TWI878355B - 用於癌症治療之多重專一性結合蛋白 - Google Patents
用於癌症治療之多重專一性結合蛋白 Download PDFInfo
- Publication number
- TWI878355B TWI878355B TW109134076A TW109134076A TWI878355B TW I878355 B TWI878355 B TW I878355B TW 109134076 A TW109134076 A TW 109134076A TW 109134076 A TW109134076 A TW 109134076A TW I878355 B TWI878355 B TW I878355B
- Authority
- TW
- Taiwan
- Prior art keywords
- seq
- amino acid
- acid sequence
- variable domain
- heavy chain
- Prior art date
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/80—Vaccine for a specifically defined cancer
- A61K2039/82—Colon
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/35—Valency
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/74—Inducing cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
Landscapes
- Health & Medical Sciences (AREA)
- Immunology (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Animal Behavior & Ethology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicinal Preparation (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
Abstract
本發明係關於新穎B7H6/CD3結合蛋白。本發明亦關於編碼該等蛋白質之核酸;用於製備該等蛋白質之方法;表現或能夠表現該等蛋白質之宿主細胞;包含該等蛋白質之組合物;及該等蛋白質或該等組合物之用途,特別在癌症疾病之領域中用於治療目的。
Description
本發明係關於多重專一性結合蛋白,其包含對B7H6 (在本文中亦稱為「B7-H6」)具有專一性之第一抗原結合單元及對CD3具有專一性之第二抗原結合單元。本發明亦係關於編碼該等結合蛋白之核酸、用於製備該等結合蛋白之方法;表現或能夠表現該等結合蛋白之宿主細胞、包含該等結合蛋白之組合物,及該等結合蛋白或該等組合物之用途,特別在癌症疾病領域中用於治療目的。
B7H6係腫瘤選擇性B7家族成員,已經闡述其吸引先天免疫至靶細胞,並與其他B7家族成員具有類似功能,在細胞外結構域中具有兩個Ig樣結構域,即N-末端IgV樣結構域及C-末端IgC1樣結構域。B7H6觸發NKp30介導之人類天然殺手(NK)細胞之活化,導致脫粒及IFNγ分泌。(Brandt等人,J. Exp. Med. 2009 206(7); 1495-1503)。目前可獲得之數據表明B7H6在對傳染性病況之發炎反應中以及在實體腫瘤中之作用。
已顯示,由於此急性疾病狀態中之發炎過程,B7H6在自敗血症患者之外周血分離之CD14+
CD16+
細胞上表現。該等發現已藉由活體外分析IL-1β及TNFα刺激時CD14+
CD16+
促炎性單核球及嗜中性球之細胞表面上之B7H6之上調而得到確認。(Matta等人,Blood 2013 122(3)),表明B7H6在對敗血症病況之發炎反應中之作用。
除了上文所提及之敗血症病況外,B7H6在腫瘤細胞中以其他方式選擇性表現,且在穩態時在正常人類組織中不能被檢測到。舉例而言,已針對T細胞淋巴瘤、骨髓性白血病、結腸癌、乳癌及卵巢癌細胞系(Brandt等人,J. Exp. Med. 2009 206(7): 1495-1503;Li等人,J. Exp.Med.2011 208(4);Greaves等人,Blood 2013 121(5);Zhang等人 Oncology Letters 2018 16:91-96)、非小細胞肺癌組織(Zhang等人,Int J clin Exp Pathol 2014;7(10):6936-6942)、胃腸腫瘤組織(Chen等人,Pathol. Oncol. Res.2014 20:203-207;Zhao等人,Cell Proliferation 2018;e12468)、卵巢癌組織(Zhou等人,Int clin Exp Pathol 2015 8(8)、口腔鱗狀癌組織(Wang等人,J Oral Pathol Med. 2017;46:766-772)及肝細胞癌組織(Li等人,Int. J. Mol. Sci. 2019, 20, 156)闡述B7H6之表現,然而,尚未完全理解B7H6在腫瘤中之功能。
WO2009/046407A2及WO2011/07044A2中闡述治療應用,包括使用參與ADCC/CDC路徑之抗B7H6抗體或抗B7H6抗體-藥物偶聯物治療癌症。
然而,基於ADCC/CDC活性之B7H6靶向療法並非最佳作用模式,此乃因B7H6之細胞表面表現低,且在實體腫瘤中使用具有ADCC/CDC活性之習用抗體之成功率低。
基於B7H6專一性抗體藥物偶聯物(ADC)之靶向療法亦可能具有侷限性,此乃因大多數患者在化學療法治療後復發,且由於細胞表面上B7H6之低表現。此外,ADC方法通常具有由游離藥物引起之脫靶毒性,此係連接體不穩定或降解之結果。
CAR-T細胞及T細胞銜接抗體係表現B7H6之實體腫瘤之靶向療法的其他方法(Wu等人,Gene 2015 22, 675-684;Hua等人 Protein Engineering, Design & Selection 201730(10), 713-721;WO2017/181001)。舉例而言,Wu等人(J Immunol. 2015年6月1日;194(11):5305-11)闡述B7H6專一性BiTE之臨床前數據,BiTE代表雙專一性T細胞銜接物,其係由兩個單鏈可變片段(scFv)組成之約55 Kda之融合蛋白)。在該情形下,基於OKT3-CD3-黏合物及先前公開之B7H6抗體,工程化B7H6-專一性BiTE (Zhang等人,J Immunol. 2012年9月1日;189(5):2290-9;WO 2013/169691)。然而,OKT3抗體不與食蟹獼猴CD3交叉反應,且因此不允許在食蟹獼猴中進行臨床前毒理學測試,該食蟹獼猴係用於準備臨床試驗之較佳測試物種(Chatenoud等人,The Rev Diabet Stud 2012;9(4):372-381)。另外之挑戰係相對小、容易降解之BiTE分子之半衰期短,此需要在臨床中連續靜脈內投藥。因此,未證明此方法是否成功。迄今為止,尚無用於表現B7-H6之腫瘤之靶向療法,且仍存在由目前方法未解決之未滿足之需要。
舉例而言,結腸直腸癌(CRC)顯示B7-H6之高盛行率及可預測之表現。其係世界範圍內癌症發病率及死亡率之主要原因之一。大約25%之CRC患者最初呈現明顯之轉移,且在40-50%之新近診斷之患者中發展轉移性疾病。儘管化學療法及靶向療法之最近改良延長轉移性CRC之存活持續時間,但大部分患者將死於其之疾病。
鑒於患有晚期疾病之癌症患者之前景不佳,需要鑑別更有效之療法,特別是具有改良之耐受性之有效療法。
因此,本發明之目的係提供與目前使用及/或業內已知之試劑、組合物及/或方法相比提供某些優點的藥理學活性劑、組合物及/或治療方法。該等優點包括尤其與業內已知之候選藥物相比,改良之治療及藥理學性質,例如活體內效能、較少之副作用、降低之免疫原性、改良之治療窗、減少之投與(例如輸注)次數、較低之劑量、延長之半衰期以允許較不頻繁之投藥及其他有利之性質,例如改良之製備容易性、穩定性、與習用抗體方法之相容性或降低之商品成本。
本發明基於雙專一性T細胞銜接方法,其採用具有與在T細胞上表現之CD3之結合臂及與在腫瘤細胞之細胞表面上表現之B7H6之結合臂的多重專一性結合蛋白。經由同時結合T細胞及腫瘤細胞,本發明之T細胞銜接器迫使在兩種細胞之間形成細胞溶解突觸,且藉此將T細胞活性選擇性地重新導向靶向腫瘤細胞。
在一態樣中,本發明提供多重專一性結合蛋白,其包含專一性結合至B7H6之第一抗原結合單元及專一性結合至CD3之第二抗原結合單元,其中該專一性結合至B7H6之第一抗原結合單元選自由i)至xxiv)組成之群:
i)
抗原結合單元,其包括包含SEQ ID NO:1 (CDR1)、SEQ ID NO:2 (CDR2)及SEQ ID NO:3 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:4 (CDR1)、SEQ ID NO:5 (CDR2)及SEQ ID NO:6 (CDR3)之胺基酸序列之重鏈CDR;
ii) 抗原結合單元,其包括包含SEQ ID NO:7 (CDR1)、SEQ ID NO:8 (CDR2)及SEQ ID NO:9 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:10 (CDR1)、SEQ ID NO:11 (CDR2)及SEQ ID NO:12 (CDR3)之胺基酸序列之重鏈CDR;
iii)
抗原結合單元,其包括包含SEQ ID NO:13 (CDR1)、SEQ ID NO:14 (CDR2)及SEQ ID NO:15 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:16 (CDR1)、SEQ ID NO:17 (CDR2)及SEQ ID NO:18 (CDR3)之胺基酸序列之重鏈CDR;
iv) 抗原結合單元,其包括包含SEQ ID NO:19 (CDR1)、SEQ ID NO:20 (CDR2)及SEQ ID NO:21 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:22 (CDR1)、SEQ ID NO:23 (CDR2)及SEQ ID NO:24 (CDR3)之胺基酸序列之重鏈CDR;
v) 抗原結合單元,其包括包含SEQ ID NO:25 (CDR1)、SEQ ID NO:26 (CDR2)及SEQ ID NO:27 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:28 (CDR1)、SEQ ID NO:29 (CDR2)及SEQ ID NO:30 (CDR3)之胺基酸序列之重鏈CDR;
vi) 抗原結合單元,其包括包含SEQ ID NO:31 (CDR1)、SEQ ID NO:32 (CDR2)及SEQ ID NO:33 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:34 (CDR1)、SEQ ID NO:35 (CDR2)及SEQ ID NO:36 (CDR3)之胺基酸序列之重鏈CDR;
vii) 抗原結合單元,其包括包含SEQ ID NO:37 (CDR1)、SEQ ID NO:38 (CDR2)及SEQ ID NO:39 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:40 (CDR1)、SEQ ID NO:41 (CDR2)及SEQ ID NO:42 (CDR3)之胺基酸序列之重鏈CDR;
viii) 抗原結合單元,其包括包含SEQ ID NO:43 (CDR1)、SEQ ID NO:44 (CDR2)及SEQ ID NO:45 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:46 (CDR1)、SEQ ID NO:47 (CDR2)及SEQ ID NO:48 (CDR3)之胺基酸序列之重鏈CDR;
ix) 抗原結合單元,其包括包含SEQ ID NO:49 (CDR1)、SEQ ID NO:50 (CDR2)及SEQ ID NO:51 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:52 (CDR1)、SEQ ID NO:53 (CDR2)及SEQ ID NO:54 (CDR3)之胺基酸序列之重鏈CDR;
x) 抗原結合單元,其包括包含SEQ ID NO:55 (CDR1)、SEQ ID NO:56 (CDR2)及SEQ ID NO:57 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:58 (CDR1)、SEQ ID NO:59 (CDR2)及SEQ ID NO:60 (CDR3)之胺基酸序列之重鏈CDR;
xi) 抗原結合單元,其包括包含SEQ ID NO:61 (CDR1)、SEQ ID NO:62 (CDR2)及SEQ ID NO:63 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:64 (CDR1)、SEQ ID NO:65 (CDR2)及SEQ ID NO:66 (CDR3)之胺基酸序列之重鏈CDR;
xii) 抗原結合單元,其包括包含SEQ ID NO:67 (CDR1)、SEQ ID NO:68 (CDR2)及SEQ ID NO:69 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:70 (CDR1)、SEQ ID NO:71 (CDR2)及SEQ ID NO:72 (CDR3)之胺基酸序列之重鏈CDR;
xiii) 抗原結合單元,其包括包含SEQ ID NO:73 (CDR1)、SEQ ID NO:74 (CDR2)及SEQ ID NO:75 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:76 (CDR1)、SEQ ID NO:77 (CDR2)及SEQ ID NO:78 (CDR3)之胺基酸序列之重鏈CDR;
xiv) 抗原結合單元,其包括包含SEQ ID NO:79 (CDR1)、SEQ ID NO:80 (CDR2)及SEQ ID NO:81 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:82 (CDR1)、SEQ ID NO:83 (CDR2)及SEQ ID NO:84 (CDR3)之胺基酸序列之重鏈CDR;
xv) 抗原結合單元,其包括包含SEQ ID NO:85 (CDR1)、SEQ ID NO:86 (CDR2)及SEQ ID NO:87 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:88 (CDR1)、SEQ ID NO:89 (CDR2)及SEQ ID NO:90 (CDR3)之胺基酸序列之重鏈CDR;
xvi) 抗原結合單元,其包括包含SEQ ID NO:91 (CDR1)、SEQ ID NO:92 (CDR2)及SEQ ID NO:93 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:94 (CDR1)、SEQ ID NO:95 (CDR2)及SEQ ID NO:96 (CDR3)之胺基酸序列之重鏈CDR;
xvii) 抗原結合單元,其包括包含SEQ ID NO:97 (CDR1)、SEQ ID NO:98 (CDR2)及SEQ ID NO:99 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:100 (CDR1)、SEQ ID NO:101 (CDR2)及SEQ ID NO:102 (CDR3)之胺基酸序列之重鏈CDR;
xviii) 抗原結合單元,其包括包含SEQ ID NO:103 (CDR1)、SEQ ID NO:104 (CDR2)及SEQ ID NO:105 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:106 (CDR1)、SEQ ID NO:107 (CDR2)及SEQ ID NO:108 (CDR3)之胺基酸序列之重鏈CDR;
xix) 抗原結合單元,其包括包含SEQ ID NO:109 (CDR1)、SEQ ID NO:110 (CDR2)及SEQ ID NO:111 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:112 (CDR1)、SEQ ID NO:113 (CDR2)及SEQ ID NO:114 (CDR3)之胺基酸序列之重鏈CDR;
xx) 抗原結合單元,其包括包含SEQ ID NO:115 (CDR1)、SEQ ID NO:116 (CDR2)及SEQ ID NO:117 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:118 (CDR1)、SEQ ID NO:119 (CDR2)及SEQ ID NO:120 (CDR3)之胺基酸序列之重鏈CDR;
xxi) 抗原結合單元,其包括包含SEQ ID NO:121 (CDR1)、SEQ ID NO:122 (CDR2)及SEQ ID NO:123 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:124 (CDR1)、SEQ ID NO:125 (CDR2)及SEQ ID NO:126 (CDR3)之胺基酸序列之重鏈CDR;
xxii) 抗原結合單元,其包括包含SEQ ID NO:127 (CDR1)、SEQ ID NO:128 (CDR2)及SEQ ID NO:129 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:130 (CDR1)、SEQ ID NO:131 (CDR2)及SEQ ID NO:132 (CDR3)之胺基酸序列之重鏈CDR;
xxiii) 抗原結合單元,其包括包含SEQ ID NO:133 (CDR1)、SEQ ID NO:134 (CDR2)及SEQ ID NO:135 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:136 (CDR1)、SEQ ID NO:137 (CDR2)及SEQ ID NO:138 (CDR3)之胺基酸序列之重鏈CDR;及
xxiv) 抗原結合單元,其包括包含SEQ ID NO:139 (CDR1)、SEQ ID NO:140 (CDR2)及SEQ ID NO:141 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:142 (CDR1)、SEQ ID NO:143 (CDR2)及SEQ ID NO:144 (CDR3)之胺基酸序列之重鏈CDR。
在本發明之結合蛋白之一些實施例中,專一性結合至B7H6之第一抗原結合單元選自由i)至xxiv)組成之群:
i) 包含SEQ ID NO:145之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:146之胺基酸序列之重鏈可變結構域;
ii) 包含SEQ ID NO:147之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:148之胺基酸序列之重鏈可變結構域;
iii) 包含SEQ ID NO:149之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:150之胺基酸序列之重鏈可變結構域;
iv) 包含SEQ ID NO:151之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:152之胺基酸序列之重鏈可變結構域;
v) 包含SEQ ID NO:153之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:154之胺基酸序列之重鏈可變結構域;
vi) 包含SEQ ID NO:155之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:156之胺基酸序列之重鏈可變結構域;
vii) 包含SEQ ID NO:157之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:158之胺基酸序列之重鏈可變結構域;
viii) 包含SEQ ID NO:159之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:160之胺基酸序列之重鏈可變結構域;
ix) 包含SEQ ID NO:161之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:162之胺基酸序列之重鏈可變結構域;
x) 包含SEQ ID NO:163之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:164之胺基酸序列之重鏈可變結構域;
xi) 包含SEQ ID NO:165之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:166之胺基酸序列之重鏈可變結構域;
xii) 包含SEQ ID NO:167之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:168之胺基酸序列之重鏈可變結構域;
xiii) 包含SEQ ID NO:169之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:170之胺基酸序列之重鏈可變結構域;
xiv) 包含SEQ ID NO:171之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:172之胺基酸序列之重鏈可變結構域;
xv) 包含SEQ ID NO:173之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:174之胺基酸序列之重鏈可變結構域;
xvi) 包含SEQ ID NO:175之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:176之胺基酸序列之重鏈可變結構域;
xvii) 包含SEQ ID NO:177之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:178之胺基酸序列之重鏈可變結構域;
xviii) 包含SEQ ID NO:179之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:180之胺基酸序列之重鏈可變結構域;
xix) 包含SEQ ID NO:181之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:182之胺基酸序列之重鏈可變結構域;
xx) 包含SEQ ID NO:183之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:184之胺基酸序列之重鏈可變結構域;
xxi) 包含SEQ ID NO:185之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:186之胺基酸序列之重鏈可變結構域;
xxii) 包含SEQ ID NO:187之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:188之胺基酸序列之重鏈可變結構域;
xxiii) 包含SEQ ID NO:189之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:190之胺基酸序列之重鏈可變結構域;及
xxiv) 包含SEQ ID NO:191之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:192之胺基酸序列之重鏈可變結構域。
在本發明之結合蛋白之一些實施例中,專一性結合至CD3之第二抗原結合單元選自由i)-vi)組成之群:
i) 抗原結合單元,其包括包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR;
ii) 抗原結合單元,其包括包含SEQ ID NO:263 (CDR1)、SEQ ID NO:264 (CDR2)及SEQ ID NO:265 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:266 (CDR1)、SEQ ID NO:267 (CDR2)及SEQ ID NO:268 (CDR3)之胺基酸序列之重鏈CDR;
iii) 抗原結合單元,其包括包含SEQ ID NO:269 (CDR1)、SEQ ID NO:270 (CDR2)及SEQ ID NO:271 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:272 (CDR1)、SEQ ID NO:273 (CDR2)及SEQ ID NO:274 (CDR3)之胺基酸序列之重鏈CDR;
iv) 抗原結合單元,其包括包含SEQ ID NO:275 (CDR1)、SEQ ID NO:276 (CDR2)及SEQ ID NO:277 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:278 (CDR1)、SEQ ID NO:279 (CDR2)及SEQ ID NO:280 (CDR3)之胺基酸序列之重鏈CDR;
v) 抗原結合單元,其包括包含SEQ ID NO:281 (CDR1)、SEQ ID NO:282 (CDR2)及SEQ ID NO:283 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:284 (CDR1)、SEQ ID NO:285 (CDR2)及SEQ ID NO:286 (CDR3)之胺基酸序列之重鏈CDR;及
vi) 抗原結合單元,其包括包含SEQ ID NO:287 (CDR1)、SEQ ID NO:288 (CDR2)及SEQ ID NO:289 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:290 (CDR1)、SEQ ID NO:291 (CDR2)及SEQ ID NO:292 (CDR3)之胺基酸序列之重鏈CDR。
在本發明之結合蛋白之一些實施例中,專一性結合至CD3之第二抗原結合單元選自由i)至vi)組成之群:
i) 包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域;
ii) 包含SEQ ID NO:295之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:296之胺基酸序列之重鏈可變結構域;
iii) 包含SEQ ID NO:297之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:298之胺基酸序列之重鏈可變結構域;
iv) 包含SEQ ID NO:299之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:300之胺基酸序列之重鏈可變結構域;
v) 包含SEQ ID NO:301之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:302之胺基酸序列之重鏈可變結構域;及
vi) 包含SEQ ID NO:303之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:304之胺基酸序列之重鏈可變結構域。
在本發明之結合蛋白之一些實施例中,專一性結合至B7H6之第一抗原結合單元自其N-末端至C-末端包含第一輕鏈可變結構域、第一輕鏈恆定結構域、第一肽連接體、第一重鏈可變結構域及第一重鏈恆定CH1結構域;且專一性結合至CD3之第二抗原結合單元自其N-末端至C-末端包含第二輕鏈可變結構域、第二輕鏈恆定結構域、第二肽連接體、第二重鏈可變結構域及第二重鏈恆定CH1結構域。在本發明之結合蛋白之一些實施例中,第一及/或第二肽連接體包含26至42個胺基酸,較佳30至40個胺基酸、34至40個胺基酸或36至39個胺基酸中之任一者,更佳38個胺基酸。在本發明之一些實施例中,第一連接體及/或第二連接體係Gly-Ser連接體,較佳包含SEQ ID NO:250之胺基酸序列,更佳地該等第一及第二肽連接體包含相同序列(例如SEQ ID NO:250)。在本發明之一些實施例中,第一輕鏈恆定結構域及第二輕鏈恆定結構域獨立地包含人類κ或λ結構域。
在一些實施例中,對本發明之結合蛋白之B7H6具有專一性的第一抗原結合單元包含選自由以下組成之群之胺基酸序列:SEQ ID NO:193、SEQ ID NO:194、SEQ ID NO:195、SEQ ID NO:196、SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201、SEQ ID NO:202、SEQ ID NO:203、SEQ ID NO:204、SEQ ID NO:205、SEQ ID NO:206、SEQ ID NO:207、SEQ ID NO:208、SEQ ID NO:209、SEQ ID NO:210、SEQ ID NO:211、SEQ ID NO:212、SEQ ID NO:213、SEQ ID NO:214、SEQ ID NO:215及SEQ ID NO:216,且對CD3具有專一性之第二抗原結合單元包含選自由以下組成之群之胺基酸序列:SEQ ID NO:305、SEQ ID NO:306、SEQ ID NO:307、SEQ ID NO:308、SEQ ID NO:309及SEQ ID NO:310,較佳SEQ ID NO:305。
在一些實施例中,本發明之結合蛋白進一步包含第一及第二Fc結構域,其中該第一Fc結構域共價連接至該第一抗原結合單元、較佳該第一抗原結合單元之C-末端,且該第二Fc結構域共價連接至該第二抗原結合單元、較佳該第二抗原結合單元之C-末端。
在本發明之一些實施例中,
i) 第一Fc結構域包含位置366之酪胺酸(Y) [T366Y],且第二Fc結構域包含位置407之蘇胺酸(T) [Y407T],或
ii) 第一Fc結構域包含位置366之色胺酸(W) [T366W],且第二Fc結構域包含位置366之絲胺酸(S) [T366S]、位置368之丙胺酸(A) [L368A]及位置407之纈胺酸(V) [Y407V],或
iii) 第二Fc結構域包含位置366之酪胺酸(Y) [T366Y],且第一Fc結構域包含位置407之蘇胺酸(T) [Y407T],或
iv) 第二Fc結構域包含位置366之色胺酸(W) [T366W],且第一Fc結構域包含位置366之絲胺酸(S) [T366S]、位置368之丙胺酸(A) [L368A]及位置407之纈胺酸(V) [Y407V],
較佳地,其中第一或第二Fc結構域進一步包含位置435之精胺酸[H435R]及位置436之苯丙胺酸[Y436F]。在一些實施例中,第一及/或第二Fc結構域包含位置234之丙胺酸[L234A]及位置235之丙胺酸[L235A]。
在一些實施例中,本發明之結合蛋白包含專一性結合至B7H6之第一多肽鏈,其包含選自由以下組成之群之胺基酸序列:SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO;224、SEQ ID NO:225、SEQ ID NO:226、SEQ ID NO:227、SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239及SEQ ID NO:240;及專一性結合至CD3之第二多肽鏈,其包含選自由以下組成之群之胺基酸序列:SEQ ID NO:311、SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315及SEQ ID NO:316,較佳SEQ ID NO:311。
在另一態樣中,本發明提供經分離核酸分子,其i) 編碼本發明之結合蛋白之第一抗原結合單元及/或第二抗原結合單元,視情況進一步編碼第一及/或第二Fc結構域,或ii) 編碼本發明之結合蛋白之第一及/或第二多肽鏈。在其他態樣中,本文提供包含本發明之核酸分子的表現載體、經該等表現載體轉染之宿主細胞及製造本發明之蛋白質之方法。
在本發明之又一態樣中,本文提供多重專一性結合蛋白,其包含專一性結合至B7H6之第一多肽鏈及專一性結合至CD3之第二多肽鏈,其中第一多肽鏈包含第一輕鏈、第一連接體及第一重鏈,且第二多肽鏈包含第二輕鏈、第二連接體及第二重鏈,較佳地,第一輕鏈之C-末端經由第一肽連接體共價結合至第一重鏈之N-末端,且第二輕鏈之C-末端經由第二肽連接體共價結合至第二重鏈之N-末端。熟練人員應理解,本文任何提及之「輕鏈」或「重鏈」分別係指抗體輕鏈或抗體重鏈。
在本發明之蛋白質之一些實施例中,專一性結合至B7H6之第一多肽鏈包含輕鏈可變及重鏈可變結構域,其包含如針對本文所述之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24中之任一者之抗原結合單元所定義的CDR序列、VH/VL序列及/或單鏈Fab序列。在一些實施例中,專一性結合至CD3之第二多肽鏈包含輕鏈可變及重鏈可變結構域,其包含如針對如本文所述之CD3#1之抗原結合單元所定義的CDR序列、VH/VL序列及/或scFab序列。
自以下本發明之實施方式及隨附申請專利範圍可明瞭涉及本發明之結合蛋白之其他態樣、實施例、用途及方法。
本發明提供允許更有效治療表現B7H6之癌症、例如(轉移性)結腸直腸癌((m)CRC)、非小細胞肺癌(NSCLC)或頭頸部鱗狀細胞癌(HNSCC)的新穎結合蛋白。
所用術語及定義 本發明之上述及其他態樣及實施例將自本文之進一步說明中明瞭,其中:
除非另外指明或定義,否則所用之所有術語具有其業內之常用含義,此為熟練人員所明瞭。參照(例如)標準手冊,例如Sambrook等人,「Molecular Cloning: A Laboratory Manual」 (第2版), 第1-3卷, Cold Spring Harbor Laboratory Press (1989);Lewin, 「Genes IV」, Oxford University Press, New York, (1990),及Roitt等人,「Immunology」 (第2版), Gower Medical Publishing, London, New York (1989),以及本文引用之一般背景技術。此外,除非另外指明,否則可實施且以本身已知之方式實施未明確詳細闡述之所有方法、步驟、技術及操縱,如熟習此項技術者所明瞭。再次參照(例如)標準手冊、上文提及之一般背景技術及其中引用之其他參考文獻。
當在本文中使用時,術語「包含(comprising)」及其變化形式(例如「包含(comprises及comprise)」可用術語「含有」或「包括」或「具有」來取代。
除非上下文需要更有限之解釋,否則如本文所用之術語「序列」 (例如在如「重/輕鏈序列」、「抗體序列」、「可變結構域序列」、「恆定結構域序列」或「蛋白序列」等術語中)通常應理解為包括相關之胺基酸序列以及編碼其之核酸序列或核苷酸序列。
如本文所用術語「抗原結合單元」包含允許結合至其專一性靶標或抗原之源自抗體之最少結構要求(即,抗體中通常存在之最少結構要求)。因此,抗原結合單元包含至少三個輕鏈及三個重鏈CDR序列;較佳其包含至少輕鏈可變結構域及重鏈可變結構域。
抗體或免疫球蛋白之一般結構為熟習此項技術者熟知。該等分子係異四聚體醣蛋白,通常約150,000道爾頓,由兩條相同之輕(L)鏈及兩條相同之重(H)鏈構成且通常稱作全長抗體。每條輕鏈藉由一個二硫鍵與重鏈共價連接以形成異二聚體,且異四聚體分子經由異二聚體之兩條相同重鏈之間之共價二硫鍵形成。儘管輕鏈及重鏈藉由一個二硫鍵連接在一起,但兩條重鏈之間之二硫鍵之數目根據免疫球蛋白同型而變化。每條重鏈及輕鏈亦具有規則間隔之鏈內二硫鍵。每條重鏈在N-末端具有可變結構域(VH),之後係三個或四個(在IgE之情形下)恆定結構域(CH1、CH2、CH3及CH4),以及CH1與CH2之間之鉸鏈區。每條輕鏈具有兩個結構域,即N-末端可變結構域(VL)及C-末端恆定結構域(CL)。VL結構域與VH結構域非共價締合,而CL結構域通常經由二硫鍵與CH1結構域共價連接。據信特定胺基酸殘基在輕鏈及重鏈可變結構域之間形成界面(Chothia等人,1985, J. Mol. Biol. 186:651-663)。可變結構域在本文中亦稱為可變區或Fv且表示藉由攜帶抗原-結合位點賦予抗體對抗原之專一性之部分。
如本文所用之「輕鏈可變結構域」 (或「輕鏈可變區」)及「重鏈可變結構域」 (或「重鏈可變區」)具有相同之一般結構,且每一結構域基本上由四個其序列廣泛保守之框架(FR)區組成,該等框架區在業內及本文下文中分別稱為「框架區1」或「FR1」、「框架區2」或「FR2」、「框架區3」或「FR3」及「框架區4」或「FR4」;該等框架區由三個超變區HVR (或CDR)中斷,該等HVR (或CDR)在業內及本文下文中分別稱為「互補決定區1」或「CDR1」、「互補決定區2」或「CDR2」及「互補決定區3」或「CDR3」。因此,免疫球蛋白可變結構域之一般結構或序列可指示如下:FR1 - CDR1 - FR2 - CDR2 - FR3 - CDR3 - FR4。框架區採用β-摺疊構象,且CDR可形成連接β-摺疊結構之環。每一鏈中之CDR藉由框架區保持其三維結構並與另一鏈之CDR一起形成抗原結合位點。
CDR之各種定義為業內已知,例如,基於CCG、亦稱為IMGT之定義(Lefranc MP, Pommié C, Ruiz M, Giudicelli V, Foulquier E, Truong L, Thouvenin-Contet V, Lefranc G. 「IMGT unique numbering for immunoglobulin and T cell receptor variable domains and Ig superfamily V-like domains.」 Dev Comp Immunol. 2003年1月;27(1):55-77;Giudicelli V, Brochet X, Lefranc MP. 「IMGT/V-QUEST: IMGT standardized analysis of the immunoglobulin (IG) and T cell receptor (TR) nucleotide sequences」. Cold Spring Harb Protoc. 2011;2011(6):695-715)或基於Chothia (Chothia及Lesk, J. Mol. Biol. 1987, 196: 901-917)以及Kabat (E.A. Kabat, T.T. Wu, H. Bilofsky, M. Reid-Miller及H. Perry, Sequence of Proteins of Immunological Interest, National Institutes of Health, Bethesda (1983))之定義。在本發明之背景內,CDR之提及係基於CCG (IMGT)之定義。
如當前申請案內所用術語「恆定結構域」或「恆定區」表示抗體中除可變區以外之結構域之和。該等恆定結構域及區在最先進技術中眾所周知且(例如)由Kabat等人 (「Sequence of proteins of immunological interest」, US Public Health Services, NIH Bethesda, MD, 公開案第91-3242號(1991))闡述。根據其重鏈之恆定區之胺基酸序列,抗體或免疫球蛋白分成以下幾類:IgA、IgD、IgE、IgG及IgM。根據重鏈恆定區,不同類別之免疫球蛋白分別稱為α、δ、ε、γ及μ。該等中之若干可進一步分成亞類(同型),例如IgG1、IgG2、IgG3及IgG4、IgA1及IgA2。
抗體之「Fc部分」或「Fc結構域」並不直接參與抗體與抗原之結合,但展現多種效應物功能。抗體之「Fc部分/結構域」係熟習此項技術者所熟知且基於抗體之木瓜蛋白酶裂解定義之術語。抗體之Fc部分基於補體活化、C1q結合及Fc受體結合而直接參與ADCC (抗體依賴性細胞介導之細胞毒性)及CDC (補體依賴性細胞毒性)。補體活化(CDC)係藉由補體因子C1q與大多數IgG抗體亞類之Fc部分結合來起始。儘管抗體對補體系統之影響取決於某些條件,但與C1q之結合係由Fc部分中之所定義結合位點來引起。該等結合位點係(例如) L234、L235、D270、N297、E318、K320、K322、P331及P329 (根據Eu編號進行編號(Edelman等人,Proc Natl Acad Sci U S A. 1969年5月;63(1):78-85))。在介導IgG1中之C1q及Fcγ受體結合之該等殘基中最關鍵者係L234及L235 (Hezareh等人,J. Virology 75 (2001) 12161- 12168, Shields等人(2001) JBC, 276 (9): 6591-6604)。亞類IgG1及IgG3之抗體通常顯示補體活化以及C1q及C3結合,而IgG2及IgG4並不活化補體系統且不結合C1q及C3。
術語「抗體」或「抗體分子」 (在本文中同義使用)涵蓋單株抗體、多株抗體、人類抗體、人類化抗體、序列最佳化抗體、嵌合抗體、多重專一性抗體(例如雙專一性抗體)、抗體之片段(具體而言Fv、Fab、Fab’或F(ab’)2片段)、單鏈抗體(具體而言單鏈可變片段(scFv)、單鏈Fab片段(scFab))、小模塊免疫醫藥(SMIP)、結構域抗體、奈米抗體®、雙價抗體。抗體可具有效應物功能,例如ADCC或CDC,其通常由抗體之Fc部分介導,或者其可不具有效應物功能,例如缺乏Fc部分或具有封閉、掩蔽之Fc部分,本質上不被或不充分地被免疫細胞或免疫系統組分(如補體系統)識別之Fc部分。
單株抗體(mAb)係胺基酸序列一致之單專一性抗體。其可藉由雜交瘤技術自雜交細胞系(稱為雜交瘤)產生,該雜交細胞系代表產生專一性抗體之B細胞與骨髓瘤(B細胞癌)細胞之融合體之純系(Kohler G, Milstein C. Continuous cultures of fused cells secreting antibody of predefined specificity. Nature 1975;256:495-7.)。或者,單株抗體可藉由在宿主細胞中重組表現而產生(Norderhaug L, Olafsen T, Michaelsen TE, Sandlie I. (1997年5月)。「Versatile vectors for transient and stable expression of recombinant antibody molecules in mammalian cells.」 J Immunol Methods 204 (1): 77-87;亦參見下文)。「重組抗體」或「重組結合蛋白」係已由重組工程化宿主細胞產生之抗體或結合蛋白。其視情況經分離或純化。
本發明之抗體分子亦包括免疫球蛋白中保留抗原結合性質之片段,如Fab、Fab'或F(ab')2片段。該等片段可藉由免疫球蛋白之片段化、例如藉由蛋白水解消化、或藉由該等片段之重組表現獲得。舉例而言,免疫球蛋白消化可藉助常規技術、例如使用木瓜酶或胃蛋白酶來完成(WO 94/29348)。木瓜酶消化抗體通常產生兩個相同之抗原結合片段(Fab)。Fab片段由重鏈及輕鏈中之每一者之一個恆定結構域及一個可變結構域構成。胃蛋白酶處理產生F(ab')2。在Fab片段中,可變結構域各自融合至較佳人類來源之免疫球蛋白恆定結構域。因此,重鏈可變結構域融合至CH1結構域(所謂Fd片段),且輕鏈可變結構域融合至CL結構域。Fab片段可藉由在宿主細胞中重組表現各別核酸來產生,參見下文。
已經開發許多技術用於將免疫球蛋白之可變結構域或衍生自該等可變結構域之分子置於不同分子環境中。彼等亦應視為係根據本發明之「抗體」或「抗體分子」。一般而言,該等抗體分子之大小與免疫球蛋白相比較小,且可包含單一胺基酸鏈或若干胺基酸鏈。舉例而言,「單鏈可變片段(scFv)」係利用短連接體(通常為絲胺酸(S)或甘胺酸(G))連接在一起之免疫球蛋白重鏈及輕鏈可變區之融合體(WO 88/01649;WO 91/17271;Huston等人;International Reviews of Immunology, 第10卷, 1993, 195 - 217) 「單一結構域抗體」或「奈米抗體®」在單一Ig樣結構域中擁有抗原結合位點(WO 94/04678;WO 03/050531, Ward等人,Nature. 1989年10月12日;341(6242):544-6;Revets等人,Expert Opin Biol Ther. 5(1):111-24, 2005)。對相同或不同抗原具有結合專一性之一或多個單一結構域抗體可連接在一起。「雙價抗體」係由包含兩個可變結構域之兩條胺基酸鏈組成之二價抗體分子(WO 94/13804, Holliger等人,Proc Natl Acad Sci U S A. 1993年7月15日;90(14):6444-8)。抗體樣分子之其他實例係「免疫球蛋白超家族抗體」 (IgSF;Srinivasan及Roeske, Current Protein Pept. Sci. 2005, 6(2): 185-96)。不同之概念導致所謂「小模塊免疫醫藥(SMIP)」,其包含連接至單鏈鉸鏈之Fv結構域及缺乏恆定結構域CH1之效應物結構域(WO 02/056910)。「單鏈Fab」或「scFab」係輕鏈Fab結構域(即與一個輕鏈恆定結構域(CL)連接之輕鏈可變結構域(VL))與重鏈Fab結構域(即與一個重鏈恆定結構域(CH1)連接之重鏈可變結構域(VH))之融合體。單鏈Fab能夠識別及結合抗原。scFab亦可視情況含有位於CL及VH結構域之間之連接體(例如肽連接體) (Hust等人 BMC Biotechnology2007, 7:14)。
對於在人類中之應用,通常期望降低治療性分子之免疫原性,該等治療性分子例如包含如本文所述之抗原結合單元之抗體或結合蛋白,其最初源自其他物種,如小鼠。此可藉由構築嵌合抗體/結合蛋白、或藉由稱為「人類化」之方法來完成。在此上下文中,「嵌合抗體」或「嵌合抗原結合單元」應理解為包含與源自不同物種(例如人類)之序列部分(例如恆定結構域)融合之源自一個物種(例如小鼠)之序列部分(例如可變結構域)的抗體或抗原結合單元。在此上下文中,「人類化抗體」、「人類化抗原結合單元」或「人類化VL/VH結構域」係包含最初源自非人類物種之可變結構域之抗體、抗原結合單元或VH/VL結構域,其中某些胺基酸已經突變以使該可變結構域之總體序列更接近地類似於人類可變結構域之序列。抗體之人類化方法為業內所熟知(Billetta R, Lobuglio AF. 「Chimeric antibodies」. Int Rev Immunol. 1993;10(2-3):165-76;Riechmann L, Clark M, Waldmann H, Winter G (1988). 「Reshaping human antibodies for therapy」. Nature: 332:323)。
如本文所用術語「人類抗體」、「人類抗原結合單元」或「人類VH/VL結構域」包括具有源自人類種系免疫球蛋白序列之可變(及若適用,恆定)區之抗體、抗原結合單元或VH/VL結構域。如本文所用術語「人類抗體」、「人類抗原結合單元」或「人類VH/VL結構域」並不欲包括源自另一(哺乳動物)物種(例如小鼠、大鼠或兔)種系之CDR序列已移植至人類框架序列上之抗體。因此,如本文所用術語「人類抗體」、「人類抗原結合單元」或「人類VH/VL結構域」係指其中蛋白質之每個部分(例如CDR、框架、CL、CH結構域(例如CH1、CH2、CH3)、鉸鏈、VL、VH)在人類中實質上無免疫原性、如本文中下文進一步闡述僅具有最少序列改變或變化的抗體、抗原結合單元或VH/VL結構域。
產生該等「人類抗體」、「人類抗原結合單元」或「人類VH/VL結構域」之技術已經闡述,且包括但不限於噬菌體展示或使用轉基因動物(WWW. Ablexis.com/technology-alivamab.php;WO 90/05144;D. Marks, H.R. Hoogenboom, T.P. Bonnert, J. McCafferty, A.D. Griffiths及G. Winter (1991) 「By-passing immunisation. Human antibodies from V-gene libraries displayed on phage.」 J.Mol.Biol., 222, 581-597;Knappik等人,J. Mol. Biol. 296: 57-86, 2000;S. Carmen及L. Jermutus, 「Concepts in antibody phage display」. Briefings in Functional Genomics and Proteomics 2002 1(2):189-203;Lonberg N, Huszar D. 「Human antibodies from transgenic mice」. Int Rev Immunol. 1995;13(1):65-93.;Brüggemann M, Taussig MJ. 「Production of human antibody repertoires in transgenic mice」. Curr Opin Biotechnol. 1997年8月;8(4):455-8.)。
因此,人類抗體、人類抗原結合單元或人類VH/VL結構域不同於(例如)嵌合或人類化抗體。應指出,人類抗體、人類抗原結合單元或人類VH/VL結構域可由能夠表現功能上重排之人類免疫球蛋白(例如重鏈及/或輕鏈)基因之非人類動物或原核或真核細胞產生。
本發明之嵌合、人類化或人類抗體、抗原結合單元或VH/VL結構域可進一步最佳化;在本文中亦稱為「最佳化之」或「序列最佳化之」抗體、抗原結合單元或VH/VL結構域。該最佳化包括但不限於去除或交換不期望之胺基酸,例如以降低人類中之免疫原性,或避免去醯胺、不期望之電荷或親脂性或非專一性結合。例如,可藉由活體外隨機或位點專一性誘變或藉由活體內體細胞突變來引入不期望胺基酸之該去除或交換。此外,關於嵌合或人類化抗體、抗原結合單元或VH/VL結構域,應理解,某些小鼠FR殘基對於最佳化抗體、抗原結合單元及VH/VL結構域之功能可為重要的。因此,該等重要之胺基酸殘基可保留在最佳化抗體、抗原結合單元及VH/VL結構域中。
術語「單體」係指如本文所述之抗體或多重專一性蛋白質之同源形式。舉例而言,對於全長抗體,單體意指具有兩條相同重鏈及兩條相同輕鏈之單體抗體。在本發明之上下文中,單體意指如本文所述之對B7H6具有專一性之單一抗原結合單元及對CD3具有專一性之單一抗原結合單元的本發明蛋白質。舉例而言,本文所述之結合蛋白之單體可具有兩條多肽鏈,即包含對B7H6具有專一性之單鏈Fab及第一Fc結構域的第一多肽鏈及包含對CD3具有專一性之單鏈Fab及第二Fc結構域的第二多肽鏈。
表位係抗原中由抗體或抗原結合部分(例如本文所述之蛋白質之抗原結合單元)結合之區。術語「表位」包括能夠專一性結合至抗體或抗原結合部分之任何多肽決定子。在某些實施例中,表位決定子包括分子之化學活性表面基團(例如胺基酸、聚醣側鏈、磷醯基或磺醯基),且在某些實施例中,可具有特定三維結構特徵及/或特定電荷特徵。構象及非構象表位之區別在於在變性溶劑之存在下喪失與前者之結合,但不喪失與後者之結合。
可「結合
」、「結合至
」、「專一性結合
」或「專一性結合至
」、係「結合( 至)
」或「專一性結合至
」、對特定表位、抗原或蛋白質(或其至少一部分、片段或表位)「具有親和性」、「專一性於
」及/或「對其具有專一性
」之抗原結合分子/蛋白質(例如免疫球蛋白、抗體、抗原結合單元或該抗原結合分子/蛋白之片段)稱為「針對
(against
或directed against
)該表位、抗原或蛋白質,或係關於該表位、抗原或蛋白質之「結合」分子/蛋白質。該等術語在本文中可互換使用。
如本文所用,術語「結合」及「專一性結合」係指在活體外分析中、較佳在電漿子共振分析((Malmqvist M., 「Surface plasmon resonance for detection and measurement of antibody-antigen affinity and kinetics.」, Curr Opin Immunol. 1993年4月;5(2):282-6.))中,用純化之野生型抗原使抗原結合分子/蛋白質(例如免疫球蛋白、抗體、抗原結合單元或該抗原結合分子/蛋白質之片段)與抗原表位結合。抗體親和性亦可使用動力學排除分析(KinExA)技術量測(Darling, R.J.及Brault P-A., 「Kinetic exclusion assay technology: Characterization of Molecular Interactions.」 ASSAY and Drug Development Technologies. 2004年12月2(6): 647-657)。舉例而言,本發明之結合蛋白或蛋白質用其第一抗原結合單元/第一多肽鏈結合至B7H6之表位,且用其第二抗原結合單元/第二多肽鏈結合至CD3之表位。
通常,術語「專一性
」係指特定抗原結合分子/蛋白質(例如免疫球蛋白、抗體、抗原結合單元或該抗原結合分子/蛋白質之片段)可結合之不同類型之抗原或表位之數目。對B7H6之結合專一性意指本發明之抗原結合蛋白/分子(例如該結合蛋白之第一抗原結合單元)對B7H6之結合親和性顯著高於對結構無關分子之結合親和性。對CD3之結合專一性係指本發明之抗原結合蛋白/分子(例如該結合蛋白之第二抗原結合單元)對CD3之結合親和性顯著高於對結構無關分子之結合親和性。抗原結合分子/蛋白質之專一性可基於其親和性及/或親合力來確定。由抗原與抗原結合蛋白解離之平衡常數(KD
)表示之親和性係抗原結合分子/蛋白質上之表位與抗原結合位點之間之結合強度的量度:KD
值愈小,表位與抗原結合位點之間之結合強度愈強(或者,親和性亦可表示為親和常數(KA
),其為1/KD
)。如熟練人員所明瞭(例如基於本文之進一步揭示內容),親和性可以本身已知之方式確定,此取決於所關注之專一性抗原。親合力係抗原結合分子/蛋白質(例如免疫球蛋白、抗體、抗原結合單元或該抗原結合分子/蛋白質之片段)與相關抗原之間之結合強度之量度。親合力與抗原結合分子/蛋白質上之表位與其抗原結合位點之間之親和性以及抗原結合分子/蛋白質上存在之相關結合位點之數目兩者相關。
當提及抗原結合單元/抗原、配體/受體或其他結合對時,術語「專一性結合」或「選擇性結合」指示決定在蛋白質及其他生物製品之異質群體中蛋白質之存在之結合反應。因此,在命名之條件下,指定抗原結合單元結合至特定抗原,且不以顯著量結合至樣品中存在之其他蛋白質。抗原結合單元在命名之條件下以比與無關抗原之親和性大至少兩倍、較佳大至少十倍、更佳大至少20倍、最佳大至少100倍之親和性結合至其抗原。
如本文所用之術語「經分離」係指自其原始或天然環境(例如,若其為天然的則為天然環境)移除之材料。舉例而言,存在於活動物中之天然多核苷酸或多肽未經分離,但藉由人類干預與天然系統中之一些或所有共存材料分離之相同多核苷酸或多肽經分離。該等多核苷酸可為載體之一部分及/或該等多核苷酸或多肽可為組合物之一部分,且仍經分離以使該載體或組合物不為在自然界中發現其之環境的一部分。舉例而言,在與獲得核酸、蛋白質/多肽分子之天然生物來源及/或反應介質或培養介質比較時-在核酸、蛋白質/多肽分子與通常在該來源或介質中結合其之至少一種另一組分(例如另一核酸、另一蛋白質/多肽、另一生物組分或大分子或至少一種污染物、雜質或次要組分)分離時,將其視為「(呈)基本上分離(形式)」。具體而言,若核酸或蛋白質/多肽純化至少2倍、具體而言至少10倍、更具體而言至少100倍及高達1000倍或更多倍,則將其視為「基本上分離」。「呈基本上分離形式」之核酸或蛋白質/多肽分子較佳基本上均勻,如使用適宜技術(例如適宜層析技術,例如聚丙烯醯胺凝膠電泳)所測定。
如本文所用,在兩個或更多個核酸或多肽序列之上下文中,術語「一致」或「一致性百分比」係指當為了最大對應性進行比較及比對時,兩個或更多個序列或子序列相同或具有指定百分比之相同核苷酸或胺基酸殘基。為了確定一致性百分比,將序列比對以用於最佳比較目的(例如,可在第一胺基酸或核酸之序列中引入缺口以用於與第二胺基酸序列或第二核酸序列進行最佳比對)。然後比較相應胺基酸位置或核苷酸位置之胺基酸殘基或核苷酸。當第一序列中之位置被與第二序列中之相應位置相同之胺基酸殘基或核苷酸佔據時,則分子在該位置一致。兩個序列之間之一致性百分比係該等序列所共享之一致位置數之函數(即,一致性% =一致位置數/總位置數(例如重疊位置) × 100)。在一些實施例中,若適當(例如,排除延伸超出所比較之序列之額外序列),在序列內引入缺口後,經比較之兩個序列具有相同長度。舉例而言,當比較可變區序列時,不考慮前導(信號肽)及/或恆定結構域序列。對於兩個序列之間之序列比較,「相應」 CDR係指兩個序列中相同位置中之CDR (例如,每一序列之CDR-H1)。
兩個序列之間之一致性百分比或相似性百分比之測定可使用數學算法來完成。用於比較兩個序列之數學算法之較佳非限制性實例係Karlin及Altschul, 1990, Proc. Natl. Acad. Sci. USA 87:2264-2268之算法,如Karlin及Altschul, 1993, Proc. Natl. Acad. Sci. USA 90:5873-5877中所修飾。該算法納入Altschul等人,1990, J. Mol. Biol. 215:403-410之NBLAST及XBLAST程式中。BLAST核苷酸檢索可用NBLAST程式(評分=100,字長=12)實施,以獲得與編碼所關注蛋白質之核酸同源的核苷酸序列。BLAST蛋白質檢索可用XBLAST程式(評分=50,字長=3)實施,以獲得與所關注蛋白質同源之胺基酸序列。為了獲得用於比較目的之缺口比對,可利用缺口BLAST,如Altschul等人, 1997, Nucleic Acids Res. 25:3389-3402所述。或者,可使用PSI-Blast以實施檢測分子之間之遠端關係之迭代搜索(同上)。當利用BLAST、缺口BLAST及PSI-Blast程式時,可使用各別程式(例如XBLAST及NBLAST)之缺省參數。用於比較序列之數學算法之另一較佳非限制性實例係Myers及Miller,CABIOS (1989)之算法。將該算法納入ALIGN程式(2.0版),該程式係GCG序列比對軟體包之一部分。當利用ALIGN程式比較胺基酸序列時,可使用PAM120權重殘基表、12之空位長度罰分及4之空位罰分。用於序列分析之額外算法為業內已知且包括如Torellis及Robotti, 1994, Comput. Appl. Biosci. 10:3-5中所述之ADVANCE及ADAM;及Pearson及Lipman, 1988, Proc. Natl. Acad. Sci. USA 85:2444-8中所述之FASTA。在FASTA內,ktup係設置搜索之靈敏度及速度之控制選項。若ktup =2,則藉由觀察比對殘基對發現所比較之兩個序列中之相似區;若ktup =1,則檢查單一比對胺基酸。ktup對於蛋白質序列可設定為2或1,或對於DNA序列可設定為1至6。若ktup未指定,則缺省值對於蛋白質為2且對於DNA為6。或者,可使用如Higgins等人, 1996, Methods Enzymol. 266:383-402所述之CLUSTAL W算法實施蛋白質序列比對。
如本文所用之術語「共價連接」或「共價結合」意指殘基之間之直接共價鍵、或間接連接/鍵,其中兩個殘基不直接鍵結,而是皆共價鍵結至中間分子或結構域,例如免疫球蛋白之中間結構域或連接體。
本發明之多重專一性結合蛋白 本發明提供多重專一性結合蛋白,其包含至少一個專一性結合至B7H6之抗原結合單元(第一抗原結合單元)及至少一個專一性結合至CD3之抗原結合單元(第二抗原結合單元)。經由同時結合至腫瘤細胞抗原及T細胞上之CD3,結合蛋白永州T細胞活化蛋白,且在本文中亦稱為T細胞銜接器。術語「(多重專一性)結合蛋白」在本文中與術語「(多重專一性)結合分子」可互換使用。本文所用之涉及本發明之多重專一性結合蛋白之其他術語係「本發明之蛋白質」、「本發明之結合蛋白」、「抗原結合蛋白」以及「多重專一性蛋白」。
本發明者驚奇地發現,本發明之多重專一性結合蛋白在T細胞存在下誘導B7H6陽性結腸直腸癌細胞系之強效及選擇性溶解,且在低效應物對靶細胞比率下已經有活性。重要的是,本發明之結合蛋白不溶解B7H6陰性細胞,且在B7H6陽性細胞不存在下不引起T細胞活化、T細胞增殖及細胞介素分泌。值得注意的是,在活體外不抑制經由NKp30之B7H6依賴性NK細胞活化之本發明之蛋白質在溶解B7H6陽性腫瘤細胞中更強效。此活性闡述於例如實例11之活體外分析中。
為了避免疑義,本文所用之B7H6係指UniProt Q68D85之人類B7H6,以及編碼該蛋白之核酸序列。如本文所用之CD3係指人類CD3ε (UniProt P07766)及CD3 γ (UniProt:P09693)複合物(人類CD3εγ複合物)。熟練人員將瞭解,術語B7H6及B7-H6在本文中可互換使用。
在一態樣中,本發明之多重專一性結合蛋白包含專一性結合至B7H6之第一抗原結合單元及專一性結合至CD3之第二抗原結合單元,其中該第一結合單元選自由i)至xxiv)組成之群:
i) 抗原結合單元,其包括包含SEQ ID NO:l (CDR1)、SEQ ID NO:2 (CDR2)及SEQ ID NO:3 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:4 (CDR1)、SEQ ID NO:5 (CDR2)及SEQ ID NO:6 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#1);
ii) 抗原結合單元,其包括包含SEQ ID NO:7 (CDR1)、SEQ ID NO:8 (CDR2)及SEQ ID NO:9 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:10 (CDR1)、SEQ ID NO:11 (CDR2)及SEQ ID NO:12 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#2);
iii) 抗原結合單元,其包括包含SEQ ID NO:13 (CDR1)、SEQ ID NO:14 (CDR2)及SEQ ID NO:15 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:16 (CDR1)、SEQ ID NO:17 (CDR2)及SEQ ID NO:18 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#3);
iv) 抗原結合單元,其包括包含SEQ ID NO:19 (CDR1)、SEQ ID NO:20 (CDR2)及SEQ ID NO:21 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:22 (CDR1)、SEQ ID NO:23 (CDR2)及SEQ ID NO:24 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#4);
v) 抗原結合單元,其包括包含SEQ ID NO:25 (CDR1)、SEQ ID NO:26 (CDR2)及SEQ ID NO:27 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:28 (CDR1)、SEQ ID NO:29 (CDR2)及SEQ ID NO:30 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#5);
vi) 抗原結合單元,其包括包含SEQ ID NO:31 (CDR1)、SEQ ID NO:32 (CDR2)及SEQ ID NO:33 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:34 (CDR1)、SEQ ID NO:35 (CDR2)及SEQ ID NO:36 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#6);
vii) 抗原結合單元,其包括包含SEQ ID NO:37 (CDR1)、SEQ ID NO:38 (CDR2)及SEQ ID NO:39 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:40 (CDR1)、SEQ ID NO:41 (CDR2)及SEQ ID NO:42 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#7);
viii) 抗原結合單元,其包括包含SEQ ID NO:43 (CDR1)、SEQ ID NO:44 (CDR2)及SEQ ID NO:45 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:46 (CDR1)、SEQ ID NO:47 (CDR2)及SEQ ID NO:48 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#8);
ix) 抗原結合單元,其包括包含SEQ ID NO:49 (CDR1)、SEQ ID NO:50 (CDR2)及SEQ ID NO:51 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:52 (CDR1)、SEQ ID NO:53 (CDR2)及SEQ ID NO:54 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#9);
x) 抗原結合單元,其包括包含SEQ ID NO:55 (CDR1)、SEQ ID NO:56 (CDR2)及SEQ ID NO:57 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:58 (CDR1)、SEQ ID NO:59 (CDR2)及SEQ ID NO:60 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#10);
xi) 抗原結合單元,其包括包含SEQ ID NO:61 (CDR1)、SEQ ID NO:62 (CDR2)及SEQ ID NO:63 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:64 (CDR1)、SEQ ID NO:65 (CDR2)及SEQ ID NO:66 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#11);
xii) 抗原結合單元,其包括包含SEQ ID NO:67 (CDR1)、SEQ ID NO:68 (CDR2)及SEQ ID NO:69 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:70 (CDR1)、SEQ ID NO:71 (CDR2)及SEQ ID NO:72 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#12);
xiii) 抗原結合單元,其包括包含SEQ ID NO:73 (CDR1)、SEQ ID NO:74 (CDR2)及SEQ ID NO:75 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:76 (CDR1)、SEQ ID NO:77 (CDR2)及SEQ ID NO:78 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#13);
xiv) 抗原結合單元,其包括包含SEQ ID NO:79 (CDR1)、SEQ ID NO:80 (CDR2)及SEQ ID NO:81 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:82 (CDR1)、SEQ ID NO:83 (CDR2)及SEQ ID NO:84 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#14);
xv) 抗原結合單元,其包括包含SEQ ID NO:85 (CDR1)、SEQ ID NO:86 (CDR2)及SEQ ID NO:87 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:88 (CDR1)、SEQ ID NO:89 (CDR2)及SEQ ID NO:90 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#15);
xvi) 抗原結合單元,其包括包含SEQ ID NO:91 (CDR1)、SEQ ID NO:92 (CDR2)及SEQ ID NO:93 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:94 (CDR1)、SEQ ID NO:95 (CDR2)及SEQ ID NO:96 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#16);
xvii) 抗原結合單元,其包括包含SEQ ID NO:97 (CDR1)、SEQ ID NO:98 (CDR2)及SEQ ID NO:99 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:100 (CDR1)、SEQ ID NO:101 (CDR2)及SEQ ID NO:102 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#17);
xviii) 抗原結合單元,其包括包含SEQ ID NO:103 (CDR1)、SEQ ID NO:104 (CDR2)及SEQ ID NO:105 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:106 (CDR1)、SEQ ID NO:107 (CDR2)及SEQ ID NO:108 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#18);
xix) 抗原結合單元,其包括包含SEQ ID NO:109 (CDR1)、SEQ ID NO:110 (CDR2)及SEQ ID NO:111 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:112 (CDR1)、SEQ ID NO:113 (CDR2)及SEQ ID NO:114 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#19);
xx) 抗原結合單元,其包括包含SEQ ID NO:115 (CDR1)、SEQ ID NO:116 (CDR2)及SEQ ID NO:117 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:118 (CDR1)、SEQ ID NO:119 (CDR2)及SEQ ID NO:120 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#20);
xxi) 抗原結合單元,其包括包含SEQ ID NO:121 (CDR1)、SEQ ID NO:122 (CDR2)及SEQ ID NO:123 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:124 (CDR1)、SEQ ID NO:125 (CDR2)及SEQ ID NO:126 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#21);
xxii) 抗原結合單元,其包括包含SEQ ID NO:127 (CDR1)、SEQ ID NO:128 (CDR2)及SEQ ID NO:129 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:130 (CDR1)、SEQ ID NO:131 (CDR2)及SEQ ID NO:132 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#22);
xxiii) 抗原結合單元,其包括包含SEQ ID NO:133 (CDR1)、SEQ ID NO:134 (CDR2)及SEQ ID NO:135 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:136 (CDR1)、SEQ ID NO:137 (CDR2)及SEQ ID NO:138 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#23);及
xxiv) 抗原結合單元,其包括包含SEQ ID NO:139 (CDR1)、SEQ ID NO:140 (CDR2)及SEQ ID NO:141 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:142 (CDR1)、SEQ ID NO:143 (CDR2)及SEQ ID NO:144 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元B7H6#24)。
在本發明之結合蛋白之一些實施例中,該專一性結合至CD3之第二抗原結合單元選自由i)-vi)組成之群:
i) 抗原結合單元,其包括包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元CD3#1);
ii) 抗原結合單元,其包括包含SEQ ID NO:263 (CDR1)、SEQ ID NO:264 (CDR2)及SEQ ID NO:265 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:266 (CDR1)、SEQ ID NO:267 (CDR2)及SEQ ID NO:268 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元CD3#2);
iii) 抗原結合單元,其包括包含SEQ ID NO:269 (CDR1)、SEQ ID NO:270 (CDR2)及SEQ ID NO:271 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:272 (CDR1)、SEQ ID NO:273 (CDR2)及SEQ ID NO:274 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元CD3#3);
iv) 抗原結合單元,其包括包含SEQ ID NO:275 (CDR1)、SEQ ID NO:276 (CDR2)及SEQ ID NO:277 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:278 (CDR1)、SEQ ID NO:279 (CDR2)及SEQ ID NO:280 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元CD3#4);
v) 抗原結合單元,其包括包含SEQ ID NO:281 (CDR1)、SEQ ID NO:282 (CDR2)及SEQ ID NO:283 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:284 (CDR1)、SEQ ID NO:285 (CDR2)及SEQ ID NO:286 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元CD3#5);及
vi) 抗原結合單元,其包括包含SEQ ID NO:287 (CDR1)、SEQ ID NO:288 (CDR2)及SEQ ID NO:289 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:290 (CDR1)、SEQ ID NO:291 (CDR2)及SEQ ID NO:292 (CDR3)之胺基酸序列之重鏈CDR (抗原結合單元CD3#6)。
如上文概述之第一抗原結合單元i)至xxiv)分別稱為B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24,且如上文概述之第二抗原結合單元i)至vi)分別稱為CD3#1、CD3#2、CD3#3、CD3#4、CD3#5及CD3#6。本文提供序列表,其容易地允許鑑別針對本發明之專一性抗原結合單元及全長結合蛋白的個別胺基酸序列。概述提供於實例2中之表1中。
如本文所用,通常關於抗原結合單元之術語「第一」及「第二」僅意欲指示,該等單元係兩個不同單元(由於其結合至不同靶抗原)。因此,該等術語不應理解為指本發明之結合蛋白內之單元之精確次序或順序。
在一些實施例中,本發明之結合蛋白包含選自由以下組成之群之第一抗原結合單元:如由表1中所示之各別CDR序列定義之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24;及選自由以下組成之群之第二抗原結合單元:如由表1中所示之各別CDR序列定義之CD3#1、CD3#2、CD3#3、CD3#4、CD3#5及CD3#6。
在一些實施例中,本發明之結合蛋白包含選自由以下組成之群之第一抗原結合單元:如由表1中所示之各別CDR序列定義之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24;及如由表1中所示之各別CDR序列定義之CD3#1之第二抗原結合單元。在較佳實施例中,本發明之結合蛋白包含選自由以下組成之群之第一抗原結合單元:如由表1中所示之各別CDR序列定義之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24;及如由表1中所示之各別CDR序列定義之CD3#1之第二抗原結合單元。在較佳實施例中,本發明之結合蛋白包含選自由以下組成之群之第一抗原結合單元:如由表1中所示之各別CDR序列定義之B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24;及如由表1中所示之各別CDR序列定義之CD3#1之第二抗原結合單元。在較佳實施例中,本發明之結合蛋白包含選自由以下組成之群之第一抗原結合單元:如由表1中所示之各別CDR序列定義之B7H6#12、B7H6#14、B7H6#15、B7H6#16及B7H6#23;及如由表1中所示之各別CDR序列定義之CD3#1之第二抗原結合單元。
除了如本文所述之CDR序列之外,本發明之結合蛋白之抗原結合單元亦包括免疫球蛋白框架區(FR)序列。該等序列較佳在人類中不具有免疫原性,且因此較佳係人類、人類化或最佳化FR序列。適宜人類、人類化或最佳化FR序列為業內已知。特別較佳之FR序列可取自本文所示之實施例,其揭示完整抗原結合單元,且藉此揭示CDR序列以及FR序列。在一個較佳實施例中,本發明之結合蛋白包含專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:67 (CDR1)、SEQ ID NO:68 (CDR2)及SEQ ID NO:69 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:70 (CDR1)、SEQ ID NO:71 (CDR2)及SEQ ID NO:72 (CDR3)之胺基酸序列之重鏈CDR;及專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR。該抗原結合蛋白在本文中稱作B7H6#14/CD3#1。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元各自包含VL/VH結構域、例如序列最佳化VL/VH結構域內之如上文所定義之CDR (B7H6#12/CD3#1)。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#12/CD3#1)各自由scFab形成且視情況各自連接至Fc結構域。
在一個較佳實施例中,本發明之結合蛋白包含專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:79 (CDR1)、SEQ ID NO:80 (CDR2)及SEQ ID NO:81 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:82 (CDR1)、SEQ ID NO:83 (CDR2)及SEQ ID NO:84 (CDR3)之胺基酸序列之重鏈CDR;及專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR。該抗原結合蛋白在本文中稱作B7H6#14/CD3#1。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元各自包含VL/VH結構域、例如序列最佳化VL/VH結構域內如上文所定義之CDR (B7H6#14/CD#1)。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#14/CD3#1)各自由scFab形成且視情況各自連接至Fc結構域。
在一個較佳實施例中,本發明之結合蛋白包含專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:85 (CDR1)、SEQ ID NO:86 (CDR2)及SEQ ID NO:87 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:88 (CDR1)、SEQ ID NO:89 (CDR2)及SEQ ID NO:90 (CDR3)之胺基酸序列之重鏈CDR;及專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR。該抗原結合蛋白在本文中稱作B7H6#15/CD3#1。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元各自包含VL/VH結構域、例如序列最佳化VL/VH結構域內之如上文所定義之CDR (B7H6#15/CD3#1)。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#15/CD3#1)各自由scFab形成且視情況各自連接至Fc結構域。
在一個較佳實施例中,本發明之結合蛋白包含專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:91 (CDR1)、SEQ ID NO:92 (CDR2)及SEQ ID NO:93 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:94 (CDR1)、SEQ ID NO:95 (CDR2)及SEQ ID NO:96 (CDR3)之胺基酸序列之重鏈CDR;及專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR。該抗原結合蛋白在本文中稱作B7H6#16/CD3#1。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元各自包含VL/VH結構域、例如序列最佳化VL/VH結構域內之如上文所定義之CDR (B7H6#16/CD3#1)。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#16/CD3#1)各自由scFab形成且視情況各自連接至Fc結構域。
在一個較佳實施例中,本發明之結合蛋白包含專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:133 (CDR1)、SEQ ID NO:134 (CDR2)及SEQ ID NO:135 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:136 (CDR1)、SEQ ID NO:137 (CDR2)及SEQ ID NO:138 (CDR3)之胺基酸序列之重鏈CDR;及專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR。該抗原結合蛋白在本文中稱作B7H6#14/CD3#1。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元各自包含VL/VH結構域、例如序列最佳化VL/VH結構域內之如上文所定義之CDR (B7H6#23/CD3#1)。在尤佳實施例中,分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#23/CD3#1)各自由scFab形成且視情況各自連接至Fc結構域。
在本發明之結合蛋白之較佳實施例中,第一及第二結合單元各自包含輕鏈可變結構域及重鏈可變結構域,對於第一抗原結合單元,該等輕/重鏈可變結構域由B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23或B7H6#24中之任一者之CDR序列定義,且對於第二抗原結合單元,該等輕/重鏈可變結構域由CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者之CDR序列定義。在本發明之結合蛋白之一些實施例中,B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23、B7H6#24、CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者之抗原結合單元之VH及/或VL結構域係人類、人類化或最佳化VH及/或VL結構域。
在本發明之結合蛋白之較佳實施例中,專一性結合至B7H6之第一抗原結合單元之輕/重鏈可變結構域如下進一步定義
i) 包含SEQ ID NO:145之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:146之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#1);或
ii) 包含SEQ ID NO:147之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:148之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#2);或
iii) 包含SEQ ID NO:149之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:150之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#3);或
iv) 包含SEQ ID NO:151之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:152之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#4);或
v) 包含SEQ ID NO:153之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:154之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#5);或
vi) 包含SEQ ID NO:155之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:156之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#6);或
vii) 包含SEQ ID NO:157之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:158之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#7);或
viii) 包含SEQ ID NO:159之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:160之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#8);或
ix) 包含SEQ ID NO:161之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:162之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#9);或
x) 包含SEQ ID NO:163之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:164之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#10);或
xi) 包含SEQ ID NO:165之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:166之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#11);或
xii) 包含SEQ ID NO:167之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:168之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#12);或
xiii) 包含SEQ ID NO:169之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:170之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#13);或
xiv) 包含SEQ ID NO:171之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:172之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#14);或
xv) 包含SEQ ID NO:173之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:174之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#15);或
xvi) 包含SEQ ID NO:175之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:176之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#16);或
xvii) 包含SEQ ID NO:177之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:178之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#17);或
xviii) 包含SEQ ID NO:179之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:180之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#18);或
xix) 包含SEQ ID NO:181之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:182之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#19);或
xx) 包含SEQ ID NO:183之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:184之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#20);或
xxi) 包含SEQ ID NO:185之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:186之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#21);或
xxii) 包含SEQ ID NO:187之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:188之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#22);或
xxiii) 包含SEQ ID NO:189之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:190之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#23);或
xxiv) 包含SEQ ID NO:191之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:192之胺基酸序列之重鏈可變結構域(抗原結合單元B7H6#24)。
在本發明之結合蛋白之較佳實施例中,專一性結合至CD3之第二抗原結合單元之輕/重鏈可變結構域如下進一步定義
i) 包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域(抗原結合單元CD3#1);或
ii) 包含SEQ ID NO:295之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:296之胺基酸序列之重鏈可變結構域(抗原結合單元CD3#2);或
iii) 包含SEQ ID NO:297之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:298之胺基酸序列之重鏈可變結構域(抗原結合單元CD3#3);或
iv) 包含SEQ ID NO:299之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:300之胺基酸序列之重鏈可變結構域(抗原結合單元CD3#4);或
v) 包含SEQ ID NO:301之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:302之胺基酸序列之重鏈可變結構域(抗原結合單元CD3#5);或
vi) 包含SEQ ID NO:303之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:304之胺基酸序列之重鏈可變結構域(抗原結合單元CD3#6)。
在較佳實施例中,本發明之結合蛋白包含選自由以下組成之群之第一及第二抗原結合單元之組合:B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#6/CD3#1、B7H6#7/CD3#1、B7H6#8/CD3#1、B7H6#9/CD3#1、B7H6#10/CD3#1、B7H6#11/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1及B7H6#24/CD3#1,該等第一及第二抗原結合單元係藉由如表1中所示之抗原結合單元之CDR及/或VH及VL序列定義。
在較佳實施例中,本發明之結合蛋白包含選自由以下組成之群之第一及第二抗原結合單元之組合:B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1及B7H6#24/CD3#1,該等第一及第二抗原結合單元係藉由如表1中所示之抗原結合單元之CDR及/或VH及VL序列定義。
在較佳實施例中,本發明之結合蛋白包含選自由以下組成之群之第一及第二抗原結合單元之組合:B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1及B7H6#24/CD3#1,該等第一及第二抗原結合單元係藉由如表1中所示之抗原結合單元之CDR及/或VH及VL序列定義。
在較佳實施例中,本發明之結合蛋白包含選自由以下組成之群之第一及第二抗原結合單元之組合:B7H6#12/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1及B7H6#23/CD3#1,該等第一及第二抗原結合單元係藉由如表1中所示之抗原結合單元之CDR及/或VH及VL序列定義。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:167之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:168之胺基酸序列之重鏈可變結構域,及(ii) 專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域。該結合蛋白在本文中稱作B7H6#12/CD3#1。在尤佳實施例中,如上文所定義之分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#12/CD3#1)各自由scFab形成,該scFab視情況共價連接至Fc結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:171之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:172之胺基酸序列之重鏈可變結構域,及(ii) 專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域。該結合蛋白在本文中稱作B7H6#14/CD3#1。在尤佳實施例中,如上文所定義之分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#14/CD3#1)各自由scFab形成,該scFab視情況共價連接至Fc結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:173之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:174之胺基酸序列之重鏈可變結構域,及(ii) 專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域。該結合蛋白在本文中稱作B7H6#15/CD3#1。在尤佳實施例中,如上文所定義之分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#15/CD3#1)各自由scFab形成,該scFab視情況共價連接至Fc結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:175之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:176之胺基酸序列之重鏈可變結構域,及(ii) 專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域。該結合蛋白在本文中稱作B7H6#16/CD3#1。在尤佳實施例中,如上文所定義之分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#16/CD3#1)各自由scFab形成,該scFab視情況共價連接至Fc結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一抗原結合單元,其包括包含SEQ ID NO:189之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:190之胺基酸序列之重鏈可變結構域,及(ii) 專一性結合至CD3之第二抗原結合單元,其包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域。該結合蛋白在本文中稱作B7H6#23/CD3#1。在尤佳實施例中,如上文所定義之分別專一性結合至B7H6及CD3之抗原結合單元(B7H6#23/CD3#1)各自由scFab形成,該scFab視情況共價連接至Fc結構域。
在一些實施例中,本發明之結合蛋白包含i) 專一性結合至B7H6之第一抗原結合單元(例如,如藉由表1中所示之各別CDR或VH/VL序列定義之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18 B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23、B7H6#24中之任一者),其包含利用第一肽連接體共價連接至第一重鏈可變結構域之第一輕鏈可變結構域,及/或ii) 專一性結合至CD3之第二抗原結合單元(例如,如藉由表1中所示之各別CDR或VH/VL序列定義之CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者),其包含利用第二肽連接體共價連接至第二重鏈可變結構域之第二輕鏈可變結構域。視情況,第一及第二抗原結合單元利用肽連接體彼此共價連接。
在本發明之結合蛋白之一些實施例中,第一及/或第二抗原結合單元進一步如在習用抗體分子之輕/重Fab片段中一樣包含CL及CH1結構域,因此該第一結合單元包含a) 共價連接(較佳直接結合)至第一CL結構域之VL結構域(例如,由B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23或B7H6#24中之任一者之輕鏈CDR (LCCDR)或VL序列所定義),及b) 共價連接(較佳直接結合)至第一CH1結構域之VH結構域(例如,由B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6 B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23或B7H6#24中之任一者之重鏈CDR (HCCDR)或VH序列所定義),及/或該第二抗原結合單元包含a) 共價連接(較佳直接結合)至第二CL結構域之VL結構域(例如,由CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者之LCCDR或VL序列所定義),及b) 共價連接(較佳直接結合)至第二CH1結構域之VH結構域(例如,由CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者之HCCDR或VH序列所定義)。
在本發明之上下文中,CL結構域係抗體輕鏈、例如卡帕(kappa,κ)或蘭姆達(lambda,λ)輕鏈之恆定結構域。κ輕鏈之恆定區之實例示於SEQ ID NO:247中。λ輕鏈之恆定區之實例示於SEQ ID NO:248中。在一些實施例中,第一及第二CL結構域相同,例如,第一及第二CL結構域二者皆係κ輕鏈恆定結構域,或第一及第二CL結構域二者皆係λ輕鏈恆定結構域。在較佳實施例中,第一及第二CL結構域不同,例如,第一CL結構域係恆定κ結構域且第二CL結構域係恆定λ結構域,或反之亦然。
在本發明之上下文中,CH1結構域係抗體重鏈之第一恆定結構域。恆定CH1結構域之實例示於SEQ ID NO:249中。
在本發明之結合蛋白之較佳實施例中中,對B7H6具有專一性之第一抗原結合單元(例如由表1中所示之CDR及/或VH/VL序列定義之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23或B7H6#24中之任一者)自N-末端至C-末端包含:第一輕鏈可變結構域、第一CL結構域、第一連接體肽、第一VH結構域及第一CH1結構域,及/或本發明之結合蛋白之第二結合單元(例如由表1中所示之CDR及/或VH/VL序列定義之CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6)自N-末端至C-末端包含:第二輕鏈可變結構域、第二CL結構域、第二連接體肽、第二VH結構域及第二CH1結構域。在該等實施例中,第一及/或第二結合單元具有單鏈Fab之結構。對於第一及/或第二抗原結合單元二者,當形成單鏈Fab時,次序可逆轉,使得抗原結合單元自N-末端至C-末端包含:VH-CH1-[連接體肽]-VL-CL。在本發明之蛋白質之一些實施例中,當第一及/或第二抗原結合單元包含Fab或單鏈Fab時,恆定結構域可為相同類型(例如兩個CL結構域皆為κ或λ輕鏈恆定結構域)或為不同類型(第一CL結構域係κ且第二CL結構域係λ輕鏈恆定結構域,或反之亦然),較佳地,第一及第二CL結構域為不同類型。在較佳實施例中,第一抗原結合單元由對B7H6具有專一性之第一單鏈Fab (較佳如由表1中所示之CDR及或VH/VL序列定義之B7H6#12、B7H6#14、B7H6#15、B7H6#16或B7H6#23中之任一者)組成,且第二抗原結合單元由對CD3具有專一性之第二單鏈Fab (例如如由表1中所示之CDR及或VH/VL序列定義之CD3#1)組成。
B7H6/CD3結合蛋白之連接體序列(例如上述B7H6/CD3 scFab)可為天然序列或非天然序列。若用於治療目的,連接體較佳在本發明之結合蛋白所投與給之個體中不具有免疫原性。較佳地,連接體包含26至42個胺基酸、例如30至40個胺基酸。在另一態樣中,本發明之蛋白質中所用之連接體包含34至40個胺基酸、例如36至39個胺基酸、例如38個胺基酸。
連接體序列之一個有用基團係源自如WO1996/34103及WO1994/04678中所述之重鏈抗體之鉸鏈區的連接體。其他實例係聚-丙胺酸連接體序列,例如Ala-Ala-Ala。
連接體序列之其他較佳實例係不同長度之Gly/Ser連接體,例如(glyxsery)z連接體,包括(例如) (gly4ser)3、(gly4ser)5、(gly4ser)7、(gly3ser)3、(gly3ser)5、(gly3ser)7、(gly3ser2)3、(gly3ser2)5及(gly3ser2)7;或SEQ ID NO: 250、251、252、253、254、255或256中之任一者、較佳SEQ ID NO: 250之連接體。
在本發明之結合蛋白之一些實施例中,第一抗原結合單元之VL結構域(例如由表1中所示之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23、B7H6#24中之任一者之輕鏈CDR (LCCDR)或VL序列所定義)經由第一Gly/Ser連接體(例如26至42個胺基酸、30至40個胺基酸、34至40個胺基酸、或36至39個胺基酸、較佳38個胺基酸中之任一者之Gly/Ser連接體)共價連接至第一抗原結合單元之VH結構域(例如由表1中所示之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18 B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23、B7H6#24中之任一者之重鏈CDR (HCCDR)或VH序列所定義);且第二抗原結合單元之VL結構域(例如由如表1中所示之CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者之輕鏈CDR (LCCDR)或VL序列所定義)經由第二Gly/Ser連接體(例如26至42個胺基酸、30至40個胺基酸、34至40個胺基酸、或36至39個胺基酸、較佳38個胺基酸中之任一者之Gly/Ser連接體)共價連接至第二抗原結合單元之VH結構域(例如由如表1中所示之CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者之重鏈CDR (HCCDR)或VH序列所定義)。更佳地,第一及第二連接體相同。甚至更佳地,第一及第二連接體各自包含SEQ ID NO:250之胺基酸序列。
在本發明之結合蛋白之較佳實施例中,專一性結合至B7H6之第一抗原結合單元自N-末端至C-末端包含i) VL結構域(例如由如表1中所示之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23、B7H6#24中之任一者之輕鏈CDR (LCCDR)或VL序列所定義),ii) 第一CL結構域,iii) 經由第一Gly/Ser連接體(例如26至42個胺基酸、30至40個胺基酸、34至40個胺基酸、或36至39個胺基酸、較佳38個胺基酸中之任一者之Gly/Ser連接體),iv) VH結構域(例如由如表1中所示之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23、B7H6#24中之任一者之重鏈CDR (HCCDR)或VH序列所定義),及v) 第一CH1結構域,及/或專一性結合至CD3之第二抗原結合單元自N末端至C末端包含i) VL結構域(例如由如表1中所示之CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者之輕鏈CDR (LCCDR)或VL序列所定義),ii) 第二CL結構域,iii) 第二Gly/Ser連接體(例如26至42個胺基酸、30至40個胺基酸、34至40個胺基酸、或36至39個胺基酸、較佳38個胺基酸中之任一者之Gly/Ser連接體),iv) 第二抗原結合單元之VH結構域(例如由如表1中所示之CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者之重鏈CDR (HCCDR)或VH序列所定義)及v) 第二CH1結構域。較佳地,i)至v)經由直接共價鍵自抗原結合單元之N末端至C末端以次序i)至v)各自連接(每一抗原結合單元因此具有scFab之結構)。更佳地,第一及第二連接體相同。甚至更佳地,第一及第二連接體各自包含SEQ ID NO:250之胺基酸序列。
在較佳實施例中,本發明之結合蛋白包含第一單鏈Fab,其形成對B7H6具有專一性之第一抗原結合單元且包含選自由SEQ ID NO:193、SEQ ID NO:194、SEQ ID NO:195、SEQ ID NO:196、SEQ ID NO:197、SEQ ID NO:198 SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201、SEQ ID NO:202、SEQ ID NO:203、SEQ ID NO:204、SEQ ID NO:205、SEQ ID NO:206、SEQ ID NO:207、SEQ ID NO:208、SEQ ID NO:209、SEQ ID NO:210、SEQ ID NO:211、SEQ ID NO:212、SEQ ID NO:213、SEQ ID NO:214、SEQ ID NO:215及SEQ ID NO:216組成之群之序列;及第二單鏈Fab,其形成對CD3具有專一性之第二抗原結合單元且包含SEQ ID NO:305之序列。
在較佳實施例中,本發明之結合蛋白包含第一單鏈Fab,其形成對B7H6具有專一性之第一抗原結合單元且包含選自由SEQ ID NO:193、SEQ ID NO:194、SEQ ID NO:195、SEQ ID NO:196、SEQ ID NO:197、SEQ ID NO:204、SEQ ID NO:205、SEQ ID NO:206、SEQ ID NO:207、SEQ ID NO:208、SEQ ID NO:209、SEQ ID NO:210、SEQ ID NO:211、SEQ ID NO:212、SEQ ID NO:213、SEQ ID NO:214、SEQ ID NO:215及SEQ ID NO:216組成之群之序列;及第二單鏈Fab,其形成對CD3具有專一性之第二抗原結合單元且包含SEQ ID NO:305之序列。
在較佳實施例中,本發明之結合蛋白包含第一單鏈Fab,其形成對B7H6具有專一性之第一抗原結合單元且包含選自由SEQ ID NO:204、SEQ ID NO:205、SEQ ID NO:206、SEQ ID NO:207、SEQ ID NO:208、SEQ ID NO:209、SEQ ID NO:210、SEQ ID NO:211、SEQ ID NO:212、SEQ ID NO:213、SEQ ID NO:214、SEQ ID NO:215及SEQ ID NO:216組成之群之序列;及第二單鏈Fab,其形成對CD3具有專一性之第二抗原結合單元且包含SEQ ID NO:305之序列。
在一個較佳實施例中,本發明之結合蛋白包括包含SEQ ID NO:204之序列之第一單鏈Fab及包含SEQ ID NO:305之序列之第二單鏈Fab,視情況每一單鏈Fab進一步連接至Fc結構域且藉此形成第一多肽鏈(「B7H6鏈」)及第二多肽鏈(「CD3鏈」)。在一個較佳實施例中,本發明之結合蛋白包括包含SEQ ID NO:206之序列之第一單鏈Fab及包含SEQ ID NO:305之序列之第二單鏈Fab,視情況每一單鏈Fab進一步連接至Fc結構域且藉此形成第一多肽鏈(B7H6鏈)及第二多肽鏈(CD3鏈)。在一個較佳實施例中,本發明之結合蛋白包括包含SEQ ID NO:207之序列之第一單鏈Fab及包含SEQ ID NO:305之序列之第二單鏈Fab,視情況每一單鏈Fab進一步連接至Fc結構域且藉此形成第一多肽鏈(B7H6鏈)及第二多肽鏈(CD3鏈)。在一個較佳實施例中,本發明之結合蛋白包括包含SEQ ID NO:208之序列之第一單鏈Fab及包含SEQ ID NO:305之序列之第二單鏈Fab,視情況每一單鏈Fab進一步連接至Fc結構域且藉此形成第一多肽鏈(B7H6鏈)及第二多肽鏈(CD3鏈)。在一個較佳實施例中,本發明之結合蛋白包括包含SEQ ID NO:215之序列之第一單鏈Fab及包含SEQ ID NO:305之序列之第二單鏈Fab,視情況每一單鏈Fab進一步連接至Fc結構域且藉此形成第一多肽鏈(B7H6鏈)及第二多肽鏈(CD3鏈)。
在一些實施例中,第一抗原結合單元(例如,如藉由表1中所示之CDR及/或VH/VL序列定義之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18 B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23或B7H6#24中之任一者)及/或第二抗原結合單元(例如,如藉由表1中所示之CDR及/或VH/VL序列定義之CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者)包含共價連接(較佳直接結合)至CL結構域之VL結構域及連接至CH1結構域之VH結構域(一起形成Fab片段),且該CH1結構域進一步共價連接(例如直接結合)至Fc結構域,藉此形成具有一條輕鏈及一條重鏈之習用Y形抗體分子之臂。在一些實施例中,第一及第二抗原結合單元各自形成Fab片段,即第一及第二Fab片段,其各自分別共價連接(較佳直接結合)至第一及第二Fc結構域,藉此形成習用異四聚體雙專一性且二價(分別對於B7H6及CD3為單價)之抗體分子。
在較佳實施例中,本發明之結合蛋白包含(i) 第一抗原結合單元,其包含專一性結合至B7H6之第一單鏈Fab,即經由肽連接體(例如26至42個胺基酸、30至40個胺基酸、34至40個胺基酸或36至39個胺基酸、較佳38個胺基酸中之任一者之Gly/Ser連接體,甚至更佳SEQ ID NO:250之連接體)共價連接至重鏈之VH-CH1結構域(如藉由表1中所示之CDR及/或VH/VL序列定義之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18 B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23或B7H6#24中之任一者之VL及VH結構域)的抗體輕鏈(VL-CL),該第一抗原結合單元共價連接(例如直接結合)至第一Fc結構域,及(ii) 第二抗原結合單元,其包含專一性結合至CD3之第二單鏈Fab,即共價連接至重鏈之VH-CH1結構域(如由表1中所示之各別CDR或VH/VL序列定義之CD3#1、CD3#2、CD3#3、CD3#4、CD3#5、CD3#6中之任一者之VL及VH結構域)的抗體輕鏈(VL-CL),該第二抗原結合單元共價連接(例如直接結合)至第二Fc結構域。因此,在較佳實施例中,本發明之結合蛋白包含(i) 第一多肽鏈,其包含(a) 對B7H6具有專一性之第一抗原結合單元,該第一抗原結合單元包含對B7H6具有專一性之第一單鏈Fab (較佳如由如表1中所示之CDR及或VH/VL序列定義之B7H6#12、B7H6#14、B7H6#15,B7H6#16或B7H6#23中之任一者),及(b) 第一Fc結構域(此第一多肽鏈在本文中亦稱作「B7H6鏈」),及(ii) 對CD3具有專一性之第二多肽鏈,其包含(a) 包含對CD3具有專一性之第二單鏈Fab的第二抗原結合單元(較佳如藉由表1中所示之CDR及/或VL/VH序列定義之CD3#1),及(b) 第二Fc結構域(此第二多肽鏈在本文中亦稱作「CD3鏈」)。因此,如本文所用術語「多肽鏈」包含至少scFab及Fc結構域。在一些實施例中,第一及第二Fc結構域相同。在較佳實施例中,第一及第二Fc結構域不同。本發明之所得結合蛋白包含兩條不同多肽鏈,其帶有完全Fc且具有兩個獨立結合位點,即由對B7H6具有專一性之第一scFab形成之第一抗原結合單元及由對CD3具有專一性之第二scFab形成之第二結合單元。
在較佳實施例中,本發明之結合蛋白包含兩條不同多肽鏈,其各自包含由scFab形成之抗原結合單元,該兩條不同多肽鏈具有不同專一性,各自共價連接至Fc結構域,多肽鏈經由二硫鍵或潛在地經由肽連接體彼此共價連接。在較佳實施例中,本發明之結合蛋白係雙專一性、二價(分別對於B7H6及CD3為單價)異二聚體蛋白質,其包含兩條多肽鏈,一條多肽鏈(第一多肽鏈或B7H6鏈)包含由專一性結合至B7H6之scFab形成的抗原結合單元(例如如藉由表1中所示之CDR及/或VH/VL序列定義之B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23或B7H6#24中之任一者)及Fc結構域(較佳SEQ ID NO:242之Fc結構域),且另一多肽鏈(第二多肽鏈或CD3鏈)包含由專一性結合至CD3之scFab形成的抗原結合單元(例如CD3#1、CD3#2、CD3#3、CD3#4、CD3#5或CD3#6中之任一者)及Fc結構域(較佳SEQ ID NO:243之Fc結構域)。在一些實施例中,第一抗原結合單元由第一單鏈Fab組成且第二抗原結合單元由第二單鏈Fab組成。在結合蛋白之一些實施例中,對B7H6具有專一性之第一多肽鏈(B7H6鏈)由以下各項組成:a) 由scFab組成之第一抗原結合單元(較佳如由表1中所示之CDR、VH/VL及/或scFab序列定義之B7H6#12、B7H6#14、B7H6#15、B7H6#16或B7H6#23中之任一者)及b) 第一Fc結構域,且對CD3具有專一性之第二多肽鏈(CD3鏈)由以下各項組成:a) 由scFab組成之第二抗原結合單元(較佳如由表1中所示之CDR、VH/VL及/或scFab序列定義之CD3#1)及b) 第二Fc結構域。較佳地,scFab之C-末端經由直接共價鍵連接至Fc結構域之N-末端。較佳地,第一及第二多肽鏈經由二硫鍵彼此共價連接,且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在本發明之上下文中,Fc結構域係例如源自IgG之重鏈,例如IgG1
、IgG2
或IgG4
。舉例而言,本發明之Fc結構域係IgG1
或IgG4
之重鏈之Fc結構域且包含鉸鏈區及兩個恆定結構域(CH2
及CH3
)。Fc結構域(包括鉸鏈區)之實例示於SEQ ID NO:241及244中。
除非另外規定,否則本發明之蛋白質之胺基酸鏈中之胺基酸的編號在本文中係根據Eu編號系統(Edelman等人,PNAS USA 1969年5月, 63(1):78-85;Cunningham等人 PNAS USA 1969年11月, 64(3):997-1003)。此意味著除非另外規定,否則根據Eu編號系統,本文中指示之胺基酸數目對應於相應亞型(例如IgG1
或IgG4
)之重鏈中之位置。
在一些實施例中,本發明之蛋白質中之第一Fc結構域及第二Fc結構域各自包含一或多個胺基酸變化,其減少第一或第二多肽鏈之同二聚體而非第一及第二多肽鏈之異二聚體之形成。經由該等變化,藉由用較大側鏈(例如酪胺酸或色胺酸)置換一條重鏈界面上之一或多條小胺基酸側鏈,在Fc結構域之一中產生「突出」。藉由用較小之胺基酸側鏈(例如丙胺酸或蘇胺酸)置換大胺基酸側鏈,在另一Fc結構域之界面上產生相同或相似大小之補償性「腔」。此提供增加異二聚體之產率、超過其他不需要之終產物(例如同二聚體,具體而言具有「突出」之Fc結構域之同二聚體)之機制(例如,參見Ridgway等人 Protein Eng, 1996.9
(7): p. 617-21;Atwell等人,JMB, 1997, 270, 26-35)。在一些實施例中,該等胺基酸變化係第一Fc結構域之位置366之酪胺酸(Y) [T366Y]及第二Fc結構域之位置407之蘇胺酸(T) [Y407T]。在一些實施例中,第一Fc結構域包含位置366之絲胺酸(S) [T366S]且第二Fc結構域包含位置366之色胺酸(W) [T366W]、位置368之丙胺酸(A) [L368A]及位置407之纈胺酸(V) [Y407V]。在較佳實施例中,第一Fc結構域包含位置366之色胺酸(W) [T366W],且第二Fc結構域包含位置366之絲胺酸(S) [T366S]、位置368之丙胺酸(A) [L368A]及位置407之纈胺酸(V) [Y407V]。舉例而言,根據Eu編號對應於SEQ ID NO:241之人類IgG1 Fc序列中之胺基酸位置146的Fc結構域之位置366自SEQ ID NO:241中位置146之T變為SEQ ID NO:242中位置146之W;且根據Eu編號分別對應於SEQ ID NO:241中胺基酸位置146、148及187的位置366、368及407自SEQ ID NO:241中該等位置之T、L及Y變為SEQ ID NO:243中該等位置之S、A及V。在該等實施例中之任一者中,針對第一Fc結構域所述之胺基酸變化可位於第二Fc結構域中且第二Fc結構域之各別胺基酸變化可位於第一Fc結構域中。換言之,術語「第一」及「第二」在該等實施例中可互換。在一些實施例中,該Fc結構域係源自IgG1
或IgG4
之重鏈之Fc結構域。
在一些實施例中,除了位置366之色胺酸(W) [T366W]之外,第一Fc結構域亦包含位置354之半胱胺酸(C) [S354C],且除了位置366之絲胺酸(S) [T366S]、位置368之丙胺酸(A) [L368A]及位置407之纈胺酸(V) [Y407V]之外,第二Fc結構域亦包含位置349之半胱胺酸(C) [Y349C]。在一態樣中,該Fc結構域係源自IgG4
之重鏈之Fc結構域。
在一些實施例中,本發明之結合蛋白中之第一Fc結構域或第二Fc結構域進一步包含一或多個胺基酸變化,其減少Fc結構域與蛋白質A之結合。在一些實施例中,該等胺基酸變化係Fc結構域之一之位置435之精胺酸[H435R]及位置436之苯丙胺酸[Y436F]。兩種變化皆源自人類IgG3之序列(IgG3不結合至蛋白質A)。該兩個突變位於CH3結構域中且納入Fc結構域之一中以減少與蛋白質A之結合(例如,參見Jendeberg等人J Immunol Methods, 1997.201
(1): 第25-34頁)。該兩個變化有利於在蛋白質純化期間去除包含該等變化之重鏈之同二聚體。
在一些實施例中,在本發明之結合蛋白中,包含位置407之蘇胺酸(T) [Y407T]之Fc結構域進一步包含位置435之精胺酸[H435R]及位置436之苯丙胺酸[Y436F]。在此情形中,另一重鏈包含位置366之酪胺酸(Y) [T366Y],但不包括位置435及436之兩個變化。或者,在一些實施例中,在本發明之蛋白質中,包含位置366之絲胺酸(S) [T366S]、位置368之丙胺酸(A) [L368A]及位置407之纈胺酸(V) [Y407V]之Fc結構域進一步包含位置435之精胺酸[H435R]及位置436之苯丙胺酸[Y436F]。在此情形中,另一Fc結構域包含位置366之色胺酸(W) [T366W],但不包括位置435及436之兩個變化。因此,包含產生如上文所述之「腔」之胺基酸變化的Fc結構域亦包含減少與蛋白質A之結合之胺基酸變化。經由與蛋白質A之結合減少,去除包含此Fc結構域之同二聚體。藉由「突出」之存在減少包含「突出」之另一Fc結構域之同二聚體之產生。
在一些實施例中,本發明蛋白質之Fc結構域可或可不進一步包含YTE突變(M252Y/S254T/T256E, Eu編號(Dall'Acqua等人J. Biol. Chem.2006, 281(33):23514-24)。已顯示該等突變可經由優先增強pH 6.0下對新生FcRn受體之結合親和性來改良Fc結構域之藥物動力學性質。
在一些實施例中,源自IgG1之本發明之第一及/或第二Fc結構域亦包括「KO」突變(L234A, L235A) (Xu等人,Cellular Immunology 2000年2月25日, 200(1):16-26)。在另一態樣中,源自IgG4之本發明之第一及/或第二Fc結構域亦包括Pro鉸鏈突變(S228P) (Angal等人,Molecular Immunology 1993, 30(1):105-108;Labrijn等人,Nature Biotechnology 2009, 27:767-771)。
在本發明之結合蛋白之較佳實施例中,第一Fc結構域包含SEQ ID NO:242之胺基酸序列且第二Fc結構域包含SEQ ID NO:243之胺基酸序列。
在本發明之較佳實施例中,結合蛋白包含i) 包含SEQ ID NO:217之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#1/CD3#1),或ii) 包含SEQ ID NO:218之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#2/CD3#1),或iii) 包含SEQ ID NO:219之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#3/CD3#1),或iv) 包含SEQ ID NO:220之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#4/CD3#1),或v) 包含SEQ ID NO:221之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#5/CD3#1),或vi) 包含SEQ ID NO:222之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#6/CD3#1);或vii) 包含SEQ ID NO:223之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#7/CD3#1);或viii) 包含SEQ ID NO:224之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#8/CD3#1);或ix) 包含SEQ ID NO:225之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#9/CD3#1);或x) 包含SEQ ID NO:226之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6 #10/CD3#1);或xi) 包含SEQ ID NO:227之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#11/CD3#1);或xii) 包含SEQ ID NO:228之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#12/CD3#1);或xiii) 包含SEQ ID NO:229之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#13/CD3#1);或xiv) 包含SEQ ID NO:230之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#14/CD3#1);或xv) 包含SEQ ID NO:231之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#15/CD3 #1),或xvi) 包含SEQ ID NO:232之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#16/CD3#1);或xvii) 包含SEQ ID NO:233之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#17/CD3#1);或xviii) 包含SEQ ID NO:234之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#18/CD3#1);或xix) 包含SEQ ID NO:235之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#19/ CD3#1);或xx) 包含SEQ ID NO:236之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#20/CD3#1);或xxi) 包含SEQ ID NO:237之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#21/CD3#1);或xxii) 包含SEQ ID NO:238之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#22/CD3#1);或xxiii) 包含SEQ ID NO:239之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#23/CD3#1);或xxiv) 包含SEQ ID NO:240之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#24/ CD3#1)。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習知Y形抗體分子之抗體樣結構(圖1)。
在較佳實施例中,第一多肽鏈包含選自由SEQ ID NO: 217、218、219、220、221、228、229、230、231、232、233、234、235、236、237、238、239及240中之任一者組成之群之胺基酸序列,且第二多肽鏈包含SEQ ID NO:311之胺基酸序列。甚至更佳地,第一多肽鏈包含SEQ ID NO: 228、229、230、231、232、233、234、235、236、237、238、239及240中之任一者之胺基酸序列且第二多肽鏈包含SEQ ID NO:311之胺基酸序列,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習知Y形抗體分子之抗體樣結構(圖1)。
在一個較佳實施例中,結合蛋白包括包含SEQ ID NO:228之胺基酸序列之對B7H6具有專一性之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之對CD3具有專一性之第二多肽鏈。
在一個較佳實施例中,結合蛋白包括包含SEQ ID NO:230之胺基酸序列之對B7H6具有專一性之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之對CD3具有專一性之第二多肽鏈。
在一個較佳實施例中,結合蛋白包括包含SEQ ID NO:231之胺基酸序列之對B7H6具有專一性之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之對CD3具有專一性之第二多肽鏈。
在一個較佳實施例中,結合蛋白包括包含SEQ ID NO:232之胺基酸序列之對B7H6具有專一性之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之對CD3具有專一性之第二多肽鏈。
在一個較佳實施例中,結合蛋白包括包含SEQ ID NO:239之胺基酸序列之對B7H6具有專一性之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之對CD3具有專一性之第二多肽鏈。
對於本文所述之所有實施例,應理解,藉由使用術語「包含」,其意欲亦包括其中各別蛋白質、分子、抗原結合單元或多肽鏈「由如指示之胺基酸序列組成」的實施例:
在一個較佳實施例中,結合蛋白包含由SEQ ID NO:228之胺基酸序列組成之對B7H6具有專一性之第一多肽鏈及由SEQ ID NO:311之胺基酸序列組成之對CD3具有專一性之第二多肽鏈。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在一個較佳實施例中,結合蛋白包含由SEQ ID NO:230之胺基酸序列組成之對B7H6具有專一性之第一多肽鏈及由SEQ ID NO:311之胺基酸序列組成之對CD3具有專一性之第二多肽鏈。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在一個較佳實施例中,結合蛋白包含由SEQ ID NO:231之胺基酸序列組成之對B7H6具有專一性之第一多肽鏈及由SEQ ID NO:311之胺基酸序列組成之對CD3具有專一性之第二多肽鏈。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在一個較佳實施例中,結合蛋白包含由SEQ ID NO:232之胺基酸序列組成之對B7H6具有專一性之第一多肽鏈及由SEQ ID NO:311之胺基酸序列組成之對CD3具有專一性之第二多肽鏈。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在一個較佳實施例中,結合蛋白包含由SEQ ID NO:239之胺基酸序列組成之對B7H6具有專一性之第一多肽鏈及由SEQ ID NO:311之胺基酸序列組成之對CD3具有專一性之第二多肽鏈。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在另一態樣中,本發明提供包含專一性結合至B7H6之第一多肽鏈(B7H6鏈)及專一性結合至CD3之第二多肽鏈(CD3鏈)的結合蛋白,其中專一性結合至B7H6之第一多肽鏈包含共價連接(較佳直接結合)至第一連接體之第一輕鏈,該第一連接體自身共價連接(例如直接結合)至第一重鏈,且其中專一性結合至CD3之第二多肽鏈包含共價連接(較佳直接結合)至第二連接體之第二輕鏈,該第二連接體自身共價連接(例如直接結合)至第二重鏈。
除非本文另有定義,否則上文關於具有專一性所述抗原-結合單元之本發明之結合蛋白的本文提供之所有定義及較佳實施例就實際之情形亦適用於包含第一及第二多肽鏈之本發明之此結合蛋白。
在一些實施例中,第一多肽鏈(在本文中亦稱為B7H6鏈)自其N-末端開始包含專一性結合至B7H6之第一輕鏈可變結構域。第一輕鏈恆定結構域、第一連接體、對B7H6具有專一性之第一重鏈可變結構域及第一重鏈恆定區。在一些實施例中,第二多肽鏈(在本文中亦稱為CD3鏈)自其N-末端包含專一性結合至CD3之第二輕鏈可變結構域、第二輕鏈恆定結構域、第二連接體、對CD3具有專一性之第二重鏈可變結構域及第二重鏈恆定結構域。
所得蛋白質帶有完全Fc,其比IgG大(由於在輕鏈與重鏈之間存在連接體)且具有兩個獨立結合位點(例如每一結合位點對於各別抗原為單價),第一結合位點針對B7H6且第二結合位點針對CD3。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接。因此,本發明之蛋白質係抗體樣結構,具有習用全長抗體之Y形結構(參見圖1),包含各自包含scFab及Fc結構域之兩個多肽鏈。在較佳實施例中,本發明之蛋白質包含(i) 由對B7H6具有專一性之第一scFab及第一Fc結構域組成的對B7H6具有專一性之第一多肽鏈(B7H6鏈),及(ii) 由對CD3具有專一性之第二單鏈Fab及第二Fc結構域組成的對CD3具有專一性之第二多肽鏈(CD3鏈)。
較佳地,第一scFab經由直接共價鍵連接至第一Fc結構域且第二scFab經由直接共價鍵連接至第二Fc結構域。此雙專一性格式通常降低表現及純化後之異質性(例如藉由避免具有不同結合專一性之輕及中可變結構域之錯配),同時維持結構內之結合部分不太可能產生不想要之免疫原性反應的功能性質。此亦使得異二聚體蛋白在例如哺乳動物細胞中良好表現。
在本發明之蛋白質之較佳實施例中,專一性結合至B7H6之第一多肽鏈(B7H6鏈)包含第一輕鏈可變結構域及第一重鏈可變結構域,其包含選自由i)至xxiv)組成之群之CDR序列:
i) 包含SEQ ID NO:1 (CDR1)、SEQ ID NO:2 (CDR2)及SEQ ID NO:3 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:4 (CDR1)、SEQ ID NO:5 (CDR2)及SEQ ID NO:6 (CDR3)之胺基酸序列之重鏈CDR;
ii) 包含SEQ ID NO:7 (CDR1)、SEQ ID NO:8 (CDR2)及SEQ ID NO:9 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:10 (CDR1)、SEQ ID NO:11 (CDR2)及SEQ ID NO:12 (CDR3)之胺基酸序列之重鏈CDR;
iii) 包含SEQ ID NO:13 (CDR1)、SEQ ID NO:14 (CDR2)及SEQ ID NO:15 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:16 (CDR1)、SEQ ID NO:17 (CDR2)及SEQ ID NO:18 (CDR3)之胺基酸序列之重鏈CDR;
iv) 包含SEQ ID NO:19 (CDR1)、SEQ ID NO:20 (CDR2)及SEQ ID NO:21 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:22 (CDR1)、SEQ ID NO:23 (CDR2)及SEQ ID NO:24 (CDR3)之胺基酸序列之重鏈CDR;
v) 包含SEQ ID NO:25 (CDR1)、SEQ ID NO:26 (CDR2)及SEQ ID NO:27 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:28 (CDR1)、SEQ ID NO:29 (CDR2)及SEQ ID NO:30 (CDR3)之胺基酸序列之重鏈CDR;
vi) 包含SEQ ID NO:31 (CDR1)、SEQ ID NO:32 (CDR2)及SEQ ID NO:33 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:34 (CDR1)、SEQ ID NO:35 (CDR2)及SEQ ID NO:36 (CDR3)之胺基酸序列之重鏈CDR;
vii) 包含SEQ ID NO:37 (CDR1)、SEQ ID NO:38 (CDR2)及SEQ ID NO:39 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:40 (CDR1)、SEQ ID NO:41 (CDR2)及SEQ ID NO:42 (CDR3)之胺基酸序列之重鏈CDR;
viii) 包含SEQ ID NO:43 (CDR1)、SEQ ID NO:44 (CDR2)及SEQ ID NO:45 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:46 (CDR1)、SEQ ID NO:47 (CDR2)及SEQ ID NO:48 (CDR3)之胺基酸序列之重鏈CDR;
ix) 包含SEQ ID NO:49 (CDR1)、SEQ ID NO:50 (CDR2)及SEQ ID NO:51 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:52 (CDR1)、SEQ ID NO:53 (CDR2)及SEQ ID NO:54 (CDR3)之胺基酸序列之重鏈CDR;
x) 包含SEQ ID NO:55 (CDR1)、SEQ ID NO:56 (CDR2)及SEQ ID NO:57 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:58 (CDR1)、SEQ ID NO:59 (CDR2)及SEQ ID NO:60 (CDR3)之胺基酸序列之重鏈CDR;
xi) 包含SEQ ID NO:61 (CDR1)、SEQ ID NO:62 (CDR2)及SEQ ID NO:63 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:64 (CDR1)、SEQ ID NO:65 (CDR2)及SEQ ID NO:66 (CDR3)之胺基酸序列之重鏈CDR;
xii) 包含SEQ ID NO:67 (CDR1)、SEQ ID NO:68 (CDR2)及SEQ ID NO:69 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:70 (CDR1)、SEQ ID NO:71 (CDR2)及SEQ ID NO:72 (CDR3)之胺基酸序列之重鏈CDR;
xiii) 包含SEQ ID NO:73 (CDR1)、SEQ ID NO:74 (CDR2)及SEQ ID NO:75 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:76 (CDR1)、SEQ ID NO:77 (CDR2)及SEQ ID NO:78 (CDR3)之胺基酸序列之重鏈CDR;
xiv) 包含SEQ ID NO:79 (CDR1)、SEQ ID NO:80 (CDR2)及SEQ ID NO:81 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:82 (CDR1)、SEQ ID NO:83 (CDR2)及SEQ ID NO:84 (CDR3)之胺基酸序列之重鏈CDR;
xv) 包含SEQ ID NO:85 (CDR1)、SEQ ID NO:86 (CDR2)及SEQ ID NO:87 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:88 (CDR1)、SEQ ID NO:89 (CDR2)及SEQ ID NO:90 (CDR3)之胺基酸序列之重鏈CDR;
xvi) 包含SEQ ID NO:91 (CDR1)、SEQ ID NO:92 (CDR2)及SEQ ID NO:93 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:94 (CDR1)、SEQ ID NO:95 (CDR2)及SEQ ID NO:96 (CDR3)之胺基酸序列之重鏈CDR;
xvii) 包含SEQ ID NO:97 (CDR1)、SEQ ID NO:98 (CDR2)及SEQ ID NO:99 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:100 (CDR1)、SEQ ID NO:101 (CDR2)及SEQ ID NO:102 (CDR3)之胺基酸序列之重鏈CDR;
xviii) 包含SEQ ID NO:103 (CDR1)、SEQ ID NO:104 (CDR2)及SEQ ID NO:105 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:106 (CDR1)、SEQ ID NO:107 (CDR2)及SEQ ID NO:108 (CDR3)之胺基酸序列之重鏈CDR;
xix) 包含SEQ ID NO:109 (CDR1)、SEQ ID NO:110 (CDR2)及SEQ ID NO:111 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:112 (CDR1)、SEQ ID NO:113 (CDR2)及SEQ ID NO:114 (CDR3)之胺基酸序列之重鏈CDR;
xx) 包含SEQ ID NO:115 (CDR1)、SEQ ID NO:116 (CDR2)及SEQ ID NO:117 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:118 (CDR1)、SEQ ID NO:119 (CDR2)及SEQ ID NO:120 (CDR3)之胺基酸序列之重鏈CDR;
xxi) 包含SEQ ID NO:121 (CDR1)、SEQ ID NO:122 (CDR2)及SEQ ID NO:123 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:124 (CDR1)、SEQ ID NO:125 (CDR2)及SEQ ID NO:126 (CDR3)之胺基酸序列之重鏈CDR;
xxii) 包含SEQ ID NO:127 (CDR1)、SEQ ID NO:128 (CDR2)及SEQ ID NO:129 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:130 (CDR1)、SEQ ID NO:131 (CDR2)及SEQ ID NO:132 (CDR3)之胺基酸序列之重鏈CDR;
xxiii) 包含SEQ ID NO:133 (CDR1)、SEQ ID NO:134 (CDR2)及SEQ ID NO:135 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:136 (CDR1)、SEQ ID NO:137 (CDR2)及SEQ ID NO:138 (CDR3)之胺基酸序列之重鏈CDR;及
xxiv) 包含SEQ ID NO:139 (CDR1)、SEQ ID NO:140 (CDR2)及SEQ ID NO:141 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:142 (CDR1)、SEQ ID NO:143 (CDR2)及SEQ ID NO:144 (CDR3)之胺基酸序列之重鏈CDR。
由該等CDR序列定義之各別輕/重鏈可變結構域分別稱為B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24。
在本發明之結合蛋白之較佳實施例中,該專一性結合至CD3之第二多肽鏈(CD3鏈)包含第二輕鏈可變結構域及第二重鏈可變結構域,其包含選自由以下組成之群之CDR序列:
i) 包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR;
ii) 包含SEQ ID NO:263 (CDR1)、SEQ ID NO:264 (CDR2)及SEQ ID NO:265 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:266 (CDR1)、SEQ ID NO:267 (CDR2)及SEQ ID NO:268 (CDR3)之胺基酸序列之重鏈CDR;
iii) 包含SEQ ID NO:269 (CDR1)、SEQ ID NO:270 (CDR2)及SEQ ID NO:271 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:272 (CDR1)、SEQ ID NO:273 (CDR2)及SEQ ID NO:274 (CDR3)之胺基酸序列之重鏈CDR;
iv) 包含SEQ ID NO:275 (CDR1)、SEQ ID NO:276 (CDR2)及SEQ ID NO:277 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:278 (CDR1)、SEQ ID NO:279 (CDR2)及SEQ ID NO:280 (CDR3)之胺基酸序列之重鏈CDR;
v) 包含SEQ ID NO:281 (CDR1)、SEQ ID NO:282 (CDR2)及SEQ ID NO:283 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:284 (CDR1)、SEQ ID NO:285 (CDR2)及SEQ ID NO:286 (CDR3)之胺基酸序列之重鏈CDR;及
vi) 包含SEQ ID NO:287 (CDR1)、SEQ ID NO:288 (CDR2)及SEQ ID NO:289 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:290 (CDR1)、SEQ ID NO:291 (CDR2)及SEQ ID NO:292 (CDR3)之胺基酸序列之重鏈CDR。
由該等CDR序列定義之各別輕/重鏈可變結構域分別稱為CD3#1、CD3#2、CD3#3、CD3#4、CD3#5及CD3#6。
較佳地,輕鏈及重鏈CDR序列選自由以下組成之群:如上文所定義之B7H6#1、B7H6#2、B7H6#、B7H6#4、B7H6#5、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈(B7H6鏈),其包含具有包含SEQ ID NO:67 (CDR1)、SEQ ID NO:68 (CDR2)及SEQ ID NO:69 (CDR3)之胺基酸序列之輕鏈CDR的第一輕鏈可變結構域及具有包含SEQ ID NO:70 (CDR1)、SEQ ID NO:71 (CDR2)及SEQ ID NO:72 (CDR3)之胺基酸序列之重鏈CDR的第一重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈,其包含具有包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR的第二輕鏈可變結構域及具有包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR的第二重鏈可變結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈(B7H6鏈),其包含具有包含SEQ ID NO:79 (CDR1)、SEQ ID NO:80 (CDR2)及SEQ ID NO:81 (CDR3)之胺基酸序列之輕鏈CDR的第一輕鏈可變結構域及具有包含SEQ ID NO:82 (CDR1)、SEQ ID NO:83 (CDR2)及SEQ ID NO:84 (CDR3)之胺基酸序列之重鏈CDR的第一重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈,其包含具有包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR的第二輕鏈可變結構域及具有包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR的第二重鏈可變結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈,其包含具有包含SEQ ID NO:85 (CDR1)、SEQ ID NO:86 (CDR2)及SEQ ID NO:87 (CDR3)之胺基酸序列之輕鏈CDR的第一輕鏈可變結構域及具有包含SEQ ID NO:88 (CDR1)、SEQ ID NO:89 (CDR2)及SEQ ID NO:90 (CDR3)之胺基酸序列之重鏈CDR的第一重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈,其包含具有包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR的第二輕鏈可變結構域及具有包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR的第二重鏈可變結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈,其包含具有包含SEQ ID NO:91 (CDR1)、SEQ ID NO:92 (CDR2)及SEQ ID NO:93 (CDR3)之胺基酸序列之輕鏈CDR的第一輕鏈可變結構域及具有包含SEQ ID NO:94 (CDR1)、SEQ ID NO:95 (CDR2)及SEQ ID NO:96 (CDR3)之胺基酸序列之重鏈CDR的第一重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈,其包含具有包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR的第二輕鏈可變結構域及具有包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR的第二重鏈可變結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈,其包含具有包含SEQ ID NO:133 (CDR1)、SEQ ID NO:134 (CDR2)及SEQ ID NO:135 (CDR3)之胺基酸序列之輕鏈CDR的第一輕鏈可變結構域及具有包含SEQ ID NO:136 (CDR1)、SEQ ID NO:137 (CDR2)及SEQ ID NO:138 (CDR3)之胺基酸序列之重鏈CDR的第一重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈,其包含具有包含SEQ ID NO:257 (CDR1)、SEQ ID NO:258 (CDR2)及SEQ ID NO:259 (CDR3)之胺基酸序列之輕鏈CDR的第二輕鏈可變結構域及具有包含SEQ ID NO:260 (CDR1)、SEQ ID NO:261 (CDR2)及SEQ ID NO:262 (CDR3)之胺基酸序列之重鏈CDR的第二重鏈可變結構域。
在本發明之蛋白質之較佳實施例中,專一性結合至B7H6之該第一多肽鏈(B7H6鏈)包含輕鏈可變結構域(第一輕鏈可變結構域)及重鏈可變結構域(第一重鏈可變結構域),其選自由i)至xiv)組成之群:
i) 包含SEQ ID NO:145之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:146之胺基酸序列之重鏈可變結構域(B7H6#1);
ii) 包含SEQ ID NO:147之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:148之胺基酸序列之重鏈可變結構域(B7H6#2);
iii) 包含SEQ ID NO:149之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:150之胺基酸序列之重鏈可變結構域(B7H6#3);
iv) 包含SEQ ID NO:151之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:152之胺基酸序列之重鏈可變結構域(B7H6#4);
v) 包含SEQ ID NO:153之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:154之胺基酸序列之重鏈可變結構域(B7H6#5);
vi) 包含SEQ ID NO:155之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:156之胺基酸序列之重鏈可變結構域(B7H6#6);
vii) 包含SEQ ID NO:157之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:158之胺基酸序列之重鏈可變結構域(B7H6#7);
viii) 包含SEQ ID NO:159之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:160之胺基酸序列之重鏈可變結構域(B7H6#8);
ix) 包含SEQ ID NO:161之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:162之胺基酸序列之重鏈可變結構域(B7H6#9);
x) 包含SEQ ID NO:163之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:164之胺基酸序列之重鏈可變結構域(B7H6#10);
xi) 包含SEQ ID NO:165之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:166之胺基酸序列之重鏈可變結構域(B7H6#11);
xii) 包含SEQ ID NO:167之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:168之胺基酸序列之重鏈可變結構域(B7H6#12);
xiii) 包含SEQ ID NO:169之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:170之胺基酸序列之重鏈可變結構域(B7H6#13);
xiv) 包含SEQ ID NO:171之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:172之胺基酸序列之重鏈可變結構域(B7H6#14);
xv) 包含SEQ ID NO:173之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:174之胺基酸序列之重鏈可變結構域(B7H6#15);
xvi) 包含SEQ ID NO:175之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:176之胺基酸序列之重鏈可變結構域(B7H6#16);
xvii) 包含SEQ ID NO:177之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:178之胺基酸序列之重鏈可變結構域(B7H6#17);
xviii) 包含SEQ ID NO:179之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:180之胺基酸序列之重鏈可變結構域(B7H6#18);
xix) 包含SEQ ID NO:181之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:182之胺基酸序列之重鏈可變結構域(B7H6#19);
xx) 包含SEQ ID NO:183之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:184之胺基酸序列之重鏈可變結構域(B7H6#20);
xxi) 包含SEQ ID NO:185之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:186之胺基酸序列之重鏈可變結構域(B7H6#21);
xxii) 包含SEQ ID NO:187之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:188之胺基酸序列之重鏈可變結構域(B7H6#22);
xxiii) 包含SEQ ID NO:189之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:190之胺基酸序列之重鏈可變結構域(B7H6#23);及
xxiv) 包含SEQ ID NO:191之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:192之胺基酸序列之重鏈可變結構域(B7H6#24)。
較佳地,輕鏈可變及重鏈可變結構域序列選自由以下組成之群:如上文所定義之B7H6#1、B7H6#2、B7H6#、B7H6#4、B7H6#5、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24。
在本發明之蛋白質之較佳實施例中,專一性結合至CD3之該第二多肽鏈(CD3鏈)包含輕鏈可變結構域(第二輕鏈可變結構域)及重鏈可變結構域(第二重鏈可變結構域),其選自由以下組成之群:
i) 包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域(CD3#1);
ii) 包含SEQ ID NO:295之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:296之胺基酸序列之重鏈可變結構域(CD3#2);
iii) 包含SEQ ID NO:297之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:298之胺基酸序列之重鏈可變結構域(CD3#3);
iv) 包含SEQ ID NO:299之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:300之胺基酸序列之重鏈可變結構域(CD3#4);
v) 包含SEQ ID NO:301之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:302之胺基酸序列之重鏈可變結構域(CD3#5);
vi) 包含SEQ ID NO:303之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:304之胺基酸序列之重鏈可變結構域(CD3#6)。
在一些實施例中,本發明之結合蛋白包含第一及第二多肽鏈,其包含選自由以下組成之清單之輕/重鏈可變結構域之CDR及/或VH及VL序列:B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#6/CD3#1、B7H6#7/CD3#1、B7H6#8/CD3#1、B7H6#9/CD3#1、B7H6#10/CD3#1、B7H6#11/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1,在較佳實施例中,本發明之結合蛋白包含第一及第二多肽鏈,其包含選自由以下組成之清單之輕/重鏈可變結構域之CDR及/或VH及VL序列:B7H6#12/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#23/CD3#1。甚至更佳地,第一多肽鏈包括包含SEQ ID NO:242之胺基酸序列之Fc結構域且該第二多肽鏈包括包含SEQ ID NO:243之胺基酸序列之Fc結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈(B7H6鏈),其包含SEQ ID NO:167之輕鏈可變結構域及SEQ ID NO:168之重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈(CD3鏈),其包含SEQ ID NO:293之輕鏈可變結構域及SEQ ID NO:294之重鏈可變結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈(B7H6鏈),其包含SEQ ID NO:171之輕鏈可變結構域及SEQ ID NO:172之重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈(CD3鏈),其包含SEQ ID NO:293之輕鏈可變結構域及SEQ ID NO:294之重鏈可變結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈(B7H6鏈),其包含SEQ ID NO:173之輕鏈可變結構域及SEQ ID NO:174之重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈(CD3鏈),其包含SEQ ID NO:293之輕鏈可變結構域及SEQ ID NO:294之重鏈可變結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈(B7H6鏈),其包含SEQ ID NO:175之輕鏈可變結構域及SEQ ID NO:176之重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈(CD3鏈),其包含SEQ ID NO:293之輕鏈可變結構域及SEQ ID NO:294之重鏈可變結構域。
在一個較佳實施例中,本發明之結合蛋白包含(i) 專一性結合至B7H6之第一多肽鏈(B7H6鏈),其包含SEQ ID NO:189之輕鏈可變結構域及SEQ ID NO:190之重鏈可變結構域;及(ii) 專一性結合至CD3之第二多肽鏈(CD3鏈),其包含SEQ ID NO:293之輕鏈可變結構域及SEQ ID NO:294之重鏈可變結構域。
在較佳實施例中,對B7H6具有專一性之第一多肽鏈包含具有SEQ ID NO:193、SEQ ID NO:194、SEQ ID NO:195、SEQ ID NO:196、SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201、SEQ ID NO:202、SEQ ID NO:203、SEQ ID NO:204、SEQ ID NO:205、SEQ ID NO:206、SEQ ID NO:207、SEQ ID NO:208、SEQ ID NO:209、SEQ ID NO:210、SEQ ID NO:211、SEQ ID NO:212、SEQ ID NO:213、SEQ ID NO:214、SEQ ID NO:215或SEQ ID NO:216中之任一者之胺基酸序列的單鏈Fab,且對CD3具有專一性之第二多肽鏈包含具有SEQ ID NO:305之胺基酸序列的單鏈Fab。
較佳地,第一多肽鏈包含單鏈Fab,其包含選自由以下組成之群之胺基酸序列:SEQ ID NO:193、SEQ ID NO:194、SEQ ID NO:195、SEQ ID NO:196、SEQ ID NO:197、SEQ ID NO:204、SEQ ID NO:205、SEQ ID NO:206、SEQ ID NO:207、SEQ ID NO:208、SEQ ID NO:209、SEQ ID NO:210、SEQ ID NO:211、SEQ ID NO:212、SEQ ID NO:213、SEQ ID NO:214、SEQ ID NO:215及SEQ ID NO:216,更佳地選自由以下組成之群之胺基酸序列:SEQ ID NO:204、SEQ ID NO:205、SEQ ID NO:206、SEQ ID NO:207、SEQ ID NO:208、SEQ ID NO:209、SEQ ID NO:210、SEQ ID NO:211、SEQ ID NO:212、SEQ ID NO:213、SEQ ID NO:214、SEQ ID NO:215及SEQ ID NO:216,且第二多肽鏈包括包含SEQ ID NO:305之胺基酸序列之單鏈Fab。
在一個較佳實施例中,對B7H6具有專一性之第一多肽鏈(B7H6鏈)包括包含SEQ ID NO:204之胺基酸序列之單鏈Fab且對CD3具有專一性之第二多肽鏈(CD3鏈)包括包含SEQ ID NO:305之胺基酸序列之單鏈Fab。
在一個較佳實施例中,對B7H6具有專一性之第一多肽鏈(B7H6鏈)包括包含SEQ ID NO:206之胺基酸序列之單鏈Fab且對CD3具有專一性之第二多肽鏈(CD3鏈)包括包含SEQ ID NO:305之胺基酸序列之單鏈Fab。
在一個較佳實施例中,對B7H6具有專一性之第一多肽鏈(B7H6鏈)包括包含SEQ ID NO:207之胺基酸序列之單鏈Fab且對CD3具有專一性之第二多肽鏈(CD3鏈)包括包含SEQ ID NO:305之胺基酸序列之單鏈Fab。
在一個較佳實施例中,對B7H6具有專一性之第一多肽鏈(B7H6鏈)包括包含SEQ ID NO:208之胺基酸序列之單鏈Fab且對CD3具有專一性之第二多肽鏈(CD3鏈)包括包含SEQ ID NO:305之胺基酸序列之單鏈Fab。
在一個較佳實施例中,對B7H6具有專一性之第一多肽鏈(B7H6鏈)包括包含SEQ ID NO:215之胺基酸序列之單鏈Fab且對CD3具有專一性之第二多肽鏈(CD3鏈)包括包含SEQ ID NO:305之胺基酸序列之單鏈Fab。
亦關於針對scFab之此具體實施例,術語包含亦意欲包括「由更一般術語中如本文上文所定義之胺基酸序列組成」。
在本發明之結合蛋白之一些實施例中,第一及第二多肽鏈包含源自IgG之重鏈(例如IgG1、IgG2或IgG4)之Fc結構域。舉例而言,本發明之Fc結構域係IgG1或IgG4之重鏈之Fc結構域且包含鉸鏈區及兩個恆定結構域(CH2及CH3)。人類IgG之Fc結構域之實例示於SEQ ID NO:241及SEQ ID NO:244中。
在本發明之結合蛋白之一些實施例中,重鏈包含一或多個胺基酸變化。舉例而言,該等胺基酸變化係第一重鏈之位置366之酪胺酸(Y) [T366Y]及第二重鏈之位置407之蘇胺酸(T) [Y407T]。在一些實施例中,第一重鏈包含位置366之絲胺酸(S) [T366S],且第二重鏈包含位置366之色胺酸(W) [T366W]、位置368之丙胺酸(A) [L368A]及位置407之纈胺酸(V) [Y407V]。在較佳實施例中,第一重鏈包含位置366之色胺酸(W) [T366W],且第二重鏈包含位置366之絲胺酸(S) [T366S]、位置368之丙胺酸(A) [L368A]及位置407之纈胺酸(V) [Y407V]。舉例而言,根據Eu編號對應於SEQ ID NO:241之人類IgG1 Fc序列中之胺基酸位置146的Fc結構域之位置366自SEQ ID NO:241中位置146之T變為SEQ ID NO:242中位置146之W;且根據Eu編號分別對應於SEQ ID NO:241中胺基酸位置146、148及187的位置366、368及407自SEQ ID NO:241中該等位置之T、L及Y變為SEQ ID NO:243中該等位置之S、A及V。在該等實施例中之任一者中,針對第一重鏈所述之胺基酸變化可位於第二重鏈中且第二重鏈之各別胺基酸變化可位於第一重鏈中。換言之,術語「第一」及「第二」在該等實施例中可互換。在一些實施例中,重鏈源自IgG1
或IgG4
之重鏈。
在一些實施例中,本發明之結合蛋白中之第一重鏈或第二重鏈進一步包含一或多個胺基酸變化,其減少重鏈與蛋白質A之結合。在一些實施例中,該等胺基酸變化係重鏈之一之位置435之精胺酸[H435R]及位置436之苯丙胺酸[Y436F]。
在一些實施例中,在本發明之蛋白質中,包含位置407之蘇胺酸(T) [Y407T]之重鏈進一步包含位置435之精胺酸[H435R]及位置436之苯丙胺酸[Y436F]。在此情形中,另一重鏈包含位置366之酪胺酸(Y) [T366Y],但不包括位置435及436之兩個變化。或者,在一些實施例中,在本發明之蛋白質中,包含位置366之絲胺酸(S) [T366S]、位置368之丙胺酸(A) [L368A]及位置407之纈胺酸(V) [Y407V]之重鏈進一步包含位置435之精胺酸[H435R]及位置436之苯丙胺酸[Y436F]。在此情形中,另一重鏈包含位置366之色胺酸(W) [T366W],但不包括位置435及436之兩個變化。因此,包含產生如上文所述之「腔」之胺基酸變化的重鏈亦包含減少與蛋白質A之結合之胺基酸變化。經由與蛋白質A之結合減少,去除包含該等重鏈之同二聚體。藉由「突出」之存在減少包含「突出」之另一重鏈之同二聚體之產生。
在一些實施例中,本發明蛋白質之重鏈可或可不進一步包含YTE突變(M252Y/S254T/T256E, Eu編號(Dall'Acqua等人 J. Biol. Chem.2006, 281(33):23514-24)。已顯示該等突變可經由優先增強pH 6.0下對新生FcRn受體之結合親和性來改良重鏈之藥物動力學性質。
在一些實施例中,源自IgG1之本發明之第一及/或第二重鏈亦包括「KO」突變(L234A, L235A) (Xu等人,Cellular Immunology 2000年2月25日, 200(1):16-26)。在另一態樣中,源自IgG4之本發明之第一及/或第二重鏈亦包括Pro鉸鏈突變(S228P) (Angal等人,Molecular Immunology 1993, 30(1):105-108;Labrijn等人,Nature Biotechnology 2009, 27:767-771)。
在本發明之結合蛋白之較佳實施例中,第一多肽鏈包括包含SEQ ID NO:242之胺基酸序列之Fc結構域且第二多肽鏈包括包含SEQ ID NO:243之胺基酸序列之Fc結構域。
在本發明之較佳實施例中,結合蛋白包含i) 包含SEQ ID NO:217之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#1/CD3#1),或ii) 包含SEQ ID NO:218之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#2/CD3#1),或iii) 包含SEQ ID NO:219之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#3/CD3#1),或iv) 包含SEQ ID NO:220之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#4/CD3#1),或v) 包含SEQ ID NO:221之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#5/CD3#1),或vi) 包含SEQ ID NO:222之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#6/CD3#1);或vii) 包含SEQ ID NO:223之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#7/CD3#1);或viii) 包含SEQ ID NO:224之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#8/CD3#1);或ix) 包含SEQ ID NO:225之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#9/CD3#1);或x) 包含SEQ ID NO:226之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#10/CD3#1);或xi) 包含SEQ ID NO:227之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#11/CD3#1);或xii) 包含SEQ ID NO:228之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#12/CD3#1);或xiii) 包含SEQ ID NO:229之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#13/CD3#1);或xiv) 包含SEQ ID NO:230之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#14/CD3#1);或xv) 包含SEQ ID NO:231之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#15/CD3#1),或xvi) 包含SEQ ID NO:232之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#16/CD3#1);或xvii) 包含SEQ ID NO:233之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#17/CD3#1);或xviii) 包含SEQ ID NO:234之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#18/CD3#1);或xix) 包含SEQ ID NO:235之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#19/CD3#1);或xx) 包含SEQ ID NO:236之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#20/CD3#1);或xxi) 包含SEQ ID NO:237之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#21/CD3#1);或xxii) 包含SEQ ID NO:238之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#22/CD3#1);或xxiii) 包含SEQ ID NO:239之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#23/CD3#1);或xxiv) 包含SEQ ID NO:240之胺基酸序列之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之第二多肽鏈(B7H6#24/CD3#1)。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在一個較佳實施例中,結合蛋白包括包含SEQ ID NO:228之胺基酸序列之對B7H6具有專一性之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之對CD3具有專一性之第二多肽鏈。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在一個較佳實施例中,結合蛋白包括包含SEQ ID NO:230之胺基酸序列之對B7H6具有專一性之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之對CD3具有專一性之第二多肽鏈。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在一個較佳實施例中,結合蛋白包括包含SEQ ID NO:231之胺基酸序列之對B7H6具有專一性之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之對CD3具有專一性之第二多肽鏈。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在一個較佳實施例中,結合蛋白包括包含SEQ ID NO:232之胺基酸序列之對B7H6具有專一性之第一多肽鏈及包含SEQ ID NO:311之胺基酸序列之對CD3具有專一性之第二多肽鏈。較佳地,第一及第二多肽鏈經由一或多個二硫鍵連接且形成類似於習用Y形抗體分子之抗體樣結構(圖1)。
在另一態樣中,本發明之蛋白質包含對B7H6具有專一性之第一抗原結合單元或多肽鏈,其中對人類及食蟹獼猴B7H6之親和性較佳≤ 10nM、更佳≤ 1nM、甚至更佳≤ 0.1nM。親和性可以在SPR (BIAcore® SPR系統(GE Healthcare Life Sciences))分析中使用重組B7H6-蛋白量測,如例如實例或熟練人員熟知之其他方法中所述。蛋白質包含對人類及食蟹獼猴CD3Ɛγ複合物具有較佳≤ 500 nM、更佳≤ 100 nM、甚至更佳≤ 10nM之親和性之第二抗原結合單元或多肽鏈。
在另一態樣中,本發明之B7H6/CD3結合蛋白不結合至B7H6陰性細胞且不與B7H1交叉反應(例如,分別參見實例10及實例4)。
在較佳實施例中,本發明之B7H6/CD3結合蛋白(例如B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)不抑制天然殺手細胞之活化。值得注意的是,在活體外不抑制自然殺手細胞之活化的本發明之B7H6/CD3結合蛋白結合至B7H6,其中NKp30相互作用位點經丙胺酸取代。
細胞表面上之B7H6結合至NK細胞之細胞表面上之NKp30,其觸發NKp30介導之NK細胞之活化、NK細胞之細胞毒性及細胞介素分泌(Brandt等人,J.Exp. Med.2009, 206(7):1495-503)。此情況可藉由在用重組B7H6細胞外結構域蛋白塗覆之板上培養NK細胞系(例如NK92MI)或原代NK細胞、隨後分析活化標記(例如CD25或CD69)之上調或NK細胞之細胞介素分泌來活體外模擬。該分析設置用於評價吾人之B7H6/CD3結合蛋白是否抑制B7H6及NKp30之相互作用,從而導致IFNγ分泌之抑制(實例11)。
使用重組Ala突變之B7H6細胞外蛋白(其中NKp30相互作用位點經丙胺酸取代),可觀察到存在兩組結合蛋白:1)發現強效結合至野生型B7H6但不結合或僅微弱結合至重組Ala突變之B7H6細胞外蛋白之結合蛋白在活體外抑制NK細胞之B7H6依賴性IFNγ分泌(「B7H6依賴性NK細胞活化之抑制劑」),及2)發現強效結合至野生型B7H6且維持亦結合至重組Ala突變之B7H6細胞外蛋白之能力之結合蛋白在活體外不抑制NK細胞之B7H6依賴性活化及相關之IFNγ分泌(「B7H6依賴性NK細胞活化之非抑制劑」) (參見實例6及11、圖4及9)。驚人地,作為B7H6依賴性NK細胞活化之非抑制劑的本發明之結合蛋白在T細胞重定向溶解表現B7H6之腫瘤細胞中更強效(參見實例12、圖10及11)。不受理論束縛,B7H6依賴性NK細胞活化之非抑制劑可能允許B7H6 NKp30相互作用,而不影響B7H6在介導先天免疫中之天然作用。
在另一態樣,本發明之B7H6/CD3結合蛋白能夠介導T細胞重定向之針對腫瘤細胞之細胞毒性,而與NK細胞活性無關(如在不存在NK細胞之小鼠異種移植物模型中所示,參見實例19、圖20及23,以及在不存在NK細胞之細胞溶解分析中所示,參見實例12、圖10及11)。
可使用多種方法量測由本發明之B7H6/CD3結合蛋白介導之細胞毒性。舉例而言,細胞毒性可使用實例12中所述之方法量測。效應細胞可為(例如)刺激或未刺激之(人類或食蟹獼猴) T細胞或其亞組(例如CD4、CD8)或未刺激之(人類或食蟹獼猴)外周血單核細胞(PBMC)。靶細胞應至少表現(人類或食蟹獼猴) B7H6之細胞外結構域,且可為具有內源(天然) B7H6表現之細胞,例如人類小細胞肺癌細胞系SHP77、NCI-H82,或者亦可為表現全長B7H6或B7H6之細胞外結構域之重組細胞。效應物對靶細胞比率(E:T)通常為約10:1,但可變化。B7H6/CD3結合分子之細胞毒性活性可例如在培育48或72小時後在LDH釋放分析中測定。用於測定細胞毒性之培育時間及讀出之修飾形式係可能的且為熟練人員已知。細胞毒性之讀出系統可包含MTT/MTS分析、基於ATP之分析、基於FACS之分析、51-鉻釋放分析、磺醯玫瑰紅B (SRB)分析、比色(WST)分析、純系形成分析、ECIS技術及生物發光分析。
由本發明之B7H6/CD3結合蛋白介導之細胞毒性活性較佳在基於細胞之細胞毒性分析中量測。細胞毒性由細胞毒性分析中量測之EC90
值表示。熟練人員明瞭,當純化之T細胞用作效應細胞時,與PBMC相比,預期EC90
更低,熟練人員亦明瞭,當使用刺激之T細胞時,EC90
甚至更低。此外,可預期,與在細胞表面上表現低數量B7H6分子之細胞相比,當靶細胞在細胞表面表現高數量B7H6時,EC90
值較低。B7H6/CD3結合蛋白之EC90
較佳<
10 nM、更佳<
5 nM且甚至更佳<
1 nM。
較佳地,本發明之多重專一性結合蛋白不誘導/介導B7H6陰性細胞之溶解。術語「不誘導/介導B7H6陰性細胞之溶解」意指B7H6/CD3結合分子不誘導或介導超過30%、較佳不超過20%、更佳不超過10%且尤其不超過5%之B7H6陰性細胞的溶解,而B7H6陽性結腸直腸細胞系之溶解設定為100%。此通常適用於高達1000 nM之結合蛋白之濃度。
此外,本發明之B7H6/CD3結合蛋白顯示在兩步純化過程中達到95%以上之單體含量(參見實例20),具有有利藥物動力學性質及良好下游可製造性,且進一步預期具有良好生物分佈(例如,參見實例18)。本發明之蛋白質進一步具有有利免疫原性特性(參見實例22)且具有良好之活體外及活體內穩定性(例如,參見實例21及18)。此外,本發明之B7H6/CD3結合蛋白在人類化活體內異種移植物小鼠模型中顯示有利效能。B7H6/CD3結合蛋白誘導強腫瘤消退,在第一次投用B7H6/CD3結合蛋白之後即已經開始(例如,參見實例19)。此外,本發明之B7H6/CD3結合蛋白在每週一次(q7d)投與之0.05 mg/kg之極低劑量下誘導腫瘤消退,進一步支持其治療適用性。具體而言,本發明之B7H6/CD3結合蛋白僅在B7H6陽性靶細胞存在下且在B7H6陰性靶細胞不存在下,誘導選擇性T細胞增殖、T細胞活化、T細胞脫粒化及細胞介素分泌(分別參見實例16、14、15、17),並進一步顯著增加T細胞浸潤至腫瘤組織中(參見實例24)。
本發明之又一態樣提供經分離核酸分子,其編碼本發明之多重專一性結合蛋白之第一及/或第二抗原結合單元(分別抗原結合單元B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24中之任一者及/或抗原結合單元CD3#1、CD3#2、CD3#3、CD3#4、CD3#5及CD3#6中之任一者,如由如表1中所示之CDR、VH/VL或scFab序列所定義)。在一些實施例中,核酸分子進一步編碼如本文所述之第一及/或第二Fc結構域,第一及/或第二Fc結構域分別連接至編碼第一及/或第二抗原結合單元之核酸分子的3’端。在一些實施例中,核酸分子編碼i) 第一多肽鏈,其包含對B7H6具有專一性之第一單鏈Fab (例如B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24中之任一者)及第一Fc結構域,及/或ii) 第二多肽鏈,其包含對CD3具有專一性之第二單鏈Fab (例如CD3#1、CD3#2、CD3#3、CD3#4、CD3#5及CD3#6中之任一者,較佳CD3#1)及第二Fc結構域。
較佳地,核酸分子包含核苷酸序列,其編碼SEQ ID NO:193、SEQ ID NO:194、SEQ ID NO:195、SEQ ID NO:196、SEQ ID NO:197、SEQ ID NO:198、SEQ ID NO:199、SEQ ID NO:200、SEQ ID NO:201、SEQ ID NO:202、SEQ ID NO:203、SEQ ID NO:204、SEQ ID NO:205、SEQ ID NO:206、SEQ ID NO:207、SEQ ID NO:208、SEQ ID NO:209、SEQ ID NO:210、SEQ ID NO:211、SEQ ID NO:212、SEQ ID NO:213、SEQ ID NO:214、SEQ ID NO:215或SEQ ID NO:216中之任一者之對B7H6具有專一性之第一單鏈Fab及/或SEQ ID NO:305之第二單鏈Fab。在較佳實施例中,核酸分子包含核苷酸序列,其編碼SEQ ID NO:204、SEQ ID NO:206、SEQ ID NO:207、SEQ ID NO:208或SEQ ID NO:215中之任一者之對B7H6具有專一性之第一scFab;及/或核苷酸序列,其編碼包含SEQ ID NO:305之胺基酸序列之對CD3具有專一性之第二scFab。
本發明之又一態樣提供表現載體,其含有包含編碼第一及/或第二抗原結合結構域(例如本發明之第一及/或第二單鏈Fab)之核苷酸序列的DNA分子。較佳地,除了核酸分子、較佳編碼連接至核酸分子之第一及/或第二Fc結構域之DNA分子之外,表現載體亦較佳包含分別編碼第一及/或第二抗原結合結構域(例如第一及/或第二單鏈Fab)之DNA分子。因此,表現載體包含編碼包含連接至第一Fc結構域之第一單鏈Fab之多肽鏈的核苷酸序列及/或編碼包含連接至第二Fc結構域之第二單鏈Fab之多肽鏈的核苷酸序列。
在較佳實施例中,表現載體含有DNA分子,其包含編碼本發明之對B7H6具有專一性之第一多肽鏈及/或對CD3具有專一性之第二多肽鏈之核苷酸序列。在較佳實施例中,表現載體包含編碼SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO;224、SEQ ID NO:225、SEQ ID NO:226、SEQ ID NO: 227、SEQ ID NO: 228、SEQ ID NO: 229、SEQ ID NO: 230、SEQ ID NO: 231、SEQ ID NO: 232、SEQ ID NO: 233、SEQ ID NO: 234、SEQ ID NO: 235、SEQ ID NO: 236、SEQ ID NO: 237、SEQ ID NO: 238、SEQ ID NO: 239或SEQ ID NO: 240中之任一者之第一多肽鏈的核苷酸序列及/或編碼包含SEQ ID NO:311之第二多肽鏈的核苷酸序列。
在其他較佳實施例中,表現載體包含編碼SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232及SEQ ID NO:239中之任一者之第一多肽鏈的核苷酸序列及/或編碼包含SEQ ID NO:311之第二多肽鏈的核苷酸序列。
在尤佳實施例中,可使用兩種表現載體,其中一者用於表現對B7H6具有專一性之第一多肽鏈,另一者用於表現對CD3具有專一性之第二多肽鏈,然後可將該兩種表現載體轉染至宿主細胞中以表現重組蛋白。
較佳地,表現載體將為包含與至少一個調控序列可操作地連接之該(等)核酸分子之載體,其中該調控序列可為啟動子、增強子或終止子序列,且最佳異源啟動子、增強子或終止子序列。
在另一態樣中,本發明係關於宿主細胞,其具有編碼本發明之對B7H6具有專一性之第一多肽鏈的表現載體及編碼本發明之對CD3具有專一性之第二多肽鏈的表現載體。
根據尤佳實施例,該等宿主細胞係真核細胞,例如哺乳動物細胞。在另一實施例中,該等宿主細胞係細菌細胞。其他有用細胞係酵母細胞或其他真菌細胞。
適宜哺乳動物細胞包括例如CHO細胞、BHK細胞、HeLa細胞、COS細胞及諸如此類。然而,亦可使用業內用於表現異源蛋白之兩棲動物細胞、昆蟲細胞、植入細胞及任何其他細胞。
抗B7H6抗體 本發明之又一態樣提供抗B7H6抗體分子,其包含
i) 包含SEQ ID NO:1 (CDR1)、SEQ ID NO:2 (CDR2)及SEQ ID NO:3 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:4 (CDR1)、SEQ ID NO:5 (CDR2)及SEQ ID NO:6 (CDR3)之胺基酸序列之重鏈CDR;或
ii) 包含SEQ ID NO:7 (CDR1)、SEQ ID NO:8 (CDR2)及SEQ ID NO:9 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:10 (CDR1)、SEQ ID NO:11 (CDR2)及SEQ ID NO:12 (CDR3)之胺基酸序列之重鏈CDR;或
iii)
包含SEQ ID NO:13 (CDR1)、SEQ ID NO:14 (CDR2)及SEQ ID NO:15 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:16 (CDR1)、SEQ ID NO:17 (CDR2)及SEQ ID NO:18 (CDR3)之胺基酸序列之重鏈CDR;或
iv) 包含SEQ ID NO:19 (CDR1)、SEQ ID NO:20 (CDR2)及SEQ ID NO:21 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:22 (CDR1)、SEQ ID NO:23 (CDR2)及SEQ ID NO:24 (CDR3)之胺基酸序列之重鏈CDR;或
v) 包含SEQ ID NO:25 (CDR1)、SEQ ID NO:26 (CDR2)及SEQ ID NO:27 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:28 (CDR1)、SEQ ID NO:29 (CDR2)及SEQ ID NO:30 (CDR3)之胺基酸序列之重鏈CDR;或
vi) 包含SEQ ID NO:31 (CDR1)、SEQ ID NO:32 (CDR2)及SEQ ID NO:33 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:34 (CDR1)、SEQ ID NO:35 (CDR2)及SEQ ID NO:36 (CDR3)之胺基酸序列之重鏈CDR;或
vii) 包含SEQ ID NO:37 (CDR1)、SEQ ID NO:38 (CDR2)及SEQ ID NO:39 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:40 (CDR1)、SEQ ID NO:41 (CDR2)及SEQ ID NO:42 (CDR3)之胺基酸序列之重鏈CDR;或
viii) 包含SEQ ID NO:43 (CDR1)、SEQ ID NO:44 (CDR2)及SEQ ID NO:45 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:46 (CDR1)、SEQ ID NO:47 (CDR2)及SEQ ID NO:48 (CDR3)之胺基酸序列之重鏈CDR;或
ix) 包含SEQ ID NO:49 (CDR1)、SEQ ID NO:50 (CDR2)及SEQ ID NO:51 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:52 (CDR1)、SEQ ID NO:53 (CDR2)及SEQ ID NO:54 (CDR3)之胺基酸序列之重鏈CDR;或
x) 包含SEQ ID NO:55 (CDR1)、SEQ ID NO:56 (CDR2)及SEQ ID NO:57 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:58 (CDR1)、SEQ ID NO:59 (CDR2)及SEQ ID NO:60 (CDR3)之胺基酸序列之重鏈CDR;或
xi) 包含SEQ ID NO:61 (CDR1)、SEQ ID NO:62 (CDR2)及SEQ ID NO:63 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:64 (CDR1)、SEQ ID NO:65 (CDR2)及SEQ ID NO:66 (CDR3)之胺基酸序列之重鏈CDR;或
xii) 包含SEQ ID NO:67 (CDR1)、SEQ ID NO:68 (CDR2)及SEQ ID NO:69 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:70 (CDR1)、SEQ ID NO:71 (CDR2)及SEQ ID NO:72 (CDR3)之胺基酸序列之重鏈CDR;或
xiii) 包含SEQ ID NO:73 (CDR1)、SEQ ID NO:74 (CDR2)及SEQ ID NO:75 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:76 (CDR1)、SEQ ID NO:77 (CDR2)及SEQ ID NO:78 (CDR3)之胺基酸序列之重鏈CDR;或
xiv) 包含SEQ ID NO:79 (CDR1)、SEQ ID NO:80 (CDR2)及SEQ ID NO:81 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:82 (CDR1)、SEQ ID NO:83 (CDR2)及SEQ ID NO:84 (CDR3)之胺基酸序列之重鏈CDR;或
xv) 包含SEQ ID NO:85 (CDR1)、SEQ ID NO:86 (CDR2)及SEQ ID NO:87 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:88 (CDR1)、SEQ ID NO:89 (CDR2)及SEQ ID NO:90 (CDR3)之胺基酸序列之重鏈CDR;或
xvi) 包含SEQ ID NO:91 (CDR1)、SEQ ID NO:92 (CDR2)及SEQ ID NO:93 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:94 (CDR1)、SEQ ID NO:95 (CDR2)及SEQ ID NO:96 (CDR3)之胺基酸序列之重鏈CDR;或
xvii) 包含SEQ ID NO:97 (CDR1)、SEQ ID NO:98 (CDR2)及SEQ ID NO:99 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:100 (CDR1)、SEQ ID NO:101 (CDR2)及SEQ ID NO:102 (CDR3)之胺基酸序列之重鏈CDR;或
xviii) 包含SEQ ID NO:103 (CDR1)、SEQ ID NO:104 (CDR2)及SEQ ID NO:105 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:106 (CDR1)、SEQ ID NO:107 (CDR2)及SEQ ID NO:108 (CDR3)之胺基酸序列之重鏈CDR;或
xix) 包含SEQ ID NO:109 (CDR1)、SEQ ID NO:110 (CDR2)及SEQ ID NO:111 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:112 (CDR1)、SEQ ID NO:113 (CDR2)及SEQ ID NO:114 (CDR3)之胺基酸序列之重鏈CDR;或
xx) 包含SEQ ID NO:115 (CDR1)、SEQ ID NO:116 (CDR2)及SEQ ID NO:117 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:118 (CDR1)、SEQ ID NO:119 (CDR2)及SEQ ID NO:120 (CDR3)之胺基酸序列之重鏈CDR;或
xxi) 包含SEQ ID NO:121 (CDR1)、SEQ ID NO:122 (CDR2)及SEQ ID NO:123 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:124 (CDR1)、SEQ ID NO:125 (CDR2)及SEQ ID NO:126 (CDR3)之胺基酸序列之重鏈CDR;或
xxii) 包含SEQ ID NO:127 (CDR1)、SEQ ID NO:128 (CDR2)及SEQ ID NO:129 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:130 (CDR1)、SEQ ID NO:131 (CDR2)及SEQ ID NO:132 (CDR3)之胺基酸序列之重鏈CDR;或
xxiii) 包含SEQ ID NO:133 (CDR1)、SEQ ID NO:134 (CDR2)及SEQ ID NO:135 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:136 (CDR1)、SEQ ID NO:137 (CDR2)及SEQ ID NO:138 (CDR3)之胺基酸序列之重鏈CDR;或
xxiv) 包含SEQ ID NO:139 (CDR1)、SEQ ID NO:140 (CDR2)及SEQ ID NO:141 (CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:142 (CDR1)、SEQ ID NO:143 (CDR2)及SEQ ID NO:144 (CDR3)之胺基酸序列之重鏈CDR。
如上文概述之抗體i)至xxiv)分別稱為B7H6#1、B7H6#2、B7H6#3、B7H6#4、B7H6#5、B7H6#6、B7H6#7、B7H6#8、B7H6#9、B7H6#10、B7H6#11、B7H6#12、B7H6#13、B7H6#14、B7H6#15、B7H6#16、B7H6#17、B7H6#18、B7H6#19、B7H6#20、B7H6#21、B7H6#22、B7H6#23及B7H6#24。本文提供序列表,其容易地允許鑑別針對本發明之專一性抗體之個別胺基酸序列。
在一些實施例中,本發明之抗B7H6抗體係嵌合、人類化、人類或最佳化抗體分子。在一些實施例中,抗體分子係單株抗體Fab、F(ab)2、Fv或scFv。在一些實施例中,本發明之抗B7H6抗體分子包含選自由IgG1、IgG2、IgG3、IgG4、IgM、IgA及IgE恆定區組成之群之重鏈恆定區。在一些實施例中,本發明之抗B7H6抗體分子之輕鏈恆定區係κ或λ。
在一些實施例中,本發明之抗B7H6抗體具有包含與SEQ ID NO:146、148、150、152、154、156、158、160、162、164、166、168、170、172、174、176、178、180、182、184、186、188、190及192中之任一者至少85%一致之胺基酸序列的重鏈可變結構域。較佳地,抗體分子具有包含SEQ ID NO: 146、148、150、152、154、156、158、160、162、164、166、168、170、172、174、176、178、180、182、184、186、188、190或192之胺基酸序列之重鏈可變結構域。
在一些實施例中,抗B7H6抗體分子具有包含與SEQ ID NO: 145、147、149、151、153、155、157、159、161、163、165、167、169、171、173、175、177、179、181、183、185、187、189及191中之任一者至少85%一致之胺基酸序列的輕鏈可變結構域。較佳地,抗體分子具有包含SEQ ID NO: 145、147、149、151、153、155、157、159、161、163、165、167、169、171、173、175、177、179、181、183、185、187、189及191之胺基酸序列之輕鏈可變結構域。
計算胺基酸序列一致性之方法為業內已知且在本文之說明書之定義部分中進一步論述。
在一些實施例中,抗B7H6抗體分子具有i) 包含SEQ ID NO:146之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:145之胺基酸序列之輕鏈可變結構域(B7H6#1),或ii) 包含SEQ ID NO: 148之胺基酸序列之重鏈可變結構域及包含SEQ ID NO: 147之胺基酸序列之輕鏈可變結構域(B7H6#2);或iii) 包含SEQ ID NO:150之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:149之胺基酸序列之輕鏈可變結構域(B7H6#3),或iv) 包含SEQ ID NO:152之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:151之胺基酸序列之輕鏈可變結構域(B7H6#4);或v) 包含SEQ ID NO:154之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:153之胺基酸序列之輕鏈可變結構域(B7H6#5);或vi) 包含SEQ ID NO:156之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:155之胺基酸序列之輕鏈可變結構域(B7H6#6);或vii) 包含SEQ ID NO:158之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:157之胺基酸序列之輕鏈可變結構域(B7H6#7);或viii) 包含SEQ ID NO:160之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:159 之胺基酸序列之輕鏈可變結構域(B7H6#8);或ix) 包含SEQ ID NO:162之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:161之胺基酸序列之輕鏈可變結構域(B7H6#9);或x) 包含SEQ ID NO:164之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:163之胺基酸序列之輕鏈可變結構域(B7H6#10);或xi) 包含SEQ ID NO:166之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:165之胺基酸序列之輕鏈可變結構域(B7H6#11);或xii) 包含SEQ ID NO:168之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:167之胺基酸序列之輕鏈可變結構域(B7H6#12);或xiii) 包含SEQ ID NO:170之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:169之胺基酸序列之輕鏈可變結構域(B7H6#13);或xiv) 包含SEQ ID NO:172之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:171之胺基酸序列之輕鏈可變結構域(B7H6#14);或xv) 包含SEQ ID NO:174之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:173之胺基酸序列之輕鏈可變結構域(B7H6#15);或xvi) 包含SEQ ID NO:176之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:175之胺基酸序列之輕鏈可變結構域(B7H6#16);或xvii) 包含SEQ ID NO:178之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:177之胺基酸序列之輕鏈可變結構域(B7H6#17);或xviii) 包含SEQ ID NO:180之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:179之胺基酸序列之輕鏈可變結構域(B7H6#18);或xix) 包含SEQ ID NO:182之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:181之胺基酸序列之輕鏈可變結構域(B7H6#19);或xx) 包含SEQ ID NO:184之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:183之胺基酸序列之輕鏈可變結構域(B7H6#20);或xxi) 包含SEQ ID NO:186之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:185之胺基酸序列之輕鏈可變結構域(B7H6#21);或xxii) 包含SEQ ID NO:188之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:187之胺基酸序列之輕鏈可變結構域(B7H6#22);或xxiii) 包含SEQ ID NO:190之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:189之胺基酸序列之輕鏈可變結構域(B7H6#23);或xxiv) 包含SEQ ID NO:192之胺基酸序列之重鏈可變結構域及包含SEQ ID NO:191之胺基酸序列之輕鏈可變結構域(B7H6#24)。
在一些實施例中,本發明之抗B7H6抗體係小鼠單株抗體。在本發明之上下文中,小鼠單株抗體包括VH及VL係自如下措施獲得之抗體:用人類B7H6蛋白對小鼠進行免疫、隨後選擇對人類B7H6具有特定親和性之適宜VH及VL序列結合、及然後藉由重組技術進一步接合該等VH及VL序列與源自小鼠(例如小鼠IgG2a)之恆定結構域;且其係藉由在宿主細胞中重組表現產生。本發明進一步涵蓋嵌合抗體,例如包含來自不同物種之可變及恆定區。在一些實施例中,本發明之抗體分子係嵌合抗體,其包含如上文所述源自小鼠之VH及VL結構域且進一步包含源自另一物種(例如人類、兔、大鼠、山羊、驢)之恆定結構域。在一些實施例中,嵌合抗體包含源自小鼠之VH及VL結構域且如上文所定義進一步經人類化或序列最佳化且進一步包含源自另一物種之恆定結構域。在一些實施例中,嵌合抗體包含源自包含人類IgG序列之轉基因動物(例如小鼠)之VH及VL結構域,因此包含人類VH及VL序列,且進一步包含源自另一物種之恆定結構域。在如上文概述之嵌合抗體之實施例之任一者中,重鏈恆定區係小鼠、人類、兔、大鼠、山羊或驢重鏈區。
在一些實施例中,本發明之抗B7H6抗體分子具有選自由IgG1、IgG2、IgG3、IgG4、IgM、IgA及IgE恆定結構域組成之群之恆定結構域。在較佳實施例中,抗B7H6抗體具有IgG2a之恆定結構域。在一些實施例中,抗B7H6抗體分子具有為κ或λ之輕鏈恆定結構域,較佳地輕鏈恆定結構域係κ輕鏈恆定結構域,較佳包含SEQ ID NO:247之序列。
本文提供之B7H6專一性抗體可藉由連接對不同抗原具有結合專一性之染料、藥物或另一分子用於標記、定位、鑑別或靶向表現B7H6之細胞(例如在ELISA分析、FACS分析、免疫組織學或諸如此類中)。
本發明之另一態樣提供經分離核酸分子,其編碼本發明之抗B7H6抗體分子之重鏈可變結構域及/或輕鏈可變結構域。
較佳地,核酸分子包含編碼SEQ ID NO: 146、148、150、152、154、156、158、160、162、164、166、168、170、172、174、176、178、180、182、184、186、188、190或192中之任一者之重鏈可變結構域的核苷酸序列。較佳地,核酸分子包含編碼SEQ ID NO: 145、147、149、151、153、155、157、159、161、163、165、167、169、171、173、175、177、179、181、183、185、187、189或191中之任一者之輕鏈可變結構域的核苷酸序列。
本發明之又一態樣提供表現載體,其含有包含編碼本發明之抗B7H6抗體分子之重鏈可變結構域及/或輕鏈可變結構域之核苷酸序列的DNA分子。
較佳地,除了核酸分子之外,表現載體亦包含較佳連接至該核酸分子之分別編碼重鏈之恆定結構域及/或輕鏈之恆定結構域的DNA分子、較佳分別編碼重鏈可變結構域及/或輕鏈可變結構域之DNA分子。
在尤佳實施例中,可使用兩種表現載體,其中一者用於表現重鏈,另一者用於表現輕鏈,然後可將該兩種表現載體轉染至宿主細胞中以表現重組蛋白。
較佳地,表現載體將為包含與至少一個調控序列可操作地連接之該(等)核酸分子之載體,其中該調控序列可為啟動子、增強子或終止子序列,且最佳異源啟動子、增強子或終止子序列。
在另一態樣中,本發明係關於宿主細胞,其具有編碼本發明之抗B7H6抗體分子之重鏈的表現載體及編碼本發明之抗B7H6抗體分子之輕鏈的表現載體。
根據尤佳實施例,該等宿主細胞係真核細胞,例如哺乳動物細胞。在另一實施例中,該等宿主細胞係細菌細胞。其他有用細胞係酵母細胞或其他真菌細胞。
適宜哺乳動物細胞包括例如CHO細胞、BHK細胞、HeLa細胞、COS細胞及諸如此類。然而,亦可使用業內用於表現異源蛋白之兩棲動物細胞、昆蟲細胞、植入細胞及任何其他細胞。
製造及純化方法 本發明進一步提供製造本發明之多重專一性結合蛋白之方法,該等方法通常包含以下步驟:
- 在允許形成本發明之結合蛋白之條件下培養包含表現載體之宿主細胞,該表現載體包含編碼本發明之結合蛋白之核酸;及
- 自培養物回收由宿主細胞表現之結合蛋白;及
- 視情況進一步純化及/或修飾及/或調配本發明之結合蛋白。
本發明進一步提供製造本發明之抗B7H6抗體之方法,該等方法通常包含以下步驟:
- 在允許形成抗體分子之條件下培養包含表現載體之宿主細胞,該表現載體包含編碼本發明之抗體分子之核酸;及
- 自培養物回收由宿主細胞表現之抗體分子;及
- 視情況進一步純化及/或修飾及/或調配本發明之抗體分子。
本發明之核酸可為例如包含編碼序列以及調節序列及視情況天然或人工內含子之DNA分子,或可為cDNA分子。其可具有其初始密碼子或可具有最佳化密碼子使用,該密碼子使用已特別地改造以用於在預期之宿主細胞或宿主生物體中表現。根據本發明之一個實施例,本發明之核酸呈如上所定義之基本上分離之形式。
本發明之核酸可以本身已知之方式(例如藉由自動化DNA合成及/或重組DNA技術)基於關於本文給出之本發明蛋白質之胺基酸序列的資訊來製備或獲得。
通常將本發明之核酸納入表現載體中,即當轉染至適宜宿主細胞或其他表現系統中時,可提供蛋白質表現之載體。
為了製造本發明之結合蛋白或抗體,熟習此項技術者可自業內熟知之多種表現系統中選擇,例如Kipriyanow及Le Gall,2004綜述之彼等。
表現載體包括質體、反轉錄病毒、黏粒、EBV源游離基因體及諸如此類。選擇與宿主細胞相容之表現載體及表現控制序列。編碼B7H6/CD3結合蛋白之第一抗原結合單元(例如,本發明之結合蛋白之B7H6專一性單鏈Fab或全長B7H6鏈)之核苷酸序列及編碼第二抗原結合單元(例如,本發明之結合蛋白之CD3專一性單鏈Fab或全長CD3鏈)之核苷酸序列可插入到單獨載體中。在某些實施例中,兩個DNA序列插入同一表現載體中。編碼B7H6抗體之輕鏈之核苷酸序列及編碼B7H6抗體之重鏈之核苷酸序列可插入單獨載體中。在某些實施例中,兩個DNA序列插入同一表現載體中。
方便之載體係編碼功能上完整之人類CH (恆定重鏈)免疫球蛋白序列之彼等,其具有經工程化之適當限制性位點,使得任何抗原結合單元(例如單鏈Fab序列)或任何重/輕鏈可變結構域可容易地插入及表現,如上所述。對於抗體重鏈,其可為但不限於任何IgG同型(IgG1、IgG2、IgG3、IgG4)或其他免疫球蛋白,包括等位基因變體。
重組表現載體亦可編碼信號肽,其促進全長CD3或B7H6鏈自宿主細胞之分泌或抗B7H6抗體之輕鏈/重鏈之分泌。編碼蛋白質鏈之DNA可選殖至載體中,使得信號肽符合讀框地連接至(linked in-frame to)成熟全長鏈DNA之胺基末端。信號肽可為免疫球蛋白信號肽或來自非免疫球蛋白之異源肽。或者,編碼本發明蛋白質之全長鏈之DNA序列可能已經含有信號肽序列。
除了編碼B7H6/CD3鏈之DNA序列或編碼B7H6抗體之重/輕鏈之DNA序列之外,重組表現載體通常亦攜帶調節序列,視情況異源調節序列,包括啟動子、增強子、終止及多聚腺苷酸化信號及控制蛋白鏈在宿主細胞中表現之其他表現控制元件。啟動子序列之實例(例示用於在哺乳動物細胞中表現)係源自CMV之啟動子及/或增強子(例如CMV猿猴病毒40 (SV40)啟動子/增強子)、腺病毒(例如腺病毒主要晚期啟動子(AdMLP))、多瘤及強哺乳動物啟動子,例如天然免疫球蛋白及肌動蛋白啟動子。多聚腺苷酸化信號之實例係BGH聚、SV40晚期或早期聚A;或者,可使用免疫球蛋白基因等之3´UTR。
重組表現載體亦可攜帶調節載體在宿主細胞中複製之序列(例如複製起點)及選擇標記物基因。編碼具有第一抗原結合單元(單鏈Fab及Fc結構域)或其抗原結合部分之全長鏈及/或具有第二抗原結合單元(單鏈Fab及Fc結構域)或其抗原結合部分之全長鏈之核酸分子、及包含該等DNA分子之載體可根據業內熟知之轉染方法(包括脂質體介導之轉染、聚陽離子介導之轉染、原生質體融合、顯微注射、磷酸鈣沈澱、電穿孔或藉由病毒載體之轉移)引入宿主細胞(例如細菌細胞或高等真核細胞,例如哺乳動物細胞)中。
較佳地,編碼本發明蛋白質之B7H6及CD3鏈之DNA分子存在於共轉染至宿主細胞(較佳哺乳動物細胞)中之兩種表現載體上。
可用作用於表現之宿主之哺乳動物細胞系為業內熟知,且尤其包括中國倉鼠卵巢(CHO)細胞、NS0、SP2/0細胞、HeLa細胞、幼小倉鼠腎(BHK)細胞、猴腎細胞(COS)、人類癌細胞(例如Hep G2及A-549細胞)、3T3細胞或任何此類細胞系之衍生物/後代。可使用其他哺乳動物細胞(包括但不限於人類、小鼠、大鼠、猴及齧齒動物細胞系)、或其他真核細胞(包括但不限於酵母、昆蟲及植物細胞)、或原核細胞(例如細菌)。
本發明之蛋白質係藉由培養宿主細胞一段足以允許蛋白質在宿主細胞中表現之時間來產生。蛋白質分子較佳作為分泌之多肽自培養基中回收,或若例如在無分泌信號之情況下表現,則可自宿主細胞溶解物中回收。需要使用用於重組蛋白及宿主細胞蛋白之標準蛋白純化方法以獲得實質上同質之蛋白製劑之方式純化蛋白質分子。舉例而言,可用於獲得本發明蛋白質分子之目前最佳狀態之純化方法包括自培養基或溶解物中去除細胞及/或顆粒細胞碎片作為第一步驟。然後自污染可溶性蛋白質、多肽及核酸,例如藉由在免疫親和或離子交換管柱上分級分離、乙醇沈澱、反相HPLC、Sephadex層析、二氧化矽或陽離子交換樹脂上層析純化蛋白質。作為獲得蛋白質分子製劑之方法之最後一步,可乾燥、例如凍乾純化之蛋白質分子,如下所述用於治療應用。
本發明係關於對至少兩種不同靶標具有結合專一性之結合蛋白。關於本發明,結合分子源自抗體。製備結合分子之技術包括但不限於具有不同專一性之兩條免疫球蛋白鏈之重組共表現(參見Milstein及Cuello,Nature 305: 537 (1983))、WO 93/08829及Traunecker等人,EMBO J. 10: 3655 (1991)),及「隆凸於孔洞中(knob-in-hole)」工程化(參見,例如,美國專利第5,731,168號;Atwell等人,JMB, 1997, 270, 26-35)。
亦可藉由以下方式來製備本發明之結合蛋白:工程化靜電轉向效應(electrostatic steering effect)用於製備抗體Fc-異源二聚體分子(WO 2009/089004A1);使兩個或更多個抗體或片段交聯(例如,參見美國專利第4,676,980號,及Brennan等人,Science, 229: 81 (1985));使用白胺酸拉鍊以產生雙專一性蛋白(例如,參見Kostelny等人,Immunol., 148(5): 1547-1553 (1992));使用「雙價抗體」技術用於製備雙專一性抗體片段(例如,參見Hollinger等人,Proc. Natl. Acad. Sci. USA, 90:6444- 6448 (1993));及使用單鏈Fv (sFv)二聚體(例如,參見Gruber等人,Immunol., 152:5368 (1994));及製備三專一性抗體,如(例如) Tutt等人 Immunol. 147: 60 (1991)中所述。
本文揭示之組合物(例如多重專一性結合蛋白及抗B7H6抗體)及方法涵蓋具有指定序列或與其實質上一致或相似之序列(例如與指定序列至少85%、90%、95%一致或更高之序列)之多肽及核酸。在胺基酸序列之背景下,術語「實質上一致」在本文中用於指第一胺基酸含有足夠或最少數量之i) 與第二胺基酸序列中之所比對胺基酸殘基一致之胺基酸殘基,或ii) 第二胺基酸序列中之所比對胺基酸殘基之保守取代,使得第一及第二胺基酸序列可具有共同結構結構域及/或共同功能活性。舉例而言,與參考序列(例如本文所提供之序列)具有至少約85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%一致性之含有共同結構結構域之胺基酸序列。在核苷酸序列之背景中,術語「實質上一致」在本文中用於指第一核酸序列,其含有足夠或最小數量之與第二核酸序列中比對之核苷酸一致之核苷酸,使得第一及第二核苷酸序列編碼具有共同功能活性之多肽,或編碼共同結構多肽結構域或共同功能多肽活性之多肽,例如,與參考序列具有至少約85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%一致性之核苷酸序列。
本發明之核酸分子包括但不限於編碼序列表中所示之多肽序列之DNA分子。此外,本發明亦係關於在高嚴格性結合及洗滌條件下與編碼序列表中所示之多肽序列之DNA分子雜交的核酸分子,如WO 2007/042309中所定義。較佳分子(自mRNA角度)係與本文所述DNA分子之一具有至少75%或80% (較佳至少85%、更佳至少90%炔最佳至少95%)同源性或序列一致性之彼等。舉例而言,鑒於在真核細胞中表現抗體,序列表中所示之DNA序列已經設計以與真核細胞中之密碼子使用相匹配。若期望在大腸桿菌中表現抗體,則可改變該等序列以匹配大腸桿菌密碼子使用。本發明DNA分子之變體可以若干不同方法構築,如例如WO 2007/042309中所述。
本發明之蛋白質可具有修飾之N-末端序列,例如缺失一或多個N-末端胺基酸,或交換例如第一個N-末端胺基酸(例如麩胺酸鹽至丙胺酸),以最佳化分子,以便藉由使用某些表現系統(例如特定載體或宿主細胞)表現,或以包涵體或以可溶形式表現,或分泌至培養基或周質空間中或包含在細胞內,或產生更同質之產物。本發明之多肽可具有修飾之C-末端序列(例如額外丙胺酸),及/或在C-末端部分或在任何框架區內之其他限定位置之進一步胺基酸交換,如例如在WO2012/175741、WO2011/075861或WO2013/024059中所解釋,以例如進一步增強該等多肽之穩定性或降低其免疫原性。
為免生疑問,關於本文所述之醫藥組合物、套組、治療方法、醫學用途、組合、投與方法及劑量之所有實施例皆考慮用於本文所述之任何多重專一性結合蛋白,單獨或與其他治療劑組合(如下文更詳細說明)。
醫藥組合物、投與方法、劑量
本發明進一步係關於用於治療疾病(如下文更詳細說明)之醫藥組合物,其中該等組合物包含至少一種本發明之多重專一性結合蛋白。本發明進一步涵蓋使用至少一種本發明之多重專一性結合蛋白或如下所述之醫藥組合物治療疾病(如下文更詳細說明)之方法,且進一步涵蓋藉由使用本發明之該結合蛋白或醫藥組合物製備用於治療該疾病之藥劑。
本發明之結合蛋白(例如B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#6/CD3#1、B7H6#7/CD3#1、B7H6#8/CD3#1、B7H6#9/CD3#1、B7H6#10/CD3#1、B7H6#11/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者,如由表1中所示之序列所定義)及/或包含其之組合物可根據欲使用之特定醫藥調配物或組合物以任何適宜方式投與給有需要之患者。因此,本發明之結合蛋白及/或包含其之組合物可(例如)靜脈內(i.v.)、皮下(s.c.)、肌內(i.m.)、腹膜內(i.p.)、經皮、經口、舌下(例如以舌下錠劑、置於舌下並穿過黏膜吸收至舌下之毛細管網中的噴霧或滴劑之形式)、經鼻(內) (例如以鼻噴霧形式及/或作為氣溶膠)、局部、藉助栓劑、藉由吸入或任何其他適宜方式以有效量或劑量投與。結合蛋白可藉由輸注、濃注或注射投與。在較佳實施例中,投與係藉由靜脈內輸注或皮下注射進行。
本發明之結合蛋白及/或包含其之組合物根據適於治療及/或緩和欲治療或緩和之疾病、病症或病況之治療方案投與。臨床醫師通常能夠根據諸如欲治療或緩和之疾病、病症或病況、疾病之嚴重程度、其症狀之嚴重程度、欲使用之本發明之專一性結合蛋白、欲使用之特定投與途徑及醫藥調配物或組合物、年齡、性別、體重、飲食、患者之一般狀況及臨床醫師熟知之類似因素等因素確定適宜治療方案。通常,治療方案將包含以治療有效量或劑量投與一或多種本發明之結合蛋白、或一或多種包含其之組合物。
通常,為了治療及/或緩和本文提及之疾病、病症及病況,且根據欲治療之具體疾病、病症或病況、欲使用之本發明之專一性結合蛋白之效力、所使用之具體投與途徑及具體醫藥調配物或組合物,本發明之結合蛋白通常以介於0.005與20.0 mg/公斤體重之量及較佳介於0.05與10.0 mg/kg/劑量之間之劑量連續(例如藉由輸注)或更佳作為單一劑量(例如每週兩次、每週一次、每兩週或三週一次或每月一次劑量;參見下文)投與,但可顯著變化,尤其取決於前文提及之參數。因此,在一些情形下,使用低於上文給出之最低劑量可能已足矣,而在其他情形下可能不得不超出上限。當大量投與時,建議將其分成在一定時段(例如兩天或更多天)內分佈之多個較小劑量。
根據本發明之專一性結合蛋白及其特定藥物動力學及其他性質,其可每日、每第二天、每第三天、每第四天、每第五天或每第六天、每週、每兩週或每三週一次、每月及諸如此類投與。投與方案可包括長期治療。「長期」意指至少兩週,且較佳幾個月或幾年之持續時間。
本發明之多重專一性結合蛋白及包含其之組合物之效能可根據所涉及之具體疾病使用任何適宜活體外分析、基於細胞之分析、活體內分析及/或本身已知之動物模型或其任何組合來測試。適宜分析及動物模型對於熟練人員將為清楚的,且例如包括在以下實例中使用之分析及動物模型。
調配物
對於醫藥用途,本發明之結合蛋白可調配為醫藥製劑,其包含(i) 至少一種本發明之結合蛋白(例如B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#6/CD3#1、B7H6#7/CD3#1、B7H6#8/CD3#1、B7H6#9/CD3#1、B7H6#10/CD3#1、B7H6#11/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)及(ii) 至少一種醫藥上可接受之載劑、稀釋劑、賦形劑、佐劑及/或穩定劑,及(iii) 視情況一或多種其他藥理學活性多肽及/或化合物。
「醫藥上可接受之」意指當投與個體時,各別材料不顯示任何生物學或其他不期望之效應,且不以有害之方式與包含其之醫藥組合物之任何其他組分(例如,醫藥活性成分)相互作用。具體實例可參見標準手冊,例如Remington's Pharmaceutical Sciences, 第18版, Mack Publishing Company, USA (1990)。
舉例而言,本發明之結合蛋白可以本身已知之用於習用抗體及抗體片段及其他醫藥活性蛋白之任何方式調配及投與。因此,根據又一實施例,本發明係關於醫藥組合物或製劑,其含有至少一種本發明之結合蛋白及至少一種醫藥上可接受之載劑、稀釋劑、賦形劑、佐劑及/或穩定劑、及視情況一或多種其他藥理學活性物質,其呈凍乾或其他乾燥調配物或水性或非水性溶液或懸浮液形式。
用於非經腸投與(例如靜脈內、肌內、皮下注射或靜脈內輸注)之醫藥製劑可為例如包含活性成分之無菌溶液、混懸液、分散液、乳液或粉劑,且其視情況在進一步溶解或稀釋步驟後適於輸注或注射。用於該等製劑之適宜載劑或稀釋劑例如包括(但不限於)無菌水及醫藥上可接受之水性緩衝液及溶液,例如生理磷酸鹽緩衝鹽水、林格氏溶液(Ringer's solutions)、右旋糖溶液及漢克氏溶液(Hank's solution);水油;甘油;乙醇;二醇,例如丙二醇;以及礦物油、動物油及植物油,例如花生油、大豆油,以及其適宜混合物。
本發明之結合蛋白之溶液亦可含有防腐劑以防止微生物之生長,例如抗細菌劑及抗真菌劑,例如對羥基苯甲酸酯、對羥苯甲酸酯、氯丁醇、酚、山梨酸、硫柳汞、(乙二胺四乙酸)之鹼金屬鹽及諸如此類。在許多情形下,較佳應包括等滲劑,例如糖、緩衝液或氯化鈉。視情況,可使用乳化劑及/或分散劑。可(例如)藉由形成脂質體、藉由維持所需粒徑(在分散液之情形中)或藉由使用表面活性劑來維持適當流動性。亦可添加其他延緩吸收之試劑,例如單硬脂酸鋁及明膠。可將溶液填充至注射小瓶、安瓿、輸液瓶及諸如此類中。
在所有情形下,最終劑型應無菌、流動且在製造及儲存條件下穩定。無菌可注射溶液係藉由以下方式進行製備:將所需量之活性化合物納入視需要具有上文所列舉其他成分之適當溶劑中,隨後過濾滅菌。在用於製備無菌可注射溶液之無菌粉劑之情形下,較佳製備方法係真空乾燥及冷凍乾燥技術,此產生存於先前經無菌過濾之溶液中之活性成分加上任一額外期望成分之粉劑。
通常,水溶液或懸浮液將較佳。通常,治療性蛋白(例如本發明之結合蛋白)之適宜調配物係緩衝溶液,例如包括適宜濃度(例如0.001至400 mg/ml、較佳0.005至200 mg/ml、更佳0.01至200 mg/ml、更佳1.0 - 100 mg/ml,例如1.0 mg/ml (i.v.
投與)或100 mg/ml (s.c.
投與))之蛋白及水性緩衝液的溶液,該等緩衝液係例如:
- 磷酸鹽緩衝鹽水,pH 7.4,
- 其他磷酸鹽緩衝液,pH 6.2至8.2,
- 乙酸鹽緩衝液,pH 3.2至7.5,較佳pH 4.8至5.5
- 組胺酸緩衝液,pH 5.5至7.0,
- 琥珀酸鹽緩衝液,pH 3.2至6.6,及
- 檸檬酸鹽緩衝液,pH 2.1至6.2,
及視情況,鹽(例如NaCl)及/或糖(例如蔗糖及海藻糖)及/或其他多元醇(例如甘露醇及甘油)用於提供溶液之等滲性。
另外,該等溶液中可包括其他試劑(例如清潔劑,例如0.02 % TWEEN™ 20或TWEEN ™-80)。用於皮下應用之調配物可包括顯著更高濃度之本發明之抗體,例如高達100 mg/ml或甚至高於100 mg/ml。然而,熟習此項技術者將清楚,如上給出之成分及其量僅代表一種較佳選擇。其替代方案及變化對於熟練人員而言係立刻顯而易見的,或可自上述揭示內容開始容易地想到。上述調配物可視情況以欲在溶液中、例如在注射用水(WFI)中重構之凍乾調配物之形式提供。
根據本發明之又一態樣,本發明之結合蛋白可與用於蛋白質投與之裝置(例如注射器、注射筆、微型幫浦或其他裝置)組合使用。
治療方法 本發明之又一態樣提供治療癌症之方法,其包含向有需要之患者投與治療有效量之本發明之結合蛋白。
本發明之又一態樣提供本發明之結合蛋白,其用於治療癌症之方法中。
本發明之又一態樣係本發明之結合蛋白之用途,其用於製備用於治療癌症之醫藥組合物。
為免生疑問,本發明之醫學用途態樣可包含任何如上文所述之本發明之專一性結合蛋白(例如B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#6/CD3#1、B7H6#7/CD3#1、B7H6#8/CD3#1、B7H6#9/CD3#1、B7H6#10/CD3#1、B7H6#11/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)。
不論侵襲之組織病理類型或階段如何,如本文所用之術語「癌症」意欲包括所有類型之癌性生長或致癌過程、轉移性組織或惡性轉化細胞、組織或器官。
可使用本文所述多重專一性結合蛋白抑制其生長之實例性癌症係任何表現B7H6之腫瘤,較佳結腸直腸癌(例如轉移性結腸直腸癌,mCRC)、非小細胞肺癌(NSCLC)、頭頸部鱗狀細胞癌(HNSCC)。
可使用本文所述多重專一性結合蛋白抑制其生長之實例性癌症係任何表現B7H6之腫瘤,包括(但不限於) T細胞淋巴瘤、骨髓性白血病、乳癌;卵巢癌、口腔鱗癌及胃腸癌。胃腸癌包括(但不限於)食管癌(例如胃食管接合部癌)、胃(stomach ,gastric)癌、肝細胞癌、膽道癌(例如膽管癌)、膽囊癌、胰臟癌或結腸直腸癌(CRC)。
在一些實施例中,以下癌症、腫瘤及其他增殖性疾病可用本發明之多重專一性結合蛋白治療:頭頸癌,較佳HNSCC;肺癌;較佳NSCLC;乳癌;甲狀腺癌;子宮頸癌;卵巢癌;子宮內膜癌;肝癌(肝母細胞瘤或肝細胞癌);胰臟癌;前列腺癌;胃肉瘤;胃腸基質瘤、食管癌;結腸癌;結腸直腸癌;腎癌;皮膚癌;腦瘤;神經膠母細胞瘤;非霍奇金氏淋巴瘤(Non-Hodgkin lymphomas) (T或B細胞淋巴瘤);白血病(慢性或急性骨髓性白血病、非淋巴球性白血病)或多發性骨髓瘤。
在本發明之較佳實施例中,癌症係mCRC。
上文提及之以其在體內之特定位置/來源為特徵之所有癌症、腫瘤、贅瘤等意欲包括原發性腫瘤及由其衍生之轉移性腫瘤。
若患者患有特徵在於具有B7H6高表現之癌症,則該患者更有可能對本發明之結合蛋白(如本文所述)之治療有反應。因此,在一些實施例中,欲用本發明之結合蛋白治療之癌症係具有高B7H6表現之癌症,例如B7H6表現高於患有相同類型之表現B7H6之癌症之患者群體之癌細胞中之平均表現。
本發明之結合蛋白可在第一線、第二線或任何其他線治療及維持治療之情況下用於治療方案中。
本發明之結合蛋白可用於預防、短期或長期治療上文提及之疾病,視情況亦與放射療法、一或多種額外治療劑及/或手術組合。
在較佳實施例中,本發明之蛋白質與PD-1拮抗劑(例如抗PD-1抗體或抗PDL-1抗體)組合用於治療癌症。較佳地,該抗PD-1抗體選自由以下組成之群:派姆單抗(pembrolizumab)、尼沃魯單抗(nivolumab)、匹利珠單抗(pidilizumab)、PD1-1、PD1-2、PD1-3、PD1-4及PD1-5,如本文所述(如下表A中之序列所定義)及WO2017/198741 (以引用方式併入本文中)中所述。較佳地,該抗PDL-1抗體選自由以下組成之群:阿替珠單抗(atezolizumab)、阿維魯單抗(avelumab)及德瓦魯單抗(durvalumab)。在尤佳實施例中,本發明之結合蛋白(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)與PD1-1組合用於治療癌症。在尤佳實施例中,本發明之結合蛋白(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)與PD1-2組合用於治療癌症。在尤佳實施例中,本發明之結合蛋白(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)與PD1-3組合用於治療癌症。在尤佳實施例中,本發明之結合蛋白(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)與PD1-4組合用於治療癌症。在尤佳實施例中,本發明之結合蛋白(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)。
表A:抗PD1抗體PD1-1、PD1-2、PD1-3、PD1-4、PD1-5之重鏈及輕鏈序列之胺基酸序列及SEQ ID NO.
| SEQ ID 號: | 序列之簡單說明 | 序列 |
| SEQ ID NO: 331 | PD1-1 HC | EVMLVESGGGLVQPGGSLRLSCTASGFTFSASAMSWVRQAPGKGLEWVAYISGGGGDTYYSSSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARHSNVNYYAMDYWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLG |
| SEQ ID NO: 332 | PD1-1 LC | EIVLTQSPATLSLSPGERATMSCRASENIDTSGISFMNWYQQKPGQAPKLLIYVASNQGSGIPARFSGSGSGTDFTLTISRLEPEDFAVYYCQQSKEVPWTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| SEQ ID NO: 333 | PD1-2 HC | EVMLVESGGGLVQPGGSLRLSCTASGFTFSASAMSWVRQAPGKGLEWVAYISGGGGDTYYSSSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARHSNPNYYAMDYWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLG |
| SEQ ID NO: 334 | PD1-2 LC | EIVLTQSPATLSLSPGERATMSCRASENIDTSGISFMNWYQQKPGQAPKLLIYVASNQGSGIPARFSGSGSGTDFTLTISRLEPEDFAVYYCQQSKEVPWTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| SEQ ID NO: 335 | PD1-3 HC | EVMLVESGGGLVQPGGSLRLSCTASGFTFSKSAMSWVRQAPGKGLEWVAYISGGGGDTYYSSSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARHSNVNYYAMDYWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLG |
| SEQ ID NO: 336 | PD1-3 LC | EIVLTQSPATLSLSPGERATMSCRASENIDVSGISFMNWYQQKPGQAPKLLIYVASNQGSGIPARFSGSGSGTDFTLTISRLEPEDFAVYYCQQSKEVPWTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| SEQ ID NO: 337 | PD1-4 HC | EVMLVESGGGLVQPGGSLRLSCTASGFTFSKSAMSWVRQAPGKGLEWVAYISGGGGDTYYSSSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARHSNVNYYAMDYWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLG |
| SEQ ID NO: 338 | PD1-4 LC | EIVLTQSPATLSLSPGERATMSCRASENIDVSGISFMNWYQQKPGQAPKLLIYVASNQGSGIPARFSGSGSGTDFTLTISRLEPEDFAVYYCQQSKEVPWTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| SEQ ID NO: 339 | PD1-5 HC | EVMLVESGGGLVQPGGSLRLSCTASGFTFSKSAMSWVRQAPGKGLEWVAYISGGGGDTYYSSSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARHSNVNYYAMDYWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLG |
| SEQ ID NO: 340 | PD1-5 LC | EIVLTQSPATLSLSPGERATMSCRASENIDVSGISFMNWYQQKPGQAPKLLIYVASNQGSGIPARFSGSGSGTDFTLTISRLEPEDFAVYYCQQSKEVPWTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
根據該等較佳實施例及本發明之任何其他態樣,抗體PD1-1、PD1-2、PD1-3、PD1-4及PD1-5係如WO2017/198741中揭示之抗體分子,且由如上表A中所示之序列定義。
因此,PD1-1具有包含SEQ ID NO:331之胺基酸序列之重鏈及包含SEQ ID NO:332之胺基酸序列之輕鏈;
PD1-2具有包含SEQ ID NO:333之胺基酸序列之重鏈及包含SEQ ID NO:334之胺基酸序列之輕鏈;
PD1-3具有包含SEQ ID NO:335之胺基酸序列之重鏈及包含SEQ ID NO:336之胺基酸序列之輕鏈;
PD1-4具有包含SEQ ID NO:337之胺基酸序列之重鏈及包含SEQ ID NO:338之胺基酸序列之輕鏈;且
PD1-5具有包含SEQ ID NO:339之胺基酸序列之重鏈及包含SEQ ID NO:340之胺基酸序列之輕鏈。
上文亦包括本發明之結合蛋白在藉由向有需要之患者投與治療有效劑量來治療上述疾病之各種方法中之用途、以及該等結合蛋白用於製造用於治療該等疾病之藥劑之用途、以及包括本發明之該等結合蛋白之醫藥組合物、以及包括本發明之該等結合蛋白之藥劑之製備及/或製造及諸如此類。
與其他活性物質或治療之組合 本發明之結合蛋白(例如B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#6/CD3#1、B7H6#7/CD3#1、B7H6#8/CD3#1、B7H6#9/CD3#1、B7H6#10/CD3#1、B7H6#11/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)可單獨使用或與其他癌症療法(例如手術、放射療法、化學療法、靶向療法、免疫療法或其組合)組合使用。舉例而言,本發明之結合蛋白可與一或多種額外治療劑組合、具體而言與細胞毒性或細胞生長抑制性化學治療劑、抑制血管生成之治療活性化合物、信號轉導路徑抑制劑(例如EGFR抑制劑、免疫調節劑、免疫檢查點抑制劑、有絲分裂檢查點抑制劑或激素治療劑)組合用於治療癌症。
額外治療劑可視情況作為同一醫藥製劑之組分與B7H6/CD3結合蛋白投與同時、或在其之前或之後投與。
可與本發明之結合分子組合投與之細胞生長抑制及/或細胞毒性活性物質包括(但不限於)激素類似物及抗激素、芳香酶抑制劑、LHRH激動劑及拮抗劑、生長因子(諸如血小板源生長因子(PDGF)、纖維母細胞生長因子(FGF)、血管內皮生長因子(VEGF)、表皮生長因子(EGF)、胰島素樣生長因子(IGF)、人類表皮生長因子(HER,例如HER2、HER3、HER4)及肝細胞生長因子(HGF)等生長因子)抑制劑,抑制劑係例如(抗)生長因子抗體、(抗)生長因子受體抗體及酪胺酸激酶抑制劑,例如西妥昔單抗(cetuximab)、吉非替尼(gefitinib)、阿法替尼(afatinib)、尼達尼布(nintedanib)、伊馬替尼(imatinib)、拉帕替尼(lapatinib)、伯舒替尼(bosutinib)及曲妥珠單抗(trastuzumab);抗代謝物(例如抗葉酸劑,例如胺甲喋呤(methotrexate)、雷替曲塞(raltitrexed),嘧啶類似物,例如5-氟尿嘧啶(5-FU)、FOLFOX (醛葉酸、5-FU及奧沙利鉑(oxaliplatin)之組合方案)、FOLFIRI (醛葉酸、5-FU及伊立替康(irinotecan)之組合方案)、吉西他濱、伊立替康、多柔比星(doxorubicin)、TAS-102、卡培他濱(capecitabine)及吉西他濱,嘌呤及腺苷類似物,例如巰嘌呤、硫鳥嘌呤、克拉屈濱(cladribine)及噴司他汀(pentostatin)、阿糖胞苷(cytarabine) (ara C)、氟達拉濱(fludarabine));抗腫瘤抗生素(例如蒽環);鉑衍生物(例如順鉑(cisplatin)、奧沙利鉑、卡鉑(carboplatin));烷基化劑(例如雌氮芥(estramustin)、二氯甲基二乙胺(meclorethamine)、美法侖(melphalan)、氮芥苯丁酸(chlorambucil)、白消安(busulphan)、達卡巴嗪(dacarbazin)、環磷醯胺(cyclophosphamide)、異環磷醯胺(ifosfamide)、替莫唑胺(temozolomide)、亞硝基脲(例如卡莫司汀(carmustin)及洛莫司汀(lomustin))、噻替派(thiotepa));抗有絲分裂劑(例如長春花生物鹼(Vinca alkaloid),例如長春鹼(vinblastine)、長春地辛(vindesin)、長春瑞濱(vinorelbin)及長春新鹼(vincristine);及紫杉烷,例如太平洋紫杉醇(paclitaxel)、多西他賽(docetaxel));血管生成抑制劑(包括貝伐珠單抗(bevacizumab)、雷莫蘆單抗(ramucirumab)及阿柏西普(aflibercept))、微管蛋白抑制劑;DNA合成抑制劑、PARP抑制劑、拓樸異構酶抑制劑(例如表鬼臼毒素(epipodophyllotoxin),例如依託泊苷(etoposide)及凡畢複(etopophos)、替尼泊苷(teniposide)、安吖啶(amsacrin)、托泊替康(topotecan)、伊立替康、米托蒽醌(mitoxantrone))、絲胺酸/蘇胺酸激酶抑制劑(例如PDK1抑制劑、Raf抑制劑、A-Raf抑制劑、B-Raf抑制劑、C-Raf抑制劑、mTOR抑制劑、mTORC1/2抑制劑、PI3K抑制劑、PI3Kα抑制劑、雙重mTOR/PI3K抑制劑、STK33抑制劑、AKT抑制劑、PLK1抑制劑(例如伏拉塞替(volasertib))、CDK抑制劑(包括CDK9抑制劑、極光激酶抑制劑)、酪胺酸激酶抑制劑(例如PTK2/FAK抑制劑)、蛋白蛋白相互作用抑制劑、MEK抑制劑、ERK抑制劑、FLT3抑制劑、BRD4抑制劑、IGF-1R抑制劑、Bcl-xL抑制劑、Bcl-2抑制劑、Bcl-2/Bcl-xL抑制劑、ErbB受體抑制劑、BCR-ABL抑制劑、ABL抑制劑、Src抑制劑、雷帕黴素(rapamycin)類似物(例如依維莫司(everolimus)、替西羅莫司(temsirolimus)、地磷莫司(ridaforolimus)、西羅莫司(sirolimus))、雄激素合成抑制劑、雄激素受體抑制劑、DNMT抑制劑、HDAC抑制劑、ANG1/2抑制劑、CYP17抑制劑、放射性醫藥、免疫治療劑,例如免疫檢查點抑制劑(例如CTLA4、PD1、PD-L1、LAG3及TIM3結合分子 / 免疫球蛋白,例如伊匹單抗、尼沃魯單抗、派姆單抗),及各種化學治療劑,例如氨磷汀(amifostin)、阿那格雷(anagrelid)、氯膦酸(clodronat)、非爾司亭(filgrastin)、干擾素、干擾素α、甲醯四氫葉酸(leucovorin)、利妥昔單抗(rituximab)、丙卡巴肼(procarbazine)、左旋咪唑(levamisole)、美司鈉(mesna)、米托坦(mitotane)、帕米膦酸(pamidronate)及卟菲爾鈉(porfimer);蛋白酶體抑制劑(例如硼替佐米(Bortezomib));Smac及BH3模擬物;恢復p53功能之藥劑,包括mdm2-p53拮抗劑;Wnt/β-連環蛋白信號傳導路徑抑制劑;及/或週期蛋白依賴性激酶9抑制劑。
尤佳者係用本發明之結合分子與一或多種免疫治療劑之組合的治療,該等免疫治療劑包括抗PD-1及抗PD-L1劑及抗LAG3劑:實例性抗PD1劑包括(但不限於)抗PD-1抗體PDR-001、派姆單抗、尼沃魯單抗、匹利珠單抗及PD1-1、PD1-2、PD1-3、PD1-4及PD1-5,如本文(表A)及WO2017/198741中所揭示。實例性抗PDL-1劑包括(但不限於)阿替珠單抗、阿維魯單抗及德瓦魯單抗。在較佳實施例中,本發明之結合分子(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)與PD1-1組合。在較佳實施例中,本發明之結合分子(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)與PD1-2組合。在較佳實施例中,本發明之結合分子(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)與PD1-3組合。在較佳實施例中,本發明之結合分子(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)與PD1-4組合。在較佳實施例中,本發明之結合分子(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)與PD1-5組合。
在某些實施例中,額外治療劑可為其他免疫治療劑,例如以下各項之調節劑:TIM-1、TIM-3、TIM-4、PD-L2、LAG3、CTLA-4、半乳糖凝集素9、半乳糖凝集素-1、CD69、CD113、GPR56、CD48、GARP、CAECAM-1、BTLA、TIGIT、CD160、LAIR1、2B4、CEACAM、CD39、TGFβ、IL-10、Fas配體、ICOS、B7家族(B7-1、B7-2、B7-H1 (PDL-1)、B7-DC (PD-L2)、B7-H2 (ICOS-L)、B7-H3、B7-H4、B7-H5 (VISTA))、gp49B、PIR-B、KIR家族受體、SIRPα(CD47)、ILT-2、ILT-4、IDO、CD39、精胺酸酶、CD73 HHLA2、嗜乳脂蛋白或A2aR。
在一些實施例中,額外免疫治療劑係結合至同源TNF受體家族成員之分子之TNF家族的成員,其包括CD40及CD40L、OX-40、OX-40L、CD70、CD27L、CD30、CD30L、4-lBBL、CD137、CD137/FAP、GITR、TRAIL/Apo2-L、TRAILR1/DR4、TRAILR2/DR5、TRAILR3、TRAILR4、OPG、RANK、RANKL、TWEAKR/Fn14、TWEAK、BAFFR、EDAR、XEDAR、TACI、APRIL、BCMA、LIGHT、DcR3、HVEM、VEGI/TLlA、TRAMP/DR3、EDAR、EDAl、XEDAR、EDA2、TNFRl、淋巴毒素α/TNFβ、TNFR2、TNFα、LTβR、淋巴毒素α1β2、FAS、FASL、RELT、DR6、TROY、NGFR。較佳地,額外免疫治療劑係CD137/FAP。
在一些實施例中,額外免疫治療劑選自(i)抑制T細胞活化之細胞介素(例如IL-6、IL-10、TGF-B、VEGF;「免疫抑制細胞介素」)之拮抗劑及/或(ii)刺激T細胞活化之細胞介素及/或刺激免疫反應之細胞介素(例如IL2)之激動劑,例如用於治療增殖性疾病,例如癌症。
在一些實施例中,額外免疫治療劑係刺激T細胞活化之蛋白質之激動劑,例如CD28、GITRL、OX40L、CD27及CD28H或STING激動劑。
在一些實施例中,額外治療劑係溶瘤病毒,包括(但不限於)源自牛痘病毒、腺病毒(AdV)、單純疱疹病毒(HSV1或HSV2)、裡奧病毒(reovirus)、黏液瘤病毒(MYXV)、脊髓灰白質炎病毒、水疱性口炎病毒(VSV)、馬拉巴病毒(Maraba virus)、水痘-帶狀疱疹病毒、麻疹病毒(MV)或新城雞瘟病毒(NDV)之溶瘤病毒。
套組 本發明亦涵蓋套組,其包含至少一種本發明之多重專一性結合蛋白(例如B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#6/CD3#1、B7H6#7/CD3#1、B7H6#8/CD3#1、B7H6#9/CD3#1、B7H6#10/CD3#1、B7H6#11/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)及視情況一或多種選自由用於治療上述疾病及病症之其他藥物組成之群的其他組分。
在一個實施例中,套組包括呈單位劑型之含有有效量之本發明之結合蛋白之組合物。
本發明亦涵蓋套組,其包含至少一種本發明之多重專一性結合蛋白及一或多種選自由用於治療上述疾病及病症之其他藥物組成之群之其他組分。
在一個實施例中,套組包括呈單位劑型之含有有效量之本發明之多重專一性結合蛋白(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)的組合物。在另一實施例中,套組包括呈單位劑型之含有有效量之本發明之多重專一性結合蛋白(較佳B7H6#1/CD3#1、B7H6#2/CD3#1、B7H6#3/CD3#1、B7H6#4/CD3#1、B7H6#5/CD3#1、B7H6#12/CD3#1、B7H6#13/CD3#1、B7H6#14/CD3#1、B7H6#15/CD3#1、B7H6#16/CD3#1、B7H6#17/CD3#1、B7H6#18/CD3#1、B7H6#19/CD3#1、B7H6#20/CD3#1、B7H6#21/CD3#1、B7H6#22/CD3#1、B7H6#23/CD3#1、B7H6#24/CD3#1中之任一者)的組合物以及呈單位劑型之含有有效量之PD-1拮抗劑(例如抗PD-1抗體、最佳如本文(例如表A)及WO2017/198741中所述之PD1-1、PD1-2、PD1-3、PD1-4及PD1-5)的組合物二者。
在一些實施例中,套組包含含有該組合物之無菌容器;該等容器可為盒子、安瓿、瓶子、小瓶、管、袋、小袋、泡罩包裝或業內已知之其他適宜容器形式。該等容器可由塑膠、玻璃、層壓紙、金屬箔或其他適於容納藥劑之材料製成。此外,套組可在第一容器及第二容器中包含醫藥組合物,該第一容器具有呈凍乾形式之本發明之結合蛋白,該第二容器具有用於注射之醫藥上可接受之稀釋劑(例如,無菌水)。醫藥上可接受之稀釋劑可用於重構或稀釋結合蛋白。
若期望,本發明之多重專一性結合蛋白與用於將多重專一性結合蛋白投與患有癌症之個體之說明書一起提供。說明書通常包括關於使用組合物治療或預防癌症之資訊。在其他實施例中,說明書包括以下各項中之至少一者:治療劑之說明;用於治療或預防癌症或其症狀之劑量時間表及投與;注意事項;警告;適應症;禁忌;超劑量資訊;不良反應;動物藥理學;臨床研究;及/或參考文獻。說明書可直接印刷在容器(存在時)上或以標記施加至容器,或呈在容器中或與其一起供應之單獨片、小冊子、卡片或文件夾形式。
經得起檢驗,該等建議之套組組分可以熟習此項技術者使用之常規方式包裝。舉例而言,該等建議之套組組分可以溶液或作為液體分散液或諸如此類提供。
實例 以下實例闡釋本發明。該等實例不應被解釋為限制本發明之範圍。
實例 1 : B7H6/CD3 結合蛋白之設計及構築
本發明者已開發多重專一性結合蛋白,其結合B7H6及CD3,並誘導T細胞活化,從而導致表現B7H6之腫瘤細胞溶解。所用之分子設計具有IgG抗體支架及IgG樣結構。其特徵在於Fc中之隆凸於孔洞中技術,用於隆凸及孔洞臂之異二聚化。此外,結合蛋白在每一臂之輕鏈及相應重鏈之間具有撓性肽序列。因此,結合蛋白包含兩個臂,一個結合至CD3,另一個結合至B7H6,每一臂包含單鏈Fab及Fc區(參見圖1)。
較佳地,結合分子係雙專一性且二價的(對於兩個靶中之每一者為單價)。
使用自雜交瘤及培養之單 B 細胞之高通量 V 基因回收製備識別 B7H6 及 CD3 之結合結構域 .
為了獲得抗B7H6結合劑,活體外培養源自B7H6免疫之野生型及ALIVAMAB™人類化小鼠(Ablexis, San Francisco, CA, USA: 具有人類免疫球蛋白基因座之ALIVAMAB MOUSE™轉基因小鼠平臺)之雜交瘤或單一B細胞。藉由ALPHALISA®免疫分析套組(PerkinElmer, Waltham, MA, USA)篩選與重組人類B7H6結合的上清液,藉由流式細胞術篩選與表現人類B7H6之NCI-H716細胞(ATCC®, CCL-251TM)結合的上清液,且亦篩選與CHO細胞上重組表現之食蟹獼猴B7-H6結合的上清液。
然後自鑑別之陽性純系擴增免疫球蛋白(Ig) VH及VL基因。為了自雜交瘤分離RNA,將單一純系之約2×106
個細胞沈澱,並用作源材料。對於單一B細胞,自單個分離之B細胞擴增之100至500個細胞用作源材料。使用RNeasy®加mini RNA提取套組(Qiagen, Hilden, Germany)分離RNA。然後使用SMARTer® cDNA合成套組(Clontech, Mountain View, CA)根據製造商之說明書合成cDNA。為了促進cDNA合成,使用oligodT引發所有信使RNA之反轉錄,然後用SMARTer IIA寡核苷酸進行「5’加帽」。隨後使用靶向SMARTer IIA帽之5’引子及靶向CH1中之共有區之3’引子,使用2步PCR擴增實施VH及VL片段之擴增。簡言之,每一50μl PCR反應物由20μM正向及反向引子混合物、25μl PrimeSTAR® Max DNA聚合酶預混物(Clontech)、2μl未純化之cDNA及21μl雙蒸餾之H2O組成。循環程式在94℃開始3 min,之後35個循環(94℃達30 Sec,50℃達1min,68℃達1min),並在72℃下結束7 min。第二輪PCR用VL及VH第2輪引子實施,該引子含有與其各別pTT5母載體(VH及VL)中各別區「重疊」之15bp互補延伸。用相同PCR循環程式實施第二輪PCR。
In-Fusion® HD選殖套組(Clontech, U.S.A.)用於將VL基因定向選殖至pTT5 huIgK載體中且將VH基因定向選殖至pTT5 huIgG1KO載體中。為了促進In-Fusion® HD選殖,純化PCR產物並在In-Fusion HD選殖之前用選殖增強子處理。選殖及轉變按照製造商之方案(Clontech, U.S.A.)實施。使小量製備之DNA經受Sanger測序以確認獲得完整V-基因片段。
使用此方法,製備編碼對B7H6具有專一性之結合結構域之Ig VH及VL基因對。藉由用相應重鏈及輕鏈編碼質體瞬時轉染CHO-E37細胞產生重組抗體。
為了獲得額外抗CD3結合劑,使用huCD3ε肽1-27構築體實施WT小鼠之免疫。篩選與重組huCD3E + G-Fc蛋白及與重組cyCD3E + G-Fc蛋白結合之雜交瘤上清液,以及與huCD3陽性及cyCD3陽性細胞結合之雜交瘤上清液。回收陽性純系之可變區並選殖為IgG或IgG樣雙專一性構築體用於進一步評估。
B7H6 及 CD3 結合劑之人類化 / 最佳化
對上述B7H6或CD3結合劑以及文獻中所述之CD3結合劑(Pessano等人,EMBO J. 1985年2月;4(2): 337-44;Salmerón A等人,J Immunol. 1991年11月1日;147(9):3047-52)的序列進行人類化及/或最佳化。抗體之序列最佳化/人類化係一種用以工程化在非人類物種中產生之抗體(針對特定抗原/表位)以用作類似於在人類中產生之抗體的治療劑且藉此消除潛在不良效應(例如免疫原性)、同時保留專一性的方法。本文利用之序列最佳化/人類化方法由Singh等人,2015 (Singh S等人,mAbs 2015: 7(4):778-91)闡述。簡言之,在電腦中鑑別緊密匹配之人類種系,並使用噬菌體篩選方法評估最佳化/人類化變體。基於結合、百分比人類評分及EpiVax® (潛在免疫原性之電腦內預測工具)選擇最終前導候選序列。
結合 B7H6 及 CD3 之雙專一性蛋白之構築
使用常見分子生物學技術將B7H6及CD3結合劑之可變區選殖至表現載體pTT5 (National Research Council,Canada)中,以形成具有一個B7H6專一性結合臂及一個CD3專一性結合臂之雙專一性結合蛋白,該B7H6專一性結合臂包含結合至B7H6之單鏈Fab及Fc區(該結合單元在本文中亦稱為「B7H6臂」或「B7H6鏈」),該CD3專一性結合臂包含結合至CD3之單鏈Fab及Fc區(該結合單元在本文中亦稱為「CD3臂」或「CD3鏈)。該B7H6及CD3臂之Fc區包括「W」或「SAV」突變(Atwell等人,JMB, 1997, 270, 26-35),且各別鏈稱為W或SAV鏈。對於多片段DNA裝配,使用Gibson-裝配及NEBuilder® HiFi DNA裝配方法,遵循製造商之方案(New England Biolabs, Ipswich, MA, USA)。對DNA小量製備物進行測序。
每一表現載體含有用於鏈編碼基因(B7H6或CD3臂/鏈)、即編碼信號序列及輕鏈及重鏈之基因之真核啟動子元件、用於原核選擇標記基因(例如胺苄青黴素)之表現盒,及複製起點。將該等DNA質體在胺苄青黴素抗性大腸桿菌菌落及培養物中繁殖並純化。
實例 2 : 結合 B7H6 及 CD3 之雙專一性結合蛋白之表現及純化
藉由用攜帶B7H6/CD3鏈編碼基因(一條鏈為W鏈且另一條鏈為SAV鏈)之pTT5載體瞬時轉染CHO-E細胞,產生結合B7H6及CD3之雙專一性分子。簡言之,將在無血清培養基中懸浮生長之轉染CHO-E細胞在搖瓶中在140 rpm攪拌、37℃及5% CO2
下培養,並保持在指數生長條件下。在轉染當天,使用Mirus Bio TransIT Pro®轉染試劑,用質量比1:3之W鏈質體及SAV鏈質體化學轉染細胞。然後將細胞以1至2×10^6個細胞/ml接種在1 L Gibco® FreeStyle™ CHO表現培養基(LifeTechnologies, NY, US)中。然後在第7天,在軌道振盪下,用一次性進料及200 ml商業進料溶液將細胞培育10天,以最佳化蛋白質之表現。使用Octet®儀器(Pall ForteBio, CA, US)及ProtA生物感測器尖端根據製造商之說明書測定細胞培養上清液中之抗體滴度。
使用GE Healthcare Life Sciences ÄKTA™純蛋白純化系統以兩步法自培養物上清液中純化重組B7H6/CD3結合蛋白。首先,使用MabSelect™管柱(GE Healthcare)藉由蛋白A親和層析自收穫之細胞培養液中捕獲樣品。在中性pH下,蛋白質結合至蛋白質A,且用高鹽(1M NaCl)洗滌以去除細胞培養基組分及任何非專一性結合至蛋白質A之蛋白質或組分。使用30 mM乙酸鈉(pH 3.5)以等度模式溶析抗體或抗體樣構築體樣品。使用1%之3M乙酸鈉溶液(pH 9.0)將溶析之樣品中和至pH 5.0。用0.22 μm過濾系統無菌過濾中和之蛋白質。藉由nanodrop 8000分光光度計藉由UV280量測濃度。在第二次純化中,使用POROS™50 HS陽離子交換樹脂管柱(Applied Biosystems, Carlsbad, CA, USA)施加陽離子交換層析或使用HiLoad® 26/600 Superdex® 200 pg管柱(GE Healthcare)施加尺寸排除層析。將兩步純化之材料儲存在50mM乙酸鈉及100mM NaCl之最終緩衝液(pH 5.0)中。藉由分析型尺寸排除層析、質譜及分析型超速離心評價樣品之純度及異質性程度。用於功能測試之先進樣品包括兩步純化之材料,具有約95至99%之單體含量。
表1:本文所述蛋白質/抗體構築體之CDR、VH、VL、scFab、B7H6臂及CD3臂序列之胺基酸序列及SEQ ID NO:
| SEQ ID 號 | 序列之簡單說明 | 序列 |
| SEQ ID NO: 1 | B7H6#1 LCCDR1 | KSSQSLFYSSNQKNYLA |
| SEQ ID NO: 2 | B7H6#1 LCCDR2 | WASTRES |
| SEQ ID NO: 3 | B7H6#1 LCCDR3 | QQYYNYPRT |
| SEQ ID NO: 4 | B7H6#1 HCCDR1 | GYTFTDYYMN |
| SEQ ID NO: 5 | B7H6#1 HCCDR2 | YIYPKTGGNGYNQKFKD |
| SEQ ID NO: 6 | B7H6#1 HCCDR3 | ENWDGYTMAY |
| SEQ ID NO: 7 | B7H6#2 LCCDR1 | RATSSLYSMH |
| SEQ ID NO: 8 | B7H6#2 LCCDR2 | ATFNLAS |
| SEQ ID NO: 9 | B7H6#2 LCCDR3 | QQWSTNPPKLT |
| SEQ ID NO: 10 | B7H6#2 HCCDR1 | GFNIKNTFIH |
| SEQ ID NO: 11 | B7H6#2 HCCDR2 | RIDPANGNTIYASKFQG |
| SEQ ID NO: 12 | B7H6#2 HCCDR3 | TYGGTNYFDY |
| SEQ ID NO: 13 | B7H6#3 LCCDR1 | KASHNVGVYVA |
| SEQ ID NO: 14 | B7H6#3 LCCDR2 | SASNRYS |
| SEQ ID NO: 15 | B7H6#3 LCCDR3 | QQYNSYPLT |
| SEQ ID NO: 16 | B7H6#3 HCCDR1 | GFTFSDYYMT |
| SEQ ID NO: 17 | B7H6#3 HCCDR2 | NIDYDGSRIYYLDSLKS |
| SEQ ID NO: 18 | B7H6#3 HCCDR3 | DDPAWLAY |
| SEQ ID NO: 19 | B7H6#4 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 20 | B7H6#4 LCCDR2 | SASNRYD |
| SEQ ID NO: 21 | B7H6#4 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 22 | B7H6#4 HCCDR1 | GYTFTNYWMN |
| SEQ ID NO: 23 | B7H6#4 HCCDR2 | GIYLNGDSTDYNEKFKG |
| SEQ ID NO: 24 | B7H6#4 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 25 | B7H6#5 LCCDR1 | RASQDIRNDLG |
| SEQ ID NO: 26 | B7H6#5 LCCDR2 | AASSLES |
| SEQ ID NO: 27 | B7H6#5 LCCDR3 | LQYYNHPLT |
| SEQ ID NO: 28 | B7H6#5 HCCDR1 | GYTFTGYYIH |
| SEQ ID NO: 29 | B7H6#5 HCCDR2 | WINPHSGATNYAQNFQG |
| SEQ ID NO: 30 | B7H6#5 HCCDR3 | ERWGSGTFNI |
| SEQ ID NO: 31 | B7H6#6 LCCDR1 | KASQSVSNDVV |
| SEQ ID NO: 32 | B7H6#6 LCCDR2 | STSNRYI |
| SEQ ID NO: 33 | B7H6#6 LCCDR3 | QQDYSSPYT |
| SEQ ID NO: 34 | B7H6#6 HCCDR1 | GYTFTDYTMH |
| SEQ ID NO: 35 | B7H6#6 HCCDR2 | GINPNYDNTGYSEKFKD |
| SEQ ID NO: 36 | B7H6#6 HCCDR3 | SGSRRSFYFDY |
| SEQ ID NO: 37 | B7H6#7 LCCDR1 | RASQGISSWLA |
| SEQ ID NO: 38 | B7H6#7 LCCDR2 | AASSLQS |
| SEQ ID NO: 39 | B7H6#7 LCCDR3 | QQANSFPRT |
| SEQ ID NO: 40 | B7H6#7 HCCDR1 | GGSISYNYWS |
| SEQ ID NO: 41 | B7H6#7 HCCDR2 | HIYYSGSTNYNPSLKS |
| SEQ ID NO: 42 | B7H6#7 HCCDR3 | VGTWGSFDD |
| SEQ ID NO: 43 | B7H6#8 LCCDR1 | RSSQSLLYNNRYNYLD |
| SEQ ID NO: 44 | B7H6#8 LCCDR2 | LGSNRAS |
| SEQ ID NO: 45 | B7H6#8 LCCDR3 | MQTLQIPIT |
| SEQ ID NO: 46 | B7H6#8 HCCDR1 | GDTLNSYGIS |
| SEQ ID NO: 47 | B7H6#8 HCCDR2 | GIIPIFDTTKYAQKFQG |
| SEQ ID NO: 48 | B7H6#8 HCCDR3 | ERGYRFSEDYYFYYGMDV |
| SEQ ID NO: 49 | B7H6#9 LCCDR1 | RASESVDNFGVSFMN |
| SEQ ID NO: 50 | B7H6#9 LCCDR2 | AASNQGS |
| SEQ ID NO: 51 | B7H6#9 LCCDR3 | QQSKEVPWT |
| SEQ ID NO: 52 | B7H6#9 HCCDR1 | DYTFTHYWIH |
| SEQ ID NO: 53 | B7H6#9 HCCDR2 | IIGPSDNEIHYNQDFKD |
| SEQ ID NO: 54 | B7H6#9 HCCDR3 | QIISMVVGTEYFDV |
| SEQ ID NO: 55 | B7H6#10 LCCDR1 | RASQGISSWLA |
| SEQ ID NO: 56 | B7H6#10 LCCDR2 | VASSLQR |
| SEQ ID NO: 57 | B7H6#10 LCCDR3 | QQANSFPRT |
| SEQ ID NO: 58 | B7H6#10 HCCDR1 | GDSISSYYWS |
| SEQ ID NO: 59 | B7H6#10 HCCDR2 | HIYTSEKNNYNPSLKS |
| SEQ ID NO: 60 | B7H6#10 HCCDR3 | VGNWGSHDA |
| SEQ ID NO: 61 | B7H6#11 LCCDR1 | RSSQSLLHSNGYNYLD |
| SEQ ID NO: 62 | B7H6#11 LCCDR2 | LGSNRAS |
| SEQ ID NO: 63 | B7H6#11 LCCDR3 | MQALQTPLT |
| SEQ ID NO: 64 | B7H6#11 HCCDR1 | GITFSYYTMN |
| SEQ ID NO: 65 | B7H6#11 HCCDR2 | SISSRSSYIYYADSVKG |
| SEQ ID NO: 66 | B7H6#11 HCCDR3 | DKGDYSKDIYYYYGMDV |
| SEQ ID NO: 67 | B7H6#12 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 68 | B7H6#12 LCCDR2 | SASNRYD |
| SEQ ID NO: 69 | B7H6#12 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 70 | B7H6#12 HCCDR1 | GYTFTNYWMN |
| SEQ ID NO: 71 | B7H6#12 HCCDR2 | GIYLNGDSTDYNEKFKG |
| SEQ ID NO: 72 | B7H6#12 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 73 | B7H6#13 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 74 | B7H6#13 LCCDR2 | SASNRYD |
| SEQ ID NO: 75 | B7H6#13 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 76 | B7H6#13 HCCDR1 | GYTFTSYWMN |
| SEQ ID NO: 77 | B7H6#13 HCCDR2 | GIYLNGDSTDYNEKFKG |
| SEQ ID NO: 78 | B7H6#13 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 79 | B7H6#14 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 80 | B7H6#14 LCCDR2 | SASNRYD |
| SEQ ID NO: 81 | B7H6#14 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 82 | B7H6#14 HCCDR1 | GYTFTNYWMN |
| SEQ ID NO: 83 | B7H6#14 HCCDR2 | GIYLNGDSTDYNEKFKG |
| SEQ ID NO: 84 | B7H6#14 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 85 | B7H6#15 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 86 | B7H6#15 LCCDR2 | SASNRYD |
| SEQ ID NO: 87 | B7H6#15 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 88 | B7H6#15 HCCDR1 | GYTFTNYWMN |
| SEQ ID NO: 89 | B7H6#15 HCCDR2 | GIYLSGDSTDYNEKFKG |
| SEQ ID NO: 90 | B7H6#15 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 91 | B7H6#16 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 92 | B7H6#16 LCCDR2 | SASNRYD |
| SEQ ID NO: 93 | B7H6#16 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 94 | B7H6#16 HCCDR1 | GYTFTSYWMN |
| SEQ ID NO: 95 | B7H6#16 HCCDR2 | GIYLSGESTDYNEKFKG |
| SEQ ID NO: 96 | B7H6#16 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 97 | B7H6#17 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 98 | B7H6#17 LCCDR2 | SASNRYD |
| SEQ ID NO: 99 | B7H6#17 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 100 | B7H6#17 HCCDR1 | GYTFTSYWMN |
| SEQ ID NO: 101 | B7H6#17 HCCDR2 | GIYLSGDSTDYNEKFKG |
| SEQ ID NO: 102 | B7H6#17 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 103 | B7H6#18 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 104 | B7H6#18 LCCDR2 | SASNRYD |
| SEQ ID NO: 105 | B7H6#18 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 106 | B7H6#18 HCCDR1 | GYTFTSYWMN |
| SEQ ID NO: 107 | B7H6#18 HCCDR2 | GIYLSGDSTDYNEKFKG |
| SEQ ID NO: 108 | B7H6#18 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 109 | B7H6#19 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 110 | B7H6#19 LCCDR2 | SASNRYD |
| SEQ ID NO: 111 | B7H6#19 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 112 | B7H6#19 HCCDR1 | GYTFTSYWMN |
| SEQ ID NO: 113 | B7H6#19 HCCDR2 | GIYLSGESTDYNEKFKG |
| SEQ ID NO: 114 | B7H6#19 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 115 | B7H6#20 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 116 | B7H6#20 LCCDR2 | SASNRYD |
| SEQ ID NO: 117 | B7H6#20 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 118 | B7H6#20 HCCDR1 | GYTFTSYWMN |
| SEQ ID NO: 119 | B7H6#20 HCCDR2 | GIYLSGDSTDYNEKFKG |
| SEQ ID NO: 120 | B7H6#20 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 121 | B7H6#21 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 122 | B7H6#21 LCCDR2 | SASNRYD |
| SEQ ID NO: 123 | B7H6#21 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 124 | B7H6#21 HCCDR1 | GYTFTSYWMN |
| SEQ ID NO: 125 | B7H6#21 HCCDR2 | GIYLSGESTDYNEKFKG |
| SEQ ID NO: 126 | B7H6#21 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 127 | B7H6#22 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 128 | B7H6#22 LCCDR2 | SASNRYD |
| SEQ ID NO: 129 | B7H6#22 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 130 | B7H6#22 HCCDR1 | GYTFTSYWMN |
| SEQ ID NO: 131 | B7H6#22 HCCDR2 | GIYLSGDSTDYNEKFKG |
| SEQ ID NO: 132 | B7H6#22 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 133 | B7H6#23 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 134 | B7H6#23 LCCDR2 | SASNRYD |
| SEQ ID NO: 135 | B7H6#23 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 136 | B7H6#23 HCCDR1 | GYTFTSYWMN |
| SEQ ID NO: 137 | B7H6#23 HCCDR2 | GIYLSGESTDYNEKFKG |
| SEQ ID NO: 138 | B7H6#23 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 139 | B7H6#24 LCCDR1 | KASQNVGKYVA |
| SEQ ID NO: 140 | B7H6#24 LCCDR2 | SASNRYD |
| SEQ ID NO: 141 | B7H6#24 LCCDR3 | QQYISYPLT |
| SEQ ID NO: 142 | B7H6#24 HCCDR1 | GYTFTNYWMN |
| SEQ ID NO: 143 | B7H6#24 HCCDR2 | GIYLSGDSTDYNEKFKG |
| SEQ ID NO: 144 | B7H6#24 HCCDR3 | RGDYFGDF |
| SEQ ID NO: 145 | B7H6#1 VL | DIVMSQSPSSLAVSVGEKVTMNCKSSQSLFYSSNQKNYLAWYQQKPGQSPKLLIYWASTRESGVPDRFTGSGSGTDFTLTISSVKAEDLAVYYCQQYYNYPRTFGGGTKLEIK |
| SEQ ID NO: 146 | B7H6#1 VH | EVQLQQSGPELVKPGTSVKMSCKASGYTFTDYYMNWVKQSQGKNLEWIAYIYPKTGGNGYNQKFKDKATLTVDKSSNTAYMELRSLTSDDSAVYYCGRENWDGYTMAYWGQGTSVTVSS |
| SEQ ID NO: 147 | B7H6#2 VL | EIVLTQSPDFLSASPGEKVTMTCRATSSLYSMHWYQQKPGSSPKPWIYATFNLASGVPARFSGSGSGTSYSLTITRVEAEDAATYYCQQWSTNPPKLTFGAGTKLELK |
| SEQ ID NO: 148 | B7H6#2 VH | EVQLQQSGAELVRPGASVKLSCTASGFNIKNTFIHWVNQRPEQGLEWIGRIDPANGNTIYASKFQGRATITTDTSSNTAYMHLSSLTSGDTAVYYCARTYGGTNYFDYWGQGTTLTVSS |
| SEQ ID NO: 149 | B7H6#3 VL | DIVMTQSQKLLSTSVGDRISVTCKASHNVGVYVAWYQQKPGHSPKALIHSASNRYSGVPDRFTGSGSGTDFTLTITNVQSEDLAEYFCQQYNSYPLTFGAGTKLELI |
| SEQ ID NO: 150 | B7H6#3 VH | EVKLVESEGGLVQPGSSMKLSCTASGFTFSDYYMTWVRQVPEKGLEWVGNIDYDGSRIYYLDSLKSRFIISRDNAKNILYLQMNSLKSEDTATYYCARDDPAWLAYWGQGTLVTVSS |
| SEQ ID NO: 151 | B7H6#4 VL | DIVMTQSQKFMSTSVGDRVSVTCKASQNVGKYVAWYQQKPGQSPKALIYSASNRYDGVPDRFTGSGSGTDFTLTITNVQSEDLTEYFCQQYISYPLTFGAGTKLELK |
| SEQ ID NO: 152 | B7H6#4 VH | QVQLQQPGSVLVRPGASVRLSCKASGYTFTNYWMNWMKQRPGQGLEWIGGIYLNGDSTDYNEKFKGKATLTVDTSSSTTYMDLSSLTYEDSAVYYCTTRGDYFGDFWGQGTTLTVSS |
| SEQ ID NO: 153 | B7H6#5 VL | AIQMTQSPSSLSASVGDRVTITCRASQDIRNDLGWFQQRPGKAPNLLIYAASSLESGVPSRFSGRGSGTDFTLTISSLQPEDFATYYCLQYYNHPLTFGGGTKVEIK |
| SEQ ID NO: 154 | B7H6#5 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTGYYIHWVRQAPGQGLEWMGWINPHSGATNYAQNFQGRVTMTRDTSISTAYMELSRLRSDDAAVYYCARERWGSGTFNIWGQGTMVTVSS |
| SEQ ID NO: 155 | B7H6#6 VL | DIVMTQSPDSLPVSAGDRVTITCKASQSVSNDVVWYQQKPGQSPKLLMYSTSNRYIGVPDRFTGSGYGTDFTFTISTVQAEDLAVYFCQQDYSSPYTFGGGTKLEIK |
| SEQ ID NO: 156 | B7H6#6 VH | EVQLQQSGPELLKPGASVKISCKTSGYTFTDYTMHWVKQSHGKSLEWIGGINPNYDNTGYSEKFKDKATLTVDKSSSTAYMELRSLTSEDSAVYYCTRSGSRRSFYFDYWGQGTTLTVSS |
| SEQ ID NO: 157 | B7H6#7 VL | DIQMTQSPSSVSASVGDRVTITCRASQGISSWLAWYQQKPGKAPNLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQANSFPRTFGQGTKVEIK |
| SEQ ID NO: 158 | B7H6#7 VH | QVQLQESGPGLVKPSETLSLTYTVSGGSISYNYWSWIRQPPEKGLEWIGHIYYSGSTNYNPSLKSRVTISVDTSKNQFSLKLNSVTAADTAVYYCARVGTWGSFDDWGQGTLVTVSS |
| SEQ ID NO: 159 | B7H6#8 VL | DIVMTQSPLSLPVTPGEPASISCRSSQSLLYNNRYNYLDWYLQKPGQSPEVLIYLGSNRASGVPDRFSGSGSGTDFTLKISRVEAEDFGVYYCMQTLQIPITFGQGTRLEIK |
| SEQ ID NO: 160 | B7H6#8 VH | QVQVVQSGAEVKKPGSSVKVSCKGSGDTLNSYGISWMRQAPGQGLEWMGGIIPIFDTTKYAQKFQGRVTITADKSTTTVYMELSSLRFEDTAVYYCARERGYRFSEDYYFYYGMDVWGQGTTVTVSS |
| SEQ ID NO: 161 | B7H6#9 VL | DIVLTQSPVSLAVSLGQRATISCRASESVDNFGVSFMNWFQQKPGQPPKLLIYAASNQGSGVPARFSGSGSGTDFSLNIHPLEEDDTAMYFCQQSKEVPWTFGGGTRLEIK |
| SEQ ID NO: 162 | B7H6#9 VH | QVQLQQPGAEMVRPGSSVKLSCKASDYTFTHYWIHWVKQRPLEGLEWIGIIGPSDNEIHYNQDFKDKATLTVDKSSNTAYLHLNSLTSEDSAVYYCARQIISMVVGTEYFDVWGTGTTVTVSS |
| SEQ ID NO: 163 | B7H6#10 VL | DIQMTQSPSSVSASVGDRVTITCRASQGISSWLAWYQQKPGKAPKLLIYVASSLQRGVPSRFSGSGSGTDFTLTISNLQPEDFATYYCQQANSFPRTFGQGTKVEIK |
| SEQ ID NO: 164 | B7H6#10 VH | QVHLQESGPGLVKPSETLSLTCTVSGDSISSYYWSWIRQPAGKGLEWIGHIYTSEKNNYNPSLKSRVIMSVDTSKNQFSLNLSSVTAADTAVYYCARVGNWGSHDAWGQGTLVTVSS |
| SEQ ID NO: 165 | B7H6#11 VL | DIVMTQSPLSLPVTPGEPASISCRSSQSLLHSNGYNYLDWYLQKPGQSPQVLIYLGSNRASGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCMQALQTPLTFGGGTKVEIK |
| SEQ ID NO: 166 | B7H6#11 VH | ELQLVNSGGGLVKSGGSLRLSCAASGITFSYYTMNWVRQAPGKGLEWVSSISSRSSYIYYADSVKGRFTISRDNAENSLYLQMNSLRAEDTAVYYCARDKGDYSKDIYYYYGMDVWGQGTTVTVSS |
| SEQ ID NO: 167 | B7H6#12 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 168 | B7H6#12 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWVKQAPGQGLEWMGGIYLNGDSTDYNEKFKGKATMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 169 | B7H6#13 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 170 | B7H6#13 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWMGGIYLNGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 171 | B7H6#14 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 172 | B7H6#14 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWMKQAPGQGLEWIGGIYLNGDSTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 173 | B7H6#15 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 174 | B7H6#15 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 175 | B7H6#16 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 176 | B7H6#16 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMRQAPGQGLEWMGGIYLSGESTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 177 | B7H6#17 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 178 | B7H6#17 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 179 | B7H6#18 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 180 | B7H6#18 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 181 | B7H6#19 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 182 | B7H6#19 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWVKQAPGQGLEWMGGIYLSGESTDYNEKFKGKATMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 183 | B7H6#20 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 184 | B7H6#20 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWVKQAPGQGLEWMGGIYLSGDSTDYNEKFKGKATMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 185 | B7H6#21 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 186 | B7H6#21 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWIGGIYLSGESTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 187 | B7H6#22 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 188 | B7H6#22 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWIGGIYLSGDSTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 189 | B7H6#23 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 190 | B7H6#23 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWIGGIYLSGESTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 191 | B7H6#24 VL | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIK |
| SEQ ID NO: 192 | B7H6#24 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSS |
| SEQ ID NO: 193 | B7H6#1 scFab | DIVMSQSPSSLAVSVGEKVTMNCKSSQSLFYSSNQKNYLAWYQQKPGQSPKLLIYWASTRESGVPDRFTGSGSGTDFTLTISSVKAEDLAVYYCQQYYNYPRTFGGGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVQLQQSGPELVKPGTSVKMSCKASGYTFTDYYMNWVKQSQGKNLEWIAYIYPKTGGNGYNQKFKDKATLTVDKSSNTAYMELRSLTSDDSAVYYCGRENWDGYTMAYWGQGTSVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 194 | B7H6#2 scFab | EIVLTQSPDFLSASPGEKVTMTCRATSSLYSMHWYQQKPGSSPKPWIYATFNLASGVPARFSGSGSGTSYSLTITRVEAEDAATYYCQQWSTNPPKLTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVQLQQSGAELVRPGASVKLSCTASGFNIKNTFIHWVNQRPEQGLEWIGRIDPANGNTIYASKFQGRATITTDTSSNTAYMHLSSLTSGDTAVYYCARTYGGTNYFDYWGQGTTLTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 195 | B7H6#3 scFab | DIVMTQSQKLLSTSVGDRISVTCKASHNVGVYVAWYQQKPGHSPKALIHSASNRYSGVPDRFTGSGSGTDFTLTITNVQSEDLAEYFCQQYNSYPLTFGAGTKLELIRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVKLVESEGGLVQPGSSMKLSCTASGFTFSDYYMTWVRQVPEKGLEWVGNIDYDGSRIYYLDSLKSRFIISRDNAKNILYLQMNSLKSEDTATYYCARDDPAWLAYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 196 | B7H6#4 scFab | DIVMTQSQKFMSTSVGDRVSVTCKASQNVGKYVAWYQQKPGQSPKALIYSASNRYDGVPDRFTGSGSGTDFTLTITNVQSEDLTEYFCQQYISYPLTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLQQPGSVLVRPGASVRLSCKASGYTFTNYWMNWMKQRPGQGLEWIGGIYLNGDSTDYNEKFKGKATLTVDTSSSTTYMDLSSLTYEDSAVYYCTTRGDYFGDFWGQGTTLTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 197 | B7H6#5 scFab | AIQMTQSPSSLSASVGDRVTITCRASQDIRNDLGWFQQRPGKAPNLLIYAASSLESGVPSRFSGRGSGTDFTLTISSLQPEDFATYYCLQYYNHPLTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTGYYIHWVRQAPGQGLEWMGWINPHSGATNYAQNFQGRVTMTRDTSISTAYMELSRLRSDDAAVYYCARERWGSGTFNIWGQGTMVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 198 | B7H6#6 scFab | DIVMTQSPDSLPVSAGDRVTITCKASQSVSNDVVWYQQKPGQSPKLLMYSTSNRYIGVPDRFTGSGYGTDFTFTISTVQAEDLAVYFCQQDYSSPYTFGGGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVQLQQSGPELLKPGASVKISCKTSGYTFTDYTMHWVKQSHGKSLEWIGGINPNYDNTGYSEKFKDKATLTVDKSSSTAYMELRSLTSEDSAVYYCTRSGSRRSFYFDYWGQGTTLTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 199 | B7H6#7 scFab | DIQMTQSPSSVSASVGDRVTITCRASQGISSWLAWYQQKPGKAPNLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQANSFPRTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLQESGPGLVKPSETLSLTYTVSGGSISYNYWSWIRQPPEKGLEWIGHIYYSGSTNYNPSLKSRVTISVDTSKNQFSLKLNSVTAADTAVYYCARVGTWGSFDDWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 200 | B7H6#8 scFab | DIVMTQSPLSLPVTPGEPASISCRSSQSLLYNNRYNYLDWYLQKPGQSPEVLIYLGSNRASGVPDRFSGSGSGTDFTLKISRVEAEDFGVYYCMQTLQIPITFGQGTRLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQVVQSGAEVKKPGSSVKVSCKGSGDTLNSYGISWMRQAPGQGLEWMGGIIPIFDTTKYAQKFQGRVTITADKSTTTVYMELSSLRFEDTAVYYCARERGYRFSEDYYFYYGMDVWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 201 | B7H6#9 scFab | DIVLTQSPVSLAVSLGQRATISCRASESVDNFGVSFMNWFQQKPGQPPKLLIYAASNQGSGVPARFSGSGSGTDFSLNIHPLEEDDTAMYFCQQSKEVPWTFGGGTRLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLQQPGAEMVRPGSSVKLSCKASDYTFTHYWIHWVKQRPLEGLEWIGIIGPSDNEIHYNQDFKDKATLTVDKSSNTAYLHLNSLTSEDSAVYYCARQIISMVVGTEYFDVWGTGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 202 | B7H6#10 scFab | DIQMTQSPSSVSASVGDRVTITCRASQGISSWLAWYQQKPGKAPKLLIYVASSLQRGVPSRFSGSGSGTDFTLTISNLQPEDFATYYCQQANSFPRTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVHLQESGPGLVKPSETLSLTCTVSGDSISSYYWSWIRQPAGKGLEWIGHIYTSEKNNYNPSLKSRVIMSVDTSKNQFSLNLSSVTAADTAVYYCARVGNWGSHDAWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 203 | B7H6#11 scFab | DIVMTQSPLSLPVTPGEPASISCRSSQSLLHSNGYNYLDWYLQKPGQSPQVLIYLGSNRASGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCMQALQTPLTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSELQLVNSGGGLVKSGGSLRLSCAASGITFSYYTMNWVRQAPGKGLEWVSSISSRSSYIYYADSVKGRFTISRDNAENSLYLQMNSLRAEDTAVYYCARDKGDYSKDIYYYYGMDVWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 204 | B7H6#12 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWVKQAPGQGLEWMGGIYLNGDSTDYNEKFKGKATMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 205 | B7H6#13 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWMGGIYLNGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 206 | B7H6#14 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWMKQAPGQGLEWIGGIYLNGDSTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 207 | B7H6#15 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 208 | B7H6#16 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMRQAPGQGLEWMGGIYLSGESTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 209 | B7H6#17 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 210 | B7H6#18 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 211 | B7H6#19 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWVKQAPGQGLEWMGGIYLSGESTDYNEKFKGKATMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 212 | B7H6#20 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWVKQAPGQGLEWMGGIYLSGDSTDYNEKFKGKATMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 213 | B7H6#21 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWIGGIYLSGESTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 214 | B7H6#22 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWIGGIYLSGDSTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 215 | B7H6#23 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWIGGIYLSGESTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 216 | B7H6#24 scFab | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 217 | B7H6#1 鏈 | DIVMSQSPSSLAVSVGEKVTMNCKSSQSLFYSSNQKNYLAWYQQKPGQSPKLLIYWASTRESGVPDRFTGSGSGTDFTLTISSVKAEDLAVYYCQQYYNYPRTFGGGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVQLQQSGPELVKPGTSVKMSCKASGYTFTDYYMNWVKQSQGKNLEWIAYIYPKTGGNGYNQKFKDKATLTVDKSSNTAYMELRSLTSDDSAVYYCGRENWDGYTMAYWGQGTSVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 218 | B7H6#2 鏈 | EIVLTQSPDFLSASPGEKVTMTCRATSSLYSMHWYQQKPGSSPKPWIYATFNLASGVPARFSGSGSGTSYSLTITRVEAEDAATYYCQQWSTNPPKLTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVQLQQSGAELVRPGASVKLSCTASGFNIKNTFIHWVNQRPEQGLEWIGRIDPANGNTIYASKFQGRATITTDTSSNTAYMHLSSLTSGDTAVYYCARTYGGTNYFDYWGQGTTLTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 219 | B7H6#3 鏈 | DIVMTQSQKLLSTSVGDRISVTCKASHNVGVYVAWYQQKPGHSPKALIHSASNRYSGVPDRFTGSGSGTDFTLTITNVQSEDLAEYFCQQYNSYPLTFGAGTKLELIRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVKLVESEGGLVQPGSSMKLSCTASGFTFSDYYMTWVRQVPEKGLEWVGNIDYDGSRIYYLDSLKSRFIISRDNAKNILYLQMNSLKSEDTATYYCARDDPAWLAYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 220 | B7H6#4 鏈 | DIVMTQSQKFMSTSVGDRVSVTCKASQNVGKYVAWYQQKPGQSPKALIYSASNRYDGVPDRFTGSGSGTDFTLTITNVQSEDLTEYFCQQYISYPLTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLQQPGSVLVRPGASVRLSCKASGYTFTNYWMNWMKQRPGQGLEWIGGIYLNGDSTDYNEKFKGKATLTVDTSSSTTYMDLSSLTYEDSAVYYCTTRGDYFGDFWGQGTTLTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 221 | B7H6#5 鏈 | AIQMTQSPSSLSASVGDRVTITCRASQDIRNDLGWFQQRPGKAPNLLIYAASSLESGVPSRFSGRGSGTDFTLTISSLQPEDFATYYCLQYYNHPLTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTGYYIHWVRQAPGQGLEWMGWINPHSGATNYAQNFQGRVTMTRDTSISTAYMELSRLRSDDAAVYYCARERWGSGTFNIWGQGTMVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 222 | B7H6#6 鏈 | DIVMTQSPDSLPVSAGDRVTITCKASQSVSNDVVWYQQKPGQSPKLLMYSTSNRYIGVPDRFTGSGYGTDFTFTISTVQAEDLAVYFCQQDYSSPYTFGGGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVQLQQSGPELLKPGASVKISCKTSGYTFTDYTMHWVKQSHGKSLEWIGGINPNYDNTGYSEKFKDKATLTVDKSSSTAYMELRSLTSEDSAVYYCTRSGSRRSFYFDYWGQGTTLTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 223 | B7H6#7 鏈 | DIQMTQSPSSVSASVGDRVTITCRASQGISSWLAWYQQKPGKAPNLLIYAASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQANSFPRTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLQESGPGLVKPSETLSLTYTVSGGSISYNYWSWIRQPPEKGLEWIGHIYYSGSTNYNPSLKSRVTISVDTSKNQFSLKLNSVTAADTAVYYCARVGTWGSFDDWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 224 | B7H6#8 鏈 | DIVMTQSPLSLPVTPGEPASISCRSSQSLLYNNRYNYLDWYLQKPGQSPEVLIYLGSNRASGVPDRFSGSGSGTDFTLKISRVEAEDFGVYYCMQTLQIPITFGQGTRLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQVVQSGAEVKKPGSSVKVSCKGSGDTLNSYGISWMRQAPGQGLEWMGGIIPIFDTTKYAQKFQGRVTITADKSTTTVYMELSSLRFEDTAVYYCARERGYRFSEDYYFYYGMDVWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 225 | B7H6#9 鏈 | DIVLTQSPVSLAVSLGQRATISCRASESVDNFGVSFMNWFQQKPGQPPKLLIYAASNQGSGVPARFSGSGSGTDFSLNIHPLEEDDTAMYFCQQSKEVPWTFGGGTRLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLQQPGAEMVRPGSSVKLSCKASDYTFTHYWIHWVKQRPLEGLEWIGIIGPSDNEIHYNQDFKDKATLTVDKSSNTAYLHLNSLTSEDSAVYYCARQIISMVVGTEYFDVWGTGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 226 | B7H6#10 鏈 | DIQMTQSPSSVSASVGDRVTITCRASQGISSWLAWYQQKPGKAPKLLIYVASSLQRGVPSRFSGSGSGTDFTLTISNLQPEDFATYYCQQANSFPRTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVHLQESGPGLVKPSETLSLTCTVSGDSISSYYWSWIRQPAGKGLEWIGHIYTSEKNNYNPSLKSRVIMSVDTSKNQFSLNLSSVTAADTAVYYCARVGNWGSHDAWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 227 | B7H6#11 鏈 | DIVMTQSPLSLPVTPGEPASISCRSSQSLLHSNGYNYLDWYLQKPGQSPQVLIYLGSNRASGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCMQALQTPLTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSELQLVNSGGGLVKSGGSLRLSCAASGITFSYYTMNWVRQAPGKGLEWVSSISSRSSYIYYADSVKGRFTISRDNAENSLYLQMNSLRAEDTAVYYCARDKGDYSKDIYYYYGMDVWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 228 | B7H6#12 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWVKQAPGQGLEWMGGIYLNGDSTDYNEKFKGKATMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 229 | B7H6#13 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWMGGIYLNGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 230 | B7H6#14 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWMKQAPGQGLEWIGGIYLNGDSTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 231 | B7H6#15 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 232 | B7H6#16 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMRQAPGQGLEWMGGIYLSGESTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 233 | B7H6#17 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 234 | B7H6#18 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 235 | B7H6#19 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWVKQAPGQGLEWMGGIYLSGESTDYNEKFKGKATMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 236 | B7H6#20 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWVKQAPGQGLEWMGGIYLSGDSTDYNEKFKGKATMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 237 | B7H6#21 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWIGGIYLSGESTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 238 | B7H6#22 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWIGGIYLSGDSTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 239 | B7H6#23 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYWMNWMKQAPGQGLEWIGGIYLSGESTDYNEKFKGKVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 240 | B7H6#24 鏈 | DIQMTQSPSSLSASVGDRVTITCKASQNVGKYVAWYQQKPGKAPKSLIYSASNRYDAVPSRFSGSGSGTDFTLTISSLQPEDFTTYYCQQYISYPLTFGAGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTNYWMNWMRQAPGQGLEWMGGIYLSGDSTDYNEKFKGRVTMTVDTSTSTVYMELSSLRSEDTAVYYCTRRGDYFGDFWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 241 | Fc結構域* (IgG1) | DKTHTCPPCP APELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 242 | Fc W結構域 (IgG1, LALA) | DKTHTCPPCP APEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG |
| SEQ ID NO: 243 | Fc, SAV結構域 (IgG1, RF/LALA) | DKTHTCPPCP APEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNRFTQKSLSLSPG |
| SEQ ID NO: 244 | Fc結構域 (IgG4Pro) | ESKYGPPCPPCP APEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLG |
| SEQ ID NO: 245 | Fc W結構域(IgG4Pro) | ESKYGPPCPPCP APEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLG |
| SEQ ID NO: 246 | Fc SAV結構域(IgG4Pro, RF) | ESKYGPPCPPCP APEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSRLTVDKSRWQEGNVFSCSVMHEALHNRFTQKSLSLSLG |
| SEQ ID NO: 247 | κ輕鏈之恆定區 | RTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC |
| SEQ ID NO: 248 | λ輕鏈之恆定區 | GQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVKVAWKADGSPVNTGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEKTVAPAECS |
| SEQ ID NO: 249 | 重鏈之恆定區 CH1 | ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 250 | 連接體 | GGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGS |
| SEQ ID NO: 251 | 連接體 | GGGGSGGGGSGGSGGSGGGGGS |
| SEQ ID NO: 252 | 連接體 | GGGGSGGGGSGGGGSGGGGSGGGGGS |
| SEQ ID NO: 253 | 連接體 | GGGGSGGGGGGSGGGGGGSGGGGSGGGGGS |
| SEQ ID NO: 254 | 連接體 | GGGGSGGGGSGGGSGGGSGGGGSGGGGSGGGGGS |
| SEQ ID NO: 255 | 連接體 | GGGGSGGGGSGGGSGGGSGGGSGGGGSGGGGSGGGGGS |
| SEQ ID NO: 256 | 連接體 | ggggsggggsgggsgggsgggsggggsgggggsgggsggggs |
| SEQ ID NO: 257 | CD3#1 LCCDR1 | RSSTGAVTTSNYAN |
| SEQ ID NO: 258 | CD3#1 LCCDR2 | GTNKRAP |
| SEQ ID NO: 259 | CD3#1 LCCDR3 | ALWYSNLWV |
| SEQ ID NO: 260 | CD3#1 HCCDR1 | GFTFNTYAMN |
| SEQ ID NO: 261 | CD3#1 HCCDR2 | RIRSKYNNYATYYADSVKD |
| SEQ ID NO: 262 | CD3#1 HCCDR3 | HGNFGNSYVSWFAY |
| SEQ ID NO: 263 | CD3#2 LCCDR1 | KSSQSLLNSRTRKNYLA |
| SEQ ID NO: 264 | CD3#2 LCCDR2 | WASTRES |
| SEQ ID NO: 265 | CD3#2 LCCDR3 | KQSFILRT |
| SEQ ID NO: 266 | CD3#2 HCCDR1 | GYSFTDYYVH |
| SEQ ID NO: 267 | CD3#2 HCCDR2 | WIYPGNGNIKYNERFRG |
| SEQ ID NO: 268 | CD3#2 HCCDR3 | DNYSAYYFAY |
| SEQ ID NO: 269 | CD3#3 LCCDR1 | KSSQSLLNSRTRKVYLA |
| SEQ ID NO: 270 | CD3#3 LCCDR2 | WASTRES |
| SEQ ID NO: 271 | CD3#3 LCCDR3 | KQSFILRT |
| SEQ ID NO: 272 | CD3#3 HCCDR1 | GYTFTSYYVH |
| SEQ ID NO: 273 | CD3#3 HCCDR2 | WIYPGGGNIKYAQKFQG |
| SEQ ID NO: 274 | CD3#3 HCCDR3 | DQYSAYYFAY |
| SEQ ID NO: 275 | CD3#4 LCCDR1 | KSSQSLLNSRTRKVYLA |
| SEQ ID NO: 276 | CD3#4 LCCDR2 | WASTRES |
| SEQ ID NO: 277 | CD3#4 LCCDR3 | KQSFILRT |
| SEQ ID NO: 278 | CD3#4 HCCDR1 | GYSFTSYYVH |
| SEQ ID NO: 279 | CD3#4 HCCDR2 | WIYPGGGNIKYNQKFQG |
| SEQ ID NO: 280 | CD3#4 HCCDR3 | DHYSAYYFAY |
| SEQ ID NO: 281 | CD3#5 LCCDR1 | KSSQSLLNSRTRKTYLA |
| SEQ ID NO: 282 | CD3#5 LCCDR2 | WASTRES |
| SEQ ID NO: 283 | CD3#5 LCCDR3 | KQSFILRT |
| SEQ ID NO: 284 | CD3#5 HCCDR1 | GYTFTGYYVH |
| SEQ ID NO: 285 | CD3#5 HCCDR2 | WIYPGGGSTKYAQKFQG |
| SEQ ID NO: 286 | CD3#5 HCCDR3 | DQYSAYYFAY |
| SEQ ID NO: 287 | CD3#6 LCCDR1 | KSSQSLLNSRTRKTYLA |
| SEQ ID NO: 288 | CD3#6 LCCDR2 | WASTRES |
| SEQ ID NO: 289 | CD3#6 LCCDR3 | KQSFILRT |
| SEQ ID NO: 290 | CD3#6 HCCDR1 | GYTFTSYYVH |
| SEQ ID NO: 291 | CD3#6 HCCDR2 | WIYPGGGNIKYAQKFQG |
| SEQ ID NO: 292 | CD3#6 HCCDR3 | DQYSAYYFAY |
| SEQ ID NO: 293 | CD3#1 VL | EAVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQEKPGQLPRGLIGGTNKRAPWVPARFSGSLLGGKAALTLSGAQPEDEAEYFCALWYSNLWVFGGGTKLTVL |
| SEQ ID NO: 294 | CD3#1 VH | EVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSA |
| SEQ ID NO: 295 | CD3#2 VL | DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIK |
| SEQ ID NO: 296 | CD3#2 VH | QVQLVQSGAEVKKPGASVKVSCKASGYSFTDYYVHWVRQAPGQGLEWMGWIYPGNGNIKYNERFRGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDNYSAYYFAYWGQGTTVTVSS |
| SEQ ID NO: 297 | CD3#3 VL | DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRTRKVYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIK |
| SEQ ID NO: 298 | CD3#3 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYYVHWVRQAPGQGLEWIGWIYPGGGNIKYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDQYSAYYFAYWGQGTTVTVSS |
| SEQ ID NO: 299 | CD3#4 VL | DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRTRKVYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIK |
| SEQ ID NO: 300 | CD3#4 VH | QVQLVQSGAEVKKPGASVKVSCKASGYSFTSYYVHWVRQAPGQGLEWIGWIYPGGGNIKYNQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDHYSAYYFAYWGQGTTVTVSS |
| SEQ ID NO: 301 | CD3#5 VL | DIVMTQSPDSLAVSLGERATISCKSSQSLLNSRTRKTYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIK |
| SEQ ID NO: 302 | CD3#5 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTGYYVHWVRQAPGQGLEWMGWIYPGGGSTKYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDQYSAYYFAYWGQGTTVTVSS |
| SEQ ID NO: 303 | CD3#6 VL | DIVMTQSPDSLAVSLGERATISCKSSQSLLNSRTRKTYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIK |
| SEQ ID NO: 304 | CD3#6 VH | QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYYVHWVRQAPGQGLEWIGWIYPGGGNIKYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDQYSAYYFAYWGQGTTVTVSS |
| SEQ ID NO: 305 | CD3#1 scFab | EAVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQEKPGQLPRGLIGGTNKRAPWVPARFSGSLLGGKAALTLSGAQPEDEAEYFCALWYSNLWVFGGGTKLTVLGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVKVAWKADGSPVNTGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEKTVAPAECSGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 306 | CD3#2 scFab | DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYSFTDYYVHWVRQAPGQGLEWMGWIYPGNGNIKYNERFRGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDNYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 307 | CD3#3 scFab | DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRTRKVYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYYVHWVRQAPGQGLEWIGWIYPGGGNIKYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDQYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 308 | CD3#4 scFab | DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRTRKVYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYSFTSYYVHWVRQAPGQGLEWIGWIYPGGGNIKYNQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDHYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 309 | CD3#5 scFab | DIVMTQSPDSLAVSLGERATISCKSSQSLLNSRTRKTYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTGYYVHWVRQAPGQGLEWMGWIYPGGGSTKYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDQYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 310 | CD3#6 scFab | DIVMTQSPDSLAVSLGERATISCKSSQSLLNSRTRKTYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYYVHWVRQAPGQGLEWIGWIYPGGGNIKYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDQYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSC |
| SEQ ID NO: 311 | CD3#1 鏈 | EAVVTQEPSLTVSPGGTVTLTCRSSTGAVTTSNYANWVQEKPGQLPRGLIGGTNKRAPWVPARFSGSLLGGKAALTLSGAQPEDEAEYFCALWYSNLWVFGGGTKLTVLGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVKVAWKADGSPVNTGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEKTVAPAECSGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSEVQLVESGGGLVQPGGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKYNNYATYYADSVKDRFTISRDDSKNTAYLQMNNLKTEDTAVYYCVRHGNFGNSYVSWFAYWGQGTLVTVSAASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNRFTQKSLSLSPG |
| SEQ ID NO: 312 | CD3#2 鏈 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRTRKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYSFTDYYVHWVRQAPGQGLEWMGWIYPGNGNIKYNERFRGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDNYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNRFTQKSLSLSPG |
| SEQ ID NO: 313 | CD3#3 鏈 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRTRKVYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYYVHWVRQAPGQGLEWIGWIYPGGGNIKYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDQYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNRFTQKSLSLSPG |
| SEQ ID NO: 314 | CD3#4 鏈 | DIVMTQSPDSLAVSLGERATINCKSSQSLLNSRTRKVYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYSFTSYYVHWVRQAPGQGLEWIGWIYPGGGNIKYNQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDHYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNRFTQKSLSLSPG |
| SEQ ID NO: 315 | CD3#5 鏈 | DIVMTQSPDSLAVSLGERATISCKSSQSLLNSRTRKTYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTGYYVHWVRQAPGQGLEWMGWIYPGGGSTKYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDQYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNRFTQKSLSLSPG |
| SEQ ID NO: 316 | CD3#6 鏈 | DIVMTQSPDSLAVSLGERATISCKSSQSLLNSRTRKTYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCKQSFILRTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGECGGGGSEGKSSGSGSESKSTEGKSSGSGSESKSTGGGGSQVQLVQSGAEVKKPGASVKVSCKASGYTFTSYYVHWVRQAPGQGLEWIGWIYPGGGNIKYAQKFQGRVTMTRDTSTSTVYMELSSLRSEDTAVYYCARDQYSAYYFAYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNRFTQKSLSLSPG |
實例 3 : 重組蛋白之生成 • 人類 B7H6-His
藉由使用Lenti-X™慢病毒系統((Clontech)之瞬時轉染,用His 6-標籤使用pTT載體(編碼人類B7H6-His,SEQ ID NO: 317)表現人類-B7H6之完全細胞外結構域。在Gibco™ Freestyle™ F17表現培養基(Thermo Fisher Scientific)中,分子轉染時使用1.6 × 106
個細胞/ml之HEK 293F細胞(Thermo Fisher)。將1:3比率之DNA:PEI複合物及1 mg/L DNA預培育5分鐘,過濾,並在添加至細胞之前在室溫下再預培育15分鐘。將細胞於37℃、5% CO2
及140 rpm振盪下培養。轉染後24小時向細胞中添加胰化蛋白N1至0.5%之最終濃度。轉染48小時後,用2 mM麩醯胺酸及2 g/L葡萄糖再次餵入細胞。同時,溫度降至33℃。轉染後120小時,向最終進料中添加2 mM麩醯胺酸及1 g/L葡萄糖。轉染後144小時,藉由以6000 rpm離心15分鐘收穫細胞。使用G4過濾器澄清上清液。
蛋白質純化分兩步實施。首先,使用Ni-NTA管柱進行親和層析,用洗滌緩衝液1 × PBS (pH 7.2) + 10 mM咪唑溶析10 CV,然後用洗滌緩衝液1 × PBS (pH 7.2) + 20 mM咪唑溶析10 CV,且溶析梯度為4-60%之1× PBS (pH 7.2),補充有0.5M咪唑。收集流份且在彙集及濃縮之前藉由SDS-PAGE進行分析。其次,使用Superdex® 200、16/600、120 ml管柱進行凝膠過濾層析(GE Healthcare Life Sciences)。將5ml親和層析後之濃縮之彙集物以0.5 ml/min之流速上樣於管柱上。調配緩衝液係20 mM HEPES、100 mM NaCl、5%蔗糖,pH 7.4。收集流份且在彙集之前藉由SDS-PAGE進行分析,且然後使用0.2 um過濾器滅菌。
•Cyno B7H6-His
藉由使用Lenti-X™慢病毒系統((Clontech)之瞬時轉染,用His6-標籤使用pTT載體(編碼cyno B7H6-His,SEQ ID NO: 320)表現Cyno-B7H6之完全細胞外結構域。在Gibco™ Freestyle™ F17表現培養基(Thermo Fisher Scientific)中,分子轉染時使用1.6 × 106
個細胞/ml之HEK 293F細胞(Thermo Fisher)。將1:3比率之DNA:PEI複合物及1 mg/L DNA預培育5分鐘,過濾,並在添加至細胞之前在室溫下再預培育15分鐘。將細胞於37℃、5% CO2
及140 rpm振盪下培養。轉染後24小時向細胞中添加胰化蛋白N1至0.5%之最終濃度。轉染48小時後,用2 mM麩醯胺酸及2 g/L葡萄糖再次餵入細胞。同時,溫度降至33℃。轉染後120小時,向最終進料中添加2 mM麩醯胺酸及1 g/L葡萄糖。轉染後144小時,藉由以6000 rpm離心15分鐘收穫細胞。使用G4過濾器澄清上清液。
蛋白質純化分兩步實施。首先,使用Ni-NTA管柱進行親和層析,用洗滌緩衝液1 × PBS、0.2 M蔗糖、0.01% CHAPS、5%甘油(pH 7.2) + 10 mM咪唑溶析10 CV,然後用洗滌緩衝液1 × PBS (pH 7.2) + 20 mM咪唑溶析10 CV,且溶析梯度為4-60%之1× PBS、0.2 M蔗糖、0.01% CHAPS、5%甘油(pH 7.2),補充有0.5M咪唑。收集流份且在彙集及濃縮之前藉由SDS-PAGE進行分析。其次,使用Superdex® 200, 16/600進行凝膠過濾層析(GE Healthcare Life Sciences)。將10ml親和層析後之濃縮之彙集物以1.0 ml/min之流速上樣於管柱上。調配緩衝液係1X PBS、0.2M蔗糖、0.01% CHAPS、5%甘油,pH 7.2。收集流份且在彙集之前藉由SDS-PAGE進行分析,且然後使用0.2 um過濾器滅菌。
• 人類 CD3 E+G HuFc-6xHis (E+G 指示 ε γ 亞單元 )
使用HEK-293細胞(Thermo Fisher)、Lenti-X™慢病毒系統(Clontech)及編碼人類CD3 E+G HuFc-6xHis之質體(人類CD3E登錄號:P07766;人類CD3E+G-HuFc-His:SEQ ID NO:322)生成用以產生人類CD3 E+G HuFc-6xHis之細胞系。為了表現,在37℃、加濕之8% CO2環境及135 rpm振盪下,在Freestyle™ 293培養基(Thermo Fisher Scientific)中培養及擴增細胞。在第6天藉由以9300xg離心30分鐘收穫條件培養物上清液。藉由SDS-PAGE及西方墨點法監測表現。用0.2M蔗糖、5%甘油、0.01% CHAPS及10mM咪唑調節條件培養物上清液。然後將pH調節至7.2。純化以兩步法實施:使用Ni/NTA樹脂進行親和純化(在4℃下過夜培育,且用250mM咪唑溶析);之後在Superdex® 200管柱(GE Healthcare Life Sciences)上在具有0.2M蔗糖、5%甘油、0.01% CHAPS、1mM TCEP (pH 7.2)之目標緩衝液PBS中進行尺寸排除層析。在最終分析及儲存之前,使用10K MWCO PES膜Vivacell® 100離心裝置濃縮彙集之物質。藉由質譜及分析型超離心對純化之物質進行定性。
•Cyno CD3 E+G HuFc-6xHis (E+G 指示 ε γ 亞單元 )
使用HEK-293細胞(Thermo Fisher)、Lenti-X™慢病毒系統(Clontech)及編碼Cyno CD3 E+G HuFc-6xHis之質體(食蟹獼猴CD3E登錄號:Q95LI5< ,
cyno CD3 E+G huFc-His:SEQ ID NO:323)生成用以產生Cyno CD3 E+G HuFc-6xHis之細胞系。為了表現,在37℃、加濕之8% CO2環境及135 rpm振盪下,在Freestyle™ 293培養基(Thermo Fisher Scientific)中培養及擴增細胞。在第6天藉由以9300xg離心30分鐘收穫條件培養物上清液。藉由SDS-PAGE及西方墨點法監測表現。用0.2M蔗糖、5%甘油、0.01% CHAPS及10mM咪唑調節條件培養物上清液。然後將pH調節至7.2。純化以兩步法實施:使用Ni/NTA樹脂進行親和純化(在4℃下過夜培育,且用250mM咪唑溶析);之後在Superdex® 200管柱(GE Healthcare Life Sciences)上在具有0.2M蔗糖、5%甘油、0.01% CHAPS、1mM TCEP (pH 7.2)之目標緩衝液PBS中進行尺寸排除層析。在最終分析及儲存之前,使用10K MWCO PES膜Vivacell® 100離心裝置濃縮彙集之物質。藉由質譜及分析型超離心對純化之物質進行定性。
•Fc-His 標記之人類 B7H6 ECD
在此構築體中,huB7H6 ECD之後係GS連接體,然後係huIgG1-Fc結構域及C-末端His6標籤(SEQ ID NO:318)。藉由使用HEK293-6E細胞用1:3之DNA:PEI比率及1mg DNA/L培養物瞬時轉染來表現構築體。PEI試劑係線性PEI MAX [Mw 40,000] (Polysciences:目錄號24765-2)。將轉染之細胞於37℃、5% CO2及130 rpm下培育。轉染後24-hr,添加胰化蛋白N1 (Organotechnie;目錄號19553)及葡萄糖分別至0.5%及1g/L之最終濃度。5天後收穫細胞。離心後,經由0.2μm膜過濾器過濾上清液。以兩步純化來純化huB7H6-ECD-Fc-His蛋白:首先藉由在Ni NTA瓊脂糖基質上進行親和層析,且其次藉由使用Superdex® 200, 26/600管柱(GE Healthcare Life Sciences)進行凝膠過濾。將彙集之流份過濾並儲存在1 x PBS、0.2 M蔗糖、5%甘油、0.01% CHAPS、pH-7.2調配緩衝液中。
•Fc-His 標記之人類 Ala 突變之 B7H6 ECD (NKp30 相互作用位點 aa35-38 及 aa102-105 由 Ala 取代 ).
此構築體(SEQ ID NO:319)具有huB7H6,其在位置35-38及102-105具有Ala取代,因此其不結合NKp30。huB7H6-Ala-ECD之後係GS連接體,然後係huIgG1Fc結構域及C-末端His6標籤。藉由瞬時轉染在HEK293-6E細胞中表現此構築體,以兩步純化法純化,並如上文針對Fc-His標記之huB7H6-ECD構築體所述儲存。
•人類 B7H1-Fc
此構築體(SEQ ID NO:324)含有huB7H1,其具有cMyc標籤、凝血酶切割位點及huFc結構域。藉由使用HEK293f細胞、1:1.5之DNA:PEI比率及1 mg DNA/L培養物瞬時轉染來表現構築體。將燒瓶在37℃下、在加濕之8% CO2
環境中、在135 rpm振盪下培育。3天後收穫細胞。離心細胞後,自上清液純化蛋白質。首先,使用nProtein A Sepharose® 4快速流動培養基(GE Healthcare, #17-5280-03)實施親和純化,並將溶析液在20 mM Tris、100 mM NaCl、10%甘油、1 mM TCEP、3 mM CaCl2
(pH 8.0)中透析。其次,將樣品與凝血酶CleanCleave™樹脂(1 mL, Sigma)一起培育。第三,將前一步驟之彙集物再次與nProtein A Sepharose® 4快速流動培養基結合。保存未結合之物質,藉由在PBS、1 mM TCEP (pH 7.2)緩衝液中平衡之Superdex® 75 (GE Healthcare)管柱上進一步凝膠過濾而拋光,並濃縮。
實例 4 : 基於 SPR 之對重組 B7H6 及 CD3 εγ 亞單元之親和性及種間交叉反應性之測定
為了測定人類及食蟹獼猴B7H6及人類B7H1對B7H6/CD3結合蛋白之親和性,在Biacore™ 8K儀器(GE Healthcare Life Sciences)上實施實驗。簡言之,經由蛋白A/G捕獲B7H6/CD3結合蛋白。在HBS-EP+中製備此實驗之運行緩衝液及所有連續稀釋液。用EDC/NHS之等量混合物以10 μL/min之流速穿過兩個流動槽達420 s將CM5感測器晶片活化,並用重組蛋白A/G (50 μG/ml,於10 mM NaOAc中,pH 4.5)以10 μL/min之流速穿過所有流動槽達420 s固定,從而在表面上產生約2500 RU之蛋白A/G。用1M乙醇胺-HCl以10 μL/min之流速穿過所有流動槽達420 s使感測器晶片失活。
以10 μL/min之流速在蛋白A/G表面之流動槽2上捕獲約700 RU之B7H6/CD3結合蛋白達60 s。以30 µL/min之流速穿過兩個流動槽在捕獲之B7H6/CD3結合蛋白上注射分析物HuB7H6、CyB7H6及HuB7H1達300s,解離1200 s。HuB7H6及CyB7H6之濃度係0 nM、6.25 nM、12.5 nM、25 nM、50 nM及100 nM。HuB7H1之濃度係0 nM及1 μM。藉由以30 µL/min之流速穿過兩個流動槽注射10 mM甘胺酸-HCl (pH 1.5)達20 s來再生表面。
自原始數據中減去參比流動槽1 (與感測器表面相互作用)及空白(HBS-EP+或0 nM分析物)。使用Biacore™ 8K評估軟體,將感測圖整體擬合至1:1之Langmuir結合,以提供締合速率常數(ka)、解離速率常數(kd)及平衡解離常數(KD)值。
為了測定B7H6/CD3結合蛋白對人類及cyno CD3E+G-hFc之親和性,在Bio-Rad ProteOn™ XPR36儀器上實施實驗。簡言之,將HuCD3E+G-hFc及CyCD3E+G在ProteOn™ GLM感測器晶片(Bio-Rad)上胺偶合,並使B7H6/CD3結合蛋白流過固定之表面。在HBS-EP+中製備此實驗之運行緩衝液及所有連續稀釋液。根據Bio-Rad之推薦正規化GLM感測器晶片。在水平方向上以30 μL/min之流速用EDC/s-NHS之等量混合物活化感測器晶片300s。將HuCD3E+G-hFc在垂直方向上以30 µL/min之流速分別以0.4 µg/mL、0.2 µg/mL及0.1 µg/mL在10 mM乙酸鹽(pH 4.5)固定至L1、L2及L3達300 s,從而在L1上產生約100 RU之HuCD3E+G-hFc,在L2上產生約40 RU之HuCD3E+G-hFc且在L3上產生約0 RU之HuCD3E+G-hFc。將CyCD3E+G-hFc在垂直方向上以30 µL/min之流速分別以0.4 µg/mL、0.2 µg/mL及0.1 µg/mL在10 mM乙酸鹽(pH 4.5)中固定至L4、L5及L6達300 s,從而在L4上產生約385 RU之HuCD3E+G-hFc,在L5上產生約170 RU之CyCD3E+G-hFc且在L6上產生約50 RU之CyCD3E+G-hFc。在水平方向上以30 µL/min之流速用1M乙醇胺-HCl使感測器晶片失活300 s。以100 µL/min之流速用18 s之0.85%磷酸水平再生感測器晶片2次且垂直再生2次。
將B7H6/CD3結合蛋白分析物以30 µL/min之流速在固定表面上水平注射300 s,解離600 s。所用B7H6/CD3結合蛋白之濃度為0 nM、1.2 nM、3.7 nM、11.1 nM、33.3 nM及100 nM。藉由以100 µL/min之流速注射0.85%磷酸達18 s水平再生表面2次。
自原始數據中減去中間點(與感測器表面之相互作用)及空白(HBS-EP+或0 nM分析物)。使用Bio-Rad ProteOn™管理軟體,將感測圖整體擬合至1:1之Langmuir結合,以提供締合速率常數(ka)、解離速率常數(kd)及平衡解離常數(KD)值。
在表2中顯示實例性B7H6/CD3結合蛋白(分別包含SEQ ID NO: 228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)的如上文所述之親和性。
表2:如藉由SPR分析測定之B7H6/CD3結合蛋白與人類B7H6、cynoB7H6、人類CD3 Ɛγ亞單元、cynoCD3 Ɛγ亞單元及人類B7H1之親和性(KD)。無可檢測之結合由「nb」表示。
nb:無結合
| B7H6 結合劑 | CD3 結合劑 | huB7-H6 [nM] | cyB7-H6 [nM] | cy/hu B7-H6 | huCD3 [nM] | cyCD3 [nM] | cy/hu CD3 | huB7-H1 |
| B7H6#12 | CD3#1 | 1.1 | 2.3 | 2.1 | 3.6 | 2.5 | 0.7 | 於1µM下nb |
| B7H6#13 | CD3#1 | 3.0 | 4.6 | 1.5 | 4.1 | 2.8 | 0.7 | 於1µM下nb |
| B7H6#14 | CD3#1 | 0.1 | 0.6 | 5.9 | 4.2 | 2.7 | 0.6 | 於1µM下nb |
| B7H6#15 | CD3#1 | 0.8 | 2.2 | 2.8 | 3.8 | 2.6 | 0.7 | 於1µM下nb |
| B7H6#16 | CD3#1 | 3.1 | 7.2 | 2.3 | 3.7 | 2.6 | 0.7 | 於1µM下nb |
| B7H6#17 | CD3#1 | 8.7 | 8.4 | 1.0 | 13.5 | 3.7 | 0.3 | 於1µM下nb |
| B7H6#18 | CD3#1 | 1.4 | 3.3 | 2.3 | 3.9 | 2.8 | 0.7 | 於1µM下nb |
| B7H6#19 | CD3#1 | 1.6 | 5.1 | 3.1 | 4.0 | 2.4 | 0.6 | 於1µM下nb |
| B7H6#20 | CD3#1 | 1.1 | 4.9 | 4.6 | 4.0 | 2.6 | 0.7 | 於1µM下nb |
| B7H6#21 | CD3#1 | 3.3 | 1.4 | 0.4 | 4.4 | 2.7 | 0.6 | 於1µM下nb |
| B7H6#22 | CD3#1 | 1.5 | 1.4 | 1.0 | 5.1 | 2.8 | 0.5 | 於1µM下nb |
| B7H6#23 | CD3#1 | 1.3 | 1.2 | 0.9 | 5.5 | 2.7 | 0.5 | 於1µM下nb |
| B7H6#24 | CD3#1 | 1.8 | 3.1 | 1.7 | 7.8 | 3.3 | 0.4 | 於1µM下nb |
| B7H6#14 | CD3#2 | 1.2 | 1.0 | 0.9 | 16.9 | 17.7 | 1.0 | 於1µM下nb |
| B7H6#14 | CD3#3 | 1.1 | 1.1 | 0.9 | 4.8 | 7.1 | 1.5 | 於1µM下nb |
| B7H6#14 | CD3#4 | 1.3 | 1.1 | 0.8 | 7.6 | 8.5 | 1.1 | 於1µM下nb |
| B7H6#14 | CD3#5 | 0.9 | 1.0 | 1.1 | 4.3 | 5.2 | 1.2 | 於1µM下nb |
| B7H6#14 | CD3#6 | 0.4 | 0.9 | 2.1 | 4.1 | 5.7 | 1.4 | 於1µM下nb |
| B7H6#23 | CD3#2 | 1.9 | 2.0 | 1.1 | 10.4 | 10.0 | 1.0 | 於1µM下nb |
| B7H6#23 | CD3#3 | 2.2 | 1.9 | 0.9 | 13.8 | 11.9 | 0.9 | 於1µM下nb |
| B7H6#23 | CD3#4 | 1.7 | 1.7 | 1.0 | 3.8 | 3.6 | 0.9 | 於1µM下nb |
| B7H6#23 | CD3#5 | 2.2 | 1.9 | 0.9 | 2.8 | 3.7 | 1.3 | 於1µM下nb |
| B7H6#23 | CD3#6 | 1.9 | 2.0 | 1.1 | 3.4 | 3.9 | 1.2 | 於1µM下nb |
實例 5 : 在細胞表面上表現食蟹獼猴 B7H6 細胞外結構域之重組 CHO-K1 細胞系之生成
為了生成在細胞表面上表現食蟹獼猴B7H6之細胞外結構域之穩定CHO-K1細胞(NCBI:XP_005578557),將各別編碼序列(XP_005578557.1之aa 25至262)選殖至pcDNA3.1 (Thermo Fisher Scientific)中。構築體含有N-末端小鼠IgG Vk前導序列,之後係6-His-myc-標籤及食蟹獼猴B7H6細胞外結構域(NCBI XP_005578557.1之aa 25-262)。為了確保B7H6細胞外結構域之細胞表面定位,構築體之後係連接體、及EpCAM之跨膜及細胞內結構域(Uniprot P16422)。使用小鼠單株抗myc抗體(AbD Serotec)藉由流式細胞術驗證B7H6結構域在細胞表面之表現。所用之序列列於表3中,構築體之示意性代表圖示於圖2中。
表3:在CHO-K1細胞上表現之B7H6亞結構域的胺基酸序列
| 名稱 | 序列 |
| Vk前導序列 | METDTLLLWVLLLWVPGSTGD (SEQ ID NO:325) |
| 6-His-myc標籤 | HHHHHHEQKLISEEDL (SEQ ID NO:326) |
| 食蟹獼猴B7-H6細胞外結構域(NCBI XP_005578557.1, aa25-262) | DLKVEMMARGIQATRLNDSVTISCKVIYSQPLNITSMGITWFRKSLTLDKEVKVFEFFGDHQKAFRPGANVSLWRLKSGDASLKLPGVQLEEAGEYRCEVVVTPLKAQGTVQLKVVASPTSRLFQDQAVVKENEGKYMCESSRFYPKDINITWEKWTQKSPHHVVISENVITGPTIKNMDGTFNITSYLKLNSSQEDPGTVYRCVIRHESLHTPVSIDFILTAPQQSLSEPEKTDIFS (SEQ ID NO:327) |
| 連接體 | SGGGGS (SEQ ID NO:328) |
| 人類EpCAM跨膜結構域(Uniprot P16422, aa266-288) | AGVIAVIVVVVIAVVAGIVVLVI (SEQ ID NO:329) |
| 人類EpCAM細胞內結構域(Uniprot P16422, aa289-314) | SRKKRMAKYEKAEIKEMGEMHRELNA (SEQ ID NO:330) |
實例 6 : 實例性 B7H6 結合蛋白與重組人類 B7H6 細胞外結構域蛋白之結合
為了評價B7H6/CD3結合蛋白與重組人類Fc-His標記之B7H6 ECD及人類Fc-His標記之Ala-突變之B7H6細胞外蛋白之結合,如實例3中所述,於4℃下將MediSorpTM
板(Nunc, 467320)用2µl/ml重組蛋白塗覆過夜。次日,於室溫(RT)下將板用磷酸鹽緩衝鹽水(PBS)中之0.5%牛血清白蛋白(BSA)封阻1小時。隨後用含有0.05% TWEEN®20黏性液體之OBS洗滌板,並將B7H6/CD3結合蛋白以0.00001至10 μg/ml範圍內之濃度培育。在額外洗滌步驟之後,藉由過氧化物酶偶聯之山羊抗人類IgG F(ab’)2
專一性二級抗體(Jackson Immunoresearch)檢測結合之B7H6/CD3結合蛋白,並藉由TMB受質溶液(Bender Med Systems)可視化。圖3A+B及4A+B顯示實例性B7H6/CD3結合蛋白(分別包含SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO:224、SEQ ID NO:225、SEQ ID NO:226、SEQ ID NO:227、SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237 、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)與重組人類B7H6 ECD (圖3A+B)及人類Ala突變之B7H6 ECD (圖4A+B)蛋白之結合。
所有測試之實例性B7H6/CD3結合蛋白皆顯示與重組人類B7H6 ECD之相當之結合(圖3A+B),而僅包含SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白分別顯示與人類Fc-His標記之Ala突變之B7H6細胞外蛋白質的強結合,其中NKp30結合位點突變成丙胺酸。包含SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO:224、SEQ ID NO:225、SEQ ID NO:226、SEQ ID NO:227之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白顯示於高濃度下僅弱結合或不結合至Fc-His標記之Ala突變之B7H6細胞外蛋白。
實例 7 :與 B7H6 陽性 HCT 細胞之結合
藉由流式細胞術測試B7H6/CD3結合蛋白與HCT-15 (人類(結腸直腸癌) CRC細胞系)之結合。在先前實驗中,已確認HCT-15細胞在RNA層面以及蛋白層面上表現B7-H6,在細胞表面上表現大約8,000個B7-H6受體(數據未顯示)。如實例2所述產生B7H6/CD3結合蛋白。用FACS緩衝液(PBS/0.5% BSA/0.05%疊氮化鈉)中之增加濃度之兩步純化之B7H6/CD3結合蛋白對HCT-15細胞進行染色。用PE偶聯之抗人類二級抗體(Sigma-Aldrich, #P8047)檢測結合之分子。圖5A+B顯示實例性B7H6/CD3結合蛋白(分別包含SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO:224、SEQ ID NO:225、SEQ ID NO:226、SEQ ID NO:227、SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)與人類HCT-15細胞之結合。
實例 8 :與食蟹獼猴 B7H6 之交叉反應
藉由流式細胞術測試B7H6/CD3結合蛋白與表現食蟹獼猴B7H6之重組CHO-K1細胞之結合。如實例2所述產生B7H6/CD3結合蛋白。如實例5所述生成表現食蟹獼猴B7H6之重組細胞系。用FACS緩衝液(PBS/0.5% BSA/0.05%疊氮化鈉)中之增加濃度之兩步純化之B7H6/CD3結合蛋白對細胞進行染色。用PE偶聯之抗人類二級抗體(Sigma-Aldrich, #P8047)檢測結合之分子。圖6顯示實例性B7H6/CD3結合蛋白(分別包含SEQ ID NO: 228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)與表現食蟹獼猴B7H6之重組細胞的結合。
實例 9 : 與人類 T 細胞之結合
藉由流式細胞術測試B7H6/CD3結合蛋白與純化之人類T細胞之結合。如實例2所述產生B7H6/CD3結合蛋白。自獲自Austrian Red Cross之膚色血球層分離T細胞。對於所有膚色血球層,獲得根據赫爾辛基宣言(Declaration of Helsinki)及澳大利亞州倫理委員會(cantonal ethical committee in Austria)之批准的知情同意書。
使用Ficoll® Paque密度梯度培養基(GE Healthcare Lifesciences)製備人類外周血單核細胞(PBMC),之後離心。人類外周血單核細胞(PBMC)係源自富集之淋巴球製劑(膚色血球層),其係收集輸血用血液之血庫的副產品。因此,藉由Ficoll®密度梯度離心(35 min,無制動,於1400 rpm下)及用PBS充分洗滌來分離單核細胞。藉由在ACK溶解緩衝液(Thermo Fisher Scientific, A1049201)中培育3分鐘、之後在PBS中洗滌、然後懸浮於含有RPMI 1640 GlutaMAX™補充物(Gibco #61870-010)、5%人類AB血清AB (Gemini, GemCell目錄號100-512 LOT#H56500I) + 1% MEM-NEAA (Gibco #11140-035)、10mM HEPES (Affymetrix #7365-49-9)、10 μM β-巰基乙醇(Gibco #21985-023)及丙酮酸鈉(Gibco #11360-039)之分析培養基中來去除其餘紅血球。
藉由使用Pan T細胞分離套組II (Miltenyi Biotec #130-091-156)負向選擇來分離T細胞。簡言之,將細胞重懸於40 μl緩衝液PBS/0,5% BSA (Gibco ref#041-94553 M)/2mM EDTA (Invitrogen ref# 15575-038)/1千萬細胞中且於4℃下與10 μl生物素-抗體混合劑/1千萬細胞一起培育5 min。隨後,添加30 µl緩衝液及20 µl抗生物素MACS® MicroBeds/1千萬細胞且於4℃下培育10 min。隨後,將混合物置於適宜MACS®微珠粒分離器(Miltenyi Biotec)之磁場中之預沖洗之25LS管柱(Miltenyi Biotec #130-042-401)中。收集流通物並在分析介質中洗滌。
用FACS緩衝液(PBS/0.5%BSA/0.05%疊氮化鈉)中之增加濃度之兩步純化之B7H6/CD3結合蛋白對T細胞進行染色。用PE偶聯之抗人類二級抗體(Sigma-Aldrich, #P8047)檢測結合之分子。圖7顯示實例性B7H6/CD3結合蛋白(分別包含SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)與人類T細胞之結合。
實例 10 : 結合選擇性
藉由流式細胞術分析測試B7H6/CD3結合蛋白與B7H6及CD3陰性CHO-K1細胞之結合。如實例2所述產生B7H6/CD3結合蛋白。用FACS緩衝液(PBS/0.5% BSA/0.05%疊氮化鈉)中之增加濃度之兩步純化之B7H6/CD3結合蛋白對CHO-K1細胞進行染色。用PE偶聯之抗人類二級抗體(Sigma-Aldrich, #P8047)檢測結合之分子。圖8顯示實例性B7H6/CD3結合蛋白(分別包含SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)與CHO-K1細胞的結合。
實例 11 : B7H6 依賴性 NK 細胞活性之抑制
細胞表面表現之B7H6結合至NK細胞上之NKp30,其觸發NKp30介導之NK細胞活化及NK細胞毒性及細胞介素分泌(Brandt等人,J.Exp. Med. 2009;206(7):1495-1503)。為了評價NK細胞之B7H6依賴性活化,於4℃下用100 nM重組人類B7H6蛋白(R&DSystems#7144-B7-050)塗覆96孔平底細胞培養板過過夜。次日,用PBS洗滌板,隨後添加增加濃度之B7H6/CD3結合蛋白或重組NKp30蛋白(R&DSystems#1849-NK-025),並在室溫下培育一小時。如實例2所述產生B7H6/CD3結合蛋白。在額外洗滌步驟後,每孔添加於100 μl培養基(MEM α含有12.5%胎牛血清、12.5%馬血清、0.2 mM D-肌醇、0.02 mM葉酸及0.1 mM β-巰基乙醇)中之100,000個NK92MI (ATCC)細胞,並培育24小時。次日,使用V-PLEX人類IFN-y套組(Meso Scal Discovery)定量IFNγ濃度。圖9A+B顯示B7H6/CD3結合蛋白(包含SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO:224、SEQ ID NO:225、SEQ ID NO:226、SEQ ID NO:227、SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:235、SEQ ID NO:236之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白)抑制由NK-92MI之IFNγ分泌之B7H6依賴性誘導的能力。
不結合或僅弱結合至Ala突變之B7H6細胞外蛋白(其中NKp30相互作用經丙胺酸取代)的B7H6結合蛋白(包含SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO:224、SEQ ID NO:225、SEQ ID NO:226、SEQ ID NO:227之B7H6鏈及SEQ ID NO:311之CD3鏈的B7-H6/CD3結合蛋白) (如圖4、實例6中所示)抑制由NK-92MI細胞之IFNγ分泌之B7H6依賴性誘導,而顯示與野生型蛋白相比與突變之B7H6細胞外蛋白強結合的結合蛋白(包含SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:235、SEQ ID NO:236之B7H6鏈及SEQ ID NO:311之CD3鏈的B7-H6/CD3結合蛋白) (如圖4、實例6中所示)不影響由NK-92MI細胞之IFNγ分泌的B7-H6依賴性誘導。
實例 12 : T 細胞重定向溶解人類 HCT-15 細胞之效力
使用乳酸去氫酶(LDH)釋放作為細胞溶解之讀出,測定未刺激之T細胞抗HCT-15細胞之效力。在此分析中,將B7H6陽性CRC細胞系HCT-15與作為效應細胞之人類T細胞及增加濃度之B7H6/CD3結合蛋白以10:1之效應物對靶細胞比率共培養72小時。如實例2所述產生B7H6/CD3結合蛋白。如實例9所述分離純化之T細胞。隨後,將HCT-15細胞及T細胞以1:10之比率與濃度為0.00001 nM至10 nM之B7H6/CD3結合蛋白一起培育72小時。
按照製造商之說明書,使用細胞毒性檢測套組+
(Roche)測定細胞毒性活性。簡言之,此方法係基於使用自死亡或質膜損傷之細胞中釋放LDH。將細胞培養上清液與來自套組之反應混合物一起培育30分鐘,並在分光光度計中在500nm處量測作為細胞溶解替代物之甲臢(Formazan)之形成,其係LDH活性之結果。根據下式計算相對於最大溶解對照之細胞毒性百分比:
背景:靶細胞 + 效應細胞
最大溶解:靶細胞 + 5% Triton X-100
最小溶解:靶細胞
使用GraphPad®Prism®5.0軟體(GraphPad Sofware, Inc),將相對於最大溶解對照之細胞毒性百分比對相應B7H6/CD3結合蛋白濃度作圖。用四參數邏輯方程模型分析劑量反應曲線,用於評估S形劑量反應曲線,並計算EC50
值。
圖10A+B及11A+B顯示由實例性B7H6/CD3結合蛋白(分別包含SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO:224、SEQ ID NO:225、SEQ ID NO:226、SEQ ID NO:227、SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)介導之HCT-15細胞之T細胞重新定向溶解的效力之實例。
圖10及11顯示結合至重組Ala突變之B7H6細胞外蛋白(其中與野生型蛋白質相比,NKp30相互作用位點經丙胺酸取代)且不抑制由NK92MI細胞之IFNγ之B7-H6依賴性分泌的B7H6結合蛋白(分別包含SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白) (如實例6、11中所示)顯示比不結合或僅弱結合至重組Ala突變之B7H6細胞外蛋白且抑制由NK92MI細胞之IFNγ之B7-H6依賴性分泌的B7H6/CD3結合蛋白(包含SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220或SEQ ID NO:221之B7H6鏈及SEQ ID NO:CD3#1之CD3鏈的B7-H6/CD3結合蛋白) (如實例6、11中所示)低的EC50
值(表4A+B)。因此,與抑制B7H6依賴性NK細胞活化之結合蛋白相比,不抑制B7H6依賴性NK細胞活化之結合蛋白驚人地顯示顯著更高之T-細胞介導之腫瘤細胞溶解。
如利用實例性B7H6/CD3結合蛋白之圖12所示,活性僅需要低之效應物對靶細胞比率。
表4A:11個實例性B7H6/CD3結合蛋白之EC50
值[nM],如在利用未刺激之T細胞(來自供體#1)作為效應細胞及HCT-15細胞作為靶細胞之72小時細胞毒性分析中所量測.
表4B:23個實例性B7H6/CD3結合蛋白之EC50
值[nM],如在利用未刺激之T細胞(來自供體#2)作為效應細胞及HCT-15細胞作為靶細胞之72小時細胞毒性分析中所量測.
| B7H6 /CD3 | EC50 [nM] |
| B7H6#1/CD3#1 | 0.14 |
| B7H6#2/CD3#1 | 0.22 |
| B7H6#3/CD3#1 | 0.40 |
| B7H6#4/CD3#1 | 0.23 |
| B7H6#5/CD3#1 | 0.22 |
| B7H6#6/CD3#1 | 0.46 |
| B7H6#7/CD3#1 | 0.36 |
| B7H6#8/CD3#1 | 0.62 |
| B7H6#9/CD3#1 | 0.44 |
| B7H6#10/CD3#1 | 0.53 |
| B7H6#11/CD3#1 | 0.77 |
| B7H6 /CD3 | EC50 [nM] |
| B7H6#12/CD3#1 | 0.004 |
| B7H6#13/CD3#1 | 0.008 |
| B7H6#14/CD3#1 | 0.003 |
| B7H6#15/CD3#1 | 0.004 |
| B7H6#16/CD3#1 | 0.011 |
| B7H6#17/CD3#1 | 0.014 |
| B7H6#18/CD3#1 | 0.014 |
| B7H6#19/CD3#1 | 0.011 |
| B7H6#20/CD3#1 | 0.010 |
| B7H6#21/CD3#1 | 0.010 |
| B7H6#22/CD3#1 | 0.005 |
| B7H6#23/CD3#1 | 0.005 |
| B7H6#24/CD3#1 | 0.005 |
| B7H6#14/CD3#2 | 0.118 |
| B7H6#23/CD3#2 | 0.215 |
| B7H6#14/CD3#3 | 0.069 |
| B7H6#23/CD3#3 | 0.107 |
| B7H6#14/CD3#4 | 0.292 |
| B7H6#23/CD3#4 | 0.447 |
| B7H6#14/CD3#5 | 0.005 |
| B7H6#23/CD3#5 | 0.003 |
| B7H6#14/CD3#6 | 0.081 |
| B7H6#23/CD3#6 | 0.129 |
實例 13 : T 細胞重定向溶解之交叉反應性及選擇性
如實例12所述,使用乳酸去氫酶(LDH)釋放作為細胞溶解之讀出測定未刺激之T細胞抗HCT-15細胞之效力。如實例2所述產生B7H6/CD3結合蛋白。如實例5所述生成表現重組食蟹獼猴B7H6之細胞系。
圖13顯示由分別包含SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的實例性B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)介導之表現cyno B7H6之細胞(圖13A)及B7H6陰性親代CHO-K1細胞(圖13B)之T細胞重新定向溶解的效力之實例。
實例 14 : T 細胞活化之選擇性
為了測定T細胞之活化,如實例12所述,設定利用未刺激之T細胞及B7H6陽性HCT-15細胞作為靶細胞之細胞毒性分析。如實例2所述產生B7H6/CD3結合蛋白。為了測定T細胞活化,離心細胞且用抗CD4 (BD #550630)、CD8 (BD #557834)及CD25 (BD #340907)之抗體染色,並藉由流式細胞術量測。圖14顯示在B7H6陽性HCT-15細胞存在及不存在下由包含SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:235或SEQ ID NO:236之B7H6鏈及SEQ ID NO:311之CD3鏈的實例性B7H6/CD3結合蛋白介導之CD4+
(圖14A)及CD8+
(圖14B)細胞活化之效力的實例。
實例 15 : T 細胞脫粒化之選擇性
為了經由穿孔蛋白及顆粒酶B之細胞內表現來測定T細胞之脫粒化,如實例12所述設定利用未刺激之T細胞及B7H6陽性HCT-15細胞作為靶細胞之細胞毒性分析。如實例2所述產生B7H6/CD3結合蛋白。為了測定粒酶B及穿孔蛋白之細胞內含量,將細胞離心且用抗CD4 (BD #550630)、CD8 (BD #557834)之抗體染色,隨後使用固定/滲透溶液(BD #554714)使細胞永久化,且用抗穿孔蛋白(Biolegend #308120)及顆粒酶B (BD #560221)之抗體染色,並藉由流式細胞術量測。圖15顯示在B7H6陽性HCT-15細胞存在及不存在下由包含SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:235或SEQ ID NO:236之B7H6鏈及SEQ ID NO:311之CD3鏈的實例性B7H6/CD3結合蛋白介導之CD4+
(圖15A)及CD8+
(圖15B)細胞中細胞內穿孔蛋白之上調之效力的實例,且圖16顯示CD4+
(圖16A)及CD8+
(圖16B)細胞中細胞內顆粒酶B表現之上調。
實例 16 : T- 細胞增殖之誘導
如實例12所述設定利用未刺激之T細胞及B7H6陽性HCT-15細胞作為靶細胞之細胞毒性分析。如實例2所述產生B7H6/CD3結合蛋白。為了測定T細胞之增殖,用5 µM Cell TraceTM
CFSE (Invitrogen, C34554)標記PBMC且用抗CD3抗體(BioLegend目錄號:317336)對T細胞進行染色。隨後將標記之PBMC與HCT-15細胞以10:1之比率以及增加濃度之B7H6/CD3結合蛋白一起培育6天。圖17顯示在B7H6陽性HCT-15細胞存在下由包含SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:235或SEQ ID NO:236之B7H6鏈及SEQ ID NO:311之CD3鏈的實例性B7H6/CD3結合蛋白之由B7H6結合蛋白之T細胞增殖的劑量依賴性誘導。
實例 17 : IFN γ 分泌之選擇性
如實例12所述設定利用未刺激之T細胞及B7H6陽性HCT-15細胞作為靶細胞之細胞毒性分析。如實例2所述產生B7H6/CD3結合蛋白。藉由V-Plex人類IFN-γ套組(MSD, CAT: K151QOD-4)測定上清液中之細胞介素含量。圖18顯示由包含SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:235或SEQ ID NO:236之B7H6鏈及SEQ ID NO:311之CD3鏈五種實例性B7H6/CD3結合蛋白誘導之IFNγ之分泌。
實例 18 : 小鼠 PK
如實例2所述產生B7H6/CD3結合蛋白。
在C57BL/6小鼠中,在單次1 mg/kgi.v.
劑量後,評估B7H6/CD3結合蛋白之PK。使用B7H6捕獲/CD3檢測分析測定B7H6/CD3結合蛋白之血清濃度。
簡言之,雄性C57BL/6小鼠接受單次1 mg/kg靜脈內(IV)劑量(n = 3/分子)。在給藥前及給藥後0.25、2、6、24、48、96、168、240及336小時收集血樣。用基於MSD之配體結合分析使用生物素化B7H6作為捕獲試劑及磺基標記之CD3ε作為檢測試劑量測血清藥物含量。使用非房室分析由血清濃度時間曲線計算藥物動力學(PK)參數。評價以下PK參數:AUCt最後(自時間零至最後一個可定量之時間點之血清濃度-時間曲線下之面積)、AUCinf (外推至無窮大之血清濃度-時間曲線下面積)、CL (全身性清除率)、Vss (穩態分佈體積)及T1/2
(終末半衰期)。
實例性B7H6/CD3結合蛋白之平均(SD)血清濃度時間曲線概述於圖19中。該等實例性BH6/CD3結合蛋白之平均(SD) PK參數概述於表5中。
表5:在單次1 mg/kg靜脈內劑量後,雄性C57BL/6小鼠中實例性B7H6/CD3結合蛋白之平均(SD) PK參數
| 劑量 (mg/kg) | Cmax (ng/mL) | AUCt 最後 (ng·hr/mL) | AUCinf * (ng·hr/mL) | CL (mL/d/kg) | Vss (mL/kg) | T1/2 ( 天 ) | MRT ( 天 ) | |
| 1 | 20500 (458) | 1200000 (78100) | 1840000 (112000) | 13.1 (0.8) | 173 (30) | 10.2 (2.2) | 13.3 (3.0) | |
| *大於20%外推之AUC | ||||||||
實例 18A :小鼠 PK
如實例18中所述評估B7H6/CD3結合蛋白之PK。平均(SD)血清濃度-時間曲線。包含SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231或SEQ ID NO:232之B7H6鏈及SEQ ID NO:311之CD3鏈的四種實例性B7H6/CD3結合蛋白概述於圖22中。
實例 19 :活體內
效能
使用用人類T細胞重構之人類異種移植物小鼠模型實施效能研究。詳細地,將人類NCI-H716結腸直腸癌細胞(2.5 × 107
)皮下(s.c.)
注射至亞致死輻照(2 Gy,第-1天)之雌性NODNOD.Cg-Prkdcscid
Il2rgtm1Sug
/JicTac小鼠(第-16天)之右背側。平行地,活體外擴增人類CD3陽性T細胞(自健康人類血液供體分離)。
如實例9中所述製備人類外周血單核細胞(PBMC)。
藉由使用Pan T細胞分離套組II (Miltenyi Biotec #130-096-535)負向選擇來分離T細胞。簡言之,將細胞重懸於40 μl緩衝液PBS/0,5% BSA (Gibco ref#041-94553 M)/2mM EDTA (Invitrogen ref# 15575-038)/10×106
個細胞中且於4℃下與10 μl生物素-抗體混合劑/10×106
個細胞一起培育5 min。隨後,添加30 µl緩衝液及20 µl抗生物素MACS®微珠粒/10×106
個細胞且於4℃下培育10 min。隨後,將混合物置於適宜MACS®微珠粒分離器(Miltenyi Biotec)之磁場中之預沖洗之25LS管柱(Miltenyi Biotec #130-042-401)中。收集流通物並在分析介質中洗滌。
隨後,使用人類T細胞活化/擴增套組(Miltenyi Biotec 目錄號130-091-441)使T細胞擴增17天。簡言之,向抗生物素MACSiBead™粒子加載CD2-、CD3-、CD28生物素加載,並以每粒子2個細胞之比率轉移至純化之T細胞,並在20單位重組IL-2 (R&D#202-IL-050/CF)存在下以0.5- 106
個細胞/ml之密度培育14天。每三天用20單位新鮮IL-2補充細胞。在注射至動物之前3天,用抗生物素MACSiBead™粒子再刺激T細胞,以每4個細胞1個珠粒之比率加載CD2-、CD3-、CD28生物素額外三天。最後,用MACSiMAG™分離器(Miltenyi Biotec)去除珠粒,並在PBS中洗滌T細胞。
在第-2天,基於腫瘤體積將動物隨機分成治療組,並腹膜內(i.p.)
注射2 × 107
個人類T細胞。如實例2所述產生B7H6/CD3結合蛋白。在第1天開始治療,並以q7d給藥方案藉由靜脈內(i.v.)
濃注注射至側尾靜脈中投與B7H6/CD3結合蛋白或媒劑緩衝液(50mM NaOAc,100mM NaCl,pH 5.0)。藉由外部測徑器量測監測腫瘤生長,並使用標準半橢球公式計算腫瘤體積。在研究期間出於倫理原因,在早期對達到處死標準之動物實施安樂死。用B7H6/CD3結合蛋白以0.05 mg/kg每週一次i.v.治療帶有腫瘤之小鼠誘導顯著腫瘤消退(圖20)。
實例 19A : 活體內效能
如實例19所述使用用人類CD3+
T細胞重構之人類NCI-H716異種移植物小鼠模型實施效能研究。用包含SEQ ID NO:228、SEQ ID No 230、SEQ ID NO:231、或SEQ ID NO:232之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白以0.05 mg/kg每週一次i.v
.治療帶有腫瘤之小鼠誘導顯著腫瘤消退(圖23)。
實例 19B : 活體內效能
如實例19所述使用用人類CD3+
T細胞重構之人類NCI-H716異種移植物小鼠模型實施效能研究。用每週一次或以0.05 mg/kg單劑量i.v
.投與之實例性B7H6/CD3結合蛋白治療帶有腫瘤之小鼠誘導顯著腫瘤消退(圖24)。
實例 20 : B7H6/CD3 結合蛋白之單體含量百分比
藉由粒徑篩析層析(aSEC)測定B7H6/CD3結合蛋白(分別包含SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO:224、SEQ ID NO:225、SEQ ID NO:225、SEQ ID NO:227、SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6/CD3結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)之單體百分比(示於表6中)。在Waters® (Milfrod, MA, USA) Acquity UPLC®系統上使用Protein BEH SEC管柱200Å, 1.7µm, 4.6×150mm (目錄號186005225)運行aSEC。運行條件如下:移動相:50mM磷酸鈉、200mM精胺酸及0.05%疊氮化鈉;流速:0.5ml/min;運行時間:5分鐘;樣品加載量:10µg;峰檢測:A280nm;層析譜之自動化處理方法。
表6:第一及第二純化步驟後之單體百分比
| B7H6 結合劑 | CD3 結合劑 | 第一步驟後之單體百分比 | 第 2 步驟後之單體百分比 |
| B7H6#1 | CD3#1 | 70.5 | 98.5 |
| B7H6#2 | CD3#1 | 38.7 | 95.1 |
| B7H6#3 | CD3#1 | 50.1 | 96.6 |
| B7H6#4 | CD3#1 | 56.0 | 99.9 |
| B7H6#5 | CD3#1 | 66.5 | 99.3 |
| B7H6#6 | CD3#1 | 63.7 | 99.1 |
| B7H6#7 | CD3#1 | 43.4 | 97.7 |
| B7H6#8 | CD3#1 | 68.3 | 96.8 |
| B7H6#9 | CD3#1 | 61.3 | 95.7 |
| B7H6#10 | CD3#1 | 66.3 | 97.7 |
| B7H6#11 | CD3#1 | 38.2 | 95.3 |
| B7H6#12 | CD3#1 | 67.4 | 99.9 |
| B7H6#13 | CD3#1 | 61.9 | 99.9 |
| B7H6#14 | CD3#1 | 64.6 | 99.9 |
| B7H6#15 | CD3#1 | 53.8 | 99.9 |
| B7H6#16 | CD3#1 | 52.4 | 99.7 |
| B7H6#17 | CD3#1 | 46.8 | 99.9 |
| B7H6#18 | CD3#1 | 50.1 | 99.8 |
| B7H6#19 | CD3#1 | 64.1 | 99.9 |
| B7H6#20 | CD3#1 | 62.3 | 99.9 |
| B7H6#21 | CD3#1 | 60.4 | 99.9 |
| B7H6#22 | CD3#1 | 57.5 | 99.9 |
| B7H6#23 | CD3#1 | 59.5 | 99.8 |
| B7H6#24 | CD3#1 | 51.7 | 99.9 |
| B7H6#14 | CD3#2 | 71.9 | 99.9 |
| B7H6#14 | CD3#3 | 68.2 | 99.9 |
| B7H6#14 | CD3#4 | 62.2 | 99.6 |
| B7H6#14 | CD3#5 | 76.5 | 99.9 |
| B7H6#14 | CD3#6 | 70.5 | 99.9 |
| B7H6#23 | CD3#2 | 69.8 | 99.8 |
| B7H6#23 | CD3#3 | 67.3 | 99.6 |
| B7H6#23 | CD3#4 | 62.2 | 99.7 |
| B7H6#23 | CD3#5 | 75 | 99.9 |
| B7H6#23 | CD3#6 | 69.6 | 99.9 |
實例 21 :熱穩定性
藉由熱位移分析(TSA)測定熱穩定性且B7H6/CD3結合蛋白(分別包含SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)之第一熔融過渡溫度(Tm1)的結果示於表7中。使用QuantStudio™ 6 Flex即時PCR系統(Applied Biosystems, Waltham, MA)利用SYPRO®橙色蛋白凝膠染料(Invitrogen, Carlsbad, CA)作為外部螢光團獲得隨溫度變化之螢光強度曲線。樣品在10 mM組胺酸(pH 6.0)中用40 mM氯化鈉及0.02%疊氮化鈉稀釋至0.4 mg/ml。以2℃/分鐘之速率以25℃至95℃之溫度斜升產生熔融曲線,其中經由「ROX」過濾器組(Ex:580 ±10 nm,Em:623 ±14 nm)大約每0.4℃收集數據。使用Protein Thermo Shift™軟體v1.3版(ThermoFisher Scientific, Waltham, MA)分析數據。
表7:熱穩定性分析
| B7H6 結合劑 | CD3 結合劑 | Tm1 ( ℃ ) |
| B7H6#12 | CD3#1 | 65.3 |
| B7H6#13 | CD3#1 | 65.2 |
| B7H6#14 | CD3#1 | 65.7 |
| B7H6#15 | CD3#1 | 65.4 |
| B7H6#16 | CD3#1 | 65.4 |
| B7H6#17 | CD3#1 | 65.4 |
| B7H6#18 | CD3#1 | 65.0 |
| B7H6#19 | CD3#1 | 64.0 |
| B7H6#20 | CD3#1 | 62.5 |
| B7H6#21 | CD3#1 | 64.9 |
| B7H6#22 | CD3#1 | 58.7 |
| B7H6#23 | CD3#1 | 64.7 |
| B7H6#24 | CD3#1 | 65.3 |
| B7H6#14 | CD3#2 | 61.7 |
| B7H6#14 | CD3#3 | 60.4 |
| B7H6#14 | CD3#4 | 60.3 |
| B7H6#14 | CD3#5 | 61.4 |
| B7H6#14 | CD3#6 | 61.4 |
| B7H6#23 | CD3#2 | 60.1 |
| B7H6#23 | CD3#3 | 64.9 |
| B7H6#23 | CD3#4 | 58.0 |
| B7H6#23 | CD3#5 | 57.9 |
| B7H6#23 | CD3#6 | 57.5 |
實例 22 : 藉由 Epivax 之電腦內預測免疫原性評分
用數學算法在電腦內評估序列之免疫原性。具體而言,測定B7H6鏈(SEQ ID NO:217、SEQ ID NO:218、SEQ ID NO:219、SEQ ID NO:220、SEQ ID NO:221、SEQ ID NO:222、SEQ ID NO:223、SEQ ID NO:224、SEQ ID NO:225、SEQ ID NO:225、SEQ ID NO:227、SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、SEQ ID NO:237、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈)及CD3鏈(SEQ ID NO:311、SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315或SEQ ID NO:316之CD3鏈)的作為免疫原性評分之量度之EpiMatrix® Treg調節之評分(EpiVax Inc., Providence RI))且將其與各種Fc序列之評分進行比較。該等評分考慮T細胞表位及Treg表位。免疫原性評分愈低,序列具有免疫原性之可能性愈小。一般而言,負性評分被認為係免疫原性之低風險,而高正性評分被視為潛在免疫原性之指示。如下表8及9所示,本文所述之實例性B7H6/CD3結合蛋白具有極低免疫原性評分,指示該等結合蛋白具有免疫原性之風險較低。
表8:B7H6/CD3結合蛋白之調節之Epivax®評分
表9:Fc結構域之調節之Epivax®評分
| B7H6 或 CD3 結合蛋白 | VH | VL | 全多肽鏈 (VL-CL- 連接體 -VH-CH1- 鉸鏈 -CH2-CH3) |
| B7H6#1 B7H6鏈 | -9.94 | 17.52 | -29.07 |
| B7H6#2 B7H6鏈 | 17.12 | 1.78 | -27.07 |
| B7H6#3 B7H6鏈 | 67.70 | 32.77 | -11.61 |
| B7H6#4 B7H6鏈 | -20.24 | -6.54 | -34.34 |
| B7H6#5 B7H6鏈 | -58.29 | -29.64 | -43.99 |
| B7H6#6 B7H6鏈 | 4.77 | -9.90 | -30.99 |
| B7H6#7 B7H6鏈 | 16.81 | -13.51 | -28.20 |
| B7H6#8 B7H6鏈 | -31.42 | 35.40 | -29.91 |
| B7H6#9 B7H6鏈 | -4.61 | -4.44 | -31.45 |
| B7H6#10 B7H6鏈 | 10.78 | 3.40 | -26.72 |
| B7H6#11 B7H6鏈 | 4.49 | 47.21 | -22.15 |
| B7H6#12 B7H6鏈 | -24.63 | -48.50 | -39.76 |
| B7H6#13 B7H6鏈 | -19.87 | -48.50 | -39.00 |
| B7H6#14 B7H6鏈 | -23.93 | -48.50 | -39.65 |
| B7H6#15 B7H6鏈 | -19.71 | -48.50 | -38.98 |
| B7H6#16 B7H6鏈 | -17.72 | -48.50 | -38.66 |
| B7H6#17 B7H6鏈 | -19.71 | -48.50 | -38.98 |
| B7H6#18 B7H6鏈 | -19.71 | -50.41 | -39.25 |
| B7H6#19 B7H6鏈 | -22.64 | -48.50 | -39.44 |
| B7H6#20 B7H6鏈 | -24.63 | -50.41 | -40.03 |
| B7H6#21 B7H6鏈 | -21.94 | -48.50 | -39.33 |
| B7H6#22 B7H6鏈 | -23.93 | -50.41 | -39.92 |
| B7H6#23 B7H6鏈 | -21.94 | -50.41 | -39.61 |
| B7H6#24 B7H6鏈 | -19.71 | -50.41 | -39.25 |
| CD3#1 CD3鏈 | -9.68 | -50.52 | -35.25 |
| CD3#2 CD3鏈 | -40.29 | -8.95 | -33.62 |
| CD3#3 CD3鏈 | -41.48 | -4.54 | -33.15 |
| CD3#4 CD3鏈 | -39.06 | -4.54 | -32.77 |
| CD3#5 CD3鏈 | -55.51 | -14.24 | -36.83 |
| CD3#6 CD3鏈 | -41.48 | -14.24 | -34.60 |
| Fc 蛋白鏈 | 調節之 Epivax 評分 |
| Fc-IgG1-WT | -25.64 |
| Fc-IgG1-LALA | -29.83 |
| Fc-IgG1-LALA-KNOB | -31.76 |
| Fc-IgG1-LALA-HOLE | -18.01 |
實例 23 :與表面之非專一性結合
在基於表面電漿共振(SPR)之分析中使用高電荷蛋白進一步測試本發明之B7H6/CD3結合蛋白之專一性。使用生物感測器技術研發非專一性結合分析,以確定結合蛋白是否與無關之帶電蛋白具有顯著結合。在此分析中,使B7H6/CD3結合蛋白通過兩個SPR表面,一個經帶負電荷之蛋白(胰蛋白酶抑制劑)塗覆且一個經帶正電荷之蛋白(溶菌酶)塗覆。當蛋白質展示與該等表面顯著之非專一性結合時,結合之原因可能係在候選物上存在帶正電荷或帶負電荷之表面碎片。蛋白質之非專一性結合可轉化為差的藥物動力學(PK)及生物分佈,且亦可具有下游可製造性影響。
該實驗在Biacore® T200 SPR系統(GE Healthcare Life Sciences)上實施。在25℃下在由10X HBS-EP製備之1X HBS-EP緩衝液中實施稀釋、表面製備及結合實驗。固定方案及結合實驗之流速皆為5 μL/min。
為了製備用於非專一性結合實驗之表面,根據製造說明書使用胺偶合套組將雞蛋清溶菌酶及來自大豆甘胺酸之胰蛋白酶抑制劑人工偶合至Biacore ® S系列CM5感測器晶片(GE Healthcare sciences),表面密度為3000-5000 RU。
在1X HBS-EP緩衝液中以1 µM製備樣品。在活化表面上注射樣品,10 min締合及15 min解離。使用Biacore® T200控制軟體2.0.1版收集數據且使用Biacore ®T200評估軟體3.0版(GE Healthcare Life Sciences)進行分析。
表10顯示實例性B7H6/CD3結合蛋白(分別包含SEQ ID NO:228、SEQ ID NO:229、SEQ ID NO:230、SEQ ID NO:231、SEQ ID NO:232、SEQ ID NO:233、SEQ ID NO:234、SEQ ID NO:235、SEQ ID NO:236、 SEQ ID NO:237 、SEQ ID NO:238、SEQ ID NO:239或SEQ ID NO:240之B7H6鏈及SEQ ID NO:311之CD3鏈的B7H6結合蛋白,及包含SEQ ID NO:230或SEQ ID NO:239之B7H6鏈及SEQ ID NO:312、SEQ ID NO:313、SEQ ID NO:314、SEQ ID NO:315、或SEQ ID NO:316之CD3鏈的B7H6結合蛋白)與兩種高電荷蛋白(即胰蛋白酶抑制劑及溶菌酶)不結合或結合極低。
表10:低RU數指示無與無關之帶電蛋白之顯著結合
| B7H6 結合劑 | CD3 結合劑 | 非專一性結合 (RU) ,溶菌酶 ( 正性 ) | 非專一性結合 (RU) , Tryp 抑制劑 ( 負性 ) |
| B7H6#12 | CD3#1 | 9.2 | 35.4 |
| B7H6#13 | CD3#1 | 7.2 | 30.6 |
| B7H6#14 | CD3#1 | 8.1 | 32.7 |
| B7H6#15 | CD3#1 | 7.2 | 32.8 |
| B7H6#16 | CD3#1 | 8.2 | 42.6 |
| B7H6#17 | CD3#1 | 15.3 | 88.4 |
| B7H6#18 | CD3#1 | 6.6 | 32.8 |
| B7H6#19 | CD3#1 | 8.2 | 40.3 |
| B7H6#20 | CD3#1 | 9.8 | 48.4 |
| B7H6#21 | CD3#1 | 8.1 | 42 |
| B7H6#22 | CD3#1 | 7.8 | 39.5 |
| B7H6#23 | CD3#1 | 8.1 | 45.7 |
| B7H6#24 | CD3#1 | 7.9 | 43.5 |
| B7H6#14 | CD3#2 | 11.2 | 12.2 |
| B7H6#14 | CD3#3 | 12.4 | 26.4 |
| B7H6#14 | CD3#4 | 8.8 | 22.6 |
| B7H6#14 | CD3#5 | 16.2 | 109.6 |
| B7H6#14 | CD3#6 | 15.7 | 34 |
| B7H6#23 | CD3#2 | 37.8 | 47.8 |
| B7H6#23 | CD3#3 | 18.9 | 38.7 |
| B7H6#23 | CD3#4 | 6.8 | 20.7 |
| B7H6#23 | CD3#5 | 15 | 114.7 |
| B7H6#23 | CD3#6 | 57.2 | 96.5 |
實例 24 :用實例性 B7H6/CD3 結合蛋白之 SHP77 異種移植物腫瘤組織中之 T 細胞浸潤 .
製備實例19中所述研究中來自小鼠之剩餘腫瘤組織,固定於福馬林(formalin)中並包埋於石蠟中。隨後製備組織切片並染色以檢測T細胞上之CD3表現(抗CD3 (2GV6),Ventana Medical Systems)。用實例性B7H6/CD3結合蛋白之NCI-H716異種移植物腫瘤組織中T細胞浸潤示於圖21中。表11中之評分用於定量異種移植物腫瘤組織中CD3之表現。
表11:用於浸潤CD3陽性T細胞之量化之評分
| 評分 | 說明 |
| 0 | < 5個CD3陽性T細胞/ HPF (高倍視野) |
| 1 | 5-99個CD3陽性T細胞/ HPF (高倍視野) |
| 2 | 100-200個CD3陽性T細胞/ HPF (高倍視野) |
| 3 | > 300個CD3陽性T細胞/ HPF (高倍視野) |
實例 25 : 用於 i.v. 投與之醫藥調配物
可選擇本發明之任何上述結合蛋白/分子用於製造用於i.v.
應用之醫藥調配物。本發明抗體之適宜醫藥調配物之實例如下。
10 mL小瓶含有10 mg/mL在包含組胺酸、海藻糖、聚山梨醇酯20及注射用水之緩衝液中之本發明之B7H6/CD3結合分子/蛋白質。
圖 1 :
本發明之雙專一性結合蛋白的示意性代表圖。圖 2 :
在CHO-K1細胞之細胞表面上表現之細胞外B7H6蛋白的示意性代表圖。圖 3 :
34種實例性B7H6/CD3結合蛋白與重組人類B7H6細胞外蛋白之結合。圖 4 :
34種實例性B7H6/CD3結合蛋白與重組人類丙胺酸突變之B7H6細胞外蛋白的結合。圖 5 :
34種實例性B7H6/CD3結合蛋白與表現內源性人類B7H6之HCT-15細胞的結合。圖 6 :
23種實例性B7H6/CD3結合蛋白與表現食蟹獼猴B7H6之重組CHO-K1細胞的結合。圖 7 :
23種實例性B7H6/CD3結合蛋白與表現CD3之人類T細胞的結合。圖 8 :
23種實例性B7H6/CD3結合蛋白與B7H6陰性CHO-K1細胞之結合。圖 9 :
由NK-92MI細胞之B7H6依賴性IFNγ分泌之17種實例性B7H6/CD3結合蛋白的抑制活性。圖 10 :
將未刺激之T細胞重新導向人類HCT-15細胞之11種實例性B7H6/CD3結合蛋白在溶解靶細胞中之效力。圖 11 :
將未刺激之T細胞重新導向人類HCT-15細胞之23種實例性B7H6/CD3結合蛋白在溶解靶細胞中之效力。圖 12 :
以各種效應物對靶(E:T)細胞比率之實例性B7H6/CD3結合蛋白在溶解靶細胞中之效力。圖 13 :
將未刺激之T細胞重新導向經B7-H6及Cho wt細胞轉染之重組CHO細胞的23種實例性B7H6/CD3結合蛋白在溶解細胞中之效力。圖 14 :
在6種實例性B7H6/CD3結合蛋白之HCT-15細胞存在下T細胞上之CD25上調中的效力。圖 15 :
在6種實例性B7H6/CD3結合蛋白之HCT-15細胞存在下T細胞中之內穿孔蛋白表現上調之效力。圖 16 :
在6種實例性B7H6/CD3結合蛋白之HCT-15細胞存在下T細胞中之細胞內顆粒酶B表現上調之效力。圖 17 :
在6種實例性B7H6/CD3結合蛋白之HCT-15細胞存在下T細胞增殖的效力。
圖18 :
在5種實例性B7H6/CD3結合蛋白之HCT-15細胞存在下T細胞分泌IFNγ的效力。圖 19 :
一種實例性B7H6/CD3結合蛋白之藥物動力學概況。圖 20 :
T細胞植入之小鼠異種移植物模型中一種實例性B7H6/CD3結合蛋白之抗腫瘤活性。圖 21 :
利用實例性B7H6/CD3結合蛋白之NCI-H716異種移植物腫瘤組織中之T細胞浸潤。圖 22 :
四種實例性B7H6結合蛋白之藥物動力學概況。圖 23 :
T細胞植入之小鼠異種移植物模型中四種實例性B7H6/CD3結合蛋白之抗腫瘤活性。圖 24 :
T細胞植入之小鼠異種移植物模型中q7d或作為一個單一劑量投與之實例性B7H6/CD3結合蛋白的抗腫瘤活性。






































































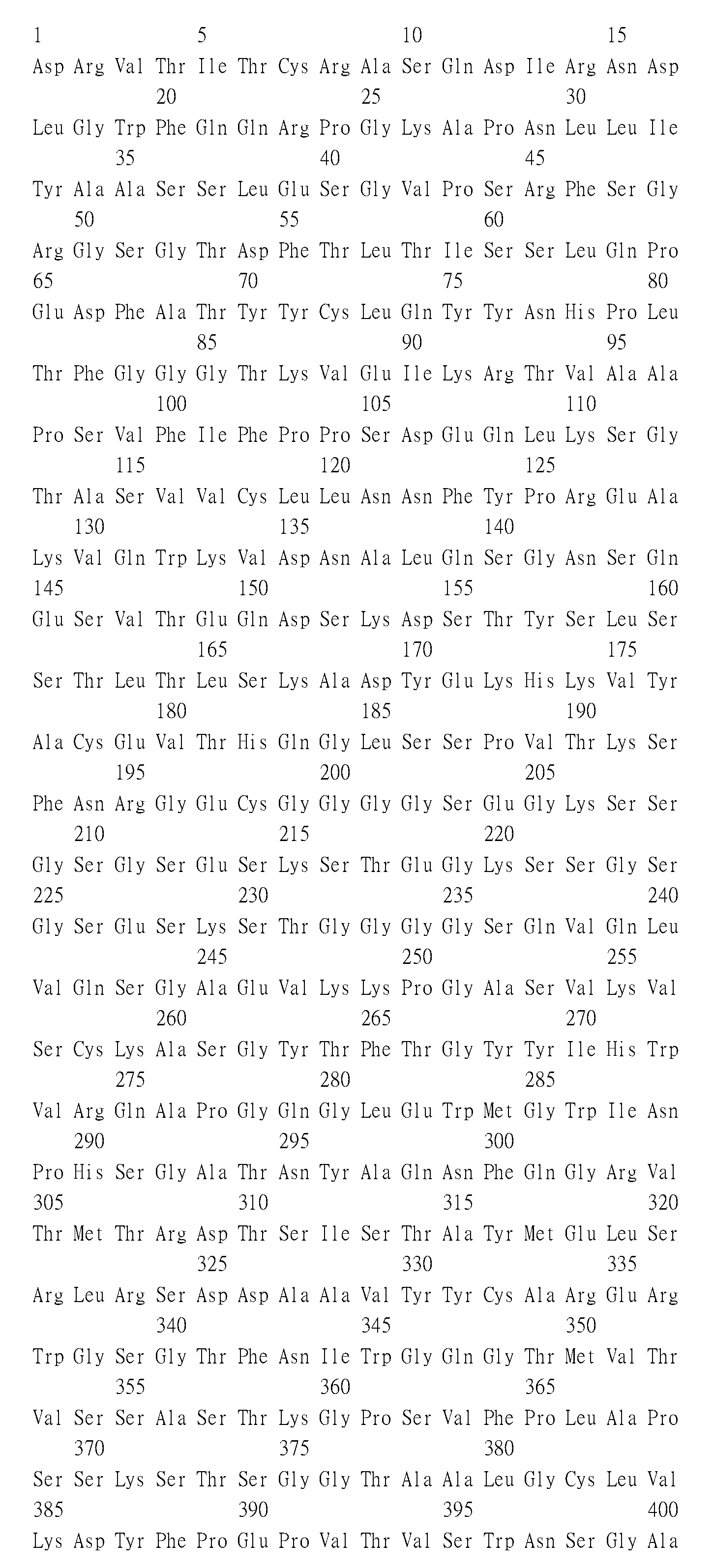





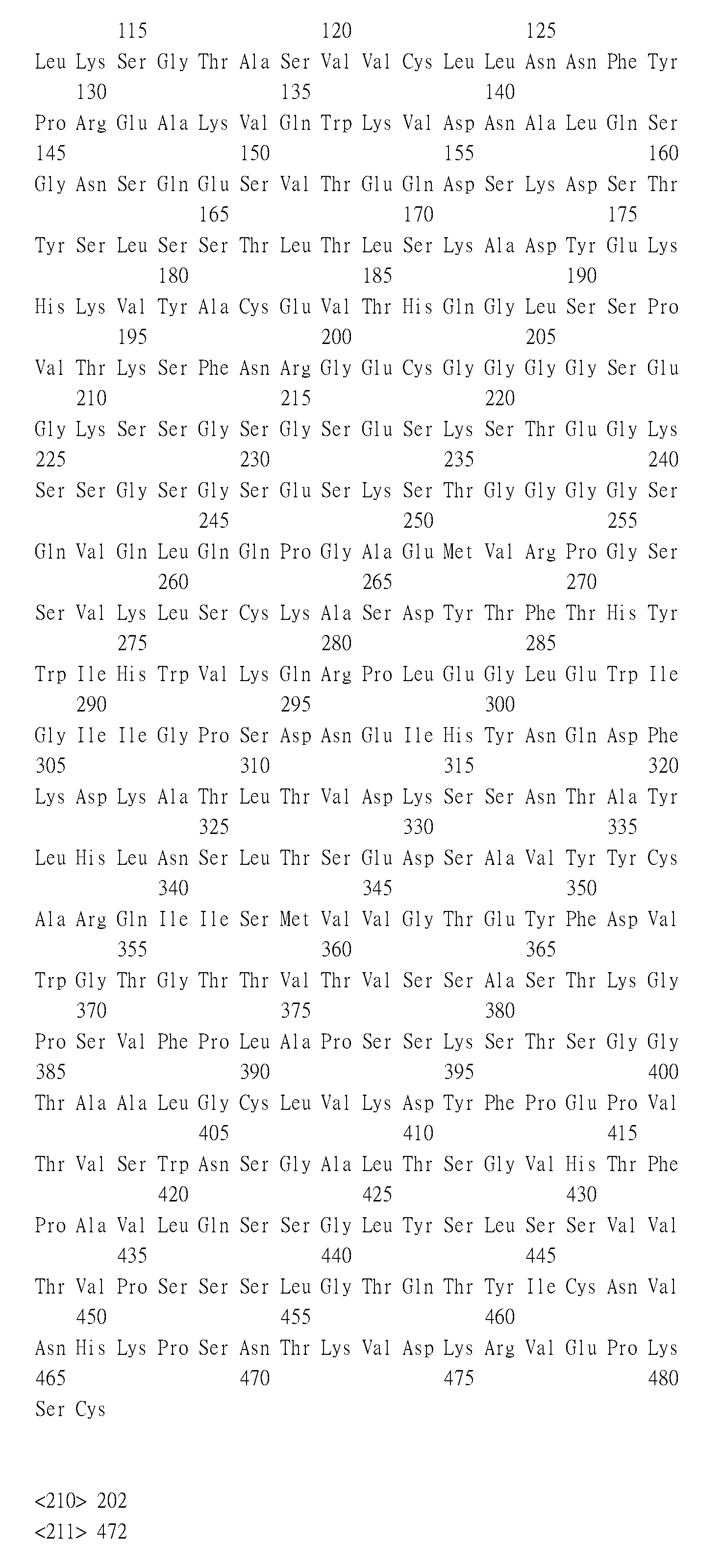










































































































































Claims (31)
- 一種蛋白質,其包含專一性結合至B7H6之第一抗原結合單元及專一性結合至CD3之第二抗原結合單元,其中專一性結合至B7H6之該第一抗原結合單元選自由i)至iii)組成之群:i)抗原結合單元,其包括包含SEQ ID NO:79(CDR1)、SEQ ID NO:80(CDR2)及SEQ ID NO:81(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:82(CDR1)、SEQ ID NO:83(CDR2)及SEQ ID NO:84(CDR3)之胺基酸序列之重鏈CDR;ii)抗原結合單元,其包括包含SEQ ID NO:85(CDR1)、SEQ ID NO:86(CDR2)及SEQ ID NO:87(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:88(CDR1)、SEQ ID NO:89(CDR2)及SEQ ID NO:90(CDR3)之胺基酸序列之重鏈CDR;及iii)抗原結合單元,其包括包含SEQ ID NO:91(CDR1)、SEQ ID NO:92(CDR2)及SEQ ID NO:93(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:94(CDR1)、SEQ ID NO:95(CDR2)及SEQ ID NO:96(CDR3)之胺基酸序列之重鏈CDR,且其中專一性結合至CD3之該第二抗原結合單元包括包含SEQ ID NO:257(CDR1)、SEQ ID NO:258(CDR2)及SEQ ID NO:259(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260(CDR1)、SEQ ID NO:261(CDR2)及SEQ ID NO:262(CDR3)之胺基酸序列之重鏈CDR。
- 如請求項1之蛋白質,其中專一性結合至B7H6之該第一抗原結合單 元選自由i)至iv)組成之群:i)包含SEQ ID NO:167之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:168之胺基酸序列之重鏈可變結構域;ii)包含SEQ ID NO:171之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:172之胺基酸序列之重鏈可變結構域;iii)包含SEQ ID NO:173之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:174之胺基酸序列之重鏈可變結構域;及iv)包含SEQ ID NO:175之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:176之胺基酸序列之重鏈可變結構域。
- 如請求項1之蛋白質,其中專一性結合至CD3之該第二抗原結合單元包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域。
- 如請求項1至3中任一項之蛋白質,其中i)專一性結合至B7H6之該第一抗原結合單元自其N端至C端包含第一輕鏈可變結構域、第一輕鏈恆定結構域、第一肽連接體、第一重鏈可變結構域及第一重鏈恆定CH1結構域;且ii)專一性結合至CD3之該第二抗原結合單元自其N端至C端包含第二輕鏈可變結構域、第二輕鏈恆定結構域、第二肽連接體、第二重鏈可變結構域及第二重鏈恆定CH1結構域。
- 如請求項4之蛋白質,其中 該第一抗原結合單元包括包含SEQ ID NO:79(CDR1)、SEQ ID NO:80(CDR2)及SEQ ID NO:81(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:82(CDR1)、SEQ ID NO:83(CDR2)及SEQ ID NO:84(CDR3)之胺基酸序列之重鏈CDR,且該第二抗原結合單元包括包含SEQ ID NO:257(CDR1)、SEQ ID NO:258(CDR2)及SEQ ID NO:259(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260(CDR1)、SEQ ID NO:261(CDR2)及SEQ ID NO:262(CDR3)之胺基酸序列之重鏈CDR。
- 如請求項4之蛋白質,其中i)該第一抗原結合單元包括包含SEQ ID NO:167之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:168之胺基酸序列之重鏈可變結構域,且該第二抗原結合單元包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域;或ii)該第一抗原結合單元包括包含SEQ ID NO:171之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:172之胺基酸序列之重鏈可變結構域,且該第二抗原結合單元包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域;或iii)該第一抗原結合單元包括包含SEQ ID NO:173之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:174之胺基酸序列之重鏈可變結構域,且該第二抗原結合單元包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域;或iv)該第一抗原結合單元包括包含SEQ ID NO:175之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:176之胺基酸序列之重鏈可變結構域,且 該第二抗原結合單元包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域。
- 如請求項4之蛋白質,其中(i)對B7H6具有專一性之該第一抗原結合單元包含SEQ ID NO:204之胺基酸序列且對CD3具有專一性之該第二抗原結合單元包含SEQ ID NO:305之胺基酸序列;或(ii)對B7H6具有專一性之該第一抗原結合單元包含SEQ ID NO:206之胺基酸序列且對CD3具有專一性之該第二抗原結合單元包含SEQ ID NO:305之胺基酸序列;(iii)對B7H6具有專一性之該第一抗原結合單元包含SEQ ID NO:207之胺基酸序列且對CD3具有專一性之該第二抗原結合單元包含SEQ ID NO:305之胺基酸序列;或(iv)對B7H6具有專一性之該第一抗原結合單元包含SEQ ID NO:208之胺基酸序列且對CD3具有專一性之該第二抗原結合單元包含SEQ ID NO:305之胺基酸序列。
- 如請求項4之蛋白質,其進一步包含第一及第二Fc結構域,該第一Fc結構域共價連接至該第一抗原結合單元之C端,且該第二Fc結構域共價連接至該第二抗原結合單元之C端。
- 如請求項8之蛋白質,其中i)該第一Fc結構域包含位置366之酪胺酸(Y)[T366Y],且該第二Fc 結構域包含位置407之蘇胺酸(T)[Y407T],或ii)該第一Fc結構域包含位置366之色胺酸(W)[T366W],且該第二Fc結構域包含位置366之絲胺酸(S)[T366S]、位置368之丙胺酸(A)[L368A]及位置407之纈胺酸(V)[Y407V],或iii)該第二Fc結構域包含位置366之酪胺酸(Y)[T366Y],且該第一Fc結構域包含位置407之蘇胺酸(T)[Y407T],或iv)該第二Fc結構域包含位置366之色胺酸(W)[T366W],且該第一Fc結構域包含位置366之絲胺酸(S)[T366S]、位置368之丙胺酸(A)[L368A]及位置407之纈胺酸(V)[Y407V]。
- 如請求項9之蛋白質,其中該第一或該第二Fc結構域進一步包含位置435之精胺酸[H435R]及位置436之苯丙胺酸[Y436F],及/或其中該第一及/或該第二Fc結構域包含位置234之丙胺酸[L234A]及位置235之丙胺酸[L235A]。
- 如請求項9之蛋白質,其中該第一Fc結構域包含SEQ ID NO:242之胺基酸序列且該第二Fc結構域包含SEQ ID NO:243之胺基酸序列。
- 如請求項4之蛋白質,其包含專一性結合至B7H6之第一多肽鏈,其包含選自由以下組成之群之胺基酸序列:SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231及SEQ ID NO:232;及專一性結合至CD3之第二多肽鏈,其包含SEQ ID NO:311之胺基酸序列。
- 如請求項12之蛋白質,其中專一性結合至B7H6之該第一多肽鏈包含SEQ ID NO:230之胺基酸序列且專一性結合至CD3之該第二多肽鏈包含SEQ ID NO:311之胺基酸序列。
- 一種宿主細胞,其經兩個表現載體轉染,一個表現載體編碼SEQ ID NO:228、SEQ ID NO:230、SEQ ID NO:231或SEQ ID NO:232中任一者之第一多肽鏈,且另一個表現載體編碼SEQ ID NO:311之第二多肽鏈。
- 一種製造如請求項12之蛋白質之方法,其包含i)如請求項14之宿主細胞在允許如請求項12之蛋白質表現之條件下培養;及ii)回收該蛋白質。
- 如請求項15之方法,其進一步包含純化及/或修飾及/或調配該蛋白質。
- 一種蛋白質,其包含專一性結合至B7H6之第一多肽鏈(B7H6鏈)及專一性結合至CD3之第二多肽鏈(CD3鏈),其中該第一多肽鏈包含第一輕鏈、第一肽連接體及第一重鏈,且該第二多肽鏈包含第二輕鏈、第二肽連接體及第二重鏈其中專一性結合至B7H6之該第一多肽鏈包含含有選自由i)至iii)組成之群之CDR序列之輕鏈可變結構域及重鏈可變結構域:i)包含SEQ ID NO:79(CDR1)、SEQ ID NO:80(CDR2)及SEQ ID NO:81(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:82(CDR1)、SEQ ID NO:83(CDR2)及SEQ ID NO:84(CDR3)之胺基酸序列之重鏈CDR;ii)包含SEQ ID NO:85(CDR1)、SEQ ID NO:86(CDR2)及SEQ ID NO:87(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:88(CDR1)、SEQ ID NO:89(CDR2)及SEQ ID NO:90(CDR3)之胺基酸序列之重鏈CDR;及iii)包含SEQ ID NO:91(CDR1)、SEQ ID NO:92(CDR2)及SEQ ID NO:93(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:94(CDR1)、SEQ ID NO:95(CDR2)及SEQ ID NO:96(CDR3)之胺基酸序列之重鏈CDR,且其中專一性結合至CD3之該第二多肽鏈包括包含SEQ ID NO:257(CDR1)、SEQ ID NO:258(CDR2)及SEQ ID NO:259(CDR3)之胺基酸序列之輕鏈CDR及包含SEQ ID NO:260(CDR1)、SEQ ID NO:261(CDR2)及SEQ ID NO:262(CDR3)之胺基酸序列之重鏈CDR。
- 如請求項17之蛋白質,其中該第一輕鏈之C端經由該第一肽連接體共價連接至該第一重鏈之N端,且其中該第二輕鏈之C端經由該第二肽連接體共價連接至該第二重鏈之N端。
- 如請求項17之蛋白質,其中專一性結合至B7H6之該第一多肽鏈包含選自由i)至iv)組成之群之輕鏈可變結構域及重鏈可變結構域: i)包含SEQ ID NO:167之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:168之胺基酸序列之重鏈可變結構域;ii)包含SEQ ID NO:171之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:172之胺基酸序列之重鏈可變結構域;iii)包含SEQ ID NO:173之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:174之胺基酸序列之重鏈可變結構域;及iv)包含SEQ ID NO:175之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:176之胺基酸序列之重鏈可變結構域。
- 如請求項17之蛋白質,其中專一性結合至CD3之該第二多肽鏈包括包含SEQ ID NO:293之胺基酸序列之輕鏈可變結構域及包含SEQ ID NO:294之胺基酸序列之重鏈可變結構域。
- 如請求項17至20中任一項之蛋白質,其中i)該第一重鏈包含位置366之酪胺酸(Y)[T366Y],且該第二重鏈包含位置407之蘇胺酸(T)[Y407T],或ii)該第一重鏈包含位置366之色胺酸(W)[T366W],且該第二重鏈包含位置366之絲胺酸(S)[T366S]、位置368之丙胺酸(A)[L368A]及位置407之纈胺酸(V)[Y407V],或iii)該第二重鏈包含位置366之酪胺酸(Y)[T366Y],且該第一重鏈包含位置407之蘇胺酸(T)[Y407T],或iv)該第二重鏈包含位置366之色胺酸(W)[T366W],且該第一重鏈包含位置366之絲胺酸(S)[T366S]、位置368之丙胺酸(A)[L368A]及位置 407之纈胺酸(V)[Y407V]。
- 如請求項21之蛋白質,其中該第一或該第二重鏈進一步包含位置435之精胺酸[H435R]及位置436之苯丙胺酸[Y436F],及/或其中該第一及/或該第二重鏈包含位置234之丙胺酸[L234A]及位置235之丙胺酸[L235A]。
- 如請求項21之蛋白質,其中該第一重鏈包含具有SEQ ID NO:242之胺基酸序列之Fc結構域且該第二重鏈結構域包含具有SEQ ID NO:243之胺基酸序列之Fc結構域。
- 一種醫藥組合物,其包含如請求項1至13或17至23中任一項之蛋白質及醫藥上可接受之載劑。
- 一種如請求項1至13或17至23中任一項之蛋白質之用途,其用於製備用於治療癌症之醫藥組合物。
- 如請求項25之用途,其中該癌症係表現B7H6之腫瘤。
- 如請求項26之用途,其中該癌症係(轉移性)結腸直腸癌((m)CRC)、非小細胞肺癌(NSCLC)或頭頸部鱗狀細胞癌(HNSCC)。
- 如請求項25之用途,其中該蛋白質與以下組合使用:細胞毒性或細胞生長抑制化學治療劑、抑制血管生成之治療活性化合物、信號轉導路徑 抑制劑、免疫調節劑、免疫檢查點抑制劑、有絲分裂檢查點抑制劑或激素治療劑。
- 如請求項28之用途,其中該蛋白質與免疫檢查點抑制劑組合使用。
- 如請求項29之用途,其中該免疫檢查點抑制劑為抗PD-1抗體或抗PD-L1抗體。
- 如請求項30之用途,其中該抗PD-1抗體選自由以下組成之群:PD1-1、PD1-2、PD1-3、PD1-4及PD1-5。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP19201200.3 | 2019-10-02 | ||
| EP19201200 | 2019-10-02 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| TW202128756A TW202128756A (zh) | 2021-08-01 |
| TWI878355B true TWI878355B (zh) | 2025-04-01 |
Family
ID=68136317
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| TW109134076A TWI878355B (zh) | 2019-10-02 | 2020-09-30 | 用於癌症治療之多重專一性結合蛋白 |
Country Status (24)
| Country | Link |
|---|---|
| US (2) | US11732045B2 (zh) |
| EP (1) | EP4038100A2 (zh) |
| JP (2) | JP7387885B2 (zh) |
| KR (1) | KR20220075383A (zh) |
| CN (1) | CN114641496B (zh) |
| AR (1) | AR120138A1 (zh) |
| AU (1) | AU2020358893A1 (zh) |
| BR (1) | BR112022004047A2 (zh) |
| CA (1) | CA3153372A1 (zh) |
| CL (1) | CL2022000664A1 (zh) |
| CO (1) | CO2022003552A2 (zh) |
| CR (1) | CR20220136A (zh) |
| DO (1) | DOP2022000060A (zh) |
| EC (1) | ECSP22019193A (zh) |
| IL (1) | IL291817A (zh) |
| JO (1) | JOP20220079A1 (zh) |
| MX (1) | MX2022004042A (zh) |
| MY (1) | MY209387A (zh) |
| PE (1) | PE20221412A1 (zh) |
| PH (1) | PH12022550693A1 (zh) |
| SA (1) | SA522432139B1 (zh) |
| TW (1) | TWI878355B (zh) |
| UA (1) | UA130106C2 (zh) |
| WO (1) | WO2021064137A2 (zh) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL298287A (en) | 2020-05-19 | 2023-01-01 | Boehringer Ingelheim Int | Binding molecules for the treatment of cancer |
| CA3207652A1 (en) | 2021-03-26 | 2022-09-29 | Stephanie Cornen | Cytokine anchors for nkp46-binding nk cell engager proteins |
| US12065427B2 (en) | 2021-04-29 | 2024-08-20 | Boehringer Ingelheim International Gmbh | Heterocyclic compounds capable of activating STING |
| JP2024521405A (ja) | 2021-06-09 | 2024-05-31 | イナート・ファルマ・ソシエテ・アノニム | Nkp46、サイトカイン受容体、腫瘍抗原およびcd16aに結合する多特異性タンパク質 |
| WO2022258678A1 (en) | 2021-06-09 | 2022-12-15 | Innate Pharma | Multispecific proteins binding to nkp30, a cytokine receptor, a tumour antigen and cd16a |
| WO2022258691A1 (en) | 2021-06-09 | 2022-12-15 | Innate Pharma | Multispecific proteins binding to nkg2d, a cytokine receptor, a tumour antigen and cd16a |
| CN114395047B (zh) * | 2021-12-07 | 2023-11-07 | 合肥天港免疫药物有限公司 | 双特异性抗体及其应用 |
| CN114395045B (zh) * | 2021-12-07 | 2023-06-09 | 合肥天港免疫药物有限公司 | B7h6抗体及其应用 |
| CN114395043B (zh) * | 2021-12-07 | 2023-07-11 | 合肥天港免疫药物有限公司 | Ncr3lg1抗体及其应用 |
| WO2024089008A1 (en) | 2022-10-26 | 2024-05-02 | Boehringer Ingelheim International Gmbh | Heterocyclic compounds capable of activating sting |
| WO2024088991A1 (en) | 2022-10-26 | 2024-05-02 | Boehringer Ingelheim International Gmbh | Heterocyclic compounds capable of activating sting |
| US20240174641A1 (en) | 2022-10-26 | 2024-05-30 | Boehringer Ingelheim International Gmbh | Heterocyclic compounds capable of activating sting |
| EP4688826A1 (en) | 2023-04-04 | 2026-02-11 | Innate Pharma | Modular chimeric antigen receptor |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013169691A1 (en) * | 2012-05-07 | 2013-11-14 | Trustees Of Dartmouth College | Anti-b7-h6 antibody, fusion proteins, and methods of using the same |
| WO2017181001A1 (en) * | 2016-04-15 | 2017-10-19 | Trustees Of Dartmouth College | High affinity b7-h6 antibodies and antibody fragments |
Family Cites Families (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5731A (en) | 1848-08-22 | Elisha k | ||
| US168A (en) | 1837-04-17 | Improvement in fire-arms | ||
| US4676980A (en) | 1985-09-23 | 1987-06-30 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Target specific cross-linked heteroantibodies |
| ATE87659T1 (de) | 1986-09-02 | 1993-04-15 | Enzon Lab Inc | Bindungsmolekuele mit einzelpolypeptidkette. |
| ES2052027T5 (es) | 1988-11-11 | 2005-04-16 | Medical Research Council | Clonacion de secuencias de dominio variable de inmunoglobulina. |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| WO1993008829A1 (en) | 1991-11-04 | 1993-05-13 | The Regents Of The University Of California | Compositions that mediate killing of hiv-infected cells |
| EP0658230B1 (en) | 1992-08-10 | 1996-09-25 | Alcan Aluminium Uk Limited | Fence |
| DK1621554T4 (da) | 1992-08-21 | 2012-12-17 | Univ Bruxelles | Immunoglobuliner blottet for lette kæder |
| US5837242A (en) | 1992-12-04 | 1998-11-17 | Medical Research Council | Multivalent and multispecific binding proteins, their manufacture and use |
| ATE183513T1 (de) | 1993-06-03 | 1999-09-15 | Therapeutic Antibodies Inc | Herstellung von antikörperfragmenten |
| EP0739981A1 (en) | 1995-04-25 | 1996-10-30 | Vrije Universiteit Brussel | Variable fragments of immunoglobulins - use for therapeutic or veterinary purposes |
| WO2002056910A1 (en) | 2001-01-17 | 2002-07-25 | Trubion Pharmaceuticals, Inc. | Binding domain-immunoglobulin fusion proteins |
| US20050214857A1 (en) | 2001-12-11 | 2005-09-29 | Algonomics N.V. | Method for displaying loops from immunoglobulin domains in different contexts |
| NL1019562C2 (nl) | 2001-12-13 | 2003-06-17 | Heineken Tech Services | Klepsamenstel voor gebruik bij drankafgifte. |
| US8764654B2 (en) | 2008-03-19 | 2014-07-01 | Zin Technologies, Inc. | Data acquisition for modular biometric monitoring system |
| ES2856451T3 (es) * | 2005-10-11 | 2021-09-27 | Amgen Res Munich Gmbh | Composiciones que comprenden anticuerpos específicos para diferentes especies, y usos de las mismas |
| SI2860192T1 (en) | 2005-10-12 | 2018-04-30 | Morphosys Ag | Generating and profiling fully human HuCAL GOLD-specific therapeutic antibodies specific to human CD38 |
| JP5496897B2 (ja) | 2007-10-04 | 2014-05-21 | ザイモジェネティクス, インコーポレイテッド | B7ファミリーメンバーのzB7H6ならびに関連する組成物および方法 |
| AU2009204501B2 (en) | 2008-01-07 | 2015-02-12 | Amgen Inc. | Method for making antibody Fc-heterodimeric molecules using electrostatic steering effects |
| FI20090280L (fi) | 2009-07-17 | 2011-01-18 | Kone Corp | Hissijärjestely ja menetelmä hissikorin liikuttamiseksi hissikuilussa |
| JP5914353B2 (ja) | 2009-12-23 | 2016-05-11 | エスバテック − ア ノバルティス カンパニー エルエルシー | 免疫原性を減少させるための方法 |
| MY173899A (en) * | 2011-05-21 | 2020-02-26 | Macrogenics Inc | Cd3-binding molecules capable of binding to human and non-human cd3 |
| PH12013502669B1 (en) | 2011-06-23 | 2018-08-10 | Ablynx Nv | Techniques for predicting, detecting and reducing aspecific protein interference in assays involving immunoglobulin single variable domains |
| MX2014001883A (es) | 2011-08-17 | 2014-05-27 | Glaxo Group Ltd | Proteinas y peptidos modificados. |
| WO2013055809A1 (en) * | 2011-10-10 | 2013-04-18 | Xencor, Inc. | A method for purifying antibodies |
| CA2878587A1 (en) * | 2012-07-23 | 2014-01-30 | Zymeworks Inc. | Immunoglobulin constructs comprising selective pairing of the light and heavy chains |
| WO2017165464A1 (en) * | 2016-03-21 | 2017-09-28 | Elstar Therapeutics, Inc. | Multispecific and multifunctional molecules and uses thereof |
| AR108516A1 (es) | 2016-05-18 | 2018-08-29 | Boehringer Ingelheim Int | Moléculas de anticuerpo anti-pd1 y anti-lag3 para el tratamiento del cáncer |
| TWI848953B (zh) * | 2018-06-09 | 2024-07-21 | 德商百靈佳殷格翰國際股份有限公司 | 針對癌症治療之多特異性結合蛋白 |
-
2020
- 2020-09-30 TW TW109134076A patent/TWI878355B/zh active
- 2020-10-01 KR KR1020227014608A patent/KR20220075383A/ko active Pending
- 2020-10-01 JP JP2022520371A patent/JP7387885B2/ja active Active
- 2020-10-01 MY MYPI2022001742A patent/MY209387A/en unknown
- 2020-10-01 CN CN202080068909.4A patent/CN114641496B/zh active Active
- 2020-10-01 AU AU2020358893A patent/AU2020358893A1/en active Pending
- 2020-10-01 JO JOP/2022/0079A patent/JOP20220079A1/ar unknown
- 2020-10-01 PH PH1/2022/550693A patent/PH12022550693A1/en unknown
- 2020-10-01 MX MX2022004042A patent/MX2022004042A/es unknown
- 2020-10-01 CR CR20220136A patent/CR20220136A/es unknown
- 2020-10-01 AR ARP200102733A patent/AR120138A1/es unknown
- 2020-10-01 UA UAA202201295A patent/UA130106C2/uk unknown
- 2020-10-01 US US17/060,111 patent/US11732045B2/en active Active
- 2020-10-01 WO PCT/EP2020/077586 patent/WO2021064137A2/en not_active Ceased
- 2020-10-01 PE PE2022000468A patent/PE20221412A1/es unknown
- 2020-10-01 IL IL291817A patent/IL291817A/en unknown
- 2020-10-01 BR BR112022004047A patent/BR112022004047A2/pt unknown
- 2020-10-01 CA CA3153372A patent/CA3153372A1/en active Pending
- 2020-10-01 EP EP20789508.7A patent/EP4038100A2/en active Pending
-
2022
- 2022-03-14 EC ECSENADI202219193A patent/ECSP22019193A/es unknown
- 2022-03-18 DO DO2022000060A patent/DOP2022000060A/es unknown
- 2022-03-18 CL CL2022000664A patent/CL2022000664A1/es unknown
- 2022-03-25 CO CONC2022/0003552A patent/CO2022003552A2/es unknown
- 2022-03-31 SA SA522432139A patent/SA522432139B1/ar unknown
-
2023
- 2023-06-20 US US18/337,693 patent/US20230340130A1/en active Pending
- 2023-11-15 JP JP2023194494A patent/JP7809680B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013169691A1 (en) * | 2012-05-07 | 2013-11-14 | Trustees Of Dartmouth College | Anti-b7-h6 antibody, fusion proteins, and methods of using the same |
| WO2017181001A1 (en) * | 2016-04-15 | 2017-10-19 | Trustees Of Dartmouth College | High affinity b7-h6 antibodies and antibody fragments |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2024020414A (ja) | 2024-02-14 |
| PE20221412A1 (es) | 2022-09-20 |
| MX2022004042A (es) | 2022-05-02 |
| EP4038100A2 (en) | 2022-08-10 |
| BR112022004047A2 (pt) | 2022-05-24 |
| PH12022550693A1 (en) | 2023-03-27 |
| WO2021064137A2 (en) | 2021-04-08 |
| JP7809680B2 (ja) | 2026-02-02 |
| AU2020358893A1 (en) | 2022-03-31 |
| US11732045B2 (en) | 2023-08-22 |
| DOP2022000060A (es) | 2022-05-31 |
| CL2022000664A1 (es) | 2023-01-06 |
| KR20220075383A (ko) | 2022-06-08 |
| SA522432139B1 (ar) | 2024-08-29 |
| CA3153372A1 (en) | 2021-04-08 |
| US20210107983A1 (en) | 2021-04-15 |
| IL291817A (en) | 2022-06-01 |
| ECSP22019193A (es) | 2022-04-29 |
| JP2022551081A (ja) | 2022-12-07 |
| JP7387885B2 (ja) | 2023-11-28 |
| MY209387A (en) | 2025-07-07 |
| CR20220136A (es) | 2022-05-27 |
| CN114641496B (zh) | 2026-01-02 |
| CO2022003552A2 (es) | 2022-04-19 |
| TW202128756A (zh) | 2021-08-01 |
| AR120138A1 (es) | 2022-02-02 |
| JOP20220079A1 (ar) | 2023-01-30 |
| US20230340130A1 (en) | 2023-10-26 |
| UA130106C2 (uk) | 2025-11-12 |
| CN114641496A (zh) | 2022-06-17 |
| WO2021064137A3 (en) | 2021-05-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| TWI878355B (zh) | 用於癌症治療之多重專一性結合蛋白 | |
| US12528879B2 (en) | Multi-specific binding proteins for cancer treatment | |
| TW202317625A (zh) | 新穎三特異性結合分子 | |
| AU2019280900B2 (en) | DLL3/CD3 binding proteins for the treatment of cancer | |
| EA049502B1 (ru) | Мультиспецифические связывающие белки для лечения рака | |
| HK40121622A (zh) | 用於治疗癌症的dll3/cd3结合蛋白 | |
| EA047971B1 (ru) | Dll3/cd3 связывающие белки для лечения рака | |
| HK40041732B (zh) | 用於癌症治疗的dll3/cd3结合蛋白 | |
| HK40041732A (zh) | 用於癌症治疗的dll3/cd3结合蛋白 |