this structure, the RNA:splint nucleic acid is contacted with an RNA ligase that forms a covalent bond between the 5′ terminal nucleotide and the 3′ terminal nucleotide of the RNA. In some embodiments of methods of circularizing an RNA, one or more of the last nucleotides of the RNA are bound to a first hybridization sequence in the splint nucleic acid, and one or more of the first nucleotides of the RNA are bound to a
second hybridization sequence in the splint nucleic acid that is 3′ to (downstream of) the first hybridization sequence. In some embodiments, the first hybridization sequence comprises 5 or more nucleotides, and the first hybridization sequence is complementary to at least the first five (5) nucleotides of the RNA. In some embodiments, the first hybridization sequence comprises 10 or more, 15 or more, 20 or more, 25 or more, 30 or more, 35 or more, 40 or more, 45 or more, or 50 or more nucleotides, and at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or up to 100% of the nucleotides of the first hybridization sequence are complementary are complementary to the last N nucleotides of the RNA, where N is the length of the first hybridization sequence. In some embodiments, the second hybridization sequence comprises 5 or more nucleotides, and the second hybridization sequence is complementary to at least the last five (5) nucleotides of the RNA. In some embodiments, the second hybridization sequence comprises 10 or more, 15 or more, 20 or more, 25 or more, 30 or more, 35 or more, 40 or more, 45 or more, or 50 or more nucleotides, and at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or up to 100% of the nucleotides of the second hybridization sequence are complementary are complementary to the last N nucleotides of the RNA, where N is the length of the second hybridization sequence. In some embodiments, at least the first five (5) nucleotides of the RNA hybridize with the first hybridization sequence. In some embodiments, at least the last five (5) nucleotides of the RNA hybridize with the second hybridization sequence. In some embodiments, at least the first five (5) nucleotides of the RNA hybridize with the first hybridization sequence, and at least the last five (5) nucleotides of the RNA hybridize with the second hybridization sequence. In some embodiments, the last nucleotide of the first hybridization sequence and the first nucleotide of the second hybridization sequence are adjacent in the splint nucleic acid, and are not separated by any other nucleotides. In some embodiments, the splint nucleic acid is a DNA. In some embodiments, the splint nucleic acid is an RNA. In some embodiments, the RNA is circularized by a ribozyme. A ribozyme is a nucleic acid that catalyzes a reaction, such as the formation of a covalent bond between two nucleotides. In some embodiments, prior to circularization, the RNA comprises a 3′ intron that is 5′ to (upstream of) the 5′ UTR of the RNA, and a 5′ intron that is 3′ to (downstream of) the poly-A region and/or one or more structural sequences of the RNA. Ribozymes and other enzymes that catalyze splicing of pre-mRNA to remove introns can catalyze the formation of a covalent bond between the nucleotide that is 5′ to the 5′ intron and the nucleotide that is 3′ to 3′ intron, resulting in the formation of a circular RNA. See, e.g., Wesselhoeft et al., Nat Commun.2018. 9:2629.
In some embodiments, the method further comprises, after the in vitro transcribing of (i) and before the circularizing of (ii), contacting the linear RNA with a polyphosphatase. Polyphosphatases are enzymes that remove excess phosphates from the 5’ terminal nucleotide of a nucleic acid, producing a nucleic acid with a 5’ monophosphate group. Treatment of linear RNAs with polyphosphates serves multiple purposes that are useful in the production of circular RNAs. First, removal of excess phosphates prevents them from interfering in the circularization reaction, as the ligation of a 3’ terminal nucleotide to a 5’ terminal nucleotide is more efficient when the 5’ terminal nucleotide comprises only a single 5’ phosphate. Furthermore, RNAs comprising terminal 5’ triphosphate groups are agonists for the innate immune receptor RIG-I. Stimulation of RIG-I triggers an innate immune response in the cell, which can result in deleterious effects such as degradation of the exogenous RNA and death of the cell. Prevention of RIG-I stimulation thus extends the stability of the exogenous RNA in a cell and preserves the health of the cell. Some embodiments of methods comprise introducing a 5′ phosphatase into a mixture comprising a linear RNA. A 5′ phosphatase removes one or more 5′ phosphates from a nucleic acid (e.g., RNA). The 5′ terminal nucleotide of a linear RNA produced by IVT may comprise multiple phosphates, such as a series of three phosphates (5′ triphosphate), with one phosphate in the series being bonded to the 5′ carbon of the 5′ terminal nucleotide.5′ triphosphates can have multiple undesired effects, such as inhibiting circularization and reducing the stability of the RNA, and thus removal of 5′ triphosphates may thus improve the efficiency of circularization. In some embodiments, a 5′ phosphate may be removed after a 3′ phosphate is introduced to the 3′ terminal nucleotide of an RNA, to produce an linear RNA with a 5′ hydroxyl and 3′ phosphate, which can be circularized using an RtcB RNA ligase. In some embodiments, the 5′ phosphatase is a calf intestinal phosphatase or Antarctic phosphatase. In some embodiments, the 5′ phosphatase is a calf intestinal phosphatase. In some embodiments, the 5′ phosphatase is an Antarctic phosphatase. Some embodiments of the methods comprise introducing a DNase into the IVT mixture or a composition comprising circular RNA, to hydrolyze DNA template that remains in the IVT mixture or was co-purified with the circular RNA. The presence of DNA in a composition can facilitate cleavage and/or degradation of circular RNA, such as by forming a DNA:RNA hybrid that is recognized by restriction enzymes or other endonucleases. Additionally, the formation of a DNA:RNA hybrid can prevent ribosome attachment, translation initiation, and/or elongation. Minimizing the presence of DNA in a circular RNA composition can thus enhance the stability and efficiency of translation of circular RNAs. In some embodiments, the concentration of DNA in a composition is 10% (%w/w) or less, 9% or less, 8% or less, 7% or less, 6% or less, 5% or
less, 4% or less, 3% or less, 2% or less, or 1% or less. In some embodiments, the concentration of DNA is 1% (%w/w) or less, 0.9% or less, 0.8% or less, 0.7% or less, 0.6% or less, 0.5% or less, 0.4% or less, 0.3% or less, 0.2% or less, or 0.1% or less. In some embodiments, the concentration of DNA is 1% (%w/w) or less. In some embodiments, the concentration of DNA is 0.75% (%w/w) or less. In some embodiments, the concentration of DNA is 0.5% (%w/w) or less. In some embodiments, the concentration of DNA is 0.25% (%w/w) or less. In some embodiments, the concentration of DNA is 0.1% (%w/w) or less. Methods of measuring the concentration of DNA in a composition are known in the art, and include spectroscopy (NanoDrop) analysis, PCR, gel electrophoresis, and Southern blotting. The concentration of DNA may be measured before or after digestion of DNA template molecules with DNAses, digestion of RNA molecules with RNAses, and/or separation of DNA molecules from RNA molecules, such as through chromatography. In some embodiments, the concentration of DNA refers to the concentration of DNA polynucleotides in the composition. In other embodiments, the concentration of DNA refers to the concentration of DNA polynucleotides and free nucleotides, including nucleotide triphosphates. In some embodiments, the DNase is introduced before the linear RNA is circularized. For example, the DNase may be introduced at least 1, at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, or at least 8 hours before the linear RNA is circularized. In some embodiments, the DNase is introduced after the linear RNA is circularized. In some embodiments, the DNase is introduced at least 1, at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, or at least 8 hours after the linear RNA is circularized. In some embodiments, the DNase is introduced at about the same as the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 2 hours before and no more than 2 hours after the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 90 minutes before and no more than 90 minutes after the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 1 hour before and no more than 1 hour after the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 30 minutes before and no more than 30 minutes after the linear RNA is circularized. The DNase may remain in the mixture after digestion of residual DNA occurs, or RNA may be purified to remove the DNase, along with DNA fragments and deoxyribonucleotides, before other steps of the method, such as circularization. In some embodiments, the DNase is incubated in the mixture for at least 30 minutes, at least 1 hour, at least 90 minutes, at least 2 hours, at least 3 hours, at least 4 hours, at least 5 hours, at least 6 hours, at least 7 hours, at least 8 hours, at least 9 hours, at least 10 hours, at least 11 hours, or at least 12 hours, up to a maximum of 24 hours. In some embodiments, the DNse is removed prior to circularization to prevent
degradation of the DNA splint. In some embodiments, DNase is added after circularization to promote degradation of the DNA splint and release of the circular RNA. Some embodiments of methods comprise contacting a circular RNA composition with one or more exonucleases. Exonucleases hydrolyze internucleoside linkages (e.g., phosphate backbone) between a terminal nucleotide and adjacent nucleotide of a nucleic acid, which releases the terminal nucleotide from the nucleic acid. Continued hydrolysis of internucleoside linkages and consequent removal of nucleotides from a nucleic acid results in degradation of linear nucleic acids, such as linear mRNAs. Exposing a composition containing circular RNAs and linear RNAs to exonucleases selectively degrades the linear RNAs, without affecting the circular RNAs, which lack terminal nucleotides. Thus, a mixed population of circular and linear RNAs can be enriched for circular RNAs through exonuclease activity. In some embodiments, at least one exonuclease is a 5′ exonuclease.5′ exonucleases remove 5′ terminal nucleotides from nucleic acids. In some embodiments, the 5′ exonuclease is an XRN-1 exonuclease. In some embodiments, at least one exonuclease is a 3′ exonuclease.3′ exonucleases remove 3′ terminal nucleotides from nucleic acids. In some embodiments, the 3′ exonuclease is RNase R. In some embodiments, a 5′ exonuclease and a 3′ exonuclease are introduced into a mixture comprising a circular RNA. The combination of a 5′ exonuclease and 3′ exonuclease increases the rate of linear RNA degradation, as nucleotides may independently be removed from both ends of a linear nucleic acid. In some embodiments, the circular RNA comprises an internal ribosome entry site (IRES). Inclusion of an IRES permits the translation of one or more open reading frames from a circular RNA. The IRES element attracts a eukaryotic ribosomal translation initiation complex and promotes translation initiation. See, e.g., Kaufman et al., Nucleic Acid Res.199119:4485- 4490; Gurtu et al., Biochem Biophys Res Commun.1996.229:295-298; Rees et al., BioTechniques.1996.20: 102-110; Kobayashi et al., BioTechniques.1996.21 :399-402; and Mosser et al., BioTechniques.1997.22:150-161. A multitude of IRES sequences are available and include sequences derived from a wide variety of viruses, such as from leader sequences of picornaviruses such as the encephalomyocarditis virus (EMCV) UTR (Jang et al., J Virol.1989. 63: 1651-1660), the polio leader sequence, the hepatitis A virus leader, the hepatitis C virus IRES, human rhinovirus type 2 IRES (Dobrikova et al., Proc Natl Acad Sci U S A.2003. 100(25): 15125- 15130), an IRES element from the foot and mouth disease virus (Ramesh et al., Nucleic Acid Res.1996.24:2697-2700), a giardiavirus IRES (Garlapati et al., J Biol Chem. 2004.279(5):3389-3397). Additionally or alternatively, a circular RNA may comprise any of a variety of nonviral IRES sequences, such as IRES sequences from yeast, as well as the human angiotensin II type 1 receptor IRES (Martin et al., Mol Cell Endocrinol. (2003) 212:51-61),
fibroblast growth factor IRESs (FGF-1 IRES and FGF-2 IRES, Martineau et al., Mol Cell Biol. 2004.24(17):7622-7635), vascular endothelial growth factor (VEGF) IRES (Baranick et al., Proc Natl Acad Sci U S A.2008.105(12):4733-4738, Stein et al., Mol Cell Biol.1998. 18(6):3112-3119, Bert et al., RNA.2006.12(6):1074-1083), and insulin-like growth factor II (IGF-II) IRES (Pedersen et al., Biochem J.2002.363(Pt l):37-44). These elements are commercially available in plasmids sold, e.g., by Clontech (Mountain View, CA), Invivogen (San Diego, CA), Addgene (Cambridge, MA) and GeneCopoeia (Rockville, MD). See also IRESite: The database of experimentally verified IRES structures (iresite.org). In some embodiments, a circular RNA comprises a coxsackievirus B3 (CVB3) IRES. See Gharbi et al., PLoS One.2022.17(10):e0274162. In some embodiments, a circular RNA comprises an EMCV IRES. In some embodiments, a circular RNA comprises a salivirus IRES. See Sweeney et al., J Virol.2012.86(3):1468–1486. In some embodiments, the salivirus IRES is present in or derived from Salivirus FHB (SaliFHB). See GenBank Accession No. KM023140.1. In some embodiments, the circular RNA comprises, in 5′-to-3′ order: a 5′ untranslated region (UTR), an IRES, an open reading frame encoding a protein, and a 3′ untranslated region. In some embodiments, the circular RNA further comprises a polyA or polyAC region. In some embodiments, the polyA or polyAC region is between the 5′ UTR and the IRES. In some embodiments, the polyA or polyAC region is between the open reading frame and the 3′ UTR. In some embodiments, the polyA or polyAC region is between the 3′ UTR and the 5′ UTR. In some embodiments, the circular RNA does not comprise a polyA or polyAC region. In some embodiments, a circular RNA comprises, in 5′-to-3′ order: a 5′ untranslated region (5′ UTR), a first polyA or polyAC region, an internal ribosome entry site (IRES), an open reading frame encoding a protein, a second polyA or polyAC region, and a 3′ untranslated region. In some embodiments, at least 70%, at least 75%, at least 80%, at least 85%, at least 95%, or up to 100% of the RNAs in the composition are circular RNAs. Methods of determining the relative fraction of RNAs that are circular RNAs are generally known in the art and include, without limitation, high-performance liquid chromatography (HPLC), column chromatography, endonuclease digestion, exonuclease digestion, and gel electrophoresis. The structure of circular RNAs allows them to be distinguished from linear RNAs of the same sequence by chromatography methods, so that the relative fraction of circular and linear RNAs can be quantified by chromatographic analysis. For example, circular RNAs produce distinct peaks on an HPLC chromatogram, and the relative areas under the curves (AUCs) of peaks that indicate linear RNAs or circular RNAs can be compared to calculate the fraction of RNAs that are
circular. Two peaks with equal AUC indicate equal abundances, while a circular RNA peak with 4 times the AUC of a linear RNA peak indicates that the composition contains 80% circular RNA and 20% linear RNA. Furthermore, single-molecule molecular biology techniques, such as long-read sequencing, limiting dilution, and/or digital droplet analysis, allow circular and linear RNAs to be distinguished based on sequence differences. For example, the design of primers that amplify the ligation junction of a circular RNA, but not a sequence present in the linear RNA, allow for the selective amplification of circular RNAs or cDNA made by reverse transcription of circular RNAs. See, e.g., Zhang et al. Nat Commun.2020.11(1):90 and Panda et al. Bio Protoc.2018.8(6):e2775. Additionally, amplification from a linear RNA template ends once a polymerase reaches the end of the RNA, while amplification of a circular RNA template may continue indefinitely, such that the size of amplicons from a given template indicate whether amplification began with a linear or circular template. See, e.g., Boss et al. Chembiochem.2020.21(6):793–796. Circular RNAs may differ from linear RNAs comprising the same nucleic acid sequence. In some embodiments, the circular RNA is more resistant to degradation by exonucleases, relative to a linear RNA. In some embodiments, the circular RNA is more resistant to phosphorylation by a kinase, relative to a linear RNA. In some embodiments, the circular RNA is more resistant to dephosphorylation by a phosphatase, relative to a linear RNA. In some embodiments, the circular RNA is supercoiled. In some embodiments, the circular RNA does not comprise a secondary structure. As a circular RNA has no 5′ terminal nucleotide, the circular RNA does not comprise a 5′ cap. In some embodiments, the circular RNA cannot be bound by a 5′ cap-binding protein. Some aspects relate to methods of improving stability of a circular RNA comprising a nucleotide sequence comprising an ORF, where the methods comprise: (i) substituting one or more nucleotides at adenosine positions in the nucleotide sequence to produce a modified nucleotide sequence in which 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 5–7%, 7–10%, 10–15%, 15–20%, 20–25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, or 90–95%; and (ii) synthesizing a circular RNA having the modified nucleotide sequence. Circular RNAs having a given modified nucleotide sequence may be synthesized by any suitable method, such IVT to produce a linear RNA followed by circularizing the linear RNA, or ligating two or more linear RNAs and circularizing the ligated RNA. Some embodiments of methods of improving circular RNA stability result in production of circular RNAs that express an encoded protein in a mammalian cell at a level that is at least 50% of the level of expression of a reference (control) circular RNA having the same nucleotide sequence, but in which all nucleotides at adenosine positions are unmodified (e.g., not N6-
methyladenosine nucleotides). Some embodiments of circular RNAs express one or more encoded proteins in a mammalian cell at a level that is at least 50% of the level of expression of a reference (control) circular RNA having the same nucleotide sequence, but in which all nucleotides at adenosine positions are unmodified (e.g., not N6-methyladenosine nucleotides). Typically, a reduction in the level of an mRNA (e.g., by degradation by exonucleases) results in a reduction in the level of a polypeptide expressed therefrom. The level of expression from a circular RNA (e.g., having N6-methyladenosine nucleotides, or a control circular RNA with no N6-methyladenosine nucleotides) may be determined using standard techniques for detecting proteins and measuring protein abundance, including western blotting, ELISA, and Bradford assays. In some embodiments, a circular RNA a level of expression in a mammalian cell that is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, at least 100%, at least 120%, at least 150%, at least 175%, at least 200%, at least 250%, at least 300%, at least 350%, at least 400%, at least 450%, or at least 500% of the level of expression of a control circular RNA having the same nucleotide sequence as the circular RNA, but in which each nucleotide at an adenosine position is an unmodified adenosine nucleotide. In some embodiments, the level of expression from the circular RNA is at least 50–80%, 80–100%, 100– 120%, 120–150%, 150–200%, 200–300%, 300–400%, or 400–500% of the level of expression from the control circular RNA. Examples of mammalian cells for use in evaluating expression of an RNA include, without limitation, humans, mice, rats, hamsters, guinea pigs, cats, dogs, chimpanzees, macaques, baboons, and gorillas. In some embodiments, the mammalian cell is a human cell. Some embodiments of methods of improving circular RNA stability result in production of circular RNAs that are stable for longer periods of time in cells than control circular RNAs having the same sequence but lacking N6-methyladenosine nucleotides (i.e., control circular RNAs in which all nucleotides at adenosine positions are unmodified adenosine nucleotides). Some embodiments of circular RNAs are stable for longer periods of time in cells than control circular RNAs having the same sequence but lacking N6-methyladenosine nucleotides (i.e., control circular RNAs in which all nucleotides at adenosine positions are unmodified adenosine nucleotides). In some embodiments, the circular RNA has a coefficient of degradation in a mammalian cell that is no more than 90% of a coefficient of degradation in the mammalian cell of a control circular RNA having the same nucleotide sequence as the circular RNA, and in which all nucleotides at adenosine positions are unmodified adenosine nucleotides. As used herein, a “coefficient of degradation” refers to a parameter of an equation describing the loss of nucleic acid over time. Circular RNAs typically have a defined sequence, which may include an open reading frame encoding a protein to be expressed in cells. Following
introduction into a cell, circular RNAs may be cleaved by endonucleases, or hydrolyzed at the phosphodiester backbone independently of a nuclease, resulting in production of a linear RNA, or multiple RNAs, neither of which contains an intact sequence encoding the full-length protein encoded by the uncleaved circular RNA. Circular RNA abundance may be measured by any method known in the art for detecting or measuring nucleic acids, such as RT-PCR or northern blotting. Loss of nucleic acid abundance may be described by a differential equation of the form ^^ ^^ = −^^, where P is nucleic acid abundance (nM), λ is the coefficient of degradation, and dP/dt is the rate of change in nucleic acid abundance. Alternatively, nucleic acid abundance over time may be described by an equation of the form P
18).
In some embodiments, 0.25 mol% to 1.0 mol% of the PEG-modified lipid is present in a core of the lipid nanoparticle. In some embodiments, 2.0 mol% to 2.75 mol% of the PEG- modified lipid is not in the core of the lipid nanoparticle. In some embodiments, the PEG- modified lipid is PEG-DMG or 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate. Some aspects relate to a method for producing a circular ribonucleic acid, the method comprising: (i) incubating an in vitro transcription (IVT) reaction mixture under conditions such that a linear RNA comprising an open reading frame (ORF) encoding a protein is transcribed, wherein the IVT reaction mixture comprises a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP), wherein 15–90%, 15–80%, 15–60%, 15–40%, 15–20%, 20–30%, 30–40%, 40–50%, 50– 75%, or 75–90% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A); and (ii) circularizing the linear RNA, wherein the circularizing comprises forming a covalent bond between a first nucleotide of the linear RNA and a subsequent nucleotide of the linear RNA to produce a circular RNA. In some embodiments, 30–75% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A). In some embodiments, the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF. In some embodiments, the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell. In some embodiments, the one or more miRNAs are specific to macrophages. In some embodiments, the one or more miRNAs are specific to Kupffer cells. In some embodiments, the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs. In some embodiments, substantially all UTPs in the IVT reaction mixture are N1- methylpseudouridine triphosphate. In some embodiments, substantially all UTPs in the IVT reaction mixture comprise 5-methyluridine, and wherein substantially all CTPs in the IVT reaction mixture comprise 5-methylcytidine. In some embodiments, the RNA polymerase is selected from the group consisting of T7 RNA polymerase, a T3 RNA polymerase, a K11 RNA polymerase, and SP6 RNA polymerase.
In some embodiments, the RNA polymerase is a T7 RNA polymerase. In some embodiments, the RNA polymerase is a T7 RNA polymerase variant having an amino acid sequence selected from any one of SEQ ID NOs: 1–4. Some aspects relate to a method for improving stability of a circular ribonucleic acid (circular RNA) comprising a nucleotide sequence, the nucleotide sequence comprising an open reading frame (ORF) encoding a protein, the method comprising: (i) substituting one or more nucleotides at adenosine positions with modified nucleotides comprising N6-methyladenosine (m6A) to produce a modified nucleotide sequence, wherein 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 5–7%, 7–10%, 10–15%, 15–20%, 20– 25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, or 90–95% of nucleotides at adenosine positions in the modified nucleotide sequence comprise m6A; and (ii) synthesizing a circular RNA comprising the modified nucleotide sequence. In some embodiments, 10–25% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF. In some embodiments, the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell. In some embodiments, the one or more miRNAs are specific to macrophages. In some embodiments, the one or more miRNAs are specific to Kupffer cells. In some embodiments, the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA. In some embodiments, the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs. In some embodiments, a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position. In some embodiments, a coefficient of degradation of the circular RNA in a mammalian cell is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to control circular RNA comprising the same nucleotide sequence as the circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position. In some embodiments, a level of expression, in a mammalian cell, of the protein encoded by the ORF of the circular RNA is at
least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position. In some embodiments, a level of expression in a mammalian cell of the protein encoded by the ORF of the circular RNA is at least 50% of a level of expression of a control linear messenger ribonucleic acid (mRNA) comprising the ORF. In some embodiments, a coefficient of degradation of the circular RNA in a mammal is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to a control linear messenger ribonucleic acid (mRNA) comprising the ORF. In some embodiments, the mammalian cell is a human cell. BRIEF DESCRIPTION OF THE DRAWINGS FIG.1 shows a flowchart describing the process of producing circular RNA, comprising the steps of 1) in vitro transcription of mRNA from a DNA template; 2) splinted ligation of linear mRNA to produce circular RNA; and 3) HPLC purification to separate circular RNA from other reaction components (e.g., linear mRNA). FIGs.2A–2B show a time course of circular RNA abundance and expression in vivo following administration to BALB/c mice of lipid nanoparticles containing circular RNAs produced by IVT in which ATPs were (i) 100% unmodified ATP; (ii) 10% m6ATP and 90% unmodified ATP (producing mRNAs with ~3% m6A nucleotides); or (iii) 30% m6ATP and 70% unmodified ATP (producing mRNAs with ~10% m6A nucleotides). FIG.2A shows kinetics of circular RNA abundance in liver, or PBS control at 24 hours post-administration. FIG.2B shows expression of the encoded protein, Antigen 1 (Ag1). FIGs.3A–3D show a second time course of circular RNA abundance and expression in vivo following administration to BALB/c mice of lipid nanoparticles containing circular RNAs produced by IVT in which ATPs were (i) 100% unmodified ATP, or (ii) 30% m6ATP and 70% unmodified ATP. FIG.3A shows abundance of circular RNA in liver tissue sections, as visualized by RNAscope. FIG.3B shows circular RNA abundance in livers as measured by qPCR. FIG.3C shows liver sections as in FIG.3A, including sections from mice administered circular RNAs containing three target sequences for miR-142. FIG.3D shows circular RNA abundance as in FIG.3B, including in livers of mice administered circular RNAs containing three target sequences for miR-142. In tissue sections, dark stain corresponds to RNA, while round areas of light staining correspond to nuclei. Irregularly shaped cells are Kupffer cells and hexagonal cells with prominent nuclei are hepatocytes. RNA staining is darker in Kupffer cells then hepatocytes but both cell types are positive for RNA.
FIG.4 shows a third time course of circular RNA abundance in vivo following administration to BALB/c mice of lipid nanoparticles containing circular RNAs lacking an IRES and produced by IVT in which ATPs were (i) 100% unmodified ATP, or (ii) 30% m6ATP and 70% unmodified ATP. FIGs.5A–5C show a fourth time course of linear and circular RNA abundance in vivo following administration to BALB/c mice of lipid nanoparticles containing (i) circular RNAs produced by IVT with 30% m6ATP and 70% unmodified ATP, (ii) circular RNAs produced by IVT with 100% unmodified ATP, or (iii) linear mRNAs produced by IVT with 100% unmodified ATP. FIG.5A shows results where circular RNAs contained a CVB3 IRES. FIG. 5B shows results where circular RNAs contained an EMCV IRES. FIG.5C shows results where circular RNAs contained a SaliFHB IRES. FIGs.6A–6B show a fifth time course of linear and circular RNA abundance in vivo following administration to BALB/c mice of lipid nanoparticles containing (i) circular RNAs produced by IVT with 30% m6ATP and 70% unmodified ATP, (ii) circular RNAs produced by IVT with 100% unmodified ATP, or (iii) linear mRNAs produced by IVT with 100% unmodified ATP. Each mRNA encoded Ag2, a different protein from Ag1 encoded by mRNAs tested in FIGs.2A–5C. FIG.6A shows results where circular RNAs contained a SaliFHB IRES. FIG.6B shows results where circular RNAs contained a CVB3 IRES. FIGs.7A–7C show results of a mouse study evaluating m6A modification on circular RNA stability and protein expression. FIGs.7A and 7B shows circular RNA and linear mRNA abundance over time in mouse livers. FIG.7C shows kinetics of protein expression from circular RNAs and linear mRNAs over time. DETAILED DESCRIPTION Provided are methods of producing circular RNAs and compositions comprising circular RNAs. Unlike linear mRNAs, circular RNAs have no 5′ or 3′ terminal nucleotides and are thus not susceptible to degradation by exonucleases. In vitro transcription (IVT) to produce linear RNA, followed by ligation of the 5′ and 3′ terminal nucleotides, produces circular RNAs with improve stability relative to the linear RNAs. These circular RNAs can be translated for extended durations in cells. The stability of circular RNAs in cells may be further improved through incorporation of N6-methyladenosine (m6A)-modified nucleotides, which reduce binding by innate immune factors (e.g., RIG-I) and consequent triggering of an antiviral response that can hinder translation and induce cleavage of the circular RNA. In addition, incorporation of one or more target sequences for an miRNA allows selective degradation of the circular RNA in a desired cell type (e.g., macrophages), which may otherwise indirectly reduce circular RNA abundance in neighboring cells (e.g., by secretion of interferons). Such targeted
degradation of circular RNA in undesired cell types increases the half-life of circular RNAs in desired cell types, thereby prolonging in vivo persistence and therapeutic efficacy. Circular RNA Some aspects relate to circular RNAs comprising N6-methyladenosine-modified nucleotides. Some aspects relate to methods of producing circular RNAs comprising N6- methyladenosine-modified nucleotides by in vitro transcription of an RNA followed by circularizing the transcribed RNA. Some aspects relate to methods of improving stability of a circular RNA comprising a nucleotide sequence comprising an ORF, where the methods comprise: (i) substituting one or more nucleotides at adenosine positions in the nucleotide sequence to produce a modified nucleotide sequence; and (ii) synthesizing a circular RNA having the modified nucleotide sequence. A circular RNA is an RNA with no 5′ terminal nucleotide or 3′ terminal nucleotide. Every nucleotide in a circular RNA is covalently bonded to both 1) a 5′ adjacent nucleotide; and 2) a 3′ adjacent nucleotide. In a circular RNA with a nucleic acid sequence comprising every nucleotide of the circular RNA in 5′-to-3′ order, the last nucleotide of the nucleic acid sequence is covalently bonded to the first nucleotide of the nucleic acid sequence. Circular RNAs may comprise one or more modified adenosine nucleotides comprising N6-methyladenosine (m6A). Incorporation of such N6-methyladenosine nucleotides increases the stability of circular RNAs in mammalian cells. Thus, some aspects relate to circular RNAs in which 5–100% of the nucleotides at adenosine positions RNA are modified nucleotides comprising N6- methyladenosine. Circular RNAs may also comprise a combination of unmodified adenosine nucleotides comprising natural adenosine and modified nucleotides at adenosine positions comprising N6-methyladenosine. For example, some aspects relate to circular RNAs in which 5–95% of the nucleotides at adenosine positions comprise N6-methyladenosine. In a circular RNA, the percentage of nucleotides at adenosine positions that comprise N6-methyladenosine may be any percentage that is at least 5% and at most 100%. For example, in some embodiments, 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 10–80%,10–60%, 10– 50%,10–40%, 10–30%,10–25%, 10–20%, 5–7%, 7–10%, 10–15%, 15–20%, 20–25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, 90–95%, or 95–100% of the nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some
embodiments, about 5% to about 40% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 5% to about 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 40% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 10% to about 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% to about 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 7% to about 9% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 7% to about 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 12% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 12% to about 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 15% to about 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 20% to about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 25% to about 30% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 30% to about 40% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 40% to about 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 50% to about 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 60% to about 70% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 70% to about 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 80% to about 90% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 90% to about 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 95% to about 100% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 10% to about 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 20% of
nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% to about 30% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 5% and less than 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 7% and less than 9% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 7% and less than 10% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 10% and less than 12% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 12% and less than 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 15% and less than 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 20% and less than 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 25% and less than 30% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 30% and less than 40% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 40% and less than 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 50% and less than 60% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 60% and less than 70% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 70% and less than 80% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 80% and less than 90% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 90% and less than 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 95% and less than 100% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 10% and less than 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 10% and less than 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, greater than 10% and less than 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, greater than 10% and less than 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 5% and up to 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 7% and up to 9% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 7% and up
embodiments, at least 10% and up to 12% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, at least 12% and up to 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 15% and up to 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 20% and up to 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 25% and up to 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 30% and up to 40% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 40% and up to 50% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 50% and up to 60% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, at least 60% and up to 70% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 70% and up to 80% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 80% and up to 90% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 90% and up to 95% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 95% and up to 100% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 10% and up to 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, at least 10% and up to 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, at least 10% and up to 30% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, or 20% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, 20%, 21%, 22%, 23%, 24%, or 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 5% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 6% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 7% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 8% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 9% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 11% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 12% of nucleotides at adenosine positions comprise N6-methyladenosine.
In some embodiments, about 13% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 14% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 16% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 17% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 18% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 19% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, about 21% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 22% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 23% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 24% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, about 25% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 5% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 6% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 7% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 8% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 9% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 10% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 11% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 12% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 13% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 14% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 15% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 16% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 17% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 18% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 19% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 20% of nucleotides at adenosine positions comprise N6- methyladenosine. In some embodiments, 21% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 22% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 23% of nucleotides at adenosine
positions comprise N6-methyladenosine. In some embodiments, 24% of nucleotides at adenosine positions comprise N6-methyladenosine. In some embodiments, 25% of nucleotides at adenosine positions comprise N6-methyladenosine. The proportion of nucleotides at adenosine positions that comprise N6-methyladenosine may be determined by any method suitable for detecting and/or measuring modified nucleotides on a nucleic acid. Methods of detecting N6-methyladenosine modification are known in the art, and reviewed, e.g., in Zhu et al., Int J Mol Med.2019.43(6):2267–2278. In some embodiments, a circular RNA further comprises one or more target sequences for a microRNA (miRNA). The inclusion of a target sequence for a miRNA allows for degradation of the circular miRNA in the presence of any one of the miRNAs that hybridize with the target sequence on the circular RNA. A target sequence of a miRNA, as used herein, refers to a nucleic acid sequence that is complementary to a miRNA. A first nucleic acid sequence is complementary to a second nucleic acid sequence if a nucleic acid comprising the first sequence binds (hybridizes) to a nucleic acid comprising the second sequence, forming a nucleic acid that is at least partially double-stranded through hydrogen bonds between base pairs on the miRNA and target sequence. A first sequence is most complementary to a second sequence when the first sequence comprises a sequence of bases that form canonical Watson- Crick base pairs (i.e., A–U, A–T, C–G) with the target sequence, in reverse order relative to the order of bases in the target sequence. A nucleic acid with this sequence of complementary bases in reverse order is said to have the reverse complement of the target sequence. For example, the reverse complement of the target sequence AAGUCCA is TGGACTT (DNA) or UGGACUU (RNA). A miRNA may still bind (hybridize) to a target sequence even if the sequence of the miRNA differs from the exact reverse complement of the target sequence by one or more nucleotides, provided the sequence of the miRNA is sufficiently similar to the reverse complement of the target sequence. The exact level of sequence identity between the sequence of a miRNA and the reverse complement of the target sequence that is sufficient for a miRNA to bind to a given target sequence will depend on the sequences of the miRNA and target sequence, for example, the nucleotide composition and/or length, as well as the binding conditions (e.g., in vivo human physiological conditions). Methods of determining whether a miRNA comprising a given sequence binds (hybridizes) to a nucleic acid comprising a target sequence are well known in the art. Following binding of a miRNA to a target sequence, the nucleic acid comprising the target sequence is degraded by an RNA-induced silencing complex. See, e.g., Pratt and MacRae. J Biol Chem.2009.284(27):17897–17901.
In some embodiments, a circular RNA comprises more than one miRNA target sequence. In some embodiments, a circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one or more miRNAs. Circular RNAs comprising multiple target sequences for one or more miRNAs may include multiple target sequences for the same miRNA. In some embodiments, a circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for the same miRNA. In some embodiments, a circular RNA comprises 1–50, 1–40, 1–30, 1–25, 1– 20, 1–15, 1–10, or 1–5 target sequences for a single miRNA. In some embodiments, a circular RNA comprises 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 target sequences for a single miRNA. In some embodiments, a circular RNA comprises 3 target sequences for a single miRNA. Circular RNAs comprising multiple target sequences for one or more miRNAs may include distinct target sequences for different miRNAs. In some embodiments, a circular RNA comprises one or more target sequences for a first miRNA, and one or more target sequences for a second miRNA that is different from the first miRNA. In some embodiments, a circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 miRNA target sequences, each target sequence being hybridized by a different miRNA. In some embodiments, a circular RNA comprises one or more target sequences for each of 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 different miRNAs. In some embodiments, the presence of a miRNA is a miRNA biomarker signature for a specific cell type in a specific stage of development. Methods of identifying a miRNA biomarker signature in a specific tissue or cell are known in the art. Information about the sequences, origins, and functions of known miRNAs maybe found in publicly available databases (e.g., mirbase.org, all versions, as described in Kozomara et al., Nucleic Acids Res 201442:D68-D73; Kozomara et al., Nucleic Acids Res 201139:D152-D157; Griffiths-Jones et al., Nucleic Acids Res 200836:D154-D158; Griffiths-Jones et al., Nucleic Acids Res 2006 34:D140-D144; and Griffiths-Jones et al., Nucleic Acids Res 200432:D109-D111, including the most recently released version miRBase 21, which contains “high confidence” miRNAs). Non-limiting examples of miRNAs that are expressed in cells, and for which target sequences may be present on a circular RNA, include: FF4, FF5, hsa-let-7a-2-3p, hsa-let-7a-3p, hsa-let-7a-5p, hsa-let-7b-3p, hsa-let-7b-5p, hsa-let-7c-5p, hsa-let-7d-3p, hsa-let-7d-5p, hsa-let- 7e-3p, hsa-let-7e-5p, hsa-let-7f-1-3p, hsa-let-7f-2-3p, hsa-let-7f-5p, hsa-let-7g-3p, hsa-let-7g-5p, hsa-let-7i-5p, hsa-miR-1, hsa-miR-1-3p, hsa-miR-1-5p, hsa-miR-100-3p, hsa-miR-100-5p, hsa- miR-101-3p, hsa-miR-101-5p, hsa-miR-103a-2-5p, hsa-miR-103a-3p, hsa-miR-105-3p, hsa- miR-105-5p, hsa-miR-106a-3p, hsa-miR-106a-5p, hsa-miR-106b-3p, hsa-miR-106b-5p, hsa- miR-107, hsa-miR-10a-3p, hsa-miR-10a-5p, hsa-miR-10b-3p, hsa-miR-10b-5p, hsa-miR-1185-
1-3p, hsa-miR-1185-2-3p, hsa-miR-1185-5p, hsa-miR-122-3p, hsa-miR-122a-5p, hsa-miR- 1249-3p, hsa-miR-1249-5p, hsa-miR-124a-3p, hsa-miR-125a-3p, hsa-miR-125a-5p, hsa-miR- 125b-1-3p, hsa-miR-125b-2-3p, hsa-miR-125b-5p, hsa-miR-126-3p, hsa-miR-126-5p, hsa-miR- 127-3p, hsa-miR-1271-3p, hsa-miR-1271-5p, hsa-miR-1278, hsa-miR-128-1-5p, hsa-miR-128- 2-5p, hsa-miR-128-3p, hsa-miR-1285-3p, hsa-miR-1285-5p, hsa-miR-1287-3p, hsa-miR-1287- 5p, hsa-miR-129-1-3p, hsa-miR-129-2-3p, hsa-miR-129-5p, hsa-miR-1296-3p, hsa-miR-1296- 5p, hsa-miR-1304-3p, hsa-miR-1304-5p, hsa-miR-1306-3p, hsa-miR-1306-5p, hsa-miR-1307- 3p, hsa-miR-1307-5p, hsa-miR-130a-3p, hsa-miR-130b-3p, hsa-miR-130b-5p, hsa-miR-132-3p, hsa-miR-132-5p, hsa-miR-133a-3p, hsa-miR-133a-5p, hsa-miR-133b, hsa-miR-134-3p, hsa- miR-134-5p, hsa-miR-135a-3p, hsa-miR-135a-5p, hsa-miR-135b-3p, hsa-miR-135b-5p, hsa- miR-136-3p, hsa-miR-136-5p, hsa-miR-138-1-3p, hsa-miR-138-5p, hsa-miR-139-3p, hsa-miR- 139-5p, hsa-miR-140-3p, hsa-miR-140-5p, hsa-miR-141-3p, hsa-miR-141-5p, hsa-miR-142-3p, hsa-miR-142-5p, hsa-miR-143-3p, hsa-miR-143-5p, hsa-miR-144-3p, hsa-miR-144-5p, hsa- miR-145-5p, hsa-miR-146a-3p, hsa-miR-146a-5p, hsa-miR-147a, hsa-miR-148a-3p, hsa-miR- 148a-5p, hsa-miR-148b-3p, hsa-miR-148b-5p, hsa-miR-149-3p, hsa-miR-144-3p, hsa-miR-150- 3p, hsa-miR-150-5p, hsa-miR-151a-3p, hsa-miR-151a-5p, hsa-miR-152-3p, hsa-miR-152-5p, hsa-miR-154-3p, hsa-miR-154-5p, hsa-miR-155-3p, hsa-miR-155-5p, hsa-miR-15a-3p, hsa- miR-15a-5p, hsa-miR-15b-3p, hsa-miR-15b-5p, hsa-miR-16-1-3p, hsa-miR-16-2-3p, hsa-miR- 16-5p, hsa-miR-17-3p, hsa-miR-17-5p, hsa-miR-181a-3p, hsa-miR-181a-5p, hsa-miR-181b-2- 3p, hsa-miR-181b-5p, hsa-miR-181c-5p, hsa-miR-181d-3p, hsa-miR-181d-5p, hsa-miR-182-3p, hsa-miR-182-5p, hsa-miR-183-3p, hsa-miR-183-5p, hsa-miR-185-3p, hsa-miR-185-5p, hsa- miR-186-3p, hsa-miR-186-5p, hsa-miR-188-3p, hsa-miR-188-5p, hsa-miR-18a-3p, hsa-miR- 18a-5p, hsa-miR-18b-5p, hsa-miR-1908-3p, hsa-miR-1908-5p, hsa-miR-190a-3p, hsa-miR- 190a-5p, hsa-miR-191-3p, hsa-miR-191-5p, hsa-miR-1910-3p, hsa-miR-1910-5p, hsa-miR-192- 3p, hsa-miR-192-5p, hsa-miR-193a-3p, hsa-miR-193a-5p, hsa-miR-193b-3p, hsa-miR-193b-5p, hsa-miR-194-3p, hsa-miR-194-5p, hsa-miR-195-3p, hsa-miR-195-5p, hsa-miR-196a-3p, hsa- miR-196a-5p, hsa-miR-196b-3p, hsa-miR-196b-5p, hsa-miR-197-3p, hsa-miR-197-5p, hsa-miR- 199a-3p, hsa-miR-199a-5p, hsa-miR-199b-3p, hsa-miR-199b-5p, hsa-miR-19a-3p, hsa-miR- 19a-5p, hsa-miR-19b-1-5p, hsa-miR-19b-2-5p, hsa-miR-19b-3p, hsa-miR-200a-3p, hsa-miR- 200a-5p, hsa-miR-200b-3p, hsa-miR-200b-5p, hsa-miR-200c-3p, hsa-miR-200c-5p, hsa-miR- 202-3p, hsa-miR-202-5p, hsa-miR-203a-3p, hsa-miR-203a-5p, hsa-miR-204-5p, hsa-miR-208b- 3p, hsa-miR-208b-5p, hsa-miR-20a-3p, hsa-miR-20a-5p, hsa-miR-20b-3p, hsa-miR-20b-5p, hsa-miR-21-5p, hsa-miR-210-3p, hsa-miR-210-5p, hsa-miR-211-3p, hsa-miR-211-5p, hsa-miR- 2116-3p, hsa-miR-2116-5p, hsa-miR-212-3p, hsa-miR-214-3p, hsa-miR-215-5p, hsa-miR-217, JG_miR-218-1-3p, hsa-miR-218-5p, hsa-miR-219a-1-3p, hsa-miR-219a-2-3p, hsa-miR-219a-5p,
hsa-miR-219b-3p, hsa-miR-219b-5p, hsa-miR-22-3p, hsa-miR-22-5p, hsa-miR-221-3p, hsa- miR-221-5p, hsa-miR-222-3p, hsa-miR-222-5p, hsa-miR-223-3p, hsa-miR-223-5p, hsa-miR- 23a-3p, hsa-miR-23a-5p, hsa-miR-23b-3p, hsa-miR-24-1-5p, hsa-miR-25-3p, hsa-miR-25-5p, hsa-miR-26a-1-3p, hsa-miR-26a-2-3p, hsa-miR-26a-5p, hsa-miR-26b-5p, hsa-miR-27a-3p, hsa- miR-27a-5p, hsa-miR-27b-3p, hsa-miR-27b-5p, hsa-miR-28-3p, hsa-miR-28-5p, hsa-miR-296- 3p, hsa-miR-296-5p, hsa-miR-299-3p, hsa-miR-299-5p, hsa-miR-29a-3p, hsa-miR-29a-5p, hsa- miR-29b-1-5p, hsa-miR-29b-3p, hsa-miR-29c-3p, hsa-miR-301a-3p, hsa-miR-301a-5p, hsa- miR-301b-3p, hsa-miR-301b-5p, hsa-miR-302a-3p, hsa-miR-302a-5p, hsa-miR-302b-5p, hsa- miR-302c-3p, hsa-miR-302c-5p, hsa-miR-3065-3p, hsa-miR-3065-5p, hsa-miR-3074-3p, hsa- miR-3074-5p, hsa-miR-30a-3p, hsa-miR-30a-5p, hsa-miR-30b-3p, hsa-miR-30b-5p, hsa-miR- 30c-1-3p, hsa-miR-30c-2-3p, hsa-miR-30c-5p, hsa-miR-30d-3p, hsa-miR-30d-5p, hsa-miR-30e- 3p, hsa-miR-30e-5p, hsa-miR-31-3p, hsa-miR-31-5p, hsa-miR-3130-3p, hsa-miR-3130-5p, hsa- miR-3140-3p, hsa-miR-3140-5p, hsa-miR-3144-3p, hsa-miR-3144-5p, hsa-miR-3158-3p, hsa- miR-3158-5p, hsa-miR-32-3p, hsa-miR-32-5p, hsa-miR-320a, hsa-miR-323a-3p, hsa-miR-323a- 5p, hsa-miR-324-3p, hsa-miR-324-5p, hsa-miR-326, hsa-miR-328-3p, hsa-miR-328-5p, hsa- miR-329-3p, hsa-miR-329-5p, hsa-miR-330-3p, hsa-miR-330-5p, hsa-miR-331-3p, hsa-miR- 331-5p, hsa-miR-335-3p, hsa-miR-335-5p, hsa-miR-337-3p, hsa-miR-337-5p, hsa-miR-338-3p, hsa-miR-338-5p, hsa-miR-339-3p, hsa-miR-339-5p, hsa-miR-33a-3p, hsa-miR-33a-5p, hsa- miR-33b-3p, hsa-miR-33b-5p, hsa-miR-340-3p, hsa-miR-340-5p, hsa-miR-342-3p, hsa-miR- 342-5p, hsa-miR-345-3p, hsa-miR-345-5p, hsa-miR-34a-3p, hsa-miR-34a-5p, hsa-miR-34b-3p, hsa-miR-34b-5p, hsa-miR-34c-3p, hsa-miR-34c-5p, hsa-miR-3605-3p, hsa-miR-3605-5p, hsa- miR-361-3p, hsa-miR-361-5p, hsa-miR-3613-3p, hsa-miR-3613-5p, hsa-miR-3614-3p, hsa- miR-3614-5p, hsa-miR-362-3p, hsa-miR-362-5p, hsa-miR-363-3p, hsa-miR-363-5p, hsa-miR- 365a-3p, hsa-miR-365a-5p, hsa-miR-365b-3p, hsa-miR-365b-5p, hsa-miR-369-3p, hsa-miR- 369-5p, hsa-miR-370-3p, hsa-miR-370-5p, hsa-miR-374a-3p, hsa-miR-374a-5p, hsa-miR-374b- 3p, hsa-miR-374b-5p, hsa-miR-375, hsa-miR-376a-2-5p, hsa-miR-376a-3p, hsa-miR-376a-5p, hsa-miR-376c-3p, hsa-miR-376c-5p, hsa-miR-377-3p, hsa-miR-377-5p, hsa-miR-378a-3p, hsa- miR-378a-5p, hsa-miR-379-3p, hsa-miR-379-5p, hsa-miR-381-3p, hsa-miR-381-5p, hsa-miR- 382-3p, hsa-miR-382-5p, hsa-miR-409-3p, hsa-miR-409-5p, hsa-miR-411-3p, hsa-miR-411-5p, hsa-miR-412-3p, hsa-miR-421, hsa-miR-423-3p, hsa-miR-423-5p, hsa-miR-424-3p, hsa-miR- 424-5p, hsa-miR-425-3p, hsa-miR-425-5p, hsa-miR-431-3p, hsa-miR-431-5p, hsa-miR-432-5p, hsa-miR-433-3p, hsa-miR-433-5p, hsa-miR-449a, hsa-miR-449b-5p, hsa-miR-450a-1-3p, hsa- miR-450a-2-3p, hsa-miR-450a-5p, hsa-miR-450b-3p, hsa-miR-450b-5p, hsa-miR-451a, hsa- miR-452-3p, hsa-miR-4524a-3p, hsa-miR-4524a-5p, hsa-miR-4536-3p, hsa-miR-4536-5p, hsa- miR-454-3p, hsa-miR-454-5p, hsa-miR-4707-3p, hsa-miR-4707-5p, hsa-miR-4755-3p, hsa-
miR-4755-5p, hsa-miR-4787-3p, hsa-miR-4787-5p, hsa-miR-483-3p, hsa-miR-483-5p, hsa- miR-484, hsa-miR-485-3p, hsa-miR-485-5p, hsa-miR-487b-3p, hsa-miR-487b-5p, hsa-miR- 488-3p, hsa-miR-488-5p, hsa-miR-489-3p, hsa-miR-490-3p, hsa-miR-490-5p, hsa-miR-491-3p, hsa-miR-491-5p, hsa-miR-493-3p, hsa-miR-493-5p, hsa-miR-494-3p, hsa-miR-494-5p, hsa- miR-495-3p, hsa-miR-495-5p, hsa-miR-497-3p, hsa-miR-497-5p, hsa-miR-498, hsa-miR-5001- 3p, hsa-miR-5001-5p, hsa-miR-500a-3p, hsa-miR-500a-5p, hsa-miR-5010-3p, hsa-miR-5010- 5p, hsa-miR-503-3p, hsa-miR-503-5p, hsa-miR-504-3p, hsa-miR-504-5p, hsa-miR-505-3p, hsa- miR-505-5p, hsa-miR-506-3p, hsa-miR-506-5p, hsa-miR-508-3p, hsa-miR-508-5p, hsa-miR- 509-3-5p, hsa-miR-509-3p, hsa-miR-509-5p, hsa-miR-510-3p, hsa-miR-510-5p, hsa-miR-512- 5p, hsa-miR-513c-3p, hsa-miR-513c-5p, hsa-miR-514a-3p, hsa-miR-514a-5p, hsa-miR-514b-3p, hsa-miR-514b-5p, hsa-miR-516b-5p, hsa-miR-518c-3p, hsa-miR-518f-3p, hsa-miR-5196-3p, hsa-miR-5196-5p, hsa-miR-519a-3p, hsa-miR-519a-5p, hsa-miR-519c-3p, hsa-miR-519e-3p, hsa-miR-520c-3p, hsa-miR-520f-3p, hsa-miR-520g-3p, hsa-miR-520h, hsa-miR-522-3p, hsa- miR-525-5p, hsa-miR-526b-5p, hsa-miR-532-3p, hsa-miR-532-5p, hsa-miR-539-3p, hsa-miR- 539-5p, hsa-miR-542-3p, hsa-miR-542-5p, hsa-miR-543, hsa-miR-545-3p, hsa-miR-545-5p, hsa-miR-548a-3p, hsa-miR-548a-5p, hsa-miR-548ar-3p, hsa-miR-548ar-5p, hsa-miR-548b-3p, hsa-miR-548d-3p, hsa-miR-548d-5p, hsa-miR-548e-3p, hsa-miR-548e-5p, hsa-miR-548h-3p, hsa-miR-548h-5p, hsa-miR-548j-3p, hsa-miR-548j-5p, hsa-miR-548o-3p, hsa-miR-548o-5p, hsa-miR-548v, hsa-miR-551b-3p, hsa-miR-551b-5p, hsa-miR-552-3p, hsa-miR-556-3p, hsa- miR-556-5p, hsa-miR-561-3p, hsa-miR-561-5p, hsa-miR-562, hsa-miR-567, hsa-miR-569, hsa- miR-570-3p, hsa-miR-570-5p, hsa-miR-571, hsa-miR-574-3p, hsa-miR-574-5p, hsa-miR-576- 3p, hsa-miR-576-5p, hsa-miR-577, hsa-miR-579-3p, hsa-miR-579-5p, hsa-miR-582-3p, hsa- miR-582-5p, hsa-miR-584-3p, hsa-miR-584-5p, hsa-miR-589-3p, hsa-miR-589-5p, hsa-miR- 590-3p, hsa-miR-590-5p, hsa-miR-595, hsa-miR-606, hsa-miR-607, hsa-miR-610, hsa-miR- 615-3p, hsa-miR-615-5p, hsa-miR-616-3p, hsa-miR-616-5p, hsa-miR-617, hsa-miR-619-5p, hsa-miR-624-3p, hsa-miR-624-5p, hsa-miR-625-3p, hsa-miR-625-5p, hsa-miR-627-3p, hsa- miR-627-5p, hsa-miR-628-3p, hsa-miR-628-5p, hsa-miR-629-3p, hsa-miR-629-5p, hsa-miR- 630, hsa-miR-633, hsa-miR-634, hsa-miR-635, hsa-miR-636, hsa-miR-640, hsa-miR-642a-3p, hsa-miR-642a-5p, hsa-miR-643, hsa-miR-645, hsa-miR-648, hsa-miR-6503-3p, hsa-miR-6503- 5p, hsa-miR-651-3p, hsa-miR-651-5p, hsa-miR-6511a-3p, hsa-miR-6511a-5p, hsa-miR-652-3p, hsa-miR-652-5p, hsa-miR-653-5p, hsa-miR-654-3p, hsa-miR-654-5p, hsa-miR-657, hsa-miR- 659-3p, hsa-miR-660-3p, hsa-miR-660-5p, hsa-miR-664b-3p, hsa-miR-664b-5p, hsa-miR-671- 3p, hsa-miR-671-5p, hsa-miR-675-3p, hsa-miR-675-5p, hsa-miR-7-1-3p, hsa-miR-7-5p, hsa- miR-708-3p, hsa-miR-708-5p, hsa-miR-744-3p, hsa-miR-744-5p, hsa-miR-758-3p, hsa-miR- 758-5p, hsa-miR-765, hsa-miR-766-3p, hsa-miR-766-5p, hsa-miR-767-3p, hsa-miR-767-5p,
hsa-miR-769-3p, hsa-miR-769-5p, hsa-miR-802, hsa-miR-873-3p, hsa-miR-873-5p, hsa-miR- 874-3p, hsa-miR-874-5p, hsa-miR-876-3p, hsa-miR-876-5p, hsa-miR-885-3p, hsa-miR-885-5p, hsa-miR-887-3p, hsa-miR-887-5p, hsa-miR-9-3p, hsa-miR-9-5p, hsa-miR-92a-1-5p, hsa-miR- 92a-2-5p, hsa-miR-92a-3p, hsa-miR-92b-3p, hsa-miR-92b-5p, hsa-miR-93-3p, hsa-miR-93-5p, hsa-miR-941, hsa-miR-942-3p, hsa-miR-942-5p, hsa-miR-96-3p, hsa-miR-96-5p, hsa-miR-98- 3p, hsa-miR-98-5p, hsa-miR-99a-3p, hsa-miR-99a-5p, hsa-miR-99b-3p, and hsa-miR-99b-5p. In some embodiments, the presence of a miRNA is a miRNA biomarker signature for an immune cell. In some embodiments, the miRNA is specific to an immune cell. A miRNA is considered specific to a particular cell type if the presence of that miRNA in a cell indicates to the skilled artisan that that cell belongs to that particular cell type. For example, miR-142 is expressed in various immune cells, and so the presence of one or more miR-142 target sequences on the circular RNA allows its selective degradation in immune cells, but maintenance in non-immune cells. Without wishing to be bound by theory, it is expected that the presence of foreign RNAs in immune cells such as macrophages stimulates innate immune receptors (e.g., STING, RIG-I, OAS), which signal to nearby cells (e.g., by secretion of type I interferons IFN-α and/or IFN-β) and cause degradation of RNA or limit translation in those cells. Selective degradation of circular RNA in immune cells therefore limits activation of such immune responses, allowing prolonged maintenance and translation of the circular RNA in other cells. Inclusion of one or more target sequences for miR-23a, miR-142, and/or miR-223, or other miRNAs specifically expressed in immune cells, thus allows prolonged maintenance and translation of the circular RNA in other cells not expressing the miRNA. Exemplary miRs identified as being abundantly and differentially expressed in macrophages include miR-33b-5p, miR-346, miR-1205, miR-548al, and miR-1228-3p, and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of an RNA (e.g., circular RNA) in macrophages. Similarly, exemplary miRs identified as being abundantly and differentially expressed in dendritic cells include miR-223- 3p, 21-5p, 23a-3p, let-7d- 3p, miR-191-5p, and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of a circular RNA in DCs. Exemplary miRs identified as being abundantly and differentially expressed in monocytes include miR-4454, miR-7975, miR-181a-5p, miR-548aa, and miR-548t-3p, and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of circular RNA in monocytes. More generally, miR-23a, miR-142, and miR-223 are expressed in multiple immune cell types (e.g., miR-142 is expressed in T cells, DCs, neutrophils, natural killer (NK) cells, monocytes, and macrophages), and so inclusion of one or more target sequences for one or more of these miRNAs allows selective degradation of circular RNA in
multiple immune cells. These and other relationships between immune cell type and miRNA abundance are described in PCT Publication No. WO 2020/227537, the contents of which are incorporated by reference to the extent they disclose miRNAs and their abundance in immune cells. In some embodiments, the circular RNA comprises one or more target sequences for miR- 23a. In some embodiments, the circular RNA comprises one or more target sequences for miR- 142. In some embodiments, the circular RNA comprises one or more target sequences for miR- 223. In some embodiments, the circular RNA comprises one or more target sequences for miR- 33b-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-346. In some embodiments, the circular RNA comprises one or more target sequences for miR-1205. In some embodiments, the circular RNA comprises one or more target sequences for miR-548a1. In some embodiments, the circular RNA comprises one or more target sequences for miR-1228-3p. In some embodiments, the circular RNA comprises one or more target sequences for miR-223-3p. In some embodiments, the circular RNA comprises one or more target sequences for miR-21-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-23a-3p. In some embodiments, the circular RNA comprises one or more target sequences for let-7d-3p. In some embodiments, the circular RNA comprises one or more target sequences for miR-191-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-4454. In some embodiments, the circular RNA comprises one or more target sequences for miR-7975. In some embodiments, the circular RNA comprises one or more target sequences for miR-181a-5p. In some embodiments, the circular RNA comprises one or more target sequences for miR-548aa. In some embodiments, the circular RNA comprises one or more target sequences for miR-548t-3p. In some embodiments, the miRNA that hybridizes to the target sequence on the circular RNA is expressed in a specific type of immune cell. In some embodiments, the miRNA is specific to an immune cell. A miRNA is considered specific to a particular cell type if the presence of that miRNA in a cell indicates to the skilled artisan that that cell belongs to that particular cell type. In some embodiments, the immune cell a T cell precursor. In some embodiments, the immune cell a hematopoietic stem cell. In some embodiments, the immune cell a macrophage or macrophage precursor. In some embodiments, the immune cell is a macrophage. In some embodiments, the immune cell a monocyte. In some embodiments, the immune cell a tissue-resident macrophage. In some embodiments, the immune cell an adipose tissue macrophage, monocyte, Kupffer cell, sinus histiocyte, alveolar macrophage, microglia, Hofbauer cell, intraglomerular mesangial cell, osteoclast, Langerhans cell, epithelioid cell, red pulp macrophage, peritoneal macrophage, or Peyer’s patch macrophage.
Circular RNAs may be produced by forming a covalent bond between two non-adjacent nucleotides of a linear RNA. For example, a circular RNA containing the entire sequence of a linear RNA by ligating the 5′ terminal nucleotide to the 3′ terminal nucleotide. Alternatively, a first nucleotide, which may be the 5′ terminal nucleotide or an internal nucleotide of the linear RNA, may form a covalent bond with a subsequent nucleotide of the linear RNA, which may be the 3′ terminal nucleotide or an internal nucleotide of the linear RNA. In embodiments where a first nucleotide that forms a covalent bond with a subsequence nucleotide is an internal nucleotide, the circular RNA formed does not comprise nucleotides upstream of that first nucleotide. Similarly, in embodiments where a subsequent nucleotide that forms a covalent bond with a first nucleotide is an internal nucleotide, the circular RNA formed does not comprise nucleotides downstream from that subsequent nucleotide. In some embodiments, a circular RNA is produced by ligating a 5′ terminal nucleotide and a 3′ terminal nucleotide of the linear RNA using an RNA ligase. In some embodiments, the 5′ terminal nucleotide comprises a 5′ terminal phosphate, and the 3′ terminal nucleotide comprises a 3′ terminal hydroxyl. In some embodiments, the RNA ligase is a T4 RNA ligase. In some embodiments, the RNA ligase is a T4 RNA ligase I. In some embodiments, the RNA ligase is a T4 RNA ligase II. In some embodiments, the 5′ terminal nucleotide comprises a 5′ terminal hydroxyl, the 3′ terminal nucleotide comprises a 3′ terminal phosphate, and the RNA ligase is an RtcB RNA ligase. In some embodiments, the RNA ligase is a SplintR ligase. For ligation to occur, the 5′ and 3′ terminal nucleotides of the RNA must be close enough for the RNA ligase to form a bond between both nucleotides. Methods of placing both nucleotides of a linear nucleic acid close enough for ligation to occur, and of circularizing an RNA, are generally known in the art. See, e.g., Petkovic et al., Nucleic Acids Res., 2015.43(4):2454–2465. Non- limiting examples of circularization methods include splinted ligation and ribozyme-mediated circularization. In some embodiments, the ligating is conducted by splinted ligation. In splinted ligation, a nucleic acid to be ligated (e.g., linear RNA), is contacted with a splint nucleic acid, such as a DNA oligonucleotide, which hybridizes to 5′ and 3′ terminal sequences, such that hybridization places the 5′ and 3′ terminal nucleotide in close proximity. In some embodiments, the 5′ terminal nucleotide of the linear RNA is adjacent to the 3′ terminal nucleotide of the RNA in an RNA:splint nucleic acid hybrid. After forming this structure, the RNA:splint nucleic acid is contacted with an RNA ligase that forms a covalent bond between the 5′ terminal nucleotide and the 3′ terminal nucleotide of the RNA. In some embodiments of methods of circularizing an RNA, one or more of the last nucleotides of the RNA are bound to a first hybridization sequence in the splint nucleic acid, and one or more of the first nucleotides of the RNA are bound to a
second hybridization sequence in the splint nucleic acid that is 3′ to (downstream of) the first hybridization sequence. In some embodiments, the first hybridization sequence comprises 5 or more nucleotides, and the first hybridization sequence is complementary to at least the first five (5) nucleotides of the RNA. In some embodiments, the first hybridization sequence comprises 10 or more, 15 or more, 20 or more, 25 or more, 30 or more, 35 or more, 40 or more, 45 or more, or 50 or more nucleotides, and at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or up to 100% of the nucleotides of the first hybridization sequence are complementary are complementary to the last N nucleotides of the RNA, where N is the length of the first hybridization sequence. In some embodiments, the second hybridization sequence comprises 5 or more nucleotides, and the second hybridization sequence is complementary to at least the last five (5) nucleotides of the RNA. In some embodiments, the second hybridization sequence comprises 10 or more, 15 or more, 20 or more, 25 or more, 30 or more, 35 or more, 40 or more, 45 or more, or 50 or more nucleotides, and at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or up to 100% of the nucleotides of the second hybridization sequence are complementary are complementary to the last N nucleotides of the RNA, where N is the length of the second hybridization sequence. In some embodiments, at least the first five (5) nucleotides of the RNA hybridize with the first hybridization sequence. In some embodiments, at least the last five (5) nucleotides of the RNA hybridize with the second hybridization sequence. In some embodiments, at least the first five (5) nucleotides of the RNA hybridize with the first hybridization sequence, and at least the last five (5) nucleotides of the RNA hybridize with the second hybridization sequence. In some embodiments, the last nucleotide of the first hybridization sequence and the first nucleotide of the second hybridization sequence are adjacent in the splint nucleic acid, and are not separated by any other nucleotides. In some embodiments, the splint nucleic acid is a DNA. In some embodiments, the splint nucleic acid is an RNA. In some embodiments, the RNA is circularized by a ribozyme. A ribozyme is a nucleic acid that catalyzes a reaction, such as the formation of a covalent bond between two nucleotides. In some embodiments, prior to circularization, the RNA comprises a 3′ intron that is 5′ to (upstream of) the 5′ UTR of the RNA, and a 5′ intron that is 3′ to (downstream of) the poly-A region and/or one or more structural sequences of the RNA. Ribozymes and other enzymes that catalyze splicing of pre-mRNA to remove introns can catalyze the formation of a covalent bond between the nucleotide that is 5′ to the 5′ intron and the nucleotide that is 3′ to 3′ intron, resulting in the formation of a circular RNA. See, e.g., Wesselhoeft et al., Nat Commun.2018. 9:2629.
In some embodiments, the method further comprises, after the in vitro transcribing of (i) and before the circularizing of (ii), contacting the linear RNA with a polyphosphatase. Polyphosphatases are enzymes that remove excess phosphates from the 5’ terminal nucleotide of a nucleic acid, producing a nucleic acid with a 5’ monophosphate group. Treatment of linear RNAs with polyphosphates serves multiple purposes that are useful in the production of circular RNAs. First, removal of excess phosphates prevents them from interfering in the circularization reaction, as the ligation of a 3’ terminal nucleotide to a 5’ terminal nucleotide is more efficient when the 5’ terminal nucleotide comprises only a single 5’ phosphate. Furthermore, RNAs comprising terminal 5’ triphosphate groups are agonists for the innate immune receptor RIG-I. Stimulation of RIG-I triggers an innate immune response in the cell, which can result in deleterious effects such as degradation of the exogenous RNA and death of the cell. Prevention of RIG-I stimulation thus extends the stability of the exogenous RNA in a cell and preserves the health of the cell. Some embodiments of methods comprise introducing a 5′ phosphatase into a mixture comprising a linear RNA. A 5′ phosphatase removes one or more 5′ phosphates from a nucleic acid (e.g., RNA). The 5′ terminal nucleotide of a linear RNA produced by IVT may comprise multiple phosphates, such as a series of three phosphates (5′ triphosphate), with one phosphate in the series being bonded to the 5′ carbon of the 5′ terminal nucleotide.5′ triphosphates can have multiple undesired effects, such as inhibiting circularization and reducing the stability of the RNA, and thus removal of 5′ triphosphates may thus improve the efficiency of circularization. In some embodiments, a 5′ phosphate may be removed after a 3′ phosphate is introduced to the 3′ terminal nucleotide of an RNA, to produce an linear RNA with a 5′ hydroxyl and 3′ phosphate, which can be circularized using an RtcB RNA ligase. In some embodiments, the 5′ phosphatase is a calf intestinal phosphatase or Antarctic phosphatase. In some embodiments, the 5′ phosphatase is a calf intestinal phosphatase. In some embodiments, the 5′ phosphatase is an Antarctic phosphatase. Some embodiments of the methods comprise introducing a DNase into the IVT mixture or a composition comprising circular RNA, to hydrolyze DNA template that remains in the IVT mixture or was co-purified with the circular RNA. The presence of DNA in a composition can facilitate cleavage and/or degradation of circular RNA, such as by forming a DNA:RNA hybrid that is recognized by restriction enzymes or other endonucleases. Additionally, the formation of a DNA:RNA hybrid can prevent ribosome attachment, translation initiation, and/or elongation. Minimizing the presence of DNA in a circular RNA composition can thus enhance the stability and efficiency of translation of circular RNAs. In some embodiments, the concentration of DNA in a composition is 10% (%w/w) or less, 9% or less, 8% or less, 7% or less, 6% or less, 5% or
less, 4% or less, 3% or less, 2% or less, or 1% or less. In some embodiments, the concentration of DNA is 1% (%w/w) or less, 0.9% or less, 0.8% or less, 0.7% or less, 0.6% or less, 0.5% or less, 0.4% or less, 0.3% or less, 0.2% or less, or 0.1% or less. In some embodiments, the concentration of DNA is 1% (%w/w) or less. In some embodiments, the concentration of DNA is 0.75% (%w/w) or less. In some embodiments, the concentration of DNA is 0.5% (%w/w) or less. In some embodiments, the concentration of DNA is 0.25% (%w/w) or less. In some embodiments, the concentration of DNA is 0.1% (%w/w) or less. Methods of measuring the concentration of DNA in a composition are known in the art, and include spectroscopy (NanoDrop) analysis, PCR, gel electrophoresis, and Southern blotting. The concentration of DNA may be measured before or after digestion of DNA template molecules with DNAses, digestion of RNA molecules with RNAses, and/or separation of DNA molecules from RNA molecules, such as through chromatography. In some embodiments, the concentration of DNA refers to the concentration of DNA polynucleotides in the composition. In other embodiments, the concentration of DNA refers to the concentration of DNA polynucleotides and free nucleotides, including nucleotide triphosphates. In some embodiments, the DNase is introduced before the linear RNA is circularized. For example, the DNase may be introduced at least 1, at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, or at least 8 hours before the linear RNA is circularized. In some embodiments, the DNase is introduced after the linear RNA is circularized. In some embodiments, the DNase is introduced at least 1, at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, or at least 8 hours after the linear RNA is circularized. In some embodiments, the DNase is introduced at about the same as the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 2 hours before and no more than 2 hours after the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 90 minutes before and no more than 90 minutes after the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 1 hour before and no more than 1 hour after the linear RNA is circularized. In some embodiments, the DNase is introduced no more than 30 minutes before and no more than 30 minutes after the linear RNA is circularized. The DNase may remain in the mixture after digestion of residual DNA occurs, or RNA may be purified to remove the DNase, along with DNA fragments and deoxyribonucleotides, before other steps of the method, such as circularization. In some embodiments, the DNase is incubated in the mixture for at least 30 minutes, at least 1 hour, at least 90 minutes, at least 2 hours, at least 3 hours, at least 4 hours, at least 5 hours, at least 6 hours, at least 7 hours, at least 8 hours, at least 9 hours, at least 10 hours, at least 11 hours, or at least 12 hours, up to a maximum of 24 hours. In some embodiments, the DNse is removed prior to circularization to prevent
degradation of the DNA splint. In some embodiments, DNase is added after circularization to promote degradation of the DNA splint and release of the circular RNA. Some embodiments of methods comprise contacting a circular RNA composition with one or more exonucleases. Exonucleases hydrolyze internucleoside linkages (e.g., phosphate backbone) between a terminal nucleotide and adjacent nucleotide of a nucleic acid, which releases the terminal nucleotide from the nucleic acid. Continued hydrolysis of internucleoside linkages and consequent removal of nucleotides from a nucleic acid results in degradation of linear nucleic acids, such as linear mRNAs. Exposing a composition containing circular RNAs and linear RNAs to exonucleases selectively degrades the linear RNAs, without affecting the circular RNAs, which lack terminal nucleotides. Thus, a mixed population of circular and linear RNAs can be enriched for circular RNAs through exonuclease activity. In some embodiments, at least one exonuclease is a 5′ exonuclease.5′ exonucleases remove 5′ terminal nucleotides from nucleic acids. In some embodiments, the 5′ exonuclease is an XRN-1 exonuclease. In some embodiments, at least one exonuclease is a 3′ exonuclease.3′ exonucleases remove 3′ terminal nucleotides from nucleic acids. In some embodiments, the 3′ exonuclease is RNase R. In some embodiments, a 5′ exonuclease and a 3′ exonuclease are introduced into a mixture comprising a circular RNA. The combination of a 5′ exonuclease and 3′ exonuclease increases the rate of linear RNA degradation, as nucleotides may independently be removed from both ends of a linear nucleic acid. In some embodiments, the circular RNA comprises an internal ribosome entry site (IRES). Inclusion of an IRES permits the translation of one or more open reading frames from a circular RNA. The IRES element attracts a eukaryotic ribosomal translation initiation complex and promotes translation initiation. See, e.g., Kaufman et al., Nucleic Acid Res.199119:4485- 4490; Gurtu et al., Biochem Biophys Res Commun.1996.229:295-298; Rees et al., BioTechniques.1996.20: 102-110; Kobayashi et al., BioTechniques.1996.21 :399-402; and Mosser et al., BioTechniques.1997.22:150-161. A multitude of IRES sequences are available and include sequences derived from a wide variety of viruses, such as from leader sequences of picornaviruses such as the encephalomyocarditis virus (EMCV) UTR (Jang et al., J Virol.1989. 63: 1651-1660), the polio leader sequence, the hepatitis A virus leader, the hepatitis C virus IRES, human rhinovirus type 2 IRES (Dobrikova et al., Proc Natl Acad Sci U S A.2003. 100(25): 15125- 15130), an IRES element from the foot and mouth disease virus (Ramesh et al., Nucleic Acid Res.1996.24:2697-2700), a giardiavirus IRES (Garlapati et al., J Biol Chem. 2004.279(5):3389-3397). Additionally or alternatively, a circular RNA may comprise any of a variety of nonviral IRES sequences, such as IRES sequences from yeast, as well as the human angiotensin II type 1 receptor IRES (Martin et al., Mol Cell Endocrinol. (2003) 212:51-61),
fibroblast growth factor IRESs (FGF-1 IRES and FGF-2 IRES, Martineau et al., Mol Cell Biol. 2004.24(17):7622-7635), vascular endothelial growth factor (VEGF) IRES (Baranick et al., Proc Natl Acad Sci U S A.2008.105(12):4733-4738, Stein et al., Mol Cell Biol.1998. 18(6):3112-3119, Bert et al., RNA.2006.12(6):1074-1083), and insulin-like growth factor II (IGF-II) IRES (Pedersen et al., Biochem J.2002.363(Pt l):37-44). These elements are commercially available in plasmids sold, e.g., by Clontech (Mountain View, CA), Invivogen (San Diego, CA), Addgene (Cambridge, MA) and GeneCopoeia (Rockville, MD). See also IRESite: The database of experimentally verified IRES structures (iresite.org). In some embodiments, a circular RNA comprises a coxsackievirus B3 (CVB3) IRES. See Gharbi et al., PLoS One.2022.17(10):e0274162. In some embodiments, a circular RNA comprises an EMCV IRES. In some embodiments, a circular RNA comprises a salivirus IRES. See Sweeney et al., J Virol.2012.86(3):1468–1486. In some embodiments, the salivirus IRES is present in or derived from Salivirus FHB (SaliFHB). See GenBank Accession No. KM023140.1. In some embodiments, the circular RNA comprises, in 5′-to-3′ order: a 5′ untranslated region (UTR), an IRES, an open reading frame encoding a protein, and a 3′ untranslated region. In some embodiments, the circular RNA further comprises a polyA or polyAC region. In some embodiments, the polyA or polyAC region is between the 5′ UTR and the IRES. In some embodiments, the polyA or polyAC region is between the open reading frame and the 3′ UTR. In some embodiments, the polyA or polyAC region is between the 3′ UTR and the 5′ UTR. In some embodiments, the circular RNA does not comprise a polyA or polyAC region. In some embodiments, a circular RNA comprises, in 5′-to-3′ order: a 5′ untranslated region (5′ UTR), a first polyA or polyAC region, an internal ribosome entry site (IRES), an open reading frame encoding a protein, a second polyA or polyAC region, and a 3′ untranslated region. In some embodiments, at least 70%, at least 75%, at least 80%, at least 85%, at least 95%, or up to 100% of the RNAs in the composition are circular RNAs. Methods of determining the relative fraction of RNAs that are circular RNAs are generally known in the art and include, without limitation, high-performance liquid chromatography (HPLC), column chromatography, endonuclease digestion, exonuclease digestion, and gel electrophoresis. The structure of circular RNAs allows them to be distinguished from linear RNAs of the same sequence by chromatography methods, so that the relative fraction of circular and linear RNAs can be quantified by chromatographic analysis. For example, circular RNAs produce distinct peaks on an HPLC chromatogram, and the relative areas under the curves (AUCs) of peaks that indicate linear RNAs or circular RNAs can be compared to calculate the fraction of RNAs that are
circular. Two peaks with equal AUC indicate equal abundances, while a circular RNA peak with 4 times the AUC of a linear RNA peak indicates that the composition contains 80% circular RNA and 20% linear RNA. Furthermore, single-molecule molecular biology techniques, such as long-read sequencing, limiting dilution, and/or digital droplet analysis, allow circular and linear RNAs to be distinguished based on sequence differences. For example, the design of primers that amplify the ligation junction of a circular RNA, but not a sequence present in the linear RNA, allow for the selective amplification of circular RNAs or cDNA made by reverse transcription of circular RNAs. See, e.g., Zhang et al. Nat Commun.2020.11(1):90 and Panda et al. Bio Protoc.2018.8(6):e2775. Additionally, amplification from a linear RNA template ends once a polymerase reaches the end of the RNA, while amplification of a circular RNA template may continue indefinitely, such that the size of amplicons from a given template indicate whether amplification began with a linear or circular template. See, e.g., Boss et al. Chembiochem.2020.21(6):793–796. Circular RNAs may differ from linear RNAs comprising the same nucleic acid sequence. In some embodiments, the circular RNA is more resistant to degradation by exonucleases, relative to a linear RNA. In some embodiments, the circular RNA is more resistant to phosphorylation by a kinase, relative to a linear RNA. In some embodiments, the circular RNA is more resistant to dephosphorylation by a phosphatase, relative to a linear RNA. In some embodiments, the circular RNA is supercoiled. In some embodiments, the circular RNA does not comprise a secondary structure. As a circular RNA has no 5′ terminal nucleotide, the circular RNA does not comprise a 5′ cap. In some embodiments, the circular RNA cannot be bound by a 5′ cap-binding protein. Some aspects relate to methods of improving stability of a circular RNA comprising a nucleotide sequence comprising an ORF, where the methods comprise: (i) substituting one or more nucleotides at adenosine positions in the nucleotide sequence to produce a modified nucleotide sequence in which 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 5–7%, 7–10%, 10–15%, 15–20%, 20–25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, or 90–95%; and (ii) synthesizing a circular RNA having the modified nucleotide sequence. Circular RNAs having a given modified nucleotide sequence may be synthesized by any suitable method, such IVT to produce a linear RNA followed by circularizing the linear RNA, or ligating two or more linear RNAs and circularizing the ligated RNA. Some embodiments of methods of improving circular RNA stability result in production of circular RNAs that express an encoded protein in a mammalian cell at a level that is at least 50% of the level of expression of a reference (control) circular RNA having the same nucleotide sequence, but in which all nucleotides at adenosine positions are unmodified (e.g., not N6-
methyladenosine nucleotides). Some embodiments of circular RNAs express one or more encoded proteins in a mammalian cell at a level that is at least 50% of the level of expression of a reference (control) circular RNA having the same nucleotide sequence, but in which all nucleotides at adenosine positions are unmodified (e.g., not N6-methyladenosine nucleotides). Typically, a reduction in the level of an mRNA (e.g., by degradation by exonucleases) results in a reduction in the level of a polypeptide expressed therefrom. The level of expression from a circular RNA (e.g., having N6-methyladenosine nucleotides, or a control circular RNA with no N6-methyladenosine nucleotides) may be determined using standard techniques for detecting proteins and measuring protein abundance, including western blotting, ELISA, and Bradford assays. In some embodiments, a circular RNA a level of expression in a mammalian cell that is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, at least 100%, at least 120%, at least 150%, at least 175%, at least 200%, at least 250%, at least 300%, at least 350%, at least 400%, at least 450%, or at least 500% of the level of expression of a control circular RNA having the same nucleotide sequence as the circular RNA, but in which each nucleotide at an adenosine position is an unmodified adenosine nucleotide. In some embodiments, the level of expression from the circular RNA is at least 50–80%, 80–100%, 100– 120%, 120–150%, 150–200%, 200–300%, 300–400%, or 400–500% of the level of expression from the control circular RNA. Examples of mammalian cells for use in evaluating expression of an RNA include, without limitation, humans, mice, rats, hamsters, guinea pigs, cats, dogs, chimpanzees, macaques, baboons, and gorillas. In some embodiments, the mammalian cell is a human cell. Some embodiments of methods of improving circular RNA stability result in production of circular RNAs that are stable for longer periods of time in cells than control circular RNAs having the same sequence but lacking N6-methyladenosine nucleotides (i.e., control circular RNAs in which all nucleotides at adenosine positions are unmodified adenosine nucleotides). Some embodiments of circular RNAs are stable for longer periods of time in cells than control circular RNAs having the same sequence but lacking N6-methyladenosine nucleotides (i.e., control circular RNAs in which all nucleotides at adenosine positions are unmodified adenosine nucleotides). In some embodiments, the circular RNA has a coefficient of degradation in a mammalian cell that is no more than 90% of a coefficient of degradation in the mammalian cell of a control circular RNA having the same nucleotide sequence as the circular RNA, and in which all nucleotides at adenosine positions are unmodified adenosine nucleotides. As used herein, a “coefficient of degradation” refers to a parameter of an equation describing the loss of nucleic acid over time. Circular RNAs typically have a defined sequence, which may include an open reading frame encoding a protein to be expressed in cells. Following
introduction into a cell, circular RNAs may be cleaved by endonucleases, or hydrolyzed at the phosphodiester backbone independently of a nuclease, resulting in production of a linear RNA, or multiple RNAs, neither of which contains an intact sequence encoding the full-length protein encoded by the uncleaved circular RNA. Circular RNA abundance may be measured by any method known in the art for detecting or measuring nucleic acids, such as RT-PCR or northern blotting. Loss of nucleic acid abundance may be described by a differential equation of the form ^^ ^^ = −^^, where P is nucleic acid abundance (nM), λ is the coefficient of degradation, and dP/dt is the rate of change in nucleic acid abundance. Alternatively, nucleic acid abundance over time may be described by an equation of the form P
 where P(t) is nucleic acid abundance (nM) at a given time, t, P0 is initial nucleic acid abundance at time t=0, e is the base of the natural logarithm, and λ is the coefficient of degradation. In both equation forms, a positive value of λ indicates exponential decay, while a negative λ indicates exponential growth, with larger absolute values of λ indicating faster decay or growth, respectively. In some embodiments, the coefficient of degradation is expressed in units of hour-1. In some embodiments, a circular RNA has a coefficient of degradation in a mammalian cell that is no more than 90%, no more than 80%, no more than 70%, no more than 60%, no more than 50%, no more than 40%, no more than 30%, no more than 20%, no more than 10%, or no more than 5% of a coefficient of degradation of a control circular RNA having the same nucleotide sequence, but in which all nucleotides at adenosine positions are unmodified adenosine nucleotides. In some embodiments, the circular RNA has a coefficient of degradation that is 40– 60%, 60–80%, or 80–95% of the coefficient of degradation of the control circular RNA. In some embodiments, the coefficient of degradation is measured over 1–168, 1–144, 1–120, 1–96, 1–72, 1–48, 1–24, 24–48, 48–72, 72–96, 96–120, 120–144, or 144–168 hours. In some embodiments, the coefficient of degradation is measured over 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 18, 24, 30, 36, 42, 48, 72, 96, 120, 144, or 168 hours. In some embodiments, the circular RNA has a half-life in a mammalian cell that is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of the control circular RNA having the same nucleotide sequence as the circular RNA, but in which all nucleotides at adenosine positions are unmodified adenosine nucleotides. In some embodiments, the circular RNA has a half-life that is 100–120%, 120– 150%, 150–200%, 200–300%, 300–400%, 400–500%, 500–600%, 600–700%, 700–800%, 800– 900%, or 900–1000% of the half-life of the control circular RNA. As used herein “half-life”
refers to the amount of time required for 50% of circular RNA molecules to be cleaved to produce one or more non-circular RNAs. For example, if 1,000 circular RNA molecules having the same nucleotide sequence and a half-life of 12 hours were introduced into a mammalian cell, only 500 of the circular RNA molecules would be intact after 12 hours, with the remaining circular RNAs having been cleaved to produce linear RNAs or multiple linear RNAs. The half- ^^ ^ life is related to the coefficient of degradation by the equation ^^ = . Examples of ^
where P(t) is nucleic acid abundance (nM) at a given time, t, P0 is initial nucleic acid abundance at time t=0, e is the base of the natural logarithm, and λ is the coefficient of degradation. In both equation forms, a positive value of λ indicates exponential decay, while a negative λ indicates exponential growth, with larger absolute values of λ indicating faster decay or growth, respectively. In some embodiments, the coefficient of degradation is expressed in units of hour-1. In some embodiments, a circular RNA has a coefficient of degradation in a mammalian cell that is no more than 90%, no more than 80%, no more than 70%, no more than 60%, no more than 50%, no more than 40%, no more than 30%, no more than 20%, no more than 10%, or no more than 5% of a coefficient of degradation of a control circular RNA having the same nucleotide sequence, but in which all nucleotides at adenosine positions are unmodified adenosine nucleotides. In some embodiments, the circular RNA has a coefficient of degradation that is 40– 60%, 60–80%, or 80–95% of the coefficient of degradation of the control circular RNA. In some embodiments, the coefficient of degradation is measured over 1–168, 1–144, 1–120, 1–96, 1–72, 1–48, 1–24, 24–48, 48–72, 72–96, 96–120, 120–144, or 144–168 hours. In some embodiments, the coefficient of degradation is measured over 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 18, 24, 30, 36, 42, 48, 72, 96, 120, 144, or 168 hours. In some embodiments, the circular RNA has a half-life in a mammalian cell that is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of the control circular RNA having the same nucleotide sequence as the circular RNA, but in which all nucleotides at adenosine positions are unmodified adenosine nucleotides. In some embodiments, the circular RNA has a half-life that is 100–120%, 120– 150%, 150–200%, 200–300%, 300–400%, 400–500%, 500–600%, 600–700%, 700–800%, 800– 900%, or 900–1000% of the half-life of the control circular RNA. As used herein “half-life”
refers to the amount of time required for 50% of circular RNA molecules to be cleaved to produce one or more non-circular RNAs. For example, if 1,000 circular RNA molecules having the same nucleotide sequence and a half-life of 12 hours were introduced into a mammalian cell, only 500 of the circular RNA molecules would be intact after 12 hours, with the remaining circular RNAs having been cleaved to produce linear RNAs or multiple linear RNAs. The half- ^^ ^ life is related to the coefficient of degradation by the equation ^^ = . Examples of ^
 mammalian cells for use in evaluating degradation (e.g., measuring a coefficient of degradation and/or half-life) of an RNA include, without limitation, humans, mice, rats, hamsters, guinea pigs, cats, dogs, chimpanzees, macaques, baboons, and gorillas. In some embodiments, the mammalian cell is a human cell. In Vitro Transcription Some aspects relate to methods of preparing linear RNA by in vitro transcription (IVT), with the transcribed linear RNA being circularized. Typically, in vitro transcription produces (e.g., synthesizes) an RNA transcript (e.g., linear RNA) by forming a reaction mixture comprising a DNA template, an RNA polymerase (e.g., T7 RNA polymerase or T7 RNA polymerase variant), NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP) (and optionally modified forms of one or more NTPs), and a transcription buffer; and incubating the reaction mixture to allow the RNA polymerase to transcribe an RNA transcript from the DNA template. This linear RNA produced by IVT may then be circularized by any suitable method. For example, two non- adjacent nucleotides of the linear RNA produced by IVT can then be ligated to produce a circular RNA. IVT methods may involve a modification in the amount (e.g., molar amount and/or quantity) and type of nucleotide triphosphates in the reaction mixture. Inclusion of N6- methyladenosine (m6A) triphosphate (m6ATP) in the reaction mixture allows for incorporation of N6-methyladenosine nucleotides into an RNA transcript. Thus, some aspects relate to IVT methods in which 15–100% of ATPs in the reaction mixture are modified ATPs comprising N6- methyladenosine (m6ATP). Further, use of a combination of unmodified ATP and m6ATP allows for transcription of an RNA that contains a mixture of unmodified adenosine nucleotides and N6-methyladenosine nucleotides. Thus, some aspects relate to IVT methods in which 15– 95% of the ATPs in the reaction mixture are modified ATPs comprising N6-methyladenosine (m6ATP). The percentage of ATPs in the reaction mixture that are m6ATP may be any percentage that is at least 15% and at most 100% or 95%. For example, in some embodiments, 15–20%, 20–
25%, 25–30%, 30–35%, 35–40%, 40–45%, 45–50%, 50–55%, 55–60%, 60–65%, 65–70%, 70– 75%, 75–80%, 80–85%, 85–90%, 90–95%, or 95–100% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15–20%, 20–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70– 80%, 80–90%, 90–95%, or 95–100% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15–30%, 30–45%, 45–60%, 60–75%, or 75–90% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15–90%, 15–80%, 15–60%, 15–40%, 15–20%, 20–30%, 30–40%, 40–50%, 50–75%, or 75–90% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 90% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 80% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 60% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 20% of ATPs in the reaction mixture are m6ATP. In some embodiments about 20% to about 30% of ATPs in the reaction mixture are m6ATP. In some embodiments about 30% to about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments about 40% to about 50% of ATPs in the reaction mixture are m6ATP. In some embodiments about 50% to about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments about 75% to about 90% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 30% to about 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 45% to about 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 60% to about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 75% to about 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 95% to about 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 30% to about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 15% and less than 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 30% and less than 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 45% and less than 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 60% and less than 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 75% and less than 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 95% and less than 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 30% and less than 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 15% and up to 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 30% and up to 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 45% and up to 60% of ATPs in the reaction mixture are
m6ATP. In some embodiments, at least 60% and up to 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 75% and up to 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 95% and up to 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 30% and up to 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, about 90%, about 95%, or about 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 25% of ATPs in the reaction mixture are of ATPs in the reaction mixture are m6ATP. In some embodiments, about 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 55% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 65% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 70% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 80% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 85% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 90% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, or 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% of ATPs in the reaction mixture are m6ATP. In some embodiments, 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, 25% of ATPs in the reaction mixture are of ATPs in the reaction mixture are m6ATP. In some embodiments, 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, 55% of ATPs in the reaction mixture are m6ATP. In some embodiments, 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, 65% of ATPs in the reaction mixture are m6ATP. In some
embodiments, 70% of ATPs in the reaction mixture are m6ATP. In some embodiments, 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, 80% of ATPs in the reaction mixture are m6ATP. In some embodiments, 85% of ATPs in the reaction mixture are m6ATP. In some embodiments, 90% of ATPs in the reaction mixture are m6ATP. In some embodiments, 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, the percentage of ATPs in the reaction mixture that comprise N6- methyladenosine (i.e., are m6ATP) is no higher than a certain amount. In some embodiments, no more than 80%, no more than 75%, no more than 70%, no more than 60%, no more than 50%, no more than 40%, no more than 30%, or no more than 20% of ATPs in the reaction mixture comprise N6-methyladenosine. In some embodiments, the percentage of ATPs in the reaction mixture that are m6ATP is no more than 80%, 75%, 70%, 60%, 50%, 45%, 40%, 35%, 30%, 25%, or 20%. In some embodiments, no more than 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 25% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 25% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 25% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, the UTP in a reaction mixture is natural (unmodified uridine triphosphate), and the reaction mixture does not comprise modified UTP. In other embodiments, at least one UTP in the reaction mixture is a modified UTP. The modified UTP may comprise any modified nucleobase, sugar, and/or phosphate. In some embodiments, the modified UTP comprises N1-methylpseudouridine. In some embodiments, the modified UTP comprises pseudouridine (ψ), N1-methylpseudouridine (m1ψ), 2-thiouridine, 4-thiouridine, 2-thio-1-
methyl-1-deaza-pseudouridine, 2-thio-1-methyl-pseudouridine, 2-thio-5-aza-uridine , 2-thio- dihydropseudouridine, 2-thio-dihydrouridine, 2-thio-pseudouridine, 4-methoxy-2-thio- pseudouridine, 4-methoxy-pseudouridine, 4-thio-1-methyl-pseudouridine, 4-thio-pseudouridine, 5-aza-uridine, dihydropseudouridine, 5-methoxyuridine, or 2′-O-methyluridine. In some embodiments, at least 10%, at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of UTPs in the reaction mixture comprise N1- methylpseudouridine. In some embodiments, 100% of UTPs in the reaction mixture comprise N1-methylpseudouridine. cDNA encoding the polynucleotides may be transcribed using an in vitro transcription (IVT) system. In vitro transcription of RNA (e.g., mRNA) is known in the art and is described in International Publication WO 2014/152027, which is incorporated by reference to the extent it discloses IVT. In some embodiments, the RNA is prepared in accordance with any one or more of the methods described in WO 2018/053209 or WO 2019/036682, each of which is incorporated by reference herein to the extent it discloses RNA preparation. In some embodiments, the RNA (e.g., pre-mRNA) transcript is generated using a non- amplified, linearized DNA template in an in vitro transcription reaction to generate the RNA transcript. In some embodiments, the template DNA is isolated DNA. In some embodiments, the template DNA is cDNA. In some embodiments, the cDNA is formed by reverse transcription of an RNA, for example, an mRNA. In some embodiments, cells, e.g., bacterial cells, e.g., E. coli, e.g., DH-1 cells are transfected with the plasmid DNA template. In some embodiments, the transfected cells are cultured to replicate the plasmid DNA which is then isolated and purified. In some embodiments, the DNA template includes an RNA polymerase promoter, e.g., a T7 promoter located 5 ' to and operably linked to the gene of interest. In some embodiments, an in vitro transcription template encodes a 5′ untranslated (UTR) region, contains an open reading frame, and encodes a 3′ UTR and a polyA or polyAC region. The particular nucleic acid sequence composition and length of an in vitro transcription template will depend on the RNA (e.g., circular RNA) encoded by the template. In some embodiments, a nucleic acid (e.g., template DNA and/or RNA) includes 200 to 3,000 nucleotides. For example, a nucleic acid may include 200 to 500, 200 to 1000, 200 to 1500, 200 to 3000, 500 to 1000, 500 to 1500, 500 to 2000, 500 to 3000, 1000 to 1500, 1000 to 2000, 1000 to 3000, 1500 to 3000, or 2000 to 3000 nucleotides. An in vitro transcription system typically comprises a transcription buffer (e.g., with magnesium), nucleotide triphosphates (NTPs), an RNase inhibitor and a polymerase (e.g., T7 RNA polymerase). In some embodiments, one or more of the NTPs is a chemically modified
NTP (e.g., with N1-methylpseudouridine or other chemical modification(s)). A chemically modified NTP may comprise a modified nucleobase, modified sugar, and/or modified phosphate. Modified NTPs may include modified nucleobases. For example, an NTP used in IVT may include a modified uracil nucleobase selected from pseudouracil (ψ), N1- methylpseudouracil (m1ψ), 1-ethylpseudouracil, 2-thiouracil, 4′-thiouracil, 2-thio-1-methyl-1- deaza-pseudouracil, 2-thio-1-methyl-pseudouracil, 2-thio-5-aza-uracil, 2-thio- dihydropseudouracil, 2-thio-dihydrouracil, 2-thio-pseudouracil, 4-methoxy-2-thio-pseudouracil, 4-methoxy-pseudouracil, 4-thio-1-methyl-pseudouracil, 4-thio-pseudouracil, 5-aza-uracil, dihydropseudouracil, 5-methyluracil, 5-methoxyuracil (mo5U) and 2′-O-methyluracil. In some embodiments, an NTP includes a modified guanine nucleobase selected from digoxigeninated guanine, 6-thioguanine, 7-deazaguanine, 7-deaza-7-propargylaminoguanine, 8-oxoguanine, araguanine, biotin-16-7-deaza-7-propargylaminoguanine, isoguanine, N2-methylguanine, O6- methylguanine, thienoguanine, and 2,6-daminoguanine. In some embodiments, an NTP used in IVT may include a modified cytosine nucleobase selected from digoxigeninated cytosine, 2- thiocytosine, 5-aminoallylcytosine, 5-bromocytosine, 5-carboxycytosine, 5-formylcytosine, 5- hydroxycytosine, 5-hydroxymethylcytosine, 5-methoxycytosine, 5-methylcytosine, 5- propargylaminocytosine, 5-propynylcytosine, 6-azacytosine, aracytosine, cyanine 3-5- propargylaminocytosine, cyanine 3-aminoallylcytosine, cyanine 5-6-propargylaminocytosine, cyanine 5-aminoallylcytosine, desthiobiotin-6-aminoallylcytosine, N4-biotin-OBEA-cytosine, N4-methylcytosine, pseudoisocytosine, and thienocytosine. In some embodiments, an NTP includes a modified adenine nucleobase selected from digoxigeninated adenine, N6- methyladenine, 7-deazaadenine, 7-deaza-7-propargylaminoadenine, 8-azaadenine, 8- azidoadenine, 8-chloroadenine, 8-oxoadenine, araadenine, N1-methyladenine, N6- methyladenine, 3-deazaadenine, 2,6-diaminoadenine, 2-methyl-thio-N6-isopentenyladenine (ms2i6A), 2-methylthio-N6-methyladenine (ms2m6A), N6-(cis-hydroxyisopentenyl)adenine (io6A), 2-methylthio-N6-(cis-hydroxyisopentenyl)adenine (ms2io6A), N6- glycinylcarbamoyladenine (g6A), N6-threonylcarbamoyladenine (t6A), 2-methylthio-N6- threonyl carbamoyladenine (ms2t6A), N6-methyl-N6-threonylcarbamoyladenine (m6t6A), N6- hydroxynorvalylcarbamoyladenine (hn6A), 2-methylthio-N6-hydroxynorvalyl carbamoyladenine (ms2hn6A), N6,N6-dimethyladenine (m62A), and N6-acetyladenine (ac6A). In some embodiments, an IVT reaction mixture includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified nucleobases. Modified NTPs may include modified sugars. For example, an NTP used in IVT may include a modified sugar selected from 2′-thioribose, 2′,3′-dideoxyribose, 2′-amino-2′-
deoxyribose, 2′ deoxyribose, 2′-azido-2′-deoxyribose, 2′-fluoro-2′-deoxyribose, 2′-O- methylribose, 2′-O-methyldeoxyribose, 3′-amino-2′,3′-dideoxyribose, 3′-azido-2′,3′- dideoxyribose, 3′-deoxyribose, 3′-O-(2-nitrobenzyl)-2′-deoxyribose, 3′-O-methylribose, 5′- aminoribose, 5′-thioribose, 5-nitro-1-indolyl-2′-deoxyribose, 5′-biotin-ribose, 2′-O,4′-C- methylene-linked, 2′-O,4′-C-amino-linked ribose, and 2′-O,4′-C-thio-linked ribose. In some embodiments, an IVT reaction mixture includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified sugars. Modified NTPs may include modified phosphates. A modified phosphate group is a phosphate group that differs from the canonical structure of phosphate. In some embodiments, an NTP used in IVT may include a modified phosphate selected from phosphorothioate (PS), thiophosphate, 5′-O-methylphosphonate, 3′-O-methylphosphonate, 5′-hydroxyphosphonate, hydroxyphosphanate, phosphoroselenoate, selenophosphate, phosphoramidate, carbophosphonate, methylphosphonate, phenylphosphonate, ethylphosphonate, H-phosphonate, guanidinium ring, triazole ring, boranophosphate (BP), methylphosphonate, and guanidinopropyl phosphoramidate. In some embodiments, an IVT reaction mixture includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified phosphates. In some embodiments, the NTPs comprise adenosine triphosphate (ATP), cytidine triphosphate (CTP), uridine triphosphate (UTP), and guanosine triphosphate (GTP). In some embodiments, one or more of the NTPs comprises a chemical modification (e.g., a modified nucleobase, modified sugar, and/or modified phosphate). The ratios of NTPs may vary. In some embodiments, the ratio of GTP:ATP:CTP:UTP is 1:1:1:1. In some embodiments, the amount of the GTP or an analogue thereof is greater than an amount of the UTP or an analogue thereof. In some embodiments, the amount of the GTP is greater than the amount of the UTP. In some embodiments, the amount of ATP is greater than the amount of UTP, and the amount of CTP is greater than the amount of UTP. In some embodiments, the amount of the GTP or an analogue thereof is greater than an amount of the UTP or an analogue thereof. In some embodiments, an IVT system comprises an at least 2:1 ratio of GTP concentration to ATP concentration, an at least 2:1 ratio of GTP concentration to CTP concentration, and an at least 4:1 ratio of GTP concentration to UTP concentration. In some embodiments, an IVT system comprises a 2:1 ratio of GTP concentration to ATP concentration, a 2:1 ratio of GTP concentration to CTP concentration, and a 4:1 ratio of GTP concentration to UTP concentration. In some embodiments, an IVT system comprises guanosine diphosphate (GDP). In some embodiments, an IVT system comprises an at least 3:1 ratio of GTP plus GDP concentration to ATP concentration, an at least 6:1 ratio of GTP plus GDP concentration to CTP concentration, and an at least 6:1 ratio of GTP plus GDP concentration to UTP concentration. In some embodiments,
an IVT system comprises guanosine monophosphate (GMP). In some embodiments, an IVT system comprises an at least 3:1 ratio of GTP plus GMP concentration to ATP concentration, an at least 6:1 ratio of GTP plus GMP concentration to CTP concentration, and an at least 6:1 ratio of GTP plus GMP concentration to UTP concentration. It is to be understood that in embodiments where two NTPs (NTP-1 and NTP-2) are present in a ratio of concentrations (e.g., a 2:1 ratio of NTP-1:NTP-2), the concentration of a given NTP (e.g., ATP) is the sum of concentrations of the natural NTP (e.g., unmodified ATP) and all analogues of that NTP (e.g., m6ATP) present in the reaction mixture. The NTPs may be manufactured in house, may be selected from a supplier, or may be synthesized. The NTPs may be natural and/or unnatural (modified) NTPs. Any number of RNA polymerases or variants may be used in IVT methods. The polymerase may be selected from, but is not limited to, a phage RNA polymerase, e.g., a T7 RNA polymerase, a T3 RNA polymerase, a SP6 RNA polymerase, and/or mutant polymerases such as, but not limited to, polymerases able to incorporate modified nucleic acids and/or modified nucleotides, including chemically modified nucleic acids and/or nucleotides. Some embodiments exclude the use of DNase. In some embodiments, an IVT reaction uses an RNA polymerase selected from the group consisting of T7 RNA polymerase, T3 RNA polymerase, K11 RNA polymerase, and SP6 RNA polymerase. In some embodiments, an IVT reaction uses a T3 RNA polymerase. In some embodiments, an IVT reaction uses an SP6 RNA polymerase. In some embodiments, an IVT reaction uses a K11 RNA polymerase. In some embodiments, an IVT reaction uses a T7 RNA polymerase. In some embodiments, a wild-type T7 polymerase is used in an IVT reaction. In some embodiments, a mutant T7 polymerase is used in an IVT reaction. In some embodiments, a T7 RNA polymerase variant comprises an amino acid sequence that shares at least 50%, 60%, 70%, 80%, 90%, 95%, or 99% identity with a wild-type T7 (WT T7) polymerase. In some embodiments, the T7 polymerase variant is a T7 polymerase variant described by International Application Publication Number WO2019/036682 or WO2020/172239, each of which is incorporated herein by reference to the extent it discloses RNA polymerases. In some embodiments, a T7 RNA polymerase variant comprises an amino acid sequence with at least 50%, 60%, 70%, 80%, 90%, 95%, or 99% sequence identity to the amino acid sequence of any one of SEQ ID NOs: 1–4. In some embodiments, the RNA polymerase (e.g., T7 RNA polymerase or T7 RNA polymerase variant) is present in a reaction (e.g., an IVT reaction) at a concentration of 0.01 mg/ml to 1 mg/ml. For example, the RNA polymerase may be present in a reaction at a concentration of 0.01 mg/mL, 0.05 mg/ml, 0.1 mg/ml, 0.5 mg/ml or 1.0 mg/ml. In some embodiments, the T7 RNA polymerase variant comprises the amino acid sequence of any
one of SEQ ID NOs: 1–4. T7 RNA polymerase variants with one or more mutations relative to WT T7 RNA polymerase have several advantages in IVT reactions, including improved speed, fidelity, and reduced production of double-stranded RNA (dsRNA) transcripts. Double-stranded RNA transcripts, in which at least a portion of an RNA transcript is hybridized to another RNA molecule, elicit an innate immune response when introduced into a cell, causing degradation of both strands of a dsRNA. Minimizing the formation of dsRNA transcripts during IVT enables the production of less immunogenic, and thus more stable, circular RNA compositions. In some embodiments, the concentration of double-stranded RNA in a composition comprising RNA is 5% (%w/w) or less, 4% or less, 3% or less, 2.5% or less, 2% or less, 1.75% or less, 1.5% or less, 1.25% or less, 1% or less, 0.9% or less, 0.8% or less, 0.7% or less, 0.6% or less, 0.5% or less, 0.4% or less, 0.3% or less, 0.25% or less, 0.2% or less, 0.175% or less, 0.15% or less, 0.125% or less, or 0.1% or less. In some embodiments, the concentration of double-stranded RNA in a composition comprising RNA is 0.05% (%w/w) or less, 0.04% or less, 0.03% or less, 0.02% or less, or 0.01% or less. Methods of measuring the presence and/or amount of dsRNA in a composition are known in the art. Non-limiting examples of methods for measuring dsRNA content of a sample include ELISAs and immunoblotting using antibodies specific to dsRNA. Additionally, the total mass of RNA in a sample can be measured using techniques such as spectroscopy (NanoDrop), qRT-PCR, and/or ddPCR, and the mass of dsRNA can be measured using an intercalating agent that fluoresces when bound to dsRNA, such as acridine orange, with the dsRNA concentration being calculated by division. In some embodiments, the concentration of dsRNA in a composition refers to the mass of RNA nucleotides that are part of a double- stranded RNA:RNA hybrid, with other unhybridized nucleotides from either RNA in the hybrid not contributing to the amount of dsRNA in a composition. In other embodiments, the concentration of dsRNA in a sample refers to the concentration of RNA molecules containing nucleotides that are part of an RNA:RNA hybrid. In some embodiments, the RNA composition produced using a T7 variant RNA polymerase is less immunogenic than an RNA composition produced using a WT T7 RNA polymerase. Methods of determining the immunogenicity of an RNA composition are known in the art, and include analysis of innate immune receptor (e.g., RIG-I, TLR3, MDA5) stimulation and/or phosphorylation, quantification of cytokine (e.g., IP- 10) production by qRT-PCR, RNAseq, and/or ELISA, measurement of RNAi pathway activity, upregulation and/or activation of antiviral proteins (e.g., MAVS), and analysis of cell death. The “percent identity,” “sequence identity,” “% identity,” or “% sequence identity” (as they may be interchangeably used herein) of two sequences (e.g., nucleic acid or amino acid) refers to a quantitative measurement of the similarity between two sequences (e.g., nucleic acid or amino acid). Percent identity can be determined using the algorithms of Karlin and Altschul,
Proc. Natl. Acad. Sci. USA 87:2264-68, 1990, modified as in Karlin and Altschul, Proc. Natl. Acad. Sci. USA 90:5873-77, 1993. Such algorithms are incorporated into the NBLAST and XBLAST programs (version 2.0) of Altschul et al., J. Mol. Biol.215:403-10, 1990. BLAST protein searches can be performed with the XBLAST program, score=50, word length=3, to obtain amino acid sequences homologous to the protein molecules of interest. Where gaps exist between two sequences, Gapped BLAST can be utilized as described in Altschul et al., Nucleic Acids Res.25(17):3389-3402, 1997. When utilizing BLAST and Gapped BLAST programs, the default parameters of the respective programs (e.g., XBLAST and NBLAST) can be used. When a percent identity is stated, or a range thereof (e.g., at least, more than, etc.), unless otherwise specified, the endpoints shall be inclusive and the range (e.g., at least 70% identity) shall include all ranges within the cited range. An IVT system, in some embodiments, comprises magnesium buffer, dithiothreitol (DTT) spermidine, pyrophosphatase, and/or RNase inhibitor. In some embodiments, an IVT system omits an RNase inhibitor. An IVT system may be incubated at 25 degrees Celsius or at 37 degrees Celsius. Other temperatures may be used, depending in part on the polymerase (e.g., use of a variant polymerase). In some embodiments, the RNA transcript is not capped via enzymatic capping prior to circularization. Nucleic acids Some aspects relate to compositions comprising nucleic acids (e.g., RNA (e.g., circular RNA)) and methods of producing nucleic acids. As used herein, the term “nucleic acid” includes multiple nucleotides (i.e., molecules comprising a sugar (e.g., ribose or deoxyribose) linked to a phosphate group and to an exchangeable organic base, which is either a substituted pyrimidine (e.g., cytosine (C), thymine (T) or uracil (U)) or a substituted purine (e.g., adenine (A) or guanine (G))). The term nucleic acid includes polyribonucleotides as well as polydeoxyribonucleotides. The term nucleic acid also includes polynucleosides (i.e., a polynucleotide minus the phosphate) and any other organic base containing polymer. Non- limiting examples of nucleic acids include chromosomes, genomic loci, genes, or gene segments that encode polynucleotides or polypeptides, coding sequences, non-coding sequences (e.g., intron, 5′-UTR, or 3′-UTR) of a gene, pri-mRNA, pre-mRNA, cDNA, mRNA, etc. A nucleic acid (e.g., circular RNA) may include a substitution and/or modification. In some embodiments, the substitution and/or modification is in one or more bases and/or sugars. For example, in some embodiments a nucleic acid (e.g., RNA) includes nucleotides having an organic group, such as a methyl group, attached to a nucleic acid base at the N6 position. Thus,
in some embodiments, an RNA comprises one or more N6-methyladenosine nucleotides. A phosphate, sugar, or nucleic acid base of a nucleotide may also be substituted for another phosphate, sugar, or nucleic acid base. For example, a uridine nucleoside may be substituted for a pseudouridine nucleoside, in which the uracil base is attached to the sugar by a carbon-carbon bond rather than a nitrogen-carbon bond. Thus, in some embodiments, a nucleic acid (e.g., circular RNA) is heterogeneous in backbone composition thereby containing any possible combination of polymer units linked together such as peptide-nucleic acids (which have an amino acid backbone with nucleic acid bases). In a nucleic acid comprising modified nucleotides, the modified nucleotides may be present at positions corresponding to a given nucleobase (e.g., adenine positions) or nucleoside comprising a given nucleobase (e.g., adenosine positions). Positions specified using a given nucleobase or nucleoside refer to the sequence information encoded by the nucleobase (e.g., adenosine or adenine positions refer to the locations of “A”s in a nucleotide sequence), and so the presence of modified nucleotides comprising a modified form of the given nucleobase at those positions does not change the sequence information (e.g., encoded amino acid sequence) of the nucleic acid. The nucleic acids may include nucleic acid sequences that have been removed from their naturally occurring environment, recombinant or cloned DNA isolates, and chemically synthesized analogues or analogues biologically synthesized by heterologous systems. An “engineered nucleic acid” is a nucleic acid that does not occur in nature. It should be understood, however, that while an engineered nucleic acid as a whole is not naturally- occurring, it may include nucleotide sequences that occur in nature. In some embodiments, an engineered nucleic acid comprises nucleotide sequences from different organisms (e.g., from different species). For example, in some embodiments, an engineered nucleic acid includes a bacterial nucleotide sequence, a human nucleotide sequence, and/or a viral nucleotide sequence. Engineered nucleic acids include recombinant nucleic acids and synthetic nucleic acids. A “recombinant nucleic acid” is a molecule that is constructed by joining nucleic acids (e.g., isolated nucleic acids, synthetic nucleic acids, or a combination thereof) and, in some embodiments, can replicate in a living cell. A “synthetic nucleic acid” is a molecule that is amplified or chemically, or by other means, synthesized. A synthetic nucleic acid includes those that are chemically modified, or otherwise modified, but can base pair with naturally-occurring nucleic acid molecules. Recombinant and synthetic nucleic acids also include those molecules that result from the replication of either of the foregoing. A nucleic may comprise naturally occurring nucleotides and/or non-naturally occurring nucleotides such as modified nucleotides.
In some embodiments, a nucleic acid is present in (or on) a vector. Examples of vectors include but are not limited to bacterial plasmids, phage, cosmids, phasmids, fosmids, bacterial artificial chromosomes, yeast artificial chromosomes, viruses, and retroviruses (for example vaccinia, adenovirus, adeno-associated virus, lentivirus, herpes-simplex virus, Epstein-Barr virus, fowlpox virus, pseudorabies, baculovirus) and vectors derived therefrom. In some embodiments, a nucleic acid (e.g., DNA) used as an input molecule for in vitro transcription (IVT) is present in a plasmid vector. When applied to a nucleic acid sequence, the term “isolated” denotes that the polynucleotide sequence has been removed from its natural genetic milieu and is thus free of other extraneous or unwanted coding sequences (but may include naturally occurring 5′ and 3′ untranslated regions such as promoters and terminators), and is in a form suitable for use within genetically engineered protein production systems. Such isolated molecules are those that are separated from their natural environment. The terms 5′ and 3′ are used herein to describe features of a nucleic acid sequence related to either the position of genetic elements and/or the direction of events (5′ to 3′), such as e.g. transcription by RNA polymerase or translation by the ribosome which proceeds in 5′ to 3′ direction. Synonyms are upstream (5′) and downstream (3′). Conventionally, DNA sequences, gene maps, vector cards and RNA sequences are drawn with 5′ to 3′ from left to right or the 5′ to 3′ direction is indicated with arrows, wherein the arrowhead points in the 3′ direction. Accordingly, 5′ (upstream) indicates genetic elements positioned towards the left-hand side, and 3′ (downstream) indicates genetic elements positioned towards the right-hand side, when following this convention. A nucleic acid (e.g., circular RNA) typically comprises a plurality of nucleotides. A nucleotide includes a nitrogenous base, a five-carbon sugar (ribose or deoxyribose), and at least one phosphate group. Nucleotides include nucleoside monophosphates, nucleoside diphosphates, and nucleoside triphosphates. A nucleoside monophosphate (NMP) includes a nucleobase linked to a ribose and a single phosphate; a nucleoside diphosphate (NDP) includes a nucleobase linked to a ribose and two phosphates; and a nucleoside triphosphate (NTP) includes a nucleobase linked to a ribose and three phosphates. Nucleotide analogs are compounds that have the general structure of a nucleotide or are structurally similar to a nucleotide. Nucleotide analogs, for example, include an analog of the nucleobase, an analog of the sugar and/or an analog of the phosphate group(s) of a nucleotide. A nucleoside includes a nitrogenous base and a 5-carbon sugar. Thus, a nucleoside plus a phosphate group yields a nucleotide. Nucleoside analogs are compounds that have the general
structure of a nucleoside or are structurally similar to a nucleoside. Nucleoside analogs, for example, include an analog of the nucleobase and/or an analog of the sugar of a nucleoside. It should be understood that the term “nucleotide” includes naturally occurring nucleotides, synthetic nucleotides and modified nucleotides, unless indicated otherwise. Examples of naturally occurring nucleotides used for the production of RNA, e.g., in an IVT reaction, include adenosine triphosphate (ATP), guanosine triphosphate (GTP), cytidine triphosphate (CTP), uridine triphosphate (UTP), and uridine triphosphate (UTP). In some embodiments, adenosine diphosphate (ADP), guanosine diphosphate (GDP), cytidine diphosphate (CDP), and/or uridine diphosphate (UDP) are used. In some embodiments, adenosine monophosphate (AMP), guanosine monophosphate (GMP), cytidine monophosphate (CMP), and/or uridine monophosphate (UMP) are used. In some embodiments, GMP is used. Use of GMP, which may initiate in vitro transcription of RNAs with 5′-terminal guanosine nucleotides, allows production of a linear RNA with a 5′-terminal monophosphate, such that the 5′ and 3′ termini of the resulting RNA may be ligated to produce a circular RNA without the need for a separate step to produce the 5′-terminal phosphate. Examples of nucleotide analogs include, but are not limited to, antiviral nucleotide analogs, phosphate analogs (soluble or immobilized, hydrolyzable or non-hydrolyzable), dinucleotide, trinucleotide, tetranucleotide, e.g., a cap analog, or a precursor/substrate for enzymatic capping (vaccinia or ligase), a nucleotide labeled with a functional group to facilitate ligation/conjugation of cap or 5 ^ moiety (IRES), a nucleotide labeled with a 5 ^ PO4 to facilitate ligation of cap or 5 ^ moiety, or a nucleotide labeled with a functional group/protecting group that can be chemically or enzymatically cleaved. Examples of antiviral nucleotide/nucleoside analogs include, but are not limited, to Ganciclovir, Entecavir, Telbivudine, Vidarabine and Cidofovir. Modified nucleotides may include modified nucleobases. For example, an RNA (e.g., RNA transcript or circular RNA) may include a modified uracil nucleobase selected from pseudouracil (ψ), N1-methylpseudouracil (m1ψ), 1-ethylpseudouracil, 2-thiouracil, 4′-thiouracil, 2-thio-1-methyl-1-deaza-pseudouracil, 2-thio-1-methyl-pseudouracil, 2-thio-5-aza-uracil, 2-thio- dihydropseudouracil, 2-thio-dihydrouracil, 2-thio-pseudouracil, 4-methoxy-2-thio-pseudouracil, 4-methoxy-pseudouracil, 4-thio-1-methyl-pseudouracil, 4-thio-pseudouracil, 5-aza-uracil, dihydropseudouracil, 5-methyluracil, 5-methoxyuracil (mo5U) and 2′-O-methyluracil. In some embodiments, an an RNA (e.g., RNA transcript or circular RNA) includes a modified guanine nucleobase selected from digoxigeninated guanine, 6-thioguanine, 7-deazaguanine, 7-deaza-7- propargylaminoguanine, 8-oxoguanine, araguanine, biotin-16-7-deaza-7- propargylaminoguanine, isoguanine, N2-methylguanine, O6-methylguanine, thienoguanine, and
2,6-daminoguanine. In some embodiments, an RNA transcript may include a modified cytosine nucleobase selected from digoxigeninated cytosine, 2-thiocytosine, 5-aminoallylcytosine, 5- bromocytosine, 5-carboxycytosine, 5-formylcytosine, 5-hydroxycytosine, 5- hydroxymethylcytosine, 5-methoxycytosine, 5-methylcytosine, 5-propargylaminocytosine, 5- propynylcytosine, 6-azacytosine, aracytosine, cyanine 3-5-propargylaminocytosine, cyanine 3- aminoallylcytosine, cyanine 5-6-propargylaminocytosine, cyanine 5-aminoallylcytosine, desthiobiotin-6-aminoallylcytosine, N4-biotin-OBEA-cytosine, N4-methylcytosine, pseudoisocytosine, and thienocytosine. In some embodiments, an RNA (e.g., RNA transcript or circular RNA) includes a modified adenine nucleobase selected from digoxigeninated adenine, N6-methyladenine, 7-deazaadenine, 7-deaza-7-propargylaminoadenine, 8-azaadenine, 8- azidoadenine, 8-chloroadenine, 8-oxoadenine, araadenine, N1-methyladenine, N6- methyladenine, 3-deazaadenine, 2,6-diaminoadenine, 2-methyl-thio-N6-isopentenyladenine (ms2i6A), 2-methylthio-N6-methyladenine (ms2m6A), N6-(cis-hydroxyisopentenyl)adenine (io6A), 2-methylthio-N6-(cis-hydroxyisopentenyl)adenine (ms2io6A), N6- glycinylcarbamoyladenine (g6A), N6-threonylcarbamoyladenine (t6A), 2-methylthio-N6- threonyl carbamoyladenine (ms2t6A), N6-methyl-N6-threonylcarbamoyladenine (m6t6A), N6- hydroxynorvalylcarbamoyladenine (hn6A), 2-methylthio-N6-hydroxynorvalyl carbamoyladenine (ms2hn6A), N6,N6-dimethyladenine (m62A), and N6-acetyladenine (ac6A). In some embodiments, an RNA (e.g., RNA transcript or circular RNA) includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified nucleobases. Modified nucleotides may include modified sugars. For example, an RNA (e.g., RNA transcript or circular RNA) may include a modified sugar selected from 2′-thioribose, 2′,3′- dideoxyribose, 2′-amino-2′-deoxyribose, 2′ deoxyribose, 2′-azido-2′-deoxyribose, 2′-fluoro-2′- deoxyribose, 2′-O-methylribose, 2′-O-methyldeoxyribose, 3′-amino-2′,3′-dideoxyribose, 3′- azido-2′,3′-dideoxyribose, 3′-deoxyribose, 3′-O-(2-nitrobenzyl)-2′-deoxyribose, 3′-O- methylribose, 5′-aminoribose, 5′-thioribose, 5-nitro-1-indolyl-2′-deoxyribose, 5′-biotin-ribose, 2′-O,4′-C-methylene-linked, 2′-O,4′-C-amino-linked ribose, and 2′-O,4′-C-thio-linked ribose. In some embodiments, an RNA (e.g., RNA transcript or circular RNA) includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified sugars. Modified nucleotides may include modified phosphates. A modified phosphate group is a phosphate group that differs from the canonical structure of phosphate. An example of a canonical structure of a phosphate is shown below:
mammalian cells for use in evaluating degradation (e.g., measuring a coefficient of degradation and/or half-life) of an RNA include, without limitation, humans, mice, rats, hamsters, guinea pigs, cats, dogs, chimpanzees, macaques, baboons, and gorillas. In some embodiments, the mammalian cell is a human cell. In Vitro Transcription Some aspects relate to methods of preparing linear RNA by in vitro transcription (IVT), with the transcribed linear RNA being circularized. Typically, in vitro transcription produces (e.g., synthesizes) an RNA transcript (e.g., linear RNA) by forming a reaction mixture comprising a DNA template, an RNA polymerase (e.g., T7 RNA polymerase or T7 RNA polymerase variant), NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP) (and optionally modified forms of one or more NTPs), and a transcription buffer; and incubating the reaction mixture to allow the RNA polymerase to transcribe an RNA transcript from the DNA template. This linear RNA produced by IVT may then be circularized by any suitable method. For example, two non- adjacent nucleotides of the linear RNA produced by IVT can then be ligated to produce a circular RNA. IVT methods may involve a modification in the amount (e.g., molar amount and/or quantity) and type of nucleotide triphosphates in the reaction mixture. Inclusion of N6- methyladenosine (m6A) triphosphate (m6ATP) in the reaction mixture allows for incorporation of N6-methyladenosine nucleotides into an RNA transcript. Thus, some aspects relate to IVT methods in which 15–100% of ATPs in the reaction mixture are modified ATPs comprising N6- methyladenosine (m6ATP). Further, use of a combination of unmodified ATP and m6ATP allows for transcription of an RNA that contains a mixture of unmodified adenosine nucleotides and N6-methyladenosine nucleotides. Thus, some aspects relate to IVT methods in which 15– 95% of the ATPs in the reaction mixture are modified ATPs comprising N6-methyladenosine (m6ATP). The percentage of ATPs in the reaction mixture that are m6ATP may be any percentage that is at least 15% and at most 100% or 95%. For example, in some embodiments, 15–20%, 20–
25%, 25–30%, 30–35%, 35–40%, 40–45%, 45–50%, 50–55%, 55–60%, 60–65%, 65–70%, 70– 75%, 75–80%, 80–85%, 85–90%, 90–95%, or 95–100% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15–20%, 20–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70– 80%, 80–90%, 90–95%, or 95–100% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15–30%, 30–45%, 45–60%, 60–75%, or 75–90% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15–90%, 15–80%, 15–60%, 15–40%, 15–20%, 20–30%, 30–40%, 40–50%, 50–75%, or 75–90% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 90% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 80% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 60% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments about 15% to about 20% of ATPs in the reaction mixture are m6ATP. In some embodiments about 20% to about 30% of ATPs in the reaction mixture are m6ATP. In some embodiments about 30% to about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments about 40% to about 50% of ATPs in the reaction mixture are m6ATP. In some embodiments about 50% to about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments about 75% to about 90% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 30% to about 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 45% to about 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 60% to about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 75% to about 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 95% to about 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 30% to about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 15% and less than 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 30% and less than 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 45% and less than 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 60% and less than 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 75% and less than 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 95% and less than 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, greater than 30% and less than 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 15% and up to 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 30% and up to 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 45% and up to 60% of ATPs in the reaction mixture are
m6ATP. In some embodiments, at least 60% and up to 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 75% and up to 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 95% and up to 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, at least 30% and up to 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, about 90%, about 95%, or about 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 25% of ATPs in the reaction mixture are of ATPs in the reaction mixture are m6ATP. In some embodiments, about 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 55% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 65% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 70% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 80% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 85% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 90% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, or 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% of ATPs in the reaction mixture are m6ATP. In some embodiments, 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, 25% of ATPs in the reaction mixture are of ATPs in the reaction mixture are m6ATP. In some embodiments, 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, 45% of ATPs in the reaction mixture are m6ATP. In some embodiments, 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, 55% of ATPs in the reaction mixture are m6ATP. In some embodiments, 60% of ATPs in the reaction mixture are m6ATP. In some embodiments, 65% of ATPs in the reaction mixture are m6ATP. In some
embodiments, 70% of ATPs in the reaction mixture are m6ATP. In some embodiments, 75% of ATPs in the reaction mixture are m6ATP. In some embodiments, 80% of ATPs in the reaction mixture are m6ATP. In some embodiments, 85% of ATPs in the reaction mixture are m6ATP. In some embodiments, 90% of ATPs in the reaction mixture are m6ATP. In some embodiments, 95% of ATPs in the reaction mixture are m6ATP. In some embodiments, 100% of ATPs in the reaction mixture are m6ATP. In some embodiments, the percentage of ATPs in the reaction mixture that comprise N6- methyladenosine (i.e., are m6ATP) is no higher than a certain amount. In some embodiments, no more than 80%, no more than 75%, no more than 70%, no more than 60%, no more than 50%, no more than 40%, no more than 30%, or no more than 20% of ATPs in the reaction mixture comprise N6-methyladenosine. In some embodiments, the percentage of ATPs in the reaction mixture that are m6ATP is no more than 80%, 75%, 70%, 60%, 50%, 45%, 40%, 35%, 30%, 25%, or 20%. In some embodiments, no more than 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 50% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 40% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 35% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 30% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 25% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 25% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 25% of ATPs in the reaction mixture are m6ATP. In some embodiments, no more than 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, about 15% to about 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, 15% to 20% of ATPs in the reaction mixture are m6ATP. In some embodiments, the UTP in a reaction mixture is natural (unmodified uridine triphosphate), and the reaction mixture does not comprise modified UTP. In other embodiments, at least one UTP in the reaction mixture is a modified UTP. The modified UTP may comprise any modified nucleobase, sugar, and/or phosphate. In some embodiments, the modified UTP comprises N1-methylpseudouridine. In some embodiments, the modified UTP comprises pseudouridine (ψ), N1-methylpseudouridine (m1ψ), 2-thiouridine, 4-thiouridine, 2-thio-1-
methyl-1-deaza-pseudouridine, 2-thio-1-methyl-pseudouridine, 2-thio-5-aza-uridine , 2-thio- dihydropseudouridine, 2-thio-dihydrouridine, 2-thio-pseudouridine, 4-methoxy-2-thio- pseudouridine, 4-methoxy-pseudouridine, 4-thio-1-methyl-pseudouridine, 4-thio-pseudouridine, 5-aza-uridine, dihydropseudouridine, 5-methoxyuridine, or 2′-O-methyluridine. In some embodiments, at least 10%, at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% of UTPs in the reaction mixture comprise N1- methylpseudouridine. In some embodiments, 100% of UTPs in the reaction mixture comprise N1-methylpseudouridine. cDNA encoding the polynucleotides may be transcribed using an in vitro transcription (IVT) system. In vitro transcription of RNA (e.g., mRNA) is known in the art and is described in International Publication WO 2014/152027, which is incorporated by reference to the extent it discloses IVT. In some embodiments, the RNA is prepared in accordance with any one or more of the methods described in WO 2018/053209 or WO 2019/036682, each of which is incorporated by reference herein to the extent it discloses RNA preparation. In some embodiments, the RNA (e.g., pre-mRNA) transcript is generated using a non- amplified, linearized DNA template in an in vitro transcription reaction to generate the RNA transcript. In some embodiments, the template DNA is isolated DNA. In some embodiments, the template DNA is cDNA. In some embodiments, the cDNA is formed by reverse transcription of an RNA, for example, an mRNA. In some embodiments, cells, e.g., bacterial cells, e.g., E. coli, e.g., DH-1 cells are transfected with the plasmid DNA template. In some embodiments, the transfected cells are cultured to replicate the plasmid DNA which is then isolated and purified. In some embodiments, the DNA template includes an RNA polymerase promoter, e.g., a T7 promoter located 5 ' to and operably linked to the gene of interest. In some embodiments, an in vitro transcription template encodes a 5′ untranslated (UTR) region, contains an open reading frame, and encodes a 3′ UTR and a polyA or polyAC region. The particular nucleic acid sequence composition and length of an in vitro transcription template will depend on the RNA (e.g., circular RNA) encoded by the template. In some embodiments, a nucleic acid (e.g., template DNA and/or RNA) includes 200 to 3,000 nucleotides. For example, a nucleic acid may include 200 to 500, 200 to 1000, 200 to 1500, 200 to 3000, 500 to 1000, 500 to 1500, 500 to 2000, 500 to 3000, 1000 to 1500, 1000 to 2000, 1000 to 3000, 1500 to 3000, or 2000 to 3000 nucleotides. An in vitro transcription system typically comprises a transcription buffer (e.g., with magnesium), nucleotide triphosphates (NTPs), an RNase inhibitor and a polymerase (e.g., T7 RNA polymerase). In some embodiments, one or more of the NTPs is a chemically modified
NTP (e.g., with N1-methylpseudouridine or other chemical modification(s)). A chemically modified NTP may comprise a modified nucleobase, modified sugar, and/or modified phosphate. Modified NTPs may include modified nucleobases. For example, an NTP used in IVT may include a modified uracil nucleobase selected from pseudouracil (ψ), N1- methylpseudouracil (m1ψ), 1-ethylpseudouracil, 2-thiouracil, 4′-thiouracil, 2-thio-1-methyl-1- deaza-pseudouracil, 2-thio-1-methyl-pseudouracil, 2-thio-5-aza-uracil, 2-thio- dihydropseudouracil, 2-thio-dihydrouracil, 2-thio-pseudouracil, 4-methoxy-2-thio-pseudouracil, 4-methoxy-pseudouracil, 4-thio-1-methyl-pseudouracil, 4-thio-pseudouracil, 5-aza-uracil, dihydropseudouracil, 5-methyluracil, 5-methoxyuracil (mo5U) and 2′-O-methyluracil. In some embodiments, an NTP includes a modified guanine nucleobase selected from digoxigeninated guanine, 6-thioguanine, 7-deazaguanine, 7-deaza-7-propargylaminoguanine, 8-oxoguanine, araguanine, biotin-16-7-deaza-7-propargylaminoguanine, isoguanine, N2-methylguanine, O6- methylguanine, thienoguanine, and 2,6-daminoguanine. In some embodiments, an NTP used in IVT may include a modified cytosine nucleobase selected from digoxigeninated cytosine, 2- thiocytosine, 5-aminoallylcytosine, 5-bromocytosine, 5-carboxycytosine, 5-formylcytosine, 5- hydroxycytosine, 5-hydroxymethylcytosine, 5-methoxycytosine, 5-methylcytosine, 5- propargylaminocytosine, 5-propynylcytosine, 6-azacytosine, aracytosine, cyanine 3-5- propargylaminocytosine, cyanine 3-aminoallylcytosine, cyanine 5-6-propargylaminocytosine, cyanine 5-aminoallylcytosine, desthiobiotin-6-aminoallylcytosine, N4-biotin-OBEA-cytosine, N4-methylcytosine, pseudoisocytosine, and thienocytosine. In some embodiments, an NTP includes a modified adenine nucleobase selected from digoxigeninated adenine, N6- methyladenine, 7-deazaadenine, 7-deaza-7-propargylaminoadenine, 8-azaadenine, 8- azidoadenine, 8-chloroadenine, 8-oxoadenine, araadenine, N1-methyladenine, N6- methyladenine, 3-deazaadenine, 2,6-diaminoadenine, 2-methyl-thio-N6-isopentenyladenine (ms2i6A), 2-methylthio-N6-methyladenine (ms2m6A), N6-(cis-hydroxyisopentenyl)adenine (io6A), 2-methylthio-N6-(cis-hydroxyisopentenyl)adenine (ms2io6A), N6- glycinylcarbamoyladenine (g6A), N6-threonylcarbamoyladenine (t6A), 2-methylthio-N6- threonyl carbamoyladenine (ms2t6A), N6-methyl-N6-threonylcarbamoyladenine (m6t6A), N6- hydroxynorvalylcarbamoyladenine (hn6A), 2-methylthio-N6-hydroxynorvalyl carbamoyladenine (ms2hn6A), N6,N6-dimethyladenine (m62A), and N6-acetyladenine (ac6A). In some embodiments, an IVT reaction mixture includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified nucleobases. Modified NTPs may include modified sugars. For example, an NTP used in IVT may include a modified sugar selected from 2′-thioribose, 2′,3′-dideoxyribose, 2′-amino-2′-
deoxyribose, 2′ deoxyribose, 2′-azido-2′-deoxyribose, 2′-fluoro-2′-deoxyribose, 2′-O- methylribose, 2′-O-methyldeoxyribose, 3′-amino-2′,3′-dideoxyribose, 3′-azido-2′,3′- dideoxyribose, 3′-deoxyribose, 3′-O-(2-nitrobenzyl)-2′-deoxyribose, 3′-O-methylribose, 5′- aminoribose, 5′-thioribose, 5-nitro-1-indolyl-2′-deoxyribose, 5′-biotin-ribose, 2′-O,4′-C- methylene-linked, 2′-O,4′-C-amino-linked ribose, and 2′-O,4′-C-thio-linked ribose. In some embodiments, an IVT reaction mixture includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified sugars. Modified NTPs may include modified phosphates. A modified phosphate group is a phosphate group that differs from the canonical structure of phosphate. In some embodiments, an NTP used in IVT may include a modified phosphate selected from phosphorothioate (PS), thiophosphate, 5′-O-methylphosphonate, 3′-O-methylphosphonate, 5′-hydroxyphosphonate, hydroxyphosphanate, phosphoroselenoate, selenophosphate, phosphoramidate, carbophosphonate, methylphosphonate, phenylphosphonate, ethylphosphonate, H-phosphonate, guanidinium ring, triazole ring, boranophosphate (BP), methylphosphonate, and guanidinopropyl phosphoramidate. In some embodiments, an IVT reaction mixture includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified phosphates. In some embodiments, the NTPs comprise adenosine triphosphate (ATP), cytidine triphosphate (CTP), uridine triphosphate (UTP), and guanosine triphosphate (GTP). In some embodiments, one or more of the NTPs comprises a chemical modification (e.g., a modified nucleobase, modified sugar, and/or modified phosphate). The ratios of NTPs may vary. In some embodiments, the ratio of GTP:ATP:CTP:UTP is 1:1:1:1. In some embodiments, the amount of the GTP or an analogue thereof is greater than an amount of the UTP or an analogue thereof. In some embodiments, the amount of the GTP is greater than the amount of the UTP. In some embodiments, the amount of ATP is greater than the amount of UTP, and the amount of CTP is greater than the amount of UTP. In some embodiments, the amount of the GTP or an analogue thereof is greater than an amount of the UTP or an analogue thereof. In some embodiments, an IVT system comprises an at least 2:1 ratio of GTP concentration to ATP concentration, an at least 2:1 ratio of GTP concentration to CTP concentration, and an at least 4:1 ratio of GTP concentration to UTP concentration. In some embodiments, an IVT system comprises a 2:1 ratio of GTP concentration to ATP concentration, a 2:1 ratio of GTP concentration to CTP concentration, and a 4:1 ratio of GTP concentration to UTP concentration. In some embodiments, an IVT system comprises guanosine diphosphate (GDP). In some embodiments, an IVT system comprises an at least 3:1 ratio of GTP plus GDP concentration to ATP concentration, an at least 6:1 ratio of GTP plus GDP concentration to CTP concentration, and an at least 6:1 ratio of GTP plus GDP concentration to UTP concentration. In some embodiments,
an IVT system comprises guanosine monophosphate (GMP). In some embodiments, an IVT system comprises an at least 3:1 ratio of GTP plus GMP concentration to ATP concentration, an at least 6:1 ratio of GTP plus GMP concentration to CTP concentration, and an at least 6:1 ratio of GTP plus GMP concentration to UTP concentration. It is to be understood that in embodiments where two NTPs (NTP-1 and NTP-2) are present in a ratio of concentrations (e.g., a 2:1 ratio of NTP-1:NTP-2), the concentration of a given NTP (e.g., ATP) is the sum of concentrations of the natural NTP (e.g., unmodified ATP) and all analogues of that NTP (e.g., m6ATP) present in the reaction mixture. The NTPs may be manufactured in house, may be selected from a supplier, or may be synthesized. The NTPs may be natural and/or unnatural (modified) NTPs. Any number of RNA polymerases or variants may be used in IVT methods. The polymerase may be selected from, but is not limited to, a phage RNA polymerase, e.g., a T7 RNA polymerase, a T3 RNA polymerase, a SP6 RNA polymerase, and/or mutant polymerases such as, but not limited to, polymerases able to incorporate modified nucleic acids and/or modified nucleotides, including chemically modified nucleic acids and/or nucleotides. Some embodiments exclude the use of DNase. In some embodiments, an IVT reaction uses an RNA polymerase selected from the group consisting of T7 RNA polymerase, T3 RNA polymerase, K11 RNA polymerase, and SP6 RNA polymerase. In some embodiments, an IVT reaction uses a T3 RNA polymerase. In some embodiments, an IVT reaction uses an SP6 RNA polymerase. In some embodiments, an IVT reaction uses a K11 RNA polymerase. In some embodiments, an IVT reaction uses a T7 RNA polymerase. In some embodiments, a wild-type T7 polymerase is used in an IVT reaction. In some embodiments, a mutant T7 polymerase is used in an IVT reaction. In some embodiments, a T7 RNA polymerase variant comprises an amino acid sequence that shares at least 50%, 60%, 70%, 80%, 90%, 95%, or 99% identity with a wild-type T7 (WT T7) polymerase. In some embodiments, the T7 polymerase variant is a T7 polymerase variant described by International Application Publication Number WO2019/036682 or WO2020/172239, each of which is incorporated herein by reference to the extent it discloses RNA polymerases. In some embodiments, a T7 RNA polymerase variant comprises an amino acid sequence with at least 50%, 60%, 70%, 80%, 90%, 95%, or 99% sequence identity to the amino acid sequence of any one of SEQ ID NOs: 1–4. In some embodiments, the RNA polymerase (e.g., T7 RNA polymerase or T7 RNA polymerase variant) is present in a reaction (e.g., an IVT reaction) at a concentration of 0.01 mg/ml to 1 mg/ml. For example, the RNA polymerase may be present in a reaction at a concentration of 0.01 mg/mL, 0.05 mg/ml, 0.1 mg/ml, 0.5 mg/ml or 1.0 mg/ml. In some embodiments, the T7 RNA polymerase variant comprises the amino acid sequence of any
one of SEQ ID NOs: 1–4. T7 RNA polymerase variants with one or more mutations relative to WT T7 RNA polymerase have several advantages in IVT reactions, including improved speed, fidelity, and reduced production of double-stranded RNA (dsRNA) transcripts. Double-stranded RNA transcripts, in which at least a portion of an RNA transcript is hybridized to another RNA molecule, elicit an innate immune response when introduced into a cell, causing degradation of both strands of a dsRNA. Minimizing the formation of dsRNA transcripts during IVT enables the production of less immunogenic, and thus more stable, circular RNA compositions. In some embodiments, the concentration of double-stranded RNA in a composition comprising RNA is 5% (%w/w) or less, 4% or less, 3% or less, 2.5% or less, 2% or less, 1.75% or less, 1.5% or less, 1.25% or less, 1% or less, 0.9% or less, 0.8% or less, 0.7% or less, 0.6% or less, 0.5% or less, 0.4% or less, 0.3% or less, 0.25% or less, 0.2% or less, 0.175% or less, 0.15% or less, 0.125% or less, or 0.1% or less. In some embodiments, the concentration of double-stranded RNA in a composition comprising RNA is 0.05% (%w/w) or less, 0.04% or less, 0.03% or less, 0.02% or less, or 0.01% or less. Methods of measuring the presence and/or amount of dsRNA in a composition are known in the art. Non-limiting examples of methods for measuring dsRNA content of a sample include ELISAs and immunoblotting using antibodies specific to dsRNA. Additionally, the total mass of RNA in a sample can be measured using techniques such as spectroscopy (NanoDrop), qRT-PCR, and/or ddPCR, and the mass of dsRNA can be measured using an intercalating agent that fluoresces when bound to dsRNA, such as acridine orange, with the dsRNA concentration being calculated by division. In some embodiments, the concentration of dsRNA in a composition refers to the mass of RNA nucleotides that are part of a double- stranded RNA:RNA hybrid, with other unhybridized nucleotides from either RNA in the hybrid not contributing to the amount of dsRNA in a composition. In other embodiments, the concentration of dsRNA in a sample refers to the concentration of RNA molecules containing nucleotides that are part of an RNA:RNA hybrid. In some embodiments, the RNA composition produced using a T7 variant RNA polymerase is less immunogenic than an RNA composition produced using a WT T7 RNA polymerase. Methods of determining the immunogenicity of an RNA composition are known in the art, and include analysis of innate immune receptor (e.g., RIG-I, TLR3, MDA5) stimulation and/or phosphorylation, quantification of cytokine (e.g., IP- 10) production by qRT-PCR, RNAseq, and/or ELISA, measurement of RNAi pathway activity, upregulation and/or activation of antiviral proteins (e.g., MAVS), and analysis of cell death. The “percent identity,” “sequence identity,” “% identity,” or “% sequence identity” (as they may be interchangeably used herein) of two sequences (e.g., nucleic acid or amino acid) refers to a quantitative measurement of the similarity between two sequences (e.g., nucleic acid or amino acid). Percent identity can be determined using the algorithms of Karlin and Altschul,
Proc. Natl. Acad. Sci. USA 87:2264-68, 1990, modified as in Karlin and Altschul, Proc. Natl. Acad. Sci. USA 90:5873-77, 1993. Such algorithms are incorporated into the NBLAST and XBLAST programs (version 2.0) of Altschul et al., J. Mol. Biol.215:403-10, 1990. BLAST protein searches can be performed with the XBLAST program, score=50, word length=3, to obtain amino acid sequences homologous to the protein molecules of interest. Where gaps exist between two sequences, Gapped BLAST can be utilized as described in Altschul et al., Nucleic Acids Res.25(17):3389-3402, 1997. When utilizing BLAST and Gapped BLAST programs, the default parameters of the respective programs (e.g., XBLAST and NBLAST) can be used. When a percent identity is stated, or a range thereof (e.g., at least, more than, etc.), unless otherwise specified, the endpoints shall be inclusive and the range (e.g., at least 70% identity) shall include all ranges within the cited range. An IVT system, in some embodiments, comprises magnesium buffer, dithiothreitol (DTT) spermidine, pyrophosphatase, and/or RNase inhibitor. In some embodiments, an IVT system omits an RNase inhibitor. An IVT system may be incubated at 25 degrees Celsius or at 37 degrees Celsius. Other temperatures may be used, depending in part on the polymerase (e.g., use of a variant polymerase). In some embodiments, the RNA transcript is not capped via enzymatic capping prior to circularization. Nucleic acids Some aspects relate to compositions comprising nucleic acids (e.g., RNA (e.g., circular RNA)) and methods of producing nucleic acids. As used herein, the term “nucleic acid” includes multiple nucleotides (i.e., molecules comprising a sugar (e.g., ribose or deoxyribose) linked to a phosphate group and to an exchangeable organic base, which is either a substituted pyrimidine (e.g., cytosine (C), thymine (T) or uracil (U)) or a substituted purine (e.g., adenine (A) or guanine (G))). The term nucleic acid includes polyribonucleotides as well as polydeoxyribonucleotides. The term nucleic acid also includes polynucleosides (i.e., a polynucleotide minus the phosphate) and any other organic base containing polymer. Non- limiting examples of nucleic acids include chromosomes, genomic loci, genes, or gene segments that encode polynucleotides or polypeptides, coding sequences, non-coding sequences (e.g., intron, 5′-UTR, or 3′-UTR) of a gene, pri-mRNA, pre-mRNA, cDNA, mRNA, etc. A nucleic acid (e.g., circular RNA) may include a substitution and/or modification. In some embodiments, the substitution and/or modification is in one or more bases and/or sugars. For example, in some embodiments a nucleic acid (e.g., RNA) includes nucleotides having an organic group, such as a methyl group, attached to a nucleic acid base at the N6 position. Thus,
in some embodiments, an RNA comprises one or more N6-methyladenosine nucleotides. A phosphate, sugar, or nucleic acid base of a nucleotide may also be substituted for another phosphate, sugar, or nucleic acid base. For example, a uridine nucleoside may be substituted for a pseudouridine nucleoside, in which the uracil base is attached to the sugar by a carbon-carbon bond rather than a nitrogen-carbon bond. Thus, in some embodiments, a nucleic acid (e.g., circular RNA) is heterogeneous in backbone composition thereby containing any possible combination of polymer units linked together such as peptide-nucleic acids (which have an amino acid backbone with nucleic acid bases). In a nucleic acid comprising modified nucleotides, the modified nucleotides may be present at positions corresponding to a given nucleobase (e.g., adenine positions) or nucleoside comprising a given nucleobase (e.g., adenosine positions). Positions specified using a given nucleobase or nucleoside refer to the sequence information encoded by the nucleobase (e.g., adenosine or adenine positions refer to the locations of “A”s in a nucleotide sequence), and so the presence of modified nucleotides comprising a modified form of the given nucleobase at those positions does not change the sequence information (e.g., encoded amino acid sequence) of the nucleic acid. The nucleic acids may include nucleic acid sequences that have been removed from their naturally occurring environment, recombinant or cloned DNA isolates, and chemically synthesized analogues or analogues biologically synthesized by heterologous systems. An “engineered nucleic acid” is a nucleic acid that does not occur in nature. It should be understood, however, that while an engineered nucleic acid as a whole is not naturally- occurring, it may include nucleotide sequences that occur in nature. In some embodiments, an engineered nucleic acid comprises nucleotide sequences from different organisms (e.g., from different species). For example, in some embodiments, an engineered nucleic acid includes a bacterial nucleotide sequence, a human nucleotide sequence, and/or a viral nucleotide sequence. Engineered nucleic acids include recombinant nucleic acids and synthetic nucleic acids. A “recombinant nucleic acid” is a molecule that is constructed by joining nucleic acids (e.g., isolated nucleic acids, synthetic nucleic acids, or a combination thereof) and, in some embodiments, can replicate in a living cell. A “synthetic nucleic acid” is a molecule that is amplified or chemically, or by other means, synthesized. A synthetic nucleic acid includes those that are chemically modified, or otherwise modified, but can base pair with naturally-occurring nucleic acid molecules. Recombinant and synthetic nucleic acids also include those molecules that result from the replication of either of the foregoing. A nucleic may comprise naturally occurring nucleotides and/or non-naturally occurring nucleotides such as modified nucleotides.
In some embodiments, a nucleic acid is present in (or on) a vector. Examples of vectors include but are not limited to bacterial plasmids, phage, cosmids, phasmids, fosmids, bacterial artificial chromosomes, yeast artificial chromosomes, viruses, and retroviruses (for example vaccinia, adenovirus, adeno-associated virus, lentivirus, herpes-simplex virus, Epstein-Barr virus, fowlpox virus, pseudorabies, baculovirus) and vectors derived therefrom. In some embodiments, a nucleic acid (e.g., DNA) used as an input molecule for in vitro transcription (IVT) is present in a plasmid vector. When applied to a nucleic acid sequence, the term “isolated” denotes that the polynucleotide sequence has been removed from its natural genetic milieu and is thus free of other extraneous or unwanted coding sequences (but may include naturally occurring 5′ and 3′ untranslated regions such as promoters and terminators), and is in a form suitable for use within genetically engineered protein production systems. Such isolated molecules are those that are separated from their natural environment. The terms 5′ and 3′ are used herein to describe features of a nucleic acid sequence related to either the position of genetic elements and/or the direction of events (5′ to 3′), such as e.g. transcription by RNA polymerase or translation by the ribosome which proceeds in 5′ to 3′ direction. Synonyms are upstream (5′) and downstream (3′). Conventionally, DNA sequences, gene maps, vector cards and RNA sequences are drawn with 5′ to 3′ from left to right or the 5′ to 3′ direction is indicated with arrows, wherein the arrowhead points in the 3′ direction. Accordingly, 5′ (upstream) indicates genetic elements positioned towards the left-hand side, and 3′ (downstream) indicates genetic elements positioned towards the right-hand side, when following this convention. A nucleic acid (e.g., circular RNA) typically comprises a plurality of nucleotides. A nucleotide includes a nitrogenous base, a five-carbon sugar (ribose or deoxyribose), and at least one phosphate group. Nucleotides include nucleoside monophosphates, nucleoside diphosphates, and nucleoside triphosphates. A nucleoside monophosphate (NMP) includes a nucleobase linked to a ribose and a single phosphate; a nucleoside diphosphate (NDP) includes a nucleobase linked to a ribose and two phosphates; and a nucleoside triphosphate (NTP) includes a nucleobase linked to a ribose and three phosphates. Nucleotide analogs are compounds that have the general structure of a nucleotide or are structurally similar to a nucleotide. Nucleotide analogs, for example, include an analog of the nucleobase, an analog of the sugar and/or an analog of the phosphate group(s) of a nucleotide. A nucleoside includes a nitrogenous base and a 5-carbon sugar. Thus, a nucleoside plus a phosphate group yields a nucleotide. Nucleoside analogs are compounds that have the general
structure of a nucleoside or are structurally similar to a nucleoside. Nucleoside analogs, for example, include an analog of the nucleobase and/or an analog of the sugar of a nucleoside. It should be understood that the term “nucleotide” includes naturally occurring nucleotides, synthetic nucleotides and modified nucleotides, unless indicated otherwise. Examples of naturally occurring nucleotides used for the production of RNA, e.g., in an IVT reaction, include adenosine triphosphate (ATP), guanosine triphosphate (GTP), cytidine triphosphate (CTP), uridine triphosphate (UTP), and uridine triphosphate (UTP). In some embodiments, adenosine diphosphate (ADP), guanosine diphosphate (GDP), cytidine diphosphate (CDP), and/or uridine diphosphate (UDP) are used. In some embodiments, adenosine monophosphate (AMP), guanosine monophosphate (GMP), cytidine monophosphate (CMP), and/or uridine monophosphate (UMP) are used. In some embodiments, GMP is used. Use of GMP, which may initiate in vitro transcription of RNAs with 5′-terminal guanosine nucleotides, allows production of a linear RNA with a 5′-terminal monophosphate, such that the 5′ and 3′ termini of the resulting RNA may be ligated to produce a circular RNA without the need for a separate step to produce the 5′-terminal phosphate. Examples of nucleotide analogs include, but are not limited to, antiviral nucleotide analogs, phosphate analogs (soluble or immobilized, hydrolyzable or non-hydrolyzable), dinucleotide, trinucleotide, tetranucleotide, e.g., a cap analog, or a precursor/substrate for enzymatic capping (vaccinia or ligase), a nucleotide labeled with a functional group to facilitate ligation/conjugation of cap or 5 ^ moiety (IRES), a nucleotide labeled with a 5 ^ PO4 to facilitate ligation of cap or 5 ^ moiety, or a nucleotide labeled with a functional group/protecting group that can be chemically or enzymatically cleaved. Examples of antiviral nucleotide/nucleoside analogs include, but are not limited, to Ganciclovir, Entecavir, Telbivudine, Vidarabine and Cidofovir. Modified nucleotides may include modified nucleobases. For example, an RNA (e.g., RNA transcript or circular RNA) may include a modified uracil nucleobase selected from pseudouracil (ψ), N1-methylpseudouracil (m1ψ), 1-ethylpseudouracil, 2-thiouracil, 4′-thiouracil, 2-thio-1-methyl-1-deaza-pseudouracil, 2-thio-1-methyl-pseudouracil, 2-thio-5-aza-uracil, 2-thio- dihydropseudouracil, 2-thio-dihydrouracil, 2-thio-pseudouracil, 4-methoxy-2-thio-pseudouracil, 4-methoxy-pseudouracil, 4-thio-1-methyl-pseudouracil, 4-thio-pseudouracil, 5-aza-uracil, dihydropseudouracil, 5-methyluracil, 5-methoxyuracil (mo5U) and 2′-O-methyluracil. In some embodiments, an an RNA (e.g., RNA transcript or circular RNA) includes a modified guanine nucleobase selected from digoxigeninated guanine, 6-thioguanine, 7-deazaguanine, 7-deaza-7- propargylaminoguanine, 8-oxoguanine, araguanine, biotin-16-7-deaza-7- propargylaminoguanine, isoguanine, N2-methylguanine, O6-methylguanine, thienoguanine, and
2,6-daminoguanine. In some embodiments, an RNA transcript may include a modified cytosine nucleobase selected from digoxigeninated cytosine, 2-thiocytosine, 5-aminoallylcytosine, 5- bromocytosine, 5-carboxycytosine, 5-formylcytosine, 5-hydroxycytosine, 5- hydroxymethylcytosine, 5-methoxycytosine, 5-methylcytosine, 5-propargylaminocytosine, 5- propynylcytosine, 6-azacytosine, aracytosine, cyanine 3-5-propargylaminocytosine, cyanine 3- aminoallylcytosine, cyanine 5-6-propargylaminocytosine, cyanine 5-aminoallylcytosine, desthiobiotin-6-aminoallylcytosine, N4-biotin-OBEA-cytosine, N4-methylcytosine, pseudoisocytosine, and thienocytosine. In some embodiments, an RNA (e.g., RNA transcript or circular RNA) includes a modified adenine nucleobase selected from digoxigeninated adenine, N6-methyladenine, 7-deazaadenine, 7-deaza-7-propargylaminoadenine, 8-azaadenine, 8- azidoadenine, 8-chloroadenine, 8-oxoadenine, araadenine, N1-methyladenine, N6- methyladenine, 3-deazaadenine, 2,6-diaminoadenine, 2-methyl-thio-N6-isopentenyladenine (ms2i6A), 2-methylthio-N6-methyladenine (ms2m6A), N6-(cis-hydroxyisopentenyl)adenine (io6A), 2-methylthio-N6-(cis-hydroxyisopentenyl)adenine (ms2io6A), N6- glycinylcarbamoyladenine (g6A), N6-threonylcarbamoyladenine (t6A), 2-methylthio-N6- threonyl carbamoyladenine (ms2t6A), N6-methyl-N6-threonylcarbamoyladenine (m6t6A), N6- hydroxynorvalylcarbamoyladenine (hn6A), 2-methylthio-N6-hydroxynorvalyl carbamoyladenine (ms2hn6A), N6,N6-dimethyladenine (m62A), and N6-acetyladenine (ac6A). In some embodiments, an RNA (e.g., RNA transcript or circular RNA) includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified nucleobases. Modified nucleotides may include modified sugars. For example, an RNA (e.g., RNA transcript or circular RNA) may include a modified sugar selected from 2′-thioribose, 2′,3′- dideoxyribose, 2′-amino-2′-deoxyribose, 2′ deoxyribose, 2′-azido-2′-deoxyribose, 2′-fluoro-2′- deoxyribose, 2′-O-methylribose, 2′-O-methyldeoxyribose, 3′-amino-2′,3′-dideoxyribose, 3′- azido-2′,3′-dideoxyribose, 3′-deoxyribose, 3′-O-(2-nitrobenzyl)-2′-deoxyribose, 3′-O- methylribose, 5′-aminoribose, 5′-thioribose, 5-nitro-1-indolyl-2′-deoxyribose, 5′-biotin-ribose, 2′-O,4′-C-methylene-linked, 2′-O,4′-C-amino-linked ribose, and 2′-O,4′-C-thio-linked ribose. In some embodiments, an RNA (e.g., RNA transcript or circular RNA) includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified sugars. Modified nucleotides may include modified phosphates. A modified phosphate group is a phosphate group that differs from the canonical structure of phosphate. An example of a canonical structure of a phosphate is shown below:
 ,
where R5 and R3 are atoms or molecules to which the canonical phosphate is bonded. For example, for a phosphate in a nucleic acid sequence, R5 may refer to the upstream nucleotide of the nucleic acid, and R3 may refer to the downstream nucleotide of the nucleic acid. The canonical structure of phosphate also refers to structures in which one or more hydroxyl groups of the phosphate are deprotonated, or in which an oxygen atom of the phosphate is bonded to an adjacent nucleotide in a nucleic acid sequence. In some embodiments, an RNA (e.g., RNA transcript or circular RNA) may include a modified phosphate selected from phosphorothioate (PS), thiophosphate, 5′-O-methylphosphonate, 3′-O-methylphosphonate, 5′- hydroxyphosphonate, hydroxyphosphanate, phosphoroselenoate, selenophosphate, phosphoramidate, carbophosphonate, methylphosphonate, phenylphosphonate, ethylphosphonate, H-phosphonate, guanidinium ring, triazole ring, boranophosphate (BP), methylphosphonate, and guanidinopropyl phosphoramidate. In some embodiments, an RNA (e.g., RNA transcript or circular RNA) includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified phosphates. In some embodiments, an RNA comprises modified nucleotide(s) at one or more uridine positions. In some embodiments, an RNA comprises N1-methylpseudouridine nucleotide(s) at one or more uridine positions. In some embodiments, at least 20%, at least 40%, at least 60%, or at least 80% of nucleotides at uridine positions comprise N1-methylpseudouridine. In some embodiments, substantially all nucleotides at uridine positions comprise N1- methylpseudouridine. In some embodiments, an RNA comprises 5-methyluridine nucleotide(s) at one or uridine positions. In some embodiments, at least 20%, at least 40%, at least 60%, or at least 80% of nucleotides at uridine positions comprise 5-methyluridine. In some embodiments, substantially all nucleotides at uridine positions comprise 5-methyluridine. In some embodiments, an RNA comprises one or more modified nucleotides at cytidine positions. In some embodiments, an RNA comprises 5-methylcytidine nucleotide(s) at one or cytidine positions. In some embodiments, at least 20%, at least 40%, at least 60%, or at least 80% of nucleotides at cytidine positions comprise 5-methylcytidine. In some embodiments, substantially all nucleotides at cytidine positions comprise 5-methylcytidine. In some embodiments, substantially all nucleotides present at uridine positions comprise 5-methyluridine, and substantially all nucleotides present at cytidine positions comprise 5- methylcytidine. RNAs may be used to produce polypeptides of interest, such as therapeutic proteins and/or vaccine antigens. In some embodiments, an RNA encodes a vaccine antigen. In some embodiments, an RNA encodes a therapeutic protein. In some embodiments, the encoded
polypeptide comprises 9–10,000, 9–9,000, 9–8,000, 9–7,000, 9–6,000, 9–5,000, 9–4,000, 9– 3,000, 9–2,000, 9–1,000, 9–500, 9–400, 9–300, 9–200, 9–100, 9–10,000, 100–9,000, 100–8,000, 100–7,000, 100–6,000, 100–5,000, 100–4,000, 100–3,000, 100–2,000, 100–1,000, 100–500, 100–400, 100–300, 100–200, 100–9,000, 200–10,000, 200–9,000200–8,000, 200–7,000, 200– 6,000, 200–5,000, 200–4,000, 200–3,000, 200–2,000, 200–1,000, 200–500, 200–400, 500– 10,000, 500–9,000, 500–8,000, 500–7,000, 500–6,000, 500–5,000, 500–4,000, 500–3,000, 500– 2,000, 500–1,000, 1,000–10,000, 1,000–9,000, 1,000–8,000, 1,000–7,000, 1,000–6,000, 1,000– 5,000, 1,000–4,000, 1,000–3,000, or 1,000–2,000 amino acids. In some embodiments, the encoded polypeptide consists of 9–10,000, 9–9,000, 9–8,000, 9–7,000, 9–6,000, 9–5,000, 9– 4,000, 9–3,000, 9–2,000, 9–1,000, 9–500, 9–400, 9–300, 9–200, 9–100, 9–10,000, 100–9,000, 100–8,000, 100–7,000, 100–6,000, 100–5,000, 100–4,000, 100–3,000, 100–2,000, 100–1,000, 100–500, 100–400, 100–300, 100–200, 100–9,000, 200–10,000, 200–9,000200–8,000, 200– 7,000, 200–6,000, 200–5,000, 200–4,000, 200–3,000, 200–2,000, 200–1,000, 200–500, 200– 400, 500–10,000, 500–9,000, 500–8,000, 500–7,000, 500–6,000, 500–5,000, 500–4,000, 500– 3,000, 500–2,000, 500–1,000, 1,000–10,000, 1,000–9,000, 1,000–8,000, 1,000–7,000, 1,000– 6,000, 1,000–5,000, 1,000–4,000, 1,000–3,000, or 1,000–2,000 amino acids. In some embodiments, the encoded polypeptide comprises 9–5,000 amino acids. In some embodiments, the encoded polypeptide consists of 9–5,000 amino acids. In some embodiments, the encoded polypeptide comprises 20–4,000 amino acids. In some embodiments, the encoded polypeptide consists of 20–4,000 amino acids. In some embodiments, the encoded polypeptide comprises 30–3,000 amino acids. In some embodiments, the encoded polypeptide consists of 30–3,000 amino acids. In some embodiments, the encoded polypeptide comprises 40–2,000 amino acids. In some embodiments, the encoded polypeptide consists of 40–2,000 amino acids. In some embodiments, the encoded polypeptide comprises 50–1,500 amino acids. In some embodiments, the encoded polypeptide consists of 50–1,500 amino acids. In some embodiments, the encoded polypeptide comprises 100–5,000 amino acids. In some embodiments, the encoded polypeptide consists of 100–5,000 amino acids. In some embodiments, the encoded polypeptide comprises 200–4,000 amino acids. In some embodiments, the encoded polypeptide consists of 200–4,000 amino acids. In some embodiments, the encoded polypeptide comprises 300–3,000 amino acids. In some embodiments, the encoded polypeptide consists of 300–3,000 amino acids. In some embodiments, the encoded polypeptide comprises 400–2,000 amino acids. In some embodiments, the encoded polypeptide consists of 400–2,000 amino acids. In some embodiments, the encoded polypeptide comprises 500–1,500 amino acids. In some embodiments, the encoded polypeptide consists of 500–1,500 amino acids.
A therapeutic RNA is an RNA that encodes a therapeutic protein (the term ‘protein’ encompasses peptides). In some embodiments, RNA compositions comprise one or more RNAs that encode peptides or proteins that interact or complex in a cell or subject to form a multi- subunit protein (e.g., an antibody comprising a heavy chain and a light chain, a multi-subunit receptor protein, a multi-subunit signaling protein, a multi-subunit antigen, etc.) or a multivalent vaccine. Therapeutic proteins mediate a variety of effects in a host cell or in a subject to treat a disease or ameliorate the signs and symptoms of a disease. For example, a therapeutic protein can replace a protein that is deficient or abnormal, augment the function of an endogenous protein, provide a novel function to a cell (e.g., inhibit or activate an endogenous cellular activity, or act as a delivery agent for another therapeutic compound (e.g., an antibody-drug conjugate). Therapeutic RNA may be useful for the treatment of the following diseases and conditions: bacterial infections, viral infections, parasitic infections, cell proliferation disorders, genetic disorders, and autoimmune disorders. Other diseases and conditions are encompassed herein. A protein or proteins of interest encoded by an RNA composition can be essentially any protein or peptide (e.g., peptide antigen). In some embodiments, a therapeutic peptide or therapeutic protein is a biologic. A biologic is a polypeptide-based molecule that may be used to treat, cure, mitigate, prevent, or diagnose a serious or life-threatening disease or medical condition. Biologics include, but are not limited to, allergenic extracts (e.g. for allergy shots and tests), blood components, gene therapy products, human tissue or cellular products used in transplantation, vaccines, monoclonal antibodies, cytokines, growth factors, enzymes, thrombolytics, and immunomodulators, among others. In some embodiments, the therapeutic protein is a cytokine, a growth factor, an antibody (e.g., monoclonal antibody), a fusion protein, or a vaccine (e.g., an RNA encoding one or more peptide antigens designed to elicit an immune response in a subject). Non-limiting examples of therapeutic proteins include blood factors (such as Factor VIII and Factor VII), complement factors, Low Density Lipoprotein Receptor (LDLR) and MUT1. Non-limiting examples of cytokines include interleukins, interferons, chemokines, lymphokines and the like. Non-limiting examples of growth factors include erythropoietin, EGFs, PDGFs, FGFs, TGFs, IGFs, TNFs, CSFs, MCSFs, GMCSFs and the like. Non-limiting examples of antibodies include adalimumab, infliximab, rituximab, ipilimumab, tocilizumab, canakinumab, itolizumab, tralokinumab, anti- influenza virus monoclonal antibody, anti-Chikungunya virus monoclonal antibody, anti-Zika virus monoclonal antibody, anti-SARS-CoV-2 monoclonal antibody. Non-limiting examples of
fusion proteins include, for example, etanercept, abatacept and belatacept. Non-limiting examples of multivalent vaccines include, for example, multivalent cytomegalovirus (CMV) vaccine, and personalized cancer vaccines. One or more biologics currently being marketed or in development may be encoded by the RNA. While not wishing to be bound by theory, it is believed that incorporation of the encoding polynucleotides of a known biologic into the RNA will result in improved therapeutic efficacy due at least in part to the specificity, purity and/or selectivity of the construct designs. An RNA composition may encode one or more antibodies (e.g., may comprise a first RNA encoding an antibody heavy chain and a second RNA encoding an antibody light chain). The term “antibody” includes monoclonal antibodies (including full length antibodies which have an immunoglobulin Fc region), antibody compositions with polyepitopic specificity, multispecific antibodies (e.g., bispecific antibodies, diabodies, and single-chain molecules), as well as antibody fragments. The term “immunoglobulin” (Ig) is used interchangeably with “antibody” herein. A monoclonal antibody is an antibody obtained from a population of substantially homogeneous antibodies, i.e., the individual antibodies comprising the population are identical except for possible naturally occurring mutations and/or post-translation modifications (e.g., isomerizations, amidations) that may be present in minor amounts. Monoclonal antibodies are highly specific, being directed against a single antigenic site. Monoclonal antibodies specifically include chimeric antibodies (immunoglobulins) in which a portion of the heavy and/or light chain is identical with or homologous to corresponding sequences in antibodies derived from a particular species or belonging to a particular antibody class or subclass, while the remainder of the chain(s) is(are) identical with or homologous to corresponding sequences in antibodies derived from another species or belonging to another antibody class or subclass, as well as fragments of such antibodies, so long as they exhibit the desired biological activity. Chimeric antibodies include, but are not limited to, “primatized” antibodies comprising variable domain antigen-binding sequences derived from a non-human primate (e.g., Old World Monkey, Ape etc.) and human constant region sequences. Antibodies encoded in the RNA compositions may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, blood, cardiovascular, CNS, poisoning (including antivenoms), dermatology, endocrinology, gastrointestinal, medical imaging, musculoskeletal, oncology, immunology, respiratory, sensory and anti-infective. An RNA may encode one or more vaccine antigens. A vaccine antigen is a biological preparation that improves immunity to a particular disease or infectious agent. One or more vaccine antigens currently being marketed or in development may be encoded by the RNA. Vaccine antigens encoded in the RNA may be utilized to treat conditions or diseases in many
therapeutic areas such as, but not limited to, cancer, allergy, and infectious disease. In some embodiments, a vaccine may be a personalized vaccine in the form of a concatemer or individual RNAs encoding peptide epitopes or a combination thereof. An RNA may encode on or more antimicrobial peptides (AMP) or antiviral peptides (AVP). AMPs and AVPs have been isolated and described from a wide range of animals such as, but not limited to, microorganisms, invertebrates, plants, amphibians, birds, fish, and mammals. The anti-microbial polypeptides may block cell fusion and/or viral entry by one or more enveloped viruses (e.g., HIV, HCV). For example, the anti-microbial polypeptide can comprise or consist of a synthetic peptide corresponding to a region, e.g., a consecutive sequence of at least about 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, or 60 amino acids of the transmembrane subunit of a viral envelope protein, e.g., HIV-1 gp120 or gp41. The amino acid and nucleotide sequences of HIV-1 gp120 or gp41 are described in, e.g., Kuiken et al., (2008). “HIV Sequence Compendium,” Los Alamos National Laboratory. In some embodiments, RNAs (e.g., circular RNAs) are used for in vitro translation and microinjection. In some embodiments, RNA transcripts are used for RNA structure, processing and catalysis studies. In some embodiments, RNA transcripts are used for RNA amplification. In some embodiments, RNA transcripts are used as anti-sense RNA for gene expression modulation. In some embodiments, an RNA is codon optimized. Codon optimization methods are known in the art. Codon optimization, in some embodiments, may be used to match codon frequencies in target and host organisms to ensure proper folding; bias %G/C content to increase RNA thermodynamic stability or reduce secondary structures; minimize tandem repeat codons or base runs that may impair gene construction or expression; customize transcriptional and translational control regions; insert or remove protein trafficking sequences; remove/add post translation modification sites in encoded protein (e.g., glycosylation sites); add, remove or shuffle protein domains; insert or delete restriction sites; modify ribosome binding sites and RNA degradation sites; adjust translational rates to allow the various domains of the protein to fold properly; or reduce or eliminate problem secondary structures within the polynucleotide. Codon optimization tools, algorithms and services are known in the art – non-limiting examples include services from GeneArt (Life Technologies), DNA2.0 (Menlo Park CA) and/or proprietary methods. In some embodiments, the open reading frame (ORF) sequence is optimized using optimization algorithms. In some embodiments, a codon optimized sequence shares less than 95% sequence identity to a naturally occurring or wild-type sequence ORF (e.g., a naturally occurring or wild- type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized
sequence shares less than 90% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares less than 85% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares less than 80% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares less than 75% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares between 65% and 85% (e.g., between about 67% and about 85% or between about 67% and about 80%) sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares between 65% and 75% or about 80% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). When transfected into mammalian host cells, some embodiments of modified RNAs have a stability of between 12-18 hours, or greater than 18 hours, e.g., 24, 36, 48, 60, 72, or greater than 72 hours and are capable of being expressed by the mammalian host cells. In some embodiments, a codon optimized RNA may be one in which the %G/C content is increased. The %G/C-content of nucleic acid molecules (e.g., circular RNA) may influence the stability of the RNA. RNA having an increased number of guanine (G) and/or cytosine (C) nucleotides may be more thermodynamically stable than RNA containing a large number of adenine (A) and uracil (U) nucleotides. As an example, WO 2002/098443 discloses a pharmaceutical composition containing an mRNA stabilized by sequence modifications in the translated region. Due to the degeneracy of the genetic code, the modifications work by substituting existing codons for those that promote greater RNA stability without changing the resulting amino acid. The approach is limited to coding regions of the RNA. Untranslated regions Untranslated regions (UTRs) are sections of a nucleic acid before a start codon (5′ UTR) and after a stop codon (3′ UTR) that are not translated. In some embodiments, a nucleic acid (e.g., a ribonucleic acid (RNA), e.g., a circular RNA) comprising an open reading frame (ORF) encoding one or more proteins or peptides further comprises one or more UTR (e.g., a 5′ UTR or functional fragment thereof, a 3′ UTR or functional fragment thereof, or a combination thereof).
A UTR can be homologous or heterologous to the coding region in a nucleic acid. In some embodiments, the UTR is homologous to the ORF encoding the one or more proteins. In some embodiments, the UTR is heterologous to the ORF encoding the one or more proteins. In some embodiments, the nucleic acid comprises two or more 5′ UTRs or functional fragments thereof, each of which have the same or different nucleotide sequences. In some embodiments, the nucleic acid comprises two or more 3′ UTRs or functional fragments thereof, each of which have the same or different nucleotide sequences. In some embodiments, the 5′ UTR or functional fragment thereof, 3′ UTR or functional fragment thereof, or any combination thereof is sequence optimized. In some embodiments, the 5′ UTR or functional fragment thereof, 3′ UTR or functional fragment thereof, or any combination thereof comprises at least one chemically modified nucleobase, e.g., 5-methoxyuracil. UTRs can have features that provide a regulatory role, e.g., increased or decreased stability, localization, and/or translation efficiency. A nucleic acid comprising a UTR can be administered to a cell, tissue, or organism, and one or more regulatory features can be measured using routine methods. In some embodiments, a functional fragment of a 5′ UTR or 3′ UTR comprises one or more regulatory features of a full length 5′ or 3′ UTR, respectively. Natural 5′ UTRs bear features that play roles in translation initiation. They harbor signatures like Kozak sequences that are commonly known to be involved in the process by which the ribosome initiates translation of many genes.5′ UTRs also have been known to form secondary structures that are involved in elongation factor binding. By engineering the features typically found in abundantly expressed genes of specific target organs, one can enhance the stability and protein production of a nucleic acid. For example, introduction of 5′ UTR of liver-expressed mRNA, such as albumin, serum amyloid A, Apolipoprotein A/B/E, transferrin, alpha fetoprotein, erythropoietin, or Factor VIII, can enhance expression of nucleic acids in hepatic cell lines or liver. Likewise, use of 5′ UTRs from other tissue-specific mRNA to improve expression in that tissue is possible for muscle (e.g., MyoD, Myosin, Myoglobin, Myogenin, Herculin), for endothelial cells (e.g., Tie-1, CD36), for myeloid cells (e.g., C/EBP, AML1, G-CSF, GM-CSF, CD11b, MSR, Fr-1, i-NOS), for leukocytes (e.g., CD45, CD18), for adipose tissue (e.g., CD36, GLUT4, ACRP30, adiponectin), and for lung epithelial cells (e.g., SP-A/B/C/D). In some embodiments, UTRs are selected from a family of transcripts whose proteins share a common function, structure, feature, or property. For example, an encoded polypeptide can belong to a family of proteins (i.e., that share at least one function, structure, feature, localization, origin, or expression pattern), which are expressed in a particular cell, tissue or at
some time during development. The UTRs from any of the genes or circular RNA can be swapped for any other UTR of the same or different family of proteins to create a new nucleic acid. In some embodiments, the 5′ UTR and the 3′ UTR can be heterologous. In some embodiments, the 5′ UTR can be derived from a different species than the 3′ UTR. In some embodiments, the 3′ UTR can be derived from a different species than the 5′ UTR. International Patent Application No. PCT/US2014/021522 (Publ. No. WO/2014/164253) provides a listing of exemplary UTRs that may be utilized in the nucleic acids as flanking regions to an ORF. This publication is incorporated by reference herein for this purpose. Additional exemplary UTRs that may be utilized in the nucleic acids include, but are not limited to, one or more 5′ UTRs and/or 3′ UTRs derived from the nucleic acid sequence of: a globin, such as an α- or β-globin (e.g., a Xenopus, mouse, rabbit, or human globin); a strong Kozak translational initiation signal; a CYBA (e.g., human cytochrome b-245 α polypeptide); an albumin (e.g., human albumin7); a HSD17B4 (hydroxysteroid (17-β) dehydrogenase); a virus (e.g., a tobacco etch virus (TEV), a Venezuelan equine encephalitis virus (VEEV), a Dengue virus, a cytomegalovirus (CMV; e.g., CMV immediate early 1 (IE1)), a hepatitis virus (e.g., hepatitis B virus), a sindbis virus, or a PAV barley yellow dwarf virus); a heat shock protein (e.g., hsp70); a translation initiation factor (e.g., elF4G); a glucose transporter (e.g., hGLUT1 (human glucose transporter 1)); an actin (e.g., human α or β actin); a GAPDH; a tubulin; a histone; a citric acid cycle enzyme; a topoisomerase (e.g., a 5′ UTR of a TOP gene lacking the 5′ TOP motif (the oligopyrimidine tract)); a ribosomal protein Large 32 (L32); a ribosomal protein (e.g., human or mouse ribosomal protein, such as, for example, rps9); an ATP synthase (e.g., ATP5A1 or the β subunit of mitochondrial H+-ATP synthase); a growth hormone (e.g., bovine (bGH) or human (hGH)); an elongation factor (e.g., elongation factor 1 α1 (EEF1A1)); a manganese superoxide dismutase (MnSOD); a myocyte enhancer factor 2A (MEF2A); a β-F1- ATPase, a creatine kinase, a myoglobin, a granulocyte-colony stimulating factor (G-CSF); a collagen (e.g., collagen type I, alpha 2 (Col1A2), collagen type I, alpha 1 (Col1A1), collagen type VI, alpha 2 (Col6A2), collagen type VI, alpha 1 (Col6A1)); a ribophorin (e.g., ribophorin I (RPNI)); a low density lipoprotein receptor-related protein (e.g., LRP1); a cardiotrophin-like cytokine factor (e.g., Nnt1); calreticulin (Calr); a procollagen-lysine, 2-oxoglutarate 5- dioxygenase 1 (Plod1); and a nucleobindin (e.g., Nucb1). In some embodiments, the 5′ UTR is selected from the group consisting of a β-globin 5′ UTR; a 5′ UTR containing a strong Kozak translational initiation signal; a cytochrome b-245 α polypeptide (CYBA) 5′ UTR; a hydroxysteroid (17-β) dehydrogenase (HSD17B4) 5′ UTR; a Tobacco etch virus (TEV) 5′ UTR; a Venezuelen equine encephalitis virus (TEEV) 5′ UTR; a 5′
proximal open reading frame of rubella virus (RV) RNA encoding nonstructural proteins; a Dengue virus (DEN) 5′ UTR; a heat shock protein 70 (Hsp70) 5′ UTR; a eIF4G 5′ UTR; a GLUT1 5′ UTR; functional fragments thereof and any combination thereof. In some embodiments, the 3′ UTR is selected from the group consisting of a β-globin 3′ UTR; a CYBA 3′ UTR; an albumin 3′ UTR; a growth hormone (GH) 3′ UTR; a VEEV 3′ UTR; a hepatitis B virus (HBV) 3′ UTR; α-globin 3′ UTR; a DEN 3′ UTR; a PAV barley yellow dwarf virus (BYDV-PAV) 3′ UTR; an elongation factor 1 α1 (EEF1A1) 3′ UTR; a manganese superoxide dismutase (MnSOD) 3′ UTR; a β subunit of mitochondrial H(+)-ATP synthase (β- mRNA) 3′ UTR; a GLUT13′ UTR; a MEF2A 3′ UTR; a β-F1-ATPase 3′ UTR; functional fragments thereof and combinations thereof. Wild-type UTRs derived from any gene or mRNA can be incorporated into the nucleic acids (e.g., circular RNAs). In some embodiments, a UTR can be altered relative to a wild type or native UTR to produce a variant UTR, e.g., by changing the orientation or location of the UTR relative to the ORF; or by inclusion of additional nucleotides, deletion of nucleotides, swapping or transposition of nucleotides. In some embodiments, variants of 5′ or 3′ UTRs can be utilized, for example, mutants of wild type UTRs, or variants wherein one or more nucleotides are added to or removed from a terminus of the UTR. Additionally, one or more synthetic UTRs can be used in combination with one or more non-synthetic UTRs. See, e.g., Mandal and Rossi, Nat. Protoc.20138(3):568-82, and sequences available at www.addgene.org, the contents of each are incorporated herein by reference in their entirety. UTRs or portions thereof can be placed in the same orientation as in the transcript from which they were selected or can be altered in orientation or location. Hence, a 5′ and/or 3′ UTR can be inverted, shortened, lengthened, or combined with one or more other 5′ UTRs or 3′ UTRs. In some embodiments, the nucleic acid may comprise multiple UTRs, e.g., a double, a triple or a quadruple 5′ UTR or 3′ UTR. For example, a double UTR comprises two copies of the same UTR either in series or substantially in series. For example, a double beta-globin 3′ UTR can be used (see, e.g., US 2010/0129877, the contents of which are incorporated herein by reference for this purpose). Nucleic acids can comprise combinations of features. For example, the ORF can be flanked by a 5′ UTR that comprises a strong Kozak translational initiation signal and/or a 3′ UTR comprising an oligo(dT) sequence for templated addition of a polyA tail. A 5′ UTR can comprise a first nucleic acid fragment and a second nucleic acid fragment from the same and/or different UTRs (see, e.g., US 2010/0293625, herein incorporated by reference for this purpose).
Other non-UTR sequences can be used as regions or subregions within nucleic acids. For example, introns or portions of intron sequences can be incorporated into nucleic acids. Incorporation of intronic sequences can increase protein production as well as nucleic acid expression levels. In some embodiments, the nucleic acid comprises an internal ribosome entry site (IRES) instead of or in addition to a UTR (see, e.g., Yakubov et al., Biochem. Biophys Res Commun.2010.394(1):189-193, the contents of which are incorporated herein by reference for this purpose). In some embodiments, the nucleic acid comprises an IRES instead of a 5′ UTR sequence. In some embodiments, the nucleic acid comprises an IRES that is located between a 5′ UTR and an open reading frame. In some embodiments, the nucleic acid comprises an ORF encoding a viral capsid sequence. In some embodiments, the nucleic acid comprises a synthetic 5′ UTR in combination with a non-synthetic 3′ UTR. In some embodiments, the UTR can also include at least one translation enhancer nucleic acid, translation enhancer element, or translational enhancer elements (collectively, “TEE,” which refers to nucleic acid sequences that increase the amount of polypeptide or protein produced from a polynucleotide. As a non-limiting example, the TEE can include those described in US2009/0226470, incorporated herein by reference for this purpose, and others known in the art. As a non-limiting example, the TEE can be located between the transcription promoter and the start codon. In some embodiments, the 5′ UTR comprises a TEE. In one aspect, a TEE is a conserved element in a UTR that can promote translational activity of a nucleic acid such as, but not limited to, cap-dependent or cap-independent translation. In one non-limiting example, the TEE comprises the TEE sequence in the 5′-leader of the Gtx homeodomain protein. See, e.g., Chappell et al., PNAS.2004.101:9590-9594, incorporated herein by reference for this purpose. PolyA and polyAC regions Some aspects relate to circular RNAs containing one or more polyA or polyAC regions, and/or methods of producing circular RNAs containing one or more polyA or polyAC regions. A “polyA region” is a region of an RNA that is downstream, e.g., directly downstream (i.e., 3′), from the open reading frame and/or the 3′ UTR that contains multiple, consecutive adenosine monophosphates. A “polyAC region” is a region of an RNA that is downstream, e.g., directly downstream from (i.e., 3′), from the open reading frame and/or the 3′ UTR that contains multiple adenosine monophosphates and multiple cytidine monophosphates. A polyA or polyAC region may contain 10 to 300 adenosine monophosphates and/or cytidine monophosphates. For example, a polyA or polyAC region may contain 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 210, 220, 230, 240,
250, 260, 270, 280, 290 or 300 adenosine monophosphates and/or cytidine monophosphates. In some embodiments, a polyA or polyAC region contains 50 to 250 nucleotides selected from adenosine monophosphates and and/or cytidine monophosphates. In a relevant biological setting (e.g., in cells, in vivo, etc.) the polyA or polyAC region functions to protect RNA from enzymatic degradation, e.g., in the cytoplasm, and aids in transcription termination, export of the RNA from the nucleus, and translation. As used herein, “polyadenylation efficiency” refers to the amount (e.g., expressed as a percentage) of RNAs having polyA or polyAC region that are produced by an IVT reaction using an input DNA relative to the total number of RNAs produced in the IVT reaction using the input DNA. The polyadenylation efficiency of an IVT reaction may vary, for example depending upon the RNA polymerase used, amount or purity of input DNA used, etc. In some embodiments, the polyadenylation efficiency of an IVT reaction is greater than 85%, 90%, 95%, or 99.9%. Methods of calculating polyadenylation efficiency are known, for example by determining the amount of polyA or polyAC region-containing RNA relative to total RNA produced in an IVT reaction by column chromatography (e.g., oligo-dT chromatography). In some embodiments, at least 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 99.9% of RNAs in a circular RNA composition comprise a polyA or polyAC region. In some embodiments, at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 99.9% of each RNA in a circular RNA composition comprise a polyA or polyAC region. The polyadenylation efficiency (e.g., percentage of polyA or polyAC region- containing RNAs in a circular RNA composition) may be measured i) after the IVT reaction and before purification, or ii) after the circular RNA composition has been purified (e.g., by chromatography, such as oligo-dT chromatography). Unique polyA or polyAC region lengths provide certain advantages to nucleic acids. Generally, the length of a polyA or polyAC region, when present, is greater than 10 nucleotides in length. In some embodiments, the polyA or polyAC region is greater In another embodiment, the polyA or polyAC region is at least 15 nucleotides in length (e.g., at least or greater than about 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 450, 500, 600, 700, 800, 900, 1,000, 1,100, 1,200, 1,300, 1,400, 1,500, 1,600, 1,700, 1,800, 1,900, 2,000, 2,500, or 3,000 nucleotides). In some embodiments, the polyA or polyAC region is designed relative to the length of the overall nucleic acid or the length of a particular region of the nucleic acid. This design can be based on the length of a coding region, the length of a particular feature or region or based on the length of the ultimate product expressed from the nucleic acids.
In this context, the polyA or polyAC region can be 10, 20, 30, 40, 50, 60, 70, 80, 90, or 100% greater in length than the nucleic acid or feature thereof. The polyA or polyAC region can also be designed as a fraction of the nucleic acid to which it belongs. In this context, the polyA or polyAC region can be 10, 20, 30, 40, 50, 60, 70, 80, or 90% or more of the total length of the construct, a construct region or the total length of the construct minus the polyA or polyAC region. Further, engineered binding sites and conjugation of nucleic acids for PolyA-binding protein can enhance expression. In some embodiments, a circular RNA comprises multiple polyA or polyAC regions that are separated by one or more intervening sequences of the circular RNA. In some embodiments, a circular RNA comprises a first polyA or polyAC region that is upstream of the open reading frame, and a second polyA or polyAC region that is downstream of the open reading frame. In some embodiments, the first polyA or polyAC region is located upstream of the 5′ UTR. In some embodiments, the first polyA or polyAC region is located downstream of the 5′ UTR and upstream of the open reading frame and/or an internal ribosome entry site (IRES). In some embodiments, the second polyA or polyAC region is downstream of the 3′ UTR. In some embodiments, the second polyA or polyAC region is downstream of the open reading frame, and upstream of the 3′ UTR. In some embodiments, a circular RNA comprises, in 5′-to-3′ order: a 5′ UTR, a first polyA or polyAC region, an IRES, an open reading frame, a second polyA or polyAC region, and a 3′ UTR. In some embodiments, each polyA or polyAC region is the same length. In other embodiments, the first and second polyA or polyAC regions are different lengths. Identification and Ratio Determination (IDR) Sequences An Identification and Ratio Determination (IDR) sequence is a sequence of a biological molecule (e.g., nucleic acid or protein) that, when combined with the sequence of a target biological molecule, serves to identify the target biological molecule. Typically, an IDR sequence is a heterologous sequence that is incorporated within or appended to a sequence of a target biological molecule and can be used as a reference to identify the target molecule. Thus, in some embodiments, a nucleic acid (e.g., circular RNA) comprises (i) a target sequence of interest (e.g., a coding sequence encoding a therapeutic and/or antigenic peptide or protein); and (ii) a unique IDR sequence. An RNA species (e.g., RNA having a given coding sequence) may comprise an IDR sequence that differs from the IDR sequence of other RNA species (e.g., RNA(s) having different coding sequence(s)). Each IDR sequence thus identifies a particular RNA species, and so the abundance of IDR sequences may be measured to determine the abundance of each RNA
species in a composition. Use of distinct IDR sequences to identify RNA species allows for analysis of multivalent RNA compositions (e.g., containing multiple RNA species) containing RNA species with similar coding sequences and/or lengths, which could otherwise be difficult to distinguish using PCR- or chromatography-based analysis of full-length RNAs. Each RNA species in a multivalent RNA composition may comprise an IDR sequence that is not a sequence isomer of an IDR sequence of another RNA species in a multivalent RNA composition (e.g., the IDR sequence does not have the same number of adenine nucleotides, the same number of cytosine nucleotides, the same number of guanine nucleotides, and the same number of uracil nucleotides, as another IDR sequence in the composition, even if those sequences have different sequences). Having identical nucleotide compositions causes sequence isomers to have the same mass, presenting a challenge to distinguishing sequence isomers using mass-based identification methods (e.g., mass spectrometry). Each RNA species in a multivalent RNA composition may comprise an IDR sequence having a mass that differs from the mass of IDR sequences of each other RNA species in a multivalent RNA composition. For example, the mass of each IDR sequence may differ from the mass of other IDR sequences by at least 9 Da, at least 25 Da, at least 25 Da, or at least 50 Da. Use of IDR sequences with distinct masses allows RNA fragments comprising different IDR sequences to be distinguished using mass-based analysis methods (e.g., mass spectrometry), which do not require reverse transcription, amplification, or sequencing of RNAs. Each RNA species in an RNA composition may comprises an IDR sequence with a different length. For example, each IDR sequence may have a length independently selected from 0 to 25 nucleotides. The length of a nucleic acid influences the rate at which the nucleic acid traverses a chromatography column, and so the use of IDR sequences of different lengths on different RNA species allows RNA fragments having different IDR sequences to be distinguished using chromatography-based methods (e.g., LC-UV). IDR sequences may be chosen such that no IDR sequence comprises a start codon, ‘AUG’. Lack of a start codon in an IDR sequence prevents undesired translation of nucleotide sequences within and/or downstream from the IDR sequence. IDR sequences may be chosen such that no IDR sequence comprises a recognition site for a restriction enzyme. In one example, no IDR sequence comprises a recognition site for XbaI, ‘UCUAG’. Lack of a recognition site for a restriction enzyme (e.g., XbaI recognition site ‘UCUAG’) allows the restriction enzyme to be used in generating and modifying a DNA template for in vitro transcription, without affecting the IDR sequence or sequence of the transcribed RNA.
Nucleic acid production Chemical synthesis Solid-phase chemical synthesis. Nucleic acids may be manufactured in whole or in part using solid phase techniques. Solid-phase chemical synthesis of nucleic acids is an automated method wherein molecules are immobilized on a solid support and synthesized step by step in a reactant solution. Solid-phase synthesis is useful in site-specific introduction of chemical modifications in the nucleic acid sequences. The synthesis of nucleic acids by the sequential addition of monomer building blocks may be carried out in a liquid phase. The synthetic methods discussed above each has its own advantages and limitations. Attempts have been conducted to combine these methods to overcome the limitations. Such combinations of methods are within the scope of methods. The use of solid-phase or liquid- phase chemical synthesis in combination with enzymatic ligation provides an efficient way to generate long chain nucleic acids that cannot be obtained by chemical synthesis alone. Ligation Assembling nucleic acids by a ligase may also be used. DNA or RNA ligases promote intermolecular ligation of the 5′ and 3′ ends of polynucleotide chains through the formation of a phosphodiester bond. Nucleic acids such as chimeric polynucleotides and/or circular nucleic acids may be prepared by ligation of one or more regions or subregions. DNA fragments can be joined by a ligase catalyzed reaction to create recombinant DNA with different functions. Two oligodeoxynucleotides, one with a 5′ phosphoryl group and another with a free 3′ hydroxyl group, serve as substrates for a DNA ligase. Purification Purification of the nucleic acids may include, but is not limited to, nucleic acid clean-up, quality assurance and quality control. Clean-up may be performed by methods known in the arts such as, but not limited to, AGENCOURT® beads (Beckman Coulter Genomics, Danvers, MA), poly-T beads, LNATM oligo-T capture probes (EXIQON® Inc, Vedbaek, Denmark) or HPLC based purification methods such as, but not limited to, strong anion exchange HPLC, weak anion exchange HPLC, reverse phase HPLC (RP-HPLC), and hydrophobic interaction HPLC (HIC- HPLC). The term “purified” when used in relation to a nucleic acid such as a “purified nucleic acid” refers to one that is separated from at least one contaminant. A “contaminant” is any substance that makes another unfit, impure or inferior. Thus, a purified nucleic acid (e.g., DNA and RNA) is present in a form or setting different from that in which it is found in nature, or a
form or setting different from that which existed prior to subjecting it to a treatment or purification method. A quality assurance and/or quality control check may be conducted using methods such as, but not limited to, gel electrophoresis, UV absorbance, or analytical HPLC. In some embodiments, the nucleic acids may be sequenced by methods including, but not limited to reverse-transcriptase-PCR. Quantification In some embodiments, the nucleic acids may be quantified in exosomes or when derived from one or more bodily fluid. Bodily fluids include peripheral blood, serum, plasma, ascites, urine, cerebrospinal fluid (CSF), sputum, saliva, bone marrow, synovial fluid, aqueous humor, amniotic fluid, cerumen, breast milk, broncheoalveolar lavage fluid, semen, prostatic fluid, cowper's fluid or pre-ejaculatory fluid, sweat, fecal matter, hair, tears, cyst fluid, pleural and peritoneal fluid, pericardial fluid, lymph, chyme, chyle, bile, interstitial fluid, menses, pus, sebum, vomit, vaginal secretions, mucosal secretion, stool water, pancreatic juice, lavage fluids from sinus cavities, bronchopulmonary aspirates, blastocyl cavity fluid, and umbilical cord blood. Alternatively, exosomes may be retrieved from an organ selected from the group consisting of lung, heart, pancreas, stomach, intestine, bladder, kidney, ovary, testis, skin, colon, breast, prostate, brain, esophagus, liver, and placenta. Assays may be performed using construct specific probes, cytometry, qRT-PCR, real- time PCR, PCR, flow cytometry, electrophoresis, mass spectrometry, or combinations thereof while the exosomes may be isolated using immunohistochemical methods such as enzyme linked immunosorbent assay (ELISA) methods. Exosomes may also be isolated by size exclusion chromatography, density gradient centrifugation, differential centrifugation, nanomembrane ultrafiltration, immunoabsorbent capture, affinity purification, microfluidic separation, or combinations thereof. These methods afford the investigator the ability to monitor, in real time, the level of nucleic acids remaining or delivered. This is possible because the nucleic acids, in some embodiments, differ from the endogenous forms due to the structural or chemical modifications. In some embodiments, the nucleic acid may be quantified using methods such as, but not limited to, ultraviolet visible spectroscopy (UV/Vis). A non-limiting example of a UV/Vis spectrometer is a NANODROP® spectrometer (ThermoFisher, Waltham, MA). The quantified nucleic acid may be analyzed in order to determine if the nucleic acid may be of proper size, check that no degradation of the nucleic acid has occurred. Degradation of the nucleic acid may be checked by methods such as, but not limited to, agarose gel electrophoresis, HPLC based
purification methods such as, but not limited to, strong anion exchange HPLC, weak anion exchange HPLC, reverse phase HPLC (RP-HPLC), and hydrophobic interaction HPLC (HIC- HPLC), liquid chromatography-mass spectrometry (LCMS), capillary electrophoresis (CE) and capillary gel electrophoresis (CGE). Multivalent in vitro transcription (IVT) Some aspects relate to multivalent in vitro transcription. Multivalent in vitro transcription refers to contacting two or more DNA templates (e.g., a first input DNA and a second input DNA) with an RNA polymerase (e.g., a T7 RNA polymerase) under conditions that result in the production of RNA transcripts. Each input DNA (e.g., in a population of input DNA templates) in a co-IVT reaction may be obtained from a different source than other input DNAs. For example, each input DNA may be obtained from a different bacterial cell or population or bacterial cells. For example, in a co-IVT reaction having three populations of input DNAs, a first input DNA can be produced in bacterial cell population A, a second input DNA can be produced in bacterial cell population B, and a third input DNA can be produced in bacterial cell population C, where each of A, B, and C are not the same bacterial culture (e.g., co-cultured in the same container or plate). In another example, different input DNAs are obtained by separate synthesis reactions or produced by separate amplification reactions. The amounts of input DNAs used in multivalent co-IVT reactions may be normalized. Normalization may be based, for example, on the molar masses, lengths, nucleotide contents, degradation rates, and/or purity of input DNAs. In some embodiments, normalization is based on the degradation rate of resulting RNAs. Normalization may be based on the lowest level of a certain characteristic present among the input DNAs (e.g., lowest molar mass, degradation rate (e.g., of the input DNA and/or output RNA), nucleotide content, purity, and/or polyadenylation efficiency). Alternatively, normalization may be based on the highest level of a certain characteristic present among the input DNAs (e.g., highest molar mass, degradation rate (e.g., of the input DNA and/or output RNA), nucleotide context, purity, and/or polyadenylation efficiency). In some embodiments, normalization is based on the rate of RNA production from the input DNAs (e.g., the highest rate of RNA production of an input DNA or the lowest rate of RNA production of an input DNA in a reaction mixture). The amount of one or more input DNAs may be adjusted and/or normalized to improve production of RNA compositions having a pre-defined or desired ratio of RNA components. Adjusting and/or normalizing amounts of input DNAs may compensate for differences between
input DNAs (e.g., large differences in lengths of two input DNAs, or different polyadenylation efficiencies) that can affect the ratio of RNAs in a multivalent RNA composition, thereby allowing for the production of RNA compositions having desired ratios of different RNAs. For example, the amount of two input DNAs present in a co-IVT reaction may be determined by selecting a desired molar ratio of a first RNA to a second RNA, calculating the mass of each DNA template necessary to achieve the same molar ratio between input DNAs, and combining input DNAs encoding each of the first and second RNAs in the same molar ratio. The number of input DNAs (e.g., populations of input DNA molecules) used in an IVT reaction may vary, depending upon the number of different RNA molecules desired to be included in the multivalent RNA composition. An IVT reaction mixture may comprise 2 or more different input DNAs (e.g., 2, 3, 4, 5, 6, 7, 8, 9, 10, or more different input DNAs). The concentration of each of the populations of DNA molecules may also vary. The input DNAs may be added to an IVT reaction are a predefined DNA ratio, which may comprise a ratio between 2, 3, 4, 5, 6, 7, 8, 9, 10, or more different input DNAs (e.g., depending on the number of different RNAs in a composition). The size of two or more input DNAs (e.g., DNAs in two or more different populations of input DNAs) may also vary. The mass of each population of input DNA molecules in an IVT reaction may also vary. The molar ratio between populations of input DNA molecules in an IVT reaction may also vary. Different input DNA molecules used in an IVT reaction may have a different length (e.g., comprises a different number of nucleotides). A co-IVT reaction may include co-transcription of at least 2 different input DNAs (e.g., at least 2 of DNA A, B, C, D, E, F, F, H, I, J, etc.) at a ratio of A:B:C:D:E:F:G:H:I:J, wherein if DNA A is normalized to 1, one or more of DNA B, C, D, E, F, G, H, I, J, etc. can each independently be present at an amount (e.g., a concentration) that is from 0.01 to 100 times the amount (e.g., a concentration) of A. One or more of DNA B, C, D, E, F, G, H, I, or J may also be absent. A multivalent RNA composition may be produced by combining RNA transcripts (e.g., circular RNA) from separate sources. For example, each of two or more DNA templates may be transcribed in separate IVT reactions, and combined to produce a multivalent RNA composition. Separate RNAs may be circularized separately before being combined, or linear RNAs may be combined and circularized in a single circularization reaction. RNAs may be combined in any desired amount to produce a multivalent RNA composition comprising two or more RNAs in a specific ratio.
RNA purification methods Some aspects relate to methods of producing circular RNAs and purifying circular RNAs by reverse phase chromatography. Chromatography refers to a process of separating components of a mixture based on differentiating characteristics of the components, such as interaction with a mobile and/or stationary phase of a chromatography column. In reverse phase chromatography, a mixture is introduced to a hydrophobic mobile phase, with the mobile phase and mixture passing over a hydrophilic stationary phase. Components of the mixture migrate through the stationary phase at different rates, depending on their relative affinity for the mobile and stationary phases. The amount of time required for a component (e.g., circular RNA) of the mixture to migrate through the stationary phase is also referred to as the “retention time” of the component. Characteristics that affect the retention time of a nucleic acid include size and secondary structure, such as whether the nucleic acid is linear or circular and/or whether it is coiled or uncoiled. Mobile phases typically comprise one or more solvent solutions, each of which comprises a solvent and one or more ion pairing agents. In some embodiments, one or more solvent solutions (e.g., 1, 2, 3, 4, 5, or more) of the mobile phase comprise a combination of at least one ion pairing agent (e.g., 1, 2, 3, 4, 5, or more). As used herein, an “ion pairing agent” or an “ion pair” refers to an agent (e.g., a small molecule) that functions as a counter ion to a charged (e.g., ionized or ionizable) functional group on an HPLC analyte (e.g., a nucleic acid) and thereby changes the retention time of the analyte as it moves through the stationary phase of an HPLC column. Generally, ion paring agents are classified as cationic ion pairing agents (which interact with negatively charged functional groups) or anionic ion pairing agents (which interact with positively charged functional groups). The terms “ion pairing agent” and “ion pair” further encompass an associated counter-ion (e.g., acetate, phosphate, bicarbonate, bromide, chloride, citrate, nitrate, nitrite, oxide, sulfate and the like, for cationic ion pairing agents, and sodium, calcium, and the like, for anionic ion pairing agents). In some embodiments, one or more ion pairing agents utilized is a cationic ion pairing agent. Examples of cationic ion pairing agents include but are not limited to certain protonated or quaternary amines (including e.g., primary, secondary and tertiary amines) and salts thereof, such as a trietheylammonium salt (e.g., triethylammonium acetate (TEAA)), a tributylammonium salt (e.g., tetrabutylammonium phosphate (TBAP) or tetrabutylammonium chloride (TBAC)), a hexylammonium salt (e.g., hexylammonium acetate (HAA)), a dibutylammonium salt (e.g., dibutylammonium acetate (DBAA)), a tetrapropylammonium salt (e.g., tetrapropylammonium bromide (TPAB)), a dodecyltrimethylammonium salt (e.g., dodecyltrimethylammonium chloride (DTMAC)), or a tetra(decyl)ammonium salt (e.g., tetra(decyl)ammonium bromide (TDAB)), a dihexylammonium
salt (e.g., dihexylammonium acetate (DHAA)), a dipropylammonium salt (e.g., dipropylammonium acetate (DPAA)), a myristyltrimethylammonium salt (e.g., myristyltrimethylammonium bromide (MTEAB)), a tetraethylammonium salt (e.g., tetraethylammonium bromide (TEAB)), a tetraheptylammonium salt (e.g., tetraheptylammonium bromide (THepAB)), a tetrahexylammonium salt (e.g., tetrahexylammonium bromide (THexAB)), a tetrakis(decyl)ammonium salt (e.g., tetrakis(decyl)ammonium bromide (TrDAB)), a tetramethylammonium salt (e.g., tetramethylammonium bromide (TMAB)), a tetraoctylammonium salt (e.g., tetraoctylammonium bromide (TOAB)), or a tetrapentylammonium salt (e.g., tetrapentylammonium bromide (TPeAB)). In some embodiments, one or more solvent solutions of the mobile phase comprise a combination of two or more ion pairing agents selected from the group consisting of a trietheylammonium salt, tributylammonium salt, hexylammonium salt, dibutylammonium salt, tetrapropylammonium salt, dodecyltrimethylammonium salt, tetra(decyl)ammonium salt, dihexylammonium salt, dipropylammonium salt, myristyltrimethylammonium salt, tetraethylammonium salt, tetraheptylammonium salt, tetrahexylammonium salt, tetrakis(decyl)ammonium salt, tetramethylammonium salt, tetraoctylammonium salt, and tetrapentylammonium salt. A salt of a cation, as used herein, refers to a composition comprising the cation and an anionic counter ion. For example, a “tetrabutylammonium salt” may refer to tetrabutylammonium phosphate, tetrabutylammonium chloride, tetrabutylammonium bromide, tetrabutylammonium phosphate, or another composition comprising the cation tetrabutylammonium and an anionic counter ion. In some embodiments, the ion pairing agent comprises a cation and an anionic counter ion, wherein the cation is selected from the group consisting of trietheylammonium, tributylammonium, hexylammonium, dibutylammonium, tetrapropylammonium, dodecyltrimethylammonium, tetra(decyl)ammonium, dihexylammonium, dipropylammonium, myristyltrimethylammonium, tetraethylammonium, tetraheptylammonium, tetrahexylammonium, tetrakis(decyl)ammonium, tetramethylammonium, tetraoctylammonium, and tetrapentylammonium, and the anionic counter ion is selected from the group consisting of a bromide, chloride, phosphate, and acetate. In some embodiments, one or more solvent solutions of the mobile phase comprise an ion pairing agent selected from the group consisting of HAA, TBAP, TPAB, TBAC, DBAA, TEAA, DTMAC, TDAB, DHAA, DPAA MTEAB, TEAB, THepAB, THexAB, TrDAB, TMAB, TOAB, and TPeAB. In some embodiments, one or more solvent solutions of the mobile phase comprise a combination of (i) TPAB and TBAC, (ii) DBAA and TEAA, or (iii) TBAP and TEAA. In some embodiments, one or more solvent solutions of the mobile phase comprise a combination of TPAB and TBAC. In some
embodiments, one or more solvent solutions of the mobile phase comprise a combination of DBAA and TEAA. Protonated and quaternary amine ion pairing agents can be represented by the following formula:
,
where R5 and R3 are atoms or molecules to which the canonical phosphate is bonded. For example, for a phosphate in a nucleic acid sequence, R5 may refer to the upstream nucleotide of the nucleic acid, and R3 may refer to the downstream nucleotide of the nucleic acid. The canonical structure of phosphate also refers to structures in which one or more hydroxyl groups of the phosphate are deprotonated, or in which an oxygen atom of the phosphate is bonded to an adjacent nucleotide in a nucleic acid sequence. In some embodiments, an RNA (e.g., RNA transcript or circular RNA) may include a modified phosphate selected from phosphorothioate (PS), thiophosphate, 5′-O-methylphosphonate, 3′-O-methylphosphonate, 5′- hydroxyphosphonate, hydroxyphosphanate, phosphoroselenoate, selenophosphate, phosphoramidate, carbophosphonate, methylphosphonate, phenylphosphonate, ethylphosphonate, H-phosphonate, guanidinium ring, triazole ring, boranophosphate (BP), methylphosphonate, and guanidinopropyl phosphoramidate. In some embodiments, an RNA (e.g., RNA transcript or circular RNA) includes a combination of at least two (e.g., 2, 3, 4 or more) of the foregoing modified phosphates. In some embodiments, an RNA comprises modified nucleotide(s) at one or more uridine positions. In some embodiments, an RNA comprises N1-methylpseudouridine nucleotide(s) at one or more uridine positions. In some embodiments, at least 20%, at least 40%, at least 60%, or at least 80% of nucleotides at uridine positions comprise N1-methylpseudouridine. In some embodiments, substantially all nucleotides at uridine positions comprise N1- methylpseudouridine. In some embodiments, an RNA comprises 5-methyluridine nucleotide(s) at one or uridine positions. In some embodiments, at least 20%, at least 40%, at least 60%, or at least 80% of nucleotides at uridine positions comprise 5-methyluridine. In some embodiments, substantially all nucleotides at uridine positions comprise 5-methyluridine. In some embodiments, an RNA comprises one or more modified nucleotides at cytidine positions. In some embodiments, an RNA comprises 5-methylcytidine nucleotide(s) at one or cytidine positions. In some embodiments, at least 20%, at least 40%, at least 60%, or at least 80% of nucleotides at cytidine positions comprise 5-methylcytidine. In some embodiments, substantially all nucleotides at cytidine positions comprise 5-methylcytidine. In some embodiments, substantially all nucleotides present at uridine positions comprise 5-methyluridine, and substantially all nucleotides present at cytidine positions comprise 5- methylcytidine. RNAs may be used to produce polypeptides of interest, such as therapeutic proteins and/or vaccine antigens. In some embodiments, an RNA encodes a vaccine antigen. In some embodiments, an RNA encodes a therapeutic protein. In some embodiments, the encoded
polypeptide comprises 9–10,000, 9–9,000, 9–8,000, 9–7,000, 9–6,000, 9–5,000, 9–4,000, 9– 3,000, 9–2,000, 9–1,000, 9–500, 9–400, 9–300, 9–200, 9–100, 9–10,000, 100–9,000, 100–8,000, 100–7,000, 100–6,000, 100–5,000, 100–4,000, 100–3,000, 100–2,000, 100–1,000, 100–500, 100–400, 100–300, 100–200, 100–9,000, 200–10,000, 200–9,000200–8,000, 200–7,000, 200– 6,000, 200–5,000, 200–4,000, 200–3,000, 200–2,000, 200–1,000, 200–500, 200–400, 500– 10,000, 500–9,000, 500–8,000, 500–7,000, 500–6,000, 500–5,000, 500–4,000, 500–3,000, 500– 2,000, 500–1,000, 1,000–10,000, 1,000–9,000, 1,000–8,000, 1,000–7,000, 1,000–6,000, 1,000– 5,000, 1,000–4,000, 1,000–3,000, or 1,000–2,000 amino acids. In some embodiments, the encoded polypeptide consists of 9–10,000, 9–9,000, 9–8,000, 9–7,000, 9–6,000, 9–5,000, 9– 4,000, 9–3,000, 9–2,000, 9–1,000, 9–500, 9–400, 9–300, 9–200, 9–100, 9–10,000, 100–9,000, 100–8,000, 100–7,000, 100–6,000, 100–5,000, 100–4,000, 100–3,000, 100–2,000, 100–1,000, 100–500, 100–400, 100–300, 100–200, 100–9,000, 200–10,000, 200–9,000200–8,000, 200– 7,000, 200–6,000, 200–5,000, 200–4,000, 200–3,000, 200–2,000, 200–1,000, 200–500, 200– 400, 500–10,000, 500–9,000, 500–8,000, 500–7,000, 500–6,000, 500–5,000, 500–4,000, 500– 3,000, 500–2,000, 500–1,000, 1,000–10,000, 1,000–9,000, 1,000–8,000, 1,000–7,000, 1,000– 6,000, 1,000–5,000, 1,000–4,000, 1,000–3,000, or 1,000–2,000 amino acids. In some embodiments, the encoded polypeptide comprises 9–5,000 amino acids. In some embodiments, the encoded polypeptide consists of 9–5,000 amino acids. In some embodiments, the encoded polypeptide comprises 20–4,000 amino acids. In some embodiments, the encoded polypeptide consists of 20–4,000 amino acids. In some embodiments, the encoded polypeptide comprises 30–3,000 amino acids. In some embodiments, the encoded polypeptide consists of 30–3,000 amino acids. In some embodiments, the encoded polypeptide comprises 40–2,000 amino acids. In some embodiments, the encoded polypeptide consists of 40–2,000 amino acids. In some embodiments, the encoded polypeptide comprises 50–1,500 amino acids. In some embodiments, the encoded polypeptide consists of 50–1,500 amino acids. In some embodiments, the encoded polypeptide comprises 100–5,000 amino acids. In some embodiments, the encoded polypeptide consists of 100–5,000 amino acids. In some embodiments, the encoded polypeptide comprises 200–4,000 amino acids. In some embodiments, the encoded polypeptide consists of 200–4,000 amino acids. In some embodiments, the encoded polypeptide comprises 300–3,000 amino acids. In some embodiments, the encoded polypeptide consists of 300–3,000 amino acids. In some embodiments, the encoded polypeptide comprises 400–2,000 amino acids. In some embodiments, the encoded polypeptide consists of 400–2,000 amino acids. In some embodiments, the encoded polypeptide comprises 500–1,500 amino acids. In some embodiments, the encoded polypeptide consists of 500–1,500 amino acids.
A therapeutic RNA is an RNA that encodes a therapeutic protein (the term ‘protein’ encompasses peptides). In some embodiments, RNA compositions comprise one or more RNAs that encode peptides or proteins that interact or complex in a cell or subject to form a multi- subunit protein (e.g., an antibody comprising a heavy chain and a light chain, a multi-subunit receptor protein, a multi-subunit signaling protein, a multi-subunit antigen, etc.) or a multivalent vaccine. Therapeutic proteins mediate a variety of effects in a host cell or in a subject to treat a disease or ameliorate the signs and symptoms of a disease. For example, a therapeutic protein can replace a protein that is deficient or abnormal, augment the function of an endogenous protein, provide a novel function to a cell (e.g., inhibit or activate an endogenous cellular activity, or act as a delivery agent for another therapeutic compound (e.g., an antibody-drug conjugate). Therapeutic RNA may be useful for the treatment of the following diseases and conditions: bacterial infections, viral infections, parasitic infections, cell proliferation disorders, genetic disorders, and autoimmune disorders. Other diseases and conditions are encompassed herein. A protein or proteins of interest encoded by an RNA composition can be essentially any protein or peptide (e.g., peptide antigen). In some embodiments, a therapeutic peptide or therapeutic protein is a biologic. A biologic is a polypeptide-based molecule that may be used to treat, cure, mitigate, prevent, or diagnose a serious or life-threatening disease or medical condition. Biologics include, but are not limited to, allergenic extracts (e.g. for allergy shots and tests), blood components, gene therapy products, human tissue or cellular products used in transplantation, vaccines, monoclonal antibodies, cytokines, growth factors, enzymes, thrombolytics, and immunomodulators, among others. In some embodiments, the therapeutic protein is a cytokine, a growth factor, an antibody (e.g., monoclonal antibody), a fusion protein, or a vaccine (e.g., an RNA encoding one or more peptide antigens designed to elicit an immune response in a subject). Non-limiting examples of therapeutic proteins include blood factors (such as Factor VIII and Factor VII), complement factors, Low Density Lipoprotein Receptor (LDLR) and MUT1. Non-limiting examples of cytokines include interleukins, interferons, chemokines, lymphokines and the like. Non-limiting examples of growth factors include erythropoietin, EGFs, PDGFs, FGFs, TGFs, IGFs, TNFs, CSFs, MCSFs, GMCSFs and the like. Non-limiting examples of antibodies include adalimumab, infliximab, rituximab, ipilimumab, tocilizumab, canakinumab, itolizumab, tralokinumab, anti- influenza virus monoclonal antibody, anti-Chikungunya virus monoclonal antibody, anti-Zika virus monoclonal antibody, anti-SARS-CoV-2 monoclonal antibody. Non-limiting examples of
fusion proteins include, for example, etanercept, abatacept and belatacept. Non-limiting examples of multivalent vaccines include, for example, multivalent cytomegalovirus (CMV) vaccine, and personalized cancer vaccines. One or more biologics currently being marketed or in development may be encoded by the RNA. While not wishing to be bound by theory, it is believed that incorporation of the encoding polynucleotides of a known biologic into the RNA will result in improved therapeutic efficacy due at least in part to the specificity, purity and/or selectivity of the construct designs. An RNA composition may encode one or more antibodies (e.g., may comprise a first RNA encoding an antibody heavy chain and a second RNA encoding an antibody light chain). The term “antibody” includes monoclonal antibodies (including full length antibodies which have an immunoglobulin Fc region), antibody compositions with polyepitopic specificity, multispecific antibodies (e.g., bispecific antibodies, diabodies, and single-chain molecules), as well as antibody fragments. The term “immunoglobulin” (Ig) is used interchangeably with “antibody” herein. A monoclonal antibody is an antibody obtained from a population of substantially homogeneous antibodies, i.e., the individual antibodies comprising the population are identical except for possible naturally occurring mutations and/or post-translation modifications (e.g., isomerizations, amidations) that may be present in minor amounts. Monoclonal antibodies are highly specific, being directed against a single antigenic site. Monoclonal antibodies specifically include chimeric antibodies (immunoglobulins) in which a portion of the heavy and/or light chain is identical with or homologous to corresponding sequences in antibodies derived from a particular species or belonging to a particular antibody class or subclass, while the remainder of the chain(s) is(are) identical with or homologous to corresponding sequences in antibodies derived from another species or belonging to another antibody class or subclass, as well as fragments of such antibodies, so long as they exhibit the desired biological activity. Chimeric antibodies include, but are not limited to, “primatized” antibodies comprising variable domain antigen-binding sequences derived from a non-human primate (e.g., Old World Monkey, Ape etc.) and human constant region sequences. Antibodies encoded in the RNA compositions may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, blood, cardiovascular, CNS, poisoning (including antivenoms), dermatology, endocrinology, gastrointestinal, medical imaging, musculoskeletal, oncology, immunology, respiratory, sensory and anti-infective. An RNA may encode one or more vaccine antigens. A vaccine antigen is a biological preparation that improves immunity to a particular disease or infectious agent. One or more vaccine antigens currently being marketed or in development may be encoded by the RNA. Vaccine antigens encoded in the RNA may be utilized to treat conditions or diseases in many
therapeutic areas such as, but not limited to, cancer, allergy, and infectious disease. In some embodiments, a vaccine may be a personalized vaccine in the form of a concatemer or individual RNAs encoding peptide epitopes or a combination thereof. An RNA may encode on or more antimicrobial peptides (AMP) or antiviral peptides (AVP). AMPs and AVPs have been isolated and described from a wide range of animals such as, but not limited to, microorganisms, invertebrates, plants, amphibians, birds, fish, and mammals. The anti-microbial polypeptides may block cell fusion and/or viral entry by one or more enveloped viruses (e.g., HIV, HCV). For example, the anti-microbial polypeptide can comprise or consist of a synthetic peptide corresponding to a region, e.g., a consecutive sequence of at least about 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, or 60 amino acids of the transmembrane subunit of a viral envelope protein, e.g., HIV-1 gp120 or gp41. The amino acid and nucleotide sequences of HIV-1 gp120 or gp41 are described in, e.g., Kuiken et al., (2008). “HIV Sequence Compendium,” Los Alamos National Laboratory. In some embodiments, RNAs (e.g., circular RNAs) are used for in vitro translation and microinjection. In some embodiments, RNA transcripts are used for RNA structure, processing and catalysis studies. In some embodiments, RNA transcripts are used for RNA amplification. In some embodiments, RNA transcripts are used as anti-sense RNA for gene expression modulation. In some embodiments, an RNA is codon optimized. Codon optimization methods are known in the art. Codon optimization, in some embodiments, may be used to match codon frequencies in target and host organisms to ensure proper folding; bias %G/C content to increase RNA thermodynamic stability or reduce secondary structures; minimize tandem repeat codons or base runs that may impair gene construction or expression; customize transcriptional and translational control regions; insert or remove protein trafficking sequences; remove/add post translation modification sites in encoded protein (e.g., glycosylation sites); add, remove or shuffle protein domains; insert or delete restriction sites; modify ribosome binding sites and RNA degradation sites; adjust translational rates to allow the various domains of the protein to fold properly; or reduce or eliminate problem secondary structures within the polynucleotide. Codon optimization tools, algorithms and services are known in the art – non-limiting examples include services from GeneArt (Life Technologies), DNA2.0 (Menlo Park CA) and/or proprietary methods. In some embodiments, the open reading frame (ORF) sequence is optimized using optimization algorithms. In some embodiments, a codon optimized sequence shares less than 95% sequence identity to a naturally occurring or wild-type sequence ORF (e.g., a naturally occurring or wild- type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized
sequence shares less than 90% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares less than 85% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares less than 80% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares less than 75% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares between 65% and 85% (e.g., between about 67% and about 85% or between about 67% and about 80%) sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). In some embodiments, a codon optimized sequence shares between 65% and 75% or about 80% sequence identity to a naturally occurring or wild-type sequence (e.g., a naturally occurring or wild-type RNA sequence encoding the polypeptide). When transfected into mammalian host cells, some embodiments of modified RNAs have a stability of between 12-18 hours, or greater than 18 hours, e.g., 24, 36, 48, 60, 72, or greater than 72 hours and are capable of being expressed by the mammalian host cells. In some embodiments, a codon optimized RNA may be one in which the %G/C content is increased. The %G/C-content of nucleic acid molecules (e.g., circular RNA) may influence the stability of the RNA. RNA having an increased number of guanine (G) and/or cytosine (C) nucleotides may be more thermodynamically stable than RNA containing a large number of adenine (A) and uracil (U) nucleotides. As an example, WO 2002/098443 discloses a pharmaceutical composition containing an mRNA stabilized by sequence modifications in the translated region. Due to the degeneracy of the genetic code, the modifications work by substituting existing codons for those that promote greater RNA stability without changing the resulting amino acid. The approach is limited to coding regions of the RNA. Untranslated regions Untranslated regions (UTRs) are sections of a nucleic acid before a start codon (5′ UTR) and after a stop codon (3′ UTR) that are not translated. In some embodiments, a nucleic acid (e.g., a ribonucleic acid (RNA), e.g., a circular RNA) comprising an open reading frame (ORF) encoding one or more proteins or peptides further comprises one or more UTR (e.g., a 5′ UTR or functional fragment thereof, a 3′ UTR or functional fragment thereof, or a combination thereof).
A UTR can be homologous or heterologous to the coding region in a nucleic acid. In some embodiments, the UTR is homologous to the ORF encoding the one or more proteins. In some embodiments, the UTR is heterologous to the ORF encoding the one or more proteins. In some embodiments, the nucleic acid comprises two or more 5′ UTRs or functional fragments thereof, each of which have the same or different nucleotide sequences. In some embodiments, the nucleic acid comprises two or more 3′ UTRs or functional fragments thereof, each of which have the same or different nucleotide sequences. In some embodiments, the 5′ UTR or functional fragment thereof, 3′ UTR or functional fragment thereof, or any combination thereof is sequence optimized. In some embodiments, the 5′ UTR or functional fragment thereof, 3′ UTR or functional fragment thereof, or any combination thereof comprises at least one chemically modified nucleobase, e.g., 5-methoxyuracil. UTRs can have features that provide a regulatory role, e.g., increased or decreased stability, localization, and/or translation efficiency. A nucleic acid comprising a UTR can be administered to a cell, tissue, or organism, and one or more regulatory features can be measured using routine methods. In some embodiments, a functional fragment of a 5′ UTR or 3′ UTR comprises one or more regulatory features of a full length 5′ or 3′ UTR, respectively. Natural 5′ UTRs bear features that play roles in translation initiation. They harbor signatures like Kozak sequences that are commonly known to be involved in the process by which the ribosome initiates translation of many genes.5′ UTRs also have been known to form secondary structures that are involved in elongation factor binding. By engineering the features typically found in abundantly expressed genes of specific target organs, one can enhance the stability and protein production of a nucleic acid. For example, introduction of 5′ UTR of liver-expressed mRNA, such as albumin, serum amyloid A, Apolipoprotein A/B/E, transferrin, alpha fetoprotein, erythropoietin, or Factor VIII, can enhance expression of nucleic acids in hepatic cell lines or liver. Likewise, use of 5′ UTRs from other tissue-specific mRNA to improve expression in that tissue is possible for muscle (e.g., MyoD, Myosin, Myoglobin, Myogenin, Herculin), for endothelial cells (e.g., Tie-1, CD36), for myeloid cells (e.g., C/EBP, AML1, G-CSF, GM-CSF, CD11b, MSR, Fr-1, i-NOS), for leukocytes (e.g., CD45, CD18), for adipose tissue (e.g., CD36, GLUT4, ACRP30, adiponectin), and for lung epithelial cells (e.g., SP-A/B/C/D). In some embodiments, UTRs are selected from a family of transcripts whose proteins share a common function, structure, feature, or property. For example, an encoded polypeptide can belong to a family of proteins (i.e., that share at least one function, structure, feature, localization, origin, or expression pattern), which are expressed in a particular cell, tissue or at
some time during development. The UTRs from any of the genes or circular RNA can be swapped for any other UTR of the same or different family of proteins to create a new nucleic acid. In some embodiments, the 5′ UTR and the 3′ UTR can be heterologous. In some embodiments, the 5′ UTR can be derived from a different species than the 3′ UTR. In some embodiments, the 3′ UTR can be derived from a different species than the 5′ UTR. International Patent Application No. PCT/US2014/021522 (Publ. No. WO/2014/164253) provides a listing of exemplary UTRs that may be utilized in the nucleic acids as flanking regions to an ORF. This publication is incorporated by reference herein for this purpose. Additional exemplary UTRs that may be utilized in the nucleic acids include, but are not limited to, one or more 5′ UTRs and/or 3′ UTRs derived from the nucleic acid sequence of: a globin, such as an α- or β-globin (e.g., a Xenopus, mouse, rabbit, or human globin); a strong Kozak translational initiation signal; a CYBA (e.g., human cytochrome b-245 α polypeptide); an albumin (e.g., human albumin7); a HSD17B4 (hydroxysteroid (17-β) dehydrogenase); a virus (e.g., a tobacco etch virus (TEV), a Venezuelan equine encephalitis virus (VEEV), a Dengue virus, a cytomegalovirus (CMV; e.g., CMV immediate early 1 (IE1)), a hepatitis virus (e.g., hepatitis B virus), a sindbis virus, or a PAV barley yellow dwarf virus); a heat shock protein (e.g., hsp70); a translation initiation factor (e.g., elF4G); a glucose transporter (e.g., hGLUT1 (human glucose transporter 1)); an actin (e.g., human α or β actin); a GAPDH; a tubulin; a histone; a citric acid cycle enzyme; a topoisomerase (e.g., a 5′ UTR of a TOP gene lacking the 5′ TOP motif (the oligopyrimidine tract)); a ribosomal protein Large 32 (L32); a ribosomal protein (e.g., human or mouse ribosomal protein, such as, for example, rps9); an ATP synthase (e.g., ATP5A1 or the β subunit of mitochondrial H+-ATP synthase); a growth hormone (e.g., bovine (bGH) or human (hGH)); an elongation factor (e.g., elongation factor 1 α1 (EEF1A1)); a manganese superoxide dismutase (MnSOD); a myocyte enhancer factor 2A (MEF2A); a β-F1- ATPase, a creatine kinase, a myoglobin, a granulocyte-colony stimulating factor (G-CSF); a collagen (e.g., collagen type I, alpha 2 (Col1A2), collagen type I, alpha 1 (Col1A1), collagen type VI, alpha 2 (Col6A2), collagen type VI, alpha 1 (Col6A1)); a ribophorin (e.g., ribophorin I (RPNI)); a low density lipoprotein receptor-related protein (e.g., LRP1); a cardiotrophin-like cytokine factor (e.g., Nnt1); calreticulin (Calr); a procollagen-lysine, 2-oxoglutarate 5- dioxygenase 1 (Plod1); and a nucleobindin (e.g., Nucb1). In some embodiments, the 5′ UTR is selected from the group consisting of a β-globin 5′ UTR; a 5′ UTR containing a strong Kozak translational initiation signal; a cytochrome b-245 α polypeptide (CYBA) 5′ UTR; a hydroxysteroid (17-β) dehydrogenase (HSD17B4) 5′ UTR; a Tobacco etch virus (TEV) 5′ UTR; a Venezuelen equine encephalitis virus (TEEV) 5′ UTR; a 5′
proximal open reading frame of rubella virus (RV) RNA encoding nonstructural proteins; a Dengue virus (DEN) 5′ UTR; a heat shock protein 70 (Hsp70) 5′ UTR; a eIF4G 5′ UTR; a GLUT1 5′ UTR; functional fragments thereof and any combination thereof. In some embodiments, the 3′ UTR is selected from the group consisting of a β-globin 3′ UTR; a CYBA 3′ UTR; an albumin 3′ UTR; a growth hormone (GH) 3′ UTR; a VEEV 3′ UTR; a hepatitis B virus (HBV) 3′ UTR; α-globin 3′ UTR; a DEN 3′ UTR; a PAV barley yellow dwarf virus (BYDV-PAV) 3′ UTR; an elongation factor 1 α1 (EEF1A1) 3′ UTR; a manganese superoxide dismutase (MnSOD) 3′ UTR; a β subunit of mitochondrial H(+)-ATP synthase (β- mRNA) 3′ UTR; a GLUT13′ UTR; a MEF2A 3′ UTR; a β-F1-ATPase 3′ UTR; functional fragments thereof and combinations thereof. Wild-type UTRs derived from any gene or mRNA can be incorporated into the nucleic acids (e.g., circular RNAs). In some embodiments, a UTR can be altered relative to a wild type or native UTR to produce a variant UTR, e.g., by changing the orientation or location of the UTR relative to the ORF; or by inclusion of additional nucleotides, deletion of nucleotides, swapping or transposition of nucleotides. In some embodiments, variants of 5′ or 3′ UTRs can be utilized, for example, mutants of wild type UTRs, or variants wherein one or more nucleotides are added to or removed from a terminus of the UTR. Additionally, one or more synthetic UTRs can be used in combination with one or more non-synthetic UTRs. See, e.g., Mandal and Rossi, Nat. Protoc.20138(3):568-82, and sequences available at www.addgene.org, the contents of each are incorporated herein by reference in their entirety. UTRs or portions thereof can be placed in the same orientation as in the transcript from which they were selected or can be altered in orientation or location. Hence, a 5′ and/or 3′ UTR can be inverted, shortened, lengthened, or combined with one or more other 5′ UTRs or 3′ UTRs. In some embodiments, the nucleic acid may comprise multiple UTRs, e.g., a double, a triple or a quadruple 5′ UTR or 3′ UTR. For example, a double UTR comprises two copies of the same UTR either in series or substantially in series. For example, a double beta-globin 3′ UTR can be used (see, e.g., US 2010/0129877, the contents of which are incorporated herein by reference for this purpose). Nucleic acids can comprise combinations of features. For example, the ORF can be flanked by a 5′ UTR that comprises a strong Kozak translational initiation signal and/or a 3′ UTR comprising an oligo(dT) sequence for templated addition of a polyA tail. A 5′ UTR can comprise a first nucleic acid fragment and a second nucleic acid fragment from the same and/or different UTRs (see, e.g., US 2010/0293625, herein incorporated by reference for this purpose).
Other non-UTR sequences can be used as regions or subregions within nucleic acids. For example, introns or portions of intron sequences can be incorporated into nucleic acids. Incorporation of intronic sequences can increase protein production as well as nucleic acid expression levels. In some embodiments, the nucleic acid comprises an internal ribosome entry site (IRES) instead of or in addition to a UTR (see, e.g., Yakubov et al., Biochem. Biophys Res Commun.2010.394(1):189-193, the contents of which are incorporated herein by reference for this purpose). In some embodiments, the nucleic acid comprises an IRES instead of a 5′ UTR sequence. In some embodiments, the nucleic acid comprises an IRES that is located between a 5′ UTR and an open reading frame. In some embodiments, the nucleic acid comprises an ORF encoding a viral capsid sequence. In some embodiments, the nucleic acid comprises a synthetic 5′ UTR in combination with a non-synthetic 3′ UTR. In some embodiments, the UTR can also include at least one translation enhancer nucleic acid, translation enhancer element, or translational enhancer elements (collectively, “TEE,” which refers to nucleic acid sequences that increase the amount of polypeptide or protein produced from a polynucleotide. As a non-limiting example, the TEE can include those described in US2009/0226470, incorporated herein by reference for this purpose, and others known in the art. As a non-limiting example, the TEE can be located between the transcription promoter and the start codon. In some embodiments, the 5′ UTR comprises a TEE. In one aspect, a TEE is a conserved element in a UTR that can promote translational activity of a nucleic acid such as, but not limited to, cap-dependent or cap-independent translation. In one non-limiting example, the TEE comprises the TEE sequence in the 5′-leader of the Gtx homeodomain protein. See, e.g., Chappell et al., PNAS.2004.101:9590-9594, incorporated herein by reference for this purpose. PolyA and polyAC regions Some aspects relate to circular RNAs containing one or more polyA or polyAC regions, and/or methods of producing circular RNAs containing one or more polyA or polyAC regions. A “polyA region” is a region of an RNA that is downstream, e.g., directly downstream (i.e., 3′), from the open reading frame and/or the 3′ UTR that contains multiple, consecutive adenosine monophosphates. A “polyAC region” is a region of an RNA that is downstream, e.g., directly downstream from (i.e., 3′), from the open reading frame and/or the 3′ UTR that contains multiple adenosine monophosphates and multiple cytidine monophosphates. A polyA or polyAC region may contain 10 to 300 adenosine monophosphates and/or cytidine monophosphates. For example, a polyA or polyAC region may contain 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 210, 220, 230, 240,
250, 260, 270, 280, 290 or 300 adenosine monophosphates and/or cytidine monophosphates. In some embodiments, a polyA or polyAC region contains 50 to 250 nucleotides selected from adenosine monophosphates and and/or cytidine monophosphates. In a relevant biological setting (e.g., in cells, in vivo, etc.) the polyA or polyAC region functions to protect RNA from enzymatic degradation, e.g., in the cytoplasm, and aids in transcription termination, export of the RNA from the nucleus, and translation. As used herein, “polyadenylation efficiency” refers to the amount (e.g., expressed as a percentage) of RNAs having polyA or polyAC region that are produced by an IVT reaction using an input DNA relative to the total number of RNAs produced in the IVT reaction using the input DNA. The polyadenylation efficiency of an IVT reaction may vary, for example depending upon the RNA polymerase used, amount or purity of input DNA used, etc. In some embodiments, the polyadenylation efficiency of an IVT reaction is greater than 85%, 90%, 95%, or 99.9%. Methods of calculating polyadenylation efficiency are known, for example by determining the amount of polyA or polyAC region-containing RNA relative to total RNA produced in an IVT reaction by column chromatography (e.g., oligo-dT chromatography). In some embodiments, at least 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 99.9% of RNAs in a circular RNA composition comprise a polyA or polyAC region. In some embodiments, at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or 99.9% of each RNA in a circular RNA composition comprise a polyA or polyAC region. The polyadenylation efficiency (e.g., percentage of polyA or polyAC region- containing RNAs in a circular RNA composition) may be measured i) after the IVT reaction and before purification, or ii) after the circular RNA composition has been purified (e.g., by chromatography, such as oligo-dT chromatography). Unique polyA or polyAC region lengths provide certain advantages to nucleic acids. Generally, the length of a polyA or polyAC region, when present, is greater than 10 nucleotides in length. In some embodiments, the polyA or polyAC region is greater In another embodiment, the polyA or polyAC region is at least 15 nucleotides in length (e.g., at least or greater than about 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 250, 300, 350, 400, 450, 500, 600, 700, 800, 900, 1,000, 1,100, 1,200, 1,300, 1,400, 1,500, 1,600, 1,700, 1,800, 1,900, 2,000, 2,500, or 3,000 nucleotides). In some embodiments, the polyA or polyAC region is designed relative to the length of the overall nucleic acid or the length of a particular region of the nucleic acid. This design can be based on the length of a coding region, the length of a particular feature or region or based on the length of the ultimate product expressed from the nucleic acids.
In this context, the polyA or polyAC region can be 10, 20, 30, 40, 50, 60, 70, 80, 90, or 100% greater in length than the nucleic acid or feature thereof. The polyA or polyAC region can also be designed as a fraction of the nucleic acid to which it belongs. In this context, the polyA or polyAC region can be 10, 20, 30, 40, 50, 60, 70, 80, or 90% or more of the total length of the construct, a construct region or the total length of the construct minus the polyA or polyAC region. Further, engineered binding sites and conjugation of nucleic acids for PolyA-binding protein can enhance expression. In some embodiments, a circular RNA comprises multiple polyA or polyAC regions that are separated by one or more intervening sequences of the circular RNA. In some embodiments, a circular RNA comprises a first polyA or polyAC region that is upstream of the open reading frame, and a second polyA or polyAC region that is downstream of the open reading frame. In some embodiments, the first polyA or polyAC region is located upstream of the 5′ UTR. In some embodiments, the first polyA or polyAC region is located downstream of the 5′ UTR and upstream of the open reading frame and/or an internal ribosome entry site (IRES). In some embodiments, the second polyA or polyAC region is downstream of the 3′ UTR. In some embodiments, the second polyA or polyAC region is downstream of the open reading frame, and upstream of the 3′ UTR. In some embodiments, a circular RNA comprises, in 5′-to-3′ order: a 5′ UTR, a first polyA or polyAC region, an IRES, an open reading frame, a second polyA or polyAC region, and a 3′ UTR. In some embodiments, each polyA or polyAC region is the same length. In other embodiments, the first and second polyA or polyAC regions are different lengths. Identification and Ratio Determination (IDR) Sequences An Identification and Ratio Determination (IDR) sequence is a sequence of a biological molecule (e.g., nucleic acid or protein) that, when combined with the sequence of a target biological molecule, serves to identify the target biological molecule. Typically, an IDR sequence is a heterologous sequence that is incorporated within or appended to a sequence of a target biological molecule and can be used as a reference to identify the target molecule. Thus, in some embodiments, a nucleic acid (e.g., circular RNA) comprises (i) a target sequence of interest (e.g., a coding sequence encoding a therapeutic and/or antigenic peptide or protein); and (ii) a unique IDR sequence. An RNA species (e.g., RNA having a given coding sequence) may comprise an IDR sequence that differs from the IDR sequence of other RNA species (e.g., RNA(s) having different coding sequence(s)). Each IDR sequence thus identifies a particular RNA species, and so the abundance of IDR sequences may be measured to determine the abundance of each RNA
species in a composition. Use of distinct IDR sequences to identify RNA species allows for analysis of multivalent RNA compositions (e.g., containing multiple RNA species) containing RNA species with similar coding sequences and/or lengths, which could otherwise be difficult to distinguish using PCR- or chromatography-based analysis of full-length RNAs. Each RNA species in a multivalent RNA composition may comprise an IDR sequence that is not a sequence isomer of an IDR sequence of another RNA species in a multivalent RNA composition (e.g., the IDR sequence does not have the same number of adenine nucleotides, the same number of cytosine nucleotides, the same number of guanine nucleotides, and the same number of uracil nucleotides, as another IDR sequence in the composition, even if those sequences have different sequences). Having identical nucleotide compositions causes sequence isomers to have the same mass, presenting a challenge to distinguishing sequence isomers using mass-based identification methods (e.g., mass spectrometry). Each RNA species in a multivalent RNA composition may comprise an IDR sequence having a mass that differs from the mass of IDR sequences of each other RNA species in a multivalent RNA composition. For example, the mass of each IDR sequence may differ from the mass of other IDR sequences by at least 9 Da, at least 25 Da, at least 25 Da, or at least 50 Da. Use of IDR sequences with distinct masses allows RNA fragments comprising different IDR sequences to be distinguished using mass-based analysis methods (e.g., mass spectrometry), which do not require reverse transcription, amplification, or sequencing of RNAs. Each RNA species in an RNA composition may comprises an IDR sequence with a different length. For example, each IDR sequence may have a length independently selected from 0 to 25 nucleotides. The length of a nucleic acid influences the rate at which the nucleic acid traverses a chromatography column, and so the use of IDR sequences of different lengths on different RNA species allows RNA fragments having different IDR sequences to be distinguished using chromatography-based methods (e.g., LC-UV). IDR sequences may be chosen such that no IDR sequence comprises a start codon, ‘AUG’. Lack of a start codon in an IDR sequence prevents undesired translation of nucleotide sequences within and/or downstream from the IDR sequence. IDR sequences may be chosen such that no IDR sequence comprises a recognition site for a restriction enzyme. In one example, no IDR sequence comprises a recognition site for XbaI, ‘UCUAG’. Lack of a recognition site for a restriction enzyme (e.g., XbaI recognition site ‘UCUAG’) allows the restriction enzyme to be used in generating and modifying a DNA template for in vitro transcription, without affecting the IDR sequence or sequence of the transcribed RNA.
Nucleic acid production Chemical synthesis Solid-phase chemical synthesis. Nucleic acids may be manufactured in whole or in part using solid phase techniques. Solid-phase chemical synthesis of nucleic acids is an automated method wherein molecules are immobilized on a solid support and synthesized step by step in a reactant solution. Solid-phase synthesis is useful in site-specific introduction of chemical modifications in the nucleic acid sequences. The synthesis of nucleic acids by the sequential addition of monomer building blocks may be carried out in a liquid phase. The synthetic methods discussed above each has its own advantages and limitations. Attempts have been conducted to combine these methods to overcome the limitations. Such combinations of methods are within the scope of methods. The use of solid-phase or liquid- phase chemical synthesis in combination with enzymatic ligation provides an efficient way to generate long chain nucleic acids that cannot be obtained by chemical synthesis alone. Ligation Assembling nucleic acids by a ligase may also be used. DNA or RNA ligases promote intermolecular ligation of the 5′ and 3′ ends of polynucleotide chains through the formation of a phosphodiester bond. Nucleic acids such as chimeric polynucleotides and/or circular nucleic acids may be prepared by ligation of one or more regions or subregions. DNA fragments can be joined by a ligase catalyzed reaction to create recombinant DNA with different functions. Two oligodeoxynucleotides, one with a 5′ phosphoryl group and another with a free 3′ hydroxyl group, serve as substrates for a DNA ligase. Purification Purification of the nucleic acids may include, but is not limited to, nucleic acid clean-up, quality assurance and quality control. Clean-up may be performed by methods known in the arts such as, but not limited to, AGENCOURT® beads (Beckman Coulter Genomics, Danvers, MA), poly-T beads, LNATM oligo-T capture probes (EXIQON® Inc, Vedbaek, Denmark) or HPLC based purification methods such as, but not limited to, strong anion exchange HPLC, weak anion exchange HPLC, reverse phase HPLC (RP-HPLC), and hydrophobic interaction HPLC (HIC- HPLC). The term “purified” when used in relation to a nucleic acid such as a “purified nucleic acid” refers to one that is separated from at least one contaminant. A “contaminant” is any substance that makes another unfit, impure or inferior. Thus, a purified nucleic acid (e.g., DNA and RNA) is present in a form or setting different from that in which it is found in nature, or a
form or setting different from that which existed prior to subjecting it to a treatment or purification method. A quality assurance and/or quality control check may be conducted using methods such as, but not limited to, gel electrophoresis, UV absorbance, or analytical HPLC. In some embodiments, the nucleic acids may be sequenced by methods including, but not limited to reverse-transcriptase-PCR. Quantification In some embodiments, the nucleic acids may be quantified in exosomes or when derived from one or more bodily fluid. Bodily fluids include peripheral blood, serum, plasma, ascites, urine, cerebrospinal fluid (CSF), sputum, saliva, bone marrow, synovial fluid, aqueous humor, amniotic fluid, cerumen, breast milk, broncheoalveolar lavage fluid, semen, prostatic fluid, cowper's fluid or pre-ejaculatory fluid, sweat, fecal matter, hair, tears, cyst fluid, pleural and peritoneal fluid, pericardial fluid, lymph, chyme, chyle, bile, interstitial fluid, menses, pus, sebum, vomit, vaginal secretions, mucosal secretion, stool water, pancreatic juice, lavage fluids from sinus cavities, bronchopulmonary aspirates, blastocyl cavity fluid, and umbilical cord blood. Alternatively, exosomes may be retrieved from an organ selected from the group consisting of lung, heart, pancreas, stomach, intestine, bladder, kidney, ovary, testis, skin, colon, breast, prostate, brain, esophagus, liver, and placenta. Assays may be performed using construct specific probes, cytometry, qRT-PCR, real- time PCR, PCR, flow cytometry, electrophoresis, mass spectrometry, or combinations thereof while the exosomes may be isolated using immunohistochemical methods such as enzyme linked immunosorbent assay (ELISA) methods. Exosomes may also be isolated by size exclusion chromatography, density gradient centrifugation, differential centrifugation, nanomembrane ultrafiltration, immunoabsorbent capture, affinity purification, microfluidic separation, or combinations thereof. These methods afford the investigator the ability to monitor, in real time, the level of nucleic acids remaining or delivered. This is possible because the nucleic acids, in some embodiments, differ from the endogenous forms due to the structural or chemical modifications. In some embodiments, the nucleic acid may be quantified using methods such as, but not limited to, ultraviolet visible spectroscopy (UV/Vis). A non-limiting example of a UV/Vis spectrometer is a NANODROP® spectrometer (ThermoFisher, Waltham, MA). The quantified nucleic acid may be analyzed in order to determine if the nucleic acid may be of proper size, check that no degradation of the nucleic acid has occurred. Degradation of the nucleic acid may be checked by methods such as, but not limited to, agarose gel electrophoresis, HPLC based
purification methods such as, but not limited to, strong anion exchange HPLC, weak anion exchange HPLC, reverse phase HPLC (RP-HPLC), and hydrophobic interaction HPLC (HIC- HPLC), liquid chromatography-mass spectrometry (LCMS), capillary electrophoresis (CE) and capillary gel electrophoresis (CGE). Multivalent in vitro transcription (IVT) Some aspects relate to multivalent in vitro transcription. Multivalent in vitro transcription refers to contacting two or more DNA templates (e.g., a first input DNA and a second input DNA) with an RNA polymerase (e.g., a T7 RNA polymerase) under conditions that result in the production of RNA transcripts. Each input DNA (e.g., in a population of input DNA templates) in a co-IVT reaction may be obtained from a different source than other input DNAs. For example, each input DNA may be obtained from a different bacterial cell or population or bacterial cells. For example, in a co-IVT reaction having three populations of input DNAs, a first input DNA can be produced in bacterial cell population A, a second input DNA can be produced in bacterial cell population B, and a third input DNA can be produced in bacterial cell population C, where each of A, B, and C are not the same bacterial culture (e.g., co-cultured in the same container or plate). In another example, different input DNAs are obtained by separate synthesis reactions or produced by separate amplification reactions. The amounts of input DNAs used in multivalent co-IVT reactions may be normalized. Normalization may be based, for example, on the molar masses, lengths, nucleotide contents, degradation rates, and/or purity of input DNAs. In some embodiments, normalization is based on the degradation rate of resulting RNAs. Normalization may be based on the lowest level of a certain characteristic present among the input DNAs (e.g., lowest molar mass, degradation rate (e.g., of the input DNA and/or output RNA), nucleotide content, purity, and/or polyadenylation efficiency). Alternatively, normalization may be based on the highest level of a certain characteristic present among the input DNAs (e.g., highest molar mass, degradation rate (e.g., of the input DNA and/or output RNA), nucleotide context, purity, and/or polyadenylation efficiency). In some embodiments, normalization is based on the rate of RNA production from the input DNAs (e.g., the highest rate of RNA production of an input DNA or the lowest rate of RNA production of an input DNA in a reaction mixture). The amount of one or more input DNAs may be adjusted and/or normalized to improve production of RNA compositions having a pre-defined or desired ratio of RNA components. Adjusting and/or normalizing amounts of input DNAs may compensate for differences between
input DNAs (e.g., large differences in lengths of two input DNAs, or different polyadenylation efficiencies) that can affect the ratio of RNAs in a multivalent RNA composition, thereby allowing for the production of RNA compositions having desired ratios of different RNAs. For example, the amount of two input DNAs present in a co-IVT reaction may be determined by selecting a desired molar ratio of a first RNA to a second RNA, calculating the mass of each DNA template necessary to achieve the same molar ratio between input DNAs, and combining input DNAs encoding each of the first and second RNAs in the same molar ratio. The number of input DNAs (e.g., populations of input DNA molecules) used in an IVT reaction may vary, depending upon the number of different RNA molecules desired to be included in the multivalent RNA composition. An IVT reaction mixture may comprise 2 or more different input DNAs (e.g., 2, 3, 4, 5, 6, 7, 8, 9, 10, or more different input DNAs). The concentration of each of the populations of DNA molecules may also vary. The input DNAs may be added to an IVT reaction are a predefined DNA ratio, which may comprise a ratio between 2, 3, 4, 5, 6, 7, 8, 9, 10, or more different input DNAs (e.g., depending on the number of different RNAs in a composition). The size of two or more input DNAs (e.g., DNAs in two or more different populations of input DNAs) may also vary. The mass of each population of input DNA molecules in an IVT reaction may also vary. The molar ratio between populations of input DNA molecules in an IVT reaction may also vary. Different input DNA molecules used in an IVT reaction may have a different length (e.g., comprises a different number of nucleotides). A co-IVT reaction may include co-transcription of at least 2 different input DNAs (e.g., at least 2 of DNA A, B, C, D, E, F, F, H, I, J, etc.) at a ratio of A:B:C:D:E:F:G:H:I:J, wherein if DNA A is normalized to 1, one or more of DNA B, C, D, E, F, G, H, I, J, etc. can each independently be present at an amount (e.g., a concentration) that is from 0.01 to 100 times the amount (e.g., a concentration) of A. One or more of DNA B, C, D, E, F, G, H, I, or J may also be absent. A multivalent RNA composition may be produced by combining RNA transcripts (e.g., circular RNA) from separate sources. For example, each of two or more DNA templates may be transcribed in separate IVT reactions, and combined to produce a multivalent RNA composition. Separate RNAs may be circularized separately before being combined, or linear RNAs may be combined and circularized in a single circularization reaction. RNAs may be combined in any desired amount to produce a multivalent RNA composition comprising two or more RNAs in a specific ratio.
RNA purification methods Some aspects relate to methods of producing circular RNAs and purifying circular RNAs by reverse phase chromatography. Chromatography refers to a process of separating components of a mixture based on differentiating characteristics of the components, such as interaction with a mobile and/or stationary phase of a chromatography column. In reverse phase chromatography, a mixture is introduced to a hydrophobic mobile phase, with the mobile phase and mixture passing over a hydrophilic stationary phase. Components of the mixture migrate through the stationary phase at different rates, depending on their relative affinity for the mobile and stationary phases. The amount of time required for a component (e.g., circular RNA) of the mixture to migrate through the stationary phase is also referred to as the “retention time” of the component. Characteristics that affect the retention time of a nucleic acid include size and secondary structure, such as whether the nucleic acid is linear or circular and/or whether it is coiled or uncoiled. Mobile phases typically comprise one or more solvent solutions, each of which comprises a solvent and one or more ion pairing agents. In some embodiments, one or more solvent solutions (e.g., 1, 2, 3, 4, 5, or more) of the mobile phase comprise a combination of at least one ion pairing agent (e.g., 1, 2, 3, 4, 5, or more). As used herein, an “ion pairing agent” or an “ion pair” refers to an agent (e.g., a small molecule) that functions as a counter ion to a charged (e.g., ionized or ionizable) functional group on an HPLC analyte (e.g., a nucleic acid) and thereby changes the retention time of the analyte as it moves through the stationary phase of an HPLC column. Generally, ion paring agents are classified as cationic ion pairing agents (which interact with negatively charged functional groups) or anionic ion pairing agents (which interact with positively charged functional groups). The terms “ion pairing agent” and “ion pair” further encompass an associated counter-ion (e.g., acetate, phosphate, bicarbonate, bromide, chloride, citrate, nitrate, nitrite, oxide, sulfate and the like, for cationic ion pairing agents, and sodium, calcium, and the like, for anionic ion pairing agents). In some embodiments, one or more ion pairing agents utilized is a cationic ion pairing agent. Examples of cationic ion pairing agents include but are not limited to certain protonated or quaternary amines (including e.g., primary, secondary and tertiary amines) and salts thereof, such as a trietheylammonium salt (e.g., triethylammonium acetate (TEAA)), a tributylammonium salt (e.g., tetrabutylammonium phosphate (TBAP) or tetrabutylammonium chloride (TBAC)), a hexylammonium salt (e.g., hexylammonium acetate (HAA)), a dibutylammonium salt (e.g., dibutylammonium acetate (DBAA)), a tetrapropylammonium salt (e.g., tetrapropylammonium bromide (TPAB)), a dodecyltrimethylammonium salt (e.g., dodecyltrimethylammonium chloride (DTMAC)), or a tetra(decyl)ammonium salt (e.g., tetra(decyl)ammonium bromide (TDAB)), a dihexylammonium
salt (e.g., dihexylammonium acetate (DHAA)), a dipropylammonium salt (e.g., dipropylammonium acetate (DPAA)), a myristyltrimethylammonium salt (e.g., myristyltrimethylammonium bromide (MTEAB)), a tetraethylammonium salt (e.g., tetraethylammonium bromide (TEAB)), a tetraheptylammonium salt (e.g., tetraheptylammonium bromide (THepAB)), a tetrahexylammonium salt (e.g., tetrahexylammonium bromide (THexAB)), a tetrakis(decyl)ammonium salt (e.g., tetrakis(decyl)ammonium bromide (TrDAB)), a tetramethylammonium salt (e.g., tetramethylammonium bromide (TMAB)), a tetraoctylammonium salt (e.g., tetraoctylammonium bromide (TOAB)), or a tetrapentylammonium salt (e.g., tetrapentylammonium bromide (TPeAB)). In some embodiments, one or more solvent solutions of the mobile phase comprise a combination of two or more ion pairing agents selected from the group consisting of a trietheylammonium salt, tributylammonium salt, hexylammonium salt, dibutylammonium salt, tetrapropylammonium salt, dodecyltrimethylammonium salt, tetra(decyl)ammonium salt, dihexylammonium salt, dipropylammonium salt, myristyltrimethylammonium salt, tetraethylammonium salt, tetraheptylammonium salt, tetrahexylammonium salt, tetrakis(decyl)ammonium salt, tetramethylammonium salt, tetraoctylammonium salt, and tetrapentylammonium salt. A salt of a cation, as used herein, refers to a composition comprising the cation and an anionic counter ion. For example, a “tetrabutylammonium salt” may refer to tetrabutylammonium phosphate, tetrabutylammonium chloride, tetrabutylammonium bromide, tetrabutylammonium phosphate, or another composition comprising the cation tetrabutylammonium and an anionic counter ion. In some embodiments, the ion pairing agent comprises a cation and an anionic counter ion, wherein the cation is selected from the group consisting of trietheylammonium, tributylammonium, hexylammonium, dibutylammonium, tetrapropylammonium, dodecyltrimethylammonium, tetra(decyl)ammonium, dihexylammonium, dipropylammonium, myristyltrimethylammonium, tetraethylammonium, tetraheptylammonium, tetrahexylammonium, tetrakis(decyl)ammonium, tetramethylammonium, tetraoctylammonium, and tetrapentylammonium, and the anionic counter ion is selected from the group consisting of a bromide, chloride, phosphate, and acetate. In some embodiments, one or more solvent solutions of the mobile phase comprise an ion pairing agent selected from the group consisting of HAA, TBAP, TPAB, TBAC, DBAA, TEAA, DTMAC, TDAB, DHAA, DPAA MTEAB, TEAB, THepAB, THexAB, TrDAB, TMAB, TOAB, and TPeAB. In some embodiments, one or more solvent solutions of the mobile phase comprise a combination of (i) TPAB and TBAC, (ii) DBAA and TEAA, or (iii) TBAP and TEAA. In some embodiments, one or more solvent solutions of the mobile phase comprise a combination of TPAB and TBAC. In some
embodiments, one or more solvent solutions of the mobile phase comprise a combination of DBAA and TEAA. Protonated and quaternary amine ion pairing agents can be represented by the following formula:
 wherein each R independently is hydrogen, optionally substituted aliphatic, optionally substituted heteroaliphatic, optionally substituted aryl or optionally substituted heteroaryl; provided that at least one instance of R is not hydrogen; and A is an anionic counter ion. The term “aliphatic” refers to alkyl, alkenyl, alkynyl, and carbocyclic groups. Likewise, the term “heteroaliphatic” refers to heteroalkyl, heteroalkenyl, heteroalkynyl, and heterocyclic groups. The term “aryl” refers to a radical of a monocyclic or polycyclic (e.g., bicyclic or tricyclic) 4n+2 aromatic ring system (e.g., having 6, 10, or 14 π electrons shared in a cyclic array) having 6–14 ring carbon atoms and zero heteroatoms provided in the aromatic ring system (“C6–14 aryl”). The term “heteroaryl” refers to a radical of a 5–14 membered monocyclic or polycyclic (e.g., bicyclic, tricyclic) 4n+2 aromatic ring system (e.g., having 6, 10, or 14 π electrons shared in a cyclic array) having ring carbon atoms and 1–4 ring heteroatoms provided in the aromatic ring system, wherein each heteroatom is independently selected from nitrogen, oxygen, and sulfur (“5–14 membered heteroaryl”). Suitable anionic counter ions include, but are not limited to, acetate, trifluoroacetate, phosphate, chloride, bromide hexafluorophosphate, sulfate, methylsulfonate, trifluoromethylsulfonate, 1,1,1,3,3,3-hexafluoro- 2-propanol (HFIP), 1,1,1,3,3,3-hexafluoro-2-methyl-2-propanol (HFMIP) and the like. The term “optionally substituted” refers to being substituted or unsubstituted. In general, the term “substituted” means that at least one hydrogen present on a group is replaced with a permissible substituent, e.g., a substituent which upon substitution results in a stable compound, e.g., a compound which does not spontaneously undergo transformation such as by rearrangement, cyclization, elimination, or other reaction. In some embodiments, a solvent solution of the mobile phase (e.g., a first solvent solution or a second solvent solution) comprising at least two ion pairing agents are in a molar ratio of between about 1:1,000 to about 1,000:1, such that the nucleic acids and if present, lipids, traverse the column at different rates. In some embodiments, the at least two ion pairing agents are in a molar ratio between about 1:1,000 to about 1,000:1, 1:900 to about 900:1, 1:800 to about 800:1, 1:700 to about 700:1, 1:600 to about 600:1, 1:500 to about 500:1, 1:400 to about 400:1, about 1:300 to about 300:1, about 1:200 to about 200:1, about 1:100 to about 100:1, about 50:1 to about 1:50, about 40:1 to about 1:40, about 30:1 to about 1:30, about 20:1 to about 1:20, or
about 10:1 to about 1:10. In some embodiments, each solvent solution comprises at least two ion pairing agents in a molar ratio of between about 1:100 to about 100:1. In some embodiments, the at least two ion pairing agents are in a molar ratio between about 1:100 to about 100:1, 1:90 to about 90:1, 1:80 to about 80:1, 1:70 to about 70:1, 1:60 to about 60:1, 1:50 to about 50:1, 1:40 to about 40:1, about 1:30 to about 30:1, about 1:20 to about 20:1, about 1:10 to about 10:1, about 5:1 to about 1:5, about 4:1 to about 1:4, about 3:1 to about 1:3, or about 2:1 to about 1:2. In some embodiments, the at least two ion pairing agents are in a 1:1 molar ratio. In some embodiments, a solvent solution of the mobile phase (e.g., a first solvent solution or a second solvent solution) comprises at least two ion pairing agents that are in a molar ratio of between about 1:6 to about 6:1, such that the nucleic acids and if present, lipids, traverse the column at different rates. In some embodiments, each solvent solution comprises at least two ion pairing agents in a molar ratio of between about 1:4 to about 4:1. In some embodiments, the at least two ion pairing agents are in a molar ratio between about 1:3 to about 3:1, about 1:2 to about 2:1, or about 1:1.5 to about 1.5:1. In some embodiments, the at least two ion pairing agents are in a 1:1 molar ratio. The concentration of each ion pairing agent in a solvent solution (e.g., a first solvent solution or a second solvent solution) may range from about 1 mM to about 25 M (e.g., about 1 mM, about 2 mM, about 5 mM, about 10 mM, about 50 mM, about 100 mM, about 200 mM, about 500 mM, about 1 M, about 1.2 M, about 1.5 M, about 1.75 M, about 2M, about 2.25 M, about 2.5 M, about 2.75 M, about 3 M, about 3.25 M, about 3.5 M, about 3.75 M, about 4 M, about 4.25 M, about 4.5 M, about 4.75 M, about 5 M, about 5.5 M, about 6 M, about 6.5 M, about 7 M, about 7.5 M, about 8 M, about 8.5 M, about 9 M, about 9.5 M, about 10 M, about 11 M, about 12 M, about 13 M, about 14 M, about 15 M, about 16 M, about 17 M, about 18 M, about 19 M, or about 20 M), inclusive. In some embodiments, the concentration of an ion pairing agent in a mobile phase (e.g., a first solvent solution or a second solvent solution) ranges from about, 10 mM–20 M, 20 mM–15 M, 30 mM–2 M, 40 mM–10 M, 50 mM–8 M, 75 mM–5 M, 100 mM–2.5 M, 125 mM–2 M, 150 mM–1.5 M, 175 mM–1 M, or 200 mM–500 mM. In some embodiments, the concentration of each of the ion pairing agents independently ranges from about, 10 mM–20 M, 20 mM–15 M, 30 mM–12 M, 40 mM–10 M, 50 mM–8 M, 75 mM–5 M, 100 mM–2.5 M, 125 mM–2 M, 150 mM–1.5 M, 175 mM–1 M, or 200 mM–500 mM. In some embodiments, a first or second solvent solution comprises a single ion pairing agent, which is present in an amount from about, 10 mM–20 M, 20 mM–15 M, 30 mM–12 M, 40 mM– 10 M, 50 mM–8 M, 75 mM–5 M, 100 mM–2.5 M, 125 mM–2 M, 150 mM–1.5 M, 175 mM–1 M, or 200 mM–500 mM.
The concentration of each ion pairing agent in a solvent solution (e.g., a first solvent solution or a second solvent solution) may range from about 1 mM to about 2 M (e.g., about 1 mM, about 2 mM, about 5 mM, about 10 mM, about 50 mM, about 100 mM, about 200 mM, about 500 mM, about 1 M, about 1.2 M, about 1.5 M, or about 2M), inclusive. In some embodiments, the concentration of an ion pairing agent in a mobile phase (e.g., a first solvent solution or a second solvent solution) ranges from about, 10 mM–1M, 40 mM–300 mM, 50 mM-500 mM, 75 mM-400 mM, 100 mM-300 mM, 200-300 mM, 200-250 mM, or 250-300 mM. In some embodiments, the concentration of each of the ion pairing agents independently ranges from about, 10 mM–1M, 40 mM–300 mM, 50 mM-500 mM, 75 mM-400 mM, 100 mM- 300 mM, 200-300 mM, 200-250 mM, or 250-300 mM. In some embodiments, two ion pairing agents are present at concentrations of about 20 mM: 40 mM, 50 mM: 50 mM, 50 mM: 60 mM, 50 mM: 75 mM, 50 mM: 100 mM, 50 mM:150 mM, 100 mM: 100 mM, 100 mM: 125 mM, 100 mM: 150 mM, 100 mM: 175 mM, 100 mM: 200 mM, 100 mM: 200 mM, 100 mM: 250 mM, 100 mM: 300 mM, 125 mM: 125 mM, 125 mM: 150 mM, 125 mM: 175 mM, 125 mM: 200 mM, 125 mM: 250 mM, 125 mM: 300 mM, 150 mM: 175 mM, 150 mM: 200 mM, 150 mM: 250 mM, 150 mM: 300 mM, 200 mM: 200 mM, 200 mM: 250 mM, 200 mM: 300 mM, 250 mM: 250 mM, 250 mM: 300 mM, or 300 mM: 300 mM. Examples of ion pairing agent concentrations include but are not limited to 40 mM TEAA: 20 mM DBAA, 100 mM TEAA: 50 mM DBAA, 50 mM TBAP: 50 mM TEAA, 250 mM TBAP: 250 mM TEAA, 300 mM TBAP: 300 mM TEAA, 50 mM TBAP: 150 mM TEAA, 125 mM TBAP: 250 mM TEAA, 250 mM TBAP: 250 mM TEAA, 300 mM TBAP: 300 mM TEAA, 50 mM DBAA: 50 mM TEAA, 60 mM DBAA: 50 mM TEAA, 75 mM DBAA: 50 mM TEAA, 175 mM DBAA: 125 mM TEAA, 100 mM DBAA: 100 mM TEAA, 50 mM TBAP: 100 mM TEAA, 100 mM TBAP: 200 mM TEAA, 125 mM TBAP: 250 mM TEAA, 150 mM TABP: 200 mM TEAA, 150 mM TBAP: 200 mM TEAA, 150 mM TBAP: 250 mM TEAA, 50 mM TBAP: 150 mM TEAA, 100 mM TBAP: 150 mM TEAA, 250 mM TBAP: 200 mM TEAA, 250 mM TBAP: 250 mM TEAA, or 200 mM TBAP: 300 mM TEAA. In some embodiments, one or more solvent solutions of the mobile phase comprise a combination of TPAB and TBAC. In some embodiments, the concentrations of TPAB and TBAC independently range from 50 mM- 300 mM. In some embodiments, one or more solvent solutions of the mobile phase comprise 200 mM TPAB: 200 mM TBAC, 250 mM TPAB: 250 mM TBAC, or 300 mM TPAB: 300 mM TBAC. In some embodiments, one or more solvent solutions of the mobile phase comprise 250 mM TPAB: 250 mM TBAC. Ion pairing agents are generally dispersed within a mobile phase. As used herein, a “mobile phase” is an aqueous solution comprising water and/or one or more organic solvents
used to carry an HPLC analyte (or analytes), such as a nucleic acid or mixture of nucleic acids or a pharmaceutical composition comprising a nucleic acid or mixture of nucleic acids, through an HPLC column. In some embodiments, a mobile phase for use in HPLC methods comprises multiple (e.g., 2, 3, 4, 5, or more) solvent solutions. In some embodiments of the HPLC methods, the mobile phase comprises two solvent solutions, a first solvent solution and a second solvent solution (e.g., Mobile Phase A, and Mobile Phase B). In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:1,000 to 1,000:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:1,000 to 1,000:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:100 to 100:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:100 to 100:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:75 to 75:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:75 to 75:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:50 to 50:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:50 to 50:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:25 to 25:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:25 to 25:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:10 to 10:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:10 to 10:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:6 to 6:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:6 to 6:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:4 to 4:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:4 to 4:1. In some embodiments, at least one solvent solution of the mobile phase comprises an organic solvent. Generally, an IP-RP HPLC mobile phase comprises a polar organic solvent. Examples of polar organic solvents suitable for inclusion in a mobile phase include but are not
limited to alcohols, ketones, nitrates, esters, amides and alkylsulfoxides. In some embodiments, the mobile phase (e.g., at least one solvent solution of the mobile phase) comprises one or more organic solvents selected from the group consisting of polar aprotic solvents, C1-4 alkanols, C1-6 alkanediols, and C2-4 alkanoic acids. In some embodiments, the mobile phase (e.g., at least one solvent solution of the mobile phase) comprises one or more organic solvents selected form the group consisting of acetone, acetonitrile, dimethylformamide, dimethylsulfoxide (DMSO), ethanol, hexylene glycol, isopropanol, methanol, methyl acetate, propanol, and tetrahydrofuran. In some embodiments, the mobile phase (e.g., at least one solvent solution of the mobile phase) comprises acetonitrile. In some embodiments, a mobile phase (e.g., at least one solvent solution of the mobile phase) comprises additional components, for example as described in U.S. Patent Publication US 2005/0011836, which is incorporated herein by reference for this purpose. The concentration of organic solvent in a mobile phase (e.g., each solvent solution of the mobile phase) can vary. For example, in some embodiments, the volume percentage (v/v) of an organic solvent in a mobile phase varies from 0% (absent) to about 100% of a mobile phase. In some embodiments, the volume percentage of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is between about 5% and about 75% v/v. In some embodiments, the volume percentage of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is between about 25% and about 60% v/v. In some embodiments, the volume percentage of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is at least about 50% v/v. In some embodiments, the volume percentage of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is about 50% to about 95%, about 55% to about 90%, about 60% to about 85%, about 65% to about 80%, or about 70% v/v to about 75% v/v. In some embodiments, the concentration of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is about 5%, about 10%, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, about 90% v/v, or about 95% v/v. In some embodiments, the first solvent solution does not comprise an organic solvent. In some embodiments, the volume percentage of organic solvent in the second solvent solution is at least about 50% v/v. In some embodiments, the volume percentage of organic solvent in the second solvent solution is about 50% to about 95%, about 55% to about 90%, about 60% to about 85%, about 65% to about 80%, or about 70% v/v to about 75% v/v. In some embodiments, the volume percentage of organic solvent in the second solvent solution is about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, about 90% v/v, or about 95% v/v.
The pH of the mobile phase (e.g., the pH of each solvent solution of the mobile phase) can vary. In some embodiments, the pH of the mobile phase is between about pH 5.0 and pH 9.5 (e.g., about 5.0, about 5.5, about 6.0, about 6.5, about 7.0, about 7.5, about 8.0, about 8.5, about 9.0, or about 9.5). In some embodiments, the pH of the mobile phase is between about pH 6.8 and pH 9.0 (e.g., about 6.8, about 7.0, about 7.2, about 7.4, about 7.6, about 7.8, about 8.0, about 8.3, about 8.5, or about 9.0). In some embodiments, the pH of the mobile phase is about 8.0. In some embodiments, the pH of the first solvent solution is between about pH 5.0 and pH 9.5 (e.g., about 5.0, about 5.5, about 6.0, about 6.5, about 7.0, about 7.5, about 8.0, about 8.5, about 9.0, or about 9.5). In some embodiments, the pH of the first solvent solution is between about pH 6.8 and pH 9.0 (e.g., about 6.8, about 7.0, about 7.2, about 7.4, about 7.6, about 7.8, about 8.0, about 8.3, about 8.5, or about 9.0). In some embodiments, the pH of the first solvent solution is about 8.0. In some embodiments, the pH of the second solvent solution is between about pH 5.0 and pH 9.5 (e.g., about 5.0, about 5.5, about 6.0, about 6.5, about 7.0, about 7.5, about 8.0, about 8.5, about 9.0, or about 9.5). In some embodiments, the pH of the second solvent solution is between about pH 6.8 and pH 9.0 (e.g., about 6.8, about 7.0, about 7.2, about 7.4, about 7.6, about 7.8, about 8.0, about 8.3, or about 8.5). In some embodiments, the pH of the second solvent solution is about 8.0. The concentration of two or more solvent solutions in a mobile phase can vary. For example, in a mobile phase comprising two solvent solutions (e.g., a first solvent solution and a second solvent solution), the volume percentage of the first solvent solution may range from about 0% (absent) to about 100%. In some embodiments, the volume percentage of the first solvent solution may range from about 5%, about 10%, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, or about 90% v/v. Conversely, in some embodiments, the volume percentage of the second solvent solution of a mobile phase may range from about 5%, about 10%, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, or about 90% v/v. In some embodiments, the ratio of the first solvent solution to the second solvent solution is held constant (e.g., isocratic) during elution of the nucleic acid. However, the skilled artisan will appreciate that in other embodiments, the relative ratio of the first solvent solution to the second solvent solution can vary throughout the elution step. For example, in some embodiments, the ratio of the first solvent solution is increased relative to the second solvent
solution during the elution step. In some embodiments, the ratio of the first solvent solution is decreased relative to the second solvent solution during the elution step. The concentration of one or more ion pairing agents in a mobile phase (e.g., a solvent solution) can vary. The relative ratios of the at least two ion pairing agents in a mobile phase (or solvent solution) may vary or be held constant (e.g., isocratic) during the eluting step. In some embodiments, the ratio of a first ion pairing agent is increased relative to a second ion pairing agent during the elution step. In some embodiments, the ratio of a first ion pairing agent is increased relative to a second ion pairing agent during the elution step. For example, in some embodiments, the ratio of TPAB to TBAC ranges from about 4:1 to about 1:4, about 3:1 to about 1:3, about 2:1 to about 1:2, or about 1:1 to 1:3. The mobile phase (e.g., a solvent solution) may be gradient or isocratic with respect to the concentration of one or more organic solvents. Any suitable HPLC column (e.g., stationary phase) may be used in an HPLC method. Generally, a “HPLC column” is a solid structure or support that contains a medium (e.g. a stationary phase) through which the mobile phase and HPLC sample (e.g., a sample containing HPLC analytes, such as nucleic acids) is eluted. Without wishing to be bound by any particular theory, the composition and chemical properties of the stationary phase determine the retention time of HPLC analytes. In some embodiments of HPLC methods, the stationary phase is non- polar. Examples of non-polar stationary phases include but are not limited to resin, silica (e.g., alkylated and non-alkylated silica), polystyrenes (e.g., alkylated and non-alkylated polystyrenes), polystyrene divinylbenzenes, etc. In some embodiments, a stationary phase comprises particles, for example porous particles. In some embodiments, a stationary phase (e.g., particles of a stationary phase) is hydrophobic (e.g., made of an intrinsically hydrophobic material, such as polystyrene divinylbenzene), or comprise hydrophobic functional groups. In some embodiments, a stationary phase is a membrane or monolithic stationary phase. The particle size (e.g., as measured by the diameter of the particle) of an HPLC stationary phase can vary. In some embodiments, the particle size of a HPLC stationary phase ranges from about 1 µm to about 100 µm (e.g., any value between 1 and 100, inclusive) in diameter. In some embodiments, the particle size of a HPLC stationary phase ranges from about 2µm to about 10µm, about 2µm to about 6µm, or about 4µm in diameter. The pore size of particles (e.g., as measured by the diameter of the pore) can also vary. In some embodiments, the particles comprise pores having a diameter of about 100Å to about 10,000Å. In some embodiments, the particles comprise pores having a diameter of about 100Å to about 5000Å, about 100Å to about 1000Å, or about 1000Å to about 2000Å. In some embodiments, the
stationary phase comprises polystyrene divinylbenzene, for example as used in PLRP-S 4000 columns or DNAPac-RP columns. A sample being added to the stationary phase (e.g., a pharmaceutical preparation) may be diluted in a surfactant. Surfactants may include, but are not limited to, one or more of Triton, polysorbate 20, 40, 60, and 80, sodium lauryl sulfate, etc. In some embodiments, the percentage of the surfactant ranges from about 1% to 5%, or about 5% to 10%. In some embodiments, the percentage of the surfactant is about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, or 10%. In some embodiments, the sample being added to the stationary phase is diluted in the first solvent solution (e.g., Mobile phase A). In some embodiments of the methods provided herein, a circular RNA is separated from other nucleic acids of a mixture (e.g., linear RNAs, DNA templates or fragments) by size exclusion chromatography. Size exclusion chromatography, also known as molecular sieving, separates components of a mixture based on size. Typically, size exclusion chromatography is conducted by adding a mixture containing a desired nucleic acid to a stationary phase containing solid particles in a column. Larger nucleic acids migrate through the stationary phase more quickly, while smaller nucleic acids interact more readily with particles of the stationary phase, and thus take longer to reach the bottom of the column. These differences in retention times allow mixtures to be separated into component parts by eluting distinct components from the column at different times. The secondary structure of a nucleic acid, such as whether it is linear or circular, also influences the retention time of a nucleic acid in size exclusion chromatography column stationary phase. Accordingly, size exclusion chromatography may be used to separate circular RNAs from linear RNAs having the same sequence, as well as RNA fragments produced by exonuclease digestion, DNA splints, DNA templates, and DNA fragments produced by DNase digestion. In some embodiments, the step of size exclusion chromatography is conducted before the step of reverse phase column chromatography. In some embodiments, the step of size exclusion chromatography is conducted after the step of reverse phase column chromatography. Lipid Compositions In some embodiments, the nucleic acids are formulated as a lipid composition, such as a composition comprising a lipid nanoparticle, a liposome, and/or a lipoplex. In some embodiments, the lipid composition (e.g., lipid nanoparticle, liposome, and/or lipoplex) does not comprise protamine. In some embodiments, the lipid composition does comprise protamine. In some embodiments, nucleic acids are formulated as lipid nanoparticle (LNP) compositions. Lipid nanoparticles typically comprise ionizable lipid (e.g., ionizable amino lipid), non-cationic
lipid (e.g., phospholipid), structural lipid (e.g., sterol), and PEG-modified lipid components along with the nucleic acid cargo of interest. The lipid nanoparticles can be generated using components, compositions, and methods as are generally known in the art, see for example PCT/US2016/052352; PCT/US2016/068300; PCT/US2017/037551; PCT/US2015/027400; PCT/US2016/047406; PCT/US2016/000129; PCT/US2016/014280; PCT/US2017/038426; PCT/US2014/027077; PCT/US2014/055394; PCT/US2016/052117; PCT/US2012/069610; PCT/US2017/027492; PCT/US2016/059575; PCT/US2016/069491; PCT/US2016/069493; and PCT/US2014/066242, all of which are incorporated by reference herein to the extent they disclose lipid nanoparticles and preparation thereof. In some embodiments, the lipid nanoparticle comprises a molar ratio of 20-60% ionizable lipid, 5-25% non-cationic lipid, 25-55% structural lipid, and 0.5-15% PEG-modified lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 20-60% ionizable lipid, 5-30% non-cationic lipid, 10-55% structural lipid, and 0.5-15% PEG-modified lipid. In some embodiments, the lipid nanoparticle comprises 40-50 mol% ionizable lipid, optionally 45-50 mol%, for example, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48-49 mol%, or 49-50 mol% for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol%. In some embodiments, the lipid nanoparticle comprises 20-60 mol% ionizable lipid. For example, the lipid nanoparticle may comprise 20-50 mol%, 20-40 mol%, 20-30 mol%, 30-60 mol%, 30-50 mol%, 30-40 mol%, 40-60 mol%, 40-50 mol%, or 50-60 mol% ionizable lipid. In some embodiments, the lipid nanoparticle comprises 20 mol%, 30 mol%, 40 mol%, 50 mol%, or 60 mol% ionizable lipid. In some embodiments, the lipid nanoparticle comprises 35 mol%, 36 mol%, 37 mol%, 38 mol%, 39 mol%, 40 mol%, 41 mol%, 42 mol%, 43 mol%, 44 mol%, 45 mol%, 46 mol%, 47 mol%, 48 mol%, 49 mol%, 50 mol%, 51 mol%, 52 mol%, 53 mol%, 54 mol%, or 55 mol% ionizable lipid. In some embodiments, the lipid nanoparticle comprises 45–55 mole percent (mol%) ionizable lipid. For example, lipid nanoparticle may comprise 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, or 55 mol% ionizable lipid. Ionizable lipids In some embodiments, the ionizable lipid is a compound of Formula (IL*)
(IL*) or a salt thereof, wherein: R1 is -OH, -NRN-C4-10 cycloalkenyl optionally substituted with one or more oxo or - N(RN’RN’’); RN is H or C1-6 alkyl; RN’ is H or C1-6 alkyl; RN’’ is H or C1-6 alkyl; o is 1, 2, 3, or 4; n is 4, 5, 6, 7, or 8; m is 4, 5, 6, 7, or 8; M is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R2; M’ is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R3;
wherein each R independently is hydrogen, optionally substituted aliphatic, optionally substituted heteroaliphatic, optionally substituted aryl or optionally substituted heteroaryl; provided that at least one instance of R is not hydrogen; and A is an anionic counter ion. The term “aliphatic” refers to alkyl, alkenyl, alkynyl, and carbocyclic groups. Likewise, the term “heteroaliphatic” refers to heteroalkyl, heteroalkenyl, heteroalkynyl, and heterocyclic groups. The term “aryl” refers to a radical of a monocyclic or polycyclic (e.g., bicyclic or tricyclic) 4n+2 aromatic ring system (e.g., having 6, 10, or 14 π electrons shared in a cyclic array) having 6–14 ring carbon atoms and zero heteroatoms provided in the aromatic ring system (“C6–14 aryl”). The term “heteroaryl” refers to a radical of a 5–14 membered monocyclic or polycyclic (e.g., bicyclic, tricyclic) 4n+2 aromatic ring system (e.g., having 6, 10, or 14 π electrons shared in a cyclic array) having ring carbon atoms and 1–4 ring heteroatoms provided in the aromatic ring system, wherein each heteroatom is independently selected from nitrogen, oxygen, and sulfur (“5–14 membered heteroaryl”). Suitable anionic counter ions include, but are not limited to, acetate, trifluoroacetate, phosphate, chloride, bromide hexafluorophosphate, sulfate, methylsulfonate, trifluoromethylsulfonate, 1,1,1,3,3,3-hexafluoro- 2-propanol (HFIP), 1,1,1,3,3,3-hexafluoro-2-methyl-2-propanol (HFMIP) and the like. The term “optionally substituted” refers to being substituted or unsubstituted. In general, the term “substituted” means that at least one hydrogen present on a group is replaced with a permissible substituent, e.g., a substituent which upon substitution results in a stable compound, e.g., a compound which does not spontaneously undergo transformation such as by rearrangement, cyclization, elimination, or other reaction. In some embodiments, a solvent solution of the mobile phase (e.g., a first solvent solution or a second solvent solution) comprising at least two ion pairing agents are in a molar ratio of between about 1:1,000 to about 1,000:1, such that the nucleic acids and if present, lipids, traverse the column at different rates. In some embodiments, the at least two ion pairing agents are in a molar ratio between about 1:1,000 to about 1,000:1, 1:900 to about 900:1, 1:800 to about 800:1, 1:700 to about 700:1, 1:600 to about 600:1, 1:500 to about 500:1, 1:400 to about 400:1, about 1:300 to about 300:1, about 1:200 to about 200:1, about 1:100 to about 100:1, about 50:1 to about 1:50, about 40:1 to about 1:40, about 30:1 to about 1:30, about 20:1 to about 1:20, or
about 10:1 to about 1:10. In some embodiments, each solvent solution comprises at least two ion pairing agents in a molar ratio of between about 1:100 to about 100:1. In some embodiments, the at least two ion pairing agents are in a molar ratio between about 1:100 to about 100:1, 1:90 to about 90:1, 1:80 to about 80:1, 1:70 to about 70:1, 1:60 to about 60:1, 1:50 to about 50:1, 1:40 to about 40:1, about 1:30 to about 30:1, about 1:20 to about 20:1, about 1:10 to about 10:1, about 5:1 to about 1:5, about 4:1 to about 1:4, about 3:1 to about 1:3, or about 2:1 to about 1:2. In some embodiments, the at least two ion pairing agents are in a 1:1 molar ratio. In some embodiments, a solvent solution of the mobile phase (e.g., a first solvent solution or a second solvent solution) comprises at least two ion pairing agents that are in a molar ratio of between about 1:6 to about 6:1, such that the nucleic acids and if present, lipids, traverse the column at different rates. In some embodiments, each solvent solution comprises at least two ion pairing agents in a molar ratio of between about 1:4 to about 4:1. In some embodiments, the at least two ion pairing agents are in a molar ratio between about 1:3 to about 3:1, about 1:2 to about 2:1, or about 1:1.5 to about 1.5:1. In some embodiments, the at least two ion pairing agents are in a 1:1 molar ratio. The concentration of each ion pairing agent in a solvent solution (e.g., a first solvent solution or a second solvent solution) may range from about 1 mM to about 25 M (e.g., about 1 mM, about 2 mM, about 5 mM, about 10 mM, about 50 mM, about 100 mM, about 200 mM, about 500 mM, about 1 M, about 1.2 M, about 1.5 M, about 1.75 M, about 2M, about 2.25 M, about 2.5 M, about 2.75 M, about 3 M, about 3.25 M, about 3.5 M, about 3.75 M, about 4 M, about 4.25 M, about 4.5 M, about 4.75 M, about 5 M, about 5.5 M, about 6 M, about 6.5 M, about 7 M, about 7.5 M, about 8 M, about 8.5 M, about 9 M, about 9.5 M, about 10 M, about 11 M, about 12 M, about 13 M, about 14 M, about 15 M, about 16 M, about 17 M, about 18 M, about 19 M, or about 20 M), inclusive. In some embodiments, the concentration of an ion pairing agent in a mobile phase (e.g., a first solvent solution or a second solvent solution) ranges from about, 10 mM–20 M, 20 mM–15 M, 30 mM–2 M, 40 mM–10 M, 50 mM–8 M, 75 mM–5 M, 100 mM–2.5 M, 125 mM–2 M, 150 mM–1.5 M, 175 mM–1 M, or 200 mM–500 mM. In some embodiments, the concentration of each of the ion pairing agents independently ranges from about, 10 mM–20 M, 20 mM–15 M, 30 mM–12 M, 40 mM–10 M, 50 mM–8 M, 75 mM–5 M, 100 mM–2.5 M, 125 mM–2 M, 150 mM–1.5 M, 175 mM–1 M, or 200 mM–500 mM. In some embodiments, a first or second solvent solution comprises a single ion pairing agent, which is present in an amount from about, 10 mM–20 M, 20 mM–15 M, 30 mM–12 M, 40 mM– 10 M, 50 mM–8 M, 75 mM–5 M, 100 mM–2.5 M, 125 mM–2 M, 150 mM–1.5 M, 175 mM–1 M, or 200 mM–500 mM.
The concentration of each ion pairing agent in a solvent solution (e.g., a first solvent solution or a second solvent solution) may range from about 1 mM to about 2 M (e.g., about 1 mM, about 2 mM, about 5 mM, about 10 mM, about 50 mM, about 100 mM, about 200 mM, about 500 mM, about 1 M, about 1.2 M, about 1.5 M, or about 2M), inclusive. In some embodiments, the concentration of an ion pairing agent in a mobile phase (e.g., a first solvent solution or a second solvent solution) ranges from about, 10 mM–1M, 40 mM–300 mM, 50 mM-500 mM, 75 mM-400 mM, 100 mM-300 mM, 200-300 mM, 200-250 mM, or 250-300 mM. In some embodiments, the concentration of each of the ion pairing agents independently ranges from about, 10 mM–1M, 40 mM–300 mM, 50 mM-500 mM, 75 mM-400 mM, 100 mM- 300 mM, 200-300 mM, 200-250 mM, or 250-300 mM. In some embodiments, two ion pairing agents are present at concentrations of about 20 mM: 40 mM, 50 mM: 50 mM, 50 mM: 60 mM, 50 mM: 75 mM, 50 mM: 100 mM, 50 mM:150 mM, 100 mM: 100 mM, 100 mM: 125 mM, 100 mM: 150 mM, 100 mM: 175 mM, 100 mM: 200 mM, 100 mM: 200 mM, 100 mM: 250 mM, 100 mM: 300 mM, 125 mM: 125 mM, 125 mM: 150 mM, 125 mM: 175 mM, 125 mM: 200 mM, 125 mM: 250 mM, 125 mM: 300 mM, 150 mM: 175 mM, 150 mM: 200 mM, 150 mM: 250 mM, 150 mM: 300 mM, 200 mM: 200 mM, 200 mM: 250 mM, 200 mM: 300 mM, 250 mM: 250 mM, 250 mM: 300 mM, or 300 mM: 300 mM. Examples of ion pairing agent concentrations include but are not limited to 40 mM TEAA: 20 mM DBAA, 100 mM TEAA: 50 mM DBAA, 50 mM TBAP: 50 mM TEAA, 250 mM TBAP: 250 mM TEAA, 300 mM TBAP: 300 mM TEAA, 50 mM TBAP: 150 mM TEAA, 125 mM TBAP: 250 mM TEAA, 250 mM TBAP: 250 mM TEAA, 300 mM TBAP: 300 mM TEAA, 50 mM DBAA: 50 mM TEAA, 60 mM DBAA: 50 mM TEAA, 75 mM DBAA: 50 mM TEAA, 175 mM DBAA: 125 mM TEAA, 100 mM DBAA: 100 mM TEAA, 50 mM TBAP: 100 mM TEAA, 100 mM TBAP: 200 mM TEAA, 125 mM TBAP: 250 mM TEAA, 150 mM TABP: 200 mM TEAA, 150 mM TBAP: 200 mM TEAA, 150 mM TBAP: 250 mM TEAA, 50 mM TBAP: 150 mM TEAA, 100 mM TBAP: 150 mM TEAA, 250 mM TBAP: 200 mM TEAA, 250 mM TBAP: 250 mM TEAA, or 200 mM TBAP: 300 mM TEAA. In some embodiments, one or more solvent solutions of the mobile phase comprise a combination of TPAB and TBAC. In some embodiments, the concentrations of TPAB and TBAC independently range from 50 mM- 300 mM. In some embodiments, one or more solvent solutions of the mobile phase comprise 200 mM TPAB: 200 mM TBAC, 250 mM TPAB: 250 mM TBAC, or 300 mM TPAB: 300 mM TBAC. In some embodiments, one or more solvent solutions of the mobile phase comprise 250 mM TPAB: 250 mM TBAC. Ion pairing agents are generally dispersed within a mobile phase. As used herein, a “mobile phase” is an aqueous solution comprising water and/or one or more organic solvents
used to carry an HPLC analyte (or analytes), such as a nucleic acid or mixture of nucleic acids or a pharmaceutical composition comprising a nucleic acid or mixture of nucleic acids, through an HPLC column. In some embodiments, a mobile phase for use in HPLC methods comprises multiple (e.g., 2, 3, 4, 5, or more) solvent solutions. In some embodiments of the HPLC methods, the mobile phase comprises two solvent solutions, a first solvent solution and a second solvent solution (e.g., Mobile Phase A, and Mobile Phase B). In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:1,000 to 1,000:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:1,000 to 1,000:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:100 to 100:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:100 to 100:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:75 to 75:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:75 to 75:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:50 to 50:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:50 to 50:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:25 to 25:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:25 to 25:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:10 to 10:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:10 to 10:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:6 to 6:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:6 to 6:1. In some embodiments, a solvent solution comprises at least two ion pairing agents in a molar ratio of 1:4 to 4:1. In some embodiments, each solvent solution (e.g., the first solvent solution and the second solvent solution) comprises at least two ion pairing agents in a molar ratio of 1:4 to 4:1. In some embodiments, at least one solvent solution of the mobile phase comprises an organic solvent. Generally, an IP-RP HPLC mobile phase comprises a polar organic solvent. Examples of polar organic solvents suitable for inclusion in a mobile phase include but are not
limited to alcohols, ketones, nitrates, esters, amides and alkylsulfoxides. In some embodiments, the mobile phase (e.g., at least one solvent solution of the mobile phase) comprises one or more organic solvents selected from the group consisting of polar aprotic solvents, C1-4 alkanols, C1-6 alkanediols, and C2-4 alkanoic acids. In some embodiments, the mobile phase (e.g., at least one solvent solution of the mobile phase) comprises one or more organic solvents selected form the group consisting of acetone, acetonitrile, dimethylformamide, dimethylsulfoxide (DMSO), ethanol, hexylene glycol, isopropanol, methanol, methyl acetate, propanol, and tetrahydrofuran. In some embodiments, the mobile phase (e.g., at least one solvent solution of the mobile phase) comprises acetonitrile. In some embodiments, a mobile phase (e.g., at least one solvent solution of the mobile phase) comprises additional components, for example as described in U.S. Patent Publication US 2005/0011836, which is incorporated herein by reference for this purpose. The concentration of organic solvent in a mobile phase (e.g., each solvent solution of the mobile phase) can vary. For example, in some embodiments, the volume percentage (v/v) of an organic solvent in a mobile phase varies from 0% (absent) to about 100% of a mobile phase. In some embodiments, the volume percentage of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is between about 5% and about 75% v/v. In some embodiments, the volume percentage of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is between about 25% and about 60% v/v. In some embodiments, the volume percentage of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is at least about 50% v/v. In some embodiments, the volume percentage of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is about 50% to about 95%, about 55% to about 90%, about 60% to about 85%, about 65% to about 80%, or about 70% v/v to about 75% v/v. In some embodiments, the concentration of organic solvent in a mobile phase (e.g., at least one solvent solution of the mobile phase) is about 5%, about 10%, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, about 90% v/v, or about 95% v/v. In some embodiments, the first solvent solution does not comprise an organic solvent. In some embodiments, the volume percentage of organic solvent in the second solvent solution is at least about 50% v/v. In some embodiments, the volume percentage of organic solvent in the second solvent solution is about 50% to about 95%, about 55% to about 90%, about 60% to about 85%, about 65% to about 80%, or about 70% v/v to about 75% v/v. In some embodiments, the volume percentage of organic solvent in the second solvent solution is about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, about 90% v/v, or about 95% v/v.
The pH of the mobile phase (e.g., the pH of each solvent solution of the mobile phase) can vary. In some embodiments, the pH of the mobile phase is between about pH 5.0 and pH 9.5 (e.g., about 5.0, about 5.5, about 6.0, about 6.5, about 7.0, about 7.5, about 8.0, about 8.5, about 9.0, or about 9.5). In some embodiments, the pH of the mobile phase is between about pH 6.8 and pH 9.0 (e.g., about 6.8, about 7.0, about 7.2, about 7.4, about 7.6, about 7.8, about 8.0, about 8.3, about 8.5, or about 9.0). In some embodiments, the pH of the mobile phase is about 8.0. In some embodiments, the pH of the first solvent solution is between about pH 5.0 and pH 9.5 (e.g., about 5.0, about 5.5, about 6.0, about 6.5, about 7.0, about 7.5, about 8.0, about 8.5, about 9.0, or about 9.5). In some embodiments, the pH of the first solvent solution is between about pH 6.8 and pH 9.0 (e.g., about 6.8, about 7.0, about 7.2, about 7.4, about 7.6, about 7.8, about 8.0, about 8.3, about 8.5, or about 9.0). In some embodiments, the pH of the first solvent solution is about 8.0. In some embodiments, the pH of the second solvent solution is between about pH 5.0 and pH 9.5 (e.g., about 5.0, about 5.5, about 6.0, about 6.5, about 7.0, about 7.5, about 8.0, about 8.5, about 9.0, or about 9.5). In some embodiments, the pH of the second solvent solution is between about pH 6.8 and pH 9.0 (e.g., about 6.8, about 7.0, about 7.2, about 7.4, about 7.6, about 7.8, about 8.0, about 8.3, or about 8.5). In some embodiments, the pH of the second solvent solution is about 8.0. The concentration of two or more solvent solutions in a mobile phase can vary. For example, in a mobile phase comprising two solvent solutions (e.g., a first solvent solution and a second solvent solution), the volume percentage of the first solvent solution may range from about 0% (absent) to about 100%. In some embodiments, the volume percentage of the first solvent solution may range from about 5%, about 10%, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, or about 90% v/v. Conversely, in some embodiments, the volume percentage of the second solvent solution of a mobile phase may range from about 5%, about 10%, about 15%, about 20%, about 25%, about 30%, about 35%, about 40%, about 45%, about 50%, about 55%, about 60%, about 65%, about 70%, about 75%, about 80%, about 85%, or about 90% v/v. In some embodiments, the ratio of the first solvent solution to the second solvent solution is held constant (e.g., isocratic) during elution of the nucleic acid. However, the skilled artisan will appreciate that in other embodiments, the relative ratio of the first solvent solution to the second solvent solution can vary throughout the elution step. For example, in some embodiments, the ratio of the first solvent solution is increased relative to the second solvent
solution during the elution step. In some embodiments, the ratio of the first solvent solution is decreased relative to the second solvent solution during the elution step. The concentration of one or more ion pairing agents in a mobile phase (e.g., a solvent solution) can vary. The relative ratios of the at least two ion pairing agents in a mobile phase (or solvent solution) may vary or be held constant (e.g., isocratic) during the eluting step. In some embodiments, the ratio of a first ion pairing agent is increased relative to a second ion pairing agent during the elution step. In some embodiments, the ratio of a first ion pairing agent is increased relative to a second ion pairing agent during the elution step. For example, in some embodiments, the ratio of TPAB to TBAC ranges from about 4:1 to about 1:4, about 3:1 to about 1:3, about 2:1 to about 1:2, or about 1:1 to 1:3. The mobile phase (e.g., a solvent solution) may be gradient or isocratic with respect to the concentration of one or more organic solvents. Any suitable HPLC column (e.g., stationary phase) may be used in an HPLC method. Generally, a “HPLC column” is a solid structure or support that contains a medium (e.g. a stationary phase) through which the mobile phase and HPLC sample (e.g., a sample containing HPLC analytes, such as nucleic acids) is eluted. Without wishing to be bound by any particular theory, the composition and chemical properties of the stationary phase determine the retention time of HPLC analytes. In some embodiments of HPLC methods, the stationary phase is non- polar. Examples of non-polar stationary phases include but are not limited to resin, silica (e.g., alkylated and non-alkylated silica), polystyrenes (e.g., alkylated and non-alkylated polystyrenes), polystyrene divinylbenzenes, etc. In some embodiments, a stationary phase comprises particles, for example porous particles. In some embodiments, a stationary phase (e.g., particles of a stationary phase) is hydrophobic (e.g., made of an intrinsically hydrophobic material, such as polystyrene divinylbenzene), or comprise hydrophobic functional groups. In some embodiments, a stationary phase is a membrane or monolithic stationary phase. The particle size (e.g., as measured by the diameter of the particle) of an HPLC stationary phase can vary. In some embodiments, the particle size of a HPLC stationary phase ranges from about 1 µm to about 100 µm (e.g., any value between 1 and 100, inclusive) in diameter. In some embodiments, the particle size of a HPLC stationary phase ranges from about 2µm to about 10µm, about 2µm to about 6µm, or about 4µm in diameter. The pore size of particles (e.g., as measured by the diameter of the pore) can also vary. In some embodiments, the particles comprise pores having a diameter of about 100Å to about 10,000Å. In some embodiments, the particles comprise pores having a diameter of about 100Å to about 5000Å, about 100Å to about 1000Å, or about 1000Å to about 2000Å. In some embodiments, the
stationary phase comprises polystyrene divinylbenzene, for example as used in PLRP-S 4000 columns or DNAPac-RP columns. A sample being added to the stationary phase (e.g., a pharmaceutical preparation) may be diluted in a surfactant. Surfactants may include, but are not limited to, one or more of Triton, polysorbate 20, 40, 60, and 80, sodium lauryl sulfate, etc. In some embodiments, the percentage of the surfactant ranges from about 1% to 5%, or about 5% to 10%. In some embodiments, the percentage of the surfactant is about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, or 10%. In some embodiments, the sample being added to the stationary phase is diluted in the first solvent solution (e.g., Mobile phase A). In some embodiments of the methods provided herein, a circular RNA is separated from other nucleic acids of a mixture (e.g., linear RNAs, DNA templates or fragments) by size exclusion chromatography. Size exclusion chromatography, also known as molecular sieving, separates components of a mixture based on size. Typically, size exclusion chromatography is conducted by adding a mixture containing a desired nucleic acid to a stationary phase containing solid particles in a column. Larger nucleic acids migrate through the stationary phase more quickly, while smaller nucleic acids interact more readily with particles of the stationary phase, and thus take longer to reach the bottom of the column. These differences in retention times allow mixtures to be separated into component parts by eluting distinct components from the column at different times. The secondary structure of a nucleic acid, such as whether it is linear or circular, also influences the retention time of a nucleic acid in size exclusion chromatography column stationary phase. Accordingly, size exclusion chromatography may be used to separate circular RNAs from linear RNAs having the same sequence, as well as RNA fragments produced by exonuclease digestion, DNA splints, DNA templates, and DNA fragments produced by DNase digestion. In some embodiments, the step of size exclusion chromatography is conducted before the step of reverse phase column chromatography. In some embodiments, the step of size exclusion chromatography is conducted after the step of reverse phase column chromatography. Lipid Compositions In some embodiments, the nucleic acids are formulated as a lipid composition, such as a composition comprising a lipid nanoparticle, a liposome, and/or a lipoplex. In some embodiments, the lipid composition (e.g., lipid nanoparticle, liposome, and/or lipoplex) does not comprise protamine. In some embodiments, the lipid composition does comprise protamine. In some embodiments, nucleic acids are formulated as lipid nanoparticle (LNP) compositions. Lipid nanoparticles typically comprise ionizable lipid (e.g., ionizable amino lipid), non-cationic
lipid (e.g., phospholipid), structural lipid (e.g., sterol), and PEG-modified lipid components along with the nucleic acid cargo of interest. The lipid nanoparticles can be generated using components, compositions, and methods as are generally known in the art, see for example PCT/US2016/052352; PCT/US2016/068300; PCT/US2017/037551; PCT/US2015/027400; PCT/US2016/047406; PCT/US2016/000129; PCT/US2016/014280; PCT/US2017/038426; PCT/US2014/027077; PCT/US2014/055394; PCT/US2016/052117; PCT/US2012/069610; PCT/US2017/027492; PCT/US2016/059575; PCT/US2016/069491; PCT/US2016/069493; and PCT/US2014/066242, all of which are incorporated by reference herein to the extent they disclose lipid nanoparticles and preparation thereof. In some embodiments, the lipid nanoparticle comprises a molar ratio of 20-60% ionizable lipid, 5-25% non-cationic lipid, 25-55% structural lipid, and 0.5-15% PEG-modified lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 20-60% ionizable lipid, 5-30% non-cationic lipid, 10-55% structural lipid, and 0.5-15% PEG-modified lipid. In some embodiments, the lipid nanoparticle comprises 40-50 mol% ionizable lipid, optionally 45-50 mol%, for example, 45-46 mol%, 46-47 mol%, 47-48 mol%, 48-49 mol%, or 49-50 mol% for example about 45 mol%, 45.5 mol%, 46 mol%, 46.5 mol%, 47 mol%, 47.5 mol%, 48 mol%, 48.5 mol%, 49 mol%, or 49.5 mol%. In some embodiments, the lipid nanoparticle comprises 20-60 mol% ionizable lipid. For example, the lipid nanoparticle may comprise 20-50 mol%, 20-40 mol%, 20-30 mol%, 30-60 mol%, 30-50 mol%, 30-40 mol%, 40-60 mol%, 40-50 mol%, or 50-60 mol% ionizable lipid. In some embodiments, the lipid nanoparticle comprises 20 mol%, 30 mol%, 40 mol%, 50 mol%, or 60 mol% ionizable lipid. In some embodiments, the lipid nanoparticle comprises 35 mol%, 36 mol%, 37 mol%, 38 mol%, 39 mol%, 40 mol%, 41 mol%, 42 mol%, 43 mol%, 44 mol%, 45 mol%, 46 mol%, 47 mol%, 48 mol%, 49 mol%, 50 mol%, 51 mol%, 52 mol%, 53 mol%, 54 mol%, or 55 mol% ionizable lipid. In some embodiments, the lipid nanoparticle comprises 45–55 mole percent (mol%) ionizable lipid. For example, lipid nanoparticle may comprise 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, or 55 mol% ionizable lipid. Ionizable lipids In some embodiments, the ionizable lipid is a compound of Formula (IL*)
(IL*) or a salt thereof, wherein: R1 is -OH, -NRN-C4-10 cycloalkenyl optionally substituted with one or more oxo or - N(RN’RN’’); RN is H or C1-6 alkyl; RN’ is H or C1-6 alkyl; RN’’ is H or C1-6 alkyl; o is 1, 2, 3, or 4; n is 4, 5, 6, 7, or 8; m is 4, 5, 6, 7, or 8; M is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R2; M’ is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R3;
 or –(C1-6 alkylene)-(C3-8 cycloalkyl)-C1-6 alkyl; R2a is -H or C1-10 alkyl; R2b is -H or C1-10 alkyl; alkenyl;
or –(C1-6 alkylene)-(C3-8 cycloalkyl)-C1-6 alkyl; R2a is -H or C1-10 alkyl; R2b is -H or C1-10 alkyl; alkenyl;
 R3a is H or C1-10 alkyl; R3b is H or C1-8 alkyl; and R3c is C1-10 alkyl or C2-8 alkenyl. In some embodiments, the ionizable lipid is of Formula (IL**-I):
R3a is H or C1-10 alkyl; R3b is H or C1-8 alkyl; and R3c is C1-10 alkyl or C2-8 alkenyl. In some embodiments, the ionizable lipid is of Formula (IL**-I):
 (IL**-I)
or a salt thereof, wherein: R1 is -OH; o is 2, 3, or 4; n is 4, 5, 6, 7, or 8; M is -C(=O)-O-*, wherein * indicates attachment to R2; m is 6, 7, or 8; M’ is -C(=O)-O-*, wherein * indicates attachment to R3; R2c is C4-8 alkyl; R3a is C7-10 alkyl; and R3c is C3-5 alkyl. In some embodiments, the ionizable lipid is of Formula (IL**-III):
(IL**-I)
or a salt thereof, wherein: R1 is -OH; o is 2, 3, or 4; n is 4, 5, 6, 7, or 8; M is -C(=O)-O-*, wherein * indicates attachment to R2; m is 6, 7, or 8; M’ is -C(=O)-O-*, wherein * indicates attachment to R3; R2c is C4-8 alkyl; R3a is C7-10 alkyl; and R3c is C3-5 alkyl. In some embodiments, the ionizable lipid is of Formula (IL**-III):
 (IL**-III) or a salt thereof, wherein: R1 is NRN-C4-10 cycloalkenyl optionally substituted with one or more oxo or -N(RN’RN’’); RN is H; RN’ is C1-2 alkyl; RN’’ is H; o is 2, 3, or 4; n is 6, 7, or 8; M is -C(=O)-O-*, wherein * indicates attachment to R2; m is 6, 7, or 8; M’ is -C(=O)-O-*, wherein * indicates attachment to R3; R2a is C7-10 alkyl; R2c is C4-6 alkyl; R3a is C1-3 alkyl; and R3c is C4-6 alkyl. In some embodiments, the ionizable lipid is of Formula (IL**-IV):
(IL**-IV) or a salt thereof, wherein: R1 is OH; o is 2, 3, or 4; n is 6, 7, or 8; M is -C(=O)-O-*, wherein * indicates attachment to R2; m is 6, 7, or 8; M’ is -C(=O)-O-*, wherein * indicates attachment to R3; R2b is C3-5 alkyl; R2c is C2-4 alkyl; R3a is C7-10 alkyl; and R3c is C4-6 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-I):
(IL**-III) or a salt thereof, wherein: R1 is NRN-C4-10 cycloalkenyl optionally substituted with one or more oxo or -N(RN’RN’’); RN is H; RN’ is C1-2 alkyl; RN’’ is H; o is 2, 3, or 4; n is 6, 7, or 8; M is -C(=O)-O-*, wherein * indicates attachment to R2; m is 6, 7, or 8; M’ is -C(=O)-O-*, wherein * indicates attachment to R3; R2a is C7-10 alkyl; R2c is C4-6 alkyl; R3a is C1-3 alkyl; and R3c is C4-6 alkyl. In some embodiments, the ionizable lipid is of Formula (IL**-IV):
(IL**-IV) or a salt thereof, wherein: R1 is OH; o is 2, 3, or 4; n is 6, 7, or 8; M is -C(=O)-O-*, wherein * indicates attachment to R2; m is 6, 7, or 8; M’ is -C(=O)-O-*, wherein * indicates attachment to R3; R2b is C3-5 alkyl; R2c is C2-4 alkyl; R3a is C7-10 alkyl; and R3c is C4-6 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-I):
 (IL*-Ia) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; and R3a is C1-8 alkyl. In some embodiments, ionizable lipid is of Formula (IL*-Ia):
or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for Formula IL*; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-Ia’):
(IL*-Ia) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; and R3a is C1-8 alkyl. In some embodiments, ionizable lipid is of Formula (IL*-Ia):
or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for Formula IL*; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-Ia’):
 (IL*-Ia’) or a salt thereof, wherein: o, M, M’, R2c and R3c are as defined for variable IL*; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-Iia):
(IL*-Ia’) or a salt thereof, wherein: o, M, M’, R2c and R3c are as defined for variable IL*; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-Iia):
 (IL*-Iia) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for Formula IL*; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-II’):
(IL*-Iia) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for Formula IL*; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-II’):
 (IL*-II’) or a salt thereof, wherein:
o, M, M’, R2c and R3c are as defined for variable IL*; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-III):
(IL*-II’) or a salt thereof, wherein:
o, M, M’, R2c and R3c are as defined for variable IL*; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-III):
 (IL*-III) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIa):
(IL*-III) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIa):
 or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; R2b is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIa):
or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; R2b is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIa):
 or a salt thereof, wherein: R1, o, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and
R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIa’):
or a salt thereof, wherein: R1, o, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and
R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIa’):
 (IL*-IIIa’) or a salt thereof, wherein: R1, o, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIb):
(IL*-IIIa’) or a salt thereof, wherein: R1, o, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIb):
 (IL*-IIIb) or a salt thereof, wherein: R1, o, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIb’):
(IL*-IIIb) or a salt thereof, wherein: R1, o, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IIIb’):
 (IL*-IIIb’) or a salt thereof, wherein: R1, o, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and
R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IV):
(IL*-IIIb’) or a salt thereof, wherein: R1, o, M, M’, R2c, and R3c are as defined for variable IL*; R2a is a C1-8 alkyl; and
R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-IV):
 (IL*-IV) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; R2b is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-Iva):
(IL*-IV) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; R2b is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-Iva):
 (IL*-Iva) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; R2b is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-Iva’):
(IL*-Iva) or a salt thereof, wherein: R1, o, m, n, M, M’, R2c, and R3c are as defined for variable IL*; R2b is a C1-8 alkyl; and R3a is C1-8 alkyl. In some embodiments, the ionizable lipid is of Formula (IL*-Iva’):
 (IL*-Iva) or a salt thereof, wherein: o, M, M’, R2c, and R3c are as defined for variable IL*;
R2a is a C1-8 alkyl; and R3a is C1-8 alkyl. Variables o, R1, RN, RN’, RN’’ of Ionizable Lipid In some embodiments of the ionizable lipid, o is 1. In some embodiments of the ionizable lipid, o is 2. In some embodiments of the ionizable lipid, o is 3. In some embodiments of the ionizable lipid, o is 4. In some embodiments of the ionizable lipid, R1 is -OH. In some embodiments of the ionizable lipid, RN is H. In some embodiments of the ionizable lipid, RN is methyl. In some embodiments of the ionizable lipid, RN is ethyl. In some embodiments of the ionizable lipid, R1 is -NRN-cyclobutenyl, wherein the cyclobutenyl is optionally substituted with one or more oxo or -N(RN’RN’’). In some embodiments of the ionizable lipid, RN’ is H. In some embodiments of the ionizable lipid, RN’ is methyl. In some embodiments of the ionizable lipid, RN’ is ethyl. In some embodiments of the ionizable lipid, RN’’ is H. In some embodiments of the ionizable lipid, RN’’ is methyl. In some embodiments of the ionizable lipid, RN’’ is ethyl. In some embodiments of the ionizable lipid, RN’ is H and RN’’ is methyl. In some embodiments of the ionizable lipid,
(IL*-Iva) or a salt thereof, wherein: o, M, M’, R2c, and R3c are as defined for variable IL*;
R2a is a C1-8 alkyl; and R3a is C1-8 alkyl. Variables o, R1, RN, RN’, RN’’ of Ionizable Lipid In some embodiments of the ionizable lipid, o is 1. In some embodiments of the ionizable lipid, o is 2. In some embodiments of the ionizable lipid, o is 3. In some embodiments of the ionizable lipid, o is 4. In some embodiments of the ionizable lipid, R1 is -OH. In some embodiments of the ionizable lipid, RN is H. In some embodiments of the ionizable lipid, RN is methyl. In some embodiments of the ionizable lipid, RN is ethyl. In some embodiments of the ionizable lipid, R1 is -NRN-cyclobutenyl, wherein the cyclobutenyl is optionally substituted with one or more oxo or -N(RN’RN’’). In some embodiments of the ionizable lipid, RN’ is H. In some embodiments of the ionizable lipid, RN’ is methyl. In some embodiments of the ionizable lipid, RN’ is ethyl. In some embodiments of the ionizable lipid, RN’’ is H. In some embodiments of the ionizable lipid, RN’’ is methyl. In some embodiments of the ionizable lipid, RN’’ is ethyl. In some embodiments of the ionizable lipid, RN’ is H and RN’’ is methyl. In some embodiments of the ionizable lipid,
 In some embodiments of the ionizable lipid,
In some embodiments of the ionizable lipid,
 Variables m and n of the Ionizable Lipid In some embodiments of the ionizable lipid, m is 4. In some embodiments of the ionizable lipid, m is 5. In some embodiments of the ionizable lipid, m is 6. In some embodiments of the ionizable lipid, m is 7. In some embodiments of the ionizable lipid, m is 8.
In some embodiments of the ionizable lipid, m is 4. In some embodiments of the ionizable lipid, n is 5. In some embodiments of the ionizable lipid, n is 6. In some embodiments of the ionizable lipid, n is 7. In some embodiments of the ionizable lipid, n is 8. In some embodiments of the ionizable lipid, n is 5 and m is 7. In some embodiments of the ionizable lipid, n is 7 and m is 7. In some embodiments of the ionizable lipid, m is 6 and n is 6. Variables M and M’ of Ionizable Lipid In some embodiments of the ionizable lipid, M is -O-C(=O)-*, wherein * indicates attachment to R2. In some embodiments of the ionizable lipid, M is -C(=O)-O-* wherein * indicates attachment to R2. In some embodiments of the ionizable lipid, M’ is -O-C(=O)-*, wherein * indicates attachment to R3. In some embodiments of the ionizable lipid, M’ is -C(=O)-O-* wherein * indicates attachment to R3. In some embodiments of the ionizable lipid, M is -O-C(=O)-*, wherein * indicates attachment to R2, and M’ is -C(=O)-O-* wherein * indicates attachment to R3 Variables R2, R2a, R2b, R2c of Ionizable Lipid In some embodiments of the ionizable lipid, R2 is
Variables m and n of the Ionizable Lipid In some embodiments of the ionizable lipid, m is 4. In some embodiments of the ionizable lipid, m is 5. In some embodiments of the ionizable lipid, m is 6. In some embodiments of the ionizable lipid, m is 7. In some embodiments of the ionizable lipid, m is 8.
In some embodiments of the ionizable lipid, m is 4. In some embodiments of the ionizable lipid, n is 5. In some embodiments of the ionizable lipid, n is 6. In some embodiments of the ionizable lipid, n is 7. In some embodiments of the ionizable lipid, n is 8. In some embodiments of the ionizable lipid, n is 5 and m is 7. In some embodiments of the ionizable lipid, n is 7 and m is 7. In some embodiments of the ionizable lipid, m is 6 and n is 6. Variables M and M’ of Ionizable Lipid In some embodiments of the ionizable lipid, M is -O-C(=O)-*, wherein * indicates attachment to R2. In some embodiments of the ionizable lipid, M is -C(=O)-O-* wherein * indicates attachment to R2. In some embodiments of the ionizable lipid, M’ is -O-C(=O)-*, wherein * indicates attachment to R3. In some embodiments of the ionizable lipid, M’ is -C(=O)-O-* wherein * indicates attachment to R3. In some embodiments of the ionizable lipid, M is -O-C(=O)-*, wherein * indicates attachment to R2, and M’ is -C(=O)-O-* wherein * indicates attachment to R3 Variables R2, R2a, R2b, R2c of Ionizable Lipid In some embodiments of the ionizable lipid, R2 is
 . In some embodiments of the ionizable lipid, R2a is hydrogen. In some embodiments of the ionizable lipid, R2a is methyl. In some embodiments of the ionizable lipid, R2a is ethyl. In some embodiments of the ionizable lipid, R2a is propyl. In some embodiments of the ionizable lipid, R2a is butyl. In some embodiments of the ionizable lipid, R2a is pentyl. In some embodiments of the ionizable lipid, R2a is hexyl. In some embodiments of the ionizable lipid, R2a is heptyl. In some embodiments of the ionizable lipid, R2a is octyl. In some embodiments of the ionizable lipid, R2b is hydrogen.
In some embodiments of the ionizable lipid, R2b is methyl. In some embodiments of the ionizable lipid, R2b is ethyl. In some embodiments of the ionizable lipid, R2b is propyl. In some embodiments of the ionizable lipid, R2b is butyl. In some embodiments of the ionizable lipid, R2b is pentyl. In some embodiments of the ionizable lipid, R2b is hexyl. In some embodiments of the ionizable lipid, R2b is heptyl. In some embodiments of the ionizable lipid, R2b is octyl. In some embodiments of the ionizable lipid, R2a is hydrogen and R2b is hydrogen. In some embodiments of the ionizable lipid, R2a is hexyl and R2b is hydrogen. In some embodiments of the ionizable lipid, R2a is octyl and R2b is hydrogen. In some embodiments of the ionizable lipid, R2a is hydrogen and R2b is butyl. In some embodiments of the ionizable lipid, R2c is methyl. In some embodiments of the ionizable lipid, R2c is ethyl. In some embodiments of the ionizable lipid, R2c is propyl. In some embodiments of the ionizable lipid, R2c is butyl. In some embodiments of the ionizable lipid, R2c is pentyl. In some embodiments of the ionizable lipid, R2c is hexyl. In some embodiments of the ionizable lipid, R2c is heptyl. In some embodiments of the ionizable lipid, R2c is octyl. In some embodiments of the ionizable lipid, R2 is –(C1-6 alkylene)-(C3-8 cycloalkyl)-C1-6 alkyl. In some embodiments of the ionizable lipid, R2 is –(C1-6 alkylene)-(cyclohexyl)-C1-6 alkyl. In some embodiments of the ionizable lipid, R2 is –(C1-6 alkylene)-(cyclopentyl)-C1-6 alkyl. Variables R3, R3a, R3b, and R3c of Ionizable Lipid In some embodiments of the ionizable lipid,
. In some embodiments of the ionizable lipid, R2a is hydrogen. In some embodiments of the ionizable lipid, R2a is methyl. In some embodiments of the ionizable lipid, R2a is ethyl. In some embodiments of the ionizable lipid, R2a is propyl. In some embodiments of the ionizable lipid, R2a is butyl. In some embodiments of the ionizable lipid, R2a is pentyl. In some embodiments of the ionizable lipid, R2a is hexyl. In some embodiments of the ionizable lipid, R2a is heptyl. In some embodiments of the ionizable lipid, R2a is octyl. In some embodiments of the ionizable lipid, R2b is hydrogen.
In some embodiments of the ionizable lipid, R2b is methyl. In some embodiments of the ionizable lipid, R2b is ethyl. In some embodiments of the ionizable lipid, R2b is propyl. In some embodiments of the ionizable lipid, R2b is butyl. In some embodiments of the ionizable lipid, R2b is pentyl. In some embodiments of the ionizable lipid, R2b is hexyl. In some embodiments of the ionizable lipid, R2b is heptyl. In some embodiments of the ionizable lipid, R2b is octyl. In some embodiments of the ionizable lipid, R2a is hydrogen and R2b is hydrogen. In some embodiments of the ionizable lipid, R2a is hexyl and R2b is hydrogen. In some embodiments of the ionizable lipid, R2a is octyl and R2b is hydrogen. In some embodiments of the ionizable lipid, R2a is hydrogen and R2b is butyl. In some embodiments of the ionizable lipid, R2c is methyl. In some embodiments of the ionizable lipid, R2c is ethyl. In some embodiments of the ionizable lipid, R2c is propyl. In some embodiments of the ionizable lipid, R2c is butyl. In some embodiments of the ionizable lipid, R2c is pentyl. In some embodiments of the ionizable lipid, R2c is hexyl. In some embodiments of the ionizable lipid, R2c is heptyl. In some embodiments of the ionizable lipid, R2c is octyl. In some embodiments of the ionizable lipid, R2 is –(C1-6 alkylene)-(C3-8 cycloalkyl)-C1-6 alkyl. In some embodiments of the ionizable lipid, R2 is –(C1-6 alkylene)-(cyclohexyl)-C1-6 alkyl. In some embodiments of the ionizable lipid, R2 is –(C1-6 alkylene)-(cyclopentyl)-C1-6 alkyl. Variables R3, R3a, R3b, and R3c of Ionizable Lipid In some embodiments of the ionizable lipid,
 . In some embodiments of the ionizable lipid, R3a is hydrogen. In some embodiments of the ionizable lipid, R3a is methyl. In some embodiments of the ionizable lipid, R3a is ethyl. In some embodiments of the ionizable lipid, R3a is propyl. In some embodiments of the ionizable lipid, R3a is butyl.
In some embodiments of the ionizable lipid, R3a is pentyl. In some embodiments of the ionizable lipid, R3a is hexyl. In some embodiments of the ionizable lipid, R3a is heptyl. In some embodiments of the ionizable lipid, R3a is octyl. In some embodiments of the ionizable lipid, R3b is hydrogen. In some embodiments of the ionizable lipid, R3b is methyl. In some embodiments of the ionizable lipid, R3b is ethyl. In some embodiments of the ionizable lipid, R3b is propyl. In some embodiments of the ionizable lipid, R3b is butyl. In some embodiments of the ionizable lipid, R3b is pentyl. In some embodiments of the ionizable lipid, R3b is hexyl. In some embodiments of the ionizable lipid, R3b is heptyl. In some embodiments of the ionizable lipid, R3b is octyl. In some embodiments of the ionizable lipid, R3a is octyl and R3b is hydrogen. In some embodiments of the ionizable lipid, R3a is ethyl and R3b is hydrogen. In some embodiments of the ionizable lipid, R3a is hexyl and R3b is hydrogen. In some embodiments of the ionizable lipid, R3c is methyl. In some embodiments of the ionizable lipid, R3c is ethyl. In some embodiments of the ionizable lipid, R3c is propyl. In some embodiments of the ionizable lipid, R3c is butyl. In some embodiments of the ionizable lipid, R3c is pentyl. In some embodiments of the ionizable lipid, R3c is hexyl. In some embodiments of the ionizable lipid, R3c is heptyl. In some embodiments of the ionizable lipid, R3c is octyl. It is understood that, for an ionizable lipid, variables o, R1, RN, RN’, RN’, m, n, M, M’, R2, R2a, R2b, R2c, R3, R3a, R3b, and R3c can each be, where applicable, selected from the groups described herein, and any group described herein for any of variables o,.R1, RN, RN’, RN’, m, n, M, M’, R2, R2a, R2b, R2c, R3, R3a, R3b, and R3c can be combined, where applicable, with any group described herein for one or more of the remainder of variables o, R1, RN, RN’, RN’, m, n, M, M’, R2, R2a, R2b, R2c, R3, R3a, R3b, and R3c.
In some embodiments, the ionizable lipid is a compound selected from:
. In some embodiments of the ionizable lipid, R3a is hydrogen. In some embodiments of the ionizable lipid, R3a is methyl. In some embodiments of the ionizable lipid, R3a is ethyl. In some embodiments of the ionizable lipid, R3a is propyl. In some embodiments of the ionizable lipid, R3a is butyl.
In some embodiments of the ionizable lipid, R3a is pentyl. In some embodiments of the ionizable lipid, R3a is hexyl. In some embodiments of the ionizable lipid, R3a is heptyl. In some embodiments of the ionizable lipid, R3a is octyl. In some embodiments of the ionizable lipid, R3b is hydrogen. In some embodiments of the ionizable lipid, R3b is methyl. In some embodiments of the ionizable lipid, R3b is ethyl. In some embodiments of the ionizable lipid, R3b is propyl. In some embodiments of the ionizable lipid, R3b is butyl. In some embodiments of the ionizable lipid, R3b is pentyl. In some embodiments of the ionizable lipid, R3b is hexyl. In some embodiments of the ionizable lipid, R3b is heptyl. In some embodiments of the ionizable lipid, R3b is octyl. In some embodiments of the ionizable lipid, R3a is octyl and R3b is hydrogen. In some embodiments of the ionizable lipid, R3a is ethyl and R3b is hydrogen. In some embodiments of the ionizable lipid, R3a is hexyl and R3b is hydrogen. In some embodiments of the ionizable lipid, R3c is methyl. In some embodiments of the ionizable lipid, R3c is ethyl. In some embodiments of the ionizable lipid, R3c is propyl. In some embodiments of the ionizable lipid, R3c is butyl. In some embodiments of the ionizable lipid, R3c is pentyl. In some embodiments of the ionizable lipid, R3c is hexyl. In some embodiments of the ionizable lipid, R3c is heptyl. In some embodiments of the ionizable lipid, R3c is octyl. It is understood that, for an ionizable lipid, variables o, R1, RN, RN’, RN’, m, n, M, M’, R2, R2a, R2b, R2c, R3, R3a, R3b, and R3c can each be, where applicable, selected from the groups described herein, and any group described herein for any of variables o,.R1, RN, RN’, RN’, m, n, M, M’, R2, R2a, R2b, R2c, R3, R3a, R3b, and R3c can be combined, where applicable, with any group described herein for one or more of the remainder of variables o, R1, RN, RN’, RN’, m, n, M, M’, R2, R2a, R2b, R2c, R3, R3a, R3b, and R3c.
In some embodiments, the ionizable lipid is a compound selected from:
 In some embodiments, the ionizable lipid is
In some embodiments, the ionizable lipid is
 In some embodiments, the ionizable lipid is
In some embodiments, the ionizable lipid is
 In some embodiments, the ionizable lipid is
In some embodiments, the ionizable lipid is
 In some embodiments, the ionizable lipid is
In some embodiments, the ionizable lipid is
 Without wishing to be bound by theory, it is understood that an ionizable lipid may have a positive or partial positive charge at physiological pH. Such lipids may be referred to as cationic or ionizable (amino)lipids. Lipids may also be zwitterionic, i.e., neutral molecules having both a positive and a negative charge. Formula (AI) In some embodiments, the ionizable amino lipid of a lipid nanoparticle is a compound of Formula (AI):
Without wishing to be bound by theory, it is understood that an ionizable lipid may have a positive or partial positive charge at physiological pH. Such lipids may be referred to as cationic or ionizable (amino)lipids. Lipids may also be zwitterionic, i.e., neutral molecules having both a positive and a negative charge. Formula (AI) In some embodiments, the ionizable amino lipid of a lipid nanoparticle is a compound of Formula (AI):
 its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched; wherein
its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched; wherein
 denotes a point of attachment; wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH, wherein n is selected from the group consisting
denotes a point of attachment; wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH, wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are each independently selected from the group consisting of -C(O)O- and -OC(O)-; R’ is a C1-12 alkyl or C2-12 alkenyl;
l is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13. In some embodiments of the compounds of Formula (AI), R’a is R’branched; R’branched is
denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are each independently selected from the group consisting of -C(O)O- and -OC(O)-; R’ is a C1-12 alkyl or C2-12 alkenyl;
l is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13. In some embodiments of the compounds of Formula (AI), R’a is R’branched; R’branched is
 denotes a point of attachment; Raα, Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments of the compounds of Formula (AI), R’a is R’branched; R’branched is
denotes a point of attachment; Raα, Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments of the compounds of Formula (AI), R’a is R’branched; R’branched is
 denotes a point of attachment; Raα, Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 3; and m is 7. In some embodiments of the compounds of Formula (AI), R’a is R’branched; R’branched is
denotes a point of attachment; Raα, Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 3; and m is 7. In some embodiments of the compounds of Formula (AI), R’a is R’branched; R’branched is
 denotes a point of attachment; Raα is C2-12 alkyl; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl;
denotes a point of attachment; Raα is C2-12 alkyl; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl;
 R10 NH(C1-6 alkyl); n2 is 2; R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments of the compounds of Formula (AI), R’a is R’branched; R’branched is
R10 NH(C1-6 alkyl); n2 is 2; R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments of the compounds of Formula (AI), R’a is R’branched; R’branched is
 denotes a point of attachment; Raα, Raβ, and Raδ are each H; Raγ is C2- 12 alkyl; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments, the compound of Formula (AI) is selected from:
denotes a point of attachment; Raα, Raβ, and Raδ are each H; Raγ is C2- 12 alkyl; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments, the compound of Formula (AI) is selected from:
 ,
. In some embodiments, the ionizable amino lipid of Formula (AI) is a compound of Formula (AIa):
,
. In some embodiments, the ionizable amino lipid of Formula (AI) is a compound of Formula (AIa):
 its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched; wherein
its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched; wherein
 denotes a point of attachment; wherein Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
denotes a point of attachment; wherein Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are each independently selected from the group consisting of -C(O)O- and -OC(O)-; R’ is a C1-12 alkyl or C2-12 alkenyl; l is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13. In some embodiments, the ionizable amino lipid of Formula (AI) is a compound of Formula (AIb):
denotes a point of attachment; wherein
R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are each independently selected from the group consisting of -C(O)O- and -OC(O)-; R’ is a C1-12 alkyl or C2-12 alkenyl; l is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13. In some embodiments, the ionizable amino lipid of Formula (AI) is a compound of Formula (AIb):
 its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched; wherein R’branched
its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched; wherein R’branched
 denotes a point of attachment; wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is -(CH2)nOH, wherein n is selected from the group consisting of 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are each independently selected from the group consisting of -C(O)O- and -OC(O)-; R’ is a C1-12 alkyl or C2-12 alkenyl;
l is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13. In some embodiments of Formula (AI) or (AIb), R’a is R’branched; R’branched is
denotes a point of attachment; wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is -(CH2)nOH, wherein n is selected from the group consisting of 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are each independently selected from the group consisting of -C(O)O- and -OC(O)-; R’ is a C1-12 alkyl or C2-12 alkenyl;
l is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13. In some embodiments of Formula (AI) or (AIb), R’a is R’branched; R’branched is
 denotes a point of attachment; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each - C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments of Formula (AI) or (AIb), R’a is R’branched; R’branched is
denotes a point of attachment; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each - C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments of Formula (AI) or (AIb), R’a is R’branched; R’branched is
 denotes a point of attachment; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each - C(O)O-; R’ is a C1-12 alkyl; l is 3; and m is 7. In some embodiments of Formula (AI) or (AIb), R’a is R’branched; R’branched is
denotes a point of attachment; Raβ, Raγ, and Raδ are each H; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each - C(O)O-; R’ is a C1-12 alkyl; l is 3; and m is 7. In some embodiments of Formula (AI) or (AIb), R’a is R’branched; R’branched is
 denotes a point of attachment; Raβ and Raδ are each H; Raγ is C2-12 alkyl; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments, the ionizable amino lipid of Formula (AI) is a compound of Formula (AIc):
denotes a point of attachment; Raβ and Raδ are each H; Raγ is C2-12 alkyl; R2 and R3 are each C1-14 alkyl; R4 is -(CH2)nOH; n is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments, the ionizable amino lipid of Formula (AI) is a compound of Formula (AIc):
 its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched; wherein
its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched; wherein
 denotes a point of attachment; wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl;
, wherein denotes a point of attachment; whereinR10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are each independently selected from the group consisting of -C(O)O- and -OC(O)-; R’ is a C1-12 alkyl or C2-12 alkenyl; l is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13. In some embodiments,
denotes a point of attachment; wherein Raα, Raβ, Raγ, and Raδ are each independently selected from the group consisting of H, C2-12 alkyl, and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl;
, wherein denotes a point of attachment; whereinR10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are each independently selected from the group consisting of -C(O)O- and -OC(O)-; R’ is a C1-12 alkyl or C2-12 alkenyl; l is selected from the group consisting of 1, 2, 3, 4, and 5; and m is selected from the group consisting of 5, 6, 7, 8, 9, 10, 11, 12, and 13. In some embodiments,
 denotes a point of attachment; Raβ, Raγ, and Raδ are each H; Raα is C2-12 alkyl; R2 and R3 are each C1-14 alkyl;
denotes a point of attachment; Raβ, Raγ, and Raδ are each H; Raα is C2-12 alkyl; R2 and R3 are each C1-14 alkyl;
 denotes a point of attachment; R10 is NH(C1-6 alkyl); n2 is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments, the compound of Formula (AIc) is:
denotes a point of attachment; R10 is NH(C1-6 alkyl); n2 is 2; each R5 is H; each R6 is H; M and M’ are each -C(O)O-; R’ is a C1-12 alkyl; l is 5; and m is 7. In some embodiments, the compound of Formula (AIc) is:
 Formula (AII) In some embodiments, the ionizable amino lipid is a compound of Formula (AII):
wherein R’a is R’branched or R’cyclic; wherein
Formula (AII) In some embodiments, the ionizable amino lipid is a compound of Formula (AII):
wherein R’a is R’branched or R’cyclic; wherein
 a Raγ and Raδ are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Raγ and Raδ is selected from the group consisting of C1- 12 alkyl and C2-12 alkenyl; Rbγ and Rbδ are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Rbγ and Rbδ is selected from the group consisting of C1- 12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
a Raγ and Raδ are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Raγ and Raδ is selected from the group consisting of C1- 12 alkyl and C2-12 alkenyl; Rbγ and Rbδ are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Rbγ and Rbδ is selected from the group consisting of C1- 12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; Ya is a C3-6 carbocycle; R*”a is selected from the group consisting of C1-15 alkyl and C2-15 alkenyl; and s is 2 or 3; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-a):
denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; Ya is a C3-6 carbocycle; R*”a is selected from the group consisting of C1-15 alkyl and C2-15 alkenyl; and s is 2 or 3; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9;
l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-a):
 wherein R’a is R’branched or R’cyclic; wherein
wherein R’a is R’branched or R’cyclic; wherein
 wherein
wherein
 denotes a point of attachment; Raγ and Raδ are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Raγ and Raδ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; Rbγ and Rbδ are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Rbγ and Rbδ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
denotes a point of attachment; Raγ and Raδ are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Raγ and Raδ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; Rbγ and Rbδ are each independently selected from the group consisting of H, C1-12 alkyl, and C2-12 alkenyl, wherein at least one of Rbγ and Rbδ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-b):
its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched or R’cyclic; wherein
denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-b):
its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched or R’cyclic; wherein
 wherein
wherein
 denotes a point of attachment; Raγ and Rbγ are each independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
denotes a point of attachment; Raγ and Rbγ are each independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein
wherein
 denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-c):
denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-c):
 wherein R’a is R’branched or R’cyclic; wherein
wherein R’a is R’branched or R’cyclic; wherein
 wherein denotes a point of attachment; wherein Raγ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5, and
wherein denotes a point of attachment; wherein Raγ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5, and
 , wherein
, wherein
 denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; R’ is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-d):
denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; R’ is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-d):
 its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched or R’cyclic; wherein
its N-oxide, or a salt or isomer thereof, wherein R’a is R’branched or R’cyclic; wherein
 wherein
wherein
 denotes a point of attachment; wherein Raγ and Rbγ are each independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
denotes a point of attachment; wherein Raγ and Rbγ are each independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-e):
wherein denotes a point of attachment; wherein R10 is N(R)2; each R is independently selected from the group consisting of C1-6 alkyl, C2-3 alkenyl, and H; and n2 is selected from the group consisting of 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10; each R’ independently is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-e):
 wherein
wherein
 denotes a point of attachment; wherein Raγ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5; R’ is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), m and l are each independently selected from 4, 5, and 6. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), m and l are each 5. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), each R’ independently is a C1-12 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), each R’ independently is a C2-5 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), R’b is: and R2 and R3 are each independently a C1-14 alkyl. In some
embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R’b is: and R2 and R3 are each independently a C6-10 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R’b is:
denotes a point of attachment; wherein Raγ is selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; R2 and R3 are each independently selected from the group consisting of C1-14 alkyl and C2-14 alkenyl; R4 is -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5; R’ is a C1-12 alkyl or C2-12 alkenyl; m is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9; l is selected from 1, 2, 3, 4, 5, 6, 7, 8, and 9. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), m and l are each independently selected from 4, 5, and 6. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), m and l are each 5. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), each R’ independently is a C1-12 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), each R’ independently is a C2-5 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), R’b is: and R2 and R3 are each independently a C1-14 alkyl. In some
embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R’b is: and R2 and R3 are each independently a C6-10 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R’b is:
 R2 and R3 are each a C8 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
R2 and R3 are each a C8 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
 and R3 are each independently a C6-10 alkyl. In some embodiments of the compound of Formula
and R3 are each independently a C6-10 alkyl. In some embodiments of the compound of Formula
 embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e),
embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e),
 alkyl, and R2 and R3 are each a C8 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
alkyl, and R2 and R3 are each a C8 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
 are each a C1-12 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b),
are each a C1-12 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b),
 and Rbγ are each a C2-6 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), m and l are each independently selected from 4, 5, and 6 and each R’ independently is a C1-12 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), m and l are each 5 and each R’ independently is a C2-5 alkyl. In some embodiments of the compound of (AII), (AII-a), (AII-b), (AII-c), (AII-d), or
and Rbγ are each a C2-6 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), m and l are each independently selected from 4, 5, and 6 and each R’ independently is a C1-12 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), m and l are each 5 and each R’ independently is a C2-5 alkyl. In some embodiments of the compound of (AII), (AII-a), (AII-b), (AII-c), (AII-d), or
 independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, and Raγ and Rbγ
are each a C1-12 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b),
independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, and Raγ and Rbγ
are each a C1-12 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b),
 are each 5, each R’ independently is a C2-5 alkyl, and Raγ and Rbγ are each a C2-6 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
are each 5, each R’ independently is a C2-5 alkyl, and Raγ and Rbγ are each a C2-6 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
 are each independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, Raγ is a C1-12 alkyl and R2 and R3 are each independently a C6-10 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
are each independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, Raγ is a C1-12 alkyl and R2 and R3 are each independently a C6-10 alkyl. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
 are each 5, R’ is a C2- 5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a C8 alkyl. In some embodiments of the compound of (AII), (AII-a), (AII-b), (AII-c), (AII-d), or
are each 5, R’ is a C2- 5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a C8 alkyl. In some embodiments of the compound of (AII), (AII-a), (AII-b), (AII-c), (AII-d), or
 wherein R10 is NH(C1-6 alkyl) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R4
wherein R10 is NH(C1-6 alkyl) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R4
 wherein R10 is NH(CH3) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
wherein R10 is NH(CH3) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
 independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, Raγ and Rbγ are each a C1-12 alkyl,
independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, Raγ and Rbγ are each a C1-12 alkyl,
 wherein R10 is NH(C1-6 alkyl), and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R’branched is:
wherein R10 is NH(C1-6 alkyl), and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R’branched is:
 is:
is:
 independently is a C2-5 alkyl, Raγ and Rbγ are each a C2-6 alkyl, , wherein R10 is NH(CH3) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
independently is a C2-5 alkyl, Raγ and Rbγ are each a C2-6 alkyl, , wherein R10 is NH(CH3) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
 are each independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, R2 and R3 are each independently a C6-10 alkyl, Raγ is a C1-12 alkyl,
are each independently selected from 4, 5, and 6, R’ is a C1-12 alkyl, R2 and R3 are each independently a C6-10 alkyl, Raγ is a C1-12 alkyl,
 wherein R10 is NH(C1-6 alkyl) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
wherein R10 is NH(C1-6 alkyl) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
 are each 5, R’ is a C2- 5 alkyl, Raγ is a C2-6 alkyl, R2 and R3 are each a C8 alkyl,
are each 5, R’ is a C2- 5 alkyl, Raγ is a C2-6 alkyl, R2 and R3 are each a C8 alkyl,
 wherein R10 is NH(CH3) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), R4 is -(CH2)nOH and n is 2, 3, or 4. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R4 is -(CH2)nOH and n is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
wherein R10 is NH(CH3) and n2 is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII- d), or (AII-e), R4 is -(CH2)nOH and n is 2, 3, or 4. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-d), or (AII-e), R4 is -(CH2)nOH and n is 2. In some embodiments of the compound of Formula (AII), (AII-a), (AII-b), (AII-c), (AII-
 independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, Raγ and Rbγ are each a C1-12 alkyl, R4 is -(CH2)nOH, and n is 2, 3, or 4. In some embodiments of the compound of Formula
independently selected from 4, 5, and 6, each R’ independently is a C1-12 alkyl, Raγ and Rbγ are each a C1-12 alkyl, R4 is -(CH2)nOH, and n is 2, 3, or 4. In some embodiments of the compound of Formula
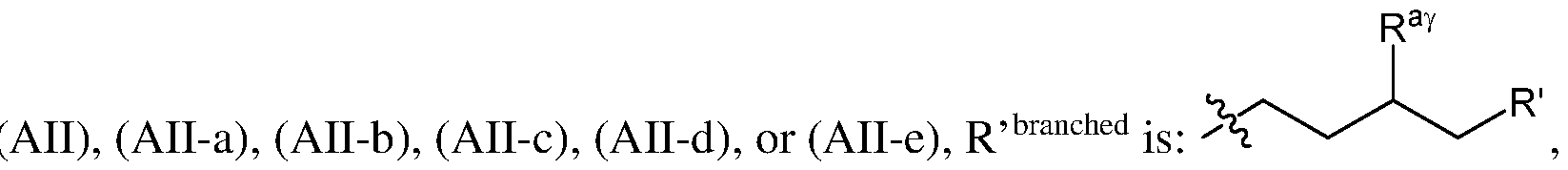 R’b is: , m and l are each 5, each R’ independently is a C2-5 alkyl, Raγ and Rbγ are each a C2-6 alkyl, R4 is -(CH2)nOH, and n is 2. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-f):
wherein denotes a point of attachment; Raγ is a C1-12 alkyl; R2 and R3 are each independently a C1-14 alkyl; R4 is -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5; R’ is a C1-12 alkyl; m is selected from 4, 5, and 6; and l is selected from 4, 5, and 6. In some embodiments of the compound of Formula (AII-f), m and l are each 5, and n is 2, 3, or 4. In some embodiments of the compound of Formula (AII-f) R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a C6-10 alkyl. In some embodiments of the compound of Formula (AII-f), m and l are each 5, n is 2, 3, or 4, R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a C6-10 alkyl. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-g):
R’b is: , m and l are each 5, each R’ independently is a C2-5 alkyl, Raγ and Rbγ are each a C2-6 alkyl, R4 is -(CH2)nOH, and n is 2. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-f):
wherein denotes a point of attachment; Raγ is a C1-12 alkyl; R2 and R3 are each independently a C1-14 alkyl; R4 is -(CH2)nOH wherein n is selected from the group consisting of 1, 2, 3, 4, and 5; R’ is a C1-12 alkyl; m is selected from 4, 5, and 6; and l is selected from 4, 5, and 6. In some embodiments of the compound of Formula (AII-f), m and l are each 5, and n is 2, 3, or 4. In some embodiments of the compound of Formula (AII-f) R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a C6-10 alkyl. In some embodiments of the compound of Formula (AII-f), m and l are each 5, n is 2, 3, or 4, R’ is a C2-5 alkyl, Raγ is a C2-6 alkyl, and R2 and R3 are each a C6-10 alkyl. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-g):
 its N-oxide, or a salt or isomer thereof; wherein Raγ is a C2-6 alkyl; R’ is a C2-5 alkyl; and
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
its N-oxide, or a salt or isomer thereof; wherein Raγ is a C2-6 alkyl; R’ is a C2-5 alkyl; and
R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
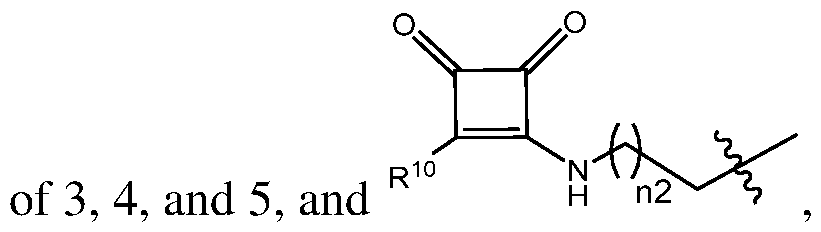 wherein denotes a point of attachment, R10 is NH(C1-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-h):
wherein denotes a point of attachment, R10 is NH(C1-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3. In some embodiments, the ionizable amino lipid of Formula (AII) is a compound of Formula (AII-h):
 its N-oxide, or a salt or isomer thereof; wherein Raγ and Rbγ are each independently a C2-6 alkyl; each R’ independently is a C2-5 alkyl; and R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
its N-oxide, or a salt or isomer thereof; wherein Raγ and Rbγ are each independently a C2-6 alkyl; each R’ independently is a C2-5 alkyl; and R4 is selected from the group consisting of -(CH2)nOH wherein n is selected from the group consisting
 wherein denotes a point of attachment, R10 is NH(C1-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3. In some embodiments of the compound of Formula (AII-g) or (AII-h), R4 is
wherein denotes a point of attachment, R10 is NH(C1-6 alkyl), and n2 is selected from the group consisting of 1, 2, and 3. In some embodiments of the compound of Formula (AII-g) or (AII-h), R4 is
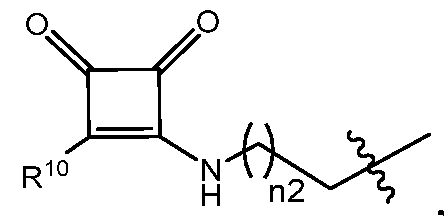 , wherein R10 is NH(CH3) and n2 is 2. In some embodiments of the compound of Formula (AII-g) or (AII-h), R4 is -(CH2)2OH. Formula (AIII) In some embodiments, the ionizable amino lipids of a lipid nanoparticle may be one or more of compounds of Formula (AIII):
or their N-oxides, or salts or isomers thereof, wherein: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of hydrogen, a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a carbocycle, heterocycle, -OR, -O(CH2)nN(R)2, -C(O)OR, -OC(O)R, -CX3, -CX2H, -CXH2, -CN, -N(R)2, -C(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)C(O)N(R)2, -N(R)C(S)N(R)2, -N(R)R8, -N(R)S(O)2R8, -O(CH2)nOR, -N(R)C(=NR9)N(R)2, -N(R)C(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O)2R, -N(OR)C(O)OR, -N(OR)C(O)N(R)2, -N(OR)C(S)N(R)2, -N(OR)C(=NR9)N(R)2, -N(OR)C(=CHR9)N(R)2, -C(=NR9)N(R)2, -C(=NR9)R, -C(O)N(R)OR, and –C(R)N(R)2C(O)OR, and each n is independently selected from 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group, in which M” is a bond, C1-13 alkyl or C2-13 alkenyl; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; R8 is selected from the group consisting of C3-6 carbocycle and heterocycle; R9 is selected from the group consisting of H, CN, NO2, C1-6 alkyl, -OR, -S(O)2R, -S(O)2N(R)2, C2-6 alkenyl, C3-6 carbocycle and heterocycle; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H;
each R” is independently selected from the group consisting of C3-15 alkyl and C3-15 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13; and wherein when R4 is -(CH2)nQ, -(CH2)nCHQR, –CHQR, or -CQ(R)2, then (i) Q is not -N(R)2 when n is 1, 2, 3, 4 or 5, or (ii) Q is not 5, 6, or 7-membered heterocycloalkyl when n is 1 or 2. In some embodiments, another subset of compounds of Formula (AIII) includes those in which: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a C3-6 carbocycle, a 5- to 14-membered heteroaryl having one or more heteroatoms selected from N, O, and S, -OR, -O(CH2)nN(R)2, -C(O)OR, -OC(O)R, -CX3, -CX2H, -CXH2, -CN, -C(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)C(O)N(R)2, -N(R)C(S)N(R)2, -CRN(R)2C(O)OR, -N(R)R8, -O(CH2)nOR, -N(R)C(=NR9)N(R)2, -N(R)C(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O)2R, -N(OR)C(O)OR, -N(OR)C(O)N(R)2, -N(OR)C(S)N(R)2,-N(OR)C(=NR9)N(R)2, -N(OR)C(=CHR9)N(R)2, -C(=NR9)N(R)2, -C(=NR9)R, -C(O)N(R)OR, and a 5- to 14-membered heterocycloalkyl having one or more heteroatoms selected from N, O, and S which is substituted with one or more substituents selected from oxo (=O), OH, amino, mono- or di-alkylamino, and C1-3 alkyl, and each n is independently selected from 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H;
R8 is selected from the group consisting of C3-6 carbocycle and heterocycle; R9 is selected from the group consisting of H, CN, NO2, C1-6 alkyl, -OR, -S(O)2R, -S(O)2N(R)2, C2-6 alkenyl, C3-6 carbocycle and heterocycle; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In some embodiments, another subset of compounds of Formula (AIII) includes those in which: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a C3-6 carbocycle, a 5- to 14-membered heterocycle having one or more heteroatoms selected from N, O, and S, -OR, -O(CH2)nN(R)2, -C(O)OR, -OC(O)R, -CX3, -CX2H, -CXH2, -CN, -C(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)C(O)N(R)2, -N(R)C(S)N(R)2, -CRN(R)2C(O)OR, -N(R)R8, -O(CH2)nOR, -N(R)C(=NR9)N(R)2, -N(R)C(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O)2R, -N(OR)C(O)OR, -N(OR)C(O)N(R)2, -N(OR)C(S)N(R)2,-N(OR)C(=NR9)N(R)2, -N(OR)C(=CHR9)N(R)2, -C(=NR9)R, -C(O)N(R)OR, and -C(=NR9)N(R)2, and each n is independently selected from 1, 2, 3, 4, and 5; and when Q is a 5- to 14-membered heterocycle and (i) R4 is -(CH2)nQ in which n is 1 or 2, or (ii) R4 is -(CH2)nCHQR in which n is 1, or (iii) R4 is -CHQR, and -CQ(R)2, then Q is either a 5- to 14-membered heteroaryl or 8- to 14-membered heterocycloalkyl;
each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; R8 is selected from the group consisting of C3-6 carbocycle and heterocycle; R9 is selected from the group consisting of H, CN, NO2, C1-6 alkyl, -OR, -S(O)2R, -S(O)2N(R)2, C2-6 alkenyl, C3-6 carbocycle and heterocycle; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In some embodiments, another subset of compounds of Formula (AIII) includes those in which: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a C3-6 carbocycle, a 5- to 14-membered heteroaryl having one or more heteroatoms selected from N, O, and S, -OR, -O(CH2)nN(R)2, -C(O)OR, -OC(O)R, -CX3, -CX2H, -CXH2, -CN, -C(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)C(O)N(R)2, -N(R)C(S)N(R)2, -CRN(R)2C(O)OR, -N(R)R8, -O(CH2)nOR,
-N(R)C(=NR9)N(R)2, -N(R)C(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O)2R, -N(OR)C(O)OR, -N(OR)C(O)N(R)2, -N(OR)C(S)N(R)2,-N(OR)C(=NR9)N(R)2, -N(OR)C(=CHR9)N(R)2, -C(=NR9)R, -C(O)N(R)OR, and -C(=NR9)N(R)2, and each n is independently selected from 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; R8 is selected from the group consisting of C3-6 carbocycle and heterocycle; R9 is selected from the group consisting of H, CN, NO2, C1-6 alkyl, -OR, -S(O)2R, -S(O)2N(R)2, C2-6 alkenyl, C3-6 carbocycle and heterocycle; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In some embodiments, another subset of compounds of Formula (AIII) includes those in which R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C2-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is -(CH2)nQ or -(CH2)nCHQR, where Q is -N(R)2, and n is selected from 3, 4, and 5;
each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C1-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In some embodiments, another subset of compounds of Formula (AIII) includes those in which R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of -(CH2)nQ, -(CH2)nCHQR, -CHQR, and -CQ(R)2, where Q is -N(R)2, and n is selected from 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-,
-N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C1-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In certain embodiments, a subset of compounds of Formula (AIII) includes those of Formula (AIII-A):
, wherein R10 is NH(CH3) and n2 is 2. In some embodiments of the compound of Formula (AII-g) or (AII-h), R4 is -(CH2)2OH. Formula (AIII) In some embodiments, the ionizable amino lipids of a lipid nanoparticle may be one or more of compounds of Formula (AIII):
or their N-oxides, or salts or isomers thereof, wherein: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of hydrogen, a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a carbocycle, heterocycle, -OR, -O(CH2)nN(R)2, -C(O)OR, -OC(O)R, -CX3, -CX2H, -CXH2, -CN, -N(R)2, -C(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)C(O)N(R)2, -N(R)C(S)N(R)2, -N(R)R8, -N(R)S(O)2R8, -O(CH2)nOR, -N(R)C(=NR9)N(R)2, -N(R)C(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O)2R, -N(OR)C(O)OR, -N(OR)C(O)N(R)2, -N(OR)C(S)N(R)2, -N(OR)C(=NR9)N(R)2, -N(OR)C(=CHR9)N(R)2, -C(=NR9)N(R)2, -C(=NR9)R, -C(O)N(R)OR, and –C(R)N(R)2C(O)OR, and each n is independently selected from 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group, in which M” is a bond, C1-13 alkyl or C2-13 alkenyl; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; R8 is selected from the group consisting of C3-6 carbocycle and heterocycle; R9 is selected from the group consisting of H, CN, NO2, C1-6 alkyl, -OR, -S(O)2R, -S(O)2N(R)2, C2-6 alkenyl, C3-6 carbocycle and heterocycle; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H;
each R” is independently selected from the group consisting of C3-15 alkyl and C3-15 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13; and wherein when R4 is -(CH2)nQ, -(CH2)nCHQR, –CHQR, or -CQ(R)2, then (i) Q is not -N(R)2 when n is 1, 2, 3, 4 or 5, or (ii) Q is not 5, 6, or 7-membered heterocycloalkyl when n is 1 or 2. In some embodiments, another subset of compounds of Formula (AIII) includes those in which: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a C3-6 carbocycle, a 5- to 14-membered heteroaryl having one or more heteroatoms selected from N, O, and S, -OR, -O(CH2)nN(R)2, -C(O)OR, -OC(O)R, -CX3, -CX2H, -CXH2, -CN, -C(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)C(O)N(R)2, -N(R)C(S)N(R)2, -CRN(R)2C(O)OR, -N(R)R8, -O(CH2)nOR, -N(R)C(=NR9)N(R)2, -N(R)C(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O)2R, -N(OR)C(O)OR, -N(OR)C(O)N(R)2, -N(OR)C(S)N(R)2,-N(OR)C(=NR9)N(R)2, -N(OR)C(=CHR9)N(R)2, -C(=NR9)N(R)2, -C(=NR9)R, -C(O)N(R)OR, and a 5- to 14-membered heterocycloalkyl having one or more heteroatoms selected from N, O, and S which is substituted with one or more substituents selected from oxo (=O), OH, amino, mono- or di-alkylamino, and C1-3 alkyl, and each n is independently selected from 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H;
R8 is selected from the group consisting of C3-6 carbocycle and heterocycle; R9 is selected from the group consisting of H, CN, NO2, C1-6 alkyl, -OR, -S(O)2R, -S(O)2N(R)2, C2-6 alkenyl, C3-6 carbocycle and heterocycle; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In some embodiments, another subset of compounds of Formula (AIII) includes those in which: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a C3-6 carbocycle, a 5- to 14-membered heterocycle having one or more heteroatoms selected from N, O, and S, -OR, -O(CH2)nN(R)2, -C(O)OR, -OC(O)R, -CX3, -CX2H, -CXH2, -CN, -C(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)C(O)N(R)2, -N(R)C(S)N(R)2, -CRN(R)2C(O)OR, -N(R)R8, -O(CH2)nOR, -N(R)C(=NR9)N(R)2, -N(R)C(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O)2R, -N(OR)C(O)OR, -N(OR)C(O)N(R)2, -N(OR)C(S)N(R)2,-N(OR)C(=NR9)N(R)2, -N(OR)C(=CHR9)N(R)2, -C(=NR9)R, -C(O)N(R)OR, and -C(=NR9)N(R)2, and each n is independently selected from 1, 2, 3, 4, and 5; and when Q is a 5- to 14-membered heterocycle and (i) R4 is -(CH2)nQ in which n is 1 or 2, or (ii) R4 is -(CH2)nCHQR in which n is 1, or (iii) R4 is -CHQR, and -CQ(R)2, then Q is either a 5- to 14-membered heteroaryl or 8- to 14-membered heterocycloalkyl;
each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; R8 is selected from the group consisting of C3-6 carbocycle and heterocycle; R9 is selected from the group consisting of H, CN, NO2, C1-6 alkyl, -OR, -S(O)2R, -S(O)2N(R)2, C2-6 alkenyl, C3-6 carbocycle and heterocycle; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In some embodiments, another subset of compounds of Formula (AIII) includes those in which: R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of a C3-6 carbocycle, -(CH2)nQ, -(CH2)nCHQR, -CHQR, -CQ(R)2, and unsubstituted C1-6 alkyl, where Q is selected from a C3-6 carbocycle, a 5- to 14-membered heteroaryl having one or more heteroatoms selected from N, O, and S, -OR, -O(CH2)nN(R)2, -C(O)OR, -OC(O)R, -CX3, -CX2H, -CXH2, -CN, -C(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)C(O)N(R)2, -N(R)C(S)N(R)2, -CRN(R)2C(O)OR, -N(R)R8, -O(CH2)nOR,
-N(R)C(=NR9)N(R)2, -N(R)C(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, -N(OR)C(O)R, -N(OR)S(O)2R, -N(OR)C(O)OR, -N(OR)C(O)N(R)2, -N(OR)C(S)N(R)2,-N(OR)C(=NR9)N(R)2, -N(OR)C(=CHR9)N(R)2, -C(=NR9)R, -C(O)N(R)OR, and -C(=NR9)N(R)2, and each n is independently selected from 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; R8 is selected from the group consisting of C3-6 carbocycle and heterocycle; R9 is selected from the group consisting of H, CN, NO2, C1-6 alkyl, -OR, -S(O)2R, -S(O)2N(R)2, C2-6 alkenyl, C3-6 carbocycle and heterocycle; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In some embodiments, another subset of compounds of Formula (AIII) includes those in which R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of H, C2-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is -(CH2)nQ or -(CH2)nCHQR, where Q is -N(R)2, and n is selected from 3, 4, and 5;
each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C1-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In some embodiments, another subset of compounds of Formula (AIII) includes those in which R1 is selected from the group consisting of C5-30 alkyl, C5-20 alkenyl, -R*YR”, -YR”, and -R”M’R’; R2 and R3 are independently selected from the group consisting of C1-14 alkyl, C2-14 alkenyl, -R*YR”, -YR”, and -R*OR”, or R2 and R3, together with the atom to which they are attached, form a heterocycle or carbocycle; R4 is selected from the group consisting of -(CH2)nQ, -(CH2)nCHQR, -CHQR, and -CQ(R)2, where Q is -N(R)2, and n is selected from 1, 2, 3, 4, and 5; each R5 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R6 is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; M and M’ are independently selected from -C(O)O-, -OC(O)-, -C(O)N(R’)-,
-N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -S-S-, an aryl group, and a heteroaryl group; R7 is selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R is independently selected from the group consisting of C1-3 alkyl, C2-3 alkenyl, and H; each R’ is independently selected from the group consisting of C1-18 alkyl, C2-18 alkenyl, -R*YR”, -YR”, and H; each R” is independently selected from the group consisting of C3-14 alkyl and C3-14 alkenyl; each R* is independently selected from the group consisting of C1-12 alkyl and C1-12 alkenyl; each Y is independently a C3-6 carbocycle; each X is independently selected from the group consisting of F, Cl, Br, and I; and m is selected from 5, 6, 7, 8, 9, 10, 11, 12, and 13, or salts or isomers thereof. In certain embodiments, a subset of compounds of Formula (AIII) includes those of Formula (AIII-A):
 or its N-oxide, or a salt or isomer thereof, wherein l is selected from 1, 2, 3, 4, and 5; m is selected from 5, 6, 7, 8, and 9; M1 is a bond or M’; R4 is hydrogen, unsubstituted C1-3 alkyl, or -(CH2)nQ, in which Q is -OH, -NHC(S)N(R)2, -NHC(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)R8, -NHC(=NR9)N(R)2, -NHC(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, heteroaryl or heterocycloalkyl; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group, and a heteroaryl group,; and R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, and C2-14 alkenyl. For example, m is 5, 7, or 9. For example, Q is OH, -NHC(S)N(R)2, or -NHC(O)N(R)2. For example, Q is -N(R)C(O)R, or -N(R)S(O)2R. In certain embodiments, a subset of compounds of Formula (AIII) includes those of Formula (AIII-B):
or its N-oxide, or a salt or isomer thereof in which all variables are as defined herein. For example, m is selected from 5, 6, 7, 8, and 9; R4 is hydrogen, unsubstituted C1-3 alkyl, or -(CH2)nQ, in which Q is H, -NHC(S)N(R)2, -NHC(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)R8, -NHC(=NR9)N(R)2, -NHC(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, heteroaryl or heterocycloalkyl; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group, and a heteroaryl group; and R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, and C2-14 alkenyl. For example, m is 5, 7, or 9. For example, Q is OH, -NHC(S)N(R)2, or -NHC(O)N(R)2. For example, Q is -N(R)C(O)R, or -N(R)S(O)2R. In certain embodiments, a subset of compounds of Formula (AIII) includes those of Formula (AIII-C):
or its N-oxide, or a salt or isomer thereof, wherein l is selected from 1, 2, 3, 4, and 5; m is selected from 5, 6, 7, 8, and 9; M1 is a bond or M’; R4 is hydrogen, unsubstituted C1-3 alkyl, or -(CH2)nQ, in which Q is -OH, -NHC(S)N(R)2, -NHC(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)R8, -NHC(=NR9)N(R)2, -NHC(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, heteroaryl or heterocycloalkyl; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group, and a heteroaryl group,; and R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, and C2-14 alkenyl. For example, m is 5, 7, or 9. For example, Q is OH, -NHC(S)N(R)2, or -NHC(O)N(R)2. For example, Q is -N(R)C(O)R, or -N(R)S(O)2R. In certain embodiments, a subset of compounds of Formula (AIII) includes those of Formula (AIII-B):
or its N-oxide, or a salt or isomer thereof in which all variables are as defined herein. For example, m is selected from 5, 6, 7, 8, and 9; R4 is hydrogen, unsubstituted C1-3 alkyl, or -(CH2)nQ, in which Q is H, -NHC(S)N(R)2, -NHC(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)R8, -NHC(=NR9)N(R)2, -NHC(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, heteroaryl or heterocycloalkyl; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group, and a heteroaryl group; and R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, and C2-14 alkenyl. For example, m is 5, 7, or 9. For example, Q is OH, -NHC(S)N(R)2, or -NHC(O)N(R)2. For example, Q is -N(R)C(O)R, or -N(R)S(O)2R. In certain embodiments, a subset of compounds of Formula (AIII) includes those of Formula (AIII-C):
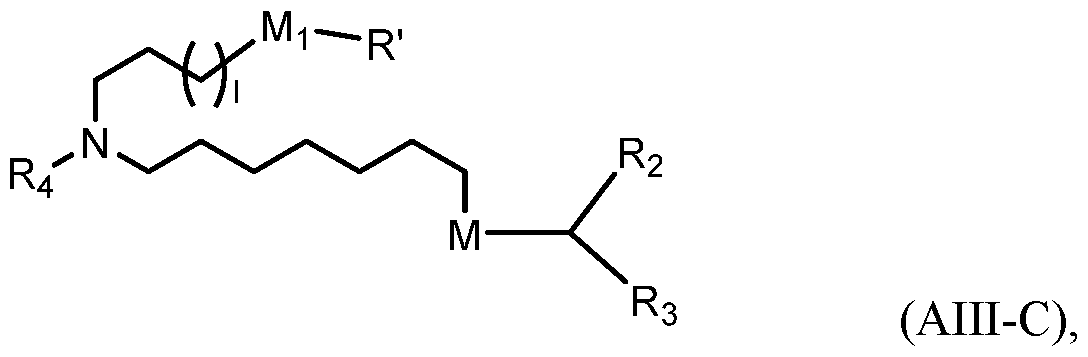 or its N-oxide, or a salt or isomer thereof, wherein l is selected from 1, 2, 3, 4, and 5; M1 is a bond or M’; R4 is hydrogen, unsubstituted C1-3 alkyl, or -(CH2)nQ, in which n is 2, 3, or 4, and Q is OH, -NHC(S)N(R)2, -NHC(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)R8, -NHC(=NR9)N(R)2, -NHC(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, heteroaryl or heterocycloalkyl; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group, and a heteroaryl group; and R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, and C2-14 alkenyl. In some embodiments, the compounds of Formula (AIII) are of Formula (AIII-D),
or its N-oxide, or a salt or isomer thereof, wherein l is selected from 1, 2, 3, 4, and 5; M1 is a bond or M’; R4 is hydrogen, unsubstituted C1-3 alkyl, or -(CH2)nQ, in which n is 2, 3, or 4, and Q is OH, -NHC(S)N(R)2, -NHC(O)N(R)2, -N(R)C(O)R, -N(R)S(O)2R, -N(R)R8, -NHC(=NR9)N(R)2, -NHC(=CHR9)N(R)2, -OC(O)N(R)2, -N(R)C(O)OR, heteroaryl or heterocycloalkyl; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group, and a heteroaryl group; and R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, and C2-14 alkenyl. In some embodiments, the compounds of Formula (AIII) are of Formula (AIII-D),
 or their N-oxides, or salts or isomers thereof, wherein R4 is as described in this Lipid Compositions section. In another embodiment, the compounds of Formula (AIII) are of Formula (AIII-E),
or their N-oxides, or salts or isomers thereof, wherein R4 is as described in this Lipid Compositions section. In another embodiment, the compounds of Formula (AIII) are of Formula (AIII-E),
 or their N-oxides, or salts or isomers thereof, wherein R4 is as described in this in this Lipid Compositions section. In another embodiment, the compounds of Formula (AIII) are of Formula (AIII-F) or (AIII-G):
or their N-oxides, or salts or isomers thereof, wherein R4 is as described in this in this Lipid Compositions section. In another embodiment, the compounds of Formula (AIII) are of Formula (AIII-F) or (AIII-G):
 or their N-oxides, or salts or isomers thereof, wherein R4 is as described in this in this Lipid Compositions section. In another embodiment, the compounds of Formula (AIII) are of Formula (AIII-H):
or their N-oxides, or salts or isomers thereof, wherein R4 is as described in this in this Lipid Compositions section. In another embodiment, the compounds of Formula (AIII) are of Formula (AIII-H):
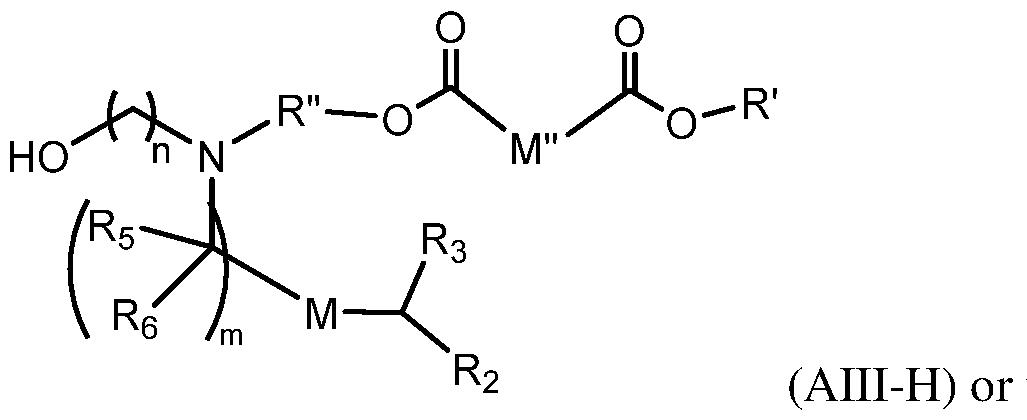 their N-oxides, or salts or isomers thereof, wherein M is -C(O)O- or –OC(O)-, M” is C1-6 alkyl or C2-6 alkenyl, R2 and R3 are independently selected from the group consisting of C5-14 alkyl and C5-14 alkenyl, and n is selected from 2, 3, and 4. In a further embodiment, the compounds of Formula (AIII) are of Formula (AIII-I):
or their N-oxides, or salts or isomers thereof, wherein n is 2, 3, or 4; and m, R’, R”, and R2 through R6 are as described in this in this Lipid Compositions section. For example, each of R2 and R3 may be independently selected from the group consisting of C5-14 alkyl and C5-14 alkenyl. In some embodiments, an ionizable amino lipid of comprises a compound having structure:
their N-oxides, or salts or isomers thereof, wherein M is -C(O)O- or –OC(O)-, M” is C1-6 alkyl or C2-6 alkenyl, R2 and R3 are independently selected from the group consisting of C5-14 alkyl and C5-14 alkenyl, and n is selected from 2, 3, and 4. In a further embodiment, the compounds of Formula (AIII) are of Formula (AIII-I):
or their N-oxides, or salts or isomers thereof, wherein n is 2, 3, or 4; and m, R’, R”, and R2 through R6 are as described in this in this Lipid Compositions section. For example, each of R2 and R3 may be independently selected from the group consisting of C5-14 alkyl and C5-14 alkenyl. In some embodiments, an ionizable amino lipid of comprises a compound having structure:
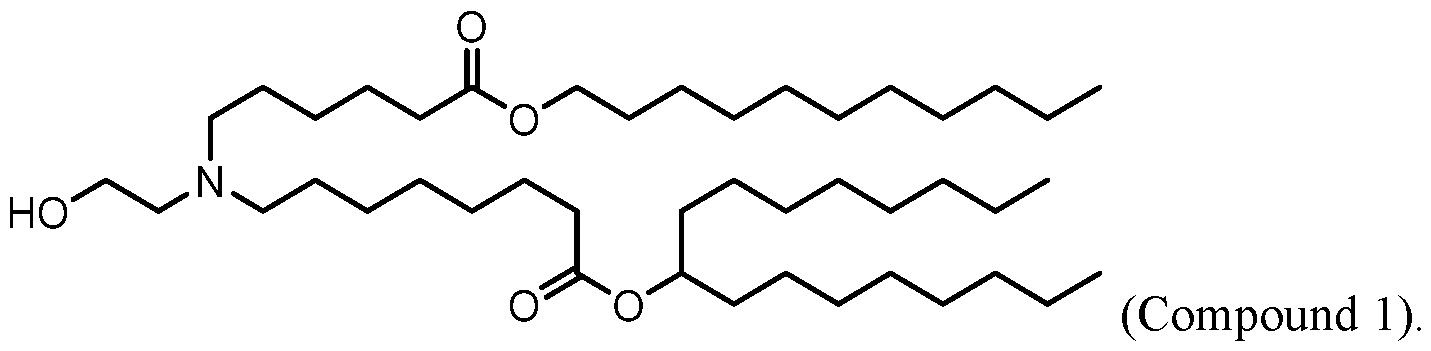 In some embodiments, an ionizable amino lipid comprises a compound having structure:
In some embodiments, an ionizable amino lipid comprises a compound having structure:
 In a further embodiment, the compounds of Formula (AIII) are of Formula (AIII-J),
In a further embodiment, the compounds of Formula (AIII) are of Formula (AIII-J),
 (AIII-J), or their N-oxides, or salts or isomers thereof, wherein l is selected from 1, 2, 3, 4, and 5; m is selected from 5, 6, 7, 8, and 9; M1 is a bond or M’; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group, and a heteroaryl group; and R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, and C2-14 alkenyl. For example, M” is C1-6 alkyl (e.g., C1-4 alkyl) or C2-6 alkenyl (e.g. C2-4 alkenyl). For example, R2 and R3 are independently selected from the group consisting of C5-14 alkyl and C5-14 alkenyl. In some embodiments, the ionizable amino lipids are one or more of the compounds described in U.S. Application Nos. 62/220,091, 62/252,316, 62/253,433, 62/266,460,
62/333,557, 62/382,740, 62/393,940, 62/471,937, 62/471,949, 62/475,140, and 62/475,166, and PCT Application No. PCT/US2016/052352. The central amine moiety of a lipid according to Formula (AIII), (AIII-A), (AIII-B), (AIII-C), (AIII-D), (AIII-E), (AIII-F), (AIII-G), (AIII-H), (AIII-I), or (AIII-J) may be protonated at a physiological pH. Thus, a lipid may have a positive or partial positive charge at physiological pH. Such amino lipids may be referred to as cationic lipids, ionizable lipids, cationic amino lipids, or ionizable amino lipids. Amino lipids may also be zwitterionic, i.e., neutral molecules having both a positive and a negative charge. Formula (AIV) In some embodiments, the ionizable amino lipids of a lipid nanoparticle may be one or more of compounds of formula (AIV),
(AIII-J), or their N-oxides, or salts or isomers thereof, wherein l is selected from 1, 2, 3, 4, and 5; m is selected from 5, 6, 7, 8, and 9; M1 is a bond or M’; M and M’ are independently selected from -C(O)O-, -OC(O)-, -OC(O)-M”-C(O)O-, -C(O)N(R’)-, -P(O)(OR’)O-, -S-S-, an aryl group, and a heteroaryl group; and R2 and R3 are independently selected from the group consisting of H, C1-14 alkyl, and C2-14 alkenyl. For example, M” is C1-6 alkyl (e.g., C1-4 alkyl) or C2-6 alkenyl (e.g. C2-4 alkenyl). For example, R2 and R3 are independently selected from the group consisting of C5-14 alkyl and C5-14 alkenyl. In some embodiments, the ionizable amino lipids are one or more of the compounds described in U.S. Application Nos. 62/220,091, 62/252,316, 62/253,433, 62/266,460,
62/333,557, 62/382,740, 62/393,940, 62/471,937, 62/471,949, 62/475,140, and 62/475,166, and PCT Application No. PCT/US2016/052352. The central amine moiety of a lipid according to Formula (AIII), (AIII-A), (AIII-B), (AIII-C), (AIII-D), (AIII-E), (AIII-F), (AIII-G), (AIII-H), (AIII-I), or (AIII-J) may be protonated at a physiological pH. Thus, a lipid may have a positive or partial positive charge at physiological pH. Such amino lipids may be referred to as cationic lipids, ionizable lipids, cationic amino lipids, or ionizable amino lipids. Amino lipids may also be zwitterionic, i.e., neutral molecules having both a positive and a negative charge. Formula (AIV) In some embodiments, the ionizable amino lipids of a lipid nanoparticle may be one or more of compounds of formula (AIV),
 t is 1 or 2; A1 and A2 are each independently selected from CH or N; Z is CH2 or absent wherein when Z is CH2, the dashed lines (1) and (2) each represent a single bond; and when Z is absent, the dashed lines (1) and (2) are both absent; R1, R2, R3, R4, and R5 are independently selected from the group consisting of C5-20 alkyl, C5-20 alkenyl, -R”MR’, -R*YR”, -YR”, and -R*OR”; RX1 and RX2 are each independently H or C1-3 alkyl; each M is independently selected from the group consisting of -C(O)O-, -OC(O)-, -OC(O)O-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -C(O)S-, -SC(O)-, an aryl group, and a heteroaryl group;
M* is C1-C6 alkyl, W1 and W2 are each independently selected from the group consisting of -O- and -N(R6)-; each R6 is independently selected from the group consisting of H and C1-5 alkyl; X1, X2, and X3 are independently selected from the group consisting of a bond, -CH2-, -(CH2)2-, -CHR-, -CHY-, -C(O)-, -C(O)O-, -OC(O)-, -(CH2)n-C(O)-, -C(O)-(CH2)n-, -(CH2)n-C(O)O-, -OC(O)-(CH2)n-, -(CH2)n-OC(O)-, -C(O)O-(CH2)n-, -CH(OH)-, -C(S)-, and -CH(SH)-; each Y is independently a C3-6 carbocycle; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each R is independently selected from the group consisting of C1-3 alkyl and a C3-6 carbocycle; each R’ is independently selected from the group consisting of C1-12 alkyl, C2-12 alkenyl, and H; each R” is independently selected from the group consisting of C3-12 alkyl, C3-12 alkenyl and -R*MR’; and n is an integer from 1-6; wherein when ring
t is 1 or 2; A1 and A2 are each independently selected from CH or N; Z is CH2 or absent wherein when Z is CH2, the dashed lines (1) and (2) each represent a single bond; and when Z is absent, the dashed lines (1) and (2) are both absent; R1, R2, R3, R4, and R5 are independently selected from the group consisting of C5-20 alkyl, C5-20 alkenyl, -R”MR’, -R*YR”, -YR”, and -R*OR”; RX1 and RX2 are each independently H or C1-3 alkyl; each M is independently selected from the group consisting of -C(O)O-, -OC(O)-, -OC(O)O-, -C(O)N(R’)-, -N(R’)C(O)-, -C(O)-, -C(S)-, -C(S)S-, -SC(S)-, -CH(OH)-, -P(O)(OR’)O-, -S(O)2-, -C(O)S-, -SC(O)-, an aryl group, and a heteroaryl group;
M* is C1-C6 alkyl, W1 and W2 are each independently selected from the group consisting of -O- and -N(R6)-; each R6 is independently selected from the group consisting of H and C1-5 alkyl; X1, X2, and X3 are independently selected from the group consisting of a bond, -CH2-, -(CH2)2-, -CHR-, -CHY-, -C(O)-, -C(O)O-, -OC(O)-, -(CH2)n-C(O)-, -C(O)-(CH2)n-, -(CH2)n-C(O)O-, -OC(O)-(CH2)n-, -(CH2)n-OC(O)-, -C(O)O-(CH2)n-, -CH(OH)-, -C(S)-, and -CH(SH)-; each Y is independently a C3-6 carbocycle; each R* is independently selected from the group consisting of C1-12 alkyl and C2-12 alkenyl; each R is independently selected from the group consisting of C1-3 alkyl and a C3-6 carbocycle; each R’ is independently selected from the group consisting of C1-12 alkyl, C2-12 alkenyl, and H; each R” is independently selected from the group consisting of C3-12 alkyl, C3-12 alkenyl and -R*MR’; and n is an integer from 1-6; wherein when ring
 then i) at least one of X1, X2, and X3 is not -CH2-; and/or ii) at least one of R1, R2, R3, R4, and R5 is -R”MR’. In some embodiments, the compound is of any of formulae (AIVa)-(AIVh):
then i) at least one of X1, X2, and X3 is not -CH2-; and/or ii) at least one of R1, R2, R3, R4, and R5 is -R”MR’. In some embodiments, the compound is of any of formulae (AIVa)-(AIVh):
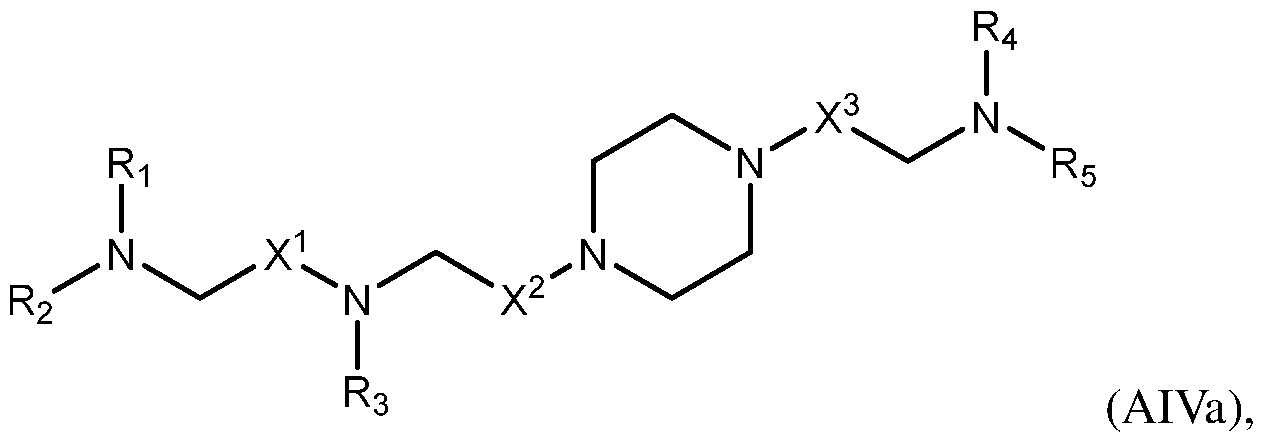 In some embodiments, the ionizable amino lipid is
In some embodiments, the ionizable amino lipid is
 salt thereof.
The central amine moiety of a lipid according to Formula (AIV), (AIVa), (AIVb), (AIVc), (AIVd), (AIVe), (AIVf), (AIVg), or (AIVh) may be protonated at a physiological pH. Thus, a lipid may have a positive or partial positive charge at physiological pH. Formula (AV) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
salt thereof.
The central amine moiety of a lipid according to Formula (AIV), (AIVa), (AIVb), (AIVc), (AIVd), (AIVe), (AIVf), (AIVg), or (AIVh) may be protonated at a physiological pH. Thus, a lipid may have a positive or partial positive charge at physiological pH. Formula (AV) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, tautomer, or stereoisomer thereof, wherein: R1 is optionally substituted C1-C24 alkyl or optionally substituted C2-C24 alkenyl; R2 and R3 are each independently optionally substituted C1-C36 alkyl; R4 and R5 are each independently optionally substituted C 4 1-C6 alkyl, or R and R5 join, along with the N to which they are attached, to form a heterocyclyl or heteroaryl; L1, L2, and L3 are each independently optionally substituted C1-C18 alkylene; G1 is a direct bond, -(CH2)nO(C=O)-, -(CH2)n(C=O)O-, or -(C=O)-; G2 and G3 are each independently -(C=O)O- or -O(C=O)-; and n is an integer greater than 0. Formula (AVI) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt, tautomer, or stereoisomer thereof, wherein: R1 is optionally substituted C1-C24 alkyl or optionally substituted C2-C24 alkenyl; R2 and R3 are each independently optionally substituted C1-C36 alkyl; R4 and R5 are each independently optionally substituted C 4 1-C6 alkyl, or R and R5 join, along with the N to which they are attached, to form a heterocyclyl or heteroaryl; L1, L2, and L3 are each independently optionally substituted C1-C18 alkylene; G1 is a direct bond, -(CH2)nO(C=O)-, -(CH2)n(C=O)O-, or -(C=O)-; G2 and G3 are each independently -(C=O)O- or -O(C=O)-; and n is an integer greater than 0. Formula (AVI) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, tautomer, or stereoisomer thereof, wherein: G1 is -N(R3)R4 or -OR5; R1 is optionally substituted branched, saturated or unsaturated C12-C36 alkyl; R2 is optionally substituted branched or unbranched, saturated or unsaturated C12-C36 alkyl when L is -C(=O)-; or R2 is optionally substituted branched or unbranched, saturated or unsaturated C4-C36 alkyl when L is C6-C12 alkylene, C6-C12 alkenylene, or C2-C6 alkynylene; R3 and R4 are each independently H, optionally substituted branched or unbranched, saturated or unsaturated C1-C6 alkyl; or R3 and R4 are each independently optionally substituted branched or unbranched, saturated or unsaturated C1-C6 alkyl when L is C6-C12 alkylene, C6-C12
alkenylene, or C2-C6 alkynylene; or R3 and R4, together with the nitrogen to which they are attached, join to form a heterocyclyl; R5 is H or optionally substituted C1-C6 alkyl; L is -C(=O)-, C6-C12 alkylene, C6-C12 alkenylene, or C2-C6 alkynylene; and n is an integer from 1 to 12. Formula (AVII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt, tautomer, or stereoisomer thereof, wherein: G1 is -N(R3)R4 or -OR5; R1 is optionally substituted branched, saturated or unsaturated C12-C36 alkyl; R2 is optionally substituted branched or unbranched, saturated or unsaturated C12-C36 alkyl when L is -C(=O)-; or R2 is optionally substituted branched or unbranched, saturated or unsaturated C4-C36 alkyl when L is C6-C12 alkylene, C6-C12 alkenylene, or C2-C6 alkynylene; R3 and R4 are each independently H, optionally substituted branched or unbranched, saturated or unsaturated C1-C6 alkyl; or R3 and R4 are each independently optionally substituted branched or unbranched, saturated or unsaturated C1-C6 alkyl when L is C6-C12 alkylene, C6-C12
alkenylene, or C2-C6 alkynylene; or R3 and R4, together with the nitrogen to which they are attached, join to form a heterocyclyl; R5 is H or optionally substituted C1-C6 alkyl; L is -C(=O)-, C6-C12 alkylene, C6-C12 alkenylene, or C2-C6 alkynylene; and n is an integer from 1 to 12. Formula (AVII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt thereof, wherein: each R1a is independently hydrogen, R1c, or R1d; each R1b is independently R1c or R1d; each R1c is independently –[CH2]2C(O)X1R3; each R1d Is independently -C(O)R4; each R2 is independently -[C(R2a)2]cR2b; each R2a is independently hydrogen or C1-C6 alkyl; R2b is -N(L1-B)2; -(OCH2CH2)6OH; or -(OCH2CH2)bOCH3; each R3 and R4 is independently C6-C30 aliphatic; each I.3 is independently C1-C10 alkylene; each B is independently hydrogen or an ionizable nitrogen-containing group; each X1 is independently a covalent bond or O; each a is independently an integer of 1-10; each b is independently an integer of 1-10; and each c is independently an integer of 1-10. Formula (AVIII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt thereof, wherein: each R1a is independently hydrogen, R1c, or R1d; each R1b is independently R1c or R1d; each R1c is independently –[CH2]2C(O)X1R3; each R1d Is independently -C(O)R4; each R2 is independently -[C(R2a)2]cR2b; each R2a is independently hydrogen or C1-C6 alkyl; R2b is -N(L1-B)2; -(OCH2CH2)6OH; or -(OCH2CH2)bOCH3; each R3 and R4 is independently C6-C30 aliphatic; each I.3 is independently C1-C10 alkylene; each B is independently hydrogen or an ionizable nitrogen-containing group; each X1 is independently a covalent bond or O; each a is independently an integer of 1-10; each b is independently an integer of 1-10; and each c is independently an integer of 1-10. Formula (AVIII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: X is N, and Y is absent; or X is CR, and Y is NR;
L1 is -O(C-O)R1, -(C=O)OR1, -C(=O)R1, -OR1, -S(O)xR1, -S-SR1, -C(=O)SR1, - SC(=O)R1, -NRaC(=O)R1, -C(=O)NRbRc, -NRaC(=O)NRbRc, -OC(=O)NRbRc, or - NRaC(=O)OR1; L2 is -O(C=O)R2, -(C=O)OR2, -C(=O)R2, -OR2, -S(O)xR2, -S-SR2, -C(=O)SR2, - SC(=O)R2, -NRdC(=O)R2, -C(=O)NReRf, -NRdC(=O)NReRf, -OC(=O)NReRf; - NRdC(=O)OR2 or a direct bond to R2;
or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: X is N, and Y is absent; or X is CR, and Y is NR;
L1 is -O(C-O)R1, -(C=O)OR1, -C(=O)R1, -OR1, -S(O)xR1, -S-SR1, -C(=O)SR1, - SC(=O)R1, -NRaC(=O)R1, -C(=O)NRbRc, -NRaC(=O)NRbRc, -OC(=O)NRbRc, or - NRaC(=O)OR1; L2 is -O(C=O)R2, -(C=O)OR2, -C(=O)R2, -OR2, -S(O)xR2, -S-SR2, -C(=O)SR2, - SC(=O)R2, -NRdC(=O)R2, -C(=O)NReRf, -NRdC(=O)NReRf, -OC(=O)NReRf; - NRdC(=O)OR2 or a direct bond to R2;
 G1 and G2 are each independently C2-C12 alkylene or C2-C12 alkenylene; G3 is C1-C24 alkylene, C2-C24 alkenylene, C1-C24 heteroalkylene or C2-C24 heteroalkenylene when X is CR, and Y is NR; and G3 is C1-C24 heteroalkylene or C2-C24 heteroalkenylene when X is N, and Y is absent; Ra, Rb, Rd and Re are each independently H or C1-C12 alkyl or C1-C12 alkenyl; Rc and Rf are each independently C1-C12 alkyl or C2-C12 alkenyl; each R is independently H or C1-C12 alkyl; R1, R2 and R3 are each independently C1-C24 alkyl or C2-C24 alkenyl; and x is 0, 1 or 2, and wherein each alkyl, alkenyl, alkylene, alkenylene, heteroalkylene and heteroalkenylene is independently substituted or unsubstituted unless otherwise specified. Formula (AIX) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
G1 and G2 are each independently C2-C12 alkylene or C2-C12 alkenylene; G3 is C1-C24 alkylene, C2-C24 alkenylene, C1-C24 heteroalkylene or C2-C24 heteroalkenylene when X is CR, and Y is NR; and G3 is C1-C24 heteroalkylene or C2-C24 heteroalkenylene when X is N, and Y is absent; Ra, Rb, Rd and Re are each independently H or C1-C12 alkyl or C1-C12 alkenyl; Rc and Rf are each independently C1-C12 alkyl or C2-C12 alkenyl; each R is independently H or C1-C12 alkyl; R1, R2 and R3 are each independently C1-C24 alkyl or C2-C24 alkenyl; and x is 0, 1 or 2, and wherein each alkyl, alkenyl, alkylene, alkenylene, heteroalkylene and heteroalkenylene is independently substituted or unsubstituted unless otherwise specified. Formula (AIX) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, tautomer, prodrug or stereoisomer thereof, wherein: L1 and L2 are each independently -O(C=O)-, -(C=O)O-, -C(=O)-, -O-, -S(O)x-, -S-S-, - C(=O)S-, -SC(=O)-, -NRaC(=O)-, -C(=O)NRa-, -NRaC(=O)NRa-, -OC(=O)NRa-, -NRaC(=O)O- or a direct bond; G1 is C1-C2 alkylene, -(C=O)-, -O(C=O)-, -SC(=O)-, -NRaC(=O)- or a direct bond; G2 is -C(O)-, -(CO)O-, -C(=O)S-, -C(=O)NRa- or a direct bond; G3 is C1-C6 alkylene;
Ra is H or C1-C12 alkyl; R1a and R1b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R1a is H or C1-C12 alkyl, and R1b together with the carbon atom to which it is bound is taken together with an adjacent R1b and the carbon atom to which it is bound to form a carbon-carbon double bond; R2a and R2b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R2a is H or C1-C12 alkyl, and R2b together with the carbon atom to which it is bound is taken together with an adjacent R2b and the carbon atom to which it is bound to form a carbon-carbon double bond; R3a and R3b are, at each occurrence, independently either (a): H or C1-C12 alkyl; or (b) R3a is H or C1-C12 alkyl, and R3b together with the carbon atom to which it is bound is taken together with an adjacent R and the carbon atom to which it is bound to form a carbon-carbon double bond; R4a and R4b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R4a is H or C 4b 1-C12 alkyl, and R together with the carbon atom to which it is bound is taken together with an adjacent R4b and the carbon atom to which it is bound to form a carbon-carbon double bond; R5 and R6 are each independently H or methyl; R7 is H or C1-C20 alkyl; R8 is OH, -N(R9)(C=O)R10, -(C=O)NR9R10, -NR9R10, -(C=O)OR"1 or -O(C=O)R", provided that G3 is C 8 4-C6 alkylene when R is -NR9R10, R9 and R10 are each independently H or C1-C12 alkyl; R" is aralkyl; a, b, c and d are each independently an integer from 1 to 24; and x is 0, 1 or 2, wherein each alkyl, alkylene and aralkyl is optionally substituted. Formula (AX) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt, tautomer, prodrug or stereoisomer thereof, wherein: L1 and L2 are each independently -O(C=O)-, -(C=O)O-, -C(=O)-, -O-, -S(O)x-, -S-S-, - C(=O)S-, -SC(=O)-, -NRaC(=O)-, -C(=O)NRa-, -NRaC(=O)NRa-, -OC(=O)NRa-, -NRaC(=O)O- or a direct bond; G1 is C1-C2 alkylene, -(C=O)-, -O(C=O)-, -SC(=O)-, -NRaC(=O)- or a direct bond; G2 is -C(O)-, -(CO)O-, -C(=O)S-, -C(=O)NRa- or a direct bond; G3 is C1-C6 alkylene;
Ra is H or C1-C12 alkyl; R1a and R1b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R1a is H or C1-C12 alkyl, and R1b together with the carbon atom to which it is bound is taken together with an adjacent R1b and the carbon atom to which it is bound to form a carbon-carbon double bond; R2a and R2b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R2a is H or C1-C12 alkyl, and R2b together with the carbon atom to which it is bound is taken together with an adjacent R2b and the carbon atom to which it is bound to form a carbon-carbon double bond; R3a and R3b are, at each occurrence, independently either (a): H or C1-C12 alkyl; or (b) R3a is H or C1-C12 alkyl, and R3b together with the carbon atom to which it is bound is taken together with an adjacent R and the carbon atom to which it is bound to form a carbon-carbon double bond; R4a and R4b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R4a is H or C 4b 1-C12 alkyl, and R together with the carbon atom to which it is bound is taken together with an adjacent R4b and the carbon atom to which it is bound to form a carbon-carbon double bond; R5 and R6 are each independently H or methyl; R7 is H or C1-C20 alkyl; R8 is OH, -N(R9)(C=O)R10, -(C=O)NR9R10, -NR9R10, -(C=O)OR"1 or -O(C=O)R", provided that G3 is C 8 4-C6 alkylene when R is -NR9R10, R9 and R10 are each independently H or C1-C12 alkyl; R" is aralkyl; a, b, c and d are each independently an integer from 1 to 24; and x is 0, 1 or 2, wherein each alkyl, alkylene and aralkyl is optionally substituted. Formula (AX) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: X and X' are each independently N or CR; Y and Y' are each independently absent, -O(C=O)-, -(C=O)O- or NR, provided that: a) Y is absent when X is N; b) Y' is absent when X' is N;
c) Y is -O(C=O)-, -(C=O)O- or NR when X is CR; and d) Y' is -O(C=O)-, -(C=O)O- or NR when X' is CR, L1 and L1' are each independently -O(C=O)R', -(C=O)OR', -C(=O)R', -OR1, -S(O)zR', -S- SR1, -C(=O)SR', -SC(=O)R', -NRaC(=O)R', -C(=O)NRbRc, -NRaC(=O)NRbRc, -OC(=O)NRbRc or -NRaC(=O)OR'; L2 and L2’ are each independently -O(C=O)R2, -(C=O)OR2, -C(=O)R2, -OR2, -S(O)zR2, -S-SR2, -C(=O)SR2, -SC(=O)R2, -NRdC(=O)R2, -C(=O)NReRf, -NRdC(=O)NReRf, -OC(=O)NReRf; -NRdC(=O)OR2 or a direct bond to R2; G1. G1’, G2 and G2’ are each independently C2-C12 alkylene or C2-C12 alkenylene; G is C2-C24 heteroalkylene or C2-C24 heteroalkenylene; Ra, Rb, Rd and Re are, at each occurrence, independently H, C1-C12 alkyl or C2-C12 alkenyl; Rc and Rf are, at each occurrence, independently C1-C12 alkyl or C2-C12 alkenyl; R is, at each occurrence, independently H or C1-C12 alkyl; R1 and R2 are, at each occurrence, independently branched C6-C24 alkyl or branched C6- C24 alkenyl; z is 0, 1 or 2, and wherein each alkyl, alkenyl, alkylene, alkenylene, heteroalkylene and heteroalkenylene is independently substituted or unsubstituted unless otherwise specified. Formula (AXI) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: X and X' are each independently N or CR; Y and Y' are each independently absent, -O(C=O)-, -(C=O)O- or NR, provided that: a) Y is absent when X is N; b) Y' is absent when X' is N;
c) Y is -O(C=O)-, -(C=O)O- or NR when X is CR; and d) Y' is -O(C=O)-, -(C=O)O- or NR when X' is CR, L1 and L1' are each independently -O(C=O)R', -(C=O)OR', -C(=O)R', -OR1, -S(O)zR', -S- SR1, -C(=O)SR', -SC(=O)R', -NRaC(=O)R', -C(=O)NRbRc, -NRaC(=O)NRbRc, -OC(=O)NRbRc or -NRaC(=O)OR'; L2 and L2’ are each independently -O(C=O)R2, -(C=O)OR2, -C(=O)R2, -OR2, -S(O)zR2, -S-SR2, -C(=O)SR2, -SC(=O)R2, -NRdC(=O)R2, -C(=O)NReRf, -NRdC(=O)NReRf, -OC(=O)NReRf; -NRdC(=O)OR2 or a direct bond to R2; G1. G1’, G2 and G2’ are each independently C2-C12 alkylene or C2-C12 alkenylene; G is C2-C24 heteroalkylene or C2-C24 heteroalkenylene; Ra, Rb, Rd and Re are, at each occurrence, independently H, C1-C12 alkyl or C2-C12 alkenyl; Rc and Rf are, at each occurrence, independently C1-C12 alkyl or C2-C12 alkenyl; R is, at each occurrence, independently H or C1-C12 alkyl; R1 and R2 are, at each occurrence, independently branched C6-C24 alkyl or branched C6- C24 alkenyl; z is 0, 1 or 2, and wherein each alkyl, alkenyl, alkylene, alkenylene, heteroalkylene and heteroalkenylene is independently substituted or unsubstituted unless otherwise specified. Formula (AXI) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: L1 is -O(C=O)R1, -(C=O)OR1, -C(=O)R1, -OR1, -S(O)xR1, -S-SR1, - C(=O)SR1, -SC(=O)R1, -NRaC(=O)R1, -C(=O)NRbRc, -NRaC(=O)NRbRc, -OC(=O)NRbRc or -NRaC(=O)OR1; L2 is -O(C=O)R2, -(C=O)OR2, -C(=O)R2, -OR2, -S(O)xR2, -S-SR2, -C(=O)SR2, -SC(=O)R2, -NRdC(=O)R2, -C(=O)NReRf, -NRdC(=O)NReRf, -OC(=O)NReRf; -NRdC(=O)OR2 or a direct bond to R2; G1 and G2 are each independently C2-C12 alkylene or C2-C12 alkenylene; G3 is C1-C24 alkylene, C2-C24 alkenylene, C3-C8 cycloalkylene or C3-C8 cycloalkenylene; Ra, Rb, Rd and Re are each independently H or C1-C12 alkyl or C1-C12 alkenyl; Rc and Rf are each independently C1-C12 alkyl or C2-C12 alkenyl; R1 and R2 are each independently branched C6-C24 alkyl or branched C6- C24 alkenyl;
R3 is -N(R4)R5; R4 is C1-C12 alkyl; R5 is substituted C1-C12 alkyl; and x is 0, 1 or 2, and wherein each alkyl, alkenyl, alkylene, alkenylene, cycloalkylene, cycloalkenylene, aryl and aralkyl is independently substituted or unsubstituted unless otherwise specified. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: L1 is -O(C=O)R1, -(C=O)OR1, -C(=O)R1, -OR1, -S(O)xR1, -S-SR1, - C(=O)SR1, -SC(=O)R1, -NRaC(=O)R1, -C(=O)NRbRc, -NRaC(=O)NRbRc, -OC(=O)NRbRc or -NRaC(=O)OR1; L2 is -O(C=O)R2, -(C=O)OR2, -C(=O)R2, -OR2, -S(O)xR2, -S-SR2, -C(=O)SR2, -SC(=O)R2, -NRdC(=O)R2, -C(=O)NReRf, -NRdC(=O)NReRf, -OC(=O)NReRf; -NRdC(=O)OR2 or a direct bond to R2; G1 and G2 are each independently C2-C12 alkylene or C2-C12 alkenylene; G3 is C1-C24 alkylene, C2-C24 alkenylene, C3-C8 cycloalkylene or C3-C8 cycloalkenylene; Ra, Rb, Rd and Re are each independently H or C1-C12 alkyl or C1-C12 alkenyl; Rc and Rf are each independently C1-C12 alkyl or C2-C12 alkenyl; R1 and R2 are each independently branched C6-C24 alkyl or branched C6- C24 alkenyl;
R3 is -N(R4)R5; R4 is C1-C12 alkyl; R5 is substituted C1-C12 alkyl; and x is 0, 1 or 2, and wherein each alkyl, alkenyl, alkylene, alkenylene, cycloalkylene, cycloalkenylene, aryl and aralkyl is independently substituted or unsubstituted unless otherwise specified. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: L1 is -O(C=O)R1, -(C=O)OR1, -C(=O)R1, -OR1, -S(O)xR1, -S-SR1, -C(=O)SR1, -SC(=O)R1, -NRaC(=O)R1, -C(=O)NRbRc, -NRaC(=O)NRbRc, -OC(=O)NRbRc or -NRaC(=O)OR1; L2 is -O(C=O)R2, -(C=O)OR2, -C(=O)R2, -OR2, -S(O)xR2, -S-SR2, -C(=O)SR2, -SC(=O)R2, -NRdC(=O)R2, -C(=O)NReRf, -NRdC(=O)NReRf, -OC(=O)NReRf; -NRdC(=O)OR2 or a direct bond to R2; G1a and G2b are each independently C2-C12 alkylene or C2-C12 alkenylene; G1b and G2b are each independently C1-C12 alkylene or C2-C12 alkenylene; G3 is C1-C24 alkylene, C2-C24 alkenylene, C3-C8 cycloalkylene or C3-C8 cycloalkenylene; Ra, Rb, Rd and Re are each independently H or C1-C12 alkyl or C2-C12 alkenyl; Rc and Rf are each independently C1-C12 alkyl or C2-C12 alkenyl; R1 and R2 are each independently branched C6-C24 alkyl or branched C6-C24 alkenyl; R3a is -C(=O)N(R4a)R5a or -C(=O)OR6; R3b is -NR4bC(=O)R5b; R4a is C1-C12 alkyl; R4b is H, C1-C12 alkyl or C2-C12 alkenyl; R5a is H, C1-C8 alkyl or C2-C8 alkenyl; R5b is C 4b 2-C12 alkyl or C2-C12 alkenyl when R is H; or R5b is C1-C12 alkyl or C2-C12 alkenyl when R4b is C1-C12 alkyl or C2-C12 alkenyl; R6 is H, aryl or aralkyl; and x is 0, 1 or 2, and wherein each alkyl, alkenyl, alkylene, alkenylene, cycloalkylene, cycloalkenylene, aryl and aralkyl is independently substituted or unsubstituted.
Formula (AXII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: L1 is -O(C=O)R1, -(C=O)OR1, -C(=O)R1, -OR1, -S(O)xR1, -S-SR1, -C(=O)SR1, -SC(=O)R1, -NRaC(=O)R1, -C(=O)NRbRc, -NRaC(=O)NRbRc, -OC(=O)NRbRc or -NRaC(=O)OR1; L2 is -O(C=O)R2, -(C=O)OR2, -C(=O)R2, -OR2, -S(O)xR2, -S-SR2, -C(=O)SR2, -SC(=O)R2, -NRdC(=O)R2, -C(=O)NReRf, -NRdC(=O)NReRf, -OC(=O)NReRf; -NRdC(=O)OR2 or a direct bond to R2; G1a and G2b are each independently C2-C12 alkylene or C2-C12 alkenylene; G1b and G2b are each independently C1-C12 alkylene or C2-C12 alkenylene; G3 is C1-C24 alkylene, C2-C24 alkenylene, C3-C8 cycloalkylene or C3-C8 cycloalkenylene; Ra, Rb, Rd and Re are each independently H or C1-C12 alkyl or C2-C12 alkenyl; Rc and Rf are each independently C1-C12 alkyl or C2-C12 alkenyl; R1 and R2 are each independently branched C6-C24 alkyl or branched C6-C24 alkenyl; R3a is -C(=O)N(R4a)R5a or -C(=O)OR6; R3b is -NR4bC(=O)R5b; R4a is C1-C12 alkyl; R4b is H, C1-C12 alkyl or C2-C12 alkenyl; R5a is H, C1-C8 alkyl or C2-C8 alkenyl; R5b is C 4b 2-C12 alkyl or C2-C12 alkenyl when R is H; or R5b is C1-C12 alkyl or C2-C12 alkenyl when R4b is C1-C12 alkyl or C2-C12 alkenyl; R6 is H, aryl or aralkyl; and x is 0, 1 or 2, and wherein each alkyl, alkenyl, alkylene, alkenylene, cycloalkylene, cycloalkenylene, aryl and aralkyl is independently substituted or unsubstituted.
Formula (AXII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: G1 is -OH, -R3R4, -(C=O)R5 or -R3(C=O)R5; G2 is -CH2- or -(C=O)-; R is, at each occurrence, independently H or OH; R1 and R2 are each independently optionally substituted branched, saturated or unsaturated C12-C36 alkyl; R3 and R4 are each independently H or optionally substituted straight or branched, saturated or unsaturated C1-C6 alkyl; R5 is optionally substituted straight or branched, saturated or unsaturated C1-C6 alkyl; n is an integer from 2 to 6. Formula (AXIII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: G1 is -OH, -R3R4, -(C=O)R5 or -R3(C=O)R5; G2 is -CH2- or -(C=O)-; R is, at each occurrence, independently H or OH; R1 and R2 are each independently optionally substituted branched, saturated or unsaturated C12-C36 alkyl; R3 and R4 are each independently H or optionally substituted straight or branched, saturated or unsaturated C1-C6 alkyl; R5 is optionally substituted straight or branched, saturated or unsaturated C1-C6 alkyl; n is an integer from 2 to 6. Formula (AXIII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: one of G1 or G2 is, at each occurrence, -O(C=O)-, -(C=O)O-, -C(=O)-, -O-, -S(O) , -S-S-, -C(=O)S-, SC(=O)-, -N(Ra)C(=O)-, -C(=O)N(Ra)-, -N(Ra)C(=O)N(Ra)-, -OC(=O)N(Ra)- or -N(Ra)C(=O)O-, and the other of G1 or G2 is, at each occurrence, -O(C=O)-, -(C=O)O-, -C(=O)-, -O-, -S(O), -S-S-, -C(=O)S-, -SC(=O)-, -N(Ra)C(=O)-, -C(=O)N(Ra)-, -N(Ra)C(=O)N(Ra)-, -OC(=O)N(Ra)- or -N(Ra)C(=O)O- or a direct bond; L is, at each occurrence, ~O(C=O)-, wherein ~ represents a covalent bond to X; X is CRa;
Z is alkyl, cycloalkyl or a monovalent moiety comprising at least one polar functional group when n is 1; or Z is alkylene, cycloalkylene or a polyvalent moiety comprising at least one polar functional group when n is greater than 1; Ra is, at each occurrence, independently H, C1-C12 alkyl, C1-C12 hydroxylalkyl, C1-C12 aminoalkyl, C1-C12 alkylaminylalkyl, C1-C12 alkoxyalkyl, C1-C12 alkoxycarbonyl, C1-C12 alkylcarbonyloxy, C1-C12 alkylcarbonyloxyalkyl or C1-C12 alkylcarbonyl; R is, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R together with the carbon atom to which it is bound is taken together with an adjacent R and the carbon atom to which it is bound to form a carbon-carbon double bond; R1 and R2 have, at each occurrence, the following structure, respectively:
or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein: one of G1 or G2 is, at each occurrence, -O(C=O)-, -(C=O)O-, -C(=O)-, -O-, -S(O) , -S-S-, -C(=O)S-, SC(=O)-, -N(Ra)C(=O)-, -C(=O)N(Ra)-, -N(Ra)C(=O)N(Ra)-, -OC(=O)N(Ra)- or -N(Ra)C(=O)O-, and the other of G1 or G2 is, at each occurrence, -O(C=O)-, -(C=O)O-, -C(=O)-, -O-, -S(O), -S-S-, -C(=O)S-, -SC(=O)-, -N(Ra)C(=O)-, -C(=O)N(Ra)-, -N(Ra)C(=O)N(Ra)-, -OC(=O)N(Ra)- or -N(Ra)C(=O)O- or a direct bond; L is, at each occurrence, ~O(C=O)-, wherein ~ represents a covalent bond to X; X is CRa;
Z is alkyl, cycloalkyl or a monovalent moiety comprising at least one polar functional group when n is 1; or Z is alkylene, cycloalkylene or a polyvalent moiety comprising at least one polar functional group when n is greater than 1; Ra is, at each occurrence, independently H, C1-C12 alkyl, C1-C12 hydroxylalkyl, C1-C12 aminoalkyl, C1-C12 alkylaminylalkyl, C1-C12 alkoxyalkyl, C1-C12 alkoxycarbonyl, C1-C12 alkylcarbonyloxy, C1-C12 alkylcarbonyloxyalkyl or C1-C12 alkylcarbonyl; R is, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R together with the carbon atom to which it is bound is taken together with an adjacent R and the carbon atom to which it is bound to form a carbon-carbon double bond; R1 and R2 have, at each occurrence, the following structure, respectively:
 a1 and a2 are, at each occurrence, independently an integer from 3 to 12; b1 and b2 are, at each occurrence, independently 0 or 1; c1 and c2 are, at each occurrence, independently an integer from 5 to 10; d1 and d2 are, at each occurrence, independently an integer from 5 to 10; y is, at each occurrence, independently an integer from 0 to 2; and n is an integer from 1 to 6, wherein each alkyl, alkylene, hydroxylalkyl, aminoalkyl, alkylaminylalkyl, alkoxyalkyl, alkoxycarbonyl, alkylcarbonyloxy, alkylcarbonyloxyalkyl and alkylcarbonyl is optionally substituted with one or more substituent. Formula (AXIV) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
a1 and a2 are, at each occurrence, independently an integer from 3 to 12; b1 and b2 are, at each occurrence, independently 0 or 1; c1 and c2 are, at each occurrence, independently an integer from 5 to 10; d1 and d2 are, at each occurrence, independently an integer from 5 to 10; y is, at each occurrence, independently an integer from 0 to 2; and n is an integer from 1 to 6, wherein each alkyl, alkylene, hydroxylalkyl, aminoalkyl, alkylaminylalkyl, alkoxyalkyl, alkoxycarbonyl, alkylcarbonyloxy, alkylcarbonyloxyalkyl and alkylcarbonyl is optionally substituted with one or more substituent. Formula (AXIV) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein:
or a pharmaceutically acceptable salt, prodrug or stereoisomer thereof, wherein:
 -C(=O)Ra-, RaC(=O)Ra-, -OC(=O)Ra- or -NRaC(=O)O- or a direct bond;
G1 and G2 are each independently unsubstituted C1-C12 alkylene or C1-C12 alkenylene; G3 is C1-C24 alkylene, C1-C24 alkenylene, C3-C8 cycloalkylene, C3-C8 cycloalkenylene; Ra is H or C1-C12 alkyl; R1 and R2 are each independently C6-C24 alkyl or C6-C24 alkenyl; R3 is H, OR5, CN, -C(=O)OR4, -OC(=O)R4 or - R5C(=O)R4; R4 is C1-C12 alkyl; R5 is H or C1-C6 alkyl; and x is 0, 1 or 2. Formula (AXV) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
-C(=O)Ra-, RaC(=O)Ra-, -OC(=O)Ra- or -NRaC(=O)O- or a direct bond;
G1 and G2 are each independently unsubstituted C1-C12 alkylene or C1-C12 alkenylene; G3 is C1-C24 alkylene, C1-C24 alkenylene, C3-C8 cycloalkylene, C3-C8 cycloalkenylene; Ra is H or C1-C12 alkyl; R1 and R2 are each independently C6-C24 alkyl or C6-C24 alkenyl; R3 is H, OR5, CN, -C(=O)OR4, -OC(=O)R4 or - R5C(=O)R4; R4 is C1-C12 alkyl; R5 is H or C1-C6 alkyl; and x is 0, 1 or 2. Formula (AXV) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, tautomer, prodrug or stereoisomer thereof, wherein: L1 and L2 are each independently -O(C=O)-, -(C=O)O-, -C(=O)-, -O-, -S(O)x-, -S-S-, -C(=O)S-, -SC(=O)-, -RaC(=O)-, -C(=O)Ra-, -RaC(=O)Ra-, -OC(=O)Ra-, -RaC(=O)O- or a direct bond; G1 is C1-C2 alkylene, -(C=O)-, -O(C=O)-, -SC(=O)-, -RaC(=O)- or a direct bond:
or a pharmaceutically acceptable salt, tautomer, prodrug or stereoisomer thereof, wherein: L1 and L2 are each independently -O(C=O)-, -(C=O)O-, -C(=O)-, -O-, -S(O)x-, -S-S-, -C(=O)S-, -SC(=O)-, -RaC(=O)-, -C(=O)Ra-, -RaC(=O)Ra-, -OC(=O)Ra-, -RaC(=O)O- or a direct bond; G1 is C1-C2 alkylene, -(C=O)-, -O(C=O)-, -SC(=O)-, -RaC(=O)- or a direct bond:
 direct bond; G3 is C1-C6 alkylene; Ra is H or C1-C12 alkyl; R1a and R1b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R1a is H or C1-C12 alkyl, and R1b together with the carbon atom to which it is bound is taken together with an adjacent R1b and the carbon atom to which it is bound to form a carbon-carbon double bond; R2a and R2b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R2a is H or C1-C12 alkyl, and R2b together with the carbon atom to which it is bound is taken together with an adjacent R2b and the carbon atom to which it is bound to form a carbon-carbon double bond;
R3a and R3b are, at each occurrence, independently either (a): H or C1-C12 alkyl; or (b) R3a is H or C1-C12 alkyl, and R3b together with the carbon atom to which it is bound is taken together with an adjacent R and the carbon atom to which it is bound to form a carbon-carbon double bond; R4a and R4b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R4a is H or C1-C12 alkyl, and R4b together with the carbon atom to which it is bound is taken together with an adjacent R4b and the carbon atom to which it is bound to form a carbon-carbon double bond; R5 and R6 are each independently H or methyl; R7 is C4-C20 alkyl; R8 and R9 are each independently C1-C12 alkyl; or R8 and R9, together with the nitrogen atom to which they are attached, form a 5, 6 or 7-membered heterocyclic ring; a, b, c and d are each independently an integer from 1 to 24; and x is 0, 1 or 2. Formula (AXVI) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
direct bond; G3 is C1-C6 alkylene; Ra is H or C1-C12 alkyl; R1a and R1b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R1a is H or C1-C12 alkyl, and R1b together with the carbon atom to which it is bound is taken together with an adjacent R1b and the carbon atom to which it is bound to form a carbon-carbon double bond; R2a and R2b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R2a is H or C1-C12 alkyl, and R2b together with the carbon atom to which it is bound is taken together with an adjacent R2b and the carbon atom to which it is bound to form a carbon-carbon double bond;
R3a and R3b are, at each occurrence, independently either (a): H or C1-C12 alkyl; or (b) R3a is H or C1-C12 alkyl, and R3b together with the carbon atom to which it is bound is taken together with an adjacent R and the carbon atom to which it is bound to form a carbon-carbon double bond; R4a and R4b are, at each occurrence, independently either: (a) H or C1-C12 alkyl; or (b) R4a is H or C1-C12 alkyl, and R4b together with the carbon atom to which it is bound is taken together with an adjacent R4b and the carbon atom to which it is bound to form a carbon-carbon double bond; R5 and R6 are each independently H or methyl; R7 is C4-C20 alkyl; R8 and R9 are each independently C1-C12 alkyl; or R8 and R9, together with the nitrogen atom to which they are attached, form a 5, 6 or 7-membered heterocyclic ring; a, b, c and d are each independently an integer from 1 to 24; and x is 0, 1 or 2. Formula (AXVI) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt, tautomer, prodrug or stereoisomer thereof, wherein: L1 and L2 are each independently -O(C=O)-, -(C=O)O- or a carbon-carbon double bond; R1a and R1b are, at each occurrence, independently either (a) H or C1-C12 alkyl, or (b) R1a is H or C1-C12 alkyl, and R1b together with the carbon atom to which it is bound is taken together with an adjacent R1b and the carbon atom to which it is bound to form a carbon-carbon double bond; R2a and R2b are, at each occurrence, independently either (a) H or C1-C12 alkyl, or (b) R2a is H or C1-C12 alkyl, and R2b together with the carbon atom to which it is bound is taken together with an adjacent R2b and the carbon atom to which it is bound to form a carbon-carbon double bond; R3a and R3b are, at each occurrence, independently either (a) H or C1-C12 alkyl, or (b) R3a is H or C1-C12 alkyl, and R3b together with the carbon atom to which it is bound is taken
together with an adjacent R3b and the carbon atom to which it is bound to form a carbon-carbon double bond; R4a and R4b are, at each occurrence, independently either (a) H or C1-C12 alkyl, or (b) R4a is H or C 4b 1-C12 alkyl, and R together with the carbon atom to which it is bound is taken together with an adjacent R4b and the carbon atom to which it is bound to form a carbon-carbon double bond; R5 and R6 are each independently methyl or cycloalkyl; R7 is, at each occurrence, independently H or C1-C12 alkyl; R8 and R9 are each independently unsubstituted C1-C12 alkyl; or R8 and R9, together with the nitrogen atom to which they are attached, form a 5, 6 or 7- membered heterocyclic ring comprising one nitrogen atom; a and d are each independently an integer from 0 to 24; b and c are each independently an integer from 1 to 24; and e is 1 or 2, provided that: at least one of R1a, R2a, R3a or R4a is C1-C12 alkyl, or at least one of L1 or L2 is -O(C=O)- or -(C=O)O-; and R1a and R1b are not isopropyl when a is 6 or n-butyl when a is 8. Formula (AXVII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt, tautomer, prodrug or stereoisomer thereof, wherein: L1 and L2 are each independently -O(C=O)-, -(C=O)O- or a carbon-carbon double bond; R1a and R1b are, at each occurrence, independently either (a) H or C1-C12 alkyl, or (b) R1a is H or C1-C12 alkyl, and R1b together with the carbon atom to which it is bound is taken together with an adjacent R1b and the carbon atom to which it is bound to form a carbon-carbon double bond; R2a and R2b are, at each occurrence, independently either (a) H or C1-C12 alkyl, or (b) R2a is H or C1-C12 alkyl, and R2b together with the carbon atom to which it is bound is taken together with an adjacent R2b and the carbon atom to which it is bound to form a carbon-carbon double bond; R3a and R3b are, at each occurrence, independently either (a) H or C1-C12 alkyl, or (b) R3a is H or C1-C12 alkyl, and R3b together with the carbon atom to which it is bound is taken
together with an adjacent R3b and the carbon atom to which it is bound to form a carbon-carbon double bond; R4a and R4b are, at each occurrence, independently either (a) H or C1-C12 alkyl, or (b) R4a is H or C 4b 1-C12 alkyl, and R together with the carbon atom to which it is bound is taken together with an adjacent R4b and the carbon atom to which it is bound to form a carbon-carbon double bond; R5 and R6 are each independently methyl or cycloalkyl; R7 is, at each occurrence, independently H or C1-C12 alkyl; R8 and R9 are each independently unsubstituted C1-C12 alkyl; or R8 and R9, together with the nitrogen atom to which they are attached, form a 5, 6 or 7- membered heterocyclic ring comprising one nitrogen atom; a and d are each independently an integer from 0 to 24; b and c are each independently an integer from 1 to 24; and e is 1 or 2, provided that: at least one of R1a, R2a, R3a or R4a is C1-C12 alkyl, or at least one of L1 or L2 is -O(C=O)- or -(C=O)O-; and R1a and R1b are not isopropyl when a is 6 or n-butyl when a is 8. Formula (AXVII) In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 or a pharmaceutically acceptable salt thereof, wherein R1 and R2 are the same or different, each a linear or branched alkyl with 1-9 carbons, or as alkenyl or alkynyl with 2 to 11 carbon atoms, L1 and L2 are the same or different, each a linear alkyl having 5 to 18 carbon atoms, or form a heterocycle with N, X1 is a bond, or is -CO-O- whereby L2-CO-O-R2 is formed, X2 is S or O, L3 is a bond or a lower alkyl, or form a heterocycle with N, R3 is a lower alkyl, and R4 and R5 are the same or different, each a lower alkyl. Compounds (A1)-(A11)
In some embodiments, the lipid nanoparticle comprises an ionizable lipid having the structure:
or a pharmaceutically acceptable salt thereof, wherein R1 and R2 are the same or different, each a linear or branched alkyl with 1-9 carbons, or as alkenyl or alkynyl with 2 to 11 carbon atoms, L1 and L2 are the same or different, each a linear alkyl having 5 to 18 carbon atoms, or form a heterocycle with N, X1 is a bond, or is -CO-O- whereby L2-CO-O-R2 is formed, X2 is S or O, L3 is a bond or a lower alkyl, or form a heterocycle with N, R3 is a lower alkyl, and R4 and R5 are the same or different, each a lower alkyl. Compounds (A1)-(A11)
In some embodiments, the lipid nanoparticle comprises an ionizable lipid having the structure:
 or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 (A2), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
(A2), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 (A3), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
(A3), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 (A4), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
(A5), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
(A4), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
(A5), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 (A6), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
(A6), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 (A7), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
(A7), or a pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
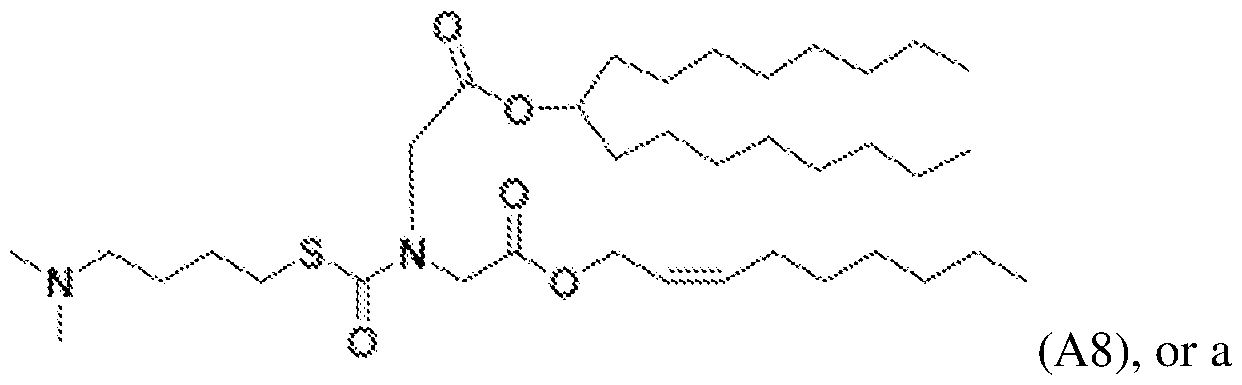 pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
 pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
pharmaceutically acceptable salt thereof. In some embodiments, the lipid nanoparticle comprises a lipid having the structure:
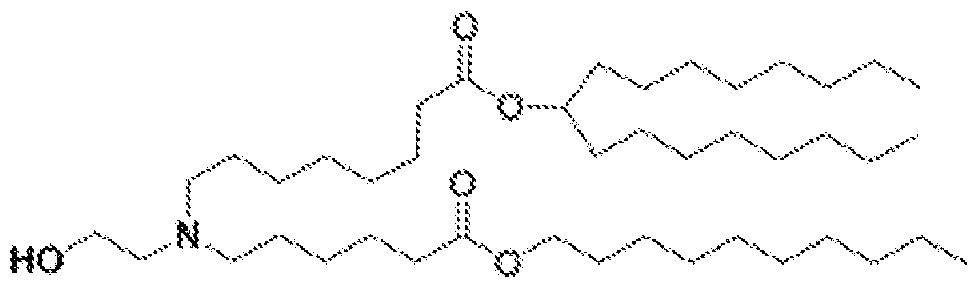 (A11), or a pharmaceutically acceptable salt thereof. Non-cationic lipids In certain embodiments, lipid nanoparticles comprise one or more non-cationic lipids. Non-cationic lipids may be phospholipids. In some embodiments, the lipid nanoparticle comprises 5-25 mol% non-cationic lipid. For example, the lipid nanoparticle may comprise 5-20 mol%, 5-15 mol%, 5-10 mol%, 10-25 mol%, 10-20 mol%, 10-25 mol%, 15-25 mol%, 15-20 mol%, or 20-25 mol% non-cationic lipid. In some embodiments, the lipid nanoparticle comprises 5 mol%, 10 mol%, 15 mol%, 20 mol%, or 25 mol% non-cationic lipid. In some embodiments, a non-cationic lipid comprises 1,2-distearoyl-sn-glycero-3- phosphocholine (DSPC), 1,2-dioleoyl-sn-glycero-3-phosphoethanolamine (DOPE), 1,2- dilinoleoyl-sn-glycero-3-phosphocholine (DLPc), 1,2-dimyristoyl-sn-gly cero-phosphocholine (DMPC), 1,2-dioleoyl-sn-glycero-3-phosphocholine (DOPC), l,2-dipalmitoyl-sn-glycero-3- phosphocholine (DPPC), 1,2-diundecanoyl-sn-glycero-phosphocholine (DUPC), 1-palmitoyl-2- oleoyl-sn-glycero-3-phosphocholine (POPC), 1,2-di-O-octadecenyl-sn-glycero-3- phosphocholine (18:0 Diether PC), 1-oleoyl-2 cholesterylhemisuccinoyl-sn-glycero-3- phosphocholine (OChemsPC), 1-hexadecyl-sn-glycero-3-phosphocholine (C16 Lyso PC), 1,2- dilinolenoyl-sn-glycero-3-phosphocholine,1,2-diarachidonoyl-sn-glycero-3-phosphocholine, 1,2-didocosahexaenoyl-sn-glycero-3-phosphocholine, 1,2-diphytanoyl-sn-glycero-3- phosphoethanolamine (ME 16.0 PE), 1,2-distearoyl-sn-glycero-3-phosphoethanolamine, 1,2- dilinoleoyl-sn-glycero-3-phosphoethanolamine, 1,2-dilinolenoyl-sn-glycero-3- phosphoethanolamine, 1,2-diarachidonoyl-sn-glycero-3-phosphoethanolamine, 1,2- didocosahexaenoyl-sn-glycero-3-phosphoethanolamine, 1,2-dioleoyl-sn-glycero-3-phospho-rac- (1-glycerol) sodium salt (DOPG), sphingomyelin, or mixtures thereof.
In some embodiments, the lipid nanoparticle comprises 5–15 mol%, 5–10 mol%, or 10– 15 mol% DSPC. For example, the lipid nanoparticle may comprise 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, or 15 mol% DSPC. In certain embodiments, the lipid composition of the lipid nanoparticle compositions can comprise one or more phospholipids, for example, one or more saturated or (poly)unsaturated phospholipids or a combination thereof. In general, phospholipids comprise a phospholipid moiety and one or more fatty acid moieties. A phospholipid moiety can be selected, for example, from the non-limiting group consisting of phosphatidyl choline, phosphatidyl ethanolamine, phosphatidyl glycerol, phosphatidyl serine, phosphatidic acid, 2-lysophosphatidyl choline, and a sphingomyelin. A fatty acid moiety can be selected, for example, from the non-limiting group consisting of lauric acid, myristic acid, myristoleic acid, palmitic acid, palmitoleic acid, stearic acid, oleic acid, linoleic acid, alpha-linolenic acid, erucic acid, phytanoic acid, arachidic acid, arachidonic acid, eicosapentaenoic acid, behenic acid, docosapentaenoic acid, and docosahexaenoic acid. Particular phospholipids can facilitate fusion to a membrane. For example, a cationic phospholipid can interact with one or more negatively charged phospholipids of a membrane (e.g., a cellular or intracellular membrane). Fusion of a phospholipid to a membrane can allow one or more elements (e.g., a therapeutic agent) of a lipid-containing composition (e.g., LNPs) to pass through the membrane permitting, e.g., delivery of the one or more elements to a target tissue. Non-natural phospholipid species including natural species with modifications and substitutions including branching, oxidation, cyclization, and alkynes are also contemplated. For example, a phospholipid can be functionalized with or cross-linked to one or more alkynes (e.g., an alkenyl group in which one or more double bonds is replaced with a triple bond). Under appropriate reaction conditions, an alkyne group can undergo a copper-catalyzed cycloaddition upon exposure to an azide. Such reactions can be useful in functionalizing a lipid bilayer of a nanoparticle composition to facilitate membrane permeation or cellular recognition or in conjugating a nanoparticle composition to a useful component such as a targeting or imaging moiety (e.g., a dye). Phospholipids include, but are not limited to, glycerophospholipids such as phosphatidylcholines, phosphatidylethanolamines, phosphatidylserines, phosphatidylinositols, phosphatidy glycerols, and phosphatidic acids. Phospholipids also include phosphosphingolipid, such as sphingomyelin. In some embodiments, a phospholipid comprises 1,2-distearoyl-sn-glycero-3- phosphocholine (DSPC), 1,2-Distearoyl-sn-glycero-3-phosphoethanolamine (DSPE), 1,2-
dioleoyl-sn-glycero-3-phosphoethanolamine (DOPE), 1,2-dilinoleoyl-sn-glycero-3- phosphocholine (DLPc), 1,2-dimyristoyl-sn-gly cero-phosphocholine (DMPC), 1,2-dioleoyl-sn- glycero-3-phosphocholine (DOPC), l,2-dipalmitoyl-sn-glycero-3-phosphocholine (DPPC), 1,2- diundecanoyl-sn-glycero-phosphocholine (DUPC), 1-palmitoyl-2-oleoyl-sn-glycero-3- phosphocholine (POPC), 1,2-di-O-octadecenyl-sn-glycero-3-phosphocholine (18:0 Diether PC), 1-oleoyl-2 cholesterylhemisuccinoyl-sn-glycero-3-phosphocholine (OChemsPC), 1-hexadecyl- sn-glycero-3-phosphocholine (C16 Lyso PC), 1,2-dilinolenoyl-sn-glycero-3-phosphocholine,1,2- diarachidonoyl-sn-glycero-3-phosphocholine, 1,2-didocosahexaenoyl-sn-glycero-3- phosphocholine, 1,2-diphytanoyl-sn-glycero-3-phosphoethanolamine (ME 16.0 PE), 1,2- distearoyl-sn-glycero-3-phosphoethanolamine, 1,2-dilinoleoyl-sn-glycero-3- phosphoethanolamine, 1,2-dilinolenoyl-sn-glycero-3-phosphoethanolamine, 1,2-diarachidonoyl- sn-glycero-3-phosphoethanolamine, 1,2-didocosahexaenoyl-sn-glycero-3-phosphoethanolamine, 1,2-dioleoyl-sn-glycero-3-phospho-rac-(1-glycerol) sodium salt (DOPG), sphingomyelin, or mixtures thereof. Formula (HI) In certain embodiments, a phospholipid is an analog or variant of DSPC. In certain embodiments, a phospholipid is a compound of Formula (HI):
(A11), or a pharmaceutically acceptable salt thereof. Non-cationic lipids In certain embodiments, lipid nanoparticles comprise one or more non-cationic lipids. Non-cationic lipids may be phospholipids. In some embodiments, the lipid nanoparticle comprises 5-25 mol% non-cationic lipid. For example, the lipid nanoparticle may comprise 5-20 mol%, 5-15 mol%, 5-10 mol%, 10-25 mol%, 10-20 mol%, 10-25 mol%, 15-25 mol%, 15-20 mol%, or 20-25 mol% non-cationic lipid. In some embodiments, the lipid nanoparticle comprises 5 mol%, 10 mol%, 15 mol%, 20 mol%, or 25 mol% non-cationic lipid. In some embodiments, a non-cationic lipid comprises 1,2-distearoyl-sn-glycero-3- phosphocholine (DSPC), 1,2-dioleoyl-sn-glycero-3-phosphoethanolamine (DOPE), 1,2- dilinoleoyl-sn-glycero-3-phosphocholine (DLPc), 1,2-dimyristoyl-sn-gly cero-phosphocholine (DMPC), 1,2-dioleoyl-sn-glycero-3-phosphocholine (DOPC), l,2-dipalmitoyl-sn-glycero-3- phosphocholine (DPPC), 1,2-diundecanoyl-sn-glycero-phosphocholine (DUPC), 1-palmitoyl-2- oleoyl-sn-glycero-3-phosphocholine (POPC), 1,2-di-O-octadecenyl-sn-glycero-3- phosphocholine (18:0 Diether PC), 1-oleoyl-2 cholesterylhemisuccinoyl-sn-glycero-3- phosphocholine (OChemsPC), 1-hexadecyl-sn-glycero-3-phosphocholine (C16 Lyso PC), 1,2- dilinolenoyl-sn-glycero-3-phosphocholine,1,2-diarachidonoyl-sn-glycero-3-phosphocholine, 1,2-didocosahexaenoyl-sn-glycero-3-phosphocholine, 1,2-diphytanoyl-sn-glycero-3- phosphoethanolamine (ME 16.0 PE), 1,2-distearoyl-sn-glycero-3-phosphoethanolamine, 1,2- dilinoleoyl-sn-glycero-3-phosphoethanolamine, 1,2-dilinolenoyl-sn-glycero-3- phosphoethanolamine, 1,2-diarachidonoyl-sn-glycero-3-phosphoethanolamine, 1,2- didocosahexaenoyl-sn-glycero-3-phosphoethanolamine, 1,2-dioleoyl-sn-glycero-3-phospho-rac- (1-glycerol) sodium salt (DOPG), sphingomyelin, or mixtures thereof.
In some embodiments, the lipid nanoparticle comprises 5–15 mol%, 5–10 mol%, or 10– 15 mol% DSPC. For example, the lipid nanoparticle may comprise 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, or 15 mol% DSPC. In certain embodiments, the lipid composition of the lipid nanoparticle compositions can comprise one or more phospholipids, for example, one or more saturated or (poly)unsaturated phospholipids or a combination thereof. In general, phospholipids comprise a phospholipid moiety and one or more fatty acid moieties. A phospholipid moiety can be selected, for example, from the non-limiting group consisting of phosphatidyl choline, phosphatidyl ethanolamine, phosphatidyl glycerol, phosphatidyl serine, phosphatidic acid, 2-lysophosphatidyl choline, and a sphingomyelin. A fatty acid moiety can be selected, for example, from the non-limiting group consisting of lauric acid, myristic acid, myristoleic acid, palmitic acid, palmitoleic acid, stearic acid, oleic acid, linoleic acid, alpha-linolenic acid, erucic acid, phytanoic acid, arachidic acid, arachidonic acid, eicosapentaenoic acid, behenic acid, docosapentaenoic acid, and docosahexaenoic acid. Particular phospholipids can facilitate fusion to a membrane. For example, a cationic phospholipid can interact with one or more negatively charged phospholipids of a membrane (e.g., a cellular or intracellular membrane). Fusion of a phospholipid to a membrane can allow one or more elements (e.g., a therapeutic agent) of a lipid-containing composition (e.g., LNPs) to pass through the membrane permitting, e.g., delivery of the one or more elements to a target tissue. Non-natural phospholipid species including natural species with modifications and substitutions including branching, oxidation, cyclization, and alkynes are also contemplated. For example, a phospholipid can be functionalized with or cross-linked to one or more alkynes (e.g., an alkenyl group in which one or more double bonds is replaced with a triple bond). Under appropriate reaction conditions, an alkyne group can undergo a copper-catalyzed cycloaddition upon exposure to an azide. Such reactions can be useful in functionalizing a lipid bilayer of a nanoparticle composition to facilitate membrane permeation or cellular recognition or in conjugating a nanoparticle composition to a useful component such as a targeting or imaging moiety (e.g., a dye). Phospholipids include, but are not limited to, glycerophospholipids such as phosphatidylcholines, phosphatidylethanolamines, phosphatidylserines, phosphatidylinositols, phosphatidy glycerols, and phosphatidic acids. Phospholipids also include phosphosphingolipid, such as sphingomyelin. In some embodiments, a phospholipid comprises 1,2-distearoyl-sn-glycero-3- phosphocholine (DSPC), 1,2-Distearoyl-sn-glycero-3-phosphoethanolamine (DSPE), 1,2-
dioleoyl-sn-glycero-3-phosphoethanolamine (DOPE), 1,2-dilinoleoyl-sn-glycero-3- phosphocholine (DLPc), 1,2-dimyristoyl-sn-gly cero-phosphocholine (DMPC), 1,2-dioleoyl-sn- glycero-3-phosphocholine (DOPC), l,2-dipalmitoyl-sn-glycero-3-phosphocholine (DPPC), 1,2- diundecanoyl-sn-glycero-phosphocholine (DUPC), 1-palmitoyl-2-oleoyl-sn-glycero-3- phosphocholine (POPC), 1,2-di-O-octadecenyl-sn-glycero-3-phosphocholine (18:0 Diether PC), 1-oleoyl-2 cholesterylhemisuccinoyl-sn-glycero-3-phosphocholine (OChemsPC), 1-hexadecyl- sn-glycero-3-phosphocholine (C16 Lyso PC), 1,2-dilinolenoyl-sn-glycero-3-phosphocholine,1,2- diarachidonoyl-sn-glycero-3-phosphocholine, 1,2-didocosahexaenoyl-sn-glycero-3- phosphocholine, 1,2-diphytanoyl-sn-glycero-3-phosphoethanolamine (ME 16.0 PE), 1,2- distearoyl-sn-glycero-3-phosphoethanolamine, 1,2-dilinoleoyl-sn-glycero-3- phosphoethanolamine, 1,2-dilinolenoyl-sn-glycero-3-phosphoethanolamine, 1,2-diarachidonoyl- sn-glycero-3-phosphoethanolamine, 1,2-didocosahexaenoyl-sn-glycero-3-phosphoethanolamine, 1,2-dioleoyl-sn-glycero-3-phospho-rac-(1-glycerol) sodium salt (DOPG), sphingomyelin, or mixtures thereof. Formula (HI) In certain embodiments, a phospholipid is an analog or variant of DSPC. In certain embodiments, a phospholipid is a compound of Formula (HI):
 or a salt thereof, wherein: each R1 is independently optionally substituted alkyl; or optionally two R1 are joined together with the intervening atoms to form optionally substituted monocyclic carbocyclyl or optionally substituted monocyclic heterocyclyl; or optionally three R1 are joined together with the intervening atoms to form optionally substituted bicyclic carbocyclyl or optionally substitute bicyclic heterocyclyl; n is 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10; m is 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10; A is of the formula:
or a salt thereof, wherein: each R1 is independently optionally substituted alkyl; or optionally two R1 are joined together with the intervening atoms to form optionally substituted monocyclic carbocyclyl or optionally substituted monocyclic heterocyclyl; or optionally three R1 are joined together with the intervening atoms to form optionally substituted bicyclic carbocyclyl or optionally substitute bicyclic heterocyclyl; n is 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10; m is 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10; A is of the formula:
 each instance of L2 is independently a bond or optionally substituted C1-6 alkylene, wherein one methylene unit of the optionally substituted C1-6 alkylene is optionally replaced with O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), OC(O)O, OC(O)N(RN), - NRNC(O)O, or NRNC(O)N(RN);
each instance of R2 is independently optionally substituted C1-30 alkyl, optionally substituted C1-30 alkenyl, or optionally substituted C1-30 alkynyl; optionally wherein one or more methylene units of R2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(RN), O, S, C(O), C(O)N(RN), NRNC(O), NRNC(O)N(RN), C(O)O, OC(O), - OC(O)O, OC(O)N(RN), NRNC(O)O, C(O)S, SC(O), C(=NRN), C(=NRN)N(RN), NRNC(=NRN), NRNC(=NRN)N(RN), C(S), C(S)N(RN), NRNC(S), NRNC(S)N(RN), S(O), OS(O), S(O)O, - OS(O)O, OS(O)2, S(O)2O, OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, S(O)2, N(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or - N(RN)S(O)2O; each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group; Ring B is optionally substituted carbocyclyl, optionally substituted heterocyclyl, optionally substituted aryl, or optionally substituted heteroaryl; and p is 1 or 2. In certain embodiments, the compound is not of the formula:
each instance of L2 is independently a bond or optionally substituted C1-6 alkylene, wherein one methylene unit of the optionally substituted C1-6 alkylene is optionally replaced with O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), OC(O)O, OC(O)N(RN), - NRNC(O)O, or NRNC(O)N(RN);
each instance of R2 is independently optionally substituted C1-30 alkyl, optionally substituted C1-30 alkenyl, or optionally substituted C1-30 alkynyl; optionally wherein one or more methylene units of R2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(RN), O, S, C(O), C(O)N(RN), NRNC(O), NRNC(O)N(RN), C(O)O, OC(O), - OC(O)O, OC(O)N(RN), NRNC(O)O, C(O)S, SC(O), C(=NRN), C(=NRN)N(RN), NRNC(=NRN), NRNC(=NRN)N(RN), C(S), C(S)N(RN), NRNC(S), NRNC(S)N(RN), S(O), OS(O), S(O)O, - OS(O)O, OS(O)2, S(O)2O, OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, S(O)2, N(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or - N(RN)S(O)2O; each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group; Ring B is optionally substituted carbocyclyl, optionally substituted heterocyclyl, optionally substituted aryl, or optionally substituted heteroaryl; and p is 1 or 2. In certain embodiments, the compound is not of the formula:
 , wherein each instance of R2 is independently unsubstituted alkyl, unsubstituted alkenyl, or unsubstituted alkynyl. In some embodiments, the phospholipids may be one or more of the phospholipids described in PCT Application No. PCT/US2018/037922. In some embodiments, the lipid nanoparticle comprises a molar ratio of 5-25% non- cationic lipid relative to the other lipid components. For example, the lipid nanoparticle may comprise a molar ratio of 5-30%, 5-15%, 5-10%, 10-25%, 10-20%, 10-25%, 15-25%, 15-20%, 20-25%, or 25-30% non-cationic lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 5%, 10%, 15%, 20%, 25%, or 30% non-cationic lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 5-25% phospholipid relative to the other lipid components. For example, the lipid nanoparticle may comprise a molar ratio of 5-30%, 5-15%, 5-10%, 10-25%, 10-20%, 10-25%, 15-25%, 15-20%, 20-25%, or 25-30% phospholipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 5%, 10%, 15%, 20%, 25%, or 30% phospholipid lipid.
Structural lipids The lipid composition of a pharmaceutical composition can comprise one or more structural lipids. As used herein, the term “structural lipid” includes sterols and also to lipids containing sterol moieties. Incorporation of structural lipids in the lipid nanoparticle may help mitigate aggregation of other lipids in the particle. Structural lipids can be selected from the group including but not limited to, cholesterol, fecosterol, sitosterol, ergosterol, campesterol, stigmasterol, brassicasterol, tomatidine, tomatine, ursolic acid, alpha-tocopherol, hopanoids, phytosterols, steroids, and mixtures thereof. In some embodiments, the structural lipid is a sterol. As defined herein, “sterols” are a subgroup of steroids consisting of steroid alcohols. In certain embodiments, the structural lipid is a steroid. In certain embodiments, the structural lipid is cholesterol. In certain embodiments, the structural lipid is an analog of cholesterol. In certain embodiments, the structural lipid is alpha-tocopherol. In some embodiments, the structural lipids may be one or more of the structural lipids described in U.S. Application No.16/493,814. In some embodiments, the lipid nanoparticle comprises a molar ratio of 25-55% structural lipid relative to the other lipid components. For example, the lipid nanoparticle may comprise a molar ratio of 10-55%, 25-50%, 25-45%, 25-40%, 25-35%, 25-30%, 30-55%, 30- 50%, 30-45%, 30-40%, 30-35%, 35-55%, 35-50%, 35-45%, 35-40%, 40-55%, 40-50%, 40-45%, 45-55%, 45-50%, or 50-55% structural lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, or 55% structural lipid. In some embodiments, the lipid nanoparticle comprises 30-45 mol% sterol, optionally 35-40 mol%, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol%, 34-35 mol%, 35-36 mol%, 36-37 mol%, 37-38 mol%, 38-39 mol%, or 39-40 mol%. In some embodiments, the lipid nanoparticle comprises 25-55 mol% sterol. For example, the lipid nanoparticle may comprise 25-50 mol%, 25-45 mol%, 25-40 mol%, 25-35 mol%, 25-30 mol%, 30-55 mol%, 30- 50 mol%, 30-45 mol%, 30-40 mol%, 30-35 mol%, 35-55 mol%, 35-50 mol%, 35-45 mol%, 35- 40 mol%, 40-55 mol%, 40-50 mol%, 40-45 mol%, 45-55 mol%, 45-50 mol%, or 50-55 mol% sterol. In some embodiments, the lipid nanoparticle comprises 25 mol%, 30 mol%, 35 mol%, 40 mol%, 45 mol%, 50 mol%, or 55 mol% sterol. In some embodiments, the lipid nanoparticle comprises 35 – 40 mol% cholesterol. For example, the lipid nanoparticle may comprise 35, 35.5, 36, 36.5, 37, 37.5, 38, 38.5, 39, 39.5, or 40 mol% cholesterol.
Polyethylene glycol (PEG)-Lipids The lipid composition of a pharmaceutical composition can comprise one or more polyethylene glycol (PEG)-modified lipids. As used herein, the term “PEG-lipid” or “PEG-modified lipid” refers to polyethylene glycol (PEG)-modified lipids. Non-limiting examples of PEG-modified lipids include PEG- modified phosphatidylethanolamine and phosphatidic acid, PEG-ceramide conjugates (e.g., PEG-CerC14 or PEG-CerC20), PEG-modified dialkylamines, and PEG-modified 1,2- diacyloxypropan-3-amines. Such lipids are also referred to as PEGylated lipids. For example, a PEG-modified lipid can be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid. In some embodiments, the PEG-modified lipid includes, but not limited to 1,2- dimyristoyl-sn-glycerol methoxypolyethylene glycol (PEG-DMG), 1,2-distearoyl-sn-glycero-3- phosphoethanolamine-N-[amino(polyethylene glycol)] (PEG-DSPE), PEG-disteryl glycerol (PEG-DSG), PEG-dipalmetoleyl, PEG-dioleyl, PEG-distearyl, PEG-diacylglycamide (PEG- DAG), PEG-dipalmitoyl phosphatidylethanolamine (PEG-DPPE), or PEG-l,2- dimyristyloxlpropyl-3-amine (PEG-c-DMA). In some embodiments, the PEG-modified lipid is selected from the group consisting of a PEG-modified phosphatidylethanolamine, a PEG-modified phosphatidic acid, a PEG-modified ceramide, a PEG-modified dialkylamine, a PEG-modified diacylglycerol, a PEG-modified dialkylglycerol, and mixtures thereof. In some embodiments, the PEG-modified lipid is PEG- DMG, PEG-c-DOMG (also referred to as PEG-DOMG), PEG-DSG, and/or PEG-DPG. In some embodiments, the lipid moiety of the PEG-modified lipids includes those having lengths of from about C14 to about C22, preferably from about C14 to about C16. In some embodiments, a PEG moiety, for example an mPEG-NH2, has a size of about 1000, 2000, 5000, 10,000, 15,000 or 20,000 daltons. In some embodiments, the PEG-modified lipid is PEG2k- DMG. In some embodiments, lipid nanoparticles can comprise a PEG-modified lipid which is a non-diffusible PEG. Non-limiting examples of non-diffusible PEGs include PEG-DSG and PEG-DSPE. PEG-modified lipids are known in the art, such as those described in U.S. Patent No. 8158601 and International Publ. No. WO 2015/130584 A2, which are incorporated herein by reference to the extent they describe PEG-modified lipids. In general, some of the other lipid components (e.g., PEG-modified lipids) of various formulae may be synthesized as described International Patent Application No. PCT/US2016/000129, filed December 10, 2016, entitled “Compositions and Methods for
Delivery of Therapeutic Agents,” which is incorporated by reference to the extent they disclose lipid components and production. The lipid component of a lipid nanoparticle composition may include one or more molecules comprising polyethylene glycol, such as PEG or PEG-modified lipids. Such species may be alternately referred to as PEGylated lipids. A PEG-modified lipid is a lipid modified with polyethylene glycol. A PEG-modified lipid may be selected from the non-limiting group including PEG-modified phosphatidylethanolamines, PEG-modified phosphatidic acids, PEG- modified ceramides, PEG-modified dialkylamines, PEG-modified diacylglycerols, PEG- modified dialkylglycerols, and mixtures thereof. For example, a PEG-modified lipid may be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid. In some embodiments the PEG-modified lipids are a modified form of PEG DMG. PEG- DMG has the following structure:
, wherein each instance of R2 is independently unsubstituted alkyl, unsubstituted alkenyl, or unsubstituted alkynyl. In some embodiments, the phospholipids may be one or more of the phospholipids described in PCT Application No. PCT/US2018/037922. In some embodiments, the lipid nanoparticle comprises a molar ratio of 5-25% non- cationic lipid relative to the other lipid components. For example, the lipid nanoparticle may comprise a molar ratio of 5-30%, 5-15%, 5-10%, 10-25%, 10-20%, 10-25%, 15-25%, 15-20%, 20-25%, or 25-30% non-cationic lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 5%, 10%, 15%, 20%, 25%, or 30% non-cationic lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 5-25% phospholipid relative to the other lipid components. For example, the lipid nanoparticle may comprise a molar ratio of 5-30%, 5-15%, 5-10%, 10-25%, 10-20%, 10-25%, 15-25%, 15-20%, 20-25%, or 25-30% phospholipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 5%, 10%, 15%, 20%, 25%, or 30% phospholipid lipid.
Structural lipids The lipid composition of a pharmaceutical composition can comprise one or more structural lipids. As used herein, the term “structural lipid” includes sterols and also to lipids containing sterol moieties. Incorporation of structural lipids in the lipid nanoparticle may help mitigate aggregation of other lipids in the particle. Structural lipids can be selected from the group including but not limited to, cholesterol, fecosterol, sitosterol, ergosterol, campesterol, stigmasterol, brassicasterol, tomatidine, tomatine, ursolic acid, alpha-tocopherol, hopanoids, phytosterols, steroids, and mixtures thereof. In some embodiments, the structural lipid is a sterol. As defined herein, “sterols” are a subgroup of steroids consisting of steroid alcohols. In certain embodiments, the structural lipid is a steroid. In certain embodiments, the structural lipid is cholesterol. In certain embodiments, the structural lipid is an analog of cholesterol. In certain embodiments, the structural lipid is alpha-tocopherol. In some embodiments, the structural lipids may be one or more of the structural lipids described in U.S. Application No.16/493,814. In some embodiments, the lipid nanoparticle comprises a molar ratio of 25-55% structural lipid relative to the other lipid components. For example, the lipid nanoparticle may comprise a molar ratio of 10-55%, 25-50%, 25-45%, 25-40%, 25-35%, 25-30%, 30-55%, 30- 50%, 30-45%, 30-40%, 30-35%, 35-55%, 35-50%, 35-45%, 35-40%, 40-55%, 40-50%, 40-45%, 45-55%, 45-50%, or 50-55% structural lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, or 55% structural lipid. In some embodiments, the lipid nanoparticle comprises 30-45 mol% sterol, optionally 35-40 mol%, for example, 30-31 mol%, 31-32 mol%, 32-33 mol%, 33-34 mol%, 34-35 mol%, 35-36 mol%, 36-37 mol%, 37-38 mol%, 38-39 mol%, or 39-40 mol%. In some embodiments, the lipid nanoparticle comprises 25-55 mol% sterol. For example, the lipid nanoparticle may comprise 25-50 mol%, 25-45 mol%, 25-40 mol%, 25-35 mol%, 25-30 mol%, 30-55 mol%, 30- 50 mol%, 30-45 mol%, 30-40 mol%, 30-35 mol%, 35-55 mol%, 35-50 mol%, 35-45 mol%, 35- 40 mol%, 40-55 mol%, 40-50 mol%, 40-45 mol%, 45-55 mol%, 45-50 mol%, or 50-55 mol% sterol. In some embodiments, the lipid nanoparticle comprises 25 mol%, 30 mol%, 35 mol%, 40 mol%, 45 mol%, 50 mol%, or 55 mol% sterol. In some embodiments, the lipid nanoparticle comprises 35 – 40 mol% cholesterol. For example, the lipid nanoparticle may comprise 35, 35.5, 36, 36.5, 37, 37.5, 38, 38.5, 39, 39.5, or 40 mol% cholesterol.
Polyethylene glycol (PEG)-Lipids The lipid composition of a pharmaceutical composition can comprise one or more polyethylene glycol (PEG)-modified lipids. As used herein, the term “PEG-lipid” or “PEG-modified lipid” refers to polyethylene glycol (PEG)-modified lipids. Non-limiting examples of PEG-modified lipids include PEG- modified phosphatidylethanolamine and phosphatidic acid, PEG-ceramide conjugates (e.g., PEG-CerC14 or PEG-CerC20), PEG-modified dialkylamines, and PEG-modified 1,2- diacyloxypropan-3-amines. Such lipids are also referred to as PEGylated lipids. For example, a PEG-modified lipid can be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid. In some embodiments, the PEG-modified lipid includes, but not limited to 1,2- dimyristoyl-sn-glycerol methoxypolyethylene glycol (PEG-DMG), 1,2-distearoyl-sn-glycero-3- phosphoethanolamine-N-[amino(polyethylene glycol)] (PEG-DSPE), PEG-disteryl glycerol (PEG-DSG), PEG-dipalmetoleyl, PEG-dioleyl, PEG-distearyl, PEG-diacylglycamide (PEG- DAG), PEG-dipalmitoyl phosphatidylethanolamine (PEG-DPPE), or PEG-l,2- dimyristyloxlpropyl-3-amine (PEG-c-DMA). In some embodiments, the PEG-modified lipid is selected from the group consisting of a PEG-modified phosphatidylethanolamine, a PEG-modified phosphatidic acid, a PEG-modified ceramide, a PEG-modified dialkylamine, a PEG-modified diacylglycerol, a PEG-modified dialkylglycerol, and mixtures thereof. In some embodiments, the PEG-modified lipid is PEG- DMG, PEG-c-DOMG (also referred to as PEG-DOMG), PEG-DSG, and/or PEG-DPG. In some embodiments, the lipid moiety of the PEG-modified lipids includes those having lengths of from about C14 to about C22, preferably from about C14 to about C16. In some embodiments, a PEG moiety, for example an mPEG-NH2, has a size of about 1000, 2000, 5000, 10,000, 15,000 or 20,000 daltons. In some embodiments, the PEG-modified lipid is PEG2k- DMG. In some embodiments, lipid nanoparticles can comprise a PEG-modified lipid which is a non-diffusible PEG. Non-limiting examples of non-diffusible PEGs include PEG-DSG and PEG-DSPE. PEG-modified lipids are known in the art, such as those described in U.S. Patent No. 8158601 and International Publ. No. WO 2015/130584 A2, which are incorporated herein by reference to the extent they describe PEG-modified lipids. In general, some of the other lipid components (e.g., PEG-modified lipids) of various formulae may be synthesized as described International Patent Application No. PCT/US2016/000129, filed December 10, 2016, entitled “Compositions and Methods for
Delivery of Therapeutic Agents,” which is incorporated by reference to the extent they disclose lipid components and production. The lipid component of a lipid nanoparticle composition may include one or more molecules comprising polyethylene glycol, such as PEG or PEG-modified lipids. Such species may be alternately referred to as PEGylated lipids. A PEG-modified lipid is a lipid modified with polyethylene glycol. A PEG-modified lipid may be selected from the non-limiting group including PEG-modified phosphatidylethanolamines, PEG-modified phosphatidic acids, PEG- modified ceramides, PEG-modified dialkylamines, PEG-modified diacylglycerols, PEG- modified dialkylglycerols, and mixtures thereof. For example, a PEG-modified lipid may be PEG-c-DOMG, PEG-DMG, PEG-DLPE, PEG-DMPE, PEG-DPPC, or a PEG-DSPE lipid. In some embodiments the PEG-modified lipids are a modified form of PEG DMG. PEG- DMG has the following structure:
 In some embodiments, PEG-modified lipids can be PEGylated lipids described in International Publication No. WO 2012/099755, which is herein incorporated by reference to the extent it discloses PEG-modified lipids. Any of these exemplary PEG-modified lipids may be modified to comprise a hydroxyl group on the PEG chain. In certain embodiments, the PEG- modified lipid is a PEG-OH lipid. As generally defined herein, a “PEG-OH lipid” (also referred to herein as “hydroxy-PEGylated lipid”) is a PEGylated lipid having one or more hydroxyl (– OH) groups on the lipid. In certain embodiments, the PEG-OH lipid includes one or more hydroxyl groups on the PEG chain. In certain embodiments, a PEG-OH or hydroxy-PEGylated lipid comprises an –OH group at the terminus of the PEG chain. Each possibility represents a separate embodiment. Formula (PI) In certain embodiments, a PEG-modified lipid is a compound of Formula (PI):
In some embodiments, PEG-modified lipids can be PEGylated lipids described in International Publication No. WO 2012/099755, which is herein incorporated by reference to the extent it discloses PEG-modified lipids. Any of these exemplary PEG-modified lipids may be modified to comprise a hydroxyl group on the PEG chain. In certain embodiments, the PEG- modified lipid is a PEG-OH lipid. As generally defined herein, a “PEG-OH lipid” (also referred to herein as “hydroxy-PEGylated lipid”) is a PEGylated lipid having one or more hydroxyl (– OH) groups on the lipid. In certain embodiments, the PEG-OH lipid includes one or more hydroxyl groups on the PEG chain. In certain embodiments, a PEG-OH or hydroxy-PEGylated lipid comprises an –OH group at the terminus of the PEG chain. Each possibility represents a separate embodiment. Formula (PI) In certain embodiments, a PEG-modified lipid is a compound of Formula (PI):
 or salts thereof, wherein: R3 is –ORO; RO is hydrogen, optionally substituted alkyl, or an oxygen protecting group; r is an integer between 1 and 100, inclusive;
L1 is optionally substituted C1-10 alkylene, wherein at least one methylene of the optionally substituted C1-10 alkylene is independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), OC(O)O, OC(O)N(RN), NRNC(O)O, or NRNC(O)N(RN); D is a moiety obtained by click chemistry or a moiety cleavable under physiological conditions; m is 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10; A is of the formula:
or salts thereof, wherein: R3 is –ORO; RO is hydrogen, optionally substituted alkyl, or an oxygen protecting group; r is an integer between 1 and 100, inclusive;
L1 is optionally substituted C1-10 alkylene, wherein at least one methylene of the optionally substituted C1-10 alkylene is independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), OC(O)O, OC(O)N(RN), NRNC(O)O, or NRNC(O)N(RN); D is a moiety obtained by click chemistry or a moiety cleavable under physiological conditions; m is 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10; A is of the formula:
 each instance of L2 is independently a bond or optionally substituted C1-6 alkylene, wherein one methylene unit of the optionally substituted C1-6 alkylene is optionally replaced with O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), OC(O)O, OC(O)N(RN), - NRNC(O)O, or NRNC(O)N(RN); each instance of R2 is independently optionally substituted C1-30 alkyl, optionally substituted C1-30 alkenyl, or optionally substituted C1-30 alkynyl; optionally wherein one or more methylene units of R2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(RN), O, S, C(O), C(O)N(RN), NRNC(O), NRNC(O)N(RN), C(O)O, OC(O), - OC(O)O, OC(O)N(RN), NRNC(O)O, C(O)S, SC(O), C(=NRN), C(=NRN)N(RN), NRNC(=NRN), NRNC(=NRN)N(RN), C(S), C(S)N(RN), NRNC(S), NRNC(S)N(RN), S(O) , OS(O), S(O)O, - OS(O)O, OS(O)2, S(O)2O, OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, S(O)2, N(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or - N(RN)S(O)2O; each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group; Ring B is optionally substituted carbocyclyl, optionally substituted heterocyclyl, optionally substituted aryl, or optionally substituted heteroaryl; and p is 1 or 2. In certain embodiments, the compound of Fomula (PI) is a PEG-OH lipid (i.e., R3 is – ORO, and RO is hydrogen). In certain embodiments, the compound of Formula (PI) is of Formula (PI-OH):
each instance of L2 is independently a bond or optionally substituted C1-6 alkylene, wherein one methylene unit of the optionally substituted C1-6 alkylene is optionally replaced with O, N(RN), S, C(O), C(O)N(RN), NRNC(O), C(O)O, OC(O), OC(O)O, OC(O)N(RN), - NRNC(O)O, or NRNC(O)N(RN); each instance of R2 is independently optionally substituted C1-30 alkyl, optionally substituted C1-30 alkenyl, or optionally substituted C1-30 alkynyl; optionally wherein one or more methylene units of R2 are independently replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(RN), O, S, C(O), C(O)N(RN), NRNC(O), NRNC(O)N(RN), C(O)O, OC(O), - OC(O)O, OC(O)N(RN), NRNC(O)O, C(O)S, SC(O), C(=NRN), C(=NRN)N(RN), NRNC(=NRN), NRNC(=NRN)N(RN), C(S), C(S)N(RN), NRNC(S), NRNC(S)N(RN), S(O) , OS(O), S(O)O, - OS(O)O, OS(O)2, S(O)2O, OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, S(O)2, N(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or - N(RN)S(O)2O; each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group; Ring B is optionally substituted carbocyclyl, optionally substituted heterocyclyl, optionally substituted aryl, or optionally substituted heteroaryl; and p is 1 or 2. In certain embodiments, the compound of Fomula (PI) is a PEG-OH lipid (i.e., R3 is – ORO, and RO is hydrogen). In certain embodiments, the compound of Formula (PI) is of Formula (PI-OH):
 (PI-OH),
or a salt thereof. Formula (PII) In certain embodiments, a PEG-modified lipid is a PEGylated fatty acid. In certain embodiments, a PEG-modified lipid is a compound of Formula (PII). In some embodiments, compounds of Formula (PII) have the following formula:
(PI-OH),
or a salt thereof. Formula (PII) In certain embodiments, a PEG-modified lipid is a PEGylated fatty acid. In certain embodiments, a PEG-modified lipid is a compound of Formula (PII). In some embodiments, compounds of Formula (PII) have the following formula:
 or a salts thereof, wherein: R3 is–ORO; RO is hydrogen, optionally substituted alkyl or an oxygen protecting group; r is an integer between 1 and 100, inclusive; R5 is optionally substituted C10-40 alkyl, optionally substituted C10-40 alkenyl, or optionally substituted C10-40 alkynyl; and optionally one or more methylene groups of R5 are replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(RN), O, S, C(O), - C(O)N(RN), NRNC(O), NRNC(O)N(RN), C(O)O, OC(O), OC(O)O, OC(O)N(RN), NRNC(O)O, C(O)S, SC(O), C(=NRN), C(=NRN)N(RN), NRNC(=NRN), NRNC(=NRN)N(RN), C(S), - C(S)N(RN), NRNC(S), NRNC(S)N(RN), S(O), OS(O), S(O)O, OS(O)O, OS(O)2, S(O)2O, - OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, s(O)2, - n(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or N(RN)S(O)2O; and each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group. In certain embodiments, the compound of Formula (PII) is of Formula (PII-OH):
or a salts thereof, wherein: R3 is–ORO; RO is hydrogen, optionally substituted alkyl or an oxygen protecting group; r is an integer between 1 and 100, inclusive; R5 is optionally substituted C10-40 alkyl, optionally substituted C10-40 alkenyl, or optionally substituted C10-40 alkynyl; and optionally one or more methylene groups of R5 are replaced with optionally substituted carbocyclylene, optionally substituted heterocyclylene, optionally substituted arylene, optionally substituted heteroarylene, N(RN), O, S, C(O), - C(O)N(RN), NRNC(O), NRNC(O)N(RN), C(O)O, OC(O), OC(O)O, OC(O)N(RN), NRNC(O)O, C(O)S, SC(O), C(=NRN), C(=NRN)N(RN), NRNC(=NRN), NRNC(=NRN)N(RN), C(S), - C(S)N(RN), NRNC(S), NRNC(S)N(RN), S(O), OS(O), S(O)O, OS(O)O, OS(O)2, S(O)2O, - OS(O)2O, N(RN)S(O), S(O)N(RN), N(RN)S(O)N(RN), OS(O)N(RN), N(RN)S(O)O, s(O)2, - n(RN)S(O)2, S(O)2N(RN), N(RN)S(O)2N(RN), OS(O)2N(RN), or N(RN)S(O)2O; and each instance of RN is independently hydrogen, optionally substituted alkyl, or a nitrogen protecting group. In certain embodiments, the compound of Formula (PII) is of Formula (PII-OH):
 or a salt thereof. In some embodiments, r is 40-50. In yet other embodiments the compound of Formula (PII) is:
or a salt thereof. In some embodiments, r is 40-50. In yet other embodiments the compound of Formula (PII) is:
 . or a salt thereof. In some embodiments, the compound of Formula (PII) is
. In some embodiments, the lipid composition of the pharmaceutical composition does not comprise a PEG-modified lipid. In some embodiments, the PEG-modified lipids may be one or more of the PEG- modified lipids described in U.S. Application No.15/674,872. In some embodiments, the lipid nanoparticle comprises a molar ratio of 0.5-15% PEG- modified lipid relative to the other lipid components. For example, the lipid nanoparticle may comprise a molar ratio of 0.5-10%, 0.5-5%, 1-15%, 1-10%, 1-5%, 2-15%, 2-10%, 2-5%, 5-15%, 5-10%, or 10-15% PEG-modified lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, or 15% PEG-modified lipid. In some embodiments, the lipid nanoparticle comprises 1-5% PEG-modified lipid, optionally 1-3 mol%, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol%. In some embodiments, the lipid nanoparticle comprises 0.5-15 mol% PEG-modified lipid. For example, the lipid nanoparticle may comprise 0.5-10 mol%, 0.5-5 mol%, 1-15 mol%, 1-10 mol%, 1-5 mol%, 2-15 mol%, 2-10 mol%, 2-5 mol%, 5-15 mol%, 5-10 mol%, or 10-15 mol%. In some embodiments, the lipid nanoparticle comprises 0.5 mol%, 1 mol%, 2 mol%, 3 mol%, 4 mol%, 5 mol%, 6 mol%, 7 mol%, 8 mol%, 9 mol%, 10 mol%, 11 mol%, 12 mol%, 13 mol%, 14 mol%, or 15 mol% PEG-modified lipid. Some embodiments comprise adding PEG to a composition comprising an LNP encapsulating a nucleic acid (e.g., which already includes PEG in the amounts listed above). In embodiments comprise adding about 0.5mo% or more PEG to an LNP composition, such as about 1mol%, about 1.5mol%, about 2mol%, about 2.5mol%, about 3mol%, about 3.5mol%, about 4mol%, about 5mol%, or more after formation of an LNP composition (e.g., which already contains PEG in amount listed elsewhere herein). In some embodiments, a lipid nanoparticle comprises a first PEG-modified lipid in a core of the LNP, and a second PEG-modified lipid outside of the core of the LNP. The first and second PEG-modified lipids of the core and outside the core may the same PEG-modified lipids (i.e., have the same structure), or be different PEG-modified lipids (i.e., have different structures). In some embodiments, both PEG-modified lipids are 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate. In some embodiments, both PEG-modified lipids are PEG-DMG. In some
embodiments, the first PEG-modified lipid is PEG-DMG and the second PEG-modified lipid is 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate. In some embodiments, the first PEG-modified lipid is 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate and the second PEG-modified lipid is PEG-DMG. In some embodiments, 0.25 mol% to 1.0 mol% (as a percentage of lipids in the LNP) of the first PEG-modified lipid is in the core of the lipid nanoparticle. In some embodiments, 0.25 mol% to 0.50 mol% of the first PEG-modified lipid is in the core of the lipid nanoparticle. In some embodiments, 0.25 mol%, 0.50 mol%, 0.75 mol%, or 1.0 mol% of the first PEG-modified lipid is in the core of the LNP. In some embodiments, 2.0 mol% to 2.75 mol% of the second PEG-modified lipid is outside the core of the LNP. In some embodiments, 2.0 mol%, 2.25 mol%, 2.5 mol%, or 2.75 mol% of the second PEG-modified lipid is outside the core of the LNP. In some embodiments, the LNP comprises 3.0 mol% PEG-modified lipids. LNPs having certain amounts of a PEG-modified lipid in the core and certain amounts of a PEG-modified lipid outside of the core, and methods of producing the same, are disclosed in PCT Publication No. WO 2023/018773, which is incorporated by reference herein to the extent it discloses lipid nanoparticles and methods of producing lipid nanoparticles. In some embodiments, the lipid nanoparticle comprises 20-60 mol% ionizable lipid, 5-25 mol% non-cationic lipid, 25-55 mol% sterol, and 0.5-15 mol% PEG-modified lipid. In some embodiments, a LNP comprises an ionizable lipid of Compound (I-18), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (I-18), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of Compound (I-25), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (I-25), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of Compound (I-301), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG- modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (I-301), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG- PEG.
In some embodiments, a LNP comprises an ionizable lipid of Compound (II-6), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (II-6), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of Compound (IL**), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (IL**), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of any of Formula (IL*), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising PEG- DMG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5- 25 mol% phospholipid comprising DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG- modified lipid comprising DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of any of Formula (IL*), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid comprising DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises an ionizable lipid of Formula (IL*), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG- modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG- modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises an ionizable lipid of Formula (IL*), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG- modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG- modified lipid modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises an ionizable lipid of Formula (IL*), a phospholipid having Formula (HI), a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII).
In some embodiments, a LNP comprises an ionizable amino lipid of Compound 1, wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG- modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound 1, 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% PEG-modified lipid DMG-PEG. In some embodiments, a LNP comprises an ionizable amino lipid of Compound 2, wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG- modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound 2, 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% PEG-modified lipid DMG-PEG. In some embodiments, a LNP comprises an ionizable amino lipid of any of Formula (AIII), (AIV), or (AV), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising PEG-DMG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of any of Formula (AIII), (AIV), or (AV), 5-25 mol% DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising DMG-PEG. In some embodiments, a LNP comprises an ionizable amino lipid of any of Formula (AIII), (AIV), or (AV), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises 20- 60 mol% ionizable lipid of any of Formula (AIII), (AIV), or (AV), 5-25 mol% DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises an ionizable amino lipid of Formula (AIII), (AIV), or (AV), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG-modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (AIII), (AIV), or (AV), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises an ionizable amino lipid of Formula (AIII), (AIV), or (AV), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG-modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (AIII), (AIV), or (AV), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises an ionizable amino lipid of Formula (AIII), (AIV), or (AV), a phospholipid having Formula (HI), a structural lipid, and a PEG-modified
lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises 20- 60 mol% ionizable lipid of Formula (AIII), (AIV), or (AV), 5-25 mol% phospholipid having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, the lipid nanoparticle comprises 49 mol% ionizable lipid, 10 mol% DSPC, 38.5 mol% cholesterol, and 2.5 mol% DMG-PEG. In some embodiments, the lipid nanoparticle comprises 49 mol% ionizable lipid, 11 mol% DSPC, 38.5 mol% cholesterol, and 1.5 mol% DMG-PEG. In some embodiments, the lipid nanoparticle comprises 48 mol% ionizable lipid, 11 mol% DSPC, 38.5 mol% cholesterol, and 2.5 mol% DMG-PEG. In some embodiments, a LNP comprises an N:P ratio of from about 2:1 to about 30:1. In some embodiments, a LNP comprises an N:P ratio of about 6:1. In some embodiments, a LNP comprises an N:P ratio of about 3:1, 4:1, or 5:1. In some embodiments, a LNP comprises a wt/wt ratio of the ionizable lipid component to the RNA of from about 10:1 to about 100:1. In some embodiments, a LNP comprises a wt/wt ratio of the ionizable lipid component to the RNA of about 20:1. In some embodiments, a LNP comprises a wt/wt ratio of the ionizable lipid component to the RNA of about 10:1. Some embodiments comprise a composition having one or more LNPs having a diameter of about 150 nm or less, such as about 140 nm, 130 nm, 120 nm, 110 nm, 100 nm, 90 nm, 80 nm, 70 nm, 60 nm, 50 nm, 40 nm, 30 nm, or 20 nm or less. Some embodiments comprise a composition having a mean LNP diameter of about 150 nm or less, such as about 140 nm, 130 nm, 120 nm, 110 nm, 100 nm, 90 nm, 80 nm, 70 nm, 60 nm, 50 nm, 40 nm, 30 nm, or 20 nm or less. In some embodiments, the composition has a mean LNP diameter from about 30nm to about 150nm, or a mean diameter from about 60nm to about 120nm. In some embodiments, an LNP further comprises one or more cargo molecules, including but not limited to nucleic acids (e.g., circular RNA, mRNA, plasmid DNA, DNA or RNA oligonucleotides, siRNA, shRNA, snRNA, snoRNA, lncRNA, etc.), small molecules, proteins and peptides. Effective in vivo delivery of nucleic acids represents a continuing medical challenge. Exogenous nucleic acids (i.e., originating from outside of a cell or organism) are readily degraded in the body, e.g., by the immune system. Accordingly, effective delivery of nucleic acids to cells often requires the use of a particulate carrier (e.g., lipid nanoparticles). The particulate carrier should be formulated to have minimal particle aggregation, be relatively
stable prior to intracellular delivery, effectively deliver nucleic acids intracellularly, and illicit no or minimal immune response. To achieve minimal particle aggregation and pre-delivery stability, many conventional particulate carriers have relied on the presence and/or concentration of certain components (e.g., PEG-modified lipid). However, it has been discovered that certain components may decrease the stability of encapsulated nucleic acids (e.g., circular RNA molecules). The reduced stability may limit the broad applicability of the particulate carriers. As such, there remains a need for methods by which to improve the stability of nucleic acid (e.g., circular RNA) encapsulated within lipid nanoparticles. In some embodiments, a LNP comprises one or more ionizable molecules (e.g., amino lipids or ionizable lipids). The ionizable molecule may comprise a charged group and may have a certain pKa. In certain embodiments, the pKa of the ionizable molecule may be greater than or equal to about 6, greater than or equal to about 6.2, greater than or equal to about 6.5, greater than or equal to about 6.8, greater than or equal to about 7, greater than or equal to about 7.2, greater than or equal to about 7.5, greater than or equal to about 7.8, greater than or equal to about 8. In some embodiments, the pKa of the ionizable molecule may be less than or equal to about 10, less than or equal to about 9.8, less than or equal to about 9.5, less than or equal to about 9.2, less than or equal to about 9.0, less than or equal to about 8.8, or less than or equal to about 8.5. Combinations of the above referenced ranges are also possible (e.g., greater than or equal to 6 and less than or equal to about 8.5). Other ranges are also possible. In embodiments in which more than one type of ionizable molecule are present in a particle, each type of ionizable molecule may independently have a pKa in one or more of the ranges described above. In general, an ionizable molecule comprises one or more charged groups. In some embodiments, an ionizable molecule may be positively charged or negatively charged. For instance, an ionizable molecule may be positively charged. For example, an ionizable molecule may comprise an amine group. As used herein, the term “ionizable molecule” has its ordinary meaning in the art and may refer to a molecule or matrix comprising one or more charged moiety. As used herein, a “charged moiety” is a chemical moiety that carries a formal electronic charge, e.g., monovalent (+1, or -1), divalent (+2, or -2), trivalent (+3, or -3), etc. The charged moiety may be anionic (i.e., negatively charged) or cationic (i.e., positively charged). Examples of positively-charged moieties include amine groups (e.g., primary, secondary, and/or tertiary amines), ammonium groups, pyridinium group, guanidine groups, and imidizolium groups. In a particular embodiment, the charged moieties comprise amine groups. Examples of negatively- charged groups or precursors thereof, include carboxylate groups, sulfonate groups, sulfate groups, phosphonate groups, phosphate groups, hydroxyl groups, and the like. The charge of the charged moiety may vary, in some cases, with the environmental conditions, for example,
changes in pH may alter the charge of the moiety, and/or cause the moiety to become charged or uncharged. In general, the charge density of the molecule and/or matrix may be selected as desired. In some cases, an ionizable molecule (e.g., an amino lipid or ionizable lipid) may include one or more precursor moieties that can be converted to charged moieties. For instance, the ionizable molecule may include a neutral moiety that can be hydrolyzed to form a charged moiety, such as those described above. As a non-limiting specific example, the molecule or matrix may include an amide, which can be hydrolyzed to form an amine, respectively. Those of ordinary skill in the art will be able to determine whether a given chemical moiety carries a formal electronic charge (for example, by inspection, pH titration, ionic conductivity measurements, etc.), and/or whether a given chemical moiety can be reacted (e.g., hydrolyzed) to form a chemical moiety that carries a formal electronic charge. The ionizable molecule (e.g., amino lipid or ionizable lipid) may have any suitable molecular weight. In certain embodiments, the molecular weight of an ionizable molecule is less than or equal to about 2,500 g/mol, less than or equal to about 2,000 g/mol, less than or equal to about 1,500 g/mol, less than or equal to about 1,250 g/mol, less than or equal to about 1,000 g/mol, less than or equal to about 900 g/mol, less than or equal to about 800 g/mol, less than or equal to about 700 g/mol, less than or equal to about 600 g/mol, less than or equal to about 500 g/mol, less than or equal to about 400 g/mol, less than or equal to about 300 g/mol, less than or equal to about 200 g/mol, or less than or equal to about 100 g/mol. In some instances, the molecular weight of an ionizable molecule is greater than or equal to about 100 g/mol, greater than or equal to about 200 g/mol, greater than or equal to about 300 g/mol, greater than or equal to about 400 g/mol, greater than or equal to about 500 g/mol, greater than or equal to about 600 g/mol, greater than or equal to about 700 g/mol, greater than or equal to about 1000 g/mol, greater than or equal to about 1,250 g/mol, greater than or equal to about 1,500 g/mol, greater than or equal to about 1,750 g/mol, greater than or equal to about 2,000 g/mol, or greater than or equal to about 2,250 g/mol. Combinations of the above ranges (e.g., at least about 200 g/mol and less than or equal to about 2,500 g/mol) are also possible. In embodiments in which more than one type of ionizable molecules are present in a particle, each type of ionizable molecule may independently have a molecular weight in one or more of the ranges described above. In some embodiments, the percentage (e.g., by weight, or by mole) of a single type of ionizable molecule (e.g., amino lipid or ionizable lipid) and/or of all the ionizable molecules within a particle may be greater than or equal to about 15%, greater than or equal to about 16%, greater than or equal to about 17%, greater than or equal to about 18%, greater than or equal to about 19%, greater than or equal to about 20%, greater than or equal to about 21%, greater than
or equal to about 22%, greater than or equal to about 23%, greater than or equal to about 24%, greater than or equal to about 25%, greater than or equal to about 30%, greater than or equal to about 35%, greater than or equal to about 40%, greater than or equal to about 42%, greater than or equal to about 45%, greater than or equal to about 48%, greater than or equal to about 50%, greater than or equal to about 52%, greater than or equal to about 55%, greater than or equal to about 58%, greater than or equal to about 60%, greater than or equal to about 62%, greater than or equal to about 65%, or greater than or equal to about 68%. In some instances, the percentage (e.g., by weight, or by mole) may be less than or equal to about 70%, less than or equal to about 68%, less than or equal to about 65%, less than or equal to about 62%, less than or equal to about 60%, less than or equal to about 58%, less than or equal to about 55%, less than or equal to about 52%, less than or equal to about 50%, or less than or equal to about 48%. Combinations of the above referenced ranges are also possible (e.g., greater than or equal to 20% and less than or equal to about 60%, greater than or equal to 40% and less than or equal to about 55%, etc.). In embodiments in which more than one type of ionizable molecule is present in a particle, each type of ionizable molecule may independently have a percentage (e.g., by weight, or by mole) in one or more of the ranges described above. The percentage (e.g., by weight, or by mole) may be determined by extracting the ionizable molecule(s) from the dried particles using, e.g., organic solvents, and measuring the quantity of the agent using high pressure liquid chromatography (i.e., HPLC), liquid chromatography-mass spectrometry (LC-MS), nuclear magnetic resonance (NMR), or mass spectrometry (MS). Those of ordinary skill in the art would be ”knowledgeable of techniques to determine the quantity of a component using the above-referenced techniques. For example, HPLC may be used to quantify the amount of a component, by, e.g., comparing the area under the curve of a HPLC chromatogram to a standard curve. It should be understood that the terms “charged” or “charged moiety” does not refer to a “partial negative charge" or “partial positive charge" on a molecule. The terms “partial negative charge" and “partial positive charge" are given their ordinary meaning in the art. A “partial negative charge" may result when a functional group comprises a bond that becomes polarized such that electron density is pulled toward one atom of the bond, creating a partial negative charge on the atom. Those of ordinary skill in the art will, in general, recognize bonds that can become polarized in this way.In some embodiments, the composition comprises a liposome. A liposome is a lipid particle comprising lipids arranged into one or more concentric lipid bilayers around a central region. The central region of a liposome may comprise an aqueous solution, suspension, or other aqueous composition. In some embodiments, the composition comprises a lipoplex. A lipoplex is a lipid particle comprising a cationic liposome and a nucleic acid (e.g., circular RNA). Lipoplexes may
be formed by contacting a liposome comprising a cationic lipid with a nucleic acid. A lipoplex may comprise multiple concentric lipid bilayers, each concentric bilayer separated by one or more nucleic acids. The central region of the lipoplex may comprise an aqueous solution, suspension, or other aqueous composition. In some embodiments, the composition comprises a lipopolyplex. A lipopolyplex is a lipid particle comprising a lipid bilayer surrounding a complex of a cationic polymer and a nucleic acid (e.g., circular RNA). See Midoux & Pichon, Expert Rev Vaccines.2015.14(2):221– 234. A lipopolyplex may be formed by contacting a cationic liposome (e.g., liposome comprising a cationic lipid) with the complex of nucleic acid and cationic polymer. The central region of the lipopolyplex may comprise an aqueous solution, suspension, or other aqueous composition. In some embodiments, the composition comprises a cationic nanoemulsion. A cationic nanoemulsion comprises a cationic lipid, hydrophilic surfactant, and hydrophobic surfactant. A liposome, lipoplex, lipopolyplex, or cationic nanoemulsion may comprise a sterol. A liposome, lipoplex, lipopolyplex, or cationic nanoemulsion may comprise a neutral lipid. A liposome, lipoplex, lipopolyplex, or cationic nanoemulsion may comprise a PEG-modified lipid. Stabilizing Compounds Some embodiments of compositions are stabilized pharmaceutical compositions. Various non-viral delivery systems, including nanoparticle formulations, present attractive opportunities to overcome many challenges associated with RNA delivery. Lipid nanoparticles (LNPs) have drawn particular attention in recent years as various LNP formulations have shown promise in a variety of pharmaceutical applications. However, lipids have been shown to degrade nucleic acids, including RNA, and lipid nanoparticle formulations undergo rapid loss of purity when stored as refrigerated liquids. Moreover, the storage stability of RNA encapsulated within LNPs is lower than that of unencapsulated RNA. A class of compounds has been found to stabilize nucleic acids within a lipid carrier such as an LNP, an unexpected and unprecedented discovery which enables applications including extended refrigerated liquid shelf-life, extended in-use periods at room temperature, and extended in-use stability at physiological temperatures up to higher temperatures such as 40°C. Such stabilizing compounds solve a critical problem, as current manufacturing processes and formulations experience a 5-10% purity loss during LNP formation and processing that is typical with current large-scale LNP production. In some embodiments, the stabilized pharmaceutical composition comprises a nucleic acid formulation comprising a nucleic acid and a stabilizing compound (e.g., a compound of
Formula (I), of Formula (II), or a tautomer or solvate thereof). In some embodiments, the stabilized pharmaceutical composition comprises a nucleic acid formulation comprising a nucleic acid and a lipid, and a compound of Formula (I):
. or a salt thereof. In some embodiments, the compound of Formula (PII) is
. In some embodiments, the lipid composition of the pharmaceutical composition does not comprise a PEG-modified lipid. In some embodiments, the PEG-modified lipids may be one or more of the PEG- modified lipids described in U.S. Application No.15/674,872. In some embodiments, the lipid nanoparticle comprises a molar ratio of 0.5-15% PEG- modified lipid relative to the other lipid components. For example, the lipid nanoparticle may comprise a molar ratio of 0.5-10%, 0.5-5%, 1-15%, 1-10%, 1-5%, 2-15%, 2-10%, 2-5%, 5-15%, 5-10%, or 10-15% PEG-modified lipid. In some embodiments, the lipid nanoparticle comprises a molar ratio of 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, or 15% PEG-modified lipid. In some embodiments, the lipid nanoparticle comprises 1-5% PEG-modified lipid, optionally 1-3 mol%, for example 1.5 to 2.5 mol%, 1-2 mol%, 2-3 mol%, 3-4 mol%, or 4-5 mol%. In some embodiments, the lipid nanoparticle comprises 0.5-15 mol% PEG-modified lipid. For example, the lipid nanoparticle may comprise 0.5-10 mol%, 0.5-5 mol%, 1-15 mol%, 1-10 mol%, 1-5 mol%, 2-15 mol%, 2-10 mol%, 2-5 mol%, 5-15 mol%, 5-10 mol%, or 10-15 mol%. In some embodiments, the lipid nanoparticle comprises 0.5 mol%, 1 mol%, 2 mol%, 3 mol%, 4 mol%, 5 mol%, 6 mol%, 7 mol%, 8 mol%, 9 mol%, 10 mol%, 11 mol%, 12 mol%, 13 mol%, 14 mol%, or 15 mol% PEG-modified lipid. Some embodiments comprise adding PEG to a composition comprising an LNP encapsulating a nucleic acid (e.g., which already includes PEG in the amounts listed above). In embodiments comprise adding about 0.5mo% or more PEG to an LNP composition, such as about 1mol%, about 1.5mol%, about 2mol%, about 2.5mol%, about 3mol%, about 3.5mol%, about 4mol%, about 5mol%, or more after formation of an LNP composition (e.g., which already contains PEG in amount listed elsewhere herein). In some embodiments, a lipid nanoparticle comprises a first PEG-modified lipid in a core of the LNP, and a second PEG-modified lipid outside of the core of the LNP. The first and second PEG-modified lipids of the core and outside the core may the same PEG-modified lipids (i.e., have the same structure), or be different PEG-modified lipids (i.e., have different structures). In some embodiments, both PEG-modified lipids are 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate. In some embodiments, both PEG-modified lipids are PEG-DMG. In some
embodiments, the first PEG-modified lipid is PEG-DMG and the second PEG-modified lipid is 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate. In some embodiments, the first PEG-modified lipid is 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate and the second PEG-modified lipid is PEG-DMG. In some embodiments, 0.25 mol% to 1.0 mol% (as a percentage of lipids in the LNP) of the first PEG-modified lipid is in the core of the lipid nanoparticle. In some embodiments, 0.25 mol% to 0.50 mol% of the first PEG-modified lipid is in the core of the lipid nanoparticle. In some embodiments, 0.25 mol%, 0.50 mol%, 0.75 mol%, or 1.0 mol% of the first PEG-modified lipid is in the core of the LNP. In some embodiments, 2.0 mol% to 2.75 mol% of the second PEG-modified lipid is outside the core of the LNP. In some embodiments, 2.0 mol%, 2.25 mol%, 2.5 mol%, or 2.75 mol% of the second PEG-modified lipid is outside the core of the LNP. In some embodiments, the LNP comprises 3.0 mol% PEG-modified lipids. LNPs having certain amounts of a PEG-modified lipid in the core and certain amounts of a PEG-modified lipid outside of the core, and methods of producing the same, are disclosed in PCT Publication No. WO 2023/018773, which is incorporated by reference herein to the extent it discloses lipid nanoparticles and methods of producing lipid nanoparticles. In some embodiments, the lipid nanoparticle comprises 20-60 mol% ionizable lipid, 5-25 mol% non-cationic lipid, 25-55 mol% sterol, and 0.5-15 mol% PEG-modified lipid. In some embodiments, a LNP comprises an ionizable lipid of Compound (I-18), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (I-18), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of Compound (I-25), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (I-25), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of Compound (I-301), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG- modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (I-301), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG- PEG.
In some embodiments, a LNP comprises an ionizable lipid of Compound (II-6), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (II-6), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of Compound (IL**), wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG-modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound (IL**), 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of any of Formula (IL*), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising PEG- DMG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5- 25 mol% phospholipid comprising DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG- modified lipid comprising DMG-PEG. In some embodiments, a LNP comprises an ionizable lipid of any of Formula (IL*), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid comprising DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises an ionizable lipid of Formula (IL*), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG- modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG- modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises an ionizable lipid of Formula (IL*), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG- modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG- modified lipid modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises an ionizable lipid of Formula (IL*), a phospholipid having Formula (HI), a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (IL*), 5-25 mol% phospholipid having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII).
In some embodiments, a LNP comprises an ionizable amino lipid of Compound 1, wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG- modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound 1, 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% PEG-modified lipid DMG-PEG. In some embodiments, a LNP comprises an ionizable amino lipid of Compound 2, wherein the non-cationic lipid is DSPC, the structural lipid that is cholesterol, and the PEG- modified lipid is DMG-PEG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Compound 2, 5-25 mol% DSPC, 25-55 mol% cholesterol, and 2-4 mol% PEG-modified lipid DMG-PEG. In some embodiments, a LNP comprises an ionizable amino lipid of any of Formula (AIII), (AIV), or (AV), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising PEG-DMG. In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of any of Formula (AIII), (AIV), or (AV), 5-25 mol% DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising DMG-PEG. In some embodiments, a LNP comprises an ionizable amino lipid of any of Formula (AIII), (AIV), or (AV), a phospholipid comprising DSPC, a structural lipid, and a PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises 20- 60 mol% ionizable lipid of any of Formula (AIII), (AIV), or (AV), 5-25 mol% DSPC, 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises an ionizable amino lipid of Formula (AIII), (AIV), or (AV), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG-modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (AIII), (AIV), or (AV), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises an ionizable amino lipid of Formula (AIII), (AIV), or (AV), a phospholipid comprising a compound having Formula (HI), a structural lipid, and the PEG-modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises 20-60 mol% ionizable lipid of Formula (AIII), (AIV), or (AV), 5-25 mol% phospholipid comprising a compound having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PI) or (PII). In some embodiments, a LNP comprises an ionizable amino lipid of Formula (AIII), (AIV), or (AV), a phospholipid having Formula (HI), a structural lipid, and a PEG-modified
lipid comprising a compound having Formula (PII). In some embodiments, a LNP comprises 20- 60 mol% ionizable lipid of Formula (AIII), (AIV), or (AV), 5-25 mol% phospholipid having Formula (HI), 25-55 mol% structural lipid, and 2-4 mol% PEG-modified lipid comprising a compound having Formula (PII). In some embodiments, the lipid nanoparticle comprises 49 mol% ionizable lipid, 10 mol% DSPC, 38.5 mol% cholesterol, and 2.5 mol% DMG-PEG. In some embodiments, the lipid nanoparticle comprises 49 mol% ionizable lipid, 11 mol% DSPC, 38.5 mol% cholesterol, and 1.5 mol% DMG-PEG. In some embodiments, the lipid nanoparticle comprises 48 mol% ionizable lipid, 11 mol% DSPC, 38.5 mol% cholesterol, and 2.5 mol% DMG-PEG. In some embodiments, a LNP comprises an N:P ratio of from about 2:1 to about 30:1. In some embodiments, a LNP comprises an N:P ratio of about 6:1. In some embodiments, a LNP comprises an N:P ratio of about 3:1, 4:1, or 5:1. In some embodiments, a LNP comprises a wt/wt ratio of the ionizable lipid component to the RNA of from about 10:1 to about 100:1. In some embodiments, a LNP comprises a wt/wt ratio of the ionizable lipid component to the RNA of about 20:1. In some embodiments, a LNP comprises a wt/wt ratio of the ionizable lipid component to the RNA of about 10:1. Some embodiments comprise a composition having one or more LNPs having a diameter of about 150 nm or less, such as about 140 nm, 130 nm, 120 nm, 110 nm, 100 nm, 90 nm, 80 nm, 70 nm, 60 nm, 50 nm, 40 nm, 30 nm, or 20 nm or less. Some embodiments comprise a composition having a mean LNP diameter of about 150 nm or less, such as about 140 nm, 130 nm, 120 nm, 110 nm, 100 nm, 90 nm, 80 nm, 70 nm, 60 nm, 50 nm, 40 nm, 30 nm, or 20 nm or less. In some embodiments, the composition has a mean LNP diameter from about 30nm to about 150nm, or a mean diameter from about 60nm to about 120nm. In some embodiments, an LNP further comprises one or more cargo molecules, including but not limited to nucleic acids (e.g., circular RNA, mRNA, plasmid DNA, DNA or RNA oligonucleotides, siRNA, shRNA, snRNA, snoRNA, lncRNA, etc.), small molecules, proteins and peptides. Effective in vivo delivery of nucleic acids represents a continuing medical challenge. Exogenous nucleic acids (i.e., originating from outside of a cell or organism) are readily degraded in the body, e.g., by the immune system. Accordingly, effective delivery of nucleic acids to cells often requires the use of a particulate carrier (e.g., lipid nanoparticles). The particulate carrier should be formulated to have minimal particle aggregation, be relatively
stable prior to intracellular delivery, effectively deliver nucleic acids intracellularly, and illicit no or minimal immune response. To achieve minimal particle aggregation and pre-delivery stability, many conventional particulate carriers have relied on the presence and/or concentration of certain components (e.g., PEG-modified lipid). However, it has been discovered that certain components may decrease the stability of encapsulated nucleic acids (e.g., circular RNA molecules). The reduced stability may limit the broad applicability of the particulate carriers. As such, there remains a need for methods by which to improve the stability of nucleic acid (e.g., circular RNA) encapsulated within lipid nanoparticles. In some embodiments, a LNP comprises one or more ionizable molecules (e.g., amino lipids or ionizable lipids). The ionizable molecule may comprise a charged group and may have a certain pKa. In certain embodiments, the pKa of the ionizable molecule may be greater than or equal to about 6, greater than or equal to about 6.2, greater than or equal to about 6.5, greater than or equal to about 6.8, greater than or equal to about 7, greater than or equal to about 7.2, greater than or equal to about 7.5, greater than or equal to about 7.8, greater than or equal to about 8. In some embodiments, the pKa of the ionizable molecule may be less than or equal to about 10, less than or equal to about 9.8, less than or equal to about 9.5, less than or equal to about 9.2, less than or equal to about 9.0, less than or equal to about 8.8, or less than or equal to about 8.5. Combinations of the above referenced ranges are also possible (e.g., greater than or equal to 6 and less than or equal to about 8.5). Other ranges are also possible. In embodiments in which more than one type of ionizable molecule are present in a particle, each type of ionizable molecule may independently have a pKa in one or more of the ranges described above. In general, an ionizable molecule comprises one or more charged groups. In some embodiments, an ionizable molecule may be positively charged or negatively charged. For instance, an ionizable molecule may be positively charged. For example, an ionizable molecule may comprise an amine group. As used herein, the term “ionizable molecule” has its ordinary meaning in the art and may refer to a molecule or matrix comprising one or more charged moiety. As used herein, a “charged moiety” is a chemical moiety that carries a formal electronic charge, e.g., monovalent (+1, or -1), divalent (+2, or -2), trivalent (+3, or -3), etc. The charged moiety may be anionic (i.e., negatively charged) or cationic (i.e., positively charged). Examples of positively-charged moieties include amine groups (e.g., primary, secondary, and/or tertiary amines), ammonium groups, pyridinium group, guanidine groups, and imidizolium groups. In a particular embodiment, the charged moieties comprise amine groups. Examples of negatively- charged groups or precursors thereof, include carboxylate groups, sulfonate groups, sulfate groups, phosphonate groups, phosphate groups, hydroxyl groups, and the like. The charge of the charged moiety may vary, in some cases, with the environmental conditions, for example,
changes in pH may alter the charge of the moiety, and/or cause the moiety to become charged or uncharged. In general, the charge density of the molecule and/or matrix may be selected as desired. In some cases, an ionizable molecule (e.g., an amino lipid or ionizable lipid) may include one or more precursor moieties that can be converted to charged moieties. For instance, the ionizable molecule may include a neutral moiety that can be hydrolyzed to form a charged moiety, such as those described above. As a non-limiting specific example, the molecule or matrix may include an amide, which can be hydrolyzed to form an amine, respectively. Those of ordinary skill in the art will be able to determine whether a given chemical moiety carries a formal electronic charge (for example, by inspection, pH titration, ionic conductivity measurements, etc.), and/or whether a given chemical moiety can be reacted (e.g., hydrolyzed) to form a chemical moiety that carries a formal electronic charge. The ionizable molecule (e.g., amino lipid or ionizable lipid) may have any suitable molecular weight. In certain embodiments, the molecular weight of an ionizable molecule is less than or equal to about 2,500 g/mol, less than or equal to about 2,000 g/mol, less than or equal to about 1,500 g/mol, less than or equal to about 1,250 g/mol, less than or equal to about 1,000 g/mol, less than or equal to about 900 g/mol, less than or equal to about 800 g/mol, less than or equal to about 700 g/mol, less than or equal to about 600 g/mol, less than or equal to about 500 g/mol, less than or equal to about 400 g/mol, less than or equal to about 300 g/mol, less than or equal to about 200 g/mol, or less than or equal to about 100 g/mol. In some instances, the molecular weight of an ionizable molecule is greater than or equal to about 100 g/mol, greater than or equal to about 200 g/mol, greater than or equal to about 300 g/mol, greater than or equal to about 400 g/mol, greater than or equal to about 500 g/mol, greater than or equal to about 600 g/mol, greater than or equal to about 700 g/mol, greater than or equal to about 1000 g/mol, greater than or equal to about 1,250 g/mol, greater than or equal to about 1,500 g/mol, greater than or equal to about 1,750 g/mol, greater than or equal to about 2,000 g/mol, or greater than or equal to about 2,250 g/mol. Combinations of the above ranges (e.g., at least about 200 g/mol and less than or equal to about 2,500 g/mol) are also possible. In embodiments in which more than one type of ionizable molecules are present in a particle, each type of ionizable molecule may independently have a molecular weight in one or more of the ranges described above. In some embodiments, the percentage (e.g., by weight, or by mole) of a single type of ionizable molecule (e.g., amino lipid or ionizable lipid) and/or of all the ionizable molecules within a particle may be greater than or equal to about 15%, greater than or equal to about 16%, greater than or equal to about 17%, greater than or equal to about 18%, greater than or equal to about 19%, greater than or equal to about 20%, greater than or equal to about 21%, greater than
or equal to about 22%, greater than or equal to about 23%, greater than or equal to about 24%, greater than or equal to about 25%, greater than or equal to about 30%, greater than or equal to about 35%, greater than or equal to about 40%, greater than or equal to about 42%, greater than or equal to about 45%, greater than or equal to about 48%, greater than or equal to about 50%, greater than or equal to about 52%, greater than or equal to about 55%, greater than or equal to about 58%, greater than or equal to about 60%, greater than or equal to about 62%, greater than or equal to about 65%, or greater than or equal to about 68%. In some instances, the percentage (e.g., by weight, or by mole) may be less than or equal to about 70%, less than or equal to about 68%, less than or equal to about 65%, less than or equal to about 62%, less than or equal to about 60%, less than or equal to about 58%, less than or equal to about 55%, less than or equal to about 52%, less than or equal to about 50%, or less than or equal to about 48%. Combinations of the above referenced ranges are also possible (e.g., greater than or equal to 20% and less than or equal to about 60%, greater than or equal to 40% and less than or equal to about 55%, etc.). In embodiments in which more than one type of ionizable molecule is present in a particle, each type of ionizable molecule may independently have a percentage (e.g., by weight, or by mole) in one or more of the ranges described above. The percentage (e.g., by weight, or by mole) may be determined by extracting the ionizable molecule(s) from the dried particles using, e.g., organic solvents, and measuring the quantity of the agent using high pressure liquid chromatography (i.e., HPLC), liquid chromatography-mass spectrometry (LC-MS), nuclear magnetic resonance (NMR), or mass spectrometry (MS). Those of ordinary skill in the art would be ”knowledgeable of techniques to determine the quantity of a component using the above-referenced techniques. For example, HPLC may be used to quantify the amount of a component, by, e.g., comparing the area under the curve of a HPLC chromatogram to a standard curve. It should be understood that the terms “charged” or “charged moiety” does not refer to a “partial negative charge" or “partial positive charge" on a molecule. The terms “partial negative charge" and “partial positive charge" are given their ordinary meaning in the art. A “partial negative charge" may result when a functional group comprises a bond that becomes polarized such that electron density is pulled toward one atom of the bond, creating a partial negative charge on the atom. Those of ordinary skill in the art will, in general, recognize bonds that can become polarized in this way.In some embodiments, the composition comprises a liposome. A liposome is a lipid particle comprising lipids arranged into one or more concentric lipid bilayers around a central region. The central region of a liposome may comprise an aqueous solution, suspension, or other aqueous composition. In some embodiments, the composition comprises a lipoplex. A lipoplex is a lipid particle comprising a cationic liposome and a nucleic acid (e.g., circular RNA). Lipoplexes may
be formed by contacting a liposome comprising a cationic lipid with a nucleic acid. A lipoplex may comprise multiple concentric lipid bilayers, each concentric bilayer separated by one or more nucleic acids. The central region of the lipoplex may comprise an aqueous solution, suspension, or other aqueous composition. In some embodiments, the composition comprises a lipopolyplex. A lipopolyplex is a lipid particle comprising a lipid bilayer surrounding a complex of a cationic polymer and a nucleic acid (e.g., circular RNA). See Midoux & Pichon, Expert Rev Vaccines.2015.14(2):221– 234. A lipopolyplex may be formed by contacting a cationic liposome (e.g., liposome comprising a cationic lipid) with the complex of nucleic acid and cationic polymer. The central region of the lipopolyplex may comprise an aqueous solution, suspension, or other aqueous composition. In some embodiments, the composition comprises a cationic nanoemulsion. A cationic nanoemulsion comprises a cationic lipid, hydrophilic surfactant, and hydrophobic surfactant. A liposome, lipoplex, lipopolyplex, or cationic nanoemulsion may comprise a sterol. A liposome, lipoplex, lipopolyplex, or cationic nanoemulsion may comprise a neutral lipid. A liposome, lipoplex, lipopolyplex, or cationic nanoemulsion may comprise a PEG-modified lipid. Stabilizing Compounds Some embodiments of compositions are stabilized pharmaceutical compositions. Various non-viral delivery systems, including nanoparticle formulations, present attractive opportunities to overcome many challenges associated with RNA delivery. Lipid nanoparticles (LNPs) have drawn particular attention in recent years as various LNP formulations have shown promise in a variety of pharmaceutical applications. However, lipids have been shown to degrade nucleic acids, including RNA, and lipid nanoparticle formulations undergo rapid loss of purity when stored as refrigerated liquids. Moreover, the storage stability of RNA encapsulated within LNPs is lower than that of unencapsulated RNA. A class of compounds has been found to stabilize nucleic acids within a lipid carrier such as an LNP, an unexpected and unprecedented discovery which enables applications including extended refrigerated liquid shelf-life, extended in-use periods at room temperature, and extended in-use stability at physiological temperatures up to higher temperatures such as 40°C. Such stabilizing compounds solve a critical problem, as current manufacturing processes and formulations experience a 5-10% purity loss during LNP formation and processing that is typical with current large-scale LNP production. In some embodiments, the stabilized pharmaceutical composition comprises a nucleic acid formulation comprising a nucleic acid and a stabilizing compound (e.g., a compound of
Formula (I), of Formula (II), or a tautomer or solvate thereof). In some embodiments, the stabilized pharmaceutical composition comprises a nucleic acid formulation comprising a nucleic acid and a lipid, and a compound of Formula (I):
 or a tautomer or solvate thereof, wherein: is a single bond or a double bond; R1 is H; R2 is OCH3, or together with R3 is OCH2O; R3 is OCH3, or together with R2 is OCH2O; R4 is H; R5 is H or OCH3; R6 is OCH3; R7 is H or OCH3; R8 is H; R9 is H or CH3; and X is a pharmaceutically acceptable anion, e.g., a halide such as chloride. In some embodiments, the compound of Formula (I) has the structure of:
or a tautomer or solvate thereof, wherein: is a single bond or a double bond; R1 is H; R2 is OCH3, or together with R3 is OCH2O; R3 is OCH3, or together with R2 is OCH2O; R4 is H; R5 is H or OCH3; R6 is OCH3; R7 is H or OCH3; R8 is H; R9 is H or CH3; and X is a pharmaceutically acceptable anion, e.g., a halide such as chloride. In some embodiments, the compound of Formula (I) has the structure of:
 Formula (Ia) Formula (Ib) Formula (Ic) or a tautomer or solvate thereof. In some embodiments, the stabilized pharmaceutical composition comprises a nucleic acid formulation comprising a nucleic acid and a lipid, and a compound of Formula (II):
Formula (Ia) Formula (Ib) Formula (Ic) or a tautomer or solvate thereof. In some embodiments, the stabilized pharmaceutical composition comprises a nucleic acid formulation comprising a nucleic acid and a lipid, and a compound of Formula (II):
 or a tautomer or solvate thereof, wherein: R10 is H; R11 is H; R12 together with R13 is OCH2O; R14 is H; R15 together with R16 is OCH2O; R17 is H; and X is a pharmaceutically acceptable anion, e.g., a halide such as chloride. In some embodiments, the compound of Formula (II) has the structure of:
Formula (IIa), or a tautomer or solvate thereof. Stabilizing compounds of Formulas (I), (Ia), (Ib), (Ic), (II), and (Iia) are described in International Application No. PCT/US2022/025967, which is incorporated by reference herein for this purpose. In some embodiments, the nucleic acid formulation comprises lipid nanoparticles. In some embodiments, the nucleic acid is circular RNA. In some embodiments, the stabilizing compound (“the compound”) has a purity of at least 70%, 80%, 90%, 95%, or 99%. In some embodiments, the compound contains fewer than 100ppm of elemental metals. In some embodiments, the stabilized pharmaceutical composition (“the composition”) comprises a pharmaceutically acceptable metal chelator, e.g., EDTA (ethylenediaminetetraacetic acid) or DTPA (diethylenetriaminepentaacetic acid). In some embodiments, the composition is an aqueous solution. In some embodiments, the compound is present at a concentration between about 0.1mM and about 10mM in the aqueous solution. In some embodiments, the aqueous solution has a pH of or about 5 to 8, including pH of about 5, 5.5, 6, 6.5, 7, 7.5, or 8. In some embodiments, the aqueous solution does not comprise NaCl. In some embodiments, the aqueous solution comprises NaCl in a concentration of or about 150mM. In some embodiments, the aqueous solution comprises a phosphate buffer, a tris buffer, an acetate buffer, a histidine buffer, or a citrate buffer. In some embodiments, microbial growth in the composition is inhibited by the compound. In some embodiments, the composition is characterized as having a circular RNA purity level of greater than 60%, greater than 70%, greater than 80%, or greater than 90% main peak circular RNA purity after at least thirty days of storage. In some embodiments, the composition comprises a circular RNA purity level of greater than 50% main peak circular RNA purity after at least six months of storage. In some embodiments, the storage is at room temperature. In some embodiments, the composition comprises a lipid nanoparticle encapsulating a circular RNA, and the composition comprises less than 50%, less than 60%, less than 70%, less than 80%, less than 90%, or less than 95% RNA fragments after at least thirty days of storage. In some embodiments, the storage temperature is greater than room temperature. In some embodiments, the storage temperature is about 4°C.
In some embodiments, the compound interacts with the nucleic acid comprised within a lipid nanostructure (e.g., a lipid nanoparticle, liposome, or lipoplex), e.g., via pi-pi stacking and/or by changing backbone helicity of the nucleic acid. In some embodiments, the compound intercalates with a nucleic acid. In some embodiments, the compound binds with a nucleic acid, e.g., reversible binding, and/or binding to the stranded regions of the nucleic acid. In some embodiments, the compound self-associates, binds to nucleic acid ribose contacts, and/or binds to nucleic acid base contacts. In some embodiments, the compound does not substantially bind to nucleic acid phosphate contacts. In some embodiments, the positive charge of the compound contributes to nucleic acid binding. In some embodiments, the interacts with the nucleic acid with a binding affinity defined by an equilibrium dissociation constant of less than 10-3 M (e.g., less than 10-4 M, less than 10-5 M, less than 10-5 M, less than 10-7 M, less than 10-8 M, or less than 10-9 M). In some embodiments, the compound interacts with a nucleic acid and provides shielding from solvent, e.g., water. In some embodiments, the compound shields ribose from solvent more than the compound shields the phosphate groups of the nucleic acid. In some embodiments, the solvent exposure is measured by the solvent accessible surface area (SASA). In some embodiments, a stabilizing compound decreases the solvent accessible area of ribose to about 5- 10 nm2. In some embodiments, a stabilizing compound decreases the solvent accessible area of ribose to about 6-8 nm2. In some embodiments, a stabilizing compound decreases the solvent accessible area of phosphate to about 9-12 nm2. In some embodiments, a stabilizing compound decreases the solvent accessible area of phosphate to about 10-11 nm2. In some embodiments, a nucleic acid that is conformationally stabilized by the compound exhibits thermal unfolding temperatures (measured by circular dichroism or DSC, for example) that are higher than in the absence of the compound. In some embodiments, the compound confers increased stability, e.g., thermal stability, to the nucleic acid in a folded structure, e.g., relative to its unfolded or less folded or more linear form. In some embodiments, the compound causes compaction of the nucleic acid upon interaction with the nucleic acid. In some embodiments, the compound causes a decrease in the hydrodynamic radius of the nucleic acid molecule upon interaction with the nucleic acid. In some embodiments, a stabilizing compound causes compaction or a decrease in the hydrodynamic radius of a nucleic acid molecule by 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, or more. In some embodiments, a stabilizing compound causes compaction or a decrease in the hydrodynamic radius of a nucleic acid molecule when the compound is in a concentration of 1 μM, 2 μM, 3 μM, 4 μM, 5 μM, 6 μM, 7 μM, 8 μM, 9 μM, 10 μM, 15 μM, 20 μM, 25 μM, 30 μM, 35 μM, 40 μM, 45 μM, 50 μM, 60 μM, 70 μM, 80 μM, 90 μM, or 100 μM.
Pharmaceutical compositions Some aspects relate to pharmaceutical compositions comprising circular RNAs. Circular RNA compositions may be formulated or administered in combination with one or more pharmaceutically acceptable excipients. As a non-limiting set of examples, circular RNA compositions can be formulated using one or more excipients to: (1) increase stability; (2) increase cell transfection; (3) permit the sustained or delayed release (e.g., from a depot formulation); (4) alter the biodistribution (e.g., target to specific tissues or cell types); (5) increase the translation of encoded protein in vivo; and/or (6) alter the release profile of encoded protein (antigen) in vivo. In addition to traditional excipients such as any and all solvents, dispersion media, diluents, or other liquid vehicles, dispersion or suspension aids, surface active agents, isotonic agents, thickening or emulsifying agents, preservatives, excipients can include, without limitation, lipidoids, liposomes, lipid nanoparticles, polymers, lipoplexes, core-shell nanoparticles, peptides, proteins, cells transfected with circular RNA compositions (e.g., for transplantation into a subject), hyaluronidase, nanoparticle mimics and combinations thereof. In some embodiments, circular RNA compositions comprise at least one additional active substance, such as, for example, a therapeutically active substance, a prophylactically active substance, or a combination of both. Circular RNA compositions may be sterile, pyrogen- free, or both sterile and pyrogen-free. General considerations in the formulation and/or manufacture of pharmaceutical agents, such as vaccine compositions, may be found, for example, in Remington: The Science and Practice of Pharmacy 21st ed., Lippincott Williams & Wilkins, 2005 (incorporated herein by reference in its entirety for this purpose). Formulations of the circular RNA compositions may be prepared by any method known or hereafter developed in the art of pharmacology. In general, such preparatory methods include the step of bringing the active ingredient(s) (e.g., circular RNA of the circular RNA composition) into association with an excipient and/or one or more other accessory ingredients, and then, if necessary and/or desirable, dividing, shaping and/or packaging the product into a desired single- or multi-dose unit. The formulation of any of the compositions can include one or more components in addition to those described above. For example, the lipid composition can include one or more permeability enhancer molecules, carbohydrates, polymers, surface altering agents (e.g., surfactants), or other components. For example, a permeability enhancer molecule can be a molecule described by U.S. Patent Application Publication No.2005/0222064. Carbohydrates can include simple sugars (e.g., glucose) and polysaccharides (e.g., glycogen and derivatives and analogs thereof).
A polymer can be included in and/or used to encapsulate or partially encapsulate a pharmaceutical composition (e.g., a pharmaceutical composition in lipid nanoparticle form). A polymer can be biodegradable and/or biocompatible. A polymer can be selected from, but is not limited to, polyamines, polyethers, polyamides, polyesters, polycarbamates, polyureas, polycarbonates, polystyrenes, polyimides, polysulfones, polyurethanes, polyacetylenes, polyethylenes, polyethyleneimines, polyisocyanates, polyacrylates, polymethacrylates, polyacrylonitriles, and polyarylates. In some embodiments, the compositions may be formulated as lipid nanoparticles (LNPs). Accordingly, some aspects relate to compositions comprising (i) a lipid composition comprising a delivery agent, and (ii) a circular RNA. In such nanoparticle compositions, the lipid composition can encapsulate the circular RNA. Nanoparticle compositions are typically sized on the order of micrometers or smaller and can include a lipid bilayer. Nanoparticle compositions encompass lipid nanoparticles (LNPs), liposomes (e.g., lipid vesicles), and lipoplexes. For example, a nanoparticle composition can be a liposome having a lipid bilayer with a diameter of 500 nm or less. Nanoparticle compositions include, for example, lipid nanoparticles (LNPs), liposomes, and lipoplexes. In some embodiments, nanoparticle compositions are vesicles including one or more lipid bilayers. In certain embodiments, a nanoparticle composition includes two or more concentric bilayers separated by aqueous compartments. Lipid bilayers can be functionalized and/or crosslinked to one another. Lipid bilayers can include one or more ligands, proteins, or channels. In some embodiments, a lipid nanoparticle comprises an ionizable lipid, a structural lipid, a phospholipid, and circular RNA. In some embodiments, the LNP comprises an ionizable lipid, a PEG-modified lipid, a phospholipid, and a structural lipid. As generally defined herein, the term “lipid” refers to a small molecule that has hydrophobic or amphiphilic properties. Lipids may be naturally occurring or synthetic. Examples of classes of lipids include, but are not limited to, fats, waxes, sterol-containing metabolites, vitamins, fatty acids, glycerolipids, glycerophospholipids, sphingolipids, saccharolipids, and polyketides, and prenol lipids. In some instances, the amphiphilic properties of some lipids lead them to form liposomes, vesicles, or membranes in aqueous media. In some embodiments, a lipid nanoparticle (LNP) may comprise an ionizable lipid. As used herein, the term “ionizable lipid” has its ordinary meaning in the art and may refer to a lipid comprising one or more charged moieties. In some embodiments, an ionizable lipid may be positively charged or negatively charged. An ionizable lipid may be positively charged, in which case it can be referred to as “cationic lipid”. In certain embodiments, an ionizable lipid molecule
may comprise an amine group, and can be referred to as an ionizable amino lipids. As used herein, a “charged moiety” is a chemical moiety that carries a formal electronic charge, e.g., monovalent (+1, or -1), divalent (+2, or -2), trivalent (+3, or -3), etc. The charged moiety may be anionic (i.e., negatively charged) or cationic (i.e., positively charged). Examples of positively- charged moieties include amine groups (e.g., primary, secondary, and/or tertiary amines), ammonium groups, pyridinium group, guanidine groups, and imidizolium groups. In a particular embodiment, the charged moieties comprise amine groups. Examples of negatively- charged groups or precursors thereof, include carboxylate groups, sulfonate groups, sulfate groups, phosphonate groups, phosphate groups, hydroxyl groups, and the like. The charge of the charged moiety may vary, in some cases, with the environmental conditions, for example, changes in pH may alter the charge of the moiety, and/or cause the moiety to become charged or uncharged. In general, the charge density of the molecule may be selected as desired. Ionizable lipids can also be the compounds disclosed in International Publication Nos.: WO2017075531, WO2015199952, WO2013086354, or WO2013116126, or selected from formulae CLI- CLXXXXII of US Patent No.7,404,969; each of which is hereby incorporated by reference to the extent it discloses ionizable lipids. It should be understood that the terms “charged” or “charged moiety” does not refer to a “partial negative charge” or “partial positive charge” on a molecule. The terms “partial negative charge” and “partial positive charge” are given their ordinary meaning in the art. A “partial negative charge” may result when a functional group comprises a bond that becomes polarized such that electron density is pulled toward one atom of the bond, creating a partial negative charge on the atom. Those of ordinary skill in the art will, in general, recognize bonds that can become polarized in this way. In some embodiments, the ionizable lipid is an ionizable amino lipid, sometimes referred to in the art as an “ionizable cationic lipid”. In some embodiments, the ionizable amino lipid may have a positively charged hydrophilic head and a hydrophobic tail that are connected via a linker structure. In addition to these, an ionizable lipid may also be a lipid including a cyclic amine group. Circular RNAs may be present in contact with lipid delivery vehicles (e.g., lipid nanoparticles). In some embodiments, the lipid nanoparticle comprises at least one ionizable amino lipid, at least one non-cationic lipid, at least one sterol, and/or at least one polyethylene glycol (PEG)-modified lipid. Nanoparticle compositions can be characterized by a variety of methods. For example, microscopy (e.g., transmission electron microscopy or scanning electron microscopy) can be used to examine the morphology and size distribution of a nanoparticle composition. Dynamic
light scattering or potentiometry (e.g., potentiometric titrations) can be used to measure zeta potentials. Dynamic light scattering can also be utilized to determine particle sizes. Instruments such as the Zetasizer Nano ZS (Malvern Instruments Ltd, Malvern, Worcestershire, UK) can also be used to measure multiple characteristics of a nanoparticle composition, such as particle size, polydispersity index, and zeta potential. Nanoparticle compositions can be characterized by a variety of methods. For example, microscopy (e.g., transmission electron microscopy or scanning electron microscopy) can be used to examine the morphology and size distribution of a nanoparticle composition. Dynamic light scattering or potentiometry (e.g., potentiometric titrations) can be used to measure zeta potentials. Dynamic light scattering can also be utilized to determine particle sizes. Instruments such as the Zetasizer Nano ZS (Malvern Instruments Ltd, Malvern, Worcestershire, UK) can also be used to measure multiple characteristics of a nanoparticle composition, such as particle size, polydispersity index, and zeta potential. The size of the nanoparticles can help counter biological reactions such as, but not limited to, inflammation, or can increase the biological effect of the polynucleotide. As used herein, “size” or “mean size” in the context of nanoparticle compositions refers to the mean diameter of a nanoparticle composition. Applications Circular RNA compositions comprise circular RNA molecules that may include but are not limited to circular mRNA (including modified circular mRNA), long non-coding circular RNA (lncRNA), and self-replicating circular RNA. In embodiments, the circular RNA encodes a peptide or polypeptide (e.g., a therapeutic peptide or therapeutic polypeptide). Thus, the circular RNAs may be used in a myriad of applications. For example, the circular RNA transcripts in a composition may be used to produce one or more polypeptides of interest, e.g., therapeutic proteins, vaccine antigens, and the like. In some embodiments, the circular RNAs are therapeutic RNAs. A therapeutic RNA is an RNA that encodes a therapeutic protein (the term “protein” encompasses peptides). In some embodiments, circular RNA compositions comprise one or more circular RNAs that encode peptides or proteins that interact or complex in a cell or subject to form a multi-subunit protein (e.g., an antibody comprising a heavy chain and a light chain, a multi-subunit receptor protein, etc.) or a multivalent vaccine. Therapeutic proteins mediate a variety of effects in a host cell or in a subject to treat a disease or ameliorate the signs and symptoms of a disease. For example, a therapeutic protein can replace a protein that is deficient or abnormal, augment the function of an endogenous
protein, provide a novel function to a cell (e.g., inhibit or activate an endogenous cellular activity, or act as a delivery agent for another therapeutic compound (e.g., an antibody-drug conjugate). Therapeutic RNA may be useful for the treatment of the following diseases and conditions: bacterial infections, viral infections, parasitic infections, cell proliferation disorders, genetic disorders, and autoimmune disorders. Other diseases and conditions are encompassed herein. A protein or proteins of interest encoded by a circular RNA composition can be essentially any protein or pool of peptides (e.g., peptide antigens). In some embodiments, a therapeutic peptide or therapeutic protein is a biologic. A biologic is a polypeptide-based molecule that may be used to treat, cure, mitigate, prevent, or diagnose a serious or life-threatening disease or medical condition. Biologics include, but are not limited to, allergenic extracts (e.g. for allergy shots and tests), blood components, gene therapy products, human tissue or cellular products used in transplantation, vaccines, monoclonal antibodies, cytokines, growth factors, enzymes, thrombolytics, and immunomodulators, among others. In some embodiments, the therapeutic protein is a cytokine, a growth factor, an antibody (e.g., monoclonal antibody), a fusion protein, or a multivalent vaccine (e.g., a circular RNA encoding peptide antigens designed to elicit an immune response in a subject). Non-limiting examples of therapeutic proteins include blood factors (such as Factor VIII and Factor VII), complement factors, Low Density Lipoprotein Receptor (LDLR) and MUT1. Non-limiting examples of cytokines include interleukins, interferons, chemokines, lymphokines and the like. Non-limiting examples of growth factors include erythropoietin, EGFs, PDGFs, FGFs, TGFs, IGFs, TNFs, CSFs, MCSFs, GMCSFs and the like. Non-limiting examples of antibodies include adalimumab, infliximab, rituximab, ipilimumab, tocilizumab, canakinumab, itolizumab, tralokinumab, anti-influenza virus monoclonal antibody, anti-Chikungunya virus monoclonal antibody, anti-Zika virus monoclonal antibody, anti-SARS-CoV-2 monoclonal antibody. Non- limiting examples of fusion proteins include, for example, etanercept, abatacept and belatacept. Non-limiting examples of multivalent vaccines include, for example, multivalent Cytomegalovirus (CMV) vaccine, and personalized cancer vaccines. One or more biologics currently being marketed or in development may be encoded by the circular RNA of the present invention. While not wishing to be bound by theory, it is believed that encoding a known biologic using a circular RNA will result in improved therapeutic efficacy due at least in part to the specificity, purity and/or selectivity of the construct designs.
A circular RNA composition may encode one or more antibodies (e.g., may comprise a first open reading frame encoding an antibody heavy chain and a second open reading frame encoding an antibody light chain). The term “antibody” includes monoclonal antibodies (including full length antibodies which have an immunoglobulin Fc region), antibody compositions with polyepitopic specificity, multispecific antibodies (e.g., bispecific antibodies, diabodies, and single-chain molecules), as well as antibody fragments. The term “immunoglobulin” (Ig) is used interchangeably with “antibody” herein. A monoclonal antibody is an antibody obtained from a population of substantially homogeneous antibodies, i.e., the individual antibodies comprising the population are identical except for possible naturally occurring mutations and/or post-translation modifications (e.g., isomerizations, amidations) that may be present in minor amounts. Monoclonal antibodies are highly specific, being directed against a single antigenic site. Monoclonal antibodies specifically include chimeric antibodies (immunoglobulins) in which a portion of the heavy and/or light chain is identical with or homologous to corresponding sequences in antibodies derived from a particular species or belonging to a particular antibody class or subclass, while the remainder of the chain(s) is(are) identical with or homologous to corresponding sequences in antibodies derived from another species or belonging to another antibody class or subclass, as well as fragments of such antibodies, so long as they exhibit the desired biological activity. Chimeric antibodies include, but are not limited to, “primatized” antibodies comprising variable domain antigen-binding sequences derived from a non-human primate (e.g., Old World Monkey, Ape etc.) and human constant region sequences. Antibodies encoded by circular RNAs may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, blood, cardiovascular, CNS, poisoning (including antivenoms), dermatology, endocrinology, gastrointestinal, medical imaging, musculoskeletal, oncology, immunology, respiratory, sensory and anti-infective. A circular RNA composition may encode one or more vaccine antigens. A vaccine antigen is a biological preparation that improves immunity to a particular disease or infectious agent. One or more vaccine antigens currently being marketed or in development may be encoded by the circular RNA. Vaccine antigens encoded by the RNA may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, cancer, allergy and infectious disease. In some embodiments, a vaccine may be a personalized vaccine in the form of a concatemer of individual linear RNAs, which are then circularized, or individual circular RNAs, collectively encoding peptide epitopes or a combination thereof. A circular RNA composition may be designed to encode on or more antimicrobial peptides (AMP) or antiviral peptides (AVP). AMPs and AVPs have been isolated and described
from a wide range of animals such as, but not limited to, microorganisms, invertebrates, plants, amphibians, birds, fish, and mammals. The anti-microbial polypeptides may block cell fusion and/or viral entry by one or more enveloped viruses (e.g., HIV, HCV). For example, the anti- microbial polypeptide can comprise or consist of a synthetic peptide corresponding to a region, e.g., a consecutive sequence of at least about 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, or 60 amino acids of the transmembrane subunit of a viral envelope protein, e.g., HIV-1 gp120 or gp41. The amino acid and nucleotide sequences of HIV-1 gp120 or gp41 are described in, e.g., Kuiken et al., (2008). “HIV Sequence Compendium,” Los Alamos National Laboratory. In some embodiments, circular RNAs are used as radiolabeled RNA probes. In some embodiments, circular RNAs are used for non-isotopic RNA labeling. In some embodiments, circular RNAs are used as guide RNA (gRNA) for gene targeting. In some embodiments, circular RNAs (e.g., mRNA) are used for in vitro translation and micro injection. In some embodiments, circular RNAs are used for RNA structure, processing and catalysis studies. In some embodiments, circular RNAs are used for RNA amplification. In some embodiments, circular RNAs are used as anti-sense RNA for gene expression experiment. EXAMPLES Example 1: Production and properties of circular RNA Circular RNA compositions were produced by 1) in vitro transcription (IVT) to produce linear RNAs, 2) splinted ligation of linear RNAs to produce circular RNAs, and 3) high- performance liquid chromatography (HPLC) purification to separate circular RNAs from linear RNAs and other reaction components (FIG.1). In vitro transcription used a plasmid as DNA template, with a T7 RNA polymerase transcribing an uncapped linear RNA containing, in 5′-to- 3′ order: a 5′ UTR, an open reading frame, and a 3′ UTR. Each of the 5′ and 3′ UTRs were polyAC spacer sequences. NTPs present in the IVT mixture included unmodified CTP, unmodified GTP, and unmodified UTP, as well as ATP in varying proportions of unmodified ATP and N6-methyladenosine triphosphate (m6ATP), as indicated, to produce RNAs containing unmodified nucleotides or some amount of N6-methyladenosine nucleotides. It was determined that m6ATP was incorporated less efficiently than unmodified ATP, with an IVT mixture containing 30% m6ATP and 70% unmodified ATP yielding RNAs containing about 10% N6- methyladenosine nucleotides and about 90% unmodified N6-methyladenosine nucleotides. Similarly, IVT using a reaction mixture containing 10% m6ATP and 90% unmodified ATP yielded RNAs containing about 3% N6-methyladenosine nucleotides and about 97% unmodified adenosine nucleotides.
For splinted ligation, the linear RNA was incubated with a DNA splint oligonucleotide that was complementary to sequences at the 5′ and 3′ ends of the RNA, so that both ends of the linear RNA hybridized with the DNA splint in a manner that placed the 5′ and 3′ terminal nucleotides of the linear RNA adjacent to each other in the linear RNA:DNA splint hybrid. An RNA ligase was added, which formed a covalent bond between the terminal nucleotides of the linear RNA to produce a circular RNA. Circular RNAs were then purified using HPLC Stability and translation of circular RNAs were tested in vivo. Mice were intravenously administered one of a panel of lipid nanoparticle (LNP)-RNA compositions listed in Table 1. At various timepoints, mice were euthanized to collect liver and serum samples to measure RNA abundance (FIG.2A) and protein concentrations (FIG.2B). Table 1: Panel of LNP compositions containing circular RNAs.
or a tautomer or solvate thereof, wherein: R10 is H; R11 is H; R12 together with R13 is OCH2O; R14 is H; R15 together with R16 is OCH2O; R17 is H; and X is a pharmaceutically acceptable anion, e.g., a halide such as chloride. In some embodiments, the compound of Formula (II) has the structure of:
Formula (IIa), or a tautomer or solvate thereof. Stabilizing compounds of Formulas (I), (Ia), (Ib), (Ic), (II), and (Iia) are described in International Application No. PCT/US2022/025967, which is incorporated by reference herein for this purpose. In some embodiments, the nucleic acid formulation comprises lipid nanoparticles. In some embodiments, the nucleic acid is circular RNA. In some embodiments, the stabilizing compound (“the compound”) has a purity of at least 70%, 80%, 90%, 95%, or 99%. In some embodiments, the compound contains fewer than 100ppm of elemental metals. In some embodiments, the stabilized pharmaceutical composition (“the composition”) comprises a pharmaceutically acceptable metal chelator, e.g., EDTA (ethylenediaminetetraacetic acid) or DTPA (diethylenetriaminepentaacetic acid). In some embodiments, the composition is an aqueous solution. In some embodiments, the compound is present at a concentration between about 0.1mM and about 10mM in the aqueous solution. In some embodiments, the aqueous solution has a pH of or about 5 to 8, including pH of about 5, 5.5, 6, 6.5, 7, 7.5, or 8. In some embodiments, the aqueous solution does not comprise NaCl. In some embodiments, the aqueous solution comprises NaCl in a concentration of or about 150mM. In some embodiments, the aqueous solution comprises a phosphate buffer, a tris buffer, an acetate buffer, a histidine buffer, or a citrate buffer. In some embodiments, microbial growth in the composition is inhibited by the compound. In some embodiments, the composition is characterized as having a circular RNA purity level of greater than 60%, greater than 70%, greater than 80%, or greater than 90% main peak circular RNA purity after at least thirty days of storage. In some embodiments, the composition comprises a circular RNA purity level of greater than 50% main peak circular RNA purity after at least six months of storage. In some embodiments, the storage is at room temperature. In some embodiments, the composition comprises a lipid nanoparticle encapsulating a circular RNA, and the composition comprises less than 50%, less than 60%, less than 70%, less than 80%, less than 90%, or less than 95% RNA fragments after at least thirty days of storage. In some embodiments, the storage temperature is greater than room temperature. In some embodiments, the storage temperature is about 4°C.
In some embodiments, the compound interacts with the nucleic acid comprised within a lipid nanostructure (e.g., a lipid nanoparticle, liposome, or lipoplex), e.g., via pi-pi stacking and/or by changing backbone helicity of the nucleic acid. In some embodiments, the compound intercalates with a nucleic acid. In some embodiments, the compound binds with a nucleic acid, e.g., reversible binding, and/or binding to the stranded regions of the nucleic acid. In some embodiments, the compound self-associates, binds to nucleic acid ribose contacts, and/or binds to nucleic acid base contacts. In some embodiments, the compound does not substantially bind to nucleic acid phosphate contacts. In some embodiments, the positive charge of the compound contributes to nucleic acid binding. In some embodiments, the interacts with the nucleic acid with a binding affinity defined by an equilibrium dissociation constant of less than 10-3 M (e.g., less than 10-4 M, less than 10-5 M, less than 10-5 M, less than 10-7 M, less than 10-8 M, or less than 10-9 M). In some embodiments, the compound interacts with a nucleic acid and provides shielding from solvent, e.g., water. In some embodiments, the compound shields ribose from solvent more than the compound shields the phosphate groups of the nucleic acid. In some embodiments, the solvent exposure is measured by the solvent accessible surface area (SASA). In some embodiments, a stabilizing compound decreases the solvent accessible area of ribose to about 5- 10 nm2. In some embodiments, a stabilizing compound decreases the solvent accessible area of ribose to about 6-8 nm2. In some embodiments, a stabilizing compound decreases the solvent accessible area of phosphate to about 9-12 nm2. In some embodiments, a stabilizing compound decreases the solvent accessible area of phosphate to about 10-11 nm2. In some embodiments, a nucleic acid that is conformationally stabilized by the compound exhibits thermal unfolding temperatures (measured by circular dichroism or DSC, for example) that are higher than in the absence of the compound. In some embodiments, the compound confers increased stability, e.g., thermal stability, to the nucleic acid in a folded structure, e.g., relative to its unfolded or less folded or more linear form. In some embodiments, the compound causes compaction of the nucleic acid upon interaction with the nucleic acid. In some embodiments, the compound causes a decrease in the hydrodynamic radius of the nucleic acid molecule upon interaction with the nucleic acid. In some embodiments, a stabilizing compound causes compaction or a decrease in the hydrodynamic radius of a nucleic acid molecule by 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, or more. In some embodiments, a stabilizing compound causes compaction or a decrease in the hydrodynamic radius of a nucleic acid molecule when the compound is in a concentration of 1 μM, 2 μM, 3 μM, 4 μM, 5 μM, 6 μM, 7 μM, 8 μM, 9 μM, 10 μM, 15 μM, 20 μM, 25 μM, 30 μM, 35 μM, 40 μM, 45 μM, 50 μM, 60 μM, 70 μM, 80 μM, 90 μM, or 100 μM.
Pharmaceutical compositions Some aspects relate to pharmaceutical compositions comprising circular RNAs. Circular RNA compositions may be formulated or administered in combination with one or more pharmaceutically acceptable excipients. As a non-limiting set of examples, circular RNA compositions can be formulated using one or more excipients to: (1) increase stability; (2) increase cell transfection; (3) permit the sustained or delayed release (e.g., from a depot formulation); (4) alter the biodistribution (e.g., target to specific tissues or cell types); (5) increase the translation of encoded protein in vivo; and/or (6) alter the release profile of encoded protein (antigen) in vivo. In addition to traditional excipients such as any and all solvents, dispersion media, diluents, or other liquid vehicles, dispersion or suspension aids, surface active agents, isotonic agents, thickening or emulsifying agents, preservatives, excipients can include, without limitation, lipidoids, liposomes, lipid nanoparticles, polymers, lipoplexes, core-shell nanoparticles, peptides, proteins, cells transfected with circular RNA compositions (e.g., for transplantation into a subject), hyaluronidase, nanoparticle mimics and combinations thereof. In some embodiments, circular RNA compositions comprise at least one additional active substance, such as, for example, a therapeutically active substance, a prophylactically active substance, or a combination of both. Circular RNA compositions may be sterile, pyrogen- free, or both sterile and pyrogen-free. General considerations in the formulation and/or manufacture of pharmaceutical agents, such as vaccine compositions, may be found, for example, in Remington: The Science and Practice of Pharmacy 21st ed., Lippincott Williams & Wilkins, 2005 (incorporated herein by reference in its entirety for this purpose). Formulations of the circular RNA compositions may be prepared by any method known or hereafter developed in the art of pharmacology. In general, such preparatory methods include the step of bringing the active ingredient(s) (e.g., circular RNA of the circular RNA composition) into association with an excipient and/or one or more other accessory ingredients, and then, if necessary and/or desirable, dividing, shaping and/or packaging the product into a desired single- or multi-dose unit. The formulation of any of the compositions can include one or more components in addition to those described above. For example, the lipid composition can include one or more permeability enhancer molecules, carbohydrates, polymers, surface altering agents (e.g., surfactants), or other components. For example, a permeability enhancer molecule can be a molecule described by U.S. Patent Application Publication No.2005/0222064. Carbohydrates can include simple sugars (e.g., glucose) and polysaccharides (e.g., glycogen and derivatives and analogs thereof).
A polymer can be included in and/or used to encapsulate or partially encapsulate a pharmaceutical composition (e.g., a pharmaceutical composition in lipid nanoparticle form). A polymer can be biodegradable and/or biocompatible. A polymer can be selected from, but is not limited to, polyamines, polyethers, polyamides, polyesters, polycarbamates, polyureas, polycarbonates, polystyrenes, polyimides, polysulfones, polyurethanes, polyacetylenes, polyethylenes, polyethyleneimines, polyisocyanates, polyacrylates, polymethacrylates, polyacrylonitriles, and polyarylates. In some embodiments, the compositions may be formulated as lipid nanoparticles (LNPs). Accordingly, some aspects relate to compositions comprising (i) a lipid composition comprising a delivery agent, and (ii) a circular RNA. In such nanoparticle compositions, the lipid composition can encapsulate the circular RNA. Nanoparticle compositions are typically sized on the order of micrometers or smaller and can include a lipid bilayer. Nanoparticle compositions encompass lipid nanoparticles (LNPs), liposomes (e.g., lipid vesicles), and lipoplexes. For example, a nanoparticle composition can be a liposome having a lipid bilayer with a diameter of 500 nm or less. Nanoparticle compositions include, for example, lipid nanoparticles (LNPs), liposomes, and lipoplexes. In some embodiments, nanoparticle compositions are vesicles including one or more lipid bilayers. In certain embodiments, a nanoparticle composition includes two or more concentric bilayers separated by aqueous compartments. Lipid bilayers can be functionalized and/or crosslinked to one another. Lipid bilayers can include one or more ligands, proteins, or channels. In some embodiments, a lipid nanoparticle comprises an ionizable lipid, a structural lipid, a phospholipid, and circular RNA. In some embodiments, the LNP comprises an ionizable lipid, a PEG-modified lipid, a phospholipid, and a structural lipid. As generally defined herein, the term “lipid” refers to a small molecule that has hydrophobic or amphiphilic properties. Lipids may be naturally occurring or synthetic. Examples of classes of lipids include, but are not limited to, fats, waxes, sterol-containing metabolites, vitamins, fatty acids, glycerolipids, glycerophospholipids, sphingolipids, saccharolipids, and polyketides, and prenol lipids. In some instances, the amphiphilic properties of some lipids lead them to form liposomes, vesicles, or membranes in aqueous media. In some embodiments, a lipid nanoparticle (LNP) may comprise an ionizable lipid. As used herein, the term “ionizable lipid” has its ordinary meaning in the art and may refer to a lipid comprising one or more charged moieties. In some embodiments, an ionizable lipid may be positively charged or negatively charged. An ionizable lipid may be positively charged, in which case it can be referred to as “cationic lipid”. In certain embodiments, an ionizable lipid molecule
may comprise an amine group, and can be referred to as an ionizable amino lipids. As used herein, a “charged moiety” is a chemical moiety that carries a formal electronic charge, e.g., monovalent (+1, or -1), divalent (+2, or -2), trivalent (+3, or -3), etc. The charged moiety may be anionic (i.e., negatively charged) or cationic (i.e., positively charged). Examples of positively- charged moieties include amine groups (e.g., primary, secondary, and/or tertiary amines), ammonium groups, pyridinium group, guanidine groups, and imidizolium groups. In a particular embodiment, the charged moieties comprise amine groups. Examples of negatively- charged groups or precursors thereof, include carboxylate groups, sulfonate groups, sulfate groups, phosphonate groups, phosphate groups, hydroxyl groups, and the like. The charge of the charged moiety may vary, in some cases, with the environmental conditions, for example, changes in pH may alter the charge of the moiety, and/or cause the moiety to become charged or uncharged. In general, the charge density of the molecule may be selected as desired. Ionizable lipids can also be the compounds disclosed in International Publication Nos.: WO2017075531, WO2015199952, WO2013086354, or WO2013116126, or selected from formulae CLI- CLXXXXII of US Patent No.7,404,969; each of which is hereby incorporated by reference to the extent it discloses ionizable lipids. It should be understood that the terms “charged” or “charged moiety” does not refer to a “partial negative charge” or “partial positive charge” on a molecule. The terms “partial negative charge” and “partial positive charge” are given their ordinary meaning in the art. A “partial negative charge” may result when a functional group comprises a bond that becomes polarized such that electron density is pulled toward one atom of the bond, creating a partial negative charge on the atom. Those of ordinary skill in the art will, in general, recognize bonds that can become polarized in this way. In some embodiments, the ionizable lipid is an ionizable amino lipid, sometimes referred to in the art as an “ionizable cationic lipid”. In some embodiments, the ionizable amino lipid may have a positively charged hydrophilic head and a hydrophobic tail that are connected via a linker structure. In addition to these, an ionizable lipid may also be a lipid including a cyclic amine group. Circular RNAs may be present in contact with lipid delivery vehicles (e.g., lipid nanoparticles). In some embodiments, the lipid nanoparticle comprises at least one ionizable amino lipid, at least one non-cationic lipid, at least one sterol, and/or at least one polyethylene glycol (PEG)-modified lipid. Nanoparticle compositions can be characterized by a variety of methods. For example, microscopy (e.g., transmission electron microscopy or scanning electron microscopy) can be used to examine the morphology and size distribution of a nanoparticle composition. Dynamic
light scattering or potentiometry (e.g., potentiometric titrations) can be used to measure zeta potentials. Dynamic light scattering can also be utilized to determine particle sizes. Instruments such as the Zetasizer Nano ZS (Malvern Instruments Ltd, Malvern, Worcestershire, UK) can also be used to measure multiple characteristics of a nanoparticle composition, such as particle size, polydispersity index, and zeta potential. Nanoparticle compositions can be characterized by a variety of methods. For example, microscopy (e.g., transmission electron microscopy or scanning electron microscopy) can be used to examine the morphology and size distribution of a nanoparticle composition. Dynamic light scattering or potentiometry (e.g., potentiometric titrations) can be used to measure zeta potentials. Dynamic light scattering can also be utilized to determine particle sizes. Instruments such as the Zetasizer Nano ZS (Malvern Instruments Ltd, Malvern, Worcestershire, UK) can also be used to measure multiple characteristics of a nanoparticle composition, such as particle size, polydispersity index, and zeta potential. The size of the nanoparticles can help counter biological reactions such as, but not limited to, inflammation, or can increase the biological effect of the polynucleotide. As used herein, “size” or “mean size” in the context of nanoparticle compositions refers to the mean diameter of a nanoparticle composition. Applications Circular RNA compositions comprise circular RNA molecules that may include but are not limited to circular mRNA (including modified circular mRNA), long non-coding circular RNA (lncRNA), and self-replicating circular RNA. In embodiments, the circular RNA encodes a peptide or polypeptide (e.g., a therapeutic peptide or therapeutic polypeptide). Thus, the circular RNAs may be used in a myriad of applications. For example, the circular RNA transcripts in a composition may be used to produce one or more polypeptides of interest, e.g., therapeutic proteins, vaccine antigens, and the like. In some embodiments, the circular RNAs are therapeutic RNAs. A therapeutic RNA is an RNA that encodes a therapeutic protein (the term “protein” encompasses peptides). In some embodiments, circular RNA compositions comprise one or more circular RNAs that encode peptides or proteins that interact or complex in a cell or subject to form a multi-subunit protein (e.g., an antibody comprising a heavy chain and a light chain, a multi-subunit receptor protein, etc.) or a multivalent vaccine. Therapeutic proteins mediate a variety of effects in a host cell or in a subject to treat a disease or ameliorate the signs and symptoms of a disease. For example, a therapeutic protein can replace a protein that is deficient or abnormal, augment the function of an endogenous
protein, provide a novel function to a cell (e.g., inhibit or activate an endogenous cellular activity, or act as a delivery agent for another therapeutic compound (e.g., an antibody-drug conjugate). Therapeutic RNA may be useful for the treatment of the following diseases and conditions: bacterial infections, viral infections, parasitic infections, cell proliferation disorders, genetic disorders, and autoimmune disorders. Other diseases and conditions are encompassed herein. A protein or proteins of interest encoded by a circular RNA composition can be essentially any protein or pool of peptides (e.g., peptide antigens). In some embodiments, a therapeutic peptide or therapeutic protein is a biologic. A biologic is a polypeptide-based molecule that may be used to treat, cure, mitigate, prevent, or diagnose a serious or life-threatening disease or medical condition. Biologics include, but are not limited to, allergenic extracts (e.g. for allergy shots and tests), blood components, gene therapy products, human tissue or cellular products used in transplantation, vaccines, monoclonal antibodies, cytokines, growth factors, enzymes, thrombolytics, and immunomodulators, among others. In some embodiments, the therapeutic protein is a cytokine, a growth factor, an antibody (e.g., monoclonal antibody), a fusion protein, or a multivalent vaccine (e.g., a circular RNA encoding peptide antigens designed to elicit an immune response in a subject). Non-limiting examples of therapeutic proteins include blood factors (such as Factor VIII and Factor VII), complement factors, Low Density Lipoprotein Receptor (LDLR) and MUT1. Non-limiting examples of cytokines include interleukins, interferons, chemokines, lymphokines and the like. Non-limiting examples of growth factors include erythropoietin, EGFs, PDGFs, FGFs, TGFs, IGFs, TNFs, CSFs, MCSFs, GMCSFs and the like. Non-limiting examples of antibodies include adalimumab, infliximab, rituximab, ipilimumab, tocilizumab, canakinumab, itolizumab, tralokinumab, anti-influenza virus monoclonal antibody, anti-Chikungunya virus monoclonal antibody, anti-Zika virus monoclonal antibody, anti-SARS-CoV-2 monoclonal antibody. Non- limiting examples of fusion proteins include, for example, etanercept, abatacept and belatacept. Non-limiting examples of multivalent vaccines include, for example, multivalent Cytomegalovirus (CMV) vaccine, and personalized cancer vaccines. One or more biologics currently being marketed or in development may be encoded by the circular RNA of the present invention. While not wishing to be bound by theory, it is believed that encoding a known biologic using a circular RNA will result in improved therapeutic efficacy due at least in part to the specificity, purity and/or selectivity of the construct designs.
A circular RNA composition may encode one or more antibodies (e.g., may comprise a first open reading frame encoding an antibody heavy chain and a second open reading frame encoding an antibody light chain). The term “antibody” includes monoclonal antibodies (including full length antibodies which have an immunoglobulin Fc region), antibody compositions with polyepitopic specificity, multispecific antibodies (e.g., bispecific antibodies, diabodies, and single-chain molecules), as well as antibody fragments. The term “immunoglobulin” (Ig) is used interchangeably with “antibody” herein. A monoclonal antibody is an antibody obtained from a population of substantially homogeneous antibodies, i.e., the individual antibodies comprising the population are identical except for possible naturally occurring mutations and/or post-translation modifications (e.g., isomerizations, amidations) that may be present in minor amounts. Monoclonal antibodies are highly specific, being directed against a single antigenic site. Monoclonal antibodies specifically include chimeric antibodies (immunoglobulins) in which a portion of the heavy and/or light chain is identical with or homologous to corresponding sequences in antibodies derived from a particular species or belonging to a particular antibody class or subclass, while the remainder of the chain(s) is(are) identical with or homologous to corresponding sequences in antibodies derived from another species or belonging to another antibody class or subclass, as well as fragments of such antibodies, so long as they exhibit the desired biological activity. Chimeric antibodies include, but are not limited to, “primatized” antibodies comprising variable domain antigen-binding sequences derived from a non-human primate (e.g., Old World Monkey, Ape etc.) and human constant region sequences. Antibodies encoded by circular RNAs may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, blood, cardiovascular, CNS, poisoning (including antivenoms), dermatology, endocrinology, gastrointestinal, medical imaging, musculoskeletal, oncology, immunology, respiratory, sensory and anti-infective. A circular RNA composition may encode one or more vaccine antigens. A vaccine antigen is a biological preparation that improves immunity to a particular disease or infectious agent. One or more vaccine antigens currently being marketed or in development may be encoded by the circular RNA. Vaccine antigens encoded by the RNA may be utilized to treat conditions or diseases in many therapeutic areas such as, but not limited to, cancer, allergy and infectious disease. In some embodiments, a vaccine may be a personalized vaccine in the form of a concatemer of individual linear RNAs, which are then circularized, or individual circular RNAs, collectively encoding peptide epitopes or a combination thereof. A circular RNA composition may be designed to encode on or more antimicrobial peptides (AMP) or antiviral peptides (AVP). AMPs and AVPs have been isolated and described
from a wide range of animals such as, but not limited to, microorganisms, invertebrates, plants, amphibians, birds, fish, and mammals. The anti-microbial polypeptides may block cell fusion and/or viral entry by one or more enveloped viruses (e.g., HIV, HCV). For example, the anti- microbial polypeptide can comprise or consist of a synthetic peptide corresponding to a region, e.g., a consecutive sequence of at least about 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, or 60 amino acids of the transmembrane subunit of a viral envelope protein, e.g., HIV-1 gp120 or gp41. The amino acid and nucleotide sequences of HIV-1 gp120 or gp41 are described in, e.g., Kuiken et al., (2008). “HIV Sequence Compendium,” Los Alamos National Laboratory. In some embodiments, circular RNAs are used as radiolabeled RNA probes. In some embodiments, circular RNAs are used for non-isotopic RNA labeling. In some embodiments, circular RNAs are used as guide RNA (gRNA) for gene targeting. In some embodiments, circular RNAs (e.g., mRNA) are used for in vitro translation and micro injection. In some embodiments, circular RNAs are used for RNA structure, processing and catalysis studies. In some embodiments, circular RNAs are used for RNA amplification. In some embodiments, circular RNAs are used as anti-sense RNA for gene expression experiment. EXAMPLES Example 1: Production and properties of circular RNA Circular RNA compositions were produced by 1) in vitro transcription (IVT) to produce linear RNAs, 2) splinted ligation of linear RNAs to produce circular RNAs, and 3) high- performance liquid chromatography (HPLC) purification to separate circular RNAs from linear RNAs and other reaction components (FIG.1). In vitro transcription used a plasmid as DNA template, with a T7 RNA polymerase transcribing an uncapped linear RNA containing, in 5′-to- 3′ order: a 5′ UTR, an open reading frame, and a 3′ UTR. Each of the 5′ and 3′ UTRs were polyAC spacer sequences. NTPs present in the IVT mixture included unmodified CTP, unmodified GTP, and unmodified UTP, as well as ATP in varying proportions of unmodified ATP and N6-methyladenosine triphosphate (m6ATP), as indicated, to produce RNAs containing unmodified nucleotides or some amount of N6-methyladenosine nucleotides. It was determined that m6ATP was incorporated less efficiently than unmodified ATP, with an IVT mixture containing 30% m6ATP and 70% unmodified ATP yielding RNAs containing about 10% N6- methyladenosine nucleotides and about 90% unmodified N6-methyladenosine nucleotides. Similarly, IVT using a reaction mixture containing 10% m6ATP and 90% unmodified ATP yielded RNAs containing about 3% N6-methyladenosine nucleotides and about 97% unmodified adenosine nucleotides.
For splinted ligation, the linear RNA was incubated with a DNA splint oligonucleotide that was complementary to sequences at the 5′ and 3′ ends of the RNA, so that both ends of the linear RNA hybridized with the DNA splint in a manner that placed the 5′ and 3′ terminal nucleotides of the linear RNA adjacent to each other in the linear RNA:DNA splint hybrid. An RNA ligase was added, which formed a covalent bond between the terminal nucleotides of the linear RNA to produce a circular RNA. Circular RNAs were then purified using HPLC Stability and translation of circular RNAs were tested in vivo. Mice were intravenously administered one of a panel of lipid nanoparticle (LNP)-RNA compositions listed in Table 1. At various timepoints, mice were euthanized to collect liver and serum samples to measure RNA abundance (FIG.2A) and protein concentrations (FIG.2B). Table 1: Panel of LNP compositions containing circular RNAs.
 The results of this study are shown in FIGs.2A–2B. RNAs containing N6- methyladenosine (m6A) nucleotides were more stable in vivo, compared to circular RNAs without m6A, with RNAs containing ~10% m6A nucleotides (made using IVT with 30% m6ATP) being more stable than those containing only ~3% m6A nucleotides (made using IVT with 10% m6ATP) (FIG.2A). While lower amounts of the encoded protein were observed in mice administered RNAs containing 10% m6A nucleotides, similar amounts of protein were detected in mice administered RNAs containing 3% m6A nucleotides and those administered unmodified RNAs for 48 hours (FIG.2B). As RNAs containing 3% m6A nucleotides persisted for longer in vivo than unmodified RNAs, protein expression was maintained for longer in mice administered 3% m6A-modified RNAs. These results indicate that m6A nucleotides may be incorporated into a circular RNA to improve stability while maintaining expression of the encoded protein in vivo. In a second experiment, mice were intravenously administered one of a panel of LNP- RNA compositions listed in Table 2. At various timepoints, mice were euthanized to collect liver samples to visualize RNA in liver cells (FIG.3A, 3C) and measure RNA abundance by qPCR (FIG.3B, 3D).
Table 2: Panel of LNP compositions containing circular RNAs.
The results of this study are shown in FIGs.2A–2B. RNAs containing N6- methyladenosine (m6A) nucleotides were more stable in vivo, compared to circular RNAs without m6A, with RNAs containing ~10% m6A nucleotides (made using IVT with 30% m6ATP) being more stable than those containing only ~3% m6A nucleotides (made using IVT with 10% m6ATP) (FIG.2A). While lower amounts of the encoded protein were observed in mice administered RNAs containing 10% m6A nucleotides, similar amounts of protein were detected in mice administered RNAs containing 3% m6A nucleotides and those administered unmodified RNAs for 48 hours (FIG.2B). As RNAs containing 3% m6A nucleotides persisted for longer in vivo than unmodified RNAs, protein expression was maintained for longer in mice administered 3% m6A-modified RNAs. These results indicate that m6A nucleotides may be incorporated into a circular RNA to improve stability while maintaining expression of the encoded protein in vivo. In a second experiment, mice were intravenously administered one of a panel of LNP- RNA compositions listed in Table 2. At various timepoints, mice were euthanized to collect liver samples to visualize RNA in liver cells (FIG.3A, 3C) and measure RNA abundance by qPCR (FIG.3B, 3D).
Table 2: Panel of LNP compositions containing circular RNAs.
 The results of this experiment are shown in FIGs.3A–3D. While both unmodified and m6A-modified RNAs were detected in liver cells 6 hours post-administration, only liver sections from mice administered m6A-modified RNAs were detectable at 24 and 48 hours post- administration (FIG.3A). RNA abundance, as measured by qPCR, corroborated this finding, as the abundance of unmodified RNA decreased by about 10-fold between 6 and 24 hours post- administration (FIG.3B). While inclusion of m6A nucleotides was observed to extend the persistence of circular RNAs in both hepatocytes and Kupffer cells, a third arm of this experiment evaluated the interaction between Kupffer cells, hepatocytes, and RNA stability. In mice administered RNAs containing three copies of a target sequence for miR-142, which is expressed in Kupffer cells, less RNA was observed in Kupffer cells due to targeted degradation in those cells (FIG.3C). However, RNA abundance was maintained at higher levels in mice administered RNAs containing miR-142 target sequences, relative to mice administered RNAs without miR target sequences (FIG.3D), and RNA was observed in hepatocytes for the duration of the study (FIG. 3C). These results suggest that the presence of RNA in Kupffer cells indirectly reduces the abundance of RNA in hepatocytes, but that degradation of RNA specifically in Kupffer cells mitigates this negative interaction. In a third experiment, mice were intravenously administered one of a panel of LNP-RNA compositions listed in Table 3. At various timepoints, mice were euthanized to collect liver samples, to measure RNA abundance in liver by qPCR (FIG.4). Table 3: Panel of LNP compositions containing circular RNAs.
The results of this experiment are shown in FIGs.3A–3D. While both unmodified and m6A-modified RNAs were detected in liver cells 6 hours post-administration, only liver sections from mice administered m6A-modified RNAs were detectable at 24 and 48 hours post- administration (FIG.3A). RNA abundance, as measured by qPCR, corroborated this finding, as the abundance of unmodified RNA decreased by about 10-fold between 6 and 24 hours post- administration (FIG.3B). While inclusion of m6A nucleotides was observed to extend the persistence of circular RNAs in both hepatocytes and Kupffer cells, a third arm of this experiment evaluated the interaction between Kupffer cells, hepatocytes, and RNA stability. In mice administered RNAs containing three copies of a target sequence for miR-142, which is expressed in Kupffer cells, less RNA was observed in Kupffer cells due to targeted degradation in those cells (FIG.3C). However, RNA abundance was maintained at higher levels in mice administered RNAs containing miR-142 target sequences, relative to mice administered RNAs without miR target sequences (FIG.3D), and RNA was observed in hepatocytes for the duration of the study (FIG. 3C). These results suggest that the presence of RNA in Kupffer cells indirectly reduces the abundance of RNA in hepatocytes, but that degradation of RNA specifically in Kupffer cells mitigates this negative interaction. In a third experiment, mice were intravenously administered one of a panel of LNP-RNA compositions listed in Table 3. At various timepoints, mice were euthanized to collect liver samples, to measure RNA abundance in liver by qPCR (FIG.4). Table 3: Panel of LNP compositions containing circular RNAs.
 The results of this experiment are shown in FIG.4. Consistent with previous results, circular RNAs lacking IRES cassettes containing m6A nucleotides were observed at higher
abundance than unmodified circular RNAs (FIG.4). This result suggested that the increase in circular RNA stability by incorporation of N6-methyladenosine nucleotides is not unique to RNAs containing a CVB3 IRES. These results were confirmed in a fourth experiment, in which mice were intravenously administered one of a panel of LNP-RNA compositions listed in Table 4. At various timepoints, mice were euthanized to collect liver samples, to measure RNA abundance in liver by qPCR (FIGs.5A–5C). Table 4: Panel of LNP compositions containing circular RNAs.
The results of this experiment are shown in FIG.4. Consistent with previous results, circular RNAs lacking IRES cassettes containing m6A nucleotides were observed at higher
abundance than unmodified circular RNAs (FIG.4). This result suggested that the increase in circular RNA stability by incorporation of N6-methyladenosine nucleotides is not unique to RNAs containing a CVB3 IRES. These results were confirmed in a fourth experiment, in which mice were intravenously administered one of a panel of LNP-RNA compositions listed in Table 4. At various timepoints, mice were euthanized to collect liver samples, to measure RNA abundance in liver by qPCR (FIGs.5A–5C). Table 4: Panel of LNP compositions containing circular RNAs.
 The results of this experiment are shown in FIGs.5A–5C. Consistent with results of previous experiments, circular RNAs containing m6A nucleotides were observed at higher abundances than either circular or linear RNAs without m6A nucleotides, indicating that increased stability of circular RNAs with N6-methyladenosine nucleotides does not require a specific IRES (FIGs.5A–5C). In a fifth experiment, mice were intravenously administered one of a panel of LNP-RNA compositions listed in Table 5. These RNAs encoded Ag2, a different protein from the Ag1 encoded by RNAs tested in the experiments described above. At various timepoints, mice were euthanized to collect liver samples, to measure RNA abundance in liver by qPCR (FIGs.6A– 6B).
Table 5: Panel of LNP compositions containing circular RNAs.
The results of this experiment are shown in FIGs.5A–5C. Consistent with results of previous experiments, circular RNAs containing m6A nucleotides were observed at higher abundances than either circular or linear RNAs without m6A nucleotides, indicating that increased stability of circular RNAs with N6-methyladenosine nucleotides does not require a specific IRES (FIGs.5A–5C). In a fifth experiment, mice were intravenously administered one of a panel of LNP-RNA compositions listed in Table 5. These RNAs encoded Ag2, a different protein from the Ag1 encoded by RNAs tested in the experiments described above. At various timepoints, mice were euthanized to collect liver samples, to measure RNA abundance in liver by qPCR (FIGs.6A– 6B).
Table 5: Panel of LNP compositions containing circular RNAs.
 The results of this experiment are shown in FIGs.6A–6B. Consistent with previous results, incorporation of m6A nucleotides extended circular RNA half-life for RNAs containing either SaliFHB or CVB IRES. This result indicate that the extension of RNA half-life is not unique to a protein encoded by the RNA. Example 2: Stability of circular RNAs containing N6-methyladenosine Circular RNAs were produced by IVT in which varying percentages of adenosine nucleotide triphosphates contained N6-methyladenosine (m6A). IVT reaction mixtures contained 30%, 50%, 75%, or 100% N6-methyladenosine triphosphate (m6ATP), and a complementary percentage (70%, 50%, 25%, or 0%) of unmodified ATP, followed by circularization. Control linear RNAs were produced by IVT in which all uridine nucleotide triphosphates were N1-methylpseudouridine triphosphate. All circular RNAs contained SaliFHB IRESes. BALB/c mice (4 mice per timepoint per RNA group) were intravenously administered an LNP-RNA composition containing one of these RNAs. RNA abundance (by qRT-PCR) and protein expression (by luminescence from encoded luciferase) was monitored over time in mouse livers. Increasing proportions of m6ATP in IVT, and consequently increased abundance of m6A nucleotides in circular RNAs, prolonged in vivo stability of circular RNAs (FIGs.7A and 7B). Additionally, while protein expression from linear RNAs dropped rapidly over 48 hours, expression from circular RNAs containing some amount of m6A nucleotides was more stable over time (FIG.7C). These data indicate that incorporation of N6-methyladenosine into circular RNAs increases the in vivo stability of both circular RNAs themselves and protein expression therefrom.
ENUMERATED EMBODIMENTS 1. A composition comprising a circular messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a protein, wherein 5–100% of the adenine nucleotides of the mRNA are modified adenine nucleotides comprising N6-methyladenosine (m6A). 2. The composition of Embodiment 1, wherein a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 3. The composition of Embodiment 1, wherein a coefficient of degradation of the circular RNA in a mammalian cell is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 4. The composition of Embodiment 1, wherein a level of expression, in a mammalian cell, of the protein encoded by the open reading frame of the circular RNA is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 5. The composition of any one of Embodiments 2–4, wherein the mammalian cell is a human cell. 6. The composition of any one of Embodiments 1–5, wherein 5–7%, 7–10%, 10–15%, 15– 20%, 20–25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, 90–95%, or 95–100% of the adenine nucleotides of the circular RNA comprise N6-methyladenosine (m6A).
7. A composition comprising a circular messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a protein, wherein 5–95% of the adenine nucleotides of the mRNA are modified adenine nucleotides comprising N6-methyladenosine (m6A). 8. The composition of any one of Embodiments 1–7, wherein one or more cytidine, guanosine, or uridine nucleotides of the circular RNA comprises a chemically modified nucleotide. 9. The composition of any one of Embodiments 1–8, wherein each uridine nucleotide of the circular RNA comprises a chemically modified nucleotide. 10. The composition of Embodiment 9, wherein each uridine nucleotide of the circular RNA comprises N1-methylpseudouridine. 11. The composition of any one of Embodiments 1–10, wherein the circular RNA comprises an open reading frame encoding a vaccine antigen or therapeutic protein. 12. The composition of Embodiment 11, wherein the circular RNA comprises an open reading frame encoding a vaccine antigen. 13. The composition of Embodiment 11, wherein the circular RNA comprises an open reading frame encoding a therapeutic protein. 14. The composition of any one of Embodiments 1–13, wherein the circular RNA comprises one or more target sequences for a miRNA. 15. The composition of Embodiment 14, wherein the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for the miRNA. 16 The composition of Embodiment 14 or 15, wherein the miRNA is miR-23a, miR-142, or miR-223. 17. The composition of any one of Embodiments 1–16, wherein the circular RNA comprises an internal ribosome entry site (IRES).
18. The composition of any one of Embodiments 1–17, wherein the circular RNA comprises, in 5′ to 3′ order, a 5′ untranslated region (UTR), an IRES, an open reading frame encoding a protein, and a 3′ UTR. 19. The composition of Embodiment 18, wherein the circular RNA further comprises a polyA or polyAC region. 20. The composition of Embodiment 19, wherein the polyA or polyAC region is between the 5′ UTR and the IRES. 21. The composition of Embodiment 19, wherein the polyA or polyAC region is between the open reading frame and the 3′ UTR. 22. The composition of any one of Embodiments 18–21, wherein a level of expression in a mammalian cell of the polypeptide encoded by the ORF of the circular RNA is at least 50% of a level of expression of a reference linear mRNA comprising the ORF. 23. The composition of any one of Embodiments 18–22, wherein a coefficient of degradation of the circular RNA in a mammal is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to a reference linear mRNA comprising the ORF. 24. The composition of any one of Embodiments 1–23, wherein the ORF is codon-optimized for expression in a mammalian cell. 25. The composition of Embodiment 23, wherein the ORF is codon-optimized for expression in a human cell. 26. The composition of any one of Embodiments 1–25, wherein the RNA is in a lipid nanoparticle. 27. The composition of Embodiment 26, wherein the lipid nanoparticle comprises: an ionizable amino lipid. 28. The composition of Embodiment 27, wherein the lipid nanoparticle further comprises: a non-cationic lipid; a sterol; and a polyethylene glycol (PEG)-modified lipid.
29. The composition of any one of Embodiments 26–28, wherein the lipid nanoparticle comprises: 40–55 mol% ionizable amino lipid; 5–15 mol% non-cationic lipid; 35–45 mol% sterol; and 1–5 mol% PEG-modified lipid. 30. A method for producing circular messenger ribonucleic acid (mRNA), the method comprising: (i)(a) forming a reaction mixture comprising a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP); (i)(b) incubating the reaction mixture under conditions such that the mRNA is transcribed, thereby producing an in vitro transcribed (IVT) linear mRNA; and (ii) circularizing the linear mRNA, wherein the circularizing comprises forming a covalent bond between a first nucleotide of the linear mRNA and a subsequent nucleotide of the linear mRNA to produce a circular RNA, wherein 15–100% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A). 31. The composition of Embodiment 30, wherein a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 32. The composition of 30, wherein a coefficient of degradation of the circular RNA in a mammalian cell is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 33. The composition of Embodiment 30, wherein a level of expression, in a mammalian cell, of a protein encoded by an open reading frame of the circular RNA is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA,
wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 34. The composition of any one of Embodiments 31–33, wherein the mammalian cell is a human cell. 35. The method of any one of Embodiments 20–34, wherein 15–20%, 20–30%, 30–40%, 40–50%, 50–75%, 75–90%, or 90–100% of the ATPs are modified ATPs comprising N6- methyladenosine (m6A). 36. A method for producing circular messenger ribonucleic acid (mRNA), the method comprising: (i)(a) forming a reaction mixture comprising a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP); (i)(b) incubating the reaction mixture under conditions such that the mRNA is transcribed, thereby producing an in vitro transcribed (IVT) linear mRNA; and (ii) circularizing the linear mRNA, wherein the circularizing comprises forming a covalent bond between a first nucleotide of the linear mRNA and a subsequent nucleotide of the linear mRNA to produce a circular RNA, wherein 15–95% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A). 37. The method of any one of Embodiments 30–36, wherein one or more of the NTPs are modified NTPs comprising a modified nucleobase, modified sugar, and/or modified phosphate. 38. The method of any one of Embodiments 30–37, wherein the UTP is a modified UTP comprising pseudouridine (ψ), N1-methylpseudouridine (m1ψ), 2-thiouridine, 4-thiouridine, 2- thio-1-methyl-1-deaza-pseudouridine, 2-thio-1-methyl-pseudouridine, 2-thio-5-aza-uridine , 2- thio-dihydropseudouridine, 2-thio-dihydrouridine, 2-thio-pseudouridine, 4-methoxy-2-thio- pseudouridine, 4-methoxy-pseudouridine, 4-thio-1-methyl-pseudouridine, 4-thio-pseudouridine, 5-aza-uridine, dihydropseudouridine, 5-methoxyuridine, or 2′-O-methyluridine. 39. The method of any one of Embodiments 30–38, wherein the UTP is a modified UTP comprising N1-methylpseudouridine.
40. The method of any one of Embodiments 30–39, wherein at least 80%, at least 90%, at least 95%, or up to 100% of UTPs in the reaction mixture comprise N1-methylpseudouridine. 41. The method of any one of Embodiments 30–38, wherein the UTP is a natural UTP. 42. The method of any one of Embodiments 30–41, wherein the RNA polymerase is selected from the group consisting of T7 RNA polymerase, a T3 RNA polymerase, a K11 RNA polymerase, and SP6 RNA polymerase. 43. The method of any one of Embodiments 30–42, wherein the RNA polymerase is a T7 RNA polymerase. 44. The method of any one of Embodiments 30–43, wherein circularizing the linear mRNA comprises contacting the linear mRNA with a splint nucleic acid and an RNA ligase, wherein the splint nucleic acid is a nucleic acid that hybridizes with the linear mRNA, wherein the linear RNA forms a circular secondary structure when hybridized to the splint nucleic acid. 45. The method of Embodiment 44, wherein the splint nucleic acid comprises: (a) a first hybridization sequence comprising 5 or more nucleotides, wherein the first hybridization sequence is complementary to at least the first 5 nucleotides of the linear mRNA; and (b) a second hybridization sequence comprising 5 or more nucleotides, wherein the second hybridization sequence is complementary to at least the last 5 nucleotides of the linear mRNA, wherein at least the first 5 nucleotides of the linear mRNA hybridize with the first hybridization sequence, and at least the last five nucleotides of the linear mRNA hybridize with the second hybridization sequence. 46. The method of Embodiment 45, wherein a last nucleotide of the first hybridization sequence and a first nucleotide of the second hybridization sequence are adjacent in the splint nucleic acid and are not separated by any other nucleotides.
47. The method of Embodiment 45 or 46, wherein a 5′ terminal nucleotide of the linear mRNA comprises a 5′ terminal phosphate, wherein a 3′ terminal nucleotide of the linear mRNA comprises a 3′ terminal hydroxyl, wherein the RNA ligase is a T4 RNA ligase. 48. The method of Embodiment 47, wherein the RNA ligase is T4 RNA ligase I. 49. The method of Embodiment 47, wherein the RNA ligase is T4 RNA ligase II. 50. The method of any one of Embodiments 45–46, wherein a 5′ terminal nucleotide of the linear mRNA comprises a 5′ terminal hydroxyl, wherein a 3′ terminal nucleotide of the linear mRNA comprises a 3′ terminal phosphate, wherein the RNA ligase is an RtcB RNA ligase. 51. The method of any one of Embodiments 30–50, wherein the method further comprises, after the in vitro transcribing of (i)(b) and before the circularizing of (ii), contacting the linear mRNA with a polyphosphatase. 52. The method of any one of Embodiments 30–51, wherein the method further comprises contacting a mixture comprising a circular RNA with one or more exonucleases, whereby the exonuclease hydrolyzes one or more internucleoside linkages of the linear mRNA, thereby releasing a terminal nucleotide from the linear mRNA. 53. The method of Embodiment 52, wherein at least one exonuclease is a 5′ exonuclease. 54. The method of Embodiment 53, wherein the 5′ exonuclease is XRN-1. 55. The method of Embodiment 52, wherein at least one exonuclease is a 3′ exonuclease. 56. The method of Embodiment 55, wherein the 3′ exonuclease is RNase R. 57. The method of any one of Embodiments 52–56, wherein a 5′ exonuclease and a 3′ exonuclease are added to the mixture comprising the circular RNA. 58. The method of any one of Embodiments 30–57, wherein the method further comprises adding a 5′ phosphatase into a mixture comprising the linear mRNA, whereby the 5′ phosphatase removes one or more 5′ phosphates from the linear mRNA.
59. The method of Embodiment 58, wherein the 5′ phosphatase is a calf intestinal phosphatase or Antarctic phosphatase. 60. The method of any one of Embodiments 30–59, wherein the method comprises adding a DNase into a mixture comprising the mRNA, whereby the Dnase hydrolyzes one or more internucleoside linkages of a DNA in the mixture. 61. The method of Embodiment 60, wherein the Dnase is introduced before the linear mRNA is circularized. 62. The method of Embodiment 60, wherein the Dnase is introduced at about the same time as the linear mRNA is circularized. 63. The method of Embodiment 62, wherein the Dnase is introduced after the linear mRNA is circularized. 64. A composition comprising a circular RNA produced by the method of any one of Embodiments 30–63. EQUIVALENTS AND SCOPE While several inventive embodiments have been described and illustrated herein, those of ordinary skill in the art will readily envision a variety of other means and/or structures for performing the function and/or obtaining the results and/or one or more of the advantages described herein, and each of such variations and/or modifications is deemed to be within the scope of the inventive embodiments described herein. More generally, those skilled in the art will readily appreciate that all parameters, dimensions, materials, and configurations described herein are meant to be exemplary and that the actual parameters, dimensions, materials, and/or configurations will depend upon the specific application or applications for which the inventive teachings is/are used. Those skilled in the art will recognize, or be able to ascertain using no more than routine experimentation, many equivalents to the specific inventive embodiments described herein. It is, therefore, to be understood that the foregoing embodiments are presented by way of example only and that, within the scope of the appended claims and equivalents thereto, inventive embodiments may be practiced otherwise than as specifically described and
claimed. Inventive embodiments of the present disclosure are directed to each individual feature, system, article, material, kit, and/or method described herein. In addition, any combination of two or more such features, systems, articles, materials, kits, and/or methods, if such features, systems, articles, materials, kits, and/or methods are not mutually inconsistent, is included within the inventive scope of the present disclosure. All definitions, as defined and used herein, should be understood to control over dictionary definitions, definitions in documents incorporated by reference, and/or ordinary meanings of the defined terms. All references, patents and patent applications disclosed herein are incorporated by reference with respect to the subject matter for which each is cited, which in some cases may encompass the entirety of the document. The indefinite articles “a” and “an,” as used herein in the specification and in the claims, unless clearly indicated to the contrary, should be understood to mean “at least one.” The phrase “and/or,” as used herein in the specification and in the claims, should be understood to mean “either or both” of the elements so conjoined, i.e., elements that are conjunctively present in some cases and disjunctively present in other cases. Multiple elements listed with “and/or” should be construed in the same fashion, i.e., “one or more” of the elements so conjoined. Other elements may optionally be present other than the elements specifically identified by the “and/or” clause, whether related or unrelated to those elements specifically identified. Thus, as a non-limiting example, a reference to “A and/or B”, when used in conjunction with open-ended language such as “comprising” can refer, in some embodiments, to A only (optionally including elements other than B); in another embodiment, to B only (optionally including elements other than A); in yet another embodiment, to both A and B (optionally including other elements); etc. As used herein in the specification and in the claims, “or” should be understood to have the same meaning as “and/or” as defined above. For example, when separating items in a list, “or” or “and/or” shall be interpreted as being inclusive, i.e., the inclusion of at least one, but also including more than one, of a number or list of elements, and, optionally, additional unlisted items. Only terms clearly indicated to the contrary, such as “only one of” or “exactly one of,” or, when used in the claims, “consisting of,” will refer to the inclusion of exactly one element of a number or list of elements. In general, the term “or” as used herein shall only be interpreted as indicating exclusive alternatives (i.e. “one or the other but not both”) when preceded by terms of exclusivity, such as “either,” “one of,” “only one of,” or “exactly one of.” “Consisting essentially of,” when used in the claims, shall have its ordinary meaning as used in the field of patent law.
As used herein in the specification and in the claims, the phrase “at least one,” in reference to a list of one or more elements, should be understood to mean at least one element selected from any one or more of the elements in the list of elements, but not necessarily including at least one of each and every element specifically listed within the list of elements and not excluding any combinations of elements in the list of elements. This definition also allows that elements may optionally be present other than the elements specifically identified within the list of elements to which the phrase “at least one” refers, whether related or unrelated to those elements specifically identified. Thus, as a non-limiting example, “at least one of A and B” (or, equivalently, “at least one of A or B,” or, equivalently “at least one of A and/or B”) can refer, in some embodiments, to at least one, optionally including more than one, A, with no B present (and optionally including elements other than B); in another embodiment, to at least one, optionally including more than one, B, with no A present (and optionally including elements other than A); in yet another embodiment, to at least one, optionally including more than one, A, and at least one, optionally including more than one, B (and optionally including other elements); etc. Each possibility represents a separate embodiment of the present invention. It should be understood that, unless clearly indicated to the contrary, the disclosure of numerical values and ranges of numerical values in the specification includes both i) the exact value(s) or range specified, and ii) values that are “about” the value(s) or ranges specified (e.g., values or ranges falling within a reasonable range (e.g., about 10% similar)) as would be understood by a person of ordinary skill in the art. It should also be understood that, unless clearly indicated to the contrary, in any methods disclosed herein that include more than one step or act, the order of the steps or acts of the method is not necessarily limited to the order in which the steps or acts of the method are disclosed. In the claims, as well as in the specification above, all transitional phrases such as “comprising,” “including,” “carrying,” “having,” “containing,” “involving,” “holding,” “composed of,” and the like are to be understood to be open-ended, i.e., to mean including but not limited to. Only the transitional phrases “consisting of” and “consisting essentially of” shall be closed or semi-closed transitional phrases, respectively, as set forth in the United States Patent Office Manual of Patent Examining Procedures, Section 2111.03.
The results of this experiment are shown in FIGs.6A–6B. Consistent with previous results, incorporation of m6A nucleotides extended circular RNA half-life for RNAs containing either SaliFHB or CVB IRES. This result indicate that the extension of RNA half-life is not unique to a protein encoded by the RNA. Example 2: Stability of circular RNAs containing N6-methyladenosine Circular RNAs were produced by IVT in which varying percentages of adenosine nucleotide triphosphates contained N6-methyladenosine (m6A). IVT reaction mixtures contained 30%, 50%, 75%, or 100% N6-methyladenosine triphosphate (m6ATP), and a complementary percentage (70%, 50%, 25%, or 0%) of unmodified ATP, followed by circularization. Control linear RNAs were produced by IVT in which all uridine nucleotide triphosphates were N1-methylpseudouridine triphosphate. All circular RNAs contained SaliFHB IRESes. BALB/c mice (4 mice per timepoint per RNA group) were intravenously administered an LNP-RNA composition containing one of these RNAs. RNA abundance (by qRT-PCR) and protein expression (by luminescence from encoded luciferase) was monitored over time in mouse livers. Increasing proportions of m6ATP in IVT, and consequently increased abundance of m6A nucleotides in circular RNAs, prolonged in vivo stability of circular RNAs (FIGs.7A and 7B). Additionally, while protein expression from linear RNAs dropped rapidly over 48 hours, expression from circular RNAs containing some amount of m6A nucleotides was more stable over time (FIG.7C). These data indicate that incorporation of N6-methyladenosine into circular RNAs increases the in vivo stability of both circular RNAs themselves and protein expression therefrom.
ENUMERATED EMBODIMENTS 1. A composition comprising a circular messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a protein, wherein 5–100% of the adenine nucleotides of the mRNA are modified adenine nucleotides comprising N6-methyladenosine (m6A). 2. The composition of Embodiment 1, wherein a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 3. The composition of Embodiment 1, wherein a coefficient of degradation of the circular RNA in a mammalian cell is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 4. The composition of Embodiment 1, wherein a level of expression, in a mammalian cell, of the protein encoded by the open reading frame of the circular RNA is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 5. The composition of any one of Embodiments 2–4, wherein the mammalian cell is a human cell. 6. The composition of any one of Embodiments 1–5, wherein 5–7%, 7–10%, 10–15%, 15– 20%, 20–25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, 90–95%, or 95–100% of the adenine nucleotides of the circular RNA comprise N6-methyladenosine (m6A).
7. A composition comprising a circular messenger ribonucleic acid (mRNA) comprising an open reading frame encoding a protein, wherein 5–95% of the adenine nucleotides of the mRNA are modified adenine nucleotides comprising N6-methyladenosine (m6A). 8. The composition of any one of Embodiments 1–7, wherein one or more cytidine, guanosine, or uridine nucleotides of the circular RNA comprises a chemically modified nucleotide. 9. The composition of any one of Embodiments 1–8, wherein each uridine nucleotide of the circular RNA comprises a chemically modified nucleotide. 10. The composition of Embodiment 9, wherein each uridine nucleotide of the circular RNA comprises N1-methylpseudouridine. 11. The composition of any one of Embodiments 1–10, wherein the circular RNA comprises an open reading frame encoding a vaccine antigen or therapeutic protein. 12. The composition of Embodiment 11, wherein the circular RNA comprises an open reading frame encoding a vaccine antigen. 13. The composition of Embodiment 11, wherein the circular RNA comprises an open reading frame encoding a therapeutic protein. 14. The composition of any one of Embodiments 1–13, wherein the circular RNA comprises one or more target sequences for a miRNA. 15. The composition of Embodiment 14, wherein the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for the miRNA. 16 The composition of Embodiment 14 or 15, wherein the miRNA is miR-23a, miR-142, or miR-223. 17. The composition of any one of Embodiments 1–16, wherein the circular RNA comprises an internal ribosome entry site (IRES).
18. The composition of any one of Embodiments 1–17, wherein the circular RNA comprises, in 5′ to 3′ order, a 5′ untranslated region (UTR), an IRES, an open reading frame encoding a protein, and a 3′ UTR. 19. The composition of Embodiment 18, wherein the circular RNA further comprises a polyA or polyAC region. 20. The composition of Embodiment 19, wherein the polyA or polyAC region is between the 5′ UTR and the IRES. 21. The composition of Embodiment 19, wherein the polyA or polyAC region is between the open reading frame and the 3′ UTR. 22. The composition of any one of Embodiments 18–21, wherein a level of expression in a mammalian cell of the polypeptide encoded by the ORF of the circular RNA is at least 50% of a level of expression of a reference linear mRNA comprising the ORF. 23. The composition of any one of Embodiments 18–22, wherein a coefficient of degradation of the circular RNA in a mammal is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to a reference linear mRNA comprising the ORF. 24. The composition of any one of Embodiments 1–23, wherein the ORF is codon-optimized for expression in a mammalian cell. 25. The composition of Embodiment 23, wherein the ORF is codon-optimized for expression in a human cell. 26. The composition of any one of Embodiments 1–25, wherein the RNA is in a lipid nanoparticle. 27. The composition of Embodiment 26, wherein the lipid nanoparticle comprises: an ionizable amino lipid. 28. The composition of Embodiment 27, wherein the lipid nanoparticle further comprises: a non-cationic lipid; a sterol; and a polyethylene glycol (PEG)-modified lipid.
29. The composition of any one of Embodiments 26–28, wherein the lipid nanoparticle comprises: 40–55 mol% ionizable amino lipid; 5–15 mol% non-cationic lipid; 35–45 mol% sterol; and 1–5 mol% PEG-modified lipid. 30. A method for producing circular messenger ribonucleic acid (mRNA), the method comprising: (i)(a) forming a reaction mixture comprising a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP); (i)(b) incubating the reaction mixture under conditions such that the mRNA is transcribed, thereby producing an in vitro transcribed (IVT) linear mRNA; and (ii) circularizing the linear mRNA, wherein the circularizing comprises forming a covalent bond between a first nucleotide of the linear mRNA and a subsequent nucleotide of the linear mRNA to produce a circular RNA, wherein 15–100% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A). 31. The composition of Embodiment 30, wherein a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 32. The composition of 30, wherein a coefficient of degradation of the circular RNA in a mammalian cell is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to control circular RNA comprising the same nucleotide sequence as the circular RNA, wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 33. The composition of Embodiment 30, wherein a level of expression, in a mammalian cell, of a protein encoded by an open reading frame of the circular RNA is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA,
wherein each adenine nucleotide of the control circular RNA is an unmodified adenine nucleotide. 34. The composition of any one of Embodiments 31–33, wherein the mammalian cell is a human cell. 35. The method of any one of Embodiments 20–34, wherein 15–20%, 20–30%, 30–40%, 40–50%, 50–75%, 75–90%, or 90–100% of the ATPs are modified ATPs comprising N6- methyladenosine (m6A). 36. A method for producing circular messenger ribonucleic acid (mRNA), the method comprising: (i)(a) forming a reaction mixture comprising a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP); (i)(b) incubating the reaction mixture under conditions such that the mRNA is transcribed, thereby producing an in vitro transcribed (IVT) linear mRNA; and (ii) circularizing the linear mRNA, wherein the circularizing comprises forming a covalent bond between a first nucleotide of the linear mRNA and a subsequent nucleotide of the linear mRNA to produce a circular RNA, wherein 15–95% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A). 37. The method of any one of Embodiments 30–36, wherein one or more of the NTPs are modified NTPs comprising a modified nucleobase, modified sugar, and/or modified phosphate. 38. The method of any one of Embodiments 30–37, wherein the UTP is a modified UTP comprising pseudouridine (ψ), N1-methylpseudouridine (m1ψ), 2-thiouridine, 4-thiouridine, 2- thio-1-methyl-1-deaza-pseudouridine, 2-thio-1-methyl-pseudouridine, 2-thio-5-aza-uridine , 2- thio-dihydropseudouridine, 2-thio-dihydrouridine, 2-thio-pseudouridine, 4-methoxy-2-thio- pseudouridine, 4-methoxy-pseudouridine, 4-thio-1-methyl-pseudouridine, 4-thio-pseudouridine, 5-aza-uridine, dihydropseudouridine, 5-methoxyuridine, or 2′-O-methyluridine. 39. The method of any one of Embodiments 30–38, wherein the UTP is a modified UTP comprising N1-methylpseudouridine.
40. The method of any one of Embodiments 30–39, wherein at least 80%, at least 90%, at least 95%, or up to 100% of UTPs in the reaction mixture comprise N1-methylpseudouridine. 41. The method of any one of Embodiments 30–38, wherein the UTP is a natural UTP. 42. The method of any one of Embodiments 30–41, wherein the RNA polymerase is selected from the group consisting of T7 RNA polymerase, a T3 RNA polymerase, a K11 RNA polymerase, and SP6 RNA polymerase. 43. The method of any one of Embodiments 30–42, wherein the RNA polymerase is a T7 RNA polymerase. 44. The method of any one of Embodiments 30–43, wherein circularizing the linear mRNA comprises contacting the linear mRNA with a splint nucleic acid and an RNA ligase, wherein the splint nucleic acid is a nucleic acid that hybridizes with the linear mRNA, wherein the linear RNA forms a circular secondary structure when hybridized to the splint nucleic acid. 45. The method of Embodiment 44, wherein the splint nucleic acid comprises: (a) a first hybridization sequence comprising 5 or more nucleotides, wherein the first hybridization sequence is complementary to at least the first 5 nucleotides of the linear mRNA; and (b) a second hybridization sequence comprising 5 or more nucleotides, wherein the second hybridization sequence is complementary to at least the last 5 nucleotides of the linear mRNA, wherein at least the first 5 nucleotides of the linear mRNA hybridize with the first hybridization sequence, and at least the last five nucleotides of the linear mRNA hybridize with the second hybridization sequence. 46. The method of Embodiment 45, wherein a last nucleotide of the first hybridization sequence and a first nucleotide of the second hybridization sequence are adjacent in the splint nucleic acid and are not separated by any other nucleotides.
47. The method of Embodiment 45 or 46, wherein a 5′ terminal nucleotide of the linear mRNA comprises a 5′ terminal phosphate, wherein a 3′ terminal nucleotide of the linear mRNA comprises a 3′ terminal hydroxyl, wherein the RNA ligase is a T4 RNA ligase. 48. The method of Embodiment 47, wherein the RNA ligase is T4 RNA ligase I. 49. The method of Embodiment 47, wherein the RNA ligase is T4 RNA ligase II. 50. The method of any one of Embodiments 45–46, wherein a 5′ terminal nucleotide of the linear mRNA comprises a 5′ terminal hydroxyl, wherein a 3′ terminal nucleotide of the linear mRNA comprises a 3′ terminal phosphate, wherein the RNA ligase is an RtcB RNA ligase. 51. The method of any one of Embodiments 30–50, wherein the method further comprises, after the in vitro transcribing of (i)(b) and before the circularizing of (ii), contacting the linear mRNA with a polyphosphatase. 52. The method of any one of Embodiments 30–51, wherein the method further comprises contacting a mixture comprising a circular RNA with one or more exonucleases, whereby the exonuclease hydrolyzes one or more internucleoside linkages of the linear mRNA, thereby releasing a terminal nucleotide from the linear mRNA. 53. The method of Embodiment 52, wherein at least one exonuclease is a 5′ exonuclease. 54. The method of Embodiment 53, wherein the 5′ exonuclease is XRN-1. 55. The method of Embodiment 52, wherein at least one exonuclease is a 3′ exonuclease. 56. The method of Embodiment 55, wherein the 3′ exonuclease is RNase R. 57. The method of any one of Embodiments 52–56, wherein a 5′ exonuclease and a 3′ exonuclease are added to the mixture comprising the circular RNA. 58. The method of any one of Embodiments 30–57, wherein the method further comprises adding a 5′ phosphatase into a mixture comprising the linear mRNA, whereby the 5′ phosphatase removes one or more 5′ phosphates from the linear mRNA.
59. The method of Embodiment 58, wherein the 5′ phosphatase is a calf intestinal phosphatase or Antarctic phosphatase. 60. The method of any one of Embodiments 30–59, wherein the method comprises adding a DNase into a mixture comprising the mRNA, whereby the Dnase hydrolyzes one or more internucleoside linkages of a DNA in the mixture. 61. The method of Embodiment 60, wherein the Dnase is introduced before the linear mRNA is circularized. 62. The method of Embodiment 60, wherein the Dnase is introduced at about the same time as the linear mRNA is circularized. 63. The method of Embodiment 62, wherein the Dnase is introduced after the linear mRNA is circularized. 64. A composition comprising a circular RNA produced by the method of any one of Embodiments 30–63. EQUIVALENTS AND SCOPE While several inventive embodiments have been described and illustrated herein, those of ordinary skill in the art will readily envision a variety of other means and/or structures for performing the function and/or obtaining the results and/or one or more of the advantages described herein, and each of such variations and/or modifications is deemed to be within the scope of the inventive embodiments described herein. More generally, those skilled in the art will readily appreciate that all parameters, dimensions, materials, and configurations described herein are meant to be exemplary and that the actual parameters, dimensions, materials, and/or configurations will depend upon the specific application or applications for which the inventive teachings is/are used. Those skilled in the art will recognize, or be able to ascertain using no more than routine experimentation, many equivalents to the specific inventive embodiments described herein. It is, therefore, to be understood that the foregoing embodiments are presented by way of example only and that, within the scope of the appended claims and equivalents thereto, inventive embodiments may be practiced otherwise than as specifically described and
claimed. Inventive embodiments of the present disclosure are directed to each individual feature, system, article, material, kit, and/or method described herein. In addition, any combination of two or more such features, systems, articles, materials, kits, and/or methods, if such features, systems, articles, materials, kits, and/or methods are not mutually inconsistent, is included within the inventive scope of the present disclosure. All definitions, as defined and used herein, should be understood to control over dictionary definitions, definitions in documents incorporated by reference, and/or ordinary meanings of the defined terms. All references, patents and patent applications disclosed herein are incorporated by reference with respect to the subject matter for which each is cited, which in some cases may encompass the entirety of the document. The indefinite articles “a” and “an,” as used herein in the specification and in the claims, unless clearly indicated to the contrary, should be understood to mean “at least one.” The phrase “and/or,” as used herein in the specification and in the claims, should be understood to mean “either or both” of the elements so conjoined, i.e., elements that are conjunctively present in some cases and disjunctively present in other cases. Multiple elements listed with “and/or” should be construed in the same fashion, i.e., “one or more” of the elements so conjoined. Other elements may optionally be present other than the elements specifically identified by the “and/or” clause, whether related or unrelated to those elements specifically identified. Thus, as a non-limiting example, a reference to “A and/or B”, when used in conjunction with open-ended language such as “comprising” can refer, in some embodiments, to A only (optionally including elements other than B); in another embodiment, to B only (optionally including elements other than A); in yet another embodiment, to both A and B (optionally including other elements); etc. As used herein in the specification and in the claims, “or” should be understood to have the same meaning as “and/or” as defined above. For example, when separating items in a list, “or” or “and/or” shall be interpreted as being inclusive, i.e., the inclusion of at least one, but also including more than one, of a number or list of elements, and, optionally, additional unlisted items. Only terms clearly indicated to the contrary, such as “only one of” or “exactly one of,” or, when used in the claims, “consisting of,” will refer to the inclusion of exactly one element of a number or list of elements. In general, the term “or” as used herein shall only be interpreted as indicating exclusive alternatives (i.e. “one or the other but not both”) when preceded by terms of exclusivity, such as “either,” “one of,” “only one of,” or “exactly one of.” “Consisting essentially of,” when used in the claims, shall have its ordinary meaning as used in the field of patent law.
As used herein in the specification and in the claims, the phrase “at least one,” in reference to a list of one or more elements, should be understood to mean at least one element selected from any one or more of the elements in the list of elements, but not necessarily including at least one of each and every element specifically listed within the list of elements and not excluding any combinations of elements in the list of elements. This definition also allows that elements may optionally be present other than the elements specifically identified within the list of elements to which the phrase “at least one” refers, whether related or unrelated to those elements specifically identified. Thus, as a non-limiting example, “at least one of A and B” (or, equivalently, “at least one of A or B,” or, equivalently “at least one of A and/or B”) can refer, in some embodiments, to at least one, optionally including more than one, A, with no B present (and optionally including elements other than B); in another embodiment, to at least one, optionally including more than one, B, with no A present (and optionally including elements other than A); in yet another embodiment, to at least one, optionally including more than one, A, and at least one, optionally including more than one, B (and optionally including other elements); etc. Each possibility represents a separate embodiment of the present invention. It should be understood that, unless clearly indicated to the contrary, the disclosure of numerical values and ranges of numerical values in the specification includes both i) the exact value(s) or range specified, and ii) values that are “about” the value(s) or ranges specified (e.g., values or ranges falling within a reasonable range (e.g., about 10% similar)) as would be understood by a person of ordinary skill in the art. It should also be understood that, unless clearly indicated to the contrary, in any methods disclosed herein that include more than one step or act, the order of the steps or acts of the method is not necessarily limited to the order in which the steps or acts of the method are disclosed. In the claims, as well as in the specification above, all transitional phrases such as “comprising,” “including,” “carrying,” “having,” “containing,” “involving,” “holding,” “composed of,” and the like are to be understood to be open-ended, i.e., to mean including but not limited to. Only the transitional phrases “consisting of” and “consisting essentially of” shall be closed or semi-closed transitional phrases, respectively, as set forth in the United States Patent Office Manual of Patent Examining Procedures, Section 2111.03.
Claims
CLAIMS What is claimed is: 1. A circular ribonucleic acid (circular RNA) comprising an open reading frame (ORF) encoding a protein, wherein 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 5–7%, 7–10%, 10–15%, 15–20%, 20–25%, 25–30%, 30–40%, 40–50%, 50–60%, 60–70%, 70–80%, 80–90%, or 90–95% of nucleotides at adenosine positions comprise N6-methyladenosine (m6A).
2. The circular RNA of claim 1, wherein 10–25% of nucleotides at adenosine positions comprise N6-methyladenosine. 3. The circular RNA of claim 1 or 2, wherein the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF. 4. The circular RNA of any one of claims 1–3, wherein the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell. 5. The circular RNA of claim 4, wherein the one or more miRNAs are specific to macrophages. 6. The circular RNA of claim 4 or 5, wherein the one or more miRNAs are specific to Kupffer cells. 7. The circular RNA of any one of claims 4–6, wherein the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223. 8. The circular RNA of any one of claims 4–7, wherein the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA. 9. The circular RNA of any one of claims 4–8, wherein the circular RNA comprises 2,
3,
4,
5,
6,
7,
8,
9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs.
10. The circular RNA of any one of claims 1–9, wherein the circular RNA comprises an open reading frame encoding a vaccine antigen or therapeutic protein.
11. The circular RNA of any one of claims 1–10, wherein the circular RNA comprises, in 5′- to-3′-order: a 5′ untranslated region (UTR), an internal ribosome entry site (IRES), the ORF, and a 3′ UTR.
12. The circular RNA of claim 11, wherein the circular RNA further comprises a polyA or polyAC region.
13. The circular RNA of claim 12, wherein the polyA or polyAC region is between the 5′ UTR and the IRES.
14. The circular RNA of claim 12, wherein the polyA or polyAC region is between the open reading frame and the 3′ UTR.
15. The circular RNA of any one of claims 1–14, wherein the ORF is codon-optimized for expression in a mammalian cell.
16. The circular RNA of claim 15, wherein the ORF is codon-optimized for expression in a human cell.
17. The circular RNA of any one of claims 1–16, wherein substantially all nucleotides at uridine positions comprise N1-methylpseudouridine.
18. The circular RNA of any one of claims 1–16, wherein substantially all nucleotides at cytidine positions comprise 5-methylcytidine, and substantially all nucleotides at uridine positions comprise 5-methyluridine.
19. The circular RNA of any one of claims 1–18, further comprising a lipid delivery vehicle in contact with the circular RNA.
20. The circular RNA of claim 19, wherein the lipid delivery vehicle is a lipid nanoparticle comprising 20–60 mol% ionizable lipid, 5–25 mol% non-cationic lipid, 2–4 mol% PEG- modified lipid, and 25–55 mol% sterol.
21. The circular RNA of claim 20, wherein the ionizable lipid is a compound of Formula (IL*):
, or a salt thereof, wherein: R1 is -OH, -NRN-C4-10 cycloalkenyl optionally substituted with one or more oxo or - N(RN’RN’’); RN is H or C1-6 alkyl; RN’ is H or C1-6 alkyl; RN’’ is H or C1-6 alkyl; o is 1, 2, 3, or 4; n is 4, 5, 6, 7, or 8; m is 4, 5, 6, 7, or 8; M is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R2; M’ is -C(=O)-O-* or -O-C(=O)-*, wherein * indicates attachment to R3; R2 is
 or –(C1-6 alkylene)-(C3-8 cycloalkyl)-C1-6 alkyl; R2a is -H or C1-10 alkyl; R2b is -H or C1-10 alkyl; alkenyl;
or –(C1-6 alkylene)-(C3-8 cycloalkyl)-C1-6 alkyl; R2a is -H or C1-10 alkyl; R2b is -H or C1-10 alkyl; alkenyl;
 R3a is H or C1-10 alkyl; R3b is H or C1-8 alkyl; and R3c is C1-10 alkyl or C2-8 alkenyl.
R3a is H or C1-10 alkyl; R3b is H or C1-8 alkyl; and R3c is C1-10 alkyl or C2-8 alkenyl.
22. The circular RNA of claim 21, wherein the ionizable lipid is

23. The circular RNA of any one of claims 20–22, wherein 0.25 mol% to 1.0 mol% of the PEG-modified lipid is present in a core of the lipid nanoparticle.
24. The circular RNA of claim 23, wherein 2.0 mol% to 2.75 mol% of the PEG-modified lipid is not in the core of the lipid nanoparticle.
25. The circular RNA of any one of claims 20–24, wherein the PEG-modified lipid is PEG- DMG or 134-hydroxy- 3,6,9,12,15,18,21,24,27,30,33,36,39,42,45,48,51,54,57,60,63,66,69,72,75,78,81,84,87,90,93,96, 99,102,105,108,111,114,117,120,123,126,129,132-tetratetracontaoxatetratriacontahectyl stearate.
26. A method for producing a circular ribonucleic acid, the method comprising: (i) incubating an in vitro transcription (IVT) reaction mixture under conditions such that a linear RNA comprising an open reading frame (ORF) encoding a protein is transcribed, wherein the IVT reaction mixture comprises a deoxyribonucleic acid (DNA) template, an RNA polymerase, a buffer, and NTPs including adenosine triphosphate (ATP), cytidine triphosphate (CTP), guanosine triphosphate (GTP), and uridine triphosphate (UTP), wherein 15–90%, 15–80%, 15–60%, 15–40%, 15–20%, 20–30%, 30–40%, 40–50%, 50– 75%, or 75–90% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A); and (ii) circularizing the linear RNA, wherein the circularizing comprises forming a covalent bond between a first nucleotide of the linear RNA and a subsequent nucleotide of the linear RNA to produce a circular RNA.
27. The method of claim 26, wherein 30–75% of the ATPs are modified ATPs comprising N6-methyladenosine (m6A).
28. The method of claim 26 or 27, wherein the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF.
29. The method of any one of claims 26–28, wherein the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell.
30. The method of claim 29, wherein the one or more miRNAs are specific to macrophages.
31. The method of claim 29 or 30, wherein the one or more miRNAs are specific to Kupffer cells.
32. The method of any one of claims 29–31, wherein the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223.
33. The method of any one of claims 29–32, wherein the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA.
34. The method of any one of claims 29–33, wherein the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs.
35. The method of any one of claims 26–34, wherein substantially all UTPs in the IVT reaction mixture are N1-methylpseudouridine triphosphate.
36. The method of any one of claims 26–34, wherein substantially all UTPs in the IVT reaction mixture comprise 5-methyluridine, and wherein substantially all CTPs in the IVT reaction mixture comprise 5-methylcytidine.
37. The method of any one of claims 26–36, wherein the RNA polymerase is selected from the group consisting of T7 RNA polymerase, a T3 RNA polymerase, a K11 RNA polymerase, and SP6 RNA polymerase.
38. The method of any one of claims 26–37, wherein the RNA polymerase is a T7 RNA polymerase.
39. The method of any one of claims 26–38, wherein the RNA polymerase is a T7 RNA polymerase variant having an amino acid sequence selected from any one of SEQ ID NOs: 1–4. 40. A method for improving stability of a circular ribonucleic acid (circular RNA) comprising a nucleotide sequence, the nucleotide sequence comprising an open reading frame (ORF) encoding a protein, the method comprising: (i) substituting one or more nucleotides at adenosine positions with modified nucleotides comprising N6-methyladenosine (m6A) to produce a modified nucleotide sequence, wherein 5–95%, 5–80%, 5–60%, 5–40%, 5–20%, 5–10%, 5–7%, 7–10%, 10–15%, 15–20%, 20– 25%, 25–30%, 30–40%,
40–50%, 50–60%, 60–70%, 70–80%, 80–90%, or 90–95% of nucleotides at adenosine positions in the modified nucleotide sequence comprise m6A; and (ii) synthesizing a circular RNA comprising the modified nucleotide sequence.
41. The method of claim 40, wherein 10–25% of nucleotides at adenosine positions comprise N6-methyladenosine.
42. The method of claim 40 or 41, wherein the circular RNA comprises a SaliFHB internal ribosome entry site (IRES) operably linked to the ORF.
43. The method of any one of claims 40–42, wherein the circular RNA comprises one or more target sequences for one or more miRNAs that are specific to an immune cell.
44. The method of claim 43, wherein the one or more miRNAs are specific to macrophages.
45. The method of claim 43 or 44, wherein the one or more miRNAs are specific to Kupffer cells.
46. The method of any one of claims 43–45, wherein the one or more miRNAs comprise miR-23a, miR-142, and/or miR-223.
47. The method of any one of claims 43–46, wherein the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for one miRNA.
48. The method of any one of claims 43–47, wherein the circular RNA comprises 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 target sequences for different miRNAs.
49. The method of any one of claims 40–48, wherein a half-life of the circular RNA in a mammalian cell is at least 105%, at least 110%, at least 115%, at least 120%, at least 125%, at least 130%, at least 140%, at least 150%, at least 175%, at least 200%, at least 225%, at least 250%, at least 300%, at least 400%, at least 500%, at least 600%, at least 700%, at least 800%, at least 900%, or at least 1000% of a half-life of a control circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position.
50. The method of any one of claims 40–49, wherein a coefficient of degradation of the circular RNA in a mammalian cell is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to control circular RNA comprising the same nucleotide sequence as the circular
RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position.
51. The method of any one of claims 40–50, wherein a level of expression, in a mammalian cell, of the protein encoded by the ORF of the circular RNA is at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% of a level of expression of the protein from a control circular RNA comprising the same nucleotide sequence as the circular RNA, the control circular RNA comprising the same nucleotide sequence as the circular RNA but with an unmodified adenosine nucleotide at each adenosine position.
52. The method of any one of claims 40–51, wherein a level of expression in a mammalian cell of the protein encoded by the ORF of the circular RNA is at least 50% of a level of expression of a control linear messenger ribonucleic acid (mRNA) comprising the ORF.
53. The method of any one of claims 40–52, wherein a coefficient of degradation of the circular RNA in a mammal is 90% or less, 80% or less, 70% or less, 60% or less, or 50% or less, relative to a control linear messenger ribonucleic acid (mRNA) comprising the ORF.
54. The method of any one of claims 49–52, wherein the mammalian cell is a human cell.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202363493182P | 2023-03-30 | 2023-03-30 | |
| US63/493,182 | 2023-03-30 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024206835A1 true WO2024206835A1 (en) | 2024-10-03 |
Family
ID=90880745
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2024/022251 Ceased WO2024206835A1 (en) | 2023-03-30 | 2024-03-29 | Circular mrna and production thereof |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2024206835A1 (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12318443B2 (en) | 2016-11-11 | 2025-06-03 | Modernatx, Inc. | Influenza vaccine |
| US12383508B2 (en) | 2018-09-19 | 2025-08-12 | Modernatx, Inc. | High-purity peg lipids and uses thereof |
| US12428577B2 (en) | 2021-05-14 | 2025-09-30 | Modernatx, Inc. | Methods of monitoring in vitro transcription of mRNA and/or post-in vitro transcription processes |
| US12460259B2 (en) | 2019-03-11 | 2025-11-04 | Modernatx, Inc. | Fed-batch in vitro transcription process |
Citations (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002098443A2 (en) | 2001-06-05 | 2002-12-12 | Curevac Gmbh | Stabilised mrna with an increased g/c content and optimised codon for use in gene therapy |
| US20050011836A1 (en) | 2003-07-17 | 2005-01-20 | Brian Bidlingmeyer | Additives for reversed-phase HPLC mobile phases |
| US20050222064A1 (en) | 2002-02-20 | 2005-10-06 | Sirna Therapeutics, Inc. | Polycationic compositions for cellular delivery of polynucleotides |
| US7404969B2 (en) | 2005-02-14 | 2008-07-29 | Sirna Therapeutics, Inc. | Lipid nanoparticle based compositions and methods for the delivery of biologically active molecules |
| US20090226470A1 (en) | 2007-12-11 | 2009-09-10 | Mauro Vincent P | Compositions and methods related to mRNA translational enhancer elements |
| US20100129877A1 (en) | 2005-09-28 | 2010-05-27 | Ugur Sahin | Modification of RNA, Producing an Increased Transcript Stability and Translation Efficiency |
| US20100293625A1 (en) | 2007-09-26 | 2010-11-18 | Interexon Corporation | Synthetic 5'UTRs, Expression Vectors, and Methods for Increasing Transgene Expression |
| US8158601B2 (en) | 2009-06-10 | 2012-04-17 | Alnylam Pharmaceuticals, Inc. | Lipid formulation |
| WO2012099755A1 (en) | 2011-01-11 | 2012-07-26 | Alnylam Pharmaceuticals, Inc. | Pegylated lipids and their use for drug delivery |
| WO2013086354A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Biodegradable lipids for the delivery of active agents |
| WO2013116126A1 (en) | 2012-02-01 | 2013-08-08 | Merck Sharp & Dohme Corp. | Novel low molecular weight, biodegradable cationic lipids for oligonucleotide delivery |
| WO2014152027A1 (en) | 2013-03-15 | 2014-09-25 | Moderna Therapeutics, Inc. | Manufacturing methods for production of rna transcripts |
| WO2014164253A1 (en) | 2013-03-09 | 2014-10-09 | Moderna Therapeutics, Inc. | Heterologous untranslated regions for mrna |
| WO2015130584A2 (en) | 2014-02-25 | 2015-09-03 | Merck Sharp & Dohme Corp. | Lipid nanoparticle vaccine adjuvants and antigen delivery systems |
| WO2015199952A1 (en) | 2014-06-25 | 2015-12-30 | Acuitas Therapeutics Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2017075531A1 (en) | 2015-10-28 | 2017-05-04 | Acuitas Therapeutics, Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2018053209A1 (en) | 2016-09-14 | 2018-03-22 | Modernatx, Inc. | High purity rna compositions and methods for preparation thereof |
| WO2019036682A1 (en) | 2017-08-18 | 2019-02-21 | Modernatx, Inc. | Rna polymerase variants |
| WO2020172239A1 (en) | 2019-02-20 | 2020-08-27 | Modernatx, Inc. | Rna polymerase variants for co-transcriptional capping |
| WO2020227537A1 (en) | 2019-05-07 | 2020-11-12 | Modernatx, Inc | Differentially expressed immune cell micrornas for regulation of protein expression |
| WO2020237227A1 (en) * | 2019-05-22 | 2020-11-26 | Massachusetts Institute Of Technology | Circular rna compositions and methods |
| CA3219570A1 (en) * | 2021-06-25 | 2022-12-29 | The Board Of Trustees Of The Leland Stanford Junior University | Compositions and methods for improved protein translation from recombinant circular rnas |
| WO2023018773A1 (en) | 2021-08-11 | 2023-02-16 | Modernatx, Inc. | Lipid nanoparticle formulations and methods of synthesis thereof |
| US20230072532A1 (en) * | 2019-03-25 | 2023-03-09 | Flagship Pioneering Innovations Vi, Llc | Compositions comprising modified circular polyribonucleotides and uses thereof |
-
2024
- 2024-03-29 WO PCT/US2024/022251 patent/WO2024206835A1/en not_active Ceased
Patent Citations (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002098443A2 (en) | 2001-06-05 | 2002-12-12 | Curevac Gmbh | Stabilised mrna with an increased g/c content and optimised codon for use in gene therapy |
| US20050222064A1 (en) | 2002-02-20 | 2005-10-06 | Sirna Therapeutics, Inc. | Polycationic compositions for cellular delivery of polynucleotides |
| US20050011836A1 (en) | 2003-07-17 | 2005-01-20 | Brian Bidlingmeyer | Additives for reversed-phase HPLC mobile phases |
| US7404969B2 (en) | 2005-02-14 | 2008-07-29 | Sirna Therapeutics, Inc. | Lipid nanoparticle based compositions and methods for the delivery of biologically active molecules |
| US20100129877A1 (en) | 2005-09-28 | 2010-05-27 | Ugur Sahin | Modification of RNA, Producing an Increased Transcript Stability and Translation Efficiency |
| US20100293625A1 (en) | 2007-09-26 | 2010-11-18 | Interexon Corporation | Synthetic 5'UTRs, Expression Vectors, and Methods for Increasing Transgene Expression |
| US20090226470A1 (en) | 2007-12-11 | 2009-09-10 | Mauro Vincent P | Compositions and methods related to mRNA translational enhancer elements |
| US8158601B2 (en) | 2009-06-10 | 2012-04-17 | Alnylam Pharmaceuticals, Inc. | Lipid formulation |
| WO2012099755A1 (en) | 2011-01-11 | 2012-07-26 | Alnylam Pharmaceuticals, Inc. | Pegylated lipids and their use for drug delivery |
| WO2013086354A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Biodegradable lipids for the delivery of active agents |
| WO2013116126A1 (en) | 2012-02-01 | 2013-08-08 | Merck Sharp & Dohme Corp. | Novel low molecular weight, biodegradable cationic lipids for oligonucleotide delivery |
| WO2014164253A1 (en) | 2013-03-09 | 2014-10-09 | Moderna Therapeutics, Inc. | Heterologous untranslated regions for mrna |
| WO2014152027A1 (en) | 2013-03-15 | 2014-09-25 | Moderna Therapeutics, Inc. | Manufacturing methods for production of rna transcripts |
| WO2015130584A2 (en) | 2014-02-25 | 2015-09-03 | Merck Sharp & Dohme Corp. | Lipid nanoparticle vaccine adjuvants and antigen delivery systems |
| WO2015199952A1 (en) | 2014-06-25 | 2015-12-30 | Acuitas Therapeutics Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2017075531A1 (en) | 2015-10-28 | 2017-05-04 | Acuitas Therapeutics, Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| WO2018053209A1 (en) | 2016-09-14 | 2018-03-22 | Modernatx, Inc. | High purity rna compositions and methods for preparation thereof |
| WO2019036682A1 (en) | 2017-08-18 | 2019-02-21 | Modernatx, Inc. | Rna polymerase variants |
| WO2020172239A1 (en) | 2019-02-20 | 2020-08-27 | Modernatx, Inc. | Rna polymerase variants for co-transcriptional capping |
| US20230072532A1 (en) * | 2019-03-25 | 2023-03-09 | Flagship Pioneering Innovations Vi, Llc | Compositions comprising modified circular polyribonucleotides and uses thereof |
| WO2020227537A1 (en) | 2019-05-07 | 2020-11-12 | Modernatx, Inc | Differentially expressed immune cell micrornas for regulation of protein expression |
| WO2020237227A1 (en) * | 2019-05-22 | 2020-11-26 | Massachusetts Institute Of Technology | Circular rna compositions and methods |
| CA3219570A1 (en) * | 2021-06-25 | 2022-12-29 | The Board Of Trustees Of The Leland Stanford Junior University | Compositions and methods for improved protein translation from recombinant circular rnas |
| WO2023018773A1 (en) | 2021-08-11 | 2023-02-16 | Modernatx, Inc. | Lipid nanoparticle formulations and methods of synthesis thereof |
Non-Patent Citations (42)
| Title |
|---|
| "GenBank", Database accession no. KM023140.1 |
| "Remington: The Science and Practice of Pharmacy", 2005, LIPPINCOTT WILLIAMS & WILKINS |
| ALTSCHUL ET AL., J. MOL. BIOL., vol. 215, 1990, pages 403 - 10 |
| ALTSCHUL ET AL., NUCLEIC ACIDS RES., vol. 25, no. 17, 1997, pages 3389 - 3402 |
| BARANICK ET AL., PROC NATL ACAD SCI U S A., vol. 105, no. 12, 2008, pages 4733 - 4738 |
| BERT ET AL., RNA, vol. 12, no. 6, 2006, pages 1074 - 1083 |
| BOSS ET AL., CHEMBIOCHEM, vol. 21, no. 6, 2020, pages 793 - 796 |
| CHAPPELL ET AL., PNAS, vol. 101, 2004, pages 9590 - 9594 |
| CHEN ROBERT ET AL: "Engineering circular RNA for enhanced protein production", NATURE BIOTECHNOLOGY, 18 July 2022 (2022-07-18), New York, XP055956542, ISSN: 1087-0156, Retrieved from the Internet <URL:https://www.nature.com/articles/s41587-022-01393-0> DOI: 10.1038/s41587-022-01393-0 * |
| CUI LIAN ET AL: "RNA modifications: importance in immune cell biology and related diseases", SIGNAL TRANSDUCTION AND TARGETED THERAPY, vol. 7, no. 1, 22 September 2022 (2022-09-22), XP093130169, ISSN: 2059-3635, Retrieved from the Internet <URL:https://www.nature.com/articles/s41392-022-01175-9> DOI: 10.1038/s41392-022-01175-9 * |
| DOBRIKOVA ET AL., PROC NATL ACAD SCI U S A., vol. 100, no. 25, 2003, pages 15125 - 15130 |
| GARLAPATI ET AL., J BIOL CHEM., vol. 279, no. 5, 2004, pages 3389 - 3397 |
| GRIFFITHS-JONES ET AL., NUCLEIC ACIDS RES, vol. 32, 2004, pages D109 - D111 |
| GRIFFITHS-JONES ET AL., NUCLEIC ACIDS RES, vol. 34, 2006, pages D140 - D144 |
| GRIFFITHS-JONES ET AL., NUCLEIC ACIDS RES, vol. 36, 2008, pages D154 - D158 |
| GURTU ET AL., BIOCHEM BIOPHYS RES COMMUN., vol. 229, 1996, pages 295 - 298 |
| HARBI ET AL., PLOS ONE, vol. 17, no. 10, 2022, pages e0274162 |
| JANG ET AL., J VIROL., vol. 63, 1989, pages 1651 - 1660 |
| KARLIN AND ALTSCHUL, PROC. NATL. ACAD. SCI. USA, vol. 87, 1990, pages 2264 - 68 |
| KARLINALTSCHUL, PROC. NATL. ACAD. SCI. USA, vol. 90, 1993, pages 5873 - 77 |
| KAUFMAN ET AL., NUCLEIC ACID RES., vol. 19, 1991, pages 4485 - 4490 |
| KOBAYASHI ET AL., BIOTECHNIQUES, vol. 21, 1996, pages 399 - 402 |
| KOZOMARA ET AL., NUCLEIC ACIDS RES, vol. 39, 2011, pages D152 - D157 |
| KOZOMARA ET AL., NUCLEIC ACIDS RES, vol. 42, 2014, pages D68 - D73 |
| KUIKEN ET AL.: "HIV Sequence Compendium", 2008, LOS ALAMOS NATIONAL LABORATORY |
| MANDALROSSI, NAT. PROTOC., vol. 8, no. 3, 2013, pages 568 - 82 |
| MARTIN ET AL., MOL CELL ENDOCRINOL., vol. 212, 2003, pages 51 - 61 |
| MARTINEAU ET AL., MOL CELL BIOL., vol. 24, no. 17, 2004, pages 7622 - 7635 |
| MIDOUXPICHON, EXPERT REV VACCINES., vol. 14, no. 2, 2015, pages 221 - 234 |
| MOSSER ET AL., BIOTECHNIQUES, vol. 22, 1997, pages 150 - 161 |
| PANDA ET AL., BIO PROTOC., vol. 8, no. 6, 2018, pages e2775 |
| PEDERSEN ET AL., BIOCHEM J., vol. 363, 2002, pages 37 - 44 |
| PETKOVIC ET AL., NUCLEIC ACIDS RES., vol. 43, no. 4, 2015, pages 2454 - 2465 |
| PRATTMACRAE, JBIOL CHEM, vol. 284, no. 27, 2009, pages 17897 - 17901 |
| RAMESH ET AL., NUCLEIC ACID RES., vol. 24, 1996, pages 2697 - 2700 |
| SLAMA KAOUTHAR: "Engineering of modified linear and circular messenger RNA and study of the influence on protein expression tuning", DISSERTATION, UNIVERSITY MAINZ, 1 January 2021 (2021-01-01), XP093125576, Retrieved from the Internet <URL:https://openscience.ub.uni-mainz.de/bitstream/20.500.12030/5752/3/slama_kaouthar-engineering_of-20210426125656292.pdf> [retrieved on 20240130] * |
| STEIN ET AL., MOL CELL BIOL., vol. 18, no. 6, 1998, pages 3112 - 3119 |
| SWEENEY ET AL., J VIROL., vol. 86, no. 3, 2012, pages 1468 - 1486 |
| WESSELHOEFT ET AL., NAT COMMUN., vol. 9, 2018, pages 2629 |
| YAKUBOV ET AL., BIOCHEM. BIOPHYS RES COMMUN., vol. 394, no. 1, 2010, pages 189 - 193 |
| ZHANG ET AL., NAT COMMUN., vol. 11, no. 1, 2020, pages 90 |
| ZHU ET AL., INT J MOL MED., vol. 43, no. 6, 2019, pages 2267 - 2278 |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12318443B2 (en) | 2016-11-11 | 2025-06-03 | Modernatx, Inc. | Influenza vaccine |
| US12409218B2 (en) | 2016-11-11 | 2025-09-09 | Modernatx, Inc. | Influenza vaccine |
| US12383508B2 (en) | 2018-09-19 | 2025-08-12 | Modernatx, Inc. | High-purity peg lipids and uses thereof |
| US12460259B2 (en) | 2019-03-11 | 2025-11-04 | Modernatx, Inc. | Fed-batch in vitro transcription process |
| US12428577B2 (en) | 2021-05-14 | 2025-09-30 | Modernatx, Inc. | Methods of monitoring in vitro transcription of mRNA and/or post-in vitro transcription processes |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7766583B2 (en) | Compositions and methods for enhanced drug delivery | |
| AU2022249357A1 (en) | Methods for identification and ratio determination of rna species in multivalent rna compositions | |
| JP2025061366A (en) | Polynucleotides Comprising Stabilizing Tail Regions | |
| WO2024206835A1 (en) | Circular mrna and production thereof | |
| JP2025061102A (en) | Compositions Comprising Modified Circular Polyribonucleotides and Uses Thereof | |
| WO2024097874A9 (en) | Chemical stability of mrna | |
| CA3024625A1 (en) | Polynucleotides encoding citrin for the treatment of citrullinemia type 2 | |
| CA3024507A1 (en) | Polynucleotides encoding .alpha.-galactosidase a for the treatment of fabry disease | |
| EP3638215A1 (en) | Rna formulations | |
| CA3024624A1 (en) | Polynucleotides encoding porphobilinogen deaminase for the treatment of acute intermittent porphyria | |
| US20220251577A1 (en) | Endonuclease-resistant messenger rna and uses thereof | |
| CN116194151A (en) | LNP compositions comprising mRNA therapeutics with extended half-life | |
| TW202231651A (en) | Large scale synthesis of messenger rna | |
| CN120858178A (en) | DNA compositions containing modified cytosine | |
| WO2019200171A1 (en) | Messenger rna comprising functional rna elements | |
| WO2019136241A1 (en) | Polynucleotides encoding anti-chikungunya virus antibodies | |
| CN119487196A (en) | Double-stranded DNA compositions and related methods | |
| US20240123034A1 (en) | Mrnas encoding granulocyte-macrophage colony stimulating factor for treating parkinson's disease | |
| WO2025054383A1 (en) | Chemical stability of mrna | |
| WO2025036272A1 (en) | Capped mrna and method of preparation thereof | |
| WO2023077170A1 (en) | Polynucleotides encoding integrin beta-6 and methods of use thereof | |
| WO2025117815A1 (en) | Lipid nanoparticle compositions and uses thereof and method for quantifying an amount of capped messenger rna | |
| WO2025010420A2 (en) | Compositions and methods for delivering molecules | |
| WO2025167868A1 (en) | Modified nucleic acid and use thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24721824 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |