TW202237638A - 烏苷酸環化酶c(gcc)抗原結合劑之組成物及其使用方法 - Google Patents
烏苷酸環化酶c(gcc)抗原結合劑之組成物及其使用方法 Download PDFInfo
- Publication number
- TW202237638A TW202237638A TW110145784A TW110145784A TW202237638A TW 202237638 A TW202237638 A TW 202237638A TW 110145784 A TW110145784 A TW 110145784A TW 110145784 A TW110145784 A TW 110145784A TW 202237638 A TW202237638 A TW 202237638A
- Authority
- TW
- Taiwan
- Prior art keywords
- cells
- seq
- gcc
- car
- cell
- Prior art date
Links
- 239000000427 antigen Substances 0.000 title claims abstract description 211
- 108091007433 antigens Proteins 0.000 title claims abstract description 211
- 102000036639 antigens Human genes 0.000 title claims abstract description 211
- 238000000034 method Methods 0.000 title claims description 126
- 239000000203 mixture Substances 0.000 title claims description 29
- 239000011230 binding agent Substances 0.000 title abstract description 67
- 102000000820 Enterotoxin Receptors Human genes 0.000 title abstract 4
- 108010001687 Enterotoxin Receptors Proteins 0.000 title abstract 4
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims abstract description 316
- 230000027455 binding Effects 0.000 claims abstract description 159
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 119
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 88
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 88
- -1 host cells Substances 0.000 claims abstract description 48
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 15
- 210000004027 cell Anatomy 0.000 claims description 511
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 164
- 101000924488 Homo sapiens Atrial natriuretic peptide receptor 3 Proteins 0.000 claims description 138
- 102100034605 Atrial natriuretic peptide receptor 3 Human genes 0.000 claims description 137
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 121
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims description 120
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 99
- 239000013598 vector Substances 0.000 claims description 97
- 108090000623 proteins and genes Proteins 0.000 claims description 88
- 206010028980 Neoplasm Diseases 0.000 claims description 77
- 230000011664 signaling Effects 0.000 claims description 69
- 201000011510 cancer Diseases 0.000 claims description 55
- 108091008874 T cell receptors Proteins 0.000 claims description 51
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims description 47
- 102000004169 proteins and genes Human genes 0.000 claims description 47
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 claims description 46
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 claims description 46
- 230000004068 intracellular signaling Effects 0.000 claims description 42
- 125000003729 nucleotide group Chemical group 0.000 claims description 32
- 239000002773 nucleotide Substances 0.000 claims description 30
- 238000011282 treatment Methods 0.000 claims description 28
- 102000040430 polynucleotide Human genes 0.000 claims description 25
- 108091033319 polynucleotide Proteins 0.000 claims description 25
- 239000002157 polynucleotide Substances 0.000 claims description 25
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 claims description 18
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 claims description 18
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 17
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 claims description 17
- 108060003951 Immunoglobulin Proteins 0.000 claims description 17
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 claims description 17
- 102000018358 immunoglobulin Human genes 0.000 claims description 17
- 101000716102 Homo sapiens T-cell surface glycoprotein CD4 Proteins 0.000 claims description 16
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 claims description 16
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 claims description 15
- 206010009944 Colon cancer Diseases 0.000 claims description 14
- 101000946843 Homo sapiens T-cell surface glycoprotein CD8 alpha chain Proteins 0.000 claims description 14
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 14
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 claims description 14
- 230000000735 allogeneic effect Effects 0.000 claims description 13
- 102100025244 T-cell surface glycoprotein CD5 Human genes 0.000 claims description 11
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 claims description 10
- 102100025390 Integrin beta-2 Human genes 0.000 claims description 10
- 108010064548 Lymphocyte Function-Associated Antigen-1 Proteins 0.000 claims description 10
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 claims description 10
- 210000002706 plastid Anatomy 0.000 claims description 10
- 206010017993 Gastrointestinal neoplasms Diseases 0.000 claims description 9
- 101000935040 Homo sapiens Integrin beta-2 Proteins 0.000 claims description 9
- 101000934341 Homo sapiens T-cell surface glycoprotein CD5 Proteins 0.000 claims description 9
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 claims description 9
- 230000000139 costimulatory effect Effects 0.000 claims description 9
- 102100038080 B-cell receptor CD22 Human genes 0.000 claims description 8
- 102100027207 CD27 antigen Human genes 0.000 claims description 8
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 claims description 8
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 claims description 8
- 101000946860 Homo sapiens T-cell surface glycoprotein CD3 epsilon chain Proteins 0.000 claims description 8
- 102100035794 T-cell surface glycoprotein CD3 epsilon chain Human genes 0.000 claims description 8
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 claims description 8
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 7
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 claims description 7
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 claims description 7
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 claims description 7
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 claims description 7
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 7
- 102100035793 CD83 antigen Human genes 0.000 claims description 6
- 101000946856 Homo sapiens CD83 antigen Proteins 0.000 claims description 6
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 claims description 6
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 claims description 6
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 claims description 6
- 102100032937 CD40 ligand Human genes 0.000 claims description 5
- 102100037904 CD9 antigen Human genes 0.000 claims description 5
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 claims description 5
- 101000738354 Homo sapiens CD9 antigen Proteins 0.000 claims description 5
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 claims description 5
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 claims description 5
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 claims description 5
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 claims description 5
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 5
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 claims description 5
- 238000003776 cleavage reaction Methods 0.000 claims description 5
- 201000004101 esophageal cancer Diseases 0.000 claims description 5
- 206010017758 gastric cancer Diseases 0.000 claims description 5
- 201000011549 stomach cancer Diseases 0.000 claims description 5
- 241001430294 unidentified retrovirus Species 0.000 claims description 5
- 102100035233 Furin Human genes 0.000 claims description 4
- 108090001126 Furin Proteins 0.000 claims description 4
- 241000713666 Lentivirus Species 0.000 claims description 4
- 241000701161 unidentified adenovirus Species 0.000 claims description 4
- 208000036764 Adenocarcinoma of the esophagus Diseases 0.000 claims description 3
- 206010052360 Colorectal adenocarcinoma Diseases 0.000 claims description 3
- 102300064574 Epidermal growth factor receptor isoform 2 Human genes 0.000 claims description 3
- 102100029360 Hematopoietic cell signal transducer Human genes 0.000 claims description 3
- 101600123877 Homo sapiens Epidermal growth factor receptor (isoform 2) Proteins 0.000 claims description 3
- 101000990188 Homo sapiens Hematopoietic cell signal transducer Proteins 0.000 claims description 3
- 101000809875 Homo sapiens TYRO protein tyrosine kinase-binding protein Proteins 0.000 claims description 3
- 208000018142 Leiomyosarcoma Diseases 0.000 claims description 3
- 206010052399 Neuroendocrine tumour Diseases 0.000 claims description 3
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 3
- 102100038717 TYRO protein tyrosine kinase-binding protein Human genes 0.000 claims description 3
- 150000001412 amines Chemical class 0.000 claims description 3
- 208000022136 colorectal lymphoma Diseases 0.000 claims description 3
- 208000028653 esophageal adenocarcinoma Diseases 0.000 claims description 3
- 201000006585 gastric adenocarcinoma Diseases 0.000 claims description 3
- 201000011587 gastric lymphoma Diseases 0.000 claims description 3
- 201000001441 melanoma Diseases 0.000 claims description 3
- 208000016065 neuroendocrine neoplasm Diseases 0.000 claims description 3
- 201000011519 neuroendocrine tumor Diseases 0.000 claims description 3
- 206010041823 squamous cell carcinoma Diseases 0.000 claims description 3
- 102100025221 CD70 antigen Human genes 0.000 claims description 2
- 101710095468 Cyclase Proteins 0.000 claims description 2
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 claims description 2
- 101000801227 Homo sapiens Tumor necrosis factor receptor superfamily member 19 Proteins 0.000 claims description 2
- 206010025323 Lymphomas Diseases 0.000 claims description 2
- 206010027476 Metastases Diseases 0.000 claims description 2
- 206010030137 Oesophageal adenocarcinoma Diseases 0.000 claims description 2
- 102100033760 Tumor necrosis factor receptor superfamily member 19 Human genes 0.000 claims description 2
- 230000009401 metastasis Effects 0.000 claims description 2
- 230000004614 tumor growth Effects 0.000 claims description 2
- 206010055008 Gastric sarcoma Diseases 0.000 claims 1
- 230000009977 dual effect Effects 0.000 claims 1
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims 1
- 201000002528 pancreatic cancer Diseases 0.000 claims 1
- 208000008443 pancreatic carcinoma Diseases 0.000 claims 1
- 239000012634 fragment Substances 0.000 abstract description 53
- 239000013604 expression vector Substances 0.000 abstract description 44
- 238000003259 recombinant expression Methods 0.000 abstract description 29
- 108010003723 Single-Domain Antibodies Proteins 0.000 abstract description 22
- 238000002560 therapeutic procedure Methods 0.000 abstract description 7
- 235000001014 amino acid Nutrition 0.000 description 118
- 150000001413 amino acids Chemical class 0.000 description 99
- 229940024606 amino acid Drugs 0.000 description 98
- 241000282414 Homo sapiens Species 0.000 description 84
- 102000004196 processed proteins & peptides Human genes 0.000 description 84
- 229920001184 polypeptide Polymers 0.000 description 77
- 230000014509 gene expression Effects 0.000 description 50
- 230000006870 function Effects 0.000 description 48
- 235000018102 proteins Nutrition 0.000 description 45
- 238000006467 substitution reaction Methods 0.000 description 45
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 33
- 239000012636 effector Substances 0.000 description 29
- 239000012642 immune effector Substances 0.000 description 26
- 229940121354 immunomodulator Drugs 0.000 description 26
- 150000002632 lipids Chemical class 0.000 description 26
- 108091028043 Nucleic acid sequence Proteins 0.000 description 24
- 230000003834 intracellular effect Effects 0.000 description 24
- 125000005647 linker group Chemical group 0.000 description 24
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 23
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 23
- 102100027268 Interferon-stimulated gene 20 kDa protein Human genes 0.000 description 23
- 201000010099 disease Diseases 0.000 description 23
- 239000003795 chemical substances by application Substances 0.000 description 22
- 230000000694 effects Effects 0.000 description 22
- 108020004414 DNA Proteins 0.000 description 21
- 238000001727 in vivo Methods 0.000 description 20
- 210000003289 regulatory T cell Anatomy 0.000 description 20
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 description 19
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 19
- 239000003446 ligand Substances 0.000 description 19
- 239000000126 substance Substances 0.000 description 19
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 18
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 18
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 18
- 230000001086 cytosolic effect Effects 0.000 description 18
- 230000002401 inhibitory effect Effects 0.000 description 18
- 230000001965 increasing effect Effects 0.000 description 17
- 238000004519 manufacturing process Methods 0.000 description 17
- 241000124008 Mammalia Species 0.000 description 16
- 230000004071 biological effect Effects 0.000 description 16
- 238000000338 in vitro Methods 0.000 description 16
- 241001465754 Metazoa Species 0.000 description 15
- 230000028993 immune response Effects 0.000 description 15
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 14
- 210000004369 blood Anatomy 0.000 description 14
- 239000008280 blood Substances 0.000 description 14
- 230000013595 glycosylation Effects 0.000 description 14
- 238000006206 glycosylation reaction Methods 0.000 description 14
- 230000004048 modification Effects 0.000 description 14
- 238000012986 modification Methods 0.000 description 14
- 210000000822 natural killer cell Anatomy 0.000 description 14
- 239000000047 product Substances 0.000 description 14
- 230000002829 reductive effect Effects 0.000 description 14
- 239000000523 sample Substances 0.000 description 14
- 239000003153 chemical reaction reagent Substances 0.000 description 13
- 239000003814 drug Substances 0.000 description 13
- 210000001519 tissue Anatomy 0.000 description 13
- 101000648507 Homo sapiens Tumor necrosis factor receptor superfamily member 14 Proteins 0.000 description 12
- 102000017182 Ikaros Transcription Factor Human genes 0.000 description 12
- 108010013958 Ikaros Transcription Factor Proteins 0.000 description 12
- 230000004913 activation Effects 0.000 description 12
- 125000000539 amino acid group Chemical group 0.000 description 12
- 238000003556 assay Methods 0.000 description 12
- 239000002502 liposome Substances 0.000 description 12
- 230000035772 mutation Effects 0.000 description 12
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 11
- 230000002950 deficient Effects 0.000 description 11
- 102000005962 receptors Human genes 0.000 description 11
- 108020003175 receptors Proteins 0.000 description 11
- 102100024263 CD160 antigen Human genes 0.000 description 10
- 101000761938 Homo sapiens CD160 antigen Proteins 0.000 description 10
- 238000010459 TALEN Methods 0.000 description 10
- 102100038929 V-set domain-containing T-cell activation inhibitor 1 Human genes 0.000 description 10
- 241000700605 Viruses Species 0.000 description 10
- 238000002659 cell therapy Methods 0.000 description 10
- 208000035475 disorder Diseases 0.000 description 10
- 238000003780 insertion Methods 0.000 description 10
- 230000037431 insertion Effects 0.000 description 10
- 230000010076 replication Effects 0.000 description 10
- 230000001225 therapeutic effect Effects 0.000 description 10
- 210000004881 tumor cell Anatomy 0.000 description 10
- 239000003981 vehicle Substances 0.000 description 10
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 9
- 108010017842 Telomerase Proteins 0.000 description 9
- 230000003993 interaction Effects 0.000 description 9
- 238000002955 isolation Methods 0.000 description 9
- 239000003550 marker Substances 0.000 description 9
- 238000012216 screening Methods 0.000 description 9
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 8
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 8
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 8
- 102000004190 Enzymes Human genes 0.000 description 8
- 108090000790 Enzymes Proteins 0.000 description 8
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 8
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 8
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 8
- 101001068133 Homo sapiens Hepatitis A virus cellular receptor 2 Proteins 0.000 description 8
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 8
- 108700008625 Reporter Genes Proteins 0.000 description 8
- 102100029215 Signaling lymphocytic activation molecule Human genes 0.000 description 8
- 108091027967 Small hairpin RNA Proteins 0.000 description 8
- 108010017070 Zinc Finger Nucleases Proteins 0.000 description 8
- 239000011324 bead Substances 0.000 description 8
- 229940088598 enzyme Drugs 0.000 description 8
- 239000011325 microbead Substances 0.000 description 8
- 210000000664 rectum Anatomy 0.000 description 8
- 230000003362 replicative effect Effects 0.000 description 8
- 230000001177 retroviral effect Effects 0.000 description 8
- 239000004055 small Interfering RNA Substances 0.000 description 8
- 239000000243 solution Substances 0.000 description 8
- 230000003612 virological effect Effects 0.000 description 8
- 102100038078 CD276 antigen Human genes 0.000 description 7
- 108020004705 Codon Proteins 0.000 description 7
- 108010087819 Fc receptors Proteins 0.000 description 7
- 102000009109 Fc receptors Human genes 0.000 description 7
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 7
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 7
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 description 7
- 108091034117 Oligonucleotide Proteins 0.000 description 7
- 108020004459 Small interfering RNA Proteins 0.000 description 7
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 7
- 239000002246 antineoplastic agent Substances 0.000 description 7
- 210000003719 b-lymphocyte Anatomy 0.000 description 7
- 230000001580 bacterial effect Effects 0.000 description 7
- 150000001720 carbohydrates Chemical group 0.000 description 7
- 230000000295 complement effect Effects 0.000 description 7
- 150000001875 compounds Chemical class 0.000 description 7
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 7
- 208000015181 infectious disease Diseases 0.000 description 7
- 230000005764 inhibitory process Effects 0.000 description 7
- 108020004999 messenger RNA Proteins 0.000 description 7
- 150000002482 oligosaccharides Chemical class 0.000 description 7
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 7
- 230000002688 persistence Effects 0.000 description 7
- 230000001105 regulatory effect Effects 0.000 description 7
- 230000004044 response Effects 0.000 description 7
- 229940124597 therapeutic agent Drugs 0.000 description 7
- 238000013518 transcription Methods 0.000 description 7
- 230000035897 transcription Effects 0.000 description 7
- 238000013519 translation Methods 0.000 description 7
- 239000013603 viral vector Substances 0.000 description 7
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 6
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 6
- 102000004127 Cytokines Human genes 0.000 description 6
- 108090000695 Cytokines Proteins 0.000 description 6
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 6
- 241000196324 Embryophyta Species 0.000 description 6
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 6
- 241000238631 Hexapoda Species 0.000 description 6
- 241000282412 Homo Species 0.000 description 6
- 101000994375 Homo sapiens Integrin alpha-4 Proteins 0.000 description 6
- 101001138062 Homo sapiens Leukocyte-associated immunoglobulin-like receptor 1 Proteins 0.000 description 6
- 101001137987 Homo sapiens Lymphocyte activation gene 3 protein Proteins 0.000 description 6
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 description 6
- 102100032818 Integrin alpha-4 Human genes 0.000 description 6
- 102100032816 Integrin alpha-6 Human genes 0.000 description 6
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 6
- 102000017578 LAG3 Human genes 0.000 description 6
- 102100020943 Leukocyte-associated immunoglobulin-like receptor 1 Human genes 0.000 description 6
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 6
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 6
- 241000699666 Mus <mouse, genus> Species 0.000 description 6
- 108010074687 Signaling Lymphocytic Activation Molecule Family Member 1 Proteins 0.000 description 6
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 6
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 description 6
- 229960005305 adenosine Drugs 0.000 description 6
- 238000002617 apheresis Methods 0.000 description 6
- 210000001072 colon Anatomy 0.000 description 6
- 238000011161 development Methods 0.000 description 6
- 230000018109 developmental process Effects 0.000 description 6
- 239000012530 fluid Substances 0.000 description 6
- 230000001976 improved effect Effects 0.000 description 6
- 230000001939 inductive effect Effects 0.000 description 6
- 210000004698 lymphocyte Anatomy 0.000 description 6
- 229920001542 oligosaccharide Polymers 0.000 description 6
- 239000002245 particle Substances 0.000 description 6
- 125000006850 spacer group Chemical group 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 102000006306 Antigen Receptors Human genes 0.000 description 5
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 5
- 108091035707 Consensus sequence Proteins 0.000 description 5
- 241000701022 Cytomegalovirus Species 0.000 description 5
- 241000588724 Escherichia coli Species 0.000 description 5
- 102100031351 Galectin-9 Human genes 0.000 description 5
- 101100229077 Gallus gallus GAL9 gene Proteins 0.000 description 5
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 5
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 5
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 5
- 101000934346 Homo sapiens T-cell surface antigen CD2 Proteins 0.000 description 5
- 101000955999 Homo sapiens V-set domain-containing T-cell activation inhibitor 1 Proteins 0.000 description 5
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 description 5
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 5
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 5
- 241000700159 Rattus Species 0.000 description 5
- 102100025237 T-cell surface antigen CD2 Human genes 0.000 description 5
- 108010079206 V-Set Domain-Containing T-Cell Activation Inhibitor 1 Proteins 0.000 description 5
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 description 5
- 239000002253 acid Substances 0.000 description 5
- 230000003213 activating effect Effects 0.000 description 5
- 235000004279 alanine Nutrition 0.000 description 5
- 230000000259 anti-tumor effect Effects 0.000 description 5
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 5
- 230000037396 body weight Effects 0.000 description 5
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 5
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- IJJVMEJXYNJXOJ-UHFFFAOYSA-N fluquinconazole Chemical compound C=1C=C(Cl)C=C(Cl)C=1N1C(=O)C2=CC(F)=CC=C2N=C1N1C=NC=N1 IJJVMEJXYNJXOJ-UHFFFAOYSA-N 0.000 description 5
- 230000008014 freezing Effects 0.000 description 5
- 238000007710 freezing Methods 0.000 description 5
- 108020001507 fusion proteins Proteins 0.000 description 5
- 102000037865 fusion proteins Human genes 0.000 description 5
- 230000001900 immune effect Effects 0.000 description 5
- 230000000968 intestinal effect Effects 0.000 description 5
- 239000012528 membrane Substances 0.000 description 5
- 210000004379 membrane Anatomy 0.000 description 5
- 125000000325 methylidene group Chemical group [H]C([H])=* 0.000 description 5
- 239000000546 pharmaceutical excipient Substances 0.000 description 5
- 238000002360 preparation method Methods 0.000 description 5
- 210000002966 serum Anatomy 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 210000000130 stem cell Anatomy 0.000 description 5
- 239000000758 substrate Substances 0.000 description 5
- 235000000346 sugar Nutrition 0.000 description 5
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 5
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 4
- 108010083359 Antigen Receptors Proteins 0.000 description 4
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 4
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 4
- 102100038077 CD226 antigen Human genes 0.000 description 4
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 4
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 4
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 4
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 4
- 102100022662 Guanylyl cyclase C Human genes 0.000 description 4
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 4
- 101000884298 Homo sapiens CD226 antigen Proteins 0.000 description 4
- 101000899808 Homo sapiens Guanylyl cyclase C Proteins 0.000 description 4
- 101001078158 Homo sapiens Integrin alpha-1 Proteins 0.000 description 4
- 101000994365 Homo sapiens Integrin alpha-6 Proteins 0.000 description 4
- 101001046687 Homo sapiens Integrin alpha-E Proteins 0.000 description 4
- 101000935043 Homo sapiens Integrin beta-1 Proteins 0.000 description 4
- 101000971538 Homo sapiens Killer cell lectin-like receptor subfamily F member 1 Proteins 0.000 description 4
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 4
- 101000633786 Homo sapiens SLAM family member 6 Proteins 0.000 description 4
- 101000633780 Homo sapiens Signaling lymphocytic activation molecule Proteins 0.000 description 4
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 4
- 102100025323 Integrin alpha-1 Human genes 0.000 description 4
- 102100022341 Integrin alpha-E Human genes 0.000 description 4
- 102100025304 Integrin beta-1 Human genes 0.000 description 4
- 102100021458 Killer cell lectin-like receptor subfamily F member 1 Human genes 0.000 description 4
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 4
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 4
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 4
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 4
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 4
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 4
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 4
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 description 4
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 4
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 4
- 102100038082 Natural killer cell receptor 2B4 Human genes 0.000 description 4
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 description 4
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 4
- 102000014128 RANK Ligand Human genes 0.000 description 4
- 108010025832 RANK Ligand Proteins 0.000 description 4
- 241000714474 Rous sarcoma virus Species 0.000 description 4
- 102100029197 SLAM family member 6 Human genes 0.000 description 4
- 102100027744 Semaphorin-4D Human genes 0.000 description 4
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 4
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- 125000003118 aryl group Chemical group 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 4
- 235000014633 carbohydrates Nutrition 0.000 description 4
- 239000000969 carrier Substances 0.000 description 4
- 230000003197 catalytic effect Effects 0.000 description 4
- 230000004663 cell proliferation Effects 0.000 description 4
- 229960004397 cyclophosphamide Drugs 0.000 description 4
- 230000001461 cytolytic effect Effects 0.000 description 4
- 231100000433 cytotoxic Toxicity 0.000 description 4
- 229940127089 cytotoxic agent Drugs 0.000 description 4
- 230000001472 cytotoxic effect Effects 0.000 description 4
- 239000008121 dextrose Substances 0.000 description 4
- 239000000539 dimer Substances 0.000 description 4
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 4
- 238000004520 electroporation Methods 0.000 description 4
- 230000002255 enzymatic effect Effects 0.000 description 4
- 210000003527 eukaryotic cell Anatomy 0.000 description 4
- 238000000684 flow cytometry Methods 0.000 description 4
- 238000001476 gene delivery Methods 0.000 description 4
- 210000005260 human cell Anatomy 0.000 description 4
- 210000002865 immune cell Anatomy 0.000 description 4
- 210000004263 induced pluripotent stem cell Anatomy 0.000 description 4
- 238000001802 infusion Methods 0.000 description 4
- 239000003112 inhibitor Substances 0.000 description 4
- 230000000977 initiatory effect Effects 0.000 description 4
- 230000010354 integration Effects 0.000 description 4
- 230000000670 limiting effect Effects 0.000 description 4
- 210000004962 mammalian cell Anatomy 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 230000001404 mediated effect Effects 0.000 description 4
- 239000000693 micelle Substances 0.000 description 4
- 210000001616 monocyte Anatomy 0.000 description 4
- 239000002953 phosphate buffered saline Substances 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 210000001236 prokaryotic cell Anatomy 0.000 description 4
- 230000035755 proliferation Effects 0.000 description 4
- 238000010188 recombinant method Methods 0.000 description 4
- 230000028327 secretion Effects 0.000 description 4
- 230000019491 signal transduction Effects 0.000 description 4
- 239000011780 sodium chloride Substances 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- 238000001890 transfection Methods 0.000 description 4
- 230000009466 transformation Effects 0.000 description 4
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 4
- 239000004474 valine Substances 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- ZDTFMPXQUSBYRL-UUOKFMHZSA-N 2-Aminoadenosine Chemical compound C12=NC(N)=NC(N)=C2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O ZDTFMPXQUSBYRL-UUOKFMHZSA-N 0.000 description 3
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- 241000701822 Bovine papillomavirus Species 0.000 description 3
- 101150013553 CD40 gene Proteins 0.000 description 3
- 241000282472 Canis lupus familiaris Species 0.000 description 3
- 102100025466 Carcinoembryonic antigen-related cell adhesion molecule 3 Human genes 0.000 description 3
- 102000000844 Cell Surface Receptors Human genes 0.000 description 3
- 108010001857 Cell Surface Receptors Proteins 0.000 description 3
- 241000282693 Cercopithecidae Species 0.000 description 3
- 206010052358 Colorectal cancer metastatic Diseases 0.000 description 3
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 3
- 108010036949 Cyclosporine Proteins 0.000 description 3
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 108091029865 Exogenous DNA Proteins 0.000 description 3
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical group NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 description 3
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 3
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 3
- 101000914337 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 3 Proteins 0.000 description 3
- 101001109503 Homo sapiens NKG2-C type II integral membrane protein Proteins 0.000 description 3
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 description 3
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 description 3
- 108091006905 Human Serum Albumin Proteins 0.000 description 3
- 102000008100 Human Serum Albumin Human genes 0.000 description 3
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 3
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 3
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 3
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 3
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 3
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 3
- 125000000510 L-tryptophano group Chemical group [H]C1=C([H])C([H])=C2N([H])C([H])=C(C([H])([H])[C@@]([H])(C(O[H])=O)N([H])[*])C2=C1[H] 0.000 description 3
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 3
- 239000000232 Lipid Bilayer Substances 0.000 description 3
- 108060001084 Luciferase Proteins 0.000 description 3
- 239000005089 Luciferase Substances 0.000 description 3
- 108010052285 Membrane Proteins Proteins 0.000 description 3
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical compound CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 description 3
- 102100022683 NKG2-C type II integral membrane protein Human genes 0.000 description 3
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 description 3
- 101710163270 Nuclease Proteins 0.000 description 3
- 102000015636 Oligopeptides Human genes 0.000 description 3
- 108010038807 Oligopeptides Proteins 0.000 description 3
- 241000283973 Oryctolagus cuniculus Species 0.000 description 3
- 239000002202 Polyethylene glycol Substances 0.000 description 3
- 241000288906 Primates Species 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 101800001494 Protease 2A Proteins 0.000 description 3
- 101800001066 Protein 2A Proteins 0.000 description 3
- 206010039491 Sarcoma Diseases 0.000 description 3
- 241000700584 Simplexvirus Species 0.000 description 3
- 230000006044 T cell activation Effects 0.000 description 3
- 102100027208 T-cell antigen CD7 Human genes 0.000 description 3
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 3
- 239000004473 Threonine Substances 0.000 description 3
- 102000006601 Thymidine Kinase Human genes 0.000 description 3
- 108020004440 Thymidine kinase Proteins 0.000 description 3
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 3
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 3
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 description 3
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 3
- 230000002378 acidificating effect Effects 0.000 description 3
- 230000002411 adverse Effects 0.000 description 3
- 230000009824 affinity maturation Effects 0.000 description 3
- 230000004075 alteration Effects 0.000 description 3
- 239000000872 buffer Substances 0.000 description 3
- 239000001506 calcium phosphate Substances 0.000 description 3
- 229910000389 calcium phosphate Inorganic materials 0.000 description 3
- 235000011010 calcium phosphates Nutrition 0.000 description 3
- 230000010261 cell growth Effects 0.000 description 3
- 239000007795 chemical reaction product Substances 0.000 description 3
- 229960001265 ciclosporin Drugs 0.000 description 3
- 230000021615 conjugation Effects 0.000 description 3
- 229930182912 cyclosporin Natural products 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 210000004443 dendritic cell Anatomy 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 238000010494 dissociation reaction Methods 0.000 description 3
- 230000005593 dissociations Effects 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 239000003937 drug carrier Substances 0.000 description 3
- 210000002919 epithelial cell Anatomy 0.000 description 3
- 210000003743 erythrocyte Anatomy 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 125000002485 formyl group Chemical group [H]C(*)=O 0.000 description 3
- 230000033581 fucosylation Effects 0.000 description 3
- 230000002496 gastric effect Effects 0.000 description 3
- 238000001415 gene therapy Methods 0.000 description 3
- 210000004602 germ cell Anatomy 0.000 description 3
- 230000012010 growth Effects 0.000 description 3
- 238000003306 harvesting Methods 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 3
- 210000004408 hybridoma Anatomy 0.000 description 3
- 210000000987 immune system Anatomy 0.000 description 3
- 230000005847 immunogenicity Effects 0.000 description 3
- 238000009169 immunotherapy Methods 0.000 description 3
- 230000008676 import Effects 0.000 description 3
- 102000006495 integrins Human genes 0.000 description 3
- 108010044426 integrins Proteins 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 230000019948 ion homeostasis Effects 0.000 description 3
- FZWBNHMXJMCXLU-BLAUPYHCSA-N isomaltotriose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H](OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O)O1 FZWBNHMXJMCXLU-BLAUPYHCSA-N 0.000 description 3
- 230000002147 killing effect Effects 0.000 description 3
- 239000007788 liquid Substances 0.000 description 3
- 230000007774 longterm Effects 0.000 description 3
- 210000001165 lymph node Anatomy 0.000 description 3
- 210000002540 macrophage Anatomy 0.000 description 3
- FVVLHONNBARESJ-NTOWJWGLSA-H magnesium;potassium;trisodium;(2r,3s,4r,5r)-2,3,4,5,6-pentahydroxyhexanoate;acetate;tetrachloride;nonahydrate Chemical compound O.O.O.O.O.O.O.O.O.[Na+].[Na+].[Na+].[Mg+2].[Cl-].[Cl-].[Cl-].[Cl-].[K+].CC([O-])=O.OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C([O-])=O FVVLHONNBARESJ-NTOWJWGLSA-H 0.000 description 3
- 230000005291 magnetic effect Effects 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 230000001394 metastastic effect Effects 0.000 description 3
- 206010061289 metastatic neoplasm Diseases 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 239000002777 nucleoside Substances 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 210000005105 peripheral blood lymphocyte Anatomy 0.000 description 3
- 230000002085 persistent effect Effects 0.000 description 3
- 150000004713 phosphodiesters Chemical class 0.000 description 3
- 150000003904 phospholipids Chemical group 0.000 description 3
- 210000001778 pluripotent stem cell Anatomy 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 238000012545 processing Methods 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 230000002285 radioactive effect Effects 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 230000007017 scission Effects 0.000 description 3
- 238000002864 sequence alignment Methods 0.000 description 3
- 230000009870 specific binding Effects 0.000 description 3
- 230000004936 stimulating effect Effects 0.000 description 3
- 210000002784 stomach Anatomy 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 238000012360 testing method Methods 0.000 description 3
- 230000002103 transcriptional effect Effects 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 102000035160 transmembrane proteins Human genes 0.000 description 3
- 108091005703 transmembrane proteins Proteins 0.000 description 3
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 3
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 3
- 210000005253 yeast cell Anatomy 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- WOXWUZCRWJWTRT-UHFFFAOYSA-N 1-amino-1-cyclohexanecarboxylic acid Chemical compound OC(=O)C1(N)CCCCC1 WOXWUZCRWJWTRT-UHFFFAOYSA-N 0.000 description 2
- VBICKXHEKHSIBG-UHFFFAOYSA-N 1-monostearoylglycerol Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(O)CO VBICKXHEKHSIBG-UHFFFAOYSA-N 0.000 description 2
- ZAYHVCMSTBRABG-JXOAFFINSA-N 5-methylcytidine Chemical compound O=C1N=C(N)C(C)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 ZAYHVCMSTBRABG-JXOAFFINSA-N 0.000 description 2
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 2
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 2
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 2
- 108090001008 Avidin Proteins 0.000 description 2
- 102100026189 Beta-galactosidase Human genes 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 108010056102 CD100 antigen Proteins 0.000 description 2
- 108010017009 CD11b Antigen Proteins 0.000 description 2
- 108010062802 CD66 antigens Proteins 0.000 description 2
- 102100027217 CD82 antigen Human genes 0.000 description 2
- 101710139831 CD82 antigen Proteins 0.000 description 2
- 238000010453 CRISPR/Cas method Methods 0.000 description 2
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 2
- 102100024533 Carcinoembryonic antigen-related cell adhesion molecule 1 Human genes 0.000 description 2
- 208000017897 Carcinoma of esophagus Diseases 0.000 description 2
- 102000004039 Caspase-9 Human genes 0.000 description 2
- 108090000566 Caspase-9 Proteins 0.000 description 2
- 108091007741 Chimeric antigen receptor T cells Proteins 0.000 description 2
- 241000938605 Crocodylia Species 0.000 description 2
- 102100027816 Cytotoxic and regulatory T-cell molecule Human genes 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- 102000001301 EGF receptor Human genes 0.000 description 2
- 108060006698 EGF receptor Proteins 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 2
- 101000585551 Equus caballus Pregnancy-associated glycoprotein Proteins 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 102100022086 GRB2-related adapter protein 2 Human genes 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 2
- 102000001398 Granzyme Human genes 0.000 description 2
- 108060005986 Granzyme Proteins 0.000 description 2
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 2
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 2
- 102000006354 HLA-DR Antigens Human genes 0.000 description 2
- 108010058597 HLA-DR Antigens Proteins 0.000 description 2
- 102000008949 Histocompatibility Antigens Class I Human genes 0.000 description 2
- 101000690301 Homo sapiens Aldo-keto reductase family 1 member C4 Proteins 0.000 description 2
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 2
- 101000935587 Homo sapiens Flavin reductase (NADPH) Proteins 0.000 description 2
- 101000900690 Homo sapiens GRB2-related adapter protein 2 Proteins 0.000 description 2
- 101001035237 Homo sapiens Integrin alpha-D Proteins 0.000 description 2
- 101001046683 Homo sapiens Integrin alpha-L Proteins 0.000 description 2
- 101001015037 Homo sapiens Integrin beta-7 Proteins 0.000 description 2
- 101001047640 Homo sapiens Linker for activation of T-cells family member 1 Proteins 0.000 description 2
- 101001090688 Homo sapiens Lymphocyte cytosolic protein 2 Proteins 0.000 description 2
- 101000589305 Homo sapiens Natural cytotoxicity triggering receptor 2 Proteins 0.000 description 2
- 101000873418 Homo sapiens P-selectin glycoprotein ligand 1 Proteins 0.000 description 2
- 101001124867 Homo sapiens Peroxiredoxin-1 Proteins 0.000 description 2
- 101000692259 Homo sapiens Phosphoprotein associated with glycosphingolipid-enriched microdomains 1 Proteins 0.000 description 2
- 101001116548 Homo sapiens Protein CBFA2T1 Proteins 0.000 description 2
- 101000702132 Homo sapiens Protein spinster homolog 1 Proteins 0.000 description 2
- 101000633778 Homo sapiens SLAM family member 5 Proteins 0.000 description 2
- 101000633784 Homo sapiens SLAM family member 7 Proteins 0.000 description 2
- 101000914496 Homo sapiens T-cell antigen CD7 Proteins 0.000 description 2
- 101000596234 Homo sapiens T-cell surface protein tactile Proteins 0.000 description 2
- 101000655352 Homo sapiens Telomerase reverse transcriptase Proteins 0.000 description 2
- 101000795169 Homo sapiens Tumor necrosis factor receptor superfamily member 13C Proteins 0.000 description 2
- 101000679857 Homo sapiens Tumor necrosis factor receptor superfamily member 3 Proteins 0.000 description 2
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 2
- 241000725303 Human immunodeficiency virus Species 0.000 description 2
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 2
- 108010073807 IgG Receptors Proteins 0.000 description 2
- 102100039904 Integrin alpha-D Human genes 0.000 description 2
- 102100022339 Integrin alpha-L Human genes 0.000 description 2
- 102100022338 Integrin alpha-M Human genes 0.000 description 2
- 108010041100 Integrin alpha6 Proteins 0.000 description 2
- 108010030465 Integrin alpha6beta1 Proteins 0.000 description 2
- 102100033016 Integrin beta-7 Human genes 0.000 description 2
- 102000003816 Interleukin-13 Human genes 0.000 description 2
- 108010002350 Interleukin-2 Proteins 0.000 description 2
- 102000000588 Interleukin-2 Human genes 0.000 description 2
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 2
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 2
- 102100024032 Linker for activation of T-cells family member 1 Human genes 0.000 description 2
- 102100034709 Lymphocyte cytosolic protein 2 Human genes 0.000 description 2
- 108091054437 MHC class I family Proteins 0.000 description 2
- 241000713869 Moloney murine leukemia virus Species 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 101100236305 Mus musculus Ly9 gene Proteins 0.000 description 2
- 108010004217 Natural Cytotoxicity Triggering Receptor 1 Proteins 0.000 description 2
- 108010004222 Natural Cytotoxicity Triggering Receptor 3 Proteins 0.000 description 2
- 102100032870 Natural cytotoxicity triggering receptor 1 Human genes 0.000 description 2
- 102100032851 Natural cytotoxicity triggering receptor 2 Human genes 0.000 description 2
- 102100032852 Natural cytotoxicity triggering receptor 3 Human genes 0.000 description 2
- 101710141230 Natural killer cell receptor 2B4 Proteins 0.000 description 2
- 206010061309 Neoplasm progression Diseases 0.000 description 2
- 102100034925 P-selectin glycoprotein ligand 1 Human genes 0.000 description 2
- 241001494479 Pecora Species 0.000 description 2
- 102100026066 Phosphoprotein associated with glycosphingolipid-enriched microdomains 1 Human genes 0.000 description 2
- RJKFOVLPORLFTN-LEKSSAKUSA-N Progesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 RJKFOVLPORLFTN-LEKSSAKUSA-N 0.000 description 2
- 108020005067 RNA Splice Sites Proteins 0.000 description 2
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 102100029216 SLAM family member 5 Human genes 0.000 description 2
- 102100029198 SLAM family member 7 Human genes 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- 102000008115 Signaling Lymphocytic Activation Molecule Family Member 1 Human genes 0.000 description 2
- 229920002472 Starch Polymers 0.000 description 2
- 102100035268 T-cell surface protein tactile Human genes 0.000 description 2
- 210000000662 T-lymphocyte subset Anatomy 0.000 description 2
- QJJXYPPXXYFBGM-LFZNUXCKSA-N Tacrolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1\C=C(/C)[C@@H]1[C@H](C)[C@@H](O)CC(=O)[C@H](CC=C)/C=C(C)/C[C@H](C)C[C@H](OC)[C@H]([C@H](C[C@H]2C)OC)O[C@@]2(O)C(=O)C(=O)N2CCCC[C@H]2C(=O)O1 QJJXYPPXXYFBGM-LFZNUXCKSA-N 0.000 description 2
- 239000004098 Tetracycline Substances 0.000 description 2
- 108010043645 Transcription Activator-Like Effector Nucleases Proteins 0.000 description 2
- 102100029690 Tumor necrosis factor receptor superfamily member 13C Human genes 0.000 description 2
- 102100033733 Tumor necrosis factor receptor superfamily member 1B Human genes 0.000 description 2
- 101710187830 Tumor necrosis factor receptor superfamily member 1B Proteins 0.000 description 2
- 102100022156 Tumor necrosis factor receptor superfamily member 3 Human genes 0.000 description 2
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 2
- 108700005077 Viral Genes Proteins 0.000 description 2
- 208000036142 Viral infection Diseases 0.000 description 2
- 101001038499 Yarrowia lipolytica (strain CLIB 122 / E 150) Lysine acetyltransferase Proteins 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 2
- 238000012867 alanine scanning Methods 0.000 description 2
- 150000001298 alcohols Chemical class 0.000 description 2
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 230000001093 anti-cancer Effects 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 239000012736 aqueous medium Substances 0.000 description 2
- 108010005774 beta-Galactosidase Proteins 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 210000001772 blood platelet Anatomy 0.000 description 2
- 210000001185 bone marrow Anatomy 0.000 description 2
- 239000011575 calcium Substances 0.000 description 2
- 229910052791 calcium Inorganic materials 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 231100000504 carcinogenesis Toxicity 0.000 description 2
- 230000036755 cellular response Effects 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 108010072917 class-I restricted T cell-associated molecule Proteins 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 2
- 238000002591 computed tomography Methods 0.000 description 2
- 210000004748 cultured cell Anatomy 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- 102000003675 cytokine receptors Human genes 0.000 description 2
- 108010057085 cytokine receptors Proteins 0.000 description 2
- 239000000824 cytostatic agent Substances 0.000 description 2
- 230000003013 cytotoxicity Effects 0.000 description 2
- 231100000135 cytotoxicity Toxicity 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 230000000779 depleting effect Effects 0.000 description 2
- 229940119744 dextran 40 Drugs 0.000 description 2
- 235000014113 dietary fatty acids Nutrition 0.000 description 2
- 229960000284 efalizumab Drugs 0.000 description 2
- 210000001671 embryonic stem cell Anatomy 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 229930195729 fatty acid Natural products 0.000 description 2
- 239000000194 fatty acid Substances 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 238000012239 gene modification Methods 0.000 description 2
- 230000009368 gene silencing by RNA Effects 0.000 description 2
- 230000005017 genetic modification Effects 0.000 description 2
- 235000013617 genetically modified food Nutrition 0.000 description 2
- 235000011187 glycerol Nutrition 0.000 description 2
- 239000005090 green fluorescent protein Substances 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- RQFCJASXJCIDSX-UUOKFMHZSA-N guanosine 5'-monophosphate Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@H]1O RQFCJASXJCIDSX-UUOKFMHZSA-N 0.000 description 2
- 229910001385 heavy metal Inorganic materials 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 102000054751 human RUNX1T1 Human genes 0.000 description 2
- 239000003018 immunosuppressive agent Substances 0.000 description 2
- 229940125721 immunosuppressive agent Drugs 0.000 description 2
- 230000001771 impaired effect Effects 0.000 description 2
- 206010022000 influenza Diseases 0.000 description 2
- 239000004615 ingredient Substances 0.000 description 2
- 229940090044 injection Drugs 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 239000000543 intermediate Substances 0.000 description 2
- WTFXARWRTYJXII-UHFFFAOYSA-N iron(2+);iron(3+);oxygen(2-) Chemical compound [O-2].[O-2].[O-2].[O-2].[Fe+2].[Fe+3].[Fe+3] WTFXARWRTYJXII-UHFFFAOYSA-N 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- 239000008101 lactose Substances 0.000 description 2
- 229910052747 lanthanoid Inorganic materials 0.000 description 2
- 150000002602 lanthanoids Chemical class 0.000 description 2
- 210000002429 large intestine Anatomy 0.000 description 2
- 208000032839 leukemia Diseases 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 238000001638 lipofection Methods 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 238000002595 magnetic resonance imaging Methods 0.000 description 2
- 230000035800 maturation Effects 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 2
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 2
- 108091070501 miRNA Proteins 0.000 description 2
- 239000002679 microRNA Substances 0.000 description 2
- 238000000520 microinjection Methods 0.000 description 2
- 230000010309 neoplastic transformation Effects 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- 210000000440 neutrophil Anatomy 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 231100000252 nontoxic Toxicity 0.000 description 2
- 230000003000 nontoxic effect Effects 0.000 description 2
- 238000013421 nuclear magnetic resonance imaging Methods 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 125000003835 nucleoside group Chemical group 0.000 description 2
- 239000003921 oil Substances 0.000 description 2
- 235000019198 oils Nutrition 0.000 description 2
- 230000005298 paramagnetic effect Effects 0.000 description 2
- 238000010647 peptide synthesis reaction Methods 0.000 description 2
- 239000012071 phase Substances 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 239000000843 powder Substances 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 238000011321 prophylaxis Methods 0.000 description 2
- 238000001959 radiotherapy Methods 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 230000002207 retinal effect Effects 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 239000002924 silencing RNA Substances 0.000 description 2
- 210000000813 small intestine Anatomy 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 239000008107 starch Substances 0.000 description 2
- 235000019698 starch Nutrition 0.000 description 2
- 230000000638 stimulation Effects 0.000 description 2
- 201000000498 stomach carcinoma Diseases 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- QJJXYPPXXYFBGM-SHYZHZOCSA-N tacrolimus Natural products CO[C@H]1C[C@H](CC[C@@H]1O)C=C(C)[C@H]2OC(=O)[C@H]3CCCCN3C(=O)C(=O)[C@@]4(O)O[C@@H]([C@H](C[C@H]4C)OC)[C@@H](C[C@H](C)CC(=C[C@@H](CC=C)C(=O)C[C@H](O)[C@H]2C)C)OC QJJXYPPXXYFBGM-SHYZHZOCSA-N 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 102000055501 telomere Human genes 0.000 description 2
- 108091035539 telomere Proteins 0.000 description 2
- 210000003411 telomere Anatomy 0.000 description 2
- 229960002180 tetracycline Drugs 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 235000019364 tetracycline Nutrition 0.000 description 2
- 150000003522 tetracyclines Chemical class 0.000 description 2
- 210000001541 thymus gland Anatomy 0.000 description 2
- 230000009258 tissue cross reactivity Effects 0.000 description 2
- 238000003325 tomography Methods 0.000 description 2
- 230000002463 transducing effect Effects 0.000 description 2
- 230000005751 tumor progression Effects 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 210000003501 vero cell Anatomy 0.000 description 2
- 108091005957 yellow fluorescent proteins Proteins 0.000 description 2
- OCLLVJCYGMCLJG-CYBMUJFWSA-N (2r)-2-azaniumyl-2-naphthalen-1-ylpropanoate Chemical compound C1=CC=C2C([C@@](N)(C(O)=O)C)=CC=CC2=C1 OCLLVJCYGMCLJG-CYBMUJFWSA-N 0.000 description 1
- KBTBZBLDKNNMDN-MIALQVPSSA-N (2r,3r,4s,5r)-2-(5-amino-1-oxo-1,2,6-thiadiazin-2-yl)-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound C1=CC(N)=NS(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 KBTBZBLDKNNMDN-MIALQVPSSA-N 0.000 description 1
- RIFDKYBNWNPCQK-IOSLPCCCSA-N (2r,3s,4r,5r)-2-(hydroxymethyl)-5-(6-imino-3-methylpurin-9-yl)oxolane-3,4-diol Chemical compound C1=2N(C)C=NC(=N)C=2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O RIFDKYBNWNPCQK-IOSLPCCCSA-N 0.000 description 1
- FFILOTSTFMXQJC-QCFYAKGBSA-N (2r,4r,5s,6s)-2-[3-[(2s,3s,4r,6s)-6-[(2s,3r,4r,5s,6r)-5-[(2s,3r,4r,5r,6r)-3-acetamido-4,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-2-[(2r,3s,4r,5r,6r)-4,5-dihydroxy-2-(hydroxymethyl)-6-[(e)-3-hydroxy-2-(octadecanoylamino)octadec-4-enoxy]oxan-3-yl]oxy-3-hy Chemical compound O[C@@H]1[C@@H](O)[C@H](OCC(NC(=O)CCCCCCCCCCCCCCCCC)C(O)\C=C\CCCCCCCCCCCCC)O[C@H](CO)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@@H]([C@@H](N)[C@H](O)C2)C(O)C(O)CO[C@]2(O[C@@H]([C@@H](N)[C@H](O)C2)C(O)C(O)CO)C(O)=O)C(O)=O)[C@@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](CO)O1 FFILOTSTFMXQJC-QCFYAKGBSA-N 0.000 description 1
- BFNDLDRNJFLIKE-ROLXFIACSA-N (2s)-2,6-diamino-6-hydroxyhexanoic acid Chemical compound NC(O)CCC[C@H](N)C(O)=O BFNDLDRNJFLIKE-ROLXFIACSA-N 0.000 description 1
- BVAUMRCGVHUWOZ-ZETCQYMHSA-N (2s)-2-(cyclohexylazaniumyl)propanoate Chemical compound OC(=O)[C@H](C)NC1CCCCC1 BVAUMRCGVHUWOZ-ZETCQYMHSA-N 0.000 description 1
- DWKNTLVYZNGBTJ-IBGZPJMESA-N (2s)-2-amino-6-(dibenzylamino)hexanoic acid Chemical compound C=1C=CC=CC=1CN(CCCC[C@H](N)C(O)=O)CC1=CC=CC=C1 DWKNTLVYZNGBTJ-IBGZPJMESA-N 0.000 description 1
- FNRJOGDXTIUYDE-ZDUSSCGKSA-N (2s)-2-amino-6-[benzyl(methyl)amino]hexanoic acid Chemical compound OC(=O)[C@@H](N)CCCCN(C)CC1=CC=CC=C1 FNRJOGDXTIUYDE-ZDUSSCGKSA-N 0.000 description 1
- WAMWSIDTKSNDCU-ZETCQYMHSA-N (2s)-2-azaniumyl-2-cyclohexylacetate Chemical compound OC(=O)[C@@H](N)C1CCCCC1 WAMWSIDTKSNDCU-ZETCQYMHSA-N 0.000 description 1
- KWTSXDURSIMDCE-QMMMGPOBSA-N (S)-amphetamine Chemical compound C[C@H](N)CC1=CC=CC=C1 KWTSXDURSIMDCE-QMMMGPOBSA-N 0.000 description 1
- 125000003088 (fluoren-9-ylmethoxy)carbonyl group Chemical group 0.000 description 1
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- UKAUYVFTDYCKQA-UHFFFAOYSA-N -2-Amino-4-hydroxybutanoic acid Natural products OC(=O)C(N)CCO UKAUYVFTDYCKQA-UHFFFAOYSA-N 0.000 description 1
- BWKMGYQJPOAASG-UHFFFAOYSA-N 1,2,3,4-tetrahydroisoquinoline-3-carboxylic acid Chemical compound C1=CC=C2CNC(C(=O)O)CC2=C1 BWKMGYQJPOAASG-UHFFFAOYSA-N 0.000 description 1
- QLOCVMVCRJOTTM-TURQNECASA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-prop-1-ynylpyrimidine-2,4-dione Chemical compound O=C1NC(=O)C(C#CC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 QLOCVMVCRJOTTM-TURQNECASA-N 0.000 description 1
- PISWNSOQFZRVJK-XLPZGREQSA-N 1-[(2r,4s,5r)-4-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-methyl-2-sulfanylidenepyrimidin-4-one Chemical compound S=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 PISWNSOQFZRVJK-XLPZGREQSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-UHFFFAOYSA-N 1-beta-D-Xylofuranosyl-NH-Cytosine Natural products O=C1N=C(N)C=CN1C1C(O)C(O)C(CO)O1 UHDGCWIWMRVCDJ-UHFFFAOYSA-N 0.000 description 1
- YKBGVTZYEHREMT-KVQBGUIXSA-N 2'-deoxyguanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@H]1C[C@H](O)[C@@H](CO)O1 YKBGVTZYEHREMT-KVQBGUIXSA-N 0.000 description 1
- CKTSBUTUHBMZGZ-SHYZEUOFSA-N 2'‐deoxycytidine Chemical compound O=C1N=C(N)C=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 CKTSBUTUHBMZGZ-SHYZEUOFSA-N 0.000 description 1
- VHVGNTVUSQUXPS-UHFFFAOYSA-N 2-amino-3-hydroxy-3-phenylpropanoic acid Chemical compound OC(=O)C(N)C(O)C1=CC=CC=C1 VHVGNTVUSQUXPS-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- JRYMOPZHXMVHTA-DAGMQNCNSA-N 2-amino-7-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1h-pyrrolo[2,3-d]pyrimidin-4-one Chemical compound C1=CC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O JRYMOPZHXMVHTA-DAGMQNCNSA-N 0.000 description 1
- ZOOGRGPOEVQQDX-UUOKFMHZSA-N 3',5'-cyclic GMP Chemical compound C([C@H]1O2)OP(O)(=O)O[C@H]1[C@@H](O)[C@@H]2N1C(N=C(NC2=O)N)=C2N=C1 ZOOGRGPOEVQQDX-UUOKFMHZSA-N 0.000 description 1
- YXDGRBPZVQPESQ-QMMMGPOBSA-N 4-[(2s)-2-amino-2-carboxyethyl]benzoic acid Chemical compound OC(=O)[C@@H](N)CC1=CC=C(C(O)=O)C=C1 YXDGRBPZVQPESQ-QMMMGPOBSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- LMMLLWZHCKCFQA-UGKPPGOTSA-N 4-amino-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)-2-prop-1-ynyloxolan-2-yl]pyrimidin-2-one Chemical compound C1=CC(N)=NC(=O)N1[C@]1(C#CC)O[C@H](CO)[C@@H](O)[C@H]1O LMMLLWZHCKCFQA-UGKPPGOTSA-N 0.000 description 1
- XXSIICQLPUAUDF-TURQNECASA-N 4-amino-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-prop-1-ynylpyrimidin-2-one Chemical compound O=C1N=C(N)C(C#CC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 XXSIICQLPUAUDF-TURQNECASA-N 0.000 description 1
- CMUHFUGDYMFHEI-QMMMGPOBSA-N 4-amino-L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N)C=C1 CMUHFUGDYMFHEI-QMMMGPOBSA-N 0.000 description 1
- GTVVZTAFGPQSPC-UHFFFAOYSA-N 4-nitrophenylalanine Chemical compound OC(=O)C(N)CC1=CC=C([N+]([O-])=O)C=C1 GTVVZTAFGPQSPC-UHFFFAOYSA-N 0.000 description 1
- 108020005029 5' Flanking Region Proteins 0.000 description 1
- ZAYHVCMSTBRABG-UHFFFAOYSA-N 5-Methylcytidine Natural products O=C1N=C(N)C(C)=CN1C1C(O)C(O)C(CO)O1 ZAYHVCMSTBRABG-UHFFFAOYSA-N 0.000 description 1
- AGFIRQJZCNVMCW-UAKXSSHOSA-N 5-bromouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(Br)=C1 AGFIRQJZCNVMCW-UAKXSSHOSA-N 0.000 description 1
- FHIDNBAQOFJWCA-UAKXSSHOSA-N 5-fluorouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(F)=C1 FHIDNBAQOFJWCA-UAKXSSHOSA-N 0.000 description 1
- KDOPAZIWBAHVJB-UHFFFAOYSA-N 5h-pyrrolo[3,2-d]pyrimidine Chemical compound C1=NC=C2NC=CC2=N1 KDOPAZIWBAHVJB-UHFFFAOYSA-N 0.000 description 1
- BXJHWYVXLGLDMZ-UHFFFAOYSA-N 6-O-methylguanine Chemical compound COC1=NC(N)=NC2=C1NC=N2 BXJHWYVXLGLDMZ-UHFFFAOYSA-N 0.000 description 1
- UEHOMUNTZPIBIL-UUOKFMHZSA-N 6-amino-9-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-7h-purin-8-one Chemical compound O=C1NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O UEHOMUNTZPIBIL-UUOKFMHZSA-N 0.000 description 1
- XZIIFPSPUDAGJM-UHFFFAOYSA-N 6-chloro-2-n,2-n-diethylpyrimidine-2,4-diamine Chemical compound CCN(CC)C1=NC(N)=CC(Cl)=N1 XZIIFPSPUDAGJM-UHFFFAOYSA-N 0.000 description 1
- HCAJQHYUCKICQH-VPENINKCSA-N 8-Oxo-7,8-dihydro-2'-deoxyguanosine Chemical compound C1=2NC(N)=NC(=O)C=2NC(=O)N1[C@H]1C[C@H](O)[C@@H](CO)O1 HCAJQHYUCKICQH-VPENINKCSA-N 0.000 description 1
- HDZZVAMISRMYHH-UHFFFAOYSA-N 9beta-Ribofuranosyl-7-deazaadenin Natural products C1=CC=2C(N)=NC=NC=2N1C1OC(CO)C(O)C1O HDZZVAMISRMYHH-UHFFFAOYSA-N 0.000 description 1
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- 102000007469 Actins Human genes 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 1
- 102100035248 Alpha-(1,3)-fucosyltransferase 4 Human genes 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 241000714230 Avian leukemia virus Species 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 208000035143 Bacterial infection Diseases 0.000 description 1
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 1
- 108010040467 CRISPR-Associated Proteins Proteins 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- 108010035563 Chloramphenicol O-acetyltransferase Proteins 0.000 description 1
- 241000251730 Chondrichthyes Species 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- 102000004420 Creatine Kinase Human genes 0.000 description 1
- 108010042126 Creatine kinase Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- MIKUYHXYGGJMLM-GIMIYPNGSA-N Crotonoside Natural products C1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1O MIKUYHXYGGJMLM-GIMIYPNGSA-N 0.000 description 1
- 241000195493 Cryptophyta Species 0.000 description 1
- UHDGCWIWMRVCDJ-PSQAKQOGSA-N Cytidine Natural products O=C1N=C(N)C=CN1[C@@H]1[C@@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-PSQAKQOGSA-N 0.000 description 1
- 102000000311 Cytosine Deaminase Human genes 0.000 description 1
- 108010080611 Cytosine Deaminase Proteins 0.000 description 1
- 101710112752 Cytotoxin Proteins 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- NYHBQMYGNKIUIF-UHFFFAOYSA-N D-guanosine Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1O NYHBQMYGNKIUIF-UHFFFAOYSA-N 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- CKTSBUTUHBMZGZ-UHFFFAOYSA-N Deoxycytidine Natural products O=C1N=C(N)C=CN1C1OC(CO)C(O)C1 CKTSBUTUHBMZGZ-UHFFFAOYSA-N 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 206010012735 Diarrhoea Diseases 0.000 description 1
- GZDFHIJNHHMENY-UHFFFAOYSA-N Dimethyl dicarbonate Chemical compound COC(=O)OC(=O)OC GZDFHIJNHHMENY-UHFFFAOYSA-N 0.000 description 1
- 229910052692 Dysprosium Inorganic materials 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 102000004533 Endonucleases Human genes 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 229910052693 Europium Inorganic materials 0.000 description 1
- NIGWMJHCCYYCSF-UHFFFAOYSA-N Fenclonine Chemical compound OC(=O)C(N)CC1=CC=C(Cl)C=C1 NIGWMJHCCYYCSF-UHFFFAOYSA-N 0.000 description 1
- 102100037362 Fibronectin Human genes 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- 108010019236 Fucosyltransferases Proteins 0.000 description 1
- 102000006471 Fucosyltransferases Human genes 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 229910052688 Gadolinium Inorganic materials 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 206010061968 Gastric neoplasm Diseases 0.000 description 1
- 208000018522 Gastrointestinal disease Diseases 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 239000004366 Glucose oxidase Substances 0.000 description 1
- 108010015776 Glucose oxidase Proteins 0.000 description 1
- JZNWSCPGTDBMEW-UHFFFAOYSA-N Glycerophosphorylethanolamin Natural products NCCOP(O)(=O)OCC(O)CO JZNWSCPGTDBMEW-UHFFFAOYSA-N 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 108700023372 Glycosyltransferases Proteins 0.000 description 1
- 208000009329 Graft vs Host Disease Diseases 0.000 description 1
- 108010078321 Guanylate Cyclase Proteins 0.000 description 1
- 102000014469 Guanylate cyclase Human genes 0.000 description 1
- 101710121697 Heat-stable enterotoxin Proteins 0.000 description 1
- 102000001554 Hemoglobins Human genes 0.000 description 1
- 108010054147 Hemoglobins Proteins 0.000 description 1
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 1
- 101001022185 Homo sapiens Alpha-(1,3)-fucosyltransferase 4 Proteins 0.000 description 1
- 101000819490 Homo sapiens Alpha-(1,6)-fucosyltransferase Proteins 0.000 description 1
- 101100005238 Homo sapiens CARTPT gene Proteins 0.000 description 1
- 101001046668 Homo sapiens Integrin alpha-X Proteins 0.000 description 1
- 101000998120 Homo sapiens Interleukin-3 receptor subunit alpha Proteins 0.000 description 1
- 108090000144 Human Proteins Proteins 0.000 description 1
- 102000003839 Human Proteins Human genes 0.000 description 1
- 241000701109 Human adenovirus 2 Species 0.000 description 1
- 241000701024 Human betaherpesvirus 5 Species 0.000 description 1
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 1
- 229920001612 Hydroxyethyl starch Polymers 0.000 description 1
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 1
- 206010061598 Immunodeficiency Diseases 0.000 description 1
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 1
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- 102100022297 Integrin alpha-X Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 102000003814 Interleukin-10 Human genes 0.000 description 1
- 102000004559 Interleukin-13 Receptors Human genes 0.000 description 1
- 108010017511 Interleukin-13 Receptors Proteins 0.000 description 1
- 108050003558 Interleukin-17 Proteins 0.000 description 1
- 102000013691 Interleukin-17 Human genes 0.000 description 1
- 108010002386 Interleukin-3 Proteins 0.000 description 1
- 102000000646 Interleukin-3 Human genes 0.000 description 1
- 102100033493 Interleukin-3 receptor subunit alpha Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 102000004388 Interleukin-4 Human genes 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 241000235058 Komagataella pastoris Species 0.000 description 1
- ZQISRDCJNBUVMM-UHFFFAOYSA-N L-Histidinol Natural products OCC(N)CC1=CN=CN1 ZQISRDCJNBUVMM-UHFFFAOYSA-N 0.000 description 1
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- ZGUNAGUHMKGQNY-ZETCQYMHSA-N L-alpha-phenylglycine zwitterion Chemical compound OC(=O)[C@@H](N)C1=CC=CC=C1 ZGUNAGUHMKGQNY-ZETCQYMHSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- ZQISRDCJNBUVMM-YFKPBYRVSA-N L-histidinol Chemical compound OC[C@@H](N)CC1=CNC=N1 ZQISRDCJNBUVMM-YFKPBYRVSA-N 0.000 description 1
- JTTHKOPSMAVJFE-VIFPVBQESA-N L-homophenylalanine Chemical compound OC(=O)[C@@H](N)CCC1=CC=CC=C1 JTTHKOPSMAVJFE-VIFPVBQESA-N 0.000 description 1
- UKAUYVFTDYCKQA-VKHMYHEASA-N L-homoserine Chemical compound OC(=O)[C@@H](N)CCO UKAUYVFTDYCKQA-VKHMYHEASA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- 125000000174 L-prolyl group Chemical group [H]N1C([H])([H])C([H])([H])C([H])([H])[C@@]1([H])C(*)=O 0.000 description 1
- VHVGNTVUSQUXPS-YUMQZZPRSA-N L-threo-3-phenylserine Chemical compound [O-]C(=O)[C@@H]([NH3+])[C@@H](O)C1=CC=CC=C1 VHVGNTVUSQUXPS-YUMQZZPRSA-N 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- PWHULOQIROXLJO-UHFFFAOYSA-N Manganese Chemical compound [Mn] PWHULOQIROXLJO-UHFFFAOYSA-N 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108090000015 Mesothelin Proteins 0.000 description 1
- 102000003735 Mesothelin Human genes 0.000 description 1
- 241000713333 Mouse mammary tumor virus Species 0.000 description 1
- 241000714177 Murine leukemia virus Species 0.000 description 1
- 101100341510 Mus musculus Itgal gene Proteins 0.000 description 1
- 101100515942 Mus musculus Nbl1 gene Proteins 0.000 description 1
- 101100519207 Mus musculus Pdcd1 gene Proteins 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 102000003505 Myosin Human genes 0.000 description 1
- 108060008487 Myosin Proteins 0.000 description 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 description 1
- 102000027581 NK cell receptors Human genes 0.000 description 1
- 108091008877 NK cell receptors Proteins 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 206010029260 Neuroblastoma Diseases 0.000 description 1
- 102000004459 Nitroreductase Human genes 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 241001452677 Ogataea methanolica Species 0.000 description 1
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 description 1
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 208000030852 Parasitic disease Diseases 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- 102000004503 Perforin Human genes 0.000 description 1
- KHGNFPUMBJSZSM-UHFFFAOYSA-N Perforine Natural products COC1=C2CCC(O)C(CCC(C)(C)O)(OC)C2=NC2=C1C=CO2 KHGNFPUMBJSZSM-UHFFFAOYSA-N 0.000 description 1
- 206010057249 Phagocytosis Diseases 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 208000002151 Pleural effusion Diseases 0.000 description 1
- 229920000805 Polyaspartic acid Polymers 0.000 description 1
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 1
- 101710101148 Probable 6-oxopurine nucleoside phosphorylase Proteins 0.000 description 1
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 1
- 102000030764 Purine-nucleoside phosphorylase Human genes 0.000 description 1
- 101710146873 Receptor-binding protein Proteins 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- QFQYGJMNIDGZSG-UHFFFAOYSA-N S-acetamidomethylcysteine Chemical compound CC(=O)NCSCC(N)C(O)=O QFQYGJMNIDGZSG-UHFFFAOYSA-N 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 1
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 101000677856 Stenotrophomonas maltophilia (strain K279a) Actin-binding protein Smlt3054 Proteins 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 108010008038 Synthetic Vaccines Proteins 0.000 description 1
- 230000005867 T cell response Effects 0.000 description 1
- 108700012920 TNF Proteins 0.000 description 1
- 102100032938 Telomerase reverse transcriptase Human genes 0.000 description 1
- 108020005038 Terminator Codon Proteins 0.000 description 1
- 210000000447 Th1 cell Anatomy 0.000 description 1
- 210000004241 Th2 cell Anatomy 0.000 description 1
- 108020004566 Transfer RNA Proteins 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 241000255993 Trichoplusia ni Species 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- GQLCLPLEEOUJQC-ZTQDTCGGSA-N [(1r)-3-(3,4-dimethoxyphenyl)-1-[3-[2-[2-[[2-[3-[(1r)-3-(3,4-dimethoxyphenyl)-1-[(2s)-1-[(2s)-2-(3,4,5-trimethoxyphenyl)butanoyl]piperidine-2-carbonyl]oxypropyl]phenoxy]acetyl]amino]ethylamino]-2-oxoethoxy]phenyl]propyl] (2s)-1-[(2s)-2-(3,4,5-trimethoxyph Chemical compound C([C@@H](OC(=O)[C@@H]1CCCCN1C(=O)[C@@H](CC)C=1C=C(OC)C(OC)=C(OC)C=1)C=1C=C(OCC(=O)NCCNC(=O)COC=2C=C(C=CC=2)[C@@H](CCC=2C=C(OC)C(OC)=CC=2)OC(=O)[C@H]2N(CCCC2)C(=O)[C@@H](CC)C=2C=C(OC)C(OC)=C(OC)C=2)C=CC=1)CC1=CC=C(OC)C(OC)=C1 GQLCLPLEEOUJQC-ZTQDTCGGSA-N 0.000 description 1
- SXEHKFHPFVVDIR-UHFFFAOYSA-N [4-(4-hydrazinylphenyl)phenyl]hydrazine Chemical compound C1=CC(NN)=CC=C1C1=CC=C(NN)C=C1 SXEHKFHPFVVDIR-UHFFFAOYSA-N 0.000 description 1
- 238000002679 ablation Methods 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 230000033289 adaptive immune response Effects 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 150000001299 aldehydes Chemical class 0.000 description 1
- 150000001338 aliphatic hydrocarbons Chemical class 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- 150000001414 amino alcohols Chemical class 0.000 description 1
- JINBYESILADKFW-UHFFFAOYSA-N aminomalonic acid Chemical compound OC(=O)C(N)C(O)=O JINBYESILADKFW-UHFFFAOYSA-N 0.000 description 1
- 229940025084 amphetamine Drugs 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 238000009175 antibody therapy Methods 0.000 description 1
- 102000025171 antigen binding proteins Human genes 0.000 description 1
- 108091000831 antigen binding proteins Proteins 0.000 description 1
- 230000030741 antigen processing and presentation Effects 0.000 description 1
- 238000010913 antigen-directed enzyme pro-drug therapy Methods 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 239000003443 antiviral agent Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 210000004507 artificial chromosome Anatomy 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 229960002170 azathioprine Drugs 0.000 description 1
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 1
- 208000022362 bacterial infectious disease Diseases 0.000 description 1
- 239000003855 balanced salt solution Substances 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- 230000006420 basal activation Effects 0.000 description 1
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 1
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 1
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 1
- SQVRNKJHWKZAKO-UHFFFAOYSA-N beta-N-Acetyl-D-neuraminic acid Natural products CC(=O)NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO SQVRNKJHWKZAKO-UHFFFAOYSA-N 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 239000003012 bilayer membrane Substances 0.000 description 1
- 239000003139 biocide Substances 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 238000010170 biological method Methods 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 229920001222 biopolymer Polymers 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 210000000601 blood cell Anatomy 0.000 description 1
- 210000004958 brain cell Anatomy 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 229940112129 campath Drugs 0.000 description 1
- 230000009702 cancer cell proliferation Effects 0.000 description 1
- 239000012830 cancer therapeutic Substances 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 230000020411 cell activation Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000007910 cell fusion Effects 0.000 description 1
- 239000002458 cell surface marker Substances 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000007969 cellular immunity Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 210000003850 cellular structure Anatomy 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 125000001549 ceramide group Chemical group 0.000 description 1
- 239000005081 chemiluminescent agent Substances 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 235000013330 chicken meat Nutrition 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 238000004140 cleaning Methods 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 238000000975 co-precipitation Methods 0.000 description 1
- 238000012761 co-transfection Methods 0.000 description 1
- 108700032673 cocaine- and amphetamine-regulated transcript Proteins 0.000 description 1
- 238000001246 colloidal dispersion Methods 0.000 description 1
- 239000000084 colloidal system Substances 0.000 description 1
- 230000024203 complement activation Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000003750 conditioning effect Effects 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- UHDGCWIWMRVCDJ-ZAKLUEHWSA-N cytidine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-ZAKLUEHWSA-N 0.000 description 1
- 238000004163 cytometry Methods 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000001085 cytostatic effect Effects 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 239000002619 cytotoxin Substances 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000004665 defense response Effects 0.000 description 1
- 238000002716 delivery method Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000002059 diagnostic imaging Methods 0.000 description 1
- 238000002405 diagnostic procedure Methods 0.000 description 1
- 238000012631 diagnostic technique Methods 0.000 description 1
- 150000001991 dicarboxylic acids Chemical class 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- GPLRAVKSCUXZTP-UHFFFAOYSA-N diglycerol Chemical compound OCC(O)COCC(O)CO GPLRAVKSCUXZTP-UHFFFAOYSA-N 0.000 description 1
- 238000007865 diluting Methods 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- BPHQZTVXXXJVHI-UHFFFAOYSA-N dimyristoyl phosphatidylglycerol Chemical compound CCCCCCCCCCCCCC(=O)OCC(COP(O)(=O)OCC(O)CO)OC(=O)CCCCCCCCCCCCC BPHQZTVXXXJVHI-UHFFFAOYSA-N 0.000 description 1
- 238000000375 direct analysis in real time Methods 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 238000012063 dual-affinity re-targeting Methods 0.000 description 1
- KBQHZAAAGSGFKK-UHFFFAOYSA-N dysprosium atom Chemical compound [Dy] KBQHZAAAGSGFKK-UHFFFAOYSA-N 0.000 description 1
- 108010011867 ecallantide Proteins 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000004993 emission spectroscopy Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 210000001842 enterocyte Anatomy 0.000 description 1
- 239000000147 enterotoxin Substances 0.000 description 1
- 231100000655 enterotoxin Toxicity 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 210000002615 epidermis Anatomy 0.000 description 1
- 210000003236 esophagogastric junction Anatomy 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- 239000003797 essential amino acid Substances 0.000 description 1
- 235000020776 essential amino acid Nutrition 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- OGPBJKLSAFTDLK-UHFFFAOYSA-N europium atom Chemical compound [Eu] OGPBJKLSAFTDLK-UHFFFAOYSA-N 0.000 description 1
- 125000005313 fatty acid group Chemical group 0.000 description 1
- 150000004665 fatty acids Chemical class 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 210000004700 fetal blood Anatomy 0.000 description 1
- 235000013312 flour Nutrition 0.000 description 1
- 229960000390 fludarabine Drugs 0.000 description 1
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 230000037406 food intake Effects 0.000 description 1
- 239000012595 freezing medium Substances 0.000 description 1
- 125000002446 fucosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)[C@@H](O1)C)* 0.000 description 1
- 101150023212 fut8 gene Proteins 0.000 description 1
- UIWYJDYFSGRHKR-UHFFFAOYSA-N gadolinium atom Chemical compound [Gd] UIWYJDYFSGRHKR-UHFFFAOYSA-N 0.000 description 1
- 229930182830 galactose Natural products 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 201000007492 gastroesophageal junction adenocarcinoma Diseases 0.000 description 1
- 210000005095 gastrointestinal system Anatomy 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000012637 gene transfection Methods 0.000 description 1
- 102000054766 genetic haplotypes Human genes 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 229940116332 glucose oxidase Drugs 0.000 description 1
- 235000019420 glucose oxidase Nutrition 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 229940075507 glyceryl monostearate Drugs 0.000 description 1
- 229930182470 glycoside Natural products 0.000 description 1
- 125000003147 glycosyl group Chemical group 0.000 description 1
- 108700014210 glycosyltransferase activity proteins Proteins 0.000 description 1
- 102000045442 glycosyltransferase activity proteins Human genes 0.000 description 1
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 1
- 208000024908 graft versus host disease Diseases 0.000 description 1
- 210000003714 granulocyte Anatomy 0.000 description 1
- 210000002503 granulosa cell Anatomy 0.000 description 1
- 230000003370 grooming effect Effects 0.000 description 1
- 229940029575 guanosine Drugs 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 229940064366 hespan Drugs 0.000 description 1
- 150000002402 hexoses Chemical class 0.000 description 1
- 231100000086 high toxicity Toxicity 0.000 description 1
- 230000004727 humoral immunity Effects 0.000 description 1
- 230000008348 humoral response Effects 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 229920001477 hydrophilic polymer Polymers 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- 102000027596 immune receptors Human genes 0.000 description 1
- 108091008915 immune receptors Proteins 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 229940127121 immunoconjugate Drugs 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 229940099472 immunoglobulin a Drugs 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 210000005008 immunosuppressive cell Anatomy 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 238000000126 in silico method Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- QNRXNRGSOJZINA-UHFFFAOYSA-N indoline-2-carboxylic acid Chemical compound C1=CC=C2NC(C(=O)O)CC2=C1 QNRXNRGSOJZINA-UHFFFAOYSA-N 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 230000008595 infiltration Effects 0.000 description 1
- 238000001764 infiltration Methods 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 230000015788 innate immune response Effects 0.000 description 1
- 210000005007 innate immune system Anatomy 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 229940047124 interferons Drugs 0.000 description 1
- 208000028774 intestinal disease Diseases 0.000 description 1
- 210000002490 intestinal epithelial cell Anatomy 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 229920000831 ionic polymer Polymers 0.000 description 1
- VBGWSQKGUZHFPS-VGMMZINCSA-N kalbitor Chemical compound C([C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]2C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=3C=CC=CC=3)C(=O)N[C@H](C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)NCC(=O)NCC(=O)N[C@H]3CSSC[C@H](NC(=O)[C@@H]4CCCN4C(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CO)NC(=O)[C@H](CC=4NC=NC=4)NC(=O)[C@H](CCSC)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O)CSSC[C@H](NC(=O)[C@H](CCSC)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC3=O)CSSC2)C(=O)N[C@@H]([C@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=2NC=NC=2)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N1)[C@@H](C)CC)[C@H](C)O)=O)[C@@H](C)CC)C1=CC=CC=C1 VBGWSQKGUZHFPS-VGMMZINCSA-N 0.000 description 1
- 229940018902 kalbitor Drugs 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 238000002357 laparoscopic surgery Methods 0.000 description 1
- 229960004942 lenalidomide Drugs 0.000 description 1
- GOTYRUGSSMKFNF-UHFFFAOYSA-N lenalidomide Chemical compound C1C=2C(N)=CC=CC=2C(=O)N1C1CCC(=O)NC1=O GOTYRUGSSMKFNF-UHFFFAOYSA-N 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 125000003473 lipid group Chemical group 0.000 description 1
- 210000005229 liver cell Anatomy 0.000 description 1
- 239000007937 lozenge Substances 0.000 description 1
- 230000002934 lysing effect Effects 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 230000005389 magnetism Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 229910052748 manganese Inorganic materials 0.000 description 1
- 239000011572 manganese Substances 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 230000013011 mating Effects 0.000 description 1
- 238000001840 matrix-assisted laser desorption--ionisation time-of-flight mass spectrometry Methods 0.000 description 1
- 210000003071 memory t lymphocyte Anatomy 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 description 1
- 238000000386 microscopy Methods 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- 210000000110 microvilli Anatomy 0.000 description 1
- 239000002480 mineral oil Substances 0.000 description 1
- 235000010446 mineral oil Nutrition 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 239000001788 mono and diglycerides of fatty acids Substances 0.000 description 1
- 150000002763 monocarboxylic acids Chemical class 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 210000000663 muscle cell Anatomy 0.000 description 1
- 229960004866 mycophenolate mofetil Drugs 0.000 description 1
- RTGDFNSFWBGLEC-SYZQJQIISA-N mycophenolate mofetil Chemical compound COC1=C(C)C=2COC(=O)C=2C(O)=C1C\C=C(/C)CCC(=O)OCCN1CCOCC1 RTGDFNSFWBGLEC-SYZQJQIISA-N 0.000 description 1
- 229960000951 mycophenolic acid Drugs 0.000 description 1
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 description 1
- 201000000050 myeloid neoplasm Diseases 0.000 description 1
- 229950006780 n-acetylglucosamine Drugs 0.000 description 1
- AEMBWNDIEFEPTH-UHFFFAOYSA-N n-tert-butyl-n-ethylnitrous amide Chemical compound CCN(N=O)C(C)(C)C AEMBWNDIEFEPTH-UHFFFAOYSA-N 0.000 description 1
- 239000002088 nanocapsule Substances 0.000 description 1
- 239000002159 nanocrystal Substances 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- 229960005027 natalizumab Drugs 0.000 description 1
- 230000007837 negative regulation of B cell activation Effects 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 208000025402 neoplasm of esophagus Diseases 0.000 description 1
- 108020001162 nitroreductase Proteins 0.000 description 1
- 150000003833 nucleoside derivatives Chemical class 0.000 description 1
- 229960003104 ornithine Drugs 0.000 description 1
- 239000006179 pH buffering agent Substances 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 230000000149 penetrating effect Effects 0.000 description 1
- GJVFBWCTGUSGDD-UHFFFAOYSA-L pentamethonium bromide Chemical compound [Br-].[Br-].C[N+](C)(C)CCCCC[N+](C)(C)C GJVFBWCTGUSGDD-UHFFFAOYSA-L 0.000 description 1
- 229930192851 perforin Natural products 0.000 description 1
- 239000003208 petroleum Substances 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 230000008782 phagocytosis Effects 0.000 description 1
- 239000008177 pharmaceutical agent Substances 0.000 description 1
- 229940124531 pharmaceutical excipient Drugs 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 150000008104 phosphatidylethanolamines Chemical group 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 230000010399 physical interaction Effects 0.000 description 1
- 238000000053 physical method Methods 0.000 description 1
- 230000006461 physiological response Effects 0.000 description 1
- 229940081858 plasmalyte a Drugs 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 108010054442 polyalanine Proteins 0.000 description 1
- 229920001281 polyalkylene Polymers 0.000 description 1
- 108010064470 polyaspartate Proteins 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 230000001323 posttranslational effect Effects 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 210000004986 primary T-cell Anatomy 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 238000007639 printing Methods 0.000 description 1
- 239000000186 progesterone Substances 0.000 description 1
- 229960003387 progesterone Drugs 0.000 description 1
- 230000000770 proinflammatory effect Effects 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 230000012846 protein folding Effects 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 230000010837 receptor-mediated endocytosis Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000004064 recycling Methods 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 229960003452 romidepsin Drugs 0.000 description 1
- OHRURASPPZQGQM-GCCNXGTGSA-N romidepsin Chemical compound O1C(=O)[C@H](C(C)C)NC(=O)C(=C/C)/NC(=O)[C@H]2CSSCC\C=C\[C@@H]1CC(=O)N[C@H](C(C)C)C(=O)N2 OHRURASPPZQGQM-GCCNXGTGSA-N 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 210000000717 sertoli cell Anatomy 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- SQVRNKJHWKZAKO-OQPLDHBCSA-N sialic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)OC1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-OQPLDHBCSA-N 0.000 description 1
- 239000000741 silica gel Substances 0.000 description 1
- 229910002027 silica gel Inorganic materials 0.000 description 1
- 229960002930 sirolimus Drugs 0.000 description 1
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 1
- 235000020183 skimmed milk Nutrition 0.000 description 1
- 239000001632 sodium acetate Substances 0.000 description 1
- 235000017281 sodium acetate Nutrition 0.000 description 1
- RYYKJJJTJZKILX-UHFFFAOYSA-M sodium octadecanoate Chemical compound [Na+].CCCCCCCCCCCCCCCCCC([O-])=O RYYKJJJTJZKILX-UHFFFAOYSA-M 0.000 description 1
- 239000008247 solid mixture Substances 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 229940035044 sorbitan monolaurate Drugs 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 238000002798 spectrophotometry method Methods 0.000 description 1
- 125000002544 sphingolipid group Chemical group 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- 239000000454 talc Substances 0.000 description 1
- 229910052623 talc Inorganic materials 0.000 description 1
- NPDBDJFLKKQMCM-UHFFFAOYSA-N tert-butylglycine Chemical compound CC(C)(C)C(N)C(O)=O NPDBDJFLKKQMCM-UHFFFAOYSA-N 0.000 description 1
- 238000010257 thawing Methods 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 210000001578 tight junction Anatomy 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- BJBUEDPLEOHJGE-IMJSIDKUSA-N trans-3-hydroxy-L-proline Chemical compound O[C@H]1CC[NH2+][C@@H]1C([O-])=O BJBUEDPLEOHJGE-IMJSIDKUSA-N 0.000 description 1
- PMMYEEVYMWASQN-IMJSIDKUSA-N trans-4-Hydroxy-L-proline Natural products O[C@@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-IMJSIDKUSA-N 0.000 description 1
- SBUXRMKDJWEXRL-ZWKOTPCHSA-N trans-body Chemical compound O=C([C@@H]1N(C2=O)[C@H](C3=C(C4=CC=CC=C4N3)C1)CC)N2C1=CC=C(F)C=C1 SBUXRMKDJWEXRL-ZWKOTPCHSA-N 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 238000003151 transfection method Methods 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 230000010474 transient expression Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 238000002054 transplantation Methods 0.000 description 1
- HDZZVAMISRMYHH-KCGFPETGSA-N tubercidin Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O HDZZVAMISRMYHH-KCGFPETGSA-N 0.000 description 1
- 230000005909 tumor killing Effects 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 1
- 229940045145 uridine Drugs 0.000 description 1
- 210000004291 uterus Anatomy 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 235000013311 vegetables Nutrition 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 230000029812 viral genome replication Effects 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
Images




















































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K40/00—Cellular immunotherapy
- A61K40/10—Cellular immunotherapy characterised by the cell type used
- A61K40/11—T-cells, e.g. tumour infiltrating lymphocytes [TIL] or regulatory T [Treg] cells; Lymphokine-activated killer [LAK] cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K40/00—Cellular immunotherapy
- A61K40/30—Cellular immunotherapy characterised by the recombinant expression of specific molecules in the cells of the immune system
- A61K40/31—Chimeric antigen receptors [CAR]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K40/00—Cellular immunotherapy
- A61K40/40—Cellular immunotherapy characterised by antigens that are targeted or presented by cells of the immune system
- A61K40/41—Vertebrate antigens
- A61K40/42—Cancer antigens
- A61K40/4244—Enzymes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/40—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y406/00—Phosphorus-oxygen lyases (4.6)
- C12Y406/01—Phosphorus-oxygen lyases (4.6.1)
- C12Y406/01002—Guanylate cyclase (4.6.1.2)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K40/00
- A61K2239/10—Indexing codes associated with cellular immunotherapy of group A61K40/00 characterized by the structure of the chimeric antigen receptor [CAR]
- A61K2239/11—Antigen recognition domain
- A61K2239/13—Antibody-based
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K40/00
- A61K2239/10—Indexing codes associated with cellular immunotherapy of group A61K40/00 characterized by the structure of the chimeric antigen receptor [CAR]
- A61K2239/17—Hinge-spacer domain
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K40/00
- A61K2239/10—Indexing codes associated with cellular immunotherapy of group A61K40/00 characterized by the structure of the chimeric antigen receptor [CAR]
- A61K2239/21—Transmembrane domain
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K40/00
- A61K2239/10—Indexing codes associated with cellular immunotherapy of group A61K40/00 characterized by the structure of the chimeric antigen receptor [CAR]
- A61K2239/22—Intracellular domain
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K40/00
- A61K2239/31—Indexing codes associated with cellular immunotherapy of group A61K40/00 characterized by the route of administration
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K40/00
- A61K2239/38—Indexing codes associated with cellular immunotherapy of group A61K40/00 characterised by the dose, timing or administration schedule
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K40/00
- A61K2239/46—Indexing codes associated with cellular immunotherapy of group A61K40/00 characterised by the cancer treated
- A61K2239/50—Colon
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/88—Lyases (4.)
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Immunology (AREA)
- Medicinal Chemistry (AREA)
- Epidemiology (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Engineering & Computer Science (AREA)
- Biophysics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Cell Biology (AREA)
- Pharmacology & Pharmacy (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Microbiology (AREA)
- Hematology (AREA)
- Developmental Biology & Embryology (AREA)
- Virology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicinal Preparation (AREA)
Abstract
本發明係揭示一種與鳥苷酸環化酶C (GCC)結合之抗原結合劑(例如單域抗體),以及包含GCC抗原結合域的嵌合抗原受體。亦揭示包含該等抗原結合劑及其片段之核酸、重組表現載體、宿主細胞、抗原結合片段及醫藥組成物。本發明亦提供利用本文所提供之抗體及抗原結合分子之治療方法。
Description
無
鳥苷酸環化酶C (GCC)為一種跨膜細胞表面受體,其功能為維持腸液、電解質體內平衡及細胞增殖,請參見例如Carrithers等人,Proc. Natl. Acad. Sci. USA 100:3018-3020 (2003)。GCC表現於小腸、大腸和直腸內襯的黏膜細胞(Carriters等人,Dis Colon Rectum 39: 171-181 (1996))。GCC的表現在腸上皮細胞腫瘤轉型之後仍維持,且表現在所有原發性及轉移性大腸直腸腫瘤中(Carriters等人,Dis Colon Rectum 39: 171-181 (1996);Buc等人,Eur J Cancer 41: 1618-1627 (2005);Carrithers等人,Genterology 107: 1653-1661 (1994))。目前需要新穎且增進的標靶GCC之方法。
GCC訊息傳遞途徑中斷與多種胃腸道疾病(包括大腸直腸癌)有關。除其它事項外,本發明提供一種新穎之抗GCC抗原結合分子(例如,單域抗體(sdAb))和嵌合抗原受體(CAR),其包括抗GCC抗原結合域(如sdAb)。此外,本發明提供表現CAR的宿主細胞(例如T細胞),以及編碼該CAR或抗GCC抗原結合分子的核酸分子。該CAR細胞包含一表現於該細胞表面上之抗GCC CAR分子。在一些實施例中,該CAR在經轉導T細胞上展現高表面表現,在體內具有高度細胞溶解及轉導T細胞擴增及持續性。亦提供使用所揭示之CAR、宿主細胞及核酸分子,以例如在個體中治療癌症之方法。
在一態樣中,本發明提供一種抗鳥苷酸環化酶C (GCC)嵌合抗原受體(CAR),其包含一與鳥苷酸環化酶C (GCC)結合之細胞外抗原結合域、一跨膜域及至少一細胞內信號傳導域。
在一些實施例中,該抗GCC CAR包含一抗原結合域,其包含:一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:HYYWS (HCDR1) (SEQ ID NO: 8)、RIYPSGSTSYNPSLKS (HCDR2) (SEQ ID NO: 11)和DRSTGWSEWNSDL (HCDR3) (SEQ ID NO: 16);一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMS (HCDR1) (SEQ ID NO: 9)、KIRHDGGEKYYVDSVKG (HCDR2) (SEQ ID NO: 12)和DYTRDV (HCDR3) (SEQ ID NO: 17);一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIKYDGSEKYYADSVKG (HCDR2) (SEQ ID NO: 13)和DYNKDY (HCDR3) (SEQ ID NO: 18);一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYPDSVKG (HCDR2) (SEQ ID NO: 14)和DYNKDL (HCDR3) (SEQ ID NO: 19);或一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYADSVKG (HCDR2) (SEQ ID NO: 15)和DYNKDY (HCDR3) (SEQ ID NO: 18)。
在一些實施例中,該抗GCC CAR之抗原結合域包含一重鏈可變區(VH),其與SEQ ID NO: 1或SEQ ID NO: 20至少90%一致。
在一些實施例中,該抗GCC CAR之抗原結合域包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 21至少90%一致的胺基酸序列;一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 26至少90%一致的胺基酸序列;一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 27至少90%一致的胺基酸序列;一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 28至少90%一致的胺基酸序列。
在一些實施例中,該抗GCC CAR之抗原結合域包含一僅具抗GCC抗原結合域之免疫球蛋白可變重鏈。
在一些實施例中,該抗GCC CAR之細胞外抗GCC抗原結合域前接有一編碼前導胜肽之前導核苷酸序列。
在一些實施例中,該前導胜肽包含SEQ ID NO: 6、SEQ ID NO: 7、或SEQ ID NO: 42。
在一些實施例中,該抗GCC CAR更包含一鉸鏈域。
在一些實施例中,該鉸鏈域包含一CD28之鉸鏈域。
在一些實施例中,該CD28鉸鏈域包含SEQ ID NO: 29。
在一些實施例中,該抗GCC CAR包含與該跨膜域融合之鉸鏈域。
在一些實施例中,該跨膜域包含一蛋白質跨膜域,該蛋白質選自於T細胞受體之α、β或ζ鏈、CD8、CD28、CD3ε、CD45、CD4、CD5、CD8、CD9、CD16、CD22、CD33、CD37、CD64、CD80、CD83、CD86、CD134、CD137、CD154、及TNFRSF19、及其任一組合。
在一些實施例中,該跨膜域包含一CD28跨膜域。
在一些實施例中,該CD28跨膜域包含SEQ ID NO: 30。
在一些實施例中,該至少一細胞內信號傳導域包含一共刺激域和一初級信號傳導域。
在一些實施例中,該共刺激結構域包含OX40、CD70、CD27、CD28、CD5、ICAM-1、LFA-1 (CD11a/CD18)、ICOS (CD278)、DAP10、DAP12、和4-1BB (CD137)、或其任一組合的功能性信號傳導域。
在一些實施例中,該共刺激域包含一CD28的功能性信號傳導域。
在一些實施例中,該CD28共刺激結構域包含SEQ ID NO: 32。
在一些實施例中,該初級信號傳導域包含CD3ζ信號傳導域。
在一些實施例中,該CD3ζ信號傳導域包含SEQ ID NO: 33。
在一態樣中,抗GCC CAR包含一胺基酸序列,其選自由以下組成之組:SEQ ID NO: 47-52。
在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 47至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 48至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 49至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 50至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 51至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 52至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。
於一態樣中,本發明提供一種編碼本文所述之抗GCC CAR之經分離聚核甘酸。
於一些實施例中,本文中所述之編碼抗GCC CAR之經分離聚核甘酸更包含經截短之表皮生長因子受體(tEGFR)序列。
在一些實施例中,該tEGFR包含一核苷酸序列,其編碼與SEQ ID NO: 43至少95%、96%、97%、98%、99%一致的胺基酸序列。
在一些實施例中,該tEGFR包含一核苷酸序列,其編碼與SEQ ID NO: 43一致的胺基酸序列。
在一些實施例中,該編碼本文所述之抗GCC CAR之經分離聚核甘酸更包含一弗林蛋白酶識別位點和下游2A自裂解胜肽序列,設計用於該標籤序列和CAR序列的同時雙順反子表現。
在一些實施例中,該2A自裂解胜肽係選自於F2A、P2A、E2A及T2A。
在一些實施例中,該2A自裂解胜肽為P2A。
在一態樣中,本發明提供一種載體,其包含編碼本文所述之抗GCC CAR之經分離聚核甘酸。
在一些實施例中,載體為腺病毒載體、腺病毒相關載體、DNA載體、慢病毒載體、質體、逆轉錄病毒載體或RNA載體。在一些實施例中,該載體為逆轉錄病毒載體。
在一態樣中,本發明提供一種細胞,其包含編碼本文所述之抗GCC CAR之經分離聚核甘酸。
在一些實施例中,該細胞表現本文所描述之抗GCC CAR。
在一些實施例中,該細胞為T細胞、同種異體T細胞、自體T細胞或腫瘤浸潤淋巴細胞(TIL)。
在一態樣中,本發明提供一種醫藥組成物,其包含表現或可表現本文所描述之抗GCC CAR的細胞群。在一些實施例中,該醫藥組成物包含一細胞群,其中該群體中大於70%、80%、90%或95%的細胞表現該抗GCC CAR。
在一態樣中,本發明提供一種治療癌症之方法,其包含向有需要治療之個體投與包含本文所述之抗GCC CAR之醫藥組成物。
在一些實施例中,該癌症係選自於胃腸癌、大腸直腸癌、大腸直腸腺癌、大腸直腸平滑肌肉瘤、大腸直腸淋巴瘤、大腸直腸黑色素瘤、大腸直腸神經內分泌腫瘤、轉移性大腸癌、胃癌、胃腺癌、胃淋巴瘤、胃肉瘤、食道癌、鱗狀細胞癌、食道腺癌或胰臟癌。
在一些實施例中,該癌症為胃腸癌。
在一些實施例中,該胃腸癌為大腸癌、大腸直腸癌、胃癌或食道癌。
在一態樣中,本發明提供一種藉由投與包含本文所描述之抗GCC CAR之醫藥組成物,以降低腫瘤生長或腫瘤大小之方法。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:HYYWS (HCDR1) (SEQ ID NO: 8)、RIYPSGSTSYNPSLKS (HCDR2) (SEQ ID NO: 11)和DRSTGWSEWNSDL (HCDR3) (SEQ ID NO: 16)。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMS (HCDR1) (SEQ ID NO: 9)、KIRHDGGEKYYVDSVKG (HCDR2) (SEQ ID NO: 12)和DYTRDV (HCDR3) (SEQ ID NO: 17)。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIKYDGSEKYYADSVKG (HCDR2) (SEQ ID NO: 13)和DYNKDY (HCDR3) (SEQ ID NO: 18)。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYPDSVKG (HCDR2) (SEQ ID NO: 14)和DYNKDL (HCDR3) (SEQ ID NO: 19)。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYADSVKG (HCDR2) (SEQ ID NO: 15)和DYNKDY (HCDR3) (SEQ ID NO: 18)。
在一些實施例中,該GCC結合劑包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 1或SEQ ID NO: 20至少90%一致的胺基酸序列。
在一些實施例中,該GCC結合劑包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 21至少90%一致的胺基酸序列。
在一些實施例中,該GCC結合劑包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 26至少90%一致的胺基酸序列。
在一些實施例中,該GCC結合劑包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 27至少90%一致的胺基酸序列。
在一些實施例中,該GCC結合劑包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 28至少90%一致的胺基酸序列。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 1或SEQ ID NO: 20至少90%一致的胺基酸序列。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 21至少90%一致的胺基酸序列。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 26至少90%一致的胺基酸序列。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 27至少90%一致的胺基酸序列。
在一態樣中,本發明提供一種鳥苷酸環化酶C (GCC)結合劑,其包含一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 28至少90%一致的胺基酸序列。
在一些實施例中,該GCC結合劑包含一VH區,其包含一與SEQ ID NO: 1、20、21、26、27或28之任一項至少95%一致之胺基酸序列。
在一些實施例中,該GCC結合劑包含一VH區,其包含一與SEQ ID NO: 1、20、21、26、27或28之任一項一致之胺基酸序列。
在一些實施例中,該GCC結合劑係選自於由以下組成之群:IgA抗體、IgG抗體、IgE抗體、IgM抗體、雙或多特異性抗體、Fab片段、Fab’片段、F(ab’)2片段、Fd’片段、Fd片段、經分離之CDR或其群組;單鏈可變異片段(scFv)、多胜肽-Fc融合物、單域抗體(sdAb)、VH、駱駝源化抗體;掩蔽抗體、小型模組化免疫製藥(「SMIPsTM」)、單鏈、串聯雙價抗體、VHHs、抗運載蛋白(Anticalin)、奈米抗體、人源化抗體(humabody)、微型抗體、BiTE、錨蛋白(ankyrin)重複蛋白、DARPIN、Avimer、DART、TCR-類似抗體、Adnectin、人類泛素(Affilin)、穿透抗體(Trans-body);親和抗體(Affibody)、TrimerX、微型蛋白、Fynomer、Centyrin;以及KALBITOR。
在一些實施例中,該GCC結合劑為單域抗體(sdAb)。
在一些實施例中,該GCC結合劑為僅具一重鏈(VH)之抗體。
在一些實施例中,該GCC結合劑係以介於約0.3奈米莫耳濃度(nM)至約10 nM之間的KD與GCC結合。
在一些實施例中,該GCC結合劑係以介於約0.5 nM至約8 nM之間的EC50與標靶細胞上的GCC結合。
在一態樣中,本發明提供一種治療癌症之方法,其包含向需要治療之個體投與本文所述之GCC結合劑。
在一些實施例中,該癌症係選自於胃腸癌、大腸直腸癌、大腸直腸腺癌、大腸直腸平滑肌肉瘤、大腸直腸淋巴瘤、大腸直腸黑色素瘤、大腸直腸神經內分泌腫瘤、轉移性大腸癌、胃癌、胃腺癌、胃淋巴瘤、胃肉瘤、食道癌、鱗狀細胞癌、食道腺癌或胰臟癌。
在一些實施例中,該癌症為胃腸癌。
在一些實施例中,該胃腸癌為大腸癌、大腸直腸癌、胃癌或食道癌。
在一態樣中,本發明提供一種醫藥組成物,其包含GCC結合劑及醫藥學上可接受之載體,其中該GCC結合劑包含:一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:HYYWS (HCDR1) (SEQ ID NO: 8)、RIYPSGSTSYNPSLKS (HCDR2) (SEQ ID NO: 11)和DRSTGWSEWNSDL (HCDR3) (SEQ ID NO: 16);一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMS (HCDR1) (SEQ ID NO: 9)、KIRHDGGEKYYVDSVKG (HCDR2) (SEQ ID NO: 12)和DYTRDV (HCDR3) (SEQ ID NO: 17);一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIKYDGSEKYYADSVKG (HCDR2) (SEQ ID NO: 13)和DYNKDY (HCDR3) (SEQ ID NO: 18);一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYPDSVKG (HCDR2) (SEQ ID NO: 14)和DYNKDL (HCDR3) (SEQ ID NO: 19);或一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYADSVKG (HCDR2) (SEQ ID NO: 15)和DYNKDY (HCDR3) (SEQ ID NO: 18)。
在一態樣中,本發明提供一種治療癌症之方法,其包含向需要治療之個體投與GCC結合劑,其中該GCC結合劑包含:一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:HYYWS (HCDR1) (SEQ ID NO: 8)、RIYPSGSTSYNPSLKS (HCDR2) (SEQ ID NO: 11)和DRSTGWSEWNSDL (HCDR3) (SEQ ID NO: 16);一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMS (HCDR1) (SEQ ID NO: 9)、KIRHDGGEKYYVDSVKG (HCDR2) (SEQ ID NO: 12)和DYTRDV (HCDR3) (SEQ ID NO: 17);一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIKYDGSEKYYADSVKG (HCDR2) (SEQ ID NO: 13)和DYNKDY (HCDR3) (SEQ ID NO: 18);一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYPDSVKG (HCDR2) (SEQ ID NO: 14)和DYNKDL (HCDR3) (SEQ ID NO: 19);或一重鏈可變區(VH),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYADSVKG (HCDR2) (SEQ ID NO: 15)和DYNKDY (HCDR3) (SEQ ID NO: 18)。
在一態樣中,本發明提供一種核酸,其編碼與SEQ ID NO: 1、20、21、26、27或28之任一者一致的VH胺基酸序列。
在一態樣中,本發明提供一種載體,其包含編碼與SEQ ID NO: 1、20、21、26、27或28之任一者一致的VH胺基酸序列之核酸。
在一態樣中,本發明提供一種經分離之細胞,其包含有包含編碼與SEQ ID NO: 1、20、21、26、27或28之任一者之VH胺基酸序列的核酸之載體。
應理解,前述一般描述及以下詳細描述二者僅為例示性及解釋性,且不限制本發明,如所申明者。
相關申請案之交互參考
本申請案主張 2020年12月9日申請之美國臨時專利申請案第63/123,331號之優先權,其以全文引用之方式併入本文中。
序列表
本申請案含有序列表,其已以ASCII格式之電子方式提交,且以全文引用之方式併入本文中。該ASCII複本於2021年11月19日建立,命名為MIL-005WO_SL.txt,其大小為140,478位元組。
定義
為使本發明更易於理解,首先在下文定義某些術語。隨附術語及其他術語之額外定義貫穿本說明書記載。
除非上下文另外明確指示,否則如本說明書及所附申請專利範圍中所使用,單數形式「一(a/an)」及「該(the)」包括複數個指示物。因此,例如,提及「方法」包括一或多種方法,及/或本文所述類型之步驟,及/或熟習此項技術者將經由閱讀本發明及類似者時,變得顯而易見。
投與 :如本文所用,向個體「投與」組成物係指提供、施用或使該組成物與該個體接觸。投與可藉由多種途徑中之任一者實現,諸如局部、口服、皮下、肌肉內、腹膜內、靜脈內、脊髓鞘內和皮內。
親和力 :如本文中所使用,術語「親和力」係指結合部分(例如,抗原結合劑(例如,本文所述之可變域)與標靶(例如,抗原(例如GCC))之間的結合交互作用特性,且指示出該結合交互作用之強度。在一些實施例中,親和力之測量係以解離常數(K
D)表示。在一些實施例中,結合部分對於標靶具有高親和力(例如,小於約10
-7M、小於約10
-8M或小於約10
-9M之K
D)。在一些實施例中,結合部分對於標靶具有低親和力(例如,高於約10
-7M、高於約10
-6M、高於約10
-5M、或高於約10
-4M之K
D)。
動物 :如本文所使用之術語「動物」係指動物界之任何成員。在一些實施例中,「動物」係指處於發育之任何階段之人類。在一些實施例中,「動物」係指處於發育之任何階段之非人類動物。在某些實施例中,該非人類動物為哺乳動物(例如嚙齒動物、小鼠、大鼠、兔、猴、狗、貓、綿羊、牛、靈長類動物及/或豬)。在一些實施例中,動物包括但不限於哺乳動物、鳥、爬蟲類、兩棲動物、魚、昆蟲及/或蟲。在一些實施例中,動物可為基因轉殖動物、經基因工程改造之動物及/或純系。
自體 :如本文所用,術語「自體」是指衍生自同一個體的任何材料,隨後將其重新引入該個體。
同種異體 :「同種異體」係指衍生自一個體的材料被投與不同的個體或個體群。
抗體或抗原結合劑 :如本文所用,術語「抗體」或「抗原結合劑」係指包括足以賦予特定標靶抗原的特異性結合之典型免疫球蛋白序列元件之多胜肽。熟習此項技術者將瞭解,該術語可在本文中互換使用。在一些實施例中,如本文中所使用,術語「抗體」或「抗原結合劑」亦指「抗體片段」或「抗體片段群」或「抗原結合部分」,其包括完整抗體之一部分,例如,例如抗體之抗原結合或可變區。「抗體片段」之實例包括Fab、Fab'、F(ab’)2及Fv片段;三抗體;四抗體;直線形抗體;單鏈抗體分子;以及由抗體片段形成之多特異性抗體中所包括之含CDR部分。熟習此項技術者應瞭解,術語「抗體片段」並不暗示且不限於任何特定產生模式。抗體片段可經由使用任何適當方法學製備,包括但不限於完整抗體的裂解、化學合成、重組製造等。如本領域中已知的,天然製造之完整抗體為約150 kD之四聚體試劑,包含兩個相同的重鏈多肽(各約50 kD)及兩個相同的輕鏈多肽(各約25 kD)相互結合形成所謂的「Y形」結構。各重鏈包含至少四個域(每個約110個胺基酸長)- 一個胺基端可變(V
H)域(位於Y結構之頂端),接著是三個恒定域:C
H1、C
H2和羧基端C
H3(位於Y型主幹的底部)。短區(稱為「開關」)連接該重鏈可變區及恆定區。「鉸鏈」將C
H2及C
H3域連接至該抗體之其餘部分。此鉸鏈區中的兩個雙硫鍵將完整抗體中的兩個重鏈多肽彼此連接。各輕鏈包含兩個域 - 胺基端可變(V
L)域,之後接著一個羧基端恆定(C
L)域,彼此以另一「開關」隔開。完整抗體四聚體是由兩個重鏈-輕鏈二聚體組成,其中重鏈及輕鏈藉由單一雙硫鍵彼此連接;兩個其他雙硫鍵將該重鏈鉸鏈區彼此連接,使得該二聚體彼此連接且形成四聚體。天然生成的抗體亦經醣基化,一般在C
H2域上。天然抗體中的每個域都具有以「免疫球蛋白折疊」為特徵的結構,該折疊由兩個β摺板(例如,3-、4-或5-股摺板),在壓縮的反向平行β桶中相互堆積而成。每個可變域包含三個高度變異環,稱為「互補決定區」(CDR1、CDR2和CDR3)和四個稍微不變的「框架」區(FR1、FR2、FR3和FR4)。當天然抗體折疊時,FR區形成β摺板,為域提供結構框架,而來自重鏈和輕鏈二者的CDR環區在三維空間中聚集在一起,因而在該Y結構的頂端創造出單一高度變異抗原結合位點。抗體多肽鏈之間的胺基酸序列比對已定義出兩種輕鏈(κ和λ)類別、數種重鏈(如μ、γ、α、ε、δ)類別,以及數種重鏈亞群(α1、α2、γ1、γ2、γ3和γ4)。抗體類別(IgA [包括IgA1、IgA2]、IgD、IgE、IgG [包括IgG1、IgG2、IgG3和IgG4]和IgM)是基於所使用的重鏈序列的類別而定義的。
出於本發明的目的,在某些實施例中,包括在天然抗體中發現的足夠免疫球蛋白域序列的任何多肽或多肽複合物,可被稱為及/或作為「抗體」或「抗原結合劑」,不論此種多肽是天然產生的(例如,由對某一抗原產生反應的生物體產生),或藉由重組工程、化學合成或其他人工系統或方法學產生。在一些實施例中,抗體為單株抗體;在一些實施例中,抗體為多株抗體。在一些實施例中,抗體具有小鼠、兔子、靈長類動物或人類抗體特徵的恆定區序列。在一些實施例中,如本領域中已知的,抗體序列元件為人類化、靈長類化、嵌合化等。此外,本文使用的術語「抗體」或「抗原結合劑」將被理解為涵蓋(除非內文另有說明或澄清)在適當的實施例中,可以指任何本領域已知的或已開發的構建體或形式,用於在替代呈現中捕捉抗體結構性和功能性特徵。舉例而言,在一些實施例中,該等術語可指稱雙-或其它多-特異性(例如,酶親體等)抗體、小型模組免疫藥物(「SMIPs™」)、單鏈抗體、駱駝源化抗體及/或抗體片段。在一些實施例中,抗體可能缺乏它在天然產生時可能具有的共價修飾(例如,連接聚醣)。在一些實施例中,抗體可包含共價修飾(例如,連接聚醣、負載[例如可偵測部分、治療部分、催化部分等]、或其他側接基[例如聚乙二醇等])。
大約或約 :如本文所使用,術語「大約」或者「約」如應用於有興趣的一或者多個數值,係指類似於所陳述參考值之數值。在某些實施例中,除非另外說明或者另外自內文顯而易見,否則術語「大約」或者「約」係指在任一方向上(大於或者小於)落於所陳述參考值之25%、20%、19%、18%、17%、16%、15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2%、1%或者更小之數值範圍內(但此數值將超出可能性值之100%的情況除外)。
互補決定區 (CDR ) :可變域的「CDR」為在可變區內,根據Kabat、Chothia之定義、Kabat和Chothia二者之累積、AbM、接觸及/或構型定義或任何本領域中所周知的CDR測定方法所辨識出的胺基酸殘基。抗體CDR可辨識為最初由Kabat等人定義的高度變異區。請參見,例如,Kabat等人,1992, Sequences of Proteins of Immunological Interest,第5版,公共衛生服務處,NIH, Washington D.C。CDR的位置亦可辨識為最初由Chothia和其他人描述的結構環結構。請見如Chothia等人,Nature 342:877-883, 1989。其他的CDR辨識方法包括「AbM定義」,此為Kabat和Chothia之間的折衷,是使用Oxford Molecular的AbM抗體模擬軟體(現在名為Accelrys®)推導而來,或基於觀察到的抗原接觸的CDR之「接觸定義」,如MacCallum等人,J. Mol. Biol., 262:732-745, 1996中所述。在另一方法中,在本文中稱為CDR的「構型定義」,該CDR的位置可辨識為對抗原結合做出焓貢獻的殘基。請參照如Makabe等人,Journal of Biological Chemistry, 283: 1 156-1166, 2008。尚有其他CDR邊界定義可能不嚴格遵循上述方法之一,但仍將與至少一部分的Kabat CDR重疊,儘管根據特定殘基或殘基組的預測或實驗結果,它們可能會縮短或延長,甚至整段CDR都不會顯著影響抗原結合。除非另有說明,如本文所用,CDR定義是根據Kabat CDR而來。
效應子功能: 如本文所用,術語「效應子功能」是指可歸因於本文所述的抗原結合劑的生物活性。抗體效應子功能的實例包括:C1q結合和補體依賴性細胞毒性;Fc受體結合性;抗體依賴性細胞介導的細胞毒性(ADCC);吞噬作用;細胞表面受體(例如,B細胞受體;和B細胞活化)的調降。「降低或最小化」抗體效應子功能是指其較野生型或未修飾的抗體降低至少50%(或者60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%)。抗體效應子功能的測定可由本領域一般技術人員容易地確定和測量。在一些實施例中,補體結合、補體依賴性細胞毒性和抗體依賴性細胞毒性的抗體效應子功能受到影響。在一些實施例中,效應子功能經由在恆定區中消除醣基化的突變而消除,例如「無效應子突變」。在一態樣中,該無效應子突變為CH2區域的N297A或DANA突變(D265A+N297A)。Shields等人,J. Biol. Chem. 276(9): 6591-6604 (2001)。此外,導致效應子功能降低或消除的額外突變包括:K322A和L234A/L235A(LALA)。或者,效應子功能可通過生產技術而降低或消除,例如在無醣基化作用的宿主細胞(例如大腸桿菌)中表現,或其中導致醣基化模式改變成在促進效應子功能方面無效或效果較差(如Shinkawa等人,J. Biol. Chem. 278 (5):3466-3473 (2003))。
抗體依賴性細胞介導之細胞毒性 或ADCC是指一種細胞毒性形式,其中分泌的Ig結合至某些細胞毒性細胞(例如,自然殺手(NK)細胞、中性顆粒細胞和巨噬細胞)上存在的Fc受體(FcR),使這些細胞毒性效應細胞能夠特異性地結合至攜帶抗原的標靶細胞,之後以細胞毒素殺死該標靶細胞。該抗體「武裝」該細胞毒性細胞,且為藉由這種機制殺死該標靶細胞所必需。介導ADCC的主要細胞為NK細胞,其僅表現FcγRIII,而單核細胞則表現FcγRI、FcγRII和FcγRIII。造血細胞上的Fc表現係摘錄於Ravetch和Kinet,Annu. Rev. Immunol. 9: 457-92 (1991)之第464頁的表3。為了評估感興趣的分子的ADCC活性,可進行體外ADCC測定法,例如美國專利號 5,500,362或5,821,337中所述。用於此種測定法的可使用效應細胞包括周邊血液單核細胞(PBMC)和自然殺手(NK)細胞。替代地或額外地,可在體內評估感興趣分子的ADCC活性,例如在動物模型中,例如在Clynes等人,PNAS USA 95: 652-656 (1998)中所揭示的動物模型。
抗原 :如本文所用,術語「抗原」是指引發免疫反應的試劑;及/或當暴露或投至生物體時,與T細胞受體(例如,當由MHC分子呈現時)或抗體(例如,由B細胞產生)結合的試劑。在一些實施例中,抗原在生物體中引發體液反應(例如,包括抗原特異性抗體的產生);替代地或額外地,在一些實施例中,抗原在生物體中引發細胞反應(例如,涉及其受體與該抗原特異性交互作用的T細胞)。本領域技術人員將理解,特定抗原可在標靶生物體(例如,小鼠、兔、靈長類動物、人類)之一或數個成員中,而非在該標靶生物體物種的所有成員中,引發免疫反應。在一些實施例中,抗原在標靶生物體物種的至少約25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的成員中引發免疫反應。在一些實施例中,抗原結合至抗體及/或T細胞受體,且可能會或可能不會在生物體中誘發特定生理反應。在一些實施例中,例如,抗原可在體外結合至抗體及/或T細胞受體,無論此作用是否在體內發生。在一些實施例中,抗原與特定體液或細胞免疫的產物反應,包括由異源性免疫原誘發者。在所揭示的組成物和方法的一些實施例中,GCC蛋白為抗原。
相關聯 :作為本文使用之術語,若其中一者與另一者之存在、程度及/或形式相關,則此二事件或者實體彼此「相關聯」。舉例而言,若特定實體(例如多肽)之存在、程度及/或形式與特定疾病、病症或者病況之發生率及/或易感性相關(例如在相關群體中),則該特定實體視為與該特定疾病、病症或者病況相關聯。在一些實施例中,若二或者更多個實體直接或者間接相互作用,以使得其彼此物理上接近且保持物理上接近,則其彼此物理上「相關聯」。在一些實施例中,彼此物理上相關聯之二或者更多個實體彼此共價連接;在一些實施例中,彼此物理上相關聯之二或者更多個實體彼此不共價連接,但以非共價形式相關聯,例如藉助於氫鍵、凡得瓦交互作用(van der Waals interaction)、疏水相互作用、磁性及其組合。
結合: 應當理解,本文所用的術語「結合」通常是指二或多個實體之間的非共價結合。「直接」結合涉及實體或部分之間的物理接觸;間接結合涉及藉由與一或多個中間實體進行物理接觸的物理交互作用。二或多個實體之間的結合可在多種情況中的任一者下進行評估- 包括相互作用的實體或部分在隔絕或在更複雜系統的情況下(例如,與載體實體及/或在生物系統或細胞中以共價或其他方式結合)。如本文所使用之「K
a」係指特定結合部分與標靶形成結合部分/標靶複合物之結合速率。如本文所使用之「K
d」係指特定結合部分/標靶複合物之解離速率。如本文所使用之「K
D」係指解離常數,其得自K
d比K
a之比率(亦即K
d/K
a),且以莫耳濃度(M)表示。K
D值可使用此項技藝中良好建立之方法(例如藉由使用表面等離子體共振)或者使用生物感測器系統(例如Biacore®系統)來測定。
載體 :如本文所用,術語「載體」係指與組成物一起投與之稀釋劑、佐劑、賦形劑或媒劑。在一些例示性實施例中,載體可包括無菌液體,諸如(例如)水及油,包括石油、動物、植物或合成來源之油,諸如(例如)花生油、大豆油、礦物油、芝麻油及類似物。在一些實施例中,載體為或包括一或多個固體成分。
特徵部分 :如本文中所用,術語「特徵部分」在最廣義而言係指稱某一物質之一部份的存在(或不存在)與特定特徵、屬性或活性之存在(或不存在)相關聯。在一些實施例中,一物質的特徵部分是在該物質和相關物質中發現具有共享特定特徵、屬性或活性的部分,而非不共享特定特徵、屬性或活性者。
密碼子最佳化 :如本文所用,「密碼子最佳化」的核酸序列是指已經改變,使得核酸序列的轉譯和所得蛋白質的表現,針對特定表現系統達增進之最佳化的核酸序列。「密碼子最佳化」的核酸序列係編碼與該「密碼子最佳化」核酸序列所基於的未最佳化親代序列相同的蛋白質。例如,一核酸序列可經「密碼子最佳化」,以在哺乳動物細胞(例如,CHO細胞、人類細胞、小鼠細胞等)、細菌細胞(例如,大腸桿菌)、昆蟲細胞、酵母細胞或植物細胞中表現。
可比較 :如本文所用,術語「可比較」是指二或多個試劑、實體、情況、條件組等,它們可能彼此不同但足夠相似,以允許在它們之間進行比較,因而可根據觀察到的差異或相似之處合理地得出結論。本領域普通技術人員將理解,在內文中,在任何特定情況下需要何種程度的一致性,才能將二或多個此類試劑、實體、情況、條件組等視為具有可比較性。
對應於 :如本文所用,術語「對應於」通常用於指定有興趣多肽的胺基酸殘基的位置/一致性。普通技術人員將理解,為簡要起見,多肽中的殘基通常使用基於參考相關多肽的規範編號系統來命名,如此,「對應於」位置190殘基之胺基酸,舉例而言,實際上不必是特定胺基酸鏈中的第190個胺基酸,而是對應於該參考多肽中第190個殘基;本領域普通技術人員容易理解如何鑑定「相對應」的胺基酸。
衍生自: 如本文所用,片語「衍生自」或「特異於指定序列」的序列是指包含大約至少6個核苷酸或至少2個胺基酸、至少約9個核苷酸或至少3個胺基酸、至少約10-12個核苷酸或4個胺基酸、或至少約15-21個核苷酸或5-7個胺基酸對應於,即,一致於或互補於例如指定序列的連續區域。在某些實施例中,該序列包含所有指定的核苷酸或胺基酸序列。如通過本領域中已知的技術確定,該序列可與特定序列獨特的序列區域互補(在聚核甘酸序列的情況下)或一致。可衍生序列的區域包括但不限於:編碼特異性表位的區域、編碼CDR的區域、編碼框架序列的區域、編碼恆定域區域的區域、編碼可變域區域的區域,以及非轉譯及/或非轉錄區域。該衍生序列不一定是從研究中的感興趣序列生理性衍生而來,而可以任何方式產生,包括但不限於化學合成、複製、逆轉錄或轉錄,其基於該聚核甘酸所衍生的區域中的鹼基序列提供的信息。因此,它可以代表該原始聚核甘酸的同義或反義方向。此外,對應於指定序列的區域組合可以本領域中已知的方式進行修飾或組合,以符合預期用途。例如,一序列可包含二或多個連續序列,每一者包含指定序列的一部分,且被與指定序列不同但用於代表衍生自該指定序列的序列的區域中斷。關於抗體分子,「衍生自」包括與比較抗體在功能或結構上相關的抗體分子,例如,「衍生自」包括具有相似或實質上相同的序列或結構,例如具有相同或類似的CDR、框架或可變區。抗體的「衍生自」亦包括殘基,例如一或多個,例如2、3、4、5、6個或更多個殘基,其可為連續或不連續,但根據編號流程,或與比較序列的一般抗體結構或三維鄰近性(即,在CDR或框架區內)的同源性,而定義出或辨識出。術語「衍生自」不限於生理性衍生,而是包括經由任何方式產生,例如藉由使用來自比較抗體的序列信息來設計另一抗體。
測定 :本文所述之許多方法學包括一「測定」步驟。閱讀本說明書的本領域普通技術人員將理解,此「測定」可利用本領域技術人員可獲得的多種技術之任一者,包括例如本文明確提及的特定技術進行。在一些實施例中,測定涉及生理樣本的操作。在一些實施例中,測定涉及對數據或信息的考量及/或操作,例如利用適於執行相關分析的電腦或其他處理單元。在一些實施例中,測定涉及從來源接收相關信息及/或材料。在一些實施例中,測定涉及將樣本或實體的一或多個特徵與可比較的參考物進行比較。
改造: 如本文所用,術語「經改造」描述已由人為設計或修飾及/或其存在和生產需要人為干預及/或動作的聚核甘酸、多肽或細胞。例如,旨在設計用於引發特定效果且與天然存在的相同類型細胞的效果不同的經改造細胞。在一些實施例中,經改造細胞表現本文所述的嵌合抗原受體。在詳細說明和實例部分中描述例示性改造方法。
表位 :如本文所用,術語「表位」包括被免疫球蛋白(例如,抗體或受體)結合成分全部或部分特異性辨識出的任一部分。在一些實施例中,表位由抗原中的複數個胺基酸組成。在一些實施例中,當抗原採用相關三維構型時,此類胺基酸殘基暴露於表面。在一些實施例中,當抗原採用此種構型時,胺基酸殘基在空間上彼此物理性接近或等高。在一些實施例中,當抗原採用替代構型(例如,直線化;例如,非直線形表位)時,至少一些胺基酸彼此呈物理上分隔。
賦形劑: 如本文所用,術語「賦形劑」是指可包括在醫藥組成物中的非治療劑,舉例而言,以提供或有助於所需的稠度或穩定作用。合適的藥物賦形劑包括例如澱粉、葡萄糖、乳糖、蔗糖、明膠、麥芽、米、麵粉、白堊、矽膠、硬脂酸鈉、單硬脂酸甘油酯、滑石、氯化鈉、脫脂奶粉、甘油、丙二醇、水、乙醇及類似物。
表現 :術語「表現」或「經表現」,當用於本文中的核酸時,是指以下事件中的一或多者:(1)DNA模板之RNA轉錄物產生(例如,藉由轉錄作用);(2)RNA轉錄物的加工(例如,藉由剪接、編輯、5'端帽形成及/或3'末端形成);(3)RNA轉譯成多肽;及/或(4)多肽的轉譯後修飾。
離體: 如本文所用,術語「離體」是指在外部環境中發生的事件,例如,在多細胞生物體外部。在一些實施例中,細胞或細胞群係於多細胞生物體(例如,哺乳動物,例如非人類靈長類動物或人類)的體外進行修飾,以表現本文所述的抗GCC分子,在將此類細胞或細胞群投與有需要的個體之前。
融合蛋白 :如本文所用,術語「融合蛋白」是指由編碼兩種不同(例如,異源性)蛋白質的至少一部分的核酸序列改造而得之核酸序列編碼的蛋白質。技術人員無疑知道,為了產生融合蛋白,係將核酸序列連接而使所得讀框不包含內部終止密碼子。在一些實施例中,如本文所述的融合蛋白包括一流感HA多肽或其片段。
鳥苷酸環化酶 C(GCC) : 如本文所用,「GCC」亦稱為「STAR」、「GUC2C」、「GUCY2C」或「ST受體」蛋白是指哺乳動物GCC,較佳為人類GCC蛋白。人類GCC是指GenBank登錄號:NM—004963中描述的蛋白質及其天然存在的等位基因蛋白質變異體。其他變異體為本領域中已知的。請參見,例如,登錄號 Ensp0000261170,Ensembl Database,European Bioinformatics Institute和Wellcome Trust Sanger Institute,美國專利申請號 20060035852;或GenBank登錄號:AAB 19934。通常,天然存在的等位基因變異體具有與SEQ ID NO: 41至少95%、97%或99%一致的胺基酸序列。該轉錄物編碼具有1073個胺基酸的蛋白質產物,並描述於GenBank登錄號:NM—004963。GCC蛋白的特徵為一種跨膜細胞表面受體蛋白,一般相信在維持腸液、電解質體內穩定和細胞增殖中扮演關鍵角色。
宿主 :術語「宿主」在本文中用於指其中存在感興趣多肽的系統(例如,細胞、生物體等)。在一些實施例中,宿主為表現感興趣之特定多肽的系統。
宿主細胞 :如本文所用,片語「宿主細胞」是指已引入外源性DNA(重組性或其他)的細胞。例如,宿主細胞可用於藉由標準重組技術產生本文所述的多肽。技術人員在閱讀本揭示內容後將理解,此類術語不僅指稱特定個體細胞,並指稱此一細胞的後代。由於某些修飾可能由於突變或環境影響而在後代中發生,因此,此後代實際上可能不與親代細胞完全一致,但仍包括在本文所用術語「
宿主細胞」的範圍內。在一些實施例中,宿主細胞包括適合於表現外源性DNA(例如,重組性核酸序列)的任何原核和真核細胞。例示性細胞包括原核生物和真核生物(單細胞或多細胞)、細菌細胞(例如大腸桿菌、芽孢桿菌屬、鏈黴菌屬等之菌株)、分枝桿菌細胞、真菌細胞、酵母細胞(例如,釀酒酵母(S. cerevisiae)、粟酒裂殖酵母(S. pombe)、巴斯德畢赤酵母(P. pastoris)、甲醇畢赤酵母(P. methanolica)等)、植物細胞、昆蟲細胞(例如,SF-9、SF-21、經桿狀病毒感染的昆蟲細胞、粉紋夜蛾(Trichoplusia ni)等)、非人類動物細胞、人類細胞或細胞融合體,例如雜交瘤或四重雜交瘤。在一些實施例中,該細胞為人類、猴、猿、倉鼠、大鼠或小鼠細胞。在一些實施例中,該細胞為真核細胞,並選自於以下細胞:CHO(例如,CHO K1、DXB-11 CHO、Veggie-CHO)、COS(例如,COS-7)、視網膜細胞、Vero、CV1、腎(例如HEK293、HEK293T、293 EBNA、MSR 293、MDCK、HaK、BHK)、HeLa、HepG2、WI38、MRC 5、Colo205、HB 8065、HL-60(例如BHK21)、Jurkat、Daudi、A431 (表皮)、CV-1、U937、3T3、L細胞、C127細胞、SP2/0、NS-0、MMT 060562、支持細胞、BRL 3A細胞、HT1080細胞、骨髓瘤細胞、腫瘤細胞和衍生自前述細胞之細胞株。在一些實施例中,該細胞包含一或多種病毒基因,例如表現病毒基因的視網膜細胞(例如PER.C6™細胞)。
免疫反應 :如本文所用,術語「免疫反應」是指免疫系統的細胞如B細胞、T細胞、樹突細胞、巨噬細胞或多形核細胞,對於刺激如抗原或疫苗之反應。免疫反應可包括參與宿主防禦反應的任何身體細胞,包括例如分泌干擾素或細胞因子的上皮細胞。免疫反應包括但不限於先天性及/或適應性免疫反應。如本文所用,保護性免疫反應是指保護個體不受感染(預防感染或防止與感染相關的疾病的發展)的免疫反應。測量免疫反應的方法為本領域中眾所周知的,包括例如測量淋巴細胞(例如B或T細胞)的增殖及/或活性、細胞因子或趨化因子的分泌、發炎、抗體產生、及類似反應。
體外 :如本文所用,術語「體外」是指在人為環境中發生的事件,例如在試管或反應容器中、在細胞培養物中等,而非在多細胞生物體內。
體內 :如本文所使用之術語「
活體內」係指事件發生在諸如人類與非人類動物之多細胞生物體內。在細胞-基礎系統的內文中,該術語可用於指稱在活細胞內發生的事件(與例如體外或離體系統相反)。
經分離: 如本文所用,術語「經分離的」是指物質及/或實體(1)與最初生產時(無論是在自然界及/或在實驗環境中)相結合的至少一些成分分離,及/或(2)在人為干預下設計、生產、製備及/或製造。經分離的物質及/或實體可與其最初結合的其他成分之約10%、約20%、約30%、約40%、約50%、約60%、約70%、約80%、約90%、約91%、約92%、約93%、約94%、約95%、約96%、約97%、約98%、約99%或超過約99%分離。在一些實施例中,經分離的試劑的純度為約80%、約85%、約90%、約91%、約92%、約93%、約94%、約95%、約96%、約97%、約98%、約99%,或超過約99%。如本文所用,如果該物質實質上不含其他成分,則該物質為「純的」。在一些實施例中,如本領域技術人員將理解的,該物質在與某些其他成分例如一或多種載體或賦形劑(例如,緩衝液、溶劑、水等)組合之後,仍可視為「經分離的」或甚至「純的」;在此類實施例中,計算該物質的經分離百分比或純度時不包括此類載體或賦形劑。僅作為一實例,在一些實施例中,在以下情況下,自然界中存在的諸如多肽或聚核甘酸的生物性聚合物被認為是「經分離的」,當:a)由於其起源或衍生來源不與某些或所有在自然狀態下伴隨它的成分結合;b)它實質上不含來自於自然界產生它的物種之相同物種的其他多肽或核酸;c)由非來自於自然界產生它的物種之細胞或其他系統表現,或與該細胞中的成分結合。因此,例如,在一些實施例中,化學合成的或在不同於天然產生它的細胞系統中合成的多肽被認為是「經分離的」多肽。替代地或額外地,在一些實施例中,已進行一或多種純化技術的多肽可被認為是「經分離的」多肽,因為它已與以下的其他成分分離:a)在天然狀態下與其結合者;及/或b)最初生產時與之結合者。在一些實施例中,細胞可與其他細胞「分離」(例如,純化或分離)。例如,在一些實施例中,可從未修飾的細胞中分離出經改造以表現本文所述的CAR之經基因修飾細胞。
核酸 :如本文所用,片語「核酸」,就最廣義而言,係指其為寡核苷酸鏈或可加入寡核苷酸鏈中的任何化合物及/或物質。在一些實施例中,核酸為寡核苷酸鏈或可經由磷酸二酯連結加入寡核苷酸鏈中的化合物及/或物質。從內文可清楚地看出,在一些實施例中,「核酸」是指各核酸殘基(例如,核苷酸及/或核苷);在一些實施例中,「核酸」是指包含各核酸殘基的寡核苷酸鏈。在一些實施例中,「核酸」為或包含RNA;在一些實施例中,「核酸」為或包含DNA。在一些實施例中,核酸為、包含或由一或多個天然核酸殘基組成。在一些實施例中,核酸為、包含或由一或多種核酸類似物組成。在一些實施例中,核酸類似物與核酸的不同之處在於它不利用磷酸二酯骨架。例如,在一些實施例中,核酸為、包含或由一或多種本領域中已知在主鏈中具有肽鍵而非磷酸二酯鍵的「肽核酸」組成,視為落入本發明範疇中。替代地或額外地,在一些實施例中,核酸具有一或多個硫代磷酸酯及/或5'-N-亞磷醯胺連結而非磷酸二酯鍵。在一些實施例中,核酸為、包含或由一或多種天然核苷(例如,腺苷、胸苷、鳥苷、胞苷、尿苷、去氧腺苷、去氧胸苷、去氧鳥苷和去氧胞苷)組成。在一些實施例中,核酸為、包含或由一或多種核苷類似物(例如,2-胺基腺苷、2-硫胸苷、肌苷、吡咯併-嘧啶、3-甲基腺苷、5-甲基胞苷、C-5丙炔基-胞苷、C-5 丙炔基-尿苷、2-胺基腺苷、C5-溴尿苷、C5-氟尿苷、C5-碘尿苷、C5-丙炔基-尿苷、C5-丙炔基-胞苷、C5-甲基胞苷、2-胺基腺苷、7-去氮腺苷、7-去氮鳥苷、8-氧代腺苷、8-氧代鳥苷、O(6)-甲基鳥嘌呤、2-硫胞苷、甲基化鹼基、嵌入鹼基及其組合)。在一些實施例中,與天然核酸相較,核酸包含一或多種經修飾的醣類(例如,2'-氟核醣、核醣、2'-去氧核醣、阿拉伯醣和己醣)。在一些實施例中,核酸具有編碼功能基因產物例如RNA或蛋白質的核苷酸序列。在一些實施例中,核酸包括一或多個內含子。在一些實施例中,核酸由自天然來源分離、以互補模板為基礎進行聚合之酵素合成(體內或體外)、在重組細胞或系統中繁殖、及化學合成之一或多者製備。在一些實施例中,核酸為至少3、4、5、6、7、8、9、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190、20、225、250、275、300、325、350、375、400、425、450、475、500、600、700、800、900、1000、1500、2000、2500、3000、3500、4000、4500、5000或更多殘基長度。在一些實施例中,核酸為單股;在一些實施例中,核酸為雙股。在一些實施例中,核酸具有一核苷酸序列,其包含至少一編碼一多肽的元件,或為編碼一多肽之序列的互補物。在一些實施例中,核酸具有酵素活性。
醫藥學上可接受的載體 :可用於本揭示的醫藥學上可接受的載體(媒劑)為常規性的。Remington's Pharmaceutical Sciences,E. W. Martin, Mack出版公司發行,Easton, PA, 第15版(1975)中,描述適用於一或多種治療組成物的藥物遞送的組成物和配方(例如,包含本文所述的嵌合性抗原受體的組成物),以及額外醫藥試劑。一般而言,載體的性質將取決於所採用的特定投藥模式。例如,腸胃外配方通常包含可注射流體,其包括醫藥學上和生理學上可接受的流體,例如水、生理食鹽水、平衡鹽類溶液、右旋糖水溶液、甘油或類似物作為媒劑。對於固體組成物而言(例如,粉末、藥片、錠劑或膠囊形式),傳統的無毒固體載體可包括例如醫藥級的甘露醇、乳糖、澱粉或硬脂酸鎂。除了生物中性載體之外,待投與的醫藥組成物可包含少量無毒性輔助物質,例如潤濕劑或乳化劑、防腐劑和pH緩衝劑及類似物,例如乙酸鈉或單月桂酸脫水山梨醣酯。
多肽 :「多肽」,一般而言,為藉由一肽鍵彼此連接的至少兩個胺基酸的串聯。在一些實施例中,多肽可包括至少3至5個胺基酸,每一胺基酸藉由至少一個肽鍵連接到其他胺基酸。本領域普通技術人員將理解,多肽有時包括「非天然」胺基酸或其他實體,儘管如此,它們仍能夠視情況整合到多肽鏈中。在一些實施例中,術語「多肽」用於指多肽的特定功能類別,例如抗體、嵌合性抗原受體或共刺激域多肽等。對於每一此種類別,本說明書提供及/或本領域已知該類別內已知例示性多肽的胺基酸序列的數個實例;在一些實施例中,一或多種此類已知多肽為該類別的參考多肽。在此類實施例中,術語「多肽」是指顯示出與相關參考多肽足夠的序列同源性或一致性的類別的任一成員,本領域技術人員將理解該參考多肽應包括在該類別中。在許多實施例中,代表性類別之成員亦與該參考多肽共享顯著的活性。例如,在一些實施例中,一成員多肽顯示出與參考多肽至少約30-40%的整體序列同源性或一致性,且通常大於約50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多,及/或包括至少一區域(即保守區域,通常包括特徵序序列元素)顯示出非常高的序列一致性,通常大於90%,甚至95%、96%、97%、98%或99%。此類保守區通常包含至少3-4個,且經常多達20個或更多個胺基酸;在一些實施例中,保守區包含至少一段至少2、3、4、5、6、7、8、9、10、11、12、13、14、15或更多個連續胺基酸。
應理解,本發明的抗體和抗原結合劑可具有額外的保守或非必需胺基酸取代,其對多肽功能沒有實質性影響。該特定取代是否可被容忍,即不會不利地影響所需的生物學特性(例如結合活性),可如Bowie, J U等人,Science 247:1306-1310 (1990)或Padlan等人,FASEB J. 9:133-139 (1995)中所述決定。「保守性胺基酸取代」是其中胺基酸殘基被具有類似側鏈的胺基酸殘基置換的取代。具有類似側鏈的胺基酸殘基家族已在本領域中定義出。這些家族包括具有鹼性側鏈(例如離胺酸、精胺酸、組胺酸)、酸性側鏈(例如天門冬胺酸、麩胺酸)、不帶電荷的極性側鏈(例如天冬醯胺、麩胺醯胺、絲胺酸、蘇胺酸、酪胺酸、半胱胺酸)、非極性側鏈(例如甘胺酸、丙胺酸、纈胺酸、亮胺酸、異亮胺酸、脯胺酸、苯丙胺酸、甲硫胺酸、色胺酸)、β-支鏈側鏈(例如蘇胺酸、纈胺酸、異亮胺酸)和芳香側鏈(例如酪胺酸、苯丙胺酸、色胺酸、組胺酸)的胺基酸。
預防 : 如本文所用,術語「預防」是指預防、避免疾病表現、延遲發作及/或降低特定疾病、病症或病況(例如,感染如流感病毒)的一或多種症狀的頻率及/或嚴重性。在一些實施例中,預防係以群體為基礎評估,若在對該疾病、病症或病況易感的人群中觀察到該疾病、病症或病症的一或多種症狀的發展、頻率及/或強度在統計學上顯著降低,則認為該試劑「預防」該特定疾病、病症或病況。
純的 :如本文所用,如果試劑或實體實質上不含其他成分,則其為「純的」。例如,包含超過約90%的特定試劑或實體的製劑通常被認為是純製劑。在一些實施例中,試劑或實體為至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、或至少為99%的純度。
重組 :如本文所用,術語「重組」係指藉由重組方式設計、改造、製備、表現、創造或分離出的多肽(例如,如本文所述的多肽),例如使用重組表現載體轉染宿主細胞而表現之多肽、由重組、組合式多肽庫中分離出的多肽、或藉由涉及將選定序列元件剪接成另一者之任何其他方式製備、表現、創造或分離出的多肽。在一些實施例中,一或多種此類的選定序列元件是在自然界中發現的。在一些實施例中,一或多種此類的選定序列元件及/或其組合是經電腦設計。在一些實施例中,一或多種此類的選定序列元件由多個(例如,二或多個)已知序列元件的組合產生,這些已知序列元件並非天然存在於同一多肽中(例如,來自兩個單獨HA多肽的兩個表位)。
參考物 :術語「參考物」在本文中經常用於描述標準或對照試劑、個體、群體、樣本、序列或數值,與感興趣的試劑、個體、群體、樣本、序列或數值進行比較。在一些實施例中,參考試劑、個體、群體、樣本、序列或數值之測試或測定,實質上同時與感興趣的試劑、個體、群體、樣本、序列或數值進行測試及/或測定。在一些實施例中,參考試劑、個體、群體、樣本、序列或數值是經驗參考物,視情況在有形媒介中具體化。通常,如本領域技術人員將理解的,參考試劑、個體、群體、樣本、序列或數值,係用於在可比較的條件下測定或鑑定有興趣的試劑、個體、群體、樣本、序列或數值。
單域抗體: 如本文所用,術語「單域抗體(sdAb)」、「可變單域」或「免疫球蛋白單可變域(ISV)」、「單重鏈可變域(VH)抗體」是指與標靶抗原結合之抗體之單一可變片段。這些術語在本文中可互換使用。sdAb為具有三個互補決定區(CDR)的單一抗原結合多肽。僅具sdAb便能夠結合抗原,而不須與相對應的含CDR多肽成對。VH單域抗體是指具有一人類重鏈可變域或一衍生自人類重鏈可變域的結構域之單域抗體。在一些情況下,單域抗體由駱駝源化HCAbs改造而成,而其重鏈可變域被稱為「VHH」。某些VHH亦可稱為奈米抗體。駱駝源化sdAb是最小的已知抗原結合抗體片段之一(請參見,例如Hamers-Casterman等人,Nature 363: 446-8 (1993);Greenberg等人,Nature 374: 168-73 (1995);Hassanzadeh-Ghassabeh等人,Nanomedicine (Lond), 8:1013-26 (2013))。基本VHH從N端到C端具有以下結構:FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4,其中FR1至FR4係分別指框架區1至4,其中CDR1至CDR3係指互補決定區1至3。如下文所解釋,本發明各態樣的一些實施例相關於一種結合試劑,其包含單一重鏈可變域抗體/免疫球蛋白重鏈單一可變域,其可在輕鏈不存在的情況下,與GCC抗原結合。
個體 :如本文所用,術語「個體」是指任何哺乳動物,包括人類。在本發明的某些實施例中,個體為成人、青少年或嬰兒。在一些實施例中,術語「個人」或「患者」被使用且可與「個體」互換。本發明亦涵蓋醫藥組成物的投與及/或子宮內治療方法的進行。例如,個體可為患有癌症(例如胃腸來源)、癌症症狀的患者(例如人類患者或動物患者),其中至少一些細胞表現GCC,或有癌症傾向的患者,其中至少一些細胞表現GCC。本發明的術語「非人類動物」包括所有非人類脊椎動物,例如非人類哺乳動物和非哺乳動物,例如非人類靈長類動物、綿羊、狗、牛、雞、兩棲動物、爬行動物等,除非另有說明。
實質上 :如本文所用,術語「實質上」是指具有感興趣的特徵或特性的全部或接近全部範圍或程度的定性條件。生物學領域的普通技術人員將理解,生物和化學現象很少(若有的話)完成及/或繼續完成或達到或避免一絕對的結果。因此,術語「實質上」在本文中用於包羅許多生物及化學現象中固有之潛在缺乏的完全性。
治療劑: 如本文所用,術語「治療試劑」是指具有生物活性的試劑(例如,抗原結合劑)。該術語在本文中用於指稱化合物、化合物的混合物、生物大分子或由生物材料製成的萃取物。在一些實施例中,該治療劑可為抗癌劑或化學治療劑。如本文所用,術語「抗癌劑」或「化療劑」是指具有抑制人類腫瘤,特別是惡性(癌性)病變,例如癌、肉瘤、淋巴瘤或白血病的發展或進展的功能特性的試劑。抑制轉移或血管生成通常是抗癌劑或化學治療劑的特性。化學治療劑可為細胞毒性劑或細胞抑制劑。術語「細胞抑制劑」是指抑制或壓抑細胞生長及/或細胞增殖的試劑。在一些實施例中,該治療劑為經基因修飾的細胞或抗體。在一些實施例中,該治療劑為抗GCC CAR。在一些實施例中,該治療劑為表現本文所述的GCC CAR的細胞(例如,細胞群)。
轉型 :如本文所用,係指將外源性DNA引入宿主細胞的任一過程。可使用本領域中眾所周知的各種方法在自然或人工條件下進行轉型。轉型可依賴於將外源核酸序列插入原核或真核宿主細胞中的任何已知方法。在一些實施例中,係基於被轉型的宿主細胞而選擇特定的轉型方法學,且可包括但不限於:病毒感染、電穿孔、交配、轉染、脂質轉染。在一些實施例中,「
經轉型的」細胞被穩定轉型,因為插入的DNA能夠作為自主複製質體或作為宿主染色體的一部分而進行複製。在一些實施例中,經轉型的細胞在有限的時間段內暫時表現引入的核酸。
治療或治療 :如本文所用,術語「治療(treat)」或「治療(treatment)」係定義為將抗GCC抗原結合劑((如抗GCC抗體或其片段、抗GCC CAR、包含抗GCC CAR之細胞等)投至一個體,例如患者,或投至(例如藉由施加)從個體分離出的組織或細胞中,之後送回該個體中。該抗GCC抗原結合劑可單獨投藥或與第二試劑組合投藥。治療可為治癒、療癒、緩解、減輕、改變、補救、改善、緩和、增進或影響該病症、該病症的症狀或該病症的傾向,例如癌症。儘管不希望受理論束縛,但一般相信治療可在體外或體內引起細胞的抑制、消融或殺傷,或以其他方式降低細胞(例如異常細胞)介導疾病,如本文所述的病症(例如,癌症)的能力。
可變區或域: :如本文所用,術語抗體的「可變區」或「可變域」是指抗體重鏈或輕鏈的胺基端域。重鏈和輕鏈的可變域可分別稱為「VH」和「VL」。這些域通常是抗體中變化最大的部分(相對於同一類別的其他抗體)並包含抗原結合位點。僅具重鏈的抗體具有單一重鏈可變區。
載體 :如本文所用,術語「載體」是指能夠傳送與其連接的另一核酸的核酸分子。其中一種載體類型為「質體」,其係指環狀雙股DNA環,其中可接合額外的DNA片段。另一種載體類型為病毒載體,其中額外的DNA片段可接合至該病毒基因組中。某些載體能夠在它們被引入的宿主細胞中自主複製(例如,具有細菌複製起點的細菌載體和附加型哺乳動物載體)。其他載體(例如,非附加型哺乳動物載體)可在引入宿主細胞後整合至宿主細胞的基因組中,因而與宿主基因組一起複製。此外,某些載體能夠主導與其操作性連接的基因之表現。此類載體在本文中稱為「表現載體」。
特定實施例之詳細描述
本發明係基於發現特異性結合至鳥苷酸環化酶C (GCC)之新穎抗原結合劑及其在治療方法中之用途。本發明提供抗GCC單域抗體(sdAb)及嵌合抗原受體(CAR),其包含一細胞外抗原結合域,該細胞外抗原結合域包含一或多個GCC結合部分(如抗GCC sdAbs)。
本發明不限於本文所述之特定方法或實驗條件,因為此方法或實驗條件可變化。亦應理解,本文中所用之術語僅用於描述特定實施例之目的,且非用於限制,除非指明,因為本發明之範疇將僅受所附申請專利範圍限制。
鳥苷酸環化酶 C
鳥苷酸環化酶C(GCC)(亦稱為STAR、ST受體、GUC2C和GUCY2C)為一種跨膜細胞表面受體,其在維持腸液、電解質穩態和細胞增殖中發揮作用(Carrithers等人,
Proc Natl Acad Sci USA100: 3018-3020 (2003);Mann等人,
Biochem Biophys Res Commun239: 463-466 (1997);Pitari等人,
Proc Natl Acad Sci USA100: 2695-2699 (2003));GenBank登錄號NM
—004963,其每一者係以引用之方式併入本文中)。此功能是經由鳥苷酸的結合而介導(Wiegand等人,FEBS Lett. 311:150-154 (1992))。GCC亦為熱穩定腸毒素(ST,例如,具有NTFYCCELCCNPACAGCY、SEQ ID NO: 40的胺基酸序列)的受體,它是由大腸桿菌以及其他感染性生物體產生的胜肽(Rao, M. C.
Ciba Found. Symp.112:74-93 (1985); Knoop F. C.及Owens、M. J.
Pharmacol. Toxicol. Methods28:67-72 (1992))。ST與GCC的結合活化導致腸道疾病(例如腹瀉)的信號級聯反應。人類GCC的核苷酸序列(GenBank登錄號NM—004963)。人類GCC之胺基酸序列(GenPept登錄號NP—004954):
MKTLLLDLALWSLLFQPGWLSFSSQVSQNCHNGSYEISVLMMGNSAFAEPLKNLEDAVNEGLEIVRGRLQNAGLNVTVNATFMYSDGLIHNSGDCRSSTCEGLDLLRKISNAQRMGCVLIGPSCTYSTFQMYLDTELSYPMISAGSFGLSCDYKETLTRLMSPARKLMYFLVNFWKTNDLPFKTYSWSTSYVYKNGTETEDCFWYLNALEASVSYFSHELGFKVVLRQDKEFQDILMDHNRKSNVIIMCGGPEFLYKLKGDRAVAEDIVIILVDLFNDQYFEDNVTAPDYMKNVLVLTLSPGNSLLNSSFSRNLSPTKRDFALAYLNGILLFGHMLKIFLENGENITTPKFAHAFRNLTFEGYDGPVTLDDWGDVDSTMVLLYTSVDTKKYKVLLTYDTHVNKTYPVDMSPTFTWKNSKLPNDITGRGPQILMIAVFTLTGAVVLLLLVALLMLRKYRKDYELRQKKWSHIPPENIFPLETNETNHVSLKIDDDKRRDTIQRLRQCKYDKKRVILKDLKHNDGNFTEKQKIELNKLLQIDYYNLTKFYGTVKLDTMIFGVIEYCERGSLREVLNDTISYPDGTFMDWEFKISVLYDIAKGMSYLHSSKTEVHGRLKSTNCVVDSRMVVKITDFGCNSILPPKKDLWTAPEHLRQANISQKGDVYSYGIIAQEIILRKETFYTLSCRDRNEKIFRVENSNGMKPFRPDLFLETAEEKELEVYLLVKNCWEEDPEKRPDFKKIETTLAKIFGLFHDQKNESYMDTLIRRLQLYSRNLEHLVEERTQLYKAERDRADRLNFMLLPRLVVKSLKEKGFVEPELYEEVTIYFSDIVGFTTICKYSTPMEVVDMLNDIYKSFDHIVDHHDVYKVETIGDAYMVASGLPKRNGNRHAIDIAKMALEILSFMGTFELEHLPGLPIWIRIGVHSGPCAAGVVGIKMPRYCLFGDTVNTASRMESTGLPLRIHVSGSTIAILKRTECQFLYEVRGETYLKGRGNETTYWLTGMKDQKFNLPTPPTVENQQRLQAEFSDMIANSLQKRQAAGIRSQKPRRVASYKKGTLEYLQLNTTDKESTYF (SEQ ID NO: 41)
GCC蛋白具有一些一般可接受的結構域,每個域都有助於GCC分子的功能。GCC的功能包括將蛋白質引導至細胞表面的信號、細胞外配體之結合、酪胺酸激酶活性和鳥苷酸環化酶催化活性。在正常人體組織中,GCC係於黏膜細胞中表現,例如在小腸、大腸和直腸內襯的頂端刷狀緣膜(Carrithers等人,
Dis Colon Rectum39: 171-181 (1996))。GCC的表現在腸上皮細胞發生腫瘤轉型後仍維持,其在所有原發性和轉移性大腸直腸腫瘤中表現(Carrithers等人,
Dis Colon Rectum39: 171-181 (1996); Buc等人,Eur J
Cancer41: 1618-1627 (2005); Carrithers等人,
Gastroenterology107: 1653-1661 (1994))。來自胃、食道和胃食道交界處的腫瘤細胞亦表現GCC(請參見例如美國專利號6,767,704;Debruyne等人,
Gastroenterology130:1191-1206 (2006))。組織特異性表現以及與癌症(例如胃腸來源的癌症(例如大腸癌、胃癌或食道癌))的關聯,可用於開發使用GCC作為該疾病的診斷標誌物(Carrithers等人,
Dis Colon Rectum39: 171-181 (1996); Buc等人,
Eur J Cancer41: 1618-1627 (2005))。
作為細胞表面蛋白,GCC亦可作為受體結合蛋白例如抗體或配體的治療標靶。在正常腸組織中,GCC在上皮細胞緊密連接的頂端表現,該緊密連接在腔內環境和血管隔室之間形成不可滲透的屏障(Almenoff等人,
Mol Microbiol8: 865-873); Guarino等人,
Dig Dis Sci32: 1017-1026 (1987))。因此,全身靜脈內投與GCC結合蛋白治療劑對腸道GCC受體的影響最小,同時可接觸胃腸系統的腫瘤細胞,包括侵襲性或轉移性大腸癌細胞、腸外或轉移性大腸腫瘤、食道腫瘤或胃腫瘤、胃食道交界處的腺癌。此外,GCC會由於配體結合而經由受體介導的內吞作用而內化(Buc等人,
Eur J Cancer41: 1618-1627 (2005); Urbanski等人,
Biochem Biophys Acta1245: 29-36 (1995))。
針對GCC的細胞外域產生的多株抗體(Nandi等人,
Protein Expr. Purif.8:151-159 (1996))能夠抑制ST胜肽結合至人類和大鼠GCC,且抑制人類GCC造成的ST-介導cGMP產生。
GCC已被鑑定為一種涉及癌症(包括大腸癌)的蛋白質。亦請參見Carrithers等人,
Dis Colon Rectum39: 171-181 (1996); Buc等人,
Eur J Cancer41: 1618-1627 (2005); Carrithers等人,
Gastroenterology107: 1653-1661 (1994); Urbanski等人,
Biochem Biophys Acta1245: 29-36 (1995)。
本文描述的針對GCC的抗原結合分子治療劑可用於抑制表現GCC的癌細胞。本發明的抗GCC抗原結合分子可結合至人類GCC。在一些實施例中,本發明的抗GCC抗原結合分子可抑制配體(例如鳥苷酸或熱穩定腸毒素)與GCC的結合。
抗原結合分子
本發明涉及抗GCC抗原結合分子。在一些實施例中,本發明的抗GCC分子在其結合之表現GCC的細胞上與GCC結合後引起細胞反應。在一些實施例中,本發明的抗GCC抗原結合劑可阻斷配體結合至GCC。
天然發生的哺乳動物抗體的典型結構單元為四聚體。每個四聚體由兩對多肽鏈組成,每對具有一條「輕」鏈(約25 kDa)和一條「重」鏈(約50-70 kDa)。每條鏈的胺基端部分包括主要負責抗原識別的約100至110個或更多個胺基酸的可變區。每條鏈的羧基端部分定義出主要負責效應子功能的恆定區。人類輕鏈可分為κ和λ輕鏈。重鏈可分為μ、δ、γ、α或ε,並將抗體的同種型分別定義為IgM、IgD、IgG、IgA和IgE。在輕鏈和重鏈內,可變區和恆定區由一具約12個或更多胺基酸的「J」區連接,其中重鏈亦包括一具約10個以上的胺基酸的「D」區。一般請參見
Fundamental ImmunologyCh. 7 (Paul, W.編,二編,Raven Press, N.Y. (1989))。每一輕/重鏈對的可變區形成抗體結合位點。抗GCC抗體分子的較佳同種型為IgG免疫球蛋白,其可分為四種亞型,IgG1、IgG2、IgG3和IgG4,各具有不同的γ重鏈。大多數治療性抗體為IgG1類型的人類、嵌合性或人源化抗體。在一特定實施例中,該抗GCC抗體分子具有IgG1同種型。
每一重鏈和輕鏈對的可變區形成抗原結合位點。因此,完整的IgG抗體具有兩個相同的結合位點。然而,雙功能或雙特異性抗體為人工雜交構建體,其具有兩個不同的重/輕鏈對,導致兩個不同的結合位點。
這些鏈都具有由三個高度變異區(亦稱為互補決定區或CDR)連接的相對保守框架區(FR)的相同一般結構。來自每對兩條鏈的CDR藉由框架區對齊,而能夠與特異性表位結合。從N端到C端,輕鏈和重鏈均包含域FR1、CDR1、FR2、CDR2、FR3、CDR3和FR4。每一結構域的胺基酸係依據下列文獻之定義指定:Kabat Sequences of Proteins of Immunological Interest (National Institutes of Health, Bethesda, Md. (1987及1991))或Chothia & Lesk
J. Mol. Biol.196:901-917 (1987); Chothia等人,
Nature342:878-883 (1989)。如本文所用,CDR係依據Kabat針對重鏈(HCDR1、HCDR2、HCDR3)和輕鏈(LCDR1、LCDR2、LCDR3)之每一者之規則而指稱。
抗GCC抗體分子可包含本文所述抗體的全部、或CDR或重鏈的抗原結合子集。本文描述的抗GCC抗原結合劑的胺基酸序列,包括可變區和CDR,可見於表1至3。
因此,在一實施例中,該抗體分子包括以下之一或二者:
(a)一、二、三個或抗原結合數目之人類抗體之輕鏈CDR (LCDR1、LCDR2及/或LCDR3),例如衍生自人類雜交瘤的抗體或鼠類抗體者(例如,US20180355062A1中描述的GCC抗體的輕鏈,其以全文引用之方式併入本文中)。在實施例中,該CDR可包含如下的LCDR1至3之一或多個或全部的胺基酸序列:LCDR1或經修飾的LCDR1,其中一到七個胺基酸經保守性取代;LCDR2或經修飾的LCDR2,其中一或兩個胺基酸經保守性取代;或LCDR3或經修飾的LCDR3,其中一或兩個胺基酸經保守性取代;以及
(b)一、二、三個或抗原結合數目之重鏈CDR (HCDR1、HCDR2及/或HCDR3),如本文所述。在實施例中,CDR可包含如下的HCDR1至3中的一或多個或全部的胺基酸序列:HCDR1或經修飾的HCDR1,其中一或兩個胺基酸經保守性取代;HCDR2或經修飾的HCDR2,其中一至四個胺基酸經保守性取代;或HCDR3或經修飾的HCDR3,其中一或兩個胺基酸經保守性取代。
在一些實施例中,本發明的抗GCC抗體分子可使表現GCC的細胞(例如腫瘤細胞)產生抗體依賴性細胞毒性(ADCC)。由於其具有結合至Fc受體的能力,具有IgG1和IgG3同種型的抗體可用於引發抗體依賴性細胞毒性能力之效應子功能。具有IgG2和IgG4同種型的抗體可用於使ADCC反應最小化,因為它們結合至Fc受體的能力低。在相關實施例中,可進行抗體的Fc區取代或醣基化組成的變化,例如藉由在經修飾的真核細胞株中生長,以增強Fc受體辨識、結合及/或介導抗GCC抗體所結合之細胞的細胞毒性(請參見,例如,美國專利號7,317,091、5,624,821、和文獻包括WO 00/42072、Shields等人,
J. Biol. Chem.276:6591-6604 (2001)、Lazar等人,
Proc. Natl. Acad. Sci. U.S.A.103:4005-4010 (2006),Satoh等人,
Expert Opin Biol. Ther.6:1161-1173 (2006))。在某些實施例中,抗體或抗原結合片段(例如,人源化抗體、人類抗體)可包括改變或裁剪功能(例如,效應子功能)的胺基酸取代或置換。例如,人類來源恆定區(例如,γ1恆定區、γ2恆定區)可設計為降低補體活化及/或Fc受體結合。(請參見,例如,美國專利第5,648,260號(Winter等人)、美國專利第5,624,821號(Winter等人)和美國專利第5,834,597號(Tso等人),其全部教示係以全文引用之方式併入本文中)。較佳地,包含此類胺基酸取代或置換的人類來源恆定區胺基酸序列,與人類來源之未經改變恆定區胺基酸序列在全長上至少約95%一致,更佳地,與人類來源之未經改變恆定區胺基酸序列在全長上至少約99%一致。額外的抗GCC抗原結合分子進一步描述於美國專利號 8,785,600 (Nam等人),其全部教示係以引用之方式併入本文中。
在又一實施例中,效應子功能亦可藉由調節抗體的醣基化模式來改變。改變是指刪除抗體中發現的一或多個醣類部分,及/或加入一或多個抗體中不存在的醣基化位點。例如,在美國專利申請公開號2003/0157108 (Presta)中描述具有增強的ADCC活性和成熟的醣類結構的抗體,該結構缺乏連接到抗體Fc區的岩藻醣。亦請參見美國專利申請公開號2004/0093621 (Kyowa Hakko Kogyo股份有限公司)。Glycofi亦開發出能夠產生抗體特異性醣型的酵母細胞株。
額外地或替代地,可製備具有醣基類型改變的抗體,例如具有降低量的岩藻醣基殘基的低岩藻醣基化抗體、或具有增加的等分GlcNac結構的抗體。此種改變的醣基化模式已被證明可增加抗體的ADCC能力。此類醣類修飾可藉由例如在具有經改變的醣基化機制的宿主細胞中表現該抗體而達成。本領域已描述具有改變的醣基化機制的細胞,且可使用作為宿主細胞,其中經改造以表現本發明的重組抗體,因而產生具有改變的醣基化的抗體。例如,EP 1,176,195 (Hang等人)中描述具有功能被破壞的FUT8基因的細胞株,該基因編碼岩藻醣基轉移酶,使得在此類細胞株中表現的抗體展現低岩藻醣基化。PCT公開號WO 03/035835 (Presta)描述一種變異性CHO細胞株--Lec13細胞,其將岩藻醣連接至Asn(297)-連接醣類上的能力降低,亦導致在該宿主細胞中表現的抗體呈現低岩藻醣基化(亦請見Shields, R. L.等人,2002
J. Biol. Chem.277:26733-26740)。PCT公開號WO 99/54342 (Umana等人)描述經改造以表現醣蛋白修飾醣基轉移酶(例如,β(1,4)-N 乙醯胺基葡萄醣基轉移酶III (GnTIII))的細胞株,使得在該經改造細胞株中表現的抗體表現出增加的等分GlcNac結構,這導致抗體的ADCC活性增加(亦請參見Umana等人,1999
Nat. Biotech.17:176-180)。
人源化抗體亦可使用CDR-嫁接方法製備。產生此類人源化抗體的技術為本領域中已知的。通常,人源化抗體是藉由獲得編碼與GCC結合的抗體之可變重鏈和可變輕鏈序列的核酸序列、辨識該可變重鏈和可變輕鏈序列中的互補決定區或「CDR」,並將該CDR核酸嫁接至人類框架核酸序列上而產生。(請參見,例如,美國專利號4,816,567和5,225,539)。CDR和框架殘基的位置可確定(請參見Kabat, E. A.等人(1991)
Sequences of Proteins of Immunological Interest,第5版,美國衛生及公共服務部,NIH出版編號91-3242,以及Chothia, C.等人,
J. Mol. Biol.196:901-917 (1987))。
本文所述的抗GCC抗體分子具有表5和6列出的CDR胺基酸序列和編碼各CDR的核酸序列。在一些實施例中,可將表5和6的序列加入可識別GCC的分子中,以用於本文描述的治療或診斷方法中。選出的人類框架為一種適合體內投藥的框架,這意味著它不具有免疫原性。例如,此種決定可經由此類抗體的體內使用和胺基酸相似性研究的先前經驗而進行。合適的框架區可選自於人類來源抗體,其在與供體抗體如抗GCC抗體分子(例如3G1)的等效部分(例如框架區)的胺基酸序列內的框架區長度上,具有至少約65%胺基酸序列一致性,較佳至少約70%、80%、90%或95%胺基酸序列一致性。可使用合適的胺基酸序列比對演算法,例如CLUSTAL W,使用預設參數來決定胺基酸序列一致性。(Thompson J. D.等人,
Nucleic Acids Res.22:4673-4680 (1994))。
一旦辨識出待人源化的複製抗體之CDR和FR,便可辨識出編碼該CDR的胺基酸序列,並將相對應的核酸序列嫁接到選定的人類FR上。此可使用已知的引子和連接子來完成,其選擇為本領域中已知的。特定人類抗體的所有CDR可被非人類CDR的至少一部分替換,或者僅部分CDR可被非人類CDR替換。僅需要替換該人源化抗體與預定抗原結合所需的CDR數量。在CDR嫁接至選定的人類FR上後,所得的「人源化」可變重鏈和可變輕鏈序列係經表現,以產生與GCC結合的人源化Fv或人源化抗體。較佳地,經CDR-嫁接的(例如,人源化的)抗體係以與供體抗體的親和力相似、實質上相同或更好的親和力與GCC蛋白結合。通常,該人源化可變重鏈和輕鏈序列係表現為具有人類恆定域序列的融合蛋白,因此獲得與GCC結合的完整抗體。然而,可產生不包含該恆定序列的人源化Fv抗體。
人源化抗體,其中特定胺基酸已經取代、刪去或加入,亦落於本發明範圍內。特別地,人源化抗體可在框架區具有胺基酸取代,例如以增進與抗原的結合。例如,經選定、小數目的人源化免疫球蛋白鏈的接受者框架殘基,可被相對應的供體胺基酸置換。取代的位置包括與CDR相鄰的胺基酸殘基,或能夠與CDR相互作用的胺基酸殘基(請參見例如美國專利號5,585,089或5,859,205)。接受者框架可為成熟的人類抗體框架序列或共通序列。如本文所用,術語「共通序列」是指在相關家族成員中的某一區域之序列的每一位置處最常見的或由最共通的殘基設計的序列。有多種人類抗體共通序列可使用,包括人類可變區不同亞群的共通序列(請參見Kabat, E. A.,等人,
Sequences of Proteins of Immunological Interest,第5版,美國衛生及公共服務部,美國政府印務局(1991))。Kabat數據庫及其應用可在線上免費獲得,例如經由IgBLAST,國家生物技術信息中心,貝塞斯達,馬里蘭州(亦請見,Johnson, G.及Wu, T. T.,
Nucleic Acids Research29:205-206 (2001))。
在某些實施例中,該GCC抗體分子為人類抗GCC IgG1抗體。由於此類抗體具有與GCC分子所希望的結合,因此此類抗體中的任一者皆可容易地進行同種型轉換,以產生人類IgG4同種型,例如,同時仍具有相同的可變區(其定義該抗體的特異性和親和力,在一定程度上)。因此,當產生滿足如上文所討論的希望「結構」屬性的抗體候選物時,它們通常可提供至少某些經由同種型轉換所希望的額外「功能」屬性。
在一些態樣中,包含一抗體片段的本發明CAR組成物的一部分係經人源化,其中保留對標靶抗原的高親和力和其他有利的生物學特性。根據本發明之一態樣,人源化抗體和抗體片段是藉由使用親本和人源化序列的三維模型分析該親本序列和各種概念性人源化產物的方法而製備。三維免疫球蛋白模型為一般可獲得,且為本領域技術人員所熟悉的。可使用電腦程式來演示和展示選定的候選免疫球蛋白序列的可能三維構形結構。檢查這些展示允許分析該殘基在候選免疫球蛋白序列的功能中可能扮演的角色,例如影響候選免疫球蛋白結合至標靶抗原的能力的殘基分析。
以此方式,可從接受和導入序列中選擇和組合FR殘基,以獲得期望的抗體或抗體片段特徵,例如對標靶抗原的親和力增加。一般而言,CDR殘基直接且最實質地涉及影響抗原結合。
人源化抗體或抗體片段可保留與原始抗體相似的抗原特異性,例如,在本發明中,與人類GCC結合的能力。在一些實施例中,人源化抗體或抗體片段可具有增進的與人類GCC結合的親和力及/或特異性。
在一些實施例中,該抗GCC抗原結合劑包含表1中提供的一或多個CDR序列。在一些實施例中,該抗GCC抗原結合劑包含具有表1中提供的CDR1的重鏈可變區。在一些實施例中,該抗GCC抗原結合劑包含具有表1中提供的CDR2的重鏈可變區。在一些實施例中,該抗GCC抗原結合劑包含具有表1中提供的CDR3的重鏈可變區。在一些實施例中,抗GCC抗原結合劑包含具有表1中提供的CDR1、CDR2和CDR3的重鏈可變區。在一些實施例中,抗GCC抗原結合劑包含表1中提供的一或多個CDR序列,其中該CDR包含1、2或3個胺基酸取代。在一實施例中,該取代不會不利地影響結合劑與其標靶之結合。
表 1. 例示性抗 GCC CDR 序列
| HCDR1 | HCDR2 | HCDR3 | |
| V1 | HYYWS (SEQ ID NO: 8) | RIYPSGSTSYNPSLKS (SEQ ID NO: 11) | DRSTGWSEWNSDL (SEQ ID NO: 16) |
| V1-01 | HYYWS (SEQ ID NO: 8) | RIYPSGSTSYNPSLKS (SEQ ID NO: 11) | DRSTGWSEWNSDL (SEQ ID NO: 16) |
| V5 | RYWMS (SEQ ID NO: 9) | KIRHDGGEKYYVDSVKG (SEQ ID NO: 12) | DYTRDV (SEQ ID NO: 17) |
| V36 | RYWMT (SEQ ID NO: 10) | KI KYDGSEKYYADSVKG (SEQ ID NO: 13) | DYNKDY (SEQ ID NO: 18) |
| V48 | RYWMT (SEQ ID NO: 10) | KI RHDGGEKYYPDSVKG (SEQ ID NO: 14) | DYNKDL (SEQ ID NO: 19) |
| V51 | RYWMT (SEQ ID NO: 10) | KIRHDGGEKYYADSVKG (SEQ ID NO: 15) | DYNKDY (SEQ ID NO: 18) |
非完整抗體的抗GCC抗體亦可用於本發明。此類抗體可衍生自上述任何抗體。此類可使用的抗體分子包括(i)Fab片段,即由VL、VH、CL和CH1域組成的單價片段;(ii)一F(ab′)
2片段,此為一個二價片段,包含在鉸鏈區經雙硫鍵連接的兩個Fab片段;(iii)由VH和CH1域組成的Fd片段;(iv)由抗體單臂的VL和VH域組成的Fv片段,(v)dAb片段(Ward等人,
Nature341:544-546 (1989)),其由VH域組成;(vii)單域功能性重鏈抗體,其由VHH域(稱為奈米抗體)組成,請參見例如Cortez-Retamozo等人,
Cancer Res.64: 2853-2857 (2004),以及引用於此的參考文獻;(vii)經分離的CDR,例如一或多個經分離的CDR與足夠的框架一起提供一抗原結合片段。此外,雖然Fv片段的兩個域VL和VH由不同的基因編碼,但可使用重組方法藉由合成連接子將它們連接起來,使它們能夠成為單一蛋白鏈,其中VL和VH區配對形成單價分子(稱為單鏈Fv(scFv);請參見例如,Bird等人,
Science242:423-426 (1988);以及Huston等人,
Proc. Natl. Acad. Sci. USA85:5879-5883 (1988)。此類單鏈抗體亦包含在術語抗體的「抗原結合片段」內。這些抗體片段是使用本領域技術人員已知的常規技術獲得,並以與完整抗體相同的方式進行效用篩選。抗體片段,例如Fv、F(ab′)
2和Fab可藉由切割完整蛋白質(例如藉由蛋白酶或化學切割)而製備。
單域抗體
單域抗體(sdAb)與傳統4-鏈抗體的不同之處在於具有單一單體抗體可變域。例如,駱駝科動物和鯊魚產生稱為僅具重鏈之抗體(HcAbs)的sdAb,其天生缺乏輕鏈。駱駝源化僅具重鏈之抗體的每一臂中的抗原結合片段,具有單一重鏈可變域(VHH),它可以在沒有輕鏈幫助的情況下對抗原具有高親和力。駱駝源化VHH被稱為最小的功能性抗原結合片段,分子量約為15 kD。在一些實施例中,該抗原結合劑為單一人類重鏈可變域(VH)抗體。此種結合分子也稱為Humabody®且在本文中可互換使用。Humabody®為Crescendo Biologics有限公司的註冊商標。
本申請案之一態樣係提供一種特異性結合至GCC(例如人類GCC)的經分離單域抗體(本文稱為「抗GCC sdAb」)。在一些實施例中,抗GCC sdAb調節GCC活性。在一些實施例中,抗GCC sdAb為拮抗劑抗體。進一步提供衍生自本文描述的任一抗GCC sdAb的抗原結合片段,以及包含本文描述的任一抗GCC sdAb的抗原結合蛋白。在一些實施例中,該抗GCC sdAb包含表1中提供的一、二及/或三個CDR序列。例示性抗GCC sdAb列於表2和3中。在一些實施例中,該抗GCC sdAb包含表2或表3中提供的可變重鏈。
在一些實施例中,一些或所有的CDR序列、重鏈,可用於另一抗原結合劑中,例如用於CDR嫁接、人源化或嵌合性抗體分子中。實施例包括一抗體分子,其包含足夠的CDR,例如來自上述重鏈可變區之一的所有三個CDR,以允許結合至細胞表面的GCC。
在一些實施例中,該CDR,例如所有的HCDR,被嵌入人類或人類衍生的框架區中。人類框架區的實例包括人類生殖系(germline)框架序列、已親和力成熟化(體內或體外)的人類生殖系序列,或合成的人類序列,例如共通序列。在一實施例中,該重鏈框架為IgG1或IgG2框架。
在一些實施例中,本發明的抗GCC抗原結合劑包含表2中提供的重鏈可變區胺基酸序列。在一些實施例中,該抗GCC抗原結合劑為僅具單域重鏈的抗體(例如,不包含免疫球蛋白輕鏈的抗原結合劑)。
表 2. 例示性重鏈可變區 (VH) 胺基酸序列
| 描述 | VH胺基酸序列 |
| V1 | QVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLNLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSS (SEQ ID NO: 1) |
| V1-01 | EVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLKLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSS (SEQ ID NO: 20) |
| V5 | QVQLVESGGGLVQPGGSLRLSCTASGFTFSRYWMSWVRQAPGKGLEWVAKIRHDGGEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDYTRDVWGQGTAVTVSS (SEQ ID NO: 21) |
| V36 | EVQLVESGGGLAQPGGSLRLSCAASGFTFSRYWMTWVRQAPGGRLEWVAKIKYDGSEKYYADSVKGRFTISRDNAKNSLYLQMDSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSS (SEQ ID NO: 26) |
| V48 | EVQLVESGGGLVQPGGSLRLTCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYPDSVKGRFTVSRDNAKNSLYLQMDNLRAEDTAMYYCTRDYNKDLWGQGTLVTVSS (SEQ ID NO: 27) |
| V51 | EVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSS (SEQ ID NO: 28) |
在一些實施例中,本發明的抗GCC抗原結合劑包含一重鏈可變區胺基酸序列,其與表2中提供的VH序列至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%一致。在一些實施例中,VH抗GCC抗原結合劑(例如,單域抗體)包含一前導序列。在一些實施例中,該VH抗GCC抗原結合劑包含一前導序列,其包含 MKHLWFFLLLVAAPRWVLS (SEQ ID NO: 6)、MELGLSWVFLVAILEGVQC (SEQ ID NO: 7)或MEFGLSWVFLVAIIKGVQC (SEQ ID NO: 42)。在一些實施例中,該VH抗GCC抗原結合劑包含一前導序列,其包含MALPVTALLLPLALLLHAARP (SEQ ID NO: 45)。
在一些實施例中,本發明的抗GCC抗原結合劑包含一重鏈可變區胺基酸序列,其與表3中提供的VH序列至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%一致。在一些實施例中,本發明的抗GCC抗原結合劑包含一重鏈可變區胺基酸序列,其與表3中提供的VH序列一致。
在一些實施例中,該VH抗GCC抗原結合劑(例如,單域抗體)包含一前導序列,其條件為與表3中提供者至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%一致。在一些實施例中,該VH抗GCC抗原結合劑(例如,單域抗體)包含表3中提供之一前導序列。
表 3. 例示性重鏈可變區 (VH) 胺基酸序列
| 前導序列 | VH序列 | |
| V1 | MKHLWFFLLLVAAPRWVLS (SEQ ID NO: 6) | QVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLNLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSS (SEQ ID NO: 1) |
| V1-01 | MKHLWFFLLLVAAPRWVLS (SEQ ID NO: 6) | EVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLKLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSS (SEQ ID NO: 20) |
| V5 | MELGLSWVFLVAILEGVQC (SEQ ID NO: 7) | QVQLVESGGGLVQPGGSLRLSCTASGFTFSRYWMSWVRQAPGKGLEWVAKIRHDGGEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDYTRDVWGQGTAVTVSS (SEQ ID NO: 21) |
| V8 | MELGLSWVFLVAILEGVQC (SEQ ID NO: 7) | QVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMSWVRQAPGKGLEWVAKIKYDGSEKYYVDSVKGRFTISRDNAKNSVYLQMNSLRAEDTGVYYCATDFTRDVWGQGTTVTVSS (SEQ ID NO: 22) |
| V9 | MELGLSWVFLVAILEGVQC (SEQ ID NO: 7) | EVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMTWVRQAPGRGLEWVAKIRYDGGEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDFTRDVWGQGTTVTVSS (SEQ ID NO: 23) |
| V30 | MELGLSWVFLVAILEGVQC (SEQ ID NO: 7) | QVQLVESGGGLVQPGGSLRLSCAASGFNFGRYWMSWVRQAPGKGREWVAKIKYDGSEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDFTRDVWGQGTTVTVSS (SEQ ID NO: 24) |
| V31 | MEFGLSWVFLVAIIKGVQC (SEQ ID NO: 42) | QVQLVESGGGVVRPGGSLRLSCAASGFTFSRYWMSWVRQAPGKGREWVAKIKYDGSEKYYADSVKGRFTISRDNAKNSLYLQMNSLRADDTAVYYCATDFTRDVWGQGTTVTVSS (SEQ ID NO: 25) |
| V36 | MELGLSWVFLVAILEGVQC (SEQ ID NO: 7) | EVQLVESGGGLAQPGGSLRLSCAASGFTFSRYWMTWVRQAPGGRLEWVAKIKYDGSEKYYADSVKGRFTISRDNAKNSLYLQMDSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSS (SEQ ID NO: 26) |
| V48 | MELGLSWVFLVAILEGVQC (SEQ ID NO: 7) | EVQLVESGGGLVQPGGSLRLTCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYPDSVKGRFTVSRDNAKNSLYLQMDNLRAEDTAMYYCTRDYNKDLWGQGTLVTVSS (SEQ ID NO: 27) |
| V51 | MELGLSWVFLVAILEGVQC (SEQ ID NO: 7) | EVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSS (SEQ ID NO: 28) |
用於體內治療或診斷用途的抗體片段可受益於增進其血清半衰期的修飾。適用於增加該抗體的體內血清半衰期的有機部分可包括一、二或更多個直線或分支片段,選自於:親水性聚合物基團(例如,直線或分支聚合物(例如,聚烷二醇如聚乙二醇、單甲氧基-聚乙二醇及類似物)、醣類(例如葡聚醣、纖維素、多醣及類似物)、親水性胺基酸的聚合物(例如聚離胺酸、聚天冬胺酸及類似物)、聚烷類氧化物和聚乙烯吡咯烷酮)、脂肪酸基團(例如單羧酸或二羧酸)、脂肪酸酯基團、脂質基團(例如二醯基甘油基團、神經鞘脂基團(例如神經醯胺基))或磷脂基團(例如,磷脂醯乙醇胺基團)。較佳地,該有機部分結合至預定位點,在該處有機部分不會損害所得免疫共軛物的功能(例如,降低抗原結合親和力),與未共軛抗體部分相較。該有機部分可具有約500 Da至約50,000 Da,較佳約2000、5000、10,000或20,000 Da的分子量。以有機部分修飾多肽(例如抗體)的實例和方法可見於例如美國專利號 4,179,337和5,612,460、PCT公開號WO 95/06058和WO 00/26256,以及美國專利申請公開號20030026805。
嵌合性抗原受體
嵌合性抗原受體(CAR)為包含三個必要單元的雜合分子:(1)一細胞外抗原結合模體,(2)連接/跨膜模體,以及(3)細胞內T細胞信號模體(Long A H, Haso W M, Orentas R J. Lessons learned from a highly-active CD22-specific chimeric antigen receptor. Oncoimmunology. 2013; 2 (4):e23621)。在本文揭示的GCC特異性CAR的各種實施例中,一般流程示於圖1中。在一些實施例中,該抗GCC CAR從N端到C端包含一信號或前導胜肽、抗原結合域、跨膜及/或鉸鏈域、共刺激域和細胞內域。
本發明提供包含一CAR (例如,CAR多肽),其包含一抗GCC結合域(例如,如本文所述的GCC結合域)、一跨膜域、和一細胞內信號傳導域,且其中該抗GCC結合域包含在表1或8中列出的任何抗GCC重鏈結合域胺基酸序列之一重鏈互補決定區1 (HC CDR1)、一重鏈互補決定區2 (HC CDR2)和一重鏈互補決定區3 (HC CDR3)。在一些實施例中,該抗GCC CAR從N端到C端包含一信號或前導胜肽、抗GCC VH、CD28跨膜和鉸鏈、CD28共刺激域和CD3ζ細胞內域。
該抗原結合域可為與該抗原結合的任何蛋白質,包括但不限於單株抗體、多株抗體、重組抗體、人類抗體、人源化抗體及其功能片段,包括但不限於:單域抗體,例如重鏈可變域(VH)、輕鏈可變域(VL)和駱駝源衍生奈米抗體的可變域(VHH),以及替代骨架,其在本領域中已知可作為抗原結合域,例如重組纖連蛋白域及類似物。在一些實施例中,該抗原結合域
CAR的抗原結合模體通常在單鏈片段可變域(ScFv)、免疫球蛋白(Ig)分子的最小結合域或單域抗體之後形成(例如,WO2018/028647A1)。替代的抗原結合模體,例如受體配體(即,IL-13已被改造為與腫瘤表現IL-13受體結合)、完整的免疫受體、基因庫衍生的胜肽、和先天免疫系統效應子分子(例如NKG2D)亦經改造。對於定義出最具CAR載體轉導活性的T細胞群、決定最佳培養和擴增技術、以及定義出CAR蛋白結構本身的分子細節方面,仍然是相當重要的工作。
CAR的連接模體可為相對穩定的結構域,例如IgG的恆定域,或被設計為延伸的彈性連接子。在一些實施例中,抗GCC結合域(例如,包含表1或表7中提供的序列之多肽)經由連接子(例如本文所述的連接子)連接至該跨膜域。在一些實施例中,該抗GCC CAR包括一(Gly4-Ser)n連接子,其中n為1、2、3、4、5或6(SEQ ID NO: 72)。在一些實施例中,該連接子包含RAAA (SEQ ID NO: 53)之胺基酸序列。
結構模體,例如衍生自IgG恆定域者,可用於將ScFv結合域延伸遠離T細胞膜表面。這對於結合域特別靠近腫瘤細胞表面膜的某些腫瘤標靶可能很重要(例如二唾液酸神經節苷脂GD2;Orentas等人,未發表的觀察)。迄今為止,CAR中使用的信號模體始終包括CD3-ζ鏈,因為此核心模體是T細胞活化的關鍵信號。首個報導的第二代CAR具有CD28信號傳導域和CD28跨膜序列。此模體也用於包含CD137 (4-1BB)信號模體的第三代CAR中(Zhao Y等人,J Immunol. 2009; 183 (9): 5563-74)。隨著新技術的出現,以與抗-CD3和抗-CD28抗體連結的微珠活化T細胞,以及來自CD28的經典「信號2」的出現,不再需要由CAR本身編碼。使用微珠活化,發現第三代載體在體外試驗中並不優於第二代載體,且它們在白血病小鼠模型中沒有明顯優於第二代載體(Haso W, Lee D W, Shah N N, Stetler-Stevenson M, Yuan C M, Pastan I H, Dimitrov D S, Morgan R A, FitzGerald D J, Barrett D M, Wayne A S, Mackall C L, Orentas R J. Anti-CD22-chimeric antigen receptors targeting B cell precursor acute lymphoblastic leukemia, Blood. 2013; 121 (7):1165-74; Kochenderfer J N等人,Blood. 2012; 119 (12):2709-20)。第二代CD28/CD3-ζ中的CD19特異性CAR (Lee D W等人,American Society of Hematology Annual Meeting. New Orleans, La.; Dec. 7-10, 2013)和CD137/CD3-ζ信號格式(Porter D L等人,N Engl J Med. 2011; 365 (8): 725-33)的臨床成功證明了這一點。除了CD137,其他腫瘤壞死因子受體超級家族成員如OX40也能夠在CAR轉導的T細胞中提供重要的持續信號(Yvon E等人,Clin Cancer Res. 2009; 15(18):5852-60)。同樣重要的是培養CAR T細胞群的培養條件。
基於T細胞之免疫療法已成為合成生物學的新前沿;多重啟動子及基因產物設計為使這些高活性細胞轉向腫瘤微環境,其中T細胞可避開負面的調節信號且介導有效腫瘤毒殺。通過用AP1903對誘導型凋亡蛋白酶9 (caspase 9)進行藥物誘導可消除不需要的T細胞,其顯現出一種以藥理學方式啟動控制T細胞群的強力開關之方法(Di Stasi A等人,N Engl J Med. 2011; 365(18):1673-83)。因此,雖然CAR呈現出可觸發T細胞活化,其方式類似於內源性T細胞受體,但迄今為止,此技術的臨床應用的主要阻礙在於CAR+ T細胞的體內擴增有限、在輸注後細胞快速消失、以及令人失望的臨床活性。因此,此項技術中存在一種迫切且長期的需要,需要找出以可展現具體且有效的抗腫瘤效果而無前述缺點(亦即高毒性、療效不足)之方式治療癌症之新穎組成物及方法。
本發明藉由提供可用於治療癌症及其他疾病及/或病況的CAR組成物及治療方法來滿足此等需求。尤其是,如本文所揭示及描述,本發明提供一種CAR,其可用於治療與GCC之失調表現相關之疾病、病症或病況,且該CAR含有GCC抗原結合域,其在經轉導T細胞上展現高表面表現、展現高度細胞溶解性、及經轉導T細胞之體內擴增及持續性。
在一些實施例中,該抗GCC抗原結合劑為嵌合抗原受體(CAR)。CAR之特徵包括其以非MHC限制之方式,將T細胞特異性及反應性重新導向至所選目標,及利用單株抗體之抗原結合特性的能力。非MHC限制性抗原辨識使表現CAR之T細胞有能力辨識出與抗原加工無關之抗原,因此繞過腫瘤逃逸之主要機制。此外,當在T細胞中表現時,CAR會有利地不使外源性T細胞受體(TCR)α及β鏈進行二聚化。
細胞外域
如本文中所描述,CAR包含一目標特異性結合元件(例如,抗GCC抗原結合劑之至少一部分),否則稱為抗原結合域或部分。域之選擇取決於定義標靶細胞表面之配位體的種類及數目。舉例而言,該抗原結合域可經選擇,以辨識作為與特定疾病狀態(例如,癌症)相關之標靶細胞上的細胞表面標記物之配位體(例如,GCC)。因此,在CAR中可作為抗原結合域之配位體的細胞表面標記物之實例包括與病毒性、細菌性及寄生蟲感染、自體免疫疾病及癌細胞相關者。
在一些實施例中,該抗GCC CAR之細胞外域包含一抗原結合劑,其包含表1中所提供之至少一個CDR。在一些實施例中,本發明的抗GCC抗原結合劑包含一重鏈可變區胺基酸序列,其與表2或表3中提供的VH序列至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%一致。在一些實施例中,該抗GCC CAR的細胞外域包含一表2中提供的可變重鏈。在一些實施例中,該抗GCC CAR的細胞外域包含一表3中提供的可變重鏈。
跨膜域
關於跨膜域,在各種實施例中,CAR可被設計為包含一連接到CAR的胞外域(例如,抗GCC抗原結合域)的跨膜域。跨膜域可包括與該跨膜區相鄰的一或多個額外胺基酸,例如與衍生該跨膜區的蛋白質的胞外區相關的一或多個胺基酸(例如,1、2、3、4、5、6、7、8、9、10至多達15個胺基酸的細胞外區域)、及/或與衍生該跨膜蛋白的蛋白質的細胞內區域相關的一或多個額外胺基酸(例如,1、2、3、4、5、6、7、8、9、10至多達15個胺基酸的細胞內區域)。
在一態樣中,該跨膜域是與所使用的CAR的其他域之一相關者。在一些情況下,該跨膜域可經由胺基酸取代來選擇或修飾,以避免此類域與該 相同或不同表面膜蛋白的跨膜域結合,例如使與該受體複合物的其他成員的相互作用最小化。在一態樣中,該跨膜域能夠與表現CAR的細胞(例如CART細胞)表面上的另一CAR進行同型二聚化。在一不同態樣中,該跨膜域的胺基酸序列可經修飾或取代,以使與該相同之表現CAR的細胞(例如CART)中存在的天然結合配偶體(partner)的結合域相互作用最小化。
如本文所述,該CAR包含一跨膜域。關於跨膜域,該CAR包含與CAR的細胞外GCC抗原結合域融合的一或多個跨膜域。該跨膜域可衍生自天然或合成來源。若來源是天然的,則該域可衍生自任何膜-結合蛋白或跨膜蛋白。
用於本文所述之CAR中之跨膜區可衍生自(亦即,包含至少以下跨膜區)T細胞受體之α、β或ζ鏈、CD28、CD3ε、CD45、CD4、CD5、CD8、CD9、CD16、CD22、間皮素(mesothelin)、CD33、CD37、CD64、CD80、CD86、CD134、CD137、CD154。
該跨膜域可衍生自天然或重組來源。若來源是天然的,則該域可衍生自任何膜-結合蛋白或跨膜蛋白。在一態樣中,當CAR已結合至目標時,該跨膜域可向細胞內域發送信號。特別可用於本發明之跨膜域可包括至少如以下之跨膜域:例如T細胞受體之α、β或ζ鏈、CD28、CD3ε、CD45、CD4、CD5、CD8 (如CD8α、CD8β)、CD9、CD16、CD22、CD33、CD37、CD64、CD80、CD86、CD134、CD137、CD154。在一些實施例中,該跨膜域可包括至少共刺激分子之跨膜域,例如:MHC第I類分子、TNF受體蛋白、類似免疫球蛋白的蛋白質、細胞激素受體、整聯蛋白(integrin)、信號傳導淋巴球活化分子(SLAM蛋白)、活化NK細胞受體、BTLA、Toll配位體受體、OX40、CD2、CD7、CD27、CD28、CD30、CD40、CDS、ICAM-1、LFA-1 (CDlla/CD18)、4-1BB (CD137)、B7-H3、CDS、ICAM-1、ICOS (CD278)、GITR、BAFFR、LIGHT、HVEM (LIGHTR)、KIRDS2、SLAMF7、NKp80 (KLRF1)、NKp44、NKp30、NKp46、CD19、CD4、CD8α、CD8β、IL2Rβ、IL2Rγ、IL7Rα、ITGA4、VLA1、CD49a、ITGA4、IA4、CD49D、ITGA6、VLA-6、CD49f、ITGAD、CDIId、ITGAE、CD103、ITGAL、CDIIa、LFA-1、ITGAM、CDIIb、ITGAX、CDIIc、ITGB1、CD29、ITGB2、CD18、LFA-1、ITGB7、NKG2D、NKG2C、TNFR2、TRANCE/RANKL、DNAM1 (CD226)、SLAMF4 (CD244、2B4)、CD84、CD96 (Tactile)、CEACAM1、CRTAM、Ly9 (CD229)、CD160 (BY55)、PSGL1、CD100 (SEMA4D)、CD69、SLAMF6 (NTB-A、Lyl08)、SLAM (SLAMF1、CD150、IPO-3)、BLAME (SLAMF8)、SELPLG (CD162)、LTBR、LAT、GADS、SLP-76、PAG/Cbp、CD19a、及特異性地與CD83結合之配位體。
在一些實施例中,該CAR分子包含一蛋白質之跨膜域,選自由以下組成之群:T細胞受體之α、β或ζ鏈、CD28、CD3ε、CD45、CD4、CD5、CD8、CD9、CD16、CD22、CD33、CD37、CD64、CD80、CD86、CD134、CD137和CD154。
或者,該跨膜域可為合成性,在此情況下,它將主要包含疏水性殘基,例如白胺酸和纈胺酸。在一些實施例中,在合成性跨膜域的每一端會發現苯丙胺酸、色胺酸和纈胺酸的三聯體。視情況,短寡-或多肽連接子,長度較佳在2到10個胺基酸之間,可形成跨膜域和CAR的細胞質信號傳導域之間的連結。在一些實施例中,該連接子為甘胺酸-絲胺酸雙聯體或丙胺酸三聯體連接子。
在一些實施例中,除了如前述之跨膜域之外,亦使用天然地與CAR的結構域之一結合的跨膜域。在一些實施例中,該跨膜域可藉由胺基酸取代來選擇,以避免此類域與相同或不同表面膜蛋白的跨膜域結合,藉此使與該受體複合物的其他成員的相互作用最小化。
在一些實施例中,本發明之CAR中之跨膜域為CD28跨膜域。在一些實施例中,該CD28跨膜域包含FWVLVVVGGVLACYSLLVTVAFIIFWV SEQ ID NO: 30之核酸序列。在一些實施例中,CD28跨膜結構域包含編碼SEQ ID NO: 30的胺基酸序列的核酸序列。在一些實施例中,該跨膜結構域包含一序列,其具有SEQ ID NO: 30的胺基酸序列之至少一、二或三個修飾(例如,取代),但不超過20、10或5個修飾(例如,取代),或與SEQ ID NO: 30的胺基酸序列至少95%、96%、97%、98%或99%一致。
在一些實施例中,跨膜結構域可經由一鉸鏈(例如來自人類蛋白質的鉸鏈)連接到CAR的細胞外域(例如CAR的抗原結合域)。舉例而言,在一實施例中,該鉸鏈可為人類Ig(免疫球蛋白)鉸鏈,例如IgG4鉸鏈或CD8a鉸鏈。
在CAR中,間隔子域(亦稱為鉸鏈域)可配置在細胞外域與跨膜域之間,或配置在細胞內域與跨膜域之間。間隔子域意謂任何作為連接跨膜域與細胞外域及/或跨膜域與細胞內域之寡胜肽或多胜肽。間隔子域包含至多300個胺基酸,較佳10至100個胺基酸,且最佳25至50個胺基酸。
在數個實施例中,該連接子可包括間隔子元件,當存在時,以增加連接子之大小,使得效應分子或可偵測標記與抗體或抗原結合片段之間的距離增加。例示性間隔子為一般技術人員所已知,且包括於美國專利號 7,964,566、7,498,298、6,884,869、6,323,315、6,239,104、6,034,065、5,780,588、5,665,860、5,663,149、5,635,483、5,599,902、5,554,725、5,530,097、5,521,284、5,504,191、5,410,024、5,138,036、5,076,973、4,986,988、4,978,744、4,879,278、4,816,444、及4,486,414,以及美國專利 公開號 20110212088和20110070248中所列者,其每一者皆以全文引用之方式併入本文中。
該間隔子域較佳具有促進CAR與抗原之結合及提高傳導至細胞中之信號的序列。預期促進結合之胺基酸實例包括半胱胺酸、帶電胺基酸、及潛在醣基化位點中之絲胺酸及蘇胺酸,且此等胺基酸可作為構成該間隔子域之胺基酸。
在一些實施例中,該CAR包含一鉸鏈域。在一些實施例中,該鉸鏈域包含IEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKP (SEQ ID NO: 29)之核酸序列。在一些實施例中,該鉸鏈域包含編碼SEQ ID NO: 29的胺基酸序列之核酸序列。在一些實施例中,該絞鏈域包含一序列,其具有SEQ ID NO: 29的胺基酸序列之至少一、二或三個修飾(例如,取代),但不超過20、10或5個修飾(例如,取代),或與SEQ ID NO: 29的胺基酸序列至少95%至99%一致。
在一些實施例中,該CAR包含一CD8鉸鏈域。在一些實施例中,鉸鏈域包含胺基酸序列TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACD (SEQ ID NO: 5)。在一些元素中,該CAR包含一CD8跨膜域。在一些實施例中,該跨膜域包含胺基酸序列IYIWAPLAGTCGVLLLSLVITLYC (SEQ ID NO: 2)。在一些實施例中,該鉸鏈及跨膜域係衍生自同一分子。在其他實施例中,該鉸鏈及跨膜域係衍生自不同分子(例如,CD8融合至CD28)。在一些實施例中,該CAR包含一鉸鏈域。在一些實施例中,該鉸鏈域包含IEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWV (SEQ ID NO: 31)之核酸序列。在一些實施例中,該鉸鏈域包含編碼SEQ ID NO: 31的胺基酸序列之核酸序列。在一些實施例中,該絞鏈域包含一序列,其具有SEQ ID NO: 31的胺基酸序列之至少一、二或三個修飾(例如,取代),但不超過20、10或5個修飾(例如,取代)。
在一實施例中,該CAR包含一編碼表皮生長因子受體之截短序列(tEGFR)的標籤序列。在一些實施例中,該tEGFR標籤包含SEQ ID NO: 43的胺基酸序列,或與其至少95%、96%、97%、98%或99%一致的序列。
細胞内域
CAR的細胞質域或細胞內信號傳導域負責活化已有CAR的免疫細胞的至少一種正常效應子功能。術語「效應子功能」是指細胞的特殊功能。例如,T細胞的效應子功能可為細胞溶解活性或輔助活性,包括細胞因子的分泌。因此,術語「細胞內信號傳導域」是指轉導效應子功能信號並指導細胞執行特定功能的蛋白質之一部分。雖然通常可以使用完整細胞內信號傳導域,但在許多情況下沒有必要使用整個鏈。就使用細胞內信號傳導域的截短部分而言,此類截短部分可用於代替完整鏈,只要它能轉導效應子功能信號即可。因此,術語「細胞內信號傳導域」意在包括足以轉導效應子功能信號的細胞內信號傳導域的任何截短部分。
用於CAR的細胞內信號傳導域的實例包括T細胞受體(TCR)和共受體的細胞質序列,其共同作用以在抗原受體接合後啟動信號轉導,以及這些序列的任何衍生物和變異體,和任何具有相同功能的合成序列。僅通過TCR產生的信號不足以完全活化T細胞,還需要次級或共刺激信號。因此,T細胞活化可視為由兩種不同類型的細胞質信號序列介導的:經由TCR(初級細胞質信號序列)啟動抗原依賴性初級活化者,以及以非抗原-依賴性的方式發揮作用,以提供次級或共刺激信號(次級細胞質信號序列)。
初級細胞質信號序列以刺激方式或抑制方式調節TCR複合物的初級活化。以刺激方式作用的初級細胞質信號序列可能包含信號模體,這些模體被稱為免疫受體酪胺酸-基礎活化模體或ITAM。在一些實施例中,CAR內的含ITAM域涵蓋與內源性TCR複合物無關之初級TCR信號傳導。在一態樣中,該初級信號由例如TCR/CD3複合物與裝載有胜肽的MHC分子結合引發,並導致T細胞反應之介導,包括但不限於增殖、活化、分化及類似作用。以刺激方式作用的初級細胞質信號序列(亦稱為「初級信號傳導域」)可包含稱為免疫受體酪胺酸-基礎活化模體或ITAM的信號模體。
本文揭示的含有特別用於CAR之初級細胞質信號傳導序列的ITAM實例包括衍生自TCRζ (CD3ζ)、FcRγ、FcRβ、CD3γ、CD3δ、CD3ε、CD5、CD22、CD79a、CD79b及CD66d者。特別地,ITAM之非限制性實例包括具有CD3ζ胺基酸序列編號51至164之胜肽。(NCBI RefSeq: NP.sub.--932170.1),Fcε.RI.γ之胺基酸編號45至86。(NCBI RefSeq: NP.sub.--004097.1),Fcε.RI.β之胺基酸編號201至244。(NCBI RefSeq: NP.sub.--000130.1),CD3γ之胺基酸編號139至182。(NCBI RefSeq: NP.sub.--000064.1),CD3δ之胺基酸編號128至171。(NCBI RefSeq: NP.sub.--000723.1),CD3ε之胺基酸編號153至207。(NCBI RefSeq: NP.sub.--000724.1),CD5之胺基酸編號402至495 (NCBI RefSeq: NP.sub.--055022.2)、0022之胺基酸編號707至847 (NCBI RefSeq: NP.sub.--001762.2)、CD79a之胺基酸編號166至226 (NCBI RefSeq: NP.sub.--001774.1)、CD79b之胺基酸編號182至229 (NCBI RefSeq: NP.sub.--000617.1)、及CD66d 之胺基酸編號177至252 (NCBI RefSeq: NP.sub.--001806.2)、以及與這些胜肽具有相同功能的變異體。基於本文所述之NCBI RefSeq ID或GenBank之胺基酸序列資訊的胺基酸編號,係基於每一蛋白質之前驅體(包含一信號胜肽序列等)的全長來編號。
在實施例中,該細胞內信號域轉導效應子功能信號並指導細胞執行特定功能。雖然可使用完整細胞內信號傳導域,但在許多情況下沒有必要使用整條鏈。就使用細胞內信號傳導域的截短部分而言,此類截短部分可用於代替完整鏈,只要它能轉導效應子功能信號即可。因此,術語「細胞內信號傳導域」意在包括足以轉導效應子功能信號的細胞內信號傳導域的任何截短部分。
細胞內信號傳導域會產生一種信號,其可促進含CAR之細胞(例如,CART細胞)的免疫效應子功能。免疫效應子功能之實例,例如,在CART細胞中,包括細胞溶解活性及輔助子活性,包括細胞激素之分泌。
在一實施例中,細胞內信號傳導域可包含初級細胞內信號傳導域。例示性初級細胞內信號傳導域包括衍生自負責初級刺激或抗原依賴性刺激的分子者。在一實施例中,該細胞內信號傳導域可包含一共刺激細胞內域。例示性共刺激細胞內信號傳導域包括衍生自負責共刺激信號或非抗原依賴性刺激的分子者。例如,在CART的情況下,初級細胞內信號傳導域可包含T細胞受體的細胞質序列,而共刺激細胞內信號傳導域可包含來自共受體或共刺激分子的細胞質序列。
在一些實施例中,該初級細胞質信號傳導序列包括,衍生自CD3ζ、FcRγ、FcRβ、CD3γ、CD3δ、CD3ε、CD5、CD22、CD79a、CD79b、CD278 (亦稱為「ICOS」)、FceRI、CD66d、DAP10及DAP12者。在一實施例中,CAR之細胞質信號傳導分子包含一衍生自CD3ζ之細胞質信號傳導序列。
在一實施例中,初級信號傳導域包含一經修飾的ITAM域,例如,與天然ITAM域相較,具有改變(例如增加或降低)活性的突變ITAM域。在一實施例中,初級信號傳導域包含經修飾的含ITAM初級細胞內信號傳導域,例如最佳化及/或截短的含ITAM初級細胞內信號傳導域。在一實施例中,初級信號傳導域包括一、二、三、四或更多個ITAM模體。
在一些實施例中,CAR之細胞內域可經設計以包含CD3-ζ信號傳導域本身,或與有關CAR的內文中可用的任何其他所需之細胞內信號傳導域結合。例如,CAR之細胞内域可包含一CD3ζ鏈部分及一共刺激信號傳導區。該共刺激信號傳導區係指包含共刺激分子之細胞内域的CAR之一部分。共刺激分子為抗原受體或其配位體以外之細胞表面分子,其為淋巴細胞對抗原產生有效反應所必需。此類共刺激分子之實例包括CD27、CD28、4-1BB (CD137)、OX40、CD30、CD40、PD-1、ICOS、淋巴細胞功能相關抗原-1 (LFA-1)、CD2、CD7、LIGHT、NKG2C、B7-H3、及特異地與CD83結合之配位體、及類似者。在一些實施例中,該共刺激域包含一蛋白質的功能性信號傳導域,選自由以下組成之組:0X40、CD2、CD27、CD28、CDS、ICAM-1、LFA-1 (CDlla/CD18)及4-1BB (CD137)。
特別地,此類共刺激分子之非限制性實施例包括具有下列序列之胜肽:CD2之胺基酸編號236至351 (NCBI RefSeq: NP.sub.--001758.2)、CD4之胺基酸編號421至458 (NCBI RefSeq: NP.sub.--000607.1)、CD5之胺基酸編號402至495 (NCBI RefSeq: NP.sub.--055022.2)、CD8α之胺基酸編號207至235 (NCBI RefSeq: NP.sub.--001759.3)、CD83之胺基酸編號196至210 (GenBank: AAA35664.1)、CD28之胺基酸編號為181至220 (NCBI RefSeq: NP.sub.-006130.1)、CD137之胺基酸編號為214至255 (4-1BB,NCBI RefSeq: NP.sub.--001552.2)、CD134之胺基酸編號241至277 (OX40,NCBI RefSeq: NP.sub.--003318.1)、及ICOS之胺基酸編號166至199 (NCBI RefSeq: NP.sub.--036224.1)、以及與這些胜肽具有相同功能的變異體。因此,雖然本發明主要使用4-1BB作為共刺激信號傳導元件範例,但其他共刺激信息傳導元件亦落於本發明的範疇中。
CAR之細胞内信號傳導域可包含初級信號傳導域,例如CD3ζ信號傳導域本身,或與本發明有關CAR的內文中可用的任何其他所需之細胞內信號傳導域結合。例如,CAR之細胞内信號傳導域可包含一初級信號傳導域,例如CD3ζ鏈部分,及一共刺激信號域。該共刺激信號傳導域係指包含一共刺激分子之細胞内域的CAR的一部分。共刺激分子為抗原受體或其配位體以外之細胞表面分子,其為淋巴細胞對抗原產生有效反應所必需。此類分子之實例包括MHC第I類分子、TNF受體蛋白、類似免疫球蛋白的蛋白質、細胞激素受體、整聯蛋白(integrin)、信號傳導淋巴球活化分子(SLAM蛋白)、活化NK細胞受體、BTLA、Toll配位體受體、OX40、CD2、CD7、CD27、CD28、CD30、CD40、CDS、ICAM-1、LFA-1 (CDlla/CD18)、4-1BB (CD137)、B7-H3、CDS、ICAM-1、ICOS (CD278)、GITR、BAFFR、LIGHT、HVEM (LIGHTR)、KIRDS2、SLAMF7、NKp80 (KLRF1)、NKp44、NKp30、NKp46、CD19、CD4、CD8α、CD8β、IL2Rβ、IL2Rγ、IL7Rα、ITGA4、VLAl、CD49a、ITGA4、IA4、CD49D、ITGA6、VLA-6、CD49f、ITGAD、CDlld、ITGAE、CD103、ITGAL、CDlla、LFA-1、ITGAM、CDllb、GG AC、CDllc、ITGB1、CD29、ITGB2、CD18、LFA-1、ITGB7、NKG2D、NKG2C、TNFR2、TRANCE/RANKL、DNAM1 (CD226)、SLAMF4 (CD244、2B4)、CD84、CD96 (Tactile)、CEACAM1、CRTAM、Ly9 (CD229)、CD160 (BY55)、PSGL1、CD100 (SEMA4D)、CD69、SLAMF6 (NTB-A、Lyl08)、SLAM (SLAMF1、CD150、IPO-3)、BLAME (SLAMF8)、SELPLG (CD162)、LTBR、LAT、GADS、SLP-76、PAG/Cbp、CD19a、及特異性地與CD83結合之配位體、以及類似物。舉例而言,已證實CD27共刺激可在體外提高人類CART細胞之擴增、效應子功能及存活,且在體內擴增人類T細胞之持續性及抗腫瘤活性(Song等人,Blood. 2012; 119(3):696-706)。在本發明之CAR的細胞質部分中之細胞內信號傳導序列,可隨機或以指定順序彼此連接。
CAR之細胞質信號傳導部分中的細胞質信號傳導序列可隨機或以指定順序彼此連接。視情況,短寡-或多胜肽連接子,長度較佳在2到10個胺基酸之間,可形成該橋聯。在一些實施例中,該連接子為甘胺酸-絲胺酸雙聯體或丙胺酸三聯體連接子。
在一些實施例中,該細胞內域可設計成包含一CD28共刺激信號傳導域。在一些實施例中,該CAR之細胞內域包含一胺基酸序列,其與RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS (SEQ ID NO: 32)至少95%、96%、97%、98%、99%或100%一致。
在一些實施例中,該細胞內域係設計成包含CD3-ζ的信號傳導域和CD28的信號傳導域。在一些實施例中,該細胞內域包含具有一或多個經修飾之免疫受體酪胺酸基礎活化模體(ITAM)的CD3-ζ。在一些實施例中,該細胞內域包含一CD3-ζ,其具有三個免疫受體酪胺酸基礎活化模體(ITAM),其中第一個未經修飾,且第二和第三個ITAM經改變,名為「1XX」。在一些實施例中,該CAR之細胞內域包含一胺基酸序列,其與RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR (SEQ ID NO: 33)至少95%、96%、97%、98%、99%或100%一致。
在另一實施例中,該細胞內域設計成包含CD3-ζ之信號傳導域及4-1BB之信號傳導域。在又一實施例中,該細胞內域係設計成包含CD3-ζ的信號傳導域和CD28和4-1BB的信號傳導域。
在一些實施例中,該CAR之細胞內域經設計,以包含4-1BB之信號傳導域及CD3-ζ之信號傳導域,其中4-1BB之信號傳導域包含KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL (SEQ ID NO: 3),
且CD3-ζ之信號傳導域包含如RVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR (SEQ ID NO: 4)或
RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR (SEQ ID NO: 71)所示之核酸序列。
在一些實施例中,該CAR域藉由一多胜肽連接子連接。舉例而言,一多胜肽連接子的長度可介於2與10個胺基酸之間(例如,2、3、4、5、6、7、8、9或10個胺基酸),可形成在細胞內信號傳導序列之間的橋聯。在一實施例中,甘胺酸-絲胺酸雙聯體可使用作為合適的連接子。在一些實施例中,可使用單一胺基酸,例如丙胺酸、甘胺酸作為合適的連接子。
在一態樣中,該細胞內信號傳導域設計成包含二或多個,例如,2、3、4、5或更多個共刺激信號傳導域。於一實施例中,該二或多個例如2、3、4、5或更多的共刺激信號傳導域,係由一連接子分子(例如本文所述之連接子分子)分隔。在一實施例中,該細胞內信號傳導域包含兩個共刺激信號傳導域。在一些實施例中,該連接子分子為甘胺酸殘基。在一些實施例中,該連接子為丙胺酸殘基。
在一態樣中,該細胞內信號傳導域係設計成包含CD3-ζ之信號傳導域及CD28之信號傳導域。在一態樣中,該細胞內信號傳導域係設計成包含CD3-ζ之信號傳導域及4-1BB之信號傳導域。
在一態樣中,該細胞內信號傳導域係設計成包含CD3-ζ之信號傳導域及CD27之信號傳導域。在一態樣中,該細胞內信號傳導域係設計成包含 CD3-ζ之信號傳導域及CD28之信號傳導域。在 一態樣中,該細胞內信號傳導域係設計成包含 CD3-ζ之信號傳導域及ICOS之信號傳導域
在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與表4中所提供之胺基酸序列至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。
表
4.
例示性抗
GCC CAR
之胺基酸序列
| CAR | 序列 |
| V1-01 CAR | MGWSCIILFLVATATGVHSEVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLKLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWV RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR (SEQ ID NO: 48) |
| V5 CAR | MELGLSWVFLVAILEGVQCQVQLVESGGGLVQPGGSLRLSCTASGFTFSRYWMSWVRQAPGKGLEWVAKIRHDGGEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDYTRDVWGQGTAVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWV RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR (SEQ ID NO: 49) |
| V36 CAR | MELGLSWVFLVAILEGVQCEVQLVESGGGLAQPGGSLRLSCAASGFTFSRYWMTWVRQAPGGRLEWVAKIKYDGSEKYYADSVKGRFTISRDNAKNSLYLQMDSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWV RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR (SEQ ID NO: 50) |
| V48 CAR | MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLTCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYPDSVKGRFTVSRDNAKNSLYLQMDNLRAEDTAMYYCTRDYNKDLWGQGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWV RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR (SEQ ID NO: 51) |
| V51 CAR | MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWV RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR (SEQ ID NO: 52) |
| V1 CAR | MGWSCIILFLVATATGVHSQVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLNLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR (SEQ ID NO: 47) |
在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 47至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。
在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 48至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。
在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 49至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。
在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 50至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。
在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 51至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。
在一些實施例中,該抗GCC CAR包含一胺基酸序列,其與SEQ ID No: 52至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致。
CAR 的功能特徵
本文中所揭示之CAR的功能部分亦明確包括在本發明範疇中。術語「功能部分」當用於指稱CAR時,係指本文中所揭露之一或多個CAR之任何部分或片段,該部分或片段保留該部分的CAR (原CAR)之生物活性。功能部分涵蓋例如CAR的彼等部分,其與原CAR保持辨識標靶細胞或偵測、治療或預防疾病之能力的程度相似、程度相同或程度較高。關於原CAR,該功能部分可包含例如約10%、25%、30%、50%、68%、80%、90%、95%或更多的原CAR。
該功能部分可包含在該部分之胺基或羧基端或兩端處之額外胺基酸,其為在原CAR之胺基酸序列中並未發現的額外胺基酸。希望的是,該額外胺基酸不干擾該功能部分的生物功能,例如,辨識標靶細胞、偵測癌症、治療或預防癌症等。更理想地,與原CAR的生物活性相較,該額外胺基酸提高該生物活性。
本發明的範圍包括本文中所揭露之CAR的功能變異體。如本文所用,術語「功能變異體」係指具有與原CAR實質上或顯著的序列一致性或相似性之CAR、多胜肽或蛋白質,該功能變異體保留由其變異之CAR的生物活性。功能變異體涵蓋例如本文所述之CAR的變異體(原CAR),其保持與原CAR程度相似、程度相同或程度較高之辨識標靶細胞的能力。相關於原CAR,該功能變異體可與原CAR之胺基酸序列例如,至少約30%、50%、75%、80%、90%、98%或更高一致。
功能變異體可例如包含原CAR之胺基酸序列,其具有至少一保守性胺基酸取代。替代地或另外地,功能變異體可例如包含原CAR之胺基酸序列,其具有至少一非保守性胺基酸取代。在此案例中,非保守性胺基酸取代較佳地不干擾或抑制該功能性變異體之生物活性。非保守性胺基酸取代可提高該功能變異體之生物活性,使得功能變異體之生物活性較原CAR增加。
該CAR之胺基酸取代較佳為保守性胺基酸取代。保守性胺基酸取代為本領域中已知的,且包括胺基酸取代,其中具有特定物理及/或化學性質之胺基酸係交換成具有相同或類似化學或物理性質之另一胺基酸。例如,該保守性胺基酸取代可為一酸性/負電荷極性胺基酸被另一酸性/負電荷極性胺基酸(如Asp或Glu)取代、一帶有非極性側鏈之胺基酸被另一帶有非極性側鏈之胺基酸(如Ala、Gly、Val、He、Leu、Met、Phe、Pro、Trp、Cys、Val等)取代、一鹼性/正電荷極性胺基酸被另一鹼性/正電荷極性胺基酸(如Lys、His、Arg等)取代、一帶有極性側鏈的不帶電胺基酸被另一帶有極性側鏈的不帶電胺基酸(如Asn、Gin、Ser、Thr、Tyr等)取代、一帶有β分支側鏈的胺基酸被另一帶有β分支側鏈的胺基酸(如He、Thr和Val)取代、一帶有芳香側鏈的胺基酸被另一帶有芳香側鏈的胺基酸(如His、Phe、Trp和Tyr)取代等。
該CAR基本上可由本文所述之特定胺基酸序列或序列組成,使得其他成分(例如,其他胺基酸)不實質改變該功能變異體的生物活性。
該CAR (包括功能部分及功能變異體)可具有任何長度,亦即,可包含任何數量的胺基酸,條件為該CAR (或其功能部分或功能變異體)保留其生物活性,例如,特異結合至抗原之能力、偵測哺乳動物之患病細胞、或治療或預防哺乳動物之疾病等。例如,該CAR可為約50至約5000個胺基酸長度,諸如長度為50、70、75、100、125、150、175、200、300、400、500、600、700、800、900、1000或更多個胺基酸。
該CAR (包括本發明之功能性部分及功能變異體)可包含合成胺基酸代替一或多種天然存在之胺基酸。此類合成胺基酸為本領域中已知的,並包括例如:胺基環己烷羧酸、正亮胺酸、-胺基正癸酸、高絲胺酸、S-乙醯胺基甲基-半胱胺酸、反式-3-和反式-4-羥脯胺酸、4-胺基苯丙胺酸、4-硝基苯丙胺酸、4-氯苯丙胺酸、4-羧基苯丙胺酸、β-苯基絲胺酸 β-羥基苯丙胺酸、苯基甘胺酸、α-萘丙胺酸、環己基丙胺酸、環己基甘胺酸、二氫吲哚-2-羧酸、1,2,3,4-四氫異喹啉-3-羧酸、胺基丙二酸、胺基丙二酸單醯胺、N'-芐基-N'-甲基-離胺酸、N',N'-二芐基-離胺酸、6-羥基離胺酸、鳥胺酸、-胺基環戊烷羧酸、α-胺基環己烷羧酸、α-胺基環庚烷羧酸、α-(2-胺基-2-降冰片烷)-羧酸、γ-二胺基丁酸、β-二胺基丙酸、高苯丙胺酸和α-第三-丁基甘胺酸。
該CAR (包括功能部分及功能變異體)可經醣基化、醯胺化、羧化、磷酸化、酯化、N-醯化、經由例如雙硫橋聯環化、或轉化為酸加成鹽及/或視情況二聚合化或聚合化或共軛。
取代和變異
在一些實施例中,其涵蓋了本文提供的抗體之胺基酸序列變異體。例如,可能希望增進抗體的結合親和力及/或其他生物學特性。抗體的胺基酸序列變異體可藉由引入適當的修飾至編碼該抗體的核酸序列中、或藉由胜肽合成而製備。此類修飾包括,例如,抗體胺基酸序列內殘基的刪去及/或插入及/或取代。可進行刪去、插入和取代的任何組合,以完成最終構建體,條件為該最終構建體具有希望的特徵,例如抗原結合。
a)取代、插入和刪除變異
在一些實施例中,提供具有一或多個胺基酸取代的抗體變異體。進行取代突變的有興趣位點包括HVR和FR。以下進一步描述胺基酸側鏈類別。可將胺基酸取代引入至有興趣的抗體中,並將產物進行希望之活性篩選,例如抗原結合度維持/增進、免疫原性降低、或ADCC或CDC增進。
胺基酸可根據共同側鏈特性來分組:
(1)疏水性:正白胺酸、Met、Ala、Val、Leu、Ile;
(2)中性親水性:Cys、Ser、Thr、Asn、Gln;
(3)酸性:Asp、Glu;
(4)鹼性:His、Lys、Arg;
(5)影響鏈位向之殘基:Gly、Pro;
(6)芳族:Trp、Tyr、Phe。
非保守性取代係為將這些類別之一的成員交換為另一類別。
在一些態樣中,該抗原結合域為人源化。非人類抗體為人源化,其中該抗體的特定序列或區域經修飾,以增加與在人類中天然產生的抗體或其片段的相似性。在一態樣中,該抗原結合域為人源化。人源化抗體(或抗原結合片段)可使用本領域中已知的各種技術產生,包括但不限於:CDR嫁接(請參見例如歐洲專利號EP 239,400;國際公開號WO 91/09967;和美國專利號5,225,539、5,530,101和5,585,089,其每一者係以全文引用之方式併入本文中)、飾面或表面重修(請參見,例如,歐洲專利號EP 592,106和EP 519,596;Padlan, 1991, Molecular Immunology, 28(4/5):489-498; Studnicka等人,1994, Protein Engineering, 7(6):805-814;以及Roguska等人,1994, PNAS, 91:969-973,其每一者係以全文引用之方式併入本文中)、鏈改組(請參見例如美國專利號5,565,332,其係以全文引用之方式併入本文中),以及揭示於例如美國專利申請公開號US2005/0042664、美國專利申請公開號US2005/0048617、美國專利號 6,407,213、美國專利號 5,766,886、國際專利公開號WO 9317105、Tan等人,J. Immunol., 169:1119-25 (2002)、Caldas等人,Protein Eng., 13(5):353-60 (2000)、Morea等人,Methods, 20(3):267-79 (2000)、Baca等人,J. Biol. Chem., 272(16): 10678-84 (1997)、Roguska等人,Protein Eng., 9(10):895-904 (1996)、Couto等人,Cancer Res., 55 (23增刊):5973s-5977s (1995)、Couto等人,Cancer Res., 55(8):1717-22 (1995)、Sandhu J S, Gene, 150(2):409-10 (1994)、以及Pedersen等人,J. Mol. Biol., 235(3):959-73 (1994),其每一者係以全文引用之方式併入本文中。通常,框架區中的框架殘基將被來自於CDR供體抗體的相對應殘基取代,以改變(例如增進)抗原結合。這些框架取代,例如保守取代是藉由本領域中眾所周知的方法辨識出,例如,藉由對CDR和框架殘基的相互作用進行模擬,以辨識出對於抗原結合和序列比對重要的框架殘基,以辨識出在特定位置的不尋常框架殘基。(請參見例如,Queen等人,美國專利號5,585,089;以及Riechmann等人,1988, Nature, 332:323,其係以全文引用之方式併入本文中)
人源化抗體或抗體片段具有一或多個來自非人類來源的胺基酸殘基保留在其中。這些非人類胺基酸殘基通常稱為「輸入」殘基,通常取自「輸入」可變域。如本文所提供,人源化抗體或抗體片段包含來自非人類免疫球蛋白分子和框架區的一或多個CDR,其中包含該框架的胺基酸殘基完全或大部分衍生自人類生殖系。用於抗體或抗體片段人源化的多種技術為本領域中已知的。
取代變異體之一種類型涉及取代親本抗體(例如,人源化或人抗體)的一或多個高度變異區殘基。通常,經選擇用於進一步研究的所得變異體,相較於親本抗體,在某些生物學特性(例如增加的親和力、降低的免疫原性)方面將具有修飾(例如,增進),及/或將實質上保留該親本抗體的某些生物學特性。例示性取代變異體為親和力成熟的抗體,其可方便地產生,例如,使用基於噬菌體展示的親和力成熟技術,如本文所述者。簡而言之,一或多個HVR殘基發生突變,而該變異抗體展示在噬菌體上,並針對特定的生物活性(例如結合親和力)進行篩選。
可在HVR中進行改變(例如,取代),以例如增進抗體親和力。此類改變可在HVR「熱點」中進行,即由在體細胞成熟過程中經歷高頻率突變的密碼子編碼的殘基(請參見,例如,Chowdhury, Methods Mol. Biol. 207: 179-196 (2008)),及/或SDR (a-CDR),其中所得變異體VH或VL的結合親和力係經測試。藉由構建及自二級庫中重新篩選而達成親和力成熟,已描述於如Hoogenboom等人,Methods in Molecular Biology 178: 1-37 (O’ Brien等人編,Human Press, Totowa, NJ (2001))。在親和力成熟的一些實施例中,在選定用於成熟化的可變基因中引入多樣性,藉由多種方法之任一者達成(例如,易錯PCR、鏈改組、或寡核苷酸-定向突變)。之後創建二級庫。之後篩選該庫,以辨識出具有希望親和力的任何抗體變異體。另一種引入多樣性的方法涉及HVR-導向法,其中數個HVR殘基(例如,一次4至6個殘基)被隨機化。參與抗原結合的HVR殘基可被特異性辨識出,例如,使用丙胺酸掃描突變或模擬。尤其是CDR-H3和CDR-L3經常成為標靶。
在一些實施例中,取代、插入或刪去可發生在一或多個HVR內,只要此類改變實質上不降低抗體結合抗原的能力。例如,可在HVR內進行實質上不會降低結合親和力的保守性改變(例如,本文提供的保守性取代)。此類改變可能在HVR「熱點」或CDR之外。在上文提供的變異體VH序列的一些實施例中,每一HVR未經改變或包含不超過一、二或三個胺基酸取代。
一種用於辨識抗體中目標用於突變的殘基或區域的可用方法被稱為「丙胺酸掃描突變」,描述於Cunningham和Wells (1989) Science, 244: 1081-1085。在此方法中,目標殘基之一殘基或殘基組(例如帶電殘基,例如Arg、Asp、His、Lys和Glu)被辨識出,並被中性或帶負電的胺基酸(例如丙胺酸或聚丙胺酸)取代,以決定抗體與抗原的相互作用是否受到影響。其他取代可引入至顯示出對初始取代的功能敏感性的胺基酸位置處。替代地或額外地,抗原-抗體複合物的晶體結構係用於辨識抗體和抗原之間的接觸位點。此類接觸殘基和相鄰殘基可被靶向或消除,而作為取代的候選物。可篩選變異體以確定其是否含有所希望的特性。
胺基酸序列的插入包括胺基及/或羧基端融合,長度範圍從一個殘基到含有一百個或更多個殘基的多肽,以及單一或多個胺基酸殘基的序列內插入。末端插入的實例包括具有N-端甲硫胺醯殘基的抗體。該抗體分子的其他插入型變異體包括抗體的N-或C-端融合至一酵素(例如,針對ADEPT)或一增加該抗體之血清半衰期的多肽。
b)醣基化變異體
在一些實施例中,本文提供的抗體經改變以增加或減少抗體被醣基化的程度。向抗體加入或刪除醣基化位點可方便地藉由改變胺基酸序列,藉此創造或移除一或多個醣基化位點而達成。
在抗體包含一Fc區時,與其相連的碳水化合物可被改變。哺乳動物細胞產生的天然抗體通常包含分支、雙觸角寡醣,其藉由N-橋聯連結至Fc區之CH2域的Asn297。請參見例如,Wright等人 TIBTECH 15: 26-32 (1997)。寡醣可包括各種碳水化合物,例如甘露醣、N-乙醯葡醣胺(GlcNAc)、半乳醣和唾液酸,以及在雙觸角寡醣結構的「主幹」中連接至GlcNAc的岩藻醣。在一些實施例中,本申請案的抗體可進行寡醣修飾,以創造具有某些增進特性的抗體變異體。
在一些實施例中,係提供具有醣類結構的抗體變異體,該醣類結構缺乏(直接或間接)連接到Fc區的岩藻醣。例如,此類抗體中岩藻醣的含量可為1至80%、1%至65%、5%至65%或20%至40%。岩藻醣的量是藉由計算Asn297醣鏈內的岩藻醣平均含量而決定的,相對於與Asn 297相連的所有醣結構(例如,複合、雜合和高度甘露醣結構)的總和,以MALDI-TOF質譜法測量,如WO 2008/077546中所述。Asn297是指位於Fc區約位置297的天冬醯胺殘基(Fc區殘基的EU編號);然而,由於抗體的微小序列差異,Asn297也可能位於位置297上游或下游約±3個胺基酸處,即介於位置294和300之間。此類岩藻醣基化變異體可具有增進的ADCC功能。請參見,例如,美國專利公開號US 2003/0157108 (Presta、L.);US 2004/0093621 (Kyowa Hakko Kogyo股份有限公司)。與「去岩藻醣基化」或「岩藻醣缺失」抗體變異體相關的文獻實例包括:US 2003/0157108; WO 2000/61739; WO 2001/29246; US 2003/0115614; US 2002/0164328; US 2004/0093621; US 2004/0132140; US 2004/0110704; US 2004/0110282; US 2004/0109865; WO 2003/085119; WO 2003/084570; WO 2005/035586; WO 2005/035778; WO2005/053742; WO2002/031140; Okazaki等人,J. Mol. Biol. 336: 1239-1249 (2004); Yamane-Ohnuki等人 Biotech. Bioeng. 87: 614 (2004)。能夠產生去岩藻醣基化抗體的細胞株實例包括缺乏蛋白質岩藻醣基化的Lec13 CHO細胞(Ripka等人,Arch. Biochem. Biophys. 249: 533-545 (1986);US專利申請案號US 2003/0157108 A1,Presta, L;及WO 2004/056312 A1,Adams等人),以及敲除細胞株,例如α-1、6-岩藻醣基轉移酶基因FUT8敲除CHO細胞(請參見例如Yamane-Ohnuki等人,Biotech. Bioeng. 87: 614 (2004);Kanda, Y.等人,Biotechnol. Bioeng., 94 (4):680-688 (2006);以及WO2003/085107)。
抗體變異體更提供二等分的寡醣,例如,其中連接到抗體Fc區的雙觸角寡醣被GlcNAc二等分。此類抗體變異體可能具有降低的岩藻醣基化及/或增進的ADCC功能。此類抗體變異體的實例描述於例如WO 2003/011878 (Jean-Mairet等人);美國專利號6,602,684 (Umana等人);以及US 2005/0123546 (Umana等人)。亦提供在連接到Fc區的寡醣中具有至少一個半乳醣殘基的抗體變異體。此類抗體變異體可具有增進的CDC功能。此類抗體變異體描述於例如WO 1997/30087 (Patel等人);WO 1998/58964 (Raju, S.);以及WO 1999/22764 (Raju, S.)。
CAR (包括其功能部分和功能變異體)可藉由本領域中已知的方法獲得。CAR可經由任何製備多肽或蛋白質的合適方法製備。自始合成多肽和蛋白質的合適方法描述於參考文獻中,例如Chan等人,Fmoc Solid Phase Peptide Synthesis, Oxford University Press, Oxford, United Kingdom, 2000; Peptide and Protein Drug Analysis, Reid, R.編,Marcel Dekker, Inc., 2000;Epitope Mapping, Westwood等人編,Oxford University Press, Oxford, United Kingdom, 2001;以及美國專利號 5,449,752。此外,多肽和蛋白質可使用本文所述的核酸使用標準重組方法重組產生。請參見例如Sambrook等人,Molecular Cloning:A Laboratory Manual,第3版,Cold Spring Harbor Press, Cold Spring Harbor, N.Y. 2001;以及Ausubel等人,Current Protocols in Molecular Biology, Greene Publishing Associates and John Wiley & Sons, N Y, 1994。此外,一些CAR (包括其功能部分和功能變異體)可從來源,例如植物、細菌、昆蟲、哺乳動物(例如大鼠、人類)等中分離及/或純化出。分離和純化的方法為本領域中已知的。或者,本文所述的CAR (包括其功能部分和功能變異體)可由工廠工業合成。在此態樣中,CAR可為合成性、重組性、經分離及/或經純化。
可偵測標記物與標籤
CAR、表現CAR的T細胞、單株抗體、其抗原結合片段,特異於本文揭示的一或多種抗原,亦可與標籤蛋白一起表現(例如,共表現)。在一些實施例中,一弗林蛋白酶識別位點和下游2A自裂解胜肽序列,設計用於該標籤序列和CAR序列的同時雙順反子表現。在一些實施例中,該2A序列包含核酸序列GSGATNFSLLKQAGDVEENPGP (SEQ ID NO: 44)。在一些實施例中,弗林蛋白酶和P2A序列包含編碼SEQ ID NO: 44之胺基酸序列的核酸序列。在一些實施例中,P2A標籤包含SEQ ID NO: 44的胺基酸序列或具有與其至少95%、至少96%、至少97%、至少98%、至少99%一致性的序列。
在一些實施例中,特異於本文揭示的一或多種抗原之CAR、表現CAR的T細胞、單株抗體、其抗原結合片段,亦可與EGFR一起表現。在一些實施例中,特異於本文揭示的一或多種抗原之CAR、表現CAR的T細胞、單株抗體、其抗原結合片段,係與截短的EGFR (tEGFR)一起表現(例如,共表現)。在一些實施例中,tEGFR包含與SEQ ID NO: 43至少95%一致、至少96%一致、至少97%一致、至少98%一致、至少99%一致或100%一致的胺基酸序列。
tEGFR: MLLLVTSLLLCELPHPAFLLIPRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGCTGPGLEGCPTNGPKIPSIATGMVGALLLLLVVALGIGLFM (SEQ ID NO: 43)
特異於本文揭示的一或多種抗原之CAR、表現CAR的T細胞、單株抗體、其抗原結合片段,亦可與可偵測標記物共軛;例如,能夠藉由ELISA、分光光度法、流式細胞術、顯微術或診斷成像技術(例如電腦斷層掃描(CT)、電腦軸向斷層掃描(CAT)掃描、磁共振成像(MRI)、核磁共振成像(NMRI)、磁共振斷層掃描(MTR)、超音波、光纖檢查和腹腔鏡檢查)偵測的可偵測標記物。可偵測標記物的具體、非限制性實例包括螢光基團、化學發光劑、酵素聯結、放射性同位素和重金屬或化合物(例如用於以MRI偵測的超順磁性氧化鐵奈米晶體)。例如,可使用的可偵測標記物包括螢光化合物,包括螢光素、異硫氰酸螢光素、羅丹明(rhodamine)、5-二甲胺-1-萘磺醯氯、藻紅蛋白、鑭系元素磷光體、及類似物。亦可使用生物發光標記物,例如螢光素酶、綠色螢光蛋白(GFP)、黃色螢光蛋白(YFP)。特異於本文揭示的一或多種抗原之CAR、表現CAR的T細胞、抗體、其抗原結合片段,亦可與用於偵測的酵素共軛,例如辣根過氧化酶、β-半乳醣苷酶、螢光素酶、鹼性磷酸酶、葡萄醣氧化酶、及類似物。當CAR、表現CAR的T細胞、抗體、其抗原結合片段,與可偵測的酵素共軛時,可藉由加入額外的試劑進行偵測,該酵素使用該額外試劑產生可辨別的反應產物。例如,當辣根過氧化酶試劑存在時,加入過氧化氫和二胺基聯苯胺會產生有色反應產物,該產物可目視偵測。CAR、表現CAR的T細胞、抗體、其抗原結合片段,亦可與生物素共軛,並經由抗生物素蛋白(avidin)或鏈黴抗生物素蛋白(streptavidin)結合的間接測量來偵測。應當注意的是,抗生物素蛋白本身可與酵素或螢光標記共軛。
CAR、表現CAR的T細胞、抗體、其抗原結合片段,可與順磁性劑例如釓共軛。順磁性試劑如超順磁性氧化鐵亦可作為標記物。抗體亦可與鑭系元素(例如銪和鏑)和錳共軛。抗體或抗原結合片段亦可標記有可被二級報導子辨識的預定多肽表位(例如白胺酸拉鍊對序列、二級抗體的結合位點、金屬結合域、表位標籤)。
CAR、表現CAR的T細胞、抗體、其抗原結合片段,亦可與經放射性標記的胺基酸共軛。放射性標記可用於診斷和治療目的。例如,放射性標記可用於藉由X射線、發射光譜或其他診斷技術偵測本文揭示的一或多種抗原及表現抗原的細胞。此外,該放射性標記可在治療上作為毒素,以治療個體的腫瘤,例如治療神經母細胞瘤。多肽之標籤的實例包括但不限於以下放射性同位素或放射性核苷酸:
3H、
14C、
15N、
35S、
90Y、
99Tc、
111In、
125I、
131I。
偵測此類可偵測標記物的方法為本領域技術人員眾所周知的。因此,例如,放射性標記可使用照相底片或閃爍計數器偵測,螢光標記物可使用光偵測器偵測發出的光線而偵測。酵素性標記物通常藉由提供酵素與受質,並偵測酵素對受質作用產生的反應產物,且藉由簡單地觀察有色標記物而偵測該顯色標記物。
核酸、表現載體及宿主細胞
本發明之一實施例進一步提供一種核酸,該核酸包含編碼本文所述的任何CAR、抗體或其抗原結合部分(包括其功能部分和功能變異體)的核苷酸序列。本發明的核酸可包含編碼本文所述的前導序列、抗原結合域、跨膜域及/或細胞內T細胞信號傳導域之任一者的核苷酸序列。
在一態樣中,本發明涵蓋包含編碼CAR的核酸分子的重組核酸構建體,其中該核酸分子包含編碼例如本文所述的抗GCC結合域的核酸序列,其相鄰於或位於該編碼細胞內信號域的核酸序列之同一讀框中。可用於CAR中之例示性之細胞內信號傳導域包括,但不限於:一或多個細胞內信號傳導域,例如CD3-ζ、CD28、4-1BB及類似物。在一些實施例中,該CAR可包含CD3-ζ、CD28、4-IBB及類似物之任何組合。
在一態樣中,本發明提供一種核酸,其包含與編碼本文所述之CAR構築體的核酸至少約70%或更高,如80%、約90%、約91%、約92%、約93%、約94%、約95%、約96%、約97%、約98%或約99%一致之核苷酸序列。
在一些實施例中,該核酸編碼一抗GCC結合域,其選自於表1-3或表7中所提供之抗GCC VH序列。在一些實施例中,該核酸包含與SEQ ID NO: 61-70之任一者至少約70%或更高,如80%、約90%、約91%、約92%、約93%、約94%、約95%、約96%、約97%、約98%或約99%一致之序列。在一些實施例中,該核酸包含與SEQ ID NO: 61-70之任一者一致之序列。
在一些實施例中,該核苷酸序列可經密碼子修飾。不受特定理論的束縛,一般相信該核苷酸序列的密碼子最佳化可增加mRNA轉錄物的轉譯效率。該核苷酸序列的密碼子最佳化可能涉及以天然密碼子取代另一個編碼相同胺基酸的密碼子,但可藉由細胞內更容易獲得的tRNA轉譯,因而提高轉譯效率。該核苷酸序列的最佳化亦可降低會干擾轉譯的二級mRNA結構,因而提高轉譯效率。
在本發明之一實施例中,該核酸可包含編碼本發明CAR之抗原結合域的密碼子-經修飾之核苷酸序列。在本發明之另一實施例中,該核酸可包含編碼本發明CAR之任一者(包括功能部分及其功能變異體)之密碼子-經修飾之核苷酸序列。
在一態樣中,本發明涉及一載體,其包含本文所述的核酸分子,例如編碼本文所述的CAR的核酸分子。在一實施例中,該載體選自於由以下組成之組:DNA、RNA、質體、慢病毒載體、腺病毒載體或逆轉錄病毒載體。
在一實施例中,該載體為慢病毒載體。在一實施例中,該載體進一步包含一啟動子。在一實施例中,該啟動子為EF-1啟動子。
表現載體包括質體、逆轉錄病毒、黏接質體、YAC、EBV衍生的附加體、及類似物。一種方便的載體為編碼功能完整人類CH或CL免疫球蛋白序列的載體,其具有經改造的適當限制性位點,以便可以輕鬆插入和表現任何VH或VL序列。在此種載體中,剪接通常發生在插入J區的剪接供體位點和人類C區之前的剪接受體位點之間,也發生在人類CH外顯子內的剪接區。合適的表現載體可包含許多組件,例如複製起點、可選擇標記基因、一或多種表現控制元件,例如轉錄控制元件(例如啟動子、增強子或終止子)、及/或一或多個轉譯信號、一信號序列或前導序列、及類似物。聚腺苷酸化和轉錄終止發生在該編碼區下游的天然染色體位點。所得嵌合性抗體可與任何強啟動子連接。可使用的合適載體實例包括適用於哺乳動物宿主並以病毒複製系統為基礎者,例如猿猴病毒40(SV40)、勞斯肉瘤病毒(RSV)、腺病毒2、牛乳頭狀瘤病毒(BPV)、乳多泡病毒BK突變異體(BKV),或小鼠和人類巨細胞病毒(CMV),以及莫洛尼氏鼠白血病病毒(MMLV)、天然Ig啟動子等。多種合適的載體為本領域中已知的,包括維持在單副本或多副本、或整合到宿主細胞染色體中的載體,例如,經由LTR,或經改造而具有多個整合位點的人工染色體(Lindenbaum等人,
Nucleic Acids Res.32:e172 (2004)、Kennard等人,
Biotechnol. Bioeng. Online May 20, 2009)。合適載體的額外實例在後面章節中列出。
本發明亦包括可直接轉染到細胞中的RNA構建體。一種產生用於轉染的mRNA的方法,涉及以特別設計的引子對模板進行體外轉錄(IVT),之後進行polyA加入步驟,以產生含有3'和5'未轉譯序列(「UTR」)、5'帽及/或內部核醣體進入位點(IRES)、待表現的核酸和polyA尾部,長度通常為50至2000個鹼基。如此產生的RNA可有效地轉染不同種類的細胞。在一實施例中,該模板包括用於該CAR之序列。在一實施例中,藉由電穿孔將RNA CAR載體轉導至細胞例如T細胞或NK細胞中。
因此,本發明提供一種包含一核酸的表現載體,該核酸編碼一抗體、抗體的抗原結合片段(例如,人類、人源化、嵌合抗體或任何前述的抗原結合片段)、抗體鏈的核酸(例如,重鏈、輕鏈)或結合至GCC蛋白的抗體鏈的抗原結合部分。
在真核宿主細胞中的表現是有用的,因為此類細胞比原核細胞更有可能組裝和分泌出正確折疊的和具有免疫學活性的抗體。然而,任何所得由於不正確折疊而失活之抗體,可根據已知方法重新恢復活性(Kim及Baldwin、“Specific Intermediates in the Folding Reactions of Small Proteins and the Mechanism of Protein Folding”,
Ann. Rev. Biochem.51、第459-89頁(1982))。宿主細胞可能會產生完整抗體的一部分,例如輕鏈二聚體或重鏈二聚體,其亦為本發明的抗體類似物。
在一實施例中,可將核酸加入重組表現載體中。在此方面,一實施例提供包含該核酸任一者的重組表現載體。出於本文目的,術語「重組表現載體」是指基因經修飾的寡核苷酸或聚核苷酸構建體,當該構建體包含編碼該mRNA、蛋白質、多肽或胜肽的核苷酸序列時,其允許宿主細胞表現該mRNA、蛋白質、多肽或胜肽,且該載體在足以在細胞內表現該mRNA、蛋白質、多肽或胜肽的條件下與該細胞接觸。這些載體並非以一個整體天然發生。
然而,該載體之一部分可為天然發生。重組表現載體可包含任一類型的核苷酸,包括但不限於DNA和RNA,其可為單鏈或雙鏈、合成或部分來自天然來源,且可包含天然的、非天然的或經改變的核苷酸。該重組表現載體可包含天然發生或非天然發生的核苷酸間聯結,或兩種類型的聯結兼具。較佳地,非天然發生或經改變的核苷酸或核苷酸間聯結並不阻礙載體的轉錄或複製。
在一實施例中,該重組表現載體可為任何合適的重組表現載體,且可用於轉型或轉染任何合適的宿主細胞。合適的載體包括設計用於繁殖和擴增或用於表現、或兩者兼有的載體,例如質體和病毒。該載體可選自於由下組成之組:pUC系列(Fermentas Life Sciences, Glen Burnie, Md.)、pBluescript系列(Stratagene, LaJolla, CA)、pET系列(Novagen, Madison, WI)、pGEX系列(Pharmacia Biotech,Uppsala,Sweden)和pEX系列(Clontech,Palo Alto,CA)。
亦可使用噬菌體載體,例如λ、λZapII (Stratagene)、EMBL4和λNMI 149。植物表現載體的實例包括pBIO1、pBI101.2、pBHO1.3、pBI121和pBIN19(Clontech)。動物表現載體的實例包括pEUK-C1、pMAM和pMAMneo (Clontech)。重組表現載體可為病毒載體,例如逆轉錄病毒載體或慢病毒載體。慢病毒載體是衍生自慢病毒基因組的至少一部分的載體,尤其包括自失活慢病毒載體,如提供於Milone等人,Mol. Ther. 17(8): 1453-1464 (2009)。可用於臨床的慢病毒載體的其他實例包括,例如但不限於,來自Oxford BioMedica plc 的LENTIVECTOR®基因遞送技術、來自Lentigen的LENTIMAX™載體系統、及類似技術。非臨床類型的慢病毒載體亦可獲得,且為本領域技術人員已知。
許多轉染技術為本領域中已知的(請參見,例如Graham等人,Virology, 52: 456-467 (1973);如前述之Sambrook等人;Davis等人,Basic Methods in Molecular Biology, Elsevier (1986);以及Chu等人,Gene, 13: 97 (1981))。
轉染方法包括磷酸鈣共沉澱(請參見例如如前述之Graham等人)、直接微量注射到培養細胞中(請參見例如Capecchi, Cell, 22: 479-488 (1980))、電穿孔(請參見例如,Shigekawa等人,BioTechniques, 6: 742-751 (1988))、微脂體介導的基因轉移(請參見例如,Mannino等人,BioTechniques, 6: 682-690 (1988))、脂質介導的轉導(請參見例如,Feigner等人,Proc. Natl. Acad. Sci. USA, 84: 7413-7417 (1987))、和使用高速微彈的核酸遞送(請參見例如,Klein等人,Nature, 327: 70-73 (1987))。
在一實施例中,重組表現載體可使用(例如)如前述之Sambrook等人及如前述之Ausubel等人所描述之標準重組DNA技術製備。可製備環狀或直線表現載體的構建體,以包含在原核或真核宿主細胞中發揮作用的複製系統。複製系統可衍生自例如ColE1、2μ質體、λ、SV40、牛乳突狀瘤病毒、及類似病毒。
重組表現載體可包含調控序列,例如轉錄和轉譯起始和終止密碼子,其特異於待引入該載體的宿主細胞類型(例如細菌、真菌、植物或動物),若合適的話,並考慮該載體是基於DNA還是基於RNA。該重組表現載體可包含限制性位點,以幫助選殖。
重組表現載體可包括一或多種標記基因,其允許篩選出經轉型或經轉染的宿主細胞。標記基因包括殺生物劑抗性,例如對抗生素、重金屬等的抗性,在營養缺陷型宿主中的互補,以提供原養型及類似物。適用於本發明表現載體的標記基因包括,例如,新黴素/G418抗性基因、潮黴素抗性基因、組胺醇抗性基因、四環素抗性基因、和胺芐青黴素抗性基因。
該重組表現載體可包含天然或非天然啟動子,其可操作地連接至編碼該CAR (包括功能部分及其功能變異體)的核苷酸序列、或與編碼該CAR的核苷酸序列互補或雜合的核苷酸序列。啟動子的選擇,例如強、弱、可誘導、組織特異性和發育特異性,係落於技術人員的一般技能範圍內。類似地,核苷酸序列與啟動子的組合也落於技術人員的一般技能範圍內。該啟動子可為非病毒啟動子或病毒啟動子,例如巨細胞病毒(CMV)啟動子、SV40啟動子、RSV啟動子、EFl α啟動子或在鼠幹細胞病毒的長末端重複序列中發現的啟動子。
重組表現載體可設計為用於暫時表現、穩定表現或兩者皆是。此外,重組表現載體可製備為用於組成型表現或誘導型表現。
此外,重組表現載體可製備為包括一自殺基因。如本文所用,術語「自殺基因」是指導致表現該自殺基因的細胞死亡的基因。自殺基因可為賦予表現基因的細胞對試劑(例如藥物)的敏感性,並在細胞與試劑接觸或暴露於試劑時導致細胞死亡的基因。自殺基因為本領域中已知的(請參見,例如,Suicide Gene Therapy: Methods and Reviews, Springer, Caroline J. (Cancer Research UK Centre for Cancer Therapeutics at the Institute of Cancer Research, Sutton, Surrey, UK), Humana Press, 2004),包括例如單純皰疹病毒(HSV)胸苷激酶(TK)基因、胞嘧啶去胺基酶、嘌呤核苷磷酸化酶和硝基還原酶。
一實施例進一步提供包含本文所述的任何重組表現載體的宿主細胞。如本文所用,術語「宿主細胞」是指可含有本發明的重組表現載體的任一類型細胞。該宿主細胞可為真核細胞,例如植物、動物、真菌或藻類,或可為原核細胞,例如細菌或原生動物。該宿主細胞可為培養細胞或初代細胞,即直接從生物體例如人類分離出。該宿主細胞可為附著細胞或懸浮細胞(即懸浮生長的細胞)。合適的宿主細胞為本領域中已知的,包括例如DH5a大腸桿菌細胞、中國倉鼠卵巢細胞、猴VERO細胞、COS細胞、HEK293細胞、HEK293T細胞、及類似細胞。為了擴增或複製該重組表現載體目的,該宿主細胞可為原核細胞,例如DH5a細胞。為了產生重組CAR之目的,該宿主細胞可為哺乳動物細胞。該宿主細胞可為人類細胞。當宿主細胞可為任何細胞類型、可衍生自任何類型的組織且可處於任何發育階段時,該宿主細胞可為周邊血液淋巴細胞(PBL)或周邊血液單核細胞(PBMC)。該宿主細胞可為T細胞。
出於本文之目的,該T細胞可為任何T細胞,諸如經培養T細胞,例如初代T細胞,或來自經培養T細胞株,例如Jurkat、SupTl等的T細胞,或自哺乳動物獲得之T細胞。若自哺乳動物獲得,則該T細胞可自多種來源獲得,包括但不限於血液、骨髓、淋巴結、胸腺或其他組織或液體。T細胞亦可經富集或純化。該T細胞可為人類細胞。該T細胞可為分離自人類之T細胞。該T細胞可為任何類型之T細胞且可為任何發育階段,包括但不限於:CD4+/CD8+雙陽性T細胞、CD4+輔助T細胞(例如Th1及Th2細胞)、CD8+ T細胞(例如,細胞毒殺T細胞)、腫瘤浸潤細胞、記憶T細胞、記憶幹細胞(即Tscm)、原始T細胞及類似細胞。該T細胞可為CD8+ T細胞或CD4+ T細胞。
於一實施例中,如本文所述的CAR可用於合適的非T細胞中。此類細胞為具有免疫效應功能者,例如由多潛能幹細胞產生之NK細胞及T-類似細胞。
本申請案之一態樣係提供一種經改造之免疫效應細胞,其包含本文所述的CAR之任一者,或上述任何一種經分離的核酸,或上述任何一種載體。在一些實施例中,該免疫效應細胞為T細胞、NK細胞、周邊血液單核細胞(PBMC)、造血幹細胞、多潛能幹細胞或胚胎幹細胞。在一些實施例中,該免疫效應細胞為T細胞。
一實施例亦提供包含至少一種本文所述之宿主細胞的細胞群。該細胞群可為異質群,其包含含有所述的任何重組表現載體的宿主細胞,以及至少一種其他細胞(例如不包含任何該重組表現載體的宿主細胞(如T細胞))、或T細胞以外的細胞,例如B細胞、巨噬細胞、中性顆粒細胞、紅血球、肝細胞、內皮細胞、上皮細胞、肌肉細胞、腦細胞等。或者,該細胞群可為實質上同質之群體,其中該群體主要包含含有該重組表現載體(例如基本上由其組成)的宿主細胞。該群體亦可為細胞的複製群體,其中該群體的所有細胞皆為包含一重組表現載體的單一宿主細胞的複製株,而使得該群體的所有細胞都包含該重組表現載體。在本發明之一實施例中,該細胞群為包含宿主細胞的複製株群,該宿主細胞包含如本文所述的重組表現載體。
CAR (包括其功能部分及其變異體)、核酸、重組表現載體、宿主細胞(包括其群體)及抗體(包括其抗原結合部分),可經分離及/或純化。例如,經純化(或經分離)的宿主細胞製備物,係為其中宿主細胞比其體內自然環境中的細胞更純。此類宿主細胞可例如藉由標準純化技術製造。在一些實施例中,宿主細胞之製備物經純化,使得宿主細胞含量為該製備物之總細胞含量的至少約50%,例如至少約70%。例如,該純度可為至少約50%、可大於約60%、約70%或約80%、或可為約100%。
編碼所希望分子的核酸序列可使用本領域中已知的重組方法獲得,例如藉由篩選來自表現該基因的細胞之基因庫、藉由從已知包括相同基因的載體中衍生出基因、或藉由使用標準技術直接從含有它們的細胞和組織中分離出。
或者,感興趣的基因可合成產生,而非複製。本發明亦提供插入本發明DNA的載體。衍生自逆轉錄病毒(如慢病毒)的載體為達成長期基因轉移的合適工具,因為它們允許轉基因長期穩定整合並在子代細胞中繁殖。慢病毒載體比衍生自癌-逆轉錄病毒(例如鼠類白血病病毒)的載體具有額外的優勢,因為它們可以轉導非增殖細胞(例如肝細胞)。它們亦具有低免疫原性的額外優勢。
編碼CAR的天然或合成核酸的表現,可藉由將編碼CAR多肽或其部分的核酸可操作地連接至一啟動子,並將該構建體整合到表現載體中而達成。該載體可適用於複製和整合至真核生物中。典型的複製載體包含轉錄和轉譯終止子、起始序列和用於調控所希望核酸序列表現的啟動子。
本發明的表現構建體亦可用於核酸免疫化和基因治療,使用標準基因遞送流程。基因遞送的方法為本領域中已知的。請參見例如,美國專利號 5,399,346、5,580,859、5,589,466,其係以全文引用之方式併入本文中。在另一實施例中,本發明提供一種基因治療載體。
可將核酸選殖至多種類型的載體中。例如,可將該核酸選殖到以下載體中,包括但不限於:質體、噬菌體、噬菌體衍生物、動物病毒和黏接質體。特別感興趣的載體包括表現載體、複製載體、探針產生載體和定序載體。此外,該表現載體可以病毒載體形式提供至細胞中。
病毒載體技術為本領域中已知的,並描述於例如Sambrook等人 (2001, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, New York),以及其他病毒學和分子生物學手冊。可作為載體的病毒包括但不限於:逆轉錄病毒、腺病毒、腺相關病毒、皰疹病毒和慢病毒。一般而言,合適的載體包含在至少一種生物體中有功能的複製起點、一啟動子序列、方便的限制性內切核酸酶位點、和一或多種可篩選標記物(例如,WO 01/96584;WO 01/29058;和美國專利號6,326,193)。
目前已開發多種基於病毒的系統,用於將基因轉移到哺乳動物細胞中。例如,逆轉錄病毒為基因傳遞系統提供一個方便的平台。可使用本領域已知的技術將選定的基因插入載體,並包裝在逆轉錄病毒顆粒中。之後可分離出該重組病毒,並將其經體內或離體遞送至個體的細胞中。許多逆轉錄病毒系統為本領域中已知的。在一些實施例中,使用腺病毒載體。有多種腺病毒載體為本領域中已知的。在一實施例中,使用慢病毒載體。
額外的啟動子元件,例如增強子,係調控轉錄啟動的頻率。通常,它們位於起始位點上游30-110 bp的區域,儘管最近證實有許多啟動子亦包含位於起始位點下游的功能元件。啟動子元件之間的間距通常是可調整的,因此當元件相互倒置或移動時,啟動子功能得以保留。在胸苷激酶(tk)啟動子中,在活性開始下降之前,啟動子元件之間的間距可增加到50 bp。取決於啟動子,單獨元件可協同或獨立地發揮功能以活化轉錄作用。
合適的啟動子之一實例為即刻早期巨細胞病毒(CMV)啟動子序列。此啟動子序列為強組成型啟動子序列,能夠驅動與其可操作地連接的任一聚核甘酸序列的高位準表現。
合適的啟動子之另一實例為延長生長因子-l a (EF-la)。然而,亦可使用其他組成型啟動子序列,包括但不限於:猿猴病毒40 (SV40)早期啟動子、小鼠乳腺腫瘤病毒(MMTV)、人類免疫缺陷病毒(HIV)長末端重複(LTR)啟動子、MoMuLV啟動子、禽類白血病病毒啟動子、愛潑斯坦-巴爾(Epstein-Barr)病毒立即早期啟動子、勞斯(Rous)肉瘤病毒啟動子,以及人類基因啟動子,例如但不限於:肌動蛋白啟動子、肌凝蛋白啟動子、血紅蛋白啟動子和肌酸激酶啟動子。此外,本發明不應限於使用組成型啟動子。誘導型啟動子亦被考慮作為本發明的一部分。誘導型啟動子的使用提供一種分子開關,當需要此種表現時,它能夠開啟與其可操作連接的聚核甘酸序列的表現,或者在不需要表現時關閉該表現。誘導型啟動子的實例包括但不限於:金屬硫胺酸啟動子、醣皮質激素啟動子、孕酮啟動子和四環素啟動子。
為了評估CAR多肽或其部分的表現,待引入細胞中的表現載體亦可包含一可篩選標記基因或報導子基因或兩者皆有,以幫助從應經病毒載體轉染或感染之細胞群中辨識和篩選出該表現細胞。在其他態樣中,該可篩選標記物可攜帶在分隔的DNA片段上,並用於共轉染程序中。
可篩選標記和報導子基因都可側接合適的調控序列,以使其能夠在宿主細胞中表現。可使用的可篩選標記物包括例如抗生素抗性基因,例如neo及類似基因。報導子基因用於辨識潛在的轉染細胞和評估調控序列的功能性。一般而言,報導子基因並不存在於接受者生物體或組織中,或不由接受者生物體或組織表現,且編碼其表現可經一些易於偵測的特性例如酵素活性來證明之多肽。在將DNA引入接受者細胞後,在合適的時間測定報導子基因的表現。合適的報導子基因可包括編碼螢光素酶、β-半乳醣苷酶、氯黴素乙醯轉移酶、分泌性鹼性磷酸酶或綠色螢光蛋白基因的基因(例如,Ui-Tei等人,2000 FEBS Letters 479: 79-82)。適合之表現系統為已知,且可使用已知技術或經商業上獲得而製備。一般而言,具有最小5'側翼區域並顯示出最高報導子基因表現位準的構建體,被辨識為啟動子。此類啟動子區域可與報導子基因連接,並用於評估試劑調控啟動子驅動轉錄的能力。
將基因引入細胞和表現的方法為本領域中已知的。在表現載體的情況下,係藉由本領域已知的任何方法將該載體輕易地引入宿主細胞中,例如哺乳動物、細菌、酵母或昆蟲細胞。例如,可藉由物理、化學或生物方法將該表現載體轉移到宿主細胞中。將聚核苷酸引入宿主細胞的物理方法包括磷酸鈣沉澱、脂質轉染、粒子轟擊、顯微注射、電穿孔及類似方法。生產包含載體及/或外源核酸之細胞的方法為本領域中已知的。請參見例如Sambrook等人 (2001, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, New York)。將聚核苷酸引入宿主細胞之一較佳方法為磷酸鈣轉染。
將感興趣的聚核苷酸引入宿主細胞的生物學方法包括使用DNA和RNA載體。病毒載體,尤其是逆轉錄病毒載體,已成為將基因插入哺乳動物(例如人類細胞)最廣泛使用的方法。其他病毒載體可衍生自慢病毒、痘病毒、單純皰疹病毒I、腺病毒和腺相關病毒及類似病毒。請參見,例如,美國專利號5,350,674和5,585,362。 將聚核苷酸引入宿主細胞的化學方法包括膠體分散系統,例如大分子複合物、奈米膠囊、微球、微珠、和基於脂質的系統,包括水包油乳液、微胞、混合微胞和微脂體。
使用作為體外和體內遞送載體的例示性膠體系統為微脂體(例如,人工脂質媒劑)。在使用非病毒遞送系統的情況下,例示性遞送媒劑為奈米顆粒,例如微脂體或其他合適的次微米尺寸遞送系統。考慮使用脂質配方將核酸引入宿主細胞中(體外、離體或體內)。在另一態樣中,核酸可與脂質結合。與脂質結合的核酸可被包裹在微脂體的水性內部,散佈在微脂體的脂質雙層內,通過同時與微脂體和寡核苷酸二者結合的連接分子連結到微脂體,包裹在微脂體中,與微脂體複合,分散在含有脂質的溶液中,與脂質混合,與脂質結合,作為懸浮液包含在脂質中,包含或與微胞複合,或以其他方式與脂質結合。脂質、脂質/DNA、或脂質/表現載體結合組成物不限於溶液中的任何特定結構。例如,它們可能以雙層結構、微胞或「坍塌」結構存在。它們也可能簡單地散佈在溶液中,可能形成大小或形狀不均勻的聚集體。脂質為脂肪物質,可以是天然發生或合成的脂質。例如,脂質包括天然存在於細胞質中的脂肪滴,以及含有長鏈脂肪烴及其衍生物的化合物類別,例如脂肪酸、醇、胺、胺基醇和醛。
適用的脂質可得自商業來源。例如,二肉荳蔻基磷脂醯膽鹼(「DMPC」)可得自Sigma、St. Louis, MO;磷酸二十六酯(「DCP」)可得自K & K Laboratories (Plainview、NY);膽固醇(「Choi」)可得自Calbiochem-Behring;二肉荳蔻基磷脂醯甘油(「DMPG」)和其他脂質可得自Avanti Polar Lipids公司(Birmingham, AL)。脂類在氯仿或氯仿/甲醇中的儲存液可在約-20°C下儲存。氯仿被用作唯一的溶劑,因為它比甲醇更容易揮發。「微脂體」為通用術語,包括藉由產生封閉的脂質雙層或聚集體而形成的各種單層和多層脂質媒劑。微脂體的特徵在於具有囊泡結構,該結構具有磷脂雙層膜和內部水性介質。多層微脂體具有由水性介質隔開的多脂質層。當磷脂懸浮在過量的水溶液中時,多脂質層會自發形成。脂質成分在形成封閉結構之前會先進行自我重排,並在脂質雙層之間捕捉水和溶解的溶質(Ghosh等人,1991 Glycobiology 5: 505-10)。
然而,亦考量在溶液中具有與正常囊泡結構不同的組成物。例如,脂質可能假設是微胞結構或僅作為脂質分子的不均勻聚集體存在。亦考量lipofectamine-核酸複合物。無論用於將外源核酸引入宿主細胞或以其他方式將細胞暴露於本發明抑制劑的方法如何,為了確認宿主細胞中重組DNA序列的存在,可進行多種測定法。此類測定法包括例如本領域技術人員熟知的「分子生物學」測定法,例如南方和北方印跡、RT-PCR和PCR;「生化」測定法,例如偵測特定胜肽的存在或不存在,例如藉由免疫學方法(ELISA和西方印跡)或藉由本文所述的測定法,來辨識出落入本發明範圍內的試劑。
本發明進一步提供一種載體,其包含編碼CAR之核酸分子。在一態樣中,CAR載體可直接轉導至細胞,例如T細胞中。在一態樣中,該載體為選殖或表現載體,例如包括但不限於一或多種質體(例如,表現質體、選殖載體、微環、微載體、雙微染色體)、逆轉錄病毒和慢病毒載體構建體的載體。在一態樣中,該載體能在哺乳動物T細胞中表現該CAR構建體。在一態樣中,該哺乳動物T細胞為人類T細胞。
在一些態樣中,非病毒方法可用於將編碼本文所述的CAR的核酸遞送至細胞或組織或個體中。在一些實施例中,該非病毒方法包括使用轉座子(也稱為轉位元)。在一些實施例中,轉座子為一段可將自身插入基因組中某個位置的DNA,例如,一段能夠自我複製並將其副本插入基因組的DNA,或一段可從更長的核酸中剪出並插入基因組中的另一位置的DNA。
額外的和例示性轉座子和非病毒遞送方法係描述於2016年4月8日申請的國際申請案WO 2016/164731的第196-198頁,其係以全文引用之方式併入本文中。
T細胞來源
在擴增及基因修飾(例如,以表現本文所述之CAR)之前,可自一個體獲得細胞來源,例如T細胞或NK細胞。術語「個體」係包括可引發免疫反應之活體生物體(例如哺乳動物)。個體之實例包括人類、犬、貓、小鼠、大鼠及其基因轉殖物種。
在實施例中,免疫效應細胞(例如免疫效應細胞群體),例如T細胞,係衍生自(例如分化自)幹細胞,例如胚胎幹細胞或多潛能幹細胞,例如誘導多潛能幹細胞(iPSC)。在實施例中,細胞為自體性或同種異體性。在細胞是同種異體的實施例中,該例如衍生自幹細胞(例如,iPSC)之細胞係經修飾以降低同種異體反應。例如,該細胞可經修飾以例如藉由修飾(例如破壞)其T細胞受體來減少其同種異體反應。在實施例中,具位置特異性之核酸酶可用於破壞T細胞受體,例如,在T細胞分化之後。在其他實例中,例如衍生自iPSC之T細胞的細胞係可由病毒特異性T細胞生成,其由於可辨識出病原體衍生的抗原而不太可能引起移植物-抗-宿主疾病。又在其它實例中,同種異體反應可例如藉由從常見HLA單倍型生成iPSC而降低(例如降至最低),使得它們與匹配之無關接受者個體之組織相容。
又在其它實例中,同種異體反應可例如藉由通過基因修飾來抑制HLA表現而降低(例如降至最低)。例如,衍生自iPSC的T細胞可如Themeli等人 Nat. Biotechnol. 31.10(2013):928-35所述來處理,其經由引用併入本文中。在一些實例中,衍生自幹細胞的免疫效應細胞(例如T細胞)可使用WO2014/165707(其經由引用併入本文)描述的方法處理/生成。
T細胞可自許多來源獲得,包括周邊血液單核細胞、骨髓、淋巴結組織、臍帶血、胸腺組織、來自感染部位的組織、腹水、肋膜積液、脾臟組織及腫瘤。在本發明的某些態樣中,可使用本領域中任何數目的T細胞株。在本發明的某些態樣中,T細胞可使用熟習此項技術者已知的任何數目的技術(諸如Ficoll™分離)而自個體收集的血液單元獲得。在一較佳態樣中,來自個體之循環血液的細胞藉由分離術獲得。分離術產物通常包含淋巴細胞,包括T細胞、單核細胞、顆粒細胞、B細胞、其他有核白血球、紅血球和血小板。在一態樣中,藉由分離術收集之細胞可經洗滌,以移除血漿分液,並將細胞置於適當緩衝液或培養基中,以用於後續處理步驟。在本發明的一態樣中,細胞係以磷酸鹽緩衝生理食鹽水(PBS)洗滌。在另一態樣中,清洗液不含鈣且可不含鎂,或不含許多二價陽離子(若非全部不含)。
缺乏鈣的初始活化步驟可能導致活化放大。正如本領域普通技術人員將容易理解的,洗滌步驟可藉由本領域技術人員已知的方法來完成,例如藉由使用半自動「流通」離心機(例如,Cobe 2991細胞處理器、Baxter CytoMate或Haemonetics Cell Saver 5),根據製造商的說明使用。在洗滌之後,細胞可再懸浮於各種生物相容緩衝液中,諸如(例如)不含鈣、不含Mg之PBS、PlasmaLyte A、或其他含或不含緩衝液之生理食鹽水溶液中。或者,可移除分離術樣本中的不希望成分,且細胞可直接重新懸浮於培養基中。
應認知到,本申請案之方法可利用包含5%或更少例如2%的人類AB血清的培養基條件,並利用已知的培養基條件和組成物,例如描述於Smith等人,“Ex vivo expansion of human T cells for adoptive immunotherapy using the novel Xeno-free CTS Immune Cell Serum Replacement” Clinical & Translational Immunology (2015) 4, e31; doi:10.1038/cti.2014.31。
在一態樣中,T細胞自周邊血液淋巴球分離出,藉由裂解紅血球且耗盡單核球,例如藉由經由PERCOLL™梯度離心,或藉由逆流離心淘析。T細胞之特定亞群,諸如CD3+、CD28+、CD4+、CD8+、CD45RA+及CD45RO+T細胞,可藉由陽性或負向篩選技術進一步分離。舉例而言,在一態樣中,T細胞藉由與抗-CD3/抗-CD28 (例如,3x28)共軛微珠(諸如DYNABEADS® M-450 CD3/CD28 T)一同靜置一段足以正向篩選出所需T細胞的時間而分離出。在一態樣中,該時間段為約30分鐘。在另一態樣中,該時間段範圍30分鐘至36小時或更長,且介於其間之所有整數值。在另一態樣中,該時間段為至少1、2、3、4、5或6小時。在又一較佳態樣中,時間段為10至24小時。在一態樣中,該靜置時間段為24小時。相較於其他細胞類型,更長的培養時間可用於在只有少量T細胞的任何情況下分離T細胞,例如自腫瘤組織或免疫受損個體中分離出腫瘤浸潤性淋巴細胞(TIL)。此外,使用更長的培養時間可增加CD8+ T細胞的捕捉效率。因此,藉由簡單地縮短或延長時間,T細胞被允許結合至CD3/CD28微珠,及/或藉由增加或降低微珠與T細胞之比率(如本文進一步描述),在培養起始或製程期間之其他時間點,T細胞亞群可優先被選擇或對抗。另外,藉由增加或降低微珠或其他表面上的抗-CD3及/或抗-CD28抗體之比率,在培養起始或其他希望之時間點,T細胞亞群可優先被選擇或對抗 熟習此項技術者應瞭解,亦可在本發明之內文中使用多個篩選回合。在某些態樣中,可能需要執行篩選程序並在活化及擴增製程中使用「未經篩選」的細胞。「未經篩選」的細胞亦可進行進一步篩選回合。
藉由負向篩選來富集T細胞群體係可藉由引導至負向篩選細胞所特有之表面標記物的抗體組合來實現。其中一種方法為細胞分選及/或篩選,其經由負磁免疫黏附或流式細胞儀進行篩選,其係使用引導至負向篩選細胞所特有之表面標記物的單株抗體混合液。舉例而言,為了藉由負向篩選來富集CD4+細胞,單株抗體混合液通常包括CD14、CD20、CDIIb、CD16、HLA-DR及CD8之抗體。在某些態樣中,希望可富集或正向篩選出典型表現CD4+、CD25+、CD62Lhi、GITR+和FoxP3+之調節T細胞。
或者,在某些態樣中,T調節細胞由抗-C25共軛微珠或其他類似選擇方法耗盡。本文所描述之方法可包括例如篩選特異性免疫效應細胞亞群,例如T細胞,其為T調節細胞-耗盡之群體、CD25+耗盡細胞,使用例如本文所描述之負向篩選技術。較佳地,T調節耗盡細胞群體含有少於30%、25%、20%、15%、10%、5%、4%、3%、2%、1%的CD25+細胞。
在一實施例中,T調節細胞(例如CD25+ T細胞)係自使用抗-CD25抗體或其片段或CD25-結合配位體IL-2之群體移出。在一實施例中,該抗-CD25抗體或其片段或CD25-結合配位體與基材(例如,微珠)共軛,或以其他方式塗覆於基材(例如微珠)上。在一實施例中,抗-CD25抗體或其片段與如本文所描述之基材共軛。
於一實施例中,該T調節細胞(例如CD25+ T細胞)係使用Miltenyi™之CD25耗盡試劑自群體移出。在一實施例中,細胞與CD25耗盡試劑之比率為1e7個細胞對20 uL、或1e7個細胞對15 uL、或1e7個細胞對10 uL、或1e7個細胞對5 uL、或1e7個細胞對2.5 uL、或1e7個細胞對1.25 uL。在一實施例中,例如針對T調節細胞,例如使用超過每毫升5億個細胞之CD25+耗盡。在另一態樣中,使用每毫升6億、7億、8億或9億個細胞之細胞濃度。於一實施例中,待耗盡的免疫效應細胞群包括約6 x 10
9個CD25+T細胞。在其他態樣中,待耗盡的免疫效應細胞群包括約1 x 10
9至l x 10
10個CD25+ T細胞,及介於其之間的任何整數值。在一實施例中,所得T調節耗竭細胞群具有2 x 10
9個T調節細胞,例如CD25+細胞,或更低(例如,1 x 10
9、5 x 10
8、1 x 10
8、5 x 10
7、1 x 10
7或更少之CD25+細胞)。
在一實施例中,該T調節細胞(例如CD25+細胞)係使用具有耗盡管組的CliniMAC系統(如,管路162-01)從群體移出。在一實施例中,該CliniMAC系統是在諸如DEPLETION2.1之耗盡設定下運行。
在不希望受特定理論束縛之情況下,在個體進行血球分離術之前或製造表現CAR的細胞產物期間減少免疫細胞之負向調節因子濃度(例如,減少不想要的免疫細胞數量,例如TREG細胞),可降低個體復發的風險。舉例而言,耗盡TREG細胞之方法為本領域中已知的。降低TREG細胞之方法包括但不限於環磷醯胺、抗GITR抗體(本文所描述之抗GITR抗體)、CD25-耗盡及其組合。
在一些實施例中,該製造方法包含在製造表現CAR的細胞之前減少(例如,耗盡)TREG細胞的數量。舉例而言,該製造方法包含使樣本(例如分離術之樣本)與抗GITR抗體及/或抗-CD25抗體(或其片段,或CD25-結合配位體)接觸,以在例如製造表現CAR的細胞(例如T細胞、NK細胞)之前耗盡TREG細胞。
在一實施例中,在收集用於製造表現CAR的細胞產物的細胞之前,個體係使用可降低TRIG細胞的一或多種療法預先治療,藉此降低個體復發風險至以表現CAR的細胞治療。在一實施例中,減少TREG細胞之方法包括,但不限於,向個體投予環磷醯胺、抗GITR抗體、CD25-耗盡或其組合中之一或多者。投與環磷醯胺、抗GITR抗體、CD25-耗盡或其組合中之一或多者,可在輸注表現CAR的細胞產物之前、期間或之後進行。
在一實施例中,在收集用於製造表現CAR的細胞產物的細胞之前,個體係以環磷醯胺進行預處理,藉此降低個體復發風險至以表現CAR的細胞治療。在一實施例中,在收集用於製造表現CAR的細胞產物的細胞之前,個體係以抗-GITR抗體進行預處理,藉此降低個體復發風險至以表現CAR的細胞治療。
在一實施例中,待移出之細胞群並非調節性T細胞或腫瘤細胞,但可以其他方式負向影響CART細胞之擴增及/或功能的細胞,例如表現CD14、CDIIb、CD33、CD15之細胞,或可能由潛在免疫抑制細胞表現之其他標記物。在一實施例中,此類細胞預期與調節性T細胞及/或腫瘤細胞同時移出、或在該耗盡之後移出、或以另一順序移出。
本文所描述之方法可包括大於一個篩選步驟,例如大於一個耗盡步驟。藉由負向篩選來富集T細胞群,可例如以可引導至負向篩選細胞之獨特表面標記物的抗體組合而完成。其中一種方法為細胞分選及/或篩選,其經由負磁免疫黏附或流式細胞儀進行篩選,其係使用引導至負向篩選細胞所特有之表面標記物的單株抗體混合液。舉例而言,為了藉由負向篩選來富集CD4+細胞,單株抗體混合液通常包括CD14、CD20、CDIIb、CD16、HLA-DR及CD8之抗體。
本文所描述之方法可進一步包括自表現腫瘤抗原之群體移除細胞,例如,不包含CD25之腫瘤抗原,例如CD19、CD30、CD38、CD123、CD20、CD14或CDIIb,藉此提供T調節耗盡群體(例如,CD25+耗盡)及腫瘤抗原表耗盡細胞,其適於表現CAR,如本文所述之CAR。在一實施例中,表現腫瘤抗原的細胞係與T調節細胞(例如CD25+細胞)同時移出。舉例而言,抗-CD25抗體或其片段及抗腫瘤抗原抗體或其片段,可附著至同一基材(例如,微珠)上,其可用於移出細胞或抗-CD25抗體或其片段,或該抗腫瘤抗原抗體或其片段可附著至別的微珠上,該混合物可用於移出該細胞。在其他實施例中,T調節細胞(例如CD25+細胞)之移出及表現腫瘤抗原的細胞之移出係依序發生,且可例如以任何順序發生。
亦提供包括從表現檢查點抑制劑的群體中移出細胞的方法,例如本文描述的檢查點抑制劑,例如PD1+細胞、FAG3+細胞和TIM3+細胞之一或多者,從而提供T調節耗盡細胞群(例如CD25+耗盡細胞),和檢查點抑制劑耗盡細胞(例如PD1+、FAG3+及/或TIM3+耗盡細胞)。例示性檢查點抑制劑包括B7-H1、B7-1、CD160、P1H、2B4、PD1、TIM3、CEACAM (例如,CEACAM-1、CEACAM-3及/或CEACAM 5)、LAG3、TIGIT、CTLA-4、BTLA及LAIR1。在一實施例中,表現檢查點抑制劑的細胞係與T調節細胞(例如CD25+細胞)同時移除。舉例而言,抗-CD25抗體或其片段及抗檢查點抑制劑抗體或其片段,可附著至同一微珠上,其可用於移除該細胞或抗-CD25抗體或其片段,以及該抗檢查點抑制劑抗體或其片段可附著至別的微珠上,該混合物可用於移除該細胞。在其他實施例中,T調節細胞(例如CD25+細胞)之移除及表現檢查點細胞之移除為依序的,且可例如以任何順序發生。
在一實施例中,表現IFN-g、TNFa、IL-17A、IL-2、IL-3、IL-4、GM-CSF、IL-10、IL-13、顆粒酶B、及穿孔素或其他適當分子(例如其他細胞激素)之一或多者的T細胞群可被篩選出。用於篩選細胞表現之方法可例如藉由PCT公開案號:WO 2013/126712描述之方法決定。
就藉由正向或負向篩選來分離所希望之細胞群而言,可改變細胞和表面(例如,顆粒如微珠)的濃度。在某些態樣中,可能需要顯著降低微珠與細胞混合之體積(例如,增加細胞濃度),以確保細胞與微珠之最大接觸。舉例而言,在一態樣中,使用每毫升20億個細胞之濃度。在一態樣中,使用每毫升10億個細胞之濃度。在另一態樣中,使用超過每毫升1億個細胞之濃度。在另一態樣中,使用每毫升1000萬、1500萬、2000萬、2500萬、3000萬、3500萬、4000萬、4500萬或5000萬個細胞之細胞濃度。在又一態樣中,使用每毫升7500萬、8000萬、8500萬、9000萬、9500萬或1億個細胞的細胞濃度。在其他態樣中,可使用每毫升1億2千5百萬或1億5千萬個細胞的濃度。
使用高濃度可導致細胞產率、細胞活化和細胞擴增之增加。此外,使用高細胞濃度可更有效捕捉弱表現標靶抗原的細胞(如CD28-陰性T細胞),或來自存在許多腫瘤細胞的樣本(例如,白血病血液、腫瘤組織等)。此類細胞群可具有治療價值且可期望獲得。例如,使用高濃度的細胞,可更有效地篩選出具有通常較弱的CD28表現之CD8+ T細胞。
在一相關態樣中,可能希望使用較低濃度的細胞。藉由顯著地稀釋T細胞混合物,在顆粒與細胞之間的表面(例如,顆粒如微珠)相互作用最小化。此篩選出表現大量希望的抗原,以結合至該顆粒之細胞。例如,CD4+ T細胞表現較高位準之CD28,且比稀釋濃度中之CD8+ T細胞更有效捕捉。
在一態樣中,使用的細胞濃度為5 X 10e6/ml。在其他態樣中,所用濃度可為約1 X 10
5/ml至1 X 10
6/ml,及介於其之間的任何整數值。
在其他態樣中,細胞可在2至10°C或室溫下、在旋轉器上以不同速度培育不同時間長度。用於刺激之T細胞亦可在洗滌步驟之後冷凍。希望不被理論束縛,冷凍及隨後解凍步驟係藉由移除細胞群中的顆粒細胞及一定程度之單核球,而提供更均一的産物。在移除血漿及血小板之洗滌步驟之後,細胞可懸浮於冷凍溶液中。雖然許多冷凍溶液和參數為本領域中已知的,且可用於本文中,但其中一種方法涉及使用含有20% DMSO和8%人類血清白蛋白的PBS,或含10%葡聚醣40和5%右旋糖、20%人類血清白蛋白和7.5% DMSO、或31.25% Plasmalyte-A 31.25%、右旋糖5%、0.45% NaCl、10%葡聚醣40和5%右旋糖、20%人類血清白蛋白、和7.5% DMSO之培養基,或其他含有例如Hespan和PlasmaLyte A的合適細胞冷凍培養基,然後將細胞以每分鐘1°的速率冷凍至-80°C,並儲存在液態氮儲存槽的氣相中。可使用其他經控制冷凍方法以及不經控制冷凍方法,立即於-20°C或液態氮中進行。
於某些態樣中,冷凍保存細胞係如本文所述解凍並洗滌,且允許在利用本發明之方法活化之前,在室溫下靜置一小時。
本發明內文中亦涵蓋在可能需要如本文所述擴增細胞之前的某一時間點,自個體收集血液樣本或分離術產物。因此,可在需要的任何時間點收集待擴增的細胞來源,及期望的細胞,如經分離及冷凍以用於隨後之T細胞療法中的T細胞,用於任何數目之可受益於T細胞療法的疾病或病況,如本文所述者。
在一態樣中,血液樣本或分離術係由一般健康之個體收集。在某些態樣中,血液樣本或分離術是取自一般健康但有罹患疾病風險之個體,但尚未發展出疾病,且感興趣細胞被分離出並冷凍,供日後使用。在某些態樣中,T細胞可擴增、冷凍且在之後的時間使用。在某些態樣中,樣本在患者被診斷出罹患本文所述的特定疾病之後不久,但在進行任何治療之前收集。
在其他態樣中,細胞係由個體的血液樣本或分離術分離出,在進行任何數量的相關治療方式之前,包括但不限於經試劑如那他珠單抗(natalizumab)、依法珠單抗(efalizumab)、抗病毒劑、化學療法、放射療法、免疫抑制劑的試劑如環孢菌素、硫唑嘌呤、胺甲喋呤、黴酚酸酯和FK506、抗體、或其他免疫清除劑如CAMPATH、抗CD3抗體、環孢素、氟達拉濱(fludarabine)、環孢菌素、FK506、雷帕黴素(rapamycin)、黴酚酸、類固醇、FR901228和放射線治療。
在本發明的另一態樣中,T細胞係獲自治療後留有功能性T細胞之患者中。在這方面,已觀察到在某些癌症治療後,特別是使用損害免疫系統的藥物治療後,在患者正常從治療中恢復的治療後不久,獲得的T細胞的品質可能是最佳的,或可增進其體外擴增的能力。
同樣地,使用本文所述之方法進行離體操作後,這些細胞可處於用於增進植入和在體內擴增的較佳狀態。因此,在本發明之上下文中預期在此恢復階段收集血細胞,包括T細胞、樹突狀細胞、或造血細胞之其他細胞。此外,在某些態樣中,驅動(例如,以GM-CSF驅動)和調理方案可用於在個體中產生有利於特定細胞類型的再增殖、再循環、再生及/或擴增的條件,尤其是在確定的治療後時間窗口中。例示性細胞類型包括T細胞、B細胞、樹突狀細胞及免疫系統之其他細胞。
在一些實施例中,T細胞群為二丙三醇激酶(DGK)缺失型。DGK缺失細胞包括不表現DGK RNA或蛋白質,或具有降低或抑制DGK活性的細胞。DGK缺失細胞可藉由基因方法生成,例如,投與RNA干擾劑,例如siRNA、shRNA、miRNA,以減少或預防DGK表現。或者,DGK缺失細胞可利用本文所述的DGK抑制劑治療生成。
在一實施例中,T細胞群為Ikaros缺失細胞。Ikaros缺失細胞包括不表現Ikaros RNA或蛋白質,或具有減少或抑制Ikaros活性的細胞,Ikaros缺失細胞可藉由基因方法生成,例如,投與RNA干擾劑,例如siRNA、shRNA、miRNA,以降低或阻止Ikaros表現。
替代地,Ikaros缺失細胞可藉由以Ikaros抑制劑(例如來那度胺(lenalidomide))治療來生成。在實施例中,T細胞群為DGK缺失且Ikaros缺失,例如不表現DGK及Ikaros,或具有降低或抑制的DGK及Ikaros活性。此類DGK及Ikaros缺失細胞可藉由本文所描述之任一方法產生。在一實施例中,該NK細胞係自該個體獲得。在另一實施例中,該NK細胞為NK細胞株,例如NK-92細胞株(Conkwest)。
同種異體CAR免疫效應細胞
在本文所描述之實施例中,免疫效應細胞可為同種異體免疫效應細胞,例如T細胞或NK細胞。舉例而言,該細胞可為同種異體T細胞,例如缺乏功能性T細胞受體(TCR)及/或人類白血球抗原(HLA),例如第I類HLA及/或第II類HLA之表現的同種異體T細胞。
缺乏功能性TCR之T細胞可例如經改造,以使其不表現任何功能性TCR於其表面上、經改造以使其不表現包含功能性TCR之一或多個次單元、或經改造使其製造非常少之功能性TCR於其表面上。或者,該T細胞可表現實質上受損之TCR,例如藉由表現TCR之一或多個次單元之突變或截短形式。術語「實質上受損之TCR」意謂此TCR不會在宿主中引起不良免疫反應。
本文所描述之T細胞可為例如經改造,使其不會表現功能性HLA於其表面上。舉例而言,本文所述之T細胞可經改造,以使得細胞表面表現的HLA,例如,第I類HLA及/或第II類HLA,向下調節。
在一些實施例中,T細胞可缺乏功能性TCR及功能性HLA,例如第I類HLA及/或第II類HLA。缺乏功能性TCR及/或HLA表現的經修飾T細胞,可藉由任何合適手段獲得,包括TCR或HLA之一或多個次單元的敲除(knock out)或壓制(knock down)。舉例而言,T細胞可包括使用siRNA、shRNA壓制TCR及/或HLA、成簇的規則間隔短回文重複序列(CRISPR)、轉錄活化劑類似效應子核酸酶(TALEN)、或鋅指核酸酶(ZFN)。
在一些實施例中,該同種異體細胞可為不表現或以低位準表現抑制分子(例如,藉由本文所述之任何方法)的細胞。舉例而言,該細胞可為不表現或以低位準表現抑制分子的細胞,例如,其可降低表現CAR的細胞建立免疫效應反應之能力。抑制性分子之實例包括PD1、PD-L1、CTLA4、TIM3、LAG3、VISTA、BTLA、TIGIT、LAIR1、CD160、2B4、CD80、CD86、B7-H3 (CD276)、B7-H4 (VTCN1)、HVEM (TNFRSF14或CD270)、KIR、A2aR、第1類MHC、第2類MHC 、GAL9、及腺苷。抑制性分子的抑制,例如藉由在DNA、RNA或蛋白質層級上的抑制,可使表現CAR的細胞的表現度最佳化。在實施例中,抑制性核酸,例如抑制性核酸,例如dsRNA,例如siRNA或shRNA、成簇的規則間隔短回文重複序列(CRISPR)、轉錄激活因子樣效應核酸酶(TALEN)、或鋅指核酸內切酶(ZFN),如本文所述,皆可使用。
siRNA及shRNA抑制TCR或HLA
在一些實施例中,TCR表現及/或HLA表現可在細胞中(如T細胞中),使用siRNA或shRNA(其靶向編碼TCR及/或HLA之核酸)抑制,及/或使用抑制性分子(例如PD1、PD-L1、PD-L2、CTLA4、TIM3、CEACAM(例如,CEACAM-1、CEACAM-3及/或CEACAM-5)、LAG3、VISTA、BTLA、TIGIT、LAIR1、CD160、2B4、CD80、CD86、B7-H3 (CD276)、B7-H4 (VTCN1)、HVEM (TNFRSF14或CD270)、KIR、A2aR、第1類MHC、第2類MHC、GAL9、及腺苷)抑制。
siRNA和shRNA以及例示性shRNA的表現系統在例如2015年3月13日提交的國際公開案號WO2015/142675的第649和650段中進行描述,其經由引用整體併入。
用以抑制TCR或HLA之CRISPR
如本文所用,「CRISPR」或「用於TCR及/或HLA之CRISPR」或「抑制TCR及/或HLA之CRISPR」係指一組成簇的規則間隔短回文重複序列,或包含此類重複組之系統。如本文所用,「Cas」係指CRISPR-相關蛋白。
「CRISPR/Cas」系統係指衍生自CRISPR及Cas之系統,其可用於在細胞中(如T細胞中),使TCR及/或HLA基因、及/或抑制分子(例如PD1、PD-L1、PD-L2、CTLA4、TIM3、CEACAM (例如,CEACAM-1、CEACAM-3及/或CEACAM-5)、LAG3、VISTA、BTLA、TIGIT、LAIR1、CD160、2B4、CD80、CD86、B7-H3 (CD276)、B7-H4 (VTCN1)、HVEM (TNFRSF14或CD270)、KIR、A2aR、第1類MHC、第2類MHC、GAL9、及腺苷)靜默及/或突變。CRISPR/Cas系統及其用途描述於例如,於2015年3月13日提交之國際公開案號WO2015/142675第651-658段中,其經由引用全部併入本文中。
用以抑制TCR及/或HLA之TALEN
「TALEN」或「用於HLA和/或TCR之TALEN」或「抑制HLA和/或TCR之TALEN」是指一種轉錄激活因子類似效應核酸酶,其為一種人工核酸酶,可用於在細胞中(如T細胞中)編輯HLA及/或TCR基因、及/或抑制分子(例如PD1、PD-L1、PD-L2、CTLA4、TIM3、CEACAM (例如,CEACAM-1、CEACAM-3及/或CEACAM-5)、LAG3、VISTA、BTLA、TIGIT、LAIR1、CD160、2B4、CD80、CD86、B7-H3 (CD276)、B7-H4 (VTCN1)、HVEM (TNFRSF14或CD270)、KIR、A2aR、第1類MHC、第2類MHC、GAL9、及腺苷)。
TALEN及其用途係描述於例如,於2015年3月13日所提交之國際公開案號WO20 15/142675第659-665段中,其經由引用全部併入本文中。
用以抑制HLA及/或TCR之鋅指核酸酶
「ZFN」或「鋅指核酸酶」或「用於HLA及/或TCR之ZFN」或「抑制HLA及/或TCR之ZFN」係指一種鋅指核酸酶,其為一種人工核酸酶,可用於在細胞中(如T細胞中)編輯HLA及/或TCR基因、及/或抑制分子(例如PD1、PD-L1、PD-L2、CTLA4、TIM3、CEACAM(例如,CEACAM-1、CEACAM-3及/或CEACAM-5)、LAG3、VISTA、BTLA、TIGIT、LAIR1、CD160、2B4、CD80、CD86、B7-H3 (CD276)、B7-H4 (VTCN1)、HVEM (TNFRSF14或CD270)、KIR、A2aR、第1類MHC、第2類MHC、GAL9、及腺苷)
ZFN及其用途描述於例如,於2015年3月13日所提出之國際公開案WO2015/142675第666-671段中,其作為參考文獻整體引述。
端粒酶之表現
雖然不希望受到任何特定理論之束縛,但在一些實施例中,治療性T細胞由於T細胞中之縮短端粒,而對患者具有短期持續性;因此,以端粒酶基因轉染可延長T細胞之端粒,並提高患者中T細胞之持續性。請參見Carl June, “Adoptive T cell therapy for cancer in the clinic”, Journal of Clinical Investigation, 117:1466-1476 (2007)。因此,在一實施例中,免疫效應細胞,例如T細胞,係異位表現端粒酶次單元,例如端粒酶之催化次單元,例如TERT,例如hTERT。在一些態樣中,本發明提供一種產生表現CAR的細胞之方法,其包含使細胞與編碼端粒酶次單元之核酸接觸,例如端粒酶之催化次單元,例如,TERT,例如hTERT。細胞可在與編碼CAR之構築體接觸之前、同時或之後與核酸接觸。
在一態樣中,本揭示提供一種製造免疫效應細胞群之方法(例如T細胞、NK細胞)。在一實施例中,該方法包含:提供一免疫效應細胞群(例如,T細胞或NK細胞)、將該免疫效應細胞群與編碼一CAR的核酸接觸;以及將該免疫效應細胞群與編碼端粒酶次單元(例如,hTERT)的核酸接觸,在允許CAR及端例酶表現之條件下。
在一實施例中,該編碼端粒酶次單元之核酸為DNA。在一實施例中,該編碼端粒酶次單元之核酸包含一驅動子,其可驅動端粒酶次單元AAC5 1724.1之表現(Meyerson等人,“hEST2, the Putative Human Telomerase Catalytic Subunit Gene, Is Up-Regulated in Tumor Cells and during Immortalization” Cell,第90卷,第4期,1997年8月22日,第785-795頁)。
治療方法
本發明係有關於包含向個體投與如本文所述的抗GCC抗原結合分子的治療方法。在一些實施例中,本文揭示的抗GCC CAR和抗原結合分子,可用於治療或預防哺乳動物疾病的方法中。在此方面,一實施例係提供一種治療或預防哺乳動物癌症的方法,包含向哺乳動物投與有效治療或預防哺乳動物癌症之量的CAR、核酸、重組表現載體、宿主細胞、細胞群、抗體及/或其抗原結合部分,及/或醫藥組成物。本發明亦相關於如本文所述的抗GCC抗原結合分子(例如sdAb或CAR),其用於治療疾病。本發明亦相關於如本文所述的抗GCC抗原結合分子(例如sdAb或CAR),其用於治療癌症。本發明亦相關於如本文所述的抗GCC抗原結合分子(例如sdAb或CAR),其用於製備治療癌症的藥物。
本文所述的組成物投與可以任何方便的方式進行,包括藉由氣霧吸入、注射、攝取、輸血、植入或移植。本文所述的組成物可經動脈、皮下、皮內、腫瘤內、結內、髓內、肌肉內、藉由靜脈內(i.v.)注射或腹膜內投與患者。在一實施例中,本文所述之例如包含有表現CAR的細胞之組成物係藉由皮內或皮下注射投與患者。在一實施例中,本文所述之例如包含有表現CAR的細胞的組成物係藉由靜脈注射投與。本文所述之例如包含有表現CAR的細胞的組成物係可直接注射到腫瘤、淋巴結或感染部位。
通常可陳述包含本文所描述之免疫效應細胞的醫藥組成物,可以10
4至10
9細胞/公斤體重之劑量投與,在一些實例中為10
5至10
6細胞/公斤體重,包括此等範圍中的所有整數值。免疫效應細胞組成物亦可以此等劑量多次投與。該細胞可使用免疫療法中通常已知的輸注技術投與(參見例如Rosenberg等人,New Eng. J. of Med. 319:1676, 1988)。
在某些態樣中,可能希望將經活化免疫效應細胞投與個體,之後再抽血(或進行分離術)、依據本發明由其中活化細胞、及將這些經活化及擴增細胞再輸注至該患者中。此流程可以每隔幾周執行數次。在某些態樣中,細胞可從10cc到400cc的抽血中活化。在某些態樣中,細胞從20cc、30cc、40cc、50cc、60cc、70cc、80cc、90cc或100cc的抽血中活化。
在一些實施例中,該抗GCC CAR係於供體細胞上表現。在一些實施例中,用於T細胞療法之供體T細胞係得自患者(例如,用於自體T細胞療法)。在其他實施例中,用於T細胞療法之供體T細胞得自非患者之個體(例如,同種異體T細胞療法)。CAR
+T細胞可以治療有效量投與。舉例而言,治療有效量之T細胞可為至少約10
4個細胞、至少約10
5個細胞、至少約10
6個細胞、至少約10
7個細胞、至少約10
8個細胞、至少約10
9個細胞、或至少約10
10個細胞。
在一些實施例中,T細胞之治療有效量為約10
4個細胞、約10
5個細胞、約10
6個細胞、約10
7個細胞或約10
8個細胞。在一些實施例中,CAR T細胞之治療有效量為約2 X 10
6個細胞/kg、約3 X 10
6個細胞/kg、約4 X 10
6個細胞/kg、約5 X 10
6個細胞/kg、約6 X 10
6個細胞/kg、約7 X 10
6個細胞/kg、約8 X 10
6個細胞/kg、約9 X 10
6個細胞/kg、約1 X 10
7個細胞/kg、約2 X 10
7個細胞/kg、約3 X 10
7個細胞/kg、約4 X 10
7個細胞/kg、約5 X 10
7個細胞/kg、約6 X 10
7個細胞/kg、約7 X 10
7個細胞/kg、約8 X 10
7個細胞/kg、或約9 X 10
7個細胞/kg。在一些實施例中,CAR陽性的活T細胞之治療有效量介於約1 X 10
6至約2 X 10
6個CAR陽性的活T細胞每公斤體重之間,直至最大劑量約1 x 10
8個CAR陽性的活T細胞。
在一些實施例中,CAR陽性的活T細胞之治療有效量在約0.25 X 10
6至2 X 10
6之間。在一些實施例中,CAR陽性的活T細胞之治療有效量為0.25 x 10
6、0.3 x 10
6、0.4 x 10
6、約0.5 x 10
6、約0.6 x 10
6、約0.7 x 10
6、約0.8 x 10
6、約0.9 x 10
6、約1.0 x 10
6、約1.1 x 10
6、約1.2 x 10
6、約1.3 x 10
6、約1.4 x 10
6、約1.5 x 10
6、約1.6 x 10
6、約1.7 x 10
6、約1.8 x 10
6、約1.9 x 10
6、或約2.0 x 10
6個CAR陽性的活T細胞。
在一些實施例中,CAR陽性的活T細胞之治療有效量在約0.4 x 10
8至約2 x 10
8個CAR陽性存活T細胞之間。在一些實施例中,CAR陽性的活T細胞之治療有效量為約0.4 x 10
8、約0.5 x 10
8、約0.6 x 10
8、約0.7 x 10
8、約0.8 x 10
8、約0.9 x 10
8、約1.0 x 10
8、約1.1 x 10
8、約1.2 x 10
8、約1.3 x 10
8、約1.4 x 10
8、約1.5 x 10
8、約1.6 x 10
8、約1.7 x 10
8、約1.8 x 10
8、約1.9 x 10
8、或約2.0 x 10
8個CAR陽性的活T細胞。
在一些實施例中,表現CAR之細胞之劑量(例如,本文所描述之表現CAR的細胞,例如,表現GCC CAR的細胞)包含約1 x 10
6細胞/m
2至約1 x 10
9細胞/m
2,例如,約1 x 10
7細胞/m
2至約5 x 10
8細胞/m
2,例如,約1.5 x 10
7細胞/m
2、約2 x 10
7細胞/m
2、約4.5 x 10
7細胞/m
2、約10
8細胞/m
2、約1.2 x 10
8細胞/m
2、或約2 x 10
8細胞/m
2。
本發明包括(除了其他事項之外)一種細胞療法,其中T細胞經基因修飾以表現嵌合抗原受體(CAR),且該CAR T細胞輸注至有需要之接受者中。該輸注細胞能殺傷接受者的腫瘤細胞。與抗體療法不同,經CAR修飾之T細胞可在體中複製,產生長期持久性,其可導致持續腫瘤控制。在各態樣中,在投與T細胞至患者後,該投與患者的T細胞在患者體內持續至少四個月、五個月、六個月、七個月、八個月、九個月、十個月、十一個月、十二個月、十三個月、十四個月、十五個月、十六個月、十七個月、十八個月、十九個月、二十個月、二十一個月、二十二個月、二十三個月、兩年、三年、四年或五年。
在一些實施例中,該表現GCC CAR的細胞係以多次劑量(例如,第一劑量、第二劑量及視情況第三劑量)投與。在實施例中,該方法包含治療患有癌症(例如大腸直腸癌)之個體(例如成人個體),其包含向該個體投與第一劑量、第二劑量及視情況一或多次額外劑量,每一劑量包含表現CAR分子(例如GCC CAR分子,例如在表7中提供之CAR分子)之免疫效應細胞。
在實施例中,該方法包含投與每公斤2至5 x 10
6個表現CAR的活細胞之劑量,其中該個體之體重小於50 kg;或投與1.0至2.5 x 10
8個表現CAR的活細胞之劑量,其中該個體之體重至少50 kg。
在實施例中,向該個體例如兒童或成人個體投與單一劑量。
在實施例中,該劑量依順序天數投與,例如,在第1天投與第一劑量,第2天投與第二劑量,且視情況在第3天投與第三劑量(若有投與)。
在實施例中,投與第四、第五或第六劑量或更多劑量。
在實施例中,該第一劑量包含約10%總劑量,第二劑量包含約30%總劑量,且第三劑量包含約60%總劑量,其中前述百分比之總和為100%。在實施例中,第一劑量包含總劑量之約9-11%、8-12%、7-13%或5-15%。在實施例中,第二劑量包含總劑量之約29-31%、28-32%、27-33%、26-34%、25-35%、24-36%、23-37%、22-38%、21-39%或20-40%。在實施例中,第三劑量包含總劑量之約55-65%、50-70%、45-75%或40-80%。在實施例中,總劑量係指在1週、2週、3週或4週期間所投與之表現CAR的活細胞總數。在投與兩個劑量的一些實施例中,總劑量係指以第一及第二劑量向個體所投與之表現CAR的活細胞數目總和。在投與三個劑量的一些實施例中,總劑量係指在第一、第二及第三劑量中向個體所投與之表現CAR的活細胞數目總和。
在實施例中,該劑量根據其中表現CAR的活細胞數目來測量。CAR的表現可使用結合至CAR分子之抗體分子及可偵測標記,例如藉由流式細胞量測術來測量。存活率可例如藉由細胞儀測量。
本發明亦包括一種細胞療法類型,其中免疫效應細胞例如NK細胞或T細胞經修飾,例如藉由體外轉錄RNA,以暫時表現嵌合抗原受體(CAR),並將表現CAR的細胞(例如,CART)輸注至有需要之接受者中。該輸注細胞能殺傷接受者的癌細胞。因此,在各態樣中,投與患者之表現CAR的細胞(例如T細胞),在投與該表現CAR的細胞(例如T細胞)之後存在於患者體內小於一個月,例如,三週、兩週、一週。
不希望受限於任何特定理論,由經CAR修飾之T細胞引發的抗癌免疫反應可為主動或被動免疫反應,或替代地可歸因於直接與間接免疫反應。在一態樣中,經CAR (例如,GCC-CAR)轉導之T細胞展現特定促發炎性細胞激素分泌,及對表現標靶抗原(例如,GCC)之人類癌細胞具有效細胞溶解活性、具可溶性標靶抗原抑制抗性、介導鄰近殺傷、並介導已建立的人類癌症的消退。舉例而言,在表現標靶抗原的癌症之非均質區域中的無抗原癌細胞,易感於先前對相鄰抗原-陽性癌細胞產生反應之標靶抗原靶向T細胞的間接破壞。
在一態樣中,本發明特徵在於一種治療個體之癌症的方法。該方法包含向該個體投與一治療,其包括投與表現CAR的細胞(例如,表現GCC CAR的細胞),以於該個體中治療該癌症。在一實施例中,該表現CAR的細胞(例如,表現GCC CAR的細胞)之治療會導致以下之一或多現象:表現CAR的細胞(例如,表現GCC CAR的細胞)的抗腫瘤活性改善或增加;表現CAR的細胞的增殖或持久性增加;表現CAR的細胞的浸潤改善或增加;改善對腫瘤進展的抑制;延緩腫瘤進展;抑制或減少癌細胞增殖;及/或減少腫瘤負荷,例如腫瘤體積或大小。在一實施例中,該治療導致表現CAR的細胞之持續性增加及/或表現CAR的細胞之持續性增加、及較低例如降低的復發風險。
本發明提供抑制或降低表現抗原的(例如,表現GCC的)細胞群之增殖的方法。在一實施例中,該方法包含投與CAR療法(例如,表現CAR的細胞群)。在某些實施例中,相對於接受不同癌症療法的個體中之細胞及/或癌細胞的數量、數目、含量或百分比,本文所描述之療法在具有抗原(例如GCC)或與表現抗原的(例如,表現GCC的)細胞相關的另一種癌症之個體或動物模型中係降低細胞及/或癌細胞的數量、數目、含量或百分比至少5%、10%、至少15%、至少20%、至少25%、至少30%、至少35%、至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%或至少99%。在一實施例中,該個體為哺乳動物。在一些實施例中,該個體為人類。
本發明亦提供用於預防、治療及/或管理一病症之方法,例如,與表現抗原的細胞(例如,表現GCC的細胞)相關之病症(例如,本文所述之癌症),該方法包含向有需要的個體投與表現CAR的細胞(例如,表現GCC CAR的細胞、表現CAR的細胞群)。在一態樣中,該個體為人類。
在一態樣中,本發明係關於一種抑制癌細胞生長(例如,表現抗原的(例如表現GCC的)癌細胞)之方法,其包含使該癌細胞與表現CAR的(例如,表現GCC CAR的)細胞,如本文所述之GCC CART細胞接觸,使得CART回應於抗原而被活化並靶向癌細胞,其中癌症的生長被抑制。
本發明亦提供用於預防、治療及/或管理一疾病之方法,例如,與表現抗原的(例如表現GCC的)細胞相關之疾病(例如,表現該抗原(如GCC)之癌症),該方法包含向有需要的個體投與表現CAR的細胞(例如,表現GCC CAR的細胞),其結合至該表現抗原的細胞。在一些實施例中,該個體為人類。
本發明亦提供用於預防、治療及/或管理與表現抗原的(例如,表現GCC的)細胞相關之疾病的方法,該方法包含向有需要的個體投與本發明之CART細胞(例如,抗GCC CART細胞),其結合至該表現抗原的細胞。在一態樣中,該個體為人類。
本發明亦提供預防與抗原表現(例如,表現GCC的)細胞相關之癌症復發之方法,該方法包含向有需要的個體投與本發明之CART細胞(例如,抗GCC CART細胞),其結合至該表現抗原的細胞。在一態樣中,該方法包含向有需要的個體投與有效量的CART細胞(例如,抗GCC CART細胞),如本文所述,其以在另一療法中有效之量結合至該表現抗原的(如表現GCC的)細胞。
一實施例進一步包含在投與本文所揭示之CAR之前,使哺乳動物進行淋巴耗盡。淋巴耗盡的實例包括但不限於:非清髓性淋巴細胞清除化療、清髓性淋巴細胞清除化療、全身輻射照射等。
在一特定例示性態樣中,個體可進行白血球分離術,其中白血球係經收集、富集或體外耗盡,以篩選及/或分離出有興趣的細胞,例如T細胞。這些T細胞分離株可藉由本領域中已知的方法擴增並經處理,使其可引入本發明之一或多個CAR構築體,藉此創造本發明之CAR T細胞。有需要的個體隨後可接受高劑量化療的標準治療,之後進行周邊血液幹細胞移植。在某些態樣中,在移植之後或同時進行移植,個體接受本發明擴增的表現CAR的細胞的輸注。在另一態樣中,在手術前或手術後投與經擴增的細胞。
就其中投與宿主細胞或細胞群的方法目的而言,細胞可為與該哺乳動物同種異體或自體的細胞。較佳地,該細胞為與該哺乳動物自體。如本文所用,同種異體是指衍生自與引入材料的個體相同物種之不同動物的任何材料。當一或多個基因座上的基因不相同時,該二或多個個體被稱為彼此同種異體。在一些態樣中,來自同一物種個體的同種異體材料可能在基因上完全不同,而有抗原性相互作用。如本文所用,「自體」是指衍生自同一個體的任何材料,之後將其重新引入該個體。
本文所提及之哺乳動物可為任何哺乳動物。如本文所用,術語「哺乳動物」是指任何哺乳動物,包括但不限於:囓齒目哺乳動物,例如小鼠和倉鼠,以及兔形目哺乳動物,例如兔。哺乳動物可來自食肉目,包括貓科動物(貓)和犬科動物(狗)。哺乳動物可來自偶蹄目,包括牛(母牛)和豬(豬),或來自偶蹄目,包括馬(馬)。哺乳動物可為靈長類、四足猴(Ceboids)或原猴(Simoids)(猴子)或類人猿目(人類和猿)。在一些實施例中,該哺乳動物為人類。
關於所述方法,該癌症可為任何癌症,包括急性淋巴細胞癌、急性骨髓性白血病、肺泡橫紋肌肉瘤、膀胱癌(例如,膀胱肉瘤)、骨癌、腦癌(例如,神經管母細胞瘤)、乳癌、肛門癌、肛管癌或肛門直腸癌、眼癌、肝內膽管癌、關節癌、頸部癌、膽囊癌或胸膜癌、鼻癌、鼻腔癌,或中耳癌、口腔癌、外陰癌、慢性淋巴細胞白血病、慢性骨髓癌、大腸癌、食道癌、子宮頸癌、纖維肉瘤、胃腸道類癌瘤、頭頸癌(如頭頸鱗狀細胞癌)、霍奇金淋巴瘤、下咽癌、腎癌、喉癌、白血病、液體腫瘤、肝癌、肺癌(例如,非小細胞肺癌和肺腺癌)、淋巴瘤、間皮瘤、肥大細胞瘤、黑色素瘤、多發性骨髓瘤、鼻咽癌、非霍奇金淋巴瘤、B-慢性淋巴細胞白血病、毛細胞白血病、急性淋巴細胞白血病(ALL)和勃氏淋巴瘤(Burkitt's lymphoma)、卵巢癌、胰臟癌、腹膜癌、大網膜癌和腸系膜癌、咽癌、前列腺癌、直腸癌、腎癌、皮膚癌、小腸癌、軟組織癌、實體瘤、滑膜肉瘤、胃癌、睾丸癌、甲狀腺癌和輸尿管癌之任一者。
在某些實施例中,該癌症是胃腸癌。在一些實施例中,該癌症是胃癌。在一些實施例中,該癌症是大腸直腸癌。在一些實施例中,該癌症是大腸癌。在一些實施例中,該癌症具有GCC的異常表現。
如本文所用,術語「治療」和「預防」以及其衍生詞不一定意味著100%或完全治療或預防。相反地,存在不同程度的治療或預防,本領域普通技術人員認為其具有潛在益處或治療效果。在此方面,該方法可提供任何量或任何位準的哺乳動物癌症的治療或預防。
此外,由該方法提供的治療或預防可包括治療或預防一或多種待治療或預防的疾病(例如癌症)的病況或症狀。此外,出於本文目的,「預防」可包括延遲疾病或其症狀或病況的發作。
另一實施例提供一種偵測哺乳動物中癌症存在的方法,包含:(a)將包含來自哺乳動物的一或多個細胞的樣本,與該抗原結合分子(例如單域抗體)、其抗原結合部分或醫藥組成物接觸,藉此形成一複合物,(b)並偵測該複合物,其中偵測到該複合物表示該哺乳動物中存在癌症。在一些實施例中,該接觸可在哺乳動物的體外或體內發生。在一些實施例中,該接觸是在活體外。
該樣本可藉由任何合適的方法獲得,例如活體切片或屍體解剖。活體切片是從個體中取出組織及/或細胞。此取出可以是從該個體收集組織及/或細胞,以便對取出的組織及/或細胞進行實驗。此實驗可包括測定該個體是否具有及/或正患有某病症或疾病狀態的實驗。該病症或疾病可為如癌症。
關於在哺乳動物中偵測增殖性病症(例如癌症)的存在之方法之一實施例,該包含哺乳動物細胞的樣本可為包含全細胞、其裂解物或全細胞裂解物之分液(例如細胞核或細胞質分液、完整蛋白分液或核酸分液)。若樣本包含全細胞,則該細胞可為哺乳動物的任何細胞,例如任何器官或組織的細胞,包括血液細胞或內皮細胞。
此外,複合物的偵測可經由本領域中已知的多種方式進行。例如,本文所述的CAR、多肽、蛋白質、核酸、重組表現載體、宿主細胞、細胞群或抗體或其抗原結合部分,可經可偵測標記物標記,例如放射性同位素、螢光基團(例如異硫氰酸螢光素(FITC)、藻紅蛋白(PE))、酵素(例如鹼性磷酸酶、辣根過氧化物酶)、及如前述所揭示之元素顆粒(例如金顆粒)。
測試CAR辨識標靶細胞的能力和抗原特異性的方法為本領域中已知的。例如,Clay等人,J. Immunol, 163: 507-513 (1999),揭示測量細胞因子(例如干擾素-γ、顆粒細胞/單核細胞集落刺激因子(GM-CSF)、腫瘤因子a (TNF-α)或介白素2 (IL-2))釋放的方法。此外,CAR功能可藉由量測細胞之細胞毒性來評估,如Zhao等人, J. Immunol, 174:4415-4423 (2005)中所述。
另一實施例提供本發明的CAR、核酸、重組表現載體、宿主細胞、細胞群、抗體或其抗原結合部分及/或藥物組合物之用途,用於治療或預防哺乳動物之增殖性疾病,例如癌症。該癌症可為本文所述的任何癌症。
任何投與方法均可用於所揭示的治療劑,包括局部和全身投與。例如可使用局部、口服、血管內(例如靜脈內)、肌肉內、腹膜內、鼻內、皮內、鞘內和皮下投與。特定的投與方式和給藥方案將由主治臨床醫生選擇,考慮到病例的細節(例如個體、疾病、所涉及的疾病狀態以及治療是否為預防性)。在投與大於一種試劑或組成物的情況下,可使用一或多種投與途徑;例如,化療劑可口服投與,而抗體或抗原結合片段或共軛物或組成物可靜脈投與。投與方法包括注射,其中CAR、CAR T細胞、共軛物、抗體、抗原結合片段或組成物,係於無毒的醫藥學上可接受的載體中提供,例如水、生理食鹽水、林格氏溶液、右旋糖溶液、5%人類血清白蛋白、非揮發性油、油酸乙酯或微脂體。在一些實施例中,可使用所揭示的化合物之局部投藥,例如藉由將抗體或抗原結合片段施加至已移除腫瘤的組織區域,或懷疑傾向於發展腫瘤的區域。在一些實施例中,包括治療有效量的抗體或抗原結合片段的醫藥製劑的持續性腫瘤內(或腫瘤附近)釋放可能有助益。在其他實例中,共軛物作為滴眼劑局部施加至角膜,或經玻璃體內施加至眼睛。
所揭示的治療劑可配製成適合精確劑量單獨投藥的單位劑型。此外,所揭示的治療劑可以單劑量或多劑量方案投藥。多劑量方案為其中主要治療過程可為大於一個單獨的劑量,例如1至10個劑量,之後根據需要在隨後的時間間隔投與其他劑量,以維持或加強該組成物的作用。治療可涉及在幾天至幾個月甚至幾年的時間內,每天或每天多次投與化合物。因此,該投藥方案也將,至少部分地,基於待治療對象的特定需要而決定,並將取決於投藥醫師的判斷。
在一實施例中,該CAR被引入免疫效應細胞中,例如,使用體外轉錄,且該個體(例如人類)接受本發明的表現CAR的細胞的初始投與,以及之後的表現CAR的細胞的一次或多次投與,其中該一或多次後續投與在少於15天的時間內投與,例如在前次投與之後的14、13、12、11、10、9、8、7、6、5、4、3或2天。在一實施例中,每周向該個體(例如人類)大於一次投與本發明之表現CAR的細胞,例如每星期投與2、3或4次。在一實施例中,該個體(例如人類個體)每週接受大於一次的表現CAR的細胞投與(例如,每週2次、3或4次投與)(本文中亦稱為一循環),接著一週不投與表現CAR的細胞,且接著向個體投與一或多次額外的表現CAR的細胞投與(例如,每週大於一次的表現CAR的細胞投與)。在另一實施例中,該個體(例如人類個體)接受大於一個表現CAR的細胞循環,且各循環之間的時間小於10、9、8、7、6、5、4或3天。在一實施例中,每隔一天投與表現CAR的細胞一次,每星期投與3次。在一實施例中,投與本發明之表現CAR的細胞至少二、三、四、五、六、七、八或更多周。
抗體或共軛物之典型劑量範圍可介於約0.01至約30 mg/kg,如約0.1至約10 mg/kg。
在特定實例中,投與該個體一治療性組成物,其包括共軛物、抗體、組成物、CAR、CAR T細胞或額外試劑之一或多者,在每日多次投藥時程下,例如至少連續兩天、連續10天等,例如數週、數月或數年。在一實例中,向該個體投與共軛物、抗體、組成物或額外試劑一段時間,至少30天如至少2個月、至少4個月、至少6個月、至少12個月、至少24個月、或至少36個月。
在一些實施例中,所揭示的方法包括向該個體提供手術、放射療法及/或化學治療,與所揭示之抗體、抗原結合片段、共軛物、CAR或表現CAR的T細胞之組合(例如,依次、實質上同時或同時)。此類試劑及治療之方法及治療劑量為熟習此項技術者已知的,且可由熟練臨床醫師決定。額外試劑之製備及投與時程可根據製造商之指示或由熟練之執業人員依經驗決定。此類化學療法之製備與投藥時程亦描述於Chemotherapy Service, (1992), M. C. Perry編,Williams & Wilkins, Baltimore, Md。
在一些實施例中,該組合療法可包括向個體投與治療有效量之額外癌症抑制劑。可與該組合療法一起使用之額外治療劑的非限制性實例包括微管結合劑、DNA嵌合劑或交聯子、DNA合成抑制劑、DNA及RNA轉錄抑制劑、抗體、酵素、酵素抑制劑、基因調節劑及血管生成抑制劑。這些試劑(其以治療有效量投與)及治療可單獨或組合使用。舉例而言,任何適合之抗癌或抗血管生成劑可與本文所揭示之CARS、CAR-T細胞、抗體、抗原結合片段或共軛物組合投與。此類試劑之方法及治療劑量為熟習此項技術者已知的,且可由熟練臨床醫師決定。
其他化學治療劑包括但不限於:烷化劑,例如氮芥(例如苯丁酸氮芥(chlorambucil)、氯甲鹼(chlormethine)、環磷醯胺、異環磷醯胺和美法崙(melphalan))、亞硝基脲(例如卡莫司汀(carmustine)、福莫司汀(fotemustine)、洛莫司汀(lomustine)和鏈脲佐菌素(streptozocin))、鉑化合物(例如,卡鉑(carboplatin)、順鉑(cisplatin)、奧沙利鉑(oxaliplatin)和BBR3464)、白消安(busulfan)、達卡巴嗪(dacarbazine)、氯乙胺(mechlorethamine)、丙卡巴肼(procarbazine)、替莫唑胺(temozolomide)、噻替帕(thiotepa)和烏拉莫司汀(uramustine);抗代謝物,例如葉酸(例如甲胺蝶呤(methotrexate)、培美曲塞(pemetrexed)和雷替曲塞(raltitrexed))、嘌呤(例如克拉屈濱(cladribine)、氯法拉濱(clofarabine)、氟達拉濱(fludarabine)、巰基嘌呤(mercaptopurine)和硫鳥嘌呤(tioguanine))、嘧啶(例如卡培他濱(capecitabine))、阿糖胞苷(cytarabine)、氟尿嘧啶(fluorouracil)和吉西他濱(gemcitabine);植物生物鹼,例如鬼臼屬(例如,依托泊苷(etoposide)和替尼泊苷(etoposide))、紫杉烷(例如,多西紫杉醇(docetaxel)和紫杉醇(paclitaxel))、長春花(例如,長春鹼(paclitaxel)、長春新鹼(paclitaxel)、長春地辛(vindesine)和長春瑞濱(vindesine));細胞毒性/抗腫瘤抗生素,例如蒽環家族抗生素(例如柔紅黴素(vindesine)、多柔比星(doxorubicin)、表柔比星(epirubicin)、伊達比星(epirubicin)、米托蒽醌(mitoxantrone)和伐柔比星(valrubicin))、博來黴素(bleomycin)、利福平(rifampicin)、羥基脲和絲裂黴素;拓撲異構酶抑制劑,例如拓撲替康(topotecan)和伊立替康(irinotecan);單克隆抗體,例如阿崙單抗(alemtuzumab)、貝伐單抗(alemtuzumab)、西妥昔單抗(cetuximab)、吉姆單抗(gemtuzumab)、利妥昔單抗(rituximab)、帕尼單抗(panitumumab)、帕妥珠單抗(pertuzumab)和曲妥珠單抗(trastuzumab);光敏劑,例如胺基乙醯丙酸、胺基乙醯丙酸甲酯、泊芬鈉(porfimer sodium)和維替泊芬(verteporfin);和其他藥物,如阿利維A酸(alitretinoin)、阿曲他明(altretamine)、安吖啶(amsacrine)、阿那格雷(anagrelide)、三氧化二砷、天冬醯胺酶、阿西替尼(axitinib)、貝沙羅汀(bexarotene)、貝伐單抗(bevacizumab)、硼替佐米(bortezomib)、塞來昔布(celecoxib)、地尼白介素(denileukin diftitox)、厄洛替尼(erlotinib)、雌莫司汀(estramustine)、吉非替尼(gefitinib)、羥基甲醯胺、伊馬替尼(imatinib)、拉帕替尼(lapatinib)、帕唑帕尼(pazopanib)、噴司他丁(pentostatin)、馬索普考(masoprocol)、米托坦(mitotane)、培門冬酶(pegaspargase)、他莫昔芬(tamoxifen)、索拉非尼(sorafenib)、舒尼替尼(sunitinib)、威羅非尼(vemurafinib)、凡德他尼(vandetanib vandetanib)和維甲酸(tretinoin)。此類試劑的選擇和治療劑量是本領域技術人員已知的,並可由熟練的臨床醫生決定。
考慮用於組合治療的一般化學治療劑包括阿那曲唑(anastrozole) (Arimidex®)、比卡魯胺(bicalutamide) (Casodex®)、硫酸博來黴素(bleomycin sulfate) (Blenoxane®)、白消安(busulfan) (Myleran®)、白消安注射液(Busulfex®)、卡培他濱(capecitabine) (Xeloda®)、N4-戊氧羰基-5-脫氧-5-氟胞苷、卡鉑(carboplatin) (Paraplatin®)、卡莫司汀(carmustine) (BiCNU®)、苯丁酸氮芥(chlorambucil) (Leukeran®)、順鉑(cisplatin) (Platinol®)、克拉屈濱(cladribine) (Leustatin®)、環磷醯胺 (Cytoxan® 或 Neosar® )、賽德薩(cytarabine)、阿糖胞苷(cytosine arabinoside) (Cytosar-U®)、阿糖胞苷脂質體注射液 (DepoCyt®)、達卡巴嗪(dacarbazine) (DTIC-Dome®)、放線菌素(dactinomycin) (Actinomycin D, Cosmegan)、鹽酸柔紅黴素(daunombicin hydrochloride)(Cembidine®)、檸檬酸柔紅黴素脂質體注射液(DaunoXome ®)、地塞米松(dexamethasone)、多西他賽(docetaxel)(Taxotere®)、鹽酸多柔比星(doxorubicin hydrochloride (Adriamycin®, Rubex®)) (Adriamycin®、Rubex®)、依托泊苷(etoposide) (Vepesid®)、磷酸氟達拉濱(fludarabine phosphate) (Fludara®)、5-氟尿嘧啶 (Adrucil®、Efudex®)、氟他胺(flutamide) (Eulexin®)、替扎西替濱(tezacitibine)、吉西他濱(Gemcitabine) (二氟脫氧胞苷)、羥基脲(Hydrea®)、伊達比星(Idarubicin) (Idamycin®)、異環磷醯胺(IFEX®)、伊立替康(irinotecan) (Camptosar®)、L-天冬醯胺酶 (ELSPAR®)、亞葉酸鈣、美法崙(melphalan) (Alkeran®)、6-巰基嘌呤 (Purinethol®)、甲胺蝶呤(Folex®)、米托蒽醌(mitoxantrone) (Novantrone®) )、美拉塔格(mylotarg)、紫杉醇(Taxol®)、必帝(phoenix)(Yttrium90/MX-DTPA)、噴司他丁(pentostatin)、普立非普山20 (polifeprosan 20 )與卡莫司汀植入物 (Gliadel®)、他莫昔芬檸檬酸鹽(tamoxifen citrate)(Nolvadex®)、替尼泊苷(teniposide) (Vumon®)、6-硫鳥嘌呤、噻替派(thiotepa)、替拉扎明(tirapazamine) (Tirazone®)、注射用鹽酸托泊替康(topotecan) (Hycamptin®)、長春鹼(vinblastine) (Velban®)、長春新鹼(vincristine) (Oncovin®)和長春瑞濱(vinorelbine) (Navelbine®)。
例示性烷化劑揭示於國際申請案WO 2016/164731,第270-271頁,其於2016年4月8日提交,其全部內容經由引用併入本文。進一步的例子包括但不限於:氮芥、乙烯亞胺衍生物、烷基磺酸鹽、亞硝基脲和三氮烯):尿嘧啶芥(Aminouracil Mustard®、Chlorethaminacil®、Demethyldopan®、Desmethyldopan®、Haemanthamine®、Nordopan®、Uracil nitrogen mustard®、Uracillost®、Uracilmostaza®、Uramustin®、Uramustine®)、氯甲鹼 (Mustargen®)、環磷醯胺 (Cytoxan®、Neosar®、Clafen®、Endoxan®、Procytox®、Revimmune™)、異環磷醯胺(Mitoxana®)、美法崙(melphalan)(Alkeran®)、苯丁酸氮芥(Chlorambucil) (Leukeran®)、哌泊溴烷(pipobroman) (Amedel®、Vercyte®)、三乙烯三聚氰胺 (Hemel®、Hexalen®、Hexastat®)、三乙烯硫代磷胺、替莫唑胺(Temozolomide) (Temodar®)、噻替哌(thiotepa)(Thioplex®)、白消安(busulfan) (Busilvex®、Myleran®)、卡莫司汀(carmustine) (BiCNU®)、洛莫司汀(lomustine) (CeeNU®)、鏈脲佐菌素(streptozocin) (Zanosar®)和達卡巴嗪(Dacarbazine) (DTIC-Dome®)。其他例示性烷化劑包括但不限於:奧沙利鉑(Oxaliplatin) (Eloxatin®);替莫唑胺(Temozolomide)(Temodar®的Temodal®);放線菌素(Dactinomycin)(也稱為放線菌素-D,Cosmegen®);美法崙(Melphalan)(也稱為L-PAM、L-肌溶素和苯丙胺酸芥末,Alkeran®);奧曲他明(Altretamine)(也稱為六甲基三聚氰胺(HMM),Hexalen®);卡莫司汀(Altretamine)(BiCNU®);苯達莫司汀(Bendamustine)(Treanda®);白消安(Busulfan)(Busulfex®的Myleran®);卡鉑(Carboplatin)(Paraplatin®);洛莫司汀(Lomustine)(也稱為 CCNU、CeeNU®);順鉑(Cisplatin)(也稱為CDDP、Platinol®和Platinol®-AQ);苯丁酸氮芥(Chlorambucil)(Leukeran®);環磷醯胺(Cytoxan®和Neosar®);達卡巴嗪(Dacarbazine)(也稱為DTIC、DIC和咪唑甲醯胺,DTIC-Dome®);奧曲他明(Altretamine)(也稱為六甲基三聚氰胺(HMM),Hexalen®);異環磷醯胺(Ifex®);普雷努莫司汀(Prednumustine);丙卡巴肼(Procarbazine)(Matulane®);甲氯乙胺(也稱為氮芥、芥子鹼和鹽酸甲氯乙胺,Mustargen®);鏈脲佐菌素(Streptozocin)(Zanosar®);噻替哌(Thiotepa)(也稱為硫代磷醯胺、TESPA和TSPA、Thioplex®);環磷醯胺(Endoxan®、Cytoxan®、Neosar®、Procytox®、Revimmune®);和普癌汰(Bendamustine HCl) (Treanda®)。
例示性的鉑基試劑包括但不限於卡鉑(carboplatin)、順鉑(cisplatin)和奧沙利鉑(oxaliplatin)。
例示性血管生成抑制劑包括但不限於:A6 (Angstrom Pharmacueticals)、ABT-510 (Abbott Laboratories)、ABT-627 (Atrasentan) (Abbott Laboratories/Xinlay)、ABT-869 (Abbott Laboratories)、阿克替米德(Actimid)(CC4047, Pomalidomide) (Celgene Corporation)、AdGVPEDF.llD (GenVec)、ADH-1 (Exherin) (Adherex Technologies)、AEE788 (Novartis)、AG-013736 (Axitinib) (Pfizer)、AG3340(普立諾司他(Prinomastat)) (Agouron Pharmaceuticals)、AGX1053 (AngioGenex)、AGX51 (AngioGenex)、ALN-VSP (ALN-VSP 02) (Alnylam Pharmaceuticals)、AMG 386 (Amgen)、AMG706 (Amgen)、阿帕替尼(Apatinib) (YN968D1) (Jiangsu Hengrui Medicine)、AP23573 (Ridaforolimus/MK8669) (Ariad Pharmaceuticals)、AQ4N (Novavea)、ARQ 197 (ArQule)、ASA404 (Novartis/Antisoma)、阿替莫德(Atiprimod) (Callisto Pharmaceuticals)、ATN-161 (Attenuon)、AV-412 (Aveo Pharmaceuticals)、AV-951 (Aveo Pharmaceuticals)、癌思停(Avastin) (貝伐單抗(Bevacizumab)) (Genentech)、AZD2171 (西地尼布(Cediranib)/雷思停(Recentin)) (AstraZeneca)、BAY 57-9352 (替拉替尼(Telatinib)) (Bayer)、BEZ235 (Novartis)、BIBF1120 (Boehringer Ingelheim Pharmaceuticals)、BIBW 2992 (Boehringer Ingelheim Pharmaceuticals)、BMS-275291 (Bristol-Myers Squibb)、BMS-582664 (布立伐尼(Brivanib)) (Bristol-Myers Squibb)、BMS-690514 (Bristol-Myers Squibb)、促鈣三醇(Calcitriol)、CCI-779 (Torisel) (Wyeth)、CDP-791 (ImClone Systems)、西服通寧(Ceflatonin) (高三尖山酯鹼(Homoharringtonine)/HHT) (ChemGenex Therapeutics)、希樂葆(Celebrex )(Celecoxib) (Pfizer)、CEP-7055 (Cephalon/Sanofi)、CHIR-265 (Chiron Corporation)、NGR-TNF、COL-3 (Metastat) (Collagenex Pharaceuticals)、考布他汀(Combretastatin)(Oxigene)、CP-751、87 l (Figitumumab) (Pfizer)、CP-547,632 (Pfizer)、CS-7017 (Daiichi Sankyo Pharma)、CT-322 (Angiocept) (Adnexus)、薑黃素(Curcumin)、達肝素(Dalteparin) (Fragmin) (Pfizer)、雙硫崙(Disulfiram) (Antabuse)、E7820 (Eisai Limited)、E7080 (Eisai Limited)、EMD 121974 (Cilengitide) (EMD Pharmaceuticals)、ENMD-1198 (EntreMed)、ENMD-2076 (EntreMed)、恩度(Endostar)(Simcere)、爾必得舒(Erbitux)(ImClone/Bristol-Myers Squibb)、EZN-2208 (Enzon Pharmaceuticals)、EZN-2968 (Enzon Pharmaceuticals)、GC1008 (Genzyme)、金雀異黃酮(Genistein)、GSK1363089(Foretinib) (GlaxoSmithKline)、GW786034 (Pazopanib) (GlaxoSmithKline)、GT-111 (Vascular Biogenics Ltd.)、IMC—1121B (Ramucirumab) (ImClone Systems)、IMC-18F1 (ImClone Systems)、IMC-3G3 (ImClone LLC)、INCB007839 (Incyte Corporation)、INGN 241 (Introgen Therapeutics)、艾瑞莎(Iressa)(ZD1839/Gefitinib)、LBH589 (Faridak/Panobinostst) (Novartis)、樂舒晴(Lucentis)(Ranibizumab) (Genentech/Novartis)、LY3 17615 (Enzastaurin) (Eli Lilly and Company)、目可健(Macugen)(Pegaptanib) (Pfizer)、MED1522 (Abegrin) (Medlmmune)、MLN518(Tandutinib) (Millennium)、新華司他(Neovastat)(AE941/Benefin) (Aeterna Zentaris)、蕾莎瓦(Nexavar) (Bayer/Onyx)、NM-3 (Genzyme Corporation)、諾斯卡賓(Noscapine) (Cougar Biotechnology)、NPT2358 (Nereus Pharmaceuticals)、OSI-930 (OSI)、帕洛米得529 (Palomid 529) (Paloma Pharmaceuticals, Inc.)、潘珊膠囊(Panzem Capsules)(2ME2) (EntreMed)、潘珊NCD (Panzem NCD) (2ME2) (EntreMed)、PF-02341066 (Pfizer)、PF-04554878 (Pfizer)、PI-88 (Progen Industries/Medigen Biotechnology)、PKC412 (Novartis)、聚苯醚E (Polyphenon E)(Green Tea Extract) (Polypheno E International、Inc)、PPI-2458 (Praecis Pharmaceuticals)、PTC299 (PTC Therapeutics)、PTK787 (Vatalanib) (Novartis)、PXD101 (Belinostat) (CuraGen Corporation)、RAD001 (Everolimus) (Novartis)、RAF265 (Novartis)、癌瑞格(Regorafenib)(BAY73-4506) (Bayer)、瑞復美(Revlimid) (Celgene)、利坦(Retaane) (Alcon Research)、SN38 (Liposomal) (Neopharm)、SNS-032 (BMS-387032) (Sunesis)、SOM230(Pasireotide) (Novartis)、角鯊胺(Squalamine) (Genaera)、蘇拉明(Suramin)、索坦(Sutent)(Pfizer)、得舒緩(Tarceva) (Genentech)、TB-403 (Thrombogenics)、坦普斯達丁(Tempostatin)(Collard Biopharmaceuticals)、四硫代鉬酸鹽(Tetrathiomolybdate)(Sigma-Aldrich)、TG100801 (TargeGen)、沙利度胺(Thalidomide)(Celgene Corporation)、低肝酯鈉(Tinzaparin Sodium)、TKI258 (Novartis)、TRC093 (Tracon Pharmaceuticals Inc.)、VEGF Trap (Aflibercept) (Regeneron Pharmaceuticals)、VEGF Trap-Eye (Regeneron Pharmaceuticals)、維格林(Veglin)(VasGene Therapeutics)、硼替佐米(Bortezomib)(Millennium)、XL184 (Exelixis)、XL647 (Exelixis)、XL784 (Exelixis)、XL820 (Exelixis)、XL999 (Exelixis)、ZD6474 (AstraZeneca)、伏立諾他(Vorinostat) (Merck)、及ZSTK474。
例示性血管內皮生長因子(VEGF)受體抑制劑包括但不限於:貝伐單抗(Bevacizumab) (Avastin®)、阿西替尼(axitinib) (Inlyta®);布利尼布丙胺酸鹽(Brivanib alaninate) (BMS-582664, (S)-((R)-1-[[4-[(4-氟-2-甲基-17-吲哚-5-基氧基]-5-甲基吡咯并[2,1-f][1,2,4]三嗪-6-基氧基]-2-丙基)2-胺基丙酸酯];索拉非尼(Sorafenib)(Nexavar®);帕唑帕尼(Pazopanib)(Votrient®);蘋果酸舒尼替尼(Sunitinib malate)(Sutent®);西地尼布(Cediranib)(AZD2171,CAS 288383-20-1);瓦爾加特夫(Vargatef)(BIBF1120, CAS 928326-83-4);福瑞替尼(Foretinib)(GSK1363089);泰拉替尼(Telatinib)(BAY57-9352,CAS 332012-40-5);阿帕替尼(Apatinib)(YN968D1,CAS 811803-05-1);伊馬替尼(Imatinib)(格列衛®);波納替尼(Ponatinib)(AP24534,CAS 943319-70-8);替沃扎尼(Tivozanib)(AV951,CAS 475108-18-0);瑞戈非尼(Regorafenib)(BAY73-4506,CAS 755037-03-7);瓦他拉尼二鹽酸鹽(Vatalanib dihydrochloride)(PTK787,CAS 212141-51-0);布立伐尼(Brivanib) (BMS-540215, CAS 649735-46-6);凡德他尼(Vandetanib)(Caprelsa®或AZD6474);莫特沙尼二磷酸鹽(Motesanib diphosphate)(AMG706, CAS 857876-30-3, N-(2,3-二氫-3,3-二甲基-1H-吲哚-6-基)-2-[(4-吡啶基甲基)胺基]-3-吡啶甲醯胺,描述於PCT公開號WO 02/066470中);多維替尼雙乳酸(Dovitinib dilactic acid)(TKI258,CAS 852433-84-2);林法尼(Linfanib)(ABT869,CAS 796967-16-3);卡博替尼(Cabozantinib)(XL184,CAS 849217-68-1);來曲替尼(Lestaurtinib)(CAS 111358-88-4);N-[5-[[[5-(1,1-二甲基乙基)-2-噁唑基]甲基]硫基]-2-噻唑基]-4-哌啶甲醯胺(BMS38703,CAS 345627-80-7);(3R,4R)-4-胺基-l-((4-((3-甲氧基苯基)胺基)吡咯並[2,1-f] [1,2,4]三嗪-5-基)甲基)哌啶-3-醇(BMS6905 14);N-(3,4-二氯-2-氟苯基)-6-甲氧基-7-[[(3aa,5P,6aa)-八氫-2-甲基環戊二烯[c]吡咯-5-基]甲氧基]-4-喹唑啉胺(BMS6905 14);N-(3,4-二氯-2-氟苯基)-6-甲氧基-7-[[(3aa,5P,6aa)-八氫-2-甲基環戊二烯[c]吡咯-5-基]甲氧基]-4-喹唑啉胺(XL647,CAS 781613-23-8);4-甲基-3-[[1-甲基-6-(3-吡啶基)-1H-吡唑並[3,4-d]嘧啶-4-基]胺基]-N-[3-(三氟甲基)苯基]-苯甲酰胺(BHG712, CAS 940310-85-0);及阿柏西普(Aflibercept)(Eylea®)。例示性EGF路徑抑制劑包括但不限於:酪磷蛋白46 (tyrphostin 46)、EKB-569、厄洛替尼(erlotinib) (Tarceva®)、吉非替尼(gefitinib) (Iressa®)、爾必得舒(Erbitux)、尼妥珠單抗(nimotuzumab)、拉帕替尼(lapatinib) (Tykerb®)、西妥昔單抗(cetuximab) (anti-EGFR mAb)、經188Re標記的尼妥珠單抗(抗EGFR mAb),以及特別描述於WO 97/02266、EP 0 564 409、WO 99/03854、EP 0 520 722、EP 0 566 226、EP 0 787 722、EP 0 837 063、US 5,747,498、WO 98/10767、WO 97/30034、WO 97/49688、WO 97/38983和WO 96/33980中者。
例示性EGFR抗體包括但不限於:西妥昔單抗(Cetuximab) (Erbitux®);帕尼單抗(Panitumumab)(Vectibix®);馬珠單抗(Matuzumab)(EMD-72000);曲妥珠單抗(Trastuzumab)(Herceptin®);尼妥珠單抗(Nimotuzumab)(hR3);扎魯木單抗(Zalutumumab);TheraCIM h-R3;MDX0447 (CAS 339151-96-1);和ch806 (mAb-806,CAS 946414-09-1)。例示性表皮生長因子受體(EGFR)抑制劑包括但不限於:厄洛替尼鹽酸鹽(Erlotinib hydrochloride)(Tarceva®)、吉非尼(Gefitnib) (Iressa®);N-[4-[(3-氯-4-氟苯基)胺基]-7-[[(3“S”)-四氫-3-呋喃基]氧基]-6-喹唑啉基]-4(二甲基胺基)-2-丁烯醯胺(Tovok®);凡德他尼(Vandetanib)(Caprelsa®);拉帕替尼(Lapatinib)(Tykerb®);(3R,4R)-4-胺基-1-[[4-[(3-甲氧基苯基)胺基]吡咯並[2,1-f][1,2,4]三嗪-5-基]甲基]哌啶-3-醇(BMS690514);卡納替尼二鹽酸鹽(Canertinib dihydrochloride)(CI-1033);6-[4-[(4-乙基-1-哌嗪基)甲基]苯基]-N-[(1R)-1-苯乙基]-7H-吡咯並[2,3-d]嘧啶-4-胺(AEE788, CAS 497839-62-0);穆布里替尼(Mubritinib)(TAK165);佩利替尼(Pelitinib)(EKB569);阿法替尼(Afatinib)(BIBW2992);來那替尼(Neratinib)(HKI-272);N-[4-[[1-[(3-氟苯基)甲基]-1H-吲唑-5-基]胺基]-5-甲基吡咯並[2,1-f][1,2,4]三嗪-6-基]-胺基甲酸,(3S)-3-嗎啉基甲酯(BMS599626);N-(3,4-二氯-2-氟苯基)-6-甲氧基-7-[[(3aα,5β,6aα)-八氫-2-甲基環戊[c]吡咯-5-基]甲氧基]-4-喹唑啉胺(XL647,CAS 781613-23-8);和4-[4-[[(1R)-1-苯乙基]胺基]-7H-吡咯並[2,3-d]-嘧啶-6-基-酚(PKI 166, CAS 187724-61-4)。
例示性mTOR抑制劑包括但不限於:雷帕黴素(rapamycin)(Rapamune®)及其類似物和衍生物;SDZ-RAD;特癌適(Temsirolimus)(Torisel®;也稱為CCI-779);截克瘤(Ridaforolimus)(正式名稱為德福莫司(deferolimus),(lR,2R,4S)-4-[(2R)-2[(1R,9S,12S,15R,16E,18R,19R,21R,23S,24E,26E,28Z,30S,32S,35R)-1,18-二羥基-19,30-二甲氧基-15,17,21,23,29,35-六甲基-2,3,10,14,20-戊側氧基-ll,36-二氧雜-4-氮雜三環[30.3.1.0
4,9]三十六-16,24,26,28-四烯-12-基]丙基]-2-甲氧基環己基二甲基亞膦酸酯,也稱為AP23573和MK8669,且於PCT公開號WO 03/064383中已有描述);依維莫司(Everolimus)(Afinitor®或RAD001);雷帕黴素(Rapamycin)(AY22989,Sirolimus®);辛匹莫德(Simapimod) (CAS 164301-51-3);(5-{2,4-雙[(3S)-3-甲基嗎啉-4-基]吡啶並[2,3-d]嘧啶-7-基]-2-甲氧基苯基)甲醇(AZD8055);2-胺基-8-[反式-4-(2-羥基乙氧基)環己基]-6-(6-甲氧基-3-吡啶基)-4-甲基-吡啶并[2,3-d]嘧啶-7(8H)-酮(PF04691502,CAS 1013101-36-4);和2-[1,4-二側氧基-4-[[4-(4-側氧基-8-苯基-4H-1-苯並吡喃-2-基)嗎啉-4-基]甲氧基]丁基]-L-精胺醯甘胺醯基-L-α-天冬胺醯基-絲胺酸(SEQ ID NO: 73)-內鹽(SF1126,CAS 936487-67-1)。
例示性免疫調節劑包括,例如:阿夫妥珠單抗(afutuzumab)(可得自Roche®);培非格司亭(pegfilgrastim)(Neulasta®);來那度胺(lenalidomide)(CC-5013,Revlimid®);沙利度胺(thalidomide) (Thalomid®)、阿克替米德(Actimid) (CC4047);和IRX-2 (人類細胞因子的混合物,包括介白素1、介白素2和干擾素g,CAS 951209-71-5,得自IRX Therapeutics)。例示性蒽環類包括,例如:多柔比星(doxorubicin)(Adriamycin®和Rubex®);博來黴素(bleomycin)(lenoxane®);柔紅黴素(daunorubicin)(柔紅黴素鹽酸鹽、柔紅黴素和柔紅黴素鹽酸鹽,Cembidine®);柔紅黴素脂質體(檸檬酸柔紅黴素脂質體,DaunoXome®);米托蒽醌(mitoxantrone)(DHAD,Novantrone®);表柔比星(epirubicin)(Ellence™);艾達比星(idambicin)(Idamycin®、Idamycin PFS®);絲裂黴素C (Mutamycin®);格爾德黴素(geldanamycin);除草霉素(herbimycin);拉維黴素(ravidomycin);和去乙醯雷維多黴素。例示性的長春花生物鹼包括,例如:酒石酸長春瑞濱(vinorelbine tartrate)(Navelbine®)、長春新鹼(Vincristine) (Oncovin®)和長春地新(Vindesine) (Eldisine®));長春鹼(vinblastine)(也稱為硫酸長春鹼、長春花鹼(vincaleukoblastine)和VLB、Alkaban-AQ®和Velban®);和長春瑞濱(vinorelbine)(Navelbine®)。例示性蛋白酶體抑制劑包括硼替佐米(bortezomib)(Velcade®);卡非唑米(carfilzomib)(PX-171-007,(S)-4-甲基-N-((S)-1-(((S)-4-甲基-1-((R)-2-甲基環氧乙烷-2-基)-1-側氧基戊-2-基)胺基)-1-側氧基-3-苯基丙-2-基)-2-((S)-2-(2-嗎啉基乙醯胺基)-4-苯基丁醯胺基)-戊醯胺);馬瑞唑米(marizomib)(NPI-0052);依薩唑米(ixazomib)檸檬酸鹽(MLN-9708);迪蘭唑米(delanzomib)(CEP-18770);及O-甲基-N-[(2-甲基-5-噻唑基)羰基]-L-絲胺醯基-O-甲基-N-[(1S)-2-[(2R)-2-甲基-2-環氧乙烷基]-2-側氧基-1-(苯基甲基)乙基]-L-絲胺醯胺(ONX-0912)。
例示性磷酸肌醇3-激酶(PI3K)抑制劑包括但不限於:4-[2-(1H-吲唑-4-基)-6-[[4-(甲基磺醯基)哌嗪-1-基]甲基]噻吩並[3,2-d]嘧啶-4-基]嗎啉(也稱為GDC 0941並描述於PCT公開號WO 09/036082和WO 09/055730中);2-甲基-2-[4-[3-甲基-2-側氧基-8-(喹啉-3-基)-2,3-二氫咪唑[4,5-c]喹啉-1-基]苯基]丙腈(也稱為BEZ 235或NVP-BEZ 235,並描述於PCT公開號WO 06/122806 中);4-(三氟甲基)-5-(2,6-二嗎啉代嘧啶-4-基)吡啶-2-胺(也稱為BKM120或NVP-BKM120,描述於PCT公開號WO2007/084786);特札沙替(Tozasertib)(VX680或MK-0457,CAS 639089-54-6);(5Z)-5-[[4-(4-吡啶基)-6-喹啉基]亞甲基]-2,4-噻唑烷二酮(GSK1059615, CAS 958852-01-2);(1E,4S,4aR,5R,6aS,9aR)-5-(乙醯氧基)-1-[(二-2-丙烯基胺基)亞甲基]-4,4a,5,6,6a,8,9,9a-八氫-ll-羥基-4-(甲氧基甲基)-4a,6a-二甲基環戊[5,6]萘並[1,2-c]吡喃-2,7,10(lH)-三酮(PX866, CAS 502632-66-8);和8-苯基-2-(嗎啉-4-基)-色烯-4-酮(LY294002, CAS 154447-36-6)。
例示性的蛋白激酶B (PKB)或AKT抑制劑包括但不限於:8-[4-(l-胺基環丁基)苯基]-9-苯基-l,2,4-三唑並[3,4-f][l,6]萘啶-3(2H)-酮(MK-2206, CAS 1032349-93-1);哌立福辛(Perifosine) (KRX0401);4-十二烷基-N-1,3,4-噻二唑-2-基苯磺醯胺(PHT-427,CAS 1191951-57-1);4-[2-(4-胺基-1,2,5-噁二唑-3-基)-1-乙基-7-[(3S)-3-哌啶基甲氧基]-1H-咪唑並[4,5-c]吡啶-4-基]-2-甲基-3-丁炔-2-醇(GSK690693, CAS 937174-76-0);8-(1-羥乙基)-2-甲氧基-3-[(4-甲氧基苯基)甲氧基]-6H-二苯並[b,d]吡喃-6-酮(palomid 529、P529或SG-00529);曲西濱(Tricirbine) (6-胺基-4-甲基-8-(P-D-呋喃核糖基)-4H,8H-吡咯並[4,3,2-de]嘧啶並[4,5-c]噠嗪);(αS)-α-[[[5-(3-甲基-1H-吲唑-5-基)-3-吡啶基]氧基]甲基]-苯乙胺(A674563, CAS 552325-73-2);4-[(4-氯苯基)甲基]-1-(7H-吡咯並[2,3-d]嘧啶-4-基)-4-哌啶胺(CCT128930, CAS 885499-61-6);4-(4-氯苯基)-4-[4-(1H-吡唑-4-基)苯基]-哌啶(AT7867,CAS 857531-00-1);和特立適(Archexin)(RX-0201, CAS 663232-27-7)。
亦可使用抑制鈣依賴性去磷酸酶鈣調磷酸酶(環孢素和FK506)或抑制p70S6激酶,其對於生長因子誘導訊息傳遞(雷帕黴素(rapamycin))相當重要。(Liu等人,Cell 66:807-815, 1991; Henderson等人,Immun. 73:316-321, 1991; Bierer等人,Curr. Opin. Immun. 5:763-773, 1993)。在另一態樣中,本發明之細胞組成物可與骨髓移植、使用化療試劑(如氟達濱(fludarabin))、外部光束放射療法(XRT)、環磷醯胺及/或抗體(如OKT3或CAMPATH之抗體)的T細胞消融治療,一起投與患者(例如,在之前、同時或之後)。在一態樣中,本發明的細胞組成物在B細胞消融治療(例如與CD20反應的試劑,例如利妥昔單抗(Rituxan))後投與。例如,在一實施例中,該個體可先接受高劑量化療的標準治療,接著進行周邊血液幹細胞移植。在某些實施例中,在移植之後,該個體接受本發明之經擴增免疫細胞的輸注。在一額外實施例中,擴增的細胞係在手術之前或之後投與。
該組合療法可提供協同作用且證明協同作用,亦即,當活性成分一起使用所導致之效果大於分開使用該等化合物的效果總和時,所達到的作用。當活性成分如下述時,可達到協同效應:(1)共同配製且在組合單位劑型中同時投與或遞送時;(2)作為單獨的配方交替或平行遞送時;或(3)藉由一些其他方案。當以交替方式遞送時,可在依序投與或依序遞送化合物時達到協同效應,例如藉由在不同注射器中進行不同注射。一般而言,在交替方式中,各活性成分之有效劑量係依序投與,而在組合療法中,兩種或多於兩種活性成分之有效劑量則一起投與。
在一實施例中,在抗癌治療後,將有效量的特異性結合至一或多種本文揭示的抗原或其共軛物的抗體或抗原結合片段,投與於患有腫瘤的個體。在經過足以允許所投與抗體或抗原結合片段或共軛物與相對應癌細胞上表現之抗原形成免疫複合物的時間之後,偵測該免疫複合物。免疫複合物的存在(或不存在)說明該治療的有效性。舉例而言,與治療前的對照相較,免疫複合物的增加說明該治療無效,而與治療前的對照相較,免疫複合物的減少說明該治療有效。
在各實施例中,如本文所述之抗GCC抗原結合劑可包括在一治療過程中,其進一步包括向個體投與至少一種額外試劑。在各實施例中,與如本文所述之抗GCC抗原結合劑組合投與之額外試劑,可為化療試劑。在各實施例中,與如本文所述之抗原結合劑組合投與之額外試劑,可為抑制發炎之試劑。
在一些實施例中,抗GCC抗原結合劑為具有人類GCC之特異性之單域抗體。在一些實施例中,該抗GCC單域抗體可共軛(例如連接)至治療劑(例如化療劑及放射性原子),以結合至癌細胞、遞送該治療劑至癌細胞,並殺傷表現人類GCC之癌細胞。在一些實施例中,抗GCC結合劑與治療劑連接。在一些實施例中,治療劑為化療劑、細胞激素、放射性原子、siRNA或毒素。在一些實施例中,該治療劑為化療劑。在一些實施例中,該試劑為放射性原子。
在一些實施例中,該方法可與針對GCC相關病症之其他療法結合進行。舉例而言,該組成物可在化學療法之前或之後同時向個體投與。在一些實施例中,該組成物可在採用之治療方法同時、之前或之後向個體投與。
在各實施例中,與如本文所述之抗GCC結合劑組合投與之額外試劑,可與抗GCC結合劑同時投與、在與抗GCC結合劑之同一天投與、或與抗GCC結合劑同一週內投與。在各實施例中,與如本文所述之抗GCC結合劑組合投與之額外試劑,可與抗GCC結合劑形成之單一調配物進行投與。在某些實施例中,額外試劑係以與本文所述之抗GCC結合劑暫時分離之方式投與,例如,在投與抗GCC結合劑之前或之後的一或多個小時、之前或之後的一或多天、之前或之後的一或多週、之前或之後的一或多月。在各實施例中,一或多種額外試劑之投與頻率可與本文所述之抗GCC結合劑之投與頻率相同、相似或不同。
在組合療法中涵蓋投與兩種如本文所述之不同抗體,及/或包括藉由複數個調配物及/或投與途徑投與如本文所描述之抗體的治療方案。
在一些實施例中,組成物可與一或多種額外治療劑一同配製,例如在個體中治療或預防GCC相關病症(例如癌症或自體免疫病症)之額外療法。在個體中用於治療GCC相關病症之額外試劑,將視所治療之特定病症而不同,但可包括但不限於:利妥昔單抗(rituximab)、環磷醯胺、多柔比星(doxorubicin)、長春新鹼(vincristine)、強的松(prednisone)、奧斯發醯胺(osfamide)、卡鉑(carboplatin)、依托泊苷(etoposide)、地塞米松(dexamethasone)、阿糖胞苷(cytarabine)、順鉑(cisplatin)、環磷醯胺或氟達拉濱(fludarabine)。
本文所描述之組成物可替代或擴增先前或目前投與之療法。舉例而言,當以本文所描述之組成物治療時,一或多種額外活性劑之投與可停止或減少,例如,在投與本文所描述之抗GCC結合劑之後,可在較低濃度下投與例如較低位準的參考抗體(其會進行GCC結合之相互競爭)。在一些實施例中,可維持先前療法之投與。在一些實施例中,先前療法將維持至組成物之位準達到足以提供治療作用之程度。兩種療法可組合投與。
在一些實施例中,可投與該個體可降低或減緩與投與本文所描述之療法或組合(例如,表現CAR的細胞(例如,表現GCC CAR的細胞)及額外試劑)相關之副作用的試劑。與投與表現CAR的細胞相關的副作用包括但不限於CRS,以及噬血細胞性淋巴組織細胞增多症(HLH),也稱為巨噬細胞激活化症候群(MAS)。CRS的症狀包括高燒、噁心、短暫性低血壓、缺氧及類似症狀。因此,本文所描述之方法可包含向個體投與本文所描述之治療,例如表現CAR的細胞(例如,表現GCC CAR的細胞),且進一步投與一試劑,以管理由表現CAR的細胞治療引起之可溶因子的位準升高。於一實施例中,個體中升高之可溶性因子為IFN-g、TNFa、IL-2及IL-6中之一或多者。因此,被投與用來治療此副作用之試劑可為可中和這些可溶性因子之一或多者的試劑。此類試劑包括但不限於類固醇、TNFa抑制劑及IL-6抑制劑。TNFa抑制劑之實例為依那西普(entanercept)。IL-6抑制劑之實例為托珠單抗(Tocilizumab)。
在一實施例中,可向個體投與增進本文所描述之治療活性之試劑,例如表現CAR的細胞(例如,表現GCC CAR的細胞)。舉例而言,在一實施例中,該試劑可為抑制該抑制性分子的試劑。例如在一些實施例中,額外抑制分子可降低表現CAR的細胞建立免疫效應反應之能力。抑制性分子之實例包括PD1、PD-F1、CTFA4、TIM3、FAG3、VISTA、BTFA、TIGIT、FAIR1、CD160及2B4。
抑制性分子的抑制,例如藉由在DNA、RNA或蛋白質層級上的抑制,可使表現CAR的細胞的表現度最佳化。在實施例中,抑制性核酸,例如抑制性核酸如dsRNA,例如siRNA或shRNA,可用於抑制表現CAR的細胞中抑制性分子的表現。在一實施例中,該抑制劑為shRNA。在一實施例中,該抑制性分子係於表現CAR的細胞中被抑制。在這些實施例中,抑制該抑制性分子之表現的dsRNA分子,係連接至編碼CAR之一成分(例如,所有成分)之核酸。
在一些實施例中,抑制信號之抑制劑可為例如結合於該抑制性分子之抗體或抗體片段。例如,該試劑可為與PD1、PD-L1、PD-L2或CTLA4結合的抗體或抗體片段(例如,易普利單抗(ipilimumab)(也稱為MDX-010和MDX-101,並以Yervoy®銷售;Bristol -Myers Squibb);曲美木單抗(Tremelimumab) (IgG2單株抗體,得自Pfizer,舊名為替西木單抗(ticilimumab), CP-675,206)。可增強例如表現CAR的細胞(例如表現GCC CAR的細胞)的活性之試劑可為例如,包含第一域和第二域的融合蛋白,其中第一域是抑制分子或其片段,且第二域是與陽性信號相關的多肽,例如,與陽性信號相關的多肽為CD28、ICOS及其片段,例如CD28和/或ICOS的細胞內信號傳導域。在一實施例中,該融合蛋白由表現該CAR之相同細胞表現。在另一實施例中,該融合蛋白由不表現抗GCC CAR之細胞(例如,T細胞)表現。
在另一實施例中,該個體接受例如表現CAR的細胞之輸注,例如在移植(如同種異體幹細胞移植)之前輸注本揭示之組成物。在一較佳實施例中,表現CAR的細胞暫時表現CAR,例如藉由將編碼CAR的mRNA進行電穿孔,藉此在輸注供體幹細胞之前終止CAR的表現,以避免移植失敗。
某些患者在投與期間或之後,可能會經歷對本揭示之化合物及/或其他抗癌藥物之過敏反應;因此,通常投與抗過敏劑以降低過敏反應的風險。合適的抗過敏劑包括皮質類固醇,例如地塞米松(dexamethasone)(例如,Decadron®)、倍氯米松(beclomethasone)(例如,Beclovent®)、氫化可的松(hydrocortisone)(也稱為可的松、氫化可的松琥珀酸鈉、氫化可的松磷酸鈉,並且以商品名Ala-Cort®出售)、磷酸氫化可的松、Solu-Cortef®、Hydrocort Acetate®的Lanacort®)、潑尼松龍(prednisolone)(以商品名Delta-Cortel®、Orapred®、Pediapred®的Prelone®出售)、潑尼松(prednisone)(以商品名Deltasone®、Liquid Red®、Meticorten®和Orasone®出售)、甲基潑尼松龍(methylprednisolone)(也稱為6-甲基潑尼松龍、醋酸甲基潑尼松龍、甲基潑尼松龍琥珀酸鈉,以商品名 Duralone®、Medralon®、Medrol®、M-Prednisol®和Solu-Medrol®出售);抗組胺藥,例如苯海拉明(diphenhydramine)(例如Benadryl®)、羥嗪和賽庚啶(cyproheptadine);和支氣管擴張劑,例如β-腎上腺素系受體促效劑、沙丁胺醇(albuterol)(例如Proventil®)和特布他林(terbutaline)(Brethine®)。某些患者在投與本揭示之化合物及/或其他抗癌藥物期間及之後可能出現噁心;因此,抗嘔吐劑被用於預防噁心(上胃)及嘔吐。適合的抗嘔吐藥物包括阿瑞匹坦(aprepitant) (Emend®)、昂丹司瓊(ondansetron) (Zofran®)、鹽酸格拉司瓊(granisetron HCl) (Kytril®)、勞拉西泮(lorazepam) (Ativan® 地塞米松(dexamethasone) (Decadron®)、丙氯拉嗪(prochlorperazine) (Compazine®)、卡索匹坦(casopitant) (Rezonic®的Zunrisa®)及其組合。
通常會開立藥物以減輕治療期間所經歷的疼痛,讓患者更加舒適。經常使用常見的非處方止痛藥,例如Tylenol®。然而,鴉片類鎮痛藥,例如氫可酮/撲熱息痛(hydrocodone/paracetamol)或氫可酮/對乙醯胺基酚 (hydrocodone/acetaminophen)(例如Vicodin®)、嗎啡(morphine)(例如Astramorph® 或 Avinza®)、羥考酮(oxycodone)(例如OxyContin®或Percocet®)、鹽酸羥嗎啡酮(oxymorphone hydrochloride)(Opana®) 和芬太尼(fentanyl)(例如,Duragesic®),也可用於中度或重度疼痛。
為了保護正常細胞免於治療毒性,並限制器官毒性,可使用細胞保護劑例如神經保護劑、自由基清除劑、心臟保護劑、蒽環類外滲中和劑、營養物質及類似物,作為輔助療法。適合的細胞保護劑包括胺磷汀(Amifostine)(Ethyol®)、麩胺醯胺、地美思納(dimesna)(Tavocept®)、美思納(mesna)(Mesnex®)、右雷佐生(dexrazoxane)(Zinecard® 或Totect®)、沙利普登(xaliproden) (Xaprila®)和亞葉酸鈣(leucovorin)(也稱為亞葉酸鈣、檸檬酸鈣因子和亞葉酸)。
以代碼、通用名或商品名辨識之活性化合物的結構,係取自標準藥典實際版本「The Merck Index」或資料庫,例如國際專利(例如IMS World Publications)。上述化合物可與本發明之化合物組合使用,可如本技術領域中所述製備及投與,如在上文所引用之文獻中所述。
在一實施例中,本發明提供一種醫藥組成物,其包含至少一本發明之治療劑(例如,本發明的治療劑)或其醫藥學上可接受的鹽、以及適合一起投與人類或動物個體之醫藥學上可接受的載體,不論是單獨或與其他抗癌劑一起使用。
在一實施例中,本發明提供治療患有細胞增殖性疾病(例如癌症)的人類或動物個體的方法。本發明提供治療需要此類治療的人類或動物個體的方法,包括向該個體投與治療有效量之本發明的治療劑或其醫藥學上可接受的鹽,不論是單獨或與其他抗癌劑一起投與。
特別地,組成物將配製為組合治療劑或分開投與。在組合治療中,本發明的化合物和其他抗癌劑可同步、同時或依序投與,沒有特定的時間限制,其中此種投與提供該二化合物在患者體內的治療有效位準。
在一些實施例中,本發明的化合物和其他抗癌劑通常藉由輸注或口服、以任何順序依次投與。投藥方案可根據疾病的階段、患者的身體健康狀況、個別藥物的安全性、個別藥物的耐受性、以及主治醫師和執業醫師熟知投與該組合的其他標準,而有所不同。本發明之治療劑(例如GCC CAR)及其他抗癌劑可彼此相隔數分鐘、數小時、數日或甚至數周投與,取決於用於治療之特定循環。此外,該循環可包括在治療循環中,其中一種藥物比另一種藥物更常被投與,且在每次投與該藥物時以不同劑量投與。
本發明之治療劑(例如,GCC CAR)亦可有利地用於與已知的治療過程(例如,投與激素或尤其是放射線)組合。本發明之化合物可特別作為放射線增敏劑,特別是用於治療對放射療法表現出不良敏感性的腫瘤。
在實施例中,可投與該個體可降低或減緩與投與表現CAR的細胞相關之副作用的試劑。與投與表現CAR的細胞相關的副作用包括但不限於CRS,以及噬血細胞性淋巴組織細胞增多症(HLH),也稱為巨噬細胞激活化症候群(MAS)。
因此,本文所描述之方法可包含向個體投與本文所描述之表現CAR的細胞,且進一步投與一或多種試劑,以管理由經表現CAR的細胞治療導致之可溶性因子的升高位準。在一實施例中,該個體中升高之可溶性因子為IFN-g、TNFa、IL-2及IL-6中之一或多者。在一實施例中,該個體中升高的因子為IL-1、GMCSF、IL-10、IL-8、IL-5及趨化因子(fraktalkine)之一或多者。因此,被投與用來治療此副作用之試劑可為可中和這些可溶性因子之一或多者的試劑。
在一實施例中,中和這些可溶性形式之一或多者的試劑為一抗體或其抗原結合片段。此類試劑之實例包括但不限於類固醇(例如皮質類固醇)、TNFa抑制劑及IL-6抑制劑。TNFa抑制劑之一實例為抗TNFa抗體分子,如英夫利昔單抗(infliximab)、阿達木單抗(adalimumab)、賽妥珠單抗聚乙二醇(certolizumab pegol)和戈利木單抗(golimumab)。TNFa抑制劑之另一實例為一融合蛋白,如依那西普(entanercept)。TNFa的小分子抑制劑包括但不限於:黃嘌呤衍生物(例如己酮可可鹼(pentoxifylline))及安非他酮(bupropion)。IL-6抑制劑之實例為抗-IL-6抗體分子,例如托珠單抗(Tocilizumab) (toe)、沙利尤單抗(sarilumab)、艾司利單抗(elsilimomab)、CNTO 328、ALD518/BMS-945429、CNTO 136、CPSI-2364、CDP6038、VX30、ARGX-109、FE301及FM101。在一實施例中,抗-IL-6抗體分子為托珠單抗(Tocilizumab)。基於IL-1R之抑制劑的實例為阿那白滯素(anakinra)。
在一些實施例中,向個體投與皮質類固醇,諸如,例如,甲基普德尼松(methylprednisolone)、氫皮質酮(hydrocortisone)等。在一些實施例中,向個體投與血管加壓劑,例如正腎上腺素、多巴胺、苯膦、腎上腺素、升壓素、或其組合。
在一實施例中,可投與該個體退熱劑。在一實施例中,可投與該個體止痛劑。
在一實施例中,可進一步向個體投與提高表現CAR的細胞之活性或適合性之試劑。例如,在一實施例中,該試劑可為抑制調控或調節(例如,抑制)T細胞功能之分子的試劑。在一些實施例中,該調控或調節T細胞功能之分子為抑制性分子。抑制性分子,例如計劃性死亡1 (PD-1)或PD-1配位體(PD-L1),在一些實施例中,可降低表現CAR的細胞建立免疫效應反應之能力。抑制性分子之實例包括PD-1、PD-L1、CTLA4、TIM3、CEACAM (例如,CEACAM-1、CEACAM-3及/或CEACAM-5)、LAG3、VISTA、BTLA、TIGIT、LAIR1、CD160、2B4、CD80、CD86、B7-H3 (CD276)、B7-H4 (VTCN1)、HVEM (TNFRSF14或CD270)、KIR、A2aR、第1類MHC、第2類MHC、GAL9和腺苷。調控或調節(例如,抑制)T細胞功能(例如,藉由在DNA、RNA或蛋白質層級抑制)之分子的抑制,可使表現CAR的細胞之表現度最佳化。在實施例中,試劑例如抑制性核酸,例如,抑制性核酸如dsRNA,例如siRNA或shRNA、成簇的規則間隔短回文重複序列(CRISPR)、轉錄激活因子樣效應核酸酶(TALEN)、或鋅指核酸內切酶(ZFN),如本文所述,可用於抑制表現CAR的細胞中抑制性分子的表現。在一實施例中,該抑制劑為shRNA。於一實施例中,調控或調節(例如抑制)T細胞功能之試劑係在表現CAR的細胞中被抑制。在這些實施例中,抑制調控或調節(例如抑制)T細胞功能之分子表現的dsRNA分子,係與編碼CAR之一成分(例如所有成分)的核酸連接。
在一實施例中,該編碼調控或調節(例如抑制)T細胞功能之分子表現的dsRNA分子之核酸分子,係可操作地連接至一啟動子,例如HI-或U6-衍生的啟動子,使得抑制調控或調節(例如抑制)T細胞功能之分子表現的dsRNA分子可被表現,例如,在表現CAR的細胞中被表現。請參見例如,Tiscomia G., “Development of Lentiviral Vectors Expressing siRNA,” 第3章,in Gene Transfer: Delivery and Expression of DNA and RNA (Friedmann及Rossi編)。Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, USA, 2007; Brummelkamp TR編,(2002) Science 296: 550-553; Miyagishi M等人,(2002) Nat. Biotechnol. 19: 497-500。
在一實施例中,編碼一dsRNA分子(其抑制調控或調節(例如抑制)T細胞功能之分子表現)的核酸分子,係存在於包含該編碼CAR之一成分(例如所有成分)的核酸之相同載體(例如,慢病毒載體)上。在此類實施例中,編碼一dsRNA分子(其抑制調控或調節(例如抑制)T細胞功能之分子表現)的核酸分子,係位於載體(例如,慢病毒載體)上相對於該編碼CAR之一成分(例如所有成分)的核酸之5'-或3’-端。編碼一dsRNA分子(其抑制調控或調節(例如抑制)T細胞功能之分子表現)的核酸分子,可在與編碼CAR之一成分(例如所有成分)的核酸相同或不同方向上進行轉譯。於一實施例中,編碼一dsRNA分子(其抑制調控或調節(例如抑制)T細胞功能之分子表現)的核酸分子,係存在於包含編碼CAR之一成分(例如所有成分)的核酸之載體以外的載體上。於一實施例中,編碼一dsRNA分子(其抑制調控或調節(例如抑制)T細胞功能之分子表現)的核酸分子,係於表現CAR的細胞中暫時表現。於一實施例中,編碼一dsRNA分子(其抑制調控或調節(例如抑制)T細胞功能之分子表現)的核酸分子,係穩定整合至表現CAR的細胞之基因組中。提供用於表現CAR之一成分(例如所有成分)與dsRNA分子(其抑制調控或調節(例如抑制)T細胞功能之分子表現)的例示性載體的配置,係提供於例如,於2014年12月19日所提交之國際公開案WO20 15/090230之圖47中,其經由引用併入本文。
在實施例中,本文所述的療法,例如表現CAR的細胞(例如,表現GCC CAR的細胞),係與抗癲癇劑例如乙醯唑胺(acetazolamide)、比伐西坦(bivaracetam)、卡馬西平(carbamazepine)、氯巴佔(clobazam)、氯硝西泮(clonazepam)、醋酸艾司利卡西平(eslicarbazepine acetate)、乙琥胺(ethosuximide)、加巴噴丁(gabapentin)、拉考沙胺(lacosamide)、拉莫三嗪(lamotrigine)、左乙拉西坦(levetiracetam)、奧卡西平(oxcarbazepine)、吡崙帕奈(perampanel)、苯巴比妥(phenobarbital)、苯妥英(phenytoin)、吡拉西坦(piracetam)、普瑞巴林(pregabalin)、撲米酮(primidone)、盧地那胺(rudinamide)、丙戊酸鈉、司替戊醇(stiripentol)、噻加賓(tiagabine)、托吡酯(topiramate)、丙戊酸、氨己烯酸(vigabatrin)、唑尼沙胺(zonisamide)組合投與。請參見,Weller等人,Lancet 13.9 (2012):e375-e382。在實施例中,抗癲癇劑在本文所描述之治療(例如表現CAR的細胞(例如表現GCC CAR的細胞))之前,以有效防止癲癇之量投與。在實施例中,抗癲癇劑之投與視情況在投與本文所描述之治療(例如表現CAR的細胞(例如,表現GCC CAR的細胞)全程與之後持續。在實施例中,本文所描述之治療,例如表現CAR的細胞(例如表現GCC CAR的細胞),可與抗癲癇劑及放射線組合治療使用。
細胞激素釋放症候群(CRS)
細胞激素釋放症候群(CRS)是一種可能危及生命的細胞激素相關毒性,可能由於癌症免疫療法(例如癌症抗體療法或T細胞免疫療法(例如CAR T細胞))而發生。CRS是由高位準的免疫活化引起的,當大量淋巴細胞及/或骨髓細胞在活化時釋放發炎性細胞激素時。CRS的嚴重程度和症狀的出現時間,可能根據免疫細胞活化的程度、投與的治療類型及/或個體的腫瘤負荷程度而有所不同。在治療癌症的T細胞治療中,症狀通常在投與T細胞療法後數天至數星期發作,例如當體內T細胞擴增達到高峰時。請參見例如Lee等人 Blood. 124.2(2014): 188-95。
CRS的症狀可能包括神經毒性、彌散性血管內凝血、心臟功能不全、成人呼吸窘迫症候群、腎功能衰竭及/或肝功能衰竭。例如,CRS的症狀包括高燒、噁心、短暫性低血壓、缺氧及類似症狀。CRS可包括臨床徵象和症狀,例如發燒、疲勞、厭食、肌肉痛、關節痛、噁心、嘔吐和頭痛。CRS可包括臨床皮膚徵象和症狀,例如紅疹。CRS可包括臨床胃腸道徵象和症狀,例如噁心、嘔吐和腹瀉。CRS可包括臨床呼吸徵象與症狀,例如呼吸急促與低氧血症。CRS可包括臨床心血管徵象與症狀,例如心搏過速、脈搏壓變寬、低血壓、心搏輸出增加(早期),以及潛在性心臟輸出降低(晚期)。CRS可包括臨床凝血徵象和症狀,例如d-二聚體升高、低纖維蛋白原血症伴隨或未伴隨出血。CRS可包括臨床腎臟徵象和症狀,例如高氮血症。CRS可包括臨床肝臟徵象和症狀,例如轉胺炎和高膽紅素血症。CRS包括臨床神經系統體徵象和症狀,例如頭痛、精神狀態改變、意識模糊、譫妄、找詞困難或明顯失語、幻覺、震顫、動幅障、步態改變和癲癇發作。
IL-6被認為是CRS毒性的介導物。參見,例如,id。高IL-6濃度可引發促發炎性IL-6信號傳導連鎖反應,而引起一或多種CRS症狀。在一些案例中,C-反應蛋白(CRP)(一種由肝臟製造的生物分子,例如,反應於IL-6)的濃度可用於IL-6活性的測量。在一些案例中,在CRS期間,CRP的濃度可能會增加數倍(例如數個log)。CRP濃度可使用本文所述之方法,及/或本領域可用的標準方法測量。
CRS評級
在一些實施例中,CRS可如下評定為1至5級。第1-3級是低於嚴重的CRS。第4-5級是嚴重的CRS。對於第1級CRS,只需要症狀性治療(例如噁心、發燒、疲倦、肌痛、不適、頭痛),且症狀並非危及生命。對於第2級CRS,症狀需要中度介入,且一般對於中度介入有反應。患有第2級CRS的個體會發展出對流體或一種低劑量血管加壓劑有反應的低血壓;或者發展出等級2之器官毒性或輕度呼吸症狀,其對於低流量氧氣(<40%氧氣)有反應。
在第3級CRS個體中,低血壓一般無法透過流體療法或一種低劑量血管加壓劑而逆轉。這些個體一般需要超過低流量的氧氣,且具有等級3之器官毒性(例如腎臟或心臟功能不全或凝血病變)及/或等級4之轉胺炎。第3級CRS個體需要更積極的介入,例如:40%或以上的氧氣、高劑量的血管加壓劑,及/或多種血管加壓劑。第4級的CRS個體會立即出現危及生命的症狀,包括等級4的器官毒性或需要機械通氣。第4級CRS個體通常不會有轉胺炎。在第5級CRS個體中,該毒性會造成死亡 例如,在此以表9提供CRS評級之條件。除非另外指明,否則如本文所用之CRS係指根據表9之CRS標準。
表9. CRS評級
CRS療法
| Grl | 僅有支持性照護 |
| Gr2 | IV療法+/- 住院。 |
| Gr3 | 需要IV輸液或低劑量血管活性劑或需要氧氣、CPAP或BIPAP的低氧血症的低血壓。 |
| Gr4 | 需要高劑量血管活性劑的低血壓或需要機械性的低血氧 |
| Gr5 | 死亡 |
用於CRS的療法包括IL-6抑制劑或IL-6受體(IL-6R)抑制劑(例如托珠單抗(Tocilizumab)或西妥昔單抗(siltuximab))、sgpl30阻斷劑、血管活化藥物、皮質類固醇、免疫抑制劑和機械通氣。用於CRS之例示性療法描述於國際申請案號W02014011984中,其經由引用併入本文。
托珠單抗(Tocilizumab)是一種人源化免疫球蛋白Glkappa抗人類IL-6R單株抗體。參見,例如,id。托珠單抗(Tocilizumab)阻斷IL-6與可溶性及膜結合IL-6受體(IL-6R)的結合,因此抑制古典和反向-IL-6訊號傳遞。在實施例中,托珠單抗(Tocilizumab)以約4-12 mg/kg之劑量進行投與,例如成人約4-8 mg/kg、及兒童個體約8-12 mg/kg,例如歷時1小時。在一些實施例中,CRS治療劑為IL-6信號傳導抑制劑,例如IL-6或IL-6受體之抑制劑。在一實施例中,該抑制劑為抗-IL-6抗體,例如抗-IL-6嵌合單株抗體,如西妥昔單抗(siltuximab)。在其他實施例中,該抑制劑包含可阻斷IL-6信號傳導之可溶性gpl30或其片段。在一些實施例中,該sgpl30或其片段與異源域(例如,Lc域)融合,例如為gpl30-Lc融合蛋白,諸如LE301。在實施例中,IL-6信號傳導之抑制劑包含抗體,例如針對IL-6受體之抗體,如沙利魯單抗(sarilumab)、奧基珠單抗(olokizumab)(CDP6038)、艾司利莫單抗(elsilimomab)、辛庫單抗(simkumab)(CNTO 136)、ALD518/BMS-945429、ARGX-109或LM101。在一些實施例中,該IL-6信號傳導之抑制劑包含小分子,例如CPST2364。
例示性的血管活化藥物包括但不限於:血管緊張素-11、內皮素-1、α-腎上腺素促效劑、rostanoids、磷酸二酯酶抑制劑、內皮素拮抗劑、正性肌力藥(例如,腎上腺素、多巴酚丁胺、異丙腎上腺素、麻黃鹼)、血管加壓劑(例如,去甲腎上腺素、升壓素、間苯二酚、升壓素、亞甲藍)、擴張劑(如米力農(milrinone)、左西孟旦(levosimendan))和多巴胺。例示性的血管加壓劑包括但不限於正腎上腺素、多巴胺、脫羥腎上腺素、腎上腺素和升壓素。在一些實施例中,高劑量血管加壓劑包括以下中的一或多種:>20 ug/min的正腎上腺素單一療法、>10 ug/kg/min的多巴胺單一療法、>200 ug/min的脫羥腎上腺素單一療法、及/或>10 ug/min的腎上腺素單一療法。在一些實施例中,如果個體使用升壓素,則高劑量血管加壓劑包括等效於>10 ug/min之升壓素+正腎上腺素,其中該正腎上腺素等效劑量=[正腎上腺素(ug/min)] + [多巴胺(ug/kg/min) / 2] + [腎上腺素(ug/min)]+[脫羥腎上腺素 (ug/min)/10]。在一些實施例中,若個體正接受血管加壓劑(非升壓素),則高劑量血管加壓劑包括等效於>20 ug/min之正腎上腺素,其中正腎上腺素等效劑量 = [正腎上腺素(ug/min)] + [多巴胺(ug/kg/min)/ 2] + [腎上腺素(ug/min)] + [脫羥腎上腺素 (ug/min)/10]。參見例如,Id。
在一些實施例中,低劑量血管加壓劑為投與劑量低於以上列出用於高劑量血管加壓劑之一或多種劑量的血管加壓劑。例示性皮質類固醇包括但不限於:地塞米松(dexamethasone)、氫化可的松(hydrocortisone)和甲基強的松龍(methylprednisolone)。在實施例中,地塞米松(dexamethasone)的使用劑量為0.5 mg/kg。在實施例中,地塞米松(dexamethasone)的最大使用劑量為10 mg/劑。在實施例中,甲基普德尼松(methylprednisolone)的使用劑量為2 mg/kg/日。
例示性免疫抑制劑包括但不限於:TNFa抑制劑或IL-1抑制劑。在實施例中,TNFa抑制劑包含抗TNFa抗體,例如單株抗體,例如英夫利昔單抗(infliximab)。在實施例中,TNFa抑制劑包含可溶性TNFa受體(例如依那西普(etanercept))。在實施例中,IL-1或IL-1R抑制劑包含阿那白滯素(anakinra)。
在一些實施例中,具有發展嚴重CRS風險之個體被投與抗IFN-γ或抗-sIF2Ra療法,例如引導對抗IFN-γ或sIF2Ra之抗體分子。
在實施例中,對於已接受如博納吐單抗(Blinatumomab)之治療性抗體分子,且具有CRS或具有發展CRS之風險的個體,該治療性抗體分子以較低劑量及/或較低頻率投與,或暫停投與治療性抗體分子。
在實施例中,患有CRS或具有發展CRS風險的個體係以退熱藥物(如對乙醯胺基酚)治療。在實施例中,對本文的個體投與或提供一或多種本文所述的CRS療法,例如IL-6抑制劑或IL-6受體(IL-6R)抑制劑(例如托珠單抗(tocilizumab))、血管活化藥物、皮質類固醇、免疫抑制劑或機械通氣之一或多者,以任一組合,例如與本文所述之表現CAR的細胞組合。
在實施例中,向具有發展CRS之風險(例如嚴重CRS)(例如,經確認具有發展為嚴重CRS之高風險狀態之個體)的個體,投與一或多種本文所述的CRS療法,例如IL-6抑制劑或IL-6受體(IL-6R)抑制劑(例如托珠單抗(tocilizumab))、血管活化藥物、皮質類固醇、免疫抑制劑或機械通氣之一或多者,以任一組合,例如與本文所述之表現CAR的細胞組合。
在實施例中,本文個體(例如具有發展為嚴重CRS之風險之個體或確定具有發展為嚴重CRS之風險之個體)轉移至加護病房中。在一些實施例中,係監測此述之個體(例如具有發展為嚴重CRS之風險之個體或確定具有發展為嚴重CRS之風險之個體)與CRS相關的一或多種症狀或病況,例如發燒、心率加快、凝血障礙、MODS(多器官功能障礙症候群)、心血管功能障礙、分佈性休克、心肌病變、肝功能障礙、腎功能障礙、腦病、臨床癲癇發作、呼吸衰竭或心搏過速。在一些實施例中,本文方法包含對與CRS相關的症狀或病況之一者投與治療。例如,在實施例中,例如若個體出現凝血障礙,則該方法包括投與冷沉澱物。在一些實施例中,例如若個體發展出心血管功能障礙,則該方法包含投與血管活化劑輸注支持療法。在一些實施例中,例如若個體發展出分佈性休克,則該方法包含投與α-促效劑療法。在一些實施例中,例如若個體發展心肌病變,該方法包含投與米力農(milrinone)療法。在一些實施例中,例如若個體出現呼吸衰竭,則該方法包括執行機械通氣(例如,侵入性機械通氣或非侵入性機械通氣)。在一些實施例中,例如若個體發展出休克,則該方法包含投與類晶體及/或膠體流體。在實施例中,該表現CAR的細胞在投與本文所述之CRS之一或多種療法(例如IL-6抑制劑或IL-6受體(IL-6R)抑制劑(例如托珠單抗(tocilizumab))、血管活化藥物、皮質類固醇、免疫抑制劑或機械通氣之一或多者)之前、同時或之後投與。在實施例中,該表現CAR的細胞在本文所述之CRS之一或多種療法(例如IL-6抑制劑或IL-6受體(IL-6R)抑制劑(例如托珠單抗(tocilizumab))、血管活化藥物、皮質類固醇、免疫抑制劑或機械通氣之一或多者)投與後2周內(例如,在2周或1周內,或在14天內,例如,在14、13、12、11、10、9、8、7、5、6、4、3、2或1天或更短時間內)投與。在實施例中,該表現CAR的細胞在本文所述之CRS之一或多種療法(例如IL-6抑制劑或IL-6受體(IL-6R)抑制劑(例如托珠單抗(tocilizumab))、血管活化藥物、皮質類固醇、免疫抑制劑或機械通氣之一或多者)投與之前或之後,投與至少1天(例如,至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20天、1週、2週、3週、4週、1個月、2個月、3個月、3個月或更長時間)。
在實施例中,向此述之個體((例如具有發展為嚴重CRS之風險之個體或確定具有發展為嚴重CRS之風險之個體)投與單次劑量之IL-6抑制劑或IL-6受體(IL-6R)抑制劑(例如,托珠單抗(tocilizumab))。在實施例中,向該個體投與多次劑量(例如2、3、4、5、6或更多次劑量)之IL-6抑制劑或IL-6受體(IL-6R)抑制劑(例如,托珠單抗(tocilizumab))。
在實施例中,低或無CRS(例如嚴重CRS)風險之個體(例如,經確認為具有發展為嚴重CRS之低風險狀態之個體)不投與本文所描述之CRS之一療法,例如,IL-6抑制劑或IL-6受體(IL-6R)抑制劑(例如托珠單抗(tocilizumab))、血管活化藥物、皮質類固醇、免疫抑制劑或機械通氣之一或多者。
在一些實施例中,藉由本文所揭示之方法治療之個體具有低嚴重性之CRS,例如,第1級、第2級或第3級。
在實施例中,表現CAR的活細胞係以遞增劑量進行投與。在實施例中,第二劑量大於第一劑量,例如,大於10%、20%、30%或50%。在實施例中,第二劑量為第一劑量之兩倍、三倍、四倍或五倍。在實施例中,第三劑量大於第二劑量,例如,大於10%、20%、30%或50%。在實施例中,該第三劑量為第二劑量之兩倍、三倍、四倍或五倍。
在某些實施例中,該方法包括下列a)-h)之一、二、三、四、五、六、七者或全部:
a)在第一劑量中所投與之表現CAR的活細胞數目不超過在第二劑量中所投與之表現CAR的活細胞數目的1/3;
b)在第一劑量中所投與之表現CAR的活細胞數目不超過所投與之表現CAR的活細胞總數的1/X,其中X為2、3、4、5、6、7、8、9,、10、15、20、30、40或50;
c)在第一劑量中所投與之表現CAR的活細胞數目不超過1 x 10
7、2 x 10
7、3 x 10
7、4 x 10
7、5 x 10
7、6 x 10
7、7 x 10
7、8 x 10
7、9 x 10
7、1 x 10
8、1.75 x 10
8、2 x 10
8、3 x 10
8、4 x 10
8或5 x 10
8個表現CAR的活細胞,且第二劑量大於第一劑量;
d)在第二劑量中所投與之表現CAR的活細胞數目不超過在第三劑量中所投與之表現CAR的活細胞數目的1/2;
e)在第二劑量中所投與之表現CAR的活細胞數目不超過所投與之表現CAR的活細胞總數的1/Y,其中Y為2、3、4、5、6、7、8、9、10、15、20、30、40或50;
f)在第二劑量中所投與之表現CAR的活細胞數目不超過1 x 10
7、2 x 10
7、3 x 10
7、4 x 10
7、5 x 10
7、6 x 107、7 x 10
7、8 x 10
7、9 x 10
7、1 x 10
8、1.75 x 10
8、2 x 10
8、3 x 10
8、4 x 10
8或5 x 10
8個表現CAR的活細胞,且第三劑量大於第二劑量;
h)該第一、第二及視情況第三劑量之投與劑量及期間係經選擇,使得該個體經歷不大於等級4、3、2、或1之CRS。
在實施例中,總劑量為約5 x 10
8個表現CAR的活細胞。在實施例中,總劑量為約5 x 10
7- 5 x 10
8個表現CAR的活細胞。在實施例中,第一劑量為約5 x 10
7個(例如,± 10%、20%或30%)表現CAR的活細胞,第二劑量為約1.5 x 10
8個(例如,± 10%、20%或30%)表現CAR的活細胞,且第三劑量為約3 x 10
8個(例如,± 10%、20%或30%)表現CAR的活細胞。
在實施例中,在接受劑量之後,例如在接受第一劑量、第二劑量及/或第三劑量之後,對個體進行CRS評估。
在實施例中,該個體接受CRS治療,例如托珠單抗(tocilizumab)、皮質類固醇、依那西普(etanercept)或西妥昔單抗(siltuximab)。在實施例中,該CRS治療在該包含CAR分子之第一劑量細胞投與之前或之後投與。在實施例中,該CRS治療在該包含CAR分子之第二劑量細胞投與之前或之後投與。在實施例中,該CRS治療在該包含CAR分子之第三劑量細胞投與之前或之後投與。在實施例中,該CRS治療在該包含CAR分子之細胞之第一及第二劑量之間投與,及/或在該包含CAR分子之細胞之第二及第三劑量之間投與。
在實施例中,在第一劑量之後具有CRS等級如第1、2、3或4級之個體中,在第一劑量之後至少2、3、4或5天投與第二劑量。在實施例中,在第二劑量之後具有CRS等級如第1、2、3或4級之個體中,在第二劑量之後至少2、3、4或5天投與第三劑量。在實施例中,對於在第一劑量後具有CRS之個體,該第二劑量之表現CAR的細胞的投與時間延後,相對於不具CRS之個體之第二劑量投與。在實施例中,對於在第二劑量後具有CRS之個體,該第三劑量之表現CAR的細胞的投與時間延後,相對於不具CRS之個體之第三劑量投與。
在實施例中,在投與第一劑量之前,該個體患有具有高疾病負荷之癌症。在實施例中,該個體之骨髓芽細胞位準為至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、25%、30%、35%、40%、45%或50%,例如至少5%。在實施例中,個體患有第I、II、III或IV期之癌症。在實施例中,個體之單一腫瘤或複數個腫瘤之腫瘤質量為至少1、2、5、10、20、50、100、200、500或1000 g。
在一些實施例中,該患者患有癌症(如大腸直腸癌)。在一些實施例中,該癌症為與如本文所述之GCC表現相關之疾病。在實施例中,該CAR分子為如本文所述之CAR分子。
在一態樣中,表現CAR的細胞(例如,表現GCC CAR的細胞)係使用慢病毒載體(如慢病毒)產生。以這方式所產生之表現CAR的細胞將能穩定表現CAR。衍生自逆轉錄病毒(如慢病毒)的載體為達成長期基因轉移的合適工具,因為它們允許轉基因長期穩定整合並在子代細胞中繁殖。慢病毒載體比衍生自癌-逆轉錄病毒(例如鼠類白血病病毒)的載體具有額外的優勢,因為它們可以轉導非增殖細胞(例如肝細胞)。它們亦具有低免疫原性的額外優勢。逆轉錄病毒載體亦可為,例如,γ逆轉錄病毒載體。γ逆轉錄病毒載體可包含例如啟動子、包裝信號(y)、引子結合位點(PBS)、一或多個
(例如
,兩個)長末端重複(LTR)、及有興趣之轉基因,例如編碼CAR之基因。γ逆轉錄病毒載體可缺乏病毒結構性基因,例如gag、pol及env。例示性的γ逆轉錄病毒載體包括鼠類白血病病毒(MLV)、脾-病灶形成病毒(SFFV)及骨髓增生性肉瘤病毒(MPSV),及衍生自該病毒之載體。其他γ逆轉錄病毒載體描述於例如Tobias Maetzig等人, “Gammaretroviral Vectors: Biology, Technology and Application” Viruses. 2011 Jun; 3(6): 677-713。
在一態樣中,在轉導之後4、5、6、7、8、9、10、11、12、13、14、15天之表現CAR的細胞會暫時表現CAR載體。CAR之暫時表現可被RNA CAR載體遞送影響。在一態樣中,該CAR RNA藉由電穿孔轉導至T細胞中。
使用暫時表現之細胞(尤其是具有鼠類scFv之表現CAR的細胞)治療患者時,可能出現之潛在問題為多次治療後之過敏反應。不受限於此理論,一般相信這種過敏反應可能是由於患者發展出體液抗-CAR反應(即具有抗IgE同種型之抗CAR抗體)所引起。一般認為,當抗原暴露中斷10到14天時,患者的抗體產生細胞會經歷從IgG同種型(不會引起過敏反應)到IgE同種型的類別轉換。
如果患者在暫時CAR治療過程中產生抗CAR抗體反應的風險很高(例如由RNA轉導產生者),則表現CAR的細胞之輸注中斷不應持續超過10到14天。
組成物
本文提供用於基因療法、免疫療法及/或細胞療法的組成物,其包括一或多種揭示之CAR或表現CAR之T細胞、抗體、抗原結合片段、共軛物、CAR或表現CAR的T細胞(其特異性結合至本文揭示的一或多種抗原),於一載體(例如藥學上可接受的載體)中。該組成物可以用於向個體投與之單位劑型來製備。投與量和時間由主治臨床醫師酌情判斷,以達到預期結果。該組成物可配製為用於全身(如靜脈內)或局部(如腫瘤內)投與。在一實例中,所揭示之CAR或表現CAR之T細胞、抗體、抗原結合片段、共軛物係經配製,以用於非經腸胃投與,如靜脈內投與。包括如本文所述之CAR或表現CAR之T細胞、共軛物、抗體或抗原結合片段之組成物,可用於如治療及偵測腫瘤,例如且不限於,神經母細胞瘤。在一些實例中,該組成物可用於治療或偵測癌症。包括如本文所述之CAR或表現CAR之T細胞、共軛物、抗體或抗原結合片段之組成物,亦用於例如偵測病理性血管生成。
用於投與之組成物可包括溶於醫藥學上可接受的載體(例如水性載體)中的CAR或表現CAR之T細胞、共軛物、抗體或抗原結合片段之溶液。可使用各種水性載體,例如,緩衝生理食鹽水及其類似物。這些溶液是無菌的,通常不含不希望的物質。這些組成物可藉由習知且熟知之滅菌技術來滅菌。該組成物可根據需要包含醫藥學上可接受的輔助物質以接近生理條件,例如pH調節劑和緩衝劑、毒性調節劑、佐劑及類似物,例如乙酸鈉、氯化鈉、氯化鉀、氯化鈣、乳酸鈉及類似物。在此等調配物中之CAR或表現CAR之T細胞、抗體或抗原結合片段或共軛物的濃度可廣泛地變化,且將主要根據所選擇的特定投與方式和個體的需要來選擇,主要基於流體體積、黏度、體重及類似因素。製備用於基因療法、免疫療法及/或細胞療法的此類劑型的實際方法,對於本領域技術人員而言是已知的或將是顯而易見的。
在一些實施例中,該組成物包含與一或多種醫藥學上或生理學上可接受之載體、稀釋劑或賦形劑組合之GCC CAR。此類組成物可包含緩衝液,例如中性緩衝生理食鹽水、磷酸鹽緩衝生理食鹽水及類似物;醣類如葡萄糖、甘露醣、蔗醣或葡聚醣、甘露醣醇;蛋白質;多肽或胺基酸如甘胺酸;抗氧化劑;螯合劑例如EDTA或穀胱甘肽;佐劑(例如氫氧化鋁);和防腐劑。本發明的組成物在一態樣中被配製成用於靜脈內投與。
本發明的醫藥組成物可以適合待治療(或預防)的疾病的方式投與。投與的量及頻率將取決於如患者之條件、患者疾病之類型及嚴重程度等因素,儘管適當劑量可藉由臨床試驗決定。
在一實施例中,該醫藥組成物實質上不含,例如,無可偵測位準的污染物,例如,選自於內毒素、黴漿菌、複製勝任慢病毒(RCL)、p24、VSV-G核酸、HIV gag、殘留的抗CD3/抗CD28包覆微珠、小鼠抗體、匯集的人類血清、牛血清白蛋白、牛血清、培養基成分、載體組裝細胞或質體成分、細菌和真菌。在一實施例中,該細菌為至少一種選自由以下組成之群:糞產鹼桿菌、白色念珠菌、大腸桿菌、流感嗜血桿菌、腦膜炎奈瑟菌、銅綠假單胞菌、金黃色葡萄球菌、肺炎鏈球菌和化膿性鏈球菌A群。
在一態樣中,本發明提供一種表現CAR的細胞群,例如,CART細胞或表現CAR的NK細胞。在一態樣中,本發明提供一種方法,其包含投與與另一試劑(例如激酶抑制劑,如本文所述之激酶抑制劑)組合的表現CAR的細胞群(例如,CART細胞或表現CAR的NK細胞)。
在另一態樣中,本發明係相關於一種包含本文所述之載體的細胞。在一實施例中,該細胞為本文所描述之細胞,例如人類T細胞,例如本文所描述之人類T細胞。在一實施例中,該人類T細胞為CD8+ T細胞。
在另一態樣中,本發明係相關於一種製造細胞之方法,包含將本文所述之細胞(例如本文所述之T細胞),以包含編碼CAR (例如本文所述之CAR)之核酸之載體進行轉染。
本發明亦提供一種產生RNA-經改造之細胞群的方法,例如本文所述之細胞,例如暫時表現外源性RNA之T細胞。該方法包含將體外轉錄的RNA或合成的RNA引入細胞,其中RNA包含編碼本文所述的CAR分子之核酸。
在本文所描述之任一方法及組成物之實施例中,該包含CAR之細胞包含編碼CAR之核酸。在一實施例中,該編碼CAR之核酸為慢病毒載體。在一實施例中,該編碼CAR之核酸藉由慢病毒轉導引入至細胞中。在一實施例中,該編碼CAR之核酸為RNA,例如體外轉錄之RNA。在一實施例中,該編碼CAR之核酸藉由電穿孔引入至細胞中。
在本文所描述之任一方法及組成物的實施例中,該細胞為T細胞或NK細胞。在一實施例中,該T細胞為自體或同種異體T細胞。
用於靜脈內投與的典型組成物包括約0.01至約30 mg/kg的抗體或抗原結合片段或共軛物每個體每日(或CAR、或表現CAR的T細胞、或包括抗體或抗原結合片段的共軛物的相對應劑量)。用於製備可投與組成物之實際方法將為熟習此項技術者所已知或顯而易見,且更詳細描述於文獻如Remington's Pharmaceutical Science,第19版,Mack Publishing Company, Easton, Pa. (1995)。
CAR或表現CAR之T細胞、抗體、抗原結合片段、或共軛物可以凍乾形式提供,且在投與之前以無菌水再水合化,儘管其亦以已知濃度之無菌溶液提供。接著將該CAR或表現CAR之T細胞、抗體、抗原結合片段、或共軛物溶液添加至含有0.9%氯化鈉、USP之輸注袋中,且在某些案例中以0.5 mg/kg至15 mg/kg體重之劑量投與。在抗體或抗原結合片段和共軛物藥物的投與方面,在本領域中已有相當多的經驗; 例如,自1997年RITUXAN® 獲核准以來,抗體藥物已在美國上市。CAR或表現CAR之T細胞、抗體、抗原結合片段、或其共軛物,可藉由緩慢輸注來投與,而非靜脈推注或大劑量投與。在一實例中,投與較高載入劑量,隨後在較低位準下投與維持劑量。舉例而言,初始載入劑量4 mg/kg抗體或抗原結合片段(或包括抗體或抗原結合片段之共軛物之對應劑量)可在90分鐘期間輸注,若先前劑量耐受良好,則隨後在30分鐘期間輸注2 mg/kg之用於4-8周之每周維持劑量。
經控制釋放腸胃外配方可製成植入物、油劑注射液或顆粒系統。有關蛋白質遞送系統的廣泛概述,可參見Banga, A. J., Therapeutic Peptides and Proteins:Formulation, Processing, and Delivery Systems, Technomic Publishing Company, Inc., Lancaster, Pa., (1995)。顆粒系統包括微球體、微顆粒、微膠囊、奈米膠囊、奈米球及奈米顆粒。微膠囊含有治療性蛋白質,如細胞毒素或藥物,作為中心核心。在微球體中,該治療劑分散在整個顆粒中。小於約1 μm之顆粒、微球體及微膠囊通常分別稱為奈米顆粒、奈米球體及奈米膠囊。微血管具有約5 μm的直徑,因此只有奈米顆粒可靜脈內投與。微粒一般直徑約100 μm,以皮下或肌肉注射方式投與。請參見例如Kreuter, J., Colloidal Drug Delivery Systems, J. Kreuter編,Marcel Dekker, Inc., New York, N.Y.,第219-342頁(1994);及Tice & Tabibi, Treatise on Controlled Drug Delivery, A. Kydonieus編,Marcel Dekker, Inc. New York, N.Y.,第315-339頁(1992)。
聚合物可用於本文揭示之CAR或表現CAR之T細胞、抗體、或抗原結合片段、或共軛物組成物之離子控制釋放。用於經控制藥物遞送的各種可降解和不可降解之聚合物基質為本領域中已知的(Langer, Accounts Chem. Res. 26:537-542, 1993)。舉例而言,嵌段共聚物polaxamer 407,在低溫下以黏稠但流動的液體形式存在,但在體溫下形成半固體凝膠。它已被證明是重組介白素-2和脲酶的配製和持續遞送的有效載體(Johnston等人, Pharm. Res. 9:425-434, 1992;及Pec等人,J. Parent. Sci. Tech. 44(2):58-65, 1990)。或者,羥基磷灰石已被使用作為蛋白質控制釋放的微載體(Ijntema等人, Int. J. Pharm. 112:215-224, 1994)。在又一態樣中,脂質體係用於脂質包裹藥物的控制釋放以及藥物靶向(Betageri等人, Liposome Drug Delivery Systems, Technomic Publishing Co., Inc., Lancaster, Pa. (1993))。已知用於控制治療性蛋白質之遞送的多種額外系統(參見美國專利號5,055,303; 5,188,837; 4,235,871; 4,501,728; 4,837,028; 4,957,735; 5,019,369; 5,055,303; 5,514,670; 5,413,797; 5,268,164; 5,004,697; 4,902,505; 5,506,206; 5,271,961; 5,254,342和5,534,496)。
套組
在一態樣中,亦提供使用本文所揭示之CAR的套組。例如,用於治療個體之腫瘤,或製造表現本文所揭示之一或多種CAR的CAR T細胞的套組。該套組通常將包括如本文所揭示之抗體、抗原結合片段、共軛物、核酸分子、CAR或表現CAR之T細胞。大於一種之如本文所揭示之抗體、抗原結合片段、共軛物、核酸分子、CAR或表現CAR之T細胞可包括在該套組中。
該套組可包括一容器及在該容器上或與其相連的標籤或包裝插頁。合適的容器包括例如瓶子、小瓶、注射器等。容器可由各種材料形成,如玻璃或塑膠。該容器通常容置一組成物,其包含所揭示之抗體、抗原結合片段、共軛物、核酸分子、CAR或表現CAR之T細胞之一或多者。在數個實施例中,該容器可具有無菌入口(例如,容器可為靜脈注射溶液袋,或具有可被皮下注射針刺穿的塞子的小瓶)。標籤或包裝插頁說明該組成物用於治療特定病況。
標籤或包裝插頁通常將進一步包括所揭示之抗體、抗原結合片段、共軛物、核酸分子、CAR或表現CAR之T細胞的使用說明,例如,用於治療或預防腫瘤或製造CAR T細胞的方法中。包裝插頁通常包括常規包含在治療產品的商業包裝中的說明,這些說明包含有關使用此類治療產品的適應症、用法、劑量、投藥、禁忌症及/或警告的信息。該說明書材料可為書面,以電子形式(例如電腦硬碟或光碟)或視覺形式(例如影片檔案)。該套組亦可包括額外組件,以幫助套組設計之特定應用。因此,例如,該套組可額外地含有偵測標記物(例如用於酵素標記的酵素受質、用於偵測螢光標記物的過濾組、合適的二級標記物(例如二級抗體)及類似物)之裝置。該套組可額外包括緩衝液及常規用於實施特定方法的其他試劑。此套組與合適內容物為熟習此項技術者所熟知的。
調節嵌合抗原受體的策略
有許多方式可調節CAR活性。在一些實施例中,其中CAR活性可經控制的可調節CAR (RCAR),是最佳化CAR治療的安全性和有效性的理想選擇。舉例而言,使用例如融合到二聚化結構域的半胱天冬酶誘導細胞凋亡(請參見例如Di等人, N Engl. J . Med. 2011 Nov. 3; 365(18):1673- 1683)),可使用作為本發明之CAR療法中的安全性開關。在另一實例中,表現CAR的細胞亦可表現誘導型Caspase-9 (iCaspase-9) 分子,該分子在投與二聚化藥物(例如,利米杜克(rimiducid)(也稱為AP1903 (Bellicum Pharmaceuticals)或AP20187 (Ariad))後,會導致Caspase-9的活化和細胞的凋亡。iCaspase-9分子含有二聚化化學誘導劑(CID)結合域,可在CID存在下介導二聚化。這導致表現CAR的細胞的誘導性和選擇性耗盡。在某些情況下,iCaspase-9分子由與編碼CAR的載體分開的核酸分子編碼。在某些情況下,iCaspase-9分子由與編碼CAR的載體相同的核酸分子編碼。該iCaspase-9可提供安全性開關,以避免表現CAR的細胞的任何毒性。請參見例如Song等人, Cancer Gene Ther. 2008; 15(10):667-75; Clinical Trial Id. No. NCT02107963;及Di Stasi等人 N. Engl. J . Med. 2011; 365:1673-83。
用於調節本發明的CAR療法的替代策略包括使用使CAR活性失活或關閉的小分子或抗體,例如藉由刪除表現CAR的細胞,例如藉由誘發抗體依賴性細胞介導的細胞毒性(ADCC)。例如,本文所述之表現CAR的細胞亦可表現一抗原,其能夠被誘導細胞死亡(例如ADCC或互補誘導細胞死亡)的分子辨識。例如,本文所描述之表現CAR的細胞也可表現能夠被抗體或抗體片段靶向的受體。此類受體的實例包括EpCAM、VEGFR、整聯蛋白(例如整聯蛋白anb3、a4、aI¾b3、a4b7、a5b1、anb3、an)、TNF受體超家族成員(例如,TRAIL-R1、TRAIL-R2)、PDGF受體、干擾素受體、葉酸受體、GPNMB、ICAM-1、HLA-DR、CEA、CA-125、MUC1、TAG-72、IL-6受體、5T4、GD2、GD3、CD2、CD3、CD4、CD5、CD1 1、 CD1 1 a/LFA-1、CD15、CD18/ITGB2、CD19、CD20、CD22、CD23/lgE受體、CD25、CD28、CD30、CD33、CD38、CD40、CD41、CD44、CD51、CD52、CD62L、CD74、CD80、CD125、CD147/basigin、CD152/CTLA-4、CD154/CD40L、CD195/CCR5、CD319/SLAMF7和EGFR及其截短形式(例如,保留一或多個細胞外表位但缺乏細胞內域中一或多個區域)。例如,本文所述之表現CAR的細胞亦可表現截短的表皮生長因子受體(EGFR),其缺乏信號傳導能力但保留表位,其可被能誘導ADCC的分子例如西妥昔單抗(ERBITUX®)辨識,使得投與西妥昔單抗可誘導ADCC和隨後的表現CAR的細胞耗盡(請參見如WO2011/056894和Jonnalagadda等人, Gene Ther. 2013; 20(8)853-860)。
另一種策略包括在本文所述之表現CAR的細胞中表現高度壓縮的標記/自殺基因,其結合至來自本文所述之CD32和CD20抗原的標靶表位,其可與利妥昔單抗結合,導致表現CAR的細胞的選擇性耗盡,例如藉由ADCC(請參見如Philip 等人,Blood. 2014; 124(8)1277-1287)。用以耗盡本文所述之表現CAR的細胞的其他方法包括投與CAMPATH®,一種單株抗-CD52抗體,其選擇性結合至且靶向成熟淋巴細胞(例如表現CAR的細胞),用於破壞(例如藉由誘導ADCC)。在其他實施例中,表現CAR的細胞可使用CAR配位體(例如抗-特應性抗體)選擇性地靶向。在一些實施例中,抗特應性抗體可引起效應細胞活性,例如ADCC或ADC活性,藉此降低表現CAR的細胞之數目。在其他實施例中,CAR配位體(例如抗特應性抗體)可耦合至可誘導細胞死亡之試劑,例如毒素,藉此降低表現CAR的細胞之數目。替代地,CAR分子本身可被配置成使得活性可被調節,例如打開和關閉,如下所述。
在一些實施例中,RCAR包含一組多肽,在最簡單的實施例中通常為兩個,其中本文描述的標準CAR之成分,例如抗原結合域和細胞內信號傳導域,被分配在不同的多肽或成員上。在一些實施例中,該多肽組包括一個二聚化開關,在二聚化分子的存在下,可將該多肽相互耦合,例如,可將抗原結合域與一細胞內信號傳導域耦合。
此類可調節CAR的額外描述和例示性配置提供於本文和國際公開號WO 2015/090229中,其經由引用整體併入本文。在一實施例中,RCAR包含兩種多肽或成員:1)細胞內信號傳導成員,其包含細胞內信號傳導域(例如本文所述的初級細胞內信號傳導域)、和第一開關域;2)抗原結合成員,其包含抗原結合域(例如,靶向本文所述的腫瘤抗原,如本文所述)、和第二開關域。視情況,該RCAR包含本文所述的跨膜域。在一實施例中,跨膜域可設置在細胞信號傳導成員、抗原結合成員、或兩者上。(除非另有說明,當在此描述RCAR的成員或元件時,順序可如本文提供,但也包括其他順序。換言之,在一實施例中,順序如其內文中所述,但在其他實施例中,順序可以不同。例如,跨膜區一側的元件順序可與實例不同,例如,開關域相對於細胞內信號結構域的位置可不同,例如,倒置)。
在一實施例中,該第一開關域和該第二開關域可形成一細胞外二聚化開關。在一實施例中,該二聚化開關可為同二聚化開關,例如,其中第一及第二開關域為相同的,或異二聚化開關,例如,第一及第二開關域彼此不同。
在實施例中,RCAR可包括一「多重開關」。多重開關可包含異二聚開關域或同二聚物開關域。多重開關在第一成員(例如抗原結合成員)和第二成員(如細胞內信號傳導成員)上,獨立地包含複數個例如2、3、4、5、6、7、8、9或10個開關域。在一實施例中,該第一成員可包含複數個第一開關域,且第二成員可包含複數個第二開關域。在一實施例中,該第一成員可包含第一及第二開關域,且第二成員可包含第一及第二開關域。
在一實施例中,該細胞內信號傳導成員包括一或多個細胞內信號傳導域,例如,一個初級細胞内信號傳導域及一或多個共刺激信號傳導域。
在一實施例中,該抗原結合成員可包含一或多個細胞內信號傳導域,例如一或多個共刺激信號傳導域。於一實施例中,該抗原結合成員包括複數個例如2或3個本文中描述之共刺激信號傳導域,例如選自4-IBB、CD28、CD27、ICOS及OX40,且在實施例中,無初級細胞內信號傳導域。於一實施例中,該抗原結合成員包含下列共刺激信號傳導域,自細胞外至細胞內方向:4-1BB-CD27; 4-1BB-CD27; CD27-4-1BB; 4-1BBCD28; CD28-4-1BB; OX40-CD28; CD28-OX40; CD28-4-1BB;或4-1BB-CD28。在此類實施例中,該細胞內結合成員包含一CD3ζ域。在一此類實施例中,該RCAR包含(1)一抗原結合成員,其包含一抗原結合域、一跨膜域、及兩個共刺激信號傳導域及一第一開關域;及(2)一細胞內信號傳導域,其包含一跨膜域或膜連結域、及至少一初級細胞內信號傳導域、及一第二開關域。
一實施例提供RCAR,其中該抗原結合成員未連接至CAR細胞表面。這允許具有一細胞内信號傳導成員之細胞與一或多個抗原結合域可方便地配對,而無需以編碼該抗原結合成員的序列轉化該細胞。在此類實施例中,RCAR包括:1) 細胞內信號傳導成員,其包含:一第一開關域、一跨膜域、一細胞內信號傳導域(例如初級細胞內信號傳導域)、和一第一開關結構域; 2)抗原結合成員,其包含:一抗原結合域和一第二開關域,其中該抗原結合成員不包含跨膜結構域或膜連結域,且視情況不包含細胞內信號傳導域。在一些實施例中,RCAR可進一步包含3)第二抗原結合成員,其包含:一第二抗原結合域(其結合至不同於該抗原結合域所結合的抗原上);和一第二開關域。
本文亦提供RCAR,其中該抗原結合成員包含雙特異性活化及靶向能力。在此實施例中,該抗原結合成員可包含複數個例如2、3、4或5個抗原結合域,例如scFvs,其中每一抗原結合域結合至標靶抗原,例如不同抗原或相同抗原,例如同一抗原上之相同或不同表位。在一實施例中,該複數個抗原結合域係串聯,且視情況,每一抗原結合域之間設置有連接子或鉸鏈區。合適的連接子及鉸鏈區描述於本文中。
一實施例係提供具有允許增殖狀態切換之組態的RCAR。在此實施例中,該RCAR包含: 1)細胞內信號傳導成員,其包含:視情況,一跨膜域或膜連結域;一或多個共刺激信號傳導域,例如選自4-IBB、CD28、CD27、ICOS和OX40,以及一開關域;以及2)抗原結合成員,其包含:一抗原結合域、一跨膜域和一初級細胞內信號傳導域,例如CD3ζ域,其中該抗原結合成員不包含開關域,或不包含與細胞內信號傳導成員上的開關域二聚化之開關域。在一實施例中,該抗原結合成員不包含共刺激信號傳導域。在一實施例中,該細胞內信號傳導成員包含來自同二聚化開關之開關域。在一實施例中,該細胞內信號傳導成員包含來自異二聚化開關之第一開關域,且該RCAR包含第二細胞內信號傳導成員,其包含來自異二聚化開關之第二開關域。在此類實施例中,該第二細胞信號傳導成員包含與該細胞內信號傳導成員相同的細胞內信號傳導域。在一實施例中,該二聚化開關為細胞內。在一實施例中,該二聚化開關為細胞外。
本文亦提供包含RCAR編碼序列之核酸及載體。編碼RCAR之各元件的序列可設置在相同核酸分子(例如,相同質體或載體,例如病毒載體,例如慢病毒載體)上。
於一實施例中,(i)編碼抗原結合成員之序列及(ii)編碼一細胞內信號傳導成員之序列,可存在於同一核酸例如載體上。相對應蛋白質之製造可例如藉由使用分開的促進子,或藉由使用雙順反子轉錄產物(其可藉由裂解單一轉譯物或藉由轉譯兩種單獨的蛋白質產物來製造兩種蛋白質)而實現。在一實施例中,編碼可裂解胜肽(例如P2A或F2A序列)之序列係設置於(i)與(ii)之間。於一實施例中,編碼IRES(例如EMCV或EV71 IRES)的序列係設置在(i)與(ii)之間。在這些實施例中,(i)及(ii)被轉錄為單一RNA。在一實施例中,該第一促進子可操作地連接於(i),且第二促進子可操作地連接於(ii),使得(i)及(ii)被轉錄為分開的mRNA。
替代地,編碼RCAR之各種元件的序列可設置在不同的核酸分子上,例如,不同的質體或載體,例如,病毒載體,例如,慢病毒載體。例如,(i)編碼抗原結合成員之序列可存在於第一核酸(例如第一載體)上,且(ii)編碼細胞內信號傳導成員之序列可存在於第二核酸(例如第二載體)上。
除非另有說明,否則本文使用的所有技術和科學術語和片語與本領域普通技術人員通常理解的含義相同。儘管在本發明的實施或測試中可使用與本文描述的那些相似或等效的任何方法和材料,但現在描述較佳的方法和材料。本文提及的所有文獻均以引用方式併入本文中。
標準技術可用於重組DNA、寡核苷酸合成以及組織培養和轉型(例如,電穿孔、脂質轉染)。酵素反應和純化技術可根據製造商的說明書或如本領域中通常完成者或如本文所述進行。前述技術和程序一般可根據本領域已知的常規方法進行,並如在本說明書整篇引用和討論的各種一般性和更具體的參考文獻中所描述的。請參見例如Sambrook等人 Molecular Cloning: A Laboratory Manual (第2版,Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. (1989)),其出於任何目的經由引用方式併入本文中。
本文提及的所有文獻、專利申請案、專利案和其他參考文獻均以全文引用方式併入本文中。本發明將藉由參考以下實例而更臻清楚。
實例
這些實例的提出是為了幫助理解本發明,但並非旨在,也不應解釋為以任何方式限制其範圍。實例不包括對本領域普通技術人員已知的常規方法(分子選殖技術等)的詳細描述。
實例 1. GCC VH 抗體之分離與篩選
製備特異性靶向人類GCC的單域重鏈抗體(VH)(例如,表1至3中提供的抗GCC結合劑)。如表5所示,評估重組單域抗GCC VH構建體在體外對GCC的結合親和力。結合動力學使用Octet結合測定法測定。這些係於即時生物層干涉儀基礎之生物感測器Octet (ForteBio)中測量。所有結合研究均在HBS-ET Octet動力學緩衝液中進行。生物感測器總是在不同步驟之間以Octet動力學緩衝液洗滌。對每一VH進行七點、兩倍的稀釋系列。結合步驟的每一者的接觸時間為300秒,解離步驟在400-600秒之間變化。動力學結合(ka)和解離(kd)速率常數藉由使用ForteBio分析軟體處理數據,並將其套用至1:1結合模型而確定。親和力計算值和動力學常數列於表5。
使用流式細胞術測量單域抗體與CT26細胞的結合。CT26細胞與系列稀釋的VH一起培養,並藉由流式細胞術測量螢光值。藉由FACS劑量反應測定法證實抗GCC VH抗體與CT26細胞結合,以獲得細胞結合EC50 (nM),如表5所示。
表 5. GCC VH 抗體之結合親和力
| GCC 抗原結合劑 | Koff (1/s) | KD(M) | 與細胞結合之 EC50 (M) |
| V1 | 0.00020795 | 3.2935E-10 | 7.2E-10 |
| V5 | 0.000718667 | 7.713E-09 | 1.52E-09 |
| V36 | 0.0035 | 0.000000105 | N/A |
| V48 | 0.000341 | 1.375E-09 | 1.01E-09 |
| V51 | 0.00185 | 9.544E-09 | N/A |
為了測定穩定性,對VH構建體進行尺寸排阻層析法(SEC)。簡而言之,將純化的VH以不同濃度儲存在PBS緩衝液中,並於4°C 過夜,之後使用SEC管柱在不同時間點進行分析。將樣本注入磷酸鈉緩衝液中。隨時間收集數據,並計算儲存後剩餘的單體峰面積,與開始時(T=0)存在者相較。獲得穩定性結果,如下表6所示。
表 6. 使用 SEC 的隔夜穩定度
| 抗GCC VH抗體 | % 4°C單體(%) | 純度(%) | RT (分鐘) |
| V1 | 108.4 | 91.5 | 3.586 |
| V5 | 123.04 | 79.2 | 3.17 |
| V36 | 92.43 | 79.36 | 3.08 |
| V48 | 104.54 | 73.91 | 3.208 |
| V51 | 109.2 | 59.22 | 3.304 |
進行ELISA以測量VH與人類輕鏈的結合。每一VH的結合值(於OD450nm測量)皆小於0.1,其為此測定法的背景訊號。
實例 2. GCC 嵌合性抗原受體的設計與鑑定
嵌合性抗原受體構建體被設計成包括一胞外結合域(例如,抗GCC結合物序列),其包含上述單域抗體(例如,表2或表3中提供的VH)。CAR T構建體是藉由將框架內的結合子序列連接到CD28鉸鏈/跨膜域和共刺激域以及CD3 ζ-1xx信號傳導域而產生。例示性CAR構建體的流程圖示於圖1A和1B。在此實例中測試的例示性CAR構築體序列係提供於表4中。V1 (SEQ ID NO: 1)及V1-01 (SEQ ID NO: 20)預期適用於以下實例中。
將編碼CAR構建體序列(SEQ ID NO: 61-70)的核酸選殖到逆轉錄病毒質體骨架中。藉由暫時轉染phenix ampho細胞(ATCC CRL-3213)產生含有逆轉錄病毒載體的上清液,收穫含有逆轉錄病毒載體的上清液,並儲存於-80°C。
來自健康供應者的人類初級T細胞,係純化自由leukopaks (購自經捐贈者書面同意的商業提供者)分離出的周邊血液單核細胞(PBMC),使用CD3+細胞進行免疫磁珠篩選,根據製造商提供的流程(EasySep™ Human T Cell Isolation Kit, Stem Cell Technologies #17951)。T 細胞在補充有10% 青黴素-鏈黴素(Gibco 15140-122)和2 ng/ml IL-2 (Milteyni 130-097-743)之X-vivo 15培養基((Lonza #04-744Q)中,以每毫升1百萬個細胞之密度培養。細胞以CD3/CD28 MACS® T Cell TransAct試劑(Miltenyi Biotec MACS #130-111-160)活化,並在第2天或第3天以編碼CAR構建體的逆轉錄病毒載體轉導過夜。隔日,將CAR-T細胞培養物轉移到G-Rex6®孔盤(WilsonWolf P/N 80240M),並在補充有10%青黴素-鏈黴素(Gibco 15140-122)和2 ng/ml IL-2 (Milteyni 130-097-743)的X-vivo 15培養基(Lonza #04-744Q)中繁殖,直到第7-10天收穫。每2-3天進行一次培養基更換和IL-2補充。
CAR T細胞表現係藉由流式細胞術評估,使用抗EGFR抗體(R&D systems: FAB9577R)或用於CAR表面表現之可溶性GCC胞外域重組蛋白。
實例 3. GCC CAR T 細胞體外活性
本實例描述體外之抗GCC CAR T細胞活性。檢驗表現抗GCC CAR (SEQ ID NO: 48-52)的CAR-T細胞對於表現GCC的及GCC陰性的標靶癌細胞株的細胞毒性。標靶癌細胞株包括內源性表現GCC的GSU、LS1034和HT55,以及HT29-GCC (一種經改造以穩定表現GCC的人類大腸直腸癌細胞株)及其載體對照細胞株(即GCC陰性) HT29-vec。每一標靶細胞株係接種在384孔盤中,並以效應子-比-標靶(E:T)為10:1、3:1、1:1 和0.3:1之比例加入GCC CAR-T或非靶向CAR-T細胞(陰性對照組)。僅包含標靶細胞之孔和僅包含效應細胞之孔作為對照組。兩天後,使用CellTiter-Glo® One Solution Assay (Promega, G8462)測量細胞存活率。標靶細胞的存活率百分比係由共培養孔的發光訊號計算,首先減去僅有效應細胞之孔的信號,之後除以僅有標靶細胞之孔的信號。殺傷百分比係藉由將100% GCC CAR-T細胞減去標靶細胞的存活率百分比而計算。
與作為對照組的非靶向CD19 CAR-T細胞(1928z-1xx)相較,VH抗GCC結合劑表現出針對表現GCC的標靶細胞株的細胞殺傷。如圖2A-2D所示,在不存在截短EGFR (tEGFR)的情況下表現抗GCC CAR的CAR-T細胞係顯現出對於表現GCC的細胞HT29-GCC細胞(被改造為可穩定表現GCC之人類大腸直腸癌細胞株HT29)的體外細胞毒性(圖2A);以及對於內源性表現GCC的細胞株GSU(圖2C)和LS1034(圖2D)的體外細胞毒性。如圖3A-3D所示,在截短的EGFR (tEGFR) (SEQ ID NO: 56-60)存在下表現抗GCC CAR的CAR-T細胞亦顯現出對於表現GCC的細胞HT29-GCC(圖3A)的體外細胞毒性;以及對於GSU(圖3C)和LS1034(圖3D)的體外細胞毒性。長條代表來自三次技術重複的平均值+SD值。數據代表來自>3個供體的抗GCC CAR T細胞進行的>3個獨立實驗。GCC CAR-T細胞並未表現出對GCC陰性HT29-vec細胞的細胞殺傷(圖2B和圖3B),表示GCC CAR-T細胞殺傷活性為抗原-依賴性。
除了抗原-依賴性細胞殺傷,GCC CAR-T細胞的體外活性亦藉由評估該細胞的IFNγ和IL2的抗原-依賴性分泌情況而評估。具有抗GCC VH結合劑的GCC CAR-T細胞與表現GCC和GCC陰性的標靶癌細胞係以E:T 比例10:1、3:1、1:1和0.3:1共培養。共培養兩天後收集上清液。使用Intellicyt QBeads Human PlexScreen套組(Sartorius, 90702)偵測上清液中分泌的IFNγ和IL2。當與表現GCC的標靶細胞共培養時,具有所有VH結合劑的GCC CAR-T細胞,在tEGFR存在(5A-5D)和不存在(4A-4D)的情況下都會分泌IFNγ,但與GCC-陰性標靶細胞共培養時則不然(圖4B和5B),指出此為抗原-依賴性細胞因子釋放。當與表現GCC的標靶細胞共培養時,具有所有VH結合劑的GCC CAR-T細胞,在tEGFR存在(7A-7D)和不存在(6A-6D)的情況下都會分泌IL2,但與GCC-陰性標靶細胞共培養時則不然(圖6B和7B),指出此為抗原-依賴性細胞因子釋放。
實例 4 : GCC CAR T 細胞體內活性
本實施例描述體內之抗GCC CAR T細胞活性。在內源性表現鳥苷酸環化酶C (GCC)的多重人類大腸直腸癌腫瘤異種移植模型中,研究具有不同VH結合子的GCC CAR-T的抗腫瘤活性。非肥胖糖尿病/嚴重聯合免疫缺陷/γ鏈-/-(NSG)小鼠,係使用HT55細胞、LS1034細胞或GSU細胞進行皮下接種。當平均腫瘤體積達到約150 mm
3時,緊急靜脈內(IV)投與GCC CAR-T細胞或模擬T細胞(非靶向CAR-T)。評估不同劑量位準及供體來源,且如圖8A-18所示。腫瘤體積及體重每星期測量兩次,至多50天。
在以由兩個不同的健康供體D393 (圖8A)和D686 (圖8B)製造之抗GCC CAR-T細胞治療的HT55模型(內源性表現之表現GCC的大腸直腸癌,GCC H分數 = 300/300)中測定平均腫瘤體積(mm
3)隨時間(40天)的變化。在以由三個不同的健康供體D393 (圖9A)、D797 (圖9B)和D954 (圖9C)製造之抗GCC CAR-T細胞治療的HT55模型中測定平均腫瘤體積(mm
3)隨時間(42天)的變化。在以由健康供體D393 (圖10A)、D797 (圖10B)和D954 (圖10C)製造之共表現tEGFR之抗GCC CAR-T細胞治療、以及由健康供體D393製造之不存有tEGFR之抗GCC CAR-T細胞治療的HT55模型中測定平均腫瘤體積(mm
3)隨時間(42天)的變化。在以由三個不同的健康供體D393 (圖11A)、D954 (圖11B)和D686 (圖11C)製造之抗GCC CAR-T細胞治療的HT55模型中測定平均腫瘤體積(mm
3)隨時間(42天)的變化。在以由健康供體D393 (圖12A)、D954 (圖12B)和D686 (圖12C)製造之共表現tEGFR之v48抗GCC CAR-T細胞治療的HT55模型中測定平均腫瘤體積(mm
3)隨時間(42天)的變化,劑量為0.25 x 10
6個CAR+細胞、0.5 x 10
6個CAR+細胞、或1 x 10
6個CAR+細胞。
在以由兩個健康供體D393 (圖13A)、D954 (圖13B)、D393 (圖15A)、D954 (圖15B)和D686 (圖15C)製造之不存有tEGFR之抗GCC CAR-T細胞治療的GSU模型(內源性表現GCC的胃癌,GCC H分數=170/300)中測定平均腫瘤體積(mm
3)隨時間(42天)的變化。在以由不同健康供體D393 (圖14A)、D954 (圖14B)、D393 (圖16A)、D954 (圖16B)和D686 (圖16C)製造之共表現tEGFR之抗GCC CAR-T細胞治療的GSU模型(內源性表現GCC的胃癌,GCC H分數=170/300)中測定平均腫瘤體積(mm
3)隨時間(42天)的變化。
在以由一個健康供體製造之共表現tEGFR (圖18)或不存有tEGFR (圖17)之抗GCC CAR-T細胞治療的LS1034模型(內源性表現GCC的大腸直腸癌,GCC H分數=300/300)中測定平均腫瘤體積(mm
3)隨時間(42天)的變化。
與各自的對照組相較,來自多個供體的GCC CAR-T細胞的緊急IV投與,會導致所有腫瘤模型中的腫瘤生長顯著抑制。與各自的對照組相較,在接受GCC CAR T細胞治療的LS1034或GSU腫瘤NSG小鼠中,沒有觀察到顯著的體重減輕。在HT-55腫瘤模型中,觀察到的體重減輕是由於腫瘤負荷造成的。GCC CAR-T細胞治療後的腫瘤負荷降低可導致體重增加。
已描述本發明的至少一實施例的幾個態樣,應當理解,各種改變、修飾和增進對於本領域技術人員來說將是顯而易見的。此類變更、修飾和增進旨在成為本揭示的一部分,且旨在落入本發明的精神和範圍內。因此,前面的描述和附圖僅作為示範,本發明由後附的申請專利範圍詳細描述。
序列表
下表7提供本文揭示之描述及序列。
表 7. 序列表
等效物
| SEQ ID NO | 描述 | 序列 |
| 1 | V1 vH | QVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLNLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSS |
| 2 | CD8跨膜域 | IYIWAPLAGTCGVLLLSLVITLYC |
| 3 | 4-1BB細胞内域 | KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL |
| 4 | CD3-ζ信號傳導域 | RVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR |
| 5 | 鉸鏈序列 | TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACD |
| 6 | 前導序列(v1) | MKHLWFFLLLVAAPRWVLS |
| 7 | 前導序列(v5、v36、v48、v51) | MELGLSWVFLVAILEGVQC |
| 8 | V1 HCDR1 | HYYWS |
| 9 | V5 HCDR1 | RYWMS |
| 10 | V36 HCDR1 | RYWMT |
| 10 | V48 HCDR1 | RYWMT |
| 10 | V51 HCDR1 | RYWMT |
| 11 | V1 HCDR2 | RIYPSGSTSYNPSLKS |
| 12 | V5 HCDR2 | KIRHDGGEKYYVDSVKG |
| 13 | V36 HCDR2 | KIKYDGSEKYYADSVKG |
| 14 | V48 HCDR2 | KIRHDGGEKYYPDSVKG |
| 15 | V51 HCDR2 | KIRHDGGEKYYADSVKG |
| 16 | V1 HCDR3 | DRSTGWSEWNSDL |
| 17 | V5 HCDR3 | DYTRDV |
| 18 | V36 HCDR3 | DYNKDY |
| 19 | V48 HCDR3 | DYNKDL |
| 18 | V51 HCDR3 | DYNKDY |
| 20 | V1 | EVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLKLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSS |
| 21 | V5 | QVQLVESGGGLVQPGGSLRLSCTASGFTFSRYWMSWVRQAPGKGLEWVAKIRHDGGEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDYTRDVWGQGTAVTVSS |
| 22 | V8 | QVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMSWVRQAPGKGLEWVAKIKYDGSEKYYVDSVKGRFTISRDNAKNSVYLQMNSLRAEDTGVYYCATDFTRDVWGQGTTVTVSS |
| 23 | V9 | EVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMTWVRQAPGRGLEWVAKIRYDGGEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDFTRDVWGQGTTVTVSS |
| 24 | V30 | QVQLVESGGGLVQPGGSLRLSCAASGFNFGRYWMSWVRQAPGKGREWVAKIKYDGSEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDFTRDVWGQGTTVTVSS |
| 25 | V31 | QVQLVESGGGVVRPGGSLRLSCAASGFTFSRYWMSWVRQAPGKGREWVAKIKYDGSEKYYADSVKGRFTISRDNAKNSLYLQMNSLRADDTAVYYCATDFTRDVWGQGTTVTVSS |
| 26 | V36 | EVQLVESGGGLAQPGGSLRLSCAASGFTFSRYWMTWVRQAPGGRLEWVAKIKYDGSEKYYADSVKGRFTISRDNAKNSLYLQMDSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSS |
| 27 | V48 | EVQLVESGGGLVQPGGSLRLTCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYPDSVKGRFTVSRDNAKNSLYLQMDNLRAEDTAMYYCTRDYNKDLWGQGTLVTVSS |
| 28 | V51 | EVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSS |
| 29 | CD28鉸鏈域 | IEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKP |
| 30 | CD28跨膜域 | FWVLVVVGGVLACYSLLVTVAFIIFWV |
| 31 | CD28鉸鏈/跨膜域 | IEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWV |
| 32 | CD28單域 | RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS |
| 33 | CD3z-1XX突變信號傳導域 | RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 34 | 組合CAR跨膜及細胞內域 | IEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 35 | V1-01 CAR | MGWSCIILFLVATATGVHSEVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLKLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSSIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 36 | V5 CAR | MELGLSWVFLVAILEGVQCQVQLVESGGGLVQPGGSLRLSCTASGFTFSRYWMSWVRQAPGKGLEWVAKIRHDGGEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDYTRDVWGQGTAVTVSSIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 37 | V36 CAR | MELGLSWVFLVAILEGVQCEVQLVESGGGLAQPGGSLRLSCAASGFTFSRYWMTWVRQAPGGRLEWVAKIKYDGSEKYYADSVKGRFTISRDNAKNSLYLQMDSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSSIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 38 | V48 CAR | MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLTCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYPDSVKGRFTVSRDNAKNSLYLQMDNLRAEDTAMYYCTRDYNKDLWGQGTLVTVSSIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 39 | V51 CAR | MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSSIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWV RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 40 | 熱穩定型腸毒素 | NTFYCCELCCNPACAGCY |
| 41 | GCC AA序列 | MKTLLLDLALWSLLFQPGWLSFSSQVSQNCHNGSYEISVLMMGNSAFAEPLKNLEDAVNEGLEIVRGRLQNAGLNVTVNATFMYSDGLIHNSGDCRSSTCEGLDLLRKISNAQRMGCVLIGPSCTYSTFQMYLDTELSYPMISAGSFGLSCDYKETLTRLMSPARKLMYFLVNFWKTNDLPFKTYSWSTSYVYKNGTETEDCFWYLNALEASVSYFSHELGFKVVLRQDKEFQDILMDHNRKSNVIIMCGGPEFLYKLKGDRAVAEDIVIILVDLFNDQYFEDNVTAPDYMKNVLVLTLSPGNSLLNSSFSRNLSPTKRDFALAYLNGILLFGHMLKIFLENGENITTPKFAHAFRNLTFEGYDGPVTLDDWGDVDSTMVLLYTSVDTKKYKVLLTYDTHVNKTYPVDMSPTFTWKNSKLPNDITGRGPQILMIAVFTLTGAVVLLLLVALLMLRKYRKDYELRQKKWSHIPPENIFPLETNETNHVSLKIDDDKRRDTIQRLRQCKYDKKRVILKDLKHNDGNFTEKQKIELNKLLQIDYYNLTKFYGTVKLDTMIFGVIEYCERGSLREVLNDTISYPDGTFMDWEFKISVLYDIAKGMSYLHSSKTEVHGRLKSTNCVVDSRMVVKITDFGCNSILPPKKDLWTAPEHLRQANISQKGDVYSYGIIAQEIILRKETFYTLSCRDRNEKIFRVENSNGMKPFRPDLFLETAEEKELEVYLLVKNCWEEDPEKRPDFKKIETTLAKIFGLFHDQKNESYMDTLIRRLQLYSRNLEHLVEERTQLYKAERDRADRLNFMLLPRLVVKSLKEKGFVEPELYEEVTIYFSDIVGFTTICKYSTPMEVVDMLNDIYKSFDHIVDHHDVYKVETIGDAYMVASGLPKRNGNRHAIDIAKMALEILSFMGTFELEHLPGLPIWIRIGVHSGPCAAGVVGIKMPRYCLFGDTVNTASRMESTGLPLRIHVSGSTIAILKRTECQFLYEVRGETYLKGRGNETTYWLTGMKDQKFNLPTPPTVENQQRLQAEFSDMIANSLQKRQAAGIRSQKPRRVASYKKGTLEYLQLNTTDKESTYF |
| 42 | v31前導序列 | MEFGLSWVFLVAIIKGVQC |
| 43 | tEGFR | MLLLVTSLLLCELPHPAFLLIPRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGCTGPGLEGCPTNGPKIPSIATGMVGALLLLLVVALGIGLFM |
| 44 | P2A | GSGATNFSLLKQAGDVEENPGP |
| 45 | 前導序列 | MALPVTALLLPLALLLHAARP |
| 46 | V1 CAR | MGWSCIILFLVATATGVHS QVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLNLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSSIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 47 | V1 CAR | MGWSCIILFLVATATGVHS QVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLNLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 48 | V1-01 CAR | MGWSCIILFLVATATGVHSEVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLKLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 49 | V5 CAR | MELGLSWVFLVAILEGVQCQVQLVESGGGLVQPGGSLRLSCTASGFTFSRYWMSWVRQAPGKGLEWVAKIRHDGGEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDYTRDVWGQGTAVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 50 | V36 CAR | MELGLSWVFLVAILEGVQCEVQLVESGGGLAQPGGSLRLSCAASGFTFSRYWMTWVRQAPGGRLEWVAKIKYDGSEKYYADSVKGRFTISRDNAKNSLYLQMDSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 51 | V48 CAR | MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLTCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYPDSVKGRFTVSRDNAKNSLYLQMDNLRAEDTAMYYCTRDYNKDLWGQGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 52 | V51 CAR | MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWV RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR |
| 53 | 連接子序列 | RAAA |
| 54 | 連接子序列 | GGGGS |
| 55 | V1 CAR (28z1xx-tEGFR) | MGWSCIILFLVATATGVHS QVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLNLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR GSGATNFSLLKQAGDVEENPGP MLLLVTSLLLCELPHPAFLLIPRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGCTGPGLEGCPTNGP KIPSIATGMVGALLLLLVVALGIGLFM |
| 56 | V1-01 CAR (28z1xx-tEGFR) | MGWSCIILFLVATATGVHSEVQLQESGPGLVKPSETLSLTCTVSGASISHYYWSWFRQPAGKGLEWIGRIYPSGSTSYNPSLKSRVAMSVDTPKNQFSLKLSSVTAADTAVYYCARDRSTGWSEWNSDLWGRGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR GSGATNFSLLKQAGDVEENPGP MLLLVTSLLLCELPHPAFLLIPRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGCTGPGLEGCPTNGP KIPSIATGMVGALLLLLVVALGIGLFM |
| 57 | V5 CAR (28z1xx-tEGFR) | MELGLSWVFLVAILEGVQCQVQLVESGGGLVQPGGSLRLSCTASGFTFSRYWMSWVRQAPGKGLEWVAKIRHDGGEKYYVDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCATDYTRDVWGQGTAVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR GSGATNFSLLKQAGDVEENPGP MLLLVTSLLLCELPHPAFLLIPRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGCTGPGLEGCPTNGP KIPSIATGMVGALLLLLVVALGIGLFM |
| 58 | V36 CAR (28z1xx-tEGFR) | MELGLSWVFLVAILEGVQCEVQLVESGGGLAQPGGSLRLSCAASGFTFSRYWMTWVRQAPGGRLEWVAKIKYDGSEKYYADSVKGRFTISRDNAKNSLYLQMDSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR GSGATNFSLLKQAGDVEENPGP MLLLVTSLLLCELPHPAFLLIPRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGCTGPGLEGCPTNGP KIPSIATGMVGALLLLLVVALGIGLFM |
| 59 | V48 CAR (28z1xx-tEGFR) | MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLTCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYPDSVKGRFTVSRDNAKNSLYLQMDNLRAEDTAMYYCTRDYNKDLWGQGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR GSGATNFSLLKQAGDVEENPGP MLLLVTSLLLCELPHPAFLLIPRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGCTGPGLEGCPTNGP KIPSIATGMVGALLLLLVVALGIGLFM |
| 60 | V51 CAR (28z1xx-tEGFR) | MELGLSWVFLVAILEGVQCEVQLVESGGGLVQPGGSLRLSCAASGFTFSRYWMTWVRQAPGKGLEWVAKIRHDGGEKYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCTRDYNKDYWGQGTLVTVSSRAAAIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLFNELQKDKMAEAFSEIGMKGERRRGKGHDGLFQGLSTATKDTFDALHMQALPPR GSGATNFSLLKQAGDVEENPGP MLLLVTSLLLCELPHPAFLLIPRKVCNGIGIGEFKDSLSINATNIKHFKNCTSISGDLHILPVAFRGDSFTHTPPLDPQELDILKTVKEITGFLLIQAWPENRTDLHAFENLEIIRGRTKQHGQFSLAVVSLNITSLGLRSLKEISDGDVIISGNKNLCYANTINWKKLFGTSGQKTKIISNRGENSCKATGQVCHALCSPEGCWGPEPRDCVSCRNVSRGRECVDKCNLLEGEPREFVENSECIQCHPECLPQAMNITCTGRGPDNCIQCAHYIDGPHCVKTCPAGVMGENNTLVWKYADAGHVCHLCHPNCTYGCTGPGLEGCPTNGP KIPSIATGMVGALLLLLVVALGIGLFM |
| 61 | V1-01 CAR 核酸序列 | ATGGGCTGGTCTTGTATTATCTTGTTTCTCGTCGCAACTGCTACAGGCGTTCATTCTGAAGTTCAACTCCAAGAATCTGGTCCTGGCCTGGTGAAACCTTCCGAAACTCTCTCACTCACCTGTACCGTCTCAGGCGCTTCAATATCACACTATTATTGGTCTTGGTTCCGGCAACCTGCAGGCAAAGGTCTCGAATGGATAGGCAGAATATATCCCAGTGGAAGCACCTCCTATAATCCCTCTCTCAAGTCAAGAGTTGCAATGAGCGTTGACACACCCAAGAACCAATTCTCCCTCAAGCTGTCATCTGTAACTGCCGCCGATACTGCCGTTTACTACTGCGCTAGAGATAGATCAACCGGATGGTCAGAATGGAATTCAGATCTGTGGGGACGGGGAACCCTCGTGACCGTATCTTCTCGGGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGC |
| 62 | V5 CAR 核酸序列 | ATGGAACTGGGACTGTCTTGGGTGTTCCTGGTCGCTATATTGGAAGGAGTACAGTGCCAGGTCCAGCTCGTCGAGTCCGGGGGTGGCCTGGTGCAGCCCGGCGGCAGCCTCCGGCTGAGCTGCACAGCCTCAGGGTTTACATTCAGCAGGTACTGGATGAGTTGGGTTAGGCAAGCCCCTGGCAAAGGCCTGGAGTGGGTGGCCAAAATCCGACATGATGGGGGCGAAAAGTACTATGTGGATAGTGTGAAGGGACGGTTCACAATATCACGAGACAATGCCAAAAACTCTTTGTACCTGCAAATGAACTCCCTGCGCGCCGAAGACACAGCTGTGTACTACTGCGCTACAGACTACACTAGGGACGTCTGGGGTCAAGGAACAGCCGTCACCGTGAGTAGTCGGGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCTAA |
| 63 | V36 CAR 核酸序列 | ATGGAGCTGGGATTGTCCTGGGTTTTCCTGGTGGCTATACTCGAAGGCGTACAGTGTGAAGTGCAGTTGGTGGAGAGTGGCGGTGGCCTGGCCCAGCCGGGAGGCTCTTTGAGACTCTCCTGCGCTGCCTCCGGCTTCACTTTCTCCCGCTATTGGATGACCTGGGTCCGGCAGGCGCCCGGCGGACGCCTGGAGTGGGTGGCTAAGATCAAGTATGATGGATCAGAAAAATATTACGCAGATAGCGTAAAAGGCCGGTTCACAATATCCAGGGATAATGCAAAAAACTCCCTGTATCTGCAGATGGATAGCCTGCGCGCTGAAGACACCGCCGTATATTATTGCACAAGAGACTACAATAAAGATTACTGGGGCCAGGGAACCCTGGTTACGGTGAGCTCACGGGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGC |
| 64 | V48 CAR 核酸序列 | ATGGAGCTGGGGCTTTCTTGGGTGTTTCTGGTAGCCATCCTCGAGGGAGTCCAGTGCGAGGTCCAGCTCGTCGAATCTGGCGGGGGGCTGGTCCAGCCTGGCGGTTCTCTCCGCCTGACCTGTGCGGCCTCAGGGTTCACTTTCAGCCGGTACTGGATGACATGGGTGAGACAGGCCCCCGGCAAGGGACTGGAATGGGTAGCAAAGATTAGGCACGACGGCGGTGAGAAATACTATCCCGACAGTGTCAAGGGGCGGTTTACTGTCTCCCGAGATAATGCCAAAAACTCACTCTACCTGCAGATGGATAATCTGCGAGCGGAGGATACTGCTATGTACTACTGTACTCGAGACTACAACAAGGACCTGTGGGGGCAGGGGACACTGGTGACGGTTAGTTCTCGGGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGC |
| 65 | V51 CAR 核酸序列 | ATGGAACTGGGACTGTCATGGGTCTTTCTCGTGGCCATTCTCGAGGGGGTCCAGTGTGAGGTTCAGCTGGTGGAGAGCGGGGGGGGTCTGGTTCAGCCAGGTGGCAGTCTTAGGTTGTCATGTGCCGCGAGCGGGTTCACGTTCTCACGATATTGGATGACCTGGGTTCGCCAGGCACCAGGGAAGGGGCTGGAGTGGGTCGCCAAGATCAGGCACGACGGCGGAGAAAAATATTACGCGGATTCCGTGAAAGGCAGATTCACAATCTCTAGGGATAACGCCAAAAATTCCCTTTATCTTCAGATGAATAGCCTGAGGGCTGAAGACACTGCCGTGTACTACTGCACGCGGGATTACAACAAAGATTATTGGGGCCAGGGAACACTGGTGACCGTCAGCTCTCGGGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGC |
| 66 | V1-01 CAR + tEGFR 核酸序列 | ATGGGCTGGTCTTGTATTATCTTGTTTCTCGTCGCAACTGCTACAGGCGTTCATTCTGAAGTTCAACTCCAAGAATCTGGTCCTGGCCTGGTGAAACCTTCCGAAACTCTCTCACTCACCTGTACCGTCTCAGGCGCTTCAATATCACACTATTATTGGTCTTGGTTCCGGCAACCTGCAGGCAAAGGTCTCGAATGGATAGGCAGAATATATCCCAGTGGAAGCACCTCCTATAATCCCTCTCTCAAGTCAAGAGTTGCAATGAGCGTTGACACACCCAAGAACCAATTCTCCCTCAAGCTGTCATCTGTAACTGCCGCCGATACTGCCGTTTACTACTGCGCTAGAGATAGATCAACCGGATGGTCAGAATGGAATTCAGATCTGTGGGGACGGGGAACCCTCGTGACCGTATCTTCTCGGGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGCTACTAACTTCAGCCTGCTGAAGCAGGCTGGAGACGTGGAGGAGAACCCTGGACCCATGCTTCTCCTGGTGACAAGCCTTCTGCTCTGTGAGTTACCACACCCAGCATTCCTCCTGATCCCACGCAAAGTGTGTAACGGAATAGGTATTGGTGAATTTAAAGACTCACTCTCCATAAATGCTACGAATATTAAACACTTCAAAAACTGCACCTCCATCAGTGGCGATCTCCACATCCTGCCGGTGGCATTTAGGGGTGACTCCTTCACACATACTCCTCCTCTGGACCCACAGGAACTGGATATTCTGAAAACCGTAAAGGAAATCACAGGGTTTTTGCTGATTCAGGCTTGGCCTGAAAACAGGACGGACCTCCATGCCTTTGAGAACCTAGAAATCATACGCGGCAGGACCAAGCAACATGGTCAGTTTTCTCTTGCAGTCGTCAGCCTGAACATAACATCCTTGGGATTACGCTCCCTCAAGGAGATAAGTGATGGAGATGTGATAATTTCAGGAAACAAAAATTTGTGCTATGCAAATACAATAAACTGGAAAAAACTGTTTGGGACCTCCGGTCAGAAAACCAAAATTATAAGCAACAGAGGTGAAAACAGCTGCAAGGCCACAGGCCAGGTCTGCCATGCCTTGTGCTCCCCCGAGGGCTGCTGGGGCCCGGAGCCCAGGGACTGCGTCTCTTGCCGGAATGTCAGCCGAGGCAGGGAATGCGTGGACAAGTGCAACCTTCTGGAGGGTGAGCCAAGGGAGTTTGTGGAGAACTCTGAGTGCATACAGTGCCACCCAGAGTGCCTGCCTCAGGCCATGAACATCACCTGCACAGGACGGGGACCAGACAACTGTATCCAGTGTGCCCACTACATTGACGGCCCCCACTGCGTCAAGACCTGCCCGGCAGGAGTCATGGGAGAAAACAACACCCTGGTCTGGAAGTACGCAGACGCCGGCCATGTGTGCCACCTGTGCCATCCAAACTGCACCTACGGATGCACTGGGCCAGGTCTTGAAGGCTGTCCCACGAATGGGCCTAAGATCCCGTCCATCGCCACTGGGATGGTGGGGGCCCTCCTCTTGCTGCTGGTGGTGGCCCTGGGGATCGGCCTCTTCATG |
| 67 | V5 CAR + tEGFR 核酸序列 | ATGGAACTGGGACTGTCTTGGGTGTTCCTGGTCGCTATATTGGAAGGAGTACAGTGCCAGGTCCAGCTCGTCGAGTCCGGGGGTGGCCTGGTGCAGCCCGGCGGCAGCCTCCGGCTGAGCTGCACAGCCTCAGGGTTTACATTCAGCAGGTACTGGATGAGTTGGGTTAGGCAAGCCCCTGGCAAAGGCCTGGAGTGGGTGGCCAAAATCCGACATGATGGGGGCGAAAAGTACTATGTGGATAGTGTGAAGGGACGGTTCACAATATCACGAGACAATGCCAAAAACTCTTTGTACCTGCAAATGAACTCCCTGCGCGCCGAAGACACAGCTGTGTACTACTGCGCTACAGACTACACTAGGGACGTCTGGGGTCAAGGAACAGCCGTCACCGTGAGTAGTGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGCTACTAACTTCAGCCTGCTGAAGCAGGCTGGAGACGTGGAGGAGAACCCTGGACCCATGCTTCTCCTGGTGACAAGCCTTCTGCTCTGTGAGTTACCACACCCAGCATTCCTCCTGATCCCACGCAAAGTGTGTAACGGAATAGGTATTGGTGAATTTAAAGACTCACTCTCCATAAATGCTACGAATATTAAACACTTCAAAAACTGCACCTCCATCAGTGGCGATCTCCACATCCTGCCGGTGGCATTTAGGGGTGACTCCTTCACACATACTCCTCCTCTGGACCCACAGGAACTGGATATTCTGAAAACCGTAAAGGAAATCACAGGGTTTTTGCTGATTCAGGCTTGGCCTGAAAACAGGACGGACCTCCATGCCTTTGAGAACCTAGAAATCATACGCGGCAGGACCAAGCAACATGGTCAGTTTTCTCTTGCAGTCGTCAGCCTGAACATAACATCCTTGGGATTACGCTCCCTCAAGGAGATAAGTGATGGAGATGTGATAATTTCAGGAAACAAAAATTTGTGCTATGCAAATACAATAAACTGGAAAAAACTGTTTGGGACCTCCGGTCAGAAAACCAAAATTATAAGCAACAGAGGTGAAAACAGCTGCAAGGCCACAGGCCAGGTCTGCCATGCCTTGTGCTCCCCCGAGGGCTGCTGGGGCCCGGAGCCCAGGGACTGCGTCTCTTGCCGGAATGTCAGCCGAGGCAGGGAATGCGTGGACAAGTGCAACCTTCTGGAGGGTGAGCCAAGGGAGTTTGTGGAGAACTCTGAGTGCATACAGTGCCACCCAGAGTGCCTGCCTCAGGCCATGAACATCACCTGCACAGGACGGGGACCAGACAACTGTATCCAGTGTGCCCACTACATTGACGGCCCCCACTGCGTCAAGACCTGCCCGGCAGGAGTCATGGGAGAAAACAACACCCTGGTCTGGAAGTACGCAGACGCCGGCCATGTGTGCCACCTGTGCCATCCAAACTGCACCTACGGATGCACTGGGCCAGGTCTTGAAGGCTGTCCCACGAATGGGCCTAAGATCCCGTCCATCGCCACTGGGATGGTGGGGGCCCTCCTCTTGCTGCTGGTGGTGGCCCTGGGGATCGGCCTCTTCATG |
| 68 | V36 CAR + tEGFR 核酸序列 | ATGGAGCTGGGATTGTCCTGGGTTTTCCTGGTGGCTATACTCGAAGGCGTACAGTGTGAAGTGCAGTTGGTGGAGAGTGGCGGTGGCCTGGCCCAGCCGGGAGGCTCTTTGAGACTCTCCTGCGCTGCCTCCGGCTTCACTTTCTCCCGCTATTGGATGACCTGGGTCCGGCAGGCGCCCGGCGGACGCCTGGAGTGGGTGGCTAAGATCAAGTATGATGGATCAGAAAAATATTACGCAGATAGCGTAAAAGGCCGGTTCACAATATCCAGGGATAATGCAAAAAACTCCCTGTATCTGCAGATGGATAGCCTGCGCGCTGAAGACACCGCCGTATATTATTGCACAAGAGACTACAATAAAGATTACTGGGGCCAGGGAACCCTGGTTACGGTGAGCTCACGGGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGCTACTAACTTCAGCCTGCTGAAGCAGGCTGGAGACGTGGAGGAGAACCCTGGACCCATGCTTCTCCTGGTGACAAGCCTTCTGCTCTGTGAGTTACCACACCCAGCATTCCTCCTGATCCCACGCAAAGTGTGTAACGGAATAGGTATTGGTGAATTTAAAGACTCACTCTCCATAAATGCTACGAATATTAAACACTTCAAAAACTGCACCTCCATCAGTGGCGATCTCCACATCCTGCCGGTGGCATTTAGGGGTGACTCCTTCACACATACTCCTCCTCTGGACCCACAGGAACTGGATATTCTGAAAACCGTAAAGGAAATCACAGGGTTTTTGCTGATTCAGGCTTGGCCTGAAAACAGGACGGACCTCCATGCCTTTGAGAACCTAGAAATCATACGCGGCAGGACCAAGCAACATGGTCAGTTTTCTCTTGCAGTCGTCAGCCTGAACATAACATCCTTGGGATTACGCTCCCTCAAGGAGATAAGTGATGGAGATGTGATAATTTCAGGAAACAAAAATTTGTGCTATGCAAATACAATAAACTGGAAAAAACTGTTTGGGACCTCCGGTCAGAAAACCAAAATTATAAGCAACAGAGGTGAAAACAGCTGCAAGGCCACAGGCCAGGTCTGCCATGCCTTGTGCTCCCCCGAGGGCTGCTGGGGCCCGGAGCCCAGGGACTGCGTCTCTTGCCGGAATGTCAGCCGAGGCAGGGAATGCGTGGACAAGTGCAACCTTCTGGAGGGTGAGCCAAGGGAGTTTGTGGAGAACTCTGAGTGCATACAGTGCCACCCAGAGTGCCTGCCTCAGGCCATGAACATCACCTGCACAGGACGGGGACCAGACAACTGTATCCAGTGTGCCCACTACATTGACGGCCCCCACTGCGTCAAGACCTGCCCGGCAGGAGTCATGGGAGAAAACAACACCCTGGTCTGGAAGTACGCAGACGCCGGCCATGTGTGCCACCTGTGCCATCCAAACTGCACCTACGGATGCACTGGGCCAGGTCTTGAAGGCTGTCCCACGAATGGGCCTAAGATCCCGTCCATCGCCACTGGGATGGTGGGGGCCCTCCTCTTGCTGCTGGTGGTGGCCCTGGGGATCGGCCTCTTCATG |
| 69 | V48 CAR + tEGFR 核酸序列 | ATGGAGCTGGGGCTTTCTTGGGTGTTTCTGGTAGCCATCCTCGAGGGAGTCCAGTGCGAGGTCCAGCTCGTCGAATCTGGCGGGGGGCTGGTCCAGCCTGGCGGTTCTCTCCGCCTGACCTGTGCGGCCTCAGGGTTCACTTTCAGCCGGTACTGGATGACATGGGTGAGACAGGCCCCCGGCAAGGGACTGGAATGGGTAGCAAAGATTAGGCACGACGGCGGTGAGAAATACTATCCCGACAGTGTCAAGGGGCGGTTTACTGTCTCCCGAGATAATGCCAAAAACTCACTCTACCTGCAGATGGATAATCTGCGAGCGGAGGATACTGCTATGTACTACTGTACTCGAGACTACAACAAGGACCTGTGGGGGCAGGGGACACTGGTGACGGTTAGTTCTCGGGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGCTACTAACTTCAGCCTGCTGAAGCAGGCTGGAGACGTGGAGGAGAACCCTGGACCCATGCTTCTCCTGGTGACAAGCCTTCTGCTCTGTGAGTTACCACACCCAGCATTCCTCCTGATCCCACGCAAAGTGTGTAACGGAATAGGTATTGGTGAATTTAAAGACTCACTCTCCATAAATGCTACGAATATTAAACACTTCAAAAACTGCACCTCCATCAGTGGCGATCTCCACATCCTGCCGGTGGCATTTAGGGGTGACTCCTTCACACATACTCCTCCTCTGGACCCACAGGAACTGGATATTCTGAAAACCGTAAAGGAAATCACAGGGTTTTTGCTGATTCAGGCTTGGCCTGAAAACAGGACGGACCTCCATGCCTTTGAGAACCTAGAAATCATACGCGGCAGGACCAAGCAACATGGTCAGTTTTCTCTTGCAGTCGTCAGCCTGAACATAACATCCTTGGGATTACGCTCCCTCAAGGAGATAAGTGATGGAGATGTGATAATTTCAGGAAACAAAAATTTGTGCTATGCAAATACAATAAACTGGAAAAAACTGTTTGGGACCTCCGGTCAGAAAACCAAAATTATAAGCAACAGAGGTGAAAACAGCTGCAAGGCCACAGGCCAGGTCTGCCATGCCTTGTGCTCCCCCGAGGGCTGCTGGGGCCCGGAGCCCAGGGACTGCGTCTCTTGCCGGAATGTCAGCCGAGGCAGGGAATGCGTGGACAAGTGCAACCTTCTGGAGGGTGAGCCAAGGGAGTTTGTGGAGAACTCTGAGTGCATACAGTGCCACCCAGAGTGCCTGCCTCAGGCCATGAACATCACCTGCACAGGACGGGGACCAGACAACTGTATCCAGTGTGCCCACTACATTGACGGCCCCCACTGCGTCAAGACCTGCCCGGCAGGAGTCATGGGAGAAAACAACACCCTGGTCTGGAAGTACGCAGACGCCGGCCATGTGTGCCACCTGTGCCATCCAAACTGCACCTACGGATGCACTGGGCCAGGTCTTGAAGGCTGTCCCACGAATGGGCCTAAGATCCCGTCCATCGCCACTGGGATGGTGGGGGCCCTCCTCTTGCTGCTGGTGGTGGCCCTGGGGATCGGCCTCTTCATG |
| 70 | V51 CAR + tEGFR 核酸序列 | ATGGAACTGGGACTGTCATGGGTCTTTCTCGTGGCCATTCTCGAGGGGGTCCAGTGTGAGGTTCAGCTGGTGGAGAGCGGGGGGGGTCTGGTTCAGCCAGGTGGCAGTCTTAGGTTGTCATGTGCCGCGAGCGGGTTCACGTTCTCACGATATTGGATGACCTGGGTTCGCCAGGCACCAGGGAAGGGGCTGGAGTGGGTCGCCAAGATCAGGCACGACGGCGGAGAAAAATATTACGCGGATTCCGTGAAAGGCAGATTCACAATCTCTAGGGATAACGCCAAAAATTCCCTTTATCTTCAGATGAATAGCCTGAGGGCTGAAGACACTGCCGTGTACTACTGCACGCGGGATTACAACAAAGATTATTGGGGCCAGGGAACACTGGTGACCGTCAGCTCTCGGGCGGCCGCAATTGAAGTTATGTATCCTCCTCCTTACCTAGACAATGAGAAGAGCAATGGAACCATTATCCATGTGAAAGGGAAACACCTTTGTCCAAGTCCCCTATTTCCCGGACCTTCTAAGCCCTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTTCAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTTCAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTTCCAGGGTCTCAGTACAGCCACCAAGGACACCTTCGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCGGAAGCGGAGCTACTAACTTCAGCCTGCTGAAGCAGGCTGGAGACGTGGAGGAGAACCCTGGACCCATGCTTCTCCTGGTGACAAGCCTTCTGCTCTGTGAGTTACCACACCCAGCATTCCTCCTGATCCCACGCAAAGTGTGTAACGGAATAGGTATTGGTGAATTTAAAGACTCACTCTCCATAAATGCTACGAATATTAAACACTTCAAAAACTGCACCTCCATCAGTGGCGATCTCCACATCCTGCCGGTGGCATTTAGGGGTGACTCCTTCACACATACTCCTCCTCTGGACCCACAGGAACTGGATATTCTGAAAACCGTAAAGGAAATCACAGGGTTTTTGCTGATTCAGGCTTGGCCTGAAAACAGGACGGACCTCCATGCCTTTGAGAACCTAGAAATCATACGCGGCAGGACCAAGCAACATGGTCAGTTTTCTCTTGCAGTCGTCAGCCTGAACATAACATCCTTGGGATTACGCTCCCTCAAGGAGATAAGTGATGGAGATGTGATAATTTCAGGAAACAAAAATTTGTGCTATGCAAATACAATAAACTGGAAAAAACTGTTTGGGACCTCCGGTCAGAAAACCAAAATTATAAGCAACAGAGGTGAAAACAGCTGCAAGGCCACAGGCCAGGTCTGCCATGCCTTGTGCTCCCCCGAGGGCTGCTGGGGCCCGGAGCCCAGGGACTGCGTCTCTTGCCGGAATGTCAGCCGAGGCAGGGAATGCGTGGACAAGTGCAACCTTCTGGAGGGTGAGCCAAGGGAGTTTGTGGAGAACTCTGAGTGCATACAGTGCCACCCAGAGTGCCTGCCTCAGGCCATGAACATCACCTGCACAGGACGGGGACCAGACAACTGTATCCAGTGTGCCCACTACATTGACGGCCCCCACTGCGTCAAGACCTGCCCGGCAGGAGTCATGGGAGAAAACAACACCCTGGTCTGGAAGTACGCAGACGCCGGCCATGTGTGCCACCTGTGCCATCCAAACTGCACCTACGGATGCACTGGGCCAGGTCTTGAAGGCTGTCCCACGAATGGGCCTAAGATCCCGTCCATCGCCACTGGGATGGTGGGGGCCCTCCTCTTGCTGCTGGTGGTGGCCCTGGGGATCGGCCTCTTCATG |
在申請專利範圍中使用諸如「第一」、「第二」、「第三」等序數術語來修飾申請專利範圍要件本身,並不意味著某一申請專利範圍要件相對於另一個申請專利範圍要件的任何優先、先行或順序,或方法執行的時間順序,而僅作為標示,以將具有特定名稱的一個申請專利範圍要件與具有相同名稱(但使用該序數術語)的另一個要件區分開來,以區分各申請專利範圍要件。
如本文在說明書和申請專利範圍中使用的冠詞「一(a)」和「一(an)」,除非明確指出相反,否則應理解為包括複數參考物。除非另有說明,否則若該群組之一個、多個或所有成員存在於、使用於或以其他方式相關於一特定產物或方法,則在一或多個群組成員之間包括「或」的申請專利範圍或描述被視為已滿足,除非上下文相反或以其他方式明顯指出。本發明包括其中該群組中恰好有一個成員存在於、使用於或以其他方式相關於特定的產品或過程的實施例。本發明亦包括其中大於一個或整個群組成員存在於、使用於或以其他方式相關於特定的產品或過程的實施例。此外,應當理解,本發明涵蓋所有變化、組合和排列,其中來自所列申請專利範圍的一或多個限制、要件、子句、描述性術語等,係引入另一從屬申請專利範圍中相同的基本申請專利範圍(或相關的任何其他申請專利範圍)中,除非另有說明或除非本領域普通技術人員可明顯看出矛盾或不一致。在要件以列表形式呈現的情況下(例如,以馬庫什組(Markush group)或類似格式),應當理解,亦揭示該要件的每個子群,且可從該群組中移除任一要件。應當理解,一般而言,本發明或本發明態樣被稱為包含特定要件、特徵等的情況下,本發明的某些實施例或本發明的各態樣由或基本上由此類要件、特徵等組成。為了簡單起見,在本文中這些實施例並未在每種情況下以如此多的詞語具體闡述。亦應當理解,本發明的任何實施例或態樣都可明確地從申請專利範圍中排除,而不論特定的排除是否在說明書中有陳述。用於描述本發明的背景並提供關於其實施的額外細節所引用的文獻、網站和其他參考資料均以引用方式併入本文中。
本文所含之圖式,其由以下各圖組成,僅用於說明目的而非限制。
圖 1A 及 1B 描繪例示性嵌合抗原受體(CAR)構築體。
圖 2A-2D 顯示使用四種腫瘤細胞株進行之例示性抗GCC CAR-T體外細胞毒性試驗。HT29-GCC細胞(一種經改造以穩定表現GCC之人類大腸直腸癌細胞株HT29)(圖2A);HT29-VEC(載體對照組GCC陰性細胞株)(圖2B);及兩種內源性表現GCC之腫瘤細胞株:GSU (圖2C)和LS1034 (圖2D)。長條代表來自三次技術重複的平均值+SD值。數據代表來自>3個供體的抗GCC CAR T細胞進行的>3個獨立實驗。CAR T細胞毒性係於截短EGFR (tEGFR)不存在的情況下測定。
圖 3A-3D 顯示使用四種腫瘤細胞株進行之例示性抗GCC CAR-T體外細胞毒性試驗。HT29-GCC細胞(一種經改造以穩定表現GCC之人類大腸直腸癌細胞株HT29)(圖3A);HT29-VEC(載體對照組GCC陰性細胞株)(圖3B);及兩種內源性表現GCC之腫瘤細胞株:GSU(圖3C)和LS1034(圖3D)。長條代表來自三次技術重複的平均值+SD值。各資料代表來自>3個供體之使用抗GCC CAR T細胞進行的>3個獨立實驗。CAR T細胞毒性係於截短EGFR (tEGFR)存在的情況下測定。
圖 4A-4D 顯示由與表現GCC(HT29-GCC)(圖4A)、GSU(圖4C)、LS1034(圖4D)及GCC-陰性(HT29-VEC,圖4B)之腫瘤細胞體外共培養之抗GCC CAR-T細胞分泌之例示性IFN-g細胞激素。上清液中之分泌IFNg係使用Intellicyt QBeads Human PlexScreen套組(Sartorius, 90702)測定。長條代表來自三次技術重複的平均值+SD值。各數據代表來自>3個供體之使用抗GCC CAR T細胞進行的>3個獨立實驗。細胞激素分泌係於截短EGFR (tEGFR)不存在的情況下測定。
圖 5A-5D 顯示由與表現GCC(HT29-GCC)(圖5A)、GSU(圖5C)、LS1034(圖5D)及GCC-陰性(HT29-VEC,圖5B)之腫瘤細胞體外共培養之抗GCC CAR-T細胞分泌之例示性IFN-g細胞激素。上清液中之分泌IFNg係使用Intellicyt QBeads Human PlexScreen套組(Sartorius、90702)測定。長條代表來自三次技術重複的平均值+SD值。各數據代表來自>3個供體之使用抗GCC CAR T細胞進行的>3個獨立實驗。細胞激素分泌係於截短EGFR (tEGFR)存在的情況下測定。
圖 6A-6D 顯示顯示由與表現GCC(HT29-GCC)(圖6A)、GSU(圖6C)、LS1034(圖6D)及GCC-陰性(HT29-VEC,圖6B)之腫瘤細胞體外共培養之抗GCC CAR-T細胞分泌之例示性IL-2細胞激素。上清液中之分泌IFL-2係使用Intellicyt QBeads Human PlexScreen套組(Sartorius, 90702)測定。長條代表來自三次技術重複的平均值+SD值。各資料代表來自>3個供體之使用抗GCC CAR T細胞進行的>3個獨立實驗。細胞激素分泌係於截短EGFR (tEGFR)不存在的情況下測定。
圖 7A-7D 顯示由與表現GCC(HT29-GCC)(圖7A)、GSU(圖7C)、LS1034(圖7D)及GCC-陰性(HT29-VEC,圖7B)之腫瘤細胞體外共培養之抗GCC CAR-T細胞分泌之例示性IL-2細胞激素。上清液中之分泌IFL-2係使用Intellicyt QBeads Human PlexScreen套組(Sartorius, 90702)測定。長條代表來自三次技術重複的平均值+SD值。各資料代表來自>3個供體之使用抗GCC CAR T細胞進行的>3個獨立實驗。細胞激素分泌係於截短EGFR (tEGFR)存在的情況下測定。
圖 8A 及 8B 顯示以來自兩個不同健康供體D393(圖8A)及D686(圖8B)製造之抗GCC CAR-T細胞處理之HT55模型(內源性表現GCC之大腸直腸癌,GCC H-分數=300/300)中,平均腫瘤體積變化(mm
3)隨時間變化(40天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)不存在的情況下測定。
圖 9A-9C 顯示以來自三個不同健康供體D393 (圖9A)、D797 (圖9B)和D954 (圖9C)所製造之抗GCC CAR-T細胞處理之HT55模型(內源性表現GCC之大腸直腸癌,GCC H-分數=300/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)不存在的情況下測定。
圖 10A-10C 顯示以來自三個不同健康供體D393 (圖10A)、D797 (圖10B)和D954 (圖10C)製造之抗GCC CAR-T細胞處理之HT55模型(內源性表現GCC之大腸直腸癌,GCC H-分數=300/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)存在的情況下測定。
圖 11A-11C 顯示以來自三個不同健康供體D393 (圖11A)、D954 (圖11B)和D686 (圖11C)製造之抗GCC CAR-T細胞處理之HT55模型(內源性表現GCC之大腸直腸癌,GCC H-分數=300/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)不存在的情況下測定。
圖 12A-12C 顯示以來自三個不同健康供體D393 (圖12A)、D954 (圖12B)和D686 (圖12C)製造之抗GCC CAR-T細胞處理之HT55模型(內源性表現GCC之大腸直腸癌,GCC H-分數=300/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)存在的情況下測定。
圖 13A 和 13B 顯示以來自兩個不同健康供體D393(圖13A)和D954(圖13B)製造之抗GCC CAR-T細胞處理之GSU模型(內源性表現GCC之胃癌,GCC H-分數=170/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)不存在的情況下測定。
圖 14A 和 14B 顯示以來自兩個不同健康供體D393(圖14A)和D954(圖14B)製造之抗GCC CAR-T細胞處理之GSU模型(內源性表現GCC之胃癌,GCC H-分數=170/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)存在的情況下測定。
圖 15A-C 顯示以來自三個不同健康供體D393 (圖15A)、D954 (圖15B)和D686(圖15C)製造之抗GCC CAR-T細胞處理之GSU模型(內源性表現GCC之胃癌,GCC H-分數=170/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)不存在的情況下測定。
圖 16A-C 顯示以來自三個不同健康供體D393 (圖16A)、D954 (圖16B)和D686(圖16C)製造之抗GCC CAR-T細胞處理之GSU模型(內源性表現GCC之胃癌,GCC H-分數=170/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)不存在的情況下測定。
圖 17 顯示以來自一個健康供體製造之抗GCC CAR-T細胞處理之LS1034模型(內源性表現GCC之大腸直腸癌,GCC H-分數=300/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)不存在的情況下測定。
圖 18 顯示以來自一個健康供體製造之抗GCC CAR-T細胞處理之LS1034模型(內源性表現GCC之大腸直腸癌,GCC H-分數=300/300)中,平均腫瘤體積變化(mm
3)隨時間變化(42天)的例示性抗腫瘤作用結果。抗腫瘤作用係於該截短EGFR (tEGFR)存在的情況下測定。
<![CDATA[<110> 日商武田藥品工業股份有限公司/TAKEDA PHARMACEUTICAL COMPANY LIMITED]]>
<![CDATA[<120> 鳥苷酸環化酶C (GCC)抗原結合劑之組成物及其使用方法]]>
<![CDATA[<130> MIL-005WO]]>
<![CDATA[<140> TW 110145784]]>
<![CDATA[<141> 2021-12-08]]>
<![CDATA[<150> US 63/123,331]]>
<![CDATA[<151> 2020-12-09]]>
<![CDATA[<160> 73]]>
<![CDATA[<170> PatentIn版本3.5]]>
<![CDATA[<210> 1]]>
<![CDATA[<211> 121]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 1]]>
Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Ala Ser Ile Ser His Tyr
20 25 30
Tyr Trp Ser Trp Phe Arg Gln Pro Ala Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Ser Gly Ser Thr Ser Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Ala Met Ser Val Asp Thr Pro Lys Asn Gln Phe Ser Leu
65 70 75 80
Asn Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Asp Arg Ser Thr Gly Trp Ser Glu Trp Asn Ser Asp Leu Trp Gly
100 105 110
Arg Gly Thr Leu Val Thr Val Ser Ser
115 120
<![CDATA[<210> 2]]>
<![CDATA[<211> 24]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 2]]>
Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu
1 5 10 15
Ser Leu Val Ile Thr Leu Tyr Cys
20
<![CDATA[<210> 3]]>
<![CDATA[<211> 42]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 3]]>
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
1 5 10 15
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
20 25 30
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
35 40
<![CDATA[<210> 4]]>
<![CDATA[<211> 112]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 4]]>
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly
1 5 10 15
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
20 25 30
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
35 40 45
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
50 55 60
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
65 70 75 80
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
85 90 95
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
100 105 110
<![CDATA[<210> 5]]>
<![CDATA[<211> 45]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 5]]>
Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala
1 5 10 15
Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly
20 25 30
Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp
35 40 45
<![CDATA[<210> 6]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 6]]>
Met Lys His Leu Trp Phe Phe Leu Leu Leu Val Ala Ala Pro Arg Trp
1 5 10 15
Val Leu Ser
<![CDATA[<210> 7]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 7]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys
<![CDATA[<210> 8]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 8]]>
His Tyr Tyr Trp Ser
1 5
<![CDATA[<210> 9]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 9]]>
Arg Tyr Trp Met Ser
1 5
<![CDATA[<210> 10]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 10]]>
Arg Tyr Trp Met Thr
1 5
<![CDATA[<210> 11]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 11]]>
Arg Ile Tyr Pro Ser Gly Ser Thr Ser Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<![CDATA[<210> 12]]>
<![CDATA[<211> 17]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 12]]>
Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Val Asp Ser Val Lys
1 5 10 15
Gly
<![CDATA[<210> 13]]>
<![CDATA[<211> 17]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 13]]>
Lys Ile Lys Tyr Asp Gly Ser Glu Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<![CDATA[<210> 14]]>
<![CDATA[<211> 17]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 14]]>
Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Pro Asp Ser Val Lys
1 5 10 15
Gly
<![CDATA[<210> 15]]>
<![CDATA[<211> 17]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 15]]>
Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<![CDATA[<210> 16]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 16]]>
Asp Arg Ser Thr Gly Trp Ser Glu Trp Asn Ser Asp Leu
1 5 10
<![CDATA[<210> 17]]>
<![CDATA[<211> 6]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 17]]>
Asp Tyr Thr Arg Asp Val
1 5
<![CDATA[<210> 18]]>
<![CDATA[<211> 6]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 18]]>
Asp Tyr Asn Lys Asp Tyr
1 5
<![CDATA[<210> 19]]>
<![CDATA[<211> 6]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 19]]>
Asp Tyr Asn Lys Asp Leu
1 5
<![CDATA[<210> 20]]>
<![CDATA[<211> 121]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 20]]>
Glu Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Ala Ser Ile Ser His Tyr
20 25 30
Tyr Trp Ser Trp Phe Arg Gln Pro Ala Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Ser Gly Ser Thr Ser Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Val Ala Met Ser Val Asp Thr Pro Lys Asn Gln Phe Ser Leu
65 70 75 80
Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Asp Arg Ser Thr Gly Trp Ser Glu Trp Asn Ser Asp Leu Trp Gly
100 105 110
Arg Gly Thr Leu Val Thr Val Ser Ser
115 120
<![CDATA[<210> 21]]>
<![CDATA[<211> 115]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 21]]>
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Asp Tyr Thr Arg Asp Val Trp Gly Gln Gly Thr Ala Val Thr
100 105 110
Val Ser Ser
115
<![CDATA[<210> 22]]>
<![CDATA[<211> 115]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 22]]>
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Lys Ile Lys Tyr Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Gly Val Tyr Tyr Cys
85 90 95
Ala Thr Asp Phe Thr Arg Asp Val Trp Gly Gln Gly Thr Thr Val Thr
100 105 110
Val Ser Ser
115
<![CDATA[<210> 23]]>
<![CDATA[<211> 115]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 23]]>
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Arg Gly Leu Glu Trp Val
35 40 45
Ala Lys Ile Arg Tyr Asp Gly Gly Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Asp Phe Thr Arg Asp Val Trp Gly Gln Gly Thr Thr Val Thr
100 105 110
Val Ser Ser
115
<![CDATA[<210> 24]]>
<![CDATA[<211> 115]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 24]]>
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Phe Gly Arg Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Arg Glu Trp Val
35 40 45
Ala Lys Ile Lys Tyr Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Asp Phe Thr Arg Asp Val Trp Gly Gln Gly Thr Thr Val Thr
100 105 110
Val Ser Ser
115
<![CDATA[<210> 25]]>
<![CDATA[<211> 115]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 25]]>
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Arg Glu Trp Val
35 40 45
Ala Lys Ile Lys Tyr Asp Gly Ser Glu Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Asp Phe Thr Arg Asp Val Trp Gly Gln Gly Thr Thr Val Thr
100 105 110
Val Ser Ser
115
<![CDATA[<210> 26]]>
<![CDATA[<211> 115]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 26]]>
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Ala Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Gly Arg Leu Glu Trp Val
35 40 45
Ala Lys Ile Lys Tyr Asp Gly Ser Glu Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Asp Tyr Asn Lys Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<![CDATA[<210> 27]]>
<![CDATA[<211> 115]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 27]]>
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Thr Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Val Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asp Asn Leu Arg Ala Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Thr Arg Asp Tyr Asn Lys Asp Leu Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<![CDATA[<210> 28]]>
<![CDATA[<211> 115]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 28]]>
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Asp Tyr Asn Lys Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<![CDATA[<210> 29]]>
<![CDATA[<211> 39]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 29]]>
Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn
1 5 10 15
Gly Thr Ile Ile His Val Lys Gly Lys His Leu Cys Pro Ser Pro Leu
20 25 30
Phe Pro Gly Pro Ser Lys Pro
35
<![CDATA[<210> 30]]>
<![CDATA[<211> 27]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 30]]>
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
1 5 10 15
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val
20 25
<![CDATA[<210> 31]]>
<![CDATA[<211> 66]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 31]]>
Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn
1 5 10 15
Gly Thr Ile Ile His Val Lys Gly Lys His Leu Cys Pro Ser Pro Leu
20 25 30
Phe Pro Gly Pro Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly
35 40 45
Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe
50 55 60
Trp Val
65
<![CDATA[<210> 32]]>
<![CDATA[<211> 41]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 32]]>
Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr
1 5 10 15
Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro
20 25 30
Pro Arg Asp Phe Ala Ala Tyr Arg Ser
35 40
<![CDATA[<210> 33]]>
<![CDATA[<211> 112]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 33]]>
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
1 5 10 15
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
20 25 30
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
35 40 45
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln Lys
50 55 60
Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly Met Lys Gly Glu Arg
65 70 75 80
Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln Gly Leu Ser Thr Ala
85 90 95
Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
100 105 110
<![CDATA[<210> 34]]>
<![CDATA[<211> 219]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 34]]>
Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn
1 5 10 15
Gly Thr Ile Ile His Val Lys Gly Lys His Leu Cys Pro Ser Pro Leu
20 25 30
Phe Pro Gly Pro Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly
35 40 45
Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe
50 55 60
Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn
65 70 75 80
Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr
85 90 95
Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser
100 105 110
Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr
115 120 125
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
130 135 140
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn
145 150 155 160
Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
165 170 175
Ala Phe Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
180 185 190
His Asp Gly Leu Phe Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe
195 200 205
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
210 215
<![CDATA[<210> 35]]>
<![CDATA[<211> 359]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 35]]>
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Glu Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys
20 25 30
Pro Ser Glu Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Ala Ser Ile
35 40 45
Ser His Tyr Tyr Trp Ser Trp Phe Arg Gln Pro Ala Gly Lys Gly Leu
50 55 60
Glu Trp Ile Gly Arg Ile Tyr Pro Ser Gly Ser Thr Ser Tyr Asn Pro
65 70 75 80
Ser Leu Lys Ser Arg Val Ala Met Ser Val Asp Thr Pro Lys Asn Gln
85 90 95
Phe Ser Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr
100 105 110
Tyr Cys Ala Arg Asp Arg Ser Thr Gly Trp Ser Glu Trp Asn Ser Asp
115 120 125
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ile Glu Val Met
130 135 140
Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile
145 150 155 160
His Val Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro
165 170 175
Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys
180 185 190
Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser
195 200 205
Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg
210 215 220
Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg
225 230 235 240
Asp Phe Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp
245 250 255
Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
260 265 270
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
275 280 285
Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly
290 295 300
Leu Phe Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu
305 310 315 320
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
325 330 335
Phe Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His
340 345 350
Met Gln Ala Leu Pro Pro Arg
355
<![CDATA[<210> 36]]>
<![CDATA[<211> 353]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 36]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Val
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Thr Asp Tyr Thr Arg Asp Val Trp Gly Gln Gly Thr
115 120 125
Ala Val Thr Val Ser Ser Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu
130 135 140
Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val Lys Gly Lys His
145 150 155 160
Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys Pro Phe Trp Val
165 170 175
Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr
180 185 190
Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu
195 200 205
His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg
210 215 220
Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg
225 230 235 240
Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln
245 250 255
Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu
260 265 270
Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly
275 280 285
Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln
290 295 300
Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly Met Lys Gly Glu
305 310 315 320
Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln Gly Leu Ser Thr
325 330 335
Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln Ala Leu Pro Pro
340 345 350
Arg
<![CDATA[<210> 37]]>
<![CDATA[<211> 353]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 37]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Ala Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Thr Trp Val Arg Gln Ala Pro Gly Gly Arg Leu
50 55 60
Glu Trp Val Ala Lys Ile Lys Tyr Asp Gly Ser Glu Lys Tyr Tyr Ala
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asp Ser Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Thr Arg Asp Tyr Asn Lys Asp Tyr Trp Gly Gln Gly Thr
115 120 125
Leu Val Thr Val Ser Ser Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu
130 135 140
Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val Lys Gly Lys His
145 150 155 160
Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys Pro Phe Trp Val
165 170 175
Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr
180 185 190
Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu
195 200 205
His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg
210 215 220
Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg
225 230 235 240
Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln
245 250 255
Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu
260 265 270
Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly
275 280 285
Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln
290 295 300
Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly Met Lys Gly Glu
305 310 315 320
Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln Gly Leu Ser Thr
325 330 335
Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln Ala Leu Pro Pro
340 345 350
Arg
<![CDATA[<210> 38]]>
<![CDATA[<211> 353]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 38]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Thr Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Pro
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Val Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asp Asn Leu Arg Ala Glu Asp Thr Ala Met
100 105 110
Tyr Tyr Cys Thr Arg Asp Tyr Asn Lys Asp Leu Trp Gly Gln Gly Thr
115 120 125
Leu Val Thr Val Ser Ser Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu
130 135 140
Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val Lys Gly Lys His
145 150 155 160
Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys Pro Phe Trp Val
165 170 175
Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr
180 185 190
Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu
195 200 205
His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg
210 215 220
Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg
225 230 235 240
Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln
245 250 255
Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu
260 265 270
Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly
275 280 285
Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln
290 295 300
Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly Met Lys Gly Glu
305 310 315 320
Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln Gly Leu Ser Thr
325 330 335
Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln Ala Leu Pro Pro
340 345 350
Arg
<![CDATA[<210> 39]]>
<![CDATA[<211> 353]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 39]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Ala
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Thr Arg Asp Tyr Asn Lys Asp Tyr Trp Gly Gln Gly Thr
115 120 125
Leu Val Thr Val Ser Ser Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu
130 135 140
Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val Lys Gly Lys His
145 150 155 160
Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys Pro Phe Trp Val
165 170 175
Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr
180 185 190
Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu
195 200 205
His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg
210 215 220
Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg
225 230 235 240
Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln
245 250 255
Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu
260 265 270
Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly
275 280 285
Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln
290 295 300
Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly Met Lys Gly Glu
305 310 315 320
Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln Gly Leu Ser Thr
325 330 335
Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln Ala Leu Pro Pro
340 345 350
Arg
<![CDATA[<210> 40]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 大腸桿菌]]>
<![CDATA[<400> 40]]>
Asn Thr Phe Tyr Cys Cys Glu Leu Cys Cys Asn Pro Ala Cys Ala Gly
1 5 10 15
Cys Tyr
<![CDATA[<210> 41]]>
<![CDATA[<211> 1073]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 41]]>
Met Lys Thr Leu Leu Leu Asp Leu Ala Leu Trp Ser Leu Leu Phe Gln
1 5 10 15
Pro Gly Trp Leu Ser Phe Ser Ser Gln Val Ser Gln Asn Cys His Asn
20 25 30
Gly Ser Tyr Glu Ile Ser Val Leu Met Met Gly Asn Ser Ala Phe Ala
35 40 45
Glu Pro Leu Lys Asn Leu Glu Asp Ala Val Asn Glu Gly Leu Glu Ile
50 55 60
Val Arg Gly Arg Leu Gln Asn Ala Gly Leu Asn Val Thr Val Asn Ala
65 70 75 80
Thr Phe Met Tyr Ser Asp Gly Leu Ile His Asn Ser Gly Asp Cys Arg
85 90 95
Ser Ser Thr Cys Glu Gly Leu Asp Leu Leu Arg Lys Ile Ser Asn Ala
100 105 110
Gln Arg Met Gly Cys Val Leu Ile Gly Pro Ser Cys Thr Tyr Ser Thr
115 120 125
Phe Gln Met Tyr Leu Asp Thr Glu Leu Ser Tyr Pro Met Ile Ser Ala
130 135 140
Gly Ser Phe Gly Leu Ser Cys Asp Tyr Lys Glu Thr Leu Thr Arg Leu
145 150 155 160
Met Ser Pro Ala Arg Lys Leu Met Tyr Phe Leu Val Asn Phe Trp Lys
165 170 175
Thr Asn Asp Leu Pro Phe Lys Thr Tyr Ser Trp Ser Thr Ser Tyr Val
180 185 190
Tyr Lys Asn Gly Thr Glu Thr Glu Asp Cys Phe Trp Tyr Leu Asn Ala
195 200 205
Leu Glu Ala Ser Val Ser Tyr Phe Ser His Glu Leu Gly Phe Lys Val
210 215 220
Val Leu Arg Gln Asp Lys Glu Phe Gln Asp Ile Leu Met Asp His Asn
225 230 235 240
Arg Lys Ser Asn Val Ile Ile Met Cys Gly Gly Pro Glu Phe Leu Tyr
245 250 255
Lys Leu Lys Gly Asp Arg Ala Val Ala Glu Asp Ile Val Ile Ile Leu
260 265 270
Val Asp Leu Phe Asn Asp Gln Tyr Phe Glu Asp Asn Val Thr Ala Pro
275 280 285
Asp Tyr Met Lys Asn Val Leu Val Leu Thr Leu Ser Pro Gly Asn Ser
290 295 300
Leu Leu Asn Ser Ser Phe Ser Arg Asn Leu Ser Pro Thr Lys Arg Asp
305 310 315 320
Phe Ala Leu Ala Tyr Leu Asn Gly Ile Leu Leu Phe Gly His Met Leu
325 330 335
Lys Ile Phe Leu Glu Asn Gly Glu Asn Ile Thr Thr Pro Lys Phe Ala
340 345 350
His Ala Phe Arg Asn Leu Thr Phe Glu Gly Tyr Asp Gly Pro Val Thr
355 360 365
Leu Asp Asp Trp Gly Asp Val Asp Ser Thr Met Val Leu Leu Tyr Thr
370 375 380
Ser Val Asp Thr Lys Lys Tyr Lys Val Leu Leu Thr Tyr Asp Thr His
385 390 395 400
Val Asn Lys Thr Tyr Pro Val Asp Met Ser Pro Thr Phe Thr Trp Lys
405 410 415
Asn Ser Lys Leu Pro Asn Asp Ile Thr Gly Arg Gly Pro Gln Ile Leu
420 425 430
Met Ile Ala Val Phe Thr Leu Thr Gly Ala Val Val Leu Leu Leu Leu
435 440 445
Val Ala Leu Leu Met Leu Arg Lys Tyr Arg Lys Asp Tyr Glu Leu Arg
450 455 460
Gln Lys Lys Trp Ser His Ile Pro Pro Glu Asn Ile Phe Pro Leu Glu
465 470 475 480
Thr Asn Glu Thr Asn His Val Ser Leu Lys Ile Asp Asp Asp Lys Arg
485 490 495
Arg Asp Thr Ile Gln Arg Leu Arg Gln Cys Lys Tyr Asp Lys Lys Arg
500 505 510
Val Ile Leu Lys Asp Leu Lys His Asn Asp Gly Asn Phe Thr Glu Lys
515 520 525
Gln Lys Ile Glu Leu Asn Lys Leu Leu Gln Ile Asp Tyr Tyr Asn Leu
530 535 540
Thr Lys Phe Tyr Gly Thr Val Lys Leu Asp Thr Met Ile Phe Gly Val
545 550 555 560
Ile Glu Tyr Cys Glu Arg Gly Ser Leu Arg Glu Val Leu Asn Asp Thr
565 570 575
Ile Ser Tyr Pro Asp Gly Thr Phe Met Asp Trp Glu Phe Lys Ile Ser
580 585 590
Val Leu Tyr Asp Ile Ala Lys Gly Met Ser Tyr Leu His Ser Ser Lys
595 600 605
Thr Glu Val His Gly Arg Leu Lys Ser Thr Asn Cys Val Val Asp Ser
610 615 620
Arg Met Val Val Lys Ile Thr Asp Phe Gly Cys Asn Ser Ile Leu Pro
625 630 635 640
Pro Lys Lys Asp Leu Trp Thr Ala Pro Glu His Leu Arg Gln Ala Asn
645 650 655
Ile Ser Gln Lys Gly Asp Val Tyr Ser Tyr Gly Ile Ile Ala Gln Glu
660 665 670
Ile Ile Leu Arg Lys Glu Thr Phe Tyr Thr Leu Ser Cys Arg Asp Arg
675 680 685
Asn Glu Lys Ile Phe Arg Val Glu Asn Ser Asn Gly Met Lys Pro Phe
690 695 700
Arg Pro Asp Leu Phe Leu Glu Thr Ala Glu Glu Lys Glu Leu Glu Val
705 710 715 720
Tyr Leu Leu Val Lys Asn Cys Trp Glu Glu Asp Pro Glu Lys Arg Pro
725 730 735
Asp Phe Lys Lys Ile Glu Thr Thr Leu Ala Lys Ile Phe Gly Leu Phe
740 745 750
His Asp Gln Lys Asn Glu Ser Tyr Met Asp Thr Leu Ile Arg Arg Leu
755 760 765
Gln Leu Tyr Ser Arg Asn Leu Glu His Leu Val Glu Glu Arg Thr Gln
770 775 780
Leu Tyr Lys Ala Glu Arg Asp Arg Ala Asp Arg Leu Asn Phe Met Leu
785 790 795 800
Leu Pro Arg Leu Val Val Lys Ser Leu Lys Glu Lys Gly Phe Val Glu
805 810 815
Pro Glu Leu Tyr Glu Glu Val Thr Ile Tyr Phe Ser Asp Ile Val Gly
820 825 830
Phe Thr Thr Ile Cys Lys Tyr Ser Thr Pro Met Glu Val Val Asp Met
835 840 845
Leu Asn Asp Ile Tyr Lys Ser Phe Asp His Ile Val Asp His His Asp
850 855 860
Val Tyr Lys Val Glu Thr Ile Gly Asp Ala Tyr Met Val Ala Ser Gly
865 870 875 880
Leu Pro Lys Arg Asn Gly Asn Arg His Ala Ile Asp Ile Ala Lys Met
885 890 895
Ala Leu Glu Ile Leu Ser Phe Met Gly Thr Phe Glu Leu Glu His Leu
900 905 910
Pro Gly Leu Pro Ile Trp Ile Arg Ile Gly Val His Ser Gly Pro Cys
915 920 925
Ala Ala Gly Val Val Gly Ile Lys Met Pro Arg Tyr Cys Leu Phe Gly
930 935 940
Asp Thr Val Asn Thr Ala Ser Arg Met Glu Ser Thr Gly Leu Pro Leu
945 950 955 960
Arg Ile His Val Ser Gly Ser Thr Ile Ala Ile Leu Lys Arg Thr Glu
965 970 975
Cys Gln Phe Leu Tyr Glu Val Arg Gly Glu Thr Tyr Leu Lys Gly Arg
980 985 990
Gly Asn Glu Thr Thr Tyr Trp Leu Thr Gly Met Lys Asp Gln Lys Phe
995 1000 1005
Asn Leu Pro Thr Pro Pro Thr Val Glu Asn Gln Gln Arg Leu Gln
1010 1015 1020
Ala Glu Phe Ser Asp Met Ile Ala Asn Ser Leu Gln Lys Arg Gln
1025 1030 1035
Ala Ala Gly Ile Arg Ser Gln Lys Pro Arg Arg Val Ala Ser Tyr
1040 1045 1050
Lys Lys Gly Thr Leu Glu Tyr Leu Gln Leu Asn Thr Thr Asp Lys
1055 1060 1065
Glu Ser Thr Tyr Phe
1070
<![CDATA[<210> 42]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 42]]>
Met Glu Phe Gly Leu Ser Trp Val Phe Leu Val Ala Ile Ile Lys Gly
1 5 10 15
Val Gln Cys
<![CDATA[<210> 43]]>
<![CDATA[<211> 357]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 43]]>
Met Leu Leu Leu Val Thr Ser Leu Leu Leu Cys Glu Leu Pro His Pro
1 5 10 15
Ala Phe Leu Leu Ile Pro Arg Lys Val Cys Asn Gly Ile Gly Ile Gly
20 25 30
Glu Phe Lys Asp Ser Leu Ser Ile Asn Ala Thr Asn Ile Lys His Phe
35 40 45
Lys Asn Cys Thr Ser Ile Ser Gly Asp Leu His Ile Leu Pro Val Ala
50 55 60
Phe Arg Gly Asp Ser Phe Thr His Thr Pro Pro Leu Asp Pro Gln Glu
65 70 75 80
Leu Asp Ile Leu Lys Thr Val Lys Glu Ile Thr Gly Phe Leu Leu Ile
85 90 95
Gln Ala Trp Pro Glu Asn Arg Thr Asp Leu His Ala Phe Glu Asn Leu
100 105 110
Glu Ile Ile Arg Gly Arg Thr Lys Gln His Gly Gln Phe Ser Leu Ala
115 120 125
Val Val Ser Leu Asn Ile Thr Ser Leu Gly Leu Arg Ser Leu Lys Glu
130 135 140
Ile Ser Asp Gly Asp Val Ile Ile Ser Gly Asn Lys Asn Leu Cys Tyr
145 150 155 160
Ala Asn Thr Ile Asn Trp Lys Lys Leu Phe Gly Thr Ser Gly Gln Lys
165 170 175
Thr Lys Ile Ile Ser Asn Arg Gly Glu Asn Ser Cys Lys Ala Thr Gly
180 185 190
Gln Val Cys His Ala Leu Cys Ser Pro Glu Gly Cys Trp Gly Pro Glu
195 200 205
Pro Arg Asp Cys Val Ser Cys Arg Asn Val Ser Arg Gly Arg Glu Cys
210 215 220
Val Asp Lys Cys Asn Leu Leu Glu Gly Glu Pro Arg Glu Phe Val Glu
225 230 235 240
Asn Ser Glu Cys Ile Gln Cys His Pro Glu Cys Leu Pro Gln Ala Met
245 250 255
Asn Ile Thr Cys Thr Gly Arg Gly Pro Asp Asn Cys Ile Gln Cys Ala
260 265 270
His Tyr Ile Asp Gly Pro His Cys Val Lys Thr Cys Pro Ala Gly Val
275 280 285
Met Gly Glu Asn Asn Thr Leu Val Trp Lys Tyr Ala Asp Ala Gly His
290 295 300
Val Cys His Leu Cys His Pro Asn Cys Thr Tyr Gly Cys Thr Gly Pro
305 310 315 320
Gly Leu Glu Gly Cys Pro Thr Asn Gly Pro Lys Ile Pro Ser Ile Ala
325 330 335
Thr Gly Met Val Gly Ala Leu Leu Leu Leu Leu Val Val Ala Leu Gly
340 345 350
Ile Gly Leu Phe Met
355
<![CDATA[<210> 44]]>
<![CDATA[<211> 22]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 44]]>
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
1 5 10 15
Glu Glu Asn Pro Gly Pro
20
<![CDATA[<210> 45]]>
<![CDATA[<211> 21]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 45]]>
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro
20
<![CDATA[<210> 46]]>
<![CDATA[<211> 359]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 46]]>
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys
20 25 30
Pro Ser Glu Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Ala Ser Ile
35 40 45
Ser His Tyr Tyr Trp Ser Trp Phe Arg Gln Pro Ala Gly Lys Gly Leu
50 55 60
Glu Trp Ile Gly Arg Ile Tyr Pro Ser Gly Ser Thr Ser Tyr Asn Pro
65 70 75 80
Ser Leu Lys Ser Arg Val Ala Met Ser Val Asp Thr Pro Lys Asn Gln
85 90 95
Phe Ser Leu Asn Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr
100 105 110
Tyr Cys Ala Arg Asp Arg Ser Thr Gly Trp Ser Glu Trp Asn Ser Asp
115 120 125
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ile Glu Val Met
130 135 140
Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile
145 150 155 160
His Val Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro
165 170 175
Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys
180 185 190
Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser
195 200 205
Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg
210 215 220
Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg
225 230 235 240
Asp Phe Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp
245 250 255
Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
260 265 270
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
275 280 285
Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly
290 295 300
Leu Phe Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu
305 310 315 320
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
325 330 335
Phe Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His
340 345 350
Met Gln Ala Leu Pro Pro Arg
355
<![CDATA[<210> 47]]>
<![CDATA[<211> 363]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 47]]>
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys
20 25 30
Pro Ser Glu Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Ala Ser Ile
35 40 45
Ser His Tyr Tyr Trp Ser Trp Phe Arg Gln Pro Ala Gly Lys Gly Leu
50 55 60
Glu Trp Ile Gly Arg Ile Tyr Pro Ser Gly Ser Thr Ser Tyr Asn Pro
65 70 75 80
Ser Leu Lys Ser Arg Val Ala Met Ser Val Asp Thr Pro Lys Asn Gln
85 90 95
Phe Ser Leu Asn Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr
100 105 110
Tyr Cys Ala Arg Asp Arg Ser Thr Gly Trp Ser Glu Trp Asn Ser Asp
115 120 125
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Arg Ala Ala Ala
130 135 140
Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn
145 150 155 160
Gly Thr Ile Ile His Val Lys Gly Lys His Leu Cys Pro Ser Pro Leu
165 170 175
Phe Pro Gly Pro Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly
180 185 190
Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe
195 200 205
Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn
210 215 220
Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr
225 230 235 240
Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser
245 250 255
Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr
260 265 270
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
275 280 285
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn
290 295 300
Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
305 310 315 320
Ala Phe Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
325 330 335
His Asp Gly Leu Phe Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe
340 345 350
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
355 360
<![CDATA[<210> 48]]>
<![CDATA[<211> 363]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 48]]>
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Glu Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys
20 25 30
Pro Ser Glu Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Ala Ser Ile
35 40 45
Ser His Tyr Tyr Trp Ser Trp Phe Arg Gln Pro Ala Gly Lys Gly Leu
50 55 60
Glu Trp Ile Gly Arg Ile Tyr Pro Ser Gly Ser Thr Ser Tyr Asn Pro
65 70 75 80
Ser Leu Lys Ser Arg Val Ala Met Ser Val Asp Thr Pro Lys Asn Gln
85 90 95
Phe Ser Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr
100 105 110
Tyr Cys Ala Arg Asp Arg Ser Thr Gly Trp Ser Glu Trp Asn Ser Asp
115 120 125
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Arg Ala Ala Ala
130 135 140
Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn
145 150 155 160
Gly Thr Ile Ile His Val Lys Gly Lys His Leu Cys Pro Ser Pro Leu
165 170 175
Phe Pro Gly Pro Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly
180 185 190
Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe
195 200 205
Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn
210 215 220
Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr
225 230 235 240
Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser
245 250 255
Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr
260 265 270
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
275 280 285
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn
290 295 300
Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
305 310 315 320
Ala Phe Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
325 330 335
His Asp Gly Leu Phe Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe
340 345 350
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
355 360
<![CDATA[<210> 49]]>
<![CDATA[<211> 357]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 49]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Val
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Thr Asp Tyr Thr Arg Asp Val Trp Gly Gln Gly Thr
115 120 125
Ala Val Thr Val Ser Ser Arg Ala Ala Ala Ile Glu Val Met Tyr Pro
130 135 140
Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val
145 150 155 160
Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys
165 170 175
Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser
180 185 190
Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg
195 200 205
Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro
210 215 220
Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe
225 230 235 240
Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
245 250 255
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
260 265 270
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
275 280 285
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe
290 295 300
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly
305 310 315 320
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln
325 330 335
Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln
340 345 350
Ala Leu Pro Pro Arg
355
<![CDATA[<210> 50]]>
<![CDATA[<211> 357]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 50]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Ala Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Thr Trp Val Arg Gln Ala Pro Gly Gly Arg Leu
50 55 60
Glu Trp Val Ala Lys Ile Lys Tyr Asp Gly Ser Glu Lys Tyr Tyr Ala
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asp Ser Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Thr Arg Asp Tyr Asn Lys Asp Tyr Trp Gly Gln Gly Thr
115 120 125
Leu Val Thr Val Ser Ser Arg Ala Ala Ala Ile Glu Val Met Tyr Pro
130 135 140
Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val
145 150 155 160
Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys
165 170 175
Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser
180 185 190
Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg
195 200 205
Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro
210 215 220
Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe
225 230 235 240
Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
245 250 255
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
260 265 270
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
275 280 285
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe
290 295 300
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly
305 310 315 320
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln
325 330 335
Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln
340 345 350
Ala Leu Pro Pro Arg
355
<![CDATA[<210> 51]]>
<![CDATA[<211> 357]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 51]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Thr Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Pro
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Val Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asp Asn Leu Arg Ala Glu Asp Thr Ala Met
100 105 110
Tyr Tyr Cys Thr Arg Asp Tyr Asn Lys Asp Leu Trp Gly Gln Gly Thr
115 120 125
Leu Val Thr Val Ser Ser Arg Ala Ala Ala Ile Glu Val Met Tyr Pro
130 135 140
Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val
145 150 155 160
Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys
165 170 175
Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser
180 185 190
Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg
195 200 205
Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro
210 215 220
Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe
225 230 235 240
Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
245 250 255
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
260 265 270
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
275 280 285
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe
290 295 300
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly
305 310 315 320
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln
325 330 335
Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln
340 345 350
Ala Leu Pro Pro Arg
355
<![CDATA[<210> 52]]>
<![CDATA[<211> 357]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 52]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Ala
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Thr Arg Asp Tyr Asn Lys Asp Tyr Trp Gly Gln Gly Thr
115 120 125
Leu Val Thr Val Ser Ser Arg Ala Ala Ala Ile Glu Val Met Tyr Pro
130 135 140
Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val
145 150 155 160
Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys
165 170 175
Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser
180 185 190
Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg
195 200 205
Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro
210 215 220
Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe
225 230 235 240
Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
245 250 255
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
260 265 270
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
275 280 285
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe
290 295 300
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly
305 310 315 320
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln
325 330 335
Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln
340 345 350
Ala Leu Pro Pro Arg
355
<![CDATA[<210> 53]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 53]]>
Arg Ala Ala Ala
1
<![CDATA[<210> 54]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 54]]>
Gly Gly Gly Gly Ser
1 5
<![CDATA[<210> 55]]>
<![CDATA[<211> 742]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 55]]>
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys
20 25 30
Pro Ser Glu Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Ala Ser Ile
35 40 45
Ser His Tyr Tyr Trp Ser Trp Phe Arg Gln Pro Ala Gly Lys Gly Leu
50 55 60
Glu Trp Ile Gly Arg Ile Tyr Pro Ser Gly Ser Thr Ser Tyr Asn Pro
65 70 75 80
Ser Leu Lys Ser Arg Val Ala Met Ser Val Asp Thr Pro Lys Asn Gln
85 90 95
Phe Ser Leu Asn Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr
100 105 110
Tyr Cys Ala Arg Asp Arg Ser Thr Gly Trp Ser Glu Trp Asn Ser Asp
115 120 125
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Arg Ala Ala Ala
130 135 140
Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn
145 150 155 160
Gly Thr Ile Ile His Val Lys Gly Lys His Leu Cys Pro Ser Pro Leu
165 170 175
Phe Pro Gly Pro Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly
180 185 190
Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe
195 200 205
Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn
210 215 220
Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr
225 230 235 240
Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser
245 250 255
Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr
260 265 270
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
275 280 285
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn
290 295 300
Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
305 310 315 320
Ala Phe Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
325 330 335
His Asp Gly Leu Phe Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe
340 345 350
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg Gly Ser Gly Ala Thr
355 360 365
Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly
370 375 380
Pro Met Leu Leu Leu Val Thr Ser Leu Leu Leu Cys Glu Leu Pro His
385 390 395 400
Pro Ala Phe Leu Leu Ile Pro Arg Lys Val Cys Asn Gly Ile Gly Ile
405 410 415
Gly Glu Phe Lys Asp Ser Leu Ser Ile Asn Ala Thr Asn Ile Lys His
420 425 430
Phe Lys Asn Cys Thr Ser Ile Ser Gly Asp Leu His Ile Leu Pro Val
435 440 445
Ala Phe Arg Gly Asp Ser Phe Thr His Thr Pro Pro Leu Asp Pro Gln
450 455 460
Glu Leu Asp Ile Leu Lys Thr Val Lys Glu Ile Thr Gly Phe Leu Leu
465 470 475 480
Ile Gln Ala Trp Pro Glu Asn Arg Thr Asp Leu His Ala Phe Glu Asn
485 490 495
Leu Glu Ile Ile Arg Gly Arg Thr Lys Gln His Gly Gln Phe Ser Leu
500 505 510
Ala Val Val Ser Leu Asn Ile Thr Ser Leu Gly Leu Arg Ser Leu Lys
515 520 525
Glu Ile Ser Asp Gly Asp Val Ile Ile Ser Gly Asn Lys Asn Leu Cys
530 535 540
Tyr Ala Asn Thr Ile Asn Trp Lys Lys Leu Phe Gly Thr Ser Gly Gln
545 550 555 560
Lys Thr Lys Ile Ile Ser Asn Arg Gly Glu Asn Ser Cys Lys Ala Thr
565 570 575
Gly Gln Val Cys His Ala Leu Cys Ser Pro Glu Gly Cys Trp Gly Pro
580 585 590
Glu Pro Arg Asp Cys Val Ser Cys Arg Asn Val Ser Arg Gly Arg Glu
595 600 605
Cys Val Asp Lys Cys Asn Leu Leu Glu Gly Glu Pro Arg Glu Phe Val
610 615 620
Glu Asn Ser Glu Cys Ile Gln Cys His Pro Glu Cys Leu Pro Gln Ala
625 630 635 640
Met Asn Ile Thr Cys Thr Gly Arg Gly Pro Asp Asn Cys Ile Gln Cys
645 650 655
Ala His Tyr Ile Asp Gly Pro His Cys Val Lys Thr Cys Pro Ala Gly
660 665 670
Val Met Gly Glu Asn Asn Thr Leu Val Trp Lys Tyr Ala Asp Ala Gly
675 680 685
His Val Cys His Leu Cys His Pro Asn Cys Thr Tyr Gly Cys Thr Gly
690 695 700
Pro Gly Leu Glu Gly Cys Pro Thr Asn Gly Pro Lys Ile Pro Ser Ile
705 710 715 720
Ala Thr Gly Met Val Gly Ala Leu Leu Leu Leu Leu Val Val Ala Leu
725 730 735
Gly Ile Gly Leu Phe Met
740
<![CDATA[<210> 56]]>
<![CDATA[<211> 742]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 56]]>
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Glu Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys
20 25 30
Pro Ser Glu Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Ala Ser Ile
35 40 45
Ser His Tyr Tyr Trp Ser Trp Phe Arg Gln Pro Ala Gly Lys Gly Leu
50 55 60
Glu Trp Ile Gly Arg Ile Tyr Pro Ser Gly Ser Thr Ser Tyr Asn Pro
65 70 75 80
Ser Leu Lys Ser Arg Val Ala Met Ser Val Asp Thr Pro Lys Asn Gln
85 90 95
Phe Ser Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr
100 105 110
Tyr Cys Ala Arg Asp Arg Ser Thr Gly Trp Ser Glu Trp Asn Ser Asp
115 120 125
Leu Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Arg Ala Ala Ala
130 135 140
Ile Glu Val Met Tyr Pro Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn
145 150 155 160
Gly Thr Ile Ile His Val Lys Gly Lys His Leu Cys Pro Ser Pro Leu
165 170 175
Phe Pro Gly Pro Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly
180 185 190
Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe
195 200 205
Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn
210 215 220
Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr
225 230 235 240
Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser
245 250 255
Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr
260 265 270
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
275 280 285
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn
290 295 300
Pro Gln Glu Gly Leu Phe Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
305 310 315 320
Ala Phe Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
325 330 335
His Asp Gly Leu Phe Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe
340 345 350
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg Gly Ser Gly Ala Thr
355 360 365
Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly
370 375 380
Pro Met Leu Leu Leu Val Thr Ser Leu Leu Leu Cys Glu Leu Pro His
385 390 395 400
Pro Ala Phe Leu Leu Ile Pro Arg Lys Val Cys Asn Gly Ile Gly Ile
405 410 415
Gly Glu Phe Lys Asp Ser Leu Ser Ile Asn Ala Thr Asn Ile Lys His
420 425 430
Phe Lys Asn Cys Thr Ser Ile Ser Gly Asp Leu His Ile Leu Pro Val
435 440 445
Ala Phe Arg Gly Asp Ser Phe Thr His Thr Pro Pro Leu Asp Pro Gln
450 455 460
Glu Leu Asp Ile Leu Lys Thr Val Lys Glu Ile Thr Gly Phe Leu Leu
465 470 475 480
Ile Gln Ala Trp Pro Glu Asn Arg Thr Asp Leu His Ala Phe Glu Asn
485 490 495
Leu Glu Ile Ile Arg Gly Arg Thr Lys Gln His Gly Gln Phe Ser Leu
500 505 510
Ala Val Val Ser Leu Asn Ile Thr Ser Leu Gly Leu Arg Ser Leu Lys
515 520 525
Glu Ile Ser Asp Gly Asp Val Ile Ile Ser Gly Asn Lys Asn Leu Cys
530 535 540
Tyr Ala Asn Thr Ile Asn Trp Lys Lys Leu Phe Gly Thr Ser Gly Gln
545 550 555 560
Lys Thr Lys Ile Ile Ser Asn Arg Gly Glu Asn Ser Cys Lys Ala Thr
565 570 575
Gly Gln Val Cys His Ala Leu Cys Ser Pro Glu Gly Cys Trp Gly Pro
580 585 590
Glu Pro Arg Asp Cys Val Ser Cys Arg Asn Val Ser Arg Gly Arg Glu
595 600 605
Cys Val Asp Lys Cys Asn Leu Leu Glu Gly Glu Pro Arg Glu Phe Val
610 615 620
Glu Asn Ser Glu Cys Ile Gln Cys His Pro Glu Cys Leu Pro Gln Ala
625 630 635 640
Met Asn Ile Thr Cys Thr Gly Arg Gly Pro Asp Asn Cys Ile Gln Cys
645 650 655
Ala His Tyr Ile Asp Gly Pro His Cys Val Lys Thr Cys Pro Ala Gly
660 665 670
Val Met Gly Glu Asn Asn Thr Leu Val Trp Lys Tyr Ala Asp Ala Gly
675 680 685
His Val Cys His Leu Cys His Pro Asn Cys Thr Tyr Gly Cys Thr Gly
690 695 700
Pro Gly Leu Glu Gly Cys Pro Thr Asn Gly Pro Lys Ile Pro Ser Ile
705 710 715 720
Ala Thr Gly Met Val Gly Ala Leu Leu Leu Leu Leu Val Val Ala Leu
725 730 735
Gly Ile Gly Leu Phe Met
740
<![CDATA[<210> 57]]>
<![CDATA[<211> 736]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 57]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Val
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Thr Asp Tyr Thr Arg Asp Val Trp Gly Gln Gly Thr
115 120 125
Ala Val Thr Val Ser Ser Arg Ala Ala Ala Ile Glu Val Met Tyr Pro
130 135 140
Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val
145 150 155 160
Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys
165 170 175
Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser
180 185 190
Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg
195 200 205
Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro
210 215 220
Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe
225 230 235 240
Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
245 250 255
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
260 265 270
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
275 280 285
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe
290 295 300
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly
305 310 315 320
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln
325 330 335
Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln
340 345 350
Ala Leu Pro Pro Arg Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
355 360 365
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Leu Leu Leu Val
370 375 380
Thr Ser Leu Leu Leu Cys Glu Leu Pro His Pro Ala Phe Leu Leu Ile
385 390 395 400
Pro Arg Lys Val Cys Asn Gly Ile Gly Ile Gly Glu Phe Lys Asp Ser
405 410 415
Leu Ser Ile Asn Ala Thr Asn Ile Lys His Phe Lys Asn Cys Thr Ser
420 425 430
Ile Ser Gly Asp Leu His Ile Leu Pro Val Ala Phe Arg Gly Asp Ser
435 440 445
Phe Thr His Thr Pro Pro Leu Asp Pro Gln Glu Leu Asp Ile Leu Lys
450 455 460
Thr Val Lys Glu Ile Thr Gly Phe Leu Leu Ile Gln Ala Trp Pro Glu
465 470 475 480
Asn Arg Thr Asp Leu His Ala Phe Glu Asn Leu Glu Ile Ile Arg Gly
485 490 495
Arg Thr Lys Gln His Gly Gln Phe Ser Leu Ala Val Val Ser Leu Asn
500 505 510
Ile Thr Ser Leu Gly Leu Arg Ser Leu Lys Glu Ile Ser Asp Gly Asp
515 520 525
Val Ile Ile Ser Gly Asn Lys Asn Leu Cys Tyr Ala Asn Thr Ile Asn
530 535 540
Trp Lys Lys Leu Phe Gly Thr Ser Gly Gln Lys Thr Lys Ile Ile Ser
545 550 555 560
Asn Arg Gly Glu Asn Ser Cys Lys Ala Thr Gly Gln Val Cys His Ala
565 570 575
Leu Cys Ser Pro Glu Gly Cys Trp Gly Pro Glu Pro Arg Asp Cys Val
580 585 590
Ser Cys Arg Asn Val Ser Arg Gly Arg Glu Cys Val Asp Lys Cys Asn
595 600 605
Leu Leu Glu Gly Glu Pro Arg Glu Phe Val Glu Asn Ser Glu Cys Ile
610 615 620
Gln Cys His Pro Glu Cys Leu Pro Gln Ala Met Asn Ile Thr Cys Thr
625 630 635 640
Gly Arg Gly Pro Asp Asn Cys Ile Gln Cys Ala His Tyr Ile Asp Gly
645 650 655
Pro His Cys Val Lys Thr Cys Pro Ala Gly Val Met Gly Glu Asn Asn
660 665 670
Thr Leu Val Trp Lys Tyr Ala Asp Ala Gly His Val Cys His Leu Cys
675 680 685
His Pro Asn Cys Thr Tyr Gly Cys Thr Gly Pro Gly Leu Glu Gly Cys
690 695 700
Pro Thr Asn Gly Pro Lys Ile Pro Ser Ile Ala Thr Gly Met Val Gly
705 710 715 720
Ala Leu Leu Leu Leu Leu Val Val Ala Leu Gly Ile Gly Leu Phe Met
725 730 735
<![CDATA[<210> 58]]>
<![CDATA[<211> 736]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 58]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Ala Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Thr Trp Val Arg Gln Ala Pro Gly Gly Arg Leu
50 55 60
Glu Trp Val Ala Lys Ile Lys Tyr Asp Gly Ser Glu Lys Tyr Tyr Ala
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asp Ser Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Thr Arg Asp Tyr Asn Lys Asp Tyr Trp Gly Gln Gly Thr
115 120 125
Leu Val Thr Val Ser Ser Arg Ala Ala Ala Ile Glu Val Met Tyr Pro
130 135 140
Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val
145 150 155 160
Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys
165 170 175
Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser
180 185 190
Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg
195 200 205
Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro
210 215 220
Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe
225 230 235 240
Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
245 250 255
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
260 265 270
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
275 280 285
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe
290 295 300
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly
305 310 315 320
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln
325 330 335
Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln
340 345 350
Ala Leu Pro Pro Arg Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
355 360 365
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Leu Leu Leu Val
370 375 380
Thr Ser Leu Leu Leu Cys Glu Leu Pro His Pro Ala Phe Leu Leu Ile
385 390 395 400
Pro Arg Lys Val Cys Asn Gly Ile Gly Ile Gly Glu Phe Lys Asp Ser
405 410 415
Leu Ser Ile Asn Ala Thr Asn Ile Lys His Phe Lys Asn Cys Thr Ser
420 425 430
Ile Ser Gly Asp Leu His Ile Leu Pro Val Ala Phe Arg Gly Asp Ser
435 440 445
Phe Thr His Thr Pro Pro Leu Asp Pro Gln Glu Leu Asp Ile Leu Lys
450 455 460
Thr Val Lys Glu Ile Thr Gly Phe Leu Leu Ile Gln Ala Trp Pro Glu
465 470 475 480
Asn Arg Thr Asp Leu His Ala Phe Glu Asn Leu Glu Ile Ile Arg Gly
485 490 495
Arg Thr Lys Gln His Gly Gln Phe Ser Leu Ala Val Val Ser Leu Asn
500 505 510
Ile Thr Ser Leu Gly Leu Arg Ser Leu Lys Glu Ile Ser Asp Gly Asp
515 520 525
Val Ile Ile Ser Gly Asn Lys Asn Leu Cys Tyr Ala Asn Thr Ile Asn
530 535 540
Trp Lys Lys Leu Phe Gly Thr Ser Gly Gln Lys Thr Lys Ile Ile Ser
545 550 555 560
Asn Arg Gly Glu Asn Ser Cys Lys Ala Thr Gly Gln Val Cys His Ala
565 570 575
Leu Cys Ser Pro Glu Gly Cys Trp Gly Pro Glu Pro Arg Asp Cys Val
580 585 590
Ser Cys Arg Asn Val Ser Arg Gly Arg Glu Cys Val Asp Lys Cys Asn
595 600 605
Leu Leu Glu Gly Glu Pro Arg Glu Phe Val Glu Asn Ser Glu Cys Ile
610 615 620
Gln Cys His Pro Glu Cys Leu Pro Gln Ala Met Asn Ile Thr Cys Thr
625 630 635 640
Gly Arg Gly Pro Asp Asn Cys Ile Gln Cys Ala His Tyr Ile Asp Gly
645 650 655
Pro His Cys Val Lys Thr Cys Pro Ala Gly Val Met Gly Glu Asn Asn
660 665 670
Thr Leu Val Trp Lys Tyr Ala Asp Ala Gly His Val Cys His Leu Cys
675 680 685
His Pro Asn Cys Thr Tyr Gly Cys Thr Gly Pro Gly Leu Glu Gly Cys
690 695 700
Pro Thr Asn Gly Pro Lys Ile Pro Ser Ile Ala Thr Gly Met Val Gly
705 710 715 720
Ala Leu Leu Leu Leu Leu Val Val Ala Leu Gly Ile Gly Leu Phe Met
725 730 735
<![CDATA[<210> 59]]>
<![CDATA[<211> 736]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 59]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Thr Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Pro
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Val Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asp Asn Leu Arg Ala Glu Asp Thr Ala Met
100 105 110
Tyr Tyr Cys Thr Arg Asp Tyr Asn Lys Asp Leu Trp Gly Gln Gly Thr
115 120 125
Leu Val Thr Val Ser Ser Arg Ala Ala Ala Ile Glu Val Met Tyr Pro
130 135 140
Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val
145 150 155 160
Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys
165 170 175
Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser
180 185 190
Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg
195 200 205
Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro
210 215 220
Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe
225 230 235 240
Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
245 250 255
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
260 265 270
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
275 280 285
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe
290 295 300
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly
305 310 315 320
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln
325 330 335
Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln
340 345 350
Ala Leu Pro Pro Arg Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
355 360 365
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Leu Leu Leu Val
370 375 380
Thr Ser Leu Leu Leu Cys Glu Leu Pro His Pro Ala Phe Leu Leu Ile
385 390 395 400
Pro Arg Lys Val Cys Asn Gly Ile Gly Ile Gly Glu Phe Lys Asp Ser
405 410 415
Leu Ser Ile Asn Ala Thr Asn Ile Lys His Phe Lys Asn Cys Thr Ser
420 425 430
Ile Ser Gly Asp Leu His Ile Leu Pro Val Ala Phe Arg Gly Asp Ser
435 440 445
Phe Thr His Thr Pro Pro Leu Asp Pro Gln Glu Leu Asp Ile Leu Lys
450 455 460
Thr Val Lys Glu Ile Thr Gly Phe Leu Leu Ile Gln Ala Trp Pro Glu
465 470 475 480
Asn Arg Thr Asp Leu His Ala Phe Glu Asn Leu Glu Ile Ile Arg Gly
485 490 495
Arg Thr Lys Gln His Gly Gln Phe Ser Leu Ala Val Val Ser Leu Asn
500 505 510
Ile Thr Ser Leu Gly Leu Arg Ser Leu Lys Glu Ile Ser Asp Gly Asp
515 520 525
Val Ile Ile Ser Gly Asn Lys Asn Leu Cys Tyr Ala Asn Thr Ile Asn
530 535 540
Trp Lys Lys Leu Phe Gly Thr Ser Gly Gln Lys Thr Lys Ile Ile Ser
545 550 555 560
Asn Arg Gly Glu Asn Ser Cys Lys Ala Thr Gly Gln Val Cys His Ala
565 570 575
Leu Cys Ser Pro Glu Gly Cys Trp Gly Pro Glu Pro Arg Asp Cys Val
580 585 590
Ser Cys Arg Asn Val Ser Arg Gly Arg Glu Cys Val Asp Lys Cys Asn
595 600 605
Leu Leu Glu Gly Glu Pro Arg Glu Phe Val Glu Asn Ser Glu Cys Ile
610 615 620
Gln Cys His Pro Glu Cys Leu Pro Gln Ala Met Asn Ile Thr Cys Thr
625 630 635 640
Gly Arg Gly Pro Asp Asn Cys Ile Gln Cys Ala His Tyr Ile Asp Gly
645 650 655
Pro His Cys Val Lys Thr Cys Pro Ala Gly Val Met Gly Glu Asn Asn
660 665 670
Thr Leu Val Trp Lys Tyr Ala Asp Ala Gly His Val Cys His Leu Cys
675 680 685
His Pro Asn Cys Thr Tyr Gly Cys Thr Gly Pro Gly Leu Glu Gly Cys
690 695 700
Pro Thr Asn Gly Pro Lys Ile Pro Ser Ile Ala Thr Gly Met Val Gly
705 710 715 720
Ala Leu Leu Leu Leu Leu Val Val Ala Leu Gly Ile Gly Leu Phe Met
725 730 735
<![CDATA[<210> 60]]>
<![CDATA[<211> 736]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 60]]>
Met Glu Leu Gly Leu Ser Trp Val Phe Leu Val Ala Ile Leu Glu Gly
1 5 10 15
Val Gln Cys Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
20 25 30
Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe
35 40 45
Ser Arg Tyr Trp Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Lys Ile Arg His Asp Gly Gly Glu Lys Tyr Tyr Ala
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
85 90 95
Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Thr Arg Asp Tyr Asn Lys Asp Tyr Trp Gly Gln Gly Thr
115 120 125
Leu Val Thr Val Ser Ser Arg Ala Ala Ala Ile Glu Val Met Tyr Pro
130 135 140
Pro Pro Tyr Leu Asp Asn Glu Lys Ser Asn Gly Thr Ile Ile His Val
145 150 155 160
Lys Gly Lys His Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser Lys
165 170 175
Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser
180 185 190
Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg
195 200 205
Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro
210 215 220
Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe
225 230 235 240
Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
245 250 255
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
260 265 270
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
275 280 285
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Phe
290 295 300
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Phe Ser Glu Ile Gly
305 310 315 320
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Phe Gln
325 330 335
Gly Leu Ser Thr Ala Thr Lys Asp Thr Phe Asp Ala Leu His Met Gln
340 345 350
Ala Leu Pro Pro Arg Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
355 360 365
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Leu Leu Leu Val
370 375 380
Thr Ser Leu Leu Leu Cys Glu Leu Pro His Pro Ala Phe Leu Leu Ile
385 390 395 400
Pro Arg Lys Val Cys Asn Gly Ile Gly Ile Gly Glu Phe Lys Asp Ser
405 410 415
Leu Ser Ile Asn Ala Thr Asn Ile Lys His Phe Lys Asn Cys Thr Ser
420 425 430
Ile Ser Gly Asp Leu His Ile Leu Pro Val Ala Phe Arg Gly Asp Ser
435 440 445
Phe Thr His Thr Pro Pro Leu Asp Pro Gln Glu Leu Asp Ile Leu Lys
450 455 460
Thr Val Lys Glu Ile Thr Gly Phe Leu Leu Ile Gln Ala Trp Pro Glu
465 470 475 480
Asn Arg Thr Asp Leu His Ala Phe Glu Asn Leu Glu Ile Ile Arg Gly
485 490 495
Arg Thr Lys Gln His Gly Gln Phe Ser Leu Ala Val Val Ser Leu Asn
500 505 510
Ile Thr Ser Leu Gly Leu Arg Ser Leu Lys Glu Ile Ser Asp Gly Asp
515 520 525
Val Ile Ile Ser Gly Asn Lys Asn Leu Cys Tyr Ala Asn Thr Ile Asn
530 535 540
Trp Lys Lys Leu Phe Gly Thr Ser Gly Gln Lys Thr Lys Ile Ile Ser
545 550 555 560
Asn Arg Gly Glu Asn Ser Cys Lys Ala Thr Gly Gln Val Cys His Ala
565 570 575
Leu Cys Ser Pro Glu Gly Cys Trp Gly Pro Glu Pro Arg Asp Cys Val
580 585 590
Ser Cys Arg Asn Val Ser Arg Gly Arg Glu Cys Val Asp Lys Cys Asn
595 600 605
Leu Leu Glu Gly Glu Pro Arg Glu Phe Val Glu Asn Ser Glu Cys Ile
610 615 620
Gln Cys His Pro Glu Cys Leu Pro Gln Ala Met Asn Ile Thr Cys Thr
625 630 635 640
Gly Arg Gly Pro Asp Asn Cys Ile Gln Cys Ala His Tyr Ile Asp Gly
645 650 655
Pro His Cys Val Lys Thr Cys Pro Ala Gly Val Met Gly Glu Asn Asn
660 665 670
Thr Leu Val Trp Lys Tyr Ala Asp Ala Gly His Val Cys His Leu Cys
675 680 685
His Pro Asn Cys Thr Tyr Gly Cys Thr Gly Pro Gly Leu Glu Gly Cys
690 695 700
Pro Thr Asn Gly Pro Lys Ile Pro Ser Ile Ala Thr Gly Met Val Gly
705 710 715 720
Ala Leu Leu Leu Leu Leu Val Val Ala Leu Gly Ile Gly Leu Phe Met
725 730 735
<![CDATA[<210> 61]]>
<![CDATA[<211> 1089]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 61]]>
atgggctggt cttgtattat cttgtttctc gtcgcaactg ctacaggcgt tcattctgaa 60
gttcaactcc aagaatctgg tcctggcctg gtgaaacctt ccgaaactct ctcactcacc 120
tgtaccgtct caggcgcttc aatatcacac tattattggt cttggttccg gcaacctgca 180
ggcaaaggtc tcgaatggat aggcagaata tatcccagtg gaagcacctc ctataatccc 240
tctctcaagt caagagttgc aatgagcgtt gacacaccca agaaccaatt ctccctcaag 300
ctgtcatctg taactgccgc cgatactgcc gtttactact gcgctagaga tagatcaacc 360
ggatggtcag aatggaattc agatctgtgg ggacggggaa ccctcgtgac cgtatcttct 420
cgggcggccg caattgaagt tatgtatcct cctccttacc tagacaatga gaagagcaat 480
ggaaccatta tccatgtgaa agggaaacac ctttgtccaa gtcccctatt tcccggacct 540
tctaagccct tttgggtgct ggtggtggtt ggtggagtcc tggcttgcta tagcttgcta 600
gtaacagtgg cctttattat tttctgggtg aggagtaaga ggagcaggct cctgcacagt 660
gactacatga acatgactcc ccgccgcccc gggcccaccc gcaagcatta ccagccctat 720
gccccaccac gcgacttcgc agcctatcgc tccagagtga agttcagcag gagcgcagac 780
gcccccgcgt accagcaggg ccagaaccag ctctataacg agctcaatct aggacgaaga 840
gaggagtacg atgttttgga caagagacgt ggccgggacc ctgagatggg gggaaagccg 900
agaaggaaga accctcagga aggcctgttc aatgaactgc agaaagataa gatggcggag 960
gccttcagtg agattgggat gaaaggcgag cgccggaggg gcaaggggca cgatggcctt 1020
ttccagggtc tcagtacagc caccaaggac accttcgacg cccttcacat gcaggccctg 1080
ccccctcgc 1089
<![CDATA[<210> 62]]>
<![CDATA[<211> 1074]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 62]]>
atggaactgg gactgtcttg ggtgttcctg gtcgctatat tggaaggagt acagtgccag 60
gtccagctcg tcgagtccgg gggtggcctg gtgcagcccg gcggcagcct ccggctgagc 120
tgcacagcct cagggtttac attcagcagg tactggatga gttgggttag gcaagcccct 180
ggcaaaggcc tggagtgggt ggccaaaatc cgacatgatg ggggcgaaaa gtactatgtg 240
gatagtgtga agggacggtt cacaatatca cgagacaatg ccaaaaactc tttgtacctg 300
caaatgaact ccctgcgcgc cgaagacaca gctgtgtact actgcgctac agactacact 360
agggacgtct ggggtcaagg aacagccgtc accgtgagta gtcgggcggc cgcaattgaa 420
gttatgtatc ctcctcctta cctagacaat gagaagagca atggaaccat tatccatgtg 480
aaagggaaac acctttgtcc aagtccccta tttcccggac cttctaagcc cttttgggtg 540
ctggtggtgg ttggtggagt cctggcttgc tatagcttgc tagtaacagt ggcctttatt 600
attttctggg tgaggagtaa gaggagcagg ctcctgcaca gtgactacat gaacatgact 660
ccccgccgcc ccgggcccac ccgcaagcat taccagccct atgccccacc acgcgacttc 720
gcagcctatc gctccagagt gaagttcagc aggagcgcag acgcccccgc gtaccagcag 780
ggccagaacc agctctataa cgagctcaat ctaggacgaa gagaggagta cgatgttttg 840
gacaagagac gtggccggga ccctgagatg gggggaaagc cgagaaggaa gaaccctcag 900
gaaggcctgt tcaatgaact gcagaaagat aagatggcgg aggccttcag tgagattggg 960
atgaaaggcg agcgccggag gggcaagggg cacgatggcc ttttccaggg tctcagtaca 1020
gccaccaagg acaccttcga cgcccttcac atgcaggccc tgccccctcg ctaa 1074
<![CDATA[<210> 63]]>
<![CDATA[<211> 1071]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 63]]>
atggagctgg gattgtcctg ggttttcctg gtggctatac tcgaaggcgt acagtgtgaa 60
gtgcagttgg tggagagtgg cggtggcctg gcccagccgg gaggctcttt gagactctcc 120
tgcgctgcct ccggcttcac tttctcccgc tattggatga cctgggtccg gcaggcgccc 180
ggcggacgcc tggagtgggt ggctaagatc aagtatgatg gatcagaaaa atattacgca 240
gatagcgtaa aaggccggtt cacaatatcc agggataatg caaaaaactc cctgtatctg 300
cagatggata gcctgcgcgc tgaagacacc gccgtatatt attgcacaag agactacaat 360
aaagattact ggggccaggg aaccctggtt acggtgagct cacgggcggc cgcaattgaa 420
gttatgtatc ctcctcctta cctagacaat gagaagagca atggaaccat tatccatgtg 480
aaagggaaac acctttgtcc aagtccccta tttcccggac cttctaagcc cttttgggtg 540
ctggtggtgg ttggtggagt cctggcttgc tatagcttgc tagtaacagt ggcctttatt 600
attttctggg tgaggagtaa gaggagcagg ctcctgcaca gtgactacat gaacatgact 660
ccccgccgcc ccgggcccac ccgcaagcat taccagccct atgccccacc acgcgacttc 720
gcagcctatc gctccagagt gaagttcagc aggagcgcag acgcccccgc gtaccagcag 780
ggccagaacc agctctataa cgagctcaat ctaggacgaa gagaggagta cgatgttttg 840
gacaagagac gtggccggga ccctgagatg gggggaaagc cgagaaggaa gaaccctcag 900
gaaggcctgt tcaatgaact gcagaaagat aagatggcgg aggccttcag tgagattggg 960
atgaaaggcg agcgccggag gggcaagggg cacgatggcc ttttccaggg tctcagtaca 1020
gccaccaagg acaccttcga cgcccttcac atgcaggccc tgccccctcg c 1071
<![CDATA[<210> 64]]>
<![CDATA[<211> 1071]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 64]]>
atggagctgg ggctttcttg ggtgtttctg gtagccatcc tcgagggagt ccagtgcgag 60
gtccagctcg tcgaatctgg cggggggctg gtccagcctg gcggttctct ccgcctgacc 120
tgtgcggcct cagggttcac tttcagccgg tactggatga catgggtgag acaggccccc 180
ggcaagggac tggaatgggt agcaaagatt aggcacgacg gcggtgagaa atactatccc 240
gacagtgtca aggggcggtt tactgtctcc cgagataatg ccaaaaactc actctacctg 300
cagatggata atctgcgagc ggaggatact gctatgtact actgtactcg agactacaac 360
aaggacctgt gggggcaggg gacactggtg acggttagtt ctcgggcggc cgcaattgaa 420
gttatgtatc ctcctcctta cctagacaat gagaagagca atggaaccat tatccatgtg 480
aaagggaaac acctttgtcc aagtccccta tttcccggac cttctaagcc cttttgggtg 540
ctggtggtgg ttggtggagt cctggcttgc tatagcttgc tagtaacagt ggcctttatt 600
attttctggg tgaggagtaa gaggagcagg ctcctgcaca gtgactacat gaacatgact 660
ccccgccgcc ccgggcccac ccgcaagcat taccagccct atgccccacc acgcgacttc 720
gcagcctatc gctccagagt gaagttcagc aggagcgcag acgcccccgc gtaccagcag 780
ggccagaacc agctctataa cgagctcaat ctaggacgaa gagaggagta cgatgttttg 840
gacaagagac gtggccggga ccctgagatg gggggaaagc cgagaaggaa gaaccctcag 900
gaaggcctgt tcaatgaact gcagaaagat aagatggcgg aggccttcag tgagattggg 960
atgaaaggcg agcgccggag gggcaagggg cacgatggcc ttttccaggg tctcagtaca 1020
gccaccaagg acaccttcga cgcccttcac atgcaggccc tgccccctcg c 1071
<![CDATA[<210> 65]]>
<![CDATA[<211> 1071]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 65]]>
atggaactgg gactgtcatg ggtctttctc gtggccattc tcgagggggt ccagtgtgag 60
gttcagctgg tggagagcgg ggggggtctg gttcagccag gtggcagtct taggttgtca 120
tgtgccgcga gcgggttcac gttctcacga tattggatga cctgggttcg ccaggcacca 180
gggaaggggc tggagtgggt cgccaagatc aggcacgacg gcggagaaaa atattacgcg 240
gattccgtga aaggcagatt cacaatctct agggataacg ccaaaaattc cctttatctt 300
cagatgaata gcctgagggc tgaagacact gccgtgtact actgcacgcg ggattacaac 360
aaagattatt ggggccaggg aacactggtg accgtcagct ctcgggcggc cgcaattgaa 420
gttatgtatc ctcctcctta cctagacaat gagaagagca atggaaccat tatccatgtg 480
aaagggaaac acctttgtcc aagtccccta tttcccggac cttctaagcc cttttgggtg 540
ctggtggtgg ttggtggagt cctggcttgc tatagcttgc tagtaacagt ggcctttatt 600
attttctggg tgaggagtaa gaggagcagg ctcctgcaca gtgactacat gaacatgact 660
ccccgccgcc ccgggcccac ccgcaagcat taccagccct atgccccacc acgcgacttc 720
gcagcctatc gctccagagt gaagttcagc aggagcgcag acgcccccgc gtaccagcag 780
ggccagaacc agctctataa cgagctcaat ctaggacgaa gagaggagta cgatgttttg 840
gacaagagac gtggccggga ccctgagatg gggggaaagc cgagaaggaa gaaccctcag 900
gaaggcctgt tcaatgaact gcagaaagat aagatggcgg aggccttcag tgagattggg 960
atgaaaggcg agcgccggag gggcaagggg cacgatggcc ttttccaggg tctcagtaca 1020
gccaccaagg acaccttcga cgcccttcac atgcaggccc tgccccctcg c 1071
<![CDATA[<210> 66]]>
<![CDATA[<211> 2226]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 66]]>
atgggctggt cttgtattat cttgtttctc gtcgcaactg ctacaggcgt tcattctgaa 60
gttcaactcc aagaatctgg tcctggcctg gtgaaacctt ccgaaactct ctcactcacc 120
tgtaccgtct caggcgcttc aatatcacac tattattggt cttggttccg gcaacctgca 180
ggcaaaggtc tcgaatggat aggcagaata tatcccagtg gaagcacctc ctataatccc 240
tctctcaagt caagagttgc aatgagcgtt gacacaccca agaaccaatt ctccctcaag 300
ctgtcatctg taactgccgc cgatactgcc gtttactact gcgctagaga tagatcaacc 360
ggatggtcag aatggaattc agatctgtgg ggacggggaa ccctcgtgac cgtatcttct 420
cgggcggccg caattgaagt tatgtatcct cctccttacc tagacaatga gaagagcaat 480
ggaaccatta tccatgtgaa agggaaacac ctttgtccaa gtcccctatt tcccggacct 540
tctaagccct tttgggtgct ggtggtggtt ggtggagtcc tggcttgcta tagcttgcta 600
gtaacagtgg cctttattat tttctgggtg aggagtaaga ggagcaggct cctgcacagt 660
gactacatga acatgactcc ccgccgcccc gggcccaccc gcaagcatta ccagccctat 720
gccccaccac gcgacttcgc agcctatcgc tccagagtga agttcagcag gagcgcagac 780
gcccccgcgt accagcaggg ccagaaccag ctctataacg agctcaatct aggacgaaga 840
gaggagtacg atgttttgga caagagacgt ggccgggacc ctgagatggg gggaaagccg 900
agaaggaaga accctcagga aggcctgttc aatgaactgc agaaagataa gatggcggag 960
gccttcagtg agattgggat gaaaggcgag cgccggaggg gcaaggggca cgatggcctt 1020
ttccagggtc tcagtacagc caccaaggac accttcgacg cccttcacat gcaggccctg 1080
ccccctcgcg gaagcggagc tactaacttc agcctgctga agcaggctgg agacgtggag 1140
gagaaccctg gacccatgct tctcctggtg acaagccttc tgctctgtga gttaccacac 1200
ccagcattcc tcctgatccc acgcaaagtg tgtaacggaa taggtattgg tgaatttaaa 1260
gactcactct ccataaatgc tacgaatatt aaacacttca aaaactgcac ctccatcagt 1320
ggcgatctcc acatcctgcc ggtggcattt aggggtgact ccttcacaca tactcctcct 1380
ctggacccac aggaactgga tattctgaaa accgtaaagg aaatcacagg gtttttgctg 1440
attcaggctt ggcctgaaaa caggacggac ctccatgcct ttgagaacct agaaatcata 1500
cgcggcagga ccaagcaaca tggtcagttt tctcttgcag tcgtcagcct gaacataaca 1560
tccttgggat tacgctccct caaggagata agtgatggag atgtgataat ttcaggaaac 1620
aaaaatttgt gctatgcaaa tacaataaac tggaaaaaac tgtttgggac ctccggtcag 1680
aaaaccaaaa ttataagcaa cagaggtgaa aacagctgca aggccacagg ccaggtctgc 1740
catgccttgt gctcccccga gggctgctgg ggcccggagc ccagggactg cgtctcttgc 1800
cggaatgtca gccgaggcag ggaatgcgtg gacaagtgca accttctgga gggtgagcca 1860
agggagtttg tggagaactc tgagtgcata cagtgccacc cagagtgcct gcctcaggcc 1920
atgaacatca cctgcacagg acggggacca gacaactgta tccagtgtgc ccactacatt 1980
gacggccccc actgcgtcaa gacctgcccg gcaggagtca tgggagaaaa caacaccctg 2040
gtctggaagt acgcagacgc cggccatgtg tgccacctgt gccatccaaa ctgcacctac 2100
ggatgcactg ggccaggtct tgaaggctgt cccacgaatg ggcctaagat cccgtccatc 2160
gccactggga tggtgggggc cctcctcttg ctgctggtgg tggccctggg gatcggcctc 2220
ttcatg 2226
<![CDATA[<210> 67]]>
<![CDATA[<211> 2205]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 67]]>
atggaactgg gactgtcttg ggtgttcctg gtcgctatat tggaaggagt acagtgccag 60
gtccagctcg tcgagtccgg gggtggcctg gtgcagcccg gcggcagcct ccggctgagc 120
tgcacagcct cagggtttac attcagcagg tactggatga gttgggttag gcaagcccct 180
ggcaaaggcc tggagtgggt ggccaaaatc cgacatgatg ggggcgaaaa gtactatgtg 240
gatagtgtga agggacggtt cacaatatca cgagacaatg ccaaaaactc tttgtacctg 300
caaatgaact ccctgcgcgc cgaagacaca gctgtgtact actgcgctac agactacact 360
agggacgtct ggggtcaagg aacagccgtc accgtgagta gtgcggccgc aattgaagtt 420
atgtatcctc ctccttacct agacaatgag aagagcaatg gaaccattat ccatgtgaaa 480
gggaaacacc tttgtccaag tcccctattt cccggacctt ctaagccctt ttgggtgctg 540
gtggtggttg gtggagtcct ggcttgctat agcttgctag taacagtggc ctttattatt 600
ttctgggtga ggagtaagag gagcaggctc ctgcacagtg actacatgaa catgactccc 660
cgccgccccg ggcccacccg caagcattac cagccctatg ccccaccacg cgacttcgca 720
gcctatcgct ccagagtgaa gttcagcagg agcgcagacg cccccgcgta ccagcagggc 780
cagaaccagc tctataacga gctcaatcta ggacgaagag aggagtacga tgttttggac 840
aagagacgtg gccgggaccc tgagatgggg ggaaagccga gaaggaagaa ccctcaggaa 900
ggcctgttca atgaactgca gaaagataag atggcggagg ccttcagtga gattgggatg 960
aaaggcgagc gccggagggg caaggggcac gatggccttt tccagggtct cagtacagcc 1020
accaaggaca ccttcgacgc ccttcacatg caggccctgc cccctcgcgg aagcggagct 1080
actaacttca gcctgctgaa gcaggctgga gacgtggagg agaaccctgg acccatgctt 1140
ctcctggtga caagccttct gctctgtgag ttaccacacc cagcattcct cctgatccca 1200
cgcaaagtgt gtaacggaat aggtattggt gaatttaaag actcactctc cataaatgct 1260
acgaatatta aacacttcaa aaactgcacc tccatcagtg gcgatctcca catcctgccg 1320
gtggcattta ggggtgactc cttcacacat actcctcctc tggacccaca ggaactggat 1380
attctgaaaa ccgtaaagga aatcacaggg tttttgctga ttcaggcttg gcctgaaaac 1440
aggacggacc tccatgcctt tgagaaccta gaaatcatac gcggcaggac caagcaacat 1500
ggtcagtttt ctcttgcagt cgtcagcctg aacataacat ccttgggatt acgctccctc 1560
aaggagataa gtgatggaga tgtgataatt tcaggaaaca aaaatttgtg ctatgcaaat 1620
acaataaact ggaaaaaact gtttgggacc tccggtcaga aaaccaaaat tataagcaac 1680
agaggtgaaa acagctgcaa ggccacaggc caggtctgcc atgccttgtg ctcccccgag 1740
ggctgctggg gcccggagcc cagggactgc gtctcttgcc ggaatgtcag ccgaggcagg 1800
gaatgcgtgg acaagtgcaa ccttctggag ggtgagccaa gggagtttgt ggagaactct 1860
gagtgcatac agtgccaccc agagtgcctg cctcaggcca tgaacatcac ctgcacagga 1920
cggggaccag acaactgtat ccagtgtgcc cactacattg acggccccca ctgcgtcaag 1980
acctgcccgg caggagtcat gggagaaaac aacaccctgg tctggaagta cgcagacgcc 2040
ggccatgtgt gccacctgtg ccatccaaac tgcacctacg gatgcactgg gccaggtctt 2100
gaaggctgtc ccacgaatgg gcctaagatc ccgtccatcg ccactgggat ggtgggggcc 2160
ctcctcttgc tgctggtggt ggccctgggg atcggcctct tcatg 2205
<![CDATA[<210> 68]]>
<![CDATA[<211> 2208]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 68]]>
atggagctgg gattgtcctg ggttttcctg gtggctatac tcgaaggcgt acagtgtgaa 60
gtgcagttgg tggagagtgg cggtggcctg gcccagccgg gaggctcttt gagactctcc 120
tgcgctgcct ccggcttcac tttctcccgc tattggatga cctgggtccg gcaggcgccc 180
ggcggacgcc tggagtgggt ggctaagatc aagtatgatg gatcagaaaa atattacgca 240
gatagcgtaa aaggccggtt cacaatatcc agggataatg caaaaaactc cctgtatctg 300
cagatggata gcctgcgcgc tgaagacacc gccgtatatt attgcacaag agactacaat 360
aaagattact ggggccaggg aaccctggtt acggtgagct cacgggcggc cgcaattgaa 420
gttatgtatc ctcctcctta cctagacaat gagaagagca atggaaccat tatccatgtg 480
aaagggaaac acctttgtcc aagtccccta tttcccggac cttctaagcc cttttgggtg 540
ctggtggtgg ttggtggagt cctggcttgc tatagcttgc tagtaacagt ggcctttatt 600
attttctggg tgaggagtaa gaggagcagg ctcctgcaca gtgactacat gaacatgact 660
ccccgccgcc ccgggcccac ccgcaagcat taccagccct atgccccacc acgcgacttc 720
gcagcctatc gctccagagt gaagttcagc aggagcgcag acgcccccgc gtaccagcag 780
ggccagaacc agctctataa cgagctcaat ctaggacgaa gagaggagta cgatgttttg 840
gacaagagac gtggccggga ccctgagatg gggggaaagc cgagaaggaa gaaccctcag 900
gaaggcctgt tcaatgaact gcagaaagat aagatggcgg aggccttcag tgagattggg 960
atgaaaggcg agcgccggag gggcaagggg cacgatggcc ttttccaggg tctcagtaca 1020
gccaccaagg acaccttcga cgcccttcac atgcaggccc tgccccctcg cggaagcgga 1080
gctactaact tcagcctgct gaagcaggct ggagacgtgg aggagaaccc tggacccatg 1140
cttctcctgg tgacaagcct tctgctctgt gagttaccac acccagcatt cctcctgatc 1200
ccacgcaaag tgtgtaacgg aataggtatt ggtgaattta aagactcact ctccataaat 1260
gctacgaata ttaaacactt caaaaactgc acctccatca gtggcgatct ccacatcctg 1320
ccggtggcat ttaggggtga ctccttcaca catactcctc ctctggaccc acaggaactg 1380
gatattctga aaaccgtaaa ggaaatcaca gggtttttgc tgattcaggc ttggcctgaa 1440
aacaggacgg acctccatgc ctttgagaac ctagaaatca tacgcggcag gaccaagcaa 1500
catggtcagt tttctcttgc agtcgtcagc ctgaacataa catccttggg attacgctcc 1560
ctcaaggaga taagtgatgg agatgtgata atttcaggaa acaaaaattt gtgctatgca 1620
aatacaataa actggaaaaa actgtttggg acctccggtc agaaaaccaa aattataagc 1680
aacagaggtg aaaacagctg caaggccaca ggccaggtct gccatgcctt gtgctccccc 1740
gagggctgct ggggcccgga gcccagggac tgcgtctctt gccggaatgt cagccgaggc 1800
agggaatgcg tggacaagtg caaccttctg gagggtgagc caagggagtt tgtggagaac 1860
tctgagtgca tacagtgcca cccagagtgc ctgcctcagg ccatgaacat cacctgcaca 1920
ggacggggac cagacaactg tatccagtgt gcccactaca ttgacggccc ccactgcgtc 1980
aagacctgcc cggcaggagt catgggagaa aacaacaccc tggtctggaa gtacgcagac 2040
gccggccatg tgtgccacct gtgccatcca aactgcacct acggatgcac tgggccaggt 2100
cttgaaggct gtcccacgaa tgggcctaag atcccgtcca tcgccactgg gatggtgggg 2160
gccctcctct tgctgctggt ggtggccctg gggatcggcc tcttcatg 2208
<![CDATA[<210> 69]]>
<![CDATA[<211> 2208]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 69]]>
atggagctgg ggctttcttg ggtgtttctg gtagccatcc tcgagggagt ccagtgcgag 60
gtccagctcg tcgaatctgg cggggggctg gtccagcctg gcggttctct ccgcctgacc 120
tgtgcggcct cagggttcac tttcagccgg tactggatga catgggtgag acaggccccc 180
ggcaagggac tggaatgggt agcaaagatt aggcacgacg gcggtgagaa atactatccc 240
gacagtgtca aggggcggtt tactgtctcc cgagataatg ccaaaaactc actctacctg 300
cagatggata atctgcgagc ggaggatact gctatgtact actgtactcg agactacaac 360
aaggacctgt gggggcaggg gacactggtg acggttagtt ctcgggcggc cgcaattgaa 420
gttatgtatc ctcctcctta cctagacaat gagaagagca atggaaccat tatccatgtg 480
aaagggaaac acctttgtcc aagtccccta tttcccggac cttctaagcc cttttgggtg 540
ctggtggtgg ttggtggagt cctggcttgc tatagcttgc tagtaacagt ggcctttatt 600
attttctggg tgaggagtaa gaggagcagg ctcctgcaca gtgactacat gaacatgact 660
ccccgccgcc ccgggcccac ccgcaagcat taccagccct atgccccacc acgcgacttc 720
gcagcctatc gctccagagt gaagttcagc aggagcgcag acgcccccgc gtaccagcag 780
ggccagaacc agctctataa cgagctcaat ctaggacgaa gagaggagta cgatgttttg 840
gacaagagac gtggccggga ccctgagatg gggggaaagc cgagaaggaa gaaccctcag 900
gaaggcctgt tcaatgaact gcagaaagat aagatggcgg aggccttcag tgagattggg 960
atgaaaggcg agcgccggag gggcaagggg cacgatggcc ttttccaggg tctcagtaca 1020
gccaccaagg acaccttcga cgcccttcac atgcaggccc tgccccctcg cggaagcgga 1080
gctactaact tcagcctgct gaagcaggct ggagacgtgg aggagaaccc tggacccatg 1140
cttctcctgg tgacaagcct tctgctctgt gagttaccac acccagcatt cctcctgatc 1200
ccacgcaaag tgtgtaacgg aataggtatt ggtgaattta aagactcact ctccataaat 1260
gctacgaata ttaaacactt caaaaactgc acctccatca gtggcgatct ccacatcctg 1320
ccggtggcat ttaggggtga ctccttcaca catactcctc ctctggaccc acaggaactg 1380
gatattctga aaaccgtaaa ggaaatcaca gggtttttgc tgattcaggc ttggcctgaa 1440
aacaggacgg acctccatgc ctttgagaac ctagaaatca tacgcggcag gaccaagcaa 1500
catggtcagt tttctcttgc agtcgtcagc ctgaacataa catccttggg attacgctcc 1560
ctcaaggaga taagtgatgg agatgtgata atttcaggaa acaaaaattt gtgctatgca 1620
aatacaataa actggaaaaa actgtttggg acctccggtc agaaaaccaa aattataagc 1680
aacagaggtg aaaacagctg caaggccaca ggccaggtct gccatgcctt gtgctccccc 1740
gagggctgct ggggcccgga gcccagggac tgcgtctctt gccggaatgt cagccgaggc 1800
agggaatgcg tggacaagtg caaccttctg gagggtgagc caagggagtt tgtggagaac 1860
tctgagtgca tacagtgcca cccagagtgc ctgcctcagg ccatgaacat cacctgcaca 1920
ggacggggac cagacaactg tatccagtgt gcccactaca ttgacggccc ccactgcgtc 1980
aagacctgcc cggcaggagt catgggagaa aacaacaccc tggtctggaa gtacgcagac 2040
gccggccatg tgtgccacct gtgccatcca aactgcacct acggatgcac tgggccaggt 2100
cttgaaggct gtcccacgaa tgggcctaag atcccgtcca tcgccactgg gatggtgggg 2160
gccctcctct tgctgctggt ggtggccctg gggatcggcc tcttcatg 2208
<![CDATA[<210> 70]]>
<![CDATA[<211> 2208]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多核苷酸"]]>
<![CDATA[<400> 70]]>
atggaactgg gactgtcatg ggtctttctc gtggccattc tcgagggggt ccagtgtgag 60
gttcagctgg tggagagcgg ggggggtctg gttcagccag gtggcagtct taggttgtca 120
tgtgccgcga gcgggttcac gttctcacga tattggatga cctgggttcg ccaggcacca 180
gggaaggggc tggagtgggt cgccaagatc aggcacgacg gcggagaaaa atattacgcg 240
gattccgtga aaggcagatt cacaatctct agggataacg ccaaaaattc cctttatctt 300
cagatgaata gcctgagggc tgaagacact gccgtgtact actgcacgcg ggattacaac 360
aaagattatt ggggccaggg aacactggtg accgtcagct ctcgggcggc cgcaattgaa 420
gttatgtatc ctcctcctta cctagacaat gagaagagca atggaaccat tatccatgtg 480
aaagggaaac acctttgtcc aagtccccta tttcccggac cttctaagcc cttttgggtg 540
ctggtggtgg ttggtggagt cctggcttgc tatagcttgc tagtaacagt ggcctttatt 600
attttctggg tgaggagtaa gaggagcagg ctcctgcaca gtgactacat gaacatgact 660
ccccgccgcc ccgggcccac ccgcaagcat taccagccct atgccccacc acgcgacttc 720
gcagcctatc gctccagagt gaagttcagc aggagcgcag acgcccccgc gtaccagcag 780
ggccagaacc agctctataa cgagctcaat ctaggacgaa gagaggagta cgatgttttg 840
gacaagagac gtggccggga ccctgagatg gggggaaagc cgagaaggaa gaaccctcag 900
gaaggcctgt tcaatgaact gcagaaagat aagatggcgg aggccttcag tgagattggg 960
atgaaaggcg agcgccggag gggcaagggg cacgatggcc ttttccaggg tctcagtaca 1020
gccaccaagg acaccttcga cgcccttcac atgcaggccc tgccccctcg cggaagcgga 1080
gctactaact tcagcctgct gaagcaggct ggagacgtgg aggagaaccc tggacccatg 1140
cttctcctgg tgacaagcct tctgctctgt gagttaccac acccagcatt cctcctgatc 1200
ccacgcaaag tgtgtaacgg aataggtatt ggtgaattta aagactcact ctccataaat 1260
gctacgaata ttaaacactt caaaaactgc acctccatca gtggcgatct ccacatcctg 1320
ccggtggcat ttaggggtga ctccttcaca catactcctc ctctggaccc acaggaactg 1380
gatattctga aaaccgtaaa ggaaatcaca gggtttttgc tgattcaggc ttggcctgaa 1440
aacaggacgg acctccatgc ctttgagaac ctagaaatca tacgcggcag gaccaagcaa 1500
catggtcagt tttctcttgc agtcgtcagc ctgaacataa catccttggg attacgctcc 1560
ctcaaggaga taagtgatgg agatgtgata atttcaggaa acaaaaattt gtgctatgca 1620
aatacaataa actggaaaaa actgtttggg acctccggtc agaaaaccaa aattataagc 1680
aacagaggtg aaaacagctg caaggccaca ggccaggtct gccatgcctt gtgctccccc 1740
gagggctgct ggggcccgga gcccagggac tgcgtctctt gccggaatgt cagccgaggc 1800
agggaatgcg tggacaagtg caaccttctg gagggtgagc caagggagtt tgtggagaac 1860
tctgagtgca tacagtgcca cccagagtgc ctgcctcagg ccatgaacat cacctgcaca 1920
ggacggggac cagacaactg tatccagtgt gcccactaca ttgacggccc ccactgcgtc 1980
aagacctgcc cggcaggagt catgggagaa aacaacaccc tggtctggaa gtacgcagac 2040
gccggccatg tgtgccacct gtgccatcca aactgcacct acggatgcac tgggccaggt 2100
cttgaaggct gtcccacgaa tgggcctaag atcccgtcca tcgccactgg gatggtgggg 2160
gccctcctct tgctgctggt ggtggccctg gggatcggcc tcttcatg 2208
<![CDATA[<210> 71]]>
<![CDATA[<211> 112]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<400> 71]]>
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
1 5 10 15
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
20 25 30
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
35 40 45
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
50 55 60
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
65 70 75 80
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
85 90 95
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
100 105 110
<![CDATA[<210> 72]]>
<![CDATA[<211> 30]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成多肽"]]>
<![CDATA[<220>]]>
<![CDATA[<221> SITE]]>
<![CDATA[<222> (1)..(30) ]]>
<![CDATA[<223> /說明="此序列可包含1-6個'Gly Gly Gly Gly Ser'重複單元"]]>
<![CDATA[<400> 72]]>
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25 30
<![CDATA[<210> 73]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> PRT]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /說明="人工序列之描述:合成肽"]]>
<![CDATA[<400> 73]]>
Arg Gly Asp Ser
1





















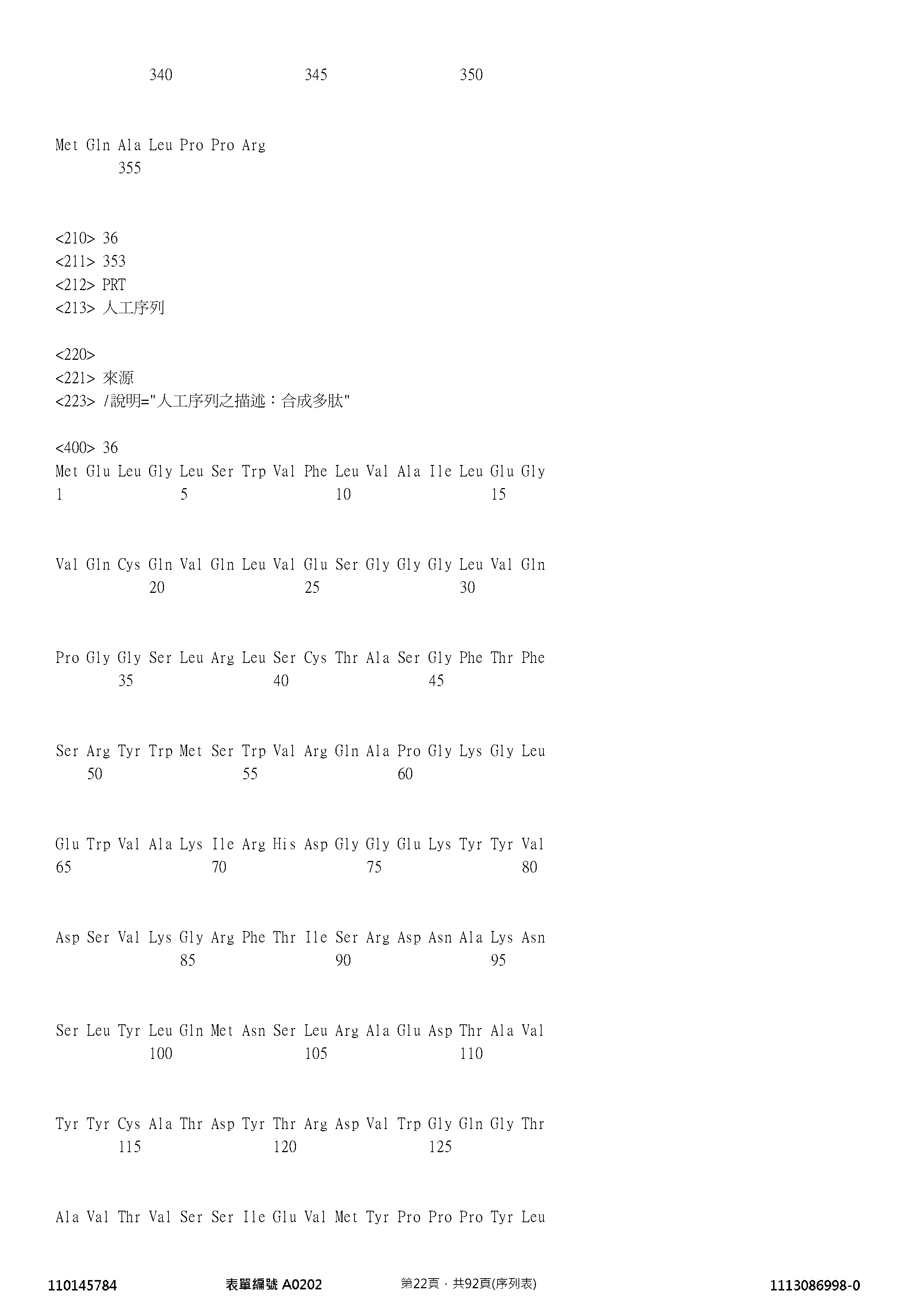







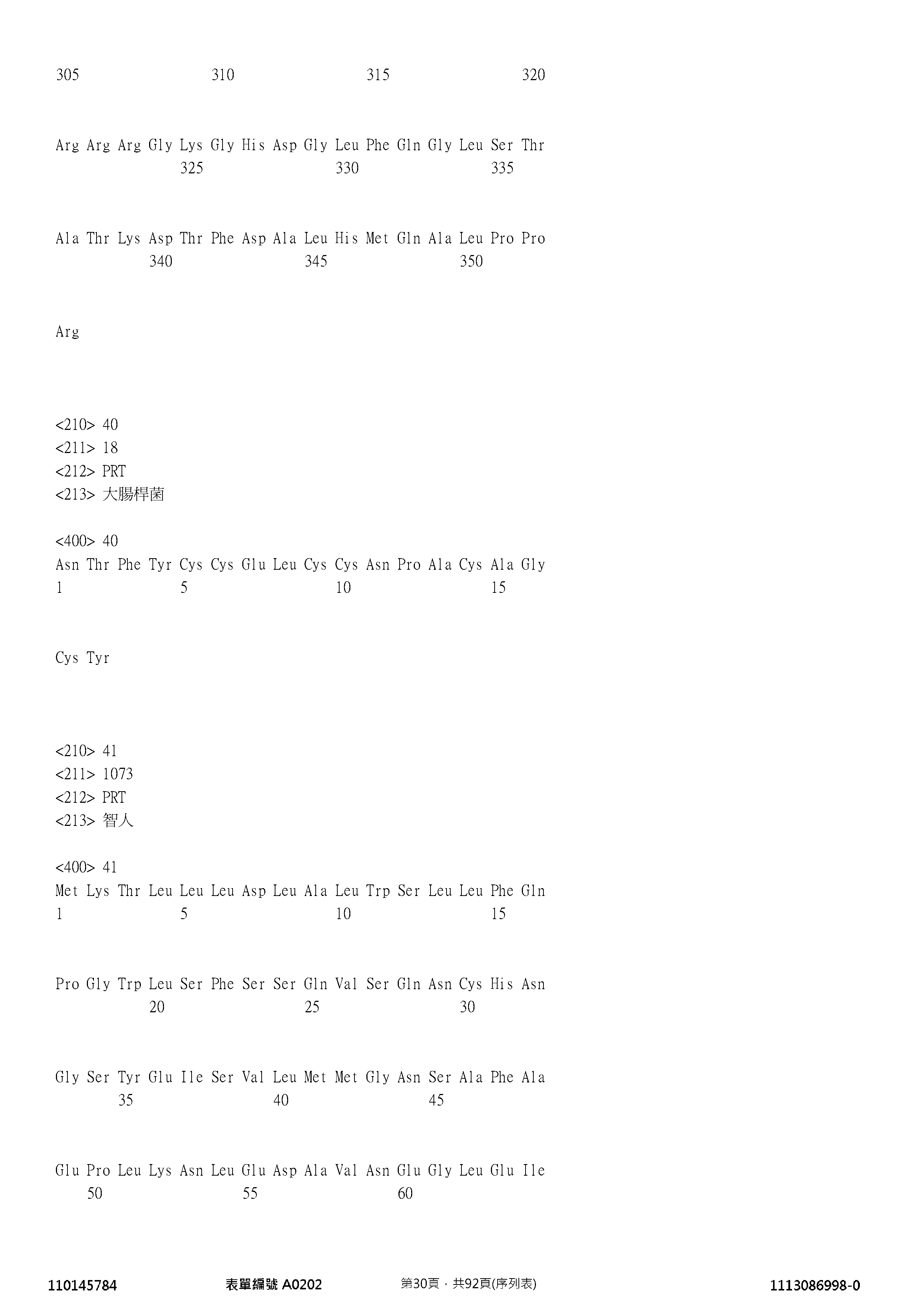
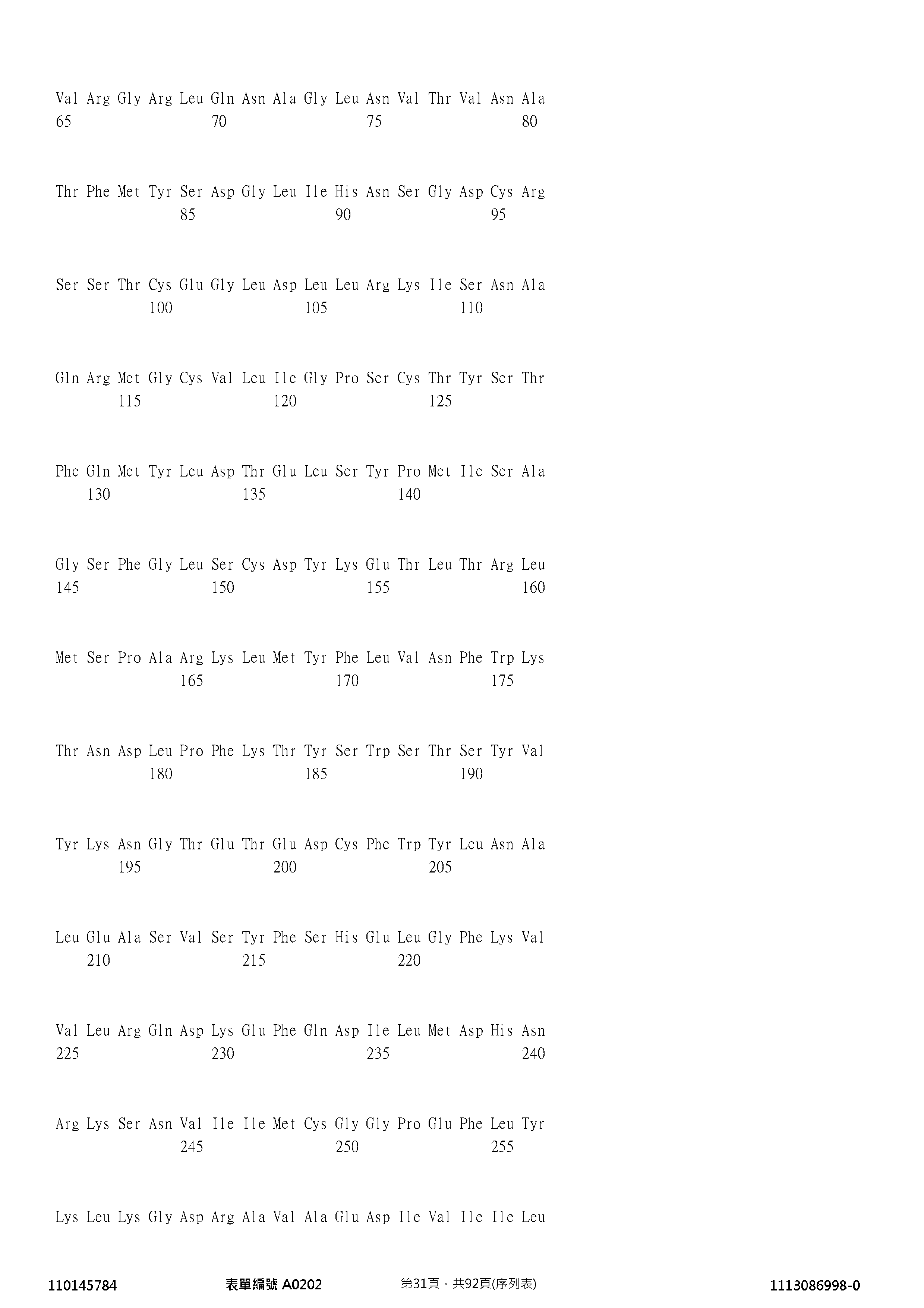



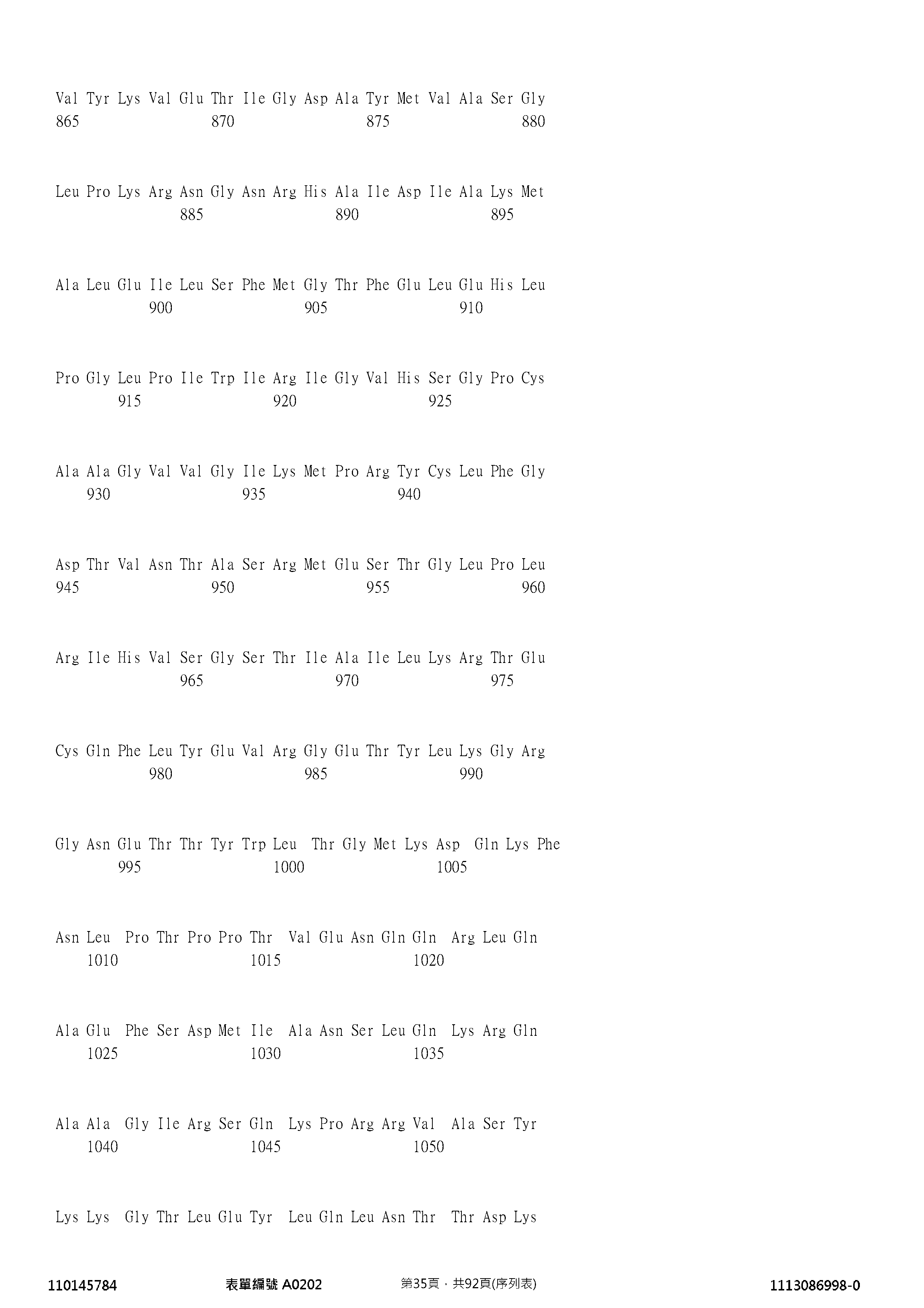
















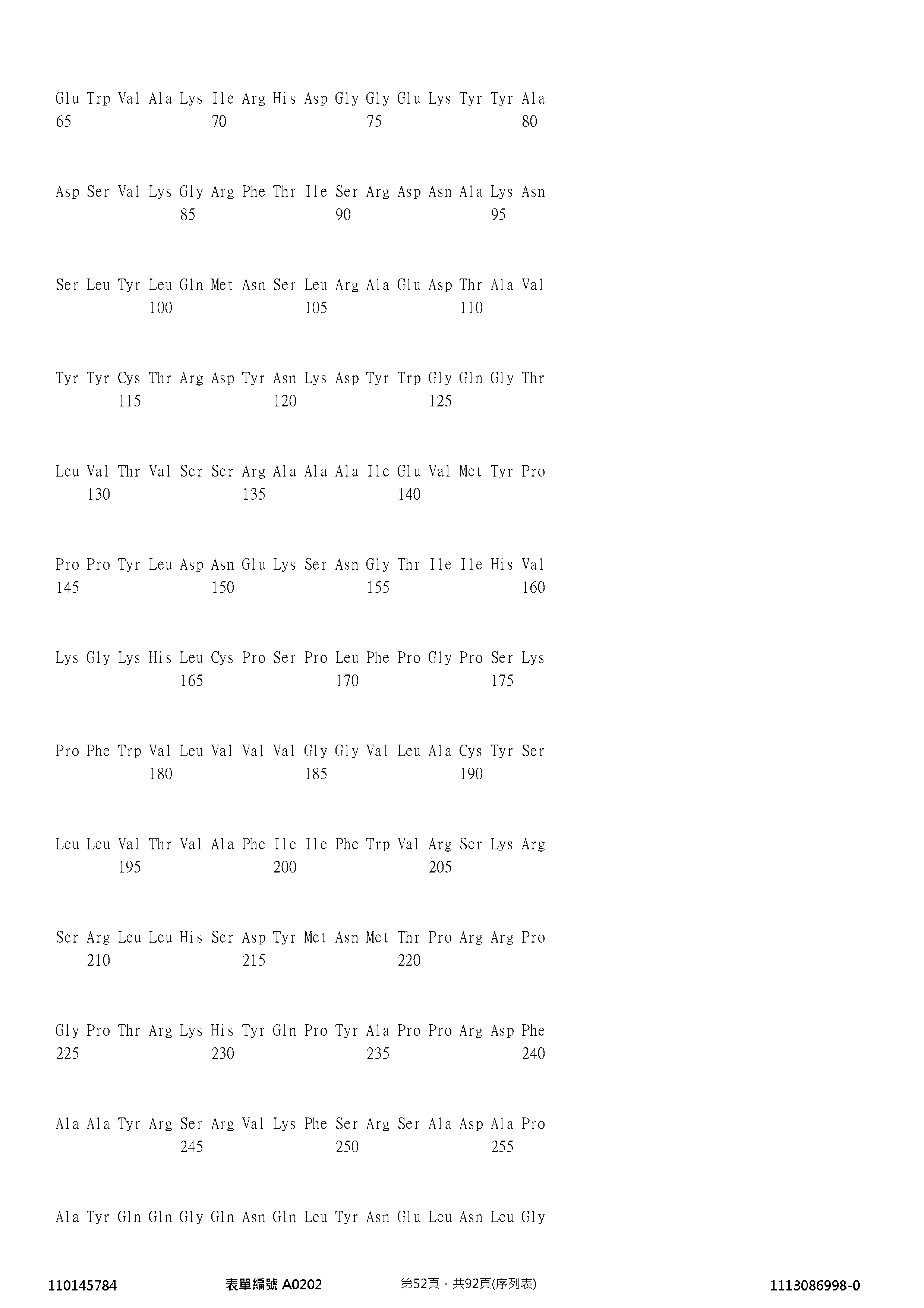








































Claims (41)
- 一種抗鳥苷酸環化酶C (GCC)嵌合抗原受體(CAR),其包含一與鳥苷酸環化酶C (GCC)結合之細胞外抗原結合域、一跨膜域、及至少一細胞內信號傳導域。
- 如請求項0所述之抗GCC CAR,其中該抗原結合域包含 一重鏈可變區(V H),其具有下列互補決定區(CDR)序列:HYYWS (HCDR1) (SEQ ID NO: 8)、RIYPSGSTSYNPSLKS (HCDR2) (SEQ ID NO: 11)和DRSTGWSEWNSDL (HCDR3) (SEQ ID NO: 16); 一重鏈可變區(V H),其具有下列互補決定區(CDR)序列:RYWMS (HCDR1) (SEQ ID NO: 9)、KIRHDGGEKYYVDSVKG (HCDR2) (SEQ ID NO: 12)和DYTRDV (HCDR3) (SEQ ID NO: 17); 一重鏈可變區(V H),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIKYDGSEKYYADSVKG (HCDR2) (SEQ ID NO: 13)和DYNKDY (HCDR3) (SEQ ID NO: 18); 一重鏈可變區(V H),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYPDSVKG (HCDR2) (SEQ ID NO: 14)和DYNKDL (HCDR3) (SEQ ID NO: 19);或 一重鏈可變區(V H),其具有下列互補決定區(CDR)序列:RYWMT (HCDR1) (SEQ ID NO: 10)、KIRHDGGEKYYADSVKG (HCDR2) (SEQ ID NO: 15)和DYNKDY (HCDR3) (SEQ ID NO: 18)。
- 如請求項1所述之抗GCC CAR,其中該抗原結合域包含一重鏈可變區(VH),其與SEQ ID NO: 1或SEQ ID NO: 20至少90%一致。
- 如請求項0所述之抗GCC CAR,其中該抗原結合域包含 一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 21至少90%一致的胺基酸序列; 一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 26至少90%一致的胺基酸序列; 一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 27至少90%一致的胺基酸序列;或 一免疫球蛋白重鏈可變(VH)區,其包含一與SEQ ID NO: 28至少90%一致的胺基酸序列。
- 如請求項0至0中任一項所述之抗GCC CAR,其中該抗原結合域包含一僅具抗GCC抗原結合域之免疫球蛋白可變重鏈。
- 如請求項0至0中任一項所述之抗GCC CAR,其中,該細胞外抗GCC抗原結合域前接有一編碼前導胜肽之前導核苷酸序列。
- 如請求項28所述之抗GCC CAR,其中該前導胜肽包含SEQ ID NO: 6、SEQ ID NO: 7、或SEQ ID NO: 42。
- 如請求項0至0中任一項所述之抗GCC CAR,其更包含一鉸鏈域。
- 如請求項0,其中該鉸鏈域包含一CD28之鉸鏈域。
- 如請求項0所述之抗GCC CAR,其中該CD28鉸鏈域包含SEQ ID NO: 29。
- 如請求項0至0中任一項所述之抗GCC CAR,其中該鉸鏈域與該跨膜域融合。
- 如請求項0至0中任一項所述之抗GCC CAR,其中該跨膜域包含一蛋白質跨膜域,該蛋白質選自於T細胞受體、CD8、CD28、CD3ε、CD45、CD4、CD5、CD8、CD9、CD16、CD22、CD33、CD37、CD64、CD80、CD83、CD86、CD134、CD137、CD154和TNFRSF19之α、β或ζ鏈,及其任一組合。
- 如請求項0所述之抗GCC CAR,其中該跨膜域包含一CD28跨膜域。
- 如請求項0所述之抗GCC CAR,其中該CD28跨膜域包含SEQ ID NO: 30。
- 如請求項0至0中任一項所述之抗GCC CAR,其中該至少一細胞內信號傳導域包含一共刺激域和一初級信號傳導域。
- 如請求項 0所述之抗GCC CAR,其中該共刺激域包含OX40、CD70、CD27、CD28、CD5、ICAM-1、LFA-1 (CD11a/CD18)、ICOS (CD278)、DAP10、DAP12、和4-1BB (CD137)的功能性信號傳導域,或其任一組合。
- 如請求項0所述之抗GCC CAR,其中該共刺激域包含一CD28的功能性信號傳導域。
- 如請求項0所述之抗GCC CAR,其中該CD28共刺激域包含SEQ ID NO: 32。
- 如請求項0至0中任一項所述之抗GCC CAR,其中該初級信號傳導域包含一CD3ζ信號傳導域。
- 如請求項0之抗GCC CAR,其中,該CD3ζ信號傳導域包含SEQ ID NO: 33。
- 一種抗GCC CAR,其包含一選自由以下組成之序列:SEQ ID NO: 47-52。
- 一種經分離聚核苷酸,其編碼如請求項0至0中任一項所述之抗GCC CAR。
- 如請求項0所述之經分離聚核苷酸,其更包含經截短之表皮生長因子受體(tEGFR)序列。
- 如請求項0所述之經分離聚核苷酸,其中該tEGFR包含一核苷酸序列,其編碼與SEQ ID NO: 43至少95%、96%、97%、98%、99%一致的胺基酸序列。
- 如請求項0所述之經分離聚核苷酸,其中該tEGFR包含一核苷酸序列,其編碼與SEQ ID NO: 43一致的胺基酸序列。
- 如請求項0至0中任一項所述之經分離聚核甘酸,其更包含一弗林蛋白酶識別位點和下游2A自裂解胜肽序列,設計用於該標籤序列和CAR序列的同時雙順反子表現。
- 如請求項0所述之經分離聚核甘酸,其中該2A自裂解胜肽係選自於F2A、P2A、E2A及T2A。
- 如請求項0所述之經分離聚核苷酸,其中該2A自裂解胜肽為P2A。
- 一種載體,其包含如請求項0至0中任一項所述之經分離聚核苷酸。
- 如請求項0所述之載體,其中該載體為腺病毒載體、腺病毒相關載體、DNA載體、慢病毒載體、質體、逆轉錄病毒載體或RNA載體。
- 一種細胞,其包含如請求項0或0所述之載體。
- 如請求項0所述之細胞,其中該細胞為T細胞、同種異體T細胞、自體T細胞或腫瘤浸潤淋巴細胞(TIL)。
- 一種細胞群,其包含如請求項0至0中任一項所述之抗GCC CAR或請求項0至0中任一項所述之核酸。
- 一種套組,其包含如請求項0所述之細胞群。
- 一種醫藥組成物,其包含如請求項0或0所述之細胞群。
- 如請求項0所述之醫藥組成物,其中該群體中大於70%、80%、90%或95%的細胞表現該抗GCC CAR。
- 一種治療癌症之方法,其包含向有需要治療之個體投與包含如請求項0至0中任一項所述之抗GCC CAR之醫藥組成物或細胞群。
- 如請求項0所述之方法,其中該癌症係選自於胃腸癌、大腸直腸癌、大腸直腸腺癌、大腸直腸平滑肌肉瘤、大腸直腸淋巴瘤、大腸直腸黑色素瘤、大腸直腸神經內分泌腫瘤、轉移性大腸癌、胃癌、胃腺癌、胃淋巴瘤、胃肉瘤、食道癌、鱗狀細胞癌、食道腺癌或胰臟癌。
- 如請求項 錯誤 ! 找不到參照來源。所述之方法,其中該癌症為胃腸癌。
- 如請求項0所述之方法,其中該胃腸癌為大腸癌、大腸直腸癌、胃癌或食道癌。
- 一種降低腫瘤生長或腫瘤大小之方法,其包含向有需要治療之個體投與包含如請求項0至0中任一項所述之抗GCC CAR之醫藥組成物或細胞群。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063123331P | 2020-12-09 | 2020-12-09 | |
| US63/123,331 | 2020-12-09 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| TW202237638A true TW202237638A (zh) | 2022-10-01 |
Family
ID=80168369
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| TW110145784A TW202237638A (zh) | 2020-12-09 | 2021-12-08 | 烏苷酸環化酶c(gcc)抗原結合劑之組成物及其使用方法 |
Country Status (16)
| Country | Link |
|---|---|
| US (1) | US20240050473A1 (zh) |
| EP (1) | EP4259656A1 (zh) |
| JP (1) | JP2023553159A (zh) |
| KR (1) | KR20230118913A (zh) |
| CN (1) | CN116601167A (zh) |
| AR (1) | AR124288A1 (zh) |
| AU (1) | AU2021397881A1 (zh) |
| CA (1) | CA3201582A1 (zh) |
| CL (1) | CL2023001666A1 (zh) |
| CO (1) | CO2023009102A2 (zh) |
| EC (1) | ECSP23050855A (zh) |
| IL (1) | IL303535A (zh) |
| MX (1) | MX2023006774A (zh) |
| PE (1) | PE20240049A1 (zh) |
| TW (1) | TW202237638A (zh) |
| WO (1) | WO2022123316A1 (zh) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024067762A1 (en) * | 2022-09-28 | 2024-04-04 | Nanjing Legend Biotech Co., Ltd. | Antibody and chimeric antigen receptors targeting gcc and methods of use thereof |
| WO2024109877A1 (en) * | 2022-11-23 | 2024-05-30 | Full-Life Technologies Hk Limited | Antibody specifically binding to gcc |
| CN116874602A (zh) * | 2022-12-09 | 2023-10-13 | 华道(上海)生物医药有限公司 | 一种抗鸟苷酸环化酶2c的纳米抗体及其应用 |
| WO2025061149A1 (zh) * | 2023-09-21 | 2025-03-27 | 南京传奇生物科技有限公司 | 抗gcc抗体、嵌合抗原受体及其用途 |
Family Cites Families (126)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4179337A (en) | 1973-07-20 | 1979-12-18 | Davis Frank F | Non-immunogenic polypeptides |
| US4235871A (en) | 1978-02-24 | 1980-11-25 | Papahadjopoulos Demetrios P | Method of encapsulating biologically active materials in lipid vesicles |
| US4501728A (en) | 1983-01-06 | 1985-02-26 | Technology Unlimited, Inc. | Masking of liposomes from RES recognition |
| US4486414A (en) | 1983-03-21 | 1984-12-04 | Arizona Board Of Reagents | Dolastatins A and B cell growth inhibitory substances |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US4957735A (en) | 1984-06-12 | 1990-09-18 | The University Of Tennessee Research Corporation | Target-sensitive immunoliposomes- preparation and characterization |
| US5019369A (en) | 1984-10-22 | 1991-05-28 | Vestar, Inc. | Method of targeting tumors in humans |
| GB8607679D0 (en) | 1986-03-27 | 1986-04-30 | Winter G P | Recombinant dna product |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US4902505A (en) | 1986-07-30 | 1990-02-20 | Alkermes | Chimeric peptides for neuropeptide delivery through the blood-brain barrier |
| US4837028A (en) | 1986-12-24 | 1989-06-06 | Liposome Technology, Inc. | Liposomes with enhanced circulation time |
| IL85035A0 (en) | 1987-01-08 | 1988-06-30 | Int Genetic Eng | Polynucleotide molecule,a chimeric antibody with specificity for human b cell surface antigen,a process for the preparation and methods utilizing the same |
| WO1988007089A1 (en) | 1987-03-18 | 1988-09-22 | Medical Research Council | Altered antibodies |
| US4816444A (en) | 1987-07-10 | 1989-03-28 | Arizona Board Of Regents, Arizona State University | Cell growth inhibitory substance |
| US5004697A (en) | 1987-08-17 | 1991-04-02 | Univ. Of Ca | Cationized antibodies for delivery through the blood-brain barrier |
| US5076973A (en) | 1988-10-24 | 1991-12-31 | Arizona Board Of Regents | Synthesis of dolastatin 3 |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US4978744A (en) | 1989-01-27 | 1990-12-18 | Arizona Board Of Regents | Synthesis of dolastatin 10 |
| US5055303A (en) | 1989-01-31 | 1991-10-08 | Kv Pharmaceutical Company | Solid controlled release bioadherent emulsions |
| US5703055A (en) | 1989-03-21 | 1997-12-30 | Wisconsin Alumni Research Foundation | Generation of antibodies through lipid mediated DNA delivery |
| US5324844A (en) | 1989-04-19 | 1994-06-28 | Enzon, Inc. | Active carbonates of polyalkylene oxides for modification of polypeptides |
| US4879278A (en) | 1989-05-16 | 1989-11-07 | Arizona Board Of Regents | Isolation and structural elucidation of the cytostatic linear depsipeptide dolastatin 15 |
| US4986988A (en) | 1989-05-18 | 1991-01-22 | Arizona Board Of Regents | Isolation and structural elucidation of the cytostatic linear depsipeptides dolastatin 13 and dehydrodolastatin 13 |
| US5399346A (en) | 1989-06-14 | 1995-03-21 | The United States Of America As Represented By The Department Of Health And Human Services | Gene therapy |
| US5585362A (en) | 1989-08-22 | 1996-12-17 | The Regents Of The University Of Michigan | Adenovirus vectors for gene therapy |
| US5271961A (en) | 1989-11-06 | 1993-12-21 | Alkermes Controlled Therapeutics, Inc. | Method for producing protein microspheres |
| US5188837A (en) | 1989-11-13 | 1993-02-23 | Nova Pharmaceutical Corporation | Lipsopheres for controlled delivery of substances |
| US5138036A (en) | 1989-11-13 | 1992-08-11 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Isolation and structural elucidation of the cytostatic cyclodepsipeptide dolastatin 14 |
| US5859205A (en) | 1989-12-21 | 1999-01-12 | Celltech Limited | Humanised antibodies |
| GB8928874D0 (en) | 1989-12-21 | 1990-02-28 | Celltech Ltd | Humanised antibodies |
| US5268164A (en) | 1990-04-23 | 1993-12-07 | Alkermes, Inc. | Increasing blood-brain barrier permeability with permeabilizer peptides |
| JP3266311B2 (ja) | 1991-05-02 | 2002-03-18 | 生化学工業株式会社 | 新規ポリペプチドおよびこれを用いる抗hiv剤 |
| EP0519596B1 (en) | 1991-05-17 | 2005-02-23 | Merck & Co. Inc. | A method for reducing the immunogenicity of antibody variable domains |
| JP4124480B2 (ja) | 1991-06-14 | 2008-07-23 | ジェネンテック・インコーポレーテッド | 免疫グロブリン変異体 |
| NZ243082A (en) | 1991-06-28 | 1995-02-24 | Ici Plc | 4-anilino-quinazoline derivatives; pharmaceutical compositions, preparatory processes, and use thereof |
| ES2136092T3 (es) | 1991-09-23 | 1999-11-16 | Medical Res Council | Procedimientos para la produccion de anticuerpos humanizados. |
| US5254342A (en) | 1991-09-30 | 1993-10-19 | University Of Southern California | Compositions and methods for enhanced transepithelial and transendothelial transport or active agents |
| CA2507749C (en) | 1991-12-13 | 2010-08-24 | Xoma Corporation | Methods and materials for preparation of modified antibody variable domains and therapeutic uses thereof |
| AU661533B2 (en) | 1992-01-20 | 1995-07-27 | Astrazeneca Ab | Quinazoline derivatives |
| GB9203459D0 (en) | 1992-02-19 | 1992-04-08 | Scotgen Ltd | Antibodies with germ-line variable regions |
| CA2129514A1 (en) | 1992-03-12 | 1993-09-16 | M. Amin Khan | Controlled released acth containing microspheres |
| TW225528B (zh) | 1992-04-03 | 1994-06-21 | Ciba Geigy Ag | |
| US5534496A (en) | 1992-07-07 | 1996-07-09 | University Of Southern California | Methods and compositions to enhance epithelial drug transport |
| US5350674A (en) | 1992-09-04 | 1994-09-27 | Becton, Dickinson And Company | Intrinsic factor - horse peroxidase conjugates and a method for increasing the stability thereof |
| US5639641A (en) | 1992-09-09 | 1997-06-17 | Immunogen Inc. | Resurfacing of rodent antibodies |
| US6034065A (en) | 1992-12-03 | 2000-03-07 | Arizona Board Of Regents | Elucidation and synthesis of antineoplastic tetrapeptide phenethylamides of dolastatin 10 |
| US5635483A (en) | 1992-12-03 | 1997-06-03 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Tumor inhibiting tetrapeptide bearing modified phenethyl amides |
| US5410024A (en) | 1993-01-21 | 1995-04-25 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Human cancer inhibitory pentapeptide amides |
| US5780588A (en) | 1993-01-26 | 1998-07-14 | Arizona Board Of Regents | Elucidation and synthesis of selected pentapeptides |
| US5514670A (en) | 1993-08-13 | 1996-05-07 | Pharmos Corporation | Submicron emulsions for delivery of peptides |
| GB9317618D0 (en) | 1993-08-24 | 1993-10-06 | Royal Free Hosp School Med | Polymer modifications |
| US5504191A (en) | 1994-08-01 | 1996-04-02 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Human cancer inhibitory pentapeptide methyl esters |
| US5530097A (en) | 1994-08-01 | 1996-06-25 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Human cancer inhibitory peptide amides |
| US5521284A (en) | 1994-08-01 | 1996-05-28 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Human cancer inhibitory pentapeptide amides and esters |
| US5554725A (en) | 1994-09-14 | 1996-09-10 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Synthesis of dolastatin 15 |
| US5599902A (en) | 1994-11-10 | 1997-02-04 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Cancer inhibitory peptides |
| US5663149A (en) | 1994-12-13 | 1997-09-02 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Human cancer inhibitory pentapeptide heterocyclic and halophenyl amides |
| GB9508538D0 (en) | 1995-04-27 | 1995-06-14 | Zeneca Ltd | Quinazoline derivatives |
| US5747498A (en) | 1996-05-28 | 1998-05-05 | Pfizer Inc. | Alkynyl and azido-substituted 4-anilinoquinazolines |
| TR199800012T1 (xx) | 1995-07-06 | 1998-04-21 | Novartis Ag | Piroloprimidinler ve preparasyon i�in tatbikler. |
| US5760041A (en) | 1996-02-05 | 1998-06-02 | American Cyanamid Company | 4-aminoquinazoline EGFR Inhibitors |
| GB9603095D0 (en) | 1996-02-14 | 1996-04-10 | Zeneca Ltd | Quinazoline derivatives |
| GB9603256D0 (en) | 1996-02-16 | 1996-04-17 | Wellcome Found | Antibodies |
| DE69710712T3 (de) | 1996-04-12 | 2010-12-23 | Warner-Lambert Co. Llc | Umkehrbare inhibitoren von tyrosin kinasen |
| US5834597A (en) | 1996-05-20 | 1998-11-10 | Protein Design Labs, Inc. | Mutated nonactivating IgG2 domains and anti CD3 antibodies incorporating the same |
| CA2258548C (en) | 1996-06-24 | 2005-07-26 | Pfizer Inc. | Phenylamino-substituted tricyclic derivatives for treatment of hyperproliferative diseases |
| AU4342997A (en) | 1996-09-13 | 1998-04-02 | Sugen, Inc. | Use of quinazoline derivatives for the manufacture of a medicament in the reatment of hyperproliferative skin disorders |
| EP0837063A1 (en) | 1996-10-17 | 1998-04-22 | Pfizer Inc. | 4-Aminoquinazoline derivatives |
| US6239104B1 (en) | 1997-02-25 | 2001-05-29 | Arizona Board Of Regents | Isolation and structural elucidation of the cytostatic linear and cyclo-depsipeptides dolastatin 16, dolastatin 17, and dolastatin 18 |
| ES2244066T3 (es) | 1997-06-24 | 2005-12-01 | Genentech, Inc. | Procedimiento y composiciones de glicoproteinas galactosiladas. |
| CO4940418A1 (es) | 1997-07-18 | 2000-07-24 | Novartis Ag | Modificacion de cristal de un derivado de n-fenil-2- pirimidinamina, procesos para su fabricacion y su uso |
| WO1999022764A1 (en) | 1997-10-31 | 1999-05-14 | Genentech, Inc. | Methods and compositions comprising glycoprotein glycoforms |
| PT1071700E (pt) | 1998-04-20 | 2010-04-23 | Glycart Biotechnology Ag | Modificação por glicosilação de anticorpos para melhorar a citotoxicidade celular dependente de anticorpos |
| PT1144452E (pt) | 1998-11-03 | 2006-05-31 | Centocor Inc | Anticorpos modificados e fragmentos de anticorpos com duracao aumentada de actividade |
| EP1141024B1 (en) | 1999-01-15 | 2018-08-08 | Genentech, Inc. | POLYPEPTIDE COMPRISING A VARIANT HUMAN IgG1 Fc REGION |
| ES2601882T5 (es) | 1999-04-09 | 2021-06-07 | Kyowa Kirin Co Ltd | Procedimiento para controlar la actividad de una molécula inmunofuncional |
| US6323315B1 (en) | 1999-09-10 | 2001-11-27 | Basf Aktiengesellschaft | Dolastatin peptides |
| WO2001029058A1 (en) | 1999-10-15 | 2001-04-26 | University Of Massachusetts | Rna interference pathway genes as tools for targeted genetic interference |
| CA2388245C (en) | 1999-10-19 | 2012-01-10 | Tatsuya Ogawa | The use of serum-free adapted rat cells for producing heterologous polypeptides |
| US6326193B1 (en) | 1999-11-05 | 2001-12-04 | Cambria Biosciences, Llc | Insect control agent |
| ATE469242T1 (de) | 2000-03-27 | 2010-06-15 | Univ Jefferson | Zusammensetzungen und methoden zur identifizierung und zum targeting von krebszellen aus dem verdauungskanal |
| GB0013810D0 (en) | 2000-06-06 | 2000-07-26 | Celltech Chiroscience Ltd | Biological products |
| WO2001096584A2 (en) | 2000-06-12 | 2001-12-20 | Akkadix Corporation | Materials and methods for the control of nematodes |
| HU231090B1 (hu) | 2000-10-06 | 2020-07-28 | Kyowa Kirin Co., Ltd. | Antitest-kompozíciót termelő sejt |
| US6995162B2 (en) | 2001-01-12 | 2006-02-07 | Amgen Inc. | Substituted alkylamine derivatives and methods of use |
| US6884869B2 (en) | 2001-04-30 | 2005-04-26 | Seattle Genetics, Inc. | Pentapeptide compounds and uses related thereto |
| EP1423510A4 (en) | 2001-08-03 | 2005-06-01 | Glycart Biotechnology Ag | ANTIBODY GLYCOSYLATION VARIANTS WITH INCREASED ANTIBODY-DEPENDENT CELLULAR CYTOTOXICITY |
| HUP0600342A3 (en) | 2001-10-25 | 2011-03-28 | Genentech Inc | Glycoprotein compositions |
| US20040093621A1 (en) | 2001-12-25 | 2004-05-13 | Kyowa Hakko Kogyo Co., Ltd | Antibody composition which specifically binds to CD20 |
| EP2407473A3 (en) | 2002-02-01 | 2012-03-21 | ARIAD Pharmaceuticals, Inc | Method for producing phosphorus-containing compounds |
| US7317091B2 (en) | 2002-03-01 | 2008-01-08 | Xencor, Inc. | Optimized Fc variants |
| WO2003085119A1 (en) | 2002-04-09 | 2003-10-16 | Kyowa Hakko Kogyo Co., Ltd. | METHOD OF ENHANCING ACTIVITY OF ANTIBODY COMPOSITION OF BINDING TO FcϜ RECEPTOR IIIa |
| CA2481656A1 (en) | 2002-04-09 | 2003-10-16 | Kyowa Hakko Kogyo Co., Ltd. | Cells in which activity of the protein involved in transportation of gdp-fucose is reduced or lost |
| WO2003084569A1 (en) | 2002-04-09 | 2003-10-16 | Kyowa Hakko Kogyo Co., Ltd. | Drug containing antibody composition |
| CN102911987B (zh) | 2002-04-09 | 2015-09-30 | 协和发酵麒麟株式会社 | 基因组被修饰的细胞 |
| US20050031613A1 (en) | 2002-04-09 | 2005-02-10 | Kazuyasu Nakamura | Therapeutic agent for patients having human FcgammaRIIIa |
| DE10254601A1 (de) | 2002-11-22 | 2004-06-03 | Ganymed Pharmaceuticals Ag | Differentiell in Tumoren exprimierte Genprodukte und deren Verwendung |
| DK2289936T3 (en) | 2002-12-16 | 2017-07-31 | Genentech Inc | IMMUNGLOBULIN VARIATIONS AND APPLICATIONS THEREOF |
| WO2005042743A2 (en) | 2003-08-18 | 2005-05-12 | Medimmune, Inc. | Humanization of antibodies |
| CA2537055A1 (en) | 2003-08-22 | 2005-04-21 | Medimmune, Inc. | Humanization of antibodies |
| WO2005035586A1 (ja) | 2003-10-08 | 2005-04-21 | Kyowa Hakko Kogyo Co., Ltd. | 融合蛋白質組成物 |
| WO2005035778A1 (ja) | 2003-10-09 | 2005-04-21 | Kyowa Hakko Kogyo Co., Ltd. | α1,6-フコシルトランスフェラーゼの機能を抑制するRNAを用いた抗体組成物の製造法 |
| DK2380910T3 (en) | 2003-11-05 | 2015-10-19 | Roche Glycart Ag | Antigen binding molecules with increased Fc receptor binding affinity and effector function |
| PT2489364E (pt) | 2003-11-06 | 2015-04-16 | Seattle Genetics Inc | Compostos de monometilvalina conjugados com anticorpos |
| WO2005053742A1 (ja) | 2003-12-04 | 2005-06-16 | Kyowa Hakko Kogyo Co., Ltd. | 抗体組成物を含有する医薬 |
| GB0510390D0 (en) | 2005-05-20 | 2005-06-29 | Novartis Ag | Organic compounds |
| US20080226635A1 (en) | 2006-12-22 | 2008-09-18 | Hans Koll | Antibodies against insulin-like growth factor I receptor and uses thereof |
| PE20090678A1 (es) | 2007-09-12 | 2009-06-27 | Genentech Inc | Combinaciones de compuestos inhibidores de fosfoinositida 3-quinasa y agentes quimioterapeuticos y los metodos de uso |
| JP5348725B2 (ja) | 2007-10-25 | 2013-11-20 | ジェネンテック, インコーポレイテッド | チエノピリミジン化合物の製造方法 |
| EP2480230A4 (en) | 2009-09-24 | 2015-06-10 | Seattle Genetics Inc | DR5 Ligand-HEILMITTELKONJUGATE |
| CA3031851C (en) | 2009-10-23 | 2020-07-07 | Amgen British Columbia | Anti-gcc antibody molecules and related compositions and methods |
| WO2011056894A2 (en) | 2009-11-03 | 2011-05-12 | Jensen Michael C | TRUNCATED EPIDERIMAL GROWTH FACTOR RECEPTOR (EGFRt) FOR TRANSDUCED T CELL SELECTION |
| WO2011106723A2 (en) | 2010-02-26 | 2011-09-01 | Lpath, Inc. | Anti-paf antibodies |
| BR112014020499A2 (pt) | 2012-02-22 | 2019-09-24 | Univ Pennsylvania | sequência de ácido nucleico isolada, célula - t, vetor, e, população persistente de células - t |
| CA2878928C (en) | 2012-07-13 | 2023-03-14 | The Trustees Of The University Of Pennsylvania | Toxicity management for anti-tumor activity of cars |
| CA2908668C (en) | 2013-04-03 | 2023-03-14 | Memorial Sloan-Kettering Cancer Center | Effective generation of tumor-targeted t cells derived from pluripotent stem cells |
| JP6779785B2 (ja) | 2013-12-19 | 2020-11-04 | ノバルティス アーゲー | ヒトメソテリンキメラ抗原受容体およびその使用 |
| WO2015090229A1 (en) | 2013-12-20 | 2015-06-25 | Novartis Ag | Regulatable chimeric antigen receptor |
| CN106163547A (zh) | 2014-03-15 | 2016-11-23 | 诺华股份有限公司 | 使用嵌合抗原受体治疗癌症 |
| IL254817B2 (en) | 2015-04-08 | 2023-12-01 | Novartis Ag | Cd20 therapies, cd22 therapies, and combination therapies with a cd19 chimeric antigen receptor (car) - expressing cell |
| CN105384825B (zh) | 2015-08-11 | 2018-06-01 | 南京传奇生物科技有限公司 | 一种基于单域抗体的双特异性嵌合抗原受体及其应用 |
| EP3436070A4 (en) * | 2016-03-29 | 2019-11-27 | University of Southern California | AGAINST CANCER, CHIMERIC ANTIGEN RECEPTORS |
| BR112019000431A2 (pt) * | 2016-07-14 | 2019-07-09 | Bristol-Myers Squibb Company | anticorpos contra tim3 e usos dos mesmos |
| JP2021520229A (ja) * | 2018-03-16 | 2021-08-19 | トーマス ジェファーソン ユニバーシティ | 抗gucy2cキメラ抗原受容体の組成物および方法 |
| CN108949789A (zh) * | 2018-06-26 | 2018-12-07 | 山东兴瑞生物科技有限公司 | 抗gcc的核酸、其制备方法、具有该核酸的免疫细胞及其应用 |
| EP3969470A4 (en) * | 2019-05-16 | 2023-06-28 | Memorial Sloan Kettering Cancer Center | Mesothelin cars and uses thereof |
-
2021
- 2021-12-08 TW TW110145784A patent/TW202237638A/zh unknown
- 2021-12-09 CN CN202180082644.8A patent/CN116601167A/zh active Pending
- 2021-12-09 US US18/256,565 patent/US20240050473A1/en active Pending
- 2021-12-09 CA CA3201582A patent/CA3201582A1/en active Pending
- 2021-12-09 PE PE2023001851A patent/PE20240049A1/es unknown
- 2021-12-09 IL IL303535A patent/IL303535A/en unknown
- 2021-12-09 JP JP2023535607A patent/JP2023553159A/ja active Pending
- 2021-12-09 AR ARP210103412A patent/AR124288A1/es unknown
- 2021-12-09 KR KR1020237023134A patent/KR20230118913A/ko active Pending
- 2021-12-09 MX MX2023006774A patent/MX2023006774A/es unknown
- 2021-12-09 AU AU2021397881A patent/AU2021397881A1/en active Pending
- 2021-12-09 EP EP21852062.5A patent/EP4259656A1/en active Pending
- 2021-12-09 WO PCT/IB2021/000873 patent/WO2022123316A1/en not_active Ceased
-
2023
- 2023-06-08 CL CL2023001666A patent/CL2023001666A1/es unknown
- 2023-07-07 CO CONC2023/0009102A patent/CO2023009102A2/es unknown
- 2023-07-07 EC ECSENADI202350855A patent/ECSP23050855A/es unknown
Also Published As
| Publication number | Publication date |
|---|---|
| JP2023553159A (ja) | 2023-12-20 |
| EP4259656A1 (en) | 2023-10-18 |
| PE20240049A1 (es) | 2024-01-09 |
| AU2021397881A1 (en) | 2023-07-27 |
| CL2023001666A1 (es) | 2024-01-19 |
| ECSP23050855A (es) | 2023-08-31 |
| WO2022123316A1 (en) | 2022-06-16 |
| US20240050473A1 (en) | 2024-02-15 |
| MX2023006774A (es) | 2023-07-12 |
| CO2023009102A2 (es) | 2023-07-21 |
| IL303535A (en) | 2023-08-01 |
| CA3201582A1 (en) | 2022-06-16 |
| KR20230118913A (ko) | 2023-08-14 |
| AU2021397881A9 (en) | 2024-09-19 |
| CN116601167A (zh) | 2023-08-15 |
| AR124288A1 (es) | 2023-03-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7524249B2 (ja) | 抗癌治療における組み合わせ使用のためのメソテリンキメラ抗原受容体(car)およびpd-l1阻害剤に対する抗体 | |
| US20240139244A1 (en) | Cells expressing multiple chimeric antigen receptor (car) molecules and uses therefore | |
| JP7526121B2 (ja) | キメラ抗原受容体を使用する癌の処置 | |
| US20240398913A1 (en) | Methods for improving the efficacy and expansion of chimeric antigen receptor-expressing cells | |
| US11872249B2 (en) | Method of treating cancer by administering immune effector cells expressing a chimeric antigen receptor comprising a CD20 binding domain | |
| US20200339651A1 (en) | Methods for b cell preconditioning in car therapy | |
| US20180092968A1 (en) | Compositions to disrupt protein kinase a anchoring and uses thereof | |
| WO2016126608A1 (en) | Car-expressing cells against multiple tumor antigens and uses thereof | |
| US20240050473A1 (en) | Compositions of guanylyl cyclase c (gcc) antigen binding agents and methods of use thereof | |
| US20220088075A1 (en) | Combination therapies of egfrviii chimeric antigen receptors and pd-1 inhibitors |