KR20190020643A - 정보 마이닝 방법, 시스템, 전자장치 및 판독 가능한 저장매체 - Google Patents
정보 마이닝 방법, 시스템, 전자장치 및 판독 가능한 저장매체 Download PDFInfo
- Publication number
- KR20190020643A KR20190020643A KR1020187023709A KR20187023709A KR20190020643A KR 20190020643 A KR20190020643 A KR 20190020643A KR 1020187023709 A KR1020187023709 A KR 1020187023709A KR 20187023709 A KR20187023709 A KR 20187023709A KR 20190020643 A KR20190020643 A KR 20190020643A
- Authority
- KR
- South Korea
- Prior art keywords
- word
- information
- separated
- speech
- separation
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 74
- 238000005065 mining Methods 0.000 title claims abstract description 43
- 238000000926 separation method Methods 0.000 claims abstract description 145
- 230000011218 segmentation Effects 0.000 claims description 36
- 238000013507 mapping Methods 0.000 claims description 16
- 108091034117 Oligonucleotide Proteins 0.000 claims description 6
- 238000004458 analytical method Methods 0.000 claims description 3
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 claims description 2
- 238000010276 construction Methods 0.000 claims 1
- 238000010586 diagram Methods 0.000 description 6
- 238000004891 communication Methods 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 3
- 230000002457 bidirectional effect Effects 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000010365 information processing Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2458—Special types of queries, e.g. statistical queries, fuzzy queries or distributed queries
- G06F16/2465—Query processing support for facilitating data mining operations in structured databases
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/374—Thesaurus
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3344—Query execution using natural language analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2228—Indexing structures
- G06F16/2246—Trees, e.g. B+trees
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2452—Query translation
- G06F16/24522—Translation of natural language queries to structured queries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/34—Browsing; Visualisation therefor
- G06F16/345—Summarisation for human users
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/903—Querying
- G06F16/90335—Query processing
- G06F16/90344—Query processing by using string matching techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/951—Indexing; Web crawling techniques
-
- G06F17/2785—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Fuzzy Systems (AREA)
- Mathematical Physics (AREA)
- Probability & Statistics with Applications (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
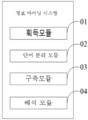
도2는 본 발명에 따른 정보 마이닝 시스템(10)의 일 실시예의 기능 모듈의 도면이다.
도3은 본 발명에 따른 정보 마이닝 방법의 일 실시예에서의 미리 설정된 구조 단어 분리 트리의 도면이다.
도4는 본 발명에 따른 정보 마이닝 방법의 일 실시예의 흐름도이다.
본 발명의 목적 실현, 기능 특징 및 장점에 대해 실시예를 통해 도면을 참조하여 설명하기로 한다.
Claims (20)
- 실시간 또는 정해진 시간으로 미리 결정된 데이터 소스로부터 특정 유형의 정보를 획득하는 단계와,
획득된 각 정보에 대해 단어 분리를 하고 각 정보와 대응되는 각 분리 단어에 대해 품사 주석을 하는 단계와,
각 정보와 대응되는 각 분리 단어의 단어 분리 순서와 품사에 따라 각 정보와 대응되는 각 분리 단어를 미리 설정된 구조 단어 분리 트리로 구축하는 단계와,
하나의 정보와 대응되는 미리 설정된 구조 단어 분리 트리가 구축된 후 이 정보와 대응되는 미리 설정된 구조 단어 분리 트리에 따라 이 정보와 대응되는 핵심 과점 정보를 해석하는 단계를 포함하는 것을 특징으로 하는 정보 마이닝 방법. - 제1항에 있어서,
상기 획득된 각 정보에 대해 단어 분리를 하는 단계는,
순방향 최대 매칭 방법에 따라 각 정보 중 처리할 문자열과 통용 글자 단어 베이스에 매칭하여 제1매칭결과를 획득하고, 상기 제1매칭결과는 제1수량의 제1구절과 제3수량의 글자를 포함하는 단계와,
역방향 최대 매칭 방법에 따라 각 정보 중 처리할 문자열과 통용 글자 단어 베이스에 매칭하여 제2매칭결과를 획득하고, 상기 제2매칭결과는 제2수량의 제2구절과 제4수량의 글자를 포함하는 단계와,
상기 제1수량과 상기 제2수량이 같고 상기 제3수량이 상기 제4수량보다 작거나 같으면 상기 제1매칭결과를 이 정보의 단어 분리 결과로 하는 단계와,
상기 제1수량과 상기 제2수량이 같고 상기 제3수량이 상기 제4수량보다 크면 상기 제2매칭결과를 이 정보의 단어 분리 결과로 하는 단계와,
상기 제1수량과 상기 제2수량이 같지 않고 상기 제1수량이 상기 제2수량보다 크면 상기 제2매칭결과를 이 정보의 단어 분리 결과로 하는 단계와,
상기 제1수량과 상기 제2수량이 같지 않고 상기 제1수량이 상기 제2수량보다 작으면 상기 제1매칭결과를 이 정보의 단어 분리 결과로 하는 단계를 포함하는 것을 특징으로 하는 정보 마이닝 방법. - 제1항 또는 제2항에 있어서,
상기 각 정보와 대응되는 각 분리 단어에 대해 품사 주석을 하는 단계는,
통용 글자 단어 베이스에서 글자와 단어가 각각 품사와의 맵핑관계, 및/또는 미리 설정된 글자와 단어가 각각 품사와의 맵핑관계에 따라 각 정보의 각 분리 단어와 대응되는 품사를 결정하는 단계와,
각 정보의 각 분리 단어에 대해 대응된 품사를 주석하는 단계를 포함하는 것을 특징으로 하는 정보 마이닝 방법. - 제1항 또는 제2항에 있어서,
상기 미리 설정된 구조 단어 분리 트리는 다 레벨 노드를 포함하고, 제 1 레벨 노드는 각 정보 자신이고, 제 2 레벨 노드는 분리 단어 구절이고, 제 2 레벨 노드 후의 각 레벨 노드는 상위 노드와 대응되는 하위 분리 단어나 분리 단어 구절이고, 각 정보와 대응되는 각 분리 단어의 단어 분리 순서와 품사에 따라 각 정보와 대응되는 각 분리 단어를 미리 설정된 구조 단어 분리 트리로 구축하는 단계는,
A1. 각 정보와 대응되는 각 분리 단어에서 각 미리 설정된 품사의 목표 분리 단어를 찾는 단계와,
A2. 각 정보 중 각 목표 분리 단어의 순서에 따라 각 제 2 레벨 노드와 대응되는 분리 단어 구절을 결정하는 단계와,
A3. 하나의 분리 단어 구절에 대해 더이상 분리하지 못하면 이 분리 단어 구절은 해당 노드 분점의 마지막 레벨 노드인 것을 결정하는 단계와,
A4. 하나의 분리 단어 구절에 대해 더 분리할 수 있으면 이 분리 단어 구절에서의 각 미리 설정된 품사의 목표 분리 단어를 찾아 이 분리 단어 구절과 대응되는 각 목표 분리 단어의 순서에 따라 각 노드 분점의 다음 레벨 노드와 대응되는 분리 단어가 결정되는 단계와,
A5. 각 노드 분점의 마지막 레벨 노드와 대응되는 분리 단어가 결정될 때까지 상기 단계A3과 A4를 반복하게 수행하는 단계를 포함하는 것을 특징으로 하는 정보 마이닝 방법. - 제4항에 있어서,
상기 이 정보와 대응되는 미리 설정된 구조 단어 분리 트리에 따라 이 정보와 대응되는 핵심 과점 정보를 해석하는 단계는,
구축된 미리 설정된 구조 단어 분리 트리에 기초하여 각 미리 설정된 제1결정적인 품사와 각 미리 설정된 제2결정적인 품사 사이의 거리를 계산하는 단계와,
각 미리 설정된 제1결정적인 품사의 분리 단어와 가장 가까운 제2결정적인 품사의 분리 단어를 각각 찾아 각 미리 설정된 제1결정적인 품사의 분리 단어와 이와 가장 가까운 제2결정적인 품사의 분리 단어에 대해 이 정보에서의 순서에 따라 대응되는 핵심 관점 정보를 구성하는 단계를 포함하는 것을 특징으로 하는 정보 마이닝 방법. - 실시간 또는 정해진 시간으로 미리 결정된 데이터 소스로부터 특정 유형의 정보를 획득하는 획득모듈과,
획득된 각 정보에 대해 단어 분리를 하고 각 정보와 대응되는 각 분리 단어에 대해 품사 주석을 하는 단어 분리 모듈과,
각 정보와 대응되는 각 분리 단어의 단어 분리 순서와 품사에 따라 각 정보와 대응되는 각 분리 단어를 미리 설정된 구조 단어 분리 트리로 구축하는 구축모듈과,
하나의 정보와 대응되는 미리 설정된 구조 단어 분리 트리가 구축된 후 이 정보와 대응되는 미리 설정된 구조 단어 분리 트리에 따라 이 정보와 대응되는 핵심 과점 정보를 해석하는 해석모듈을 포함하는 것을 특징으로 하는 정보 마이닝 시스템. - 제6항에 있어서,
상기 단어 분리 모듈은,
순방향 최대 매칭 방법에 따라 각 정보 중 처리할 문자열과 통용 글자 단어 베이스에 매칭하여 제1매칭결과를 획득하고, 상기 제1매칭결과는 제1수량의 제1구절과 제3수량의 글자를 포함하는 용도와,
역방향 최대 매칭 방법에 따라 각 정보 중 처리할 문자열과 통용 글자 단어 베이스에 매칭하여 제2매칭결과를 획득하고, 상기 제2매칭결과는 제2수량의 제2구절과 제4수량의 글자를 포함하는 용도와,
상기 제1수량과 상기 제2수량이 같고 상기 제3수량이 상기 제4수량보다 작거나 같으면 상기 제1매칭결과를 이 정보의 단어 분리 결과로 하는 용도와,
상기 제1수량과 상기 제2수량이 같고 상기 제3수량이 상기 제4수량보다 크면 상기 제2매칭결과를 이 정보의 단어 분리 결과로 하는 용도와,
상기 제1수량과 상기 제2수량이 같지 않고 상기 제1수량이 상기 제2수량보다 크면 상기 제2매칭결과를 이 정보의 단어 분리 결과로 하는 용도와,
상기 제1수량과 상기 제2수량이 같지 않고 상기 제1수량이 상기 제2수량보다 작으면 상기 제1매칭결과를 이 정보의 단어 분리 결과로 하는 용도를 포함하는 것을 특징으로 하는 정보 마이닝 시스템. - 제6항 또는 제7항에 있어서,
상기 단어 분리 모듈은,
통용 글자 단어 베이스에서 글자와 단어가 각각 품사와의 맵핑관계, 및/또는 미리 설정된 글자와 단어가 각각 품사와의 맵핑관계에 따라 각 정보의 각 분리 단어와 대응되는 품사를 결정하는 용도와,
각 정보의 각 분리 단어에 대해 대응된 품사를 주석하는 용도를 포함하는 것을 특징으로 하는 정보 마이닝 스시템. - 제6항 또는 제7항에 있어서,
상기 미리 설정된 구조 단어 분리 트리는 다 레벨 노드를 포함하고, 제 1 레벨 노드는 각 정보 자신이고, 제 2 레벨 노드는 분리 단어 구절이고, 제 2 레벨 노드 후의 각 레벨 노드는 상위 노드와 대응되는 하위 분리 단어나 분리 단어 구절이고, 싱기 구축모듈의 용도는,
각 정보와 대응되는 각 분리 단어에서 각 미리 설정된 품사의 목표 분리 단어를 찾으며, 각 정보 중 각 목표 분리 단어의 순서에 따라 각 제 2 레벨 노드와 대응되는 분리 단어 구절을 결정하며, 하나의 분리 단어 구절에 대해 더이상 분리하지 못하면 이 분리 단어 구절은 해당 노드 분점의 마지막 레벨 노드인 것을 결정하며, 하나의 분리 단어 구절에 대해 더 분리할 수 있으면 이 분리 단어 구절에서의 각 미리 설정된 품사의 목표 분리 단어를 찾아 이 분리 단어 구절과 대응되는 각 목표 분리 단어의 순서에 따라 각 노드 분점의 마지막 레벨 노드와 대응되는 분리 단어가 결정될 때까지 각 노드 분점의 다음 레벨 노드와 대응되는 분리 단어가 결정되는 것을 특징으로 하는 정보 마이닝 시스템. - 제9항에 있어서,
상기 해석 모듈은,
구축된 미리 설정된 구조 단어 분리 트리에 기초하여 각 미리 설정된 제1결정적인 품사와 각 미리 설정된 제2결정적인 품사 사이의 거리를 계산하는 용도와,
각 미리 설정된 제1결정적인 품사의 분리 단어와 가장 가까운 제2결정적인 품사의 분리 단어를 각각 찾아 각 미리 설정된 제1결정적인 품사의 분리 단어와 이와 가장 가까운 제2결정적인 품사의 분리 단어에 대해 이 정보에서의 순서에 따라 대응되는 핵심 관점 정보를 구성하는 용도를 포함하는 것을 특징으로 하는 정보 마이닝 시스템. - 전자장치에 있어서, 상기 전자장치는 저장 장치, 프로세서, 상기 저장 장치에 저장되어 상기 프러세서 상에서 실행될 수 있는 정보 마이닝 시스템을 포함하고, 상기 정보 마이닝 시스템은 프로세서에 의해 실행되어,
실시간 또는 정해진 시간으로 미리 결정된 데이터 소스로부터 특정 유형의 정보를 획득하는 단계와,
획득된 각 정보에 대해 단어 분리를 하고 각 정보와 대응되는 각 분리 단어에 대해 품사 주석을 하는 단계와,
각 정보와 대응되는 각 분리 단어의 단어 분리 순서와 품사에 따라 각 정보와 대응되는 각 분리 단어를 미리 설정된 구조 단어 분리 트리로 구축하는 단계와,
하나의 정보와 대응되는 미리 설정된 구조 단어 분리 트리가 구축된 후 이 정보와 대응되는 미리 설정된 구조 단어 분리 트리에 따라 이 정보와 대응되는 핵심 과점 정보를 해석하는 단계를 구현하는 것을 특징으로 하는 전자장치. - 제11항에 있어서,
상기 획득된 각 정보에 대해 단어 분리를 하는 단계는,
순방향 최대 매칭 방법에 따라 각 정보 중 처리할 문자열과 통용 글자 단어 베이스에 매칭하여 제1매칭결과를 획득하고, 상기 제1매칭결과는 제1수량의 제1구절과 제3수량의 글자를 포함하는 단계와,
역방향 최대 매칭 방법에 따라 각 정보 중 처리할 문자열과 통용 글자 단어 베이스에 매칭하여 제2매칭결과를 획득하고, 상기 제2매칭결과는 제2수량의 제2구절과 제4수량의 글자를 포함하는 단계와,
상기 제1수량과 상기 제2수량이 같고 상기 제3수량이 상기 제4수량보다 작거나 같으면 상기 제1매칭결과를 이 정보의 단어 분리 결과로 하는 단계와,
상기 제1수량과 상기 제2수량이 같고 상기 제3수량이 상기 제4수량보다 크면 상기 제2매칭결과를 이 정보의 단어 분리 결과로 하는 단계와,
상기 제1수량과 상기 제2수량이 같지 않고 상기 제1수량이 상기 제2수량보다 크면 상기 제2매칭결과를 이 정보의 단어 분리 결과로 하는 단계와,
상기 제1수량과 상기 제2수량이 같지 않고 상기 제1수량이 상기 제2수량보다 작으면 상기 제1매칭결과를 이 정보의 단어 분리 결과로 하는 단계를 포함하는 것을 특징으로 하는 전자장치. - 제11항 또는 제12항에 있어서,
상기 각 정보와 대응되는 각 분리 단어에 대해 품사 주석을 하는 단계는,
통용 글자 단어 베이스에서 글자와 단어가 각각 품사와의 맵핑관계, 및/또는 미리 설정된 글자와 단어가 각각 품사와의 맵핑관계에 따라 각 정보의 각 분리 단어와 대응되는 품사를 결정하는 단계와, 각 정보의 각 분리 단어에 대해 대응된 품사를 주석하는 단계를 포함하는 것을 특징으로 하는 전자장치. - 제11항 또는 제12항에 있어서,
상기 미리 설정된 구조 단어 분리 트리는 다 레벨 노드를 포함하고, 제 1 레벨 노드는 각 정보 자신이고, 제 2 레벨 노드는 분리 단어 구절이고, 제 2 레벨 노드 후의 각 레벨 노드는 상위 노드와 대응되는 하위 분리 단어나 분리 단어 구절이고, 각 정보와 대응되는 각 분리 단어의 단어 분리 순서와 품사에 따라 각 정보와 대응되는 각 분리 단어를 미리 설정된 구조 단어 분리 트리로 구축하는 단계는,
각 정보와 대응되는 각 분리 단어에서 각 미리 설정된 품사의 목표 분리 단어를 찾으며, 각 정보 중 각 목표 분리 단어의 순서에 따라 각 제 2 레벨 노드와 대응되는 분리 단어 구절을 결정하며, 하나의 분리 단어 구절에 대해 더이상 분리하지 못하면 이 분리 단어 구절은 해당 노드 분점의 마지막 레벨 노드인 것을 결정하며, 하나의 분리 단어 구절에 대해 더 분리할 수 있으면 이 분리 단어 구절에서의 각 미리 설정된 품사의 목표 분리 단어를 찾아 이 분리 단어 구절과 대응되는 각 목표 분리 단어의 순서에 따라 각 노드 분점의 마지막 레벨 노드와 대응되는 분리 단어가 결정될 때까지 각 노드 분점의 다음 레벨 노드와 대응되는 분리 단어가 결정되는 것을 특징으로 하는 전자장치. - 제14항에 있어서,
상기 이 정보와 대응되는 미리 설정된 구조 단어 분리 트리에 따라 이 정보와 대응되는 핵심 과점 정보를 해석하는 단계는,
구축된 미리 설정된 구조 단어 분리 트리에 기초하여 각 미리 설정된 제1결정적인 품사와 각 미리 설정된 제2결정적인 품사 사이의 거리를 계산하는 단계와,
각 미리 설정된 제1결정적인 품사의 분리 단어와 가장 가까운 제2결정적인 품사의 분리 단어를 각각 찾아 각 미리 설정된 제1결정적인 품사의 분리 단어와 이와 가장 가까운 제2결정적인 품사의 분리 단어에 대해 이 정보에서의 순서에 따라 대응되는 핵심 관점 정보를 구성하는 단계를 포함하는 것을 특징으로 하는 전자장치. - 컴퓨터 판독 가능한 저장매체에 있어서, 이에 포로세서에 의해 실행될 수 있는 적어도 하나의 컴퓨터 판독 가능한 명령이 저장되어,
실시간 또는 정해진 시간으로 미리 결정된 데이터 소스로부터 특정 유형의 정보를 획득하는 동작과,
획득된 각 정보에 대해 단어 분리를 하고 각 정보와 대응되는 각 분리 단어에 대해 품사 주석을 하는 동작과,
각 정보와 대응되는 각 분리 단어의 단어 분리 순서와 품사에 따라 각 정보와 대응되는 각 분리 단어를 미리 설정된 구조 단어 분리 트리로 구축하는 동작과,
하나의 정보와 대응되는 미리 설정된 구조 단어 분리 트리가 구축된 후 이 정보와 대응되는 미리 설정된 구조 단어 분리 트리에 따라 이 정보와 대응되는 핵심 과점 정보를 해석하는 동작을 수행하는 것을 특징으로 하는 컴퓨터 판독 가능한 저장매체. - 제16항에 있어서,
상기 획득된 각 정보에 대해 단어 분리를 하는 동작은,
순방향 최대 매칭 방법에 따라 각 정보 중 처리할 문자열과 통용 글자 단어 베이스에 매칭하여 제1매칭결과를 획득하고, 상기 제1매칭결과는 제1수량의 제1구절과 제3수량의 글자를 포함하는 동작과,
역방향 최대 매칭 방법에 따라 각 정보 중 처리할 문자열과 통용 글자 단어 베이스에 매칭하여 제2매칭결과를 획득하고, 상기 제2매칭결과는 제2수량의 제2구절과 제4수량의 글자를 포함하는 동작과,
상기 제1수량과 상기 제2수량이 같고 상기 제3수량이 상기 제4수량보다 작거나 같으면 상기 제1매칭결과를 이 정보의 단어 분리 결과로 하는 동작과,
상기 제1수량과 상기 제2수량이 같고 상기 제3수량이 상기 제4수량보다 크면 상기 제2매칭결과를 이 정보의 단어 분리 결과로 하는 동작과,
상기 제1수량과 상기 제2수량이 같지 않고 상기 제1수량이 상기 제2수량보다 크면 상기 제2매칭결과를 이 정보의 단어 분리 결과로 하는 동작과,
상기 제1수량과 상기 제2수량이 같지 않고 상기 제1수량이 상기 제2수량보다 작으면 상기 제1매칭결과를 이 정보의 단어 분리 결과로 하는 동작을 포함하는 것을 특징으로 하는 컴퓨터 판독 가능한 저장매체. - 제16항 또는 제17항에 있어서,
상기 각 정보와 대응되는 각 분리 단어에 대해 품사 주석을 하는 동작은,
통용 글자 단어 베이스에서 글자와 단어가 각각 품사와의 맵핑관계, 및/또는 미리 설정된 글자와 단어가 각각 품사와의 맵핑관계에 따라 각 정보의 각 분리 단어와 대응되는 품사를 결정하는 동작과,
각 정보의 각 분리 단어에 대해 대응된 품사를 주석하는 동작을 포함하는 것을 특징으로 하는 컴퓨터 판독 가능한 저장매체. - 제16항 또는 제17항에 있어서,
상기 미리 설정된 구조 단어 분리 트리는 다 레벨 노드를 포함하고, 제 1 레벨 노드는 각 정보 자신이고, 제 2 레벨 노드는 분리 단어 구절이고, 제 2 레벨 노드 후의 각 레벨 노드는 상위 노드와 대응되는 하위 분리 단어나 분리 단어 구절이고, 각 정보와 대응되는 각 분리 단어의 단어 분리 순서와 품사에 따라 각 정보와 대응되는 각 분리 단어를 미리 설정된 구조 단어 분리 트리로 구축하는 단계는,
A1. 각 정보와 대응되는 각 분리 단어에서 각 미리 설정된 품사의 목표 분리 단어를 찾는 단계와,
A2. 각 정보 중 각 목표 분리 단어의 순서에 따라 각 제 2 레벨 노드와 대응되는 분리 단어 구절을 결정하는 단계와,
A3. 하나의 분리 단어 구절에 대해 더이상 분리하지 못하면 이 분리 단어 구절은 해당 노드 분점의 마지막 레벨 노드인 것을 결정하는 단계와,
A4. 하나의 분리 단어 구절에 대해 더 분리할 수 있으면 이 분리 단어 구절에서의 각 미리 설정된 품사의 목표 분리 단어를 찾아 이 분리 단어 구절과 대응되는 각 목표 분리 단어의 순서에 따라 각 노드 분점의 다음 레벨 노드와 대응되는 분리 단어가 결정되는 단계와,
A5. 각 노드 분점의 마지막 레벨 노드와 대응되는 분리 단어가 결정될 때까지 상기 단계A3과 A4를 반복하게 수행하는 단계를 포함하는 것을 특징으로 하는 컴퓨터 판독 가능한 저장매체. - 제19항에 있어서,
상기 이 정보와 대응되는 미리 설정된 구조 단어 분리 트리에 따라 이 정보와 대응되는 핵심 과점 정보를 해석하는 단계는,
구축된 미리 설정된 구조 단어 분리 트리에 기초하여 각 미리 설정된 제1결정적인 품사와 각 미리 설정된 제2결정적인 품사 사이의 거리를 계산하는 단계와,
각 미리 설정된 제1결정적인 품사의 분리 단어와 가장 가까운 제2결정적인 품사의 분리 단어를 각각 찾아 각 미리 설정된 제1결정적인 품사의 분리 단어와 이와 가장 가까운 제2결정적인 품사의 분리 단어에 대해 이 정보에서의 순서에 따라 대응되는 핵심 관점 정보를 구성하는 단계를 포함하는 것을 특징으로 하는 컴퓨터 판독 가능한 저장매체.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710313993.1A CN107220300B (zh) | 2017-05-05 | 2017-05-05 | 信息挖掘方法、电子装置及可读存储介质 |
| CN2017103139931 | 2017-05-05 | ||
| PCT/CN2017/091360 WO2018201600A1 (zh) | 2017-05-05 | 2017-06-30 | 信息挖掘方法、系统、电子装置及可读存储介质 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20190020643A true KR20190020643A (ko) | 2019-03-04 |
| KR102157202B1 KR102157202B1 (ko) | 2020-09-18 |
Family
ID=59945172
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187023709A KR102157202B1 (ko) | 2017-05-05 | 2017-06-30 | 정보 마이닝 방법, 시스템, 전자장치 및 판독 가능한 저장매체 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US20200301919A1 (ko) |
| EP (1) | EP3425532A4 (ko) |
| JP (1) | JP6687741B2 (ko) |
| KR (1) | KR102157202B1 (ko) |
| CN (1) | CN107220300B (ko) |
| AU (1) | AU2017408800B2 (ko) |
| SG (1) | SG11201900261QA (ko) |
| WO (1) | WO2018201600A1 (ko) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110569496B (zh) * | 2018-06-06 | 2022-05-17 | 腾讯科技(深圳)有限公司 | 实体链接方法、装置及存储介质 |
| CN109253728A (zh) * | 2018-08-31 | 2019-01-22 | 平安科技(深圳)有限公司 | 语音导航方法、装置、计算机设备及存储介质 |
| CN109753648B (zh) * | 2018-11-30 | 2022-12-20 | 平安科技(深圳)有限公司 | 词链模型的生成方法、装置、设备及计算机可读存储介质 |
| CN109710946A (zh) * | 2019-01-15 | 2019-05-03 | 福州大学 | 一种基于依赖解析树的联合论辩挖掘系统及方法 |
| CN110390101B (zh) * | 2019-07-22 | 2023-04-25 | 中新软件(上海)有限公司 | 实体合同备注的非标设计判断方法、装置及计算机设备 |
| CN110971754B (zh) * | 2019-10-28 | 2022-09-27 | 深圳绿米联创科技有限公司 | 信息处理方法、装置、电子设备及存储介质 |
| CN112668324B (zh) * | 2020-12-04 | 2023-12-08 | 北京达佳互联信息技术有限公司 | 语料数据处理方法、装置、电子设备及存储介质 |
| CN113051913A (zh) * | 2021-04-09 | 2021-06-29 | 中译语通科技股份有限公司 | 藏文分词信息处理方法、系统、存储介质、终端及应用 |
| CN113919329B (zh) * | 2021-09-26 | 2024-11-22 | 用友网络科技股份有限公司 | 识别方法、识别系统、电子设备和存储介质 |
| CN114064793A (zh) * | 2021-11-29 | 2022-02-18 | 大箴(杭州)科技有限公司 | 文本关键词的挖掘方法及装置、存储介质、计算机设备 |
| CN114154502B (zh) * | 2022-02-09 | 2022-05-24 | 浙江太美医疗科技股份有限公司 | 医学文本的分词方法、装置、计算机设备和存储介质 |
| CN114647639B (zh) * | 2022-03-21 | 2024-11-19 | 中国地质大学(武汉) | 基于分词模式匹配的非标准地名地址数据清洗方法及装置 |
| CN116226362B (zh) * | 2023-05-06 | 2023-07-18 | 湖南德雅曼达科技有限公司 | 一种提升搜索医院名称准确度的分词方法 |
| CN116227488B (zh) * | 2023-05-09 | 2023-07-04 | 北京拓普丰联信息科技股份有限公司 | 一种文本分词的方法、装置、电子设备及存储介质 |
| CN117391076B (zh) * | 2023-12-11 | 2024-02-27 | 东亚银行(中国)有限公司 | 敏感数据的识别模型的获取方法、装置、电子设备及介质 |
| CN117807190B (zh) * | 2024-02-28 | 2024-05-31 | 国网河南省电力公司经济技术研究院 | 一种能源大数据敏感数据智能化识别方法 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006031143A (ja) * | 2004-07-13 | 2006-02-02 | Fuji Xerox Co Ltd | 文書解析装置、および文書解析方法、並びにコンピュータ・プログラム |
| US7315861B2 (en) * | 2000-05-24 | 2008-01-01 | Reachforce, Inc. | Text mining system for web-based business intelligence |
| US8577924B2 (en) * | 2008-12-15 | 2013-11-05 | Raytheon Company | Determining base attributes for terms |
| CN105224640A (zh) * | 2015-09-25 | 2016-01-06 | 杭州朗和科技有限公司 | 一种提取观点的方法和设备 |
| CN106202285A (zh) * | 2016-06-30 | 2016-12-07 | 北京百度网讯科技有限公司 | 搜索结果展示方法和装置 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101000764B (zh) * | 2006-12-18 | 2011-05-18 | 黑龙江大学 | 基于韵律结构的语音合成文本处理方法 |
| JP5224953B2 (ja) * | 2008-07-17 | 2013-07-03 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 情報処理装置、情報処理方法およびプログラム |
| US9720903B2 (en) * | 2012-07-10 | 2017-08-01 | Robert D. New | Method for parsing natural language text with simple links |
| CN104765838A (zh) * | 2012-10-23 | 2015-07-08 | 海信集团有限公司 | 一种分词方法及装置 |
| CN103678564B (zh) * | 2013-12-09 | 2017-02-15 | 国家计算机网络与信息安全管理中心 | 一种基于数据挖掘的互联网产品调研系统 |
| CN104050256B (zh) * | 2014-06-13 | 2017-05-24 | 西安蒜泥电子科技有限责任公司 | 基于主动学习的问答方法及采用该方法的问答系统 |
| CN106372232B (zh) * | 2016-09-09 | 2020-01-10 | 北京百度网讯科技有限公司 | 基于人工智能的信息挖掘方法和装置 |
| CN106484676B (zh) * | 2016-09-30 | 2019-04-12 | 西安交通大学 | 基于句法树和领域特征的生物文本蛋白质指代消解方法 |
-
2017
- 2017-05-05 CN CN201710313993.1A patent/CN107220300B/zh active Active
- 2017-06-30 AU AU2017408800A patent/AU2017408800B2/en active Active
- 2017-06-30 US US16/084,564 patent/US20200301919A1/en not_active Abandoned
- 2017-06-30 JP JP2018537630A patent/JP6687741B2/ja active Active
- 2017-06-30 KR KR1020187023709A patent/KR102157202B1/ko active IP Right Grant
- 2017-06-30 EP EP17899234.3A patent/EP3425532A4/en not_active Ceased
- 2017-06-30 SG SG11201900261QA patent/SG11201900261QA/en unknown
- 2017-06-30 WO PCT/CN2017/091360 patent/WO2018201600A1/zh active Application Filing
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7315861B2 (en) * | 2000-05-24 | 2008-01-01 | Reachforce, Inc. | Text mining system for web-based business intelligence |
| JP2006031143A (ja) * | 2004-07-13 | 2006-02-02 | Fuji Xerox Co Ltd | 文書解析装置、および文書解析方法、並びにコンピュータ・プログラム |
| US8577924B2 (en) * | 2008-12-15 | 2013-11-05 | Raytheon Company | Determining base attributes for terms |
| CN105224640A (zh) * | 2015-09-25 | 2016-01-06 | 杭州朗和科技有限公司 | 一种提取观点的方法和设备 |
| CN106202285A (zh) * | 2016-06-30 | 2016-12-07 | 北京百度网讯科技有限公司 | 搜索结果展示方法和装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102157202B1 (ko) | 2020-09-18 |
| AU2017408800B2 (en) | 2020-02-20 |
| CN107220300A (zh) | 2017-09-29 |
| AU2017408800A1 (en) | 2018-11-22 |
| SG11201900261QA (en) | 2019-02-27 |
| EP3425532A4 (en) | 2019-02-13 |
| US20200301919A1 (en) | 2020-09-24 |
| WO2018201600A1 (zh) | 2018-11-08 |
| CN107220300B (zh) | 2018-07-20 |
| EP3425532A1 (en) | 2019-01-09 |
| JP6687741B2 (ja) | 2020-04-28 |
| JP2019520616A (ja) | 2019-07-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20190020643A (ko) | 정보 마이닝 방법, 시스템, 전자장치 및 판독 가능한 저장매체 | |
| TWI636452B (zh) | 語音識別方法及系統 | |
| CN107679144B (zh) | 基于语义相似度的新闻语句聚类方法、装置及存储介质 | |
| WO2021135469A1 (zh) | 基于机器学习的信息抽取方法、装置、计算机设备及介质 | |
| CN108932294B (zh) | 基于索引的简历数据处理方法、装置、设备及存储介质 | |
| WO2022222300A1 (zh) | 开放关系抽取方法、装置、电子设备及存储介质 | |
| US9753905B2 (en) | Generating a document structure using historical versions of a document | |
| WO2017177809A1 (zh) | 语言文本的分词方法和系统 | |
| JP6532088B2 (ja) | 自律学習整列ベースの整列コーパス生成装置およびその方法と、整列コーパスを用いた破壊表現の形態素分析装置およびその形態素分析方法 | |
| CN111309910A (zh) | 文本信息挖掘方法及装置 | |
| WO2017012327A1 (zh) | 句法分析的方法和装置 | |
| CN102662953B (zh) | 与输入法集成的语义标注系统和方法 | |
| CN110929518A (zh) | 一种使用重叠拆分规则的文本序列标注算法 | |
| US8666987B2 (en) | Apparatus and method for processing documents to extract expressions and descriptions | |
| US9336197B2 (en) | Language recognition based on vocabulary lists | |
| CN116361441A (zh) | 基于用户画像的问题意图识别方法、装置、设备及介质 | |
| Balahur et al. | Multilingual feature-driven opinion extraction and summarization from customer reviews | |
| CN101425087A (zh) | 构建词典的方法和系统 | |
| WO2014114117A1 (en) | Language recognition based on vocabulary lists | |
| CN109933788B (zh) | 类型确定方法、装置、设备和介质 | |
| CN102110087A (zh) | 字符数据中实体消解的方法和装置 | |
| Li et al. | Word embedding and topic modeling enhanced multiple features for content linking and argument/sentiment labeling in online forums | |
| CN104536948A (zh) | 版式文档的处理方法及装置 | |
| JP2014235584A (ja) | 文書分析システム、文書分析方法およびプログラム | |
| CN113268600B (zh) | 检索名称的错别字纠正方法、装置、电子设备和存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20180817 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20190124 Comment text: Request for Examination of Application |
|
| PG1501 | Laying open of application | ||
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20200331 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20200909 |
|
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20200911 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20200911 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration | ||
| PR1001 | Payment of annual fee |
Payment date: 20240729 Start annual number: 5 End annual number: 5 |