WO2024112866A1 - Engineered t cells - Google Patents
Engineered t cells Download PDFInfo
- Publication number
- WO2024112866A1 WO2024112866A1 PCT/US2023/080879 US2023080879W WO2024112866A1 WO 2024112866 A1 WO2024112866 A1 WO 2024112866A1 US 2023080879 W US2023080879 W US 2023080879W WO 2024112866 A1 WO2024112866 A1 WO 2024112866A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- cells
- gdt
- seq
- sequence
- cell
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K40/00—Cellular immunotherapy
- A61K40/10—Cellular immunotherapy characterised by the cell type used
- A61K40/11—T-cells, e.g. tumour infiltrating lymphocytes [TIL] or regulatory T [Treg] cells; Lymphokine-activated killer [LAK] cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K40/00—Cellular immunotherapy
- A61K40/30—Cellular immunotherapy characterised by the recombinant expression of specific molecules in the cells of the immune system
- A61K40/33—Antibodies; T-cell engagers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K40/00—Cellular immunotherapy
- A61K40/40—Cellular immunotherapy characterised by antigens that are targeted or presented by cells of the immune system
- A61K40/41—Vertebrate antigens
- A61K40/42—Cancer antigens
- A61K40/4202—Receptors, cell surface antigens or cell surface determinants
- A61K40/421—Immunoglobulin superfamily
- A61K40/4211—CD19 or B4
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K40/00—Cellular immunotherapy
- A61K40/40—Cellular immunotherapy characterised by antigens that are targeted or presented by cells of the immune system
- A61K40/41—Vertebrate antigens
- A61K40/42—Cancer antigens
- A61K40/4202—Receptors, cell surface antigens or cell surface determinants
- A61K40/4224—Molecules with a "CD" designation not provided for elsewhere
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/33—Fusion polypeptide fusions for targeting to specific cell types, e.g. tissue specific targeting, targeting of a bacterial subspecies
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Definitions
- nucleic and amino acid sequences listed in the accompanying sequence listing are shown using standard letter abbreviations for nucleotide bases, and three letter code for amino acids, as defined in 37 C.F.R. 1.822. Only one strand of each nucleic acid sequence is shown, but the complementary strand is understood as included by any reference to the displayed strand.
- the Sequence Listing is submitted as an ASCII text file in the form of the file named “231121_103- 3002PCT2_Seq_Listing.xml” ( ⁇ 140kb), whicAh was created on November 21, 2023 which is incorporated by reference herein.
- bispecific antibodies may be used to engaged cytotoxic T cells against tumor cells.
- Engineered gamma delta T cells secreting bispecific therapeutics (antibody-based and/or ligand-based) for enhanced cytotoxicity towards various tumor antigens.
- FIG. 1 provides an exemplary STAR framework.
- FIG. 2 provides a schematic representing variable elements of a generic STAR design and exemplary specific element identities.
- FIG. 3 demonstrates further schematics representing variable elements of STAR designs.
- FIG. 4 demonstrates a schematic of an alternative STAR design capable of binding gamma delta T cells.
- FIG. 5 is a LentET STAR schematic.
- FIG. 6 provides a schematic of methods of manufacturing and genetically engineered gamma delta T cells.
- FIG. 7 is a schematic of STARS Mechanism of action.
- FIG. 8 is a flow diagram of a method for gdT cell production.
- FIG. 9 is an overview of gdT cell expansion process.
- FIG. 10 shows identification of donors with acceptable ex vivo expansion of gdT cells from peripheral blood mononuclear cells (PBMCs).
- PBMCs peripheral blood mononuclear cells
- FIG. 11 shows screening of ex vivo expanded gdT cells to identify donors that generate gdT cells with high cytotoxicity toward K562 human cancer cells.
- FIG. 12 is chart of GFP expression in LentET transduced gdT cells.
- FIG. 13 is a chart of GFP MFI in LentET transduced gdT cells.
- FIG. 14 is a chart of data showing cytotoxicity of secreted media from PTK7 and GD2 STAR expressing 293T cells.
- FIG. 15 is data related to mRNA transfected gdT-CMK cytotoxicity.
- FIG. 16 is a Western blot analysis of the designated STAR proteins.
- FIG. 17 is quantitation of STAR secretion.
- FIG. 18 is a characterization of secretion with the albumin linker.
- FIG. 19 is a characterization of gdT cells transduced with STAR-encoding lentivirus gain cytotoxic potential against target cells.
- FIG. 20 is data characterizing Integrin aV B3 CD3 STAR.
- FIG. 21 is data characterizing 1L2 CD19 CD3 STAR.
- FIG. 22 is data characterizing mSA PTK7 CD3 STAR.
- FIG. 23 is data characterizing mSA PTK7 CD3 STAR.
- FIG. 24 is data characterizing mSA and native signal peptide hSCF CD3 STARs.
- FIG. 25 shows gdT cells (effector [E]) were transfected with mRNA encoding the mSA and native signal peptide versions of the hSCF CD3 STAR and mixed with IMR5 cells (target [T]).
- FIG. 26 is data characterizing mSA and IL2 GD2 CD3 STARs.
- FIG. 27 is data characterizing mSA and IL2 GD2 CD3 STARs.
- FIG. 28 demonstrates IL2 SSTR HL and LH CD3 STAR.
- FIG. 29 demonstrates IL2 SSTR HL and LH CD3 STAR.
- FIG. 30 demonstrates a humanized/deimmunized version of the CD3 scFv directs gdT mediated killing.
- FIG. 31 demonstrates a humanized/deimmunized version of the CD3 scFv directs gdT mediated killing.
- FIG. 32 demonstrates Lcntiviral delivery of shRNA knocks down HLA Class I and II surface expression.
- FIG. 33 demonstrates Lentiviral delivery of shRNA knocks down HLA Class I and II surface expression.
- FIG. 34 demonstrates alternative gdT targeting moieties direct gdT mediated cy toxicity.
- FIG. 35 demonstrates alternative gdT targeting moieties direct gdT mediated cy toxicity.
- FIG. 36 demonstrates Somatostain ligand gdT mediated cy toxicity toward NET cells.
- FIG. 37 demonstrates Somatostain ligand gdT mediated cytoxicity toward NET cells.
- FIG. 38 demonstrates IL2 TPO BR CD3 STAR expression.
- FIG. 39 demonstrates mRNA mediated protein expression correlates with mRNA free energy.
- FIG. 40 demonstrates flow cytometry data representing percent killing activity at 1 : 1 and 5:1 ratios, comparing killing activity of PTK7-14, SSTR2-3, and SSTR2-8.
- FIG. 41 is a Western Blot evidencing that the desired proteins were expressed from the plasmid DNA.
- FIG. 42 demonstrates flow cytometry data representing percent killing activity of target cells comparing untreated versus GD2-3.
- the present disclosure relates to peptides, proteins, nucleic acids and cells for use in immunotherapeutic methods.
- hematopoietic cells capable of secreting one or more synthetic fusion proteins and/or therapeutics.
- the present disclosure relates to the immunotherapy of cancer, including, e.g., B cell malignancies, neuroblastoma, osteosarcoma, neuroendocrine tumors (NETs), and acute myeloid leukemia (AML).
- the present disclosure furthermore relates to target cell cytotoxicity and secreted T cell actuators (referred to herein as “STARs”).
- ‘STARs” is an umbrella term to describe the proteins genetically engineered to be expressed from gamma delta T cells.
- the disclosed STARs provide a unique advantage over existing soluble immune-oncology therapies, e.g., cytokines, monoclonal antibodies, and bispecific immune cell engagers.
- the STARs disclosed herein provide a solution to the side effects encountered by existing soluble immune-oncology therapies (i.e., side effects related to dosing, pharmacokinetics, and pharmacodynamics).
- the STARs disclosed herein are ECO optimized using a proprietary method of codon optimization.
- STARs are novel ECO optimized secreted T cell Actuators which are secreted from gamma delta T cells following gene transfer (e.g., viral vector transduction or mRNA electroporation).
- gdT cells novel gamma delta T cells
- gdT cells are engineered to secrete proteins that act to alter the growth, expansion, and viability of a T cell population.
- the gamma delta T cells secrete bi-specific T-cell actuators.
- bi-specific T cell engagers were injected directly into patients via bolus therapy of Fc containing bi-specific antibodies (bsAbs), or continuous infusion of Fc-free bsAbs.
- STARs STARs
- T cell actuators and/or other bispecific molecules e.g., T cell actuators and/or other bispecific molecules, and/or other secreted proteins
- gdT cells delivered to the patients can secrete the proteins of interest.
- a gdT T cell expressing STARs, a STAR(e.g., a bi-specific T cell engager) is inserted into a patient.
- the present disclosure includes STAR designs that target gdT cells to somatostatin receptor 2 (SSTR2) + tumor cells.
- SSTR2 somatostatin receptor 2
- a monoclonal antibody targeting SSTR2 was adapted by converting it into several single chain variable fragment (scFv) designs and used them to direct the STARs/gdT cells to the SSTR2+ tumor.
- the STAR designs can be secreted in vivo from ex vivo modified gdT cells.
- the protein designs have use as recombinant proteins injected directly.
- the gdT cells can be modified to express the STARs by a number of methods, including lenti viral transduction, AAV transduction, mRNA electroporation, mRNA transfection, and non-viral gene transfer technologies, CRISPR knock in, etc.
- Codon optimization is an approach in genetic engineering to improve gene expression by changing synonymous codons based on an organism's codon bias.
- amino acid sequences non-optimized DNA sequences
- ECO Expression Codon Optimized
- gamma delta T-cell ECOg sequences.
- Expression codon optimized for gamma delta T-cell expression is using an algorithm with novel codon usage indices generated from target cell, in this case, gamma delta T-cell, expression data.
- sequences are optimized for expression in or by gamma delta T-cells, they may be referred to alternately a ECOg or gamma delta T-cell optimized.
- sequences in our LentET lentiviral backbone use two different promoters active in gdT cells (see FIG. 5). The first is the synthetic MND promoter; (SEQ ID NO: 152); the second is the human genome derived Heat shock 70 kDa protein 8 promoter HSPA8 (SEQ ID NO: 153). The latter promoter was found to have high activity in gamma delta T cells. Use of this promoter to drive gene expression in gamma delta T-cells, especially from a lenti vector, is a novel use of this sequence.
- T cells secreting a therapeutic e.g., a STAR
- a therapeutic e.g., a STAR
- a fur ther advantage of this method is that a STAR disclosed can also recruit the patient’s T cells to also fight the cancer.
- molecules can be added which enhance T cell function, for example but not limited to, gamma delta T cell function. Molecules can also be added which improve expansion and survival of T cells in vivo. Some examples of additional molecules are IL-2, IL-15.
- the STAR is a bi-specific T cell actuator. In other variations, the STAR operates without engaging a T cell to a cancer cell. In some variations, the STAR mediates the expansion of T cells.
- a STAR has a unique property of being a protein secreted from gdT cells. Secretion from gdT cells has not been demonstrated before. In fact, secretion from gdT cells required extensive optimization of the expression construct. To achieve the disclosed construct capable of expression from gdT cells, we optimized the system at several points in the protein expression chain, which will be discussed further below. [0058] A STAR (e.g., in a single chain-based antibody and/or ligand-based format) optimized for expression and secretion from engineered gamma delta (“(gd) T cells” or “gdT”).
- the STAR When expressed from engineered gdT cells, the STAR will be secreted and mediate engagement between gdT cells and antigen/receptor on target cells. Binding mediates the formation of a cytolytic synapse between the gdT cell and the target cell leading to activation the gdT cells to release proteolytic enzymes that kill target cells.
- STARs e.g., in a scFv-based antibody and/or ligand-based format
- IL-2 signal peptide sequence or another signal peptide optimized for gdT cell expression and secretion (IL-2 signal peptide sequence or another signal peptide).
- Adeno-associated virus A small, replication-defective, non-enveloped virus that infects humans and some other primate species. AAV is not known to cause disease and elicits a very mild immune response. Gene therapy vectors that utilize AAV can infect both dividing and quiescent cells and can persist in an extrachromosomal state without integrating into the genome of the host cell. These features make AAV an attractive viral vector for gene therapy. There are currently 1 1 recognized serotypes of AAV (AAV1 -1 1 ).
- Administration/Administer To provide or give a subject an agent, such as a therapeutic agent (e.g., a recombinant AAV, recombinant lentivirus, STAR, vector expressing a star-, modified gdT cell capable of expressing a STAR), by any effective route.
- a therapeutic agent e.g., a recombinant AAV, recombinant lentivirus, STAR, vector expressing a star-, modified gdT cell capable of expressing a STAR
- routes of administration include, but are not limited to, injection (such as subcutaneous, intramuscular-, intradermal, intraperitoneal, and intravenous), oral, intraductal, sublingual, rectal, transdermal, intranasal, vaginal and inhalation routes.
- Antigen Binding Moiety refers to a polypeptide molecule that specifically binds to an antigenic determinant.
- an antigen binding moiety is able to direct the entity to which it is attached (e.g. a second antigen binding moiety) to a target site, for example to a specific type of tumor cell bearing the antigenic determinant.
- an antigen binding moiety is able to activate signaling through its target antigen, for example a T cell receptor complex antigen.
- Antigen binding moieties include antibodies and fragments thereof as further defined herein.
- antigen binding moieties include an antigen binding domain of an antibody, comprising an antibody heavy chain variable region and an antibody light chain variable region.
- the antigen binding moieties comprise antibody constant regions as further defined herein and known in the art.
- Useful heavy chain constant regions include any of the five isotypes: a, 5, £, y, or p.
- Useful light chain constant regions include any of the two isotypes: K and I.
- Antigenic Determinant is synonymous with “antigen” and “epitope”, and refers to a site (e.g. a contiguous stretch of amino acids or a conformational configuration made up of different regions of non-contiguous amino acids) on a polypeptide macromolecule to which an antigen binding moiety binds, forming an antigen binding moiety-antigen complex.
- Useful antigenic determinants can be found, for example, on the surfaces of tumor cells, on the surfaces of virus-infected cells, on the surfaces of other diseased cells, on the surface of immune cells, free in blood serum, and/or in the extracellular matrix (ECM).
- ECM extracellular matrix
- Specific Binding By “specific binding” is meant that the binding is selective for the antigen and can be discriminated from unwanted or non-specific interactions.
- the ability of an antigen binding moiety to bind to a specific antigenic determinant can be measured either through an enzyme-linked immunosorbent assay (ELISA) or other techniques familiar to one of skill in the ait.
- ELISA enzyme-linked immunosorbent assay
- the extent of binding of an antigen binding moiety to an unrelated protein is less than about 10% of the binding of the antigen binding moiety to the antigen as measured, e.g., by SPR.
- an antigen binding moiety that binds to the antigen, or an antibody comprising that antigen binding moiety has a dissociation constant (KD) of ⁇ 1 pM, ⁇ 100 nM, ⁇ 10 nM, ⁇ 1 nM, ⁇ 0.1 nM, ⁇ 0.01 nM, or ⁇ 0.001 nM (e.g. 10“ 8 M or less, e.g. from 10 -8 M to 10“ 13 M, e.g., from 10“ 9 M to 10“ 13 M).
- KD dissociation constant
- Affinity refers to the strength of the sum total of non-covalent interactions between a single binding site of a molecule (e.g., a receptor) and its binding partner (e.g., a ligand).
- binding affinity refers to intrinsic binding affinity which reflects a 1:1 interaction between members of a binding pair (e.g., an antigen binding moiety and an antigen, or a receptor and its ligand).
- the affinity of a molecule X for its partner Y can generally be represented by the dissociation constant (KD), which is the ratio of dissociation and association rate constants (k O ff and k on , respectively).
- KD dissociation constant
- equivalent affinities arc capable of comprising different rate constants, as long as the ratio of the rate constants remains the same. Affinity can be measured by well established methods known in the art, including those described herein.
- the terms “first”, “second” or “third” with respect to Fab molecules etc. are used for convenience of distinguishing when there is more than one of each type of moiety. Use of these terms is not intended to confer a specific order or orientation of the bispecific antibody unless explicitly so stated.
- Valent The term “valent” as used herein denotes the presence of a specified number of antigen binding sites in an antibody. As such, the term “monovalent binding to an antigen” denotes the presence of one (and not more than one) antigen binding site specific for the antigen in the antibody.
- Antibody The term “antibody” herein is used in the broadest sense and encompasses various antibody structures, including but not limited to monoclonal antibodies, polyclonal antibodies, multispecific antibodies (e.g. bispecific antibodies), and antibody fragments so long as they exhibit the desired antigen-binding activity.
- full length antibody “intact antibody,” and “whole antibody” are used herein interchangeably to refer to an antibody having a structure substantially similar' to a native antibody structure.
- Antibody Fragment refers to a molecule other than an intact antibody that comprises a portion of an intact antibody that binds the antigen to which the intact antibody binds.
- antibody fragments include but are not limited to Fv, Fab, Fab', Fab'-SH, F(ab')2, diabodies, linear- antibodies, single-chain antibody molecules (e.g. scFv), and single-domain antibodies.
- Single-domain antibodies are antibody fragments comprising all or a portion of the heavy chain variable domain or all or a portion of the light chain variable domain of an antibody.
- a single-domain antibody is a human single-domain antibody.
- Antibody fragments can be made by various techniques, including but not limited to proteolytic digestion of an intact antibody as well as production by recombinant host cells (e.g. E. coli or phage), as described herein.
- variable region refers to the domain of an antibody heavy or light chain that is involved in binding the antibody to antigen.
- the variable domains of the heavy chain and light chain (VH and VL, respectively) of a native antibody generally have similar structures, with each domain comprising four conserved framework regions (FRs) and three hypervariable regions (HVRs). See, e.g., Kuby Immunology, 6 th ed., W.H. Freeman and Co., page 91 (2007).
- a single VH or VL domain may be sufficient to confer antigen-binding specificity.
- “Framework” or “FR” refers to variable domain residues other than hypcrvariablc region (HVR) residues.
- the FR of a variable domain generally consists of four FR domains: FR1, FR2, FR3, and FR4. Accordingly, the HVR and FR sequences generally appear in the following order in VH (or VL): FR1-H1(L1)-FR2-H2(L2)-FR3-H3(L3)-FR4.
- the “class” of an antibody or immunoglobulin refers to the type of constant domain or constant region possessed by its heavy chain.
- the heavy chain constant domains that correspond to the different classes of immunoglobulins are called a, 5, s, y, and p, respectively.
- a “Fab molecule” refers to a protein consisting of the VH and CHI domain of the heavy chain (the “Fab heavy chain”) and the VL and CL domain of the light chain (the “Fab light chain”) of an immunoglobulin.
- a “crossover” Fab molecule (also termed “Crossfab”) is meant a Fab molecule wherein the variable domains or the constant domains of the Fab heavy and light chain are exchanged (i.e. replaced by each other), i.e. the crossover Fab molecule comprises a peptide chain composed of the light chain variable domain VL and the heavy chain constant domain 1 CHI (VL-CH1, in N- to C -terminal direction), and a peptide chain composed of the heavy chain variable domain VH and the light chain constant domain CL (VH-CL, in N- to C-terminal direction).
- the peptide chain comprising the heavy chain constant domain 1 CHI is referred to herein as the “heavy chain” of the (crossover) Fab molecule.
- the peptide chain comprising the heavy chain variable domain VH is referred to herein as the “heavy chain” of the (crossover) Fab molecule.
- a “conventional” Fab molecule is meant a Fab molecule in its natural format, i.e. comprising a heavy chain composed of the heavy chain variable and constant domains (VH-CH1 , in N- to C-terminal direction), and a light chain composed of the light chain variable and constant domains (VL-CL, in N- to C-terminal direction).
- immunoglobulin molecule refers to a protein having the structure of a naturally occurring antibody.
- immunoglobulins of the IgG class are heterotetrameric glycoproteins of about 150,000 daltons, composed of two light chains and two heavy chains that are disulfide-bonded. From N- to C-terminus, each heavy chain has a variable domain (VH), also called a variable heavy domain or a heavy chain variable region, followed by three constant domains (CHI, CH2, and CH3), also called a heavy chain constant region.
- each light chain has a variable domain (VL), also called a var iable light domain or a light chain variable region, followed by a constant light (CL) domain, also called a light chain constant region.
- VL variable domain
- the heavy chain of an immunoglobulin may be assigned to one of five types, called a (IgA), 5 (IgD), s (IgE), y (IgG), or p (IgM), some of which may be further divided into subtypes, e.g. yi (IgGi), 72 (IgG2), ya (IgGs), ?4 (IgG 4 ), on (IgAi) and co (IgAz).
- the light chain of an immunoglobulin may be assigned to one of two types, called kappa (K) and lambda (X), based on the amino acid sequence of its constant domain.
- K kappa
- X lambda
- An immunoglobulin essentially consists of two Fab molecules and an Fc domain, linked via the immunoglobulin hinge region.
- Fc domain or “Fc region” herein is used to define a C-terminal region of an immunoglobulin heavy chain that contains at least a portion of the constant region.
- the term includes native sequence Fc regions and variant Fc regions.
- the boundar ies of the Fc region of an IgG heavy chain might vary slightly, the human IgG heavy chain Fc region is usually defined to extend from Cys226, or from Pro230, to the carboxyl-terminus of the heavy chain.
- antibodies produced by host cells may undergo post-translational cleavage of one or more, particularly one or two, amino acids from the C-terminus of the heavy chain.
- an antibody produced by a host cell by expression of a specific nucleic acid molecule encoding a full-length heavy chain may include the full-length heavy chain, or it may include a cleaved variant of the full-length heavy chain.
- This may be the case where the final two C-terminal amino acids of the heavy chain are glycine (G446) and lysine (K447, numbering according to Kabat EU index). Therefore, the C- terminal lysine (Lys447), or the C-terminal glycine (Gly446) and lysine (K447), of the Fc region may or may not be present.
- Reduced binding for example reduced binding to an Fc receptor, refers to a decrease in affinity for the respective interaction, as measured for example by SPR.
- the term includes also reduction of the affinity to zero (or below the detection limit of the analytic method), i.e. complete abolishment of the interaction.
- increased binding refers to an increase in binding affinity for the respective interaction.
- fused is meant that the components (e.g. a Fab molecule and an Fc domain subunit) are linked by peptide bonds, either directly or via one or more peptide linkers.
- Gamma delta T cells are T cells that have a distinctive T cell receptor (TCR) on their surface. Most T cells are a0 (alpha beta) T cells with TCR composed of two glycoprotein chains called a (alpha) and 0 (beta) TCR chains. In contrast, gamma delta (y6) T cells have a TCR that is made up of one y (gamma) chain and one 5 (delta) chain. This group of T cells is usually less common than a0 T cells.
- Hematopoietic cells are cells capable of developing into blood cells through hematopoiesis.
- Human peripheral blood mononuclear cells PBMCs
- PBMCs are immune cells with a single nucleus. PBMCs originate in bone marrow. PBMCs are secreted into peripheral circulation. PBMCs are involved in both humoral and cell-mediated immunity.
- PBMCs include lymphocytes (T cells, B cells, NK cells) and monocytes.
- CD3 refers to any native CD3 from any vertebrate source, including mammals such as primates (e.g. humans), non-human primates (e.g. cynomolgus monkeys) and rodents (e.g. mice and rats), unless otherwise indicated.
- the term encompasses “full-length,” unprocessed CD3 as well as any form of CD3 that results from processing in the cell.
- the term also encompasses naturally occurring variants of CD3, e.g., splice variants or allelic variants.
- CD3 is human CD3, particularly the epsilon subunit of human CD3 (CD3c).
- the BiTE format also known as a tandem scFv or (scFv)2, is a small-sized Fc-free molecule composed of two scFvs connected by a flexible linker on a single polypeptide.
- the in vivo transfer of bsAb-encoding genetic information might be performed using viral and nonviral vectors.
- bispecific means that the antibody is able to specifically bind to at least two distinct antigenic determinants.
- a bispecific antibody comprises two antigen binding sites, each of which is specific for a different antigenic determinant.
- the bispecific antibody is capable of simultaneously binding two antigenic determinants, particularly two antigenic determinants expressed on two distinct cells.
- Bispecific antibodies include at least one or more antigen binding domains; multimerization core that forms a homo- or hetero-mulitmer; and linkers connecting the elements.
- the antigen-binding domain may be an antibody fragment, such as a Fab, single-chain garment variable (scFv), or single domain antibody (sdAb), or alternatively, an antibody mimetic.
- Another approach is the use of extracellular domains of natural receptors or ligands for the design of bsAbs.
- the multitargeting concept that bsAbs make possible is particularly appealing from a therapeutic point of view because many diseases are multifactorial, involving multiple receptors, ligands, and signaling cascades.
- T-cell engaging bsAbs are designed to simultaneously bind to a selected tumor- associated antigen (TA A) on the tumor cell surface and one of the extracellular CD3 subunits (most commonly CD3e) on the T-cell surface.
- cDNA complementary DNA: A piece of DNA lacking internal, non-coding segments (introns) and regulatory sequences that determine transcription. cDNA is synthesized in the laboratory by reverse transcription from messenger RNA extracted from cells. cDNA can also contain untranslated regions (UTRs) that are responsible for translational control in the corresponding RNA molecule.
- UTRs untranslated regions
- Codon-optimized nucleic acid refers to a nucleic acid sequence that has been altered such that the codons are optimal for expression in a particular system (such as a particular species or group of species).
- a nucleic acid sequence can be optimized for expression in mammalian cells or in a particular mammalian species (such as human cells). Codon optimization does not alter the amino acid sequence of the encoded protein.
- CAI ‘ ‘CAI” is the codon adaptation index. CAI is used as a quantitative method of predicting the level of expression of a gene based on its codon sequence.
- Control A reference standard.
- the control is a negative control sample obtained from a healthy patient.
- the control is a positive control sample obtained from a patient diagnosed with cancer.
- the control is a historical control or standard reference value or range of values (such as a previously tested control sample, such as a group of cancer patients with known prognosis or outcome, or group of samples that represent baseline or normal values).
- a difference between a test sample and a control can be an increase or conversely a decrease.
- the difference can be a qualitative difference or a quantitative difference, for example a statistically significant difference.
- a difference is an increase or decrease, relative to a control, of at least about 5%, such as at least about 10%, at least about 20%, at least about 30%, at least about 40%, at least about 50%, at least about 60%, at least about 70%, at least about 80%, at least about 90%, at least about 100%, at least about 150%, at least about 200%, at least about 250%, at least about 300%, at least about 350%, at least about 400%, at least about 500%, or greater than 500%.
- DNA deoxyribonucleic acid
- DNA is a long chain polymer which comprises the genetic material of most living organisms (some viruses have genes comprising ribonucleic acid (RNA)).
- the repeating units in DNA polymers are four different nucleotides, each of which comprises one of the four bases, adenine (A), guanine (G), cytosine (C), and thymine (T) bound to a deoxyribose sugar to which a phosphate group is attached.
- Triplets of nucleotides (referred to as codons) code for each amino acid in a polypeptide, or for a stop signal.
- codon is also used for the corresponding (and complementary) sequences of three nucleotides in the mRNA into which the DNA sequence is transcribed.
- any reference to a DNA molecule is intended to include the reverse complement of that DNA molecule. Except where singlc-strandcdncss is required by the text herein, DNA molecules, though written to depict only a single strand, encompass both strands of a double-stranded DNA molecule. Thus, a reference to the nucleic acid molecule that encodes a specific protein, or a fragment thereof, encompasses both the sense strand and its reverse complement. For instance, it is appropriate to generate probes or primers from the reverse complement sequence of the disclosed nucleic acid molecules.
- Enhancer A nucleic acid sequence that increases the rate of transcription by increasing the activity of a promoter.
- Flanking Near or next to, also, including adjoining, for instance in a linear or circular polynucleotide, such as a DNA molecule.
- Gene A nucleic acid sequence, typically a DNA sequence, that comprises control and coding sequences necessary for the transcription of an RNA, whether an mRNA or otherwise.
- a gene may comprise a promoter, one or more enhancers or silencers, a nucleic acid sequence that encodes an RNA and/or a polypeptide, downstream regulatory sequences and, possibly, other nucleic acid sequences involved in regulation of the expression of an mRNA.
- exon refers to a nucleic acid sequence found in genomic DNA that is bioinformatically predicted and/or experimentally confirmed to contribute a contiguous sequence to a mature mRNA transcript.
- intron refers to a nucleic acid sequence found in genomic DNA that is predicted and/or confirmed not to contribute to a mature mRNA transcript, but rather to be “spliced out” during processing of the transcript.
- Gene therapy The introduction of a heterologous nucleic acid molecule into one or more recipient cells, wherein expression of the heterologous nucleic acid in the recipient cell affects the cell’s function and results in a therapeutic effect in a subject.
- the heterologous nucleic acid molecule may encode a protein, which affects a function of the recipient cell.
- Hybridizes Hybridization assays for the characterization of nucleic acids with a certain level of identity to the nucleic acid sequences as provided herein are well known in the art; see e.g. Sambrook, Russell “Molecular Cloning, A Laboratory Manual”, Cold Spring Harbor Laboratory, N.Y. (2001); Ausubel, “Current Protocols in Molecular Biology”, Green Publishing Associates and Wiley Interscience, N.Y. (1989).
- the term “hybridization” or “hybridizes” as used herein may relate to hybridizations under stringent or non-stringentconditions. If not further specified, the conditions are preferably non-stringent.
- Said hybridization conditions may be established according to conventional protocols described, e.g., in Sambrook (2001) loc. cit.; Ausubel (1989) loc. cit., or Higgins and Hames (Eds.) “Nucleic acid hybridization, a practical approach” IRL Press Oxford, Washington D.C., (1985).
- the setting of conditions is well within the skill of the artisan and can be determined according to protocols described in the art.
- the detection of only specifically hybridizing sequences will usually require stringent hybridization and washing conditions such as, for example, the highly stringent hybridization conditions of O.lxSSC, 0.1% SDS at 65° C. or 2xSSC, 60° C., 0.1% SDS.
- Low stringent hybridization conditions for the detection of homologous or not exactly complementary sequences may, for example, be set at 6xSSC, 1% SDS at 65° C.
- the length of the probe and the composition of the nucleic acid to be determined constitute further parameters of the hybridization conditions.
- Intron A stretch of DNA within a gene that does not contain coding information for a protein. Introns are removed before translation of a messenger RNA.
- ITR Inverted terminal repeat
- Isolated An “isolated” biological component (such as a nucleic acid molecule, protein, virus or cell) has been substantially separated or purified away from other biological components in the cell or tissue of the organism, or the organism itself, in which the component naturally occurs, such as other chromosomal and extra-chromosomal DNA and RNA, proteins and cells.
- Nucleic acid molecules and proteins that have been “isolated” include those purified by standard purification methods. The term also embraces nucleic acid molecules and proteins prepared by recombinant expression in a host cell as well as chemically synthesized nucleic acid molecules and proteins.
- Nucleic acid molecule A polymeric form of nucleotides, which may include both sense and anti-sense strands of RNA, cDNA, genomic DNA, and synthetic forms and mixed polymers of the above.
- a nucleotide refers to a ribonucleotide, deoxynucleotide or a modified form of either type of nucleotide.
- the term “nucleic acid molecule” as used herein is synonymous with “nucleic acid” and “polynucleotide.”
- a nucleic acid molecule is usually at least 10 bases in length, unless otherwise specified. The term includes single and double stranded forms of DNA.
- a polynucleotide may include either or both naturally occurring and modified nucleotides linked together by naturally occurring and/or non naturally occurring nucleotide linkages.
- cDNA refers to a DNA that is complementary or identical to an mRNA, in either single stranded or double stranded form.
- Encoding refers to the inherent property of specific sequences of nucleotides in a polynucleotide, such as a gene, a cDNA, or an mRNA, to serve as templates for synthesis of other polymers and macromolecules in biological processes having either a defined sequence of nucleotides (i.e., rRNA, tRNA and mRNA) or a defined sequence of amino acids and the biological properties resulting therefrom.
- Nucleotide This term includes, but is not limited to, a monomer that includes a base linked to a sugar, such as a pyrimidine, purine or synthetic analogs thereof, or a base linked to an amino acid, as in a peptide nucleic acid (PNA).
- a nucleotide is one monomer in a polynucleotide.
- a nucleotide sequence refers to the sequence of bases in a polynucleotide.
- Operably linked A first nucleic acid sequence is operably linked with a second nucleic acid sequence when the first nucleic acid sequence is placed in a functional relationship with the second nucleic acid sequence.
- a promoter is operably linked to a coding sequence if the promoter affects the transcription or expression of the coding sequence.
- operably linked DNA sequences are contiguous and, where necessary to join two protein-coding regions, in the same reading frame.
- ORF open reading frame: A series of nucleotide triplets (codons) coding for amino acids. These sequences are usually translatable into a peptide.
- compositions and formulations suitable for pharmaceutical delivery of the disclosed vectors are conventional. Remington’s Pharmaceutical Sciences, by E. W. Martin, Mack Publishing Co., Easton, PA, 19th Edition, 1995, describes compositions and formulations suitable for pharmaceutical delivery of the disclosed vectors.
- parenteral formulations usually comprise injectable fluids that include pharmaceutically and physiologically acceptable fluids such as water, physiological saline, balanced salt solutions, aqueous dextrose, glycerol or the like as a vehicle.
- pharmaceutically and physiologically acceptable fluids such as water, physiological saline, balanced salt solutions, aqueous dextrose, glycerol or the like as a vehicle.
- solid compositions e.g., powder, pill, tablet, or capsule forms
- conventional non-toxic solid carriers can include, for example, pharmaceutical grades of mannitol, lactose, starch, or magnesium stear ate.
- compositions such as vector compositions
- pharmaceutical compositions can contain minor amounts of non-toxic auxiliary substances, such as wetting or emulsifying agents, preservatives, and pH buffering agents and the like, for example sodium acetate or sorbitan monolaurate.
- auxiliary substances such as wetting or emulsifying agents, preservatives, and pH buffering agents and the like, for example sodium acetate or sorbitan monolaurate.
- suitable for administration to a subject the carrier may be sterile, and/or suspended or otherwise contained in a unit dosage form containing one or more measured doses of the composition suitable to induce the desired immune response. It may also be accompanied by medications for its use for treatment purposes.
- the unit dosage form may be, for example, in a sealed vial that contains sterile contents or a syringe for injection into a subject, or lyophilized for subsequent solubilization and administration or in a solid or controlled release dosage.
- Polypeptide Any chain of amino acids, regardless of length or post-translational modification (e.g., glycosylation or phosphorylation). “Polypeptide” applies to amino acid polymers including naturally occurring amino acid polymers and non-naturally occurring amino acid polymer as well as in which one or more amino acid residue is a non-natural amino acid, for example, an artificial chemical mimetic of a corresponding naturally occurring amino acid.
- a “residue” refers to an amino acid or amino acid mimetic incorporated in a polypeptide by an amide bond or amide bond mimetic.
- a polypeptide has an amino terminal (N-terminal) end and a carboxy terminal (C-terminal) end. “Polypeptide” is used interchangeably with peptide or protein, and is used herein to refer to a polymer of amino acid residues.
- Preventing refers to inhibiting the full development of a disease.
- Treating refers to a therapeutic intervention that ameliorates a sign or symptom of a disease or pathological condition after it has begun to develop.
- Treating refers to the reduction in the number or severity of signs or symptoms of a disease.
- Promoter A region of DNA that directs/initiates transcription of a nucleic acid (e.g., a gene).
- a promoter includes necessary nucleic acid sequences near the start site of transcription. Typically, promoters are located near the genes they transcribe.
- a promoter also optionally includes distal enhancer or repressor elements which can be located as much as several thousand base pairs from the start site of transcription.
- a tissue-specific promoter is a promoter that directs/initiated transcription primarily in a single type of tissue or cell.
- Protein A biological molecule expressed by a gene or other encoding nucleic acid (e.g., a cDNA) and comprised of amino acids.
- purified does not require absolute purity; rather, it is intended as a relative term.
- a purified peptide, protein, virus, or other active compound is one that is isolated in whole or in part from naturally associated proteins and other contaminants.
- substantially purified refers to a peptide, protein, virus or other active compound that has been isolated from a cell, cell culture medium, or other crude preparation and subjected to fractionation to remove various components of the initial preparation, such as proteins, cellular debris, and other components.
- a recombinant nucleic acid molecule is one that has a sequence that is not naturally occurring, for example, includes one or more nucleic acid substitutions, deletions or insertions, and/or has a sequence that is made by an artificial combination of two otherwise separated segments of sequence. This artificial combination can be accomplished by chemical synthesis or, more commonly, by the artificial manipulation of isolated segments of nucleic acids, for example, by genetic engineering techniques.
- a recombinant virus is one that includes a genome that includes a recombinant nucleic acid molecule.
- “recombinant AAV” refers to an AAV particle in which a recombinant nucleic acid molecule has been packaged.
- a recombinant protein is one that has a sequence that is not naturally occurring or has a sequence that is made by an artificial combination of two otherwise separated segments of sequence.
- a recombinant protein is encoded by a heterologous (for example, recombinant) nucleic acid that has been introduced into a host cell, such as a bacterial or eukaryotic cell, or into the genome of a recombinant virus.
- Response element A DNA sequence included in a promoter to which one or more transcription factors can bind to and confer an aspect of control of gene expression.
- Sequence identity The identity or similarity between two or more nucleic acid sequences, or two or more amino acid sequences, is expressed in terms of the identity or similarity between the sequences. Sequence identity can be measured in terms of percentage identity; the higher the percentage, the more identical the sequences are. Sequence similarity can be measured in terms of percentage similarity (which takes into account conservative amino acid substitutions); the higher the percentage, the more similar the sequences are. Homologs or orthologs of nucleic acid or amino acid sequences possess a relatively high degree of sequence identity/similarity when aligned using standard methods. This homology is more significant when the orthologous proteins or cDNAs are derived from species which are more closely related (such as human and mouse sequences), compared to species more distantly related (such as human and C. elegans sequences).
- percent (%) amino acid sequence identity with respect to a reference polypeptide sequence is defined as the percentage of amino acid residues in a candidate sequence that are identical with the amino acid residues in the reference polypeptide sequence, after aligning the sequences and introducing gaps, if necessary, to achieve the maximum percent sequence identity, and not considering any conservative substitutions as part of the sequence identity. Alignment for purposes of determining percent amino acid sequence identity can be achieved in various ways that are within the skill in the art, for instance, using publicly available computer software such as BLAST, BLAST-2, Clustal W, Megalign (DNASTAR) software or the FASTA program package. Those skilled in the art can determine appropriate parameters for aligning sequences, including any algorithms needed to achieve maximal alignment over the full length of the sequences being compared, amino acid identity is given in the output alignment header.
- NCBI Basic Local Alignment Search Tool (BLAST) (Altschul et al., J. Mol. Biol. 215:403-10, 1990) is available from several sources, including the National Center for Biological Information (NCBI) and on the internet, for use in connection with the sequence analysis programs blastp, blastn, blastx, tblastn and tblastx. Additional information can be found at the NCBI web site.
- NCBI National Center for Biological Information
- reference to “at least 90% identity” refers to “at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or even 100% identity” to a specified reference sequence.
- Subject Living multi-cellular vertebrate organisms, a category that includes human and non-human mammals.
- Synthetic Produced by artificial means in a laboratory, for example a synthetic nucleic acid can be chemically synthesized in a laboratory.
- TATA box A DNA sequence found in the promoter region of a gene that can be bound by TATA binding protein and transcription factor II D during DNA unwinding and binding by RNA polymerase II.
- a TATA box sequence typically includes a TATAAA sequence and often includes additional 3’ adenine nucleotides.
- Therapeutically effective amount A quantity of a specified pharmaceutical or therapeutic agent (e.g., a recombinant AAV) sufficient to achieve a desired effect in a subject, or in a cell, being treated with the agent.
- a specified pharmaceutical or therapeutic agent e.g., a recombinant AAV
- the effective amount of the agent will be dependent on several factors, including, but not limited to the subject or cells being treated, and the manner of administration of the therapeutic composition.
- Transcription factor A protein that binds to specific DNA sequences and thereby controls the transfer (or transcription) of genetic information from DNA to RNA. TFs perform this function alone or with other proteins in a complex, by promoting (as an activator), or blocking (as a repressor) the recruitment of RNA polymerase (the enzyme that performs the transcription of genetic information from DNA to RNA) to specific genes.
- the specific DNA sequences to which a TF binds is known as a response element (RE) or regulatory element.
- RE response element
- Other names include cis-clcmcnt and cis-acting transcriptional regulatory element.
- Transcription factors interact with their binding sites using a combination of electrostatic (of which hydrogen bonds are a special case) and Van der Waals forces. Due to the nature of these chemical interactions, most transcription factors bind DNA in a sequence specific manner. However, not all bases in the transcription factor-binding site may actually interact with the transcription factor. In addition, some of these interactions may be weaker than others. Thus, many transcription factors do not bind just one sequence but are capable of binding a subset of closely related sequences, each with a different strength of interaction.
- TBP TATA-binding protein
- TBP transcription factor can also bind similar sequences such as TAT AT AT or TATATAA.
- Transcription factors are classified based on many aspects. For example, the secondary, tertiary and quaternary structures of the protein structures DNA-binding sequence and properties, the interaction with the double helix of the DNA, and the metal and other binding characteristics.
- the JASPAR database and TRANSFAC are two web-based transcription factor databases, their experimentally-proven binding sites, and regulated genes.
- Transcription Start Site The location where transcription starts at the 5’ end of a gene sequence.
- Therapeutically effective amount The amount of agent, such as a recombinant AAV vector, that is sufficient to prevent, treat (including prophylaxis), reduce and/or ameliorate the symptoms and/or underlying causes of a disorder or disease, for example to prevent, inhibit, and/or treat cancer. For instance, this can be the amount necessary to inhibit or prevent viral replication or to measurably alter outward symptoms of the disease or condition.
- agent such as a recombinant AAV vector
- administration of a therapeutically effective amount of a vector as disclosed herein can decrease a symptom by a desired amount, for example by at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, at least 95%, at least 98%, at least 100% or more, as compared to a suitable control.
- a therapeutically effective amount encompasses a fractional dose that contributes in combination with previous or subsequent administrations to attaining a therapeutic outcome in the patient.
- a therapeutically effective amount of an agent can be administered in a single dose, or in several doses, for example daily, during a course of treatment.
- the therapeutically effective amount can depend on the subject being treated, the severity and type of the condition being treated, and the manner of administration.
- a unit dosage form of the agent can be packaged in a therapeutic amount, or in multiples of the therapeutic amount, for example, in a vial (e.giller with a pierceable lid) or syringe having sterile components.
- a vector is a nucleic acid molecule allowing insertion of foreign nucleic acid without disrupting the ability of the vector to replicate and/or integrate in a host cell.
- a vector can include nucleic acid sequences that permit it to replicate in a host cell, such as an origin of replication.
- a vector can also include one or more selectable marker genes and other genetic elements.
- An expression vector is a vector that contains the necessary regulatory sequences to allow transcription and translation of inserted gene or genes.
- the vector is an adeno-associated virus (AAV) vector.
- the vector is a gamma-retroviral vector, a lentiviral vector, or an adenoviral vector.
- STARs refers to secreted T cell Actuators.
- the term “actuator” is used to encompass T cell engagers and/or activators.
- the term “actuator” indicates secreted molecules capable of making the gamma delta T cells capable of performing therapeutic functions.
- STARs may be composed of STAR (scFv-based antibody or ligand-based) on one end and a T cell actuator molecule (scFv-based antibody or ligand-based) on the other end.
- STAR scFv-based antibody or ligand-based
- scFv-based antibody or ligand-based T cell actuator molecule
- STARs are a a bispecific and/or a bi-active therapeutic molecule secreted from the engineered gdT cell. STARs mediate binding to CD3 on gdT cells and ligand molecule on target cell to form an immunological synapse which in turn activates gdT cell cytotoxicity.
- FIG. 1 provides a schematic of an exemplary STAR framework.
- the STAR may include at least one of the following elements: Starting on the amino terminus and traveling to the carboxy terminus, the STAR may include: (a) a signal peptide, which signal peptide may be cleaved off prior to secretion from the cell (b) a tumor cell surface protein binding (examples follow), (c) a flexible linker (optional) (also referred to herein as “Central linker”), (d) a T cell surface protein binder.
- signal peptides include but are not limited to IL2, mSA (modified serum albumin) (SEQ ID NO: 3)(SEQ ID NO: 5), and hSCF (human stem cell factor)(SEQ ID NO: 4)(SEQ ID NO: 6).
- the tumor cell surface binding protein may be one or more of, e.g., an scFv, Fab, or natural cell ligand.
- the tumor cell surface binding protein may target cancer cell surface protein targets, e.g., CD19, SSTR2, GD2, PTK7, CD5, CD20, CD22, CD110, CD117, CD19 LH scFv, PTK7 HL scFv, GD2 HL scFv, GD2 LH scFv, Integrin aVB3 HL ScFv, SSTR2 HL scFv, SSTR2 LH scFv, 2xSST28 3xG4S, 2xSST28 4xG2s, TPO ligand, hSCF ligand (SEQ ID NO: 4).
- the tumor cell binding domain may be a single chain antibody variable domain fragment or a tumor cell receptor ligand that binds one selected from the group consisting of SSTR2, PTK7, GD2, SSTR5, CD19, aVB3, CD110, and CD5.
- the tumor cell binding domain may be SSTR2 scFv (SEQ ID NO: 52-58) (either LH or HL), PTK7 HL scFv (SEQ ID NO: 17-23) , SSTR2 HL scFv, CD19 scFv (SEQ ID NO: 7-11) (LH or HL orientation), GD2 scFv (SEQ ID NOS.
- Integrin aVB3 ScFv (in LH or HL orientations), Integrin aVB3 ScFv (SEQ ID NOS: 45-51)(in LH or HL orientations), 2xSST28 3xG4S (SEQ ID NOS: 59-65), 2xSST28, 4xG2s (SEQ ID NOS: 66-72), TPO (ligand) (SEQ ID NOS: 80-86), and SCF (ligand) (SEQ ID NOS: 87-93), SSTR2-8 (SEQ ID NOS: 156-160), GD2-3 (SEQ ID NOS: 161-165), PTK7-14 (SEQ ID NOS: 166-170).
- the flexible linker may be, e.g., G4S (SED ID NO: 155), albumin (SEQ ID NOS: 31-37), Fc (SEQ ID NOS: 87-93).
- the linkers may be combined, e.g, G4S refers to AA Sequence (GGGGS)(SEQ ID NO: 155); G4S -albumin-G4S (e.g., (based on AA Seq) SEQ ID NO: 155 - SEQ ID NO: 31 - SEQ ID NO: 155); G4S - Fc-G4S (e.g., based on AA Seq.) SEQ ID NO: 155 - SEQ ID NO: 87 - SEQ ID NO: 155).
- the gamma delta T cell surface protein binding may be one or more of, e.g., scFV, Fab, and/or natural gamma delta T cell ligand.
- an example of gamma delta T cell surface antigen proteins targets disclosed herein include, e.g., CD3D > subunits, > TCR (T cell receptor) subunits, CD 16, NKG2D, FasL, TRAIL.
- the gamma delta T cell surface antigen protein actuators, engagers and/or activators may be at least one of CD3 HL scFv, CD3 (Hum2) HL scFv, JAML HL scFv, CDXAR ligand, gd-c (VI) HL scFv, gd-c(V6) HL scFv.
- FIG. 2 provides a schematic representing variable elements of a generic STAR design and exemplary specific element identities.
- FIG. 3 demonstrates further schematics representing variable elements of STAR designs.
- the N terminus vs C terminus arrangement of the elements can be arbitrary.
- an exemplary CD19/CD3 molecule can be arranged with CD 19 scFV at/toward the N terminus and CD3 at/toward the C terminus.
- the CD3 could likely be located at the N terminus and the CD 19 at the C terminus.
- the IL2 signal sequence (or alternative) might always be at the N terminus.
- This general scheme may apply to all the described molecules according to the present disclosure.
- it is possible that the protein sequences may be reversed relative to their location within the protein.
- FIG. 4 demonstrates a schematic of an alternative STAR design capable of binding gamma delta T cells.
- the ligand based STAR is shown with cytokind actuators on each end of the construct.
- the signal peptide can be, e.g., IL2, mSA (SEQ ID NO: 3), or hSCF (SEQ ID NO: 4).
- Cytokine 1 may be IL2 or IL15.
- the optional linker e.g., the flexible linker or Central linker
- Cytokine 2 may be IL 15 or IL2.
- FIG. 5 is a LentET STAR schematic. It shows the elements that may be variably present in the transgene design on a lentiviral cassette for the expression of a STAR from a target cell.
- the transgene may include one or more of an (optional) shRNA cassette, internal promoter (e.g., MND or HSPA8), and WPRE sequence (optional).
- LentET is a lentiviral packaging system.
- the transgene packaging plasmid is driven by an external CMV promoter which drives the expression of a transgene cassette RNA including one or more of: 1 ) the cis-viral elements necessary for viral assembly and packaging, 2) an internal promoter sufficient for gene expression in the tar get tissue (e.g, the MND promoter (SEQ ID NO: 152) or HSPA8 promoter(SEQ ID NO: 153)), 3) an ECO optimized STAR-encoding cDNA sequence, 4) optionally a mutated version of the Woodchuck Hepatitis Vims Posttranscriptional Regulatory element (WPREmut) and 5) optionally an shRNA expression cassette driving the expression of on shRNA directed against a component of the major histocompatibility class (MHC) I or II complexes.
- MHC major histocompatibility class
- FIG. 6 provides a schematic of methods of manufacturing and genetically engineered gamma delta T cells.
- Donor peripheral blood mononuclear cells (PBMCs) of autologous or allogenic sources that can be pre-screened for disease-specific profiles may be used as star ting material for the expansion, genetic engineering, and purification of genetically modified gamma delta T cells.
- Final products can include various compositions of gamma delta T cells which may include, e.g., gamma delta 1+ and gamma delta 2+ T cells, at various ratios for the adoptive transfer and treatment of various blood cancers and solid tumors.
- gamma delta T cells which may include, e.g., gamma delta 1+ and gamma delta 2+ T cells genetically engineered to express and/or secret therapeutics against tumor antigens for the treatment of various blood cancers and solid tumors.
- Gamma delta T cells can be expanded from autologous or allogeneic donors under serum-free conditions. Donors can be selected from a set of screening criteria that include, but are not limited to, disease-specific/target specific profiles such as cytotoxicity assay in the presence or absence of other drugs and/or immunotherapies.
- Expansion of gamma delta T cells can be performed under serum-free conditions in a two-phase expansion procedure using PBMCs of autologous or allogenic source as starting material.
- PBMCs may be divided into two cultures for 1) gamma delta 2+ T cell expansion in the presence of zoledronic acid and IL-2 and 2) gamma delta 1+ T cell expansion by delta 1 monoclonal antibody-based activation in the presence of IL-2.
- Both expansion procedures may include two-phases: Phase 1 in the presence of the indicated supplements followed by an alpha beta T cell depletion; and Phase 2 in the presence of only IL-2.
- gamma delta 1+ T cell expansion can also be performed by exposure to concanavalin A (Con A) or phytohaemagglutinin (PHA) stimulation in the presence of IL-2.
- Con A concanavalin A
- PHA phytohaemagglutinin
- Phase 1 modifications may be achieved using modalities that heritably modify chromosomal DNA using, for example, viral or non-viral approaches. These approaches include but are not limited to lentivirus, gamma retrovirus, CRISPR, TALENs, etc. Modification of the genome at this phase can pass the modification to all daughter cells produced during further expansion. Phase 2 modifications can be achieved using non-integrating approaches such as AAV or mRNA which are not passed to daughter cells.
- STARs may be secreted from genetically engineered gamma delta T cell. Actuation may occur through several mechanisms occurring alone or in combination. STARs may mediate binding to CD3 (or other T cell ligands) on gamma delta T cells and ligand molecules on target cells to form an immunological synapse which in turn activates T cell cytotoxicity. The secreted STARs can also mediate engagement between non-genetically modified gamma delta T cells and ligand molecules on target cells to form an immunological synapse which in turn activates T cell cytotoxicity. [0155] In the present disclosure, genetic modification can take place with STARs and/or chimeric antigen receptors (CARs) in gamma delta 1+ and gamma delta 2+ T cells in combination or separately.
- CARs chimeric antigen receptors
- FIG. 7 is a schematic of STARS Mechanism of action.
- the mechanism of action can include STARs expression and secretion from genetically engineered T cells which mediates engagement between T cells and antigen/receptors on target cells.
- the formation of a cytolytic synapse between the T cell and the target cell by the STARs leads to T cell activation and the release of proteolytic enzymes that mediates cytotoxicity of target cells.
- Secretion of STARs from genetically modified T cells also leads to the engagement of non-modified T cells with target cells, resulting in enhanced cytotoxicity.
- T cells with STARs can be combined with other immunotherapeutic approaches (such as, but not limited to, chimeric antigen receptors or CARs, monoclonal antibodies, and/or cytotoxic enhancing molecules).
- immunotherapeutic approaches such as, but not limited to, chimeric antigen receptors or CARs, monoclonal antibodies, and/or cytotoxic enhancing molecules.
- the present molecules could also be produced and purified from in vitro expression systems and delivered as a recombinant protein product.
- T cells may be genetically engineered via plasmid, mRNA, AAV, lentivirus, retrovirus. According to the present disclosure, the engineered T cells may provide endogenous expression and secretion of STARs for enhanced cytotoxicity and be used for adoptive cell transfer.
- the production of recombinant STARs can be used as a therapeutic agent for cancers and solid tumors, including neuroendocrine tumors (NETs) and neuroblastoma.
- the therapeutic mechanism may include sequence optimized expression and secretion of STARs from the engineered T cells for autocrine/paracrine engagement between T cells and target tumor cells.
- the STARs may be a recombinant protein product or a recombinant purified molecule for direct use as a therapeutic agent.
- the present disclosure may include the endogenous expression of STARs and/or adoptive cell transfer of T cells to enhance cytotoxic function of not only adoptively transferred cells but also endogenous T cells.
- IL-2 and other leader sequences for secretion from genetically modified T cells there can be provided IL-2 and other leader sequences for secretion from genetically modified T cells.
- the treatment of cancers and tumors expressing a target antigen can use T cell therapeutics expressing and secreting STARs which can be combined with other immunotherapeutic agents.
- the present disclosure can be a recombinant protein that can be delivered directly, and which can be combined with other immunotherapeutic agents.
- a product can include one or more autologous or allogeneic derived T cells, STARs, and/or other immunotherapeutic agents expressed from genetically modified gamma delta T cells or co-administered with genetically modified gamma delta T cells.
- gdT cells gamma delta T cells
- gdT cells gamma delta T cells secreting one or more synthetic fusion proteins targeted for secretion by inclusion of a modified serum albumin (mSA) signal peptide or stem cell factor signal peptide to enhance fusion protein production.
- mSA modified serum albumin
- gdT cells gamma delta T cells
- gdT cells gamma delta T cells
- gdT cells secreting one or more synthetic fusion proteins that have been expression cassette optimized for expression in gamma delta T cells
- gdT cells engineered gamma delta T cells secreting one or more synthetic fusion proteins that have been expression cassette optimized for expression in gamma delta T cells possessing gamma 9 and delta 2 T cell receptor subunits.
- gdT cells gamma delta T cells secreting a STAR agent, where the therapeutic agent is a bispecific T cell actuator.
- gamma delta T cells secreting one or more synthetic fusion proteins, where the synthetic fusion proteins are bispecific T cell actuators.
- gdT cells gamma delta T cells secreting one or more synthetic fusion proteins where the synthetic fusion proteins are bispecific T cell actuators including an anti-CD3 scFv fused to an scFv capable of binding at least one of CD19, PTK7, GD2, SSTR2, and/or alpha-V beta-3 integrin.
- gdT cells gamma delta T cells secreting one or more synthetic fusion proteins where the synthetic fusion proteins are bispecific T cell actuators comprised of an anti-CD3 scFv fused to a cognate receptor ligand domain.
- gdT cells gamma delta T cells secreting synthetic fusion proteins where the synthetic fusion proteins are bispecific T cell actuators including an anti-CD3 scFv fused to the receptor ligand domain from stem cell factor (SCF), thrombopoietin (TPO), SSTR2, or SSTR5.
- SCF stem cell factor
- TPO thrombopoietin
- SSTR2 SSTR5
- gdT cells gamma delta T cells secreting synthetic fusion proteins are bispecific T cell actuators including an anti-CD3 scFv fused to two or more copies of the receptor ligand SSTR2 and/or SSTR5.
- gdT cells gamma delta T cells secreting synthetic fusion proteins ar e bispecific T cell actuators including an anti-gamma delta TCR scFv fused to an scFv that binds at least one of CD19, PTK7, GD2, SSTR2, and/or alpha-V beta-3 integrin.
- an engineered gamma delta T cells secreting synthetic fusion proteins are bispecific T cell actuators an anti-gamma delta TCR scFv fused to the receptor ligand domain from stem cell factor (SCF), thrombopoietin (TPO), SSTR2, or SSTR5.
- SCF stem cell factor
- TPO thrombopoietin
- SSTR2 SSTR5
- SCF stem cell factor
- TPO thrombopoietin
- SSTR2 thrombopoietin
- SSTR5 stem cell factor
- an engineered gamma delta T cells secreting synthetic fusion proteins are bispecific T cell actuators including an anti-JAML scFv fused to an scFv that binds CD19, PTK7, GD2, SSTR2, or alpha-V beta-3 integrin.
- T cell secreting one or more synthetic fusion proteins where the synthetic fusion proteins are bispecific T cell actuators including an anti-JAML scFv fused to the receptor ligand domain from stem cell factor (SCF), thrombopoietin (TPO), SSTR2, or SSTR5.
- SCF stem cell factor
- TPO thrombopoietin
- SSTR2 thrombopoietin
- T cell secreting one or more synthetic fusion proteins where the synthetic fusion proteins are bispecific T cell actuators including a cognate JAML ligand fused to the receptor ligand domain from stem cell factor (SCF), thrombopoietin (TPO), SSTR2, or SSTR5.
- SCF stem cell factor
- TPO thrombopoietin
- SSTR2 thrombopoietin
- the synthetic fusion proteins include a dual cytokine, the dual cytokine being one or more of IL2 and/or IL15 (e.g., IL2-IL2, IL2-IL15, IL15-IL15).
- IL2 and/or IL15 e.g., IL2-IL2, IL2-IL15, IL15-IL15.
- the engineered T cell secreting one or more synthetic fusion proteins where the engineered T cell, which may be a gamma delta T cell, and which may further be with a gamma delta T cell gamma 9 and delta 2 T cell receptor subunits, is modified for synthetic protein production by lentiviral or Retroviral vector transduction or mRNA transfection.
- a recombinant vector which may be any vector known by one of skill in the ait including but not limited to a recombinant lentiviral or recombinant retroviral vector, encoding one or more synthetic fusion proteins as disclosed herein.
- a recombinant vector e.g., lentiviral or retroviral
- the internal promoter may be a e.g., MND or HSPA8 promoter.
- the disclosed engineered cells may be applied as a cancer therapeutic agent capable of treating cancers including but not limited to B cell malignancies, neuroblastoma, osteosarcoma, neuroendocrine tumors (NETs), and acute myeloid leukemia (AML).
- cancers including but not limited to B cell malignancies, neuroblastoma, osteosarcoma, neuroendocrine tumors (NETs), and acute myeloid leukemia (AML).
- a therapeutic agent comprising a single chain antibody variable domain that binds SSTR2, wherein the single chain antibody variable region that binds SSTR2 has an amino acid sequence at least 96% identical to SEQ ID NO: 156.
- a therapeutic agent comprising a single chain antibody variable domain that binds GD2-3, wherein the single chain antibody variable region that binds GD2-3 has an amino acid sequence at least 96% identical to SEQ ID NO: 161.
- a therapeutic agent having, from N-terminus to C-terminus, a gamma delta T cell optimized signal peptide that is cleaved off prior to secretion, a linker that is SEQ ID NO: 155 (G4S) and a T cell binding protein that is SEQ ID NO: 94 (HUM2).
- an engineered gamma delta T cell capable of secreting at least one therapeutic protein, the therapeutic protein, from N-terminus to C-terminus, including a gamma delta T cell optimized signal peptide, a tumor cell binding domain, a linker, and a T cell binding domain, where the tumor cell binding domain has an amino acid sequence at least 96% identical to SEQ ID NO: 156 or SEQ ID NO: 161.
- the engineered gamma delta T cell optionally includes a linker with the sequence of SEQ ID NO: 155 (G4S).
- the engineered gamma delta T cell optionally includes a T cell binding protein with the sequence of SEQ ID NO: 94 (HUM2).
- the engineered gamma delta T cell has a tumor cell binding domain that is encoded by a nucleic acid sequence at least 96% identical to SEQ ID NO: 157, 158, 159, or 160.
- the engineered gamma delta T cell has a tumor cell binding domain that is encoded by a nucleic acid sequence at least 96% identical to SEQ ID NO: 162, 163, 164, or 165.
- a recombinant viral vector encoding a therapeutic protein capable of biosynthesis and secretion by a gamma delta T cell, the therapeutic protein comprising, from N- terminus to C-terminus, a gamma delta T cell optimized signal peptide that is cleaved off prior to secretion, a tumor cell-binding protein domain, a linker, and a T cell binding protein, wherein the tumor cell-binding protein domain binds either of SSTR2 or GD2-3, where the tumor cell-binding protein domain that binds SSTR2 has an amino acid sequence at least 96% identical to SEQ ID NO: 156, or the tumor cell-binding protein domain that binds GD2-3 and has an amino acid sequence at least 96% identical to SEQ ID NO: 161.
- the linker is SEQ ID NO: 155.
- the T cell binding protein is SEQ ID NO: 94.
- the tumor cell-binding protein domain that binds SSTR2 is encoded by a nucleic acid sequence at least 96% identical to at least one of SEQ ID NO: 157, 158, 159, or 160.
- the tumor cell-binding protein domain that binds GD2-3 is encoded by a nucleic acid sequence at least 96% identical to at least one of SEQ ID NO: 162, 163, 164, or 165.
- FIG. 1 provides a schematic of an exemplary STAR framework.
- the STARs disclosed by construct and through the Sequence Listings provided below, are optimized for improved expression over corresponding, human codon optimized and/or nonoptimized constructs.
- the STAR constructs provided were optimized specifically for improved expression in gamma delta T cells. This optimization improved the ability of gamma delta T cells to more efficiently produce and express therapeutic proteins, as demonstrated by improved cytotoxicity.
- the optimizations targeted each step of the protein production pathway to increase translation and expression in the gamma delta T cell environment.
- the promoter element of the STAR has been optimized for improved gamma delta T cell expression of therapeutic molecules.
- HSP8 promoter SEQ ID NO: 153
- FIG. 12 and FIG. 13 for a data demonstrating the retained expression of GFP in cells driven by the novel disclosed HSP8 promoters when compared to the MND promoters.
- MND and HSPA8 GFP expression in lentivirally transduced gdT cells are examples of the promoter element of the STAR.
- Fresh gdT cells were transduced with lentiviral particles carrying a GFP expression cassette driven by either the MND (myeloproliferative sarcoma virus MPSV enhancer, negative control region NCR deletion) or HSPA8 (Heat shock 70 kDa protein 8) (FIG. 12)
- MND myeloproliferative sarcoma virus MPSV enhancer, negative control region NCR deletion
- HSPA8 Heat shock 70 kDa protein 8
- HSPA8 promoter SEQ ID NO: 153 which was optimized to provide a non-viral promoter capable of reaching expression levels comparable to that of the viral promoter MND.
- HSPA8 promoter we disclose a STAR with a preferable composition which, by using a non-viral promoter, reduces known problems created by the MND viral promoter.
- the novel HSPA8 promoter was optimized to reach expression levels comparable to the MND promoter while providing a desirable non-viral promoter.
- STARs were specialized for expression in gamma delta T cells through optimization of the signal peptide components. The increased expression generated by the optimized signal peptide components were demonstrated by improved cytotoxicity of the STAR expressing cells.
- the mSA signal peptide (SEQ ID NO: 3) was optimized for gamma delta T cell expression. The disclosed signal peptides improved cytotoxicity of the gamma delta T cells through increased expression.
- FIG. 14 shows that the mSA signal peptide improves cytotoxicity of secreted media from PTK7 and GD2 STAR expressing 293T cells.
- 293T cells were transfected with the respective STARs and conditioned media was collected 48 hours post-transfection.
- effector Gamma delta cells (effector) and IMR5 cells (target) were co-incubated in the presence of the conditioned media and the percent killing of IMR5 cells was measured after 4 hours. Ratios of effector:target cells are shown on the X axis label.
- linkers e.g, flexible linkers or Central linkers.
- the linkers were optimized specifically for improved ability to be secreted from gamma delta T cells.
- FIG. 16 and FIG. 17 demonstrate the improvements provided by the disclosed linkers.
- albumin fusion and mSA signal peptide increase STAR secretion over IL2 design.
- Various STAR designs were transfected into 293T cells and conditioned media was collected 48 hours post transfection.
- FIG. 16 provides Western blot analysis of the designated STAR proteins.
- FIG. 17 shows quantitation of STAR secretion in the media normalized to the IL2 PTK7 CD3 STAR design.
- FIG. 18 further characterizes improvements provided by the disclosed optimized albumin linker, referred to as albumin fusion.
- FIG. 18 demonstrates that the central albumin fusion improves STAR secretion.
- the albumin fusion was tested positioned between the tumor targeting end gdT targeting end of the STAR. 293T cells were transfected with the IL2 SSTR2 LH STAR with and without a centrally located albumin molecule. Conditioned media was collected 48 hours posttransfection and subjected to quantitative western blot.
- FIG. 19 gdT cells transduced with STAR-encoding lentivirus gain cytotoxic potential against target cells.
- Fresh gdT cells were transduced with lentiviral particles carrying the IL2 CD19 LH CD3 STAR (e.g., SEQ ID NOS: 1-2). After several days of expansion the transduced and mock-transduced gdT cells (Effector, [E]) were coincubated with 697 cells (Target [T] ) and toxicity toward the 697 cells was measured. Ratios of E:T cells are shown on the X axis. This demonstrates that gdT cells transduced with STAR-encoding lentivirus gain cytotoxic potential against target cells.
- FIG. 20 Integrin aV B3 CD3 STAR (e.g., SEQ ID NOS: 45-51) promotes killing of target cells.
- A Plasmid expressing the integrin aV B3 CD3 STAR was transfected into 293T cells and conditioned supernatant was collected 48 hours post transfection. Western blot of the conditioned media shows the correct size of the integrin aV B3 STAR.
- B Fresh gdT cells were transfected with RNA encoding the integrin aV B3 CD3 STAR.
- gdT (effector, [E]) cells were mixed with Human ErythroLeukemia (HEL) cells (target, [T]) and cytotoxicity against the HEL cells was measured. Ratios of effector to target cells are shown along the X axis.
- HEL Human ErythroLeukemia
- FIG. 21 IL2 CD19 CD3 STAR (e.g., SEQ ID NOS: 1-2) promotes killing of target cells.
- 293T cells were transduced with lentivirus encoding GFP or the IL2 CD19 CD3 STAR (e.g., SEQ ID NOS: 1-2) driven by either the HSPA8 or MND promoters.
- Conditioned media was collected 48 hours after transduction.
- gdT cells (effector [E]) and 697 cells (target [T]) were mixed and conditioned media was added and cytotoxicity against the target cells was measured. Effector to target ratios are shown along the X axis.
- This figure shows both the efficacy of the IL2 CD19 CD3 STAR (e.g., SEQ ID NOS: 1-2) variations and demonstrates that the novel HSPA8 promoter provides a comparable non-viral option to the MND promoter.
- FIG. 22 and FIG. 23 demonstrate mSA PTK7 CD3 STAR (e.g., SEQ ID NO: 3, SEQ ID NOS: 17-23) promotes killing of target cells.
- 293T cells were transfected with plasmid expressing the mSA PTK7 CD3 STAR (FIG. 22).
- Conditioned media was collected 48 hours after transfection.
- Western blot of the conditioned media shows a product of the expected size.
- gdT cells (effector [E]) and IMR5 cells (target [T]) were mixed and conditioned media was added and cytotoxicity against the target cells was measured. Effector to target ratios arc shown along the X axis.
- FIG. 24 and FIG. 25 show mSA (SEQ ID NO: 3) and native signal peptide hSCF CD3 STARs promote killing of target cells.
- FIG. 24 shows 293T cells were transfected with plasmid expressing the SCF CD3 STAR using the native SCF signal peptide (hSCF STAR). Conditioned media was collected 48 hours after transfection. Western blot of the conditioned media shows a product of the expected size.
- FIG. 25 shows gdT cells (effector [E]) were transfected with mRNA encoding the mSA (SEQ ID NO: 3) and native signal peptide versions of the hSCF CD3 STAR and mixed with IMR5 cells (target [T]). Cytotoxicity against the target cells was measured. Effector to target ratios are shown along the X axis.
- FIG. 26 and FIG. 27 demonstrate mSA and IL2 GD2 (e.g., SEQ ID NOS: 38-44) CD3 STARs promote killing of target cells.
- 293T cells were transfected with plasmid expressing the mSA or IL2 GD2 HL CD3 STAR.
- Conditioned media was collected 48 hours after transfection.
- Western blot of the conditioned media shows a product of the expected size.
- gdT cells (effector [E]) and IMR5 cells (target [T]) were mixed and conditioned media was added and cytotoxicity against the target cells was measured. Effector to target ratios are shown along the X axis.
- FIG. 29 demonstrate IL2 SSTR HL and LH CD3 STAR promote killing of target cells.
- Plasmids expressing the heavy/light (HL) and light/heavy (LH) arrangement of the SSTR2 scFv in the IL2 SSTR2 CD3 STAR chassis were transfected into 293T cells. Conditioned media was collected 48 hours post transfection where western blot detected bands of the appropriate size.
- mRNA encoding the IL2 SSTR2 HL or LH CD3 STAR were transfected into gdT cells. The transfected cells gdT cells (effectors [E]) were mixed with IMR5 cells (target [T] and the resulting cytotoxicity against the target cells were measured.
- FIG. 30 and FIG. 31 demonstrate a humanized/deimmunized version of the CD3 scFv directs gdT mediated killing.
- 293T cells were transfected with plasmid expressing the CD3 (control) and Hum2 scFV (e.g., SEQ ID NOS: 94-100)(humanized/deimmunized) versions of the IL2 SSTR2 LH STAR.
- Conditioned media was collected 48 hours after transfection. Western blot of the conditioned media shows products of the expected sizes.
- gdT cells effector [E]
- IMR5 cells target [T]
- Cytotoxicity against the target cells was measured. Effector to target ratios are shown along the X axis.
- FIG. 32 and FIG. 33 demonstrate Lentiviral delivery of shRNA knocks down HLA Class I and II surface expression.
- gdT cells were transduced with concentrated and unconcentrated LentET vector carrying a cassette driving the expression of an anti B2m shRNA (B2m shRNAl) and percent knockdown of B2m (HLA Class I) was measured by flow cytometry.
- gdT cells were transduced with LentET vector carrying a cassette driving the expression of an anti CIITA shRNA (CIITA shRNA7) and knockdown of CIITA (HLA Class II) was measured by flow cytometry.
- CIITA shRNA7 anti CIITA shRNA
- our disclosed STARs are uniquely modifed to preemptively address and avoid HLA mismatch to improve chances of graft survival.
- our disclosed gdT-cell product (STAR) is allogeneic, meaning they are derived from non-donor PBMCs. It is generally observed that graft vs host disease (GVHD) is not a major concern for gdT cells as they kill in an MHC-independent manner. However, in an abundance of caution we preemptively try to circumvent immunogenicity ever being an issue my making our cell product more “universal” given that these gdT-cell therapies will probably be administered to patients who are already severely immunosuppressed.
- GVHD graft vs host disease
- HLA II Major Histocompatibility Complex Transcriptional Transactivator
- FIG. 34 and FIG. 35 demonstrate alternative gdT targeting moieties direct gdT mediated cytoxicity.
- FIG. 34 shows 293T cells were transfected with plasmid expressing STARs directed towaid target cells with an anti GD2 scFv and directed toward gdT cells with anti-gdT TCR scFv (gd-c VI and gc-c V6) or anti CD3 scFv.
- Conditioned media was collected 48 hours after transfection.
- gdT cells effector [E]
- IMR5 cells target [T]
- Cytotoxicity against the target cells was measured. Effector to target ratios are shown along the X axis.
- FIG. 36 and FIG 37 demonstrates Somatostain ligand gdT mediated cytoxicity toward NET cells.
- 293T cells were transfected with plasmid expressing STARs directed towaid target cells with somatostain ligand (SST28) and directed towaid gdT cells with anti CD3 scFv.
- Conditioned media was collected 48 hours after transfection.
- gdT cells effector [E]
- IMR5 cells target [T]
- FIG. 38 demonstrates IL2 TPO BR CD3 STAR expression.
- plasmid carrying the IL2 TPO BR CD3 STAR transfected into 293T cells express the expected protein product as detected by western blot.
- FIG. 39 demonstrates mRNA mediated protein expression correlates with mRNA free energy.
- Jurkat cells were transfected with a panel of ECOg optimized mRNA constructs encoding varying from low to high mRNA free energy. GFP expression was measured 8 hours post transfection.
- PTK7-14 and SSTR2-8 STAR plasmids were transfected into 293T-17 cells and conditioned media was harvested 48 hours after transfection.
- IMR5 tumor target model cells were co-incubated with the gamma delta T cells at ratios of 1:1 or 5:1 in the presence of the STAR- containing conditioned media. Percent killing of target cells was determined by flow cytometry.
- 7AAD refers to 7-aminoactinomycin D, a dye used to assess cell death. Annexin is use to measure apoptosis or cell death.
- FIG. 41 293T-17 cells were transfected with STAR-expressing plasmid DNA. Conditioned media was harvested 48 hours post transfection and analyzed for STAR protein presence by anti-his detection western blot assay. Row 1 is blank. Row 2 is mSA PTK7-4 CD3-2 His. Row 3 is mSA PTK7-13 CD302 His. Row 4 is blank. Row 5 is IL2 SSTR2-3 CD3-2 His. Row 6 is IL2 SSTR2- 8 CD3-2 His. Row 7 is mSA PTK7-4 CD3-2 His. Row 8 is mSA PTK7-14 CD3-2 His. Row 9 is blank.
- gd2-3 plasmid was transfected into 293T-17 cells and conditioned media was harvested 48 hours after transfection.
- IMR5 tumor target model cells were co-incubated with the gamma delta T cells at ratios of 1:1 or 5:1 in the presence of the STAR-containing conditioned media. Percent killing of target cells was determined by flow cytometry.
- Gamma delta T cells can be expanded from autologous or allogeneic donors under serum-free conditions. Donors may be selected from a set of screening criteria that include, but are not limited to, disease-specific/target specific profiles such as cytotoxicity assay in the presence or absence of other drugs and/or immunotherapies. (FIG.
- Expansion of gamma delta T cells can be performed under serum-free conditions in a two-phase expansion procedure consisting of Days 0-6 in IL-2 and zoledronic acid in T-flask based culture (Phase 1) and Days 6-12 in IL-2 in Bioreactor based culture (Phase 2).
- An alpha beta T cell depletion step can be performed at Day 6 of culture, prior to Bioreactor based culture.
- Vir al based genetic modification lentiviral and/or gamma retroviral
- AAV-based or mRNA based genetic modification can be performed on Phase 2 of gamma delta T cell expansion for expression and secretion of STARs and/or other immunomodulators such as IL2-IL5 bispecific molecules.
- the manufacturing of genetically engineered gamma delta T cells from autologous or allogeneic donor PBMCs under serum-free conditions can be in a two- phascd expansion procedure. Genetic modification can take place during cither phase 1 or phase 2 of gamma delta T cell expansion.
- Donor pre-screening may be performed under a set of criteria to allow for optimal expansion, genetic modification, and cytotoxicity. Donor pre-screening may be based on diseasespecific selection criteria such as disease/target specific cytotoxicity assay in the presence or absence of other drugs and/or immunotherapies.
- the manufacturing method can solve the problems of: serum-free expansion conditions; screening of donors for optimal expansion, genetic modification, and cytotoxicity towards disease specific target.
- a two-phase expansion procedure can include an alpha beta depletion step for optimal product safety profile. Genetic modification may occur either in phase 1 or phase 2 or a combination thereof for optimal STARs secretion and/or other immunomodulators such as IL2-IL5 bispecific molecules secretion.
- the expansion and genetic modification of gamma delta T cells can be capable of expression and secretion of STARs and/or other immunomodulators for disease-specific enhanced efficacy.
- a method can include: serum-free expansion conditions in a two-phased expansion method, genetic modification in either phase of expansion for combinatorial engineering with STARs and/or immunomodulators, expression and secretion of immunomodulators that promote gamma delta T cell expansion and viability both in vitro and in vivo.
- An autologous or allogeneic gamma delta T cell genetically engineered with STARs harboring target tumor antigen for the treatment of cancers and solid tumors can be provided according to the present disclosure.
- the following can be provided: two phased expansions; genetic modification in either or both phases of the expansion; serum-free expansion conditions; and IL2-IL5 bispecific molecule expressed and secreted endogenously to enhance expansion, viability, and function.
- FIG. 8 a method according to the present disclosure is disclosed and summarized below.
- Step 1 Isolate PBMCs from leukopak (Day 0)
- Step 2 Seed T-flasks with PBMCs (Day 0)
- Step 3 Change media (Day3)
- Step 4 a
- Step 5 Seed Bioreactor with gdT cells (Day 6)
- Step 6 IL-2 supplementation (Day 9)
- Step 7 Harvest cells and cry opreserve (Day 12) [0254] Full leukopak from American Red Cross, typically 1 - 1.5e 10 total nucleated cells per leukopak and typically 150-400ml total volume.
- Step 1 Isolate PBMCs from leukopak (Day 0). This step includes the following protocol: Obtain 22ml whole blood, Add 18ml of Ficoll-Paque to 50ml conical tubes (2 per donor), Remove blood from collection tubes and pipette into a 50 mL conical tube for each donor. Record the starting volume of blood. This volume does not include the PBS washing volume in the next step. Wash collection tubes with 4 ml PBS to remove residual blood and cells off the sides of the tube, then put into 50 mL conical tube with the rest of the blood. Add additional PBS to make final PBS:Blood 1 : 1 ratio by volume. Total diluted blood volume/donoi- 44ml.
- Step 2 Seed T-flasks with PBMCs (Day 0). This step involves the following protocol: Resuspend cell pellet in lOmL OpTmizer media. Count cells. Remove 1ml (500K) cells for immunotyping CD3/gdTCR. Include gdTCR FMO control from pooled samples. Use -100K cells/flow tube. Bring final cell density to 1.5 x 10 6 cells/mL in OpTmizer. Add IL2 and zoledronate to make concentr ations of these 500 lU/mL IL-2 and 5 pmol/L zoledronic acid. Culture cells at 37C/5% CO2 tilting flask (propped) to concentrate cell culture to bottom half of T-75 flask.
- Step 3 Change media (Day3). This step includes the following protocol: Transfer cells to 50 mL conical and gently pipette up/down with a 10ml pipette to break up cell aggregates. Centrifuge cells at 250xg lOmin RT. Resuspend cells in OpTmizer media. Count cells. Bring final cell density to 1.5 x 10 6 cells/mL in complete OpTmizer supplemented with 500IU/mL of IL-2 and 5pmol/L zoledronic acid and replating in the same T-75 flask. Culture cells at 37C/5% CO2 tilting flask (propped) to concentrate cell culture to bottom half of T-75 flask. Lentiviral/Retroviral transduction.
- Step 4 bring cells to a final density of 1.5 x 10 6 cells/mL in complete OpTmizer supplemented with 500IU/mL of IL-2 and 5pmol/L zoledronic acid and lentivirus/retrovirus at desired TU/mL in the presence of transduction enhancers and replate in the same T-75 flask.
- Culture cells at 37C/5% CO2 tilting flask (propped) to concentrate cell culture to bottom half of T-75 flask.
- Day 4 includes the following protocol. Perform a second round of transduction at same TU/mL by removing half of the cells and transferring to a 50 mL conical tube. Centrifuge cells at 250xg lOmin RT.
- Day 5 This step includes the following protocol. Transfer cells to 50 mL conical tube. Centrifuge cells at 250xg lOmin RT. Resuspend cells in complete OpTmizer supplemented with 500IU/mL of IL-2 and 5pmol/L zoledronic acid and replating in the same T-75 flask. Culture cells at 37C/5% CO2 tilting flask (propped) to concentrate cell culture to bottom half of T-75 flask.
- Step 4 a
- Step 5 Seed Bioreactor 500M-CS with gdT cells (Day 6). This step includes the following protocol. Resuspend cells in OpTmizer media. Count cells. Add 2e9 total live cells to each Bioreactor 500M-CS device containing 2.5L of complete OpTmizer media supplemented lOOOIU/mL of IL-2. Culture cells at 37C/5% CO2.
- Day 9 Step 6 IL-2 supplementation (Day 9). This step includes the following protocol. Add lOOOU/ml IL-2 to each Bioreactor device through the needle port/tubing on the top of the device. Return GRex devices to 37C/5% CO2 incubator.
- AAV Transduction This step includes the following protocol. Reduce media in GRex devices by 1/2 to 3/4 of culture volume. Add desired AAV VG/cell supplemented with desired transduction enhancers directly into the GRex. Return GRex devices to 37C/5% CO2 incubator.
- Step 7 Harvest cells and cryopreserve (Day 12). This step includes the following protocol. Remove top 2L (80%) of media from each Bioreactor device without disturbing the cell layer on the Bioreactor membrane using the Gather-Rex pump. Recover cells in remaining 500ml media and tr ansfer cells to a 500ml centrifuge bottle. Remove a sample of the cells for immunotyping analysis and count live cell numbers and determine viability by trypan blue. Centrifuge cells at 300xg 20 min RT. Resuspend cells in cry opreservation solution (PBS + 5% HSA + 10% DMSO) at 10e6 cells/ml. Distribute cells into cryobags. Load bags into control rate freezer and run specified freezing program.
- cry Operaeservation solution PBS + 5% HSA + 10% DMSO
- Step 7 #4 centrifugation
- electroporation buffer resuspend cells in electroporation buffer and add mRNA.
- Electroporate cells using appropriate instrument settings. Cells are either returned to complete media for 2hrs for incubation at 37C/5% CO2 prior to, or immediately resuspended in cryomedia for freezing as described in Step 7 #5.
- Example 1 Gamma Delta T cells were thawed. Cells were incubated for 2 hours at 37C in complete media. Cells (le7) were electroporated with 15ug mRNA. 24 hours later, set up 697 cell cytotoxicity assay with gdT cells + 50% conditioned media in assay tube.
- FIGS. 9-11 show experimental results.
- FIG. 9 is an overview of gdT cell expansion process.
- FIG. 10 shows identification of donors with acceptable ex vivo expansion of gdT cells from peripheral blood mononuclear cells (PBMCs).
- FIG. 11 shows screening of ex vivo expanded gdT cells to identify donors that generate gdT cells with high cytotoxicity toward K562 human cancer cells.
- PBMCs peripheral blood mononuclear cells
- Protocol includes:
- IL-2 (lOOOU/ul), stored at -80 Reconstitute in 250 pg of IL-2 (Peprotech, Cat. # AF-200-02) in 100 mM acetic acid, add 16.25 mL of sterile 1% BSA. Aliquot and store at -80 degrees for long-term storage (up to 1 year) and store at -20 degrees for short-term storage during expansion.
- CD19/CD3 bispecific antibody BPS Biosciences item 100441-1, 0.82mg/ml, for this experiment the ab was taken from a lOul aliquot frozen at -80. Dilute this stock 1:100 in OpTmizer media, Add 2.4ul of ab to each 200ul reaction tube to give a final concentration of lOOng/ml.
- thawing media 2ml of 25% HSA into 8ml PBS. Warm to 37C. take vial directly from -80C to 37C water bath to thaw thaw until just a small chunk of ice remains.
- Target cells (697 cells and Nalm6 cells)
- VPD450 Add I pL of ImM VPD450 stock to 1ml PBS and mix.
- Filter conditioned media with a 0.45um filter attached to a 5ml syringe Filter conditioned media with a 0.45um filter attached to a 5ml syringe.
- VPD450 stained target cells mixture of 1:1 stained and unstained target cells.
- Comp3 7-ADD stained target cells (mix 1:1 of live and dead target cells).
- Comp4 Annexin V-APC stained target cells (1:1 of live and dead target cells).
- This example supports FIGS 12, 13, 15, 19, 25, and 26.
- Day 1 - Transduction #1 (1) Thaw frozen Day 12 gdTCs cells, (2) Thaw lentivirus on ice, (3) Thaw LentiBoost and IL-2, (4) Warm Optimizer at 37 degrees C, (5) Count gdTCs, (6) Aliquot 750,000 cells per 1.5 mL tube, (7) Spin gdT cells down at 300g for 5 minutes, (8) Carefully pipette off the media from the gdTCs, (9) Replace with 500 microliters of the designated or complete OpTmizer media for the Mock transduced cells, (10) Add 10.5 microliters of the LentiBoost + IL-2 master mix, (11) Pipette up and down three times to mix, then dispense into a labeled well in a 48-well plate, (12) Add PBS to all surounding wells to prevent the plate from drying out, (13) Incubate at 37 degrees C overnight.
- FIG. 12 and FIG. 13 See FIG. 12 and FIG. 13 for a data demonstrating the retained expression of GFP in cells driven by the novel disclosed HSP8 promoters when compared to the MND promoters.
- MND and HSPA8 GFP expression in lentivirally transduced gdT cells Fresh gdT cells were transduced with lentiviral particles carrying a GFP expression cassette driven by either the MND (myeloproliferative sarcoma virus MPSV enhancer, negative control region NCR deletion) or HSPA8 (Heat shock 70 kDa protein 8) (FIG. 12) The percent of GFP+ cells was measured at day 6 of gdT expansion. (FIG. 13) The mean fluorescent intensity (MFI) of all cells was measured at day 6 of gdT expansion.
- MND myeloproliferative sarcoma virus MPSV enhancer, negative control region NCR deletion
- HSPA8 Heat shock 70 kDa protein 8
- FIG. 25 shows gdT cells (effector [E]) were transfected with mRNA encoding the mSA (SEQ ID NO: 3) and native signal peptide versions of the hSCF CD3 STAR and mixed with IMR5 cells (target [T]). Cytotoxicity against the target cells was measured. Effector to target ratios are shown along the X axis.
- This example supports FIGS. 14, 16-18, 20-24, 27-31, 34-37, and 40-42.
- Break up cell aggregates by pipetting up/down with a P1000 pipette.
- This example supports FIGS 16-18, 20, 22, 24, 26, 28, 30, 35, 38 and 41.
- Load samples onto gel include a lane loaded w/5uL protein standard.
- the assembly can be made with either 1 or 2 (as pictured) blotting pads on each side of the sandwich. During the assembly of this sandwich, take care not to introduce air bubbles between any of the materials.
- the starting current should be approximately 100mA with an a current at the end of the transfer of approximately ⁇ 20mA.
- This example supports FIGS. 19 and 21 .
- VPD450 Add IpL of ImM VPD450 stock to 1ml PBS and mix.
- Break up cell aggregates by pipetting up/down with a P1000 pipette.
- VPD labelling Target cells Kasumil or HEL cells
- VPD450 Add IpL of ImM VPD450 stock to 1ml PBS and mix.
- Break up cell aggregates by pipetting up/down with a P1000 pipette.
- Target scFv which in the following paragraphs is short hand for the residues of the sequence making up the scFv portion of the targeting scFv, followed by the residues
- Target VL which in the following is short hand for the residues of the sequence making of the VL portion of the targeting scFv, followed by the residues
- Target linker which in the following is short hand for the residues of the sequence making up the linker portion: followed by the residues
- Target VH which in the following is short hand for the residues of the sequence making up the VH of the targeting scFv: followed by the residues
- Central Linker which is shorthand for what is referred to herein also as a flexible linker, see, e.g., FIG. 1: followed by the residues; gdT scFv; gdT VH;
- SEQ ID NO: 1 is the sequence name for IL2 CD 19 CD3 STAR. It is a Complete STAR construct. It is an Amino Acid sequence. The sequence is: MYRMQLLSCIALSLALVTNSDIQLTQSPASLAVSLGQRATISCKASQSVDYDGDSYLNWYQQ IPGQPPKLLIYDASNLVSGIPPRFSGSGSGTDFTLNIHPVEKVDAATYHCQQSTEDPWTFGGGT KLEIKGGGGSGGGGSGGGGSQVQLQQSGAELVRPGSSVKISCKASGYAFSSYWMNWVKQR PGQGLEWIGQIWPGDGDTNYNGKFKGKATLTADESSSTAYMQLSSLASEDSAVYFC ARRET TTVGRYYYAMDYWGQGTTVTVSSGGGGSDIKLQQSGAELARPGASVKMSCKTSGYTFTRY TMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFK
- SEQ ID NO: 1 includes Signal Peptide: 1-20; Target scFv: 21-270; Target VL: 21- 131; Target linker: 132-146; Target VH: 147-270; Central Linker: 271-275; gdT scFv: 276-518; gdT VH: 397-410; gdT Linker: 397-410; gdT VL: 411-518.
- SEQ ID NO: 2 is the sequence name for IL2 CD 19 CD3 STAR. It is a Complete STAR constuct. It is a DNA sequence. The sequence is: ATGTACAGGATGCAGCTGCTGTCCTGCATTGCCCTGTCCCTGGCCCTGGTGACCAACTCC GACATTCAATTGACACAAAGCCCGGCAAGCCTGGCTGTGTCCCTGGGCCAGCGGGCGAC TATTTCATGTAAAGCAAGTCAGCGTAGACTACGATGGTGATAGCTATCTGAACTGGT ATCAGCAGATTCCAGGACAACCTCCCAAATTGCTGATTTACGACGCCTCGAACCTGGTCA GCGGGATTCCACCACGATTCTCTGGAAGCGGCAGTGGAACCGATTTTACGCTGAATATA CACCCAGTGGAAAAGGTGGACGCTGCGACTTATCATTGTCAGCAGTCTACCGAGGACCC ATGGACCTTCGGCGGGGGAACAAAGCTGGATCAAGGGTGGTGGTGGAAGCGGTGGT GGTGGAT
- SEQ ID NO: 2 includes Signal Peptide: 1-60; Target scFv: 61-810; Target VL: 61- 393; Target linker: 394-438; Target VH: 439-810; Central Linker: 811-825; gdT scFv: 826-1544; gdT VH: 1189-1230; gdT Linker: 1189-1230; gdT VL: 1231-1544.
- SEQ ID NO: 3 is the sequence name for modified serum albumin (mSA). It is a Signal Peptide construct. It is an AA sequence. The sequence is: MKWVTFISLLFLFSSSSRA.
- SEQ ID NO: 3 includes Signal Peptide: 1-19.
- SEQ ID NO: 4 is the sequence name for human stem cell factor (hSCF). It is a Signal Peptide construct. It is an AA sequence. The sequence is: MKKTQTWILTCIYLQLLLFNPLVKT.
- SEQ ID NO: 4 includes Signal Peptide: 1-25.
- SEQ ID NO: 5 is the sequence name for modified serum albumin (mSA). It is a Signal Peptide construct. It is a DNA sequence. The sequence is: ATGAAATGGGTTACTTTTATTAGTTTATTATTCCTGTTCAGCTCCAGCTCCAGGGCC.
- SEQ ID NO: 5 includes Signal Peptide: 1-57.
- SEQ ID NO: 6 is the sequence name for human stem cell factor (hSCF). It is a Signal Peptide construct. It is a DNA sequence. The sequence is: ATGAAGAAAACTCAAACTTGGATACTAACTTGCATCTACCTGCAGCTGCTGCTCTTCAAC CCCTTGGTGAAGACG.
- SEQ ID NO: 6 includes Signal Peptide: 1-75.
- SEQ ID NO: 7 is the sequence name for CD19 scFv ECOg (154). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is: GACATCCAGCTCACCCAGAGCCCCGCATCCCTGGCCGTGTCCCTGGGGCAGCGCGCAAC CATCTCCTGCAAGGCTTCCCAGTCCGTGGACTACGACGGGGACTCCTACCTGAACTGGTA CCAGCAGATCCCCGGGCAGCCACCGAAGCTGCTGATCTACGACGCCTCCAACCTGGTGT CCGGGATTCCTCCGCGGTTCTCCGGGAGCGGGTCCGGGACCGACTTCACCCTGAACATCC ATCCCGTGGAGAAGGTGGACGCCGCCACCTACCACTGCCAGCAGTCCACCGAGGACCCC TGGACCTTCGGCGGCGGCACCAAGCTGGAGATCAAAGGTGGCGGAGGCTCCGGTGGCGG AGGTTCCGGTGGCGGCGGCTCCCAGGTGGCGGAGGCTCCGGTGGCGG AGGTTCCGGTG
- SEQ ID NO: 7 includes Target scFv: 1-750; Target VL: 1-333; Target linker: 334- 378; Target VH: 379-750; Free energy: -345.2; gdT CAI: 0.89467859593316; ORF count: 1.
- SEQ ID NO: 8 is the sequence name for CD19 scFv ECOg (94). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is: GACATCCAGCTGACCCAGTCGCCCGCTAGCCTGGCGGTCTCGCTGGGCCAGCGAGCCAC CATCAGCTGCAAGGCCAGCCAGTCGGTCGACTACGACGGCGACAGCTACCTCAACTGGT ACCAGCAGATCCCCGGCCAGCCACCGAAGCTGCTGATCTACGACGCCAGCAACCTGGTG AGCGGGATACCACCGCGGTTCTCGGGGTCGGTCGGGGACCGACTTCACCCTCAACAT CCATCCCGTCGAGAAGGTCGACGCCGCCACCTACCACTGCCAGCAGTCGACCGAGGACC CCTGGACCTTCGGCGGCGGCACCAAGCTGGAGATCAAAGGTGGCGGTGGCTCCGGTGGC GGTGGTAGCGGTGGCGGCGGCTCCCAGGTCCAGCTCCAGCAGTCTGGGGCCGA
- SEQ ID NO: 8 includes Target scFv: 1-750; Target VL: 1-333; Target linker: 334- 378; Target VH: 379-750; Free energy: -360.7; gdT CAI: 0.767359962199379; ORF count: 2.
- SEQ ID NO: 9 is the sequence name for CD19 scFv ECOg (139). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is: GACATCCAGCTGACGCAGTCGCCCGCGTCGCTCGCCGTGTCGCTCGGGCAACGCGCGAC GATCTCGTGCAAGGCGTCGCAGTCCGTCGACTACGACGGCGACTCGTACCTGAACTGGT ACCAGCAGATCCCCGGGCAGCCGCCGAAGCTGCTGATCTACGACGCGAGCAACCTCGTG TCCGGCATTCCGCCGCGGTTCAGCGGCAGCGGCACCGACTTCACGCTGAACAT TCACCCCGTCGAGAAGGTCGACGCCGCGACGTACCACTGCCAGCAGTCCACCGAGGACC CGTGGACGTTCGGCGGCGGCACGAAGCTGGATCAAAGGTGGCGGCGGTTCCGGTGGC GGTGGTTCCGGTGGCGGCGGCAGGTGGTTCCGGTGGC GGTGGTTCCGGTGGCGGCGGGCG
- SEQ ID NO: 9 includes Target scFv: 1-750; Target VL: 1-333; Target linker: 334- 378; Target VH: 379-750; Free energy: -357.7; gdT CAI: 0.724573751544555; ORF count: 1.
- SEQ ID NO: 10 is the sequence name for CD19 scFv ECOg (195). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is: GACATCCAGCTGACCCAGAGCCCCGCGAGCCTGGCCGTGAGCCTGGGGCAGAGGGCCAC CATCAGCTGCAAGGCGTCCCAGAGCGTGGACTACGACGGGGACAGCTACCTGAACTGGT ACCAGCAGATCCCCGGGCAGCCGCCGAAGCTGCTGATCTACGACGCCTCCAACCTGGTG TCCGGGATACCGCCGCGGTTCTCCGGGTCCGGGTCCGGGACCGACTTCACCCTGAACATT CACCCCGTGGAGAAGGTGGACGCCGCCACCTACCACTGCCAGCAGAGCACCC CTGGACCTTCGGCGGCGGCACCAAGCTGGAGATCAAAGGTGGCGGAGGCTCCGGTGGCG GTGGTAGCGGTGGCGGCGGCTCCCAGGTGCAGCTGCAGCAGTCTGGGGCC
- SEQ ID NO: 10 includes Target scFv: 1-750; Target VL: 1-333; Target linker: 334- 378; Target VH: 379-750; Free energy: -356; gdT CAI: 0.858340915819879; ORF count: 2.
- SEQ ID NO: 11 is the sequence name for CD19 scFv ECOg (160). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is: GACATCCAGCTGACCCAGTCACCCGCTAGCCTGGCCGTGTCCCTGGGCCAGCGAGCCAC GATCTCCTGCAAGGCCAGCCAGTCCGTGGACTACGACGGGGACTCCTACCTCAACTGGT ACCAGCAGATCCCCGGCCAGCCACCGAAGCTGCTGATCTACGACGCCTCCAACCTGGTG AGCGGGATTCCGCCGCGGTTCAGCGGGTCCGGGACCGACTTCACCCTCAACAT CCATCCCGTGGAGAAGGTGGACGCCGCCACCTACCACTGCCAGCAGTCCACCGAGGACC CCTGGACCTTCGGCGGCGGCACCAAGCTGGAGATCAAAGGCGGTGGTGGCTCCGGAGGC GGTGGCTCTGGTGGCGGCGGCTCCCAGGTGCAGCTCCAGCAGAGCGGCTGGACC CCTGGACCTTCG
- SEQ ID NO: 11 includes Target scFv: 1-750; Target VL: 1-333; Target linker: 334- 378; Target VH: 379-750; Free energy: -354.8; gdT CAI: 0.876843948859594; ORF count: 2.
- SEQ ID NO: 12 is the sequence name for CD3 scFv ECOg (70). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GATATCAAGCTCCAGCAGTCCGGGGCTGAGCTGGCTAGGCCCGGGGCCTCCGTGAAGAT GTCCTGCAAGACCTCCGGGTACACCTTCACCAGGTACACCATGCACTGGGTGAAGCAGA GGCCCGGGCAGGGGCTGGAGTGGATCGGGTACATCAACCCCAGCCGCGGGTACACCAAC TACAACCAGAAGTTCAAGGACAAGGCCACCTTGACCACCGACAAGTCCTCCTCCACCGC CTACATGCAGCTGAGCTCCCTGACCTCCGAGGACTCCGCCGTCTACTACTGCGCCAGGTA CTACGACGACCACTACTGCCTGGACTACTGGGGCCAGGGGACTACCCTGACCGTGAGCT CCGTGGAAGGTGGCTCCGGCGGCTCCGGAGGTTCCGGAGGCTCCGGCGGCGTGGAGGTTCC
- SEQ ID NO: 12 includes gdT scFv: 1-729; gdT VH: 364-405; gdT Linker: 364-405; gdT VL: 406-729; Free energy: -320.1; gdT CAI: 0.924743; ORF count: 1.
- SEQ ID NO: 13 is the sequence name for CD3 scFv ECOg (197). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GACATCAAGCTCCAGCAGTCCGGGGCTGAGCTTGCTCGCCCCGGGGCCAGCGTGAAGAT GTCCTGCAAGACCTCGGGGTACACCTTCACCAGGTACACCATGCACTGGGTGAAGCAGC GCCCAGGGCAGGGCCTGGAGTGGATAGGGTACATCAACCCCAGCCGCGGGTACACAAA CTACAACCAGAAGTTCAAGGACAAGGCCACGCTGACCACGGACAAGTCCTCGTCCACGG CGTACATGCAGCTGTCCTCGCTGACCTCCGAGGACAGCGCGGTGTACTACTGCGCGCGGT ACTACGACGACCACTACTGCCTGGACTACTGGGGCCAGGGGACAACGCTGACCGTGAGC AGCGTGGAAGGCGGCAGCGGCGGCAGCGGAGGTAGCGGAGGCTCCGGCGGCGTGGAGGTAGCGG
- SEQ ID NO: 13 includes gdT scFv: 1-729; gdT VH: 364-405; gdT Linker: 364-405; gdT VL: 406-729; Free energy: -341.1; gdT CAI: 0.803206301402276; ORF count: 2.
- SEQ ID NO: 14 is the sequence name for CD3 scFv ECOg (109). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GACATCAAGCTGCAGCAGAGCGGCGCTGAGCTCGCGCGACCAGGCGCGAGCGTGAAGA TGAGCTGCAAGACGAGCGGCTACACGTTCACGCGCTACACGATGCACTGGGTGAAGCAG CGTCCCGGGCAGGGGCTGGAGTGGATCGGCTACATCAACCCGTCGCGCGGCTACACGAA CTACAACCAGAAGTTCAAGGACAAGGCGACGCTGACGACCGACAAGAGCAGCAGCACC GCGTACATGCAGCTGAGCTCGCTGACGAGCGAGGACAGCGCCGTGTACTACTGCGCGCG CTACTACGACGACCACTACTGCCTCGACTGGGGCCAGGGCACGACGCTGACCGTGA GCAGCGTCGAAGCGTCGAAGCGTCGAAGCGATGCTGACCGTGA GCAGCTCGACGCTGACCGTGA
- SEQ ID NO: 14 includes gdT scFv: 1-729; gdT VH: 364-405; gdT Linker: 364-405; gdT VL: 406-729; Free energy: -334.7; gdT CAI: 0.70167404462703; ORF count: 1.
- SEQ ID NO: 15 is the sequence name for CD3 scFv ECOg (119). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GACATCAAGCTGCAGCAGAGCGGCGCGGAATTAGCGCGCCCCGGGGCGTCCGTCAAGAT GTCCTGCAAGACCTCCGGGTACACCTTCACGCGGTACACCATGCACTGGGTGAAGCAAC GCCCCGGGCAGGGCCTGGAGTGGATCGGGTACATCAACCCGTCGCGGGGCTACACGAAC TACAACCAGAAGTTCAAGGACAAGGCGACCCTCACGACCGACAAGTCGAGCAGCACGG CGTACATGCAGCTCTCCTCGCTGACCAGCGAGGACTCCGCGGTGTACTACTGCGCGCGGT ACTACGACGACCACTACTGCCTGGACTACTGGGGCCAGGGCACCACGCTGACCGTCAGC TCGGTGGAAGGCGGCTCCGGCGGCTCCGGAGGTTCCGGAGGTTCCGGCGGAGT
- SEQ ID NO: 15 includes gdT scFv: 1-729; gdT VH: 364-405; gdT Linker: 364-405; gdT VL: 406-729; Free energy: -328.1; gdT CAI: 0.739432850740138; ORF count: 0.
- SEQ ID NO: 16 is the sequence name for CD3 scFv ECOg (45). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GACATCAAGCTGCAGCAGTCCGGAGCCGAGTTGGCACGGCCCGGGGCCTCCGTGAAGAT GTCCTGCAAGACGTCCGGGTACACGTTCACCCGGTACACCATGCACTGGGTGAAGCAGC GGCCCGGGCAGGGGCTGGAATGGATCGGGTACATCAACCCCAGCCGCGGGTACACCAAC TACAACCAGAAGTTCAAGGACAAGGCCACGCTGACCACCGACAAGTCGTCGTCGACCGC CTACATGCAGCTGAGCTCGCTGACCAGCGAGGACAGCGCCGTCTACTACTGCGCCCGCT
- SEQ ID NO: 16 includes gdT scFv: 1-729; gdT VH: 364-405; gdT Linker: 364-405; gdT VL: 406-729; Free energy: -323.7; gdT CAI: 0.817020513172323; ORF count: 0.
- SEQ ID NO: 17 is the sequence name for PTK7 scFv. It is a Tumor Targeting scFv construct. It is an AA sequence. The sequence is EVQLVQSGGGLVHPGGSLRLSCAGSGFTFSTYLMYWVRQAPGKTLEWVSAIGSGGDTYYA DSVKGRFTISRDNAKNSLYLQMNSLRAEDMAVYYCARGLGYWGQGTLVTVSSGGGGSGGG GSGGGGSEIVLTQSPGTLSLSPGERATLSCRASQSVSSSYLAWYQQKPGQAPRLLIYGASSRA TGIPDRFSGSGSGTDFTLTISRLEPEDFAVYYCQQYGSSPMYTFGQGTKLEIK.
- SEQ ID NO: 17 includes Target scFv: 1-236; Target VL: 128-236; Target linker: 113-127; Target VH: 1-236.
- SEQ ID NO: 18 is the sequence name for PTK7 scFv. It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTGGTGCAGTCCGGAGGAGGTTTAGTTCACCCAGGAGGCTCGCTGCGACT GTCCTGTGCAGGGAGCGGCTTTACCTTCAGCACATATCTGATGTACTGGGTGAGACAGGC CCCCGGCAAGACGCTGGAGTGGGTCTCAGCTATCGGATCAGGTGGCGACACCTATTACG CTGATAGCGTGAAGGGCCGGTTTACCATAAGCCGCGACAACGCCAAAAATAGTCTTTAC CTGCAGATGAACAGCCTCCGAGCAGAGGATATGGCCGTCTATTACTGCGCTCGGGGACT CGGGTATTGGGGGCAGGGCACCTTGGTGACTGTCTCTCTTCAGGGGGAGGTGGTTCAGGTG GTGGAGGTTCTGGCGGCGGCGGTTCCGAAATTGTACTAACCCAATCTCCTGGCACACTTA GTCT
- SEQ ID NO: 18 includes Target scFv: 1-708; Target VL: 382-708; Target linker: 337-381; Target VH: 1-336; Free energy: -268.3; gdT CAI: 0.722372746155158; ORF count: 6.
- SEQ ID NO: 19 is the sequence name for PTK7 ECOg (74). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTCGTGCAGTCCGGCGGAGGCCTCGTGCACCCAGGCGGCTCCCTGCGCCT GTCCTGCGCCGGGTCAGGCTTCACCTTCTCCACGTACCTCATGTACTGGGTGCGGCAGGC CCCAGGGAAGACCCTGGAGTGGGTGTCCGCCATCGGGTCCGGCGGCGACACGTACTACG CCGACTCCGTGAAGGGGCGCTTCACCATCTCCCGGGACAACGCCAAGAACTCCCTGTAC CTGCAGATGAACTCCCTGCGGGCCGAGGACATGGCCGTGTACTACTGCGCCAGGGGCCT GGGGTACTGGGGCCAGGGGACCCTCGTGACCGTGTCCTCCGGCGGCGGAGGCTCAGGAG GAGGAGGCTCAGGAGGCGGCGGCAGCGAAATCGTCCTGACGCAGAGCCCCGGGACCCT GT
- SEQ ID NO: 19 includes Target scFv: 1-708; Target VL: 382-708; Target linker: 337-381 ; Target VH: 1-336; Free energy: -336.8; gdT CAI: 0.861 158; ORF count: 0.
- SEQ ID NO: 20 is the sequence name for PTK7 ECOg (18). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is GAGGTCCAGCTGGTGCAGTCCGGCGGTGGCCTGGTGCACCCAGGCGGCAGCCTGCGGCT GTCGTGCGCCGGCAGTGGGTTCACCTTCTCCACCTACCTGATGTACTGGGTGCGCCAGGC CCCAGGGAAGACCCTGGAGTGGGTGTCCGCCATCGGCTCCGGCGGCGACACCTACTACG CCGATAGCGTCAAGGGGCGCTTCACCATCTCCCGCGACAACGCCAAGAACTCCCTCTAC CTCCAGATGAACTCCCTGCGGGCCGAGGACATGGCCGTCTACTACTGCGCCAGGGGCCT GGGCTACTGGGGCCAGGGGACCCTGGTGACCGTGTCCTCCGGCGGCGGTGGCTCTGGTG GTGGTGGCTCTGGTGGCGGCGGCAGCGAGATCGTGCTGACCCAGTCGCCCGGGACCCTGACCCTG TCCG
- SEQ ID NO: 20 includes Target scFv: 1-708; Target VL: 382-708; Target linker:
- SEQ ID NO: 21 is the sequence name for PTK7 ECOg (70). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is:
- SEQ ID NO: 21 includes Target scFv: 1-708; Target VL: 382-708; Target linker:
- SEQ ID NO: 22 is the sequence name for PTK7 ECOg (68). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is:
- SEQ ID NO: 22 includes Target scFv: 1-708; Target VL: 382-708; Target linker: 337-381; Target VH: 1-336; Free energy: -355.5; gdT CAI: 0.811107619741586; ORF count: 2.
- SEQ ID NO: 23 is the sequence name for PTK7 ECOg (2). It is a Tumor Targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTGGTGCAGAGCGGCGGAGGCCTGGTGCACCCAGGCGGCTCCCTGCGGCT CAGCTGCGCCGGTTCCGGGTTCACCTTTTCCACGTATCTGATGTACTGGGTGCGCCAGGC CCCGGGGAAGACCCTGGAATGGGTCTCCGCCATCGGCTCCGGCGGCGACACCTACTACG CCGACTCCGTGAAGGGGCGCTTCACCATTTCCCGGGACAACGCGAAGAATTCCCTGTAC CTGCAGATGAACAGTCTCCGCGCCGAGGACATGGCCGTGTACTACTGTGCCCGGGGCCT CGGATACTGGGGCCAGGGGACCCTGGTCACCGTGTCCAGCGGCGGCGGAGGCTCAGGAG GAGGAGGCTCAGGAGGCGGCGGCTCCGAGATCGTGTTGACCCAGAGCCCCGGGACCCTG T
- SEQ ID NO: 23 includes Target scFv: 1-708; Target VL: 382-708; Target linker: 337-381; Target VH: 1-336; Free energy: -350.2; gdT CAI: 0.803914913406133; ORF count: 2.
- SEQ ID NO: 24 is the sequence name for hSCF ligand. It is a Tumor Targeting Ligand construct. It is an AA sequence. The sequence is: EGICRNRVTNNVKDVTKLVANLPKDYMITLKYVPGMDVLPSHCWISEMVVQLSDSLTDLLD KFSNISEGLSNYSIIDKLVNIVDDLVECVKENSSKDLKKSFKSPEPRLFTPEEFFRIFNRSIDAFK DFVVASETSDCVVSS.
- SEQ ID NO: 24 includes Target Ligand: 1-142.
- SEQ ID NO: 25 is the sequence name for hSCF ligand. It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: GAGGGGATCTGCAGGAACAGGGTGACCAACAATGTGAAGGATGTGACCAAGCTGGTGG CCAACCTGCCCAAGGACTACATGATCACCCTGAAGTATGTGCCAGGGATGGATGTGCTG CCCAGCCACTGCTGGATCTCTGAGATGGTGGTGCAGCTGTCTGACTCCCTGACAGACCTG CTGGACAAGTTCTCCAACATCAGAGGGGCTGTCCAACTACTCCATCATTGACAAGCTG GTGAACATAGTGGATGACCTGGTGGAGTGTGTGAAGGAACTCCTCCAAGGACCTGAA GAAGTCCTTCAAGTCCCCTGAGCCCAGGCTGTTCACCCCTGAGGAGTTCTTCAGGATCTT CAACAGGTCCATTGATGCCTTCAAGGACTTTGTGGTGGCCTCTGAGACCTCTGACTGTGT GGTGTCCTCA.
- SEQ ID NO: 25 includes Target Ligand: 1-426; Free energy: -157.8; gdT CAI: 0.937866445503855; ORF count: 3.
- SEQ ID NO: 26 is the sequence name for hSCF ligand ECOg (87). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: GAGGGGATCTGCCGGAACCGGGTGACCAACAACGTGAAGGACGTGACCAAGCTGGTGG CCAACCTGCCCAAGGACTACATGATCACCCTGAAGTACGTGCCCGGGATGGACGTGCTG CCCAGCCACTGCTGGATCAGCGAGATGGTGGTGCAGCTGTCCGACTCCCTGACCGACCT GCTGGACAAGTTCTCCAACATCAGCGAGGGGCTGAGCAACTACTCCATCATCGACAAGC TGGTGAACATCGTGGACGACCTGGTGGAGTGCGTGAAGGAACAGCAGCAAGGACCT GAAGAAGTCCTTCAAGAGCCCCGAGCCCCGGCTGTTCACGCCCGAGGAGTTCTTCCGGA TCTTCAACCGGAGCATCGACGTGGTGGCTGTTCACGCCCGAGGAGTTCTTCCGGA TCTTCAACCGG
- SEQ ID NO: 26 includes Target Ligand: 1-426; Free energy: -160.7; gdT CAI: 0.928424; ORF count: 0.
- SEQ ID NO: 27 is the sequence name for hSCF ligand ECOg (62). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: GAGGGGATCTGCCGGAACCGGGTGACCAACAATGTGAAGGACGTCACAAAGTTGGTCGC CAATCTGCCGAAGGACTACATGATTACGCTGAAGTACGTCCCCGGAATGGATGTGCTGC CCAGCCACTGCTGGATTTCGGAGATGGTGGTGCAGCTGTCCGACAGTCTGACCGATCTGC TGGACAAGTTCAGCAACATCTCCGAAGGGCTGTCCAACTACAGCATCATCGATAAGCTG GTCAACATCGTCGACGATCTGGTGGAGTGCGTCAAAGAGAACAGCAGCAAAGATCTGAA GAAGTCGTTCAAATCGCCGGAGCCGCGGCTGTTCACACCGGAGGAGTTCTTCCGGATCTT CAATCGGTCGATCGACGCCTTCAAAGATTTTGTGGTGGCCAGCGAAACCAGCGACTGCG T
- SEQ ID NO: 27 includes Target Ligand: 1-426; Free energy: -164.6; gdT CAI: 0.805174371566857; ORF count: 2.
- SEQ ID NO: 28 is the sequence name for hSCF ligand ECOg (61). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: GAGGGGATCTGCCGGAACCGCGTGACGAACAACGTGAAGGACGTCACGAAGCTCGTCG CGAACCTGCCGAAGGACTACATGATCACCCTGAAGTACGTCCCCGGGATGGACGTGCTC CCCTCGCACTGCTGGATCTCCGAGATGGTCGTCCAGCTGTCCGACTCCCTGACGGACCTC CTCGACAAGTTCTCCAACATCTCCGAGGGGCTCCAACTACTCGATCATCGACAAGCTG GTGAACATCGTGGACGACCTCGTGGAGTGCGTCAAGGAGAACTCCTCGAAGGACCTCAA GAAGAGCTTCAAGTCGCCCGAGCCGCGGCTCTTCACGCCCGAGGAGTTCTTCCGGATCTT CAACCGGAGCATCGACGCCTTCAAGGACTTCGTGGTGGCCTCCGAGACGTCCGACTGCG TCG
- SEQ ID NO: 28 includes Target Ligand: 1-426; Free energy: -163.9; gdT CAI: 0.83416441300645; ORF count: 0.
- SEQ ID NO: 29 is the sequence name for hSCF ligand ECOg (2). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: GAGGGGATCTGCCGGAACCGGGTGACCAACAACGTGAAGGACGTCACCAAGCTGGTCG CCAACCTGCCCAAGGACTACATGATCACCTTGAAGTACGTGCCCGGCATGGACGTCCTG CCCAGCCACTGCTGGATCTCCGAGATGGTCGTCCAGCTCAGCGACTCCCTGACCGACCTC CTCGACAAGTTCTCCAACATCTCCGAGGGGCTCAGCAACTACTCCATCATCGACAAGCTC GTGAACATAGTGGATGACCTCGTGGAGTGCGTGAAGGAACAGCTCCAAGGACTTGAA GAAGTCCTTCAAGTCCCCGGAGCCCAGGCTGTTCACGCCCGAGGAGTTCTTCAGGATCTT CAACCGATCCATTGACGCCTTCAAGGACTTCGTGGTGGCCTCCGAGACCAGCGACTGCGT GGTGGTCGAGACC
- SEQ ID NO: 29 includes Target Ligand: 1-426; Free energy: -163.7; gdT CAI: 0.886419970682739; ORF count: 2.
- SEQ ID NO: 30 is the sequence name for hSCF ligand ECOg (48). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: GAGGGGATCTGCCGCAACCGCGTGACGAACAACGTGAAGGACGTGACGAAGCTCGTGG CGAACCTGCCCAAGGACTACATGATCACCCTGAAGTACGTCCCCGGGATGGACGTGCTG CCCAGCCACTGCTGGATCTCCGAGATGGTGGTGCAGCTGAGCGACAGCCTGACGGACCT GCTGGACAAGTTCAGCAACATCTCCGAGGGGCTGAGCAACTACAGCATCATCGACAAGC TGGTGAACATCGTGGACGACCTGGTGGAGTGCGTGAAGGAACAGCTCCAAGGACCTG AAGAAGAGCTTCAAGTCGCCCGAGCCCCGGCTGTTCACGCCCGAGGAGTTCTTCCGGAT CTTCAACCGGAGCATCGACGCCTTCAAGGACTTCGTCGTGGCGAGCGACGTCTTCCGGAT CTTCAACC
- SEQ ID NO: 30 includes Target Ligand: 1-426; Free energy: -163.5; gdT CAI: 0.876702550243938; ORF count: 0.
- SEQ ID NO: 31 is the sequence name for Albumin. It is a Fusion Moety construct. It is an AA sequence. The sequence is: DAHKSEVAHRFKDLGEENFKALVLIAFAQYLQQCPFEDHVKLVNEVTEFAKTCVADESAEN CDKSLHTLFGDKLCTVATLRETYGEMADCCAKQEPERNECFLQHKDDNPNLPRLVRPEVDV
- SEQ ID NO: 31 includes Fusion Moeity: 1-590.
- SEQ ID NO: 32 is the sequence name for Albumin. It is a Fusion Moety construct. It is a DNA sequence. The sequence is:
- SEQ ID NO: 32 includes Fusion Moeity: 1-1770; Free energy: -557.6; gdT CAI: 0.787786351918606; ORF count: 21.
- SEQ ID NO: 33 is the sequence name for Albumin ECOg (8). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GACGCCCACAAGTCCGAGGTGGCCCACAGGTTCAAGGACCTGGGCGAGGAGAACTTCAA GGCCCTGGTGCTGATCGCCTTCGCCCAGTACCTGCAGCAGTGCCCCTTCGAGGACCACGT GAAGTTGGTGAACGAGGTGACCGAGTTCGCCAAGACCTGCGTGGCCGACGAGAGCGCCG AGAACTGCGACAAGTCCCTGCACACCCTGTTCGGGGACAAGCTGTGCACCGTGGCCACG CTGCGGGAGACCTACGGGGAGATGGCCGACTGCTGCGCCAAGCAGGAGCCCGAGCGGA ACGAGTGCTTCCTGCAGCACAAGGACGACAACCCCAACCTGCCCCGACTGGTCCGGCCC GAGGTGGACGTGATGTGCACCGCCTTCCACGACAACGTACGAAAAAAAAAAAAAGCAGGAGCGGA ACGAGTGCTTCCTG
- SEQ ID NO: 33 includes Fusion Moeity: 1-1770; Free energy: -755.4; gdT CAI: 0.932865573516391; ORF count: 0.
- SEQ ID NO: 34 is the sequence name for Albumin ECOg (60). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GACGCCCACAAGAGCGAGGTGGCGCACCGCTTCAAGGACCTGGGCGAGGAGAACTTCA AGGCGCTGGTGCTGATCGCGTTCGCCCAGTACCTCCAGCAGTGCCCCTTCGAGGACCACG TGAAGCTGGTGAACGAGGTGACCGAGTTCGCCAAGACCTGCGTGGCCGACGAGAGCGCC GAGAACTGCGACAAGAGCCTCCACACCCTGTTCGGGGACAAGCTGTGCACCGTGGCCAC GCTGCGCGAGACCTACGGGGAGATGGCCGACTGCTGCGCCAAGCAGGAGCCCGAGCGC AACGAGTGCTTCCTCCAGCACAAGGACGACAACCCCAACCTACCCCGTCTGGTGCCC CGAGGTGGACGTGATGTGCACCGCGTTCCACGACAACGAGGAGACCTTCCTCAAGAAGT ACCTCTACGA
- SEQ ID NO: 34 includes Fusion Moeity: 1-1770; Free energy: -753.1; gdT CAI: 0.893692649517376; ORF count: 0.
- SEQ ID NO: 35 is the sequence name for Albumin ECOg (91). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GACGCCCACAAGTCTGAGGTCGCCCATCGGTTCAAGGATCTCGGCGAGGAGAACTTCAA GGCCCTCGTGCTGATCGCCTTCGCGCAGTACCTCCAGCAGTGCCCCTTCGAGGACCACGT GAAGCTGGTCAACGAGGTGACCGAGTTCGCCAAGACCTGCGTGGCCGACGAGAGCGCCG AGAACTGCGATAAGAGCCTGCACACCCTGTTCGGCGACAAGCTGTGCACCGTGGCGACC CTCAGGGAGACCTACGGGGAGATGGCCGACTGCTGCGCCAAGCAGGAGCCCGAGCGGA ACGAGTGCTTCCTGCAGCACAAGGATGACAACCCCAATCTGCCCCGCTTGGTGCGCCCC GAGGTGGACGTGATGTGCACCGCGTTCCACGACAACGAGGAGACCTTCCTGAAGAAGTA CCTCTACGAGATCGCCAGG
- SEQ ID NO: 35 includes Fusion Moeity: 1-1770; Free energy: -750.9; gdT CAI: 0.909026600521571; ORF count: 7.
- SEQ ID NO: 36 is the sequence name for Albumin ECOg (51). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GACGCCCACAAGTCCGAGGTGGCGCACCGCTTCAAGGACCTCGGGGAAGAGAACTTCAA GGCCCTGGTGCTGATCGCCTTCGCAGTACCTGCAGCAGTGCCCCTTCGAGGACCACGT GAAGCTCGTGAACGAGGTCACGGAGTTCGCCAAGACCTGCGTCGCCGACGAGAGCGCCG AGAACTGCGACAAGAGCCTCCACACCCTGTTCGGGGACAAGCTCTGCACCGTGGCGACG CTGCGGGAGACCTACGGCGAGATGGCGGACTGCTGCGCCAAGCAGGAGCCCGAGCGCA ACGAGTGCTTCCTGCAGCACAAGGACGACAACCCCAACCTGCCGCGGCTCGTGAGGCCC GAGGTCGACGTGATGTGCACCGCGTTCCACGACAACGAGGAGAT CCTACGAGATC
- SEQ ID NO: 36 includes Fusion Moeity: 1-1770; Free energy: -749.1; gdT CAI: 0.879685715389261; ORF count: 0.
- SEQ ID NO: 37 is the sequence name for Albumin ECOg (62). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GACGCCCACAAGTCCGAGGTGGCGCACCGCTTCAAGGACCTGGGCGAGGAGAACTTCAA GGCCCTGGTGCTGATCGCCTTCGCCCAGTACCTGCAGCAGTGCCCCTTCGAGGACCACGT GAAGCTGGTGAACGAGGTGACCGAGTTCGCCAAGACCTGCGTGGCCGACGAGTCCGCCG AGAACTGCGACAAGTCCCTGCACACCCTGTTCGGGGACAAGCTGTGCACCGTGGCCACG CTGCGGGAGACCTACGGGGAGATGGCCGACTGCTGCGCCAAGCAGGAGCCCGAGCGGA ACGAGTGCTTCCTGCAGCACAAGGACGACAACCCCAACCTGCCCAGGCTGGTGCGGCCC GAGGTGGACGTGATGTGCACCGCCTTCCACGACAACGAGGAGACCTTCCTGAAGAAGTA CCTGTACGAGATCGCCC
- SEQ ID NO: 37 includes Fusion Moeity: 1-1770; Free energy: -745.2; gdT CAI: 0.955655916201255; ORF count: 4.
- SEQ ID NO: 38 is the sequence name for GD2 scFv. It is a Tumor targeting scFv construct. It is an AA sequence. The sequence is: EVQLLQSGPELEKPGASVMISCKASGSSFTGYNMNWVRQNIGKSLEWIGAIDPYYGGTSYNQ KFKGRATLTVDKSSSTAYMHLKSLTSEDSAVYYCVSGMKYWGQGTSVTVSSGGGGSGGGG SGGGGSDVVMTQTPLSLPVSLGDQAS1SCRSSQSLVHRNGNTYLHWYLQKPGQSPKLLIHKV SNRFSGVPDRFSGSGSGTDFTLKISRVEAEDLGVYFCSQSTHVPPLTFGAGTKLELKRAD.
- SEQ ID NO: 38 includes Target scFv: 1-244; Target VL: 129-244; Target linker: 114-128; Target VH: 1-113.
- SEQ ID NO: 39 is the sequence name for GD2 scFv. It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAAGTGCAGTTGCTGCAGTCTGGACCCGAGCTGGAGAAGCCTGGGGCTTCAGTGATGAT AAGTTGTAAAGCGAGCGGCTCTTCGTTCACGGGATACAACATGAATTGGGTAAGACAGA ACATCGGAAAGTCCCTCGAATGGATTGGTGCAATCGATCCATACTATGGGGGCACAAGC TATAATCAGAAGTTTAAAGGCAGGGCCACTCTGACCGTCGACAAATCCTCATCCACCGCT TATATGCACTTAAAGAGTCTTACTTCTGAAGACAGCGCCGTTTATTACTGCGTGTCAGGC ATGAAGTACTGGGGTCAAGGGACAAGCGTGACCGTCAGTTCCGGTGGTGGTGGAAGCGG TGGTGGTGGATCTGGTGGAAGTGATGTAGTGATGACCCAGACTCCTCTGAGTCTGAGTCTGAGTC
- SEQ ID NO: 39 includes Target scFv: 1-732; Target VL: 385-732; Target linker: 340-384; Target VH: 1-339; Free energy: -243.8; gdT CAI: 0.70651634854966; ORF count: 9.
- SEQ ID NO: 40 is the sequence name for GD2 scFv ECOg (18). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTCCAGCTCCTCCAGTCCGGGCCCGAGCTGGAGAAGCCCGGGGCCTCCGTGATGAT CTCCTGCAAGGCCTCCGGGTCCTCCTTCACCGGGTACAACATGAACTGGGTCCGCCAGAA CATCGGGAAGAGCCTGGAGTGGATCGGGGCCATCGACCCCTACTACGGAGGCACCTCCT ACAACCAGAAGTTCAAGGGCCGGGCCACTCTGACCGTGGACAAGTCCTCCTCCACCGCC TACATGCACCTGAAGAGCCTGACCTCCGAGGACTCCGCCGTCTACTACTGCGTCTCCGGG ATGAAGTACTGGGGCCAGGGGACCTCCGTGACCGTCTCCTCCGGAGGAGGAGGCTCCGG AGGAGGAGGCTCCGGAGGAGGAGGCTCCGACGTGGTGATGACCCAGACCCCTCTGGTCTCC
- SEQ ID NO: 40 includes Target scFv: 1-732; Target VL: 385-732; Target linker: 340-384; Target VH: 1-339; Free energy: -328.1; gdT CAI: 0.877232; ORF count: 0.
- SEQ ID NO: 41 is the sequence name for GD2 scFv ECOg (84). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTCCAGCTGCTGCAGTCGGGGCCCGAGCTGGAGAAGCCCGGGGCCTCCGTCATGAT CTCGTGCAAGGCCTCCGGGTCCTCGTTCACCGGGTACAACATGAACTGGGTGCCAGA ACATCGGGAAGTCGCTGGAGTGGATCGGGGCCATCGACCCCTACTACGGCGGCACCAGC TACAACCAGAAGTTCAAGGGGCGCGCCACGCTGACGGTGGACAAGTCGTCGTCGACCGC CTACATGCACCTGAAGTCGCTGACGTCGGAGGACTCCGCCGTCTACTACTGCGTCAGCGG GATGAAGTACTGGGGCCAGGGGACCTCGGTCACCGTGTCCTCCGGCGGCGGAGGAAGCG GAGGAGGAGGCTCCGGCGGAGGAGGCTCCGACGTCGTGATGACGCAGACCCCGCGGTCCTCC
- SEQ ID NO: 41 includes Target scFv: 1-732; Target VL: 385-732; Target linker: 340-384; Target VH: 1-339; Free energy: -351.8; gdT CAI: 0.797734389193656; ORF count: 0.
- SEQ ID NO: 42 is the sequence name for GD2 scFv ECOg (88). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTCCAGCTGCTCCAGTCCGGGCCCGAGCTGGAGAAGCCCGGGGCCTCGGTGATGAT CAGCTGCAAGGCCTCCGGGTCGAGCTTCACCGGGTACAACATGAACTGGGTCCGGCAGA ACATCGGGAAGTCGCTGGAGTGGATCGGGGCGATCGACCCCTACTACGGCGGCACCAGC TACAACCAGAAGTTCAAGGGGCGCGCGACCCTGACCGTCGACAAGTCGAGCTCGACCGC CTACATGCACCTGAAGTCGCTGACCTCCGAGGACTCCGCGGTCTACTACTGCGTGAGCGG GATGAAGTACTGGGGCCAGGGGACCTCGGTGACCGTGAGCTCCGGCGGCGGCGGATCTG GTGGTGGCGGTTCCGGCGGTGGCGGTTCCGACGTGGTGATGACCCAGACCCCGCTCTCGGCT
- SEQ ID NO: 42 includes Target scFv: 1-732; Target VL: 385-732; Target linker: 340-384; Target VH: 1-339; Free energy: -340; gdT CAI: 0.799370908165938; ORF count: 1.
- SEQ ID NO: 43 is the sequence name for GD2 scFv ECOg (2). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTGCTGCAGTCCGGCCCCGAGCTGGAGAAGCCCGGGGCCAGCGTGATGAT CAGCTGCAAGGCCAGCGGGTCCAGCTTCACGGGGTACAACATGAACTGGGTGCGGCAGA ACATCGGGAAGAGCCTGGAGTGGATCGGGGCCATCGACCCGTACTACGGCGGCACGTCG TACAACCAGAAGTTCAAGGGGCGCGCCACGCTGACCGTGGACAAGTCCAGCAGCACGGC CTACATGCACCTCAAGTCGCTGACCAGCGAGGACAGCGCGGTGTACTACTGCGTGTCCG GCATGAAGTACTGGGGCCAGGGGACCAGCGTGACGGTGAGCAGCGGCGGTGGTGGTGGCGGTGGTGGTGGCGGTGGTGGTGGCGGTGGTGGTGGCGGTGGTGGTGGCGGTGGTGGTGGCA
- SEQ ID NO: 43 includes Target scFv: 1-732; Target VL: 385-732; Target linker: 340-384; Target VH: 1-339; Free energy: -339.9; gdT CAI: 0.78785010580307; ORF count: 2.
- SEQ ID NO: 44 is the sequence name for GD2 scFv ECOg (86). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTCCAGCTCCTCCAGTCCGGGCCCGAGCTGGAGAAGCCCGGGGCCTCCGTGATGAT CTCCTGCAAGGCCTCCGGGTCCTCGTTCACCGGGTACAACATGAACTGGGTGAGGCAGA ACATCGGGAAGAGCCTGGAGTGGATCGGGGCCATCGACCCCTACTACGGCGGAACCTCG TACAACCAGAAGTTCAAGGGGAGAGCCACGCTGACCGTGGACAAGTCCTCGTCCACCGC GTACATGCACCTGAAGAGCCTGACCTCCGAGGACTCCGCCGTCTACTACTGCGTCTCCGG GATGAAGTACTGGGGACAGGGGGGACCTCCGTGACCGTCCTCCGGCGGAGGAGGCTCAG GCGGAGGAGGCTCCGGCGGAGGAGGCTCCGACGTGGTGATGACCCAGACTCCCCTCTCTCTCTC
- SEQ ID NO: 44 includes Target scFv: 1-732; Target VL: 385-732; Target linker: 340-384; Target VH: 1-339; Free energy: -336.5; gdT CAI: 0.849533769168508; ORF count: 0.
- SEQ ID NO: 45 is the sequence name for integrin aVb3 scFv. It is a Tumor targeting scFv construct. It is an AA sequence. The sequence is: EVQLEESGGGLVKPGGSLKLSCAASGFAFSSYDMSWVRQIPEKRLEWVAKVSSGGGSTYYL DTVQGRFTLSRDNAKNTLYLQMSSLNSEDTAMYYCARHNYGSFAYWGQGTLVTVSAAKGG GGSGGGGSGGGGSELVMTQTPATLSVTPGDSVSLSCRASQSISNHLHWYQQKSHESPRLLIK YASQSISGIPSRFSGSGSGTDFTLSINSVETEDFGMYFCQQSNSWPHTFGGGTKLEIK.
- SEQ ID NO: 45 includes Target scFv: 1-241; Target VL: 135-241; Target linker: 120-134; Tar-get VH: 1-119.
- SEQ ID NO: 46 is the sequence name for integrin aVb3 scFv. It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTGGAGGAGTCTGGAGGTGGCCTGGTGAAGCCAGGAGGCAGCCTGAAGC TGAGCTGTGCTGCCTCTGGGTTTGCCTTCAGCTCCTATGACATGAGCTGGGTGAGGCAGA TCCCTGAGAAGAGGCTGGAGTGGGTAGCTAAGGTGAGCTCTGGAGGTGGCAGCACCTAC TACCTGGACACAGTGCAGGGCAGGTTCACCATCAGCAGGGACAATGCTAAGAACACCCT GTACCTGCAGATGAGCAGCCTGAACTCTGAGGACACAGCTATGTACTACTGTGCCAGGC ACAACTATGGGTCCTTTGCCTACTGGGGCCAGGGGACCCTGGTGACAGTGTCTGCAGCTA AAGGTGGCTCTGGAGGTGGAGGCTCTGGAGGTGGAGGCTCTGA
- SEQ ID NO: 46 includes Target scFv: 1-723; Target VL: 403-723; Target linker: 358-402; Target VH: 1-357; Free energy: -326.8; gdT CAI: 0.836939021276497; ORF count: 8.
- SEQ ID NO: 47 is the sequence name for integrin aVb3 scFv ECOg (62). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTGGAGGAGTCCGGCGGCGGCTTGGTGAAGCCCGGCGGCTCCCTGAAGCT GTCCTGCGCCGCCTCCGGGTTCGCCTTCTCCAGCTACGACATGTCCTGGGTGCGGCAGAT CCCCGAGAAGCGGCTGGAGTGGGTCGCCAAGGTGTCCTCCGGCGGCGGCTCCACCTACT ACCTGGACACCGTGCAGGGGCGCTTCACCATCTCCCGGGACAACGCCAAGAACACCCTG TACCTGCAGATGAGCTCCCTGAACAGCGAGGACACCGCCATGTACTACTGCGCCCGGCA CAACTACGGGTCCTTCGCCTACTGGGGCCAGGGGACCCTGGTGACCGTGTCCGCCGCCA AAGGAGGCGGCGGCTCCGGAGGAGGTGGCTCAGGCGGCGGAGGCGGA
- SEQ ID NO: 47 includes Target scFv: 1-723; Target VL: 403-723; Target linker: 358-402; Target VH: 1-357; Free energy: -324.4; gdT CAI: 0.868908; ORF count: 1.
- SEQ ID NO: 48 is the sequence name for integrin aVb3 scFv ECOg (26). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAAGTCCAGCTGGAGGAGAGCGGCGGTGGCCTCGTGAAGCCCGGCGGTTCGCTCAAGCT GAGCTGCGCGGCCAGCGGGTTCGCCTTCAGCTCGTACGACATGAGCTGGGTGCGGCAGA TCCCCGAGAAGCGCCTGGAGTGGGTCGCCAAGGTGTCCTCCGGCGGCGGCTCGACGTAC TACCTGGACACCGTGCAGGGGCGCTTCACGATCAGCCGGGACAACGCGAAGAACACCCT GTACCTCCAGATGTCCTCGCTGAACTCCGAGGACACCGCGATGTACTACTGCGCGGC ACAACTACGGGAGCTTCGCCTACTGGGGTCACCGTGAGCGGCG AAAGGCGGTGGCGGCAGTGGTGGCGGAGGCTCTGGCGGGCTGGCTGGCTGGCTGGCTGGCTGGGGCG
- SEQ ID NO: 48 includes Target scFv: 1-723; Target VL: 403-723; Target linker: 358-402; Target VH: 1-357; Free energy: -342.6; gdT CAI: 0.773341369143768; ORF count: 1.
- SEQ ID NO: 49 is the sequence name for integrin aVb3 scFv ECOg (12). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTCCAGCTGGAGGAATCCGGCGGCGGCCTCGTGAAGCCAGGCGGCAGCCTGAAGCT GTCGTGCGGCCTCCGGGTTCGCCTTCAGCTCGTACGACATGAGCTGGGTGCGCCAGAT CCCCGAGAAGCGCCTGGAGTGGGTCGCCAAGGTGTCCTCCGGCGGCGGCAGCACGTACT ACTTGGACACCGTGCAGGGGCGCTTCACGATCTCGCGGGACAACGCGAAGAACACGCTG TACCTCCAGATGTCCTCGCTGAACTCGGAGGACACCGCGATGTACTACTGCGCGGCA CAACTATGGGTCCTTCGCCTACTGGGGCCAGGGGACCCTGGTGACCGTGAGCGCGGCCA AAGGTGGCGGCGGCTCAGGTGGCGGAGGCAGCGGTGGCGGTGGCGGCA
- SEQ ID NO: 49 includes Target scFv: 1-723; Target VL: 403-723; Target linker: 358-402; Target VH: 1-357; Free energy: -339.8; gdT CAI: 0.762733907249084; ORF count: 2.
- SEQ ID NO: 50 is the sequence name for integrin aVb3 scFv ECOg (48). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTCCAGCTGGAGGAGTCCGGCGGAGGCCTGGTCAAGCCCGGCGGCAGCCTGAAGCT GTCCTGCGCCGCCTCCGGCTTCGCCTTCAGCAGCTACGACATGTCCTGGGTCCGGCAGAT CCCGGAGAAGCGGCTGGAGTGGGTCGCCAAGGTCAGCTCCGGCGGCGGCAGCACCTACT ACCTGGACACCGTCCAGGGCCGGTTCACCATCAGCCGGGACAACGCCAAGAACACCCTG TACCTGCAGATGTCCAGCCTGAACTCCGAGGACACGGCCATGTACTACTGCGCCCGGCA CAACTACGGCAGCTTCGCCTACTGGGGCCAGGGGACCCTGGTGACCGTGTCGGCCGCCA AAGGCGGAGGCGGCTCAGGAGGTTCCGGCGGCGACCCTGGGGCTGT
- SEQ ID NO: 50 includes Target scFv: 1-723; Target VL: 403-723; Target linker: 358-402; Target VH: 1-357; Free energy: -329.4; gdT CAI: 0.82265589760209; ORF count: 0.
- SEQ ID NO: 51 is the sequence name for integrin aVb3 scFv ECOg (97). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTCCAGCTGGAGGAGTCCGGAGGAGGACTCGTGAAGCCCGGAGGCTCCCTGAAGCT CTCCTGCGCCGCCTCCGGGTTCGCCTTCTCCTCCTACGACATGTCCTGGGTCCGGCAGAT CCCCGAGAAGAGGCTGGAGTGGGTCGCGAAGGTCCTCCGGAGGAGGCTCGACCTACT ATCTCGACACGGTCCAGGGCCGGTTCACGATCTCCCGGGACAACGCGAAGAACACGCTC TACCTCCAGATGTCGAGCCTGAACTCCGAGGACACCGCGATGTACTACTGCGCCCGGCA CAACTACGGGAGCTTCGCCTACTGGGGCCAGGGGACTCTCGTGACCGTCTCCGCCGCGA AAGGCGGAGGAGGCTCCGGAGGAGGAGGCTCCGGAGGAGGCTCGACC
- SEQ ID NO: 51 includes Target scFv: 1-723; Target VL: 403-723; Target linker: 358-402; Target VH: 1-357; Free energy: -329.3; gdT CAI: 0.777965026449684; ORF count: 0.
- SEQ ID NO: 52 is the sequence name for SSTR2 scFv. It is a Tumor targeting scFv construct. It is an AA sequence. The sequence is: DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRNRKNYLAWYQQKPDQSPKLLIYWASTRES GVPDRFSGSGTDFTLTISSLQAEDVAVYYCKQSYYLWTFGGGTKVEIKGGGGSGGGGSG GGGSEVQLVESGGGLVQPGGSLRLSCAASGFTFSDYGMAWFRQAPGKGLEWVSFISNLGYSI YYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARAPYDYDSFDPMDYWGQGTLV TVS.
- SEQ ID NO: 52 includes Target scFv: 1-248; Target VL: 1-112; Target linker: 113- 127; Target VH: 128-248.
- SEQ ID NO: 53 is the sequence name for SSTR2 scFv. It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GACATTGTGATGACCCAGAGCCCAGACTCCCTGGCTGTGAGCCTAGGGGAGAGGGCCAC CATCAACTGCAAGTCCTCTCAGAGCCTCCTCAACTCCAGGAACAGGAAGAACTACCTGG CCTGGTACCAGCAGAAGCCAGACCAGAGCCCCAAGCTGCTCATCTACTGGGCCTCCACC AGGGAGTCTGGGGTGCCTGACAGGTTCTCTGGGTCTGGGTCTGGGTCTGGGACTGACTTCACCCTG ACCATCAGCTCCCTGCAGGCTGAGGATGTGGCTGTGTGTACTACTGCAAGCAGAGCTACTA CCTGTGGACCTTTGGTGGAGGCACCAAGGTGGAGATCAAAGGAGGTGGAGGCTCTGGTG GTGGAGGCTCTGGTGGTGGAGGCTCTCTGGTGGTGGCTGGTGCAGCTGGTGGTGGCCTG GTCCAG
- SEQ ID NO: 53 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -344; gdT CAI: 0.841055073258909; ORF count: 7.
- SEQ ID NO: 54 is the sequence name for SSTR2 svFv ECOg (72). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GACATCGTGATGACCCAGAGCCCCGACTCCCTGGCCGTGAGCCTCGGGGAGAGGGCCAC GATCAACTGCAAGAGCTCCCAGAGCCTGCTCAACTCCCGGAACCGGAAGAACTACCTGG CCTGGTACCAGCAGAAGCCCGACCAGTCGCCCAAGCTGCTCATCTACTGGGCCTCCACC AGGGAGAGCGGGGTGCCCGACCGCTTCTCCGGGAGCGGGTCCGGGACCGACTTCACCCT GACCATCTCCTCTCTGCAGGCCGAGGACGTGGCCGTGTACTACTGCAAGCAGAGCTACT ACCTGTGGACATTCGGCGGCGGCACCAAGGTGGAGATCAAAGGCGGCGGCGGCAGTGG TGGAGGAGGCAGCGGCGGCGGTGGCTCAGAGGTGCAGCTGCAGCTGGTGGAGAGCGGAGGCGGC CT
- SEQ ID NO: 54 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -325.1; gdT CAI: 0.865568; ORF count: 1.
- SEQ ID NO: 55 is the sequence name for SSTR2 svFv ECOg (64). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GACATCGTGATGACGCAGAGCCCCGACTCTTTGGCGGTGAGCCTCGGGGAGAGGGCCAC CATCAACTGCAAGTCGTCGCAGAGCCTCCTCAACAGCCGCAACCGGAAGAACTACCTCG CCTGGTATCAGCAGAAGCCCGACCAAAGCCCCAAGCTGCTGATCTACTGGGCCTCCACA CGGGAGTCTGGGGTGCCCGACCGCTTCAGCGGCAGCGGCAGCGGCACCGACTTCACCCT CACCATCAGCAGCCTGCAGGCGGAGGATGTGGCGGTGTACTACTGCAAACAGTCCTACT ATCTGTGGACCTTCGGCGGCGGCACAAAGGTGGAGATCAAAGGCGGCGGCGGCAGTGG AGGAGGAGGCAGCGGCGGCGGAGGCTCTGAGGTGCAGCTGGTGGAGAGCGGCGGCAGTGG AGGAGG
- SEQ ID NO: 55 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -333.3; gdT CAI: 0.782038165701074; ORF count: 4.
- SEQ ID NO: 56 is the sequence name for SSTR2 svFv ECOg (15). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GACATCGTCATGACCCAGTCACCTGACAGCCTGGCCGTCAGCCTGGGCGAACGGGCCAC CATCAACTGTAAGTCATCTCAGAGCCTGCTGAACAGCCGGAACCGGAAGAACTACCTGG CCTGGTATCAGCAGAAGCCTGATCAGTCACCTAAGCTGCTGATCTACTGGGCCTCAACCA GAGAGTCCGGCGTGCCTGACAGGTTCAGCGGGTCCGGGTCCGGGACCGACTTCACCCTG ACCATCAGCAGCCTGCAGGCCGAGGACGTGGCCGTCTATTACTGTAAGCAGTCTTATTAC CTGTGGACCTTCGGCGGCGGCACCAAGGTCGAGATCAAAGGCGGCGGCGGCGGTGGCTCTGAGGTCCAGCTGGTGGCTCTGAGGTCCAGTGGTCTTATTAC CTGTGGACCTTCGGCGGCGGCACCAA
- SEQ ID NO: 56 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -331.6; gdT CAI: 0.812422023876491; ORF count: 8.
- SEQ ID NO: 57 is the sequence name for SSTR2 svFv ECOg (50). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GACATCGTGATGACCCAGAGCCCCGACTCCCTGGCCGTGTCCCTCGGGGAGAGGGCCAC CATCAACTGCAAGAGCTCCCAGTCCCTGCTGAACTCCCGGAACCGGAAGAACTACCTGG CCTGGTACCAGCAGAAGCCCGACCAGAGCCCCAAGCTGCTGATCTACTGGGCCAGCACC AGGGAGAGCGGGGTGCCCGACCGCTTCTCCGGGTCCGGGTCCGGGACCGACTTCACCCT GACCATCAGCTCCCTGCAGGCCGAGGACGTGGCCGTGTACTACTGCAAGCAGAGCTACT ACCTGTGGACCTTCGGCGGCGGCACCAAGGTGGAGATCAAAGGCGGCGGCGGCTCAGG AGGAGGTGGCTCCGGCGGCGGAGGCTCTGAGGTGCAGCTGGTGGAGAGCGGCGGCTCAGG AGGA
- SEQ ID NO: 57 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -328.9; gdT CAI: 0.878055710303915; ORF count: 3.
- SEQ ID NO: 58 is the sequence name for SSTR2 svFv ECOg (42). It is a Tumor targeting scFv construct. It is a DNA sequence. The sequence is: GATATCGTGATGACCCAGTCCCCGGACTCCCTGGCAGTGTCCCTCGGGGAGCGGGCCAC CATCAACTGCAAGAGCTCCCAGTCCCTGCTGAACTCCCGGAACCGGAAGAACTACCTGG CCTGGTACCAGCAGAAGCCCGACCAGTCCCCGAAGCTGCTGATCTACTGGGCCAGCACC CGGGAATCCGGGGTGCCCGACCGCTTCTCCGGGTCCGGGTCCGGGTCCGGGACCGACTTCACCCT GACCATCAGCTCCCTGCAGGCCGAGGACGTGGCAGTGTACTACTGCAAGCAGTCCTACT ACCTGTGGACCTTCGGCGGCGGCACCAAGGTGGAGATCAAAGGCGGCGGCGGCTCTGGA GGAGCTCCGGCGGCGGAGGTTCCGAGGTGCAGCTGGTGGAGTCCGGCGGGGGGGAG
- SEQ ID NO: 58 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -328.6; gdT CAI: 0.886975497635559; ORF count: 1.
- SEQ ID NO: 59 is the sequence name for 2xSST28 3xG4S ligand. It is a Tumor targeting ligand construct. It is an A A sequence. The sequence is: SANSNPAMAPRERKAGCKNFFWKTFTSCGGGGSGGGGSGGGGSSANSNPAMAPRERKAGC KNFFWKTFTSC.
- SEQ ID NO: 59 includes Target Ligand: 1-71.
- SEQ ID NO: 60 is the sequence name for 2xSST28 3xG4S ligand. It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCGCGAACAGCAACCCGGCGATGGCGCCGCGCGAACGCAAAGCGGGCTGCAAAAACT TTTTTTGGAAAACCTTTACCAGCTGCGGCGGCGGCGGCAGCGGCGGCGGCGGCAGCGGC GGCGGCGGCAGCAGCGCGAACAGCAACCCGGCGATGGCGCCGCGCGAACGCAAAGCGG GCTGCAAAAACTTTTTTTGGAAAACCTTTACCAGCTGCGGCGGCGGCGGCAGCGGCGGC GGCGGCAGCGGCGGCGGCGGCAGC.
- SEQ ID NO: 60 includes Target Ligand: 1-213; Free energy: -117; gdT CAI: 0.603084331934136; ORF count: 0.
- SEQ ID NO: 61 is the sequence name for 2xSST28 3xG4S ligand ECOg (192). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCTGCCAACTCCAACCCCGCTATGGCTCCCAGGGAGCGGAAGGCCGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCTCCTGCGGAGGCGGAGGCTCAGGAGGCGGAGGCTCCGGAG GAGGCGGCTCCTCCGCCAACTCCAACCCCGCTATGGCTCCCAGGGAGCGGAAGGCCGGG TGCAAGAACTTCTTCTGGAAGACCTTCACCTCCTGCGGAGGCGGAGGCTCCGGAGGAGG CGGCTCAGGAGGCGGCGGCAGC.
- SEQ ID NO: 61 includes Target Ligand: 1-213; Free energy: -138.2; gdT CAI: 0.800017929945784; ORF count: 0.
- SEQ ID NO: 62 is the sequence name for 2xSST28 3xG4S ligand ECOg (141). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCCGCCAACTCCAACCCCGCTATGGCTCCCCGGGAGCGGAAGGCTGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCTCCTGCGGAGGCGGAGGTTCCGGAGGCGGAGGTTCCGGCG GAGGCGGCTCCTCCGCCAACTCCAACCCCGCGATGGCTCCCAGGGAGCGGAAGGCCGGG TGCAAGAACTTCTTCTGGAAGACCTTCACCTCCTGCGGAGGCGGAGGTTCCGGCGGAGG AGGTTCCGGAGGCGGCGGCTCC. [0450] SEQ ID NO: 62 includes Target Ligand: 1-213; Free energy: -146.7; gdT CAI: 0.786043171489395; ORF count: 0.
- SEQ ID NO: 63 is the sequence name for 2xSST28 3xG4S ligand ECOg (241). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCGCCAACTCCAACCCCGCTATGGCTCCCCGGGAGCGCAAGGCTGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCTCCTGCGGAGGCGGAGGCTCTGGAGGCGGAGGCTCTGGCG GAGGCGGCTCCTCCGCCAACTCCAACCCCGCGATGGCTCCCAGGGAGCGCAAGGCCGGG TGCAAGAACTTCTTCTGGAAGACCTTCACCTCCTGCGGAGGCGGAGGCTCTGGCGGAGG AGGCTCTGGAGGCGGCGGCTCC .
- SEQ ID NO: 63 includes Target Ligand: 1-213; Free energy: -142.6; gdT CAI: 0.788525759670669; ORF count: 0.
- SEQ ID NO: 64 is the sequence name for 2xSST28 3xG4S ligand ECOg (172). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCCGCCAACTCCAACCCGGCCATGGCTCCCCGGGAGAGGAAGGCCGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCTCCTGCGGAGGAGGAGGAAGCGGAGGAGGAGGAAGCGGA GGAGGAGGCTCCTCGGCCAACTCCAACCCGGCCATGGCTCCCCGGGAGAGGAAGGCCGG GTGCAAGAACTTCTTCTGGAAGACCTTCACCTCCTGCGGAGGAGGAGGAAGCGGAGGAG GAGGAAGCGGAGGAGGAGGATCT.
- SEQ ID NO: 64 includes Target Ligand: 1-213; Free energy: -140; gdT CAI: 0.719392416533176; ORF count: 0.
- SEQ ID NO: 65 is the sequence name for 2xSST28 3xG4S ligand ECOg (266). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCCGCCAACTCCAACCCCGCTATGGCTCCCCGGGAGCGGAAGGCTGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCTCCTGTGGCGGCGGCGGATCTGGCGGAGGAGGCTCTGGCG GAGGCGGCTCCTCCGCCAACTCCAACCCCGCTATGGCTCCCAGGGAGCGGAAGGCCGGG TGCAAGAACTTCTTCTGGAAGACCTTCACCTCCTGTGGCGGCGGCGGATCTGGCGGAGG AGGCTCTGGCGGAGGCGGA AGC .
- SEQ ID NO: 65 includes Target Ligand: 1-213; Free energy: -135.3; gdT CAI: 0.799023029714678; ORF count: 0.
- SEQ ID NO: 66 is the sequence name for 2xSST28 2xG4S ligand. It is a Tumor Targeting Ligand construct. It is an AA sequence. The sequence is: SANSNPAMAPRERKAGCKNFFWKTFTSCGGSGGSGGSGGSGGSANSNPAMAPRERKAGCK NFFWKTFTSCGGSGGSGGSGGSGG. [0458] SEQ ID NO: 66 includes Target Ligand: 1-70; Central Linker: 71-84.SEQ ID NO: 67 is the sequence name for 2xSST28 2xG4S ligand. It is a Tumor Targeting Ligand construct. It is a DNA sequence.
- the sequence is: AGCGCGAACAGCAACCCGGCGATGGCGCCGCGCGAACGCAAAGCGGGCTGCAAAAACT TTTTTTGGAAAACCTTTACCAGCTGCGGCGGCAGCGGCGGCAGCGGCGGCAGCGGCGGC AGCGGCGGCAGCGGCGGC.
- SEQ ID NO: 67 includes Target Ligand: 1-210; Central Linker: 221-252; Free energy: -110.4; gdT CAI: 0.602525074392084; ORF count: 0.
- SEQ ID NO: 68 is the sequence name for 2xSST28 2xG4S ligand ECOg (114). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCCGCCAACTCCAACCCCGCAATGGCTCCCCGGGAGAGGAAGGCCGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCAGCTGCGGAGGCTCCGGAGGCTCCGGAGGCTCCGGAGGCT CCGGAGGCTCCGCCAACTCCAACCCCGCAATGGCTCCCCGGGAGAGGAAGGCCGGGTGC AAGAACTTCTTCTGGAAGACCTTCACCAGCTGCGGAGGCTCCGGAGGCTCCGGAGGCTC CGGAGGCTCCGGAGGCTC CGGAGGCTCCGGAGGC.
- SEQ ID NO: 68 includes Target Ligand: 1-210; Central Linker: 221-252; Free energy: -140.6; gdT CAI: 0.815587600211903; ORF count: 0.
- SEQ ID NO: 69 is the sequence name for 2xSST28 2xG4S ligand ECOg (86). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCTGCCAATTCCAACCCCGCGATGGCCCCTCGGGAGAGGAAGGCCGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCTCCTGCGGAGGCTCCGGAGGCTCCGGAGGCTCCGGAGGCT CCGGAGGCTCTGCCAATTCCAACCCCGCGATGGCCCCTCGGGAGAGGAAGGCCGGGTGC AAGAACTTCTTCTGGAAGACCTTCACCTCCTGCGGAGGCTCCGGAGGCTCCGGAGGCTCC GGAGGCTCCGGAGGC.
- SEQ ID NO: 69 includes Target Ligand: 1-210; Central Linker: 221-252; Free energy: -146.5; gdT CAI: 0.793448781755408; ORF count: 0.
- SEQ ID NO: 70 is the sequence name for 2xSST28 2xG4S ligand ECOg (132). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCCGCGAACTCCAACCCCGCGATGGCTCCCCGGGAGAGGAAGGCCGGGTGCAAGAACTT CTTCTGGAAGACGTTCACGTCCTGCGGAGGCTCCGGAGGCTCCGGAGGCTCCGGAGGCT CCGGAGGCTCCGCGAACTCCAACCCCGCGATGGCTCCCCGGGAGAGGAAGGCCGGGTGC AAGAACTTCTTCTGGAAGACGTTCACGTCCTGCGGAGGCTCCGGAGGCTCCGGAGGCTC CGGAGGCTCCGGAGGA.
- SEQ ID NO: 70 includes Target Ligand: 1-210; Central Linker: 221-252; Free energy: -141.6; gdT CAI: 0.768520163043281; ORF count: 0.
- SEQ ID NO: 71 is the sequence name for 2xSST28 2xG4S ligand ECOg (131). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCGCCAACTCCAACCCCGCGATGGCTCCCAGGGAGCGGAAGGCCGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCTCCTGCGGAGGCTCCGGAGGCTCCGGAGGCTCCGGAGGCT CCGGAGGCTCCGCCAACTCCAACCCCGCGATGGCTCCCAGGGAGCGGAAGGCCGGGTGC AAGAACTTCTTCTGGAAGACCTTCACCTCCTGCGGAGGCTCCGGAGGCTCCGGAGGCTCC GGAGGCTCCGGTGGC.
- SEQ ID NO: 71 includes Target Ligand: 1-210; Central Linker: 221-252; Free energy: -140.8; gdT CAI: 0.805786107124917; ORF count: 0.
- SEQ ID NO: 72 is the sequence name for 2xSST28 2xG4S ligand ECOg (137). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCCGCCAACTCCAACCCCGCTATGGCCCCTAGGGAGAGGAAGGCCGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCTCCTGCGGAGGCTCCGGAGGCTCCGGAGGCTCCGGAGGCT CCGGAGGCTCCGCCAACTCCAACCCCGCTATGGCCCCTAGGGAGAGGAAGGCCGGGTGC AAGAACTTCTTCTGGAAGACCTTCACCTCCTGCGGAGGCTCCGGAGGCTCCGGAGGCTCC GGAGGCTCCGGAGGA.
- SEQ ID NO: 72 includes Target Ligand: 1-210; Central Linker: 221-252; Free energy: -140; gdT CAI: 0.822267579371957; ORF count: 1.
- SEQ ID NO: 73 is the sequence name for SST28 ligand. It is a Tumor Targeting Ligand construct. It is an AA sequence. The sequence is: SANSNPAMAPRERKAGCKNFFWKTFTSC.
- SEQ ID NO: 73 includes Target Ligand: 1-28.
- SEQ ID NO: 74 is the sequence name for SST28 ligand. It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCCGCCAACTCCAACCCGGCCATGGCTCCCCGGGAGAGGAAGGCCGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCAGCTGC.
- SEQ ID NO: 74 includes Target Ligand: 1-84; Free energy: -26.1; gdT CAI: 0.909139392619506; ORF count: 0.
- SEQ ID NO: 75 is the sequence name for SST28 ligand ECOg (10). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCGCCAACAGCAACCCCGCTATGGCTCCCAGGGAGCGCAAGGCCGGGTGCAAGAACTT CTTCTGGAAGACCTTCACCTCTTGC.
- SEQ ID NO: 75 includes Target Ligand: 1-84; Free energy: -27.4; gdT CAI: 0.925222356313033; ORF count: 0.
- SEQ ID NO: 76 is the sequence name for SST28 ligand ECOg (172). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCGCGAACAGCAACCCGGCCATGGCCCCTCGCGAGCGAAAGGCCGGGTGCAAGAACT TCTTCTGGAAGACCTTCACCTCGTGC.
- SEQ ID NO: 76 includes Target Ligand: 1-84; Free energy: -31.1; gdT CAI: 0.762381535851502; ORF count: 0.
- SEQ ID NO: 77 is the sequence name for SST28 ligand ECOg (38). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCGCCAACTCCAACCCGGCTATGGCGCCCAGGGAGAGGAAGGCCGGCTGCAAGAACTT CTTCTGGAAGACCTTC ACCTCCTGC .
- SEQ ID NO: 77 includes Target Ligand: 1-84; Free energy: -31; gdT CAI: 0.866223933524215; ORF count: 0.
- SEQ ID NO: 78 is the sequence name for SST28 ligand ECOg (5). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGTGCGAACTCGAACCCGGCCATGGCGCCCAGAGAGCGCAAGGCCGGGTGCAAGAACT TTTTCTGGA A A ACGTTC AC ATCGTGC .
- SEQ ID NO: 78 includes Target Ligand: 1-84; Free energy: -30.7; gdT CAI: 0.714442287269154; ORF count: 0.
- SEQ ID NO: 79 is the sequence name for SST28 ligand ECOg (44). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCGCGAACTCGAACCCGGCCATGGCTCCGCGCGAGCGTAAGGCCGGGTGCAAGAACTT TTTCTGGAAAACCTTCACGAGTTGT.
- SEQ ID NO: 79 includes Target Ligand: 1-84; Free energy: -30.1; gdT CAI: 0.688444421590185; ORF count: 0.
- SEQ ID NO: 80 is the sequence name for TPO. It is a Tumor Targeting Ligand construct. It is an AA sequence. The sequence is: SPAPPACDLRVLSKLLRDSHVLHSRLSQCPEVHPLPTPVLLPAVDFSLGEWKTQMEETKAQDI LGAVTLLLEGVMAARGQLGPTCLSSLLGQLSGQVRLLLGALQSLLGTQGRTTAHKDPNAIFL SFQHLLRGKVRFLMLVGGSTLCVRRAPPTTAVPSRTSLVLTLNELG. [0485] SEQ ID NO: 80 includes Target Ligand: 1-171. SEQ ID NO: 81 is the sequence name for TPO. It is a Tumor Targeting Ligand construct.
- SEQ ID NO: 81 includes Target Ligand: 1-513; Free energy: -251.6; gdT CAI: 0.86805332586369; ORF count: 4.
- SEQ ID NO: 82 is the sequence name for TPO ECOg (6). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCCCCGCACCACCTGCCTGCGACCTGCGGGTGCTGTCCAAGCTGCTGCGGGACAGCCA CGTGCTGCACAGCAGGCTGTCCCAGTGCCCCGAGGTGCACCCACTGCCCACGCCCGTGCT GCTGCCCGCTGTGGACTTCTCCCTGGGCGAGTGGAAGACACAGATGGAGGAGACCAAGG CCCAGGACATCCTGGGCGCCGTGACCCTGCTGCTGGAAGGGGTGATGGCCGCCAGAGGG CAGCTGGGGCCAACGTGCCTGTCCTCACTGCTGGGGCAGCTGTCCGGGCAGGTGCGGCT GCTGCTGGGCGCCCTGCAGTCCCTGCTGGGCACCCAGGGGCACCACAGCTCACAAGG ACCCCAACGCCATCTTCCTGTCCTTCCAGCACCTGCTGCGGGGCAAGGTGCGGTTCCTGA T
- SEQ ID NO: 82 includes Target Ligand: 1-513; Free energy: -258.8; gdT CAI: 0.891232089689473; ORF count: 1.
- SEQ ID NO: 83 is the sequence name for TPO ECOg (42). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCCCGGCTCCTCCGGCCTGCGACCTGCGCGTGCTGAGCAAGCTCCTGCGGGACTCGCA CGTGCTGCACTCGCGCCTGAGCCAGTGCCCCGAGGTGCATCCCCTGCCTACCCCGGTGCT CCTGCCCGCGGTGGACTTCTCGCTCGGGGAGTGGAAGACCCAGATGGAGGAGACCAAGG CCCAGGACATACTCGGGGCCGTGACCCTGCTCCTGGAAGGGGTCATGGCAGCTCGGGGC CAGCTCGGGCCTACGTGCCTGAGCTCCCTGCTCGGGCAGCTGTCCGGGCAGGTCCGGCTC CTGCTCGGGGCCCTGCAGAGCCTGCTCGGGACCCAGGGCCGGACCACGGCTCACAAGGA CCCGAACGCGATCTTCCTGAGCTTCCAGCACCTGCTCCGGGGCAAGGTCAGGTTCCTGAT GCTGAT GC
- SEQ ID NO: 83 includes Target Ligand: 1-513; Free energy: -273.6; gdT CAI: 0.779630301042555; ORF count: 0.
- SEQ ID NO: 84 is the sequence name for TPO ECOg (19). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: TCTCCGGCTCCGCCTGCCTGCGACCTGCGGGTGCTGTCGAAGCTGCTGCGGGACAGCCAC GTCCTCCACAGCCGCCTGAGCCAGTGCCCGGAGGTGCACCCGCTGCCTACGCCGGTGCT GCTGCCGGCCGTGGACTTCAGCCTCGGGGAGTGGAAGACGCAGATGGAGGAGACCAAG GCCCAGGACATCCTCGGGGCCGTGACCCTGCTCCTGGAAGGGGTGATGGCAGCGCGAGG GCAGCTGGGGCCTACCTGCCTCAGCTCCCTGCTGGGGCAGCTGTCGGGGCAGGTGCGGC TGCTGCTCGGGGCCCTGCAGTCCCTGCTCGGGACCCAGGGCCGGACCACAGCCCACAAG GACCCCAACGCCATCTTCCTCCTTCCAGCACCTGCTCCGGGGCAAGGTCCGGTTCC
- SEQ ID NO: 84 includes Target Ligand: 1-513; Free energy: -269.4; gdT CAI: 0.79850475511585; ORF count: 1.
- SEQ ID NO: 85 is the sequence name for TPO ECOg (53). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCCCCGCGCCGCCAGCGTGCGATCTGCGCGTGCTGAGCAAGCTGCTGCGCGACTCGCA CGTGCTGCACTCGCGCGGCTCTCGCAGTGCCCCGAGGTGCACCCGCTGCCCACACCCGTGCT GCTGCCCGCGGTGGACTTCTCGCTCGGCGAGTGGAAGACGCAGATGGAGGAGACGAAA GCGCAGGACATCCTCGGCGCGGTGACGCTGCTGCTCGAAGGCGTGATGGCTGCTCGCGG GCAGCTCGGGCCTACGTGCCTGAGCTCGCTGCTCGGGCAGCTGAGCGGGCAGGTGCGGC TGCTCGGCACGCAGGGGCACCACAGCACAAG GACCCGAACGCGATCTTCCTGAGCTTCCAGCACCTGCTGCGCGGGAAGGTGCTTCCTG A
- SEQ ID NO: 86 is the sequence name for TPO ECOg (57). It is a Tumor Targeting Ligand construct. It is a DNA sequence. The sequence is: AGCCCCGCTCCGCCAGCCTGCGACCTGCGGGTGCTGAGCAAGCTGCTGCGGGACAGCCA CGTGCTGCACAGCCGGCTGAGCCAGTGCCCCGAGGTGCACCCGCTGCCCACGCCCGTGC TGCTGCCCGCTGTGGACTTCAGCCTGGGCGAGTGGAAGACCCAGATGGAGGAGACCAAG
- SEQ ID NO: 86 includes Target Ligand: 1-513; Free energy: -267.9; gdT CAI: 0.853835989559969; ORF count: 2.
- SEQ ID NO: 87 is the sequence name for Fc. It is a Fusion Moety construct. It is an
- the sequence is:
- SEQ ID NO: 87 includes Fusion Moeity: 1-227.
- SEQ ID NO: 88 is the sequence name for Fc. It is a Fusion Moety construct. It is a
- DNA sequence The sequence is:
- SEQ ID NO: 88 includes Fusion Moeity: 1-681; Free energy: -199.9; gdT CAI: 0.747707161534413; ORF count: 6.
- SEQ ID NO: 89 is the sequence name for FC ECOg (85). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GATAAGACCCACACCTGTCCGCCGTGCCCCGCACCCGAGCTTCTCGGCGGCCCCAGCGT GTTCCTGTTTCCGCCGAAGCCCAAGGACACCCTGATGATCTCCCGGACGCCCGAGGTGAC CTGCGTGGTGGTGGACGTGTCCCACGAGGACCCCGAGGTGAAGTTCAACTGGTACGTGG ACGGGGTCGAGGTGCACAACGCCAAGACCAAGCCCCGCGAGGAGCAGTACAACTCCAC CTACCGGGTCGTGTCCGTGCTGACCGTGCTGCACCAGGACTGGCTGAACGGGAAGGAGT ACAAGTGCAAGGTGTCCAACAAGGCCCTGCCCGCGCCCATCGAGAAGACCATCTCCAAG GCCAAGGGGCAGCCCAGGGAGCCAGGTGTACACCCTGCCTCCGTCCCGGGACGAGCT GACCAAGAAAAAGGCA
- SEQ ID NO: 89 includes Fusion Moeity: 1-681; Free energy: -269.2; gdT CAI: 0.894515513769793; ORF count: 0.
- SEQ ID NO: 90 is the sequence name for FC ECOg (59). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GACAAGACGCACACGTGTCCGCCGTGCCCCGCACCCGAACTGCTCGGCGGCCCCAGCGT GTTCCTGTTTCCGCCGAAGCCCAAGGACACGCTGATGATCTCGCGCACGCCCGAGGTGA CGTGCGTCGTCGTCGACGTGTCGCACGAGGACCCCGAGGTGAAGTTCAACTGGTACGTC GACGGCGTCGAGGTGCACAACGCCAAGACGAAGCCGCGCGAGGAGCAGTACAACAGCA CGTACCGCGTCGTGAGCGTGCTGACCGTGCTGCACCAGGACTGGCTGAACGGCAAGGAG TACAAGTGCAAGGTGAGCAACAAGGCGCTGCCCGCGCCGATCGAGAAGACGATCAGCA AGGCCAAGGGGCAGCCACGCGAGCCGCAGGTACACGCTGCCGCCGTCGCGCCGATCGAAGACGATCAGCA AGGCCAAG
- SEQ ID NO: 90 includes Fusion Moeity: 1-681; Free energy: -299.3; gdT CAI: 0.760430405503452; ORF count: 0.
- SEQ ID NO: 91 is the sequence name for FC ECOg (5). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GACAAGACGCACACCTGTCCGCCGTGCCCGGCTCCCGAACTGCTCGGCGGCCCGTCCGT CTTCCTGTTTCCGCCGAAGCCGAAGGACACCCTGATGATCAGCCGGACGCCGGAGGTGA CCTGCGTCGTCGTCGACGTCAGCCACGAGGACCCCGAGGTCAAGTTCAACTGGTACGTC GACGGCGTCGAGGTCCACAACGCCAAGACGAAGCCCCGCGAGGAGCAGTACAACTCGA CGTACCGGGTCGTCTCCGTCCTGACCGTCCTCCACCAGGACTGGCTGAACGGCAAGGAG TACAAGTGCAAGGTCAGCAACAAGGCCCTGCCGGCCGATCGAAGACGATCTCGAA GGCCAAGGGCCAGCCTCGGGAGCCAGGTCTACACGCTGCCGCCGTCCCGGGACGAAAGGGCCAGTCTACACGCTGCCG
- SEQ ID NO: 91 includes Fusion Moeity: 1-681; Free energy: -278.1; gdT CAI: 0.766513451450202; ORF count: 0.
- SEQ ID NO: 92 is the sequence name for FC ECOg (23). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GACAAGACCCATACCTGTCCGCCGTGCCCGGCTCCGGAACTGCTCGGCGGCCCGTCCGTC TTCCTGTTTCCGCCGAAGCCGAAGGACACCCTGATGATCAGCCGGACGCCGGAGGTGAC CTGCGTCGTCGTCGACGTCAGCCACGAGGACCCGGAGGTCAAGTTCAACTGGTACGTCG ACGGCGTCGAGGTCCACAACGCCAAGACCAAGCCCCGGGAAGAGCAGTACAACAGCAC CTACCGGGTCGTGTCCGTCCTGACCGTCCTGCACCAGGACTGGCTGAACGGCAAGGAGT ACAAGTGCAAGGTCAGCAACAAGGCCCTGCCGGCCCCGATCGAAGACCATCAGCAA GGCCAAGGGCCAGCCCAGGGAGGGAGCCGCAGGTCTACACCCTGCCGCCGTCCCGGGACGAGC TGACCAAGGCC
- SEQ ID NO: 92 includes Fusion Moeity: 1-681; Free energy: -276.3; gdT CAI: 0.769448727316174; ORF count: 0.
- SEQ ID NO: 93 is the sequence name for FC ECOg (56). It is a Fusion Moety construct. It is a DNA sequence. The sequence is: GACAAGACGCACACGTGTCCGCCGTGCCCAGCCCCGGAGCTTCTCGGCGGCCCCTCGGT GTTCCTGTTTCCGCCGAAGCCCAAGGACACGCTGATGATCTCCCGGACCCCGGAGGTGA CCTGCGTCGTCGTCGACGTGTCCCACGAGGACCCCGAGGTGAAGTTCAACTGGTACGTC GACGGCGTCGAGGTGCACAACGCGAAGACGAAGCCCCGCGAGGAGCAGTACAACTCCA CGTACCGCGTCGTCTCCGTGCTCACCGTGCTGCACCAGGACTGGCTCAACGGCAAGGAG TACAAGTGCAAGGTGTCCAACAAGGCGCTGCCCGCGCCCATCGAGAAGACCATCTCCAA GGCCAAGGGGCAGCCCCGGGAACCCCAGGTGTACACGCTGCCGCCGAGCCGCGACGAG CTGACCAAGAACCATCTCC
- SEQ ID NO: 93 includes Fusion Moeity: 1-681; Free energy: -275.4; gdT CAI: 0.816569307205555; ORF count: 0.
- SEQ ID NO: 94 is the sequence name for Hum2 scFv. It is a gdT Targeting scFv construct. It is an AA sequence. The sequence is: IQLVQSGAEVKKPGASVKVSCKASGYTFTRYTMHWVRQAPGQGLEWIGYINPSRGYTNYNQ KFKDRATLTTDKSTSTAYMELSSLRSEDTAVYYCARYYDDHYCLDYWGQGTLVTVSSGGS GGSGGSGGSGGDIQLTQSPSSLSASVGDRVTITCRASSSVSYMNWYQQKPGKAPKRWIYDTS KVASGAPSRFTGSGSGTDYTLTISSLQPEDFATYYCQQWSSNPLTFGGGTKLEIK.
- SEQ ID NO: 94 includes gdT scFv: 1-238; gdT VH: 119-132; gdT Linker: 119-132; gdT VL: 133-238.
- SEQ ID NO: 95 is the sequence name for Hum2 scFv ECOg (0). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: ATCCAGCTGGTGCAGTCCGGGGCCGAGGTGAAGAAGCCCGGGGCCTCCGTGAAGGTGTC CTGCAAGGCCTCCGGGTACACCTTCACCCGGTACACCATGCACTGGGTGAGGCAGGCTC CCGGGCAGGGGCTGGAGTGGATCGGGTACATCAACCCCAGCCGCGGGTACACCAACTAC AACCAGAAGTTCAAGGACCGGGCCACGCTGACCACCGACAAGTCCACCTCCACCGCCTA CATGGAGCTGAGCTCCCTGCGGTCCGAGGACACCGCCGTGTACTACTGCGCCCGGTACT ACGACGACCACTACTGCCTGGACTACTGGGGCCAGGGGACCCTGGTGACCGTGTCCTCC GGCGGCTCAGGCGGCTCAGGAGGCTCAGGCGGCTCAGGCGGCGACATCCAGC
- SEQ ID NO: 95 includes gdT scFv: 1-714; gdT VH: 355-396; gdT Linker: 355-396; gdT VL: 397-714; Free energy: -325.7; gdT CAI: 0.910798811448247; ORF count: 0.
- SEQ ID NO: 96 is the sequence name for Hum2 scFv ECOg (183). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: ATCCAGCTCGTGCAGAGCGGGGCCGAGGTGAAGAAGCCCGGGGCGAGCGTGAAGGTGT CGTGCAAGGCGAGCGGGTACACCTTCACGCGCTACACCATGCACTGGGTGCCAAGCT CCCGGGCAGGGGCTGGAGTGGATCGGGTACATCAACCCCTCGCGCGGGTACACCAACTA CAACCAGAAGTTCAAGGACCGCGCCACGCTCACCACCGACAAGTCCACCTCCACCGCCT ACATGGAGCTCTCCTCGCTGCGCTCCGAGGACACCGCGGTGTACTACTGCGCGCGCTACT ACGACGACCACTACTGCCTCGACTGGGGCCAGGGGACCCTCGTGACCGTGTCGAGT GGTGGTAGTGGTGGTAGTGGTGGCGACATCCAGCTCTCGCCACCACCGCCTACCACCACCGCCT ACAT
- SEQ ID NO: 96 includes gdT scFv: 1-714; gdT VH: 355-396; gdT Linker: 355-396; gdT VL: 397-714; Free energy: -331.6; gdT CAI: 0.766742326650226; ORF count: 2.
- SEQ ID NO: 97 is the sequence name for Hum2 scFv ECOg (6). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: ATCCAGCTGGTGCAGAGCGGCGCCGAGGTGAAGAAGCCCGGGGCCTCGGTGAAGGTCTC CTGCAAGGCCTCGGGGTACACCTTCACCCGGTACACCATGCACTGGGTGCGCCAAGCCC CAGGGCAGGGCCTGGAGTGGATCGGGTACATCAACCCCAGCCGCGGGTACACCAACTAC AACCAGAAGTTCAAGGACCGGGCCACGCTGACCACGGACAAGTCCACGTCCACGGCGTA CATGGAGCTGAGCTCCCTGCGCTCCGAGGACACCGCGGTGTACTACTGCGCCCGGTACT ACGACGACCACTACTGCCTGGACTACTGGGGCCAGGGGACCCTGGTCACCGTGTCCTCC GGAGGCTCCGGAGGCTCCGGAGGCTCCGGAGGCTCCGGAGGCGACATCCAGC
- SEQ ID NO: 97 includes gdT scFv: 1-714; gdT VH: 355-396; gdT Linker: 355-396; gdT VL: 397-714; Free energy: -331; gdT CAI: 0.825626192459745; ORF count: 1.
- SEQ ID NO: 98 is the sequence name for Hum2 scFv ECOg (42). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: ATCCAGCTGGTCCAGTCCGGGGCCGAGGTGAAGAAGCCCGGGGCCTCCGTGAAGGTCTC CTGCAAGGCCTCCGGGTACACCTTCACCCGGTACACCATGCACTGGGTCCGGCAGGCTCC AGGGCAGGGGCTGGAGTGGATCGGGTACATCAACCCCAGCCGCGGGTACACCAACTACA ACCAGAAGTTCAAGGACCGGGCCACGCTGACCACCGACAAGTCCACCTCCACCGCCTAC ATGGAGCTGAGCTCCCTGCGGTCCGAGGACACCGCCGTCTACTACTGCGCCCGGTACTAC GACGACCACTACTGCCTGGACTACTGGGGCCAGGGGACCCTGGTGACCGTCTCCTCCGG AGGCTCCGGAGGCTCCGGAGGCTCCGGAGGCTCCGGAGGCGACATCCAGCTGACCCTGACC
- SEQ ID NO: 98 includes gdT scFv: 1-714; gdT VH: 355-396; gdT Linker: 355-396; gdT VL: 397-714; Free energy: -330; gdT CAI: 0.887375945709965; ORF count: 1.
- SEQ ID NO: 99 is the sequence name for Hum2 scFv ECOg (196). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: ATCCAGCTGGTGCAGTCCGGGGCCGAGGTGAAGAAGCCCGGGGCCTCCGTGAAGGTGTC CTGCAAGGCCTCCGGGTACACCTTCACCCGGTACACCATGCACTGGGTGAGGCAGGCTC CCGGGCAGGGGCTGGAGTGGATCGGGTACATCAACCCCTCGCGCGGGTACACCAACTAC AACCAGAAGTTCAAGGACCGGGCCACGCTGACCACCGACAAGAGCACCTCCACCGCCTA CATGGAGCTGTCCAGCCTGCGGTCCGAGGACACCGCCGTGTACTACTGCGCCCGGTACT ACGACGACCACTACTGCCTGGACTACTGGGGCCAGGGGACCCTGGTGACCGTGTCCAGC GGCGGCTCTGGCGGCTCTGGAGGCTCCGGCGGCTCTGGAGGCGACATCCAGC
- SEQ ID NO: 99 includes gdT scFv: 1-714; gdT VH: 355-396; gdT Linker: 355-396; gdT VL: 397-714; Free energy: -324.7; gdT CAI: 0.892144940351689; ORF count: 1.
- SEQ ID NO: 100 is the sequence name for Hum2 scFv ECOg (172). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: ATCCAGCTCGTCCAGTCCGGGGCCGAGGTGAAGAAGCCCGGGGCGTCCGTGAAGGTGTC CTGCAAGGCGTCCGGGTACACGTTCACCCGGTACACGATGCACTGGGTCCGTCAGGCTC CCGGGCAGGGGCTGGAGTGGATCGGGTACATCAACCCGTCCCGCGGGTACACGAACTAC AACCAGAAGTTCAAGGACCGGGCGACCCTGACGACCGACAAGTCCACGTCCACCGCGTA CATGGAGCTGTCGTCCCTGCGGTCCGAGGACACCGCCGTGTACTACTGCGCCCGGTACTA CGACGACCACTACTGCCTCGACTGGGGCCAGGGGACCCTCGTGACCGTGTCCTCCG GAGGTTCCGGCGGCTCCGGAGGATCTGGCGGCTCCGGCGGCGACATCCAGCTG
- SEQ ID NO: 100 includes gdT scFv: 1-714; gdT VH: 355-396; gdT Linker: 355-396; gdT VL: 397-714; Free energy: -324.5; gdT CAI: 0.827859696643083; ORF count: 0.
- SEQ ID NO: 101 is the sequence name for gd-c V6 scFv. It is a gdT Targeting scFv construct. It is an AA sequence. The sequence is: QVQLQQSGPGLVKPSQTLSLTCAISGDSVSSNRAAWNWIRQSPSKGLEWLGRTYYRSKWYN EYAASVKSRMSINPDTSKNQFSLQLNSVTPEDTALYYCARDLWELREACDIWGQGTMVTVS SGGSGGSGGSGGSGGDIVMTQSPSFLSTFVGDRVTITCRASQGISSYLAWYQQKPGKVPKLLI YVASTLQSGVPSRFSGSGSGTEFTLTISSLQPEDFATYYCQLNSYPFTFGPGTKVDIK.
- SEQ ID NO: 101 includes gdT scFv: 1-244; gdT VH: 124-137; gdT Linker: 124-137; gdT VL: 138-244.
- SEQ ID NO: 102 is the sequence name for gd-C V6 scFv. It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: CAGGTGCAGCTGCAGCAGTCCGGGCCCGGGCTGGTGAAGCCCAGCCAGACCCTGAGCCT GACCTGCCATCAGCGGGGACTCCGTCAGCTCCAACCGGGCCGCCTGGAACTGGATCA GGCAGTCCCCGTCCAAGGGGCTGGAGTGGCTCGGCCGGACCTACTACCGCTCCAAGTGG TACAACGAGTACGCCGCCTCCGTGAAGTCCCGGATGAGCATCAACCCCGATACCTCCAA GAACCAGTTCAGCCTGCAGCTGAACTCCGTGACGCCCGAGGATACGGCCCTGTACTACT GCGCCAGGGACCTGTGGGAGCTGCGCGAGGCCTGCGACATCTGGGGCCAGGGGACCATG GTGACCGTGTCCTCCGGCGGCTCAGGCGGCTCAGGTGGCTCCGGCGGATCAGGTGGCT
- SEQ ID NO: 102 includes gdT scFv: 1-732; gdT VH: 369-411; gdT Linker: 369-411; gdT VL: 412-732; Free energy: -325.2; gdT CAI: 0.901042; ORF count: 1.
- SEQ ID NO: 103 is the sequence name for gd-c V6 scFv ECOg (69). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: CAGGTGCAGCTGCAGCAGTCCGGGCCCGGGCTGGTGAAGCCTTCCCAGACCCTCTCCCTC ACCTGCGCCATCTCCGGGGATTCCGTGTCCTCCAACCGCGCCGCCTGGAACTGGATCAGG CAGTCCCCTTCCAAGGGGCTGGAGTGGCTGGGGCGCACGTACTACCGCTCCAAGTGGTA CAACGAGTACGCCGCTTCCGTGAAGTCCCGCATGAGCATCAACCCCGATACCTCCAAGA ACCAGTTCTCCCTGCAGCTGAACTCCGTGACCCCGGAGGATACCGCGCTGTACTACTGCG CCCGGGACCTGTGGGAGCTGCGGGAAGCCTGCGACATCTGGGGCCAGGGGACCATGGTG ACCGTGTCCTCCGGAGGCTCCGGAGGCTCCGGAGG
- SEQ ID NO: 103 includes gdT scFv: 1-732; gdT VH: 369-411; gdT Linker: 369-411; gdT VL: 412-732; Free energy: -328.2; gdT CAI: 0.885003557188278; ORF count: 0.
- SEQ ID NO: 104 is the sequence name for gd-c V6 scFv ECOg (34). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: CAAGTGCAGCTGCAGCAGAGCGGGCCCGGGCTGGTGAAGCCGTCGCAGACGCTGTCGCT GACGTGCCATCAGCGGCGACAGCGTGAGCAGCAACCGCGCCGCGTGGAACTGGATCA GGCAGTCGCCCAGCAAGGGGCTGGAGTGGCTGGGGCGCACGTACTACCGCAGCAAGTG GTACAACGAGTACGCCGCCAGCGTGAAGAGCCGCATGAGCATCAACCCCGACACCAGCA AGAACCAGTTCTCGCTGCAGCTGAACAGCGTGACGCCCGAGGACACCGCGCTGTACTAC TGCGCGCGACTTGTGGGAGCTGCGCGAGGCGTGCGACATCTGGGGCCAGGGCACCAT GGTGACCGTGAGCAGCGGCGGCAGTGGTGGCAGCGGTGGTGGCAGCGGT
- SEQ ID NO: 104 includes gdT scFv: 1-732; gdT VH: 369-411; gdT Linker: 369-411; gdT VL: 412-732; Free energy: -353.6; gdT CAI: 0.744822337548797; ORF count: 2.
- SEQ ID NO: 105 is the sequence name for gd-c V6 scFv ECOg (55). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: CAGGTGCAGCTGCAGCAGAGCGGCCCCGGGCTCGTGAAGCCGTCGCAGACCCTGAGCCT CACCTGCCATCTCCGGGGACTCCGTGTCCTCGAACCGCGCCGCGTGGAACTGGATTCG GCAGAGCCCCAGCAAGGGCCTGGAGTGGCTGGGGCACCTACTACCGCTCCAAGTGGT ACAACGAGTACGCCGCCTCGGTGAAGTCCCGGATGAGCATCAACCCCGACACCTCGAAG AACCAGTTCTCGCTGCAGCTGAACTCCGTGACCCCGGAGGACACGGCGCTGTACTACTG CGCCCGGGACCTCTGGGAGCTCCGCGAGGACACGGCGCTGTACTACTG CGGGACCTCTGGGAGCTCCGCGAGGACACGGCGCTGTACTACTG CGCCCGGGACCTCTG
- SEQ ID NO: 105 includes gdT scFv: 1-732; gdT VH: 369-411; gdT Linker: 369-411; gdT VL: 412-732; Free energy: -351.8; gdT CAI: 0.812038056353435; ORF count: 0.
- SEQ ID NO: 106 is the sequence name for gd-c V6 scFv ECOg (21). It is a gdT Targeting scFv construct. It is a DNA sequence.
- SEQ ID NO: 106 includes gdT scFv: 1-732; gdT VH: 369-411; gdT Linker: 369-411; gdT VL: 412-732; Free energy: -338.7; gdT CAI: 0.860184134678756; ORF count: 3.
- SEQ ID NO: 107 is the sequence name for gd-c V6 scFv ECOg (99). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: CAGGTGCAGCTGCAGCAGAGCGGGCCCGGGCTCGTGAAGCCCTCGCAGACCCTCTCCCT CACGTGCGATCTCCGGGGACTCCGTGTCCTCCAACCGCGCCGCGTGGAACTGGATAC GGCAGAGCCCCTCGAAGGGGCTGGAGTGGCTGGGGCGCACGTACTACCGCTCCAAGTGG TACAACGAGTACGCCGCCTCCGTGAAGTCCCGCATGAGCATCAACCCCGACACCTCCAA GAACCAGTTCTCCCTGCAGCTGAACTCCGTGACTCCCGAGGACACCGCGCTGTACTACTG CGCGCGGGACCTGTGGGAGCTGCGCGAGGCGTGCGACATCTGGACAGGGGGGACCATG GTGACCGTGTCCTCCGGAGGAAGCGGAGGAAGCGGAGG
- SEQ ID NO: 107 includes gdT scFv: 1-732; gdT VH: 369-411; gdT Linker: 369-411; gdT VL: 412-732; Free energy: -335; gdT CAI: 0.835639819762746; ORF count: 0.
- SEQ ID NO: 108 is the sequence name for gd-c VI HL scFv. It is a gdT Targeting scFv construct. It is an AA sequence. The sequence is: EVQLLESGGGLVKPGGSLRLSCAASRFTLSSYDMNWVRQAPGKGLEWVSSISSSSSYIYYAD SVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARDRGVGGTDYYYYGLDVWGQGTTV TVSSGGSGGSGGSGGSGGEIVMTQSPGTLSLSPGERATLSCRASQSVSSSYLAWYQQKPGQA PRLLIYGASSRATGIPDRFSGSGSGTDFTLTISRLEPEDFAVYYCQQYGSSPPYTFGQGTKVEIK [0538] SEQ ID NO: 108 includes gdT scFv: 1-248; gdT VH: 126-139; gdT Linker: 126-139
- SEQ ID NO: 109 is the sequence name for gd-c VI HL scFv. It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTGCTGGAGAGCGGCGGCGGCCTGGTGAAACCCGGCGGCTCCCTGCGGCT GTCCTGCGCCGCCTCCAGGTTCACCCTGTCCAGCTACGACATGAACTGGGTGAGGCAGG CTCCCGGGAAGGGGCTGGAGTGGGTCCTCCATCTCCTCCAGCTCCAGCTACATCTACT ACGCCGATTCCGTGAAGGGGAGATTCACCATCTCCAGGGACAACGCCAAGAACTCCCTG TACCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGA CAGGGGCGTTGGCGGCACCGACTACTACTACTACGGGCTGGACGTGTGGGGCCAGGGGA CCACCGTGTCCAGCGGCGGCTCTGGCGGCTCTGGAGGCTCTGGCTGGGG
- SEQ ID NO: 109 includes gdT scFv: 1-744; gdT VH: 376-417; gdT Linker: 376-417; gdT VL: 418-744; Free energy: -341.2; gdT CAI: 0.91246469035254; ORF count: 2.
- SEQ ID NO: 110 is the sequence name for gd-c V 1 HL scFv (63). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTCCAGCTCCTGGAGAGCGGAGGAGGCCTGGTGAAGCCCGGAGGCTCCCTGAGGCT CTCCTGCGCCGCCTCCAGGTTCACCCTCTACGACATGAACTGGGTGAGGCAGGC CCCGGGGAAGGGGCTGGAGTGGGTCTCCTCCATCTCCTCCTCCTACATCTACTA CGCCGACTCCGTGAAGGGGCGCTTCACCATCTCCCGGGACAACGCCAAGAACTCCCTCT ACCTCCAGATGAACTCCCTGAGGGCCGAGGACACGGCCGTCTACTACTGCGCCCGGGAC CGAGGGGTAGGAGGCACCGACTACTACTACGGGCTGGACGTCTGGGGCCAGGGGAC CACCGTGACCGACCGACCGACCGACTACTACTACTACGGGCTGGACGTCTGGGGCCAGGGGAC
- SEQ ID NO: 110 includes gdT scFv: 1-744; gdT VH: 376-417; gdT Linker: 376-417; gdT VL: 418-744; Free energy: -362.6; gdT CAI: 0.854971378798751; ORF count: 1.
- SEQ ID NO: 111 is the sequence name for gd-c V 1 HL scFv (72). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTGCTGGAGTCCGGCGGCGGCCTGGTGAAACCCGGCGGCAGCCTGCGGCT GTCCTGCGCGGCAAGCCGCTTCACGCTGTCCAGCTACGACATGAACTGGGTGCGCCAGG CACCCGGCAAGGGGCTGGAGTGGGTCCAGCATATCCAGCTCGTCAAGCTACATATAC TACGCGGACAGCGTGAAGGGCCGGTTTACCATCTCGCGGGATAACGCCAAGAACAGCCT GTACCTGCAGATGAACAGCCTGCGGGCCGAGGACACCGCGGTGTACTACTGCGCAAGGG ACCGCGGGGTAGGCGGCACGGATTACTACTACTACGGGCTGGACGTGTGGGGCCAGGGG ACCACCGTGACGGTGTCCTCCGGCGGCTCAGGCGGTTCCGGTGGTGACGGT
- SEQ ID NO: 111 includes gdT scFv: 1-744; gdT VH: 376-417; gdT Linker: 376-417; gdT VL: 418-744; Free energy: -366.6; gdT CAI: 0.761156065773582; ORF count: 4.
- SEQ ID NO: 112 is the sequence name for gd-c V 1 HL scFv (14). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTCCAGCTGCTGGAGAGCGGCGGCGGCCTGGTCAAACCCGGCGGCTCGCTGCGGCT GAGCTGCGCCGCCAGCAGGTTCACCCTGAGCTCCTACGACATGAACTGGGTGCCAGG CCCCAGGCAAGGGGCTGGAGTGGGTGAGCTCGATCAGCTCGTCGTCGAGCTACATCTAC TACGCCGACAGCGTCAAGGGGCGCTTCACCATCTCGCGCGACAACGCCAAGAACTCGCT CTACCTCCAGATGAACTCGCTGCGGGCCGAGGACACCGCCGTCTACTACTGCGCCCGAG ATCGCGGGGTTGGCGGCACCGACTACTACTACTACGGGCTCGACGTGTGGGGCCAGGGGACCACCGTGACCGTGAGCTCCGGCGGCTCTGGCGGCTCAGGTGGCTGGCGCT
- SEQ ID NO: 112 includes gdT scFv: 1-744; gdT VH: 376-417; gdT Linker: 376-417; gdT VL: 418-744; Free energy: -366.1; gdT CAI: 0.774531811261147; ORF count: 3.
- SEQ ID NO: 113 is the sequence name for gd-c V 1 HL scFv (22). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTGCTGGAGTCCGGCGGCGGCCTGGTGAAACCCGGCGGCTCCCTGCGGCT GTCCTGCGCCGCCAGCAGGTTCACCCTCTCCTCCTACGACATGAACTGGGTGCGGCAGGC CCCAGGGAAGGGCCTGGAGTGGGTGAGCAGCATCAGCAGCAGCAGCAGCTACATCTACT ACGCCGACAGCGTCAAGGGGCGCTTCACCATCAGCAGGGACAACGCCAAGAACAGCCT GTACCTGCAGATGAACAGCCTCCGGGCCGAGGACACGGCCGTGTACTACTGCGCCCGTG ATCGTGGCGTCGGCGGCACCGACTACTACTACTACGGGCTGGACGTGTGGGGCCAGGGG ACGACCGTGACCGTCTCCTCCGGCGGCTCCGGAGGCTCTGGTGGTT
- SEQ ID NO: 113 includes gdT scFv: 1-744; gdT VH: 376-417; gdT Linker: 376-417; gdT VL: 418-744; Free energy: -359.3; gdT CAI: 0.831881016856322; ORF count: 3.
- SEQ ID NO: 114 is the sequence name for gd-c V 1 HL scFv (11). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAGGTGCAGCTGCTGGAGAGCGGCGGCGGCCTCGTGAAACCCGGCGGCTCGCTGCGGCT CTCGTGCGCCGCTTCGCGCTTCACGCTCTCGTCGTACGACATGAACTGGGTGCGGCAGGC TCCCGGGAAGGGGCTGGAGTGGGTCTCGTCGATCGTCGTCGTCGAGCTACATCTACTA CGCCGACTCCGTGAAGGGGCGCTTCACGATCTCGCGCGACAACGCGAAGAACTCGCTCT ACCTGCAGATGAACTCGCTGCGCGCCGAGGACACCGCCGTCTACTACTGCGCTCGCGAT CGCGGAGTCGGCGGCACCGACTACTACTACTACGGGCTCGACGTCTGGGGCCAGGAC GACCGTGTCGAGCGGCGGAAGCGGCGGAAGCGACCAGCGGCGGAAGGAG
- SEQ ID NO: 114 includes gdT scFv: 1-744; gdT VH: 376-417; gdT Linker: 376-417; gdT VL: 418-744; Free energy: -358.3; gdT CAI: 0.705025041042151; ORF count: 1.
- SEQ ID NO: 115 is the sequence name for JAML scFv. It is a gdT Targeting scFv construct. It is an AA sequence. The sequence is: DVQLVESGAELVRPGASKLSCKALAYTFTDYEMHWVKQTPVHGLEWIGIIHPGSGGTVYNQ KFKGKATLTADKSSSTAYMELSSLTSEDSTVYYCTRRRYYGSSYNWYFDVWGAGNGGSGG SGGSGGSGGVLTQSPASLAASVGETVTITCRASENIYYSLAWYQQKQGKSPQLLIYNANSLE DGVPSRFSGSGSGTQYSLKINSMQPEDTATYFCEQTYDVPLTFGAGTKLEL.
- SEQ ID NO: 115 includes gdT scFv: 1-234; gdT VH: 117-130; gdT Linker: 117-130; gdT VL: 131-234; Free energy: -328.2; gdT CAI: 0.850906150801958; ORF count: 2.
- SEQ ID NO: 116 is the sequence name for JAML scFv. It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GATGTCCAGCTGGTGGAGTCTGGGGCTGAGCTGGTGAGGCCTGGGGCCAGCAAGCTGTC CTGCAAGGCCCTGGCCTACACCTTCACAGACTATGAGATGCACTGGGTGAAGCAGACCC CAGTGCATGGGCTGGAGTGGATTGGGATCATCCATCCAGGCTCTGGTGGCACAGTCTAC AACCAGAAGTTCAAGGGGAAGGCCACACTCACAGCTGACAAGTCCAGCTCCACAGCCTA CATGGAGCTGTCCAGCCTGACCTCTGAGGACTCCACAGTCTACTACTGCACCAGGAGGA GGTACTATGGCTCCAGCTACAACTGGTACTTTGATGTGTGGGGAGCTGGGAATGGTGGCT CTGGTGGCTCTGGTGGCTCTGGTGGCTCTGGTGGAGTGCTGACCCAGTCCCCAG
- SEQ ID NO: 1 16 includes gdT scFv: 1 -702; gdT VH: 349-390; gdT Linker: 349-390; gdT VL: 391-702; Free energy: -302; gdT CAI: 0.868315362715317; ORF count: 10.
- SEQ ID NO: 117 is the sequence name for JAML scFv (88). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GACGTGCAGCTGGTGGAGTCCGGGGCTGAGCTGGTGAGGCCCGGGGCCTCCAAGCTGAG CTGCAAGGCCCTGGCCTACACCTTCACCGACTACGAGATGCACTGGGTGAAGCAGACCC CGGTGCACGGGCTGGAGTGGATCGGGATCATCCATCCCGGGTCCGGCGGCACCGTGTAC AACCAGAAGTTCAAGGGGAAGGCCACGCTGACCGCCGACAAGTCCAGCTCCACCGCCTA CATGGAGCTGTCCAGCCTGACCTCCGAGGACTCCACCGTGTACTACTGCACCCGGCGGC GGTACTACGGGTCCTCCTACAACTGGTACTTCGACGTGTGGGGCGCCGGGAACGGCGGA TCAGGCGGCTCCGGCGCCGGGAACGGCGGA TCAGGCGGCTCCGGCGCCGG
- SEQ ID NO: 117 includes gdT scFv: 1-702; gdT VH: 349-390; gdT Linker: 349-390; gdT VL: 391-702; Free energy: -323.6; gdT CAI: 0.915740281407777; ORF count: 1.
- SEQ ID NO: 118 is the sequence name for JAML scFv (84). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GATGTCCAGCTCGTGGAGTCCGGGGCTGAGCTCGTGAGGCCCGGGGCCTCGAAGCTGAG CTGCAAGGCCCTGGCCTACACCTTCACGGACTACGAGATGCACTGGGTGAAGCAGACCC CGGTGCACGGCCTGGAGTGGATCGGGATCATTCACCCCGGGTCCGGCGGCACCGTGTAC AACCAGAAGTTCAAGGGCAAGGCCACGCTGACCGCGGACAAGTCCTCGTCCACGGCGTA CATGGAGCTGAGCTCCCTGACCTCCGAGGACTCCACGGTGTACTACTGCACACGGCGGC GGTACTACGGGAGCTCCTACAACTGGTACTTCGACGTCTGGGGCGCCGGGAACGGAGGCTCCCTGACCTCCGAGGACTCCACGGTGTACTACTGCACACGGCGGC GGTACTACGG
- SEQ ID NO: 118 includes gdT scFv: 1-702; gdT VH: 349-390; gdT Linker: 349-390; gdT VL: 391-702; Free energy: -328.2; gdT CAI: 0.850906150801958; ORF count: 2.
- SEQ ID NO: 119 is the sequence name for JAML scFv (44). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GATGTGCAGCTGGTGGAGTCCGGGGCTGAGCTGGTGAGGCCCGGGGCCTCCAAGCTGTC CTGCAAGGCCCTGGCCTACACCTTCACCGACTACGAGATGCACTGGGTGAAGCAGACGC CCGTGCACGGGCTGGAGTGGATCGGGATCATTCACCCCGGGTCCGGCGGCACCGTGTAC AACCAGAAGTTCAAGGGGAAGGCCACGCTGACCGCCGACAAGTCCTCCTCCACCGCCTA CATGGAGCTGAGCTCCCTGACCTCCGAGGACTCCACCGTGTACTACTGCACCCGGCGGC GGTACTACGGGTCCTCCTACAACTGGTACTTCGACGTGTGGGGCGCCGGGAACGGCGGA TCTGGCGGCTCCGGCGCCGGGAACGGCGGA TCTGGCGGCTCCGGCGCCGGGA
- SEQ ID NO: 119 includes gdT scFv: 1-702; gdT VH: 349-390; gdT Linker: 349-390; gdT VL: 391-702; Free energy: -318.2; gdT CAI: 0.934766339108284; ORF count: 2.
- SEQ ID NO: 120 is the sequence name for JAML scFv (23). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GACGTGCAGCTGGTGGAGTCCGGGGCCGAGCTGGTACGGCCAGGCGCCAGCAAGCTGTC CTGCAAGGCGCTCGCCTACACCTTCACCGACTACGAGATGCACTGGGTGAAGCAGACGC CCGTGCACGGGCTGGAGTGGATCGGGATCATACACCCCGGGTCCGGCGGCACCGTCTAC AACCAGAAGTTCAAGGGGAAGGCTACCCTTACGGCCGACAAGTCCTCCTCTACCGCCTA CATGGAGCTGTCCAGCCTGACGAGCGAGGACTCTACCGTCTACTACTGCACCCGCAGGC GGTACTACGGGTCCAGCTACAACTGGTACTTCGACGTGTGGGGCGCCGGGAACGGCGGT AGTGGCGGTAGCGGCGGTAGTGGCGGTAGCGGCGGGCGCCGGGAACGGCGGT AGTGGC
- SEQ ID NO: 120 includes gdT scFv: 1-702; gdT VH: 349-390; gdT Linker: 349-390; gdT VL: 391-702; Free energy: -314.5; gdT CAI: 0.828248130876822; ORF count: 3.
- SEQ ID NO: 121 is the sequence name for JAML scFv (78). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GACGTGCAGCTCGTGGAGAGCGGCGCAGAGCTTGTGCGCCCCGGGGCCTCCAAGCTGTC CTGCAAGGCGCTCGCCTACACCTTCACGGACTACGAGATGCACTGGGTGAAGCAGACCC CTGTGCACGGCCTGGAGTGGATCGGGATCATTCACCCCGGGTCAGGAGGCACCGTGTAC AACCAGAAGTTCAAGGGGAAGGCCACGCTGACCGCCGACAAGTCCTCCTCCACGGCCTA CATGGAGCTCTCCTCGCTGACCTCCGAGGACTCCACGGTGTACTACTGCACGCGGAGGA GGTACTACGGGTCCTCCTACAACTGGTACTTCGACGTGTGGGGCGCGGGGAATGGCGGC TCAGGAGGCTCAGGAGGCTCAGCCTCAG
- SEQ ID NO: 121 includes gdT scFv: 1-702; gdT VH: 349-390; gdT Linker: 349-390; gdT VL: 391-702; Free energy: -314.4; gdT CAI: 0.837369130789258; ORF count: 3.
- SEQ ID NO: 122 is the sequence name for CDXAR ligand. It is a gdT Targeting ligand construct. It is an A A sequence. The sequence is: LSITTPEEMIEKAKGETAYLPCKFTLSPEDQGPLDIEWLISPADNQKVDQVIILYSGDKIYDDY YPDLKGRVHFTSNDLKSGDASINVTNLQLSDIGTYQCKVKKAPGVANKKIHLVVLVKPSGA RCYVDGSEEIGSDFKIKCEPKEGSLPLQYEWQKLSDSQKMPTSWLAGKMCHLQRAVRPLPE ATSAVIIHPWGPCLLPTWKDIPRLSITKYQVKTLNALLRVRLSHLLR.
- SEQ ID NO: 122 includes gdT ligand: 1-233.
- SEQ ID NO: 123 is the sequence name for CDXAR ligand. It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: CTGAGCATCACTACCCCTGAGGAGATGATTGAGAAGGCTAAGGGTGAGACAGCCTACCT GCCCTGCAAGTTCACCCTGAGCCCTGAGGACCAGGGGCCCCTGGACATTGAGTGGCTGA TCAGCCCAGCTGACAACCAGAAGGTGGACCAGGTCATCATCCTGTACTCAGGGGACAAG ATCTATGATGACTACTACCCTGACCTGAAGGGCAGGGTGCACTTCACCAGCAATGACCT GAAGTCAGGGGATGCCAGCATCAATGTGACCAACCTGCAGCTGTCTGACATAGGCACCT ACCAGTGCAAGGTCAAGAAGGCCCCAGGGGTAGCCAACAAGAAGATCCACCTGGTGGT GCTGGTCAAGCCCTCAGGGGCCAGGTGCTATGTGGATGGCTCTGTGGATGGCTCTGGCTGGAGATAGGCTCTG
- SEQ ID NO: 123 includes gdT ligand: 1-233; Free energy: -284.1; gdT CAI: 0.86860152001121; ORF count: 7.
- SEQ ID NO: 124 is the sequence name for CDXAR ligand (6). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: CTGAGCATCACCACGCCCGAGGAGATGATCGAGAAGGCCAAGGGCGAGACCGCCTACCT GCCCTGCAAGTTCACCCTGAGCCCCGAGGACCAGGGGCCCCTGGACATCGAGTGGCTGA TCTCGCCCGCGGACAACCAGAAGGTGGACCAGGTGATCATCCTGTACTCCGGGGACAAG ATCTACGACGACTACTACCCCGACCTGAAGGGGCGCGTGCACTTCACCTCCAACGACCT GAAGTCCGGGGACGCCAGCATCAACGTGACCAACCTGCAGCTGTCCGACATCGGGACCT ACCAGTGCAAGGTGAAGAAGGCGCCCGGGGTCGCCAACAAGAAGATCCACCTGGTGGT GCTGGTGAAGCCCAGCTACGTGGACGGGAGCGAGGAGATCGGGTCC
- SEQ ID NO: 124 includes gdT ligand: 1-233; Free energy: -291.4; gdT CAI: 0.912300179663014; ORF count: 1.
- SEQ ID NO: 125 is the sequence name for CDXAR ligand (57). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: CTCTCGATCACCACACCCGAGGAGATGATCGAGAAGGCGAAGGGCGAGACCGCCTACTT GCCCTGCAAGTTCACCCTCTCGCCCGAGGACCAGGGGCCCCTCGATATCGAGTGGCTCAT CTCGCCCGCGGACAACCAAAAGGTGGACCAGGTGATCATCCTCTATAGTGGGGACAAGA TCTACGACGACTACTACCCCGATCTCAAGGGGCGCGTCCACTTCACCTCCAACGACCTCA AGAGCGGGGACGCCTCGATCAACGTGACCAACCTCCAATTGAGCGACATCGGGACCTAC CAGTGCAAGGTGAAGAAGGCGCCCGGGGTCGCCAACAAGAAGATCCACCTCGTGGTGCT CGTGAAGCCCAGTGGGGCGCGGTGCTACGTGGATGGGTCGGAGGATCGGGAGCGAC T
- SEQ ID NO: 125 includes gdT ligand: 1-233; Free energy: -290.9; gdT CAI: 0.776501808272779; ORF count: 4.
- SEQ ID NO: 126 is the sequence name for CDXAR ligand (56). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: CTGAGCATCACCACGCCGGAGGAGATGATCGAGAAGGCGAAGGGCGAGACCGCGTACC TGCCCTGCAAGTTCACCCTGAGCCCGGAGGACCAGGGGCCGCTGGACATCGAGTGGCTG ATCAGCCCCGCGGACAACCAGAAGGTGGACCAGGTGATCATCCTGTACAGCGGGGACAA GATCTACGACGACTACTACCCGGACCTGAAGGGGCGCGTGCACTTCACCTCCAACGACC TGAAGAGCGGGGACGCCAGCATCAACGTGACCAACCTGCAGCTGAGCGACATCGGGAC CTACCAGTGCAAGGTGAAGAAGGCGCCCGGGGTCGCGAACAAGAAGATCCACCTGGTG GTGCTGGTGAAGCCCAGCGGGGCCCGGTGCTACGTGGACGGGTCCGAGGATCGGGTCGGGTCGG
- SEQ ID NO: 126 includes gdT ligand: 1-233; Free energy: -287.5; gdT CAI: 0.835151871227941; ORF count: 2.
- SEQ ID NO: 127 is the sequence name for CDXAR ligand (73). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: CTCTCGATCACCACGCCCGAGGAGATGATCGAGAAGGCCAAGGGCGAGACCGCCTACTT GCCCTGCAAGTTCACCCTCTCGCCCGAGGACCAGGGGCCCCTCGACATCGAGTGGCTCAT CTCGCCCGCGGACAACCAGAAGGTGGACCAGGTGATCATCCTCTACTCGGGCGACAAGA TCTACGACGACTACTACCCCGACCTCAAGGGGCGCGTGCACTTCACGAGCAACGACCTC AAGAGCGGGGACGCCTCGATCAACGTGACCAACCTCCAGCTCTCCGACATCGGGACCTA CCAGTGCAAGGTGAAGAAGGCGCCCGGGGTCGCCAACAAGAAGATCCACCTCGTGGTGT TGGTGAAGCCCAGCGGGGCGCGGTGCTACGTGGACGGGAGCGAGGAGATCGGGAGCGAGCGAGC
- SEQ ID NO: 127 includes gdT ligand: 1-233; Free energy: -287.4; gdT CAI: 0.810082913563651; ORF count: 0.
- SEQ ID NO: 128 is the sequence name for CDXAR ligand (63). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: CTGAGCATCACGACGCCCGAGGAGATGATCGAGAAGGCCAAAGGGGAGACCGCCTACC TGCCCTGCAAGTTCACCCTGAGCCCCGAGGACCAGGGGCCCCTGGACATCGAGTGGCTG ATCTCCCCGGCGGACAACCAGAAGGTCGACCAGGTGATCATCCTGTACTCCGGGGACAA GATCTACGACGACTACTACCCCGACCTGAAGGGCCGGGTGCACTTCACGTCGAACGACC TGAAGTCCGGGGACGCCTCGATCAACGTGACCAACCTGCAGCTGTCCGACATCGGGACC TACCAGTGCAAGGTGAAGAAGGCGCCCGGCGTGGCCAACAAGAAGATCCACCTGGTGGT CCTCGTGAAGCCCAGCGGGGCGCGGTGCTACGTGGACGGCAGCGAGCGAGGTGCTACGTGGACG
- SEQ ID NO: 128 includes gdT ligand: 1-233; Free energy: -286; gdT CAI: 0.861258772692867; ORF count: 0.
- SEQ ID NO: 129 is the sequence name for CD5 scFv. It is a gdT Targeting scFv construct. It is an AA sequence. The sequence is: EIQLVQSGGGLVKPGGSVRISCAASGYTFTNYGMNWVRQAPGKGLEWMGWINTHTGEPTY ADSFKGRFTFSLDDSKNTAYLQINSLRAEDTAVYFCTRRGYDWYFDVWGQGTTVTVSSGGG GSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCRASQDINSYLSWFQQKPGKAPKTLIYRA NRLESGVPSRFSGSGSGTDYTLTISSLQYEDFGIYYCQQYDESPWTFGGGTKLEIK.
- SEQ ID NO: 129 includes gdT scFv: 1-240; gdT VH: 119-133; gdT Linker: 119-133; gdT VL: 134-240.
- SEQ ID NO: 130 is the sequence name for CD5 scFv. It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAGATCCAGCTGGTGCAGTCTGGGGGGGGGCTGGTGAAGCCTGGGGGGTCAGTGAGGAT CAGCTGTGCTGCCTCAGGGTACACCTTCACCAACTATGGGATGAACTGGGTGAGGCAGG CCCCAGGGAAGGGGCTGGAGTGGATGGGGTGGATCAACACCCACACTGGGGAGCCCAC CTATGCTGACAGCTTCAAGGGGAGGTTCACCTTCAGCCTGGATGACTCCAAGAACACAG CCTACCTGCAGATCAACTCCCTGAGGGCTGAGGACACAGCTGTGTACTTCTGCACCAGG AGGGGGTATGACTGGTACTTTGATGTGTGGGGGCAGGACCACAGTGACAGTGTCCTC TGGGGGGGGGGGGTCTGGGGGGGGGGGGGGGTCTGACATCCAGA
- SEQ ID NO: 130 includes gdT scFv: 1-720; gdT VH: 355-399; gdT Linker: 355-399; gdT VL: 400-720; Free energy: -346.2; gdT CAI: 0.943955363575702; ORF count: 8.
- SEQ ID NO: 131 is the sequence name for CD5 scFv (11). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAGATCCAGCTGGTGCAGTCCGGCGGCGGCCTGGTGAAACCCGGCGGCTCCGTGCGGAT CTCCTGCGCCGCCTCCGGGTACACCTTCACCAACTACGGGATGAACTGGGTGCGGCAGG CTCCCGGGAAGGGGCTGGAGTGGATGGGCTGGATCAACACCCACACCGGGGAGCCCAC ATACGCCGACTCCTTCAAGGGGCGCTTCACCTTCTCCCTGGACGACTCCAAGAACACCGC CTACCTGCAGATCAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTTCTGCACCCGGCG CGGGTACGACTGGTACTTCGACGTGTGGGGCCAGGGGACCACCGTGACCGTGTCCTCTG GCGGCGGAGGTTCCGGCGGAGGAGGCTCCGGAGGAGGCGGCAGCGACATCCA
- SEQ ID NO: 131 includes gdT scEv: 1-720; gdT VH: 355-399; gdT Linker: 355-399; gdT VL: 400-720; Free energy: -345.9; gdT CAI: 0.885961949519618; ORF count: 1.
- SEQ ID NO: 132 is the sequence name for CD5 scFv (9). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAGATCCAGCTGGTGCAGTCCGGCGGCGGCCTGGTGAAACCCGGCGGCTCCGTGCGGAT CTCCTGCGCCGCCTCCGGGTACACCTTCACCAACTACGGGATGAACTGGGTGCGGCAGG CTCCCGGGAAGGGGCTGGAGTGGATGGGCTGGATCAACACCCACACCGGGGAGCCCAC GTACGCCGACTCCTTCAAGGGGCGCTTCACCTTCTCCCTCGACGACTCCAAGAACACCGC CTACCTGCAGATCAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTTCTGCACCCGGCG CGGGTACGACTGGTACTTCGACGTGTGGGGCCAGGGGACCACCGTGACCGTGTCCTCCG GAGGCGGCGGCTCTGGAGGAGGCGGCTCTGGAGGCGGAGGCTCCGACATCCAGAT
- SEQ ID NO: 132 includes gdT scFv: 1-720; gdT VH: 355-399; gdT Linker: 355-399; gdT VL: 400-720; Free energy: -344.1; gdT CAI: 0.8842887077719; ORF count: 1.
- SEQ ID NO: 133 is the sequence name for CD5 scFv (41). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is: GAAATCCAGCTGGTGCAGTCCGGCGGCGGCCTGGTGAAACCCGGCGGCTCCGTGCGGAT CAGCTGCGCGGCCAGCGGGTACACCTTTACGAACTACGGGATGAACTGGGTGCGCCAGG CACCCGGCAAGGGGCTCGAATGGATGGGCTGGATCAACACGCACACCGGGGAGCCAAC
- SEQ ID NO: 133 includes gdT scEv: 1-720; gdT VH: 355-399; gdT Linker: 355-399; gdT VL: 400-720; Free energy: -342.6; gdT CAI: 0.78445426326926; ORF count: 1.
- SEQ ID NO: 134 is the sequence name for CD5 scFv (21). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is:
- SEQ ID NO: 134 includes gdT scFv: 1-720; gdT VH: 355-399; gdT Linker: 355-399; gdT VL: 400-720; Free energy: -338.3; gdT CAI: 0.760359380692982; ORF count: 1.
- SEQ ID NO: 135 is the sequence name for CD5 scFv (29). It is a gdT Targeting scFv construct. It is a DNA sequence. The sequence is:
- SEQ ID NO: 135 includes gdT scEv: 1-720; gdT VH: 355-399; gdT Linker: 355-399; gdT VL: 400-720; Free energy: -334.2; gdT CAI: 0.774216148765874; ORF count: 1.
- SEQ ID NO: 136 is the sequence name for IL2r ligand. It is a gdT Targeting ligand construct. It is an AA sequence. The sequence is: APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEE LKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQ S1ISTLT.
- SEQ ID NO: 136 includes gdT ligand: 1-333.
- SEQ ID NO: 137 is the sequence name for IL2r ligand. It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: GCACCAACAAGCAGTAGCACCAAAAAGACGCAGCTTCAGTTAGAGCACCTCCTACTCGA CCTACAGATGATATTGAATGGTATTAATAACTACAAAAATCCTAAATTGACTCGAATGTT GACATTTAAATTTTATATGCCCAAAAAGGCAACCGAACTCAAGCATCTGCAGTGCCTGG AGGAGGAACTCAAGCCACTTGAAGAGGTCCTGAACCTGGCTCAGTCAAAAAAAATTTTCAT CTGCGCCCCCGGGACTTAATCAGCAATATCAACGTGATTGTTCTGGAGCTCAAGGGGTCT GAGACCACTTTTATGTGTGAATACGCTGATGAAACTGCGACAATCGTCGAGTTCCTCAAT AGATGGATCACTTTCTGTCAATCCATTATTAGCACCCTGACC.
- SEQ ID NO: 137 includes gdT ligand: 1-459; Free energy: -92.6; gdT CAI: 0.749692927682812; ORF count: 2.
- SEQ ID NO: 138 is the sequence name for IL2r ligand. It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: GCTCCTACCAGCTCCAGCACCAAGAAGACCCAGCTGCAGCTGGAGCACCTGCTGCTGGA CCTGCAGATGATCCTGAACGGGATCAACAACTACAAGAACCCCAAGCTGACCCGGATGC TGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCACCTGCAGTGCCTG GAGGAGGAGCTGAAGCCCCTGGAGGAGGTGCTGAACCTGGCCCAGAGCAAGAACTTCC ACCTGCGGCCCCGGGACCTGATCAGCAACATCAACGTGATCGTGCTGGAGCTGAAGGGG TCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTCCT GAACCGCTGGATCACCTTCTGCCAGAGCATCATCATCTCCACGCTGACC.
- SEQ ID NO: 138 includes gdT ligand: 1-459; Free energy: -140.2; gdT CAI: 0.948946971021626; ORF count: 0.
- SEQ ID NO: 139 is the sequence name for IL2r ligand. It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: GCCCCGACCAGCAGCAGCACCAAGAAGACGCAGCTGCAGCTGGAGCACCTGCTGCTGGA CCTGCAGATGATCCTGAACGGGATCAACAACTACAAGAACCCCAAGCTGACCCGGATGC TGACCTTCAAGTTCTACATGCCCAAGAAGGCGACCGAGCTGAAGCACCTGCAGTGCCTG GAGGAGGAGCTGAAGCCCCTGGAGGAGGTGCTGAACCTGGCCCAGTCCAAGAACTTCCA CCTGCGGCCCCGGGACCTGATCAGCAACATCAACGTGATCGTGCTGGAGCTGAAGGGGT CCGAGACCACCTTCATGTGCGAGTACGCGGACGAGACCGCCACAATCGTGGAGTTCCTG AACCGCTGGATCACCTTCTGCCAGTCCATCATCAGCACCCTGACG.
- SEQ ID NO: 139 includes gdT ligand: 1-459; Free energy: -142.5; gdT CAI: 0.925399648745741; ORF count: 0.
- SEQ ID NO: 140 is the sequence name for IL2r ligand. It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: GCCCCAACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCACCTGCTGCTGGA CCTGCAGATGATCCTGAACGGGATCAACAACTACAAGAACCCCAAGCTGACCCGGATGC TCACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCACCTGCAGTGCCTG GAGGAGGAGCTGAAGCCCCTGGAGGAGGTGCTGAACCTGGCCCAGTCCAAGAACTTCCA CCTGCGGCCCCGGGACCTGATCTCCAACATCAACGTGATCGTGCTGGAGCTGAAGGGGT CCGAGACCACCTTCATGTGCGAGTACGCAGATGAGACGGCTACAATCGTGGAGTTCCTG AACAGGTGGATCACCTTCTGCCAGTCCATCATCTCCACCTTGACA.
- SEQ ID NO: 140 includes gdT ligand: 1-459; Free energy: -139.3; gdT CAI: 0.966990185804835; ORF count: 1.
- SEQ ID NO: 141 is the sequence name for IL2r ligand. It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: GCGCCCACGTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCACCTGCTGCTGGA CCTGCAGATGATCCTGAACGGGATCAACAACTACAAGAACCCCAAGCTGACCCGGATGC TGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCACCTGCAGTGCCTG GAGGAGGAGCTGAAGCCCCTGGAGGAGGTGCTGAACCTGGCCCAGTCCAAGAACTTCCA CCTGCGGCCCCGGGACCTGATCTCCAACATCAACGTGATCGTGCTGGAGCTGAAGGGGT CCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTCCTG AACCGCTGGATCACCTTCTGCCAGAGCATCATCATCAGCACCCTCACC.
- SEQ ID NO: 141 includes gdT ligand: 1-459; Free energy: -136; gdT CAI: 0.957989396711122; ORF count: 0.
- SEQ ID NO: 142 is the sequence name for IL2r ligand. It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: GCCCCTACCTCCTCCTCCACCAAGAAGACCCAGCTCCAGCTGGAGCACCTCCTCCTGGAC CTCCAGATGATCCTCAACGGGATCAACAACTACAAGAACCCCAAGCTCACCCGGATGCT GACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCACCTCCAGTGCCTGG AGGAGGAGCTGAAGCCCCTGGAGGAGGTGCTGAACCTGGCCCAGTCCAAGAACTTCCAC CTCCGGCCCAGGGACCTGATCTCCAACATCAACGTGATCGTCCTGGAGCTGAAGGGGTC CGAGACCACCTTCATGTGCGAGTACGCCGATGAGACAGCCACCATCGTGGAGTTCCTCA ACAGGTGGATCACCTTCTGCCAGTCCATCATCAGCACCCTCACC.
- SEQ ID NO: 142 includes gdT ligand: 1-459; Free energy: -135.6; gdT CAI: 0.950256495713545; ORF count: 1.
- SEQ ID NO: 143 is the sequence name for lL15r ligand. It is a gdT Targeting ligand construct. It is an AA sequence. The sequence is: NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTV ENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS.
- SEQ ID NO: 143 includes gdT ligand: 1-114.
- SEQ ID NO: 144 is the sequence name for IL15r ligand. It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: AACTGGGTTAACGTGATCAGCGATCTGAAGAAGATTGAAGATCTCATACAATCCATGCA CATCGACGCTACCCTGTATACAGAGTCCGACGTTCACCCTAGCTGTAAGGTGACTGCCAT GAAGTGCTTTTTACTGGAACTGCAGGTAATCAGTCTGGAGTCTGGTGATGCCTCAATTCA CGACACGGTAGAGAATCTAATAATCCTTGCCAACAACTCTTTGAGTTCCAATGGCAATGT GACAGAATCTGGCTGCAAGGAGTGTGAAGAGCTTGAAGAGAAAAACATTAAAGAGTTC CTGCAATCCTTCGTGCATATAGTGCAGATGTTCATCAACACCTCG.
- SEQ ID NO: 144 includes gdT ligand: 1-342; Free energy: -86.8; gdT CAI: 0.773146219024413; ORF count: 3.
- SEQ ID NO: 145 is the sequence name for IL15r ligand (12). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: AACTGGGTGAACGTGATCAGCGATCTGAAGAAGATCGAGGACCTGATCCAGTCCATGCA CATCGACGCTACCCTGTACACCGAGTCGGACGTTCACCCCAGCTGCAAGGTGACCGCGA TGAAGTGCTTCCTGCTCGAACTGCAGGTGATCAGCCTGGAGAGCGGGGACGCGAGCATC CACGATACGGTGGAGAACCTGATCATCCTGGCCAACAACTCGCTCAGCTCGAACGGGAA CGTGACCGAGAGCGGGTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAG TTCCTCCAGTCGTTCGTGCACATCGTGCAGATGTTCATCAACACCTCC.
- SEQ ID NO: 145 includes gdT ligand: 1-342; Free energy: -125.8; gdT CAI: 0.877487412777548; ORF count: 0.
- SEQ ID NO: 146 is the sequence name for IL15r ligand (31). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: AACTGGGTGAACGTCATCTCCGACCTGAAGAAGATCGAGGATCTGATCCAGTCGATGCA CATCGACGCGACGCTCTACACCGAGTCGGACGTTCACCCCTCGTGCAAGGTCACGGCGA TGAAGTGCTTCCTCCTGGAGCTGCAGGTGATCTCCCTGGAGTCGGGCGACGCCTCGATCC ACGACACGGTCGAGAACCTGATCATCCTCGCGAACAACTCCCTCTCGTCCAACGGGAAC GTGACCGAGAGCGGGTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGT TCCTCCAGTCGTTCGTCCACATCGTCCAGATGTTCATCAACACCTCC.
- SEQ ID NO: 146 includes gdT ligand: 1-342; Free energy: -124.3; gdT CAI: 0.830363621275029; ORF count: 0.
- SEQ ID NO: 147 is the sequence name for IL15r ligand (29). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: AACTGGGTGAACGTGATCAGCGACCTGAAGAAGATCGAGGACCTGATCCAGTCCATGCA CATCGACGCCACGCTGTACACCGAGTCCGACGTGCACCCCAGCTGCAAGGTGACCGCCA TGAAGTGCTTCCTGCTGGAGCTGCAGGTGATCTCCCTGGAGTCCGGGGACGCCTCCATCC ACGACACCGTGGAGAACCTGATCATCCTGGCCAACAACTCCCTGTCCTCCAACGGGAAC GTGACCGAGTCCGGGTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGT TCCTGCAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACGTCG.
- SEQ ID NO: 147 includes gdT ligand: 1-342; Free energy: -123.2; gdT CAI: 0.953480352366457; ORF count: 0.
- SEQ ID NO: 148 is the sequence name for IL15r ligand (29). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: AATTGGGTGAACGTCATCTCCGACCTCAAGAAGATCGAGGACCTCATCCAGTCCATGCA CATCGACGCCACGCTCTACACGGAGTCCGACGTGCACCCGTCCTGCAAGGTGACGGCCA TGAAGTGCTTCCTGCTGGAGCTGCAGGTCATCTCCTTGGAGTCCGGGGACGCCTCCATCC ACGACACCGTCGAGAACCTCATCATCCTGGCCAACAACTCCTTGAGCTCCAACGGGAAC GTGACGGAGTCCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGT TCCTGCAGTCCTTCGTGCACATCGTGCAGATGTTCATCAACACGTCC.
- SEQ ID NO: 148 includes gdT ligand: 1-342; Free energy: -122.3; gdT CAI: 0.905077015244385; ORF count: 0.
- SEQ ID NO: 149 is the sequence name for IL15r ligand (32). It is a gdT Targeting ligand construct. It is a DNA sequence. The sequence is: AACTGGGTGAACGTGATCTCCGACCTCAAGAAGATCGAGGACCTCATCCAGTCGATGCA CATCGACGCGACCCTCTACACGGAGAGCGACGTCCATCCGAGCTGCAAGGTGACCGCGA TGAAGTGCTTCCTCCTGGAGCTCCAGGTGATCTCCCTGGAGTCCGGGGACGCGAGCATCC ACGACACCGTCGAGAACCTGATCATCCTCGCGAACAACTCGCTCTCCTCGAACGGGAAC GTCACCGAGAGCGGCTGCAAGGAGTGCGAGGAGCTCGAAGAAGAACATCAAGGAGT TCCTCCAGAGCTTCGTCCACATCGTCCAGATGTTCATCAACACGTCG.
- SEQ ID NO: 149 includes gdT ligand: 1-342; Free energy: -122.1; gdT CAI: 0.814639976789479; ORF count: 0.
- SEQ ID NO: 150 is the sequence name for B2m shRNAl . It is a HLA siRNA construct. It is a DNA sequence. The sequence is: GAATGGAGAGAGAATTGAA.
- SEQ ID NO: 151 is the sequence name for OITA shRNA7. It is a HLA siRNA construct. It is a DNA sequence. The sequence is: GCTCAGGCTAAGCTTGTACAA.SEQ ID NO: 152 is MND promoter. It is a DNA sequence.
- SEQ ID NO: 153 is HSPA8 promoter. It is a DNA sequence. The sequence is: CCCCTCCCTTCAGGCCCCGCGCGATTCCGCCCCCAGTTCTGTGCCGGCCAAGATCCCGGC TAGCCGCTATCATTGGTTAGTTCCAAGTTTGCCCGCCCCTCTTCCTCCTCCTTTTTCCG CCCCCTCCCGCGGAAGCTGGGGGCGCATGCGTAGAGGTGGACGCTCCCCTCCCCCCC GCCCGGGGTAACTGAGGACTCCCGCGCGCGGACTCGCTGCGCCCCACCCTCCCTTTCCCC GGGGCCGTCCGGAGAGCGGGGGCGAGCTTGAAAGTTCCAGAACGCTGCGGTGAGTGCGT TATCGTGAGGCGGAGCGCGGTGGGGTGGGTGCGGAAGGGCGAGGCCCGAGGAGTGG AGCCGGGCTTGTGATTGGGTCTTGTAAGGGCAGCCGGGCGTCTATTGGCCGGGGAAGCC GTAATGGCAGGCAGCAGGGGCGGGCCCCTCTTTTCCG CCC
- SEQ ID NO: 154 is WPREmut. It is a DNA sequence. The sequence is: ATCAACCTCTGGATTACAAAATTTGTGAAAGATTGACTGATATTCTTAACTATGTTGCTC CTTTTACGCTGTGTGGATATGCTGCTTTAATGCCTCTGTATCATGCTATTGCTTCCCGTAC GGCTTTCGTTTTCTCCTCCTTGTATAAATCCTGGTTGCTGTCTCTTTATGAGGAGTTGTGG CCCGTTGTCCGTCAACGTGGCGTGGTGTGCTCTGTTTGCTGACGCAACCCCCACTGGC TGGGGCATTGCCACCACCTGTCAACTCCTTTCTGGGACTTTCGCTTTCCCTCCCGATCG CCACGGCAGAACTCATCGCCGCCTGCCTGCCGCTGCTGGACAGGGGCTAGGTTGCTG GGCACTGATAATTCCGTGGTGTTGTCGGAAATCATCGTCCTTTCCTTGGCTGCTCGCCTGTGTTGCTCGCC TGTGTTGCCAACTGGATCCTGCGCGGGACGTCCTT
- SEQ ID NO: 155 is 4Gs. It is an A A sequence. The sequence is: GGGGS
- SEQ ID NO: 156 is the sequence name for SSTR2-8. It is a Tumor targeting scFv construct. It is an AA sequence. The sequence is: EIVMTQSPDSLAVSLGERATISCKSSQSLINSRNRKNYLAWYQQNPGQPPKLLIYWASTRESG VPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSYYLWTFGQGTKVEIKGGGGSGGGGSGG GGSQVQLVESGGRLVQPGGSLRVSCEASGFTFSDYGMAWVRQAPGKGLEWVSFISNLGYSL YYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARAPYDYDSFDPMDYWGQGTM VTVS.
- SEQ ID NO: 156 includes Target scFv: 1-248; Target VL: 1-112; Target linker: 113- 127; Target VH: 128-248.
- SEQ ID NO: 157 is the sequence name for SSTR2-8 vl. It is a Tumor targeting scFv construct. It is an expression codon optimized DNA sequence encoding the amino acid of SEQ ID NO: 156. The sequence is: GAGATCGTGATGACCCAGAGCCCCGACTCCCTGGCCGTTTCCCTCGGGGAGCGGGCCAC CATCTCCTGCAAGAGCTCCCAGAGCCTGATCAACTCCCGGAACCGGAAGAACTACCTGG CCTGGTACCAGCAGAACCCCGGGCAGCCGCCGAAGCTGCTGATCTACTGGGCCTCCACG CGGGAGAGCGGGGTGCCCGATCGCTTCTCCGGCTCCGGCTCCGGGACCGACTTCACCCT GACCATCTCCAGCCTGCAGGCCGAGGACGTGGCCGTCTACTACTGCAAGCAGAGCTACT ACCTCTGGACCTTCGGGCAGGGGACCAAGGTGGAGATCAAAGGCGGCGGAGGCTCTGGC GGAGCCCGGCTCCCCCGCCGCCCGCCCG CGG
- SEQ ID NO: 157 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -340.2; gdT CAI: 0.902; ORF count: 1.
- SEQ ID NO: 158 is the sequence name for SSTR2-8 v2. It is a Tumor targeting scFv construct. It is an expression codon optimized DNA sequence encoding the amino acid of SEQ ID NO: 156. The sequence is: GAAATAGTAATGACGCAATCGCCGGACTCGTTGGCCGTGTCCCTGGGCGAGAGGGCCAC CATCAGCTGCAAGAGCTCCCAGTCCCTGATCAACTCCCGCAACCGCAAGAACTACCTGG CCTGGTACCAGCAGAACCCCGGCCAGCCTCCCAAGCTGCTGATCTACTGGGCCAGCACC CGGGAGAGCGGCGTGCCCGACAGGTTCAGCGGCAGCGGCAGCGGCACCGACTTCACCCT GACCATCAGCTCCCTGCAGGCCGAGGACGTGGCCGTGTACTACTGCAAGCAGAGCTACT ACCTGTGGACCTTCGGCCAGGGCACCAAGGTGGAGATCAAGGGAGGTGGCGGCAGCGG CGGAGGTGGCTCTGGCGGCAGCGG CGGAGGTGGCTCTG
- SEQ ID NO: 158 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -322.5; gdT CAI: 0.915155531601317; ORF count: 0.
- SEQ ID NO: 159 is the sequence name for SSTR2-8 v3. It is a Tumor targeting scFv construct. It is an expression codon optimized DNA sequence encoding SEQ ID NO: 156. The sequence is: GAAATAGTAATGACGCAATCGCCGGACTCGTTGGCCGTGAGCCTGGGCGAGCGTGCCAC CATCTCCTGCAAGTCCTCCCAGAGCCTGATCAACTCCCGGAACCGCAAGAACTACCTGGC CTGGTACCAGCAGAACCCCGGCCAGCCTCCCAAGCTGCTGATCTACTGGGCCTCCACCCG GGAGTCCGGCGTGCCCGACAGATTCTCCGGCTCCGGCTCCGGCACCGACTTCACCCTGAC CATCTCCAGCCTGCAGGCCGAGGATGTGGCAGTGTACTACTGCAAGCAGTCCTACTACCT GTGGACCTTCGGCCAGGGCACCAAGGTGGAGATCAAGGGTGGCGGAGGCTCTGGCGGTG GCGGTTCCGGAGGCGGAGGCTCCCAGGTGCAGCTGGTTCCG
- SEQ ID NO: 159 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -320; gdT CAI: 0.913669760876946; ORF count: 0.
- SEQ ID NO: 160 is the sequence name for SSTR2-8 v4. It is a Tumor targeting scFv construct. It is an expression codon optimized DNA sequence encoding SEQ ID NO: 156. The sequence is: GAAATTGTAATGACACAATCGCCTGACAGTTTGGCCGTCTCCCTCGGGGAGAGGGCCAC CATCTCCTGCAAGTCCTCCCAGTCCCTCATCAACTCCCGGAATCGGAAGAACTACCTCGC CTGGTACCAGCAGAACCCCGGCCAGCCTCCCAAGCTCCTCATCTATTGGGCCTCCACCCG GGAGAGTGGGGTCCCCGATCGGTTCTCGGGGAGTGGGAGTGGGACCGATTTCACCCTCA CCATCTCTTCCCTCCAGGCCGAGGATGTGGCCGTCTACTATTGCAAGCAGTCCTACTACC TCTGGACCTTCGGCCAGGGGACCAAGGTGGAGATCAAGGGAGGAGGTGGGAGTGGAGG AGGTGGGAGTGGAGGAGGTGGGTCCCAGGTCCAGCTCGTGGAGAGT
- SEQ ID NO: 160 includes Target scFv: 1-744; Target VL: 1-336; Target linker: 337- 381; Target VH: 382-744; Free energy: -319.399993896484; gdT CAI: 0.812998307048897; ORF count: 0.
- SEQ ID NO: 161 is the sequence name for GD2-3. It is a Tumor targeting scFv construct. It is an AA sequence.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Engineering & Computer Science (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Biophysics (AREA)
- Medicinal Chemistry (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Epidemiology (AREA)
- Biomedical Technology (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- Cell Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Microbiology (AREA)
- Oncology (AREA)
- Hematology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- General Engineering & Computer Science (AREA)
- Peptides Or Proteins (AREA)
- Medicinal Preparation (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
Abstract
Description
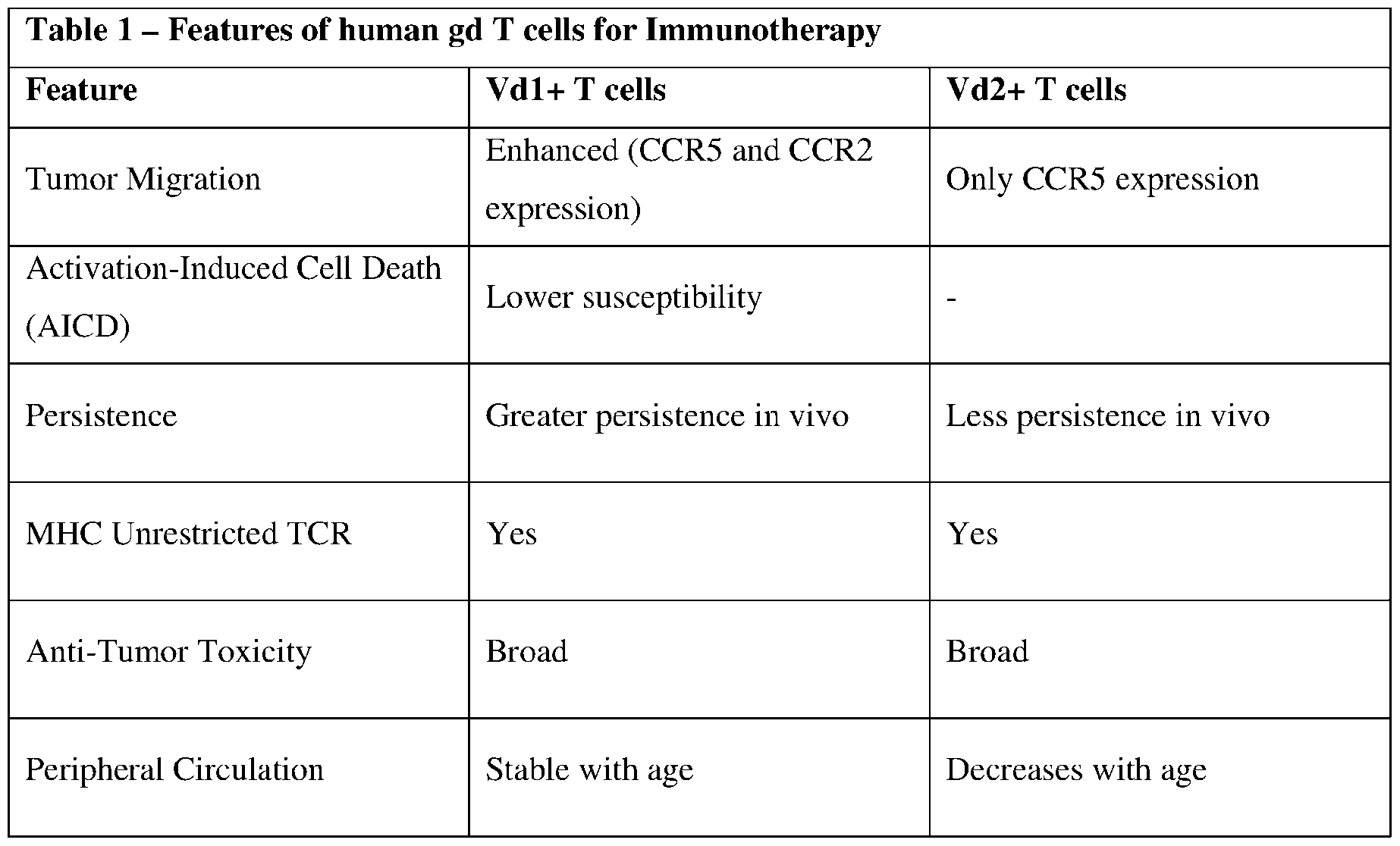
Claims
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP23821462.1A EP4622715A1 (en) | 2022-11-22 | 2023-11-22 | Engineered t cells |
| JP2025530051A JP2025539364A (en) | 2022-11-22 | 2023-11-22 | Genetically engineered T cells |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202263427128P | 2022-11-22 | 2022-11-22 | |
| US63/427,128 | 2022-11-22 | ||
| US202363438181P | 2023-01-10 | 2023-01-10 | |
| US63/438,181 | 2023-01-10 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024112866A1 true WO2024112866A1 (en) | 2024-05-30 |
Family
ID=89164480
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2023/080879 Ceased WO2024112866A1 (en) | 2022-11-22 | 2023-11-22 | Engineered t cells |
Country Status (3)
| Country | Link |
|---|---|
| EP (1) | EP4622715A1 (en) |
| JP (1) | JP2025539364A (en) |
| WO (1) | WO2024112866A1 (en) |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050079170A1 (en) * | 2001-09-14 | 2005-04-14 | Fabrice Le Gall | Dimeric and multimeric antigen binding structure |
| WO2015006482A1 (en) * | 2013-07-09 | 2015-01-15 | Duke University | CERTAIN IMPROVED HUMAN BISPECIFIC EGFRvIII ANTIBODY ENGAGING MOLECULES |
| WO2019001474A1 (en) * | 2017-06-27 | 2019-01-03 | Nanjing Legend Biotech Co., Ltd. | Chimeric antibody immune effctor cell engagers and methods of use thereof |
| WO2020047473A1 (en) * | 2018-08-30 | 2020-03-05 | HCW Biologics, Inc. | Single-chain and multi-chain chimeric polypeptides and uses thereof |
| WO2020076791A2 (en) * | 2018-10-08 | 2020-04-16 | The Uab Research Foundation | Neuroendocrine cancer targeted therapy |
| WO2021148788A1 (en) * | 2020-01-22 | 2021-07-29 | Ucl Business Ltd | Engineered immune cells |
| WO2023133357A2 (en) * | 2022-01-10 | 2023-07-13 | Expression Therapeutics, Llc | Engineered t cells |
-
2023
- 2023-11-22 JP JP2025530051A patent/JP2025539364A/en active Pending
- 2023-11-22 EP EP23821462.1A patent/EP4622715A1/en active Pending
- 2023-11-22 WO PCT/US2023/080879 patent/WO2024112866A1/en not_active Ceased
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050079170A1 (en) * | 2001-09-14 | 2005-04-14 | Fabrice Le Gall | Dimeric and multimeric antigen binding structure |
| WO2015006482A1 (en) * | 2013-07-09 | 2015-01-15 | Duke University | CERTAIN IMPROVED HUMAN BISPECIFIC EGFRvIII ANTIBODY ENGAGING MOLECULES |
| WO2019001474A1 (en) * | 2017-06-27 | 2019-01-03 | Nanjing Legend Biotech Co., Ltd. | Chimeric antibody immune effctor cell engagers and methods of use thereof |
| WO2020047473A1 (en) * | 2018-08-30 | 2020-03-05 | HCW Biologics, Inc. | Single-chain and multi-chain chimeric polypeptides and uses thereof |
| WO2020076791A2 (en) * | 2018-10-08 | 2020-04-16 | The Uab Research Foundation | Neuroendocrine cancer targeted therapy |
| WO2021148788A1 (en) * | 2020-01-22 | 2021-07-29 | Ucl Business Ltd | Engineered immune cells |
| WO2023133357A2 (en) * | 2022-01-10 | 2023-07-13 | Expression Therapeutics, Llc | Engineered t cells |
Non-Patent Citations (17)
| Title |
|---|
| "UniProt", Database accession no. P07766 |
| ALTSCHUL ET AL., J. MOL. BIOL., vol. 215, 1990, pages 403 - 10 |
| ATTALLAH CAROLINA ET AL: "A highly efficient modified human serum albumin signal peptide to secrete proteins in cells derived from different mammalian species", PROTEIN EXPRESSION AND PURIFICATION, ACADEMIC PRESS, SAN DIEGO, CA, vol. 132, 10 January 2017 (2017-01-10), pages 27 - 33, XP029968219, ISSN: 1046-5928, DOI: 10.1016/J.PEP.2017.01.003 * |
| CORPET ET AL., NUC. ACIDS RES., vol. 16, 1988, pages 10881 - 90 |
| E. W. MARTIN: "Molecular Biology and Biotechnology: a Comprehensive Desk Reference", 1995, VCH PUBLISHERS, INC. |
| GANESAN RAJKUMAR ET AL: "Selective recruitment of [gamma][delta] T cells by a bispecific antibody for the treatment of acute myeloid leukemia", LEUKEMIA, NATURE PUBLISHING GROUP UK, LONDON, vol. 35, no. 8, 1 February 2021 (2021-02-01), pages 2274 - 2284, XP037525442, ISSN: 0887-6924, [retrieved on 20210201], DOI: 10.1038/S41375-021-01122-7 * |
| H.-H. OBERG ET AL: "Novel Bispecific Antibodies Increase T-Cell Cytotoxicity against Pancreatic Cancer Cells", CANCER RESEARCH, vol. 74, no. 5, 21 January 2014 (2014-01-21), US, pages 1349 - 1360, XP055268793, ISSN: 0008-5472, DOI: 10.1158/0008-5472.CAN-13-0675 * |
| HIGGINSSHARP, CABIOS, vol. 5, 1989, pages 151 - 3 |
| HIGGINSSHARP, GENE, vol. 73, 1988, pages 237 - 44 |
| HUANG ET AL., COMPUTER APPLS. IN THE BIOSCIENCES, vol. 8, 1992, pages 155 - 65 |
| KUFER P ET AL: "A revival of bispecific antibodies", TRENDS IN BIOTECHNOLOGY, ELSEVIER PUBLICATIONS, CAMBRIDGE, GB, vol. 22, no. 5, 1 May 2004 (2004-05-01), pages 238 - 244, XP004504363, ISSN: 0167-7799, DOI: 10.1016/J.TIBTECH.2004.03.006 * |
| NEEDLEMANWUNSCH, J. MOL. BIOL., vol. 48, 1970, pages 443 |
| PEARSON ET AL., METH. MOL. BIO., vol. 24, 1994, pages 307 - 31 |
| PEARSONLIPMAN, PROC. NATL. ACAD. SCI. USA, vol. 85, 1988, pages 2444 |
| RUDIKOFF S ET AL: "Single amino acid substitution altering antigen-binding specificity", PROCEEDINGS OF THE NATIONAL ACADEMY OF SCIENCES, NATIONAL ACADEMY OF SCIENCES, vol. 79, 1 March 1982 (1982-03-01), pages 1979 - 1983, XP007901436, ISSN: 0027-8424, DOI: 10.1073/PNAS.79.6.1979 * |
| SAMBROOKRUSSELL: "Molecular Cloning, A Laboratory Manual", 2001, COLD SPRING HARBOR LABORATORY |
| SMITHWATERMAN, ADV. APPL. MATH., vol. 2, 1981, pages 482 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4622715A1 (en) | 2025-10-01 |
| JP2025539364A (en) | 2025-12-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7264954B2 (en) | Chimeric antigen receptor targeting HER2 | |
| JP6849600B6 (en) | Chimeric antigen receptor, composition and method | |
| US9469684B2 (en) | Therapeutic and diagnostic cloned MHC-unrestricted receptor specific for the MUC1 tumor associated antigen | |
| US20230227575A1 (en) | Engineered T Cells | |
| KR102316091B1 (en) | Chimeric antigen receptor targeting BCMA and use thereof | |
| CN107709353A (en) | The method and composition for the treatment of cancer | |
| BR112019017629A2 (en) | antigen-binding receptor, isolated polynucleotide, vector, transduced t cell, methods for treating a disease and for inducing lysis, use of the receptor and receptor | |
| JP7645500B2 (en) | Improved T cell receptor costimulatory molecule chimeras | |
| CA2881981A1 (en) | Method and compositions for cellular immunotherapy | |
| CN114591444A (en) | Humanized chimeric antigen receptor based on CD7 and application thereof | |
| CN114514247B (en) | CAR-CD123 vector and use thereof | |
| JP7591772B2 (en) | Enhanced synthetic T cell receptors and antigen receptors | |
| EP4622715A1 (en) | Engineered t cells | |
| WO2024151784A1 (en) | Engineered t cells | |
| RU2825816C2 (en) | Improved antigen-binding receptors | |
| HK40074512A (en) | Chimeric antigen receptors targeting her2 | |
| HK1242705B (en) | Chimeric antigen receptors, compositions, and methods |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23821462 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2025530051 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2025530051 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023821462 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2023821462 Country of ref document: EP Effective date: 20250623 |
|
| WWP | Wipo information: published in national office |
Ref document number: 2023821462 Country of ref document: EP |