WO2022256577A1 - A method of speech enhancement and a mobile computing device implementing the method - Google Patents
A method of speech enhancement and a mobile computing device implementing the method Download PDFInfo
- Publication number
- WO2022256577A1 WO2022256577A1 PCT/US2022/032027 US2022032027W WO2022256577A1 WO 2022256577 A1 WO2022256577 A1 WO 2022256577A1 US 2022032027 W US2022032027 W US 2022032027W WO 2022256577 A1 WO2022256577 A1 WO 2022256577A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- speech signal
- mobile computing
- computing device
- speech
- enhanced
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/35—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception using translation techniques
- H04R25/353—Frequency, e.g. frequency shift or compression
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2201/00—Details of transducers, loudspeakers or microphones covered by H04R1/00 but not provided for in any of its subgroups
- H04R2201/40—Details of arrangements for obtaining desired directional characteristic by combining a number of identical transducers covered by H04R1/40 but not provided for in any of its subgroups
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2225/00—Details of deaf aids covered by H04R25/00, not provided for in any of its subgroups
- H04R2225/43—Signal processing in hearing aids to enhance the speech intelligibility
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2420/00—Details of connection covered by H04R, not provided for in its groups
- H04R2420/07—Applications of wireless loudspeakers or wireless microphones
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2430/00—Signal processing covered by H04R, not provided for in its groups
- H04R2430/20—Processing of the output signals of the acoustic transducers of an array for obtaining a desired directivity characteristic
Definitions
- This application is directed, in general, to speech enhancement and, more specifically, to speech enhancement implemented on a mobile computing device.
- SE speech enhancement
- the mobile computing device includes: (1) at least one microphone to receive a noisy speech signal that includes a clean speech signal and noise, and (2) at least one processor to perform operations including estimating a gain function of a magnitude spectrum of the clean speech signal, generating, a time-domain impulse response by processing the estimated gain function in a Mel-frequency domain, providing an enhanced speech signal by filtering the noisy speech signal using a weighted impulse response based on the time- domain impulse response, and generating an enhanced clean speech signal by filtering the enhanced speech signal using a super-Gaussian extension of the joint maximum a posteriori (SGJMAP) filter.
- SGJMAP joint maximum a posteriori
- the disclosure provides a computer program product having a series of operating instructions stored on a non-transitory computer readable medium that direct operations of at least one processor when initiated thereby to generate an enhanced clean speech signal from a noisy speech signal that includes a clean speech signal and noise.
- the operations include: (1) estimating a gain function of a magnitude spectrum of the clean speech signal, (2) generating, a time- domain impulse response by processing the estimated gain function in a Mel-frequency domain, (3) providing an enhanced speech signal by filtering the noisy speech signal using a weighted impulse response based on the time-domain impulse response, and (4) generating an enhanced clean speech signal by filtering the enhanced speech signal using a super-Gaussian extension of the joint maximum a posteriori (SGJMAP) filter.
- SGJMAP joint maximum a posteriori
- FIG. 1 illustrates a block diagram of an example of a speech enhancement system (SES) constructed according to the principles of the disclosure
- FIG. 2 illustrates a block diagram of an example of a SE method 200 carried out according to the principles of the disclosure
- FIG. 3 illustrates a block diagram of an example of a CRNN-based SE method representing the algorithm that can be used on a mobile computing device
- FIG. 4 shows the block diagram of an example representation of the disclosed CRNN architecture
- FIG. 5 illustrates Table 1, which is associated with the CRNN model
- FIG. 6 illustrates a block diagram of an example of the dual-channel RNN-based algorithm disclosed herein;
- Fig. 7A shows the entire working of the training and testing phase for the dual-channel RNN model
- FIG. 7B shows Equations 29 and 30 associated with the RNN model SE
- FIG. 8 illustrates a diagram showing an example of stacking of RNN cells; and [0017]
- FIG. 9 illustrates an example of a network architecture associated with the RNN model.
- HADs and CIs have provided many solutions for HI listeners, including the implementation of signal processing algorithms on suitable HADs and CIs. Nevertheless, the performance of HADs and CIs can deteriorate in the presence of numerous and often strong environmental noise. Many of these devices also lack the computational power to operate complex signal processing algorithms because of the physical design constraints.
- Some HAD manufacturers are using RMTs to increase the signal-to-noise (SNR) with the help of a separate microphone at the speaker while the speech signal is transmitted to the listener’s hearing device. Unfortunately, RMTs are an additional expense in addition to the cost of the HAD.
- SNR signal-to-noise
- the disclosure provides speech enhancement solution to address the above problems.
- the speech enhancement features disclosed herein can be advantageously implemented on mobile computing devices, such as a smartphone, a computing pad, a computing tablet, or another mobile computing devices having at least one microphone and one or more comparable processors.
- the mobile computing devices having in-built microphones can replace the traditional RMTs as a standalone device with no external component or additional hardware.
- An application with access to the inbuilt microphone can be downloaded to the mobile computing devices and provide speech enhancement for speech signals received via the microphone.
- the mobile computing devices can send an enhanced speech signal, such as an enhanced clean speech signal, to one or more speakers, such as ear speakers.
- the speaker can be integrated with the mobile computing device or can be communicatively coupled thereto via a wired or wireless connection.
- the mobile computing device can be connected to one or more ear speakers via a short-range wireless technology, such as Bluetooth, and can transmit the enhanced speech signal to ear speakers using the wireless technology.
- the ear speakers have receiving circuitry or receivers for receiving the enhanced speech signal and can also have software, hardware, or a combination thereof for operating as hearing aids.
- Various types of ear speakers, external and internal to the ear can be used.
- various types of ear speakers, earphones, headphones, or HADs are connectable via Bluetooth to smartphones with iOS or Android operating systems.
- manufacturers also have their smartphone-based applications.
- the smartphone can stream phone calls and media sound directly to the HADs. Additionally, some of these applications enable the fine-tuning of the HADs in real-time.
- the speech enhancement disclosed herein can be used with the applications to stream enhance speech signals to the HADs.
- FIG. 1 illustrates a block diagram of an example of a speech enhancement system (SES) 100 constructed according to the principles of the disclosure.
- the SES 100 includes a mobile computing device 110 and an ear speaker 160.
- the mobile computing device 110 is represented as a smartphone in FIG. 1 but other mobile computing devices can be used.
- the ear speaker 160 is represented by a HAD in FIG. 1 but a non-hearing aid speaker can also be used.
- the mobile computing device 110 includes a microphone array 120, at least one processor 130, a screen 140, and a transmitter 150.
- the microphone array 120, screen 140, and transmitter 150 can be conventional components typically found in a mobile computing device, such as a smartphone.
- the screen 140 can be a touch screen and the transmitter 150 can be a Bluetooth (or another short-range wireless compliant) compliant transmitter (or transceiver).
- the ear speaker 160 can also be a conventional device that includes a receiver corresponding to the transmitter 150 and a speaker.
- the at least one processor 130 can include an ARM processor (or comparable processor capability) or ARM- based processing platform that is typically found in smartphones.
- the mobile computing device 110 can include other components typically included in such devices, such as communication circuitry for cellular communication and a non-transitory memory for storing computing program products, such as mobile applications. The mobile computing device 110 does not require communication circuitry for performing the speech enhancement.
- a speech processing pipeline that is implemented on the at least one processor 130 illustrates a mobile computing device-based adaptive signal processing pipeline that uses the microphone array 120 (1, 2 or 3 microphones) to captures a noisy speech signal and generates an enhanced speech signal, such as an enhanced clean speech signal that can be transmitted to the ear speaker 160.
- the pipeline is represented by different functional blocks including a voice activity detector (VAD) 131, an adaptive acoustic feedback cancellation block (AAFC) 133, a speech enhancement block (SE) 135, and a multichannel dynamic range audio-compression or automatic gain control block (AC/AG) 137.
- VAD voice activity detector
- AAFC adaptive acoustic feedback cancellation block
- SE speech enhancement block
- AC/AG multichannel dynamic range audio-compression or automatic gain control block
- the output of the VAD 132 helps separate noisy speech signal from the noise part without speech signal so they can be used for SE and other stages of the signal processing pipeline.
- the noisy input speech is then passed through the AAFC 133 to suppress the background noise and the SE 135 and AC/AG 137 to extract the speech with minimum or no distortion.
- a direction of arrival (DOA) estimation block DOA 139 can also be used to allow a user to find the direction of the desired speaker.
- the SE 135 is configured to suppress the noise and enhance the quality and intelligibility of speech for optimum speech perception, thus improving speech communication performance for the user ( e.g ., listener).
- FIG. 2 illustrates an example of a SE method that can be used by the SE 135 to generate an enhanced clean speech signal by filtering the enhanced speech signal using a super-Gaussian extension of the joint maximum a posteriori (SGJMAP) filter.
- FIG. 2 illustrates a block diagram of an example of a SE method 200 carried out according to the principles of the disclosure.
- the SE method 200 is a statistical model-based SE method that can be executed as a processing pipeline on a mobile computing device, such as a smartphone, in real time and without external components.
- the SE method 200 represents an algorithm that has at least two stages based on the SGJMAP cost function.
- the SGJMAP gain estimate of the noisy speech mixture is smoothed along the frequency axis by a Mel filter-bank, leading to a Mel-warped frequency-domain SGJMAP estimate.
- a Mel filter-bank By applying a Mel-warped inverse discrete cosine transform (Mel-IDCT), the impulse response of the Mel-warped estimate can be derived, which filters out the background noise from the input noisy speech signal.
- Mel-IDCT Mel-warped inverse discrete cosine transform
- Traditional SGJMAP SE is used in the second stage as a post-filter to minimize the residual noise present in the first stage output.
- the proposed two- stage SE method 200 suppresses background noise with minimal speech distortion in real time.
- the SE method 200 can be implemented on a processor of a mobile computing device, such as mobile computing device 110, that receives and can record the noisy speech and processes the signal using the adaptive SE method 200.
- Blocks of the SE method 200 in FIG. 2 correspond to functional blocks of the algorithm that can be implemented on the processor.
- the output enhanced speech is then transmitted to a user’s ear speaker through a wired or wireless connection, which can provide an effective assistance platform for NH and HI users.
- the SE method 200 of FIG. 2 reflects the usability and real-time implementation on a mobile computing device, such as a smartphone.
- a time-domain noisy speech signal y(t) which is an additive mixture model of clean speech s(t) and noise z(t), is received by block
- the noisy speech signal can be received via a microphone, such a microphone array 120.
- the input noisy speech signal is transformed from time-domain into the frequency-domain by taking STFT in block 210.
- y( ⁇ ) s( ⁇ ) + z ( ⁇ ) (2)
- Y k ( ⁇ ), S k ( ⁇ ), and Z k ( ⁇ ) represent the STFT of y(t), s(t), and z(t) respectively for the frame
- Eq. (2) can be written as, where Rk ( ⁇ ), A k ( ⁇ ), B k ( ⁇ ) are the magnitude spectra of noisy speech, clean speech, and noise respectively.
- ⁇ y ( ⁇ ), ⁇ ( ⁇ ), ⁇ z ( ⁇ ) represents the phase of noisy speech, clean speech, and noise respectively.
- the frequency domain output of block 210 is provided to blocks 215 and 220 for SNR estimation and SGJMAP gain estimation.
- a non-Gaussian property in the spectral domain noise reduction framework can be considered and a super Gaussian speech model can be used.
- a result of the SE method 200 is to obtain an estimate of the clean speech magnitude spectrum A k ( ⁇ ). ⁇ can be eliminated for swiftness in further derivation.
- the JMAP estimator in block 220 jointly maximizes the magnitude and phase spectra probability conditioned on the observed complex coefficient,
- the p(.) denotes the probability density function (PDF) of its argument.
- PDF probability density function
- G( ) denotes the Gamma function.
- the logarithm function of Eq. (4) is differentiated with respect to A k and equated to zero.
- Steps 210, 215, and 220 can be considered a preprocessing stage for SE.
- Step 230 begins the first stage of processing that generates an enhanced speech signal by smoothing coefficients of the gain function, transforming the coefficients to a Mel-frequency scale, and filtering.
- the Mel-frequency is considered to be a perceptual domain and is used for processing in the first stage.
- the SGJMAP SE gain coefficients computed in Eq. (10) are smoothed and transformed to the Mel-frequency scale in block 230.
- the Mel-warped frequency-domain SGJMAP coefficients are estimated by using triangle-shaped, half-overlapped frequency windows. The relation between Mel-scale and frequency-domain is given by,
- Eq. (12) represents the central frequencies of the filter-bank bands, where filter-bank bands.
- the sampling frequency f set to be 16 kHz and the upper frequency/ in Eq. (11) is limited to 8 kHz.
- DCT discrete cosine transform
- the time-domain impulse response for SGJMAP SE is, where M t d ; is the Mel-IDCT defined as corresponding to the Mel filter-bank.
- the d f (n) is computed as follows, The time-domain impulse response of the SGJMAP SE in Eq. (19) is mirrored and the causal impulse response is obtained. The impulse response is then weighted using a Hanning window. And, the input noisy speech time-domain signal y ' (t) is filtered using the weighted impulse response in block 250. The output of applied filter block is the enhanced speech signal which goes to the post filter SGJMAP SE block 260 of the second stage.
- the single microphone SGJMAP SE is used as a post-filter to eliminate the residual background noise present in .
- the enhanced clean speech signal generated in block 260 can then be transmitted from the mobile computing device to the ear speakers through a wired or wireless connection as shown in Fig. 2.
- the SE method 200 can be implemented on ARM-based processing platforms to operate in real time, such as an iPhone XR smartphone running on iOS 13.1.1 as the processing platform, without requiring external or additional hardware for the smartphone.
- the SE method 200 can benefit from the use of the smartphone’s computational power, features, and in-built microphones.
- the input noisy speech data can be captured on the smartphone with 16ms frame size and overlap of 50% at 48 kHz sampling rate. By lowpass filtering and decimation factor of 3, the noisy speech data can be down-sampled to 16 kHz. Therefore, for every frame processing 256 samples are available (16ms data frame in time) using STFT size set to be 256 points.
- the SE method 200 can be implemented as an application and downloaded to the smartphone.
- the application can be stored on a non-transitory memory on the smartphone (or other mobile computing device).
- a user interface can be displayed on the screen, such as screen 140 of FIG. 1, and used for activation of the SE method 200.
- the user interface can include a switch button on the touch-screen that can used for activation or deactivation.
- the application When set in OFF’ mode, the application simply plays out the input noisy speech from the smartphones’ microphone without the SE method 200 processing. Switching the ON’ button allows the proposed SE module to process the input noisy speech audio signal.
- the enhanced output signal can then be transmitted to a HAD, earphone, or other type of ear speaker through a wired or wireless connection (via, for example, Bluetooth of the smartphone).
- the SE method 200 can use the initial few seconds (1-2 sec) to estimate the noise power at the beginning when the switch is in ON’ mode. Therefore, when the switch is triggered to ON’ there is no speech activity for those one to two seconds.
- a volume control slider is provided to the user via the user interface to adjust the output volume depending on their comfort listening level.
- the algorithm represented by SE method 200 is an example of speech enhancement that can be used in a speech processing pipeline, such as shown in FIG. 1. Other types of speech enhancement systems and methods can also be used.
- DNN deep neural networks
- the supervised SE methods are typically divided into masking and mapping-based techniques depending on the description of the clean speech targets for training.
- An ideal binary mask (IBM) from noisy input speech can be estimated by a feed- forward neural network.
- IBM binary mask
- LPS clean speech log-power spectra
- CNN convolutional neural network
- a fully convolutional neural network (FCN)-based SE can be used with input raw audio data.
- RNN Recurrent neural network
- LSTM long short-term memory
- a mixture of convolutional and LSTM networks may outperform other neural networks for SE at lower SNRs.
- RNN layers are much more complex than CNN layers as they do not have weight sharing.
- RNNs can be more suitable for time series data, as they can be used for processing random input data sequences with their internal memory.
- a real-time single-channel SE that can be used on edge devices (e.g mobile computing devices), where a DNN model, such as a convolutional recurrent neural network (CRNN) model, is trained to predict the clean speech magnitude spectrum.
- the CRNN is computationally efficient and can be used for real-time processing.
- a smartphone with an inbuilt microphone, such as mobile communication device 110 is used as an example of an edge device to capture the noisy speech data and perform complex computations using the CRNN model-based SE algorithm.
- the enhanced speech signal from the developed model implemented on the smartphone can be transmitted through wired or wireless earphone connection to the user and can be a real-time implementation on the smartphone.
- the algorithm can run on a standalone platform such as a smartphone and can be a critical element in the signal processing or communication pipeline.
- a single channel CRNN-based SE application is disclosed.
- the disclosed application operates in real-time on an edge device.
- the developed algorithm is computationally efficient and implemented on an iPhone with minimal audio latency.
- the CRNN-based SE method can outperform at least some conventional and neural network-based single-channel SE algorithms in terms of speech quality and intelligibility.
- FIG. 3 illustrates a block diagram of an example of the CRNN-based SE method 300 representing the algorithm that can be used on a mobile computing device.
- input noisy speech signal is transformed into STFT and ⁇ y ( ⁇ ), ⁇ y , ( ⁇ ), ⁇ ( ⁇ ) represents the phase of noisy speech, clean speech, and noise respectively (d and D represent noise for method 300 and correspond to z and Z which represent noise in method 200).
- the time domain signal output is obtained by taking Inverse Fast Fourier Transform (IFFT) of IFFT
- CNNs process the input image or matrix by performing convolution and pooling functions.
- a small image region can be compacted by a series of weighted learning filters (kernels) to form a convolutional layer.
- the kernel generates a feature map for every forward pass of input.
- Maxpooling layers follow the convolution layers to reduce the size or dimension of the feature maps.
- RNNs permit modeling sequential data since they have feedback connections.
- the RNN cell has a dynamic behavior to make use of its internal state memory for processing. Thus, making it very reliable for speech analysis.
- the CRNN model is a combination of both CNN and RNN layers.
- the CRNN model takes in one frame of noisy speech magnitude spectrum and outputs one frame of enhanced/clean speech magnitude spectrum.
- the input noisy magnitude spectrum is reshaped to form an image input, due to the presence of convolutional layers at the start. This is then fed into a neural network twice as shown in FIG 4.
- FIG. 4 shows the block diagram of an example representation of the disclosed CRNN architecture.
- Different hidden layers such as convolutional layers, maxpool layers, long short-term memory (LSTM) layers, and fully connected (FC) layers can be used to design the CRNN model.
- LSTM long short-term memory
- FC fully connected
- the first, second, third, and fourth convolutional layer uses 257, 129, 65, and 33 feature maps respectively.
- the feature maps gradually decrease in order to reduce the computational complexity and number of parameters, making the developed model suitable for real-time applications.
- the kernel and bias for all the convolution layers is given in Table 1, which is shown in FIG. 5.
- the convolutional layers there are two LSTM layers consisting of 33 neurons each.
- the output of the LSTM layer is flattened out and the respective outputs from both the paths are added together before sending them to the FC layer.
- the FC hidden layer has 257 neurons and is followed by a linear output layer to predict the speech spectrum.
- the CRNN architecture is given in Table 1. The specific numbers for designing the CRNN model was fixed in this example after several experiments and training.
- Adam optimization algorithm can be used with a mean absolute error loss function to train the model.
- Activation functions are used in each hidden layer to allow the network to learn complex and non-linear functional mapping between the input and output labels.
- the rectified linear unit (ReLU) was selected as an example activation function because it has been successful in solving the vanishing gradient problem.
- a clean speech dataset can be built from a dataset, such as the Librivox dataset of public audiobooks.
- Librivox has individual recordings in several languages, most of them are in English, that is read over 10,000 audio public domain books. Overall, there are 11,350 speakers present in the dataset. A portion of this dataset is considered to generate the noisy speech input features and clean speech labels for training the model.
- the noise dataset from Audioset and Freesound is also considered. Audioset is a series of approximately two million ten seconds sound clips made of YouTube videos, belonging to 600 audio classes. Finally, 150 audio classes, 60000 noise clips from Audioset, and 10000 noise clips from Freesound are mixed with the clean speech dataset considered.
- the resulting noisy speech audio clips are sampled to 16 kHz before feature extraction.
- a total of 100 hours of clean speech and noisy speech constitutes an example of a training set.
- the clean speech files are normalized, and each noise clip is scaled up to have one of the five SNRs (0, 10, 20, 30, 40 dB).
- a clip of clean speech and noise is randomly selected, before combining them together to create a noisy speech clip. Due to the real-time application of the CRNN method, reverberation can be added to a portion of clean speech (30 hours).
- the reverberation time (T60) can be randomly drawn from 0.2 s to 0.8 s with a step of 0.2 s.
- the CRNN model can be trained using the entire training dataset and can be evaluated once the training is complete using a blind validation test set.
- the blind test set can include real noisy speech recordings with and without reverberation. Challenging non- stationary noise cases can be included in the blind set such as Multi-talker babble, keyboard typing, a person eating chips, etc.
- the blind test set can include 150 noisy speech clips.
- the audio clips can be sampled at 16 kHz with a frame size of 32ms with a 50% overlap.
- a 512-point STFT can be computed to determine the input magnitude spectrum features.
- the first 257 magnitude spectrum values are taken into consideration due to the complex conjugate property in STFT and reshaped to form an image of 257 x 1 x 1.
- the final output layer predicts the clean speech signal magnitude spectrum.
- the model can be trained for a total of 50 epochs.
- the proposed CRNN based SE algorithm can be implemented on an iPhone, another smartphone, or another type of mobile computing device. However, due to the real-time usability of the proposed application, it can be implemented on other processing platforms, also.
- the microphone on the smartphone captures the input noisy speech at, for example, a 48 kHz sampling rate and then can be downsampled to 16 kHz with the help of a low-pass filter and a decimation factor of 3.
- the input frame size is set to be 32ms.
- a user interface can be displayed on a screen, such as touch screen 140, and used to initial the CRNN model for speech enhancement. By pressing a button on the user interface, the implemented model is initialized. The application simply replays the audio on the smartphone without processing when an ON/OFF switch of the user interface is in off mode. By clicking on the ON/OFF switch button, the CRNN based SE module will process the input audio stream and suppress the background noise.
- a slider is provided to the smartphone user to control the amount of output volume.
- TensorFlow Fite offers a C/C++ API.
- the CRNN model is compressed and deployed on the smartphone using libraries such as the TensorFlow Fite converter and interpreter.
- the trained weights can be frozen, thus eliminating backpropagation, training, and regularization layers.
- the final frozen model with the weights is saved into a file that includes, for example, a .pb extension.
- an iPhone 11 smartphone is considered.
- the audio latency for the iPhone 11 was 12- 14ms.
- the processing time for the input frame of 32ms is 0.705ms. Since the processing time is lower than the length of the input frame, the CRNN model SE application works smoothly at low audio latency on the smartphone. Based on our measurements, the application runs on a fully charged iPhone 11 with a 3046 mAh battery for approximately 5 hours.
- the CPU usage of the app running on the iOS smartphone is 28% and the maximum memory consumption after the processing is turned on is 75.4 MB.
- the obtained frozen model with the trained weights is of size 11.5 MB, meaning the actual memory consumption of the CRNN SE application is around 65 MB.
- the smartphones present in the market usually have 12- 16 GB memory; thus, the proposed application uses only 0.5 % of the entire smartphone memory.
- Another example of speech enhancement that can be used in a speech processing pipeline is a dual-channel RNN-based speech enhancement application using a basic recurrent neural net- work cell.
- the disclosed dual-channel RNN-based algorithm can operate in real-time with a low audio input-output latency.
- the dual-channel RNN-based method can be implemented on a mobile computing device, such as an Android-based smartphone, proving the real-time usability of the dual-channel RNN-based algorithm.
- the dual-channel RNN-based application is another example of a SE application disclosed herein that is computationally efficient and acts as an assistive hearing platform.
- the dual-channel RNN-based method can be used for various realtime speech enhancement and noise reduction applications on different edge computing platforms.
- the dual-channel RNN-based method provides an efficient approach of using the basic RNN cells for enhancing speech in the presence of background noise using the two microphones of a mobile computing device, such as a smart- phone.
- the smartphone is considered as an example to prove the real-time working of the dual-channel RNN-based method.
- the smartphone can be used as a stand-alone processing platform, without any external component or device, for implementing and running the dual-channel RNN-based method SE algorithm in real-time.
- the real and imaginary part of the frequency domain signal can be used as the primary input feature for the model.
- the RNN-based method works in real-time on a frame by frame processing of the data with a minimal input-output delay and can be implemented on any other processing platform (edge device).
- Another possible solution disclosed is the use of popular smartphones to capture the noisy speech data, process the signal, perform complex computations using the SE algorithm, and pass on the enhanced speech signal to the ear speakers, such as HADs through wired or wireless connection.
- the proposed application can also be used by a normal hearing user with the help of wired or wireless earphones/headphones.
- a computationally efficient RNN architecture is developed for SE using a simple but efficient input feature set and its real- time implementation on the smartphone without the help of any external hardware components.
- the dual-channel RNN-based SE algorithm can act as a vital component in the signal processing pipeline consisting of other blocks like adaptive feedback cancellation and dynamic range compression. Objective evaluations and subjective test scores of the RNN- based SE method signify the operational capability of the developed approach in several different noisy environments and low SNRs.
- the dual-channel RNN-based SE pipeline is described below and a block diagram of an example of the dual-channel RNN-based algorithm is shown in Fig. 6, which represents the real- time usability and application of the dual-channel RNN-based method using a smartphone and HAD.
- yi(t), si(t), and wi(t) are noisy input speech, clean speech, and noise signals, respectively picked up by the ith microphone at time t.
- Audio/acoustic plane wave is assumed to arrive at the microphones.
- c is the speed of sound in free air.
- the incidence angle of the target speech source is ⁇ d . .s 1 (t ) is considered to be the clean speech captured by the reference microphone. All the signals are considered to be real and zero-mean.
- the input noisy speech is transformed to frequency domain by taking short-time Fourier transform (STFT) and re-written as Eq.
- STFT short-time Fourier transform
- Yi( ⁇ k ), Si( ⁇ k ), and Wi( ⁇ k ) are the Fourier transforms of yi(t), si(t), and wi(t), respectively.
- the frequency bins are represented by k, and N is the STFT size.
- the mathematical representation of the STFT of the noisy input signal is a complex number consisting of both real and imaginary parts.
- the real and imaginary parts of Eq. 28 are used as primary input features for the proposed RNN-based dual-channel SE.
- Computing the real and imaginary part of the noisy and clean speech recordings is part of the training approach.
- the input features from both the channels are concatenated together to form an input vector of dimension 2C(F+1) x1.
- F N/2 and N is the STFT size
- Fig. 7 A shows the entire working of the training and testing phase.
- the training phase is shown in dashed lines.
- the real and imaginary parts of the respective channels are concatenated together as shown in Eq. 29.
- This input feature vector is then fed as input to the RNN architecture. Similar to Eq. 29, the output feature vector for the single-channel clean speech was also obtained, as shown in Eq. 30.
- Eq. 29 and 30 are shown in FIG. 7B.
- the output vector in Eq. 30 behaves as a label for training the RNN model.
- the size of the output vector is 2 (F+1) x 1.
- the estimated clean speech real-imaginary frequency domain values from the RNN model are used for time-domain signal reconstruction by taking the inverse fast Fourier transform (IFFT). Usage of real and imaginary values as input features helps in achieving a distortion less reconstruction.
- IFFT inverse fast Fourier transform
- the disclosed novel RNN architecture uses basic RNN cells to lower the complexity of the model.
- RNNs consist of at least one feedback connection, allowing modeling sequential data.
- Due to the vanishing gradient problem it can be difficult to train them.
- the dynamic behavior of the RNN cell to use its internal state memory for processing sequences makes it very reliable for speech analysis.
- the entire architecture is interpreted as a filter in the frequency domain for enhancing speech in noisy environments.
- the model consists of basic RNN cells stacked together to form a RNN layer.
- the output from the RNN layer is then flattened and connected to a fully connected layer. This is then connected to a non-linear output layer in the end.
- the RNN layer comprises the basic RNN cells stacked on top of each other, and the cells are wrapped together into a single-layer cell.
- Each basic RNN cell can consist of R number of hidden units or neurons.
- Activation functions are used in the hidden layers to help the neural network learn complicated, non-linear relations between the input and the output labels.
- Rectified linear unit (ReLU) is selected as the activation function, which acts as a solution for the abovementioned vanishing gradient problem.
- ReLU is given by s(.) and Eq. 31:
- a sequence of input vector v can be processed by applying a recurrence formula at every time frame t (Eq. 32): h is taken to be the hidden vector, where ht is for the new state (current state), and ht-1 is for the previous state, vt is the input vector for the current state.
- the above equation 32 shows that the current state depends on the previous state.
- W hh is the weight parameters between the previous and the current hidden state.
- W vh is the weights between the input sequence at time t (current state) and the hidden state.
- the dimensions of the abovementioned vectors depend on the input feature set and the number of hidden neurons in the RNN cell.
- the parameters for all time steps remain the same when RNN is trained, and the gradient at each output layer depends on the current time step calculation as well as on all previous time steps. This is called backpropagation through time (BPTT).
- BPTT backpropagation through time
- a fully connected layer is present right before the output layer, comprising D nodes.
- the linear activation function is used to map the predicted output features.
- the RNN SE architecture is further explained below based on experimental analysis.
- the 2-channel noisy speech files can be created by using the image- source model (ISM)).
- ISM image- source model
- the noise and the speech sources are separated by different angles from 0° to 180° with a resolution of 30° (0°, 30° , 60° , 90° , 120° , 150° , and 180° ).
- the noise source location was fixed and the speech source was varied to achieve the angle separation between the two sources.
- the noise source location was varied by fixing the speech source location at 0°.
- Two different room sizes are assumed, and the two- microphone array is positioned at the center of the room. The size of the two rooms considered for generating the data is 5 m 3 and 10 m 3 , respectively.
- the distance between the microphones is 13 cm (similar to the distance between the two microphones on the smartphone).
- Three different SNRs of -5, 0, and +5 dB are considered, with sampling frequency set to 16 kHz.
- the clean speech dataset used for training the model can be a combination of TIMET and LibriSpeech corpus.
- DCASE 2017 challenge dataset is used as the noise dataset, which consists of 15 different types of background noise signals.
- the 15 types of noise are further categorized into 3 important types of noise, namely machinery, traffic, and multi-talker babble. There are around 300 noise files per type, which are commonly seen in real-life environments. In addition to these noise types, 20 different Pixel 1 smart- phone recordings of realistic noise can be collected and half of which are used for testing phase only.
- the clean speech and noise files are randomized and selected to generate the simulated noisy speech.
- real recorded data can be collected using a Pixel 3 smartphone placed on the center of a round table in 3 different rooms.
- the setup is as follows: Five loudspeakers are equally spaced and placed around the smartphone to generate a diffuse noise environment with one speaker playing clean speech and the rest playing noise. The 5 loudspeakers play the clean speech sequentially to make sure that the speech source direction is not fixed.
- the distance between the smartphone and the loudspeaker is set to be 0.6 m and 2.4 m in room 1, and 1.3 m and 0.92 m in rooms 2 and 3, respectively.
- the distance between the smartphone and the loudspeaker can be varied to make sure that the recorded database is a collection of both near and far end speakers.
- the dimensions for rooms 1, 2, and 3 are 7 m x 4 m x 2.5 m, 6.5 m x 5.5 m x 3 m, and 5m x 4.5 m x 3 m, respectively.
- the reverberation time (RT60) for rooms 1, 2, and 3 is measured to be around 400, 350, and 300 ms, respectively.
- the abovementioned clean speech and noise files were played in the loudspeakers during data collection. To generate the clean speech labels for training the model, the noise files and the clean speech files are recorded separately on the smartphone, and then added together to generate noisy speech at different SNR. This additional dataset for training helped in increasing the realistic use and robustness of the real-time application.
- the RNN architecture developed for experimental analysis has an input layer, 4 basic RNN cells stacked upon each other to form a single RNN layer, 1 fully connected layer, and an output layer.
- the architecture remains the same for both offline and real-time evaluations.
- the audio signal is sampled at 16 kHz with a frame size of 16 ms (50% overlap) and a 512-point (N) STFT is computed. Due to complex-conjugate property in STFT, the first 257, i.e., N/2 + 1 , real and imaginary values are considered. The real and the imaginary values are then arranged on top of each other, thus, leading to 514 (257 real and 257 imaginary values) input features per channel. Since performing dual-channel SE, the input feature vector will consist of real and imaginary values from both the channels, leading to an input matrix of size 1028 x 1. This is as shown in Eq. 29.
- the 4 basic RNN cells comprise of R 100 neurons each and are stacked upon each other.
- the stacking of RNN cells together can be further understood by referring to Fig. 8.
- the number for R was fixed after many trials with different values and comparing the performances for each.
- STFT of the single-channel clean speech is computed and used to set output labels for training the RNN model. Similar to the input-feature vector, we generate an output- feature vector as shown in Eq. 30. Since the output matrix is of size 514 x 1, the output layer has 514 neurons.
- ReLU is used as an activation function for the 4 RNN cells and the fully connected layer. Whereas, the linear activation function is used for the final output layer, which predicts real and imaginary values of the enhanced speech signal.
- An example of a network architecture is illustrated in Fig.
- the proposed model has nearly 0.9 x 10 6 parameters.
- the Adam optimization algorithm with mean squared error loss function can be used for training the RNN model.
- the training vectors are initialized, which include weights and biases for the nodes with a truncated normal distribution of zero mean and 0.05 standard deviation. With a learning rate of 10 "6 and an appropriate batch size of 500, the RNN model is trained for 15 epochs.
- the complete modeling and training for offline evaluations can be carried out using Tensorflow in Python (Google TensorFlow, 2019). Chameleon cloud computing is used to train the proposed RNN model.
- the proposed RNN-based SE method is a real-time approach that can be used on any processing platform (e.g., a C/C++ API for running deep learning models on Android-based platforms.
- Libraries such as the TensorFlow Lite converter and interpreter can be used to compress and deploy the proposed model on the smartphone.
- the trained weights are frozen by removing backpropagation, training, and regularization layers.
- the final model with the required weights can be saved to a file with a pb extension and later used for real-time implementation.
- the input frame size and STFT size can remain the same as mentioned above for analysis.
- Each input frame is multiplied with a Hanning window, and overlap is considered between the frames with the help of an overlap-add technique that is widely used in.
- the two inbuilt microphones (13 cm apart) on the smartphone capture the audio signal; the signal is then enhanced, and the output signal (the clean speech) is transmitted to a wired or wireless headset.
- HADs can also be connected either through a wire or wirelessly through Bluetooth to the smart- phone.
- the smartphone device can have an M3/T3 HA compatibility rating and meets the requirements set by the Federal Communications Commission (FCC).
- Android Studio Google Android Developer, 2019
- An efficient stereo input/output framework can be used to carry out the real-time dual microphone input/output handling for the audio processing.
- the input data on the smartphone can be acquired at a 48 kHz sampling rate and then downsampled to 16 kHz by low-pass filtering and a decimation factor of 3.
- a user interface can be displayed on a screen, such as touch screen 140, for operating the RNN application. Clicking on a Mic button can turn on the inbuilt microphones on the smartphone, and a pause button can turn off the microphones.
- Three models specific to three different types of noise i.e., machinery, multi-talker babble, and traffic) are stored in the application on the smartphone.
- the hearing- aid user can select any one of the RNN models by simply clicking on a button corresponding to the name of the noise type, depending on the noisy environment they are in.
- a button can be used on the user interface to place the RNN application in “OFF” mode, wherein no SE processing is carried out on the audio input, so the application performs simple audio playback through the smartphone.
- the input feature vector is passed through the proposed and user-selected RNN model.
- the desired speech is extracted from the background noise and enhanced.
- the input feature vector passed through the frozen RNN model stored on the smartphone generates an output feature vector of size 514 x 1.
- the enhanced output speech signal so obtained is then transmitted to/played back to the HADs or other ear speakers by either wire or wireless connections.
- the RNN method can easily be used with outdoor and numerous other indoor noise types and implemented on different stand-alone platforms (laptop) in a similar way to that discussed here.
- Portions of disclosed embodiments may relate to computer storage products with a non- transitory computer-readable medium that have program code thereon for performing various computer-implemented operations that embody a part of an apparatus, device or carry out the steps of a method set forth herein.
- Non-transitory used herein refers to all computer-readable media except for transitory, propagating signals. Examples of non-transitory computer-readable media include, but are not limited to: magnetic media such as hard disks, floppy disks, and magnetic tape; optical media such as CD-ROM disks; magneto-optical media such as floptical disks; and hardware devices that are specially configured to store and execute program code, such as ROM and RAM devices.
- program code examples include both machine code, such as produced by a compiler, and files containing higher level code that may be executed by the computer using an interpreter.
- the software instructions of such programs may represent algorithms and be encoded in machine-executable form on non-transitory digital data storage media, e.g., magnetic or optical disks, random-access memory (RAM), magnetic hard disks, flash memories, and/or read-only memory (ROM), to enable various types of digital data processors or computers to perform one, multiple or all of the steps of one or more of the above- described methods, or functions, systems or apparatuses described herein.
- the data storage media can be part of or associated with the digital data processors or computers.
Landscapes
- Engineering & Computer Science (AREA)
- Acoustics & Sound (AREA)
- Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Quality & Reliability (AREA)
- Computational Linguistics (AREA)
- Multimedia (AREA)
- General Health & Medical Sciences (AREA)
- Neurosurgery (AREA)
- Otolaryngology (AREA)
- Telephone Function (AREA)
Abstract
Speech enhancement methods or processing pipelines that can be implemented on a mobile computing device, such as a smartphone, are disclosed. A computer program product can include the method and can be downloaded as a mobile. In one example, the mobile computing device includes: (1) at least one microphone to receive a noisy speech signal that includes a clean speech signal and noise, and (2) at least one processor to perform operations including estimating a gain function of a magnitude spectrum of the clean speech signal, generating, a time-domain impulse response by processing the estimated gain function in a Mel-frequency domain, providing an enhanced speech signal by filtering the noisy speech signal using a weighted impulse response based on the time-domain impulse response, and generating an enhanced clean speech signal by filtering the enhanced speech signal using a super-Gaussian extension of the joint maximum a posteriori (SGJMAP) filter.
Description
A METHOD OF SPEECH ENHANCEMENT AND A MOBILE COMPUTING DEVICE
IMPLEMENTING THE METHOD
CROSS-REFERENCE TO RELATED APPLICATION
[0001] This application claims the benefit of U.S. Provisional Application Serial No. 63/196,031, filed by Board of Regents, The University of Texas System on June 2, 2021, entitled “Hearing Device System,” commonly assigned with this application and incorporated herein by reference in its entirety.
STATEMENT OF GOVERNMENT INTEREST
[0002] This invention was made with government support under Grant No. R01 DC015430 awarded by the National Institutes of Health. The government has certain rights in the invention.
TECHNICAL FIELD
[0003] This application is directed, in general, to speech enhancement and, more specifically, to speech enhancement implemented on a mobile computing device.
BACKGROUND
[0004] In the last three decades, significant developments in speech enhancement (SE) have been achieved. Researchers continue to show interest in developing novel, computationally efficient methods that can help suppress background noise with no or minimum distortion to speech. SE algorithms are finding numerous applications for hearing aid devices (HADs), cochlear implants (CIs), and other assistive strategies like remote microphone technology (RMT). SE remains a challenging problem to resolve in the presence of non- stationary background noises and reverberant conditions. In the case of complex and dominant background noise, understanding speech and words are difficult for normal-hearing (NH) listeners and are nearly intolerable for hearing-impaired (HI) listeners. SUMMARY
[0005] One aspect provides a mobile computing device. In one example, the mobile computing device includes: (1) at least one microphone to receive a noisy speech signal that includes a clean speech signal and noise, and (2) at least one processor to perform operations including estimating a gain function of a magnitude spectrum of the clean speech signal, generating, a time-domain impulse response by processing the estimated gain function in a Mel-frequency domain, providing an enhanced speech signal by filtering the noisy speech signal using a weighted impulse response based on the time- domain impulse response, and generating an enhanced clean speech signal by filtering the enhanced speech signal using a super-Gaussian extension of the joint maximum a posteriori (SGJMAP) filter.
[0006] In another aspect, the disclosure provides a computer program product having a series of operating instructions stored on a non-transitory computer readable medium that direct operations of at least one processor when initiated thereby to generate an enhanced clean speech signal from a noisy speech signal that includes a clean speech signal and noise. In one example, the operations include: (1) estimating a gain function of a magnitude spectrum of the clean speech signal, (2) generating, a time- domain impulse response by processing the estimated gain function in a Mel-frequency domain, (3) providing an enhanced speech signal by filtering the noisy speech signal using a weighted impulse response based on the time-domain impulse response, and (4) generating an enhanced clean speech signal by filtering the enhanced speech signal using a super-Gaussian extension of the joint maximum a posteriori (SGJMAP) filter.
BRIEF DESCRIPTION
[0007] Reference is now made to the following descriptions taken in conjunction with the accompanying drawings, in which:
[0008] FIG. 1 illustrates a block diagram of an example of a speech enhancement system (SES) constructed according to the principles of the disclosure;
[0009] FIG. 2 illustrates a block diagram of an example of a SE method 200 carried out according to the principles of the disclosure;
[0010] FIG. 3 illustrates a block diagram of an example of a CRNN-based SE method representing the algorithm that can be used on a mobile computing device;
[0011] FIG. 4 shows the block diagram of an example representation of the disclosed CRNN architecture;
[0012] FIG. 5 illustrates Table 1, which is associated with the CRNN model;
[0013] FIG. 6 illustrates a block diagram of an example of the dual-channel RNN-based algorithm disclosed herein;
[0014] Fig. 7A shows the entire working of the training and testing phase for the dual-channel RNN model;
[0015] FIG. 7B shows Equations 29 and 30 associated with the RNN model SE;
[0016] FIG. 8 illustrates a diagram showing an example of stacking of RNN cells; and [0017] FIG. 9 illustrates an example of a network architecture associated with the RNN model.
DETAILED DESCRIPTION
[0018] Researchers and designers have provided many solutions for HI listeners, including the implementation of signal processing algorithms on suitable HADs and CIs. Nevertheless, the
performance of HADs and CIs can deteriorate in the presence of numerous and often strong environmental noise. Many of these devices also lack the computational power to operate complex signal processing algorithms because of the physical design constraints. Some HAD manufacturers are using RMTs to increase the signal-to-noise (SNR) with the help of a separate microphone at the speaker while the speech signal is transmitted to the listener’s hearing device. Unfortunately, RMTs are an additional expense in addition to the cost of the HAD.
[0019] The disclosure provides speech enhancement solution to address the above problems. The speech enhancement features disclosed herein can be advantageously implemented on mobile computing devices, such as a smartphone, a computing pad, a computing tablet, or another mobile computing devices having at least one microphone and one or more comparable processors. The mobile computing devices having in-built microphones can replace the traditional RMTs as a standalone device with no external component or additional hardware. An application with access to the inbuilt microphone can be downloaded to the mobile computing devices and provide speech enhancement for speech signals received via the microphone. The mobile computing devices can send an enhanced speech signal, such as an enhanced clean speech signal, to one or more speakers, such as ear speakers. The speaker can be integrated with the mobile computing device or can be communicatively coupled thereto via a wired or wireless connection. For example, the mobile computing device can be connected to one or more ear speakers via a short-range wireless technology, such as Bluetooth, and can transmit the enhanced speech signal to ear speakers using the wireless technology. The ear speakers have receiving circuitry or receivers for receiving the enhanced speech signal and can also have software, hardware, or a combination thereof for operating as hearing aids. Various types of ear speakers, external and internal to the ear, can be used. For example, various types of ear speakers, earphones, headphones, or HADs are connectable via Bluetooth to smartphones with iOS or Android operating systems. To give the HI listeners more control over the HAD, manufacturers also have their smartphone-based applications. The smartphone can stream phone calls and media sound directly to the HADs. Additionally, some of these applications enable the fine-tuning of the HADs in real-time. The speech enhancement disclosed herein can be used with the applications to stream enhance speech signals to the HADs.
[0020] FIG. 1 illustrates a block diagram of an example of a speech enhancement system (SES) 100 constructed according to the principles of the disclosure. The SES 100 includes a mobile computing device 110 and an ear speaker 160. The mobile computing device 110 is represented as a smartphone in FIG. 1 but other mobile computing devices can be used. Additionally, the ear speaker 160 is
represented by a HAD in FIG. 1 but a non-hearing aid speaker can also be used. The mobile computing device 110 includes a microphone array 120, at least one processor 130, a screen 140, and a transmitter 150. The microphone array 120, screen 140, and transmitter 150 can be conventional components typically found in a mobile computing device, such as a smartphone. For example, the screen 140 can be a touch screen and the transmitter 150 can be a Bluetooth (or another short-range wireless compliant) compliant transmitter (or transceiver). The ear speaker 160 can also be a conventional device that includes a receiver corresponding to the transmitter 150 and a speaker. The at least one processor 130 can include an ARM processor (or comparable processor capability) or ARM- based processing platform that is typically found in smartphones. The mobile computing device 110 can include other components typically included in such devices, such as communication circuitry for cellular communication and a non-transitory memory for storing computing program products, such as mobile applications. The mobile computing device 110 does not require communication circuitry for performing the speech enhancement.
[0021] A speech processing pipeline that is implemented on the at least one processor 130 illustrates a mobile computing device-based adaptive signal processing pipeline that uses the microphone array 120 (1, 2 or 3 microphones) to captures a noisy speech signal and generates an enhanced speech signal, such as an enhanced clean speech signal that can be transmitted to the ear speaker 160. The pipeline is represented by different functional blocks including a voice activity detector (VAD) 131, an adaptive acoustic feedback cancellation block (AAFC) 133, a speech enhancement block (SE) 135, and a multichannel dynamic range audio-compression or automatic gain control block (AC/AG) 137. The VAD 132 helps to determine whether the input frame received via the microphone array 120 is a noisy speech or a noise only frame. The output of the VAD 132 helps separate noisy speech signal from the noise part without speech signal so they can be used for SE and other stages of the signal processing pipeline. The noisy input speech is then passed through the AAFC 133 to suppress the background noise and the SE 135 and AC/AG 137 to extract the speech with minimum or no distortion. A direction of arrival (DOA) estimation block DOA 139 can also be used to allow a user to find the direction of the desired speaker. The SE 135 is configured to suppress the noise and enhance the quality and intelligibility of speech for optimum speech perception, thus improving speech communication performance for the user ( e.g ., listener). FIG. 2 illustrates an example of a SE method that can be used by the SE 135 to generate an enhanced clean speech signal by filtering the enhanced speech signal using a super-Gaussian extension of the joint maximum a posteriori (SGJMAP) filter.
[0022] FIG. 2 illustrates a block diagram of an example of a SE method 200 carried out according to the principles of the disclosure. The SE method 200 is a statistical model-based SE method that can be executed as a processing pipeline on a mobile computing device, such as a smartphone, in real time and without external components. The SE method 200 represents an algorithm that has at least two stages based on the SGJMAP cost function. In the first stage, the SGJMAP gain estimate of the noisy speech mixture is smoothed along the frequency axis by a Mel filter-bank, leading to a Mel-warped frequency-domain SGJMAP estimate. By applying a Mel-warped inverse discrete cosine transform (Mel-IDCT), the impulse response of the Mel-warped estimate can be derived, which filters out the background noise from the input noisy speech signal. Traditional SGJMAP SE is used in the second stage as a post-filter to minimize the residual noise present in the first stage output. The proposed two- stage SE method 200 suppresses background noise with minimal speech distortion in real time. The SE method 200 can be implemented on a processor of a mobile computing device, such as mobile computing device 110, that receives and can record the noisy speech and processes the signal using the adaptive SE method 200. Blocks of the SE method 200 in FIG. 2 correspond to functional blocks of the algorithm that can be implemented on the processor. The output enhanced speech is then transmitted to a user’s ear speaker through a wired or wireless connection, which can provide an effective assistance platform for NH and HI users.
[0023] The SE method 200 of FIG. 2 reflects the usability and real-time implementation on a mobile computing device, such as a smartphone. A time-domain noisy speech signal y(t), which is an additive mixture model of clean speech s(t) and noise z(t), is received by block
210. y (t) = s(t) + z(t) (1)
The noisy speech signal can be received via a microphone, such a microphone array 120. The input noisy speech signal is transformed from time-domain into the frequency-domain by taking STFT in block 210. y(λ) = s(λ) + z (λ) (2)
Yk (λ), Sk (λ), and Zk (λ) represent the STFT of y(t), s(t), and z(t) respectively for the frame
A and frequency bin k. In polar coordinates, Eq. (2) can be written as,
 where Rk (λ), Ak (λ), Bk(λ) are the magnitude spectra of noisy speech, clean speech, and noise respectively. θy (λ), θ (λ), θz (λ) represents the phase of noisy speech, clean speech, and noise respectively.
where Rk (λ), Ak (λ), Bk(λ) are the magnitude spectra of noisy speech, clean speech, and noise respectively. θy (λ), θ (λ), θz (λ) represents the phase of noisy speech, clean speech, and noise respectively.
[0024]The frequency domain output of block 210 is provided to blocks 215 and 220 for SNR estimation and SGJMAP gain estimation. A non-Gaussian property in the spectral domain noise reduction framework can be considered and a super Gaussian speech model can be used. A result of the SE method 200 is to obtain an estimate of the clean speech magnitude spectrum Ak (λ). λ can be eliminated for swiftness in further derivation. The JMAP estimator in block 220 jointly maximizes the magnitude and phase spectra probability conditioned on the observed complex coefficient,
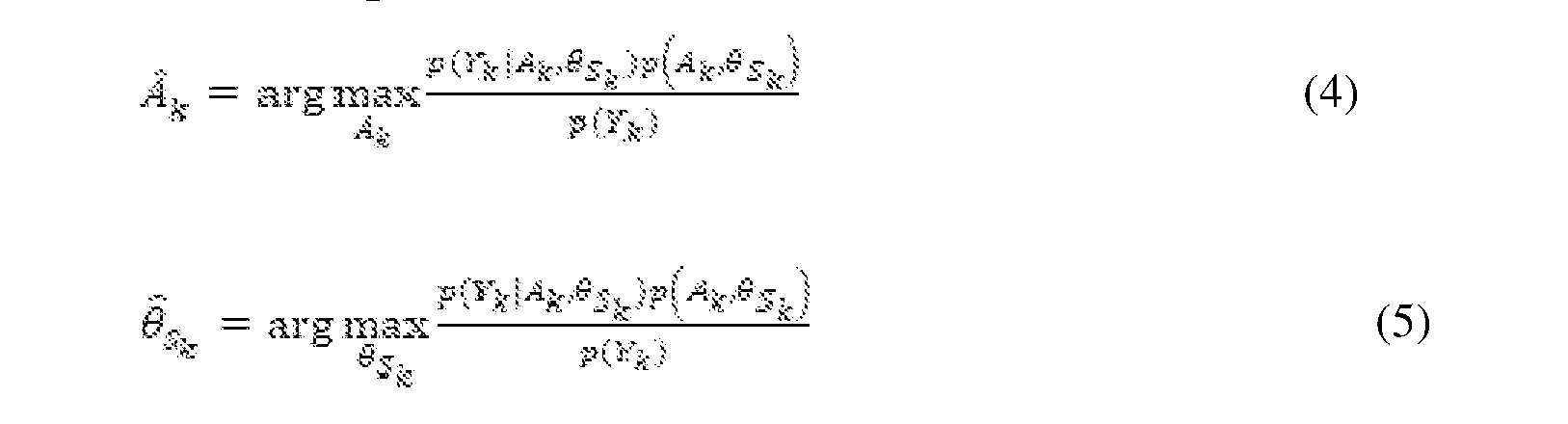
[0025] The p(.) denotes the probability density function (PDF) of its argument. By approximating the PDF of speech spectral magnitude with respect to individualized parameters m and the super-Gaussian PDF of the magnitude spectral coefficient is given as,
 where G( ) denotes the Gamma function. The logarithm function of Eq. (4) is differentiated with respect to Ak and equated to zero. By considering Yk = ,
where G( ) denotes the Gamma function. The logarithm function of Eq. (4) is differentiated with respect to Ak and equated to zero. By considering Yk = ,

[0026] Further simplification of Eq. (7) yields the quadratic equation

Solving the obtained quadratic equation in terms of <7 and yk gives
 where is the a priori SNR and is the a posteriori SNR as determined in
where is the a priori SNR and is the a posteriori SNR as determined in

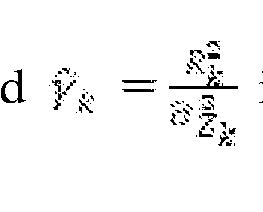 block 215. is the noise power estimated with the help of a VAD. is the estimated
block 215. is the noise power estimated with the help of a VAD. is the estimated

 power spectral density of clean speech, v = 0.1 and m = 1.5 are shown to give good results.
power spectral density of clean speech, v = 0.1 and m = 1.5 are shown to give good results.
The estimate of output speech magnitude spectrum is J4a, = Gk Rk, where the SE gain function is given by

[0027] Steps 210, 215, and 220 can be considered a preprocessing stage for SE. Step 230 begins the first stage of processing that generates an enhanced speech signal by smoothing coefficients of the gain function, transforming the coefficients to a Mel-frequency scale, and filtering. The Mel-frequency is considered to be a perceptual domain and is used for processing in the
first stage. The SGJMAP SE gain coefficients computed in Eq. (10) are smoothed and transformed to the Mel-frequency scale in block 230. The Mel-warped frequency-domain SGJMAP coefficients are estimated by using triangle-shaped, half-overlapped frequency windows. The relation between Mel-scale and frequency-domain is given by,

Eq. (12) represents the central frequencies of the filter-bank bands, where
 filter-bank bands. The sampling frequency f, set to be 16 kHz and the upper frequency/ in Eq. (11) is limited to 8 kHz. In addition to the 23 filter-bank bands, two marginal filter-bank bands with central frequencies fc (0) = 0 and f (FB+ 1) = f/2 are considered for the purpose of discrete cosine transform (DCT) to the time-domain conversion; thus leading to a total of 25 Mel-warped SGJMAP coefficients. The frequency bin index corresponding to the central frequencies is obtained as follows,
filter-bank bands. The sampling frequency f, set to be 16 kHz and the upper frequency/ in Eq. (11) is limited to 8 kHz. In addition to the 23 filter-bank bands, two marginal filter-bank bands with central frequencies fc (0) = 0 and f (FB+ 1) = f/2 are considered for the purpose of discrete cosine transform (DCT) to the time-domain conversion; thus leading to a total of 25 Mel-warped SGJMAP coefficients. The frequency bin index corresponding to the central frequencies is obtained as follows,
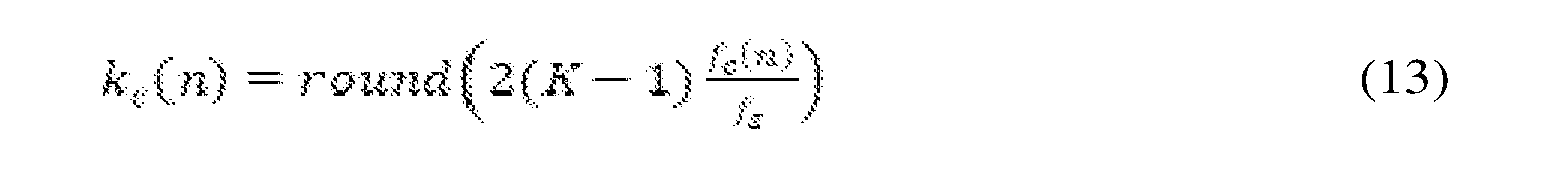
Due to the complex conjugate property in STFT, Frequency windows
 f) for 1 ≤ n ≤ FB are,
f) for 1 ≤ n ≤ FB are,


For other i, W(nf i) = 0. If n = 0,

For other i, W(QS i) = 0. If n = FB + 1,
 For other i, W(FB + 1., t) = 0. The Mel-warped SGJMAP coefficients are given by,
For other i, W(FB + 1., t) = 0. The Mel-warped SGJMAP coefficients are given by,
 where GR re the computed SGJMAP SE gain values in Eq. (10) and 0 ≤ n ≤ FB + 1.
where GR re the computed SGJMAP SE gain values in Eq. (10) and 0 ≤ n ≤ FB + 1.
By applying Mel-warped inverse discrete cosine transform (Mel-IDCT) to Eq. (18) in block 240, the time-domain impulse response for SGJMAP SE is,
 where Mt d ; is the Mel-IDCT defined as
where Mt d ; is the Mel-IDCT defined as

 corresponding to the Mel filter-bank. ft( O) = 0 and ft(FB F 1) = f1/ 2.
corresponding to the Mel filter-bank. ft( O) = 0 and ft(FB F 1) = f1/ 2.
The df (n) is computed as follows,
 The time-domain impulse
The time-domain impulse
 response of the SGJMAP SE in Eq. (19) is mirrored and the causal impulse response is obtained. The impulse response is then weighted using a Hanning window. And, the
input noisy speech time-domain signal y'(t) is filtered using the weighted impulse response in block 250. The output of applied filter block is the enhanced speech signal which goes to the post filter SGJMAP SE block 260 of the second stage.
response of the SGJMAP SE in Eq. (19) is mirrored and the causal impulse response is obtained. The impulse response is then weighted using a Hanning window. And, the
input noisy speech time-domain signal y'(t) is filtered using the weighted impulse response in block 250. The output of applied filter block is the enhanced speech signal which goes to the post filter SGJMAP SE block 260 of the second stage.

[0028] In block 260, the single microphone SGJMAP SE is used as a post-filter to eliminate the residual background noise present in . The SGJMAP gain values in

Eq. (10) are calculated for the enhanced signal The estimate of magnitude
 spectrum of final clean speech is given by
spectrum of final clean speech is given by


[0029] Where
 represents the STFT of The speech phase can be considered to be
represents the STFT of The speech phase can be considered to be
 perceptually insignificant. Hence, the phase of noisy speech signal and the from (25)
perceptually insignificant. Hence, the phase of noisy speech signal and the from (25)
 is used to obtain the time-domain speech signal using Inverse Fourier transform
is used to obtain the time-domain speech signal using Inverse Fourier transform

(IFFT). The enhanced clean speech signal generated in block 260 can then be
 transmitted from the mobile computing device to the ear speakers through a wired or wireless connection as shown in Fig. 2.
transmitted from the mobile computing device to the ear speakers through a wired or wireless connection as shown in Fig. 2.
[0030] The SE method 200 can be implemented on ARM-based processing platforms to operate in real time, such as an iPhone XR smartphone running on iOS 13.1.1 as the processing platform, without requiring external or additional hardware for the smartphone. The SE method 200 can benefit from the use of the smartphone’s computational power, features, and in-built microphones. The input noisy speech data can be captured on the smartphone with 16ms frame size and overlap of 50% at 48 kHz sampling rate. By lowpass filtering and decimation factor of 3, the noisy speech data can be down-sampled to 16 kHz. Therefore, for every frame processing 256 samples are available (16ms data frame in time) using STFT size set to be 256 points.
[0031] The SE method 200 can be implemented as an application and downloaded to the smartphone. The application can be stored on a non-transitory memory on the smartphone (or other mobile computing device). A user interface can be displayed on the screen, such as screen 140 of FIG. 1, and used for activation of the SE method 200. The user interface can include a switch button on the touch-screen that can used for activation or deactivation. When set in OFF’ mode, the application simply plays out the input noisy speech from the smartphones’ microphone without the SE method 200 processing. Switching the ON’ button allows the proposed SE module to process the input noisy speech audio signal. The enhanced output signal can then be transmitted to a HAD, earphone, or other type of ear speaker through a wired or wireless connection (via, for example, Bluetooth of the smartphone). The SE method 200 can use the initial few seconds (1-2 sec) to estimate the noise power at the beginning when the switch is in ON’ mode. Therefore, when the switch is triggered to ON’ there is no speech activity for those one to two seconds. A volume control slider is provided to the user via the user interface to adjust the output volume depending on their comfort listening level.
[0032] The algorithm represented by SE method 200 is an example of speech enhancement that can be used in a speech processing pipeline, such as shown in FIG. 1. Other types of speech enhancement systems and methods can also be used.
[0033] Based on progression in deep neural networks (DNN) for different signal processing tasks, several deep learning methods for single-channel SE have been developed. The supervised SE methods are typically divided into masking and mapping-based techniques depending on the description of the clean speech targets for training. An ideal binary mask (IBM) from noisy input speech can be estimated by a feed- forward neural network. Compared to mask-based techniques, signal-based approximations reduce the difference between predicted and target gain. DNN-based SE framework can be used to predict the clean speech log-power spectra (LPS) from noisy speech input LPS features. Innovations in the convolutional neural network (CNN) make them beneficial for SE to train the model using spectrogram features. A fully convolutional neural network (FCN)-based SE can be used with input raw audio data. Recurrent neural network (RNN) layers and long short-term memory (LSTM) layers can be implemented to perform SE. A mixture of convolutional and LSTM networks may outperform other neural networks for SE at lower SNRs. In general, RNN layers are much more complex than CNN
layers as they do not have weight sharing. However, RNNs can be more suitable for time series data, as they can be used for processing random input data sequences with their internal memory. [0034] Disclosed herein is a real-time single-channel SE that can be used on edge devices ( e.g mobile computing devices), where a DNN model, such as a convolutional recurrent neural network (CRNN) model, is trained to predict the clean speech magnitude spectrum. The CRNN is computationally efficient and can be used for real-time processing. A smartphone with an inbuilt microphone, such as mobile communication device 110, is used as an example of an edge device to capture the noisy speech data and perform complex computations using the CRNN model-based SE algorithm. The enhanced speech signal from the developed model implemented on the smartphone can be transmitted through wired or wireless earphone connection to the user and can be a real-time implementation on the smartphone. The algorithm can run on a standalone platform such as a smartphone and can be a critical element in the signal processing or communication pipeline.
[0035] A single channel CRNN-based SE application is disclosed. The disclosed application operates in real-time on an edge device. The developed algorithm is computationally efficient and implemented on an iPhone with minimal audio latency. The CRNN-based SE method can outperform at least some conventional and neural network-based single-channel SE algorithms in terms of speech quality and intelligibility.
[0036] FIG. 3 illustrates a block diagram of an example of the CRNN-based SE method 300 representing the algorithm that can be used on a mobile computing device. As with SE method 200 and Equations 1-3, input noisy speech signal is transformed into STFT and θy (λ), θy , (λ ),θ (λ) represents the phase of noisy speech, clean speech, and noise respectively (d and D represent noise for method 300 and correspond to z and Z which represent noise in method 200).
[0037] For effective neural network training, suitable features are selected and magnitude spectrum is considered as the input feature. The CRNN system is trained with the noisy speech magnitude spectrum Rk(λ) as input and the clean speech spectrum Ak(λ) as the output label. Hence, the CRNN model focuses on estimating a speech spectrum (2). The noisy phase for reconstruction is considered. Finally, the estimate of clean speech for reconstruction is,

The time domain signal output is obtained by taking Inverse Fast Fourier Transform (IFFT) of

[0038] CNNs process the input image or matrix by performing convolution and pooling functions. In CNNs, a small image region can be compacted by a series of weighted learning filters (kernels) to form a convolutional layer. The kernel generates a feature map for every forward pass of input. Maxpooling layers follow the convolution layers to reduce the size or dimension of the feature maps. Compared to CNN, RNNs permit modeling sequential data since they have feedback connections. The RNN cell has a dynamic behavior to make use of its internal state memory for processing. Thus, making it very reliable for speech analysis.
[0039] The CRNN model is a combination of both CNN and RNN layers. The CRNN model takes in one frame of noisy speech magnitude spectrum and outputs one frame of enhanced/clean speech magnitude spectrum. The input noisy magnitude spectrum is reshaped to form an image input, due to the presence of convolutional layers at the start. This is then fed into a neural network twice as shown in FIG 4. FIG. 4 shows the block diagram of an example representation of the disclosed CRNN architecture. Different hidden layers such as convolutional layers, maxpool layers, long short-term memory (LSTM) layers, and fully connected (FC) layers can be used to design the CRNN model. There are 4 convolutional layers with a maxpool layer in between them. The first, second, third, and fourth convolutional layer uses 257, 129, 65, and 33 feature maps respectively. The feature maps gradually decrease in order to reduce the computational complexity and number of parameters, making the developed model suitable for real-time applications. The kernel and bias for all the convolution layers is given in Table 1, which is shown in FIG. 5. Followed by the convolutional layers, there are two LSTM layers consisting of 33 neurons each. The output of the LSTM layer is flattened out and the respective outputs from both the paths are added together before sending them to the FC layer. The FC hidden layer has 257 neurons and is followed by a linear output layer to predict the speech spectrum. The CRNN architecture is given in Table 1. The specific numbers for designing the CRNN model was fixed in this example after several experiments and training. Adam optimization algorithm can be used with a mean absolute error loss function to train the model.
[0040] Activation functions are used in each hidden layer to allow the network to learn complex and non-linear functional mapping between the input and output labels. The rectified linear unit (ReLU) was selected as an example activation function because it has been successful in solving the vanishing gradient problem.
[0041] For the training and evaluation of the CRNN model, a clean speech dataset can be built from a dataset, such as the Librivox dataset of public audiobooks. Librivox has individual recordings in several languages, most of them are in English, that is read over 10,000 audio public domain books. Overall, there are 11,350 speakers present in the dataset. A portion of this dataset is considered to generate the noisy speech input features and clean speech labels for training the model. The noise dataset from Audioset and Freesound is also considered. Audioset is a series of approximately two million ten seconds sound clips made of YouTube videos, belonging to 600 audio classes. Finally, 150 audio classes, 60000 noise clips from Audioset, and 10000 noise clips from Freesound are mixed with the clean speech dataset considered. The resulting noisy speech audio clips are sampled to 16 kHz before feature extraction. A total of 100 hours of clean speech and noisy speech constitutes an example of a training set. The clean speech files are normalized, and each noise clip is scaled up to have one of the five SNRs (0, 10, 20, 30, 40 dB). A clip of clean speech and noise is randomly selected, before combining them together to create a noisy speech clip. Due to the real-time application of the CRNN method, reverberation can be added to a portion of clean speech (30 hours). The reverberation time (T60) can be randomly drawn from 0.2 s to 0.8 s with a step of 0.2 s. The CRNN model can be trained using the entire training dataset and can be evaluated once the training is complete using a blind validation test set. The blind test set can include real noisy speech recordings with and without reverberation. Challenging non- stationary noise cases can be included in the blind set such as Multi-talker babble, keyboard typing, a person eating chips, etc. The blind test set can include 150 noisy speech clips.
[0042] The audio clips can be sampled at 16 kHz with a frame size of 32ms with a 50% overlap. A 512-point STFT can be computed to determine the input magnitude spectrum features. The first 257 magnitude spectrum values are taken into consideration due to the complex conjugate property in STFT and reshaped to form an image of 257 x 1 x 1. The final output layer predicts the clean speech signal magnitude spectrum. The model can be trained for a total of 50 epochs.
[0043] The proposed CRNN based SE algorithm can be implemented on an iPhone, another smartphone, or another type of mobile computing device. However, due to the real-time usability of the proposed application, it can be implemented on other processing platforms, also. The microphone on the smartphone captures the input noisy speech at, for example, a 48 kHz sampling rate and then can be downsampled to 16 kHz with the help of a low-pass filter and a decimation factor of 3. The input frame size is set to be 32ms. A user interface can be displayed on a screen, such as touch screen 140, and used to initial the CRNN model for speech enhancement. By pressing a button on the user interface, the implemented model is initialized. The application simply replays the audio on the smartphone without processing when an ON/OFF switch of the user interface is in off mode. By clicking on the ON/OFF switch button, the CRNN based SE module will process the input audio stream and suppress the background noise. A slider is provided to the smartphone user to control the amount of output volume.
[0044] To run deep learning models on the smartphone, TensorFlow Fite offers a C/C++ API. The CRNN model is compressed and deployed on the smartphone using libraries such as the TensorFlow Fite converter and interpreter. The trained weights can be frozen, thus eliminating backpropagation, training, and regularization layers. The final frozen model with the weights is saved into a file that includes, for example, a .pb extension. To test the computational complexity of the proposed application, an iPhone 11 smartphone is considered. For these appliances, the audio latency for the iPhone 11 was 12- 14ms. The processing time for the input frame of 32ms is 0.705ms. Since the processing time is lower than the length of the input frame, the CRNN model SE application works smoothly at low audio latency on the smartphone. Based on our measurements, the application runs on a fully charged iPhone 11 with a 3046 mAh battery for approximately 5 hours.
[0045] The CPU usage of the app running on the iOS smartphone is 28% and the maximum memory consumption after the processing is turned on is 75.4 MB. The obtained frozen model with the trained weights is of size 11.5 MB, meaning the actual memory consumption of the CRNN SE application is around 65 MB. The smartphones present in the market usually have 12- 16 GB memory; thus, the proposed application uses only 0.5 % of the entire smartphone memory.
[0046] Another example of speech enhancement that can be used in a speech processing pipeline is a dual-channel RNN-based speech enhancement application using a basic recurrent neural net-
work cell. The disclosed dual-channel RNN-based algorithm can operate in real-time with a low audio input-output latency. The dual-channel RNN-based method can be implemented on a mobile computing device, such as an Android-based smartphone, proving the real-time usability of the dual-channel RNN-based algorithm. The dual-channel RNN-based application is another example of a SE application disclosed herein that is computationally efficient and acts as an assistive hearing platform. The dual-channel RNN-based method can be used for various realtime speech enhancement and noise reduction applications on different edge computing platforms.
[0047] The dual-channel RNN-based method provides an efficient approach of using the basic RNN cells for enhancing speech in the presence of background noise using the two microphones of a mobile computing device, such as a smart- phone. The smartphone is considered as an example to prove the real-time working of the dual-channel RNN-based method. It should be noted that the smartphone can be used as a stand-alone processing platform, without any external component or device, for implementing and running the dual-channel RNN-based method SE algorithm in real-time. The real and imaginary part of the frequency domain signal can be used as the primary input feature for the model. The RNN-based method works in real-time on a frame by frame processing of the data with a minimal input-output delay and can be implemented on any other processing platform (edge device).
[0048] Another possible solution disclosed is the use of popular smartphones to capture the noisy speech data, process the signal, perform complex computations using the SE algorithm, and pass on the enhanced speech signal to the ear speakers, such as HADs through wired or wireless connection. This makes the dual-channel RNN-based application on the smartphone an efficient assistive tool for the HAD users. However, the proposed application can also be used by a normal hearing user with the help of wired or wireless earphones/headphones. Thus, a computationally efficient RNN architecture is developed for SE using a simple but efficient input feature set and its real- time implementation on the smartphone without the help of any external hardware components. The dual-channel RNN-based SE algorithm can act as a vital component in the signal processing pipeline consisting of other blocks like adaptive feedback cancellation and dynamic range compression. Objective evaluations and subjective test scores of the RNN- based SE method signify the operational capability of the developed approach in several different noisy environments and low SNRs.
[0049] The dual-channel RNN-based SE pipeline is described below and a block diagram of an example of the dual-channel RNN-based algorithm is shown in Fig. 6, which represents the real- time usability and application of the dual-channel RNN-based method using a smartphone and HAD. A simple signal model with a noisy signal is received by the z'th microphone (i=1, 2) written as Eq. 27:

Where yi(t), si(t), and wi(t) are noisy input speech, clean speech, and noise signals, respectively picked up by the ith microphone at time t. Audio/acoustic plane wave is assumed to arrive at the microphones. Thus,
 is the relative time delay between the ith microphone and reference sensor, and with
is the relative time delay between the ith microphone and reference sensor, and with
 being the distance between the two
being the distance between the two
 microphones (13 cm in case of smartphone), and c is the speed of sound in free air. The incidence angle of the target speech source is θd. .s 1 (t ) is considered to be the clean speech captured by the reference microphone. All the signals are considered to be real and zero-mean. The input noisy speech is transformed to frequency domain by taking short-time Fourier transform (STFT) and re-written as Eq. 28:
microphones (13 cm in case of smartphone), and c is the speed of sound in free air. The incidence angle of the target speech source is θd. .s 1 (t ) is considered to be the clean speech captured by the reference microphone. All the signals are considered to be real and zero-mean. The input noisy speech is transformed to frequency domain by taking short-time Fourier transform (STFT) and re-written as Eq. 28:
 where Yi(ω k), Si(ω k), and Wi(ω k) are the Fourier transforms of yi(t), si(t), and wi(t), respectively. This is the discrete version of the STFT by sampling the frequency variable w at N uniformly spaced frequencies (i.e., ω k = 2πk/N, k=0,1, , N-1). The frequency bins are represented by k, and N is the STFT size.
where Yi(ω k), Si(ω k), and Wi(ω k) are the Fourier transforms of yi(t), si(t), and wi(t), respectively. This is the discrete version of the STFT by sampling the frequency variable w at N uniformly spaced frequencies (i.e., ω k = 2πk/N, k=0,1, , N-1). The frequency bins are represented by k, and N is the STFT size.
[0050] The mathematical representation of the STFT of the noisy input signal is a complex number consisting of both real and imaginary parts. The real and imaginary parts of Eq. 28 are used as primary input features for the proposed RNN-based dual-channel SE. Computing the real and imaginary part of the noisy and clean speech recordings is part of the training approach. The input features from both the channels are concatenated together to form an input vector of dimension 2C(F+1) x1. Where F=N/2 and N is the STFT size, C= 2 is the number of input channels (microphones).
[0051] Since the second half of the STFT signal is a complex conjugate of the first half, only the first half of the frequency domain data is considered. Fig. 7 A shows the entire working of the training and testing phase. The training phase is shown in dashed lines. The real and imaginary parts of the respective channels are concatenated together as shown in Eq. 29. This input feature vector is then fed as input to the RNN architecture. Similar to Eq. 29, the output feature vector for the single-channel clean speech was also obtained, as shown in Eq. 30. Eq. 29 and 30 are shown in FIG. 7B. The output vector in Eq. 30 behaves as a label for training the RNN model. The size of the output vector is 2 (F+1) x 1. Finally, the estimated clean speech real-imaginary frequency domain values from the RNN model are used for time-domain signal reconstruction by taking the inverse fast Fourier transform (IFFT). Usage of real and imaginary values as input features helps in achieving a distortion less reconstruction. Overall, the noisy frequency domain signals act as input to the model to obtain an estimate of clean frequency domain speech as the output of the RNN model.
[0052] The disclosed novel RNN architecture uses basic RNN cells to lower the complexity of the model. RNNs consist of at least one feedback connection, allowing modeling sequential data. However, due to the vanishing gradient problem, it can be difficult to train them. The dynamic behavior of the RNN cell to use its internal state memory for processing sequences makes it very reliable for speech analysis. For this work, the entire architecture is interpreted as a filter in the frequency domain for enhancing speech in noisy environments.
[0053] The model consists of basic RNN cells stacked together to form a RNN layer. The output from the RNN layer is then flattened and connected to a fully connected layer. This is then connected to a non-linear output layer in the end. The RNN layer comprises the basic RNN cells stacked on top of each other, and the cells are wrapped together into a single-layer cell. Each basic RNN cell can consist of R number of hidden units or neurons.
[0054] Activation functions are used in the hidden layers to help the neural network learn complicated, non-linear relations between the input and the output labels. Rectified linear unit (ReLU) is selected as the activation function, which acts as a solution for the abovementioned vanishing gradient problem. ReLU is given by s(.) and Eq. 31:
[0055] In RNN, a sequence of input vector v can be processed by applying a recurrence formula at every time frame t (Eq. 32): h is taken to be the hidden vector, where ht is for the new state (current state), and ht-1 is for the previous state, vt is the input vector for the current state. The above equation 32 shows that the current state depends on the previous state. Whh is the weight parameters between the previous and the current hidden state. Wvh is the weights between the input sequence at time t (current state) and the hidden state. The dimensions of the abovementioned vectors depend on the input feature set and the number of hidden neurons in the RNN cell. The parameters for all time steps remain the same when RNN is trained, and the gradient at each output layer depends on the current time step calculation as well as on all previous time steps. This is called backpropagation through time (BPTT).
[0056] A fully connected layer is present right before the output layer, comprising D nodes. The linear activation function is used to map the predicted output features. The RNN SE architecture is further explained below based on experimental analysis.
[0057] For offline training of the proposed RNN model, the 2-channel noisy speech files can be created by using the image- source model (ISM)). The noise and the speech sources are separated by different angles from 0° to 180° with a resolution of 30° (0°, 30° , 60° , 90° , 120° , 150° , and 180° ). First, the noise source location was fixed and the speech source was varied to achieve the angle separation between the two sources. Later on, the noise source location was varied by fixing the speech source location at 0°. Two different room sizes are assumed, and the two- microphone array is positioned at the center of the room. The size of the two rooms considered for generating the data is 5 m3 and 10 m3, respectively. The distance between the microphones is 13 cm (similar to the distance between the two microphones on the smartphone). Three different SNRs of -5, 0, and +5 dB are considered, with sampling frequency set to 16 kHz. The clean speech dataset used for training the model can be a combination of TIMET and LibriSpeech corpus. DCASE 2017 challenge dataset is used as the noise dataset, which consists of 15 different types of background noise signals. The 15 types of noise are further categorized into 3 important types of noise, namely machinery, traffic, and multi-talker babble. There are around 300 noise files per type, which are commonly seen in real-life environments. In addition to these
noise types, 20 different Pixel 1 smart- phone recordings of realistic noise can be collected and half of which are used for testing phase only. Finally, the clean speech and noise files are randomized and selected to generate the simulated noisy speech. In addition to the abovementioned dataset, real recorded data can be collected using a Pixel 3 smartphone placed on the center of a round table in 3 different rooms. The setup is as follows: Five loudspeakers are equally spaced and placed around the smartphone to generate a diffuse noise environment with one speaker playing clean speech and the rest playing noise. The 5 loudspeakers play the clean speech sequentially to make sure that the speech source direction is not fixed. The distance between the smartphone and the loudspeaker is set to be 0.6 m and 2.4 m in room 1, and 1.3 m and 0.92 m in rooms 2 and 3, respectively. The distance between the smartphone and the loudspeaker can be varied to make sure that the recorded database is a collection of both near and far end speakers. The dimensions for rooms 1, 2, and 3 are 7 m x 4 m x 2.5 m, 6.5 m x 5.5 m x 3 m, and 5m x 4.5 m x 3 m, respectively. The reverberation time (RT60) for rooms 1, 2, and 3 is measured to be around 400, 350, and 300 ms, respectively. The abovementioned clean speech and noise files were played in the loudspeakers during data collection. To generate the clean speech labels for training the model, the noise files and the clean speech files are recorded separately on the smartphone, and then added together to generate noisy speech at different SNR. This additional dataset for training helped in increasing the realistic use and robustness of the real-time application.
[0058] The RNN architecture developed for experimental analysis has an input layer, 4 basic RNN cells stacked upon each other to form a single RNN layer, 1 fully connected layer, and an output layer. The architecture remains the same for both offline and real-time evaluations.
[0059] The audio signal is sampled at 16 kHz with a frame size of 16 ms (50% overlap) and a 512-point (N) STFT is computed. Due to complex-conjugate property in STFT, the first 257, i.e., N/2 + 1 , real and imaginary values are considered. The real and the imaginary values are then arranged on top of each other, thus, leading to 514 (257 real and 257 imaginary values) input features per channel. Since performing dual-channel SE, the input feature vector will consist of real and imaginary values from both the channels, leading to an input matrix of size 1028 x 1. This is as shown in Eq. 29. The 4 basic RNN cells comprise of R 100 neurons each and are stacked upon each other. The stacking of RNN cells together can be further understood by referring to Fig. 8. The number for R was fixed after many trials with different values and
comparing the performances for each. The fully connected layer, after the RNN layer, consists of D = 1024 neurons. STFT of the single-channel clean speech is computed and used to set output labels for training the RNN model. Similar to the input-feature vector, we generate an output- feature vector as shown in Eq. 30. Since the output matrix is of size 514 x 1, the output layer has 514 neurons. ReLU is used as an activation function for the 4 RNN cells and the fully connected layer. Whereas, the linear activation function is used for the final output layer, which predicts real and imaginary values of the enhanced speech signal. An example of a network architecture is illustrated in Fig. 9. The proposed model has nearly 0.9 x 106 parameters. For training the RNN model, the Adam optimization algorithm with mean squared error loss function can be used. The training vectors are initialized, which include weights and biases for the nodes with a truncated normal distribution of zero mean and 0.05 standard deviation. With a learning rate of 10"6 and an appropriate batch size of 500, the RNN model is trained for 15 epochs. The complete modeling and training for offline evaluations can be carried out using Tensorflow in Python (Google TensorFlow, 2019). Chameleon cloud computing is used to train the proposed RNN model.
[0060] The proposed RNN-based SE method is a real-time approach that can be used on any processing platform (e.g., a C/C++ API for running deep learning models on Android-based platforms. Libraries such as the TensorFlow Lite converter and interpreter can be used to compress and deploy the proposed model on the smartphone. After obtaining the trained model, the trained weights are frozen by removing backpropagation, training, and regularization layers. The final model with the required weights can be saved to a file with a pb extension and later used for real-time implementation.
[0061] The input frame size and STFT size can remain the same as mentioned above for analysis. Each input frame is multiplied with a Hanning window, and overlap is considered between the frames with the help of an overlap-add technique that is widely used in. The two inbuilt microphones (13 cm apart) on the smartphone capture the audio signal; the signal is then enhanced, and the output signal (the clean speech) is transmitted to a wired or wireless headset. HADs can also be connected either through a wire or wirelessly through Bluetooth to the smart- phone. The smartphone device can have an M3/T3 HA compatibility rating and meets the requirements set by the Federal Communications Commission (FCC). Android Studio (Google Android Developer, 2019) can be used for the real-time implementation of the RNN algorithm.
An efficient stereo input/output framework can be used to carry out the real-time dual microphone input/output handling for the audio processing.
[0062] The input data on the smartphone can be acquired at a 48 kHz sampling rate and then downsampled to 16 kHz by low-pass filtering and a decimation factor of 3. A user interface can be displayed on a screen, such as touch screen 140, for operating the RNN application. Clicking on a Mic button can turn on the inbuilt microphones on the smartphone, and a pause button can turn off the microphones. Three models specific to three different types of noise (i.e., machinery, multi-talker babble, and traffic) are stored in the application on the smartphone. The hearing- aid user can select any one of the RNN models by simply clicking on a button corresponding to the name of the noise type, depending on the noisy environment they are in. A button can be used on the user interface to place the RNN application in “OFF” mode, wherein no SE processing is carried out on the audio input, so the application performs simple audio playback through the smartphone. When it is in “ON” mode, the input feature vector is passed through the proposed and user-selected RNN model. Then, the desired speech is extracted from the background noise and enhanced. The input feature vector passed through the frozen RNN model stored on the smartphone generates an output feature vector of size 514 x 1. After applying IFFT and reconstruction, the enhanced output speech signal so obtained is then transmitted to/played back to the HADs or other ear speakers by either wire or wireless connections. The RNN method can easily be used with outdoor and numerous other indoor noise types and implemented on different stand-alone platforms (laptop) in a similar way to that discussed here.
[0063] Portions of disclosed embodiments may relate to computer storage products with a non- transitory computer-readable medium that have program code thereon for performing various computer-implemented operations that embody a part of an apparatus, device or carry out the steps of a method set forth herein. Non-transitory used herein refers to all computer-readable media except for transitory, propagating signals. Examples of non-transitory computer-readable media include, but are not limited to: magnetic media such as hard disks, floppy disks, and magnetic tape; optical media such as CD-ROM disks; magneto-optical media such as floptical disks; and hardware devices that are specially configured to store and execute program code, such as ROM and RAM devices. Examples of program code include both machine code, such as produced by a compiler, and files containing higher level code that may be executed by the computer using an interpreter.
[0064] A portion of the above-described apparatus, systems or methods may be embodied in or performed by various digital data processors or computers, wherein the computers are programmed or store executable programs of sequences of software instructions to perform one or more of the steps of the methods. The software instructions of such programs may represent algorithms and be encoded in machine-executable form on non-transitory digital data storage media, e.g., magnetic or optical disks, random-access memory (RAM), magnetic hard disks, flash memories, and/or read-only memory (ROM), to enable various types of digital data processors or computers to perform one, multiple or all of the steps of one or more of the above- described methods, or functions, systems or apparatuses described herein. The data storage media can be part of or associated with the digital data processors or computers.
[0065] Those skilled in the art to which this application relates will appreciate that other and further additions, deletions, substitutions and modifications may be made to the described embodiments.
Claims
1. A mobile computing device, comprising: at least one microphone to receive a noisy speech signal that includes a clean speech signal and noise; and at least one processor to perform operations including: estimating a gain function of a magnitude spectrum of the clean speech signal, generating, a time-domain impulse response by processing the estimated gain function in a Mel-frequency domain; providing an enhanced speech signal by filtering the noisy speech signal using a weighted impulse response based on the time-domain impulse response; and generating an enhanced clean speech signal by filtering the enhanced speech signal using a super-Gaussian extension of the joint maximum a posteriori (SGJMAP) filter.
2. The mobile computing device as recited in Claim 1, further comprising a transmitter that transmits the enhanced clean speech signal to one or more ear speakers.
3. The mobile computing device as recited in Claim 2, wherein the one or more ear speakers is a hearing aid device.
4. The mobile computing device as recited in Claim 1, wherein the estimating the gain function employs SGJMAP and an individually adjustable parameter.
5. The mobile computing device as recited in Claim 4, further comprising a touch screen, where the individually adjustable parameter is adjustable via a user interface on the screen.
6. The mobile computing device as recited in Claim 1, wherein the noisy speech signal is a time-domain signal and the operations further include transforming the noisy speech signal into a frequency-domain signal before estimating the gain function.
7. The mobile computing device as recited in Claim 1, wherein the mobile computing device is a smartphone.
8. A computer program product having a series of operating instructions stored on a non-transitory computer readable medium that direct operations of at least one processor when initiated thereby to generate an enhanced clean speech signal from a noisy speech signal that includes a clean speech signal and noise, the operations including:
estimating a gain function of a magnitude spectrum of the clean speech signal, generating, a time-domain impulse response by processing the estimated gain function in a Mel-frequency domain; providing an enhanced speech signal by filtering the noisy speech signal using a weighted impulse response based on the time-domain impulse response; and generating an enhanced clean speech signal by filtering the enhanced speech signal using a super-Gaussian extension of the joint maximum a posteriori (SGJMAP) filter.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202163196031P | 2021-06-02 | 2021-06-02 | |
| US63/196,031 | 2021-06-02 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022256577A1 true WO2022256577A1 (en) | 2022-12-08 |
Family
ID=84323585
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2022/032027 Ceased WO2022256577A1 (en) | 2021-06-02 | 2022-06-02 | A method of speech enhancement and a mobile computing device implementing the method |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2022256577A1 (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116527461A (en) * | 2023-04-28 | 2023-08-01 | 哈尔滨工程大学 | Electromagnetic signal time domain enhancement method based on shielding analysis |
| CN116665693A (en) * | 2023-07-28 | 2023-08-29 | 合肥朗永智能科技有限公司 | Speech enhancement method based on artificial intelligence |
| US20230292063A1 (en) * | 2022-03-09 | 2023-09-14 | Starkey Laboratories, Inc. | Apparatus and method for speech enhancement and feedback cancellation using a neural network |
| CN117172135A (en) * | 2023-11-02 | 2023-12-05 | 山东省科霖检测有限公司 | An intelligent noise monitoring and management method and system |
| CN121054016A (en) * | 2025-11-03 | 2025-12-02 | 大象声科(深圳)科技有限公司 | A speech spectrum reconstruction method, system, terminal, and medium combining time-domain half-wave rectification and weighted Gaussian mixture model decoder. |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070255535A1 (en) * | 2004-09-16 | 2007-11-01 | France Telecom | Method of Processing a Noisy Sound Signal and Device for Implementing Said Method |
| US20100076769A1 (en) * | 2007-03-19 | 2010-03-25 | Dolby Laboratories Licensing Corporation | Speech Enhancement Employing a Perceptual Model |
| US8639502B1 (en) * | 2009-02-16 | 2014-01-28 | Arrowhead Center, Inc. | Speaker model-based speech enhancement system |
-
2022
- 2022-06-02 WO PCT/US2022/032027 patent/WO2022256577A1/en not_active Ceased
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070255535A1 (en) * | 2004-09-16 | 2007-11-01 | France Telecom | Method of Processing a Noisy Sound Signal and Device for Implementing Said Method |
| US20100076769A1 (en) * | 2007-03-19 | 2010-03-25 | Dolby Laboratories Licensing Corporation | Speech Enhancement Employing a Perceptual Model |
| US8639502B1 (en) * | 2009-02-16 | 2014-01-28 | Arrowhead Center, Inc. | Speaker model-based speech enhancement system |
Non-Patent Citations (1)
| Title |
|---|
| KARADAGUR ANANDA REDDY CHANDAN, SHANKAR NIKHIL, SHREEDHAR BHAT GAUTAM, CHARAN RAM, PANAHI ISSA: "An Individualized Super-Gaussian Single Microphone Speech Enhancement for Hearing Aid Users With Smartphone as an Assistive Device", IEEE SIGNAL PROCESSING LETTERS, IEEE, USA, vol. 24, no. 11, 1 November 2017 (2017-11-01), USA, pages 1601 - 1605, XP093014553, ISSN: 1070-9908, DOI: 10.1109/LSP.2017.2750979 * |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20230292063A1 (en) * | 2022-03-09 | 2023-09-14 | Starkey Laboratories, Inc. | Apparatus and method for speech enhancement and feedback cancellation using a neural network |
| US12413916B2 (en) * | 2022-03-09 | 2025-09-09 | Starkey Laboratories, Inc. | Apparatus and method for speech enhancement and feedback cancellation using a neural network |
| CN116527461A (en) * | 2023-04-28 | 2023-08-01 | 哈尔滨工程大学 | Electromagnetic signal time domain enhancement method based on shielding analysis |
| CN116527461B (en) * | 2023-04-28 | 2024-05-24 | 哈尔滨工程大学 | A method for electromagnetic signal time domain enhancement based on occlusion analysis |
| CN116665693A (en) * | 2023-07-28 | 2023-08-29 | 合肥朗永智能科技有限公司 | Speech enhancement method based on artificial intelligence |
| CN116665693B (en) * | 2023-07-28 | 2023-10-03 | 合肥朗永智能科技有限公司 | Speech enhancement method based on artificial intelligence |
| CN117172135A (en) * | 2023-11-02 | 2023-12-05 | 山东省科霖检测有限公司 | An intelligent noise monitoring and management method and system |
| CN117172135B (en) * | 2023-11-02 | 2024-02-06 | 山东省科霖检测有限公司 | Intelligent noise monitoring management method and system |
| CN121054016A (en) * | 2025-11-03 | 2025-12-02 | 大象声科(深圳)科技有限公司 | A speech spectrum reconstruction method, system, terminal, and medium combining time-domain half-wave rectification and weighted Gaussian mixture model decoder. |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102191736B1 (en) | Method and apparatus for speech enhancement with artificial neural network | |
| CN112017681B (en) | Method and system for enhancing directional voice | |
| CN111418010B (en) | Multi-microphone noise reduction method and device and terminal equipment | |
| JP6703525B2 (en) | Method and device for enhancing sound source | |
| WO2022256577A1 (en) | A method of speech enhancement and a mobile computing device implementing the method | |
| US12073818B2 (en) | System and method for data augmentation of feature-based voice data | |
| CN101622669B (en) | Systems, methods, and apparatus for signal separation | |
| JP6572894B2 (en) | Information processing apparatus, information processing method, and program | |
| US20140025374A1 (en) | Speech enhancement to improve speech intelligibility and automatic speech recognition | |
| US20240177726A1 (en) | Speech enhancement | |
| CN108235181B (en) | Method for noise reduction in an audio processing apparatus | |
| WO2020041580A1 (en) | System and method for acoustic speaker localization | |
| EP3757993A1 (en) | Pre-processing for automatic speech recognition | |
| Shankar et al. | Efficient two-microphone speech enhancement using basic recurrent neural network cell for hearing and hearing aids | |
| US12520080B2 (en) | Audio processing based on target signal-to-noise ratio | |
| JP7591848B2 (en) | Beamforming method and system using neural network | |
| WO2023287782A1 (en) | Data augmentation for speech enhancement | |
| WO2017045512A1 (en) | Voice recognition method and apparatus, terminal, and voice recognition device | |
| EP3029671A1 (en) | Method and apparatus for enhancing sound sources | |
| EP4258263A1 (en) | Apparatus and method for noise suppression | |
| Shankar | Real-Time Single and Dual-Channel Speech Enhancement on Edge Devices for Hearing Applications | |
| CN120434550A (en) | Dual-headphone sound effect adjustment method, system, storage medium and program product | |
| CN121056569A (en) | Acoustic echo cancellation method and processing terminal |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22816887 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22816887 Country of ref document: EP Kind code of ref document: A1 |